
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
10,457 | Turtl:Evernote 的开源替代品 | https://opensource.com/article/17/12/using-turtl-open-source-alternative-evernote | 2019-01-19T13:38:50 | [
"Evernote",
"笔记"
] | https://linux.cn/article-10457-1.html |
>
> 如果你正在寻找一个 Evernote 和 Google Keep 的替代品,那么 Turtl 是一个可靠的记笔记工具。
>
>
>

我认识的每个人都会记笔记,许多人使用在线笔记应用,如 Evernote、Simplenote 或 Google Keep。这些都是很好的工具,但你不得不担忧信息的安全性和隐私性 —— 特别是考虑到 [Evernote 2016 年的隐私策略变更](https://blog.evernote.com/blog/2016/12/15/evernote-revisits-privacy-policy/)。如果你想要更好地控制笔记和数据,你需要转向开源工具。
无论你离开 Evernote 的原因是什么,都有开源替代品。让我们来看看其中一个选择:Turtl。
### 入门
[Turtl](https://turtlapp.com/) 背后的开发人员希望你将其视为“具有绝对隐私的 Evernote”。说实话,我不能保证 Turtl 提供的隐私级别,但它是一个非常好的笔记工具。
要开始使用 Turtl,[下载](https://turtlapp.com/download/)适用于 Linux、Mac OS 或 Windows 的桌面客户端,或者获取它的 [Android 应用](https://turtlapp.com/download/)。安装它,然后启动客户端或应用。系统会要求你输入用户名和密码。Turtl 使用密码来生成加密密钥,根据开发人员的说法,加密密钥会在将笔记存储在设备或服务器上之前对其进行加密。
### 使用 Turtl
你可以使用 Turtl 创建以下类型的笔记:
* 密码
* 档案
* 图片
* 书签
* 文字笔记
无论你选择何种类型的笔记,你都可以在类似的窗口中创建:

*在 Turtl 中创建新笔记*
添加笔记标题、文字并(如果你正在创建文件或图像笔记)附加文件或图像等信息。然后单击“保存”。
你可以通过 [Markdown](https://en.wikipedia.org/wiki/Markdown) 为你的笔记添加格式。因为没有工具栏快捷方式,所以你需要手动添加格式。
如果你需要整理笔记,可以将它们添加到“白板”中。白板就像 Evernote 中的笔记本。要创建新的白板,请单击 “Board” 选项卡,然后单击“创建”按钮。输入白板的标题,然后单击“创建”。

*在 Turtl 中创建新的白板*
要向白板中添加笔记,请创建或编辑笔记,然后单击笔记底部的“此笔记不在任何白板”的链接。选择一个或多个白板,然后单击“完成”。
要为笔记添加标记,请单击记事本底部的“标记”图标,输入一个或多个以逗号分隔的关键字,然后单击“完成”。
### 跨设备同步你的笔记
例如,如果你在多台计算机和 Android 设备上使用 Turtl,Turtl 会在你上线时同步你的笔记。但是,我在同步时遇到了一个小问题:我手机上创建的笔记经常不会同步到我的笔记本电脑上。我尝试通过单击窗口左上角的图标手动同步,然后单击立即同步,但这并不总是有效。我发现偶尔需要单击“设置”图标,然后单击“清除本地数据”。然后我需要重新登录 Turtl,但所有数据都能正确同步了。
### 一个疑问和一些问题
当我开始使用 Turtl 时,我被一个疑问所困扰:我的笔记保存在哪里?事实证明,Turtl 背后的开发人员位于美国,这也是他们服务器的所在地。虽然 Turtl 使用的加密[非常强大](https://turtlapp.com/docs/security/encryption-specifics/)并且你的笔记在服务器上加密,但我偏执地认为你不应该在 Turtl 中保存任何敏感内容(或在任何类似的在线笔记中)。
Turtl 以平铺视图显示笔记,让人想起 Google Keep:

*Turtl 中的一系列笔记*
无法在桌面或 Android 应用上将其更改为列表视图。这对我来说不是问题,但我听说有些人因为它没有列表视图而不喜欢 Turtl。
说到 Android 应用,它并不差。但是,它没有与 Android 共享菜单集成。如果你想把在其他应用中看到或阅读的内容添加到 Turtl 笔记中,则需要手动复制并粘贴。
我已经在我的 Linux 笔记本,[运行 GalliumOS 的 Chromebook](https://opensource.com/article/17/4/linux-chromebook-gallium-os),还有一台 Android 手机上使用 Turtl 几个月了。对所有这些设备来说这都是一种非常无缝的体验。虽然它不是我最喜欢的开源笔记工具,但 Turtl 做得非常好。试试看它,它可能是你正在寻找的简单的笔记工具。
---
via: <https://opensource.com/article/17/12/using-turtl-open-source-alternative-evernote>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Just about everyone I know takes notes, and many people use an online note-taking application like Evernote, Simplenote, or Google Keep. Those are all good tools, but you have to wonder about the security and privacy of your information—especially in light of [Evernote's privacy flip-flop of 2016](https://blog.evernote.com/blog/2016/12/15/evernote-revisits-privacy-policy/). If you want more control over your notes and your data, you really need to turn to an open source tool.
Whatever your reasons for moving away from Evernote, there are open source alternatives out there. Let's look at one of those alternatives: Turtl.
## Getting started
The developers behind [Turtl](https://turtlapp.com/) want you to think of it as "Evernote with ultimate privacy." To be honest, I can't vouch for the level of privacy that Turtl offers, but it is a quite a good note-taking tool.
To get started with Turtl, [download](https://turtlapp.com/download/) a desktop client for Linux, Mac OS, or Windows, or grab the [Android app](https://turtlapp.com/download/). Install it, then fire up the client or app. You'll be asked for a username and passphrase. Turtl uses the passphrase to generate a cryptographic key that, according to the developers, encrypts your notes before storing them anywhere on your device or on their servers.
## Using Turtl
You can create the following types of notes with Turtl:
- Password
- File
- Image
- Bookmark
- Text note
No matter what type of note you choose, you create it in a window that's similar for all types of notes:
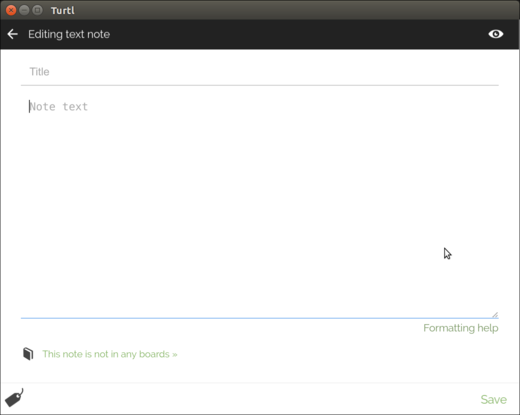
Creating a new text note with Turtl
Add information like the title of the note, some text, and (if you're creating a File or Image note) attach a file or an image. Then click **Save**.
You can add formatting to your notes via [Markdown](https://en.wikipedia.org/wiki/Markdown). You need to add the formatting by hand—there are no toolbar shortcuts.
If you need to organize your notes, you can add them to **Boards**. Boards are just like notebooks in Evernote. To create a new board, click on the **Boards** tab, then click the **Create a board** button. Type a title for the board, then click **Create**.
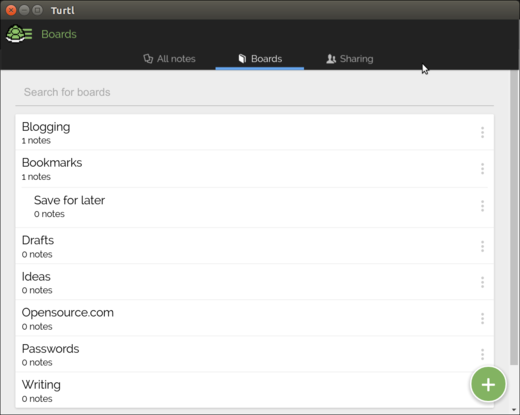
Create a new board in Turtl
To add a note to a board, create or edit the note, then click the **This note is not in any boards** link at the bottom of the note. Select one or more boards, then click **Done**.
To add tags to a note, click the **Tags** icon at the bottom of a note, enter one or more keywords separated by commas, and click **Done**.
## Syncing your notes across your devices
If you use Turtl across several computers and an Android device, for example, Turtl will sync your notes whenever you're online. However, I've encountered a small problem with syncing: Every so often, a note I've created on my phone doesn't sync to my laptop. I tried to sync manually by clicking the icon in the top left of the window and then clicking **Sync Now**, but that doesn't always work. I found that I occasionally need to click that icon, click **Your settings**, and then click **Clear local data**. I then need to log back into Turtl, but all the data syncs properly.
## A question, and a couple of problems
When I started using Turtl, I was dogged by one question: *Where are my notes kept online?* It turns out that the developers behind Turtl are based in the U.S., and that's also where their servers are. Although the encryption that Turtl uses is [quite strong](https://turtlapp.com/docs/security/encryption-specifics/) and your notes are encrypted on the server, the paranoid part of me says that you shouldn't save anything sensitive in Turtl (or any online note-taking tool, for that matter).
Turtl displays notes in a tiled view, reminiscent of Google Keep:
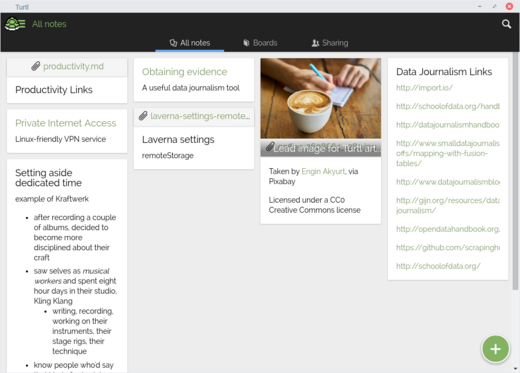
A collection of notes in Turtl
There's no way to change that to a list view, either on the desktop or on the Android app. This isn't a problem for me, but I've heard some people pan Turtl because it lacks a list view.
Speaking of the Android app, it's not bad; however, it doesn't integrate with the Android **Share** menu. If you want to add a note to Turtl based on something you've seen or read in another app, you need to copy and paste it manually.
I've been using a Turtl for several months on a Linux-powered laptop, my [Chromebook running GalliumOS](https://opensource.com/article/17/4/linux-chromebook-gallium-os), and an Android-powered phone. It's been a pretty seamless experience across all those devices. Although it's not my favorite open source note-taking tool, Turtl does a pretty good job. Give it a try; it might be the simple note-taking tool you're looking for.
## 7 Comments |
10,458 | 计算机实验室之树莓派:课程 1 OK01 | https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok01.html | 2019-01-19T16:36:00 | [
"树莓派"
] | https://linux.cn/article-10458-1.html | 
OK01 课程讲解了树莓派如何入门,以及在树莓派上如何启用靠近 RCA 和 USB 端口的 OK 或 ACT 的 LED 指示灯。这个指示灯最初是为了指示 OK 状态的,但它在第二版的树莓派上被改名为 ACT。
### 1、入门
我们假设你已经访问了[下载](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads.html)页面,并且已经获得了必需的 GNU 工具链。也下载了一个称为操作系统模板的文件。请下载这个文件并在一个新目录中解开它。
### 2、开始
现在,你已经展开了这个模板文件,在 `source` 目录中创建一个名为 `main.s` 的文件。这个文件包含了这个操作系统的代码。具体来看,这个文件夹的结构应该像下面这样:
```
build/
(empty)
source/
main.s
kernel.ld
LICENSE
Makefile
```
用文本编辑器打开 `main.s` 文件,这样我们就可以输入汇编代码了。树莓派使用了称为 ARMv6 的汇编代码变体,这就是我们即将要写的汇编代码类型。
>
> 扩展名为 `.s` 的文件一般是汇编代码,需要记住的是,在这里它是 ARMv6 的汇编代码。
>
>
>
首先,我们复制下面的这些命令。
```
.section .init
.globl _start
_start:
```
实际上,上面这些指令并没有在树莓派上做任何事情,它们是提供给汇编器的指令。汇编器是一个转换程序,它将我们能够理解的汇编代码转换成树莓派能够理解的机器代码。在汇编代码中,每个行都是一个新的命令。上面的第一行告诉汇编器 <sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup> 在哪里放我们的代码。我们提供的模板中将它放到一个名为 `.init` 的节中的原因是,它是输出的起始点。这很重要,因为我们希望确保我们能够控制哪个代码首先运行。如果不这样做,首先运行的代码将是按字母顺序排在前面的代码!`.section` 命令简单地告诉汇编器,哪个节中放置代码,从这个点开始,直到下一个 `.section` 或文件结束为止。
>
> 在汇编代码中,你可以跳行、在命令前或后放置空格去提升可读性。
>
>
>
接下来两行是停止一个警告消息,它们并不重要。<sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup>
### 3、第一行代码
现在,我们正式开始写代码。计算机执行汇编代码时,是简单地一行一行按顺序执行每个指令,除非明确告诉它不这样做。每个指令都是开始于一个新行。
复制下列指令。
```
ldr r0,=0x20200000
```
>
> `ldr reg,=val` 将数字 `val` 加载到名为 `reg` 的寄存器中。
>
>
>
那是我们的第一个命令。它告诉处理器将数字 `0x20200000` 保存到寄存器 `r0` 中。在这里我需要去回答两个问题,<ruby> 寄存器 <rt> register </rt></ruby>是什么?`0x20200000` 是一个什么样的数字?
寄存器在处理器中就是一个极小的内存块,它是处理器保存正在处理的数字的地方。处理器中有很多寄存器,很多都有专门的用途,我们在后面会一一接触到它们。最重要的有十三个(命名为 `r0`、`r1`、`r2`、…、`r9`、`r10`、`r11`、`r12`),它们被称为通用寄存器,你可以使用它们做任何计算。由于是写我们的第一行代码,我们在示例中使用了 `r0`,当然你可以使用它们中的任何一个。只要后面始终如一就没有问题。
>
> 树莓派上的一个单独的寄存器能够保存任何介于 `0` 到 `4,294,967,295`(含)之间的任意整数,它可能看起来像一个很大的内存,实际上它仅有 32 个二进制比特。
>
>
>
`0x20200000` 确实是一个数字。只不过它是以十六进制表示的。下面的内容详细解释了十六进制的相关信息:
>
> 延伸阅读:十六进制解释
>
>
> 十六进制是另一种表示数字的方式。你或许只知道十进制的数字表示方法,十进制共有十个数字:`0`、`1`、`2`、`3`、`4`、`5`、`6`、`7`、`8` 和 `9`。十六进制共有十六个数字:`0`、`1`、`2`、`3`、`4`、`5`、`6`、`7`、`8`、`9`、`a`、`b`、`c`、`d`、`e` 和 `f`。
>
>
> 你可能还记得十进制是如何用位制来表示的。即最右侧的数字是个位,紧接着的左边一位是十位,再接着的左边一位是百位,依此类推。也就是说,它的值是 100 × 百位的数字,再加上 10 × 十位的数字,再加上 1 × 个位的数字。
>
>
> 
>
>
> 从数学的角度来看,我们可以发现规律,最右侧的数字是 10<sup> 0</sup> = 1s,紧接着的左边一位是 10<sup> 1</sup> = 10s,再接着是 10<sup> 2</sup> = 100s,依此类推。我们设定在系统中,0 是最低位,紧接着是 1,依此类推。但如果我们使用一个不同于 10 的数字为幂底会是什么样呢?我们在系统中使用的十六进制就是这样的一个数字。
>
>
> 
>
>
> 
>
>
> 上面的数学等式表明,十进制的数字 567 等于十六进制的数字 237。通常我们需要在系统中明确它们,我们使用下标 <sub> 10</sub> 表示它是十进制数字,用下标 <sub> 16</sub> 表示它是十六进制数字。由于在汇编代码中写上下标的小数字很困难,因此我们使用 0x 来表示它是一个十六进制的数字,因此 0x237 的意思就是 237<sub> 16</sub> 。
>
>
> 那么,后面的 `a`、`b`、`c`、`d`、`e` 和 `f` 又是什么呢?好问题!在十六进制中为了能够写每个数字,我们就需要额外的东西。例如 9<sub> 16</sub> = 9×16<sup> 0</sup> = 9<sub> 10</sub> ,但是 10<sub> 16</sub> = 1×16<sup> 1</sup> + 1×16<sup> 0</sup> = 16<sub> 10</sub> 。因此,如果我们只使用 0、1、2、3、4、5、6、7、8 和 9,我们就无法写出 10<sub> 10</sub> 、11<sub> 10</sub> 、12<sub> 10</sub> 、13<sub> 10</sub> 、14<sub> 10</sub> 、15<sub> 10</sub> 。因此我们引入了 6 个新的数字,这样 a<sub> 16</sub> = 10<sub> 10</sub> 、b<sub> 16</sub> = 11<sub> 10</sub> 、c<sub> 16</sub> = 12<sub> 10</sub> 、d<sub> 16</sub> = 13<sub> 10</sub> 、e<sub> 16</sub> = 14<sub> 10</sub> 、f<sub> 16</sub> = 15<sub> 10</sub> 。
>
>
> 所以,我们就有了另一种写数字的方式。但是我们为什么要这么麻烦呢?好问题!由于计算机总是工作在二进制中,事实证明,十六进制是非常有用的,因为每个十六进制数字正好是四个二进制数字的长度。这种方法还有另外一个好处,那就是许多计算机的数字都是十六进制的整数倍,而不是十进制的整数倍。比如,我在上面的汇编代码中使用的一个数字 20200000<sub> 16</sub> 。如果我们用十进制来写,它就是一个不太好记住的数字 538968064<sub> 10</sub> 。
>
>
> 我们可以用下面的简单方法将十进制转换成十六进制:
>
>
> 
>
>
> 1. 我们以十进制数字 567 为例来说明。
> 2. 将十进制数字 567 除以 16 并计算其余数。例如 567 ÷ 16 = 35 余数为 7。
> 3. 在十六进制中余数就是答案中的最后一位数字,在我们的例子中它是 7。
> 4. 重复第 2 步和第 3 步,直到除法结果的整数部分为 0。例如 35 ÷ 16 = 2 余数为 3,因此 3 就是答案中的下一位。2 ÷ 16 = 0 余数为 2,因此 2 就是答案的接下来一位。
> 5. 一旦除法结果的整数部分为 0 就结束了。答案就是反序的余数,因此 567<sub> 10</sub> = 237<sub> 16</sub>。
>
>
> 转换十六进制数字为十进制,也很容易,将数字展开即可,因此 237<sub> 16</sub> = 2×16<sup> 2</sup> + 3×16<sup> 1</sup> +7 ×16<sup> 0</sup> = 2×256 + 3×16 + 7×1 = 512 + 48 + 7 = 567。
>
>
>
因此,我们所写的第一个汇编命令是将数字 20200000<sub> 16</sub> 加载到寄存器 `r0` 中。那个命令看起来似乎没有什么用,但事实并非如此。在计算机中,有大量的内存块和设备。为了能够访问它们,我们给每个内存块和设备指定了一个地址。就像邮政地址或网站地址一样,它用于标识我们想去访问的内存块或设备的位置。计算机中的地址就是一串数字,因此上面的数字 20200000<sub> 16</sub> 就是 GPIO 控制器的地址。这个地址是由制造商的设计所决定的,他们也可以使用其它地址(只要不与其它的冲突即可)。我之所以知道这个地址是 GPIO 控制器的地址是因为我看了它的手册,<sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup> 地址的使用没有专门的规范(除了它们都是以十六进制表示的大数以外)。
### 4、启用输出

阅读了手册可以得知,我们需要给 GPIO 控制器发送两个消息。我们必须用它的语言告诉它,如果我们这样做了,它将非常乐意实现我们的意图,去打开 OK 的 LED 指示灯。幸运的是,它是一个非常简单的芯片,为了让它能够理解我们要做什么,只需要给它设定几个数字即可。
```
mov r1,#1
lsl r1,#18
str r1,[r0,#4]
```
>
> `mov reg,#val` 将数字 `val` 放到名为 `reg` 的寄存器中。
>
>
> `lsl reg,#val` 将寄存器 `reg` 中的二进制操作数左移 `val` 位。
>
>
> `str reg,[dest,#val]` 将寄存器 `reg` 中的数字保存到地址 `dest + val` 上。
>
>
>
这些命令的作用是在 GPIO 的第 16 号插针上启用输出。首先我们在寄存器 `r1` 中获取一个必需的值,接着将这个值发送到 GPIO 控制器。因此,前两个命令是尝试取值到寄存器 `r1` 中,我们可以像前面一样使用另一个命令 `ldr` 来实现,但 `lsl` 命令对我们后面能够设置任何给定的 GPIO 针比较有用,因此从一个公式中推导出值要比直接写入来好一些。表示 OK 的 LED 灯是直接连线到 GPIO 的第 16 号针脚上的,因此我们需要发送一个命令去启用第 16 号针脚。
寄存器 `r1` 中的值是启用 LED 针所需要的。第一行命令将数字 1<sub> 10</sub> 放到 `r1` 中。在这个操作中 `mov` 命令要比 `ldr` 命令快很多,因为它不需要与内存交互,而 `ldr` 命令是将需要的值从内存中加载到寄存器中。尽管如此,`mov` 命令仅能用于加载某些值。<sup id="fnref4"> <a href="#fn4" rel="footnote"> 4 </a></sup> 在 ARM 汇编代码中,基本上每个指令都使用一个三字母代码表示。它们被称为助记词,用于表示操作的用途。`mov` 是 “move” 的简写,而 `ldr` 是 “load register” 的简写。`mov` 是将第二个参数 `#1` 移动到前面的 `r1` 寄存器中。一般情况下,`#` 肯定是表示一个数字,但我们已经看到了不符合这种情况的一个反例。
第二个指令是 `lsl`(逻辑左移)。它的意思是将第一个参数的二进制操作数向左移第二个参数所表示的位数。在这个案例中,将 1<sub> 10</sub> (即 1<sub> 2</sub> )向左移 18 位(将它变成 1000000000000000000<sub> 2</sub>=262144<sub> 10</sub> )。
如果你不熟悉二进制表示法,可以看下面的内容:
>
> 延伸阅读: 二进制解释
>
>
> 与十六进制一样,二进制是写数字的另一种方法。在二进制中只有两个数字,即 `0` 和 `1`。它在计算机中非常有用,因为我们可以用电路来实现它,即电流能够通过电路表示为 `1`,而电流不能通过电路表示为 `0`。这就是计算机能够完成真实工作和做数学运算的原理。尽管二进制只有两个数字,但它却能够表示任何一个数字,只是写起来有点长而已。
>
>
> 
>
>
> 这个图片展示了 567<sub> 10</sub> 的二进制表示是 1000110111<sub> 2</sub> 。我们使用下标 2 来表示这个数字是用二进制写的。
>
>
> 我们在汇编代码中大量使用二进制的其中一个巧合之处是,数字可以很容易地被 `2` 的幂(即 `1`、`2`、`4`、`8`、`16`)乘或除。通常乘法和除法都是非常难的,而在某些特殊情况下却变得非常容易,所以二进制非常重要。
>
>
> 
>
>
> 将一个二进制数字左移 `n` 位就相当于将这个数字乘以 2<sup> n</sup>。因此,如果我们想将一个数乘以 4,我们只需要将这个数字左移 2 位。如果我们想将它乘以 256,我们只需要将它左移 8 位。如果我们想将一个数乘以 12 这样的数字,我们可以有一个替代做法,就是先将这个数乘以 8,然后再将那个数乘以 4,最后将两次相乘的结果相加即可得到最终结果(N × 12 = N × (8 + 4) = N × 8 + N × 4)。
>
>
> 
>
>
> 右移一个二进制数 `n` 位就相当于这个数除以 2<sup> n</sup> 。在右移操作中,除法的余数位将被丢弃。不幸的是,如果对一个不能被 2 的幂次方除尽的二进制数字做除法是非常难的,这将在 [课程 9 Screen04](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html) 中讲到。
>
>
> 
>
>
> 这个图展示了二进制常用的术语。一个<ruby> 比特 <rt> bit </rt></ruby>就是一个单独的二进制位。一个“<ruby> 半字节 <rt> nibble </rt></ruby>“ 是 4 个二进制位。一个<ruby> 字节 <rt> byte </rt></ruby>是 2 个半字节,也就是 8 个比特。<ruby> 半字 <rt> half </rt></ruby>是指一个字长度的一半,这里是 2 个字节。<ruby> 字 <rt> word </rt></ruby>是指处理器上寄存器的大小,因此,树莓派的字长是 4 字节。按惯例,将一个字最高有效位标识为 31,而将最低有效位标识为 0。顶部或最高位表示最高有效位,而底部或最低位表示最低有效位。一个 kilobyte(KB)就是 1000 字节,一个 megabyte 就是 1000 KB。这样表示会导致一些困惑,到底应该是 1000 还是 1024(二进制中的整数)。鉴于这种情况,新的国际标准规定,一个 KB 等于 1000 字节,而一个 Kibibyte(KiB)是 1024 字节。一个 Kb 是 1000 比特,而一个 Kib 是 1024 比特。
>
>
> 树莓派默认采用小端法,也就是说,从你刚才写的地址上加载一个字节时,是从一个字的低位字节开始加载的。
>
>
>
再强调一次,我们只有去阅读手册才能知道我们所需要的值。手册上说,GPIO 控制器中有一个 24 字节的集合,由它来决定 GPIO 针脚的设置。第一个 4 字节与前 10 个 GPIO 针脚有关,第二个 4 字节与接下来的 10 个针脚有关,依此类推。总共有 54 个 GPIO 针脚,因此,我们需要 6 个 4 字节的一个集合,总共是 24 个字节。在每个 4 字节中,每 3 个比特与一个特定的 GPIO 针脚有关。我们想去启用的是第 16 号 GPIO 针脚,因此我们需要去设置第二组 4 字节,因为第二组的 4 字节用于处理 GPIO 针脚的第 10-19 号,而我们需要第 6 组 3 比特,它在上面的代码中的编号是 18(6×3)。
最后的 `str`(“store register”)命令去保存第一个参数中的值,将寄存器 `r1` 中的值保存到后面的表达式计算出来的地址上。这个表达式可以是一个寄存器,在上面的例子中是 `r0`,我们知道 `r0` 中保存了 GPIO 控制器的地址,而另一个值是加到它上面的,在这个例子中是 `#4`。它的意思是将 GPIO 控制器地址加上 `4` 得到一个新的地址,并将寄存器 `r1` 中的值写到那个地址上。那个地址就是我们前面提到的第二组 4 字节的位置,因此,我们发送我们的第一个消息到 GPIO 控制器上,告诉它准备启用 GPIO 第 16 号针脚的输出。
### 5、生命的信号
现在,LED 已经做好了打开准备,我们还需要实际去打开它。意味着需要给 GPIO 控制器发送一个消息去关闭 16 号针脚。是的,你没有看错,就是要发送一个关闭的消息。芯片制造商认为,在 GPIO 针脚关闭时打开 LED 更有意义。<sup id="fnref5"> <a href="#fn5" rel="footnote"> 5 </a></sup> 硬件工程师经常做这种反常理的决策,似乎是为了让操作系统开发者保持警觉。可以认为是给自己的一个警告。
```
mov r1,#1
lsl r1,#16
str r1,[r0,#40]
```
希望你能够认识上面全部的命令,先不要管它的值。第一个命令和前面一样,是将值 `1` 推入到寄存器 `r1` 中。第二个命令是将二进制的 `1` 左移 16 位。由于我们是希望关闭 GPIO 的 16 号针脚,我们需要在下一个消息中将第 16 比特设置为 1(想设置其它针脚只需要改变相应的比特位即可)。最后,我们写这个值到 GPIO 控制器地址加上 40<sub> 10</sub> 的地址上,这将使那个针脚关闭(加上 28 将打开针脚)。
### 6、永远幸福快乐
似乎我们现在就可以结束了,但不幸的是,处理器并不知道我们做了什么。事实上,处理器只要通电,它就永不停止地运转。因此,我们需要给它一个任务,让它一直运转下去,否则,树莓派将进入休眠(本示例中不会,LED 灯会一直亮着)。
```
loop$:
b loop$
```
>
> `name:` 下一行的名字。
>
>
> `b label` 下一行将去标签 `label` 处运行。
>
>
>
第一行不是一个命令,而是一个标签。它给下一行命名为 `loop$`,这意味着我们能够通过名字来指向到该行。这就称为一个标签。当代码被转换成二进制后,标签将被丢弃,但这对我们通过名字而不是数字(地址)找到行比较有用。按惯例,我们使用一个 `$` 表示这个标签只对这个代码块中的代码起作用,让其它人知道,它不对整个程序起作用。`b`(“branch”)命令将去运行指定的标签中的命令,而不是去运行它后面的下一个命令。因此,下一行将再次去运行这个 `b` 命令,这将导致永远循环下去。因此处理器将进入一个无限循环中,直到它安全关闭为止。
代码块结尾的一个空行是有意这样写的。GNU 工具链要求所有的汇编代码文件都是以空行结束的,因此,这就可以你确实是要结束了,并且文件没有被截断。如果你不这样处理,在汇编器运行时,你将收到烦人的警告。
### 7、树莓派上场
由于我们已经写完了代码,现在,我们可以将它上传到树莓派中了。在你的计算机上打开一个终端,改变当前工作目录为 `source` 文件夹的父级目录。输入 `make` 然后回车。如果报错,请参考排错章节。如果没有报错,你将生成三个文件。 `kernel.img` 是你的编译后的操作系统镜像。`kernel.list` 是你写的汇编代码的一个清单,它实际上是生成的。这在将来检查程序是否正确时非常有用。`kernel.map` 文件包含所有标签结束位置的一个映射,这对于跟踪值非常有用。
为安装你的操作系统,需要先有一个已经安装了树莓派操作系统的 SD 卡。如果你浏览 SD 卡中的文件,你应该能看到一个名为 `kernel.img` 的文件。将这个文件重命名为其它名字,比如 `kernel_linux.img`。然后,复制你编译的 `kernel.img` 文件到 SD 卡中原来的位置,这将用你的操作系统镜像文件替换现在的树莓派操作系统镜像。想切换回来时,只需要简单地删除你自己的 `kernel.img` 文件,然后将前面重命名的文件改回 `kernel.img` 即可。我发现,保留一个原始的树莓派操作系统的备份是非常有用的,万一你要用到它呢。
将这个 SD 卡插入到树莓派,并打开它的电源。这个 OK 的 LED 灯将亮起来。如果不是这样,请查看故障排除页面。如果一切如愿,恭喜你,你已经写出了你的第一个操作系统。[课程 2 OK02](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok02.html) 将指导你让 LED 灯闪烁和关闭闪烁。
---
1. 是的,我说错了,它告诉的是链接器,它是另一个程序,用于将汇编器转换过的几个代码文件链接到一起。直接说是汇编器也没有大问题。 [↩](#fnref1)
2. 其实它们对你很重要。由于 GNU 工具链主要用于开发操作系统,它要求入口点必须是名为 `_start` 的地方。由于我们是开发一个操作系统,无论什么时候,它总是从 `_start` 开时的,而我们可以使用 `.section .init` 命令去设置它。因此,如果我们没有告诉它入口点在哪里,就会使工具链困惑而产生警告消息。所以,我们先定义一个名为 `_start` 的符号,它是所有人可见的(全局的),紧接着在下一行生成符号 `_start` 的地址。我们很快就讲到这个地址了。 [↩](#fnref2)
3. 本教程的设计减少了你阅读树莓派开发手册的难度,但是,如果你必须要阅读它,你可以在这里 [SoC-Peripherals.pdf](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads/SoC-Peripherals.pdf) 找到它。由于添加了混淆,手册中 GPIO 使用了不同的地址系统。我们的操作系统中的地址 0x20200000 对应到手册中是 0x7E200000。 [↩](#fnref3)
4. `mov` 能够加载的值只有前 8 位是 `1` 的二进制表示的值。换句话说就是一个 0 后面紧跟着 8 个 `1` 或 `0`。 [↩](#fnref4)
5. 一个很友好的硬件工程师是这样向我解释这个问题的: [↩](#fnref5)
原因是现在的芯片都是用一种称为 CMOS 的技术来制成的,它是互补金属氧化物半导体的简称。互补的意思是每个信号都连接到两个晶体管上,一个是使用 N 型半导体的材料制成,它用于将电压拉低,而另一个使用 P 型半导体材料制成,它用于将电压升高。在任何时刻,仅有一个半导体是打开的,否则将会短路。P 型材料的导电性能不如 N 型材料。这意味着三倍大的 P 型半导体材料才能提供与 N 型半导体材料相同的电流。这就是为什么 LED 总是通过降低为低电压来打开它,因为 N 型半导体拉低电压比 P 型半导体拉高电压的性能更强。
还有一个原因。早在上世纪七十年代,芯片完全是由 N 型材料制成的(NMOS),P 型材料部分使用了一个电阻来代替。这意味着当信号为低电压时,即便它什么事都没有做,芯片仍然在消耗能量(并发热)。你的电话装在口袋里什么事都不做,它仍然会发热并消耗你的电池电量,这不是好的设计。因此,信号设计成 “活动时低”,而不活动时为高电压,这样就不会消耗能源了。虽然我们现在已经不使用 NMOS 了,但由于 N 型材料的低电压信号比 P 型材料的高电压信号要快,所以仍然使用了这种设计。通常在一个 “活动时低” 信号名字上方会有一个条型标记,或者写作 `SIGNAL_n` 或 `/SIGNAL`。但是即便这样,仍然很让人困惑,那怕是硬件工程师,也不可避免这种困惑!
---
via: <https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok01.html>
作者:[Robert Mullins](http://www.cl.cam.ac.uk/%7Erdm34) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Raspberry Pi
# Lesson 1 OK01
The OK01 lesson contains an explanation about how to get started and teaches how
to enable the 'OK' or 'ACT' **LED** on the Raspberry
Pi board near the RCA and USB ports. This light was originally labelled OK but has been renamed to ACT on the revision
2 Raspberry Pi boards.
Contents |
## 1 Getting Started
I am assuming at this point that you have already visited the [
Downloads](downloads.html) page, and got the necessary GNU Toolchain. Also on the downloads
page is a file called OS Template. Please download this and extract its contents
to a new directory.
## 2 The Beginning
The '.s' file extension is commonly used for all forms of assembly code, it is up to us to remember this is ARMv6.
Now that you have extracted the template, create a new file in the 'source' directory called 'main.s'. This file will contain the code for this operating system. To be explicit, the folder structure should look like:
build/(empty)source/ main.s kernel.ld LICENSE Makefile
Open 'main.s' in a text editor so that we can begin typing assembly code. The Raspberry Pi uses a variety of assembly code called ARMv6, so that is what we'll need to write in.
Copy in these first commands.
.section .init
.globl _start
_start:
As it happens, none of these actually do anything on the Raspberry Pi, these are
all instructions to the assembler. The assembler is the program that will translate
between assembly code that we understand, and binary machine code that the Raspberry
Pi understands. In Assembly Code, each line is a new command. The first line here
tells the Assembler[ [1]](#note1)
where to put our code. The template I provided causes the code in the section called
.init to be put at the start of the output. This
is important, as we want to make sure we can control which code runs first. If we
don't do this, the code in the alphabetically first file name will run first! The
.section command simply tells the assembler which
section to put the code in, from this point until the next
.section or the end of the file.
In assembly code, you may skip lines, and put spaces before and after commands to aid readability.
The next two lines are there to stop a warning message and aren't all that important.[2]
## 3 The First Line
Now we're actually going to code something. In assembly code, the computer simply goes through the code, doing each instruction in order, unless told otherwise. Each instruction starts on a new line.
Copy the following instruction.
ldr r0,=0x20200000
ldr reg,=val puts the number val into the register named reg.
That is our first command. It tells the processor to store the number 0x20200000 into the register r0. I shall need to answer two questions here, what is a register, and how is 0x20200000 a number?
A single register can store any integer between 0 and 4,294,967,295 inclusive on the Raspberry Pi, which might seem like a large amount of memory, but it is only 32 binary bits.
A register is a tiny piece of memory in the processor, which is where the processor stores the numbers it is working on right now. There are quite a few of these, many of which have a special meaning, which we will come to later. Importantly there are 13 (named r0,r1,r2,...,r9,r10,r11,r12) which are called General Purpose, and you can use them for whatever calculations you need to do. Since it's the first, I've used r0 in this example, but I could very well have used any of the others. As long as you're consistent, it doesn't matter.
0x20200000 is indeed a number. However it is written in Hexadecimal notation. To learn more about hexadecimal expand the box below:
So our first command is to put the number 2020000016 into r0. That doesn't
sound like it would be much use, but it is. In computers, there are an awful lot
of chunks of memory and devices. In order to access them all, we give each one an
address. Much like a postal address or a web address this is just a means of identifying
the location of the device or chunks of memory we want. Addresses in computers are
just numbers, and so the number 2020000016 happens to be the address
of the GPIO controller. This is just a design decision taken by the manufacturers,
they could have used any other address (providing it didn't conflict with anything
else). I know this address only because I looked it up in a manual[ [3]](#note3), there is no particular
system to the addresses (other than that they are all large round numbers in hexadecimal).
## 4 Enabling Output

