
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
10,676 | 计算机实验室之树莓派:课程 10 输入01 | https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html | 2019-04-02T12:23:00 | [
"键盘",
"树莓派"
] | https://linux.cn/article-10676-1.html | 
欢迎进入输入课程系列。在本系列,你将会学会如何使用键盘接收输入给树莓派。我们将会从揭示输入开始本课,然后转向更传统的文本提示符。
这是第一堂输入课,会教授一些关于驱动和链接的理论,同样也包含键盘的知识,最后以在屏幕上显示文本结束。
### 1、开始
希望你已经完成了 OK 系列课程,这会对你完成屏幕系列课程很有帮助。很多 OK 课程上的文件会被使用而不会做解释。如果你没有这些文件,或者希望使用一个正确的实现,可以从该堂课的[下载页](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads.html)下载模板。如果你使用你自己的实现,请删除调用了 `SetGraphicsAddress` 之后全部的代码。
### 2、USB
如你所知,树莓派 B 型有两个 USB 接口,通常用来连接一个鼠标和一个键盘。这是一个非常好的设计决策,USB 是一个非常通用的接口,很多种设备都可以使用它。这就很容易为它设计新外设,很容易为它编写设备驱动,而且通过 USB 集线器可以非常容易扩展。还能更好吗?当然是不能,实际上对一个操作系统开发者来说,这就是我们的噩梦。USB 标准太大了。我是说真的,在你思考如何连接设备之前,它的文档将近 700 页。
>
> USB 标准的设计目的是通过复杂的软件来简化硬件交互。
>
>
>
我和很多爱好操作系统的开发者谈过这些,而他们全部都说几句话:不要抱怨。“实现这个需要花费很久时间”,“你不可能写出关于 USB 的教程”,“收益太小了”。在很多方面,他们是对的,我不可能写出一个关于 USB 标准的教程,那得花费几周时间。我同样不能教授如何为全部所有的设备编写外设驱动,所以使用自己写的驱动是没什么用的。然而,即便不能做到最好,我仍然可以获取一个正常工作的 USB 驱动,拿一个键盘驱动,然后教授如何在操作系统中使用它们。我开始寻找可以运行在一个甚至不知道文件是什么的操作系统的自由驱动,但是我一个都找不到,它们都太高层了,所以我尝试写一个。大家说的都对,这耗费了我几周时间。然而我可以高兴的说我做的这些工作没有获取操作系统以外的帮助,并且可以和鼠标和键盘通信。这绝不是完整的、高效的,或者正确的,但是它能工作。驱动是以 C 编写的,而且有兴趣的可以在下载页找到全部源代码。
所以,这一个教程不会是 USB 标准的课程(一点也没有)。实际上我们将会看到如何使用其他人的代码。
### 3、链接
既然我们要引进外部代码到操作系统,我们就需要谈一谈<ruby> 链接 <rt> linking </rt></ruby>。链接是一种过程,可以在程序或者操作系统中链接函数。这意味着当一个程序生成之后,我们不必要编写每一个函数(几乎可以肯定,实际上并非如此)。链接就是我们做的用来把我们程序和别人代码中的函数连结在一起。这个实际上已经在我们的操作系统进行了,因为链接器把所有不同的文件链接在一起,每个都是分开编译的。
>
> 链接允许我们制作可重用的代码库,所有人都可以在他们的程序中使用。
>
>
>
有两种链接方式:静态和动态。静态链接就像我们在制作自己的操作系统时进行的。链接器找到全部函数的地址,然后在链接结束前,将这些地址都写入代码中。动态链接是在程序“完成”之后。当程序加载后,动态链接器检查程序,然后在操作系统的库找到所有不在程序里的函数。这就是我们的操作系统最终应该能够完成的一项工作,但是现在所有东西都将是静态链接的。
>
> 程序经常调用调用库,这些库会调用其它的库,直到最终调用了我们写的操作系统的库。
>
>
>
我编写的 USB 驱动程序适合静态编译。这意味着我给你的是每个文件的编译后的代码,然后链接器找到你的代码中的那些没有实现的函数,就将这些函数链接到我的代码。在本课的 [下载页](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads.html) 是一个 makefile 和我的 USB 驱动,这是接下来需要的。下载并使用这个 makefile 替换你的代码中的 makefile, 同事将驱动放在和这个 makefile 相同的文件夹。
### 4、键盘
为了将输入传给我们的操作系统,我们需要在某种程度上理解键盘是如何实际工作的。键盘有两种按键:普通键和修饰键。普通按键是字母、数字、功能键,等等。它们构成了键盘上几乎全部按键。修饰键是多达 8 个的特殊键。它们是左 shift、右 shift、左 ctrl、右 ctrl、左 alt、右 alt、左 GUI 和右 GUI。键盘可以检测出所有的组合中那个修饰键被按下了,以及最多 6 个普通键。每次一个按钮变化了(例如,是按下了还是释放了),键盘就会报告给电脑。通常,键盘也会有 3 个 LED 灯,分别指示大写锁定,数字键锁定,和滚动锁定,这些都是由电脑控制的,而不是键盘自己。键盘也可能有更多的灯,比如电源、静音,等等。
对于标准 USB 键盘,有一个按键值的表,每个键盘按键都一个唯一的数字,每个可能的 LED 也类似。下面的表格列出了前 126 个值。
表 4.1 USB 键盘值
| 序号 | 描述 | 序号 | 描述 | 序号 | 描述 | 序号 | 描述 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 4 | `a` 和 `A` | 5 | `b` 和 `B` | 6 | `c` 和 `C` | 7 | `d` 和 `D` |
| 8 | `e` 和 `E` | 9 | `f` 和 `F` | 10 | `g` 和 `G` | 11 | `h` 和 `H` |
| 12 | `i` 和 `I` | 13 | `j` 和 `J` | 14 | `k` 和 `K` | 15 | `l` 和 `L` |
| 16 | `m` 和 `M` | 17 | `n` 和 `N` | 18 | `o` 和 `O` | 19 | `p` 和 `P` |
| 20 | `q` 和 `Q` | 21 | `r` 和 `R` | 22 | `s` 和 `S` | 23 | `t` 和 `T` |
| 24 | `u` 和 `U` | 25 | `v` 和 `V` | 26 | `w` 和 `W` | 27 | `x` 和 `X` |
| 28 | `y` 和 `Y` | 29 | `z` 和 `Z` | 30 | `1` 和 `!` | 31 | `2` 和 `@` |
| 32 | `3` 和 `#` | 33 | `4` 和 `$` | 34 | `5` 和 `%` | 35 | `6` 和 `^` |
| 36 | `7` 和 `&` | 37 | `8` 和 `*` | 38 | `9` 和 `(` | 39 | `0` 和 `)` |
| 40 | `Return`(`Enter`) | 41 | `Escape` | 42 | `Delete`(`Backspace`) | 43 | `Tab` |
| 44 | `Spacebar` | 45 | `-` 和 `_` | 46 | `=` 和 `+` | 47 | `[` 和 `{` |
| 48 | `]` 和 `}` | 49 | `\` 和 `|` | 50 | `#` 和 `~` | 51 | `;` 和 `:` |
| 52 | `'` 和 `"` | 53 | ``` 和 `~` | 54 | `,` 和 `<` | 55 | `.` 和 `>` |
| 56 | `/` 和 `?` | 57 | `Caps Lock` | 58 | `F1` | 59 | `F2` |
| 60 | `F3` | 61 | `F4` | 62 | `F5` | 63 | `F6` |
| 64 | `F7` | 65 | `F8` | 66 | `F9` | 67 | `F10` |
| 68 | `F11` | 69 | `F12` | 70 | `Print Screen` | 71 | `Scroll Lock` |
| 72 | `Pause` | 73 | `Insert` | 74 | `Home` | 75 | `Page Up` |
| 76 | `Delete forward` | 77 | `End` | 78 | `Page Down` | 79 | `Right Arrow` |
| 80 | `Left Arrow` | 81 | `Down Arrow` | 82 | `Up Arrow` | 83 | `Num Lock` |
| 84 | 小键盘 `/` | 85 | 小键盘 `*` | 86 | 小键盘 `-` | 87 | 小键盘 `+` |
| 88 | 小键盘 `Enter` | 89 | 小键盘 `1` 和 `End` | 90 | 小键盘 `2` 和 `Down Arrow` | 91 | 小键盘 `3` 和 `Page Down` |
| 92 | 小键盘 `4` 和 `Left Arrow` | 93 | 小键盘 `5` | 94 | 小键盘 `6` 和 `Right Arrow` | 95 | 小键盘 `7` 和 `Home` |
| 96 | 小键盘 `8` 和 `Up Arrow` | 97 | 小键盘 `9` 和 `Page Up` | 98 | 小键盘 `0` 和 `Insert` | 99 | 小键盘 `.` 和 `Delete` |
| 100 | `\` 和 `|` | 101 | `Application` | 102 | `Power` | 103 | 小键盘 `=` |
| 104 | `F13` | 105 | `F14` | 106 | `F15` | 107 | `F16` |
| 108 | `F17` | 109 | `F18` | 110 | `F19` | 111 | `F20` |
| 112 | `F21` | 113 | `F22` | 114 | `F23` | 115 | `F24` |
| 116 | `Execute` | 117 | `Help` | 118 | `Menu` | 119 | `Select` |
| 120 | `Stop` | 121 | `Again` | 122 | `Undo` | 123 | `Cut` |
| 124 | `Copy` | 125 | `Paste` | 126 | `Find` | 127 | `Mute` |
| 128 | `Volume Up` | 129 | `Volume Down` | | | | |
完全列表可以在[HID 页表 1.12](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads/hut1_12v2.pdf)的 53 页,第 10 节找到。
### 5、车轮后的螺母
通常,当你使用其他人的代码,他们会提供一份自己代码的总结,描述代码都做了什么,粗略介绍了是如何工作的,以及什么情况下会出错。下面是一个使用我的 USB 驱动的相关步骤要求。
>
> 这些总结和代码的描述组成了一个 API - 应用程序产品接口。
>
>
>
表 5.1 CSUD 中和键盘相关的函数
| 函数 | 参数 | 返回值 | 描述 |
| --- | --- | --- | --- |
| `UsbInitialise` | 无 | `r0` 是结果码 | 这个方法是一个集多种功能于一身的方法,它加载 USB 驱动程序,枚举所有设备并尝试与它们通信。这种方法通常需要大约一秒钟的时间来执行,但是如果插入几个 USB 集线器,执行时间会明显更长。在此方法完成之后,键盘驱动程序中的方法就可用了,不管是否确实插入了键盘。返回代码如下解释。 |
| `UsbCheckForChange` | 无 | 无 | 本质上提供与 `UsbInitialise` 相同的效果,但不提供相同的一次初始化。该方法递归地检查每个连接的集线器上的每个端口,如果已经添加了新设备,则添加它们。如果没有更改,这应该是非常快的,但是如果连接了多个设备的集线器,则可能需要几秒钟的时间。 |
| `KeyboardCount` | 无 | `r0` 是计数 | 返回当前连接并检测到的键盘数量。`UsbCheckForChange` 可能会对此进行更新。默认情况下最多支持 4 个键盘。可以通过这个驱动程序访问多达这么多的键盘。 |
| `KeyboardGetAddress` | `r0` 是索引 | `r0` 是地址 | 检索给定键盘的地址。所有其他函数都需要一个键盘地址,以便知道要访问哪个键盘。因此,要与键盘通信,首先要检查计数,然后检索地址,然后使用其他方法。注意,在调用 `UsbCheckForChange` 之后,此方法返回的键盘顺序可能会改变。 |
| `KeyboardPoll` | `r0` 是地址 | `r0` 是结果码 | 从键盘读取当前键状态。这是通过直接轮询设备来操作的,与最佳实践相反。这意味着,如果没有频繁地调用此方法,可能会错过一个按键。所有读取方法只返回上次轮询时的值。 |
| `KeyboardGetModifiers` | `r0` 是地址 | `r0` 是修饰键状态 | 检索上次轮询时修饰键的状态。这是两边的 `shift` 键、`alt` 键和 `GUI` 键。这回作为一个位字段返回,这样,位 0 中的 1 表示左控件被保留,位 1 表示左 `shift`,位 2 表示左 `alt` ,位 3 表示左 `GUI`,位 4 到 7 表示前面几个键的右版本。如果有问题,`r0` 包含 0。 |
| `KeyboardGetKeyDownCount` | `r0` 是地址 | `r0` 是计数 | 检索当前按下键盘的键数。这排除了修饰键。这通常不能超过 6。如果有错误,这个方法返回 0。 |
| `KeyboardGetKeyDown` | `r0` 是地址,`r1` 键号 | `r0` 是扫描码 | 检索特定按下键的扫描码(见表 4.1)。通常,要计算出哪些键是按下的,可以调用 `KeyboardGetKeyDownCount`,然后多次调用 `KeyboardGetKeyDown` ,将 `r1` 的值递增,以确定哪些键是按下的。如果有问题,返回 0。可以(但不建议这样做)在不调用 `KeyboardGetKeyDownCount` 的情况下调用此方法将 0 解释为没有按下的键。注意,顺序或扫描代码可以随机更改(有些键盘按数字排序,有些键盘按时间排序,没有任何保证)。 |
| `KeyboardGetKeyIsDown` | `r0` 是地址,`r1` 扫描码 | `r0` 是状态 | 除了 `KeyboardGetKeyDown` 之外,还可以检查按下的键中是否有特定的扫描码。如果没有,返回 0;如果有,返回一个非零值。当检测特定的扫描码(例如寻找 `ctrl+c`)时更快。出错时,返回 0。 |
| `KeyboardGetLedSupport` | `r0` 是地址 | `r0` 是 LED | 检查特定键盘支持哪些 LED。第 0 位代表数字锁定,第 1 位代表大写锁定,第 2 位代表滚动锁定,第 3 位代表合成,第 4 位代表假名,第 5 位代表电源,第 6 位代表 Shift ,第 7 位代表静音。根据 USB 标准,这些 LED 都不是自动更新的(例如,当检测到大写锁定扫描代码时,必须手动设置大写锁定 LED)。 |
| `KeyboardSetLeds` | `r0` 是地址, `r1` 是 LED | `r0` 是结果码 | 试图打开/关闭键盘上指定的 LED 灯。查看下面的结果代码值。参见 `KeyboardGetLedSupport` 获取 LED 的值。 |
有几种方法返回“返回值”。这些都是 C 代码的老生常谈了,就是用数字代表函数调用发生了什么。通常情况, 0 总是代表操作成功。下面的是驱动用到的返回值。
>
> 返回值是一种处理错误的简单方法,但是通常更优雅的解决途径会出现于更高层次的代码。
>
>
>
表 5.2 - CSUD 返回值
| 代码 | 描述 |
| --- | --- |
| 0 | 方法成功完成。 |
| -2 | 参数:函数调用了无效参数。 |
| -4 | 设备:设备没有正确响应请求。 |
| -5 | 不匹配:驱动不适用于这个请求或者设备。 |
| -6 | 编译器:驱动没有正确编译,或者被破坏了。 |
| -7 | 内存:驱动用尽了内存。 |
| -8 | 超时:设备没有在预期的时间内响应请求。 |
| -9 | 断开连接:被请求的设备断开连接,或者不能使用。 |
驱动的通常用法如下:
1. 调用 `UsbInitialise`
2. 调用 `UsbCheckForChange`
3. 调用 `KeyboardCount`
4. 如果返回 0,重复步骤 2。
5. 针对你支持的每个键盘:
1. 调用 `KeyboardGetAddress`
2. 调用 `KeybordGetKeyDownCount`
3. 针对每个按下的按键:
1. 检查它是否已经被按下了
2. 保存按下的按键
4. 针对每个保存的按键:
1. 检查按键是否被释放了
2. 如果释放了就删除
6. 根据按下/释放的案件执行操作
7. 重复步骤 2
最后,你可以对键盘做所有你想做的任何事了,而这些方法应该允许你访问键盘的全部功能。在接下来的两节课,我们将会着眼于完成文本终端的输入部分,类似于大部分的命令行电脑,以及命令的解释。为了做这些,我们将需要在更有用的形式下得到一个键盘输入。你可能注意到我的驱动是(故意的)没有太大帮助,因为它并没有方法来判断是否一个按键刚刚按下或释放了,它只有方法来判断当前那个按键是按下的。这就意味着我们需要自己编写这些方法。
### 6、可用更新
首先,让我们实现一个 `KeyboardUpdate` 方法,检查第一个键盘,并使用轮询方法来获取当前的输入,以及保存最后一个输入来对比。然后我们可以使用这个数据和其它方法来将扫描码转换成按键。这个方法应该按照下面的说明准确操作:
>
> 重复检查更新被称为“轮询”。这是针对驱动 IO 中断而言的,这种情况下设备在准备好后会发一个信号。
>
>
>
1. 提取一个保存好的键盘地址(初始值为 0)。
2. 如果不是 0 ,进入步骤 9.
3. 调用 `UsbCheckForChange` 检测新键盘。
4. 调用 `KeyboardCount` 检测有几个键盘在线。
5. 如果返回 0,意味着没有键盘可以让我们操作,只能退出了。
6. 调用 `KeyboardGetAddress` 参数是 0,获取第一个键盘的地址。
7. 保存这个地址。
8. 如果这个值是 0,那么退出,这里应该有些问题。
9. 调用 `KeyboardGetKeyDown` 6 次,获取每次按键按下的值并保存。
10. 调用 `KeyboardPoll`
11. 如果返回值非 0,进入步骤 3。这里应该有些问题(比如键盘断开连接)。
要保存上面提到的值,我们将需要下面 `.data` 段的值。
```
.section .data
.align 2
KeyboardAddress:
.int 0
KeyboardOldDown:
.rept 6
.hword 0
.endr
```
```
.hword num 直接将半字的常数插入文件。
```
```
.rept num [commands] .endr 复制 `commands` 命令到输出 num 次。
```
试着自己实现这个方法。对此,我的实现如下:
1、我们加载键盘的地址。
```
.section .text
.globl KeyboardUpdate
KeyboardUpdate:
push {r4,r5,lr}
kbd .req r4
ldr r0,=KeyboardAddress
ldr kbd,[r0]
```
2、如果地址非 0,就说明我们有一个键盘。调用 `UsbCheckForChanges` 慢,所以如果一切正常,我们要避免调用这个函数。
```
teq kbd,#0
bne haveKeyboard$
```
3、如果我们一个键盘都没有,我们就必须检查新设备。
```
getKeyboard$:
bl UsbCheckForChange
```
4、如果有新键盘添加,我们就会看到这个。
```
bl KeyboardCount
```
5、如果没有键盘,我们就没有键盘地址。
```
teq r0,#0
ldreq r1,=KeyboardAddress
streq r0,[r1]
beq return$
```
6、让我们获取第一个键盘的地址。你可能想要支持更多键盘。
```
mov r0,#0
bl KeyboardGetAddress
```
7、保存键盘地址。
```
ldr r1,=KeyboardAddress
str r0,[r1]
```
8、如果我们没有键盘地址,这里就没有其它活要做了。
```
teq r0,#0
beq return$
mov kbd,r0
```
9、循环查询全部按键,在 `KeyboardOldDown` 保存下来。如果我们询问的太多了,返回 0 也是正确的。
```
saveKeys$:
mov r0,kbd
mov r1,r5
bl KeyboardGetKeyDown
ldr r1,=KeyboardOldDown
add r1,r5,lsl #1
strh r0,[r1]
add r5,#1
cmp r5,#6
blt saveKeys$
```
10、现在我们得到了新的按键。
```
mov r0,kbd
bl KeyboardPoll
```
11、最后我们要检查 `KeyboardOldDown` 是否工作了。如果没工作,那么我们可能是断开连接了。
```
teq r0,#0
bne getKeyboard$
return$:
pop {r4,r5,pc}
.unreq kbd
```
有了我们新的 `KeyboardUpdate` 方法,检查输入变得简单,固定周期调用这个方法就行,而它甚至可以检查键盘是否断开连接,等等。这是一个有用的方法,因为我们实际的按键处理会根据条件不同而有所差别,所以能够用一个函数调以它的原始方式获取当前的输入是可行的。下一个方法我们希望它是 `KeyboardGetChar`,简单的返回下一个按下的按钮的 ASCII 字符,或者如果没有按键按下就返回 0。这可以扩展到支持如果它按下一个特定时间当做多次按下按键,也支持锁定键和修饰键。
如果我们有一个 `KeyWasDown` 方法可以使这个方法有用起来,如果给定的扫描代码不在 `KeyboardOldDown` 值中,它只返回 0,否则返回一个非零值。你可以自己尝试一下。与往常一样,可以在下载页面找到解决方案。
### 7、查找表
`KeyboardGetChar` 方法如果写得不好,可能会非常复杂。有 100 多种扫描码,每种代码都有不同的效果,这取决于 shift 键或其他修饰符的存在与否。并不是所有的键都可以转换成一个字符。对于一些字符,多个键可以生成相同的字符。在有如此多可能性的情况下,一个有用的技巧是查找表。查找表与物理意义上的查找表非常相似,它是一个值及其结果的表。对于一些有限的函数,推导出答案的最简单方法就是预先计算每个答案,然后通过检索返回正确的答案。在这种情况下,我们可以在内存中建立一个序列的值,序列中第 n 个值就是扫描代码 n 的 ASCII 字符代码。这意味着如果一个键被按下,我们的方法只需要检测到,然后从表中检索它的值。此外,我们可以为当按住 shift 键时的值单独创建一个表,这样按下 shift 键就可以简单地换个我们用的表。
>
> 在编程的许多领域,程序越大,速度越快。查找表很大,但是速度很快。有些问题可以通过查找表和普通函数的组合来解决。
>
>
>
在 `.section .data` 命令之后,复制下面的表:
```
.align 3
KeysNormal:
.byte 0x0, 0x0, 0x0, 0x0, 'a', 'b', 'c', 'd'
.byte 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l'
.byte 'm', 'n', 'o', 'p', 'q', 'r', 's', 't'
.byte 'u', 'v', 'w', 'x', 'y', 'z', '1', '2'
.byte '3', '4', '5', '6', '7', '8', '9', '0'
.byte '\n', 0x0, '\b', '\t', ' ', '-', '=', '['
.byte ']', '\\\', '#', ';', '\'', '`', ',', '.'
.byte '/', 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
.byte 0x0, 0x0, 0x0, 0x0, '/', '*', '-', '+'
.byte '\n', '1', '2', '3', '4', '5', '6', '7'
.byte '8', '9', '0', '.', '\\\', 0x0, 0x0, '='
.align 3
KeysShift:
.byte 0x0, 0x0, 0x0, 0x0, 'A', 'B', 'C', 'D'
.byte 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L'
.byte 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T'
.byte 'U', 'V', 'W', 'X', 'Y', 'Z', '!', '"'
.byte '£', '$', '%', '^', '&', '*', '(', ')'
.byte '\n', 0x0, '\b', '\t', ' ', '_', '+', '{'
.byte '}', '|', '~', ':', '@', '¬', '<', '>'
.byte '?', 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
.byte 0x0, 0x0, 0x0, 0x0, '/', '*', '-', '+'
.byte '\n', '1', '2', '3', '4', '5', '6', '7'
.byte '8', '9', '0', '.', '|', 0x0, 0x0, '='
```
这些表直接将前 104 个扫描码映射到 ASCII 字符作为一个字节表。我们还有一个单独的表来描述 `shift` 键对这些扫描码的影响。我使用 ASCII `null` 字符(`0`)表示所有没有直接映射的 ASCII 键(例如功能键)。退格映射到 ASCII 退格字符(8 表示 `\b`),`enter` 映射到 ASCII 新行字符(10 表示 `\n`), `tab` 映射到 ASCII 水平制表符(9 表示 `\t`)。
>
> `.byte num` 直接插入字节常量 num 到文件。
>
>
>
.
>
> 大部分的汇编器和编译器识别转义序列;如 `\t` 这样的字符序列会插入该特殊字符。
>
>
>
`KeyboardGetChar` 方法需要做以下工作:
1. 检查 `KeyboardAddress` 是否返回 `0`。如果是,则返回 0。
2. 调用 `KeyboardGetKeyDown` 最多 6 次。每次:
1. 如果按键是 0,跳出循环。
2. 调用 `KeyWasDown`。 如果返回是,处理下一个按键。
3. 如果扫描码超过 103,进入下一个按键。
4. 调用 `KeyboardGetModifiers`
5. 如果 `shift` 是被按着的,就加载 `KeysShift` 的地址,否则加载 `KeysNormal` 的地址。
6. 从表中读出 ASCII 码值。
7. 如果是 0,进行下一个按键,否则返回 ASCII 码值并退出。
3. 返回 0。
试着自己实现。我的实现展示在下面:
1、简单的检查我们是否有键盘。
```
.globl KeyboardGetChar
KeyboardGetChar:
ldr r0,=KeyboardAddress
ldr r1,[r0]
teq r1,#0
moveq r0,#0
moveq pc,lr
```
2、`r5` 将会保存按键的索引,`r4` 保存键盘的地址。
```
push {r4,r5,r6,lr}
kbd .req r4
key .req r6
mov r4,r1
mov r5,#0
keyLoop$:
mov r0,kbd
mov r1,r5
bl KeyboardGetKeyDown
```
2.1、 如果扫描码是 0,它要么意味着有错,要么说明没有更多按键了。
```
teq r0,#0
beq keyLoopBreak$
```
2.2、如果按键已经按下了,那么他就没意义了,我们只想知道按下的按键。
```
mov key,r0
bl KeyWasDown
teq r0,#0
bne keyLoopContinue$
```
2.3、如果一个按键有个超过 104 的扫描码,它将会超出我们的表,所以它是无关的按键。
```
cmp key,#104
bge keyLoopContinue$
```
2.4、我们需要知道修饰键来推断字符。
```
mov r0,kbd
bl KeyboardGetModifiers
```
2.5、当将字符更改为其 shift 变体时,我们要同时检测左 `shift` 键和右 `shift` 键。记住,`tst` 指令计算的是逻辑和,然后将其与 0 进行比较,所以当且仅当移位位都为 0 时,它才等于 0。
```
tst r0,#0b00100010
ldreq r0,=KeysNormal
ldrne r0,=KeysShift
```
2.6、现在我们可以从查找表加载按键了。
```
ldrb r0,[r0,key]
```
2.7、如果查找码包含一个 0,我们必须继续。为了继续,我们要增加索引,并检查是否到 6 次了。
```
teq r0,#0
bne keyboardGetCharReturn$
keyLoopContinue$:
add r5,#1
cmp r5,#6
blt keyLoop$
```
3、在这里我们返回我们的按键,如果我们到达 `keyLoopBreak$` ,然后我们就知道这里没有按键被握住,所以返回 0。
```
keyLoopBreak$:
mov r0,#0
keyboardGetCharReturn$:
pop {r4,r5,r6,pc}
.unreq kbd
.unreq key
```
### 8、记事本操作系统
现在我们有了 `KeyboardGetChar` 方法,可以创建一个操作系统,只打印出用户对着屏幕所写的内容。为了简单起见,我们将忽略所有非常规的键。在 `main.s`,删除 `bl SetGraphicsAddress` 之后的所有代码。调用 `UsbInitialise`,将 `r4` 和 `r5` 设置为 0,然后循环执行以下命令:
1. 调用 `KeyboardUpdate`
2. 调用 `KeyboardGetChar`
3. 如果返回 0,跳转到步骤 1
4. 复制 `r4` 和 `r5` 到 `r1` 和 `r2` ,然后调用 `DrawCharacter`
5. 把 `r0` 加到 `r4`
6. 如果 `r4` 是 1024,将 `r1` 加到 `r5`,然后设置 `r4` 为 0。
7. 如果 `r5` 是 768,设置 `r5` 为0
8. 跳转到步骤 1
现在编译,然后在树莓派上测试。你几乎可以立即开始在屏幕上输入文本。如果没有工作,请参阅我们的故障排除页面。
当它工作时,祝贺你,你已经实现了与计算机的接口。现在你应该开始意识到,你几乎已经拥有了一个原始的操作系统。现在,你可以与计算机交互、发出命令,并在屏幕上接收反馈。在下一篇教程[输入02](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input02.html)中,我们将研究如何生成一个全文本终端,用户在其中输入命令,然后计算机执行这些命令。
---
via: <https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html>
作者:[Alex Chadwick](https://www.cl.cam.ac.uk) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ezio](https://github.com/oska874) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Raspberry Pi
# Lesson 10 Input01
Welcome to the Input lesson series. In this series, you will learn how to receive inputs to the Raspberry Pi using the keyboard. We will start with just revealing the input, and then move to a more traditional text prompt.
This first input lesson teaches some theory about drivers and linking, as well as about keyboards and ends up displaying text on the screen.
Contents |
## 1 Getting Started
It is expected that you have completed the OK series, and it would be helpful to
have completed the Screen series. Many of the files from that series will be called,
without comment. If you do not have these files, or prefer to use a correct implementation,
download the template for this lesson from the [Downloads](downloads.html)
page. If you're using your own implementation, please remove everything after your
call to SetGraphicsAddress.
## 2 USB
The USB standard was designed to make simple hardware in exchange for complex software.
As you are no doubt aware, the Raspberry Pi model B has two USB ports, commonly used for connecting a mouse and keyboard. This was a very good design decision, USB is a very generic connector, and many different kinds of device use it. It's simple to build new devices for, simple to write device drivers for, and is highly extensible thanks to USB hubs. Could it get any better? Well, no, in fact for an Operating Systems developer this is our worst nightmare. The USB standard is huge. I really mean it this time, it is over 700 pages, before you've even thought about connecting a device.
I spoke to a number of other hobbyist Operating Systems developers about this and they all say one thing: don't bother. "It will take too long to implement", "You won't be able to write a tutorial on it" and "It will be of little benefit". In many ways they are right, I'm not able to write a tutorial on the USB standard, as it would take weeks. I also can't teach how to write device drivers for all the different devices, so it is useless on its own. However, I can do the next best thing: Get a working USB driver, get a keyboard driver, and then teach how to use these in an Operating System. I set out searching for a free driver that would run in an operating system that doesn't even know what a file is yet, but I couldn't find one. They were all too high level. So, I attempted to write one. Everybody was right, this took weeks to do. However, I'm pleased to say I did get one that works with no external help from the Operating System, and can talk to a mouse and keyboard. It is by no means complete, efficient, or correct, but it does work. It has been written in C and the full source code can be found on the downloads page for those interested.
So, this tutorial won't be a lesson on the USB standard (at all). Instead we'll look at how to work with other people's code.
## 3 Linking
Linking allows us to make reusable code 'libraries' that anyone can use in their program.
Since we're about to incorporate external code into the Operating System, we need to talk about linking. Linking is a process which is applied to programs or Operating System to link in functions. What this means is that when a program is made, we don't necessarily code every function (almost certainly not in fact). Linking is what we do to make our program link to functions in other people's code. This has actually been going on all along in our Operating Systems, as the linker links together all of the different files, each of which is compiled separately.
Programs often just call libraries, which call other libraries and so on until eventually they call an Operating System library which we would write.
There are two types of linking: static and dynamic. Static linking is like what goes on when we make our Operating Systems. The linker finds all the addresses of the functions, and writes them into the code, before the program is finished. Dynamic linking is linking that occurs after the program is 'complete'. When it is loaded, the dynamic linker goes through the program and links any functions which are not in the program to libraries in the Operating System. This is one of the jobs our Operating System should eventually be capable of, but for now everything will be statically linked.
The USB driver I have written is suitable for static linking. This means I give
you the compiled code for each of my files, and then the linker finds functions
in your code which are not defined in your code, and links them to functions in
my code. On the [Downloads](downloads.html) page for this lesson is a
makefile and my USB driver, which you will need to continue. Download them and replace
the makefile in your code with this one, and also put the driver in the same folder
as that makefile.
## 4 Keyboards
In order to get input into our Operating System, we need to understand at some level how keyboards actually work. Keyboards have two types of keys: Normal and Modifier keys. The normal keys are the letters, numbers, function keys, etc. They constitute almost every key on the keyboard. The modifiers are up to 8 special keys. These are left shift, right shift, left control, right control, left alt, right alt, left GUI and right GUI. The keyboard can detect any combination of the modifier keys being held, as well as up to 6 normal keys. Every time a key changes (i.e. is pushed or released), it reports this to the computer. Typically, keyboards also have three LEDs for Caps Lock, Num Lock and Scroll Lock, which are controlled by the computer, not the keyboard itself. Keyboards may have many more lights such as power, mute, etc.
In order to help standardise USB keyboards, a table of values was produced, such that every keyboard key ever is given a unique number, as well as every conceivable LED. The table below lists the first 126 of values.
Number | Description | Number | Description | Number | Description | Number | Description |
---|---|---|---|---|---|---|---|
4 | a and A | 5 | b and B | 6 | c and C | 7 | d and D |
8 | e and E | 9 | f and F | 10 | g and G | 11 | h and H |
12 | i and I | 13 | j and J | 14 | k and K | 15 | l and L |
16 | m and M | 17 | n and N | 18 | o and O | 19 | p and P |
20 | q and Q | 21 | r and R | 22 | s and S | 23 | t and T |
24 | u and U | 25 | v and V | 26 | w and W | 27 | x and X |
28 | y and Y | 29 | z and Z | 30 | 1 and ! | 31 | 2 and @ |
32 | 3 and # | 33 | 4 and $ | 34 | 5 and % | 35 | 6 and ^ |
36 | 7 and & | 37 | 8 and * | 38 | 9 and ( | 39 | 0 and ) |
40 | Return (Enter) | 41 | Escape | 42 | Delete (Backspace) | 43 | Tab |
44 | Spacebar | 45 | - and _ | 46 | = and + | 47 | [ and { |
48 | ] and } | 49 | \ and | | 50 | # and ~ | 51 | ; and : |
52 | ' and " | 53 | ` and ~ | 54 | , and < | 55 | . and > |
56 | / and ? | 57 | Caps Lock | 58 | F1 | 59 | F2 |
60 | F3 | 61 | F4 | 62 | F5 | 63 | F6 |
64 | F7 | 65 | F8 | 66 | F9 | 67 | F10 |
68 | F11 | 69 | F12 | 70 | Print Screen | 71 | Scroll Lock |
72 | Pause | 73 | Insert | 74 | Home | 75 | Page Up |
76 | Delete forward | 77 | End | 78 | Page Down | 79 | Right Arrow |
80 | Left Arrow | 81 | Down Arrow | 82 | Up Arrow | 83 | Num Lock |
84 | Keypad / | 85 | Keypad * | 86 | Keypad - | 87 | Keypad + |
88 | Keypad Enter | 89 | Keypad 1 and End | 90 | Keypad 2 and Down Arrow | 91 | Keypad 3 and Page Down |
92 | Keypad 4 and Left Arrow | 93 | Keypad 5 | 94 | Keypad 6 and Right Arrow | 95 | Keypad 7 and Home |
96 | Keypad 8 and Up Arrow | 97 | Keypad 9 and Page Up | 98 | Keypad 0 and Insert | 99 | Keypad . and Delete |
100 | \ and | | 101 | Application | 102 | Power | 103 | Keypad = |
104 | F13 | 105 | F14 | 106 | F15 | 107 | F16 |
108 | F17 | 109 | F18 | 110 | F19 | 111 | F20 |
112 | F21 | 113 | F22 | 114 | F23 | 115 | F24 |
116 | Execute | 117 | Help | 118 | Menu | 119 | Select |
120 | Stop | 121 | Again | 122 | Undo | 123 | Cut |
124 | Copy | 125 | Paste | 126 | Find | 127 | Mute |
128 | Volume Up | 129 | Volume Down |
The full list can be found in section 10, page 53 of [
HID Usage Tables 1.12](downloads/hut1_12v2.pdf).
## 5 The Nut Behind the Wheel
These summaries and the code they describe form an API - Application Product Interface.
Normally, when you work with someone else's code, they provide a summary of their methods, what they do and roughly how they work, as well as how they can go wrong. Here is a table of the relevant instructions required to use my USB driver.
Function | Arguments | Returns | Description |
---|---|---|---|
UsbInitialise | None | r0 is result code | This method is the all-in-one method that loads the USB driver, enumerates all devices and attempts to communicate with them. This method generally takes about a second to execute, though with a few USB hubs plugged in this can be significantly longer. After this method is completed methods in the keyboard driver become available, regardless of whether or not a keyboard is indeed inserted. Result code explained below. |
UsbCheckForChange | None | None | Essentially provides the same effect as UsbInitialise, but does not provide the same one time initialisation. This method checks every port on every connected hub recursively, and adds new devices if they have been added. This should be very quick if there are no changes, but can take up to a few seconds if a hub with many devices is attached. |
KeyboardCount | None | r0 is count | Returns the number of keyboards currently connected and detected. UsbCheckForChange may update this. Up to 4 keyboards are supported by default. Up to this many keyboards may be accessed through this driver. |
KeyboardGetAddress | r0 is index | r0 is address | Retrieves the address of a given keyboard. All other functions take a keyboard address in order to know which keyboard to access. Thus, to communicate with a keyboard, first check the count, then retrieve the address, then use other methods. Note, the order of keyboards that this method returns may change after calls to UsbCheckForChange. |
KeyboardPoll | r0 is address | r0 is result code | Reads in the current key state from the keyboard. This operates via polling the device directly, contrary to the best practice. This means that if this method is not called frequently enough, a key press could be missed. All reading methods simply return the value as of the last poll. |
KeyboardGetModifiers | r0 is address | r0 is modifier state | Retrieves the status of the modifier keys as of the last poll. These are the shift, alt control and GUI keys on both sides. This is returned as a bit field, such that a 1 in the bit 0 means left control is held, bit 1 means left shift, bit 2 means left alt, bit 3 means left GUI and bits 4 to 7 mean the right versions of those previous. If there is a problem r0 contains 0. |
KeyboardGetKeyDownCount | r0 is address | r0 is count | Retrieves the number of keys currently held down on the keyboard. This excludes modifier keys. Normally, this cannot go above 6. If there is an error this method returns 0. |
KeyboardGetKeyDown | r0 is address, r1 is key number | r0 is scan code | Retrieves the scan code (see Table 4.1) of a particular held down key. Normally, to work out which keys are down, call KeyboardGetKeyDownCount and then call KeyboardGetKeyDown up to that many times with increasing values of r1 to determine which keys are down. Returns 0 if there is a problem. It is safe (but not recommended) to call this method without calling KeyboardGetKeyDownCount and interpret 0s as keys not held. Note, the order or scan codes can change randomly (some keyboards sort numerically, some sort temporally, no guarantees are made). |
KeyboardGetKeyIsDown | r0 is address, r1 is scan code | r0 is status | Alternative to KeyboardGetKeyDown, checks if a particular scan code is among the held down keys. Returns 0 if not, or a non-zero value if so. Faster when detecting particular scan codes (e.g. looking for ctrl+c). On error, returns 0. |
KeyboardGetLedSupport | r0 is address | r0 is LEDs | Checks which LEDs a particular keyboard supports. Bit 0 being 1 represents Number Lock, bit 1 represents Caps Lock, bit 2 represents Scroll Lock, bit 3 represents Compose, bit 4 represents Kana, bit 5 represents Power, bit 6 represents Mute and bit 7 represents Compose. As per the USB standard, none of these LEDs update automatically (e.g. Caps Lock must be set manually when the Caps Lock scan code is detected). |
KeyboardSetLeds | r0 is address, r1 is LEDs | r0 is result code | Attempts to turn on/off the specified LEDs on the keyboard. See below for result code values. See KeyboardGetLedSupport for LEDs' values. |
Result codes are an easy way to handle errors, but often more elegant solutions exist in higher level code.
Several methods return 'result codes'. These are commonplace in C code, and are just numbers which represent what happened in a method call. By convention, 0 always indicates success. The following result codes are used by this driver.
Code | Description |
---|---|
0 | Method completed successfully. |
-2 | Argument: A method was called with an invalid argument. |
-4 | Device: The device did not respond correctly to the request. |
-5 | Incompatible: The driver is not compatible with this request or device. |
-6 | Compiler: The driver was compiled incorrectly, and is broken. |
-7 | Memory: The driver ran out of memory. |
-8 | Timeout: The device did not respond in the expected time. |
-9 | Disconnect: The device requested has disconnected, and cannot be used. |
The general usage of the driver is as follows:
- Call UsbInitialise
- Call UsbCheckForChange
- Call KeyboardCount
- If this is 0, go to 2.
- For each keyboard you support:
- Call KeyboardGetAddress
- Call KeybordGetKeyDownCount
- For each key down:
- Check whether or not it has just been pushed
- Store that the key is down
- For each key stored:
- Check whether or not key is released
- Remove key if released
- Perform actions based on keys pushed/released
- Go to 2.
Ultimately, you may do whatever you wish to with the keyboard, and these methods should allow you to access all of its functionality. Over the next 2 lessons, we shall look at completing the input side of a text terminal, similarly to most command line computers, and interpreting the commands. In order to do this, we're going to need to have keyboard inputs in a more useful form. You may notice that my driver is (deliberately) unhelpful, because it doesn't have methods to deduce whether or not a key has just been pushed down or released, it only has methods about what is currently held down. This means we'll need to write such methods ourselves.
## 6 Updates Available
Repeatedly checking for updates is called 'polling'. This is in contrast to interrupt driven IO, where the device sends a signal when data is ready.
First of all, let's implement a method KeyboardUpdate which detects the first keyboard and uses its poll method to get the current input, as well as saving the last inputs for comparison. We can then use this data with other methods to translate scan codes to keys. The method should do precisely the following:
- Retrieve a stored keyboard address (initially 0).
- If this is not 0, go to 9.
- Call UsbCheckForChange to detect new keyboards.
- Call KeyboardCount to detect how many keyboards are present.
- If this is 0 store the address as 0 and return; we can't do anything with no keyboard.
- Call KeyboardGetAddress with parameter 0 to get the first keyboard's address.
- Store this address.
- If this is 0, return; there is some problem.
- Call KeyboardGetKeyDown 6 times to get each key currently down and store them
- Call KeyboardPoll
- If the result is non-zero go to 3. There is some problem (such as disconnected keyboard).
To store the values mentioned above, we will need the following values in the .data section.
.section .data
.align 2
KeyboardAddress:
.int 0
KeyboardOldDown:
.rept 6
.hword 0
.endr
.hword num inserts the half word constant num into the file directly.
.rept num [commands] .endr copies the commands commands to the output num times.
Try to implement the method yourself. My implementation for this is as follows:
-
.section .text
.globl KeyboardUpdate
KeyboardUpdate:
push {r4,r5,lr}
kbd .req r4
ldr r0,=KeyboardAddress
ldr kbd,[r0]
-
teq kbd,#0
bne haveKeyboard$
-
getKeyboard$:
bl UsbCheckForChange
-
bl KeyboardCount
-
teq r0,#0
ldreq r1,=KeyboardAddress
streq r0,[r1]
beq return$
-
mov r0,#0
bl KeyboardGetAddress
-
ldr r1,=KeyboardAddress
str r0,[r1]
-
teq r0,#0
beq return$
mov kbd,r0
-
saveKeys$:
mov r0,kbd
mov r1,r5
bl KeyboardGetKeyDown
ldr r1,=KeyboardOldDown
add r1,r5,lsl #1
strh r0,[r1]
add r5,#1
cmp r5,#6
blt saveKeys$
-
mov r0,kbd
bl KeyboardPoll
-
teq r0,#0
bne getKeyboard$
return$:
pop {r4,r5,pc}
.unreq kbd
With our new KeyboardUpdate method, checking for inputs becomes as simple as calling this method at regular intervals, and it will even check for disconnections etc. This is a useful method to have, as our actual key processing may differ based on the situation, and so being able to get the current input in its raw form with one method call is generally applicable. The next method we ideally want is KeyboardGetChar, a method that simply returns the next key pressed as an ASCII character, or returns 0 if no key has just been pressed. This could be extended to support typing a key multiple times if it is held for a certain duration, and to support the 'lock' keys as well as modifiers.
To make this method it is useful if we have a method KeyWasDown, which simply returns 0 if a given scan code is not in the KeyboardOldDown values, and returns a non-zero value otherwise. Have a go at implementing this yourself. As always, a solution can be found on the downloads page.
## 7 Look Up Tables
In many areas of programming, the larger the program, the faster it is. Look up tables are large, but are very fast. Some problems can be solved by a mixture of look up tables and normal functions.
The KeyboardGetChar method could be quite complex if we write it poorly. There are 100s of scan codes, each with different effects depending on the presence or absence of the shift key or other modifiers. Not all of the keys can be translated to a character. For some characters, multiple keys can produce the same character. A useful trick in situations with such vast arrays of possibilities is look up tables. A look up table, much like in the physical sense, is a table of values and their results. For some limited functions, the simplest way to deduce the answer is just to precompute every answer, and just return the correct one by retrieving it. In this case, we could build up a sequence of values in memory such that the nth value into the sequence is the ASCII character code for the scan code n. This means our method would simply have to detect if a key was pressed, and then retrieve its value from the table. Further, we could have a separate table for the values when shift is held, so that the shift key simply changes which table we're working with.
After the .section .data command, copy the following tables:
.align 3
KeysNormal:
.byte 0x0, 0x0, 0x0, 0x0, 'a', 'b', 'c', 'd'
.byte 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l'
.byte 'm', 'n', 'o', 'p', 'q', 'r', 's', 't'
.byte 'u', 'v', 'w', 'x', 'y', 'z', '1', '2'
.byte '3', '4', '5', '6', '7', '8', '9', '0'
.byte '\n', 0x0, '\b', '\t', ' ', '-', '=', '['
.byte ']', '\\', '#', ';', '\'', '`', ',', '.'
.byte '/', 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
.byte 0x0, 0x0, 0x0, 0x0, '/', '*', '-', '+'
.byte '\n', '1', '2', '3', '4', '5', '6', '7'
.byte '8', '9', '0', '.', '\\', 0x0, 0x0, '='
.align 3
KeysShift:
.byte 0x0, 0x0, 0x0, 0x0, 'A', 'B', 'C', 'D'
.byte 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L'
.byte 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T'
.byte 'U', 'V', 'W', 'X', 'Y', 'Z', '!', '"'
.byte '£', '$', '%', '^', '&', '*', '(', ')'
.byte '\n', 0x0, '\b', '\t', ' ', '_', '+', '{'
.byte '}', '|', '~', ':', '@', '¬', '<', '>'
.byte '?', 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
.byte 0x0, 0x0, 0x0, 0x0, '/', '*', '-', '+'
.byte '\n', '1', '2', '3', '4', '5', '6', '7'
.byte '8', '9', '0', '.', '|', 0x0, 0x0, '='
.byte num inserts the byte constant num into the file directly.
Most assemblers and compilers recognise escape sequences; character sequences such as \t which insert special characters instead.
These tables map directly the first 104 scan codes onto the ASCII characters as a table of bytes. We also have a separate table describing the effects of the shift key on those scan codes. I've used the ASCII null character (0) for all keys without direct mappings in ASCII (such as the function keys). Backspace is mapped to the ASCII backspace character (8 denoted \b), enter is mapped to the ASCII new line character (10 denoted \n) and tab is mapped to the ASCII horizontal tab character (9 denoted \t).
The KeyboardGetChar method will need to do the following:
- Check if KeyboardAddress is 0. If so, return 0.
- Call KeyboardGetKeyDown up to 6 times. Each time:
- If key is 0, exit loop.
- Call KeyWasDown. If it was, go to the next key.
- If the scan code is more than 103, go to the next key.
- Call KeyboardGetModifiers
- If shift is held, load the address of KeysShift. Otherwise load KeysNormal.
- Read the ASCII value from the table.
- If it is 0, go to the next key otherwise return this ASCII code and exit.
- Return 0.
Try to implement this yourself. My implementation is presented below:
-
.globl KeyboardGetChar
KeyboardGetChar:
ldr r0,=KeyboardAddress
ldr r1,[r0]
teq r1,#0
moveq r0,#0
moveq pc,lr
Simple check to see if we have a keyboard.
-
push {r4,r5,r6,lr}
kbd .req r4
key .req r6
mov r4,r1
mov r5,#0
keyLoop$:mov r0,kbd
mov r1,r5
bl KeyboardGetKeyDownr5 will hold the index of the key, r4 holds the keyboard address.
-
teq r0,#0
beq keyLoopBreak$
If a scan code is 0, it either means there is an error, or there are no more keys.
-
mov key,r0
bl KeyWasDown
teq r0,#0
bne keyLoopContinue$
If a key was already down it is uninteresting, we only want ot know about key presses.
-
cmp key,#104
bge keyLoopContinue$
If a key has a scan code higher than 104, it will be outside our table, and so is not relevant.
-
mov r0,kbd
bl KeyboardGetModifiers
We need to know about the modifier keys in order to deduce the character.
-
tst r0,#0b00100010
ldreq r0,=KeysNormal
ldrne r0,=KeysShift
We detect both a left and right shift key as changing the characters to their shift variants. Remember, a tst instruction computes the logical AND and then compares it to zero, so it will be equal to 0 if and only if both of the shift bits are zero.
-
ldrb r0,[r0,key]
Now we can load in the key from the look up table.
-
teq r0,#0
bne keyboardGetCharReturn$
keyLoopContinue$:
add r5,#1
cmp r5,#6
blt keyLoop$
If the look up code contains a zero, we must continue. To continue, we increment the index, and check if we've reached 6.
-
-
keyLoopBreak$:
mov r0,#0
keyboardGetCharReturn$:
pop {r4,r5,r6,pc}
.unreq kbd
.unreq key
We return our key here, if we reach keyLoopBreak$, then we know there is no key held, so return 0.
## 8 Notepad OS
Now we have our KeyboardGetChar method, we can make an operating system that just types what the user writes to the screen. For simplicity we'll ignore all the unusual keys. In 'main.s' delete all code after bl SetGraphicsAddress. Call UsbInitialise, set r4 and r5 to 0, then loop forever over the following commands:
- Call KeyboardUpdate
- Call KeyboardGetChar
- If it is 0, got to 1
- Copy r4 and r5 to r1 and r2 then call DrawCharacter
- Add r0 to r4
- If r4 is 1024, add r1 to r5 and set r4 to 0
- If r5 is 768 set r5 to 0
- Go to 1
Now compile this and test it on the Pi. You should almost immediately be able to start typing text to the screen when the Pi starts. If not, please see our troubleshooting page.
When it works, congratulations, you've achieved an interface with the computer.
You should now begin to realise that you've almost got a primitive operating system
together. You can now interface with the computer, issuing it commands, and receive
feedback on screen. In the next tutorial, [Input02](input02.html) we
will look at producing a full text terminal, in which the user types commands, and
the computer executes them. |
10,677 | 我的去 Google 化的安卓之旅 | https://lushka.al/my-android-setup/ | 2019-04-02T13:34:56 | [
"安卓",
"Goole"
] | https://linux.cn/article-10677-1.html | 
>
> 一篇介绍如何在你的生活中和设备里去 Google 化的文章。
>
>
>
最近人们经常问我有关我手机的事情,比如安卓怎么安装,怎样绕过 Google Service 使用手机。好吧,这篇文章就来详细的解决那些问题。我尽可能让这篇文章适合初学者,因此我会慢慢介绍,一个一个来讲并且附上截图,你就能更好地看到它是怎样运作的。
首先我会告诉你为什么 Google Services(在我看来)对你的设备不好。我可以一言以概之,并让你看 [Richard Stallman](https://en.wikipedia.org/wiki/Richard_Stallman) 写的这篇[文章](https://stallman.org/google.html),但我决定抓住几个要点附在这。
* 要用<ruby> 非自由软件 <rt> Nonfree software </rt></ruby>
+ 大体上,大多数 Google Services 需要运行在非自由的 Javascript 代码之上。现如今,如果禁用掉 Javascript,什么都没有了,甚至 Google 帐号都需要运行非自由软件(由站点发送的 JavaScript),对于登录也是。
* 被监视
+ Google 悄悄地把它的<ruby> 广告跟踪方式 <rt> ad-tracking profiles </rt></ruby>与浏览方式结合在一起,并存储了每个用户的大量数据。
* 服务条款
+ Google 会终止转卖了 Pixel 手机的用户账户。他们无法访问帐户下保存在 Google Services 中的所有邮件和文档。
* 审查
+ Amazon 和 Google 切断了<ruby> 域前置 <rt> domain-fronting </rt></ruby>,该技术能使身处某些国家的人们访问到在那里禁止的通信系统。
+ Google 已经同意为巴基斯坦政府执行特殊的 Youtube 审查,删除对立观点。这将有助于压制异议。
+ Youtube 的“content ID”会自动删除已发布的视频,这并不包含在版权法中。
这只是几个原因,你可以阅读上面我提到的 RMS 的文章,他详细解释了这几点。尽管听起来骇人听闻,但这些行为在现实生活中已经每天在发生。
### 下一步,我的搭建教程
我有一款[小米红米 Note 5 Pro](https://www.gsmarena.com/xiaomi_redmi_note_5_pro-8893.php) 智能手机(代号 whyred),生产于中国的[小米](https://en.wikipedia.org/wiki/Xiaomi)。它是 4 个月之前(距写这篇文章的时候)我花了大约 185 欧元买的。
现在你也许会想,“但你为什么买中国品牌,他们不可靠”。是的,它不是通常你所期望的(品牌)所生产的,例如三星(人们通常会将它和安卓联系在一起,这显然是错的)、一加、诺基亚等。但你应当知道几乎所有的手机都生产于中国。
我选择这款手机有几个原因,首先当然是价格。它是一款<ruby> 性价比 <rt> budget-friendly </rt></ruby>相当高的产品,大多数人都能买得起。下一个原因是说明书上的规格(不仅仅是),在这个<ruby> 价位 <rt> price tag </rt></ruby>上相当合适。拥有 6 英尺屏幕(<ruby> 全高清分辨率 <rt> Full HD resolution </rt></ruby>),4000 毫安电池(一流的电池寿命),4GB RAM,64GB 存储,双后摄像头(12 MP + 5 MP),一个带闪光灯的前摄像头(13 MP)和一个高性能的<ruby> 骁龙 <rt> Snapdragon </rt></ruby> 636,它可能是那时候最好的选择。
随之而来的问题是 [MIUI](https://en.wikipedia.org/wiki/MIUI),大多数小米设备所附带的安卓外壳(除了 Android One 项目设备)。是的,它没有那么可怕,它有一些额外的功能,但问题在更深的地方。小米设备如此便宜(据我所知销售利润仅有 5-10%)的一个原因是**他们在系统里伴随 MIUI 添加了数据挖掘和广告**。这样的话,系统应用需要额外不必要的权限来获取你的数据并且进行广告轰炸,从中获取利润。
更有趣的是,所包含的“天气”应用想要访问我的联系人并且拨打电话,如果它仅是显示天气的话为什么需要访问联系人呢。另一个例子是“录音机”应用,它也需要联系人和网络权限,可能想把录音发送回小米。
为了解决它,我不得不格式化手机并且摆脱 MIUI。在市场上近来的手机上这就变得极为艰难。
格式化手机的想法很简单,删除掉现有的系统然后安装一个新的喜欢的系统(这次是原生安卓)。为了实现它,你先得解锁 [bootloader](https://forum.xda-developers.com/wiki/Bootloader)。
>
> bootloader 是一个在计算机完成自检后为其加载操作系统或者运行环境的计算机程序。—[维基百科](https://en.wikipedia.org/wiki/Booting)
>
>
>
问题是小米关于解锁 bootloader 有明确的政策。几个月之前,流程就像这样:你需向小米[申请](https://en.miui.com/unlock/)解锁代码,并提供真实的原因,但不是每次都成功,因为他们可以拒绝你的请求并且不提供理由。
现在,流程变了。你要从小米那下载一个软件,叫做 [Mi Unlock](http://www.miui.com/unlock/apply.php),在 Windows 电脑上安装它,在手机的[开发者模式中打开调试选项](https://www.youtube.com/watch?v=7zhEsJlivFA),重启到 bootloader 模式(关机状态下长按向下音量键 + 电源键)并将手机连接到电脑上,开始一个叫做“许可”的流程。这个过程会在小米的服务器上启动一个定时器,允许你**在 15 天之后解锁手机**(在一些少数情况下或者一个月,完全随机)。

15 天过去后,重新连接手机并重复之前的步骤,这时候按下解锁键,你的 bootloader 就会解锁,并且能够安装其他 ROM(系统)。**注意,确保你已经备份好了数据,因为解锁 bootloader 会清空手机。**
下一步就是找一个兼容的系统([ROM](https://www.xda-developers.com/what-is-custom-rom-android/))。我在 [XDA 开发者论坛上](https://forum.xda-developers.com/)找了个遍,它是 Android 开发者和用户们交流想法、应用等东西的地方。幸运的是,我的手机相当流行,因此论坛上有它[专门的版块](https://forum.xda-developers.com/redmi-note-5-pro)。在那儿,我略过一些流行的 ROM 并决定使用 [AOSiP ROM](https://forum.xda-developers.com/redmi-note-5-pro/development/rom-aosip-8-1-t3804473)。(AOSiP 代表<ruby> 安卓开源 illusion 项目 <rt> Android Open Source illusion Project </rt></ruby>)
>
> **校订**:有人发邮件告诉我说文章里写的就是[/e/](https://e.foundation)的目的与所做的事情。我想说谢谢你的帮助,但完全不是这样。我关于 /e/ 的看法背后的原因可以见此[网站](https://ewwlo.xyz/evil),但我仍会在此列出一些原因。
>
>
> eelo 是一个从 Kickstarter 和 IndieGoGo 上集资并超过 200K € 的“基金会”,承诺创造一个开放、安全且保护隐私的移动 OS 和网页服务器。
>
>
> 1. 他们的 OS 基于 LineageOS 14.1 (Android 7.1) 且搭载 microG 和其他开源应用,此系统已经存在很长一段时间了并且现在叫做 [Lineage for microG](https://lineage.microg.org/)。
> 2. 所有的应用程序并非从源代码构建,而是从 [APKPure](https://apkpure.com/) 上下载安装包并推送进 ROM,不知道那些安装包中是否包含<ruby> 专有代码 <rt> proprietary code </rt></ruby>或<ruby> 恶意软件 <rt> malware </rt></ruby>。
> 3. 有一段时间,它们就那样随意地从代码中删除 Lineage 的<ruby> 版权标头 <rt> copyright header </rt></ruby>并加入自己的。
> 4. 他们喜欢删除负面反馈并且监视用户 Telegram 群聊中的舆论。
>
>
> 总而言之,我**不建议使用 /e/** ROM。(至少现在)
>
>
>
另一件你有可能要做的事情是获取手机的 [root 权限](https://lifehacker.com/5789397/the-always-up-to-date-guide-to-rooting-any-android-phone),让它真正的成为你的手机,并且修改系统中的文件,例如使用系统范围的 adblocker 等。为了实现它,我决定使用 [Magisk](https://forum.xda-developers.com/apps/magisk/official-magisk-v7-universal-systemless-t3473445),一个天赐的应用,它由一个学生开发,可以帮你获取设备的 root 权限并安装一种叫做[模块](https://forum.xda-developers.com/apps/magisk)的东西,基本上是软件。
下载 ROM 和 Magisk 之后,我得在手机上安装它们。为了完成安装,我将文件移动到了 SD 卡上。现在,若要安装系统,我需要使用 [恢复系统](http://www.smartmobilephonesolutions.com/content/android-system-recovery)。我用的是较为普遍的 [TWRP](https://dl.twrp.me/whyred/)(代表 TeamWin Recovery Project)。
要安装恢复系统(听起来有点难,我知道),我需要将文件[烧录](https://lifehacker.com/5789397/the-always-up-to-date-guide-to-rooting-any-android-phone)进手机。为了完成烧录,我将手机用一个叫做 [ADB 的工具](https://developer.android.com/studio/command-line/adb)连接上电脑(Fedora Linux 系统)。使用命令让自己定制的恢复系统覆盖掉原先的。
```
fastboot flash recovery twrp.img
```
完成之后,我关掉手机并按住音量上和电源键,直到 TWRP 界面显示。这意味着我进行顺利,并且它已经准备好接收我的指令。

下一步是**发送擦除命令**,在你第一次为手机安装自定义 ROM 时是必要的。如上图所示,擦除命令会清除掉<ruby> 数据 <rt> Data </rt></ruby>,<ruby> 缓存 <rt> Cache </rt></ruby>和 Dalvik 。(这里也有高级选项让我们可以勾选以删除掉系统,如果我们不再需要旧系统的话)
这需要几分钟去完成,之后,你的手机基本上就干净了。现在是时候**安装系统了**。通过按下主屏幕上的安装按钮,我们选择之前添加进的 zip 文件(ROM 文件)并滑动屏幕安装它。下一步,我们需要安装 Magisk,它可以给我们访问设备的 root 权限。
>
> **校订**:一些有经验的安卓用户或发烧友也许注意到了,手机上不包含 [GApps](谷歌应用)。这在安卓世界里称之为 GApps-less,一个 GAps 应用也不安装。
>
>
> 注意有一个不好之处在于若不安装 Google Services 有的应用无法正常工作,例如它们的通知也许会花更长的时间到达或者根本不起作用。(对我来说这一点是最影响应用程序使用的)原因是这些应用使用了 [Google Cloud Messaging](https://developers.google.com/cloud-messaging/)(现在叫做 [Firebase](https://firebase.google.com/docs/cloud-messaging/))唤醒手机并推送通知。
>
>
> 你可以通过安装使用 [microG](https://microg.org/)(部分地)解决它,microG 提供一些 Google Services 的特性且允许你拥有更多的控制。我不建议使用它,因为它仍然有助于 Google Services 并且你不一定信任它。但是,如果你没法<ruby> 立刻放弃使用 <rt> go cold turkey on it </rt> <ruby> ,只想慢慢地退出谷歌,这便是一个好的开始。 </ruby></ruby>
>
>
>
都成功地安装之后,现在我们重启手机,就进入了主屏幕。
### 下一个部分,安装应用并配置一切
事情开始变得简单了。为了安装应用,我使用了 [F-Droid](https://f-droid.org/),一个可替代的应用商店,里面**只包含自由及开源应用**。如果这里没有你要的应用,你可以使用 [Aurora Store](https://f-droid.org/en/packages/com.dragons.aurora/),一个从应用商店里下载应用且不需要使用谷歌帐号或被追踪的客户端。
F-Droid 里面有名为 repos 的东西,它是一个包含你可以安装应用的“仓库”。我使用默认的仓库,并从 [IzzyOnDroid](https://android.izzysoft.de/repo) 添加了另一个,它有更多默认仓库中没有的应用,并且它更新地更频繁。

从下面你可以发现我所安装的应用清单,它们替代的应用与用途。
* [AdAway](https://f-droid.org/en/packages/org.adaway) > 系统广告拦截器,使用 hosts 文件拦截所有的广告
* [AfWall+](https://f-droid.org/en/packages/dev.ukanth.ufirewall) > 一个防火墙,可以阻止不想要的连接
* [Amaze](https://f-droid.org/en/packages/com.amaze.filemanager) > 替代系统的文件管理器,允许文件的 root 访问权限,并且拥有 zip/unzip 功能
* [Ameixa](https://f-droid.org/en/packages/org.xphnx.ameixa) > 大多数应用的图标包
* [andOTP](https://f-droid.org/en/packages/org.shadowice.flocke.andotp) > 替代谷歌验证器/Authy,一个可以用来登录启用了<ruby> 双因子验证 <rt> 2FA </rt></ruby>的网站账户的 TOTP 应用,可以使用 PIN 码备份和锁定
* [AnySoftKeyboard/AOSP Keyboard](https://f-droid.org/packages/com.menny.android.anysoftkeyboard/) > 开源键盘,它有许多主题和语言包,我也是该[项目](https://anysoftkeyboard.github.io/)的一员
* [Audio Recorder](https://f-droid.org/en/packages/com.github.axet.audiorecorder) > 如其名字,允许你从麦克风录制不同格式的音频文件
* [Battery Charge Limit](https://f-droid.org/en/packages/com.slash.batterychargelimit) > 当到 80% 时自动停止充电,降低<ruby> 电池磨损 <rt> battery wear </rt></ruby>并增加寿命
* [DAVx5](https://f-droid.org/en/packages/at.bitfire.davdroid) > 这是我最常用的应用之一,对我来说它基本上替代了谷歌联系人、谷歌日历和谷歌 Tasks,它连接着我的 Nextcloud 环境可以让我完全控制自己的数据
* [Document Viewer](https://f-droid.org/en/packages/org.sufficientlysecure.viewer) > 一个可以打开数百种文件格式的查看器应用,快速、轻量
* [Deezloader Remix](https://gitlab.com/Nick80835/DeezLoader-Android/) > 让我可以在 Deezer 上下载高质量 MP3 的应用
* [Easy xkcd](https://f-droid.org/en/packages/de.tap.easy_xkcd) > xkcd 漫画阅读器,我喜欢这些 xkcd 漫画
* [Etar](https://f-droid.org/en/packages/ws.xsoh.etar) > 日历应用,替代谷歌日历,与 DAVx5 一同工作
* [FastHub-Libre](https://f-droid.org/en/packages/com.fastaccess.github.libre) > 一个 GitHub 客户端,完全 FOSS(自由及开源软件),非常实用如果你像我一样喜欢使用 Github 的话
* [Fennec F-Droid](https://f-droid.org/en/packages/org.mozilla.fennec_fdroid) > 替代谷歌 Chrome 和其他类似的应用,一个为 F-Droid 打造的火狐浏览器,不含专有二进制代码并允许安装扩展提升浏览体验
* [Gadgetbridge](https://f-droid.org/en/packages/nodomain.freeyourgadget.gadgetbridge) > 替代小米运动,可以用来配对小米硬件的应用,追踪你的健康、步数、睡眠等。
* [K-9 Mail](https://f-droid.org/en/packages/com.fsck.k9) > 邮件客户端,替代 GMail 应用,可定制并可以添加多个账户
* [Lawnchair](https://f-droid.org/en/packages/ch.deletescape.lawnchair.plah) > 启动器,可以替代 Nova Launcher 或 Pixel Launcher,允许自定义和各种改变,也支持图标包
* [Mattermost](https://f-droid.org/en/packages/com.mattermost.mattermost) > 可以连接 Mattermost 服务器的应用。Mattermost 是一个 Slack 替代品
* [NewPipe](https://f-droid.org/en/packages/org.schabi.newpipe) > 最好的 YouTube 客户端(我认为),可以替代 YoubTube,它完全是 FOSS,免除 YouTube 广告,占用更少空间,允许背景播放,允许下载视频/音频等。试一试吧
* [Nextcloud SMS](https://f-droid.org/en/packages/fr.unix_experience.owncloud_sms) > 允许备份/同步 SMS 到我的 Nextcloud 环境
* [Nextcloud Notes](https://f-droid.org/en/packages/it.niedermann.owncloud.notes) > 允许我创建,修改,删除,分享笔记并同步/备份到 Nextcloud 环境
* [OpenTasks](https://f-droid.org/en/packages/org.dmfs.tasks) > 允许我创建、修改、删除任务并同步到我的 Nextcloud 环境
* [OsmAnd~](https://f-droid.org/en/packages/net.osmand.plus) > 一个地图应用,使用 [OpenStreetMap](https://openstreetmap.org/),允许下载离线地图和导航
* [QKSMS](https://f-droid.org/en/packages/com.moez.QKSMS) > 我最喜欢的短信应用,可以替代原来的 Messaging 应用,拥有漂亮的界面,拥有备份、个性化、延迟发送等特性。
* [Resplash/Mysplash](https://f-droid.org/en/packages/com.wangdaye.mysplash) > 允许你无限地从 [Unsplash](https://unsplash.com/) 下载无数的漂亮壁纸,全都可以免费使用和修改。
* [ScreenCam](https://f-droid.org/en/packages/com.orpheusdroid.screenrecorder) > 一个录屏工具,允许各样的自定义和录制模式,没有广告并且免费
* [SecScanQR](https://f-droid.org/en/packages/de.t_dankworth.secscanqr) > 二维码识别应用,快速轻量
* [Send Reduced Free](https://f-droid.org/en/packages/mobi.omegacentauri.SendReduced) > 这个应用可以在发送之前通过移除 PII(<ruby> 个人识别信息 <rt> personally identifiable information </rt></ruby>)和减小尺寸,让你立即分享大图
* [Slide](https://f-droid.org/en/packages/me.ccrama.redditslide/) > 开源 Reddit 客户端
* [Telegram FOSS](https://f-droid.org/en/packages/org.telegram.messenger) > 没有追踪和 Google Services 的纯净版 Telegram 安卓客户端
* [TrebleShot](https://f-droid.org/en/packages/com.genonbeta.TrebleShot) > 这个天才般的应用可以让你通过 WIFI 分享文件给其它设备,真的超快,甚至无需连接网络
* [Tusky](https://f-droid.org/en/packages/com.keylesspalace.tusky) > Tusky 是 [Mastodon](https://joinmastodon.org/) 平台的客户端(替代 Twitter)
* [Unit Converter Ultimate](https://f-droid.org/en/packages/com.physphil.android.unitconverterultimate) > 这款应用可以一键在 200 种单位之间来回转换,非常快并且完全离线
* [Vinyl Music Player](https://f-droid.org/en/packages/com.poupa.vinylmusicplayer) > 我首选的音乐播放器,可以替代谷歌音乐播放器或其他你已经安装的音乐播放器,它有漂亮的界面和许多特性
* [VPN Hotspot](https://f-droid.org/en/packages/be.mygod.vpnhotspot) > 这款应用可以让我打开热点的时候分享 VPN,因此我可以在笔记本上什么都不用做就可以安全地浏览网页
这些差不多就是我列出的一张**最实用的 F-Droid 应用**清单,但不巧,这些并不是所有应用。我使用的专有应用如下(我知道,我也许听起来是一个伪君子,但并不是所有的应用都可以替代,至少现在不是):
* Google Camera(与 Camera API 2 结合起来,需要 F-Droid 的基本的 microG 才能工作)
* Instagram
* MyVodafoneAL (运营商应用)
* ProtonMail (email 应用)
* Titanium Backup(备份应用数据,wifi 密码,通话记录等)
* WhatsApp (专有的端到端聊天应用,几乎我认识的所有人都有它)
差不多就是这样,这就是我用的手机上所有的应用。**配置非常简单明了,我可以给几点提示**。
1. 仔细阅读和检查应用的权限,不要无脑地点“安装”。
2. 尽可能多地使用开源应用,它们即尊重你的隐私又是免费的(且自由)。
3. 尽可能地使用 VPN,找一个有名气的,别用免费的,否则你将被收割数据然后成为产品。
4. 不要一直打开 WIFI/移动数据/定位,有可能引起安全隐患。
5. 不要只依赖指纹解锁,或者尽可能只用 PIN/密码/模式解锁,因为生物数据可以被克隆后针对你,例如解锁你的手机盗取你的数据。
作为坚持读到这儿的奖励,**一张主屏幕的截图奉上。**

---
via: <https://lushka.al/my-android-setup/>
作者:[Anxhelo Lushka](https://lushka.al/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LuuMing](https://github.com/luuming) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
10,679 | 10 个 Python 图像编辑工具 | https://opensource.com/article/19/3/python-image-manipulation-tools | 2019-04-03T11:39:05 | [
"Python",
"图像"
] | https://linux.cn/article-10679-1.html |
>
> 以下提到的这些 Python 工具在编辑图像、操作图像底层数据方面都提供了简单直接的方法。
>
>
>

当今的世界充满了数据,而图像数据就是其中很重要的一部分。但只有经过处理和分析,提高图像的质量,从中提取出有效地信息,才能利用到这些图像数据。
常见的图像处理操作包括显示图像,基本的图像操作,如裁剪、翻转、旋转;图像的分割、分类、特征提取;图像恢复;以及图像识别等等。Python 作为一种日益风靡的科学编程语言,是这些图像处理操作的最佳选择。同时,在 Python 生态当中也有很多可以免费使用的优秀的图像处理工具。
下文将介绍 10 个可以用于图像处理任务的 Python 库,它们在编辑图像、查看图像底层数据方面都提供了简单直接的方法。
### 1、scikit-image
[scikit-image](https://scikit-image.org/) 是一个结合 [NumPy](http://docs.scipy.org/doc/numpy/reference/index.html#module-numpy) 数组使用的开源 Python 工具,它实现了可用于研究、教育、工业应用的算法和应用程序。即使是对于刚刚接触 Python 生态圈的新手来说,它也是一个在使用上足够简单的库。同时它的代码质量也很高,因为它是由一个活跃的志愿者社区开发的,并且通过了<ruby> 同行评审 <rt> peer review </rt></ruby>。
#### 资源
scikit-image 的[文档](http://scikit-image.org/docs/stable/user_guide.html)非常完善,其中包含了丰富的用例。
#### 示例
可以通过导入 `skimage` 使用,大部分的功能都可以在它的子模块中找到。
<ruby> 图像滤波 <rt> image filtering </rt></ruby>:
```
import matplotlib.pyplot as plt
%matplotlib inline
from skimage import data,filters
image = data.coins() # ... or any other NumPy array!
edges = filters.sobel(image)
plt.imshow(edges, cmap='gray')
```

使用 [match\_template()](http://scikit-image.org/docs/dev/auto_examples/features_detection/plot_template.html#sphx-glr-auto-examples-features-detection-plot-template-py) 方法实现<ruby> 模板匹配 <rt> template matching </rt></ruby>:

在[展示页面](https://scikit-image.org/docs/dev/auto_examples)可以看到更多相关的例子。
### 2、NumPy
[NumPy](http://www.numpy.org/) 提供了对数组的支持,是 Python 编程的一个核心库。图像的本质其实也是一个包含像素数据点的标准 NumPy 数组,因此可以通过一些基本的 NumPy 操作(例如切片、<ruby> 掩膜 <rt> mask </rt></ruby>、<ruby> 花式索引 <rt> fancy indexing </rt></ruby>等),就可以从像素级别对图像进行编辑。通过 NumPy 数组存储的图像也可以被 skimage 加载并使用 matplotlib 显示。
#### 资源
在 NumPy 的[官方文档](http://www.numpy.org/)中提供了完整的代码文档和资源列表。
#### 示例
使用 NumPy 对图像进行<ruby> 掩膜 <rt> mask </rt></ruby>操作:
```
import numpy as np
from skimage import data
import matplotlib.pyplot as plt
%matplotlib inline
image = data.camera()
type(image)
numpy.ndarray #Image is a NumPy array:
mask = image < 87
image[mask]=255
plt.imshow(image, cmap='gray')
```

### 3、SciPy
像 NumPy 一样,[SciPy](https://www.scipy.org/) 是 Python 的一个核心科学计算模块,也可以用于图像的基本操作和处理。尤其是 SciPy v1.1.0 中的 [scipy.ndimage](https://docs.scipy.org/doc/scipy/reference/ndimage.html#module-scipy.ndimage) 子模块,它提供了在 n 维 NumPy 数组上的运行的函数。SciPy 目前还提供了<ruby> 线性和非线性滤波 <rt> linear and non-linear filtering </rt></ruby>、<ruby> 二值形态学 <rt> binary morphology </rt></ruby>、<ruby> B 样条插值 <rt> B-spline interpolation </rt></ruby>、<ruby> 对象测量 <rt> object measurements </rt></ruby>等方面的函数。
#### 资源
在[官方文档](https://docs.scipy.org/doc/scipy/reference/tutorial/ndimage.html#correlation-and-convolution)中可以查阅到 `scipy.ndimage` 的完整函数列表。
#### 示例
使用 SciPy 的[高斯滤波](https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.gaussian_filter.html)对图像进行模糊处理:
```
from scipy import misc,ndimage
face = misc.face()
blurred_face = ndimage.gaussian_filter(face, sigma=3)
very_blurred = ndimage.gaussian_filter(face, sigma=5)
#Results
plt.imshow(<image to be displayed>)
```

### 4、PIL/Pillow
PIL (Python Imaging Library) 是一个免费 Python 编程库,它提供了对多种格式图像文件的打开、编辑、保存的支持。但在 2009 年之后 PIL 就停止发布新版本了。幸运的是,还有一个 PIL 的积极开发的分支 [Pillow](https://python-pillow.org/),它的安装过程比 PIL 更加简单,支持大部分主流的操作系统,并且还支持 Python 3。Pillow 包含了图像的基础处理功能,包括像素点操作、使用内置卷积内核进行滤波、颜色空间转换等等。
#### 资源
Pillow 的[官方文档](https://pillow.readthedocs.io/en/3.1.x/index.html)提供了 Pillow 的安装说明自己代码库中每一个模块的示例。
#### 示例
使用 Pillow 中的 ImageFilter 模块实现图像增强:
```
from PIL import Image,ImageFilter
#Read image
im = Image.open('image.jpg')
#Display image
im.show()
from PIL import ImageEnhance
enh = ImageEnhance.Contrast(im)
enh.enhance(1.8).show("30% more contrast")
```

* [源码](http://sipi.usc.edu/database/)
### 5、OpenCV-Python
OpenCV(Open Source Computer Vision 库)是计算机视觉领域最广泛使用的库之一,[OpenCV-Python](https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_setup/py_intro/py_intro.html) 则是 OpenCV 的 Python API。OpenCV-Python 的运行速度很快,这归功于它使用 C/C++ 编写的后台代码,同时由于它使用了 Python 进行封装,因此调用和部署的难度也不大。这些优点让 OpenCV-Python 成为了计算密集型计算机视觉应用程序的一个不错的选择。
#### 资源
入门之前最好先阅读 [OpenCV2-Python-Guide](https://github.com/abidrahmank/OpenCV2-Python-Tutorials) 这份文档。
#### 示例
使用 OpenCV-Python 中的<ruby> 金字塔融合 <rt> Pyramid Blending </rt></ruby>将苹果和橘子融合到一起:

* [源码](https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_pyramids/py_pyramids.html#pyramids)
### 6、SimpleCV
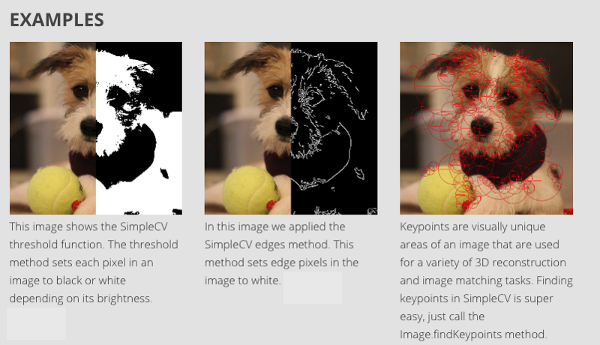
[SimpleCV](http://simplecv.org/) 是一个开源的计算机视觉框架。它支持包括 OpenCV 在内的一些高性能计算机视觉库,同时不需要去了解<ruby> 位深度 <rt> bit depth </rt></ruby>、文件格式、<ruby> 色彩空间 <rt> color space </rt></ruby>之类的概念,因此 SimpleCV 的学习曲线要比 OpenCV 平缓得多,正如它的口号所说,“将计算机视觉变得更简单”。SimpleCV 的优点还有:
* 即使是刚刚接触计算机视觉的程序员也可以通过 SimpleCV 来实现一些简易的计算机视觉测试
* 录像、视频文件、图像、视频流都在支持范围内
#### 资源
[官方文档](http://examples.simplecv.org/en/latest/)简单易懂,同时也附有大量的学习用例。
#### 示例

### 7、Mahotas
[Mahotas](https://mahotas.readthedocs.io/en/latest/) 是另一个 Python 图像处理和计算机视觉库。在图像处理方面,它支持滤波和形态学相关的操作;在计算机视觉方面,它也支持<ruby> 特征计算 <rt> feature computation </rt></ruby>、<ruby> 兴趣点检测 <rt> interest point detection </rt></ruby>、<ruby> 局部描述符 <rt> local descriptors </rt></ruby>等功能。Mahotas 的接口使用了 Python 进行编写,因此适合快速开发,而算法使用 C++ 实现,并针对速度进行了优化。Mahotas 尽可能做到代码量少和依赖项少,因此它的运算速度非常快。可以参考[官方文档](https://openresearchsoftware.metajnl.com/articles/10.5334/jors.ac/)了解更多详细信息。
#### 资源
[文档](https://mahotas.readthedocs.io/en/latest/install.html)包含了安装介绍、示例以及一些 Mahotas 的入门教程。
#### 示例
Mahotas 力求使用少量的代码来实现功能。例如这个 [Finding Wally](https://blog.clarifai.com/wheres-waldo-using-machine-learning-to-find-all-the-waldos) 游戏:


* [源码](https://mahotas.readthedocs.io/en/latest/wally.html)
### 8、SimpleITK
[ITK](https://itk.org/)(Insight Segmentation and Registration Toolkit)是一个为开发者提供普适性图像分析功能的开源、跨平台工具套件,[SimpleITK](http://www.simpleitk.org/) 则是基于 ITK 构建出来的一个简化层,旨在促进 ITK 在快速原型设计、教育、解释语言中的应用。SimpleITK 作为一个图像分析工具包,它也带有[大量的组件](https://itk.org/ITK/resources/resources.html),可以支持常规的滤波、图像分割、<ruby> 图像配准 <rt> registration </rt></ruby>功能。尽管 SimpleITK 使用 C++ 编写,但它也支持包括 Python 在内的大部分编程语言。
#### 资源
有很多 [Jupyter Notebooks](http://insightsoftwareconsortium.github.io/SimpleITK-Notebooks/) 用例可以展示 SimpleITK 在教育和科研领域中的应用,通过这些用例可以看到如何使用 Python 和 R 利用 SimpleITK 来实现交互式图像分析。
#### 示例
使用 Python + SimpleITK 实现的 CT/MR 图像配准过程:

* [源码](https://github.com/InsightSoftwareConsortium/SimpleITK-Notebooks/blob/master/Utilities/intro_animation.py)
### 9、pgmagick
[pgmagick](https://pypi.org/project/pgmagick/) 是使用 Python 封装的 GraphicsMagick 库。[GraphicsMagick](http://www.graphicsmagick.org/) 通常被认为是图像处理界的瑞士军刀,因为它强大而又高效的工具包支持对多达 88 种主流格式图像文件的读写操作,包括 DPX、GIF、JPEG、JPEG-2000、PNG、PDF、PNM、TIFF 等等。
#### 资源
pgmagick 的 [GitHub 仓库](https://github.com/hhatto/pgmagick)中有相关的安装说明、依赖列表,以及详细的[使用指引](https://pgmagick.readthedocs.io/en/latest/)。
#### 示例
图像缩放:

* [源码](https://pgmagick.readthedocs.io/en/latest/cookbook.html#scaling-a-jpeg-image)
边缘提取:

* [源码](https://pgmagick.readthedocs.io/en/latest/cookbook.html#edge-extraction)
### 10、Pycairo
[Cairo](https://cairographics.org/) 是一个用于绘制矢量图的二维图形库,而 [Pycairo](https://pypi.org/project/pycairo/) 是用于 Cairo 的一组 Python 绑定。矢量图的优点在于做大小缩放的过程中不会丢失图像的清晰度。使用 Pycairo 可以在 Python 中调用 Cairo 的相关命令。
#### 资源
Pycairo 的 [GitHub 仓库](https://github.com/pygobject/pycairo)提供了关于安装和使用的详细说明,以及一份简要介绍 Pycairo 的[入门指南](https://pycairo.readthedocs.io/en/latest/tutorial.html)。
#### 示例
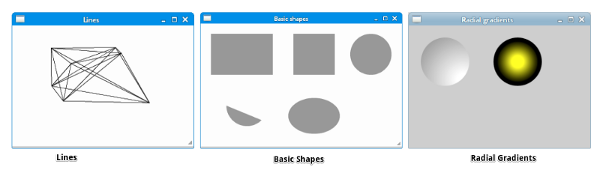
使用 Pycairo 绘制线段、基本图形、<ruby> 径向渐变 <rt> radial gradients </rt></ruby>:

* [源码](http://zetcode.com/gfx/pycairo/basicdrawing/)
### 总结
以上就是 Python 中的一些有用的图像处理库,无论你有没有听说过、有没有使用过,都值得试用一下并了解它们。
---
via: <https://opensource.com/article/19/3/python-image-manipulation-tools>
作者:[Parul Pandey](https://opensource.com/users/parul-pandey) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Today's world is full of data, and images form a significant part of this data. However, before they can be used, these digital images must be processed—analyzed and manipulated in order to improve their quality or extract some information that can be put to use.
Common image processing tasks include displays; basic manipulations like cropping, flipping, rotating, etc.; image segmentation, classification, and feature extractions; image restoration; and image recognition. Python is an excellent choice for these types of image processing tasks due to its growing popularity as a scientific programming language and the free availability of many state-of-the-art image processing tools in its ecosystem.
This article looks at 10 of the most commonly used Python libraries for image manipulation tasks. These libraries provide an easy and intuitive way to transform images and make sense of the underlying data.
## 1. scikit-image
is an open source Python package that works with
**scikit**-image
[NumPy](http://docs.scipy.org/doc/numpy/reference/index.html#module-numpy)arrays. It implements algorithms and utilities for use in research, education, and industry applications. It is a fairly simple and straightforward library, even for those who are new to Python's ecosystem. The code is high-quality, peer-reviewed, and written by an active community of volunteers.
### Resources
scikit-image is very well [documented](http://scikit-image.org/docs/stable/user_guide.html) with a lot of examples and practical use cases.
### Usage
The package is imported as **skimage**, and most functions are found within the submodules.
Image filtering:
```
import matplotlib.pyplot as plt
%matplotlib inline
from skimage import data,filters
image = data.coins() # ... or any other NumPy array!
edges = filters.sobel(image)
plt.imshow(edges, cmap='gray')
```
Template matching using the [match_template](http://scikit-image.org/docs/dev/auto_examples/features_detection/plot_template.html#sphx-glr-auto-examples-features-detection-plot-template-py) function:

You can find more examples in the [gallery](https://scikit-image.org/docs/dev/auto_examples).
## 2. NumPy
[ NumPy](http://www.numpy.org/) is one of the core libraries in Python programming and provides support for arrays. An image is essentially a standard NumPy array containing pixels of data points. Therefore, by using basic NumPy operations, such as slicing, masking, and fancy indexing, you can modify the pixel values of an image. The image can be loaded using
**skimage**and displayed using Matplotlib.
### Resources
A complete list of resources and documentation is available on NumPy's [official documentation page](http://www.numpy.org/).
### Usage
Using Numpy to mask an image:
```
import numpy as np
from skimage import data
import matplotlib.pyplot as plt
%matplotlib inline
image = data.camera()
type(image)
numpy.ndarray #Image is a NumPy array:
mask = image < 87
image[mask]=255
plt.imshow(image, cmap='gray')
```

## 3. SciPy
** SciPy** is another of Python's core scientific modules (like NumPy) and can be used for basic image manipulation and processing tasks. In particular, the submodule
[(in SciPy v1.1.0) provides functions operating on n-dimensional NumPy arrays. The package currently includes functions for linear and non-linear filtering, binary morphology, B-spline interpolation, and object measurements.](https://docs.scipy.org/doc/scipy/reference/ndimage.html#module-scipy.ndimage)
**scipy.ndimage**### Resources
For a complete list of functions provided by the **scipy.ndimage** package, refer to the [documentation](https://docs.scipy.org/doc/scipy/reference/tutorial/ndimage.html#correlation-and-convolution).
### Usage
Using SciPy for blurring using a [Gaussian filter](https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.gaussian_filter.html):
```
from scipy import misc,ndimage
face = misc.face()
blurred_face = ndimage.gaussian_filter(face, sigma=3)
very_blurred = ndimage.gaussian_filter(face, sigma=5)
#Results
plt.imshow(<image to be displayed>)
```

## 4. PIL/Pillow
**PIL** (Python Imaging Library) is a free library for the Python programming language that adds support for opening, manipulating, and saving many different image file formats. However, its development has stagnated, with its last release in 2009. Fortunately, there is [ Pillow](https://python-pillow.org/), an actively developed fork of PIL, that is easier to install, runs on all major operating systems, and supports Python 3. The library contains basic image processing functionality, including point operations, filtering with a set of built-in convolution kernels, and color-space conversions.
### Resources
The [documentation](https://pillow.readthedocs.io/en/3.1.x/index.html) has instructions for installation as well as examples covering every module of the library.
### Usage
Enhancing an image in Pillow using ImageFilter:
```
from PIL import Image,ImageFilter
#Read image
im = Image.open('image.jpg')
#Display image
im.show()
from PIL import ImageEnhance
enh = ImageEnhance.Contrast(im)
enh.enhance(1.8).show("30% more contrast")
```

## 5. OpenCV-Python
**OpenCV** (Open Source Computer Vision Library) is one of the most widely used libraries for computer vision applications. [ OpenCV-Python](https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_setup/py_intro/py_intro.html) is the Python API for OpenCV. OpenCV-Python is not only fast, since the background consists of code written in C/C++, but it is also easy to code and deploy (due to the Python wrapper in the foreground). This makes it a great choice to perform computationally intensive computer vision programs.
### Resources
The [OpenCV2-Python-Guide](https://github.com/abidrahmank/OpenCV2-Python-Tutorials) makes it easy to get started with OpenCV-Python.
### Usage
Using *Image Blending using Pyramids* in OpenCV-Python to create an "Orapple":

## 6. SimpleCV
[ SimpleCV](http://simplecv.org/) is another open source framework for building computer vision applications. It offers access to several high-powered computer vision libraries such as OpenCV, but without having to know about bit depths, file formats, color spaces, etc. Its learning curve is substantially smaller than OpenCV's, and (as its tagline says), "it's computer vision made easy." Some points in favor of SimpleCV are:
- Even beginning programmers can write simple machine vision tests
- Cameras, video files, images, and video streams are all interoperable
### Resources
The official [documentation](http://examples.simplecv.org/en/latest/) is very easy to follow and has tons of examples and use cases to follow.
### Usage
## 7. Mahotas
** Mahotas** is another computer vision and image processing library for Python. It contains traditional image processing functions such as filtering and morphological operations, as well as more modern computer vision functions for feature computation, including interest point detection and local descriptors. The interface is in Python, which is appropriate for fast development, but the algorithms are implemented in C++ and tuned for speed. Mahotas' library is fast with minimalistic code and even minimum dependencies. Read its
[official paper](https://openresearchsoftware.metajnl.com/articles/10.5334/jors.ac/)for more insights.
### Resources
The [documentation](https://mahotas.readthedocs.io/en/latest/install.html) contains installation instructions, examples, and even some tutorials to help you get started using Mahotas easily.
### Usage
The Mahotas library relies on simple code to get things done. For example, it does a good job with the [Finding Wally](https://blog.clarifai.com/wheres-waldo-using-machine-learning-to-find-all-the-waldos) problem with a minimum amount of code.
Solving the Finding Wally problem:
## 8. SimpleITK
[ ITK](https://itk.org/) (Insight Segmentation and Registration Toolkit) is an "open source, cross-platform system that provides developers with an extensive suite of software tools for image analysis.
**is a simplified layer built on top of ITK, intended to facilitate its use in rapid prototyping, education, [and] interpreted languages." It's also an image analysis toolkit with a**
[SimpleITK](http://www.simpleitk.org/)[large number of components](https://itk.org/ITK/resources/resources.html)supporting general filtering operations, image segmentation, and registration. SimpleITK is written in C++, but it's available for a large number of programming languages including Python.
### Resources
There are a large number of [Jupyter Notebooks](http://insightsoftwareconsortium.github.io/SimpleITK-Notebooks/) illustrating the use of SimpleITK for educational and research activities. The notebooks demonstrate using SimpleITK for interactive image analysis using the Python and R programming languages.
### Usage
Visualization of a rigid CT/MR registration process created with SimpleITK and Python:
## 9. pgmagick
[ pgmagick](https://pypi.org/project/pgmagick/) is a Python-based wrapper for the GraphicsMagick library. The
[image processing system is sometimes called the Swiss Army Knife of image processing. Its robust and efficient collection of tools and libraries supports reading, writing, and manipulating images in over 88 major formats including DPX, GIF, JPEG, JPEG-2000, PNG, PDF, PNM, and TIFF.](http://www.graphicsmagick.org/)
**GraphicsMagick**### Resources
pgmagick's [GitHub repository](https://github.com/hhatto/pgmagick) has installation instructions and requirements. There is also a detailed [user guide](https://pgmagick.readthedocs.io/en/latest/).
### Usage
Image scaling:

Edge extraction:

## 10. Pycairo
[ Pycairo](https://pypi.org/project/pycairo/) is a set of Python bindings for the
[Cairo](https://cairographics.org/)graphics library. Cairo is a 2D graphics library for drawing vector graphics. Vector graphics are interesting because they don't lose clarity when resized or transformed. Pycairo can call Cairo commands from Python.
### Resources
The Pycairo [GitHub repository](https://github.com/pygobject/pycairo) is a good resource with detailed instructions on installation and usage. There is also a [getting started guide](https://pycairo.readthedocs.io/en/latest/tutorial.html), which has a brief tutorial on Pycairo.
### Usage
Drawing lines, basic shapes, and radial gradients with Pycairo:
## Conclusion
These are some of the useful and freely available image processing libraries in Python. Some are well known and others may be new to you. Try them out to get to know more about them!
## 2 Comments |
10,680 | iWant:一个去中心化的点对点共享文件的命令行工具 | https://www.ostechnix.com/iwant-decentralized-peer-peer-file-sharing-commandline-application/ | 2019-04-03T12:48:10 | [
"P2P",
"文件共享"
] | https://linux.cn/article-10680-1.html | 
不久之前,我们编写了一个指南,内容是一个文件共享实用程序,名为 [transfer.sh](https://www.ostechnix.com/easy-fast-way-share-files-internet-command-line/),它是一个免费的 Web 服务,允许你在 Internet 上轻松快速地共享文件,还有 [PSiTransfer](https://www.ostechnix.com/psitransfer-simple-open-source-self-hosted-file-sharing-solution/),一个简单的开源自托管文件共享解决方案。今天,我们将看到另一个名为 “iWant” 的文件共享实用程序。它是一个基于命令行的自由开源的去中心化点对点文件共享应用程序。
你可能想知道,它与其它文件共享应用程序有什么不同?以下是 iWant 的一些突出特点。
* 它是一个命令行应用程序。这意味着你不需要消耗内存来加载 GUI 实用程序。你只需要一个终端。
* 它是去中心化的。这意味着你的数据不会在任何中心位置存储。因此,不会因为中心点失败而失败。
* iWant 允许中断下载,你可以在以后随时恢复。你不需要从头开始下载,它会从你停止的位置恢复下载。
* 共享目录中文件所作的任何更改(如删除、添加、修改)都会立即反映在网络中。
* 就像种子一样,iWant 从多个节点下载文件。如果任何节点离开群组或未能响应,它将继续从另一个节点下载。
* 它是跨平台的,因此你可以在 GNU/Linux、MS Windows 或者 Mac OS X 中使用它。
### 安装 iWant
iWant 可以使用 PIP 包管理器轻松安装。确保你在 Linux 发行版中安装了 pip。如果尚未安装,参考以下指南。
[如何使用 Pip 管理 Python 包](https://www.ostechnix.com/manage-python-packages-using-pip/)
安装 pip 后,确保你有以下依赖项:
* libffi-dev
* libssl-dev
比如说,在 Ubuntu 上,你可以使用以下命令安装这些依赖项:
```
$ sudo apt-get install libffi-dev libssl-dev
```
安装完所有依赖项后,使用以下命令安装 iWant:
```
$ sudo pip install iwant
```
现在我们的系统中已经有了 iWant,让我们来看看如何使用它来通过网络传输文件。
### 用法
首先,使用以下命令启动 iWant 服务器:
(LCTT 译注:虽然这个软件是叫 iWant,但是其命令名为 `iwanto`,另外这个软件至少一年没有更新了。)
```
$ iwanto start
```
第一次启动时,iWant 会询问想要分享和下载文件夹的位置,所以需要输入两个文件夹的位置。然后,选择要使用的网卡。
示例输出:
```
Shared/Download folder details looks empty..
Note: Shared and Download folder cannot be the same
SHARED FOLDER(absolute path):/home/sk/myshare
DOWNLOAD FOLDER(absolute path):/home/sk/mydownloads
Network interface available
1. lo => 127.0.0.1
2. enp0s3 => 192.168.43.2
Enter index of the interface:2
now scanning /home/sk/myshare
[Adding] /home/sk/myshare 0.0
Updating Leader 56f6d5e8-654e-11e7-93c8-08002712f8c1
[Adding] /home/sk/myshare 0.0
connecting to 192.168.43.2:1235 for hashdump
```
如果你看到类似上面的输出,你可以立即开始使用 iWant 了。
同样,在网络中的所有系统上启动 iWant 服务,指定有效的分享和下载文件夹的位置,并选择合适的网卡。
iWant 服务将继续在当前终端窗口中运行,直到你按下 `CTRL+C` 退出为止。你需要打开一个新选项卡或新的终端窗口来使用 iWant。
iWant 的用法非常简单,它的命令很少,如下所示。
* `iwanto start` – 启动 iWant 服务。
* `iwanto search <name>` – 查找文件。
* `iwanto download <hash>` – 下载一个文件。
* `iwanto share <path>` – 更改共享文件夹的位置。
* `iwanto download to <destination>` – 更改下载文件夹位置。
* `iwanto view config` – 查看共享和下载文件夹。
* `iwanto –version` – 显示 iWant 版本。
* `iwanto -h` – 显示帮助信息。
让我向你展示一些例子。
#### 查找文件
要查找一个文件,运行:
```
$ iwanto search <filename>
```
请注意,你无需指定确切的名称。
示例:
```
$ iwanto search command
```
上面的命令将搜索包含 “command” 字符串的所有文件。
我的 Ubuntu 系统会输出:
```
Filename Size Checksum
------------------------------------------- ------- --------------------------------
/home/sk/myshare/THE LINUX COMMAND LINE.pdf 3.85757 efded6cc6f34a3d107c67c2300459911
```
#### 下载文件
你可以在你的网络上的任何系统下载文件。要下载文件,只需提供文件的哈希(校验和),如下所示。你可以使用 `iwanto search` 命令获取共享的哈希值。
```
$ iwanto download efded6cc6f34a3d107c67c2300459911
```
文件将保存在你的下载位置,在本文中是 `/home/sk/mydownloads/` 位置。
```
Filename: /home/sk/mydownloads/THE LINUX COMMAND LINE.pdf
Size: 3.857569 MB
```
#### 查看配置
要查看配置,例如共享和下载文件夹的位置,运行:
```
$ iwanto view config
```
示例输出:
```
Shared folder:/home/sk/myshare
Download folder:/home/sk/mydownloads
```
#### 更改共享和下载文件夹的位置
你可以更改共享文件夹和下载文件夹。
```
$ iwanto share /home/sk/ostechnix
```
现在,共享位置已更改为 `/home/sk/ostechnix`。
同样,你可以使用以下命令更改下载位置:
```
$ iwanto download to /home/sk/Downloads
```
要查看所做的更改,运行命令:
```
$ iwanto view config
```
#### 停止 iWant
一旦你不想用 iWant 了,可以按下 `CTRL+C` 退出。
如果它不起作用,那可能是由于防火墙或你的路由器不支持多播。你可以在 `~/.iwant/.iwant.log` 文件中查看所有日志。有关更多详细信息,参阅最后提供的项目的 GitHub 页面。
差不多就是全部了。希望这个工具有所帮助。下次我会带着另一个有趣的指南再次来到这里。
干杯!
### 资源
-[iWant GitHub](https://github.com/nirvik/iWant)
---
via: <https://www.ostechnix.com/iwant-decentralized-peer-peer-file-sharing-commandline-application/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,681 | 重新发现 make: 规则背后的力量 | https://monades.roperzh.com/rediscovering-make-power-behind-rules/ | 2019-04-04T11:10:37 | [
"Makefile",
"make"
] | /article-10681-1.html | 
我过去认为 makefile 只是一种将一组组的 shell 命令列出来的简便方法;过了一段时间我了解到它们是有多么的强大、灵活以及功能齐全。这篇文章带你领略其中一些有关规则的特性。
>
> 备注:这些全是针对 GNU Makefile 的,如果你希望支持 BSD Makefile ,你会发现有些新的功能缺失。感谢 [zge](https://lobste.rs/u/zge) 指出这点。
>
>
>
### 规则
<ruby> 规则 <rt> rule </rt></ruby>是指示 `make` 应该如何并且何时构建一个被称作为<ruby> 目标 <rt> target </rt></ruby>的文件的指令。目标可以依赖于其它被称作为<ruby> 前提 <rt> prerequisite </rt></ruby>的文件。
你会指示 `make` 如何按<ruby> 步骤 <rt> recipe </rt></ruby>构建目标,那就是一套按照出现顺序一次执行一个的 shell 命令。语法像这样:
```
target_name : prerequisites
recipe
```
一但你定义好了规则,你就可以通过从命令行执行以下命令构建目标:
```
$ make target_name
```
目标一经构建,除非前提改变,否则 `make` 会足够聪明地不再去运行该步骤。
### 关于前提的更多信息
前提表明了两件事情:
* 当目标应当被构建时:如果其中一个前提比目标更新,`make` 假定目的应当被构建。
* 执行的顺序:鉴于前提可以反过来在 makefile 中由另一套规则所构建,它们同样暗示了一个执行规则的顺序。
如果你想要定义一个顺序但是你不想在前提改变的时候重新构建目标,你可以使用一种特别的叫做“<ruby> 唯顺序 <rt> order only </rt></ruby>”的前提。这种前提可以被放在普通的前提之后,用管道符(`|`)进行分隔。
### 样式
为了便利,`make` 接受目标和前提的样式。通过包含 `%` 符号可以定义一种样式。这个符号是一个可以匹配任何长度的文字符号或者空隔的通配符。以下有一些示例:
* `%`:匹配任何文件
* `%.md`:匹配所有 `.md` 结尾的文件
* `prefix%.go`:匹配所有以 `prefix` 开头以 `.go` 结尾的文件
### 特殊目标
有一系列目标名字,它们对于 `make` 来说有特殊的意义,被称作<ruby> 特殊目标 <rt> special target </rt></ruby>。
你可以在这个[文档](https://www.gnu.org/software/make/manual/make.html#Special-Targets)发现全套特殊目标。作为一种经验法则,特殊目标以点开始后面跟着大写字母。
以下是几个有用的特殊目标:
* `.PHONY`:向 `make` 表明此目标的前提可以被当成伪目标。这意味着 `make` 将总是运行,无论有那个名字的文件是否存在或者上次被修改的时间是什么。
* `.DEFAULT`:被用于任何没有指定规则的目标。
* `.IGNORE`:如果你指定 `.IGNORE` 为前提,`make` 将忽略执行步骤中的错误。
### 替代
当你需要以你指定的改动方式改变一个变量的值,<ruby> 替代 <rt> substitution </rt></ruby>就十分有用了。
替代的格式是 `$(var:a=b)`,它的意思是获取变量 `var` 的值,用值里面的 `b` 替代词末尾的每个 `a` 以代替最终的字符串。例如:
```
foo := a.o
bar : = $(foo:.o=.c) # sets bar to a.c
```
注意:特别感谢 [Luis Lavena](https://twitter.com/luislavena/) 让我们知道替代的存在。
### 档案文件
档案文件是用来一起将多个数据文档(类似于压缩文件的概念)收集成一个文件。它们由 `ar` Unix 工具所构建。`ar` 可以用于为任何目的创建档案,但除了[静态库](http://tldp.org/HOWTO/Program-Library-HOWTO/static-libraries.html),它已经被 `tar` 大量替代。
在 `make` 中,你可以使用一个档案文件中的单独一个成员作为目标或者前提,就像这样:
```
archive(member) : prerequisite
recipe
```
### 最后的想法
关于 `make` 还有更多可探索的,但是至少这是一个起点,我强烈鼓励你去查看[文档](https://www.gnu.org/software/make/manual/make.html),创建一个笨拙的 makefile 然后就可以探索它了。
---
via: <https://monades.roperzh.com/rediscovering-make-power-behind-rules/>
作者:[Roberto Dip](https://monades.roperzh.com) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='monades.roperzh.com', port=443): Max retries exceeded with url: /rediscovering-make-power-behind-rules/ (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x7b83409d3490>: Failed to resolve 'monades.roperzh.com' ([Errno -2] Name or service not known)")) | null |
10,682 | 树莓派使用入门:树莓派上的模拟器和原生 Linux 游戏 | https://opensource.com/article/19/3/play-games-raspberry-pi | 2019-04-04T11:23:26 | [
"树莓派",
"游戏"
] | /article-10682-1.html |
>
> 树莓派是一个很棒的游戏平台。在我们的系列文章的第九篇中学习如何开始使用树莓派。
>
>
>

回到我们关于树莓派入门系列文章的[第五篇](/article-10653-1.html),我提到 Minecraft 是一种教孩子们使用游戏平台进行编程的方法。作为一个不错的游戏平台,今天我们将讨论在树莓派上使用或者不使用模拟器来玩游戏的方式。
### 使用模拟器玩游戏
模拟器是一种能让你在树莓派上玩不同系统、不同年代游戏的软件。在如今众多的模拟器中,[RetroPi](https://retropie.org.uk/) 是树莓派中最受欢迎的。你可以用它来玩 Apple II、Amiga、Atari 2600、Commodore 64、Game Boy Advance 和[其他许多](https://retropie.org.uk/about/systems)游戏。
如果 RetroPi 听起来有趣,请阅读[这些说明](https://opensource.com/article/19/1/retropie)开始使用,玩得开心!
### 原生 Linux 游戏
树莓派的操作系统 Raspbian 上也有很多原生 Linux 游戏。“Make Use Of” 有一篇关于如何在树莓派上[玩 10 个老经典游戏](https://www.makeuseof.com/tag/classic-games-raspberry-pi-without-emulators/),如 Doom 和 Nuke Dukem 3D 的文章。
你也可以将树莓派用作[游戏服务器](https://www.makeuseof.com/tag/raspberry-pi-game-servers/)。例如,你可以在树莓派上安装 Terraria、Minecraft 和 QuakeWorld 服务器。
---
via: <https://opensource.com/article/19/3/play-games-raspberry-pi>
作者:[Anderson Silva](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,683 | Oomox:定制和创建你自己的 GTK2、GTK3 主题 | https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/ | 2019-04-04T11:49:03 | [
"主题"
] | https://linux.cn/article-10683-1.html | 
主题和可视化定制是 Linux 的主要优势之一。由于所有代码都是开源的,因此你可以比 Windows/Mac OS 更大程度上地改变 Linux 系统的外观和行为方式。GTK 主题可能是人们定制 Linux 桌面的最流行方式。GTK 工具包被各种桌面环境使用,如 Gnome、Cinnamon、Unity、XFC E和 budgie。这意味着为 GTK 制作的单个主题只需很少的修改就能应用于任何这些桌面环境。
有很多非常高品质的流行 GTK 主题,例如 **Arc**、**Numix** 和 **Adapta**。但是如果你想自定义这些主题并创建自己的视觉设计,你可以使用 **Oomox**。
Oomox 是一个图形应用,可以完全使用自己的颜色、图标和终端风格自定义和创建自己的 GTK 主题。它自带几个预设,你可以在 Numix、Arc 或 Materia 主题样式上创建自己的 GTK 主题。
### 安装 Oomox
在 Arch Linux 及其衍生版中:
Oomox 可以在 [AUR](https://aur.archlinux.org/packages/oomox/) 中找到,所以你可以使用任何 AUR 助手程序安装它,如 [yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/)。
```
$ yay -S oomox
```
在 Debian/Ubuntu/Linux Mint 中,在[这里](https://github.com/themix-project/oomox/releases)下载 `oomox.deb` 包并按如下所示进行安装。在写本指南时,最新版本为 `oomox_1.7.0.5.deb`。
```
$ sudo dpkg -i oomox_1.7.0.5.deb
$ sudo apt install -f
```
在 Fedora 上,Oomox 可以在第三方 **COPR** 仓库中找到。
```
$ sudo dnf copr enable tcg/themes
$ sudo dnf install oomox
```
Oomox 也有 [Flatpak 应用](https://flathub.org/apps/details/com.github.themix_project.Oomox)。确保已按照[本指南](https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/)中的说明安装了 Flatpak。然后,使用以下命令安装并运行 Oomox:
```
$ flatpak install flathub com.github.themix_project.Oomox
$ flatpak run com.github.themix_project.Oomox
```
对于其他 Linux 发行版,请进入 Github 上的 Oomox 项目页面(本指南末尾给出链接),并从源代码手动编译和安装。
### 自定义并创建自己的 GTK2、GTK3 主题
#### 主题定制

你可以更改几乎每个 UI 元素的颜色,例如:
1. 标题
2. 按钮
3. 标题内的按钮
4. 菜单
5. 选定的文字
在左边,有许多预设主题,如汽车主题、现代主题,如 Materia 和 Numix,以及复古主题。在窗口的顶部,有一个名为**主题样式**的选项,可让你设置主题的整体视觉样式。你可以在 Numix、Arc 和 Materia 之间进行选择。
使用某些像 Numix 这样的样式,你甚至可以更改标题渐变,边框宽度和面板透明度等内容。你还可以为主题添加黑暗模式,该模式将从默认主题自动创建。

#### 图标集定制
你可以自定义用于主题图标的图标集。有两个选项:Gnome Colors 和 Archdroid。你可以更改图标集的基础和笔触颜色。
#### 终端定制
你还可以自定义终端颜色。该应用有几个预设,但你可以为每个颜色,如红色,绿色,黑色等自定义确切的颜色代码。你还可以自动交换前景色和背景色。
#### Spotify 主题
这个应用的一个独特功能是你可以根据喜好定义 spotify 主题。你可以更改 spotify 的前景色、背景色和强调色来匹配整体的 GTK 主题。
然后,只需按下“应用 Spotify 主题”按钮,你就会看到这个窗口:

点击应用即可。
#### 导出主题
根据自己的喜好自定义主题后,可以通过单击左上角的重命名按钮重命名主题:

然后,只需点击“导出主题”将主题导出到你的系统。

你也可以只导出图标集或终端主题。
之后你可以打开桌面环境中的任何可视化自定义应用,例如基于 Gnome 桌面的 Tweaks,或者 “XFCE 外观设置”。选择你导出的 GTK 或者 shell 主题。
### 总结
如果你是一个 Linux 主题迷,并且你确切知道系统中的每个按钮、每个标题应该怎样,Oomox 值得一试。 对于极致的定制者,它可以让你几乎更改系统外观的所有内容。对于那些只想稍微调整现有主题的人来说,它有很多很多预设,所以你可以毫不费力地得到你想要的东西。
你试过吗? 你对 Oomox 有什么看法? 请在下面留言!
### 资源
* [Oomox GitHub 仓库](https://github.com/themix-project/oomox)
---
via: <https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/>
作者:[EDITOR](https://www.ostechnix.com/author/editor/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,685 | Rancher:一个全面的可用于产品环境的容器管理平台 | https://www.2daygeek.com/rancher-a-complete-container-management-platform-for-production-environment/ | 2019-04-05T11:04:00 | [
"容器",
"编排"
] | https://linux.cn/article-10685-1.html | 
Docker 作为一款容器化应用的新兴软件,被大多数 IT 公司使用来减少基础设施平台的成本。
通常,没有 GUI 的 Docker 软件对于 Linux 管理员来说很容易,但是对于开发者来就有点困难。当把它搬到生产环境上来,那么它对 Linux 管理员来说也相当不友好。那么,轻松管理 Docker 的最佳解决方案是什么呢?
唯一的办法就是提供 GUI。Docker API 允许第三方应用接入 Docker。在市场上有许多 Docker GUI 应用。我们已经写过一篇关于 Portainer 应用的文章。今天我们来讨论另一个应用,Rancher。
容器让软件开发更容易,让开发者更快的写代码、更好的运行它们。但是,在生产环境上运行容器却很困难。
**推荐阅读:** [Portainer:一个简单的 Docker 管理图形工具](https://www.2daygeek.com/portainer-a-simple-docker-management-gui/)
### Rancher 简介
[Rancher](http://rancher.com/) 是一个全面的容器管理平台,它可以让容器在各种基础设施平台的生产环境上部署和运行更容易。它提供了诸如多主机网络、全局/本地负载均衡和卷快照等基础设施服务。它整合了原生 Docker 的管理能力,如 Docker Machine 和 Docker Swarm。它提供了丰富的用户体验,让 DevOps 管理员在更大规模的生产环境上运行 Docker。
访问以下文章可以了解 Linux 系统上安装 Docker。
**推荐阅读:**
* [如何在 Linux 上安装 Docker](https://www.2daygeek.com/install-docker-on-centos-rhel-fedora-ubuntu-debian-oracle-archi-scentific-linux-mint-opensuse/)
* [如何在 Linux 上使用 Docker 镜像](https://www.2daygeek.com/list-search-pull-download-remove-docker-images-on-linux/)
* [如何在 Linux 上使用 Docker 容器](https://www.2daygeek.com/create-run-list-start-stop-attach-delete-interactive-daemonized-docker-containers-on-linux/)
* [如何在 Docker 容器内安装和运行应用](https://www.2daygeek.com/install-run-applications-inside-docker-containers/)
### Rancher 特性
* 可以在两分钟内安装 Kubernetes。
* 一键启动应用(90 个流行的 Docker 应用)。
* 部署和管理 Docker 更容易。
* 全面的生产级容器管理平台。
* 可以在生产环境上快速部署容器。
* 强大的自动部署和运营容器技术。
* 模块化基础设施服务。
* 丰富的编排工具。
* Rancher 支持多种认证机制。
### 怎样安装 Rancher
由于 Rancher 是以轻量级的 Docker 容器方式运行,所以它的安装非常简单。Rancher 是由一组 Docker 容器部署的。只需要简单的启动两个容器就能运行 Rancher。一个容器用作管理服务器,另一个容器在各个节点上作为代理。在 Linux 系统下简单的运行下列命令就能部署 Rancher。
Rancher 服务器提供了两个不同的安装包标签如 `stable` 和 `latest`。下列命令将会拉取适合的 Rancher 镜像并安装到你的操作系统上。Rancher 服务器仅需要两分钟就可以启动。
* `latest`:这个标签是他们的最新开发构建。这些构建将通过 Rancher CI 的自动化框架进行验证,不建议在生产环境使用。
* `stable`:这是最新的稳定发行版本,推荐在生产环境使用。
Rancher 的安装方法有多种。在这篇教程中我们仅讨论两种方法。
* 以单一容器的方式安装 Rancher(内嵌 Rancher 数据库)
* 以单一容器的方式安装 Rancher(外部数据库)
### 方法 - 1
运行下列命令以单一容器的方式安装 Rancher 服务器(内嵌数据库)
```
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server:stable
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server:latest
```
### 方法 - 2
你可以在启动 Rancher 服务器时指向外部数据库,而不是使用自带的内部数据库。首先创建所需的数据库,数据库用户为同一个。
```
> CREATE DATABASE IF NOT EXISTS cattle COLLATE = 'utf8_general_ci' CHARACTER SET = 'utf8';
> GRANT ALL ON cattle.* TO 'cattle'@'%' IDENTIFIED BY 'cattle';
> GRANT ALL ON cattle.* TO 'cattle'@'localhost' IDENTIFIED BY 'cattle';
```
运行下列命令启动 Rancher 去连接外部数据库。
```
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server \
--db-host myhost.example.com --db-port 3306 --db-user username --db-pass password --db-name cattle
```
如果你想测试 Rancher 2.0,使用下列的命令去启动。
```
$ sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/server:preview
```
### 通过 GUI 访问 & 安装 Rancher
浏览器输入 `http://hostname:8080` 或 `http://server_ip:8080` 去访问 rancher GUI.

### 怎样注册主机
注册你的主机 URL 允许它连接到 Rancher API。这是一次性设置。
接下来,点击主菜单下面的 “Add a Host” 链接或者点击主菜单上的 “INFRASTRUCTURE >> Add Hosts”,点击 “Save” 按钮。

默认情况下,Rancher 里的访问控制认证禁止了访问,因此我们首先需要通过一些方法打开访问控制认证,否则任何人都不能访问 GUI。
点击 “>> Admin >> Access Control”,输入下列的值最后点击 “Enable Authentication” 按钮去打开它。在我这里,是通过 “local authentication” 的方式打开的。
* “Login UserName”: 输入你期望的登录名
* “Full Name”: 输入你的全名
* “Password”: 输入你期望的密码
* “Confirm Password”: 再一次确认密码

注销然后使用新的登录凭证重新登录:

现在,我能看到本地认证已经被打开。

### 怎样添加主机
注册你的主机后,它将带你进入下一个页面,在那里你能选择不同云服务提供商的 Linux 主机。我们将添加一个主机运行 Rancher 服务,因此选择“custom”选项然后输入必要的信息。
在第 4 步输入你服务器的公有 IP,运行第 5 步列出的命令,最后点击 “close” 按钮。
```
$ sudo docker run -e CATTLE_AGENT_IP="192.168.56.2" --rm --privileged -v /var/run/docker.sock:/var/run/docker.sock -v /var/lib/rancher:/var/lib/rancher rancher/agent:v1.2.11 http://192.168.56.2:8080/v1/scripts/16A52B9BE2BAB87BB0F5:1546214400000:ODACe3sfis5V6U8E3JASL8jQ
INFO: Running Agent Registration Process, CATTLE_URL=http://192.168.56.2:8080/v1
INFO: Attempting to connect to: http://192.168.56.2:8080/v1
INFO: http://192.168.56.2:8080/v1 is accessible
INFO: Configured Host Registration URL info: CATTLE_URL=http://192.168.56.2:8080/v1 ENV_URL=http://192.168.56.2:8080/v1
INFO: Inspecting host capabilities
INFO: Boot2Docker: false
INFO: Host writable: true
INFO: Token: xxxxxxxx
INFO: Running registration
INFO: Printing Environment
INFO: ENV: CATTLE_ACCESS_KEY=9946BD1DCBCFEF3439F8
INFO: ENV: CATTLE_AGENT_IP=192.168.56.2
INFO: ENV: CATTLE_HOME=/var/lib/cattle
INFO: ENV: CATTLE_REGISTRATION_ACCESS_KEY=registrationToken
INFO: ENV: CATTLE_REGISTRATION_SECRET_KEY=xxxxxxx
INFO: ENV: CATTLE_SECRET_KEY=xxxxxxx
INFO: ENV: CATTLE_URL=http://192.168.56.2:8080/v1
INFO: ENV: DETECTED_CATTLE_AGENT_IP=172.17.0.1
INFO: ENV: RANCHER_AGENT_IMAGE=rancher/agent:v1.2.11
INFO: Launched Rancher Agent: e83b22afd0c023dabc62404f3e74abb1fa99b9a178b05b1728186c9bfca71e8d
```

等待几秒钟后新添加的主机将会出现。点击 “Infrastructure >> Hosts” 页面。

### 怎样查看容器
只需要点击下列位置就能列出所有容器。点击 “Infrastructure >> Containers” 页面。

### 怎样创建容器
非常简单,只需点击下列位置就能创建容器。
点击 “Infrastructure >> Containers >> Add Container” 然后输入每个你需要的信息。为了测试,我将创建一个 `latest` 标签的 CentOS 容器。

在同样的列表位置,点击 “ Infrastructure >> Containers”。

点击容器名展示容器的性能信息,如 CPU、内存、网络和存储。

选择特定容器,然后点击最右边的“三点”按钮或者点击“Actions”按钮对容器进行管理,如停止、启动、克隆、重启等。

如果你想控制台访问容器,只需要点击 “Actions” 按钮中的 “Execute Shell” 选项即可。

### 怎样从应用目录部署容器
Rancher 提供了一个应用模版目录,让部署变的很容易,只需要单击一下就可以。 它维护了多数流行应用,这些应用由 Rancher 社区贡献。

点击 “Catalog >> All >> Choose the required application”,最后点击 “Launch” 去部署。

---
via: <https://www.2daygeek.com/rancher-a-complete-container-management-platform-for-production-environment/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 译者:[arrowfeng](https://github.com/arrowfeng) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,687 | 树莓派使用入门:进入物理世界 —— 如何使用树莓派的 GPIO 针脚 | https://opensource.com/article/19/3/gpio-pins-raspberry-pi | 2019-04-05T22:48:46 | [
"树莓派",
"GPIO"
] | https://linux.cn/article-10687-1.html |
>
> 在树莓派使用入门的第十篇文章中,我们将学习如何使用 GPIO。
>
>
>

到目前为止,本系列文章主要专注于树莓派的软件方面,而今天我们将学习硬件。在树莓派最初发布时,最让我感兴趣的主要特性之一就是它的 [通用输入输出](https://www.raspberrypi.org/documentation/usage/gpio/)(GPIO)针脚。GPIO 可以让你的树莓派程序与连接到它上面的传感器、继电器、和其它类型的电子元件与物理世界来交互。

树莓派上的每个 GPIO 针脚要么有一个预定义的功能,要么被设计为通用的。另外,不同的树莓派型号要么 26 个,要么有 40 个 GPIO 针脚,你可以根据情况使用的。在维基百科上有一个 [关于每个针脚的非常详细的说明](https://en.wikipedia.org/wiki/Raspberry_Pi#General_purpose_input-output_(GPIO)_connector) 以及它的功能介绍。
你可以使用树莓派的 GPIO 针脚做更多的事情。关于它的 GPIO 的使用我写过一些文章,包括使用树莓派来控制节日彩灯的三篇文章([第一篇](https://opensource.com/life/15/2/music-light-show-with-raspberry-pi)、 [第二篇](https://opensource.com/life/15/12/ssh-your-christmas-tree-raspberry-pi)、和 [第三篇](https://opensource.com/article/18/12/lightshowpi-raspberry-pi)),在这些文章中我通过使用开源程序让灯光随着音乐起舞。
树莓派社区在用不同编程语言创建不同的库方面做了非常好的一些工作,因此,你能够使用 [C](https://www.bigmessowires.com/2018/05/26/raspberry-pi-gpio-programming-in-c/)、[Python](https://www.raspberrypi.org/documentation/usage/gpio/python/README.md)、 [Scratch](https://www.raspberrypi.org/documentation/usage/gpio/scratch2/README.md) 和其它语言与 GPIO 进行交互。
另外,如果你想在树莓派与物理世界交互方面获得更好的体验,你可以选用 [Raspberry Pi Sense Hat](https://opensource.com/life/16/4/experimenting-raspberry-pi-sense-hat),它是插入树莓派 GPIO 针脚上的一个很便宜的电路板,借助它你可以通过程序与 LED、驾驶杆、气压计、温度计、温度计、 陀螺仪、加速度计以及磁力仪来交互。
---
via: <https://opensource.com/article/19/3/gpio-pins-raspberry-pi>
作者:[Anderson Silva](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Until now, this series has focused on the Raspberry Pi's software side, but today we'll get into the hardware. The availability of [general-purpose input/output](https://www.raspberrypi.org/documentation/usage/gpio/) (GPIO) pins was one of the main features that interested me in the Pi when it first came out. GPIO allows you to programmatically interact with the physical world by attaching sensors, relays, and other types of circuitry to the Raspberry Pi.

Each pin on the board either has a predefined function or is designated as general purpose. Also, different Raspberry Pi models have either 26 or 40 pins for you to use at your discretion. Wikipedia has a [good overview of each pin](https://en.wikipedia.org/wiki/Raspberry_Pi#General_purpose_input-output_(GPIO)_connector) and its functionality.
You can do many things with the Pi's GPIO pins. I've written some other articles about using the GPIOs, including a trio of articles ([Part I](https://opensource.com/life/15/2/music-light-show-with-raspberry-pi), [Part II](https://opensource.com/life/15/12/ssh-your-christmas-tree-raspberry-pi), and [Part III](https://opensource.com/article/18/12/lightshowpi-raspberry-pi)) about controlling holiday lights with the Raspberry Pi while using open source software to pair the lights with music.
The Raspberry Pi community has done a great job in creating libraries in different programming languages, so you should be able to interact with the pins using [C](https://www.bigmessowires.com/2018/05/26/raspberry-pi-gpio-programming-in-c/), [Python](https://www.raspberrypi.org/documentation/usage/gpio/python/README.md), [Scratch](https://www.raspberrypi.org/documentation/usage/gpio/scratch2/README.md), and other languages.
Also, if you want the ultimate experience to interact with the physical world, pick up a [Raspberry Pi Sense Hat](https://opensource.com/life/16/4/experimenting-raspberry-pi-sense-hat). It is an affordable expansion board for the Pi that plugs into the GPIO pins so you can programmatically interact with LEDs, joysticks, and barometric pressure, temperature, humidity, gyroscope, accelerometer, and magnetometer sensors.
## Comments are closed. |
10,688 | 加密邮件服务 Tutanota 现在有桌面应用了 | https://itsfoss.com/tutanota-desktop | 2019-04-06T15:20:26 | [
"邮件",
"加密"
] | https://linux.cn/article-10688-1.html | 
[Tutanota](https://itsfoss.com/tutanota-review/) 最近[宣布](https://tutanota.com/blog/posts/desktop-clients/)发布针对其电子邮件服务的桌面应用。该 Beta 版适用于 Linux、Windows 和 macOS。
### 什么是 Tutanota?
网上有大量免费的、带有广告的电子邮件服务。但是,大多数电子邮件服务并不完全安全或在意隐私。在这个后[斯诺登](https://en.wikipedia.org/wiki/Edward_Snowden)世界中,[Tutanota](https://tutanota.com/) 提供了免费、安全的电子邮件服务,它专注于隐私。
Tutanota 有许多引人注目的功能,例如:
* 端到端加密邮箱
* 端到端加密地址簿
* 用户之间自动端到端加密邮件
* 通过分享密码将端到端加密电子邮件发送到任何电子邮件地址
* 安全密码重置,使 Tutanota 完全无法访问
* 从发送和接收的电子邮件中去除 IP 地址
* 运行 Tutanota 的代码是[开源](https://tutanota.com/blog/posts/open-source-email)的
* 双因子身份验证
* 专注于隐私
* 加盐的密码,并本地使用 Bcrypt 哈希
* 位于德国的安全服务器
* 支持 PFS、DMARC、DKIM、DNSSEC 和 DANE 的 TLS
* 本地执行加密数据的全文搜索

*web 中的 Tutanota*
你可以[免费注册一个帐户](https://tutanota.com/pricing)。你还可以升级帐户获取其他功能,例如自定义域、自定义域登录、域规则、额外的存储和别名。他们还提供企业帐户。
Tutanota 也可以在移动设备上使用。事实上,它的 [Android 应用也是开源的](https://itsfoss.com/tutanota-fdroid-release/)。
这家德国公司计划扩展邮件之外的其他业务。他们希望提供加密的日历和云存储。你可以通过 PayPal 和加密货币[捐赠](https://tutanota.com/community)帮助他们实现目标。
### Tutanota 的新桌面应用
Tutanota 在去年圣诞节前宣布了桌面应用的 [Beta 版](https://tutanota.com/blog/posts/desktop-clients/)。该应用基于 [Electron](https://electronjs.org/)。

*Tutanota 桌面应用*
他们选择 Electron 的原因:
* 以最小的成本支持三个主流操作系统。
* 快速调整新桌面客户端,使其与添加到网页客户端的新功能一致。
* 将开发时间留给桌面功能,例如离线可用、电子邮件导入,将同时在所有三个桌面客户端中提供。
由于这是 Beta 版,因此应用中缺少一些功能。Tutanota 的开发团队正在努力添加以下功能:
* 电子邮件导入和与外部邮箱同步。这将“使 Tutanota 能够从外部邮箱导入电子邮件,并在将数据存储在 Tutanota 服务器上之前在设备本地加密数据。”
* 电子邮件的离线可用
* 双因子身份验证
### 如何安装 Tutanota 桌面客户端?