Having read the manual, I know we're going to need to send two messages to the GPIO controller. We need to talk its language, but if we do, it will obligingly do what we want and turn on the OK LED. Fortunately, it is such a simple chip, that it only needs a few numbers in order to understand what to do.
mov r1,#1
lsl r1,#18
str r1,[r0,#4]
mov reg,#val puts the number val into the register named reg.
lsl reg,#val shifts the binary representation of the number in reg by val places to the left.
str reg,[dest,#val] stores the number in reg at the address given by dest + val.
These commands enable output to the 16th GPIO pin. First we get a necessary value in r1, then send it to the GPIO controller. Since the first two instructions are just trying to get a value into r1, we could use another ldr command as before, but it will be useful to us later to be able to set any given GPIO pin, so it is better to deduce the value from a formula than write it straight in. The OK LED is wired to the 16th GPIO pin, and so we need to send a command to enable the 16th pin.
The value in r1 is needed to enable the LED pin. The first line puts the number
110 into r1. The mov command is faster
than the ldr command, because it does not involve
a memory interaction, whereas ldr loads the value
we want to put into the register from memory. However, mov
can only be used to load certain values[ [4]](#note4). In ARM assembly code, almost every instruction
begins with a three letter code. This is called the mnemonic, and is supposed to
hint at what the operation does. mov is short
for move and ldr is short for load register.
mov moves the second argument
#1 into the first r1. In general,
# must be used to denote numbers, but we have
already seen a counterexample to this.
The second instruction is lsl or logical shift
left. This means shift the binary representation for the first argument left by
the second argument. In this case this will shift the binary representation of 110
(which is 12) left by 18 places (making it 10000000000000000002=26214410).
If you are unfamiliar with binary, expand the box below:
Once again, I only know that we need this value from reading the manual[ [3]](#note3). The manual says
that there is a set of 24 bytes in the GPIO controller, which determine the settings
of the GPIO pin. The first 4 relate to the first 10 GPIO pins, the second 4 relate
to the next 10 and so on. There are 54 GPIO pins, so we need 6 sets of 4 bytes,
which is 24 bytes in total. Within each 4 byte section, every 3 bits relates to
a particular GPIO pin. Since we want the 16th GPIO pin, we need the second set of
4 bytes because we're dealing with pins 10-19, and we need the 6th set of 3 bits,
which is where the number 18 (6×3) comes from in the code above.
Finally the str 'store register' command stores the value in the first argument, r1 into the address computed from the expression afterwards. The expression can be a register, in this case r0, which we know to be the GPIO controller address, and another value to add to it, in this case #4. This means we add 4 to the GPIO controller address and write the value in r1 to that location. This happens to be the location of the second set of 4 bytes that I mentioned before, and so we send our first message to the GPIO controller, telling it to ready the 16th GPIO pin for output.
## 5 A Sign Of Life
Now that the LED is ready to turn on, we need to actually turn it on. This means
sending a message to the GPIO controller to turn pin 16 off. Yes, *turn it off*.
The chip manufacturers decided it made more sense[ [5]](#note5) to have the LED turn on when
the GPIO pin is off. Hardware engineers often seem to take these sorts of decisions,
seemingly just to keep OS Developers on their toes. Consider yourself warned.
mov r1,#1
lsl r1,#16
str r1,[r0,#40]
Hopefully you should recognise all of the above commands, if not their values. The
first puts a 1 into r1 as before. The second
shifts the binary representation of this 1 left by 16 places. Since we want to turn
pin 16 off, we need to have a 1 in the 16th bit of this next message (other values
would work for other pins). Finally we write it out to the address which is 4010
added to the GPIO controller address, which happens to be the address to write to
turn a pin off (28 would turn the pin on).
## 6 Happily Ever After
It might be tempting to finish now, but unfortunately the processor doesn't know we're done. In actuality, the processor never will stop. As long as it has power, it continues working. Thus, we need to give it a task to do forever more, or the Raspberry Pi will crash (not much of a problem in this example, the light is already on).
loop$:
b loop$
name: labels the next line name.
b label causes the next line to be executed to be label.
The first line here is not a command, but a label. It names the next line loop$. This means we can now refer to the line by name. This is called a label. Labels get discarded when the code is turned into binary, but they're useful for our benefit for referring to lines by name, not number (address). By convention we use a $ for labels which are only important to the code in this block of code, to let others know they're not important to the overall program. The b (branch) command causes the next line to be executed to be the one at the label specified, rather than the one after it. Therefore, the next line to be executed will be this b, which will cause it to be executed again, and so on forever. Thus the processor is stuck in a nice infinite loop until it is switched off safely.
The new line at the end of the block is intentional. The GNU toolchain expects all assembly code files to end in an empty line, so that it is sure you were really finished, and the file hasn't been cut off. If you don't put one, you get an annoying warning when the assembler runs.
## 7 Pi Time
So we've written the code, now to get it onto the pi. Open a terminal on your computer and change the current working directory to the parent directory of the source directory. Type make and then press enter. If any errors occur, please refer to the troubleshooting section. If not, you will have generated three files. kernel.img is the compiled image of your operating system. kernel.list is a listing of the assembly code you wrote, as it was actually generated. This is useful to check that things were generated correctly in future. The kernel.map file contains a map of where all the labels ended up, which can be useful for chasing around values.
To install your operating system, first of all get a Raspberry PI SD card which has an operating system installed already. If you browse the files in the SD card, you should see one called kernel.img. Rename this file to something else, such as kernel_linux.img. Then, copy the file kernel.img that make generated onto the SD Card. You've just replaced the existing operating system with your own. To switch back, simply delete your kernel.img file, and rename the other one back to kernel.img. I find it is always helpful to keep a backup of you original Raspberry Pi operating system, in case you need it again.
Put the SD card into a Raspberry Pi and turn it on. The OK LED should turn on. If
not please see the troubleshooting page. If so, congratulations, you just wrote
your first operating system. See [Lesson 2: OK02](ok02.html) for a guide
to making the LED flash on and off. |
10,459 | Flatpak 新手指南 | https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/ | 2019-01-20T11:31:08 | [
"Flatpak"
] | https://linux.cn/article-10459-1.html | 
以前,我们介绍 Ubuntu 推出的 [Snaps](http://www.ostechnix.com/introduction-ubuntus-snap-packages/)。Snaps 是由 Canonical 公司为 Ubuntu 开发的,并随后移植到其他的 Linux 发行版,如 Arch、Gentoo、Fedora 等等。由于一个 snap 包中含有软件的二进制文件和其所需的所有依赖和库,所以可以在无视软件版本、在任意 Linux 发行版上安装软件。和 Snaps 类似,还有一个名为 Flatpak 的工具。也许你已经知道,为不同的 Linux 发行版打包并分发应用是一件多么费时又复杂的工作,因为不同的 Linux 发行版的库不同,库的版本也不同。现在,Flatpak 作为分发桌面应用的新框架可以让开发者完全摆脱这些负担。开发者只需构建一个 Flatpak app 就可以在多种发行版上安装使用。这真是又酷又棒!
用户也完全不用担心库和依赖的问题了,所有的东西都和 app 打包在了一起。更重要的是 Flatpak app 们都自带沙箱,而且与宿主操作系统的其他部分隔离。对了,Flatpak 还有一个很棒的特性,它允许用户在同一个系统中安装同一应用的多个版本,例如 VLC 播放器的 2.1 版、2.2 版、2.3 版。这使开发者测试同一个软件的多个版本变得更加方便。
在本文中,我们将指导你如何在 GNU/Linux 中安装 Flatpak。
### 安装 Flatpak
Flatpak 可以在大多数的主流 Linux 发行版上安装使用,如 Arch Linux、Debian、Fedora、Gentoo、Red Hat、Linux Mint、openSUSE、Solus、Mageia 还有 Ubuntu。
在 Arch Linux 上,使用这一条命令来安装 Flatpak:
```
$ sudo pacman -S flatpak
```
对于 Debian 用户,Flatpak 被收录进 Stretch 或之后版本的默认软件源中。要安装 Flatpak,直接执行:
```
$ sudo apt install flatpak
```
对于 Fedora 用户,Flatpak 是发行版默认安装的软件。你可以直接跳过这一步。
如果因为某种原因没有安装的话,可以执行:
```
$ sudo dnf install flatpak
```
对于 RHEL 7 用户,安装 Flatpak 的命令为:
```
$ sudo yum install flatpak
```
如果你在使用 Linux Mint 18.3,那么 Flatpat 也随系统默认安装,所以跳过这一步。
在 openSUSE Tumbleweed 中,使用 Zypper 包管理来安装 Flatpak:
```
$ sudo zypper install flatpak
```
而 Ubuntu 需要添加下面的软件源再安装 Flatpak,命令如下:
```
$ sudo add-apt-repository ppa:alexlarsson/flatpak
$ sudo apt update
$ sudo apt install flatpak
```
Gnome 提供了一个 Flatpak 插件,安装它就可以使用图形界面来安装 Flatpak app 了。插件的安装命令为:
```
$ sudo apt install gnome-software-plugin-flatpak
```
如果你是用发行版没有在上述的说明里,请你参考官方[安装指南](https://flatpak.org/setup/)。
### 开始使用 Flatpak
有不少流行应用都支持 Flatpak 安装,如 Gimp、Kdenlive、Steam、Spotify、Visual Sudio Code 等。
下面让我来一起学习 flatpak 的基本操作命令。
首先,我们需要添加远程仓库。
#### 添加软件仓库
**添加 Flathub 仓库:**
**Flathub** 是一个包含了几乎所有 flatpak 应用的仓库。运行这条命令来启用它:
```
$ sudo flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```
对于流行应用来说,Flathub 已经可以满足需求。如果你想试试 GNOME 应用的话,可以添加 GNOME 的仓库。
**添加 GNOME 仓库:**
GNOME 仓库包括了所有的 GNOME 核心应用,它提供了两种版本:<ruby> 稳定版 <rt> stable </rt></ruby>和<ruby> 每日构建版 <rt> nightly </rt></ruby>。
使用下面的命令来添加 GNOME 稳定版仓库:
```
$ wget https://sdk.gnome.org/keys/gnome-sdk.gpg
$ sudo flatpak remote-add --gpg-import=gnome-sdk.gpg --if-not-exists gnome-apps https://sdk.gnome.org/repo-apps/
```
需要注意的是,GNOME 稳定版仓库中的应用需要 **3.20 版本的 org.gnome.Platform 运行时环境**。
安装稳定版运行时环境,请执行:
```
$ sudo flatpak remote-add --gpg-import=gnome-sdk.gpg gnome https://sdk.gnome.org/repo/
```
如果想使用每日构建版的 GNOME 仓库,使用如下的命令:
```
$ wget https://sdk.gnome.org/nightly/keys/nightly.gpg
$ sudo flatpak remote-add --gpg-import=nightly.gpg --if-not-exists gnome-nightly-apps https://sdk.gnome.org/nightly/repo-apps/
```
同样,每日构建版的 GNOME 仓库也需要 **org.gnome.Platform 运行时环境的每日构建版本**。
执行下面的命令安装每日构建版的运行时环境:
```
$ sudo flatpak remote-add --gpg-import=nightly.gpg gnome-nightly https://sdk.gnome.org/nightly/repo/
```
#### 查看软件仓库
要查看已经添加的软件仓库,执行下面的命令:
```
$ flatpak remotes
Name Options
flathub system
gnome system
gnome-apps system
gnome-nightly system
gnome-nightly-apps system
```
如你所见,上述命令会列出你添加到系统中的软件仓库。此外,执行结果还表明了软件仓库的配置是<ruby> 用户级 <rt> per-user </rt></ruby>还是<ruby> 系统级 <rt> system-wide </rt></ruby>。
#### 删除软件仓库
要删除软件仓库,例如 flathub,用这条命令:
```
$ sudo flatpak remote-delete flathub
```
这里的 flathub 是软件仓库的名字。
#### 安装 Flatpak 应用
这一节,我们将学习如何安装 flatpak 应用。
要安装一个应用,只要一条命令就能完成:
```
$ sudo flatpak install flathub com.spotify.Client
```
所有的稳定版 GNOME 软件仓库中的应用,都使用“stable”作为版本名。
例如,想从稳定版 GNOME 软件仓库中安装稳定版 Evince,就执行:
```
$ sudo flatpak install gnome-apps org.gnome.Evince stable
```
所有的每日构建版 GNOME 仓库中的应用,都使用“master”作为版本名。
例如,要从每日构建版 GNOME 软件仓库中安装 gedit 的每次构建版本,就执行:
```
$ sudo flatpak install gnome-nightly-apps org.gnome.gedit master
```
如果不希望应用安装在<ruby> 系统级 <rt> system-wide </rt></ruby>,而只安装在<ruby> 用户级 <rt> per-user </rt></ruby>,那么你可以这样安装软件:
```
$ flatpak install --user <name-of-app>
```
所有的应用都会被存储在 `$HOME/.var/app/` 目录下.
```
$ ls $HOME/.var/app/
com.spotify.Client
```
#### 执行 Flatpak 应用
你可以直接使用<ruby> 应用启动器 <rt> application launcher </rt></ruby>来运行已安装的 Flatpak 应用。如果你想从命令行启动的话,以 Spotify 为例,执行下面的命令:
```
$ flatpak run com.spotify.Client
```
#### 列出已安装的 Flatpak 应用
要查看已安装的应用程序和运行时环境,执行:
```
$ flatpak list
```
想只查看已安装的应用,那就用这条命令:
```
$ flatpak list --app
```
如果想查询已添加的软件仓库中的可安装程序和可安装的运行时环境,使用命令:
```
$ flatpak remote-ls
```
只列出可安装的应用程序的命令是:
```
$ flatpak remote-ls --app
```
查询指定远程仓库中的所有可安装的应用程序和运行时环境,这里以 gnome-apps 为例,执行命令:
```
$ flatpak remote-ls gnome-apps
```
只列出可安装的应用程序,这里以 flathub 为例:
```
$ flatpak remote-ls flathub --app
```
#### 更新应用程序
更新所有的 Flatpak 应用程序,执行:
```
$ flatpak update
```
更新指定的 Flatpak 应用程序,执行:
```
$ flatpak update com.spotify.Client
```
#### 获取应用详情
执行下面的命令来查看已安装应用程序的详细信息:
```
$ flatpak info io.github.mmstick.FontFinder
```
输出样例:
```
Ref: app/io.github.mmstick.FontFinder/x86_64/stable
ID: io.github.mmstick.FontFinder
Arch: x86_64
Branch: stable
Origin: flathub
Date: 2018-04-11 15:10:31 +0000
Subject: Workaround appstream issues (391ef7f5)
Commit: 07164e84148c9fc8b0a2a263c8a468a5355b89061b43e32d95008fc5dc4988f4
Parent: dbff9150fce9fdfbc53d27e82965010805f16491ec7aa1aa76bf24ec1882d683
Location: /var/lib/flatpak/app/io.github.mmstick.FontFinder/x86_64/stable/07164e84148c9fc8b0a2a263c8a468a5355b89061b43e32d95008fc5dc4988f4
Installed size: 2.5 MB
Runtime: org.gnome.Platform/x86_64/3.28
```
#### 删除应用程序
要删除一个 Flatpak 应用程序,这里以 spotify 为例,执行:
```
$ sudo flatpak uninstall com.spotify.Client
```
如果你需要更多信息,可以参考 Flatpak 的帮助。
```
$ flatpak --help
```
到此,希望你对 Flatpak 有了一些基础了解。
如果你觉得这篇指南有些帮助,请在你的社交媒体上分享它来支持我们。
稍后还有更多精彩内容,敬请期待~
---
via: <https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wwhio](https://github.com/wwhio) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,460 | 理解 Linux 中的 /etc/services 文件 | https://kerneltalks.com/linux/understanding-etc-services-file-in-linux/ | 2019-01-20T12:16:00 | [
"inetd",
"services"
] | https://linux.cn/article-10460-1.html | 
这篇文章将帮助你了解 Linux 中 `/etc/services` 文件,包括它的内容,格式以及重要性。
Internet 守护程序(`ineted`)是 Linux 世界中的重要服务。它借助 `/etc/services` 文件来处理所有网络服务。在本文中,我们将向你介绍这个文件的内容,格式以及它对于 Linux 系统的意义。
`/etc/services` 文件包含网络服务和它们映射端口的列表。`inetd` 或 `xinetd` 会查看这些细节,以便在数据包到达各自的端口或服务有需求时,它会调用特定的程序。
作为普通用户,你可以查看此文件,因为文件一般都是可读的。要编辑此文件,你需要有 root 权限。
```
$ ll /etc/services
-rw-r--r--. 1 root root 670293 Jun 7 2013 /etc/services
```
### /etc/services 文件格式
```
service-name port/protocol [aliases..] [#comment]
```
最后两个字段是可选的,因此用 `[` `]` 表示。
其中:
* `service-name` 是网络服务的名称。例如 [telnet](https://kerneltalks.com/config/configure-telnet-server-linux/)、[ftp](https://kerneltalks.com/config/ftp-server-configuration-steps-rhel-6/) 等。
* `port/protocol` 是网络服务使用的端口(一个数值)和服务通信使用的协议(TCP/UDP)。
* `alias` 是服务的别名。
* `comment` 是你可以添加到服务的注释或说明。以 `#` 标记开头。
### /etc/services 文件示例
```
# 每行描述一个服务,形式如下:
#
# service-name port/protocol [aliases ...] [# comment]
tcpmux 1/tcp # TCP port service multiplexer
rje 5/tcp # Remote Job Entry
echo 7/udp
discard 9/udp sink null
```
在这里,你可以看到可选的最后两个字段的用处。`discard` 服务的别名为 `sink` 或 `null`。
---
via: <https://kerneltalks.com/linux/understanding-etc-services-file-in-linux/>
作者:[kerneltalks](https://kerneltalks.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *The article helps you to understand /etc/services file in Linux. Learn about content, format & importance of this file.*
Internet daemon is an important service in the Linux world. It takes care of all network services with the help of `/etc/services`
file. In this article, we will walk you through the content, format of this file, and what it means to a Linux system.
`/etc/services`
file contains a list of network services and ports mapped to them. `inetd`
or `xinetd`
looks at these details so that it can call a particular program when a packet hits respective port and demand for service.
As a normal user, you can view this file since the file is world-readable. To edit this file you need to have root privileges.
```
$ ll /etc/services
-rw-r--r--. 1 root root 670293 Jun 7 2013 /etc/services
```
`/etc/services`
file format
```
service-name port/protocol [aliases..] [#comment]
```
Last two fields are optional hence denoted in `[`
`]`
where –
- service-name is the name of the network service. e.g.
[telnet](https://kerneltalks.com/config/configure-telnet-server-linux/),[FTP](https://kerneltalks.com/config/ftp-server-configuration-steps-rhel-6/), etc. - port/protocol is the port being used by that network service (numerical value) and protocol (TCP/UDP) used for communication by service.
- alias is an alternate name for service.
- a comment is a note or description you can add to service. Starts with
`#`
mark
#### Sample` /etc/services`
file
```
# Each line describes one service, and is of the form:
#
# service-name port/protocol [aliases ...] [# comment]
tcpmux 1/tcp # TCP port service multiplexer
rje 5/tcp # Remote Job Entry
echo 7/udp
discard 9/udp sink null
```
Here, you can see the use of optional last two fields as well. `discard`
service has an alternate name as `sink`
or `null`
.
## Share Your Comments & Feedback: Cancel reply |
10,461 | Caffeinated 6.828:实验 7:最终的 JOS 项目 | https://pdos.csail.mit.edu/6.828/2018/labs/lab7/ | 2019-01-20T20:57:00 | [
"6.828"
] | https://linux.cn/article-10461-1.html | 
### 简介
对于最后的项目,你有两个选择:
* 继续使用你自己的 JOS 内核并做 [实验 6](https://pdos.csail.mit.edu/6.828/2018/labs/lab6/index.html),包括实验 6 中的一个挑战问题。(你可以随意地、以任何有趣的方式去扩展实验 6 或者 JOS 的任何部分,当然了,这不是课程规定的。)
* 在一个、二个或三个人组成的团队中,你选择去做一个涉及了你的 JOS 的项目。这个项目必须是涉及到与实验 6 相同或更大的领域(如果你是团队中的一员)。
目标是为了获得乐趣或探索更高级的 O/S 的话题;你不需要做最新的研究。
如果你做了你自己的项目,我们将根据你的工作量有多少、你的设计有多优雅、你的解释有多高明、以及你的解决方案多么有趣或多有创意来为你打分。我们知道时间有限,因此也不期望你能在本学期结束之前重写 Linux。要确保你的目标是合理的;合理地设定一个绝对可以实现的最小目标(即:控制你的实验 6 的规模),如果进展顺利,可以设定一个更大的目标。
如果你做了实验 6,我们将根据你是否通过了测试和挑战练习来为你打分。
### 交付期限
>
> 11 月 3 日:Piazza 讨论和 1、2、或 3 年级组选择(根据你的最终选择来定)。使用在 Piazza 上的 lab7 标记/目录。在 Piazza 上的文章评论区与其它人计论想法。使用这些文章帮你去找到有类似想法的其它学生一起组建一个小组。课程的教学人员将在 Piazza 上为你的项目想法给出反馈;如果你想得到更详细的反馈,可以与我们单独讨论。
>
>
>
.
>
> 11 月 9 日:在 [提交网站](https://6828.scripts.mit.edu/2018/handin.py/) 上提交一个提议,只需要一到两个段落就可以。提议要包括你的小组成员列表、你的计划、以及明确的设计和实现打算。(如果你做实验 6,就不用做这个了)
>
>
>
.
>
> 12 月 7 日:和你的简短报告一起提交源代码。将你的报告放在与名为 “README.pdf” 的文件相同的目录下。由于你只是这个实验任务小组中的一员,你可能需要去使用 git 在小组成员之间共享你的项目代码。因此你需要去决定哪些源代码将作为你的小组项目的共享起始点。一定要为你的最终项目去创建一个分支,并且命名为 `lab7`。(如果你做了实验 6,就按实验 6 的提交要求做即可。)
>
>
>
.
>
> 12 月 11 日这一周:简短的课堂演示。为你的 JOS 项目准备一个简短的课堂演示。为了你的项目演示,我们将提供一个投影仪。根据小组数量和每个小组选择的项目类型,我们可能会限制总的演讲数,并且有些小组可能最终没有机会上台演示。
>
>
>
.
>
> 12 月 11 日这一周:助教们验收。向助教演示你的项目,因此我们可能会提问一些问题,去了解你所做的一些细节。
>
>
>
### 项目想法
如果你不做实验 6,下面是一个启迪你的想法列表。但是,你应该大胆地去实现你自己的想法。其中一些想法只是一个开端,并且本身不在实验 6 的领域内,并且其它的可能是在更大的领域中。
* 使用 [x86 虚拟机支持](http://www.intel.com/technology/itj/2006/v10i3/1-hardware/3-software.htm) 去构建一个能够运行多个访客系统(比如,多个 JOS 实例)的虚拟机监视器。
* 使用 Intel SGX 硬件保护机制做一些有用的事情。[这是使用 Intel SGX 的最新的论文](https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-baumann.pdf)。
* 让 JOS 文件系统支持写入、文件创建、为持久性使用日志、等等。或许你可以从 Linux EXT3 上找到一些启示。
* 从 [软更新](http://www.ece.cmu.edu/%7Eganger/papers/osdi94.pdf)、[WAFL](https://ng.gnunet.org/sites/default/files/10.1.1.40.3691.pdf)、ZFS、或其它较高级的文件系统上找到一些使用文件系统的想法。
* 给一个文件系统添加快照功能,以便于用户能够查看过去的多个时间点上的文件系统。为了降低空间使用量,你或许要使用一些写时复制技术。
* 使用分页去提供实时共享的内存,来构建一个 [分布式的共享内存](http://www.cdf.toronto.edu/%7Ecsc469h/fall/handouts/nitzberg91.pdf)(DSM)系统,以便于你在一个机器集群上运行多线程的共享内存的并行程序。当一个线程尝试去访问位于另外一个机器上的页时,页故障将给 DSM 系统提供一个机会,让它基于网络去从当前存储这个页的任意一台机器上获取这个页。
* 允许进程在机器之间基于网络进行迁移。你将需要做一些关于一个进程状态的多个片段方面的事情,但是由于在 JOS 中许多状态是在用户空间中,它或许从 Linux 上的进程迁移要容易一些。
* 在 JOS 中实现 [分页](http://en.wikipedia.org/wiki/Paging) 到磁盘,这样那个进程使用的内存就可以大于真实的内存。使用交换空间去扩展你的内存。
* 为 JOS 实现文件的 [mmap()](http://en.wikipedia.org/wiki/Mmap)。
* 使用 [xfi](http://static.usenix.org/event/osdi06/tech/erlingsson.html) 将一个进程的代码沙箱化。
* 支持 x86 的 [2MB 或 4MB 的页大小](http://en.wikipedia.org/wiki/Page_(computer_memory))。
* 修改 JOS 让内核支持进程内的线程。从查看 [课堂上的 uthread 任务](http://pdos.csail.mit.edu/6.828/2018/homework/xv6-uthread.html) 去开始。实现调度器触发将是实现这个项目的一种方式。
* 在 JOS 的内核中或文件系统中(实现多线程之后),使用细粒度锁或无锁并发。Linux 内核使用 [读复制更新](http://en.wikipedia.org/wiki/Read-copy-update) 去执行无需上锁的读取操作。通过在 JOS 中实现它来探索 RCU,并使用它去支持无锁读取的名称缓存。
* 实现 [外内核论文](http://pdos.csail.mit.edu/6.828/2018/readings/engler95exokernel.pdf) 中的想法。例如包过滤器。
* 使 JOS 拥有软实时行为。用它来辨识一些应用程序时非常有用。
* 使 JOS 运行在 64 位 CPU 上。这包括重设计虚拟内存让它使用 4 级页表。有关这方面的文档,请查看 [参考页](http://pdos.csail.mit.edu/6.828/2018/reference.html)。
* 移植 JOS 到一个不同的微处理器。这个 [osdev wiki](http://wiki.osdev.org/Main_Page) 或许对你有帮助。
* 为 JOS 系统增加一个“窗口”系统,包括图形驱动和鼠标。有关这方面的文档,请查看 [参考页](http://pdos.csail.mit.edu/6.828/2018/reference.html)。[sqrt(x)](http://web.mit.edu/amdragon/www/pubs/sqrtx-6.828.html) 就是一个 JOS “窗口” 系统的示例。
* 在 JOS 中实现 [dune](https://www.usenix.org/system/files/conference/osdi12/osdi12-final-117.pdf),以提供特权硬件指令给用户空间应用程序。
* 写一个用户级调试器,添加类似跟踪的功能;硬件寄存器概要(即:Oprofile);调用跟踪等等。
* 为(静态的)Linux 可运行程序做一个二进制仿真。
---
via: <https://pdos.csail.mit.edu/6.828/2018/labs/lab7/>
作者:[csail.mit](https://pdos.csail.mit.edu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Lab 7: Final JOS project
**
Piazza Discussion Due, November 2, 2018 **
Proposals Due, November 8, 2018
Code repository Due, December 6, 2018
Check-off and in-class demos, Week of December 10, 2018
## Introduction
For the final project you have two options:
- Work on your own and do
[lab 6](../lab6/index.html), including
one challenge exercise in lab 6. (You are free, of course, to extend lab 6,
or any part of JOS, further in interesting ways, but it isn't required.)
- Work in a team of one, two or three, on a project of your choice that
involves your JOS. This project must be of the same scope as lab 6 or larger
(if you are working in a team).
The goal is to have fun and explore more advanced O/S topics; you don't have to
do novel research.
If you are doing your own project, we'll grade you on how much you got
working, how elegant your design is, how well you can explain it, and how
interesting and creative your solution is. We do realize that time is limited,
so we don't expect you to re-write Linux by the end of the semester. Try to make
sure your goals are reasonable; perhaps set a minimum goal that's definitely
achievable (e.g., something of the scale of lab 6) and a more ambitious goal if
things go well.
If you are doing lab 6, we will grade you on whether you pass the tests and
the challenge exercise.
## Deliverables
Nov 3: Piazza discussion and form groups of 1, 2, or 3 (depending on which
final project option you are choosing). Use the lab7
tag/folder on Piazza. Discuss ideas with others in comments on their Piazza
posting. Use these postings to help find other students interested in similar
ideas for forming a group. Course staff will provide feedback on project ideas
on Piazza; if you'd like more detailed feedback, come chat with us in
person.
Nov 9: Submit a proposal at [ the submission website](https://6828.scripts.mit.edu/2018/handin.py/),
just a paragraph or two. The proposal should include your group members list,
the problem you want to address, how you plan to address it, and what are you
proposing to specifically design and implement. (If you are doing lab 6, there
is nothing to do for this deliverable.)
Dec 7: submit source code along with a brief write-up.
Put the write-up under the top-level source directory with the
name "`README.pdf`". Since some of you will be working in groups for this lab assignment, you may
want to use git to share your project code between group members. You will need
to decide on whose source code you will use as a starting point for your group
project. Make sure to create a branch for your final project, and name it
**lab7**. (If you do lab 6, follow the lab 6 submission instructions.)
Week of Dec 11: short in-class demonstration. Prepare a short in-class
demo of your JOS project. We will provide a projector that you can use to
demonstrate your project. Depending on the number of groups and the kinds of
projects that each group chooses, we may decide to limit the total number of
presentations, and some groups might end up not presenting in class.
Week of Dec 11: check-off with TAs. Demo your project to the TAs so that
we can ask you some questions and find out in more detail what you did.
## Project ideas
If you are not doing lab 6, here's a list of ideas to get you started
thinking. But, you should feel free to pursue your own ideas. Some of the ideas
are starting points and by themselves not of the scope of lab 6, and others are
likely to be much of larger scope.
- Build a virtual machine monitor that can run multiple guests (for
example, multiple instances of JOS), using
[x86 VM support](http://www.intel.com/technology/itj/2006/v10i3/1-hardware/3-software.htm).
- Do something useful with the hardware protection of Intel SGX.
[Here
is a recent paper using Intel SGX](https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-baumann.pdf).
- Make the JOS file system support writing, file creation, logging for
durability, etc., perhaps taking ideas from Linux EXT3.
- Use file system ideas from
[Soft
updates](http://www.ece.cmu.edu/~ganger/papers/osdi94.pdf),
[WAFL](https://ng.gnunet.org/sites/default/files/10.1.1.40.3691.pdf),
ZFS, or another advanced file system.
- Add snapshots to a file system, so that a user can look at
the file system as it appeared at various points in the past.
You'll probably want to use some kind of copy-on-write for disk
storage to keep space consumption down.
- Build a
[distributed shared memory](http://www.cdf.toronto.edu/~csc469h/fall/handouts/nitzberg91.pdf) (DSM) system, so that you can run
multi-threaded shared memory parallel programs on a cluster of
machines, using paging to give the appearance of real shared memory.
When a thread tries to access a page that's on another machine, the
page fault will give the DSM system a chance to fetch the page over
the network from whatever machine currently stores it.
- Allow processes to migrate from one machine to another over the
network. You'll need to do something about the various pieces of a process's
state, but since much state in JOS is in user-space it may be easier than
process migration on Linux.
- Implement
[paging](http://en.wikipedia.org/wiki/Paging) to disk
in JOS, so that processes can be bigger than RAM. Extend your pager
with swapping.
- Implement
[mmap()](http://en.wikipedia.org/wiki/Mmap) of files
for JOS.
- Use
[xfi](http://static.usenix.org/event/osdi06/tech/erlingsson.html) to
sandbox code within a process.
- Support x86
[2MB or 4MB pages](http://en.wikipedia.org/wiki/Page_(computer_memory)).
- Modify JOS to have kernel-supported threads inside processes. See
[in-class
uthread assignment](http://pdos.csail.mit.edu/6.828/2018/homework/xv6-uthread.html) to get started. Implementing scheduler activations
would be one way to do this project.
- Use fine-grained locking or lock-free concurrency in JOS in the kernel or
in the file server (after making it multithreaded). The linux kernel uses
[read copy
update](http://en.wikipedia.org/wiki/Read-copy-update) to be able to perform read operations without holding locks.
Explore RCU by implementing it in JOS and use it to support a name cache with
lock-free reads.
- Implement ideas from the
[Exokernel papers](http://pdos.csail.mit.edu/6.828/2018/readings/engler95exokernel.pdf), for example the packet filter.
- Make JOS have soft real-time behavior. You will have to identify some
application for which this is useful.
- Make JOS run on 64-bit CPUs. This includes redoing the virtual
memory system to use 4-level pages tables. See
[reference page](http://pdos.csail.mit.edu/6.828/2018/reference.html)
for some documentation.
- Port JOS to a different microprocessor. The
[osdev wiki](http://wiki.osdev.org/Main_Page) may be helpful.
- A window system for JOS, including graphics driver and mouse. See
[reference
page](http://pdos.csail.mit.edu/6.828/2018/reference.html) for some documentation. [sqrt(x)](http://web.mit.edu/amdragon/www/pubs/sqrtx-6.828.html) is
an example JOS window system (and writeup).
- Implement
[dune](https://www.usenix.org/system/files/conference/osdi12/osdi12-final-117.pdf)
to export privileged hardware instructions to user-space applications in JOS.
- Write a user-level debugger; add strace-like functionality;
hardware register profiling (e.g. Oprofile); call-traces
- Binary emulation for (static) Linux executables |
10,462 | 4 个值得一提的 Firefox 扩展插件 | https://opensource.com/article/18/6/firefox-open-source-extensions | 2019-01-21T11:09:09 | [
"Firefox",
"扩展",
"插件"
] | /article-10462-1.html |
>
> 这些扩展可以使火狐更具生产力和使用乐趣。
>
>
>

自从大约 12 年前 Firefox(火狐浏览器)v2.0 推出以来, 我一直是它的用户。它不是那时最好的网络浏览器,但是总会有一个理由让我回到它:我最喜爱的浏览器扩展插件不能工作在其它浏览器上。
如今,我喜欢现下的 Firefox,因为它快速、可定制和开源,我也很欣赏那些体现了原开发人员从未想到过的想法的扩展插件:如果你想在没有鼠标的情况下浏览网页呢?如果你不喜欢盯着晚上从显示器里发出来的强光呢?如何在 YouTube 和其他视频托管网站上使用一个更专业的播放器来获得更好的性能和更多播放控制呢?如果你需要更复杂的方法来禁用跟踪器和加快加载页面,该怎么办?
幸运的是,这些问题都有答案,我将展现给你我最喜爱的扩展 —— 所有这些都是免费软件或开源的 (即,在 [GNU GPL](https://www.gnu.org/licenses/gpl-3.0.en.html)、[MPL](https://www.mozilla.org/en-US/MPL/) 或 [Apache](https://www.apache.org/licenses/LICENSE-2.0) 许可帧下) ,它们可以使一个优秀的浏览器更优秀。
尽管术语<ruby> 加载项 <rt> add-on </rt></ruby>和<ruby> 扩展 <rt> extension </rt></ruby>的含义稍微不同,但我在本文中的使用不会区分它们。
### Tridactyl

*Tridactyl 的新选项卡页面,展示了链接的指引。*
[Tridactyl](https://addons.mozilla.org/en-US/firefox/addon/tridactyl-vim/) 使你能够在大多数浏览活动中使用键盘。它的灵感来自于现已不复存在的 [Vimperator](https://github.com/vimperator/vimperator-labs) 和 [Pentadactyl](https://addons.mozilla.org/en-US/firefox/addon/pentadactyl/),而它们受到了 [Vim](https://www.vim.org/) 的默认键绑定的启发。由于我已经习惯了 Vim 和其他命令行应用程序,我发现了它的功能类似于使用键值 `h/j/k/l` 进行导航,用 `f/F` 可以与超链接进行交互,而且创建自定义的键绑定和命令非常方便。
Tridactyl 最近刚刚实现了一个可选的本地信使(目前,仅适用于 GNU/Linux 和 Mac OSX),提供了更酷的功能。例如,有了它,你可以隐藏 Firefox 用户界面上的一些元素(以 Vimperator 和 Pentadactyl 的方式)、在外部程序中打开链接或当前页(我经常用 [mpv](https://mpv.io/) 和 [youtube-dl](https://rg3.github.io/youtube-dl/index.html) 播放视频)、通过按 `Ctrl-I`(或者任意你选择的组合键)用你喜爱的编辑器来编辑文本框的内容。
话虽如此,但要记住,这是一个相对早期的项目,细节可能还是很粗糙。另一方面,它的开发非常活跃,当你回顾它早期的缺陷时,未尝不是一种乐趣。
### Open With

*Open With 提供的菜单。我可以用这里列出的一个外部程序打开当前页面。*
说到与外部程序的互动,有时能够用鼠标来做到这一点还是让人很高兴的。这是 [Open With](https://addons.mozilla.org/en-US/firefox/addon/open-with/) 的用武之地。
除了添加的上下文菜单(如屏幕截图所示)之外,你还可以通过单击加载项栏上的扩展图标来找到自己定义的命令。如[它在 Mozilla Add-ons 页面上](https://addons.mozilla.org/en-US/firefox/addon/open-with/) 的图标和描述所示,它主要是为了切换到其它的 web 浏览器,但我也可以轻松地将它与 mpv 和 youtube-dl 相配合。
它也提供了键盘快捷方式,但它们受到了严重限制。可以在扩展设置的下拉列表中选择的组合不超过三种。相反,Tridactyl 允许我将命令分配给几乎任何没有被 Firefox 所阻止的东西。没错,Open With 目前为鼠标而准备的。
### Stylus
!")
*在这个屏幕截图中,我刚刚搜索并为当前正在浏览的 Stylus 的网站安装了一个黑暗主题。即使是弹出窗口也可以定制风格(称为 Deepdark Stylus)!*
[Stylus](https://addons.mozilla.org/en-US/firefox/addon/styl-us/) 是一个用户样式管理器,这意味着可以通过编写自定义 CSS 规则并将其加载到 Stylus 中来更改任何网页的外观。如果你不懂 CSS,在如 [userstyles.org](https://userstyles.org/) 这样网站上有大量的其他人制作的样式。
现在,你可能会问,“这不就是 [Stylish](https://addons.mozilla.org/en-US/firefox/addon/stylish/) 么?” 你是对的!Stylus 是基于 Stylish 的,并提供了更多的改进:它不包含任何远程记录、尊重你的隐私,所有开发都是公开的(尽管 Stylish 仍在积极开发,我一直未能找到最新版本的源代码),而且它还支持 [UserCSS](https://github.com/openstyles/stylus/wiki/Usercss)。
UserCSS 是一种有趣的格式,尤其是对于开发人员来说。我已经为不同的网站写了几种用户样式(主要是黑暗主题,和为了提高可读性的调整),虽然 Stylus 的内部编辑器很好,我还是喜欢用 Neovim 编辑代码。为了做到这样我所需要做的就是用 “.user.css” 作为本地加载文件的后缀名,在 Stylus 里启动 “Live Reload” 选项,只要我在 Neovim 中保存文件就会应用所有的更改。它也支持远程 UserCSS 文件,因此,每当我将更改推送到 GitHub 或任何基于 git 的开发平台时,它们将自动对用户可用。(我提供了指向该文件的原始版本的链接,以便他们可以轻松地访问它。)
### uMatrix

*uMatrix 的用户界面,显示当前访问过的网页的当前规则。*
Jeremy Garcia 在他发表在 Opensource.com 的[文章](https://opensource.com/article/18/5/firefox-extensions)中提到了一个优秀的拦截器 uBlock Origin。我想提请大家关注另一个由 [gorhill](https://addons.mozilla.org/en-US/firefox/user/gorhill/) 开发的扩展插件: uMatrix 。
[uMatrix](https://addons.mozilla.org/en-US/firefox/addon/umatrix) 允许你为网页上的某些请求设置拦截规则,可以通过点击该加载项的弹出窗口来切换(在上面的屏幕截图中可以看到)。这些请求的区别在于脚本的类别、脚本发起的请求、cookies、CSS 规则、图像、媒体、帧,和被 uMatrix 标记为“other” 的其它内容。例如,你可以设置全局规则,以便在默认情况下允许所有请求,并将特定的请求添加到黑名单中(更方便的方法),或在默认情况下阻止所有内容,并手动将某些请求列入白名单(更安全的方法)。如果你一直在使用 NoScript 或 RequestPolicy,你可以从它们 [导入](https://github.com/gorhill/uMatrix/wiki/FAQ) 你的白名单规则。
另外 uMatrix 支持 [hosts 文件](https://en.wikipedia.org/wiki/Hosts_(file)),可用于阻止来自某些域的请求。不要与 uBlock Origin 所使用的筛选列表混淆,它使用的语法同 Adblock Plus 一样。默认情况下,uMatrix 会通过几个 hosts 文件阻止已知的分发广告、跟踪器和恶意软件的服务器,如果需要,你可以添加更多外部数据源。
那么你将选择哪一个:uBlock Origin 或 uMatrix ?就个人而言,我在电脑上两个都用,而只在安卓手机上用 uMatrix 。[据 gorhill 所说](https://github.com/gorhill/uMatrix/issues/32#issuecomment-61372436),两者之间存在某种重叠,但它们有不同的目标用户和目地。如果你想要的只是阻止跟踪器和广告的简单方法,uBlock Origine 是更好的选择;另一方面,如果你希望对网页在浏览器中可以执行或不能执行的操作进行精细的控制,即使需要一些时间来进行配置,并且可能会阻止某些网站如预期的工作,uMatrix 也是更好的选择。
### 结论
目前,这些是 Firefox 里我最喜欢的扩展。Tridactyl 通过依靠键盘和与外部程序交互,加快了浏览导航速度;Open With 能让我用鼠标在另外一个程序中打开页面;Stylus 是全面的用户样式管理器,对用户和开发人员都很有吸引力;uMatrix 本质上是 Firefox 的防火墙,可以用于过滤未知的请求。
尽管我基本上只是讨论了这些加载项的好处,但没有一个软件是完美的。如果你喜欢它们中的任何一个,并认为它们的某些方面可以改进,我建议你去它们的 Github 页面,并查看它们的贡献指南。通常情况下,自由开源软件的开发人员是欢迎错误报告和提交请求的。告诉你的朋友或道谢也是帮助开发者的好方法,特别是如果这些开发者是在业余时间从事他们的项目的话。
---
via: <https://opensource.com/article/18/6/firefox-open-source-extensions>
作者:[Zsolt Szakács](https://opensource.com/users/zsolt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lixinyuxx](https://github.com/lixinyuxx) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,463 | 红宝石(Ruby)史话 | https://twobithistory.org/2017/11/19/the-ruby-story.html | 2019-01-21T11:35:00 | [
"Ruby",
"Rails",
"RoR"
] | https://linux.cn/article-10463-1.html | 
尽管我很难说清楚为什么,但 Ruby 一直是我最喜爱的一门编程语言。如果用音乐来类比的话,Python 给我的感觉像是<ruby> 朋克摇滚 <rt> punk rock </rt></ruby>,简单、直接,但略显单调,而 Ruby 则像是爵士乐,从根本上赋予了程序员表达自我的自由,虽然这可能会让代码变复杂,编写出来的程序对其他人来说不直观。
Ruby 社区一直将<ruby> 灵活表达 <rt> freedom of expression </rt></ruby>视为其核心价值。可我不认同这对于 Ruby 的开发和普及是最重要的。创建一门编程语言也许是为了更高的性能,也许是为了在抽象上节省更多的时间,可 Ruby 就有趣在它并不关心这些,从它诞生之初,它的目标就是让程序员更快乐。
### 松本·行弘
<ruby> 松本·行弘 <rt> Yukihiro Matsumoto </rt></ruby>,亦称为 “Matz”,于 1990 年毕业于筑波大学。筑波是东京东北方向上的一个小城市,是科学研究与技术开发的中心之一。筑波大学以其 STEM 计划广为流传。松本·行弘在筑波大学的信息科学专业学习过,且专攻编程语言。他也在 Ikuo Nakata 的编程语言实验室工作过。(LCTT 译注:STEM 是<ruby> 科学 <rt> Science </rt></ruby>、<ruby> 技术 <rt> Technology </rt></ruby>、<ruby> 工程 <rt> Engineering </rt></ruby>、<ruby> 数学 <rt> Mathematics </rt></ruby>四门学科英文首字母的缩写。)
松本从 1993 年开始制作 Ruby,那时他才刚毕业几年。他制作 Ruby 的起因是觉得那时的脚本语言缺乏一些特性。他在使用 Perl 的时候觉得这门语言过于“玩具”,此外 Python 也有点弱,用他自己的话说:
>
> 我那时就知道 Python 了,但我不喜欢它,因为我认为它不是一门真正的面向对象的语言。面向对象就像是 Python 的一个附件。作为一个编程语言狂热者,我在 15 年里一直是面向对象的忠实粉丝。我真的想要一门生来就面向对象而且易用的脚本语言。我为此特地寻找过,可事实并不如愿。<sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup>
>
>
>
所以一种解释松本创造 Ruby 的动机就是他想要创造一门更好,且面向对象的 Perl。
但在其他场合,松本说他创造 Ruby 主要是为了让他自己和别人更快乐。2008 年,松本在谷歌技术讲座结束时放映了这张幻灯片:

他对听众说到,
>
> 我希望 Ruby 能帮助世界上的每一个程序员更有效率地工作,享受编程并感到快乐。这也是制作 Ruby 语言的主要意图。<sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup>
>
>
>
松本开玩笑的说他制作 Ruby 的原因很自私,因为他觉得其它的语言乏味,所以需要创造一点让自己开心的东西。
这张幻灯片展现了松本谦虚的一面。其实,松本是一位摩门教践行者,因此我很好奇他传奇般的友善有多少归功于他的宗教信仰。无论如何,他的友善在 Ruby 社区广为流传,甚至有一条称为 MINASWAN 的原则,即“<ruby> 松本人很好,我们也一样 <rt> Matz Is Nice And So We Are Nice </rt></ruby>”。我想那张幻灯片一定震惊了来自 Google 的观众。我想谷歌技术讲座上的每张幻灯片都充满着代码和运行效率的指标,来说明一个方案比另一个更快更有效,可仅仅放映崇高的目标的幻灯片却寥寥无几。
Ruby 主要受到 Perl 的影响。Perl 则是由 Larry Wall 于 20 世纪 80 年代晚期创造的语言,主要用于处理和转换基于文本的数据。Perl 因其文本处理和正则表达式而闻名于世。对于 Ruby 程序员,Perl 程序中的很多语法元素都不陌生,例如符号 `$`、符号 `@`、`elsif` 等等。虽然我觉得,这些不是 Ruby 应该具有的特征。除了这些符号外,Ruby 还借鉴了 Perl 中的正则表达式的处理和标准库。
但影响了 Ruby 的不仅仅只有 Perl 。在 Ruby 之前,松本制作过一个仅用 Emacs Lisp 编写的邮件客户端。这一经历让他对 Emacs 和 Lisp 语言运行的内部原理有了更多的认识。松本说 Ruby 底层的对象模型也受其启发。在那之上,松本添加了一个 Smalltalk 风格的信息传递系统,这一系统随后成为了 Ruby 中任何依赖 `#method_missing` 的操作的基石。松本也表示过 Ada 和 Eiffel 也影响了 Ruby 的设计。
当时间来到了给这门新语言命名的时候,松本和他的同事 Keiju Ishitsuka 挑选了很多个名字。他们希望名字能够体现新语言和 Perl、shell 脚本间的联系。在[这一段非常值得一读的即时消息记录](http://blade.nagaokaut.ac.jp/cgi-bin/scat.rb/ruby/ruby-talk/88819)中,Ishitsuka 和 松本也许花了太多的时间来思考 <ruby> shell <rt> 贝壳 </rt></ruby>、<ruby> clam <rt> 蛤蛎 </rt></ruby>、<ruby> oyster <rt> 牡蛎 </rt></ruby>和<ruby> pearl <rt> 珍珠 </rt></ruby>之间的关系了,以至于差点把 Ruby 命名为“<ruby> Coral <rt> 珊瑚虫 </rt></ruby>”或“<ruby> Bisque <rt> 贝类浓汤 </rt></ruby>”。幸好,他们决定使用 Ruby,因为它就像 pearl 一样,是一种珍贵的宝石。此外,<ruby> Ruby <rt> 红宝石 </rt></ruby> 还是 7 月的生辰石,而 <ruby> Pearl <rt> 珍珠 </rt></ruby> 则是 6 月的生辰石,采用了类似 C++ 和 C# 的隐喻,暗示着她们是改进自前辈的编程语言。(LCTT 译注:Perl 和 Pearl 发音相同,所以也常以“珍珠”来借喻 Perl;shell 是操作系统提供的用户界面,这里指的是命令行界面;更多有关生辰石的[信息](https://zh.wikipedia.org/zh-hans/%E8%AA%95%E7%94%9F%E7%9F%B3)。)
### Ruby 西渐
Ruby 在日本的普及很快。1995 年 Ruby 刚刚发布后不久后,松本就被一家名为 Netlab 的日本软件咨询财团(全名 Network Applied Communication Laboratory)雇用,并全职为 Ruby 工作。到 2000 年时,在 Ruby 发布仅仅 5 年后,Ruby 在日本的流行度就超过了 Python。可这时的 Ruby 才刚刚进入英语国家。虽然从 Ruby 的诞生之初就存在讨论它的日语邮件列表,但是英语的邮件列表直到 1998 年才建立起来。起初,在英语的邮件列表中交流的大多是日本的 Ruby 狂热者,可随着 Ruby 在西方的逐渐普及而得以改变。
在 2000 年,Dave Thomas 出版了第一本涵盖 Ruby 的英文书籍《Programming Ruby》。因为它的封面上画着一把锄头,所以这本书也被称为锄头书。这是第一次向身处西方的程序员们介绍了 Ruby。就像在日本那样,Ruby 的普及很快,到 2002 年时,英语的 Ruby 邮件列表的通信量就超过了日语邮件列表。
时间来到了 2005 年,Ruby 更流行了,但它仍然不是主流的编程语言。然而,Ruby on Rails 的发布让一切都不一样了。Ruby on Rails 是 Ruby 的“杀手级应用”,没有别的什么项目能比它更推动 Ruby 的普及了。在 Ruby on Rails 发布后,人们对 Ruby 的兴趣爆发式的增长,看看 TIOBE 监测的语言排行:

有时人们开玩笑的说,Ruby 程序全是基于 Ruby-on-Rails 的网站。虽然这听起来就像是 Ruby on Rails 占领了整个 Ruby 社区,但在一定程度上,这是事实。因为编写 Rails 应用时使用的语言正是 Ruby。Rails 欠 Ruby 的和 Ruby 欠 Rails 的一样多。
Ruby 的设计哲学也深深地影响了 Rails 的设计与开发。Rails 之父 David Heinemeier Hansson 常常提起他第一次与 Ruby 的接触的情形,那简直就是一次传教。他说,那种经历简直太有感召力了,让他感受到要为松本的杰作(指 Ruby)“传教”的使命。<sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup> 对于 Hansson 来说,Ruby 的灵活性简直就是对 Python 或 Java 语言中自上而下的设计哲学的反抗。他很欣赏 Ruby 这门能够信任自己的语言,Ruby 赋予了他自由选择<ruby> 程序表达方式 <rt> express his programs </rt></ruby>的权力。
就像松本那样,Hansson 声称他创造 Rails 时因为对现状的不满并想让自己能更开心。他也认同让程序员更快乐高于一切的观点,所以检验 Rails 是否需要添加一项新特性的标准是“<ruby> 更灿烂的笑容标准 <rt> The Principle of The Bigger Smile </rt></ruby>”。什么功能能让 Hansson 更开心就给 Rails 添加什么。因此,Rails 中包括了很多非正统的功能,例如 “Inflector” 类和 `Time` 扩展(“Inflector”类试图将单个类的名字映射到多个数据库表的名字;`Time` 扩展允许程序员使用 `2.days.ago` 这样的表达式)。可能会有人觉得这些功能太奇怪了,但 Rails 的成功表明它的确能让很多人的生活得更快乐。
因此,虽然 Rails 的火热带动了 Ruby 的普及看起来是一个偶然,但事实上 Rails 体现了 Ruby 的很多核心准则。此外,很难看到使用其他语言开发的 Rails,正是因为 Rails 的实现依赖于 Ruby 中<ruby> 类似于宏的类方法调用 <rt> macro-like class method calls </rt></ruby>来实现模型关联这样的功能。一些人认为这么多的 Ruby 开发需要基于 Ruby on Rails 是 Ruby 生态不健康的表现,但 Ruby 和 Ruby on Rails 结合的如此紧密并不是没有道理的。
### Ruby 之未来
人们似乎对 Ruby(及 Ruby on Rails)是否正在消亡有着异常的兴趣。早在 2011 年,Stack Overflow 和 Quora 上就充斥着程序员在咨询“如果几年后不再使用 Ruby 那么现在是否有必要学它”的话题。这些担忧对 Ruby 并非没有道理,根据 TIOBE 指数和 Stack Overflow 趋势,Ruby 和 Ruby on Rails 的人气一直在萎缩,虽然它也曾是热门新事物,但在更新更热的框架面前它已经黯然失色。
一种解释这种趋势的理论是程序员们正在舍弃动态类型的语言转而选择静态类型的。TIOBE 指数的趋势中可以看出对软件质量的需求在上升,这意味着出现在运行时的异常变得难以接受。他们引用 TypeScript 来说明这一趋势,TypeScript 是 JavaScript 的全新版本,而创造它的目的正是为了保证客户端运行的代码能受益于编译所提供的安全保障。
我认为另一个更可能的原因是比起 Ruby on Rails 推出的时候,现在存在着更多有竞争力的框架。2005 年它刚刚发布的时候,还没有那么多用于创建 Web 程序的框架,其主要的替代者还是 Java。可在今天,你可以使用为 Go、Javascript 或者 Python 开发的各种优秀的框架,而这还仅仅是主流的选择。Web 的世界似乎正走向更加分布式的结构,与其使用一块代码来完成从数据库读取到页面渲染所有事务,不如将事务拆分到多个组件,其中每个组件专注于一项事务并将其做到最好。在这种趋势下,Rails 相较于那些专攻于 JavaScript 前端通信的 JSON API 就显得过于宽泛和臃肿。
总而言之,我们有理由对 Ruby 的未来持乐观态度。因为不管是 Ruby 还是 Rails 的开发都还很活跃。松本和其他的贡献者们都在努力开发 Ruby 的第三个主要版本。新的版本将比现在的版本快上 3 倍,以减轻制约着 Ruby 发展的性能问题。虽然从 2005 年起,越来越多的 Web 框架被开发出来,但这并不意味着 Ruby on Rails 就失去了其生存空间。Rails 是一个富有大量功能的成熟的工具,对于一些特定类型的应用开发一直是非常好的选择。
但就算 Ruby 和 Rails 走上了消亡的道路,Ruby 让程序员更快乐的信条一定会存活下来。Ruby 已经深远的影响了许多新的编程语言的设计,这些语言的设计中能够看到来自 Ruby 的很多理念。而其他的新生语言则试着变成 Ruby 更现代的实现,例如 Elixir 是一个强调函数式编程范例的语言,仍在开发中的 Crystal 目标是成为使用静态类型的 Ruby 。世界上许多程序员都喜欢上了 Ruby 及其语法,因此它的影响必将会在未来持续很长一段时间。
喜欢这篇文章吗?这里每两周都会发表一篇这样的文章。请在推特上关注我们 [@TwoBitHistory](https://twitter.com/TwoBitHistory) 或者订阅我们的 [RSS](https://twobithistory.org/feed.xml),这样新文章发布的第一时间你就能得到通知。
---
1. <http://ruby-doc.org/docs/ruby-doc-bundle/FAQ/FAQ.html> [↩](#fnref1)
2. <https://www.youtube.com/watch?v=oEkJvvGEtB4?t=30m55s> [↩](#fnref2)
3. <http://rubyonrails.org/doctrine/>
---
via: <https://twobithistory.org/2017/11/19/the-ruby-story.html>
作者:[Two-Bit History](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wwhio](https://github.com/wwhio) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Ruby has always been one of my favorite languages, though I’ve sometimes found it hard to express why that is. The best I’ve been able to do is this musical analogy: Whereas Python feels to me like punk rock—it’s simple, predictable, but rigid—Ruby feels like jazz. Ruby gives programmers a radical freedom to express themselves, though that comes at the cost of added complexity and can lead to programmers writing programs that don’t make immediate sense to other people.
I’ve always been aware that freedom of expression is a core value of the Ruby community. But what I didn’t appreciate is how deeply important it was to the development and popularization of Ruby in the first place. One might create a programming lanugage in pursuit of better peformance, or perhaps timesaving abstractions—the Ruby story is interesting because instead the goal was, from the very beginning, nothing more or less than the happiness of the programmer.
## Yukihiro Matsumoto
Yukihiro Matsumoto, also known as “Matz,” graduated from the University of Tsukuba in 1990. Tsukuba is a small town just northeast of Tokyo, known as a center for scientific research and technological devlopment. The University of Tsukuba is particularly well-regarded for its STEM programs. Matsumoto studied Information Science, with a focus on programming languages. For a time he worked in a programming language lab run by Ikuo Nakata.
Matsumoto started working on Ruby in 1993, only a few years after graduating. He began working on Ruby because he was looking for a scripting language with features that no existing scripting language could provide. He was using Perl at the time, but felt that it was too much of a “toy language.” Python also fell short; in his own words:
I knew Python then. But I didn’t like it, because I didn’t think it was a true object-oriented language—OO features appeared to be an add-on to the language. As a language maniac and OO fan for 15 years, I really wanted a genuine object-oriented, easy-to-use scripting language. I looked for one, but couldn’t find one.
[1]
So one way of understanding Matsumoto’s motivations in creating Ruby is that he was trying to create a better, object-oriented version of Perl.
But at other times, Matsumoto has said that his primary motivation in creating Ruby was simply to make himself and others happier. Toward the end of a Google tech talk that Matsumoto gave in 2008, he showed the following slide:
He told his audience,
I hope to see Ruby help every programmer in the world to be productive, and to enjoy programming, and to be happy. That is the primary purpose of the Ruby language.
[2]
Matsumoto goes on to joke that he created Ruby for selfish reasons, because he was so underwhelmed by other languages that he just wanted to create something that would make him happy.
The slide epitomizes Matsumoto’s humble style. Matsumoto, it turns out, is a practicing Mormon, and I’ve wondered whether his religious commitments have any bearing on his legendary kindness. In any case, this kindness is so well known that the Ruby community has a principle known as MINASWAN, or “Matz Is Nice And So We Are Nice.” The slide must have struck the audience at Google as an unusual one—I imagine that any random slide drawn from a Google tech talk is dense with code samples and metrics showing how one engineering solution is faster or more efficient than another. Few, I suspect, come close to stating nobler goals more simply.
Ruby was influenced primarily by Perl. Perl was created by Larry Wall in the
late 1980s as a means of processing and transforming text-based reports. It
became well-known for its text processing and regular expression capabilities.
A Perl program contains many syntactic elements that would be familiar to a
Ruby programmer—there are `$`
signs, `@`
signs, and even `elsif`
s, which I’d
always thought were one of Ruby’s less felicitous idiosyncracies. On a deeper
level, Ruby borrows much of Perl’s regular expression handling and standard
library.
But Perl was by no means the only influence on Ruby. Prior to beginning work on
Ruby, Matsumoto worked on a mail client written entirely in Emacs Lisp. The
experience taught him a lot about the inner workings of Emacs and the Lisp
language, which Matsumoto has said influenced the underlying object model of
Ruby. On top of that he added a Smalltalk-style messsage passing system which
forms the basis for any behavior relying on Ruby’s `#method_missing`
. Matsumoto
has also claimed Ada and Eiffel as influences on Ruby.
When it came time to decide on a name for Ruby, Matsumoto and a colleague,
Keiju Ishitsuka, considered several alternatives. They were looking for
something that suggested Ruby’s relationship to Perl and also to shell
scripting. In an [instant message
exchange](http://blade.nagaokaut.ac.jp/cgi-bin/scat.rb/ruby/ruby-talk/88819)
that is well-worth reading, Ishitsuka and Matsumoto probably spend too much
time thinking about the relationship between shells, clams, oysters, and
pearls and get close to calling the Ruby language “Coral” or “Bisque” instead.
Thankfully, they decided to go with “Ruby”, the idea being that it was, like
“pearl”, the name of a valuable jewel. It also turns out that the birthstone
for June is a pearl while the birthstone for July is a ruby, meaning that the
name “Ruby” is another tongue-in-cheek “incremental improvement” name like C++
or C#.
## Ruby Goes West
Ruby grew popular in Japan very quickly. Soon after its initial release in 1995, Matz was hired by a Japanese software consulting group called Netlab (also known as Network Applied Communication Laboratory) to work on Ruby full-time. By 2000, only five years after it was initially released, Ruby was more popular in Japan than Python. But it was only just beginning to make its way to English-speaking countries. There had been a Japanese-language mailing list for Ruby discussion since almost the very beginning of Ruby’s existence, but the English-language mailing list wasn’t started until 1998. Initially, the English-language mailing list was used by Japanese Rubyists writing in English, but this gradually changed as awareness of Ruby grew.
In 2000, Dave Thomas published *Programming Ruby*, the first English-language
book to cover Ruby. The book became known as the “pickaxe” book for the pickaxe
it featured on its cover. It introduced Ruby to many programmers in the West
for the first time. Like it had in Japan, Ruby spread quickly, and by 2002 the
English-language Ruby mailing list had more traffic than the original
Japanese-language mailing list.
By 2005, Ruby had become more popular, but it was still not a mainstream programming language. That changed with the release of Ruby on Rails. Ruby on Rails was the “killer app” for Ruby, and it did more than any other project to popularize Ruby. After the release of Ruby on Rails, interest in Ruby shot up across the board, as measured by the TIOBE language index:
It’s sometimes joked that the only programs anybody writes in Ruby are Ruby-on-Rails web applications. That makes it sound as if Ruby on Rails completely took over the Ruby community, which is only partly true. While Ruby has certainly come to be known as that language people write Rails apps in, Rails owes as much to Ruby as Ruby owes to Rails.
The Ruby philosophy heavily informed the design and implementation of Rails.
David Heinemeier Hansson, who created Rails, often talks about how his first
contact with Ruby was an almost religious experience. He has said that the
encounter was so transformative that it “imbued him with a calling to do
missionary work in service of Matz’s creation.” 3 For Hansson, Ruby’s
no-shackles approach was a politically courageous rebellion against the
top-down impositions made by languages like Python and Java. He appreciated
that the language trusted him and empowered him to make his own judgements
about how best to express his programs.
Like Matsumoto, Hansson claims that he created Rails out of a frustration with
the status quo and a desire to make things better for himself. He, like
Matsumoto, prioritized programmer happiness above all else, evaluating
additions to Rails by what he calls “The Principle of The Bigger Smile.”
Whatever made Hansson smile more was what made it into the Rails codebase.
As a result, Rails would come to include unorthodox features like the
“Inflector” class (which tries to map singular class names to plural database
table names automatically) and Rails’ `Time`
extensions (allowing programmers
to write cute expressions like `2.days.ago`
). To some, these features were
truly weird, but the success of Rails is testament to the number of people who
found it made their lives much easier.
And so, while it might seem that Rails was an incidental application of Ruby that happened to become extremely popular, Rails in fact embodies many of Ruby’s core principles. Futhermore, it’s hard to see how Rails could have been built in any other language, given its dependence on Ruby’s macro-like class method calls to implement things like model associations. Some people might take the fact that so much of Ruby development revolves around Ruby on Rails as a sign of an unhealthy ecosystem, but there are good reasons that Ruby and Ruby on Rails are so intertwined.
## The Future of Ruby
People seem to have an inordinate amount of interest in whether or not Ruby (and Ruby on Rails) are dying. Since as early as 2011, it seems that Stack Overflow and Quora have been full of programmers asking whether or not they should bother learning Ruby if it will no longer be around in the next few years. These concerns are not unjustified; according to the TIOBE index and to Stack Overflow trends, Ruby and Ruby on Rails have been shrinking in popularity. Though Ruby on Rails was once the hot new thing, it has since been eclipsed by hotter and newer frameworks.
One theory for why this has happened is that programmers are abandoning dynamically typed languages for statically typed ones. Analysts at TIOBE index figure that a rise in quality requirements have made runtime exceptions increasingly unacceptable. They cite TypeScript as an example of this trend—a whole new version of JavaScript was created just to ensure that client-side code could be written with the benefit of compile-time safety guarantees.
A more likely answer, I think, is just that Ruby on Rails now has many more competitors than it once did. When Rails was first introduced in 2005, there weren’t that many ways to create web applications—the main alternative was Java. Today, you can create web applications using great frameworks built for Go, JavaScript, or Python, to name only the most popular options. The web world also seems to be moving toward a more distributed architecture for applications, meaning that, rather than having one codebase responsible for everything from database access to view rendering, responsibilites are split between different components that focus on doing one thing well. Rails feels overbroad and bloated for something as focused as a JSON API that talks to a JavaScript frontend.
All that said, there are reasons to be optimistic about Ruby’s future. Both Rails and Ruby continue to be actively developed. Matsumoto and others are working hard on Ruby’s third major release, which they aim to make three times faster than the existing version of Ruby, possibly alleviating the performance concerns that have always dogged Ruby. And even if the world of web frameworks has become more diverse since 2005, that doesn’t mean that there won’t always be room for Ruby on Rails. It is now a mature tool with an enormous amount of built-in power that will always be a good choice for certain kinds of applications.
But even if Ruby and Rails go the way of the dinosaurs, one thing that seems certain to survive is the Ruby ethos of programmer happiness. Ruby has had a profound influence on the design of many new programming languages, which have adopted many of its best ideas. Other new lanuages have tried to be “more modern” interpretations of Ruby: Elixir, for example, is a version of Ruby that emphasizes the functional programming paradigm, while Crystal, which is still in development, aims to be a statically typed version of Ruby. Many programmers around the world have fallen in love with Ruby and its syntax, so we can count on its influence persisting for a long while to come.
*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
* |
10,464 | 如何从命令行同时移动多种文件类型 | https://www.ostechnix.com/how-to-move-multiple-file-types-simultaneously-from-commandline/ | 2019-01-21T22:44:00 | [
"文件",
"移动"
] | https://linux.cn/article-10464-1.html | 
前几天,我想知道如何将多个文件类型从一个目录移动(不复制)到另一个目录。我已经知道如何[查找并将某些类型的文件从一个目录复制到另一个目录](https://www.ostechnix.com/find-copy-certain-type-files-one-directory-another-linux/)。但是,我不知道如何同时移动多种文件类型。如果你曾遇到这样的情况,我知道在类 Unix 系统中从命令行执行该操作的一个简单方法。
### 同时移动多种文件类型
想象一下这种场景,你在名为 `dir1` 的目录中有多种类型的文件,例如 .pdf、 .doc、 .mp3、 .mp4、 .txt 等等。我们来看看 `dir1` 的内容:
```
$ ls dir1
file.txt image.jpg mydoc.doc personal.pdf song.mp3 video.mp4
```
你希望将某些文件类型(不是所有文件类型)移动到另一个位置。例如,假设你想将 .doc、 .pdf 和 .txt 文件一次性移动到名为 `dir2` 的另一个目录中。
要同时将 .doc、 .pdf 和 .txt 文件从 `dir1` 移动到 `dir2`,命令是:
```
$ mv dir1/*.{doc,pdf,txt} dir2/
```
很容易,不是吗?
现在让我们来查看一下 `dir2` 的内容:
```
$ ls dir2/
file.txt mydoc.doc personal.pdf
```
看到了吗?只有 .doc、 .pdf 和 .txt 从 `dir1` 移到了 `dir2`。

在上面的命令中,你可以在花括号内添加任意数量的文件类型,以将它们移动到不同的目录中。它在 Bash 上非常适合我。
另一种移动多种文件类型的方法是转到源目录,在我们的例子中即为 `dir1`:
```
$ cd ~/dir1
```
将你选择的文件类型移动到目的地(即 `dir2`),如下所示:
```
$ mv *.doc *.txt *.pdf /home/sk/dir2/
```
要移动具有特定扩展名的所有文件,例如 .doc,运行:
```
$ mv dir1/*.doc dir2/
```
更多细节,参考 man 页:
```
$ man mv
```
移动一些相同或不同的文件类型很容易!你可以在 GUI 模式下单击几下鼠标,或在 CLI 模式下使用一行命令来完成。但是,如果目录中有数千种不同的文件类型,并且希望一次将多种文件类型移动到不同的目录,这将是一项繁琐的任务。对我来说,上面的方法很容易完成工作!如果你知道任何其它一行命令可以一次移动多种文件类型,请在下面的评论部分与我们分享。我会核对并更新指南。
这些就是全部了,希望这很有用。更多好东西将要来了,敬请关注!
共勉!
---
via: <https://www.ostechnix.com/how-to-move-multiple-file-types-simultaneously-from-commandline/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,465 | Linux 工具:点的含义 | https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot | 2019-01-22T00:02:00 | [
"shell",
"bash"
] | https://linux.cn/article-10465-1.html |
>
> Paul Brown 解释了 Linux shell 命令中那个不起眼的“点”的各种意思和用法。
>
>
>

在现实情况中,使用 shell 命令编写的单行命令或脚本可能会令人很困惑。你使用的很多工具的名称与它们的实际功能相差甚远(`grep`、`tee` 和 `awk`,还有吗?),而当你将两个或更多个组合起来时,所组成的 “句子” 看起来更像某种外星人的天书。
因此,上面说的这些对于你并无帮助,因为你用来编写一连串的指令所使用的符号根据你使用的场景有着不同的意义。
### 位置、位置、位置
就拿这个不起眼的点(`.`)来说吧。当它放在一个需要一个目录名称的命令的参数处时,表示“当前目录”:
```
find . -name "*.jpg"
```
意思就是“在当前目录(包括子目录)中寻找以 `.jpg` 结尾的文件”。
`ls .` 和 `cd .` 结果也如你想的那样,它们分别列举和“进入”到当前目录,虽然在这两种情况下这个点都是多余的。
而一个紧接着另一个的两个点呢,在同样的场景下(即当你的命令期望一个文件目录的时候)表示“当前目录的父目录”。如果你当前在 `/home/your_directory` 下并且运行:
```
cd ..
```
你就会进入到 `/home`。所以,你可能认为这仍然适合“点代表附近目录”的叙述,并且毫不复杂,对吧?
那下面这样会怎样呢?如果你在一个文件或目录的开头加上点,它表示这个文件或目录会被隐藏:
```
$ touch somedir/file01.txt somedir/file02.txt somedir/.secretfile.txt
$ ls -l somedir/
total 0
-rw-r--r-- 1 paul paul 0 Jan 13 19:57 file01.txt
-rw-r--r-- 1 paul paul 0 Jan 13 19:57 file02.txt
$ # 注意上面列举的文件中没有 .secretfile.txt
$ ls -la somedir/
total 8
drwxr-xr-x 2 paul paul 4096 Jan 13 19:57 .
drwx------ 48 paul paul 4096 Jan 13 19:57 ..
-rw-r--r-- 1 paul paul 0 Jan 13 19:57 file01.txt
-rw-r--r-- 1 paul paul 0 Jan 13 19:57 file02.txt
-rw-r--r-- 1 paul paul 0 Jan 13 19:57 .secretfile.txt
$ # 这个 -a 选项告诉 ls 去展示“all”文件,包括那些隐藏的
```
然后就是你可以将 `.` 当作命令。是的,你听我说:`.` 是个真真正正的命令。它是 `source` 命令的代名词,所以你可以用它在当前 shell 中执行一个文件,而不是以某种其它的方式去运行一个脚本文件(这通常指的是 Bash 会产生一个新的 shell 去运行它)
很困惑?别担心 —— 试试这个:创建一个名为 `myscript` 的脚本,内容包含下面一行:
```
myvar="Hello"
```
然后通过常规的方法执行它,也就是用 `sh myscript`(或者通过 `chmod a+x myscript` 命令让它可执行,然后运行 `./myscript`)。现在尝试并且观察 `myvar` 的内容,通过 `echo $myvar`(理所当然你什么也得不到)。那是因为,当你的脚本赋值 `"Hello"` 给 `myvar` 时,它是在一个隔离的bash shell 实例中进行的。当脚本运行结束时,这个新产生的实例会消失并且将控制权转交给原来的shell,而原来的 shell 里甚至都不存在 `myvar` 变量。
然而,如果你这样运行 `myscript`:
```
. myscript
```
`echo $myvar` 就会打印 `Hello` 到命令行上。
当你的 `.bashrc` 文件发生变化后,你经常会用到 `.`(或 `source`)命令,[就像当你要扩展 `PATH` 变量那样](https://www.linux.com/blog/learn/2018/12/bash-variables-environmental-and-otherwise)。在你的当前 shell 实例中,你可以使用 `.` 来让变化立即生效。
### 双重麻烦
就像看似无关紧要的一个点有多个含义一样,两个点也是如此。除了指向当前目录的父级之外,两个点(`..`)也用于构建序列。
尝试下这个:
```
echo {1..10}
```
它会打印出从 1 到 10 的序列。在这种场景下,`..` 表示 “从左边的值开始,计数到右边的值”。
现在试下这个:
```
echo {1..10..2}
```
你会得到 `1 3 5 7 9`。`..2` 这部分命令告诉 Bash 输出这个序列,不过不是每个相差 1,而是相差 2。换句话说,就是你会得到从 1 到 10 之间的奇数。
它反着也仍然有效:
```
echo {10..1..2}
```
你也可以用多个 0 填充你的数字。这样:
```
echo {000..121..2}
```
会这样打印出从 0 到 121 之间的偶数(填充了前置 0):
```
000 002 004 006 ... 050 052 054 ... 116 118 120
```
不过这样的序列发生器有啥用呢?当然,假设您的新年决心之一是更加谨慎控制您的帐户花销。作为决心的一部分,您需要创建目录,以便对过去 10 年的数字发票进行分类:
```
mkdir {2009..2019}_Invoices
```
工作完成。
或者你可能有数百个带编号的文件,比如从视频剪辑中提取的帧,或许因为某种原因,你只想从第 43 帧到第 61 帧每隔三帧删除一帧:
```
rm frame_{043..61..3}
```
很可能,如果你有超过 100 个帧,它们将以填充 0 命名,如下所示:
```
frame_000 frame_001 frame_002 ...
```
那就是为什么你在命令中要用 `043`,而不是`43` 的原因。
### 花括号花招
说实话,序列的神奇之处不在于双点,而是花括号(`{}`)的巫术。看看它对于字母是如何工作的。这样做:
```
touch file_{a..z}.txt
```
它创建了从 `file_a.txt` 到 `file_z.txt` 的文件。
但是,你必须小心。使用像 `{Z..a}` 这样的序列将产生一大堆大写字母和小写字母之间的非字母、数字的字符(既不是数字或字母的字形)。其中一些字形是不可打印的或具有自己的特殊含义。使用它们来生成文件名称可能会导致一系列意外和可能令人不快的影响。
最后一件值得指出的事:包围在 `{...}` 的序列,它们也可以包含字符串列表:
```
touch {blahg,splurg,mmmf}_file.txt
```
将创建了 `blahg_file.txt`、`splurg_file.txt` 和 `mmmf_file.txt`。
当然,在别的场景中,大括号也有不同的含义(惊喜吗!)。不过那是别的文章的内容了。
### 总结
Bash 以及运行于其中的各种工具已经被寻求解决各种特定问题的系统管理员们把玩了数十年。要说这种有自己之道的系统管理员是一种特殊物种的话,那是有点轻描淡写。总而言之,与其他语言相反,Bash 的设计目标并不是为了用户友好、简单、甚至合乎逻辑。
但这并不意味着它不强大 —— 恰恰相反。Bash 的语法和 shell 工具可能不一致且很庞大,但它们也提供了一系列令人眼花缭乱的方法来完成您可能想象到的一切。就像有一个工具箱,你可以从中找到从电钻到勺子的所有东西,以及橡皮鸭、一卷胶带和一些指甲钳。
除了引人入胜之外,探明你可以直接在 shell 中达成的所有能力也很有趣,所以下次我们将深入探讨如何构建更大更好的 Bash 命令行。
在那之前,玩得开心!
---
via: <https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[asche910](https://github.com/asche910) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,466 | 用 rcm 管理隐藏文件 | https://fedoramagazine.org/managing-dotfiles-rcm/ | 2019-01-22T10:46:23 | [
"配置文件",
"隐藏文件"
] | https://linux.cn/article-10466-1.html | 
许多 GNU/Linux 程序的一个特点是有个易于编辑的配置文件。几乎所有常见的自由软件都将配置设置保存在纯文本文件中,通常采用结构化格式,如 JSON、YAML 或[“类似 ini”](https://en.wikipedia.org/wiki/INI_file) 的文件中。这些配置文件经常隐藏在用户的主目录中。但是,基本的 `ls` 不会显示它们。UNIX 标准要求以点开头的任何文件或目录名称都被视为“隐藏”,除非用户特意要求,否则不会列在目录列表中。例如,要使用 `ls` 列出所有文件,要传递 `-a` 选项。
随着时间的推移,这些配置文件会有很多定制配置,管理它们变得越来越具有挑战性。不仅如此,在多台计算机之间保持同步是大型组织所面临的共同挑战。最后,许多用户也对其独特的配置感到自豪,并希望以简单的方式与朋友分享。这就是用到 rcm 介入的地方。
rcm 是一个 “rc” 文件管理套件(“rc” 是命名配置文件的另一种约定,它已被某些 GNU/Linux 程序采用,如 `screen` 或 `bash`)。 rcm 提供了一套命令来管理和列出它跟踪的文件。使用 `dnf` 安装 rcm。
### 开始使用
默认情况下,rcm 使用 `~/.dotfiles` 来存储它管理的所有隐藏文件。一个被管理的隐藏文件实际保存在 `~/.dotfiles` 目录中,而它的符号链接会放在文件原本的位置。例如,如果 `~/.bashrc` 由 rcm 所管理,那么详细列表将如下所示。
```
[link@localhost ~]$ ls -l ~/.bashrc
lrwxrwxrwx. 1 link link 27 Dec 16 05:19 .bashrc -> /home/link/.dotfiles/bashrc
[link@localhost ~]$
```
rcm 包含 4 个命令:
* `mkrc` – 将文件转换为由 rcm 管理的隐藏文件
* `lsrc` – 列出由 rcm 管理的文件
* `rcup` – 同步由 rcm 管理的隐藏文件
* `rcdn` – 删除 rcm 管理的所有符号链接
### 在两台计算机上共享 bashrc
如今用户在多台计算机上拥有 shell 帐户并不罕见。在这些计算机之间同步隐藏文件可能是一个挑战。这里将提供一种可能的解决方案,仅使用 rcm 和 git。
首先使用 `mkrc` 将文件转换成由 rcm 管理的文件。
```
[link@localhost ~]$ mkrc -v ~/.bashrc
Moving...
'/home/link/.bashrc' -> '/home/link/.dotfiles/bashrc'
Linking...
'/home/link/.dotfiles/bashrc' -> '/home/link/.bashrc'
[link@localhost ~]$
```
接下来使用 `lsrc` 验证列表是否正确。
```
[link@localhost ~]$ lsrc
/home/link/.bashrc:/home/link/.dotfiles/bashrc
[link@localhost ~]$
```
现在在 `~/.dotfiles` 中创建一个 git 仓库,并使用你选择的 git 仓库托管设置一个远程仓库。提交 `bashrc` 文件并推送一个新分支。
```
[link@localhost ~]$ cd ~/.dotfiles
[link@localhost .dotfiles]$ git init
Initialized empty Git repository in /home/link/.dotfiles/.git/
[link@localhost .dotfiles]$ git remote add origin [email protected]:linkdupont/dotfiles.git
[link@localhost .dotfiles]$ git add bashrc
[link@localhost .dotfiles]$ git commit -m "initial commit"
[master (root-commit) b54406b] initial commit
1 file changed, 15 insertions(+)
create mode 100644 bashrc
[link@localhost .dotfiles]$ git push -u origin master
...
[link@localhost .dotfiles]$
```
在第二台机器上,克隆这个仓库到 `~/.dotfiles` 中。
```
[link@remotehost ~]$ git clone [email protected]:linkdupont/dotfiles.git ~/.dotfiles
...
[link@remotehost ~]$
```
现在使用 `rcup` 更新受 rcm 管理的符号链接。
```
[link@remotehost ~]$ rcup -v
replacing identical but unlinked /home/link/.bashrc
removed '/home/link/.bashrc'
'/home/link/.dotfiles/bashrc' -> '/home/link/.bashrc'
[link@remotehost ~]$
```
覆盖现有的 `~/.bashrc`(如果存在)并重启 shell。
就是这些了!指定主机选项 (`-o`) 是对上面这种情况的有用补充。如往常一样,请阅读手册页。它们包含了很多示例命令。
---
via: <https://fedoramagazine.org/managing-dotfiles-rcm/>
作者:[Link Dupont](https://fedoramagazine.org/author/linkdupont/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A hallmark feature of many GNU/Linux programs is the easy-to-edit configuration file. Nearly all common free software programs store configuration settings inside a plain text file, often in a structured format like JSON, YAML or [“INI-like”](https://en.wikipedia.org/wiki/INI_file). These configuration files are frequently found hidden inside a user’s home directory. However, a basic *ls* won’t reveal them. UNIX standards require that any file or directory name that begins with a period (or “dot”) is considered “hidden” and will not be listed in directory listings unless requested by the user. For example, to list all files using the *ls* program, pass the *-a* command-line option.
Over time, these configuration files become highly customized, and managing them becomes increasingly more challenging as time goes on. Not only that, but keeping them synchronized between multiple computers is a common challenge in large organizations. Finally, many users find a sense of pride in their unique configuration settings and want an easy way to share them with friends. That’s where **rcm** steps in.
**rcm** is a “rc” file management suite (“rc” is another convention for naming configuration files that has been adopted by some GNU/Linux programs like screen or bash). **rcm** provides a suite of commands to manage and list files it tracks. Install **rcm** using **dnf**.
## Getting started
By default, **rcm** uses *~/.dotfiles* for storing all the dotfiles it manages. A managed dotfile is actually stored inside *~/.dotfiles*, and a symlink is placed in the expected file’s location. For example, if *~/.bashrc* is tracked by **rcm**, a long listing would look like this.
[link@localhost ~]$ ls -l ~/.bashrc lrwxrwxrwx. 1 link link 27 Dec 16 05:19 .bashrc -> /home/link/.dotfiles/bashrc [link@localhost ~]$
**rcm** consists of 4 commands:
*mkrc*– convert a file into a dotfile managed by rcm*lsrc*– list files managed by rcm*rcup*– synchronize dotfiles managed by rcm*rcdn*– remove all the symlinks managed by rcm
## Share bashrc across two computers
It is not uncommon today for a user to have shell accounts on more than one computer. Keeping dotfiles synchronized between those computers can be a challenge. This scenario will present one possible solution, using only **rcm** and **git**.
First, convert (or “bless”) a file into a dotfile managed by **rcm** with *mkrc*.
[link@localhost ~]$ mkrc -v ~/.bashrc Moving... '/home/link/.bashrc' -> '/home/link/.dotfiles/bashrc' Linking... '/home/link/.dotfiles/bashrc' -> '/home/link/.bashrc' [link@localhost ~]$
Next, verify the listings are correct with *lsrc*.
[link@localhost ~]$ lsrc /home/link/.bashrc:/home/link/.dotfiles/bashrc [link@localhost ~]$
Now create a git repository inside *~/.dotfiles* and set up an accessible remote repository using your choice of hosted git repositories. Commit the *bashrc* file and push a new branch.
[link@localhost ~]$ cd ~/.dotfiles [link@localhost .dotfiles]$ git init Initialized empty Git repository in /home/link/.dotfiles/.git/ [link@localhost .dotfiles]$ git remote add origin [email protected]:linkdupont/dotfiles.git [link@localhost .dotfiles]$ git add bashrc [link@localhost .dotfiles]$ git commit -m "initial commit" [master (root-commit) b54406b] initial commit 1 file changed, 15 insertions(+) create mode 100644 bashrc [link@localhost .dotfiles]$ git push -u origin master ... [link@localhost .dotfiles]$
On the second machine, clone this repository into *~/.dotfiles*.
[link@remotehost ~]$ git clone [email protected]:linkdupont/dotfiles.git ~/.dotfiles ... [link@remotehost ~]$
Now update the symlinks managed by **rcm** with *rcup*.
[link@remotehost ~]$ rcup -v replacing identical but unlinked /home/link/.bashrc removed '/home/link/.bashrc' '/home/link/.dotfiles/bashrc' -> '/home/link/.bashrc' [link@remotehost ~]$
Overwrite the existing *~/.bashrc *(if it exists) and restart the shell.
That’s it! The host-specific option (*-o*) is a useful addition to the scenario above. And as always, be sure to read the manpages; they contain a wealth of example commands.
## Leslie Satenstein
Very nice write up.
I have a desktop with multiple versions of Fedora (Gnome, KDE) and releases. I use a commen disk to store the configuration files. I go one step further and do likewise for /Documents, /Videos /Templates, /Music and other directories/ files I wish to share.
Is RCM suitable for sharing other than for files?
RCM is now on my Todo list. Thank you.
## Link Dupont
At its core,
rcmis a symlink manager. It’s not a file synchronization tool. It does very well at managing symlinks, but it won’t synchronize those files to other computers. You need to use a separate synchronization tool (rsync, syncthing, etc.) to keep files across computers in sync.## gt
my mc asm me about symlinks
every time when i edit it. how turn off this functions?
## Sascha Peilicke
The only drawback of this solution is that it isn’t self-hosting and depends on a distro package that might not be available everywhere. Instead I recommend using DFM (https://github.com/justone/dfm). It’s a single-file Perl script that works exactly the same as rcm but can be versioned right inside your dotfiles.git.
Example project: https://github.com/saschpe/dotfiles/blob/master/bin/dfm
I just clone that on any new machine and invoke dfm:
$ git clone github.com/saschpe/dotfiles .dotfiles
$ .dotfiles/bin/dfm install
It’s trivial, self-hosting and works on macOS as well.
## Link Dupont
True. I have only used it on Fedora (in full disclosure, I am the Fedora package maintainer), but the upstream project repository has a number of distributions listed. It’s trivial to install and version using GNU stow too; it uses the GNU autotools.
## aairey
You need to know some Perl though to dissect the script in case of issues.
Personally I just use a bash script for this.
## Adolfina
@Author:Thanks for the solution.
BTW It also works nicely for directories …
$ mkrc ~/.config/Clementine
[me@tower .dotfiles]$ lsrc
/home/me/.bashrc:/home/me/.dotfiles/bashrc
/home/me/.config/Clementine/Clementine.conf:/home/me/.dotfiles/config/Clementine/Clementine.conf
/home/me/.config/Clementine/clementine.db:/home/me/.dotfiles/config/Clementine/clementine.db
/home/me/.config/Clementine/clementine.db.bak:/home/me/.dotfiles/config/Clementine/clementine.db.bak
/home/me/.config/Clementine/jamendo.db:/home/me/.dotfiles/config/Clementine/jamendo.db
/home/me/.README.md:/home/me/.dotfiles/README.md
## aairey
Storing an sqlite in a git repository is not exactly “nice”,
## maweki
Is there any major difference to stow?
## Steve
rcm is not nearly as powerful as stow. |
10,467 | s-tui:在 Linux 中监控 CPU 温度、频率、功率和使用率的终端工具 | https://www.2daygeek.com/s-tui-stress-terminal-ui-monitor-linux-cpu-temperature-frequency/ | 2019-01-22T23:44:53 | [
"监控",
"压力测试"
] | https://linux.cn/article-10467-1.html | 
一般每个 Linux 管理员都会使用 [lm\_sensors 监控 CPU 温度](https://www.2daygeek.com/view-check-cpu-hard-disk-temperature-linux/)。lm\_sensors (Linux 监控传感器)是一个自由开源程序,它提供了监控温度、电压和风扇的驱动和工具。
如果你正在找替代的 CLI 工具,我会建议你尝试 s-tui。
它其实是一个压力测试的终端 UI,可以帮助管理员通过颜色查看 CPU 温度。
### s-tui 是什么
s-tui 是一个用于监控计算机的终端 UI。s-tui 可以在终端以图形方式监控 CPU 温度、频率、功率和使用率。此外,它还显示由发热量限制引起的性能下降,它需要很少的资源并且不需要 X 服务器。它是用 Python 编写的,需要 root 权限才能使用它。
s-tui 是一个独立的程序,可以开箱即用,并且不需要配置文件就可以使用其基本功能。
s-tui 使用 psutil 来探测你的一些硬件信息。如果不支持你的一些硬件,你可能看不到所有信息。
以 root 身份运行 s-tui 时,当压测所有 CPU 核心时,可以将 CPU 发挥到最大睿频频率。它在后台使用 Stress 压力测试工具,通过对系统施加某些类型的计算压力来检查其组件的温度是否超过其可接受的范围。只要计算机稳定并且其组件的温度不超过其可接受的范围,PC 超频就没问题。有几个程序可以通过压力测试得到系统的稳定性,从而评估超频水平。
### 如何在 Linux 中安装 s-tui
它是用 Python 写的,`pip` 是在 Linux 上安装 s-tui 的推荐方法。确保你在系统上安装了 python-pip 软件包。如果还没有,请使用以下命令进行安装。
对于 Debian/Ubuntu 用户,使用 [apt 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 或 [apt-get 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 `pip`。
```
$ sudo apt install python-pip stress
```
对于 Archlinux 用户,使用 [pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 `pip`。
```
$ sudo pacman -S python-pip stress
```
对于 Fedora 用户,使用 [dnf 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 `pip`。
```
$ sudo dnf install python-pip stress
```
对于 CentOS/RHEL 用户,使用 [yum 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 `pip`。
```
$ sudo yum install python-pip stress
```
对于 openSUSE 用户,使用 [zypper 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 `pip`。
```
$ sudo zypper install python-pip stress
```
最后运行下面的 [pip 命令](https://www.2daygeek.com/install-pip-manage-python-packages-linux/) 在 Linux 中安装 s-tui 工具。
对于 Python 2.x:
```
$ sudo pip install s-tui
```
对于Python 3.x:
```
$ sudo pip3 install s-tui
```
### 如何使用 s-tui
正如我在文章开头所说的那样。它需要 root 权限才能从系统获取所有信息。只需运行以下命令即可启动 s-tui。
```
$ sudo s-tui
```

默认情况下,它启用硬件监控并选择 “Stress” 选项以对系统执行压力测试。

要查看其他选项,请到帮助页面查看。
```
$ s-tui --help
```
---
via: <https://www.2daygeek.com/s-tui-stress-terminal-ui-monitor-linux-cpu-temperature-frequency/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,468 | 软件 bug 的生命周期 | https://opensource.com/article/18/6/life-cycle-software-bug | 2019-01-23T00:23:14 | [
"bug",
"软件开发"
] | https://linux.cn/article-10468-1.html |
>
> 从发现软件故障到解决它们,这里讲述是开发团队如何压制软件 bug。
>
>
>

1947 年,发现了第一个计算机 bug —— 被困在计算机继电器中的飞蛾。
要是所有的 bug 都能如此简单地发现就好了。随着软件变得越来越复杂,测试和调试的过程也变得更加复杂。如今,软件 bug 的生命周期可能会很长,尽管正确的技术和业务流程可能会有所帮助。对于开源软件,开发人员使用严格的工单服务和协作来查找和解决 bug。
### 确认计算机 bug
在测试过程中,发现的 bug 会报告给开发团队。质量保证测试人员尽可能详细地描述 bug ,报告他们的系统状态、他们正在进行的过程以及 bug 是如何表现出来的。
尽管如此,一些 bug 从未得到确认;它们可能会在测试中报告,但永远无法在可控环境中重现。在这种情况下,它们可能得不到解决,而是被关闭。
有些计算机 bug 可能很难确认,因为使用的平台种类繁多,用户行为也非常多。有些 bug 只是间歇性地或在非常特殊的情况下发生的,而另一些 bug 可能会出现在随机的情况下。
许多人使用开源软件并与之交互,许多 bug 和问题可能是不可重复的,或者可能没有得到充分的描述。不过,由于每个用户和开发人员也都扮演质量保证测试人员的角色,至少在一定程度上,bug 还是很有可能会发现的。
确认 bug 后,修复工作就开始了。
### 分配要修复的 bug
已确认的 bug 被分配给负责解决的开发人员或开发团队。在此阶段,需要重现 bug,发现问题,并修复相关代码。如果 bug 的优先级较低,开发人员可以将此 bug 分类为稍后要修复的问题,也可以在该 bug 具有高优先级的情况下直接指派某人修复。无论哪种方式,都会在开发过程中打开一个工单,并且 bug 将成为已知的问题。
在开源解决方案中,开发人员可以进行选择他们想要解决的 bug,要么选择他们最熟悉的程序区域,要么从优先级最高的的开始。综合解决方案,如 [GitHub](https://github.com/) 使得多个开发人员能够轻松地着手解决,而不会干扰彼此的工作。
当将 bug 设置为需要修复时,bug 报告者还可以为该 bug 选择优先级。主要的 bug 可能具有较高的优先级,而仅与外观相关的 bug 可能具有较低的级别。优先级确定开发团队解决这些问题的方式和时间。无论哪种方式,所有的 bug 都需要先解决,然后才能认为产品已完成。在这方面,适当的回溯到优先级高的需求也会很有帮助。
### 解决 bug
一旦修复了 bug ,通常会将其作为已解决的 bug 发送回质量保证测试人员。然后,质量保证测试人员再次将产品置于其工作中,以重现 bug。如果无法重现 bug ,质量保证测验人员将假定它已得到适当解决。
在开源情况下,任何更改都会被分发,通常是作为正在测试的暂定版本。此测试版本分发给用户,用户再次履行质量保证测试人员的职责并测试产品。
如果 bug 再次出现,问题将被发送回开发团队。在此阶段,该 bug 将重新触发,开发团队有责任重复解决该 bug 的循环。这种情况可能会发生多次,尤其是在 bug 不可预知或间歇性发生的情况下。众所周知,间歇性的 bug 很难解决。
如果该 bug 不再出现,则该问题将被标记为已解决。在某些情况下,最初的 bug 得到了解决,但由于所做的更改,会出现其他 bug。发生这种情况时,可能需要新的 bug 报告,然后重新开始该过程。
### 关闭 bug
在处理、识别和解决 bug 后,该 bug 将被关闭,开发人员可以转到软件开发和测试的其他阶段。如果始终找不到 bug ,或者开发人员无法重现 bug ,则该 bug 也将被关闭 —— 无论哪种方式,都将开始开发和测试的下一阶段。
在测试版本中对解决方案所做的任何更改都将滚动到产品的下一个版本中。如果 bug 是严重的,则在下一个版本发布之前,可能会为当前用户提供修补程序或修补程序。这在安全问题中很常见。
软件 bug 可能很难找到,但通过遵循过程,开发人员可以使开发更快、更容易、更一致。质量保证是这一过程的重要组成部分,因为质量保证测试人员必须发现和识别 bug ,并帮助开发人员重现这些 bug 。在 bug 不再发生之前,无法关闭和解决 bug。
开源的解决方案分散了质量保证测试、开发和缓解的负担,这往往导致 bug 被更快、更全面地发现和缓解。但是,由于开源技术的性质,此过程的速度和准确性通常取决于解决方案的受欢迎程度及其维护和开发团队的敬业精神。
Rich Butkevic 是一个 PMP 项目经理认证,,敏捷开发框架认证(certified scrum master) 并且 维护 [Project Zendo](https://projectzendo.com),这是供项目管理专业人员去发现、简化和改进其项目成果策略的网站。可以在 [Richbutkevic.com](https://richbutkevic.com) 或者使用 [LinkedIn](https://www.linkedin.com/in/richbutkevic) 与 Rich 联系。
---
via: <https://opensource.com/article/18/6/life-cycle-software-bug>
作者:[Rich Butkevic](https://opensource.com/users/rich-butkevic) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lixinyuxx](https://github.com/lixinyuxx) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In 1947, the first computer bug was found—a moth trapped in a computer relay.
If only all bugs were as simple to uncover. As software has become more complex, so too has the process of testing and debugging. Today, the life cycle of a software bug can be lengthy—though the right technology and business processes can help. For open source software, developers use rigorous ticketing services and collaboration to find and mitigate bugs.
## Confirming a computer bug
During the process of testing, bugs are reported to the development team. Quality assurance testers describe the bug in as much detail as possible, reporting on their system state, the processes they were undertaking, and how the bug manifested itself.
Despite this, some bugs are never confirmed; they may be reported in testing but can never be reproduced in a controlled environment. In such cases they may not be resolved but are instead closed.
It can be difficult to confirm a computer bug due to the wide array of platforms in use and the many different types of user behavior. Some bugs only occur intermittently or under very specific situations, and others may occur seemingly at random.
Many people use and interact with open source software, and many bugs and issues may be non-repeatable or may not be adequately described. Still, because every user and developer also plays the role of quality assurance tester, at least in part, there is a good chance that bugs will be revealed.
When a bug is confirmed, work begins.
## Assigning a bug to be fixed
A confirmed bug is assigned to a developer or a development team to be addressed. At this stage, the bug needs to be reproduced, the issue uncovered, and the associated code fixed. Developers may categorize this bug as an issue to be fixed later if the bug is low-priority, or they may assign someone directly if it is high-priority. Either way, a ticket is opened during the process of development, and the bug becomes a known issue.
In open source solutions, developers may select from the bugs that they want to tackle, either choosing the areas of the program with which they are most familiar or working from the top priorities. Consolidated solutions such as [GitHub](https://github.com/) make it easy for multiple developers to work on solutions without interfering with each other's work.
When assigning bugs to be fixed, reporters may also select a priority level for the bug. Major bugs may have a high priority level, whereas bugs related to appearance only, for example, may have a lower level. This priority level determines how and when the development team is assigned to resolve these issues. Either way, all bugs need to be resolved before a product can be considered complete. Using proper traceability back to prioritized requirements can also be helpful in this regard.
## Resolving the bug
Once a bug has been fixed, it is usually be sent back to Quality Assurance as a resolved bug. Quality Assurance then puts the product through its paces again to reproduce the bug. If the bug cannot be reproduced, Quality Assurance will assume that it has been properly resolved.
In open source situations, any changes are distributed—often as a tentative release that is being tested. This test release is distributed to users, who again fulfill the role of Quality Assurance and test the product.
If the bug occurs again, the issue is sent back to the development team. At this stage, the bug is reopened, and it is up to the development team to repeat the cycle of resolving the bug. This may occur multiple times, especially if the bug is unpredictable or intermittent. Intermittent bugs are notoriously difficult to resolve.
If the bug does not occur again, the issue will be marked as resolved. In some cases, the initial bug is resolved, but other bugs emerge as a result of the changes made. When this happens, new bug reports may need to be initiated, starting the process over again.
## Closing the bug
After a bug has been addressed, identified, and resolved, the bug is closed and developers can move on to other areas of software development and testing. A bug will also be closed if it was never found or if developers were never able to reproduce it—either way, the next stage of development and testing will begin.
Any changes made to the solution in the testing version will be rolled into the next release of the product. If the bug was a serious one, a patch or a hotfix may be provided for current users until the release of the next version. This is common for security issues.
Software bugs can be difficult to find, but by following set processes and procedures, developers can make the process faster, easier, and more consistent. Quality Assurance is an important part of this process, as QA testers must find and identify bugs and help developers reproduce them. Bugs cannot be closed and resolved until the error no longer occurs.
Open source solutions distribute the burden of quality assurance testing, development, and mitigation, which often leads to bugs being discovered and mitigated more quickly and comprehensively. However, because of the nature of open source technology, the speed and accuracy of this process often depends upon the popularity of the solution and the dedication of its maintenance and development team.
*Rich Butkevic is a PMP certified project manager, certified scum master, and runs Project Zendo , a website for project management professionals to discover strategies to simplify and improve their project results. Connect with Rich at Richbutkevic.com or on LinkedIn.*
## 2 Comments |
10,469 | 你(多半)不需要 Kubernetes | https://arp242.net/weblog/dont-need-k8s.html | 2019-01-23T01:10:41 | [
"Kubernetes",
"K8S"
] | https://linux.cn/article-10469-1.html | 
这也许是一个不太受欢迎的观点,但大多数主流公司最好不要再使用 k8s 了。
你知道那个古老的“以程序员技能写 Hello world ”笑话吗?—— 从一个新手程序员的 `printf("hello, world\n")` 语句开始,最后结束于高级软件架构工程师令人费解的 Java OOP 模式设计。使用 k8s 就有点像这样。
* 新手系统管理员:
`./binary`
* 有经验的系统管理员:
在 EC2 上的 `./binary`
* DevOp:
在 EC2 上自部署的 CI 管道运行 `./binary`
* 高级云编排工程师:
在 EC2 上通过 k8s 编排的自部署 CI 管道运行 `./binary`
¯\\\_(ツ)\_/¯
这不意味着 Kubernetes 或者任何这样的东西本身都是*坏的*,就像 Java 或者 OOP 设计本身并不是坏的一样,但是,在很多情况下,它们被严重地误用,就像在一个 hello world 的程序中可怕地误用 Java 面向对象设计模式一样。对大多数公司而言,系统运维从根本上来说并不十分复杂,此时在这上面应用 k8s 起效甚微。
复杂性本质上来说创造了工作,我十分怀疑使用 k8s 对大多数使用者来说是省时的这一说法。这就好像花一天时间来写一个脚本,用来自动完成一些你一个月进行一次,每次只花 10 分钟完成的工作。这不是一个好的时间投资(特别是你可能会在未来由于扩展或调试这个脚本而进一步投入的更多时间)。
你的部署大概应该*需要*自动化 – 以免你 [最终像 Knightmare](https://dougseven.com/2014/04/17/knightmare-a-devops-cautionary-tale/) 那样 —— 但 k8s 通常可以被一个简单的 shell 脚本所替代。
在我们公司,系统运维团队用了很多时间来设置 k8s 。他们还不得不用了很大一部分时间来更新到新一点的版本(1.6 ➙ 1.8)。结果是如果没有真正深入理解 k8s ,有些东西就没人会真的明白,甚至连深入理解 k8s 这一点也很难(那些 YAML 文件,哦呦!)
在我能自己调试和修复部署问题之前 —— 现在这更难了,我理解基本概念,但在真正调试实际问题的时候,它们并不是那么有用。我不经常用 k8s 足以证明这点。
---
k8s 真的很难这点并不是什么新看法,这也是为什么现在会有这么多 “k8s 简单用”的解决方案。在 k8s 上再添一层来“让它更简单”的方法让我觉得,呃,不明智。复杂性并没有消失,你只是把它藏起来了。
以前我说过很多次:在确定一样东西是否“简单”时,我最关心的不是写东西的时候有多简单,而是当失败的时候调试起来有多容易。包装 k8s 并不会让调试更加简单,恰恰相反,它让事情更加困难了。
---
Blaise Pascal 有一句名言:
>
> 几乎所有的痛苦都来自于我们不善于在房间里独处。
>
>
>
k8s —— 略微拓展一下,Docker —— 似乎就是这样的例子。许多人似乎迷失在当下的兴奋中,觉得 “k8s 就是这么回事!”,就像有些人迷失在 Java OOP 刚出来时的兴奋中一样,所以一切都必须从“旧”方法转为“新”方法,即使“旧”方法依然可行。
有时候 IT 产业挺蠢的。
或者用 [一条推特](https://twitter.com/sahrizv/status/1018184792611827712) 来总结:
>
> * 2014 - 我们必须采用 #微服务 来解决独石应用的所有问题
> * 2016 - 我们必须采用 #docker 来解决微服务的所有问题
> * 2018 - 我们必须采用 #kubernetes 来解决 docker 的所有问题
>
>
>
你可以通过 [[email protected]](mailto:[email protected]) 给我发邮件或者 [创建 GitHub issue](https://github.com/Carpetsmoker/arp242.net/issues/new) 来给我反馈或提出问题等。
---
via: <https://arp242.net/weblog/dont-need-k8s.html>
作者:[Martin Tournoij](https://arp242.net/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[beamrolling](https://github.com/beamrolling) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,470 | 如何构建一台网络引导服务器(四) | https://fedoramagazine.org/how-to-build-a-netboot-server-part-4/ | 2019-01-23T22:26:12 | [
"网络引导"
] | https://linux.cn/article-10470-1.html | 
在本系列教程中所构建的网络引导服务器有一个很重要的限制,那就是所提供的操作系统镜像是只读的。一些使用场景或许要求终端用户能够修改操作系统镜像。例如,一些教师或许希望学生能够安装和配置一些像 MariaDB 和 Node.js 这样的包来做为他们课程练习的一部分。
可写镜像的另外的好处是,终端用户“私人定制”的操作系统,在下次不同的工作站上使用时能够“跟着”他们。
### 修改 Bootmenu 应用程序以使用 HTTPS
为 bootmenu 应用程序创建一个自签名的证书:
```
$ sudo -i
# MY_NAME=$(</etc/hostname)
# MY_TLSD=/opt/bootmenu/tls
# mkdir $MY_TLSD
# openssl req -newkey rsa:2048 -nodes -keyout $MY_TLSD/$MY_NAME.key -x509 -days 3650 -out $MY_TLSD/$MY_NAME.pem
```
验证你的证书的值。确保 `Subject` 行中 `CN` 的值与你的 iPXE 客户端连接你的网络引导服务器所使用的 DNS 名字是相匹配的:
```
# openssl x509 -text -noout -in $MY_TLSD/$MY_NAME.pem
```
接下来,更新 bootmenu 应用程序去监听 HTTPS 端口和新创建的证书及密钥:
```
# sed -i "s#listen => .*#listen => ['https://$MY_NAME:443?cert=$MY_TLSD/$MY_NAME.pem\&key=$MY_TLSD/$MY_NAME.key\&ciphers=AES256-SHA256:AES128-SHA256:AES256-SHA:AES128-SHA'],#" /opt/bootmenu/bootmenu.conf
```
注意 [iPXE 当前支持的](http://ipxe.org/crypto) 加密算法是有限制的。
GnuTLS 要求 “CAPDACREAD\_SEARCH” 能力,因此将它添加到 bootmenu 应用程序的 systemd 服务:
```
# sed -i '/^AmbientCapabilities=/ s/$/ CAP_DAC_READ_SEARCH/' /etc/systemd/system/bootmenu.service
# sed -i 's/Serves iPXE Menus over HTTP/Serves iPXE Menus over HTTPS/' /etc/systemd/system/bootmenu.service
# systemctl daemon-reload
```
现在,在防火墙中为 bootmenu 服务添加一个例外规则并重启动该服务:
```
# MY_SUBNET=192.0.2.0
# MY_PREFIX=24
# firewall-cmd --add-rich-rule="rule family='ipv4' source address='$MY_SUBNET/$MY_PREFIX' service name='https' accept"
# firewall-cmd --runtime-to-permanent
# systemctl restart bootmenu.service
```
使用 `wget` 去验证是否工作正常:
```
$ MY_NAME=server-01.example.edu
$ MY_TLSD=/opt/bootmenu/tls
$ wget -q --ca-certificate=$MY_TLSD/$MY_NAME.pem -O - https://$MY_NAME/menu
```
### 添加 HTTPS 到 iPXE
更新 `init.ipxe` 去使用 HTTPS。接着使用选项重新编译 ipxe 引导加载器,以便它包含和信任你为 bootmenu 应用程序创建的自签名证书:
```
$ echo '#define DOWNLOAD_PROTO_HTTPS' >> $HOME/ipxe/src/config/local/general.h
$ sed -i 's/^chain http:/chain https:/' $HOME/ipxe/init.ipxe
$ cp $MY_TLSD/$MY_NAME.pem $HOME/ipxe
$ cd $HOME/ipxe/src
$ make clean
$ make bin-x86_64-efi/ipxe.efi EMBED=../init.ipxe CERT="../$MY_NAME.pem" TRUST="../$MY_NAME.pem"
```
你现在可以将启用了 HTTPS 的 iPXE 引导加载器复制到你的客户端上,并测试它能否正常工作:
```
$ cp $HOME/ipxe/src/bin-x86_64-efi/ipxe.efi $HOME/esp/efi/boot/bootx64.efi
```
### 添加用户验证到 Mojolicious 中
为 bootmenu 应用程序创建一个 PAM 服务定义:
```
# dnf install -y pam_krb5
# echo 'auth required pam_krb5.so' > /etc/pam.d/bootmenu
```
添加一个库到 bootmenu 应用程序中,它使用 Authen-PAM 的 Perl 模块去执行用户验证:
```
# dnf install -y perl-Authen-PAM;
# MY_MOJO=/opt/bootmenu
# mkdir $MY_MOJO/lib
# cat << 'END' > $MY_MOJO/lib/PAM.pm
package PAM;
use Authen::PAM;
sub auth {
my $success = 0;
my $username = shift;
my $password = shift;
my $callback = sub {
my @res;
while (@_) {
my $code = shift;
my $msg = shift;
my $ans = "";
$ans = $username if ($code == PAM_PROMPT_ECHO_ON());
$ans = $password if ($code == PAM_PROMPT_ECHO_OFF());
push @res, (PAM_SUCCESS(), $ans);
}
push @res, PAM_SUCCESS();
return @res;
};
my $pamh = new Authen::PAM('bootmenu', $username, $callback);
{
last unless ref $pamh;
last unless $pamh->pam_authenticate() == PAM_SUCCESS;
$success = 1;
}
return $success;
}
return 1;
END
```
以上的代码是一字不差是从 Authen::PAM::FAQ 的 man 页面中复制来的。
重定义 bootmenu 应用程序,以使它仅当提供了有效的用户名和密码之后返回一个网络引导模板:
```
# cat << 'END' > $MY_MOJO/bootmenu.pl
#!/usr/bin/env perl
use lib 'lib';
use PAM;
use Mojolicious::Lite;
use Mojolicious::Plugins;
use Mojo::Util ('url_unescape');
plugin 'Config';
get '/menu';
get '/boot' => sub {
my $c = shift;
my $instance = $c->param('instance');
my $username = $c->param('username');
my $password = $c->param('password');
my $template = 'menu';
{
last unless $instance =~ /^fc[[:digit:]]{2}$/;
last unless $username =~ /^[[:alnum:]]+$/;
last unless PAM::auth($username, url_unescape($password));
$template = $instance;
}
return $c->render(template => $template);
};
app->start;
END
```
bootmenu 应用程序现在查找 `lib` 命令去找到相应的 `WorkingDirectory`。但是,默认情况下,对于 systemd 单元它的工作目录设置为服务器的 root 目录。因此,你必须更新 systemd 单元去设置 `WorkingDirectory` 为 bootmenu 应用程序的根目录:
```
# sed -i "/^RuntimeDirectory=/ a WorkingDirectory=$MY_MOJO" /etc/systemd/system/bootmenu.service
# systemctl daemon-reload
```
更新模块去使用重定义后的 bootmenu 应用程序:
```
# cd $MY_MOJO/templates
# MY_BOOTMENU_SERVER=$(</etc/hostname)
# MY_FEDORA_RELEASES="28 29"
# for i in $MY_FEDORA_RELEASES; do echo '#!ipxe' > fc$i.html.ep; grep "^kernel\|initrd" menu.html.ep | grep "fc$i" >> fc$i.html.ep; echo "boot || chain https://$MY_BOOTMENU_SERVER/menu" >> fc$i.html.ep; sed -i "/^:f$i$/,/^boot /c :f$i\nlogin\nchain https://$MY_BOOTMENU_SERVER/boot?instance=fc$i\&username=\${username}\&password=\${password:uristring} || goto failed" menu.html.ep; done
```
上面的最后的命令将生成类似下面的三个文件:
`menu.html.ep`:
```
#!ipxe
set timeout 5000
:menu
menu iPXE Boot Menu
item --key 1 lcl 1. Microsoft Windows 10
item --key 2 f29 2. RedHat Fedora 29
item --key 3 f28 3. RedHat Fedora 28
choose --timeout ${timeout} --default lcl selected || goto shell
set timeout 0
goto ${selected}
:failed
echo boot failed, dropping to shell...
goto shell
:shell
echo type 'exit' to get the back to the menu
set timeout 0
shell
goto menu
:lcl
exit
:f29
login
chain https://server-01.example.edu/boot?instance=fc29&username=${username}&password=${password:uristring} || goto failed
:f28
login
chain https://server-01.example.edu/boot?instance=fc28&username=${username}&password=${password:uristring} || goto failed
```
`fc29.html.ep`:
```
#!ipxe
kernel --name kernel.efi ${prefix}/vmlinuz-4.19.5-300.fc29.x86_64 initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=192.0.2.91 nameserver=192.0.2.92 root=/dev/disk/by-path/ip-192.0.2.158:3260-iscsi-iqn.edu.example.server-01:fc29-lun-1 netroot=iscsi:192.0.2.158::::iqn.edu.example.server-01:fc29 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet
initrd --name initrd.img ${prefix}/initramfs-4.19.5-300.fc29.x86_64.img
boot || chain https://server-01.example.edu/menu
```
`fc28.html.ep`:
```
#!ipxe
kernel --name kernel.efi ${prefix}/vmlinuz-4.19.3-200.fc28.x86_64 initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=192.0.2.91 nameserver=192.0.2.92 root=/dev/disk/by-path/ip-192.0.2.158:3260-iscsi-iqn.edu.example.server-01:fc28-lun-1 netroot=iscsi:192.0.2.158::::iqn.edu.example.server-01:fc28 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet
initrd --name initrd.img ${prefix}/initramfs-4.19.3-200.fc28.x86_64.img
boot || chain https://server-01.example.edu/menu
```
现在,重启动 bootmenu 应用程序,并验证用户认证是否正常工作:
```
# systemctl restart bootmenu.service
```
### 使得 iSCSI Target 可写
现在,用户验证通过 iPXE 可以正常工作,在用户连接时,你可以按需在只读镜像的上面创建每用户可写的<ruby> overlay <rt> 叠加层 </rt></ruby>。使用一个 [写时复制](https://en.wikipedia.org/wiki/Copy-on-write) 的叠加层与简单地为每个用户复制原始镜像相比有三个好处:
1. 副本创建非常快。这样就可以按需创建。
2. 副本并不增加服务器上的磁盘使用。除了原始镜像之外,仅存储用户写入个人镜像的内容。
3. 由于每个副本的扇区大多都是服务器的存储器上的相同扇区,在随后的用户访问这些操作系统的副本时,它们可能已经加载到内存中,这样就提升了服务器的性能,因为对内存的访问速度要比磁盘 I/O 快得多。
使用写时复制的一个潜在隐患是,一旦叠加层创建后,叠加层之下的镜像就不能再改变。如果它们改变,所有它们之上的叠加层将出错。因此,叠加层必须被删除并用新的、空白的进行替换。即便只是简单地以读写模式加载的镜像,也可能因为某些文件系统更新导致叠加层出错。
由于这个隐患,如果原始镜像被修改将导致叠加层出错,因此运行下列的命令,将原始镜像标记为不可改变:
```
# chattr +i </path/to/file>
```
你可以使用 `lsattr </path/to/file>` 去查看不可改变标志,并可以使用 `chattr -i </path/to/file>` 取消设置不可改变标志。在设置了不可改变标志之后,即便是 root 用户或以 root 运行的系统进程也不修改或删除这个文件。
停止 tgtd.service 之后,你就可以改变镜像文件:
```
# systemctl stop tgtd.service
```
当仍有连接打开的时候,运行这个命令一般需要一分钟或更长的时间。
现在,移除只读的 iSCSI 出口。然后更新模板中的 `readonly-root` 配置文件,以使镜像不再是只读的:
```
# MY_FC=fc29
# rm -f /etc/tgt/conf.d/$MY_FC.conf
# TEMP_MNT=$(mktemp -d)
# mount /$MY_FC.img $TEMP_MNT
# sed -i 's/^READONLY=yes$/READONLY=no/' $TEMP_MNT/etc/sysconfig/readonly-root
# sed -i 's/^Storage=volatile$/#Storage=auto/' $TEMP_MNT/etc/systemd/journald.conf
# umount $TEMP_MNT
```
将 journald 日志从发送到内存修改回缺省值(如果 `/var/log/journal` 存在的话记录到磁盘),因为一个用户报告说,他的客户端由于应用程序生成了大量的系统日志而产生内存溢出错误,导致它的客户端被卡住。而将日志记录到磁盘的负面影响是客户端产生了额外的写入流量,这将在你的网络引导服务器上可能增加一些没有必要的 I/O。你应该去决定到底使用哪个选择 —— 记录到内存还是记录到硬盘 —— 哪个更合适取决于你的环境。
因为你的模板镜像在以后不能做任何的更改,因此在它上面设置不可更改标志,然后重启动 tgtd.service:
```
# chattr +i /$MY_FC.img
# systemctl start tgtd.service
```
现在,更新 bootmenu 应用程序:
```
# cat << 'END' > $MY_MOJO/bootmenu.pl
#!/usr/bin/env perl
use lib 'lib';
use PAM;
use Mojolicious::Lite;
use Mojolicious::Plugins;
use Mojo::Util ('url_unescape');
plugin 'Config';
get '/menu';
get '/boot' => sub {
my $c = shift;
my $instance = $c->param('instance');
my $username = $c->param('username');
my $password = $c->param('password');
my $chapscrt;
my $template = 'menu';
{
last unless $instance =~ /^fc[[:digit:]]{2}$/;
last unless $username =~ /^[[:alnum:]]+$/;
last unless PAM::auth($username, url_unescape($password));
last unless $chapscrt = `sudo scripts/mktgt $instance $username`;
$template = $instance;
}
return $c->render(template => $template, username => $username, chapscrt => $chapscrt);
};
app->start;
END
```
新版本的 bootmenu 应用程序调用一个定制的 `mktgt` 脚本,如果成功,它将为每个它自己创建的新的 iSCSI 目标返回一个随机的 [CHAP](https://en.wikipedia.org/wiki/Challenge-Handshake_Authentication_Protocol) 密码。这个 CHAP 密码可以防止其它用户的 iSCSI 目标以间接方式挂载这个用户的目标。这个应用程序只有在用户密码认证成功之后才返回一个正确的 iSCSI 目标密码。
`mktgt` 脚本要加 `sudo` 前缀来运行,因为它需要 root 权限去创建目标。
`$username` 和 `$chapscrt` 变量也传递给 `render` 命令,因此在需要的时候,它们也能够被纳入到模板中返回给用户。
接下来,更新我们的引导模板,以便于它们能够读取用户名和 `chapscrt` 变量,并传递它们到所属的终端用户。也要更新模板以 rw(读写)模式加载根文件系统:
```
# cd $MY_MOJO/templates
# sed -i "s/:$MY_FC/:$MY_FC-<%= \$username %>/g" $MY_FC.html.ep
# sed -i "s/ netroot=iscsi:/ netroot=iscsi:<%= \$username %>:<%= \$chapscrt %>@/" $MY_FC.html.ep
# sed -i "s/ ro / rw /" $MY_FC.html.ep
```
运行上面的命令后,你应该会看到如下的引导模板:
```
#!ipxe
kernel --name kernel.efi ${prefix}/vmlinuz-4.19.5-300.fc29.x86_64 initrd=initrd.img rw ip=dhcp rd.peerdns=0 nameserver=192.0.2.91 nameserver=192.0.2.92 root=/dev/disk/by-path/ip-192.0.2.158:3260-iscsi-iqn.edu.example.server-01:fc29-<%= $username %>-lun-1 netroot=iscsi:<%= $username %>:<%= $chapscrt %>@192.0.2.158::::iqn.edu.example.server-01:fc29-<%= $username %> console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet
initrd --name initrd.img ${prefix}/initramfs-4.19.5-300.fc29.x86_64.img
boot || chain https://server-01.example.edu/menu
```
注意:如果在 [插入](https://en.wikipedia.org/wiki/String_interpolation) 变量后需要查看引导模板,你可以在 `boot` 命令之前,在它自己的行中插入 `shell` 命令。然后在你网络引导你的客户端时,iPXE 将在那里给你提供一个用于交互的 shell,你可以在 shell 中输入 `imgstat` 去查看传递到内核的参数。如果一切正确,你可以输入 `exit` 去退出 shell 并继续引导过程。
现在,通过 `sudo` 允许 bootmenu 用户以 root 权限去运行 `mktgt` 脚本(仅这个脚本):
```
# echo "bootmenu ALL = NOPASSWD: $MY_MOJO/scripts/mktgt *" > /etc/sudoers.d/bootmenu
```
bootmenu 用户不应该写访问 `mktgt` 脚本或在它的家目录下的任何其它文件。在 `/opt/bootmenu` 目录下的所有文件的属主应该是 root,并且不应该被其它任何 root 以外的用户可写。
`sudo` 在使用 systemd 的 `DynamicUser` 选项下不能正常工作,因此创建一个普通用户帐户,并设置 systemd 服务以那个用户运行:
```
# useradd -r -c 'iPXE Boot Menu Service' -d /opt/bootmenu -s /sbin/nologin bootmenu
# sed -i 's/^DynamicUser=true$/User=bootmenu/' /etc/systemd/system/bootmenu.service
# systemctl daemon-reload
```
最后,为写时复制覆盖创建一个目录,并创建管理 iSCSI 目标的 `mktgt` 脚本和它们的覆盖支持存储:
```
# mkdir /$MY_FC.cow
# mkdir $MY_MOJO/scripts
# cat << 'END' > $MY_MOJO/scripts/mktgt
#!/usr/bin/env perl
# if another instance of this script is running, wait for it to finish
"$ENV{FLOCKER}" eq 'MKTGT' or exec "env FLOCKER=MKTGT flock /tmp $0 @ARGV";
# use "RETURN" to print to STDOUT; everything else goes to STDERR by default
open(RETURN, '>&', STDOUT);
open(STDOUT, '>&', STDERR);
my $instance = shift or die "instance not provided";
my $username = shift or die "username not provided";
my $img = "/$instance.img";
my $dir = "/$instance.cow";
my $top = "$dir/$username";
-f "$img" or die "'$img' is not a file";
-d "$dir" or die "'$dir' is not a directory";
my $base;
die unless $base = `losetup --show --read-only --nooverlap --find $img`;
chomp $base;
my $size;
die unless $size = `blockdev --getsz $base`;
chomp $size;
# create the per-user sparse file if it does not exist
if (! -e "$top") {
die unless system("dd if=/dev/zero of=$top status=none bs=512 count=0 seek=$size") == 0;
}
# create the copy-on-write overlay if it does not exist
my $cow="$instance-$username";
my $dev="/dev/mapper/$cow";
if (! -e "$dev") {
my $over;
die unless $over = `losetup --show --nooverlap --find $top`;
chomp $over;
die unless system("echo 0 $size snapshot $base $over p 8 | dmsetup create $cow") == 0;
}
my $tgtadm = '/usr/sbin/tgtadm --lld iscsi';
# get textual representations of the iscsi targets
my $text = `$tgtadm --op show --mode target`;
my @targets = $text =~ /(?:^T.*\n)(?:^ .*\n)*/mg;
# convert the textual representations into a hash table
my $targets = {};
foreach (@targets) {
my $tgt;
my $sid;
foreach (split /\n/) {
/^Target (\d+)(?{ $tgt = $targets->{$^N} = [] })/;
/I_T nexus: (\d+)(?{ $sid = $^N })/;
/Connection: (\d+)(?{ push @{$tgt}, [ $sid, $^N ] })/;
}
}
my $hostname;
die unless $hostname = `hostname`;
chomp $hostname;
my $target = 'iqn.' . join('.', reverse split('\.', $hostname)) . ":$cow";
# find the target id corresponding to the provided target name and
# close any existing connections to it
my $tid = 0;
foreach (@targets) {
next unless /^Target (\d+)(?{ $tid = $^N }): $target$/m;
foreach (@{$targets->{$tid}}) {
die unless system("$tgtadm --op delete --mode conn --tid $tid --sid $_->[0] --cid $_->[1]") == 0;
}
}
# create a new target if an existing one was not found
if ($tid == 0) {
# find an available target id
my @ids = (0, sort keys %{$targets});
$tid = 1; while ($ids[$tid]==$tid) { $tid++ }
# create the target
die unless -e "$dev";
die unless system("$tgtadm --op new --mode target --tid $tid --targetname $target") == 0;
die unless system("$tgtadm --op new --mode logicalunit --tid $tid --lun 1 --backing-store $dev") == 0;
die unless system("$tgtadm --op bind --mode target --tid $tid --initiator-address ALL") == 0;
}
# (re)set the provided target's chap password
my $password = join('', map(chr(int(rand(26))+65), 1..8));
my $accounts = `$tgtadm --op show --mode account`;
if ($accounts =~ / $username$/m) {
die unless system("$tgtadm --op delete --mode account --user $username") == 0;
}
die unless system("$tgtadm --op new --mode account --user $username --password $password") == 0;
die unless system("$tgtadm --op bind --mode account --tid $tid --user $username") == 0;
# return the new password to the iscsi target on stdout
print RETURN $password;
END
# chmod +x $MY_MOJO/scripts/mktgt
```
上面的脚本将做以下五件事情:
1. 创建 `/<instance>.cow/<username>` 稀疏文件(如果不存在的话)。
2. 创建 `/dev/mapper/<instance>-<username>` 设备节点作为 iSCSI 目标的写时复制支持存储(如果不存在的话)。
3. 创建 `iqn.<reverse-hostname>:<instance>-<username>` iSCSI 目标(如果不存在的话)。或者,如果已存在了,它将关闭任何已存在的连接,因为在任何时刻,镜像只能以只读模式从一个地方打开。
4. 它在 `iqn.<reverse-hostname>:<instance>-<username>` iSCSI 目标上(重新)设置 chap 密码为一个新的随机值。
5. (如果前面的所有任务都成功的话)它在 [标准输出](https://en.wikipedia.org/wiki/Standard_streams) 上显示新的 chap 密码。
你应该可以在命令行上通过使用有效的测试参数来运行它,以测试 `mktgt` 脚本能否正常工作。例如:
```
# echo `$MY_MOJO/scripts/mktgt fc29 jsmith`
```
当你从命令行上运行时,`mktgt` 脚本应该会输出 iSCSI 目标的一个随意的八字符随机密码(如果成功的话)或者是出错位置的行号(如果失败的话)。
有时候,你可能需要在不停止整个服务的情况下删除一个 iSCSI 目标。例如,一个用户可能无意中损坏了他的个人镜像,在那种情况下,你可能需要按步骤撤销上面的 `mktgt` 脚本所做的事情,以便于他下次登入时他将得到一个原始镜像。
下面是用于撤销的 `rmtgt` 脚本,它以相反的顺序做了上面 `mktgt` 脚本所做的事情:
```
# mkdir $HOME/bin
# cat << 'END' > $HOME/bin/rmtgt
#!/usr/bin/env perl
@ARGV >= 2 or die "usage: $0 <instance> <username> [+d|+f]\n";
my $instance = shift;
my $username = shift;
my $rmd = ($ARGV[0] eq '+d'); #remove device node if +d flag is set
my $rmf = ($ARGV[0] eq '+f'); #remove sparse file if +f flag is set
my $cow = "$instance-$username";
my $hostname;
die unless $hostname = `hostname`;
chomp $hostname;
my $tgtadm = '/usr/sbin/tgtadm';
my $target = 'iqn.' . join('.', reverse split('\.', $hostname)) . ":$cow";
my $text = `$tgtadm --op show --mode target`;
my @targets = $text =~ /(?:^T.*\n)(?:^ .*\n)*/mg;
my $targets = {};
foreach (@targets) {
my $tgt;
my $sid;
foreach (split /\n/) {
/^Target (\d+)(?{ $tgt = $targets->{$^N} = [] })/;
/I_T nexus: (\d+)(?{ $sid = $^N })/;
/Connection: (\d+)(?{ push @{$tgt}, [ $sid, $^N ] })/;
}
}
my $tid = 0;
foreach (@targets) {
next unless /^Target (\d+)(?{ $tid = $^N }): $target$/m;
foreach (@{$targets->{$tid}}) {
die unless system("$tgtadm --op delete --mode conn --tid $tid --sid $_->[0] --cid $_->[1]") == 0;
}
die unless system("$tgtadm --op delete --mode target --tid $tid") == 0;
print "target $tid deleted\n";
sleep 1;
}
my $dev = "/dev/mapper/$cow";
if ($rmd or ($rmf and -e $dev)) {
die unless system("dmsetup remove $cow") == 0;
print "device node $dev deleted\n";
}
if ($rmf) {
my $sf = "/$instance.cow/$username";
die "sparse file $sf not found" unless -e "$sf";
die unless system("rm -f $sf") == 0;
die unless not -e "$sf";
print "sparse file $sf deleted\n";
}
END
# chmod +x $HOME/bin/rmtgt
```
例如,使用上面的脚本去完全删除 fc29-jsmith 目标,包含它的支持存储设备节点和稀疏文件,可以按下列方式运行命令:
```
# rmtgt fc29 jsmith +f
```
一旦你验证 `mktgt` 脚本工作正常,你可以重启动 bootmenu 服务。下次有人从网络引导时,他们应该能够接收到一个他们可以写入的、可”私人定制“的网络引导镜像的副本:
```
# systemctl restart bootmenu.service
```
现在,就像下面的截屏示范的那样,用户应该可以修改根文件系统了:

---
via: <https://fedoramagazine.org/how-to-build-a-netboot-server-part-4/>
作者:[Gregory Bartholomew](https://fedoramagazine.org/author/glb/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One significant limitation of the netboot server built in this series is the operating system image being served is read-only. Some use cases may require the end user to modify the image. For example, an instructor may want to have the students install and configure software packages like MariaDB and Node.js as part of their course walk-through.
An added benefit of writable netboot images is the end user’s “personalized” operating system can follow them to different workstations they may use at later times.
## Change the Bootmenu Application to use HTTPS
Create a self-signed certificate for the bootmenu application:
$ sudo -i # MY_NAME=$(</etc/hostname) # MY_TLSD=/opt/bootmenu/tls # mkdir $MY_TLSD # openssl req -newkey rsa:2048 -nodes -keyout $MY_TLSD/$MY_NAME.key -x509 -days 3650 -out $MY_TLSD/$MY_NAME.pem
Verify your certificate’s values. Make sure the “CN” value in the “Subject” line matches the DNS name that your iPXE clients use to connect to your bootmenu server:
# openssl x509 -text -noout -in $MY_TLSD/$MY_NAME.pem
Next, update the bootmenu application’s *listen* directive to use the HTTPS port and the newly created certificate and key:
# sed -i "s#listen => .*#listen => ['https://$MY_NAME:443?cert=$MY_TLSD/$MY_NAME.pem\&key=$MY_TLSD/$MY_NAME.key\&ciphers=AES256-SHA256:AES128-SHA256:AES256-SHA:AES128-SHA'],#" /opt/bootmenu/bootmenu.conf
Note the ciphers have been restricted to [those currently supported by iPXE](http://ipxe.org/crypto).
GnuTLS requires the “CAP_DAC_READ_SEARCH” capability, so add it to the bootmenu application’s systemd service:
# sed -i '/^AmbientCapabilities=/ s/$/ CAP_DAC_READ_SEARCH/' /etc/systemd/system/bootmenu.service # sed -i 's/Serves iPXE Menus over HTTP/Serves iPXE Menus over HTTPS/' /etc/systemd/system/bootmenu.service # systemctl daemon-reload
Now, add an exception for the bootmenu service to the firewall and restart the service:
# MY_SUBNET=192.0.2.0 # MY_PREFIX=24 # firewall-cmd --add-rich-rule="rule family='ipv4' source address='$MY_SUBNET/$MY_PREFIX' service name='https' accept" # firewall-cmd --runtime-to-permanent # systemctl restart bootmenu.service
Use *wget* to verify it’s working:
$ MY_NAME=server-01.example.edu $ MY_TLSD=/opt/bootmenu/tls $ wget -q --ca-certificate=$MY_TLSD/$MY_NAME.pem -O - https://$MY_NAME/menu
## Add HTTPS to iPXE
Update *init.ipxe* to use HTTPS. Then recompile the ipxe bootloader with options to embed and trust the self-signed certificate you created for the bootmenu application:
$ echo '#define DOWNLOAD_PROTO_HTTPS' >> $HOME/ipxe/src/config/local/general.h $ sed -i 's/^chain http:/chain https:/' $HOME/ipxe/init.ipxe $ cp $MY_TLSD/$MY_NAME.pem $HOME/ipxe $ cd $HOME/ipxe/src $ make clean $ make bin-x86_64-efi/ipxe.efi EMBED=../init.ipxe CERT="../$MY_NAME.pem" TRUST="../$MY_NAME.pem"
You can now copy the HTTPS-enabled iPXE bootloader out to your clients and test that everything is working correctly:
$ cp $HOME/ipxe/src/bin-x86_64-efi/ipxe.efi $HOME/esp/efi/boot/bootx64.efi
## Add User Authentication to Mojolicious
Create a PAM service definition for the bootmenu application:
# dnf install -y pam_krb5 # echo 'auth required pam_krb5.so' > /etc/pam.d/bootmenu
Add a library to the bootmenu application that uses the Authen-PAM perl module to perform user authentication:
# dnf install -y perl-Authen-PAM; # MY_MOJO=/opt/bootmenu # mkdir $MY_MOJO/lib # cat << 'END' > $MY_MOJO/lib/PAM.pm package PAM; use Authen::PAM; sub auth { my $success = 0; my $username = shift; my $password = shift; my $callback = sub { my @res; while (@_) { my $code = shift; my $msg = shift; my $ans = ""; $ans = $username if ($code == PAM_PROMPT_ECHO_ON()); $ans = $password if ($code == PAM_PROMPT_ECHO_OFF()); push @res, (PAM_SUCCESS(), $ans); } push @res, PAM_SUCCESS(); return @res; }; my $pamh = new Authen::PAM('bootmenu', $username, $callback); { last unless ref $pamh; last unless $pamh->pam_authenticate() == PAM_SUCCESS; $success = 1; } return $success; } return 1; END
The above code is taken almost verbatim from the Authen::PAM::FAQ man page.
Redefine the bootmenu application so it returns a netboot template only if a valid username and password are supplied:
# cat << 'END' > $MY_MOJO/bootmenu.pl #!/usr/bin/env perl use lib 'lib'; use PAM; use Mojolicious::Lite; use Mojolicious::Plugins; use Mojo::Util ('url_unescape'); plugin 'Config'; get '/menu'; get '/boot' => sub { my $c = shift; my $instance = $c->param('instance'); my $username = $c->param('username'); my $password = $c->param('password'); my $template = 'menu'; { last unless $instance =~ /^fc[[:digit:]]{2}$/; last unless $username =~ /^[[:alnum:]]+$/; last unless PAM::auth($username, url_unescape($password)); $template = $instance; } return $c->render(template => $template); }; app->start; END
The bootmenu application now looks for the *lib* directory relative to its *WorkingDirectory*. However, by default the working directory is set to the root directory of the server for systemd units. Therefore, you must update the systemd unit to set *WorkingDirectory* to the root of the bootmenu application instead:
# sed -i "/^RuntimeDirectory=/ a WorkingDirectory=$MY_MOJO" /etc/systemd/system/bootmenu.service # systemctl daemon-reload
Update the templates to work with the redefined bootmenu application:
# cd $MY_MOJO/templates # MY_BOOTMENU_SERVER=$(</etc/hostname) # MY_FEDORA_RELEASES="28 29" # for i in $MY_FEDORA_RELEASES; do echo '#!ipxe' > fc$i.html.ep; grep "^kernel\|initrd" menu.html.ep | grep "fc$i" >> fc$i.html.ep; echo "boot || chain https://$MY_BOOTMENU_SERVER/menu" >> fc$i.html.ep; sed -i "/^:f$i$/,/^boot /c :f$i\nlogin\nchain https://$MY_BOOTMENU_SERVER/boot?instance=fc$i\&username=\${username}\&password=\${password:uristring} || goto failed" menu.html.ep; done
The result of the last command above should be three files similar to the following:
**menu.html.ep**:
#!ipxe set timeout 5000 :menu menu iPXE Boot Menu item --key 1 lcl 1. Microsoft Windows 10 item --key 2 f29 2. RedHat Fedora 29 item --key 3 f28 3. RedHat Fedora 28 choose --timeout ${timeout} --default lcl selected || goto shell set timeout 0 goto ${selected} :failed echo boot failed, dropping to shell... goto shell :shell echo type 'exit' to get the back to the menu set timeout 0 shell goto menu :lcl exit :f29 login chain https://server-01.example.edu/boot?instance=fc29&username=${username}&password=${password:uristring} || goto failed :f28 login chain https://server-01.example.edu/boot?instance=fc28&username=${username}&password=${password:uristring} || goto failed
**fc29.html.ep**:
#!ipxe kernel --name kernel.efi ${prefix}/vmlinuz-4.19.5-300.fc29.x86_64 initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=192.0.2.91 nameserver=192.0.2.92 root=/dev/disk/by-path/ip-192.0.2.158:3260-iscsi-iqn.edu.example.server-01:fc29-lun-1 netroot=iscsi:192.0.2.158::::iqn.edu.example.server-01:fc29 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet initrd --name initrd.img ${prefix}/initramfs-4.19.5-300.fc29.x86_64.img boot || chain https://server-01.example.edu/menu
**fc28.html.ep**:
#!ipxe kernel --name kernel.efi ${prefix}/vmlinuz-4.19.3-200.fc28.x86_64 initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=192.0.2.91 nameserver=192.0.2.92 root=/dev/disk/by-path/ip-192.0.2.158:3260-iscsi-iqn.edu.example.server-01:fc28-lun-1 netroot=iscsi:192.0.2.158::::iqn.edu.example.server-01:fc28 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet initrd --name initrd.img ${prefix}/initramfs-4.19.3-200.fc28.x86_64.img boot || chain https://server-01.example.edu/menu
Now, restart the bootmenu application and verify authentication is working:
# systemctl restart bootmenu.service
## Make the iSCSI Target Writeable
Now that user authentication works through iPXE, you can create per-user, writeable overlays on top of the read-only image on demand when users connect. Using a [copy-on-write](https://en.wikipedia.org/wiki/Copy-on-write) overlay has three advantages over simply copying the original image file for each user:
- The copy can be created very quickly. This allows creation on-demand.
- The copy does not increase the disk usage on the server. Only what the user writes to their personal copy of the image is stored in addition to the original image.
- Since most sectors for each copy are the same sectors on the server’s storage, they’ll likely already be loaded in RAM when subsequent users access their copies of the operating system. This improves the server’s performance because RAM is faster than disk I/O.
One potential pitfall of using copy-on-write is that once overlays are created, the images on which they are overlayed *must not be changed*. If they are changed, all the overlays will be corrupted. Then the overlays must be deleted and replaced with new, blank overlays. Even simply mounting the image file in read-write mode can cause sufficient filesystem updates to corrupt the overlays.
Due to the potential for the overlays to be corrupted if the original image is modified, mark the original image as *immutable* by running:
# chattr +i </path/to/file>
You can use *lsattr </path/to/file>* to view the status of the immutable flag and use to *chattr -i </path/to/file>* unset the immutable flag. While the immutable flag is set, even the root user or a system process running as root cannot modify or delete the file.
Begin by stopping the *tgtd.service* so you can change the image files:
# systemctl stop tgtd.service
It’s normal for this command to take a minute or so to stop when there are connections still open.
Now, remove the read-only iSCSI export. Then update the *readonly-root* configuration file in the template so the image is no longer read-only:
# MY_FC=fc29 # rm -f /etc/tgt/conf.d/$MY_FC.conf # TEMP_MNT=$(mktemp -d) # mount /$MY_FC.img $TEMP_MNT # sed -i 's/^READONLY=yes$/READONLY=no/' $TEMP_MNT/etc/sysconfig/readonly-root # sed -i 's/^Storage=volatile$/#Storage=auto/' $TEMP_MNT/etc/systemd/journald.conf # umount $TEMP_MNT
Journald was changed from logging to volatile memory back to its default (log to disk if */var/log/journal* exists) because a user reported his clients would freeze with an out-of-memory error due to an application generating excessive system logs. The downside to setting logging to disk is that extra write traffic is generated by the clients, and might burden your netboot server with unnecessary I/O. You should decide which option — log to memory or log to disk — is preferable depending on your environment.
Since you won’t make any further changes to the template image, set the immutable flag on it and restart the *tgtd.service*:
# chattr +i /$MY_FC.img # systemctl start tgtd.service
Now, update the bootmenu application:
# cat << 'END' > $MY_MOJO/bootmenu.pl #!/usr/bin/env perl use lib 'lib'; use PAM; use Mojolicious::Lite; use Mojolicious::Plugins; use Mojo::Util ('url_unescape'); plugin 'Config'; get '/menu'; get '/boot' => sub { my $c = shift; my $instance = $c->param('instance'); my $username = $c->param('username'); my $password = $c->param('password'); my $chapscrt; my $template = 'menu'; { last unless $instance =~ /^fc[[:digit:]]{2}$/; last unless $username =~ /^[[:alnum:]]+$/; last unless PAM::auth($username, url_unescape($password)); last unless $chapscrt = `sudo scripts/mktgt $instance $username`; $template = $instance; } return $c->render(template => $template, username => $username, chapscrt => $chapscrt); }; app->start; END
This new version of the bootmenu application calls a custom *mktgt* script which, on success, returns a random [CHAP](https://en.wikipedia.org/wiki/Challenge-Handshake_Authentication_Protocol) password for each new iSCSI target that it creates. The CHAP password prevents one user from mounting another user’s iSCSI target by indirect means. The app only returns the correct iSCSI target password to a user who has successfully authenticated.
The *mktgt* script is prefixed with *sudo* because it needs root privileges to create the target.
The *$username* and *$chapscrt* variables also pass to the *render* command so they can be incorporated into the templates returned to the user when necessary.
Next, update our boot templates so they can read the *username* and *chapscrt* variables and pass them along to the end user. Also update the templates to mount the root filesystem in *rw* (read-write) mode:
# cd $MY_MOJO/templates # sed -i "s/:$MY_FC/:$MY_FC-<%= \$username %>/g" $MY_FC.html.ep # sed -i "s/ netroot=iscsi:/ netroot=iscsi:<%= \$username %>:<%= \$chapscrt %>@/" $MY_FC.html.ep # sed -i "s/ ro / rw /" $MY_FC.html.ep
After running the above commands, you should have boot templates like the following:
#!ipxe kernel --name kernel.efi ${prefix}/vmlinuz-4.19.5-300.fc29.x86_64 initrd=initrd.img rw ip=dhcp rd.peerdns=0 nameserver=192.0.2.91 nameserver=192.0.2.92 root=/dev/disk/by-path/ip-192.0.2.158:3260-iscsi-iqn.edu.example.server-01:fc29-<%= $username %>-lun-1 netroot=iscsi:<%= $username %>:<%= $chapscrt %>@192.0.2.158::::iqn.edu.example.server-01:fc29-<%= $username %> console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet initrd --name initrd.img ${prefix}/initramfs-4.19.5-300.fc29.x86_64.img boot || chain https://server-01.example.edu/menu
NOTE: If you need to view the boot template after the variables have been [interpolated](https://en.wikipedia.org/wiki/String_interpolation), you can insert the “shell” command on its own line just before the “boot” command. Then, when you netboot your client, iPXE gives you an interactive shell where you can enter “imgstat” to view the parameters being passed to the kernel. If everything looks correct, you can type “exit” to leave the shell and continue the boot process.
Now allow the *bootmenu* user to run the *mktgt* script (and only that script) as root via *sudo*:
# echo "bootmenu ALL = NOPASSWD: $MY_MOJO/scripts/mktgt *" > /etc/sudoers.d/bootmenu
The bootmenu user should not have write access to the *mktgt* script or any other files under its home directory. All the files under */opt/bootmenu* should be owned by root, and should not be writable by any user other than root.
Sudo does not work well with systemd’s *DynamicUser* option, so create a normal user account and set the systemd service to run as that user:
# useradd -r -c 'iPXE Boot Menu Service' -d /opt/bootmenu -s /sbin/nologin bootmenu # sed -i 's/^DynamicUser=true$/User=bootmenu/' /etc/systemd/system/bootmenu.service # systemctl daemon-reload
Finally, create a directory for the copy-on-write overlays and create the *mktgt* script that manages the iSCSI targets and their overlayed backing stores:
# mkdir /$MY_FC.cow # mkdir $MY_MOJO/scripts # cat << 'END' > $MY_MOJO/scripts/mktgt #!/usr/bin/env perl # if another instance of this script is running, wait for it to finish "$ENV{FLOCKER}" eq 'MKTGT' or exec "env FLOCKER=MKTGT flock /tmp $0 @ARGV"; # use "RETURN" to print to STDOUT; everything else goes to STDERR by default open(RETURN, '>&', STDOUT); open(STDOUT, '>&', STDERR); my $instance = shift or die "instance not provided"; my $username = shift or die "username not provided"; my $img = "/$instance.img"; my $dir = "/$instance.cow"; my $top = "$dir/$username"; -f "$img" or die "'$img' is not a file"; -d "$dir" or die "'$dir' is not a directory"; my $base; die unless $base = `losetup --show --read-only --nooverlap --find $img`; chomp $base; my $size; die unless $size = `blockdev --getsz $base`; chomp $size; # create the per-user sparse file if it does not exist if (! -e "$top") { die unless system("dd if=/dev/zero of=$top status=none bs=512 count=0 seek=$size") == 0; } # create the copy-on-write overlay if it does not exist my $cow="$instance-$username"; my $dev="/dev/mapper/$cow"; if (! -e "$dev") { my $over; die unless $over = `losetup --show --nooverlap --find $top`; chomp $over; die unless system("echo 0 $size snapshot $base $over p 8 | dmsetup create $cow") == 0; } my $tgtadm = '/usr/sbin/tgtadm --lld iscsi'; # get textual representations of the iscsi targets my $text = `$tgtadm --op show --mode target`; my @targets = $text =~ /(?:^T.*\n)(?:^ .*\n)*/mg; # convert the textual representations into a hash table my $targets = {}; foreach (@targets) { my $tgt; my $sid; foreach (split /\n/) { /^Target (\d+)(?{ $tgt = $targets->{$^N} = [] })/; /I_T nexus: (\d+)(?{ $sid = $^N })/; /Connection: (\d+)(?{ push @{$tgt}, [ $sid, $^N ] })/; } } my $hostname; die unless $hostname = `hostname`; chomp $hostname; my $target = 'iqn.' . join('.', reverse split('\.', $hostname)) . ":$cow"; # find the target id corresponding to the provided target name and # close any existing connections to it my $tid = 0; foreach (@targets) { next unless /^Target (\d+)(?{ $tid = $^N }): $target$/m; foreach (@{$targets->{$tid}}) { die unless system("$tgtadm --op delete --mode conn --tid $tid --sid $_->[0] --cid $_->[1]") == 0; } } # create a new target if an existing one was not found if ($tid == 0) { # find an available target id my @ids = (0, sort {$a <=> $b} keys %{$targets}); $tid = 1; while ($ids[$tid]==$tid) { $tid++ } # create the target die unless -e "$dev"; die unless system("$tgtadm --op new --mode target --tid $tid --targetname $target") == 0; die unless system("$tgtadm --op new --mode logicalunit --tid $tid --lun 1 --backing-store $dev") == 0; die unless system("$tgtadm --op bind --mode target --tid $tid --initiator-address ALL") == 0; } # (re)set the provided target's chap password my $password = join('', map(chr(int(rand(26))+65), 1..8)); my $accounts = `$tgtadm --op show --mode account`; if ($accounts =~ / $username$/m) { die unless system("$tgtadm --op delete --mode account --user $username") == 0; } die unless system("$tgtadm --op new --mode account --user $username --password $password") == 0; die unless system("$tgtadm --op bind --mode account --tid $tid --user $username") == 0; # return the new password to the iscsi target on stdout print RETURN $password; END # chmod +x $MY_MOJO/scripts/mktgt
The above script does five things:
- It creates the /<instance>.cow/<username> sparse file if it does not already exist.
- It creates the /dev/mapper/<instance>-<username> device node that serves as the copy-on-write backing store for the iSCSI target if it does not already exist.
- It creates the iqn.<reverse-hostname>:<instance>-<username> iSCSI target if it does not exist. Or, if the target does exist, it closes any existing connections to it because the image can only be opened in read-write mode from one place at a time.
- It (re)sets the chap password on the iqn.<reverse-hostname>:<instance>-<username> iSCSI target to a new random value.
- It prints the new chap password on
[standard output](https://en.wikipedia.org/wiki/Standard_streams)if all of the previous tasks compeleted successfully.
You should be able to test the *mktgt* script from the command line by running it with valid test parameters. For example:
# echo `$MY_MOJO/scripts/mktgt fc29 jsmith`
When run from the command line, the *mktgt* script should print out either the eight-character random password for the iSCSI target if it succeeded or the line number on which something went wrong if it failed.
On occasion, you may want to delete an iSCSI target without having to stop the entire service. For example, a user might inadvertently corrupt their personal image, in which case you would need to systematically undo everything that the above *mktgt* script does so that the next time they log in they will get a copy of the original image.
Below is an *rmtgt* script that undoes, in reverse order, what the above *mktgt* script did:
# mkdir $HOME/bin # cat << 'END' > $HOME/bin/rmtgt #!/usr/bin/env perl @ARGV >= 2 or die "usage: $0 <instance> <username> [+d|+f]\n"; my $instance = shift; my $username = shift; my $rmd = ($ARGV[0] eq '+d'); #remove device node if +d flag is set my $rmf = ($ARGV[0] eq '+f'); #remove sparse file if +f flag is set my $cow = "$instance-$username"; my $hostname; die unless $hostname = `hostname`; chomp $hostname; my $tgtadm = '/usr/sbin/tgtadm'; my $target = 'iqn.' . join('.', reverse split('\.', $hostname)) . ":$cow"; my $text = `$tgtadm --op show --mode target`; my @targets = $text =~ /(?:^T.*\n)(?:^ .*\n)*/mg; my $targets = {}; foreach (@targets) { my $tgt; my $sid; foreach (split /\n/) { /^Target (\d+)(?{ $tgt = $targets->{$^N} = [] })/; /I_T nexus: (\d+)(?{ $sid = $^N })/; /Connection: (\d+)(?{ push @{$tgt}, [ $sid, $^N ] })/; } } my $tid = 0; foreach (@targets) { next unless /^Target (\d+)(?{ $tid = $^N }): $target$/m; foreach (@{$targets->{$tid}}) { die unless system("$tgtadm --op delete --mode conn --tid $tid --sid $_->[0] --cid $_->[1]") == 0; } die unless system("$tgtadm --op delete --mode target --tid $tid") == 0; print "target $tid deleted\n"; sleep 1; } my $dev = "/dev/mapper/$cow"; if ($rmd or ($rmf and -e $dev)) { die unless system("dmsetup remove $cow") == 0; print "device node $dev deleted\n"; } if ($rmf) { my $sf = "/$instance.cow/$username"; die "sparse file $sf not found" unless -e "$sf"; die unless system("rm -f $sf") == 0; die unless not -e "$sf"; print "sparse file $sf deleted\n"; } END # chmod +x $HOME/bin/rmtgt
For example, to use the above script to completely remove the *fc29-jsmith* target including its backing store device node and its sparse file, run the following:
# rmtgt fc29 jsmith +f
Once you’ve verified that the *mktgt* script is working properly, you can restart the bootmenu service. The next time someone netboots, they should receive a personal copy of the the netboot image they can write to:
# systemctl restart bootmenu.service
Users should now be able to modify the root filesystem as demonstrated in the below screenshot:
## OK
Wow. This is awesome! This series is like what the … Really good job
## Gregory Bartholomew
Thanks. I would love to get feedback from anyone who has attempted to set this sort of netboot server up — what sort of problems did you encounter, what work-arounds did you implement, etc. I’m sure there is plenty of room for improvement. ☺
My hope is that this solution will help to bring Linux to some school labs that otherwise would not be able to serve it.
Also, I see that comments are automatically closed after a time. I am OK with being emailed questions. My address is gbartho at siue dot edu. I’m cannot guaranteeing a response though; especially if a lot of time has passed. But of course, as the RedHat folks say, it’s best to default to open!
## Israel
Can there be links in these article series that point to earlier parts? There’s no other way to follow these than look for them manually in Fedora Magazine
## Gregory Bartholomew
Oops, my previous reply (below) was meant to be in response to this comment.
## Gregory Bartholomew
Just a quick follow-up to anyone who may be trying to implement this — if you have a client that locks up when idle, you might try disabling power management by adding
acpi=offto the list of kernel parameters.If there are many who see this problem, I may try to get the editors to revise the guides to include that parameter. One downside to having that parameter though is that the computer will not be able to power itself off when shutting down.
Some BIOS’s allow configuring how aggressive the power saving is (S1 to S4). Setting it to the least-aggressive power saving mode (S1) may fix the problem. Is there a way to set that on the kernel command line?
Feedback is welcome, I have limited hardware to test on.
## Gregory Bartholomew
When viewed in a desktop browser, there should be an “In this series” column near the top-left of the page with links to the other articles.
Alternatively, you should be able to just change the last digit of the URL in the address bar to hope between the different parts.
Enjoy. ????
## Gregory Bartholomew
s/hope/hop/
## DNS Server Not Responding
The DNS is nothing but the distributed name resolution service that is used by the ISPs or the Internet Service Providers around the globe.
## Gregory Bartholomew
TIP:
Disable systemd’s power-save states:
I also like to increase the screen blanking timeout:
[org/gnome/desktop/session]
idle-delay=uint32 900
END
chroot /fc29 dconf update
## Gregory Bartholomew
TIP:
Improve performance and stability of your iSCSI server by using stateless firewall rules.
By default, firewalld’s “–add-service” option uses connection tracking. Use the following command to see the details of how your firewall is configured:
Rules that are using connection tracking will show in the output of the above command as lines containing “-m conntrack”.
Connection tracking can drop packets under high loads and it can lose track of UDP connections that are silent for more than 30 seconds. The netboot server generates a lot of network traffic and it uses UDP. Personally, I’ve switched to using the following:
# firewall-cmd --direct --add-rule ipv4 filter INPUT 1 -p udp -m udp --dport 3260 -j ACCEPT
# firewall-cmd --remove-service=iscsi-target
# firewall-cmd --runtime-to-permanent
Use the following command to list the
directrules that are active in your firewall: |
10,471 | Pelican 入门:一个 Python 静态网站生成器 | https://opensource.com/article/19/1/getting-started-pelican | 2019-01-23T23:24:00 | [
"Python",
"静态网站",
"Pelican"
] | https://linux.cn/article-10471-1.html |
>
> Pelican 是那些想要自我托管简单网站或博客的 Python 用户的绝佳选择。
>
>
>

如果你想创建一个自定义网站或博客,有很多选择。许多提供商可以托管你的网站并为你完成大部分工作。(WordPress 是一个非常受欢迎的选项。)但是使用托管方式,你会失去一些灵活性。作为一名软件开发人员,我更喜欢管理我自己的服务器,并在我的网站如何运行方面保持更多的自由。
然而,管理 Web 服务器需要大量的工作。安装它并获得一个简单的应用程序来提供内容是非常容易的。但是,维护安全补丁和更新是非常耗时得。如果你只想提供静态网页,那么拥有一个 Web 服务器和一系列应用程序可能会得不偿失。手动创建 HTML 页面也不是一个好选择。
这是静态网站生成器的用武之地。这些应用程序使用模板来创建所需的静态页面,并将它们与关联的元数据交叉链接。(例如,所有显示的页面都带有公共标签或关键词。)静态网站生成器可以帮助你使用导航区域、页眉和页脚等元素创建一个具有公共外观的网站。
我使用 [Pyhton](https://opensource.com/resources/python) 已经很多年了,所以,当我第一次开始寻找生成静态 HTML 页面的东西时,我想要用 Python 编写的东西。主要原因是我经常想要了解应用程序如何工作的内部细节,而使用一种我已经了解的语言使这一点更容易。(如果这对你不重要或者你不使用 Python,那么还有一些其他很棒的[静态网站生成器](https://opensource.com/sitewide-search?search_api_views_fulltext=static%20site%20generator),它们使用 Ruby、JavaScript 和其它语言。)
我决定试试 [Pelican](http://docs.getpelican.com/en/stable/)。它是一个用 Python 编写的常用静态网站生成器。它支持 [reStructuredText](http://docutils.sourceforge.net/rst.html)(LCTT 译注:这是一种用于文本数据的文件格式,主要用于 Python 社区的技术文档),并且也支持 [Markdown](https://daringfireball.net/projects/markdown/),这需要通过安装必需的包来完成。所有任务都是通过命令行界面(CLI)工具执行的,这使得熟悉命令行的任何人都可以轻松完成。它简单的 quickstart CLI 工具使得创建一个网站非常容易。
在本文中,我将介绍如何安装 Pelican 4,添加一篇文章以及更改默认主题。(注意:我是在 MacOS 上开发的,使用其它 Unix/Linux 实验结果都将相同,但我没有 Windows 主机可以测试。)
### 安装和配置
第一步是创建一个[虚拟环境](https://virtualenv.pypa.io/en/latest/),在虚拟环境中安装 Pelican。
```
$ mkdir test-site
$ cd test-site
$ python3 -m venv venv
$ ./venv/bin/pip install --upgrade pip
...
Successfully installed pip-18.1
$ ./venv/bin/pip install pelican
Collecting pelican
...
Successfully installed MarkupSafe-1.1.0 blinker-1.4 docutils-0.14 feedgenerator-1.9 jinja2-2.10 pelican-4.0.1 pygments-2.3.1 python-dateutil-2.7.5 pytz-2018.7 six-1.12.0 unidecode-1.0.23
```
Pelican 的 quickstart CLI 工具将创建基本布局和一些文件来帮助你开始,运行 `pelican-quickstart` 命令。为了简单起见,我输入了**网站标题**和**作者**的名字,并对 URL 前缀和文章分页选择了 “N”。(对于其它选项,我使用了默认值。)稍后在配置文件中更改这些设置非常容易。
```
$ ./venv/bin/pelicanquickstart
Welcome to pelicanquickstart v4.0.1.
This script will help you create a new Pelican-based website.
Please answer the following questions so this script can generate the files needed by Pelican.
> Where do you want to create your new web site? [.]
> What will be the title of this web site? My Test Blog
> Who will be the author of this web site? Craig
> What will be the default language of this web site? [en]
> Do you want to specify a URL prefix? e.g., https://example.com (Y/n) n
> Do you want to enable article pagination? (Y/n) n
> What is your time zone? [Europe/Paris]
> Do you want to generate a tasks.py/Makefile to automate generation and publishing? (Y/n)
> Do you want to upload your website using FTP? (y/N)
> Do you want to upload your website using SSH? (y/N)
> Do you want to upload your website using Dropbox? (y/N)
> Do you want to upload your website using S3? (y/N)
> Do you want to upload your website using Rackspace Cloud Files? (y/N)
> Do you want to upload your website using GitHub Pages? (y/N)
Done. Your new project is available at /Users/craig/tmp/pelican/test-site
```
你需要启动的所有文件都准备好了。
quickstart 默认为欧洲/巴黎时区,所以在继续之前更改一下。在你喜欢的文本编辑器中打开 `pelicanconf.py` 文件,寻找 `TIMEZONE` 变量。
```
TIMEZONE = 'Europe/Paris'
```
将其改为 `UTC`。
```
TIMEZONE = 'UTC'
```
要更新公共设置,在 `pelicanconf.py` 中查找 `SOCIAL` 变量。
```
SOCIAL = (('You can add links in your config file', '#'),
('Another social link', '#'),)
```
我将添加一个我的 Twitter 账户链接。
```
SOCIAL = (('Twitter (#craigs55)', 'https://twitter.com/craigs55'),)
```
注意末尾的逗号,它很重要。这个逗号将帮助 Python 识别变量实际上是一个集合。确保你没有删除这个逗号。
现在你已经有了网站的基本知识。quickstart 创建了一个包含许多目标的 `Makefile`。将 `devserver` 传给 `make` 命令将在你的计算机上启动一个开发服务器,以便你可以预览所有内容。`Makefile` 中使用的 CLI 命令假定放在 `PATH` 搜索路径中,因此你需要首先激活该虚拟环境。
```
$ source ./venv/bin/activate
$ make devserver
pelican -lr /Users/craig/tmp/pelican/test-site/content o
/Users/craig/tmp/pelican/test-site/output -s /Users/craig/tmp/pelican/test-site/pelicanconf.py
-> Modified: theme, settings. regenerating...
WARNING: No valid files found in content for the active readers:
| BaseReader (static)
| HTMLReader (htm, html)
| RstReader (rst)
Done: Processed 0 articles, 0 drafts, 0 pages, 0 hidden pages and 0 draft pages in 0.18 seconds.
```
在你最喜欢的浏览器中打开 <http://localhost:8000> 来查看你的简单测试博客。

你可以在右侧看到 Twitter 链接,左侧有 Pelican、Python 和 Jinja 的一些链接。(Jinja 是 Pelican 可以使用的一种很棒的模板语言。你可以在 [Jinja 的文档](http://jinja.pocoo.org/docs/2.10/)中了解更多相关信息。)
### 添加内容
现在你又了一个基本的网站,试着添加一些内容。首先,将名为 `welcome.rst` 的文件添加到网站的 `content` 目录中。在你喜欢的文本编辑器中,使用以下文本创建一个文件:
```
$ pwd
/Users/craig/tmp/pelican/test-site
$ cat content/welcome.rst
Welcome to my blog!
###################
:date: 20181216 08:30
:tags: welcome
:category: Intro
:slug: welcome
:author: Craig
:summary: Welcome document
Welcome to my blog.
This is a short page just to show how to put up a static page.
```
Pelican 会自动解析元数据行,包括日期、标签等。
编写完文件后,开发服务器应该输出以下内容:
```
-> Modified: content. regenerating...
Done: Processed 1 article, 0 drafts, 0 pages, 0 hidden pages and 0 draft pages in 0.10 seconds.
```
在浏览器中刷新你的测试网站来查看更改。

元数据(例如日期和标签)会自动添加到页面中。此外,Pelican 会自动检测到 intro 栏目,并将该部分添加到顶部导航中。
### 更改主题
使用像 Pelican 这样流行的开源软件的好处之一是,非常多的用户会做出更改并将其贡献给项目。许多都是以主题形式贡献的。
网站的主题会设置颜色、布局选项等。尝试一个新主题非常容易,你可以在 [Pelican 主题](http://www.pelicanthemes.com/)中预览其中的许多内容。
首先,克隆 GitHub 仓库:
```
$ cd ..
$ git clone --recursive https://github.com/getpelican/pelicanthemes
Cloning into 'pelicanthemes'...
```
我喜欢蓝色,那么试试 [blueidea](https://github.com/nasskach/pelican-blueidea/tree/58fb13112a2707baa7d65075517c40439ab95c0a)。
编辑 `pelicanconf.py`,添加以下行:
```
THEME = '/Users/craig/tmp/pelican/pelican-themes/blueidea/'
```
开发服务器将重新生成你的输出。在浏览器中刷新网页来查看新主题。

主题控制布局的方方面面。例如,在默认主题中,你可以看到文章旁边带有元标记的栏目(Intro),但这个栏目并未显示在 blueidea 主题中。
### 其他考虑因素
本文是对 Pelican 的快速介绍,所以我并没有涉及一些重要的主题。
首先,我对迁移到静态站点犹豫不决的一个原因是它无法对文章评论。幸运的是,有一些第三方服务商将为你提供评论功能。我目前正在关注的是 [Disqus](https://disqus.com/)。
接下来,上面的所有内容都是在我的本地机器上完成的。如果我希望其他人查看我的网站,我将不得不将预先生成的 HTML 文件上传到某个地方。如果你查看 `pelican-quickstart` 输出,你将看到使用 FTP、 SSH、S3 甚至 GitHub 页面的选项,每个选项都有其优点和缺点。但是,如果我必须选择一个,那么我可能会选择发布到 GitHub 页面。
Pelican 还有许多其他功能,我每天都在学习它。如果你想自托管一个网站或博客,内容简单并且是静态内容,同时你想使用 Python,那么 Pelican 是一个很好的选择。它有一个活跃的用户社区,可以修复 bug,添加特性,而且还会创建新的和有趣的主题。试试看吧!
---
via: <https://opensource.com/article/19/1/getting-started-pelican>
作者:[Craig Sebenik](https://opensource.com/users/craig5) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you want to create a custom website or blog, you have a lot of options. Many providers will host your website and do much of the work for you. (WordPress is an extremely popular option.) But you lose some flexibility by using a hosted solution. As a software developer, I prefer to manage my own server and keep more freedom in how my website operates.
However, it is a fair amount of work to manage a web server. Installing it and getting a simple application up to serve content is easy enough. But keeping on top of security patches and updates is very time-consuming. If you just want to serve static web pages, having a web server and a host of applications may be more effort than it's worth. Creating HTML pages by hand is also not a good option.
This is where a static site generator can come in. These applications use templates to create all the static pages you want and cross-link them with associated metadata. (e.g., showing all the pages with a common tag or keyword.) Static site generators help you create a site with a common look and feel using elements like navigation areas and a header and footer.
I have been using [Python](https://opensource.com/resources/python) for years now. So, when I first started looking for something to generate static HTML pages, I wanted something written in Python. The main reason is that I often want to peek into the internals of how an application works, and using a language that I already know makes that easier. (If that isn't important to you or you don't use Python, there are some other great [static site generators](https://opensource.com/sitewide-search?search_api_views_fulltext=static%20site%20generator) that use Ruby, JavaScript, and other languages.)
I decided to give [Pelican](http://docs.getpelican.com/en/stable/) a try. It is a commonly used static site generator written in Python. It directly supports [reStructuredText](http://docutils.sourceforge.net/rst.html) and can support [Markdown](https://daringfireball.net/projects/markdown/) when the required package is installed. All the tasks are performed via command-line interface (CLI) tools, which makes it simple for anyone familiar with the command line. And its simple quickstart CLI tool makes creating a website extremely easy.
In this article, I'll explain how to install Pelican 4, add an article, and change the default theme. (Note: This was all developed on MacOS; it should work the same using any flavor of Unix/Linux, but I don't have a Windows host to test on.)
## Installation and configuration
The first step is to create a [virtualenv](https://virtualenv.pypa.io/en/latest/) and install Pelican.
```
$ mkdir test-site
$ cd test-site
$ python3 -m venv venv
$ ./venv/bin/pip install --upgrade pip
...
Successfully installed pip-18.1
$ ./venv/bin/pip install pelican
Collecting pelican
...
Successfully installed MarkupSafe-1.1.0 blinker-1.4 docutils-0.14 feedgenerator-1.9 jinja2-2.10 pelican-4.0.1 pygments-2.3.1 python-dateutil-2.7.5 pytz-2018.7 six-1.12.0 unidecode-1.0.23
```
To keep things simple, I entered values for the title and author and replied N to URL prefix and article pagination. (For the rest of the questions, I used the default given.)
Pelican's quickstart CLI tool will create the basic layout and a few files to get you started. Run the **pelican-quickstart** command. To keep things simple, I entered values for the **title** and **author** and replied **N** to URL prefix and article pagination. It is very easy to change these settings in the configuration file later.
```
$ ./venv/bin/pelican-quickstart
Welcome to pelican-quickstart v4.0.1.
This script will help you create a new Pelican-based website.
Please answer the following questions so this script can generate the files needed by Pelican.
> Where do you want to create your new web site? [.]
> What will be the title of this web site? My Test Blog
> Who will be the author of this web site? Craig
> What will be the default language of this web site? [en]
> Do you want to specify a URL prefix? e.g., https://example.com (Y/n) n
> Do you want to enable article pagination? (Y/n) n
> What is your time zone? [Europe/Paris]
> Do you want to generate a tasks.py/Makefile to automate generation and publishing? (Y/n)
> Do you want to upload your website using FTP? (y/N)
> Do you want to upload your website using SSH? (y/N)
> Do you want to upload your website using Dropbox? (y/N)
> Do you want to upload your website using S3? (y/N)
> Do you want to upload your website using Rackspace Cloud Files? (y/N)
> Do you want to upload your website using GitHub Pages? (y/N)
Done. Your new project is available at /Users/craig/tmp/pelican/test-site
```
All the files you need to get started are ready to go.
The quickstart defaults to the Europe/Paris time zone, so change that before proceeding. Open the **pelicanconf.py** file in your favorite text editor. Look for the **TIMEZONE** variable.
`TIMEZONE = 'Europe/Paris'`
Change it to **UTC**.
`TIMEZONE = 'UTC'`
To update the social settings, look for the **SOCIAL** variable in **pelicanconf.py**.
```
SOCIAL = (('You can add links in your config file', '#'),
('Another social link', '#'),)
```
I'll add a link to my Twitter account.
`SOCIAL = (('Twitter (#craigs55)', 'https://twitter.com/craigs55'),)`
Notice that trailing comma—it's important. That comma helps Python recognize the variable is actually a set. Make sure you don't delete that comma.
Now you have the basics of a site. The quickstart created a Makefile with a number of targets. Giving the **devserver** target to **make** will start a development server on your machine so you can preview everything. The CLI commands used in the Makefile are assumed to be part of your **PATH**, so you need to **activate** the **virtualenv** first.
```
$ source ./venv/bin/activate
$ make devserver
pelican -lr /Users/craig/tmp/pelican/test-site/content o
/Users/craig/tmp/pelican/test-site/output -s /Users/craig/tmp/pelican/test-site/pelicanconf.py
-> Modified: theme, settings. regenerating...
WARNING: No valid files found in content for the active readers:
| BaseReader (static)
| HTMLReader (htm, html)
| RstReader (rst)
Done: Processed 0 articles, 0 drafts, 0 pages, 0 hidden pages and 0 draft pages in 0.18 seconds.
```
Point your favorite browser to [http://localhost:8000](http://localhost:8000) to see your simple test blog.
You can see the Twitter link on the right side and some links to Pelican, Python, and Jinja to the left of it. (Jinja is a great templating language that Pelican can use. You can learn more about it in [Jinja's documentation](http://jinja.pocoo.org/docs/2.10/).)
## Adding content
Now that you have a basic site, add some content. First, add a file called **welcome.rst** to the site's **content** directory. In your favorite text editor, create a file with the following text:
```
$ pwd
/Users/craig/tmp/pelican/test-site
$ cat content/welcome.rst
Welcome to my blog!
###################
:date: 20181216 08:30
:tags: welcome
:category: Intro
:slug: welcome
:author: Craig
:summary: Welcome document
Welcome to my blog.
This is a short page just to show how to put up a static page.
```
The metadata lines—date, tags, etc.—are automatically parsed by Pelican.
After you write the file, the **devserver** should output something like this:
```
-> Modified: content. regenerating...
Done: Processed 1 article, 0 drafts, 0 pages, 0 hidden pages and 0 draft pages in 0.10 seconds.
```
Reload your test site in your browser to view the changes.
The metadata (e.g., date and tags) were automatically added to the page. Also, Pelican automatically detected the **intro** category and added the section to the top navigation.
## Change the theme
One of the nicest parts of working with popular, open source software like Pelican is that many users will make changes and contribute them back to the project. Many of the contributions are in the form of themes.
A site's theme sets colors, layout options, etc. It's really easy to try out new themes. You can preview many of them at [Pelican Themes](http://www.pelicanthemes.com/).
First, clone the GitHub repo:
```
$ cd ..
$ git clone --recursive https://github.com/getpelican/pelicanthemes
Cloning into 'pelicanthemes'...
```
Since I like the color blue, I'll try [blueidea](https://github.com/nasskach/pelican-blueidea/tree/58fb13112a2707baa7d65075517c40439ab95c0a).
Edit **pelicanconf.py** and add the following line:
`THEME = '/Users/craig/tmp/pelican/pelican-themes/blueidea/'`
The **devserver** will regenerate your output. Reload the webpage in your browser to see the new theme.
The theme controls many aspects of the layout. For example, in the default theme, you can see the category (Intro) with the meta tags next to the article. But that category is not displayed in the blueidea theme.
## Other considerations
This was a pretty quick introduction to Pelican. There are a couple of important topics that I did not cover.
First, one reason I was hesitant to move to a static site was that it wouldn't allow discussions on the articles. Fortunately, there are some third-party providers that will host discussions for you. The one I am currently looking at is [Disqus](https://disqus.com/).
Next, everything above was done on my local machine. If I want others to view my site, I'll have to upload the pre-generated HTML files somewhere. If you look at the **pelican-quickstart** output, you will see options for using FTP, SSH, S3, and even GitHub Pages. Each option has its pros and cons. But, if I had to choose one, I would likely publish to GitHub Pages.
Pelican has many other features—I am still learning more about it every day. If you want to self-host a website or a blog with simple, static content and you want to use Python, Pelican is a great choice. It has an active user community that is fixing bugs, adding features, and creating new and interesting themes. Give it a try!
## 3 Comments |
10,472 | 关于团队敏捷开发实践的 6 个常见问题 | https://opensource.com/article/18/3/agile-mindset | 2019-01-23T23:48:00 | [
"敏捷开发"
] | https://linux.cn/article-10472-1.html |
>
> 专家回答了敏捷实践如何帮助团队更有效的 6 个常见问题。
>
>
>

“有问题么?”
你可能听过演讲者在演讲结束的时候提出这个问题。这是演讲中最重要的部分 —— 毕竟,你不仅仅是听讲座, 而是参加讨论和社群交流。
最近,我有机会听到我的同伴 Red Hatters 给当地一所大学的一群技术型学生做一个名为 “[敏捷实践](http://zijemeit.cz/sessions/agile-in-practice/)” 的讲座。讲座中有软件工程师 Tomas Tomecek 和敏捷开发的从业者 Fernando Colleone 、Pavel Najman 合作解释了敏捷开发方法的基础,并展示最佳实践在日常活动中的应用。
知道了学生们参加这个课程是为了了解什么是敏捷实践以及如何将其应用于项目,我想知道学生们的问题会与我作为敏捷从业者在 Red Hat 每天听到的问题相比有什么不同。结果学生的疑问和我的同事们如出一辙。这些问题都直指敏捷实践的核心。
### 1、完美的团队规模是多大?
学生们想知道一个小团队和一个大团队的规模是多少。这个问题与任何曾经合作过做项目的人都是相关的。根据 Tomas 作为技术领导的经验,12 个人从事的项目被认为是一个大型团队。现实中,团队规模通常与生产力没有直接关系。在有些时候,在一个地方或同一个时区的小团队也许会比一个成员分布在满世界的大团队更具有生产力。最终,该讲座建议理想的团队大小大概是 5 个人(正如 scrum 开发方法的 7,+-2)。
### 2、团队会面临哪些实际挑战?
演讲者比较了由本地团队组成的项目(团队成员都是一个办公室的,或者相邻近的人)与分散型的团队(位于不同时区)。当项目需要团队成员之间密切合作时,工程师更喜欢本地的团队,因为时间差异造成的延迟可能会破坏软件开发的“流”。同时,分散型团队可以将可能不适用与当地项目但适用于某些开发用例的技能集合在一起。此外,还有各种最佳方法可用于改进分散型团队中的合作方式。
### 3、整理堆积的工作需要多少时间?
因为这是一个对于新学习敏捷的学生的介绍性质的演讲,演讲者着重把 [Scrum](https://www.scrum.org/resources/what-is-scrum) 和 [Kanban](https://en.wikipedia.org/wiki/Kanban) 作为介绍敏捷开发的方法。他们使用 Scrum 框架来作为说明软件编写的方法,并且用 Kanban 作为工作规划和沟通的系统。关于需要多少时间来整理项目堆积的工作,演讲者解释说并没有固定的准则,相对的,实践出真知:在开发的早期阶段,当一个崭新的项目 —— 特别如果团队里有新人 —— 每周可能会花费数个小时在整理工作上。随着时间推移和不断地练习,会越来越高效。
### 4、产品负责人是否是必要的? 他们扮演什么样的角色?
产品负责人会帮助团队更方便的拓展,然而,职位名称并不重要,重要的是你的团队中有人能够传递用户的意愿。在许多团队中,特别是在大型团队中从事单个任务的团队,首席工程师就可以担任产品负责人。
### 5、建议使用哪些敏捷开发的工具?使用 Scrum 或 Kanban 做敏捷开发的时候必须用特定的软件么?
尽管使用一些专业软件例如 Jira 或 Trello 会很有帮助,特别是在与大量从事大型企业项目的工作者合作时,但它们不是必需的。Scrum 和 Kanban 可以使用像纸卡这样简单的工具完成。关键是在团队中要有一个清晰的信息来源和紧密的交流。推荐两个优秀的 kanban 开源工具 [Taiga](https://taiga.io/) 和 [Wekan](https://wekan.github.io/)。更多信息请查看 [Trello 的 5 个开源替代品](https://opensource.com/alternatives/trello) 和 [敏捷团队的最好的 7 个开源项目管理工具](https://opensource.com/article/18/2/agile-project-management-tools) 。
### 6、学生如何在学校项目中使用敏捷开发技术?
演讲者鼓励学生使用 kanban 在项目结束前使用可视化和概述要完成的任务。关键是要创建一个公共板块,这样整个团队就可以看到项目的状态。通过使用 kanban 或者类似的高度可视化的策略,学生不会在项目后期才发现个别成员没有跟上进度。
Scrum 实践比如 sprints 和 daily standups 也是确认每个人都在进步以及项目的各个部分最终会一起发挥作用的绝佳方法。定期检查和信息共享也至关重要。更多关于 Scrum 的信息,访问 [什么是 scrum?](https://opensource.com/resources/scrum) 。
牢记 Kanban 和 Scrum 只是敏捷开发中众多框架和工具中的两个而已。它们可能不是应对每一种情况的最佳方法。
---
via: <https://opensource.com/article/18/3/agile-mindset>
作者:[Dominika Bula](https://opensource.com/users/dominika) 译者:[lixinyuxx](https://github.com/lixinyuxx) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | "Any questions?"
You’ve probably heard a speaker ask this question at the end of their presentation. This is the most important part of the presentation—after all, you didn't attend just to hear a lecture but to participate in a conversation and a community.
Recently I had the opportunity to hear my fellow Red Hatters present a session called "[Agile in Practice](http://zijemeit.cz/sessions/agile-in-practice/)" to a group of technical students at a local university. During the session, software engineer Tomas Tomecek and agile practitioners Fernando Colleone and Pavel Najman collaborated to explain the foundations of agile methodology and showcase best practices for day-to-day activities.
Knowing that students attended this session to learn what agile practice is and how to apply it to projects, I wondered how the students' questions would compare to those I hear every day as an agile practitioner at Red Hat. It turns out that the students asked the same questions as my colleagues. These questions drive straight into the core of agile in practice.
## 1. What is the perfect team size?
Students wanted to know the size of a small team versus a large team. This issue is relevant to anyone who has ever teamed up to work on a project. Based on Tomas's experience as a tech leader, 12 people working on a project would be considered a large team. In the real world, team size is not often directly correlated to productivity. In some cases, a smaller team located in a single location or time zone might be more productive than a larger team that's spread around the world. Ultimately, the presenters suggested that the ideal team size is probably five people (which aligns with scrum 7, +-2).
## 2. What operational challenges do teams face?
The presenters compared projects supported by local teams (teams with all members in one office or within close proximity to each other) with distributed teams (teams located in different time zones). Engineers prefer local teams when the project requires close cooperation among team members because delays caused by time differences can destroy the "flow" of writing software. At the same time, distributed teams can bring together skill sets that may not be available locally and are great for certain development use cases. Also, there are various best practices to improve cooperation in distributed teams.
## 3. How much time is needed to groom the backlog?
Because this was an introductory talk targeting students who were new to agile, the speakers focused on [Scrum](https://www.scrum.org/resources/what-is-scrum) and [Kanban](https://en.wikipedia.org/wiki/Kanban) as ways to make agile specific for them. They used the Scrum framework to illustrate a method of writing software and Kanban for a communication and work planning system. On the question of time needed to groom a project's backlog, the speakers explained that there is no fixed rule. Rather, practice makes perfect: During the early stages of development, when a project is new—and especially if some members of the team are new to agile—grooming can consume several hours per week. Over time and with practice, it becomes more efficient.
## 4. Is a product owner necessary? What is their role?
Product owners help facilitate scaling; however, what matters is not the job title, but that you have someone on your team who represents the customer's voice and goals. In many teams, especially those that are part of a larger group of engineering teams working on a single output, a lead engineer can serve as the product owner.
## 5. What agile tools do you suggest using? Is specific software necessary to implement Scrum or Kanban in practice?
Although using proprietary software such as Jira or Trello can be helpful, especially when working with large numbers of contributors working on big enterprise projects, they are not required. Scrum and Kanban can be done with tools as simple as paper cards. The key is to have a clear source of information and strong communication across the entire team. That said, two excellent open source kanban tools are [Taiga](https://taiga.io/) and [Wekan](https://wekan.github.io/). For more information, see [5 open source alternatives to Trello](https://opensource.com/alternatives/trello) and [Top 7 open source project management tools for agile teams](https://opensource.com/article/18/2/agile-project-management-tools).
## 6. How can students use agile techniques for school projects?
The presenters encouraged students to use kanban to visualize and outline tasks to be completed before the end of the project. The key is to create a common board so the entire team can see the status of the project. By using kanban or a similar high-visibility strategy, students won’t get to the end of the project and discover that any particular team member has not been keeping up.
Scrum practices such as sprints and daily standups are also excellent ways to ensure that everyone is making progress and that the various parts of the project will work together at the end. Regular check-ins and information-sharing are also essential. To learn more about Scrum, see [What is scrum?](https://opensource.com/resources/scrum).
Remember that Kanban and Scrum are just two of many tools and frameworks that make up agile. They may not be the best approach for every situation.
## 1 Comment |
10,473 | Arch-Audit:一款在 Arch Linux 上检查易受攻击的软件包的工具 | https://www.2daygeek.com/arch-audit-a-tool-to-check-vulnerable-packages-in-arch-linux/ | 2019-01-24T19:43:03 | [
"安全",
"Arch"
] | https://linux.cn/article-10473-1.html | 
我们必须经常更新我们的系统以减少宕机时间和问题。每月给系统打一次补丁,60 天一次或者最多 90 天一次,这是 Linux 管理员的例行任务之一。这是忙碌的工作计划,我们不能在不到一个月内做到这一点,因为它涉及到多种活动和环境。
基本上,基础设施会一同提供测试、开发、 QA 环境(即各个分段和产品)。
最初,我们会在测试环境中部署补丁,相应的团队将监视系统一周,然后他们将给出一份或好或坏的状态的报告。如果成功的话,我们将会在其他环境中继续测试,若正常运行,那么最后我们会给生产服务器打上补丁。
许多组织会对整个系统打上补丁,我的意思是全系统更新,对于典型基础设施这是一种常规修补计划。
某些基础设施中可能只有生产环境,因此,我们不应该做全系统更新,而是应该使用安全修补程序来使系统更加稳定和安全。
由于 Arch Linux 及其衍生的发行版属于滚动更新版本,因此可以认为它们始终是最新的,因为它使用上游软件包的最新版本。
在某些情况下,如果要单独更新安全修补程序,则必须使用 arch-audit 工具来标识和修复安全修补程序。
### 漏洞是什么?
漏洞是软件程序或硬件组件(固件)中的安全漏洞。这是一个可以让它容易受到攻击的缺陷。
为了缓解这种情况,我们需要相应地修补漏洞,就像应用程序/硬件一样,它可能是代码更改或配置更改或参数更改。
### Arch-Audit 工具是什么?
[Arch-audit](https://github.com/ilpianista/arch-audit) 是一个类似于 Arch Linux 的 pkg-audit 工具。它使用了令人称赞的 Arch 安全小组收集的数据。它不会扫描以发现系统中易受攻击的包(就像 `yum –security check-update & yum updateinfo` 一样列出可用的软件包),它只需解析 <https://security.archlinux.org/> 页面并在终端中显示结果,因此,它将显示准确的数据。(LCTT 译注:此处原作者叙述不清晰。该功能虽然不会像病毒扫描软件一样扫描系统上的文件,但是会读取已安装的软件列表,并据此查询上述网址列出风险报告。)
Arch 安全小组是一群以跟踪 Arch Linux 软件包的安全问题为目的的志愿者。所有问题都在 Arch 安全追踪者的监视下。
该小组以前被称为 Arch CVE 监测小组,Arch 安全小组的使命是为提高 Arch Linux 的安全性做出贡献。
### 如何在 Arch Linux 上安装 Arch-Audit 工具
Arch-audit 工具已经存在社区的仓库中,所以你可以使用 Pacman 包管理器来安装它。
```
$ sudo pacman -S arch-audit
```
运行 `arch-audit` 工具以查找在基于 Arch 的发行版本上的存在缺陷的包。
```
$ arch-audit
Package cairo is affected by CVE-2017-7475. Low risk!
Package exiv2 is affected by CVE-2017-11592, CVE-2017-11591, CVE-2017-11553, CVE-2017-17725, CVE-2017-17724, CVE-2017-17723, CVE-2017-17722. Medium risk!
Package libtiff is affected by CVE-2018-18661, CVE-2018-18557, CVE-2017-9935, CVE-2017-11613. High risk!. Update to 4.0.10-1!
Package openssl is affected by CVE-2018-0735, CVE-2018-0734. Low risk!
Package openssl-1.0 is affected by CVE-2018-5407, CVE-2018-0734. Low risk!
Package patch is affected by CVE-2018-6952, CVE-2018-1000156. High risk!. Update to 2.7.6-7!
Package pcre is affected by CVE-2017-11164. Low risk!
Package systemd is affected by CVE-2018-6954, CVE-2018-15688, CVE-2018-15687, CVE-2018-15686. Critical risk!. Update to 239.300-1!
Package unzip is affected by CVE-2018-1000035. Medium risk!
Package webkit2gtk is affected by CVE-2018-4372. Critical risk!. Update to 2.22.4-1!
```
上述结果显示了系统的脆弱性风险状况,比如:低、中和严重三种情况。
若要仅显示易受攻击的包及其版本,请执行以下操作。
```
$ arch-audit -q
cairo
exiv2
libtiff>=4.0.10-1
openssl
openssl-1.0
patch>=2.7.6-7
pcre
systemd>=239.300-1
unzip
webkit2gtk>=2.22.4-1
```
仅显示已修复的包。
```
$ arch-audit --upgradable --quiet
libtiff>=4.0.10-1
patch>=2.7.6-7
systemd>=239.300-1
webkit2gtk>=2.22.4-1
```
为了交叉检查上述结果,我将测试在 <https://www.archlinux.org/packages/> 列出的一个包以确认漏洞是否仍处于开放状态或已修复。是的,它已经被修复了,并于昨天在社区仓库中发布了更新后的包。

仅打印包名称和其相关的 CVE。
```
$ arch-audit -uf "%n|%c"
libtiff|CVE-2018-18661,CVE-2018-18557,CVE-2017-9935,CVE-2017-11613
patch|CVE-2018-6952,CVE-2018-1000156
systemd|CVE-2018-6954,CVE-2018-15688,CVE-2018-15687,CVE-2018-15686
webkit2gtk|CVE-2018-4372
```
---
via: <https://www.2daygeek.com/arch-audit-a-tool-to-check-vulnerable-packages-in-arch-linux/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Auk7F7](https://github.com/Auk7F7) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,474 | 用这个吃豆人游戏在你的终端中玩街机 | https://opensource.com/article/18/12/linux-toy-myman | 2019-01-24T20:44:19 | [
"吃豆人"
] | https://linux.cn/article-10474-1.html |
>
> 想要重现你最喜欢的街机游戏的魔力么?今天的命令行玩具将带你回到过去。
>
>
>

欢迎来到今天的 Linux 命令行玩具日历。如果这是你第一次访问该系列,你会问什么是命令行玩具。基本上,它们是游戏和简单的消遣,可以帮助你在终端玩得开心。
有些是新的,有些是古老的经典。我们希望你喜欢。
今天的玩具,MyMan,是经典街机游戏<ruby> <a href="https://en.wikipedia.org/wiki/Pac-Man"> 吃豆人 </a> <rt> Pac-Man </rt></ruby>(你不会认为这是[类似命名的](https://wiki.archlinux.org/index.php/pacman) Linux 包管理器对吧?)的有趣克隆。 如果你和我一样,为了在吃豆人游戏中取得高分,你过去在其中花费了很多时间,那么有机会的话,你应该试试这个。
MyMan 并不是 Linux 终端上唯一的吃豆人克隆版,但是我选择介绍它,因为 1)我喜欢它与原版一致的视觉风格,2)它为我的 Linux 发行版打包了,因此安装很容易。但是你也应该看看其他的克隆。这是[另一个](https://github.com/YoctoForBeaglebone/pacman4console)看起来可能不错的,但我没有尝试过。
由于 MyMan 已为 Fedora 打包,因此安装非常简单:
```
$ dnf install myman
```
MyMan 在 MIT 许可下可用,你可以在 [SourceForge](https://myman.sourceforge.io/) 上查看源代码。

你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。如果你有特别想了解的可以评论留言,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
了解一下昨天的玩具,[Linux 终端能做其他事](https://opensource.com/article/18/12/linux-toy-ponysay),还有记得明天再来!
---
via: <https://opensource.com/article/18/12/linux-toy-myman>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Welcome back to another day of the Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what command-line toys are all about. Basically, they're games and simple diversions that help you have fun at the terminal.
Some are new, and some are old classics. We hope you enjoy.
Today's toy, MyMan, is a fun clone of the classic arcade game [Pac-Man](https://en.wikipedia.org/wiki/Pac-Man). (You didn't think this was going to be about the [similarly-named](https://wiki.archlinux.org/index.php/pacman) Linux package manager, did you?) If you're anything like me, you spent more than your fair share of quarters trying to hit a high score Pac-Man back in the day, and still give it a go whenever you get a chance.
MyMan isn't the only Pac-Man clone for the Linux terminal, but it's the one I chose to include because 1) I like its visual style, which rings true to the original and 2) it's conveniently packaged for my Linux distribution so it was an easy install. But you should check out your other options as well. Here's [another one](https://github.com/YoctoForBeaglebone/pacman4console) that looks like it may be promising, but I haven't tried it.
Since MyMan was packaged for Fedora, installation was as simple as:
`$ dnf install myman`
MyMan is made available under an MIT license and you can check out the source code on [SourceForge](https://myman.sourceforge.io/).
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Check out yesterday's toy, [The Linux terminal is no one-trick pony](https://opensource.com/article/18/12/linux-toy-ponysay), and check back tomorrow for another!
## 2 Comments |
10,475 | DevSecOps 提升安全性的五种方式 | https://opensource.com/article/18/9/devsecops-changes-security | 2019-01-25T00:17:39 | [
"安全",
"DevSecOps"
] | /article-10475-1.html |
>
> 安全必须进化以跟上当今的应用开发和部署方式。
>
>
>

对于我们是否需要扩展 DevOps 以确实提升安全性,我们一直都有争议。毕竟,我们认为,DevOps 一直是一系列的新实践的简写,使用新工具(通常是开源的)并且在这之上构建更多的协作文化。为什么 [DevBizOps](https://opensource.com/article/18/5/steps-apply-devops-culture-beyond-it) 不能更好地满足商业的需求?或者说 DevChatOps 强调的是更快更好的沟通?
然而,如 [John Willis](https://www.devsecopsdays.com/articles/its-just-a-name) 在今年(LCTT 译注:此处是 2018 年)的早些时候写的关于他对 [DevSecOps](https://opensource.com/article/18/4/devsecops) 术语的理解,“我希望,有一天我们能在任何地方都不再使用 DevSecOps 这个词,安全会是所有关于服务交付的讨论中理所应当的部分。在那一天到来前,在这一点上,我的一般性结论是,这个词只是三个新的特性而已。更重要的是,我们作为一个产业,在信息安全方面并没有做的很好,而这个名称切实地区分出了问题的状况。”
所以,为什么我们在[信息安全](https://opensource.com/article/18/6/where-cycle-security-devops)方面做的不好,在 DevSecOps 的语境下安全做的好又是什么意思呢?
尽管(也可能是因为)庞大的复杂行业的单点产品解决了特定方面的问题,但我们可以说是从未做好过信息安全。我们仍然可以在这个时代把工作做得足够好,以此来防范威胁,这些威胁主要集中在一个范围内,网络的连接是受限的,而且大多数的用户都是公司的员工,使用的是公司提供的设备。
这些年来,这些情况并没有能准确地描述出大多数组织的真实现状。但在现在这个时代,不止引入了 DevSecOps,也同时引入了新的应用架构模型、开发实践,和越来越多的安全威胁,这些一起定义了一个需要更快迭代的新常态。与其说 DevSecOps 孤立地改变了安全,不如说信息安全公司在 2018 年需要新的方法。
请仔细思考下面这五个领域。
### 自动化
大量的自动化通常是 DevOps 的标志,这部分是关于速度的,如果你要快速变化(并且不会造成破坏),你需要有可重复的过程,而且这个过程不需要太多的人工干预。实际上,自动化是 DevOps 最好的切入点之一,甚至是在仍然主要使用老式的<ruby> 独石应用 <rt> monolithic app </rt></ruby>的组织里也是如此。使用像 Ansible 这样易于使用的工具来自动化地处理相关的配置或者是测试,这是快速开始 DevOps 之路的常用方法。
DevSecOps 也不例外,在今天,安全已经变成了一个持续性的过程,而不是在应用的生命周期里进行不定期的检查,甚至是每周、每月的检查。当漏洞被厂商发现并修复的时候,这些修复能被快速地应用是很重要的,这样对这些漏洞的利用程序很快就会被淘汰。
### “左移”
在开发流程结束时,传统的安全通常被视作一个守门人。检查所有的部分确保没有问题,然后这个应用程序就可以投入生产了。否则,就要再来一次。安全小组以说“不”而闻名。
因此,我们想的是,为什么不把安全这个部分提到前面呢(在一个典型的从左到右的开发流程图的“左边”)?安全团队仍然可以说“不”,但在开发的早期进行重构的影响要远远小于开发已经完成并且准备上线时进行重构的影响。
不过,我不喜欢“左移”这个词,这意味着安全仍然是一个只不过提前进行的一次性工作。在应用程序的整个生命周期里,从供应链到开发,再到测试,直到上线部署,安全都需要进行大量的自动化处理。
### 管理依赖
我们在现代应用程序开发过程中看到的一个最大的改变,就是你通常不需要去编写这个程序的大部分代码。使用开源的函数库和框架就是一个明显的例子。而且你也可以从公共的云服务商或其他来源那里获得额外的服务。在许多情况下,这些额外的代码和服务比你给自己写的要好得多。
因此,DevSecOps 需要你把重点放在你的[软件供应链](https://opensource.com/article/17/1/be-open-source-supply-chain)上,你是从可信的来源那里获取你的软件的吗?这些软件是最新的吗?它们已经集成到了你为自己的代码所使用的安全流程中了吗?对于这些你能使用的代码和 API 你有哪些策略?你为自己的产品代码使用的组件是否有可用的商业支持?
没有一套标准答案可以应对所有的情况。对于概念验证和大规模的生产,它们可能会有所不同。但是,正如制造业长期存在的情况(DevSecOps 和制造业的发展方面有许多相似之处),供应链的可信是至关重要的。
### 可见性
关于贯穿应用程序整个生命周期里所有阶段的自动化的需求,我已经谈过很多了。这里假设我们能看见每个阶段里发生的情况。
有效的 DevSecOps 需要有效的检测,以便于自动化程序知道要做什么。这个检测分了很多类别。一些长期的和高级别的指标能帮助我们了解整个 DevSecOps 流程是否工作良好。严重威胁级别的警报需要立刻有人进行处理(安全扫描系统已经关闭!)。有一些警报,比如扫描失败,需要进行修复。我们记录了许多参数的志以便事后进行分析(随着时间的推移,哪些发生了改变?导致失败的原因是什么?)。
### 分散服务 vs 一体化解决方案
虽然 DevSecOps 实践可以应用于多种类型的应用架构,但它们对小型且松散耦合的组件最有效,这些组件可以进行更新和复用,而且不会在应用程序的其他地方进行强制更改。在纯净版的形式里,这些组件可以是微服务或者函数,但是这个一般性原则适用于通过网络进行通信的松散耦合服务的任何地方。
这种方法确实带来了一些新的安全挑战,组件之间的交互可能会很复杂,总的攻击面会更大,因为现在应用程序通过网络有了更多的切入点。
另一方面,这种类型的架构还意味着自动化的安全和监视可以更加精细地查看应用程序的组件,因为它们不再深埋在一个独石应用程序之中。
不要过多地关注 DevSecOps 这个术语,但要提醒一下,安全正在不断地演变,因为我们编写和部署程序的方式也在不断地演变。
---
via: <https://opensource.com/article/18/9/devsecops-changes-security>
作者:[Gordon Haff](https://opensource.com/users/ghaff) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,476 | 开始使用 Joplin 吧,一款开源笔记应用 | https://opensource.com/article/19/1/productivity-tool-joplin | 2019-01-25T22:26:00 | [
"生产力",
"笔记"
] | https://linux.cn/article-10476-1.html |
>
> 了解开源工具如何帮助你在 2019 年提高工作效率。先从 Joplin 开始。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源项目来帮助你在 2019 年更有效率。
### Joplin
在生产力工具领域,笔记应用**非常**方便。是的,你可以使用开源 [NixNote](http://nixnote.org/NixNote-Home/) 访问 [Evernote](https://evernote.com/) 笔记,但它仍然与 Evernote 服务器相关联,并且仍然依赖于第三方的安全性。虽然你**可以**从 NixNote 导出 Evernote 笔记,但可选格式只有 NixNote XML 或 PDF。

*Joplin 的图形界面*
看看 [Joplin](https://joplin.cozic.net/)。Joplin 是一个 NodeJS 应用,它在本地运行和存储笔记,它允许你加密笔记并支持多种同步方法。Joplin 可在 Windows、Mac 和 Linux 上作为控制台应用或图形应用运行。Joplin 还有适用于 Android 和 iOS 的移动应用,这意味着你可以随身携带笔记而不会有任何麻烦。Joplin 甚至允许你使用 Markdown、HTML 或纯文本格式笔记。

*Joplin 的 Android 应用*
关于 Joplin 很棒的一件事是它支持两种类型笔记:普通笔记和待办事项笔记。普通笔记是你所想的包含文本的文档。另一个,待办事项笔记在笔记列表中有一个复选框,允许你将其标记为“已完成”。由于待办事项仍然是一个笔记,因此你可以在待办事项中添加列表、文档和其他待办事项。
当使用图形界面时,你可以在纯文本、WYSIWYG 和同时显示源文本和渲染视图的分屏之间切换编辑器视图。你还可以在图形界面中指定外部编辑器,以便使用 Vim、Emacs 或任何其他能够处理文本文档的编辑器轻松更新笔记。

*控制台中的 Joplin*
控制台界面非常棒。虽然它缺少 WYSIWYG 编辑器,但默认登录使用文本编辑器。它还有强大的命令模式,它允许执行在图形版本中几乎所有的操作。并且能够在视图中正确渲染 Markdown。
你可以将笔记本中的笔记分组,还能为笔记打上标记,以便于在笔记本中进行分组。它甚至还有内置的搜索功能,因此如果你忘了笔记在哪,你可以通过它找到它们。
总的来说,Joplin 是一款一流的笔记应用([还是 Evernote 的一个很好的替代品](https://opensource.com/article/17/12/joplin-open-source-evernote-alternative)),它能帮助你在明年组织化并提高工作效率。
---
via: <https://opensource.com/article/19/1/productivity-tool-joplin>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the first of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## Joplin
In the realm of productivity tools, note-taking apps are VERY handy. Yes, you can use the open source [NixNote](http://nixnote.org/NixNote-Home/) to access [Evernote](https://evernote.com/) notes, but it's still linked to the Evernote servers and still relies on a third party for security. And while you CAN export your Evernote notes from NixNote, the only format options are NixNote XML or PDF files.
Enter [Joplin](https://joplin.cozic.net/). Joplin is a NodeJS application that runs and stores notes locally, allows you to encrypt your notes and supports multiple sync methods. Joplin can run as a console or graphical application on Windows, Mac, and Linux. Joplin also has mobile apps for Android and iOS, meaning you can take your notes with you without a major hassle. Joplin even allows you to format notes with Markdown, HTML, or plain text.
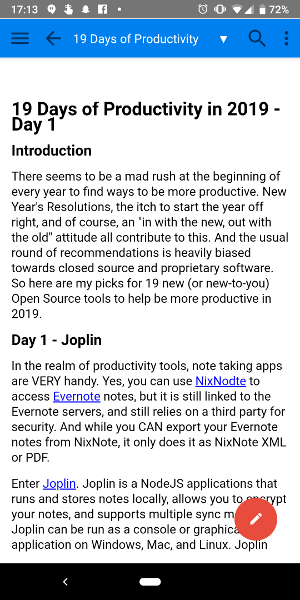
Joplin on Android.
One really nice thing about Joplin is it supports two kinds of notes: plain notes and to-do notes. Plain notes are what you expect—documents containing text. To-do notes, on the other hand, have a checkbox in the notes list that allows you to mark them "done." And since the to-do note is still a note, you can include lists, documentation, and additional to-do items in a to-do note.
When using the GUI, you can toggle editor views between plain text, WYSIWYG, and a split screen showing both the source text and the rendered view. You can also specify an external editor in the GUI, making it easy to update notes with Vim, Emacs, or any other editor capable of handling text documents.
Joplin in the console.
The console interface is absolutely fantastic. While it lacks a WYSIWYG editor, it defaults to the text editor for your login. It also has a powerful command mode that allows you to do almost everything you can do in the GUI version. And it renders Markdown correctly in the viewer.
You can group notes in notebooks and tag notes for easy grouping across your notebooks. And it even has built-in search, so you can find things if you forget where you put them.
Overall, Joplin is a first-class note-taking app ([and a great alternative to Evernote](https://opensource.com/article/17/12/joplin-open-source-evernote-alternative)) that will help you be organized and more productive over the next year.
## 2 Comments |
10,477 | Bash 5.0 发布及其新功能 | https://itsfoss.com/bash-5-release | 2019-01-25T23:03:15 | [
"bash",
"shell"
] | https://linux.cn/article-10477-1.html | [邮件列表](https://lists.gnu.org/archive/html/bug-bash/2019-01/msg00063.html)证实最近发布了 Bash-5.0。而且,令人兴奋的是它还有新的功能和变量。
如果你一直在使用 Bash 4.4.XX,那么你一定会喜欢 [Bash](https://www.gnu.org/software/bash/) 的第五个主要版本。
第五个版本侧重于新的 shell 变量和许多重大漏洞修复。它还引入了一些新功能,以及一些与 bash-4.4 不兼容的更改。

### 新功能怎么样?
在邮件列表解释了此版本中修复的 bug:
>
> 此版本修复了 bash-4.4 中的几个主要错误,并引入了几个新功能。最重要的 bug 修复是对 nameref 变量的解析以及通过模糊测试发现的许多潜在的内存越界错误。在为了符合 Posix 标准解释而不进行单词拆分的上下文中,对 `$@` 和 `$*` 的展开做了许多改变,另外还有解决极端情况中 Posix 一致性的修改。
>
>
>
它还引入了一些新功能。根据其发布说明,最值得注意的新功能是几个新的 shell 变量:
>
> `BASH_ARGV0`、`EPOCHSECONDS` 和 `EPOCHREALTIME`。内置命令 `history` 可以删除指定范围的条目,并能将负数理解为从历史末端开始的偏移量。有一个选项允许局部变量继承前一个范围内具有相同名称的变量的值。有一个新的 shell 选项,在启用它时,会导致 shell 只尝试一次扩展关联数组下标(这在算术表达式中使用时会出现问题)。`globasciiranges` 这个 shell 选项现在默认启用。可以在配置时默认关闭它。
>
>
>
### Bash-4.4 和 Bash-5.0 之间有哪些变化?
其更新日志提到了不兼容的更改和所支持的 readline 版本历史记录。它是这么说的:
>
> bash-4.4 和 bash-5.0 之间存在一些不兼容的变化。尽管我已经尽量最小化兼容性问题,但是对 `nameref` 变量解析的更改意味着对变量名引用的某些使用会有不同的行为。默认情况下,如果启用了扩展调试模式,shell 仅在启动时设置 `BASH_ARGC` 和 `BASH_ARGV`。它被无条件地设置是一个疏忽,并且在脚本传递大量参数时会导致性能问题。
>
>
> 如果需要,可以将 Bash 链接到已安装的 Readline 库,而不是 `lib/readline` 中的私有版本。只有 readline-8.0 及更高版本能够提供 bash-5.0 所需的所有符号。早期版本的 Readline 库无法正常工作。
>
>
>
我相信一些添加的功能/变量非常有用。我最喜欢的一些是:
* 有一个新的(默认情况下禁用,文档中没有说明)shell 选项,用于在运行时启用/禁用向 syslog 发送历史记录。
* 正如文档一直所说的那样,除非 shell 处于调试模式,否则它不会在启动时自动设置 `BASH_ARGC` 和 `BASH_ARGV`,但如果脚本在上层引用它们且没有启用调试模式,那么 shell 将动态创建它们。
* 现在可以使用 `-d start-end` 删除指定范围的 `history` 条目。
* 如果启用了作业控制的非交互式 shell 检测到前台作业因 SIGINT 而死亡,则其行为就像接收到 SIGINT 一样。
* `BASH_ARGV0`:一个新变量,扩展为 `$0`,并在赋值时设置为 `$0`。
要查看完整的更改和功能列表,请参阅[邮件列表文章](https://lists.gnu.org/archive/html/bug-bash/2019-01/msg00063.html)。
### 总结
你可以使用下面的命令检查你当前的 Bash 版本:
```
bash --version
```
你很可能安装了 Bash 4.4。如果你想获得新版本,我建议等待你的发行版提供它。
你怎么看待 Bash-5.0 发布?你在使用其他 bash 的替代品么?如果有的话,这个更新会改变你的想法么?
请在下面的评论中告诉我们你的想法。
---
via: <https://itsfoss.com/bash-5-release>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,478 | 计算机实验室之树莓派:课程 2 OK02 | https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok02.html | 2019-01-26T12:01:05 | [
"树莓派"
] | https://linux.cn/article-10478-1.html | 
OK02 课程构建于 OK01 课程的基础上,通过不停地打开和关闭 OK 或 ACT LED 指示灯来实现闪烁。假设你已经有了 [课程 1:OK01](/article-10458-1.html) 操作系统的代码,它将是这一节课的基础。
### 1、等待
等待是操作系统开发中非常有用的部分。操作系统经常发现自己无事可做,以及必须要延迟。在这个例子中,我们希望通过等待,让 LED 灯打开、关闭的闪烁可以看到。如果你只是打开和关闭它,你将看到这个视觉效果,因为计算机每秒种可以打开和关闭它好几千次(LCTT 译注:视觉暂留效应会使你难以发觉它的闪烁)。在后面的课程中,我们将看到精确的等待,但是现在,我们只要简单地去消耗时间就足够了。
```
mov r2,#0x3F0000
wait1$:
sub r2,#1
cmp r2,#0
bne wait1$
```
>
> `sub reg,#val` 从寄存器 `reg` 中的值上减去数字 `val`
>
>
> `cmp reg,#val` 将寄存器中的值与数字 `val` 进行比较。
>
>
> 如果最后的比较结果是不相等,那么执行后缀了 `ne` 的 `b` 命令。
>
>
>
上面是一个很常见的产生延迟的代码片段,由于每个树莓派基本上是相同的,所以产生的延迟大致也是相同的。它的工作原理是,使用一个 `mov` 命令将值 3F0000<sub> 16</sub> 推入到寄存器 `r2` 中,然后将这个值减 1,直到这个值减到 0 为止。在这里使用了三个新命令 `sub`、 `cmp` 和 `bne`。
`sub` 是减法命令,它只是简单地从第一个参数中的值减去第二个参数中的值。
`cmp` 是个很有趣的命令。它将第一个参数与第二个参数进行比较,然后将比较结果记录到一个称为当前处理器状态寄存器的专用寄存器中。你其实不用担心它,它记住的只是两个数谁大或谁小,或是相等而已。<sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup>
`bne` 其实是一个伪装的分支命令。在 ARM 汇编语言家族中,任何指令都可以有条件地运行。这意味着如果上一个比较结果是某个确定的结果,那个指令才会运行。这是个非常有意思的技巧,我们在后面将大量使用到它,但在本案例中,我们在 `b` 命令后面的 `ne` 后缀意思是 “只有在上一个比较的结果是值不相等,才去运行该分支”。`ne` 后缀可以使用在任何命令上,其它几个(总共 16 个)条件也是如此,比如 `eq` 表示等于,而 `lt` 表示小于。
### 2、组合到一起
上一节讲我提到过,通过将 GPIO 地址偏移量设置为 28(即:`str r1,[r0,#28]`)而不是 40 即可实现 LED 的关闭。因此,你需要去修改课程 OK01 的代码,在打开 LED 后,运行等待代码,然后再关闭 LED,再次运行等待代码,并包含一个回到开始位置的分支。注意,不需要重新启用 GPIO 的 16 号针脚的输出功能,这个操作只需要做一次就可以了。如果你想更高效,我建议你复用 `r1` 寄存器的值。所有课程都一样,你可以在 [下载页面](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads.html) 找到所有的解决方案。需要注意的是,必须保证你的所有标签都是唯一的。当你写了 `wait1$:` 你其它行上的标签就不能再使用 `wait1$` 了。
在我的树莓派上,它大约是每秒闪两次。通过改变我们所设置的 `r2` 寄存器中的值,可以很轻松地修改它。但是,不幸的是,我不能够精确地预测它的运行速度。如果你的树莓派未按预期正常工作,请查看我们的故障排除页面,如果它正常工作,恭喜你。
在这个课程中,我们学习了另外两个汇编命令:`sub` 和 `cmp`,同时学习了 ARM 中如何实现有条件运行。
在下一个课程,[课程 3:OK03](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok03.html) 中我们将学习如何编写代码,以及建立一些代码复用的标准,并且如果需要的话,可能会使用 C 或 C++ 来写代码。
---
1. 如果你点了这个链接,说明你一定想知道它的具体内容。CPSR 是一个由许多独立的比特位组成的 32 比特寄存器。它有一个位用于表示正数、零和负数。当一个 `cmp` 指令运行后,它从第一个参数上减去第二个参数,然后用这个位记下它的结果是正数、零还是负数。如果是零意味着它们相等(`a-b=0` 暗示着 `a=b`)如果为正数意味着 a 大于 b(`a-b>0` 暗示着 `a>b`),如果为负数意味着小于。还有其它比较指令,但 `cmp` 指令最直观。 [↩](#fnref1)
---
via: <https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok02.html>
作者:[Robert Mullins](http://www.cl.cam.ac.uk/%7Erdm34) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Raspberry Pi
# Lesson 2 OK02
The OK02 lesson builds on OK01, by causing the 'OK' or 'ACT' LED to turn on and off repeatedly.
It is assumed you have the code for the [Lesson 1: OK01](ok01.html) operating
system as a basis.
Contents |
## 1 Waiting
Waiting is a surprisingly useful part of Operating System development. Often Operating Systems find themselves with nothing to do, and must delay. In this example, we wish to do so in order to allow the LED flashing off and on to be visible. If you just turned it off and on, it would not be visible, as the computer would be able to turn it off and on many thousands of times per second. In later lessons we will look at accurate waiting, but for now it is sufficient to simply waste time.
mov r2,#0x3F0000
wait1$:
sub r2,#1
cmp r2,#0
bne wait1$
sub reg,#val subtracts the number val from the value in reg.
cmp reg,#val compares the value in reg with the number val.
Suffix ne causes the command to be executed only if the last comparison determined that the numbers were not equal.
The code above is a generic piece of code that creates a delay, which thanks to
every Raspberry Pi being basically the same, is roughly the same time. How it does
this is using a mov command to put the value
3F000016 into r2, and then subtracting
1 from this value until it is 0. The new commands here are
sub, cmp, and
bne.
sub is the subtract command, and simply subtracts the second argument from the first.
cmp is a more interesting command. It compares
the first argument with the second, and remembers the result of the comparison in
a special register called the current processor status register. You don't really
need to worry about this, suffice to say it remembers, among other things, which
of the two numbers was bigger or smaller, or if they were equal.[[1]](#note1)
bne is actually just a branch command in disguise. In the ARM assembly language family, any instruction can be executed conditionally. This means that the instruction is only run if the last comparison had a certain result. We will use this extensively later for interesting tricks, but in this case we use the ne suffix on the b command to mean 'only branch if the last comparison's result was that the values were not equal'. The ne suffix can be used on any command, as can several other (16 in all) conditions such as eq for equal and lt for less than.
## 2 The All Together
I mentioned briefly last time that the status LED can be turned off again by writing
to an offset of 28 from the GPIO controller instead of 40 (i.e.
str r1,[r0,#28]). Thus, you need to modify the code from OK01 to turn
the LED on, run the wait code, turn it off, run the wait code again, and then include
a branch back to the beginning. Note, it is not necessary to re-enable the output
to GPIO 16, we need only do that once. If you're being efficient, which I strongly
encourage, you should be able to reuse the value of r1.
As with all lessons, a full solution to this can be found on the [
download page](downloads.html). Be careful to make sure all of your labels are unique. When
you write wait1$: you cannot label another line
wait1$.
On my Raspberry Pi it flashes about twice a second. this could easily be altered by changing the value we set r2 to. However, unfortunately we can't precisely predict the speed this runs at. If you didn't manage to get this working see our trouble shooting page, otherwise, congratulations.
In this lesson we've learnt two more assembly commands, sub and cmp, as well as learning about conditional execution in ARM.
In the next lesson, [Lesson 3: OK03](ok03.html) we will evaluate how we're
coding, and establish some standards so that we can reuse code, and if necessary,
work with C or C++ code. |
10,479 | Fedora 28 服务器版的模块化 | https://fedoramagazine.org/working-modules-fedora-28/ | 2019-01-26T15:59:18 | [
"Fedora",
"模块化"
] | https://linux.cn/article-10479-1.html | 
### 什么是模块化
所有开源发行版都面临的一个经典难题是“太快/太慢”的问题。用户安装操作系统是为了能够使用其应用程序。像 Fedora 这样的全面的发行版在大量可用软件方面有其优势和劣势。虽然有用户想要的软件包,但可能无法使用其所需的版本。以下是<ruby> 模块化 <rt> Modularity </rt></ruby>如何帮助解决该问题。
对于某些用户,Fedora 有时升级得太快。其快速发布周期以及尽可能提供最新稳定软件的愿望可能导致与应用程序的兼容性下降。如果因为 Fedora 将 Web 框架升级为不兼容的版本而导致用户无法运行 Web 应用程序,则会非常令人沮丧。对“太快”问题的经典回答是“Fedora 应该有一个 LTS 版本。”然而,这种方法只能解决问题的一半,并使这个难题的另一面变得更糟。
有时候 Fedora 对某些用户而言又升级速度太慢。例如,Fedora 的发布可能与其它想要的软件的发布时间不匹配。一旦 Fedora 版本宣布稳定,打包者必须遵守 [稳定更新政策](https://fedoraproject.org/wiki/Updates_Policy#Stable_Releases) 并且不能在系统中引入不兼容的更改。
Fedora 的模块化从两个方面解决了这个问题。Fedora 仍将根据其传统政策发布标准版本。但是,它还将提供一组模块给出流行软件的限定替代版本。那些处于“太快”阵营的人仍然可以享受 Fedora 的新内核和其它通用平台增强功能。此外,他们仍然可以访问支持其应用程序的旧框架或工具链。
此外,那些喜欢更新潮一些的用户可以访问比发布时更新的软件。
### 模块化不是什么?
模块化不是 <ruby> <a href="https://www.softwarecollections.org/"> 软件集合 </a> <rt> Software Collections </rt></ruby> 的直接替代品。这两种技术试图解决许多相同的问题,但有明显的差异。
软件集合可以在系统上并行安装不同版本的软件包。但是,它们的缺点是每份安装包都存在于文件系统上的它们自己的命名空间里面。此外,需要告诉每个依赖它们的应用程序在哪里找到它们。
使用模块化,系统上只存在一个版本的软件包,但用户可以选择哪个版本。优点是该版本位于系统的标准位置。该程序包不需要对依赖它的应用程序进行特殊更改。来自用户研究的反馈表明,大多数用户实际上并不依赖于并行安装。容器化和虚拟化解决了这个问题。
### 为什么不干脆使用容器化?
这是另一个常见问题。为什么用户在可以使用容器时还需要模块?答案是,人们仍然需要维护容器中的软件。 模块为那些用户不需要自己维护、更新和修补的容器提供预打包的内容。这就是 Fedora 如何利用发行版的传统价值并将其转移到新的容器化的世界。
以下是模块化如何为 Node.js 和 Review Board 的用户解决问题的示例。
### Node.js
许多读者可能熟悉 Node.js,这是一个流行的服务器端 JavaScript 运行时环境。Node.js 采用偶数/奇数版本策略。它的社区支持偶数版本(6.x、8.x、10.x 等)约 30 个月。同时,他们也支持奇数版本,基本上是 9 个月的开发者预览版。
由于这个周期的原因,Fedora 在其稳定的仓库中只携带最新的偶数版本的 Node.js。它完全避免了奇数版本,因为它们的生命周期比 Fedora 短,并且通常与 Fedora 发布周期不一致。对于一些希望获得最新和最大增强功能的 Fedora 用户来说,这并不合适。
由于模块化,Fedora 28 不是提供了一个版本,而是提供了三个版本的 Node.js,以满足开发人员和稳定部署的需求。Fedora 28 的传统仓库带有 Node.js 8.x。此版本是发布时最新的长期稳定版本。模块仓库(默认情况下在 Fedora 28 Server 版本上可用)也使得更旧的 Node.js 6.x 版本和更新的 Node.js 9.x 开发版本可用。
另外,Node.js 在 Fedora 28 之后几天发布了 10.x 上游版本。过去,想要部署该版本的用户必须等到 Fedora 29,或者使用来自 Fedora 之外的源代码。但是,再次感谢模块化,Node.js 10.x 已经在 Fedora 28 的 Modular Updates-Testing 仓库中 [可用](https://bodhi.fedoraproject.org/updates/FEDORA-MODULAR-2018-2b0846cb86) 了。
### Review Board
Review Board 是一个流行的 Django 应用程序,用于执行代码审查。Fedora 从 Fedora 13 到 Fedora 21 都包括了 Review Board。此时,Fedora 转移到了 Django 1.7。由于 Django 数据库支持的向后兼容性在不断变化,而 Review Board 无法跟上。它在 RHEL / CentOS 7 的 EPEL 仓库中仍然存在,而仅仅是因为这些发行版的版本幸运地被冻结在 Django 1.6上。尽管如此,它在 Fedora 的时代显然已经过去了。
然而,随着模块化的出现,Fedora 能够再次将旧的 Django 作为非默认模块流发布。因此,Review Board 已作为一个模块在 Fedora 上恢复了。Fedora 承载了来自上游的两个受支持的版本:2.5.x 和 3.0.x。
### 组合在一起
Fedora 一直为用户提供非常广泛的软件使用。Fedora 模块化现在为他们所需的软件版本提供了更深入的选择。接下来的几年对于 Fedora 来说将是非常令人兴奋的,因为开发人员和用户可以以新的和令人兴奋的(或旧的和令人兴奋的)方式组合他们的软件。
---
via: <https://fedoramagazine.org/working-modules-fedora-28/>
作者:[Stephen Gallagher](https://fedoramagazine.org/author/sgallagh/) 选题:[wxy](https://github.com/wxy) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The recent Fedora Magazine article entitled [ Modularity in Fedora 28 Server Edition](https://fedoramagazine.org/modularity-fedora-28-server-edition/) did a great job of explaining Modularity in Fedora 28. It also pointed out a few example modules and explained the problems they solve. This article puts one of those modules to practical use, covering installation and setup of Review Board 3.0 using modules.
## Getting started
To follow along with this article and use modules, you need a system running [Fedora 28 Server Edition](https://getfedora.org/server/) along with [ sudo administrative privileges](https://fedoramagazine.org/howto-use-sudo/). Also, run this command to make sure all the packages on the system are current:
sudo dnf -y update
While you can use modules on Fedora 28 non-server editions, be aware of the [caveats described in the comments of the previous article](https://fedoramagazine.org/modularity-fedora-28-server-edition/#comment-476696).
## Examining modules
First, take a look at what modules are available for Fedora 28. Run the following command:
dnf module list
The output lists a collection of modules that shows the associated stream, version, and available installation profiles for each. A *[d]* next to a particular module stream indicates the default stream used if the named module is installed.
The output also shows most modules have a profile named *default*. That’s not a coincidence, since *default* is the name used for the default profile.
To see where all those modules are coming from, run:
dnf repolist
Along with the usual [ fedora and updates package repositories](https://fedoraproject.org/wiki/Repositories), the output shows the
*fedora-modular*and
*updates-modular*repositories.
The introduction stated you’d be setting up Review Board 3.0. Perhaps a module named *reviewboard* caught your attention in the earlier output. Next, to get some details about that module, run this command:
dnf module info reviewboard
The description confirms it is the Review Board module, but also says it’s the 2.5 stream. However, you want 3.0. Look at the available *reviewboard* modules:
dnf module list reviewboard
The *[d]* next to the 2.5 stream means it is configured as the default stream for *reviewboard*. Therefore, be explicit about the stream you want:
dnf module info reviewboard:3.0
Now for even more details about the *reviewboard:3.0* module, add the verbose option:
dnf module info reviewboard:3.0 -v
## Installing the Review Board 3.0 module
Now that you’ve tracked down the module you want, install it with this command:
sudo dnf -y module install reviewboard:3.0
The output shows the ReviewBoard package was installed, along with several other dependent packages, including several from the *django:1.6* module. The installation also enabled the *reviewboard:3.0* module and the dependent *django:1.6* module.
Next, to see enabled modules, use this command:
dnf module list --enabled
The output shows *[e]* for enabled streams, and *[i]* for installed profiles. In the case of the *reviewboard:3.0* module, the *default* profile was installed. You could have specified a different profile when installing the module. In fact, you still can — and this time you don’t need to specify the 3.0 stream since it was already enabled:
sudo dnf -y module install reviewboard/server
However, installation of the *reviewboard:3.0/server* profile is rather uneventful. The *reviewboard:3.0* module’s *server* profile is the same as the *default* profile — so there’s nothing more to install.
## Spin up a Review Board site
Now that the Review Board 3.0 module and its dependent packages are installed, [create a Review Board site](https://www.reviewboard.org/docs/manual/dev/admin/installation/creating-sites/) running on the local system. Without further ado or explanation, copy and paste the following commands to do that:
sudo rb-site install --noinput \ --domain-name=localhost --db-type=sqlite3 \ --db-name=/var/www/rev.local/data/reviewboard.db \ --admin-user=rbadmin --admin-password=secret \ /var/www/rev.local sudo chown -R apache /var/www/rev.local/htdocs/media/uploaded \ /var/www/rev.local/data sudo ln -s /var/www/rev.local/conf/apache-wsgi.conf \ /etc/httpd/conf.d/reviewboard-localhost.conf sudo setsebool -P httpd_can_sendmail=1 httpd_can_network_connect=1 \ httpd_can_network_memcache=1 httpd_unified=1 sudo systemctl enable --now httpd
Now fire up a web browser on the system, point it at *http://localhost*, and enjoy the shiny new Review Board site! To login as the Review Board admin, use the userid and password seen in the *rb-site* command above.
## Module cleanup
It’s good practice to clean up after yourself. To do that, remove the Review Board module and the site directory:
sudo dnf -y module remove reviewboard:3.0 sudo rm -rf /var/www/rev.local
## Closing remarks
Now that you’ve explored how to examine and administer the Review Board module, go experiment with the other modules available in Fedora 28.
Learn more about using modules in Fedora 28 on the [Fedora Modularity](https://docs.pagure.org/modularity/) web site. The *dnf* manual page’s *Module Command* section also contains useful information.
## Ricky Tigg
$ dnf module list
Fedora 28 – x86_64 – Updates 2.7 MB/s | 15 MB 00:05
Fedora 28 – x86_64 12 MB/s | 60 MB 00:05
Last metadata expiration check: 0:00:00 ago on Thu 07 Jun 2018 09:33:28 CEST.
Nothing to show.
## Merlin Mathesius
You don’t appear to have the modular repos enabled. If you’re using a Fedora 28 Server Edition system, something is wrong with your installation. If you’re using a non-server system, follow the link in the “Getting started” section above–but beware of the caveats!
## Ricky Tigg
Fedora 28 Desktop Edition. Repository named ‘Modular’ was not yet added.
## Matěj Koudelka
Try to install package fedora-repos-modular |
10,480 | tmux:适用于重度命令行 Linux 用户的终端复用器 | https://www.2daygeek.com/tmux-a-powerful-terminal-multiplexer-emulator-for-linux/ | 2019-01-27T11:57:36 | [
"tmux",
"终端"
] | https://linux.cn/article-10480-1.html | 
tmux 是<ruby> 终端复用器 <rt> terminal multiplexer </rt></ruby>的缩写,它允许用户在单个窗口中创建或启用多个终端(垂直或水平),当你处理不同的问题时,可以在单个窗口中轻松访问和控制它们。
它使用客户端-服务器模型,允许在用户之间共享会话,也可以将终端连接到 tmux 会话。我们可以根据需要轻松移动或重新排列虚拟控制台。终端会话可以从一个虚拟控制台自由切换到另一个。
tmux 依赖于 `libevent` 和 `ncurses` 库。tmux 在屏幕底部提供了一个状态行,它显示当前 tmux 会话的有关信息,例如当前窗口编号、窗口名称、用户名、主机名、当前时间和日期。
启动 tmux 时,它会在一个单独窗口上创建一个新的会话,并将其显示在屏幕上。它允许用户在同一个会话中创建任意数量的窗口。
许多人说它类似于 `screen`,但我不这么认为,因为它提供了许多配置选项。
**注意:** `Ctrl+b` 是 tmux 中的默认命令前缀,因此,要在 tmux 中执行任何操作,你必须先输入该前缀然后输入所需的选项。
### tmux 特性
* 创建任意数量的窗口
* 在一个窗口中创建任意数量的窗格
* 它允许垂直和水平分割
* 分离并重新连接窗口
* 客户端-服务器架构,这允许用户之间共享会话
* tmux 提供许多配置技巧
**建议阅读:**
* [tmate - 马上与其他人分享你的终端会话](https://www.2daygeek.com/tmate-instantly-share-your-terminal-session-to-anyone-in-seconds/)
* [Teleconsole - 一个与其他人分享终端会话的工具](https://www.2daygeek.com/teleconsole-share-terminal-session-instantly-to-anyone-in-seconds/)
### 如何安装 tmux 命令
大多数 Linux 系统默认预安装 tmux 命令。如果没有,按照以下步骤安装。
对于 Debian/Ubuntu,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/)或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/)来安装:
```
$ sudo apt install tmux
```
对于 RHEL/CentOS,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/)来安装:
```
$ sudo yum install tmux
```
对于 Fedora,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/)来安装:
```
$ sudo dnf install tmux
```
对于 Arch Linux,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/)来安装:
```
$ sudo pacman -S tmux
```
对于 openSUSE,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/)来安装:
```
$ sudo zypper in tmux
```
### 如何使用 tmux
在终端上运行以下命令来启动 tmux 会话。启动 tmux 后,它会在一个新窗口中创建新会话,并将使用你的用户账户自动登录到你的默认 shell。
```
$ tmux
```

你会得到类似于我们上面的截图。tmux 附带状态栏,显示有关当前会话详细信息、日期、时间等。
状态栏信息如下:
* `[0]`:它表示由 tmux 服务器创建的会话号。默认情况下,它从 0 开始。
* `0:bash`:表示会话号、命令行提示符(这里的 `bash` 表示 shell 名称)。
* `*`:这表示该窗口现在处于活动状态。
* 主机名:显示服务器的完全主机名。
* 日期与时间:显示当前日期和时间。
(LCTT 译注:tmux 的状态可以根据需要定制,也会因环境、版本的不同而不同。)
### 如何拆分窗口
tmux 允许用户垂直或水平分割窗口,称为窗格。每个窗格都包含自己独立运行的终端实例。我们来看看如何做到这一点。
按下 `Ctrl+b, %` 来垂直分割窗格。

按下 `Ctrl+b, "` 来水平分割窗格。

### 如何在窗格之间移动
假设,我们创建了一些窗格,希望在它们之间移动,这该怎么做?如果你不知道怎么做,那么使用 tmux 就没有意义了。使用以下控制键执行操作。在窗格之间移动有许多方法。
* 按 `Ctrl+b, ←` - 选择左边的窗格
* 按 `Ctrl+b, →` - 选择右边的窗格
* 按 `Ctrl+b, ↑` - 选择上边的窗格
* 按 `Ctrl+b, ↓` - 选择下边的窗格
* 按 `Ctrl+b, {` - 来向左交换窗格
* 按 `Ctrl+b, }` - 来向右交换窗格
* 按 `Ctrl+b, o` - 切换到下一个窗格(从左到右,从上到下)
* 按 `Ctrl+b, ;` - 移动到先前活动的窗格
出于测试目的,我们将在窗格之间移动。现在我们在 `pane2` 中,它展示了 `lsb_release -a` 命令的输出。

我们将移动到 `pane0`,它显示 `uname -a` 命令的输出。

### 如何打开/创建新窗口
你可以在一个终端内打开任意数量的窗口。
* 按 `Ctrl+b, c` 来创建一个新窗口。
* 按 `Ctrl+b, n` 移动到下一个窗口。
* 按 `Ctrl+b, p` 移动到上一个窗口。
* 按 `Ctrl+b, 0` ~ `Ctrl+b, 9` 立即移动到特定窗口。
* 按 `Ctrl+b, l` 移动到先前选择的窗口。
我有两个窗口,第一个窗口有三个窗格,其中包含操作系统版本信息,`top` 命令输出和内核信息。

第二个窗口有两个窗格,其中包含 Linux 发行版 logo 信息。使用以下命令执行操作:

按 `Ctrl+b, w` 以交互方式选择当前窗口。

### 如何缩放窗格
你正在一些非常小的窗格中工作,并且你希望将其缩小以进行进一步的工作。要做到这一点,使用以下键绑定。
目前我们有三个窗格,我在 `pane1` 工作,它使用 `top` 命令显示系统活动信息,我将缩放它。

缩放窗格时,它将隐藏所有其它窗格,并只显示窗口中的缩放窗格。

按 `Ctrl+b, z` 缩放窗格,并再次按下它使缩放窗格恢复原状。
### 显示窗格信息
要了解窗格编号及其大小,运行以下命令。
按 `Ctrl+b, q` 可简单显示窗格索引。

### 显示窗口信息
要知道窗口编号、布局大小,与窗口关联的窗格数量及其大小等,运行以下命令。
只需运行 `tmux list-windows` 即可查看窗口信息。

### 如何调整窗格大小
你可能需要调整窗格大小来满足你的要求。你必须按下 `Ctrl+b, :`,然后在页面底部的黄色颜色条上输入以下详细信息。

在上一部分中,我们打印了窗格索引,它同时也显示了窗格大小。为了测试,我们要向增加 `10` 个单元。参考以下输出,该窗格将 pane1 和 pane2 的大小从 `55x21` 增加到 `55x31`。

**语法:** `Ctrl+b, :` 然后输入 `resize-pane [options] [cells size]`
* `Ctrl+b, :` 然后输入 `resize-pane -D 10` 将当前窗格大小向下调整 10 个单元。
* `Ctrl+b, :` 然后输入 `resize-pane -U 10` 将当前窗格大小向上调整 10 个单元。
* `Ctrl+b, :` 然后输入 `resize-pane -L 10` 将当前窗格大小向左调整 10 个单元。
* `Ctrl+b, :` 然后输入 `resize-pane -R 10` 将当前窗格大小向右调整 10 个单元。
### 分离并重新连接 tmux 会话
tmux 最强大的功能之一是能够在需要时分离和重新连接会话。
运行一个长时间运行的进程,然后按下 `Ctrl+b`,接着按 `d`,通过离开正在运行的进程安全地分离你的 tmux 会话。
**建议阅读:** [如何在断开 SSH 会话后保持进程/命令继续运行](https://www.2daygeek.com/how-to-keep-a-process-command-running-after-disconnecting-ssh-session/)
现在,运行一个长时间运行的进程。出于演示目的,我们将把此服务器备份移动到另一个远程服务器以进行灾难恢复(DR)。
```
$ rsync -avzhe ssh /backup [email protected]:/backups/week-1/
```
在分离 tmux 会话之后,你将获得类似下面的输出。
```
[detached (from session 0)]
```
运行以下命令以列出可用的 tmux 会话。
```
$ tmux ls
0: 3 windows (created Tue Jan 30 06:17:47 2018) [109x45]
```
现在,使用适当的会话 ID 重新连接 tmux 会话,如下所示:
```
$ tmux attach -t 0
```
### 如何关闭窗格和窗口
只需在相应的窗格中输入 `exit` 或按下 `Ctrl-d` 即可关闭它,和终端关闭类似。要关闭窗口,按下 `Ctrl+b, &`。
好了,就到这里了,希望你喜欢上它。
---
via: <https://www.2daygeek.com/tmux-a-powerful-terminal-multiplexer-emulator-for-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,481 | 如何即时设置一个静态文件服务器 | https://www.ostechnix.com/how-to-setup-static-file-server-instantly/ | 2019-01-27T12:12:56 | [
"文件服务"
] | https://linux.cn/article-10481-1.html | 
曾经想通过网络共享你的文件或项目,但不知道怎么做?别担心!这里有一个名为 **serve** 的简单实用程序,可以通过网络即时共享你的文件。这个简单的实用程序会立即将你的系统变成一个静态文件服务器,允许你通过网络提供文件。你可以从任何设备访问这些文件,而不用担心它们的操作系统是什么。你所需的只是一个 Web 浏览器。这个实用程序还可以用来服务静态网站。它以前称为 “list” 或 “micri-list”,但现在名称已改为 “serve”(提供),这更适合这个实用程序的目的。
### 使用 Serve 来设置一个静态文件服务器
要安装 serve,首先你需要安装 NodeJS 和 NPM。参考以下链接在 Linux 中安装 NodeJS 和 NPM。
* [如何在 Linux 上安装 NodeJS](https://www.ostechnix.com/install-node-js-linux/)
NodeJS 和 NPM 安装完成后,运行以下命令来安装 serve:
```
$ npm install -g serve
```
完成!现在是时候 serve 文件或文件夹了。
使用 serve 的典型语法是:
```
$ serve [options] <path-to-files-or-folders>
```
### 提供特定文件或文件夹
例如,让我们共享 `Documents` 目录里的内容。为此,运行:
```
$ serve Documents/
```
示例输出:

正如你在上图中看到的,给定目录的内容已通过两个 URL 提供网络支持。
要从本地系统访问内容,你只需打开 Web 浏览器,输入 URL `http://localhost:5000/`:

serve 实用程序以简单的布局显示给定目录的内容。你可以下载(右键单击文件并选择“将链接另存为…”)或只在浏览器中查看它们。
如果想要在浏览器中自动打开本地地址,使用 `-o` 选项。
```
$ serve -o Documents/
```
运行上述命令后,serve 实用程序将自动打开 Web 浏览器并显示共享项的内容。
同样,要通过网络从远程系统访问共享目录,可以在浏览器地址栏中输入 `http://192.168.43.192:5000`。用你系统的 IP 替换 192.168.43.192。
### 通过不同的端口提供内容
你可能已经注意到,默认情况下,serve 实用程序使用端口 5000。因此,确保防火墙或路由器中允许使用端口 5000。如果由于某种原因被阻止,你可以使用 `-p` 选项使用不同端口来提供内容。
```
$ serve -p 1234 Documents/
```
上面的命令将通过端口 1234 提供 `Documents` 目录的内容。

要提供文件而不是文件夹,只需给它完整的路径,如下所示。
```
$ serve Documents/Papers/notes.txt
```
只要知道路径,网络上的任何用户都可以访问共享目录的内容。
### 提供整个 `$HOME` 目录
打开终端输入
```
$ serve
```
这将通过网络共享整个 `$HOME` 目录的内容。
要停止共享,按下 `CTRL+C`。
### 提供选定的文件或文件夹
你可能不想共享所有文件或目录,只想共享其中的一些。你可以使用 `-i` 选项排除文件或目录。
```
$ serve -i Downloads/
```
以上命令将提供整个文件系统,除了 `Downloads` 目录。
### 仅在本地主机上提供内容
有时,你只想在本地系统而不是整个网络上提供内容。为此,使用 `-l` 标志,如下所示:
```
$ serve -l Documents/
```
此命令会仅在本地提供 `Documents` 目录。

当你在共享服务器上工作时,这可能会很有用。系统中的所有用户都可以访问共享,但远程用户不能。
### 使用 SSL 提供内容
由于我们通过本地网络提供内容,因此我们不需要使用 SSL。但是,serve 实用程序可以使用 `-ssl` 选项来使用 SSL 共享内容。
```
$ serve --ssl Documents/
```

要通过 Web 浏览器访问共享,输入 `https://localhost:5000` 或 `https://ip:5000`。

### 通过身份验证提供内容
在上面的所有示例中,我们在没有任何身份验证的情况下提供内容,所以网络上的任何人都可以在没有任何身份验证的情况下访问共享内容。你可能会觉得应该使用用户名和密码访问某些内容。
为此,使用:
```
$ SERVE_USER=ostechnix SERVE_PASSWORD=123456 serve --auth
```
现在用户需要输入用户名(即 `ostechnix`)和密码(`123456`)来访问共享。(LCTT 译注:123456 是非常不好的密码,仅在实验情况下使用)

serve 实用程序还有一些其它功能,例如禁用 [Gzip 压缩](https://www.ostechnix.com/how-to-compress-and-decompress-files-in-linux/),设置 CORS 头以允许来自任河源的请求,防止自动复制地址到剪贴板等。通过以下命令,你可以阅读完整的帮助部分。
```
$ serve help
```
好了,这就是全部了。希望这可以帮助到你。更多好东西要来了,敬请关注!
共勉!
资源:
* [Serve GitHub 仓库](https://github.com/zeit/serve)
---
via: <https://www.ostechnix.com/how-to-setup-static-file-server-instantly/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,482 | 微型计算机的始祖:Altair 8800 | https://twobithistory.org/2018/07/22/dawn-of-the-microcomputer.html | 2019-01-27T20:21:00 | [
"计算机",
"Altair"
] | https://linux.cn/article-10482-1.html | 
《<ruby> 大众电子 <rt> Popular Electronics </rt></ruby>》的订阅者们是个复杂的群体,该杂志的编辑 Arthur Salsberg 不得不在 [1974 年 12 月刊](https://www.americanradiohistory.com/Archive-Poptronics/70s/1974/Poptronics-1974-12.pdf) 中的前言部分指出这点。此前,杂志编辑组曾收到了对《如何搭建家庭媒体中心》文章的抱怨,称这篇文章激励了许多业余电视爱好者走出去,削弱了专业修理人员存在的必要性,这对许多人的电视造成了极大伤害。Salsberg 认为,这个担忧的产生可能是因为大家不清楚《大众电子》读者们的真实水平。他解释道,据杂志内部调查的数据显示,52% 的订阅者都是某方面的电子专家,并且其中的 150,000 人在最近 60 天之内都修过电视。此外,订阅者们平均在电子产品上花费了 470 美金(2018 年则是 3578 美金),并且他们拥有万用表、真空管伏特计、电子管测试仪、晶体管测试仪、射频讯号产生器和示波器等必要设备。“《大众电子》的读者们并不全都是新手。”Salsberg 总结道。
熟悉《大众电子》的人居然会质疑它的订阅者,这令我十分吃惊。不过最近 60 天我的确没修过电视。我的电脑对我来说就是一块铝,我甚至没把它拆开看过。1974 年 12 月的《大众电子》刊登的像《驻波比是什么以及如何处理它》和《对万用表的测试》之类的特色文章,甚至连广告都令人生畏。它们中有个看起来像某种立体声系统的东西大胆地写道“除了‘四通道单元(即内建的 SQ、RM 和 CD-4 解码接收器)’,没有任何音频设备是值得期待的”。这也表明了《大众电子》的订阅者一定对电子有很多深入的了解。
不过在 [1975 年 1 月刊](https://www.americanradiohistory.com/Archive-Poptronics/70s/1975/Poptronics-1975-01.pdf) 中,该杂志为读者们带来了一些他们从没见过的东西。在标题“突破性项目”下面,杂志的封面是一个大大的黑灰色盒子,其前面板上有一组复杂开关和灯。这便是 Altair 8800,“世界上首个有商业竞争力的小型机”,它的售价低于 400 美元。尽管 Altair 被宣传作“<ruby> 小型机 <rt> minicomputer </rt></ruby>”,但它实际上是首个商业上成功的新型计算机成员,它首先被称为“<ruby> 微型计算机 <rt> microcomputers </rt></ruby>”,最终被称为 PC(<ruby> 个人计算机 <rt> Personal Computer </rt></ruby>)。Altair 十分小巧而且很便宜,以至于它成为了当时家家户户都能用起的电脑。正如 Salsberg 所写道,它在《大众电子》上的出现意味着:“家用电脑的时代终于到来了。”

此前,我曾写过 [关于 Altair 的文章](/article-10181-1.html),但我觉得 Altair 值得重新审视。与当时其它的计算机相比,它并不是一台性能强劲的计算机(尽管它的成本要低得多),它也不是首个采用微处理器的通用计算机(在它之前已经至少有三个基于微处理器的计算机)。但是 Altair 是一种可供我们所有人使用的计算机。它是历史上我们所拥有的设备中首台流行的计算机,而早于 Altair 计算机都是完全不同的机器,那些大型机和笨重的迷你计算机由穿孔卡编程并且很少与之直接交互。不过 Altair 也是台极其简单的计算机,它没有附带任何操作系统甚至是引导程序。除非你为它购买外围设备,否则 Altair 就是一台装配了 RAM、前面板只有一组开关和灯泡的机器。由于 Altair 操作简单,使得重新理解基本的计算概念都成了十分简单的事情,正如模拟信号时代的人们第一次接触到数字设备一样。
### Roberts 和他的公司
Altair 是由一家名为<ruby> 微型仪器和遥测系统 <rt> Micro Instrumentation and Telemetry Systems </rt></ruby>(MITS)的公司所设计制造,这家公司位于美国新墨西哥州的阿尔布开克。MITS 由一个叫 H. Edward Roberts 的人经营。在进入计算器市场之前,该公司已经开始制造模型火箭的遥测系统,该市场在 20 世纪 70 年代初期蓬勃发展。集成电路大大降低了计算器的成本,突然之间它就成了美国每个在职的专业人士的必需品。不幸的是,由于计算器市场竞争过于激烈,到了 1974 年初,MITS 便负债累累。
1974 年在计算机界是<ruby> 奇迹迭出的一年 <rt> annus mirabilis </rt></ruby>。<sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup> 一月的时候,惠普公司推出了世界首个可编程的手持计算器 HP-65。四月的时候,Intel 发布了 Intel 8080,这是他们的第二款 8 位微处理器,它也是首款广受欢迎的微处理器。接着,六月的时候,《<ruby> 无线电电子 <rt> Radio Electronics </rt></ruby>》杂志宣传了一台名为 Mark-8 的自制小型计算机,它使用了 Intel 在 1972 年推出的 Intel 8008 微处理器。Mark-8 是有史以来使用微处理器搭建的第三台电脑,它的首次登场是在杂志的封面上。<sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup> Mark-8 在《无线电电子》上的出现促使了《大众电子》寻找他们要自己宣传的小型机项目。
《大众电子》的订阅者们其实早在 1974 年 12 月就通过邮件获得了 1975 年 1 月刊的刊物。<sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup> 所以 Altair 的宣布为这个<ruby> 奇迹迭出的一年 <rt> annus mirabilis </rt></ruby>画上了圆满的句号。Altair 的出现是十分重要的,因为此前从未有过向公众提供的价格公道而又功能齐全的电脑。当时,作为最受欢迎的小型计算机之一的 PDP-8 要几千美金才能买到。然而作为 Altair 核心的 Intel 8080 芯片几乎能与 PDP-8 匹敌,甚至更强;8080 支持更广泛的指令集,而且 Altair 可以扩展到 64 kb 内存,显然强于仅有 4 kb 内存的 PDP-8。并且,Mark-8 也不是它的对手,因为它搭载的是只能处理 16 kb 内存的 Intel 8008。在 Mark-8 必须由用户按照说明书在印刷电路板上手动拼装的情况下,Altair 在购买时就已经被组装好了(不过由于后来 MITS 被大量订单淹没,最后真正能获得 Altair 的方式也只有买套件拼装了)。
对许多《大众电子》的读者来说,Altair 是他们了解数字计算的起点。1975 年 1 月刊上那篇介绍 Altair 的文章由 Roberts 和 Altair 的共同设计师 William Yates 所写。Roberts 和 Yates 煞费苦心地用电工和无线电狂热者们所熟悉的词汇来介绍了数字硬件和计算机编程的基本概念。他们写道:“一台计算机其实由一块可变的硬件。仅需修改储存于内存之中的位组合形式,便可改变硬件设备的种类。”同时,Roberts 和 Yates 认为编程的基本概念是“足够简单并能在较短时间内掌握,但是想要成为一个高效的程序员必须经验丰富且富有创造力。”对此我十分认同。尽管该部分已经完全组装好了,文章仍包含了用来讲解 Intel 8080 的组成电路的详细图表。文章解释了 CPU 和计算机内存单元的区别,堆栈指针的用法,和汇编语言以及更高级的语言(例如 FORTRAN 和 BASIC)比起手动输入机器码所带来的巨大优势。
其实,《大众电子》在 1975 年 1 月刊之前就出版过 Roberts 撰写的系列文章。这一系列作为短期课程被收录在“数字逻辑”专栏中。在 1974 年 12 月刊中,Roberts 为读者们带来了关于构建“超低成本计算机终端”的文章,文章中介绍了可以用于 8 位电脑中输入值的八进制键盘。在介绍这个键盘时,Roberts 解释了晶体管到晶体管的逻辑工作原理,以及关于构建一种可以“记住”数字值的触发器的方法。Roberts 承诺说,这个键盘可以在下个月即将公布的 Altair 电脑中使用。
有多少《大众电子》的读者制作了这个键盘我们无从得知,但是那个键盘的确是个很有用的东西。如果没有键盘和其它输入设备,我们只能通过拨动 Altair 面板上的开关来输入值。Altair 的前面板上有一行 16 个开关被用来设置地址,而下方的 8 个则是用来操作计算机的。一行 16 个开关中最右边的 8 个开关也能用来指定要储存在内存中的值。这么做不无道理,因为 Intel 8080 使用 16 位的值来寻址 8 位的字。而前面板的这 16 个开关每一个都代表了一个位,当开关向上时代表 1,向下则代表 0。用这样的方式与计算机交互是个启示(一会儿我们就会讲到),因为 Altair 的面板是真正的二进制界面。这使得你可以尽可能地接触到计算机实体。
尽管在当下 Altair 的界面对我们来说完全不像是人用的,不过在那个时代却并不罕见。比如 PDP-8 的面板上有个类似的但更漂亮的二进制输入装置,而且它被涂上了吸引人的黄色和橙色,不过讲真,它真的应该卷土重来。然而 PDP-8 经常与纸带阅读器或电传打字机配合使用,这使得程序输入更加容易。这些 I/O 设备价格高昂,这意味着 Altair 的用户们大都会被那个前面板拦住。正如你可能想象的那样,通过这一堆开关输入一个大型程序是个苦差事。不过幸运的是,Altair 可以与盒式记录器连接,这样一来载入程序就不是什么难事了。Bill Gates 和 Paul Allen 在 MITS 的授权下为 Altair 编写了一个 BASIC 语言版本,并在 1975 年中期发行,这成为了微软有史以来的首次商业尝试。此后,那些买得起电传打字机的用户就能 [通过纸带来将 BASIC 载入 Altair](https://www.youtube.com/watch?v=qv5b1Xowxdk) 了,并能使得用户能够通过文字与 Altair 交互。之后,BASIC 便成为了学生们最爱的入门编程语言,并成了早期小型机时代的标准接口。
### z80pack
多亏了网络上一些人,特别是 Udo Munk 的努力,你可以在你的计算机上运行 Altair 的模拟器。这个模拟器是在 Zilog Z80 CPU 的虚拟套件上构建的,这个 CPU 可以运行 Intel 8080 的软件。Altair 模拟器允许你像 Altair 的早期用户们一样拨动前面板上的开关。尽管点击这些开关的感觉不如拨动真实开关的触觉,但是使用 Altair 模拟器仍是一个能让你感受二进制人机交互效率有多低的途径,至少在我看来这非常简明直观。
z80pack 是 Udo Munk 开发的 Z80 模拟器套件,你可以在 z80pack 的官网上找到它的下载链接。我在 [上一篇介绍 Altair 的文章中](/article-10181-1.html) 写到过在 macOS 上使用它的详细过程。如果你能编译 FrontPanel 库和 `altairsim` 可执行程序,你应该能直接运行 `altairsim` 并看到这个窗口:

在新版的 z80pack 中(比如我正在使用的 1.36 版本),你可以使用一个叫 Tarbell boot ROM 的功能,我觉得这是用来加载磁盘镜像的。经我测试,这意味着你不能写入到 RAM 中的前几个字。在编辑 `/altairsim/conf/system.conf` 之后,你可以构建带有一个 16 页 RAM 且没有 ROM 或引导加载器的 Altair。除此之外,你还可以用这个配置文件来扩大运行模拟器的窗口大小,不得不说这还是挺方便的。
Altair 的面板看起来令人生畏,不过事实上并没有我们想象中的这么可怕。[Altair 说明书](http://www.classiccmp.org/dunfield/altair/d/88opman.pdf) 对解释开关和指示灯起到了很大的作用,这个 [YouTube 视频](https://www.youtube.com/watch?v=suyiMfzmZKs) 也是如此。若想输入和运行一个简易的程序,你只需要了解一点点东西。Altair 右上方标签为 D0 到 D7 的指示灯代表当前寻址的字的内容。标签为 A0 到 A15 的指示灯表示当前的地址。地址指示灯下的 16 个开关可以用来设置新地址;当 “EXAMINE” 开关被向上推动时,数据指示灯才会更新以显示新地址上的内容。用这个功能,你便能“观察”到内存中所有的信息了。你也可以将 “EXAMINE” 推下来“EXAMINE NEXT”位置,以自动检查下一个位置上的信息,这使得查看连续的信息更容易了。
要将位组合方式保存到内存信息中,请使用最右边的 8 个标签为 0 到 7 的开关。然后,请向上推动 “DEPOSIT” 按钮。
在《大众电子》 的 [1975 年 2 月刊](https://www.americanradiohistory.com/Archive-Poptronics/70s/1975/Poptronics-1975-02.pdf) 中,Roberts 和 Yates 引导用户输入一小段程序来确保他们的 Altair 正常工作。这个程序从内存中读取两个整型数据并相加之后将和存回内存中。这个小程序仅由 6 条指令组成,但是这 6 条指令涉及了 14 个字的内存,所以要正确地输入它们需要一点时间。这个示例程序也被写入了 Altair 的说明书,原文如下:
| Address | Mnemonic | Bit Pattern | Octal Equivalent |
| --- | --- | --- | --- |
| 0 | LDA | 00 111 010 | 0 7 2 |
| 1 | (address) | 10 000 000 | 2 0 0 |
| 2 | (address) | 00 000 000 | 0 0 0 |
| 3 | MOV B, A | 01 000 111 | 1 0 7 |
| 4 | LDA | 00 111 010 | 0 7 2 |
| 5 | (address) | 10 000 001 | 2 0 1 |
| 6 | (address) | 00 000 000 | 0 0 0 |
| 7 | ADD B | 10 000 000 | 2 0 0 |
| 8 | STA | 00 110 010 | 0 6 2 |
| 9 | (address) | 10 000 010 | 2 0 2 |
| 10 | (address) | 00 000 000 | 0 0 0 |
| 11 | JMP | 11 000 011 | 3 0 3 |
| 12 | (address) | 00 000 000 | 0 0 0 |
| 13 | (address) | 00 000 000 | 0 0 0 |
如果你通过开关来将上表的这些值输入到 Altair,最终会得到一个程序,它会读取内存 128 中的值,并将其与 129 中的值相加,最终将其保存至 130 中。伴随每条取一个地址的指令的地址,它们最开始会给出最低有效位,这便是第二个字节总会被清零的原因了(没有高于 255 的地址)。在输入这个程序并在 128 和 129 中输入了一些值之后,你可以向下短暂推动 “RUN” ,之后再将它推到 “STOP” 位置。因为程序循环执行,以一秒内执行上千次的速度反复地添加并保存那些值。并且最后得到的值总是相同的,如果你停止该程序并查看 130 的内容,你应该能找到正确答案。
我不知道普通的 Altair 用户是否使用过汇编程序,不过 z80pack 包括了一个:`z80asm`,意思是<ruby> 适用于 Z80 的汇编程序 <rt> Z80 assembly </rt></ruby>,所以它使用了一组不同的助记符。不过因为 Z80 是被设计来兼容为 Intel 8080 写的软件的,所以即使助记符不一样,它们的操作码也是相同的。你可以直接将 `z80asm` 汇编码装载进 Altair:
```
ORG 0000H
START: LD A,(80H) ;Load from address 128.
LD B,A ;Move loaded value from accumulator (A) to reg B.
LD A,(81H) ;Load from address 129.
ADD A,B ;Add A and B.
LD (82H),A ;Store A at address 130.
JP START ;Jump to start.
```
编译之后,你可以调用汇编程序来将其转换为 Intel HEX 文件:
```
$ ./z80asm -fh -oadd.hex add.asm
```
我们用带有 `h` 参数的 `-f` 标识来定义输出的 HEX 文件。你可以用 `-x` 标识来传递 HEX 文件,从而使得 Altair 能够加载该程序:
```
$ ./altairsim -x add.hex
```
这会在内存中自动设置前 14 个字,就和你通过开关手动输入这些值一样。你可以直接使用 “RUN” 按钮来替代以前那些繁琐的步骤,这是如此的简单!
我不觉得有很多 Altair 用户以这种方式来编写软件。Altair BASIC 发布后,使得 BASIC 成为了 Altair 编程最简单的方法。z80pack 同时也包括了一些不同版本 Altair BASIC 的 HEX 文件;在模拟器中,你可以用这个方式加载 4.0 版本的 4K BASIC:
```
$ ./altairsim -x basic4k40.hex
```
当你开启模拟器并按下 “RUN” 按钮之后,你就会看到 BASIC 开始执行了,同时它会在终端中与你交互。它首先会提示你输入你的内存可用量,我们输入 4000 字节。随后,在显示 “OK” 提示符之前,它会问你几个问题,Gates 和 Allen 用这个“OK”来代替标准的 “READY” 并以此节省内存。在这之后,你便可以使用 BASIC 了:
```
OK
PRINT 3 + 4
7
```
虽然运行 BASIC 只有 4kb 的内存并没有给你足够的空间,但你可以看到它是如何从使用前面板迈出了重要的一步。
很显然,Altair 远不及如今的家用电脑和笔记本电脑,并且比它晚十多年发布的 Mac 电脑看上去也是对这个简朴的 Altair 电脑的巨大飞跃。但是对第一批购买并亲手组装了 Altair 的《大众电子》的读者们来说,Altair 才是他们拥有的第一个真正的全功能电脑,而这一切只用了 400 美金低价和一半的书柜空间。对那时只能用 [一叠卡片](/article-10382-1.html) 或一卷磁带来与计算机交互的人们来说,Altair 是个令人眼前一亮的玩意。这之后的微型计算机基本都是在对 Altair 改进,使得它更易用。从某种意义上来说,它们只是更复杂的 Altair。Altair,一个野兽派的极简作品,却为之后的许多微型计算机打下了铺垫。
如果你觉得这篇文章写的不错,你可以在推特上关注 [@TwoBitHistory](https://twitter.com/TwoBitHistory) 或订阅 [RSS feed](https://twobithistory.org/feed.xml) 来获得我们文章的更新提醒。文章每两周就会更新一次!
---
1. Paul E. Ceruzzi, A History of Modern Computing (Cambridge, Mass: MIT Press, 2003), 226. [↩](#fnref1)
2. “Mark-8 Minicomputer,” Byran’s Old Computers, accessed July 21, 2018, <http://bytecollector.com/mark_8.htm>. [↩](#fnref2)
3. Paul E. Ceruzzi, A History of Modern Computing (Cambridge, Mass: MIT Press, 2003), 226. [↩](#fnref3)
---
via: <https://twobithistory.org/2018/07/22/dawn-of-the-microcomputer.html>
作者:[Sinclair Target](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zhs852](https://github.com/zhs852) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Subscribers to *Popular Electronics* were a sophisticated group. The magazine’s
editor, Arthur Salsberg, felt compelled to point out as much in the editorial
section of the [December 1974
issue](https://www.americanradiohistory.com/Archive-Poptronics/70s/1974/Poptronics-1974-12.pdf).
The magazine had received letters complaining that a recent article, titled
“How to Set Up a Home TV Service Shop,” would inspire a horde of amateur TV
technicians to go out and undercut professional repairmen, doing great damage
to everyone’s TVs in the process. Salsberg thought this concern was based on a
misunderstanding about who read *Popular Electronics*. He explained that,
according to the magazine’s own surveys, 52% of *Popular Electronics*
subscribers were electronics professionals of some kind and 150,000 of them had
repaired a TV in the last 60 days. Moreover, the average *Popular Electronics*
subscriber had spent $470 on electronics equipment ($3578 in 2018) and
possessed such necessities as VOMs, VTVMs, tube testers, transistor testers,
r-f signal generators, and scopes. “*Popular Electronics* readers are not
largely neophytes,” Salsberg concluded.
I am surprised that anyone familiar with *Popular Electronics* could ever have
doubted its subscribers. I certainly haven’t repaired a TV in the last 60 days.
My computer is a block of aluminum that I have never seen the inside of. Yet
the December 1974 issue of *Popular Electronics* features articles such as
“Standing Wave Ratio: What It Is and How to Deal with It” and “Test Scene: Uses
for Your Multimeter.” Even the ads are intimidating. One of them, which seems
to be for some kind of stereo system, boldly proclaims that “no piece of audio
equipment is as eagerly awaited as the ‘one four-channel unit that does
everything—i.e. the receiver with built-in circuitry for SQ, RM and CD-4 record
decoding.’” The mere hobbyists subscribed to *Popular Electronics*, let alone
the professionals, must have been very knowledgeable indeed.
But *Popular Electronics* readers were introduced to something in the [January
1975
issue](https://www.americanradiohistory.com/Archive-Poptronics/70s/1975/Poptronics-1975-01.pdf)
that they had never encountered before. Below a heading that read “PROJECT
BREAKTHROUGH,” the magazine’s cover showed a large gray and black box whose
front panel bore a complicated array of lights and toggles. This was the Altair
8800, the “world’s first minicomputer kit to rival commercial models,”
available for under $400. Though advertised as a “minicomputer,” the Altair
would actually be the first commercially successful member of a new class of
computers, first known as “microcomputers” and then eventually as PCs. The
Altair was small enough and cheap enough that the average family could have one
at home. Its appearance in *Popular Electronics* magazine meant that, as
Salsberg wrote in that issue, “the home computer age is here—finally.”
I have written briefly about [the Altair before](/2017/12/02/simulating-the-altair.html), but I think the Altair is worth
revisiting. It was not an especially powerful computer compared to others
available at the time (though it cost significantly less money). Nor was it
the first general-purpose computer to incorporate a microprocessor chip—at
least three microprocessor-based computers preceded it. But the Altair was and
is a kind of Ur-Computer for all of us. It was the first popular computer in a
lineage that includes our own devices, whereas the mainframes and bulky
minicomputers that predated the Altair were an entirely different kind of
machine, programmed by punched card or else rarely interacted with directly.
The Altair was also a radically simple computer, without any kind of operating
system or even a bootloader. Unless you bought peripherals for it, the Altair
was practically a bank of RAM with switches and lights on the front. The
Altair’s simplicity makes learning about it a great way to reacquaint yourself
with the basic concepts of computing, exactly as they were encountered by the
denizens of the old analog world as they first ventured into our digital one.
## Roberts and Co.
The Altair was designed and manufactured by a company called Micro Instrumentation and Telemetry Systems (MITS), based in Albuquerque, New Mexico. MITS was run by a man named H. Edward Roberts. The company had started off making telemetry systems for model rocket kits before moving into the calculator market, which in the early 1970s was booming. Integrated circuits were bringing the cost of a calculator down dramatically and suddenly every working American professional had to have one. But the calculator market was ruthlessly competitive and, by the beginning of 1974, MITS was deeply in debt.
The year 1974 would prove to be an “annus mirabilis” in computing. 1 In
January, Hewlett-Packard introduced the HP-65, the world’s first programmable
handheld calculator. In April, Intel released the Intel 8080, its second 8-bit
microprocessor and the first microprocessor to become widely popular. Then, in
July,
*Radio Electronics*magazine advertised a build-it-yourself minicomputer called the Mark-8, which employed the Intel 8008 microprocessor that Intel had released in 1972. The Mark-8 was only the third computer ever built using a microprocessor and it was the first to be appear on the cover of a magazine.
The Mark-8’s appearance in
[2](#fn:2)*Radio Electronics*pushed
*Popular Electronics*to look for a minicomputer project of their own to feature.
*Popular Electronics* subscribers actually received their copies of the January
1975 issue in the mail in December of 1974. 3 So the announcement of the
Altair closed out the “annus mirabilis” that was that year. The Altair’s
introduction was so momentous because never before had such a fully capable
computer been offered to the public at an affordable price. The PDP-8, one the
most popular minicomputers at the time, could only be bought for several
thousand dollars. Yet the Intel 8080 chip at the heart of the Altair made it
almost as capable as the PDP-8, if not more so; the 8080 supported a wider
instruction set and the Altair could be expanded to have up to 64kb of memory,
while the stock PDP-8 typically only had 4kb. The Altair was also more powerful
than the Mark-8, which, because it was based on the Intel 8008, could only
address 16kb of memory. And whereas the Mark-8 had to be built from scratch by
customers with only a booklet and printed circuit boards to guide them, the
Altair could be purchased fully assembled, though MITS soon became so inundated
with orders that the only real way to get an Altair was to order the
construction kit.
For many *Popular Electronics* readers, the Altair was their first window into
the world of digital computing. The article introducing the Altair in the
January 1975 issue was written by Roberts and the Altair’s co-designer, William
Yates. Roberts and Yates took pains to explain, in terms familiar to the
electricians and radio enthusiasts in their audience, the basic concepts
underlying digital hardware and computer programming. “A computer,” they wrote,
“is basically a piece of variable hardware. By changing the bit pattern stored
in the memory, the hardware can be altered from one type of device to another.”
Of programming, meanwhile, Roberts and Yates wrote that the basic concepts are
“simple enough to master in a relatively short time,” but that becoming “an
efficient programmer requires a lot of experience and a large amount of
creativity,” which sounds about right to me. The article included a detailed
diagram explaining all the constituent circuits of the Intel 8080 CPU, even
though readers would receive at least that part fully assembled. It explained
the difference between a CPU and a computer’s memory unit, the uses of a stack
pointer, and the enormous advantages offered by assembly languages and
higher-level languages like FORTRAN and BASIC over manual entry of machine
code.
*Popular Electronics* had in fact been running a series written by Roberts for
several issues before January 1975. The series was billed as a short course in
“digital logic.” In the December 1974 issue, Roberts walked readers through
building a “very low cost computer terminal,” which was basically an octal
keypad that could input values into an 8-bit computer. In the course of
describing the keypad, Roberts explained how transistor-to-transistor logic
works and also how to construct a flip-flop, a kind of circuit capable of
“remembering” digital values. The keypad, Roberts promised, could be used with
the Altair computer, to be announced the following month.
It’s unclear how many *Popular Electronics* readers actually built the keypad,
but it would have been a very useful thing to have. Without a keypad or
some other input mechanism, the only way to input values into the Altair was
through the switches on the front panel. The front panel had a row of 16
switches that could be used to set an address and a lower row of eight switches
that could be used to control the operation of the computer. The eight
right-most switches in the row of 16 could also be used to specify a value to
be stored in memory. This made sense because the Intel 8080 used 16-bit values
to address 8-bit words. The 16 switches on the front panel each represented a
bit—the up position represented a one, while the down position represented a
zero. Interacting with a computer this way is a revelation (more on that in a
minute), because the Altair’s front panel is a true binary interface. It’s as
close as you can get to the bare metal.
As alien as the Altair’s interface is to us today, it was not unusual for its
time. The PDP-8, for example, had a similar binary input mechanism on its front
panel, though the PDP-8’s switches were nicer and colored in that attractive
orange and yellow color scheme that really ought to make a comeback. The PDP-8,
however, was often paired with a paper-tape reader or a teletype machine, which
made program entry much easier. These I/O devices were expensive, meaning that
most Altair users in the early days were stuck with the front panel. As you
might imagine, entering long programs via the switches was a chore. Eventually
the Altair could be hooked up to a cassette recorder and programs could be
loaded that way. Bill Gates and Paul Allen, in what would become Microsoft’s
first ever commercial venture, also wrote a version of BASIC for the Altair
that MITS licensed and released in the middle of 1975. Users that could afford
a teletype could then [load BASIC into the Altair via paper
tape](https://www.youtube.com/watch?v=qv5b1Xowxdk) and interact with their
Altair through text. BASIC, which had become everyone’s favorite introductory
programming language in schools, would go on to become the standard interface
to the machines produced in the early microcomputer era.
## z80pack
Thanks to the efforts of several internet people, in particular a person named Udo Munk, you can run a simulation of the Altair on your computer. The simulation is built on top of some software that emulates the Zilog Z80 CPU, a CPU designed to be software-compatible with the Intel 8080. The Altair simulation allows you to input programs entirely via the front panel switches like early users of the Altair had to do. Though clicking on switches does not offer the same tactile satisfaction as flipping real switches, playing with the Altair simulation is a great way to appreciate how a binary human/computer interface was both horribly inefficient and, at least in my opinion, charmingly straightforward.
z80pack, Udo Munk’s Z80 emulation package, can be downloaded from the z80pack
website. There are instructions in [my last Altair post](/2017/12/02/simulating-the-altair.html) explaining how to get it set up
on Mac OS. If you are able to compile both the FrontPanel library and the
`altairsim`
executable, you should be able to run `altairsim`
and see the
following window:
By default, at least with the version of z80pack that I am using (1.36), the
Altair is configured with something called Tarbell boot ROM, which I think is
used to load disk images. In practice, what this means is that you can’t write
values into the first several words in RAM. If you edit the file
`/altairsim/conf/system.conf`
, you can instead set up a simple Altair that has
16 pages of RAM and no ROM or bootloader software at all. You can also use this
configuration file to increase the size of the window the simulation runs in,
which is handy.
The front panel of the Altair is intimidating, but in reality there isn’t that
much going on. The [Altair
manual](http://www.classiccmp.org/dunfield/altair/d/88opman.pdf) does a good
job of explaining the many switches and status lights, as does this [YouTube
video](https://www.youtube.com/watch?v=suyiMfzmZKs). To enter and run a simple
program, you only really need to know a few things. The lights labeled D0
through D7 near the top right of the Altair indicate the contents of the
currently addressed word. The lights labeled A0 through A15 indicate the
current address. The 16 switches below the address lights can be used to set a
new address; when the “EXAMINE” switch is pressed upward, the data lights
update to show the contents of the newly addressed word. In this way, you can
“peek” at all the words in memory. You can also press the “EXAMINE” switch down
to the “EXAMINE NEXT” position, which automatically examines the next memory
address, which makes peeking at sequential words significantly easier.
To save a bit pattern to a word, you have to set the bit pattern using the right-most eight switches labeled 0 through 7. You then press the “DEPOSIT” switch upward.
In the [February 1975
issue](https://www.americanradiohistory.com/Archive-Poptronics/70s/1975/Poptronics-1975-02.pdf)
of *Popular Electronics*, Roberts and Yates walked Altair owners through
inputting a small sample program to ensure that their Altair was functioning.
The program loads two integers from memory, adds them, and saves the sum back
into memory. The program consists of only six instructions, but those six
instructions involve 14 words of memory altogether, which takes some time to
input correctly. The sample program also appears in the Altair manual in table
form, which I’ve reproduced here:
Address | Mnemonic | Bit Pattern | Octal Equivalent |
---|---|---|---|
0 | LDA | 00 111 010 | 0 7 2 |
1 | (address) | 10 000 000 | 2 0 0 |
2 | (address) | 00 000 000 | 0 0 0 |
3 | MOV B, A | 01 000 111 | 1 0 7 |
4 | LDA | 00 111 010 | 0 7 2 |
5 | (address) | 10 000 001 | 2 0 1 |
6 | (address) | 00 000 000 | 0 0 0 |
7 | ADD B | 10 000 000 | 2 0 0 |
8 | STA | 00 110 010 | 0 6 2 |
9 | (address) | 10 000 010 | 2 0 2 |
10 | (address) | 00 000 000 | 0 0 0 |
11 | JMP | 11 000 011 | 3 0 3 |
12 | (address) | 00 000 000 | 0 0 0 |
13 | (address) | 00 000 000 | 0 0 0 |
If you input each word in the above table into the Altair via the switches, you end up with a program that loads the value in word 128, adds it to the value in the word 129, and finally saves it into word 130. The addresses that accompany each instruction taking an address are given with the least-significant bits first, which is why the second byte is always zeroed out (no addresses are higher than 255). Once you’ve input the program and entered some values into words 128 and 129, you can press the “RUN” switch into the down position briefly before pushing it into the “STOP” position. Since the program loops, it repeatedly adds those values and saves the sum thousands of times a second. The sum is always the same though, so if you peek at word 130 after stopping the program, you should find the correct answer.
I don’t know whether any regular users of the Altair ever had access to an
assembler, but z80pack includes one. The z80pack assembler, `z80asm`
, is meant
for Z80 assembly, so it uses a different set of mnemonics altogether. But since
the Z80 was designed to be compatible with software written for the Intel 8080,
the opcodes are all the same, even if the mnemonics are different. So just to
illustrate what it might have been like to write the same program in assembly,
here is a version that can be assembled by `z80asm`
and loaded into the Altair:
```
ORG 0000H
START: LD A,(80H) ;Load from address 128.
LD B,A ;Move loaded value from accumulator (A) to reg B.
LD A,(81H) ;Load from address 129.
ADD A,B ;Add A and B.
LD (82H),A ;Store A at address 130.
JP START ;Jump to start.
```
You can turn this into something called an Intel HEX file by invoking the assembler like so (after you have compiled it):
```
$ ./z80asm -fh -oadd.hex add.asm
```
The `-f`
flag, here taking `h`
as an argument, specifies that a HEX file should
be output. You can then load the program into the Altair by passing the HEX
file in using the `-x`
flag:
```
$ ./altairsim -x add.hex
```
This sets up the first 14 words in memory as if you had input the values manually via the switches. Instead of doing all that again, you can just run the program by using the “RUN” switch as before. Much easier!
As I said, I don’t think many Altair users wrote software this way. Once Altair BASIC became available, writing BASIC programs was probably the easiest way to program the Altair. z80pack also includes several HEX files containing different versions of Altair BASIC; the one I’ve been able to get working is version 4.0 of 4K BASIC, which you can load into the simulator like so:
```
$ ./altairsim -x basic4k40.hex
```
If you turn the simulated machine on and hit the “RUN” switch, you should see that BASIC has started talking to you in your terminal window. It first prompts you to enter the amount of memory you have available, which should be 4000 bytes. It then asks you a few more questions before presenting you with the “OK” prompt, which Gates and Allen used instead of the standard “READY” to save memory. From there, you can just use BASIC:
```
OK
PRINT 3 + 4
7
```
Though running BASIC with only 4kb of memory didn’t give you a lot of room, you can see how it would have been a significant step up from using the front panel.
The Altair, of course, was nowhere near as capable as the home desktops and
laptops we have available to us today. Even something like the Macintosh,
released less than a decade later, seems like a quantum leap forward over the
spartan Altair. But to those first *Popular Electronics* readers that bought
the kit and assembled it, the Altair was a real, fully capable computer that
they could own for themselves, all for the low cost of $400 and half the
surface space of the credenza. This would have been an amazing thing for people
that had thus far only been able to interact with computers by handing [a stack
of cards](/2018/06/23/ibm-029-card-punch.html) or a roll of tape
to another human being entrusted with the actual operation of the computer.
Subsequent microcomputers would improve upon what the Altair offered and
quickly become much easier to use, but they were all, in some sense, just more
complicated Altairs. The Altair—almost Brutalist in its minimalism—was the
bare-essentials blueprint for all that would follow.
*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
*
*Previously on TwoBitHistory…*
"I invite you to come along with me on an exciting journey and spend the next ten minutes of your life learning about a piece of software nobody has used in the last decade."
— TwoBitHistory (@TwoBitHistory)[https://t.co/R9zA5ibFMs][July 7, 2018] |
10,483 | 使用 Fedora 28 中的模块 | https://fedoramagazine.org/working-modules-fedora-28/ | 2019-01-27T20:50:56 | [
"Fedora",
"模块化"
] | https://linux.cn/article-10483-1.html | 
最近 Fedora Magazine 中题为 [Fedora 28 服务器版的模块化](/article-10479-1.html)在解释 Fedora 28 中的模块化方面做得很好。它还给出了一些示例模块并解释了它们解决的问题。本文将其中一个模块用于实际应用,包括使用模块安装设置 Review Board 3.0。
### 入门
想要继续并使用模块,你需要一个 [Fedora 28 服务器版](https://getfedora.org/server/)并拥有 [sudo 管理权限](https://fedoramagazine.org/howto-use-sudo/)。另外,运行此命令以确保系统上的所有软件包都是最新的:
```
sudo dnf -y update
```
虽然你可以在 Fedora 28 非服务器版本上使用模块,但请注意[上一篇文章评论中提到的警告](https://fedoramagazine.org/modularity-fedora-28-server-edition/#comment-476696)。
### 检查模块
首先,看看 Fedora 28 可用的模块。运行以下命令:
```
dnf module list
```
输出列出了一组模块,这些模块显示了每个模块的关联的流、版本和可用安装配置文件。模块流旁边的 `[d]` 表示安装命名模块时使用的默认流。
输出还显示大多数模块都有名为 `default` 的配置文件。这不是巧合,因为 `default` 是默认配置文件使用的名称。
要查看所有这些模块的来源,请运行:
```
dnf repolist
```
与通常的 [fedora 和更新包仓库](https://fedoraproject.org/wiki/Repositories)一起,输出还显示了 fedora-modular 和 updates-modular 仓库。
介绍声明你将设置 Review Board 3.0。也许名为 reviewboard 的模块在之前的输出中引起了你的注意。接下来,要获取有关该模块的一些详细信息,请运行以下命令:
```
dnf module info reviewboard
```
根据描述确认它是 Review Board 模块,但也说明是 2.5 的流。然而你想要 3.0 的。查看可用的 reviewboard 模块:
```
dnf module list reviewboard
```
2.5 旁边的 `[d]` 表示它被配置为 reviewboard 的默认流。因此,请明确你想要的流:
```
dnf module info reviewboard:3.0
```
有关 reviewboard:3.0 模块的更多详细信息,请添加详细选项:
```
dnf module info reviewboard:3.0 -v
```
### 安装 Review Board 3.0 模块
现在你已经跟踪了所需的模块,请使用以下命令安装它:
```
sudo dnf -y module install reviewboard:3.0
```
输出显示已安装 ReviewBoard 以及其他几个依赖软件包,其中包括 django:1.6 模块中的几个软件包。安装还启用了 reviewboard:3.0 模块和相关的 django:1.6 模块。
接下来,要查看已启用的模块,请使用以下命令:
```
dnf module list --enabled
```
输出中,`[e]` 表示已启用的流,`[i]` 表示已安装的配置。对于 reviewboard:3.0 模块,已安装默认配置。你可以在安装模块时指定其他配置。实际上,你仍然可以安装它,而且这次你不需要指定 3.0,因为它已经启用:
```
sudo dnf -y module install reviewboard/server
```
但是,安装 reviewboard:3.0/server 配置非常平常。reviewboard:3.0 模块的服务器配置与默认配置文件相同 —— 因此无需安装。
### 启动 Review Board 网站
现在已经安装了 Review Board 3.0 模块及其相关软件包,[创建一个本地运行的 Review Board 网站](https://www.reviewboard.org/docs/manual/dev/admin/installation/creating-sites/)。无需解释,请复制并粘贴以下命令:
```
sudo rb-site install --noinput \
--domain-name=localhost --db-type=sqlite3 \
--db-name=/var/www/rev.local/data/reviewboard.db \
--admin-user=rbadmin --admin-password=secret \
/var/www/rev.local
sudo chown -R apache /var/www/rev.local/htdocs/media/uploaded \
/var/www/rev.local/data
sudo ln -s /var/www/rev.local/conf/apache-wsgi.conf \
/etc/httpd/conf.d/reviewboard-localhost.conf
sudo setsebool -P httpd_can_sendmail=1 httpd_can_network_connect=1 \
httpd_can_network_memcache=1 httpd_unified=1
sudo systemctl enable --now httpd
```
现在启动系统中的 Web 浏览器,打开 <http://localhost>,然后享受全新的 Review Board 网站!要以 Review Board 管理员身份登录,请使用上面 `rb-site` 命令中的用户 ID 和密码。
### 模块清理
完成后清理是个好习惯。为此,删除 Review Board 模块和站点目录:
```
sudo dnf -y module remove reviewboard:3.0
sudo rm -rf /var/www/rev.local
```
### 总结
现在你已经探索了如何检测和管理 Review Board 模块,那么去体验 Fedora 28 中提供的其他模块吧。
在 [Fedora 模块化](https://docs.pagure.org/modularity/)网站上了解有关在 Fedora 28 中使用模块的更多信息。dnf 手册页中的 module 命令部分也包含了有用的信息。
---
via: <https://fedoramagazine.org/working-modules-fedora-28/>
作者:[Merlin Mathesius](https://fedoramagazine.org/author/merlinm/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The recent Fedora Magazine article entitled [ Modularity in Fedora 28 Server Edition](https://fedoramagazine.org/modularity-fedora-28-server-edition/) did a great job of explaining Modularity in Fedora 28. It also pointed out a few example modules and explained the problems they solve. This article puts one of those modules to practical use, covering installation and setup of Review Board 3.0 using modules.
## Getting started
To follow along with this article and use modules, you need a system running [Fedora 28 Server Edition](https://getfedora.org/server/) along with [ sudo administrative privileges](https://fedoramagazine.org/howto-use-sudo/). Also, run this command to make sure all the packages on the system are current:
sudo dnf -y update
While you can use modules on Fedora 28 non-server editions, be aware of the [caveats described in the comments of the previous article](https://fedoramagazine.org/modularity-fedora-28-server-edition/#comment-476696).
## Examining modules
First, take a look at what modules are available for Fedora 28. Run the following command:
dnf module list
The output lists a collection of modules that shows the associated stream, version, and available installation profiles for each. A *[d]* next to a particular module stream indicates the default stream used if the named module is installed.
The output also shows most modules have a profile named *default*. That’s not a coincidence, since *default* is the name used for the default profile.
To see where all those modules are coming from, run:
dnf repolist
Along with the usual [ fedora and updates package repositories](https://fedoraproject.org/wiki/Repositories), the output shows the
*fedora-modular*and
*updates-modular*repositories.
The introduction stated you’d be setting up Review Board 3.0. Perhaps a module named *reviewboard* caught your attention in the earlier output. Next, to get some details about that module, run this command:
dnf module info reviewboard
The description confirms it is the Review Board module, but also says it’s the 2.5 stream. However, you want 3.0. Look at the available *reviewboard* modules:
dnf module list reviewboard
The *[d]* next to the 2.5 stream means it is configured as the default stream for *reviewboard*. Therefore, be explicit about the stream you want:
dnf module info reviewboard:3.0
Now for even more details about the *reviewboard:3.0* module, add the verbose option:
dnf module info reviewboard:3.0 -v
## Installing the Review Board 3.0 module
Now that you’ve tracked down the module you want, install it with this command:
sudo dnf -y module install reviewboard:3.0
The output shows the ReviewBoard package was installed, along with several other dependent packages, including several from the *django:1.6* module. The installation also enabled the *reviewboard:3.0* module and the dependent *django:1.6* module.
Next, to see enabled modules, use this command:
dnf module list --enabled
The output shows *[e]* for enabled streams, and *[i]* for installed profiles. In the case of the *reviewboard:3.0* module, the *default* profile was installed. You could have specified a different profile when installing the module. In fact, you still can — and this time you don’t need to specify the 3.0 stream since it was already enabled:
sudo dnf -y module install reviewboard/server
However, installation of the *reviewboard:3.0/server* profile is rather uneventful. The *reviewboard:3.0* module’s *server* profile is the same as the *default* profile — so there’s nothing more to install.
## Spin up a Review Board site
Now that the Review Board 3.0 module and its dependent packages are installed, [create a Review Board site](https://www.reviewboard.org/docs/manual/dev/admin/installation/creating-sites/) running on the local system. Without further ado or explanation, copy and paste the following commands to do that:
sudo rb-site install --noinput \ --domain-name=localhost --db-type=sqlite3 \ --db-name=/var/www/rev.local/data/reviewboard.db \ --admin-user=rbadmin --admin-password=secret \ /var/www/rev.local sudo chown -R apache /var/www/rev.local/htdocs/media/uploaded \ /var/www/rev.local/data sudo ln -s /var/www/rev.local/conf/apache-wsgi.conf \ /etc/httpd/conf.d/reviewboard-localhost.conf sudo setsebool -P httpd_can_sendmail=1 httpd_can_network_connect=1 \ httpd_can_network_memcache=1 httpd_unified=1 sudo systemctl enable --now httpd
Now fire up a web browser on the system, point it at *http://localhost*, and enjoy the shiny new Review Board site! To login as the Review Board admin, use the userid and password seen in the *rb-site* command above.
## Module cleanup
It’s good practice to clean up after yourself. To do that, remove the Review Board module and the site directory:
sudo dnf -y module remove reviewboard:3.0 sudo rm -rf /var/www/rev.local
## Closing remarks
Now that you’ve explored how to examine and administer the Review Board module, go experiment with the other modules available in Fedora 28.
Learn more about using modules in Fedora 28 on the [Fedora Modularity](https://docs.pagure.org/modularity/) web site. The *dnf* manual page’s *Module Command* section also contains useful information.
## Ricky Tigg
$ dnf module list
Fedora 28 – x86_64 – Updates 2.7 MB/s | 15 MB 00:05
Fedora 28 – x86_64 12 MB/s | 60 MB 00:05
Last metadata expiration check: 0:00:00 ago on Thu 07 Jun 2018 09:33:28 CEST.
Nothing to show.
## Merlin Mathesius
You don’t appear to have the modular repos enabled. If you’re using a Fedora 28 Server Edition system, something is wrong with your installation. If you’re using a non-server system, follow the link in the “Getting started” section above–but beware of the caveats!
## Ricky Tigg
Fedora 28 Desktop Edition. Repository named ‘Modular’ was not yet added.
## Matěj Koudelka
Try to install package fedora-repos-modular |
10,484 | 开始使用 WTF 吧,一款终端仪表板 | https://opensource.com/article/19/1/wtf-information-dashboard | 2019-01-27T23:29:00 | [
"监控",
"WTF"
] | https://linux.cn/article-10484-1.html |
>
> 使用 WTF 将关键信息置于视野之中,这个系列中第六个开源工具可使你在 2019 年更有工作效率。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源项目来帮助你在 2019 年更有效率。
### WTF
曾几何时,我在一家使用[彭博终端](https://en.wikipedia.org/wiki/Bloomberg_Terminal)的公司做咨询。我的反应是,“哇,在一个屏幕上显示的信息太多了。” 然而,现在,当我正在工作并且打开多个网页、仪表板和控制台应用程序以试图跟踪事物时,我似乎无法在屏幕上获得足够的信息。
虽然 [tmux](https://github.com/tmux/tmux) 和 [Screen](https://www.gnu.org/software/screen/) 可以进行分屏和打开多个窗口,但它们很难设置,并且它们的键绑定可能需要一段时间才能学会(还经常与其他应用程序冲突)。
[WTF](https://wtfutil.com/) 是一个简单的、易于配置的终端信息仪表板。它是用 [Go](https://golang.org/) 语言编写的,使用 YAML 配置文件,可以从几个不同的源提取数据。所有的数据源都包含在[模块](https://wtfutil.com/posts/modules/)中,包括天气、问题跟踪器、日期和时间、Google 表格以及更多内容。有些窗格是交互式的,有些窗格只是使用最新的信息进行更新。
安装它就像下载适用于您的操作系统的最新版本并运行命令一样简单。因为它是用 Go 编写的,所以它的移植性很好,应该可以在任何可以编译它的地方运行(尽管开发人员目前只为 Linux 和 MacOS 做了构建)。

当您第一次运行 WTF 时,您将看到如上图的默认屏幕。

其默认配置文件在 `~/.wtf/config.yml`,您可以编辑该文件以满足您的需要。网格布局的配置在文件的顶部。
```
grid:
columns: [45, 45]
rows: [7, 7, 7, 4]
```
网格设置中的数字表示每个块的字符尺寸。默认配置是两列,每列 40 个字符,两行 13 个字符高,一行 4 个字符高。在上面的代码中,我使列更宽(`45,45`),行更小,并添加了第四行,所以我可以放更多的小部件。

我喜欢在仪表板上看到当天的天气。有两个天气模块可供选择:[Weather](https://wtfutil.com/posts/modules/weather/),它只显示文本信息;[Pretty Weather](https://wtfutil.com/posts/modules/prettyweather/) 则色彩丰富,并使用基于文本的图形显示。
```
prettyweather:
enabled: true
position:
top: 0
left: 1
height: 2
width: 1
```
此代码创建了一个窗格,高为两个块(`height: 2`),宽为一个块(`width: 1`),位于顶行(`top: 0`)的第二列(`left: 1`)上,包含 Pretty Weather 模块.
一些模块是交互式的,如 Jira、GitHub 和 Todo,您可以在其中滚动、更新和保存信息。您可以使用 Tab 键在交互式窗格之间移动。`\` 键会显示活动窗格的帮助屏幕,以便您可以查看可以执行的操作以及操作方式。Todo 模块允许您添加、编辑和删除待办事项,并在完成后勾掉它们。

还有一些模块可以执行命令并显示输出、监视文本文件,以及监视构建和集成服务器的输出。所有文档都做得很好。
对于需要在不同来源的一个屏幕上查看大量数据的人来说,WTF 是一个有价值的工具。
---
via: <https://opensource.com/article/19/1/wtf-information-dashboard>
作者:[Kevein Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the sixth of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## WTF
Once upon a time, I was doing some consulting at a firm that used [Bloomberg Terminals](https://en.wikipedia.org/wiki/Bloomberg_Terminal). My reaction was, "Wow, that's WAY too much information on one screen." These days, however, it seems like I can't get enough information on a screen when I'm working and have multiple web pages, dashboards, and console apps open to try to keep track of things.
While [tmux](https://github.com/tmux/tmux) and [Screen](https://www.gnu.org/software/screen/) can do split screens and multiple windows, they are a pain to set up, and the keybindings can take a while to learn (and often conflict with other applications).
[WTF](https://wtfutil.com/) is a simple, easily configured information dashboard for the terminal. It is written in [Go](https://golang.org/), uses a YAML configuration file, and can pull data from several different sources. All the data sources are contained in [modules](https://wtfutil.com/posts/modules/) and include things like weather, issue trackers, date and time, Google Sheets, and a whole lot more. Some panes are interactive, and some just update with the most recent information available.
Setup is as easy as downloading the latest release for your operating system and running the command. Since it is written in Go, it is very portable and should run anywhere you can compile it (although the developer only builds for Linux and MacOS at this time).
When you run WTF for the first time, you'll get the default screen, identical to the image above.

You also get the default configuration file in **~/.wtf/config.yml**, and you can edit the file to suit your needs. The grid layout is configured in the top part of the file.
```
``````
grid:
columns: [45, 45]
rows: [7, 7, 7, 4]
```
The numbers in the grid settings represent the character dimensions of each block. The default configuration is two columns of 40 characters, two rows 13 characters tall, and one row 4 characters tall. In the code above, I made the columns wider (45, 45), the rows smaller, and added a fourth row so I can have more widgets.
I like to see the day's weather on my dashboard. There are two weather modules to chose from: [Weather](https://wtfutil.com/posts/modules/weather/), which shows just the text information, and [Pretty Weather](https://wtfutil.com/posts/modules/prettyweather/), which is colorful and uses text-based graphics in the display.
```
``````
prettyweather:
enabled: true
position:
top: 0
left: 1
height: 2
width: 1
```
This code creates a pane two blocks tall (height: 2) and one block wide (height: 1), positioned on the second column (left: 1) on the top row (top: 0) containing the Pretty Weather module.
Some modules, like Jira, GitHub, and Todo, are interactive, and you can scroll, update, and save information in them. You can move between the interactive panes using the Tab key. The \ key brings up a help screen for the active pane so you can see what you can do and how. The Todo module lets you add, edit, and delete to-do items, as well as check them off as you complete them.
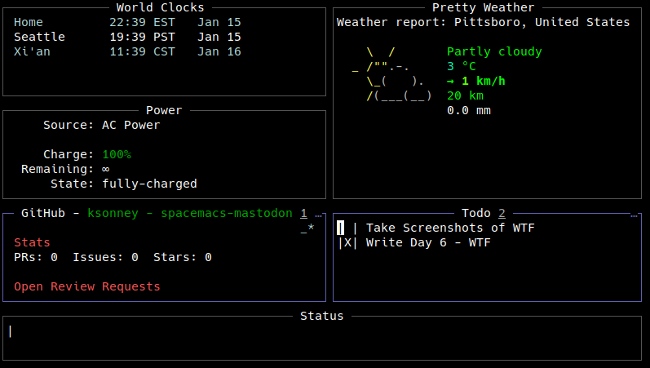
There are also modules to execute commands and present the output, watch a text file, and monitor build and integration server output. All the documentation is very well done.
WTF is a valuable tool for anyone who needs to see a lot of data on one screen from different sources.
## 2 Comments |
10,485 | Hello World 的由来 | https://www.thesoftwareguild.com/blog/the-history-of-hello-world/ | 2019-01-28T22:34:00 | [
"编程"
] | /article-10485-1.html | 
资深软件开发人员都知道 [Hello World](http://en.wikipedia.org/wiki/%22Hello,_World!%22_program) 程序,这是一个能在设备显示器上输出某种变体的 “Hello, World!” 的程序,是学习编程的第一步。在这个编程中只涉及到一些最基本语法的程序,可以用大多数编程语言了来编写。事实上,路易斯安纳理工学院计算机协会(ACM)在最近统计[发现](http://whatis.techtarget.com/definition/Hello-World)这个程序至少有 204 个版本。
传统意义上,Hello World 程序是用于说明编码过程是如何工作的,以及确保编程语言或系统能正常运行。它们经常是新手程序员学习的第一个程序,因为即使是经验很少或者没有经验的人也能轻松正确的执行 Hello World。
首先,Hello World 简单,这就是为什么它经常被用做程序执行成功的晴雨表。如果 Hello World 在该框架中无法有效执行,那么其它更复杂的程序中也可能会失败。正如 [Win-Vector](http://www.win-vector.com/blog/2008/02/hello-world-an-instance-rhetoric-in-computer-science/) 的一位专家所说,Hello World 实际上是一个对抗性程序。“该作者还说道,‘你的计算机系统能不能工作并不是一目了然,除非我能看到它至少能打印一行文字,否则我不会在上面浪费太多时间。’” Win-Vector 博主 John Mount 说。
但是这个两词短语在计算机科学领域有着重大的影响。以 Hello World 为基础,新手程序员可以轻松的理解计算机科学原理或元素,而拥有多年编码经验的程序员可以用它来学习编程语言的工作原理,特别是在结构与语法方面。这样的一个小程序,在任何难度的应用程序和几乎所有语言中都有着悠久的历史。
### 用途
以上概括了 Hello World 程序的主要用途:这是新手程序员熟悉新语言的一种方式。然而,这些程序不仅仅是对编码世界的介绍。例如,Hello World 可以作为测试,以确保语言的组件(编译器、开发和运行环境)安装正确。因为配置完整的编程工具链的过程复杂而漫长,所以像 Hello World 这样简单的程序通常用作新工具链的首次运行测试。
根据 Cunningham & Cunningham(C2)的编程顾问所说,在系统设计人员并不预期可以执行代码的地方,黑客经常使用 Hello World 程序作为一个可以通过漏洞执行任意代码的概念验证(POC)。事实上,它是在设备上使用自制内容或者“自酿”的第一步,当[有经验的编码人员](http://c2.com/cgi/wiki?HelloWorld)正在配置环境或在学习新事物时,他们会通过 Hello World 来验证其行为是否正确。
它也作为调试过程的一部分,允许程序员检查他们是否正确地编辑了可在运行时修改的程序并重新加载。
Hello World 的一个更常用的用途是作为基础比较。根据 C2 的 wiki 所讲,程序员可以“比较语言生成的可执行文件的大小,以及程序背后必须存在多少支持的基础设施才能执行。”
### 开端
虽然 Hello World 的起源还有些不太明了,不过人们普遍认为它作为测试用语,最早出现在 Brian Kernigham 在 1972 年发布的《<ruby> B 语言简介教程 <rt> A Tutorial Introduction to the Language B </rt></ruby>》中。在此文中,该程序的第一个已知版本用于说明外部变量。因为该教程中的前一个例子在终端上打印了 “hi!”,而需要更多的字符常量来表达相对复杂的 “hello,world!”,这是学习过程的下一步。
在那以后,它还被用于 1974 年的贝尔实验室备忘录,以及 1987 年的《<ruby> C 语言程序设计 <rt> The C Programming Language </rt></ruby>》。这两篇著名的文字是让 Hello World 闻名于世的主要原因。在书中的一个例子(第一个,也是最著名的例子)打印了没有大写字母和感叹号的 “hello,world”。此时的 Hello World 几乎只是用于说明语言的一些功能,而不是测试系统是否正常运行。
在 Kernigham 的关于 B 语言和 C 语言的开创性文章之前,没有真正意义上的第一个程序,甚至直到 1974 年,它也没被广泛使用。著名的 BASIC 教程 “<ruby> 我的电脑喜欢我用 BASIC 跟它讲话 <rt> My Computer Likes Me,When I Speak BASIC </rt></ruby>”,从一个写一行文本的简单程序开始,不过那句话是 “MY HUMAN UNDERSTANDS ME”,跟如今程序员侃侃而谈的这个双词问候语差的有点远。不过,当 Hello World 被发明后,它就迅速传播,并在 20 世纪 70 年代后变成了众所周知。直到今天它也依然受欢迎。
### 一个声明,多种语言
以下是目前正在被使用的一些流行的编程语言中的 Hello World 代码。
#### Java
```
class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, world!");
}
}
```
#### C#
```
using System;
class Program
{
public static void Main(string[] args)
{
Console.WriteLine("Hello, world!");
}
}
```
#### Python
```
print("Hello, world!")
```
#### Ruby
```
puts "Hello, world!"
```
#### Scala
```
object HelloWorld extends App {
println("Hello, world!")
}
```
#### ASP.NET
```
Response.Write("Hello World!");
```
#### Lisp
```
(princ "Hello, world!")
```
#### Haskell
```
main = putStrLn "Hello, world!"
```
#### Malbolge
```
('&%:9]!~}|z2Vxwv-,POqponl$Hjig%eB@@>}=<M:9wv6WsU2T|nm-,jcL(I&%$#"
`CB]V?Tx<uVtT`Rpo3NlF.Jh++FdbCBA@?]!~|4XzyTT43Qsqq(Lnmkj"Fhg${z@>
```
#### Go
```
package main
import "fmt"
func main() {
fmt.Println("Hello, world!")
}
```
### 如今的 Hello world:各种形式下的标准实践
在现在的编程语言中,Hello World 有着不同的复杂程度。例如,Go 语言中引入一个多语言版的 Hello World 程序,XL 则会提供一个具有图形、可旋转的 3D 版本。一些编程语言,像 Ruby、Python,仅仅需要一个语句去打印“Hello World”,但是低级汇编语言则需要几个命令才能做到这样。现在的编程语言还引入对标点符号和大小写的变化,包括是否有逗号或者感叹号,以及两个词的大写形式。举个例子,当系统只支持大写字母,会呈现像“HELLO WORLD”的短语。值得纪念的第一个 Malbolge 程序打印出了“HEllO WORld”(LCTT 译注:Malbolge 是最难的编程语言之一。事实上,在它诞生后,花了 2 年时间才完成第一个 Malbolge 程序)。它的变体跨越了原本的字面意思。像 Lisp、Haskell 这样函数语言,用阶乘程序替代了 Hello World,从而注重递归技术。这与原来的示例不同,后者更强调 I/O 以及产生的副作用。
随着现在的编程语言越来越复杂,Hello World 比以往显得更加重要。作为测试和教学工具,它已经成为程序员测试配置的编程环境的标准方法。没有人能确切说出为什么 Hello World 能在快速创新著称的行业中经受住时间的考验,但是它又确实留下来了。
---
via: <https://www.thesoftwareguild.com/blog/the-history-of-hello-world/>
作者:[thussong](https://www.thesoftwareguild.com/blog/author/thussong/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zzzzzzmj](https://github.com/zzzzzzmj) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='www.thesoftwareguild.com', port=443): Max retries exceeded with url: /blog/the-history-of-hello-world/ (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x7b83409d2e90>: Failed to resolve 'www.thesoftwareguild.com' ([Errno -2] Name or service not known)")) | null |
10,486 | 如何为你的 Linux 终端带来好运 | https://opensource.com/article/18/12/linux-toy-fortune | 2019-01-28T23:13:10 | [
"幸运",
"fortune"
] | https://linux.cn/article-10486-1.html |
>
> 使用 fortune 实用程序将名言和俏皮话带到命令行。
>
>
>

这是 12 月,如果你还没有找到一款能激发你灵感的[科技降临节日历](https://opensource.com/article/16/11/7-tech-advent-calendars-holiday-season),那么,也许这个系列可以。从现在到 24 日,每天我们都会为你带来一个不同的 Linux 命令行玩具。你可能会问,什么是命令行玩具?它可能是一个游戏或任何简单的娱乐程序,为你的终端带来一点点快乐。
你可能之前已经看过其中的一些,我们希望你也能发现一些新的东西。不管怎样,我们都希望你在关注时保有乐趣。
今天的玩具是 `fortune`,它很古老。它的版本可以追溯到 1980 年,当时它包含在 Unix 中。我在 Fedora 中安装的版本是在 BSD 许可下提供的,我可以使用以下命令获取它。(LCTT 译注:fortune 这个命令得名于 fortune cookies,是流行于西方的中餐馆的一种脆饼干,里面包含格言、幸运数字等。)
```
$ sudo dnf install fortune-mod -y
```
你的发行版可能会有所不同。在某些情况下,你可能需要在 `fortune` 命令之外单独安装那些“幸运饼干”(尝试在你的包管理器中搜索 “fortunes”)。你还可以在 [GitHub](https://github.com/shlomif/fortune-mod) 上查看它的源代码,然后,只需运行 `fortune` 即可获得好运。
```
$ fortune
"Time is an illusion. Lunchtime doubly so."
-- Ford Prefect, _Hitchhiker's Guide to the Galaxy_
```
那么,你为什么会在终端上需要 `fortune` 呢?当然是为了好玩啦。也许你想将它们添加到系统上的每天消息(motd)中?
就我个人而言,当我使用终端来解析文本时,我喜欢使用 `fortune` 命令作为一段内置的虚拟数据,特别是使用[正则表达式](https://opensource.com/article/18/5/getting-started-regular-expressions)时,我想要一些简单的东西来尝试一下。
例如,假设我使用 `tr` 命令来测试转换,用数字 3 替换字母 e。
```
$ fortune | tr 'eE' '3'
Unix 3xpr3ss:
All pass3ng3r bring a pi3c3 of th3 a3roplan3 and a box of tools with th3m to
th3 airport. Th3y gath3r on th3 tarmac, arguing constantly about what kind
of plan3 th3y want to build and how to put it tog3th3r. 3v3ntually, th3
pass3ng3rs split into groups and build s3v3ral diff3r3nt aircraft, but giv3
th3m all th3 sam3 nam3. Som3 pass3ng3rs actually r3ach th3ir d3stinations.
All pass3ng3rs b3li3v3 th3y got th3r3.
```
那么你的发行版带来了什么幸运饼干呢?看看你的 `/usr/share/games/fortune` 目录,找到它们。以下我最喜欢的几个。
```
Never laugh at live dragons.
-- Bilbo Baggins [J.R.R. Tolkien, "The Hobbit"]
I dunno, I dream in Perl sometimes...
-- Larry Wall in <[email protected]>
I have an existential map. It has "You are here" written all over it.
-- Steven Wright
```
关于 `fortune`想要了解更多?当然,你可以经常查看 man 页来了解更多选项,或者在[维基百科](https://en.wikipedia.org/wiki/Fortune_%28Unix%29)上阅读更多关于此命令的历史信息。
你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。请在评论区留言,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
看看昨天的玩具:[驾驶火车头通过你的 Linux 终端](https://opensource.com/article/18/12/linux-toy-sl)。记得明天再来!
---
via: <https://opensource.com/article/18/12/linux-toy-fortune>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's December, and if you haven't found a [tech advent calendar](https://opensource.com/article/16/11/7-tech-advent-calendars-holiday-season) that sparks your fancy yet, well, maybe this one will do the trick. Every day, from now to the 24th, we're bringing you a different Linux command-line toy. What's a command-line toy, you ask? It could be a game or any simple diversion to bring a little happiness to your terminal.
You may have seen some of these before. We hope you'll find something new, too. Either way, we hope you have fun following along.
Today's toy, **fortune**, is an old one. Versions of it date back to the 1980s when it was included with Unix. The version I installed in Fedora was available under a BSD license, and I grabbed it with the following.
`$ sudo dnf install fortune-mod`
Your distribution may be different. On some, you may need to install the fortunes separately from **fortune** itself (try searching your package manager for "fortunes*"). You can also check out the source code on [GitHub](https://github.com/shlomif/fortune-mod). Then, just run **fortune** to get, well, a fortune.
```
$ fortune
"Time is an illusion. Lunchtime doubly so."
-- Ford Prefect, _Hitchhiker's Guide to the Galaxy_
```
So why do you need fortunes at the terminal? For fun, of course. Perhaps you'd like to add them to the message of the day on your system?
Personally, I like using the **fortune** command as a built-in piece of dummy data when I'm using the terminal to parse text, particularly with [regular expressions](https://opensource.com/article/18/5/getting-started-regular-expressions), and want something simple to try it out on.
For example, let's say I was testing our a transformation with the **tr** command to replace letter the letter e with a numeral 3.
```
$ fortune | tr 'eE' '3'
Unix 3xpr3ss:
All pass3ng3r bring a pi3c3 of th3 a3roplan3 and a box of tools with th3m to
th3 airport. Th3y gath3r on th3 tarmac, arguing constantly about what kind
of plan3 th3y want to build and how to put it tog3th3r. 3v3ntually, th3
pass3ng3rs split into groups and build s3v3ral diff3r3nt aircraft, but giv3
th3m all th3 sam3 nam3. Som3 pass3ng3rs actually r3ach th3ir d3stinations.
All pass3ng3rs b3li3v3 th3y got th3r3.
```
So what fortunes come with your distribution? Take a look in your **/****usr****/share/games/fortune** directory to find them all. Here are a few of my favorites.
```
Never laugh at live dragons.
-- Bilbo Baggins [J.R.R. Tolkien, "The Hobbit"]
```
```
I dunno, I dream in Perl sometimes...
-- Larry Wall in <[email protected]>
```
```
I have an existential map. It has "You are here" written all over it.
-- Steven Wright
```
Looking for more on **fortune**? You can, of course, always check out the man page to learn more about the options, or read a little bit more about the history of the command on [Wikipedia](https://en.wikipedia.org/wiki/Fortune_%28Unix%29).
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Check out yesterday's toy, [Drive a locomotive through your Linux terminal](https://opensource.com/article/18/12/linux-toy-sl), and check back tomorrow for another!
## Comments are closed. |
10,487 | 使用 PyHamcrest 执行健壮的单元测试 | https://opensource.com/article/18/8/robust-unit-tests-hamcrest | 2019-01-29T00:33:20 | [
"断言",
"测试",
"Python"
] | https://linux.cn/article-10487-1.html |
>
> 使用此框架编写断言,提高开发测试的准确性。
>
>
>

在[测试金字塔](https://martinfowler.com/bliki/TestPyramid.html)的底部是单元测试。单元测试每次只测试一个代码单元,通常是一个函数或方法。
通常,设计单个单元测试是为了测试通过一个函数或特定分支的特定执行流程,这使得将失败的单元测试和导致失败的 bug 对应起来变得容易。
理想情况下,单元测试很少使用或不使用外部资源,从而隔离它们并使它们更快。
单元测试套件通过在开发过程的早期发现问题来帮助维护高质量的产品。有效的单元测试可以在代码离开开发人员机器之前捕获 bug,或者至少可以在特定分支上的持续集成环境中捕获 bug。这标志着好的和坏的单元测试之间的区别:*好的*测试通过尽早捕获 bug 并使测试更快来提高开发人员的生产力。*坏的*测试降低了开发人员的工作效率。
当测试*附带的特性*时,生产率通常会降低。当代码更改时测试会失败,即使它仍然是正确的。发生这种情况是因为输出的不同,但在某种程度上是因为它不是<ruby> 函数契约 <rt> function’s contract </rt></ruby>的一部分。
因此,一个好的单元测试可以帮助执行函数所提交的契约。
如果单元测试中断,那意味着该契约被违反了,应该(通过更改文档和测试)明确修改,或者(通过修复代码并保持测试不变)来修复。
虽然将测试限制为只执行公共契约是一项需要学习的复杂技能,但有一些工具可以提供帮助。
其中一个工具是 [Hamcrest](http://hamcrest.org/),这是一个用于编写断言的框架。最初是为基于 Java 的单元测试而发明的,但它现在支持多种语言,包括 [Python](https://www.python.org/)。
Hamcrest 旨在使测试断言更容易编写和更精确。
```
def add(a, b):
return a + b
from hamcrest import assert_that, equal_to
def test_add():
assert_that(add(2, 2), equal_to(4))
```
这是一个用于简单函数的断言。如果我们想要断言更复杂的函数怎么办?
```
def test_set_removal():
my_set = {1, 2, 3, 4}
my_set.remove(3)
assert_that(my_set, contains_inanyorder([1, 2, 4]))
assert_that(my_set, is_not(has_item(3)))
```
注意,我们可以简单地断言其结果是任何顺序的 `1`、`2` 和 `4`,因为集合不保证顺序。
我们也可以很容易用 `is_not` 来否定断言。这有助于我们编写*精确的断言*,使我们能够把自己限制在执行函数的公共契约方面。
然而,有时候,内置的功能都不是我们*真正*需要的。在这些情况下,Hamcrest 允许我们编写自己的<ruby> 匹配器 <rt> matchers </rt></ruby>。
想象一下以下功能:
```
def scale_one(a, b):
scale = random.randint(0, 5)
pick = random.choice([a,b])
return scale * pick
```
我们可以自信地断言其结果均匀地分配到至少一个输入。
匹配器继承自 `hamcrest.core.base_matcher.BaseMatcher`,重写两个方法:
```
class DivisibleBy(hamcrest.core.base_matcher.BaseMatcher):
def __init__(self, factor):
self.factor = factor
def _matches(self, item):
return (item % self.factor) == 0
def describe_to(self, description):
description.append_text('number divisible by')
description.append_text(repr(self.factor))
```
编写高质量的 `describe_to` 方法很重要,因为这是测试失败时显示的消息的一部分。
```
def divisible_by(num):
return DivisibleBy(num)
```
按照惯例,我们将匹配器包装在一个函数中。有时这给了我们进一步处理输入的机会,但在这种情况下,我们不需要进一步处理。
```
def test_scale():
result = scale_one(3, 7)
assert_that(result,
any_of(divisible_by(3),
divisible_by(7)))
```
请注意,我们将 `divisible_by` 匹配器与内置的 `any_of` 匹配器结合起来,以确保我们只测试函数提交的内容。
在编辑这篇文章时,我听到一个传言,取 “Hamcrest” 这个名字是因为它是 “matches” 字母组成的字谜。嗯…
```
>>> assert_that("matches", contains_inanyorder(*"hamcrest")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/moshez/src/devops-python/build/devops/lib/python3.6/site-packages/hamcrest/core/assert_that.py", line 43, in assert_that
_assert_match(actual=arg1, matcher=arg2, reason=arg3)
File "/home/moshez/src/devops-python/build/devops/lib/python3.6/site-packages/hamcrest/core/assert_that.py", line 57, in _assert_match
raise AssertionError(description)
AssertionError:
Expected: a sequence over ['h', 'a', 'm', 'c', 'r', 'e', 's', 't'] in any order
but: no item matches: 'r' in ['m', 'a', 't', 'c', 'h', 'e', 's']
```
经过进一步的研究,我找到了传言的来源:它是 “matchers” 字母组成的字谜。
```
>>> assert_that("matchers", contains_inanyorder(*"hamcrest"))
>>>
```
如果你还没有为你的 Python 代码编写单元测试,那么现在是开始的好时机。如果你正在为你的 Python 代码编写单元测试,那么使用 Hamcrest 将允许你使你的断言更加*精确*,既不会比你想要测试的多也不会少。这将在修改代码时减少误报,并减少修改工作代码的测试所花费的时间。
---
via: <https://opensource.com/article/18/8/robust-unit-tests-hamcrest>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | At the base of the [testing pyramid](https://martinfowler.com/bliki/TestPyramid.html) are unit tests. Unit tests test one unit of code at a time—usually one function or method.
Often, a single unit test is designed to test one particular flow through a function, or a specific branch choice. This enables easy mapping of a unit test that fails and the bug that made it fail.
Ideally, unit tests use few or no external resources, isolating them and making them faster.
Unit test suites help maintain high-quality products by signaling problems early in the development process. An effective unit test catches bugs before the code has left the developer machine, or at least in a continuous integration environment on a dedicated branch. This marks the difference between good and bad unit tests: *Good* tests increase developer productivity by catching bugs early and making testing faster. *Bad* tests decrease developer productivity.
Productivity usually decreases when testing *incidental features*. The test fails when the code changes, even if it is still correct. This happens because the output is different, but in a way that is not part of the function's contract.
A good unit test, therefore, is one that helps enforce the contract to which the function is committed.
If a unit test breaks, the contract is violated and should be either explicitly amended (by changing the documentation and tests), or fixed (by fixing the code and leaving the tests as is).
While limiting tests to enforce only the public contract is a complicated skill to learn, there are tools that can help.
One of these tools is [Hamcrest](http://hamcrest.org/), a framework for writing assertions. Originally invented for Java-based unit tests, today the Hamcrest framework supports several languages, including [Python](https://www.python.org/).
Hamcrest is designed to make test assertions easier to write and more precise.
```
def add(a, b):
return a + b
from hamcrest import assert_that, equal_to
def test_add():
assert_that(add(2, 2), equal_to(4))
```
This is a simple assertion, for simple functionality. What if we wanted to assert something more complicated?
```
def test_set_removal():
my_set = {1, 2, 3, 4}
my_set.remove(3)
assert_that(my_set, contains_inanyorder([1, 2, 4]))
assert_that(my_set, is_not(has_item(3)))
```
Note that we can succinctly assert that the result has `1`
, `2`
, and `4`
in any order since sets do not guarantee order.
We also easily negate assertions with `is_not`
. This helps us write *precise assertions*, which allow us to limit ourselves to enforcing public contracts of functions.
Sometimes, however, none of the built-in functionality is *precisely* what we need. In those cases, Hamcrest allows us to write our own matchers.
Imagine the following function:
```
def scale_one(a, b):
scale = random.randint(0, 5)
pick = random.choice([a,b])
return scale * pick
```
We can confidently assert that the result divides into at least one of the inputs evenly.
A matcher inherits from `hamcrest.core.base_matcher.BaseMatcher`
, and overrides two methods:
```
class DivisibleBy(hamcrest.core.base_matcher.BaseMatcher):
def __init__(self, factor):
self.factor = factor
def _matches(self, item):
return (item % self.factor) == 0
def describe_to(self, description):
description.append_text('number divisible by')
description.append_text(repr(self.factor))
```
Writing high-quality `describe_to`
methods is important, since this is part of the message that will show up if the test fails.
```
def divisible_by(num):
return DivisibleBy(num)
```
By convention, we wrap matchers in a function. Sometimes this gives us a chance to further process the inputs, but in this case, no further processing is needed.
```
def test_scale():
result = scale_one(3, 7)
assert_that(result,
any_of(divisible_by(3),
divisible_by(7)))
```
Note that we combined our `divisible_by`
matcher with the built-in `any_of`
matcher to ensure that we test only what the contract commits to.
While editing this article, I heard a rumor that the name "Hamcrest" was chosen as an anagram for "matches". Hrm...
```
>>> assert_that("matches", contains_inanyorder(*"hamcrest")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/moshez/src/devops-python/build/devops/lib/python3.6/site-packages/hamcrest/core/assert_that.py", line 43, in assert_that
_assert_match(actual=arg1, matcher=arg2, reason=arg3)
File "/home/moshez/src/devops-python/build/devops/lib/python3.6/site-packages/hamcrest/core/assert_that.py", line 57, in _assert_match
raise AssertionError(description)
AssertionError:
Expected: a sequence over ['h', 'a', 'm', 'c', 'r', 'e', 's', 't'] in any order
but: no item matches: 'r' in ['m', 'a', 't', 'c', 'h', 'e', 's']
```
Researching more, I found the source of the rumor: It is an anagram for "matchers".
```
>>> assert_that("matchers", contains_inanyorder(*"hamcrest"))
>>>
```
If you are not yet writing unit tests for your Python code, now is a good time to start. If you are writing unit tests for your Python code, using Hamcrest will allow you to make your assertion *precise*—neither more nor less than what you intend to test. This will lead to fewer false positives when modifying code and less time spent modifying tests for working code.
## Comments are closed. |
10,488 | Linux 终端上的漂亮小马 | https://opensource.com/article/18/12/linux-toy-ponysay | 2019-01-29T20:18:59 | [
"终端"
] | https://linux.cn/article-10488-1.html |
>
> 将小马宝莉的魔力带到终端
>
>
>

欢迎再次来到 Linux 命令行玩具日历。如果这是你第一次访问该系列,你甚至可能会问自己什么是命令行玩具。我们正在思考中,但一般来说,它可能是一个游戏,或任何简单的消遣,可以帮助你在终端玩得开心。
很可能你们中的一些人之前已经看过我们日历中的各种玩具,但我们希望每个人至少见到一件新事物。
读者 [Lori](https://opensource.com/users/n8chz) 在我之前关于 [cowsay](https://opensource.com/article/18/12/linux-toy-cowsay) 的文章的评论中提出了今天玩具的建议:
“嗯,我一直在玩一个叫 ponysay 的东西,它似乎是你的 cowsay 的彩色变种。”
我对此感到好奇,并去看了一下,发现没有让我失望。
简而言之,[ponysay](https://github.com/erkin/ponysay) 的 cowsay 的重写,它包括了来自[小马宝莉](https://en.wikipedia.org/wiki/My_Little_Pony)中的许多全彩色人物,你可以用它在 Linux 命令行输出短句。它实际上是一个非常完善的项目,拥有超过 400 个字符和字符组合,它还有让人难以置信的的 [78 页的 PDF 文档](https://github.com/erkin/ponysay/blob/master/ponysay.pdf?raw=true)涵盖了所有的用法。
要安装 `ponysay`,你需要查看项目的 [README](https://github.com/erkin/ponysay/blob/master/README.md) 来选择最适合你的发行版和情况的安装方法。由于 `ponysay` 似乎没有为我的 Fedora 发行版打包,我选择试用 Docker 容器镜像,但你可以选择最适合你的方法。从源码安装可能也适合你。
作为一个业余容器用户,我很想试试 [podman](https://opensource.com/article/18/10/podman-more-secure-way-run-containers) 来代替 docker。至少对于我而言,它可以正常工作。
```
$ podman run -ti --rm mpepping/ponysay 'Ponytastic'
```
输出很神奇,我建议你也试下,然后告诉我你最喜欢的。这是我其中一个:

它的开发人员选择用 [Pony](https://opensource.com/article/18/5/pony) 来编写代码。(更新:很遗憾我写错了。虽然 Gihutb 根据它的文件扩展名认为它是 Pony,但是它是用 Python 写的。)Ponysay 使用 GPLv3 许可,你可以在 [GitHub](https://github.com/erkin/ponysay) 中获取它的源码。
你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。如果你有特别想了解的可以评论留言,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
查看昨天的玩具,[在 Linux 终端中用火焰放松](https://opensource.com/article/18/12/linux-toy-aafire),记得明天再来!
---
via: <https://opensource.com/article/18/12/linux-toy-ponysay>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Welcome to another day of the Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is. We’re figuring that out as we go, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
Some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
Reader [Lori](https://opensource.com/users/n8chz) made the suggestion of today's toy in a comment on my previous article on [cowsay](https://opensource.com/article/18/12/linux-toy-cowsay):
*"Hmmm, I've been playing with something called **ponysay** which seems to be a full-color variant on your cowsay."*
Intrigued, I had to check it out, and I was not disappointed with what I found.
In a nutshell, ** ponysay** is exactly that: a rewrite of
**cowsay**that includes many full-color characters from
[My Little Pony](https://en.wikipedia.org/wiki/My_Little_Pony), that you can use to output phrases at the Linux command line. It's actually a really well-done project, that features over 400 characters and character combinations, and is incredibly well documented in a
[78-page PDF](https://github.com/erkin/ponysay/blob/master/ponysay.pdf?raw=true)covering full usage.
To install **ponysay**, you'll want to check out the project [README](https://github.com/erkin/ponysay/blob/master/README.md) to select the installation method that works best for your distribution and situation. Since ponysay didn't appear to be packaged for my distribution, Fedora, I opted to try out the Docker container image, but do what works best for you; installation from source may also work for you.
I was curious to try out [ podman](https://opensource.com/article/18/10/podman-more-secure-way-run-containers) as a drop-in replacement for
**docker**for a casual container users, and for me at least, it just worked!
`$ podman run -ti --rm mpepping/ponysay 'Ponytastic'`
The outputs are amazing, and I challenge you to try it out and let me know your favorite. Here was one of mine:

~~It's~~~~ developers chose to write the code in ~~ [Pony](https://opensource.com/article/18/5/pony)!*(Update: Sadly, I was wrong about this. It's written in Python, though GitHub believes it to be Pony because of the file extensions.)* Ponysay is licensed under the GPL version 3, and you can pick up its source code [on GitHub](https://github.com/erkin/ponysay).
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Check out yesterday's toy, [Relax by the fire at your Linux terminal](https://opensource.com/article/18/12/linux-toy-aafire), and check back tomorrow for another!
## 5 Comments |
10,490 | 5 个用于 SOHO 的 Linux 服务器发行版 | https://www.linux.com/blog/learn/2019/1/top-5-linux-server-distributions | 2019-01-29T21:54:38 | [
"服务器",
"SOHO"
] | https://linux.cn/article-10490-1.html |
>
> Jack Wallen 为 Linux 服务器发行版提供了一些可靠的选择,绝对值回票价。
>
>
>

啊,这个古老的问题:哪种 Linux 发行版最适合做服务器?通常,问这种问题时,所浮现出来的标准的答复就是:
* RHEL
* SUSE
* Ubuntu 服务器
* Debian
* CentOS
然而,假如你将眼界放得更宽(不将服务器只看做是 IDC 托管的那种互联网服务器时),可能答案会有点不同。我准备稍微来点不同的。我想做出一个满足入选标准的发行版列表,这些发行版不仅是优秀的候选者,而且易于使用,可以为你的业务中的许多功能提供服务。在某些情况下,我选择的是一些替代品,可以取代其它需要一些工作才能达成要求的操作系统。
我的一些选择是企业级服务器的社区版本,它们可以被视为购买更强大平台的入门级产品。你甚至可以在这里找到一两个作为特定任务平台的候选者。然而,最重要的是,你在此列表中找到的并非寻常的泛泛之辈。
### ClearOS
什么是 ClearOS?对于家庭和小型企业用途,你可能找不到比它更好的解决方案。ClearOS 开箱即用,包括了入侵检测、强大的防火墙、带宽管理工具、邮件服务器、域控制器等工具。其目的是将服务器作为一个简单的家庭和 SOHO 服务器,并具有用户友好的基于 Web 的图形化界面,这使得 ClearOS 在某些评比中脱颖而出。从其界面中,你可以找到一个应用程序市场(图 1),其中包含数百个应用程序(其中一些是免费的,而另一些则具有相关费用),这使得扩展 ClearOS 功能集非常容易。换句话说,你可以将 ClearOS 作为你的家庭和小型企业所需的平台。最重要的是,与许多其他替代方案不同,你只需支付所需的软件和支持。

*图 1:ClearOS 应用程序市场*
有三种版本的 ClearOS:
* [ClearOS Community](https://www.clearos.com/clearfoundation/software/clearos-7-community) - 免费版 ClearOS
* [ClearOS Home](https://www.clearos.com/products/clearos-editions/clearos-7-home) - 适于家庭办公
* [ClearOS Business](https://www.clearos.com/products/clearos-editions/clearos-7-business) - 适于小型企业,包括了付费支持。
为了使软件安装更加容易,ClearOS 应用市场允许你通过以下方式进行选择软件:
\* 按功能(根据任务显示应用程序) \* 按类别(显示相关应用程序组) \* 快速选择文件(允许你按预先配置的模板选择,以帮助你快速启动和运行)
换句话说,如果你正在寻找 Linux 的家庭、SOHO 或 SMB 服务器,ClearOS 是一个出色的选择(特别是如果你没有启动和运行标准的 Linux 服务器的能力时)。
### Fedora 服务器
你肯定听说过 Fedora Linux。它是市场上最好的前沿发行版之一。但是你知道这个出色的 Fedora 桌面发行版的开发者们也开发了服务器版吗?Fedora 服务器平台是一个短生命周期的、社区支持的服务器操作系统。这使得经验丰富的、或对任何类型的 Linux(或任何操作系统)有经验的系统管理员,可以使用开源社区中提供的最新技术。在这段描述中有三个关键词:
* 经验丰富
* 系统
* 管理员
换言之,新用户就不要考虑了。虽然 Fedora 服务器完全能够处理你抛出的任何任务,但它需要一些拥有更多的 Linux 功夫的人来使它工作并且运行良好。Fedora 服务器非常好的一点是,开箱即用,它包括了市场上用于服务器的开源的基于 Web 的最好的界面之一。通过 Cockpit(图 2),你可以快速浏览系统资源、日志、存储、网络以及拥有管理帐户、服务、应用程序和更新的能力。

*图 2:运行在 Fedora 服务器上的 Cockpit*
如果你可以使用最前沿的软件,并想要一个出色的管理仪表板,Fedora 服务器可能就是你要的平台。
### NethServer
正如你所发现的那样,NethServer 是每个人都知道的简单 SMB Linux 服务器。通过 NethServer 的最新版本,你的小型企业将得到:
* 内置 Samba 活动目录控制器 \* 与 Nextcloud 的无缝集成 \* 证书管理 \* HTTPS 透明代理 \* 防火墙 \* 邮件服务器和过滤器 \* Web 服务器和过滤器 \* 群件 \* IPS / IDS 或 VPN
所有包含的功能都可以通过用户友好的基于 Web 的界面轻松配置,包括单击安装模块以扩展 NethServer 功能集(图 3)。NethServer 与 ClearOS 的区别在于它的设计目的是使管理工作更轻松。换句话说,这个平台提供了更多的灵活性和功能。与面向家庭办公室和 SOHO 部署的 ClearOS 不同,NethServer 在小型商业环境中用起来就像在家庭里使用一样方便。

*图 3:给 NethServer 添加模块*
### Rockstor
Rockstor 是采用 Linux 和 Btfrs 的高级网络附加存储(NAS)和云存储服务器,可部署用于家庭、SOHO 以及中小型企业。借助 Rockstor,你可以获得一个完整的 NAS /云解决方案,其中包含一个用户友好的基于 Web 的 GUI 工具,管理员可以像普通用户一样轻松使用它来设置。一旦部署好了 Rockstor,你就可以创建存储池、共享、快照、管理复制和用户、共享文件(借助 Samba、NFS、SFTP 和 AFP),甚至扩展它的功能集,这要归功于附加组件(称为 Rock-ons)。Rock-ons 列表包括:
* CouchPotato(Usenet 和 BitTorrent 用户的下载器)
* Deluge(BitTorrent 用户的电影下载器)
* EmbyServer(Emby 媒体服务器)
* Ghost(专业博主的发布平台)
* GitLab CE(Git 仓库托管和协作)
* Gogs Go Git Service(轻量级 Git 版本控制服务器和前端)
* Headphones(NZB 和 Torrent 的音乐自动下载器)
* 用于 Squeezebox 设备的罗技 Squeezebox 服务器
* MariaDB(关系型数据管理系统)
* NZBGet(高效的 usenet 下载器)
* OwnCloud-Official(安全的文件共享和托管)
* Plexpy(基于 Python 的 Plex 用量跟踪器)
* Rocket.Chat(开源聊天平台)
* SaBnzbd(Usenet 下载器)
* Sickbeard(用于电视节目的互联网个人视频录像机)
* Sickrage(电视节目的自动视频库管理器)
* Sonarr(Usenet 和 BitTorrent 用户的个人视频录像机)
* Symform(备份设备)
Rockstor 还包括了一目了然的仪表板,使管理员可以快速访问他们所需的有关其服务器的所有信息(图 4)。

*图 4: Rockstor 面板*
### Zentyal
Zentyal 是另一个小型企业服务器,可以很好地处理多个任务。如果你正在寻找可以处理以下内容的 Linux 发行版:
* 目录和域服务器
* 邮件服务器
* 网关
* DHCP、DNS 和 NTP 服务器
* 认证机构(CA)
* VPN
* 实时消息(IM)
* FTP 服务器
* 反病毒
* SSO 认证
* 文件共享
* RADIUS 认证
* 虚拟化管理
* 等等
Zentyal 可能是你的新选择。从 2004 年 Zentyal 就存在了,它基于 Ubuntu Server,因此它拥有坚实的基础和丰富的应用程序。在 Zentyal 仪表板的帮助下(图 5),管理员可以轻松管理:
* 系统
* 网络
* 日志
* 软件更新和安装
* 用户/组
* 域
* 文件共享
* 邮件
* DNS
* 防火墙
* 证书
* 等等

*图 5:Zentyal 仪表板*
向 Zentyal 服务器添加新组件只需要打开仪表板,单击“软件管理” -> “Zentyal 组件”,选择要添加的组件,然后单击安装。Zentyal 可能会遇到的一个问题是,它提供不了与 Nethserver 和 ClearOS 一样多的插件。但它提供的服务,则做得非常好。
### 更多来自于
这个 Linux 服务器列表显然不是详尽无遗的。然而,这是一种对你可能没有听说过的五大服务器发行版的独特视角。当然,如果你更愿意使用更传统的 Linux 服务器发行版,你可以随时坚持使用 [CentOS](https://www.centos.org/)、[Ubuntu 服务器](https://www.ubuntu.com/download/server)、[SUSE](https://www.suse.com/)、[RHEL](https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux) 或 [Debian](https://www.debian.org/)……它们大多都出现在市场上最好的服务器发行版列表中。但是,如果你正在寻找一些不同的东西,那么试试这五个发行版中的一个。
通过 Linux 基金会和 edX 的免费[“Linux 简介”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)课程了解有关 Linux 的更多信息。
---
via: <https://www.linux.com/blog/learn/2019/1/top-5-linux-server-distributions>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,491 | 如何开源你的 Python 库 | https://opensource.com/article/18/12/tips-open-sourcing-python-libraries | 2019-01-30T17:52:39 | [
"Python"
] | /article-10491-1.html |
>
> 这 12 个步骤能确保成功发布。
>
>
>

你写了一个 Python 库。自己觉着这太棒了!如果让人们能够轻松使用它不是很优雅么?这有一个需要考虑的清单,以及在开源 Python 库时要采取的具体步骤。
### 1、源码
将代码放在 [GitHub](https://github.com/) 上,这里有很多开源项目,并且人们很容易提交拉取请求。
### 2、许可证
选择一个开源许可证。一般来说 [MIT 许可证](https://en.wikipedia.org/wiki/MIT_License)是一个挺好的宽容许可证。如果你有特定要求,Creative Common 的[选择许可证](https://choosealicense.com/)可以指导你完成其它选择。最重要的是,在选择许可证时要记住三条规则:
* 不要创建自己的许可证。
* 不要创建自己的许可证。
* 不要创建自己的许可证。
### 3、README
将一个名为 `README.rst` 的文件(使用 ReStructured Text 格式化)放在项目树的顶层。
GitHub 将像 Markdown 一样渲染 ReStructured Text,而 ReST 在 Python 的文档生态系统中的表现更好。
### 4、测试
写测试。这对你来说没有用处。但对于想要编写避免破坏相关功能的补丁的人来说,它非常有用。
测试可帮助协作者进行协作。
通常情况下,如果可以用 [pytest](https://docs.pytest.org/en/latest/) 运行就最好了。还有其他测试工具 —— 但很少有理由去使用它们。
### 5、样式
使用 linter 制定样式:PyLint、Flake8 或者带上 `--check` 的 Black 。除非你使用 Black,否则请确保在一个文件中指定配置选项,并签入到版本控制系统中。
### 6、API 文档
使用 docstrings 来记录模块、函数、类和方法。
你可以使用几种样式。我更喜欢 [Google 风格的 docstrings](https://github.com/google/styleguide/blob/gh-pages/pyguide.md),但 [ReST docstrings](https://www.python.org/dev/peps/pep-0287/) 也是一种选择。
Sphinx 可以同时处理 Google 风格和 ReST 的 docstrings,以将零散的文档集成为 API 文档。
### 7、零散文档
使用 [Sphinx](http://www.sphinx-doc.org/en/master/)。(阅读[我们这篇文章](https://opensource.com/article/18/11/building-custom-workflows-sphinx)。)教程很有用,但同样重要的是要指明这是什么、它有什么好处、它有什么坏处、以及任何特殊的考虑因素。
### 8、构建
使用 tox 或 nox 自动运行测试和 linter,并构建文档。这些工具支持“依赖矩阵”。这些矩阵往往会快速增长,但你可以尝试针对合理的样本进行测试,例如 Python 版本、依赖项版本以及可能安装的可选依赖项。
### 9、打包
使用 [setuptools](https://pypi.org/project/setuptools/) 工具。写一个 `setup.py` 和一个 `setup.cfg`。如果同时支持 Python 2 和 3,请在 `setup.cfg` 中指定 universal 格式的 wheel。
tox 或 nox 应该做的一件事是构建 wheel 并对已安装的 wheel 进行测试。
避免使用 C 扩展。如果出于性能或绑定的原因一定需要它们,请将它们放在单独的包中。正确打包 C 扩展可以写一篇新的文章。这里有很多问题!
### 10、持续集成
使用公共持续工具。[TravisCI](https://travis-ci.org/) 和 [CircleCI](https://circleci.com/) 为开源项目提供免费套餐。将 GitHub 或其他仓库配置为在合并拉请求之前需要先通过检查,那么你就不必担心在代码评审中告知用户修复测试或样式。
### 11、版本
使用 [SemVer](https://semver.org/) 或 [CalVer](https://calver.org/)。有许多工具可以帮助你管理版本:[incremental](https://pypi.org/project/incremental/)、[bumpversion](https://pypi.org/project/bumpversion/) 和 [setuptools\_scm](https://pypi.org/project/setuptools_scm/) 等都是 PyPI 上的包,都可以帮助你管理版本。
### 12、发布
通过运行 tox 或 nox 并使用 twine 将文件上传到 PyPI 上发布。你可以通过在 [DevPI](https://opensource.com/article/18/7/setting-devpi) 中“测试上传”。
---
via: <https://opensource.com/article/18/12/tips-open-sourcing-python-libraries>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,492 | 5 款开源的 Linux 策略模拟游戏 | https://opensource.com/article/18/8/strategy-simulation-games-linux | 2019-01-30T18:40:00 | [
"游戏"
] | https://linux.cn/article-10492-1.html |
>
> 用这些开源游戏来挑战你的战略技能,探索新世界。
>
>
>

长久以来,游戏都是 Linux 的软肋。近些年,Steam、GOG 等游戏发布平台上不少商业游戏都开始支持 Linux,这对于 Linux 的游戏生态来说是件好事,但是我们能在这些平台上玩到的游戏通常是不开源的商业作品。当然,这些游戏在一个开源的操作系统上运行,但对于一个开源提倡者来说这似乎还不够纯粹。
那么,我们能找到既自由开源又能给玩家带来完整游戏体验的优质游戏吗?当然!虽然绝大多数的开源游戏很难和 3A 商业游戏大作竞争,但仍然有不少各种类型的开源游戏,不仅内容有趣而且直接可以通过几大 Linux 发行版本库中直接安装。就算某个游戏在不在某个发行版本的库中,我们也可以在这个游戏项目的网站上找到直接的安装方法。
本篇文章将会介绍策略和模拟类游戏。我已经写了[街机游戏](/article-10433-1.html)、[桌面卡牌游戏](https://opensource.com/article/18/3/card-board-games-linux)、[解谜游戏](https://opensource.com/article/18/6/puzzle-games-linux)、[竞速飞行游戏](https://opensource.com/article/18/7/racing-flying-games-linux)以及[角色扮演游戏](https://opensource.com/article/18/8/role-playing-games-linux)。
### 开源版“文明”(Freeciv)

[Freeciv](http://www.freeciv.org/) 可以被视为是[文明系列](https://en.wikipedia.org/wiki/Civilization_(series))游戏的开源版本。游戏玩法和文明系列最早期的游戏十分类似,Freeciv 可以让玩家选择选用文明 1 或者文明 2 中的游戏规则设置。Freeciv 中包含了很多元素,例如建造城市、探索世界地图、发展科技以及和其他扩张中的文明竞争。胜利条件包括打败所有其他的文明或建立一个外星殖民地,如果在前两者都没有达成的话,在游戏时间期限前存活下来也可以算作胜利。这个游戏可以和其他玩家联机也可以和 AI 对战,不同的地图集可以改变游戏的外观。
安装 Freeciv,你只需要在终端下运行以下指令。
* Fedora 用户: `dnf install freeciv`
* Debian/Ubuntu 用户:`apt install freeciv`
### MegaGlest

[MegaGlest](https://megaglest.org/) 是一个开源的实时战略游戏,类似暴雪公司制作的游戏[魔兽世界](https://en.wikipedia.org/wiki/Warcraft)和[星际争霸](https://en.wikipedia.org/wiki/StarCraft)。玩家控制不同派别的人员、建造新建筑、招募士兵、拓展领土并与敌人作战。在游戏比赛的最开始,玩家仅能建造最基础的建筑和招募最基础的士兵。为了建造更高级的建筑并招募级别更高的人员,玩家必须通过增加建筑和人员从而一路提高科技树、解锁更加高级的选项。当敌人进入国土领域之中,战斗单元将会迎战。但是最好的应对策略是,通过控制战斗单元直接操控每一场战斗。在管理新建筑的建立,新人员的招募的同时控制战斗局势听上去十分困难,但是这就是 RTS(实时战略游戏)游戏的精华所在。MegaGlest 这个游戏提供了大量的人员派别,玩家可以不断尝试这些不同的技巧。
安装 MegaGlest,你只需要在终端下运行以下指令:
* Fedora 用户: `dnf install megaglest`
* Debian/Ubuntu 用户:`apt install megaglest`
### 开源版“运输大亨”(OpenTTD)

[OpenTTD](https://www.openttd.org/)(见我们的 [评测](https://opensource.com/life/15/7/linux-game-review-openttd) )是一个开源实现的 [运输大亨](https://en.wikipedia.org/wiki/Transport_Tycoon#Transport_Tycoon_Deluxe) 。该游戏的目的在于创建一个交通运输网络并获得金钱,从而建立更加复杂的运输网络。这个运输网络包括了船只、巴士、火车、货车和飞机。默认的游戏时间在 1950 和 2050 之间,玩家的目标就是在规定时间内拿到最高的游戏分数。游戏的最终分数基于很多因素,例如货物运输的数量、玩家所拥有的汽车数量以及他们赚到的钱。
安装 OpenTTD,你只需要在终端运行以下指令:
* Fedora 用户: `dnf install openttd`
* Debian/Ubuntu 用户 `apt install openttd`
### <ruby> 韦诺之战 <rt> The Battle for Wesnoth </rt></ruby>

[韦诺之战](https://www.wesnoth.org/) 是目前最完善的开源游戏之一。这个回合制游戏在一个奇幻的故事设定下。游戏在一个六角形网格中进行,各个单元可以互相操作进行战斗。每个类型的单元都有它独特的能力和弱点,因此玩家需要根据这些特点来设计不同的行动。韦诺之战中有很多不同的行动分支,每个行动分支都有它特别的故事线和目标。韦诺之战同时也有一个地图编辑器,感兴趣的玩家可以创作自己的地图以及行动分支。
安装韦诺之战,你只需要在终端运行以下指令:
* Fedora 用户: `dnf install wesnoth`
* Debian/Ubuntu 用户: `apt install wesnoth`
### <ruby> UFO:外星入侵 <rt> UFO: Alien Invasion </rt></ruby>

[UFO: Alien Invasion](https://ufoai.org/) 是一个开源策略游戏,基于 <ruby> <a href="https://en.wikipedia.org/wiki/X-COM"> 幽浮系列 </a> <rt> X-COM </rt></ruby>。 有两个不同的游戏模式: geoscape 和 tactical。在 geoscape 模式下,玩家控制大局、管理基地、开发新技术以及掌控整体策略。 在 tactical 游戏模式下,玩家控制一群士兵并且以回合制的形式直接迎战外星侵略者。两个游戏模式提供了不同的游戏玩法,两者都需要相当复杂的策略和战术。
安装这个游戏,你只需要在终端下运行以下指令:
* Debian/Ubuntu 用户: `apt install ufoai`
遗憾的是,UFO: 外星入寝不支持 Fedora 发行版。
如果你知道除了这些以外的开源策略模拟游戏的话,欢迎在评论中分享。
---
via: <https://opensource.com/article/18/8/strategy-simulation-games-linux>
作者:[Joshua Allen Holm](https://opensource.com/users/holmja) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Scoutydren](https://github.com/Scoutydren) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Gaming has traditionally been one of Linux's weak points. That has changed somewhat in recent years thanks to Steam, GOG, and other efforts to bring commercial games to multiple operating systems, but those games are often not open source. Sure, the games can be played on an open source operating system, but that is not good enough for an open source purist.
So, can someone who only uses free and open source software find games that are polished enough to present a solid gaming experience without compromising their open source ideals? Absolutely. While open source games are unlikely ever to rival some of the AAA commercial games developed with massive budgets, there are plenty of open source games, in many genres, that are fun to play and can be installed from the repositories of most major Linux distributions. Even if a particular game is not packaged for a particular distribution, it is usually easy to download the game from the project's website to install and play it.
This article looks at strategy and simulation games. I have already written about [arcade-style games](https://opensource.com/article/18/1/arcade-games-linux), [board & card games](https://opensource.com/article/18/3/card-board-games-linux), [puzzle games](https://opensource.com/article/18/6/puzzle-games-linux), [racing & flying games](https://opensource.com/article/18/7/racing-flying-games-linux), and [role-playing games](https://opensource.com/article/18/8/role-playing-games-linux).
## Freeciv
[Freeciv](http://www.freeciv.org/) is an open source version of the [Civilization series](https://en.wikipedia.org/wiki/Civilization_(series)) of computer games. Gameplay is most similar to the earlier games in the Civilization series, and Freeciv even has options to use Civilization 1 and Civilization 2 rule sets. Freeciv involves building cities, exploring the world map, developing technologies, and competing with other civilizations trying to do the same. Victory conditions include defeating all the other civilizations, developing a space colony, or hitting deadline if neither of the first two conditions are met. The game can be played against AI opponents or other human players. Different tile-sets are available to change the look of the game's map.
To install Freeciv, run the following command:
- On Fedora:
`dnf install freeciv`
- On Debian/Ubuntu:
`apt install freeciv`
## MegaGlest
[MegaGlest](https://megaglest.org/) is an open source real-time strategy game in the style of Blizzard Entertainment's [Warcraft](https://en.wikipedia.org/wiki/Warcraft) and [StarCraft](https://en.wikipedia.org/wiki/StarCraft) games. Players control one of several different factions, building structures and recruiting units to explore the map and battle their opponents. At the beginning of the match, a player can build only the most basic buildings and recruit the weakest units. To build and recruit better things, players must work their way up their factions technology tree by building structures and recruiting units that unlock more advanced options. Combat units will attack when enemy units come into range, but for optimal strategy, it is best to manage the battle directly by controlling the units. Simultaneously managing the construction of new structures, recruiting new units, and managing battles can be a challenge, but that is the point of a real-time strategy game. MegaGlest provides a nice variety of factions, so there are plenty of reasons to try new and different strategies.
To install MegaGlest, run the following command:
- On Fedora:
`dnf install megaglest`
- On Debian/Ubuntu:
`apt install megaglest`
## OpenTTD
[OpenTTD](https://www.openttd.org/) (see also [our review](https://opensource.com/life/15/7/linux-game-review-openttd)) is an open source implementation of [Transport Tycoon Deluxe](https://en.wikipedia.org/wiki/Transport_Tycoon#Transport_Tycoon_Deluxe). The object of the game is to create a transportation network and earn money, which allows the player to build an even bigger transportation network. The network can include boats, buses, trains, trucks, and planes. By default, gameplay takes place between 1950 and 2050, with players aiming to get the highest performance rating possible before time runs out. The performance rating is based on things like the amount of cargo delivered, the number of vehicles they have, and how much money they earned.
To install OpenTTD, run the following command:
- On Fedora:
`dnf install openttd`
- On Debian/Ubuntu:
`apt install openttd`
## The Battle for Wesnoth
[The Battle for Wesnoth](https://www.wesnoth.org/) is one of the most polished open source games available. This turn-based strategy game has a fantasy setting. Play takes place on a hexagonal grid, where individual units battle each other for control. Each type of unit has unique strengths and weaknesses, which requires players to plan their attacks accordingly. There are many different campaigns available for The Battle for Wesnoth, each with different objectives and storylines. The Battle for Wesnoth also comes with a map editor for players interested in creating their own maps or campaigns.
To install The Battle for Wesnoth, run the following command:
- On Fedora:
`dnf install wesnoth`
- On Debian/Ubuntu:
`apt install wesnoth`
## UFO: Alien Invasion
UFO: Alien Invasion is an open source tactical strategy game inspired by the [X-COM series](https://en.wikipedia.org/wiki/X-COM). There are two distinct gameplay modes: geoscape and tactical. In geoscape mode, the player takes control of the big picture and deals with managing their bases, researching new technologies, and controlling overall strategy. In tactical mode, the player controls a squad of soldiers and directly confronts the alien invaders in a turn-based battle. Both modes provide different gameplay styles, but both require complex strategy and tactics.
To install UFO: Alien Invasion, run the following command:
- On Debian/Ubuntu:
`apt install ufoai`
Unfortunately, UFO: Alien Invasion is not packaged for Fedora.
Did I miss one of your favorite open source strategy or simulation games? Share it in the comments below.
## 6 Comments |
10,494 | 开始使用 Isotope 吧,一款开源的 Web 邮件客户端 | https://opensource.com/article/19/1/productivity-tool-isotope | 2019-01-31T21:42:31 | [
"邮件",
"Web邮件"
] | https://linux.cn/article-10494-1.html |
>
> 使用轻量级的电子邮件客户端 Isotope 阅读富文本电子邮件,这个开源工具系列的第十一个工具将使你在 2019 年更高效。
>
>
>

在每年的年初,似乎都有一股疯狂的寻找提高工作效率方法的冲动。新年决心,渴望以正确的方式开始新的一年。当然,“旧不去的,新的不来”的态度都会导致这种情况。一般的建议都偏向于闭源和专有软件,然而并不是必须这样。
以下是我挑选的 19 个新的(或者对你来说是新的)开源工具中的第 11 个,它将帮助你在 2019 年提高工作效率。
### Isotope
正如我们在[本系列的第四篇文章](https://opensource.com/article/19/1/productivity-tool-cypht-email)(Cypht)中所讨论的那样,我们花了很多时间来处理电子邮件。有很多方法可以解决它,我已经花了很多时间来寻找最适合我的电子邮件客户端。我认为这是一个重要的区别:对我有效的方法并不总是对其它人有效。有时对我有用的是像 [Thunderbird](https://www.thunderbird.net/) 这样的完整客户端,有时是像 [Mutt](http://www.mutt.org/) 这样的控制台客户端,有时是像 [Gmail](https://mail.google.com/) 和 [RoundCube](https://roundcube.net/) 这样基于 Web 的界面。

[Isotope](https://blog.marcnuri.com/isotope-mail-client-introduction/) 是一个本地托管的、基于 Web 的电子邮件客户端。它非常轻巧,只使用 IMAP 协议,占用的磁盘空间非常小。与 Cypht 不同,Isotope 具有完整的 HTML 邮件支持,这意味着显示富文本电子邮件没有问题。

如果你安装了 [Docker](https://www.docker.com/),那么安装 Isotope 非常容易。你只需将文档中的命令复制到控制台中,然后按下回车键。在浏览器中输入 `localhost` 来访问 Isotope 登录界面,输入你的 IMAP 服务器,登录名和密码将打开收件箱视图。

在这一点上,Isotope 的功能和你想象的差不多。单击消息进行查看,单击铅笔图标以创建新邮件等。你会注意到用户界面(UI)非常简单,没有“移动到文件夹”、“复制到文件夹”和“存档”等常规按钮。你可以通过拖动来移动消息,因此其实你并不太需要这些按钮。

总的来说,Isotope 干净、速度快、工作得非常好。更棒的是,它正在积极开发中(最近一次的提交是在我撰写本文的两小时之前),所以它正在不断得到改进。你可以查看代码并在 [GitHub](https://github.com/manusa/isotope-mail) 上为它做出贡献。
---
via: <https://opensource.com/article/19/1/productivity-tool-isotope>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the 11th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## Isotope
As we discussed in the [fourth article in this series](https://opensource.com/article/19/1/productivity-tool-cypht-email) (about Cypht), we all spend a whole lot of time dealing with email. There are many options for dealing with it, and I've spent hours upon hours trying to find the best email client that works for me. I think that is an important distinction: What works for me doesn't always work for everyone else. And sometimes what works for me is a full client like [Thunderbird](https://www.thunderbird.net/), sometimes it is a console client like [Mutt](http://www.mutt.org/), and sometimes it's a web-based interface like [Gmail](https://mail.google.com/) or [RoundCube](https://roundcube.net/).

[Isotope](https://blog.marcnuri.com/isotope-mail-client-introduction/) is a locally hosted, web-based email client. It is exceptionally lightweight, uses IMAP exclusively, and takes up very little disk space. Unlike Cypht, Isotope has full HTML mail support, which means there are no issues displaying rich-text only emails.
Installing Isotope is very easy if you have [Docker](https://www.docker.com/) installed. You only need to copy the commands from the documentation into a console and press Enter. Point a browser at **localhost** to get the Isotope login screen, and entering your IMAP server, login name, and password will open the inbox view.
At this point, Isotope functions pretty much as you'd expect. Click a message to view it, click the pencil icon to create a new message, etc. You will note that the user interface (UI) is very minimalistic and doesn't have the typical buttons for things like "move to folder," "copy to folder," and "archive." You move messages around with drag and drop, so you don't really miss the buttons anyway.
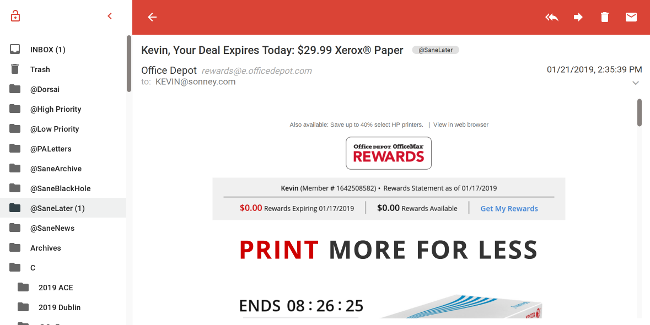
Overall, Isotope is clean, fast, and works exceptionally well. Even better, it is under active development (the most recent commit was two hours before I wrote this article), so it is constantly getting improvements. You can check out the code and contribute to it on [GitHub](https://github.com/manusa/isotope-mail).
## 4 Comments |
10,495 | 在 Linux 命令行中规划你的假期日历 | https://opensource.com/article/18/12/linux-toy-cal | 2019-01-31T21:53:10 | [
"日历"
] | /article-10495-1.html |
>
> 将命令链接在一起,构建一个彩色日历,然后在暴风雪中将其拂去。
>
>
>

欢迎阅读今天推出的 Linux 命令行玩具降临日历。如果这是你第一次访问本系列,你可能会问:什么是命令行玩具。即使我不太确定,但一般来说,它可以是一个游戏或任何简单的娱乐,可以帮助你在终端玩得开心。
很可能你们中的一些人之前已经看过我们日历上的各种选择,但我们希望给每个人至少一件新东西。
我们在没有创建实际日历的情况下完成了本系列的第 7 天,所以今天让我们使用命令行工具来做到这一点:`cal`。就其本身而言,`cal` 可能不是最令人惊奇的工具,但我们可以使用其它一些实用程序来为它增添一些趣味。
很可能,你的系统上已经安装了 `cal`。要使用它,只需要输入 `cal` 即可。
```
$ cal
December 2018
Su Mo Tu We Th Fr Sa
1
2 3 4 5 6 7 8
9 10 11 12 13 14 15
16 17 18 19 20 21 22
23 24 25 26 27 28 29
30 31
```
我们不打算在本文中深入介绍高级用法,因此如果你想了解有关 `cal` 的更多信息,查看 Opensouce.com 社区版主 Don Watkin 的优秀文章 [date 和 cal 命令概述](https://opensource.com/article/16/12/using-calendar-function-linux)。
现在,让我们用一个漂亮的盒子来为它增添趣味,就像我们在上一篇 Linux 玩具文章中介绍的那样。我将使用钻石块,用一点内边距来对齐。
```
$ cal | boxes -d diamonds -p a1l4t2
/\ /\ /\
/\//\\/\ /\//\\/\ /\//\\/\
/\//\\\///\\/\//\\\///\\/\//\\\///\\/\
//\\\//\/\\///\\\//\/\\///\\\//\/\\///\\
\\//\/ \/\\//
\/ \/
/\ December 2018 /\
//\\ Su Mo Tu We Th Fr Sa //\\
\\// 1 \\//
\/ 2 3 4 5 6 7 8 \/
/\ 9 10 11 12 13 14 15 /\
//\\ 16 17 18 19 20 21 22 //\\
\\// 23 24 25 26 27 28 29 \\//
\/ 30 31 \/
/\ /\
//\\/\ /\//\\
\\///\\/\//\\\///\\/\//\\\///\\/\//\\\//
\/\\///\\\//\/\\///\\\//\/\\///\\\//\/
\/\\//\/ \/\\//\/ \/\\//\/
\/ \/ \/
```
看起来很不错,但是为了更规整,让我们把整个东西放到另一个盒子里,为了好玩,这次我们将使用卷轴式设计。
```
cal | boxes -d diamonds -p a1t2l3 | boxes -a c -d scroll
/ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ \
| /~~\ /~~\ |
|\ \ | /\ /\ /\ | / /|
| \ /| /\//\\/\ /\//\\/\ /\//\\/\ |\ / |
| ~~ | /\//\\\///\\/\//\\\///\\/\//\\\///\\/\ | ~~ |
| | //\\\//\/\\///\\\//\/\\///\\\//\/\\///\\ | |
| | \\//\/ \/\\// | |
| | \/ \/ | |
| | /\ December 2018 /\ | |
| | //\\ Su Mo Tu We Th Fr Sa //\\ | |
| | \\// 1 \\// | |
| | \/ 2 3 4 5 6 7 8 \/ | |
| | /\ 9 10 11 12 13 14 15 /\ | |
| | //\\ 16 17 18 19 20 21 22 //\\ | |
| | \\// 23 24 25 26 27 28 29 \\// | |
| | \/ 30 31 \/ | |
| | /\ /\ | |
| | //\\/\ /\//\\ | |
| | \\///\\/\//\\\///\\/\//\\\///\\/\//\\\// | |
| | \/\\///\\\//\/\\///\\\//\/\\///\\\//\/ | |
| | \/\\//\/ \/\\//\/ \/\\//\/ | |
| | \/ \/ \/ | |
| | | |
\ |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~| /
\ / \ /
~~~ ~~~
```
完美。现在,这事有点小激动了。我喜欢我们的设计,但我想更妙一些,所以我要给它上色。但是 Opensource.com 员工所在的北卡罗来版纳州罗利办公室,本周末很有可能下雪。所以,让我们享受彩色降临日历,然后用雪擦掉它。
关于雪,我抓取了一些 Bash 和 Gawk 的漂亮[代码片段](http://climagic.org/coolstuff/let-it-snow.html),幸亏我发现了 CLIMagic。如果你不熟悉 CLIMagic,去查看他们的[网站](http://climagic.org/),在 [Twitter](https://twitter.com/climagic) 上关注他们。你会满意的。
我们开始吧。让我们清除屏幕,扔掉四四方方的日历,给它上色,等几秒钟,然后用暴风雪把它吹走。这些在终端可以用一行命令完成。
```
$ clear;cal|boxes -d diamonds -p a1t2l3|boxes -a c -d scroll|lolcat;sleep 3;while :;do echo $LINES $COLUMNS $(($RANDOM%$COLUMNS)) $(printf "\u2744\n");sleep 0.1;done|gawk '{a[$3]=0;for(x in a) {o=a[x];a[x]=a[x]+1;printf "\033[%s;%sH ",o,x;printf "\033[%s;%sH%s \033[0;0H",a[x],x,$4;}}'
```
大功告成。

要使它在你的系统上工作,你需要所有它引用的实用程序(`box`、`lolcat`、`gawk` 等),还需要使用支持 Unicode 的终端仿真器。
你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。请在评论区留言,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
看看昨天的玩具:[使用 Nyan Cat 在 Linux 命令行休息](https://opensource.com/article/18/12/linux-toy-nyancat)。记得明天再来!
---
via: <https://opensource.com/article/18/12/linux-toy-cal>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,496 | 快速开发游戏的十个关键 | https://opensource.com/article/17/12/10-keys-rapid-open-source-game-development | 2019-01-31T23:28:00 | [
"游戏",
"开发"
] | https://linux.cn/article-10496-1.html | 
十月初,由 Opensource.com 赞助的首届 [Open Jam](https://itch.io/jam/open-jam-1) 吸引了来自世界各地的团队的 45 个参赛项目。这些队伍只用了三天时间就用开源软件制作出一个游戏来参与角逐,[有三支队伍取得了胜利](https://opensource.com/article/17/11/open-jam)。
我们在我们的大学为每一位愿意参与的人举办了我们自己的 Open Jam 活动。我们预留了周末的计算机实验室,并教大家使用开源软件来创建游戏和游戏素材:游戏引擎:[Godot](https://godotengine.org/)、音乐:[LMMS](https://lmms.io/)、2D 素材:[GIMP](https://www.gimp.org/)、3D 素材:[Blender](https://www.blender.org/)。我们的活动产出了三个游戏:[Loathsome](https://astropippin.itch.io/loathsome)、[Lost Artist](https://masonraus.itch.io/lost-artist) 和 [Paint Rider](https://figytuna.itch.io/paint-rider)(我做的)。
根据我在游戏开发和游戏开发方面的经验,这里有 10 条关于游戏引擎、编码和快速游戏开发的经验教训。
### 1、限定规模
很容易想要去做一个规模宏大的冒险游戏或者可以比拟你最喜欢的游戏的东西。如果你有一些经验,追求超乎游戏 Jam 活动的东西可能很酷,但不要高估自己拥有的时间。我欣赏游戏 Jam 活动的一点是它强制你快速将一个游戏从概念阶段变成最终产品,因为你的时间非常有限。这也就是限定规模如此重要的原因。
这个 Open Jam 的主题是“留下痕迹”,题目一出来,我和朋友就开始讨论什么样的游戏适合该主题。一个想法就是做玩家能在敌人身上留下伤痕的 3D 拳击游戏。我几乎没有做 3D 游戏的经验,我想做好的话,在我甚至还没发掘出可玩性之前,就得花太多时间在学习如何让痕迹合理和打击有效。
### 2、尽早可玩
这是我对游戏 Jam 活动最中肯的建议。试着做出核心机制,快速写出代码,这样你就可以测试并决定它是否值得做成一个完整的游戏。不应该只剩几个小时截止了,你的游戏才可玩。像 Open Jam 这样的三天的活动,不应该花费几个小时以上来做一个可以运行的演示。
### 3、保持简单
你想加入的每个特性都会延长整个开发时间。因为你不能迅速使之运行,所以无从得知提交一个新特性是否会消耗大量时间。街机风格的高分作品往往会在游戏 Jam 活动中表现良好,它们天生就很简单。一旦核心部分完成,你可以开始加入特性并润色,无需担心最后游戏是否功能正常。
### 4、从其他游戏获取灵感
可能你想做出完全原创的作品,但有个可以基于它开发的原型极其有用。这将节省重复劳动的时间,因为你已经知道什么有趣。告诉自己实践的经验越多,越容易做出包含自己想法的大型游戏,所以你也能从再创作其他人的作品中得到很好地练习。
考虑到 Open Jam 的“留下痕迹”主题,我觉得创作一个玩的时候可以留下颜料痕迹的游戏会很有趣,这样也可以看到你留下的标记。我记得有款老式动画游戏 [Line Rider 2 Beta](http://www.andkon.com/arcade/racing/lineriderbeta2/) (后来叫 Paint Rider),而且知道玩的时候按住 Control 键可以画出痕迹的彩蛋。我简化了这个概念,甚至只需要一个按键来垂直移动。(更像老式飞机游戏)。进入到 Jam 活动大概一两个小时后,我就有了基本模型,可以用一个按钮上下移动和留下小黑圈的痕迹。
### 5、不要忽视可得性
确保尽可能多的人能玩你的游戏。某个提交到 Open Jam 的游戏是虚拟现实游戏。尽管那很酷,但几乎没有人可以玩,因为拥有 VR 设备的人不多。所幸它的开发者并不期望取得好名次,只是想练手。但如果你想和人们分享你的游戏(或者赢得游戏 Jam 活动),注意可得性是很重要的。
Godot (和其他大多数游戏引擎)允许你在所有主流平台发布游戏。提交游戏时,特别是在 [Itch.io](https://itch.io/),有个浏览器版本就可以支持大多数人玩。但尽你所能去发布在更多的平台和操作系统上。我甚至试着在移动端发布 Paint Rider,但技术有限。
### 6、不要做得太难
如果游戏需要花费过多精力去学或者玩,你将失去一部分玩家。要保持简单和限定规模,这在游戏计划阶段非常重要。再次重申,想出一个需要花上十天半个月开发的宏大的游戏创意很容易;难的是做出好玩、简单的游戏。
给我的妈妈介绍了 Paint Rider 之后,她很快开始玩起来,我认为不需要跟她说明更多。
### 7、不用太整洁
如果你习惯于花时间在设计模式上和确保代码可复用、可适应,试着放松一点。如果你花太多时间考虑设计,当你最后到了可以玩游戏的时候,你可能发现游戏不是很有趣,那时候就来不及修改了。
这过程也适用于简化更严格的游戏:快速码出验证概念性展示模型,直到找出值得做成完整游戏的,然后你可以潜心建立完美的代码来支持它。为游戏 Jame 活动创作的游戏就像是个快速开发一个可验证的模型一样。
### 8、但也不要太随意
另一方面, [意大利面式代码](https://en.wikipedia.org/wiki/Spaghetti_code) 容易失控,即使游戏开发没有大量代码。还好大多是游戏引擎都考虑到了设计模式。就拿 Godot 的[信号](http://kidscancode.org/blog/2017/03/godot_101_07/) 功能来说,节点可以发送数据信息给它们“连上了”的节点 —— 这是你的设计自动成型的[观察者模式](https://en.wikipedia.org/wiki/Observer_pattern)。只要你知道如何利用这种游戏引擎的特性的优势,就可以快速写代码,你的代码也不会特别难读。
### 9、取得反馈
向人们展示你正在做的。让他们试一试并看看他们说些啥。看看他们如何玩你的游戏,找找他们有没有发现你预料之外的事。如果游戏 Jam 活动有 [Discord](https://discordapp.com/) 频道或者类似的,把你的游戏放上去,人们会反馈给你想法。Paint Rider 的一个确定的功能是画布循环,所以你可以看到之前留下来的画。在有人问我为什么这个游戏没有之前,我甚至没有考虑那个机制。
团队协作的话,确保有可以传递周围反馈的人参与这个开发。
而且不要忘了用相同的方式帮助其他人;如果你在玩其他人游戏的时候发现了有助于你游戏的东西,这就是双赢。
### 10、哪里找资源
做出所有你自己的资源真的会拖你后腿。Open Jam 期间,当我忙于组装新特性和修漏洞时,我注意到 Loathsome 的开发者花了大量时间在绘制主要角色上。你可以简化游戏的艺术风格创作并且用一些视听效果尚可的东西,但这里还有其他选择。试着寻找 [Creative Commons](https://creativecommons.org/) 许可的或免费音乐站点(比如 [Anttis Instrumentals](http://www.soundclick.com/bands/default.cfm?bandID=1277008))的资源。或者,可行的话,组建一个有专门艺术家、作家或者音乐家的团队。
其他你可能觉得有用的软件有 [Krita](https://krita.org/en/),这是一款适合数字绘画的开源 2D 图像生成软件,特别是如果你有一块绘图板的话;还有 [sfxr](http://www.drpetter.se/project_sfxr.html),这是一款游戏音效生成软件,很多参数可以调,但正如它的开发者所说:“它的基本用法包括了按下随机按钮。”(Paint Rider 的所有音效都是用 Sfxr 做的。)你也可以试试 [Calinou](https://notabug.org/Calinou/awesome-gamedev/src/master/README.md) 的众多但有序的开源游戏开发软件列表。
你参加 Open Jam 或者其他游戏 Jam 并有别的建议吗?对我未提及的有问题吗?有的话,请在评论中分享。
---
via: <https://opensource.com/article/17/12/10-keys-rapid-open-source-game-development>
作者:[Ryan Estes](https://opensource.com/users/figytuna) 译者:[XYenChi](https://github.com/XYenChi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In early October, the inaugural [Open Jam](https://itch.io/jam/open-jam-1) sponsored by Opensource.com drew 45 entries from teams located around the world. The teams had just three days to create a game using open source software to enter into the competition, and [three teams came out on top](https://opensource.com/article/17/11/open-jam).
We hosted our own Open Jam event at our university for anyone who wanted to participate. We reserved a computer lab for the weekend and taught people how to use open source software—[Godot](https://godotengine.org/) for the game engine, [LMMS](https://lmms.io/) for music creation, [GIMP](https://www.gimp.org/) for 2D art, and [Blender](https://www.blender.org/) for 3D art—to create games and game art assets. Three games were submitted from our event: [Loathsome](https://astropippin.itch.io/loathsome), [Lost Artist](https://masonraus.itch.io/lost-artist), and [Paint Rider](https://figytuna.itch.io/paint-rider) (which I created).
From my experience with game jams and game development in general, here are 10 lessons I've learned about game engines, coding, and rapid game development.
## 1. Narrow your scope
It's easy to get carried away with ideas to make an expansive adventure game or something that compares to your favorite game. Pursuing that outside of a game jam can be awesome, once you have some experience, but don't overestimate what you have time for. What I love about game jams is they force you to focus on getting a game from the conceptual stage to a final product quickly, since you have such a limited amount of time. This is why narrowing your scope is so important.
The theme for Open Jam was "Leave a Mark." As soon as it was announced, my friends and I started brainstorming games that could fit that theme. One idea was a 3D boxing game where the player left bruises on their enemy. I had very little experience making 3D games and, while I would have loved to get better at them, I probably would have spent too much time learning how to get all the textures situated and hit boxes working before I could even start to figure out what would make a fun game.
## 2. Have something playable very early
This is my favorite advice for game jams. Try to come up with the core mechanics and code them to a working state quickly so you can test them and decide whether it's worthy of making a full game. You shouldn't be hours away from the deadline and still trying to get your game playable. For a three-day jam like Open Jam, it shouldn't take more than a few hours to have some sort of demo running.
## 3. Keep it simple
Every feature that you want to include extends your total development time. You never know if committing to a feature will lead to a major time sink because you just can't quite get it to work. Arcade-style high-score games typically work well for game jams because they're usually simple by nature. Once you've finished the core, you can start adding features and polish without having to worry whether you'll have a functioning game in the end.
## 4. Take inspiration from other games
You may be tempted to create something totally original, but having models to base your work on is extremely helpful. It will decrease the time it takes to come up with the mechanics, since you'll already have an idea of what is fun. Remind yourself that the more experience you have under your belt, the easier it is to create that massive game you have so many ideas for, so you might as well practice by trying to recreate things other people have done.
Considering Open Jam's "Leave a Mark" theme, I thought it would be fun to create a game where you leave a trail of paint as you played, so you could see the mark you left. I remembered the old Flash game [Line Rider 2 Beta](http://www.andkon.com/arcade/racing/lineriderbeta2/) (hence the name Paint Rider), and about the secret feature where you could draw a track if you held the Control button down while you played. I simplified that concept even more by requiring only one button for vertical movement (much like old helicopter games). About an hour or two into the jam, I had a basic demo where you could move up or down with one button and leave a trail of little black circles.
## 5. Don't overlook accessibility
Make sure as many people as possible can play your game. One of the games submitted to Open Jam was a virtual-reality game. As cool as that was, hardly anyone was able to play it, because not many people have a VR device. Luckily, its developer didn't expect it would do well in the ratings, and instead considered it practice. But, if you want to share your game with lots of people (or win game jams), it's important to pay attention to accessibility.
Godot (and most other game engines) allow you to export your game to all major platforms. When submitting a game specifically to [Itch.io](https://itch.io/), having an in-browser version will allow most people to play it. But always look into exporting to as many platforms and operating systems as you can. I even tried exporting Paint Rider to mobile, but technical difficulties got in the way.
## 6. Don't make it too difficult
If your game takes too much effort to learn or play, you'll lose a portion of your audience. This aligns nicely with keeping your game simple and within scope, and it puts even more importance on the game planning phase. Again, it's easy to come up with an epic game idea you could spend weeks or months developing; it's harder to come up with a good, simple game.
I showed Paint Rider to my Mom and she was able to play it immediately. I don't think I need to say anything more about that.
## 7. Don't be too neat
If you're used to taking your time applying design patterns everywhere and making sure that your code will be reusable and readable, try to loosen up a bit. If you spend too much time worrying about design, when you finally get to the point when you can play your game, you may find out it's not very fun. By then, it's too late to make changes.
This process is also used for prototyping more serious games: You quickly code up messy proof-of-concept demos until you find one that's worth making into a full game, then you dive into building a perfect code base to support it. Creating a game for a game jam is like quickly coding up a proof of concept.
## 8. But don't be too messy, either
On the other hand, [spaghetti code](https://en.wikipedia.org/wiki/Spaghetti_code) can easily get out of control, even if there's not a ton of code in a game. Luckily, most game engines are built with design patterns in mind. Take Godot's [Signals](http://kidscancode.org/blog/2017/03/godot_101_07/) functionality, which allows nodes to send messages with data to nodes they've been "connected" with—it's the [observer pattern](https://en.wikipedia.org/wiki/Observer_pattern) automatically baked into your design. As long as you know how to take advantage of the game engine's features, you should be able to code quickly without making your code too painful to look at.
## 9. Get feedback
Show people what you're working on. Have them try it out and see what they say about it. Watch how they play your game and see if they find something you didn't expect. If the game jam has a [Discord](https://discordapp.com/) channel or something similar, post your game there, or bounce your ideas off people. One of Paint Rider's defining features is that the canvas loops, so you see the paint you left before. I hadn't even considered that mechanic until someone asked me why the game didn't have it.
Working on a team will ensure that there are other people built into the process who can pass feedback around.
And don't forget to help other people out in the same way; it's a win-win if you realize something that could help your game while you're playing someone else's game.
## 10. Know where to find resources
Creating all your own assets can really slow you down. During Open Jam, I noticed that Loathsome's developer was spending multiple hours drawing the main character while I was busy incorporating new features and fixing bugs. You could simplify your art style for the game and still come up with something that looks and sounds good, but there are other options. Try looking for assets in [Creative Commons](https://creativecommons.org/) or on free music sites like [Anttis Instrumentals](http://www.soundclick.com/bands/default.cfm?bandID=1277008). Or, if possible, form a team with a dedicated artist, writer, or musician.
Other software you might find useful includes [Krita](https://krita.org/en/), an open source 2D image creator that's nice for digital painting, especially if you have a drawing tablet, and [sfxr](http://www.drpetter.se/project_sfxr.html), a game sound-effect creator that has a lot of parameters to play with, but as its creator says: "Basic usage involves hitting the randomize button." (All sound effects in Paint Rider were made with Sfxr.) You can also check out [Calinou](https://notabug.org/Calinou/awesome-gamedev/src/master/README.md)'s large and neatly organized list of open source game development software.
Have you participated in Open Jam or another a game jam and have other advice? Or do you have questions I didn't address? If so, please share them in the comments.
## Comments are closed. |
10,497 | 五大最流行的配置管理工具 | https://opensource.com/article/18/12/configuration-management-tools | 2019-02-01T17:52:58 | [
"配置管理",
"DevOps"
] | https://linux.cn/article-10497-1.html |
>
> 了解一下配置管理工具,以找出哪个最适合你的 DevOps 组织。
>
>
>