*在 Tutanota 中写邮件*
你可以直接从 Tutanota 的网站[下载](https://tutanota.com/blog/posts/desktop-clients/) Beta 版应用。它们有[适用于 Linux 的 AppImage 文件](https://itsfoss.com/use-appimage-linux/)、适用于 Windows 的 .exe 文件和适用于 macOS 的 .app 文件。你可以将你遇到的任何 bug 发布到 Tutanota 的 [GitHub 帐号中](https://github.com/tutao/tutanota)。
为了证明应用的安全性,Tutanota 签名了每个版本。“签名确保桌面客户端以及任何更新直接来自我们且未被篡改。”你可以使用 Tutanota 的 [GitHub 页面](https://github.com/tutao/tutanota/blob/master/buildSrc/installerSigner.js)来验证签名。
请记住,你需要先创建一个 Tutanota 帐户才能使用它。该邮件客户端设计上只能用在 Tutanota。
### 总结
我在 Linux Mint MATE 上测试了 Tutanota 的邮件应用。正如所料,它是网络应用的镜像。同时,我发现桌面应用和 Web 应用程序之间没有任何区别。我目前觉得使用该应用的唯一场景是在自己的窗口中使用。
你曾经使用过 [Tutanota](https://tutanota.com/polo/) 么?如果没有,你最喜欢的关心隐私的邮件服务是什么?请在下面的评论中告诉我们。
如果你觉得这篇文章很有趣,请花些时间在社交媒体上分享。
---
via: <https://itsfoss.com/tutanota-desktop>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,689 | 区块链 2.0:重新定义金融服务(三) | https://www.ostechnix.com/blockchain-2-0-redefining-financial-services/ | 2019-04-06T17:03:00 | [
"区块链"
] | https://linux.cn/article-10689-1.html | 
[本系列的前一篇文章](/article-10668-1.html)侧重于建立背景,以阐明为什么将现有的金融系统向充满未来主义的[区块链](/article-10650-1.html)体系迈进是“货币”改革的下一个自然步骤。我们将继续了解哪些区块链特性将有助于这一迁移。但是,金融市场十分复杂,并且人们的交易由众多组成部分组成,而不仅仅是货币。
本部分将探索哪些区块链特性能够让金融机构向区块链平台迁移,并将传统银行和金融系统与其合并。如之前讨论证明的那样,如果有足够的人参与到给定的区块链网络并且支持交易协议,则赋给“代币”的面值将提升并变得更稳定。以比特币(BTC)为例,就和我们习惯使用的纸币一样,像比特币和以太币这样的加密货币,都可以用于所有前者的目的,从购买食物到船只,乃至贷款和购买保险。
事实上,你所涉及的银行或其他金融机构很可能已经[利用了区块链分类账本技术](https://www.forbes.com/sites/bernardmarr/2018/01/22/35-amazing-real-world-examples-of-how-blockchain-is-changing-our-world/#170df8de43b5)。金融行业中区块链技术最显著的用途是建立支付基础设施、基金交易技术和数字身份管理。传统上,后两者是由金融服务业传统的系统处理的。但由于区块链处理上的效率,这些系统正逐渐的向区块链迁移合并。区块链还为这些金融服务业的公司提供了高质量的数据分析解决方案,这一方面之所以能够快速的得到重视,主要得益于最近的数据科学的发展。
从这一领域前沿阵地的初创企业和项目入手考察,区块链似乎能有所保证,因为这些企业或项目的产品已经开始在市场上扩展开来。
PayPal,这是一家创建于 1998 年的在线支付公司,现为此类平台中最大的一个,常被视作运营和技术能力的基准。PayPal 很大程度上派生自现有的货币体系。它的创新贡献来自于如何收集并利用消费者数据,以提供即时的在线服务。如今,在线交易已被认为是理所当然的事,其所基于的技术方面,在该行业里的创新极少。拥有坚实的基础是一件好事,但在快速发展的 IT 行业里并不能提供任何竞争力,毕竟每天都有新的标准和新的技术。2014 年,PayPal 子公司 **Braintree** [宣布](https://publicpolicy.paypal-corp.com/issues/blockchain)与流行的加密货币支付方案解决商 [Coinbase](https://blog.coinbase.com/coinbase-adds-support-for-paypal-and-credit-cards-21968661d508) 和 **GoCoin** 建立了合作关系,以便逐步将比特币和其它加密货币整合到它们的服务平台上。这基本上给了加密货币支付方案解决商的消费者在 PayPal 可靠且熟悉的平台下探索和体验的一个机会。事实上,打车公司 **Uber** 和 Braintree 具有独家合作关系,允许消费者在打车的时候使用比特币。
**瑞波(Ripple)** 正在让人们在多个区块链之间的操作变得更简单。瑞波已经成为美国各地区银行向前发展的头条新闻,比如,在不需要第三方中介的情况下,将资金双边转移给其他地区银行,从而降低了成本和时间管理费用。[瑞波的 Codius 平台](http://fortune.com/2018/06/06/ripple-codius/)允许区块链之间互相操作,并为智能合约编入系统提供了方便之门,以最大限度地减少篡改和混乱。建立在这种先进、安全并且可根据需要扩展的平台上,瑞波拥有像瑞银和[渣打银行](https://www.finextra.com/newsarticle/32048/standard-chartered-to-extend-use-of-ripplenet-to-more-countries) 在内的客户列表,更多的银行客户也在期待加入。
**Kraken**,是一个在全球各地运营的美国加密货币交易所,因其可靠的**加密货币量**估算而闻名,甚至向彭博终端实时提供比特币定价数据。在 2015 年,[他们与菲多尔银行](https://99bitcoins.com/fidor-and-kraken-team-up-for-cryptocurrency-bank/)合作建立世界上第一个提供银行业务和加密货币交易的加密货币银行。
另一家金融科技公司 [Circle](https://www.bloomberg.com/research/stocks/private/snapshot.asp?privcapId=249292386) 则是目前同类公司中规模最大的一家,允许用户投资和交易加密货币衍生资产,类似于传统的货币市场资产。
如今,像 [Wyre](https://www.forbes.com/sites/julianmitchell/2018/07/31/wyre-the-blockchain-platform-taking-the-lead-in-cross-border-transactions/#6bc69ade69d7) 和 **Stellar** 这样的公司已经将国际电汇的提前期从平均 3 天降到了 6 小时。有人声称,一旦建立了适当的监管体系,同样的 6 小时可以缩短至几秒钟。
虽然现在上述内容集中在相关的初创项目上,但是不应忽视更受尊敬的老派金融机构的影响力和能力。这些全球范围内交易量达数十亿美元,已经存在了数十年乃至上百年的机构,在利用区块链及其潜力上有着相当的兴趣。
前面的文章中我们已经提到,**摩根大通**最近披露了他们在开发加密货币和企业级别的区块链基础分类帐本上的计划。该项目被称为 [Quorum](https://www.jpmorgan.com/global/Quorum),被定义为 **“企业级分布式分类帐和智能合约平台”**。这一平台的主要目标是将大量的银行操作逐渐的迁移到 Quorum 中,从而削减像摩根大通这样的公司在保证隐私、安全和透明度上的重大开销。他们声称自己是行业中唯一完整拥有全部的区块链、协议和代币系统的玩家。他们也发布了一个称为 **JPM 硬币** 的加密货币,用于大额即时结算。JPM 硬币是由摩根大通等主要银行支持的首批“稳定币”。稳定币是其价格与现存主要货币系统相关联的加密货币。Quorum 也因其每秒几近 100 次远高于同行的交易量而倍受吹捧,这远远领先于同时代。
据报道,英国跨国金融巨头巴克莱已经[注册了两项基于区块链的专利](https://cointelegraph.com/news/barclays-files-two-digital-currency-and-blockchain-patents-with-u-s-patent-office),旨在简化资金转移和 KYC 规程。巴克莱更多的是旨在提高自身的银行操作效率。其中一个应用是创建一个私有区块链网络,用于存储客户的 KYC 信息。经过验证、存储和确认后,这些详细信息将不可变,并且无需再进一步验证。若能实施这一应用,该协议将取消对 KYC 信息多次验证的需求。像印度这样有着高密度人口的发展中国家,其中大部分人口的 KYC 信息尚未被引入正式的银行系统中,若能引入这种具有革新意义的 KYC 系统,将有助于减少随机错误并减少交付时间。据传,巴克莱同时也在探索区块链系统的功能,以便解决信用状态评级和保险赔偿问题。
这种以区块链作支撑的系统,被用来消除不必要的维护成本,并利用智能合约来为那些需要慎重、安全和速度的企业在行业内赢得竞争力。这些企业产品建立在一个能够确保完整交易以及合同隐私的协议之上,同时建立了可使腐败和贿赂无效的共识机制。
[普华永道 2017 年的全球金融科技报告](https://www.pwc.com/jg/en/media-release/global-fintech-survey-2017.html)表示到 2020 年,所有金融科技公司中约有 77% 将转向基于区块链的技术和流程。高达 90% 的受访者表示他们计划在 2020 年之前将区块链技术作为生产系统的一部分。他们的判断没错,因为从监管的角度来看,通过转移到基于区块链的系统上,可以确保显著的成本节约和透明度增加。
由于区块链平台默认内置了监管能力,因此企业从传统系统迁移到运行区块链分类账本的现代网络也是行业监管机构所欢迎的举措。交易和贸易运动可以一劳永逸地进行验证和跟踪。从长远来看,这可能会带来更好的监管和风险管理,更不用说改善了公司和个人的责任。
虽然对跨越式创新的投资是由企业进行的大量投资顺带所致,但如果认为这些措施不会渗透到最终用户的利益中是具有误导性的。随着银行和金融机构开始采用区块链,这将为他们带来更多的成本节约和效率,而这最终也将对终端消费者有利。透明度和欺诈保护带来的额外好处将改善客户的感受,更重要的是提高人们对银行和金融系统的信任。通过区块链及其与传统服务的整合,金融服务行业急需的革命将成为可能。 在本系列的下一部分中,我们将讨论[房地产中的区块链](https://www.ostechnix.com/blockchain-2-0-blockchain-in-real-estate/)。
---
via: <https://www.ostechnix.com/blockchain-2-0-redefining-financial-services/>
作者:[ostechnix](https://www.ostechnix.com/author/editor/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[sanfusu](https://github.com/sanfusu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,690 | 树莓派使用入门:通过树莓派和 kali Linux 学习计算机安全 | https://opensource.com/article/19/3/computer-security-raspberry-pi | 2019-04-07T10:16:12 | [
"树莓派",
"安全"
] | https://linux.cn/article-10690-1.html |
>
> 树莓派是学习计算机安全的一个好方法。在我们这个系列的第十一篇文章中会进行学习。
>
>
>

在技术方面是否有比保护你的计算机更热门的话题?一些专家会告诉你,没有绝对安全的系统。他们开玩笑说,如果你想要你的服务器或者应用程序真正的安全,就关掉你的服务器,从网络上断线,然后把它放在一个安全的地方。但问题是显而易见的:没人能用的应用程序或者服务器有什么用?
这是围绕安全的一个难题,我们如何才能在保证安全性的同时,让服务器或应用程序依然可用且有价值?我无论如何都不是一个安全专家,虽然我希望有一天我能是。因此,分享可以用树莓派来做些什么以学习计算机安全的知识,我认为是有意义的。
我要提示一下,就像本系列中其他写给树莓派初学者的文章一样,我的目标不是深入研究,而是起个头,让你有兴趣去了解更多与这些主题相关的东西。
### Kali Linux
当我们谈到“做一些安全方面的事”的时候,出现在脑海中的一个 Linux 发行版就是 [Kali Linux](https://www.kali.org/)。Kali Linux 的开发主要集中在调查取证和渗透测试方面。它有超过 600 个已经预先安装好了的用来测试你的计算机的安全性的[渗透测试工具](https://en.wikipedia.org/wiki/Kali_Linux#Development),还有一个[取证模式](https://docs.kali.org/general-use/kali-linux-forensics-mode),它可以避免自身接触到被检查系统的内部的硬盘驱动器或交换空间。

就像 Raspbian 一样,Kali Linux 基于 Debian 的发行版,你可以在 Kali 的主要[文档门户](https://docs.kali.org/kali-on-arm/install-kali-linux-arm-raspberry-pi)的网页上找到将它安装在树莓派上的文档。如果你已经在你的树莓派上安装了 Raspbian 或者是其它的 Linux 发行版。那么你装 Kali 应该是没问题的,Kali 的创造者甚至将[培训、研讨会和职业认证](https://www.kali.org/penetration-testing-with-kali-linux/)整合到了一起,以此来帮助提升你在安全领域内的职业生涯。
### 其他的 Linux 发行版
大多数的标准 Linux 发行版,比如 Raspbian、Ubuntu 和 Fedora 这些,在它们的仓库里同样也有[很多可用的安全工具](https://linuxblog.darkduck.com/2019/02/9-best-linux-based-security-tools.html)。一些很棒的探测工具你可以试试,包括 [Nmap](https://nmap.org/)、[Wireshark](https://www.wireshark.org/)、[auditctl](https://linux.die.net/man/8/auditctl),和 [SELinux](https://opensource.com/article/18/7/sysadmin-guide-selinux)。
### 项目
你可以在树莓派上运行很多其他的安全相关的项目,例如[蜜罐](https://trustfoundry.net/honeypi-easy-honeypot-raspberry-pi/),[广告拦截器](https://pi-hole.net/)和 [USB 清洁器](https://www.circl.lu/projects/CIRCLean/)。花些时间了解它们!
---
via: <https://opensource.com/article/19/3/computer-security-raspberry-pi>
作者:[Anderson Silva](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Is there a hotter topic in technology than securing your computer? Some experts will tell you that there is no such thing as perfect security. They joke that if you want your server or application to be truly secure, then turn off your server, unplug it from the network, and put it in a safe somewhere. The problem with that should be obvious: What good is an app or server that nobody can use?
That's the conundrum around security. How can we make something secure enough and still usable and valuable? I am not a security expert by any means, although I hope to be one day. With that in mind, I thought it would make sense to share some ideas about what you can do with a Raspberry Pi to learn more about security.
I should note that, like the other articles in this series dedicated to Raspberry Pi beginners, my goal is not to dive in deep, rather to light a fire of interest for you to learn more about these topics.
## Kali Linux
When it comes to "doing security things," one of the Linux distributions that comes to mind is [Kali Linux](https://www.kali.org/). Kali's development is primarily focused on forensics and penetration testing. It has more than 600 preinstalled [penetration-testing programs](https://en.wikipedia.org/wiki/Kali_Linux#Development) to test your computer's security, and a [forensics mode](https://docs.kali.org/general-use/kali-linux-forensics-mode), which prevents it from touching the internal hard drive or swap space of the system being examined.
Like Raspbian, Kali Linux is based on the Debian distribution, and you can find directions on installing it on the Raspberry Pi in its main [documentation portal](https://docs.kali.org/kali-on-arm/install-kali-linux-arm-raspberry-pi). If you installed Raspbian or another Linux distribution on your Raspberry Pi, you should have no problem installing Kali. Kali Linux's creators have even put together [training, workshops, and certifications](https://www.kali.org/penetration-testing-with-kali-linux/) to help boost your career in the security field.
## Other Linux distros
Most standard Linux distributions, like Raspbian, Ubuntu, and Fedora, also have [many security tools available](https://linuxblog.darkduck.com/2019/02/9-best-linux-based-security-tools.html) in their repositories. Some great tools to explore include [Nmap](https://nmap.org/), [Wireshark](https://www.wireshark.org/), [auditctl](https://linux.die.net/man/8/auditctl), and [SELinux](https://opensource.com/article/18/7/sysadmin-guide-selinux).
## Projects
There are many other security-related projects you can run on your Raspberry Pi, such as [Honeypots](https://trustfoundry.net/honeypi-easy-honeypot-raspberry-pi/), [Ad blockers](https://pi-hole.net/), and [USB sanitizers](https://www.circl.lu/projects/CIRCLean/). Take some time and learn about them!
## Comments are closed. |
10,691 | 2019 年最好的 7 款虚拟私人网络服务 | https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/ | 2019-04-07T10:43:03 | [
"VPN"
] | https://linux.cn/article-10691-1.html | 在过去三年中,全球至少有 67% 的企业面临着数据泄露,亿万用户受到影响。研究表明,如果事先对数据安全采取最基本的保护措施,那么预计有 93% 的安全问题是可以避免的。
糟糕的数据安全会带来极大的代价,特别是对企业而言。它会大致大规模的破坏并影响你的品牌声誉。尽管有些企业可以艰难地收拾残局,但仍有一些企业无法从事故中完全恢复。不过现在,你很幸运地可以得到数据及网络安全软件。

到了 2019 年,你可以通过**虚拟私人网络**,也就是我们熟知的 **VPN** 来保护你免受网络攻击。当涉及到在线隐私和安全时,常常存在许多不确定因素。有数百个不同的 VPN 提供商,选择合适的供应商也同时意味着在定价、服务和易用性之间谋取恰当的平衡。
如果你正在寻找一个可靠的 100% 经过测试和安全的 VPN,你可能需要进行详尽的调查并作出最佳选择。这里为你提供在 2019 年 7 款最好用并经过测试的 VPN 服务。
### 1、Vpnunlimitedapp
通过 VPN Unlimited,你的数据安全将得到全面的保障。此 VPN 允许你连接任何 WiFi ,而无需担心你的个人数据可能被泄露。你的数据通过 AES-256 算法加密,保护你不受第三方和黑客的窥探。无论你身处何处,这款 VPN 都可确保你在所有网站上保持匿名且不受跟踪。它提供 7 天的免费试用和多种协议支持:openvpn、IKEv2 和 KeepSolidWise。有特殊需求的用户会获得特殊的额外服务,如个人服务器、终身 VPN 订阅和个人 IP 选项。
### 2、VPN Lite
VPN Lite 是一款易于使用而且**免费**的用于上网的 VPN 服务。你可以通过它在网络上保持匿名并保护你的个人隐私。它会模糊你的 IP 并加密你的数据,这意味着第三方无法跟踪你的所有线上活动。你还可以访问网络上的全部内容。使用 VPN Lite,你可以访问在被拦截的网站。你还放心地可以访问公共 WiFi 而不必担心敏感信息被间谍软件窃取和来自黑客的跟踪和攻击。
### 3、HotSpot Shield
这是一款在 2005 年推出的大受欢迎的 VPN。这套 VPN 协议至少被全球 70% 的数据安全公司所集成,并在全球有数千台服务器。它提供两种免费模式:一种为完全免费,但会有线上广告;另一种则为七天试用。它提供军事级的数据加密和恶意软件防护。HotSpot Shield 保证网络安全并保证高速网络。
### 4、TunnelBear
如果你是一名 VPN 新手,那么 TunnelBear 将是你的最佳选择。它带有一个用户友好的界面,并配有动画熊引导。你可以在 TunnelBear 的帮助下以极快的速度连接至少 22 个国家的服务器。它使用 **AES 256-bit** 加密算法,保证无日志记录,这意味着你的数据将得到保护。你还可以在最多五台设备上获得无限流量。
### 5、ProtonVPN
这款 VPN 为你提供强大的优质服务。你的连接速度可能会受到影响,但你也可以享受到无限流量。它具有易于使用的用户界面,提供多平台兼容。 ProtonVPN 的服务据说是因为为种子下载提供了优化因而无法访问 Netflix。你可以获得如协议和加密等安全功能来保证你的网络安全。
### 6、ExpressVPN
ExpressVPN 被认为是最好的用于接触封锁和保护隐私的离岸 VPN。凭借强大的客户支持和快速的速度,它已成为全球顶尖的 VPN 服务。它提供带有浏览器扩展和自定义固件的路由。 ExpressVPN 拥有一系列令人赞叹高质量应用程序,配有大量的服务器,并且最多只能支持三台设备。
ExpressVPN 并不是完全免费的,恰恰相反,正是由于它所提供的高质量服务而使之成为了市场上最贵的 VPN 之一。ExpressVPN 有 30 天内退款保证,因此你可以免费试用一个月。好消息是,这是完全没有风险的。例如,如果你在短时间内需要 VPN 来绕过在线审查,这可能是你的首选解决方案。用过它之后,你就不会随意想给一个会发送垃圾邮件、缓慢的免费的程序当成试验品。
ExpressVPN 也是享受在线流媒体和户外安全的最佳方式之一。如果你需要继续使用它,你只需要续订或取消你的免费试用。ExpressVPN 在 90 多个国家架设有 2000 多台服务器,可以解锁 Netflix,提供快速连接,并为用户提供完全隐私。
### 7、PureVPN
虽然 PureVPN 可能不是完全免费的,但它却是此列表中最实惠的一个。用户可以注册获得 7 天的免费试用,并在之后选择任一付费计划。通过这款 VPN,你可以访问到至少 140 个国家中的 750 余台服务器。它还可以在几乎所有设备上轻松安装。它的所有付费特性仍然可以在免费试用期间使用。包括无限数据流量、IP 泄漏保护和 ISP 不可见性。它支持的系统有 iOS、Android、Windows、Linux 和 macOS。
### 总结
如今,可用的免费 VPN 服务越来越多,为什么不抓住这个机会来保护你自己和你的客户呢?在了解到有那么多优秀的 VPN 服务后,我们知道即使是最安全的免费服务也不一定就完全没有风险。你可能需要付费升级到高级版以增强保护。高级版的 VPN 为你提供了免费试用,提供无风险退款保证。无论你打算花钱购买 VPN 还是准备使用免费 VPN,我们都强烈建议你使用一个。
**关于作者:**
**Renetta K. Molina** 是一个技术爱好者和健身爱好者。她撰写有关技术、应用程序、 WordPress 和其他任何领域的文章。她喜欢在空余时间打高尔夫球和读书。她喜欢学习和尝试新事物。
---
via: <https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/>
作者:[Editor](https://www.ostechnix.com/author/editor/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Modrisco](https://github.com/Modrisco) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,693 | 更开放的分布式事务 | Fescar 品牌升级,更名为 Seata | https://tech.antfin.com/open-source?chInfo=zx | 2019-04-08T11:52:00 | [
"分布式",
"事务",
"Seata"
] | https://linux.cn/article-10693-1.html | 
Thanks, Fescar ️
Hello, Seata ?
升级后,一起再出发。
近日,分布式事务 Fescar 更名为 Seata。在 GitHub 上的项目地址相应的变更成: <https://github.com/seata/seata>。
### 分布式事务产生背景
随着互联网技术快速发展,数据规模增大,分布式系统越来越普及,采用分布式数据库或者跨多个数据库的应用在中大规模企业普遍存在,而一个业务活动执行过程中可能会被意外中断(比如网络超时、数据库超时、机器重启、机器宕机等),我们很难保证一个业务活动的所有操作能 100% 全部成功。因此,微服务化过程中急需一种能保证业务一致性的方案,分布式事务应运而生。
### 分布式事务在阿里巴巴和蚂蚁金服的发展历程
作为覆盖金融、云计算、新零售等多重领域的阿里经济体两端,蚂蚁金服和阿里巴巴在分布式事务上共同发力,在内部技术架构的演进中沉淀实践经验,通过不断的技术迭代支撑高速增长的 618、双十一等高并发业务场景。2007 开始,蚂蚁金服自主研发分布式事务中间件 XTS(eXtended Transaction Service),在内部广泛应用并解决金融核心场景下的跨数据库、跨服务数据一致性问题,最终以 DTX(Distributed Transaction eXtended)的云产品化展现并对外开放。与此同时,阿里巴巴中间件团队发布 TXC(Taobao Transaction Constructor),为集团内应用提供分布式事务服务,经过多年的技术沉淀,于 2016 年产品化改造为 GTS(Global Transaction Service),通过阿里云解决方案在众多外部客户中落地实施。
2019 年 1 月,基于技术积累,阿里巴巴中间件团队发起了开源项目 Fescar(Fast & EaSy Commit And Rollback, Fescar),和社区一起共建分布式事务解决方案。Fescar 为解决微服务架构下的分布式事务问题交出了一份与众不同的答卷。而 Fescar 的愿景是让分布式事务的使用像本地事务的使用一样简单和高效。最终的目标是希望可以让 Fescar 适用于所有的分布式事务场景。
为了达到适用于更多的分布式事务业务场景的目标,蚂蚁金服加入 Fescar 社区共建,在 Fescar 0.4.0 版本中加入了 TCC 模式。
### 更开放的分布式事务
**蚂蚁金服的加入引发了社区核心成员的讨论,为了达到适用于所有的分布式事务业务场景的目标,也为了社区****更中立、更开放、生态更加丰富,社区核心成员们决定进行品牌升级,改名 Seata。Seata 意为:****Simple Extensible Autonomous Transaction Architecture****,是一套一站式分布式事务解决方案。**
项目地址:<https://github.com/seata/seata>

*Hello Seata!*
### 分布式事务 Seata 的近期规划
Seata 目前产生于阿里巴巴和蚂蚁金服的业务需求,而市场上真实的生产情况更加多样化。我们决定建立一个完全中立的分布式事务组织,未来,希望更多的企业、开发者能够加入一起创造。
自开源以来,Seata 一直受益于社区的参与者的贡献。感谢开发者们的关注和贡献,截止目前,分布式事务 Seata 已经拥有超过 7000 的 Star ,超 55 位 Contributors,开发者们的加入,使得社区的生态更加丰富也更有活力。
2019 年 5 月,Seata 将加入服务端 HA 集群支持,从此,Seata 可以达到生产环境使用的标准。
欢迎对分布式事务有热情的开发者们加入社区的共建中来,为 Seata 带来更多的想象空间。

关于蚂蚁金融科技开源,点击“[此处](https://tech.antfin.com/open-source?chInfo=zx)”可了解更多。
| 302 | Moved Temporarily | null |
10,694 | Arch-Wiki-Man:一个以 Linux Man 手册样式离线浏览 Arch Wiki 的工具 | https://www.2daygeek.com/arch-wiki-man-a-tool-to-browse-the-arch-wiki-pages-as-linux-man-page-from-offline/ | 2019-04-08T12:13:28 | [
"Arch",
"man"
] | https://linux.cn/article-10694-1.html | 
现在上网已经很方便了,但技术上会有限制。看到技术的发展,我很惊讶,但与此同时,各种地方也都会出现衰退。
当你搜索有关其他 Linux 发行版的某些东西时,大多数时候你会得到的是一个第三方的链接,但是对于 Arch Linux 来说,每次你都会得到 Arch Wiki 页面的结果。
因为 Arch Wiki 提供了除第三方网站以外的大多数解决方案。
到目前为止,你也许可以使用 Web 浏览器为你的 Arch Linux 系统找到一个解决方案,但现在你可以不用这么做了。
一个名为 arch-wiki-man 的工具提供了一个在命令行中更快地执行这个操作的方案。如果你是一个 Arch Linux 爱好者,我建议你阅读 [Arch Linux 安装后指南](https://www.2daygeek.com/arch-linux-post-installation-30-things-to-do-after-installing-arch-linux/),它可以帮助你调整你的系统以供日常使用。
### arch-wiki-man 是什么?
[arch-wiki-man](https://github.com/greg-js/arch-wiki-man) 工具允许用户从命令行(CLI)中离线搜索 Arch Wiki 页面。它允许用户以 Linux Man 手册样式访问和搜索整个 Wiki 页面。
而且,你无需切换到 GUI。更新将每两天自动推送一次,因此,你的 Arch Wiki 本地副本页面将是最新的。这个工具的名字是 `awman`, `awman` 是 “Arch Wiki Man” 的缩写。
我们之前写过一篇类似工具 [Arch Wiki 命令行实用程序](https://www.2daygeek.com/search-arch-wiki-website-command-line-terminal/)(arch-wiki-cli)的文章。这个工具允许用户从互联网上搜索 Arch Wiki。但你需要在线使用这个实用程序。
### 如何安装 arch-wiki-man 工具?
arch-wiki-man 工具可以在 AUR 仓库(LCTT 译注:AUR 即<ruby> Arch 用户软件仓库 <rt> Arch User Repository </rt></ruby>)中获得,因此,我们需要使用 AUR 工具来安装它。有许多 AUR 工具可用,而且我们曾写了一篇关于流行的 AUR 辅助工具: [Yaourt AUR helper](https://www.2daygeek.com/install-yaourt-aur-helper-on-arch-linux/) 和 [Packer AUR helper](https://www.2daygeek.com/install-packer-aur-helper-on-arch-linux/) 的文章。
```
$ yaourt -S arch-wiki-man
```
或
```
$ packer -S arch-wiki-man
```
或者,我们可以使用 npm 包管理器来安装它,确保你已经在你的系统上安装了 [NodeJS](https://www.2daygeek.com/install-nodejs-on-ubuntu-centos-debian-fedora-mint-rhel-opensuse/)。然后运行以下命令来安装它。
```
$ npm install -g arch-wiki-man
```
### 如何更新 Arch Wiki 本地副本?
正如前面更新的那样,更新每两天自动推送一次,也可以通过运行以下命令来完成更新。
```
$ sudo awman-update
[sudo] password for daygeek:
[email protected] /usr/lib/node_modules/arch-wiki-man
└── [email protected]
arch-wiki-md-repo has been successfully updated or reinstalled.
```
`awman-update` 是一种更快、更方便的更新方法。但是,你也可以通过运行以下命令重新安装 arch-wiki-man 来获取更新。
```
$ yaourt -S arch-wiki-man
```
或
```
$ packer -S arch-wiki-man
```
### 如何在终端中使用 Arch Wiki ?
它有着简易的接口且易于使用。想要搜索,只需要运行 `awman` 加搜索项目。一般语法如下所示。
```
$ awman Search-Term
```
### 如何搜索多个匹配项?
如果希望列出包含 “installation” 字符串的所有结果的标题,运行以下格式的命令,如果输出有多个结果,那么你将会获得一个选择菜单来浏览每个项目。
```
$ awman installation
```

详细页面的截屏:

### 在标题和描述中搜索给定的字符串
`-d` 或 `--desc-search` 选项允许用户在标题和描述中搜索给定的字符串。
```
$ awman -d mirrors
```
或
```
$ awman --desc-search mirrors
? Select an article: (Use arrow keys)
❯ [1/3] Mirrors: Related articles
[2/3] DeveloperWiki-NewMirrors: Contents
[3/3] Powerpill: Powerpill is a pac
```
### 在内容中搜索给定的字符串
`-k` 或 `--apropos` 选项也允许用户在内容中搜索给定的字符串。但须注意,此选项会显著降低搜索速度,因为此选项会扫描整个 Wiki 页面的内容。
```
$ awman -k openjdk
```
或
```
$ awman --apropos openjdk
? Select an article: (Use arrow keys)
❯ [1/26] Hadoop: Related articles
[2/26] XDG Base Directory support: Related articles
[3/26] Steam-Game-specific troubleshooting: See Steam/Troubleshooting first.
[4/26] Android: Related articles
[5/26] Elasticsearch: Elasticsearch is a search engine based on Lucene. It provides a distributed, mul..
[6/26] LibreOffice: Related articles
[7/26] Browser plugins: Related articles
(Move up and down to reveal more choices)
```
### 在浏览器中打开搜索结果
`-w` 或 `--web` 选项允许用户在 Web 浏览器中打开搜索结果。
```
$ awman -w AUR helper
```
或
```
$ awman --web AUR helper
```

### 以其他语言搜索
想要查看支持的语言列表,请运行以下命令。
```
$ awman --list-languages
arabic
bulgarian
catalan
chinesesim
chinesetrad
croatian
czech
danish
dutch
english
esperanto
finnish
greek
hebrew
hungarian
indonesian
italian
korean
lithuanian
norwegian
polish
portuguese
russian
serbian
slovak
spanish
swedish
thai
ukrainian
```
使用你的首选语言运行 `awman` 命令以查看除英语以外的其他语言的结果。
```
$ awman -l chinesesim deepin
```

---
via: <https://www.2daygeek.com/arch-wiki-man-a-tool-to-browse-the-arch-wiki-pages-as-linux-man-page-from-offline/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Auk7F7](https://github.com/Auk7F7) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,695 | 在 Linux 中使用 bd 命令快速返回到特定的父目录 | https://www.2daygeek.com/bd-quickly-go-back-to-a-specific-parent-directory-in-linux/ | 2019-04-08T12:28:03 | [
"目录",
"bd"
] | https://linux.cn/article-10695-1.html | 
两天前我们写了一篇关于 `autocd` 的文章,它是一个内置的 shell 变量,可以帮助我们在[没有 cd 命令的情况下导航到目录中](https://www.2daygeek.com/navigate-switch-directory-without-using-cd-command-in-linux/)。
如果你想回到上一级目录,那么你需要输入 `cd ..`。
如果你想回到上两级目录,那么你需要输入 `cd ../..`。
这在 Linux 中是正常的,但如果你想从第九级目录回到第三级目录,那么使用 `cd` 命令是很糟糕的。
有什么解决方案呢?
是的,在 Linux 中有一个解决方案。我们可以使用 `bd` 命令来轻松应对这种情况。
### 什么是 bd 命令?
`bd` 命令允许用户快速返回 Linux 中的父目录,而不是反复输入 `cd ../../..`。
你可以列出给定目录的内容,而不用提供完整路径 ls `bd Directory_Name`。它支持以下其它命令,如 `ls`、`ln`、`echo`、`zip`、`tar` 等。
另外,它还允许我们执行 shell 文件而不用提供完整路径 bd p`/shell_file.sh`。
### 如何在 Linux 中安装 bd 命令?
除了 Debian/Ubuntu 之外,`bd` 没有官方发行包。因此,我们需要手动执行方法。
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/)或[APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/)来安装 `bd`。
```
$ sudo apt install bd
```
对于其它 Linux 发行版,使用 [wget 命令](https://www.2daygeek.com/wget-command-line-download-utility-tool/)下载 `bd` 可执行二进制文件。
```
$ sudo wget --no-check-certificate -O /usr/local/bin/bd https://raw.github.com/vigneshwaranr/bd/master/bd
```
设置 `bd` 二进制文件的可执行权限。
```
$ sudo chmod +rx /usr/local/bin/bd
```
在 `.bashrc` 文件中添加以下值。
```
$ echo 'alias bd=". bd -si"' >> ~/.bashrc
```
运行以下命令以使更改生效。
```
$ source ~/.bashrc
```
要启用自动完成,执行以下两个步骤。
```
$ sudo wget -O /etc/bash_completion.d/bd https://raw.github.com/vigneshwaranr/bd/master/bash_completion.d/bd
$ sudo source /etc/bash_completion.d/bd
```
我们已经在系统上成功安装并配置了 `bd` 实用程序,现在是时候测试一下了。
我将使用下面的目录路径进行测试。
运行 `pwd` 命令或 `dirs` 命令,亦或是 `tree` 命令来了解你当前的路径。
```
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ pwd
或
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ dirs
/usr/share/icons/Adwaita/256x256/apps
```
我现在在 `/usr/share/icons/Adwaita/256x256/apps` 目录,如果我想快速跳转到 `icons` 目录,那么只需输入以下命令即可。
```
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ bd icons
/usr/share/icons/
daygeek@Ubuntu18:/usr/share/icons$
```
甚至,你不需要输入完整的目录名称,也可以输入几个字母。
```
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ bd i
/usr/share/icons/
daygeek@Ubuntu18:/usr/share/icons$
```
注意:如果层次结构中有多个同名的目录,`bd` 会将你带到最近的目录。(不考虑直接的父目录)
如果要列出给定的目录内容,使用以下格式。它会打印出 `/usr/share/icons/` 的内容。
```
$ ls -lh `bd icons`
或
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ ls -lh `bd i`
total 64K
drwxr-xr-x 12 root root 4.0K Jul 25 2018 Adwaita
lrwxrwxrwx 1 root root 51 Feb 25 14:32 communitheme -> /snap/communitheme/current/share/icons/communitheme
drwxr-xr-x 2 root root 4.0K Jul 25 2018 default
drwxr-xr-x 3 root root 4.0K Jul 25 2018 DMZ-Black
drwxr-xr-x 3 root root 4.0K Jul 25 2018 DMZ-White
drwxr-xr-x 9 root root 4.0K Jul 25 2018 gnome
drwxr-xr-x 3 root root 4.0K Jul 25 2018 handhelds
drwxr-xr-x 20 root root 4.0K Mar 9 14:52 hicolor
drwxr-xr-x 9 root root 4.0K Jul 25 2018 HighContrast
drwxr-xr-x 12 root root 4.0K Jul 25 2018 Humanity
drwxr-xr-x 7 root root 4.0K Jul 25 2018 Humanity-Dark
drwxr-xr-x 4 root root 4.0K Jul 25 2018 locolor
drwxr-xr-x 3 root root 4.0K Feb 25 15:46 LoginIcons
drwxr-xr-x 3 root root 4.0K Jul 25 2018 redglass
drwxr-xr-x 10 root root 4.0K Feb 25 15:46 ubuntu-mono-dark
drwxr-xr-x 10 root root 4.0K Feb 25 15:46 ubuntu-mono-light
drwxr-xr-x 3 root root 4.0K Jul 25 2018 whiteglass
```
如果要在父目录中的某个位置执行文件,使用以下格式。它将运行 shell 文件 `/usr/share/icons/users-list.sh`。
```
$ `bd i`/users-list.sh
或
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ `bd icon`/users-list.sh
daygeek
thanu
renu
2gadmin
testuser
demouser
sudha
suresh
user1
user2
user3
```
如果你位于 `/usr/share/icons/Adwaita/256x256/apps` 中,想要导航到不同的父目录,使用以下格式。以下命令将导航到 `/usr/share/icons/gnome` 目录。
```
$ cd `bd i`/gnome
或
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ cd `bd icon`/gnome
daygeek@Ubuntu18:/usr/share/icons/gnome$
```
如果你位于 `/usr/share/icons/Adwaita/256x256/apps` ,你想在 `/usr/share/icons/` 下创建一个新目录,使用以下格式。
```
$ daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ sudo mkdir `bd icons`/2g
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ ls -ld `bd icon`/2g
drwxr-xr-x 2 root root 4096 Mar 16 05:44 /usr/share/icons//2g
```
本教程允许你快速返回到特定的父目录,但没有快速前进的选项。
我们有另一个解决方案,很快就会提出,请保持关注。
---
via: <https://www.2daygeek.com/bd-quickly-go-back-to-a-specific-parent-directory-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,696 | Linux 爸爸怒怼社交媒体:在座的各位都是垃圾 | https://www.cnet.com/news/facebook-twitter-and-instagram-are-garbage-says-linux-founder/ | 2019-04-09T00:09:00 | [] | https://linux.cn/article-10696-1.html | 
科技先锋 Linus Torvalds 表示,当今社交媒体运作的方式暗中鼓励人们的不良行为。“它们就是一种恶疾。”
让我们来数数当今社会里还有多少不对社交媒体表示“喜欢”的人。
Linus Torvalds,芬兰裔美国人,自由软件 Linux 的创始人。Linux 是一款同苹果的 MacOS 和微软的 Windows 竞争的操作系统。在本周 [Linux Journal 的采访中](https://www.linuxjournal.com/content/25-years-later-interview-linus-torvalds),Torvalds 在谈到 Facebook、Twitter 和 Instagram 时并没有小心翼翼地斟酌词语,而是大胆表示它们是如今技术产业最大的毒瘤之一。
>
> “我真的很讨厌现代的`社交媒体‘ —— Twitter,Facebook,Instagram。它们就是一种恶疾,它们鼓励人们作出不良行为。”这是他对于『在现代科技产业中你想修正什么』这个问题的回答。“那些`喜欢’和`分享‘的机制完全就是垃圾,对于内容质量的把控根本没有帮助。事实上,它起到了反效果。为了吸引更大的用户群体和尽可能多的用户点击,那些传播广泛的文章都旨在引起人们强烈的情感反应,因此它们总是打破道德底线。”
>
>
>
Torvlads,这位在 1994 年推出初版 Linux 的 Linux 创始人,[他在技术社区里就以言行粗鲁闻名](https://www.wired.com/2013/07/linus-torvalds-right-to-offend/)。不过他并不是唯一一个不喜欢社交媒体的人。
研究表示,人们对于社交媒体的好感度在近几年[显著下降](https://www.cnet.com/news/facebook-twitter-and-google-have-a-lot-to-prove-to-congress/)。主要是因为,它们在一定程度上促进了骚扰、不良行为甚至恐怖活动。这给 Facebook、Twitter 以及 Instagram 蒙上了一层阴影,即使它们的正常活动也受到人们猜忌。
Torvalds 认为,导致这些事故的根本原因是匿名性。
“如果你不把你的真实姓名放在你的垃圾(或者你分享 & 喜欢的垃圾)上面,那么它们就是垃圾。”反之,他认为,人们不应该在没有首先证明自己身份的情况下分享或喜欢事物。
Facebook、Twitter 和 Instagram 目前并没有回应记者的置评要求。
---
via: <https://www.cnet.com/news/facebook-twitter-and-instagram-are-garbage-says-linux-founder/>
作者:Ian Sherr 译者:[acyanbird](https://github.com/acyanbird) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,698 | 如何设置 Linux 系统的密码策略 | https://www.ostechnix.com/how-to-set-password-policies-in-linux/ | 2019-04-09T07:37:00 | [
"密码"
] | https://linux.cn/article-10698-1.html | 
虽然 Linux 的设计是安全的,但还是存在许多安全漏洞的风险,弱密码就是其中之一。作为系统管理员,你必须为用户提供一个强密码。因为大部分的系统漏洞就是由于弱密码而引发的。本教程描述了在基于 DEB 系统的 Linux,比如 Debian、Ubuntu、Linux Mint 等和基于 RPM 系统的 Linux,比如 RHEL、CentOS、Scientific Linux 等的系统下设置像**密码长度**、**密码复杂度**、**密码有效期**等密码策略。
### 在基于 DEB 的系统中设置密码长度
默认情况下,所有的 Linux 操作系统要求用户**密码长度最少 6 个字符**。我强烈建议不要低于这个限制。并且不要使用你的真实名称、父母、配偶、孩子的名字,或者你的生日作为密码。即便是一个黑客新手,也可以很快地破解这类密码。一个好的密码必须是至少 6 个字符,并且包含数字、大写字母和特殊符号。
通常地,在基于 DEB 的操作系统中,密码和身份认证相关的配置文件被存储在 `/etc/pam.d/` 目录中。
设置最小密码长度,编辑 `/etc/pam.d/common-password` 文件;
```
$ sudo nano /etc/pam.d/common-password
```
找到下面这行:
```
password [success=2 default=ignore] pam_unix.so obscure sha512
```

在末尾添加额外的文字:`minlen=8`。在这里我设置的最小密码长度为 `8`。
```
password [success=2 default=ignore] pam_unix.so obscure sha512 minlen=8
```

保存并关闭该文件。这样一来,用户现在不能设置小于 8 个字符的密码。
### 在基于 RPM 的系统中设置密码长度
**在 RHEL、CentOS、Scientific Linux 7.x** 系统中, 以 root 身份执行下面的命令来设置密码长度。
```
# authconfig --passminlen=8 --update
```
查看最小密码长度,执行:
```
# grep "^minlen" /etc/security/pwquality.conf
```
**输出样例:**
```
minlen = 8
```
**在 RHEL、CentOS、Scientific Linux 6.x** 系统中,编辑 `/etc/pam.d/system-auth` 文件:
```
# nano /etc/pam.d/system-auth
```
找到下面这行并在该行末尾添加:
```
password requisite pam_cracklib.so try_first_pass retry=3 type= minlen=8
```

如上设置中,最小密码长度是 `8` 个字符。
### 在基于 DEB 的系统中设置密码复杂度
此设置会强制要求密码中应该包含多少类型,比如大写字母、小写字母和其他字符。
首先,用下面命令安装密码质量检测库:
```
$ sudo apt-get install libpam-pwquality
```
之后,编辑 `/etc/pam.d/common-password` 文件:
```
$ sudo nano /etc/pam.d/common-password
```
为了设置密码中至少有一个**大写字母**,则在下面这行的末尾添加文字 `ucredit=-1`。
```
password requisite pam_pwquality.so retry=3 ucredit=-1
```

设置密码中至少有一个**小写字母**,如下所示。
```
password requisite pam_pwquality.so retry=3 lcredit=-1
```
设置密码中至少含有其他字符,如下所示。
```
password requisite pam_pwquality.so retry=3 ocredit=-1
```
正如你在上面样例中看到的一样,我们设置了密码中至少含有一个大写字母、一个小写字母和一个特殊字符。你可以设置被最大允许的任意数量的大写字母、小写字母和特殊字符。
你还可以设置密码中被允许的字符类的最大或最小数量。
下面的例子展示了设置一个新密码中被要求的字符类的最小数量:
```
password requisite pam_pwquality.so retry=3 minclass=2
```
### 在基于 RPM 的系统中设置密码复杂度
**在 RHEL 7.x / CentOS 7.x / Scientific Linux 7.x 中:**
设置密码中至少有一个小写字母,执行:
```
# authconfig --enablereqlower --update
```
查看该设置,执行:
```
# grep "^lcredit" /etc/security/pwquality.conf
```
**输出样例:**
```
lcredit = -1
```
类似地,使用以下命令去设置密码中至少有一个大写字母:
```
# authconfig --enablerequpper --update
```
查看该设置:
```
# grep "^ucredit" /etc/security/pwquality.conf
```
**输出样例:**
```
ucredit = -1
```
设置密码中至少有一个数字,执行:
```
# authconfig --enablereqdigit --update
```
查看该设置,执行:
```
# grep "^dcredit" /etc/security/pwquality.conf
```
**输出样例:**
```
dcredit = -1
```
设置密码中至少含有一个其他字符,执行:
```
# authconfig --enablereqother --update
```
查看该设置,执行:
```
# grep "^ocredit" /etc/security/pwquality.conf
```
**输出样例:**
```
ocredit = -1
```
在 **RHEL 6.x / CentOS 6.x / Scientific Linux 6.x systems** 中,以 root 身份编辑 `/etc/pam.d/system-auth` 文件:
```
# nano /etc/pam.d/system-auth
```
找到下面这行并且在该行末尾添加:
```
password requisite pam_cracklib.so try_first_pass retry=3 type= minlen=8 dcredit=-1 ucredit=-1 lcredit=-1 ocredit=-1
```
如上设置中,密码必须要至少包含 `8` 个字符。另外,密码必须至少包含一个大写字母、一个小写字母、一个数字和一个其他字符。
### 在基于 DEB 的系统中设置密码有效期
现在,我们将要设置下面的策略。
1. 密码被使用的最长天数。
2. 密码更改允许的最小间隔天数。
3. 密码到期之前发出警告的天数。
设置这些策略,编辑:
```
$ sudo nano /etc/login.defs
```
在你的每个需求后设置值。
```
PASS_MAX_DAYS 100
PASS_MIN_DAYS 0
PASS_WARN_AGE 7
```

正如你在上面样例中看到的一样,用户应该每 `100` 天修改一次密码,并且密码到期之前的 `7` 天开始出现警告信息。
请注意,这些设置将会在新创建的用户中有效。
为已存在的用户设置修改密码的最大间隔天数,你必须要运行下面的命令:
```
$ sudo chage -M <days> <username>
```
设置修改密码的最小间隔天数,执行:
```
$ sudo chage -m <days> <username>
```
设置密码到期之前的警告,执行:
```
$ sudo chage -W <days> <username>
```
显示已存在用户的密码,执行:
```
$ sudo chage -l sk
```
这里,**sk** 是我的用户名。
**输出样例:**
```
Last password change : Feb 24, 2017
Password expires : never
Password inactive : never
Account expires : never
Minimum number of days between password change : 0
Maximum number of days between password change : 99999
Number of days of warning before password expires : 7
```
正如你在上面看到的输出一样,该密码是无限期的。
修改已存在用户的密码有效期,
```
$ sudo chage -E 24/06/2018 -m 5 -M 90 -I 10 -W 10 sk
```
上面的命令将会设置用户 `sk` 的密码期限是 `24/06/2018`。并且修改密码的最小间隔时间为 `5` 天,最大间隔时间为 `90` 天。用户账号将会在 `10` 天后被自动锁定,而且在到期之前的 `10` 天前显示警告信息。
### 在基于 RPM 的系统中设置密码效期
这点和基于 DEB 的系统是相同的。
### 在基于 DEB 的系统中禁止使用近期使用过的密码
你可以限制用户去设置一个已经使用过的密码。通俗的讲,就是说用户不能再次使用相同的密码。
为设置这一点,编辑 `/etc/pam.d/common-password` 文件:
```
$ sudo nano /etc/pam.d/common-password
```
找到下面这行并且在末尾添加文字 `remember=5`:
```
password [success=2 default=ignore] pam_unix.so obscure use_authtok try_first_pass sha512 remember=5
```
上面的策略将会阻止用户去使用最近使用过的 5 个密码。
### 在基于 RPM 的系统中禁止使用近期使用过的密码
这点对于 RHEL 6.x 和 RHEL 7.x 和它们的衍生系统 CentOS、Scientific Linux 是相同的。
以 root 身份编辑 `/etc/pam.d/system-auth` 文件,
```
# vi /etc/pam.d/system-auth
```
找到下面这行,并且在末尾添加文字 `remember=5`。
```
password sufficient pam_unix.so sha512 shadow nullok try_first_pass use_authtok remember=5
```
现在你了解了 Linux 中的密码策略,以及如何在基于 DEB 和 RPM 的系统中设置不同的密码策略。
就这样,我很快会在这里发表另外一天有趣而且有用的文章。在此之前请保持关注。如果您觉得本教程对你有帮助,请在您的社交,专业网络上分享并支持我们。
---
via: <https://www.ostechnix.com/how-to-set-password-policies-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[liujing97](https://github.com/liujing97) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,700 | 计算机实验室之树莓派:课程 11 输入02 | https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input02.html | 2019-04-09T21:22:50 | [
"树莓派"
] | https://linux.cn/article-10700-1.html | 
课程输入 02 是以课程输入 01 为基础讲解的,通过一个简单的命令行实现用户的命令输入和计算机的处理和显示。本文假设你已经具备 [课程11:输入01](/article-10676-1.html) 的操作系统代码基础。
### 1、终端
几乎所有的操作系统都是以字符终端显示启动的。经典的黑底白字,通过键盘输入计算机要执行的命令,然后会提示你拼写错误,或者恰好得到你想要的执行结果。这种方法有两个主要优点:键盘和显示器可以提供简易、健壮的计算机交互机制,几乎所有的计算机系统都采用这个机制,这个也广泛被系统管理员应用。
>
> 早期的计算一般是在一栋楼里的一个巨型计算机系统,它有很多可以输命令的'终端'。计算机依次执行不同来源的命令。
>
>
>
让我们分析下真正想要哪些信息:
1. 计算机打开后,显示欢迎信息
2. 计算机启动后可以接受输入标志
3. 用户从键盘输入带参数的命令
4. 用户输入回车键或提交按钮
5. 计算机解析命令后执行可用的命令
6. 计算机显示命令的执行结果,过程信息
7. 循环跳转到步骤 2
这样的终端被定义为标准的输入输出设备。用于(显示)输入的屏幕和打印输出内容的屏幕是同一个(LCTT 译注:最早期的输出打印真是“打印”到打印机/电传机的,而用于输入的终端只是键盘,除非做了回显,否则输出终端是不会显示输入的字符的)。也就是说终端是对字符显示的一个抽象。字符显示中,单个字符是最小的单元,而不是像素。屏幕被划分成固定数量不同颜色的字符。我们可以在现有的屏幕代码基础上,先存储字符和对应的颜色,然后再用方法 `DrawCharacter` 把其推送到屏幕上。一旦我们需要字符显示,就只需要在屏幕上画出一行字符串。
新建文件名为 `terminal.s`,如下:
```
.section .data
.align 4
terminalStart:
.int terminalBuffer
terminalStop:
.int terminalBuffer
terminalView:
.int terminalBuffer
terminalColour:
.byte 0xf
.align 8
terminalBuffer:
.rept 128*128
.byte 0x7f
.byte 0x0
.endr
terminalScreen:
.rept 1024/8 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 768/16
.byte 0x7f
.byte 0x0
.endr
```
这是文件终端的配置数据文件。我们有两个主要的存储变量:`terminalBuffer` 和 `terminalScreen`。`terminalBuffer` 保存所有显示过的字符。它保存 128 行字符文本(1 行包含 128 个字符)。每个字符有一个 ASCII 字符和颜色单元组成,初始值为 0x7f(ASCII 的删除字符)和 0(前景色和背景色为黑)。`terminalScreen` 保存当前屏幕显示的字符。它保存 128x48 个字符,与 `terminalBuffer` 初始化值一样。你可能会觉得我仅需要 `terminalScreen` 就够了,为什么还要`terminalBuffer`,其实有两个好处:
1. 我们可以很容易看到字符串的变化,只需画出有变化的字符。
2. 我们可以回滚终端显示的历史字符,也就是缓冲的字符(有限制)
这种独特的技巧在低功耗系统里很常见。画屏是很耗时的操作,因此我们仅在不得已的时候才去执行这个操作。在这个系统里,我们可以任意改变 `terminalBuffer`,然后调用一个仅拷贝屏幕上字节变化的方法。也就是说我们不需要持续画出每个字符,这样可以节省一大段跨行文本的操作时间。
>
> 你总是需要尝试去设计一个高效的系统,如果在很少变化的情况下这个系统会运行的更快。
>
>
>
其他在 `.data` 段的值得含义如下:
* `terminalStart` 写入到 `terminalBuffer` 的第一个字符
* `terminalStop` 写入到 `terminalBuffer` 的最后一个字符
* `terminalView` 表示当前屏幕的第一个字符,这样我们可以控制滚动屏幕
* `temrinalColour` 即将被描画的字符颜色
`terminalStart` 需要保存起来的原因是 `termainlBuffer` 是一个环状缓冲区。意思是当缓冲区变满时,末尾地方会回滚覆盖开始位置,这样最后一个字符变成了第一个字符。因此我们需要将 `terminalStart` 往前推进,这样我们知道我们已经占满它了。如何实现缓冲区检测:如果索引越界到缓冲区的末尾,就将索引指向缓冲区的开始位置。环状缓冲区是一个比较常见的存储大量数据的高明方法,往往这些数据的最近部分比较重要。它允许无限制的写入,只保证最近一些特定数据有效。这个常常用于信号处理和数据压缩算法。这样的情况,可以允许我们存储 128 行终端记录,超过128行也不会有问题。如果不是这样,当超过第 128 行时,我们需要把 127 行分别向前拷贝一次,这样很浪费时间。

>
> 环状缓冲区是**数据结构**一个例子。这是一个组织数据的思路,有时我们通过软件实现这种思路。
>
>
>
之前已经提到过 `terminalColour` 几次了。你可以根据你的想法实现终端颜色,但这个文本终端有 16 个前景色和 16 个背景色(这里相当于有 16<sup> 2</sup> = 256 种组合)。[CGA](https://en.wikipedia.org/wiki/Color_Graphics_Adapter)终端的颜色定义如下:
表格 1.1 - CGA 颜色编码
| 序号 | 颜色 (R, G, B) |
| --- | --- |
| 0 | 黑 (0, 0, 0) |
| 1 | 蓝 (0, 0, ⅔) |
| 2 | 绿 (0, ⅔, 0) |
| 3 | 青色 (0, ⅔, ⅔) |
| 4 | 红色 (⅔, 0, 0) |
| 5 | 品红 (⅔, 0, ⅔) |
| 6 | 棕色 (⅔, ⅓, 0) |
| 7 | 浅灰色 (⅔, ⅔, ⅔) |
| 8 | 灰色 (⅓, ⅓, ⅓) |
| 9 | 淡蓝色 (⅓, ⅓, 1) |
| 10 | 淡绿色 (⅓, 1, ⅓) |
| 11 | 淡青色 (⅓, 1, 1) |
| 12 | 淡红色 (1, ⅓, ⅓) |
| 13 | 浅品红 (1, ⅓, 1) |
| 14 | 黄色 (1, 1, ⅓) |
| 15 | 白色 (1, 1, 1) |
我们将前景色保存到颜色的低字节,背景色保存到颜色高字节。除了棕色,其他这些颜色遵循一种模式如二进制的高位比特代表增加 ⅓ 到每个组件,其他比特代表增加 ⅔ 到各自组件。这样很容易进行 RGB 颜色转换。
>
> 棕色作为替代色(黑黄色)既不吸引人也没有什么用处。
>
>
>
我们需要一个方法从 `TerminalColour` 读取颜色编码的四个比特,然后用 16 比特等效参数调用 `SetForeColour`。尝试你自己实现。如果你感觉麻烦或者还没有完成屏幕系列课程,我们的实现如下:
```
.section .text
TerminalColour:
teq r0,#6
ldreq r0,=0x02B5
beq SetForeColour
tst r0,#0b1000
ldrne r1,=0x52AA
moveq r1,#0
tst r0,#0b0100
addne r1,#0x15
tst r0,#0b0010
addne r1,#0x540
tst r0,#0b0001
addne r1,#0xA800
mov r0,r1
b SetForeColour
```
### 2、文本显示
我们的终端第一个真正需要的方法是 `TerminalDisplay`,它用来把当前的数据从 `terminalBuffer`拷贝到 `terminalScreen` 和实际的屏幕。如上所述,这个方法必须是最小开销的操作,因为我们需要频繁调用它。它主要比较 `terminalBuffer` 与 `terminalDisplay` 的文本,然后只拷贝有差异的字节。请记住 `terminalBuffer` 是以环状缓冲区运行的,这种情况,就是从 `terminalView` 到 `terminalStop`,或者 128\*48 个字符,要看哪个来的最快。如果我们遇到 `terminalStop`,我们将会假定在这之后的所有字符是 7f<sub> 16</sub> (ASCII 删除字符),颜色为 0(黑色前景色和背景色)。
让我们看看必须要做的事情:
1. 加载 `terminalView`、`terminalStop` 和 `terminalDisplay` 的地址。
2. 对于每一行:
1. 对于每一列:
1. 如果 `terminalView` 不等于 `terminalStop`,根据 `terminalView` 加载当前字符和颜色
2. 否则加载 0x7f 和颜色 0
3. 从 `terminalDisplay` 加载当前的字符
4. 如果字符和颜色相同,直接跳转到第 10 步
5. 存储字符和颜色到 `terminalDisplay`
6. 用 `r0` 作为背景色参数调用 `TerminalColour`
7. 用 `r0 = 0x7f`(ASCII 删除字符,一个块)、 `r1 = x`、`r2 = y` 调用 `DrawCharacter`
8. 用 `r0` 作为前景色参数调用 `TerminalColour`
9. 用 `r0 = 字符`、`r1 = x`、`r2 = y` 调用 `DrawCharacter`
10. 对位置参数 `terminalDisplay` 累加 2
11. 如果 `terminalView` 不等于 `terminalStop`,`terminalView` 位置参数累加 2
12. 如果 `terminalView` 位置已经是文件缓冲器的末尾,将它设置为缓冲区的开始位置
13. x 坐标增加 8
2. y 坐标增加 16
尝试去自己实现吧。如果你遇到问题,我们的方案下面给出来了:
1、我这里的变量有点乱。为了方便起见,我用 `taddr` 存储 `textBuffer` 的末尾位置。
```
.globl TerminalDisplay
TerminalDisplay:
push {r4,r5,r6,r7,r8,r9,r10,r11,lr}
x .req r4
y .req r5
char .req r6
col .req r7
screen .req r8
taddr .req r9
view .req r10
stop .req r11
ldr taddr,=terminalStart
ldr view,[taddr,#terminalView - terminalStart]
ldr stop,[taddr,#terminalStop - terminalStart]
add taddr,#terminalBuffer - terminalStart
add taddr,#128*128*2
mov screen,taddr
```
2、从 `yLoop` 开始运行。
```
mov y,#0
yLoop$:
```
2.1、
```
mov x,#0
xLoop$:
```
从 `xLoop` 开始运行。
2.1.1、为了方便起见,我把字符和颜色同时加载到 `char` 变量了
```
teq view,stop
ldrneh char,[view]
```
2.1.2、这行是对上面一行的补充说明:读取黑色的删除字符
```
moveq char,#0x7f
```
2.1.3、为了简便我把字符和颜色同时加载到 `col` 里。
```
ldrh col,[screen]
```
2.1.4、 现在我用 `teq` 指令检查是否有数据变化
```
teq col,char
beq xLoopContinue$
```
2.1.5、我可以容易的保存当前值
```
strh char,[screen]
```
2.1.6、我用比特偏移指令 `lsr` 和 `and` 指令从切分 `char` 变量,将颜色放到 `col` 变量,字符放到 `char` 变量,然后再用比特偏移指令 `lsr` 获取背景色后调用 `TerminalColour` 。
```
lsr col,char,#8
and char,#0x7f
lsr r0,col,#4
bl TerminalColour
```
2.1.7、写入一个彩色的删除字符
```
mov r0,#0x7f
mov r1,x
mov r2,y
bl DrawCharacter
```
2.1.8、用 `and` 指令获取 `col` 变量的低半字节,然后调用 `TerminalColour`
```
and r0,col,#0xf
bl TerminalColour
```
2.1.9、写入我们需要的字符
```
mov r0,char
mov r1,x
mov r2,y
bl DrawCharacter
```
2.1.10、自增屏幕指针
```
xLoopContinue$:
add screen,#2
```
2.1.11、如果可能自增 `view` 指针
```
teq view,stop
addne view,#2
```
2.1.12、很容易检测 `view` 指针是否越界到缓冲区的末尾,因为缓冲区的地址保存在 `taddr` 变量里
```
teq view,taddr
subeq view,#128*128*2
```
2.1.13、 如果还有字符需要显示,我们就需要自增 `x` 变量然后到 `xLoop` 循环执行
```
add x,#8
teq x,#1024
bne xLoop$
```
2.2、 如果还有更多的字符显示我们就需要自增 `y` 变量,然后到 `yLoop` 循环执行
```
add y,#16
teq y,#768
bne yLoop$
```
3、不要忘记最后清除变量
```
pop {r4,r5,r6,r7,r8,r9,r10,r11,pc}
.unreq x
.unreq y
.unreq char
.unreq col
.unreq screen
.unreq taddr
.unreq view
.unreq stop
```
### 3、行打印
现在我有了自己 `TerminalDisplay` 方法,它可以自动显示 `terminalBuffer` 内容到 `terminalScreen`,因此理论上我们可以画出文本。但是实际上我们没有任何基于字符显示的例程。 首先快速容易上手的方法便是 `TerminalClear`, 它可以彻底清除终端。这个方法不用循环也很容易实现。可以尝试分析下面的方法应该不难:
```
.globl TerminalClear
TerminalClear:
ldr r0,=terminalStart
add r1,r0,#terminalBuffer-terminalStart
str r1,[r0]
str r1,[r0,#terminalStop-terminalStart]
str r1,[r0,#terminalView-terminalStart]
mov pc,lr
```
现在我们需要构造一个字符显示的基础方法:`Print` 函数。它将保存在 `r0` 的字符串和保存在 `r1` 的字符串长度简单的写到屏幕上。有一些特定字符需要特别的注意,这些特定的操作是确保 `terminalView` 是最新的。我们来分析一下需要做什么:
1. 检查字符串的长度是否为 0,如果是就直接返回
2. 加载 `terminalStop` 和 `terminalView`
3. 计算出 `terminalStop` 的 x 坐标
4. 对每一个字符的操作:
1. 检查字符是否为新起一行
2. 如果是的话,自增 `bufferStop` 到行末,同时写入黑色删除字符
3. 否则拷贝当前 `terminalColour` 的字符
4. 检查是否在行末
5. 如果是,检查从 `terminalView` 到 `terminalStop` 之间的字符数是否大于一屏
6. 如果是,`terminalView` 自增一行
7. 检查 `terminalView` 是否为缓冲区的末尾,如果是的话将其替换为缓冲区的起始位置
8. 检查 `terminalStop` 是否为缓冲区的末尾,如果是的话将其替换为缓冲区的起始位置
9. 检查 `terminalStop` 是否等于 `terminalStart`, 如果是的话 `terminalStart` 自增一行。
10. 检查 `terminalStart` 是否为缓冲区的末尾,如果是的话将其替换为缓冲区的起始位置
5. 存取 `terminalStop` 和 `terminalView`
试一下自己去实现。我们的方案提供如下:
1、这个是 `Print` 函数开始快速检查字符串为0的代码
```
.globl Print
Print:
teq r1,#0
moveq pc,lr
```
2、这里我做了很多配置。 `bufferStart` 代表 `terminalStart`, `bufferStop` 代表`terminalStop`, `view` 代表 `terminalView`,`taddr` 代表 `terminalBuffer` 的末尾地址。
```
push {r4,r5,r6,r7,r8,r9,r10,r11,lr}
bufferStart .req r4
taddr .req r5
x .req r6
string .req r7
length .req r8
char .req r9
bufferStop .req r10
view .req r11
mov string,r0
mov length,r1
ldr taddr,=terminalStart
ldr bufferStop,[taddr,#terminalStop-terminalStart]
ldr view,[taddr,#terminalView-terminalStart]
ldr bufferStart,[taddr]
add taddr,#terminalBuffer-terminalStart
add taddr,#128*128*2
```
3、和通常一样,巧妙的对齐技巧让许多事情更容易。由于需要对齐 `terminalBuffer`,每个字符的 x 坐标需要 8 位要除以 2。
```
and x,bufferStop,#0xfe
lsr x,#1
```
4.1、我们需要检查新行
```
charLoop$:
ldrb char,[string]
and char,#0x7f
teq char,#'\n'
bne charNormal$
```
4.2、循环执行值到行末写入 0x7f;黑色删除字符
```
mov r0,#0x7f
clearLine$:
strh r0,[bufferStop]
add bufferStop,#2
add x,#1
teq x,#128 blt clearLine$
b charLoopContinue$
```
4.3、存储字符串的当前字符和 `terminalBuffer` 末尾的 `terminalColour` 然后将它和 x 变量自增
```
charNormal$:
strb char,[bufferStop]
ldr r0,=terminalColour
ldrb r0,[r0]
strb r0,[bufferStop,#1]
add bufferStop,#2
add x,#1
```
4.4、检查 x 是否为行末;128
```
charLoopContinue$:
cmp x,#128
blt noScroll$
```
4.5、设置 x 为 0 然后检查我们是否已经显示超过 1 屏。请记住,我们是用的循环缓冲区,因此如果 `bufferStop` 和 `view` 之前的差是负值,我们实际上是环绕了缓冲区。
```
mov x,#0
subs r0,bufferStop,view
addlt r0,#128*128*2
cmp r0,#128*(768/16)*2
```
4.6、增加一行字节到 `view` 的地址
```
addge view,#128*2
```
4.7、 如果 `view` 地址是缓冲区的末尾,我们就从它上面减去缓冲区的长度,让其指向开始位置。我会在开始的时候设置 `taddr` 为缓冲区的末尾地址。
```
teq view,taddr
subeq view,taddr,#128*128*2
```
4.8、如果 `stop` 的地址在缓冲区末尾,我们就从它上面减去缓冲区的长度,让其指向开始位置。我会在开始的时候设置 `taddr` 为缓冲区的末尾地址。
```
noScroll$:
teq bufferStop,taddr
subeq bufferStop,taddr,#128*128*2
```
4.9、检查 `bufferStop` 是否等于 `bufferStart`。 如果等于增加一行到 `bufferStart`。
```
teq bufferStop,bufferStart
addeq bufferStart,#128*2
```
4.10、如果 `start` 的地址在缓冲区的末尾,我们就从它上面减去缓冲区的长度,让其指向开始位置。我会在开始的时候设置 `taddr` 为缓冲区的末尾地址。
```
teq bufferStart,taddr
subeq bufferStart,taddr,#128*128*2
```
循环执行知道字符串结束
```
subs length,#1
add string,#1
bgt charLoop$
```
5、保存变量然后返回
```
charLoopBreak$:
sub taddr,#128*128*2
sub taddr,#terminalBuffer-terminalStart
str bufferStop,[taddr,#terminalStop-terminalStart]
str view,[taddr,#terminalView-terminalStart]
str bufferStart,[taddr]
pop {r4,r5,r6,r7,r8,r9,r10,r11,pc}
.unreq bufferStart
.unreq taddr
.unreq x
.unreq string
.unreq length
.unreq char
.unreq bufferStop
.unreq view
```
这个方法允许我们打印任意字符到屏幕。然而我们用了颜色变量,但实际上没有设置它。一般终端用特性的组合字符去行修改颜色。如 ASCII 转义(1b<sub> 16</sub>)后面跟着一个 0 - f 的 16 进制的数,就可以设置前景色为 CGA 颜色号。如果你自己想尝试实现;在下载页面有一个我的详细的例子。
### 4、标志输入
现在我们有一个可以打印和显示文本的输出终端。这仅仅是说对了一半,我们需要输入。我们想实现一个方法:`ReadLine`,可以保存文件的一行文本,文本位置由 `r0` 给出,最大的长度由 `r1` 给出,返回 `r0` 里面的字符串长度。棘手的是用户输出字符的时候要回显功能,同时想要退格键的删除功能和命令回车执行功能。它们还需要一个闪烁的下划线代表计算机需要输入。这些完全合理的要求让构造这个方法更具有挑战性。有一个方法完成这些需求就是存储用户输入的文本和文件大小到内存的某个地方。然后当调用 `ReadLine` 的时候,移动 `terminalStop` 的地址到它开始的地方然后调用 `Print`。也就是说我们只需要确保在内存维护一个字符串,然后构造一个我们自己的打印函数。
>
> 按照惯例,许多编程语言中,任意程序可以访问 stdin 和 stdin,它们可以连接到终端的输入和输出流。在图形程序其实也可以进行同样操作,但实际几乎不用。
>
>
>
让我们看看 `ReadLine` 做了哪些事情:
1. 如果字符串可保存的最大长度为 0,直接返回
2. 检索 `terminalStop` 和 `terminalStop` 的当前值
3. 如果字符串的最大长度大约缓冲区的一半,就设置大小为缓冲区的一半
4. 从最大长度里面减去 1 来确保输入的闪烁字符或结束符
5. 向字符串写入一个下划线
6. 写入一个 `terminalView` 和 `terminalStop` 的地址到内存
7. 调用 `Print` 打印当前字符串
8. 调用 `TerminalDisplay`
9. 调用 `KeyboardUpdate`
10. 调用 `KeyboardGetChar`
11. 如果是一个新行直接跳转到第 16 步
12. 如果是一个退格键,将字符串长度减 1(如果其大于 0)
13. 如果是一个普通字符,将它写入字符串(字符串大小确保小于最大值)
14. 如果字符串是以下划线结束,写入一个空格,否则写入下划线
15. 跳转到第 6 步
16. 字符串的末尾写入一个新行字符
17. 调用 `Print` 和 `TerminalDisplay`
18. 用结束符替换新行
19. 返回字符串的长度
为了方便读者理解,然后然后自己去实现,我们的实现提供如下:
1. 快速处理长度为 0 的情况
```
.globl ReadLine
ReadLine:
teq r1,#0
moveq r0,#0
moveq pc,lr
```
2、考虑到常见的场景,我们初期做了很多初始化动作。`input` 代表 `terminalStop` 的值,`view` 代表 `terminalView`。`Length` 默认为 `0`。
```
string .req r4
maxLength .req r5
input .req r6
taddr .req r7
length .req r8
view .req r9
push {r4,r5,r6,r7,r8,r9,lr}
mov string,r0
mov maxLength,r1
ldr taddr,=terminalStart
ldr input,[taddr,#terminalStop-terminalStart]
ldr view,[taddr,#terminalView-terminalStart]
mov length,#0
```
3、我们必须检查异常大的读操作,我们不能处理超过 `terminalBuffer` 大小的输入(理论上可行,但是 `terminalStart` 移动越过存储的 terminalStop`,会有很多问题)。
```
cmp maxLength,#128*64
movhi maxLength,#128*64
```
4、由于用户需要一个闪烁的光标,我们需要一个备用字符在理想状况在这个字符串后面放一个结束符。
```
sub maxLength,#1
```
5、写入一个下划线让用户知道我们可以输入了。
```
mov r0,#'_'
strb r0,[string,length]
```
6、保存 `terminalStop` 和 `terminalView`。这个对重置一个终端很重要,它会修改这些变量。严格讲也可以修改 `terminalStart`,但是不可逆。
```
readLoop$:
str input,[taddr,#terminalStop-terminalStart]
str view,[taddr,#terminalView-terminalStart]
```
7、写入当前的输入。由于下划线因此字符串长度加 1
```
mov r0,string
mov r1,length
add r1,#1
bl Print
```
8、拷贝下一个文本到屏幕
```
bl TerminalDisplay
```
9、获取最近一次键盘输入
```
bl KeyboardUpdate
```
10、检索键盘输入键值
```
bl KeyboardGetChar
```
11、如果我们有一个回车键,循环中断。如果有结束符和一个退格键也会同样跳出循环。
```
teq r0,#'\n'
beq readLoopBreak$
teq r0,#0
beq cursor$
teq r0,#'\b'
bne standard$
```
12、从 `length` 里面删除一个字符
```
delete$:
cmp length,#0
subgt length,#1
b cursor$
```
13、写回一个普通字符
```
standard$:
cmp length,maxLength
bge cursor$
strb r0,[string,length]
add length,#1
```
14、加载最近的一个字符,如果不是下划线则修改为下换线,如果是则修改为空格
```
cursor$:
ldrb r0,[string,length]
teq r0,#'_'
moveq r0,#' '
movne r0,#'_'
strb r0,[string,length]
```
15、循环执行值到用户输入按下
```
b readLoop$
readLoopBreak$:
```
16、在字符串的结尾处存入一个新行字符
```
mov r0,#'\n'
strb r0,[string,length]
```
17、重置 `terminalView` 和 `terminalStop` 然后调用 `Print` 和 `TerminalDisplay` 显示最终的输入
```
str input,[taddr,#terminalStop-terminalStart]
str view,[taddr,#terminalView-terminalStart]
mov r0,string
mov r1,length
add r1,#1
bl Print
bl TerminalDisplay
```
18、写入一个结束符
```
mov r0,#0
strb r0,[string,length]
```
19、返回长度
```
mov r0,length
pop {r4,r5,r6,r7,r8,r9,pc}
.unreq string
.unreq maxLength
.unreq input
.unreq taddr
.unreq length
.unreq view
```
### 5、终端:机器进化
现在我们理论用终端和用户可以交互了。最显而易见的事情就是拿去测试了!删除 `main.s` 里 `bl UsbInitialise` 后面的代码后如下:
```
reset$:
mov sp,#0x8000
bl TerminalClear
ldr r0,=welcome
mov r1,#welcomeEnd-welcome
bl Print
loop$:
ldr r0,=prompt
mov r1,#promptEnd-prompt
bl Print
ldr r0,=command
mov r1,#commandEnd-command
bl ReadLine
teq r0,#0
beq loopContinue$
mov r4,r0
ldr r5,=command
ldr r6,=commandTable
ldr r7,[r6,#0]
ldr r9,[r6,#4]
commandLoop$:
ldr r8,[r6,#8]
sub r1,r8,r7
cmp r1,r4
bgt commandLoopContinue$
mov r0,#0
commandName$:
ldrb r2,[r5,r0]
ldrb r3,[r7,r0]
teq r2,r3
bne commandLoopContinue$
add r0,#1
teq r0,r1
bne commandName$
ldrb r2,[r5,r0]
teq r2,#0
teqne r2,#' '
bne commandLoopContinue$
mov r0,r5
mov r1,r4
mov lr,pc
mov pc,r9
b loopContinue$
commandLoopContinue$:
add r6,#8
mov r7,r8
ldr r9,[r6,#4]
teq r9,#0
bne commandLoop$
ldr r0,=commandUnknown
mov r1,#commandUnknownEnd-commandUnknown
ldr r2,=formatBuffer
ldr r3,=command
bl FormatString
mov r1,r0
ldr r0,=formatBuffer
bl Print
loopContinue$:
bl TerminalDisplay
b loop$
echo:
cmp r1,#5
movle pc,lr
add r0,#5
sub r1,#5
b Print
ok:
teq r1,#5
beq okOn$
teq r1,#6
beq okOff$
mov pc,lr
okOn$:
ldrb r2,[r0,#3]
teq r2,#'o'
ldreqb r2,[r0,#4]
teqeq r2,#'n'
movne pc,lr
mov r1,#0
b okAct$
okOff$:
ldrb r2,[r0,#3]
teq r2,#'o'
ldreqb r2,[r0,#4]
teqeq r2,#'f'
ldreqb r2,[r0,#5]
teqeq r2,#'f'
movne pc,lr
mov r1,#1
okAct$:
mov r0,#16
b SetGpio
.section .data
.align 2
welcome: .ascii "Welcome to Alex's OS - Everyone's favourite OS"
welcomeEnd:
.align 2
prompt: .ascii "\n> "
promptEnd:
.align 2
command:
.rept 128
.byte 0
.endr
commandEnd:
.byte 0
.align 2
commandUnknown: .ascii "Command `%s' was not recognised.\n"
commandUnknownEnd:
.align 2
formatBuffer:
.rept 256
.byte 0
.endr
formatEnd:
.align 2
commandStringEcho: .ascii "echo"
commandStringReset: .ascii "reset"
commandStringOk: .ascii "ok"
commandStringCls: .ascii "cls"
commandStringEnd:
.align 2
commandTable:
.int commandStringEcho, echo
.int commandStringReset, reset$
.int commandStringOk, ok
.int commandStringCls, TerminalClear
.int commandStringEnd, 0
```
这块代码集成了一个简易的命令行操作系统。支持命令:`echo`、`reset`、`ok` 和 `cls`。`echo` 拷贝任意文本到终端,`reset` 命令会在系统出现问题的是复位操作系统,`ok` 有两个功能:设置 OK 灯亮灭,最后 `cls` 调用 TerminalClear 清空终端。
试试树莓派的代码吧。如果遇到问题,请参照问题集锦页面吧。
如果运行正常,祝贺你完成了一个操作系统基本终端和输入系列的课程。很遗憾这个教程先讲到这里,但是我希望将来能制作更多教程。有问题请反馈至 [[email protected]](mailto:[email protected])。
你已经在建立了一个简易的终端操作系统。我们的代码在 commandTable 构造了一个可用的命令表格。每个表格的入口是一个整型数字,用来表示字符串的地址,和一个整型数字表格代码的执行入口。 最后一个入口是 为 0 的 `commandStringEnd`。尝试实现你自己的命令,可以参照已有的函数,建立一个新的。函数的参数 `r0` 是用户输入的命令地址,`r1` 是其长度。你可以用这个传递你输入值到你的命令。也许你有一个计算器程序,或许是一个绘图程序或国际象棋。不管你的什么点子,让它跑起来!
---
via: <https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input02.html>
作者:[Alex Chadwick](https://www.cl.cam.ac.uk) 选题:[lujun9972](https://github.com/lujun9972) 译者:[guevaraya](https://github.com/guevaraya) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Raspberry Pi
# Lesson 11 Input02
The Input02 lesson builds on Input01, by building a simple command line interface
where the user can type commands and the computer interprets and displays them.
It is assumed you have the code for the [Lesson 11: Input01](input01.html)
operating system as a basis.
Contents |
## 1 Terminal 1
In the early days of computing, there would usually be one large computer in a building, and many 'terminals' which sent commands to it. The computer would take it in turns to execute different incoming commands.
Almost every operating system starts life out as a text terminal. This is typically a black screen with white writing, where you type commands for the computer to execute on the keyboard, and it explains how you've mistyped them, or very occasionally, does what you want. This approach has two main advantages: it provides a simple, robust control mechanism for the computer using only a keyboard and monitor, and it is done by almost every operating system, so is widely understood by system administrators.
Let's analyse what we want to do precisely:
- Computer turns on, displays some sort of welcome message
- Computer indicates its ready for input
- User types a command, with parameters, on the keyboard
- User presses return or enter to commit the command
- Computer interprets command and performs actions if command is acceptable
- Computer displays messages to indicate if command was successful, and also what happened
- Loop back to 2
One defining feature of such terminals is that they are unified for both input and output. The same screen is used to enter inputs as is used to print outputs. This means it is useful to build an abstraction of a character based display. In a character based display, the smallest unit is a character, not a pixel. The screen is divided into a fixed number of characters which have varying colours. We can build this on top of our existing screen code, by storing the characters and their colours, and then using the DrawCharacter method to push them to the screen. Once we have a character based display, drawing text becomes a matter of drawing a line of characters.
In a new file called terminal.s copy the following code:
.section .data
.align 4
terminalStart:
.int terminalBuffer
terminalStop:
.int terminalBuffer
terminalView:
.int terminalBuffer
terminalColour:
.byte 0xf
.align 8
terminalBuffer:
.rept 128*128
.byte 0x7f
.byte 0x0
.endr
terminalScreen:
.rept 1024/8 * 768/16
.byte 0x7f
.byte 0x0
.endr
This sets up the data we need for the text terminal. We have two main storages: terminalBuffer and terminalScreen. terminalBuffer is storage for all of the text we have displayed. It stores up to 128 lines of text (each containing 128 characters). Each character consists of an ASCII character code and a colour, all of which are initially set to 0x7f (ASCII delete) and 0 (black on a black background). terminalScreen stores the characters that are currently displayed on the screen. It is 128 by 48 characters, similarly initialised. You may think that we only need this terminalScreen, not the terminalBuffer, but storing the buffer has 2 main advantages:
- We can easily see which characters are different, so we only have to draw those.
- We can 'scroll' back through the terminal's history because it is stored (to a limit).
You should always try to design systems that do the minimum amount of work, as they run much faster for things which don't often change.
The differing trick is really common on low power Operating Systems. Drawing the screen is a slow operation, and so we only want to draw thing that we absolutely have to. In this system, we can freely alter the terminalBuffer, and then call a method which copies the bits that change to the screen. This means we don't have to draw each character as we go along, which may save time in the long run on very long sections of text that span many lines.
The other values in the .data section are as follows:
- terminalStart
- The first character which has been written in terminalBuffer.
- terminalStop
- The last character which has been written in terminalBuffer.
- terminalView
- The first character on the screen at present. We can use this to scroll the screen.
- temrinalColour
- The colour to draw new characters with.
Circular buffers are an example of an **data structure**. These are
just ideas we have for organising data, that we sometimes implement in software.
The reason why terminalStart needs to be stored is because termainlBuffer should
be a circular buffer. This means that when the buffer is completely full, the end
'wraps' round to the start, and so the character after the very last one is the
first one. Thus, we need to advance terminalStart so we know that we've done this.
When wokring with the buffer this can easily be implemented by checking if the index
goes beyond the end of the buffer, and setting it back to the beginning if it does.
Circular buffers are a common and clever way of storing a lot of data, where only
the most recent data is important. It allows us to keep writing indefinitely, while
always being sure there is a certain amount of recent data available. They're often
used in signal processing or compression algorithms. In this case, it allows us
to store a 128 line history of the terminal, without any penalties for writing over
128 lines. If we didn't have this, we would have to copy 127 lines back a line very
time we went beyond the 128th line, wasting valuable time.
I've mentioned the terminalColour here a few times. You can implement this however
you, wish, however there is something of a standard on text terminals to have only
16 colours for foreground, and 16 colours for background (meaning there are 162
= 256 combinations). The colours on a CGA terminal are defined as follows:
Number | Colour (R, G, B) |
---|---|
0 | Black (0, 0, 0) |
1 | Blue (0, 0, ⅔) |
2 | Green (0, ⅔, 0) |
3 | Cyan (0, ⅔, ⅔) |
4 | Red (⅔, 0, 0) |
5 | Magenta (⅔, 0, ⅔) |
6 | Brown (⅔, ⅓, 0) |
7 | Light Grey (⅔, ⅔, ⅔) |
8 | Grey (⅓, ⅓, ⅓) |
9 | Light Blue (⅓, ⅓, 1) |
10 | Light Green (⅓, 1, ⅓) |
11 | Light Cyan (⅓, 1, 1) |
12 | Light Red (1, ⅓, ⅓) |
13 | Light Magenta (1, ⅓, 1) |
14 | Yellow (1, 1, ⅓) |
15 | White (1, 1, 1) |
Brown was used as the alternative (dark yellow) was unappealing and not useful.
We store the colour of each character by storing the fore colour in the low nibble of the colour byte, and the background colour in the high nibble. Apart from brown, all of these colours follow a pattern such that in binary, the top bit represents adding ⅓ to each component, and the other bits represent adding ⅔ to individual components. This makes it easy to convert to RGB colour values.
We need a method, TerminalColour, to read these 4 bit colour codes, and then call SetForeColour with the 16 bit equivalent. Try to implement this on your own. If you get stuck, or have not completed the Screen series, my implementation is given below:
.section .text
TerminalColour:
teq r0,#6
ldreq r0,=0x02B5
beq SetForeColour
tst r0,#0b1000
ldrne r1,=0x52AA
moveq r1,#0
tst r0,#0b0100
addne r1,#0x15
tst r0,#0b0010
addne r1,#0x540
tst r0,#0b0001
addne r1,#0xA800
mov r0,r1
b SetForeColour
## 2 Showing the Text
The first method we really need for our terminal is TerminalDisplay, one that copies
the current data from terminalBuffer to terminalScreen and the actual screen. As
mentioned, this method should do a minimal amount of work, because we need to be
able to call it often. It should compare the text in terminalBuffer with that in
terminalDisplay, and copy it across if they're different. Remember, terminalBuffer
is a circular buffer running, in this case, from terminalView to terminalStop or
128*48 characters, whichever comes sooner. If we hit terminalStop, we'll assume
all characters after that point are 7f16 (ASCII delete), and have colour
0 (black on a black background).
Let's look at what we have to do:
- Load in terminalView, terminalStop and the address of terminalDisplay.
- For each row:
- For each column:
- If view is not equal to stop, load the current character and colour from view
- Otherwise load the character as 0x7f and the colour as 0
- Load the current character from terminalDisplay
- If the character and colour are equal, go to 10
- Store the character and colour to terminalDisplay
- Call TerminalColour with the background colour in r0
- Call DrawCharacter with r0 = 0x7f (ASCII delete, a block), r1 = x, r2 = y
- Call TerminalColour with the foreground colour in r0
- Call DrawCharacter with r0 = character, r1 = x, r2 = y
- Increment the position in terminalDisplay by 2
- If view and stop are not equal, increment the view position by 2
- If the view position is at the end of textBuffer, set it to the start
- Increment the x co-ordinate by 8
- Increment the y co-ordinate by 16
- For each column:
Try to implement this yourself. If you get stuck, my solution is given below:
-
.globl TerminalDisplay
TerminalDisplay:
push {r4,r5,r6,r7,r8,r9,r10,r11,lr}
x .req r4
y .req r5
char .req r6
col .req r7
screen .req r8
taddr .req r9
view .req r10
stop .req r11
ldr taddr,=terminalStart
ldr view,[taddr,#terminalView - terminalStart]
ldr stop,[taddr,#terminalStop - terminalStart]
add taddr,#terminalBuffer - terminalStart
add taddr,#128*128*2
mov screen,taddr
I go a little wild with variables here. I'm using taddr to store the location of the end of the textBuffer for ease.
-
mov y,#0
yLoop$:
Start off the y loop.
-
mov x,#0
xLoop$:
Start off the x loop.
-
teq view,stop
ldrneh char,[view]
I load both the character and the colour into char simultaneously for ease.
-
moveq char,#0x7f
This line complements the one above by acting as though a black delete character was read.
-
ldrh col,[screen]
For simplicity I load both the character and colour into col simultaneously.
-
teq col,char
beq xLoopContinue$
Now we can check if anything has changed with a teq.
-
strh char,[screen]
We can also easily save the current value.
-
lsr col,char,#8
and char,#0x7f
lsr r0,col,#4
bl TerminalColour
I split up char into the colour in col and the character in char with a bitshift and an and, then use a bitshift to get the background colour to call TerminalColour.
-
mov r0,#0x7f
mov r1,x
mov r2,y
bl DrawCharacter
Write out a delete character which is a coloured block.
-
and r0,col,#0xf
bl TerminalColour
Use an and to get the low nibble of col then call TerminalColour.
-
mov r0,char
mov r1,x
mov r2,y
bl DrawCharacter
Write out the character we're supposed to write.
-
xLoopContinue$:
add screen,#2
Increment the screen pointer.
-
teq view,stop
addne view,#2
Increment the view pointer if necessary.
-
teq view,taddr
subeq view,#128*128*2
It's easy to check for view going past the end of the buffer because the end of the buffer's address is stored in taddr.
-
add x,#8
teq x,#1024
bne xLoop$
We increment x and then loop back if there are more characters to go.
-
-
add y,#16
teq y,#768
bne yLoop$
We increment y and then loop back if there are more characters to go.
pop {r4,r5,r6,r7,r8,r9,r10,r11,pc}
.unreq x
.unreq y
.unreq char
.unreq col
.unreq screen
.unreq taddr
.unreq view
.unreq stop
Don't forget to clean up at the end!
-
## 3 Printing Lines
Now we have our TerminalDisplay method, which will automatically display the contents of terminalBuffer to terminalScreen, so theoretically we can draw text. However, we don't actually have any drawing routines that work on a character based display. A quick method that will come in handy first of all is TerminalClear, which completely clears the terminal. This can actually very easily be achieved with no loops. Try to deduce why the following method suffices:
.globl TerminalClear
TerminalClear:
ldr r0,=terminalStart
add r1,r0,#terminalBuffer-terminalStart
str r1,[r0]
str r1,[r0,#terminalStop-terminalStart]
str r1,[r0,#terminalView-terminalStart]
mov pc,lr
Now we need to make a basic method for character based displays; the Print function. This takes in a string address in r0, and a length in r1, and simply writes it to the current location at the screen. There are a few special characters to be wary of, as well as special behaviour to ensure that terminalView is kept up to date. Let's analyse what it has to do:
- Check if string length is 0, if so return
- Load in terminalStop and terminalView
- Deduce the x-coordinate of terminalStop
- For each character:
- Check if the character is a new line
- If so, increment bufferStop to the end of the line storing a black on black delete character.
- Otherwise, copy the character in the current terminalColour
- Check if we're at the end of a line
- If so, check if the number of characters between terminalView and terminalStop is more than one screen
- If so, increment terminalView by one line
- Check if terminalView is at the end of the buffer, replace it with the start if so
- Check if terminalStop is at the end of the buffer, replace it with the start if so
- Check if terminalStop equals terminalStart, increment terminalStart by one line if so
- Check if terminalStart is at the end of the buffer, replace it with the start if so
- Store back terminalStop and terminalView.
See if you can implement this yourself. My solution is provided below:
-
.globl Print
Print:
teq r1,#0
moveq pc,lr
This quick check at the beginning makes a call to Print with a string of length 0 almost instant.
-
push {r4,r5,r6,r7,r8,r9,r10,r11,lr}
bufferStart .req r4
taddr .req r5
x .req r6
string .req r7
length .req r8
char .req r9
bufferStop .req r10
view .req r11
mov string,r0
mov length,r1
ldr taddr,=terminalStart
ldr bufferStop,[taddr,#terminalStop-terminalStart]
ldr view,[taddr,#terminalView-terminalStart]
ldr bufferStart,[taddr]
add taddr,#terminalBuffer-terminalStart
add taddr,#128*128*2
I do a lot of setup here. bufferStart contains terminalStart, bufferStop contains terminalStop, view contains terminalView, taddr is the address of the end of terminalBuffer.
-
and x,bufferStop,#0xfe
lsr x,#1
As per usual, a sneaky alignment trick makes everything easier. Because of the aligment of terminalBuffer, the x-coordinate of any character address is simply the last 8 bits divided by 2.
-
-
charLoop$:
ldrb char,[string]
and char,#0x7f
teq char,#'\n'
bne charNormal$
We need to check for new lines.
-
mov r0,#0x7f
clearLine$:
strh r0,[bufferStop]
add bufferStop,#2
add x,#1
teq x,#128 blt clearLine$
b charLoopContinue$
Loop until the end of the line, writing out 0x7f; a delete character in black on a black background.
-
charNormal$:
strb char,[bufferStop]
ldr r0,=terminalColour
ldrb r0,[r0]
strb r0,[bufferStop,#1]
add bufferStop,#2
add x,#1
Store the current character in the string and the terminalColour to the end of the terminalBuffer and then increment it and x.
-
charLoopContinue$:
cmp x,#128
blt noScroll$
Check if x is at the end of a line; 128.
-
mov x,#0
subs r0,bufferStop,view
addlt r0,#128*128*2
cmp r0,#128*(768/16)*2
Set x back to 0 and check if we're currently showing more than one screen. Remember, we're using a circular buffer, so if the difference between bufferStop and view is negative, we're actually wrapping around the buffer.
-
addge view,#128*2
Add one lines worth of bytes to the view address.
-
teq view,taddr
subeq view,taddr,#128*128*2
If the view address is at the end of the buffer we subtract the buffer length from it to move it back to the start. I set taddr to the address of the end of the buffer at the beginning.
-
noScroll$:
teq bufferStop,taddr
subeq bufferStop,taddr,#128*128*2
If the stop address is at the end of the buffer we subtract the buffer length from it to move it back to the start. I set taddr to the address of the end of the buffer at the beginning.
-
teq bufferStop,bufferStart
addeq bufferStart,#128*2
Check if bufferStop equals bufferStart. If so, add one line to bufferStart.
-
teq bufferStart,taddr
subeq bufferStart,taddr,#128*128*2
If the start address is at the end of the buffer we subtract the buffer length from it to move it back to the start. I set taddr to the address of the end of the buffer at the beginning.
subs length,#1
add string,#1
bgt charLoop$
Loop until the string is done.
-
-
charLoopBreak$:
sub taddr,#128*128*2
sub taddr,#terminalBuffer-terminalStart
str bufferStop,[taddr,#terminalStop-terminalStart]
str view,[taddr,#terminalView-terminalStart]
str bufferStart,[taddr]
pop {r4,r5,r6,r7,r8,r9,r10,r11,pc}
.unreq bufferStart
.unreq taddr
.unreq x
.unreq string
.unreq length
.unreq char
.unreq bufferStop
.unreq view
Store back the variables and return.
This method allows us to print arbitrary text to the screen. Throughout, I've been
using the colour variable, but no where have we actually set it. Normally, terminals
use special combinations of characters to change the colour. For example ASCII Escape
(1b16) followed by a number 0 to f in hexadecimal could set the foreground
colour to that CGA colour number. You can try implementing this yourself; my version
is in the further examples section on the download page.
## 4 Standard Input
By convention, in many programming languages, every program has access to stdin and stdout, which are an input and and output stream linked to the terminal. This is still true on graphical programs, though many don't use it.
Now we have an output terminal that in theory can print out text and display it. That is only half the story however, we want input. We want to implement a method, ReadLine, which stores the next line of text a user types to a location given in r0, up to a maximum length given in r1, and returns the length of the string read in r0. The tricky thing is, the user annoyingly wants to see what they're typing as they type it, they want to use backspace to delete mistakes and they want to use return to submit commands. They probably even want a flashing underscore character to indicate the computer would like input! These perfectly reasonable requests make this method a real challenge. One way to achieve all of this is to store the text they type in memory somewhere along with its length, and then after every character, move the terminalStop address back to where it started when ReadLine was called and calling Print. This means we only have to be able to manipulate a string in memory, and then make use of our Print function.
Lets have a look at what ReadLine will do:
- If the maximum length is 0, return 0
- Retrieve the current values of terminalStop and terminalView
- If the maximum length is bigger than half the buffer size, set it to half the buffer size
- Subtract one from maximum length to ensure it can store our flashing underscore or a null terminator
- Write an underscore to the string
- Write the stored terminalView and terminalStop addresses back to the memory
- Call Print on the current string
- Call TerminalDisplay
- Call KeyboardUpdate
- Call KeyboardGetChar
- If it is a new line character go to 16
- If it is a backspace character, subtract 1 from the length of the string (if it is > 0)
- If it is an ordinary character, write it to the string (if the length < maximum length)
- If the string ends in an underscore, write a space, otherwise write an underscore
- Go to 6
- Write a new line character to the end of the string
- Call Print and TerminalDisplay
- Replace the new line with a null terminator
- Return the length of the string
Convince yourself that this will work, and then try to implement it yourself. My implementation is given below:
-
.globl ReadLine
ReadLine:
teq r1,#0
moveq r0,#0
moveq pc,lr
Quick special handling for the zero case, which is otherwise difficult.
-
string .req r4
maxLength .req r5
input .req r6
taddr .req r7
length .req r8
view .req r9
push {r4,r5,r6,r7,r8,r9,lr}
mov string,r0
mov maxLength,r1
ldr taddr,=terminalStart
ldr input,[taddr,#terminalStop-terminalStart]
ldr view,[taddr,#terminalView-terminalStart]
mov length,#0
As per the general theme, I do a lot of initialisations early. input contains the value of terminalStop and view contains terminalView. Length starts at 0.
-
cmp maxLength,#128*64
movhi maxLength,#128*64
We have to check for unusually large reads, as we can't process them beyond the size of the terminalBuffer (I suppose we CAN, but it would be very buggy, as terminalStart could move past the stored terminalStop).
-
sub maxLength,#1
Since the user wants a flashing cursor, and we ideally want to put a null terminator on this string, we need 1 spare character.
-
mov r0,#'_'
strb r0,[string,length]
Write out the underscore to let the user know they can input.
-
readLoop$:
str input,[taddr,#terminalStop-terminalStart]
str view,[taddr,#terminalView-terminalStart]
Save the stored terminalStop and terminalView. This is important to reset the terminal after each call to Print, which changes these variables. Strictly speaking it can change terminalStart too, but this is irreversible.
-
mov r0,string
mov r1,length
add r1,#1
bl Print
Write the current input. We add 1 to the length for the underscore.
-
bl TerminalDisplay
Copy the new text to the screen.
-
bl KeyboardUpdate
Fetch the latest keyboard input.
-
bl KeyboardGetChar
Retrieve the key pressed.
-
teq r0,#'\n'
beq readLoopBreak$
teq r0,#0
beq cursor$
teq r0,#'\b'
bne standard$
Break out of the loop if we have an enter key. Also skip these conditions if we have a null terminator and process a backspace if we have one.
-
delete$:
cmp length,#0
subgt length,#1
b cursor$
Remove one from the length to delete a character.
-
standard$:
cmp length,maxLength
bge cursor$
strb r0,[string,length]
add length,#1
Write out an ordinary character where possible.
-
cursor$:
ldrb r0,[string,length]
teq r0,#'_'
moveq r0,#' '
movne r0,#'_'
strb r0,[string,length]
Load in the last character, and change it to an underscore if it isn't one, and a space if it is.
-
b readLoop$
readLoopBreak$:
Loop until the user presses enter.
-
mov r0,#'\n'
strb r0,[string,length]
Store a new line at the end of the string.
-
str input,[taddr,#terminalStop-terminalStart]
str view,[taddr,#terminalView-terminalStart]
mov r0,string
mov r1,length
add r1,#1
bl Print
bl TerminalDisplay
Reset the terminalView and terminalStop and then Print and TerminalDisplay the final input.
-
mov r0,#0
strb r0,[string,length]
Write out the null terminator.
-
mov r0,length
pop {r4,r5,r6,r7,r8,r9,pc}
.unreq string
.unreq maxLength
.unreq input
.unreq taddr
.unreq length
.unreq view
Return the length.
## 5 The Terminal: Rise of the Machine
So, now we can theoretically interact with the user on the terminal. The most obvious thing to do is to put this to the test! In 'main.s' delete everything after bl UsbInitialise and copy in the following code:
reset$:
mov sp,#0x8000
bl TerminalClear
ldr r0,=welcome
mov r1,#welcomeEnd-welcome
bl Print
loop$:
ldr r0,=prompt
mov r1,#promptEnd-prompt
bl Print
ldr r0,=command
mov r1,#commandEnd-command
bl ReadLine
teq r0,#0
beq loopContinue$
mov r4,r0
ldr r5,=command
ldr r6,=commandTable
ldr r7,[r6,#0]
ldr r9,[r6,#4]
commandLoop$:
ldr r8,[r6,#8]
sub r1,r8,r7
cmp r1,r4
bgt commandLoopContinue$
mov r0,#0
commandName$:
ldrb r2,[r5,r0]
ldrb r3,[r7,r0]
teq r2,r3
bne commandLoopContinue$
add r0,#1
teq r0,r1
bne commandName$
ldrb r2,[r5,r0]
teq r2,#0
teqne r2,#' '
bne commandLoopContinue$
mov r0,r5
mov r1,r4
mov lr,pc
mov pc,r9
b loopContinue$
commandLoopContinue$:
add r6,#8
mov r7,r8
ldr r9,[r6,#4]
teq r9,#0
bne commandLoop$
ldr r0,=commandUnknown
mov r1,#commandUnknownEnd-commandUnknown
ldr r2,=formatBuffer
ldr r3,=command
bl FormatString
mov r1,r0
ldr r0,=formatBuffer
bl Print
loopContinue$:
bl TerminalDisplay
b loop$
echo:
cmp r1,#5
movle pc,lr
add r0,#5
sub r1,#5
b Print
ok:
teq r1,#5
beq okOn$
teq r1,#6
beq okOff$
mov pc,lr
okOn$:
ldrb r2,[r0,#3]
teq r2,#'o'
ldreqb r2,[r0,#4]
teqeq r2,#'n'
movne pc,lr
mov r1,#0
b okAct$
okOff$:
ldrb r2,[r0,#3]
teq r2,#'o'
ldreqb r2,[r0,#4]
teqeq r2,#'f'
ldreqb r2,[r0,#5]
teqeq r2,#'f'
movne pc,lr
mov r1,#1
okAct$:
mov r0,#16
b SetGpio
.section .data
.align 2
welcome: .ascii "Welcome to Alex's OS - Everyone's favourite OS"
welcomeEnd:
.align 2
prompt: .ascii "\n> "
promptEnd:
.align 2
command:
.rept 128
.byte 0
.endr
commandEnd:
.byte 0
.align 2
commandUnknown: .ascii "Command `%s' was not recognised.\n"
commandUnknownEnd:
.align 2
formatBuffer:
.rept 256
.byte 0
.endr
formatEnd:
.align 2
commandStringEcho: .ascii "echo"
commandStringReset: .ascii "reset"
commandStringOk: .ascii "ok"
commandStringCls: .ascii "cls"
commandStringEnd:
.align 2
commandTable:
.int commandStringEcho, echo
.int commandStringReset, reset$
.int commandStringOk, ok
.int commandStringCls, TerminalClear
.int commandStringEnd, 0
This code brings everything together into a simple command line operating system. The commands available are echo, reset, ok and cls. echo copies any text after it back to the terminal, reset resets the operating system if things go wrong, ok has two functions: ok on turns the OK LED on, and ok off turns the OK LED off, and cls clears the terminal using TerminalClear.
Have a go with this code on the Raspberry Pi. If it doesn't work, please see our troubleshooting page.
When it works, congratulations you've completed a basic terminal Operating System,
and have completed the input series. Unfortunately, this is as far as these tutorials
go at the moment, but I hope to make more in the future. Please send feedback to
[[Javascript required]].
You're now in position to start building some simple terminal Operating Systems. My code above builds up a table of available commands in commandTable. Each entry in the table is an int for the address of the string, and an int for the address of the code to run. The last entry has to be commandStringEnd, 0. Try implementing some of your own commands, using our existing functions, or making new ones. The parameters for the functions to run are r0 is the address of the command the user typed, and r1 is the length. You can use this to pass inputs to your commands. Maybe you could make a calculator program, perhaps a drawing program or a chess program. Whatever ideas you've got, give them a go! |
10,702 | Git 十四周年:你喜欢 Git 的哪一点? | https://opensource.com/article/19/4/what-do-you-love-about-git | 2019-04-10T00:23:00 | [
"Git"
] | /article-10702-1.html |
>
> Git 为软件开发所带来的巨大影响是其它工具难以企及的。
>
>
>

在 Linus Torvalds 开发 Git 后的十四年间,它为软件开发所带来的影响是其它工具难以企及的:在 [StackOverflow 的 2018 年开发者调查](https://insights.stackoverflow.com/survey/2018/#work-_-version-control) 中,87% 的受访者都表示他们使用 Git 来作为他们项目的版本控制工具。显然,没有其它工具能撼动 Git 版本控制管理工具(SCM)之王的地位。
为了在 4 月 7 日 Git 的十四周年这一天向 Git 表示敬意,我问了一些爱好者他们最喜欢 Git 的哪一点。以下便是他们所告诉我的:
(为了便于理解,部分回答已经进行了小幅修改)
>
> “我无法忍受 Git。无论是难以理解的术语还是它的分布式。使用 Gerrit 这样的插件才能使它像 Subversion 或 Perforce 这样的集中式仓库管理器使用的工具的一半好用。不过既然这次的问题是‘你喜欢 Git 的什么?’,我还是希望回答:Git 使得对复杂的源代码树操作成为可能,并且它的回滚功能使得实现一个要 20 次修改才能更正的问题变得简单起来。”
>
>
> — [Sweet Tea Dorminy](https://github.com/sweettea)
>
>
>
>
> “我喜欢 Git 是因为它不会强制我执行特定的工作流程,并且开发团队可以自由地以适合自己的方式来进行团队开发,无论是拉取请求、以电子邮件递送差异文件或是给予所有人推送的权限。”
>
>
> — [Andy Price](https://www.linkedin.com/in/andrew-price-8771796/)
>
>
>
>
> “我从 2006、2007 年的样子就开始使用 Git 了。我喜欢 Git 是因为,它既适用于那种从未离开过我电脑的小项目,也适用于大型的团队合作的分布式项目。Git 使你可以从(几乎)所有的错误提交中回滚到先前版本,这个功能显著地减轻了我在软件版本管理方面的压力。”
>
>
> — [Jonathan S. Katz](https://opensource.com/users/jkatz05)
>
>
>
>
> “我很欣赏 Git 那种 [底层命令和高层命令](https://git-scm.com/book/en/v2/Git-Internals-Plumbing-and-Porcelain) 的理念。用户可以使用 Git 有效率地分享任何形式的信息,而不需要知道其内部工作原理。而好奇的人可以透过其表层的命令,而发现其为许多代码分享平台提供了支持的可以定位内容的文件系统。”
>
>
> — [Matthew Broberg](https://opensource.com/users/mbbroberg)
>
>
>
>
> “我喜欢 Git 是因为浏览、开发、构建、测试和向我的 Git 仓库中提交代码的工作几乎都能用它来完成。它经常会调动起我参与开源项目的积极性。”
>
>
> — [Daniel Oh](https://opensource.com/users/daniel-oh)
>
>
>
>
> “Git 是我用过的首个版本控制工具。数年间,它从一个可怕的工具变成了一个友好的工具。我喜欢它使你在修改代码的时候更加自信,因为它能保证你主分支的安全(除非你强制提交了一段考虑不周的代码到主分支)。你可以检出先前的提交来撤销更改,这一点也是很棒的。”
>
>
> — [Kedar Vijay Kulkarni](https://opensource.com/users/kkulkarn)
>
>
>
>
> “我之所以喜欢 Git 是因为它淘汰了一些其它的版本控制工具。没人使用 VSS,而 Subversion 可以和 git-svn 一起使用(如果必要),BitKeeper 则和 Monotone 一样只为老一辈所知。当然,我们还有 Mercurial,不过在我几年之前用它来为 Firefox 添加 AArch64 支持时,我觉得它仍是那种还未完善的工具。部分人可能还会提到 Perforce、SourceSafe 或是其它企业级的解决方案,我只想说它们在开源世界里并不流行。”
>
>
> — [Marcin Juszkiewicz](https://github.com/hrw)
>
>
>
>
> “我喜欢内置的 SHA1 化对象模型(commit → tree → blob)的简易性。我也喜欢它的高层命令。同时我也将它作为对 JBoss/Red Hat Fuse 的补丁机制。并且这种机制确实有效。我还喜欢 Git 的 [三棵树的故事](https://speakerdeck.com/schacon/a-tale-of-three-trees)。”
>
>
> — [Grzegorz Grzybek](https://github.com/grgrzybek)
>
>
>
>
> “我喜欢 [自动生成的 Git 说明页](https://git-man-page-generator.lokaltog.net/)(这个页面虽然听起来是有关 Git 的,但是事实上这是一个没有实际意义的页面,不过它总是会给人一种像是真的 Git 页面的感觉…),这使得我对 Git 的敬意油然而生。”
>
>
> — [Marko Myllynen](https://github.com/myllynen)
>
>
>
>
> “Git 改变了我作为开发者的生活。它使得 SCM 问题从世界上消失得无影无踪。”
>
>
> — [Joel Takvorian](https://github.com/jotak)
>
>
>
看完这十个爱好者的回答之后,就轮到你了:你最欣赏 Git 的什么?请在评论区分享你的看法!
---
via: <https://opensource.com/article/19/4/what-do-you-love-about-git>
作者:[Jen Wike Huger](https://opensource.com/users/jen-wike/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zhs852](https://github.com/zhs852) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,705 | 如何在 Linux 分区或逻辑卷中创建文件系统 | https://opensource.com/article/19/4/create-filesystem-linux-partition | 2019-04-10T09:14:00 | [
"文件系统"
] | https://linux.cn/article-10705-1.html |
>
> 学习在你的系统中创建一个文件系统,并且长期或者非长期地挂载它。
>
>
>

在计算技术中,文件系统控制如何存储和检索数据,并且帮助组织存储媒介中的文件。如果没有文件系统,信息将被存储为一个大数据块,而且你无法知道一条信息在哪结束,下一条信息在哪开始。文件系统通过为存储数据的文件提供名称,并且在文件系统中的磁盘上维护文件和目录表以及它们的开始和结束位置、总的大小等来帮助管理所有的这些信息。
在 Linux 中,当你创建一个硬盘分区或者逻辑卷之后,接下来通常是通过格式化这个分区或逻辑卷来创建文件系统。这个操作方法假设你已经知道如何创建分区或逻辑卷,并且你希望将它格式化为包含有文件系统,并且挂载它。
### 创建文件系统
假设你为你的系统添加了一块新的硬盘并且在它上面创建了一个叫 `/dev/sda1` 的分区。
1、为了验证 Linux 内核已经发现这个分区,你可以 `cat` 出 `/proc/partitions` 的内容,就像这样:
```
[root@localhost ~]# cat /proc/partitions
major minor #blocks name
253 0 10485760 vda
253 1 8192000 vda1
11 0 1048575 sr0
11 1 374 sr1
8 0 10485760 sda
8 1 10484736 sda1
252 0 3145728 dm-0
252 1 2097152 dm-1
252 2 1048576 dm-2
8 16 1048576 sdb
```
2、决定你想要去创建的文件系统种类,比如 ext4、XFS,或者其他的一些。这里是一些可选项:
```
[root@localhost ~]# mkfs.<tab><tab>
mkfs.btrfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.minix mkfs.xfs
```
3、为了这次练习的目的,选择 ext4。(我喜欢 ext4,因为如果你需要的话,它可以允许你去压缩文件系统,这对于 XFS 并不简单。)这里是完成它的方法(输出可能会因设备名称或者大小而不同):
```
[root@localhost ~]# mkfs.ext4 /dev/sda1
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=8191 blocks
194688 inodes, 778241 blocks
38912 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=799014912
24 block groups
32768 blocks per group, 32768 fragments per group
8112 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
```
4、在上一步中,如果你想去创建不同的文件系统,请使用不同变种的 `mkfs` 命令。
### 挂载文件系统
当你创建好文件系统后,你可以在你的操作系统中挂载它。
1、首先,识别出新文件系统的 UUID 编码。使用 `blkid` 命令列出所有可识别的块存储设备并且在输出信息中查找 `sda1`:
```
[root@localhost ~]# blkid
/dev/vda1: UUID="716e713d-4e91-4186-81fd-c6cfa1b0974d" TYPE="xfs"
/dev/sr1: UUID="2019-03-08-16-17-02-00" LABEL="config-2" TYPE="iso9660"
/dev/sda1: UUID="wow9N8-dX2d-ETN4-zK09-Gr1k-qCVF-eCerbF" TYPE="LVM2_member"
/dev/mapper/test-test1: PTTYPE="dos"
/dev/sda1: UUID="ac96b366-0cdd-4e4c-9493-bb93531be644" TYPE="ext4"
[root@localhost ~]#
```
2、运行下面的命令挂载 `/dev/sd1` 设备:
```
[root@localhost ~]# mkdir /mnt/mount_point_for_dev_sda1
[root@localhost ~]# ls /mnt/
mount_point_for_dev_sda1
[root@localhost ~]# mount -t ext4 /dev/sda1 /mnt/mount_point_for_dev_sda1/
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 7.9G 920M 7.0G 12% /
devtmpfs 443M 0 443M 0% /dev
tmpfs 463M 0 463M 0% /dev/shm
tmpfs 463M 30M 434M 7% /run
tmpfs 463M 0 463M 0% /sys/fs/cgroup
tmpfs 93M 0 93M 0% /run/user/0
/dev/sda1 2.9G 9.0M 2.7G 1% /mnt/mount_point_for_dev_sda1
[root@localhost ~]#
```
命令 `df -h` 显示了每个文件系统被挂载的挂载点。查找 `/dev/sd1`。上面的挂载命令使用的设备名称是 `/dev/sda1`。用 `blkid` 命令中的 UUID 编码替换它。注意,在 `/mnt` 下一个被新创建的目录挂载了 `/dev/sda1`。
3、直接在命令行下使用挂载命令(就像上一步一样)会有一个问题,那就是挂载不会在设备重启后存在。为使永久性地挂载文件系统,编辑 `/etc/fstab` 文件去包含你的挂载信息:
```
UUID=ac96b366-0cdd-4e4c-9493-bb93531be644 /mnt/mount_point_for_dev_sda1/ ext4 defaults 0 0
```
4、编辑完 `/etc/fstab` 文件后,你可以 `umount /mnt/mount_point_for_fev_sda1` 并且运行 `mount -a` 命令去挂载被列在 `/etc/fstab` 文件中的所有设备文件。如果一切顺利的话,你可以使用 `df -h` 列出并且查看你挂载的文件系统:
```
root@localhost ~]# umount /mnt/mount_point_for_dev_sda1/
[root@localhost ~]# mount -a
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 7.9G 920M 7.0G 12% /
devtmpfs 443M 0 443M 0% /dev
tmpfs 463M 0 463M 0% /dev/shm
tmpfs 463M 30M 434M 7% /run
tmpfs 463M 0 463M 0% /sys/fs/cgroup
tmpfs 93M 0 93M 0% /run/user/0
/dev/sda1 2.9G 9.0M 2.7G 1% /mnt/mount_point_for_dev_sda1
```
5、你也可以检测文件系统是否被挂载:
```
[root@localhost ~]# mount | grep ^/dev/sd
/dev/sda1 on /mnt/mount_point_for_dev_sda1 type ext4 (rw,relatime,seclabel,stripe=8191,data=ordered)
```
现在你已经知道如何去创建文件系统并且长期或者非长期的挂载在你的系统中。
---
via: <https://opensource.com/article/19/4/create-filesystem-linux-partition>
作者:[Kedar Vijay Kulkarni (Red Hat)](https://opensource.com/users/kkulkarn) 选题:[lujun9972](https://github.com/lujun9972) 译者:[liujing97](https://github.com/liujing97) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In computing, a filesystem controls how data is stored and retrieved and helps organize the files on the storage media. Without a filesystem, information in storage would be one large block of data, and you couldn't tell where one piece of information stopped and the next began. A filesystem helps manage all of this by providing names to files that store data and maintaining a table of files and directories—along with their start/end location, total size, etc.—on disks within the filesystem.
In Linux, when you create a hard disk partition or a logical volume, the next step is usually to create a filesystem by formatting the partition or logical volume. This how-to assumes you know how to create a partition or a logical volume, and you just want to format it to contain a filesystem and mount it.
## Create a filesystem
Imagine you just added a new disk to your system and created a partition named **/dev/sda1** on it.
- To verify that the Linux kernel can see the partition, you can
**cat**out**/proc/partitions**like this:
`[root@localhost ~]# cat /proc/partitions major minor #blocks name 253 0 10485760 vda 253 1 8192000 vda1 11 0 1048575 sr0 11 1 374 sr1 8 0 10485760 sda 8 1 10484736 sda1 252 0 3145728 dm-0 252 1 2097152 dm-1 252 2 1048576 dm-2 8 16 1048576 sdb`
- Decide what kind of filesystem you want to create, such as ext4, XFS, or anything else. Here are a few options:
`[root@localhost ~]# mkfs.<tab><tab> mkfs.btrfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.minix mkfs.xfs`
- For the purposes of this exercise, choose ext4. (I like ext4 because it allows you to shrink the filesystem if you need to, a thing that isn't as straightforward with XFS.) Here's how it can be done (the output may differ based on device name/sizes):
`[root@localhost ~]# mkfs.ext4 /dev/sda1 mke2fs 1.42.9 (28-Dec-2013) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=8191 blocks 194688 inodes, 778241 blocks 38912 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=799014912 24 block groups 32768 blocks per group, 32768 fragments per group 8112 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912 Allocating group tables: done Writing inode tables: done Creating journal (16384 blocks): done Writing superblocks and filesystem accounting information: done`
- In the previous step, if you want to create a different kind of filesystem, use a different
**mkfs**command variation.
## Mount a filesystem
After you create your filesystem, you can mount it in your operating system.
- First, identify the UUID of your new filesystem. Issue the
**blkid**command to list all known block storage devices and look for**sda1**in the output:
`[root@localhost ~]# blkid /dev/vda1: UUID="716e713d-4e91-4186-81fd-c6cfa1b0974d" TYPE="xfs" /dev/sr1: UUID="2019-03-08-16-17-02-00" LABEL="config-2" TYPE="iso9660" /dev/sda1: UUID="wow9N8-dX2d-ETN4-zK09-Gr1k-qCVF-eCerbF" TYPE="LVM2_member" /dev/mapper/test-test1: PTTYPE="dos" /dev/sda1: UUID="ac96b366-0cdd-4e4c-9493-bb93531be644" TYPE="ext4" [root@localhost ~]#`
- Run the following command to mount the
**/dev/sd1**device :
`[root@localhost ~]# mkdir /mnt/mount_point_for_dev_sda1 [root@localhost ~]# ls /mnt/ mount_point_for_dev_sda1 [root@localhost ~]# mount -t ext4 /dev/sda1 /mnt/mount_point_for_dev_sda1/ [root@localhost ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/vda1 7.9G 920M 7.0G 12% / devtmpfs 443M 0 443M 0% /dev tmpfs 463M 0 463M 0% /dev/shm tmpfs 463M 30M 434M 7% /run tmpfs 463M 0 463M 0% /sys/fs/cgroup tmpfs 93M 0 93M 0% /run/user/0 /dev/sda1 2.9G 9.0M 2.7G 1% /mnt/mount_point_for_dev_sda1 [root@localhost ~]#`
The
**df -h**command shows which filesystem is mounted on which mount point. Look for**/dev/sd1**. The mount command above used the device name**/dev/sda1**. Substitute it with the UUID identified in the**blkid**command. Also, note that a new directory was created to mount**/dev/sda1**under**/mnt**.
- A problem with using the mount command directly on the command line (as in the previous step) is that the mount won't persist across reboots. To mount the filesystem persistently, edit the
**/etc/fstab**file to include your mount information:
`UUID=ac96b366-0cdd-4e4c-9493-bb93531be644 /mnt/mount_point_for_dev_sda1/ ext4 defaults 0 0`
- After you edit
**/etc/fstab**, you can**umount /mnt/mount_point_for_dev_sda1**and run the command**mount -a**to mount everything listed in**/etc/fstab**. If everything went right, you can still list**df -h**and see your filesystem mounted:
`root@localhost ~]# umount /mnt/mount_point_for_dev_sda1/ [root@localhost ~]# mount -a [root@localhost ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/vda1 7.9G 920M 7.0G 12% / devtmpfs 443M 0 443M 0% /dev tmpfs 463M 0 463M 0% /dev/shm tmpfs 463M 30M 434M 7% /run tmpfs 463M 0 463M 0% /sys/fs/cgroup tmpfs 93M 0 93M 0% /run/user/0 /dev/sda1 2.9G 9.0M 2.7G 1% /mnt/mount_point_for_dev_sda1`
- You can also check whether the filesystem was mounted:
`[root@localhost ~]# mount | grep ^/dev/sd /dev/sda1 on /mnt/mount_point_for_dev_sda1 type ext4 (rw,relatime,seclabel,stripe=8191,data=ordered)`
Now you know how to create a filesystem and mount it persistently or non-persistently within your system.
## 2 Comments |
10,707 | 学习使用树莓派的 7 个资源 | https://opensource.com/article/19/3/resources-raspberry-pi | 2019-04-11T10:09:48 | [
"树莓派"
] | https://linux.cn/article-10707-1.html |
>
> 一些缩短树莓派学习曲线的书籍、课程和网站。
>
>
>

[树莓派](https://opensource.com/resources/raspberry-pi)是一款小型单板计算机,最初用于教学和学习编程和计算机科学。但如今它有更多用处。它是一种经济的低功耗计算机,人们将它用于各种各样的事情 —— 从家庭娱乐到服务器应用,再到物联网(IoT) 项目。
关于这个主题有很多资源,你可以做很多不同的项目,却很难知道从哪里开始。以下是一些资源,可以帮助你开始使用树莓派。看看这篇文章,但不要满足于此。到处看下,深入下去你就会发现树莓派的新世界。
### 书籍
关于树莓派有很多不同语言的书籍。这两本书将帮助你开始了解,然后深入了解树莓派。
#### 由 Simon Monk 编写的《树莓派手边书:软件和硬件问题及解决方案》
Simon Monk 是一名软件工程师,并且多年来一直是业余手工爱好者。他最初被 Arduino 这块易于使用的开发板所吸引,后来出版了一本关于它的[书](http://simonmonk.org/progardui2ed/)。后来,他开始使用树莓派并写了《[树莓派手边书:软件和硬件问题和解决方案](http://simonmonk.org/raspberry-pi-cookbook-ed2/)》这本书。在本书中,你可以找到大量树莓派项目的最佳时间,以及你可能面对的各种挑战的解决方案。
#### 由 Simon Monk 编写的《树莓派编程:从 Python 入门》
Python 已经发展成为开始一个树莓派项目的首选编程语言,因为它易于学习和使用,即使你没有任何编程经验。此外,它的许多库可以帮助你专注于使你的项目变得特别,而不是实现协议以与传感器反复通信。Monk 在《树莓派手边书》中写了两章关于 Python 编程,但《[树莓派编程:从 Python 入门](http://simonmonk.org/programming-raspberry-pi-ed2/)》是一个更全面的快速入门。它向你介绍了 Python,并向你展示了可以在树莓派上使用它创建的一些项目。
### 在线课程
新的树莓派用户可以选择许多在线课程和教程,包括这个入门课程。
#### 树莓派课程
Instructables 免费的在线[树莓派课程](https://www.instructables.com/class/Raspberry-Pi-Class/)提供了对树莓派的全面介绍。它从树莓派和 Linux 操作基础开始,然后进入 Python 编程和 GPIO 通信。如果你是这方面的新手,并希望快速入门,这使它成为一个很好的自上而下的树莓派指南。
### 网站
网络中充斥着关于树莓派的优秀信息,但这四个网站对于新用户而言应该首先知道。
#### RaspberryPi.org
官方的[树莓派](https://raspberrypi.org)网站是最好的入门之一。有许多关于特定项目的文章会链接到这里的基础知识,如将 Raspbian 安装到树莓派上。(这是我倾向的做法,而不是在每篇文章中重复说明。)你还可以找到学生技术[教育](https://www.raspberrypi.org/training/online)方面的[示例项目](https://projects.raspberrypi.org/)和课程。
#### Opensource.com
在 Opensource.com 上,你可以找到许多不同的树莓派项目指导、入门指南、成功案例、更新等。看一下[树莓派主题页面](https://opensource.com/tags/raspberry-pi),了解人们在树莓派上做了什么。
#### Instructables 和 Hackaday
你想造自己的复古街机么?或者在镜子上显示当天的天气信息、时间和第一事务?你是否想要为派对创建一个文字时钟或者相簿?你可以在 [Instructables](https://www.instructables.com/technology/raspberry-pi/) 和 [Hackaday](https://hackaday.io/projects?tag=raspberry%20pi) 这样的网站上找到如何使用树莓派完成所有这些(以及更多!)的说明。如果你不确定是否要买树莓派,请浏览这些网站,你会发现有很多理由值得购买。
你最喜欢的树莓派资源是什么?请在评论中分享!
---
via: <https://opensource.com/article/19/3/resources-raspberry-pi>
作者:[Manuel Dewald](https://opensource.com/users/ntlx) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [Raspberry Pi](https://opensource.com/resources/raspberry-pi) is a small, single-board computer originally intended for teaching and learning programming and computer science. But today it's so much more. It is affordable, low-energy computing power that people can use for all kinds of things—from home entertainment over server applications to Internet of Things (IoT) projects.
There are so many resources on the topic and so many different projects you can do, it's hard to know where to begin. Following are some resources that will help you get started with the Raspberry Pi. Have fun browsing through it, but don't stop here. By looking left and right you will find a lot to discover and get deeper into the rabbit hole of the Raspberry Pi wonderland.
## Books
There are many books available in different languages about the Raspberry Pi. These two will help you start—then dive deep—into Raspberry Pi topics.
*Raspberry Pi Cookbook: Software and Hardware Problems and Solutions* by Simon Monk
Simon Monk is a software engineer and was a hobbyist maker for years. He was first attracted to the Arduino as an easy-to-use board for electronics development and later published a [book](http://simonmonk.org/progardui2ed/) about it. Later, he moved on to the Raspberry Pi and wrote * Raspberry Pi Cookbook: Software and Hardware Problems and Solutions*. In the book, you can find a lot of best practices for Raspberry Pi projects and solutions for all kinds of challenges you may face.
*Programming the Raspberry Pi: Getting Started with Python* by Simon Monk
Python has evolved as the go-to programming language for getting started with Raspberry Pi projects, as it is easy to learn and use, even if you don't have any programming experience. Also, a lot of its libraries help you focus on what makes your project special instead of implementing protocols to communicate with your sensors again and again. Monk wrote two chapters about Python programming in the *Raspberry Pi Cookbook*, but * Programming the Raspberry Pi: Getting Started with Python* is a more thorough quickstart. It introduces you to Python and shows you some projects you can create with it on the Raspberry Pi.
## Online course
There are many online courses and tutorials new Raspberry Pi users can choose from, including this introductory class.
### Raspberry Pi Class
Instructables' free [Raspberry Pi Class](https://www.instructables.com/class/Raspberry-Pi-Class/) online course offers you an all-around introduction to the Raspberry Pi. It starts with Raspberry Pi and Linux operating basics, then gets into Python programming and GPIO communication. This makes it a good top-to-bottom Raspberry Pi guide if you are new to the topic and want to get started quickly.
## Websites
The web is rife with excellent information about Raspberry Pi, but these four sites should be on the top of any new user's list.
### RaspberryPi.org
The official [Raspberry Pi](https://raspberrypi.org) website is one of the best places to get started. Many articles about specific projects link to the site for the basics like installing Raspbian onto the Raspberry Pi. (This is what I tend to do, instead of repeating the instructions in every how-to.) You can also find [sample projects](https://projects.raspberrypi.org/) and courses on [teaching](https://www.raspberrypi.org/training/online) tech topics to students.
### Opensource.com
On Opensource.com, you can find a number of different Raspberry Pi project how-to's, getting started guides, success stories, updates, and more. Take a look at the [Raspberry Pi topic page](https://opensource.com/tags/raspberry-pi) to find out what people are doing with Raspberry Pi.
### Instructables and Hackaday
Do you want to build your own retro arcade gaming console? Or for your mirror to display weather information, the time, and the first event on the day's calendar? Are you looking to create a word clock or maybe a photo booth for a party? Chances are good that you will find instructions on how to do all of this (and more!) with a Raspberry Pi on sites like [Instructables](https://www.instructables.com/technology/raspberry-pi/) and [Hackaday](https://hackaday.io/projects?tag=raspberry%20pi). If you're not sure if you should get a Raspberry Pi, browse these sites, and you'll find plenty of reasons to buy one.
What are your favorite Raspberry Pi resources? Please share them in the comments!
## Comments are closed. |
10,709 | 使用 FlightGear 翱翔天空 | https://opensource.com/article/19/1/flightgear | 2019-04-11T10:38:02 | [
"飞行",
"飞机"
] | https://linux.cn/article-10709-1.html |
>
> 你梦想驾驶飞机么?试试开源飞行模拟器 FlightGear 吧。
>
>
>

如果你曾梦想驾驶飞机,你会喜欢 [FlightGear](http://home.flightgear.org/) 的。它是一个功能齐全的[开源](http://wiki.flightgear.org/GNU_General_Public_License)飞行模拟器,可在 Linux、MacOS 和 Windows 中运行。
FlightGear 项目始于 1996 年,原因是对商业飞行模拟程序的不满,因为这些程序无法扩展。它的目标是创建一个复杂、强大、可扩展、开放的飞行模拟器框架,来用于学术界和飞行员培训,以及任何想要玩飞行模拟场景的人。
### 入门
FlightGear 的硬件要求适中,包括支持 OpenGL 以实现平滑帧速的加速 3D 显卡。它在我的配备 i5 处理器和仅 4GB 的内存的 Linux 笔记本上运行良好。它的文档包括[在线手册](http://flightgear.sourceforge.net/getstart-en/getstart-en.html)、一个面向[用户](http://wiki.flightgear.org/Portal:User)和[开发者](http://wiki.flightgear.org/Portal:Developer)的 [wiki](http://wiki.flightgear.org/FlightGear_Wiki) 门户网站,还有大量的教程(例如它的默认飞机 [Cessna 172p](http://wiki.flightgear.org/Cessna_172P))教你如何操作它。
在 [Fedora](http://rpmfind.net/linux/rpm2html/search.php?query=flightgear) 和 [Ubuntu](https://launchpad.net/%7Esaiarcot895/+archive/ubuntu/flightgear) Linux 中很容易安装。Fedora 用户可以参考 [Fedora 安装页面](https://apps.fedoraproject.org/packages/FlightGear/)来运行 FlightGear。
在 Ubuntu 18.04 中,我需要安装一个仓库:
```
$ sudo add-apt-repository ppa:saiarcot895/flightgear
$ sudo apt-get update
$ sudo apt-get install flightgear
```
安装完成后,我从 GUI 启动它,但你也可以通过输入以下命令从终端启动应用:
```
$ fgfs
```
### 配置 FlightGear
应用窗口左侧的菜单提供配置选项。

“Summary” 返回应用的主页面。
“Aircraft” 显示你已安装的飞机,并提供了 FlightGear 的默认“机库”中安装多达 539 种其他飞机的选项。我安装了 Cessna 150L、Piper J-3 Cub 和 Bombardier CRJ-700。一些飞机(包括 CRJ-700)有教你如何驾驶商用喷气式飞机的教程。我发现这些教程内容翔实且准确。

要选择驾驶的飞机,请将其高亮显示,然后单击菜单底部的 “Fly!”。我选择了默认的 Cessna 172p 并发现驾驶舱的刻画非常准确。

默认机场是檀香山,但你在 “Location” 菜单中提供你最喜欢机场的 [ICAO 机场代码](https://en.wikipedia.org/wiki/ICAO_airport_code)进行修改。我找到了一些小型的本地无塔机场,如 Olean 和 Dunkirk,纽约,以及包括 Buffalo,O'Hare 和 Raleigh 在内的大型机场,甚至可以选择特定的跑道。
在 “Environment” 下,你可以调整一天中的时间、季节和天气。模拟包括高级天气建模和从 [NOAA](https://www.noaa.gov/) 下载当前天气的能力。
“Settings” 提供在暂停模式中开始模拟的选项。同样在设置中,你可以选择多人模式,这样你就可以与 FlightGear 支持者的全球服务器网络上的其他玩家一起“飞行”。你必须有比较快速的互联网连接来支持此功能。
“Add-ons” 菜单允许你下载飞机和其他场景。
### 开始飞行
为了“起飞”我的 Cessna,我使用了罗技操纵杆,它用起来不错。你可以使用顶部 “File” 菜单中的选项校准操纵杆。
总的来说,我发现模拟非常准确,图形界面也很棒。你自己试下 FlightGear —— 我想你会发现它是一个非常有趣和完整的模拟软件。
---
via: <https://opensource.com/article/19/1/flightgear>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you've ever dreamed of piloting a plane, you'll love [FlightGear](http://home.flightgear.org/). It's a full-featured, [open source](http://wiki.flightgear.org/GNU_General_Public_License) flight simulator that runs on Linux, MacOS, and Windows.
The FlightGear project began in 1996 due to dissatisfaction with commercial flight simulation programs, which were not scalable. Its goal was to create a sophisticated, robust, extensible, and open flight simulator framework for use in academia and pilot training or by anyone who wants to play with a flight simulation scenario.
## Getting started
FlightGear's hardware requirements are fairly modest, including an accelerated 3D video card that supports OpenGL for smooth framerates. It runs well on my Linux laptop with an i5 processor and only 4GB of RAM. Its documentation includes an [online manual](http://flightgear.sourceforge.net/getstart-en/getstart-en.html); a [wiki](http://wiki.flightgear.org/FlightGear_Wiki) with portals for [users](http://wiki.flightgear.org/Portal:User) and [developers](http://wiki.flightgear.org/Portal:Developer); and extensive tutorials (such as one for its default aircraft, the [Cessna 172p](http://wiki.flightgear.org/Cessna_172P)) to teach you how to operate it.
It's easy to install on both [Fedora](http://rpmfind.net/linux/rpm2html/search.php?query=flightgear) and [Ubuntu](https://launchpad.net/~saiarcot895/+archive/ubuntu/flightgear) Linux. Fedora users can consult the [Fedora installation page](https://apps.fedoraproject.org/packages/FlightGear/) to get FlightGear running.
On Ubuntu 18.04, I had to install a repository:
```
$ sudo add-apt-repository ppa:saiarcot895/flightgear
$ sudo apt-get update
$ sudo apt-get install flightgear
```
Once the installation finished, I launched it from the GUI, but you can also launch the application from a terminal by entering:
`$ fgfs`
## Configuring FlightGear
The menu on the left side of the application window provides configuration options.
**Summary** returns you to the application's home screen.
**Aircraft** shows the aircraft you have installed and offers the option to install up to 539 other aircraft available in FlightGear's default "hangar." I installed a Cessna 150L, a Piper J-3 Cub, and a Bombardier CRJ-700. Some of the aircraft (including the CRJ-700) have tutorials to teach you how to fly a commercial jet; I found the tutorials informative and accurate.
To select an aircraft to pilot, highlight it and click on **Fly!** at the bottom of the menu. I chose the default Cessna 172p and found the cockpit depiction extremely accurate.
The default airport is Honolulu, but you can change it in the **Location** menu by providing your favorite airport's [ICAO airport code](https://en.wikipedia.org/wiki/ICAO_airport_code) identifier. I found some small, local, non-towered airports like Olean and Dunkirk, New York, as well as larger airports including Buffalo, O'Hare, and Raleigh—and could even choose a specific runway.
Under **Environment**, you can adjust the time of day, the season, and the weather. The simulation includes advance weather modeling and the ability to download current weather from [NOAA](https://www.noaa.gov/).
**Settings** provides an option to start the simulation in Paused mode by default. Also in Settings, you can select multi-player mode, which allows you to "fly" with other players on FlightGear supporters' global network of servers that allow for multiple users. You must have a moderately fast internet connection to support this functionality.
The **Add-ons** menu allows you to download aircraft and additional scenery.
## Take flight
To "fly" my Cessna, I used a Logitech joystick that worked well. You can calibrate your joystick using an option in the **File** menu at the top.
Overall, I found the simulation very accurate and think the graphics are great. Try FlightGear yourself — I think you will find it a very fun and complete simulation package.
## 4 Comments |
10,711 | 树莓派使用入门:在树莓派上使用 Mathematica 进行高级数学运算 | https://opensource.com/article/19/3/do-math-raspberry-pi | 2019-04-11T15:09:01 | [
"树莓派",
"数学"
] | /article-10711-1.html |
>
> Wolfram 在 Raspbian 中捆绑了一个版本的 Mathematica。在我们的树莓派入门系列的第 12 篇文章中将学习如何使用它。
>
>
>

在 90 年代中期,我进入了大学数学专业,虽然我是以计算机科学学位毕业的,但是我就差两门课程就拿到了双学位,包括数学专业的学位。当时,我接触到了 [Wolfram](https://wolfram.com/) 的一个名为 [Mathematica](https://en.wikipedia.org/wiki/Wolfram_Mathematica) 的应用,我们可以将黑板上的许多代数和微分方程输入计算机。我每月花几个小时在实验室学习 Wolfram 语言,并在 Mathematica 上解决积分等问题。
对于大学生来说 Mathematica 是闭源而且昂贵的,因此在差不多 20 年后,看到 Wolfram 将一个版本的 Mathematica 与 Raspbian 和 Raspberry Pi 捆绑在一起是一个惊喜。如果你决定使用另一个基于 Debian 的发行版,你可以从这里[下载](https://www.wolfram.com/raspberry-pi/)。请注意,此版本仅供非商业用途免费使用。
树莓派基金会的 [Mathematica 简介](https://projects.raspberrypi.org/en/projects/getting-started-with-mathematica/)页面介绍了一些基本概念,如变量和循环、解决一些数学问题、创建图形、做线性代数,甚至通过应用与 GPIO 引脚交互。

要深入了解 Mathematica,请查看 [Wolfram 语言文档](https://www.wolfram.com/language/)。如果你只是想解决一些基本的微积分问题,请[查看它的函数](https://reference.wolfram.com/language/guide/Calculus.html)部分。如果你想[绘制一些 2D 和 3D 图形](https://reference.wolfram.com/language/howto/PlotAGraph.html),请阅读链接的教程。
或者,如果你想在做数学运算时坚持使用开源工具,请查看命令行工具 `expr`、`factor` 和 `bc`。(记住使用 [man 命令](https://opensource.com/article/19/3/learn-linux-raspberry-pi) 阅读使用帮助)如果想画图,[Gnuplot](http://gnuplot.info/) 是个不错的选择。
---
via: <https://opensource.com/article/19/3/do-math-raspberry-pi>
作者:[Anderson Silva](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,714 | 回顾 Firefox 历史 | https://itsfoss.com/history-of-firefox | 2019-04-12T11:18:00 | [
"浏览器",
"Firefox"
] | https://linux.cn/article-10714-1.html | 
从很久之前开始,火狐浏览器就一直是开源社区的一根顶梁柱。这些年来它几乎是所有 Linux 发行版的默认浏览器,并且曾是阻挡微软彻底争霸浏览器界的最后一块磐石。这款浏览器的起源可以一直回溯到互联网创生的时代。本周(LCTT 译注:此文发布于 2019.3.14)是互联网成立 30 周年的纪念日,趁这个机会回顾一下我们熟悉并爱戴的火狐浏览器实在是再好不过了。
### 发源
在上世纪 90 年代早期,一个叫 [Marc Andreessen](https://en.wikipedia.org/wiki/Marc_Andreessen) 的年轻人正在伊利诺伊大学攻读计算机科学学士学位。在那里,他开始为[国家超算应用中心(NCSA)](https://en.wikipedia.org/wiki/National_Center_for_Supercomputing_Applications)工作。就在这段时间内,<ruby> <a href="https://en.wikipedia.org/wiki/Tim_Berners-Lee"> 蒂姆·伯纳斯·李 </a> <rt> Tim Berners-Lee </rt></ruby> 爵士发布了今天已经为我们所熟知的 Web 的早期标准。Marc 在那时候[了解](https://www.w3.org/DesignIssues/TimBook-old/History.html)到了一款叫 [ViolaWWW](http://viola.org/) 的化石级浏览器。Marc 和 Eric Bina 看到了这种技术的潜力,他们开发了一个易于安装的基于 Unix 平台的浏览器,并取名 [NCSA Mosaic](https://en.wikipedia.org/wiki/Mosaic_(web_browser))。第一个 alpha 版本发布于 1993 年 6 月。到 9 月的时候,浏览器已经有 Windows 和 Macintosh 移植版本了。因为比当时其他任何浏览器软件都易于使用,Mosaic 很快变得相当流行。
1994 年,Marc 毕业并移居到加州。一个叫 Jim Clark 的人结识了他,Clark 那时候通过卖电脑软硬件赚了点钱。Clark 也用过 Mosaic 浏览器并且看到了互联网的经济前景。Clark 创立了一家公司并且雇了 Marc 和 Eric 专做互联网软件。公司一开始叫 “Mosaic 通讯”,但是伊利诺伊大学并不喜欢他们用 [Mosaic 这个名字](http://www.computinghistory.org.uk/det/1789/Marc-Andreessen/)。所以公司转而改名为 “<ruby> 网景 <rt> Netscape </rt></ruby>通讯”。
该公司的第一个项目是给任天堂 64 开发在线对战网络,然而不怎么成功。他们第一个以公司名义发布的产品是一款叫做 Mosaic Netscape 0.9 的浏览器,很快这款浏览器被改名叫 Netscape Navigator。在内部,浏览器的开发代号就是 mozilla,意即 “Mosaic 杀手”。一位员工还创作了一幅[哥斯拉风格的](http://www.davetitus.com/mozilla/)卡通画。他们当时想在竞争中彻底胜出。

*早期 Mozilla 在 Netscape 的吉祥物*
他们取得了辉煌的胜利。那时,Netscape 最大的优势是他们的浏览器在各种操作系统上体验极为一致。Netscape 将其宣传为给所有人平等的互联网体验。
随着越来越多的人使用 Netscape Navigator,NCSA Mosaic 的市场份额逐步下降。到了 1995 年,Netscape 公开上市了。[上市首日](https://www.marketwatch.com/story/netscape-ipo-ignited-the-boom-taught-some-hard-lessons-20058518550),股价从开盘的 $28,直窜到 $78,收盘于 $58。Netscape 那时所向披靡。
但好景不长。在 1994 年的夏天,微软发布了 Internet Explorer 1.0,这款浏览器基于 Spyglass Mosaic,而后者又直接基于 NCSA Mosaic。[浏览器战争](https://en.wikipedia.org/wiki/Browser_wars) 就此展开。
在接下来的几年里,Netscape 和微软就浏览器霸主地位展开斗争。他们各自加入了很多新特性以取得优势。不幸的是,IE 有和 Windows 操作系统捆绑的巨大优势。更甚于此,微软也有更多的程序员和资本可以调动。在 1997 年年底,Netscape 公司开始遇到财务问题。
### 迈向开源

1998 年 1 月,Netscape 开源了 Netscape Communicator 4.0 软件套装的代码。[旨在](https://web.archive.org/web/20021001071727/wp.netscape.com/newsref/pr/newsrelease558.html) “集合互联网成千上万的程序员的才智,把最好的功能加入 Netscape 的软件。这一策略旨在加速开发,并且让 Netscape 在未来能向个人和商业用户免费提供高质量的 Netscape Communicator 版本”。
这个项目由新创立的 Mozilla 机构管理。然而,Netscape Communicator 4.0 的代码由于大小和复杂程度而很难开发。雪上加霜的是,浏览器的一些组件由于第三方的许可证问题而不能被开源。到头来,他们决定用新兴的 [Gecko](https://en.wikipedia.org/wiki/Gecko_(software)) 渲染引擎重新开发浏览器。
到了 1998 年的 11 月,Netscape 被美国在线(AOL)以[价值 42 亿美元的股权](http://news.cnet.com/2100-1023-218360.html)收购。
从头来过是一项艰巨的任务。Mozilla Firefox(最初名为 Phoenix)直到 2002 年 6 月才面世,它同样可以运行在多种操作系统上:Linux、Mac OS、Windows 和 Solaris。
1999 年,AOL 宣布他们将停止浏览器开发。随后创建了 Mozilla 基金会,用于管理 Mozilla 的商标和项目相关的融资事宜。最早 Mozilla 基金会从 AOL、IBM、Sun Microsystems 和红帽(Red Hat)收到了总计 200 万美金的捐赠。
到了 2003 年 3 月,因为套件越来越臃肿,Mozilla [宣布](https://web.archive.org/web/20050618000315/http://www.mozilla.org/roadmap/roadmap-02-Apr-2003.html) 计划把该套件分割成单独的应用。这个单独的浏览器一开始起名 Phoenix。但是由于和 BIOS 制造企业凤凰科技的商标官司,浏览器改名 Firebird(火鸟) —— 结果和火鸟数据库的开发者又起了冲突。浏览器只能再次被重命名,才有了现在家喻户晓的 Firefox(火狐)。
那时,[Mozilla 说](https://www-archive.mozilla.org/projects/firefox/firefox-name-faq.html),”我们在过去一年里学到了很多关于起名的技巧(不是因为我们愿意才学的)。我们现在很小心地研究了名字,确保不会再有什么夭蛾子了。我们已经开始向美国专利商标局注册我们新商标”。

*Firefox 1.0 : [图片致谢](https://www.iceni.com/blog/firefox-1-0-introduced-2004/)*
第一个正式的 Firefox 版本是 [0.8](https://en.wikipedia.org/wiki/Firefox_version_history),发布于 2004 年 2 月 8 日。紧接着 11 月 9 日他们发布了 1.0 版本。2.0 和 3.0 版本分别在 06 年 10 月 和 08 年 6 月问世。每个大版本更新都带来了很多新的特性和提升。从很多角度上讲,Firefox 都领先 IE 不少,无论是功能还是技术先进性,即便如此 IE 还是有更多用户。
一切都在 Google 发布 Chrome 浏览器的时候改变了。在 Chrome 发布(2008 年 9 月)的前几个月,Firefox 占有 30% 的[浏览器份额](https://en.wikipedia.org/wiki/Usage_share_of_web_browsers) 而 IE 有超过 60%。而在 StatCounter 的 [2019 年 1 月](http://gs.statcounter.com/browser-market-share/desktop/worldwide/#monthly-201901-201901-bar)报告里,Firefox 有不到 10% 的份额,而 Chrome 有超过 70%。
>
> 趣味知识点
>
>
> 和大家以为的不一样,火狐的 logo 其实没有狐狸。那其实是个 <ruby> <a href="https://en.wikipedia.org/wiki/Red_panda"> 小熊猫 </a> <rt> Red Panda </rt></ruby>。在中文里,“火狐狸”是小熊猫的另一个名字。
>
>
>
### 展望未来
如上文所说的一样,Firefox 正在经历很长一段以来的份额低谷。曾经有那么一段时间,有很多浏览器都基于 Firefox 开发,比如早期的 [Flock 浏览器](https://en.wikipedia.org/wiki/Flock_(web_browser))。而现在大多数浏览器都基于谷歌的技术了,比如 Opera 和 Vivaldi。甚至连微软都放弃开发自己的浏览器而转而[加入 Chromium 帮派](https://www.windowscentral.com/microsoft-building-chromium-powered-web-browser-windows-10)。
这也许看起来和 Netscape 当年的辉煌形成鲜明的对比。但让我们不要忘记 Firefox 已经有的许多成就。一群来自世界各地的程序员,就这么开发出了这个星球上第二大份额的浏览器。他们在微软垄断如日中天的时候还占据这 30% 的份额,他们可以再次做到这一点。无论如何,他们都有我们。开源社区坚定地站在他们身后。
抗争垄断是我使用 Firefox [的众多原因之一](https://itsfoss.com/why-firefox/)。随着 Mozilla 在改头换面的 [Firefox Quantum](https://itsfoss.com/firefox-quantum-ubuntu/) 上赢回了一些份额,我相信它将一路向上攀爬。
你还想了解 Linux 和开源历史上的什么其他事件?欢迎在评论区告诉我们。
如果你觉得这篇文章不错,请在社交媒体上分享!比如 Hacker News 或者 [Reddit](http://reddit.com/r/linuxusersgroup)。
---
via: <https://itsfoss.com/history-of-firefox>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Moelf](https://github.com/Moelf) 校对:[acyanbird](https://github.com/acyanbird), [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,715 | 如何在 Fedora 30 中设置内核命令行参数 | https://fedoramagazine.org/setting-kernel-command-line-arguments-with-fedora-30/ | 2019-04-12T11:33:35 | [
"内核"
] | https://linux.cn/article-10715-1.html | 
在调试或试验内核时,向内核命令行添加选项是一项常见任务。即将发布的 Fedora 30 版本改为使用 Bootloader 规范([BLS](https://fedoraproject.org/wiki/Changes/BootLoaderSpecByDefault))。根据你修改内核命令行选项的方式,你的工作流可能会更改。继续阅读获取更多信息。
要确定你的系统是使用 BLS 还是旧的规范,请查看文件:
```
/etc/default/grub
```
如果你看到:
```
GRUB_ENABLE_BLSCFG=true
```
看到这个,你运行的是 BLS,你可能需要更改设置内核命令行参数的方式。
如果你只想修改单个内核条目(例如,暂时解决显示问题),可以使用 `grubby` 命令:
```
$ grubby --update-kernel /boot/vmlinuz-5.0.1-300.fc30.x86_64 --args="amdgpu.dc=0"
```
要删除内核参数,可以传递 `--remove-args` 参数给 `grubby`:
```
$ grubby --update-kernel /boot/vmlinuz-5.0.1-300.fc30.x86_64 --remove-args="amdgpu.dc=0"
```
如果有应该添加到每个内核命令行的选项(例如,你希望禁用 `rdrand` 指令生成随机数),则可以运行 `grubby` 命令:
```
$ grubby --update-kernel=ALL --args="nordrand"
```
这将更新所有内核条目的命令行,并保存作为将来条目的命令行选项。
如果你想要从所有内核中删除该选项,则可以再次使用 `--remove-args` 和 `--update-kernel=ALL`:
```
$ grubby --update-kernel=ALL --remove-args="nordrand"
```
---
via: <https://fedoramagazine.org/setting-kernel-command-line-arguments-with-fedora-30/>
作者:[Laura Abbott](https://fedoramagazine.org/makes-fedora-kernel/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Adding options to the kernel command line is a common task when debugging or experimenting with the kernel. The upcoming Fedora 30 release made a change to use Bootloader Spec ([BLS](https://fedoraproject.org/wiki/Changes/BootLoaderSpecByDefault)). Depending on how you are used to modifying kernel command line options, your workflow may now change. Read on for more information.
To determine if your system is running with BLS or the older layout, look in the file
If you only want to modify a single kernel entry (for example, to temporarily work around a display problem) you can use a grubby command
$ grubby --update-kernel /boot/vmlinuz-5.0.1-300.fc30.x86_64 --args="amdgpu.dc=0"
To remove a kernel argument, you can use the
argument to grubby
$ grubby --update-kernel /boot/vmlinuz-5.0.1-300.fc30.x86_64 --remove-args="amdgpu.dc=0"
If there is an option that should be added to every kernel command line (for example, you always want to disable the use of the rdrand instruction for random number generation) you can run a grubby command:
$ grubby --update-kernel=ALL --args="nordrand"
This will update the command line of all kernel entries and save the option to the saved kernel command line for future entries.
If you later want to remove the option from all kernels, you can again use
$ grubby --update-kernel=ALL --remove-args="nordrand"
## Michal Konečný
Thanks for the article. Nice to know about BLS.
## gnu
Thanks for the tip. I would like to not change my habits about the sensitive kernel commands to avoid waste of time and big risks. Should I set GRUB_ENABLE_BLSCFG to false to work as usual?
## Colin Walters
FWIW this only applies to traditional Fedora Server/Workstation etc. today – for rpm-ostree based systems like Fedora CoreOS and Silverblue, you need to use
because kernel commandline changes are part of the general OSTree transaction system. At some point we’ll likely wrap
to tell you to do this instead.
(Ultimately this ends up writing a BLS fragment though)
## svsv sarma
When ever kernel update is involved, i invariably get the error “failed to start load kernel modules………..” at boot time and i had to resort to dracut after boot up. With the recent kernel 5 update even dracut is not working as i get the alert permanently. Any help from kernel wizards?
## dac.override
In the early BLS-day’s I manually edited grubenv to append kernel options because grub2-mkconfig was not doing it. This was later addressed. I kept getting environment blocks too big and too small messages on kernel updates. This blog post inspired me to look into this.
It turns out the the environment block messages were due to me editing grubenv manually. I set out to fix this and ran into a bugzilla. There it was suggested one run grub2-editenv clear. I did this. Then i ran grubby –update-kernel=ALL –args=”mykernelopt” and i rebooted. I selected one of my kernel entries from the grub menu and the boot process hung. I then tried again and edited the kernel entry in the grub menu to get it to boot. Turned out it has left out some important bits and pieces.
Once i was able to boot into the system I ran grub2-mkconfig -o /boot/efi/EFI/fedora/grub.cfg. This fixed things. I found it somewhat ironic that I had to use grub2-mkconfig to fix my grub entries.
## A Seda
Why on earth do they want to complicate things? Just a text file or two was working fine. Now is a new “tool” to modify a bunch of files with instructions we cant understand, making this difficult to diagnose.
## Sebastiaan Franken
As far as I know this is based on working with systemd’s boot commands (which is a pure EFI bootloader). The “pure” systemd approach is pretty minimal and easy, but for some reason Fedora had to make it complicated by using grub as well… I’m confused as well, but I’m sure Fedora devs have their reasons.
## Yazan Al Monshed
Great Article. Big Thanks
## Sebastiaan
It would have been good to cover the ‘why?’ this new way has been implemented.
## Steven Snow
The why is covered pretty extensively in the BLS link provided in the article. Specifically WRT systemd “TL;DR: Currently there’s no common boot scheme across architectures and platforms for open-source operating systems. There’s also little cooperation between multiple distributions in dual-boot (or triple, … multi-boot) setups. We’d like to improve this situation by getting everybody to commit to a single boot configuration format that is based on drop-in files, and thus is robust, simple, works without rewriting configuration files and is free of namespace clashes.”
## Justin W. Flory
Thanks for the simple explanation! I was wondering the same thing.
## Carl Bennett
So how would someone boot to single user mode from the grub menu using this new “BLS” configuration?
## Ben
That’s still the same just add an s to get to single user mode.
## Justin W. Flory
It is unclear to me how
is used. Is this from the grub CLI or from a logged-in user’s Bash shell? I was wondering how someone, for example, battling graphics drivers might debug their system if they are unable to log into their system to change kernel boot parameters.
## Joe Giles
What if I want to just add something quick to the kernel line before boot or after an install…
For example, I have an ASUS laptop with integrated Intel and Nvidia, so I have to add nouveau.modeset=0 and acpi_osi=Linux to handle some drivers correctly and it doesnt boot to a black screen cause the OS doesnt know what GPU to use.
Can we just add this to the kernel command still and boot or is this process changing too?
Joe
## Steven Snow
Grubby is being used at the command line in a terminal likely using bash for the shell. If you follow the link above, then further to this page https://systemd.io/BOOT_LOADER_SPECIFICATION you can get the whole scope pretty much. |
10,716 | 怎样理解和识别 Linux 中的文件类型 | https://www.2daygeek.com/how-to-understand-and-identify-file-types-in-linux/ | 2019-04-12T12:00:00 | [
"文件"
] | https://linux.cn/article-10716-1.html | 
众所周知,在 Linux 中一切皆为文件,包括硬盘和显卡等。在 Linux 中导航时,大部分的文件都是普通文件和目录文件。但是也有其他的类型,对应于 5 类不同的作用。因此,理解 Linux 中的文件类型在许多方面都是非常重要的。
如果你不相信,那只需要浏览全文,就会发现它有多重要。如果你不能理解文件类型,就不能够毫无畏惧的做任意的修改。
如果你做了一些错误的修改,会毁坏你的文件系统,那么当你操作的时候请小心一点。在 Linux 系统中文件是非常重要的,因为所有的设备和守护进程都被存储为文件。
### 在 Linux 中有多少种可用类型?
据我所知,在 Linux 中总共有 7 种类型的文件,分为 3 大类。具体如下。
* 普通文件
* 目录文件
* 特殊文件(该类有 5 个文件类型)
+ 链接文件
+ 字符设备文件
+ Socket 文件
+ 命名管道文件
+ 块文件
参考下面的表可以更好地理解 Linux 中的文件类型。
| 符号 | 意义 |
| --- | --- |
| `–` | 普通文件。长列表中以中划线 `-` 开头。 |
| `d` | 目录文件。长列表中以英文字母 `d` 开头。 |
| `l` | 链接文件。长列表中以英文字母 `l` 开头。 |
| `c` | 字符设备文件。长列表中以英文字母 `c` 开头。 |
| `s` | Socket 文件。长列表中以英文字母 `s` 开头。 |
| `p` | 命名管道文件。长列表中以英文字母 `p` 开头。 |
| `b` | 块文件。长列表中以英文字母 `b` 开头。 |
### 方法1:手动识别 Linux 中的文件类型
如果你很了解 Linux,那么你可以借助上表很容易地识别文件类型。
#### 在 Linux 中如何查看普通文件?
在 Linux 中使用下面的命令去查看普通文件。在 Linux 文件系统中普通文件可以出现在任何地方。 普通文件的颜色是“白色”。
```
# ls -la | grep ^-
-rw-------. 1 mageshm mageshm 1394 Jan 18 15:59 .bash_history
-rw-r--r--. 1 mageshm mageshm 18 May 11 2012 .bash_logout
-rw-r--r--. 1 mageshm mageshm 176 May 11 2012 .bash_profile
-rw-r--r--. 1 mageshm mageshm 124 May 11 2012 .bashrc
-rw-r--r--. 1 root root 26 Dec 27 17:55 liks
-rw-r--r--. 1 root root 104857600 Jan 31 2006 test100.dat
-rw-r--r--. 1 root root 104874307 Dec 30 2012 test100.zip
-rw-r--r--. 1 root root 11536384 Dec 30 2012 test10.zip
-rw-r--r--. 1 root root 61 Dec 27 19:05 test2-bzip2.txt
-rw-r--r--. 1 root root 61 Dec 31 14:24 test3-bzip2.txt
-rw-r--r--. 1 root root 60 Dec 27 19:01 test-bzip2.txt
```
#### 在 Linux 中如何查看目录文件?
在 Linux 中使用下面的命令去查看目录文件。在 Linux 文件系统中目录文件可以出现在任何地方。目录文件的颜色是“蓝色”。
```
# ls -la | grep ^d
drwxr-xr-x. 3 mageshm mageshm 4096 Dec 31 14:24 links/
drwxrwxr-x. 2 mageshm mageshm 4096 Nov 16 15:44 perl5/
drwxr-xr-x. 2 mageshm mageshm 4096 Nov 16 15:37 public_ftp/
drwxr-xr-x. 3 mageshm mageshm 4096 Nov 16 15:37 public_html/
```
#### 在 Linux 中如何查看链接文件?
在 Linux 中使用下面的命令去查看链接文件。在 Linux 文件系统中链接文件可以出现在任何地方。 链接文件有两种可用类型,软连接和硬链接。链接文件的颜色是“浅绿宝石色”。
```
# ls -la | grep ^l
lrwxrwxrwx. 1 root root 31 Dec 7 15:11 s-link-file -> /links/soft-link/test-soft-link
lrwxrwxrwx. 1 root root 38 Dec 7 15:12 s-link-folder -> /links/soft-link/test-soft-link-folder
```
#### 在 Linux 中如何查看字符设备文件?
在 Linux 中使用下面的命令查看字符设备文件。字符设备文件仅出现在特定位置。它出现在目录 `/dev` 下。字符设备文件的颜色是“黄色”。
```
# ls -la | grep ^c
# ls -la | grep ^c
crw-------. 1 root root 5, 1 Jan 28 14:05 console
crw-rw----. 1 root root 10, 61 Jan 28 14:05 cpu_dma_latency
crw-rw----. 1 root root 10, 62 Jan 28 14:05 crash
crw-rw----. 1 root root 29, 0 Jan 28 14:05 fb0
crw-rw-rw-. 1 root root 1, 7 Jan 28 14:05 full
crw-rw-rw-. 1 root root 10, 229 Jan 28 14:05 fuse
```
#### 在 Linux 中如何查看块文件?
在 Linux 中使用下面的命令查看块文件。块文件仅出现在特定位置。它出现在目录 `/dev` 下。块文件的颜色是“黄色”。
```
# ls -la | grep ^b
brw-rw----. 1 root disk 7, 0 Jan 28 14:05 loop0
brw-rw----. 1 root disk 7, 1 Jan 28 14:05 loop1
brw-rw----. 1 root disk 7, 2 Jan 28 14:05 loop2
brw-rw----. 1 root disk 7, 3 Jan 28 14:05 loop3
brw-rw----. 1 root disk 7, 4 Jan 28 14:05 loop4
```
#### 在 Linux 中如何查看 Socket 文件?
在 Linux 中使用下面的命令查看 Socket 文件。Socket 文件可以出现在任何地方。Scoket 文件的颜色是“粉色”。(LCTT 译注:此处及下面关于 Socket 文件、命名管道文件可出现的位置原文描述有误,已修改。)
```
# ls -la | grep ^s
srw-rw-rw- 1 root root 0 Jan 5 16:36 system_bus_socket
```
#### 在 Linux 中如何查看命名管道文件?
在 Linux 中使用下面的命令查看命名管道文件。命名管道文件可以出现在任何地方。命名管道文件的颜色是“黄色”。
```
# ls -la | grep ^p
prw-------. 1 root root 0 Jan 28 14:06 replication-notify-fifo|
prw-------. 1 root root 0 Jan 28 14:06 stats-mail|
```
### 方法2:在 Linux 中如何使用 file 命令识别文件类型
在 Linux 中 `file` 命令允许我们去确定不同的文件类型。这里有三个测试集,按此顺序进行三组测试:文件系统测试、魔术字节测试和用于识别文件类型的语言测试。
#### 在 Linux 中如何使用 file 命令查看普通文件
在你的终端简单地输入 `file` 命令跟着普通文件。`file` 命令将会读取提供的文件内容并且准确地显示文件的类型。
这就是我们看到对于每个普通文件有不同结果的原因。参考下面普通文件的不同结果。
```
# file 2daygeek_access.log
2daygeek_access.log: ASCII text, with very long lines
# file powertop.html
powertop.html: HTML document, ASCII text, with very long lines
# file 2g-test
2g-test: JSON data
# file powertop.txt
powertop.txt: HTML document, UTF-8 Unicode text, with very long lines
# file 2g-test-05-01-2019.tar.gz
2g-test-05-01-2019.tar.gz: gzip compressed data, last modified: Sat Jan 5 18:22:20 2019, from Unix, original size 450560
```
#### 在 Linux 中如何使用 file 命令查看目录文件?
在你的终端简单地输入 `file` 命令跟着目录。参阅下面的结果。
```
# file Pictures/
Pictures/: directory
```
#### 在 Linux 中如何使用 file 命令查看链接文件?
在你的终端简单地输入 `file` 命令跟着链接文件。参阅下面的结果。
```
# file log
log: symbolic link to /run/systemd/journal/dev-log
```
#### 在 Linux 中如何使用 file 命令查看字符设备文件?
在你的终端简单地输入 `file` 命令跟着字符设备文件。参阅下面的结果。
```
# file vcsu
vcsu: character special (7/64)
```
#### 在 Linux 中如何使用 file 命令查看块文件?
在你的终端简单地输入 `file` 命令跟着块文件。参阅下面的结果。
```
# file sda1
sda1: block special (8/1)
```
#### 在 Linux 中如何使用 file 命令查看 Socket 文件?
在你的终端简单地输入 `file` 命令跟着 Socket 文件。参阅下面的结果。
```
# file system_bus_socket
system_bus_socket: socket
```
#### 在 Linux 中如何使用 file 命令查看命名管道文件?
在你的终端简单地输入 `file` 命令跟着命名管道文件。参阅下面的结果。
```
# file pipe-test
pipe-test: fifo (named pipe)
```
### 方法 3:在 Linux 中如何使用 stat 命令识别文件类型?
`stat` 命令允许我们去查看文件类型或文件系统状态。该实用程序比 `file` 命令提供更多的信息。它显示文件的大量信息,例如大小、块大小、IO 块大小、Inode 值、链接、文件权限、UID、GID、文件的访问/更新和修改的时间等详细信息。
#### 在 Linux 中如何使用 stat 命令查看普通文件?
在你的终端简单地输入 `stat` 命令跟着普通文件。参阅下面的结果。
```
# stat 2daygeek_access.log
File: 2daygeek_access.log
Size: 14406929 Blocks: 28144 IO Block: 4096 regular file
Device: 10301h/66305d Inode: 1727555 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ daygeek) Gid: ( 1000/ daygeek)
Access: 2019-01-03 14:05:26.430328867 +0530
Modify: 2019-01-03 14:05:26.460328868 +0530
Change: 2019-01-03 14:05:26.460328868 +0530
Birth: -
```
#### 在 Linux 中如何使用 stat 命令查看目录文件?
在你的终端简单地输入 `stat` 命令跟着目录文件。参阅下面的结果。
```
# stat Pictures/
File: Pictures/
Size: 4096 Blocks: 8 IO Block: 4096 directory
Device: 10301h/66305d Inode: 1703982 Links: 3
Access: (0755/drwxr-xr-x) Uid: ( 1000/ daygeek) Gid: ( 1000/ daygeek)
Access: 2018-11-24 03:22:11.090000828 +0530
Modify: 2019-01-05 18:27:01.546958817 +0530
Change: 2019-01-05 18:27:01.546958817 +0530
Birth: -
```
#### 在 Linux 中如何使用 stat 命令查看链接文件?
在你的终端简单地输入 `stat` 命令跟着链接文件。参阅下面的结果。
```
# stat /dev/log
File: /dev/log -> /run/systemd/journal/dev-log
Size: 28 Blocks: 0 IO Block: 4096 symbolic link
Device: 6h/6d Inode: 278 Links: 1
Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2019-01-05 16:36:31.033333447 +0530
Modify: 2019-01-05 16:36:30.766666768 +0530
Change: 2019-01-05 16:36:30.766666768 +0530
Birth: -
```
#### 在 Linux 中如何使用 stat 命令查看字符设备文件?
在你的终端简单地输入 `stat` 命令跟着字符设备文件。参阅下面的结果。
```
# stat /dev/vcsu
File: /dev/vcsu
Size: 0 Blocks: 0 IO Block: 4096 character special file
Device: 6h/6d Inode: 16 Links: 1 Device type: 7,40
Access: (0660/crw-rw----) Uid: ( 0/ root) Gid: ( 5/ tty)
Access: 2019-01-05 16:36:31.056666781 +0530
Modify: 2019-01-05 16:36:31.056666781 +0530
Change: 2019-01-05 16:36:31.056666781 +0530
Birth: -
```
#### 在 Linux 中如何使用 stat 命令查看块文件?
在你的终端简单地输入 `stat` 命令跟着块文件。参阅下面的结果。
```
# stat /dev/sda1
File: /dev/sda1
Size: 0 Blocks: 0 IO Block: 4096 block special file
Device: 6h/6d Inode: 250 Links: 1 Device type: 8,1
Access: (0660/brw-rw----) Uid: ( 0/ root) Gid: ( 994/ disk)
Access: 2019-01-05 16:36:31.596666806 +0530
Modify: 2019-01-05 16:36:31.596666806 +0530
Change: 2019-01-05 16:36:31.596666806 +0530
Birth: -
```
#### 在 Linux 中如何使用 stat 命令查看 Socket 文件?
在你的终端简单地输入 `stat` 命令跟着 Socket 文件。参阅下面的结果。
```
# stat /var/run/dbus/system_bus_socket
File: /var/run/dbus/system_bus_socket
Size: 0 Blocks: 0 IO Block: 4096 socket
Device: 15h/21d Inode: 576 Links: 1
Access: (0666/srw-rw-rw-) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2019-01-05 16:36:31.823333482 +0530
Modify: 2019-01-05 16:36:31.810000149 +0530
Change: 2019-01-05 16:36:31.810000149 +0530
Birth: -
```
#### 在 Linux 中如何使用 stat 命令查看命名管道文件?
在你的终端简单地输入 `stat` 命令跟着命名管道文件。参阅下面的结果。
```
# stat pipe-test
File: pipe-test
Size: 0 Blocks: 0 IO Block: 4096 fifo
Device: 10301h/66305d Inode: 1705583 Links: 1
Access: (0644/prw-r--r--) Uid: ( 1000/ daygeek) Gid: ( 1000/ daygeek)
Access: 2019-01-06 02:00:03.040394731 +0530
Modify: 2019-01-06 02:00:03.040394731 +0530
Change: 2019-01-06 02:00:03.040394731 +0530
Birth: -
```
---
via: <https://www.2daygeek.com/how-to-understand-and-identify-file-types-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[liujing97](https://github.com/liujing97) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,717 | 在 Bash 中使用[方括号] (一) | https://www.linux.com/blog/2019/3/using-square-brackets-bash-part-1 | 2019-04-13T00:08:43 | [
"方括号"
] | https://linux.cn/article-10717-1.html | 
>
> 这篇文章将要介绍方括号及其在命令行中的不同用法。
>
>
>
看完[花括号在命令行中的用法](/article-10624-1.html)之后,现在我们继续来看方括号(`[]`)在上下文中是如何发挥作用的。
### 通配
方括号最简单的用法就是通配。你可能在知道“<ruby> <rt> Globbing </rt></ruby>”这个概念之前就已经通过通配来匹配内容了,列出具有相同特征的多个文件就是一个很常见的场景,例如列出所有 JPEG 文件:
```
ls *.jpg
```
使用<ruby> 通配符 <rt> wildcard </rt></ruby>来得到符合某个模式的所有内容,这个过程就叫通配。
在上面的例子当中,星号(`*`)就代表“0 个或多个字符”。除此以外,还有代表“有且仅有一个字符”的问号(`?`)。因此
```
ls d*k*
```
可以列出 `darkly` 和 `ducky`,而且 `dark` 和 `duck` 也是可以被列出的,因为 `*` 可以匹配 0 个字符。而
```
ls d*k?
```
则只能列出 `ducky`,不会列出 `darkly`、`dark` 和 `duck`。
方括号也可以用于通配。为了便于演示,可以创建一个用于测试的目录,并在这个目录下创建文件:
```
touch file0{0..9}{0..9}
```
(如果你还不清楚上面这个命令的原理,可以看一下[另一篇介绍花括号的文章](/article-10624-1.html))
执行上面这个命令之后,就会创建 `file000`、`file001`、……、`file099` 这 100 个文件。
如果要列出这些文件当中第二位数字是 7 或 8 的文件,可以执行:
```
ls file0[78]?
```
如果要列出 `file022`、`file027`、`file028`、`file052`、`file057`、`file058`、`file092`、`file097`、`file098`,可以执行:
```
ls file0[259][278]
```
当然,不仅仅是 `ls`,很多其它的命令行工具都可以使用方括号来进行通配操作。但在删除文件、移动文件、复制文件的过程中使用通配,你需要有一点横向思维。
例如将 `file010` 到 `file029` 这 30 个文件复制成 `archive010` 到 `archive029` 这 30 个副本,不可以这样执行:
```
cp file0[12]? archive0[12]?
```
因为通配只能针对已有的文件,而 `archive` 开头的文件并不存在,不能进行通配。
而这条命令
```
cp file0[12]? archive0[1..2][0..9]
```
也同样不行,因为 `cp` 并不允许将多个文件复制到多个文件。在复制多个文件的情况下,只能将多个文件复制到一个指定的目录下:
```
mkdir archive
cp file0[12]? archive
```
这条命令是可以正常运行的,但它只会把这 30 个文件以同样的名称复制到 `archive/` 目录下,而这并不是我们想要的效果。
如果你阅读过我[关于花括号的文章](/article-10624-1.html),你大概会记得可以使用 `%` 来截掉字符串的末尾部分,而使用 `#` 则可以截掉字符串的开头部分。
例如:
```
myvar="Hello World"
echo Goodbye Cruel ${myvar#Hello}
```
就会输出 `Goodbye Cruel World`,因为 `#Hello` 将 `myvar` 变量中开头的 `Hello` 去掉了。
在通配的过程中,也可以使用这一个技巧。
```
for i in file0[12]?;\
do\
cp $i archive${i#file};\
done
```
上面的第一行命令告诉 Bash 需要对所有 `file01` 开头或者 `file02` 开头,且后面只跟一个任意字符的文件进行操作,第二行的 `do` 和第四行的 `done` 代表需要对这些文件都执行这一块中的命令。
第三行就是实际的复制操作了,这里使用了两次 `$i` 变量:第一次在 `cp` 命令中直接作为源文件的文件名使用,第二次则是截掉文件名开头的 `file` 部分,然后在开头补上一个 `archive`,也就是这样:
```
"archive" + "file019" - "file" = "archive019"
```
最终整个 `cp` 命令展开为:
```
cp file019 archive019
```
最后,顺带说明一下反斜杠 `\` 的作用是将一条长命令拆分成多行,这样可以方便阅读。
在下一节,我们会了解方括号的更多用法,敬请关注。
---
via: <https://www.linux.com/blog/2019/3/using-square-brackets-bash-part-1>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,720 | 12 个最佳 GNOME(GTK)主题 | https://itsfoss.com/best-gtk-themes/ | 2019-04-14T09:45:22 | [
"主题",
"GNOME"
] | https://linux.cn/article-10720-1.html | 
>
> 让我们来看一些漂亮的 GTK 主题,你不仅可以用在 Ubuntu 上,也可以用在其它使用 GNOME 的 Linux 发行版上。
>
>
>
对于我们这些使用 Ubuntu 的人来说,默认的桌面环境从 Unity 变成了 Gnome 使得主题和定制变得前所未有的简单。Gnome 有个相当大的定制用户社区,其中不乏可供用户选择的漂亮的 GTK 主题。最近几个月,我不断找到了一些喜欢的主题。我相信这些是你所能找到的最好的主题之一了。
### Ubuntu 和其它 Linux 发行版的最佳主题
这不是一个详细清单,可能不包括一些你已经使用和喜欢的主题,但希望你能至少找到一个能让你喜爱的没见过的主题。所有这里提及的主题都可以工作在 Gnome 3 上,不管是 Ubuntu 还是其它 Linux 发行版。有一些主题的屏幕截屏我没有,所以我从官方网站上找到了它们的图片。
在这里列出的主题没有特别的次序。
但是,在你看这些最好的 GNOME 主题前,你应该学习一下 [如何在 Ubuntu GNOME 中安装主题](https://itsfoss.com/install-themes-ubuntu/)。
#### 1、Arc-Ambiance

Arc 和 Arc 变体主题已经出现了相当长的时间,普遍认为它们是最好的主题之一。在这个示例中,我选择了 Arc-Ambiance ,因为它是 Ubuntu 中的默认 Ambiance 主题。
我是 Arc 主题和默认 Ambiance 主题的粉丝,所以不用说,当我遇到一个融合了两者优点的主题,我不禁长吸了一口气。如果你是 Arc 主题的粉丝,但不是这个特定主题的粉丝,Gnome 的外观上当然还有适合你口味的大量的选择。
* [下载 Arc-Ambiance 主题](https://www.gnome-look.org/p/1193861/)
#### 2、Adapta Colorpack

Adapta 主题是我所见过的最喜欢的扁平主题之一。像 Arc 一样,Adapata 被很多 Linux 用户广泛采用。我选择这个配色包,是因为一次下载你就有数个可选择的配色方案。事实上,有 19 个配色方案可以选择,是的,你没看错,19 个呢!
所以,如果你是如今常见的扁平风格/<ruby> 材料设计风格 <rt> Material Design Language </rt></ruby>的粉丝,那么,在这个主题包中很可能至少有一个能满足你喜好的变体。
* [下载 Adapta Colorpack 主题](https://www.gnome-look.org/p/1190851/)
#### 3、Numix Collection

啊,Numix! 让我想起了我们一起度过的那些年!对于那些在过去几年装点过桌面环境的人来说,你肯定在某个时间点上遇到过 Numix 主题或图标包。Numix 可能是我爱上的第一个 Linux 现代主题,现在我仍然爱它。虽然经过这些年,但它仍然魅力不失。
灰色色调贯穿主题,尤其是默认的粉红色高亮,带来了真正干净而完整的体验。你可能很难找到一个像 Numix 一样精美的主题包。而且在这个主题包中,你还有很多可供选择的余地,简直不要太棒了!
* [下载 Numix Collection 主题](https://www.gnome-look.org/p/1170667/)
#### 4、Hooli

Hooli 是一个已经出现了一段时间的主题,但是我最近才偶然发现它。我是很多扁平主题的粉丝,但是通常不太喜欢材料设计风格的主题。Hooli 像 Adapta 一样吸取了那些设计风格,但是我认为它和其它的那些有所不同。绿色高亮是我对这个主题最喜欢的部分之一,并且,它在不冲击整个主题方面做的很好。
* [下载 Hooli 主题](https://www.gnome-look.org/p/1102901/)
#### 5、Arrongin/Telinkrin

福利:二合一主题!它们是在主题领域中的相对新的竞争者。它们都吸取了 Ubuntu 接近完成的 “[communitheme](https://itsfoss.com/ubuntu-community-theme/)” 的思路,并带它到了你的桌面。这两个主题我能找到的唯一真正的区别就是颜色。Arrongin 以 Ubuntu 家族的橙色颜色为中心,而 Telinkrin 则更偏向于 KDE Breeze 系的蓝色,我个人更喜欢蓝色,但是两者都是极好的选择!
* [下载 Arrongin/Telinkrin 主题](https://www.gnome-look.org/p/1215199/)
#### 6、Gnome-osx

我不得不承认,通常,当我看到一个主题有 “osx” 或者在标题中有类似的内容时我就不会不期望太多。大多数受 Apple 启发的主题看起来都比较雷同,我真不能找到使用它们的原因。但我想这两个主题能够打破这种思维定式:这就是 Arc-osc 主题和 Gnome-osx 主题。
我喜欢 Gnome-osx 主题的原因是它在 Gnome 桌面上看起来确实很像 OSX。它在融入桌面环境而不至于变的太扁平方面做得很好。所以,对于那些喜欢稍微扁平的主题的人来说,如果你喜欢红黄绿按钮样式(用于关闭、最小化和最大化),这个主题非常适合你。
* [下载 Gnome-osx 主题](https://www.opendesktop.org/s/Gnome/p/1171688/)
#### 7、Ultimate Maia

曾经有一段时间我使用 Manjaro Gnome。尽管那以后我又回到了 Ubuntu,但是,我希望我能打包带走的一个东西是 Manjaro 主题。如果你对 Manjaro 主题和我一样感受相同,那么你是幸运的,因为你可以带它到你想运行 Gnome 的任何 Linux 发行版!
丰富的绿色颜色,Breeze 式的关闭、最小化、最大化按钮,以及全面雕琢过的主题使它成为一个不可抗拒的选择。如果你不喜欢绿色,它甚至为你提供一些其它颜色的变体。但是说实话……谁会不喜欢 Manjaro 的绿色呢?
* [下载 Ultimate Maia 主题](https://www.opendesktop.org/s/Gnome/p/1193879/)
#### 8、Vimix

这是一个让我激动的主题。它是现代风格的,吸取了 macOS 的红黄绿按钮的风格,但并不是直接复制了它们,并且减少了多变的主题颜色,使之成为了大多数主题的独特替代品。它带来三个深色的变体和几个彩色配色,我们中大多数人都可以从中找到我们喜欢的。
* [下载 Vimix 主题](https://www.gnome-look.org/p/1013698/)
#### 9、Ant

像 Vimix 一样,Ant 从 macOS 的按钮颜色中吸取了灵感,但不是直接复制了样式。在 Vimix 减少了颜色花哨的地方,Ant 却增加了丰富的颜色,在我的 System 76 Galago Pro 屏幕看起来绚丽极了。三个主题变体的变化差异大相径庭,虽然它可能不见得符合每个人的口味,它无疑是最适合我的。
* [下载 Ant 主题](https://www.opendesktop.org/p/1099856/)
#### 10、Flat Remix

如果你还没有注意到这点,对于一些关注关闭、最小化、最大化按钮的人来说我就是一个傻瓜。Flat Remix 使用的颜色主题是我从未在其它地方看到过的,它采用红色、蓝色和橙色方式。把这些添加到一个几乎看起来像是一个混合了 Arc 和 Adapta 的主题的上面,就有了 Flat Remix。
我本人喜欢它的深色主题,但是换成亮色的也是非常好的。因此,如果你喜欢稍稍透明、风格一致的深色主题,以及偶尔的一点点颜色,那 Flat Remix 就适合你。
* [下载 Flat Remix 主题](https://www.opendesktop.org/p/1214931/)
#### 11、Paper

[Paper](https://itsfoss.com/install-paper-theme-linux/) 已经出现一段时间。我记得第一次使用它是在 2014 年。可以说,Paper 的图标包比其 GTK 主题更出名,但是这并不意味着它自身的主题不是一个极好的选择。即使我从一开始就倾心于 Paper 图标,我不能说当我第一次尝试它的时候我就是一个 Paper 主题忠实粉丝。
我觉得鲜亮的色彩和有趣的方式被放到一个主题里是一种“不成熟”的体验。现在,几年后,Paper 在我心目中已经长大,至少可以这样说,这个主题采取的轻快方式是我非常欣赏的一个。
* [下载 Paper 主题](https://snwh.org/paper/download)
#### 12、Pop

Pop 在这个列表上是一个较新的主题,是由 [System 76](https://system76.com/) 的人们创造的,Pop GTK 主题是前面列出的 Adapta 主题的一个分支,并带有一个匹配的图标包,图标包是先前提到的 Paper 图标包的一个分支。
该主题是在 System 76 发布了 [他们自己的发行版](https://itsfoss.com/system76-popos-linux/) Pop!\_OS 之后不久发布的。你可以阅读我的 [Pop!\_OS 点评](https://itsfoss.com/pop-os-linux-review/) 来了解更多信息。不用说,我认为 Pop 是一个极好的主题,带有华丽的装饰,并为 Gnome 桌面带来了一股清新之风。
* [下载 Pop 主题](https://github.com/pop-os/gtk-theme/blob/master/README.md)
#### 结束语
很明显,我们有比文中所描述的主题更多的选择,但是这些大多是我在最近几月所使用的最完整、最精良的主题。如果你认为我们错过一些你确实喜欢的主题,或你确实不喜欢我在上面描述的主题,那么在下面的评论区让我们知道,并分享你喜欢的主题更好的原因!
---
via: <https://itsfoss.com/best-gtk-themes/>
作者:[Phillip Prado](https://itsfoss.com/author/phillip/) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy) 选题:[lujun9972](https://github.com/lujun9972)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Even though we have plenty of Linux distributions that offer a good user experience, using a custom theme can take you on a rollercoaster ride.
Of course, if you are someone who does not want to tinker around, the default choices in modern Linux distributions should suffice. But, you might want to check some of the best GTK themes available for the GNOME [desktop environment](https://itsfoss.com/what-is-desktop-environment/) before you look away from enhancing your user experience!
## Best GTK themes for Ubuntu and other Linux distributions
You probably already know most of the popular options out there. Here, I have tried to keep things fresh along with a few mention to the popular (old) options.
I believe you know [how to install and change themes in GNOME](https://itsfoss.com/install-switch-themes-gnome-shell/), so I am not going to repeat the steps here.
[How to Install and Change GNOME Theme in LinuxBy changing your GNOME theme, you can give your Linux desktop a brand-new look and feel. In this tutorial, I’ll show you how to install new themes on a Linux system running GNOME desktop environment. There are two aspects of GNOME theme: * Application theme: changes the appearance of…](https://itsfoss.com/install-switch-themes-gnome-shell/)

*The themes listed here are in no particular order.*
### 1. Orchis GTK Theme
Orchis GTK theme is a stunning theme pack that gives your desktop a clean, unique, and a modern look.
It is one of the first themes to add GNOME 40 support as well. If you are using Firefox as your browser, it even has a theme for it. And, yes, it also mentions the link to the wallpaper (appreciate that!) in Pling’s store page if you want it to look just like the screenshot above.
### 2. Yaru Colors
If you like Ubuntu 20.04 LTS default theme style, this should be exciting for you.
With Yaru colors, you no longer have to stick to the dated orange color scheme and try a wide range of colors of your choice.
It also offers snap support. So, if you are using any snap applications where most of the other themes do not work with, try this instead. You can also change the [folder color in Ubuntu 20.04](https://itsfoss.com/folder-color-ubuntu/), thanks to it.
### 3. WhiteSur
This theme is tailored for users who want a macOS-like user experience on Linux. Of course, this is not apples-to-apples kind of similarity, but it is quite impressive.
You also get a cursor theme, icon theme, Firefox theme, and dash-to-dock theme if you want to make it look as good as it looks in the screenshot.
### 4. Ultimate Dark
If you want all things dark but a variety of black shades in a theme, this could look good for your desktop.
This should be easy on your eyes while also offering a good dark mode experience. You also get a flat and gradient version in the theme pack to choose when setting up.
### 5. Vimix
This was a theme I easily got excited about. It is modern, pulls from the macOS red, yellow, green buttons without directly copying them, and tones down the vibrancy of the theme, making for one unique alternative to most other themes. It comes with three dark variants and several colors to choose from so most of us will find something we like.
### 6. Prof-Gnome-theme
You will find several interesting dark themes out there. However, for some reason, if you do not prefer the pitch-dark shade in most of the dark mode themes, this theme can be a good pick.
It might look a bit dated, but it helps distinguish different elements of the user interface clearly. And, it is also pleasing to the eyes with a dark-grey shade. I’d say it also gives a classic macOS-touch, if that is a good thing for you.
### 7. Ant

Like Vimix, Ant pulls inspiration from macOS for the button colors without directly copying the style. Where Vimix tones down the color options, Ant adds a richness to the colors that look fantastic on my System 76 Galago Pro screen. The variation between the three theme options is pretty dramatic, and though it may not be to everyone’s taste, it is most certainly to mine.
### 8. Flat Remix
If you haven’t noticed by this point, I am a sucker for someone who pays attention to the details in the close, minimize, maximize buttons. The color theme that Flat Remix uses is one I have not seen anywhere else, with a red, blue, and orange color way. Add that on top of a theme that looks almost like a mix between Arc and Adapta, and you have Flat Remix.
I am personally a fan of the dark option, but the light alternative is very nice as well. So if you like subtle transparencies, a cohesive dark theme, and a touch of color here and there, Flat Remix is for you.
### 9. Paper
[Paper](https://itsfoss.com/install-paper-theme-linux/) has been around for some time now. I remember using it for the first back in 2014. I would say, at this point, Paper is more known for its icon pack than for its GTK theme, but that doesn’t mean that the theme isn’t a wonderful option in and of its self. Even though I adored the Paper icons from the beginning, I can’t say that I was a huge fan of the Paper theme when I first tried it out.
I felt like the bright colors and fun approach to a theme made for an “immature” experience. Now, years later, Paper has grown on me, to say the least, and the light-hearted approach that the theme takes is one I greatly appreciate.
### 10. Pop
Pop is one of the newer offerings on this list. Created by the folks over at [System 76](https://system76.com/?ref=itsfoss.com), the Pop GTK theme is a fork of the Adapta theme listed earlier and comes with a matching icon pack, which is a fork of the previously mentioned Paper icon pack.
The theme was released soon after System 76 announced that they were releasing [their own distribution,](https://itsfoss.com/system76-popos-linux/) Pop!_OS. You can read my [Pop!_OS review](https://itsfoss.com/pop-os-linux-review/) to know more about it. Needless to say, I think Pop is a fantastic theme with a superb amount of polish and offers a fresh feel to any Gnome desktop.
### 11. Sweet
This is indeed a flashy GTK theme with a dark mode that blends very well with almost everything. Personally, I feel like – candy icon pack theme would match this GTK theme – but that’s just me.
A colorful and modern GTK theme that you should take a look at.
### 12. Qogir
Qogir theme is quite similar to what you get on Solus Budgie Linux distro. It includes both light/dark themes to compliment your icon pack (if you have any).
If you do not want something very colorful but yet a modern user experience, you should try this out.
### 13. Material Black Frost
If you’re a fan of material design – this comes close to what you would want to have on your Linux distro.
Unfortunately, you do not get color options here but the default color is pretty decent and pleasant to look at.
### 14. Avidity
Avidity is quite similar to a remix theme. However, this is not a flat design.
So, if you’re not a fan of flat theme designs, this could be worth taking a look at. It includes two theme colors, try them out!
### 15. Solarized Colorpack

Not picky with the designs or themes? But, looking for a contrasting theme?
If that’s the case, the Solarized dark gtk theme color pack should be your choice. It includes almost 7 different color palettes to try with. Your desktop should look very interesting after applying this theme.
### 16. Cloudy
A simple and basic theme that should look good on any Linux distro. This might appear to resemble the look of a modern XFCE desktop-like Zorin Lite but closer.
You will find a variety of color shades available to download. Try it and see what works for you.
### 17. Nordic
The color palette of this theme might seem dull to look at. But, when you apply it with the right combination of [icon themes](https://itsfoss.com/best-icon-themes-ubuntu-16-04/) – this should look beautiful (as you can see in the image above).
It looks great on Pop!_OS – you can try it on other GNOME-based distros and see it for yourself.
### 18. Juno Theme
Fond of using Microsoft’s [Visual Studio Code on Linux](https://itsfoss.com/install-visual-studio-code-ubuntu/)? This theme is inspired from one of the available VS Code themes.
It blends in perfectly with a dark background, and it should help you rest your eyes easy. Not just limited to VS Code, but if you are coding, a dark theme always looks good paired with any code editor.
## Conclusion
Obviously, there are way more themes to choose from than I could feature in one article, but these are some of the most complete and polished themes I have used in recent months.
If you like dark themes more, we have a dedicated list of dark themes as well.
[13 Best Dark GTK Themes for Your Linux DesktopWith the near infinite customization options you have on any given Linux distribution, the most visually noticeable difference is customizing the theme. Let’s take a look at some of the GTK themes with dark mode. Yeah, we have covered the best Linux themes in the past but this one](https://itsfoss.com/dark-gtk-themes/)

If you think I missed any that you really like or you just really dislike one that I featured above, then feel free to let me know in the comment section below and share why you think your favorite themes are better! |
10,722 | 3 个很酷的基于文本的邮件客户端 | https://fedoramagazine.org/3-cool-text-based-email-clients/ | 2019-04-14T10:23:37 | [
"电子邮件",
"mutt",
"alpine"
] | https://linux.cn/article-10722-1.html | 
编写和接收电子邮件是每个人日常工作的重要组成部分,选择电子邮件客户端通常是一个重要决定。Fedora 系统提供了大量的电子邮件客户端可供选择,其中包括基于文本的电子邮件应用。
### Mutt
Mutt 可能是最受欢迎的基于文本的电子邮件客户端之一。它有人们期望的所有常用功能。Mutt 支持颜色代码、邮件会话、POP3 和 IMAP。但它最好的功能之一是它具有高度可配置性。实际上,用户可以轻松地更改键绑定,并创建宏以使工具适应特定的工作流程。
要尝试 Mutt,请[使用 sudo](https://fedoramagazine.org/howto-use-sudo/) 和 `dnf` 安装它:
```
$ sudo dnf install mutt
```
为了帮助新手入门,Mutt 有一个非常全面的充满了宏示例和配置技巧的 [wiki](https://gitlab.com/muttmua/mutt/wikis/home)。
### Alpine
Alpine 也是最受欢迎的基于文本的电子邮件客户端。它比 Mutt 更适合初学者,你可以通过应用本身配置大部分功能而无需编辑配置文件。Alpine 的一个强大功能是能够对电子邮件进行评分。这对那些订阅含有大量邮件的邮件列表如 Fedora 的[开发列表](https://lists.fedoraproject.org/archives/list/[email protected]/)的用户来说尤其有趣。通过使用分数,Alpine 可以根据用户的兴趣对电子邮件进行排序,首先显示高分的电子邮件。
也可以使用 `dnf` 从 Fedora 的仓库安装 Alpine。
```
$ sudo dnf install alpine
```
使用 Alpine 时,你可以按 `Ctrl+G` 组合键轻松访问文档。
### nmh
nmh(new Mail Handling)遵循 UNIX 工具哲学。它提供了一组用于发送、接收、保存、检索和操作电子邮件的单一用途程序。这使你可以将 `nmh` 命令与其他程序交换,或利用 `nmh` 编写脚本来创建更多自定义工具。例如,你可以将 Mutt 与 `nmh` 一起使用。
使用 `dnf` 可以轻松安装 `nmh`。
```
$ sudo dnf install nmh
```
要了解有关 `nmh` 和邮件处理的更多信息,你可以阅读这本 GPL 许可的[书](https://rand-mh.sourceforge.io/book/)。
---
via: <https://fedoramagazine.org/3-cool-text-based-email-clients/>
作者:[Clément Verna](https://fedoramagazine.org/author/cverna/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Writing and receiving email is a big part of everyone’s daily routine and choosing an email client is usually a major decision. The Fedora OS provides a large choice of email clients and among these are text-based email applications.
### Mutt
Mutt is probably one of the most popular text-based email clients. It supports all the common features that one would expect from an email client. Color coding, mail threading, POP3, and IMAP are all supported by Mutt. But one of its best features is it’s highly configurable. Indeed, the user can easily change the keybindings, and create macros to adapt the tool to a particular workflow.
To give Mutt a try, install it [using sudo](https://fedoramagazine.org/howto-use-sudo/) and dnf:
$ sudo dnf install mutt
To help newcomers get started, Mutt has a very comprehensive [wiki](https://gitlab.com/muttmua/mutt/wikis/home) full of macro examples and configuration tricks.
### Alpine
Alpine is also among the most popular text-based email clients. It’s more beginner friendly than Mutt, and you can configure most of Alpine via the application itself — no need to edit a configuration file. One powerful feature of Alpine is the ability to score emails. This is particularly interesting for users that are registered to a high volume mailing list like Fedora’s [devel list](https://lists.fedoraproject.org/archives/list/[email protected]/). Using scores, Alpine can sort the email based on the user’s interests, showing emails with a high score first.
Alpine is also available to install from Fedora’s repository using dnf.
$ sudo dnf install alpine
While using Alpine, you can easily access the documentation by pressing the *Ctrl+G* key combination.
### nmh
nmh (new Mail Handling) follows the UNIX tools philosophy. It provides a collection of single purpose programs to send, receive, save, retrieve, and manipulate e-mail messages. This lets you swap the *nmh* command with other programs, or create scripts around *nmh* to create more customized tools. For example, you can use Mutt with nmh.
nmh can be easily installed using dnf.
$ sudo dnf install nmh
To learn more about nmh and mail handling in general you can read this GPL licenced [book](https://rand-mh.sourceforge.io/book/).
## Luca
Used PINE (the previous name of Alpine) for many years at my university (1996-2002)… I have good memories about it and its very user-friendly interface.
## milhan
same here..
## elken
Shoutout should go to Neomutt too
Differences between mutt upstream: https://neomutt.org/feature.html
## Steven Bakker
I used nmh (and MH before that) for many years, until frequent travel required me to switch to an IMAP-based client. I still wish nmh had IMAP capabilities!
## Paul Mellors
I love mutt, it’s the perfect client for the i3wm I use 🙂
## eMBee
check out sup ( https://github.com/sup-heliotrope/sup )
while it’s not actively maintained, it’s stable and working.
and it’s the only commandline email client that supports virtual folders by search or tags and keeping multiple folders open at the same time.
greetings, eMBee.
## ucup
Mut is cool but can’t connecting with gmai 🙁
## Christian Dannie Storgaard
I use gmailieer to sync my gmail to my local maildir, which mutt can interface with. I general though, I prefer alot for its “build it yourself” attitude.
## dac.override
For that to work you would have tell gmail to “allow less secure apps”. You can find more info about how to do this with your favorite search engine.
## Christian Dannie Storgaard
Not necessarily. gmailieer uses an API certificate that you can generate for yourself, so you can keep “allow less secure apps” off an still have access to your email.
## baux
Emacs and gnus forever and ever
## Bob
What? No screenshots?
## B Scott
I use alpine for both work and personal e-mail; have been for MANY (12) years. Before that I used the original Pine implementation. Occasionally I’ll try a GUI based mail client, get frustrated and go right back to alpine. For personal use I have multiple mail accounts configured that I can read and manage in one instance: G-Mail, Yahoo and my own personal mail server. At work I just use it to connect to s-imap implementation on Microsoft Exchange.
Once you figure out multiple account configurations, all the shortcuts and configuring address books, there just is no GUI (usually interpreted bloated) mail application that can come close. It is still by far the best and most flexible mail program pretty much anywhere.
## fgwef
how automaticaly download email in mutt?
i must shift+g to download in pop
how to do automatic? |
10,723 | Ubuntu 14.04 即将结束支持,你该怎么办? | https://itsfoss.com/ubuntu-14-04-end-of-life/ | 2019-04-14T10:34:47 | [
"Ubuntu"
] | https://linux.cn/article-10723-1.html | Ubuntu 14.04 即将于 2019 年 4 月 30 日结束支持。这意味着在此日期之后 Ubuntu 14.04 用户将无法获得安全和维护更新。
你甚至不会获得已安装应用的更新,并且不手动修改 `sources.list` 则无法使用 `apt` 命令或软件中心安装新应用。
Ubuntu 14.04 大约在五年前发布。这是 Ubuntu 长期支持版本(LTS)。
[检查 Ubuntu 版本](https://itsfoss.com/how-to-know-ubuntu-unity-version/)并查看你是否仍在使用 Ubuntu 14.04。如果是桌面或服务器版,你可能想知道在这种情况下你应该怎么做。
我来帮助你。告诉你在这种情况下你有些什么选择。

### 升级到 Ubuntu 16.04 LTS(最简单的方式)
如果你可以连接互联网,你可以从 Ubuntu 14.04 升级到 Ubuntu 16.04 LTS。
Ubuntu 16.04 也是一个长期支持版本,它将支持到 2021 年 4 月。这意味着下次升级前你还有两年的时间。
我建议阅读这个[升级 Ubuntu 版本](https://itsfoss.com/upgrade-ubuntu-version/)的教程。它最初是为了将 Ubuntu 16.04 升级到 Ubuntu 18.04 而编写的,但这些步骤也适用于你的情况。
### 做好备份,全新安装 Ubuntu 18.04 LTS(非常适合桌面用户)
另一个选择是备份你的文档、音乐、图片、下载和其他任何你不想丢失数据的文件夹。
我说的备份指的是将这些文件夹复制到外部 USB 盘。换句话说,你应该有办法将数据复制回计算机,因为你将格式化你的系统。
我建议桌面用户使用此选项。Ubuntu 18.04 是目前的长期支持版本,它将至少在 2023 年 4 月之前得到支持。在你被迫进行下次升级之前,你将有四年的时间。
### 支付扩展安全维护费用并继续使用 Ubuntu 14.04
这适用于企业客户。Canonical 是 Ubuntu 的母公司,它提供 Ubuntu Advantage 计划,客户可以支付电话电子邮件支持和其他益处。
Ubuntu Advantage 计划用户还有[扩展安全维护](https://www.ubuntu.com/esm)(ESM)功能。即使给定版本的生命周期结束后,此计划也会提供安全更新。
这需要付出金钱。服务器用户每个物理节点每年花费 225 美元。对于桌面用户,价格为每年 150 美元。你可以在[此处](https://www.ubuntu.com/support/plans-and-pricing)了解 Ubuntu Advantage 计划的详细定价。
### 还在使用 Ubuntu 14.04 吗?
如果你还在使用 Ubuntu 14.04,那么你应该开始了解这些选择,因为你还有不到一个月的时间。
在任何情况下,你都不能在 2019 年 4 月 30 日之后使用 Ubuntu 14.04,因为你的系统由于缺乏安全更新而容易受到攻击。无法安装新应用将是一个额外的痛苦。
那么,你会做什么选择?升级到 Ubuntu 16.04 或 18.04 或付费 ESM?
---
via: <https://itsfoss.com/ubuntu-14-04-end-of-life/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Ubuntu 14.04 reached its end of life on April 30, 2019. This means there will be no security and maintenance updates for Ubuntu 14.04 users anymore unless they pay for extended security (explained later).
You won’t even get updates for installed applications and you won’t be able to install a new application [using the apt command](https://itsfoss.com/apt-command-guide/) or the Software Center without manually modifying sources.list.
Ubuntu 14.04 was released almost five years ago. That’s the life of a long term support release of Ubuntu.
[Check your Ubuntu version](https://itsfoss.com/how-to-know-ubuntu-unity-version/) and see if you’re still using Ubuntu 14.04. If that’s the case for a desktop or a server you run, you might be wondering what you should do in such a situation.
Let me help you out there and tell you what options you have in this case.

## Upgrade to Ubuntu 16.04 LTS (easiest of them all)
If you have a good internet connection, you can upgrade to Ubuntu 16.04 LTS from within Ubuntu 14.04.
Ubuntu 16.04 is also a [long term support release](https://itsfoss.com/long-term-support-lts/) and it will be supported till April, 2021. That means you’ll have two years before another upgrade.
I recommend reading this tutorial about [upgrading your Ubuntu version](https://itsfoss.com/upgrade-ubuntu-version/). It was originally written for upgrading Ubuntu 16.04 to Ubuntu 18.04 but the steps are applicable in your case as well.
## Make a backup, do a fresh install of Ubuntu 18.04 LTS (ideal for desktop users)
Another option is that you make a backup of your Documents, Music, Pictures, Downloads and any other folders where you have kept essential data that you cannot afford to lose.
When I say backup, I simply mean copying these folders to an external USB disk. In other words, you should have a way to copy the data back to your computer because you’ll be formatting your system.
I would recommend this option for desktop users. Ubuntu 18.04 is the current long term support release and it will be supported till at least April, 2023. You have four long years before you’ll be forced into another upgrade.
## Pay for extended security maintenance and continue using Ubuntu 14.04
This is suited to
Ubuntu Advantage program users also have the [Extended Security Maintenance](https://www.ubuntu.com/esm) (ESM) feature. This program provides security updates even after a given version reaches end of life.
This comes at a cost. It costs $225 per year per physical node for server users. For desktop users, the price is $150 per year. You can see detailed pricing for the Ubuntu Advantage program [here](https://www.ubuntu.com/support/plans-and-pricing).
## Still using Ubuntu 14.04?
If you’re still using Ubuntu 14.04, you should start exploring your options as you have less than two months to go.
In any case, you must not use Ubuntu 14.04 after 30 April 2019 because your system will be vulnerable due to the lack of security updates. Not being able to install new applications will be an additional major pain.
So which option will you choose here? Upgrading to Ubuntu 16.04 or 18.04 or paying for ESM? |
10,725 | Bash vs Python:你该使用哪个? | https://opensource.com/article/19/4/bash-vs-python | 2019-04-15T10:55:00 | [
"Python",
"Bash"
] | /article-10725-1.html |
>
> 两种编程语言都各有优缺点,它们在某些任务方面互有胜负。
>
>
>

[Bash](/article/18/7/admin-guide-bash) 和 [Python](/article/17/11/5-approaches-learning-python) 是大多数自动化工程师最喜欢的编程语言。它们都各有优缺点,有时很难选择应该使用哪一个。所以,最诚实的答案是:这取决于任务、范围、背景和任务的复杂性。
让我们来比较一下这两种语言,以便更好地理解它们各自的优点。
### Bash
* 是一种 Linux/Unix shell 命令语言
* 非常适合编写使用命令行界面(CLI)实用程序的 shell 脚本,利用一个命令的输出传递给另一个命令(管道),以及执行简单的任务(可以多达 100 行代码)
* 可以按原样使用命令行命令和实用程序
* 启动时间比 Python 快,但执行时性能差
* Windows 中默认没有安装。你的脚本可能不会兼容多个操作系统,但是 Bash 是大多数 Linux/Unix 系统的默认 shell
* 与其它 shell (如 csh、zsh、fish) *不* 完全兼容。
* 通过管道(`|`)传递 CLI 实用程序如 `sed`、`awk`、`grep` 等会降低其性能
* 缺少很多函数、对象、数据结构和多线程支持,这限制了它在复杂脚本或编程中的使用
* 缺少良好的调试工具和实用程序
### Python
* 是一种面对对象编程语言(OOP),因此它比 Bash 更加通用
* 几乎可以用于任何任务
* 适用于大多数操作系统,默认情况下它在大多数 Unix/Linux 系统中都有安装
* 与伪代码非常相似
* 具有简单、清晰、易于学习和阅读的语法
* 拥有大量的库、文档以及一个活跃的社区
* 提供比 Bash 更友好的错误处理特性
* 有比 Bash 更好的调试工具和实用程序,这使得它在开发涉及到很多行代码的复杂软件应用程序时是一种很棒的语言
* 应用程序(或脚本)可能包含许多第三方依赖项,这些依赖项必须在执行前安装
* 对于简单任务,需要编写比 Bash 更多的代码
我希望这些列表能够让你更好地了解该使用哪种语言以及在何时使用它。
你在日常工作中更多会使用哪种语言,Bash 还是 Python?请在评论中分享。
---
via: <https://opensource.com/article/19/4/bash-vs-python>
作者:[Archit Modi (Red Hat)](https://opensource.com/users/architmodi/users/greg-p/users/oz123) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,727 | Linux 中获取硬盘分区或文件系统的 UUID 的七种方法 | https://www.2daygeek.com/check-partitions-uuid-filesystem-uuid-universally-unique-identifier-linux/ | 2019-04-15T11:34:58 | [
"UUID",
"分区"
] | https://linux.cn/article-10727-1.html | 
作为一个 Linux 系统管理员,你应该知道如何去查看分区的 UUID 或文件系统的 UUID。因为现在大多数的 Linux 系统都使用 UUID 挂载分区。你可以在 `/etc/fstab` 文件中可以验证。
有许多可用的实用程序可以查看 UUID。本文我们将会向你展示多种查看 UUID 的方法,并且你可以选择一种适合于你的方法。
### 何为 UUID?
UUID 意即<ruby> 通用唯一识别码 <rt> Universally Unique Identifier </rt></ruby>,它可以帮助 Linux 系统识别一个磁盘分区而不是块设备文件。
自内核 2.15.1 起,libuuid 就是 util-linux-ng 包中的一部分,它被默认安装在 Linux 系统中。UUID 由该库生成,可以合理地认为在一个系统中 UUID 是唯一的,并且在所有系统中也是唯一的。
这是在计算机系统中用来标识信息的一个 128 位(比特)的数字。UUID 最初被用在<ruby> 阿波罗网络计算机系统 <rt> Apollo Network Computing System </rt></ruby>(NCS)中,之后 UUID 被<ruby> 开放软件基金会 <rt> Open Software Foundation </rt></ruby>(OSF)标准化,成为<ruby> 分布式计算环境 <rt> Distributed Computing Environment </rt></ruby>(DCE)的一部分。
UUID 以 32 个十六进制的数字表示,被连字符分割为 5 组显示,总共的 36 个字符的格式为 8-4-4-4-12(32 个字母或数字和 4 个连字符)。
例如: `d92fa769-e00f-4fd7-b6ed-ecf7224af7fa`
我的 `/etc/fstab` 文件示例:
```
# cat /etc/fstab
# /etc/fstab: static file system information.
#
# Use 'blkid' to print the universally unique identifier for a device; this may
# be used with UUID= as a more robust way to name devices that works even if
# disks are added and removed. See fstab(5).
#
#
UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f / ext4 defaults,noatime 0 1
UUID=a2092b92-af29-4760-8e68-7a201922573b swap swap defaults,noatime 0 2
```
我们可以使用下面的 7 个命令来查看。
* `blkid` 命令:定位或打印块设备的属性。
* `lsblk` 命令:列出所有可用的或指定的块设备的信息。
* `hwinfo` 命令:硬件信息工具,是另外一个很好的实用工具,用于查询系统中已存在硬件。
* `udevadm` 命令:udev 管理工具
* `tune2fs` 命令:调整 ext2/ext3/ext4 文件系统上的可调文件系统参数。
* `dumpe2fs` 命令:查询 ext2/ext3/ext4 文件系统的信息。
* 使用 `by-uuid` 路径:该目录下包含有 UUID 和实际的块设备文件,UUID 与实际的块设备文件链接在一起。
### Linux 中如何使用 blkid 命令查看磁盘分区或文件系统的 UUID?
`blkid` 是定位或打印块设备属性的命令行实用工具。它利用 libblkid 库在 Linux 系统中获得到磁盘分区的 UUID。
```
# blkid
/dev/sda1: UUID="d92fa769-e00f-4fd7-b6ed-ecf7224af7fa" TYPE="ext4" PARTUUID="eab59449-01"
/dev/sdc1: UUID="d17e3c31-e2c9-4f11-809c-94a549bc43b7" TYPE="ext2" PARTUUID="8cc8f9e5-01"
/dev/sdc3: UUID="ca307aa4-0866-49b1-8184-004025789e63" TYPE="ext4" PARTUUID="8cc8f9e5-03"
/dev/sdc5: PARTUUID="8cc8f9e5-05"
```
### Linux 中如何使用 lsblk 命令查看磁盘分区或文件系统的 UUID?
`lsblk` 列出所有有关可用或指定块设备的信息。`lsblk` 命令读取 sysfs 文件系统和 udev 数据库以收集信息。
如果 udev 数据库不可用或者编译的 lsblk 不支持 udev,它会试图从块设备中读取卷标、UUID 和文件系统类型。这种情况下,必须以 root 身份运行。该命令默认会以类似于树的格式打印出所有的块设备(RAM 盘除外)。
```
# lsblk -o name,mountpoint,size,uuid
NAME MOUNTPOINT SIZE UUID
sda 30G
└─sda1 / 20G d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
sdb 10G
sdc 10G
├─sdc1 1G d17e3c31-e2c9-4f11-809c-94a549bc43b7
├─sdc3 1G ca307aa4-0866-49b1-8184-004025789e63
├─sdc4 1K
└─sdc5 1G
sdd 10G
sde 10G
sr0 1024M
```
### Linux 中如何使用 by-uuid 路径查看磁盘分区或文件系统的 UUID?
该目录包含了 UUID 和实际的块设备文件,UUID 与实际的块设备文件链接在一起。
```
# ls -lh /dev/disk/by-uuid/
total 0
lrwxrwxrwx 1 root root 10 Jan 29 08:34 ca307aa4-0866-49b1-8184-004025789e63 -> ../../sdc3
lrwxrwxrwx 1 root root 10 Jan 29 08:34 d17e3c31-e2c9-4f11-809c-94a549bc43b7 -> ../../sdc1
lrwxrwxrwx 1 root root 10 Jan 29 08:34 d92fa769-e00f-4fd7-b6ed-ecf7224af7fa -> ../../sda1
```
### Linux 中如何使用 hwinfo 命令查看磁盘分区或文件系统的 UUID?
[hwinfo](https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/) 意即硬件信息工具,是另外一种很好的实用工具。它被用来检测系统中已存在的硬件,并且以可读的格式显示各种硬件组件的细节信息。
```
# hwinfo --block | grep by-uuid | awk '{print $3,$7}'
/dev/sdc1, /dev/disk/by-uuid/d17e3c31-e2c9-4f11-809c-94a549bc43b7
/dev/sdc3, /dev/disk/by-uuid/ca307aa4-0866-49b1-8184-004025789e63
/dev/sda1, /dev/disk/by-uuid/d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
```
### Linux 中如何使用 udevadm 命令查看磁盘分区或文件系统的 UUID?
`udevadm` 需要命令和命令特定的操作。它控制 systemd-udevd 的运行时行为,请求内核事件、管理事件队列并且提供简单的调试机制。
```
# udevadm info -q all -n /dev/sdc1 | grep -i by-uuid | head -1
S: disk/by-uuid/d17e3c31-e2c9-4f11-809c-94a549bc43b7
```
### Linux 中如何使用 tune2fs 命令查看磁盘分区或文件系统的 UUID?
`tune2fs` 允许系统管理员在 Linux 的 ext2、ext3、ext4 文件系统中调整各种可调的文件系统参数。这些选项的当前值可以使用选项 `-l` 显示。
```
# tune2fs -l /dev/sdc1 | grep UUID
Filesystem UUID: d17e3c31-e2c9-4f11-809c-94a549bc43b7
```
### Linux 中如何使用 dumpe2fs 命令查看磁盘分区或文件系统的 UUID?
`dumpe2fs` 打印出现在设备文件系统中的超级块和块组的信息。
```
# dumpe2fs /dev/sdc1 | grep UUID
dumpe2fs 1.43.5 (04-Aug-2017)
Filesystem UUID: d17e3c31-e2c9-4f11-809c-94a549bc43b7
```
---
via: <https://www.2daygeek.com/check-partitions-uuid-filesystem-uuid-universally-unique-identifier-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[liujing97](https://github.com/liujing97) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,730 | 5 款适合程序员的开源字体 | https://opensource.com/article/17/11/how-select-open-source-programming-font | 2019-04-16T10:47:32 | [
"字体",
"编程"
] | https://linux.cn/article-10730-1.html |
>
> 编程字体有些在普通字体中没有的特点,这五种字体你可以看看。
>
>
>

什么是最好的编程字体呢?首先,你需要考虑到字体被设计出来的初衷可能并不相同。当选择一款用于休闲阅读的字体时,读者希望该字体的字母能够顺滑地衔接,提供一种轻松愉悦的体验。一款标准字体的每个字符,类似于拼图的一块,它需要被仔细的设计,从而与整个字体的其他部分融合在一起。
然而,在编写代码时,通常来说对字体的要求更具功能性。这也是为什么大多数程序员在选择时更偏爱使用固定宽度的等宽字体。选择一款带有容易分辨的数字和标点的字体在美学上令人愉悦;但它是否拥有满足你需求的版权许可也是非常重要的。
某些功能使得字体更适合编程。首先要清楚是什么使得等宽字体看上去井然有序。这里,让我们对比一下字母 `w` 和字母 `i`。当选择一款字体时,重要的是要考虑字母本身及周围的空白。在纸质的书籍和报纸中,有效地利用空间是极为重要的,为瘦小的 `i` 分配较小的空间,为宽大的字母 `w` 分配较大的空间是有意义的。
然而在终端中,你没有这些限制。每个字符享有相等的空间将非常有用。这么做的首要好处是你可以随意扫过一段代码来“估测”代码的长度。第二个好处是能够轻松地对齐字符和标点,高亮在视觉上更加明显。另外打印纸张上的等宽字体比均衡字体更加容易通过 OCR 识别。
在本篇文章中,我们将探索 5 款卓越的开源字体,使用它们来编程和写代码都非常理想。
### 1、Firacode:最佳整套编程字体

*FiraCode, Andrew Lekashman*
在我们列表上的首款字体是 [FiraCode](https://github.com/tonsky/FiraCode),一款真正符合甚至超越了其职责的编程字体。FiraCode 是 Fira 的扩展,而后者是由 Mozilla 委托设计的开源字体族。使得 FiraCode 与众不同的原因是它修改了在代码中常使用的一些符号的组合或连字,使得它看上去更具可读性。这款字体有几种不同的风格,特别是还包含 Retina 选项。你可以在它的 [GitHub](https://github.com/tonsky/FiraCode) 主页中找到它被使用到多种编程语言中的例子。

*FiraCode 与 Fira Mono 的对比,[Nikita Prokopov](https://github.com/tonsky/FiraCode),源自 GitHub*
### 2、Inconsolata:优雅且由卓越设计者创造

*Inconsolata, Andrew Lekashman*
[Inconsolata](http://www.levien.com/type/myfonts/inconsolata.html) 是最为漂亮的等宽字体之一。从 2006 年开始它便一直是一款开源和可免费获取的字体。它的创造者 Raph Levien 在设计 Inconsolata 时秉承的一个基本原则是:等宽字体并不应该那么糟糕。使得 Inconsolata 如此优秀的两个原因是:对于 `0` 和 `o` 这两个字符它们有很大的不同,另外它还特别地设计了标点符号。
### 3、DejaVu Sans Mono:许多 Linux 发行版的标准配置,庞大的字形覆盖率

*DejaVu Sans Mono, Andrew Lekashman*
受在 GNOME 中使用的带有版权和闭源的 Vera 字体的启发,[DejaVu Sans Mono](https://dejavu-fonts.github.io/) 是一个非常受欢迎的编程字体,几乎在每个现代的 Linux 发行版中都带有它。在 Book Variant 风格下 DejaVu 拥有惊人的 3310 个字形,相比于一般的字体,它们含有 100 个左右的字形。在工作中你将不会出现缺少某些字符的情况,它覆盖了 Unicode 的绝大部分,并且一直在活跃地增长着。
### 4、Source Code Pro:优雅、可读性强,由 Adobe 中一个小巧但天才的团队打造

*Source Code Pro, Andrew Lekashman*
由 Paul Hunt 和 Teo Tuominen 设计,[Source Code Pro](https://github.com/adobe-fonts/source-code-pro) 是[由 Adobe 创造的](https://blog.typekit.com/2012/09/24/source-code-pro/),成为了它的首款开源字体。Source Code Pro 值得注意的地方在于它极具可读性,且对于容易混淆的字符和标点,它有着非常好的区分度。Source Code Pro 也是一个字体族,有 7 中不同的风格:Extralight、Light、Regular、Medium、Semibold、Bold 和 Black,每种风格都还有斜体变体。

*潜在易混淆的字符之间的区别,[Paul D. Hunt](https://blog.typekit.com/2012/09/24/source-code-pro/) 源自 Adobe Typekit 博客。*

*在计算机领域中有特别含义的特殊元字符, [Paul D. Hunt](https://blog.typekit.com/2012/09/24/source-code-pro/) 源自 Adobe Typekit 博客。*
### 5、Noto Mono:巨量的语言覆盖率,由 Google 中的一个大团队打造

*Noto Mono, Andrew Lekashman*
在我们列表上的最后一款字体是 [Noto Mono](https://www.google.com/get/noto/#mono-mono),这是 Google 打造的庞大 Note 字体族中的等宽版本。尽管它并不是专为编程所设计,但它在 209 种语言(包括 emoji 颜文字!)中都可以使用,并且一直在维护和更新。该项目非常庞大,是 Google 宣称 “组织全世界信息” 的使命的延续。假如你想更多地了解它,可以查看这个绝妙的[关于这些字体的视频](https://www.youtube.com/watch?v=AAzvk9HSi84)。
### 选择合适的字体
无论你选择那个字体,你都有可能在每天中花费数小时面对它,所以请确保它在审美和哲学层面上与你产生共鸣。选择正确的开源字体是确保你拥有最佳生产环境的一个重要部分。这些字体都是很棒的选择,每个都具有让它脱颖而出的功能强大的特性。
---
via: <https://opensource.com/article/17/11/how-select-open-source-programming-font>
作者:[Andrew Lekashman](https://opensource.com) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | What is the best programming font? First, you need to consider that not all fonts are created equally. When choosing a font for casual reading, the reader expects the letters to smoothly flow into one another, giving an easy and enjoyable experience. A single character for a standard font is akin to puzzle piece designed to carefully mesh with every other part of the overall typeface.
When writing code, however, your font requirements are typically more functional in nature. This is why most programmers prefer to use monospaced fonts with fixed-width letters, when given the option. Selecting a font that has distinguishable numbers and punctuation, is aesthetically pleasing, and has a copyright license that meets your needs is also important.
There are certain features that make a font optimal for programming. First, a detailed definition of what makes a monospaced font is in order. Consider the letter "w" as it compares to the letter "i" for a moment. When you are dealing with a font, it is important to think about the whitespace around the letter, as well as the letter itself. In the world of physical books and newspapers, where efficient use of space is often critical, it makes sense to assign less width to the thin "i" than the wide "w."
Inside a terminal, however, you are blessed with no such restrictions, and it can be very useful for every character to share an identical amount of space. The main functional benefit is that you can effectively "guesstimate" how long your code is by casually glancing at a block of text. Secondary benefits include the ability to align characters and punctuation easily, highlighting is much more visually obvious, and optical character recognition on printed sheets is more effective for monospaced fonts than proportional fonts.In this article we will explore five excellent open source font options that are ideal for programming and writing code.
## 1. Firacode: The best overall programming font

opensource.com
The first font on our list is [FiraCode](https://github.com/tonsky/FiraCode), a programming font that truly goes above and beyond the call of duty. FiraCode is an extension of Fira, the open source font family commissioned by Mozilla. What makes FiraCode different is that it modifies the common symbol combinations or ligatures used in code to be extraordinarily readable. This font family comes in several styles, notably including a Retina option. You can find examples for how it applies to many programming languages on its [GitHub](https://github.com/tonsky/FiraCode) page.

opensource.com
## 2. Inconsolata: Elegant and created by a brilliant designer

opensource.com
[Inconsolata](http://www.levien.com/type/myfonts/inconsolata.html) is one of the most beautiful monospaced fonts. It has been around since 2006 as an open source and freely available option. The creator, Raph Levien designed Inconsolata with one basic statement in mind: "monospaced fonts do not have to suck." Two things that stand out about Inconsolata are its extremely clear differences between 0 and O and its well-defined punctuation.
## 3. DejaVu Sans Mono: Standard issue with many Linux distros and huge glyph coverage

opensource.com
Inspired by the copyrighted and closed Vera font family used in GNOME, [DejaVu Sans Mono](https://dejavu-fonts.github.io/) is an extremely popular programming font that comes bundled with nearly every modern Linux distribution. DejaVu comes packed with a whopping 3,310 glyphs under the Book Variant, compared to a standard font, which normally rests easy at around 100 glyphs. You'll have no shortage of characters to work with, it has enormous coverage over Unicode, and it is actively growing all of the time.
## 4. Source Code Pro: Elegant and readable, created by a small, talented team at Adobe

opensource.com
Designed by Paul Hunt and Teo Tuominen, [Source Code Pro](https://github.com/adobe-fonts/source-code-pro) was [produced by Adobe](https://blog.typekit.com/2012/09/24/source-code-pro/) to be one of its first open source fonts. Source Code Pro is notable in that it is extremely readable and has excellent differentiation between potentially confusing characters and punctuation. Source Code Pro is also a font family and comes in seven different styles: Extralight, Light, Regular, Medium, Semibold, Bold, and Black, with italic variants of each.
opensource.com
opensource.com
## 5. Noto Mono: Enormous language coverage, created by a large team at Google
opensource.com
The last font on our list is [Noto Mono](https://www.google.com/get/noto/#mono-mono), the monospaced version of the expansive Noto font family by Google. While not specifically designed for programming, Noto Mono is available in 209 languages (including emoji!) and is actively supported and updated. The project is enormous and is an extension of Google's stated mission to organize the world's information. If you want to learn more about it, check out this excellent [video about the font](https://www.youtube.com/watch?v=AAzvk9HSi84).
## Choosing the right font
Whichever typeface you select, you will most likely spend hours each day immersed within it, so make sure it resonates with you on an aesthetic and philosophical level. Choosing the right open source font is an important part of making sure that you have the best possible environment for productivity. Any of these fonts is a fantastic choice, and each option has a powerful feature set that lets it stand out from the rest.
## 11 Comments |
10,731 | 树莓派使用入门:如何为树莓派社区做出贡献 | https://opensource.com/article/19/3/contribute-raspberry-pi-community | 2019-04-16T10:55:00 | [
"树莓派"
] | https://linux.cn/article-10731-1.html |
>
> 在我们的入门系列的第 13 篇文章中,发现参与树莓派社区的方法。
>
>
>

这个系列已经逐渐接近尾声,我已经写了很多它的乐趣,我大多希望它能帮助人们使用树莓派进行教育或娱乐。也许这些文章能说服你买你的第一个树莓派,或者让你重新发现抽屉里的吃灰设备。如果这里有真的,那么我认为这个系列就是成功的。
如果你想买一台,并宣传这块绿色的小板子有多么多功能,这里有几个方法帮你与树莓派社区建立连接:
* 帮助改进[官方文档](https://www.raspberrypi.org/documentation/CONTRIBUTING.md) \* 贡献代码给依赖的[项目](https://www.raspberrypi.org/github/) \* 用 Raspbian 报告 [bug](https://www.raspbian.org/RaspbianBugs) \* 报告不同 ARM 架构分发版的的 bug \* 看一眼英国国内的树莓派基金会的[代码俱乐部](https://www.codeclub.org.uk/)或英国境外的[国际代码俱乐部](https://www.codeclubworld.org/),帮助孩子学习编码 \* 帮助[翻译](https://www.raspberrypi.org/translate/) \* 在 [Raspberry Jam](https://www.raspberrypi.org/jam/) 当志愿者
这些只是你可以为树莓派社区做贡献的几种方式。最后但同样重要的是,你可以加入我并[投稿文章](https://opensource.com/participate)到你最喜欢的开源网站 [Opensource.com](http://Opensource.com)。 :-)
---
via: <https://opensource.com/article/19/3/contribute-raspberry-pi-community>
作者:[Anderson Silva (Red Hat)](https://opensource.com/users/ansilva/users/kepler22b/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Things are starting to wind down in this series, and as much fun as I've had writing it, mostly I hope it has helped someone out there use start using a Raspberry Pi for education or entertainment. Maybe the articles convinced you to buy your first Raspberry Pi or perhaps helped you rediscover the device that was collecting dust in a drawer. If any of that is true, I'll consider the series a success.
If you now want to pay it forward and help spread the word on how versatile this little green digital board is, here are a few ways you can get connected to the Raspberry Pi community:
- Contribute to improving the
[official documentation](https://www.raspberrypi.org/documentation/CONTRIBUTING.md) - Contribute code to
[projects](https://www.raspberrypi.org/github/)the Raspberry Pi depends on - File
[bugs](https://www.raspbian.org/RaspbianBugs)with Raspbian - File bugs with the different ARM architecture platform distributions
- Help kids learn to code by taking a look at the Raspberry Pi Foundation's
[Code Club](https://www.codeclub.org.uk/)in the UK or[Code Club International](https://www.codeclubworld.org/)outside the UK - Help with
[translation](https://www.raspberrypi.org/translate/) - Volunteer on a
[Raspberry Jam](https://www.raspberrypi.org/jam/)
These are just a few of the ways you can contribute to the Raspberry Pi community. Last but not least, you can join me and [contribute articles](https://opensource.com/participate) to your favorite open source website, [Opensource.com](http://Opensource.com). :-)
## 2 Comments |
10,732 | Sweet Home 3D:一个帮助你寻找梦想家庭的开源工具 | https://opensource.com/article/19/3/tool-find-home | 2019-04-16T11:08:27 | [
"开源"
] | https://linux.cn/article-10732-1.html |
>
> 室内设计应用可以轻松渲染你喜欢的房子,不管是真实的或是想象的。
>
>
>

我最近接受了一份在弗吉尼亚州的新工作。由于我妻子一直在纽约工作,看着我们在纽约的房子直至出售,我有责任出去为我们和我们的猫找一所新房子。在我们搬进去之前她看不到新房子。
我和一个房地产经纪人签约,并看了几间房子,拍了许多照片,写下了潦草的笔记。晚上,我会将照片上传到 Google Drive 文件夹中,我和我老婆会通过手机同时查看这些照片,同时我还要记住房间是在右边还是左边,是否有风扇等。
由于这是一个相当繁琐且不太准确的展示我的发现的方式,我因此去寻找一个开源解决方案,以更好地展示我们未来的梦想之家将会是什么样的,而不会取决于我的模糊记忆和模糊的照片。
[Sweet Home 3D](https://sourceforge.net/projects/sweethome3d/) 完全满足了我的要求。Sweet Home 3D 可在 Sourceforge 上获取,并在 GNU 通用公共许可证下发布。它的[网站](http://www.sweethome3d.com/)信息非常丰富,我能够立即启动并运行。Sweet Home 3D 由总部位于巴黎的 eTeks 的 Emmanuel Puybaret 开发。
### 绘制内墙
我将 Sweet Home 3D 下载到我的 MacBook Pro 上,并添加了 PNG 版本的平面楼层图,用作背景底图。
在此处,使用 Rooms 面板跟踪图案并设置“真实房间”尺寸是一件简单的事情。在我绘制房间后,我添加了墙壁,我可以定制颜色、厚度、高度等。

现在我画完了“内墙”,我从网站下载了各种“家具”,其中包括实际的家具以及门、窗、架子等。每个项目都以 ZIP 文件的形式下载,因此我创建了一个包含所有未压缩文件的文件夹。我可以自定义每件家具和重复的物品比如门,可以方便地复制粘贴到指定的地方。
在我将所有墙壁和门窗都布置完后,我就使用这个应用的 3D 视图浏览房屋。根据照片和记忆,我对所有物体进行了调整,直到接近房屋的样子。我可以花更多时间添加纹理,附属家具和物品,但这已经达到了我需要的程度。

完成之后,我将该项目导出为 OBJ 文件,它可在各种程序中打开,例如 [Blender](https://opensource.com/article/18/5/blender-hotkey-cheat-sheet) 和 Mac 上的“预览”中,方便旋转房屋并从各个角度查看。视频功能最有用,我可以创建一个起点,然后在房子中绘制一条路径,并记录“旅程”。我将视频导出为 MOV 文件,并使用 QuickTime 在 Mac 上打开和查看。
我的妻子能够(几乎)能看到所有我看到的,我们甚至可以开始在搬家前布置家具。现在,我所要做的就是把行李装上卡车搬到新家。
Sweet Home 3D 在我的新工作中也是有用的。我正在寻找一种方法来改善学院建筑的地图,并计划在 [Inkscape](https://opensource.com/article/19/1/inkscape-cheat-sheet) 或 Illustrator 或其他软件中重新绘制它。但是,由于我有平面地图,我可以使用 Sweet Home 3D 创建平面图的 3D 版本并将其上传到我们的网站以便更方便地找到地方。
### 开源犯罪现场?
一件有趣的事:根据 [Sweet Home 3D 的博客](http://www.sweethome3d.com/blog/2018/12/10/customization_for_the_forensic_police.html),“法国法医办公室(科学警察)最近选择 Sweet Home 3D 作为设计规划表示路线和犯罪现场的工具。这是法国政府建议优先考虑自由开源解决方案的具体应用。“
这是公民和政府如何利用开源解决方案创建个人项目、解决犯罪和建立世界的又一点证据。
---
via: <https://opensource.com/article/19/3/tool-find-home>
作者:[Jeff Macharyas (Community Moderator)](https://opensource.com/users/jeffmacharyas) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I recently accepted a new job in Virginia. Since my wife was working and watching our house in New York until it sold, it was my responsibility to go out and find a new house for us and our cat. A house that she would not see until we moved into it!
I contracted with a real estate agent and looked at a few houses, taking many pictures and writing down illegible notes. At night, I would upload the photos into a Google Drive folder, and my wife and I would review them simultaneously over the phone while I tried to remember whether the room was on the right or the left, whether it had a fan, etc.
Since this was a rather tedious and not very accurate way to present my findings, I went in search of an open source solution to better illustrate what our future dream house would look like that wouldn't hinge on my fuzzy memory and blurry photos.
[Sweet Home 3D](https://sourceforge.net/projects/sweethome3d/) did exactly what I wanted it to do. Sweet Home 3D is available on Sourceforge and released under the GNU General Public License. The [website](http://www.sweethome3d.com/) is very informative, and I was able to get it up and running in no time. Sweet Home 3D was developed by Paris-based Emmanuel Puybaret of eTeks.
## Hanging the drywall
I downloaded Sweet Home 3D onto my MacBook Pro and added a PNG version of a flat floorplan of a house to use as a background base map.
From there, it was a simple matter of using the Rooms palette to trace the pattern and set the "real life" dimensions. After I mapped the rooms, I added the walls, which I could customize by color, thickness, height, etc.
Now that I had the "drywall" built, I downloaded various pieces of "furniture" from a large array that includes actual furniture as well as doors, windows, shelves, and more. Each item downloads as a ZIP file, so I created a folder of all my uncompressed pieces. I could customize each piece of furniture, and repetitive items, such as doors, were easy to copy-and-paste into place.
Once I had all my walls and doors and windows in place, I used the application's 3D view to navigate through the house. Drawing upon my photos and memory, I made adjustments to all the objects until I had a close representation of the house. I could have spent more time modifying the house by adding textures, additional furniture, and objects, but I got it to the point I needed.

After I finished, I exported the plan as an OBJ file, which can be opened in a variety of programs, such as [Blender](https://opensource.com/article/18/5/blender-hotkey-cheat-sheet) and Preview on the Mac, to spin the house around and examine it from various angles. The Video function was most useful, as I could create a starting point, draw a path through the house, and record the "journey." I exported the video as a MOV file, which I opened and viewed on the Mac using QuickTime.
My wife was able to see (almost) exactly what I saw, and we could even start arranging furniture ahead of the move, too. Now, all I have to do is load up the moving truck and head south.
Sweet Home 3D will also prove useful at my new job. I was looking for a way to improve the map of the college's buildings and was planning to just re-draw it in [Inkscape](https://opensource.com/article/19/1/inkscape-cheat-sheet) or Illustrator or something. However, since I have the flat map, I can use Sweet Home 3D to create a 3D version of the floorplan and upload it to our website to make finding the bathrooms so much easier!
## An open source crime scene?
An interesting aside: according to the [Sweet Home 3D blog](http://www.sweethome3d.com/blog/2018/12/10/customization_for_the_forensic_police.html), "the French Forensic Police Office (Scientific Police) recently chose Sweet Home 3D as a tool to design plans [to represent roads and crime scenes]. This is a concrete application of the recommendation of the French government to give the preference to free open source solutions."
This is one more bit of evidence of how open source solutions are being used by citizens and governments to create personal projects, solve crimes, and build worlds.
## 4 Comments |
10,734 | 树莓派使用入门:庆祝树莓派的 14 天 | https://opensource.com/article/19/3/happy-pi-day | 2019-04-16T18:09:06 | [
"树莓派"
] | https://linux.cn/article-10734-1.html |
>
> 在我们关于树莓派入门系列的第 14 篇也是最后一篇文章中,回顾一下我们学到的所有东西。
>
>
>

### 派节快乐!
每年的 3 月 14 日,我们这些极客都会庆祝派节。我们用这种方式缩写日期: `MMDD`,3 月 14 于是写成 03/14,它的数字上提醒我们 3.14,或者说 [π](https://www.piday.org/million/) 的前三位数字。许多美国人没有意识到的是,世界上几乎没有其他国家使用这种[日期格式](https://en.wikipedia.org/wiki/Date_format_by_country),因此派节几乎只适用于美国,尽管它在全球范围内得到了庆祝。
无论你身在何处,让我们一起庆祝树莓派,并通过回顾过去两周我们所涉及的主题来结束本系列:
* 第 1 天:[你应该选择哪种树莓派?](/article-10611-1.html)
* 第 2 天:[如何购买树莓派](/article-10615-1.html)
* 第 3 天:[如何启动一个新的树莓派](/article-10644-1.html)
* 第 4 天:[用树莓派学习 Linux](/article-10645-1.html)
* 第 5 天:[教孩子们用树莓派学编程的 5 种方法](/article-10653-1.html)
* 第 6 天:[可以使用树莓派学习的 3 种流行编程语言](/article-10661-1.html)
* 第 7 天:[如何更新树莓派](/article-10665-1.html)
* 第 8 天:[如何使用树莓派来娱乐](/article-10669-1.html)
* 第 9 天:[树莓派上的模拟器和原生 Linux 游戏](/article-10682-1.html)
* 第 10 天:[进入物理世界 —— 如何使用树莓派的 GPIO 针脚](/article-10687-1.html)
* 第 11 天:[通过树莓派和 kali Linux 学习计算机安全](/article-10690-1.html)
* 第 12 天:[在树莓派上使用 Mathematica 进行高级数学运算](/article-10711-1.html)
* 第 13 天:[如何为树莓派社区做出贡献](/article-10731-1.html)

我将结束本系列,感谢所有关注的人,尤其是那些在过去 14 天里从中学到了东西的人!我还想鼓励大家不断扩展他们对树莓派以及围绕它构建的所有开源(和闭源)技术的了解。
我还鼓励你了解其他文化、哲学、宗教和世界观。让我们成为人类的是这种惊人的 (有时是有趣的) 能力,我们不仅要适应外部环境,而且要适应智力环境。
不管你做什么,保持学习!
---
via: <https://opensource.com/article/19/3/happy-pi-day>
作者:[Anderson Silva (Red Hat)](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Happy Pi Day!**
Every year on March 14th, we geeks celebrate Pi Day. In the way we abbreviate dates—MMDD—March 14 is written 03/14, which numerically reminds us of 3.14, or the first three numbers of [pi](https://www.piday.org/million/). What many Americans don't realize is that virtually no other country in the world uses this [date format](https://en.wikipedia.org/wiki/Date_format_by_country), so Pi Day pretty much only works in the US, though it is celebrated globally.
Wherever you are in the world, let's celebrate the Raspberry Pi and wrap up this series by reviewing the topics we've covered in the past two weeks:
- Day 1:
[Which Raspberry Pi should you choose?](https://opensource.com/article/19/3/which-raspberry-pi-choose) - Day 2:
[How to buy a Raspberry Pi](https://opensource.com/article/19/3/how-buy-raspberry-pi) - Day 3:
[How to boot up a new Raspberry Pi](https://opensource.com/article/19/3/how-boot-new-raspberry-pi) - Day 4:
[Learn Linux with the Raspberry Pi](https://opensource.com/article/19/3/learn-linux-raspberry-pi) - Day 5:
[5 ways to teach kids to program with Raspberry Pi](https://opensource.com/article/19/3/teach-kids-program-raspberry-pi) - Day 6:
[3 popular programming languages you can learn with Raspberry Pi](https://opensource.com/article/19/3/programming-languages-raspberry-pi) - Day 7:
[How to keep your Raspberry Pi updated](https://opensource.com/article/19/3/how-raspberry-pi-update) - Day 8:
[How to use your Raspberry Pi for entertainment](https://opensource.com/article/19/3/raspberry-pi-entertainment) - Day 9:
[Play games on the Raspberry Pi](https://opensource.com/article/19/3/play-games-raspberry-pi) - Day 10:
[Let's get physical: How to use GPIO pins on the Raspberry Pi](https://opensource.com/article/19/3/gpio-pins-raspberry-pi) - Day 11:
[Learn about computer security with the Raspberry Pi](https://opensource.com/article/19/3/learn-about-computer-security-raspberry-pi) - Day 12:
[Do advanced math with Mathematica on the Raspberry Pi](https://opensource.com/article/19/3/do-math-raspberry-pi) - Day 13:
[Contribute to the Raspberry Pi community](https://opensource.com/article/19/3/contribute-raspberry-pi-community)

I'll end this series by thanking everyone who was brave enough to follow along and especially those who learned something from it during these past 14 days! I also want to encourage everyone to keep expanding their knowledge about the Raspberry Pi and all of the open (and closed) source technology that has been built around it.
I also encourage you to learn about other cultures, philosophies, religions, and worldviews. What makes us human is this amazing (and sometimes amusing) ability that we have to adapt not only to external environmental circumstances—but also intellectual ones.
No matter what you do, keep learning!
## 4 Comments |
10,735 | 开源如何在云上存活? | https://venturebeat.com/2019/04/14/how-open-source-can-survive-the-cloud/ | 2019-04-16T23:19:00 | [
"开源",
"云服务"
] | https://linux.cn/article-10735-1.html | 
在过去十年中,从 Linux 和 MySQL 到 Kubernetes、Spark、Presto 和 MongoDB,开源一直是云的创新支柱。但最近的一些事态发展为开源背后的商业模式带来了阴霾,业界现在必须采取行动,以避免扼杀其最大的创新来源之一。
作为 Apache Hive 项目的共同创始人和前负责人,我知道激励对于开源生态系统的蓬勃发展至关重要。独立开发者需要激励他们为开源项目贡献自己的时间和技能,而那些具有创业思维的人需要激励他们围绕这些项目建立公司以帮助它们蓬勃发展。
公有云可能会破坏这些激励因素,因为它改变了开源的形态。大型云服务商很容易将开源项目拿来,并将其作为托管服务提供个客户。如果它是在没有回馈社区的情况下这样做的,它就是从别人的工作中获得不公平的利润,从而破坏了开源所需要的蓬勃发展的动力。
我们在围绕 [AWS](https://venturebeat.com/2019/01/17/amazons-aws-launches-full-managed-data-backup-service/) 的当前讨论中已经看到了这一点,AWS [被指责](https://techcrunch.com/2019/01/09/aws-gives-open-source-the-middle-finger/) 将开源项目作为服务而提供,并对这些开源项目进行品牌重塑,却不总是回馈这些开源社区。这促使包括 [Confluent](https://www.confluent.io/blog/license-changes-confluent-platform)、 [Redis Labs](https://redislabs.com/blog/redis-license-bsd-will-remain-bsd/) 和 [MongoDB](https://www.mongodb.com/press/mongodb-issues-new-server-side-public-license-for-mongodb-community-server) 在内的开源软件供应商使用了新的许可证,以阻止大型商业云服务商将其代码作为托管服务提供。
我不认为这是一种正确的方法。这些新的许可证尚未得到<ruby> 开源推进组织 <rp> ( </rp> <rt> Open Source Initiative </rt> <rp> ) </rp></ruby>(OSI)的认可,并且它们有可能会混淆开源软件的使用权。正如<ruby> 软件自由保护协会 <rp> ( </rp> <rt> Software Freedom Conservancy </rt> <rp> ) </rp></ruby>主席 Bradley M. Kuhn [所说](https://www.businessinsider.com/amazon-web-services-open-source-licensing-undermine-2018-12),软件自由应该“对所有人来说都是平等的,无论他们是否是商业行为者。”开源之所以蓬勃发展,是因为这个原则一直受到尊重,任何模糊不清的地方都可能会阻止人们加入社区。
我同情那些寻求保护其业务的开源公司。尽管独立开发人员付出了很多的努力,但开源项目需要公司的资源和管理工作才能被视为足够稳定,才足以供企业广泛使用。Linux 在企业领域中起飞,是因为 Red Hat 和 IBM 全力支持它。Kubernetes 的发展是如此的快,也是因为它得到了谷歌的支持。当然也有例外,但如果一个开源项目背后有一家公司,那么这个开源项目更有可能在大型企业中取得成功。
我需要说明一下我的利益相关立场。我的公司提供了一个基于云的数据分析平台,该平台严重依赖 Spark、Presto 和 Hive 等开源组件。与此同时,我们通过两个项目回馈社区,成为优秀的开源公民:Sparklens,一个提高 Spark 应用程序性能的框架;以及 RubiX,一个提升 Presto 和 Spark 性能的缓存框架。
在云中提供开源软件有助于这些项目吸引更多用户和开发人员。但是,如果商业云服务商获利不公平,则会对下一代企业家程序员们构建开源公司和投资者支持他们产生抑制作用。
因此,如果新的许可证不是解决方案,那么什么是呢?
部分要靠大型云服务商的公平竞争。我不认为 AWS 是“邪恶的”,他们的行为是他们认为最符合他们商业利益的行为。但他们需要认识到,从长远来看,破坏开源对他们的伤害会像对其它人的伤害一样。开源倡导者应该继续提高对这个问题的认识,并对云服务商施加公众压力,以便让他们采取负责任的行动。我们已经看到证据表明这种压力[可行](https://www.geekwire.com/2018/firecracker-amazon-web-services-reinvents-serverless-computing-infrastructure-open-source-reputation/)。
我们还需要一个开源的“<ruby> 道德规范 <rp> ( </rp> <rt> code of ethics </rt> <rp> ) </rp></ruby>”,由社区(贡献者、项目负责人)和开源组织(如 OSI 和 Apache)创建。一个企业的行为即便是 100% 符合开源许可证,但仍然能够以损害社区的方式行事。这个道德规范能够指出一个广泛认可的道德准则,列出了不可接受的做法,这将使公司和个人对他们的行为负责。
最终的推动力来自于竞争。确实,大型云服务商在吸引客户方面具有优势;它们被 CIO 们视为“简单”和“安全”之选。但客户也可以选择最好的软件和支持。如果开源公司能够为他们自己的发布版本提供更好的功能和更好的支持,他们可以说服客户选择他们自己的产品。
我已经概述了社区可以采取的改善这种情况的行动,但我们每个人也都可以以个人身份采取行动。通过让云服务商了解我们的担忧,我们能够对市场产生一定的影响。要求他们通过反馈表和产品论坛向社区提供特定功能,这是让你发出自己的声音的一种方式。这些云服务商的开发人员也在开源论坛中闲逛,并希望成为开源社区的一员;让这些要求引起他们的注意会促使这种改变。
我们所面临的这个挑战并没有简单的解决方案,但我们需要认真对待。开源模式并不脆弱,不会在一夜之间崩坏。但是,如果商业云服务商继续利用开源项目而不给予回馈,那么他们就会削弱帮助开源成功的激励措施。杀死产下金蛋的鸡并不符合他们的利益,这肯定也不符合开发者和客户的利益。
---
via: <https://venturebeat.com/2019/04/14/how-open-source-can-survive-the-cloud/>
作者:[Ashish Thusoo](https://venturebeat.com/author/ashish-thusoo-qubole/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,736 | 如何检查 Linux 中的开放端口列表? | https://www.2daygeek.com/linux-scan-check-open-ports-using-netstat-ss-nmap/ | 2019-04-17T08:51:00 | [
"端口"
] | https://linux.cn/article-10736-1.html | 
最近,我们就同一主题写了两篇文章。这些文章内容帮助你如何检查远程服务器中给定的端口是否打开。
如果你想 [检查远程 Linux 系统上的端口是否打开](/article-10675-1.html) 请点击链接浏览。如果你想 [检查多个远程 Linux 系统上的端口是否打开](/article-10766-1.html) 请点击链接浏览。如果你想 [检查多个远程 Linux 系统上的多个端口状态](/article-10766-1.html) 请点击链接浏览。
但是本文帮助你检查本地系统上的开放端口列表。
在 Linux 中很少有用于此目的的实用程序。然而,我提供了四个最重要的 Linux 命令来检查这一点。
你可以使用以下四个命令来完成这个工作。这些命令是非常出名的并被 Linux 管理员广泛使用。
* `netstat`:netstat (“network statistics”) 是一个显示网络连接(进和出)相关信息命令行工具,例如:路由表, 伪装连接,多点传送成员和网络端口。
* `nmap`:Nmap (“Network Mapper”) 是一个网络探索与安全审计的开源工具。它旨在快速扫描大型网络。
* `ss`: ss 被用于转储套接字统计信息。它也可以类似 netstat 使用。相比其他工具它可以展示更多的TCP状态信息。
* `lsof`: lsof 是 List Open File 的缩写. 它用于输出被某个进程打开的所有文件。
### 如何使用 Linux 命令 netstat 检查系统中的开放端口列表
`netstat` 是 Network Statistics 的缩写,是一个显示网络连接(进和出)相关信息命令行工具,例如:路由表、伪装连接、多播成员和网络端口。
它可以列出所有的 tcp、udp 连接和所有的 unix 套接字连接。
它用于发现发现网络问题,确定网络连接数量。
```
# netstat -tplugn
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:25 0.0.0.0:* LISTEN 2038/master
tcp 0 0 127.0.0.1:199 0.0.0.0:* LISTEN 1396/snmpd
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 1398/httpd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1388/sshd
tcp6 0 0 :::25 :::* LISTEN 2038/master
tcp6 0 0 :::22 :::* LISTEN 1388/sshd
udp 0 0 0.0.0.0:39136 0.0.0.0:* 1396/snmpd
udp 0 0 0.0.0.0:56130 0.0.0.0:* 1396/snmpd
udp 0 0 0.0.0.0:40105 0.0.0.0:* 1396/snmpd
udp 0 0 0.0.0.0:11584 0.0.0.0:* 1396/snmpd
udp 0 0 0.0.0.0:30105 0.0.0.0:* 1396/snmpd
udp 0 0 0.0.0.0:50656 0.0.0.0:* 1396/snmpd
udp 0 0 0.0.0.0:1632 0.0.0.0:* 1396/snmpd
udp 0 0 0.0.0.0:28265 0.0.0.0:* 1396/snmpd
udp 0 0 0.0.0.0:40764 0.0.0.0:* 1396/snmpd
udp 0 0 10.90.56.21:123 0.0.0.0:* 895/ntpd
udp 0 0 127.0.0.1:123 0.0.0.0:* 895/ntpd
udp 0 0 0.0.0.0:123 0.0.0.0:* 895/ntpd
udp 0 0 0.0.0.0:53390 0.0.0.0:* 1396/snmpd
udp 0 0 0.0.0.0:161 0.0.0.0:* 1396/snmpd
udp6 0 0 :::123 :::* 895/ntpd
IPv6/IPv4 Group Memberships
Interface RefCnt Group
--------------- ------ ---------------------
lo 1 224.0.0.1
eth0 1 224.0.0.1
lo 1 ff02::1
lo 1 ff01::1
eth0 1 ff02::1
eth0 1 ff01::1
```
你也可以使用下面的命令检查特定的端口。
```
# # netstat -tplugn | grep :22
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1388/sshd
tcp6 0 0 :::22 :::* LISTEN 1388/sshd
```
### 如何使用 Linux 命令 ss 检查系统中的开放端口列表?
`ss` 被用于转储套接字统计信息。它也可以显示类似 `netstat` 的信息。相比其他工具它可以展示更多的 TCP 状态信息。
```
# ss -lntu
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
udp UNCONN 0 0 *:39136 *:*
udp UNCONN 0 0 *:56130 *:*
udp UNCONN 0 0 *:40105 *:*
udp UNCONN 0 0 *:11584 *:*
udp UNCONN 0 0 *:30105 *:*
udp UNCONN 0 0 *:50656 *:*
udp UNCONN 0 0 *:1632 *:*
udp UNCONN 0 0 *:28265 *:*
udp UNCONN 0 0 *:40764 *:*
udp UNCONN 0 0 10.90.56.21:123 *:*
udp UNCONN 0 0 127.0.0.1:123 *:*
udp UNCONN 0 0 *:123 *:*
udp UNCONN 0 0 *:53390 *:*
udp UNCONN 0 0 *:161 *:*
udp UNCONN 0 0 :::123 :::*
tcp LISTEN 0 100 *:25 *:*
tcp LISTEN 0 128 127.0.0.1:199 *:*
tcp LISTEN 0 128 *:80 *:*
tcp LISTEN 0 128 *:22 *:*
tcp LISTEN 0 100 :::25 :::*
tcp LISTEN 0 128 :::22 :::*
```
你也可以使用下面的命令检查特定的端口。
```
# # ss -lntu | grep ':25'
tcp LISTEN 0 100 *:25 *:*
tcp LISTEN 0 100 :::25 :::*
```
### 如何使用 Linux 命令 nmap 检查系统中的开放端口列表?
Nmap (“Network Mapper”) 是一个网络探索与安全审计的开源工具。它旨在快速扫描大型网络,当然它也可以工作在独立主机上。
Nmap 使用裸 IP 数据包以一种新颖的方式来确定网络上有哪些主机可用,这些主机提供什么服务(应用程序名称和版本),它们运行什么操作系统(版本),使用什么类型的数据包过滤器/防火墙,以及许多其他特征。
虽然 Nmap 通常用于安全审计,但许多系统和网络管理员发现它对于日常工作也非常有用,例如网络资产清点、管理服务升级计划以及监控主机或服务正常运行时间。
```
# nmap -sTU -O localhost
Starting Nmap 6.40 ( http://nmap.org ) at 2019-03-20 09:57 CDT
Nmap scan report for localhost (127.0.0.1)
Host is up (0.00028s latency).
Other addresses for localhost (not scanned): 127.0.0.1
Not shown: 1994 closed ports
PORT STATE SERVICE
22/tcp open ssh
25/tcp open smtp
80/tcp open http
199/tcp open smux
123/udp open ntp
161/udp open snmp
Device type: general purpose
Running: Linux 3.X
OS CPE: cpe:/o:linux:linux_kernel:3
OS details: Linux 3.7 - 3.9
Network Distance: 0 hops
OS detection performed. Please report any incorrect results at http://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 1.93 seconds
```
你也可以使用下面的命令检查特定的端口。
```
# nmap -sTU -O localhost | grep 123
123/udp open ntp
```
### 如何使用 Linux 命令 lsof 检查系统中的开放端口列表?
它向你显示系统上打开的文件列表以及打开它们的进程。还会向你显示与文件相关的其他信息。
```
# lsof -i
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
ntpd 895 ntp 16u IPv4 18481 0t0 UDP *:ntp
ntpd 895 ntp 17u IPv6 18482 0t0 UDP *:ntp
ntpd 895 ntp 18u IPv4 18487 0t0 UDP localhost:ntp
ntpd 895 ntp 20u IPv4 23020 0t0 UDP CentOS7.2daygeek.com:ntp
sshd 1388 root 3u IPv4 20065 0t0 TCP *:ssh (LISTEN)
sshd 1388 root 4u IPv6 20067 0t0 TCP *:ssh (LISTEN)
snmpd 1396 root 6u IPv4 22739 0t0 UDP *:snmp
snmpd 1396 root 7u IPv4 22729 0t0 UDP *:40105
snmpd 1396 root 8u IPv4 22730 0t0 UDP *:50656
snmpd 1396 root 9u IPv4 22731 0t0 UDP *:pammratc
snmpd 1396 root 10u IPv4 22732 0t0 UDP *:30105
snmpd 1396 root 11u IPv4 22733 0t0 UDP *:40764
snmpd 1396 root 12u IPv4 22734 0t0 UDP *:53390
snmpd 1396 root 13u IPv4 22735 0t0 UDP *:28265
snmpd 1396 root 14u IPv4 22736 0t0 UDP *:11584
snmpd 1396 root 15u IPv4 22737 0t0 UDP *:39136
snmpd 1396 root 16u IPv4 22738 0t0 UDP *:56130
snmpd 1396 root 17u IPv4 22740 0t0 TCP localhost:smux (LISTEN)
httpd 1398 root 3u IPv4 20337 0t0 TCP *:http (LISTEN)
master 2038 root 13u IPv4 21638 0t0 TCP *:smtp (LISTEN)
master 2038 root 14u IPv6 21639 0t0 TCP *:smtp (LISTEN)
sshd 9052 root 3u IPv4 1419955 0t0 TCP CentOS7.2daygeek.com:ssh->Ubuntu18-04.2daygeek.com:11408 (ESTABLISHED)
httpd 13371 apache 3u IPv4 20337 0t0 TCP *:http (LISTEN)
httpd 13372 apache 3u IPv4 20337 0t0 TCP *:http (LISTEN)
httpd 13373 apache 3u IPv4 20337 0t0 TCP *:http (LISTEN)
httpd 13374 apache 3u IPv4 20337 0t0 TCP *:http (LISTEN)
httpd 13375 apache 3u IPv4 20337 0t0 TCP *:http (LISTEN)
```
你也可以使用下面的命令检查特定的端口。
```
# lsof -i:80
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
httpd 1398 root 3u IPv4 20337 0t0 TCP *:http (LISTEN)
httpd 13371 apache 3u IPv4 20337 0t0 TCP *:http (LISTEN)
httpd 13372 apache 3u IPv4 20337 0t0 TCP *:http (LISTEN)
httpd 13373 apache 3u IPv4 20337 0t0 TCP *:http (LISTEN)
httpd 13374 apache 3u IPv4 20337 0t0 TCP *:http (LISTEN)
httpd 13375 apache 3u IPv4 20337 0t0 TCP *:http (LISTEN)
```
---
via: <https://www.2daygeek.com/linux-scan-check-open-ports-using-netstat-ss-nmap/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[heguangzhi](https://github.com/heguangzhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,740 | 破除对 AWS Fargate 的幻觉 | https://leebriggs.co.uk/blog/2019/04/13/the-fargate-illusion.html | 2019-04-17T10:56:00 | [
"无服务器",
"Serverless"
] | https://linux.cn/article-10740-1.html | 
我在 $work 建立了一个基于 Kubernetes 的平台已经快一年了,而且有点像 Kubernetes 的布道者了。真的,我认为这项技术太棒了。然而我并没有对它的运营和维护的困难程度抱过什么幻想。今年早些时候我读了[这样](https://matthias-endler.de/2019/maybe-you-dont-need-kubernetes/)的一篇文章,并对其中某些观点深以为然。如果我在一家规模较小的、有 10 到 15 个工程师的公司,假如有人建议管理和维护一批 Kubernetes 集群,那我会感到害怕的,因为它的运维开销太高了!
尽管我现在对 Kubernetes 的一切都很感兴趣,但我仍然对“<ruby> 无服务器 <rt> Serverless </rt></ruby>”计算会消灭运维工程师的说法抱有好奇。这种好奇心主要来源于我希望在未来仍然能有一份有报酬的工作 —— 如果我们前景光明的未来不需要运维工程师,那我得明白到底是怎么回事。我已经在 Lamdba 和Google Cloud Functions 上做了一些实验,结果让我印象十分深刻,但我仍然坚信无服务器解决方案只是解决了一部分问题。
我关注 [AWS Fargate](https://aws.amazon.com/fargate/) 已经有一段时间了,这就是 $work 的开发人员所推崇为“无服务器计算”的东西 —— 主要是因为 Fargate,用它你就可以无需管理底层节点而运行你的 Docker 容器。我想看看它到底意味着什么,所以我开始尝试从头开始在 Fargate 上运行一个应用,看看是否可以成功。这里我对成功的定义是一个与“生产级”应用程序相近的东西,我想应该包含以下内容:
* 一个在 Fargate 上运行的容器
* 配置信息以环境变量的形式下推
* “秘密信息” 不能是明文的
* 位于负载均衡器之后
* 有效的 SSL 证书的 TLS 通道
我以“基础设施即代码”的角度来开始整个任务,不遵循默认的 AWS 控制台向导,而是使用 terraform 来定义基础架构。这很可能让整个事情变得复杂,但我想确保任何部署都是可重现的,任何想要遵循此步骤的人都可发现我的结论。
上述所有标准通常都可以通过基于 Kubernetes 的平台使用一些外部的附加组件和插件来实现,所以我确实是以一种比较的心态来处理整个任务的,因为我要将它与我的常用工作流程进行比较。我的主要目标是看看Fargate 有多容易,特别是与 Kubernetes 相比时。结果让我感到非常惊讶。
### AWS 是有开销的
我有一个干净的 AWS 账户,并决定从零到部署一个 webapp。与 AWS 中的其它基础设施一样,我必须首先使基本的基础设施正常工作起来,因此我需要先定义一个 VPC。
遵循最佳实践,因此我将这个 VPC 划分为跨可用区(AZ)的子网,一个公共子网和私有子网。这时我想到,只要这种设置基础设施的需求存在,我就能找到一份这种工作。AWS 是免运维的这一概念一直让我感到愤怒。开发者社区中的许多人理所当然地认为在设置和定义一个设计良好的 AWS 账户和基础设施是不需要付出多少工作和努力的。而这种想当然甚至发生在开始谈论多帐户架构*之前*就有了——现在我仍然使用单一帐户,我已经必须定义好基础设施和传统的网络设备。
这里也值得记住,我已经做了很多次,所以我*很清楚*该做什么。我可以在我的帐户中使用默认的 VPC 以及预先提供的子网,我觉得很多刚开始的人也可以使用它。这大概花了我半个小时才运行起来,但我不禁想到,即使我想运行 lambda 函数,我仍然需要某种连接和网络。定义 NAT 网关和在 VPC 中路由根本不会让你觉得很“Serverless”,但要往下进行这就是必须要做的。
### 运行简单的容器
在我启动运行了基本的基础设施之后,现在我想让我的 Docker 容器运行起来。我开始翻阅 Fargate 文档并浏览 [入门](https://docs.aws.amazon.com/AmazonECS/latest/developerguide/ECS_GetStarted.html) 文档,这些就马上就展现在了我面前:

等等,只是让我的容器运行就至少要有**三个**步骤?这完全不像我所想的,不过还是让我们开始吧。
#### 任务定义
“<ruby> 任务定义 <rt> Task Definition </rt> <rt> </rt></ruby>”用来定义要运行的实际容器。我在这里遇到的问题是,任务定义这件事非常复杂。这里有很多选项都很简单,比如指定 Docker 镜像和内存限制,但我还必须定义一个网络模型以及我并不熟悉的其它各种选项。真需要这样吗?如果我完全没有 AWS 方面的知识就进入到这个过程里,那么在这个阶段我会感觉非常的不知所措。可以在 AWS 页面上找到这些 [参数](https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task_definition_parameters.html) 的完整列表,这个列表很长。我知道我的容器需要一些环境变量,它需要暴露一个端口。所以我首先在一个神奇的 [terraform 模块](https://github.com/cloudposse/terraform-aws-ecs-container-definition) 的帮助下定义了这一点,这真的让这件事更容易了。如果没有这个模块,我就得手写 JSON 来定义我的容器定义。
首先我定义了一些环境变量:
```
container_environment_variables = [
{
name = "USER"
value = "${var.user}"
},
{
name = "PASSWORD"
value = "${var.password}"
}
]
```
然后我使用上面提及的模块组成了任务定义:
```
module "container_definition_app" {
source = "cloudposse/ecs-container-definition/aws"
version = "v0.7.0"
container_name = "${var.name}"
container_image = "${var.image}"
container_cpu = "${var.ecs_task_cpu}"
container_memory = "${var.ecs_task_memory}"
container_memory_reservation = "${var.container_memory_reservation}"
port_mappings = [
{
containerPort = "${var.app_port}"
hostPort = "${var.app_port}"
protocol = "tcp"
},
]
environment = "${local.container_environment_variables}"
}
```
在这一点上我非常困惑,我需要在这里定义很多配置才能运行,而这时什么都没有开始呢,但这是必要的 —— 运行 Docker 容器肯定需要了解一些容器配置的知识。我 [之前写过](https://leebriggs.co.uk/blog/2018/05/08/kubernetes-config-mgmt.html) 关于 Kubernetes 和配置管理的问题的文章,在这里似乎遇到了同样的问题。
接下来,我在上面的模块中定义了任务定义(幸好从我这里抽象出了所需的 JSON —— 如果我不得不手写JSON,我可能已经放弃了)。
当我定义模块参数时,我突然意识到我漏掉了一些东西。我需要一个 IAM 角色!好吧,让我来定义:
```
resource "aws_iam_role" "ecs_task_execution" {
name = "${var.name}-ecs_task_execution"
assume_role_policy = <<EOF
{
"Version": "2008-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "ecs-tasks.amazonaws.com"
},
"Effect": "Allow"
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "ecs_task_execution" {
count = "${length(var.policies_arn)}"
role = "${aws_iam_role.ecs_task_execution.id}"
policy_arn = "${element(var.policies_arn, count.index)}"
}
```
这样做是有意义的,我需要在 Kubernetes 中定义一个 RBAC 策略,所以在这里我还未完全错失或获得任何东西。这时我开始觉得从 Kubernetes 的角度来看,这种感觉非常熟悉。
```
resource "aws_ecs_task_definition" "app" {
family = "${var.name}"
network_mode = "awsvpc"
requires_compatibilities = ["FARGATE"]
cpu = "${var.ecs_task_cpu}"
memory = "${var.ecs_task_memory}"
execution_role_arn = "${aws_iam_role.ecs_task_execution.arn}"
task_role_arn = "${aws_iam_role.ecs_task_execution.arn}"
container_definitions = "${module.container_definition_app.json}"
}
```
现在,为了运行起来我已经写了很多行代码,我阅读了很多 ECS 文档,我所做的就是定义一个任务定义。我还没有让这个东西运行起来。在这一点上,我真的很困惑这个基于 Kubernetes 的平台到底增值了什么,但我继续前行。
#### 服务
服务,一定程度上是将容器如何暴露给外部,另外是如何定义它拥有的副本数量。我的第一个想法是“啊!这就像一个 Kubernetes 服务!”我开始着手映射端口等。这是我第一次在 terraform 上跑:
```
resource "aws_ecs_service" "app" {
name = "${var.name}"
cluster = "${module.ecs.this_ecs_cluster_id}"
task_definition = "${data.aws_ecs_task_definition.app.family}:${max(aws_ecs_task_definition.app.revision, data.aws_ecs_task_definition.app.revision)}"
desired_count = "${var.ecs_service_desired_count}"
launch_type = "FARGATE"
deployment_maximum_percent = "${var.ecs_service_deployment_maximum_percent}"
deployment_minimum_healthy_percent = "${var.ecs_service_deployment_minimum_healthy_percent}"
network_configuration {
subnets = ["${values(local.private_subnets)}"]
security_groups = ["${module.app.this_security_group_id}"]
}
}
```
当我必须定义允许访问所需端口的安全组时,我再次感到沮丧,当我这样做了并将其插入到网络配置中后,我就像被扇了一巴掌。
我还需要定义自己的负载均衡器?
什么?
当然不是吗?
##### 负载均衡器从未远离
老实说,我很满意,我甚至不确定为什么。我已经习惯了 Kubernetes 的服务和 Ingress 对象,我一心认为用 Kubernetes 将我的应用程序放到网上是多么容易。当然,我们在 $work 花了几个月的时间建立一个平台,以便更轻松。我是 [external-dns](https://github.com/kubernetes-incubator/external-dns) 和 [cert-manager](https://github.com/jetstack/cert-manager) 的重度用户,它们可以自动填充 Ingress 对象上的 DNS 条目并自动化 TLS 证书,我非常了解进行这些设置所需的工作,但老实说,我认为在 Fargate 上做这件事会更容易。我认识到 Fargate 并没有声称自己是“如何运行应用程序”这件事的全部和最终目的,它只是抽象出节点管理,但我一直被告知这比 Kubernetes *更加容易*。我真的很惊讶。定义负载均衡器(即使你不想使用 Ingress 和 Ingress Controller)也是向 Kubernetes 部署服务的重要组成部分,我不得不在这里再次做同样的事情。这一切都让人觉得如此熟悉。
我现在意识到我需要:
* 一个负载均衡器
* 一个 TLS 证书
* 一个 DNS 名字
所以我着手做了这些。我使用了一些流行的 terraform 模块,并做了这个:
```
# Define a wildcard cert for my app
module "acm" {
source = "terraform-aws-modules/acm/aws"
version = "v1.1.0"
create_certificate = true
domain_name = "${var.route53_zone_name}"
zone_id = "${data.aws_route53_zone.this.id}"
subject_alternative_names = [
"*.${var.route53_zone_name}",
]
tags = "${local.tags}"
}
# Define my loadbalancer
resource "aws_lb" "main" {
name = "${var.name}"
subnets = [ "${values(local.public_subnets)}" ]
security_groups = ["${module.alb_https_sg.this_security_group_id}", "${module.alb_http_sg.this_security_group_id}"]
}
resource "aws_lb_target_group" "main" {
name = "${var.name}"
port = "${var.app_port}"
protocol = "HTTP"
vpc_id = "${local.vpc_id}"
target_type = "ip"
depends_on = [ "aws_lb.main" ]
}
# Redirect all traffic from the ALB to the target group
resource "aws_lb_listener" "main" {
load_balancer_arn = "${aws_lb.main.id}"
port = "80"
protocol = "HTTP"
default_action {
target_group_arn = "${aws_lb_target_group.main.id}"
type = "forward"
}
}
resource "aws_lb_listener" "main-tls" {
load_balancer_arn = "${aws_lb.main.id}"
port = "443"
protocol = "HTTPS"
certificate_arn = "${module.acm.this_acm_certificate_arn}"
default_action {
target_group_arn = "${aws_lb_target_group.main.id}"
type = "forward"
}
}
```
我必须承认,我在这里搞砸了好几次。我不得不在 AWS 控制台中四处翻弄,以弄清楚我做错了什么。这当然不是一个“轻松”的过程,而且我之前已经做过很多次了。老实说,在这一点上,Kubernetes 看起来对我很有启发性,但我意识到这是因为我对它非常熟悉。幸运的是我能够使用托管的 Kubernetes 平台(预装了 external-dns 和 cert-manager),我真的很想知道我漏掉了 Fargate 什么增值的地方。它真的感觉不那么简单。
经过一番折腾,我现在有一个可以工作的 ECS 服务。包括服务在内的最终定义如下所示:
```
data "aws_ecs_task_definition" "app" {
task_definition = "${var.name}"
depends_on = ["aws_ecs_task_definition.app"]
}
resource "aws_ecs_service" "app" {
name = "${var.name}"
cluster = "${module.ecs.this_ecs_cluster_id}"
task_definition = "${data.aws_ecs_task_definition.app.family}:${max(aws_ecs_task_definition.app.revision, data.aws_ecs_task_definition.app.revision)}"
desired_count = "${var.ecs_service_desired_count}"
launch_type = "FARGATE"
deployment_maximum_percent = "${var.ecs_service_deployment_maximum_percent}"
deployment_minimum_healthy_percent = "${var.ecs_service_deployment_minimum_healthy_percent}"
network_configuration {
subnets = ["${values(local.private_subnets)}"]
security_groups = ["${module.app_sg.this_security_group_id}"]
}
load_balancer {
target_group_arn = "${aws_lb_target_group.main.id}"
container_name = "app"
container_port = "${var.app_port}"
}
depends_on = [
"aws_lb_listener.main",
]
}
```
我觉得我已经接近完成了,但后来我记起了我只完成了最初的“入门”文档中所需的 3 个步骤中的 2 个,我仍然需要定义 ECS 群集。
#### 集群
感谢 [定义模块](https://github.com/terraform-aws-modules/terraform-aws-ecs),定义要所有这些运行的集群实际上非常简单。
```
module "ecs" {
source = "terraform-aws-modules/ecs/aws"
version = "v1.1.0"
name = "${var.name}"
}
```
这里让我感到惊讶的是为什么我必须定义一个集群。作为一个相当熟悉 ECS 的人,你会觉得你需要一个集群,但我试图从一个必须经历这个过程的新人的角度来考虑这一点 —— 对我来说,Fargate 标榜自己“ Serverless”而你仍需要定义集群,这似乎很令人惊讶。当然这是一个小细节,但它确实盘旋在我的脑海里。
### 告诉我你的 Secret
在这个阶段,我很高兴我成功地运行了一些东西。然而,我的原始的成功标准缺少一些东西。如果我们回到任务定义那里,你会记得我的应用程序有一个存放密码的环境变量:
```
container_environment_variables = [
{
name = "USER"
value = "${var.user}"
},
{
name = "PASSWORD"
value = "${var.password}"
}
]
```
如果我在 AWS 控制台中查看我的任务定义,我的密码就在那里,明晃晃的明文。我希望不要这样,所以我开始尝试将其转化为其他东西,类似于 [Kubernetes 的Secrets管理](https://kubernetes.io/docs/concepts/configuration/secret/)。
#### AWS SSM
Fargate / ECS 执行<ruby> secret 管理 <rt> secret management </rt></ruby>部分的方式是使用 [AWS SSM](https://docs.aws.amazon.com/systems-manager/latest/userguide/systems-manager-paramstore.html)(此服务的全名是 AWS 系统管理器参数存储库 Systems Manager Parameter Store,但我不想使用这个名称,因为坦率地说这个名字太愚蠢了)。
AWS 文档很好的[涵盖了这个内容](https://docs.aws.amazon.com/AmazonECS/latest/developerguide/specifying-sensitive-data.html),因此我开始将其转换为 terraform。
##### 指定秘密信息
首先,你必须定义一个参数并为其命名。在 terraform 中,它看起来像这样:
```
resource "aws_ssm_parameter" "app_password" {
name = "${var.app_password_param_name}" # The name of the value in AWS SSM
type = "SecureString"
value = "${var.app_password}" # The actual value of the password, like correct-horse-battery-stable
}
```
显然,这里的关键部分是 “SecureString” 类型。这会使用默认的 AWS KMS 密钥来加密数据,这对我来说并不是很直观。这比 Kubernetes 的 Secret 管理具有巨大优势,默认情况下,这些 Secret 在 etcd 中是不加密的。
然后我为 ECS 指定了另一个本地值映射,并将其作为 Secret 参数传递:
```
container_secrets = [
{
name = "PASSWORD"
valueFrom = "${var.app_password_param_name}"
},
]
module "container_definition_app" {
source = "cloudposse/ecs-container-definition/aws"
version = "v0.7.0"
container_name = "${var.name}"
container_image = "${var.image}"
container_cpu = "${var.ecs_task_cpu}"
container_memory = "${var.ecs_task_memory}"
container_memory_reservation = "${var.container_memory_reservation}"
port_mappings = [
{
containerPort = "${var.app_port}"
hostPort = "${var.app_port}"
protocol = "tcp"
},
]
environment = "${local.container_environment_variables}"
secrets = "${local.container_secrets}"
```
##### 出了个问题
此刻,我重新部署了我的任务定义,并且非常困惑。为什么任务没有正确拉起?当新的任务定义(版本 8)可用时,我一直在控制台中看到正在运行的应用程序仍在使用先前的任务定义(版本 7)。解决这件事花费的时间比我预期的要长,但是在控制台的事件屏幕上,我注意到了 IAM 错误。我错过了一个步骤,容器无法从 AWS SSM 中读取 Secret 信息,因为它没有正确的 IAM 权限。这是我第一次真正对整个这件事情感到沮丧。从用户体验的角度来看,这里的反馈非常*糟糕*。如果我没有发觉的话,我会认为一切都很好,因为仍然有一个任务正在运行,我的应用程序仍然可以通过正确的 URL 访问 —— 只不过是旧的配置而已。
在 Kubernetes 里,我会清楚地看到 pod 定义中的错误。Fargate 可以确保我的应用不会停止,这绝对是太棒了,但作为一名运维,我需要一些关于发生了什么的实际反馈。这真的不够好。我真的希望 Fargate 团队的人能够读到这篇文章,改善这种体验。
### 就这样了
到这里就结束了,我的应用程序正在运行,也符合我的所有标准。我确实意识到我做了一些改进,其中包括:
* 定义一个 cloudwatch 日志组,这样我就可以正确地写日志了
* 添加了一个 route53 托管区域,使整个事情从 DNS 角度更容易自动化
* 修复并重新调整了 IAM 权限,这里太宽泛了
但老实说,现在我想反思一下这段经历。我写了一个关于我的经历的 [推特会话](https://twitter.com/briggsl/status/1116870900719030272),然后花了其余时间思考我在这里的真实感受。
### 代价
经过一夜的反思,我意识到无论你是使用 Fargate 还是 Kubernetes,这个过程都大致相同。最让我感到惊讶的是,尽管我经常听说 Fargate “更容易”,但我真的没有看到任何超过 Kubernetes 平台的好处。现在,如果你正在构建 Kubernetes 集群,我绝对可以看到这里的价值 —— 管理节点和控制面板只是不必要的开销,问题是 —— 基于 Kubernetes 的平台的大多数消费者都*没有*这样做。如果你很幸运能够使用 GKE,你几乎不需要考虑集群的管理,你可以使用单个 `gcloud` 命令来运行集群。我经常使用 Digital Ocean 的 Kubernetes 托管服务,我可以肯定地说它就像操作 Fargate 集群一样简单,实际上在某种程度上它更容易。
必须定义一些基础设施来运行你的容器就是此时的代价。谷歌本周可能刚刚使用他们的 [Google Cloud Run](https://cloud.google.com/run/) 产品改变了游戏规则,但他们在这一领域的领先优势远远领先于其他所有人。
从这整个经历中,我可以肯定的说:*大规模运行容器仍然很难。*它需要思考,需要领域知识,需要运维和开发人员之间的协作。它还需要一个基础来构建 —— 任何基于 AWS 的操作都需要事先定义和运行一些基础架构。我对一些公司似乎渴望的 “NoOps” 概念非常感兴趣。我想如果你正在运行一个无状态应用程序,你可以把它全部放在一个 lambda 函数和一个 API 网关中,这可能不错,但我们是否真的适合在任何一种企业环境中这样做?我真的不这么认为。
#### 公平比较
令我印象深刻的另一个现实是,技术 A 和技术 B 之间的比较通常不太公平,我经常在 AWS 上看到这一点。这种实际情况往往与 Jeff Barr 博客文章截然不同。如果你是一家足够小的公司,你可以使用 AWS 控制台在 AWS 中部署你的应用程序并接受所有默认值,这绝对更容易。但是,我不想使用默认值,因为默认值几乎是不适用于生产环境的。一旦你开始剥离掉云服务商服务的层面,你就会开始意识到最终你仍然是在运行软件 —— 它仍然需要设计良好、部署良好、运行良好。我相信 AWS 和 Kubernetes 以及所有其他云服务商的增值服务使得它更容易运行、设计和操作,但它绝对不是免费的。
#### Kubernetes 的争议
最后就是:如果你将 Kubernetes 纯粹视为一个容器编排工具,你可能会喜欢 Fargate。然而,随着我对 Kubernetes 越来越熟悉,我开始意识到它作为一种技术的重要性 —— 不仅因为它是一个伟大的容器编排工具,而且因为它的设计模式 —— 它是声明性的、API 驱动的平台。 在*整个* Fargate 过程期间发生的一个简单的事情是,如果我删除这里某个东西,Fargate 不一定会为我重新创建它。自动缩放很不错,不需要管理服务器和操作系统的补丁及更新也很棒,但我觉得因为无法使用 Kubernetes 自我修复和 API 驱动模型而失去了很多。当然,Kubernetes 有一个学习曲线,但从这里的体验来看,Fargate 也是如此。
### 总结
尽管我在这个过程中遭遇了困惑,但我确实很喜欢这种体验。我仍然相信 Fargate 是一项出色的技术,AWS 团队对 ECS/Fargate 所做的工作确实非常出色。然而,我的观点是,这绝对不比 Kubernetes “更容易”,只是……难点不同。
在生产环境中运行容器时出现的问题大致相同。如果你从这篇文章中有所收获,它应该是这样的:*不管你选择的哪种方式都有运维开销*。不要相信你选择一些东西你的世界就变得更轻松。我个人的意见是:如果你有一个运维团队,而你的公司要为多个应用程序团队部署容器 —— 选择一种技术并围绕它构建流程和工具以使其更容易。
人们说的一点肯定没错,用点技巧可以更容易地使用某种技术。在这个阶段,谈到 Fargate,下面的漫画这总结了我的感受:

---
via: <https://leebriggs.co.uk/blog/2019/04/13/the-fargate-illusion.html>
作者:[Lee Briggs](https://leebriggs.co.uk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Bestony](https://github.com/Bestony) 校对:[wxy](https://github.com/wxy), 临石(阿里云智能技术专家)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 308 | Permanent Redirect | null |
10,741 | 使用 RadioDroid 流传输网络广播 | https://opensource.com/article/19/4/radiodroid-internet-radio-player | 2019-04-17T19:26:41 | [
"Chromecast"
] | https://linux.cn/article-10741-1.html |
>
> 通过简单的设置使用你家中的音响收听你最爱的网络电台。
>
>
>

最近网络媒体对 [Google 的 Chromecast 音频设备的下架](https://www.theverge.com/2019/1/11/18178751/google-chromecast-audio-discontinued-sale)发出叹息。该设备在音频媒体界备受[好评](https://www.whathifi.com/google/chromecast-audio/review),因此我已经在考虑入手一个。基于 Chromecast 退场的消息,我决定在它们全部被打包扔进垃圾堆之前以一个合理价位买一个。
我在 [MobileFun](https://www.mobilefun.com/google-chromecast-audio-black-70476) 上找到一个放进我的订单中。这个设备最终到货了。它被包在一个普普通通、简简单单的 Google 包装袋中,外面打印着非常简短的使用指南。

我通过我的数模转换器的光纤 S/PDIF 连接接入到家庭音响,希望以此能提供最佳的音质。
安装过程并无纰漏,在五分钟后我就可以播放一些音乐了。我知道一些安卓应用支持 Chromecast,因此我决定用 Google Play Music 测试它。意料之中,它工作得不错,音乐效果听上去也相当好。然而作为一个具有开源精神的人,我决定看看我能找到什么开源播放器能兼容 Chromecast。
### RadioDroid 的救赎
[RadioDroid 安卓应用](https://play.google.com/store/apps/details?id=net.programmierecke.radiodroid2) 满足条件。它是开源的,并且可从 [GitHub](https://github.com/segler-alex/RadioDroid)、Google Play 以及 [F-Droid](https://f-droid.org/en/packages/net.programmierecke.radiodroid2/) 上获取。根据帮助文档,RadioDroid 从 [Community Radio Browser](http://www.radio-browser.info/gui/#!/) 网页寻找播放流。因此我决定在我的手机上安装尝试一下。

安装过程快速顺利,RadioDroid 打开展示当地电台十分迅速。你可以在这个屏幕截图的右上方附近看到 Chromecast 按钮(看上去像一个有着波阵面的长方形图标)。
我尝试了几个当地电台。这个应用可靠地在我手机喇叭上播放了音乐。但是我不得不摆弄 Chromecast 按钮来通过 Chromecast 把音乐传到流上。但是它确实可以做到流传输。
我决定找一下我喜爱的网络广播电台:法国马赛的 [格雷诺耶广播电台](http://www.radiogrenouille.com/)。在 RadioDroid 上有许多找到电台的方法。其中一种是使用标签——“当地”、“最流行”等——就在电台列表上方。其中一个标签是国家,我找到法国,在其 1500 个电台中划来划去寻找格雷诺耶广播电台。另一种办法是使用屏幕上方的查询按钮;查询迅速找到了那家美妙的电台。我尝试了其它几次查询它们都返回了合理的信息。
回到“当地”标签,我在列表中翻来覆去,发现“当地”的定义似乎是“在同一个国家”。因此尽管西雅图、波特兰、旧金山、洛杉矶和朱诺比多伦多更靠近我的家,我并没有在“当地”标签中看到它们。然而通过使用查询功能,我可以发现所有名字中带有西雅图的电台。
“语言”标签使我找到所有用葡语(及葡语方言)播报的电台。我很快发现了另一个最爱的电台 [91 Rock Curitiba](https://91rock.com.br/)。
接着灵感来了,虽然现在是春天了,但又如何呢?让我们听一些圣诞音乐。意料之中,搜寻圣诞把我引到了 [181.FM – Christmas Blender](http://player.181fm.com/?station=181-xblender)。不错,一两分钟的欣赏对我就够了。
因此总的来说,我推荐把 RadioDroid 和 Chromecast 的组合作为一种用家庭音响以合理价位播放网络电台的良好方式。
### 对于音乐方面……
最近我从 [Blue Coast Music](https://bluecoastmusic.com/store) 商店里选了一个 [Qua Continuum](https://bluecoastmusic.com/artists/qua-continuum) 创作的叫作 [Continuum One](https://www.youtube.com/watch?v=PqLCQXPS8iQ) 的有趣的氛围(甚至无节拍)音乐专辑。
Blue Coast 有许多可提供给开源音乐爱好者的。音乐可以无需通过那些奇怪的平台专用下载管理器下载(有时以物理形式)。它通常提供几种形式,包括 WAV、FLAC 和 DSD;WAV 和 FLAC 还提供不同的字长和比特率,包括 16/44.1、24/96 和 24/192,针对 DSD 则有 2.8、5.6 和 11.2 MHz。音乐是用优秀的仪器精心录制的。不幸的是,我并没有找到许多符合我口味的音乐,尽管我喜欢 Blue Coast 上能获取的几个艺术家,包括 Qua Continuum,[Art Lande](https://bluecoastmusic.com/store?f%5B0%5D=search_api_multi_aggregation_1%3Aart%20lande) 以及 [Alex De Grassi](https://bluecoastmusic.com/store?f%5B0%5D=search_api_multi_aggregation_1%3Aalex%20de%20grassi)。
在 [Bandcamp](https://bandcamp.com/) 上,我挑选了 [Emancipator’s Baralku](https://emancipator.bandcamp.com/album/baralku) 和 [Framework’s Tides](https://frameworksuk.bandcamp.com/album/tides),两个都是我喜欢的。两位艺术家创作的音乐符合我的口味——电音但又(总体来说)不是舞蹈,它们的音乐旋律优美,副歌也很好听。有许多可以让开源音乐发烧友爱上 Bandcamp 的东西,比如买前试听整首歌的服务;没有垃圾软件下载器;与大量音乐家的合作;以及对 [Creative Commons music](https://bandcamp.com/tag/creative-commons) 的支持。
---
via: <https://opensource.com/article/19/4/radiodroid-internet-radio-player>
作者:[Chris Hermansen (Community Moderator)](https://opensource.com/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Online news outlets have recently lamented the [passing of Google's Chromecast Audio device](https://www.theverge.com/2019/1/11/18178751/google-chromecast-audio-discontinued-sale). The device received [favorable reviews](https://www.whathifi.com/google/chromecast-audio/review) in the audio press, so I had already been thinking about acquiring one. Given the news of Chromecast's demise, I decided to look for one at a reasonable price—before they were all snapped up or thrown in the dumpster.
I found one at [MobileFun](https://www.mobilefun.com/google-chromecast-audio-black-70476) and put in my order. The device eventually arrived, packaged in the usual serviceable but minimal Google wrapping, with a very brief Get Started guide printed on the outside.