DevOps 正因为有提高产品质量、缩短产品开发时间等优势,目前备受业界关注,同时也在长足发展当中。
[DevOps 的核心价值观](https://www.oreilly.com/learning/why-use-terraform)是<ruby> 团队文化 <rt> Culture </rt></ruby>、<ruby> 自动化 <rt> Automation </rt></ruby>、<ruby> 评估 <rt> Measurement </rt></ruby>和<ruby> 分享 <rt> Sharing </rt></ruby>(CAMS),同时,团队对 DevOps 的执行力也是 DevOps 能否成功的重要因素。
* **团队文化**让大家团结一致;
* **自动化**是 DevOps 的基础;
* **评估**保证了及时的改进;
* **分享**让 CAMS 成为一个完整的循环过程。
DevOps 的另一个思想是任何东西,包括服务器、数据库、网络、日志文件、应用配置、文档、自动化测试、部署流程等,都可以通过代码来管理。
在本文中,我主要介绍配置管理的自动化。配置管理工具作为[<ruby> 基础架构即代码 <rt> Infrastructure as Code </rt></ruby>](https://www.oreilly.com/library/view/infrastructure-as-code/9781491924334/ch04.html)(IaC)的一部分,支持使用经过测试和验证的软件开发实践,通过明文定义文件管理和配置数据中心。
DevOps 团队只需要通过操作简单的配置文件,就可以实现应用开发中包括版本控制、测试、小型部署、设计模式在内的这些最佳实践。总而言之,配置管理工具实现了通过编写代码来使基础架构的配置和管理变得自动化。
### 为什么要使用配置管理工具?
配置管理工具可以提高应用部署和变更的效率,还可以让这些流程变得可重用、可扩展、可预测,甚至让它们维持在期望的状态,从而让资产的可控性提高。
使用配置管理工具的优势还包括:
* 让代码遵守编码规范,提高代码可读性;
* 具有<ruby> 幂等性 <rt> Idempotency </rt></ruby>,也就是说,无论执行多少次重复的配置管理操作,得到的结果都是一致的;
* 分布式的设计可以方便地管理大量的远程服务器。
配置管理工具主要分为<ruby> 拉取 <rt> pull </rt></ruby>模式和<ruby> 推送 <rt> push </rt></ruby>模式。拉取模式是指安装在各台服务器上的<ruby> 代理 <rt> agent </rt></ruby>定期从<ruby> 中央存储库 <rt> central repository </rt></ruby>拉取最新的配置并应用到对应的服务器上;而推送模式则由<ruby> 中央服务器 <rt> central server </rt></ruby>的中央服务器会触发其它受管服务器的更新。
### 五大最流行的配置管理工具
目前配置管理工具有很多,不同的配置管理工具都有自己最适合的使用场景。而对于下面五个我按照字母顺序列出的配置管理工具,都对 DevOps 有明显的帮助:全都具有开源许可证、使用外部配置文件、支持无人值守运行、可以通过脚本自定义运行。下面对它们的介绍都来源于它们的软件库和官网内容。
#### Ansible
“Ansible 是一个极其简洁的 IT 自动化平台,可以让你的应用和系统以更简单的方式部署。不需要安装任何代理,只需要使用 SSH 的方式和简单的语言,就可以免去脚本或代码部署应用的过程。”——[GitHub Ansible 代码库](https://github.com/ansible/ansible)
* [官网](https://www.ansible.com/)
* [文档](https://docs.ansible.com/ansible/)
* [社区](https://www.ansible.com/community)
Ansible 是我最喜欢的工具之一,我在几年前就开始使用了。你可以使用 Ansible 在命令行中让多个服务器执行同一个命令,也可以使用 YAML 格式的<ruby> 剧本 <rt> playbook </rt></ruby>来让它自动执行特定的操作,这促进了技术团队和非技术团队之间的沟通。简洁、无代理、配置文件对非技术人员友好是它的几个主要优点。
由于 Ansible 不需要代理,因此对服务器的资源消耗会很少。Ansible 默认使用的推送模式需要借助 SSH 连接,但 Ansible 也支持拉取模式。[剧本](https://opensource.com/article/18/8/ansible-playbooks-you-should-try) 可以使用最少的命令集编写,当然也可以扩展为更加精细的自动化任务,包括引入角色、变量和其它人写的模块。
你可以将 Ansible 和其它工具(包括 Ansible Works、Jenkins、RunDeck、[ARA](https://github.com/openstack/ara) 等)结合起来使用,因为这些工具 [提供了运行剧本时的可追溯性](https://opensource.com/article/18/5/analyzing-ansible-runs-using-ara),这样就可以创建控制流程的中央控制台。
### CFEngine
“CFEngine 3 是一个流行的开源配置管理系统,它主要用于为大规模的系统提供自动化配置和维护。”——[GitHub CFEngine 代码库](https://github.com/cfengine/core)
* [官网](https://cfengine.com/)
* [文档](https://docs.cfengine.com/docs/3.12/)
* [社区](https://cfengine.com/community/)
CFEngine 最早在 1993 年由 Mark Burgess 作为自动配置管理的科学方法提出,目的是降低计算机系统配置中的熵,最终收敛到期望的配置状态,同时还阐述了幂等性是让系统达到期望状态的能力。Burgess 在 2004 年又提出了<ruby> <a href="https://en.wikipedia.org/wiki/Promise_theory"> 承诺理论 </a> <rt> Promise Theory </rt></ruby>,这个理论描述了代理之间自发合作的模型。
CFEngine 的最新版本已经用到了承诺理论,在各个服务器上的代理程序会从中央存储库拉取配置。CFEngine 的配置对专业技能要求较高,因此它比较适合技术团队使用。
### Chef
“为整个基础架构在配置管理上带来便利的一个系统集成框架。”——[GitHub Chef 代码库](https://github.com/chef/chef)
* [官网](http://www.chef.io/chef/)
* [文档](https://docs.chef.io/)
* [社区](https://www.chef.io/community/)
Chef 通过由 Ruby 编写的“<ruby> 菜谱 <rt> recipe </rt></ruby>”来让你的基础架构保持在最新、最兼容的状态,这些“菜谱”描述了一系列应处于某种状态的资源。Chef 既可以通过客户端-服务端的模式运行,也可以在 [chef-solo](https://docs.chef.io/chef_solo.html) 这种独立配置的模式下运行。大部分云提供商都很好地集成了 Chef,因此可以使用它为新机器做自动配置。
Chef 有广泛的用户基础,同时也提供了完备的工具包,让不同技术背景的团队可以通过“菜谱”进行沟通。尽管如此,它仍然算是一个技术导向的工具。
### Puppet
“Puppet 是一个可以在 Linux、Unix 和 Windows 系统上运行的自动化管理引擎,它可以根据集中的规范来执行诸如添加用户、安装软件包、更新服务器配置等等管理任务。”——[GitHub Puppet 代码库](https://github.com/puppetlabs/puppet)
* [官网](https://puppet.com/)
* [文档](https://puppet.com/docs)
* [社区](https://puppet.com/community)
Puppet 作为一款面向运维工程师和系统管理员的工具,在更多情况下是作为配置管理工具来使用。它通过客户端-服务端的模式工作,使用代理从主服务器获取配置指令。
Puppet 使用<ruby> 声明式语言 <rt> declarative language </rt></ruby>或 Ruby 来描述系统配置。它包含了不同的模块,并使用<ruby> 清单文件 <rt> manifest files </rt></ruby>记录期望达到的目标状态。Puppet 默认使用推送模式,但也支持拉取模式。
### Salt
“为大规模基础结构或应用程序实现自动化管理的软件。”——[GitHub Salt 代码库](https://github.com/saltstack/salt)
* [官网](https://www.saltstack.com/)
* [文档](https://docs.saltstack.com/en/latest/contents.html)
* [社区](https://www.saltstack.com/resources/community/)
Salt 的专长就是快速收集数据,即使是上万台服务器也能够轻松完成任务。它使用 Python 模块来管理配置信息和执行特定的操作,这些模块可以让 Salt 实现所有远程操作和状态管理。但配置 Salt 模块对技术水平有一定的要求。
Salt 使用客户端-服务端的结构(Salt minions 是客户端,而 Salt master 是服务端),并以 Salt 状态文件记录需要达到的目标状态。
### 总结
DevOps 工具领域一直在发展,因此必须时刻关注其中的最新动态。希望这篇文章能够鼓励读者进一步探索相关的概念和工具。为此,<ruby> 云原生计算基金会 <rt> Cloud Native Computing Foundation </rt></ruby>(CNCF)在 [Cloud Native Landscape Project](https://github.com/cncf/landscape) 中也提供了很好的参考案例。
---
via: <https://opensource.com/article/18/12/configuration-management-tools>
作者:[Marco Bravo](https://opensource.com/users/marcobravo) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | DevOps is evolving and gaining traction as organizations discover how it enables them to produce better applications and reduce their software products' time to market.
[DevOps' core values](https://www.oreilly.com/learning/why-use-terraform) are Culture, Automation, Measurement, and Sharing (CAMS), and an organization's adherence to them influences how successful it is.
**Culture**brings people and processes together;**Automation**creates a fabric for DevOps;**Measurement**permits improvements; and**Sharing**enables the feedback loop in the CAMS cycle.
Another DevOps concept is the idea that almost everything can be managed in code: servers, databases, networks, log files, application configurations, documentation, automated tests, deployment processes, and more.
In this article, I'll focus on one aspect of automation: Configuration management. As part of [Infrastructure as Code](https://www.oreilly.com/library/view/infrastructure-as-code/9781491924334/ch04.html) (IaC), configuration management tools enable the use of tested and proven software development practices for managing and provisioning data centers through plaintext definition files.
By manipulating simple configuration files, a DevOps team can use application development best practices, such as version control, testing, small deployments, and design patterns. In short, this means code can be written to provision and manage an infrastructure as well as automate processes.
## Why use configuration management tools?
Configuration management tools enable changes and deployments to be faster, repeatable, scalable, predictable, and able to maintain the desired state, which brings controlled assets into an expected state.
Some advantages of using configuration management tools include:
- Adherence to coding conventions that make it easier to navigate code
- Idempotency, which means that the end state remains the same, no matter how many times the code is executed
- Distribution design to improve managing large numbers of remote servers
Some configuration management tools use a pull model, in which an agent installed on the servers runs periodically to pull the latest definitions from a central repository and apply them to the server. Other tools use a push model, where a central server triggers updates to managed servers.
## Top 5 configuration management tools
There are a variety of configuration management tools available, and each has specific features that make it better for some situations than others. Yet the top five configuration management tools, presented below in alphabetical order, have several things in common that I believe are essential for DevOps success: all have an open source license, use externalized configuration definition files, run unattended, and are scriptable. All of the descriptions are based on information from the tools' software repositories and websites.
## Ansible
"Ansible is a radically simple IT automation platform that makes your applications and systems easier to deploy. Avoid writing scripts or custom code to deploy and update your applications—automate in a language that approaches plain English, using SSH, with no agents to install on remote systems." —[GitHub repository](https://github.com/ansible/ansible)
Ansible is one of my favorite tools; I started using it several years ago and fell in love with it. You can use Ansible to execute the same command for a list of servers from the command line. You can also use it to automate tasks using "playbooks" written into a YAML file, which facilitate communication between teams and non-technical people. Its main advantages are that it is simple, agentless, and easy to read (especially for non-programmers).
Because agents are not required, there is less overhead on servers. An SSH connection is necessary when running in push mode (which is the default), but pull mode is available if needed. [Playbooks](https://opensource.com/article/18/8/ansible-playbooks-you-should-try) can be written with a minimal set of commands or they can be scaled for more elaborate automation tasks that could include roles, variables, and modules written by other people.
You can combine Ansible with other tools to create a central console to control processes. Those tools include Ansible Works (AWX), Jenkins, RunDeck, and [ARA](https://github.com/openstack/ara), which offers [traceability when running playbooks](https://opensource.com/article/18/5/analyzing-ansible-runs-using-ara).
## CFEngine
"CFEngine 3 is a popular open source configuration management system. Its primary function is to provide automated configuration and maintenance of large-scale computer systems." —[GitHub repository](https://github.com/cfengine/core)
CFEngine was introduced by Mark Burgess in 1993 as a scientific approach to automated configuration management. The goal was to deal with the entropy in computer systems' configuration and resolve it with end-state "convergence." Convergence means a desired end-state and elaborates on idempotence as a capacity to reach the desired end-state. Burgess' research evolved in 2004 when he proposed the [Promise theory](https://en.wikipedia.org/wiki/Promise_theory) as a model of voluntary cooperation between agents.
The current version of CFEngine incorporates Promise theory and uses agents running on each server that pull the configuration from a central repository. It requires some expert knowledge to deal with configurations, so it's best suited for technical people.
## Chef
"A systems integration framework, built to bring the benefits of configuration management to your entire infrastructure." —[GitHub repository](https://github.com/chef/chef)
Chef uses "recipes" written in Ruby to keep your infrastructure running up-to-date and compliant. The recipes describe a series of resources that should be in a particular state. Chef can run in client/server mode or in a standalone configuration named [chef-solo](https://docs.chef.io/chef_solo.html). It has good integration with the major cloud providers to automatically provision and configure new machines.
Chef has a solid user base and provides a full toolset to allow people with different technical backgrounds and skills to interact around the recipes. But, at its base, it is more technically oriented tool.
## Puppet
"Puppet, an automated administrative engine for your Linux, Unix, and Windows systems, performs administrative tasks (such as adding users, installing packages, and updating server configurations) based on a centralized specification." —[GitHub repository](https://github.com/puppetlabs/puppet)
Conceived as a tool oriented toward operations and sysadmins, Puppet has consolidated as a configuration management tool. It usually works in a client-server architecture, and an agent communicates with the server to fetch configuration instructions.
Puppet uses a declarative language or Ruby to describe the system configuration. It is organized in modules, and manifest files contain the desired-state goals to keep everything as required. Puppet uses the push model by default, and the pull model can be configured.
## Salt
"Software to automate the management and configuration of any infrastructure or application at scale." — [GitHub repository](https://github.com/saltstack/salt)
Salt was created for high-speed data collection and scale beyond tens of thousands of servers. It uses Python modules to handle configuration details and specific actions. These modules manage all of Salt's remote execution and state management behavior. Some level of technical skills are required to configure the modules.
Salt uses a client-server topology (with the Salt master as server and Salt minions as clients). Configurations are kept in Salt state files, which describe everything required to keep a system in the desired state.
## Conclusion
The landscape of DevOps tools is evolving all the time, and it is important to keep an eye on the changes. I hope this article will encourage you to explore these concepts and tools further. If so, the Cloud Native Computing Foundation (CNCF) maintains a good reference in the [Cloud Native Landscape Project](https://github.com/cncf/landscape).
## 5 Comments |
10,498 | 监控 Linux 服务器活动的几个命令 | https://www.networkworld.com/article/3335200/linux/how-to-monitor-activity-on-your-linux-server.html | 2019-02-01T19:33:02 | [
"watch",
"top",
"监控"
] | https://linux.cn/article-10498-1.html |
>
> `watch`、`top` 和 `ac` 命令为我们监视 Linux 服务器上的活动提供了一些十分高效的途径。
>
>
>