I cabled it to my home stereo via my digital-analog converter's optical S/PDIF connection, hoping that would provide the best sound quality.
The setup ran flawlessly, and in about five minutes I was ready to play some tunes. I knew that a number of Android applications support Chromecast, so I decided to test it out with Google Play Music; sure enough, it worked just fine and sounded quite good. However, being an open source kind of person, I decided to see what I could find in the way of open source players that work with Chromecast.
## RadioDroid to the rescue
The [RadioDroid Android application](https://play.google.com/store/apps/details?id=net.programmierecke.radiodroid2) fit the bill. It is open source and available on [GitHub](https://github.com/segler-alex/RadioDroid), Google Play, and [F-Droid](https://f-droid.org/en/packages/net.programmierecke.radiodroid2/). According to the documentation, RadioDroid looks up and plays streams from the [Community Radio Browser](http://www.radio-browser.info/gui/#!/) website. So I decided to install it on my handset and give it a shot.
The installation was quick and smooth, and RadioDroid opened rapidly to display local stations. You can see the Chromecast button (the icon that looks like a rectangle with wavefronts) near the top-right side of this screenshot.
I played around with a few of the local stations. The application reliably played music on my handset's speaker, but I had to futz around with the Chromecast button to get the music to stream over the Chromecast. But stream it did!
I decided to seek out my favorite internet radio station, [Radio Grenouille](http://www.radiogrenouille.com/) in Marseille, France. There are various ways to find stations in RadioDroid. One is to use the tabs—Local, Topclick, etc.—located above the list of stations. One of the tabs is Countries; I found France, with some 1,500 stations, on the list and scrolled—and scrolled, and scrolled—down through the list to find Radio Grenouille. Another way is to use the Search button at the top of the screen; the search was rapid and returned that wonderful radio station. I tried a few other searches, and they all returned reasonable info.
Going back to the Local tab, I scrolled through the listings and learned that "local" seems to be defined as "in the same country." So, even though Seattle, Portland, San Francisco, Los Angeles, and Juneau are closer to my home than Toronto, I didn't see any of them in Local. However, by using Search, I could find all stations with "Seattle" in their name.
The Languages tab let me find all stations broadcasting in Portugues, Portuguese, Português, Português Brasil, Português do Brasil, Portuguẽs, and Portugês. I quickly found another favorite station, [91 Rock Curitiba](https://91rock.com.br/).
Then inspiration struck—it's springtime, but who cares? Let's listen to some Christmas music. And sure enough, searching for Christmas led me to [181.FM – Christmas Blender](http://player.181fm.com/?station=181-xblender). Well, a minute or two of that was enough for me…
So, all in all, I recommend the RadioDroid and Chromecast combo as a nice way to play internet radio on a home stereo at a reasonable cost.
## As for the music…
Recently I picked up an interesting album of very ambient (even beatless) music called [Continuum One](https://www.youtube.com/watch?v=PqLCQXPS8iQ) by [Qua Continuum](https://bluecoastmusic.com/artists/qua-continuum) from the [Blue Coast Music](https://bluecoastmusic.com/store) store. Blue Coast has a lot to offer the open source music enthusiast: music is available by download (and sometimes physical format) without resorting to those grotesque platform-specific download managers; it typically provides several formats, including WAV, FLAC, and DSD; different word lengths and bitrates are provided for WAV and FLAC, including 16/44.1, 24/96, and 24/192, and for DSD, 2.8, 5.6, and 11.2 MHz; and the music is recorded with great care using wonderful facilities. Unfortunately, I don't find a lot of music there to my taste, though I like a few of the artists available on Blue Coast, including Qua Continuum, [Art Lande](https://bluecoastmusic.com/store?f%5B0%5D=search_api_multi_aggregation_1%3Aart%20lande), and [Alex De Grassi](https://bluecoastmusic.com/store?f%5B0%5D=search_api_multi_aggregation_1%3Aalex%20de%20grassi).
Over on [Bandcamp](https://bandcamp.com/), I picked up [Emancipator's Baralku](https://emancipator.bandcamp.com/album/baralku) and [Framework's Tides](https://frameworksuk.bandcamp.com/album/tides), both of which I enjoy. The music created by these two artists hits my sweet spot—it's electronic but not (generally) dance, it's melodic, and it tends to have some great hooks. There are many things for open source aficionados to like about Bandcamp, such as the ability to listen to the work in its entirety before buying; the lack of bloatware downloaders; the amounts shared with the musicians; and its support for [Creative Commons music](https://bandcamp.com/tag/creative-commons).
## Comments are closed. |
10,742 | 使用 Dask 在 Python 中进行并行计算 | https://opensource.com/article/19/4/parallel-computation-python-dask | 2019-04-17T22:24:50 | [
"并行",
"Python"
] | /article-10742-1.html |
>
> Dask 库可以将 Python 计算扩展到多个核心甚至是多台机器。
>
>
>

关于 Python 性能的一个常见抱怨是[全局解释器锁](https://wiki.python.org/moin/GlobalInterpreterLock)(GIL)。由于 GIL,同一时刻只能有一个线程执行 Python 字节码。因此,即使在现代的多核机器上,使用线程也不会加速计算。
但当你需要并行化到多核时,你不需要放弃使用 Python:[Dask](https://github.com/dask/dask) 库可以将计算扩展到多个内核甚至多个机器。某些设置可以在数千台机器上配置 Dask,每台机器都有多个内核。虽然存在扩展规模的限制,但一般达不到。
虽然 Dask 有许多内置的数组操作,但举一个非内置的例子,我们可以计算[偏度](https://en.wikipedia.org/wiki/Skewness#Definition):
```
import numpy
import dask
from dask import array as darray
arr = dask.from_array(numpy.array(my_data), chunks=(1000,))
mean = darray.mean()
stddev = darray.std(arr)
unnormalized_moment = darry.mean(arr * arr * arr)
## See formula in wikipedia:
skewness = ((unnormalized_moment - (3 * mean * stddev ** 2) - mean ** 3) /
stddev ** 3)
```
请注意,每个操作将根据需要使用尽可能多的内核。这将在所有核心上并行化执行,即使在计算数十亿个元素时也是如此。
当然,并不是我们所有的操作都可由这个库并行化,有时我们需要自己实现并行性。
为此,Dask 有一个“延迟”功能:
```
import dask
def is_palindrome(s):
return s == s[::-1]
palindromes = [dask.delayed(is_palindrome)(s) for s in string_list]
total = dask.delayed(sum)(palindromes)
result = total.compute()
```
这将计算字符串是否是回文并返回回文的数量。
虽然 Dask 是为数据科学家创建的,但它绝不仅限于数据科学。每当我们需要在 Python 中并行化任务时,我们可以使用 Dask —— 无论有没有 GIL。
---
via: <https://opensource.com/article/19/4/parallel-computation-python-dask>
作者:[Moshe Zadka (Community Moderator)](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,746 | 如何在 Linux 中配置 sudo 访问权限 | https://www.2daygeek.com/how-to-configure-sudo-access-in-linux/ | 2019-04-18T22:44:59 | [
"sudo"
] | https://linux.cn/article-10746-1.html | 
Linux 系统中 root 用户拥有 Linux 中全部控制权力。Linux 系统中 root 是拥有最高权力的用户,可以在系统中实施任意的行为。
如果其他用户想去实施一些行为,不能为所有人都提供 root 访问权限。因为如果他或她做了一些错误的操作,没有办法去纠正它。
为了解决这个问题,有什么方案吗?
我们可以把 sudo 权限发放给相应的用户来克服这种情况。
`sudo` 命令提供了一种机制,它可以在不用分享 root 用户的密码的前提下,为信任的用户提供系统的管理权限。
他们可以执行大部分的管理操作,但又不像 root 一样有全部的权限。
### 什么是 sudo?
`sudo` 是一个程序,普通用户可以使用它以超级用户或其他用户的身份执行命令,是由安全策略指定的。
sudo 用户的访问权限是由 `/etc/sudoers` 文件控制的。
### sudo 用户有什么优点?
在 Linux 系统中,如果你不熟悉一个命令,`sudo` 是运行它的一个安全方式。
* Linux 系统在 `/var/log/secure` 和 `/var/log/auth.log` 文件中保留日志,并且你可以验证 sudo 用户实施了哪些行为操作。
* 每一次它都为当前的操作提示输入密码。所以,你将会有时间去验证这个操作是不是你想要执行的。如果你发觉它是不正确的行为,你可以安全地退出而且没有执行此操作。
基于 RHEL 的系统(如 Redhat (RHEL)、 CentOS 和 Oracle Enterprise Linux (OEL))和基于 Debian 的系统(如 Debian、Ubuntu 和 LinuxMint)在这点是不一样的。
我们将会教你如何在本文中提及的两种发行版中执行该操作。
这里有三种方法可以应用于两个发行版本。
* 增加用户到相应的组。基于 RHEL 的系统,我们需要添加用户到 `wheel` 组。基于 Debain 的系统,我们添加用户到 `sudo` 或 `admin` 组。
* 手动添加用户到 `/etc/group` 文件中。
* 用 `visudo` 命令添加用户到 `/etc/sudoers` 文件中。
### 如何在 RHEL/CentOS/OEL 系统中配置 sudo 访问权限?
在基于 RHEL 的系统中(如 Redhat (RHEL)、 CentOS 和 Oracle Enterprise Linux (OEL)),使用下面的三个方法就可以做到。
#### 方法 1:在 Linux 中如何使用 wheel 组为普通用户授予超级用户访问权限?
wheel 是基于 RHEL 的系统中的一个特殊组,它提供额外的权限,可以授权用户像超级用户一样执行受到限制的命令。
注意,应该在 `/etc/sudoers` 文件中激活 `wheel` 组来获得该访问权限。
```
# grep -i wheel /etc/sudoers
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
# %wheel ALL=(ALL) NOPASSWD: ALL
```
假设我们已经创建了一个用户账号来执行这些操作。在此,我将会使用 `daygeek` 这个用户账号。
执行下面的命令,添加用户到 `wheel` 组。
```
# usermod -aG wheel daygeek
```
我们可以通过下面的命令来确定这一点。
```
# getent group wheel
wheel:x:10:daygeek
```
我将要检测用户 `daygeek` 是否可以访问属于 root 用户的文件。
```
$ tail -5 /var/log/secure
tail: cannot open /var/log/secure for reading: Permission denied
```
当我试图以普通用户身份访问 `/var/log/secure` 文件时出现错误。 我将使用 `sudo` 访问同一个文件,让我们看看这个魔术。
```
$ sudo tail -5 /var/log/secure
[sudo] password for daygeek:
Mar 17 07:01:56 CentOS7 sudo: daygeek : TTY=pts/0 ; PWD=/home/daygeek ; USER=root ; COMMAND=/bin/tail -5 /var/log/secure
Mar 17 07:01:56 CentOS7 sudo: pam_unix(sudo:session): session opened for user root by daygeek(uid=0)
Mar 17 07:01:56 CentOS7 sudo: pam_unix(sudo:session): session closed for user root
Mar 17 07:05:10 CentOS7 sudo: daygeek : TTY=pts/0 ; PWD=/home/daygeek ; USER=root ; COMMAND=/bin/tail -5 /var/log/secure
Mar 17 07:05:10 CentOS7 sudo: pam_unix(sudo:session): session opened for user root by daygeek(uid=0)
```
#### 方法 2:在 RHEL/CentOS/OEL 中如何使用 /etc/group 文件为普通用户授予超级用户访问权限?
我们可以通过编辑 `/etc/group` 文件来手动地添加用户到 `wheel` 组。
只需打开该文件,并在恰当的组后追加相应的用户就可完成这一点。
```
$ grep -i wheel /etc/group
wheel:x:10:daygeek,user1
```
在该例中,我将使用 `user1` 这个用户账号。
我将要通过在系统中重启 Apache httpd 服务来检查用户 `user1` 是不是拥有 sudo 访问权限。让我们看看这个魔术。
```
$ sudo systemctl restart httpd
[sudo] password for user1:
$ sudo grep -i user1 /var/log/secure
[sudo] password for user1:
Mar 17 07:09:47 CentOS7 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ; COMMAND=/bin/systemctl restart httpd
Mar 17 07:10:40 CentOS7 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ; COMMAND=/bin/systemctl restart httpd
Mar 17 07:12:35 CentOS7 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ; COMMAND=/bin/grep -i httpd /var/log/secure
```
#### 方法 3:在 Linux 中如何使用 /etc/sudoers 文件为普通用户授予超级用户访问权限?
sudo 用户的访问权限是被 `/etc/sudoers` 文件控制的。因此,只需将用户添加到 `sudoers` 文件中 的 `wheel` 组下即可。
只需通过 `visudo` 命令将期望的用户追加到 `/etc/sudoers` 文件中。
```
# grep -i user2 /etc/sudoers
user2 ALL=(ALL) ALL
```
在该例中,我将使用 `user2` 这个用户账号。
我将要通过在系统中重启 MariaDB 服务来检查用户 `user2` 是不是拥有 sudo 访问权限。让我们看看这个魔术。
```
$ sudo systemctl restart mariadb
[sudo] password for user2:
$ sudo grep -i mariadb /var/log/secure
[sudo] password for user2:
Mar 17 07:23:10 CentOS7 sudo: user2 : TTY=pts/0 ; PWD=/home/user2 ; USER=root ; COMMAND=/bin/systemctl restart mariadb
Mar 17 07:26:52 CentOS7 sudo: user2 : TTY=pts/0 ; PWD=/home/user2 ; USER=root ; COMMAND=/bin/grep -i mariadb /var/log/secure
```
### 在 Debian/Ubuntu 系统中如何配置 sudo 访问权限?
在基于 Debian 的系统中(如 Debian、Ubuntu 和 LinuxMint),使用下面的三个方法就可以做到。
#### 方法 1:在 Linux 中如何使用 sudo 或 admin 组为普通用户授予超级用户访问权限?
`sudo` 或 `admin` 是基于 Debian 的系统中的特殊组,它提供额外的权限,可以授权用户像超级用户一样执行受到限制的命令。
注意,应该在 `/etc/sudoers` 文件中激活 `sudo` 或 `admin` 组来获得该访问权限。
```
# grep -i 'sudo\|admin' /etc/sudoers
# Members of the admin group may gain root privileges
%admin ALL=(ALL) ALL
# Allow members of group sudo to execute any command
%sudo ALL=(ALL:ALL) ALL
```
假设我们已经创建了一个用户账号来执行这些操作。在此,我将会使用 `2gadmin` 这个用户账号。
执行下面的命令,添加用户到 `sudo` 组。
```
# usermod -aG sudo 2gadmin
```
我们可以通过下面的命令来确定这一点。
```
# getent group sudo
sudo:x:27:2gadmin
```
我将要检测用户 `2gadmin` 是否可以访问属于 root 用户的文件。
```
$ less /var/log/auth.log
/var/log/auth.log: Permission denied
```
当我试图以普通用户身份访问 `/var/log/auth.log` 文件时出现错误。 我将要使用 `sudo` 访问同一个文件,让我们看看这个魔术。
```
$ sudo tail -5 /var/log/auth.log
[sudo] password for 2gadmin:
Mar 17 20:39:47 Ubuntu18 sudo: 2gadmin : TTY=pts/0 ; PWD=/home/2gadmin ; USER=root ; COMMAND=/bin/bash
Mar 17 20:39:47 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by 2gadmin(uid=0)
Mar 17 20:40:23 Ubuntu18 sudo: pam_unix(sudo:session): session closed for user root
Mar 17 20:40:48 Ubuntu18 sudo: 2gadmin : TTY=pts/0 ; PWD=/home/2gadmin ; USER=root ; COMMAND=/usr/bin/tail -5 /var/log/auth.log
Mar 17 20:40:48 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by 2gadmin(uid=0)
```
或者,我们可以通过添加用户到 `admin` 组来执行相同的操作。
运行下面的命令,添加用户到 `admin` 组。
```
# usermod -aG admin user1
```
我们可以通过下面的命令来确定这一点。
```
# getent group admin
admin:x:1011:user1
```
让我们看看输出信息。
```
$ sudo tail -2 /var/log/auth.log
[sudo] password for user1:
Mar 17 20:53:36 Ubuntu18 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ; COMMAND=/usr/bin/tail -2 /var/log/auth.log
Mar 17 20:53:36 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by user1(uid=0)
```
#### 方法 2:在 Debian/Ubuntu 中如何使用 /etc/group 文件为普通用户授予超级用户访问权限?
我们可以通过编辑 `/etc/group` 文件来手动地添加用户到 `sudo` 组或 `admin` 组。
只需打开该文件,并在恰当的组后追加相应的用户就可完成这一点。
```
$ grep -i sudo /etc/group
sudo:x:27:2gadmin,user2
```
在该例中,我将使用 `user2` 这个用户账号。
我将要通过在系统中重启 Apache httpd 服务来检查用户 `user2` 是不是拥有 `sudo` 访问权限。让我们看看这个魔术。
```
$ sudo systemctl restart apache2
[sudo] password for user2:
$ sudo tail -f /var/log/auth.log
[sudo] password for user2:
Mar 17 21:01:04 Ubuntu18 systemd-logind[559]: New session 22 of user user2.
Mar 17 21:01:04 Ubuntu18 systemd: pam_unix(systemd-user:session): session opened for user user2 by (uid=0)
Mar 17 21:01:33 Ubuntu18 sudo: user2 : TTY=pts/0 ; PWD=/home/user2 ; USER=root ; COMMAND=/bin/systemctl restart apache2
```
#### 方法 3:在 Linux 中如何使用 /etc/sudoers 文件为普通用户授予超级用户访问权限?
sudo 用户的访问权限是被 `/etc/sudoers` 文件控制的。因此,只需将用户添加到 `sudoers` 文件中的 `sudo` 或 `admin` 组下即可。
只需通过 `visudo` 命令将期望的用户追加到 `/etc/sudoers` 文件中。
```
# grep -i user3 /etc/sudoers
user3 ALL=(ALL:ALL) ALL
```
在该例中,我将使用 `user3` 这个用户账号。
我将要通过在系统中重启 MariaDB 服务来检查用户 `user3` 是不是拥有 `sudo` 访问权限。让我们看看这个魔术。
```
$ sudo systemctl restart mariadb
[sudo] password for user3:
$ sudo tail -f /var/log/auth.log
[sudo] password for user3:
Mar 17 21:12:32 Ubuntu18 systemd-logind[559]: New session 24 of user user3.
Mar 17 21:12:49 Ubuntu18 sudo: user3 : TTY=pts/0 ; PWD=/home/user3 ; USER=root ; COMMAND=/bin/systemctl restart mariadb
Mar 17 21:12:49 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by user3(uid=0)
Mar 17 21:12:53 Ubuntu18 sudo: pam_unix(sudo:session): session closed for user root
Mar 17 21:13:08 Ubuntu18 sudo: user3 : TTY=pts/0 ; PWD=/home/user3 ; USER=root ; COMMAND=/usr/bin/tail -f /var/log/auth.log
Mar 17 21:13:08 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by user3(uid=0)
```
---
via: <https://www.2daygeek.com/how-to-configure-sudo-access-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[liujing97](https://github.com/liujing97) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,747 | 思科、谷歌重新赋能多/混合云共同开发 | https://www.networkworld.com/article/3388218/cisco-google-reenergize-multicloudhybrid-cloud-joint-development.html | 2019-04-19T00:09:12 | [
"混合云",
"多云"
] | https://linux.cn/article-10747-1.html |
>
> 思科、VMware、HPE 等公司开始采用了新的 Google Cloud Athos 云技术。
>
>
>