为了在获取系统活动时更加轻松,Linux 系统提供了一系列相关的命令。在这篇文章中,我们就一起来看看这些对我们很有帮助的命令吧。
### watch 命令
`watch` 是一个用来轻松地重复检测 Linux 系统中一系列数据命令,例如用户活动、正在运行进程、登录、内存使用等。这个命令实际上是重复地运行一个特定的命令,每次都会重写之前显示的输出,它提供了一个比较方便的方式用以监测在你的系统中发生的活动。
首先以一个基础且不是特别有用的命令开始,你可以运行 `watch -n 5 date`,然后你可以看到在终端中显示了当前的日期和时间,这些数据会每五秒更新一次。你可能已经猜到了,`-n 5` 选项指定了运行接下来一次命令需要等待的秒数。默认是 2 秒。这个命令将会一直运行并按照指定的时间更新显示,直到你使用 `^C` 停下它。
```
Every 5.0s: date butterfly: Wed Jan 23 15:59:14 2019
Wed Jan 23 15:59:14 EST 2019
```
下面是一个更有趣的命令实例,你可以监控一个在服务器中登录用户的列表,该列表会按照指定的时间定时更新。就像下面写到的,这个命令会每 10 秒更新一次这个列表。登出的用户将会从当前显示的列表中消失,那些新登录的将会被添加到这个表格当中。如果没有用户再登录或者登出,这个表格跟之前显示的将不会有任何不同。
```
$ watch -n 10 who
Every 10.0s: who butterfly: Tue Jan 23 16:02:03 2019
shs :0 2019-01-23 09:45 (:0)
dory pts/0 2019-01-23 15:50 (192.168.0.5)
nemo pts/1 2019-01-23 16:01 (192.168.0.15)
shark pts/3 2019-01-23 11:11 (192.168.0.27)
```
如果你只是想看有多少用户登录进来,可以通过 `watch` 调用 `uptime` 命令获取用户数和负载的平均水平,以及系统的工作状况。
```
$ watch uptime
Every 2.0s: uptime butterfly: Tue Jan 23 16:25:48 2019
16:25:48 up 22 days, 4:38, 3 users, load average: 1.15, 0.89, 1.02
```
如果你想使用 `watch` 重复一个包含了管道的命令,就需要将该命令用引号括起来,就比如下面这个每五秒显示一次有多少进程正在运行的命令。
```
$ watch -n 5 'ps -ef | wc -l'
Every 5.0s: ps -ef | wc -l butterfly: Tue Jan 23 16:11:54 2019
245
```
要查看内存使用,你也许会想要试一下下面的这个命令组合:
```
$ watch -n 5 free -m
Every 5.0s: free -m butterfly: Tue Jan 23 16:34:09 2019
Every 5.0s: free -m butterfly: Tue Jan 23 16:34:09 2019
total used free shared buff/cache available
Mem: 5959 776 3276 12 1906 4878
Swap: 2047 0 2047
```
你可以在 `watch` 后添加一些选项查看某个特定用户下运行的进程,不过 `top` 为此提供了更好的选择。
### top 命令
如果你想查看某个特定用户下的进程,`top` 命令的 `-u` 选项可以很轻松地帮你达到这个目的。
```
$ top -u nemo
top - 16:14:33 up 2 days, 4:27, 3 users, load average: 0.00, 0.01, 0.02
Tasks: 199 total, 1 running, 198 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 5959.4 total, 3277.3 free, 776.4 used, 1905.8 buff/cache
MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 4878.4 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
23026 nemo 20 0 46340 7820 6504 S 0.0 0.1 0:00.05 systemd
23033 nemo 20 0 149660 3140 72 S 0.0 0.1 0:00.00 (sd-pam)
23125 nemo 20 0 63396 5100 4092 S 0.0 0.1 0:00.00 sshd
23128 nemo 20 0 16836 5636 4284 S 0.0 0.1 0:00.03 zsh
```
你可能不仅可以看到某个用户下的进程,还可以查看每个进程所占用的资源,以及系统总的工作状况。
### ac 命令
如果你想查看系统中每个用户登录的时长,可以使用 `ac` 命令。运行该命令之前首先需要安装 `acct`(Debian 等)或者 `psacct`(RHEL、Centos 等)包。
`ac` 命令有一系列的选项,该命令从 `wtmp` 文件中拉取数据。这个例子展示的是最近用户登录的总小时数。
```
$ ac
total 1261.72
```
这个命令显示了用户登录的总的小时数:
```
$ ac -p
shark 5.24
nemo 5.52
shs 1251.00
total 1261.76
```
这个命令显示了每天登录的用户小时数:
```
$ ac -d | tail -10
Jan 11 total 0.05
Jan 12 total 1.36
Jan 13 total 16.39
Jan 15 total 55.33
Jan 16 total 38.02
Jan 17 total 28.51
Jan 19 total 48.66
Jan 20 total 1.37
Jan 22 total 23.48
Today total 9.83
```
### 总结
Linux 系统上有很多命令可以用于检查系统活动。`watch` 命令允许你以重复的方式运行任何命令,并观察输出有何变化。`top` 命令是一个专注于用户进程的最佳选项,以及允许你以动态方式查看进程的变化,还可以使用 `ac` 命令检查用户连接到系统的时间。
---
via: <https://www.networkworld.com/article/3335200/linux/how-to-monitor-activity-on-your-linux-server.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,499 | Linux 下如何避免重复性压迫损伤(RSI) | https://www.cyberciti.biz/tips/repetitive-strain-injury-prevention-software.html | 2019-02-01T22:43:00 | [
"RSI"
] | https://linux.cn/article-10499-1.html | 
<ruby> <a href="https://en.wikipedia.org/wiki/Repetitive_strain_injury"> 重复性压迫损伤 </a> <rt> Repetitive Strain Injury </rt></ruby>(RSI)是职业性损伤综合症,非特异性手臂疼痛或工作引起的上肢障碍。RSI 是由于过度使用双手从事重复性任务导致的,如打字、书写和使用鼠标. 不幸的是,大部分人不了解什么是 RSI 以及它的危害有多大。你可以使用名叫 Workrave 的开源软件轻松的预防 RSI。
### RSI 有哪些症状?
我从这个[页面](https://web.eecs.umich.edu/%7Ecscott/rsi.html##symptoms)引用过来的,看看哪些你被说中了:
1. 疲惫缺乏忍耐力?
2. 手掌及上肢乏力
3. 疼痛麻木甚至失去知觉?
4. 沉重:你有没有感觉手很沉?
5. 笨拙: 你有没有感觉抓不紧东西?
6. 你有没有感觉手上无力?很难打开罐子或切菜无力?
7. 缺乏协调和控制?
8. 手总是冰凉的?
9. 健康意识有待提高?稍不注意身体就发现有毛病了。
10. 是否过敏?
11. 频繁的自我按摩(潜意识的)?
12. 共鸣的疼痛?当别人在谈论手痛的时候,你是否也感觉到了手疼?
### 如何减少发展为 RSI 的风险
* 使用计算机的时候每隔 30 分钟间隔休息一下。借助软件如 workrave 预防 RSI。
* 有规律的锻炼可以预防各种损伤,包括 RSI。
* 使用合理的姿势。调整你的电脑桌和椅子使身体保持一个肌肉放松状态。
### Workrave

Workrave 是一款预防计算机用户发展为 RSI 或近视的自由开源软件。软件会定期锁屏为一个动画: “Workrave 小姐”,引导用户做各种伸展运动并敦促其休息一下。这个软件经常提醒你暂停休息一下,并限制你每天的限度。程序可以运行在 MS-Window、Linux 以及类 UNIX 操作系统下。
#### 安装 workrave
在 Debian/Ubuntu Linux 系统运行以下 [apt 命令](https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/)/[apt-get 命令](https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html):
```
$ sudo apt-get install workrave
```
Fedora Linux 发行版用户运行以下 dnf 命令:
```
$ sudo dnf install workrave
```
RHEL/CentOS Linux 用户可以启动 EPEL 仓库并用 [yum 命令](https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/)安装:
```
### [ **在CentOS/RHEL 7.x 及衍生版本上测试** ] ###
$ sudo yum install epel-release
$ sudo yum install https://rpms.remirepo.net/enterprise/remi-release-7.rpm
$ sudo yum install workrave
```
Arch Linux 用户运行以下 pacman 命令来安装:
```
$ sudo pacman -S workrave
```
FreeBSD 用户可用以下 pkg 命令安装:
```
# pkg install workrave
```
OpenBSD 用户可用以下 pkg\_add 命令安装:
```
$ doas pkg_add workrave
```
#### 如何配置 workrave
Workrave 以一个小程序运行,它的用户界面位于面板中。你可以为 workrave 增加一个面板来控制软件的动作和外观。
增加一个新 workrave 对象到面板:
* 在面板空白区域右键,打开面板弹出菜单
* 选择新增到面板
* 新增面板对话框打开,在加载器顶部,可以看到可用的面板对象按照字母排列。选中 workrave 程序并单击新增。

*图 01:新增 workrave 对象到面板*
如果修改 workrave 对象的属性,执行以下步骤:
* 右键 workrave 对象打开面板对象弹出
* 选中偏好。使用属性对话框修改对应属性

*图 02:修改 Workrave 对象属性*
#### Workrave 运行展示
主窗口显示下一次提醒休息的剩余时间,这个窗口可以关闭,时间提示窗口会显示在面板上。

*图 03:时间计数器*

*图 04:Workrave 小姐 - 引导你做伸展运动的动画*
休息提示窗口,请求你暂停一下工作:

*图 05:休息提示倒计时*

*图 06:你可以跳过休息*
#### 参考链接:
1. [Workrave 项目](http://www.workrave.org/) 主页
2. [pokoy](https://github.com/ttygde/pokoy) 防止 RSI 和其他计算机压力的轻量级守护进程
3. GNOME3 下的 [Pomodoro](http://gnomepomodoro.org) 计数器
4. [RSI](https://en.wikipedia.org/wiki/Repetitive_strain_injury) 的维基百科
### 关于作者
作者是 nixCraft 创始人,经验丰富的系统管理员,同时也是一个 Linux/Unix 系统下的 shell 脚本培训师。他曾服务于全球客户,并与多个行业合作包括 IT、教育、国防和航天研究,以及非盈利机构。可以在 [Twitter](https://twitter.com/nixcraft)、[Facebook](https://facebook.com/nixcraft)、[Google+](https://plus.google.com/+CybercitiBiz) 上关注他。
---
via: <https://www.cyberciti.biz/tips/repetitive-strain-injury-prevention-software.html>
作者:[Vivek Gite](https://www.cyberciti.biz/) 译者:[guevaraya](https://github.com/guevaraya) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,500 | 开始使用 HomeBank 吧,一款开源个人财务应用 | https://opensource.com/article/19/1/productivity-tools-homebank | 2019-02-02T14:11:26 | [
"财务",
"记账"
] | https://linux.cn/article-10500-1.html |
>
> 使用 HomeBank 跟踪你的资金流向,这是我们开源工具系列中的第八个工具,它将在 2019 年提高你的工作效率。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源项目来帮助你在 2019 年更有效率。
### HomeBank
管理我的财务可能会很有压力。我不会每天查看我的银行余额,有时也很难跟踪我的钱流向哪里。我经常会花更多的时间来管理我的财务,挖掘账户和付款历史并找出我的钱去了哪里。了解我的财务状况可以帮助我保持冷静,并让我专注于其他事情。

[HomeBank](http://homebank.free.fr/en/index.php) 是一款个人财务桌面应用,帮助你轻松跟踪你的财务状况,来帮助减少此类压力。它有很好的报告可以帮助你找出你花钱的地方,允许你设置导入交易的规则,并支持大多数现代格式。
HomeBank 默认可在大多数发行版上可用,因此安装它非常简单。当你第一次启动它时,它将引导你完成设置并让你创建一个帐户。之后,你可以导入任意一种支持的文件格式或开始输入交易。交易簿本身就是一个交易列表。[与其他一些应用不同](https://www.gnucash.org/),你不必学习[复式记账法](https://en.wikipedia.org/wiki/Double-entry_bookkeeping_system)来使用 HomeBank。

从银行导入文件将使用另一个分步向导进行处理,该向导提供了创建新帐户或填充现有帐户的选项。导入新帐户可节省一点时间,因为你无需在开始导入之前预先创建所有帐户。你还可以一次将多个文件导入帐户,因此不需要对每个帐户中的每个文件重复相同的步骤。

我在导入和管理帐户时遇到的一个痛点是指定类别。一般而言,类别可以让你分解你的支出,看看你花钱的方式。HomeBank 与一些商业服务(以及一些商业程序)不同,它要求你手动设置所有类别。但这通常是一次性的事情,它可以在添加/导入交易时自动添加类别。还有一个按钮来分析帐户并跳过已存在的内容,这样可以加快对大量导入的分类(就像我第一次做的那样)。HomeBank 提供了大量可用的类别,你也可以添加自己的类别。
HomeBank 还有预算功能,允许你计划未来几个月的开销。

对我来说,最棒的功能是 HomeBank 的报告。主页面上不仅有一个图表显示你花钱的地方,而且还有许多其他报告可供你查看。如果你使用预算功能,还会有一份报告会根据预算跟踪你的支出情况。你还可以以饼图和条形图的方式查看报告。它还有趋势报告和余额报告,因此你可以回顾并查看一段时间内的变化或模式。
总的来说,HomeBank 是一个非常友好,有用的程序,可以帮助你保持良好的财务状况。如果跟踪你的钱是你生活中的一件麻烦事,它使用起来很简单并且非常有用。
---
via: <https://opensource.com/article/19/1/productivity-tools-homebank>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the eighth of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## HomeBank
Managing my finances can be really stressful. I don't look at my bank balance every day and sometimes have trouble keeping track of where my money is going. I often spend more time managing my finances than I need to, digging into accounts and payment histories to figure out where my money went. Knowing my finances are OK helps keep me calm and allows me to focus on other things.
[HomeBank](http://homebank.free.fr/en/index.php) is a personal finance desktop application that helps decrease this type of stress by making it fairly easy to keep track of your finances. It has some nice reports to help you figure out where you're spending your money, allows you to set up rules for importing transactions, and supports most modern formats.
HomeBank is available on most distributions by default, so installation is very easy. When you start it up for the first time, it will walk you through setup and allow you to create an account. From there, you can either import one of the supported file formats or start entering transactions. The transaction register itself is just that—a list of transactions. [Unlike some other apps](https://www.gnucash.org/), you don't have to learn [double-entry bookkeeping](https://en.wikipedia.org/wiki/Double-entry_bookkeeping_system) to use HomeBank.
Importing files from your bank is handled with another step-by-step wizard, with options to create a new account or populate an existing one. Importing into a new account saves a little time since you don't have to pre-create all the accounts before starting the import. You can also import multiple files into an account at once, so you don't need to repeat the same steps for every file in every account.
The one pain point I've had with importing and managing accounts is category assignment. Categories are what allow you to break down your spending and see what you are spending money on, in general terms. HomeBank, unlike commercial services (and some commercial programs), requires you to manually set up all the assignments. But this is generally a one-time thing, and then the categories can be auto-applied as transactions are added/imported. There is also a button to analyze the account and auto-apply things that already exist, which speeds up categorizing a large import (like I did the first time). HomeBank comes with a large number of categories you can start with, and you can add your own as well.
HomeBank also has budgeting features, allowing you to plan for the months ahead.
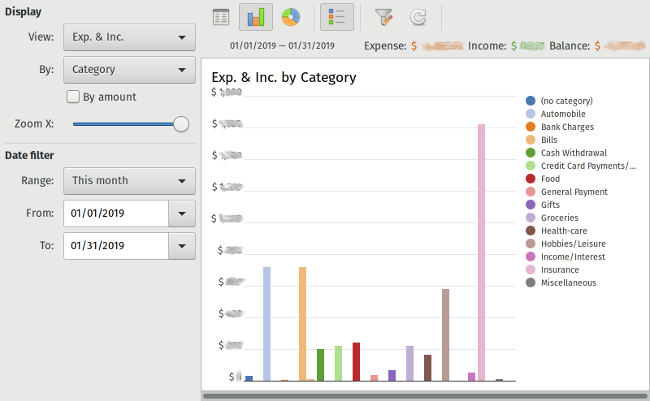
The big win, for me, is HomeBank's reports feature. Not only is there a chart on the main screen showing where you are spending your money, but there are a whole host of other reports you can look at. If you use the budget feature, there is a report that tracks your spending against your budget. You can also view those reports as pie and bar charts. There is also a trend report and a balance report, so you can look back and see changes or patterns over time.
Overall, HomeBank is a very friendly, useful application to help you keep your finances in order. It is simple to use and really helpful if keeping track of your money is a major stress point in your life.
## 1 Comment |
10,501 | 极客漫画:僵尸进程 | http://turnoff.us/geek/zombie-processes/ | 2019-02-02T14:15:31 | [
"僵尸进程"
] | https://linux.cn/article-10501-1.html | 
在 Unix 进程模型中,父进程和其所产生的子进程是异步运行的,所以如果子进程在结束后,会留下一些信息需要父进程使用 `wait`/`waitpid` 来接收。而如果父进程太忙了,没有调用 `wait`/`waitpid` 的话,子进程就会变成僵尸进程。
---
via: <http://turnoff.us/geek/zombie-processes/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者 & 点评:[wxy](https://github.com/wxy) 校对 & 合成 :[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,502 | 理解 Bash 中的尖括号 | https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash | 2019-02-02T20:35:29 | [
"shell",
"尖括号"
] | https://linux.cn/article-10502-1.html |
>
> 为初学者介绍尖括号。
>
>
>

[Bash](https://www.linux.com/blog/2019/1/bash-shell-utility-reaches-50-milestone) 内置了很多诸如 `ls`、`cd`、`mv` 这样的重要的命令,也有很多诸如 `grep`、`awk`、`sed` 这些有用的工具。但除此之外,其实 [Bash](https://www.linux.com/blog/2019/1/bash-shell-utility-reaches-50-milestone) 中还有很多可以[起到胶水作用](https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot)的标点符号,例如点号(`.`)、逗号(`,`)、括号(`<>`)、引号(`"`)之类。下面我们就来看一下可以用来进行数据转换和转移的尖括号(`<>`)。
### 转移数据
如果你对其它编程语言有所了解,你会知道尖括号 `<` 和 `>` 一般是作为逻辑运算符,用来比较两个值之间的大小关系。如果你还编写 HTML,尖括号作为各种标签的一部分,就更不会让你感到陌生了。
在 shell 脚本语言中,尖括号可以将数据从一个地方转移到另一个地方。例如可以这样把数据存放到一个文件当中:
```
ls > dir_content.txt
```
在上面的例子中,`>` 符号让 shell 将 `ls` 命令的输出结果写入到 `dir_content.txt` 里,而不是直接显示在命令行中。需要注意的是,如果 `dir_content.txt` 这个文件不存在,Bash 会为你创建;但是如果 `dir_content.txt` 是一个已有的非空文件,它的内容就会被覆盖掉。所以执行类似的操作之前务必谨慎。
你也可以不使用 `>` 而使用 `>>`,这样就可以把新的数据追加到文件的末端而不会覆盖掉文件中已有的数据了。例如:
```
ls $HOME > dir_content.txt; wc -l dir_content.txt >> dir_content.txt
```
在这串命令里,首先将家目录的内容写入到 `dir_content.txt` 文件中,然后使用 `wc -l` 计算出 `dir_content.txt` 文件的行数(也就是家目录中的文件数)并追加到 `dir_content.txt` 的末尾。
在我的机器上执行上述命令之后,`dir_content.txt` 的内容会是以下这样:
```
Applications
bin
cloud
Desktop
Documents
Downloads
Games
ISOs
lib
logs
Music
OpenSCAD
Pictures
Public
Templates
test_dir
Videos
17 dir_content.txt
```
你可以将 `>` 和 `>>` 作为箭头来理解。当然,这个箭头的指向也可以反过来。例如,Coen brothers (LCTT 译注:科恩兄弟,一个美国电影导演组合)的一些演员以及他们出演电影的次数保存在 `CBActors` 文件中,就像这样:
```
John Goodman 5
John Turturro 3
George Clooney 2
Frances McDormand 6
Steve Buscemi 5
Jon Polito 4
Tony Shalhoub 3
James Gandolfini 1
```
你可以执行这样的命令:
```
sort < CBActors
Frances McDormand 6 # 你会得到这样的输出
George Clooney 2
James Gandolfini 1
John Goodman 5
John Turturro 3
Jon Polito 4
Steve Buscemi 5
Tony Shalhoub 3
```
就可以使用 [sort](https://linux.die.net/man/1/sort) 命令将这个列表按照字母顺序输出。但是,`sort` 命令本来就可以接受传入一个文件,因此在这里使用 `<` 会略显多余,直接执行 `sort CBActors` 就可以得到期望的结果。
如果你想知道 Coens 最喜欢的演员是谁,你可以这样操作。首先:
```
while read name surname films; do echo $films $name $surname > filmsfirst.txt; done < CBActors
```
上面这串命令写在多行中可能会比较易读:
```
while read name surname films;\
do
echo $films $name $surname >> filmsfirst;\
done < CBActors
```
下面来分析一下这些命令做了什么:
* [while …; do … done](http://tldp.org/HOWTO/Bash-Prog-Intro-HOWTO-7.html) 是一个循环结构。当 `while` 后面的条件成立时,`do` 和 `done` 之间的部分会一直重复执行;
* [read](https://linux.die.net/man/2/read) 语句会按行读入内容。`read` 会从标准输入中持续读入,直到没有内容可读入;
* `CBActors` 文件的内容会通过 `<` 从标准输入中读入,因此 `while` 循环会将 `CBActors` 文件逐行完整读入;
* `read` 命令可以按照空格将每一行内容划分为三个字段,然后分别将这三个字段赋值给 `name`、`surname` 和 `films` 三个变量,这样就可以很方便地通过 `echo $films $name $surname >> filmsfirst;\` 来重新排列几个字段的放置顺序并存放到 `filmfirst` 文件里面了。
执行完以后,查看 `filmsfirst` 文件,内容会是这样的:
```
5 John Goodman
3 John Turturro
2 George Clooney
6 Frances McDormand
5 Steve Buscemi
4 Jon Polito
3 Tony Shalhoub
1 James Gandolfini
```
这时候再使用 `sort` 命令:
```
sort -r filmsfirst
```
就可以看到 Coens 最喜欢的演员是 Frances McDormand 了。(`-r` 参数表示降序排列,因此 McDormand 会排在最前面)
---
via: <https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,503 | Hegemon:一个 Linux 的模块化系统和硬件监控工具 | https://www.2daygeek.com/hegemon-a-modular-system-and-hardware-monitoring-tool-for-linux/ | 2019-02-02T21:07:00 | [
"监控"
] | https://linux.cn/article-10503-1.html | 
我知道每个人都更喜欢使用 [top 命令](https://www.2daygeek.com/top-command-examples-to-monitor-server-performance/)来监控系统利用率。这是被 Linux 系统管理员大量使用的原生命令之一。
在 Linux 中,每个包都有一个替代品。Linux 中有许多可用于此的工具,我更喜欢 [htop 命令](https://www.2daygeek.com/linux-htop-command-linux-system-performance-resource-monitoring-tool/)。
如果你想了解其他替代方案,我建议你浏览每个链接了解更多信息。它们有 htop、CorFreq、glances、atop、Dstat、Gtop、Linux Dash、Netdata、Monit 等。
所有这些只允许我们监控系统利用率而不能监控系统硬件。但是 Hegemon 允许我们在单个仪表板中监控两者。
如果你正在寻找系统硬件监控软件,那么我建议你看下 [lm\_sensors](https://www.2daygeek.com/view-check-cpu-hard-disk-temperature-linux/) 和 [s-tui 压力终端 UI](https://www.2daygeek.com/s-tui-stress-terminal-ui-monitor-linux-cpu-temperature-frequency/)。
### Hegemon 是什么?
Hegemon 是一个正在开发中的模块化系统监视器,以安全的 Rust 编写。
它允许用户在单个仪表板中监控两种使用情况。分别是系统利用率和硬件温度。
### Hegemon 目前的特性
* 监控 CPU 和内存使用情况、温度和风扇速度
* 展开任何数据流以显示更详细的图表和其他信息
* 可调整的更新间隔
* 干净的 MVC 架构,具有良好的代码质量
* 单元测试
### 计划的特性包括
* macOS 和 BSD 支持(目前仅支持 Linux) \* 监控磁盘和网络 I/O、GPU 使用情况(可能)等 \* 选择并重新排序数据流 \* 鼠标控制
### 如何在 Linux 中安装 Hegemon?
Hegemon 需要 Rust 1.26 或更高版本以及 libsensors 的开发文件。因此,请确保在安装 Hegemon 之前安装了这些软件包。
libsensors 库在大多数发行版官方仓库中都有,因此,使用以下命令进行安装。
对于 Debian/Ubuntu 系统,使用 [apt-get 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或 [apt 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 在你的系统上安装 libsensors。
```
# apt install lm_sensors-devel
```
对于 Fedora 系统,使用 [dnf 包管理器](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/)在你的系统上安装 libsensors。
```
# dnf install libsensors4-dev
```
运行以下命令安装 Rust 语言,并按照指示来做。如果你想要看 [Rust 安装](https://www.2daygeek.com/how-to-install-rust-programming-language-in-linux/)的方便教程,请进入该 URL。
```
$ curl https://sh.rustup.rs -sSf | sh
```
如果你已成功安装 Rust。运行以下命令安装 Hegemon。
```
$ cargo install hegemon
```
### 如何在 Linux 中启动 Hegemon?
成功安装 Hegemon 包后,运行下面的命令启动。
```
$ hegemon
```

由于 libsensors.so.4 库的问题,我在启动 Hegemon 时遇到了一个问题。
```
$ hegemon
error while loading shared libraries: libsensors.so.4: cannot open shared object file: No such file or directory manjaro
```
我使用的是 Manjaro 18.04。它存在 libsensors.so 和 libsensors.so.5 共享库,而没有 libsensors.so.4。所以,我刚刚创建了以下符号链接来解决问题。
```
$ sudo ln -s /usr/lib/libsensors.so /usr/lib/libsensors.so.4
```
这是从我的 Lenovo-Y700 笔记本中截取的示例 gif。

默认它仅显示总体摘要,如果你想查看详细输出,则需要展开每个部分。如下是 Hegemon 的展开视图。

---
via: <https://www.2daygeek.com/hegemon-a-modular-system-and-hardware-monitoring-tool-for-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,504 | 极客漫画:当 Git 有了智能 | http://turnoff.us/geek/when-ai-meets-git/ | 2019-02-03T11:56:49 | [
"Git",
"AI",
"极客漫画"
] | https://linux.cn/article-10504-1.html | 
要是你的 Git 有了人工智能,会不会嫌弃你的提交?
当你想修复一个游戏防沉迷的时间验证 bug 时,却被 Git 鄙视了——你确认你的老板还需要你吗,而不是一个 Git?
就算是你恼羞成怒想要删除 Git 怕是也会被智能的 Yum 拒绝吧——它们肯定是一伙的。
---
via: <http://turnoff.us/geek/when-ai-meets-git/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者 & 点评:[wxy](https://github.com/wxy) 校对 & 合成:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,506 | 如何搜索一个包是否在你的 Linux 发行版中 | https://www.2daygeek.com/how-to-search-if-a-package-is-available-on-your-linux-distribution-or-not/ | 2019-02-03T21:31:13 | [
"软件包",
"包管理器"
] | https://linux.cn/article-10506-1.html | 
如果你知道包名称,那么你可以直接安装所需的包。
在某些情况下,如果你不知道确切的包名称或者你想搜索某些包,那么你可以在发行版的包管理器的帮助下轻松搜索该包。搜索会自动包括已安装和可用的包。结果的格式取决于选项。如果你的查询没有输出任何信息,那么意味着没有匹配条件的包。这可以通过发行版的包管理器的各种选项来完成。我已经在本文中添加了所有可能的选项,你可以选择最好的和最合适你的选项。
或者,我们可以通过 `whohas` 命令实现这一点。它会从所有的主流发行版(例如 Debian、Ubuntu、 Fedora 等)中搜索,而不仅仅是你自己的系统发行版。
建议阅读:
* [适用于 Linux 的命令行包管理器列表以及用法](https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/)
* [Linux 包管理器的图形前端工具](https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/)
### 如何在 Debian/Ubuntu 中搜索一个包
我们可以使用 `apt`、`apt-cache` 和 `aptitude` 包管理器在基于 Debian 的发行版上查找给定的包。我为这个包管理器中包括了大量的选项。
我们可以在基于 Debian 的系统中使用三种方式完成此操作。
* `apt` 命令
* `apt-cache` 命令
* `aptitude` 命令
#### 如何使用 apt 命令搜索一个包
APT 代表<ruby> 高级包管理工具 <rt> Advanced Packaging Tool </rt></ruby>(APT),它取代了 `apt-get`。它有功能丰富的命令行工具,包括所有功能包含在一个命令(`apt`)里,包括 `apt-cache`、`apt-search`、`dpkg`、`apt-cdrom`、`apt-config`、`apt-key` 等,还有其他几个独特的功能。
APT 是一个强大的命令行工具,它可以访问 libapt-pkg 底层库的所有特性,它可以用于安装、下载、删除、搜索和管理以及查询包的信息,另外它还包含一些较少使用的与包管理相关的命令行实用程序。
```
$ apt -q list nano vlc
Listing...
nano/artful,now 2.8.6-3 amd64 [installed]
vlc/artful 2.2.6-6 amd64
```
或者,我们可以使用以下格式搜索指定的包。
```
$ apt search ^vlc
Sorting... Done
Full Text Search... Done
vlc/artful 2.2.6-6 amd64
multimedia player and streamer
vlc-bin/artful 2.2.6-6 amd64
binaries from VLC
vlc-data/artful,artful 2.2.6-6 all
Common data for VLC
vlc-l10n/artful,artful 2.2.6-6 all
Translations for VLC
vlc-plugin-access-extra/artful 2.2.6-6 amd64
multimedia player and streamer (extra access plugins)
vlc-plugin-base/artful 2.2.6-6 amd64
multimedia player and streamer (base plugins)
```
#### 如何使用 apt-cache 命令搜索一个包
`apt-cache` 会在 APT 的包缓存上执行各种操作。它会显示有关指定包的信息。`apt-cache` 不会改变系统的状态,但提供了从包的元数据中搜索和生成有趣输出的操作。
```
$ apt-cache search nano | grep ^nano
nano - small, friendly text editor inspired by Pico
nano-tiny - small, friendly text editor inspired by Pico - tiny build
nanoblogger - Small weblog engine for the command line
nanoblogger-extra - Nanoblogger plugins
nanoc - static site generator written in Ruby
nanoc-doc - static site generator written in Ruby - documentation
nanomsg-utils - nanomsg utilities
nanopolish - consensus caller for nanopore sequencing data
```
或者,我们可以使用以下格式搜索指定的包。
```
$ apt-cache policy vlc
vlc:
Installed: (none)
Candidate: 2.2.6-6
Version table:
2.2.6-6 500
500 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 Packages
```
或者,我们可以使用以下格式搜索给定的包。
```
$ apt-cache pkgnames vlc
vlc-bin
vlc-plugin-video-output
vlc-plugin-sdl
vlc-plugin-svg
vlc-plugin-samba
vlc-plugin-fluidsynth
vlc-plugin-qt
vlc-plugin-skins2
vlc-plugin-visualization
vlc-l10n
vlc-plugin-notify
vlc-plugin-zvbi
vlc-plugin-vlsub
vlc-plugin-jack
vlc-plugin-access-extra
vlc
vlc-data
vlc-plugin-video-splitter
vlc-plugin-base
```
#### 如何使用 aptitude 命令搜索一个包
`aptitude` 是一个基于文本的 Debian GNU/Linux 软件包系统的命令行界面。它允许用户查看包列表,并执行包管理任务,例如安装、升级和删除包,它可以从可视化界面或命令行执行操作。
```
$ aptitude search ^vlc
p vlc - multimedia player and streamer
p vlc:i386 - multimedia player and streamer
p vlc-bin - binaries from VLC
p vlc-bin:i386 - binaries from VLC
p vlc-data - Common data for VLC
v vlc-data:i386 -
p vlc-l10n - Translations for VLC
v vlc-l10n:i386 -
p vlc-plugin-access-extra - multimedia player and streamer (extra access plugins)
p vlc-plugin-access-extra:i386 - multimedia player and streamer (extra access plugins)
p vlc-plugin-base - multimedia player and streamer (base plugins)
p vlc-plugin-base:i386 - multimedia player and streamer (base plugins)
p vlc-plugin-fluidsynth - FluidSynth plugin for VLC
p vlc-plugin-fluidsynth:i386 - FluidSynth plugin for VLC
p vlc-plugin-jack - Jack audio plugins for VLC
p vlc-plugin-jack:i386 - Jack audio plugins for VLC
p vlc-plugin-notify - LibNotify plugin for VLC
p vlc-plugin-notify:i386 - LibNotify plugin for VLC
p vlc-plugin-qt - multimedia player and streamer (Qt plugin)
p vlc-plugin-qt:i386 - multimedia player and streamer (Qt plugin)
p vlc-plugin-samba - Samba plugin for VLC
p vlc-plugin-samba:i386 - Samba plugin for VLC
p vlc-plugin-sdl - SDL video and audio output plugin for VLC
p vlc-plugin-sdl:i386 - SDL video and audio output plugin for VLC
p vlc-plugin-skins2 - multimedia player and streamer (Skins2 plugin)
p vlc-plugin-skins2:i386 - multimedia player and streamer (Skins2 plugin)
p vlc-plugin-svg - SVG plugin for VLC
p vlc-plugin-svg:i386 - SVG plugin for VLC
p vlc-plugin-video-output - multimedia player and streamer (video output plugins)
p vlc-plugin-video-output:i386 - multimedia player and streamer (video output plugins)
p vlc-plugin-video-splitter - multimedia player and streamer (video splitter plugins)
p vlc-plugin-video-splitter:i386 - multimedia player and streamer (video splitter plugins)
p vlc-plugin-visualization - multimedia player and streamer (visualization plugins)
p vlc-plugin-visualization:i386 - multimedia player and streamer (visualization plugins)
p vlc-plugin-vlsub - VLC extension to download subtitles from opensubtitles.org
p vlc-plugin-zvbi - VBI teletext plugin for VLC
p vlc-plugin-zvbi:i386
```
### 如何在 RHEL/CentOS 中搜索一个包
Yum(Yellowdog Updater Modified)是 Linux 操作系统中的包管理器实用程序之一。Yum 命令用于在一些基于 RedHat 的 Linux 发行版上,它用来安装、更新、搜索和删除软件包。
```
# yum search ftpd
Loaded plugins: fastestmirror, refresh-packagekit, security
Loading mirror speeds from cached hostfile
* base: centos.hyve.com
* epel: mirrors.coreix.net
* extras: centos.hyve.com
* rpmforge: www.mirrorservice.org
* updates: mirror.sov.uk.goscomb.net
============================================================== N/S Matched: ftpd ===============================================================
nordugrid-arc-gridftpd.x86_64 : ARC gridftp server
pure-ftpd.x86_64 : Lightweight, fast and secure FTP server
vsftpd.x86_64 : Very Secure Ftp Daemon
Name and summary matches only, use "search all" for everything.
```
或者,我们可以使用以下命令搜索相同内容。
```
# yum list ftpd
```
### 如何在 Fedora 中搜索一个包
DNF 代表 Dandified yum。我们可以说 DNF 是下一代 yum 包管理器(Yum 的衍生品),它使用 hawkey/libsolv 库作为底层。Aleš Kozumplík 从 Fedora 18 开始开发 DNF,最终在 Fedora 22 中发布。
```
# dnf search ftpd
Last metadata expiration check performed 0:42:28 ago on Tue Jun 9 22:52:44 2018.
============================== N/S Matched: ftpd ===============================
proftpd-utils.x86_64 : ProFTPD - Additional utilities
pure-ftpd-selinux.x86_64 : SELinux support for Pure-FTPD
proftpd-devel.i686 : ProFTPD - Tools and header files for developers
proftpd-devel.x86_64 : ProFTPD - Tools and header files for developers
proftpd-ldap.x86_64 : Module to add LDAP support to the ProFTPD FTP server
proftpd-mysql.x86_64 : Module to add MySQL support to the ProFTPD FTP server
proftpd-postgresql.x86_64 : Module to add PostgreSQL support to the ProFTPD FTP
: server
vsftpd.x86_64 : Very Secure Ftp Daemon
proftpd.x86_64 : Flexible, stable and highly-configurable FTP server
owfs-ftpd.x86_64 : FTP daemon providing access to 1-Wire networks
perl-ftpd.noarch : Secure, extensible and configurable Perl FTP server
pure-ftpd.x86_64 : Lightweight, fast and secure FTP server
pyftpdlib.noarch : Python FTP server library
nordugrid-arc-gridftpd.x86_64 : ARC gridftp server
```
或者,我们可以使用以下命令搜索相同的内容。
```
# dnf list proftpd
Failed to synchronize cache for repo 'heikoada-terminix', disabling.
Last metadata expiration check: 0:08:02 ago on Tue 26 Jun 2018 04:30:05 PM IST.
Available Packages
proftpd.x86_64
```
### 如何在 Arch Linux 中搜索一个包
pacman 代表包管理实用程序(pacman)。它是一个用于安装、构建、删除和管理 Arch Linux 软件包的命令行实用程序。pacman 使用 libalpm(Arch Linux Package Management(ALPM)库)作为底层来执行所有操作。
在本例中,我将要搜索 chromium 包。
```
# pacman -Ss chromium
extra/chromium 48.0.2564.116-1
The open-source project behind Google Chrome, an attempt at creating a safer, faster, and more stable browser
extra/qt5-webengine 5.5.1-9 (qt qt5)
Provides support for web applications using the Chromium browser project
community/chromium-bsu 0.9.15.1-2
A fast paced top scrolling shooter
community/chromium-chromevox latest-1
Causes the Chromium web browser to automatically install and update the ChromeVox screen reader extention. Note: This
package does not contain the extension code.
community/fcitx-mozc 2.17.2313.102-1
Fcitx Module of A Japanese Input Method for Chromium OS, Windows, Mac and Linux (the Open Source Edition of Google Japanese
Input)
```
默认情况下,`-s` 选项内置 ERE(扩展正则表达式)会导致很多不需要的结果。使用以下格式会仅匹配包名称。
```
# pacman -Ss '^chromium-'
```
`pkgfile` 是一个用于在 Arch Linux 官方仓库的包中搜索文件的工具。
```
# pkgfile chromium
```
### 如何在 openSUSE 中搜索一个包
Zypper 是 SUSE 和 openSUSE 发行版的命令行包管理器。它用于安装、更新、搜索和删除包以及管理仓库,执行各种查询等。Zypper 命令行对接到 ZYpp 系统管理库(libzypp)。
```
# zypper search ftp
or
# zypper se ftp
Loading repository data...
Reading installed packages...
S | Name | Summary | Type
--+----------------+-----------------------------------------+--------
| proftpd | Highly configurable GPL-licensed FTP -> | package
| proftpd-devel | Development files for ProFTPD | package
| proftpd-doc | Documentation for ProFTPD | package
| proftpd-lang | Languages for package proftpd | package
| proftpd-ldap | LDAP Module for ProFTPD | package
| proftpd-mysql | MySQL Module for ProFTPD | package
| proftpd-pgsql | PostgreSQL Module for ProFTPD | package
| proftpd-radius | Radius Module for ProFTPD | package
| proftpd-sqlite | SQLite Module for ProFTPD | package
| pure-ftpd | A Lightweight, Fast, and Secure FTP S-> | package
| vsftpd | Very Secure FTP Daemon - Written from-> | package
```
### 如何使用 whohas 命令搜索一个包
`whohas` 命令是一个智能工具,从所有主流发行版中搜索指定包,如 Debian、Ubuntu、Gentoo、Arch、AUR、Mandriva、Fedora、Fink、FreeBSD 和 NetBSD。
```
$ whohas nano
Mandriva nano-debug 2.3.1-1mdv2010.2.x http://sophie.zarb.org/rpms/0b33dc73bca710749ad14bbc3a67e15a
Mandriva nano-debug 2.2.4-1mdv2010.1.i http://sophie.zarb.org/rpms/d9dfb2567681e09287b27e7ac6cdbc05
Mandriva nano-debug 2.2.4-1mdv2010.1.x http://sophie.zarb.org/rpms/3299516dbc1538cd27a876895f45aee4
Mandriva nano 2.3.1-1mdv2010.2.x http://sophie.zarb.org/rpms/98421c894ee30a27d9bd578264625220
Mandriva nano 2.3.1-1mdv2010.2.i http://sophie.zarb.org/rpms/cea07b5ef9aa05bac262fc7844dbd223
Mandriva nano 2.2.4-1mdv2010.1.s http://sophie.zarb.org/rpms/d61f9341b8981e80424c39c3951067fa
Mandriva spring-mod-nanoblobs 0.65-2mdv2010.0.sr http://sophie.zarb.org/rpms/74bb369d4cbb4c8cfe6f6028e8562460
Mandriva nanoxml-lite 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/287a4c37bc2a39c0f277b0020df47502
Mandriva nanoxml-manual-lite 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/17dc4f638e5e9964038d4d26c53cc9c6
Mandriva nanoxml-manual 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/a1b5092cd01fc8bb78a0f3ca9b90370b
Gentoo nano 9999 http://packages.gentoo.org/package/app-editors/nano
Gentoo nano 9999 http://packages.gentoo.org/package/app-editors/nano
Gentoo nano 2.9.8 http://packages.gentoo.org/package/app-editors/nano
Gentoo nano 2.9.7
```
如果你希望只从当前发行版仓库中搜索指定包,使用以下格式:
```
$ whohas -d Ubuntu vlc
Ubuntu vlc 2.1.6-0ubuntu14.04 1M all http://packages.ubuntu.com/trusty/vlc
Ubuntu vlc 2.1.6-0ubuntu14.04 1M all http://packages.ubuntu.com/trusty-updates/vlc
Ubuntu vlc 2.2.2-5ubuntu0.16. 1M all http://packages.ubuntu.com/xenial/vlc
Ubuntu vlc 2.2.2-5ubuntu0.16. 1M all http://packages.ubuntu.com/xenial-updates/vlc
Ubuntu vlc 2.2.6-6 40K all http://packages.ubuntu.com/artful/vlc
Ubuntu vlc 3.0.1-3build1 32K all http://packages.ubuntu.com/bionic/vlc
Ubuntu vlc 3.0.2-0ubuntu0.1 32K all http://packages.ubuntu.com/bionic-updates/vlc
Ubuntu vlc 3.0.3-1 33K all http://packages.ubuntu.com/cosmic/vlc
Ubuntu browser-plugin-vlc 2.0.6-2 55K all http://packages.ubuntu.com/trusty/browser-plugin-vlc
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/xenial/browser-plugin-vlc
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/artful/browser-plugin-vlc
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/bionic/browser-plugin-vlc
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/cosmic/browser-plugin-vlc
Ubuntu libvlc-bin 2.2.6-6 27K all http://packages.ubuntu.com/artful/libvlc-bin
Ubuntu libvlc-bin 3.0.1-3build1 17K all http://packages.ubuntu.com/bionic/libvlc-bin
Ubuntu libvlc-bin 3.0.2-0ubuntu0.1 17K all
```
---
via: <https://www.2daygeek.com/how-to-search-if-a-package-is-available-on-your-linux-distribution-or-not/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,507 | 开始使用 Roland 吧,一款命令行随机选择工具 | https://opensource.com/article/19/1/productivity-tools-roland | 2019-02-04T17:23:00 | [
"选择",
"决定"
] | https://linux.cn/article-10507-1.html |
>
> Roland 可以帮你做出艰难的决定,它是我们在开源工具系列中的第七个工具,将帮助你在 2019 年提高工作效率。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第七个工具来帮助你在 2019 年更有效率。
### Roland
当一周的工作结束后,我唯一想做的就是躺到沙发上打一个周末的游戏。但即使我的职业义务在工作日结束后停止了,但我仍然需要管理我的家庭。洗衣、宠物护理、确保我孩子有他所需要的东西,以及最重要的是:决定晚餐吃什么。
像许多人一样,我经常受到[决策疲劳](https://en.wikipedia.org/wiki/Decision_fatigue)的困扰,根据速度、准备难易程度以及(坦白地说)任何让我压力最小的方式都会导致不太健康的晚餐选择。

[Roland](https://github.com/rjbs/Roland) 让我计划饭菜变得容易。Roland 是一款专为桌面角色扮演游戏设计的 Perl 应用。它从怪物和雇佣者等项目列表中随机挑选。从本质上讲,Roland 在命令行做的事情就像游戏管理员在桌子上掷骰子,以便在《要对玩家做的坏事全书》中找个东西一样。
通过微小的修改,Roland 可以做得更多。例如,只需添加一张表,我就可以让 Roland 帮我选择晚餐。
第一步是安装 Roland 及其依赖项。
```
git clone [email protected]:rjbs/Roland.git
cpan install Getopt::Long::Descriptive Moose \
namespace::autoclean List:AllUtils Games::Dice \
Sort::ByExample Data::Bucketeer Text::Autoformat \
YAML::XS
cd oland
```
接下来,创建一个名为 `dinner` 的 YAML 文档,并输入我们所有的用餐选项。
```
type: list
pick: 1
items:
- "frozen pizza"
- "chipotle black beans"
- "huevos rancheros"
- "nachos"
- "pork roast"
- "15 bean soup"
- "roast chicken"
- "pot roast"
- "grilled cheese sandwiches"
```
运行命令 `bin/roland dinner` 将读取文件并选择其中一项。

我想提前计划一周,这样我可以提前购买所有食材。 `pick` 命令确定列表中要选择的物品数量,现在,`pick` 设置为 1。如果我想计划一周的晚餐菜单,我可以将 `pick: 1` 变成 `pick: 7`,它会提供一周的菜单。你还可以使用 `-m` 选项手动输入选择。

你也可以用 Roland 做些有趣的事情,比如用经典短语添加一个名为 `8ball` 的文件。

你可以创建各种文件来帮助做出长时间工作后看起来非常难做的常见决策。即使你不用来做这个,你仍然可以用它来为今晚的游戏设置哪个狡猾的陷阱做个决定。
---
via: <https://opensource.com/article/19/1/productivity-tools-roland>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the seventh of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## Roland
By the time the workday has ended, often the only thing I want to think about is hitting the couch and playing the video game of the week. But even though my professional obligations stop at the end of the workday, I still have to manage my household. Laundry, pet care, making sure my teenager has what he needs, and most important: deciding what to make for dinner.
Like many people, I often suffer from [decision fatigue](https://en.wikipedia.org/wiki/Decision_fatigue), and I make less-than-healthy choices for dinner based on speed, ease of preparation, and (quite frankly) whatever causes me the least stress.

[Roland](https://github.com/rjbs/Roland) makes planning my meals much easier. Roland is a Perl application designed for tabletop role-playing games. It picks randomly from a list of items, such as monsters and hirelings. In essence, Roland does the same thing at the command line that a game master does when rolling physical dice to look up things in a table from the *Game Master's Big Book of Bad Things to Do to Players*.
With minor modifications, Roland can do so much more. For example, just by adding a table, I can enable Roland to help me choose what to cook for dinner.
The first step is installing Roland and all its dependencies.
```
``````
git clone [email protected]:rjbs/Roland.git
cpan install Getopt::Long::Descriptive Moose \
namespace::autoclean List:AllUtils Games::Dice \
Sort::ByExample Data::Bucketeer Text::Autoformat \
YAML::XS
cd oland
```
Next, I create a YAML document named **dinner** and enter all our meal options.
```
``````
type: list
pick: 1
items:
- "frozen pizza"
- "chipotle black beans"
- "huevos rancheros"
- "nachos"
- "pork roast"
- "15 bean soup"
- "roast chicken"
- "pot roast"
- "grilled cheese sandwiches"
```
Running the command **bin/roland dinner** will read the file and pick one of the options.
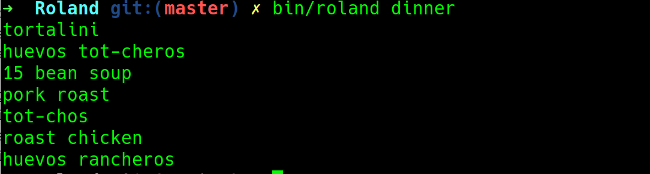
I like to plan for the week ahead so I can shop for all my ingredients in advance. The **pick** command determines how many items from the list to chose, and right now, the **pick** option is set to 1. If I want to plan a full week's dinner menu, I can just change **pick: 1** to **pick: 7** and it will give me a week's worth of dinners. You can also use the **-m** command line option to manually enter the choices.
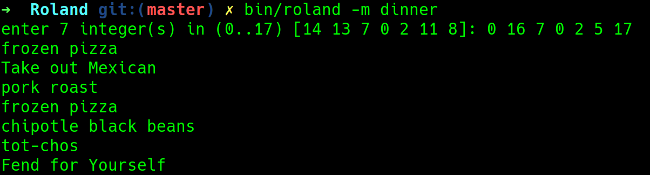
You can also do fun things with Roland, like adding a file named **8ball** with some classic phrases.

You can create all kinds of files to help with common decisions that seem so stressful after a long day of work. And even if you don't use it for that, you can still use it to decide which devious trap to set up for tonight's game.
## 4 Comments |
10,508 | fdisk:Linux 下管理磁盘分区的利器 | https://www.2daygeek.com/linux-fdisk-command-to-manage-disk-partitions/ | 2019-02-04T18:06:00 | [
"分区",
"硬盘",
"fdisk"
] | https://linux.cn/article-10508-1.html | 
一块硬盘可以被划分成一个或多个逻辑磁盘,我们将其称作分区。我们对硬盘进行的划分信息被储存于建立在扇区 0 的分区表(MBR 或 GPT)中。
Linux 需要至少一个分区来当作根文件系统,所以我们不能在没有分区的情况下安装 Linux 系统。当我们创建一个分区时,我们必须将它格式化为一个适合的文件系统,否则我们就没办法往里面储存文件了。
要在 Linux 中完成分区的相关工作,我们需要一些工具。Linux 下有很多可用的相关工具,我们曾介绍过 [Parted 命令](https://www.2daygeek.com/how-to-manage-disk-partitions-using-parted-command/)。不过,今天我们的主角是 `fdisk`。
人人都喜欢用 `fdisk`,它是 Linux 下管理磁盘分区的最佳利器之一。它可以操作最大 2TB 的分区。大量 Linux 管理员都喜欢使用这个工具,因为当下 LVM 和 SAN 的原因,并没有多少人会用到 2TB 以上的分区。并且这个工具被世界上许多的基础设施所使用。如果你还是想创建比 2TB 更大的分区,请使用 `parted` 命令 或 `cfdisk` 命令。
对磁盘进行分区和创建文件系统是 Linux 管理员的日常。如果你在许多不同的环境中工作,你一定每天都会重复几次这项操作。
### Linux 内核是如何理解硬盘的?
作为人类,我们可以很轻松地理解一些事情;但是电脑就不是这样了,它们需要合适的命名才能理解这些。
在 Linux 中,外围设备都位于 `/dev` 挂载点,内核通过以下的方式理解硬盘:
* `/dev/hdX[a-z]:` IDE 硬盘被命名为 hdX
* `/dev/sdX[a-z]:` SCSI 硬盘被命名为 sdX
* `/dev/xdX[a-z]:` XT 硬盘被命名为 xdX
* `/dev/vdX[a-z]:` 虚拟硬盘被命名为 vdX
* `/dev/fdN:` 软盘被命名为 fdN
* `/dev/scdN or /dev/srN:` CD-ROM 被命名为 `/dev/scdN` 或 `/dev/srN`
### 什么是 fdisk 命令?
`fdisk` 的意思是 <ruby> 固定磁盘 <rt> Fixed Disk </rt></ruby> 或 <ruby> 格式化磁盘 <rt> Format Disk </rt></ruby>,它是命令行下允许用户对分区进行查看、创建、调整大小、删除、移动和复制的工具。它支持 MBR、Sun、SGI、BSD 分区表,但是它不支持 GUID 分区表(GPT)。它不是为操作大分区设计的。
`fdisk` 允许我们在每块硬盘上创建最多四个主分区。它们中的其中一个可以作为扩展分区,并下设多个逻辑分区。1-4 扇区作为主分区被保留,逻辑分区从扇区 5 开始。

### 如何在 Linux 下安装 fdisk?
`fdisk` 作为核心组件内置于 Linux 中,所以你不必手动安装它。
### 如何用 fdisk 列出可用磁盘?
在执行操作之前,我们必须知道的是哪些磁盘被加入了系统。要想列出所有可用的磁盘,请执行下文的命令。这个命令将会列出磁盘名称、分区数量、分区表类型、磁盘识别代号、分区 ID 和分区类型。
```
$ sudo fdisk -l
Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xeab59449
Device Boot Start End Sectors Size Id Type
/dev/sda1 * 20973568 62914559 41940992 20G 83 Linux
Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/sdd: 10 GiB, 10737418240 bytes, 20971520 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/sde: 10 GiB, 10737418240 bytes, 20971520 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
```
### 如何使用 fdisk 列出特定分区信息?
如果你希望查看指定分区的信息,请使用以下命令:
```
$ sudo fdisk -l /dev/sda
Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xeab59449
Device Boot Start End Sectors Size Id Type
/dev/sda1 * 20973568 62914559 41940992 20G 83 Linux
```
### 如何列出 fdisk 所有的可用操作?
在 `fdisk` 中敲击 `m`,它便会列出所有可用操作:
```
$ sudo fdisk /dev/sdc
Welcome to fdisk (util-linux 2.30.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table.
Created a new DOS disklabel with disk identifier 0xe944b373.
Command (m for help): m
Help:
DOS (MBR)
a toggle a bootable flag
b edit nested BSD disklabel
c toggle the dos compatibility flag
Generic
d delete a partition
F list free unpartitioned space
l list known partition types
n add a new partition
p print the partition table
t change a partition type
v verify the partition table
i print information about a partition
Misc
m print this menu
u change display/entry units
x extra functionality (experts only)
Script
I load disk layout from sfdisk script file
O dump disk layout to sfdisk script file
Save & Exit
w write table to disk and exit
q quit without saving changes
Create a new label
g create a new empty GPT partition table
G create a new empty SGI (IRIX) partition table
o create a new empty DOS partition table
s create a new empty Sun partition table
```
### 如何使用 fdisk 列出分区类型?
在 `fdisk` 中敲击 `l`,它便会列出所有可用分区的类型:
```
$ sudo fdisk /dev/sdc
Welcome to fdisk (util-linux 2.30.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table.
Created a new DOS disklabel with disk identifier 0x9ffd00db.
Command (m for help): l
0 Empty 24 NEC DOS 81 Minix / old Lin bf Solaris
1 FAT12 27 Hidden NTFS Win 82 Linux swap / So c1 DRDOS/sec (FAT-
2 XENIX root 39 Plan 9 83 Linux c4 DRDOS/sec (FAT-
3 XENIX usr 3c PartitionMagic 84 OS/2 hidden or c6 DRDOS/sec (FAT-
4 FAT16 <32M 40 Venix 80286 85 Linux extended c7 Syrinx
5 Extended 41 PPC PReP Boot 86 NTFS volume set da Non-FS data
6 FAT16 42 SFS 87 NTFS volume set db CP/M / CTOS / .
7 HPFS/NTFS/exFAT 4d QNX4.x 88 Linux plaintext de Dell Utility
8 AIX 4e QNX4.x 2nd part 8e Linux LVM df BootIt
9 AIX bootable 4f QNX4.x 3rd part 93 Amoeba e1 DOS access
a OS/2 Boot Manag 50 OnTrack DM 94 Amoeba BBT e3 DOS R/O
b W95 FAT32 51 OnTrack DM6 Aux 9f BSD/OS e4 SpeedStor
c W95 FAT32 (LBA) 52 CP/M a0 IBM Thinkpad hi ea Rufus alignment
e W95 FAT16 (LBA) 53 OnTrack DM6 Aux a5 FreeBSD eb BeOS fs
f W95 Ext'd (LBA) 54 OnTrackDM6 a6 OpenBSD ee GPT
10 OPUS 55 EZ-Drive a7 NeXTSTEP ef EFI (FAT-12/16/
11 Hidden FAT12 56 Golden Bow a8 Darwin UFS f0 Linux/PA-RISC b
12 Compaq diagnost 5c Priam Edisk a9 NetBSD f1 SpeedStor
14 Hidden FAT16 <3 61 SpeedStor ab Darwin boot f4 SpeedStor
16 Hidden FAT16 63 GNU HURD or Sys af HFS / HFS+ f2 DOS secondary
17 Hidden HPFS/NTF 64 Novell Netware b7 BSDI fs fb VMware VMFS
18 AST SmartSleep 65 Novell Netware b8 BSDI swap fc VMware VMKCORE
1b Hidden W95 FAT3 70 DiskSecure Mult bb Boot Wizard hid fd Linux raid auto
1c Hidden W95 FAT3 75 PC/IX bc Acronis FAT32 L fe LANstep
1e Hidden W95 FAT1 80 Old Minix be Solaris boot ff BBT
```
### 如何使用 fdisk 创建一个磁盘分区?
如果你希望新建磁盘分区,请参考下面的步骤。比如我希望在 `/dev/sdc` 中新建四个分区(三个主分区和一个扩展分区),只需要执行下文的命令。
首先,请在操作 “First sector” 的时候先按下回车,然后在 “Last sector” 中输入你希望创建分区的大小(可以在数字后面加 KB、MB、G 和 TB)。例如,你希望为这个分区扩容 1GB,就应该在 “Last sector” 中输入 `+1G`。当你创建三个分区之后,`fdisk` 默认会将分区类型设为扩展分区,如果你希望创建第四个主分区,请输入 `p` 来替代它的默认值 `e`。
```
$ sudo fdisk /dev/sdc
Welcome to fdisk (util-linux 2.30.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
Select (default p): Enter
Using default response p.
Partition number (1-4, default 1): Enter
First sector (2048-20971519, default 2048): Enter
Last sector, +sectors or +size{K,M,G,T,P} (2048-20971519, default 20971519): +1G
Created a new partition 1 of type 'Linux' and of size 1 GiB.
Command (m for help): p
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x8cc8f9e5
Device Boot Start End Sectors Size Id Type
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
```
### 如何使用 fdisk 创建扩展分区?
请注意,创建扩展分区时,你应该使用剩下的所有空间,以便之后在扩展分区下创建逻辑分区。
```
$ sudo fdisk /dev/sdc
Welcome to fdisk (util-linux 2.30.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): n
Partition type
p primary (3 primary, 0 extended, 1 free)
e extended (container for logical partitions)
Select (default e): Enter
Using default response e.
Selected partition 4
First sector (6293504-20971519, default 6293504): Enter
Last sector, +sectors or +size{K,M,G,T,P} (6293504-20971519, default 20971519): Enter
Created a new partition 4 of type 'Extended' and of size 7 GiB.
Command (m for help): p
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x8cc8f9e5
Device Boot Start End Sectors Size Id Type
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
/dev/sdc2 2099200 4196351 2097152 1G 83 Linux
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
```
### 如何用 fdisk 查看未分配空间?
上文中,我们总共创建了四个分区(三个主分区和一个扩展分区)。在创建逻辑分区之前,扩展分区的容量将会以未分配空间显示。
使用以下命令来显示磁盘上的未分配空间,下面的示例中显示的是 7GB:
```
$ sudo fdisk /dev/sdc
Welcome to fdisk (util-linux 2.30.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): F
Unpartitioned space /dev/sdc: 7 GiB, 7515144192 bytes, 14678016 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
Start End Sectors Size
6293504 20971519 14678016 7G
Command (m for help): q
```
### 如何使用 fdisk 创建逻辑分区?
创建扩展分区后,请按照之前的步骤创建逻辑分区。在这里,我创建了位于 `/dev/sdc5` 的 `1GB` 逻辑分区。你可以查看分区表值来确认这点。
```
$ sudo fdisk /dev/sdc
Welcome to fdisk (util-linux 2.30.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): n
All primary partitions are in use.
Adding logical partition 5
First sector (6295552-20971519, default 6295552): Enter
Last sector, +sectors or +size{K,M,G,T,P} (6295552-20971519, default 20971519): +1G
Created a new partition 5 of type 'Linux' and of size 1 GiB.
Command (m for help): p
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x8cc8f9e5
Device Boot Start End Sectors Size Id Type
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
/dev/sdc2 2099200 4196351 2097152 1G 83 Linux
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
```
### 如何使用 fdisk 命令删除分区?
如果我们不再使用某个分区,请按照下面的步骤删除它。
请确保你输入了正确的分区号。在这里,我准备删除 `/dev/sdc2` 分区:
```
$ sudo fdisk /dev/sdc
Welcome to fdisk (util-linux 2.30.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): d
Partition number (1-5, default 5): 2
Partition 2 has been deleted.
Command (m for help): p
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x8cc8f9e5
Device Boot Start End Sectors Size Id Type
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
```
### 如何在 Linux 下格式化分区或建立文件系统?
在计算时,文件系统控制了数据的储存方式,并通过 <ruby> 索引节点 <rt> Inode Tables </rt></ruby> 来检索数据。如果没有文件系统,操作系统是无法找到信息储存的位置的。
在此,我准备在 `/dev/sdc1` 上创建分区。有三种方式创建文件系统:
```
$ sudo mkfs.ext4 /dev/sdc1
或
$ sudo mkfs -t ext4 /dev/sdc1
或
$ sudo mke2fs /dev/sdc1
mke2fs 1.43.5 (04-Aug-2017)
Creating filesystem with 262144 4k blocks and 65536 inodes
Filesystem UUID: c0a99b51-2b61-4f6a-b960-eb60915faab0
Superblock backups stored on blocks:
32768, 98304, 163840, 229376
Allocating group tables: done
Writing inode tables: done
Creating journal (8192 blocks): done
Writing superblocks and filesystem accounting information: done
```
当你在分区上建立文件系统时,以下重要信息会同时被创建:
* `Filesystem UUID:` UUID 代表了通用且独一无二的识别符,UUID 在 Linux 中通常用来识别设备。它 128 位长的数字代表了 32 个十六进制数。
* `Superblock:` 超级块储存了文件系统的元数据。如果某个文件系统的超级块被破坏,我们就无法挂载它了(也就是说无法访问其中的文件了)。
* `Inode:` Inode 是类 Unix 系统中文件系统的数据结构,它储存了所有除名称以外的文件信息和数据。
* `Journal:` 日志式文件系统包含了用来修复电脑意外关机产生下错误信息的日志。
### 如何在 Linux 中挂载分区?
在你创建完分区和文件系统之后,我们需要挂载它们以便使用。我们需要创建一个挂载点来挂载分区,使用 `mkdir` 来创建一个挂载点。
```
$ sudo mkdir -p /mnt/2g-new
```
如果你希望进行临时挂载,请使用下面的命令。在计算机重启之后,你会丢失这个挂载点。
```
$ sudo mount /dev/sdc1 /mnt/2g-new
```
如果你希望永久挂载某个分区,请将分区详情加入 `fstab` 文件。我们既可以输入设备名称,也可以输入 UUID。
使用设备名称来进行永久挂载:
```
# vi /etc/fstab
/dev/sdc1 /mnt/2g-new ext4 defaults 0 0
```
使用 UUID 来进行永久挂载(请使用 `blkid` 来获取 UUID):
```
$ sudo blkid
/dev/sdc1: UUID="d17e3c31-e2c9-4f11-809c-94a549bc43b7" TYPE="ext2" PARTUUID="8cc8f9e5-01"
/dev/sda1: UUID="d92fa769-e00f-4fd7-b6ed-ecf7224af7fa" TYPE="ext4" PARTUUID="eab59449-01"
/dev/sdc3: UUID="ca307aa4-0866-49b1-8184-004025789e63" TYPE="ext4" PARTUUID="8cc8f9e5-03"
/dev/sdc5: PARTUUID="8cc8f9e5-05"
# vi /etc/fstab
UUID=d17e3c31-e2c9-4f11-809c-94a549bc43b7 /mnt/2g-new ext4 defaults 0 0
```
使用 `df` 命令亦可:
```
$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 969M 0 969M 0% /dev
tmpfs 200M 7.0M 193M 4% /run
/dev/sda1 20G 16G 3.0G 85% /
tmpfs 997M 0 997M 0% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 997M 0 997M 0% /sys/fs/cgroup
tmpfs 200M 28K 200M 1% /run/user/121
tmpfs 200M 25M 176M 13% /run/user/1000
/dev/sdc1 1008M 1.3M 956M 1% /mnt/2g-new
```
---
via: <https://www.2daygeek.com/linux-fdisk-command-to-manage-disk-partitions/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zhs852](https://github.com/zhs852) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,509 | 极客漫画:云锁定 | http://turnoff.us/geek/cloud-lock-in/ | 2019-02-04T18:38:15 | [
"云服务商",
"锁定"
] | https://linux.cn/article-10509-1.html | 
避免被某一家(云)服务商锁定,这样你就再也离不开它了——当你就是那偏偏遇到问题的 0.05% 时,你也需要找工作了。
---
via: <http://turnoff.us/geek/cloud-lock-in/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者 & 点评:[wxy](https://github.com/wxy) 校对 & 合成:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,510 | 作为 CEO 使用 Emacs 的两年经验之谈 | https://www.fugue.co/blog/2018-08-09-two-years-with-emacs-as-a-cto.html | 2019-02-05T14:15:21 | [
"emacs"
] | https://linux.cn/article-10510-1.html | 
两年前,我写了一篇[博客](/article-10401-1.html),并取得了一些反响。这让我有点受宠若惊。那篇博客写的是我准备将 Emacs 作为我的主办公软件,当时我还是 CEO,现在已经是 CTO 了。现在回想起来,我发现我之前不是做程序员就是做软件架构师,而且那时我也喜欢用 Emacs 写代码。重新考虑使用 Emacs 是一次令我振奋的尝试,但我不太清楚这次行动会造成什么反响。在网上,那篇博客的评论也是褒贬不一,但是还是有数万的阅读量,所以总的来说,我写的是一个蛮有意思的题材。在 [Reddit](https://www.reddit.com/r/emacs/comments/7efpkt/a_ceos_guide_to_emacs/) 和 [HackerNews](https://news.ycombinator.com/item?id=10642088) 上有些令人哭笑不得的回复,说我的手会变成鸡爪,或者说我会因白色的背景而近视。在这里我可以很高兴地回答,到目前为止并没有出现什么特别糟糕的后果,相反,我的手腕还因此变得更灵活了。还有一些人担心,说使用 Emacs 会耗费一个 CEO 的精力。把 Fugue 从一个在我家后院的灵感变成强大的产品,并有一大批忠实的顾客,我发现在做这种真正复杂之事的时候,Emacs 可以给你带来安慰。还有,我现在仍然在用白色的背景。
近段时间那篇博客又被翻出来了,并发到了 [HackerNews](https://news.ycombinator.com/item?id=15753150) 上。我收到了大量的跟帖者问我现在使用状况如何,所以我写了这篇博客来回应他们。在本文中,我还将重点讨论为什么 Emacs 和函数式编程有很高的关联性,以及我们是怎样使用 Emacs 来开发我们的产品 —— Fugue,一个使用函数式编程的自动化的云计算平台的。由于我收到了很多反馈,其众多细节和评论很有用,因此这篇博客比较长,而我确实也需要费点精力来解释我如此作为时的想法,但这篇文章的主要内容还是反映了我担任 CEO 时处理的事务。而我想在之后更频繁地用 Emacs 写代码,所以需要提前做一些准备。一如既往,本文因人而异,后果自负。
### 意外之喜
我大部分时间都在不断的处理公司内外沟通。交流是解决问题的唯一方法,但也是反思及思考困难或复杂问题的敌人。对我来说,作为创业公司的 CEO,最需要的是能专注工作而不被打扰的时间。一旦你决定投入时间来学习一些有用的命令,Emacs 就能帮助创造这种不被打扰的可贵环境。其他的应用会弹出提示,但是一个配置好了的 Emacs 可以完全不影响你 —— 无论是视觉上还是精神上。除非你想,否则的话它不会改变,况且没有比空白屏幕和漂亮的字体更干净的界面了。不断被打扰是我的日常状况,因此这种简洁让我能够专注于我在想的事情,而不是电脑本身。好的程序能够默默地操纵电脑,并且不会夺取你的注意力。
一些人指出,我原来的博客有太多对现代图形界面的批判和对 Emacs 的赞许。我既不赞同,也不否认。现代的界面,特别是那些以应用程序为中心的方法(相对于以内容为中心的方法),既不是以用户为中心的,也不是面向任务的。Emacs 避免了这种错误,这也是我如此喜欢它的部分原因,而它也带来了其他优点。Emacs 是带领你体会计算机魅力的传送门,一个值得跳下去的兔子洞(LCTT 译注:爱丽丝梦游仙境里的兔子洞,跳进去会有新世界)。它的核心是发现和创造属于自己的道路,对我来说这本身就是创造了。现代计算的悲哀之处在于,它很大程度上是由带有闪亮界面的黑盒组成的,这些黑盒提供的是瞬间的喜悦,而不是真正的满足感。这让我们变成了消费者,而不是技术的创造者。无论你是谁或者你的背景是什么;你都可以理解你的电脑,你可以用它创造事物。它很有趣,能令人满意,而且不是你想的那么难学!
我们常常低估了环境对我们心理的影响。Emacs 给人一种平静和自由的感觉,而不是紧迫感、烦恼或兴奋 —— 后者是思考和沉思的敌人。我喜欢那些持久的、不碍事的东西,当我花时间去关注它们的时候,它们会给我带来真知灼见。Emacs 满足我的所有这些标准。我每天都使用 Emacs 来工作,我也很高兴我很少需要注意到它。Emacs 确实有一个学习曲线,但不会比学自行车的学习曲线来的更陡,而且一旦你掌握了它,你会得到相应的回报,而且不必再去想它了。它赋予你一种其他工具所没有的自由感。这是一个优雅的工具,来自一个更加文明的计算时代。我很高兴我们步入了另一个文明的计算时代,我相信 Emacs 也将越来越受欢迎。
### 弃用 Org 模式处理日程和待办事项
在原来的文章中,我花了一些时间介绍如何使用 Org 模式来规划日程。不过现在我放弃了使用 Org 模式来处理待办事项一类的事物,因为我每天都有很多会议要开,很多电话要打,我也不能让其他人来适应我选的工具,而且也没有时间将事务转换或是自动移动到 Org 上。我们主要是 Mac 一族,使用谷歌日历等工具,而且原生的 Mac OS/iOS 工具可以很好的进行团队协作。我还有支老钢笔用来在会议中做笔记,因为我发现在会议中使用笔记本电脑或者说键盘记录很不礼貌,而且这也限制了我的聆听和思考。因此,我基本上放弃了用 Org 模式帮我规划日程或安排生活。当然,Org 模式对其他的方面也很有用,它是我编写文档的首选,包括本文。换句话说,我使用它的方式与其作者的想法背道而驰,但它的确做得很好。我也希望有一天也有人如此评价并使用我们的 Fugue。
### Emacs 已经在 Fugue 公司中扩散
我在上篇博客就有说,你可能会喜欢 Emacs,也可能不会。因此,当 Fugue 的文档组将 Emacs 作为标准工具时,我是有点担心的,因为我觉得他们可能是受了我的影响才做出这种选择。不过在两年后,我确信他们做出了正确的选择。文档组的组长是一个很聪明的程序员,但是另外两个编写文档的人却没有怎么接触过技术。我想,如果这是一个经理强迫员工使用错误工具的案例,我就会收到投诉要去解决它,因为 Fugue 有反威权文化,大家不怕挑战任何事和任何人。之前的组长在去年辞职了,但[文档组](https://docs.fugue.co/)现在有了一个灵活的集成的 CI/CD 工具链,并且文档组的人已经成为了 Emacs 的忠实用户。Emacs 有一条学习曲线,但即使在最陡的时候,也不至于多么困难,并且翻过顶峰后,对生产力和总体幸福感都得到了提升。这也提醒我们,学文科的人在技术方面和程序员一样聪明,一样能干,也许不那么容易受到技术崇拜与习俗产生的影响。
### 我的手腕感激我的决定
上世纪 80 年代中期以来,我每天花 12 个小时左右在电脑前工作,这给我的手腕(以及后背)造成了很大的损伤(因此我强烈安利 Tag Capisco 的椅子)。Emacs 和人机工程学键盘的结合让手腕的 [RSI](https://baike.baidu.com/item/RSI/21509642)(<ruby> 重复性压迫损伤 <rt> Repetitive Strain Injury </rt></ruby>)问题消失了,我已经一年多没有想过这种问题了。在那之前,我的手腕每天都会疼,尤其是右手。如果你也有这种问题,你就知道这疼痛很让人分心和忧虑。有几个人问过关于选购键盘和鼠标的问题,如果你也对此有兴趣,那么在过去两年里,我主要使用的是 Truly Ergonomic 键盘,不过我现在用的是[这款键盘](https://shop.keyboard.io/)。我已经换成现在的键盘有几个星期,而且我爱死它了。大写键的形状很神奇,因为你不用看就能知道它在哪里。而人体工学的拇指键也设计的十分合理,尤其是对于 Emacs 用户而言,Control 和 Meta 是你的坚实伴侣,不要再需要用小指做高度重复的任务了!
我使用鼠标的次数比使用 Office 和 IDE 时要少得多,这对我的工作效率有很大帮助,但我还是需要一个鼠标。我一直在使用外观相当过时,但功能和人体工程学非常优秀的 Clearly Superior 轨迹球,恰如其名。
撇开具体的工具不谈,事实证明,一个很棒的键盘,再加上避免使用鼠标,在减少身体的磨损方面很有效。Emacs 是达成这方面的核心,因为我不需要在菜单上滑动鼠标来完成任务,而且导航键就在我的手指下面。我现在十分肯定,我的手离开标准打字位置会给我的肌腱造成很大的压力。不过这也因人而异,我不是医生不好下定论。
### 我并没有做太多配置……
有人说我会在界面配置上耗费很多的时间。我想验证下他们说的对不对,所以我特别留意了下。我不仅在很多程度上不用配置,关注这个问题还让我意识到,我使用的其他工具是多么的耗费我的精力和时间。Emacs 是我用过的维护成本最低的软件。Mac OS 和 Windows 一直要求我更新它,但在我看来,这远没有 Adobe 套件和 Office 的更新给我带来的困扰那么大。我只是偶尔更新 Emacs,但对我来说它也没什么变化,所以从我的个人观点而言,更新基本上是一个接近于零成本的操作,我高兴什么时候更新就什么时候更新。
有一点让你们失望了,因为许多人想知道我为跟上重新打造的 Emacs 社区的更新做了些什么,但是在过去的两年中,我只在配置中添加了少部分内容。我认为这也是一种成功,因为 Emacs 只是一个工具,而不是我的爱好。但即便如此,如果你想和我分享关于 Emacs 的新鲜事物,我很乐意聆听。
### 期望实现云端控制
在我们 Fugue 公司有很多 Emacs 的粉丝,所以我们有一段时间在用 [Ludwing 模式](https://github.com/fugue/ludwig-mode)。Ludwig 模式是我们用于自动化云基础设施和服务的声明式、功能性的 DSL。最近,Alex Schoof 利用在飞机上和晚上的时间来构建 fugue 模式,它在 Fugue CLI 上充当 Emacs 控制台。要是你不熟悉 Fugue,这是我们开发的一个云自动化和治理工具,它利用函数式编程为用户提供与云的 API 交互的良好体验。但它做的不止这些。fugue 模式很酷的原因有很多,它有一个不断报告云基础设施状态的缓冲区,由于我经常修改这些基础设施,这样我就可以快速看到代码的效果。Fugue 将云工作负载当成进程处理,fugue 模式非常类似于为云工作负载设计的 `top` 工具。它还允许我执行一些操作,比如创建新的设备或删除过期的东西,而且也不需要太多输入。Fugue 模式只是个雏形,但它非常方便,而我现在也经常使用它。

### 模式及监控
我添加了一些模式和集成插件,但并不是真正用于工作或 CEO 职能。我喜欢在周末时写写 Haskell 和 Scheme 娱乐,所以我添加了 haskell 模式和 geiser。Emacs 很适合拥有 REPL 的语言,因为你可以在不同的窗口中运行不同的模式,包括 REPL 和 shell。geiser 和 Scheme 很配,要是你还没有用过 Scheme,那么阅读《计算机程序的构造和解释》(SICP)也不失为一种乐趣,在这个有很多货物崇拜编程(LCTT 译注:是一种计算机程序设计中的反模式,其特征为不明就里地、仪式性地使用代码或程序架构)例子的时代,阅读此书或许可以启发你。安装 MIT Scheme 和 geiser,你就会感觉有点像 lore 的符号环境。
这就引出了我在 2015 年的文章中没有提到的另一个话题:屏幕管理。我喜欢使用单独一个纵向模式的显示器来写作,我在家里和我的主要办公室都有这个配置。对于编程或混合使用,我喜欢我们提供给所有 Fugue 人的新型超宽显示器。对于它来说,我更喜欢将屏幕分成三列,中间是主编辑缓冲区,左边是水平分隔的 shell 和 fugue 模式缓冲区,右边是文档缓冲区或另外一、两个编辑缓冲区。这个很简单,首先按 `Ctl-x 3` 两次,然后使用 `Ctl-x =` 使窗口的宽度相等。这将提供三个相等的列,你也可以使用 `Ctl-x 2` 对分割之后的窗口再次进行水平分割。以下是我的截图。

### 这将是最后一篇 CEO/Emacs 文章
首先是因为我现在是 Fugue 的 CTO 而并非 CEO,其次是我有好多要写的博客主题,而我现在刚好有时间。我还打算写些更深入的东西,比如说函数式编程、基础设施即代码的类型安全,以及我们即将推出的一些 Fugue 的新功能、关于 Fugue 在云上可以做什么的博文等等。
---
via: <https://www.fugue.co/blog/2018-08-09-two-years-with-emacs-as-a-cto.html>
作者:[Josh Stella](https://www.fugue.co/blog/author/josh-stella) 选题:[lujun9972](https://github.com/lujun9972) 译者:[oneforalone](https://github.com/oneforalone) 校对:[acyanbird](https://github.com/acyanbird), [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,511 | 开始使用 Tint2 吧,一款 Linux 中的开源任务栏 | https://opensource.com/article/19/1/productivity-tool-tint2 | 2019-02-05T22:16:00 | [
"任务栏"
] | https://linux.cn/article-10511-1.html |
>
> Tint2 是我们在开源工具系列中的第 14 个工具,它将在 2019 年提高你的工作效率,能在任何窗口管理器中提供一致的用户体验。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 14个工具来帮助你在 2019 年更有效率。
### Tint2
让我提高工作效率的最佳方法之一是使用尽可能不让我分心的干净界面。作为 Linux 用户,这意味着使用一种极简的窗口管理器,如 [Openbox](http://openbox.org/wiki/Main_Page)、[i3](https://i3wm.org/) 或 [Awesome](https://awesomewm.org/)。它们每种都有让我更有效率的自定义选项。但让我失望的一件事是,它们都没有一致的配置,所以我不得不经常重新调整我的窗口管理器。

[Tint2](https://gitlab.com/o9000/tint2) 是一个轻量级面板和任务栏,它可以为任何窗口管理器提供一致的体验。它包含在大多数发行版中,因此它与任何其他软件包一样易于安装。
它包括两个程序,Tint2 和 Tint2conf。首次启动时,Tint2 以默认布局和主题启动。默认配置包括多个 Web 浏览器、tint2conf 程序,任务栏和系统托盘。

启动该配置工具能让你选择主题并自定义屏幕的顶部、底部和侧边栏。我建议从最接近你想要的主题开始,然后从那里进行自定义。

在主题中,你可以自定义面板项目的位置以及面板上每个项目的背景和字体选项。你还可以在启动器中添加和删除项目。

Tint2 是一个轻量级的任务栏,可以帮助你快速有效地获得所需的工具。它是高度可定制的,不显眼的 (除非用户不希望这样),并且几乎与 Linux 桌面中的任何窗口管理器兼容。
---
via: <https://opensource.com/article/19/1/productivity-tool-tint2>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the 14th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## Tint2
One of the best ways for me to be more productive is to use a clean interface with as little distraction as possible. As a Linux user, this means using a minimal window manager like [Openbox](http://openbox.org/wiki/Main_Page), [i3](https://i3wm.org/), or [Awesome](https://awesomewm.org/). Each has customization options that make me more efficient. The one thing that slows me down is that none has a consistent configuration, so I have to tweak and re-tune my window manager constantly.

[Tint2](https://gitlab.com/o9000/tint2) is a lightweight panel and taskbar that provides a consistent experience with any window manager. It is included with most distributions, so it is as easy to install as any other package.
It includes two programs, Tint2 and Tint2conf. At first launch, Tint2 starts with its default layout and theme. The default configuration includes multiple web browsers, the tint2conf program, a taskbar, and a system tray.
Launching the configuration tool allows you to select from the included themes and customize the top, bottom, and sides of the screen. I recommend starting with the theme that is closest to what you want and customizing from there.
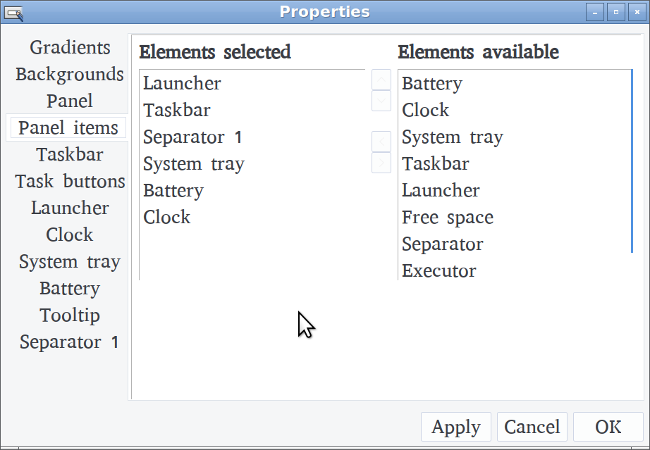
Within the themes, you can customize where panel items are placed as well as background and font options for every item on the panel. You can also add and remove items from the launcher.

Tint2 is a lightweight taskbar that helps you get to the tools you need quickly and efficiently. It is highly customizable, unobtrusive (unless the user wants it not to be), and compatible with almost any window manager on a Linux desktop.
## 3 Comments |
10,512 | 开源数据库 PostgreSQL、MariaDB 和 SQLite 的对比 | https://opensource.com/article/19/1/open-source-databases | 2019-02-06T11:05:34 | [
"数据库",
"PostgreSQL",
"MariaDB",
"SQLite"
] | https://linux.cn/article-10512-1.html |
>
> 了解如何选择最适合你的需求的开源数据库。
>
>
>

在现代的企业级技术领域中,开源软件已经成为了一股不可忽视的重要力量。借助<ruby> <a href="https://opensource.com/article/18/2/pivotal-moments-history-open-source"> 开源运动 </a> <rt> open source movement </rt></ruby>的东风,涌现除了许多重大的技术突破。
个中原因显而易见,尽管一些基于 Linux 的开源网络标准可能不如专有厂商的那么受欢迎,但是不同制造商的智能设备之间能够互相通信,开源技术功不可没。当然也有不少人认为开源开发出来的应用比厂商提供的产品更加好,所以无论如何,使用开源数据库进行开发确实是相当有利的。
和其它类型的应用软件一样,不同的开源数据库管理系统之间在功能和特性上可能会存在着比较大的差异。换言之,[不是所有的开源数据库都是平等的](https://blog.capterra.com/free-database-software/)。因此,如果要为整个组织选择一个开源数据库,那么应该重点考察数据库是否对用户友好、是否能够持续适应团队需求、是否能够提供足够安全的功能等方面的因素。
出于这方面考虑,我们在这篇文章中对一些开源数据库进行了概述和优缺点对比。遗憾的是,我们必须忽略一些最常用的数据库。值得注意的是,MongoDB 最近更改了它的许可证,因此它已经不是真正的开源产品了。从商业角度来看,这个决定是很有意义的,因为 MongoDB 已经成为了数据库托管实际上的解决方案,[约 27000 家公司](https://idatalabs.com/tech/products/mongodb)在使用它,但这也意味着 MongoDB 已经不再被视为真正的开源产品。
另外,自从 MySQL 被 Oracle 收购之后,这个产品就已经不再具有开源性质了,MySQL 可以说是数十年来首选的开源数据库。然而,这为其它真正的开源数据库解决方案提供了挑战它的空间。
下面是三个值得考虑的开源数据库。
### PostgreSQL
没有 [PostgreSQL](https://www.postgresql.org/) 的开源数据库清单肯定是不完整的。PostgreSQL 一直都是各种规模企业的首选解决方案。Oracle 对 MySQL 的收购在当时来说可能具有一定的商业意义,但是随着云存储的日益壮大,[开发者对 MySQL 的依赖程度或许并不如以前那么大了](https://www.theregister.co.uk/2018/05/31/rise_of_the_open_source_data_strategies/)。
尽管 PostgreSQL 不是一个最近几年才面世的新产品,但它却是借助了 [MySQL 相对衰落](https://www.itworld.com/article/2721995/big-data/signs-of-mysql-decline-on-horizon.html)的机会才逐渐成为最受欢迎的开源数据库之一。由于它和 MySQL 的工作方式非常相似,因此很多热衷于使用开源软件的开发者都纷纷转向 PostgreSQL。
#### 优势
* 目前 PostgreSQL 最显著的优点是它的核心算法的效率,这意味着它的性能优于许多宣称更先进数据库。这一点在处理大型数据集的时候就可以很明显地体现出来了,否则 I/O 处理会成为瓶颈。
* PostgreSQL 也是最灵活的开源数据库之一,使用 Python、Perl、Java、Ruby、C 或者 R 都能够很方便地调用数据库。
* 作为最常用的几个开源数据库之中,PostgreSQL 的社区支持是做得最好的。
#### 劣势
* 在数据量比较大的时候,PostgreSQL 的效率毋庸置疑是很高的,但对于数据量较小的情况,使用 PostgreSQL 就显得不如其它的一些工具快了。
* 尽管拥有一个很优秀的社区支持,但 PostgreSQL 的核心文档仍然需要作出改进。
* 如果你需要使用并行计算或者集群化等高级工具,就需要安装 PostgreSQL 的第三方插件。尽管官方有计划将这些功能逐步添加到主要版本当中,但可能会需要再等待好几年才能出现在标准版本中。
### MariaDB
[MariaDB](https://mariadb.org/) 是 MySQL 的真正开源的发行版本(在 [GNU GPLv2](https://github.com/MariaDB/server/blob/10.4/COPYING) 下发布)。在 Oracle 收购 MySQL 之后,MySQL 的一些核心开发人员认为 Oracle 会破坏 MySQL 的开源理念,因此建立了 MariaDB 这个独立的分支。
MariaDB 在开发过程中替换了 MySQL 的几个关键组件,但仍然尽可能地保持兼容 MySQL。MariaDB 使用了 Aria 作为存储引擎,这个存储引擎既可以作为事务式引擎,也可以作为非事务式引擎。在 MariaDB 分叉出来之前,就[有一些人推测](http://kb.askmonty.org/en/aria-faq) Aria 会成为 MySQL 未来版本中的标准引擎。
#### 优势
* 由于 MariaDB [频繁进行安全发布](https://mariadb.org/tag/security/),很多用户选择使用 MariaDB 而不选择 MySQL。尽管这不一定代表 MariaDB 会比 MySQL 更加安全,但确实表明它的开发社区对安全性十分重视。
* 有一些人认为,MariaDB 的主要优点就是它在坚持开源的同时会与 MySQL 保持高度兼容,这就意味着从 MySQL 向 MariaDB 的迁移会非常容易。
* 也正是由于这种兼容性,MariaDB 也可以和其它常用于 MySQL 的语言配合使用,因此从 MySQL 迁移到 MariaDB 之后,学习和调试代码的时间成本会非常低。
* 你可以将 WordPress 和 MariaDB(而不是 MySQL)[配合使用](https://mariadb.com/resources/blog/how-to-install-and-run-wordpress-with-mariadb/)从而获得更好的性能和更丰富的功能。WordPress 是[最受欢迎的](https://websitesetup.org/popular-cms/)<ruby> 内容管理系统 <rt> Content Management System </rt></ruby>(CMS),占据了一半的互联网份额,并且拥有活跃的开源开发者社区。各种第三方插件在 WordPress 和 MariaDB 配合使用时都能够正常工作。
#### 劣势
* MariaDB 有时会变得比较臃肿,尤其是它的 IDX 日志文件在长期使用之后会变得非常大,最终导致性能下降。
* 缓存是 MariaDB 的另一个工作领域,并没有期望中那么快,这可能会让人有所失望。
* 尽管 MariaDB 最初承诺兼容 MySQL,但目前 MariaDB 已经不是完全兼容 MySQL。如果要从 MySQL 迁移到 MariaDB,就需要额外做一些兼容工作。
### SQLite
[SQLite](https://www.sqlite.org/index.html) 可以说是世界上实现最多的数据库引擎,因为它被很多流行的 web 浏览器、操作系统和手机所采用。它最初是作为 MySQL 的轻量级分支所开发的。SQLite 和很多其它的数据库不同,它不采用客户端-服务端的引擎架构,而是将整个软件嵌入到每个实现当中。
这样的架构让 SQLite 拥有一个强大的优势,就是在嵌入式系统或者分布式系统中,每台机器都搭载了数据库的整个实现。这样的做法减少了系统间的调用,从而大大提高了数据库的性能。
#### 优势
* 如果你需要构建和实现一个小型数据库,SQLite [可能是最好的选择](https://www.sqlite.org/aff_short.html)。它小而灵活,不需要费工夫寻求各种变通方案,就可以在嵌入式系统中实现。
* SQLite 体积很小,因此速度极快。其它的一些高级数据库可能会使用复杂的优化方式来提高效率,但SQLite 采用了一种更简单的方法:通过减小数据库及其处理软件的大小,以使处理的数据更少。
* SQLite 被广泛采用也导致它可能是兼容性最高的数据库。如果你希望将应用程序集成到智能手机上,这一点尤为重要:只要是可以工作于广泛环境中的第三方应用程序,就可以原生运行于 iOS 上。
#### 劣势
* SQLite 的体积小意味着它缺少了很多其它大型数据库的常见功能。例如数据加密就是[抵御黑客攻击](https://hostingcanada.org/most-common-website-vulnerabilities/)的标准功能,而 SQLite 却没有内置这个功能。
* SQLite 的广泛流行和源码公开使它易于使用,但是也让它更容易遭受攻击。这是它最大的劣势。SQLite 经常被发现高危的漏洞,例如最近的 [Magellan](https://www.securitynewspaper.com/2018/12/18/critical-vulnerability-in-sqlite-you-should-update-now/)。
* 尽管 SQLite 单文件的方式拥有速度上的优势,但是要使用它实现多用户环境却比较困难。
### 哪个开源数据库才是最好的?
当然,对于开源数据库的选择还是取决于业务的需求,尤其是系统的体量。对于小型数据库或者是使用量比较小的数据库,可以使用比较轻量级的解决方案,这样不仅可以加快实现的速度,而且由于系统的复杂程度不算太高,花在调试上的时间成本也不会太高。
而对于大型的系统,尤其是在成长性企业中,最好还是花时间使用更复杂的数据库(例如 PostgreSQL)。这是一个磨刀不误砍柴工的选择,能够让你不至于在后期再重新选择另一款数据库。
---
via: <https://opensource.com/article/19/1/open-source-databases>
作者:[Sam Bocetta](https://opensource.com/users/sambocetta) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the world of modern enterprise technologies, open source software has firmly established itself as one of the biggest forces to reckon with. After all, some of the biggest technology developments have emerged because of the [open source movement](https://opensource.com/article/18/2/pivotal-moments-history-open-source).
It's not difficult to see why: even though Linux-based open source network standards may not be as popular as proprietary options, they are the reason smart devices from different manufacturers can communicate with each other. In addition, many argue that open source development produces applications that are superior to their proprietary counterparts. This is one reason why the chances are good that your favorite tools (whether open source or proprietary) were developed using open source databases.
Like any other category of software, the functionality and features of open source database management systems can differ quite significantly. To put that in plainer terms, [not all open source database management systems are equal](https://blog.capterra.com/free-database-software/). If you are choosing an open source database for your organization, it's important to choose one that is user-friendly, can grow with your organization, and offers more-than-adequate security features.
With that in mind, we've compiled this overview of open source databases and their respective advantages and disadvantages. Sadly, we had to leave out some of the most used databases. Notably, MongoDB has recently changed its licensing model, so it is no longer truly open source. This decision probably made sense from a business perspective, since MongoDB has become the de facto solution for database hosting [with nearly 27,000 companies](https://idatalabs.com/tech/products/mongodb) using it, but it also means MongoDB can no longer be considered a truly open source system.
In addition, since it acquired MySQL, Oracle has all but killed the open source nature of that project, which was arguably the go-to open source database for decades. However, this has opened space for other truly open source database solutions to challenge it. Here are three of them to consider.
## PostgreSQL
No list of open source databases would be complete without [PostgreSQL](https://www.postgresql.org/), which has long been the preferred solution for businesses of all sizes. Oracle's acquisition of MySQL might have made good business sense at the time, but the rise of cloud storage has meant that the database [has gradually fallen out of favor with developers](https://www.theregister.co.uk/2018/05/31/rise_of_the_open_source_data_strategies/).
Although PostgreSQL has been around for a while, the relative [decline of MySQL](https://www.itworld.com/article/2721995/big-data/signs-of-mysql-decline-on-horizon.html) has made it a serious contender for the title of most used open source database. Since it works very similarly to MySQL, developers who prefer open source software are converting in droves.
### Advantages
-
By far, PostgreSQL's most mentioned advantage is the efficiency of its central algorithm, which means it outperforms many databases that are advertised as more advanced. This is especially useful if you are working with large datasets, for which I/O processes can otherwise become a bottleneck.
-
It is also one of the most flexible open source databases around; you can write functions in a wide range of server-side languages: Python, Perl, Java, Ruby, C, and R.
-
As one of the most commonly used open source databases, PostgreSQL's community support is some of the best around.
### Disadvantages
-
PostgreSQL's efficiency with large datasets is well known, but there are quicker tools available for smaller databases.
-
While its community support is very good, PostgreSQL's core documentation could be improved.
-
If you are used to advanced tools like parallelization and clustering, be aware that these require third-party plugins in PostgreSQL. There are plans to gradually add these features to the main release, but it will likely be a few years before they are offered as standard.
## MariaDB
[MariaDB](https://mariadb.org/) is a truly open source distribution of MySQL (released under the [GNU GPLv2](https://github.com/MariaDB/server/blob/10.4/COPYING)). It was [created after Oracle's acquisition](https://mariadb.com/about-us/) of MySQL, when some of MySQL's core developers were concerned that Oracle would undermine its open source philosophy.
MariaDB was developed to be as compatible with MySQL as possible while replacing several key components. It uses a storage engine, Aria, that functions as both a transactional and non-transactional engine. [Some even speculated](http://kb.askmonty.org/en/aria-faq) Aria would become the standard engine for MySQL in future releases, before MariaDB diverged.
### Advantages
-
Many users choose MariaDB over MySQL due to MariaDB's
[frequent security releases](https://mariadb.org/tag/security/). While this does not necessarily mean MariaDB is more secure, it does indicate the development community takes security seriously. -
Others say MariaDB's major advantages are that it will almost definitely remain open source and highly compatible with MySQL. This means migrating from one system to the other is extremely fast.
-
Because of this compatibility, MariaDB also plays well with many other languages that are commonly used with MySQL. This means less time is spent learning and debugging code.
-
You can
[install and run](https://mariadb.com/resources/blog/how-to-install-and-run-wordpress-with-mariadb/)WordPress with MariaDB instead of MySQL for better performance and a richer feature set. WordPress is the[most popular CMS by marketshare](https://websitesetup.org/popular-cms/)—powering nearly half the internet—and has an active open source developer community. Third-party themes and plugins work as intended when WordPress is installed with MariaDB.
### Disadvantages
-
MariaDB is somewhat liable to bloating. Its central IDX log file, in particular, tends to become very large after protracted use, ultimately slowing performance.
-
Caching is another area where MariaDB could use work—it is not as fast as it could be, which can be frustrating.
-
Despite all the initial promises, MariaDB is no longer completely compatible with MySQL. If you are migrating from MySQL, you will have some re-coding to do.
## SQLite
[SQLite](https://www.sqlite.org/index.html) is arguably the most implemented database engine in the world, thanks to its adoption by many popular web browsers, operating systems, and mobile phones. Originally developed as a lightweight fork of MySQL, unlike many other databases it is not a client-server engine; rather, the full software is embedded into each implementation.
This creates SQLite's major advantage: on embedded or distributed systems, each machine carries an entire implementation of the database. This can greatly speed up the performance of databases because it reduces the need for inter-system calls.
### Advantages
-
If you are looking to build and implement a small database, SQLite is
[arguably the best way to go](https://www.sqlite.org/aff_short.html). It is extremely small, so it can be implemented across a wide range of embedded systems without time-consuming workarounds. -
Its small size makes the system extremely fast. While some more advanced databases use complex ways of producing efficiency savings, SQLite takes a much simpler approach: By reducing the size of your database and its associated processing software, there is simply less data to work with.
-
Its widespread adoption also means SQLite is probably the most compatible database out there. This is particularly important if you need or plan to integrate your system with smartphones: the system has been native on iOS for as long as there have been third-party apps and works flawlessly in a wide range of environments.
### Disadvantages
-
SQLite's tiny size means it lacks some features found in larger databases. It lacks built-in data encryption, for example, something that has become standard to prevent the
[most common online hacker attacks](https://hostingcanada.org/most-common-website-vulnerabilities/). -
While the wide adoption and publicly available code makes SQLite easy to work with, it also increases its attack surface area. This is its most commonly cited disadvantage. New critical vulnerabilities are frequently discovered in SQLite, such as the recent remote attack vector called
[Magellan](https://www.securitynewspaper.com/2018/12/18/critical-vulnerability-in-sqlite-you-should-update-now/). -
Although SQLite's single-file approach creates speed advantages, there is no easy way to implement a multi-user environment using the system.
## Which open source database is best?
Ultimately, your choice of open source database will depend on your business needs and particularly on the size of your system. For small databases or those with limited use, go for a lightweight solution: not only will it speed up implementation but a less-complex system means you will spend less time debugging.
For larger systems, especially in growing businesses, invest the time to implement a more complex database like PostgreSQL. This will save you time—eventually—by removing the need to re-code your databases as your business grows.
## 4 Comments |
10,513 | 采用 snaps 为 Linux 社区构建 Slack | https://insights.ubuntu.com/2018/02/06/building-slack-for-the-linux-community-and-adopting-snaps/ | 2019-02-06T17:25:00 | [
"Slack"
] | https://linux.cn/article-10513-1.html | 
作为一个被数以百万计用户使用的企业级软件平台,[Slack](https://slack.com/) 可以让各种规模的团队和企业有效地沟通。Slack 通过在一个单一集成环境中与其它软件工具无缝衔接,为一个组织内的通讯、信息和项目提供了一个易于接触的档案馆。尽管自从诞生后 Slack 就在过去四年中快速成长,但是他们负责该平台的 Windows、MacOS 和 Linux 桌面的工程师团队仅由四人组成。我们采访了这个团队的主任工程师 Felix Rieseberg(他负责追踪[上月首次发布的 Slack snap](https://insights.ubuntu.com/2018/01/18/canonical-brings-slack-to-the-snap-ecosystem/),LCTT 译注:原文发布于 2018.2),来了解更多有关该公司对于 Linux 社区的态度,以及他们决定构建一个 snap 软件包的原因。
* [安装 Slack snap](https://snapcraft.io/slack/)
### 你们能告诉我们更多关于已发布的 Slack snap 的信息吗?
作为发布给 Linux 社区的一种新形式,我们上月发布了我们的第一个 snap。在企业界,我们发现人们更倾向于以一种相对于个人消费者来说较慢的速度来采用新科技,因此我们将会在未来继续提供 .deb 形式的软件包。
### 你们觉得 Linux 社区会对 Slack 有多大的兴趣呢?
我很高兴在所有的平台上人们都对 Slack 的兴趣越来越大。因此,很难说来自 Linux 社区的兴趣和我们大体上所见到的兴趣有什么区别。当然,不管用户们在什么平台上面工作,满足他们对我们都是很重要的。我们有一个专门负责 Linux 的测试工程师,并且我们同时也会尽全力提供最好的用户体验。
只是我们发现总体相对于 Windows 来说,为 Linux 搭建 snap 略微有点难度,因为我们是在一个较难以预测的平台上工作——而这正是 Linux 社区之光照耀的领域。在汇报程序缺陷以及寻找程序崩溃原因方面,我们有相当多极有帮助的用户。
### 你们是如何得知 snap 的?
Canonical 公司的 Martin Wimpress 接触了我,并向我解释了 snap 的概念。说实话尽管我也用 Ubuntu 但最初我还是迟疑的,因为它看起来像需要搭建与维护的另一套标准。然而,一当我了解到其中的好处之后,我确信这是一笔值得的投入。
### snap 的什么方面吸引了你们并使你们决定投入其中?
毫无疑问,我们决定搭建 snap 最重要的原因是它的更新特性。在 Slack 上我们大量运用了网页技术,这些技术反过来也使得我们提供大量的特性——比如将 YouTube 视频或者 Spotify 播放列表集成在 Slack 中。与浏览器十分相似,这意味着我们需要频繁更新应用。
在 MacOS 和 Windows 上,我们已经有了一个专门的自动更新器,甚至无需用户关注更新。任何形式的中断都是一种我们需要避免的烦恼,哪怕是为了更新。因此通过 snap 自动化的更新就显得更加无缝和便捷。
### 相比于其它形式的打包方式,构建 snap 感觉如何?将它与现有的设施和流程集成在一起有多简便呢?
就 Linux 而言,我们尚未尝试其它的“新”打包方式,但我们迟早会的。鉴于我们的大多数用户都使用 Ubuntu,snap 是一个自然的选择。同时 snap 在其它发行版上同样也可以使用,这也是一个巨大的加分项。Canonical 正将 snap 做到跨发行版,而不是仅仅集中在 Ubuntu 上,这一点我认为是很好的。
搭建 snap 极其简单,我们有一个创建安装器和软件包的统一流程,我们的 snap 创建过程就是从一个 .deb 软件包炮制出一个 snap。对于其它技术而言,有时候我们为了支持构建链而先打造一个内部工具。但是 snapcraft 工具正是我们需要的东西。在整个过程中 Canonical 的团队非常有帮助,因为我们一路上确实碰到了一些问题。
### 你们觉得 snap 商店是如何改变用户们寻找、安装你们软件的方式的呢?
Slack 真正的独特之处在于人们不仅仅是碰巧发现它,他们从别的地方知道它并积极地试图找到它。因此尽管我们已经有了相当高的觉悟,我希望对于我们的用户来说,在商店中可以获得 snap 能够让安装过程变得简单一点。
我们总是尽力为用户服务。当我们觉得它比其他安装方式更好,我们就会向用户更多推荐它。
### 通过使用 snap 而不是为其它发行版打包,你期待或者已经看到的节省是什么?
我们希望 snap 可以给予我们的用户更多的便利,并确保他们能够更加喜欢使用 Slack。在我们看来,鉴于用户们不必被困在之前的版本,这自然而然地解决了许多问题,因此 snap 可以让我们在客户支持方面节约时间。snap 对我们来说也是一个额外的加分项,因为我们能有一个可供搭建的平台,而不是替换我们现有的东西。
### 如果存在的话,你们正使用或者准备使用边缘 (edge)、测试 (beta)、候选 (candidate)、稳定 (stable) 中的哪种发行频道?
我们开发中专门使用边缘 (edge) 频道以与 Canonical 团队合作。为 Linux 打造的 Slack 总体仍处于测试 (beta) 频道中。但是长远来看,拥有不同频道的选择十分有意思,同时能够提早一点为感兴趣的客户发布版本也肯定是有好处的。
### 你们如何认为将软件打包成一个 snap 能够帮助用户?你们从用户那边得到了什么反馈吗?
对我们的用户来说一个很大的好处是安装和更新总体来说都会变得简便一点。长远来看,问题是“那些安装 snap 的用户是不是比其它用户少碰到一些困难?”,我十分期望 snap 自带的依赖关系能够使其变成可能。
### 你们对刚使用 snap 的新用户们有什么建议或知识呢?
我会推荐从 Debian 软件包来着手搭建你们的 snap ——那出乎意料得简单。这同样也缩小了范围,避免变得不堪重负。这只需要投入相当少的时间,并且很大可能是一笔值得的投入。同样如果你们可以的话,尽量试着找到 Canonical 的人员来协作——他们拥有了不起的工程师。
### 对于开发来说,你们在什么地方看到了最大的机遇?
我们现在正一步步来,先是让人们接受 snap,再从那里开始搭建。正在使用 snap 的人们将会感到更加稳健,因为他们将会得益于最新的更新。
---
via: <https://insights.ubuntu.com/2018/02/06/building-slack-for-the-linux-community-and-adopting-snaps/>
作者:[Sarah](https://insights.ubuntu.com/author/sarahfd/) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | null |
|
10,514 | 如何使用不同的方式更改 Linux 用户密码 | https://www.2daygeek.com/linux-passwd-chpasswd-command-set-update-change-users-password-in-linux-using-shell-script/ | 2019-02-06T18:22:10 | [
"passwd",
"密码"
] | https://linux.cn/article-10514-1.html | 
在 Linux 中创建用户账号时,设置用户密码是一件基本的事情。每个人都使用 `passwd` 命令跟上用户名,比如 `passwd USERNAME` 来为用户设置密码。
确保你一定要设置一个难以猜测的密码,这可以帮助你使系统更安全。我的意思是,密码应该是字母、符号和数字的组合。此外,出于安全原因,我建议你至少每月更改一次密码。
当你使用 `passwd` 命令时,它会要求你输入两次密码来设置。这是一种设置用户密码的原生方法。
如果你不想两次更新密码,并希望以不同的方式进行更新,怎么办呢?当然,这可以的,有可能做到。
如果你是 Linux 管理员,你可能已经多次问过下面的问题。你可能、也可能没有得到这些问题的答案。
无论如何,不要担心,我们会回答你所有的问题。
* 如何用一条命令更改用户密码?
* 如何在 Linux 中为多个用户更改为相同的密码?
* 如何在 Linux 中更改多个用户的密码?
* 如何在 Linux 中为多个用户更改为不同的密码?
* 如何在多个 Linux 服务器中更改用户的密码?
* 如何在多个 Linux 服务器中更改多个用户的密码?
### 方法-1:使用 passwd 命令
`passwd` 命令是在 Linux 中为用户设置、更改密码的标准方法。以下是标准方法。
```
# passwd renu
Changing password for user renu.
New password:
BAD PASSWORD: The password contains the user name in some form
Retype new password:
passwd: all authentication tokens updated successfully.
```
如果希望在一条命令中设置或更改密码,运行以下命令。它允许用户在一条命令中更新密码。
```
# echo "new_password" | passwd --stdin thanu
Changing password for user thanu.
passwd: all authentication tokens updated successfully.
```
### 方法-2:使用 chpasswd 命令
`chpasswd` 是另一个命令,允许我们为 Linux 中的用户设置、更改密码。如果希望在一条命令中使用 `chpasswd` 命令更改用户密码,用以下格式。
```
# echo "thanu:new_password" | chpasswd
```
### 方法-3:如何为多个用户设置不同的密码
如果你要为 Linux 中的多个用户设置、更改密码,并且使用不同的密码,使用以下脚本。
为此,首先我们需要使用以下命令获取用户列表。下面的命令将列出拥有 `/home` 目录的用户,并将输出重定向到 `user-list.txt` 文件。
```
# cat /etc/passwd | grep "/home" | cut -d":" -f1 > user-list.txt
```
使用 `cat` 命令列出用户。如果你不想重置特定用户的密码,那么从列表中移除该用户。
```
# cat user-list.txt
centos
magi
daygeek
thanu
renu
```
创建以下 shell 小脚本来实现此目的。
```
# vi password-update.sh
#!/bin/sh
for user in `more user-list.txt`
do
echo "[email protected]" | passwd --stdin "$user"
chage -d 0 $user
done
```
给 `password-update.sh` 文件设置可执行权限。
```
# chmod +x password-update.sh
```
最后运行脚本来实现这一目标。
```
# ./password-up.sh
magi
Changing password for user magi.
passwd: all authentication tokens updated successfully.
daygeek
Changing password for user daygeek.
passwd: all authentication tokens updated successfully.
thanu
Changing password for user thanu.
passwd: all authentication tokens updated successfully.
renu
Changing password for user renu.
passwd: all authentication tokens updated successfully.
```
### 方法-4:如何为多个用户设置相同的密码
如果要在 Linux 中为多个用户设置、更改相同的密码,使用以下脚本。
```
# vi password-update.sh
#!/bin/sh
for user in `more user-list.txt`
do
echo "new_password" | passwd --stdin "$user"
chage -d 0 $user
done
```
### 方法-5:如何在多个服务器中更改用户密码
如果希望更改多个服务器中的用户密码,使用以下脚本。在本例中,我们将更改 `renu` 用户的密码,确保你必须提供你希望更新密码的用户名而不是我们的用户名。
确保你必须将服务器列表保存在 `server-list.txt` 文件中,每个服务器应该在单独一行中。
```
# vi password-update.sh
#!/bin/bash
for server in `cat server-list.txt`
do
ssh [email protected]$server 'passwd --stdin renu <<EOF
new_passwd
new_passwd
EOF';
done
```
你将得到与我们类似的输出。
```
# ./password-update.sh
New password: BAD PASSWORD: it is based on a dictionary word
BAD PASSWORD: is too simple
Retype new password: Changing password for user renu.
passwd: all authentication tokens updated successfully.
New password: BAD PASSWORD: it is based on a dictionary word
BAD PASSWORD: is too simple
Retype new password: Changing password for user renu.
passwd: all authentication tokens updated successfully.
```
### 方法-6:如何使用 pssh 命令更改多个服务器中的用户密码
`pssh` 是一个在多个主机上并行执行 ssh 连接的程序。它提供了一些特性,例如向所有进程发送输入,向 ssh 传递密码,将输出保存到文件以及超时处理。导航到以下链接以了解关于 [PSSH 命令](https://www.2daygeek.com/pssh-parallel-ssh-run-execute-commands-on-multiple-linux-servers/)的更多信息。
```
# pssh -i -h /tmp/server-list.txt "printf '%s\n' new_pass new_pass | passwd --stdin root"
```
你将获得与我们类似的输出。
```
[1] 07:58:07 [SUCCESS] CentOS.2daygeek.com
Changing password for user root.
passwd: all authentication tokens updated successfully.
Stderr: New password: BAD PASSWORD: it is based on a dictionary word
BAD PASSWORD: is too simple
Retype new password:
[2] 07:58:07 [SUCCESS] ArchLinux.2daygeek.com
Changing password for user root.
passwd: all authentication tokens updated successfully.
Stderr: New password: BAD PASSWORD: it is based on a dictionary word
BAD PASSWORD: is too simple
```
### 方法-7:如何使用 chpasswd 命令更改多个服务器中的用户密码
或者,我们可以使用 `chpasswd` 命令更新多个服务器中的用户密码。
```
# ./password-update.sh
#!/bin/bash
for server in `cat server-list.txt`
do
ssh [email protected]$server 'echo "magi:new_password" | chpasswd'
done
```
### 方法-8:如何使用 chpasswd 命令在 Linux 服务器中更改多个用户的密码
为此,首先创建一个文件,以下面的格式更新用户名和密码。在本例中,我创建了一个名为 `user-list.txt` 的文件。
参考下面的详细信息。
```
# cat user-list.txt
magi:new@123
daygeek:new@123
thanu:new@123
renu:new@123
```
创建下面的 shell 小脚本来实现这一点。
```
# vi password-update.sh
#!/bin/bash
for users in `cat user-list.txt`
do
echo $users | chpasswd
done
```
---
via: <https://www.2daygeek.com/linux-passwd-chpasswd-command-set-update-change-users-password-in-linux-using-shell-script/>
作者:[Vinoth Kumar](https://www.2daygeek.com/author/vinoth/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对: [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,515 | XML 与 JSON 优劣对比 | https://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html | 2019-02-06T22:39:59 | [
"JSON",
"XML"
] | https://linux.cn/article-10515-1.html | 
### 简介
XML 和 JSON 是现今互联网中最常用的两种数据交换格式。XML 格式由 W3C 于 1996 年提出。JSON 格式由 Douglas Crockford 于 2002 年提出。虽然这两种格式的设计目标并不相同,但它们常常用于同一个任务,也就是数据交换中。XML 和 JSON 的文档都很完善([RFC 7159](https://tools.ietf.org/html/rfc7159)、[RFC 4825](https://tools.ietf.org/html/rfc4825)),且都同时具有<ruby> 人类可读性 <rt> human-readable </rt></ruby>和<ruby> 机器可读性 <rt> machine-readable </rt></ruby>。这两种格式并没有哪一个比另一个更强,只是各自适用的领域不用。(LCTT 译注:W3C 是[互联网联盟](https://www.w3.org/),制定了各种 Web 相关的标准,如 HTML、CSS 等。Douglas Crockford 除了制定了 JSON 格式,还致力于改进 JavaScript,开发了 JavaScript 相关工具 [JSLint](http://jslint.com/) 和 [JSMin](http://www.crockford.com/javascript/jsmin.html))
### XML 的优点
XML 与 JSON 相比有很多优点。二者间最大的不同在于 XML 可以通过在标签中添加属性这一简单的方法来存储<ruby> 元数据 <rt> metadata </rt></ruby>。而使用 JSON 时需要创建一个对象,把元数据当作对象的成员来存储。虽然二者都能达到存储元数据的目的,但在这一情况下 XML 往往是更好的选择,因为 JSON 的表达形式会让客户端程序开发人员误以为要将数据转换成一个对象。举个例子,如果你的 C++ 程序需要使用 JSON 格式发送一个附带元数据的整型数据,需要创建一个对象,用对象中的一个<ruby> 名称/值对 <rt> name/value pair </rt></ruby>来记录整型数据的值,再为每一个附带的属性添加一个名称/值对。接收到这个 JSON 的程序在读取后很可能把它当成一个对象,可事实并不是这样。虽然这是使用 JSON 传递元数据的一种变通方法,但他违背了 JSON 的核心理念:“<ruby> JSON 的结构与常规的程序语言中的结构相对应,而无需修改。 <rt> JSON’s structures look like conventional programming language structures. No restructuring is necessary. </rt></ruby>”<sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup>
虽然稍后我会说这也是 XML 的一个缺点,但 XML 中对命名冲突、<ruby> 前缀 <rt> prefix </rt></ruby>的处理机制赋予了它 JSON 所不具备的能力。程序员们可以通过前缀来把统一名称给予两个不同的实体。<sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup> 当不同的实体在客户端中使用的名称相同时,这一特性会非常有用。
XML 的另一个优势在于大多数的浏览器可以把它以<ruby> 具有高可读性和强组织性的方式 <rt> highly readable and organized way </rt></ruby>展现给用户。XML 的树形结构让它易于结构化,浏览器也让用户可以自行展开或折叠树中的元素,这简直就是调试的福音。
XML 对比 JSON 有一个很重要的优势就是它可以记录<ruby> 混合内容 <rt> mixed content </rt></ruby>。例如在 XML 中处理包含结构化标记的字符串时,程序员们只要把带有标记的文本放在一个标签内就可以了。可因为 JSON 只包含数据,没有用于指明标签的简单方式,虽然可以使用处理元数据的解决方法,但这总有点滥用之嫌。
### JSON 的优点
JSON 自身也有很多优点。其中最显而易见的一点就是 JSON 比 XML 简洁得多。因为 XML 中需要打开和关闭标签,而 JSON 使用名称/值对表示数据,使用简单的 `{` 和 `}` 来标记对象,`[` 和 `]` 来标记数组,`,` 来表示数据的分隔,`:` 表示名称和值的分隔。就算是使用 gzip 压缩,JSON 还是比 XML 要小,而且耗时更少。<sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup> 正如 Sumaray 和 Makki 在实验中指出的那样,JSON 在很多方面都比 XML 更具优势,得出同样结果的还有 Nurseitov、Paulson、Reynolds 和 Izurieta。首先,由于 JSON 文件天生的简洁性,与包含相同信息的 XML 相比,JSON 总是更小,这意味着更快的传输和处理速度。第二,在不考虑大小的情况下,两组研究 <sup id="fnref4"> <a href="#fn4" rel="footnote"> 4 </a></sup> <sup id="fnref5"> <a href="#fn5" rel="footnote"> 5 </a></sup> 表明使用 JSON 执行序列化和反序列化的速度显著优于使用 XML。第三,后续的研究指出 JSON 的处理在 CPU 资源的使用上也优于 XML。研究人员发现 JSON 在总体上使用的资源更少,其中更多的 CPU 资源消耗在用户空间,系统空间消耗的 CPU 资源较少。这一实验是在 RedHat 的设备上进行的,RedHat 表示更倾向于在用户空间使用 CPU 资源。<sup id="fnref6"> <a href="#fn6" rel="footnote"> 6 </a></sup> 不出意外,Sumaray 和 Makki 在研究里还说明了在移动设备上 JSON 的性能也优于 XML。<sup id="fnref7"> <a href="#fn7" rel="footnote"> 7 </a></sup> 这是有道理的,因为 JSON 消耗的资源更少,而移动设备的性能也更弱。
JSON 的另一个优点在于其对对象和数组的表述和<ruby> 宿主语言 <rt> host language </rt></ruby>中的数据结构相对应,例如<ruby> 对象 <rt> object </rt></ruby>、<ruby> 记录 <rt> record </rt></ruby>、<ruby> 结构体 <rt> struct </rt></ruby>、<ruby> 字典 <rt> dictionary </rt></ruby>、<ruby> 哈希表 <rt> hash table </rt></ruby>、<ruby> 键值列表 <rt> keyed list </rt></ruby>还有<ruby> 数组 <rt> array </rt></ruby>、<ruby> 向量 <rt> vector </rt></ruby>、<ruby> 列表 <rt> list </rt></ruby>,以及对象组成的数组等等。<sup id="fnref8"> <a href="#fn8" rel="footnote"> 8 </a></sup> 虽然 XML 里也能表达这些数据结构,也只需调用一个函数就能完成解析,而往往需要更多的代码才能正确的完成 XML 的序列化和反序列化处理。而且 XML 对于人类来说不如 JSON 那么直观,XML 标准缺乏对象、数组的标签的明确定义。当结构化的标记可以替代嵌套的标签时,JSON 的优势极为突出。JSON 中的花括号和中括号则明确表示了数据的结构,当然这一优势也包含前文中的问题,在表示元数据时 JSON 不如 XML 准确。
虽然 XML 支持<ruby> 命名空间 <rt> namespace </rt></ruby>与<ruby> 前缀 <rt> prefix </rt></ruby>,但这不代表 JSON 没有处理命名冲突的能力。比起 XML 的前缀,它处理命名冲突的方式更简洁,在程序中的处理也更自然。在 JSON 里,每一个对象都在它自己的命名空间中,因此不同对象内的元素名称可以随意重复。在大多数编程语言中,不同的对象中的成员可以包含相同的名字,所以 JSON 根据对象进行名称区分的规则在处理时更加自然。
也许 JSON 比 XML 更优的部分是因为 JSON 是 JavaScript 的子集,所以在 JavaScript 代码中对它的解析或封装都非常的自然。虽然这看起来对 JavaScript 程序非常有用,而其他程序则不能直接从中获益,可实际上这一问题已经被很好的解决了。现在 JSON 的网站的列表上展示了 64 种不同语言的 175 个工具,它们都实现了处理 JSON 所需的功能。虽然我不能评价大多数工具的质量,但它们的存在明确了开发者社区拥抱 JSON 这一现象,而且它们切实简化了在不同平台使用 JSON 的难度。
### 二者的动机
简单地说,XML 的目标是标记文档。这和 JSON 的目标想去甚远,所以只要用得到 XML 的地方就尽管用。它使用树形的结构和包含语义的文本来表达混合内容以实现这一目标。在 XML 中可以表示数据的结构,但这并不是它的长处。
JSON 的目标是用于数据交换的一种结构化表示。它直接使用对象、数组、数字、字符串、布尔值这些元素来达成这一目标。这完全不同于文档标记语言。正如上面说的那样,JSON 没有原生支持<ruby> 混合内容 <rt> mixed content </rt></ruby>的记录。
### 软件
这些主流的开放 API 仅提供 XML:<ruby> 亚马逊产品广告 API <rt> Amazon Product Advertising API </rt></ruby>。
这些主流 API 仅提供 JSON:<ruby> 脸书图 API <rt> Facebook Graph API </rt></ruby>、<ruby> 谷歌地图 API <rt> Google Maps API </rt></ruby>、<ruby> 推特 API <rt> Twitter API </rt></ruby>、AccuWeather API、Pinterest API、Reddit API、Foursquare API。
这些主流 API 同时提供 XML 和 JSON:<ruby> 谷歌云存储 <rt> Google Cloud Storage </rt></ruby>、<ruby> 领英 API <rt> Linkedin API </rt></ruby>、Flickr API。
根据<ruby> 可编程网络 <rt> Programmable Web </rt></ruby> <sup id="fnref9"> <a href="#fn9" rel="footnote"> 9 </a></sup> 的数据,最流行的 10 个 API 中只有一个是仅提供 XML 且不支持 JSON 的。其他的要么同时支持 XML 和 JSON,要么只支持 JSON。这表明了大多数应用开发者都更倾向于使用支持 JSON 的 API,原因大概是 JSON 更快的处理速度与良好口碑,加之与 XML 相比更加轻量。此外,大多数 API 只是传递数据而非文档,所以 JSON 更加合适。例如 Facebook 的重点在于用户的交流与帖子,谷歌地图则主要处理坐标和地图信息,AccuWeather 就只传递天气数据。总之,虽然不能说天气 API 在使用时究竟是 JSON 用的多还是 XML 用的多,但是趋势明确偏向了 JSON。<sup id="fnref10"> <a href="#fn10" rel="footnote"> 10 </a></sup> <sup id="fnref11"> <a href="#fn11" rel="footnote"> 11 </a></sup>
这些主流的桌面软件仍然只是用 XML:Microsoft Word、Apache OpenOffice、LibraOffice。
因为这些软件需要考虑引用、格式、存储等等,所以比起 JSON,XML 优势更大。另外,这三款程序都支持混合内容,而 JSON 在这一点上做得并不如 XML 好。举例说明,当用户使用 Microsoft Word 编辑一篇论文时,用户需要使用不同的文字字形、文字大小、文字颜色、页边距、段落格式等,而 XML 结构化的组织形式与标签属性生来就是为了表达这些信息的。
这些主流的数据库支持 XML:IBM DB2、Microsoft SQL Server、Oracle Database、PostgresSQL、BaseX、eXistDB、MarkLogic、MySQL。
这些是支持 JSON 的主流数据库:MongoDB、CouchDB、eXistDB、Elastisearch、BaseX、MarkLogic、OrientDB、Oracle Database、PostgreSQL、Riak。
在很长一段时间里,SQL 和关系型数据库统治着整个数据库市场。像<ruby> 甲骨文 <rt> Oracle </rt></ruby>和<ruby> 微软 <rt> Microsoft </rt></ruby>这样的软件巨头都提供这类数据库,然而近几年 NoSQL 数据库正逐步受到开发者的青睐。也许是正巧碰上了 JSON 的普及,大多数 NoSQL 数据库都支持 JSON,像 MongoDB、CouchDB 和 Riak 这样的数据库甚至使用 JSON 来存储数据。这些数据库有两个重要的特性是它们适用于现代网站:一是它们与关系型数据库相比<ruby> 更容易扩展 <rt> more scalable </rt></ruby>;二是它们设计的目标就是 web 运行所需的核心组件。<sup id="fnref12"> <a href="#fn12" rel="footnote"> 12 </a></sup> 由于 JSON 更加轻量,又是 JavaScript 的子集,所以很适合 NoSQL 数据库,并且让这两个品质更容易实现。此外,许多旧的关系型数据库增加了 JSON 支持,例如 Oracle Database 和 PostgreSQL。由于 XML 与 JSON 间的转换比较麻烦,所以大多数开发者会直接在他们的应用里使用 JSON,因此开发数据库的公司才有支持 JSON 的理由。(LCTT 译注:NoSQL 是对不同于传统的关系数据库的数据库管理系统的统称。[参考来源](https://zh.wikipedia.org/wiki/NoSQL)) <sup id="fnref13"> <a href="#fn13" rel="footnote"> 13 </a></sup>
### 未来
对互联网的种种变革中,最让人期待的便是<ruby> 物联网 <rt> Internet of Things </rt></ruby>(IoT)。这会给互联网带来大量计算机之外的设备,例如手表、温度计、电视、冰箱等等。这一势头的发展良好,预期在不久的将来迎来爆发式的增长。据估计,到 2020 年时会有 260 亿 到 2000 亿的物联网设备被接入互联网。<sup id="fnref14"> <a href="#fn14" rel="footnote"> 14 </a></sup> <sup id="fnref15"> <a href="#fn15" rel="footnote"> 15 </a></sup> 几乎所有的物联网设备都是小型设备,因此性能比笔记本或台式电脑要弱很多,而且大多数都是嵌入式系统。因此,当它们需要与互联网上的系统交换数据时,更轻量、更快速的 JSON 自然比 XML 更受青睐。<sup id="fnref16"> <a href="#fn16" rel="footnote"> 16 </a></sup> 受益于 JSON 在 web 上的快速普及,与 XML 相比,这些新的物联网设备更有可能从使用 JSON 中受益。这是一个典型的梅特卡夫定律的例子,无论是 XML 还是 JSON,抑或是什么其他全新的格式,现存的设备和新的设备都会从支持最广泛使用的格式中受益。
Node.js 是一款服务器端的 JavaScript 框架,随着她的诞生与快速成长,与 MongoDB 等 NoSQL 数据库一起,让全栈使用 JavaScript 开发成为可能。这些都预示着 JSON 光明的未来,这些软件的出现让 JSON 运用在全栈开发的每一个环节成为可能,这将使应用更加轻量,响应更快。这也是任何应用的追求之一,所以,全栈使用 JavaScript 的趋势在不久的未来都不会消退。<sup id="fnref17"> <a href="#fn17" rel="footnote"> 17 </a></sup>
此外,另一个应用开发的趋势是从 SOAP 转向 REST。<sup id="fnref18"> <a href="#fn18" rel="footnote"> 18 </a></sup> <sup id="fnref19"> <a href="#fn19" rel="footnote"> 19 </a></sup> <sup id="fnref20"> <a href="#fn20" rel="footnote"> 20 </a></sup> XML 和 JSON 都可以用于 REST,可 SOAP 只能使用 XML。
从这些趋势中可以推断,JSON 的发展将统一 Web 的信息交换格式,XML 的使用率将继续降低。虽然不应该把 JSON 吹过头了,因为 XML 在 Web 中的使用依旧很广,而且它还是 SOAP 的唯一选择,可考虑到 SOAP 到 REST 的迁移,NoSQL 数据库和全栈 JavaScript 的兴起,JSON 卓越的性能,我相信 JSON 很快就会在 Web 开发中超过 XML。至于其他领域,XML 比 JSON 更好的情况并不多。
### 角注
---
1. [Introducing JSON](http://www.json.org/) [↩](#fnref1)
2. [XML Tutorial](http://www.w3schools.com/xml/default.asp) [↩](#fnref2)
3. [JSON vs. XML: Some hard numbers about verbosity](http://www.codeproject.com/Articles/604720/JSON-vs-XML-Some-hard-numbers-about-verbosity) [↩](#fnref3)
4. [Comparison of JSON and XML Data Interchange Formats: A Case Study](http://www.cs.montana.edu/izurieta/pubs/caine2009.pdf) [↩](#fnref4)
5. [A comparison of data serialization formats for optimal efficiency on a mobile platform](http://dl.acm.org/citation.cfm?id=2184810) [↩](#fnref5)
6. [Comparison of JSON and XML Data Interchange Formats: A Case Study](http://www.cs.montana.edu/izurieta/pubs/caine2009.pdf) [↩](#fnref6)
7. [A comparison of data serialization formats for optimal efficiency on a mobile platform](http://dl.acm.org/citation.cfm?id=2184810) [↩](#fnref7)
8. [Introducing JSON](http://www.json.org/) [↩](#fnref8)
9. [Most Popular APIs: At Least One Will Surprise You](http://www.programmableweb.com/news/most-popular-apis-least-one-will-surprise-you/2014/01/23) [↩](#fnref9)
10. [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/) [↩](#fnref10)
11. [Thousands of APIs Paint a Bright Future for the Web](http://www.webmonkey.com/2011/03/thousand-of-apis-paint-a-bright-future-for-the-web/) [↩](#fnref11)
12. [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/) [↩](#fnref12)
13. [How JSON sparked NoSQL – and will return to the RDBMS fold](http://www.infoworld.com/article/2608293/nosql/how-json-sparked-nosql----and-will-return-to-the-rdbms-fold.html) [↩](#fnref13)
14. [A Simple Explanation Of ‘The Internet Of Things’](http://www.forbes.com/sites/jacobmorgan/2014/05/13/simple-explanation-internet-things-that-anyone-can-understand/) [↩](#fnref14)
15. [Proofpoint Uncovers Internet of Things (IoT) Cyberattack](http://www.proofpoint.com/about-us/press-releases/01162014.php) [↩](#fnref15)
16. [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/) [↩](#fnref16)
17. [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/) [↩](#fnref17)
18. [Thousands of APIs Paint a Bright Future for the Web](http://www.webmonkey.com/2011/03/thousand-of-apis-paint-a-bright-future-for-the-web/) [↩](#fnref18)
19. [3,000 Web APIs: Trends From A Quickly Growing Directory](http://www.programmableweb.com/news/3000-web-apis-trends-quickly-growing-directory/2011/03/08) [↩](#fnref19)
20. [How REST replaced SOAP on the Web: What it means to you](http://www.infoq.com/articles/rest-soap) [↩](#fnref20)
---
via: <https://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html>
作者:[TOM STRASSNER]([email protected]) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wwhio](https://github.com/wwhio) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,516 | dcp:采用对等网络传输文件的方式 | https://www.2daygeek.com/dcp-dat-copy-secure-way-to-transfer-files-between-linux-systems/ | 2019-02-07T15:49:00 | [
"scp",
"dcp"
] | https://linux.cn/article-10516-1.html | 
Linux 本就有 `scp` 和 `rsync` 可以完美地完成这个任务。然而我们今天还是想试点新东西。同时我们也想鼓励那些使用不同的理论和新技术开发新东西的开发者。
我们也写过其他很多有关这个主题的文章,你可以点击下面的链接访问这些内容。
它们分别是 [OnionShare](https://www.2daygeek.com/onionshare-secure-way-to-share-files-sharing-tool-linux/)、[Magic Wormhole](https://www.2daygeek.com/wormhole-securely-share-files-from-linux-command-line/)、[Transfer.sh](https://www.2daygeek.com/transfer-sh-easy-fast-way-share-files-over-internet-from-command-line/) 和 ffsend。
### 什么是 dcp?
[dcp](https://github.com/tom-james-watson/dat-cp) 可以在不同主机之间使用 Dat 对等网络复制文件。
`dcp` 被视作一个像是 `scp` 这样工具的替代品,而无需在主机间进行 SSH 授权。
这可以让你在两个主机间传输文件时,无需操心所述主机之间互相访问的细节,以及这些主机是否使用了 NAT。
`dcp` 零配置、安全、快速、且是 P2P 传输。这并不是一个商用软件,使用产生的风险将由使用者自己承担。
### 什么是 Dat 协议
Dat 是一个 P2P 协议,是一个致力于下一代 Web 的由社区驱动的项目。
### dcp 如何工作
`dcp` 将会为指定的文件或者文件夹创建一个 dat 归档,并生成一个公开密钥,使用这个公开密钥可以让其他人从另外一台主机上下载上面的文件。
使用网络共享的任何数据都使用该归档的公开密钥加密,也就是说文件的接收权仅限于那些拥有该公开密钥的人。
### dcp 使用案例
* 向多个同事发送文件 —— 只需要告诉他们生成的公开密钥,然后他们就可以在他们的机器上收到对应的文件了。
* 无需设置 SSH 授权就可以在你本地网络的两个不同物理机上同步文件。
* 无需压缩文件并把文件上传到云端就可以轻松地发送文件。
* 当你有 shell 授权而没有 SSH 授权时也可以复制文件到远程服务器上。
* 在没有很好的 SSH 支持的 Linux/macOS 以及 Windows 系统之间分享文件。
### 如何在 Linux 上安装 NodeJS & npm?
`dcp` 是用 JavaScript 写成的,所以在安装 `dcp` 前,需要先安装 NodeJS。在 Linux 上使用下面的命令安装 NodeJS。
Fedora 系统,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 安装 NodeJS & npm。
```
$ sudo dnf install nodejs npm
```
Debian/Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或者 [APT 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 安装 NodeJS & npm。
```
$ sudo apt install nodejs npm
```
Arch Linux 系统,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 安装 NodeJS & npm。
```
$ sudo pacman -S nodejs npm
```
RHEL/CentOS 系统,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 安装 NodeJS & npm。
```
$ sudo yum install epel-release
$ sudo yum install nodejs npm
```
openSUSE Leap 系统,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 安装 NodeJS & npm。
```
$ sudo zypper nodejs6
```
### 如何在 Linux 上安装 dcp?
在安装好 NodeJS 后,使用下面的 `npm` 命令安装 `dcp`。
`npm` 是一个 JavaScript 的包管理器。它是 JavaScript 的运行环境 Node.js 的默认包管理器。
```
# npm i -g dat-cp
```
### 如何通过 dcp 发送文件?
在 `dcp` 命令后跟你想要传输的文件或者文件夹。而且无需注明目标机器的名字。
```
# dcp [File Name Which You Want To Transfer]
```
在你运行 `dcp` 命令时将会为传送的文件生成一个 dat 归档。一旦执行完成将会在页面底部生成一个公开密钥。(LCTT 译注:此处并非非对称加密中的公钥/私钥对,而是一种公开的密钥,属于对称加密。)
### 如何通过 dcp 接收文件
在远程服务器上输入公开密钥即可接收对应的文件或者文件夹。
```
# dcp [Public Key]
```
以递归形式复制目录。
```
# dcp [Folder Name Which You Want To Transfer] -r
```
下面这个例子我们将会传输单个文件。