思科与谷歌已扩展它们的混合云开发活动,以帮助其客户可以在从本地数据中心到公共云上的任何地方更轻松地搭建安全的多云以及混合云应用。
这次扩张围绕着谷歌被称作 Anthos 的新的开源混合云包展开,它是在这周的 Google Next 活动上推出的。Anthos 基于并取代了谷歌现有的谷歌云服务测试版。Anthos 将让客户们无须修改应用就可以在现有的本地硬件或公共云上运行应用。据谷歌说,它可以在[谷歌云平台](https://cloud.google.com/) (GCP) 与 [谷歌 Kubernetes 引擎](https://cloud.google.com/kubernetes-engine/) (GKE) 或者在数据中心中与 [GKE On-Prem](https://cloud.google.com/gke-on-prem/) 一同使用。谷歌说,Anthos 首次让客户们可以无需管理员和开发者了解不同的坏境和 API 就能从谷歌平台上管理在第三方云上(如 AWS 和 Azure)的工作负荷。
关键在于,Athos 提供了一个单一的托管服务,它使得客户们无须担心不同的环境或 API 就能跨云管理、部署工作负荷。
作为首秀的一部分,谷歌也宣布一个叫做 [Anthos Migrate](https://cloud.google.com/contact/) 的测试计划,它能够从本地环境或者其它云自动迁移虚拟机到 GKE 上的容器中。谷歌说,“这种独特的迁移技术使你无须修改原来的虚拟机或者应用就能以一种行云流水般的方式迁移、更新你的基础设施”。谷歌称它给予了公司按客户节奏转移本地应用到云环境的灵活性。
### 思科和谷歌
就思科来说,它宣布对 Anthos 的支持并承诺将它紧密集成进思科的数据中心技术中,例如 HyperFlex 超融合包、应用中心基础设施(思科的旗舰 SDN 方案)、SD-WAN 和 StealthWatch 云。思科说,无论是本地的还是在云端的,这次集成将通过自动更新到最新版本和安全补丁,给予一种一致的、云般的感觉。
“谷歌云在容器(Kubernetes)和<ruby> 服务网格 <rt> service mesh </rt></ruby>(Istio)上的专业与它们在开发者社区的领导力,再加上思科的企业级网络、计算、存储和安全产品及服务,将为我们的顾客促成一次强强联合。”思科的云平台和解决方案集团资深副总裁 Kip Compton 这样[写道](https://blogs.cisco.com/news/next-phase-cisco-google-cloud),“思科对于 Anthos 的集成将会帮助顾客跨本地数据中心和公共云搭建、管理多云/混合云应用,让他们专注于创新和灵活性,同时不会影响安全性或增加复杂性。”
### 谷歌云和思科
谷歌云工程副总裁 Eyal Manor [写道](https://cloud.google.com/blog/topics/partners/google-cloud-partners-with-cisco-on-hybrid-cloud-next19?utm_medium=unpaidsocial&utm_campaign=global-googlecloud-liveevent&utm_content=event-next) 通过思科对 Anthos 的支持,客户将能够:
* 受益于全托管服务例如 GKE 以及思科的超融合基础设施、网络和安全技术;
* 在企业数据中心和云中一致运行
* 在企业数据中心使用云服务
* 用最新的云技术更新本地基础设施
思科和谷歌从 2017 年 10 月就在紧密合作,当时他们表示正在开发一个能够连接本地基础设施和云环境的开放混合云平台。该套件,即[思科为谷歌云打造的混合云平台](https://cloud.google.com/cisco/),大致在 2018 年 9 月上市。它使得客户们能通过谷歌云托管 Kubernetes 容器开发企业级功能,包含思科网络和安全技术以及来自 Istio 的服务网格监控。
谷歌说开源的 Istio 的容器和微服务优化技术给开发者提供了一种一致的方式,通过服务级的 mTLS (双向传输层安全)身份验证访问控制来跨云连接、保护、管理和监听微服务。因此,客户能够轻松实施新的可移植的服务,并集中配置和管理这些服务。
思科不是唯一宣布对 Anthos 支持的供应商。谷歌表示,至少 30 家大型合作商包括 [VMware](https://blogs.vmware.com/networkvirtualization/2019/04/vmware-and-google-showcase-hybrid-cloud-deployment.html/)、[Dell EMC](https://www.dellemc.com/en-us/index.htm)、[HPE](https://www.hpe.com/us/en/newsroom/blog-post/2019/04/hpe-and-google-cloud-join-forces-to-accelerate-innovation-with-hybrid-cloud-solutions-optimized-for-containerized-applications.html)、Intel 和联想致力于为他们的客户在它们自己的超融合基础设施上提供 Anthos 服务。
---
via: <https://www.networkworld.com/article/3388218/cisco-google-reenergize-multicloudhybrid-cloud-joint-development.html>
作者:[Michael Cooney](https://www.networkworld.com/author/Michael-Cooney/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,751 | 如何在 Linux 上安装并启用 Flatpak 支持? | https://www.2daygeek.com/how-to-install-and-enable-flatpak-support-on-linux/ | 2019-04-20T00:08:51 | [
"Flatpak"
] | https://linux.cn/article-10751-1.html | 
目前,我们都在使用 Linux 发行版的官方软件包管理器来安装所需的软件包。
在 Linux 中,它做得很好,没有任何问题。(它不打折扣地很好的完成了它应该做的工作)
但在一些方面它也有一些限制,所以会让我们考虑其他替代解决方案来解决。
是的,默认情况下,我们不能从发行版官方软件包管理器获取到最新版本的软件包,因为这些软件包是在构建当前 OS 版本时构建的。它们只会提供安全更新,直到下一个主要版本发布。
那么,这种情况有什么解决办法吗?是的,我们有多种解决方案,而且我们大多数人已经开始使用其中的一些了。
有些什么呢,它们有什么好处?
* **对于基于 Ubuntu 的系统:** PPA
* **对于基于 RHEL 的系统:** [EPEL 仓库](https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/)、[ELRepo 仓库](https://www.2daygeek.com/install-enable-elrepo-on-rhel-centos-scientific-linux/)、[nux-dextop 仓库](https://www.2daygeek.com/install-enable-nux-dextop-repository-on-centos-rhel-scientific-linux/)、[IUS 社区仓库](https://www.2daygeek.com/install-enable-ius-community-repository-on-rhel-centos/)、[RPMfusion 仓库](https://www.2daygeek.com/install-enable-rpm-fusion-repository-on-centos-fedora-rhel/) 和 [Remi 仓库](https://www.2daygeek.com/install-enable-remi-repository-on-centos-rhel-fedora/)
使用上面的仓库,我们将获得最新的软件包。这些软件包通常都得到了很好的维护,还有大多数社区的推荐。但这些只是建议,可能并不总是安全的。
近年来,出现了一下通用软件包封装格式,并且得到了广泛的应用。
* **Flatpak**:它是独立于发行版的包格式,主要贡献者是 Fedora 项目团队。大多数主要的 Linux 发行版都采用了 Flatpak 框架。
* **Snaps**:Snappy 是一种通用的软件包封装格式,最初由 Canonical 为 Ubuntu 手机及其操作系统设计和构建的。后来,更多的发行版都接纳了它。
* **AppImage**:AppImage 是一种可移植的包格式,可以在不安装和不需要 root 权限的情况下运行。
我们之前已经介绍过 [Snap 包管理器和包封装格式](https://www.2daygeek.com/linux-snap-package-manager-ubuntu/)。今天我们将讨论 Flatpak 包封装格式。
### 什么是 Flatpak?
Flatpak(以前称为 X Desktop Group 或 xdg-app)是一个软件实用程序。它提供了一种通用的包封装格式,可以在任何 Linux 发行版中使用。
它提供了一个沙箱(隔离的)环境来运行应用程序,不会影响其他应用程序和发行版核心软件包。我们还可以安装并运行不同版本的软件包。
Flatpak 的一个缺点是不像 Snap 和 AppImage 那样支持服务器操作系统,它只在少数桌面环境下工作。
比如说,如果你想在系统上运行两个版本的 php,那么你可以轻松安装并按照你的意愿运行。
这就是现在通用包封装格式非常有名的地方。
### 如何在 Linux 中安装 Flatpak?
大多数 Linux 发行版官方仓库都提供 Flatpak 软件包。因此,可以使用它们来进行安装。
对于 Fedora 系统,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 flatpak。
```
$ sudo dnf install flatpak
```
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 flatpak。
```
$ sudo apt install flatpak
```
对于较旧的 Ubuntu 版本:
```
$ sudo add-apt-repository ppa:alexlarsson/flatpak
$ sudo apt update
$ sudo apt install flatpak
```
对于基于 Arch Linux 的系统,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 flatpak。
```
$ sudo pacman -S flatpak
```
对于 RHEL/CentOS 系统,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 来安装 flatpak。
```
$ sudo yum install flatpak
```
对于 openSUSE Leap 系统,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 来安装 flatpak。
```
$ sudo zypper install flatpak
```
### 如何在 Linux 上启用 Flathub 支持?
Flathub 网站是一个应用程序商店,你可以在其中找到 flatpak 软件包。它是一个中央仓库,所有的 flatpak 应用程序都可供用户使用。
运行以下命令在 Linux 上启用 Flathub 支持:
```
$ sudo flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```
为 GNOME 桌面环境安装 Software Flatpak 插件。
```
$ sudo apt install gnome-software-plugin-flatpak
```
此外,如果你使用的是 GNOME 桌面环境,则可以启用 GNOME 仓库。它包含所有 GNOME 核心应用程序。
```
$ wget https://sdk.gnome.org/keys/gnome-sdk.gpg
$ sudo flatpak remote-add --gpg-import=gnome-sdk.gpg --if-not-exists gnome-apps https://sdk.gnome.org/repo-apps/
```
### 如何列出已配置的 flakpak 仓库?
如果要查看系统上已配置的 flatpak 仓库列表,运行以下命令:
```
$ flatpak remotes
Name Options
flathub system
gnome-apps system
```
### 如何列出已配置仓库中的可用软件包?
如果要查看已配置仓库中的可用软件包的列表(它将显示所有软件包,如应用程序和运行环境),运行以下命令:
```
$ flatpak remote-ls | head -10
org.freedesktop.GlxInfo gnome-apps
org.gnome.Books gnome-apps
org.gnome.Builder gnome-apps
org.gnome.Calculator gnome-apps
org.gnome.Calendar gnome-apps
org.gnome.Characters gnome-apps
org.gnome.Devhelp gnome-apps
org.gnome.Dictionary gnome-apps
org.gnome.Documents gnome-apps
org.gnome.Epiphany gnome-apps
```
仅列出应用程序:
```
$ flatpak remote-ls --app
```
列出特定的仓库应用程序:
```
$ flatpak remote-ls gnome-apps
```
### 如何从 flatpak 安装包?
运行以下命令从 flatpak 仓库安装软件包:
```
$ sudo flatpak install flathub com.github.muriloventuroso.easyssh
Required runtime for com.github.muriloventuroso.easyssh/x86_64/stable (runtime/org.gnome.Platform/x86_64/3.30) found in remote flathub
Do you want to install it? [y/n]: y
Installing in system:
org.gnome.Platform/x86_64/3.30 flathub 4e93789f42ac
org.gnome.Platform.Locale/x86_64/3.30 flathub 6abf9c0e2b72
org.freedesktop.Platform.html5-codecs/x86_64/18.08 flathub d6abde36c0be
com.github.muriloventuroso.easyssh/x86_64/stable flathub 337db43043d2
permissions: ipc, network, wayland, x11, dri
file access: home, xdg-run/dconf, ~/.config/dconf:ro
dbus access: ca.desrt.dconf
com.github.muriloventuroso.easyssh.Locale/x86_64/stable flathub af837356b222
Is this ok [y/n]: y
Installing: org.gnome.Platform/x86_64/3.30 from flathub
[####################] 1 metadata, 14908 content objects fetched; 228018 KiB transferred in 364 seconds
Now at 4e93789f42ac.
Installing: org.gnome.Platform.Locale/x86_64/3.30 from flathub
[####################] 4 metadata, 1 content objects fetched; 16 KiB transferred in 2 seconds
Now at 6abf9c0e2b72.
Installing: org.freedesktop.Platform.html5-codecs/x86_64/18.08 from flathub
[####################] 26 metadata, 131 content objects fetched; 2737 KiB transferred in 8 seconds
Now at d6abde36c0be.
Installing: com.github.muriloventuroso.easyssh/x86_64/stable from flathub
[####################] 191 metadata, 3633 content objects fetched; 24857 KiB transferred in 117 seconds
Now at 337db43043d2.
Installing: com.github.muriloventuroso.easyssh.Locale/x86_64/stable from flathub
[####################] 3 metadata, 1 content objects fetched; 14 KiB transferred in 2 seconds
Now at af837356b222.
```
所有已安装的应用程序都将放在以下位置:
```
$ ls /var/lib/flatpak/app/
com.github.muriloventuroso.easyssh
```
### 如何运行已安装的应用程序?
运行以下命令以启动所需的应用程序,确保替换为你的应用程序名称:
```
$ flatpak run com.github.muriloventuroso.easyssh
```
### 如何查看已安装的应用程序?
运行以下命令来查看已安装的应用程序:
```
$ flatpak list
Ref Options
com.github.muriloventuroso.easyssh/x86_64/stable system,current
org.freedesktop.Platform.html5-codecs/x86_64/18.08 system,runtime
org.gnome.Platform/x86_64/3.30 system,runtime
```
### 如何查看有关已安装应用程序的详细信息?
运行以下命令以查看有关已安装应用程序的详细信息:
```
$ flatpak info com.github.muriloventuroso.easyssh
Ref: app/com.github.muriloventuroso.easyssh/x86_64/stable
ID: com.github.muriloventuroso.easyssh
Arch: x86_64
Branch: stable
Origin: flathub
Collection ID: org.flathub.Stable
Date: 2019-01-08 13:36:32 +0000
Subject: Update com.github.muriloventuroso.easyssh.json (cd35819c)
Commit: 337db43043d282c74d14a9caecdc780464b5e526b4626215d534d38b0935049f
Parent: 6e49096146f675db6ecc0ce7c5347b4b4f049b21d83a6cc4d01ff3f27c707cb6
Location: /var/lib/flatpak/app/com.github.muriloventuroso.easyssh/x86_64/stable/337db43043d282c74d14a9caecdc780464b5e526b4626215d534d38b0935049f
Installed size: 100.0 MB
Runtime: org.gnome.Platform/x86_64/3.30
Sdk: org.gnome.Sdk/x86_64/3.30
```
### 如何更新已安装的应用程序?
运行以下命令将已安装的应用程序更新到最新版本:
```
$ flatpak update
```
对于特定应用程序,使用以下格式:
```
$ flatpak update com.github.muriloventuroso.easyssh
```
### 如何移除已安装的应用程序?
运行以下命令来移除已安装的应用程序:
```
$ sudo flatpak uninstall com.github.muriloventuroso.easyssh
```
进入 man 页面以获取更多细节和选项:
```
$ flatpak --help
```
---
via: <https://www.2daygeek.com/how-to-install-and-enable-flatpak-support-on-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,752 | Vim 入门:基础 | https://opensource.com/article/19/3/getting-started-vim | 2019-04-20T10:42:59 | [
"vim",
"vi"
] | https://linux.cn/article-10752-1.html |
>
> 为工作或者新项目学习足够的 Vim 知识。
>
>
>

我还清晰地记得我第一次接触 Vim 的时候。那时我还是一名大学生,计算机学院的机房里都装着 Ubuntu 系统。尽管我在上大学前也曾接触过不同的 Linux 发行版(比如 RHEL —— Red Hat 在百思买出售它的 CD),但这却是我第一次要在日常中频繁使用 Linux 系统,因为我的课程要求我这样做。当我开始使用 Linux 时,正如我的前辈和将来的后继者们一样,我感觉自己像是一名“真正的程序员”了。

*真正的程序员,来自 [xkcd](https://xkcd.com/378/)*
学生们可以使用像 [Kate](https://kate-editor.org) 一样的图形文本编辑器,这也安装在学校的电脑上了。对于那些可以使用 shell 但不习惯使用控制台编辑器的学生,最流行的选择是 [Nano](https://www.nano-editor.org),它提供了很好的交互式菜单和类似于 Windows 图形文本编辑器的体验。
我有时会用 Nano,但当我听说 [Vi/Vim](https://www.vim.org) 和 [Emacs](https://www.gnu.org/software/emacs) 能做一些很棒的事情时我决定试一试它们(主要是因为它们看起来很酷,而且我也很好奇它们有什么特别之处)。第一次使用 Vim 时吓到我了 —— 我不想搞砸任何事情!但是,一旦我掌握了它的诀窍,事情就变得容易得多,我就可以欣赏这个编辑器的强大功能了。至于 Emacs,呃,我有点放弃了,但我很高兴我坚持和 Vim 在一起。
在本文中,我将介绍一下 Vim(基于我的个人经验),这样你就可以在 Linux 系统上用它来作为编辑器使用了。这篇文章不会让你变成 Vim 的专家,甚至不会触及 Vim 许多强大功能的皮毛。但是起点总是很重要的,我想让开始的经历尽可能简单,剩下的则由你自己去探索。
### 第 0 步:打开一个控制台窗口
在使用 Vim 前,你需要做一些准备工作。在 Linux 操作系统打开控制台终端。(因为 Vim 也可以在 MacOS 上使用,Mac 用户也可以使用这些说明)。
打开终端窗口后,输入 `ls` 命令列出当前目录下的内容。然后,输入 `mkdir Tutorial` 命令创建一个名为 `Tutorial` 的新目录。通过输入 `cd Tutorial` 来进入该目录。

这就是全部的准备工作。现在是时候转到有趣的部分了——开始使用 Vim。
### 第 1 步:创建一个 Vim 文件和不保存退出
还记得我一开始说过我不敢使用 Vim 吗?我当时在害怕“如果我改变了一个现有的文件,把事情搞砸了怎么办?”毕竟,一些计算机科学作业要求我修改现有的文件。我想知道:如何在不保存更改的情况下打开和关闭文件?
好消息是你可以使用相同的命令在 Vim 中创建或打开文件:`vim <FILE_NAME>`,其中 `<FILE_NAME>` 表示要创建或修改的目标文件名。让我们通过输入 `vim HelloWorld.java` 来创建一个名为 `HelloWorld.java` 的文件。
你好,Vim!现在,讲一下 Vim 中一个非常重要的概念,可能也是最需要记住的:Vim 有多种模式,下面是 Vim 基础中需要知道的的三种:
| 模式 | 描述 |
| --- | --- |
| 正常模式 | 默认模式,用于导航和简单编辑 |
| 插入模式 | 用于直接插入和修改文本 |
| 命令行模式 | 用于执行如保存,退出等命令 |
Vim 也有其他模式,例如可视模式、选择模式和命令模式。不过上面的三种模式对我们来说已经足够用了。
你现在正处于正常模式,如果有文本,你可以用箭头键移动或使用其他导航键(将在稍后看到)。要确定你正处于正常模式,只需按下 `esc` (Escape)键即可。
>
> **提示:** `Esc` 切换到正常模式。即使你已经在正常模式下,点击 `Esc` 只是为了练习。
>
>
>
现在,有趣的事情发生了。输入 `:` (冒号键)并接着 `q!` (完整命令:`:q!`)。你的屏幕将显示如下:

在正常模式下输入冒号会将 Vim 切换到命令行模式,执行 `:q!` 命令将退出 Vim 编辑器而不进行保存。换句话说,你放弃了所有的更改。你也可以使用 `ZQ` 命令;选择你认为更方便的选项。
一旦你按下 `Enter` (回车),你就不再在 Vim 中。重复练习几次来掌握这条命令。熟悉了这部分内容之后,请转到下一节,了解如何对文件进行更改。
### 第 2 步:在 Vim 中修改并保存
通过输入 `vim HelloWorld.java` 和回车键来再次打开这个文件。你可以在插入模式中修改文件。首先,通过 `Esc` 键来确定你正处于正常模式。接着输入 `i` 来进入插入模式(没错,就是字母 **i**)。
在左下角,你将看到 `-- INSERT --`,这标志着你这处于插入模式。

写一些 Java 代码。你可以写任何你想写的,不过这也有一份你可以参照的例子。你的屏幕将显示如下:
```
public class HelloWorld {
public static void main([String][11][] args) {
}
}
```
非常漂亮!注意文本是如何在 Java 语法中高亮显示的。因为这是个 Java 文件,所以 Vim 将自动检测语法并高亮颜色。
保存文件:按下 `Esc` 来退出插入模式并进入命令行模式。输入 `:` 并接着 `x!` (完整命令:`:x!`),按回车键来保存文件。你也可以输入 `wq` 来执行相同的操作。
现在,你知道了如何使用插入模式输入文本并使用以下命令保存文件:`:x!` 或者 `:wq`。
### 第 3 步:Vim 中的基本导航
虽然你总是可以使用上箭头、下箭头、左箭头和右箭头在文件中移动,但在一个几乎有数不清行数的大文件中,这将是非常困难的。能够在一行中跳跃光标将会是很有用的。虽然 Vim 提供了不少很棒的导航功能,不过在一开始,我想向你展示如何在 Vim 中到达某一特定的行。
单击 `Esc` 来确定你处于正常模式,接着输入 `:set number` 并键入回车。
瞧!你现在可以在每一行的左侧看到行号。

好,你也许会说,“这确实很酷,不过我该怎么跳到某一行呢?”再一次的,确认你正处于正常模式。接着输入 `:<LINE_NUMBER>`,在这里 `<LINE_NUMBER>` 是你想去的那一行的行数。按下回车键来试着移动到第二行。
```
:2
```
现在,跳到第三行。

但是,假如你正在处理一个一千多行的文件,而你正想到文件底部。这该怎么办呢?确认你正处于正常模式,接着输入 `:$` 并按下回车。
你将来到最后一行!
现在,你知道如何在行间跳跃了,作为补充,我们来学一下如何移动到一行的行尾。确认你正处于有文本内容的一行,如第三行,接着输入 `$`。

你现在来到这行的最后一个字节了。在此示例中,高亮左大括号以显示光标移动到的位置,右大括号被高亮是因为它是高亮的左大括号的匹配字符。
这就是 Vim 中的基本导航功能。等等,别急着退出文件。让我们转到 Vim 中的基本编辑。不过,你可以暂时顺便喝杯咖啡或茶休息一下。
### 第 4 步:Vim 中的基本编辑
现在,你已经知道如何通过跳到想要的一行来在文件中导航,你可以使用这个技能在 Vim 中进行一些基本编辑。切换到插入模式。(还记得怎么做吗?是不是输入 `i` ?)当然,你可以使用键盘逐一删除或插入字符来进行编辑,但是 Vim 提供了更快捷的方法来编辑文件。
来到第三行,这里的代码是 `public static void main(String[] args) {`。双击 `d` 键,没错,就是 `dd`。如果你成功做到了,你将会看到,第三行消失了,剩下的所有行都向上移动了一行。(例如,第四行变成了第三行)。

这就是<ruby> 删除 <rt> delete </rt></ruby>命令。不要担心,键入 `u`,你会发现这一行又回来了。喔,这就是<ruby> 撤销 <rt> undo </rt></ruby>命令。

下一课是学习如何复制和粘贴文本,但首先,你需要学习如何在 Vim 中突出显示文本。按下 `v` 并向左右移动光标来选择或反选文本。当你向其他人展示代码并希望标识你想让他们注意到的代码时,这个功能也非常有用。

来到第四行,这里的代码是 `System.out.println("Hello, Opensource");`。高亮这一行的所有内容。好了吗?当第四行的内容处于高亮时,按下 `y`。这就叫做<ruby> 复制 <rt> yank </rt></ruby>模式,文本将会被复制到剪贴板上。接下来,输入 `o` 来创建新的一行。注意,这将让你进入插入模式。通过按 `Esc` 退出插入模式,然后按下 `p`,代表<ruby> 粘贴 <rt> paste </rt></ruby>。这将把复制的文本从第三行粘贴到第四行。

作为练习,请重复这些步骤,但也要修改新创建的行中的文字。此外,请确保这些行对齐工整。
>
> **提示:** 您需要在插入模式和命令行模式之间来回切换才能完成此任务。
>
>
>
当你完成了,通过 `x!` 命令保存文件。以上就是 Vim 基本编辑的全部内容。
### 第 5 步:Vim 中的基本搜索
假设你的团队领导希望你更改项目中的文本字符串。你该如何快速完成任务?你可能希望使用某个关键字来搜索该行。
Vim 的搜索功能非常有用。通过 `Esc` 键来进入命令模式,然后输入冒号 `:`,我们可以通过输入 `/<SEARCH_KEYWORD>` 来搜索关键词, `<SEARCH_KEYWORD>` 指你希望搜索的字符串。在这里,我们搜索关键字符串 `Hello`。在下面的图示中没有显示冒号,但这是必须输入的。

但是,一个关键字可以出现不止一次,而这可能不是你想要的那一个。那么,如何找到下一个匹配项呢?只需按 `n` 键即可,这代表<ruby> 下一个 <rt> next </rt></ruby>。执行此操作时,请确保你没有处于插入模式!
### 附加步骤:Vim 中的分割模式
以上几乎涵盖了所有的 Vim 基础知识。但是,作为一个额外奖励,我想给你展示 Vim 一个很酷的特性,叫做<ruby> 分割 <rt> split </rt></ruby>模式。
退出 `HelloWorld.java` 并创建一个新文件。在控制台窗口中,输入 `vim GoodBye.java` 并按回车键来创建一个名为 `GoodBye.java` 的新文件。
输入任何你想输入的让内容,我选择输入 `Goodbye`。保存文件(记住你可以在命令模式中使用 `:x!` 或者 `:wq`)。
在命令模式中,输入 `:split HelloWorld.java`,来看看发生了什么。

Wow!快看! `split` 命令将控制台窗口水平分割成了两个部分,上面是 `HelloWorld.java`,下面是 `GoodBye.java`。该怎么能在窗口之间切换呢? 按住 `Control` 键(在 Mac 上)或 `Ctrl` 键(在 PC 上),然后按下 `ww` (即双击 `w` 键)。
作为最后一个练习,尝试通过复制和粘贴 `HelloWorld.java` 来编辑 `GoodBye.java` 以匹配下面屏幕上的内容。

保存两份文件,成功!
>
> **提示 1:** 如果你想将两个文件窗口垂直分割,使用 `:vsplit <FILE_NAME>` 命令。(代替 `:split <FILE_NAME>` 命令,`<FILE_NAME>` 指你想要使用分割模式打开的文件名)。
>
>
> **提示 2:** 你可以通过调用任意数量的 `split` 或者 `vsplit` 命令来打开两个以上的文件。试一试,看看它效果如何。
>
>
>
### Vim 速查表
在本文中,您学会了如何使用 Vim 来完成工作或项目,但这只是你开启 Vim 强大功能之旅的开始,可以查看其他很棒的教程和技巧。
为了让一切变得简单些,我已经将你学到的一切总结到了 [一份方便的速查表](https://opensource.com/downloads/cheat-sheet-vim) 中。
---
via: <https://opensource.com/article/19/3/getting-started-vim>
作者:[Bryant Son](https://opensource.com/users/brson) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Modrisco](https://github.com/Modrisco) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I remember the very first time I encountered Vim. I was a university student, and the computers in the computer science department's lab were installed with Ubuntu Linux. While I had been exposed to different Linux variations (like RHEL) even before my college years (Red Hat sold its CDs at Best Buy!), this was the first time I needed to use the Linux operating system regularly, because my classes required me to do so. Once I started using Linux, like many others before and after me, I began to feel like a "real programmer."

Real Programmers, by xkcd
Students could use a graphical text editor like [Kate](https://kate-editor.org), which was installed on the lab computers by default. For students who could use the shell but weren't used to the console-based editor, the popular choice was [Nano](https://www.nano-editor.org), which provided good interactive menus and an experience similar to Windows' graphical text editor.
I used Nano sometimes, but I heard awesome things about [Vi/Vim](https://www.vim.org) and [Emacs](https://www.gnu.org/software/emacs) and really wanted to give them a try (mainly because they looked cool, and I was also curious to see what was so great about them). Using Vim for the first time scared me—I did not want to mess anything up! But once I got the hang of it, things became much easier and I could appreciate the editor's powerful capabilities. As for Emacs, well, I sort of gave up, but I'm happy I stuck with Vim.
In this article, I will walk through Vim (based on my personal experience) just enough so you can get by with it as an editor on a Linux system. This will neither make you an expert nor even scratch the surface of many of Vim's powerful capabilities. But the starting point always matters, and I want to make the beginning experience as easy as possible, and you can explore the rest on your own.
## Step 0: Open a console window
Before jumping into Vim, you need to do a little preparation. Open a console terminal from your Linux operating system. (Since Vim is also available on MacOS, Mac users can use these instructions, also.)
Once a terminal window is up, type the **ls** command to list the current directory. Then, type **mkdir Tutorial** to create a new directory called **Tutorial**. Go inside the directory by typing **cd Tutorial**.
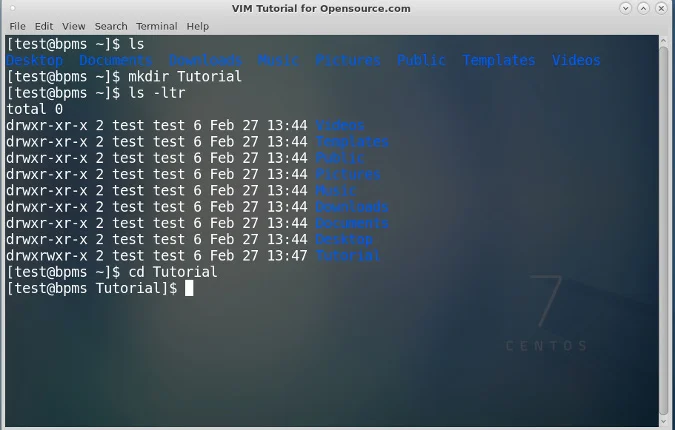
That's it for preparation. Now it's time to move on to the fun part—starting to use Vim.
## Step 1: Create and close a Vim file without saving
Remember when I said I was scared to use Vim at first? Well, the scary part was thinking, "what if I change an existing file and mess things up?" After all, several computer science assignments required me to work on existing files by modifying them. I wanted to know: *How can I open and close a file without saving my changes?*
The good news is you can use the same command to create or open a file in Vim: **vim <FILE_NAME**>, where **<FILE_NAME>** represents the target file name you want to create or modify. Let's create a file named **HelloWorld.java** by typing **vim HelloWorld.java**.
Hello, Vim! Now, here is a very important concept in Vim, possibly the most important to remember: Vim has multiple modes. Here are three you need to know to do Vim basics:
Mode | Description |
---|---|
Normal | Default; for navigation and simple editing |
Insert | For explicitly inserting and modifying text |
Command Line | For operations like saving, exiting, etc. |
Vim has other modes, like Visual, Select, and Ex-Mode, but Normal, Insert, and Command Line modes are good enough for us.
You are now in Normal mode. If you have text, you can move around with your arrow keys or other navigation keystrokes (which you will see later). To make sure you are in Normal mode, simply hit the **Esc** (Escape) key.
Tip:Escswitches to Normal mode. Even though you are already in Normal mode, hitEscjust for practice's sake.
Now, this will be interesting. Press ** ****:** (the colon key) followed by **q!** (i.e., **:q!**). Your screen will look like this:
Pressing the colon in Normal mode switches Vim to Command Line mode, and the **:q!** command quits the Vim editor without saving. In other words, you are abandoning all changes. You can also use **ZQ**; choose whichever option is more convenient.
Once you hit **Enter**, you should no longer be in Vim. Repeat the exercise a few times, just to get the hang of it. Once you've done that, move on to the next section to learn how to make a change to this file.
## Step 2: Make and save modifications in Vim
Reopen the file by typing **vim HelloWorld.java** and pressing the **Enter** key. Insert mode is where you can make changes to a file. First, hit **Esc** to make sure you are in Normal mode, then press **i** to go into Insert mode. (Yes, that is the letter **i**.)
In the lower-left, you should see **-- INSERT --**. This means you are in Insert mode.
Type some Java code. You can type anything you want, but here is an example for you to follow. Your screen will look like this:
```
public class HelloWorld {
public static void main(String[] args) {
}
}
```
Very pretty! Notice how the text is highlighted in Java syntax highlight colors. Because you started the file in Java, Vim will detect the syntax color.
Save the file. Hit **Esc** to leave Insert mode and enter Command Line mode. Type **:** and follow that with **x!** (i.e., a colon followed by x and !). Hit **Enter** to save the file. You can also type **wq** to perform the same operation.
Now you know how to enter text using Insert mode and save the file using **:x!** or **:wq**.
## Step 3: Basic navigation in Vim
While you can always use your friendly Up, Down, Left, and Right arrow buttons to move around a file, that would be very difficult in a large file with almost countless lines. It's also helpful to be able to be able to jump around within a line. Although Vim has a ton of awesome navigation features, the first one I want to show you is how to go to a specific line.
Press the **Esc** key to make sure you are in Normal mode, then type **:set number** and hit **Enter** .
Voila! You see line numbers on the left side of each line.
OK, you may say, "that's cool, but how do I jump to a line?" Again, make sure you are in Normal mode, then press **:<LINE_NUMBER>**, where **<****LINE_NUMBER>** is the number of the line you want to go to, and press **Enter**. Try moving to line 2.
`:2`
Now move to line 3.
But imagine a scenario where you are dealing with a file that is 1,000 lines long and you want to go to the end of the file. How do you get there? Make sure you are in Normal mode, then type **:$** and press **Enter**.
You will be on the last line!
Now that you know how to jump among the lines, as a bonus, let's learn how to move to the end of a line. Make sure you are on a line with some text, like line 3, and type **$**.
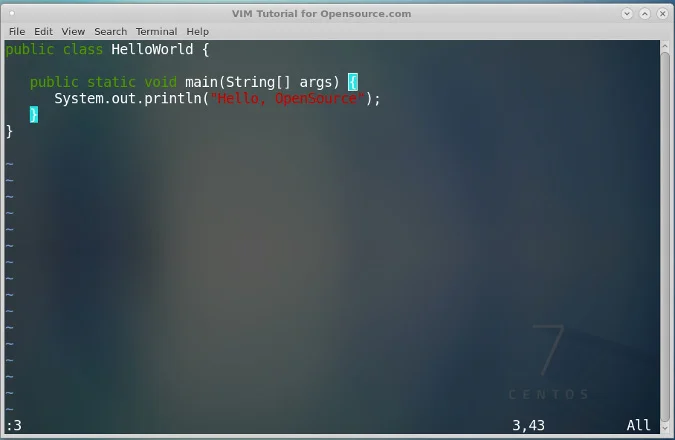
You're now at the last character on the line. In this example, the open curly brace is highlighted to show where your cursor moved to, and the closing curly brace is highlighted because it is the opening curly brace's matching character.
That's it for basic navigation in Vim. Wait, don't exit the file, though. Let's move to basic editing in Vim. Feel free to grab a cup of coffee or tea, though.
## Step 4: Basic editing in Vim
Now that you know how to navigate around a file by hopping onto the line you want, you can use that skill to do some basic editing in Vim. Switch to Insert mode. (Remember how to do that, by hitting the **i** key?) Sure, you can edit by using the keyboard to delete or insert characters, but Vim offers much quicker ways to edit files.
Move to line 3, where it shows **public static void main(String[] args) {**. Quickly hit the **d** key twice in succession. Yes, that is **dd**. If you did it successfully, you will see a screen like this, where line 3 is gone, and every following line moved up by one (i.e., line 4 became line 3).
That's the *delete* command. Don't fear! Hit **u** and you will see the deleted line recovered. Whew. This is the *undo* command.
The next lesson is learning how to copy and paste text, but first, you need to learn how to highlight text in Vim. Press **v** and move your Left and Right arrow buttons to select and deselect text. This feature is also very useful when you are showing code to others and want to identify the code you want them to see.
Move to line 4, where it says **System.out.println("Hello, Opensource");**. Highlight all of line 4. Done? OK, while line 4 is still highlighted, press **y**. This is called *yank* mode, and it will copy the text to the clipboard. Next, create a new line underneath by entering **o**. Note that this will put you into Insert mode. Get out of Insert mode by pressing **Esc**, then hit **p**, which stands for *paste*. This will paste the copied text from line 3 to line 4.
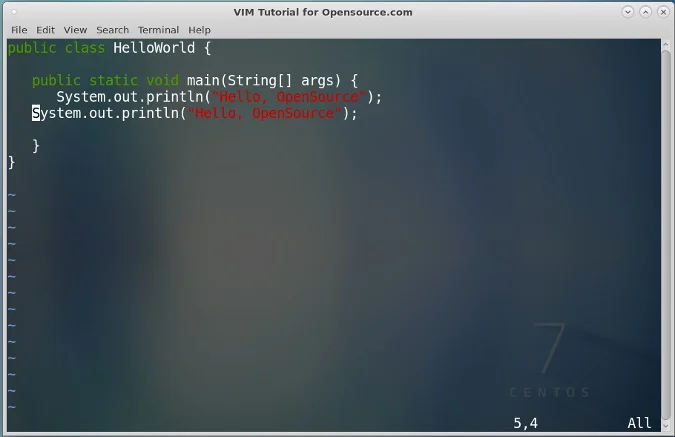
As an exercise, repeat these steps but also modify the text on your newly created lines. Also, make sure the lines are aligned well.
Hint:You need to switch back and forth between Insert mode and Command Line mode to accomplish this task.
Once you are finished, save the file with the **x!** command. That's all for basic editing in Vim.
## Step 5: Basic searching in Vim
Imagine your team lead wants you to change a text string in a project. How can you do that quickly? You might want to search for the line using a certain keyword.
Vim's search functionality can be very useful. Go into the Command Line mode by (1) pressing **Esc** key, then (2) pressing colon **:**** **key. We can search a keyword by entering :**/<SEARCH_KEYWORD>**, where **<SEARCH_KEYWORD>** is the text string you want to find. Here we are searching for the keyword string "Hello." In the image below, the colon is missing but required.
However, a keyword can appear more than once, and this may not be the one you want. So, how do you navigate around to find the next match? You simply press the **n** key, which stands for *next*. Make sure that you aren't in Insert mode when you do this!
## Bonus step: Use split mode in Vim
That pretty much covers all the Vim basics. But, as a bonus, I want to show you a cool Vim feature called *split mode*.
Get out of *HelloWorld.java* and create a new file. In a terminal window, type **vim GoodBye.java** and hit **Enter** to create a new file named *GoodBye.java*.
Enter any text you want; I decided to type "Goodbye." Save the file. (Remember you can use **:x!** or **:wq** in Command Line mode.)
In Command Line mode, type **:split HelloWorld.java**, and see what happens.
Wow! Look at that! The **split** command created horizontally divided windows with *HelloWorld.java* above and *GoodBye.java* below. How can you switch between the windows? Hold **Control** (on a Mac) or **CTRL** (on a PC) then hit **ww** (i.e., **w** twice in succession).
As a final exercise, try to edit *GoodBye.java* to match the screen below by copying and pasting from *HelloWorld.java*.
Save both files, and you are done!
TIP 1:If you want to arrange the files vertically, use the command:vsplit <FILE_NAME>(instead of:split <FILE_NAME>, where<FILE_NAME>is the name of the file you want to open in Split mode.
TIP 2:You can open more than two files by calling as many additionalsplitorvsplitcommands as you want. Try it and see how it looks.
## Vim cheat sheet
In this article, you learned how to use Vim just enough to get by for work or a project. But this is just the beginning of your journey to unlock Vim's powerful capabilities. Be sure to check out other great tutorials and tips on Opensource.com.
To make things a little easier, I've summarized everything you've learned into [a handy cheat sheet](https://opensource.com/downloads/cheat-sheet-vim).
## 6 Comments |
10,756 | 解决 Ubuntu 在启动时冻结的问题 | https://itsfoss.com/fix-ubuntu-freezing/ | 2019-04-21T09:50:53 | [
"Ubuntu",
"NVIDIA",
"冻结"
] | https://linux.cn/article-10756-1.html |
>
> 本文将向你一步步展示如何通过安装 NVIDIA 专有驱动来处理 Ubuntu 在启动过程中冻结的问题。本教程仅在一个新安装的 Ubuntu 系统上操作验证过,不过在其它情况下也理应可用。
>
>
>
不久前我买了台[宏碁掠夺者](https://amzn.to/2YVV6rt)笔记本电脑来测试各种 Linux 发行版。这台庞大且笨重的机器与我喜欢的,类似[戴尔 XPS](https://itsfoss.com/dell-xps-13-ubuntu-review/)那般小巧轻便的笔记本电脑大相径庭。
我即便不打游戏也选择这台电竞笔记本电脑的原因,就是为了 [NVIDIA 的显卡](https://www.nvidia.com/en-us/)。宏碁掠夺者 Helios 300 上搭载了一块 [NVIDIA Geforce](https://www.nvidia.com/en-us/geforce/) GTX 1050Ti 显卡。
NVIDIA 那糟糕的 Linux 兼容性为人们所熟知。过去很多 It’s FOSS 的读者都向我求助过关于 NVIDIA 笔记本电脑的问题,而我当时无能为力,因为我手头上没有使用 NVIDIA 显卡的系统。
所以当我决定搞一台专门的设备来测试 Linux 发行版时,我选择了带有 NVIDIA 显卡的笔记本电脑。
这台笔记本原装的 Windows 10 系统安装在 120 GB 的固态硬盘上,并另外配有 1 TB 的机械硬盘来存储数据。在此之上我配置好了 [Windows 10 和 Ubuntu 18.04 双系统](https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/)。整个的安装过程舒适、方便、快捷。
随后我启动了 [Ubuntu](https://www.ubuntu.com/)。那熟悉的紫色界面展现了出来,然后我就发现它卡在那儿了。鼠标一动不动,我也输入不了任何东西,然后除了长按电源键强制关机以外我啥事儿都做不了。
然后再次尝试启动,结果一模一样。整个系统就一直卡在那个紫色界面,随后的登录界面也出不来。
这听起来很耳熟吧?下面就让我来告诉你如何解决这个 Ubuntu 在启动过程中冻结的问题。
>
> 如果你用的不是 Ubuntu
>
>
> 请注意,尽管是在 Ubuntu 18.04 上操作的,本教程应该也能用于其他基于 Ubuntu 的发行版,例如 Linux Mint、elementary OS 等等。关于这点我已经在 Zorin OS 上确认过。
>
>
>
### 解决 Ubuntu 启动中由 NVIDIA 驱动引起的冻结问题

我介绍的解决方案适用于配有 NVIDIA 显卡的系统,因为你所面临的系统冻结问题是由开源的 [NVIDIA Nouveau 驱动](https://nouveau.freedesktop.org/wiki/)所导致的。
事不宜迟,让我们马上来看看如何解决这个问题。
#### 步骤 1:编辑 Grub
在启动系统的过程中,请你在如下图所示的 Grub 界面上停下。如果你没看到这个界面,在启动电脑时请按住 `Shift` 键。
在这个界面上,按 `E` 键进入编辑模式。

你应该看到一些如下图所示的代码。此刻你应关注于以 “linux” 开头的那一行。

#### 步骤 2:在 Grub 中临时修改 Linux 内核参数
回忆一下,我们的问题出在 NVIDIA 显卡驱动上,是开源版 NVIDIA 驱动的不适配导致了我们的问题。所以此处我们能做的就是禁用这些驱动。
此刻,你有多种方式可以禁用这些驱动。我最喜欢的方式是通过 `nomodeset` 来禁用所有显卡的驱动。
请把下列文本添加到以 “linux” 开头的那一行的末尾。此处你应该可以正常输入。请确保你把这段文本加到了行末。
```
nomodeset
```
现在你屏幕上的显示应如下图所示:

按 `Ctrl+X` 或 `F10` 保存并退出。下次你就将以修改后的内核参数来启动。
>
> 对以上操作的解释
>
>
> 所以我们究竟做了些啥?那个 `nomodeset` 又是个什么玩意儿?让我来向你简单地解释一下。
>
>
> 通常来说,显卡是在 X 或者是其他显示服务器开始执行后才被启用的,也就是在你登录系统并看到图形界面以后。
>
>
> 但近来,视频模式的设置被移进了内核。这么做的众多优点之一就是能你看到一个漂亮且高清的启动画面。
>
>
> 若你往内核中加入 `nomodeset` 参数,它就会指示内核在显示服务启动后才加载显卡驱动。
>
>
> 换句话说,你在此时禁止视频驱动的加载,由此产生的冲突也会随之消失。你在登录进系统以后,还是能看到一切如旧,那是因为显卡驱动在随后的过程中被加载了。
>
>
>
#### 步骤 3:更新你的系统并安装 NVIDIA 专有驱动
别因为现在可以登录系统了就过早地高兴起来。你之前所做的只是临时措施,在下次启动的时候,你的系统依旧会尝试加载 Nouveau 驱动而因此冻结。
这是否意味着你将不得不在 Grub 界面上不断地编辑内核?可喜可贺,答案是否定的。
你可以在 Ubuntu 上为 NVIDIA 显卡[安装额外的驱动](https://itsfoss.com/install-additional-drivers-ubuntu/)。在使用专有驱动后,Ubuntu 将不会在启动过程中冻结。
我假设这是你第一次登录到一个新安装的系统。这意味着在做其他事情之前你必须先[更新 Ubuntu](https://itsfoss.com/update-ubuntu/)。通过 Ubuntu 的 `Ctrl+Alt+T` [系统快捷键](https://itsfoss.com/ubuntu-shortcuts/)打开一个终端,并输入以下命令:
```
sudo apt update && sudo apt upgrade -y
```
在上述命令执行完以后,你可以尝试安装额外的驱动。不过根据我的经验,在安装新驱动之前你需要先重启一下你的系统。在你重启时,你还是需要按我们之前做的那样修改内核参数。
当你的系统已经更新和重启完毕,按下 `Windows` 键打开一个菜单栏,并搜索“<ruby> 软件与更新 <rt> Software & Updates </rt></ruby>”。

然后切换到“<ruby> 额外驱动 <rt> Additional Drivers </rt></ruby>”标签页,并等待数秒。然后你就能看到可供系统使用的专有驱动了。在这个列表上你应该可以找到 NVIDIA。
选择专有驱动并点击“<ruby> 应用更改 <rt> Apply Changes </rt></ruby>”。

新驱动的安装会费点时间。若你的系统启用了 UEFI 安全启动,你将被要求设置一个密码。*你可以将其设置为任何容易记住的密码*。它的用处我将在步骤 4 中说明。

安装完成后,你会被要求重启系统以令之前的更改生效。

#### 步骤 4:处理 MOK(仅针对启用了 UEFI 安全启动的设备)
如果你之前被要求设置安全启动密码,此刻你会看到一个蓝色界面,上面写着 “MOK management”。这是个复杂的概念,我试着长话短说。
对 MOK([设备所有者密码](https://firmware.intel.com/blog/using-mok-and-uefi-secure-boot-suse-linux))的要求是因为安全启动的功能要求所有内核模块都必须被签名。Ubuntu 中所有随 ISO 镜像发行的内核模块都已经签了名。由于你安装了一个新模块(也就是那个额外的驱动),或者你对内核模块做了修改,你的安全系统可能视之为一个未经验证的外部修改,从而拒绝启动。
因此,你可以自己对系统模块进行签名(以告诉 UEFI 系统莫要大惊小怪,这些修改是你做的),或者你也可以简单粗暴地[禁用安全启动](https://itsfoss.com/disable-secure-boot-in-acer/)。
现在你对[安全启动和 MOK](https://wiki.ubuntu.com/UEFI/SecureBoot/DKMS) 有了一定了解,那咱们就来看看在遇到这个蓝色界面后该做些什么。
如果你选择“继续启动”,你的系统将有很大概率如往常一样启动,并且你啥事儿也不用做。不过在这种情况下,新驱动的有些功能有可能工作不正常。
这就是为什么,你应该“选择注册 MOK”。

它会在下一个页面让你点击“继续”,然后要你输入一串密码。请输入在上一步中,在安装额外驱动时设置的密码。
>
> 别担心!
>
>
> 如果你错过了这个关于 MOK 的蓝色界面,或不小心点了“继续启动”而不是“注册 MOK”,不必惊慌。你的主要目的是能够成功启动系统,而通过禁用 Nouveau 显卡驱动,你已经成功地实现了这一点。
>
>
> 最坏的情况也不过就是你的系统切换到 Intel 集成显卡而不再使用 NVIDIA 显卡。你可以之后的任何时间安装 NVIDIA 显卡驱动。你的首要任务是启动系统。
>
>
>
#### 步骤 5:享受安装了专有 NVIDIA 驱动的 Linux 系统
当新驱动被安装好后,你需要再次重启系统。别担心!目前的情况应该已经好起来了,并且你不必再去修改内核参数,而是能够直接启动 Ubuntu 系统了。
我希望本教程帮助你解决了 Ubuntu 系统在启动中冻结的问题,并让你能够成功启动 Ubuntu 系统。
如果你有任何问题或建议,请在下方评论区给我留言。
---
via: <https://itsfoss.com/fix-ubuntu-freezing/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Raverstern](https://github.com/Raverstern) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The other day I bought an [Acer Predator laptop](https://amzn.to/2YVV6rt?ref=itsfoss.com) ([affiliate](https://itsfoss.com/affiliate-policy/) link) to test various Linux distributions. It’s a bulky, heavy-built laptop which is in contrast to my liking of smaller, lightweight laptops like the [awesome Dell XPS](https://itsfoss.com/dell-xps-13-ubuntu-review/).
The reason why I opted for this gaming laptop even though I don’t game on PC is [NVIDIA Graphics](https://www.nvidia.com/en-us/?ref=itsfoss.com). Acer Predator Helios 300 comes with [NVIDIA Geforce](https://www.nvidia.com/en-us/geforce/?ref=itsfoss.com) GTX 1050Ti. It would allow me to cover NVIDIA Graphics related tutorials.
This laptop has Windows 10 installed on the 120 GB SSD and 1 TB HDD for storing data. I [dual booted Windows 10 with Ubuntu 18.04](https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/). The installation was quick, easy and painless.
I booted into [Ubuntu](https://www.ubuntu.com/?ref=itsfoss.com). It was showing the familiar purple screen and then I noticed that it froze there. The mouse won’t move, I couldn’t type anything and nothing else could be done except turning off the device by holding the power button.
And it was the same story at the next login try. Ubuntu gets stuck at the purple screen even before reaching the login screen.

Sounds familiar? Let me show you how you can fix this problem of Ubuntu freezing at login.
## Fix Ubuntu freezing at boot time because of graphics drivers
You can see how to fix this issue in the following video.
[check which graphics card do you have on your Linux system](https://itsfoss.com/check-graphics-card-linux/).
Without further delay, let’s see how to fix this problem.
### Step 1: Editing Grub
When you boot your system, just stop at the Grub screen like the one below. If you don’t see this screen, keep holding Shift key at the boot time.
At this screen, press ‘E’ key to go into the editing mode.
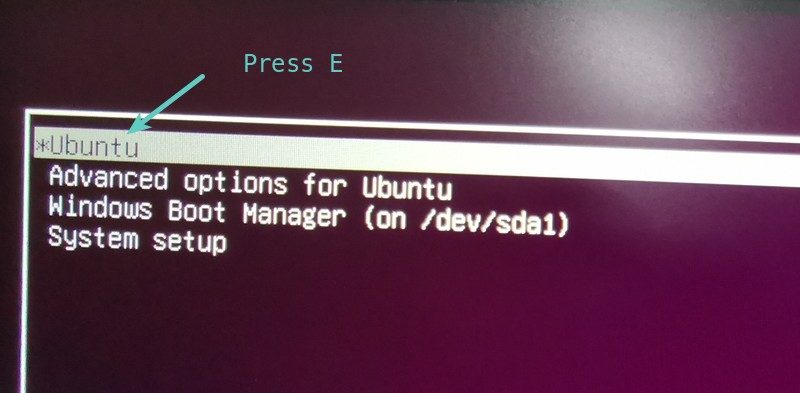
You should see some sort of code like the one below. You should focus on the line that starts with Linux.
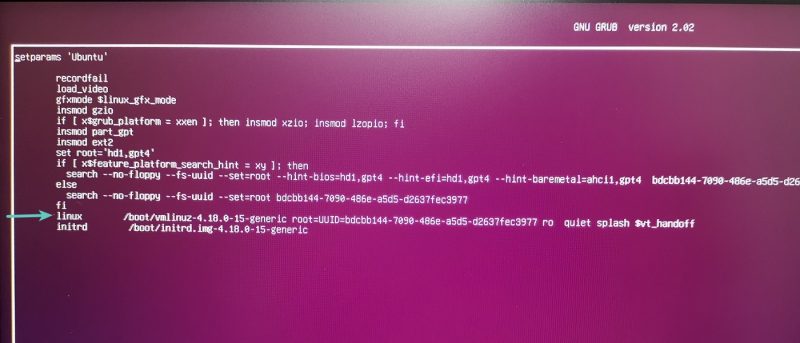
### Step 2: Temporarily Modifying Linux kernel parameters in Grub
Remember, our problem is with the NVIDIA Graphics drivers. This incompatibility with open source version of NVIDIA drivers caused the issue so what we can do here is to disable these drivers.
Now, there are several ways you can try to disable these drivers. My favorite way is to disable all video/graphics card using nomodeset.
Just add the following text at the end of the line starting with Linux. You should be able to type normally. Just make sure that you are adding it at the end of the line.
`nomodeset`
Now your screen should look like this:
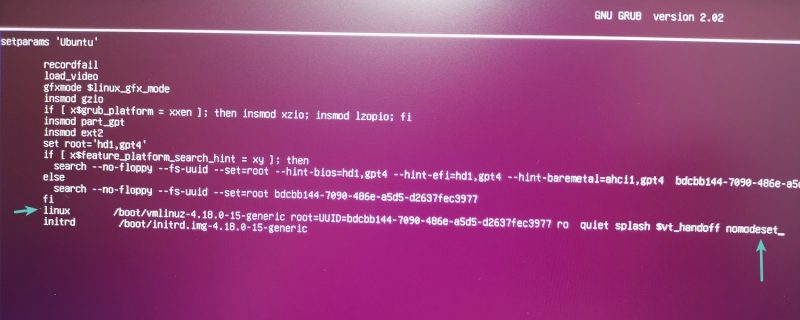
Press Ctrl+X or F10 to save and exit. Now you’ll boot with the newly modified kernel parameters here.
#### Explanation of what I did here
**So, what did **I** just do here? What’s that nomodeset thing? Let me explain it to you briefly.**
Normally, the video/graphics cards were used after the X or any other [display server](https://itsfoss.com/display-server/) was started. In other words, when you log in to your system and see a graphical user interface.
But lately, the video mode settings were moved to the kernel. Among other benefits, it enables you to have beautiful, high-resolution boot splash screens.
If you add the nomodeset parameter to the kernel, it instructs the kernel to load the video/graphics drivers after the display server is started.
In other words, you disabled loading the graphics driver at this time and the conflict it was causing goes away. After you login to the system and see everything because the graphics card is loaded again.
### Troubleshoot: Cannot boot even after using nomodeset?
If using `nomodeset`
in the grub didn’t work and you can still not boot, try some other parameters instead of `nomodeset`
.
Follow the same steps as mentioned above. While editing grub, add in place of
`nouveau.noaccel=1`
*. Save and exit grub and see if you can boot now.*
**nomodeset**
If even that doesn’t work, try adding instead of
**noapic noacpi nosplash irqpoll**
**in the grub.**
**quiet splash**
**If you are using Nvidia's open source Nouveau driver**, you may try disabling it by adding this in the Grub:
`modprobe.blacklist=nouveau`
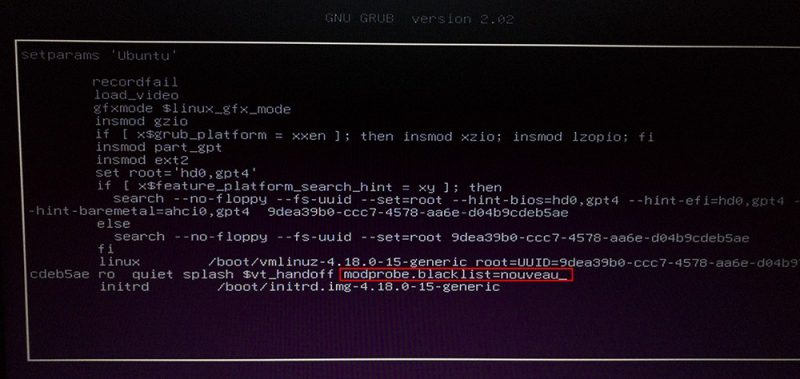
### Step 3: Make permanent changes in Grub (if you can boot and there is no issue with graphics)
Don’t be too happy yet just because you are able to login to your system now. What you did was temporary and the next time you boot into your system, your system will still freeze because it will still try to load the graphics drivers.
Does this mean you’ll always have to edit Kernel from the grub screen? Thankfully, the answer is no.
What you can do here to change the grub configuration so that the Linux kernel will not try to load the graphics driver before the display server.
To do that, open the terminal (use Ctrl+Alt+T shortcut) and then use the following command to open the grub configuration file in Gedit editor:
`sudo gedit /etc/default/grub `
You’ll have to use your password to open this file. Once you have the text file opened, look for the line that contains: .
**GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"**
Change this line to: **GRUB_CMDLINE_LINUX_DEFAULT="quiet splash nomodeset"**
It should look something like this:
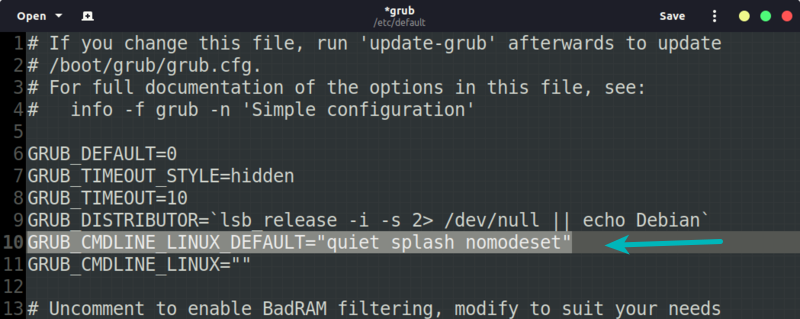
Save the file and [update grub](https://itsfoss.com/update-grub/) so that changes are taken into effect. Use this command:
`sudo update-grub`
Once it is complete, reboot your system and it should not freeze anymore.
### Alternate Step 3: You can boot but the graphics look weird. Update your system and install proprietary graphics drivers
If you don’t want to change the Grub config as mentioned in the previous step, alternatively, you can [install additional drivers in Ubuntu](https://itsfoss.com/install-additional-drivers-ubuntu/) for NVIDIA and AMD. Ubuntu won’t freeze at boot time while using these proprietary drivers.
In Ubuntu and many other distributions, you have an easy way to install proprietary drivers. Search for “Additional Drivers” in Ubuntu menu. In here, you may find additional graphics drivers for your system.
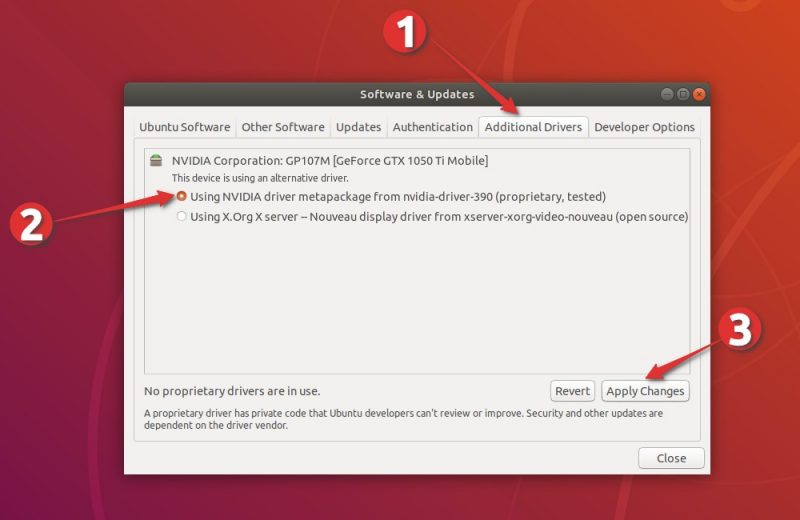
#### Installing proprietary NVIDIA drivers (detailed steps)
I am assuming that it’s your first login to a freshly installed system. This means you must [update Ubuntu](https://itsfoss.com/update-ubuntu/) before you do anything else. Open a terminal using Ctrl+Alt+T [keyboard shortcut in Ubuntu](https://itsfoss.com/ubuntu-shortcuts/) and use the following command:
`sudo apt update && sudo apt upgrade -y`
You may try installing additional drivers in Ubuntu right after the completion of the above command but in my experience, you’ll have to restart your system before you could successfully install the new drivers. And when you restart, you’ll have to change the kernel parameter again the same way we did earlier.
After your system is updated and restarted, press Windows key to go to the menu and search for Software & Updates.

Now go to the Additional Drivers tab and wait for a few seconds. Here you’ll see proprietary drivers available for your system. You should see NVIDIA in the list here.
Select the proprietary driver and click on Apply Changes.

It will take some time in the installation of the new drivers. If you have UEFI secure boot enabled on your system, you’ll be also asked to set a password. * You can set it to anything that is easy to remember*. I’ll show you its implications later in step 4.
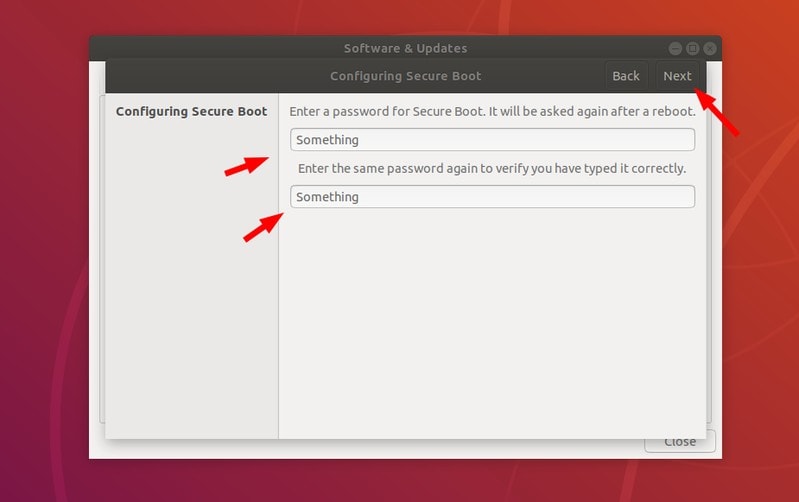
Once the installation finishes, you’ll be asked to restart the system to take changes into effect.
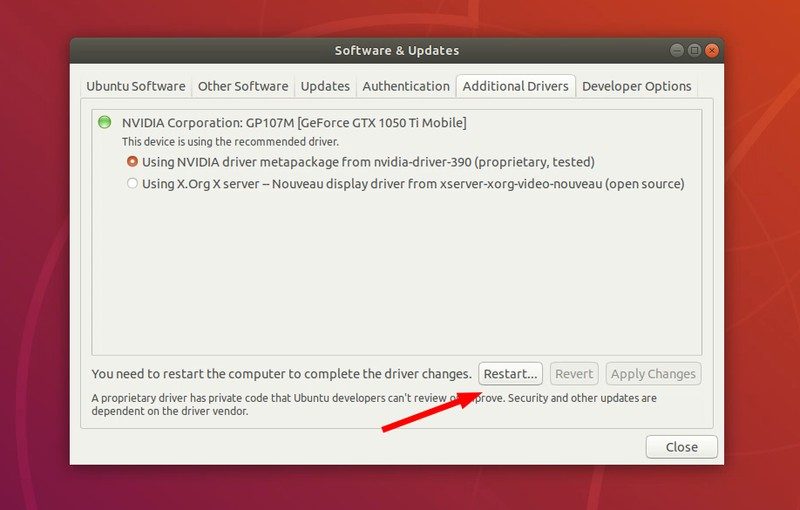
##### Dealing with MOK (only for UEFI Secure Boot enabled devices)
If you were asked to setup a secure boot password, you’ll see a blue screen that says something about “MOK management”. It’s a complicated topic and I’ll try to explain it in simpler terms.
MOK ([Machine Owner Key](https://firmware.intel.com/blog/using-mok-and-uefi-secure-boot-suse-linux?ref=itsfoss.com)) is needed due to the secure boot feature that requires all kernel modules to be signed. Ubuntu does that for all the kernel modules that it ships in the ISO. Because you installed a new module (the additional driver) or made a change in the kernel modules, your secure system may treat it as an unwarranted/foreign change in your system and may refuse to boot.
Hence, you can either sign the kernel module on your own (telling your UEFI system not to panic because you made these changes) or you simply [disable the secure boot](https://itsfoss.com/disable-secure-boot-in-acer/).
Now that you know a little about [secure boot and MOK](https://wiki.ubuntu.com/UEFI/SecureBoot/DKMS?ref=itsfoss.com), let’s see what to do at the next boot when you see the blue screen at the next boot.
If you select “Continue boot”, chances are that your system will boot like normal and you won’t have to do anything at all. But it’s possible that not all features of the new driver work correctly.
This is why, you should ** choose Enroll MOK**.
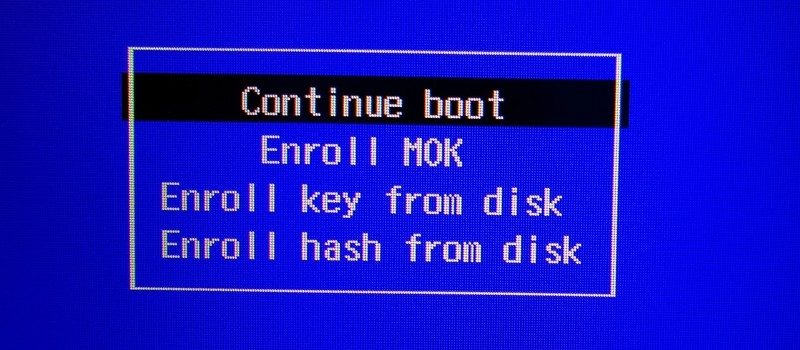
It will ask you to Continue in the next screen followed by asking a password. Use the password you had set while installing the additional drivers in the previous step. You’ll be asked to reboot now.
Once the new driver is installed, you’ll have to restart your system again. Don’t worry! Things should be better now and you won’t need to edit the kernel parameters anymore. You’ll be booting into Ubuntu straightaway.
### Step 4: Enjoy Ubuntu Linux


I hope this tutorial helped you to fix the problem of Ubuntu freezing at the boot time and you were able to boot into your Ubuntu system.
If you have any questions or suggestions, please let me know in the comment section below. |
10,757 | 5 个有用的开源日志分析工具 | https://opensource.com/article/19/4/log-analysis-tools | 2019-04-21T10:51:00 | [
"日志"
] | https://linux.cn/article-10757-1.html |
>
> 监控网络活动既重要又繁琐,以下这些工具可以使它更容易。
>
>
>

监控网络活动是一项繁琐的工作,但有充分的理由这样做。例如,它允许你查找和调查工作站和连接到网络的设备及服务器上的可疑登录,同时确定管理员滥用了什么。你还可以跟踪软件安装和数据传输,以实时识别潜在问题,而不是在损坏发生后才进行跟踪。
这些日志还有助于使你的公司遵守适用于在欧盟范围内运营的任何实体的[通用数据保护条例](https://opensource.com/article/18/4/gdpr-impact)(GDPR)。如果你的网站在欧盟可以浏览,那么你就有遵守的该条例的资格。
日志记录,包括跟踪和分析,应该是任何监控基础设置中的一个基本过程。要从灾难中恢复 SQL Server 数据库,需要事务日志文件。此外,通过跟踪日志文件,DevOps 团队和数据库管理员(DBA)可以保持最佳的数据库性能,又或者,在网络攻击的情况下找到未经授权活动的证据。因此,定期监视和分析系统日志非常重要。这是一种重新创建导致出现任何问题的事件链的可靠方式。
现在有很多开源日志跟踪器和分析工具可供使用,这使得为活动日志选择合适的资源比你想象的更容易。自由和开源软件社区提供的日志设计适用于各种站点和操作系统。以下是五个我用过的最好的工具,它们并没有特别的顺序。
### Graylog
[Graylog](https://www.graylog.org/products/open-source) 于 2011 年在德国创立,现在作为开源工具或商业解决方案提供。它被设计成一个集中式日志管理系统,接受来自不同服务器或端点的数据流,并允许你快速浏览或分析该信息。

Graylog 在系统管理员中有着良好的声誉,因为它易于扩展。大多数 Web 项目都是从小规模开始的,但它们可能指数级增长。Graylog 可以均衡后端服务网络中的负载,每天可以处理几 TB 的日志数据。
IT 管理员会发现 Graylog 的前端界面易于使用,而且功能强大。Graylog 是围绕仪表板的概念构建的,它允许你选择你认为最有价值的指标或数据源,并快速查看一段时间内的趋势。
当发生安全或性能事件时,IT 管理员希望能够尽可能地根据症状追根溯源。Graylog 的搜索功能使这变得容易。它有内置的容错功能,可运行多线程搜索,因此你可以同时分析多个潜在的威胁。
### Nagios
[Nagios](https://www.nagios.org/downloads/) 始于 1999 年,最初是由一个开发人员开发的,现在已经发展成为管理日志数据最可靠的开源工具之一。当前版本的 Nagios 可以与运行 Microsoft Windows、Linux 或 Unix 的服务器集成。

它的主要产品是日志服务器,旨在简化数据收集并使系统管理员更容易访问信息。Nagios 日志服务器引擎将实时捕获数据,并将其提供给一个强大的搜索工具。通过内置的设置向导,可以轻松地与新端点或应用程序集成。
Nagios 最常用于需要监控其本地网络安全性的组织。它可以审核一系列与网络相关的事件,并帮助自动分发警报。如果满足特定条件,甚至可以将 Nagios 配置为运行预定义的脚本,从而允许你在人员介入之前解决问题。
作为网络审计的一部分,Nagios 将根据日志数据来源的地理位置过滤日志数据。这意味着你可以使用地图技术构建全面的仪表板,以了解 Web 流量是如何流动的。
### Elastic Stack (ELK Stack)
[Elastic Stack](https://www.elastic.co/products),通常称为 ELK Stack,是需要筛选大量数据并理解其日志系统的组织中最受欢迎的开源工具之一(这也是我个人的最爱)。

它的主要产品由三个独立的产品组成:Elasticsearch、Kibana 和 Logstash:
* 顾名思义, Elasticsearch 旨在帮助用户使用多种查询语言和类型在数据集之中找到匹配项。速度是它最大的优势。它可以扩展成由数百个服务器节点组成的集群,轻松处理 PB 级的数据。
* Kibana 是一个可视化工具,与 Elasticsearch 一起工作,允许用户分析他们的数据并构建强大的报告。当你第一次在服务器集群上安装 Kibana 引擎时,你会看到一个显示着统计数据、图表甚至是动画的界面。
* ELK Stack 的最后一部分是 Logstash,它作为一个纯粹的服务端管道进入 Elasticsearch 数据库。你可以将 Logstash 与各种编程语言和 API 集成,这样你的网站和移动应用程序中的信息就可以直接提供给强大的 Elastic Stalk 搜索引擎中。
ELK Stack 的一个独特功能是,它允许你监视构建在 WordPress 开源网站上的应用程序。与[跟踪管理日志和 PHP 日志](https://www.wpsecurityauditlog.com/benefits-wordpress-activity-log/)的大多数开箱即用的安全审计日志工具相比,ELK Stack 可以筛选 Web 服务器和数据库日志。
糟糕的日志跟踪和数据库管理是导致网站性能不佳的最常见原因之一。没有定期检查、优化和清空数据库日志,不仅会降低站点的运行速度,还可能导致其完全崩溃。因此,ELK Stack 对于每个 WordPress 开发人员的工具包来说都是一个优秀的工具。
### LOGalyze
[LOGalyze](http://www.logalyze.com/) 是一个位于匈牙利的组织,它为系统管理员和安全专家构建开源工具,以帮助他们管理服务器日志,并将其转换为有用的数据点。其主要产品可供个人或商业用户免费下载。

LOGalyze 被设计成一个巨大的管道,其中多个服务器、应用程序和网络设备可以使用简单对象访问协议(SOAP)方法提供信息。它提供了一个前端界面,管理员可以登录界面来监控数据集并开始分析数据。
在 LOGalyze 的 Web 界面中,你可以运行动态报告,并将其导出到 Excel 文件、PDF 文件或其他格式。这些报告可以基于 LOGalyze 后端管理的多维统计信息。它甚至可以跨服务器或应用程序组合数据字段,借此来帮助你发现性能趋势。
LOGalyze 旨在不到一个小时内完成安装和配置。它具有预先构建的功能,允许它以法律所要求的格式收集审计数据。例如,LOGalyze 可以很容易地运行不同的 HIPAA 报告,以确保你的组织遵守健康法律并保持合规性。
### Fluentd
如果你所在组织的数据源位于许多不同的位置和环境中,那么你的目标应该是尽可能地将它们集中在一起。否则,你将难以监控性能并防范安全威胁。
[Fluentd](https://www.fluentd.org/) 是一个强大的数据收集解决方案,它是完全开源的。它没有提供完整的前端界面,而是作为一个收集层来帮助组织不同的管道。Fluentd 在被世界上一些最大的公司使用,但是也可以在较小的组织中实施。

Fluentd 最大的好处是它与当今最常用的技术工具兼容。例如,你可以使用 Fluentd 从 Web 服务器(如 Apache)、智能设备传感器和 MongoDB 的动态记录中收集数据。如何处理这些数据完全取决于你。
Fluentd 基于 JSON 数据格式,它可以与由卓越的开发人员创建的 [500 多个插件](https://opensource.com/article/18/9/open-source-log-aggregation-tools)一起使用。这使你可以将日志数据扩展到其他应用程序中,并通过最少的手工操作从中获得更好的分析。
### 写在最后
如果出于安全原因、政府合规性和衡量生产力的原因,你还没有使用活动日志,那么现在开始改变吧。市场上有很多插件,它们可以与多种环境或平台一起工作,甚至可以在内部网络上使用。不要等发生了严重的事件,才采取一个积极主动的方法去维护和监督日志。
---
via: <https://opensource.com/article/19/4/log-analysis-tools>
作者:[Sam Bocetta](https://opensource.com/users/sambocetta) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Monitoring network activity can be a tedious job, but there are good reasons to do it. For one, it allows you to find and investigate suspicious logins on workstations, devices connected to networks, and servers while identifying sources of administrator abuse. You can also trace software installations and data transfers to identify potential issues in real time rather than after the damage is done.
Those logs also go a long way towards keeping your company in compliance with the [General Data Protection Regulation](https://opensource.com/article/18/4/gdpr-impact) (GDPR) that applies to any entity operating within the European Union. If you have a website that is viewable in the EU, you qualify.
Logging—both tracking and analysis—should be a fundamental process in any monitoring infrastructure. A transaction log file is necessary to recover a SQL server database from disaster. Further, by tracking log files, DevOps teams and database administrators (DBAs) can maintain optimum database performance or find evidence of unauthorized activity in the case of a cyber attack. For this reason, it's important to regularly monitor and analyze system logs. It's a reliable way to re-create the chain of events that led up to whatever problem has arisen.
There are quite a few open source log trackers and analysis tools available today, making choosing the right resources for activity logs easier than you think. The free and open source software community offers log designs that work with all sorts of sites and just about any operating system. Here are five of the best I've used, in no particular order.
## Graylog
[Graylog](https://www.graylog.org/products/open-source) started in Germany in 2011 and is now offered as either an open source tool or a commercial solution. It is designed to be a centralized log management system that receives data streams from various servers or endpoints and allows you to browse or analyze that information quickly.
Graylog has built a positive reputation among system administrators because of its ease in scalability. Most web projects start small but can grow exponentially. Graylog can balance loads across a network of backend servers and handle several terabytes of log data each day.
IT administrators will find Graylog's frontend interface to be easy to use and robust in its functionality. Graylog is built around the concept of dashboards, which allows you to choose which metrics or data sources you find most valuable and quickly see trends over time.
When a security or performance incident occurs, IT administrators want to be able to trace the symptoms to a root cause as fast as possible. Search functionality in Graylog makes this easy. It has built-in fault tolerance that can run multi-threaded searches so you can analyze several potential threats together.
## Nagios
[Nagios](https://www.nagios.org/downloads/) started with a single developer back in 1999 and has since evolved into one of the most reliable open source tools for managing log data. The current version of Nagios can integrate with servers running Microsoft Windows, Linux, or Unix.

Its primary product is a log server, which aims to simplify data collection and make information more accessible to system administrators. The Nagios log server engine will capture data in real-time and feed it into a powerful search tool. Integrating with a new endpoint or application is easy thanks to the built-in setup wizard.
Nagios is most often used in organizations that need to monitor the security of their local network. It can audit a range of network-related events and help automate the distribution of alerts. Nagios can even be configured to run predefined scripts if a certain condition is met, allowing you to resolve issues before a human has to get involved.
As part of network auditing, Nagios will filter log data based on the geographic location where it originates. That means you can build comprehensive dashboards with mapping technology to understand how your web traffic is flowing.
## Elastic Stack (the "ELK Stack")
[Elastic Stack](https://www.elastic.co/products), often called the ELK Stack, is one of the most popular open source tools among organizations that need to sift through large sets of data and make sense of their system logs (and it's a personal favorite, too).
Its primary offering is made up of three separate products: Elasticsearch, Kibana, and Logstash:
-
As its name suggests,
is designed to help users find matches within datasets using a wide range of query languages and types. Speed is this tool's number one advantage. It can be expanded into clusters of hundreds of server nodes to handle petabytes of data with ease.*Elasticsearch* -
is a visualization tool that runs alongside Elasticsearch to allow users to analyze their data and build powerful reports. When you first install the Kibana engine on your server cluster, you will gain access to an interface that shows statistics, graphs, and even animations of your data.*Kibana* -
The final piece of ELK Stack is
, which acts as a purely server-side pipeline into the Elasticsearch database. You can integrate Logstash with a variety of coding languages and APIs so that information from your websites and mobile applications will be fed directly into your powerful Elastic Stalk search engine.*Logstash*
A unique feature of ELK Stack is that it allows you to monitor applications built on open source installations of WordPress. In contrast to most out-of-the-box security audit log tools that track admin and PHP logs but little else, ELK Stack can sift through web server and database logs.
Poor log tracking and database management are one of the [most common causes of poor website performance](https://websitesetup.org/how-to-speed-up-wordpress/). Failure to regularly check, optimize, and empty database logs can not only slow down a site but could lead to a complete crash as well. Thus, the ELK Stack is an excellent tool for every WordPress developer's toolkit.
## LOGalyze
[LOGalyze](http://www.logalyze.com/) is an organization based in Hungary that builds open source tools for system administrators and security experts to help them manage server logs and turn them into useful data points. Its primary product is available as a free download for either personal or commercial use.
LOGalyze is designed to work as a massive pipeline in which multiple servers, applications, and network devices can feed information using the Simple Object Access Protocol (SOAP) method. It provides a frontend interface where administrators can log in to monitor the collection of data and start analyzing it.
From within the LOGalyze web interface, you can run dynamic reports and export them into Excel files, PDFs, or other formats. These reports can be based on multi-dimensional statistics managed by the LOGalyze backend. It can even combine data fields across servers or applications to help you spot trends in performance.
LOGalyze is designed to be installed and configured in less than an hour. It has prebuilt functionality that allows it to gather audit data in formats required by regulatory acts. For example, LOGalyze can easily run different HIPAA reports to ensure your organization is adhering to health regulations and remaining compliant.
## Fluentd
If your organization has data sources living in many different locations and environments, your goal should be to centralize them as much as possible. Otherwise, you will struggle to monitor performance and protect against security threats.
[Fluentd](https://www.fluentd.org/) is a robust solution for data collection and is entirely open source. It does not offer a full frontend interface but instead acts as a collection layer to help organize different pipelines. Fluentd is used by some of the largest companies worldwide but can be implemented in smaller organizations as well.
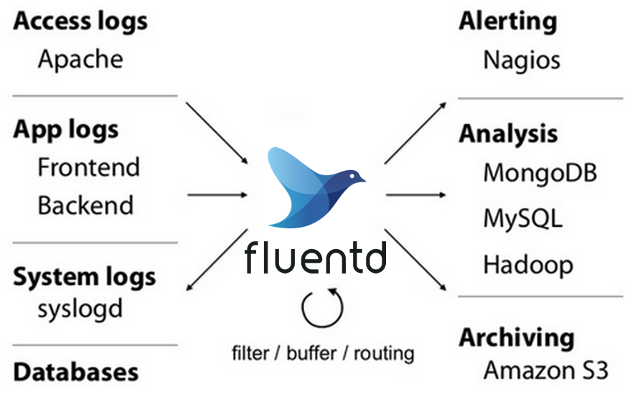
The biggest benefit of Fluentd is its compatibility with the most common technology tools available today. For example, you can use Fluentd to gather data from web servers like Apache, sensors from smart devices, and dynamic records from MongoDB. What you do with that data is entirely up to you.
Fluentd is based around the JSON data format and can be used in conjunction with [more than 500 plugins](https://opensource.com/article/18/9/open-source-log-aggregation-tools) created by reputable developers. This allows you to extend your logging data into other applications and drive better analysis from it with minimal manual effort.
## The bottom line
If you aren't already using activity logs for security reasons, governmental compliance, and measuring productivity, commit to changing that. There are plenty of plugins on the market that are designed to work with multiple environments and platforms, even on your internal network. Don't wait for a serious incident to justify taking a proactive approach to logs maintenance and oversight.
## Comments are closed. |
10,761 | 在 Bash 中使用[方括号](二) | https://www.linux.com/blog/learn/2019/4/using-square-brackets-bash-part-2 | 2019-04-22T10:09:00 | [
"方括号"
] | https://linux.cn/article-10761-1.html | 
>
> 我们继续来看方括号的用法,它们甚至还可以在 Bash 当中作为一个命令使用。
>
>
>
欢迎回到我们的方括号专题。在[前一篇文章](/article-10717-1.html)当中,我们介绍了方括号在命令行中可以用于通配操作,如果你已经读过前一篇文章,就可以从这里继续了。
方括号还可以以一个命令的形式使用,就像这样:
```
[ "a" = "a" ]
```
上面这种 `[ ... ]` 的形式就可以看成是一个可执行的命令。要注意,方括号内部的内容 `"a" = "a"` 和方括号 `[`、`]` 之间是有空格隔开的。因为这里的方括号被视作一个命令,因此要用空格将命令和它的参数隔开。
上面这个命令的含义是“判断字符串 `"a"` 和字符串 `"a"` 是否相同”,如果判断结果为真,那么 `[ ... ]` 就会以<ruby> 状态码 <rt> status code </rt></ruby> 0 退出,否则以状态码 1 退出。在[之前的文章](/article-10596-1.html)中,我们也有介绍过状态码的概念,可以通过 `$?` 变量获取到最近一个命令的状态码。
分别执行
```
[ "a" = "a" ]
echo $?
```
以及
```
[ "a" = "b" ]
echo $?
```
这两段命令中,前者会输出 0(判断结果为真),后者则会输出 1(判断结果为假)。在 Bash 当中,如果一个命令的状态码是 0,表示这个命令正常执行完成并退出,而且其中没有出现错误,对应布尔值 `true`;如果在命令执行过程中出现错误,就会返回一个非零的状态码,对应布尔值 `false`。而 `[ ... ]` 也同样遵循这样的规则。
因此,`[ ... ]` 很适合在 `if ... then`、`while` 或 `until` 这种在代码块结束前需要判断是否达到某个条件结构中使用。
对应使用的逻辑判断运算符也相当直观:
```
[ STRING1 = STRING2 ] => 检查字符串是否相等
[ STRING1 != STRING2 ] => 检查字符串是否不相等
[ INTEGER1 -eq INTEGER2 ] => 检查整数 INTEGER1 是否等于 INTEGER2
[ INTEGER1 -ge INTEGER2 ] => 检查整数 INTEGER1 是否大于等于 INTEGER2
[ INTEGER1 -gt INTEGER2 ] => 检查整数 INTEGER1 是否大于 INTEGER2
[ INTEGER1 -le INTEGER2 ] => 检查整数 INTEGER1 是否小于等于 INTEGER2
[ INTEGER1 -lt INTEGER2 ] => 检查整数 INTEGER1 是否小于 INTEGER2
[ INTEGER1 -ne INTEGER2 ] => 检查整数 INTEGER1 是否不等于 INTEGER2
等等……
```
方括号的这种用法也可以很有 shell 风格,例如通过带上 `-f` 参数可以判断某个文件是否存在:
```
for i in {000..099}; \
do \
if [ -f file$i ]; \
then \
echo file$i exists; \
else \
touch file$i; \
echo I made file$i; \
fi; \
done
```
如果你在上一篇文章使用到的测试目录中运行以上这串命令,其中的第 3 行会判断那几十个文件当中的某个文件是否存在。如果文件存在,会输出一条提示信息;如果文件不存在,就会把对应的文件创建出来。最终,这个目录中会完整存在从 `file000` 到 `file099` 这一百个文件。
上面这段命令还可以写得更加简洁:
```
for i in {000..099};\
do\
if [ ! -f file$i ];\
then\
touch file$i;\
echo I made file$i;\
fi;\
done
```
其中 `!` 运算符表示将判断结果取反,因此第 3 行的含义就是“如果文件 `file$i` 不存在”。
可以尝试一下将测试目录中那几十个文件随意删除几个,然后运行上面的命令,你就可以看到它是如何把被删除的文件重新创建出来的。
除了 `-f` 之外,还有很多有用的参数。`-d` 参数可以判断某个目录是否存在,`-h` 参数可以判断某个文件是不是一个符号链接。可以用 `-G` 参数判断某个文件是否属于某个用户组,用 `-ot` 参数判断某个文件的最后更新时间是否早于另一个文件,甚至还可以判断某个文件是否为空文件。
运行下面的几条命令,可以向几个文件中写入一些内容:
```
echo "Hello World" >> file023
echo "This is a message" >> file065
echo "To humanity" >> file010
```
然后运行:
```
for i in {000..099};\
do\
if [ ! -s file$i ];\
then\
rm file$i;\
echo I removed file$i;\
fi;\
done
```
你就会发现所有空文件都被删除了,只剩下少数几个非空的文件。
如果你还想了解更多别的参数,可以执行 `man test` 来查看 `test` 命令的 man 手册(`test` 是 `[ ... ]` 的命令别名)。
有时候你还会看到 `[[ ... ]]` 这种双方括号的形式,使用起来和单方括号差别不大。但双方括号支持的比较运算符更加丰富:例如可以使用 `==` 来判断某个字符串是否符合某个<ruby> 模式 <rt> pattern </rt></ruby>,也可以使用 `<`、`>` 来判断两个字符串的出现顺序。
可以在 [Bash 表达式文档](https://www.gnu.org/software/bash/manual/bashref.html#Bash-Conditional-Expressions)中了解到双方括号支持的更多运算符。
### 下一集
在下一篇文章中,我们会开始介绍圆括号 `()` 在 Linux 命令行中的用法,敬请关注!
### 更多
* [Linux 工具:点的含义](/article-10465-1.html)
* [理解 Bash 中的尖括号](/article-10502-1.html)
* [Bash 中尖括号的更多用法](/article-10529-1.html)
* [Linux 中的 &](/article-10587-1.html)
* [Bash 中的 & 符号和文件描述符](/article-10591-1.html)
* [Bash 中的逻辑和(&)](/article-10596-1.html)
* [浅析 Bash 中的 {花括号}](/article-10624-1.html)
* [在 Bash 中使用[方括号] (一)](/article-10717-1.html)
---
via: <https://www.linux.com/blog/learn/2019/4/using-square-brackets-bash-part-2>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,762 | 怎样在 Kubernetes 上运行 PostgreSQL | https://opensource.com/article/19/3/how-run-postgresql-kubernetes | 2019-04-22T10:56:49 | [
"Kubernetes",
"PostgreSQL"
] | https://linux.cn/article-10762-1.html |
>
> 创建统一管理的,具备灵活性的云原生生产部署来部署一个个性化的数据库即服务(DBaaS)。
>
>
>

通过在 [Kubernetes](https://www.postgresql.org/) 上运行 [PostgreSQL](https://kubernetes.io/) 数据库,你能创建统一管理的,具备灵活性的云原生生产部署应用来部署一个个性化的数据库即服务为你的特定需求进行量身定制。
对于 Kubernetes,使用 Operator 允许你提供额外的上下文去[管理有状态应用](https://opensource.com/article/19/2/scaling-postgresql-kubernetes-operators)。当使用像PostgreSQL 这样开源的数据库去执行包括配置、扩展、高可用和用户管理时,Operator 也很有帮助。
让我们来探索如何在 Kubernetes 上启动并运行 PostgreSQL。
### 安装 PostgreSQL Operator
将 PostgreSQL 和 Kubernetes 结合使用的第一步是安装一个 Operator。在针对 Linux 系统的Crunchy 的[快速启动脚本](https://crunchydata.github.io/postgres-operator/stable/installation/#quickstart-script)的帮助下,你可以在任意基于 Kubernetes 的环境下启动和运行开源的[Crunchy PostgreSQL Operator](https://github.com/CrunchyData/postgres-operator)。
快速启动脚本有一些必要前提:
* [Wget](https://www.gnu.org/software/wget/) 工具已安装。
* [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/) 工具已安装。
* 在你的 Kubernetes 中已经定义了一个 [StorageClass](https://kubernetes.io/docs/concepts/storage/storage-classes/)。
* 拥有集群权限的可访问 Kubernetes 的用户账号,以安装 Operator 的 [RBAC](https://kubernetes.io/docs/reference/access-authn-authz/rbac/) 规则。
* 一个 PostgreSQL Operator 的 [命名空间](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/)。
执行这个脚本将提供给你一个默认的 PostgreSQL Operator 部署,其默认假设你采用 [动态存储](https://kubernetes.io/docs/concepts/storage/dynamic-provisioning/)和一个名为 `standard` 的 StorageClass。这个脚本允许用户采用自定义的值去覆盖这些默认值。
通过下列命令,你能下载这个快速启动脚本并把它的权限设置为可执行:
```
wget <https://raw.githubusercontent.com/CrunchyData/postgres-operator/master/examples/quickstart.sh>
chmod +x ./quickstart.sh
```
然后你运行快速启动脚本:
```
./examples/quickstart.sh
```
在脚本提示你相关的 Kubernetes 集群基本信息后,它将执行下列操作:
* 下载 Operator 配置文件
* 将 `$HOME/.pgouser` 这个文件设置为默认设置
* 以 Kubernetes [Deployment](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/) 部署 Operator
* 设置你的 `.bashrc` 文件包含 Operator 环境变量
* 设置你的 `$HOME/.bash_completion` 文件为 `pgo bash_completion` 文件
在快速启动脚本的执行期间,你将会被提示在你的 Kubernetes 集群设置 RBAC 规则。在另一个终端,执行快速启动命令所提示你的命令。
一旦这个脚本执行完成,你将会得到提示设置一个端口以转发到 PostgreSQL Operator pod。在另一个终端,执行这个端口转发操作;这将允许你开始对 PostgreSQL Operator 执行命令!尝试输入下列命令创建集群:
```
pgo create cluster mynewcluster
```
你能输入下列命令测试你的集群运行状况:
```
pgo test mynewcluster
```
现在,你能在 Kubernetes 环境下管理你的 PostgreSQL 数据库了!你可以在[官方文档](https://crunchydata.github.io/postgres-operator/stable/#documentation)找到非常全面的命令,包括扩容,高可用,备份等等。
这篇文章部分参考了该作者为 Crunchy 博客而写的[在 Kubernetes 上开始运行 PostgreSQL](https://info.crunchydata.com/blog/get-started-runnning-postgresql-on-kubernetes)。
---
via: <https://opensource.com/article/19/3/how-run-postgresql-kubernetes>
作者:[Jonathan S. Katz](https://opensource.com/users/jkatz05) 选题:[lujun9972](https://github.com/lujun9972) 译者:[arrowfeng](https://github.com/arrowfeng) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | By running a [PostgreSQL](https://www.postgresql.org/) database on [Kubernetes](https://kubernetes.io/), you can create uniformly managed, cloud-native production deployments with the flexibility to deploy a personalized database-as-a-service tailored to your specific needs.
Using an Operator allows you to provide additional context to Kubernetes to [manage a stateful application](https://opensource.com/article/19/2/scaling-postgresql-kubernetes-operators). An Operator is also helpful when using an open source database like PostgreSQL to help with actions including provisioning, scaling, high availability, and user management.
Let's explore how to get PostgreSQL up and running on Kubernetes.
## Set up the PostgreSQL operator
The first step to using PostgreSQL with Kubernetes is installing an Operator. You can get up and running with the open source [Crunchy PostgreSQL Operator](https://github.com/CrunchyData/postgres-operator) on any Kubernetes-based environment with the help of Crunchy's [quickstart script](https://crunchydata.github.io/postgres-operator/stable/installation/#quickstart-script) for Linux.
The quickstart script has a few prerequisites:
- The
[Wget](https://www.gnu.org/software/wget/)utility installed [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/)installed- A
[StorageClass](https://kubernetes.io/docs/concepts/storage/storage-classes/)defined on your Kubernetes cluster - Access to a Kubernetes user account with cluster-admin privileges. This is required to install the Operator
[RBAC](https://kubernetes.io/docs/reference/access-authn-authz/rbac/)rules - A
[namespace](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/)to hold the PostgreSQL Operator
Executing the script will give you a default PostgreSQL Operator deployment that assumes [dynamic storage](https://kubernetes.io/docs/concepts/storage/dynamic-provisioning/) and a StorageClass named **standard**. User-provided values are allowed by the script to override these defaults.
You can download the quickstart script and set it to be executable with the following commands:
```
wget https://raw.githubusercontent.com/CrunchyData/postgres-operator/master/examples/quickstart.sh
chmod +x ./quickstart.sh
```
Then you can execute the quickstart script:
`./examples/quickstart.sh`
After the script prompts you for some basic information about your Kubernetes cluster, it performs the following operations:
- Downloads the Operator configuration files
- Sets the
**$HOME/.pgouser**file to default settings - Deploys the Operator as a Kubernetes
[Deployment](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/) - Sets your
**.bashrc**to include the Operator environmental variables - Sets your
**$HOME/.bash_completion**file to be the**pgo bash_completion**file
During the quickstart's execution, you'll be prompted to set up the RBAC rules for your Kubernetes cluster. In a separate terminal, execute the command the quickstart command tells you to use.
Once the script completes, you'll get information on setting up a port forward to the PostgreSQL Operator pod. In a separate terminal, execute the port forward; this will allow you to begin executing commands to the PostgreSQL Operator! Try creating a cluster by entering:
`pgo create cluster mynewcluster`
You can test that your cluster is up and running with by entering:
`pgo test mynewcluster`
You can now manage your PostgreSQL databases in your Kubernetes environment! You can find a full reference to commands, including those for scaling, high availability, backups, and more, in the [documentation](https://crunchydata.github.io/postgres-operator/stable/#documentation).
*Parts of this article are based on *[Get Started Running PostgreSQL on Kubernetes](https://info.crunchydata.com/blog/get-started-runnning-postgresql-on-kubernetes) that the author wrote for the Crunchy blog.
## Comments are closed. |
10,765 | HTTPie:替代 Curl 和 Wget 的现代 HTTP 命令行客户端 | https://www.2daygeek.com/httpie-curl-wget-alternative-http-client-linux/ | 2019-04-22T12:30:48 | [
"HTTPie",
"curl",
"wget"
] | https://linux.cn/article-10765-1.html | 
大多数时间我们会使用 `curl` 命令或是 `wget` 命令下载文件或者做其他事。
我们以前曾写过 [最佳命令行下载管理器](https://www.2daygeek.com/best-4-command-line-download-managers-accelerators-for-linux/) 的文章。你可以点击相应的 URL 连接来浏览这些文章。
* [aria2 – Linux 下的多协议命令行下载工具](https://www.2daygeek.com/aria2-linux-command-line-download-utility-tool/)
* [Axel – Linux 下的轻量级命令行下载加速器](https://www.2daygeek.com/axel-linux-command-line-download-accelerator/)
* [Wget – Linux 下的标准命令行下载工具](https://www.2daygeek.com/wget-linux-command-line-download-utility-tool/)
* [curl – Linux 下的实用的命令行下载工具](https://www.2daygeek.com/curl-linux-command-line-download-manager/)
今天我们将讨论同样的话题。这个实用程序名为 HTTPie。
它是现代命令行 http 客户端,也是 `curl` 和 `wget` 命令的最佳替代品。
### 什么是 HTTPie?
HTTPie (发音是 aitch-tee-tee-pie) 是一个 HTTP 命令行客户端。
HTTPie 工具是现代的 HTTP 命令行客户端,它能通过命令行界面与 Web 服务进行交互。
它提供一个简单的 `http` 命令,允许使用简单而自然的语法发送任意的 HTTP 请求,并会显示彩色的输出。
HTTPie 能用于测试、调试及与 HTTP 服务器交互。
### 主要特点
* 具表达力的和直观语法
* 格式化的及彩色化的终端输出
* 内置 JSON 支持
* 表单和文件上传
* HTTPS、代理和认证
* 任意请求数据
* 自定义头部
* 持久化会话
* 类似 `wget` 的下载
* 支持 Python 2.7 和 3.x
### 在 Linux 下如何安装 HTTPie
大部分 Linux 发行版都提供了系统包管理器,可以用它来安装。
Fedora 系统,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 httpie:
```
$ sudo dnf install httpie
```
Debian/Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 HTTPie。
```
$ sudo apt install httpie
```
基于 Arch Linux 的系统,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 HTTPie。
```
$ sudo pacman -S httpie
```
RHEL/CentOS 的系统,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 来安装 HTTPie。
```
$ sudo yum install httpie
```
openSUSE Leap 系统,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 来安装 HTTPie。
```
$ sudo zypper install httpie
```
### 用法
#### 如何使用 HTTPie 请求 URL?
HTTPie 的基本用法是将网站的 URL 作为参数。
```
# http 2daygeek.com
HTTP/1.1 301 Moved Permanently
CF-RAY: 4c4a618d0c02ce6d-LHR
Cache-Control: max-age=3600
Connection: keep-alive
Date: Tue, 09 Apr 2019 06:21:28 GMT
Expires: Tue, 09 Apr 2019 07:21:28 GMT
Location: https://2daygeek.com/
Server: cloudflare
Transfer-Encoding: chunked
Vary: Accept-Encoding
```
#### 如何使用 HTTPie 下载文件
你可以使用带 `--download` 参数的 HTTPie 命令下载文件。类似于 `wget` 命令。
```
# http --download https://www.2daygeek.com/wp-content/uploads/2019/04/Anbox-Easy-Way-To-Run-Android-Apps-On-Linux.png
HTTP/1.1 200 OK
Accept-Ranges: bytes
CF-Cache-Status: HIT
CF-RAY: 4c4a65d5ca360a66-LHR
Cache-Control: public, max-age=7200
Connection: keep-alive
Content-Length: 32066
Content-Type: image/png
Date: Tue, 09 Apr 2019 06:24:23 GMT
Expect-CT: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
Expires: Tue, 09 Apr 2019 08:24:23 GMT
Last-Modified: Mon, 08 Apr 2019 04:54:25 GMT
Server: cloudflare
Set-Cookie: __cfduid=dd2034b2f95ae42047e082f59f2b964f71554791063; expires=Wed, 08-Apr-20 06:24:23 GMT; path=/; domain=.2daygeek.com; HttpOnly; Secure
Vary: Accept-Encoding
Downloading 31.31 kB to "Anbox-Easy-Way-To-Run-Android-Apps-On-Linux.png"
Done. 31.31 kB in 0.01187s (2.58 MB/s)
```
你还可以使用 `-o` 参数用不同的名称保存输出文件。
```
# http --download https://www.2daygeek.com/wp-content/uploads/2019/04/Anbox-Easy-Way-To-Run-Android-Apps-On-Linux.png -o Anbox-1.png
HTTP/1.1 200 OK
Accept-Ranges: bytes
CF-Cache-Status: HIT
CF-RAY: 4c4a68194daa0a66-LHR
Cache-Control: public, max-age=7200
Connection: keep-alive
Content-Length: 32066
Content-Type: image/png
Date: Tue, 09 Apr 2019 06:25:56 GMT
Expect-CT: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
Expires: Tue, 09 Apr 2019 08:25:56 GMT
Last-Modified: Mon, 08 Apr 2019 04:54:25 GMT
Server: cloudflare
Set-Cookie: __cfduid=d3eea753081690f9a2d36495a74407dd71554791156; expires=Wed, 08-Apr-20 06:25:56 GMT; path=/; domain=.2daygeek.com; HttpOnly; Secure
Vary: Accept-Encoding
Downloading 31.31 kB to "Anbox-1.png"
Done. 31.31 kB in 0.01551s (1.97 MB/s)
```
#### 如何使用 HTTPie 恢复部分下载?
你可以使用带 `-c` 参数的 HTTPie 继续下载。
```
# http --download --continue https://speed.hetzner.de/100MB.bin -o 100MB.bin
HTTP/1.1 206 Partial Content
Connection: keep-alive
Content-Length: 100442112
Content-Range: bytes 4415488-104857599/104857600
Content-Type: application/octet-stream
Date: Tue, 09 Apr 2019 06:32:52 GMT
ETag: "5253f0fd-6400000"
Last-Modified: Tue, 08 Oct 2013 11:48:13 GMT
Server: nginx
Strict-Transport-Security: max-age=15768000; includeSubDomains
Downloading 100.00 MB to "100MB.bin"
| 24.14 % 24.14 MB 1.12 MB/s 0:01:07 ETA^C
```
你根据下面的输出验证是否同一个文件:
```
[email protected]:/var/log# ls -lhtr 100MB.bin
-rw-r--r-- 1 root root 25M Apr 9 01:33 100MB.bin
```
#### 如何使用 HTTPie 上传文件?
你可以通过使用带有小于号 `<` 的 HTTPie 命令上传文件
```
$ http https://transfer.sh < Anbox-1.png
```
#### 如何使用带有重定向符号 > 下载文件?
你可以使用带有重定向 `>` 符号的 HTTPie 命令下载文件。
```
# http https://www.2daygeek.com/wp-content/uploads/2019/03/How-To-Install-And-Enable-Flatpak-Support-On-Linux-1.png > Flatpak.png
# ls -ltrh Flatpak.png
-rw-r--r-- 1 root root 47K Apr 9 01:44 Flatpak.png
```
#### 发送一个 HTTP GET 请求?
您可以在请求中发送 HTTP GET 方法。GET 方法会使用给定的 URI,从给定服务器检索信息。
```
# http GET httpie.org
HTTP/1.1 301 Moved Permanently
CF-RAY: 4c4a83a3f90dcbe6-SIN
Cache-Control: max-age=3600
Connection: keep-alive
Date: Tue, 09 Apr 2019 06:44:44 GMT
Expires: Tue, 09 Apr 2019 07:44:44 GMT
Location: https://httpie.org/
Server: cloudflare
Transfer-Encoding: chunked
Vary: Accept-Encoding
```
#### 提交表单?
使用以下格式提交表单。POST 请求用于向服务器发送数据,例如客户信息、文件上传等。要使用 HTML 表单。
```
# http -f POST Ubuntu18.2daygeek.com hello='World'
HTTP/1.1 200 OK
Accept-Ranges: bytes
Connection: Keep-Alive
Content-Encoding: gzip
Content-Length: 3138
Content-Type: text/html
Date: Tue, 09 Apr 2019 06:48:12 GMT
ETag: "2aa6-5844bf1b047fc-gzip"
Keep-Alive: timeout=5, max=100
Last-Modified: Sun, 17 Mar 2019 15:29:55 GMT
Server: Apache/2.4.29 (Ubuntu)
Vary: Accept-Encoding
```
运行下面的指令以查看正在发送的请求。
```
# http -v Ubuntu18.2daygeek.com
GET / HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate
Connection: keep-alive
Host: ubuntu18.2daygeek.com
User-Agent: HTTPie/0.9.8
hello=World
HTTP/1.1 200 OK
Accept-Ranges: bytes
Connection: Keep-Alive
Content-Encoding: gzip
Content-Length: 3138
Content-Type: text/html
Date: Tue, 09 Apr 2019 06:48:30 GMT
ETag: "2aa6-5844bf1b047fc-gzip"
Keep-Alive: timeout=5, max=100
Last-Modified: Sun, 17 Mar 2019 15:29:55 GMT
Server: Apache/2.4.29 (Ubuntu)
Vary: Accept-Encoding
```
#### HTTP 认证?
当前支持的身份验证认证方案是基本认证(Basic)和摘要验证(Digest)。
基本认证:
```
$ http -a username:password example.org
```
摘要验证:
```
$ http -A digest -a username:password example.org
```
提示输入密码:
```
$ http -a username example.org
```
---
via: <https://www.2daygeek.com/httpie-curl-wget-alternative-http-client-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zgj1024](https://github.com/zgj1024) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,766 | 如何检查多个远程 Linux 系统是否打开了指定端口? | https://www.2daygeek.com/check-a-open-port-on-multiple-remote-linux-server-using-nc-command/ | 2019-04-22T23:08:11 | [
"端口",
"nc"
] | https://linux.cn/article-10766-1.html | 
我们最近写了一篇文章关于如何检查远程 Linux 服务器是否打开指定端口。它能帮助你检查单个服务器。
如果要检查五个服务器有没有问题,可以使用以下任何一个命令,如 `nc`(netcat)、`nmap` 和 `telnet`。但是如果想检查 50 多台服务器,那么你的解决方案是什么?
要检查所有服务器并不容易,如果你一个一个这样做,完全没有必要,因为这样你将会浪费大量的时间。为了解决这种情况,我使用 `nc` 命令编写了一个 shell 小脚本,它将允许我们扫描任意数量服务器给定的端口。
如果你要查找单个服务器扫描,你有多个选择,你只需阅读 [检查远程 Linux 系统上的端口是否打开?](/article-10675-1.html) 了解更多信息。
本教程中提供了两个脚本,这两个脚本都很有用。这两个脚本都用于不同的目的,你可以通过阅读标题轻松理解其用途。
在你阅读这篇文章之前,我会问你几个问题,如果你不知道答案你可以通过阅读这篇文章来获得答案。
如何检查一个远程 Linux 服务器上指定的端口是否打开?
如何检查多个远程 Linux 服务器上指定的端口是否打开?
如何检查多个远程 Linux 服务器上是否打开了多个指定的端口?
### 什么是 nc(netcat)命令?
`nc` 即 netcat。它是一个简单实用的 Unix 程序,它使用 TCP 或 UDP 协议进行跨网络连接进行数据读取和写入。
它被设计成一个可靠的 “后端” 工具,我们可以直接使用或由其他程序和脚本轻松驱动它。
同时,它也是一个功能丰富的网络调试和探索工具,因为它可以创建你需要的几乎任何类型的连接,并具有几个有趣的内置功能。
netcat 有三个主要的模式。分别是连接模式,监听模式和隧道模式。
`nc`(netcat)的通用语法:
```
$ nc [-options] [HostName or IP] [PortNumber]
```
### 如何检查多个远程 Linux 服务器上的端口是否打开?
如果要检查多个远程 Linux 服务器上给定端口是否打开,请使用以下 shell 脚本。
在我的例子中,我们将检查端口 22 是否在以下远程服务器中打开,确保你已经更新文件中的服务器列表而不是使用我的服务器列表。
你必须确保已经更新服务器列表 :`server-list.txt` 。每个服务器(IP)应该在单独的行中。
```
# cat server-list.txt
192.168.1.2
192.168.1.3
192.168.1.4
192.168.1.5
192.168.1.6
192.168.1.7
```
使用以下脚本可以达到此目的。
```
# vi port_scan.sh
#!/bin/sh
for server in `more server-list.txt`
do
#echo $i
nc -zvw3 $server 22
done
```
设置 `port_scan.sh` 文件的可执行权限。
```
$ chmod +x port_scan.sh
```
最后运行脚本来达到此目的。
```
# sh port_scan.sh
Connection to 192.168.1.2 22 port [tcp/ssh] succeeded!
Connection to 192.168.1.3 22 port [tcp/ssh] succeeded!
Connection to 192.168.1.4 22 port [tcp/ssh] succeeded!
Connection to 192.168.1.5 22 port [tcp/ssh] succeeded!
Connection to 192.168.1.6 22 port [tcp/ssh] succeeded!
Connection to 192.168.1.7 22 port [tcp/ssh] succeeded!
```
### 如何检查多个远程 Linux 服务器上是否打开多个端口?
如果要检查多个服务器中的多个端口,请使用下面的脚本。
在我的例子中,我们将检查给定服务器的 22 和 80 端口是否打开。确保你必须替换所需的端口和服务器名称而不使用是我的。
你必须确保已经将要检查的端口写入 `port-list.txt` 文件中。每个端口应该在一个单独的行中。
```
# cat port-list.txt
22
80
```
你必须确保已经将要检查的服务器(IP 地址)写入 `server-list.txt` 到文件中。每个服务器(IP) 应该在单独的行中。
```
# cat server-list.txt
192.168.1.2
192.168.1.3
192.168.1.4
192.168.1.5
192.168.1.6
192.168.1.7
```
使用以下脚本来达成此目的。
```
# vi multiple_port_scan.sh
#!/bin/sh
for server in `more server-list.txt`
do
for port in `more port-list.txt`
do
#echo $server
nc -zvw3 $server $port
echo ""
done
done
```
设置 `multiple_port_scan.sh` 文件的可执行权限。
```
$ chmod +x multiple_port_scan.sh
```
最后运行脚本来实现这一目的。
```
# sh multiple_port_scan.sh
Connection to 192.168.1.2 22 port [tcp/ssh] succeeded!
Connection to 192.168.1.2 80 port [tcp/http] succeeded!
Connection to 192.168.1.3 22 port [tcp/ssh] succeeded!
Connection to 192.168.1.3 80 port [tcp/http] succeeded!
Connection to 192.168.1.4 22 port [tcp/ssh] succeeded!
Connection to 192.168.1.4 80 port [tcp/http] succeeded!
Connection to 192.168.1.5 22 port [tcp/ssh] succeeded!
Connection to 192.168.1.5 80 port [tcp/http] succeeded!
Connection to 192.168.1.6 22 port [tcp/ssh] succeeded!
Connection to 192.168.1.6 80 port [tcp/http] succeeded!
Connection to 192.168.1.7 22 port [tcp/ssh] succeeded!
Connection to 192.168.1.7 80 port [tcp/http] succeeded!
```
---
via: <https://www.2daygeek.com/check-a-open-port-on-multiple-remote-linux-server-using-nc-command/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zero-MK](https://github.com/zero-mk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,768 | 在 Linux 中把用户添加到组的四个方法 | https://www.2daygeek.com/linux-add-user-to-group-primary-secondary-group-usermod-gpasswd/ | 2019-04-23T13:03:00 | [
"用户",
"用户组"
] | https://linux.cn/article-10768-1.html | 
Linux 组是用于管理 Linux 中用户帐户的组织单位。对于 Linux 系统中的每一个用户和组,它都有惟一的数字标识号。它被称为 用户 ID(UID)和组 ID(GID)。组的主要目的是为组的成员定义一组特权。它们都可以执行特定的操作,但不能执行其他操作。
Linux 中有两种类型的默认组。每个用户应该只有一个 <ruby> 主要组 <rt> primary group </rt></ruby> 和任意数量的 <ruby> 次要组 <rt> secondary group </rt></ruby>。
* **主要组:** 创建用户帐户时,已将主要组添加到用户。它通常是用户的名称。在执行诸如创建新文件(或目录)、修改文件或执行命令等任何操作时,主要组将应用于用户。用户的主要组信息存储在 `/etc/passwd` 文件中。
* **次要组:** 它被称为次要组。它允许用户组在同一组成员文件中执行特定操作。例如,如果你希望允许少数用户运行 Apache(httpd)服务命令,那么它将非常适合。
你可能对以下与用户管理相关的文章感兴趣。
* [在 Linux 中创建用户帐户的三种方法?](https://www.2daygeek.com/linux-user-account-creation-useradd-adduser-newusers/)
* [如何在 Linux 中创建批量用户?](https://www.2daygeek.com/how-to-create-the-bulk-users-in-linux/)
* [如何在 Linux 中使用不同的方法更新/更改用户密码?](https://www.2daygeek.com/linux-passwd-chpasswd-command-set-update-change-users-password-in-linux-using-shell-script/)
可以使用以下四种方法实现。
* `usermod`:修改系统帐户文件,以反映在命令行中指定的更改。
* `gpasswd`:用于管理 `/etc/group` 和 `/etc/gshadow`。每个组都可以有管理员、成员和密码。
* Shell 脚本:可以让管理员自动执行所需的任务。
* 手动方式:我们可以通过编辑 `/etc/group` 文件手动将用户添加到任何组中。
我假设你已经拥有此操作所需的组和用户。在本例中,我们将使用以下用户和组:`user1`、`user2`、`user3`,另外的组是 `mygroup` 和 `mygroup1`。
在进行更改之前,我希望检查一下用户和组信息。详见下文。
我可以看到下面的用户与他们自己的组关联,而不是与其他组关联。
```
# id user1
uid=1008(user1) gid=1008(user1) groups=1008(user1)
# id user2
uid=1009(user2) gid=1009(user2) groups=1009(user2)
# id user3
uid=1010(user3) gid=1010(user3) groups=1010(user3)
```
我可以看到这个组中没有关联的用户。
```
# getent group mygroup
mygroup:x:1012:
# getent group mygroup1
mygroup1:x:1013:
```
### 方法 1:使用 usermod 命令
`usermod` 命令修改系统帐户文件,以反映命令行上指定的更改。
#### 如何使用 usermod 命令将现有的用户添加到次要组或附加组?
要将现有用户添加到辅助组,请使用带有 `-G` 选项和组名称的 `usermod` 命令。
语法:
```
# usermod [-G] [GroupName] [UserName]
```
如果系统中不存在给定的用户或组,你将收到一条错误消息。如果没有得到任何错误,那么用户已经被添加到相应的组中。
```
# usermod -a -G mygroup user1
```
让我使用 `id` 命令查看输出。是的,添加成功。
```
# id user1
uid=1008(user1) gid=1008(user1) groups=1008(user1),1012(mygroup)
```
#### 如何使用 usermod 命令将现有的用户添加到多个次要组或附加组?
要将现有用户添加到多个次要组中,请使用带有 `-G` 选项的 `usermod` 命令和带有逗号分隔的组名称。
语法:
```
# usermod [-G] [GroupName1,GroupName2] [UserName]
```
在本例中,我们将把 `user2` 添加到 `mygroup` 和 `mygroup1` 中。
```
# usermod -a -G mygroup,mygroup1 user2
```
让我使用 `id` 命令查看输出。是的,`user2` 已成功添加到 `myGroup` 和 `myGroup1` 中。
```
# id user2
uid=1009(user2) gid=1009(user2) groups=1009(user2),1012(mygroup),1013(mygroup1)
```
#### 如何改变用户的主要组?
要更改用户的主要组,请使用带有 `-g` 选项和组名称的 `usermod` 命令。
语法:
```
# usermod [-g] [GroupName] [UserName]
```
我们必须使用 `-g` 改变用户的主要组。
```
# usermod -g mygroup user3
```
让我们看看输出。是的,已成功更改。现在,显示`user3` 主要组是 `mygroup` 而不是 `user3`。
```
# id user3
uid=1010(user3) gid=1012(mygroup) groups=1012(mygroup)
```
### 方法 2:使用 gpasswd 命令
`gpasswd` 命令用于管理 `/etc/group` 和 `/etc/gshadow`。每个组都可以有管理员、成员和密码。
#### 如何使用 gpasswd 命令将现有用户添加到次要组或者附加组?
要将现有用户添加到次要组,请使用带有 `-M` 选项和组名称的 `gpasswd` 命令。
语法:
```
# gpasswd [-M] [UserName] [GroupName]
```
在本例中,我们将把 `user1` 添加到 `mygroup` 中。
```
# gpasswd -M user1 mygroup
```
让我使用 `id` 命令查看输出。是的,`user1` 已成功添加到 `mygroup` 中。
```
# id user1
uid=1008(user1) gid=1008(user1) groups=1008(user1),1012(mygroup)
```
#### 如何使用 gpasswd 命令添加多个用户到次要组或附加组中?
要将多个用户添加到辅助组中,请使用带有 `-M` 选项和组名称的 `gpasswd` 命令。
语法:
```
# gpasswd [-M] [UserName1,UserName2] [GroupName]
```
在本例中,我们将把 `user2` 和 `user3` 添加到 `mygroup1` 中。
```
# gpasswd -M user2,user3 mygroup1
```
让我使用 `getent` 命令查看输出。是的,`user2` 和 `user3` 已成功添加到 `myGroup1` 中。
```
# getent group mygroup1
mygroup1:x:1013:user2,user3
```
#### 如何使用 gpasswd 命令从组中删除一个用户?
要从组中删除用户,请使用带有 `-d` 选项的 `gpasswd` 命令以及用户和组的名称。
语法:
```
# gpasswd [-d] [UserName] [GroupName]
```
在本例中,我们将从 `mygroup` 中删除 `user1` 。
```
# gpasswd -d user1 mygroup
Removing user user1 from group mygroup
```
### 方法 3:使用 Shell 脚本
基于上面的例子,我知道 `usermod` 命令没有能力将多个用户添加到组中,可以通过 `gpasswd` 命令完成。但是,它将覆盖当前与组关联的现有用户。
例如,`user1` 已经与 `mygroup` 关联。如果要使用 `gpasswd` 命令将 `user2` 和 `user3` 添加到 `mygroup` 中,它将不会按预期生效,而是对组进行修改。
如果要将多个用户添加到多个组中,解决方案是什么?
两个命令中都没有默认选项来实现这一点。
因此,我们需要编写一个小的 shell 脚本来实现这一点。
#### 如何使用 gpasswd 命令将多个用户添加到次要组或附加组?
如果要使用 `gpasswd` 命令将多个用户添加到次要组或附加组,请创建以下 shell 脚本。
创建用户列表。每个用户应该在单独的行中。
```
$ cat user-lists.txt
user1
user2
user3
```
使用以下 shell 脚本将多个用户添加到单个次要组。
```
vi group-update.sh
#!/bin/bash
for user in `cat user-lists.txt`
do
usermod -a -G mygroup $user
done
```
设置 `group-update.sh` 文件的可执行权限。
```
# chmod + group-update.sh
```
最后运行脚本来实现它。
```
# sh group-update.sh
```
让我看看使用 `getent` 命令的输出。 是的,`user1`、`user2` 和 `user3` 已成功添加到 `mygroup` 中。
```
# getent group mygroup
mygroup:x:1012:user1,user2,user3
```
#### 如何使用 gpasswd 命令将多个用户添加到多个次要组或附加组?
如果要使用 `gpasswd` 命令将多个用户添加到多个次要组或附加组中,请创建以下 shell 脚本。
创建用户列表。每个用户应该在单独的行中。
```
$ cat user-lists.txt
user1
user2
user3
```
创建组列表。每组应在单独的行中。
```
$ cat group-lists.txt
mygroup
mygroup1
```
使用以下 shell 脚本将多个用户添加到多个次要组。
```
#!/bin/sh
for user in `more user-lists.txt`
do
for group in `more group-lists.txt`
do
usermod -a -G $group $user
done
```
设置 `group-update-1.sh` 文件的可执行权限。
```
# chmod +x group-update-1.sh
```
最后运行脚本来实现它。
```
# sh group-update-1.sh
```
让我看看使用 `getent` 命令的输出。 是的,`user1`、`user2` 和 `user3` 已成功添加到 `mygroup` 中。
```
# getent group mygroup
mygroup:x:1012:user1,user2,user3
```
此外,`user1`、`user2` 和 `user3` 已成功添加到 `mygroup1` 中。
```
# getent group mygroup1
mygroup1:x:1013:user1,user2,user3
```
### 方法 4:在 Linux 中将用户添加到组中的手动方法
我们可以通过编辑 `/etc/group` 文件手动将用户添加到任何组中。
打开 `/etc/group` 文件并搜索要更新用户的组名。最后将用户更新到相应的组中。
```
# vi /etc/group
```
---
via: <https://www.2daygeek.com/linux-add-user-to-group-primary-secondary-group-usermod-gpasswd/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[NeverKnowsTomorrow](https://github.com/NeverKnowsTomorrow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,769 | 你应该学习哪种编程语言? | https://opensource.com/article/19/2/which-programming-languages-should-you-learn | 2019-04-24T08:28:55 | [
"编程",
"语言"
] | https://linux.cn/article-10769-1.html |
>
> 学习一门新的编程语言是在你的职业生涯中继续前进的好方法,但是应该学习哪一门呢?
>
>
>

如果你想要开始你的编程生涯或继续前进,那么学习一门新语言是一个聪明的主意。但是,大量活跃使用的语言引发了一个问题:哪种编程语言是最好的?要回答这个问题,让我们从一个简单的问题开始:你想做什么样的程序?
如果你想在客户端进行网络编程,那么特定语言 HTML、CSS 和 JavaScript(看似无穷无尽的方言之一)是必须要学习的。
如果你想在服务器端进行 Web 编程,那么选择包括常见的通用语言:C++、Golang、Java、C#、 Node.js、Perl、Python、Ruby 等等。当然,服务器程序与数据存储(例如关系数据库和其他数据库)打交道,这意味着 SQL 等查询语言可能会发挥作用。
如果你正在为移动设备编写原生应用程序,那么了解目标平台非常重要。对于 Apple 设备,Swift 已经取代 Objective C 成为首选语言。对于 Android 设备,Java(带有专用库和工具集)仍然是主要语言。有一些特殊语言,如与 C# 一起使用的 Xamarin,可以为 Apple、Android 和 Windows 设备生成特定于平台的代码。
那么通用语言呢?通常有各种各样的选择。在*动态*或*脚本*语言(如 Perl、Python 和 Ruby)中,有一些新东西,如 Node.js。而 Java 和 C# 的相似之处比它们的粉丝愿意承认的还要多,仍然是针对虚拟机(分别是 JVM 和 CLR)的主要*静态编译*语言。在可以编译为*原生可执行文件*的语言中,C++ 仍在使用,还有后来出现的 Golang 和 Rust 等。通用的*函数式*语言比比皆是(如 Clojure、Haskell、Erlang、F#、Lisp 和 Scala),它们通常都有热情投入的社区。值得注意的是,面向对象语言(如 Java 和 C#)已经添加了函数式构造(特别是 lambdas),而动态语言从一开始就有函数式构造。
让我以 C 语言结尾,它是一种小巧、优雅、可扩展的语言,不要与 C++ 混淆。现代操作系统主要用 C 语言编写,其余部分用汇编语言编写。任何平台上的标准库大多数都是用 C 语言编写的。例如,任何打印 `Hello, world!` 这种问候都是通过调用名为 `write` 的 C 库函数来实现的。
C 作为一种可移植的汇编语言,公开了其他高级语言有意隐藏的底层系统的详细信息。因此,理解 C 可以更好地掌握程序如何竞争执行所需的共享系统资源(如处理器、内存和 I/O 设备)。C 语言既高级又接近硬件,因此在性能方面无与伦比,当然,汇编语言除外。最后,C 是编程语言中的通用语言,几乎所有通用语言都支持某种形式的 C 调用。
有关现代 C 语言的介绍,参考我的书籍《[C 语言编程:可移植的汇编器介绍](https://www.amazon.com/dp/1977056954?ref_=pe_870760_150889320)》。无论你怎么做,学习 C 语言,你会学到比另一种编程语言多得多的东西。
你认为学习哪些编程语言很重要?你是否同意这些建议?在评论告知我们!
---
via: <https://opensource.com/article/19/2/which-programming-languages-should-you-learn>
作者:[Marty Kalin](https://opensource.com/users/mkalindepauledu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you want to get started or get ahead in your programming career, learning a new language is a smart idea. But the huge number of languages in active use invites the question: Which programming language is the best one to know? To answer that, let's start with a simplifying question: What sort of programming do you want to do?
If you want to do web programming on the client side, then the specialized languages HTML, CSS, and JavaScript—in one of its seemingly infinite dialects—are de rigueur.
If you want to do web programming on the server side, the options include all of the familiar general-purpose languages: C++, Golang, Java, C#, Node.js, Perl, Python, Ruby, and so on. As a matter of course, server-side programs interact with datastores, such as relational and other databases, which means query languages such as SQL may come into play.
If you're writing native apps for mobile devices, knowing the target platform is important. For Apple devices, Swift has supplanted Objective C as the language of choice. For Android devices, Java (with dedicated libraries and toolsets) remains the dominant language. There are special languages such as Xamarin, used with C#, that can generate platform-specific code for Apple, Android, and Windows devices.
What about general-purpose languages? There are various choices within the usual pigeonholes. Among the *dynamic* or *scripting* languages (e.g., Perl, Python, and Ruby), there are newer offerings such as Node.js. Java and C#, which are more alike than their fans like to admit, remain the dominant *statically compiled* languages targeted at a virtual machine (the JVM and CLR, respectively). Among languages that compile into *native executables*, C++ is still in the mix, along with later arrivals such as Golang and Rust. General-purpose *functional* languages abound (e.g., Clojure, Haskell, Erlang, F#, Lisp, and Scala), often with passionately devoted communities. It's worth noting that object-oriented languages such as Java and C# have added functional constructs (in particular, lambdas), and the dynamic languages have had functional constructs from the start.
Let me end with a pitch for C, which is a small, elegant, and extensible language not to be confused with C++. Modern operating systems are written mostly in C, with the rest in assembly language. The standard libraries on any platform are likewise mostly in C. For example, any program that issues the *Hello, world!* greeting does so through a call to the C library function named **write**.
C serves as a portable assembly language, exposing details about the underlying system that other high-level languages deliberately hide. To understand C is thus to gain a better grasp of how programs contend for the shared system resources (processors, memory, and I/O devices) required for execution. C is at once high-level and close-to-the-metal, so unrivaled in performance—except, of course, for assembly language. Finally, C is the lingua franca among programming languages, and almost every general-purpose language supports C calls in one form or another.
For a modern introduction to C, consider my book [ C Programming: Introducing Portable Assembler](https://www.amazon.com/dp/1977056954?ref_=pe_870760_150889320). No matter how you go about it, learn C and you'll learn a lot more than just another programming language.
What programming languages do you think are important to know? Do you agree or disagree with these recommendations? Let us know in the comments!
## 21 Comments |
10,771 | 使用 sgdisk 管理分区 | https://fedoramagazine.org/managing-partitions-with-sgdisk/ | 2019-04-24T11:33:00 | [
"分区",
"sgdisk"
] | https://linux.cn/article-10771-1.html | 
[Roderick W. Smith](https://www.rodsbooks.com/) 的 `sgdisk` 命令可在命令行中管理硬盘的分区。下面将介绍使用它所需的基础知识。
使用 sgdisk 的大多数基本功能只需要了解以下六个参数:
1、`-p` *打印* 分区表:
```
# sgdisk -p /dev/sda
```
2、 `-d x` *删除* 分区 x:
```
# sgdisk -d 1 /dev/sda
```
3、 `-n x:y:z` 创建一个编号 x 的*新*分区,从 y 开始,从 z 结束:
```
# sgdisk -n 1:1MiB:2MiB /dev/sda
```
4、`-c x:y` *更改*分区 x 的名称为 y:
```
# sgdisk -c 1:grub /dev/sda
```
5、`-t x:y` 将分区 x 的*类型*更改为 y:
```
# sgdisk -t 1:ef02 /dev/sda
```
6、`–list-types` 列出分区类型代码:
```
# sgdisk --list-types
```

如你在上面的例子中所见,大多数命令都要求将要操作的硬盘的[设备文件名](https://en.wikipedia.org/wiki/Device_file)指定为最后一个参数。
可以组合上面的参数,这样你可以一次定义所有分区:
```
# sgdisk -n 1:1MiB:2MiB -t 1:ef02 -c 1:grub /dev/sda
```
在值的前面加上 `+` 或 `–` 符号,可以为某些字段指定相对值。如果你使用相对值,`sgdisk` 会为你做数学运算。例如,上面的例子可以写成:
```
# sgdisk -n 1:1MiB:+1MiB -t 1:ef02 -c 1:grub /dev/sda
```
`0` 值对于以下几个字段有特殊意义:
* 对于*分区号*字段,0 表示应使用下一个可用编号(编号从 1 开始)。
* 对于*起始地址*字段,0 表示使用最大可用空闲块的头。硬盘开头的一些空间始终保留给分区表本身。
* 对于*结束地址*字段,0 表示使用最大可用空闲块的末尾。
通过在适当的字段中使用 `0` 和相对值,你可以创建一系列分区,而无需预先计算任何绝对值。例如,如果在一块空白硬盘中,以下 `sgdisk` 命令序列将创建典型 Linux 安装所需的所有基本分区:
```
# sgdisk -n 0:0:+1MiB -t 0:ef02 -c 0:grub /dev/sda
# sgdisk -n 0:0:+1GiB -t 0:ea00 -c 0:boot /dev/sda
# sgdisk -n 0:0:+4GiB -t 0:8200 -c 0:swap /dev/sda
# sgdisk -n 0:0:0 -t 0:8300 -c 0:root /dev/sda
```
上面的例子展示了如何为基于 BIOS 的计算机分区硬盘。基于 UEFI 的计算机上不需要 [grub 分区](https://en.wikipedia.org/wiki/BIOS_boot_partition)。由于 `sgdisk` 在上面的示例中为你计算了所有绝对值,因此你可以在基于 UEFI 的计算机上跳过第一个命令,并且可以无需修改即可运行其余命令。同样,你可以跳过创建交换分区,并且不需要修改其余命令。
还有使用一个命令删除硬盘上所有分区的快捷方式:
```
# sgdisk --zap-all /dev/sda
```
关于最新和详细信息,请查看手册页:
```
$ man sgdisk
```
---
via: <https://fedoramagazine.org/managing-partitions-with-sgdisk/>
作者:[Gregory Bartholomew](https://fedoramagazine.org/author/glb/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Roderick W. Smith](https://www.rodsbooks.com/)‘s *sgdisk* command can be used to manage the partitioning of your hard disk drive from the command line. The basics that you need to get started with it are demonstrated below.
The following six parameters are all that you need to know to make use of sgdisk’s most basic features:
**-p**the partition table:__P__rint
# sgdisk -p /dev/sda**-d x**partition x:__D__elete
# sgdisk -d 1 /dev/sda**-n x:y:z**
Create apartition numbered x, starting at y and ending at z:__n__ew
# sgdisk -n 1:1MiB:2MiB /dev/sda**-c x:y**the name of partition x to y:__C__hange
# sgdisk -c 1:grub /dev/sda**-t x:y**
Change theof partition x to y:__t__ype
# sgdisk -t 1:ef02 /dev/sda**–list-types**
List the partition type codes:
# sgdisk --list-types
As you can see in the above examples, most of the commands require that the [device file name](https://en.wikipedia.org/wiki/Device_file) of the hard disk drive to operate on be specified as the last parameter.
The parameters shown above can be combined so that you can completely define a partition with a single run of the sgdisk command:
Relative values can be specified for some fields by prefixing the value with a **+** or **–** symbol. If you use a relative value, sgdisk will do the math for you. For example, the above example could be written as:
The value **0** has a special-case meaning for several of the fields:
- In the
*partition number*field, 0 indicates that the next available number should be used (numbering starts at 1). - In the
*starting address*field, 0 indicates that the start of the largest available block of free space should be used. Some space at the start of the hard drive is always reserved for the partition table itself. - In the
*ending address*field, 0 indicates that the end of the largest available block of free space should be used.
By using **0** and relative values in the appropriate fields, you can create a series of partitions without having to pre-calculate any absolute values. For example, the following sequence of sgdisk commands would create all the basic partitions that are needed for a typical Linux installation if in run sequence against a blank hard drive:
# sgdisk -n 0:0:+1GiB -t 0:ea00 -c 0:boot /dev/sda
# sgdisk -n 0:0:+4GiB -t 0:8200 -c 0:swap /dev/sda
# sgdisk -n 0:0:0 -t 0:8300 -c 0:root /dev/sda
The above example shows how to partition a hard disk for a BIOS-based computer. The [grub partition](https://en.wikipedia.org/wiki/BIOS_boot_partition) is not needed on a UEFI-based computer. Because sgdisk is calculating all the absolute values for you in the above example, you can just skip running the first command on a UEFI-based computer and the remaining commands can be run without modification. Likewise, you could skip creating the swap partition and the remaining commands would not need to be modified.
There is also a short-cut for deleting all the partitions from a hard disk with a single command:
For the most up-to-date and detailed information, check the man page:
## Leslie Satenstein
Clear explanation. Thank you.
## Stuart D Gathman
The man page gives a good acount of using sgdisk to convert MBR to GPT. It involves a risk of making the system unbootable – but nothing a live USB stick can’t fix. A backup is probably a good idea, though.
## Gregory Bartholomew
Thanks for pointing that out Stuart. I probably should have mentioned the dangers of converting an existing MBR partition table in the article. Thankfully, it looks like the sgdisk command includes a bit of a safty:
-g, –mbrtogpt
Convert an MBR or BSD disklabel disk to a GPT disk. As a safety measure, use of this option is required on MBR or BSD disklabel disks if you intend to save your changes, in order to prevent accidentally damaging such disks.
The following would probably be a good idea for anyone thinking about converting an MBR disk to GPT to run:
$ sudo sfdisk -d /dev/sda > partition-table-backup.dat
That could then be restored from a rescue disk with:
# cat partition-table-backup.dat | sfdisk /dev/sda
## Stuart D Gathman
When I try converting to GPT on a VM, sgdisk complains that the last partition overlaps secondary partition table by 33 sectors. The same complaint is given on
anyMBR disk I’ve looked at with sgdisk. I’m guessing that a second copy of the GPT is kept at the end of the disk, and the last partition (usually a PV) needs to be made 33 sectors smaller. Is this correct?## Gregory Bartholomew
You are exactly correct. The backup copy is referred to as the “second-header” in the man page. It is just a backup and is only used in case the original gets corrupted somehow. So you could safely ignore the error if you want. The older MBR never kept a backup copy of its data.
I’m not sure that I would recommend people convert their partition tables though. Its not something that I ever do. That said, I think you
shouldbe able to get away with it on UEFI systems because UEFIshouldfall back to using the /efi/boot/bootx64.efi (more accurately /efi/boot/boot{machine type short-name}.efi) when the partition IDs change.If you want to tell Anaconda to use GPT by default when you first install your OS, you can pass the
inst.gptoption on the kernel command line when you boot your installation disk: Anaconda Boot OptionsSee also: An Introduction to Disk Partitions
P.S. I would always recommend rounding your partition alignments to the nearest 1MiB to reduce the changes of hitting the double-write problem: Disk Partition Alignment Is Still Important
## ignition
Cool way of explaining the ideas. Loved it.
## Anil
Why you used sfdisk instead of sgdisk to take the backup?
You can use sgdisk itself to take backup.
sgdisk –backup=/root/sda-part.bkp /dev/sda
To restore
sgdisk –load-backup=/root/sda-part.bkp /dev/sda
## Gregory Bartholomew
As a general rule, sfdisk is used to manage MBR partition tables and sgdisk is used to manage GPT partition tables. Admittedly though, sgdisks backup option is probably an exception to that rule and it
probablybacks up and restores MBR data (I’m not 100% certain of that though).Even better, of course, would be to keep a backup copy of your entire hard drive. In fact, I’m working on an article to demonstrate how to do that right now.
## commenter
what are the pros when compared to fdisk/gdisk?
## Gregory Bartholomew
The only real advantage of sgdisk over gdisk is that it can be scripted. The reason that I wrote this post is because I am using sgdisk in an upcoming article on how to convert your system drive to use software RAID and the editors requested that I write individual posts for several of the commands I used in that article — dracut, mdadm, and sgdisk (Fedora Magazine Meeting 2019-03-27 time index 20:27:09 if you are curious). The upcoming article will link back to this one for further details. |
10,772 | Shell 脚本编程陷阱 | https://arp242.net/weblog/shell-scripting-trap.html | 2019-04-24T12:14:59 | [
"shell",
"脚本"
] | https://linux.cn/article-10772-1.html | 
Shell 脚本很棒,你可以非常轻松地写出有用的东西来。甚至像是下面这个傻瓜式的命令:
```
# 用含有 Go 的词汇起名字:
$ grep -i ^go /usr/share/dict/* | cut -d: -f2 | sort -R | head -n1
goldfish
```
如果用其他编程语言,就需要花费更多的脑力,用多行代码实现,比如用 Ruby 的话:
```
puts(Dir['/usr/share/dict/*-english'].map do |f|
File.open(f)
.readlines
.select { |l| l[0..1].downcase == 'go' }
end.flatten.sample.chomp)
```
Ruby 版本的代码虽然不是那么长,也并不复杂。但是 shell 版是如此简单,我甚至不用实际测试就可以确保它是正确的。而 Ruby 版的我就没法确定它不会出错了,必须得测试一下。而且它要长一倍,看起来也更复杂。
这就是人们使用 Shell 脚本的原因,它简单却实用。下面是另一个例子:
```
curl https://nl.wikipedia.org/wiki/Lijst_van_Nederlandse_gemeenten |
grep '^<li><a href=' |
sed -r 's|<li><a href="/wiki/.+" title=".+">(.+)</a>.*</li>|\1|' |
grep -Ev '(^Tabel van|^Lijst van|Nederland)'
```
这个脚本可以从维基百科上获取荷兰基层政权的列表。几年前我写了这个临时的脚本,用来快速生成一个数据库,到现在它仍然可以正常运行,当时写它并没有花费我多少精力。但要用 Ruby 完成同样的功能则会麻烦得多。
---
现在来说说 shell 的缺点吧。随着代码量的增加,你的脚本会变得越来越难以维护,但你也不会想用别的语言重写一遍,因为你已经在这个 shell 版上花费了很多时间。
我把这种情况称为“Shell 脚本编程陷阱”,这是[沉没成本谬论](https://youarenotsosmart.com/2011/03/25/the-sunk-cost-fallacy/)的一种特例(LCTT 译注:“沉没成本谬论”是一个经济学概念,可以简单理解为,对已经投入的成本可能被浪费而念念不忘)。
实际上许多脚本会增长到超出预期的大小,你经常会花费过多的时间来“修复某个 bug”,或者“添加一个小功能”。如此循环往复,让人头大。
如果你从一开始就使用 Python、Ruby 或是其他类似的语言来写这个程序,你可能会在写第一版的时候多花些时间,但以后维护起来就容易很多,bug 也肯定会少很多。
以我的 [packman.vim](https://github.com/Carpetsmoker/packman.vim) 脚本为例。它起初只包含一个简单的用来遍历所有目录的 `for` 循环,外加一个 `git pull`,但在这之后就刹不住车了,它现在有 200 行左右的代码,这肯定不能算是最复杂的脚本,但假如我一上来就按计划用 Go 来编写它的话,那么增加一些像“打印状态”或者“从配置文件里克隆新的 git 库”这样的功能就会轻松很多;添加“并行克隆”的支持也几乎不算个事儿了,而在 shell 脚本里却很难实现(尽管不是不可能)。事后看来,我本可以节省时间,并且获得更好的结果。
出于类似的原因,我很后悔写出了许多这样的 shell 脚本,而我在 2018 年的新年誓言就是不要再犯类似的错误了。
### 附录:问题汇总
需要指出的是,shell 编程的确存在一些实际的限制。下面是一些例子:
* 在处理一些包含“空格”或者其他“特殊”字符的文件名时,需要特别注意细节。绝大多数脚本都会犯错,即使是那些经验丰富的作者(比如我)编写的脚本,因为太容易写错了,[只添加引号是不够的](https://dwheeler.com/essays/filenames-in-shell.html)。
* 有许多所谓“正确”和“错误”的做法。你应该用 `which` 还是 `command`?该用 `$@` 还是 `$*`,是不是得加引号?你是该用 `cmd $arg` 还是 `cmd "$arg"`?等等等等。
* 你没法在变量里存储空字节(0x00);shell 脚本处理二进制数据很麻烦。
* 虽然你可以非常快速地写出有用的东西,但实现更复杂的算法则要痛苦许多,即使用 ksh/zsh/bash 扩展也是如此。我上面那个解析 HTML 的脚本临时用用是可以的,但你真的不会想在生产环境中使用这种脚本。
* 很难写出跨平台的通用型 shell 脚本。`/bin/sh` 可能是 `dash` 或者 `bash`,不同的 shell 有不同的运行方式。外部工具如 `grep`、`sed` 等,不一定能支持同样的参数。你能确定你的脚本可以适用于 Linux、macOS 和 Windows 的所有版本吗(无论是过去、现在还是将来)?
* 调试 shell 脚本会很难,特别是你眼中的语法可能会很快变得记不清了,并不是所有人都熟悉 shell 编程的语境。
* 处理错误会很棘手(检查 `$?` 或是 `set -e`),排查一些超过“出了个小错”级别的复杂错误几乎是不可能的。
* 除非你使用了 `set -u`,变量未定义将不会报错,而这会导致一些“搞笑事件”,比如 `rm -r ~/$undefined` 会删除用户的整个家目录([瞅瞅 Github 上的这个悲剧](https://github.com/ValveSoftware/steam-for-linux/issues/3671))。
* 所有东西都是字符串。一些 shell 引入了数组,能用,但是语法非常丑陋和费解。带分数的数字运算仍然难以应付,并且依赖像 `bc` 或 `dc` 这样的外部工具(`$(( .. ))` 这种方式只能对付一下整数)。
**反馈**
你可以发邮件到 [[email protected]](mailto:[email protected]),或者[在 GitHub 上创建 issue](https://github.com/Carpetsmoker/arp242.net/issues/new) 来向我反馈,提问等。
---
via: <https://arp242.net/weblog/shell-scripting-trap.html>
作者:[Martin Tournoij](https://arp242.net/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jdh8383](https://github.com/jdh8383) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,773 | 增强边缘计算的安全性 | https://www.networkworld.com/article/3388130/enhanced-security-at-the-edge.html | 2019-04-24T23:02:00 | [
"IoT",
"边缘计算"
] | https://linux.cn/article-10773-1.html |
>
> 边缘计算环境带来的安全风险迫使公司必须特别关注它的安全措施。
>
>
>

说数据安全是高管们和董事会最关注的问题已经是陈词滥调了。但问题是:数据安全问题不会自己消失。
骇客和攻击者一直在寻找利用缺陷的新方法。就像公司开始使用人工智能和机器学习等新兴技术来自动化地保护他们的组织一样,那些不良分子们也在使用这些技术来达成他们的目的。
简而言之,安全问题是一定不能忽视的。现在,随着越来越多的公司开始使用边缘计算,如何保护这些边缘计算环境,需要有新的安全考量。
### 边缘计算的风险更高
正如 Network World 的一篇文章所说,边缘计算的安全架构应该将重点放在物理安全上。这并不是说要忽视保护传输过程中的数据。而是说,实际的物理环境和物理设备更加值得关注。
例如,边缘计算的硬件设备通常位于较大的公司或者广阔空间中,有时候是在很容易进入的共享办公室和公共区域里。从表面上看,这节省了成本,能更快地访问到相关的数据,而不必在后端的数据中心和前端的设备之间往返。
但是,如果没有任何级别的访问控制,这台设备就会暴露在恶意操作和简单人为错误的双重风险之下。想象一下办公室的清洁工意外地关掉了设备,以及随之而来的停机所造成的后果。
另一个风险是 “影子边缘 IT”。有时候非 IT 人员会部署一个边缘设备来快速启动项目,却没有及时通知 IT 部门这个设备正在连接到网络。例如,零售商店可能会主动安装他们自己的数字标牌,或者,销售团队会将物联网传感器应用到电视中,并在销售演示中实时地部署它们。
在这种情况下,IT 部门很少甚至完全看不到这些边缘设备,这就使得网络可能暴露在外。
### 保护边缘计算环境
部署微型数据中心(MDC)是规避上述风险的一个简单方法。
>
> “在历史上,大多数这些[边缘]环境都是不受控制的,”施耐德电气安全能源部门的首席技术官和创新高级副总裁 Kevin Brown 说。“它们可能是第 1 级,但很可能是第 0 级类型的设计 —— 它们就像开放的配线柜。它们现在需要像微型数据中心一样的对待。你管理它需要像管理关键任务数据中心一样”
>
>
>
单说听起来的感觉,这个解决方案是一个安全、独立的机箱,它包括在室内和室外运行程序所需的所有存储空间、处理性能和网络资源。它同样包含必要的电源、冷却、安全和管理工具。
而它最重要的是高级别的安全性。这个装置是封闭的,有上锁的门,可以防止非法入侵。通过合适的供应商,DMC 可以进行定制,包括用于远程数字化管理的监控摄像头、传感器和监控技术。
随着越来越多的公司开始利用边缘计算的优势,他们必须利用安全解决方案的优势来保护他们的数据和边缘环境。
在 APC.com 上了解保护你的边缘计算环境的最佳方案。
---
via: <https://www.networkworld.com/article/3388130/enhanced-security-at-the-edge.html#tk.rss_all>
作者:[Anne Taylor](https://www.networkworld.com/author/Anne-Taylor/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,774 | 喜欢 Netflix 么?你应该感谢 FreeBSD | https://itsfoss.com/netflix-freebsd-cdn/ | 2019-04-24T23:49:38 | [
"Netflix",
"FreeBSD"
] | https://linux.cn/article-10774-1.html | 
Netflix 是世界上最受欢迎的流媒体服务之一。对,你已经知道了。但你可能不知道的是 Netflix 使用 [FreeBSD](https://www.freebsd.org/) 向你提供内容。
是的。Netflix 依靠 FreeBSD 来构建其内部内容交付网络(CDN)。
[CDN](https://www.cloudflare.com/learning/cdn/what-is-a-cdn/) 是一组位于世界各地的服务器。它主要用于向终端用户分发像图像和视频这样的“大文件”。
Netflix 没有选择商业 CDN 服务,而是建立了自己的内部 CDN,名为 [Open Connect](https://openconnect.netflix.com/en/)。
Open Connect 使用[自定义硬件](https://openconnect.netflix.com/en/hardware/):Open Connect Appliance。你可以在下面的图片中看到它。它可以每秒处理 40Gb 的数据,存储容量为 248 TB。

Netflix 免费为合格的互联网服务提供商(ISP) 提供 Open Connect Appliance。通过这种方式,大量的 Netflix 流量得到了本地化,ISP 可以更高效地提供 Netflix 内容。
Open Connect Appliance 运行在 FreeBSD 操作系统上,并且[几乎完全运行开源软件](https://openconnect.netflix.com/en/software/)。
### Open Connect 使用最新版 FreeBSD
你或许会觉得 Netflix 会在这样一个关键基础设施上使用 FreeBSD 的稳定版本,但 Netflix 会跟踪 [FreeBSD 最新/当前版本](https://www.bsdnow.tv/tutorials/stable-current)。Netflix 表示,跟踪“最新版”可以让他们“保持前瞻性,专注于创新”。
以下是 Netflix 跟踪最新版 FreeBSD 的好处:
* 更快的功能迭代
* 更快地使用 FreeBSD 的新功能
* 更快的 bug 修复
* 实现协作
* 尽量减少合并冲突
* 摊销合并“成本”
>
> 运行 FreeBSD “最新版” 可以让我们非常高效地向用户分发大量数据,同时保持高速的功能开发。
>
>
> Netflix
>
>
>
请记得,甚至[谷歌也使用 Debian](https://itsfoss.com/goobuntu-glinux-google/) 测试版而不是 Debian 稳定版。也许这些企业更喜欢最先进的功能。
与谷歌一样,Netflix 也计划向上游提供代码。这应该有助于 FreeBSD 和其他基于 FreeBSD 的 BSD 发行版。
那么 Netflix 用 FreeBSD 实现了什么?以下是一些统计数据:
>
> 使用 FreeBSD 和商业硬件,我们在 16 核 2.6 GHz CPU 上使用约 55% 的 CPU,实现了 90 Gb/s 的 TLS 加密连接。
>
>
> Netflix
>
>
>
如果你想了解更多关于 Netflix 和 FreeBSD 的信息,可以参考 [FOSDEM 的这个演示文稿](https://fosdem.org/2019/schedule/event/netflix_freebsd/attachments/slides/3103/export/events/attachments/netflix_freebsd/slides/3103/FOSDEM_2019_Netflix_and_FreeBSD.pdf)。你还可以在[这里](http://mirror.onet.pl/pub/mirrors/video.fosdem.org/2019/Janson/netflix_freebsd.webm)观看演示文稿的视频。
目前,大型企业主要依靠 Linux 来实现其服务器基础架构,但 Netflix 已经信任了 BSD。这对 BSD 社区来说是一件好事,因为如果像 Netflix 这样的行业领导者重视 BSD,那么其他人也可以跟上。你怎么看?
---
via: <https://itsfoss.com/netflix-freebsd-cdn/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Netflix is one of the most popular streaming services in the world.
But you already know that. Don’t you?
What you probably did not know is that Netflix uses [FreeBSD](https://www.freebsd.org/) to deliver its content to you.
Yes, that’s right. Netflix relies on FreeBSD to build its in-house content delivery network (CDN).
A [CDN](https://www.cloudflare.com/learning/cdn/what-is-a-cdn/) is a
Instead of opting for a commercial CDN service, Netflix has built its own in-house CDN called [Open Connect](https://openconnect.netflix.com/en/).
Open Connect utilizes [custom hardware](https://openconnect.netflix.com/en/hardware/), Open Connect Appliance. You can see it in the image below. It can handle 40Gb/s data and has a storage capacity of 248TB.

Netflix provides Open Connect Appliance to qualifying Internet Service Providers (ISP) for free. This way, substantial Netflix traffic gets localized and the ISPs deliver the Netflix content more efficiently.
This Open Connect Appliance runs on FreeBSD operating system and [almost exclusively runs open source software](https://openconnect.netflix.com/en/software/).
## Open Connect uses FreeBSD “Head”

You would expect Netflix to use a stable release of FreeBSD for such a critical infrastructure but Netflix tracks the [FreeBSD head/current version](https://www.bsdnow.tv/tutorials/stable-current). Netflix says that tracking “head” lets them “stay forward-looking and focused on innovation”.
Here are the benefits Netflix sees of tracking FreeBSD:
- Quicker feature iteration
- Quicker access to new FreeBSD features
- Quicker bug fixes
- Enables collaboration
- Minimizes merge conflicts
- Amortizes merge “cost”
Running FreeBSD “head” lets us deliver large amounts of data to our users very efficiently, while maintaining a high velocity of feature development.
Netflix
Remember, even [Google uses Debian](https://itsfoss.com/goobuntu-glinux-google/) testing instead of Debian stable. Perhaps these enterprises prefer the cutting edge features more than anything else.
Like Google, Netflix also plans to upstream any code they can. This should help FreeBSD and other BSD distributions based on FreeBSD.
So what does Netflix achieves with FreeBSD? Here are some quick stats:
Using FreeBSD and commodity parts, we achieve 90 Gb/s serving TLS-encrypted connections with ~55% CPU on a 16-core 2.6-GHz CPU.
Netflix
If you want to know more about Netflix and FreeBSD, you can refer to [this presentation from FOSDEM](https://fosdem.org/2019/schedule/event/netflix_freebsd/attachments/slides/3103/export/events/attachments/netflix_freebsd/slides/3103/FOSDEM_2019_Netflix_and_FreeBSD.pdf). You can also watch the video of the presentation [here](http://mirror.onet.pl/pub/mirrors/video.fosdem.org/2019/Janson/netflix_freebsd.webm).
These days big enterprises rely mostly on Linux for their server infrastructure but Netflix has put their trust in BSD. This is a good thing for BSD community because if an industry leader like Netflix throws its weight behind BSD, others could follow the lead. What do you think? |
10,777 | 如何识别 Linux 上的文件分身 | https://www.networkworld.com/article/3387961/how-to-identify-duplicate-files-on-linux.html | 2019-04-25T11:23:34 | [
"文件",
"相同"
] | https://linux.cn/article-10777-1.html |
>
> Linux 系统上的一些文件可能出现在多个位置。按照本文指示查找并识别这些“同卵双胞胎”,还可以了解为什么硬链接会如此有利。
>
>
>

识别使用同一个磁盘空间的文件依赖于利用文件使用相同的 inode 这一事实。这种数据结构存储除了文件名和内容之外的所有信息。如果两个或多个文件具有不同的名称和文件系统位置,但共享一个 inode,则它们还共享内容、所有权、权限等。
这些文件通常被称为“硬链接”,不像符号链接(即软链接)那样仅仅通过包含它们的名称指向其他文件,符号链接很容易在文件列表中通过第一个位置的 `l` 和引用文件的 `->` 符号识别出来。
```
$ ls -l my*
-rw-r--r-- 4 shs shs 228 Apr 12 19:37 myfile
lrwxrwxrwx 1 shs shs 6 Apr 15 11:18 myref -> myfile
-rw-r--r-- 4 shs shs 228 Apr 12 19:37 mytwin
```
在单个目录中的硬链接并不是很明显,但它仍然非常容易找到。如果使用 `ls -i` 命令列出文件并按 inode 编号排序,则可以非常容易地挑选出硬链接。在这种类型的 `ls` 输出中,第一列显示 inode 编号。
```
$ ls -i | sort -n | more
...
788000 myfile <==
788000 mytwin <==
801865 Name_Labels.pdf
786692 never leave home angry
920242 NFCU_Docs
800247 nmap-notes
```
扫描输出,查找相同的 inode 编号,任何匹配都会告诉你想知道的内容。
另一方面,如果你只是想知道某个特定文件是否是另一个文件的硬链接,那么有一种方法比浏览数百个文件的列表更简单,即 `find` 命令的 `-samefile` 选项将帮助你完成工作。
```
$ find . -samefile myfile
./myfile
./save/mycopy
./mytwin
```
注意,提供给 `find` 命令的起始位置决定文件系统会扫描多少来进行匹配。在上面的示例中,我们正在查看当前目录和子目录。
使用 `find` 的 `-ls` 选项添加输出的详细信息可能更有说服力:
```
$ find . -samefile myfile -ls
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 ./myfile
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 ./save/mycopy
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 ./mytwin
```
第一列显示 inode 编号,然后我们会看到文件权限、链接、所有者、文件大小、日期信息以及引用相同磁盘内容的文件的名称。注意,在这种情况下,链接字段是 “4” 而不是我们可能期望的 “3”。这告诉我们还有另一个指向同一个 inode 的链接(但不在我们的搜索范围内)。
如果你想在一个目录中查找所有硬链接的实例,可以尝试以下的脚本来创建列表并为你查找副本:
```
#!/bin/bash
# seaches for files sharing inodes
prev=""
# list files by inode
ls -i | sort -n > /tmp/$0
# search through file for duplicate inode #s
while read line
do
inode=`echo $line | awk '{print $1}'`
if [ "$inode" == "$prev" ]; then
grep $inode /tmp/$0
fi
prev=$inode
done < /tmp/$0
# clean up
rm /tmp/$0
```
```
$ ./findHardLinks
788000 myfile
788000 mytwin
```
你还可以使用 `find` 命令按 inode 编号查找文件,如命令中所示。但是,此搜索可能涉及多个文件系统,因此可能会得到错误的结果。因为相同的 inode 编号可能会在另一个文件系统中使用,代表另一个文件。如果是这种情况,文件的其他详细信息将不相同。
```
$ find / -inum 788000 -ls 2> /dev/null
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 /tmp/mycopy
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 /home/shs/myfile
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 /home/shs/save/mycopy
788000 4 -rw-r--r-- 4 shs shs 228 Apr 12 19:37 /home/shs/mytwin
```
注意,错误输出被重定向到 `/dev/null`,这样我们就不必查看所有 “Permission denied” 错误,否则这些错误将显示在我们不允许查看的其他目录中。
此外,扫描包含相同内容但不共享 inode 的文件(即,简单的文本拷贝)将花费更多的时间和精力。
---
via: <https://www.networkworld.com/article/3387961/how-to-identify-duplicate-files-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,778 | 初级:如何在 Linux 中 zip 压缩文件和文件夹 | https://itsfoss.com/linux-zip-folder/ | 2019-04-26T00:10:00 | [
"压缩",
"zip"
] | https://linux.cn/article-10778-1.html |
>
> 本文向你展示了如何在 Ubuntu 和其他 Linux 发行版中创建一个 zip 文件夹。终端和 GUI 方法都有。
>
>
>
zip 是最流行的归档文件格式之一。使用 zip,你可以将多个文件压缩到一个文件中。这不仅节省了磁盘空间,还节省了网络带宽。这就是为什么你几乎一直会看到 zip 文件的原因。
作为普通用户,大多数情况下你会在 Linux 中解压缩文件夹。但是如何在 Linux 中压缩文件夹?本文可以帮助你回答这个问题。
**先决条件:验证是否安装了 zip**
通常 [zip](https://en.wikipedia.org/wiki/Zip_(file_format)) 已经安装,但验证下也没坏处。你可以运行以下命令来安装 `zip` 和 `unzip`。如果它尚未安装,它将立即安装。
```
sudo apt install zip unzip
```
现在你知道你的系统有 zip 支持,你可以继续了解如何在 Linux 中压缩一个目录。

### 在 Linux 命令行中压缩文件夹
`zip` 命令的语法非常简单。
```
zip [option] output_file_name input1 input2
```
虽然有几个选项,但我不希望你将它们混淆。如果你只想要将一堆文件变成一个 zip 文件夹,请使用如下命令:
```
zip -r output_file.zip file1 folder1
```
`-r` 选项将递归目录并压缩其内容。输出文件中的 .zip 扩展名是可选的,因为默认情况下会添加 .zip。
你应该会在 zip 操作期间看到要添加到压缩文件夹中的文件。
```
zip -r myzip abhi-1.txt abhi-2.txt sample_directory
adding: abhi-1.txt (stored 0%)
adding: abhi-2.txt (stored 0%)
adding: sample_directory/ (stored 0%)
adding: sample_directory/newfile.txt (stored 0%)
adding: sample_directory/agatha.txt (deflated 41%)
```
你可以使用 `-e` 选项[在 Linux 中创建密码保护的 zip 文件夹](https://itsfoss.com/password-protect-zip-file/)。
你并不是只能通过终端创建 zip 归档文件。你也可以用图形方式做到这一点。下面是如何做的!
### 在 Ubuntu Linux 中使用 GUI 压缩文件夹
*虽然我在这里使用 Ubuntu,但在使用 GNOME 或其他桌面环境的其他发行版中,方法应该基本相同。*
如果要在 Linux 桌面中压缩文件或文件夹,只需点击几下即可。
进入到你想将文件(和文件夹)压缩到一个 zip 文件夹的所在文件夹。
在这里,选择文件和文件夹。现在,右键单击并选择“压缩”。你也可以对单个文件执行相同操作。

现在,你可以使用 zip、tar xz 或 7z 格式创建压缩归档文件。如果你好奇,这三个都是各种压缩算法,你可以使用它们来压缩文件。
输入一个你想要的名字,并点击“创建”。

这不会花很长时间,你会同一目录中看到一个归档文件。

好了,就是这些。你已经成功地在 Linux 中创建了一个 zip 文件夹。
我希望这篇文章能帮助你了解 zip 文件。请随时分享你的建议。
---
via: <https://itsfoss.com/linux-zip-folder/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Zip is one of the most popular archive file format out there. With zip, you can compress multiple files into one file. This not only saves disk space, it also saves network bandwidth. This is why you’ll encounter zip files almost all the time.
As a normal user, mostly you’ll [unzip files in Linux](https://itsfoss.com/unzip-linux/). But how do you zip a folder in Linux? This article helps you answer that question.
**Prerequisite: Verify if zip is installed**
Normally [zip](https://en.wikipedia.org/wiki/Zip_(file_format)?ref=itsfoss.com) support is installed but no harm in verifying. Open a terminal and use the following command:
`zip --version`
If you see some details on the zip version, you have zip installed already. If it displays ‘zip command not found’, you can run the below command to install zip and unzip support in Ubuntu and Debian based distributions.
`sudo apt install zip unzip`
Now that you know your system has zip support, you can read on to learn how to zip a directory in Linux.
## Zip a folder in Linux Command Line
The syntax for using the zip command is pretty straightforward.
`zip [option] output_file_name input1 input2`
While there could be several options, I don’t want you to confuse with them. If your only aim is to **create a zip folder** from a bunch of files and directories, use the command like this:
`zip -r output_file.zip file1 folder1`
The `-r`
option will recurse into directories and compress its contents as well.
You should see the files being added to the compressed folder during the zip operation.
```
zip -r myzip abhi-1.txt abhi-2.txt sample_directory
adding: abhi-1.txt (stored 0%)
adding: abhi-2.txt (stored 0%)
adding: sample_directory/ (stored 0%)
adding: sample_directory/newfile.txt (stored 0%)
adding: sample_directory/agatha.txt (deflated 41%)
```
You can use the `-e`
option to [create a password protect zip folder in Linux](https://itsfoss.com/password-protect-zip-file/).
[How to Create a Password Protected Zip File in LinuxBrief: This simple tutorial shows you how to create a password protected zip file in Linux both in command line and graphical way. We have seen how to password protect folders in Ubuntu earlier. We have also seen encrypted text editor for Linux. Today, we’ll see how to create](https://itsfoss.com/password-protect-zip-file/)

You are not always restricted to the terminal for creating zip archive files. You can do that graphically as well. Here’s how!
## Zip a folder in Linux Using GUI
If you want to compress a file or folder in desktop Linux, it’s just a matter of a few clicks.
Go to the folder where you have the desired files (and folders) you want to compress into one zip folder.
Here, select the files and folders. Now, right-click and select Compress. You can do the same for a single file as well.
Now you can create a compressed archive file in `zip`
, `tar xz`
or `7z`
format. In case you are wondering, all three are various compression algorithms that you can use for compressing your files.
Give it the name you desire and click on Create.
It shouldn’t take long and you should see an archive file in the same directory.
Well, that’s it. You successfully created a zip folder in Linux. The next step is to [learn to unzip a zipped file in the Linux command line](https://itsfoss.com/unzip-linux/).
[How to Unzip Files in Ubuntu & Other Linux [Terminal & GUI]This quick tip shows you how to unzip a file in Ubuntu and other Linux distributions. Both terminal and GUI methods have been discussed.](https://itsfoss.com/unzip-linux/)

I hope this quick little tip helped you with the zip files. Please feel free to share your suggestions. |
10,780 | Mercurial 版本控制入门 | https://opensource.com/article/19/4/getting-started-mercurial | 2019-04-26T08:20:24 | [
"Mercurial",
"版本控制"
] | /article-10780-1.html |
>
> 了解 Mercurial 的基础知识,它是一个用 Python 写的分布式版本控制系统。
>
>
>

[Mercurial](https://www.mercurial-scm.org/) 是一个用 Python 编写的分布式版本控制系统。因为它是用高级语言编写的,所以你可以用 Python 函数编写一个 Mercurial 扩展。
在[官方文档中](https://www.mercurial-scm.org/wiki/UnixInstall)说明了几种安装 Mercurial 的方法。我最喜欢的一种方法不在里面:使用 `pip`。这是开发本地扩展的最合适方式!
目前,Mercurial 仅支持 Python 2.7,因此你需要创建一个 Python 2.7 虚拟环境:
```
python2 -m virtualenv mercurial-env
./mercurial-env/bin/pip install mercurial
```
为了让命令简短一些,以及满足人们对化学幽默的渴望,该命令称之为 `hg`。
```
$ source mercurial-env/bin/activate
(mercurial-env)$ mkdir test-dir
(mercurial-env)$ cd test-dir
(mercurial-env)$ hg init
(mercurial-env)$ hg status
(mercurial-env)$
```
由于还没有任何文件,因此状态为空。添加几个文件:
```
(mercurial-env)$ echo 1 > one
(mercurial-env)$ echo 2 > two
(mercurial-env)$ hg status
? one
? two
(mercurial-env)$ hg addremove
adding one
adding two
(mercurial-env)$ hg commit -m 'Adding stuff'
(mercurial-env)$ hg log
changeset: 0:1f1befb5d1e9
tag: tip
user: Moshe Zadka <[[email protected]][4]>
date: Fri Mar 29 12:42:43 2019 -0700
summary: Adding stuff
```
`addremove` 命令很有用:它将任何未被忽略的新文件添加到托管文件列表中,并移除任何已删除的文件。
如我所说,Mercurial 扩展用 Python 写成,它们只是常规的 Python 模块。
这是一个简短的 Mercurial 扩展示例:
```
from mercurial import registrar
from mercurial.i18n import _
cmdtable = {}
command = registrar.command(cmdtable)
@command('say-hello',
[('w', 'whom', '', _('Whom to greet'))])
def say_hello(ui, repo, `opts):
ui.write("hello ", opts['whom'], "\n")
```
简单的测试方法是将它手动加入虚拟环境中的文件中:
```
`$ vi ../mercurial-env/lib/python2.7/site-packages/hello_ext.py`
```
然后你需要*启用*扩展。你可以仅在当前仓库中启用它:
```
$ cat >> .hg/hgrc
[extensions]
hello_ext =
```
现在,问候有了:
```
(mercurial-env)$ hg say-hello --whom world
hello world
```
大多数扩展会做更多有用的东西,甚至可能与 Mercurial 有关。 `repo` 对象是 `mercurial.hg.repository` 的对象。
有关 Mercurial API 的更多信息,请参阅[官方文档](https://www.mercurial-scm.org/wiki/MercurialApi#Repositories)。并访问[官方仓库](https://www.mercurial-scm.org/repo/hg/file/tip/hgext)获取更多示例和灵感。
---
via: <https://opensource.com/article/19/4/getting-started-mercurial>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,783 | Sensu 监控入门 | https://opensource.com/article/18/8/getting-started-sensu-monitoring-solution | 2019-04-27T13:17:00 | [
"监控",
"Sensu"
] | https://linux.cn/article-10783-1.html |
>
> 这个开源解决方案可以简单而有效地监控你的云基础设施。
>
>
>

Sensu 是一个开源的基础设施和应用程序监控解决方案,它可以监控服务器、相关服务和应用程序健康状况,并通过第三方集成发送警报和通知。Sensu 用 Ruby 编写,可以使用 [RabbitMQ](https://www.rabbitmq.com/) 或 [Redis](https://redis.io/topics/config) 来处理消息,它使用 Redis 来存储数据。
如果你想以一种简单而有效的方式监控云基础设施,Sensu 是一个不错的选择。它可以与你的组织已经使用的许多现代 DevOps 组件集成,比如 [Slack](https://slack.com/)、[HipChat](https://en.wikipedia.org/wiki/HipChat) 或 [IRC](http://www.irc.org/),它甚至可以用 [PagerDuty](https://www.pagerduty.com/) 发送移动或寻呼机的警报。
Sensu 的[模块化架构](https://docs.sensu.io/sensu-core/1.4/overview/architecture/)意味着每个组件都可以安装在同一台服务器上或者在完全独立的机器上。
### 结构
Sensu 的主要通信机制是 Transport。每个 Sensu 组件必须连接到 Transport 才能相互发送消息。Transport 可以使用 RabbitMQ(在生产环境中推荐使用)或 Redis。
Sensu 服务器处理事件数据并采取行动。它注册客户端并使用过滤器、增变器和处理程序检查结果和监视事件。服务器向客户端发布检查说明,Sensu API 提供 RESTful API,提供对监控数据和核心功能的访问。
[Sensu 客户端](https://docs.sensu.io/sensu-core/1.4/installation/install-sensu-client/)执行 Sensu 服务器安排的检查或本地检查定义。Sensu 使用数据存储(Redis)来保存所有的持久数据。最后,[Uchiwa](https://uchiwa.io/#/) 是与 Sensu API 进行通信的 Web 界面。

### 安装 Sensu
#### 条件
* 一个 Linux 系统作为服务器节点(本文使用了 CentOS 7)
* 要监控的一台或多台 Linux 机器(客户机)
#### 服务器侧
Sensu 需要安装 Redis。要安装 Redis,启用 EPEL 仓库:
```
$ sudo yum install epel-release -y
```
然后安装 Redis:
```
$ sudo yum install redis -y
```
修改 `/etc/redis.conf` 来禁用保护模式,监听每个地址并设置密码:
```
$ sudo sed -i 's/^protected-mode yes/protected-mode no/g' /etc/redis.conf
$ sudo sed -i 's/^bind 127.0.0.1/bind 0.0.0.0/g' /etc/redis.conf
$ sudo sed -i 's/^# requirepass foobared/requirepass password123/g' /etc/redis.conf
```
启用并启动 Redis 服务:
```
$ sudo systemctl enable redis
$ sudo systemctl start redis
```
Redis 现在已经安装并准备好被 Sensu 使用。
现在让我们来安装 Sensu。
首先,配置 Sensu 仓库并安装软件包:
```
$ sudo tee /etc/yum.repos.d/sensu.repo << EOF
[sensu]
name=sensu
baseurl=https://sensu.global.ssl.fastly.net/yum/\$releasever/\$basearch/
gpgcheck=0
enabled=1
EOF
$ sudo yum install sensu uchiwa -y
```
让我们为 Sensu 创建最简单的配置文件:
```
$ sudo tee /etc/sensu/conf.d/api.json << EOF
{
"api": {
"host": "127.0.0.1",
"port": 4567
}
}
EOF
```
然后,配置 `sensu-api` 在本地主机上使用端口 4567 监听:
```
$ sudo tee /etc/sensu/conf.d/redis.json << EOF
{
"redis": {
"host": "<IP of server>",
"port": 6379,
"password": "password123"
}
}
EOF
$ sudo tee /etc/sensu/conf.d/transport.json << EOF
{
"transport": {
"name": "redis"
}
}
EOF
```
在这两个文件中,我们将 Sensu 配置为使用 Redis 作为传输机制,还有 Reids 监听的地址。客户端需要直接连接到传输机制。每台客户机都需要这两个文件。
```
$ sudo tee /etc/sensu/uchiwa.json << EOF
{
"sensu": [
{
"name": "sensu",
"host": "127.0.0.1",
"port": 4567
}
],
"uchiwa": {
"host": "0.0.0.0",
"port": 3000
}
}
EOF
```
在这个文件中,我们配置 Uchiwa 监听每个地址(0.0.0.0)的端口 3000。我们还配置 Uchiwa 使用 `sensu-api`(已配置好)。
出于安全原因,更改刚刚创建的配置文件的所有者:
```
$ sudo chown -R sensu:sensu /etc/sensu
```
启用并启动 Sensu 服务:
```
$ sudo systemctl enable sensu-server sensu-api sensu-client
$ sudo systemctl start sensu-server sensu-api sensu-client
$ sudo systemctl enable uchiwa
$ sudo systemctl start uchiwa
```
尝试访问 Uchiwa 网站:`http://<服务器的 IP 地址>:3000`
对于生产环境,建议运行 RabbitMQ 集群作为 Transport 而不是 Redis(虽然 Redis 集群也可以用于生产环境),运行多个 Sensu 服务器实例和 API 实例,以实现负载均衡和高可用性。
Sensu 现在安装完成,让我们来配置客户端。
#### 客户端侧
要添加一个新客户端,你需要通过创建 `/etc/yum.repos.d/sensu.repo` 文件在客户机上启用 Sensu 仓库。
```
$ sudo tee /etc/yum.repos.d/sensu.repo << EOF
[sensu]
name=sensu
baseurl=https://sensu.global.ssl.fastly.net/yum/\$releasever/\$basearch/
gpgcheck=0
enabled=1
EOF
```
启用仓库后,安装 Sensu:
```
$ sudo yum install sensu -y
```
要配置 `sensu-client`,创建在服务器中相同的 `redis.json` 和 `transport.json`,还有 `client.json` 配置文件:
```
$ sudo tee /etc/sensu/conf.d/client.json << EOF
{
"client": {
"name": "rhel-client",
"environment": "development",
"subscriptions": [
"frontend"
]
}
}
EOF
```
在 `name` 字段中,指定一个名称来标识此客户机(通常是主机名)。`environment` 字段可以帮助你过滤,而 `subscriptions` 定义了客户机将执行哪些监视检查。
最后,启用并启动服务并签入 Uchiwa,因为客户机会自动注册:
```
$ sudo systemctl enable sensu-client
$ sudo systemctl start sensu-client
```
### Sensu 检查
Sensu 检查有两个组件:一个插件和一个定义。
Sensu 与 [Nagios 检查插件规范](https://assets.nagios.com/downloads/nagioscore/docs/nagioscore/4/en/pluginapi.html)兼容,因此无需修改即可使用用于 Nagios 的任何检查。检查是可执行文件,由 Sensu 客户机运行。
检查定义可以让 Sensu 知道如何、在哪以及何时运行插件。
#### 客户端侧
让我们在客户机上安装一个检查插件。请记住,此插件将在客户机上执行。
启用 EPEL 并安装 `nagios-plugins-http`:
```
$ sudo yum install -y epel-release
$ sudo yum install -y nagios-plugins-http
```
现在让我们通过手动执行它来了解这个插件。尝试检查客户机上运行的 Web 服务器的状态。它应该会失败,因为我们并没有运行 Web 服务器:
```
$ /usr/lib64/nagios/plugins/check_http -I 127.0.0.1
connect to address 127.0.0.1 and port 80: Connection refused
HTTP CRITICAL - Unable to open TCP socket
```
不出所料,它失败了。检查执行的返回值:
```
$ echo $?
2
```
Nagios 检查插件规范定义了插件执行的四个返回值:
| 插件返回码 | 状态 |
| --- | --- |
| 0 | OK |
| 1 | WARNING |
| 2 | CRITICAL |
| 3 | UNKNOWN |
有了这些信息,我们现在可以在服务器上创建检查定义。
#### 服务器侧
在服务器机器上,创建 `/etc/sensu/conf.d/check_http.json` 文件:
```
{
"checks": {
"check_http": {
"command": "/usr/lib64/nagios/plugins/check_http -I 127.0.0.1",
"interval": 10,
"subscribers": [
"frontend"
]
}
}
}
```
在 `command` 字段中,使用我们之前测试过的命令。`interval` 会告诉 Sensu 这个检查的频率,以秒为单位。最后,`subscribers` 将定义执行检查的客户机。
重新启动 `sensu-api` 和 `sensu-server` 并确认新检查在 Uchiwa 中可用。
```
$ sudo systemctl restart sensu-api sensu-server
```
### 接下来
Sensu 是一个功能强大的工具,本文只简要介绍它可以干什么。参阅[文档](https://docs.sensu.io/)了解更多信息,访问 Sensu 网站了解有关 [Sensu 社区](https://sensu.io/community)的更多信息。
---
via: <https://opensource.com/article/18/8/getting-started-sensu-monitoring-solution>
作者:[Michael Zamot](https://opensource.com/users/mzamot) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Sensu is an open source infrastructure and application monitoring solution that monitors servers, services, and application health, and sends alerts and notifications with third-party integration. Written in Ruby, Sensu can use either [RabbitMQ](https://www.rabbitmq.com/) or [Redis](https://redis.io/topics/config) to handle messages. It uses Redis to store data.
If you want to monitor your cloud infrastructure in a simple and efficient manner, Sensu is a good option. It can be integrated with many of the modern DevOps stacks your organization may already be using, such as [Slack](https://slack.com/), [HipChat](https://en.wikipedia.org/wiki/HipChat), or [IRC](http://www.irc.org/), and it can even send mobile/pager alerts with [PagerDuty](https://www.pagerduty.com/).
Sensu's [modular architecture](https://docs.sensu.io/sensu-core/1.4/overview/architecture/) means every component can be installed on the same server or on completely separate machines.
## Architecture
Sensu's main communication mechanism is the Transport. Every Sensu component must connect to the Transport in order to send messages to each other. Transport can use either RabbitMQ (recommended in production) or Redis.
Sensu Server processes event data and takes action. It registers clients and processes check results and monitoring events using filters, mutators, and handlers. The server publishes check definitions to the clients and the Sensu API provides a RESTful API, providing access to monitoring data and core functionality.
[Sensu Client](https://docs.sensu.io/sensu-core/1.4/installation/install-sensu-client/) executes checks either scheduled by Sensu Server or local checks definitions. Sensu uses a data store (Redis) to keep all the persistent data. Finally, [Uchiwa](https://uchiwa.io/#/) is the web interface to communicate with Sensu API.
## Installing Sensu
### Prerequisites
-
One Linux installation to act as the server node (I used CentOS 7 for this article)
-
One or more Linux machines to monitor (clients)
### Server side
Sensu requires Redis to be installed. To install Redis, enable the EPEL repository:
`$ sudo yum install epel-release -y`
Then install Redis:
`$ sudo yum install redis -y`
Modify `/etc/redis.conf`
to disable protected mode, listen on every interface, and set a password:
```
$ sudo sed -i 's/^protected-mode yes/protected-mode no/g' /etc/redis.conf
$ sudo sed -i 's/^bind 127.0.0.1/bind 0.0.0.0/g' /etc/redis.conf
$ sudo sed -i 's/^# requirepass foobared/requirepass password123/g' /etc/redis.conf
```
Enable and start Redis service:
```
$ sudo systemctl enable redis
$ sudo systemctl start redis
```
Redis is now installed and ready to be used by Sensu.
Now let’s install Sensu.
First, configure the Sensu repository and install the packages:
```
$ sudo tee /etc/yum.repos.d/sensu.repo << EOF
[sensu]
name=sensu
baseurl=https://sensu.global.ssl.fastly.net/yum/\$releasever/\$basearch/
gpgcheck=0
enabled=1
EOF
$ sudo yum install sensu uchiwa -y
```
Let’s create the bare minimum configuration files for Sensu:
```
$ sudo tee /etc/sensu/conf.d/api.json << EOF
{
"api": {
"host": "127.0.0.1",
"port": 4567
}
}
EOF
```
Next, configure `sensu-api`
to listen on localhost, with Port 4567:
```
$ sudo tee /etc/sensu/conf.d/redis.json << EOF
{
"redis": {
"host": "<IP of server>",
"port": 6379,
"password": "password123"
}
}
EOF
$ sudo tee /etc/sensu/conf.d/transport.json << EOF
{
"transport": {
"name": "redis"
}
}
EOF
```
In these two files, we configure Sensu to use Redis as the transport mechanism and the address where Redis will listen. Clients need to connect directly to the transport mechanism. These two files will be required on each client machine.
```
$ sudo tee /etc/sensu/uchiwa.json << EOF
{
"sensu": [
{
"name": "sensu",
"host": "127.0.0.1",
"port": 4567
}
],
"uchiwa": {
"host": "0.0.0.0",
"port": 3000
}
}
EOF
```
In this file, we configure Uchiwa to listen on every interface (0.0.0.0) on Port 3000. We also configure Uchiwa to use `sensu-api`
(already configured).
For security reasons, change the owner of the configuration files you just created:
`$ sudo chown -R sensu:sensu /etc/sensu`
Enable and start the Sensu services:
```
$ sudo systemctl enable sensu-server sensu-api sensu-client
$ sudo systemctl start sensu-server sensu-api sensu-client
$ sudo systemctl enable uchiwa
$ sudo systemctl start uchiwa
```
Try accessing the Uchiwa website: http://<IP of server>:3000
For production environments, it’s recommended to run a cluster of RabbitMQ as the Transport instead of Redis (a Redis cluster can be used in production too), and to run more than one instance of Sensu Server and API for load balancing and high availability.
Sensu is now installed. Now let’s configure the clients.
### Client side
To add a new client, you will need to enable Sensu repository on the client machines by creating the file `/etc/yum.repos.d/sensu.repo`
.
```
$ sudo tee /etc/yum.repos.d/sensu.repo << EOF
[sensu]
name=sensu
baseurl=https://sensu.global.ssl.fastly.net/yum/\$releasever/\$basearch/
gpgcheck=0
enabled=1
EOF
```
With the repository enabled, install the package Sensu:
`$ sudo yum install sensu -y`
To configure `sensu-client`
, create the same `redis.json`
and `transport.json`
created in the server machine, as well as the `client.json`
configuration file:
```
$ sudo tee /etc/sensu/conf.d/client.json << EOF
{
"client": {
"name": "rhel-client",
"environment": "development",
"subscriptions": [
"frontend"
]
}
}
EOF
```
In the name field, specify a name to identify this client (typically the hostname). The environment field can help you filter, and subscription defines which monitoring checks will be executed by the client.
Finally, enable and start the services and check in Uchiwa, as the new client will register automatically:
```
$ sudo systemctl enable sensu-client
$ sudo systemctl start sensu-client
```
## Sensu checks
Sensu checks have two components: a plugin and a definition.
Sensu is compatible with the [Nagios check plugin specification](https://assets.nagios.com/downloads/nagioscore/docs/nagioscore/4/en/pluginapi.html), so any check for Nagios can be used without modification. Checks are executable files and are run by the Sensu client.
Check definitions let Sensu know how, where, and when to run the plugin.
### Client side
Let’s install one check plugin on the client machine. Remember, this plugin will be executed on the clients.
Enable EPEL and install `nagios-plugins-http`
:
```
$ sudo yum install -y epel-release
$ sudo yum install -y nagios-plugins-http
```
Now let’s explore the plugin by executing it manually. Try checking the status of a web server running on the client machine. It should fail as we don’t have a web server running:
```
$ /usr/lib64/nagios/plugins/check_http -I 127.0.0.1
connect to address 127.0.0.1 and port 80: Connection refused
HTTP CRITICAL - Unable to open TCP socket
```
It failed, as expected. Check the return code of the execution:
```
$ echo $?
2
```
The Nagios check plugin specification defines four return codes for the plugin execution:
|
|
0 |
OK |
1 |
WARNING |
2 |
CRITICAL |
3 |
UNKNOWN |
With this information, we can now create the check definition on the server.
### Server side
On the server machine, create the file `/etc/sensu/conf.d/check_http.json`
:
```
{
"checks": {
"check_http": {
"command": "/usr/lib64/nagios/plugins/check_http -I 127.0.0.1",
"interval": 10,
"subscribers": [
"frontend"
]
}
}
}
```
In the command field, use the command we tested before. `Interval`
will tell Sensu how frequently, in seconds, this check should be executed. Finally, `subscribers`
will define the clients where the check will be executed.
Restart both sensu-api and sensu-server and confirm that the new check is available in Uchiwa.
`$ sudo systemctl restart sensu-api sensu-server`
## What’s next?
Sensu is a powerful tool, and this article covers just a glimpse of what it can do. See the [documentation](https://docs.sensu.io/) to learn more, and visit the Sensu site to learn more about the [Sensu community](https://sensu.io/community).
## Comments are closed. |
10,785 | 使用 mdadm 管理 RAID 阵列 | https://fedoramagazine.org/managing-raid-arrays-with-mdadm/ | 2019-04-27T15:45:17 | [
"RAID",
"mdadm"
] | https://linux.cn/article-10785-1.html | 
mdadm 是<ruby> 多磁盘和设备管理 <rt> Multiple Disk and Device Administration </rt></ruby> 的缩写。它是一个命令行工具,可用于管理 Linux 上的软件 [RAID](https://en.wikipedia.org/wiki/RAID) 阵列。本文概述了使用它的基础知识。
以下 5 个命令是你使用 mdadm 的基础功能:
1. **创建 RAID 阵列**:`mdadm --create /dev/md/test --homehost=any --metadata=1.0 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1`
2. **组合(并启动)RAID 阵列**:`mdadm --assemble /dev/md/test /dev/sda1 /dev/sdb1`
3. **停止 RAID 阵列**:`mdadm --stop /dev/md/test`
4. **删除 RAID 阵列**:`mdadm --zero-superblock /dev/sda1 /dev/sdb1`
5. **检查所有已组合的 RAID 阵列的状态**:`cat /proc/mdstat`
### 功能说明
#### mdadm –create
上面的创建命令除了 `-create` 参数自身和设备名之外,还包括了四个参数:
1、`–homehost`:
默认情况下,`mdadm` 将你的计算机名保存为 RAID 阵列的属性。如果你的计算机名与存储的名称不匹配,则阵列将不会自动组合。此功能在共享硬盘的服务器群集中很有用,因为如果多个服务器同时尝试访问同一驱动器,通常会发生文件系统损坏。名称 `any` 是保留字段,并禁用 `-homehost` 限制。
2、 `–metadata`:
`-mdadm` 保留每个 RAID 设备的一小部分空间,以存储有关 RAID 阵列本身的信息。 `-metadata` 参数指定信息的格式和位置。`1.0` 表示使用版本 1 格式,并将元数据存储在设备的末尾。
3、`–level`:
`-level` 参数指定数据应如何在底层设备之间分布。级别 `1` 表示每个设备应包含所有数据的完整副本。此级别也称为[磁盘镜像](https://en.wikipedia.org/wiki/Disk_mirroring)。
4、`–raid-devices`:
`-raid-devices` 参数指定将用于创建 RAID 阵列的设备数。
通过将 `-level=1`(镜像)与 `-metadata=1.0` (将元数据存储在设备末尾)结合使用,可以创建一个 RAID1 阵列,如果不通过 mdadm 驱动访问,那么它的底层设备会正常显示。这在灾难恢复的情况下很有用,因为即使新系统不支持 mdadm 阵列,你也可以访问该设备。如果程序需要在 mdadm 可用之前以*只读*访问底层设备时也很有用。例如,计算机中的 [UEFI](https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface) 固件可能需要在启动 mdadm 之前从 [ESP](https://en.wikipedia.org/wiki/EFI_system_partition) 读取引导加载程序。
#### mdadm –assemble
如果成员设备丢失或损坏,上面的组合命令将会失败。要强制 RAID 阵列在其中一个成员丢失时进行组合并启动,请使用以下命令:
```
# mdadm --assemble --run /dev/md/test /dev/sda1
```
### 其他重要说明
避免直接写入底层是 RAID1 的设备。这导致设备不同步,并且 mdadm 不会知道它们不同步。如果你访问了在其他地方被修改了设备的某个 RAID1 阵列,则可能导致文件系统损坏。如果你在其他地方修改 RAID1 设备并需要强制阵列重新同步,请从要覆盖的设备中删除 mdadm 元数据,然后将其重新添加到阵列,如下所示:
```
# mdadm --zero-superblock /dev/sdb1
# mdadm --assemble --run /dev/md/test /dev/sda1
# mdadm /dev/md/test --add /dev/sdb1
```
以上用 sda1 的内容完全覆盖 sdb1 的内容。
要指定在计算机启动时自动激活的 RAID 阵列,请创建 `/etc/mdadm.conf` 配置。
有关最新和详细信息,请查看手册页:
```
$ man mdadm
$ man mdadm.conf
```
本系列的下一篇文章将展示如何将现有的单磁盘 Linux 系统变为镜像磁盘安装,这意味着即使其中一个硬盘突然停止工作,系统仍将继续运行!
---
via: <https://fedoramagazine.org/managing-raid-arrays-with-mdadm/>
作者:[Gregory Bartholomew](https://fedoramagazine.org/author/glb/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Mdadm stands for __M__ultiple __D__isk and Device __Adm__inistration. It is a command line tool that can be used to manage software [RAID](https://en.wikipedia.org/wiki/RAID) arrays on your Linux PC. This article outlines the basics you need to get started with it.
The following five commands allow you to make use of mdadm’s most basic features:
**Create a RAID array**:
# mdadm --create /dev/md/test --homehost=any --metadata=1.0 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1**Assemble (and start) a RAID array**:
# mdadm --assemble /dev/md/test /dev/sda1 /dev/sdb1**Stop a RAID array**:
# mdadm --stop /dev/md/test**Delete a RAID array**:
# mdadm --zero-superblock /dev/sda1 /dev/sdb1**Check the status of all assembled RAID arrays**:
# cat /proc/mdstat
## Notes on features
`mdadm --create`
The *create* command shown above includes the following four parameters in addition to the create parameter itself and the device names:
**–homehost**:
By default, mdadm stores your computer’s name as an attribute of the RAID array. If your computer name does not match the stored name, the array will not automatically assemble. This feature is useful in server clusters that share hard drives because file system corruption usually occurs if multiple servers attempt to access the same drive at the same time. The name*any*is reserved and disables the*homehost*restriction.**–metadata**:*mdadm*reserves a small portion of each RAID device to store information about the RAID array itself. The*metadata*parameter specifies the format and location of the information. The value*1.0*indicates to use version-1 formatting and store the metadata at the end of the device.**–level**:
The*level*parameter specifies how the data should be distributed among the underlying devices. Level*1*indicates each device should contain a complete copy of all the data. This level is also known as[disk mirroring](https://en.wikipedia.org/wiki/Disk_mirroring).**–raid-devices**:
The*raid-devices*parameter specifies the number of devices that will be used to create the RAID array.
By using *level=1* (mirroring) in combination with *metadata=1.0* (store the metadata at the end of the device), you create a RAID1 array whose underlying devices appear normal if accessed without the aid of the mdadm driver. This is useful in the case of disaster recovery, because you can access the device even if the new system doesn’t support mdadm arrays. It’s also useful in case a program needs *read-only* access to the underlying device before mdadm is available. For example, the [UEFI](https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface) firmware in a computer may need to read the bootloader from the [ESP](https://en.wikipedia.org/wiki/EFI_system_partition) before mdadm is started.
`mdadm --assemble`
The *assemble* command above fails if a member device is missing or corrupt. To force the RAID array to assemble and start when one of its members is missing, use the following command:
# mdadm --assemble --run /dev/md/test /dev/sda1
## Other important notes
Avoid writing directly to any devices that underlay a mdadm RAID1 array. That causes the devices to become out-of-sync and mdadm won’t know that they are out-of-sync. If you access a RAID1 array with a device that’s been modified out-of-band, you can cause file system corruption. If you modify a RAID1 device out-of-band and need to force the array to re-synchronize, delete the mdadm metadata from the device to be overwritten and then re-add it to the array as demonstrated below:
# mdadm --zero-superblock /dev/sdb1
# mdadm --assemble --run /dev/md/test /dev/sda1
# mdadm /dev/md/test --add /dev/sdb1
These commands completely overwrite the contents of sdb1 with the contents of sda1.
To specify any RAID arrays to automatically activate when your computer starts, create an */etc/mdadm.conf* configuration file.
For the most up-to-date and detailed information, check the man pages:
$ man mdadm
$ man mdadm.conf
The next article of this series will show a step-by-step guide on how to convert an existing single-disk Linux installation to a mirrored-disk installation, that will continue running even if one of its hard drives suddenly stops working!
## Norbert J.
Great idea to shed some light on this quite complex matter, thanks!
I have been using MD RAIDs on 2 desktop computers for some years and always wondered what “homehost” is good for. It took me also some time to figure out that a kernel parameter “rd.md.uuid=…” is needed if the root fs resides on a MD RAID and a generic (not host-only) initramfs is used; maybe you want to mention this in a later article.
## Gregory Bartholomew
Interesting. I didn’t know that an initramfs compiled with “hostonly=no” will exclude the /etc/mdadm.conf file. I just checked with the current version of dracut (049-26.git20181204), and indeed /etc/mdadm.conf does get excluded. So, your options with a “hostonly=no” initramfs are to specify the UUID on the kernel command line, manually include the /etc/mdadm.conf file when you build the initramfs, or specify the rd.auto kernel command line option to have all RAID arrays automatically assembled. The latter probably makes the most sense if you are really going for a “generic” system.
I’m adding a note about this problem to the upcoming article right now. Thanks!
## Göran Uddeborg
You hint this will become a series. It would be very much appreciated if you could include one post on debugging. I have tried to create a RAID-1 setup quite similar to what you describe above. It seems to work functionally, but a lot of the time it feels like it goes VERY slowly. When running on only one of the disks, I don’t see the issue. I would expect to see a slight speedup for reads and a slight slowdown for writes, but not as much as this.
Note: I’m not asking you to help debugging my system! I’m only suggesting debugging as a topic for one of the parts in the series, and just gave the description above to explain what I mean.
## Gregory Bartholomew
Sure. I’ll see what I can put together. Thanks for the idea! ????
## Mark
Thanks for this, the other important notes section is what I will find most useful as at some point a disk will need to be replaced; so jotted that down as a starting point for the day I need it.
I found the article at https://www.tecmint.com/create-raid1-in-linux/ an easy how-to in setting up software raid1 on two additional disks and using mdadm to create the contents needed for mdadm.conf.
Looking forward on the upcoming article on how to convert a single disk system to mirrored, if it can be done without losing data.
## Stuart D Gathman
I like to use raid10 (which is different from raid1+0) because you can mirror and stripe with any number of devices, including 3. The stripes are arranged in a pattern to get performance like striping (raid0), but with mirroring. Raid 1+0 also does that, but only with more drives (starting with 4).
I use raid1, when I need to mirror boot partitions.
## Gregory Bartholomew
Sure. I’ve heard that the answer to the problem “I need more disk speed” is to “throw more spindles” (i.e. disk drives in RAID arrays) at the problem; even for big companies and datacenters.
One thing to beware of though is how hard it will be to recover from the situation if your computer were to fail. Which is yet another advantage of software RAID — it is a bit more “portable” than a proprietary hardware RAID controller (and I have seen hardware RAID controllers fail). If you have a more complicated software RAID configuration, it may be difficult to reconstruct in the event that your computer dies. So there are trade-offs.
## Stuart D Gathman
One huge advantage of software RAID, is that you don’t need to match drive size or waste space. E.g., suppose you have 2 1T drives, with raid1 (for simplicity). Now you add a 3rd 2T drive. How do you use the space while maintaining mirroring? Simple:
o allocate 2 1T partitions on the 2T drive
o migrate one of the 1T mirror legs to the first 1T partition.
o create a new RAID array from the 2nd 1T partition and the vacated 1T drive
o add the new RAID array to your Volume Group
## Gregory Bartholomew
Indeed. Another thing that I like about it is that it is easy to configure email notifications to be sent in case a drive fails. You can even configure an arbitrary program to be run if, for example, you wanted a text message instead of an email. The possibilities are endless. ????
## Stuart D Gathman
I’ve also seen some benchmarks indicating that software RAID is faster than hardware for raid0, raid1 (and presumably raid10 if that were an option on hardware) with comparable controllers. The hardware is mainly for raid5 and 6, where handling the checksums and read, modify, write cycles is expensive.
## Gregory Bartholomew
Makes sense. The OS knows a lot more about the processes that are running and their access patterns than the hard drive or RAID controller ever could. It has a lot more memory with which to hold and reorder read and write operations too.
## Daniel Letai
Can a CPU extension such as AES-NI be used for the checksum calculations as well? I would imagine that would speed up raid5/6 considerably, if possible.
Also see https://lkml.org/lkml/2013/5/1/449
## Gregory Bartholomew
Oops, my below reply was meant to be in reply to this comment.
## Gregory Bartholomew
I think RAID5/6 normally uses XOR for the parity calculations that allow it to reconstruct data when blocks are missing or corrupt. AES (Advanced Encryption Standard) is something a little different. It is used to encrypt data. But, yes, some common algorithms for encryption and checksums (like AES and CRC32, respectively) are hardware accelerated. |
10,787 | COPR 仓库中 4 个很酷的新软件(2019.4) | https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-april-2019/ | 2019-04-28T08:09:00 | [
"CORP"
] | https://linux.cn/article-10787-1.html | 
COPR 是个人软件仓库[集合](https://fedoramagazine.org/wp-content/uploads/2017/08/4-copr-945x400.jpg),它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己背书的。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
这是 COPR 中一组新的有趣项目。
### Joplin
[Joplin](https://joplin.cozic.net/) 是一个笔记和待办事项应用。笔记以 Markdown 格式编写,并通过使用标签和将它们分类到各种笔记本中进行组织。Joplin 可以从任何 Markdown 源导入笔记或从 Evernote 导出笔记。除了桌面应用之外,还有一个 Android 版本,通过使用 Nextcloud、Dropbox 或其他云服务同步笔记。最后,它还有 Chrome 和 Firefox 的浏览器扩展程序,用于保存网页和屏幕截图。

#### 安装说明
[COPR 仓库](https://copr.fedorainfracloud.org/coprs/taw/joplin/)目前为 Fedora 29 和 30 以及 EPEL 7 提供 Joplin。要安装 Joplin,请[带上 sudo](https://fedoramagazine.org/howto-use-sudo/) 使用这些命令:
```
sudo dnf copr enable taw/joplin
sudo dnf install joplin
```
### Fzy
[Fzy](https://github.com/jhawthorn/fzy) 是用于模糊字符串搜索的命令行程序。它从标准输入读取并根据最有可能的搜索结果进行排序,然后打印所选行。除了命令行,`fzy` 也可以在 vim 中使用。你可以在这个在线 [demo](https://jhawthorn.github.io/fzy-demo/) 中尝试 `fzy`。
#### 安装说明
[COPR 仓库](https://copr.fedorainfracloud.org/coprs/lehrenfried/fzy/)目前为 Fedora 29、30 和 Rawhide 以及其他发行版提供了 `fzy`。要安装 `fzy`,请使用以下命令:
```
sudo dnf copr enable lehrenfried/fzy
sudo dnf install fzy
```
### Fondo
Fondo 是一个浏览 [unsplash.com](https://unsplash.com/) 网站照片的程序。它有一个简单的界面,允许你一次查找某个主题或所有主题的图片。然后,你可以通过单击将找到的图片设置为壁纸,或者共享它。

#### 安装说明
[COPR 仓库](https://copr.fedorainfracloud.org/coprs/atim/fondo/)目前为 Fedora 29、30 和 Rawhide 提供 Fondo。要安装 Fondo,请使用以下命令:
```
sudo dnf copr enable atim/fondo
sudo dnf install fondo
```
### YACReader
[YACReader](https://www.yacreader.com/) 是一款数字漫画阅读器,它支持许多漫画和图像格式,例如 cbz、cbr、pdf 等。YACReader 会跟踪阅读进度,并可以从 [Comic Vine](https://comicvine.gamespot.com/) 下载漫画信息。它还有一个 YACReader 库,用于组织和浏览你的漫画集。

#### 安装说明
[COPR 仓库](https://copr.fedorainfracloud.org/coprs/atim/yacreader/)目前为 Fedora 29、30 和 Rawhide 提供 YACReader。要安装 YACReader,请使用以下命令:
```
sudo dnf copr enable atim/yacreader
sudo dnf install yacreader
```
---
via: <https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-april-2019/>
作者:[Dominik Turecek](https://fedoramagazine.org/author/dturecek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | COPR is a [collection](https://copr.fedorainfracloud.org/) of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
Here’s a set of new and interesting projects in COPR.
### Joplin
[Joplin](https://joplin.cozic.net/) is a note-taking and to-do app. Notes are written in the Markdown format, and organized by sorting them into various notebooks and using tags.
Joplin can import notes from any Markdown source or exported from Evernote. In addition to the desktop app, there’s an Android version with the ability to synchronize notes between them — using Nextcloud, Dropbox or other cloud services. Finally, there’s a browser extension for Chrome and Firefox to save web pages and screenshots.
#### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/taw/joplin/) currently provides Joplin for Fedora 29 and 30, and for EPEL 7. To install Joplin, use these commands [with sudo](https://fedoramagazine.org/howto-use-sudo/):
sudo dnf copr enable taw/joplin
sudo dnf install joplin
### Fzy
[Fzy](https://github.com/jhawthorn/fzy) is a command-line utility for fuzzy string searching. It reads from a standard input and sorts the lines based on what is most likely the sought after text, and then prints the selected line. In addition to command-line, fzy can be also used within vim. You can try fzy in this online [demo](https://jhawthorn.github.io/fzy-demo/).
#### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/lehrenfried/fzy/) currently provides fzy for Fedora 29, 30, and Rawhide, and other distributions. To install fzy, use these commands:
sudo dnf copr enable lehrenfried/fzy
sudo dnf install fzy
### Fondo
[Fondo] is a program for browsing many photographs from the [unsplash.com](https://unsplash.com/) website. It has a simple interface that allows you to look for pictures of one of several themes, or all of them at once. You can then set a found picture as a wallpaper with a single click, or share it.
#### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/atim/fondo/) currently provides Fondo for Fedora 29, 30, and Rawhide. To install Fondo, use these commands:
sudo dnf copr enable atim/fondo
sudo dnf install fondo
### YACReader
[YACReader](https://www.yacreader.com/) is a digital comic book reader that supports many comics and image formats, such as *cbz*, *cbr*, *pdf* and others. YACReader keeps track of reading progress, and can download comics’ information from [Comic Vine.](https://comicvine.gamespot.com/) It also comes with a YACReader Library for organizing and browsing your comic book collection.
#### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/atim/yacreader/) currently provides YACReader for Fedora 29, 30, and Rawhide. To install YACReader, use these commands:
sudo dnf copr enable atim/yacreader
sudo dnf install yacreader
## mark mcintyre
Joplin looks slick. I’ll try that out for sure.
## Morten Juhl-Johansen Zölde-Fejér
Nextcloud Notes for Android and the Markdown editor in the web interface have made good progress, but I still really like having Joplin on desktop and phone syncing with me Nextcloud instance.
## Volker
Hi Morten,
Syncing Joplin works fine. I use it on my Windows and Linux Desktop. And the sync is fine even with the Android App.
## Orv
Tried to install joplin on a bone-stock Fedora 29 system. Got:
[obeach@w6bi-house-pc ~]$ joplin &
[1] 14314
[obeach@w6bi-house-pc ~]$ internal/modules/cjs/loader.js:583
throw err;
^
Error: Cannot find module ‘app-module-path’
at Function.Module._resolveFilename (internal/modules/cjs/loader.js:581:15)
at Function.Module._load (internal/modules/cjs/loader.js:507:25)
at Module.require (internal/modules/cjs/loader.js:637:17)
at require (internal/modules/cjs/helpers.js:22:18)
at Object. (/usr/share/joplin/cli/main.js:7:1)
at Module._compile (internal/modules/cjs/loader.js:689:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:700:10)
at Module.load (internal/modules/cjs/loader.js:599:32)
at tryModuleLoad (internal/modules/cjs/loader.js:538:12)
at Function.Module._load (internal/modules/cjs/loader.js:530:3)
Some investigation is called for… Wonder what’s missing/mismatched?
## Stephen
Perhaps a missing javascript interpreter?
## Niels Borne
I have exactly the same issue on fedora 29.
## Fred Finster
I hit the “windows” key, then typed ‘jop’ and saw the Blue Joplin command and then typed the key and Joplin came up properly for my. Like you, if I entered typed ‘joplin ‘ in a terminal window I get the same exact error messages as you posted above.
I previously had installed the flatpak app-image version 140 of Joplin and that seemed to run correctly when using the <activities search function and typed in 'jop' to search for the joplin app and hit the key. How do you start joplin?
I have installed Joplin app from Google App store on my Android Smart phone. I loved being able to speak ‘english’ to my phone and have it produce ‘speech to text’ input creating a joplin note for saving.
## qoheniac
The blue icon runs joplin-desktop (GUI version) not joblin (CLI version). The first one works fine but the second one has missing dependencies. There are planty of Node.js modules in /usr/share/joplin/desktop/resources/app/node_modules while in /usr/share/joplin/cli/node_modules not even exists. So if you do not want to use the CLI you do not have a problem.
## qoheniac
Same here: desktop version works, terminal version does not
## qoheniac
I tried ´npm install -g npm-install-all; cd /usr/share/joplin/cli; npm-install-all´ as root and it installed a lot of modules, but there were still missing dependencies.
## netvor
I tried to report the traceback to upstream
https://github.com/laurent22/joplin/issues/1456
turns out the COPR method is not maintained by the upstream so they can’t provide assistance.
## Benjamin Hetz
I have been using YACReader for a fair while now (I just manually downloaded and installed the .rpm). I’ve been very happy with it! Definitely gets a recommendation from me if you like reading digital comics. |
10,789 | 怎样在 Ubuntu Linux 上安装 MySQL | https://itsfoss.com/install-mysql-ubuntu/ | 2019-04-28T08:48:41 | [
"MySQL"
] | https://linux.cn/article-10789-1.html |
>
> 本教程教你如何在基于 Ubuntu 的 Linux 发行版上安装 MySQL。对于首次使用的用户,你将会学习到如何验证你的安装和第一次怎样去连接 MySQL。
>
>
>
[MySQL](https://www.mysql.com/) 是一个典型的数据库管理系统。它被用于许多技术栈中,包括流行的 [LAMP](https://en.wikipedia.org/wiki/LAMP_(software_bundle)) (Linux、Apache、MySQL、PHP)技术栈。它已经被证实了其稳定性。另一个让 MySQL 受欢迎的原因是它是开源的。
MySQL 是关系型数据库(基本上是表格数据)。以这种方式它很容易去存储、组织和访问数据。它使用SQL(结构化查询语言)来管理数据。
这这篇文章中,我将向你展示如何在 Ubuntu 18.04 安装和使用 MySQL 8.0。让我们一起来看看吧!
### 在 Ubuntu 上安装 MySQL

我将会介绍两种在 Ubuntu 18.04 上安装 MySQL 的方法:
1. 从 Ubuntu 仓库上安装 MySQL。非常简单,但不是最新版(5.7)
2. 从官方仓库安装 MySQL。你将额外增加一些步处理过程,但不用担心。你将会拥有最新版的MySQL(8.0)
有必要的时候,我将会提供屏幕截图去引导你。但这篇文章中的大部分步骤,我将直接在终端(默认热键: `CTRL+ALT+T`)输入命令。别害怕!
#### 方法 1、从 Ubuntu 仓库安装 MySQL
首先,输入下列命令确保你的仓库已经被更新:
```
sudo apt update
```
现在,安装 MySQL 5.7,简单输入下列命令:
```
sudo apt install mysql-server -y
```
就是这样!简单且高效。
#### 方法 2、使用官方仓库安装 MySQL
虽然这个方法多了一些步骤,但我将逐一介绍,并尝试写下清晰的笔记。
首先浏览 MySQL 官方网站的[下载页面](https://dev.mysql.com/downloads/repo/apt/)。

在这里,选择 DEB 软件包,点击“Download”链接。

滑到有关于 Oracle 网站信息的底部,右键 “No thanks, just start my download.”,然后选择 “Copy link location”。
现在回到终端,我们将使用 [Curl](https://linuxhandbook.com/curl-command-examples/) 命令去下载这个软件包:
```
curl -OL https://dev.mysql.com/get/mysql-apt-config_0.8.12-1_all.deb
```
`https://dev.mysql.com/get/mysql-apt-config_0.8.12-1_all.deb` 是我刚刚从网页上复制的链接。根据当前的 MySQL 版本,它有可能不同。让我们使用 `dpkg` 去开始安装 MySQL:
```
sudo dpkg -i mysql-apt-config*
```
更新你的仓库:
```
sudo apt update
```
要实际安装 MySQL,我们将使用像第一个方法中同样的命令来安装:
```
sudo apt install mysql-server -y
```
这样做会在你的终端中打开包配置的提示。使用向下箭头选择“Ok”选项。

点击回车。这应该会提示你输入密码:这是在为 MySQL 设置 root 密码。不要与 [Ubuntu 的 root 密码混淆](https://itsfoss.com/change-password-ubuntu/)。

输入密码然后点击 Tab 键去选择“Ok“。点击回车键,你将重新输入密码。操作完之后,再次键入 Tab 去选择 “Ok”。按下回车键。

将会展示一些关于 MySQL Server 的配置信息。再次按下 Tab 去选择 “Ok” 和按下回车键:

这里你需要去选择默认验证插件。确保选择了“Use Strong Password Encryption”。按下 Tab 键和回车键。
就是这样!你已经成功地安装了 MySQL。
#### 验证你的 MySQL 安装
要验证 MySQL 已经正确安装,使用下列命令:
```
sudo systemctl status mysql.service
```
这将展示一些关于 MySQL 服务的信息:

你应该在那里看到 “Active: active (running)”。如果你没有看到,使用下列命令去开始这个服务:
```
sudo systemctl start mysql.service
```
#### 配置/保护 MySQL
对于刚安装的 MySQL,你应该运行它提供的安全相关的更新命令。就是:
```
sudo mysql_secure_installation
```
这样做首先会询问你是否想使用 “<ruby> 密码有效强度 <rt> validate password component </rt></ruby>”。如果你想使用它,你将必须选择一个最小密码强度(0 – 低,1 – 中,2 – 高)。你将无法输入任何不遵守所选规则的密码。如果你没有使用强密码的习惯(本应该使用),这可能会配上用场。如果你认为它可能有帮助,那你就键入 `y` 或者 `Y`,按下回车键,然后为你的密码选择一个强度等级和输入一个你想使用的密码。如果成功,你将继续强化过程;否则你将重新输入一个密码。
但是,如果你不想要此功能(我不会),只需按回车或任何其他键即可跳过使用它。
对于其他选项,我建议开启它们(对于每一步输入 `y` 或者 `Y` 和按下回车)。它们(依序)是:“<ruby> 移除匿名用户 <rt> remove anonymous user </rt></ruby>”,“<ruby> 禁止 root 远程登录 <rt> disallow root login remotely </rt></ruby>”,“<ruby> 移除测试数据库及其访问 <rt> remove test database and access to it </rt></ruby>”。“<ruby> 重新载入权限表 <rt> reload privilege tables now </rt></ruby>”。
#### 链接与断开 MySQL Server
为了运行 SQL 查询,你首先必须使用 MySQL 连到服务器并在 MySQL 提示符使用。
执行此操作的命令是:
```
mysql -h host_name -u user -p
```
* `-h` 用来指定一个主机名(如果这个服务被安装到其他机器上,那么会有用;如果没有,忽略它)
* `-u` 指定登录的用户
* `-p` 指定你想输入的密码.
虽然出于安全原因不建议,但是你可以在命令行最右边的 `-p` 后直接输入密码。例如,如果用户`test_user` 的密码是 `1234`,那么你可以在你使用的机器上尝试去连接,你可以这样使用:
```
mysql -u test_user -p1234
```
如果你成功输入了必要的参数,你将会收到由 MySQL shell 提示符提供的欢迎(`mysql >`):

要从服务端断开连接和离开 MySQL 提示符,输入:
```
QUIT
```
输入 `quit` (MySQL 不区分大小写)或者 `\q` 也能工作。按下回车退出。
你使用简单的命令也能输出关于版本的信息:
```
sudo mysqladmin -u root version -p
```
如果你想看命令行选项列表,使用:
```
mysql --help
```
#### 卸载 MySQL
如果您决定要使用较新版本或只是想停止使用 MySQL。
首先,关闭服务:
```
sudo systemctl stop mysql.service && sudo systemctl disable mysql.service
```
确保你备份了你的数据库,以防你之后想使用它们。你可以通过运行下列命令卸载 MySQL:
```
sudo apt purge mysql*
```
清理依赖:
```
sudo apt autoremove
```
### 小结
在这篇文章中,我已经介绍如何在 Ubuntu Linux 上安装 Mysql。我很高兴如果这篇文章能帮助到那些正为此挣扎的用户或者刚刚开始的用户。
如果你发现这篇文章是一个很有用的资源,在评论里告诉我们。你为了什么使用 MySQL? 我们渴望收到你的任何反馈、印象和建议。感谢阅读,并毫不犹豫地尝试这个很棒的工具!
---
via: <https://itsfoss.com/install-mysql-ubuntu/>
作者:[Sergiu](https://itsfoss.com/author/sergiu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[arrowfeng](https://github.com/arrowfeng) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: This tutorial teaches you to install MySQL in Ubuntu based Linux distributions. You’ll also learn how to verify your install and how to connect to MySQL for the first time.*
** MySQL** is the quintessential database management system. It is used in many tech stacks, including the popular
**(Linux, Apache, MySQL, PHP) stack. It has proven its stability. Another thing that makes**
[LAMP](https://en.wikipedia.org/wiki/LAMP_(software_bundle))**MySQL**so great is that it is
**open-source**.
**MySQL** uses **relational databases** (basically **tabular data**). It is really easy to store, organize and access data this way. For managing data, **SQL** (**Structured Query Language**) is used.
In this article I’ll show you how to **install** and **use** MySQL in Ubuntu Linux. Let’s get to it!
## Installing MySQL in Ubuntu

I’ll be covering two ways you can install **MySQL** in Ubuntu 18.04:
- Install MySQL from the Ubuntu repositories. Very basic, not the latest version (5.7)
- Install MySQL using the official repository. There is a bigger step that you’ll have to add to the process, but nothing to worry about. Also, you’ll have the latest version (8.0)
When needed, I’ll provide screenshots to guide you. For most of this guide, I’ll be entering commands in the **terminal** (**default hotkey**: CTRL+ALT+T). Don’t be scared of it!
### Method 1. Installing MySQL from the Ubuntu repositories
First of all, make sure your repositories are updated by entering:
`sudo apt update`
Now, to install **MySQL 5.7**, simply type:
`sudo apt install mysql-server -y`
That’s it! Simple and efficient.
### Method 2. Installing MySQL using the official repository
Although this method has a few more steps, I’ll go through them one by one and I’ll try writing down clear notes.
The first step is browsing to the [download page](https://dev.mysql.com/downloads/repo/apt/) of the official MySQL website.
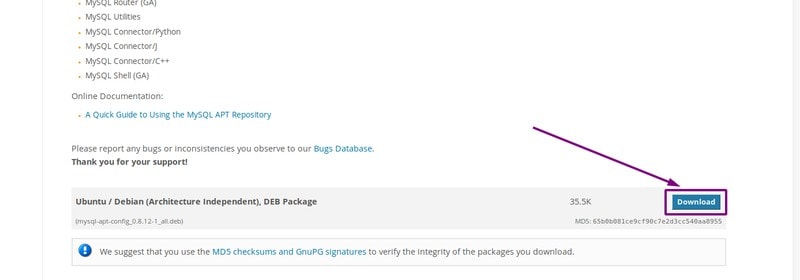
Here, go down to the **download link** for the **DEB Package**.
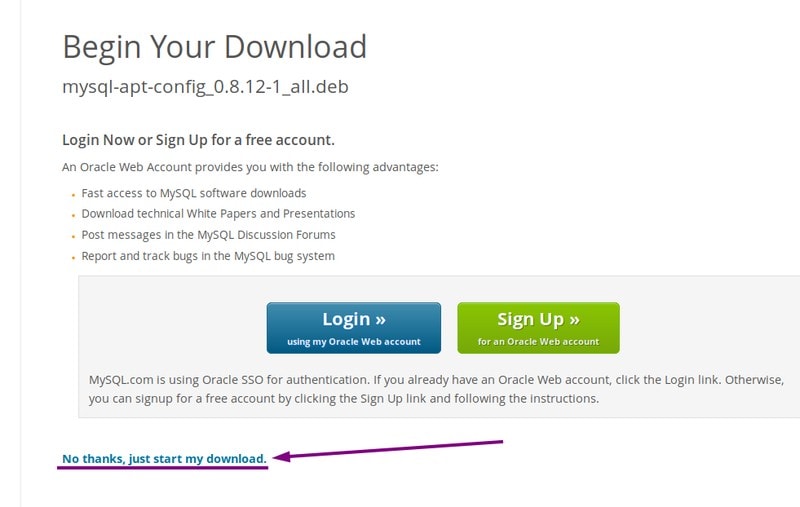
Scroll down past the info about Oracle Web and right-click on **No thanks, just start my download.** Select **Copy link location**.
Now go back to the terminal. We’ll [use ](https://linuxhandbook.com/curl-command-examples/)[Curl](https://linuxhandbook.com/curl-command-examples/)[ command](https://linuxhandbook.com/curl-command-examples/) to the download the package:
`curl -OL https://dev.mysql.com/get/mysql-apt-config_0.8.12-1_all.deb`
**https://dev.mysql.com/get/mysql-apt-config_0.8.12-1_all.deb** is the link I copied from the website. It might be different based on the current version of MySQL. Let’s use **dpkg** to start installing MySQL:
`sudo dpkg -i mysql-apt-config*`
Update your repositories:
`sudo apt update`
To actually install MySQL, we’ll use the same command as in the first method:
`sudo apt install mysql-server -y`
Doing so will open a prompt in your terminal for **package configuration**. Use the **down arrow** to select the **Ok** option.
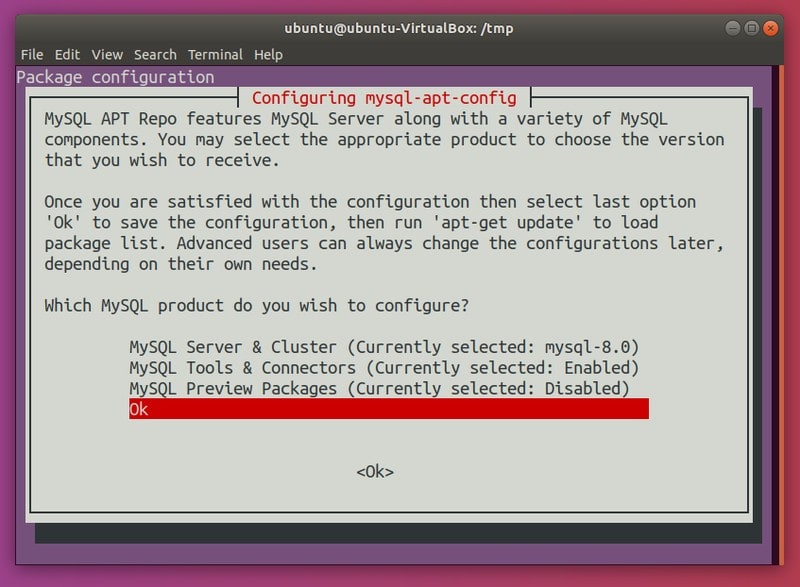
Press **Enter**. This should prompt you to enter a **password**:. Your are basically setting the root password for MySQL. Don’t confuse it with [root password of Ubuntu](https://itsfoss.com/change-password-ubuntu/) system.
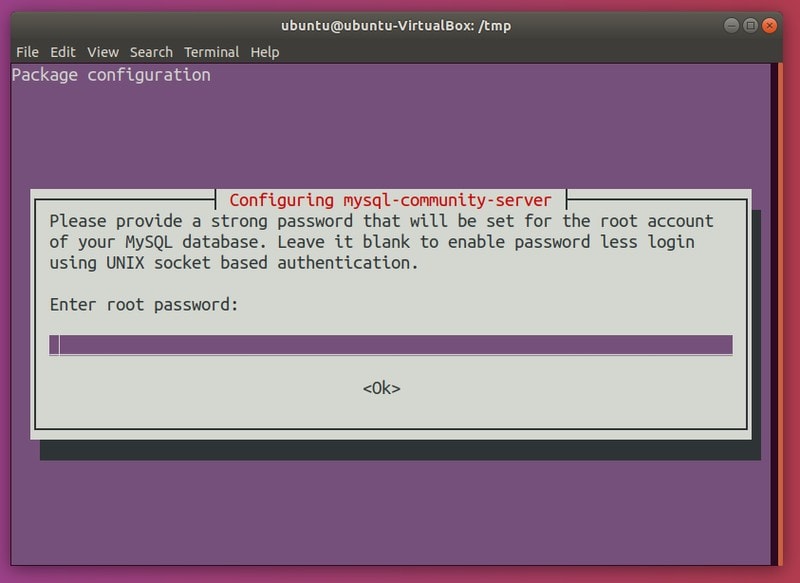
Type in a password and press **Tab** to select **<Ok>**. Press **Enter.** You’ll now have to **re-enter** the **password**. After doing so, press **Tab** again to select **<Ok>**. Press **Enter**.
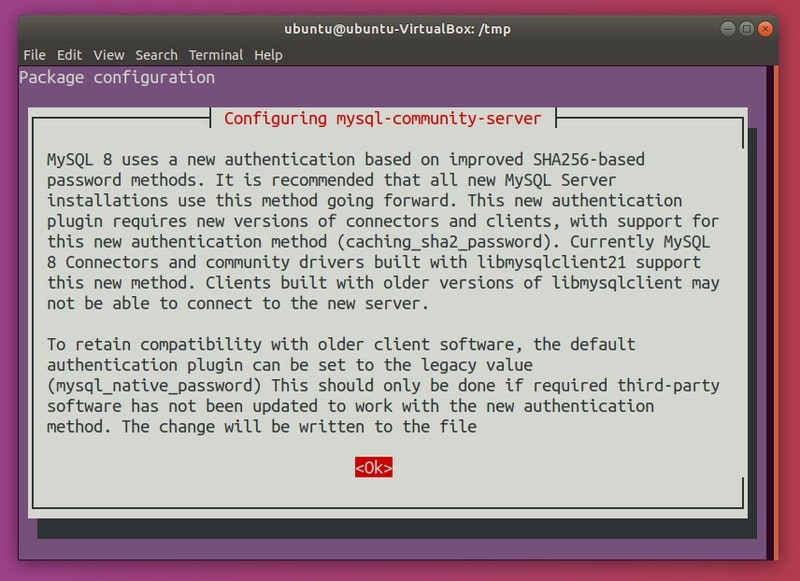
Some** information** on configuring MySQL Server will be presented. Press **Tab** to select **<Ok>** and **Enter** again:
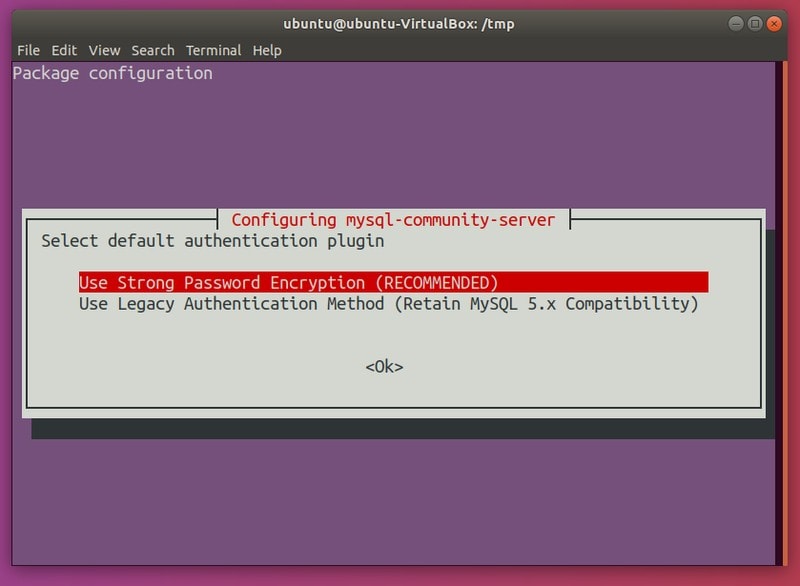
Here you need to choose a **default authentication plugin**. Make sure **Use Strong Password Encryption** is selected. Press **Tab** and then **Enter**.
That’s it! You have successfully installed MySQL.
### Verify your MySQL installation
To **verify** that MySQL installed correctly, use:
`sudo systemctl status mysql.service`
This will show some information about the service:
You should see **Active: active (running)** in there somewhere. If you don’t, use the following command to start the **service**:
`sudo systemctl start mysql.service`
### Configuring/Securing MySQL
For a new install, you should run the provided command for security-related updates. That’s:
`sudo mysql_secure_installation`
Doing so will first of all ask you if you want to use the **VALIDATE PASSWORD COMPONENT**. If you want to use it, you’ll have to select a minimum password strength (**0 – Low, 1 – Medium, 2 – High**). You won’t be able to input any password doesn’t respect the selected rules. If you don’t have the habit of using strong passwords (you should!), this could come in handy. If you think it might help, type in **y** or **Y** and press **Enter**, then choose a **strength level** for your password and input the one you want to use. If successful, you’ll continue the **securing** process; otherwise you’ll have to re-enter a password.
If, however, you do not want this feature (I won’t), just press **Enter** or **any other key** to skip using it.
For the other options, I suggest **enabling** them (typing in **y** or **Y** and pressing **Enter** for each of them). They are (in this order): **remove anonymous user, disallow root login remotely, remove test database and access to it, reload privilege tables now**.
### Connecting to & Disconnecting from the MySQL Server
To be able to run SQL queries, you’ll first have to connect to the server using MySQL and use the MySQL prompt. The command for doing this is:
`mysql -h host_name -u user -p`
**-h**is used to specify a**host name**(if the server is located on another machine; if it isn’t, just omit it)**-u**mentions the**user****-p**specifies that you want to input a**password**.
Although not recommended (for safety reasons), you can enter the password directly in the command by typing it in right after **-p**. For example, if the password for **test_user** is **1234** and you are trying to connect on the machine you are using, you could use:
`mysql -u test_user -p1234`
If you successfully inputted the required parameters, you’ll be greeted by the **MySQL shell prompt** (**mysql>**):
To **disconnect** from the server and **leave** the mysql prompt, type:
`QUIT`
Typing **quit** (MySQL is case insensitive) or **\q** will also work. Press **Enter** to exit.
You can also output info about the **version**with a simple command:
`sudo mysqladmin -u root version -p`
If you want to see a **list of options**, use:
`mysql --help`
### Uninstalling MySQL
If you decide that you want to use a newer release or just want to stop using MySQL.
First, disable the service:
`sudo systemctl stop mysql.service && sudo systemctl disable mysql.service`
Make sure you backed up your databases, in case you want to use them later on. You can uninstall MySQL by running:
`sudo apt purge mysql*`
To clean up dependecies:
`sudo apt autoremove`
**Wrapping Up**
In this article, I’ve covered **installing MySQL** in Ubuntu Linux. I’d be glad if this guide helps struggling users and beginners.
Tell us in the comments if you found this post to be a useful resource. What do you use MySQL for? We’re eager to receive any feedback, impressions or suggestions. Thanks for reading and have don’t hesitate to experiment with this incredible tool! |
10,790 | 即将到来的 Debian 10 Buster 发布版的新特点 | https://itsfoss.com/new-features-coming-to-debian-10-buster-release/ | 2019-04-28T12:11:31 | [
"Debian"
] | https://linux.cn/article-10790-1.html | 
Debian 10 Buster 即将发布。第一个发布候选版已经发布,我们预期可以在几周内见到待最终版。
如果你期待对这个新的主要发布版本,让我告诉你里面有什么。
### Debian 10 Buster 发布计划
[Debian 10 Buster](https://wiki.debian.org/DebianBuster) 的发布日期并没有确定。为什么这样呢?不像其他分发版,[Debian](https://www.debian.org/) 并不基于时间发布。相反地它主要关注于修复<ruby> 发布版重要 Bug <rt> release-critical bug </rt></ruby>。发布版重要 Bug 要么是严重的安全问题([CVE](https://en.wikipedia.org/wiki/Common_Vulnerabilities_and_Exposures)),要么是一些其他阻止 Debian 发布的严重问题。
Debian 在它的软件归档中分为三个部分,叫做 Main、contrib 和 non-free。在这三者之中,Debian 开发者和发布管理者最关心的包组成了该分发版的基石。Main 是像石头一样稳定的。因此他们要确保那里没有主要的功能或者安全问题。他们同样给予了不同的优先级,例如 Essential、Required、Important、Standard、Optional 和 Extra。更多关于此方面的知识参考后续的 Debian 文章。
这是必要的,因为 Debian 在很多环境中被用作服务器,人们已经变得依赖 Debian。他们同样看重升级周期是否有破环,因此他们寻找人们来测试,来查看当升级的时候是否有破坏并通知 Debian 有这样的问题。
这种提交方式带来的稳定性[是我喜欢 Debian 的众多原因之一](https://itsfoss.com/reasons-why-i-love-debian/)。
### Debian 10 Buster 版本的新内容
这里是即将到来的 Debian 主要发布版的一些视觉上和内部的改变。
#### 新的主题和壁纸
Buster 的 Debian 主题被称为 [FuturePrototype](https://wiki.debian.org/DebianArt/Themes/futurePrototype) 并且看起来如下图:

#### 1、GNOME 桌面 3.30
Debian Stretch 版中的 GNOME 桌面在 Buster 中从 1.3.22 升级到了 1.3.30。在 GNOME 桌面发布版中新包含的一些包是 gnome-todo、tracker 替代了 tracker-gui、gstreamer1.0-packagekit 的依赖,因此可以通过自动地安装编码解码器来做播放电影之类的事。对于所有包来说一个大的改变是从 libgtk2+ 到 libgtk3+。
#### 2、Linux 内核 4.19.0-4
Debian 使用 LTS 内核版本,因此你可以期待更好的硬件支持和长达 5 年的维护和支持周期。我们已经从内核 4.9.0.3 到 4.19.0-4。
```
$ uname -r
4.19.0-4-amd64
```
#### 3、OpenJDK 11.0
Debian 在很长时间里都是 OpenJDK 8.0。现在在 Debian Buster 里我们已经升级为 OpenJDK 11.0,并且会有一个团队维护新的版本。
#### 4、默认启用 AppArmor
在 Debian Buster 中是默认启用 [AppArmor](https://wiki.debian.org/AppArmor) 的。这是一个好事,谨慎是系统管理员必须采取的正确策略。这仅仅是第一步,并且可能需要修复很多对用户觉得有用的脚本。
#### 5、Nodejs 10.15.2
在很长一段时间里 Debian 在仓库中都只有 Nodejs 4.8。在这个周期里 Debian 已经移到 Nodejs 10.15.2。事实上,Debian Buster 有很多 javascript 库例如 yarnpkg (一个 nmp 的替代品)等等。
当然,你可以从该项目仓库[在 Debian 中安装最新的 Nodejs](https://itsfoss.com/install-nodejs-ubuntu/),但是从 Debian 仓库中看到更新的版本是很棒的。
#### 6、NFtables 替代了 iptables
Debian Buster 提供了 nftables 来完整地替代了 iptables,因为它有更好、更简单的语法,更好的支持双栈 ipv4/v6 防火墙等等。
#### 7、支持更多的 ARM 64 和 ARMHF 的单板机。
Debian 已经支持一些常见的新的单板机,其中最新的包括 pine64\_plus、ARM64 的 pinebook、Firefly-RK3288、ARMHF 64 的 u-boot-rockchip 以及 Odroid HC1/HC2 板、SolidRun Cubox-i 双核/四核(1.5som)和 SolidRun Cubox-i 双核/四核(1.5som+emmc)板、Cubietruckplus 等。同样支持 Rock 64、Banana Pi M2 Berry、Pine A64 LTS Board、Olimex A64 Teres-1 与 Rapberry Pi 1、Zero 和 Pi 3。对于 RISC-V 系统同样支持开箱即用。
#### 8、Python 2 已死,Python 3 长存
在 2020 年 1 月 1 日,Python 2 将被 python.org 废弃。在 Debian 将所有的软件包从 Python 2.7 移到 Python 3 以后,Python 2.7 将从软件仓库中移除。这可能发生在 Buster 发布版或者将来的某个发布版,这是肯定要来临的。因此 Python 开发者被鼓励移植他们的代码库来兼容 Python 3。在写本文的时候,在 Debian Buster 中同时支持 python2 和 pythone3。
#### 9、Mailman 3
在 Debian 中终于可以使用 Mailman3 了。同时 [Mailman](https://www.list.org/) 已经被细分成为组件。要安装整个软件栈,可以安装 mailman3-full 来获取所有组件。
#### 10、任意已有的 Postgresql 数据库将需要重新索引
由于 glibc 本地数据的更新,放入文本索引中的信息排序的方式将会改变,因为重新索引是有益的,这样在将来就不会有数据破坏发生。
#### 11、默认 Bash 5.0
你可能已经了解了 [Bash 5.0 的新特点](https://itsfoss.com/bash-5-release/),在 Debian 中已经是该版本了。
#### 12、Debian 实现 /usr/merge
我们已经分享过一个优秀的 freedesktop [读物](https://www.freedesktop.org/wiki/Software/systemd/TheCaseForTheUsrMerge/),介绍了 `/usr/merge` 带来了什么。有一些事项需要注意。当 Debian 想要整个过渡时,可能由于未预见的情况,一些二进制文件可能并没有做这些改变。需要指出的一点是,`/var` 和 `/etc` 不会被触及,因此使用容器或者云技术的不需要考虑太多 :)。
#### 13、支持安全启动
在 Buster RC1 中,Debian 现在支持<ruby> 安全启动 <rt> secure-boot </rt></ruby>。这意味着打开了安全启动设置的机器应该能够轻松安装 Debian。不再需要禁止或者处理安全启动的事 :)
#### 14、Debian-Live 镜像的 Calameres Live-installer
对于 Debian Buster 的 Live 版,Debian 引入了 [Calameres 安装器](https://calamares.io/about/)来替代老的 Debian-installer。Debian-installer 比 Calameres 功能更多,但对于初学者,Calameres 相对于 Debian-installer 提供了另外一种全新的安装方式。安装过程的截图:

如图所见,在 Calamares 下安装 Debian 相当简单,只要经历 5 个步骤你就能在你的机器上安装 Debian。
### 下载 Debian 10 Live 镜像 (只用于测试)
现在还不要将它用于生产机器。可以在测试机上尝试或者一个虚拟机。
你可以从 Debian Live [目录](https://cdimage.debian.org/cdimage/weekly-live-builds/)获取 Debian 64 位和 32 位的镜像。如果你想要 64 位的就进入 `64-bit` 目录,如果你想要 32 位的,就进入 `32-bit` 目录。
* [下载 Debian 10 Buster Live Images](https://cdimage.debian.org/cdimage/weekly-live-builds/)
如果你从已存在的稳定版升级并且出现了一些问题,查看它是否在预安装的[升级报告](https://bugs.debian.org/cgi-bin/pkgreport.cgi?pkg=upgrade-reports;dist=unstable)中提及了,使用 [reportbug](https://itsfoss.com/bug-report-debian/) 报告你看到的问题。如果 bug 没有被报告,那么请尽可能地报告和分享更多地信息。
### 总结
当上千个包被升级时,看起来不可能一一列出。我已经列出了一些你在 Debian Buster 可以找到的一些主要的改变。你怎么看呢?
---
via: <https://itsfoss.com/new-features-coming-to-debian-10-buster-release/>
作者:[Shirish](https://itsfoss.com/author/shirish/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,792 | 用来记笔记的三个 Emacs 模式 | https://opensource.com/article/18/7/emacs-modes-note-taking | 2019-04-29T10:24:16 | [
"Emacs",
"笔记"
] | https://linux.cn/article-10792-1.html |
>
> 借助这些 Emacs 模式轻松记录信息。
>
>
>

不管你从事哪种工作,你都无可避免地需要记笔记。而且可能还不是一点点。现在这年头,大家都开始以数字的形式来记笔记了。
开源软件爱好者有多种途径来以电子的方式记下他们的创意、想法和研究过程。你可以使用 [网页工具](https://opensource.com/alternatives/evernote),可以使用 [桌面应用](https://opensource.com/life/16/9/4-desktop-note-taking-applications),或者你也可以 [使用命令行工具](https://opensource.com/article/18/3/command-line-note-taking-applications)。
如果你使用 [Emacs](https://www.gnu.org/software/emacs/)(伪装成文本编辑器的强力操作系统),有多个<ruby> 模式 <rt> mode </rt></ruby>可以帮你有效地记录笔记。我们这里列举三个例子。
### Deft

在少数情况下,我只能使用 Mac时,有一个工具是我不能缺少的:[nvALT](http://brettterpstra.com/projects/nvalt/) 笔记应用。[Deft 模式](https://jblevins.org/projects/deft/) 为 Emacs 带来了 nvALT 式的体验。
Deft 将你的笔记以文本文件的形式存储在电脑中的某个文件夹中。当你进入 Deft 模式,你会看到一系列的笔记及其摘要。这些摘要其实就是文本文件的第一行。若第一行是 Markdown、LaTeX,甚至 Emacs Org 模式的格式的话,Deft 会忽略掉这些格式而只显示文本内容。
要打开笔记,只需要向下滚动到该笔记的位置然后按下回车即可。然而 Deft 不仅仅只是这样。根据 Deft 开发者 Jason Blevins 的说法,它的*主要操作是搜索和过滤*。Deft 的实现方式简单而有效。输入关键字然后 Deft 会只显示标题中包含关键字的笔记。这在你要从大量笔记中找到某条笔记时非常有用。
### Org 模式

如果本文没有包含 [Org 模式](https://orgmode.org/) 的话,那么我可能会被人所诟病。为什么?它可以说是 Emacs 中最灵活、使用最广泛的记录笔记的方式了。以正确的方式使用它,Org 模式可以极大地增强记笔记的能力。
Org 模式的主要优势在于它组织笔记的方式。在 Org 模式中,一个笔记文件会被组织成一个巨大的大纲。每个章节就是大纲里的一个节点,你可以对它进行展开和折叠。这些章节又可以有子章节,这些子章节也可以展开和折叠。这不仅使你一次只关注于某个章节,而且可以让你浏览整个大纲。
你可以在多个章节之间 [进行互联](https://orgmode.org/org.html#Hyperlinks),无需通过剪切和复制就能快速移动章节,以及 [附加文件](https://orgmode.org/org.html#Attachments) 到笔记中。Org 模式支持带格式的字符和表格。如果你需要转换笔记到其他格式,Org 模式也有大量的[导出选项](https://orgmode.org/org.html#Exporting)。
### Howm

当我使用 Emacs 已经成为一种习惯时,[howm](https://howm.osdn.jp/) 马上就成为我严重依赖的模式之一了。虽然我特别喜欢使用 Org 模式,但 howm 依然占有一席之地。
Howm 就好像是一个小型维基。你可以创建笔记和任务列表,还能在它们之间创建链接。通过输入或点击某个链接,你可以在笔记之间跳转。如果你需要,还可以使用关键字为笔记添加标签。不仅如此,你可以对笔记进行搜索、排序和合并。
Howm 不是最漂亮的 Emacs 模式,它的用户体验也不是最佳。它需要你花一点时间来适应它,而一旦你适应了它,记录和查找笔记就是轻而易举的事情了。
---
via: <https://opensource.com/article/18/7/emacs-modes-note-taking>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | No matter what line of work you're in, it's inevitable you have to take a few notes. Often, more than a few. If you're like many people in this day and age, you take your notes digitally.
Open source enthusiasts have a variety of options for jotting down their ideas, thoughts, and research in electronic format. You might use a [web-based tool](https://opensource.com/alternatives/evernote). You might go for a [desktop application](https://opensource.com/life/16/9/4-desktop-note-taking-applications). Or, you might [turn to the command line](https://opensource.com/article/18/3/command-line-note-taking-applications).
If you use [Emacs](https://www.gnu.org/software/emacs/), that wonderful operating system disguised as a text editor, there are modes that can help you take notes more efficiently. Let's look at three of them.
## Deft
On those rare occasions I'm forced to use a Mac, there's one tool I can't do without: the [nvALT](http://brettterpstra.com/projects/nvalt/) note-taking application. [Deft mode](https://jblevins.org/projects/deft/) brings the nvALT experience to Emacs.
Deft stores your notes as text files in a single folder on your computer. When you enter Deft mode, it displays a list of your notes along with a short summary. The summary is taken from the first line of the text file. If you add, say, Markdown, LaTeX, or even Emacs Org mode formatting to the first line, Deft ignores the formatting and displays only the text.
To open a note, just scroll down to it and press Enter. Deft does a bit more, though. According to Deft's developer, Jason Blevins, its *primary operation is searching and filtering*. Deft does that simply but efficiently. Type a keyword and Deft displays only the notes that have that keyword in their title. That's useful if you have a lot of notes and want to find one quickly.
## Org mode
There would be a couple or three people who would have jumped all over me if I didn't include [Org mode](https://orgmode.org/) in this article. Why? It's arguably the most flexible and the most widely used Emacs mode for taking notes. Used in the right way, Org mode can supercharge your note-taking.
Org mode's main strength is how it organizes your notes. In Org mode, a note file is set up as a large outline. Each section is a node in the outline, which you can expand and collapse. Those sections can have subsections, which also expand and collapse. That not only lets you focus on one section at a time, but it also gives you an at-a-glance overview of the information you have.
You can [link](https://orgmode.org/org.html#Hyperlinks) between sections of your notes, quickly move sections without cutting and pasting, and [attach files](https://orgmode.org/org.html#Attachments) to your notes. Org mode supports character formatting and tables. If you need to convert your notes to something else, Org mode has a number of [export options](https://orgmode.org/org.html#Exporting).
## Howm
When I started using Emacs regularly, [howm](https://howm.osdn.jp/) quickly became one of the modes I leaned heavily on. And even though I'm deep into using Org mode, I still have a soft spot for howm.
Howm acts like a small wiki. You can create notes and task lists and link between them. By typing or clicking a link, you can jump between notes. If you need to, you can also tag your notes with a keyword. On top of that, you can search, sort, and concatenate your notes.
Howm isn't the prettiest Emacs mode, and it doesn't have the best UX. It takes a bit of getting used to. Once you do, taking and maneuvering around notes is a breeze.
Do you have a favorite Emacs mode for taking notes? Feel free to share it by leaving a comment.
## Comments are closed. |
10,795 | 下载安装 Ubuntu 19.04 “Disco Dingo” | https://itsfoss.com/ubuntu-19-04-release/ | 2019-04-29T18:03:26 | [
"Ubuntu"
] | https://linux.cn/article-10795-1.html | Ubuntu 19.04 “Disco Dingo” 已经发布,可以下载了。虽然我们已经知道 [Ubuntu 19.04 中的新功能](https://itsfoss.com/ubuntu-19-04-release-features/) —— 我将在下面提到一些重要的地方,还会给出官方的下载链接。
### Ubuntu 19.04:你需要知道什么
以下是你应该了解的有关 Ubuntu 19.04 Disco Dingo 发布的一些内容。
#### Ubuntu 19.04 不是 LTS 版本
与 Ubuntu 18.04 LTS 不同,它不会[支持 10 年](https://itsfoss.com/ubuntu-18-04-ten-year-support/)。相反,非 LTS 的 19.04 将支持 **9 个月,直到 2020 年 1 月。**
因此,如果你有生产环境,我们可能不会立即建议你进行升级。例如,如果你有一台运行在 Ubuntu 18.04 LTS 上的服务器 —— 只是因为它是一个新的版本就将它升级到 19.04 可能不是一个好主意。
但是,对于希望在计算机上安装最新版本的用户,可以尝试一下。

#### Ubuntu 19.04 对 NVIDIA GPU 用户是个不错的更新
Martin Wimpress(来自 Canonical)在 Ubuntu MATE 19.04(Ubuntu 版本之一)的 [GitHub](https://github.com/ubuntu-mate/ubuntu-mate.org/blob/master/blog/20190418-ubuntu-mate-disco-final-release.md) 的最终发布说明中提到 Ubuntu 19.04 对 NVIDIA GPU 用户来说特别重要。
换句话说,在安装专有图形驱动时 —— 它现在会选择与你特定 GPU 型号兼容最佳的驱动程序。
#### Ubuntu 19.04 功能
尽管我们已经讨论过 [Ubuntu 19.04](https://itsfoss.com/ubuntu-19-04-release-features/) Disco Dingo 的[最佳功能](https://itsfoss.com/ubuntu-19-04-release-features/),但值得一提的是,我对本次发布的主要变化:桌面更新 (GNOME 3.32) 和 Linux 内核 (5.0)感到兴奋。
#### 从 Ubuntu 18.10 升级到 19.04
显而易见,如果你安装了 Ubuntu 18.10,你应该升级它。18.10 将于 2019 年 7 月停止支持 —— 所以我们建议你将其升级到 19.04。
要做到这一点,你可以直接进入“软件和更新”设置,然后选择“更新”选项卡。
现在将选项从“通知我新的 Ubuntu 版本” 变成 “任何新版本都通知我”。
现在再次运行更新管理器时,你应该会看到 Ubuntu 19.04。

#### 从 Ubuntu 18.04 升级到 19.04
建议不要直接从 18.04 升级到 19.04,因为你需要先将操作系统更新到 18.10,然后再继续升级到 19.04。
相反,你只需下载 Ubuntu 19.04 的官方 ISO 映像,然后在你的系统上重新安装 Ubuntu。
### Ubuntu 19.04:所有版本都可下载
根据[发行说明](https://wiki.ubuntu.com/DiscoDingo/ReleaseNotes),现在可以下载 Ubuntu 19.04。你可以在其官方发布下载页面上获取种子或 ISO 文件。
* [下载 Ubuntu 19.04](https://www.ubuntu.com/download/desktop)
如果你需要不同的桌面环境或需要特定的东西,你应该查看 Ubuntu 的官方版本:
* [Ubuntu MATE](https://ubuntu-mate.org/download/)
* [Kubuntu](https://kubuntu.org/getkubuntu/)
* [Lubuntu](https://lubuntu.me/cosmic-released/)
* [Ubuntu Budgie](https://ubuntubudgie.org/downloads)
* [Ubuntu Studio](https://ubuntustudio.org/2019/04/ubuntu-studio-19-04-released/)
* [Xubuntu](https://xubuntu.org/download/)
上面提到的一些 Ubuntu 版本还没有在页面提供 19.04。但你可以[仍然在 Ubuntu 的发行说明网页上找到 ISO](https://wiki.ubuntu.com/DiscoDingo/ReleaseNotes)。就个人而言,我使用带 GNOME 桌面的 Ubuntu。你可以选择你喜欢的。
### 总结
你如何看待 Ubuntu 19.04 Disco Dingo?这些新功能是否足够令人兴奋?你试过了吗?请在下面的评论中告诉我们。
---
via: <https://itsfoss.com/ubuntu-19-04-release/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It’s the time to disco! Why? Well, Ubuntu 19.04 ‘Disco Dingo’ is here and finally available to download. Although, we are aware of the [new features in Ubuntu 19.04](https://itsfoss.com/ubuntu-19-04-release-features/) – I will mention a few important things below and would also point you to the official links to download it and get started.
## Ubuntu 19.04: What You Need To Know
Here are a few things you should know about Ubuntu 19.04 Disco Dingo release.
[interaction id=”5cb812356fdf9a2885e428cb”]
### Ubuntu 19.04 is not an LTS Release
Unlike Ubuntu 18.04 LTS, this will not be [supported for 10 years](https://itsfoss.com/ubuntu-18-04-ten-year-support/). Instead, the non-LTS 19.04 will be supported for **9 months until January 2020.**
So, if you have a production environment, we may not recommend upgrading it right away. For example, if you have a server that runs on Ubuntu 18.04 LTS – it may not be a good idea to upgrade it to 19.04 just because it is an exciting release.
However, for users who want the latest and greatest installed on their machines can try it out.

### Ubuntu 19.04 is a sweet update for NVIDIA GPU Owners
*Martin Wimpress* (from Canonical) mentioned that Ubuntu 19.04 is particularly a big deal for NVIDIA GPU owners in the final release notes of Ubuntu MATE 19.04 (one of the Ubuntu flavors) on [GitHub](https://github.com/ubuntu-mate/ubuntu-mate.org/blob/master/blog/20190418-ubuntu-mate-disco-final-release.md).
In other words, while installing the proprietary graphics driver – it now selects the best driver compatible with your particular GPU model.
### Ubuntu 19.04 Features
Even though we have already discussed the [best features of Ubuntu 19.04](https://itsfoss.com/ubuntu-19-04-release-features/) Disco Dingo, it is worth mentioning that I’m exciting about the desktop updates (GNOME 3.32) and the Linux Kernel (5.0) that comes as one of the major changes in this release.
### Upgrading from Ubuntu 18.10 to 19.04
If you have Ubuntu 18.10 installed, you should upgrade it for obvious reasons. 18.10 will reach its end of life in July 2019 – so we recommend you to upgrade it to 19.04.
To do that, you can simply head on to the “**Software and Updates**” settings and then navigate your way to the “**Updates**” tab.
Now, change the option for – **Notify me of a new Ubuntu version** to “*For any new version*“.
When you run the update manager now, you should see that Ubuntu 19.04 is available now.
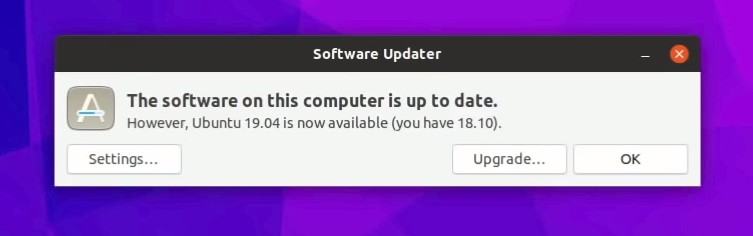
### Upgrading from Ubuntu 18.04 to 19.04
It is not recommended to directly upgrade from 18.04 to 19.04 because you will have to update the OS to 18.10 first and then proceed to get 19.04 on board.
Instead, you can simply download the official ISO image of Ubuntu 19.04 and then re-install Ubuntu on your system.
## Ubuntu 19.04: Downloads Available for all flavors
As per the [release notes](https://wiki.ubuntu.com/DiscoDingo/ReleaseNotes), Ubuntu 19.04 is available to download now. You can get the torrent or the ISO file on its official release download page.
If you need a different desktop environment or need something specific, you should check out the official flavors of Ubuntu available:
Some of the above mentioned Ubuntu flavors haven’t put the 19.04 release on their download yet. But you can [still find the ISOs on the Ubuntu’s release note webpage](https://wiki.ubuntu.com/DiscoDingo/ReleaseNotes). Personally, I use Ubuntu with GNOME desktop. You can choose whatever you like.
**Wrapping Up**
What do you think about Ubuntu 19.04 Disco Dingo? Are the new features exciting enough? Have you tried it yet? Let us know in the comments below. |
10,796 | Linux 初学者:移动文件 | https://www.linux.com/blog/2018/8/linux-beginners-moving-things-around | 2019-04-30T12:20:43 | [
"文件",
"目录"
] | https://linux.cn/article-10796-1.html | 
在之前的该系列的部分中,[你学习了有关目录](/article-10066-1.html)和[访问目录](/article-10399-1.html)[的权限](/article-10370-1.html)是如何工作的。你在这些文章中学习的大多数内容都可应用于文件,除了如何让一个文件变成可执行文件。
因此让我们在开始之前先解决这个问题。
### 不需要 .exe 扩展名
在其他操作系统中,一个文件的性质通常由它的后缀决定。如果一个文件有一个 .jpg 扩展,操作系统会认为它是一幅图像;如果它以 .wav 结尾,它是一个音频文件;如果它在文件名末尾以 .exe 结尾,它就是一个你可以执行的程序。
这导致了严重的问题,比如说木马可以伪装成文档文件。幸运的是,在 Linux 下事物不是这样运行的。可以确定的是,你可能会看到有些可执行文件是以 .sh 结尾暗示它们是可执行的脚本,但是这大部分是为了便于人眼找到文件,就像你使用 `ls --color` 将可执行文件的名字以亮绿色显示的方式相同。
事实上大多数应用根本没有扩展名。决定一个文件是否是一个真正程序的是 `x` (指*可执行的*)位。你可以通过运行以下命令使任何文件变得可执行,
```
chmod a+x some_program
```
而不管它的扩展名是什么或者是否存在。在上面命令中的 `x` 设置了 `x` 位,`a` 说明你为*所有*用户设置它。你同样可以为一组用户设置成拥有这个文件(`g+x`),或者只为一个用户——拥有者——设置 (`u+x`)。
尽管我们会在该系列之后的部分包含从命令行创建和运行脚本的内容,并学习通过输入它的路径并在结尾加上程序名的方式运行一个程序:
```
path/to/directory/some_program
```
或者,如果你当前在相同目录,你可以使用:
```
./some_program
```
还有其他方式可以使你的程序在目录树的任意位置运行 (提示:查询 `$PATH` 环境变量),但是当我们讨论 shell 脚本的时候你会读到这些。
### 复制、移动、链接
明显地,从命令行修改和处理文件有很多的方式,而不仅仅是处理它们的权限。当你试图打开一个不存在的文件是,大多数应用会创建一个新文件。如果 `test.txt` 当前并不存在,下列命令:
```
nano test.txt
```
```
vim test.txt
```
([nano](https://www.nano-editor.org/) 和 [vim](https://www.vim.org/) 是流行的命令行文本编辑器)都将为你创建一个空的 `test.txt` 文件来编辑。
你可以通过 “触摸” (`touch`)来创建一个空的文件,
```
touch test.txt
```
会创建一个文件,但是不会在任何应用中打开它。
你可以使用 `cp` 来拷贝一个文件到另一个位置,或者使用一个不同的名字:
```
cp test.txt copy_of_test.txt
```
你也可以拷贝一堆文件:
```
cp *.png /home/images
```
上面的命令拷贝当前目录下的所有 PNG 文件到相对你的主目录下的 `images/` 目录。在你尝试之前 `images/` 目录必须存在, 不然 `cp` 将显示一个错误。同样的,警惕,当你复制一个文件到一个已经包含相同名字的文件的目录时,`cp` 会静默地用新文件覆盖老的文件。
你可以使用:
```
cp -i *.png /home/images
```
如果你想要 `cp` 命令在有任何危险时警告你 (`-i` 选项代表*交互式的*)。
你同样可以复制整个目录,但是为了做到这样,你需要 `-r` 选项:
```
cp -rv directory_a/ directory_b
```
`-r` 选项代表*递归*,意味着 `cp` 会向下探索目录 `directory_a`,复制所有的文件和子目录下内部包含的。我个人喜欢包含 `-v` 选项,因为它使 `cp` 冗长而啰嗦,意味着它会显示你当前它正在做什么而不是仅仅静默的复制然后存在。
`mv` 命令移动东西。也就是说,它移动文件从一个位置到另一个位置。最简单的形式,`mv` 表现的更像 `cp`:
```
mv test.txt new_test.txt
```
上面的命令使 `new_test.txt` 出现,`test.txt` 消失。
```
mv *.png /home/images
```
移动当前目录下所有的 PNG 文件到相对于你的主目录的 `images/` 目录。同样的你必须小心你没有意外的覆盖已存在的文件。使用
```
mv -i *.png /home/images
```
如果你想站在安全的角度,你可以使用与 `cp` 相同的方式。
除了移动与拷贝的不同外,另一个 `mv` 和 `cp` 之间的不同是当你移动目录时:
```
mv directory_a/ directory_b
```
不需要添加递归的标志。这是因为你实际做的是重命名一个目录,与第一个例子相同,你做的是重命名文件。实际上,即使你从一个目录到另一个目录 “移动” 一个文件,只要两个目录在相同的存储设备和分区,你就是在重命名文件。
你可以做一个实验来证明。 `time` 是一个工具来让你测量一个命令花费多久来执行。找一个非常大的文件,可以是几百 MB 甚至 几 GB (例如一个长视频),像下方这样尝试拷贝到另一个目录:
```
$ time cp hefty_file.mkv another_directory/
real 0m3,868s
user 0m0,016s
sys 0m0,887s
```
下面是 `time` 的输出。需要关注的是第一行, real 时间。它花费了几乎 4 秒来拷贝 355 MB 的 `hefty_file.mkv` 到 `another_directory/` 目录。
现在让我们尝试移动它:
```
$ time mv hefty_file.mkv another_directory/
real 0m0,004s
user 0m0,000s
sys 0m0,003s
```
移动几乎是瞬时的!这是违反直觉的,因为看起来 `mv` 必须复制这个文件然后删除原来的。这是 `mv` 对比 `cp` 命令必须做的两件事。但是,实际上,`mv` 快了 1000 倍。
这是因为文件系统结构中,它的所有目录树,只为了让用户便利而存在。在每个分区的开始,有一个称作*分区表*的东西告诉操作系统在实际的物理磁盘上去哪找每个文件。在磁盘上,数据没有分为目录甚至是文件。[作为替代的是轨道、扇区和簇](https://en.wikipedia.org/wiki/Disk_sector)。当你在相同分区 “移动” 一个文件时,操作系统实际做的仅仅是在分区表中改变了那个文件的入口,但它仍然指向磁盘上相同的簇信息。
是的!移动是一个谎言!至少在相同分区下是。如果你试图移动一个文件到一个不同的分区或者不同的设备, `mv` 仍然很快,但可以察觉到它比在相同分区下移动文件慢了。这是因为实际上发生了复制和清除数据。
### 重命名
有几个不同的命令行 `rename` 工具。没有一个像 `cp` 和 `mv` 那样固定,并且它们工作的方式都有一点不同,相同的一点是它们都被用来改变文件名的部分。
在 Debian 和 Ubuntu 中, 默认的 `rename` 工具使用 [正则表达式](https://en.wikipedia.org/wiki/Regular_expression)(字符组成的字符串模式)来大量的改变目录中的文件。命令:
```
rename 's/\.JPEG$/.jpg/' *
```
将改变所有扩展名为 `JPEG` 的文件为 `jpg`。文件 `IMG001.JPEG` 变成 `IMG001.jpg`、 `my_pic.JPEG` 变成 `my_pic.jpg`,等等。
另一个 `rename` 版本默认在 Manjaro 上可获得,这是一个 Arch 的衍生版,更简单,但是可能没有那么强大:
```
rename .JPEG .jpg *
```
这和你之前看到的上面做相同的重命名操作。在这个版本,`.JPEG` 是你想改变的字符组成的字符串,`.jpg` 是你想要改变成为的,`*` 表示当前目录下的所有文件。
基本原则是如果你所做的仅仅是重命名一个文件或者目录,你最好用 `mv`,这是因为 `mv` 在所有分发版上都是可靠一致的。
### 了解更多
查看 `mv` 和 `cp` 的 man 页面了解更多。运行
```
man cp
```
或者 `man mv`
来阅读这些命令自带的所有选项,这些使他们使用起来更强大和安全。
---
via: <https://www.linux.com/blog/2018/8/linux-beginners-moving-things-around>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,797 | 许多数据中心的工作者很满意他们的工作,将鼓励他们的孩子继续从事这份工作 | https://www.networkworld.com/article/3389359/most-data-center-workers-happy-with-their-jobs-despite-the-heavy-demands.html | 2019-04-30T13:39:21 | [
"工作"
] | https://linux.cn/article-10797-1.html |
>
> 一份 Informa Engage 和 Data Center Knowledge 的报告调查发现,在数据中心工作的人很满意他们的工作,因此他们将会鼓励他们的孩子从事这份工作。
>
>
>

一份由 [Informa Engage 和 Data Center Knowledge](https://informa.tradepub.com/c/pubRD.mpl?sr=oc&_t=oc:&qf=w_dats04&ch=datacenterkids) 主导的调查报告显示,数据中心的工作者总体上对他们的工作很满意。尽管对时间和大脑的要求很高,但是他们还是鼓励自己的孩子能从事这项工作。
总体满意度非常好,72% 的受访者普遍同意“我喜欢我目前的工作”这一说法,三分之一的受访者则表示非常同意。75% 的人同意声明,“如果我的孩子、侄女或侄子问,我将建议他们进入 IT 行业。”
在数据中心工作的员工之中,有一种很重要的感觉,88% 的人觉得他们自己对于雇主的成功非常重要。
尽管存在一些挑战,其中最主要的是技能和认证的缺乏。调查的受访者认为缺乏技能是最受关注的领域。只有 56% 的人认为他们需要完成工作所需的培训,74% 的人表示他们已经在 IT 行业工作了十多年。
这个行业提供认证计划,每个主要的 IT 硬件供应商都有,但是 61% 的人表示在过去的 12 个月里他们并没有完成或者重新续订证书。有几个原因:
三分之一(34%)说是由于他们工作的组织缺乏培训预算,而 24% 的人认为是缺乏时间,16% 的人表示管理者认为不需要培训,以及另外 16% 的人表示在他们的工作地点没有培训计划。
这并不让我感到惊讶,因为科技是世界上最开放的行业之一,在那里你可以找到培训和教育材料并自学。已经证实了[许多程序员是自学成才](https://www.networkworld.com/article/3046178/survey-finds-most-coders-are-self-taught.html),包括行业巨头比尔·盖茨、史蒂夫·沃兹尼亚克、约翰·卡马克和杰克·多尔西。
### 数据中心工作者们的薪水
数据中心工作者不会抱怨酬劳。当然,大部分不会。50% 的人每年可以赚到 $100,000 甚至更多,然而 11% 的人赚的少于 $40,000。三分之二的受访者来自于美国,因此那些低端收入人士可能在国外。
有一个值得注意的差异。史蒂夫·布朗是伦敦数据中心人力资源的总经理,他说软件工程师获得的薪水比硬件工程师多。
布朗在这篇报道中说,“数据中心软件工程方面的工作可以与高收入的职业媲美,而在物理基础设施——机械/电气方面的工作——情况并非如此。它更像是中层管理。”
### 数据中心的专业人士仍然主要是男性
最不令人惊讶的发现?10 个受访者中有 9 个是男性。该行业正在调整解决性别歧视问题,但是现在没什么改变。
这篇报告的结论有一点不太好,但是我认为是错的:
>
> “随着数据中心基础设施完成云计算模式的过渡,软件进入到容器和微服务时代,数据中心剩下来的珍贵领导者——在 20 世纪获得技能的人——可能会发现没有任何他们了解的东西需要管理,也没有人需要他们领导。当危机最终来临时,我们可能会感到震惊,但是我们不能说我们没有受到警告。"
>
>
>
我说过了很多次,[数据中心不会消失](https://www.networkworld.com/article/3289509/two-studies-show-the-data-center-is-thriving-instead-of-dying.html)。
---
via: <https://www.networkworld.com/article/3389359/most-data-center-workers-happy-with-their-jobs-despite-the-heavy-demands.html>
作者:[Andy Patrizio](https://www.networkworld.com/author/Andy-Patrizio/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[arrowfeng](https://github.com/arrowfeng) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,799 | Apache 基金会将其所有项目双主镜像至 GitHub | https://blogs.apache.org/foundation/entry/the-apache-software-foundation-expands | 2019-04-30T23:40:00 | [
"GitHub",
"Apache",
"ASF"
] | https://linux.cn/article-10799-1.html | 
Apache 基金会(ASF)[正式宣布](https://blogs.apache.org/foundation/entry/the-apache-software-foundation-expands),该基金会已经将其旗下的 350 多个项目、多达 2 亿行的代码从内部的 Git 基础设施迁移至 GitHub。
作为全球最大的开源基金会,ASF 拥有 730 名个人 ASF <ruby> 成员 <rp> ( </rp> <rt> Member </rt> <rp> ) </rp></ruby>和超过 7000 名的 Apache 代码<ruby> 提交者 <rp> ( </rp> <rt> Commiter </rt> <rp> ) </rp></ruby>,在其 20 年的历史当中,已经通过 300 万个代码提交累计贡献了多达 10 亿行的代码。
Apache 项目最初在 [ASF 基础设施](https://www.apache.org/dev/infrastructure.html)中提供了两种版本控制服务:Apache Subversion 和 Git。而多年来,越来越多的项目及其社区希望在 GitHub 上看到他们的源代码。但是由于这些代码在 GitHub 只是只读的镜像,因此在这些代码存储库上只能使用有限的 GitHub 工具。
“2016 年,基金会开始将 GitHub 的代码存储库和工具与我们自己的服务集成在一起。这使得部分选定的项目能够使用 GitHub 的优秀工具,”ASF 基础设施管理员 Greg Stein 说。 “随着时间的推移,我们改进、调试并巩固了这种集成。在 2018 年末,我们要求所有项目从我们内部的 git 服务转移到 GitHub 提供的服务。这种转变会将 GitHub 所有的工具带到我们的项目中,而我们在我们的基础设施上维护一个备用镜像。”
GitHub CEO Nat Friedman 表示:“我们很自豪能让开源社区这么长期的成员转移到 GitHub。……无论是与个人开源维护者和贡献者,还是与一些世界上最大的开源基金会(如 Apache)合作,GitHub 的使命是通过支持开源社区,满足他们的独特需求和帮助开源来成为所有开发人员的家,让项目茁壮成长。”
在 2019 年 2 月,迁移到 GitHub 的工作已经完成,ASF 自己的 git 服务退役。
“我们将继续试验和扩展 GitHub,以根据我们自己的需求和要求为我们的社区提供服务,”Stein 补充道。 “基金会已经开始与 GitHub 管理层密切合作,探索实现这一目标的方法,以及将来可能实现的目标。”
### 补充:Apache 基金会的项目并未“迁移”至 GitHub,而是做了个双主镜像
经过多位 Apache 基金会的贡献者解释,这则消息存在一定的误读,特此做个澄清。
据 Apache 基金会官方的[解释](https://blogs.apache.org/infra/entry/apache-and-github-a-friendly),之前,Apache 基金会“有两个不同的 git 服务:gitbox 和 git-wip-us,后者是自 2010 年以来一直可用的最初的 git 服务”,而通常会在 GitHub 上建立一个只读镜像。
随着 Apache 基金会旗下各个项目表示出对利用 GitHub 基础设施服务的兴趣,从 2016 年中期,Apache 基金会建立了 [gitbox](https://gitbox.apache.org/),以使项目能够正常使用 GitHub 服务。gitbox 提供的是一种双主镜像的仓库,即使用者可以在 GitHub 上进行提交、处理 PR 和工单等,也可以采用 Apache 内部账户进行相同的操作——而无论在任何一端的操作都是双向同步的。
到了 2018 年,基金会决定将所有使用 git 服务项目都迁移至 gitbox,使之可以利用 GitHub 生态的更多工具,并将 git-wip-us 服务废弃。这个工作已于 2019 年 2 月完成。
所以,现在的状态是:Apache 基金会旗下采用 git 作为版本仓库的项目,都迁移至 gitbox 了。这些项目既可以使用 GitHub 的基础设施和工具,也可以使用 Apache 基金会账户在 gitbox 上进行相同的操作。因此,这就是“通过集成了 GitHub 而扩展了 Apache 基金会的基础设施”(原新闻标题)。
感谢 Apache 基金会的贡献者“吴晟@skywalking”、“刘天栋Ted.开源社”和华为的姜宁提供的信息。
| 302 | Found | null |
10,800 | 4 种在 Linux 中检查默认网关或者路由器 IP 地址的方法 | https://www.2daygeek.com/check-find-default-gateway-or-router-ip-address-in-linux/ | 2019-05-01T00:43:16 | [
"网关",
"路由"
] | https://linux.cn/article-10800-1.html | 
你应该意识到你的默认网关是你的路由器的 IP 地址。一般这是在安装过程中由操作系统自动检测的,如果没有,你可能需要改变它。如果你的系统不能 ping 自身,那么很可能是一个网关问题,你必须修复它。在网络中,当你有多个网络适配器或路由器时,这种情况可能会发生。
网关是一个扮演着入口点角色的路由器,可以从一个网络传递网络数据到另一个网络。
下面是一些可能帮助你收集到与该话题相似的一些信息。
* [在 Linux 命令行检查你的公网 IP 地址的 9 种方法](https://www.2daygeek.com/check-find-server-public-ip-address-linux/)
* [如何在 Linux 启用和禁用网卡?](https://www.2daygeek.com/enable-disable-up-down-nic-network-interface-port-linux-using-ifconfig-ifdown-ifup-ip-nmcli-nmtui/)
这可以通过下面的四个命令完成。
* `route` 命令:被用来显示和操作 IP 路由表。
* `ip` 命令:类似于 `ifconfig`,常用于设置静态 IP 地址、路由 & 默认网关,等等。
* `netstat` 命令:是一个命令行工具,用来显示网络连接相关的信息(包括入站和出站的),例如路由表、伪装连接、多播成员和网络接口。
* `routel` 命令:被用来以好看的输出格式列出路由。
### 1)在 Linux 中如何使用 route 命令检查默认的网关或者路由 IP 地址?
`route` 命令被用来显示和操作 IP 路由表。
它主要用于通过一个已经配置的接口给特定的主机或者网络设置静态的路由。
当使用 `add` 或者 `del` 选项时,`route` 修改路由表。没有这些选项,`route` 显示路由表的当前内容。
```
# route
或
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default www.routerlogin 0.0.0.0 UG 600 0 0 wlp8s0
192.168.1.0 0.0.0.0 255.255.255.0 U 600 0 0 wlp8s0
```
### 2)如何在 Linux 中使用 ip 命令检查默认网关或者路由 IP 地址?
[IP 命令](https://www.2daygeek.com/ip-command-configure-network-interface-usage-linux/) 类似于 `ifconfig`,常用于配置静态 IP 地址、路由 & 默认网关,等等。
`ifconfig` 命令因为多年没有维护而被遗弃了,即使它仍然在大多数 Linux 发行版上可获得。
`ifconfig` 命令已经被 `ip` 命令替代了,`ip` 命令是非常强大的,只要一个命令就能执行几个网络管理任务。
`ip` 命令工具附带在 iproute2 包中。在主要的 Linux 发行版中都默认预装了 iproute2 。
如果没有,你可以在你的终端中在包管理器的帮助下通过指定 iproute2 来安装它。
```
# ip r
或
# ip route
或
# ip route show
default via 192.168.1.1 dev wlp8s0 proto dhcp metric 600
192.168.1.0/24 dev wlp8s0 proto kernel scope link src 192.168.1.6 metric 600
```
### 3)如何在 Linux 中使用 netstat 命令检查默认网关或者路由 IP 地址?
`netstat` 代表 Network Statistics,是一个用来显示网络连接相关的信息(包括入站和出站)的命令行工具,例如路由表、伪装连接,多播成员和网络接口。
它列出所有的 tcp、udp 套接字连接和 unix 套接字连接。
它在网络中被用来诊断网络问题并判断网络中的流量总量来作为性能测量指标。
```
# netstat -r
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
default www.routerlogin 0.0.0.0 UG 0 0 0 wlp8s0
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 wlp8s0
```
### 4)如何在 Linux 中使用 routel 命令检查默认网关或者路由 IP 地址?
它用来以好看的输出格式列出路由信息。这些程序是一系列你可以用来替代 iproute2 的帮助脚本(`routel` 和 `routef`)。
`routel` 脚本以一种被认为更容易解释并且等价于 `route` 输出列表的格式来输出路由信息。
如果 `routef` 脚本不加任何参数,将仅仅简单的将路由表清空。小心!这意味着删除所有的路由,让你的网络不再可用。
```
# routel
target gateway source proto scope dev tbl
default 192.168.1.1 dhcp wlp8s0
192.168.1.0/ 24 192.168.1.6 kernel link wlp8s0
127.0.0.0 broadcast 127.0.0.1 kernel link lo local
127.0.0.0/ 8 local 127.0.0.1 kernel host lo local
127.0.0.1 local 127.0.0.1 kernel host lo local
127.255.255.255 broadcast 127.0.0.1 kernel link lo local
192.168.1.0 broadcast 192.168.1.6 kernel link wlp8s0 local
192.168.1.6 local 192.168.1.6 kernel host wlp8s0 local
192.168.1.255 broadcast 192.168.1.6 kernel link wlp8s0 local
::1 kernel lo
fe80::/ 64 kernel wlp8s0
::1 local kernel lo local
fe80::ad00:2f7e:d882:5add local kernel wlp8s0 local
ff00::/ 8 wlp8s0 local
```
如果你只想打印默认的网关那么使用下面的格式。
```
# routel | grep default
default 192.168.1.1 dhcp wlp8s0
```
---
via: <https://www.2daygeek.com/check-find-default-gateway-or-router-ip-address-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,803 | 清华大学开源软件镜像站推出一键使用服务,将来或支持 42 操作系统 | https://mirrors.tuna.tsinghua.edu.cn/news/oh-my-tuna/ | 2019-05-01T17:38:00 | [
"镜像",
"TUNA"
] | https://linux.cn/article-10803-1.html | 
[清华大学开源软件镜像站](https://mirrors.tuna.tsinghua.edu.cn/) 是国内著名的开源软件镜像站,在去年某个节日推出了“一键使用 TUNA”服务,并发布了一篇热情洋溢的[公告](https://mirrors.tuna.tsinghua.edu.cn/news/oh-my-tuna/),特此将此[服务](https://tuna.moe/oh-my-tuna)及公告分享给大家: XD
> **# 号外:现推出“一键使用TUNA”服务**
> 2018-04-01 TUNA Staff
>
>
> 随着 TUNA 协会的现代化建设进入新时代,镜像站面临的主要矛盾已经转化为用户日益增长的高速下载需要和各类软件不简单不直观的配置之间的矛盾。只有正确认识这一主要矛盾,才能确定正确的战略、策略、政策和办法,促进矛盾解决,推动 TUNA 协会进步。
>
>
> 必须认识到,TUNA 主要矛盾的变化,是关系全局的历史性变化,对协会工作提出了许多新要求。在新任会长 Xavier Yao (a.k.a. Pero) 的带领下,TUNA 协会的同学们勇于担当,攻坚克难,开发出了适应时代潮流、贴合用户需要的新一代工具“一键使用 TUNA” 脚本,又名 `oh-my-tuna` 。它目前支持更改下列软件的配置,将其直接指向 TUNA 镜像站:
>
>
> * Anaconda
> * Arch Linux
> * TeX Live (by tlmgr)
> * Debian GNU/Linux
> * Homebrew
> * PyPI
> * Ubuntu Linux
>
>
> 您可以选择仅更改当前用户的配置,也可以更改全局配置。如果不满意,随时可以撤销这些更改。这一切,只需要一行命令:`python oh-my-tuna.py` !
>
>
> 项目托管在 [TUNA 主页](https://tuna.moe/oh-my-tuna) 上,您也可以访问 [GitHub](https://github.com/tuna/oh-my-tuna) 阅读源码、获取更详细的说明,也欢迎各位对本项目作出贡献!
>
>
> 在将来,我们的目标是将其支持的系统/软件范围进一步扩展到(包括且不限于):
>
>
> * TUNA 镜像的尽可能多的系统/软件
> * Macrohard<sup> TM</sup> Windoge<sup> TM</sup>
> * 42
>
>
> TUNA 成员要紧密团结在会长周围,高举开源精神伟大旗帜,锐意进取,埋头苦干,为实现推进镜像站建设、完成 Linux 发行版统一、维护开源界和平与促进共同发展三大历史任务,为决胜全面建成中国最好的镜像站、夺取新时代开源精神伟大胜利、实现社区伟大复兴的开源梦、实现用户对高速下载的向往继续奋斗!
>
>
>
| 200 | OK | ### # 号外:现推出“一键使用TUNA”服务
随着 TUNA 协会的现代化建设进入新时代,镜像站面临的主要矛盾已经转化为用户日益增长的高速下载需要和各类软件不简单不直观的配置之间的矛盾。只有正确认识这一主要矛盾,才能确定正确的战略、策略、政策和办法,促进矛盾解决,推动 TUNA 协会进步。
必须认识到,TUNA 主要矛盾的变化,是关系全局的历史性变化,对协会工作提出了许多新要求。在新任会长 Xavier Yao (a.k.a. Pero) 的带领下,TUNA 协会的同学们勇于担当,攻坚克难,开发出了适应时代潮流、贴合用户需要的新一代工具“一键使用 TUNA” 脚本,又名 `oh-my-tuna`
。它目前支持更改下列软件的配置,将其直接指向 TUNA 镜像站:
- Anaconda
- Arch Linux
- TeX Live (by tlmgr)
- Debian GNU/Linux
- Homebrew
- PyPI
- Ubuntu Linux
您可以选择仅更改当前用户的配置,也可以更改全局配置。如果不满意,随时可以撤销这些更改。这一切,只需要一行命令:`python oh-my-tuna.py`
!
项目托管在 [TUNA 主页](https://tuna.moe/oh-my-tuna) 上,您也可以访问 [GitHub](https://github.com/tuna/oh-my-tuna) 阅读源码、获取更详细的说明,也欢迎各位对本项目作出贡献!
在将来,我们的目标是将其支持的系统/软件范围进一步扩展到(包括且不限于):
- TUNA 镜像的尽可能多的系统/软件
- Macrohard
TMWindogeTM - 42
TUNA 成员要紧密团结在会长周围,高举开源精神伟大旗帜,锐意进取,埋头苦干,为实现推进镜像站建设、完成 Linux 发行版统一、维护开源界和平与促进共同发展三大历史任务,为决胜全面建成中国最好的镜像站、夺取新时代开源精神伟大胜利、实现社区伟大复兴的开源梦、实现用户对高速下载的向往继续奋斗! |
10,804 | Linux 初学者:如何在 Ubuntu 中重启网络 | https://itsfoss.com/restart-network-ubuntu | 2019-05-01T23:20:00 | [
"网络"
] | https://linux.cn/article-10804-1.html | 你[是否正在使用基于 Ubuntu 的系统,然后发现无法连接网络](https://itsfoss.com/fix-no-wireless-network-ubuntu/)?你一定会很惊讶,很多的问题都可以简单地通过重启服务解决。
在这篇文章中,我会介绍在 Ubuntu 或者其他 Linux 发行版中重启网络的几种方法,你可以根据自身需要选择对应的方法。这些方法基本分为两类:

### 通过命令行方式重启网络
如果你使用的 Ubuntu 服务器版,那么你已经在使用命令行终端了。如果你使用的是桌面版,那么你可以通过快捷键 `Ctrl+Alt+T` [Ubuntu 键盘快捷键](https://itsfoss.com/ubuntu-shortcuts/) 打开命令行终端。
在 Ubuntu 中,有多个命令可以重启网络。这些命令,一部分或者说大部分,也适用于在 Debian 或者其他的 Linux 发行版中重启网络。
#### 1、network manager 服务
这是通过命令行方式重启网络最简单的方法。它相当于是通过图形化界面重启网络(重启 Network-Manager 服务)。
```
sudo service network-manager restart
```
此时,网络图标会消失一会儿然后重新显示。
#### 2、systemd
`service` 命令仅仅是这个方式的一个封装(同样的也是 init.d 系列脚本和 Upstart 相关命令的封装)。`systemctl` 命令的功能远多于 `service` 命令。通常我更喜欢使用这个命令。
```
sudo systemctl restart NetworkManager.service
```
这时,网络图标又会消失一会儿。 如果你想了解 `systemctl` 的其他选项, 可以参考 man 帮助文档。
#### 3、nmcli
这是 Linux 上可以管理网络的另一个工具。这是一个功能强大而且实用的工具。很多系统管理员都喜欢使用该工具,因为它非常容易使用。
这种方法有两个操作步骤:关闭网络,再开启网络。
```
sudo nmcli networking off
```
这样就会关闭网络,网络图标会消失。接下来,再开启网络:
```
sudo nmcli networking on
```
你可以通过 man 帮助文档了解 nmcli 的更多用法。
#### 4、ifup & ifdown
这两个命令直接操作网口,切换网口是否可以收发包的状态。这是 [Linux 中最应该了解的网络命令](https://itsfoss.com/basic-linux-networking-commands/) 之一。
使用 `ifdown` 关闭所有网口,再使用 `ifup` 重新启用网口。
通常推荐的做法是将这两个命令一起使用。
```
sudo ifdown -a && sudo ifup -a
```
注意:这种方法不会让网络图标从系统托盘中消失,另外,各种网络连接也会断。
#### 补充工具: nmtui
这是系统管理员们常用的另外一种方法。它是在命令行终端中管理网络的文本菜单工具。
```
nmtui
```
打开如下菜单:

注意:在 nmtui 中,可以通过 `up` 和 `down` 方向键选择选项。
选择 “Activate a connection”:

按下回车键,打开 “connections” 菜单。

接下来,选择前面带星号(\*)的网络。在这个例子中,就是 MGEO72。

按下回车键。 这就将“停用”你的网络连接。

选择你要连接的网络:

按下回车键。这样就重新激活了所选择的网络连接。

按下 `Tab` 键两次,选择 “Back”:

按下回车键,回到 nmtui 的主菜单。

选择 “Quit” :

退出该界面,返回到命令行终端。
就这样,你已经成功重启网络了。
### 通过图形化界面重启网络
显然,这是 Ubuntu 桌面版用户重启网络最简单的方法。如果这个方法不生效,你可以尝试使用前文提到的命令行方式重启网络。
NM 小程序是 [NetworkManager](https://wiki.gnome.org/Projects/NetworkManager) 的系统托盘程序标志。我们将使用它来重启网络。
首先,查看顶部状态栏。你会在系统托盘找到一个网络图标 (因为我使用 Wi-Fi,所以这里是一个 Wi-Fi 图标)。
接下来,点击该图标(也可以点击音量图标或电池图标)。打开菜单。选择 “Turn Off” 关闭网络。

网络图标会在状态栏中消失,这表示你已经成功关闭网络了。
再次点击系统托盘重新打开菜单,选择 “Turn On”,重新开启网络。

恭喜!你现在已经重启你的网络了。
#### 其他提示:刷新可用网络列表
如果你已经连接上一个网络,但是你想连接到另外一个网络,你如何刷新 WiFi 列表,查找其他可用的网络呢?我来向你展示一下。
Ubuntu 没有可以直接 “刷新 WiFi 网络” 的选项,它有点隐蔽。
你需要再次打开配置菜单,然后点击 “Select Network” 。

选择对应的网络修改你的 WiFi 连接。
你无法马上看到可用的无线网络列表。打开网络列表之后,大概需要 5 秒才会显示其它可用的无线网络。

等待大概 5 秒钟,看到其他可用的网络。
现在,你就可以选择你想要连接的网络,点击连接。这样就完成了。
### 总结
重启网络连接是每个 Linux 用户在使用过程中必须经历的事情。
我们希望这些方法可以帮助你处理这样的问题!
你是如何重启或管理你的网络的?我们是否还有遗漏的?请在下方留言。
---
via: <https://itsfoss.com/restart-network-ubuntu>
作者:[Sergiu](https://itsfoss.com/author/sergiu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[bodhix](https://github.com/bodhix) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,807 | 使用 Python 和 Prometheus 跟踪天气 | https://opensource.com/article/19/4/weather-python-prometheus | 2019-05-03T13:16:25 | [
"天气",
"Prometheus"
] | https://linux.cn/article-10807-1.html |
>
> 创建自定义 Prometheus 集成以跟踪最大的云端提供商:地球母亲。
>
>
>

开源监控系统 [Prometheus](https://prometheus.io/) 集成了跟踪多种类型的时间序列数据,但如果没有集成你想要的数据,那么很容易构建一个。一个经常使用的例子使用云端提供商的自定义集成,它使用提供商的 API 抓取特定的指标。但是,在这个例子中,我们将与最大云端提供商集成:地球。
幸运的是,美国政府已经测量了天气并为集成提供了一个简单的 API。获取红帽总部下一个小时的天气预报很简单。
```
import requests
HOURLY_RED_HAT = "<https://api.weather.gov/gridpoints/RAH/73,57/forecast/hourly>"
def get_temperature():
result = requests.get(HOURLY_RED_HAT)
return result.json()["properties"]["periods"][0]["temperature"]
```
现在我们已经完成了与地球的集成,现在是确保 Prometheus 能够理解我们想要内容的时候了。我们可以使用 [Prometheus Python 库](https://github.com/prometheus/client_python)中的 gauge 创建一个注册项:红帽总部的温度。
```
from prometheus_client import CollectorRegistry, Gauge
def prometheus_temperature(num):
registry = CollectorRegistry()
g = Gauge("red_hat_temp", "Temperature at Red Hat HQ", registry=registry)
g.set(num)
return registry
```
最后,我们需要以某种方式将它连接到 Prometheus。这有点依赖 Prometheus 的网络拓扑:是 Prometheus 与我们的服务通信更容易,还是反向更容易。
第一种是通常建议的情况,如果可能的话,我们需要构建一个公开注册入口的 Web 服务器,并配置 Prometheus 收刮(scrape)它。
我们可以使用 [Pyramid](https://trypyramid.com/) 构建一个简单的 Web 服务器。
```
from pyramid.config import Configurator
from pyramid.response import Response
from prometheus_client import generate_latest, CONTENT_TYPE_LATEST
def metrics_web(request):
registry = prometheus_temperature(get_temperature())
return Response(generate_latest(registry),
content_type=CONTENT_TYPE_LATEST)
config = Configurator()
config.add_route('metrics', '/metrics')
config.add_view(metrics_web, route_name='metrics')
app = config.make_wsgi_app()
```
这可以使用任何 Web 网关接口(WSGI)服务器运行。例如,假设我们将代码放在 `earth.py` 中,我们可以使用 `python -m twisted web --wsgi earth.app` 来运行它。
或者,如果我们的代码连接到 Prometheus 更容易,我们可以定期将其推送到 Prometheus 的[推送网关](https://github.com/prometheus/pushgateway)。
```
import time
from prometheus_client import push_to_gateway
def push_temperature(url):
while True:
registry = prometheus_temperature(get_temperature())
push_to_gateway(url, "temperature collector", registry)
time.sleep(60*60)
```
这里的 URL 是推送网关的 URL。它通常以 `:9091` 结尾。
祝你构建自定义 Prometheus 集成成功,以便跟踪一切!
---
via: <https://opensource.com/article/19/4/weather-python-prometheus>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Open source monitoring system [Prometheus](https://prometheus.io/) has integrations to track many types of time-series data, but if you want an integration that doesn't yet exist, it's easy to build one. An often-used example is a custom integration with a cloud provider that uses the provider's APIs to grab specific metrics. In this example, though, we will integrate with the biggest cloud provider of all: Earth.
Luckily, the US government already measures the weather and provides an easy API for integrations. Getting the weather forecast for the next hour at Red Hat headquarters is simple.
```
import requests
HOURLY_RED_HAT = "https://api.weather.gov/gridpoints/RAH/73,57/forecast/hourly"
def get_temperature():
result = requests.get(HOURLY_RED_HAT)
return result.json()["properties"]["periods"][0]["temperature"]
```
Now that our integration with Earth is done, it's time to make sure Prometheus can understand what we are saying. We can use the [Prometheus Python library](https://github.com/prometheus/client_python) to create a registry with one *gauge*: the temperature at Red Hat HQ.
```
from prometheus_client import CollectorRegistry, Gauge
def prometheus_temperature(num):
registry = CollectorRegistry()
g = Gauge("red_hat_temp", "Temperature at Red Hat HQ", registry=registry)
g.set(num)
return registry
```
Finally, we need to connect this to Prometheus in some way. That depends a little on the network topology for Prometheus: whether it is easier for Prometheus to talk to our service, or whether the reverse is easier.
The first case is the one usually recommended, if possible, so we need to build a web server exposing the registry and then configure Prometheus to *scrape* it.
We can build a simple web server with [Pyramid](https://trypyramid.com/).
```
from pyramid.config import Configurator
from pyramid.response import Response
from prometheus_client import generate_latest, CONTENT_TYPE_LATEST
def metrics_web(request):
registry = prometheus_temperature(get_temperature())
return Response(generate_latest(registry),
content_type=CONTENT_TYPE_LATEST)
config = Configurator()
config.add_route('metrics', '/metrics')
config.add_view(metrics_web, route_name='metrics')
app = config.make_wsgi_app()
```
This can be run with any Web Server Gateway Interface (WSGI) server. For example, we can use **python -m twisted web --wsgi earth.app** to run it, assuming we put the code in **earth.py**.
Alternatively, if it is easier for our code to connect to Prometheus, we can push it to Prometheus's [Push gateway](https://github.com/prometheus/pushgateway) periodically.
```
import time
from prometheus_client import push_to_gateway
def push_temperature(url):
while True:
registry = prometheus_temperature(get_temperature())
push_to_gateway(url, "temperature collector", registry)
time.sleep(60*60)
```
The URL is the one for the Push gateway; it often ends in **:9091**.
Good luck building your own custom Prometheus integration so you can track all the things!
## 1 Comment |
10,808 | System76 是如何打造开源硬件的 | https://opensource.com/article/19/4/system76-hardware | 2019-05-03T14:07:31 | [
"System76",
"开源硬件"
] | /article-10808-1.html |
>
> 是什么让新的 Thelio 台式机系列与众不同。
>
>
>

大多数人对他们电脑的硬件一无所知。作为一个长期的 Linux 用户,当我想让我的无线网卡、视频卡、显示器和其他硬件与我选择的发行版共同运行时,也一样遇到了挫折。商业品牌的硬件通常使判断这些问题变得很困难:为什么以太网驱动、无线驱动或者鼠标驱动和我们预期的不太一样?随着 Linux 发行版变得成熟,这可能不再是问题,但是我们仍能发现触控板和其它外部设备的怪异行为,尤其是当我们对底层的硬件知道的不多时。
像 [System76](https://system76.com/) 这样的公司致力于解决这些问题,以提升 Linux 用户体验。System76 生产了一系列的 Linux 笔记本、台式机和服务器,甚至提供了它自己的 Linux 发行版 [Pop! OS](https://opensource.com/article/18/1/behind-scenes-popos-linux) 作为客户的一个选择。最近我有幸参观了 System76 在 Devnver 的工厂并揭开它的新台式机产品线 [Thelio](https://system76.com/desktops) [的神秘面纱](https://system76.com/desktops)。
### 关于 Thelio
System76 宣称 Thelio 的开源硬件子板(被命名为木星之后的第 5 个卫星的名字 Thelio Io)是它在市场上独特的特点之一。Thelio Io 取得了开源硬件协会的认证 [OSHWA #us000145](https://certification.oshwa.org/us000145.html),并且有 4 个用于存储的 SATA 端口和一个控制风扇和用于电源按钮控制的嵌入式控制器。Thelio IO SAS 取得了 [OSHWA #us000146](https://certification.oshwa.org/us000146.html) 认证,并且有 4 个用于存储的 U.2 端口,没有嵌入式控制器。在展示时,System76 显示了这些组件如何调整风扇通过底盘来优化部件的性能。
该控制器还管理电源键,和围绕该电源键的 LED 光环,当被按下时它以 100% 的亮度发光。这提供了触觉和视觉上的确认:该主机已经启动电源了。当电脑在使用中,该按钮被设置为 35% 的亮度,当在睡眠模式,它的亮度在 2.35% 和 25% 之间跳动。当计算机关闭后,LED 保持朦胧的亮度,因此能够在黑暗的房间里找到电源控制。
Thelio 的嵌入式控制器是一个低功耗的 [ATmega32U4](https://www.microchip.com/wwwproducts/ATmega32u4) 微控制器,并且控制器的设置可以使用 Arduino Micro 进行原型设计。Thelio Io 主板变化的多少取决于你购买哪种 Thelio 型号。
Thelio 可能是我见过的设计的最好的电脑机箱和系统。如果你曾经亲身体验过在一个常规的 PC 的内部进行操作的话,你可能会同意我的观点。我已经做了很多次了,因此我能以自己过往的糟糕经历来证明这点。
### 为什么做开源硬件?
该主板是在 [KiCAD](http://kicad-pcb.org/) 设计的,你可以在 [GitHub](https://github.com/system76/thelio-io) 上按 GPL 许可证访问 Thelio 所有的设计文件。因此,为什么一个与其他 PC 制造商竞争的公司会设计一个独特的接口并公开授权呢?可能是该公司认识到开源设计及根据你的需要调整和分享一个 I/O 主板设计的能力的价值,即便你是市场上的竞争者。

*在 [Thelio 发布会](https://trevgstudios.smugmug.com/System76/121418-Thelio-Press-Event/i-FKWFxFv) Don Watkins 与 System76 的 CEO Carl Richell 谈话。*
我问 System76 的设计者和 CEO [Carl Richell](https://www.linkedin.com/in/carl-richell-9435781),该公司是否担心过公开许可它的硬件设计意味着有人可以采取它的独特设计并用它来将 System76 驱逐出市场。他说:
>
> 开源硬件对我们所有人都有益。这是我们未来提升技术的方式,并且使得每个人获取技术更容易。我们欢迎任何想要提高 Thelio 设计的人来这么做。开源该硬件不仅可以帮助我们更快的改进我们的电脑,并且能够使我们的消费者 100% 信任他们的设备。我们的目标是尽可能地移除专利功能,同时仍然能够为消费者提供一个有竞争力的 Linux 主机。
>
>
> 我们已经与 Linux 社区一起合作了 13 年之久,来为我们的笔记本、台式机、服务器创造一个完美顺滑的体验。我们长期专注于为 Linux 社区提供服务,提供给我们的客户高水准的服务,我们的个性使 System76 变得独特。
>
>
>
我还问 Carl 为什么开源硬件对 System76 和 PC 市场是有意义的。他回复道:
>
> System76 创立之初的想法是技术应该对每个人是开放和可获取的。我们还没有到达 100% 开源创造一个电脑的程度,但是有了开源硬件,我们迈出了接近目标的必不可少的一大步。
>
>
> 我们生活在技术变成工具的时代。计算机在各级教育和很多行业当中是人们的工具。由于每个人特定的需要,每个人对于如何提升电脑和软件作为他们的主要工具有他们自己的想法。开源我们的计算机可以让这些想法成为现实,从而反过来促进技术成为一个更强大的工具。在一个开源环境中,我们持续迭代来生产更好的 PC。这有点酷。
>
>
>
我们总结了我们讨论的关于 System76 技术路线的对话,包含了开源硬件 mini PC,甚至是笔记本。在 System76 品牌下的已售出的 mini PC 和笔记本是由其他供应商制造的,并不是基于开源硬件的(尽管它们用的是 Linux 软件,是开源的)。
设计和支持开放式硬件是 PC 产业中的变革者,也正是它造就了 System76 的新 Thelio 台式机电脑产品线的不同。
---
via: <https://opensource.com/article/19/4/system76-hardware>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,809 | 命令行技巧:分割文件内容 | https://fedoramagazine.org/command-line-quick-tips-cutting-content-out-of-files/ | 2019-05-03T16:21:45 | [
"cut"
] | https://linux.cn/article-10809-1.html | 
Fedora 发行版是一个功能齐全的操作系统,有出色的图形化桌面环境。用户可以很容易地通过单击动作来完成任何典型任务。所有这些美妙的易用性掩盖了其底层强大的命令行细节。本文是向你展示一些常见命令行实用程序的系列文章的一部分。让我们进入 shell 来看看 `cut`。
通常,当你在命令行中工作时,你处理的是文本文件。有时这些文件可能很长,虽然可以完整地阅读它们,但是可能会耗费大量时间,并且容易出错。在本文中,你将学习如何从文本文件中提取内容,并从中获取你所需的信息。
重要的是要意识到,在 Fedora 中有许多方法可以完成类似的命令行任务。例如,Fedora 仓库含有用于解析和处理文本的完整语言系统。此外,还有多个命令行实用程序可用于 shell 中任何可能的用途。本文只关注使用其中几个实用程序选项,从文件中提取一些信息并以可读的格式呈现。
### cut 使用
为了演示这个例子,在系统上使用一个标准的大文件,如 `/etc/passwd`。正如本系列的前一篇文章所示,你可以执行 `cat` 命令来查看整个文件:
```
$ cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
...
```
此文件包含系统上所有所有账户的信息。它有一个特定的格式:
```
name:password:user-id:group-id:comment:home-directory:shell
```
假设你只想要系统上所有账户名的列表,如果你只能从每一行中删除 “name” 值。这就是 `cut` 命令派上用场的地方!它一次处理一行输入,并提取该行的特定部分。
`cut` 命令提供了以不同方式选择一行的部分的选项,在本示例中需要两个,`-d` 和 `-f`。`-d` 选项允许你声明用于分隔行中值的分隔符。在本例中,冒号(`:`)用于分隔值。`-f` 选项允许你选择要提取哪些字段值。因此,在本例中,输入的命令是:
```
$ cut -d: -f1 /etc/passwd
root
bin
daemon
adm
...
```
太棒了,成功了!但是你将输出打印到标准输出,在终端会话中意味着它需要占据屏幕。如果你需要稍后完成另一项任务所需的信息,这该怎么办?如果有办法将 `cut` 命令的输出保存到文本文件中,那就太好了。对于这样的任务,shell 有一个简单的内置功能,重定向功能(`>`)。
```
$ cut -d: -f1 /etc/passwd > names.txt
```
这会将 `cut` 的输出放到一个名为 `names.txt` 的文件中,你可以使用 `cat` 来查看它的内容:
```
$ cat names.txt
root
bin
daemon
adm
...
```
使用两个命令和一个 shell 功能,可以很容易地使用 `cat` 从一个文件进行识别、提取和重定向一些信息,并将其保存到另一个文件以供以后使用。
---
via: <https://fedoramagazine.org/command-line-quick-tips-cutting-content-out-of-files/>
作者:[Stephen Snow](https://fedoramagazine.org/author/jakfrost/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Fedora distribution is a full featured operating system with an excellent graphical desktop environment. A user can point and click their way through just about any typical task easily. All of this wonderful ease of use masks the details of a powerful command line under the hood. This article is part of a series that shows you some common command line utilities. So let’s drop into the shell, and have a look at **cut**.
Often when you work in the command line, you are working with text files. Sometimes these files may be quite long. Reading them in their entirety, while feasible, can be time consuming and prone to errors. In this installment you’ll learn how to extract content from text files, and get the information you want from them.
It’s important to recognize that there are many ways to accomplish similar command line tasks in Fedora. The Fedora repositories include entire language systems for parsing and working with text, as an example. Also, there are multiple command line utilities available for just about any purpose conceivable in the shell. This article will only focus on using a few of those utility choices, to extract some information from a file and present it in a readable format.
## Making the cut
To illustrate this example use a standard sizable file on the system like */etc/passwd*. As seen in a prior article in this series, you can execute the *cat* command to view an entire file:
$cat /etc/passwdroot:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin ...
This file contains information on all accounts present on the system. It has a specific format:
name:password:user-id:group-id:comment:home-directory:shell
Imagine that you want to simply have a list of all the account names on the system. If you could only cut out the *name* value from each line. This is where the *cut* command comes in handy! This command treats any input one line at a time, and extracts a specific part of the line.
The *cut* command provides options for selecting parts of a line differently, and in this example two of them are needed, *-d* which is an option to specify a delimiter type to use, and *-f* which is an option to specify which field of the line to cut. The *-d* option lets you declare the *delimiter* that separates values in a line. In this case a colon (:) is used to separate values. The *-f* option lets you choose which field value or values to extract. So for this example the command entered would be:
$cut -d: -f1 /etc/passwd
root
bin
daemon
adm
...
That’s great, it worked! But you get the printout to the standard output, which in a terminal session at least means the screen. What if you needed the information for another task to be done later? It would be really nice if there was a way to put the output of the *cut* command into a text file to save it. There is an easy builtin shell function for such a task, the redirect function (*>*).
$cut -d: -f1 /etc/passwd > names.txt
This will place the output of cut into a file called *names.txt* and you can check the contents with *cat:*
$cat names.txt
root
bin
daemon
adm
...
With two commands and one shell function, it was easy to identify using *cat*, extract using *cut*, and redirect the extracted information from one file, saving it to another file for later use.
*Photo by **Joel Mbugua** on **Unsplash**.*
## Mark
Cut is great for what it does. You will quickly run into situations with multiple delimiters and inconsistent lengths that awk is better suited to handle.
## Stephen Snow
Yeah, I was going to talk a bit about awk and gawk since they are much better at parsing more complex files, but the idea (which was started by Paul Frields) is a series of articles about useful command line tools. So I would suspect awk and gawk to appear in one at some point.
## John
Looking forward to the awk series
## Leslie Satenstein
I generally do cut -d: f1 /etc/passwd | sort > names.txt
Because I like my list in alphabetical order.
## Stephen Snow
That is the beauty of the command line tools available on a Linux system normally OOTB. They are flexible and combined with piping, redirects and other tools offer capabilities that super-cede their stand alone do one thing and do it well.
## Stuart D Gathman
I remember an SQL implementation a while back that compiled queries to shell scripts that did grep, cut, join, sort. The data was in plain text files. It was faster than database implementations for up to 1000s of records. Obviously, it is not going to scale – but so many applications are within the golden range for plain text files.
## Mark Senn
You may want to write about Perl (I especially recommend Perl 6) instead of awk,
or at least mention Perl in your awk article.
## rapra
Nice article. I have used ‘cut’ for years, but learnt awk a couple of years ago and was blown away by its awesome power. |
10,811 | 如何在 Linux 上安装、配置 NTP 服务器和客户端? | https://www.2daygeek.com/install-configure-ntp-server-ntp-client-in-linux/ | 2019-05-04T13:39:17 | [
"NTP",
"时间"
] | https://linux.cn/article-10811-1.html | 
你也许听说过这个词很多次或者你可能已经在使用它了。在这篇文章中我将会清晰的告诉你 NTP 服务器和客户端的安装。
之后我们将会了解 **[Chrony NTP 客户端的安装](https://www.2daygeek.com/configure-ntp-client-using-chrony-in-linux/)**。
### 什么是 NTP 服务?
NTP 意即<ruby> 网络时间协议 <rt> Network Time Protocol </rt></ruby>。它是通过网络在计算机系统之间进行时钟同步的网络协议。换言之,它可以让那些通过 NTP 或者 Chrony 客户端连接到 NTP 服务器的系统保持时间上的一致(它能保持一个精确的时间)。
NTP 在公共互联网上通常能够保持时间延迟在几十毫秒以内的精度,并在理想条件下,它能在局域网下达到低于一毫秒的延迟精度。
它使用用户数据报协议(UDP)在端口 123 上发送和接受时间戳。它是个 C/S 架构的应用程序。
### NTP 客户端
NTP 客户端将其时钟与网络时间服务器同步。
### Chrony 客户端
Chrony 是 NTP 客户端的替代品。它能以更精确的时间更快的同步系统时钟,并且它对于那些不总是在线的系统很有用。
### 为什么我们需要 NTP 服务?
为了使你组织中的所有服务器与基于时间的作业保持精确的时间同步。
为了说明这点,我将告诉你一个场景。比如说,我们有两个服务器(服务器 1 和服务器 2)。服务器 1 通常在 10:55 完成离线作业,然后服务器 2 在 11:00 需要基于服务器 1 完成的作业报告去运行其他作业。
如果两个服务器正在使用不同的时间(如果服务器 2 时间比服务器 1 提前,服务器 1 的时间就落后于服务器 2),然后我们就不能去执行这个作业。为了达到时间一致,我们应该安装 NTP。
希望上述能清除你对于 NTP 的疑惑。
在这篇文章中,我们将使用下列设置去测试。
* **NTP 服务器:** 主机名:CentOS7.2daygeek.com,IP:192.168.1.8,OS:CentOS 7
* **NTP 客户端:** 主机名:Ubuntu18.2daygeek.com,IP:192.168.1.5,OS:Ubuntu 18.04
### NTP 服务器端:如何在 Linux 上安装 NTP?
因为它是 C/S 架构,所以 NTP 服务器端和客户端的安装包没有什么不同。在发行版的官方仓库中都有 NTP 安装包,因此可以使用发行版的包管理器安装它。
对于 Fedora 系统,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 去安装 ntp。
```
$ sudo dnf install ntp
```
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或者 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 去安装 ntp。
```
$ sudo apt install ntp
```
对基于 Arch Linux 的系统,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 去安装 ntp。
```
$ sudo pacman -S ntp
```
对 RHEL/CentOS 系统,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 去安装 ntp。
```
$ sudo yum install ntp
```
对于 openSUSE Leap 系统,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 去安装 ntp。
```
$ sudo zypper install ntp
```
### 如何在 Linux 上配置 NTP 服务器?
安装 NTP 软件包后,请确保在服务器端的 `/etc/ntp.conf` 文件中取消以下配置的注释。
默认情况下,NTP 服务器配置依赖于 `X.distribution_name.pool.ntp.org`。 如果有必要,可以使用默认配置,也可以访问<https://www.ntppool.org/zone/@>站点,根据你所在的位置(特定国家/地区)进行更改。
比如说如果你在印度,然后你的 NTP 服务器将是 `0.in.pool.ntp.org`,并且这个地址适用于大多数国家。
```
# vi /etc/ntp.conf
restrict default kod nomodify notrap nopeer noquery
restrict -6 default kod nomodify notrap nopeer noquery
restrict 127.0.0.1
restrict -6 ::1
server 0.asia.pool.ntp.org
server 1.asia.pool.ntp.org
server 2.asia.pool.ntp.org
server 3.asia.pool.ntp.org
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
driftfile /var/lib/ntp/drift
keys /etc/ntp/keys
```
我们仅允许 `192.168.1.0/24` 子网的客户端访问这个 NTP 服务器。
由于默认情况下基于 RHEL7 的发行版的防火墙是打开的,因此要允许 ntp 服务通过。
```
# firewall-cmd --add-service=ntp --permanent
# firewall-cmd --reload
```
更新配置后要重启服务:
对于 sysvinit 系统。基于 Debian 的系统需要去运行 `ntp` 而不是 `ntpd`。
```
# service ntpd restart
# chkconfig ntpd on
```
对于 systemctl 系统。基于 Debian 的需要去运行 `ntp` 和 `ntpd`。
```
# systemctl restart ntpd
# systemctl enable ntpd
```
### NTP 客户端:如何在 Linux 上安装 NTP 客户端?
正如我在这篇文章中前面所说的。NTP 服务器端和客户端的安装包没有什么不同。因此在客户端上也安装同样的软件包。
对于 Fedora 系统,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 去安装 ntp。
```
$ sudo dnf install ntp
```
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或者 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 去安装 ntp。
```
$ sudo apt install ntp
```
对基于 Arch Linux 的系统,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 去安装 ntp。
```
$ sudo pacman -S ntp
```
对 RHEL/CentOS 系统,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 去安装 ntp。
```
$ sudo yum install ntp
```
对于 openSUSE Leap 系统,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 去安装 ntp。
```
$ sudo zypper install ntp
```
我已经在 CentOS7.2daygeek.com` 这台主机上安装和配置了 NTP 服务器,因此将其附加到所有的客户端机器上。
```
# vi /etc/ntp.conf
```
```
restrict default kod nomodify notrap nopeer noquery
restrict -6 default kod nomodify notrap nopeer noquery
restrict 127.0.0.1
restrict -6 ::1
server CentOS7.2daygeek.com prefer iburst
driftfile /var/lib/ntp/drift
keys /etc/ntp/keys
```
更新配置后重启服务:
对于 sysvinit 系统。基于 Debian 的系统需要去运行 `ntp` 而不是 `ntpd`。
```
# service ntpd restart
# chkconfig ntpd on
```
对于 systemctl 系统。基于 Debian 的需要去运行 `ntp` 和 `ntpd`。
```
# systemctl restart ntpd
# systemctl enable ntpd
```
重新启动 NTP 服务后等待几分钟以便从 NTP 服务器获取同步的时间。
在 Linux 上运行下列命令去验证 NTP 服务的同步状态。
```
# ntpq –p
或
# ntpq -pn
remote refid st t when poll reach delay offset jitter
==============================================================================
*CentOS7.2daygee 133.243.238.163 2 u 14 64 37 0.686 0.151 16.432
```
运行下列命令去得到 ntpd 的当前状态。
```
# ntpstat
synchronised to NTP server (192.168.1.8) at stratum 3
time correct to within 508 ms
polling server every 64 s
```
最后运行 `date` 命令。
```
# date
Tue Mar 26 23:17:05 CDT 2019
```
如果你观察到 NTP 中输出的时间偏移很大。运行下列命令从 NTP 服务器手动同步时钟。当你执行下列命令的时候,确保你的 NTP 客户端应该为未活动状态。(LCTT 译注:当时间偏差很大时,客户端的自动校正需要花费很长时间才能逐步追上,因此应该手动运行以更新)
```
# ntpdate –uv CentOS7.2daygeek.com
```
---
via: <https://www.2daygeek.com/install-configure-ntp-server-ntp-client-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[arrowfeng](https://github.com/arrowfeng) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,812 | 什么是 5G?它比 4G 好在哪里? | https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html | 2019-05-04T14:21:01 | [
"5G",
"4G"
] | https://linux.cn/article-10812-1.html |
>
> 5G 网络将使无线网络吞吐量提高 10 倍并且能够替代有线宽带。但是它们什么时候能够投入使用呢,为什么 5G 和物联网如此紧密地联系在一起呢?
>
>
>

[5G 无线](https://www.networkworld.com/article/3203489/what-is-5g-wireless-networking-benefits-standards-availability-versus-lte.html) 是一个概括的术语,用来描述一系列更快的无线互联网的标准和技术,理论上比 4G 快了 20 倍并且延迟降低了 120 倍,为物联网的发展和对新的高带宽应用的支持奠定了基础。
### 什么是 5G?科技还是流行词?
这个技术在世界范围内完全发挥它的潜能还需要数年时间,但同时当今一些 5G 网络服务已经投入使用。5G 不仅是一个技术术语,也是一个营销术语,并不是市场上的所有 5G 服务是标准的。
* [来自世界移动大会:[5G 时代即将来到](https://www.networkworld.com/article/3354477/mobile-world-congress-the-time-of-5g-is-almost-here.html)]
### 5G 与 4G 的速度对比
无线技术的每一代,最大的呼吁是增加速度。5G 网络潜在的峰值下载速度可以达到[20 Gbps,一般在 10 Gbps](https://www.networkworld.com/article/3330603/5g-versus-4g-how-speed-latency-and-application-support-differ.html)。这不仅仅比当前 4G 网络更快,4G 目前峰值大约 1 Gbps,并且比更多家庭的有线网络连接更快。5G 提供的网络速度能够与光纤一较高下。
吞吐量不是 5G 仅有的速度提升;它还有的特点是极大降低了网络延迟。这是一个重要的区分:吞吐量用来测量花费多久来下载一个大文件,而延迟由网络瓶颈决定,延迟在往返的通讯中减慢了响应速度。
延迟很难量化,因为它因各种网络状态变化而变化,但是 5G 网络在理想情况下有能力使延迟率在 1 ms 内。总的来说,5G 延迟将比 4G 降低 60 到 120 倍。这会使很多应用变得可能,例如当前虚拟现实的延迟使它变得不实际。
### 5G 技术
5G 技术的基础有一系列标准定义,在过去的 10 年里一直在研究更好的部分。这些里面最重要的是 5G New Radio(5G NR),由 3GPP(一个为移动电话开发协议的标准化组织)组织标准化。5G NR 规定了很多 5G 设备操作的方式,[于 2018 年 7 月 完成终版](https://www.theverge.com/2018/6/15/17467734/5g-nr-standard-3gpp-standalone-finished)。
很多独特的技术同时出现来尽可能地提升 5G 的速度并降低延迟,下面是一些重要的。
### 毫米波
5G 网络大部分使用在 30 到 300 GHz 范围的频率。(正如名称一样,这些频率的波长在 1 到 10 毫米之间)这些高频范围能够[在每个时间单元比低频信号携带更多的信息](https://www.networkworld.com/article/3291323/millimeter-wave-wireless-could-help-support-5g-and-iot.html),4G LTE 当前使用的就是通常频率在 1 GHz 以下的低频信号,或者 WiFi,最高 6 GHz。
毫米波技术传统上是昂贵并且难于部署的。科技进步已经克服了这些困难,这也是 5G 在如今成为了可能的原因。
### 小蜂窝
毫米波传输的一个缺点是当它们传输通过物理对象的时候比 4G 或 WiFi 信号更容易被干扰。
为了克服这些,5G 基础设施的模型将不同于 4G。替代了大的像景观一样移动天线桅杆,5G 网络将由[分布在城市中大概间距 250 米的更小的基站](https://spectrum.ieee.org/video/telecom/wireless/5g-bytes-small-cells-explained)提供支持,创建更小的服务区域。
这些 5G 基站的功率要求低于 4G,并且可以更容易地连接到建筑物和电线杆上。
### 大量的 MIMO
尽管 5G 基站比 4G 的对应部分小多了,但它们却带了更多的天线。这些天线是[多输入多输出的(MIMO)](https://www.networkworld.com/article/3250268/what-is-mu-mimo-and-why-you-need-it-in-your-wireless-routers.html),意味着在相同的数据信道能够同时处理多个双向会话。5G 网络能够处理比 4G 网络超过 20 倍的会话。
大量的 MIMO 保证了[基站容量限制下的极大提升](https://spectrum.ieee.org/tech-talk/telecom/wireless/5g-researchers-achieve-new-spectrum-efficiency-record),允许单个基站承载更多的设备会话。这就是 5G 可能推动物联网更广泛应用的原因。理论上,更多的连接到互联网的无线设备能够部署在相同的空间而不会使网络被压垮。
### 波束成形
确保所有的会话来回地到达正确的地方是比较棘手的,尤其是前面提到的毫米波信号的干涉问题。为了克服这些问题,5G 基站部署了更高级的波束技术,使用建设性和破坏性的无线电干扰来使信号有向而不是广播。这在一个特定的方向上有效地加强了信号强度和范围。
### 5G 可获得性
第一个 5G 商用网络 [2018 年 5 月在卡塔尔推出](https://venturebeat.com/2018/05/14/worlds-first-commercial-5g-network-launches-in-qatar/)。自那以后,5G 网络已经扩展到全世界,从阿根廷到越南。[Lifewire 有一个不错的,经常更新的列表](https://www.lifewire.com/5g-availability-world-4156244).
牢记一点的是,尽管这样,目前不是所有的 5G 网络都履行了所有的技术承诺。一些早期的 5G 产品依赖于现有的 4G 基础设施,减少了可以获得的潜在速度;其它服务为了市场目的而标榜 5G 但是并不符合标准。仔细观察美国无线运营商的产品都会发现一些陷阱。
### 无线运营商和 5G
技术上讲,5G 服务如今在美国已经可获得了。但声明中包含的注意事项因运营商而异,表明 5G 普及之前还有很长的路要走。
Verizon 可能是早期 5G 最大的推动者。它宣告到 2018 年 10 月 将有 4 个城市成为 [5G 家庭](https://www.digitaltrends.com/computing/verizon-5g-home-promises-up-to-gigabit-internet-speeds-for-50/)的一部分,这是一项需要你的其他设备通过 WiFi 来连接特定的 5G 热点,由热点连接到网络的服务。
Verizon 计划四月在 [Minneapolis 和 Chicago 发布 5G 移动服务](https://lifehacker.com/heres-your-cheat-sheet-for-verizons-new-5g-data-plans-1833278817),该服务将在这一年内传播到其他城市。访问 5G 网络将需要消费者每月额外花费费用,加上购买能够实际访问 5G 的手机花费(稍后会详细介绍)。另外,Verizon 的部署被称作 [5G TF](https://www.theverge.com/2018/10/2/17927712/verizon-5g-home-internet-real-speed-meaning),实际上不符合 5G NR 的标准。
AT&T [声明在 2018 年 12 月将有美国的 12 个城市可以使用 5G](https://www.cnn.com/2018/12/18/tech/5g-mobile-att/index.html),在 2019 年的末尾将增加 9 个城市,但最终在这些城市里,只有市中心商业区能够访问。为了访问 5G 网络,需要一个特定的 Netgear 热点来连接到 5G 服务,然后为手机和其他设备提供一个 Wi-Fi 信号。
与此同时,AT&T 也在推出 4G 网络的速度提升计划,被成为 5GE,即使这些提升和 5G 网络没有关系。([这会向后兼容](https://www.networkworld.com/article/3339720/like-4g-before-it-5g-is-being-hyped.html?nsdr=true))
Sprint 将在 2019 年 5 月之前在四个城市提供 5G 服务,在年末将有更多。但是 Sprint 的 5G 产品充分利用了 MIMO 单元,他们[没有使用毫米波信道](https://www.digitaltrends.com/mobile/sprint-5g-rollout/),意味着 Sprint 的用户不会看到像其他运营商一样的速度提升。
T-Mobile 采用相似的模型,它[在 2019 年年底之前不会推出 5G 服务](https://www.cnet.com/news/t-mobile-delays-full-600-mhz-5g-launch-until-second-half/),因为他们没有手机能够连接到它。
一个可能阻止 5G 速度的迅速传播的障碍是需要铺开所有这些小蜂窝基站。它们小的尺寸和较低的功耗需求使它们技术上比 4G 技术更容易部署,但这不意味着它能够很简单的使政府和财产拥有者信服到处安装一堆基站。Verizon 实际上建立了[向本地民选官员请愿的网站](https://lets5g.com/)来加速 5G 基站的部署。
### 5G 手机:何时可获得?何时可以买?
第一部声称为 5G 手机的是 Samsung Galaxy S10 5G,将在 2019 年夏末首发。你也可以从 Verizon 订阅一个“[Moto Mod](https://www.verizonwireless.com/support/5g-moto-mod-faqs/?AID=11365093&SID=100098X1555750Xbc2e857934b22ebca1a0570d5ba93b7c&vendorid=CJM&PUBID=7105813&cjevent=2e2150cb478c11e98183013b0a1c0e0c)”,用来[转换 Moto Z3 手机为 5G 兼容设备](https://www.digitaltrends.com/cell-phone-reviews/moto-z3-review/)。
但是除非你不能忍受作为一个早期使用者的诱惑,你会希望再等待一下;一些关于运营商的奇怪和突显的问题意味着可能你的手机[不兼容你的运营商的整个 5G 网络](https://www.businessinsider.com/samsung-galaxy-s10-5g-which-us-cities-have-5g-networks-2019-2)。
一个可能令你吃惊的落后者是苹果:分析者确信最早直到 2020 年以前 iPhone 不会与 5G 兼容。但这符合该公司的特点;苹果在 2012 年末也落后于三星发布兼容 4G 的手机。
不可否认,5G 洪流已经到来。5G 兼容的设备[在 2019 年统治了巴塞罗那世界移动大会](https://www.networkworld.com/article/3354477/mobile-world-congress-the-time-of-5g-is-almost-here.html),因此期待视野里有更多的选择。
### 为什么人们已经在讨论 6G 了?
一些专家说缺点是[5G 不能够达到延迟和可靠性的目标](https://www.networkworld.com/article/3305359/6g-will-achieve-terabits-per-second-speeds.html)。这些完美主义者已经在探寻 6G,来试图解决这些缺点。
有一个[研究新的能够融入 6G 技术的小组](https://www.networkworld.com/article/3285112/get-ready-for-upcoming-6g-wireless-too.html),自称为“融合 TeraHertz 通信与传感中心”(ComSenTer)。根据说明,他们努力让每个设备的带宽达到 100Gbps。
除了增加可靠性,还突破了可靠性并增加速度,6G 同样试图允许上千的并发连接。如果成功的话,这个特点将帮助物联网设备联网,使在工业设置中部署上千个传感器。
即使仍在胚胎当中,6G 已经由于新发现的 [在基于 tera-hretz 的网络中潜在的中间人攻击](https://www.networkworld.com/article/3315626/5g-and-6g-wireless-technologies-have-security-issues.html)的紧迫性面临安全的考虑。好消息是有大量时间来解决这个问题。6G 网络直到 2030 之前才可能出现。
阅读更多关于 5G 网络:
* [企业如何为 5G 网络做准备](https://%20https//www.networkworld.com/article/3306720/mobile-wireless/how-enterprises-can-prep-for-5g.html)
* [5G 与 4G:速度、延迟和应用支持的差异](https://%20https//www.networkworld.com/article/3330603/mobile-wireless/5g-versus-4g-how-speed-latency-and-application-support-differ.html)
* [私人 5G 网络即将到来](https://%20https//www.networkworld.com/article/3319176/mobile-wireless/private-5g-networks-are-coming.html)
* [5G 和 6G 无线存在安全问题](https://www.networkworld.com/article/3315626/network-security/5g-and-6g-wireless-technologies-have-security-issues.html)
* [毫米波无线技术如何支持 5G 和物联网](https://www.networkworld.com/article/3291323/mobile-wireless/millimeter-wave-wireless-could-help-support-5g-and-iot.html)
---
via: <https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html>
作者:[Josh Fruhlinger](https://www.networkworld.com/author/Josh-Fruhlinger/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,814 | 8 个你应该了解的环保开源项目 | https://opensource.com/article/19/4/environment-projects | 2019-05-04T14:48:55 | [
"环保",
"地球日"
] | https://linux.cn/article-10814-1.html |
>
> 通过给这些致力于提升环境的项目做贡献来庆祝地球日。
>
>
>

在过去的几年里,我一直在帮助 [Greenpeace](http://www.greenpeace.org) 建立其第一个完全开源的软件项目,Planet 4. [Planet 4](http://medium.com/planet4) 是一个全球参与平台,Greenpeace 的支持者和活动家可以互动并参与组织。它的目标是让人们代表我们的星球采取行动。我们希望邀请参与并利用人力来应对气候变化和塑料污染等全球性问题。开发者、设计师、作者、贡献者和其他通过开源支持环保主义的人都非常欢迎[参与进来](https://planet4.greenpeace.org/community/#partners-open-sourcers)!
Planet 4 远非唯一关注环境的开源项目。对于地球日,我会分享其他七个关注我们星球的开源项目。
[Eco Hacker Farm](https://wiki.ecohackerfarm.org/start) 致力于支持可持续社区。它建议并支持将黑客空间/黑客基地和永续农业生活结合在一起的项目。该组织还有在线项目。访问其 [wiki](https://wiki.ecohackerfarm.org/) 或 [Twitter](https://twitter.com/EcoHackerFarm) 了解有关 Eco Hacker Farm 正在做的更多信息。