上述文件传输的输出。

如果你想传输不止一个文件,使用下面的格式。

上述文件传输的输出。

递归复制文件夹。

上述文件夹传输的输出。

这种方式下你只能够下载一次文件或者文件夹,不可以多次下载。这也就意味着一旦你下载了这些文件或者文件夹,这个链接就会立即失效。

也可以在手册页查看更多的相关选项。
```
# dcp --help
```
---
via: <https://www.2daygeek.com/dcp-dat-copy-secure-way-to-transfer-files-between-linux-systems/>
作者:[Vinoth Kumar](https://www.2daygeek.com/author/vinoth/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,517 | 如何把 Google 云端硬盘当做虚拟磁盘一样挂载到 Linux | https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/ | 2019-02-07T16:38:06 | [
"Google",
"云端硬盘",
"Dropbox"
] | https://linux.cn/article-10517-1.html | 
[Google 云端硬盘](https://www.google.com/drive/) 是全球比较受欢迎的云存储平台. 直到 2017 年, 全球有超过 8 亿的活跃用户在使用它。即使用户数在持续增长,但直到现在 Google 还是没有发布一款可以在 Linux 平台使用的客户端。但这难不倒 Linux 社区。不时就有一些开发者给 Linux 操作系统带来一些客户端。下面我将会介绍三个用于 Linux 系统非官方开发的 Google 云端硬盘客户端。使用这些客户端,你能把 Google 云端硬盘像虚拟磁盘一样挂载到 Linux 系统。请继续阅读。
### 1、Google-drive-ocamlfuse
google-drive-ocamlfuse 把 Google 云端硬盘当做是一个 FUSE 类型的文件系统,它是用 OCam 语言写的。FUSE 意即<ruby> 用户态文件系统 <rt> Filesystem in Userspace </rt></ruby>,此项目允许非管理员用户在用户空间创建虚拟文件系统。google-drive-ocamlfuse 可以让你把 Google 云端硬盘当做磁盘一样挂载到 Linux 系统。支持对普通文件和目录的读写操作,支持对 Google dock、表单和演示稿的只读操作,支持多个 Googe 云端硬盘用户,重复文件处理,支持访问回收站等等。
#### 安装 google-drive-ocamlfuse
google-drive-ocamlfuse 能在 Arch 系统的 [AUR](https://aur.archlinux.org/packages/google-drive-ocamlfuse/) 上直接找到,所以你可以使用 AUR 助手程序,如 [Yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/) 来安装。
```
$ yay -S google-drive-ocamlfuse
```
在 Ubuntu 系统:
```
$ sudo add-apt-repository ppa:alessandro-strada/ppa
$ sudo apt-get update
$ sudo apt-get install google-drive-ocamlfuse
```
安装最新的测试版本:
```
$ sudo add-apt-repository ppa:alessandro-strada/google-drive-ocamlfuse-beta
$ sudo apt-get update
$ sudo apt-get install google-drive-ocamlfuse
```
#### 使用方法
安装完成后,直接在终端里面输入如下命令,就可以启动 google-drive-ocamlfuse 程序了:
```
$ google-drive-ocamlfuse
```
当你第一次运行该命令,程序会直接打开你的浏览器并要求你确认是否对 Google 云端硬盘的文件的操作进行授权。当你确认授权后,挂载 Google 云端硬盘所需要的配置文件和目录都会自动进行创建。

当成功授权后,你会在终端里面看到如下的信息。
```
Access token retrieved correctly.
```
好了,我们可以进行下一步操作了。关闭浏览器并为我们的 Google 云端硬盘创建一个挂载点吧。
```
$ mkdir ~/mygoogledrive
```
最后操作,使用如下命令挂载 Google 云端硬盘:
```
$ google-drive-ocamlfuse ~/mygoogledrive
```
恭喜你了!你可以使用终端或文件管理器来访问 Google 云端硬盘里面的文件了。
使用终端:
```
$ ls ~/mygoogledrive
```
使用文件管理器:

如何你有不止一个账户,可以使用 `label` 命令对其进行区分不同的账户,就像下面一样:
```
$ google-drive-ocamlfuse -label label [mountpoint]
```
当操作完成后,你可以使用如下的命令卸载 Google 云端硬盘:
```
$ fusermount -u ~/mygoogledrive
```
获取更多信息,你可以参考 man 手册。
```
$ google-drive-ocamlfuse --help
```
当然你也可以看看[官方文档](https://github.com/astrada/google-drive-ocamlfuse/wiki/Configuration)和该项目的 [GitHub 项目](https://github.com/astrada/google-drive-ocamlfuse)以获取更多内容。
### 2. GCSF
GCSF 是基于 Google 云端硬盘的 FUSE 文件系统,使用 Rust 语言编写。GCSF 得名于罗马尼亚语中的“ **G** oogle **C** onduce **S** istem de **F** ișiere”,翻译成英文就是“Google Drive Filesystem”(即 Google 云端硬盘文件系统)。使用 GCSF,你可以把 Google 云端硬盘当做虚拟磁盘一样挂载到 Linux 系统,可以通过终端和文件管理器对其进行操作。你肯定会很好奇,这到底与其它的 Google 云端硬盘 FUSE 项目有什么不同,比如 google-drive-ocamlfuse。GCSF 的开发者回应 [Reddit 上的类似评论](https://www.reddit.com/r/DataHoarder/comments/8vlb2v/google_drive_as_a_file_system/e1oh9q9/):“GCSF 意在某些方面更快(递归列举文件、从 Google 云端硬盘中读取大文件)。当文件被缓存后,在消耗更多的内存后,其缓存策略也能让读取速度更快(相对于 google-drive-ocamlfuse 4-7 倍的提升)”。
#### 安装 GCSF
GCSF 能在 [AUR](https://aur.archlinux.org/packages/gcsf-git/) 上面找到,对于 Arch 用户来说直接使用 AUR 助手来安装就行了,例如[Yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/)。
```
$ yay -S gcsf-git
```
对于其它的发行版,需要进行如下的操作来进行安装。
首先,你得确认系统中是否安装了Rust语言。
* [在 Linux 上安装 Rust](https://www.ostechnix.com/install-rust-programming-language-in-linux/)
确保 `pkg-config` 和 `fuse` 软件包是否安装了。它们在绝大多数的 Linux 发行版的默认仓库中都能找到。例如,在 Ubuntu 及其衍生版本中,你可以使用如下的命令进行安装:
```
$ sudo apt-get install -y libfuse-dev pkg-config
```
当所有的依赖软件安装完成后,你可以使用如下的命令来安装 GCSF:
```
$ cargo install gcsf
```
#### 使用方法
首先,我们需要对 Google 云端硬盘的操作进行授权,简单输入如下命令:
```
$ gcsf login ostechnix
```
你必须指定一个会话名称。请使用自己的会话名称来代 `ostechnix`。你会看到像下图的提示信息和Google 云端硬盘账户的授权验证连接。

直接复制并用浏览器打开上述 URL,并点击 “allow” 来授权访问你的 Google 云端硬盘账户。当完成授权后,你的终端会显示如下的信息。
```
Successfully logged in. Credentials saved to "/home/sk/.config/gcsf/ostechnix".
```
GCSF 会把配置保存文件在 `$XDG_CONFIG_HOME/gcsf/gcsf.toml`,通常位于 `$HOME/.config/gcsf/gcsf.toml`。授权凭证也会保存在此目录当中。
下一步,创建一个用来挂载 Google 云端硬盘的目录。
```
$ mkdir ~/mygoogledrive
```
之后,修改 `/etc/fuse.conf` 文件:
```
$ sudo vi /etc/fuse.conf
```
注释掉以下的行,以允许非管理员用 `allow_other` 或 `allow_root` 挂载选项来挂载。
```
user_allow_other
```
保存并关闭文件。
最后一步,使用如下命令挂载 Google 云端硬盘:
```
$ gcsf mount ~/mygoogledrive -s ostechnix
```
示例输出:
```
INFO gcsf > Creating and populating file system...
INFO gcsf > File sytem created.
INFO gcsf > Mounting to /home/sk/mygoogledrive
INFO gcsf > Mounted to /home/sk/mygoogledrive
INFO gcsf::gcsf::file_manager > Checking for changes and possibly applying them.
INFO gcsf::gcsf::file_manager > Checking for changes and possibly applying them.
```
重复一次,使用自己的会话名来更换 `ostechnix`。你可以使用如下的命令来查看已经存在的会话:
```
$ gcsf list
Sessions:
- ostechnix
```
你现在可以使用终端和文件管理器对 Google 云端硬盘进行操作了。
使用终端:
```
$ ls ~/mygoogledrive
```
使用文件管理器:

如果你不知道自己把 Google 云端硬盘挂载到哪个目录了,可以使用 `df` 或者 `mount` 命令,就像下面一样。
```
$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 968M 0 968M 0% /dev
tmpfs 200M 1.6M 198M 1% /run
/dev/sda1 20G 7.5G 12G 41% /
tmpfs 997M 0 997M 0% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 997M 0 997M 0% /sys/fs/cgroup
tmpfs 200M 40K 200M 1% /run/user/1000
GCSF 15G 857M 15G 6% /home/sk/mygoogledrive
$ mount | grep GCSF
GCSF on /home/sk/mygoogledrive type fuse (rw,nosuid,nodev,relatime,user_id=1000,group_id=1000,allow_other)
```
当操作完成后,你可以使用如下命令来卸载 Google 云端硬盘:
```
$ fusermount -u ~/mygoogledrive
```
浏览[GCSF GitHub 项目](https://github.com/harababurel/gcsf)以获取更多内容。
### 3、Tuxdrive
Tuxdrive 也是一个非官方 Linux Google 云端硬盘客户端。我们之前有写过一篇关于 Tuxdrive 比较详细的使用方法。可以查看如下链接:
* [Tuxdrive: 一个 Linux 下的 Google 云端硬盘客户端](https://www.ostechnix.com/tuxdrive-commandline-google-drive-client-linux/)
当然,之前还有过其它的非官方 Google 云端硬盘客户端,例如 Grive2、Syncdrive。但它们好像都已经停止开发了。当有更受欢迎的 Google 云端硬盘客户端出现,我会对这个列表进行持续的跟进。
谢谢你的阅读。
---
via: <https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[sndnvaps](https://github.com/sndnvaps) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,518 | 远程工作生存指南 | https://www.jonobacon.com/2019/01/14/remote-working-survival/ | 2019-02-07T20:11:07 | [
"远程工作"
] | https://linux.cn/article-10518-1.html | 
远程工作似乎是最近的一个热门话题。CNBC 报道称,[70% 的专业人士至少每周在家工作一次](https://www.cnbc.com/2018/05/30/70-percent-of-people-globally-work-remotely-at-least-once-a-week-iwg-study.html)。同样地,CoSo Cloud 调查发现, [77% 的人在远程工作时效率更高](http://www.cosocloud.com/press-release/connectsolutions-survey-shows-working-remotely-benefits-employers-and-employees) ,而 aftercollege 的一份调查显示,[8% 的千禧一代会更多地考虑提供远程工作的公司](https://www.aftercollege.com/cf/2015-annual-survey)。 这看起来很合理:技术、网络以及文化似乎越来越推动了远程工作的发展。哦,自制咖啡也比以前任何时候更好喝了。
目前,我准备写另一篇关于公司如何优化远程工作的文章(所以请确保你加入我们的会员以持续关注——这是免费的)。
但今天,我想 **分享一些个人如何做好远程工作的建议**。不管你是全职远程工作者,或者是可以选择一周某几天在家工作的人,希望这篇文章对你有用。
眼下,你需要明白,**远程工作不是万能药**。当然,穿着睡衣满屋子乱逛,听听反社会音乐,喝一大杯咖啡看起来似乎挺完美的,但这不适合每个人。
有的人需要办公室的空间。有的人需要办公室的社会元素。有的人需要从家里走出来。有的人在家里缺乏保持专注的自律。有的人因为好几年未缴退税而怕政府工作人员来住处敲门。
**远程工作就好像一块肌肉:如果你锻炼并且保持它,那么它能带来极大的力量和能力**。如果不这么做,结果就不一样了。
在我职业生涯的大多数时间里,我在家工作。我喜欢这么做。当我在家工作的时候,我更有效率,更开心,更有能力。我并非不喜欢在办公室工作,我享受办公室的社会元素,但我更喜欢在家工作时我的“空间”。我喜欢听重金属音乐,但当整个办公室的人不想听到 [After The Burial](https://www.facebook.com/aftertheburial/) 的时候,这会引起一些问题。

*“Squirrel.” [图片来源](https://skullsnbones.com/burial-live-photos-vans-warped-tour-denver-co/)*
我已经学会了如何正确平衡工作、旅行以及其他元素来管理我的远程工作,以下是我的一些建议。请务必**在评论中分享一些你的建议**。
### 1、你需要纪律和习惯(以及了解你的“波动”)
远程工作确实是需要训练的一块肌肉。就像练出真正的肌肉一样,它需要一个明确的习惯混以健康的纪律。
永远保持穿戴整齐(不要穿睡衣)。设置你一天工作的开始和结束时间(大多时候我从早上 9 点工作到下午 6 点)。选好你的午餐休息时间(我的是中午 12 点)。选好你的早晨仪式(我的是电子邮件,紧接着是全面审查客户需求)。决定你的主工作场所在哪(我的主工作场所是我家庭办公室)。决定好每天你什么时候运动(大多数时候我在下午 5 点运动)。
**设计一个实际的习惯并坚持 66 天**。建立一个习惯需要很长时间,尽量不要偏离你的习惯。你越坚持这个习惯,做下去所花费的功夫越少。在这 66 天的末尾,你想都不会想,自然而然地就按习惯去做了。
话虽这么说,我们又不住在真空里 ([更干净,或者别的什么](https://www.youtube.com/watch?v=wK1PNNEKZBY))。我们都有自己的“波动”。
“波动”是你为了改变做事的方法时,对日常做出的一些改变。举个例子,夏天的时候我通常需要更多的阳光。那时我经常会在室外的花园工作。临近假期的时候我更容易分心,所以我在上班时间会更需要呆在室内。有时候我只想要多点人际接触,因此我会在咖啡馆里工作几周。有时候我就是喜欢在厨房或者长椅上工作。你需要认识你的“波动”并倾听你的身体。 **首先养成习惯,然后在你认识到自己的“波动”的时候再对它进行适当的调整**。
### 2、与你的上司及同事一起设立预期目标
不是每个人都知道怎么远程工作,如果你的公司对远程工作没那么熟悉,你尤其需要和同事一起设立预期目标。
这件事十分简单:**当你要设计自己的日常工作的时候,清楚地跟你的上司和团队进行交流。**让他们知道如何找到你,紧急情况下如何联系你,以及你在家的时候如何保持合作。
在这里通信方式至关重要。有些远程工作者很怕离开他们的电脑,因为害怕当他们不在的时候有人给他们发消息(他们担心别人会觉得他们在边吃奇多边看 Netflix)。
你需要离开一会的时间。你需要在吃午餐的时候眼睛不用一直盯着电脑屏幕。你又不是 911 接线员。**设定预期:有时候你可能不能立刻回复,但你会尽快回复**。
同样地,设定你的通常可响应的时间范围的预期。举个例子,我对客户设立的预期是我一般每天早上 9 点到下午 6 点工作。当然,如果某个客户急需某样东西,我很乐意在这段时间外回应他,但作为一个一般性规则,我通常只在这段时间内工作。这对于生活的平衡是必要的。
### 3、分心是你的敌人,它们需要管理
我们都会分心,这是人类的本能。让你分心的事情可能是你的孩子回家了,想玩救援机器人;可能是看看Facebook、Instagram,或者 Twitter 以确保你不会错过任何不受欢迎的政治观点,或者某人的午餐图片;可能是你生活中即将到来的某件事带走了你的注意力(例如,即将举办的婚礼、活动,或者一次大旅行)。
**你需要明白什么让你分心以及如何管理它**。举个例子,我知道我的电子邮件和 Twitter 会让我分心。我经常查看它们,并且每次查看都会让我脱离我正在工作的空间。拿水或者咖啡的时候我总会分心去吃零食,看 Youtube 的视频。

*我的分心克星*
由数字信息造成的分心有一个简单对策:**锁起来**。关闭选项卡,直到你完成了你手头的事情。有一大堆工作的时候我总这么干:我把让我分心的东西锁起来,直到做完手头的工作。这需要控制能力,但所有的一切都需要。
因为别人影响而分心的元素更难解决。如果你是有家庭的人,你需要明确表示,在你工作的时候常需要独处。这也是为什么家庭办公室这么重要:你需要设一些“爸爸/妈妈正在工作”的界限。如果有急事才能进来,否则让孩子自个儿玩去。
把让你分心的事锁起来有许多方法:把你的电话静音;把自己的 Facebook 状态设成“离开”;换到一个没有让你分心的事的房间(或建筑物)。再重申一次,了解是什么让你分心并控制好它。如果不这么做,你会永远被分心的事摆布。
### 4、(良好的)关系需要面对面的关注
有些角色比其他角色更适合远程工作。例如,我见过工程、质量保证、支持、安全以及其他团队(通常更专注于数字信息协作)的出色工作。其他团队,如设计或营销,往往在远程环境下更难熬(因为它们更注重触觉性)。
但是,对于任何团队而言,建立牢固的关系至关重要,而现场讨论、协作和社交很有必要。我们的许多感官(例如肢体语言)在数字环境中被剔除,而这些在我们建立信任和关系的方式中发挥着关键作用。

*火箭也很有帮助*
这尤为重要,如果(a)你初来这家公司,需要建立关系;(b)对某种角色不熟悉,需要和你的团队建立关系;或者(c)你处于领导地位,构建团队融入和参与是你工作的关键部分。
**解决方法是?合理搭配远程工作与面对面的时间。** 如果你的公司就在附近,可以用一部分的时间在家工作,一部分时间在公司工作。如果你的公司比较远,安排定期前往办公室(并对你的上司设定你需要这么做的预期)。例如,当我在 XPRIZE 工作的时候,我每几周就会飞往洛杉矶几天。当我在 Canonical 工作时(总部在伦敦),我们每三个月来一次冲刺。
### 5、保持专注,不要松懈
本文所有内容的关键在于构建一种(远程工作的)能力,并培养远程工作的肌肉。这就像建立你的日常惯例,坚持它,并认识你的“波动”和让你分心的事情以及如何管理它们一样简单。
我以一种相当具体的方式来看待这个世界:**我们所做的一切都有机会得到改进和完善**。举个例子,我已经公开演讲超过 15 年,但我总是能发现新的改进方法,以及修复新的错误(说到这些,请参阅我的 [提升你公众演讲的10个方法](https://www.jonobacon.com/2018/12/11/10-ways-to-up-your-public-speaking-game/))。
发现新的改善方法,以及把每个绊脚石和错误视为一个开启新的不同的“啊哈!”时刻让人兴奋。远程工作和这没什么不同:寻找有助于解锁方式的模式,让你的远程工作时间更高效,更舒适,更有趣。

*看看这些书。它们非常适合个人发展。参阅我的 [150 美元个人发展工具包](https://www.jonobacon.com/2017/11/13/150-dollar-personal-development-kit/) 文章*
……但别为此狂热。有的人花尽他们每一分钟来寻求如何变得更好,他们经常以“做得还不够好”、“完成度不够高”等为由打击自己,无法达到他们内心关于完美的不切实际的观点。
我们都是人,我们是有生命的,不是机器人。始终致力于改进,但要明白不是所有东西都是完美的。你应该有一些休息日或休息周。你也会因为压力和倦怠而挣扎。你也会遇到一些在办公室比远程工作更容易的情况。从这些时刻中学习,但不要沉迷于此。生命太短暂了。
**你有什么提示,技巧和建议吗?你如何管理远程工作?我的建议中还缺少什么吗?在评论区中与我分享!**
---
via: <https://www.jonobacon.com/2019/01/14/remote-working-survival/>
作者:[Jono Bacon](https://www.jonobacon.com/author/admin/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[beamrolling](https://github.com/beamrolling) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Remote working seems to be all the buzz. Apparently, [70% of professionals work from home at least once a week](https://www.cnbc.com/2018/05/30/70-percent-of-people-globally-work-remotely-at-least-once-a-week-iwg-study.html). Similarly, [77% of people work more productively](https://www.cosocloud.com/press-release/connectsolutions-survey-shows-working-remotely-benefits-employers-and-employees) and [68% of millennials would consider a company more if they offered remote working](https://www.aftercollege.com/cf/2015-annual-survey). It seems to make sense: technology, connectivity, and culture seem to be setting the world up more and more for remote working. Oh, and home-brewed coffee is better than ever too.
Now, I am going to write another piece for how companies should optimize for remote working (so make sure you [Join As a Member](https://www.jonobacon.com/join/) to stay tuned — it is free).
Today though I want to** share recommendations for how individuals can do remote working well themselves**. Whether you are a full-time remote worker or have the option of working from home a few days a week, this article should hopefully be helpful.
## Setting Expectations
Now, you need to know that **remote working is not a panacea**. Sure, it seems like hanging around at home in your jimjams, listening to your antisocial music, and sipping on buckets of coffee is perfect, but it isn’t for everyone.
Some people *need* the structure of an office. Some people *need* the social element of an office. Some people *need* to get out the house. Some people lack the discipline to stay focused at home. Some people are avoiding the government coming and knocking on the door due to years of unpaid back taxes.
**Remote working is like a muscle: it can bring enormous strength and capabilities IF you train and maintain it**. If you don’t, your results are going to vary.
I have worked from home for the vast majority of my career. I love it. I am more productive, happier, and empowered when I work from home. I don’t dislike working in an office, and I enjoy the social element, but I am more in my “zone” when I work from home. I also love blisteringly heavy metal, which can pose a problem when the office don’t want to listen to * After The Burial*.

[Credit](https://skullsnbones.com/burial-live-photos-vans-warped-tour-denver-co/)
I have learned how I need to manage remote work, using the right balance of work routine, travel, and other elements, and here are some of my recommendations.
## 1. You need discipline and routine (and to understand your “waves”)
Remote work really is a muscle that needs to be trained. Just like building actual muscle, there needs to be a clear routine and a healthy dollop of discipline mixed in.
*Always* get dressed (no jimjams). Set your start and end time for your day (*I work 9am – 6pm most days*). Choose your lunch break (*mine is 12pm*). Choose your morning ritual (*mine is email followed by a full review of my client needs*). Decide where your main workplace will be (*mine is my home office*). Decide when you will exercise each day (*I do it at 5pm most days*).
**Design a realistic routine and do it for 66 days**. It takes this long to build a habit. Try not to deviate from the routine. The more you stick the routine, the less work it will seem further down the line. By the end of the 66 days it will feel natural and you won’t have to think about it.
Here’s the deal though, we don’t live in a vacuum ([cleaner, or otherwise](https://www.youtube.com/watch?v=wK1PNNEKZBY)). We all have *waves*.
A wave is when you need a change of routine to mix things up.
For example, in summertime I generally want more sunlight. I will often work outside in the garden. Near the holidays I get more distracted, so I need more structure in my day. Sometimes I just need more human contact, so I will work from coffee shops for a few weeks. Sometimes I just fancy working in the kitchen or on the couch.
You need to learn your waves and listen to your body. **Build your habit first, and then modify it as you learn your waves**.
## 2. Set expectations with your management and colleagues
Not everyone knows how to do remote working, and if your company is less familiar with remote working, you especially need to set expectations with colleagues.
This can be pretty simple: **when you have designed your routine, communicate it clearly to your management and team**. Let them know how they can get hold of you, how to contact you in an emergency, and how you will be collaborating while at home.
The communication component here is *critical*. There are some remote workers who are scared to leave their computer for fear that someone will send them a message while they are away (and they are worried people may think they are just eating Cheetos and watching Netflix).
You need time away. You need to eat lunch without one eye on your computer. You are not a 911 emergency responder. **Set expectations that sometimes you may not be immediately responsive, but you will get back to them as soon as possible**.
Similarly, set expectations on your general availability. For example, I set expectations with clients that I generally work from 9am – 6pm every day. Sure, if a client needs something urgently, I am more than happy to respond outside of those hours, but as a general rule I am usually working between those hours. This is necessary for a balanced life.
## 3. Distractions are your enemy and they need managing
We all get distracted. It is human nature. It could be your young kid getting home and wanting to play *Rescue Bots*. It could be checking Facebook, Instagram, or Twitter to ensure you don’t miss any unwanted political opinions or photos of people’s lunches. It could be that there is something else going on your life that is taking your attention (such as an upcoming wedding, event, or big trip.)
**You need to learn what distracts you and how to manage it**. For example, I know I get distracted by my email and Twitter. I check it religiously and every check gets me out of the zone of what I am working on. I also get distracted by grabbing coffee and water, which then may turn into a snack and a YouTube video.

The digital distractions have a simple solution: **lock them out**.
Close down the tabs until you complete what you are doing. I do this all the time with big chunks of work: I lock out the distractions until I am done. It requires discipline, but all of this does.
The human elements are tougher. If you have a family you need to make it clear that when you are work, you need to be generally left alone. This is why a home office is so important: you need to set boundaries that mum or dad is working. Come in if there is emergency, but otherwise they need to be left alone.
There are all kinds of opportunities for locking these distractions out. Put your phone on silent. Set yourself as away. Move to a different room (or building) where the distraction isn’t there.
Again, be honest in what distracts you and manage it. If you don’t, you will always be at their mercy.
## 4. Relationships need in-person attention
Some roles are more attuned to remote working than others. For example, I have seen great work from engineering, quality assurance, support, security, and other teams (typically more focused on digital collaboration). Other teams such as design or marketing often struggle more in remote environments (as they are often more tactile.)
With any team though, having strong relationship is critical, and in-person discussion, collaboration, and socializing is essential to this. So many of our senses (such as body language) are removed in a digital environment, and these play a key role in how we build trust and relationships.

This is especially important if (a) you are new a company and need to build these relationships, (b) are new to a role and need to build relationships with your team, or (c) are in a leadership position where building buy-in and engagement is a key part of your job.
**The solution? A sensible mix of remote and in-person time. **If your company is nearby, work from home part of the week and at the office part of the week. If your company is further a away, schedule regular trips to the office (and set expectations with your management that you need this).
For example, when I worked at XPRIZE I flew to LA every few weeks for a few days. When I worked at Canonical (who were based in London), we had sprints every three months.
## 5. Stay focused, but cut yourself some slack
The crux of everything in this article is about building a *capability*, and developing a remote working muscle. This is as simple as building a routine, sticking to it, and having an honest view of your “waves” and distractions and how to manage them.
I see the world in a fairly specific way: **everything we do has the opportunity to be refined and improved**.
For example, I have been public speaking now for over 15 years, but I am always discovering new ways to improve, and new mistakes to fix (speaking of which, see my [10 Ways To Up Your Public Speaking Game](https://www.jonobacon.com/2018/12/11/10-ways-to-up-your-public-speaking-game/).)
There is a thrill in the discovery of new ways to get better, and to see every stumbling block and mistake as an “aha!” moment to kick ass in new and different ways. It is no different with remote working: look for patterns that help to unlock ways in which you can make your remote working time more efficient, more comfortable, and more fun.

See my
[$150 Personal Development Kit](https://www.jonobacon.com/2017/11/13/150-dollar-personal-development-kit/)article
…but don’t go crazy over it. There are some people who obsesses every minute of their day about how to get better. They beat themselves up constantly for “not doing well enough”, “not getting more done”, and not meeting their internal unrealistic view of perfection.
We are humans and as such, we are animals and not robots.
Always strive to improve, but be realistic that not everything will be perfect. You are going to have some off-days or off-weeks. You are going to struggle at times with stress and burnout. You are going to handle a situation poorly remotely that would have been easier in the office.
Learn from these moments but don’t obsess over them. Life is too damn short. |
10,519 | 计算机实验室之树莓派:课程 3 OK03 | https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok03.html | 2019-02-08T22:59:55 | [
"树莓派"
] | https://linux.cn/article-10519-1.html | 
OK03 课程基于 OK02 课程来构建,它教你在汇编中如何使用函数让代码可复用和可读性更好。假设你已经有了 [课程 2:OK02](/article-10478-1.html) 的操作系统,我们将以它为基础。
### 1、可复用的代码
到目前为止,我们所写的代码都是以我们希望发生的事为顺序来输入的。对于非常小的程序来说,这种做法很好,但是如果我们以这种方式去写一个完整的系统,所写的代码可读性将非常差。我们应该去使用函数。
>
> 一个函数是一段可复用的代码片断,可以用于去计算某些答案,或执行某些动作。你也可以称它们为<ruby> 过程 <rt> procedure </rt></ruby>、<ruby> 例程 <rt> routine </rt></ruby>或<ruby> 子例程 <rt> subroutine </rt></ruby>。虽然它们都是不同的,但人们几乎都没有正确地使用这个术语。
>
>
> 你应该在数学上遇到了函数的概念。例如,余弦函数应用于一个给定的数时,会得到介于 -1 到 1 之间的另一个数,这个数就是角的余弦。一般我们写成 `cos(x)` 来表示应用到一个值 `x` 上的余弦函数。
>
>
> 在代码中,函数可以有多个输入(也可以没有输入),然后函数给出多个输出(也可以没有输出),并可能导致副作用。例如一个函数可以在一个文件系统上创建一个文件,第一个输入是它的名字,第二个输入是文件的长度。
>
>
> 
>
>
> 函数可以认为是一个“黑匣子”。我们给它输入,然后它给我们输出,而我们不需要知道它是如何工作的。
>
>
>
在像 C 或 C++ 这样的高级代码中,函数是语言的组成部分。在汇编代码中,函数只是我们的创意。
理想情况下,我们希望能够在我们的寄存器中设置一些输入值,然后分支切换到某个地址,然后预期在某个时刻分支返回到我们代码,并通过代码来设置输出值到寄存器。这就是我们所设想的汇编代码中的函数。困难之处在于我们用什么样的方式去设置寄存器。如果我们只是使用平时所接触到的某种方法去设置寄存器,每个程序员可能使用不同的方法,这样你将会发现你很难理解其他程序员所写的代码。另外,编译器也不能像使用汇编代码那样轻松地工作,因为它们压根不知道如何去使用函数。为避免这种困惑,为每个汇编语言设计了一个称为<ruby> 应用程序二进制接口 <rt> Application Binary Interface </rt></ruby>(ABI)的标准,由它来规范函数如何去运行。如果每个人都使用相同的方法去写函数,这样每个人都可以去使用其他人写的函数。在这里,我将教你们这个标准,而从现在开始,我所写的函数将全部遵循这个标准。
该标准规定,寄存器 `r0`、`r1`、`r2` 和 `r3` 将被依次用于函数的输入。如果函数没有输入,那么它不会在意值是什么。如果只需要一个输入,那么它应该总是在寄存器 `r0` 中,如果它需要两个输入,那么第一个输入在寄存器 `r0` 中,而第二个输入在寄存器 `r1` 中,依此类推。输出值也总是在寄存器 `r0` 中。如果函数没有输出,那么 `r0` 中是什么值就不重要了。
另外,该标准要求当一个函数运行之后,寄存器 `r4` 到 `r12` 的值必须与函数启动时的值相同。这意味着当你调用一个函数时,你可以确保寄存器 `r4` 到 `r12` 中的值没有发生变化,但是不能确保寄存器 `r0` 到 `r3` 中的值也没有发生变化。
当一个函数运行完成后,它将返回到启动它的代码分支处。这意味着它必须知道启动它的代码的地址。为此,需要一个称为 `lr`(链接寄存器)的专用寄存器,它总是在保存调用这个函数的指令后面指令的地址。
表 1.1 ARM ABI 寄存器用法
| 寄存器 | 简介 | 保留 | 规则 |
| --- | --- | --- | --- |
| `r0` | 参数和结果 | 否 | `r0` 和 `r1` 用于给函数传递前两个参数,以及函数返回的结果。如果函数返回值不使用它,那么在函数运行之后,它们可以携带任何值。 |
| `r1` | 参数和结果 | 否 | |
| `r2` | 参数 | 否 | `r2` 和 `r3` 用去给函数传递后两个参数。在函数运行之后,它们可以携带任何值。 |
| `r3` | 参数 | 否 | |
| `r4` | 通用寄存器 | 是 | `r4` 到 `r12` 用于保存函数运行过程中的值,它们的值在函数调用之后必须与调用之前相同。 |
| `r5` | 通用寄存器 | 是 | |
| `r6` | 通用寄存器 | 是 | |
| `r7` | 通用寄存器 | 是 | |
| `r8` | 通用寄存器 | 是 | |
| `r9` | 通用寄存器 | 是 | |
| `r10` | 通用寄存器 | 是 | |
| `r11` | 通用寄存器 | 是 | |
| `r12` | 通用寄存器 | 是 | |
| `lr` | 返回地址 | 否 | 当函数运行完成后,`lr` 中保存了分支的返回地址,但在函数运行完成之后,它将保存相同的地址。 |
| `sp` | 栈指针 | 是 | `sp` 是栈指针,在下面有详细描述。它的值在函数运行完成后,必须是相同的。 |
通常,函数需要使用很多的寄存器,而不仅是 `r0` 到 `r3`。但是,由于 `r4` 到 `r12` 必须在函数完成之后值必须保持相同,因此它们需要被保存到某个地方。我们将它们保存到称为栈的地方。
>
> 
>
>
> 一个<ruby> 栈 <rt> stack </rt></ruby>就是我们在计算中用来保存值的一个很形象的方法。就像是摞起来的一堆盘子,你可以从上到下来移除它们,而添加它们时,你只能从下到上来添加。
>
>
> 在函数运行时,使用栈来保存寄存器值是个非常好的创意。例如,如果我有一个函数需要去使用寄存器 `r4` 和 `r5`,它将在一个栈上存放这些寄存器的值。最后用这种方式,它可以再次将它拿回来。更高明的是,如果为了运行完我的函数,需要去运行另一个函数,并且那个函数需要保存一些寄存器,在那个函数运行时,它将把寄存器保存在栈顶上,然后在结束后再将它们拿走。而这并不会影响我保存在寄存器 `r4` 和 `r5` 中的值,因为它们是在栈顶上添加的,拿走时也是从栈顶上取出的。
>
>
> 用来表示使用特定的方法将值放到栈上的专用术语,我们称之为那个方法的“<ruby> 栈帧 <rt> stack frame </rt></ruby>”。不是每种方法都使用一个栈帧,有些是不需要存储值的。
>
>
>
因为栈非常有用,它被直接实现在 ARMv6 的指令集中。一个名为 `sp`(栈指针)的专用寄存器用来保存栈的地址。当需要有值添加到栈上时,`sp` 寄存器被更新,这样就总是保证它保存的是栈上第一个值的地址。`push {r4,r5}` 将推送 `r4` 和 `r5` 中的值到栈顶上,而 `pop {r4,r5}` 将(以正确的次序)取回它们。
### 2、我们的第一个函数
现在,关于函数的原理我们已经有了一些概念,我们尝试来写一个函数。由于是我们的第一个很基础的例子,我们写一个没有输入的函数,它将输出 GPIO 的地址。在上一节课程中,我们就是写到这个值上,但将它写成函数更好,因为我们在真实的操作系统中经常需要用到它,而我们不可能总是能够记住这个地址。
复制下列代码到一个名为 `gpio.s` 的新文件中。就像在 `source` 目录中使用的 `main.s` 一样。我们将把与 GPIO 控制器相关的所有函数放到一个文件中,这样更好查找。
```
.globl GetGpioAddress
GetGpioAddress:
ldr r0,=0x20200000
mov pc,lr
```
>
> `.globl lbl` 使标签 `lbl` 从其它文件中可访问。
>
>
> `mov reg1,reg2` 复制 `reg2` 中的值到 `reg1` 中。
>
>
>
这就是一个很简单的完整的函数。`.globl GetGpioAddress` 命令是通知汇编器,让标签 `GetGpioAddress` 在所有文件中全局可访问。这意味着在我们的 `main.s` 文件中,我们可以使用分支指令到标签 `GetGpioAddress` 上,即便这个标签在那个文件中没有定义也没有问题。
你应该认得 `ldr r0,=0x20200000` 命令,它将 GPIO 控制器地址保存到 `r0` 中。由于这是一个函数,我们必须要让它输出到寄存器 `r0` 中,我们不能再像以前那样随意使用任意一个寄存器了。
`mov pc,lr` 将寄存器 `lr` 中的值复制到 `pc` 中。正如前面所提到的,寄存器 `lr` 总是保存着方法完成后我们要返回的代码的地址。`pc` 是一个专用寄存器,它总是包含下一个要运行的指令的地址。一个普通的分支命令只需要改变这个寄存器的值即可。通过将 `lr` 中的值复制到 `pc` 中,我们就可以将要运行的下一行命令改变成我们将要返回的那一行。
理所当然这里有一个问题,那就是我们如何去运行这个代码?我们将需要一个特殊的分支类型 `bl` 指令。它像一个普通的分支一样切换到一个标签,但它在切换之前先更新 `lr` 的值去包含一个在该分支之后的行的地址。这意味着当函数执行完成后,将返回到 `bl` 指令之后的那一行上。这就确保了函数能够像任何其它命令那样运行,它简单地运行,做任何需要做的事情,然后推进到下一行。这是理解函数最有用的方法。当我们使用它时,就将它们按“黑匣子”处理即可,不需要了解它是如何运行的,我们只了解它需要什么输入,以及它给我们什么输出即可。
到现在为止,我们已经明白了函数如何使用,下一节我们将使用它。
### 3、一个大的函数
现在,我们继续去实现一个更大的函数。我们的第一项任务是启用 GPIO 第 16 号针脚的输出。如果它是一个函数那就太好了。我们能够简单地指定一个针脚号和一个函数作为输入,然后函数将设置那个针脚的值。那样,我们就可以使用这个代码去控制任意的 GPIO 针脚,而不只是 LED 了。
将下列的命令复制到 `gpio.s` 文件中的 `GetGpioAddress` 函数中。
```
.globl SetGpioFunction
SetGpioFunction:
cmp r0,#53
cmpls r1,#7
movhi pc,lr
```
>
> 带后缀 `ls` 的命令只有在上一个比较命令的结果是第一个数字小于或与第二个数字相同的情况下才会被运行。它是无符号的。
>
>
> 带后缀 `hi` 的命令只有上一个比较命令的结果是第一个数字大于第二个数字的情况下才会被运行。它是无符号的。
>
>
>
在写一个函数时,我们首先要考虑的事情就是输入,如果输入错了我们怎么办?在这个函数中,我们有一个输入是 GPIO 针脚号,而它必须是介于 0 到 53 之间的数字,因为只有 54 个针脚。每个针脚有 8 个函数,被编号为 0 到 7,因此函数编号也必须是 0 到 7 之间的数字。我们可以假设输入应该是正确的,但是当在硬件上使用时,这种做法是非常危险的,因为不正确的值将导致非常糟糕的副作用。所以,在这个案例中,我们希望确保输入值在正确的范围。
为了确保输入值在正确的范围,我们需要做一个检查,即 `r0` <= 53 并且 `r1` <= 7。首先我们使用前面看到的比较命令去将 `r0` 的值与 53 做比较。下一个指令 `cmpls` 仅在前一个比较指令结果是小于或与 53 相同时才会去运行。如果是这种情况,它将寄存器 `r1` 的值与 7 进行比较,其它的部分都和前面的是一样的。如果最后的比较结果是寄存器值大于那个数字,最后我们将返回到运行函数的代码处。
这正是我们所希望的效果。如果 `r0` 中的值大于 53,那么 `cmpls` 命令将不会去运行,但是 `movhi` 会运行。如果 `r0` 中的值 <= 53,那么 `cmpls` 命令会运行,它会将 `r1` 中的值与 7 进行比较,如果 `r1` > 7,`movhi` 会运行,函数结束,否则 `movhi` 不会运行,这样我们就确定 `r0` <= 53 并且 `r1` <= 7。
`ls`(低于或相同)与 `le`(小于或等于)有一些细微的差别,以及后缀 `hi`(高于)和 `gt`(大于)也一样有一些细微差别,我们在后面将会讲到。
将这些命令复制到上面的代码的下面位置。
```
push {lr}
mov r2,r0
bl GetGpioAddress
```
>
> `push {reg1,reg2,...}` 复制列出的寄存器 `reg1`、`reg2`、… 到栈顶。该命令仅能用于通用寄存器和 `lr` 寄存器。
>
>
> `bl lbl` 设置 `lr` 为下一个指令的地址并切换到标签 `lbl`。
>
>
>
这三个命令用于调用我们第一个方法。`push {lr}` 命令复制 `lr` 中的值到栈顶,这样我们在后面可以获取到它。当我们调用 `GetGpioAddress` 时必须要这样做,我们将需要使用 `lr` 去保存我们函数要返回的地址。
如果我们对 `GetGpioAddress` 函数一无所知,我们必须假设它改变了 `r0`、`r1`、`r2` 和 `r3` 的值 ,并移动我们的值到 `r4` 和 `r5` 中,以在函数完成之后保持它们的值一样。幸运的是,我们知道 `GetGpioAddress` 做了什么,并且我们也知道它仅改变了 `r0` 为 GPIO 地址,它并没有影响 `r1`、`r2` 或 `r3` 的值。因此,我们仅去将 GPIO 针脚号从 `r0` 中移出,这样它就不会被覆盖掉,但我们知道,可以将它安全地移到 `r2` 中,因为 `GetGpioAddress` 并不去改变 `r2`。
最后我们使用 `bl` 指令去运行 `GetGpioAddress`。通常,运行一个函数,我们使用一个术语叫“调用”,从现在开始我们将一直使用这个术语。正如我们前面讨论过的,`bl` 调用一个函数是通过更新 `lr` 为下一个指令的地址并切换到该函数完成的。
当一个函数结束时,我们称为“返回”。当一个 `GetGpioAddress` 调用返回时,我们已经知道了 `r0` 中包含了 GPIO 的地址,`r1` 中包含了函数编号,而 `r2` 中包含了 GPIO 针脚号。
我前面说过,GPIO 函数每 10 个保存在一个块中,因此首先我们需要去判断我们的针脚在哪个块中。这似乎听起来像是要使用一个除法,但是除法做起来非常慢,因此对于这些比较小的数来说,不停地做减法要比除法更好。
将下面的代码复制到上面的代码中最下面的位置。
```
functionLoop$:
cmp r2,#9
subhi r2,#10
addhi r0,#4
bhi functionLoop$
```
>
> `add reg,#val` 将数字 `val` 加到寄存器 `reg` 的内容上。
>
>
>
这个简单的循环代码将针脚号(`r2`)与 9 进行比较。如果它大于 9,它将从针脚号上减去 10,并且将 GPIO 控制器地址加上 4,然后再次运行检查。
这样做的效果就是,现在,`r2` 中将包含一个 0 到 9 之间的数字,它是针脚号除以 10 的余数。`r0` 将包含这个针脚的函数所设置的 GPIO 控制器的地址。它就如同是 “GPIO 控制器地址 + 4 × (GPIO 针脚号 ÷ 10)”。
最后,将下面的代码复制到上面的代码中最下面的位置。
```
add r2, r2,lsl #1
lsl r1,r2
str r1,[r0]
pop {pc}
```
>
> 移位参数 `reg,lsl #val` 表示将寄存器 `reg` 中二进制表示的数逻辑左移 `val` 位之后的结果作为与前面运算的操作数。
>
>
> `lsl reg,amt` 将寄存器 `reg` 中的二进制数逻辑左移 `amt` 中的位数。
>
>
> `str reg,[dst]` 与 `str reg,[dst,#0]` 相同。
>
>
> `pop {reg1,reg2,...}` 从栈顶复制值到寄存器列表 `reg1`、`reg2`、… 仅有通用寄存器与 `pc` 可以这样弹出值。
>
>
>
这个代码完成了这个方法。第一行其实是乘以 3 的变体。乘法在汇编中是一个大而慢的指令,因为电路需要很长时间才能给出答案。有时使用一些能够很快给出答案的指令会让它变得更快。在本案例中,我们知道 `r2` × 3 与 `r2` × 2 + `r2` 是相同的。一个寄存器乘以 2 是非常容易的,因为它可以通过将二进制表示的数左移一位来很方便地实现。
ARMv6 汇编语言其中一个非常有用的特性就是,在使用它之前可以先移动参数所表示的位数。在本案例中,我将 `r2` 加上 `r2` 中二进制表示的数左移一位的结果。在汇编代码中,你可以经常使用这个技巧去更快更容易地计算出答案,但如果你觉得这个技巧使用起来不方便,你也可以写成类似 `mov r3,r2`; `add r2,r3`; `add r2,r3` 这样的代码。
现在,我们可以将一个函数的值左移 `r2` 中所表示的位数。大多数对数量的指令(比如 `add` 和 `sub`)都有一个可以使用寄存器而不是数字的变体。我们执行这个移位是因为我们想去设置表示针脚号的位,并且每个针脚有三个位。
然后,我们将函数计算后的值保存到 GPIO 控制器的地址上。我们在循环中已经算出了那个地址,因此我们不需要像 OK01 和 OK02 中那样在一个偏移量上保存它。
最后,我们从这个方法调用中返回。由于我们将 `lr` 推送到了栈上,因此我们 `pop pc`,它将复制 `lr` 中的值并将它推送到 `pc` 中。这个操作类似于 `mov pc,lr`,因此函数调用将返回到运行它的那一行上。
敏锐的人可能会注意到,这个函数其实并不能正确工作。虽然它将 GPIO 针脚函数设置为所要求的值,但它会导致在同一个块中的所有的 10 个针脚的函数都归 0!在一个大量使用 GPIO 针脚的系统中,这将是一个很恼人的问题。我将这个问题留给有兴趣去修复这个函数的人,以确保只设置相关的 3 个位而不去覆写其它位,其它的所有位都保持不变。关于这个问题的解决方案可以在本课程的下载页面上找到。你可能会发现非常有用的几个函数是 `and`,它是计算两个寄存器的布尔与函数,`mvns` 是计算布尔非函数,而 `orr` 是计算布尔或函数。
### 4、另一个函数
现在,我们已经有了能够管理 GPIO 针脚函数的函数。我们还需要写一个能够打开或关闭 GPIO 针脚的函数。我们不需要写一个打开的函数和一个关闭的函数,只需要一个函数就可以做这两件事情。
我们将写一个名为 `SetGpio` 的函数,它将 GPIO 针脚号作为第一个输入放入 `r0` 中,而将值作为第二个输入放入 `r1` 中。如果该值为 `0`,我们将关闭针脚,而如果为非零则打开针脚。
将下列的代码复制粘贴到 `gpio.s` 文件的结尾部分。
```
.globl SetGpio
SetGpio:
pinNum .req r0
pinVal .req r1
```
>
> `alias .req reg` 设置寄存器 `reg` 的别名为 `alias`。
>
>
>
我们再次需要 `.globl` 命令,标记它为其它文件可访问的全局函数。这次我们将使用寄存器别名。寄存器别名允许我们为寄存器使用名字而不仅是 `r0` 或 `r1`。到目前为止,寄存器别名还不是很重要,但随着我们后面写的方法越来越大,它将被证明非常有用,现在开始我们将尝试使用别名。当在指令中使用到 `pinNum .req r0` 时,它的意思是 `pinNum` 表示 `r0`。
将下面的代码复制粘贴到上述的代码下面位置。
```
cmp pinNum,#53
movhi pc,lr
push {lr}
mov r2,pinNum
.unreq pinNum
pinNum .req r2
bl GetGpioAddress
gpioAddr .req r0
```
>
> `.unreq alias` 删除别名 `alias`。
>
>
>
就像在函数 `SetGpio` 中所做的第一件事情是检查给定的针脚号是否有效一样。我们需要同样的方式去将 `pinNum`(`r0`)与 53 进行比较,如果它大于 53 将立即返回。一旦我们想要再次调用 `GetGpioAddress`,我们就需要将 `lr` 推送到栈上来保护它,将 `pinNum` 移动到 `r2` 中。然后我们使用 `.unreq` 语句来删除我们给 `r0` 定义的别名。因为针脚号现在保存在寄存器 `r2` 中,我们希望别名能够反映这个变化,因此我们从 `r0` 移走别名,重新定义到 `r2`。你应该每次在别名使用结束后,立即删除它,这样当它不再存在时,你就不会在后面的代码中因它而产生错误。
然后,我们调用了 `GetGpioAddress`,并且我们创建了一个指向 `r0`的别名以反映此变化。
将下面的代码复制粘贴到上述代码的后面位置。
```
pinBank .req r3
lsr pinBank,pinNum,#5a
lsl pinBank,#2
add gpioAddr,pinBank
.unreq pinBank
```
>
> `lsr dst,src,#val` 将 `src` 中二进制表示的数右移 `val` 位,并将结果保存到 `dst`。
>
>
>
对于打开和关闭 GPIO 针脚,每个针脚在 GPIO 控制器上有两个 4 字节组。第一个 4 字节组每个位控制前 32 个针脚,而第二个 4 字节组控制剩下的 22 个针脚。为了判断我们要设置的针脚在哪个 4 字节组中,我们需要将针脚号除以 32。幸运的是,这很容易,因为它等价于将二进制表示的针脚号右移 5 位。因此,在本案例中,我们将 `r3` 命名为 `pinBank`,然后计算 `pinNum` ÷ 32。因为它是一个 4 字节组,我们需要将它与 4 相乘的结果。它与二进制表示的数左移 2 位相同,这就是下一行的命令。你可能想知道我们能否只将它右移 3 位呢,这样我们就不用先右移再左移。但是这样做是不行的,因为当我们做 ÷ 32 时答案有些位可能被舍弃,而如果我们做 ÷ 8 时却不会这样。
现在,`gpioAddr` 的结果有可能是 20200000<sub> 16</sub>(如果针脚号介于 0 到 31 之间),也有可能是 20200004<sub> 16</sub>(如果针脚号介于 32 到 53 之间)。这意味着如果加上 28<sub> 10</sub>,我们将得到打开针脚的地址,而如果加上 40<sub> 10</sub> ,我们将得到关闭针脚的地址。由于我们用完了 `pinBank` ,所以在它之后立即使用 `.unreq` 去删除它。
将下面的代码复制粘贴到上述代码的下面位置。
```
and pinNum,#31
setBit .req r3
mov setBit,#1
lsl setBit,pinNum
.unreq pinNum
```
>
> `and reg,#val` 计算寄存器 `reg` 中的数与 `val` 的布尔与。
>
>
>
该函数的下一个部分是产生一个正确的位集合的数。至于 GPIO 控制器去打开或关闭针脚,我们在针脚号除以 32 的余数里设置了位的数。例如,设置 16 号针脚,我们需要第 16 位设置数字为 1 。设置 45 号针脚,我们需要设置第 13 位数字为 1,因为 45 ÷ 32 = 1 余数 13。
这个 `and` 命令计算我们需要的余数。它是这样计算的,在两个输入中所有的二进制位都是 1 时,这个 `and` 运算的结果就是 1,否则就是 0。这是一个很基础的二进制操作,`and` 操作非常快。我们给定的输入是 “pinNum and 31<sub> 10</sub> = 11111<sub> 2</sub>”。这意味着答案的后 5 位中只有 1,因此它肯定是在 0 到 31 之间。尤其是在 `pinNum` 的后 5 位的位置是 1 的地方它只有 1。这就如同被 32 整除的余数部分。就像 31 = 32 - 1 并不是巧合。

代码的其余部分使用这个值去左移 1 位。这就有了创建我们所需要的二进制数的效果。
将下面的代码复制粘贴到上述代码的下面位置。
```
teq pinVal,#0
.unreq pinVal
streq setBit,[gpioAddr,#40]
strne setBit,[gpioAddr,#28]
.unreq setBit
.unreq gpioAddr
pop {pc}
```
>
> `teq reg,#val` 检查寄存器 `reg` 中的数字与 `val` 是否相等。
>
>
>
这个代码结束了该方法。如前面所说,当 `pinVal` 为 0 时,我们关闭它,否则就打开它。`teq`(等于测试)是另一个比较操作,它仅能够测试是否相等。它类似于 `cmp` ,但它并不能算出哪个数大。如果你只是希望测试数字是否相同,你可以使用 `teq`。
如果 `pinVal` 是 0,我们将 `setBit` 保存在 GPIO 地址偏移 40 的位置,我们已经知道,这样会关闭那个针脚。否则将它保存在 GPIO 地址偏移 28 的位置,它将打开那个针脚。最后,我们通过弹出 `pc` 返回,这将设置它为我们推送链接寄存器时保存的值。
### 5、一个新的开始
在完成上述工作后,我们终于有了我们的 GPIO 函数。现在,我们需要去修改 `main.s` 去使用它们。因为 `main.s` 现在已经有点大了,也更复杂了。将它分成两节将是一个很好的设计。到目前为止,我们一直使用的 `.init` 应该尽可能的让它保持小。我们可以更改代码来很容易地反映出这一点。
将下列的代码插入到 `main.s` 文件中 `_start:` 的后面:
```
b main
.section .text
main:
mov sp,#0x8000
```
在这里重要的改变是引入了 `.text` 节。我设计了 `makefile` 和链接器脚本,它将 `.text` 节(它是默认节)中的代码放在地址为 8000<sub> 16</sub> 的 `.init` 节之后。这是默认加载地址,并且它给我们提供了一些空间去保存栈。由于栈存在于内存中,它也有一个地址。栈向下增长内存,因此每个新值都低于前一个地址,所以,这使得栈顶是最低的一个地址。

>
> 图中的 “ATAGs” 节的位置保存了有关树莓派的信息,比如它有多少内存,默认屏幕分辨率是多少。
>
>
>
用下面的代码替换掉所有设置 GPIO 函数针脚的代码:
```
pinNum .req r0
pinFunc .req r1
mov pinNum,#16
mov pinFunc,#1
bl SetGpioFunction
.unreq pinNum
.unreq pinFunc
```
这个代码将使用针脚号 16 和函数编号 1 去调用 `SetGpioFunction`。它的效果就是启用了 OK LED 灯的输出。
用下面的代码去替换打开 OK LED 灯的代码:
```
pinNum .req r0
pinVal .req r1
mov pinNum,#16
mov pinVal,#0
bl SetGpio
.unreq pinNum
.unreq pinVal
```
这个代码使用 `SetGpio` 去关闭 GPIO 第 16 号针脚,因此将打开 OK LED。如果我们(将第 4 行)替换成 `mov pinVal,#1` 它将关闭 LED 灯。用以上的代码去替换掉你关闭 LED 灯的旧代码。
### 6、继续向目标前进
但愿你能够顺利地在你的树莓派上测试我们所做的这一切。到目前为止,我们已经写了一大段代码,因此不可避免会出现错误。如果有错误,可以去查看我们的排错页面。
如果你的代码已经正常工作,恭喜你。虽然我们的操作系统除了做 [课程 2:OK02](/article-10478-1.html) 中的事情,还做不了别的任何事情,但我们已经学会了函数和格式有关的知识,并且我们现在可以更好更快地编写新特性了。现在,我们在操作系统上修改 GPIO 寄存器将变得非常简单,而它就是用于控制硬件的!
在 [课程 4:OK04](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html) 中,我们将处理我们的 `wait` 函数,目前,它的时间控制还不精确,这样我们就可以更好地控制我们的 LED 灯了,进而最终控制所有的 GPIO 针脚。
---
via: <https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok03.html>
作者:[Robert Mullins](http://www.cl.cam.ac.uk/%7Erdm34) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Raspberry Pi
# Lesson 3 OK03
The OK03 lesson builds on OK02 by teaching how to use functions in assembly to make
more reusable and rereadable code. It is assumed you have the code for the [
Lesson 2: OK02](ok02.html) operating system as a basis.
Contents |
## 1 Reusable Code
So far we've made code for our operating system by typing the things we want to happen in order. This is fine for such tiny programs, but if we wrote the whole system like this, the code would be completely unreadable. Instead we use functions.

Functions are said to be 'black boxes'. We put inputs in, and outputs come out, but we don't need to know how they work.
In higher level code such as C or C++, functions are part of the language itself. In assembly code, functions are just ideas we have.
Ideally we want to be able to set our registers to some input values, branch to an address, and expect that at some point the code will branch back to our code having set the registers to output values. This is what a function is in assembly code. The difficulty comes in what system we use for setting the registers. If we just used any system we felt like, each programmer may use a different system, and would find other programmers' work hard to understand. Further, compilers would not be able to work with assembly code as easily, as they would not know how to use the functions. To prevent confusion, a standard called the Application Binary Interface (ABI) was devised for each assembly language which is an agreement on how functions should be run. If everyone makes functions in the same way, then everyone will be able to use each others' functions. I will teach that standard here, and from now on I will code all of my functions to meet the standard.
The standard says that r0,r1,r2 and r3 will be used as inputs to a function in order. If a function needs no inputs, then it doesn't matter what value it takes. If it needs only one it always goes in r0, if it needs two, the first goes in r0, and the second goes on r1, and so on. The output will always be in r0. If a function has no output, it doesn't matter what value r0 takes.
Further, it also requires that after a function is run, r4 to r12 must have the same values as they had when the function started. This means that when you call a function, you can be sure the r4 to r12 will not change value, but you cannot be so sure about r0 to r3.
When a function completes it has to branch back to the code that started it. This means it must know the address of the code that started it. To facilitate this, there is a special register called lr (link register) which always holds the address of the instruction after the one that called this function.
Register | Brief | Preserved | Rules |
---|---|---|---|
r0 | Argument and result | No | r0 and r1 are used for passing the first two arguments to functions, and returning the results of functions. If a function does not use them for a return value, they can take any value after a function. |
r1 | Argument and result | No | |
r2 | Argument | No | r2 and r3 are used for passing the second two arguments to functions. There values after a function is called can be anything. |
r3 | Argument | No | |
r4 | General purpose | Yes | r4 to r12 are used for working values, and their value after a function is called must be the same as before. |
r5 | General purpose | Yes | |
r6 | General purpose | Yes | |
r7 | General purpose | Yes | |
r8 | General purpose | Yes | |
r9 | General purpose | Yes | |
r10 | General purpose | Yes | |
r11 | General purpose | Yes | |
r12 | General purpose | Yes | |
lr | Return address | No | lr is the address to branch back to when a function is finished, but this does have to contain the same address after the function has finished. |
sp | Stack pointer | Yes | sp is the stack pointer, described below. Its value must be the same after the function has finished. |
Often functions need to use more registers than just r0 to r3. But, since r4 to r12 must stay the same after the method has run, they must be saved somewhere. We save them on something called the stack.
Because the stack is so useful, it has been implemented in the ARMv6 instruction set directly. A special register called sp (stack pointer) holds the address of the stack. When items are added to the stack, the sp register updates so that it always holds the address of the first item on the stack. push {r4,r5} would put the values in r4 and r5 onto the top of the stack and pop {r4,r5} would take them back off again (in the correct order).
## 2 Our First Function
Now that we have some idea about how functions work, let's try to make one. For a basic first example, we are going to make a function that takes no input, and gives an output of the GPIO address. In the last lesson, we just wrote in this value, but it would be better as a function, since it is something we might need to do often in a real operating system, and we might not always remember the address.
Copy the following code into a new file called 'gpio.s'. Just make the new file in the 'source' directory with 'main.s'. We're going to put all functions related to the GPIO controller in one file to make them easier to find.
.globl GetGpioAddress
GetGpioAddress:
ldr r0,=0x20200000
mov pc,lr
.globl lbl makes the label lbl accessible from other files.
mov reg1,reg2 copies the value in reg2 into reg1.
This is a very simple complete function. The .globl GetGpioAddress command is a message to the assembler to make the label GetGpioAddress accessible to all files. This means that in our main.s file we can branch to the label GetGpioAddress even though it is not defined in that file.
You should recognise the ldr r0,=0x20200000 command, which stores the GPIO controller address in r0. Since this is a function, we have to give the output in r0, so we are not as free to use any register as we once were.
mov pc,lr copies the value in lr to pc. As mentioned earlier lr always contains the address of the code that we have to go back to when a method finishes. pc is a special register which always contains the address of the next instruction to be run. A normal branch command just changes the value of this register. By copying the value in lr to pc we just change the next line to be run to be the one we were told to go back to.
A reasonable question would now be, how would we actually run this code? A special type of branch bl does what we need. It branches to a label like a normal branch, but before it does it updates lr to contain the address of the line after the branch. That means that when the function finishes, the line it will go back to will be the one after the bl command. This makes a function running just look like any other command, it simply runs, does whatever it needs to do, and then carries on to the next line. This is a really useful way of thinking about functions. We treat them as 'black boxes' in that when we use them, we don't need to think about how they work, we just need to know what inputs they need, and what outputs they give.
For now, don't worry about using the function, we will use it in the next section.
## 3 A Big Function
Now we're going to implement a bigger function. Our first job was to enable output on GPIO pin 16. It would be nice if this was a function. We could simply specify a pin and a function as the input, and the function would set the function of that pin to that value. That way, we could use the code to control any GPIO pin, not just the LED.
Copy the following commands below the GetGpioAddress function in gpio.s.
.globl SetGpioFunction
SetGpioFunction:
cmp r0,#53
cmpls r1,#7
movhi pc,lr
Suffix ls causes the command to be executed only if the last comparison determined that the first number was less than or the same as the second. Unsigned.
Suffix hi causes the command to be executed only if the last comparison determined that the first number was higher than the second. Unsigned.
One of the first things we should always think about when writing functions is our inputs. What do we do if they are wrong? In this function, we have one input which is a GPIO pin number, and so must be a number between 0 and 53, since there are 54 pins. Each pin has 8 functions, numbered 0 to 7 and so the function code must be too. We could just assume that the inputs will be correct, but this is very dangerous when working with hardware, as incorrect values could cause very bad side effects. Therefore, in this case, we wish to make sure the inputs are in the right ranges.
To do this we need to check that r0 <= 53 and r1 <= 7. First of all, we can use the comparison we've seen before to compare the value of r0 with 53. The next instruction, cmpls is a normal comparison instruction that will only be run if r0 was lower than or the same as 53. If that was the case, it compares r1 with 7, otherwise the result of the comparison is the same as before. Finally we go back to the code that ran the function if the result of the last comparison was that the register was higher than the number.
The effect of this is exactly what we want. If r0 was bigger than 53, then the cmpls command doesn't run, but the movhi does. If r0 is <= 53, then the cmpls command does run, and so r1 is compared with 7, and then if it is higher than 7, movhi is run, and the function ends, otherwise movhi does not run, and we know for sure that r0 <= 53 and r1 <= 7.
There is a subtle difference between the ls (lower or same) and le (less or equal) as well as between hi (higher) and gt (greater) suffixes, but I will cover this later.
Copy these commands below the above.
push {lr}
mov r2,r0
bl GetGpioAddress
push {reg1,reg2,...} copies the registers in the list reg1,reg2,... onto the top of the stack. Only general purpose registers and lr can be pushed.
bl lbl sets lr to the address of the next instruction and then branches to the label lbl.
These next three commands are focused on calling our first method. The push {lr} command copies the value in lr onto the top of the stack, so that we can retrieve it later. We must do this because when we call GetGpioAddress, we will need to use lr to store the address to come back to in our function.
If we did not know anything about the GetGpioAddress function, we would have to assume it changes r0,r1,r2 and r3, and would have to move our values to r4 and r5 to keep them the same after it finishes. Fortunately, we do know about GetGpioAddress, and we know it only changes r0 to the address, it doesn't affect r1,r2 or r3. Thus, we only have to move the GPIO pin number out of r0 so it doesn't get overwritten, but we know we can safely move it to r2, as GetGpioAddress doesn't change r2.
Finally we use the bl instruction to run GetGpioAddress. Normally we use the term 'call' for running a function, and I will from now. As discussed earlier bl calls a function by updating the lr to the next instruction's address, and then branching to the function.
When a function ends we say it has 'returned'. When the call to GetGpioAddress returns, we now know that r0 contains the GPIO address, r1 contains the function code and r2 contains the GPIO pin number. I mentioned earlier that the GPIO functions are stored in blocks of 10, so first we need to determine which block of ten our pin number is in. This sounds like a job we would use a division for, but divisions are very slow indeed, so it is better for such small numbers to do repeated subtraction.
Copy the following code below the above.
functionLoop$:
cmp r2,#9
subhi r2,#10
addhi r0,#4
bhi functionLoop$
add reg,#val adds the number val to the contents of the register reg.
This simple loop code compares the pin number to 9. If it is higher than 9, it subtracts 10 from the pin number, and adds 4 to the GPIO Controller address then runs the check again.
The effect of this is that r2 will now contain a number from 0 to 9 which represents the remainder of dividing the pin number by 10. r0 will now contain the address in the GPIO controller of this pin's function settings. This would be the same as GPIO Controller Address + 4 × (GPIO Pin Number ÷ 10).
Finally, copy the following code below the above.
add r2, r2,lsl #1
lsl r1,r2
str r1,[r0]
pop {pc}
Argument shift reg,lsl #val shifts the binary representation of the number in reg left by val before using it in the operation before.
lsl reg,amt shifts the binary representation of the number in reg left by the number in amt.
str reg,[dst] is the same as str reg,[dst,#0].
pop {reg1,reg2,...} copies the values from the top of the stack into the register list reg1,reg2,.... Only general purpose registers and pc can be popped.
This code finishes off the method. The first line is actually a multiplication by 3 in disguise. Multiplication is a big and slow instruction in assembly code, as the circuit can take a long time to come up with the answer. It is much faster sometimes to use some instructions which can get the answer quicker. In this case, I know that r2 × 3 is the same as r2 × 2 + r2. It is very easy to multiply a register by 2 as this is conveniently the same as shifting the binary representation of the number left by one place.
One of the very useful features of the ARMv6 assembly code language is the ability to shift an argument before using it. In this case, I add r2 to the result of shifting the binary representation of r2 to the left by one place. In assembly code, you often use tricks such as this to compute answers more easily, but if you're uncomfortable with this, you could also write something like mov r3,r2; add r2,r3; add r2,r3.
Now we shift the function value left by a number of places equal to r2. Most instructions such as add and sub have a variant which uses a register rather than a number for the amount. We perform this shift because we want to set the bits that correspond to our pin number, and there are three bits per pin.
We then store the the computed function value at the address in the GPIO controller. We already worked out the address in the loop, so we don't need to store it at an offset like we did in OK01 and OK02.
Finally, we can return from this method call. Since we pushed lr onto the stack, if we pop pc, it will copy the value that was in lr at the time we pushed it into pc. This would be the same as having used mov pc,lr and so the function call will return when this line is run.
The very keen may notice that this function doesn't actually work correctly. Although it sets the function of the GPIO pin to the requested value, it causes all the pins in the same block of 10's functions to go back to 0! This would likely be quite annoying in a system which made heavy use of the GPIO pins. I leave it as a challenge to the interested to fix this function so that it does not overwrite other pins values by ensuring that all bits other than the 3 that must be set remain the same. A solution to this can be found on the downloads page for this lesson. Functions that you may find useful are and which computes the Boolean and function of two registers, mvns which computes the Boolean not and orr which computes the Boolean or.
## 4 Another Function
So, we now have a function which takes care of the GPIO pin function setting. We now need to make a function to turn a GPIO pin on or off. Rather than having one function for off and one function for on, it would be handy to have a single function which does either.
We will make a function called SetGpio which takes a GPIO pin number as its first input in r0, and a value as its second in r1. If the value is 0 we will turn the pin off, and if it is not zero we will turn it on.
Copy and paste the following code at the end of 'gpio.s'.
.globl SetGpio
SetGpio:
pinNum .req r0
pinVal .req r1
alias .req reg sets alias to mean the register reg.
Once again we need the .globl command and the label to make the function accessible from other files. This time we're going to use register aliases. Register aliases allow us to use a name other than just r0 or r1 for registers. This may not be so important now, but it will prove invaluable when writing big methods later, and you should try to use aliases from now on. pinNum .req r0 means that pinNum now means r0 when used in instructions.
Copy and paste the following code after the above.
cmp pinNum,#53
movhi pc,lr
push {lr}
mov r2,pinNum
.unreq pinNum
pinNum .req r2
bl GetGpioAddress
gpioAddr .req r0
.unreq alias removes the alias alias.
Like in SetGpioFunction the first thing we must do is check that we were actually given a valid pin number. We do this in exactly the same way by comparing pinNum (r0) with 53, and returning immediately if it is higher. Once again we wish to call GetGpioAddress, so we have to preserve lr by pushing it onto the stack, and to move pinNum to r2. We then use the .unreq statement to remove our alias from r0. Since the pin number is now stored in r2 we want our alias to reflect this, so we remove the alias from r0 and remake it on r2. You should always .unreq every alias as soon as it is done with, so that you cannot make the mistake of using it further down the code when it no longer exists.
We then call GetGpioAddress, and we create an alias for r0 to reflect this.
Copy and paste the following code after the above.
pinBank .req r3
lsr pinBank,pinNum,#5
lsl pinBank,#2
add gpioAddr,pinBank
.unreq pinBank
lsr dst,src,#val shifts the binary representation of the number in src right by val, but stores the result in dst.
The GPIO controller has two sets of 4 bytes each for turning pins on and off. The first set in each case controls the first 32 pins, and the second set controls the remaining 22. In order to determine which set it is in, we need to divide the pin number by 32. Fortunately this is very easy, at is the same as shifting the binary representation of the pin number right by 5 places. Hence, in this case I've named r3 as pinBank and then computed pinNum ÷ 32. Since it is a set of 4 bytes, we then need to multiply the result of this by 4. This is the same as shifting the binary representation left by 2 places, which is the command that follows. You may wonder if we could just shift it right by 3 places, as we went right then left. This won't work however, as some of the answer may have been rounded away when we did ÷ 32 which may not be if we just ÷ 8.
The result of this is that gpioAddr now contains
either 2020000016 if the pin number is 0-31, and 2020000416
if the pin number is 32-53. This means if we add 2810 we get the address
for turning the pin on, and if we add 4010 we get the address for turning
the pin off. Since we are done with pinBank,
I use .unreq immediately afterwards.
Copy and paste the following code after the above.
and pinNum,#31
setBit .req r3
mov setBit,#1
lsl setBit,pinNum
.unreq pinNum
and reg,#val computes the Boolean and function of the number in reg with val.
This next part of the function is for generating a number with the correct bit set. For the GPIO controller to turn a pin on or off, we give it a number with a bit set in the place of the remainder of that pin's number divided by 32. For example, to set pin 16, we need a number with the 16th bit a 1. To set pin 45 we would need a number with the 13th bit 1 as 45 ÷ 32 = 1 remainder 13.
The and command computes the remainder we need.
How it does this is that the result of an and operation is a number with 1s in all
binary digits which had 1s in both of the inputs, and 0s elsewhere. This is a fundamental
binary operation, and is very quick. We have given it inputs of
pinNum and 3110 = 111112. This means that the answer
can only have 1 bits in the last 5 places, and so is definitely between 0 and 31.
Specifically it only has 1s where there were 1s in pinNum's
last 5 places. This is the same as the remainder of a division by 32. It is no coincidence
that 31 = 32 - 1.