[Public Lab](https://publiclab.org/) 是一个开放社区和非营利组织,它致力于将科学掌握在公民手中。它于 2010 年在 BP 石油灾难后形成,Public Lab 与开源合作,协助环境勘探和调查。它是一个多元化的社区,有很多方法可以做[贡献](https://publiclab.org/contribute)。
不久前,Opensource.com 的社区管理者 Don Watkins 撰写了一篇 [Open Climate Workbench](https://opensource.com/article/17/1/apache-open-climate-workbench) 的文章,该项目来自 Apache 基金会。 [OCW](https://climate.apache.org/) 提供了进行气候建模和评估的软件,可用于各种应用。
[Open Source Ecology](https://wiki.opensourceecology.org/wiki/Project_needs) 是一个旨在改善经济运作方式的项目。该项目着眼于环境再生和社会公正,它旨在重新界定我们的一些肮脏的生产和分配技术,以创造一个更可持续的文明。
促进开源和大数据工具之间的合作,以实现海洋、大气、土地和气候的研究,“ [Pangeo](http://pangeo.io/) 是第一个推广开放、可重复和可扩展科学的社区。”大数据可以改变世界!
[Leaflet](https://leafletjs.com/) 是一个著名的开源 JavaScript 库。它可以做各种各样的事情,包括环保项目,如 [Arctic Web Map](https://webmap.arcticconnect.ca/#ac_3573/2/20.8/-65.5),它能让科学家准确地可视化和分析北极地区,这是气候研究的关键能力。
当然,没有我在 Mozilla 的朋友就没有这个列表(这不是个完整的列表!)。[Mozilla Science Lab](https://science.mozilla.org/) 社区就像所有 Mozilla 项目一样,非常开放,它致力于将开源原则带给科学界。它的项目和社区使科学家能够进行我们世界所需的各种研究,以解决一些最普遍的环境问题。
### 如何贡献
在这个地球日,做为期六个月的承诺,将一些时间贡献给一个有助于应对气候变化的开源项目,或以其他方式鼓励人们保护地球母亲。肯定还有许多关注环境的开源项目,所以请在评论中留言!
---
via: <https://opensource.com/article/19/4/environment-projects>
作者:[Laura Hilliger](https://opensource.com/users/laurahilliger) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For the last few years, I've been helping [Greenpeace](http://www.greenpeace.org) build its first fully open source software project, Planet 4. [Planet 4](http://medium.com/planet4) is a global engagement platform where Greenpeace supporters and activists can interact and engage with the organization. The goal is to drive people to action on behalf of our planet. We want to invite participation and use people power to battle global issues like climate change and plastic pollution. Developers, designers, writers, contributors, and others who are looking for an open source way to support environmentalism are more than welcome to [get involved](https://planet4.greenpeace.org/community/#partners-open-sourcers)!
Planet 4 is far from the only open source project focused on the environment. For Earth Day, I thought I'd share seven other open source projects that have our planet in mind.
** Eco Hacker Farm** works to support sustainable communities. It advises and supports projects combining hackerspaces/hackbases and permaculture living. The organization also has online software projects. Visit its
[wiki](https://wiki.ecohackerfarm.org/)or reach out on
** Public Lab** is an open community and nonprofit organization that works to put science in the hands of citizens. Formed after the BP oil disaster in 2010, Public Lab works with open source to aid environmental exploration and investigation. It's a diverse community with lots of ways to
[contribute](https://publiclab.org/contribute).
A while back, Don Watkins, a community moderator here on Opensource.com, wrote about ** Open Climate Workbench**, a project from the Apache Foundation. The
[OCW](https://climate.apache.org/)provides software to do climate modeling and evaluation, which can have all sorts of applications.
** Open Source Ecology** is a project that aims to improve how our economy functions. With an eye on environmental regeneration and social justice, the project seeks to redefine some of our dirty production and distribution techniques to create a more sustainable civilization.
Fostering collaboration around open source and big data tools to enable research in ocean, atmosphere, land, and climate, "** Pangeo** is first and foremost a community promoting open, reproducible, and scalable science." Big data can change the world!
is a well-known open source JavaScript library. It can be used for all sorts of things, including environmentally friendly projects like the
**Leaflet**
[Arctic Web Map](https://webmap.arcticconnect.ca/#ac_3573/2/20.8/-65.5), which allows scientists to accurately visualize and analyze the arctic region, a critical ability for climate research.
And of course, no list would be complete (not that this is a complete list!) without pointing to my friends at Mozilla. The ** Mozilla Science Lab** community is, like all of Mozilla, fiercely open, and it's committed to bringing open source principles to the scientific community. Its projects and communities enable scientists to do the sorts of research our world needs to address some of the most pervasive environmental issues.
## How you can contribute
This Earth Day, make a six-month commitment to contribute some of your time to an open source project that helps fight climate change or otherwise encourages people to step up for Mother Earth. There must be scores of environmentally minded open source projects out there, so please leave your favorites in the comments!
## Comments are closed. |
10,815 | 在 Linux 中如何使用 iotop 和 iostat 监控磁盘 I/O 活动? | https://www.2daygeek.com/check-monitor-disk-io-in-linux-using-iotop-iostat-command/ | 2019-05-05T10:11:09 | [
"I/O",
"性能",
"iostat",
"iotop"
] | https://linux.cn/article-10815-1.html | 
你知道在 Linux 中我们使用什么工具检修和监控实时的磁盘活动吗?如果 [Linux 系统性能](https://www.2daygeek.com/category/monitoring-tools/)变慢,我们会用 [top 命令](https://www.2daygeek.com/linux-top-command-linux-system-performance-monitoring-tool/) 来查看系统性能。它被用来检查是什么进程在服务器上占有如此高的使用率,对于大多数 Linux 系统管理员来说很常见,现实世界中被 Linux 系统管理员广泛采用。
如果在进程输出中你没有看到很大的不同,你仍然有选择查看其他东西。我会建议你在 `top` 输出中检查 `wa` 状态,因为大多数时间里服务器性能由于在硬盘上的高 I/O 读和写降低了性能。如果它很高或者波动,很可能就是它造成的。因此,我们需要检查硬盘上的 I/O 活动。
我们可以在 Linux 中使用 `iotop` 和 `iostat` 命令监控所有的磁盘和文件系统的磁盘 I/O 统计。
### 什么是 iotop?
`iotop` 是一个类似 `top` 的工具,用来显示实时的磁盘活动。
`iotop` 监控 Linux 内核输出的 I/O 使用信息,并且显示一个系统中进程或线程的当前 I/O 使用情况。
它显示每个进程/线程读写 I/O 带宽。它同样显示当等待换入和等待 I/O 的线程/进程花费的时间的百分比。
`Total DISK READ` 和 `Total DISK WRITE` 的值一方面表示了进程和内核线程之间的总的读写带宽,另一方面也表示内核块设备子系统的。
`Actual DISK READ` 和 `Actual DISK WRITE` 的值表示在内核块设备子系统和下面硬件(HDD、SSD 等等)对应的实际磁盘 I/O 带宽。
### 如何在 Linux 中安装 iotop ?
我们可以轻松在包管理器的帮助下安装,因为该软件包在所有的 Linux 发行版仓库中都可以获得。
对于 Fedora 系统,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 `iotop`。
```
$ sudo dnf install iotop
```
对于 Debian/Ubuntu 系统,使用 [API-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或者 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 `iotop`。
```
$ sudo apt install iotop
```
对于基于 Arch Linux 的系统,使用 [Pacman Command](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 `iotop`。
```
$ sudo pacman -S iotop
```
对于 RHEL/CentOS 的系统,使用 [YUM Command](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 来安装 `iotop`。
```
$ sudo yum install iotop
```
对于使用 openSUSE Leap 的系统,使用 [Zypper Command](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 来安装 `iotop`。
```
$ sudo zypper install iotop
```
### 在 Linux 中如何使用 iotop 命令来监控磁盘 I/O 活动/统计?
`iotop` 命令有很多参数来检查关于磁盘 I/O 的变化:
```
# iotop
```

如果你想检查那个进程实际在做 I/O,那么运行 `iotop` 命令加上 `-o` 或者 `--only` 参数。
```
# iotop --only
```

细节:
* `IO`:它显示每个进程的 I/O 利用率,包含磁盘和交换。
* `SWAPIN`: 它只显示每个进程的交换使用率。
### 什么是 iostat?
`iostat` 被用来报告中央处理单元(CPU)的统计和设备与分区的输出/输出的统计。
`iostat` 命令通过观察与它们平均传输率相关的设备活跃时间来监控系统输入/输出设备负载。
`iostat` 命令生成的报告可以被用来改变系统配置来更好的平衡物理磁盘之间的输入/输出负载。
所有的统计都在 `iostat` 命令每次运行时被报告。该报告包含一个 CPU 头部,后面是一行 CPU 统计。
在多处理器系统中,CPU 统计被计算为系统层面的所有处理器的平均值。设备头行后紧跟显示每个配置的设备一行的统计。
`iostat` 命令生成两种类型的报告,CPU 利用率报告和设备利用率报告。
### 在 Linux 中怎样安装 iostat?
`iostat` 工具是 `sysstat` 包的一部分,所以我们可以轻松地在包管理器地帮助下安装,因为在所有的 Linux 发行版的仓库都是可以获得的。
对于 Fedora 系统,使用 [DNF Command](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 `sysstat`。
```
$ sudo dnf install sysstat
```
对于 Debian/Ubuntu 系统,使用 [APT-GET Command](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或者 [APT Command](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 `sysstat`。
```
$ sudo apt install sysstat
```
对于基于 Arch Linux 的系统,使用 [Pacman Command](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 `sysstat`。
```
$ sudo pacman -S sysstat
```
对于 RHEL/CentOS 系统,使用 [YUM Command](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 来安装 `sysstat`。
```
$ sudo yum install sysstat
```
对于 openSUSE Leap 系统,使用 [Zypper Command](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 来安装 `sysstat`。
```
$ sudo zypper install sysstat
```
### 在 Linux 中如何使用 sysstat 命令监控磁盘 I/O 活动/统计?
在 `iostat` 命令中有很多参数来检查关于 I/O 和 CPU 的变化统计信息。
不加参数运行 `iostat` 命令会看到完整的系统统计。
```
# iostat
Linux 4.19.32-1-MANJARO (daygeek-Y700) Thursday 18 April 2019 _x86_64_ (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
29.45 0.02 16.47 0.12 0.00 53.94
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
nvme0n1 6.68 126.95 124.97 0.00 58420014 57507206 0
sda 0.18 6.77 80.24 0.00 3115036 36924764 0
loop0 0.00 0.00 0.00 0.00 2160 0 0
loop1 0.00 0.00 0.00 0.00 1093 0 0
loop2 0.00 0.00 0.00 0.00 1077 0 0
```
运行 `iostat` 命令加上 `-d` 参数查看所有设备的 I/O 统计。
```
# iostat -d
Linux 4.19.32-1-MANJARO (daygeek-Y700) Thursday 18 April 2019 _x86_64_ (8 CPU)
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
nvme0n1 6.68 126.95 124.97 0.00 58420030 57509090 0
sda 0.18 6.77 80.24 0.00 3115292 36924764 0
loop0 0.00 0.00 0.00 0.00 2160 0 0
loop1 0.00 0.00 0.00 0.00 1093 0 0
loop2 0.00 0.00 0.00 0.00 1077 0 0
```
运行 `iostat` 命令加上 `-p` 参数查看所有的设备和分区的 I/O 统计。
```
# iostat -p
Linux 4.19.32-1-MANJARO (daygeek-Y700) Thursday 18 April 2019 _x86_64_ (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
29.42 0.02 16.45 0.12 0.00 53.99
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
nvme0n1 6.68 126.94 124.96 0.00 58420062 57512278 0
nvme0n1p1 6.40 124.46 118.36 0.00 57279753 54474898 0
nvme0n1p2 0.27 2.47 6.60 0.00 1138069 3037380 0
sda 0.18 6.77 80.23 0.00 3116060 36924764 0
sda1 0.00 0.01 0.00 0.00 3224 0 0
sda2 0.18 6.76 80.23 0.00 3111508 36924764 0
loop0 0.00 0.00 0.00 0.00 2160 0 0
loop1 0.00 0.00 0.00 0.00 1093 0 0
loop2 0.00 0.00 0.00 0.00 1077 0 0
```
运行 `iostat` 命令加上 `-x` 参数显示所有设备的详细的 I/O 统计信息。
```
# iostat -x
Linux 4.19.32-1-MANJARO (daygeek-Y700) Thursday 18 April 2019 _x86_64_ (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
29.41 0.02 16.45 0.12 0.00 54.00
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz aqu-sz %util
nvme0n1 2.45 126.93 0.60 19.74 0.40 51.74 4.23 124.96 5.12 54.76 3.16 29.54 0.00 0.00 0.00 0.00 0.00 0.00 0.31 30.28
sda 0.06 6.77 0.00 0.00 8.34 119.20 0.12 80.23 19.94 99.40 31.84 670.73 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.13
loop0 0.00 0.00 0.00 0.00 0.08 19.64 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop1 0.00 0.00 0.00 0.00 0.40 12.86 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop2 0.00 0.00 0.00 0.00 0.38 19.58 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
```
运行 `iostat` 命令加上 `-d [设备名]` 参数查看具体设备和它的分区的 I/O 统计信息。
```
# iostat -p [Device_Name]
# iostat -p sda
Linux 4.19.32-1-MANJARO (daygeek-Y700) Thursday 18 April 2019 _x86_64_ (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
29.38 0.02 16.43 0.12 0.00 54.05
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda 0.18 6.77 80.21 0.00 3117468 36924764 0
sda2 0.18 6.76 80.21 0.00 3112916 36924764 0
sda1 0.00 0.01 0.00 0.00 3224 0 0
```
运行 `iostat` 命令加上 `-m` 参数以 MB 为单位而不是 KB 查看所有设备的统计。默认以 KB 显示输出。
```
# iostat -m
Linux 4.19.32-1-MANJARO (daygeek-Y700) Thursday 18 April 2019 _x86_64_ (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
29.36 0.02 16.41 0.12 0.00 54.09
Device tps MB_read/s MB_wrtn/s MB_dscd/s MB_read MB_wrtn MB_dscd
nvme0n1 6.68 0.12 0.12 0.00 57050 56176 0
sda 0.18 0.01 0.08 0.00 3045 36059 0
loop0 0.00 0.00 0.00 0.00 2 0 0
loop1 0.00 0.00 0.00 0.00 1 0 0
loop2 0.00 0.00 0.00 0.00 1 0 0
```
运行 `iostat` 命令使用特定的间隔使用如下的格式。在这个例子中,我们打算以 5 秒捕获的间隔捕获两个报告。
```
# iostat [Interval] [Number Of Reports]
# iostat 5 2
Linux 4.19.32-1-MANJARO (daygeek-Y700) Thursday 18 April 2019 _x86_64_ (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
29.35 0.02 16.41 0.12 0.00 54.10
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
nvme0n1 6.68 126.89 124.95 0.00 58420116 57525344 0
sda 0.18 6.77 80.20 0.00 3118492 36924764 0
loop0 0.00 0.00 0.00 0.00 2160 0 0
loop1 0.00 0.00 0.00 0.00 1093 0 0
loop2 0.00 0.00 0.00 0.00 1077 0 0
avg-cpu: %user %nice %system %iowait %steal %idle
3.71 0.00 2.51 0.05 0.00 93.73
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
nvme0n1 19.00 0.20 311.40 0.00 1 1557 0
sda 0.20 25.60 0.00 0.00 128 0 0
loop0 0.00 0.00 0.00 0.00 0 0 0
loop1 0.00 0.00 0.00 0.00 0 0 0
loop2 0.00 0.00 0.00 0.00 0 0 0
```
运行 `iostat` 命令与 `-N` 参数来查看 LVM 磁盘 I/O 统计报告。
```
# iostat -N
Linux 4.15.0-47-generic (Ubuntu18.2daygeek.com) Thursday 18 April 2019 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.38 0.07 0.18 0.26 0.00 99.12
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 3.60 57.07 69.06 968729 1172340
sdb 0.02 0.33 0.00 5680 0
sdc 0.01 0.12 0.00 2108 0
2g-2gvol1 0.00 0.07 0.00 1204 0
```
运行 `nfsiostat` 命令来查看 Network File System(NFS)的 I/O 统计。
```
# nfsiostat
```
---
via: <https://www.2daygeek.com/check-monitor-disk-io-in-linux-using-iotop-iostat-command/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,816 | 关于 /dev/urandom 的流言终结 | https://www.2uo.de/myths-about-urandom/ | 2019-05-05T11:49:00 | [
"随机"
] | https://linux.cn/article-10816-1.html | 
有很多关于 `/dev/urandom` 和 `/dev/random` 的流言在坊间不断流传。然而流言终究是流言。
>
> 本篇文章里针对的都是近来的 Linux 操作系统,其它类 Unix 操作系统不在讨论范围内。
>
>
>
**`/dev/urandom` 不安全。加密用途必须使用 `/dev/random`**
*事实*:`/dev/urandom` 才是类 Unix 操作系统下推荐的加密种子。
**`/dev/urandom` 是<ruby> 伪随机数生成器 <rt> pseudo random number generator </rt></ruby>(PRND),而 `/dev/random` 是“真”随机数生成器。**
*事实*:它们两者本质上用的是同一种 CSPRNG (一种密码学伪随机数生成器)。它们之间细微的差别和“真”“不真”随机完全无关。(参见:“Linux 随机数生成器的构架”一节)
**`/dev/random` 在任何情况下都是密码学应用更好地选择。即便 `/dev/urandom` 也同样安全,我们还是不应该用它。**
*事实*:`/dev/random` 有个很恶心人的问题:它是阻塞的。(参见:“阻塞有什么问题?”一节)(LCTT 译注:意味着请求都得逐个执行,等待前一个请求完成)
**但阻塞不是好事吗!`/dev/random` 只会给出电脑收集的信息熵足以支持的随机量。`/dev/urandom` 在用完了所有熵的情况下还会不断吐出不安全的随机数给你。**
*事实*:这是误解。就算我们不去考虑应用层面后续对随机种子的用法,“用完信息熵池”这个概念本身就不存在。仅仅 256 位的熵就足以生成计算上安全的随机数很长、很长的一段时间了。(参见:“那熵池快空了的情况呢?”一节)
问题的关键还在后头:`/dev/random` 怎么知道有系统会*多少*可用的信息熵?接着看!
**但密码学家老是讨论重新选种子(re-seeding)。这难道不和上一条冲突吗?**
*事实*:你说的也没错!某种程度上吧。确实,随机数生成器一直在使用系统信息熵的状态重新选种。但这么做(一部分)是因为别的原因。(参见:“重新选种”一节)
这样说吧,我没有说引入新的信息熵是坏的。更多的熵肯定更好。我只是说在熵池低的时候阻塞是没必要的。
**好,就算你说的都对,但是 `/dev/(u)random` 的 man 页面和你说的也不一样啊!到底有没有专家同意你说的这堆啊?**
*事实*:其实 man 页面和我说的不冲突。它看似好像在说 `/dev/urandom` 对密码学用途来说不安全,但如果你真的理解这堆密码学术语你就知道它说的并不是这个意思。(参见:“random 和 urandom 的 man 页面”一节)
man 页面确实说在一些情况下推荐使用 `/dev/random` (我觉得也没问题,但绝对不是说必要的),但它也推荐在大多数“一般”的密码学应用下使用 `/dev/urandom` 。
虽然诉诸权威一般来说不是好事,但在密码学这么严肃的事情上,和专家统一意见是很有必要的。
所以说呢,还确实有一些*专家*和我的一件事一致的:`/dev/urandom` 就应该是类 UNIX 操作系统下密码学应用的首选。显然的,是他们的观点说服了我而不是反过来的。(参见:“正道”一节)
---
难以相信吗?觉得我肯定错了?读下去看我能不能说服你。
我尝试不讲太高深的东西,但是有两点内容必须先提一下才能让我们接着论证观点。
首当其冲的,*什么是随机性*,或者更准确地:我们在探讨什么样的随机性?(参见:“真随机”一节)
另外一点很重要的是,我*没有尝试以说教的态度*对你们写这段话。我写这篇文章是为了日后可以在讨论起的时候指给别人看。比 140 字长(LCTT 译注:推特长度)。这样我就不用一遍遍重复我的观点了。能把论点磨炼成一篇文章本身就很有助于将来的讨论。(参见:“你是在说我笨?!”一节)
并且我非常乐意听到不一样的观点。但我只是认为单单地说 `/dev/urandom` 坏是不够的。你得能指出到底有什么问题,并且剖析它们。
### 你是在说我笨?!
绝对没有!
事实上我自己也相信了 “`/dev/urandom` 是不安全的” 好些年。这几乎不是我们的错,因为那么德高望重的人在 Usenet、论坛、推特上跟我们重复这个观点。甚至*连 man 手册*都似是而非地说着。我们当年怎么可能鄙视诸如“信息熵太低了”这种看上去就很让人信服的观点呢?(参见:“random 和 urandom 的 man 页面”一节)
整个流言之所以如此广为流传不是因为人们太蠢,而是因为但凡有点关于信息熵和密码学概念的人都会觉得这个说法很有道理。直觉似乎都在告诉我们这流言讲的很有道理。很不幸直觉在密码学里通常不管用,这次也一样。
### 真随机
随机数是“真正随机”是什么意思?
我不想搞的太复杂以至于变成哲学范畴的东西。这种讨论很容易走偏因为对于随机模型大家见仁见智,讨论很快变得毫无意义。
在我看来“真随机”的“试金石”是量子效应。一个光子穿过或不穿过一个半透镜。或者观察一个放射性粒子衰变。这类东西是现实世界最接近真随机的东西。当然,有些人也不相信这类过程是真随机的,或者这个世界根本不存在任何随机性。这个就百家争鸣了,我也不好多说什么了。
密码学家一般都会通过不去讨论什么是“真随机”来避免这种哲学辩论。他们更关心的是<ruby> 不可预测性 <rt> unpredictability </rt></ruby>。只要没有*任何*方法能猜出下一个随机数就可以了。所以当你以密码学应用为前提讨论一个随机数好不好的时候,在我看来这才是最重要的。
无论如何,我不怎么关心“哲学上安全”的随机数,这也包括别人嘴里的“真”随机数。
### 两种安全,一种有用
但就让我们退一步说,你有了一个“真”随机变量。你下一步做什么呢?
你把它们打印出来然后挂在墙上来展示量子宇宙的美与和谐?牛逼!我支持你。
但是等等,你说你要*用*它们?做密码学用途?额,那这就废了,因为这事情就有点复杂了。
事情是这样的,你的真随机、量子力学加护的随机数即将被用进不理想的现实世界算法里去。
因为我们使用的几乎所有的算法都并不是<ruby> 信息论安全性 <rt> information-theoretic security </rt></ruby>的。它们“只能”提供**计算意义上的安全**。我能想到为数不多的例外就只有 Shamir 密钥分享和<ruby> 一次性密码本 <rt> One-time pad </rt></ruby>(OTP)算法。并且就算前者是名副其实的(如果你实际打算用的话),后者则毫无可行性可言。
但所有那些大名鼎鼎的密码学算法,AES、RSA、Diffie-Hellman、椭圆曲线,还有所有那些加密软件包,OpenSSL、GnuTLS、Keyczar、你的操作系统的加密 API,都仅仅是计算意义上安全的。
那区别是什么呢?信息论安全的算法肯定是安全的,绝对是,其它那些的算法都可能在理论上被拥有无限计算力的穷举破解。我们依然愉快地使用它们是因为全世界的计算机加起来都不可能在宇宙年龄的时间里破解,至少现在是这样。而这就是我们文章里说的“不安全”。
除非哪个聪明的家伙破解了算法本身 —— 在只需要更少量计算力、在今天可实现的计算力的情况下。这也是每个密码学家梦寐以求的圣杯:破解 AES 本身、破解 RSA 本身等等。
所以现在我们来到了更底层的东西:随机数生成器,你坚持要“真随机”而不是“伪随机”。但是没过一会儿你的真随机数就被喂进了你极为鄙视的伪随机算法里了!
真相是,如果我们最先进的哈希算法被破解了,或者最先进的分组加密算法被破解了,你得到的这些“哲学上不安全”的随机数甚至无所谓了,因为反正你也没有安全的应用方法了。
所以把计算性上安全的随机数喂给你的仅仅是计算性上安全的算法就可以了,换而言之,用 `/dev/urandom`。
### Linux 随机数生成器的构架
#### 一种错误的看法
你对内核的随机数生成器的理解很可能是像这样的:

“真正的随机性”,尽管可能有点瑕疵,进入操作系统然后它的熵立刻被加入内部熵计数器。然后经过“矫偏”和“漂白”之后它进入内核的熵池,然后 `/dev/random` 和 `/dev/urandom` 从里面生成随机数。
“真”随机数生成器,`/dev/random`,直接从池里选出随机数,如果熵计数器表示能满足需要的数字大小,那就吐出数字并且减少熵计数。如果不够的话,它会阻塞程序直至有足够的熵进入系统。
这里很重要一环是 `/dev/random` 几乎只是仅经过必要的“漂白”后就直接把那些进入系统的随机性吐了出来,不经扭曲。
而对 `/dev/urandom` 来说,事情是一样的。除了当没有足够的熵的时候,它不会阻塞,而会从一直在运行的伪随机数生成器(当然,是密码学安全的,CSPRNG)里吐出“低质量”的随机数。这个 CSPRNG 只会用“真随机数”生成种子一次(或者好几次,这不重要),但你不能特别相信它。
在这种对随机数生成的理解下,很多人会觉得在 Linux 下尽量避免 `/dev/urandom` 看上去有那么点道理。
因为要么你有足够多的熵,你会相当于用了 `/dev/random`。要么没有,那你就会从几乎没有高熵输入的 CSPRNG 那里得到一个低质量的随机数。
看上去很邪恶是吧?很不幸的是这种看法是完全错误的。实际上,随机数生成器的构架更像是下面这样的。
#### 更好地简化
##### Linux 4.8 之前

你看到最大的区别了吗?CSPRNG 并不是和随机数生成器一起跑的,它在 `/dev/urandom` 需要输出但熵不够的时候进行填充。CSPRNG 是整个随机数生成过程的内部组件之一。从来就没有什么 `/dev/random` 直接从池里输出纯纯的随机性。每个随机源的输入都在 CSPRNG 里充分混合和散列过了,这一切都发生在实际变成一个随机数,被 `/dev/urandom` 或者 `/dev/random` 吐出去之前。
另外一个重要的区别是这里没有熵计数器的任何事情,只有预估。一个源给你的熵的量并不是什么很明确能直接得到的数字。你得预估它。注意,如果你太乐观地预估了它,那 `/dev/random` 最重要的特性——只给出熵允许的随机量——就荡然无存了。很不幸的,预估熵的量是很困难的。
>
> 这是个很粗糙的简化。实际上不仅有一个,而是三个熵池。一个主池,另一个给 `/dev/random`,还有一个给 `/dev/urandom`,后两者依靠从主池里获取熵。这三个池都有各自的熵计数器,但二级池(后两个)的计数器基本都在 0 附近,而“新鲜”的熵总在需要的时候从主池流过来。同时还有好多混合和回流进系统在同时进行。整个过程对于这篇文档来说都过于复杂了,我们跳过。
>
>
>
Linux 内核只使用事件的到达时间来预估熵的量。根据模型,它通过多项式插值来预估实际的到达时间有多“出乎意料”。这种多项式插值的方法到底是不是好的预估熵量的方法本身就是个问题。同时硬件情况会不会以某种特定的方式影响到达时间也是个问题。而所有硬件的取样率也是个问题,因为这基本上就直接决定了随机数到达时间的颗粒度。
说到最后,至少现在看来,内核的熵预估还是不错的。这也意味着它比较保守。有些人会具体地讨论它有多好,这都超出我的脑容量了。就算这样,如果你坚持不想在没有足够多的熵的情况下吐出随机数,那你看到这里可能还会有一丝紧张。我睡的就很香了,因为我不关心熵预估什么的。
最后要明确一下:`/dev/random` 和 `/dev/urandom` 都是被同一个 CSPRNG 饲喂的。只有它们在用完各自熵池(根据某种预估标准)的时候,它们的行为会不同:`/dev/random` 阻塞,`/dev/urandom` 不阻塞。
##### Linux 4.8 以后

在 Linux 4.8 里,`/dev/random` 和 `/dev/urandom` 的等价性被放弃了。现在 `/dev/urandom` 的输出不来自于熵池,而是直接从 CSPRNG 来。
*我们很快会理解*为什么这不是一个安全问题。(参见:“CSPRNG 没问题”一节)
### 阻塞有什么问题?
你有没有需要等着 `/dev/random` 来吐随机数?比如在虚拟机里生成一个 PGP 密钥?或者访问一个在生成会话密钥的网站?
这些都是问题。阻塞本质上会降低可用性。换而言之你的系统不干你让它干的事情。不用我说,这是不好的。要是它不干活你干嘛搭建它呢?
>
> 我在工厂自动化里做过和安全相关的系统。猜猜看安全系统失效的主要原因是什么?操作问题。就这么简单。很多安全措施的流程让工人恼火了。比如时间太长,或者太不方便。你要知道人很会找捷径来“解决”问题。
>
>
>
但其实有个更深刻的问题:人们不喜欢被打断。它们会找一些绕过的方法,把一些诡异的东西接在一起仅仅因为这样能用。一般人根本不知道什么密码学什么乱七八糟的,至少正常的人是这样吧。
为什么不禁止调用 `random()`?为什么不随便在论坛上找个人告诉你用写奇异的 ioctl 来增加熵计数器呢?为什么不干脆就把 SSL 加密给关了算了呢?
到头来如果东西太难用的话,你的用户就会被迫开始做一些降低系统安全性的事情——你甚至不知道它们会做些什么。
我们很容易会忽视可用性之类的重要性。毕竟安全第一对吧?所以比起牺牲安全,不可用、难用、不方便都是次要的?
这种二元对立的想法是错的。阻塞不一定就安全了。正如我们看到的,`/dev/urandom` 直接从 CSPRNG 里给你一样好的随机数。用它不好吗!
### CSPRNG 没问题
现在情况听上去很惨淡。如果连高质量的 `/dev/random` 都是从一个 CSPRNG 里来的,我们怎么敢在高安全性的需求上使用它呢?
实际上,“看上去随机”是现存大多数密码学基础组件的基本要求。如果你观察一个密码学哈希的输出,它一定得和随机的字符串不可区分,密码学家才会认可这个算法。如果你生成一个分组加密,它的输出(在你不知道密钥的情况下)也必须和随机数据不可区分才行。
如果任何人能比暴力穷举要更有效地破解一个加密,比如它利用了某些 CSPRNG 伪随机的弱点,那这就又是老一套了:一切都废了,也别谈后面的了。分组加密、哈希,一切都是基于某个数学算法,比如 CSPRNG。所以别害怕,到头来都一样。
### 那熵池快空了的情况呢?
毫无影响。
加密算法的根基建立在攻击者不能预测输出上,只要最一开始有足够的随机性(熵)就行了。“足够”的下限可以是 256 位,不需要更多了。
介于我们一直在很随意的使用“熵”这个概念,我用“位”来量化随机性希望读者不要太在意细节。像我们之前讨论的那样,内核的随机数生成器甚至没法精确地知道进入系统的熵的量。只有一个预估。而且这个预估的准确性到底怎么样也没人知道。
### 重新选种
但如果熵这么不重要,为什么还要有新的熵一直被收进随机数生成器里呢?
>
> djb [提到](http://blog.cr.yp.to/20140205-entropy.html) 太多的熵甚至可能会起到反效果。
>
>
>
首先,一般不会这样。如果你有很多随机性可以拿来用,用就对了!
但随机数生成器时不时要重新选种还有别的原因:
想象一下如果有个攻击者获取了你随机数生成器的所有内部状态。这是最坏的情况了,本质上你的一切都暴露给攻击者了。
你已经凉了,因为攻击者可以计算出所有未来会被输出的随机数了。
但是,如果不断有新的熵被混进系统,那内部状态会再一次变得随机起来。所以随机数生成器被设计成这样有些“自愈”能力。
但这是在给内部状态引入新的熵,这和阻塞输出没有任何关系。
### random 和 urandom 的 man 页面
这两个 man 页面在吓唬程序员方面很有建树:
>
> 从 `/dev/urandom` 读取数据不会因为需要更多熵而阻塞。这样的结果是,如果熵池里没有足够多的熵,取决于驱动使用的算法,返回的数值在理论上有被密码学攻击的可能性。发动这样攻击的步骤并没有出现在任何公开文献当中,但这样的攻击从理论上讲是可能存在的。如果你的应用担心这类情况,你应该使用 `/dev/random`。
>
>
>
> >
> > 实际上已经有 `/dev/random` 和 `/dev/urandom` 的 Linux 内核 man 页面的更新版本。不幸的是,随便一个网络搜索出现我在结果顶部的仍然是旧的、有缺陷的版本。此外,许多 Linux 发行版仍在发布旧的 man 页面。所以不幸的是,这一节需要在这篇文章中保留更长的时间。我很期待删除这一节!
> >
> >
> >
>
>
>
没有“公开的文献”描述,但是 NSA 的小卖部里肯定卖这种攻击手段是吧?如果你真的真的很担心(你应该很担心),那就用 `/dev/random` 然后所有问题都没了?
然而事实是,可能某个什么情报局有这种攻击,或者某个什么邪恶黑客组织找到了方法。但如果我们就直接假设这种攻击一定存在也是不合理的。
而且就算你想给自己一个安心,我要给你泼个冷水:AES、SHA-3 或者其它什么常见的加密算法也没有“公开文献记述”的攻击手段。难道你也不用这几个加密算法了?这显然是可笑的。
我们在回到 man 页面说:“使用 `/dev/random`”。我们已经知道了,虽然 `/dev/urandom` 不阻塞,但是它的随机数和 `/dev/random` 都是从同一个 CSPRNG 里来的。
如果你真的需要信息论安全性的随机数(你不需要的,相信我),那才有可能成为唯一一个你需要等足够熵进入 CSPRNG 的理由。而且你也不能用 `/dev/random`。
man 页面有毒,就这样。但至少它还稍稍挽回了一下自己:
>
> 如果你不确定该用 `/dev/random` 还是 `/dev/urandom` ,那你可能应该用后者。通常来说,除了需要长期使用的 GPG/SSL/SSH 密钥以外,你总该使用`/dev/urandom` 。
>
>
>
> >
> > 该手册页的[当前更新版本](http://man7.org/linux/man-pages/man4/random.4.html)毫不含糊地说:
> >
> >
> > `/dev/random` 接口被认为是遗留接口,并且 `/dev/urandom` 在所有用例中都是首选和足够的,除了在启动早期需要随机性的应用程序;对于这些应用程序,必须替代使用 `getrandom(2)`,因为它将阻塞,直到熵池初始化完成。
> >
> >
> >
>
>
>
行。我觉得没必要,但如果你真的要用 `/dev/random` 来生成 “长期使用的密钥”,用就是了也没人拦着!你可能需要等几秒钟或者敲几下键盘来增加熵,但这没什么问题。
但求求你们,不要就因为“你想更安全点”就让连个邮件服务器要挂起半天。
### 正道
本篇文章里的观点显然在互联网上是“小众”的。但如果问一个真正的密码学家,你很难找到一个认同阻塞 `/dev/random` 的人。
比如我们看看 [Daniel Bernstein](http://www.mail-archive.com/[email protected]/msg04763.html)(即著名的 djb)的看法:
>
> 我们密码学家对这种胡乱迷信行为表示不负责。你想想,写 `/dev/random` man 页面的人好像同时相信:
>
>
> * (1) 我们不知道如何用一个 256 位长的 `/dev/random` 的输出来生成一个无限长的随机密钥串流(这是我们需要 `/dev/urandom` 吐出来的),但与此同时
> * (2) 我们却知道怎么用单个密钥来加密一条消息(这是 SSL,PGP 之类干的事情)
>
>
> 对密码学家来说这甚至都不好笑了
>
>
>
或者 [Thomas Pornin](http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key/3939#3939) 的看法,他也是我在 stackexchange 上见过最乐于助人的一位:
>
> 简单来说,是的。展开说,答案还是一样。`/dev/urandom` 生成的数据可以说和真随机完全无法区分,至少在现有科技水平下。使用比 `/dev/urandom` “更好的“随机性毫无意义,除非你在使用极为罕见的“信息论安全”的加密算法。这肯定不是你的情况,不然你早就说了。
>
>
> urandom 的 man 页面多多少少有些误导人,或者干脆可以说是错的——特别是当它说 `/dev/urandom` 会“用完熵”以及 “`/dev/random` 是更好的”那几句话;
>
>
>
或者 [Thomas Ptacek](http://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/) 的看法,他不设计密码算法或者密码学系统,但他是一家名声在外的安全咨询公司的创始人,这家公司负责很多渗透和破解烂密码学算法的测试:
>
> 用 urandom。用 urandom。用 urandom。用 urandom。用 urandom。
>
>
>
### 没有完美
`/dev/urandom` 不是完美的,问题分两层:
在 Linux 上,不像 FreeBSD,`/dev/urandom` 永远不阻塞。记得安全性取决于某个最一开始决定的随机性?种子?
Linux 的 `/dev/urandom` 会很乐意给你吐点不怎么随机的随机数,甚至在内核有机会收集一丁点熵之前。什么时候有这种情况?当你系统刚刚启动的时候。
FreeBSD 的行为更正确点:`/dev/random` 和 `/dev/urandom` 是一样的,在系统启动的时候 `/dev/random` 会阻塞到有足够的熵为止,然后它们都再也不阻塞了。
>
> 与此同时 Linux 实行了一个新的<ruby> 系统调用 <rt> syscall </rt></ruby>,最早由 OpenBSD 引入叫 `getentrypy(2)`,在 Linux 下这个叫 `getrandom(2)`。这个系统调用有着上述正确的行为:阻塞到有足够的熵为止,然后再也不阻塞了。当然,这是个系统调用,而不是一个字节设备(LCTT 译注:不在 `/dev/` 下),所以它在 shell 或者别的脚本语言里没那么容易获取。这个系统调用 自 Linux 3.17 起存在。
>
>
>
在 Linux 上其实这个问题不太大,因为 Linux 发行版会在启动的过程中保存一点随机数(这发生在已经有一些熵之后,因为启动程序不会在按下电源的一瞬间就开始运行)到一个种子文件中,以便系统下次启动的时候读取。所以每次启动的时候系统都会从上一次会话里带一点随机性过来。
显然这比不上在关机脚本里写入一些随机种子,因为这样的显然就有更多熵可以操作了。但这样做显而易见的好处就是它不用关心系统是不是正确关机了,比如可能你系统崩溃了。
而且这种做法在你真正第一次启动系统的时候也没法帮你随机,不过好在 Linux 系统安装程序一般会保存一个种子文件,所以基本上问题不大。
虚拟机是另外一层问题。因为用户喜欢克隆它们,或者恢复到某个之前的状态。这种情况下那个种子文件就帮不到你了。
但解决方案依然和用 `/dev/random` 没关系,而是你应该正确的给每个克隆或者恢复的镜像重新生成种子文件。
### 太长不看
别问,问就是用 `/dev/urandom` !
---
via: <https://www.2uo.de/myths-about-urandom/>
作者:[Thomas Hühn](https://www.2uo.de/) 译者:[Moelf](https://github.com/Moelf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,817 | 在树莓派上安装 Ubuntu MATE | https://itsfoss.com/ubuntu-mate-raspberry-pi/ | 2019-05-05T13:40:49 | [
"树莓派",
"MATE"
] | https://linux.cn/article-10817-1.html |
>
> 这篇快速指南告诉你如何在树莓派设备上安装 Ubuntu MATE。
>
>
>

[树莓派](https://www.raspberrypi.org/) 是目前最流行的单板机并且是创客首选的板子。[Raspbian](https://www.raspberrypi.org/downloads/) 是基于 Debian 的树莓派官方操作系统。它是轻量级的,内置了教育工具和能在大部分场景下完成工作的工具。
[安装 Raspbian](https://itsfoss.com/tutorial-how-to-install-raspberry-pi-os-raspbian-wheezy/) 安装同样简单,但是与 [Debian](https://www.debian.org/) 随同带来的问题是慢的升级周期和旧的软件包。
在树莓派上运行 Ubuntu 可以给你带来一个更丰富的体验和最新的软件。当在你的树莓派上运行 Ubuntu 时我们有几个选择。
1. [Ubuntu MATE](https://ubuntu-mate.org/) :Ubuntu MATE 是仅有的原生支持树莓派且包含一个完整的桌面环境的发行版。
2. [Ubuntu Server 18.04](https://wiki.ubuntu.com/ARM/RaspberryPi#Recovering_a_system_using_the_generic_kernel) + 手动安装一个桌面环境。
3. 使用 [Ubuntu Pi Flavor Maker](https://ubuntu-pi-flavour-maker.org/download/) 社区构建的镜像,这些镜像只支持树莓派 2B 和 3B 的变种,并且**不能**更新到最新的 LTS 发布版。
第一个选择安装是最简单和快速的,而第二个选择给了你自由选择安装桌面环境的机会。我推荐选择前两个中的任一个。
这里是一些磁盘镜像下载链接。在这篇文章里我只会提及 Ubuntu MATE 的安装。
### 在树莓派上安装 Ubuntu MATE
去 Ubuntu MATE 的下载页面获取推荐的镜像。

试验性的 ARM64 版本只应在你需要在树莓派服务器上运行像 MongoDB 这样的 64 位应用时使用。
* [下载为树莓派准备的 Ubuntu MATE](https://ubuntu-mate.org/download/)
#### 第 1 步:设置 SD 卡
镜像文件一旦下载完成后需要解压。你可以简单的右击来提取它。
也可以使用下面命令做同样的事。
```
xz -d ubuntu-mate***.img.xz
```
如果你在 Windows 上你可以使用 [7-zip](https://www.7-zip.org/download.html) 替代。
安装 [Balena Etcher](https://www.balena.io/etcher/),我们将使用这个工具将镜像写入 SD 卡。确保你的 SD 卡有至少 8 GB 的容量。
启动 Etcher,选择镜像文件和 SD 卡。

一旦进度完成 SD 卡就准备好了。
#### 第 2 步:设置树莓派
你可能已经知道你需要一些外设才能使用树莓派,例如鼠标、键盘、HDMI 线等等。你同样可以[不用键盘和鼠标安装树莓派](https://linuxhandbook.com/raspberry-pi-headless-setup/),但是这篇指南不是那样。
* 插入一个鼠标和一个键盘。
* 连接 HDMI 线缆。
* 插入 SD 卡 到 SD 卡槽。
插入电源线给它供电。确保你有一个好的电源供应(5V、3A 至少)。一个不好的电源供应可能降低性能。
#### Ubuntu MATE 安装
一旦你给树莓派供电,你将遇到非常熟悉的 Ubuntu 安装过程。在这里的安装过程相当直接。


选择你的 WiFi 网络并且在网络连接中输入密码。

在设置了键盘布局、时区和用户凭证后,在几分钟后你将被带到登录界面。瞧!你快要完成了。

一旦登录,第一件事你应该做的是[更新 Ubuntu](https://itsfoss.com/update-ubuntu/)。你应该使用下列命令。
```
sudo apt update
sudo apt upgrade
```
你同样可以使用软件更新器。

一旦更新完成安装你就可以开始了。你可以根据你的需要继续安装树莓派平台为 GPIO 和其他 I/O 准备的特定软件包。
是什么让你考虑在 Raspberry 上安装 Ubuntu,你对 Raspbian 的体验如何呢?请在下方评论来让我知道。
---
via: <https://itsfoss.com/ubuntu-mate-raspberry-pi/>
作者:[Chinmay](https://itsfoss.com/author/chinmay/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Raspberry Pi](https://www.raspberrypi.org/?ref=itsfoss.com) is by far the most popular SBC (Single Board Computer) and the go-to board for makers. [Raspbian](https://www.raspberrypi.org/downloads/?ref=itsfoss.com) which is based on Debian is the official operating system for the Pi. It is lightweight, comes bundled with educational tools and gets the job done for most scenarios.
[Installing Raspbian](https://itsfoss.com/tutorial-how-to-install-raspberry-pi-os-raspbian-wheezy/) is easy as well but the problem with [Debian](https://www.debian.org/?ref=itsfoss.com) is its slow upgrade cycles and older packages.
There is a [huge list of Raspberry Pi OS ](https://itsfoss.com/raspberry-pi-os/)and Ubuntu is one of them. Running Ubuntu on the Raspberry Pi gives you a richer experience and up to date software. We have a few options when it comes to running Ubuntu on your Pi.
[Ubuntu MATE](https://ubuntu-mate.org/?ref=itsfoss.com): Ubuntu MATE is the only distribution which natively supports the Raspberry Pi with a complete desktop environment.[Ubuntu Server 18.04](https://wiki.ubuntu.com/ARM/RaspberryPi?ref=itsfoss.com#Recovering_a_system_using_the_generic_kernel)+ Installing a desktop environment manually.- Using Images built by the
[Ubuntu Pi Flavor Maker](https://ubuntu-pi-flavour-maker.org/download/?ref=itsfoss.com)community,and are*these images only support the Raspberry Pi 2B and 3B variants***not**updated to the latest LTS release.
The first option is the easiest and the quickest to set up while the second option gives you the freedom to install the desktop environment of your choice. I recommend going with either of the first two options.
Here are the links to download the Disc Images. In this article I’ll be covering Ubuntu MATE installation only.
## Installing Ubuntu MATE on Raspberry Pi
Go to the download page of Ubuntu MATE and get the recommended images.
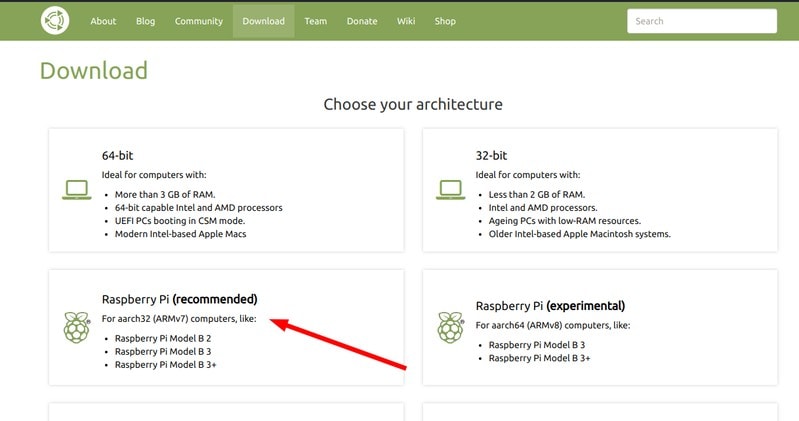
The experimental ARM64 version should only be used if you need to run 64-bit only applications like MongoDB on a Raspberry Pi server.
### Step 1: Setting Up the SD Card
The image file needs to be decompressed once downloaded. You can simply right click on it to extract it.
Alternatively, the following command will do the job.
`xz -d ubuntu-mate***.img.xz`
Alternatively, you can use [7-zip](https://www.7-zip.org/download.html?ref=itsfoss.com) if you are on Windows.
Install [Balena Etcher](https://etcher.balena.io/). We’ll use this tool to write the image to the SD card. Make sure that your SD card is at least 8 GB capacity.
Launch [Etcher](https://itsfoss.com/install-etcher-linux/) and select the image file and your SD card.
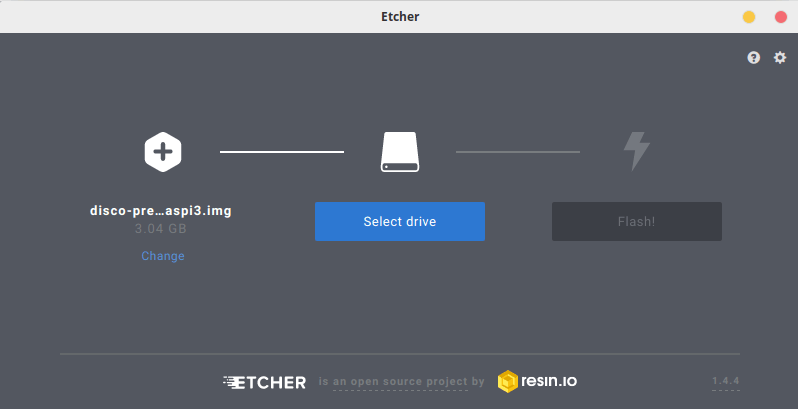
Once the flashing process is complete the SD card is ready.
### Step 2: Setting Up the Raspberry Pi
You probably already know that you need a few things to get started with Raspberry Pi such as a mouse, keyboard, HDMI cable etc. You can also [install Raspberry Pi headlessly without keyboard and mouse](https://linuxhandbook.com/raspberry-pi-headless-setup/?ref=itsfoss.com) but this tutorial is not about that.
- Plug in a mouse and a keyboard.
- Connect the HDMI cable.
- Insert the SD card into the SD card slot.
Power it on by plugging in the power cable. Make sure you have a good power supply (5V, 3A minimum). A bad power supply can reduce the performance.
### Ubuntu MATE installation
Once you power on the Raspberry Pi, you’ll be greeted with a very familiar Ubuntu installation process. The process is pretty much straight forward from here.
Select your WiFi network and enter the password in the network connection screen.
After setting the keyboard layout, timezone and user credentials you’ll be taken to the login screen after a few minutes. And voila! you are almost done.
Once logged in, the first thing you should do is to [update Ubuntu](https://itsfoss.com/update-ubuntu/). You can use the command line for that.
```
sudo apt update
sudo apt upgrade
```
You can also use the Software Updater.
Once the updates are finished installing you are good to go. You can now go ahead and create [some awesome Raspberry Pi project](https://itsfoss.com/raspberry-pi-projects/).
What made you think about installing Ubuntu on the Raspberry and how has your experience been with Raspbian? Let me know in the comments below. |
10,819 | DomTerm:一款为 Linux 打造的终端模拟器 | https://opensource.com/article/18/1/introduction-domterm-terminal-emulator | 2019-05-06T09:12:52 | [
"DomTerm",
"终端"
] | https://linux.cn/article-10819-1.html |
>
> 了解一下 DomTerm,这是一款终端模拟器和复用器,带有 HTML 图形和其它不多见的功能。
>
>
>

[DomTerm](http://domterm.org/) 是一款现代化的终端模拟器,它使用浏览器引擎作为 “GUI 工具包”。这就支持了一些相关的特性,例如可嵌入图像和链接、HTML 富文本以及可折叠(显示/隐藏)命令。除此以外,它看起来感觉就像一个功能完整、独立的终端模拟器,有着出色 xterm 兼容性(包括鼠标处理和 24 位色)和恰当的 “装饰” (菜单)。另外它内置支持了会话管理和副窗口(如同 `tmux` 和 `GNU Screen` 中一样)、基本输入编辑(如在 `readline` 中)以及分页(如在 `less` 中)。

*图 1: DomTerminal 终端模拟器。*
在以下部分我们将看一看这些特性。我们将假设你已经安装好了 `domterm` (如果你需要获取并构建 Dormterm 请跳到本文最后)。开始之前先让我们概览一下这项技术。
### 前端 vs. 后端
DomTerm 大部分是用 JavaScript 写的,它运行在一个浏览器引擎中。它可以是像例如 Chrome 或者 Firefox 一样的桌面浏览器(见图 3),也可以是一个内嵌的浏览器。使用一个通用的网页浏览器没有问题,但是用户体验却不够好(因为菜单是为通用的网页浏览而不是为了终端模拟器所打造),并且其安全模型也会妨碍使用。因此使用内嵌的浏览器更好一些。
目前以下这些是支持的:
* qdomterm,使用了 Qt 工具包 和 QtWebEngine
* 一个内嵌的 [Electron](https://electronjs.org/)(见图 1)
* atom-domterm 以 [Atom 文本编辑器](https://atom.io/)(同样基于 Electron)包的形式运行 DomTerm,并和 Atom 面板系统集成在一起(见图 2)
* 一个为 JavaFX 的 WebEngine 包装器,这对 Java 编程十分有用(见图 4)
* 之前前端使用 [Firefox-XUL](https://en.wikipedia.org/wiki/XUL) 作为首选,但是 Mozilla 已经终止了 XUL

*图 2:在 Atom 编辑器中的 DomTerm 终端面板。*
目前,Electron 前端可能是最佳选择,紧随其后的是 Qt 前端。如果你使用 Atom,atom-domterm 也工作得相当不错。
后端服务器是用 C 写的。它管理着伪终端(PTY)和会话。它同样也是一个为前端提供 Javascript 和其它文件的 HTTP 服务器。`domterm` 命令启动终端任务和执行其它请求。如果没有服务器在运行,domterm 就会自己来服务。后端与服务器之间的通讯通常是用 WebSockets(在服务器端是[libwebsockets](https://libwebsockets.org/))完成的。然而,JavaFX 的嵌入既不用 Websockets 也不用 DomTerm 服务器。相反 Java 应用直接通过 Java-Javascript 桥接进行通讯。
### 一个稳健的可兼容 xterm 的终端模拟器
DomTerm 看上去感觉像一个现代的终端模拟器。它处理鼠标事件、24 位色、Unicode、倍宽字符(CJK)以及输入方式。DomTerm 在 [vttest 测试套件](http://invisible-island.net/vttest/) 上工作地十分出色。
其不同寻常的特性包括:
**展示/隐藏按钮(“折叠”):** 小三角(如上图 2)是隐藏/展示相应输出的按钮。仅需在[提示符](http://domterm.org/Shell-prompts.html)中添加特定的[转义字符](http://domterm.org/Wire-byte-protocol.html)就可以创建按钮。
**对于 readline 和类似输入编辑器的鼠标点击支持:** 如果你点击输入区域(黄色),DomTerm 会向应用发送正确的方向键按键序列。(可以通过提示符中的转义字符启用这一特性,你也可以通过 `Alt+点击` 强制使用。)
**用 CSS 样式化终端:** 这通常是在 `~/.domterm/settings.ini` 里完成的,保存时会自动重载。例如在图 2 中,设置了终端专用的背景色。
### 一个更好的 REPL 控制台
一个经典的终端模拟器基于长方形的字符单元格工作的。这在 REPL(命令行)上没问题,但是并不理想。这里有些通常在终端模拟器中不常见的 REPL 很有用的 DomTerm 特性:
**一个能“打印”图片、图形、数学公式或者一组可点击的链接的命令:** 应用可以发送包含几乎任何 HTML 的转义字符。(HTML 会被剔除部分,以移除 JavaScript 和其它危险特性。)
图 3 显示了来自 [gnuplot](http://www.gnuplot.info/) 会话的一个片段。Gnuplot(2.1 或者跟高版本)支持 DormTerm 作为终端类型。图形输出被转换成 [SVG 图片](https://developer.mozilla.org/en-US/docs/Web/SVG),然后被打印到终端。我的博客帖子[在 DormTerm 上的 Gnuplot 展示](http://per.bothner.com/blog/2016/gnuplot-in-domterm/)在这方面提供了更多信息。

*图 3:Gnuplot 截图。*
[Kawa](https://www.gnu.org/software/kawa/) 语言有一个创建并转换[几何图像值](https://www.gnu.org/software/kawa/Composable-pictures.html)的库。如果你将这样的图片值打印到 DomTerm 终端,图片就会被转换成 SVG 形式并嵌入进输出中。

*图 4:Kawa 中可计算的几何形状。*
**富文本输出:** 有着 HTML 样式的帮助信息更加便于阅读,看上去也更漂亮。图片 1 的下面面板展示 `dormterm help` 的输出。(如果没在 DomTerm 下运行的话输出的是普通文本。)注意自带的分页器中的 `PAUSED` 消息。
**包括可点击链接的错误消息:** DomTerm 可以识别语法 `filename:line:column` 并将其转化成一个能在可定制文本编辑器中打开文件并定位到行的链接。(这适用于相对路径的文件名,如果你用 `PROMPT_COMMAND` 或类似的跟踪目录。)
编译器可以侦测到它在 DomTerm 下运行,并直接用转义字符发出文件链接。这比依赖 DomTerm 的样式匹配要稳健得多,因为它可以处理空格和其他字符并且无需依赖目录追踪。在图 4 中,你可以看到来自 [Kawa Compiler](https://www.gnu.org/software/kawa/) 的错误消息。悬停在文件位置上会使其出现下划线,`file:` URL 出现在 `atom-domterm` 消息栏(窗口底部)中。(当不用 atom-domterm 时,这样的消息会在一个浮层的框中显示,如图 1 中所看到的 `PAUSED` 消息所示。)
点击链接时的动作是可以配置的。默认对于带有 `#position` 后缀的 `file:` 链接的动作是在文本编辑器中打开那个文件。
**结构化内部表示:**以下内容均以内部节点结构表示:命令、提示符、输入行、正常和错误输出、标签,如果“另存为 HTML”,则保留结构。HTML 文件与 XML 兼容,因此你可以使用 XML 工具搜索或转换输出。命令 `domterm view-saved` 会以一种启用命令折叠(显示/隐藏按钮处于活动状态)和重新调整窗口大小的方式打开保存的 HTML 文件。
**内建的 Lisp 样式优美打印:** 你可以在输出中包括优美打印指令(比如,grouping),这样断行会根据窗口大小调整而重新计算。查看我的文章 [DomTerm 中的动态优美打印](http://per.bothner.com/blog/2017/dynamic-prettyprinting/)以更深入探讨。
**基本的内建行编辑**,带着历史记录(像 GNU readline 一样): 这使用浏览器自带的编辑器,因此它有着优秀的鼠标和选择处理机制。你可以在正常字符模式(大多数输入的字符被指接送向进程);或者行模式(通常的字符是直接插入的,而控制字符导致编辑操作,回车键会向进程发送被编辑行)之间转换。默认的是自动模式,根据 PTY 是在原始模式还是终端模式中,DomTerm 在字符模式与行模式间转换。
**自带的分页器**(类似简化版的 `less`):键盘快捷键控制滚动。在“页模式”中,输出在每个新的屏幕(或者单独的行,如果你想一行行地向前移)后暂停;页模式对于用户输入简单智能,因此(如果你想的话)你无需阻碍交互式程序就可以运行它。
### 多路复用和会话
**标签和平铺:** 你不仅可以创建多个终端标签,也可以平铺它们。你可以要么使用鼠标或键盘快捷键来创建或者切换面板和标签。它们可以用鼠标重新排列并调整大小。这是通过 [GoldenLayout](https://golden-layout.com/) JavaScript 库实现的。图 1 展示了一个有着两个面板的窗口。上面的有两个标签,一个运行 [Midnight Commander](https://midnight-commander.org/);底下的面板以 HTML 形式展示了 `dormterm help` 输出。然而相反在 Atom 中我们使用其自带的可拖拽的面板和标签。你可以在图 2 中看到这个。
**分离或重接会话:** 与 `tmux` 和 GNU `screen` 类似,DomTerm 支持会话安排。你甚至可以给同样的会话接上多个窗口或面板。这支持多用户会话分享和远程链接。(为了安全,同一个服务器的所有会话都需要能够读取 Unix 域接口和一个包含随机密钥的本地文件。当我们有了良好、安全的远程链接,这个限制将会有所放松。)
**domterm 命令** 类似与 `tmux` 和 GNU `screen`,它有多个选项可以用于控制或者打开单个或多个会话的服务器。主要的差别在于,如果它没在 DomTerm 下运行,`dormterm` 命令会创建一个新的顶层窗口,而不是在现有的终端中运行。
与 `tmux` 和 `git` 类似,`dormterm` 命令有许多子命令。一些子命令创建窗口或者会话。另一些(例如“打印”一张图片)仅在现有的 DormTerm 会话下起作用。
命令 `domterm browse` 打开一个窗口或者面板以浏览一个指定的 URL,例如浏览文档的时候。
### 获取并安装 DomTerm
DomTerm 可以从其 [Github 仓库](https://github.com/PerBothner/DomTerm)获取。目前没有提前构建好的包,但是有[详细指导](http://domterm.org/Downloading-and-building.html)。所有的前提条件在 Fedora 27 上都有,这使得其特别容易被搭建。
---
via: <https://opensource.com/article/18/1/introduction-domterm-terminal-emulator>
作者:[Per Bothner](https://opensource.com/users/perbothner) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,820 | 如何安装和配置 Chrony 作为 NTP 客户端? | https://www.2daygeek.com/configure-ntp-client-using-chrony-in-linux/ | 2019-05-06T14:56:18 | [
"NTP"
] | https://linux.cn/article-10820-1.html | 
NTP 服务器和 NTP 客户端可以让我们通过网络来同步时钟。之前,我们已经撰写了一篇关于 [NTP 服务器和 NTP 客户端的安装与配置](/article-10811-1.html) 的文章。
如果你想看这些内容,点击上述的 URL 访问。
### Chrony 客户端
Chrony 是 NTP 客户端的替代品。它能以更精确的时间和更快的速度同步时钟,并且它对于那些不是全天候在线的系统非常有用。
chronyd 更小、更节能,它占用更少的内存且仅当需要时它才唤醒 CPU。即使网络拥塞较长时间,它也能很好地运行。它支持 Linux 上的硬件时间戳,允许在本地网络进行极其准确的同步。
它提供下列两个服务。
* `chronyc`:Chrony 的命令行接口。
* `chronyd`:Chrony 守护进程服务。
### 如何在 Linux 上安装和配置 Chrony?
由于安装包在大多数发行版的官方仓库中可用,因此直接使用包管理器去安装它。
对于 Fedora 系统,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 去安装 chrony。
```
$ sudo dnf install chrony
```
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或者 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 去安装 chrony。
```
$ sudo apt install chrony
```
对基于 Arch Linux 的系统,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 去安装 chrony。
```
$ sudo pacman -S chrony
```
对于 RHEL/CentOS 系统,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 去安装 chrony。
```
$ sudo yum install chrony
```
对于 openSUSE Leap 系统,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 去安装 chrony。
```
$ sudo zypper install chrony
```
在这篇文章中,我们将使用下列设置去测试。
* NTP 服务器:主机名:CentOS7.2daygeek.com,IP:192.168.1.5,OS:CentOS 7
* Chrony 客户端:主机名:Ubuntu18.2daygeek.com,IP:192.168.1.3,OS:Ubuntu 18.04
服务器的安装请访问 [在 Linux 上安装和配置 NTP 服务器](/article-10811-1.html) 的 URL。
我已经在 CentOS7.2daygeek.com 这台主机上安装和配置了 NTP 服务器,因此,将其附加到所有的客户端机器上。此外,还包括其他所需信息。
`chrony.conf` 文件的位置根据你的发行版不同而不同。
对基于 RHEL 的系统,它位于 `/etc/chrony.conf`。
对基于 Debian 的系统,它位于 `/etc/chrony/chrony.conf`。
```
# vi /etc/chrony/chrony.conf
server CentOS7.2daygeek.com prefer iburst
keyfile /etc/chrony/chrony.keys
driftfile /var/lib/chrony/chrony.drift
logdir /var/log/chrony
maxupdateskew 100.0
makestep 1 3
cmdallow 192.168.1.0/24
```
更新配置后需要重启 Chrony 服务。
对于 sysvinit 系统。基于 RHEL 的系统需要去运行 `chronyd` 而不是 `chrony`。
```
# service chronyd restart
# chkconfig chronyd on
```
对于 systemctl 系统。 基于 RHEL 的系统需要去运行 `chronyd` 而不是 `chrony`。
```
# systemctl restart chronyd
# systemctl enable chronyd
```
使用像 `tacking`、`sources` 和 `sourcestats` 这样的子命令去检查 chrony 的同步细节。
去检查 chrony 的追踪状态。
```
# chronyc tracking
Reference ID : C0A80105 (CentOS7.2daygeek.com)
Stratum : 3
Ref time (UTC) : Thu Mar 28 05:57:27 2019
System time : 0.000002545 seconds slow of NTP time
Last offset : +0.001194361 seconds
RMS offset : 0.001194361 seconds
Frequency : 1.650 ppm fast
Residual freq : +184.101 ppm
Skew : 2.962 ppm
Root delay : 0.107966967 seconds
Root dispersion : 1.060455322 seconds
Update interval : 2.0 seconds
Leap status : Normal
```
运行 `sources` 命令去显示当前时间源的信息。
```
# chronyc sources
210 Number of sources = 1
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* CentOS7.2daygeek.com 2 6 17 62 +36us[+1230us] +/- 1111ms
```
`sourcestats` 命令显示有关 chronyd 当前正在检查的每个源的漂移率和偏移估计过程的信息。
```
# chronyc sourcestats
210 Number of sources = 1
Name/IP Address NP NR Span Frequency Freq Skew Offset Std Dev
==============================================================================
CentOS7.2daygeek.com 5 3 71 -97.314 78.754 -469us 441us
```
当 chronyd 配置为 NTP 客户端或对等端时,你就能通过 `chronyc ntpdata` 命令向每一个 NTP 源发送/接收时间戳模式和交错模式的报告。
```
# chronyc ntpdata
Remote address : 192.168.1.5 (C0A80105)
Remote port : 123
Local address : 192.168.1.3 (C0A80103)
Leap status : Normal
Version : 4
Mode : Server
Stratum : 2
Poll interval : 6 (64 seconds)
Precision : -23 (0.000000119 seconds)
Root delay : 0.108994 seconds
Root dispersion : 0.076523 seconds
Reference ID : 85F3EEF4 ()
Reference time : Thu Mar 28 06:43:35 2019
Offset : +0.000160221 seconds
Peer delay : 0.000664478 seconds
Peer dispersion : 0.000000178 seconds
Response time : 0.000243252 seconds
Jitter asymmetry: +0.00
NTP tests : 111 111 1111
Interleaved : No
Authenticated : No
TX timestamping : Kernel
RX timestamping : Kernel
Total TX : 46
Total RX : 46
Total valid RX : 46
```
最后运行 `date` 命令。
```
# date
Thu Mar 28 03:08:11 CDT 2019
```
为了立即跟进系统时钟,绕过任何正在进行的缓步调整,请以 root 身份运行以下命令(以手动调整系统时钟)。
```
# chronyc makestep
```
---
via: <https://www.2daygeek.com/configure-ntp-client-using-chrony-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[arrowfeng](https://github.com/arrowfeng) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,822 | 比容器快 10-20 倍的 unikernel 应用 | https://www.networkworld.com/article/3387299/how-to-quickly-deploy-run-linux-applications-as-unikernels.html | 2019-05-06T15:36:00 | [
"应用",
"unikernel"
] | https://linux.cn/article-10822-1.html | unikernel 是一种用于在云基础架构上部署应用程序的更小、更快、更安全的方式。使用 NanoVMs OPS,任何人都可以将 Linux 应用程序作为 unikernel 运行而无需额外编码。

随着 unikernel 的出现,构建和部署轻量级应用变得更容易、更可靠。虽然功能有限,但 unikernal 在速度和安全性方面有许多优势。
### 什么是 unikernel?
unikernel 是一种非常特殊的<ruby> 单一地址空间 <rt> single-address-space </rt></ruby>的机器镜像,类似于已经主导大批互联网的云应用,但它们相当小并且是单一用途的。它们很轻,只提供所需的资源。它们加载速度非常快,而且安全性更高 —— 攻击面非常有限。单个可执行文件中包含所需的所有驱动、I/O 例程和支持库。其最终生成的虚拟镜像可以无需其它部分就可以引导和运行。它们通常比容器快 10 到 20 倍。
潜在的攻击者无法进入 shell 并获得控制权,因为它没有 shell。他们无法获取系统的 `/etc/passwd`或 `/etc/shadow` 文件,因为这些文件不存在。创建一个 unikernel 就像应用将自己变成操作系统。使用 unikernel,应用和操作系统将成为一个单一的实体。你忽略了不需要的东西,从而消除了漏洞并大幅提高性能。
简而言之,unikernel:
* 提供更高的安全性(例如,shell 破解代码无用武之地)
* 比标准云应用占用更小空间
* 经过高度优化
* 启动非常快
### unikernel 有什么缺点吗?
unikernel 的唯一严重缺点是你必须构建它们。对于许多开发人员来说,这是一个巨大的进步。由于应用的底层特性,将应用简化为所需的内容然后生成紧凑、平稳运行的应用可能很复杂。在过去,你几乎必须是系统开发人员或底层程序员才能生成它们。
### 这是怎么改变的?
最近(2019 年 3 月 24 日)[NanoVMs](https://nanovms.com/) 宣布了一个将任何 Linux 应用加载为 unikernel 的工具。使用 NanoVMs OPS,任何人都可以将 Linux 应用作为 unikernel 运行而无需额外编码。该应用还可以更快、更安全地运行,并且成本和开销更低。
### 什么是 NanoVMs OPS?
NanoVMs 是给开发人员的 unikernel 工具。它能让你运行各种企业级软件,但仍然可以非常严格地控制它的运行。
使用 OPS 的其他好处包括:
* 无需经验或知识,开发人员就可以构建 unikernel。
* 该工具可在笔记本电脑上本地构建和运行 unikernel。
* 无需创建帐户,只需下载并一个命令即可执行 OPS。
NanoVMs 的介绍可以在 [Youtube 上的 NanoVMs 视频](https://www.youtube.com/watch?v=VHWDGhuxHPM) 上找到。你还可以查看该公司的 [LinkedIn 页面](https://www.linkedin.com/company/nanovms/)并在[此处](https://nanovms.com/security)阅读有关 NanoVMs 安全性的信息。
还有有关如何[入门](https://nanovms.gitbook.io/ops/getting_started)的一些信息。
---
via: <https://www.networkworld.com/article/3387299/how-to-quickly-deploy-run-linux-applications-as-unikernels.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,823 | 12 个可替代树莓派的单板机 | https://itsfoss.com/raspberry-pi-alternatives/ | 2019-05-07T10:30:00 | [
"树莓派",
"单板机"
] | https://linux.cn/article-10823-1.html |
>
> 正在寻找树莓派的替代品?这里有一些单板机可以满足你的 DIY 渴求。
>
>
>
树莓派是当前最流行的单板机。你可以在你的 DIY 项目中使用它,或者用它作为一个成本效益高的系统来学习编代码,或者为了你的便利,利用一个[流媒体软件](https://itsfoss.com/best-linux-media-server/)运行在上面作为流媒体设备。
你可以使用树莓派做很多事,但它不是各种极客的最终解决方案。一些人可能在寻找更便宜的开发板,一些可能在寻找更强大的。
无论是哪种情况,我们都有很多原因需要树莓派的替代品。因此,在这片文章里,我们将讨论最好的 12 个我们认为能够替代树莓派的单板机。

### 满足你 DIY 渴望的树莓派替代品
这个列表没有特定的顺序排名。链接的一部分是赞助链接。请阅读我们的[赞助政策](https://itsfoss.com/affiliate-policy/)。
#### 1、Onion Omega2+

只要 $13,Omega2+ 是这里你可以找到的最便宜的 IoT 单板机设备。它运行 LEDE(Linux 嵌入式开发环境)Linux 系统 —— 这是一个基于 [OpenWRT](https://openwrt.org/) 的发行版。
由于运行一个自定义 Linux 系统,它的组成元件、花费和灵活性使它完美适合几乎所有类型的 IoT 应用。
你可以在[亚马逊商城的 Onion Omega 套件](https://amzn.to/2Xj8pkn)或者从他们的网站下单,可能会收取额外的邮费。
**关键参数:**
* MT7688 SoC
* 2.4 GHz IEEE 802.11 b/g/n WiFi
* 128 MB DDR2 RAM
* 32 MB on-board flash storage
* MicroSD Slot
* USB 2.0
* 12 GPIO Pins
[查看官网](https://onion.io/store/omega2p/)
#### 2、NVIDIA Jetson Nano Developer Kit
这是来自 NVIDIA 的只要 **$99** 的非常独特和有趣的树莓派替代品。是的,它不是每个人都能充分利用的设备 —— 只为特定的一组极客或者开发者而生。
NVIDIA 使用下面的用例解释它:
>
> NVIDIA® Jetson Nano™ Developer Kit 是一个小的、强大的计算机,可以让你并行运行多个神经网络的应用像图像分类、对象侦察、图像分段、语音处理。全部在一个易于使用的、运行功率只有 5 瓦特的平台上。
>
>
> nvidia
>
>
>
因此,基本上,如果你正在研究 AI 或者深度学习,你可以充分利用开发设备。如果你很好奇,该设备的产品计算模块将在 2019 年 7 月到来。
**关键参数:**
* CPU: Quad-core ARM A57 @ 1.43 GHz
* GPU: 128-core Maxwell
* RAM: 4 GB 64-bit LPDDR4 25.6 GB/s
* Display: HDMI 2.0
* 4 x USB 3.0 and eDP 1.4
[查看官网](https://developer.nvidia.com/embedded/buy/jetson-nano-devkit)
#### 3、ASUS Tinker Board S

ASUS Tinker Board S 不是大多数人可负担得起的树莓派的替换设备 (**$82**,[亚马逊商城](https://amzn.to/2XfkOFT)),但是它是一个强大的替代品。它的特点是它有你通常可以发现与标准树莓派 3 一样的 40 针脚的连接器,但是提供了强大的处理器和 GPU。同样的,Tinker Board S 的大小恰巧和标准的树莓派3 一样大。
这个板子的主要亮点是 16 GB [eMMC](https://en.wikipedia.org/wiki/MultiMediaCard) (用外行术语说,它的板上有一个类似 SSD 的存储单元使它工作时运行的更快。) 的存在。
**关键参数:**
* Rockchip Quad-Core RK3288 processor
* 2 GB DDR3 RAM
* Integrated Graphics Processor
* ARM® Mali™-T764 GPU
* 16 GB eMMC
* MicroSD Card Slot
* 802.11 b/g/n, Bluetooth V4.0 + EDR
* USB 2.0
* 28 GPIO pins
* HDMI Interface
[查看网站](https://www.asus.com/in/Single-Board-Computer/Tinker-Board-S/)
#### 4、ClockworkPi

如果你正在想方设法组装一个模块化的复古的游戏控制台,Clockwork Pi 可能就是你需要的,它通常是 [GameShell Kit](https://itsfoss.com/gameshell-console/) 的一部分。然而,你可以 使用 $49 单独购买板子。
它紧凑的大小、WiFi 连接性和 micro HDMI 端口的存在使它成为许多方面的选择。
**关键参数:**
* Allwinner R16-J Quad-core Cortex-A7 CPU @1.2GHz
* Mali-400 MP2 GPU
* RAM: 1GB DDR3
* WiFi & Bluetooth v4.0
* Micro HDMI output
* MicroSD Card Slot
[查看官网](https://www.clockworkpi.com/product-page/cpi-v3-1)
#### 5、Arduino Mega 2560

如果你正在研究机器人项目或者你想要一个 3D 打印机 —— Arduino Mega 2560 将是树莓派的便利的替代品。不像树莓派,它是基于微控制器而不是微处理器的。
在他们的[官网](https://store.arduino.cc/usa/mega-2560-r3),你需要花费 $38.50,或者在[在亚马逊商城是 $33](https://amzn.to/2KCi041)。
**关键参数:**
* Microcontroller: ATmega2560
* Clock Speed: 16 MHz
* Digital I/O Pins: 54
* Analog Input Pins: 16
* Flash Memory: 256 KB of which 8 KB used by bootloader
[查看官网](https://store.arduino.cc/usa/mega-2560-r3)
#### 6、Rock64 Media Board

用与你可能想要的树莓派 3 B+ 相同的价格,你将在 Rock64 Media Board 上获得更快的处理器和双倍的内存。除此之外,如果你想要 1 GB RAM 版的,它提供了一个比树莓派更便宜的替代品,花费更少,只要 $10 。
不像树莓派,它没有无线连接支持,但是 USB 3.0 和 HDMI 2.0 的存在使它与众不同,如果它对你很重要的话。
**关键参数:**
* Rockchip RK3328 Quad-Core ARM Cortex A53 64-Bit Processor
* Supports up to 4GB 1600MHz LPDDR3 RAM
* eMMC module socket
* MicroSD Card slot
* USB 3.0
* HDMI 2.0
[查看官网](https://www.pine64.org/?product=rock64-media-board-computer)
#### 7、Odroid-XU4

Odroid-XU4 是一个完美的树莓派的替代品,如果你有能够稍微提高预算的空间($80-$100 甚至更低,取决于存储的容量)。
它确实是一个强大的替代品并且体积更小。支持 eMMC 和 USB 3.0 使它工作起来更快。
**关键参数:**
* Samsung Exynos 5422 Octa ARM Cortex™-A15 Quad 2Ghz and Cortex™-A7 Quad 1.3GHz CPUs
* 2Gbyte LPDDR3 RAM
* GPU: Mali-T628 MP6
* USB 3.0
* HDMI 1.4a
* eMMC 5.0 module socket
* MicroSD Card Slot
[查看官网](https://www.hardkernel.com/shop/odroid-xu4-special-price/)
#### 8、PocketBeagle

它是一个难以置信的小的单板机 —— 几乎和树莓派Zero 相似。然而它的价格相当于完整大小的树莓派 3。主要的亮点是你可以用它作为一个 USB 便携式信息终端,并且进入 Linux 命令行工作。
**关键参数:**
* Processor: Octavo Systems OSD3358 1GHz ARM® Cortex-A8
* RAM: 512 MB DDR3
* 72 expansion pin headers
* microUSB
* USB 2.0
[查看官网](https://beagleboard.org/p/products/pocketbeagle)
#### 9、Le Potato

由 [Libre Computer](https://libre.computer/) 出品的 Le Potato,其型号是 AML-S905X-CC。它需要花费你 [$45](https://amzn.to/2DpG3xl)。
如果你花费的比树莓派更多的钱,你就能得到双倍内存和 HDMI 2.0 接口,这可能是一个完美的选择。尽管,你还是不能找到嵌入的无线连接。
**关键参数:**
* Amlogic S905X SoC
* 2GB DDR3 SDRAM
* USB 2.0
* HDMI 2.0
* microUSB
* MicroSD Card Slot
* eMMC Interface
[查看官网](https://libre.computer/products/boards/aml-s905x-cc/)
#### 10、Banana Pi M64

它自带了 8G 的 eMMC —— 这是替代树莓派的主要亮点。因此,它需要花费 $60。
HDMI 接口的存在使它胜任 4K。除此之外,Banana Pi 提供了更多种类的开源单板机作为树莓派的替代。
**关键参数:**
* 1.2 Ghz Quad-Core ARM Cortex A53 64-Bit Processor-R18
* 2GB DDR3 SDRAM
* 8 GB eMMC
* WiFi & Bluetooth
* USB 2.0
* HDMI
[查看官网](http://www.banana-pi.org/m64.html)
#### 11、Orange Pi Zero

Orange Pi Zero 相对于树莓派来说难以置信的便宜。你可以在 Aliexpress 或者亚马逊上以最多 $10 就能够获得。如果[稍微多花点,你能够获得 512 MB RAM](https://amzn.to/2IlI81g)。
如果这还不够,你可以花费大概 $25 获得更好的配置,比如 Orange Pi 3。
**关键参数:**
* H2 Quad-core Cortex-A7
* Mali400MP2 GPU
* RAM: Up to 512 MB
* TF Card support
* WiFi
* USB 2.0
[查看官网](http://www.orangepi.org/orangepizero/index.html)
#### 12、VIM 2 SBC by Khadas

由 Khadas 出品的 VIM 2 是最新的单板机,因此你能够在板上得到蓝牙 5.0 支持。它的价格范围[从 $99 的基础款到上限 $140](https://amzn.to/2UDvrFE)。
基础款包含 2 GB RAM、16 GB eMMC 和蓝牙 4.1。然而,Pro/Max 版包含蓝牙 5.0,更多的内存,更多的 eMMC 存储。
**关键参数:**
* Amlogic S912 1.5GHz 64-bit Octa-Core CPU
* T820MP3 GPU
* Up to 3 GB DDR4 RAM
* Up to 64 GB eMMC
* Bluetooth 5.0 (Pro/Max)
* Bluetooth 4.1 (Basic)
* HDMI 2.0a
* WiFi
### 总结
我们知道有很多不同种类的单板机电脑。一些比树莓派更好 —— 它的一些小规格的版本有更便宜的价格。同样的,像 Jetson Nano 这样的单板机已经被裁剪用于特定用途。因此,取决于你需要什么 —— 你应该检查一下单板机的配置。
如果你知道比上述提到的更好的东西,请随意在下方评论来让我们知道。
---
via: <https://itsfoss.com/raspberry-pi-alternatives/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Raspberry Pi is the most popular single-board computer right now. You can use it for your DIY projects or as a cost-effective system for learning to code – or you can even install [media server software](https://itsfoss.com/best-linux-media-server/) on it to stream media at your convenience.
You can do many things with the Raspberry Pi, but it may not be the ultimate solution for every tinkerer. Some might be looking for a cheaper board, and others might be looking for a powerful one.
Whatever the case, we need Raspberry Pi alternatives for various reasons. So in this article, we’ll talk about the **top single-board computers** that we think are the **best** **Raspberry Pi alternatives**.
[affiliate policy](https://itsfoss.com/affiliate-policy/).
## 1. ArmSoM Sige7

While it is a lot more expensive than Raspberry Pi, it is also a lot more powerful. It boasts of RK3588 system on chip that has built-in GPU and NPU (for AI processing). It supports up to 32 GB of RAM, has built-in eMMC storage, an NVMe slot and a lot more ports than Raspberry Pi.
[This SBC Puts Raspberry Pi 5 to ShameCheeky headline apart, ArmSom Sige7 is actually a pretty impressive device.](https://itsfoss.com/arosom-sige7-review/)

**Key Specifications**
- RK3588 system on chip
- GPU Mali-G610
- NPU 6 TOPS
- Upto 32 GB RAM
- eMMC, Micro SD and NVMe storage options
- 2 Gigabit Ethernet, Bluetooth 5 and WiFi 6
- Fully compatible with Raspberry Pi's 40-pin header
## 2. Onion Omega2+

For just **$13**, the Omega2+ is one of the cheapest IoT single-board computers you can find out there. It runs on **LEDE (Linux Embedded Development Environment) Linux OS** – a distribution based on [OpenWRT](https://openwrt.org/).
Its form factor, cost, and flexibility that come from running a customized version of the Linux OS make it a perfect fit for almost any type of IoT application.
You can find it on [Amazon](https://www.amazon.com/dp/B06XP12X2R/) or order it from their website, which involves extra shipping charges.
**Key Specifications**
- MT7688 SoC
- 2.4 GHz IEEE 802.11 b/g/n WiFi
- 128 MB DDR2 RAM
- 32 MB on-board flash storage
- MicroSD slot
- USB 2.0
- 12 GPIO pins
## 3. NVIDIA Jetson Nano Developer Kit

This unique and exciting Raspberry Pi alternative from NVIDIA is for just **$99**. Yes, it’s not something everyone can use – but it’s excellent for a **specific group of tinkerers and developers working with AI.**
NVIDIA explains it for the following use case:
NVIDIA®Jetson Nano™Developer Kit is a small, powerful computer that lets you run multiple neural networks in parallel for applications like image classification, object detection, segmentation, and speech processing. All in an easy-to-use platform that runs in as little as 5 watts.
So, if you’re into **AI and deep learning,** you can use this developer kit.
**Key Specifications**
- CPU: Quad-core ARM A57 @ 1.43 GHz
- GPU: 128-core Maxwell
- RAM: 4 GB 64-bit LPDDR4 25.6 GB/s
- Display: HDMI 2.0
- 4 x USB 3.0 and eDP 1.4
## 4. ASUS Tinker Board S

ASUS Tinker Board S isn’t the most affordable Raspberry Pi alternative at **$82,** but a **powerful one**. It features the same 40-pin connector you’d normally find in the standard Raspberry Pi 3 Model but offers a powerful processor and a GPU. Also, the Tinker Board S size is precisely the same as a standard Raspberry Pi 3.
The main highlight of this board is the presence of a 16 GB [eMMC](https://en.wikipedia.org/wiki/MultiMediaCard) (in layman’s terms, it has SSD-like storage on board, making it faster to work on).
You can find it listed on **Amazon****.**
**Key Specifications**
- Rockchip Quad-Core RK3288 processor
- 2 GB DDR3 RAM
- Integrated graphics processor
- ARM® Mali™-T764 GPU
- 16 GB eMMC
- MicroSD card slot
- 802.11 b/g/n, Bluetooth V4.0 + EDR
- USB 2.0
- 28 GPIO pins
- HDMI interface
## 5. ClockworkPi

ClockworkPi is usually a part of the [GameShell Kit](https://itsfoss.com/gameshell-console/) if you want to assemble a modular retro gaming console. However, you can purchase the board separately for **$49**.
Its **compact size, WiFi connectivity, and the presence of a micro HDMI** port make it an excellent choice for a lot of things.
**Key Specifications**
- Allwinner R16-J Quad-core Cortex-A7 CPU @1.2GHz
- Mali-400 MP2 GPU
- RAM: 1GB DDR3
- WiFi & Bluetooth v4.0
- Micro HDMI output
- MicroSD card slot
**Suggested Read 📖**
[Best Accessories to Supercharge Your Raspberry PiHere are the best Raspberry Pi accessories that you need to get started with it and take it to the next level!](https://itsfoss.com/raspberry-pi-accessories/)

## 6. Arduino Mega 2560

If **you’re into robotic projects or you want something for a 3D printer**, the Arduino Mega 2560 will be a handy replacement for the Raspberry Pi. Unlike Raspberry Pi, it’s based on a microcontroller, not a microprocessor.
It costs **$48.50** on their [official site](https://store.arduino.cc/usa/mega-2560-r3) and the same on [Amazon](https://www.amazon.com/dp/B0046AMGW0?tag=chmod7mediate-20). So, purchase it from any place you find convenient.
**Key Specifications**
- Microcontroller: ATmega2560
- Clock speed: 16 MHz
- Digital I/O pins: 54
- Analog input pins: 16
- Flash memory: 256 KB, of which 8 KB is used by the bootloader
## 7. Rock64 Media Board

For the same investment that you would make on a Raspberry Pi 3 B+, you’ll get a **faster processor and double the memory with the Rock64 Media Board**. In addition, it also offers a cheaper alternative to the Raspberry Pi if you want the 1 GB RAM model, which costs $10 less.
Unlike the Raspberry Pi, you don’t have wireless connectivity support here, but the presence of USB 3.0 and HDMI 2.0 does make a big\ difference if that matters to you.
**Key Specifications**
- Rockchip RK3328 Quad-Core ARM Cortex A53 64-bit processor
- Supports up to 4GB 1600MHz LPDDR3 RAM
- eMMC module socket
- MicroSD card slot
- USB 3.0
- HDMI 2.0
## 8. Odroid-XU4
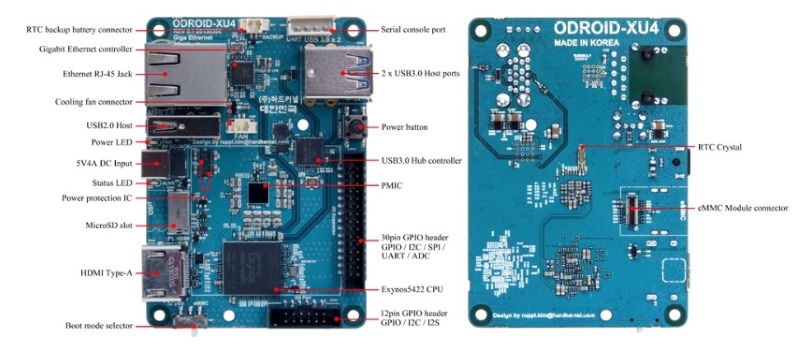
Odroid-XU4 is the perfect alternative to Raspberry Pi if you have room to spend a little more ($80-$100 or sometimes less, depending on the store/availability).
It is indeed a **powerful replacement and technically a bit smaller in size**. The support for eMMC and USB 3.0 makes it faster to work with.
You can get it from [Amazon](https://www.amazon.com/dp/B0761YN732?tag=chmod7mediate-20) or check with its official site for **$53.**
**Key Specifications:**
- Samsung Exynos 5422 Octa ARM Cortex™-A15 Quad 2Ghz and Cortex™-A7 Quad 1.3GHz CPUs
- 2 GB LPDDR3 RAM
- GPU: Mali-T628 MP6
- USB 3.0
- HDMI 1.4a
- eMMC 5.0 module socket
- MicroSD card slot
## 9. PocketBeagle

Pocketbeagle is an incredibly small SBC – quite **similar to the Raspberry Pi Zero**. However, it costs the same as a full-sized Raspberry Pi 3 model. The main highlight is that you can use it as a USB key fob and then access the Linux terminal to work on it.
It is also available on [Amazon](https://www.amazon.com/dp/B07663NS35?tag=chmod7mediate-20) for **$57.**
**Key Specifications**
- Processor: Octavo Systems OSD3358 1GHz ARM® Cortex-A8
- RAM: 512 MB DDR3
- 72 expansion pin headers
- microUSB
- USB 2.0
## 10. Le Potato

Le Potato by [Libre Computer](https://libre.computer/) is also identified by its model number AML-S905X-CC.
If you want to **double the memory and an HDMI 2.0 interface** and don’t mind spending a bit more than a Raspberry Pi would cost you – this is a perfect choice. However, you won’t find wireless connectivity baked in.
It is available on [Amazon](https://www.amazon.com/dp/B074P6BNGZ?tag=chmod7mediate-20) for **$35**.
**Key Specifications**
- Amlogic S905X SoC
- 2GB DDR3 SDRAM
- USB 2.0
- HDMI 2.0
- microUSB
- MicroSD card slot
- eMMC interface
**Suggested Read 📖**
[36 Raspberry Pi Projects Anyone Can Follow [2023]Here we list some of the cool Raspberry Pi projects and ideas. The projects have been divided into easy, intermediate, and advanced categories.](https://itsfoss.com/raspberry-pi-projects/)

## 11. Banana Pi M64

This one comes loaded with an **8 GB eMMC** – which is the key highlight of this Raspberry Pi alternative. Because of this, it will cost you **$60**.
The presence of an HDMI interface makes it 4K-ready. In addition, Banana Pi offers a much **greater variety of open-source SBCs** as an alternative to Raspberry Pi.
**Key Specifications**
- 1.2 Ghz Quad-Core ARM Cortex A53 64-Bit Processor-R18
- 2GB DDR3 SDRAM
- 8 GB eMMC
- WiFi & Bluetooth
- USB 2.0
- HDMI
## 12. Orange Pi Zero LTS

The Orange Pi Zero was originally an incredibly cheap alternative to the Raspberry Pi. You could get it for less than $10 on AliExpress or Amazon.
Now, it has a revised version called Orange Pi Zero LTS, which comes packed with **good hardware specifications** for around **$20**.
If that isn’t sufficient, you can also go for the Orange Pi 3 with better specifications, which will cost you around $25.
**Key Specifications:**
- H3 Quad-core Cortex-A7
- Mali400MP2 GPU
- RAM: Up to 512 MB
- TF Card support
- WiFi
- USB 2.0 OTG
## 13. VIM2 SBC by Khadas

VIM 2 by Khadas is one of the latest SBCs you can grab with **Bluetooth 5.0**. It starts at **$99** and may or may not be available on [Amazon](https://www.amazon.com/dp/B07BS8J6RT?tag=chmod7mediate-20).
The basic model includes 2 GB of RAM, a 16 GB eMMC, and Bluetooth 4.1. However, the Pro/Max versions include Bluetooth 5.0, more memory, and more eMMC storage.
**Key Specifications**
- Amlogic S912 1.5GHz 64-bit Octa-Core CPU
- T820MP3 GPU
- Up to 3 GB DDR4 RAM
- Up to 64 GB eMMC
- Bluetooth 5.0 (Pro/Max)
- Bluetooth 4.1 (Basic)
- HDMI 2.0a
- WiFi
## 14. UDOO BOLT v3
UDOO is another exciting board manufacturer with different options. If you want a portable supercomputer that can handle a wide range of resource-intensive tasks, [BOLT v3](https://shop.udoo.org/en/udoo-bolt-v3.html) is for you.
Of course, it may not be a Raspberry Pi alternative for the budget. Still, if you want a compact board packed with power, you can expect that here, with its AMD Ryzen embedded SoC, a mobile GPU, and an **integrated Arduino-compatible platform**.
It wasn't listed on Amazon at the time of updating this article. So, you can refer to its official website for details.
**Key Specifications**
- AMD Ryzen v1202b Dual Core @ 2.3 GHz
- 32 Gb Emmc
- Radeon Vega 3
## 15. ODROID N2+

Yet another ODROID board, but this is a tad bit expensive when compared to the other in this list.
When comparing it with Raspberry Pi, it should be a powerful option and a **versatile offering** for what it features out-of-the-box.
**Key Specifications:**
- Quad-core Cortex-A73 Max 2.4 Ghz
- 4 GB RAM
- 1 x HDMI 2.0
- 4 x USB 3.0
- 40 GPIO pins
- 1 IR receiver
- UART
## Wrapping Up
We do know that there are different types of single-board computers.
**Some are better than the Raspberry Pi – and some are scaled-down versions with a cheaper price tag**. SBCs like the Jetson Nano has been tailored for a specific use. So depending on what you require, you should verify the specifications of the single-board computer and pick one.
The gadgets discussed here are more in the range of ~$50-100 (with exceptions that cost more). If you want something cheaper, explore our Raspberry Pi Zero alternatives list.
[Tiny Yet Useful: 13 Raspberry Pi Zero Alternatives That Cost Less Than $20The Raspberry Pi Zero and the Raspberry Pi Zero W were added to the line up of Raspberry Pi’s in the last few years. These ultra-small form-factor SBC’s have been a big hit and continue to be a part of Raspberry Pi projects from the maker and DIY](https://itsfoss.com/raspberry-pi-zero-alternatives/)

💬 *Do you know of anything better? Feel free to let us know in the comments below.* |
10,824 | ping 多台服务器并在类似 top 的界面中显示 | https://www.ostechnix.com/ping-multiple-servers-and-show-the-output-in-top-like-text-ui/ | 2019-05-07T10:59:22 | [
"ping"
] | https://linux.cn/article-10824-1.html | 
不久前,我们写了篇关于 [fping](https://www.ostechnix.com/ping-multiple-hosts-linux/) 的文章,该程序能使我们能够同时 ping 多台主机。与传统的 `ping` 不同,`fping` 不会等待一台主机的超时。它使用循环法,这表示它将 ICMP Echo 请求发送到一台主机,然后转到另一台主机,最后一次显示哪些主机开启或关闭。今天,我们将讨论一个名为 `pingtop` 的类似程序。顾名思义,它会一次 ping 多台服务器,并在类似 `top` 的终端 UI 中显示结果。它是用 Python 写的自由开源程序。
### 安装 pingtop
可以使用 `pip` 安装 `pingtop`,`pip` 是一个软件包管理器,用于安装用 Python 开发的程序。确保已在 Linux 中安装了 Python 3.7.x 和 pip。
要在 Linux 上安装 `pip`,请参阅以下链接。
* [如何使用 pip 管理 Python 包](/article-10110-1.html)
安装 `pip` 后,运行以下命令安装 `pingtop`:
```
$ pip install pingtop
```
现在让我们继续使用 `pingtop` ping 多个系统。
### ping 多台服务器并在类似 top 的终端 UI 中显示
要 ping 多个主机/系统,请运行:
```
$ pingtop ostechnix.com google.com facebook.com twitter.com
```
现在,你将在一个漂亮的类似 `top` 的终端 UI 中看到结果,如下所示。

*使用 pingtop ping 多台服务器*
建议阅读:
* [一些你可能想知道的替代 “top” 命令的程序](https://www.ostechnix.com/some-alternatives-to-top-command-line-utility-you-might-want-to-know/)
我个人目前没有使用 pingtop 的情况。但我喜欢在这个在文本界面中展示 ping 命令输出的想法。试试看它,也许有帮助。
就是这些了。还有更多好东西。敬请期待!干杯!
资源:
* [pingtop GitHub 仓库](https://github.com/laixintao/pingtop)
---
via: <https://www.ostechnix.com/ping-multiple-servers-and-show-the-output-in-top-like-text-ui/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,826 | Linux 下的进程间通信:共享存储 | https://opensource.com/article/19/4/interprocess-communication-linux-storage | 2019-05-07T12:26:00 | [
"IPC"
] | https://linux.cn/article-10826-1.html |
>
> 学习在 Linux 中进程是如何与其他进程进行同步的。
>
>
>

本篇是 Linux 下[进程间通信](https://en.wikipedia.org/wiki/Inter-process_communication)(IPC)系列的第一篇文章。这个系列将使用 C 语言代码示例来阐明以下 IPC 机制:
* 共享文件
* 共享内存(使用信号量)
* 管道(命名的或非命名的管道)
* 消息队列
* 套接字
* 信号
在聚焦上面提到的共享文件和共享内存这两个机制之前,这篇文章将带你回顾一些核心的概念。
### 核心概念
*进程*是运行着的程序,每个进程都有着它自己的地址空间,这些空间由进程被允许访问的内存地址组成。进程有一个或多个执行*线程*,而线程是一系列执行指令的集合:*单线程*进程就只有一个线程,而*多线程*的进程则有多个线程。一个进程中的线程共享各种资源,特别是地址空间。另外,一个进程中的线程可以直接通过共享内存来进行通信,尽管某些现代语言(例如 Go)鼓励一种更有序的方式,例如使用线程安全的通道。当然对于不同的进程,默认情况下,它们**不**能共享内存。
有多种方法启动之后要进行通信的进程,下面所举的例子中主要使用了下面的两种方法:
* 一个终端被用来启动一个进程,另外一个不同的终端被用来启动另一个。
* 在一个进程(父进程)中调用系统函数 `fork`,以此生发另一个进程(子进程)。
第一个例子采用了上面使用终端的方法。这些[代码示例](http://condor.depaul.edu/mkalin)的 ZIP 压缩包可以从我的网站下载到。
### 共享文件
程序员对文件访问应该都已经很熟识了,包括许多坑(不存在的文件、文件权限损坏等等),这些问题困扰着程序对文件的使用。尽管如此,共享文件可能是最为基础的 IPC 机制了。考虑一下下面这样一个相对简单的例子,其中一个进程(生产者 `producer`)创建和写入一个文件,然后另一个进程(消费者 `consumer`)从这个相同的文件中进行读取:
```
writes +-----------+ reads
producer-------->| disk file |<-------consumer
+-----------+
```
在使用这个 IPC 机制时最明显的挑战是*竞争条件*可能会发生:生产者和消费者可能恰好在同一时间访问该文件,从而使得输出结果不确定。为了避免竞争条件的发生,该文件在处于*读*或*写*状态时必须以某种方式处于被锁状态,从而阻止在*写*操作执行时和其他操作的冲突。在标准系统库中与锁相关的 API 可以被总结如下:
* 生产者应该在写入文件时获得一个文件的排斥锁。一个*排斥*锁最多被一个进程所拥有。这样就可以排除掉竞争条件的发生,因为在锁被释放之前没有其他的进程可以访问这个文件。
* 消费者应该在从文件中读取内容时得到至少一个共享锁。多个*读取者*可以同时保有一个*共享*锁,但是没有*写入者*可以获取到文件内容,甚至在当只有一个*读取者*保有一个共享锁时。
共享锁可以提升效率。假如一个进程只是读入一个文件的内容,而不去改变它的内容,就没有什么原因阻止其他进程来做同样的事。但如果需要写入内容,则很显然需要文件有排斥锁。
标准的 I/O 库中包含一个名为 `fcntl` 的实用函数,它可以被用来检查或者操作一个文件上的排斥锁和共享锁。该函数通过一个*文件描述符*(一个在进程中的非负整数值)来标记一个文件(在不同的进程中不同的文件描述符可能标记同一个物理文件)。对于文件的锁定, Linux 提供了名为 `flock` 的库函数,它是 `fcntl` 的一个精简包装。第一个例子中使用 `fcntl` 函数来暴露这些 API 细节。
#### 示例 1. 生产者程序
```
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define FileName "data.dat"
#define DataString "Now is the winter of our discontent\nMade glorious summer by this sun of York\n"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1); /* EXIT_FAILURE */
}
int main() {
struct flock lock;
lock.l_type = F_WRLCK; /* read/write (exclusive versus shared) lock */
lock.l_whence = SEEK_SET; /* base for seek offsets */
lock.l_start = 0; /* 1st byte in file */
lock.l_len = 0; /* 0 here means 'until EOF' */
lock.l_pid = getpid(); /* process id */
int fd; /* file descriptor to identify a file within a process */
if ((fd = open(FileName, O_RDWR | O_CREAT, 0666)) < 0) /* -1 signals an error */
report_and_exit("open failed...");
if (fcntl(fd, F_SETLK, &lock) < 0) /** F_SETLK doesn't block, F_SETLKW does **/
report_and_exit("fcntl failed to get lock...");
else {
write(fd, DataString, strlen(DataString)); /* populate data file */
fprintf(stderr, "Process %d has written to data file...\n", lock.l_pid);
}
/* Now release the lock explicitly. */
lock.l_type = F_UNLCK;
if (fcntl(fd, F_SETLK, &lock) < 0)
report_and_exit("explicit unlocking failed...");
close(fd); /* close the file: would unlock if needed */
return 0; /* terminating the process would unlock as well */
}
```
上面生产者程序的主要步骤可以总结如下:
* 这个程序首先声明了一个类型为 `struct flock` 的变量,它代表一个锁,并对它的 5 个域做了初始化。第一个初始化
```
lock.l_type = F_WRLCK; /* exclusive lock */
```
使得这个锁为排斥锁(read-write)而不是一个共享锁(read-only)。假如生产者获得了这个锁,则其他的进程将不能够对文件做读或者写操作,直到生产者释放了这个锁,或者显式地调用 `fcntl`,又或者隐式地关闭这个文件。(当进程终止时,所有被它打开的文件都会被自动关闭,从而释放了锁)
* 上面的程序接着初始化其他的域。主要的效果是*整个*文件都将被锁上。但是,有关锁的 API 允许特别指定的字节被上锁。例如,假如文件包含多个文本记录,则单个记录(或者甚至一个记录的一部分)可以被锁,而其余部分不被锁。
* 第一次调用 `fcntl`
```
if (fcntl(fd, F_SETLK, &lock) < 0)
```
尝试排斥性地将文件锁住,并检查调用是否成功。一般来说, `fcntl` 函数返回 `-1` (因此小于 0)意味着失败。第二个参数 `F_SETLK` 意味着 `fcntl` 的调用*不是*堵塞的;函数立即做返回,要么获得锁,要么显示失败了。假如替换地使用 `F_SETLKW`(末尾的 `W` 代指*等待*),那么对 `fcntl` 的调用将是阻塞的,直到有可能获得锁的时候。在调用 `fcntl` 函数时,它的第一个参数 `fd` 指的是文件描述符,第二个参数指定了将要采取的动作(在这个例子中,`F_SETLK` 指代设置锁),第三个参数为锁结构的地址(在本例中,指的是 `&lock`)。
* 假如生产者获得了锁,这个程序将向文件写入两个文本记录。
* 在向文件写入内容后,生产者改变锁结构中的 `l_type` 域为 `unlock` 值:
```
lock.l_type = F_UNLCK;
```
并调用 `fcntl` 来执行解锁操作。最后程序关闭了文件并退出。
#### 示例 2. 消费者程序
```
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#define FileName "data.dat"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1); /* EXIT_FAILURE */
}
int main() {
struct flock lock;
lock.l_type = F_WRLCK; /* read/write (exclusive) lock */
lock.l_whence = SEEK_SET; /* base for seek offsets */
lock.l_start = 0; /* 1st byte in file */
lock.l_len = 0; /* 0 here means 'until EOF' */
lock.l_pid = getpid(); /* process id */
int fd; /* file descriptor to identify a file within a process */
if ((fd = open(FileName, O_RDONLY)) < 0) /* -1 signals an error */
report_and_exit("open to read failed...");
/* If the file is write-locked, we can't continue. */
fcntl(fd, F_GETLK, &lock); /* sets lock.l_type to F_UNLCK if no write lock */
if (lock.l_type != F_UNLCK)
report_and_exit("file is still write locked...");
lock.l_type = F_RDLCK; /* prevents any writing during the reading */
if (fcntl(fd, F_SETLK, &lock) < 0)
report_and_exit("can't get a read-only lock...");
/* Read the bytes (they happen to be ASCII codes) one at a time. */
int c; /* buffer for read bytes */
while (read(fd, &c, 1) > 0) /* 0 signals EOF */
write(STDOUT_FILENO, &c, 1); /* write one byte to the standard output */
/* Release the lock explicitly. */
lock.l_type = F_UNLCK;
if (fcntl(fd, F_SETLK, &lock) < 0)
report_and_exit("explicit unlocking failed...");
close(fd);
return 0;
}
```
相比于锁的 API,消费者程序会相对复杂一点儿。特别的,消费者程序首先检查文件是否被排斥性的被锁,然后才尝试去获得一个共享锁。相关的代码为:
```
lock.l_type = F_WRLCK;
...
fcntl(fd, F_GETLK, &lock); /* sets lock.l_type to F_UNLCK if no write lock */
if (lock.l_type != F_UNLCK)
report_and_exit("file is still write locked...");
```
在 `fcntl` 调用中的 `F_GETLK` 操作指定检查一个锁,在本例中,上面代码的声明中给了一个 `F_WRLCK` 的排斥锁。假如特指的锁不存在,那么 `fcntl` 调用将会自动地改变锁类型域为 `F_UNLCK` 以此来显示当前的状态。假如文件是排斥性地被锁,那么消费者将会终止。(一个更健壮的程序版本或许应该让消费者*睡*会儿,然后再尝试几次。)
假如当前文件没有被锁,那么消费者将尝试获取一个共享(read-only)锁(`F_RDLCK`)。为了缩短程序,`fcntl` 中的 `F_GETLK` 调用可以丢弃,因为假如其他进程已经保有一个读写锁,`F_RDLCK` 的调用就可能会失败。重新调用一个只读锁能够阻止其他进程向文件进行写的操作,但可以允许其他进程对文件进行读取。简而言之,共享锁可以被多个进程所保有。在获取了一个共享锁后,消费者程序将立即从文件中读取字节数据,然后在标准输出中打印这些字节的内容,接着释放锁,关闭文件并终止。
下面的 `%` 为命令行提示符,下面展示的是从相同终端开启这两个程序的输出:
```
% ./producer
Process 29255 has written to data file...
% ./consumer
Now is the winter of our discontent
Made glorious summer by this sun of York
```
在本次的代码示例中,通过 IPC 传输的数据是文本:它们来自莎士比亚的戏剧《理查三世》中的两行台词。然而,共享文件的内容还可以是纷繁复杂的,任意的字节数据(例如一个电影)都可以,这使得文件共享变成了一个非常灵活的 IPC 机制。但它的缺点是文件获取速度较慢,因为文件的获取涉及到读或者写。同往常一样,编程总是伴随着折中。下面的例子将通过共享内存来做 IPC,而不是通过共享文件,在性能上相应的有极大的提升。
### 共享内存
对于共享内存,Linux 系统提供了两类不同的 API:传统的 System V API 和更新一点的 POSIX API。在单个应用中,这些 API 不能混用。但是,POSIX 方式的一个坏处是它的特性仍在发展中,并且依赖于安装的内核版本,这非常影响代码的可移植性。例如,默认情况下,POSIX API 用*内存映射文件*来实现共享内存:对于一个共享的内存段,系统为相应的内容维护一个*备份文件*。在 POSIX 规范下共享内存可以被配置为不需要备份文件,但这可能会影响可移植性。我的例子中使用的是带有备份文件的 POSIX API,这既结合了内存获取的速度优势,又获得了文件存储的持久性。
下面的共享内存例子中包含两个程序,分别名为 `memwriter` 和 `memreader`,并使用*信号量*来调整它们对共享内存的获取。在任何时候当共享内存进入一个*写入者*场景时,无论是多进程还是多线程,都有遇到基于内存的竞争条件的风险,所以,需要引入信号量来协调(同步)对共享内存的获取。
`memwriter` 程序应当在它自己所处的终端首先启动,然后 `memreader` 程序才可以在它自己所处的终端启动(在接着的十几秒内)。`memreader` 的输出如下:
```
This is the way the world ends...
```
在每个源程序的最上方注释部分都解释了在编译它们时需要添加的链接参数。
首先让我们复习一下信号量是如何作为一个同步机制工作的。一般的信号量也被叫做一个*计数信号量*,因为带有一个可以增加的值(通常初始化为 0)。考虑一家租用自行车的商店,在它的库存中有 100 辆自行车,还有一个供职员用于租赁的程序。每当一辆自行车被租出去,信号量就增加 1;当一辆自行车被还回来,信号量就减 1。在信号量的值为 100 之前都还可以进行租赁业务,但如果等于 100 时,就必须停止业务,直到至少有一辆自行车被还回来,从而信号量减为 99。
*二元信号量*是一个特例,它只有两个值:0 和 1。在这种情况下,信号量的表现为*互斥量*(一个互斥的构造)。下面的共享内存示例将把信号量用作互斥量。当信号量的值为 0 时,只有 `memwriter` 可以获取共享内存,在写操作完成后,这个进程将增加信号量的值,从而允许 `memreader` 来读取共享内存。
#### 示例 3. memwriter 进程的源程序
```
/** Compilation: gcc -o memwriter memwriter.c -lrt -lpthread **/
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <semaphore.h>
#include <string.h>
#include "shmem.h"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1);
}
int main() {
int fd = shm_open(BackingFile, /* name from smem.h */
O_RDWR | O_CREAT, /* read/write, create if needed */
AccessPerms); /* access permissions (0644) */
if (fd < 0) report_and_exit("Can't open shared mem segment...");
ftruncate(fd, ByteSize); /* get the bytes */
caddr_t memptr = mmap(NULL, /* let system pick where to put segment */
ByteSize, /* how many bytes */
PROT_READ | PROT_WRITE, /* access protections */
MAP_SHARED, /* mapping visible to other processes */
fd, /* file descriptor */
0); /* offset: start at 1st byte */
if ((caddr_t) -1 == memptr) report_and_exit("Can't get segment...");
fprintf(stderr, "shared mem address: %p [0..%d]\n", memptr, ByteSize - 1);
fprintf(stderr, "backing file: /dev/shm%s\n", BackingFile );
/* semaphore code to lock the shared mem */
sem_t* semptr = sem_open(SemaphoreName, /* name */
O_CREAT, /* create the semaphore */
AccessPerms, /* protection perms */
0); /* initial value */
if (semptr == (void*) -1) report_and_exit("sem_open");
strcpy(memptr, MemContents); /* copy some ASCII bytes to the segment */
/* increment the semaphore so that memreader can read */
if (sem_post(semptr) < 0) report_and_exit("sem_post");
sleep(12); /* give reader a chance */
/* clean up */
munmap(memptr, ByteSize); /* unmap the storage */
close(fd);
sem_close(semptr);
shm_unlink(BackingFile); /* unlink from the backing file */
return 0;
}
```
下面是 `memwriter` 和 `memreader` 程序如何通过共享内存来通信的一个总结:
* 上面展示的 `memwriter` 程序调用 `shm_open` 函数来得到作为系统协调共享内存的备份文件的文件描述符。此时,并没有内存被分配。接下来调用的是令人误解的名为 `ftruncate` 的函数
```
ftruncate(fd, ByteSize); /* get the bytes */
```
它将分配 `ByteSize` 字节的内存,在该情况下,一般为大小适中的 512 字节。`memwriter` 和 `memreader` 程序都只从共享内存中获取数据,而不是从备份文件。系统将负责共享内存和备份文件之间数据的同步。
* 接着 `memwriter` 调用 `mmap` 函数:
```
caddr_t memptr = mmap(NULL, /* let system pick where to put segment */
ByteSize, /* how many bytes */
PROT_READ | PROT_WRITE, /* access protections */
MAP_SHARED, /* mapping visible to other processes */
fd, /* file descriptor */
0); /* offset: start at 1st byte */
```
来获得共享内存的指针。(`memreader` 也做一次类似的调用。) 指针类型 `caddr_t` 以 `c` 开头,它代表 `calloc`,而这是动态初始化分配的内存为 0 的一个系统函数。`memwriter` 通过库函数 `strcpy`(字符串复制)来获取后续*写*操作的 `memptr`。
* 到现在为止,`memwriter` 已经准备好进行写操作了,但首先它要创建一个信号量来确保共享内存的排斥性。假如 `memwriter` 正在执行写操作而同时 `memreader` 在执行读操作,则有可能出现竞争条件。假如调用 `sem_open` 成功了:
```
sem_t* semptr = sem_open(SemaphoreName, /* name */
O_CREAT, /* create the semaphore */
AccessPerms, /* protection perms */
0); /* initial value */
```
那么,接着写操作便可以执行。上面的 `SemaphoreName`(任意一个唯一的非空名称)用来在 `memwriter` 和 `memreader` 识别信号量。初始值 0 将会传递给信号量的创建者,在这个例子中指的是 `memwriter` 赋予它执行*写*操作的权利。
* 在写操作完成后,`memwriter* 通过调用`sem\_post` 函数将信号量的值增加到 1:
```
if (sem_post(semptr) < 0) ..
```
增加信号了将释放互斥锁,使得 `memreader` 可以执行它的*读*操作。为了更好地测量,`memwriter` 也将从它自己的地址空间中取消映射,
```
munmap(memptr, ByteSize); /* unmap the storage *
```
这将使得 `memwriter` 不能进一步地访问共享内存。
#### 示例 4. memreader 进程的源代码
```
/** Compilation: gcc -o memreader memreader.c -lrt -lpthread **/
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <semaphore.h>
#include <string.h>
#include "shmem.h"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1);
}
int main() {
int fd = shm_open(BackingFile, O_RDWR, AccessPerms); /* empty to begin */
if (fd < 0) report_and_exit("Can't get file descriptor...");
/* get a pointer to memory */
caddr_t memptr = mmap(NULL, /* let system pick where to put segment */
ByteSize, /* how many bytes */
PROT_READ | PROT_WRITE, /* access protections */
MAP_SHARED, /* mapping visible to other processes */
fd, /* file descriptor */
0); /* offset: start at 1st byte */
if ((caddr_t) -1 == memptr) report_and_exit("Can't access segment...");
/* create a semaphore for mutual exclusion */
sem_t* semptr = sem_open(SemaphoreName, /* name */
O_CREAT, /* create the semaphore */
AccessPerms, /* protection perms */
0); /* initial value */
if (semptr == (void*) -1) report_and_exit("sem_open");
/* use semaphore as a mutex (lock) by waiting for writer to increment it */
if (!sem_wait(semptr)) { /* wait until semaphore != 0 */
int i;
for (i = 0; i < strlen(MemContents); i++)
write(STDOUT_FILENO, memptr + i, 1); /* one byte at a time */
sem_post(semptr);
}
/* cleanup */
munmap(memptr, ByteSize);
close(fd);
sem_close(semptr);
unlink(BackingFile);
return 0;
}
```
`memwriter` 和 `memreader` 程序中,共享内存的主要着重点都在 `shm_open` 和 `mmap` 函数上:在成功时,第一个调用返回一个备份文件的文件描述符,而第二个调用则使用这个文件描述符从共享内存段中获取一个指针。它们对 `shm_open` 的调用都很相似,除了 `memwriter` 程序创建共享内存,而 `memreader 只获取这个已经创建的内存:
```
int fd = shm_open(BackingFile, O_RDWR | O_CREAT, AccessPerms); /* memwriter */
int fd = shm_open(BackingFile, O_RDWR, AccessPerms); /* memreader */
```
有了文件描述符,接着对 `mmap` 的调用就是类似的了:
```
caddr_t memptr = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
```
`mmap` 的第一个参数为 `NULL`,这意味着让系统自己决定在虚拟内存地址的哪个地方分配内存,当然也可以指定一个地址(但很有技巧性)。`MAP_SHARED` 标志着被分配的内存在进程中是共享的,最后一个参数(在这个例子中为 0 ) 意味着共享内存的偏移量应该为第一个字节。`size` 参数特别指定了将要分配的字节数目(在这个例子中是 512);另外的保护参数(`AccessPerms`)暗示着共享内存是可读可写的。
当 `memwriter` 程序执行成功后,系统将创建并维护备份文件,在我的系统中,该文件为 `/dev/shm/shMemEx`,其中的 `shMemEx` 是我为共享存储命名的(在头文件 `shmem.h` 中给定)。在当前版本的 `memwriter` 和 `memreader` 程序中,下面的语句
```
shm_unlink(BackingFile); /* removes backing file */
```
将会移除备份文件。假如没有 `unlink` 这个语句,则备份文件在程序终止后仍然持久地保存着。
`memreader` 和 `memwriter` 一样,在调用 `sem_open` 函数时,通过信号量的名字来获取信号量。但 `memreader` 随后将进入等待状态,直到 `memwriter` 将初始值为 0 的信号量的值增加。
```
if (!sem_wait(semptr)) { /* wait until semaphore != 0 */
```
一旦等待结束,`memreader` 将从共享内存中读取 ASCII 数据,然后做些清理工作并终止。
共享内存 API 包括显式地同步共享内存段和备份文件。在这次的示例中,这些操作都被省略了,以免文章显得杂乱,好让我们专注于内存共享和信号量的代码。
即便在信号量代码被移除的情况下,`memwriter` 和 `memreader` 程序很大几率也能够正常执行而不会引入竞争条件:`memwriter` 创建了共享内存段,然后立即向它写入;`memreader` 不能访问共享内存,直到共享内存段被创建好。然而,当一个*写操作*处于混合状态时,最佳实践需要共享内存被同步。信号量 API 足够重要,值得在代码示例中着重强调。
### 总结
上面共享文件和共享内存的例子展示了进程是怎样通过*共享存储*来进行通信的,前者通过文件而后者通过内存块。这两种方法的 API 相对来说都很直接。这两种方法有什么共同的缺点吗?现代的应用经常需要处理流数据,而且是非常大规模的数据流。共享文件或者共享内存的方法都不能很好地处理大规模的流数据。按照类型使用管道会更加合适一些。所以这个系列的第二部分将会介绍管道和消息队列,同样的,我们将使用 C 语言写的代码示例来辅助讲解。
---
via: <https://opensource.com/article/19/4/interprocess-communication-linux-storage>
作者:[Marty Kalin](https://opensource.com/users/mkalindepauledu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the first article in a series about [interprocess communication](https://en.wikipedia.org/wiki/Inter-process_communication) (IPC) in Linux. The series uses code examples in C to clarify the following IPC mechanisms:
- Shared files
- Shared memory (with semaphores)
- Pipes (named and unnamed)
- Message queues
- Sockets
- Signals
This article reviews some core concepts before moving on to the first two of these mechanisms: shared files and shared memory.
## Core concepts
A *process* is a program in execution, and each process has its own address space, which comprises the memory locations that the process is allowed to access. A process has one or more *threads* of execution, which are sequences of executable instructions: a *single-threaded* process has just one thread, whereas a *multi-threaded* process has more than one thread. Threads within a process share various resources, in particular, address space. Accordingly, threads within a process can communicate straightforwardly through shared memory, although some modern languages (e.g., Go) encourage a more disciplined approach such as the use of thread-safe channels. Of interest here is that different processes, by default, do *not* share memory.
There are various ways to launch processes that then communicate, and two ways dominate in the examples that follow:
- A terminal is used to start one process, and perhaps a different terminal is used to start another.
- The system function
**fork**is called within one process (the parent) to spawn another process (the child).
The first examples take the terminal approach. The [code examples](http://condor.depaul.edu/mkalin) are available in a ZIP file on my website.
## Shared files
Programmers are all too familiar with file access, including the many pitfalls (non-existent files, bad file permissions, and so on) that beset the use of files in programs. Nonetheless, shared files may be the most basic IPC mechanism. Consider the relatively simple case in which one process (*producer*) creates and writes to a file, and another process (*consumer*) reads from this same file:
```
writes +-----------+ reads
producer-------->| disk file |<-------consumer
+-----------+
```
The obvious challenge in using this IPC mechanism is that a *race condition* might arise: the producer and the consumer might access the file at exactly the same time, thereby making the outcome indeterminate. To avoid a race condition, the file must be locked in a way that prevents a conflict between a *write* operation and any another operation, whether a *read* or a *write*. The locking API in the standard system library can be summarized as follows:
- A producer should gain an exclusive lock on the file before writing to the file. An
*exclusive*lock can be held by one process at most, which rules out a race condition because no other process can access the file until the lock is released. - A consumer should gain at least a shared lock on the file before reading from the file. Multiple
*readers*can hold a*shared*lock at the same time, but no*writer*can access a file when even a single*reader*holds a shared lock.
A shared lock promotes efficiency. If one process is just reading a file and not changing its contents, there is no reason to prevent other processes from doing the same. Writing, however, clearly demands exclusive access to a file.
The standard I/O library includes a utility function named **fcntl** that can be used to inspect and manipulate both exclusive and shared locks on a file. The function works through a *file descriptor*, a non-negative integer value that, within a process, identifies a file. (Different file descriptors in different processes may identify the same physical file.) For file locking, Linux provides the library function **flock**, which is a thin wrapper around **fcntl**. The first example uses the **fcntl** function to expose API details.
### Example 1. The *producer* program
```
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define FileName "data.dat"
#define DataString "Now is the winter of our discontent\nMade glorious summer by this sun of York\n"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1); /* EXIT_FAILURE */
}
int main() {
struct flock lock;
lock.l_type = F_WRLCK; /* read/write (exclusive versus shared) lock */
lock.l_whence = SEEK_SET; /* base for seek offsets */
lock.l_start = 0; /* 1st byte in file */
lock.l_len = 0; /* 0 here means 'until EOF' */
lock.l_pid = getpid(); /* process id */
int fd; /* file descriptor to identify a file within a process */
if ((fd = open(FileName, O_RDWR | O_CREAT, 0666)) < 0) /* -1 signals an error */
report_and_exit("open failed...");
if (fcntl(fd, F_SETLK, &lock) < 0) /** F_SETLK doesn't block, F_SETLKW does **/
report_and_exit("fcntl failed to get lock...");
else {
write(fd, DataString, strlen(DataString)); /* populate data file */
fprintf(stderr, "Process %d has written to data file...\n", lock.l_pid);
}
/* Now release the lock explicitly. */
lock.l_type = F_UNLCK;
if (fcntl(fd, F_SETLK, &lock) < 0)
report_and_exit("explicit unlocking failed...");
close(fd); /* close the file: would unlock if needed */
return 0; /* terminating the process would unlock as well */
}
```
The main steps in the *producer* program above can be summarized as follows:
- The program declares a variable of type
**struct flock**, which represents a lock, and initializes the structure's five fields. The first initialization:
`lock.l_type = F_WRLCK; /* exclusive lock */`
makes the lock an exclusive (
*read-write*) rather than a shared (*read-only*) lock. If the*producer*gains the lock, then no other process will be able to write or read the file until the*producer*releases the lock, either explicitly with the appropriate call to**fcntl**or implicitly by closing the file. (When the process terminates, any opened files would be closed automatically, thereby releasing the lock.) - The program then initializes the remaining fields. The chief effect is that the
*entire*file is to be locked. However, the locking API allows only designated bytes to be locked. For example, if the file contains multiple text records, then a single record (or even part of a record) could be locked and the rest left unlocked. - The first call to
**fcntl**:
`if (fcntl(fd, F_SETLK, &lock) < 0)`
tries to lock the file exclusively, checking whether the call succeeded. In general, the
**fcntl**function returns**-1**(hence, less than zero) to indicate failure. The second argument**F_SETLK**means that the call to**fcntl**does*not*block: the function returns immediately, either granting the lock or indicating failure. If the flag**F_SETLKW**(the**W**at the end is for*wait*) were used instead, the call to**fcntl**would block until gaining the lock was possible. In the calls to**fcntl**, the first argument**fd**is the file descriptor, the second argument specifies the action to be taken (in this case,**F_SETLK**for setting the lock), and the third argument is the address of the lock structure (in this case,**&lock**). - If the
*producer*gains the lock, the program writes two text records to the file. - After writing to the file, the
*producer*changes the lock structure's**l_type**field to the*unlock*value:
`lock.l_type = F_UNLCK;`
and calls
**fcntl**to perform the unlocking operation. The program finishes up by closing the file and exiting.
### Example 2. The *consumer* program
```
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#define FileName "data.dat"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1); /* EXIT_FAILURE */
}
int main() {
struct flock lock;
lock.l_type = F_WRLCK; /* read/write (exclusive) lock */
lock.l_whence = SEEK_SET; /* base for seek offsets */
lock.l_start = 0; /* 1st byte in file */
lock.l_len = 0; /* 0 here means 'until EOF' */
lock.l_pid = getpid(); /* process id */
int fd; /* file descriptor to identify a file within a process */
if ((fd = open(FileName, O_RDONLY)) < 0) /* -1 signals an error */
report_and_exit("open to read failed...");
/* If the file is write-locked, we can't continue. */
fcntl(fd, F_GETLK, &lock); /* sets lock.l_type to F_UNLCK if no write lock */
if (lock.l_type != F_UNLCK)
report_and_exit("file is still write locked...");
lock.l_type = F_RDLCK; /* prevents any writing during the reading */
if (fcntl(fd, F_SETLK, &lock) < 0)
report_and_exit("can't get a read-only lock...");
/* Read the bytes (they happen to be ASCII codes) one at a time. */
int c; /* buffer for read bytes */
while (read(fd, &c, 1) > 0) /* 0 signals EOF */
write(STDOUT_FILENO, &c, 1); /* write one byte to the standard output */
/* Release the lock explicitly. */
lock.l_type = F_UNLCK;
if (fcntl(fd, F_SETLK, &lock) < 0)
report_and_exit("explicit unlocking failed...");
close(fd);
return 0;
}
```
The *consumer* program is more complicated than necessary to highlight features of the locking API. In particular, the *consumer* program first checks whether the file is exclusively locked and only then tries to gain a shared lock. The relevant code is:
```
lock.l_type = F_WRLCK;
...
fcntl(fd, F_GETLK, &lock); /* sets lock.l_type to F_UNLCK if no write lock */
if (lock.l_type != F_UNLCK)
report_and_exit("file is still write locked...");
```
The **F_GETLK** operation specified in the **fcntl** call checks for a lock, in this case, an exclusive lock given as **F_WRLCK** in the first statement above. If the specified lock does not exist, then the **fcntl** call automatically changes the lock type field to **F_UNLCK** to indicate this fact. If the file is exclusively locked, the *consumer* terminates. (A more robust version of the program might have the *consumer* **sleep** a bit and try again several times.)
If the file is not currently locked, then the *consumer* tries to gain a shared (*read-only*) lock (**F_RDLCK**). To shorten the program, the **F_GETLK** call to **fcntl** could be dropped because the **F_RDLCK** call would fail if a *read-write* lock already were held by some other process. Recall that a *read-only* lock does prevent any other process from writing to the file, but allows other processes to read from the file. In short, a *shared* lock can be held by multiple processes. After gaining a shared lock, the *consumer* program reads the bytes one at a time from the file, prints the bytes to the standard output, releases the lock, closes the file, and terminates.
Here is the output from the two programs launched from the same terminal with **%** as the command line prompt:
```
% ./producer
Process 29255 has written to data file...
% ./consumer
Now is the winter of our discontent
Made glorious summer by this sun of York
```
In this first code example, the data shared through IPC is text: two lines from Shakespeare's play *Richard III*. Yet, the shared file's contents could be voluminous, arbitrary bytes (e.g., a digitized movie), which makes file sharing an impressively flexible IPC mechanism. The downside is that file access is relatively slow, whether the access involves reading or writing. As always, programming comes with tradeoffs. The next example has the upside of IPC through shared memory, rather than shared files, with a corresponding boost in performance.
## Shared memory
Linux systems provide two separate APIs for shared memory: the legacy System V API and the more recent POSIX one. These APIs should never be mixed in a single application, however. A downside of the POSIX approach is that features are still in development and dependent upon the installed kernel version, which impacts code portability. For example, the POSIX API, by default, implements shared memory as a *memory-mapped file*: for a shared memory segment, the system maintains a *backing file* with corresponding contents. Shared memory under POSIX can be configured without a backing file, but this may impact portability. My example uses the POSIX API with a backing file, which combines the benefits of memory access (speed) and file storage (persistence).
The shared-memory example has two programs, named *memwriter* and *memreader*, and uses a *semaphore* to coordinate their access to the shared memory. Whenever shared memory comes into the picture with a *writer*, whether in multi-processing or multi-threading, so does the risk of a memory-based race condition; hence, the semaphore is used to coordinate (synchronize) access to the shared memory.
The *memwriter* program should be started first in its own terminal. The *memreader* program then can be started (within a dozen seconds) in its own terminal. The output from the *memreader* is:
`This is the way the world ends...`
Each source file has documentation at the top explaining the link flags to be included during compilation.
Let's start with a review of how semaphores work as a synchronization mechanism. A general semaphore also is called a *counting semaphore*, as it has a value (typically initialized to zero) that can be incremented. Consider a shop that rents bicycles, with a hundred of them in stock, with a program that clerks use to do the rentals. Every time a bike is rented, the semaphore is incremented by one; when a bike is returned, the semaphore is decremented by one. Rentals can continue until the value hits 100 but then must halt until at least one bike is returned, thereby decrementing the semaphore to 99.
A *binary semaphore* is a special case requiring only two values: 0 and 1. In this situation, a semaphore acts as a *mutex*: a mutual exclusion construct. The shared-memory example uses a semaphore as a mutex. When the semaphore's value is 0, the *memwriter* alone can access the shared memory. After writing, this process increments the semaphore's value, thereby allowing the *memreader* to read the shared memory.
### Example 3. Source code for the *memwriter* process
```
/** Compilation: gcc -o memwriter memwriter.c -lrt -lpthread **/
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <semaphore.h>
#include <string.h>
#include "shmem.h"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1);
}
int main() {
int fd = shm_open(BackingFile, /* name from smem.h */
O_RDWR | O_CREAT, /* read/write, create if needed */
AccessPerms); /* access permissions (0644) */
if (fd < 0) report_and_exit("Can't open shared mem segment...");
ftruncate(fd, ByteSize); /* get the bytes */
caddr_t memptr = mmap(NULL, /* let system pick where to put segment */
ByteSize, /* how many bytes */
PROT_READ | PROT_WRITE, /* access protections */
MAP_SHARED, /* mapping visible to other processes */
fd, /* file descriptor */
0); /* offset: start at 1st byte */
if ((caddr_t) -1 == memptr) report_and_exit("Can't get segment...");
fprintf(stderr, "shared mem address: %p [0..%d]\n", memptr, ByteSize - 1);
fprintf(stderr, "backing file: /dev/shm%s\n", BackingFile );
/* semaphore code to lock the shared mem */
sem_t* semptr = sem_open(SemaphoreName, /* name */
O_CREAT, /* create the semaphore */
AccessPerms, /* protection perms */
0); /* initial value */
if (semptr == (void*) -1) report_and_exit("sem_open");
strcpy(memptr, MemContents); /* copy some ASCII bytes to the segment */
/* increment the semaphore so that memreader can read */
if (sem_post(semptr) < 0) report_and_exit("sem_post");
sleep(12); /* give reader a chance */
/* clean up */
munmap(memptr, ByteSize); /* unmap the storage */
close(fd);
sem_close(semptr);
shm_unlink(BackingFile); /* unlink from the backing file */
return 0;
}
```
Here's an overview of how the *memwriter* and *memreader* programs communicate through shared memory:
- The
*memwriter*program, shown above, calls the**shm_open**function to get a file descriptor for the backing file that the system coordinates with the shared memory. At this point, no memory has been allocated. The subsequent call to the misleadingly named function**ftruncate**:
`ftruncate(fd, ByteSize); /* get the bytes */`
allocates
**ByteSize**bytes, in this case, a modest 512 bytes. The*memwriter*and*memreader*programs access the shared memory only, not the backing file. The system is responsible for synchronizing the shared memory and the backing file. - The
*memwriter*then calls the**mmap**function:
`caddr_t memptr = mmap(NULL, /* let system pick where to put segment */ ByteSize, /* how many bytes */ PROT_READ | PROT_WRITE, /* access protections */ MAP_SHARED, /* mapping visible to other processes */ fd, /* file descriptor */ 0); /* offset: start at 1st byte */`
to get a pointer to the shared memory. (The
*memreader*makes a similar call.) The pointer type**caddr_t**starts with a**c**for**calloc**, a system function that initializes dynamically allocated storage to zeroes. The*memwriter*uses the**memptr**for the later*write*operation, using the library**strcpy**(string copy) function. - At this point, the
*memwriter*is ready for writing, but it first creates a semaphore to ensure exclusive access to the shared memory. A race condition would occur if the*memwriter*were writing while the*memreader*was reading. If the call to**sem_open**succeeds:
`sem_t* semptr = sem_open(SemaphoreName, /* name */ O_CREAT, /* create the semaphore */ AccessPerms, /* protection perms */ 0); /* initial value */`
then the writing can proceed. The
**SemaphoreName**(any unique non-empty name will do) identifies the semaphore in both the*memwriter*and the*memreader*. The initial value of zero gives the semaphore's creator, in this case, the*memwriter*, the right to proceed, in this case, to the*write*operation. - After writing, the
*memwriter*increments the semaphore value to 1:
`if (sem_post(semptr) < 0) ..`
with a call to the
**sem_post**function. Incrementing the semaphore releases the mutex lock and enables the*memreader*to perform its*read*operation. For good measure, the*memwriter*also unmaps the shared memory from the*memwriter*address space:`munmap(memptr, ByteSize); /* unmap the storage *`
This bars the
*memwriter*from further access to the shared memory.
### Example 4. Source code for the *memreader* process
```
/** Compilation: gcc -o memreader memreader.c -lrt -lpthread **/
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <semaphore.h>
#include <string.h>
#include "shmem.h"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1);
}
int main() {
int fd = shm_open(BackingFile, O_RDWR, AccessPerms); /* empty to begin */
if (fd < 0) report_and_exit("Can't get file descriptor...");
/* get a pointer to memory */
caddr_t memptr = mmap(NULL, /* let system pick where to put segment */
ByteSize, /* how many bytes */
PROT_READ | PROT_WRITE, /* access protections */
MAP_SHARED, /* mapping visible to other processes */
fd, /* file descriptor */
0); /* offset: start at 1st byte */
if ((caddr_t) -1 == memptr) report_and_exit("Can't access segment...");
/* create a semaphore for mutual exclusion */
sem_t* semptr = sem_open(SemaphoreName, /* name */
O_CREAT, /* create the semaphore */
AccessPerms, /* protection perms */
0); /* initial value */
if (semptr == (void*) -1) report_and_exit("sem_open");
/* use semaphore as a mutex (lock) by waiting for writer to increment it */
if (!sem_wait(semptr)) { /* wait until semaphore != 0 */
int i;
for (i = 0; i < strlen(MemContents); i++)
write(STDOUT_FILENO, memptr + i, 1); /* one byte at a time */
sem_post(semptr);
}
/* cleanup */
munmap(memptr, ByteSize);
close(fd);
sem_close(semptr);
unlink(BackingFile);
return 0;
}
```
In both the *memwriter* and *memreader* programs, the shared-memory functions of main interest are **shm_open** and **mmap**: on success, the first call returns a file descriptor for the backing file, which the second call then uses to get a pointer to the shared memory segment. The calls to **shm_open** are similar in the two programs except that the *memwriter* program creates the shared memory, whereas the *memreader* only accesses this already created memory:
```
int fd = shm_open(BackingFile, O_RDWR | O_CREAT, AccessPerms); /* memwriter */
int fd = shm_open(BackingFile, O_RDWR, AccessPerms); /* memreader */
```
With a file descriptor in hand, the calls to **mmap** are the same:
`caddr_t memptr = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);`
The first argument to **mmap** is **NULL**, which means that the system determines where to allocate the memory in virtual address space. It's possible (but tricky) to specify an address instead. The **MAP_SHARED** flag indicates that the allocated memory is shareable among processes, and the last argument (in this case, zero) means that the offset for the shared memory should be the first byte. The **size** argument specifies the number of bytes to be allocated (in this case, 512), and the protection argument indicates that the shared memory can be written and read.
When the *memwriter* program executes successfully, the system creates and maintains the backing file; on my system, the file is */dev/shm/shMemEx*, with *shMemEx* as my name (given in the header file *shmem.h*) for the shared storage. In the current version of the *memwriter* and *memreader* programs, the statement:
`shm_unlink(BackingFile); /* removes backing file */`
removes the backing file. If the **unlink** statement is omitted, then the backing file persists after the program terminates.
The *memreader*, like the *memwriter*, accesses the semaphore through its name in a call to **sem_open**. But the *memreader* then goes into a wait state until the *memwriter* increments the semaphore, whose initial value is 0:
`if (!sem_wait(semptr)) { /* wait until semaphore != 0 */`
Once the wait is over, the *memreader* reads the ASCII bytes from the shared memory, cleans up, and terminates.
The shared-memory API includes operations explicitly to synchronize the shared memory segment and the backing file. These operations have been omitted from the example to reduce clutter and keep the focus on the memory-sharing and semaphore code.
The *memwriter* and *memreader* programs are likely to execute without inducing a race condition even if the semaphore code is removed: the *memwriter* creates the shared memory segment and writes immediately to it; the *memreader* cannot even access the shared memory until this has been created. However, best practice requires that shared-memory access is synchronized whenever a *write* operation is in the mix, and the semaphore API is important enough to be highlighted in a code example.
## Wrapping up
The shared-file and shared-memory examples show how processes can communicate through *shared storage*, files in one case and memory segments in the other. The APIs for both approaches are relatively straightforward. Do these approaches have a common downside? Modern applications often deal with streaming data, indeed, with massively large streams of data. Neither the shared-file nor the shared-memory approaches are well suited for massive data streams. Channels of one type or another are better suited. Part 2 thus introduces channels and message queues, again with code examples in C.
**[ Download the complete guide to inter-process communication in Linux]**
## 1 Comment |
10,830 | 如何使用 autofs 挂载 NFS 共享 | https://opensource.com/article/18/6/using-autofs-mount-nfs-shares | 2019-05-08T11:54:05 | [
"NFS",
"共享"
] | https://linux.cn/article-10830-1.html |
>
> 给你的网络文件系统(NFS)配置一个基本的自动挂载功能。
>
>
>

大多数 Linux 文件系统在引导时挂载,并在系统运行时保持挂载状态。对于已在 `fstab` 中配置的任何远程文件系统也是如此。但是,有时你可能希望仅按需挂载远程文件系统。例如,通过减少网络带宽使用来提高性能,或出于安全原因隐藏或混淆某些目录。[autofs](https://wiki.archlinux.org/index.php/autofs) 软件包提供此功能。在本文中,我将介绍如何配置基本的自动挂载。
首先做点假设:假设有台 NFS 服务器 `tree.mydatacenter.net` 已经启动并运行。另外假设一个名为 `ourfiles` 的数据目录还有供 Carl 和 Sarah 使用的用户目录,它们都由服务器共享。
一些最佳实践可以使工作更好:服务器上的用户和任何客户端工作站上的帐号有相同的用户 ID。此外,你的工作站和服务器应有相同的域名。检查相关配置文件应该确认。
```
alan@workstation1:~$ sudo getent passwd carl sarah
[sudo] password for alan:
carl:x:1020:1020:Carl,,,:/home/carl:/bin/bash
sarah:x:1021:1021:Sarah,,,:/home/sarah:/bin/bash
alan@workstation1:~$ sudo getent hosts
127.0.0.1 localhost
127.0.1.1 workstation1.mydatacenter.net workstation1
10.10.1.5 tree.mydatacenter.net tree
```
如你所见,客户端工作站和 NFS 服务器都在 `hosts` 文件中配置。我假设这是一个基本的家庭甚至小型办公室网络,可能缺乏适合的内部域名服务(即 DNS)。
### 安装软件包
你只需要安装两个软件包:用于 NFS 客户端的 `nfs-common` 和提供自动挂载的 `autofs`。
```
alan@workstation1:~$ sudo apt-get install nfs-common autofs
```
你可以验证 autofs 相关的文件是否已放在 `/etc` 目录中:
```
alan@workstation1:~$ cd /etc; ll auto*
-rw-r--r-- 1 root root 12596 Nov 19 2015 autofs.conf
-rw-r--r-- 1 root root 857 Mar 10 2017 auto.master
-rw-r--r-- 1 root root 708 Jul 6 2017 auto.misc
-rwxr-xr-x 1 root root 1039 Nov 19 2015 auto.net*
-rwxr-xr-x 1 root root 2191 Nov 19 2015 auto.smb*
alan@workstation1:/etc$
```
### 配置 autofs
现在你需要编辑其中几个文件并添加 `auto.home` 文件。首先,将以下两行添加到文件 `auto.master` 中:
```
/mnt/tree /etc/auto.misc
/home/tree /etc/auto.home
```
每行以挂载 NFS 共享的目录开头。继续创建这些目录:
```
alan@workstation1:/etc$ sudo mkdir /mnt/tree /home/tree
```
接下来,将以下行添加到文件 `auto.misc`:
```
ourfiles -fstype=nfs tree:/share/ourfiles
```
该行表示 autofs 将挂载 `auto.master` 文件中匹配 `auto.misc` 的 `ourfiles` 共享。如上所示,这些文件将在 `/mnt/tree/ourfiles` 目录中。
第三步,使用以下行创建文件 `auto.home`:
```
* -fstype=nfs tree:/home/&
```
该行表示 autofs 将挂载 `auto.master` 文件中匹配 `auto.home` 的用户共享。在这种情况下,Carl 和 Sarah 的文件将分别在目录 `/home/tree/carl` 或 `/home/tree/sarah`中。星号 `*`(称为通配符)使每个用户的共享可以在登录时自动挂载。`&` 符号也可以作为表示服务器端用户目录的通配符。它们的主目录会相应地根据 `passwd` 文件映射。如果你更喜欢本地主目录,则无需执行此操作。相反,用户可以将其用作特定文件的简单远程存储。
最后,重启 `autofs` 守护进程,以便识别并加载这些配置的更改。
```
alan@workstation1:/etc$ sudo service autofs restart
```
### 测试 autofs
如果更改文件 `auto.master` 中的列出目录,并运行 `ls` 命令,那么不会立即看到任何内容。例如,切换到目录 `/mnt/tree`。首先,`ls` 的输出不会显示任何内容,但在运行 `cd ourfiles` 之后,将自动挂载 `ourfiles` 共享目录。 `cd` 命令也将被执行,你将进入新挂载的目录中。
```
carl@workstation1:~$ cd /mnt/tree
carl@workstation1:/mnt/tree$ ls
carl@workstation1:/mnt/tree$ cd ourfiles
carl@workstation1:/mnt/tree/ourfiles$
```
为了进一步确认正常工作,`mount` 命令会显示已挂载共享的细节。
```
carl@workstation1:~$ mount
tree:/mnt/share/ourfiles on /mnt/tree/ourfiles type nfs4 (rw,relatime,vers=4.0,rsize=131072,wsize=131072,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.10.1.22,local_lock=none,addr=10.10.1.5)
```
对于 Carl 和 Sarah,`/home/tree` 目录工作方式相同。
我发现在我的文件管理器中添加这些目录的书签很有用,可以用来快速访问。
---
via: <https://opensource.com/article/18/6/using-autofs-mount-nfs-shares>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Most Linux file systems are mounted at boot and remain mounted while the system is running. This is also true of any remote file systems that have been configured in the `fstab`
file. However, there may be times when you prefer to have a remote file system mount only on demand—for example, to boost performance by reducing network bandwidth usage, or to hide or obfuscate certain directories for security reasons. The package [autofs](https://wiki.archlinux.org/index.php/autofs) provides this feature. In this article, I'll describe how to get a basic automount configuration up and running.
First, a few assumptions: Assume the NFS server named `tree.mydatacenter.net`
is up and running. Also assume a data directory named `ourfiles`
and two user directories, for Carl and Sarah, are being shared by this server.
A few best practices will make things work a bit better: It is a good idea to use the same user ID for your users on the server and any client workstations where they have an account. Also, your workstations and server should have the same domain name. Checking the relevant configuration files should confirm.
```
alan@workstation1:~$ sudo getent passwd carl sarah
[sudo] password for alan:
carl:x:1020:1020:Carl,,,:/home/carl:/bin/bash
sarah:x:1021:1021:Sarah,,,:/home/sarah:/bin/bash
alan@workstation1:~$ sudo getent hosts
127.0.0.1 localhost
127.0.1.1 workstation1.mydatacenter.net workstation1
10.10.1.5 tree.mydatacenter.net tree
```
As you can see, both the client workstation and the NFS server are configured in the `hosts`
file. I’m assuming a basic home or even small office network that might lack proper internal domain name service (i.e., DNS).
## Install the packages
You need to install only two packages: `nfs-common`
for NFS client functions, and `autofs`
to provide the automount function.
`alan@workstation1:~$ sudo apt-get install nfs-common autofs`
You can verify that the autofs files have been placed in the `etc`
directory:
```
alan@workstation1:~$ cd /etc; ll auto*
-rw-r--r-- 1 root root 12596 Nov 19 2015 autofs.conf
-rw-r--r-- 1 root root 857 Mar 10 2017 auto.master
-rw-r--r-- 1 root root 708 Jul 6 2017 auto.misc
-rwxr-xr-x 1 root root 1039 Nov 19 2015 auto.net*
-rwxr-xr-x 1 root root 2191 Nov 19 2015 auto.smb*
alan@workstation1:/etc$
```
## Configure autofs
Now you need to edit several of these files and add the file `auto.home`
. First, add the following two lines to the file `auto.master`
:
```
/mnt/tree /etc/auto.misc
/home/tree /etc/auto.home
```
Each line begins with the directory where the NFS shares will be mounted. Go ahead and create those directories:
`alan@workstation1:/etc$ sudo mkdir /mnt/tree /home/tree`
Second, add the following line to the file `auto.misc`
:
`ourfiles -fstype=nfs tree:/share/ourfiles`
This line instructs autofs to mount the `ourfiles`
share at the location matched in the `auto.master`
file for `auto.misc`
. As shown above, these files will be available in the directory `/mnt/tree/ourfiles`
.
Third, create the file `auto.home`
with the following line:
`* -fstype=nfs tree:/home/&`
This line instructs autofs to mount the users share at the location matched in the `auto.master`
file for `auto.home`
. In this case, Carl and Sarah's files will be available in the directories `/home/tree/carl`
or `/home/tree/sarah`
, respectively. The asterisk (referred to as a wildcard) makes it possible for each user's share to be automatically mounted when they log in. The ampersand also works as a wildcard representing the user's directory on the server side. Their home directory should be mapped accordingly in the `passwd`
file. This doesn’t have to be done if you prefer a local home directory; instead, the user could use this as simple remote storage for specific files.
Finally, restart the `autofs`
daemon so it will recognize and load these configuration file changes.
`alan@workstation1:/etc$ sudo service autofs restart`
## Testing autofs
If you change to one of the directories listed in the file `auto.master`
and run the `ls`
command, you won’t see anything immediately. For example, change directory `(cd)`
to `/mnt/tree`
. At first, the output of `ls`
won’t show anything, but after running `cd ourfiles`
, the `ourfiles`
share directory will be automatically mounted. The `cd`
command will also be executed and you will be placed into the newly mounted directory.
```
carl@workstation1:~$ cd /mnt/tree
carl@workstation1:/mnt/tree$ ls
carl@workstation1:/mnt/tree$ cd ourfiles
carl@workstation1:/mnt/tree/ourfiles$
```
To further confirm that things are working, the `mount`
command will display the details of the mounted share.
```
carl@workstation1:~$ mount
tree:/mnt/share/ourfiles on /mnt/tree/ourfiles type nfs4 (rw,relatime,vers=4.0,rsize=131072,wsize=131072,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.10.1.22,local_lock=none,addr=10.10.1.5)
```
The `/home/tree`
directory will work the same way for Carl and Sarah.
I find it useful to bookmark these directories in my file manager for quicker access.
## Comments are closed. |
10,833 | Python 的加密库入门 | https://opensource.com/article/19/4/cryptography-python | 2019-05-09T10:27:23 | [
"加密",
"Python"
] | https://linux.cn/article-10833-1.html |
>
> 加密你的数据并使其免受攻击者的攻击。
>
>
>

密码学俱乐部的第一条规则是:永远不要自己*发明*密码系统。密码学俱乐部的第二条规则是:永远不要自己*实现*密码系统:在现实世界中,在*实现*以及设计密码系统阶段都找到过许多漏洞。
Python 中的一个有用的基本加密库就叫做 [cryptography](https://cryptography.io/en/latest/)。它既是一个“安全”方面的基础库,也是一个“危险”层。“危险”层需要更加小心和相关的知识,并且使用它很容易出现安全漏洞。在这篇介绍性文章中,我们不会涵盖“危险”层中的任何内容!
cryptography 库中最有用的高级安全功能是一种 Fernet 实现。Fernet 是一种遵循最佳实践的加密缓冲区的标准。它不适用于非常大的文件,如千兆字节以上的文件,因为它要求你一次加载要加密或解密的内容到内存缓冲区中。
Fernet 支持<ruby> 对称 <rt> symmetric </rt></ruby>(即<ruby> 密钥 <rt> secret key </rt></ruby>)加密方式\*:加密和解密使用相同的密钥,因此必须保持安全。
生成密钥很简单:
```
>>> k = fernet.Fernet.generate_key()
>>> type(k)
<class 'bytes'>
```
这些字节可以写入有适当权限的文件,最好是在安全的机器上。
有了密钥后,加密也很容易:
```
>>> frn = fernet.Fernet(k)
>>> encrypted = frn.encrypt(b"x marks the spot")
>>> encrypted[:10]
b'gAAAAABb1'
```
如果在你的机器上加密,你会看到略微不同的值。不仅因为(我希望)你生成了和我不同的密钥,而且因为 Fernet 将要加密的值与一些随机生成的缓冲区连接起来。这是我之前提到的“最佳实践”之一:它将阻止对手分辨哪些加密值是相同的,这有时是攻击的重要部分。
解密同样简单:
```
>>> frn = fernet.Fernet(k)
>>> frn.decrypt(encrypted)
b'x marks the spot'
```
请注意,这仅加密和解密*字节串*。为了加密和解密*文本串*,通常需要对它们使用 [UTF-8](https://en.wikipedia.org/wiki/UTF-8) 进行编码和解码。
20 世纪中期密码学最有趣的进展之一是<ruby> 公钥 <rt> public key </rt></ruby>加密。它可以在发布加密密钥的同时而让*解密密钥*保持保密。例如,它可用于保存服务器使用的 API 密钥:服务器是唯一可以访问解密密钥的一方,但是任何人都可以保存公共加密密钥。
虽然 cryptography 没有任何支持公钥加密的*安全*功能,但 [PyNaCl](https://pynacl.readthedocs.io/en/stable/) 库有。PyNaCl 封装并提供了一些很好的方法来使用 Daniel J. Bernstein 发明的 [NaCl](https://nacl.cr.yp.to/) 加密系统。
NaCl 始终同时<ruby> 加密 <rt> encrypt </rt></ruby>和<ruby> 签名 <rt> sign </rt></ruby>或者同时<ruby> 解密 <rt> decrypt </rt></ruby>和<ruby> 验证签名 <rt> verify signature </rt></ruby>。这是一种防止<ruby> 基于可伸缩性 <rt> malleability-based </rt></ruby>的攻击的方法,其中攻击者会修改加密值。
加密是使用公钥完成的,而签名是使用密钥完成的:
```
>>> from nacl.public import PrivateKey, PublicKey, Box
>>> source = PrivateKey.generate()
>>> with open("target.pubkey", "rb") as fpin:
... target_public_key = PublicKey(fpin.read())
>>> enc_box = Box(source, target_public_key)
>>> result = enc_box.encrypt(b"x marks the spot")
>>> result[:4]
b'\xe2\x1c0\xa4'
```
解密颠倒了角色:它需要私钥进行解密,需要公钥验证签名:
```
>>> from nacl.public import PrivateKey, PublicKey, Box
>>> with open("source.pubkey", "rb") as fpin:
... source_public_key = PublicKey(fpin.read())
>>> with open("target.private_key", "rb") as fpin:
... target = PrivateKey(fpin.read())
>>> dec_box = Box(target, source_public_key)
>>> dec_box.decrypt(result)
b'x marks the spot'
```
最后,[PocketProtector](https://github.com/SimpleLegal/pocket_protector/blob/master/USER_GUIDE.md) 库构建在 PyNaCl 之上,包含完整的密钥管理方案。
---
via: <https://opensource.com/article/19/4/cryptography-python>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The first rule of cryptography club is: never *invent* a cryptography system yourself. The second rule of cryptography club is: never *implement* a cryptography system yourself: many real-world holes are found in the *implementation* phase of a cryptosystem as well as in the design.
One useful library for cryptographic primitives in Python is called simply [ cryptography](https://cryptography.io/en/latest/). It has both "secure" primitives as well as a "hazmat" layer. The "hazmat" layer requires care and knowledge of cryptography and it is easy to implement security holes using it. We will not cover anything in the "hazmat" layer in this introductory article!
The most useful high-level secure primitive in **cryptography** is the Fernet implementation. Fernet is a standard for encrypting buffers in a way that follows best-practices cryptography. It is not suitable for very big files—anything in the gigabyte range and above—since it requires you to load the whole buffer that you want to encrypt or decrypt into memory at once.
Fernet supports *symmetric*, or *secret key*, cryptography: the same key is used for encryption and decryption, and therefore must be kept safe.
Generating a key is easy:
```
>>> k = fernet.Fernet.generate_key()
>>> type(k)
<class 'bytes'>
```
Those bytes can be written to a file with appropriate permissions, ideally on a secure machine.
Once you have key material, encrypting is easy as well:
```
>>> frn = fernet.Fernet(k)
>>> encrypted = frn.encrypt(b"x marks the spot")
>>> encrypted[:10]
b'gAAAAABb1'
```
You will get slightly different values if you encrypt on your machine. Not only because (I hope) you generated a different key from me, but because Fernet concatenates the value to be encrypted with some randomly generated buffer. This is one of the "best practices" I alluded to earlier: it will prevent an adversary from being able to tell which encrypted values are identical, which is sometimes an important part of an attack.
Decryption is equally simple:
```
>>> frn = fernet.Fernet(k)
>>> frn.decrypt(encrypted)
b'x marks the spot'
```
Note that this only encrypts and decrypts *byte strings*. In order to encrypt and decrypt *text strings*, they will need to be encoded and decoded, usually with [UTF-8](https://en.wikipedia.org/wiki/UTF-8).
One of the most interesting advances in cryptography in the mid-20th century was *public key* cryptography. It allows the encryption key to be published while the *decryption key* is kept secret. It can, for example, be used to store API keys to be used by a server: the server is the only thing with access to the decryption key, but anyone can add to the store by using the public encryption key.
While **cryptography** does not have any public key cryptographic *secure* primitives, the [ PyNaCl](https://pynacl.readthedocs.io/en/stable/) library does. PyNaCl wraps and offers some nice ways to use the
[encryption system invented by Daniel J. Bernstein.](https://nacl.cr.yp.to/)
**NaCl**NaCl always *encrypts* and *signs* or *decrypts* and *verifies signatures* simultaneously. This is a way to prevent malleability-based attacks, where an adversary modifies the encrypted value.
Encryption is done with a public key, while signing is done with a secret key:
```
>>> from nacl.public import PrivateKey, PublicKey, Box
>>> source = PrivateKey.generate()
>>> with open("target.pubkey", "rb") as fpin:
... target_public_key = PublicKey(fpin.read())
>>> enc_box = Box(source, target_public_key)
>>> result = enc_box.encrypt(b"x marks the spot")
>>> result[:4]
b'\xe2\x1c0\xa4'
```
Decryption reverses the roles: it needs the private key for decryption and the public key to verify the signature:
```
>>> from nacl.public import PrivateKey, PublicKey, Box
>>> with open("source.pubkey", "rb") as fpin:
... source_public_key = PublicKey(fpin.read())
>>> with open("target.private_key", "rb") as fpin:
... target = PrivateKey(fpin.read())
>>> dec_box = Box(target, source_public_key)
>>> dec_box.decrypt(result)
b'x marks the spot'
```
The [ PocketProtector](https://github.com/SimpleLegal/pocket_protector/blob/master/USER_GUIDE.md) library builds on top of PyNaCl and contains a complete secrets management solution.
## Comments are closed. |
10,834 | 为何 DevOps 是如今最重要的技术策略 | https://opensource.com/article/19/3/devops-most-important-tech-strategy | 2019-05-09T11:30:32 | [
"DevOps"
] | https://linux.cn/article-10834-1.html |
>
> 消除一些关于 DevOps 的疑惑。
>
>
>

很多人初学 [DevOps](https://opensource.com/resources/devops) 时,看到它其中一个结果就问这个是如何得来的。其实理解这部分 Devops 的怎样实现并不重要,重要的是——理解(使用) DevOps 策略的原因——这是做一个行业的领导者还是追随者的差别。
你可能会听过些 Devops 的难以置信的成果,例如生产环境非常有弹性,就算是有个“<ruby> <a href="https://github.com/Netflix/chaosmonkey"> 癫狂的猴子 </a> <rt> Chaos Monkey </rt></ruby>)跳来跳去将不知道哪个插头随便拔下,每天仍可以处理数千个发布。这是令人印象深刻的,但就其本身而言,这是一个 DevOps 的证据不足的案例,其本质上会被一个[反例](https://en.wikipedia.org/wiki/Burden_of_proof_(philosophy)#Proving_a_negative)困扰:DevOps 环境有弹性是因为严重的故障还没有被观测到。
有很多关于 DevOps 的疑惑,并且许多人还在尝试弄清楚它的意义。下面是来自我 LinkedIn Feed 中的某个人的一个案例:
>
> 最近我参加一些 #DevOps 的交流会,那里一些演讲人好像在倡导 #敏捷开发是 DevOps 的子集。不知为何,我的理解恰恰相反。
>
>
> 能听一下你们的想法吗?你认为敏捷开发和 DevOps 之间是什么关系呢?
>
>
> 1. DevOps 是敏捷开发的子集
> 2. 敏捷开发是 DevOps 的子集
> 3. DevOps 是敏捷开发的扩展,从敏捷开发结束的地方开始
> 4. DevOps 是敏捷开发的新版本
>
>
>
科技行业的专业人士在那篇 LinkedIn 的帖子上表达了各种各样的答案,你会怎样回复呢?
### DevOps 源于精益和敏捷
如果我们从亨利福特的战略和丰田生产系统对福特车型的改进(的历史)开始, DevOps 就更有意义了。精益制造就诞生在那段历史中,人们对精益制作进行了良好的研究。James P. Womack 和 Daniel T. Jones 将精益思维([Lean Thinking](https://www.amazon.com/dp/B0048WQDIO/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1))提炼为五个原则:
1. 指明客户所需的价值
2. 确定提供该价值的每个产品的价值流,并对当前提供该价值所需的所有浪费步骤提起挑战
3. 使产品通过剩余的增值步骤持续流动
4. 在可以连续流动的所有步骤之间引入拉力
5. 管理要尽善尽美,以便为客户服务所需的步骤数量和时间以及信息量持续下降
精益致力于持续消除浪费并增加客户的价值流动。这很容易识别并明白精益的核心原则:单一流。我们可以做一些游戏去了解为何同一时间移动单个比批量移动要快得多。其中的两个游戏是[硬币游戏](https://youtu.be/5t6GhcvKB8o?t=54)和[飞机游戏](https://www.shmula.com/paper-airplane-game-pull-systems-push-systems/8280/)。在硬币游戏中,如果一批 20 个硬币到顾客手中要用 2 分钟,顾客等 2 分钟后能拿到整批硬币。如果一次只移动一个硬币,顾客会在 5 秒内得到第一枚硬币,并会持续获得硬币,直到在大约 25 秒后第 20 个硬币到达。(LCTT 译注:有相关的视频的)
这是巨大的不同,但是不是生活中的所有事都像硬币游戏那样简单并可预测的。这就是敏捷的出现的原因。我们当然看到了高效绩敏捷团队的精益原则,但这些团队需要的不仅仅是精益去做他们要做的事。
为了能够处理典型的软件开发任务的不可预见性和变化,敏捷开发的方法论会将重点放在意识、审议、决策和行动上,以便在不断变化的现实中调整。例如,敏捷框架(如 srcum)通过每日站立会议和冲刺评审会议等仪式提高意识。如果 scrum 团队意识到新的事实,框架允许并鼓励他们在必要时及时调整路线。
要使团队做出这些类型的决策,他们需要高度信任的环境中的自我组织能力。以这种方式工作的高效绩敏捷团队在不断调整的同时实现快速的价值流,消除错误方向上的浪费。
### 最佳批量大小
要了解 DevOps 在软件开发中的强大功能,这会帮助我们理解批处理大小的经济学。请考虑以下来自Donald Reinertsen 的[产品开发流程原则](https://www.amazon.com/dp/B00K7OWG7O/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1)的U曲线优化示例:

这可以类比杂货店购物来解释。假设你需要买一些鸡蛋,而你住的地方离商店只有 30 分钟的路程。买一个鸡蛋(图中最左边)意味着每次要花 30 分钟的路程,这就是你的*交易成本*。*持有成本*可能是鸡蛋变质和在你的冰箱中持续地占用空间。*总成本*是*交易成本*加上你的*持有成本*。这个 U 型曲线解释了为什么对大部分人来说,一次买一打鸡蛋是他们的*最佳批量大小*。如果你就住在商店的旁边,步行到那里不会花费你任何的时候,你可能每次只会买一小盒鸡蛋,以此来节省冰箱的空间并享受新鲜的鸡蛋。
这 U 型优化曲线可以说明为什么在成功的敏捷转换中生产力会显著提高。考虑敏捷转换对组织决策的影响。在传统的分级组织中,决策权是集中的。这会导致较少的人做更大的决策。敏捷方法论会有效地降低组织决策中的交易成本,方法是将决策分散到最被人熟知的认识和信息的位置:跨越高度信任,自组织的敏捷团队。
下面的动画演示了降低事务成本后,最佳批量大小是如何向左移动。在更频繁地做出更快的决策方面,你不能低估组织的价值。

### DevOps 适合哪些地方
自动化是 DevOps 最知名的事情之一。前面的插图非常详细地展示了自动化的价值。通过自动化,我们将交易成本降低到接近于零,实质上是可以免费进行测试和部署。这使我们可以利用越来越小的批量工作。较小批量的工作更容易理解、提交、测试、审查和知道何时能完成。这些较小的批量大小也包含较少的差异和风险,使其更易于部署,如果出现问题,可以进行故障排除和恢复。通过自动化与扎实的敏捷实践相结合,我们可以使我们的功能开发非常接近单件流程,从而快速、持续地为客户提供价值。
更传统地说,DevOps 被理解为一种打破开发团队和运营团队之间混乱局面的方法。在这个模型中,开发团队开发新的功能,而运营团队则保持系统的稳定和平稳运行。摩擦的发生是因为开发过程中的新功能将更改引入到系统中,从而增加了停机的风险,运营团队并不认为要对此负责,但无论如何都必须处理这一问题。DevOps 不仅仅尝试让人们一起工作,更重要的是尝试在复杂的环境中安全地进行更频繁的更改。
我们可以看看 [Ron Westrum](https://en.wikipedia.org/wiki/Ron_Westrum) 在有关复杂组织中实现安全性的研究。在研究为什么有些组织比其他组织更安全时,他发现组织的文化可以预测其安全性。他确定了三种文化:病态的、官僚主义的和生产式的。他发现病态的可以预测其安全性较低,而生产式文化被预测为更安全(例如,在他的主要研究领域中,飞机坠毁或意外住院死亡的数量要少得多)。

高效的 DevOps 团队通过精益和敏捷的实践实现了一种生成性文化,这表明速度和安全性是互补的,或者说是同一个问题的两个方面。通过将决策和功能的最佳批量大小减少到非常小,DevOps 实现了更快的信息流和价值,同时消除了浪费并降低了风险。
与 Westrum 的研究一致,在提高安全性和可靠性的同时,变化也很容易发生。当一个敏捷的 DevOps 团队被信任做出自己的决定时,我们将获得 DevOps 目前最为人所知的工具和技术:自动化和持续交付。通过这种自动化,交易成本比以往任何时候都进一步降低,并且实现了近乎单一的精益流程,每天创造数千个决策和发布的潜力,正如我们在高效绩的 DevOps 组织中看到的那样
### 流动、反馈、学习
DevOps 并不止于此。我们主要讨论了 DevOps 实现了革命性的流程,但通过类似的努力可以进一步放大精益和敏捷实践,从而实现更快的反馈循环和更快的学习。在[DevOps手册](https://www.amazon.com/DevOps-Handbook-World-Class-Reliability-Organizations/dp/1942788002/ref=sr_1_3?keywords=DevOps+handbook&qid=1553197361&s=books&sr=1-3) 中,作者除了详细解释快速流程外, DevOps 如何在整个价值流中实现遥测,从而获得快速且持续的反馈。此外,利用[精益求精的突破](https://en.wikipedia.org/wiki/Kaizen)和 scrum 的[回顾](https://www.scrum.org/resources/what-is-a-sprint-retrospective),高效的 DevOps 团队将不断推动学习和持续改进深入到他们的组织的基础,实现软件产品开发行业的精益制造革命。
### 从 DevOps 评估开始
利用 DevOps 的第一步是,经过大量研究或在 DevOps 顾问和教练的帮助下,对高效绩 DevOps 团队中始终存在的一系列维度进行评估。评估应确定需要改进的薄弱或不存在的团队规范。对评估的结果进行评估,以找到具有高成功机会的快速获胜焦点领域,从而产生高影响力的改进。快速获胜非常重要,能让团队获取解决更具挑战性领域所需的动力。团队应该产生可以快速尝试的想法,并开始关注 DevOps 转型。
一段时间后,团队应重新评估相同的维度,以衡量改进并确立新的高影响力重点领域,并再次采纳团队的新想法。一位好的教练将根据需要进行咨询、培训、指导和支持,直到团队拥有自己的持续改进方案,并通过不断地重新评估、试验和学习,在所有维度上实现近乎一致。
在本文的[第二部分](https://opensource.com/article/19/3/where-drupal-community-stands-devops-adoption)中,我们将查看 Drupal 社区中 DevOps 调查的结果,并了解最有可能找到快速获胜的位置。
---
via: <https://opensource.com/article/19/3/devops-most-important-tech-strategy>
作者:[Kelly Albrecht](https://opensource.com/users/ksalbrecht/users/brentaaronreed/users/wpschaub/users/wpschaub/users/ksalbrecht) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zgj1024](https://github.com/zgj1024) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Many people first learn about [DevOps](https://opensource.com/resources/devops) when they see one of its outcomes and ask how it happened. It's not necessary to understand why something is part of DevOps to implement it, but knowing that—and why a DevOps strategy is important—can mean the difference between being a leader or a follower in an industry.
Maybe you've heard some the incredible outcomes attributed to DevOps, such as production environments that are so resilient they can handle thousands of releases per day while a "[Chaos Monkey](https://github.com/Netflix/chaosmonkey)" is running around randomly unplugging things. This is impressive, but on its own, it's a weak business case, essentially burdened with [proving a negative](https://en.wikipedia.org/wiki/Burden_of_proof_(philosophy)#Proving_a_negative): The DevOps environment is resilient because a serious failure hasn't been observed… yet.
There is a lot of confusion about DevOps and many people are still trying to make sense of it. Here's an example from someone in my LinkedIn feed:
Recently attended few #DevOps sessions where some speakers seemed to suggest #Agile is a subset of DevOps. Somehow, my understanding was just the opposite.
Would like to hear your thoughts. What do you think is the relationship between Agile and DevOps?
- DevOps is a subset of Agile
- Agile is a subset of DevOps
- DevOps is an extension of Agile, starts where Agile ends
- DevOps is the new version of Agile
Tech industry professionals have been weighing in on the LinkedIn post with a wide range of answers. How would you respond?
## DevOps' roots in lean and agile
DevOps makes a lot more sense if we start with the strategies of Henry Ford and the Toyota Production System's refinements of Ford's model. Within this history is the birthplace of lean manufacturing, which has been well studied. In [ Lean Thinking](https://www.amazon.com/dp/B0048WQDIO/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1), James P. Womack and Daniel T. Jones distill it into five principles:
- Specify the value desired by the customer
- Identify the value stream for each product providing that value and challenge all of the wasted steps currently necessary to provide it
- Make the product flow continuously through the remaining value-added steps
- Introduce pull between all steps where continuous flow is possible
- Manage toward perfection so that the number of steps and the amount of time and information needed to serve the customer continually falls
Lean seeks to continuously remove waste and increase the flow of value to the customer. This is easily recognizable and understood through a core tenet of lean: single piece flow. We can do a number of activities to learn why moving single pieces at a time is magnitudes faster than batches of many pieces; the [Penny Game](https://youtu.be/5t6GhcvKB8o?t=54) and the [Airplane Game](https://www.shmula.com/paper-airplane-game-pull-systems-push-systems/8280/) are two of them. In the Penny Game, if a batch of 20 pennies takes two minutes to get to the customer, they get the whole batch after waiting two minutes. If you move one penny at a time, the customer gets the first penny in about five seconds and continues getting pennies until the 20th penny arrives approximately 25 seconds later.
This is a huge difference, but not everything in life is as simple and predictable as the penny in the Penny Game. This is where agile comes in. We certainly see lean principles on high-performing agile teams, but these teams need more than lean to do what they do.
To be able to handle the unpredictability and variance of typical software development tasks, agile methodology focuses on awareness, deliberation, decision, and action to adjust course in the face of a constantly changing reality. For example, agile frameworks (like scrum) increase awareness with ceremonies like the daily standup and the sprint review. If the scrum team becomes aware of a new reality, the framework allows and encourages them to adjust course if necessary.
For teams to make these types of decisions, they need to be self-organizing in a high-trust environment. High-performing agile teams working this way achieve a fast flow of value while continuously adjusting course, removing the waste of going in the wrong direction.
## Optimal batch size
To understand the power of DevOps in software development, it helps to understand the economics of batch size. Consider the following U-curve optimization illustration from Donald Reinertsen's [Principles of Product Development Flow](https://www.amazon.com/dp/B00K7OWG7O/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1):
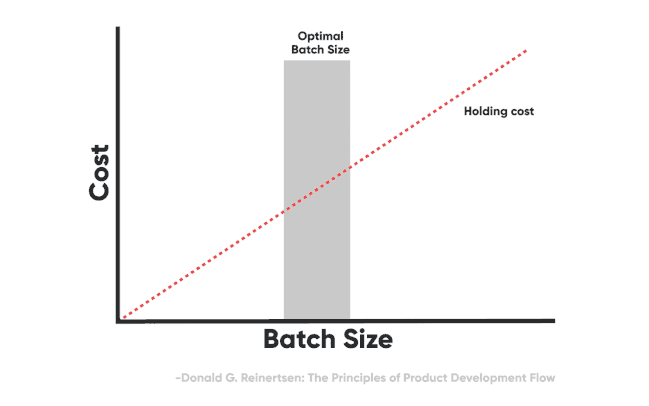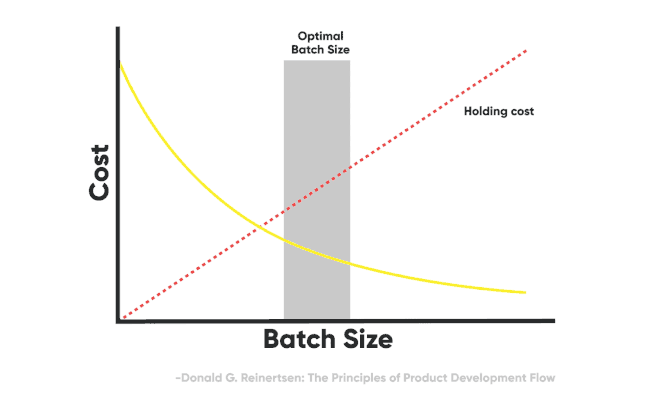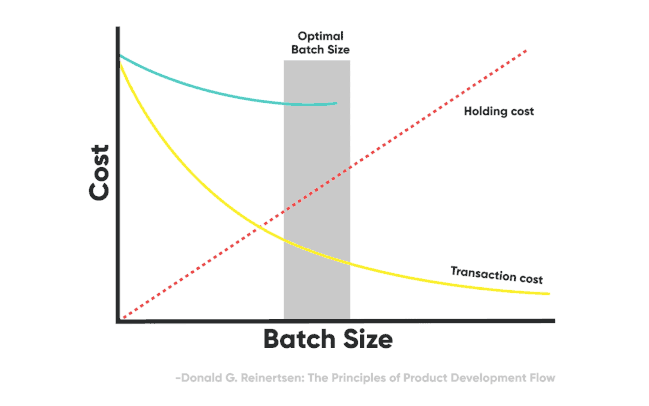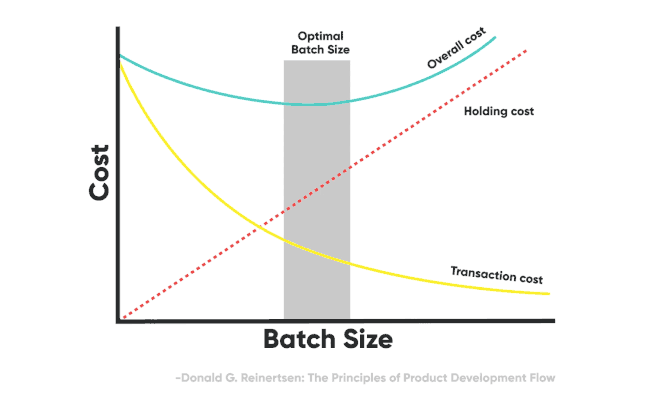
This can be explained with an analogy about grocery shopping. Suppose you need to buy some eggs and you live 30 minutes from the store. Buying one egg (far left on the illustration) at a time would mean a 30-minute trip each time. This is your *transaction cost*. The *holding cost* might represent the eggs spoiling and taking up space in your refrigerator over time. The *total cost* is the *transaction cost* plus your *holding cost*. This U-curve explains why, for most people, buying a dozen eggs at a time is their *optimal batch size*. If you lived next door to the store, it'd cost you next to nothing to walk there, and you'd probably buy a smaller carton each time to save room in your refrigerator and enjoy fresher eggs.
This U-curve optimization illustration can shed some light on why productivity increases significantly in successful agile transformations. Consider the effect of agile transformation on decision making in an organization. In traditional hierarchical organizations, decision-making authority is centralized. This leads to larger decisions made less frequently by fewer people. An agile methodology will effectively reduce an organization's transaction cost for making decisions by decentralizing the decisions to where the awareness and information is the best known: across the high-trust, self-organizing agile teams.
The following animation shows how reducing transaction cost shifts the optimal batch size to the left. You can't understate the value to an organization in making faster decisions more frequently.
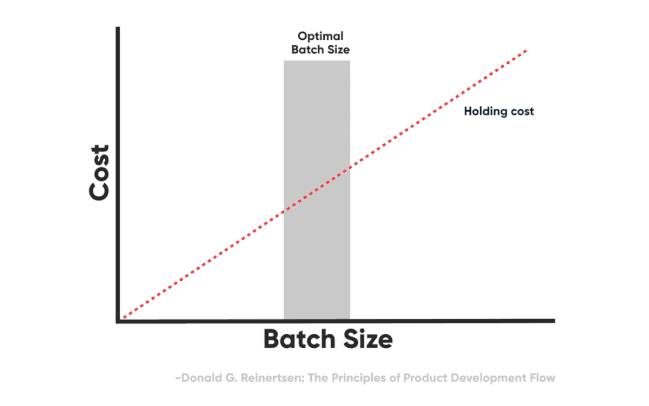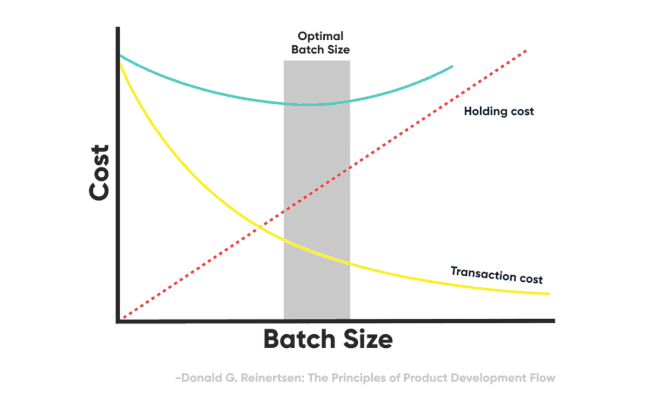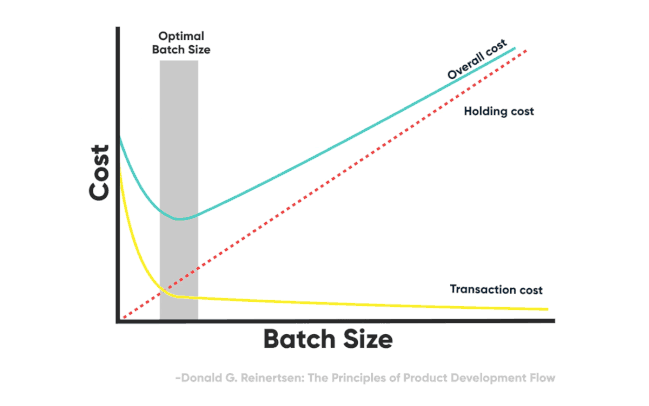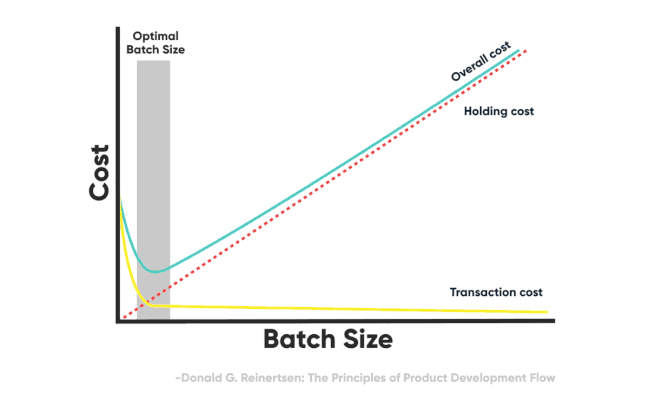
## Where does DevOps fit in?
Automation is one of the things DevOps is most known for. The previous illustration shows the value of automation in great detail. Through automation, we reduce our transaction costs to nearly zero, essentially getting our testing and deployments for free. This lets us take advantage of smaller and smaller batch sizes of work. Smaller batches of work are easier to understand, commit to, test, review, and know when they are done. These smaller batch sizes also contain less variance and risk, making them easier to deploy and, if something goes wrong, to troubleshoot and recover from. With automation combined with a solid agile practice, we can get our feature development very close to single piece flow, providing value to customers quickly and continuously.
More traditionally, DevOps is understood as a way to knock down the walls of confusion between the dev and ops teams. In this model, development teams develop new features, while operations teams keep the system stable and running smoothly. Friction occurs because new features from development introduce change into the system, increasing the risk of an outage, which the operations team doesn't feel responsible for—but has to deal with anyway. DevOps is not just trying to get people working together, it's more about trying to make more frequent changes safely in a complex environment.
We can look to [Ron Westrum](https://en.wikipedia.org/wiki/Ron_Westrum) for research about achieving safety in complex organizations. In researching why some organizations are safer than others, he found that an organization's culture is predictive of its safety. He identified three types of culture: Pathological, Bureaucratic, and Generative. He found that the Pathological culture was predictive of less safety and the Generative culture was predictive of more safety (e.g., far fewer plane crashes or accidental hospital deaths in his main areas of research).
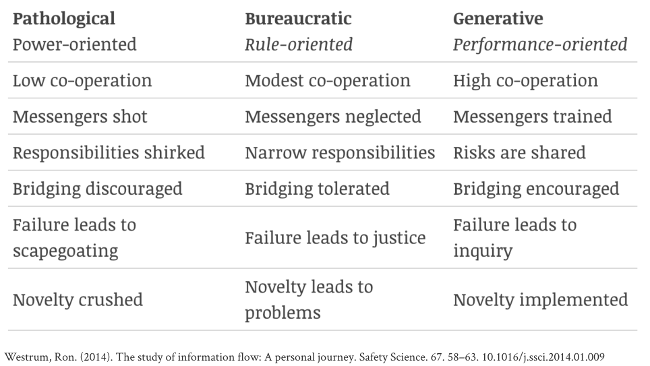
Effective DevOps teams achieve a Generative culture with lean and agile practices, showing that speed and safety are complementary, or two sides of the same coin. By reducing the optimal batch sizes of decisions and features to become very small, DevOps achieves a faster flow of information and value while removing waste and reducing risk.
In line with Westrum's research, change can happen easily with safety and reliability improving at the same time. When an agile DevOps team is trusted to make its own decisions, we get the tools and techniques DevOps is most known for today: automation and continuous delivery. Through this automation, transaction costs are reduced further than ever, and a near single piece lean flow is achieved, creating the potential for thousands of decisions and releases per day, as we've seen happen in high-performing DevOps organizations.
## Flow, feedback, learning
DevOps doesn't stop there. We've mainly been talking about DevOps achieving a revolutionary flow, but lean and agile practices are further amplified through similar efforts that achieve faster feedback loops and faster learning. In the [ DevOps Handbook](https://www.amazon.com/DevOps-Handbook-World-Class-Reliability-Organizations/dp/1942788002/ref=sr_1_3?keywords=DevOps+handbook&qid=1553197361&s=books&sr=1-3), the authors explain in detail how, beyond its fast flow, DevOps achieves telemetry across its entire value stream for fast and continuous feedback. Further, leveraging the
[kaizen](https://en.wikipedia.org/wiki/Kaizen)bursts of lean and the
[retrospectives](https://www.scrum.org/resources/what-is-a-sprint-retrospective)of scrum, high-performing DevOps teams will continuously drive learning and continuous improvement deep into the foundations of their organizations, achieving a lean manufacturing revolution in the software product development industry.
## Start with a DevOps assessment
The first step in leveraging DevOps is, either after much study or with the help of a DevOps consultant and coach, to conduct an assessment across a suite of dimensions consistently found in high-performing DevOps teams. The assessment should identify weak or non-existent team norms that need improvement. Evaluate the assessment's results to find quick wins—focus areas with high chances for success that will produce high-impact improvement. Quick wins are important for gaining the momentum needed to tackle more challenging areas. The teams should generate ideas that can be tried quickly and start to move the needle on the DevOps transformation.
After some time, the team should reassess on the same dimensions to measure improvements and identify new high-impact focus areas, again with fresh ideas from the team. A good coach will consult, train, mentor, and support as needed until the team owns its own continuous improvement and achieves near consistency on all dimensions by continually reassessing, experimenting, and learning.
In the [second part](https://opensource.com/article/19/3/where-drupal-community-stands-devops-adoption) of this article, we'll look at results from a DevOps survey in the Drupal community and see where the quick wins are most likely to be found.
*Rob** Bayliss and Kelly Albrecht will present DevOps: Why, How, and What and host a follow-up Birds of a *
*Feather*
## Comments are closed. |
10,836 | 为何《贡献者许可协议》不利于开源社区? | https://opensource.com/article/19/2/cla-problems | 2019-05-10T09:16:01 | [
"CLA"
] | https://linux.cn/article-10836-1.html |
>
> 开源社区中很少有法律话题像《贡献者许可协议》一样具有争议性。
>
>
>

开源社区中很少有法律话题像《[贡献者许可协议](https://opensource.com/article/18/3/cla-vs-dco-whats-difference)》(CLA)一样具有争议性。除非你算上《[Fedora 项目贡献者协议](https://opensource.com/law/10/6/new-contributor-agreement-fedora)》(我一直被视为非 CLA)的特殊历史案例,或者像 [Karl Fogel](https://www.red-bean.com/kfogel/) 一样,将《[开发者原创证书](https://developercertificate.org/)》(DCO)归类为[一种 CLA](https://producingoss.com/en/contributor-agreements.html#developer-certificate-of-origin)。目前红帽公司在其维护的项目中没有使用 CLA。
过去情况并非如此。红帽公司最早的项目遵循我称之为<ruby> “入站=出站” <rp> ( </rp> <rt> inbound=outbound </rt> <rp> ) </rp></ruby>的传统做法,其中对项目的贡献仅根据项目的开源许可协议提供,不需要执行外部非自由和开源许可协议。但在 21 世纪初,红帽公司开始尝试使用贡献者协议。Fedora 开始要求贡献者签署基于广泛采用的 [Apache ICLA](https://www.apache.org/licenses/icla.pdf) 制定的 CLA,而自由软件基金会衍生的版权转让协议和一对定制的 CLA 分别继承自 Cygnus 和 JBoss 的收购。我们甚至采取了[一些措施](https://www.freeipa.org/page/Why_CLA%3F),在快速增长的红帽公司主导项目中采用 Apache 风格的 CLA。
这种情况已经结束,很大程度上是因为我们红帽公司法律团队成员听到并理解了红帽工程师和更广泛的技术社区提出的担忧和异议。我们继续成为一些人称之为反 CLA 运动的事实上的领导者,特别是我们[反对 Project Harmony](https://opensource.com/law/11/7/trouble-harmony-part-1) 以及我们[努力](https://wiki.openstack.org/wiki/OpenStackAndItsCLA)让 OpenStack 用 DCO 取代其 CLA。(我们[不情愿地](https://opensource.com/article/19/1/cla-proliferation)签署可容忍的不符合实际需要的上游项目 CLA)
### 为什么 CLA 存在问题
我们不使用 CLA 的选择反映了我们作为一个真正的开源公司的价值观,它在自由软件运动中有着深厚的根源。多年来,许多开源社区已经解释了为什么 CLA 以及类似的版权分配机制对于开源来说是一个糟糕的政策。
其中一个原因是繁文缛节问题。通常情况下,开源开发的特点是<ruby> 无障碍 <rp> ( </rp> <rt> frictionless </rt> <rp> ) </rp></ruby>贡献,这可以通过“入站=出站”来实现,而不需要进行进一步的法律仪式或流程。这使得新贡献者相对容易参与项目,允许贡献者社区更有效的增长并推动上游的技术创新。无障碍贡献是开源开发针对专有替代品享有优势的关键部分。但是,CLA 否定了无障碍的贡献。在贡献被接受之前签署不寻常的法律协议会造成官僚主义障碍,从而减缓发展并阻碍参与。尽管采用 CLA 的项目越来越多地使用自动化手段,但这种成本仍然存在。
CLA 还会导致项目参与者之间的法律权力不对称,这也阻碍了项目周边主要贡献者和用户社区的增长。使用 Apache 风格的 CLA,领导项目的公司或组织获得其他贡献者无法获得的特殊权利,而其他贡献者必须承担项目负责人免除的某些法律义务(除了繁文缛节负担)。在<ruby> 左版 <rp> ( </rp> <rt> copyleft </rt> <rp> ) </rp></ruby>项目中,不对称问题最为严重,即使出站许可协议是宽松的,它也存在。
在评估支持和反对 CLA 的论据时,请记住,今天与过去一样,任何产品中的绝大多数开源代码都源于遵循“入站=出站”实践的项目。相对较少数量的项目使用 CLA 会对所有其他项目造成附带损害,因为它表明,由于某些原因,开源许可协议不足以处理流入项目的贡献。
### CLA 的案例
由于 CLA 仍然是少数人的做法,并且源自外部开源社区文化,我认为 CLA 的支持者应该解释清楚为什么它们相对于其成本是必要或有益的。我怀疑大多数使用 CLA 的公司只是在没有经过严格审查的情况下模仿同行公司的行为。肤浅的来说,对于那些倾向于采用更复杂的手续、纸张和流程而不管业务成本如何的风险规避律师而言,CLA 是正常的。尽管如此,一些支持 CLA 的论据往往是先进的,值得考虑。
**易于<ruby> 再许可 <rp> ( </rp> <rt> relicensing </rt> <rp> ) </rp></ruby>**:如果管理得当,Apache 风格的 CLA 可以根据管理员的选择,为其提供有效的无限权力来进行分许可。这种做法有时被认为是可取的,因为可能需要依据一些其他开源许可协议再许可该项目。但是,回顾一些涉及大量贡献者的项目(所有这些项目都是在没有使用 CLA 的情况下取得成功)的重要再许可活动的历史案例,易于再许可的价值被夸大了。再许可变得困难很有好处,因为它会让项目产生稳定的法律期望,并鼓励项目在进行重大法律政策变更之前咨询其贡献者社区。在任何情况下,大多数“入站=出站”开源项目在其生命周期中从不尝试再许可,而对于少数这样做的项目来说,再许可将相对轻松,因为通常需要去联系的过去的贡献者的数量不会很大。
**原创追踪**:有的人声称 CLA 使项目能够严格跟踪具有一定法律效益的贡献的来源。目前尚不清楚在这方面使用 CLA 所取得的成就是因为通过保留 Git 提交历史这样的非 CLA 手段无法更好地处理。DCO 似乎更适合跟踪贡献,因为它通常在每个提交的基础上使用,而 CLA 是每个贡献者签署一次,并且在行政上与代码贡献分开。此外,原创跟踪通常被描述为对公众有益,但我知道项目无法对 CLA 接受记录提供透明的随时可行的公开访问。
**许可撤销**:一些 CLA 支持者警告说可能有一天,贡献者可能会试图撤销过去授予的许可。如果关注的范围是大量没有供职公司的具有判断力的个人贡献者,则不清楚为什么 Apache 风格的 CLA 与使用开源许可协议相比提供了更有意义的保护。而且,正如在讨论开源法律政策时提出的许多法律风险一样,这似乎是一种幻想的风险。多年来,我只听说过少数声称的许可撤销尝试活动,所有这些都在贡献者面临社区压力而退步时得到迅速解决。
**未经授权的员工贡献**:这是许可撤销问题的一个特例,最近已成为 CLA 倡导者共同提出的观点。当员工为上游项目提供贡献时,通常雇主拥有项目给予许可的版权和专利,并且只有某些管理人员有权授予此类许可。假设一名员工在未经雇主批准的情况下向项目提供了专有代码,雇主后来发现这一点并要求删除该项贡献或起诉该项目的用户。通过使用类似 [Apache CCLA](https://www.apache.org/licenses/cla-corporate.txt) 及其陈述和签名要求的材料,加上一些适当的审查程序以确定 CCLA 签名者可能被授权签署(我怀疑大多数使用 CLA 的公司没有采取任何有意义的措施),可以将这种未经授权的贡献风险最小化。
基于常识和共同经验,我认为,在今天的几乎所有案例中,员工的贡献都是在雇主的实际或建设性知识基础上和同意下完成的。如果围绕开源软件存在高度诉讼风险,也许应该更加重视这种风险,但开源项目引发的诉讼仍然非常罕见。
更重要的是,我不知道任何针对“入站=出站”项目的非源自涉嫌开源许可协议违规的版权或专利侵权指控因使用CLA而被阻止的案例。特别是,当指出未经授权的贡献风险时,CLA 支持者经常引用专利风险,但 Apache 风格的 CLA 中的专利许可授权的设计范围非常狭窄。此外,企业对开源项目的贡献通常很少,规模较小(因此很容易更换),并且随着时间的推移可能会被丢弃。
### 备选方案
如果您的公司没有对反 CLA 案例买账并且对简单使用“入站=出站”感到不舒服,那么还有其他方法可以替代非对称且管理上繁琐的 Apache 风格的 CLA 要求。使用 DCO 作为“入站=出站”的补充至少消除了厌恶风险的 CLA 倡导者的一些担忧。如果必须使用真正的 CLA,则无需使 用Apach e模式(更不用说它的[怪异衍生物](https://opensource.com/article/19/1/cla-proliferation))。考虑“[Eclipse 贡献者协议](https://www.eclipse.org/legal/ECA.php)”的非规范核心(基本上是包含在 CLA 内的 DCO),或者<ruby> 软件自由保护协会 <rp> ( </rp> <rt> Software Freedom Conservancy </rt> <rp> ) </rp></ruby>的 [Selenium CLA](https://docs.google.com/forms/d/e/1FAIpQLSd2FsN12NzjCs450ZmJzkJNulmRC8r8l8NYwVW5KWNX7XDiUw/viewform?hl=en_US&formkey=dFFjXzBzM1VwekFlOWFWMjFFRjJMRFE6MQ#gid=0),它仅仅是对“入站=出站”贡献策略进行仪式化。
---
作者简介:Richard Fontana 是红帽公司法律部门产品和技术团队的高级商业顾问。 他的大部分工作都集中在开源相关的法律问题上。
译者简介:薛亮,集慧智佳知识产权咨询公司总监,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 200 | OK | Few legal topics in open source are as controversial as [contributor license agreements](https://opensource.com/article/18/3/cla-vs-dco-whats-difference) (CLAs). Unless you count the special historical case of the [Fedora Project Contributor Agreement](https://opensource.com/law/10/6/new-contributor-agreement-fedora) (which I've always seen as an *un*-CLA), or, like [Karl Fogel](https://www.red-bean.com/kfogel/), you classify the [DCO](https://developercertificate.org) as a [type of CLA](https://producingoss.com/en/contributor-agreements.html#developer-certificate-of-origin), today Red Hat makes no use of CLAs for the projects it maintains.
It wasn't always so. Red Hat's earliest projects followed the traditional practice I've called "inbound=outbound," in which contributions to a project are simply provided under the project's open source license with no execution of an external, non-FOSS contract required. But in the early 2000s, Red Hat began experimenting with the use of contributor agreements. Fedora started requiring contributors to sign a CLA based on the widely adapted [Apache ICLA](https://www.apache.org/licenses/icla.pdf), while a Free Software Foundation-derived copyright assignment agreement and a pair of bespoke CLAs were inherited from the Cygnus and JBoss acquisitions, respectively. We even took [a few steps](https://www.freeipa.org/page/Why_CLA%3F) towards adopting an Apache-style CLA across the rapidly growing set of Red Hat-led projects.
This came to an end, in large part because those of us on the Red Hat legal team heard and understood the concerns and objections raised by Red Hat engineers and the wider technical community. We went on to become de facto leaders of what some have called the anti-CLA movement, marked notably by our [opposition to Project Harmony](https://opensource.com/law/11/7/trouble-harmony-part-1) and our [efforts](https://wiki.openstack.org/wiki/OpenStackAndItsCLA) to get OpenStack to replace its CLA with the DCO. (We [reluctantly](https://opensource.com/article/19/1/cla-proliferation) sign tolerable upstream project CLAs out of practical necessity.)
## Why CLAs are problematic
Our choice not to use CLAs is a reflection of our values as an authentic open source company with deep roots in the free software movement. Over the years, many in the open source community have explained why CLAs, and the very similar mechanism of copyright assignment, are a bad policy for open source.
One reason is the red tape problem. Normally, open source development is characterized by frictionless contribution, which is enabled by inbound=outbound without imposition of further legal ceremony or process. This makes it relatively easy for new contributors to get involved in a project, allowing more effective growth of contributor communities and driving technical innovation upstream. Frictionless contribution is a key part of the advantage open source development holds over proprietary alternatives. But frictionless contribution is negated by CLAs. Having to sign an unusual legal agreement before a contribution can be accepted creates a bureaucratic hurdle that slows down development and discourages participation. This cost persists despite the growing use of automation by CLA-using projects.
CLAs also give rise to an asymmetry of legal power among a project's participants, which also discourages the growth of strong contributor and user communities around a project. With Apache-style CLAs, the company or organization leading the project gets special rights that other contributors do not receive, while those other contributors must shoulder certain legal obligations (in addition to the red tape burden) from which the project leader is exempt. The problem of asymmetry is most severe in copyleft projects, but it is present even when the outbound license is permissive.
When assessing the arguments for and against CLAs, bear in mind that today, as in the past, the vast majority of the open source code in any product originates in projects that follow the inbound=outbound practice. The use of CLAs by a relatively small number of projects causes collateral harm to all the others by signaling that, for some reason, open source licensing is insufficient to handle contributions flowing into a project.
## The case for CLAs
Since CLAs continue to be a minority practice and originate from outside open source community culture, I believe that CLA proponents should bear the burden of explaining why they are necessary or beneficial *relative to their costs*. I suspect that most companies using CLAs are merely emulating peer company behavior without critical examination. CLAs have an understandable, if superficial, appeal to risk-averse lawyers who are predisposed to favor greater formality, paper, and process regardless of the business costs. Still, some arguments in favor of CLAs are often advanced and deserve consideration.
**Easy relicensing:** If administered appropriately, Apache-style CLAs give the project steward effectively unlimited power to sublicense contributions under terms of the steward's choice. This is sometimes seen as desirable because of the potential need to relicense a project under some other open source license. But the value of easy relicensing has been greatly exaggerated by pointing to a few historical cases involving major relicensing campaigns undertaken by projects with an unusually large number of past contributors (all of which were successful without the use of a CLA). There are benefits in relicensing being hard because it results in stable legal expectations around a project and encourages projects to consult their contributor communities before undertaking significant legal policy changes. In any case, most inbound=outbound open source projects never attempt to relicense during their lifetime, and for the small number that do, relicensing will be relatively painless because typically the number of past contributors to contact will not be large.
**Provenance tracking:** It is sometimes claimed that CLAs enable a project to rigorously track the provenance of contributions, which purportedly has some legal benefit. It is unclear what is achieved by the use of CLAs in this regard that is not better handled through such non-CLA means as preserving Git commit history. And the DCO would seem to be much better suited to tracking contributions, given that it is normally used on a per-commit basis, while CLAs are signed once per contributor and are administratively separate from code contributions. Moreover, provenance tracking is often described as though it were a benefit for the public, yet I know of no case where a project provides transparent, ready public access to CLA acceptance records.
**License revocation:** Some CLA advocates warn of the prospect that a contributor may someday attempt to revoke a past license grant. To the extent that the concern is about largely judgment-proof individual contributors with no corporate affiliation, it is not clear why an Apache-style CLA provides more meaningful protection against this outcome compared to the use of an open source license. And, as with so many of the legal risks raised in discussions of open source legal policy, this appears to be a phantom risk. I have heard of only a few purported attempts at license revocation over the years, all of which were resolved quickly when the contributor backed down in the face of community pressure.
**Unauthorized employee contribution:** This is a special case of the license revocation issue and has recently become a point commonly raised by CLA advocates. When an employee contributes to an upstream project, normally the employer owns the copyrights and patents for which the project needs licenses, and only certain executives are authorized to grant such licenses. Suppose an employee contributed proprietary code to a project without approval from the employer, and the employer later discovers this and demands removal of the contribution or sues the project's users. This risk of unauthorized contributions is thought to be minimized by use of something like the [Apache CCLA](https://www.apache.org/licenses/cla-corporate.txt) with its representations and signature requirement, coupled with some adequate review process to ascertain that the CCLA signer likely was authorized to sign (a step which I suspect is not meaningfully undertaken by most CLA-using companies).
Based on common sense and common experience, I contend that in nearly all cases today, employee contributions are done with the actual or constructive knowledge and consent of the employer. If there were an atmosphere of high litigation risk surrounding open source software, perhaps this risk should be taken more seriously, but litigation arising out of open source projects remains remarkably uncommon.
More to the point, I know of no case where an allegation of copyright or patent infringement against an inbound=outbound project, not stemming from an alleged open source license violation, would have been prevented by use of a CLA. Patent risk, in particular, is often cited by CLA proponents when pointing to the risk of unauthorized contributions, but the patent license grants in Apache-style CLAs are, by design, quite narrow in scope. Moreover, corporate contributions to an open source project will typically be few in number, small in size (and thus easily replaceable), and likely to be discarded as time goes on.
## Alternatives
If your company does not buy into the anti-CLA case and cannot get comfortable with the simple use of inbound=outbound, there are alternatives to resorting to an asymmetric and administratively burdensome Apache-style CLA requirement. The use of the DCO as a complement to inbound=outbound addresses at least some of the concerns of risk-averse CLA advocates. If you must use a true CLA, there is no need to use the Apache model (let alone a [monstrous derivative](https://opensource.com/article/19/1/cla-proliferation) of it). Consider the non-specification core of the [Eclipse Contributor Agreement](https://www.eclipse.org/legal/ECA.php)—essentially the DCO wrapped inside a CLA—or the Software Freedom Conservancy's [Selenium CLA](https://docs.google.com/forms/d/e/1FAIpQLSd2FsN12NzjCs450ZmJzkJNulmRC8r8l8NYwVW5KWNX7XDiUw/viewform?hl=en_US&formkey=dFFjXzBzM1VwekFlOWFWMjFFRjJMRFE6MQ#gid=0), which merely ceremonializes an inbound=outbound contribution policy.
## 2 Comments |
10,837 | apt-clone:备份已安装的软件包并在新的 Ubuntu 系统上恢复它们 | https://www.2daygeek.com/apt-clone-backup-installed-packages-and-restore-them-on-fresh-ubuntu-system/ | 2019-05-10T09:43:59 | [
"apt"
] | https://linux.cn/article-10837-1.html | 
当我们在基于 Ubuntu/Debian 的系统上使用 `apt-clone`,包安装会变得更加容易。如果你需要在少量系统上安装相同的软件包时,`apt-clone` 会适合你。
如果你想在每个系统上手动构建和安装必要的软件包,这是一个耗时的过程。它可以通过多种方式实现,Linux 中有许多程序可用。我们过去曾写过一篇关于 [Aptik](https://www.2daygeek.com/aptik-backup-restore-ppas-installed-apps-users-data/) 的文章。它是能让 Ubuntu 用户备份和恢复系统设置和数据的程序之一。
### 什么是 apt-clone?
[apt-clone](https://github.com/mvo5/apt-clone) 能让你为 Debian/Ubuntu 系统创建所有已安装软件包的备份,这些软件包可以在新安装的系统(或容器)或目录中恢复。
该备份可以在相同操作系统版本和架构的多个系统上还原。
### 如何安装 apt-clone?
`apt-clone` 包可以在 Ubuntu/Debian 的官方仓库中找到,所以,使用 [apt 包管理器](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 或 [apt-get 包管理器](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 来安装它。
使用 `apt` 包管理器安装 `apt-clone`。
```
$ sudo apt install apt-clone
```
使用 `apt-get` 包管理器安装 `apt-clone`。
```
$ sudo apt-get install apt-clone
```
### 如何使用 apt-clone 备份已安装的软件包?
成功安装 `apt-clone` 之后。只需提供一个保存备份文件的位置。我们将在 `/backup` 目录下保存已安装的软件包备份。
`apt-clone` 会将已安装的软件包列表保存到 `apt-clone-state-Ubuntu18.2daygeek.com.tar.gz` 中。
```
$ sudo apt-clone clone /backup
```
我们同样可以通过运行 `ls` 命令来检查。
```
$ ls -lh /backup/
total 32K
-rw-r--r-- 1 root root 29K Apr 20 19:06 apt-clone-state-Ubuntu18.2daygeek.com.tar.gz
```
运行以下命令,查看备份文件的详细信息。
```
$ apt-clone info /backup/apt-clone-state-Ubuntu18.2daygeek.com.tar.gz
Hostname: Ubuntu18.2daygeek.com
Arch: amd64
Distro: bionic
Meta: libunity-scopes-json-def-desktop, ubuntu-desktop
Installed: 1792 pkgs (194 automatic)
Date: Sat Apr 20 19:06:43 2019
```
根据上面的输出,备份文件中总共有 1792 个包。
### 如何恢复使用 apt-clone 进行备份的软件包?
你可以使用任何远程复制程序来复制远程服务器上的文件。
```
$ scp /backup/apt-clone-state-ubunt-18-04.tar.gz Destination-Server:/opt
```
复制完成后,使用 `apt-clone` 执行还原。
使用以下命令进行还原。
```
$ sudo apt-clone restore /opt/apt-clone-state-Ubuntu18.2daygeek.com.tar.gz
```
请注意,还原将覆盖现有的 `/etc/apt/sources.list` 并安装/删除包。所以要小心。
如果你要将所有软件包还原到文件夹而不是实际还原,可以使用以下命令。
```
$ sudo apt-clone restore /opt/apt-clone-state-Ubuntu18.2daygeek.com.tar.gz --destination /opt/oldubuntu
```
---
via: <https://www.2daygeek.com/apt-clone-backup-installed-packages-and-restore-them-on-fresh-ubuntu-system/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,840 | 用 OpenStack Designate 构建一个 DNS 即服务(DNSaaS) | https://opensource.com/article/19/4/getting-started-openstack-designate | 2019-05-11T11:09:00 | [
"DNS",
"OpenStack"
] | https://linux.cn/article-10840-1.html |
>
> 学习如何安装和配置 Designate,这是一个 OpenStack 的多租户 DNS 即服务(DNSaaS)。
>
>
>

[Designate](https://docs.openstack.org/designate/latest/) 是一个多租户的 DNS 即服务,它包括一个用于域名和记录管理的 REST API 和集成了 [Neutron](https://opensource.com/article/19/3/openstack-neutron) 的框架,并支持 Bind9。
DNSaaS 可以提供:
* 一个管理区域和记录的干净利落的 REST API
* 自动生成记录(集成 OpenStack)
* 支持多个授权名字服务器
* 可以托管多个项目/组织

这篇文章解释了如何在 CentOS 和 RHEL 上手动安装和配置 Designate 的最新版本,但是同样的配置也可以用在其它发行版上。
### 在 OpenStack 上安装 Designate
在我的 [GitHub 仓库](https://github.com/ayaseen/designate)里,我已经放了 Ansible 的 bind 和 Designate 角色的示范设置。
这个设置假定 bing 服务是安装 OpenStack 控制器节点之外(即使你可以在本地安装 bind)。
1、在 OpenStack 控制节点上安装 Designate 和 bind 软件包:
```
# yum install openstack-designate-* bind bind-utils -y
```
2、创建 Designate 数据库和用户:
```
MariaDB [(none)]> CREATE DATABASE designate CHARACTER SET utf8 COLLATE utf8_general_ci;
MariaDB [(none)]> GRANT ALL PRIVILEGES ON designate.* TO \
'designate'@'localhost' IDENTIFIED BY 'rhlab123';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON designate.* TO 'designate'@'%' \
IDENTIFIED BY 'rhlab123';
```
注意:bind 包必须安装在控制节点之外才能使<ruby> 远程名字服务控制 <rt> Remote Name Daemon Control </rt></ruby>(RNDC)功能正常。
### 配置 bind(DNS 服务器)
1、生成 RNDC 文件:
```
rndc-confgen -a -k designate -c /etc/rndc.key -r /dev/urandom
cat <<EOF> etcrndc.conf
include "/etc/rndc.key";
options {
default-key "designate";
default-server {{ DNS_SERVER_IP }};
default-port 953;
};
EOF
```
2、将下列配置添加到 `named.conf`:
```
include "/etc/rndc.key";
controls {
inet {{ DNS_SERVER_IP }} allow { localhost;{{ CONTROLLER_SERVER_IP }}; } keys { "designate"; };
};
```
在 `option` 节中,添加:
```
options {
...
allow-new-zones yes;
request-ixfr no;
listen-on port 53 { any; };
recursion no;
allow-query { 127.0.0.1; {{ CONTROLLER_SERVER_IP }}; };
};
```
添加正确的权限:
```
chown named:named /etc/rndc.key
chown named:named /etc/rndc.conf
chmod 600 /etc/rndc.key
chown -v root:named /etc/named.conf
chmod g+w /var/named
# systemctl restart named
# setsebool named_write_master_zones 1
```
3、把 `rndc.key` 和 `rndc.conf` 推入 OpenStack 控制节点:
```
# scp -r /etc/rndc* {{ CONTROLLER_SERVER_IP }}:/etc/
```
### 创建 OpenStack Designate 服务和端点
输入:
```
# openstack user create --domain default --password-prompt designate
# openstack role add --project services --user designate admin
# openstack service create --name designate --description "DNS" dns
# openstack endpoint create --region RegionOne dns public http://{{ CONTROLLER_SERVER_IP }}:9001/
# openstack endpoint create --region RegionOne dns internal http://{{ CONTROLLER_SERVER_IP }}:9001/
# openstack endpoint create --region RegionOne dns admin http://{{ CONTROLLER_SERVER_IP }}:9001/
```
### 配置 Designate 服务
1、编辑 `/etc/designate/designate.conf`:
在 `[service:api]` 节配置 `auth_strategy`:
```
[service:api]
listen = 0.0.0.0:9001
auth_strategy = keystone
api_base_uri = http://{{ CONTROLLER_SERVER_IP }}:9001/
enable_api_v2 = True
enabled_extensions_v2 = quotas, reports
```
在 `[keystone_authtoken]` 节配置下列选项:
```
[keystone_authtoken]
auth_type = password
username = designate
password = rhlab123
project_name = service
project_domain_name = Default
user_domain_name = Default
www_authenticate_uri = http://{{ CONTROLLER_SERVER_IP }}:5000/
auth_url = http://{{ CONTROLLER_SERVER_IP }}:5000/
```
在 `[service:worker]` 节,启用 worker 模型:
```
enabled = True
notify = True
```
在 `[storage:sqlalchemy]` 节,配置数据库访问:
```
[storage:sqlalchemy]
connection = mysql+pymysql://designate:rhlab123@{{ CONTROLLER_SERVER_IP }}/designate
```
填充 Designate 数据库:
```
# su -s /bin/sh -c "designate-manage database sync" designate
```
2、 创建 Designate 的 `pools.yaml` 文件(包含 target 和 bind 细节):
编辑 `/etc/designate/pools.yaml`:
```
- name: default
# The name is immutable. There will be no option to change the name after
# creation and the only way will to change it will be to delete it
# (and all zones associated with it) and recreate it.
description: Default Pool
attributes: {}
# List out the NS records for zones hosted within this pool
# This should be a record that is created outside of designate, that
# points to the public IP of the controller node.
ns_records:
- hostname: {{Controller_FQDN}}. # Thisis mDNS
priority: 1
# List out the nameservers for this pool. These are the actual BIND servers.
# We use these to verify changes have propagated to all nameservers.
nameservers:
- host: {{ DNS_SERVER_IP }}
port: 53
# List out the targets for this pool. For BIND there will be one
# entry for each BIND server, as we have to run rndc command on each server
targets:
- type: bind9
description: BIND9 Server 1
# List out the designate-mdns servers from which BIND servers should
# request zone transfers (AXFRs) from.
# This should be the IP of the controller node.
# If you have multiple controllers you can add multiple masters
# by running designate-mdns on them, and adding them here.
masters:
- host: {{ CONTROLLER_SERVER_IP }}
port: 5354
# BIND Configuration options
options:
host: {{ DNS_SERVER_IP }}
port: 53
rndc_host: {{ DNS_SERVER_IP }}
rndc_port: 953
rndc_key_file: /etc/rndc.key
rndc_config_file: /etc/rndc.conf
```
填充 Designate 池:
```
su -s /bin/sh -c "designate-manage pool update" designate
```
3、启动 Designate 中心和 API 服务:
```
systemctl enable --now designate-central designate-api
```
4、验证 Designate 服务运行:
```
# openstack dns service list
+--------------+--------+-------+--------------+
| service_name | status | stats | capabilities |
+--------------+--------+-------+--------------+
| central | UP | - | - |
| api | UP | - | - |
| mdns | UP | - | - |
| worker | UP | - | - |
| producer | UP | - | - |
+--------------+--------+-------+--------------+
```
### 用外部 DNS 配置 OpenStack Neutron
1、为 Designate 服务配置 iptables:
```
# iptables -I INPUT -p tcp -m multiport --dports 9001 -m comment --comment "designate incoming" -j ACCEPT
# iptables -I INPUT -p tcp -m multiport --dports 5354 -m comment --comment "Designate mdns incoming" -j ACCEPT
# iptables -I INPUT -p tcp -m multiport --dports 53 -m comment --comment "bind incoming" -j ACCEPT
# iptables -I INPUT -p udp -m multiport --dports 53 -m comment --comment "bind/powerdns incoming" -j ACCEPT
# iptables -I INPUT -p tcp -m multiport --dports 953 -m comment --comment "rndc incoming - bind only" -j ACCEPT
# service iptables save; service iptables restart
# setsebool named_write_master_zones 1
```
2、 编辑 `/etc/neutron/neutron.conf` 的 `[default]` 节:
```
external_dns_driver = designate
```
3、 在 `/etc/neutron/neutron.conf` 中添加 `[designate]` 节:
```
[designate]
url = http://{{ CONTROLLER_SERVER_IP }}:9001/v2 ## This end point of designate
auth_type = password
auth_url = http://{{ CONTROLLER_SERVER_IP }}:5000
username = designate
password = rhlab123
project_name = services
project_domain_name = Default
user_domain_name = Default
allow_reverse_dns_lookup = True
ipv4_ptr_zone_prefix_size = 24
ipv6_ptr_zone_prefix_size = 116
```
4、编辑 `neutron.conf` 的 `dns_domain`:
```
dns_domain = rhlab.dev.
```
重启:
```
# systemctl restart neutron-*
```
5、在 `/etc/neutron/plugins/ml2/ml2_conf.ini` 中的组成层 2(ML2)中添加 `dns`:
```
extension_drivers=port_security,qos,dns
```
6、在 Designate 中添加区域:
```
# openstack zone create –[email protected] rhlab.dev.
```
在 `rhlab.dev` 区域中添加记录:
```
# openstack recordset create --record '192.168.1.230' --type A rhlab.dev. Test
```
Designate 现在就安装和配置好了。
---
via: <https://opensource.com/article/19/4/getting-started-openstack-designate>
作者:[Amjad Yaseen](https://opensource.com/users/ayaseen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Designate](https://docs.openstack.org/designate/latest/) is a multi-tenant DNS-as-a-service that includes a REST API for domain and record management, a framework for integration with [Neutron](https://opensource.com/article/19/3/openstack-neutron), and integration support for Bind9.
You would want to consider a DNSaaS for the following:
- A clean REST API for managing zones and records
- Automatic records generated (with OpenStack integration)
- Support for multiple authoritative name servers
- Hosting multiple projects/organizations
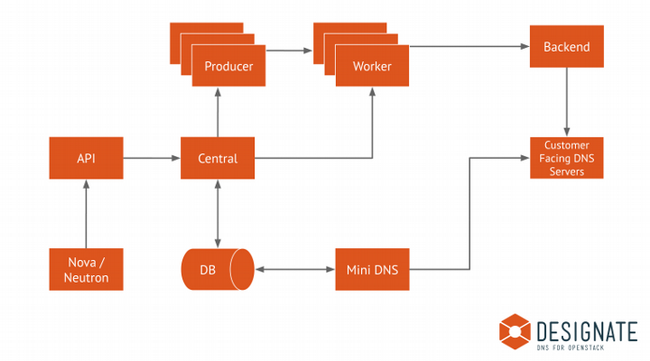
This article explains how to manually install and configure the latest release of Designate service on CentOS or Red Hat Enterprise Linux 7 (RHEL 7), but you can use the same configuration on other distributions.
## Install Designate on OpenStack
I have Ansible roles for bind and Designate that demonstrate the setup in my [GitHub repository](https://github.com/ayaseen/designate).
This setup presumes bind service is external (even though you can install bind locally) on the OpenStack controller node.
- Install Designate's packages and bind (on OpenStack controller):
`# yum install openstack-designate-* bind bind-utils -y`
- Create the Designate database and user:
`MariaDB [(none)]> CREATE DATABASE designate CHARACTER SET utf8 COLLATE utf8_general_ci; MariaDB [(none)]> GRANT ALL PRIVILEGES ON designate.* TO \ 'designate'@'localhost' IDENTIFIED BY 'rhlab123'; MariaDB [(none)]> GRANT ALL PRIVILEGES ON designate.* TO 'designate'@'%' \ IDENTIFIED BY 'rhlab123';`
Note: Bind packages must be installed on the controller side for Remote Name Daemon Control (RNDC) to function properly.
## Configure bind (DNS server)
- Generate RNDC files:
`rndc-confgen -a -k designate -c /etc/rndc.key -r /dev/urandom cat <<EOF> etcrndc.conf include "/etc/rndc.key"; options { default-key "designate"; default-server {{ DNS_SERVER_IP }}; default-port 953; }; EOF`
- Add the following into
**named.conf**:
`include "/etc/rndc.key"; controls { inet {{ DNS_SERVER_IP }} allow { localhost;{{ CONTROLLER_SERVER_IP }}; } keys { "designate"; }; };`
In the
**option**section, add:`options { ... allow-new-zones yes; request-ixfr no; listen-on port 53 { any; }; recursion no; allow-query { 127.0.0.1; {{ CONTROLLER_SERVER_IP }}; }; };`
Add the right permissions:
`chown named:named /etc/rndc.key chown named:named /etc/rndc.conf chmod 600 /etc/rndc.key chown -v root:named /etc/named.conf chmod g+w /var/named # systemctl restart named # setsebool named_write_master_zones 1`
- Push
**rndc.key**and**rndc.conf**into the OpenStack controller:
`# scp -r /etc/rndc* {{ CONTROLLER_SERVER_IP }}:/etc/`
## Create OpenStack Designate service and endpoints
Enter:
```
# openstack user create --domain default --password-prompt designate
# openstack role add --project services --user designate admin
# openstack service create --name designate --description "DNS" dns
# openstack endpoint create --region RegionOne dns public http://{{ CONTROLLER_SERVER_IP }}:9001/
# openstack endpoint create --region RegionOne dns internal http://{{ CONTROLLER_SERVER_IP }}:9001/
# openstack endpoint create --region RegionOne dns admin http://{{ CONTROLLER_SERVER_IP }}:9001/
```
## Configure Designate service
- Edit
**/etc/designate/designate.conf**:- In the
**[service:api]**section, configure**auth_strategy**:
`[service:api] listen = 0.0.0.0:9001 auth_strategy = keystone api_base_uri = http://{{ CONTROLLER_SERVER_IP }}:9001/ enable_api_v2 = True enabled_extensions_v2 = quotas, reports`
- In the
**[keystone_authtoken]**section, configure the following options:
`[keystone_authtoken] auth_type = password username = designate password = rhlab123 project_name = service project_domain_name = Default user_domain_name = Default www_authenticate_uri = http://{{ CONTROLLER_SERVER_IP }}:5000/ auth_url = http://{{ CONTROLLER_SERVER_IP }}:5000/`
- In the
**[service:worker]**section, enable the worker model:
`enabled = True notify = True`
- In the
**[storage:sqlalchemy]**section, configure database access:
`[storage:sqlalchemy] connection = mysql+pymysql://designate:rhlab123@{{ CONTROLLER_SERVER_IP }}/designate`
- Populate the Designate database:
`# su -s /bin/sh -c "designate-manage database sync" designate`
- In the
- Create Designate's
**pools.yaml**file (has target and bind details):- Edit
**/etc/designate/pools.yaml**:
`- name: default # The name is immutable. There will be no option to change the name after # creation and the only way will to change it will be to delete it # (and all zones associated with it) and recreate it. description: Default Pool attributes: {} # List out the NS records for zones hosted within this pool # This should be a record that is created outside of designate, that # points to the public IP of the controller node. ns_records: - hostname: {{Controller_FQDN}}. # Thisis mDNS priority: 1 # List out the nameservers for this pool. These are the actual BIND servers. # We use these to verify changes have propagated to all nameservers. nameservers: - host: {{ DNS_SERVER_IP }} port: 53 # List out the targets for this pool. For BIND there will be one # entry for each BIND server, as we have to run rndc command on each server targets: - type: bind9 description: BIND9 Server 1 # List out the designate-mdns servers from which BIND servers should # request zone transfers (AXFRs) from. # This should be the IP of the controller node. # If you have multiple controllers you can add multiple masters # by running designate-mdns on them, and adding them here. masters: - host: {{ CONTROLLER_SERVER_IP }} port: 5354 # BIND Configuration options options: host: {{ DNS_SERVER_IP }} port: 53 rndc_host: {{ DNS_SERVER_IP }} rndc_port: 953 rndc_key_file: /etc/rndc.key rndc_config_file: /etc/rndc.conf`
- Populate Designate's pools:
`su -s /bin/sh -c "designate-manage pool update" designate`
- Edit
- Start Designate central and API services:
`systemctl enable --now designate-central designate-api`
- Verify Designate's services are up:
`# openstack dns service list +--------------+--------+-------+--------------+ | service_name | status | stats | capabilities | +--------------+--------+-------+--------------+ | central | UP | - | - | | api | UP | - | - | | mdns | UP | - | - | | worker | UP | - | - | | producer | UP | - | - | +--------------+--------+-------+--------------+`
## Configure OpenStack Neutron with external DNS
- Configure iptables for Designate services:
`# iptables -I INPUT -p tcp -m multiport --dports 9001 -m comment --comment "designate incoming" -j ACCEPT # iptables -I INPUT -p tcp -m multiport --dports 5354 -m comment --comment "Designate mdns incoming" -j ACCEPT # iptables -I INPUT -p tcp -m multiport --dports 53 -m comment --comment "bind incoming" -j ACCEPT # iptables -I INPUT -p udp -m multiport --dports 53 -m comment --comment "bind/powerdns incoming" -j ACCEPT # iptables -I INPUT -p tcp -m multiport --dports 953 -m comment --comment "rndc incoming - bind only" -j ACCEPT # service iptables save; service iptables restart # setsebool named_write_master_zones 1`
- Edit the
**[default]**section of**/etc/neutron/neutron.conf**:
`external_dns_driver = designate`
- Add the
**[designate]**section in**/_etc/_neutron/neutron.conf**:
`[designate] url = http://{{ CONTROLLER_SERVER_IP }}:9001/v2 ## This end point of designate auth_type = password auth_url = http://{{ CONTROLLER_SERVER_IP }}:5000 username = designate password = rhlab123 project_name = services project_domain_name = Default user_domain_name = Default allow_reverse_dns_lookup = True ipv4_ptr_zone_prefix_size = 24 ipv6_ptr_zone_prefix_size = 116`
- Edit
**dns_domain**in**neutron.conf**:
`dns_domain = rhlab.dev. # systemctl restart neutron-*`
- Add
**dns**to the list of Modular Layer 2 (ML2) drivers in**/etc/neutron/plugins/ml2/ml2_conf.ini**:
`extension_drivers=port_security,qos,dns`
- Add
**zone**in Designate:
`# openstack zone create –[email protected] rhlab.dev.`
Add a new record in
**zone rhlab.dev**:`# openstack recordset create --record '192.168.1.230' --type A rhlab.dev. Test`
Designate should now be installed and configured.
## 1 Comment |
10,841 | 2 个给使用 Fedora 工作站的音乐爱好者的新应用 | https://fedoramagazine.org/2-new-apps-for-music-tweakers-on-fedora-workstation/ | 2019-05-11T13:21:12 | [
"音乐",
"播放器"
] | https://linux.cn/article-10841-1.html | 
Linux 操作系统非常适合进行独特的自定义和调整,以使你的计算机更好地为你工作。例如,[i3 窗口管理器](https://fedoramagazine.org/getting-started-i3-window-manager/) 就让用户认识到了构成现代 Linux 桌面的各种组件和部分。
Fedora 上有两个音乐爱好者会感兴趣的新软件包:mpris-scrobbler 和 playerctl。mpris-scrobbler 可以在 Last.fm 和/或 ListenBrainz 等音乐跟踪服务上[跟踪你的音乐收听历史](https://github.com/mariusor/mpris-scrobbler)。 playerctl 是一个命令行的[音乐播放器的控制器](https://github.com/acrisci/playerctl)。
### mpris-scrobbler:记录你的音乐收听趋势
mpris-scrobbler 是一个命令行应用程序,用于将音乐的播放历史记录提交给 [Last.fm](https://www.last.fm/)、[Libre.fm](https://libre.fm/) 或 [ListenBrainz](https://listenbrainz.org/) 等服务。它监听 [MPRIS D-Bus 接口](https://specifications.freedesktop.org/mpris-spec/latest/) 以检测正在播放的内容。它可以连接几个不同的音乐客户端,如 spotify 客户端、[vlc](https://www.videolan.org/vlc/)、audacious、bmp、[cmus](https://cmus.github.io/) 等。

#### 安装和配置 mpris-scrobbler
mpris-scrobbler 在 Fedora 28 或更高版本以及 EPEL 7 存储库中可用。在终端中运行以下命令进行安装:
```
sudo dnf install mpris-scrobbler
```
安装完成后,使用 `systemctl` 启动并启用该服务。以下命令启动 mpris-scrobbler 并始终在系统重启后启动它:
```
systemctl --user enable --now mpris-scrobbler.service
```
#### 提交播放信息给 ListenBrainz
这里将介绍如何将 mpris-scrobbler 与 ListenBrainz 帐户相关联。要使用 Last.fm 或 Libre.fm,请参阅其[上游文档](https://github.com/mariusor/mpris-scrobbler#authenticate-to-the-service)。
要将播放信息提交到 ListenBrainz 服务器,你需要有一个 ListenBrainz API 令牌。如果你有帐户,请从[个人资料设置页面](https://listenbrainz.org/profile/)中获取该令牌。如果有了令牌,请运行此命令以使用 ListenBrainz API 令牌进行身份验证:
```
$ mpris-scrobbler-signon token listenbrainz
Token for listenbrainz.org:
```
最后,通过在 Fedora 上用你的音乐客户端播放一首歌来测试它。你播放的歌曲会出现在 ListenBrainz 个人资料页中。

### playerctl 可以控制音乐回放
`playerctl` 是一个命令行工具,它可以控制任何实现了 MPRIS D-Bus 接口的音乐播放器。你可以轻松地将其绑定到键盘快捷键或媒体热键上。以下是如何在命令行中安装、使用它,以及为 i3 窗口管理器创建键绑定的方法。
#### 安装和使用 playerctl
`playerctl` 在 Fedora 28 或更高版本中可用。在终端运行如下命令以安装:
```
sudo dnf install playerctl
```
现在已安装好,你可以立即使用它。在 Fedora 上打开你的音乐播放器。接下来,尝试用以下命令来控制终端的播放。
播放或暂停当前播放的曲目:
```
playerctl play-pause
```
如果你想跳过下一首曲目:
```
playerctl next
```
列出所有正在运行的播放器:
```
playerctl -l
```
仅使用 spotify 客户端播放或暂停当前播放的内容:
```
playerctl -p spotify play-pause
```
#### 在 i3wm 中创建 playerctl 键绑定
你是否使用窗口管理器,比如 [i3 窗口管理器](https://fedoramagazine.org/getting-started-i3-window-manager/)?尝试使用 `playerctl` 进行键绑定。你可以将不同的命令绑定到不同的快捷键,例如键盘上的播放/暂停按钮。参照下面的 [i3wm 配置摘录](https://github.com/jwflory/swiss-army/blob/ba6ac0c71855e33e3caa1ee1fe51c05d2df0529d/roles/apps/i3wm/files/config#L207-L210) 看看如何做:
```
# Media player controls
bindsym XF86AudioPlay exec "playerctl play-pause"
bindsym XF86AudioNext exec "playerctl next"
bindsym XF86AudioPrev exec "playerctl previous"
```
### 体验一下音乐播放器
想了解关于在 Fedora 上定制音乐聆听体验的更多信息吗?Fedora Magazine 为你提供服务。看看 Fedora 上这[五个很酷的音乐播放器](https://fedoramagazine.org/5-cool-music-player-apps/)。
也可以通过使用 MusicBrainz Picard 对音乐库进行排序和组织,[为你的混乱的音乐库带来秩序](https://fedoramagazine.org/picard-brings-order-music-library/)。
---
via: <https://fedoramagazine.org/2-new-apps-for-music-tweakers-on-fedora-workstation/>
作者:[Justin W. Flory](https://fedoramagazine.org/author/jflory7/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux operating systems are great for making unique customizations and tweaks to make your computer work better for you. For example, the [i3 window manager](https://fedoramagazine.org/getting-started-i3-window-manager/) encourages users to think about the different components and pieces that make up the modern Linux desktop.
Fedora has two new packages of interest for music tweakers: **mpris-scrobbler** and **playerctl**. *mpris-scrobbler* [tracks your music listening history](https://github.com/mariusor/mpris-scrobbler) on a music-tracking service like Last.fm and/or ListenBrainz. *playerctl* is a command-line [music player controller](https://github.com/acrisci/playerctl).
*mpris-scrobbler* records your music listening trends
*mpris-scrobbler* is a CLI application to submit play history of your music to a service like [Last.fm](https://www.last.fm/), [Libre.fm](https://libre.fm/), or [ListenBrainz](https://listenbrainz.org/). It listens on the [MPRIS D-Bus interface](https://specifications.freedesktop.org/mpris-spec/latest/) to detect what’s playing. It connects with several different music clients like spotify-client, [vlc](https://www.videolan.org/vlc/), audacious, bmp, [cmus](https://cmus.github.io/), and others.
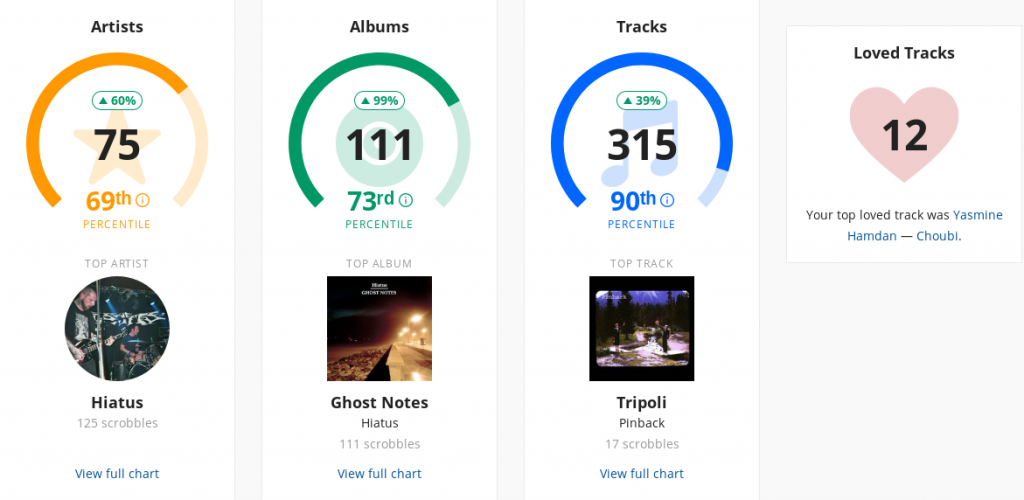
### Install and configure *mpris-scrobbler*
*mpris-scrobbler* is available for Fedora 28 or later, as well as the EPEL 7 repositories. Run the following command in a terminal to install it:
sudo dnf install mpris-scrobbler
Once it is installed, use *systemctl* to start and enable the service. The following command starts *mpris-scrobbler* and always starts it after a system reboot:
systemctl --user enable --now mpris-scrobbler.service
### Submit plays to ListenBrainz
This article explains how to link *mpris-scrobbler* with a ListenBrainz account. To use Last.fm or Libre.fm, see the [upstream documentation](https://github.com/mariusor/mpris-scrobbler#authenticate-to-the-service).
To submit plays to a ListenBrainz server, you need a ListenBrainz API token. If you have an account, get the token from your [profile settings page](https://listenbrainz.org/profile/). When you have a token, run this command to authenticate with your ListenBrainz API token:
$ mpris-scrobbler-signon token listenbrainz
Token for listenbrainz.org:
Finally, test it by playing a song in your preferred music client on Fedora. The songs you play appear on your ListenBrainz profile.
*playerctl* controls your music playback
*playerctl* is a CLI tool to control any music player implementing the MPRIS D-Bus interface. You can easily bind it to keyboard shortcuts or media hotkeys. Here’s how to install it, use it in the command line, and create key bindings for the i3 window manager.
### Install and use *playerctl*
*playerctl* is available for Fedora 28 or later. Run the following command in a terminal to install it:
sudo dnf install playerctl
Now that it’s installed, you can use it right away. Open your preferred music player on Fedora. Next, try the following commands to control playback from a terminal.
To play or pause the currently playing track:
playerctl play-pause
If you want to skip to the next track:
playerctl next
For a list of all running players:
playerctl -l
To play or pause what’s currently playing, only on the spotify-client app:
playerctl -p spotify play-pause
### Create *playerctl* key bindings in i3wm
Do you use a window manager like the [i3 window manager?](https://fedoramagazine.org/getting-started-i3-window-manager/) Try using *playerctl* for key bindings. You can bind different commands to different key shortcuts, like the play/pause buttons on your keyboard. Look at the following [i3wm config excerpt](https://github.com/jwflory/swiss-army/blob/ba6ac0c71855e33e3caa1ee1fe51c05d2df0529d/roles/apps/i3wm/files/config#L207-L210) to see how:
# Media player controls
bindsym XF86AudioPlay exec "playerctl play-pause"
bindsym XF86AudioNext exec "playerctl next"
bindsym XF86AudioPrev exec "playerctl previous"
## Try it out with your favorite music players
Need to know more about customizing the music listening experience on Fedora? The Fedora Magazine has you covered. Check out these five cool music players on Fedora:
Bring order to your music library chaos by sorting and organizing it with MusicBrainz Picard:
*Photo by **Frank Septillion** on **Unsplash**.*
## Cyber Trekker
Doesn’t appear to be available for F30 beta.
## Cyber Trekker
Silly billy, I meant to mention that my comment was pertaining to playerctl for F30 Beta. |
10,843 | Anbox:在 Linux 上运行 Android 应用程序的简单方式 | https://www.2daygeek.com/anbox-best-android-emulator-for-linux/ | 2019-05-12T10:10:10 | [
"Android",
"Anbox"
] | https://linux.cn/article-10843-1.html | 
Android 模拟器允许我们直接从 Linux 系统上运行我们最喜欢的 Android 应用程序或游戏。对于 Linux 来说,有很多的这样的 Android 模拟器,在过去我们介绍过几个此类应用程序。
你可以通过导航到下面的网址回顾它们。
* [如何在 Linux 上安装官方 Android 模拟器 (SDK)](https://www.2daygeek.com/install-configure-sdk-android-emulator-on-linux/)
* [如何在 Linux 上安装 GenyMotion (Android 模拟器)](https://www.2daygeek.com/install-genymotion-android-emulator-on-ubuntu-debian-fedora-arch-linux/)
今天我们将讨论 Anbox Android 模拟器。
### Anbox 是什么?
Anbox 是 “Android in a box” 的缩写。Anbox 是一个基于容器的方法,可以在普通的 GNU/Linux 系统上启动完整的 Android 系统。
它是现代化的新模拟器之一。
Anbox 可以让你在 Linux 系统上运行 Android,而没有虚拟化的迟钝,因为核心的 Android 操作系统已经使用 Linux 命名空间(LXE)放置到容器中了。
Android 容器不能直接访问到任何硬件,所有硬件的访问都是通过在主机上的守护进程进行的。
每个应用程序将在一个单独窗口打开,就像其它本地系统应用程序一样,并且它可以显示在启动器中。
### 如何在 Linux 中安装 Anbox ?
Anbox 也可作为 snap 软件包安装,请确保你已经在你的系统上启用了 snap 支持。
Anbox 软件包最近被添加到 Ubuntu 18.10 (Cosmic) 和 Debian 10 (Buster) 软件仓库。如果你正在运行这些版本,那么你可以轻松地在官方发行版的软件包管理器的帮助下安装。否则可以用 snap 软件包安装。
为使 Anbox 工作,确保需要的内核模块已经安装在你的系统中。对于基于 Ubuntu 的用户,使用下面的 PPA 来安装它。
```
$ sudo add-apt-repository ppa:morphis/anbox-support
$ sudo apt update
$ sudo apt install linux-headers-generic anbox-modules-dkms
```
在你安装 `anbox-modules-dkms` 软件包后,你必须手动重新加载内核模块,或需要系统重新启动。
```
$ sudo modprobe ashmem_linux
$ sudo modprobe binder_linux
```
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 anbox。
```
$ sudo apt install anbox
```
对于基于 Arch Linux 的系统,我们总是习惯从 AUR 储存库中获取软件包。所以,使用任一个的 [AUR 助手](https://www.2daygeek.com/category/aur-helper/) 来安装它。我喜欢使用 [Yay 工具](https://www.2daygeek.com/install-yay-yet-another-yogurt-aur-helper-on-arch-linux/)。
```
$ yuk -S anbox-git
```
否则,你可以通过导航到下面的文章来 [在 Linux 中安装和配置 snap](https://www.2daygeek.com/linux-snap-package-manager-ubuntu/)。如果你已经在你的系统上安装 snap,其它的步骤可以忽略。
```
$ sudo snap install --devmode --beta anbox
```
### Anbox 的必要条件
默认情况下,Anbox 并没有带有 Google Play Store。因此,我们需要手动下载每个应用程序(APK),并使用 Android 调试桥(ADB)安装它。
ADB 工具在大多数的发行版的软件仓库是轻易可获得的,我们可以容易地安装它。
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 ADB。
```
$ sudo apt install android-tools-adb
```
对于 Fedora 系统,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 ADB。
```
$ sudo dnf install android-tools
```
对于基于 Arch Linux 的系统,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 ADB。
```
$ sudo pacman -S android-tools
```
对于 openSUSE Leap 系统,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 来安装 ADB。
```
$ sudo zypper install android-tools
```
### 在哪里下载 Android 应用程序?
既然我们不能使用 Play Store ,你就得从信得过的网站来下载 APK 软件包,像 [APKMirror](https://www.apkmirror.com/) ,然后手动安装它。
### 如何启动 Anbox?
Anbox 可以从 Dash 启动。这是默认的 Anbox 外貌。

### 如何把应用程序推到 Anbox ?
像我先前所说,我们需要手动安装它。为测试目的,我们将安装 YouTube 和 Firefox 应用程序。
首先,你需要启动 ADB 服务。为做到这样,运行下面的命令。
```
$ adb devices
```
我们已经下载 YouTube 和 Firefox 应用程序,现在我们将安装。
语法格式:
```
$ adb install Name-Of-Your-Application.apk
```
安装 YouTube 和 Firefox 应用程序:
```
$ adb install 'com.google.android.youtube_14.13.54-1413542800_minAPI19(x86_64)(nodpi)_apkmirror.com.apk'
Success
$ adb install 'org.mozilla.focus_9.0-330191219_minAPI21(x86)(nodpi)_apkmirror.com.apk'
Success
```
我已经在我的 Anbox 中安装 YouTube 和 Firefox。查看下面的截图。

像我们在文章的开始所说,它将以新的标签页打开任何的应用程序。在这里,我们将打开 Firefox ,并访问 [2daygeek.com](https://www.2daygeek.com/) 网站。

---
via: <https://www.2daygeek.com/anbox-best-android-emulator-for-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,844 | Linux 中如何启用和禁用网卡? | https://www.2daygeek.com/enable-disable-up-down-nic-network-interface-port-linux-using-ifconfig-ifdown-ifup-ip-nmcli-nmtui/ | 2019-05-12T11:25:47 | [
"网卡"
] | https://linux.cn/article-10844-1.html | 
你可能会根据你的需要执行以下命令。我会在这里列举一些你会用到这些命令的例子。
当你添加一个网卡或者从一个物理网卡创建出一个虚拟网卡的时候,你可能需要使用这些命令将新网卡启用起来。另外,如果你对网卡做了某些修改或者网卡本身没有启用,那么你也需要使用以下的某个命令将网卡启用起来。
启用、禁用网卡有很多种方法。在这篇文章里,我们会介绍我们使用过的最好的 5 种方法。
启用禁用网卡可以使用以下 5 个方法来完成:
* `ifconfig` 命令:用于配置网卡。它可以提供网卡的很多信息。
* `ifdown/up` 命令:`ifdown` 命令用于禁用网卡,`ifup` 命令用于启用网卡。
* `ip` 命令:用于管理网卡,用于替代老旧的、不推荐使用的 `ifconfig` 命令。它和 `ifconfig` 命令很相似,但是提供了很多 `ifconfig` 命令所不具有的强大的特性。
* `nmcli` 命令:是一个控制 NetworkManager 并报告网络状态的命令行工具。
* `nmtui` 命令:是一个与 NetworkManager 交互的、基于 curses 图形库的终端 UI 应用。
以下显示的是我的 Linux 系统中可用网卡的信息。
```
# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:c2:e4:e8 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.4/24 brd 192.168.1.255 scope global dynamic noprefixroute enp0s3
valid_lft 86049sec preferred_lft 86049sec
inet6 fe80::3899:270f:ae38:b433/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: enp0s8: mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:30:5d:52 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.3/24 brd 192.168.1.255 scope global dynamic noprefixroute enp0s8
valid_lft 86049sec preferred_lft 86049sec
inet6 fe80::32b7:8727:bdf2:2f3/64 scope link noprefixroute
valid_lft forever preferred_lft forever
```
### 1、如何使用 ifconfig 命令启用禁用网卡?
`ifconfig` 命令用于配置网卡。
在系统启动过程中如果需要启用网卡,调用的命令就是 `ifconfig`。`ifconfig` 可以提供很多网卡的信息。不管我们想修改网卡的什么配置,都可以使用该命令。
`ifconfig` 的常用语法:
```
# ifconfig [NIC_NAME] Down/Up
```
执行以下命令禁用 `enp0s3` 网卡。注意,这里你需要输入你自己的网卡名字。
```
# ifconfig enp0s3 down
```
从以下输出结果可以看到网卡已经被禁用了。
```
# ip a | grep -A 1 "enp0s3:"
2: enp0s3: mtu 1500 qdisc fq_codel state DOWN group default qlen 1000
link/ether 08:00:27:c2:e4:e8 brd ff:ff:ff:ff:ff:ff
```
执行以下命令启用 `enp0s3` 网卡。
```
# ifconfig enp0s3 up
```
从以下输出结果可以看到网卡已经启用了。
```
# ip a | grep -A 5 "enp0s3:"
2: enp0s3: mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:c2:e4:e8 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.4/24 brd 192.168.1.255 scope global dynamic noprefixroute enp0s3
valid_lft 86294sec preferred_lft 86294sec
inet6 fe80::3899:270f:ae38:b433/64 scope link noprefixroute
valid_lft forever preferred_lft forever
```
### 2、如何使用 ifdown/up 命令启用禁用网卡?
`ifdown` 命令用于禁用网卡,`ifup` 命令用于启用网卡。
注意:这两个命令不支持以 `enpXXX` 命名的新的网络设备。
`ifdown`/`ifup` 的常用语法:
```
# ifdown [NIC_NAME]
# ifup [NIC_NAME]
```
执行以下命令禁用 `eth1` 网卡。
```
# ifdown eth1
```
从以下输出结果可以看到网卡已经被禁用了。
```
# ip a | grep -A 3 "eth1:"
3: eth1: mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
link/ether 08:00:27:d5:a0:18 brd ff:ff:ff:ff:ff:ff
```
执行以下命令启用 `eth1` 网卡。
```
# ifup eth1
```
从以下输出结果可以看到网卡已经启用了。
```
# ip a | grep -A 5 "eth1:"
3: eth1: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:d5:a0:18 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.7/24 brd 192.168.1.255 scope global eth1
inet6 fe80::a00:27ff:fed5:a018/64 scope link tentative dadfailed
valid_lft forever preferred_lft forever
```
`ifup` 和 `ifdown` 不支持以 `enpXXX` 命名的网卡。当执行该命令时得到的结果如下:
```
# ifdown enp0s8
Unknown interface enp0s8
```
### 3、如何使用 ip 命令启用禁用网卡?
`ip` 命令用于管理网卡,用于替代老旧的、不推荐使用的 `ifconfig` 命令。
它和 `ifconfig` 命令很相似,但是提供了很多 `ifconfig` 命令不具有的强大的特性。
`ip` 的常用语法:
```
# ip link set Down/Up
```
执行以下命令禁用 `enp0s3` 网卡。
```
# ip link set enp0s3 down
```
从以下输出结果可以看到网卡已经被禁用了。
```
# ip a | grep -A 1 "enp0s3:"
2: enp0s3: mtu 1500 qdisc fq_codel state DOWN group default qlen 1000
link/ether 08:00:27:c2:e4:e8 brd ff:ff:ff:ff:ff:ff
```
执行以下命令启用 `enp0s3` 网卡。
```
# ip link set enp0s3 up
```
从以下输出结果可以看到网卡已经启用了。
```
# ip a | grep -A 5 "enp0s3:"
2: enp0s3: mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:c2:e4:e8 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.4/24 brd 192.168.1.255 scope global dynamic noprefixroute enp0s3
valid_lft 86294sec preferred_lft 86294sec
inet6 fe80::3899:270f:ae38:b433/64 scope link noprefixroute
valid_lft forever preferred_lft forever
```
### 4、如何使用 nmcli 命令启用禁用网卡?
`nmcli` 是一个控制 NetworkManager 并报告网络状态的命令行工具。
`nmcli` 可以用做 nm-applet 或者其他图形化客户端的替代品。它可以用于展示、创建、修改、删除、启用和停用网络连接。除此之后,它还可以用来管理和展示网络设备状态。
`nmcli` 命令大部分情况下都是使用“配置名称”工作而不是“设备名称”。所以,执行以下命令,获取网卡对应的配置名称。(LCTT 译注:在使用 `nmtui` 或者 `nmcli` 管理网络连接的时候,可以为网络连接配置一个名称,就是这里提到的<ruby> 配置名称 <rt> Profile name </rt></ruby>`)
```
# nmcli con show
NAME UUID TYPE DEVICE
Wired connection 1 3d5afa0a-419a-3d1a-93e6-889ce9c6a18c ethernet enp0s3
Wired connection 2 a22154b7-4cc4-3756-9d8d-da5a4318e146 ethernet enp0s8
```
`nmcli` 的常用语法:
```
# nmcli con Down/Up
```
执行以下命令禁用 `enp0s3` 网卡。在禁用网卡的时候,你需要使用配置名称而不是设备名称。
```
# nmcli con down 'Wired connection 1'
Connection 'Wired connection 1' successfully deactivated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/6)
```
从以下输出结果可以看到网卡已经禁用了。
```
# nmcli dev status
DEVICE TYPE STATE CONNECTION
enp0s8 ethernet connected Wired connection 2
enp0s3 ethernet disconnected --
lo loopback unmanaged --
```
执行以下命令启用 `enp0s3` 网卡。同样的,这里你需要使用配置名称而不是设备名称。
```
# nmcli con up 'Wired connection 1'
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/7)
```
从以下输出结果可以看到网卡已经启用了。
```
# nmcli dev status
DEVICE TYPE STATE CONNECTION
enp0s8 ethernet connected Wired connection 2
enp0s3 ethernet connected Wired connection 1
lo loopback unmanaged --
```
### 5、如何使用 nmtui 命令启用禁用网卡?
`nmtui` 是一个与 NetworkManager 交互的、基于 curses 图形库的终端 UI 应用。
在启用 `nmtui` 的时候,如果第一个参数没有特别指定,它会引导用户选择对应的操作去执行。
执行以下命令打开 `mntui` 界面。选择 “Active a connection” 然后点击 “OK”。
```
# nmtui
```

选择你要禁用的网卡,然后点击 “Deactivate” 按钮,就可以将网卡禁用。

如果要启用网卡,使用上述同样的步骤即可。

---
via: <https://www.2daygeek.com/enable-disable-up-down-nic-network-interface-port-linux-using-ifconfig-ifdown-ifup-ip-nmcli-nmtui/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[bodhix](https://github.com/bodhix) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,845 | Linux 下的进程间通信:使用管道和消息队列 | https://opensource.com/article/19/4/interprocess-communication-linux-channels | 2019-05-12T13:43:00 | [
"IPC"
] | https://linux.cn/article-10845-1.html |
>
> 学习在 Linux 中进程是如何与其他进程进行同步的。
>
>
>

本篇是 Linux 下[进程间通信](https://en.wikipedia.org/wiki/Inter-process_communication)(IPC)系列的第二篇文章。[第一篇文章](/article-10826-1.html) 聚焦于通过共享文件和共享内存段这样的共享存储来进行 IPC。这篇文件的重点将转向管道,它是连接需要通信的进程之间的通道。管道拥有一个*写端*用于写入字节数据,还有一个*读端*用于按照先入先出的顺序读入这些字节数据。而这些字节数据可能代表任何东西:数字、员工记录、数字电影等等。
管道有两种类型,命名管道和无名管道,都可以交互式的在命令行或程序中使用它们;相关的例子在下面展示。这篇文章也将介绍内存队列,尽管它们有些过时了,但它们不应该受这样的待遇。
在本系列的第一篇文章中的示例代码承认了在 IPC 中可能受到竞争条件(不管是基于文件的还是基于内存的)的威胁。自然地我们也会考虑基于管道的 IPC 的安全并发问题,这个也将在本文中提及。针对管道和内存队列的例子将会使用 POSIX 推荐使用的 API,POSIX 的一个核心目标就是线程安全。
请查看一些 [mq\_open 函数的 man 页](http://man7.org/linux/man-pages/man2/mq_open.2.html),这个函数属于内存队列的 API。这个 man 页中有关 [特性](http://man7.org/linux/man-pages/man2/mq_open.2.html#ATTRIBUTES) 的章节带有一个小表格:
| 接口 | 特性 | 值 |
| --- | --- | --- |
| `mq_open()` | 线程安全 | MT-Safe |
上面的 MT-Safe(MT 指的是<ruby> 多线程 <rt> multi-threaded </rt></ruby>)意味着 `mq_open` 函数是线程安全的,进而暗示是进程安全的:一个进程的执行和它的一个线程执行的过程类似,假如竞争条件不会发生在处于*相同*进程的线程中,那么这样的条件也不会发生在处于不同进程的线程中。MT-Safe 特性保证了调用 `mq_open` 时不会出现竞争条件。一般来说,基于通道的 IPC 是并发安全的,尽管在下面例子中会出现一个有关警告的注意事项。
### 无名管道
首先让我们通过一个特意构造的命令行例子来展示无名管道是如何工作的。在所有的现代系统中,符号 `|` 在命令行中都代表一个无名管道。假设我们的命令行提示符为 `%`,接下来考虑下面的命令:
```
## 写入方在 | 左边,读取方在右边
% sleep 5 | echo "Hello, world!"
```
`sleep` 和 `echo` 程序以不同的进程执行,无名管道允许它们进行通信。但是上面的例子被特意设计为没有通信发生。问候语 “Hello, world!” 出现在屏幕中,然后过了 5 秒后,命令行返回,暗示 `sleep` 和 `echo` 进程都已经结束了。这期间发生了什么呢?
在命令行中的竖线 `|` 的语法中,左边的进程(`sleep`)是写入方,右边的进程(`echo`)为读取方。默认情况下,读取方将会阻塞,直到从通道中能够读取到字节数据,而写入方在写完它的字节数据后,将发送 <ruby> 流已终止 <rt> end-of-stream </rt></ruby>的标志。(即便写入方过早终止了,一个流已终止的标志还是会发给读取方。)无名管道将保持到写入方和读取方都停止的那个时刻。
在上面的例子中,`sleep` 进程并没有向通道写入任何的字节数据,但在 5 秒后就终止了,这时将向通道发送一个流已终止的标志。与此同时,`echo` 进程立即向标准输出(屏幕)写入问候语,因为这个进程并不从通道中读入任何字节,所以它并没有等待。一旦 `sleep` 和 `echo` 进程都终止了,不会再用作通信的无名管道将会消失然后返回命令行提示符。
下面这个更加实用的示例将使用两个无名管道。我们假定文件 `test.dat` 的内容如下:
```
this
is
the
way
the
world
ends
```
下面的命令:
```
% cat test.dat | sort | uniq
```
会将 `cat`(<ruby> 连接 <rt> concatenate </rt></ruby>的缩写)进程的输出通过管道传给 `sort` 进程以生成排序后的输出,然后将排序后的输出通过管道传给 `uniq` 进程以消除重复的记录(在本例中,会将两次出现的 “the” 缩减为一个):
```
ends
is
the
this
way
world
```
下面展示的情景展示的是一个带有两个进程的程序通过一个无名管道通信来进行通信。
#### 示例 1. 两个进程通过一个无名管道来进行通信
```
#include <sys/wait.h> /* wait */
#include <stdio.h>
#include <stdlib.h> /* exit functions */
#include <unistd.h> /* read, write, pipe, _exit */
#include <string.h>
#define ReadEnd 0
#define WriteEnd 1
void report_and_exit(const char* msg) {
perror(msg);
exit(-1); /** failure **/
}
int main() {
int pipeFDs[2]; /* two file descriptors */
char buf; /* 1-byte buffer */
const char* msg = "Nature's first green is gold\n"; /* bytes to write */
if (pipe(pipeFDs) < 0) report_and_exit("pipeFD");
pid_t cpid = fork(); /* fork a child process */
if (cpid < 0) report_and_exit("fork"); /* check for failure */
if (0 == cpid) { /*** child ***/ /* child process */
close(pipeFDs[WriteEnd]); /* child reads, doesn't write */
while (read(pipeFDs[ReadEnd], &buf, 1) > 0) /* read until end of byte stream */
write(STDOUT_FILENO, &buf, sizeof(buf)); /* echo to the standard output */
close(pipeFDs[ReadEnd]); /* close the ReadEnd: all done */
_exit(0); /* exit and notify parent at once */
}
else { /*** parent ***/
close(pipeFDs[ReadEnd]); /* parent writes, doesn't read */
write(pipeFDs[WriteEnd], msg, strlen(msg)); /* write the bytes to the pipe */
close(pipeFDs[WriteEnd]); /* done writing: generate eof */
wait(NULL); /* wait for child to exit */
exit(0); /* exit normally */
}
return 0;
}
```
上面名为 `pipeUN` 的程序使用系统函数 `fork` 来创建一个进程。尽管这个程序只有一个单一的源文件,在它正确执行的情况下将会发生多进程的情况。
>
> 下面的内容是对库函数 `fork` 如何工作的一个简要回顾:
>
>
> * `fork` 函数由*父*进程调用,在失败时返回 `-1` 给父进程。在 `pipeUN` 这个例子中,相应的调用是:
>
>
>
> ```
> pid_t cpid = fork(); /* called in parent */
> ```
>
> 函数调用后的返回值也被保存下来了。在这个例子中,保存在整数类型 `pid_t` 的变量 `cpid` 中。(每个进程有它自己的*进程 ID*,这是一个非负的整数,用来标记进程)。复刻一个新的进程可能会因为多种原因而失败,包括*进程表*满了的原因,这个结构由系统维持,以此来追踪进程状态。明确地说,僵尸进程假如没有被处理掉,将可能引起进程表被填满的错误。
> * 假如 `fork` 调用成功,则它将创建一个新的子进程,向父进程返回一个值,向子进程返回另外的一个值。在调用 `fork` 后父进程和子进程都将执行相同的代码。(子进程继承了到此为止父进程中声明的所有变量的拷贝),特别地,一次成功的 `fork` 调用将返回如下的东西:
>
>
> + 向子进程返回 `0`
> + 向父进程返回子进程的进程 ID
> * 在一次成功的 `fork` 调用后,一个 `if`/`else` 或等价的结构将会被用来隔离针对父进程和子进程的代码。在这个例子中,相应的声明为:
>
>
>
> ```
> if (0 == cpid) { /*** child ***/
> ...
> }
> else { /*** parent ***/
> ...
> }
> ```
>
>
>
假如成功地复刻出了一个子进程,`pipeUN` 程序将像下面这样去执行。在一个整数的数列里:
```
int pipeFDs[2]; /* two file descriptors */
```
来保存两个文件描述符,一个用来向管道中写入,另一个从管道中写入。(数组元素 `pipeFDs[0]` 是读端的文件描述符,元素 `pipeFDs[1]` 是写端的文件描述符。)在调用 `fork` 之前,对系统 `pipe` 函数的成功调用,将立刻使得这个数组获得两个文件描述符:
```
if (pipe(pipeFDs) < 0) report_and_exit("pipeFD");
```
父进程和子进程现在都有了文件描述符的副本。但*分离关注点*模式意味着每个进程恰好只需要一个描述符。在这个例子中,父进程负责写入,而子进程负责读取,尽管这样的角色分配可以反过来。在 `if` 子句中的第一个语句将用于关闭管道的读端:
```
close(pipeFDs[WriteEnd]); /* called in child code */
```
在父进程中的 `else` 子句将会关闭管道的读端:
```
close(pipeFDs[ReadEnd]); /* called in parent code */
```
然后父进程将向无名管道中写入某些字节数据(ASCII 代码),子进程读取这些数据,然后向标准输出中回放它们。
在这个程序中还需要澄清的一点是在父进程代码中的 `wait` 函数。一旦被创建后,子进程很大程度上独立于它的父进程,正如简短的 `pipeUN` 程序所展示的那样。子进程可以执行任意的代码,而它们可能与父进程完全没有关系。但是,假如当子进程终止时,系统将会通过一个信号来通知父进程。
要是父进程在子进程之前终止又该如何呢?在这种情形下,除非采取了预防措施,子进程将会变成在进程表中的一个*僵尸*进程。预防措施有两大类型:第一种是让父进程去通知系统,告诉系统它对子进程的终止没有任何兴趣:
```
signal(SIGCHLD, SIG_IGN); /* in parent: ignore notification */
```
第二种方法是在子进程终止时,让父进程执行一个 `wait`。这样就确保了父进程可以独立于子进程而存在。在 `pipeUN` 程序中使用了第二种方法,其中父进程的代码使用的是下面的调用:
```
wait(NULL); /* called in parent */
```
这个对 `wait` 的调用意味着*一直等待直到任意一个子进程的终止发生*,因此在 `pipeUN` 程序中,只有一个子进程。(其中的 `NULL` 参数可以被替换为一个保存有子程序退出状态的整数变量的地址。)对于更细粒度的控制,还可以使用更灵活的 `waitpid` 函数,例如特别指定多个子进程中的某一个。
`pipeUN` 将会采取另一个预防措施。当父进程结束了等待,父进程将会调用常规的 `exit` 函数去退出。对应的,子进程将会调用 `_exit` 变种来退出,这类变种将快速跟踪终止相关的通知。在效果上,子进程会告诉系统立刻去通知父进程它的这个子进程已经终止了。
假如两个进程向相同的无名管道中写入内容,字节数据会交错吗?例如,假如进程 P1 向管道写入内容:
```
foo bar
```
同时进程 P2 并发地写入:
```
baz baz
```
到相同的管道,最后的结果似乎是管道中的内容将会是任意错乱的,例如像这样:
```
baz foo baz bar
```
只要没有写入超过 `PIPE_BUF` 字节,POSIX 标准就能确保写入不会交错。在 Linux 系统中, `PIPE_BUF` 的大小是 4096 字节。对于管道我更喜欢只有一个写入方和一个读取方,从而绕过这个问题。
### 命名管道
无名管道没有备份文件:系统将维持一个内存缓存来将字节数据从写方传给读方。一旦写方和读方终止,这个缓存将会被回收,进而无名管道消失。相反的,命名管道有备份文件和一个不同的 API。
下面让我们通过另一个命令行示例来了解命名管道的要点。下面是具体的步骤:
* 开启两个终端。这两个终端的工作目录应该相同。
* 在其中一个终端中,键入下面的两个命令(命令行提示符仍然是 `%`,我的注释以 `##` 打头。):
```
% mkfifo tester ## 创建一个备份文件,名为 tester
% cat tester ## 将管道的内容输出到 stdout
```
在最开始,没有任何东西会出现在终端中,因为到现在为止没有在命名管道中写入任何东西。
* 在第二个终端中输入下面的命令:
```
% cat > tester ## redirect keyboard input to the pipe
hello, world! ## then hit Return key
bye, bye ## ditto
<Control-C> ## terminate session with a Control-C
```
无论在这个终端中输入什么,它都会在另一个终端中显示出来。一旦键入 `Ctrl+C`,就会回到正常的命令行提示符,因为管道已经被关闭了。
* 通过移除实现命名管道的文件来进行清理:
```
% unlink tester
```
正如 `mkfifo` 程序的名字所暗示的那样,命名管道也被叫做 FIFO,因为第一个进入的字节,就会第一个出,其他的类似。有一个名为 `mkfifo` 的库函数,用它可以在程序中创建一个命名管道,它将在下一个示例中被用到,该示例由两个进程组成:一个向命名管道写入,而另一个从该管道读取。
#### 示例 2. fifoWriter 程序
```
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <time.h>
#include <stdlib.h>
#include <stdio.h>
#define MaxLoops 12000 /* outer loop */
#define ChunkSize 16 /* how many written at a time */
#define IntsPerChunk 4 /* four 4-byte ints per chunk */
#define MaxZs 250 /* max microseconds to sleep */
int main() {
const char* pipeName = "./fifoChannel";
mkfifo(pipeName, 0666); /* read/write for user/group/others */
int fd = open(pipeName, O_CREAT | O_WRONLY); /* open as write-only */
if (fd < 0) return -1; /* can't go on */
int i;
for (i = 0; i < MaxLoops; i++) { /* write MaxWrites times */
int j;
for (j = 0; j < ChunkSize; j++) { /* each time, write ChunkSize bytes */
int k;
int chunk[IntsPerChunk];
for (k = 0; k < IntsPerChunk; k++)
chunk[k] = rand();
write(fd, chunk, sizeof(chunk));
}
usleep((rand() % MaxZs) + 1); /* pause a bit for realism */
}
close(fd); /* close pipe: generates an end-of-stream marker */
unlink(pipeName); /* unlink from the implementing file */
printf("%i ints sent to the pipe.\n", MaxLoops * ChunkSize * IntsPerChunk);
return 0;
}
```
上面的 `fifoWriter` 程序可以被总结为如下:
* 首先程序创建了一个命名管道用来写入数据:
```
mkfifo(pipeName, 0666); /* read/write perms for user/group/others */
int fd = open(pipeName, O_CREAT | O_WRONLY);
```
其中的 `pipeName` 是备份文件的名字,传递给 `mkfifo` 作为它的第一个参数。接着命名管道通过我们熟悉的 `open` 函数调用被打开,而这个函数将会返回一个文件描述符。
* 在实现层面上,`fifoWriter` 不会一次性将所有的数据都写入,而是写入一个块,然后休息随机数目的微秒时间,接着再循环往复。总的来说,有 768000 个 4 字节整数值被写入到命名管道中。
* 在关闭命名管道后,`fifoWriter` 也将使用 `unlink` 取消对该文件的连接。
```
close(fd); /* close pipe: generates end-of-stream marker */
unlink(pipeName); /* unlink from the implementing file */
```
一旦连接到管道的每个进程都执行了 `unlink` 操作后,系统将回收这些备份文件。在这个例子中,只有两个这样的进程 `fifoWriter` 和 `fifoReader`,它们都做了 `unlink` 操作。
这个两个程序应该在不同终端的相同工作目录中执行。但是 `fifoWriter` 应该在 `fifoReader` 之前被启动,因为需要 `fifoWriter` 去创建管道。然后 `fifoReader` 才能够获取到刚被创建的命名管道。
#### 示例 3. fifoReader 程序
```
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <unistd.h>
unsigned is_prime(unsigned n) { /* not pretty, but efficient */
if (n <= 3) return n > 1;
if (0 == (n % 2) || 0 == (n % 3)) return 0;
unsigned i;
for (i = 5; (i * i) <= n; i += 6)
if (0 == (n % i) || 0 == (n % (i + 2))) return 0;
return 1; /* found a prime! */
}
int main() {
const char* file = "./fifoChannel";
int fd = open(file, O_RDONLY);
if (fd < 0) return -1; /* no point in continuing */
unsigned count = 0, total = 0, primes_count = 0;
while (1) {
int next;
int i;
ssize_t count = read(fd, &next, sizeof(int));
if (0 == count) break; /* end of stream */
else if (count == sizeof(int)) { /* read a 4-byte int value */
total++;
if (is_prime(next)) primes_count++;
}
}
close(fd); /* close pipe from read end */
unlink(file); /* unlink from the underlying file */
printf("Received ints: %u, primes: %u\n", total, primes_count);
return 0;
}
```
上面的 `fifoReader` 的内容可以总结为如下:
* 因为 `fifoWriter` 已经创建了命名管道,所以 `fifoReader` 只需要利用标准的 `open` 调用来通过备份文件来获取到管道中的内容:
```
const char* file = "./fifoChannel";
int fd = open(file, O_RDONLY);
```
这个文件的是以只读打开的。
* 然后这个程序进入一个潜在的无限循环,在每次循环时,尝试读取 4 字节的块。`read` 调用:
```
ssize_t count = read(fd, &next, sizeof(int));
```
返回 0 来暗示该流的结束。在这种情况下,`fifoReader` 跳出循环,关闭命名管道,并在终止前 `unlink` 备份文件。
* 在读入 4 字节整数后,`fifoReader` 检查这个数是否为质数。这个操作代表了一个生产级别的读取器可能在接收到的字节数据上执行的逻辑操作。在示例运行中,在接收到的 768000 个整数中有 37682 个质数。
重复运行示例, `fifoReader` 将成功地读取 `fifoWriter` 写入的所有字节。这不是很让人惊讶的。这两个进程在相同的机器上执行,从而可以不用考虑网络相关的问题。命名管道是一个可信且高效的 IPC 机制,因而被广泛使用。
下面是这两个程序的输出,它们在不同的终端中启动,但处于相同的工作目录:
```
% ./fifoWriter
768000 ints sent to the pipe.
###
% ./fifoReader
Received ints: 768000, primes: 37682
```
### 消息队列
管道有着严格的先入先出行为:第一个被写入的字节将会第一个被读,第二个写入的字节将第二个被读,以此类推。消息队列可以做出相同的表现,但它又足够灵活,可以使得字节块可以不以先入先出的次序来接收。
正如它的名字所提示的那样,消息队列是一系列的消息,每个消息包含两部分:
* 荷载,一个字节序列(在 C 中是 char)
* 类型,以一个正整数值的形式给定,类型用来分类消息,为了更灵活的回收
看一下下面对一个消息队列的描述,每个消息由一个整数类型标记:
```
+-+ +-+ +-+ +-+
sender--->|3|--->|2|--->|2|--->|1|--->receiver
+-+ +-+ +-+ +-+
```
在上面展示的 4 个消息中,标记为 1 的是开头,即最接近接收端,然后另个标记为 2 的消息,最后接着一个标记为 3 的消息。假如按照严格的 FIFO 行为执行,消息将会以 1-2-2-3 这样的次序被接收。但是消息队列允许其他收取次序。例如,消息可以被接收方以 3-2-1-2 的次序接收。
`mqueue` 示例包含两个程序,`sender` 将向消息队列中写入数据,而 `receiver` 将从这个队列中读取数据。这两个程序都包含的头文件 `queue.h` 如下所示:
#### 示例 4. 头文件 queue.h
```
#define ProjectId 123
#define PathName "queue.h" /* any existing, accessible file would do */
#define MsgLen 4
#define MsgCount 6
typedef struct {
long type; /* must be of type long */
char payload[MsgLen + 1]; /* bytes in the message */
} queuedMessage;
```
上面的头文件定义了一个名为 `queuedMessage` 的结构类型,它带有 `payload`(字节数组)和 `type`(整数)这两个域。该文件也定义了一些符号常数(使用 `#define` 语句),前两个常数被用来生成一个 `key`,而这个 `key` 反过来被用来获取一个消息队列的 ID。`ProjectId` 可以是任何正整数值,而 `PathName` 必须是一个存在的、可访问的文件,在这个示例中,指的是文件 `queue.h`。在 `sender` 和 `receiver` 中,它们都有的设定语句为:
```
key_t key = ftok(PathName, ProjectId); /* generate key */
int qid = msgget(key, 0666 | IPC_CREAT); /* use key to get queue id */
```
ID `qid` 在效果上是消息队列文件描述符的对应物。
#### 示例 5. sender 程序
```
#include <stdio.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <stdlib.h>
#include <string.h>
#include "queue.h"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1); /* EXIT_FAILURE */
}
int main() {
key_t key = ftok(PathName, ProjectId);
if (key < 0) report_and_exit("couldn't get key...");
int qid = msgget(key, 0666 | IPC_CREAT);
if (qid < 0) report_and_exit("couldn't get queue id...");
char* payloads[] = {"msg1", "msg2", "msg3", "msg4", "msg5", "msg6"};
int types[] = {1, 1, 2, 2, 3, 3}; /* each must be > 0 */
int i;
for (i = 0; i < MsgCount; i++) {
/* build the message */
queuedMessage msg;
msg.type = types[i];
strcpy(msg.payload, payloads[i]);
/* send the message */
msgsnd(qid, &msg, sizeof(msg), IPC_NOWAIT); /* don't block */
printf("%s sent as type %i\n", msg.payload, (int) msg.type);
}
return 0;
}
```
上面的 `sender` 程序将发送出 6 个消息,每两个为一个类型:前两个是类型 1,接着的连个是类型 2,最后的两个为类型 3。发送的语句:
```
msgsnd(qid, &msg, sizeof(msg), IPC_NOWAIT);
```
被配置为非阻塞的(`IPC_NOWAIT` 标志),是因为这里的消息体量上都很小。唯一的危险在于一个完整的序列将可能导致发送失败,而这个例子不会。下面的 `receiver` 程序也将使用 `IPC_NOWAIT` 标志来接收消息。
#### 示例 6. receiver 程序
```
#include <stdio.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <stdlib.h>
#include "queue.h"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1); /* EXIT_FAILURE */
}
int main() {
key_t key= ftok(PathName, ProjectId); /* key to identify the queue */
if (key < 0) report_and_exit("key not gotten...");
int qid = msgget(key, 0666 | IPC_CREAT); /* access if created already */
if (qid < 0) report_and_exit("no access to queue...");
int types[] = {3, 1, 2, 1, 3, 2}; /* different than in sender */
int i;
for (i = 0; i < MsgCount; i++) {
queuedMessage msg; /* defined in queue.h */
if (msgrcv(qid, &msg, sizeof(msg), types[i], MSG_NOERROR | IPC_NOWAIT) < 0)
puts("msgrcv trouble...");
printf("%s received as type %i\n", msg.payload, (int) msg.type);
}
/** remove the queue **/
if (msgctl(qid, IPC_RMID, NULL) < 0) /* NULL = 'no flags' */
report_and_exit("trouble removing queue...");
return 0;
}
```
这个 `receiver` 程序不会创建消息队列,尽管 API 尽管建议那样。在 `receiver` 中,对
```
int qid = msgget(key, 0666 | IPC_CREAT);
```
的调用可能因为带有 `IPC_CREAT` 标志而具有误导性,但是这个标志的真实意义是*如果需要就创建,否则直接获取*。`sender` 程序调用 `msgsnd` 来发送消息,而 `receiver` 调用 `msgrcv` 来接收它们。在这个例子中,`sender` 以 1-1-2-2-3-3 的次序发送消息,但 `receiver` 接收它们的次序为 3-1-2-1-3-2,这显示消息队列没有被严格的 FIFO 行为所拘泥:
```
% ./sender
msg1 sent as type 1
msg2 sent as type 1
msg3 sent as type 2
msg4 sent as type 2
msg5 sent as type 3
msg6 sent as type 3
% ./receiver
msg5 received as type 3
msg1 received as type 1
msg3 received as type 2
msg2 received as type 1
msg6 received as type 3
msg4 received as type 2
```
上面的输出显示 `sender` 和 `receiver` 可以在同一个终端中启动。输出也显示消息队列是持久的,即便 `sender` 进程在完成创建队列、向队列写数据、然后退出的整个过程后,该队列仍然存在。只有在 `receiver` 进程显式地调用 `msgctl` 来移除该队列,这个队列才会消失:
```
if (msgctl(qid, IPC_RMID, NULL) < 0) /* remove queue */
```
### 总结
管道和消息队列的 API 在根本上来说都是单向的:一个进程写,然后另一个进程读。当然还存在双向命名管道的实现,但我认为这个 IPC 机制在它最为简单的时候反而是最佳的。正如前面提到的那样,消息队列已经不大受欢迎了,尽管没有找到什么特别好的原因来解释这个现象;而队列仍然是 IPC 工具箱中的一个工具。这个快速的 IPC 工具箱之旅将以第 3 部分(通过套接字和信号来示例 IPC)来终结。
---
via: <https://opensource.com/article/19/4/interprocess-communication-linux-channels>
作者:[Marty Kalin](https://opensource.com/users/mkalindepauledu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the second article in a series about [interprocess communication](https://en.wikipedia.org/wiki/Inter-process_communication) (IPC) in Linux. The [first article](https://opensource.com/article/19/4/interprocess-communication-ipc-linux-part-1) focused on IPC through shared storage: shared files and shared memory segments. This article turns to pipes, which are channels that connect processes for communication. A channel has a *write end* for writing bytes, and a *read end* for reading these bytes in FIFO (first in, first out) order. In typical use, one process writes to the channel, and a different process reads from this same channel. The bytes themselves might represent anything: numbers, employee records, digital movies, and so on.
Pipes come in two flavors, named and unnamed, and can be used either interactively from the command line or within programs; examples are forthcoming. This article also looks at memory queues, which have fallen out of fashion—but undeservedly so.
The code examples in the first article acknowledged the threat of race conditions (either file-based or memory-based) in IPC that uses shared storage. The question naturally arises about safe concurrency for the channel-based IPC, which will be covered in this article. The code examples for pipes and memory queues use APIs with the POSIX stamp of approval, and a core goal of the POSIX standards is thread-safety.
Consider the [man pages for the mq_open](http://man7.org/linux/man-pages/man2/mq_open.2.html) function, which belongs to the memory queue API. These pages include a section on
[Attributes](http://man7.org/linux/man-pages/man2/mq_open.2.html#ATTRIBUTES)with this small table:
Interface | Attribute | Value |
mq_open() | Thread safety | MT-Safe |
The value **MT-Safe** (with **MT** for multi-threaded) means that the **mq_open** function is thread-safe, which in turn implies process-safe: A process executes in precisely the sense that one of its threads executes, and if a race condition cannot arise among threads in the *same* process, such a condition cannot arise among threads in different processes. The **MT-Safe** attribute assures that a race condition does not arise in invocations of **mq_open**. In general, channel-based IPC is concurrent-safe, although a cautionary note is raised in the examples that follow.
## Unnamed pipes
Let's start with a contrived command line example that shows how unnamed pipes work. On all modern systems, the vertical bar **|** represents an unnamed pipe at the command line. Assume **%** is the command line prompt, and consider this command:
`% sleep 5 | echo "Hello, world!" ## writer to the left of |, reader to the right`
The *sleep* and *echo* utilities execute as separate processes, and the unnamed pipe allows them to communicate. However, the example is contrived in that no communication occurs. The greeting *Hello, world!* appears on the screen; then, after about five seconds, the command line prompt returns, indicating that both the *sleep* and *echo* processes have exited. What's going on?
In the vertical-bar syntax from the command line, the process to the left (*sleep*) is the writer, and the process to the right (*echo*) is the reader. By default, the reader blocks until there are bytes to read from the channel, and the writer—after writing its bytes—finishes up by sending an end-of-stream marker. (Even if the writer terminates prematurely, an end-of-stream marker is sent to the reader.) The unnamed pipe persists until both the writer and the reader terminate.
**[ Download the complete guide to inter-process communication in Linux]**
In the contrived example, the *sleep* process does not write any bytes to the channel but does terminate after about five seconds, which sends an end-of-stream marker to the channel. In the meantime, the *echo* process immediately writes the greeting to the standard output (the screen) because this process does not read any bytes from the channel, so it does no waiting. Once the *sleep* and *echo* processes terminate, the unnamed pipe—not used at all for communication—goes away and the command line prompt returns.
Here is a more useful example using two unnamed pipes. Suppose that the file *test.dat* looks like this:
```
this
is
the
way
the
world
ends
```
The command:
`% cat test.dat | sort | uniq`
pipes the output from the *cat* (concatenate) process into the *sort* process to produce sorted output, and then pipes the sorted output into the *uniq* process to eliminate duplicate records (in this case, the two occurrences of **the** reduce to one):
```
ends
is
the
this
way
world
```
The scene now is set for a program with two processes that communicate through an unnamed pipe.
### Example 1. Two processes communicating through an unnamed pipe.
```
#include <sys/wait.h> /* wait */
#include <stdio.h>
#include <stdlib.h> /* exit functions */
#include <unistd.h> /* read, write, pipe, _exit */
#include <string.h>
#define ReadEnd 0
#define WriteEnd 1
void report_and_exit(const char* msg) {
perror(msg);
exit(-1); /** failure **/
}
int main() {
int pipeFDs[2]; /* two file descriptors */
char buf; /* 1-byte buffer */
const char* msg = "Nature's first green is gold\n"; /* bytes to write */
if (pipe(pipeFDs) < 0) report_and_exit("pipeFD");
pid_t cpid = fork(); /* fork a child process */
if (cpid < 0) report_and_exit("fork"); /* check for failure */
if (0 == cpid) { /*** child ***/ /* child process */
close(pipeFDs[WriteEnd]); /* child reads, doesn't write */
while (read(pipeFDs[ReadEnd], &buf, 1) > 0) /* read until end of byte stream */
write(STDOUT_FILENO, &buf, sizeof(buf)); /* echo to the standard output */
close(pipeFDs[ReadEnd]); /* close the ReadEnd: all done */
_exit(0); /* exit and notify parent at once */
}
else { /*** parent ***/
close(pipeFDs[ReadEnd]); /* parent writes, doesn't read */
write(pipeFDs[WriteEnd], msg, strlen(msg)); /* write the bytes to the pipe */
close(pipeFDs[WriteEnd]); /* done writing: generate eof */
wait(NULL); /* wait for child to exit */
exit(0); /* exit normally */
}
return 0;
}
```
The *pipeUN* program above uses the system function **fork** to create a process. Although the program has but a single source file, multi-processing occurs during (successful) execution. Here are the particulars in a quick review of how the library function **fork** works:
- The
**fork**function, called in the*parent*process, returns**-1**to the parent in case of failure. In the*pipeUN*example, the call is:
`pid_t cpid = fork(); /* called in parent */`
The returned value is stored, in this example, in the variable
**cpid**of integer type**pid_t**. (Every process has its own*process ID*, a non-negative integer that identifies the process.) Forking a new process could fail for several reasons, including a full*process table*, a structure that the system maintains to track processes. Zombie processes, clarified shortly, can cause a process table to fill if these are not harvested. - If the
**fork**call succeeds, it thereby spawns (creates) a new child process, returning one value to the parent but a different value to the child. Both the parent and the child process execute the*same*code that follows the call to**fork**. (The child inherits copies of all the variables declared so far in the parent.) In particular, a successful call to**fork**returns:- Zero to the child process
- The child's process ID to the parent
- An
*if/else*or equivalent construct typically is used after a successful**fork**call to segregate code meant for the parent from code meant for the child. In this example, the construct is:
`if (0 == cpid) { /*** child ***/ ... } else { /*** parent ***/ ... }`
If forking a child succeeds, the *pipeUN* program proceeds as follows. There is an integer array:
`int pipeFDs[2]; /* two file descriptors */`
to hold two file descriptors, one for writing to the pipe and another for reading from the pipe. (The array element **pipeFDs[0]** is the file descriptor for the read end, and the array element **pipeFDs[1]** is the file descriptor for the write end.) A successful call to the system **pipe** function, made immediately before the call to **fork**, populates the array with the two file descriptors:
`if (pipe(pipeFDs) < 0) report_and_exit("pipeFD");`
The parent and the child now have copies of both file descriptors, but the *separation of concerns* pattern means that each process requires exactly one of the descriptors. In this example, the parent does the writing and the child does the reading, although the roles could be reversed. The first statement in the child *if*-clause code, therefore, closes the pipe's write end:
`close(pipeFDs[WriteEnd]); /* called in child code */`
and the first statement in the parent *else*-clause code closes the pipe's read end:
`close(pipeFDs[ReadEnd]); /* called in parent code */`
The parent then writes some bytes (ASCII codes) to the unnamed pipe, and the child reads these and echoes them to the standard output.
One more aspect of the program needs clarification: the call to the **wait** function in the parent code. Once spawned, a child process is largely independent of its parent, as even the short *pipeUN* program illustrates. The child can execute arbitrary code that may have nothing to do with the parent. However, the system does notify the parent through a signal—if and when the child terminates.
What if the parent terminates before the child? In this case, unless precautions are taken, the child becomes and remains a *zombie* process with an entry in the process table. The precautions are of two broad types. One precaution is to have the parent notify the system that the parent has no interest in the child's termination:
`signal(SIGCHLD, SIG_IGN); /* in parent: ignore notification */`
A second approach is to have the parent execute a **wait** on the child's termination, thereby ensuring that the parent outlives the child. This second approach is used in the *pipeUN* program, where the parent code has this call:
`wait(NULL); /* called in parent */`
This call to **wait** means *wait until the termination of any child occurs*, and in the *pipeUN* program, there is only one child process. (The **NULL** argument could be replaced with the address of an integer variable to hold the child's exit status.) There is a more flexible **waitpid** function for fine-grained control, e.g., for specifying a particular child process among several.
The *pipeUN* program takes another precaution. When the parent is done waiting, the parent terminates with the call to the regular **exit** function. By contrast, the child terminates with a call to the **_exit** variant, which fast-tracks notification of termination. In effect, the child is telling the system to notify the parent ASAP that the child has terminated.
If two processes write to the same unnamed pipe, can the bytes be interleaved? For example, if process P1 writes:
`foo bar`
to a pipe and process P2 concurrently writes:
`baz baz`
to the same pipe, it seems that the pipe contents might be something arbitrary, such as:
`baz foo baz bar`
The POSIX standard ensures that writes are not interleaved so long as no write exceeds **PIPE_BUF** bytes. On Linux systems, **PIPE_BUF** is 4,096 bytes in size. My preference with pipes is to have a single writer and a single reader, thereby sidestepping the issue.
## Named pipes
An unnamed pipe has no backing file: the system maintains an in-memory buffer to transfer bytes from the writer to the reader. Once the writer and reader terminate, the buffer is reclaimed, so the unnamed pipe goes away. By contrast, a named pipe has a backing file and a distinct API.
Let's look at another command line example to get the gist of named pipes. Here are the steps:
- Open two terminals. The working directory should be the same for both.
- In one of the terminals, enter these two commands (the prompt again is
**%**, and my comments start with**##**):
`% mkfifo tester ## creates a backing file named tester % cat tester ## type the pipe's contents to stdout`
At the beginning, nothing should appear in the terminal because nothing has been written yet to the named pipe.
- In the second terminal, enter the command:
`% cat > tester ## redirect keyboard input to the pipe hello, world! ## then hit Return key bye, bye ## ditto <Control-C> ## terminate session with a Control-C`
Whatever is typed into this terminal is echoed in the other. Once
**Ctrl+C**is entered, the regular command line prompt returns in both terminals: the pipe has been closed. - Clean up by removing the file that implements the named pipe:
`% unlink tester`
As the utility's name *mkfifo* implies, a named pipe also is called a FIFO because the first byte in is the first byte out, and so on. There is a library function named **mkfifo** that creates a named pipe in programs and is used in the next example, which consists of two processes: one writes to the named pipe and the other reads from this pipe.
### Example 2. The *fifoWriter* program
```
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <time.h>
#include <stdlib.h>
#include <stdio.h>
#define MaxLoops 12000 /* outer loop */
#define ChunkSize 16 /* how many written at a time */
#define IntsPerChunk 4 /* four 4-byte ints per chunk */
#define MaxZs 250 /* max microseconds to sleep */
int main() {
const char* pipeName = "./fifoChannel";
mkfifo(pipeName, 0666); /* read/write for user/group/others */
int fd = open(pipeName, O_CREAT | O_WRONLY); /* open as write-only */
if (fd < 0) return -1; /* can't go on */
int i;
for (i = 0; i < MaxLoops; i++) { /* write MaxWrites times */
int j;
for (j = 0; j < ChunkSize; j++) { /* each time, write ChunkSize bytes */
int k;
int chunk[IntsPerChunk];
for (k = 0; k < IntsPerChunk; k++)
chunk[k] = rand();
write(fd, chunk, sizeof(chunk));
}
usleep((rand() % MaxZs) + 1); /* pause a bit for realism */
}
close(fd); /* close pipe: generates an end-of-stream marker */
unlink(pipeName); /* unlink from the implementing file */
printf("%i ints sent to the pipe.\n", MaxLoops * ChunkSize * IntsPerChunk);
return 0;
}
```
The *fifoWriter* program above can be summarized as follows:
- The program creates a named pipe for writing:
`mkfifo(pipeName, 0666); /* read/write perms for user/group/others */ int fd = open(pipeName, O_CREAT | O_WRONLY);`
where
**pipeName**is the name of the backing file passed to**mkfifo**as the first argument. The named pipe then is opened with the by-now familiar call to the**open**function, which returns a file descriptor. - For a touch of realism, the
*fifoWriter*does not write all the data at once, but instead writes a chunk, sleeps a random number of microseconds, and so on. In total, 768,000 4-byte integer values are written to the named pipe. - After closing the named pipe, the
*fifoWriter*also unlinks the file:
`close(fd); /* close pipe: generates end-of-stream marker */ unlink(pipeName); /* unlink from the implementing file */`
The system reclaims the backing file once every process connected to the pipe has performed the unlink operation. In this example, there are only two such processes: the
*fifoWriter*and the*fifoReader*, both of which do an*unlink*operation.
The two programs should be executed in different terminals with the same working directory. However, the *fifoWriter* should be started before the *fifoReader*, as the former creates the pipe. The *fifoReader* then accesses the already created named pipe.
### Example 3. The *fifoReader* program
```
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <unistd.h>
unsigned is_prime(unsigned n) { /* not pretty, but efficient */
if (n <= 3) return n > 1;
if (0 == (n % 2) || 0 == (n % 3)) return 0;
unsigned i;
for (i = 5; (i * i) <= n; i += 6)
if (0 == (n % i) || 0 == (n % (i + 2))) return 0;
return 1; /* found a prime! */
}
int main() {
const char* file = "./fifoChannel";
int fd = open(file, O_RDONLY);
if (fd < 0) return -1; /* no point in continuing */
unsigned count = 0, total = 0, primes_count = 0;
while (1) {
int next;
int i;
ssize_t count = read(fd, &next, sizeof(int));
if (0 == count) break; /* end of stream */
else if (count == sizeof(int)) { /* read a 4-byte int value */
total++;
if (is_prime(next)) primes_count++;
}
}
close(fd); /* close pipe from read end */
unlink(file); /* unlink from the underlying file */
printf("Received ints: %u, primes: %u\n", total, primes_count);
return 0;
}
```
The *fifoReader* program above can be summarized as follows:
- Because the
*fifoWriter*creates the named pipe, the*fifoReader*needs only the standard call**open**to access the pipe through the backing file:
`const char* file = "./fifoChannel"; int fd = open(file, O_RDONLY);`
The file opens as read-only.
- The program then goes into a potentially infinite loop, trying to read a 4-byte chunk on each iteration. The
**read**call:
`ssize_t count = read(fd, &next, sizeof(int));`
returns 0 to indicate end-of-stream, in which case the
*fifoReader*breaks out of the loop, closes the named pipe, and unlinks the backing file before terminating. - After reading a 4-byte integer, the
*fifoReader*checks whether the number is a prime. This represents the business logic that a production-grade reader might perform on the received bytes. On a sample run, there were 37,682 primes among the 768,000 integers received.
On repeated sample runs, the *fifoReader* successfully read all of the bytes that the *fifoWriter* wrote. This is not surprising. The two processes execute on the same host, taking network issues out of the equation. Named pipes are a highly reliable and efficient IPC mechanism and, therefore, in wide use.
Here is the output from the two programs, each launched from a separate terminal but with the same working directory:
```
% ./fifoWriter
768000 ints sent to the pipe.
###
% ./fifoReader
Received ints: 768000, primes: 37682
```
## Message queues
Pipes have strict FIFO behavior: the first byte written is the first byte read, the second byte written is the second byte read, and so forth. Message queues can behave in the same way but are flexible enough that byte chunks can be retrieved out of FIFO order.
As the name suggests, a message queue is a sequence of messages, each of which has two parts:
- The payload, which is an array of bytes (
**char**in C) - A type, given as a positive integer value; types categorize messages for flexible retrieval
Consider the following depiction of a message queue, with each message labeled with an integer type:
```
+-+ +-+ +-+ +-+
sender--->|3|--->|2|--->|2|--->|1|--->receiver
+-+ +-+ +-+ +-+
```
Of the four messages shown, the one labeled 1 is at the front, i.e., closest to the receiver. Next come two messages with label 2, and finally, a message labeled 3 at the back. If strict FIFO behavior were in play, then the messages would be received in the order 1-2-2-3. However, the message queue allows other retrieval orders. For example, the messages could be retrieved by the receiver in the order 3-2-1-2.
The *mqueue* example consists of two programs, the *sender* that writes to the message queue and the *receiver* that reads from this queue. Both programs include the header file *queue.h* shown below:
### Example 4. The header file *queue.h*
```
#define ProjectId 123
#define PathName "queue.h" /* any existing, accessible file would do */
#define MsgLen 4
#define MsgCount 6
typedef struct {
long type; /* must be of type long */
char payload[MsgLen + 1]; /* bytes in the message */
} queuedMessage;
```
The header file defines a structure type named **queuedMessage**, with **payload** (byte array) and **type** (integer) fields. This file also defines symbolic constants (the **#define** statements), the first two of which are used to generate a key that, in turn, is used to get a message queue ID. The **ProjectId** can be any positive integer value, and the **PathName** must be an existing, accessible file—in this case, the file *queue.h*. The setup statements in both the *sender* and the *receiver* programs are:
```
key_t key = ftok(PathName, ProjectId); /* generate key */
int qid = msgget(key, 0666 | IPC_CREAT); /* use key to get queue id */
```
The ID **qid** is, in effect, the counterpart of a file descriptor for message queues.
### Example 5. The message *sender* program
```
#include <stdio.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <stdlib.h>
#include <string.h>
#include "queue.h"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1); /* EXIT_FAILURE */
}
int main() {
key_t key = ftok(PathName, ProjectId);
if (key < 0) report_and_exit("couldn't get key...");
int qid = msgget(key, 0666 | IPC_CREAT);
if (qid < 0) report_and_exit("couldn't get queue id...");
char* payloads[] = {"msg1", "msg2", "msg3", "msg4", "msg5", "msg6"};
int types[] = {1, 1, 2, 2, 3, 3}; /* each must be > 0 */
int i;
for (i = 0; i < MsgCount; i++) {
/* build the message */
queuedMessage msg;
msg.type = types[i];
strcpy(msg.payload, payloads[i]);
/* send the message */
msgsnd(qid, &msg, sizeof(msg), IPC_NOWAIT); /* don't block */
printf("%s sent as type %i\n", msg.payload, (int) msg.type);
}
return 0;
}
```
The *sender* program above sends out six messages, two each of a specified type: the first messages are of type 1, the next two of type 2, and the last two of type 3. The sending statement:
`msgsnd(qid, &msg, sizeof(msg), IPC_NOWAIT);`
is configured to be non-blocking (the flag **IPC_NOWAIT**) because the messages are so small. The only danger is that a full queue, unlikely in this example, would result in a sending failure. The *receiver* program below also receives messages using the **IPC_NOWAIT** flag.
### Example 6. The message *receiver* program
```
#include <stdio.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <stdlib.h>
#include "queue.h"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1); /* EXIT_FAILURE */
}
int main() {
key_t key= ftok(PathName, ProjectId); /* key to identify the queue */
if (key < 0) report_and_exit("key not gotten...");
int qid = msgget(key, 0666 | IPC_CREAT); /* access if created already */
if (qid < 0) report_and_exit("no access to queue...");
int types[] = {3, 1, 2, 1, 3, 2}; /* different than in sender */
int i;
for (i = 0; i < MsgCount; i++) {
queuedMessage msg; /* defined in queue.h */
if (msgrcv(qid, &msg, sizeof(msg), types[i], MSG_NOERROR | IPC_NOWAIT) < 0)
puts("msgrcv trouble...");
printf("%s received as type %i\n", msg.payload, (int) msg.type);
}
/** remove the queue **/
if (msgctl(qid, IPC_RMID, NULL) < 0) /* NULL = 'no flags' */
report_and_exit("trouble removing queue...");
return 0;
}
```
The *receiver* program does not create the message queue, although the API suggests as much. In the *receiver*, the call:
`int qid = msgget(key, 0666 | IPC_CREAT);`
is misleading because of the **IPC_CREAT** flag, but this flag really means *create if needed, otherwise access*. The *sender* program calls **msgsnd** to send messages, whereas the *receiver* calls **msgrcv** to retrieve them. In this example, the *sender* sends the messages in the order 1-1-2-2-3-3, but the *receiver* then retrieves them in the order 3-1-2-1-3-2, showing that message queues are not bound to strict FIFO behavior:
```
% ./sender
msg1 sent as type 1
msg2 sent as type 1
msg3 sent as type 2
msg4 sent as type 2
msg5 sent as type 3
msg6 sent as type 3
% ./receiver
msg5 received as type 3
msg1 received as type 1
msg3 received as type 2
msg2 received as type 1
msg6 received as type 3
msg4 received as type 2
```
The output above shows that the *sender* and the *receiver* can be launched from the same terminal. The output also shows that the message queue persists even after the *sender* process creates the queue, writes to it, and exits. The queue goes away only after the *receiver* process explicitly removes it with the call to **msgctl**:
`if (msgctl(qid, IPC_RMID, NULL) < 0) /* remove queue */`
## Wrapping up
The pipes and message queue APIs are fundamentally *unidirectional*: one process writes and another reads. There are implementations of bidirectional named pipes, but my two cents is that this IPC mechanism is at its best when it is simplest. As noted earlier, message queues have fallen in popularity—but without good reason; these queues are yet another tool in the IPC toolbox. Part 3 completes this quick tour of the IPC toolbox with code examples of IPC through sockets and signals.
## Comments are closed. |
10,847 | Kindd:一个图形化 dd 命令前端 | https://www.ostechnix.com/kindd-a-graphical-frontend-to-dd-command/ | 2019-05-12T23:17:37 | [
"dd",
"iso"
] | https://linux.cn/article-10847-1.html | 
前不久,我们已经学习如何在类 Unix 系统中 [使用 dd 命令创建可启动的 ISO](https://www.ostechnix.com/how-to-create-bootable-usb-drive-using-dd-command/)。请记住,`dd` 命令是最具危险性和破坏性的命令之一。如果你不确定你实际在做什么,你可能会在几分钟内意外地擦除你的硬盘数据。`dd` 命令仅仅从 `if` 参数获取数据,并写入数据到 `of` 参数。它将不关心它正在覆盖什么,它也不关心是否在磁道上有一个分区表,或一个启动扇区,或者一个家文件夹,或者任何重要的东西。它将简单地做它被告诉去做的事。如果你是初学者,一般地尝试避免使用 `dd` 命令来做实验。幸好,这有一个支持 `dd` 命令的简单的 GUI 实用程序。向 “Kindd” 问好,一个属于 `dd` 命令的图形化前端。它是自由开源的、用 Qt Quick 所写的工具。总的来说,这个工具对那些对命令行不适应的初学者是非常有用的。
它的开发者创建这个工具主要是为了提供:
1. 一个用于 `dd` 命令的现代化的、简单而安全的图形化用户界面,
2. 一种简单地创建可启动设备的图形化方法,而不必使用终端。
### 安装 Kindd
Kindd 在 [AUR](https://aur.archlinux.org/packages/kindd-git/) 中是可用的。所以,如果你是 Arch 用户,使用任一的 AUR 助手工具来安装它,例如 [Yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/) 。
要安装其 Git 发布版,运行:
```
$ yay -S kindd-git
```
要安装正式发布版,运行:
```
$ yay -S kindd
```
在安装后,从菜单或应用程序启动器启动 Kindd。
对于其它的发行版,你需要从源文件手动编译和安装它,像下面所示。
确保你已经安装下面的必要条件。
* git
* coreutils
* polkit
* qt5-base
* qt5-quickcontrols
* qt5-quickcontrols2
* qt5-graphicaleffects
一旦所有必要条件安装,使用 `git` 克隆 Kindd 储存库:
```
git clone https://github.com/LinArcX/Kindd/
```
转到你刚刚克隆 Kindd 的目录,并编译和安装它:
```
cd Kindd
qmake
make
```
最后运行下面的命令来启动 Kindd 应用程序:
```
./kindd
```
Kindd 内部使用 pkexec。pkexec 代理被默认安装在大多数桌面环境中。但是,如果你使用 i3 (或者可能还有一些其它的桌面环境),你应该首先安装 polkit-gnome ,然后粘贴下面的行到 i3 配置文件:
```
exec /usr/lib/polkit-gnome/polkit-gnome-authentication-agent-1 &
```
### 使用 Kindd 创建可启动的 ISO
为从一个 ISO 创建一个可启动的 USB,插入 USB 驱动器。然后,从菜单或终端启动 Kindd 。
这是 Kindd 默认界面的外观:

*Kindd 界面*
正如你所能看到的,Kindd 界面是非常简单的和明白易懂的。这里仅有两部分,即设备列表,它显示你的系统上的可用的设备(hdd 和 Usb),并创建可启动的 .iso 。默认情况下,你将在“创建可启动 .iso”部分。
在第一列中输入块大小,在第二列中选择 ISO 文件的路径,并在第三列中选择正确的设备(USB 驱动器路径)。单击“转换/复制”按钮来开始创建可启动的 ISO 。

一旦进程被完成,你将看到成功的信息。

现在,拔出 USB 驱动器,并用该 USB 启动器启动你的系统,来检查它是否真地工作。
如果你不知道真实的设备名称(目标路径),只需要在列出的设备上单击,并检查 USB 驱动器名称。

Kindd 还处在早期开发阶段。因此,可能有错误。如果你找到一些错误,请在这篇的指南的结尾所给的 GitHub 页面报告它们。
这就是全部。希望这是有用的。更多的好东西将会来。敬请期待!
谢谢!
资源:
* [Kindd GitHub 储存库](https://github.com/LinArcX/Kindd)
相关阅读:
* [Etcher:一个来创建可启动 SD 卡或 USB 驱动器的漂亮的应用程序](https://www.ostechnix.com/etcher-beauitiful-app-create-bootable-sd-cards-usb-drives/)
* [Bootiso 让你安全地创建可启动的 USB 驱动器](https://www.ostechnix.com/bootiso-lets-you-safely-create-bootable-usb-drive/)
---
via: <https://www.ostechnix.com/kindd-a-graphical-frontend-to-dd-command/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.