The rest of this code simply uses this value to shift the number 1 left. This has the effect of creating the binary number we need.
Copy and paste the following code after the above.
teq pinVal,#0
.unreq pinVal
streq setBit,[gpioAddr,#40]
strne setBit,[gpioAddr,#28]
.unreq setBit
.unreq gpioAddr
pop {pc}
teq reg,#val checks if the number in reg is equal to val.
This code ends the method. As stated before, we turn the pin off if pinVal is zero, and on otherwise. teq (test equal) is another comparison operation that can only be used to test for equality. It is similar to cmp but it does not work out which number is bigger. If all you wish to do is test if to numbers are the same, you can use teq.
If pinVal is zero, we store the setBit at 40 away from the GPIO address, which we already know turns the pin off. Otherwise we store it at 28, which turns the pin on. Finally, we return by popping the pc, which sets it to the value that we stored when we pushed the link register.
## 5 A New Beginning
Finally, after all that work we have our GPIO functions. We now need to alter 'main.s' to use them. Since 'main.s' is now getting a lot bigger and more complicated, it is better design to split it into two sections. The '.init' we've been using so far is best kept as small as possible. We can change the code to reflect this easily.
Insert the following just after _start: in main.s:
b main
.section .text
main:
mov sp,#0x8000
The key change we have made here is to introduce the .text
section. I have designed the makefile and linker scripts such that code in the .text
section (which is the default section) is placed after the .init section which is placed at address 800016.
This is the default load address and gives us some
space to store the stack. As the stack exists in memory, it has to have an address.
The stack grows down memory, so that each new value is at a lower address, thus
making the 'top' of the stack, the lowest address.
The 'ATAGs' section in the diagram is a place where information about the Raspberry Pi is stored such as how much memory it has, and what its default screen resolution is.

Replace all the code that set the function of the GPIO pin with the following:
pinNum .req r0
pinFunc .req r1
mov pinNum,#16
mov pinFunc,#1
bl SetGpioFunction
.unreq pinNum
.unreq pinFunc
This code calls SetGpioFunction with the pin number 16 and the pin function code 1. This has the effect of enabling output to the OK LED.
Replace any code which turns the OK LED on with the following:
pinNum .req r0
pinVal .req r1
mov pinNum,#16
mov pinVal,#0
bl SetGpio
.unreq pinNum
.unreq pinVal
This code uses SetGpio to turn off GPIO pin 16, thus turning on the OK LED. If we instead used mov pinVal,#1, it would turn the LED off. Replace your old code to turn the LED off with that.
## 6 Onwards
Hopefully now, you should be able to test what you have made on the Raspberry Pi. We've done a large amount of code this time, so there is a lot that can go wrong. If it does, head to the troubleshooting page.
When you get it working, congratulations. Although our operating system does nothing
more than it did in [Lesson 2: OK02](ok02.html), we've learned a lot about
functions and formatting, and we can now code new features much more quickly. It
would be very simple now to make an Operating System that alters any GPIO register,
which could be used to control hardware!
In [Lesson 4: OK04](ok04.html), we will address our wait function, which
is currently imprecise, so that we can gain better control over our LED, and ultimately
over all of the GPIO pins. |
10,520 | Asciinema:在云端记录并分享你的终端会话 | https://www.2daygeek.com/linux-asciinema-record-your-terminal-sessions-share-them-on-web/ | 2019-02-08T23:30:50 | [
"asciinema",
"终端",
"会话"
] | https://linux.cn/article-10520-1.html | 
这个众所周知的话题我们早已经写过了足够多的文章。即使这样,我们今天也要去讨论相同的话题。
其他的工具都是在本地运行的,但是 Asciinema 可以以相同的方式在本地和 Web 端运行。我的意思是我们可以在 Web 上分享这个录像。
默认情况下,每个人都更愿意使用 `history` 命令来回看、调用之前在终端内输入的命令。不过,不行的是,这个命令只展示了我们运行的命令却没有展示这些命令上次运行时的输出。
在 Linux 下有很多的组件来记录终端会话活动。在过去,我们也写了一些组件,不过今天我们依然要讨论这同一类心的工具。
如果你想要使用其他工具来记录你的 Linux 终端会话活动,你可以试试 [Script 命令](https://www.2daygeek.com/script-command-record-save-your-terminal-session-activity-linux/)、[Terminalizer 工具](https://www.2daygeek.com/terminalizer-a-tool-to-record-your-terminal-and-generate-animated-gif-images/) 和 [Asciinema 工具](https://www.2daygeek.com/Asciinema-record-your-terminal-sessions-as-svg-animations-in-linux/)。
不过如果你想要找一个 [GIF 录制工具](https://www.2daygeek.com/category/gif-recorder/),可以试试 [Gifine](https://www.2daygeek.com/gifine-create-animated-gif-vedio-recorder-linux-mint-debian-ubuntu/)、[Kgif](https://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/) 和 [Peek](https://www.2daygeek.com/peek-create-animated-gif-screen-recorder-capture-arch-linux-mint-fedora-ubuntu/)。
### 什么是 Asciinema
`asciinema` 是一个自由开源的用于录制终端会话并将它们分享到网络上的解决方案。
当你在你的终端内运行 `asciinema rec` 来启动录像时,你输入命令的时候,终端内的所有输出都会被抓取。
当抓取停止时(通过按下 `Ctrl-D` 或输出 `exit`),抓取的输出将会被上传到 asciinema.org 的网站,并为后续的回放做准备。
Asciinema 项目由多个不同的完整的部分组成,比如 `asciinema` 命令行工具、asciinema.org API 和 JavaScript 播放器。
Asciinema 的灵感来自于 `script` 和 `scriptreplay` 命令。
### 如何在 Linux 上安装 Asciinema
Asciinema 由 Python 写就,在 Linux 上,推荐使用 `pip` 安装的方法来安装。
确保你已经在你的系统里安装了 python-pip 包。如果没有,使用下述命令来安装它。
对于 Debian/Ubuntu 用户,使用 [Apt 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 或 [Apt-Get 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 pip 包。
```
$ sudo apt install python-pip
```
对于 Archlinux 用户,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 pip 包。
```
$ sudo pacman -S python-pip
```
对于 Fedora 用户,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 pip 包。
```
$ sudo dnf install python-pip
```
对于 CentOS/RHEL 用户,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 来安装 pip 包。
```
$ sudo yum install python-pip
```
对于 openSUSE 用户,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 来安装 pip 包。
```
$ sudo zypper install python-pip
```
最后,运行如下的 [pip 命令](https://www.2daygeek.com/install-pip-manage-python-packages-linux/) 来在 Linux 上安装 Asciinema 工具。
```
$ sudo pip3 install asciinema
```
### 如何使用 Asciinema 工具来记录你的终端会话
一旦你成功的安装了 Asciinema,只需要运行如下命令来开始录制:
```
$ asciinema rec 2g-test
asciinema: recording asciicast to 2g-test
asciinema: press "ctrl-d" or type "exit" when you're done
```
出于测试的目的,运行一些简单的命令,并看一看它是否运行良好。
```
$ free
total used free shared buff/cache available
Mem: 15867 2783 10537 1264 2546 11510
Swap: 17454 0 17454
$ hostnamectl
Static hostname: daygeek-Y700
Icon name: computer-laptop
Chassis: laptop
Machine ID: 31bdeb7b833547368d230a2025d475bc
Boot ID: c84f7e6f39394d1f8fdc4bcaa251aee2
Operating System: Manjaro Linux
Kernel: Linux 4.19.8-2-MANJARO
Architecture: x86-64
$ uname -a
Linux daygeek-Y700 4.19.8-2-MANJARO #1 SMP PREEMPT Sat Dec 8 14:45:36 UTC 2018 x86_64 GNU/Linux
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 94
Model name: Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
Stepping: 3
CPU MHz: 800.047
CPU max MHz: 3500.0000
CPU min MHz: 800.0000
BogoMIPS: 5186.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 6144K
NUMA node0 CPU(s): 0-7
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_add fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp flush_l1d
```
当你完成后,简单的按下 `CTRL+D` 或输入 `exit` 来退出录制。这个结果将会被保存在同一个目录。
```
$ exit
exit
asciinema: recording finished
asciinema: asciicast saved to 2g-test
```
如果你想要保存输出到不同的目录中,就需要提醒 Asciinema 你想要保存文件的目录。
```
$ asciinema rec /opt/session-record/2g-test1
```
我们可以使用如下命令来回放录制的会话。
```
$ asciinema play 2g-test
```
我们能够以两倍速来回放录制的会话。
```
$ asciinema play -s 2 2g-test
```
或者,我们可以以正常速度播放录制的会话,限制空闲时间为 2 秒。
```
$ asciinema play -i 2 2g-test
```
### 如何在网络上分享已经录制的会话
如果你想要分享录制的会话给你的朋友,只要运行下述命令上传你的会话到 asciinema.org,就可以获得一个唯一链接。
它将会在被上传 7 天后被归档。
```
$ asciinema upload 2g-test
View the recording at:
https://asciinema.org/a/jdJrxhDLboeyrhzZRHsve0x8i
This installation of asciinema recorder hasn't been linked to any asciinema.org
account. All unclaimed recordings (from unknown installations like this one)
are automatically archived 7 days after upload.
If you want to preserve all recordings made on this machine, connect this
installation with asciinema.org account by opening the following link:
https://asciinema.org/connect/10cd4f24-45b6-4f64-b737-ae0e5d12baf8
```

如果你想要分享录制的会话在社交媒体上,只需要点击页面底部的 “Share” 按钮。
如果任何人想要去下载这个录制,只需要点击页面底部的 “Download” 按钮,就可以将其保存在你系统里。
### 如何管理 asciinema.org 中的录制片段
如果你想要留存所有在这个机器上录制的片段,点击上述显示的链接并使用你在 asciinema.org 的账户登录,然后跟随这个说明继续操作,来将你的机器和该网站连接起来。
```
https://asciinema.org/connect/10cd4f24-45b6-4f64-b737-ae0e5d12baf8
```
如果你早已录制了一份,但是你没有在你的 asciinema.org 账户界面看到它,只需要运行 `asciinema auth` 命令来移动它们。
```
$ asciinema auth
Open the following URL in a web browser to link your install ID with your asciinema.org user account:
https://asciinema.org/connect/10cd4f24-45b6-4f64-b737-ae0e5d12baf8
This will associate all recordings uploaded from this machine (past and future ones) to your account, and allow you to manage them (change title/theme, delete) at asciinema.org.
```

如果你想直接上传文件而不是将其保存在本地,直接运行如下命令:
```
$ asciinema rec
asciinema: recording asciicast to /tmp/tmp6kuh4247-ascii.cast
asciinema: press "ctrl-d" or type "exit" when you're done
```
出于测试目的,运行下述命令,并看一看它是否运行的很好。
```
$ free
total used free shared buff/cache available
Mem: 15867 2783 10537 1264 2546 11510
Swap: 17454 0 17454
$ hostnamectl
Static hostname: daygeek-Y700
Icon name: computer-laptop
Chassis: laptop
Machine ID: 31bdeb7b833547368d230a2025d475bc
Boot ID: c84f7e6f39394d1f8fdc4bcaa251aee2
Operating System: Manjaro Linux
Kernel: Linux 4.19.8-2-MANJARO
Architecture: x86-64
$ uname -a
Linux daygeek-Y700 4.19.8-2-MANJARO #1 SMP PREEMPT Sat Dec 8 14:45:36 UTC 2018 x86_64 GNU/Linux
```
如果你完成了,简单的按下 `CTRL+D` 或输入 `exit` 来停止录制,然后按下回车来上传文件到 asciinema.org 网站。
这将会花费一些时间来为你的录制生成唯一链接。一旦它完成,你会看到和下面一样的样式:
```
$ exit
exit
asciinema: recording finished
asciinema: press "enter" to upload to asciinema.org, "ctrl-c" to save locally
View the recording at:
https://asciinema.org/a/b7bu5OhuCy2vUH7M8RRPjsSxg
```
---
via: <https://www.2daygeek.com/linux-asciinema-record-your-terminal-sessions-share-them-on-web/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Bestony](https://github.com/bestony) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,521 | Go 编程语言的简单介绍 | https://blog.jak-linux.org/2018/12/24/introduction-to-go/ | 2019-02-09T00:07:53 | [
"Go"
] | https://linux.cn/article-10521-1.html | 
(以下内容是我的硕士论文的摘录,几乎是整个 2.1 章节,向具有 CS 背景的人快速介绍 Go)
Go 是一门用于并发编程的命令式编程语言,它主要由创造者 Google 进行开发,最初主要由 Robert Griesemer、Rob Pike 和 Ken Thompson 开发。这门语言的设计起始于 2007 年,并在 2009 年推出最初版本;而第一个稳定版本是 2012 年发布的 1.0 版本。<sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup>
Go 有 C 风格的语法(没有预处理器)、垃圾回收机制,而且类似它在贝尔实验室里被开发出来的前辈们:Newsqueak(Rob Pike)、Alef(Phil Winterbottom)和 Inferno(Pike、Ritchie 等人),使用所谓的 <ruby> Go 协程 <rt> goroutines </rt></ruby>和<ruby> 信道 <rt> channels </rt></ruby>(一种基于 Hoare 的“通信顺序进程”理论的协程)提供内建的并发支持。<sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup>
Go 程序以包的形式组织。包本质是一个包含 Go 文件的文件夹。包内的所有文件共享相同的命名空间,而包内的符号有两种可见性:以大写字母开头的符号对于其他包是可见,而其他符号则是该包私有的:
```
func PublicFunction() {
fmt.Println("Hello world")
}
func privateFunction() {
fmt.Println("Hello package")
}
```
### 类型
Go 有一个相当简单的类型系统:没有子类型(但有类型转换),没有泛型,没有多态函数,只有一些基本的类型:
1. 基本类型:`int`、`int64`、`int8`、`uint`、`float32`、`float64` 等
2. `struct`
3. `interface`:一组方法的集合
4. `map[K, V]`:一个从键类型到值类型的映射
5. `[number]Type`:一些 Type 类型的元素组成的数组
6. `[]Type`:某种类型的切片(具有长度和功能的数组的指针)
7. `chan Type`:一个线程安全的队列
8. 指针 `*T` 指向其他类型
9. 函数
10. 具名类型:可能具有关联方法的其他类型的别名(LCTT 译注:这里的别名并非指 Go 1.9 中的新特性“类型别名”):
```
type T struct { foo int }
type T *T
type T OtherNamedType
```
具名类型完全不同于它们的底层类型,所以你不能让它们互相赋值,但一些操作符,例如 `+`,能够处理同一底层数值类型的具名类型对象们(所以你可以在上面的示例中把两个 `T` 加起来)。
映射、切片和信道是类似于引用的类型——它们实际上是包含指针的结构。包括数组(具有固定长度并可被拷贝)在内的其他类型则是值传递(拷贝)。
#### 类型转换
类型转换类似于 C 或其他语言中的类型转换。它们写成这样子:
```
TypeName(value)
```
#### 常量
Go 有“无类型”字面量和常量。
```
1 // 无类型整数字面量
const foo = 1 // 无类型整数常量
const foo int = 1 // int 类型常量
```
无类型值可以分为以下几类:`UntypedBool`、`UntypedInt`、`UntypedRune`、`UntypedFloat`、`UntypedComplex`、`UntypedString` 以及 `UntypedNil`(Go 称它们为基础类型,其他基础种类可用于具体类型,如 `uint8`)。一个无类型值可以赋值给一个从基础类型中派生的具名类型;例如:
```
type someType int
const untyped = 2 // UntypedInt
const bar someType = untyped // OK: untyped 可以被赋值给 someType
const typed int = 2 // int
const bar2 someType = typed // error: int 不能被赋值给 someType
```
### 接口和对象
正如上面所说的,接口是一组方法的集合。Go 本身不是一种面向对象的语言,但它支持将方法关联到具名类型上:当声明一个函数时,可以提供一个接收者。接收者是函数的一个额外参数,可以在函数之前传递并参与函数查找,就像这样:
```
type SomeType struct { ... }
type SomeType struct { ... }
func (s *SomeType) MyMethod() {
}
func main() {
var s SomeType
s.MyMethod()
}
```
如果对象实现了所有方法,那么它就实现了接口;例如,`*SomeType`(注意指针)实现了下面的接口 `MyMethoder`,因此 `*SomeType` 类型的值就能作为 `MyMethoder` 类型的值使用。最基本的接口类型是 `interface{}`,它是一个带空方法集的接口 —— 任何对象都满足该接口。
```
type MyMethoder interface {
MyMethod()
}
```
合法的接收者类型是有些限制的;例如,具名类型可以是指针类型(例如,`type MyIntPointer *int`),但这种类型不是合法的接收者类型。
### 控制流
Go 提供了三个主要的控制了语句:`if`、`switch` 和 `for`。这些语句同其他 C 风格语言内的语句非常类似,但有一些不同:
* 条件语句没有括号,所以条件语句是 `if a == b {}` 而不是 `if (a == b) {}`。大括号是必须的。
* 所有的语句都可以有初始化,比如这个 `if result, err := someFunction(); err == nil { // use result }`
* `switch` 语句在分支里可以使用任何表达式
* `switch` 语句可以处理空的表达式(等于 `true`)
* 默认情况下,Go 不会从一个分支进入下一个分支(不需要 `break` 语句),在程序块的末尾使用 `fallthrough` 则会进入下一个分支。
* 循环语句 `for` 不仅能循环值域:`for key, val := range map { do something }`
### Go 协程
关键词 `go` 会产生一个新的 <ruby> Go 协程 <rt> goroutine </rt></ruby>,这是一个可以并行执行的函数。它可以用于任何函数调用,甚至一个匿名函数:
```
func main() {
...
go func() {
...
}()
go some_function(some_argument)
}
```
### 信道
Go 协程通常和信道channels结合,用来提供一种通信顺序进程的扩展。信道是一个并发安全的队列,而且可以选择是否缓冲数据:
```
var unbuffered = make(chan int) // 直到数据被读取时完成数据块发送
var buffered = make(chan int, 5) // 最多有 5 个未读取的数据块
```
运算符 `<-` 用于和单个信道进行通信。
```
valueReadFromChannel := <- channel
otherChannel <- valueToSend
```
语句 `select` 允许多个信道进行通信:
```
select {
case incoming := <- inboundChannel:
// 一条新消息
case outgoingChannel <- outgoing:
// 可以发送消息
}
```
### defer 声明
Go 提供语句 `defer` 允许函数退出时调用执行预定的函数。它可以用于进行资源释放操作,例如:
```
func myFunc(someFile io.ReadCloser) {
defer someFile.close()
/* 文件相关操作 */
}
```
当然,它允许使用匿名函数作为被调函数,而且编写被调函数时可以像平常一样使用任何变量。
### 错误处理
Go 没有提供异常类或者结构化的错误处理。然而,它通过第二个及后续的返回值来返回错误从而处理错误:
```
func Read(p []byte) (n int, err error)
// 内建类型:
type error interface {
Error() string
}
```
必须在代码中检查错误或者赋值给 `_`:
```
n0, _ := Read(Buffer) // 忽略错误
n, err := Read(buffer)
if err != nil {
return err
}
```
有两个函数可以快速跳出和恢复调用栈:`panic()` 和 `recover()`。当 `panic()` 被调用时,调用栈开始弹出,同时每个 `defer` 函数都会正常运行。当一个 `defer` 函数调用 `recover()`时,调用栈停止弹出,同时返回函数 `panic()` 给出的值。如果我们让调用栈正常弹出而不是由于调用 `panic()` 函数,`recover()` 将只返回 `nil`。在下面的例子中,`defer` 函数将捕获 `panic()` 抛出的任何 `error` 类型的值并储存在错误返回值中。第三方库中有时会使用这个方法增强递归代码的可读性,如解析器,同时保持公有函数仍使用普通错误返回值。
```
func Function() (err error) {
defer func() {
s := recover()
switch s := s.(type) { // type switch
case error:
err = s // s has type error now
default:
panic(s)
}
}
}
```
### 数组和切片
正如前边说的,数组是值类型,而切片是指向数组的指针。切片可以由现有的数组切片产生,也可以使用 `make()` 创建切片,这会创建一个匿名数组以保存元素。
```
slice1 := make([]int, 2, 5) // 分配 5 个元素,其中 2 个初始化为0
slice2 := array[:] // 整个数组的切片
slice3 := array[1:] // 除了首元素的切片
```
除了上述例子,还有更多可行的切片运算组合,但需要明了直观。
使用 `append()` 函数,切片可以作为一个变长数组使用。
```
slice = append(slice, value1, value2)
slice = append(slice, arrayOrSlice...)
```
切片也可以用于函数的变长参数。
### 映射
<ruby> 映射 <rt> maps </rt> <rt> </rt></ruby>是简单的键值对储存容器,并支持索引和分配。但它们不是线程安全的。
```
someValue := someMap[someKey]
someValue, ok := someMap[someKey] // 如果键值不在 someMap 中,变量 ok 会赋值为 `false`
someMap[someKey] = someValue
```
---
via: <https://blog.jak-linux.org/2018/12/24/introduction-to-go/>
作者:[Julian Andres Klode](https://blog.jak-linux.org/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LazyWolfLin](https://github.com/LazyWolfLin) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
---
1. Frequently Asked Questions (FAQ) - The Go Programming Language <https://golang.org/doc/faq#history> [return] [↩](#fnref1)
2. HOARE, Charles Antony Richard. Communicating sequential processes. Communications of the ACM, 1978, 21. Jg., Nr. 8, S. 666-677. [return] [↩](#fnref2)
| 200 | OK | (What follows is an excerpt from my master’s thesis, almost all of section 2.1, quickly introducing Go to people familiar with CS)
Go is an imperative programming language for concurrent programming created at and mainly developed by Google, initially mostly by Robert Griesemer, Rob Pike, and Ken Thompson.
Design of the language started in 2007, and an initial version was released in 2009; with the first stable version, 1.0 released in 2012 1.
Go has a C-like syntax (without a preprocessor), garbage collection, and, like its predecessors devloped at Bell Labs – Newsqueak (Rob Pike), Alef (Phil Winterbottom), and Inferno (Pike, Ritchie, et al.) – provides built-in support for concurrency using so-called goroutines and channels, a form of co-routines, based on the idea of Hoare’s ‘Communicating Sequential Processes’ 2.
Go programs are organised in packages. A package is essentially a directory containing Go files. All files in a package share the same namespace, and there are two visibilities for symbols in a package: Symbols starting with an upper case character are visible to other packages, others are private to the package:
```
func PublicFunction() {
fmt.Println("Hello world")
}
func privateFunction() {
fmt.Println("Hello package")
}
```
## Types
Go has a fairly simple type system: There is no subtyping (but there are conversions), no generics, no polymorphic functions, and there are only a few basic categories of types:
-
base types:
`int`
,`int64`
,`int8`
,`uint`
,`float32`
,`float64`
, etc. -
`struct`
-
`interface`
- a set of methods -
`map[K, V]`
- a map from a key type to a value type -
`[number]Type`
- an array of some element type -
`[]Type`
- a slice (pointer to array with length and capability) of some type -
`chan Type`
- a thread-safe queue -
pointer
`*T`
to some other type -
functions
-
named type - aliases for other types that may have associated methods:
`type T struct { foo int } type T *T type T OtherNamedType`
Named types are mostly distinct from their underlying types, so you cannot assign them to each other, but some operators like
`+`
do work on objects of named types with an underlying numerical type (so you could add two`T`
in the example above).
Maps, slices, and channels are reference-like types - they essentially are structs containing pointers. Other types are passed by value (copied), including arrays (which have a fixed length and are copied).
### Conversions
Conversions are the similar to casts in C and other languages. They are written like this:
```
TypeName(value)
```
### Constants
Go has “untyped” literals and constants.
```
1 // untyped integer literal
const foo = 1 // untyped integer constant
const foo int = 1 // int constant
```
Untyped values are classified into the following categories: `UntypedBool`
, `UntypedInt`
, `UntypedRune`
, `UntypedFloat`
, `UntypedComplex`
, `UntypedString`
, and `UntypedNil`
(Go calls them *basic kinds*,
other basic kinds are available for the concrete types like `uint8`
). An untyped value can be assigned to a named type derived from a base type; for example:
```
type someType int
const untyped = 2 // UntypedInt
const bar someType = untyped // OK: untyped can be assigned to someType
const typed int = 2 // int
const bar2 someType = typed // error: int cannot be assigned to someType
```
## Interfaces and ‘objects’
As mentioned before, interfaces are a set of methods.
Go is not an object-oriented language per se, but it has some support for associating methods with
named types: When declaring a function, a *receiver* can be provided - a receiver is an additional
function argument that is passed before the function and involved in the function lookup, like this:
```
type SomeType struct { ... }
func (s *SomeType) MyMethod() {
}
func main() {
var s SomeType
s.MyMethod()
}
```
An object implements an interface if it implements all methods; for example, the following interface `MyMethoder`
is implemented by `*SomeType`
(note the pointer), and values of `*SomeType`
can thus be used as values of `MyMethoder`
. The most basic interface is `interface{}`
, that is an interface with an empty method set - any object satisfies that interface.
```
type MyMethoder interface {
MyMethod()
}
```
There are some restrictions on valid receiver types; for example, while a named type could be a pointer (for example, `type MyIntPointer *int`
), such a type is not a valid receiver type.
## Control flow
Go provides three primary statements for control flow: `if`
, `switch`
, and `for`
.
The statements are fairly similar to their equivalent in other C-like languages, with some exceptions:
-
There are no parentheses around conditions, so it is
`if a == b {}`
, not`if (a == b) {}`
. The braces are mandatory. -
All of them can have initialisers, like this
`if result, err := someFunction(); err == nil { // use result }`
-
The
`switch`
statement can use arbitrary expressions in cases -
The
`switch`
statement can switch over nothing (equals switching over true) -
Cases do not fall through by default (no
`break`
needed), use`fallthrough`
at the end of a block to fall through. -
The
`for`
loop can loop over ranges:`for key, val := range map { do something }`
## Goroutines
The keyword `go`
spawns a new goroutine, a concurrently executed function. It can be used with any function call, even a function literal:
```
func main() {
...
go func() {
...
}()
go some_function(some_argument)
}
```
## Channels
Goroutines are often combined with channels to provide an extended form of Communicating Sequential Processes 2. A channel is a concurrent-safe queue, and can be buffered or unbuffered:
```
var unbuffered = make(chan int) // sending blocks until value has been read
var buffered = make(chan int, 5) // may have up to 5 unread values queued
```
The `<-`
operator is used to communicate with a single channel.
```
valueReadFromChannel := <- channel
otherChannel <- valueToSend
```
The `select`
statement allows communication with multiple channels:
```
select {
case incoming := <- inboundChannel:
// A new message for me
case outgoingChannel <- outgoing:
// Could send a message, yay!
}
```
## The `defer`
statement
Go provides a `defer`
statement that allows a function call to be scheduled for execution when the function exits. It can be used for resource clean-up, for example:
```
func myFunc(someFile io.ReadCloser) {
defer someFile.close()
/* Do stuff with file */
}
```
It is of course possible to use function literals as the function to call, and any variables can be used as usual when writing the call.
## Error handling
Go does not provide exceptions or structured error handling. Instead, it handles errors by returning them in a second or later return value:
```
func Read(p []byte) (n int, err error)
// Built-in type:
type error interface {
Error() string
}
```
Errors have to be checked in the code, or can be assigned to `_`
:
```
n0, _ := Read(Buffer) // ignore error
n, err := Read(buffer)
if err != nil {
return err
}
```
There are two functions to quickly unwind and recover the call stack, though: `panic()`
and `recover()`
.
When `panic()`
is called, the call stack is unwound, and any deferred functions are run as usual.
When a deferred function invokes `recover()`
, the unwinding stops, and the value given to `panic()`
is returned.
If we are unwinding normally and not due to a panic, `recover()`
simply returns `nil`
.
In the example below, a function is deferred and any `error`
value that is given to `panic()`
will be recovered and stored in an error return value.
Libraries sometimes use that approach to make highly recursive code like parsers more readable, while still maintaining the usual error return value for public functions.
```
func Function() (err error) {
defer func() {
s := recover()
switch s := s.(type) { // type switch
case error:
err = s // s has type error now
default:
panic(s)
}
}
}
```
## Arrays and slices
As mentioned before, an array is a value type and a slice is a pointer into an array, created either by slicing an existing array or by using `make()`
to create a slice, which will create an anonymous array to hold the elements.
```
slice1 := make([]int, 2, 5) // 5 elements allocated, 2 initialized to 0
slice2 := array[:] // sliced entire array
slice3 := array[1:] // slice of array without first element
```
There are some more possible combinations for the slicing operator than mentioned above, but this should give a good first impression.
A slice can be used as a dynamically growing array, using the `append()`
function.
```
slice = append(slice, value1, value2)
slice = append(slice, arrayOrSlice...)
```
Slices are also used internally to represent variable parameters in variable length functions.
## Maps
Maps are simple key-value stores and support indexing and assigning. They are *not* thread-safe.
```
someValue := someMap[someKey]
someValue, ok := someMap[someKey] // ok is false if key not in someMap
someMap[someKey] = someValue
```
-
Frequently Asked Questions (FAQ) - The Go Programming Language
[https://golang.org/doc/faq#history](https://golang.org/doc/faq#history)[↩︎](#fnref:1) -
HOARE, Charles Antony Richard. Communicating sequential processes. Communications of the ACM, 1978, 21. Jg., Nr. 8, S. 666-677.
[↩︎](#fnref:2)[↩︎](#fnref1:2)
## Reactions from Mastodon |
10,522 | Python Web 应用程序 Tornado 框架简介 | https://opensource.com/article/18/6/tornado-framework | 2019-02-09T18:03:06 | [
"Python",
"Tornado",
"协程"
] | https://linux.cn/article-10522-1.html |
>
> 在比较 Python 框架的系列文章的第三部分中,我们来了解 Tornado,它是为处理异步进程而构建的。
>
>
>

在这个由四部分组成的系列文章的前两篇中,我们介绍了 [Pyramid](https://opensource.com/article/18/5/pyramid-framework) 和 [Flask](https://opensource.com/article/18/4/flask) Web 框架。我们已经构建了两次相同的应用程序,看到了一个完整的 DIY 框架和包含了更多功能的框架之间的异同。
现在让我们来看看另一个稍微不同的选择:[Tornado 框架](https://tornado.readthedocs.io/en/stable/)。Tornado 在很大程度上与 Flask 一样简单,但有一个主要区别:Tornado 是专门为处理异步进程而构建的。在我们本系列所构建的应用程序中,这种特殊的酱料(LCTT 译注:这里意思是 Tornado 的异步功能)在我们构建的 app 中并不是非常有用,但我们将看到在哪里可以使用它,以及它在更一般的情况下是如何工作的。
让我们继续前两篇文章中模式,首先从处理设置和配置开始。
### Tornado 启动和配置
如果你一直关注这个系列,那么第一步应该对你来说习以为常。
```
$ mkdir tornado_todo
$ cd tornado_todo
$ pipenv install --python 3.6
$ pipenv shell
(tornado-someHash) $ pipenv install tornado
```
创建一个 `setup.py` 文件来安装我们的应用程序相关的东西:
```
(tornado-someHash) $ touch setup.py
# setup.py
from setuptools import setup, find_packages
requires = [
'tornado',
'tornado-sqlalchemy',
'psycopg2',
]
setup(
name='tornado_todo',
version='0.0',
description='A To-Do List built with Tornado',
author='<Your name>',
author_email='<Your email>',
keywords='web tornado',
packages=find_packages(),
install_requires=requires,
entry_points={
'console_scripts': [
'serve_app = todo:main',
],
},
)
```
因为 Tornado 不需要任何外部配置,所以我们可以直接编写 Python 代码来让程序运行。让我们创建 `todo` 目录,并用需要的前几个文件填充它。
```
todo/
__init__.py
models.py
views.py
```
就像 Flask 和 Pyramid 一样,Tornado 也有一些基本配置,放在 `__init__.py` 中。从 `tornado.web` 中,我们将导入 `Application` 对象,它将处理路由和视图的连接,包括数据库(当我们谈到那里时再说)以及运行 Tornado 应用程序所需的其它额外设置。
```
# __init__.py
from tornado.web import Application
def main():
"""Construct and serve the tornado application."""
app = Application()
```
像 Flask 一样,Tornado 主要是一个 DIY 框架。当构建我们的 app 时,我们必须设置该应用实例。因为 Tornado 用它自己的 HTTP 服务器来提供该应用,我们必须设置如何提供该应用。首先,在 `tornado.options.define` 中定义要监听的端口。然后我们实例化 Tornado 的 `HTTPServer`,将该 `Application` 对象的实例作为参数传递给它。
```
# __init__.py
from tornado.httpserver import HTTPServer
from tornado.options import define, options
from tornado.web import Application
define('port', default=8888, help='port to listen on')
def main():
"""Construct and serve the tornado application."""
app = Application()
http_server = HTTPServer(app)
http_server.listen(options.port)
```
当我们使用 `define` 函数时,我们最终会在 `options` 对象上创建属性。第一个参数位置的任何内容都将是属性的名称,分配给 `default` 关键字参数的内容将是该属性的值。
例如,如果我们将属性命名为 `potato` 而不是 `port`,我们可以通过 `options.potato` 访问它的值。
在 `HTTPServer` 上调用 `listen` 并不会启动服务器。我们必须再做一步,找一个可以监听请求并返回响应的工作应用程序,我们需要一个输入输出循环。幸运的是,Tornado 以 `tornado.ioloop.IOLoop` 的形式提供了开箱即用的功能。
```
# __init__.py
from tornado.httpserver import HTTPServer
from tornado.ioloop import IOLoop
from tornado.options import define, options
from tornado.web import Application
define('port', default=8888, help='port to listen on')
def main():
"""Construct and serve the tornado application."""
app = Application()
http_server = HTTPServer(app)
http_server.listen(options.port)
print('Listening on http://localhost:%i' % options.port)
IOLoop.current().start()
```
我喜欢某种形式的 `print` 语句,来告诉我什么时候应用程序正在提供服务,这是我的习惯。如果你愿意,可以不使用 `print`。
我们以 `IOLoop.current().start()` 开始我们的 I/O 循环。让我们进一步讨论输入,输出和异步性。
### Python 中的异步和 I/O 循环的基础知识
请允许我提前说明,我绝对,肯定,一定并且放心地说不是异步编程方面的专家。就像我写的所有内容一样,接下来的内容源于我对这个概念的理解的局限性。因为我是人,可能有很深很深的缺陷。
异步程序的主要问题是:
```
* 数据如何进来?
* 数据如何出去?
* 什么时候可以在不占用我全部注意力情况下运行某个过程?
```
由于[全局解释器锁](https://realpython.com/python-gil/)(GIL),Python 被设计为一种[单线程](https://en.wikipedia.org/wiki/Thread_(computing))语言。对于 Python 程序必须执行的每个任务,其线程执行的全部注意力都集中在该任务的持续时间内。我们的 HTTP 服务器是用 Python 编写的,因此,当接收到数据(如 HTTP 请求)时,服务器的唯一关心的是传入的数据。这意味着,在大多数情况下,无论是程序需要运行还是处理数据,程序都将完全消耗服务器的执行线程,阻止接收其它可能的数据,直到服务器完成它需要做的事情。
在许多情况下,这不是太成问题。典型的 Web 请求,响应周期只需要几分之一秒。除此之外,构建 HTTP 服务器的套接字可以维护待处理的传入请求的积压。因此,如果请求在该套接字处理其它内容时进入,则它很可能只是在处理之前稍微排队等待一会。对于低到中等流量的站点,几分之一秒的时间并不是什么大问题,你可以使用多个部署的实例以及 [NGINX](https://www.nginx.com/) 等负载均衡器来为更大的请求负载分配流量。
但是,如果你的平均响应时间超过一秒钟,该怎么办?如果你使用来自传入请求的数据来启动一些长时间的过程(如机器学习算法或某些海量数据库查询),该怎么办?现在,你的单线程 Web 服务器开始累积一个无法寻址的积压请求,其中一些请求会因为超时而被丢弃。这不是一种选择,特别是如果你希望你的服务在一段时间内是可靠的。
异步 Python 程序登场。重要的是要记住因为它是用 Python 编写的,所以程序仍然是一个单线程进程。除非特别标记,否则在异步程序中仍然会阻塞执行。
但是,当异步程序结构正确时,只要你指定某个函数应该具有这样的能力,你的异步 Python 程序就可以“搁置”长时间运行的任务。然后,当搁置的任务完成并准备好恢复时,异步控制器会收到报告,只要在需要时管理它们的执行,而不会完全阻塞对新输入的处理。
这有点夸张,所以让我们用一个人类的例子来证明。
### 带回家吧
我经常发现自己在家里试图完成很多家务,但没有多少时间来做它们。在某一天,积压的家务可能看起来像:
```
* 做饭(20 分钟准备,40 分钟烹饪)
* 洗碗(60 分钟)
* 洗涤并擦干衣物(30 分钟洗涤,每次干燥 90 分钟)
* 真空清洗地板(30 分钟)
```
如果我是一个传统的同步程序,我会亲自完成每项任务。在我考虑处理任何其他事情之前,每项任务都需要我全神贯注地完成。因为如果没有我的全力关注,什么事情都完成不了。所以我的执行顺序可能如下:
```
1. 完全专注于准备和烹饪食物,包括等待食物烹饪(60 分钟)
2. 将脏盘子移到水槽中(65 分钟过去了)
3. 清洗所有盘子(125 分钟过去了)
4. 开始完全专注于洗衣服,包括等待洗衣机洗完,然后将衣物转移到烘干机,再等烘干机完成( 250 分钟过去了)
5. 对地板进行真空吸尘(280 分钟了)
```
从头到尾完成所有事情花费了 4 小时 40 分钟。
我应该像异步程序一样聪明地工作,而不是努力工作。我的家里到处都是可以为我工作的机器,而不用我一直努力工作。同时,现在我可以将注意力转移真正需要的东西上。
我的执行顺序可能看起来像:
```
1. 将衣物放入洗衣机并启动它(5 分钟)
2. 在洗衣机运行时,准备食物(25 分钟过去了)
3. 准备好食物后,开始烹饪食物(30 分钟过去了)
4. 在烹饪食物时,将衣物从洗衣机移到烘干机机中开始烘干(35 分钟过去了)
5. 当烘干机运行中,且食物仍在烹饪时,对地板进行真空吸尘(65 分钟过去了)
6. 吸尘后,将食物从炉子中取出并装盘子入洗碗机(70 分钟过去了)
7. 运行洗碗机(130 分钟完成)
```
现在花费的时间下降到 2 小时 10 分钟。即使我允许在作业之间切换花费更多时间(总共 10-20 分钟)。如果我等待着按顺序执行每项任务,我花费的时间仍然只有一半左右。这就是将程序构造为异步的强大功能。
#### 那么 I/O 循环在哪里?
一个异步 Python 程序的工作方式是从某个外部源(输入)获取数据,如果某个进程需要,则将该数据转移到某个外部工作者(输出)进行处理。当外部进程完成时,Python 主程序会收到提醒,然后程序获取外部处理(输入)的结果,并继续这样其乐融融的方式。
当数据不在 Python 主程序手中时,主程序就会被释放来处理其它任何事情。包括等待全新的输入(如 HTTP 请求)和处理长时间运行的进程的结果(如机器学习算法的结果,长时间运行的数据库查询)。主程序虽仍然是单线程的,但成了事件驱动的,它对程序处理的特定事件会触发动作。监听这些事件并指示应如何处理它们的主要是 I/O 循环在工作。
我知道,我们走了很长的路才得到这个重要的解释,但我希望在这里传达的是,它不是魔术,也不是某种复杂的并行处理或多线程工作。全局解释器锁仍然存在,主程序中任何长时间运行的进程仍然会阻塞其它任何事情的进行,该程序仍然是单线程的。然而,通过将繁琐的工作外部化,我们可以将线程的注意力集中在它需要注意的地方。
这有点像我上面的异步任务。当我的注意力完全集中在准备食物上时,它就是我所能做的一切。然而,当我能让炉子帮我做饭,洗碗机帮我洗碗,洗衣机和烘干机帮我洗衣服时,我的注意力就会被释放出来,去做其它事情。当我被提醒,我的一个长时间运行的任务已经完成并准备再次处理时,如果我的注意力是空闲的,我可以获取该任务的结果,并对其做下一步需要做的任何事情。
### Tornado 路由和视图
尽管经历了在 Python 中讨论异步的所有麻烦,我们还是决定暂不使用它。先来编写一个基本的 Tornado 视图。
与我们在 Flask 和 Pyramid 实现中看到的基于函数的视图不同,Tornado 的视图都是基于类的。这意味着我们将不在使用单独的、独立的函数来规定如何处理请求。相反,传入的 HTTP 请求将被捕获并将其分配为我们定义的类的一个属性。然后,它的方法将处理相应的请求类型。
让我们从一个基本的视图开始,即在屏幕上打印 “Hello, World”。我们为 Tornado 应用程序构造的每个基于类的视图都必须继承 `tornado.web` 中的 `RequestHandler` 对象。这将设置我们需要(但不想写)的所有底层逻辑来接收请求,同时构造正确格式的 HTTP 响应。
```
from tornado.web import RequestHandler
class HelloWorld(RequestHandler):
"""Print 'Hello, world!' as the response body."""
def get(self):
"""Handle a GET request for saying Hello World!."""
self.write("Hello, world!")
```
因为我们要处理 `GET` 请求,所以我们声明(实际上是重写)了 `get` 方法。我们提供文本或 JSON 可序列化对象,用 `self.write` 写入响应体。之后,我们让 `RequestHandler` 来做在发送响应之前必须完成的其它工作。
就目前而言,此视图与 Tornado 应用程序本身并没有实际连接。我们必须回到 `__init__.py`,并稍微更新 `main` 函数。以下是新的内容:
```
# __init__.py
from tornado.httpserver import HTTPServer
from tornado.ioloop import IOLoop
from tornado.options import define, options
from tornado.web import Application
from todo.views import HelloWorld
define('port', default=8888, help='port to listen on')
def main():
"""Construct and serve the tornado application."""
app = Application([
('/', HelloWorld)
])
http_server = HTTPServer(app)
http_server.listen(options.port)
print('Listening on http://localhost:%i' % options.port)
IOLoop.current().start()
```
#### 我们做了什么
我们将 `views.py` 文件中的 `HelloWorld` 视图导入到脚本 `__init__.py` 的顶部。然后我们添加了一个路由-视图对应的列表,作为 `Application` 实例化的第一个参数。每当我们想要在应用程序中声明一个路由时,它必须绑定到一个视图。如果需要,可以对多个路由使用相同的视图,但每个路由必须有一个视图。
我们可以通过在 `setup.py` 中启用的 `serve_app` 命令来运行应用程序,从而确保这一切都能正常工作。查看 `http://localhost:8888/` 并看到它显示 “Hello, world!”。
当然,在这个领域中我们还能做更多,也将做更多,但现在让我们来讨论模型吧。
### 连接数据库
如果我们想要保留数据,就需要连接数据库。与 Flask 一样,我们将使用一个特定于框架的 SQLAchemy 变体,名为 [tornado-sqlalchemy](https://tornado-sqlalchemy.readthedocs.io/en/latest/)。
为什么要使用它而不是 [SQLAlchemy](https://www.sqlalchemy.org/) 呢?好吧,其实 `tornado-sqlalchemy` 具有简单 SQLAlchemy 的所有优点,因此我们仍然可以使用通用的 `Base` 声明模型,并使用我们习以为常的所有列数据类型和关系。除了我们已经惯常了解到的,`tornado-sqlalchemy` 还为其数据库查询功能提供了一种可访问的异步模式,专门用于与 Tornado 现有的 I/O 循环一起工作。
我们通过将 `tornado-sqlalchemy` 和 `psycopg2` 添加到 `setup.py` 到所需包的列表并重新安装包来创建环境。在 `models.py` 中,我们声明了模型。这一步看起来与我们在 Flask 和 Pyramid 中已经看到的完全一样,所以我将跳过全部声明,只列出了 `Task` 模型的必要部分。
```
# 这不是完整的 models.py, 但是足够看到不同点
from tornado_sqlalchemy import declarative_base
Base = declarative_base
class Task(Base):
# 等等,因为剩下的几乎所有的东西都一样 ...
```
我们仍然需要将 `tornado-sqlalchemy` 连接到实际应用程序。在 `__init__.py` 中,我们将定义数据库并将其集成到应用程序中。
```
# __init__.py
from tornado.httpserver import HTTPServer
from tornado.ioloop import IOLoop
from tornado.options import define, options
from tornado.web import Application
from todo.views import HelloWorld
# add these
import os
from tornado_sqlalchemy import make_session_factory
define('port', default=8888, help='port to listen on')
factory = make_session_factory(os.environ.get('DATABASE_URL', ''))
def main():
"""Construct and serve the tornado application."""
app = Application([
('/', HelloWorld)
],
session_factory=factory
)
http_server = HTTPServer(app)
http_server.listen(options.port)
print('Listening on http://localhost:%i' % options.port)
IOLoop.current().start()
```
就像我们在 Pyramid 中传递的会话工厂一样,我们可以使用 `make_session_factory` 来接收数据库 URL 并生成一个对象,这个对象的唯一目的是为视图提供到数据库的连接。然后我们将新创建的 `factory` 传递给 `Application` 对象,并使用 `session_factory` 关键字参数将它绑定到应用程序中。
最后,初始化和管理数据库与 Flask 和 Pyramid 相同(即,单独的 DB 管理脚本,与 `Base` 对象一起工作等)。它看起来很相似,所以在这里我就不介绍了。
### 回顾视图
Hello,World 总是适合学习基础知识,但我们需要一些真实的,特定应用程序的视图。
让我们从 info 视图开始。
```
# views.py
import json
from tornado.web import RequestHandler
class InfoView(RequestHandler):
"""只允许 GET 请求"""
SUPPORTED_METHODS = ["GET"]
def set_default_headers(self):
"""设置默认响应头为 json 格式的"""
self.set_header("Content-Type", 'application/json; charset="utf-8"')
def get(self):
"""列出这个 API 的路由"""
routes = {
'info': 'GET /api/v1',
'register': 'POST /api/v1/accounts',
'single profile detail': 'GET /api/v1/accounts/<username>',
'edit profile': 'PUT /api/v1/accounts/<username>',
'delete profile': 'DELETE /api/v1/accounts/<username>',
'login': 'POST /api/v1/accounts/login',
'logout': 'GET /api/v1/accounts/logout',
"user's tasks": 'GET /api/v1/accounts/<username>/tasks',
"create task": 'POST /api/v1/accounts/<username>/tasks',
"task detail": 'GET /api/v1/accounts/<username>/tasks/<id>',
"task update": 'PUT /api/v1/accounts/<username>/tasks/<id>',
"delete task": 'DELETE /api/v1/accounts/<username>/tasks/<id>'
}
self.write(json.dumps(routes))
```
有什么改变吗?让我们从上往下看。
我们添加了 `SUPPORTED_METHODS` 类属性,它是一个可迭代对象,代表这个视图所接受的请求方法,其他任何方法都将返回一个 [405](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#4xx_Client_errors) 状态码。当我们创建 `HelloWorld` 视图时,我们没有指定它,主要是当时有点懒。如果没有这个类属性,此视图将响应任何试图绑定到该视图的路由的请求。
我们声明了 `set_default_headers` 方法,它设置 HTTP 响应的默认头。我们在这里声明它,以确保我们返回的任何响应都有一个 `"Content-Type"` 是 `"application/json"` 类型。
我们将 `json.dumps(some_object)` 添加到 `self.write` 的参数中,因为它可以很容易地构建响应主体的内容。
现在已经完成了,我们可以继续将它连接到 `__init__.py` 中的主路由。
```
# __init__.py
from tornado.httpserver import HTTPServer
from tornado.ioloop import IOLoop
from tornado.options import define, options
from tornado.web import Application
from todo.views import InfoView
# 添加这些
import os
from tornado_sqlalchemy import make_session_factory
define('port', default=8888, help='port to listen on')
factory = make_session_factory(os.environ.get('DATABASE_URL', ''))
def main():
"""Construct and serve the tornado application."""
app = Application([
('/', InfoView)
],
session_factory=factory
)
http_server = HTTPServer(app)
http_server.listen(options.port)
print('Listening on http://localhost:%i' % options.port)
IOLoop.current().start()
```
我们知道,还需要编写更多的视图和路由。每个都会根据需要放入 `Application` 路由列表中,每个视图还需要一个 `set_default_headers` 方法。在此基础上,我们还将创建 `send_response` 方法,它的作用是将响应与我们想要给响应设置的任何自定义状态码打包在一起。由于每个视图都需要这两个方法,因此我们可以创建一个包含它们的基类,这样每个视图都可以继承基类。这样,我们只需要编写一次。
```
# views.py
import json
from tornado.web import RequestHandler
class BaseView(RequestHandler):
"""Base view for this application."""
def set_default_headers(self):
"""Set the default response header to be JSON."""
self.set_header("Content-Type", 'application/json; charset="utf-8"')
def send_response(self, data, status=200):
"""Construct and send a JSON response with appropriate status code."""
self.set_status(status)
self.write(json.dumps(data))
```
对于我们即将编写的 `TaskListView` 这样的视图,我们还需要一个到数据库的连接。我们需要 `tornado_sqlalchemy` 中的 `SessionMixin` 在每个视图类中添加一个数据库会话。我们可以将它放在 `BaseView` 中,这样,默认情况下,从它继承的每个视图都可以访问数据库会话。
```
# views.py
import json
from tornado_sqlalchemy import SessionMixin
from tornado.web import RequestHandler
class BaseView(RequestHandler, SessionMixin):
"""Base view for this application."""
def set_default_headers(self):
"""Set the default response header to be JSON."""
self.set_header("Content-Type", 'application/json; charset="utf-8"')
def send_response(self, data, status=200):
"""Construct and send a JSON response with appropriate status code."""
self.set_status(status)
self.write(json.dumps(data))
```
只要我们修改 `BaseView` 对象,在将数据发布到这个 API 时,我们就应该定位到这里。
当 Tornado(从 v.4.5 开始)使用来自客户端的数据并将其组织起来到应用程序中使用时,它会将所有传入数据视为字节串。但是,这里的所有代码都假设使用 Python 3,因此我们希望使用的唯一字符串是 Unicode 字符串。我们可以为这个 `BaseView` 类添加另一个方法,它的工作是将输入数据转换为 Unicode,然后再在视图的其他地方使用。
如果我们想要在正确的视图方法中使用它之前转换这些数据,我们可以重写视图类的原生 `prepare` 方法。它的工作是在视图方法运行前运行。如果我们重写 `prepare` 方法,我们可以设置一些逻辑来运行,每当收到请求时,这些逻辑就会执行字节串到 Unicode 的转换。
```
# views.py
import json
from tornado_sqlalchemy import SessionMixin
from tornado.web import RequestHandler
class BaseView(RequestHandler, SessionMixin):
"""Base view for this application."""
def prepare(self):
self.form_data = {
key: [val.decode('utf8') for val in val_list]
for key, val_list in self.request.arguments.items()
}
def set_default_headers(self):
"""Set the default response header to be JSON."""
self.set_header("Content-Type", 'application/json; charset="utf-8"')
def send_response(self, data, status=200):
"""Construct and send a JSON response with appropriate status code."""
self.set_status(status)
self.write(json.dumps(data))
```
如果有任何数据进入,它将在 `self.request.arguments` 字典中找到。我们可以通过键访问该数据库,并将其内容(始终是列表)转换为 Unicode。因为这是基于类的视图而不是基于函数的,所以我们可以将修改后的数据存储为一个实例属性,以便以后使用。我在这里称它为 `form_data`,但它也可以被称为 `potato`。关键是我们可以存储提交给应用程序的数据。
### 异步视图方法
现在我们已经构建了 `BaseaView`,我们可以构建 `TaskListView` 了,它会继承 `BaseaView`。
正如你可以从章节标题中看到的那样,以下是所有关于异步性的讨论。`TaskListView` 将处理返回任务列表的 `GET` 请求和用户给定一些表单数据来创建新任务的 `POST` 请求。让我们首先来看看处理 `GET` 请求的代码。
```
# all the previous imports
import datetime
from tornado.gen import coroutine
from tornado_sqlalchemy import as_future
from todo.models import Profile, Task
# the BaseView is above here
class TaskListView(BaseView):
"""View for reading and adding new tasks."""
SUPPORTED_METHODS = ("GET", "POST",)
@coroutine
def get(self, username):
"""Get all tasks for an existing user."""
with self.make_session() as session:
profile = yield as_future(session.query(Profile).filter(Profile.username == username).first)
if profile:
tasks = [task.to_dict() for task in profile.tasks]
self.send_response({
'username': profile.username,
'tasks': tasks
})
```
这里的第一个主要部分是 `@coroutine` 装饰器,它从 `tornado.gen` 导入。任何具有与调用堆栈的正常流程不同步的 Python 可调用部分实际上是“协程”,即一个可以与其它协程一起运行的协程。在我的家务劳动的例子中,几乎所有的家务活都是一个共同的例行协程。有些阻止了例行协程(例如,给地板吸尘),但这种例行协程只会阻碍我开始或关心其它任何事情的能力。它没有阻止已经启动的任何其他协程继续进行。
Tornado 提供了许多方法来构建一个利用协程的应用程序,包括允许我们设置函数调用锁,同步异步协程的条件,以及手动修改控制 I/O 循环的事件系统。
这里使用 `@coroutine` 装饰器的唯一条件是允许 `get` 方法将 SQL 查询作为后台进程,并在查询完成后恢复,同时不阻止 Tornado I/O 循环去处理其他传入的数据源。这就是关于此实现的所有“异步”:带外数据库查询。显然,如果我们想要展示异步 Web 应用程序的魔力和神奇,那么一个任务列表就不是好的展示方式。
但是,这就是我们正在构建的,所以让我们来看看方法如何利用 `@coroutine` 装饰器。`SessionMixin` 混合到 `BaseView` 声明中,为我们的视图类添加了两个方便的,支持数据库的属性:`session` 和 `make_session`。它们的名字相似,实现的目标也相当相似。
`self.session` 属性是一个关注数据库的会话。在请求-响应周期结束时,在视图将响应发送回客户端之前,任何对数据库的更改都被提交,并关闭会话。
`self.make_session` 是一个上下文管理器和生成器,可以动态构建和返回一个全新的会话对象。第一个 `self.session` 对象仍然存在。无论如何,反正 `make_session` 会创建一个新的。`make_session` 生成器还为其自身提供了一个功能,用于在其上下文(即缩进级别)结束时提交和关闭它创建的会话。
如果你查看源代码,则赋值给 `self.session` 的对象类型与 `self.make_session` 生成的对象类型之间没有区别,不同之处在于它们是如何被管理的。
使用 `make_session` 上下文管理器,生成的会话仅属于上下文,在该上下文中开始和结束。你可以使用 `make_session` 上下文管理器在同一个视图中打开,修改,提交以及关闭多个数据库会话。
`self.session` 要简单得多,当你进入视图方法时会话已经打开,在响应被发送回客户端之前会话就已提交。
虽然[读取文档片段](https://tornado-sqlalchemy.readthedocs.io/en/latest/#usage)和 [PyPI 示例](https://pypi.org/project/tornado-sqlalchemy/#description)都说明了上下文管理器的使用,但是没有说明 `self.session` 对象或由 `self.make_session` 生成的 `session` 本质上是不是异步的。当我们启动查询时,我们开始考虑内置于 `tornado-sqlalchemy` 中的异步行为。
`tornado-sqlalchemy` 包为我们提供了 `as_future` 函数。它的工作是装饰 `tornado-sqlalchemy` 会话构造的查询并 yield 其返回值。如果视图方法用 `@coroutine` 装饰,那么使用 `yield as_future(query)` 模式将使封装的查询成为一个异步后台进程。I/O 循环会接管等待查询的返回值和 `as_future` 创建的 `future` 对象的解析。
要访问 `as_future(query)` 的结果,你必须从它 `yield`。否则,你只能获得一个未解析的生成器对象,并且无法对查询执行任何操作。
这个视图方法中的其他所有内容都与之前课堂上的类似,与我们在 Flask 和 Pyramid 中看到的内容类似。
`post` 方法看起来非常相似。为了保持一致性,让我们看一下 `post` 方法以及它如何处理用 `BaseView` 构造的 `self.form_data`。
```
@coroutine
def post(self, username):
"""Create a new task."""
with self.make_session() as session:
profile = yield as_future(session.query(Profile).filter(Profile.username == username).first)
if profile:
due_date = self.form_data['due_date'][0]
task = Task(
name=self.form_data['name'][0],
note=self.form_data['note'][0],
creation_date=datetime.now(),
due_date=datetime.strptime(due_date, '%d/%m/%Y %H:%M:%S') if due_date else None,
completed=self.form_data['completed'][0],
profile_id=profile.id,
profile=profile
)
session.add(task)
self.send_response({'msg': 'posted'}, status=201)
```
正如我所说,这是我们所期望的:
\* 与我们在 `get` 方法中看到的查询模式相同 \* 构造一个新的 `Task` 对象的实例,用 `form_data` 的数据填充 \* 添加新的 `Task` 对象(但不提交,因为它由上下文管理器处理!)到数据库会话 \* 将响应发送给客户端
这样我们就有了 Tornado web 应用程序的基础。其他内容(例如,数据库管理和更多完整应用程序的视图)实际上与我们在 Flask 和 Pyramid 应用程序中看到的相同。
### 关于使用合适的工具完成合适的工作的一点想法
在我们继续浏览这些 Web 框架时,我们开始看到它们都可以有效地处理相同的问题。对于像这样的待办事项列表,任何框架都可以完成这项任务。但是,有些 Web 框架比其它框架更适合某些工作,这具体取决于对你来说什么“更合适”和你的需求。
虽然 Tornado 显然和 Pyramid 或 Flask 一样可以处理相同工作,但将它用于这样的应用程序实际上是一种浪费,这就像开车从家走一个街区(LCTT 译注:这里意思应该是从家开始走一个街区只需步行即可)。是的,它可以完成“旅行”的工作,但短途旅行不是你选择汽车而不是自行车或者使用双脚的原因。
根据文档,Tornado 被称为 “Python Web 框架和异步网络库”。在 Python Web 框架生态系统中很少有人喜欢它。如果你尝试完成的工作需要(或将从中获益)以任何方式、形状或形式的异步性,使用 Tornado。如果你的应用程序需要处理多个长期连接,同时又不想牺牲太多性能,选择 Tornado。如果你的应用程序是多个应用程序,并且需要线程感知以准确处理数据,使用 Tornado。这是它最有效的地方。
用你的汽车做“汽车的事情”,使用其他交通工具做其他事情。
### 向前看,进行一些深度检查
谈到使用合适的工具来完成合适的工作,在选择框架时,请记住应用程序的范围和规模,包括现在和未来。到目前为止,我们只研究了适用于中小型 Web 应用程序的框架。本系列的下一篇也是最后一篇将介绍最受欢迎的 Python 框架之一 Django,它适用于可能会变得更大的大型应用程序。同样,尽管它在技术上能够并且将会处理待办事项列表问题,但请记住,这不是它的真正用途。我们仍然会通过它来展示如何使用它来构建应用程序,但我们必须牢记框架的意图以及它是如何反映在架构中的:
* **Flask**: 适用于小型,简单的项目。它可以使我们轻松地构建视图并将它们快速连接到路由,它可以简单地封装在一个文件中。
* **Pyramid**: 适用于可能增长的项目。它包含一些配置来启动和运行。应用程序组件的独立领域可以很容易地划分并构建到任意深度,而不会忽略中央应用程序。
* **Tornado**: 适用于受益于精确和有意识的 I/O 控制的项目。它允许协程,并轻松公开可以控制如何接收请求或发送响应以及何时发生这些操作的方法。
* **Django**:(我们将会看到)意味着可能会变得更大的东西。它有着非常庞大的生态系统,包括大量插件和模块。它非常有主见的配置和管理,以保持所有不同部分在同一条线上。
无论你是从本系列的第一篇文章开始阅读,还是稍后才加入的,都要感谢阅读!请随意留下问题或意见。下次再见时,我手里会拿着 Django。
### 感谢 Python BDFL
我必须把功劳归于它应得的地方,非常感谢 [Guido van Rossum](https://www.twitter.com/gvanrossum),不仅仅是因为他创造了我最喜欢的编程语言。
在 [PyCascades 2018](https://www.pycascades.com) 期间,我很幸运的不仅做了基于这个文章系列的演讲,而且还被邀请参加了演讲者的晚宴。整个晚上我都坐在 Guido 旁边,不停地问他问题。其中一个问题是,在 Python 中异步到底是如何工作的,但他没有一点大惊小怪,而是花时间向我解释,让我开始理解这个概念。他后来[推特给我](https://twitter.com/gvanrossum/status/956186585493458944)发了一条消息:是用于学习异步 Python 的广阔资源。我随后在三个月内阅读了三次,然后写了这篇文章。你真是一个非常棒的人,Guido!
---
via: <https://opensource.com/article/18/6/tornado-framework>
作者:[Nicholas Hunt-Walker](https://opensource.com/users/nhuntwalker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the first two articles in this four-part series comparing different Python web frameworks, we've covered the [Pyramid](https://opensource.com/article/18/5/pyramid-framework) and [Flask](https://opensource.com/article/18/4/flask) web frameworks. We've built the same app twice and seen the similarities and differences between a complete DIY framework and a framework with a few more batteries included.
Now let's look at a somewhat different option: [the Tornado framework](https://tornado.readthedocs.io/en/stable/). Tornado is, for the most part, as bare-bones as Flask, but with a major difference: Tornado is built specifically to handle asynchronous processes. That special sauce isn't *terribly* useful in the app we're building in this series, but we'll see where we can use it and how it works in a more general situation.
Let's continue the pattern we set in the first two articles and start by tackling the setup and config.
## Tornado startup and configuration
If you've been following along with this series, what we do first shouldn't come as much of a surprise.
```
$ mkdir tornado_todo
$ cd tornado_todo
$ pipenv install --python 3.6
$ pipenv shell
(tornado-someHash) $ pipenv install tornado
```
Create a `setup.py`
for installing our application:
`(tornado-someHash) $ touch setup.py`
```
# setup.py
from setuptools import setup, find_packages
requires = [
'tornado',
'tornado-sqlalchemy',
'psycopg2',
]
setup(
name='tornado_todo',
version='0.0',
description='A To-Do List built with Tornado',
author='<Your name>',
author_email='<Your email>',
keywords='web tornado',
packages=find_packages(),
install_requires=requires,
entry_points={
'console_scripts': [
'serve_app = todo:main',
],
},
)
```
Because Tornado doesn't require any external configuration, we can dive right into writing the Python code that'll run our application. Let's make our inner `todo`
directory and fill it with the first few files we'll need.
```
todo/
__init__.py
models.py
views.py
```
Like Flask and Pyramid, Tornado has some central configuration that will go in `__init__.py`
. From `tornado.web`
, we'll import the `Application`
object. This will handle the hookups for routing and views, including our database (when we get there) and any extra settings needed to run our Tornado app.
```
# __init__.py
from tornado.web import Application
def main():
"""Construct and serve the tornado application."""
app = Application()
```
Like Flask, Tornado is a mostly DIY framework. While building our app, we have to set up the application instance. Because Tornado serves the application with its own HTTP server, we also have to set up how the application is served. First, we define a port to listen on with `tornado.options.define`
. Then we instantiate Tornado's `HTTPServer`
, passing the instance of the `Application`
object as its argument.
```
# __init__.py
from tornado.httpserver import HTTPServer
from tornado.options import define, options
from tornado.web import Application
define('port', default=8888, help='port to listen on')
def main():
"""Construct and serve the tornado application."""
app = Application()
http_server = HTTPServer(app)
http_server.listen(options.port)
```
When we use the `define`
function, we end up creating attributes on the `options`
object. Anything that goes in the position of the first argument will be the attribute's name, and what's assigned to the `default`
keyword argument will be the value of that attribute.
As an example, if we name the attribute `potato`
instead of `port`
, we can access its value via `options.potato`
.
Calling `listen`
on the `HTTPServer`
doesn't start the server yet. We must do one more step to have a working application that can listen for requests and return responses. We need an input-output loop. Thankfully, Tornado comes with that out of the box in the form of `tornado.ioloop.IOLoop`
.
```
# __init__.py
from tornado.httpserver import HTTPServer
from tornado.ioloop import IOLoop
from tornado.options import define, options
from tornado.web import Application
define('port', default=8888, help='port to listen on')
def main():
"""Construct and serve the tornado application."""
app = Application()
http_server = HTTPServer(app)
http_server.listen(options.port)
print('Listening on http://localhost:%i' % options.port)
IOLoop.current().start()
```
I like some kind of a `print`
statement somewhere that tells me when I'm serving my application, but that's me. You could do without the `print`
line if you so chose.
We begin our I/O loop with `IOLoop.current().start()`
. Let's talk a little more about input, output, and asynchronicity.
## The basics of async in Python and the I/O loop
Allow me to preface by saying that I am absolutely, positively, surely, and securely not an expert in asynchronous programming. As with all things I write, what follows stems from the limits of my understanding of the concept. As I am human, it may be deeply, deeply flawed.
The main concerns of an asynchronous program are:
- How is data coming in?
- How is data going out?
- When can some procedure be left to run without consuming my full attention?
Due to the [global interpreter lock](https://realpython.com/python-gil/) (GIL), Python is—by design—a [single-threaded](https://en.wikipedia.org/wiki/Thread_(computing)) language. For every task a Python program must execute, the full attention of its thread of execution is on that task for the duration of that task. Our HTTP server is written in Python. Thus, when data (e.g., an HTTP request) is received, the server's *sole focus* is that incoming data. This means that, in most cases, whatever procedures need to run in handling and processing that data will completely consume your server's thread of execution, blocking other potential data from being received until your server finishes whatever it needed to do.
In many cases this isn't too problematic; a typical web request-response cycle will take only fractions of a second. Along with that, the sockets that HTTP servers are built from can maintain a backlog of incoming requests to be handled. So, if a request comes in while that socket is handling something else, chances are it'll just wait in line a bit before being addressed. For a low to intermediate traffic site, a fraction of a second isn't that big of a deal, and you can use multiple deployed instances along with a load-balancer like [NGINX](https://www.nginx.com/) to distribute traffic for the larger request loads.
What if, however, your average response time takes more than a fraction of a second? What if you use data from the incoming request to start some long-running process like a machine-learning algorithm or some massive database query? Now, your single-threaded web server starts to accumulate an unaddressable backlog of requests, some of which will get dropped due to simply timing out. This is not an option, especially if you want your service to be seen as reliable on a regular basis.
In comes the asynchronous Python program. It's important to keep in mind that because it's written in Python, the program is still a single-threaded process. Anything that would block execution in a synchronous program, unless specifically flagged, will still block execution in an asynchronous one.
When it's structured correctly, however, your asynchronous Python program can "shelve" long-running tasks whenever you designate that a certain function should have the ability to do so. Your async controller can then be alerted when the shelved tasks are complete and ready to resume, managing their execution only when needed without completely blocking the handling of new input.
That was somewhat jargony, so let's demonstrate with a human example.
### Bringing it home
I often find myself trying to get multiple chores done at home with little time to do them. On a given day, that backlog of chores may look like:
- Cook a meal (20 min. prep, 40 min. cook)
- Wash dishes (60 min.)
- Wash and dry laundry (30 min. wash, 90 min. dry per load)
- Vacuum floors (30 min.)
If I were acting as a traditional, synchronous program, I'd be doing each task myself, by hand. Each task would require my full attention to complete before I could consider handling anything else, as nothing would get done without my active attention. So my sequence of execution might look like:
- Focus fully on preparing and cooking the meal, including waiting around for food to just… cook (60 min.).
- Transfer dirty dishes to sink (65 min. elapsed).
- Wash all the dishes (125 min. elapsed).
- Start laundry with my full focus on that, including waiting around for the washing machine to finish, then transferring laundry to the dryer, and waiting for the dryer to finish (250 min. elapsed).
- Vacuum the floors (280 min. elapsed).
That's 4 hours and 40 minutes to complete my chores from end-to-end.
Instead of working hard, I should work smart like an asynchronous program. My home is full of machines that can do my work for me without my continuous effort. Meanwhile, I can switch my attention to what may actively need it *right now*.
My execution sequence might instead look like:
- Load clothes into and start the washing machine (5 min.).
- While the washing machine is running, prep food (25 min. elapsed).
- After prepping food, start cooking food (30 min. elapsed).
- While the food is cooking, move clothes from the washing machine into the dryer and start dryer (35 min. elapsed).
- While dryer is running and food is still cooking, vacuum the floors (65 min. elapsed).
- After vacuuming the floors, take food off the stove and load the dishwasher (70 min. elapsed).
- Run the dishwasher (130 min. when done).
Now I'm down to 2 hours and 10 minutes. Even if I allow more time for switching between jobs (10-20 more minutes total), I'm still down to about half the time I would've spent if I'd waited to perform each task in sequential order. This is the power of structuring your program to be asynchronous.
### So where does the I/O loop come in?
An asynchronous Python program works by taking in data from some external source (input) and, should the process require it, offloading that data to some external worker (output) for processing. When that external process finishes, the main Python program is alerted. The program then picks up the result of that external processing (input) and continues on its merry way.
Whenever that data isn't actively in the hands of the main Python program, that main program is freed to work on just about anything else. This includes awaiting completely new inputs (e.g., HTTP requests) and handling the results of long-running processes (e.g., results of machine-learning algorithms, long-running database queries). The main program, while still single-threaded, becomes event-driven, triggered into action for specific occurrences handled by the program. The main worker that listens for those events and dictates how they should be handled is the I/O loop.
We traveled a long road to get to this nugget of an explanation, I know, but what I'm hoping to communicate here is that it's not magic, nor is it some type of complex parallel processing or multi-threaded work. The global interpreter lock is still in place; any long-running process within the main program will still block anything else from happening. The program is also still single-threaded; however, by externalizing tedious work, we conserve the attention of that thread to only what it needs to be attentive to.
This is kind of like my asynchronous chores above. When my attention is fully necessary for prepping food, that's all I'm doing. However, when I can get the stove to do work for me by cooking my food, and the dishwasher to wash my dishes, and the washing machine and dryer to handle my laundry, my attention is freed to work on other things. When I am alerted that one of my long-running tasks is finished and ready to be handled once again, if my attention is free, I can pick up the results of that task and do whatever needs to be done with it next.
## Tornado routes and views
Despite having gone through all the trouble of talking about async in Python, we're going to hold off on using it for a bit and first write a basic Tornado view.
Unlike the *function-based* views we've seen in the Flask and Pyramid implementations, Tornado's views are all *class-based*. This means we'll no longer use individual, standalone functions to dictate how requests are handled. Instead, the incoming HTTP request will be caught and assigned to be an attribute of our defined class. Its methods will then handle the corresponding request types.
Let's start with a basic view that prints "Hello, World" to the screen. Every class-based view we construct for our Tornado app *must* inherit from the `RequestHandler`
object found in `tornado.web`
. This will set up all the ground-level logic that we'll need (but don't want to write) to take in a request and construct a properly formatted HTTP response.
```
from tornado.web import RequestHandler
class HelloWorld(RequestHandler):
"""Print 'Hello, world!' as the response body."""
def get(self):
"""Handle a GET request for saying Hello World!."""
self.write("Hello, world!")
```
Because we're looking to handle a `GET`
request, we declare (really override) the `get`
method. Instead of returning anything, we provide text or a JSON-serializable object to be written to the response body with `self.write`
. After that, we let the `RequestHandler`
take on the rest of the work that must be done before a response can be sent.
As it stands, this view has no actual connection to the Tornado application itself. We have to go back into `__init__.py`
and update the `main`
function a bit. Here's the new hotness:
```
# __init__.py
from tornado.httpserver import HTTPServer
from tornado.ioloop import IOLoop
from tornado.options import define, options
from tornado.web import Application
from todo.views import HelloWorld
define('port', default=8888, help='port to listen on')
def main():
"""Construct and serve the tornado application."""
app = Application([
('/', HelloWorld)
])
http_server = HTTPServer(app)
http_server.listen(options.port)
print('Listening on http://localhost:%i' % options.port)
IOLoop.current().start()
```
### What'd we do?
We imported the `HelloWorld`
view from the `views.py`
file into `__init__.py`
at the top of the script. Then we added a list of route-view pairs as the first argument to the instantiation to `Application`
. Whenever we want to declare a route in our application, it *must* be tied to a view. You can use the same view for multiple routes if you want, but there must always be a view for every route.
We can make sure this all works by running our app with the `serve_app`
command we enabled in the `setup.py`
. Check `http://localhost:8888/`
and see that it says "Hello, world!"
Of course, there's more we can and will do in this space, but let's move on to models.
## Connecting the database
If we want to hold onto data, we need to connect a database. Like with Flask, we'll be using a framework-specific variant of SQLAlchemy called [tornado-sqlalchemy](https://tornado-sqlalchemy.readthedocs.io/en/latest/).
Why use this instead of just the bare [SQLAlchemy](https://www.sqlalchemy.org/)? Well, `tornado-sqlalchemy`
has all the goodness of straightforward SQLAlchemy, so we can still declare models with a common `Base`
as well as use all the column data types and relationships to which we've grown accustomed. Alongside what we already know from habit, `tornado-sqlalchemy`
provides an accessible async pattern for its database-querying functionality specifically to work with Tornado's existing I/O loop.
We set the stage by adding `tornado-sqlalchemy`
and `psycopg2`
to `setup.py`
to the list of required packages and reinstall the package. In `models.py`
, we declare our models. This step looks pretty much exactly like what we've already seen in Flask and Pyramid, so I'll skip the full-class declarations and just put up the necessaries of the `Task`
model.
```
# this is not the complete models.py, but enough to see the differences
from tornado_sqlalchemy import declarative_base
Base = declarative_base
class Task(Base):
# and so on, because literally everything's the same...
```
We still have to connect `tornado-sqlalchemy`
to the actual application. In `__init__.py`
, we'll be defining the database and integrating it into the application.
```
# __init__.py
from tornado.httpserver import HTTPServer
from tornado.ioloop import IOLoop
from tornado.options import define, options
from tornado.web import Application
from todo.views import HelloWorld
# add these
import os
from tornado_sqlalchemy import make_session_factory
define('port', default=8888, help='port to listen on')
factory = make_session_factory(os.environ.get('DATABASE_URL', ''))
def main():
"""Construct and serve the tornado application."""
app = Application([
('/', HelloWorld)
],
session_factory=factory
)
http_server = HTTPServer(app)
http_server.listen(options.port)
print('Listening on http://localhost:%i' % options.port)
IOLoop.current().start()
```
Much like the session factory we passed around in Pyramid, we can use `make_session_factory`
to take in a database URL and produce an object whose sole purpose is to provide connections to the database for our views. We then tie it into our application by passing the newly created `factory`
into the `Application`
object with the `session_factory`
keyword argument.
Finally, initializing and managing the database will look the same as it did for Flask and Pyramid (i.e., separate DB management script, working with respect to the `Base`
object, etc.). It'll look so similar that I'm not going to reproduce it here.
## Revisiting views
Hello, World is always nice for learning the basics, but we need some real, application-specific views.
Let's start with the info view.
```
# views.py
import json
from tornado.web import RequestHandler
class InfoView(RequestHandler):
"""Only allow GET requests."""
SUPPORTED_METHODS = ["GET"]
def set_default_headers(self):
"""Set the default response header to be JSON."""
self.set_header("Content-Type", 'application/json; charset="utf-8"')
def get(self):
"""List of routes for this API."""
routes = {
'info': 'GET /api/v1',
'register': 'POST /api/v1/accounts',
'single profile detail': 'GET /api/v1/accounts/<username>',
'edit profile': 'PUT /api/v1/accounts/<username>',
'delete profile': 'DELETE /api/v1/accounts/<username>',
'login': 'POST /api/v1/accounts/login',
'logout': 'GET /api/v1/accounts/logout',
"user's tasks": 'GET /api/v1/accounts/<username>/tasks',
"create task": 'POST /api/v1/accounts/<username>/tasks',
"task detail": 'GET /api/v1/accounts/<username>/tasks/<id>',
"task update": 'PUT /api/v1/accounts/<username>/tasks/<id>',
"delete task": 'DELETE /api/v1/accounts/<username>/tasks/<id>'
}
self.write(json.dumps(routes))
```
So what changed? Let's go from the top down.
The `SUPPORTED_METHODS`
class attribute was added. This will be an iterable of only the request methods that are accepted by this view. Any other method will return a [405](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#4xx_Client_errors) status code. When we made the `HelloWorld`
view, we didn't specify this, mostly out of laziness. Without this class attribute, this view would respond to any request trying to access the route tied to the view.
The `set_default_headers`
method is declared, which sets the default headers of the outgoing HTTP response. We declare this here to ensure that any response we send back has a `"Content-Type"`
of `"application/json"`
.
We added `json.dumps(some_object)`
to the argument of `self.write`
because it makes it easy to construct the content for the body of the outgoing response.
Now that's done, and we can go ahead and connect it to the home route in `__init__.py`
.
```
# __init__.py
from tornado.httpserver import HTTPServer
from tornado.ioloop import IOLoop
from tornado.options import define, options
from tornado.web import Application
from todo.views import InfoView
# add these
import os
from tornado_sqlalchemy import make_session_factory
define('port', default=8888, help='port to listen on')
factory = make_session_factory(os.environ.get('DATABASE_URL', ''))
def main():
"""Construct and serve the tornado application."""
app = Application([
('/', InfoView)
],
session_factory=factory
)
http_server = HTTPServer(app)
http_server.listen(options.port)
print('Listening on http://localhost:%i' % options.port)
IOLoop.current().start()
```
As we know, more views and routes will need to be written. Each one will get dropped into the `Application`
route listing as needed. Each will also need a `set_default_headers`
method. On top of that, we'll create our `send_response`
method, whose job it will be to package our response along with any custom status codes we want to set for a given response. Since each one will need both methods, we can create a base class containing them that each of our views can inherit from. That way, we have to write them only once.
```
# views.py
import json
from tornado.web import RequestHandler
class BaseView(RequestHandler):
"""Base view for this application."""
def set_default_headers(self):
"""Set the default response header to be JSON."""
self.set_header("Content-Type", 'application/json; charset="utf-8"')
def send_response(self, data, status=200):
"""Construct and send a JSON response with appropriate status code."""
self.set_status(status)
self.write(json.dumps(data))
```
For a view like the `TaskListView`
we'll soon write, we'll also need a connection to the database. We'll need `tornado_sqlalchemy`
's `SessionMixin`
to add a database session within every view class. We can fold that into the `BaseView`
so that, by default, every view inheriting from it has access to a database session.
```
# views.py
import json
from tornado_sqlalchemy import SessionMixin
from tornado.web import RequestHandler
class BaseView(RequestHandler, SessionMixin):
"""Base view for this application."""
def set_default_headers(self):
"""Set the default response header to be JSON."""
self.set_header("Content-Type", 'application/json; charset="utf-8"')
def send_response(self, data, status=200):
"""Construct and send a JSON response with appropriate status code."""
self.set_status(status)
self.write(json.dumps(data))
```
As long as we're modifying this `BaseView`
object, we should address a quirk that will come up when we consider data being posted to this API.
When Tornado (as of v.4.5) consumes data from a client and organizes it for use in the application, it keeps all the incoming data as bytestrings. However, all the code here assumes Python 3, so the only strings that we want to work with are Unicode strings. We can add another method to this `BaseView`
class whose job it will be to convert the incoming data to Unicode before using it anywhere else in the view.
If we want to convert this data before we use it in a proper view method, we can override the view class's native `prepare`
method. Its job is to run before the view method runs. If we override the `prepare`
method, we can set some logic to run that'll do the bytestring-to-Unicode conversion whenever a request is received.
```
# views.py
import json
from tornado_sqlalchemy import SessionMixin
from tornado.web import RequestHandler
class BaseView(RequestHandler, SessionMixin):
"""Base view for this application."""
def prepare(self):
self.form_data = {
key: [val.decode('utf8') for val in val_list]
for key, val_list in self.request.arguments.items()
}
def set_default_headers(self):
"""Set the default response header to be JSON."""
self.set_header("Content-Type", 'application/json; charset="utf-8"')
def send_response(self, data, status=200):
"""Construct and send a JSON response with appropriate status code."""
self.set_status(status)
self.write(json.dumps(data))
```
If there's any data coming in, it'll be found within the `self.request.arguments`
dictionary. We can access that data by key and convert its contents (always a list) to Unicode. Because this is a class-based view instead of a function-based view, we can store the modified data as an instance attribute to be used later. I called it `form_data`
here, but it can just as easily be called `potato`
. The point is that we can store data that has been submitted to the application.
## Asynchronous view methods
Now that we've built our `BaseView`
, we can build the `TaskListView`
that will inherit from it.
As you can probably tell from the section heading, this is where all that talk about asynchronicity comes in. The `TaskListView`
will handle `GET`
requests for returning a list of tasks and `POST`
requests for creating new tasks given some form data. Let's first look at the code to handle the `GET`
request.
```
# all the previous imports
import datetime
from tornado.gen import coroutine
from tornado_sqlalchemy import as_future
from todo.models import Profile, Task
# the BaseView is above here
class TaskListView(BaseView):
"""View for reading and adding new tasks."""
SUPPORTED_METHODS = ("GET", "POST",)
@coroutine
def get(self, username):
"""Get all tasks for an existing user."""
with self.make_session() as session:
profile = yield as_future(session.query(Profile).filter(Profile.username == username).first)
if profile:
tasks = [task.to_dict() for task in profile.tasks]
self.send_response({
'username': profile.username,
'tasks': tasks
})
```
The first major piece here is the `@coroutine`
decorator, imported from `tornado.gen`
. Any Python callable that has a portion that acts out of sync with the normal flow of the call stack is effectively a "co-routine"; a routine that can run alongside other routines. In the example of my household chores, pretty much every chore was a co-routine. Some were blocking routines (e.g., vacuuming the floor), but that routine simply blocked my ability to start or attend to anything else. It didn't block any of the other routines that were already set in motion from continuing.
Tornado offers a number of ways to build an app that take advantage of co-routines, including allowing us to set locks on function calls, conditions for synchronizing asynchronous routines, and a system for manually modifying the events that control the I/O loop.
The *only* way the `@coroutine`
decorator is used here is to allow the `get`
method to farm out the SQL query as a background process and resume once the query is complete, while not blocking the Tornado I/O loop from handling other sources of incoming data. That is all that's "asynchronous" about this implementation: out-of-band database queries. Clearly if we wanted to showcase the magic and wonder of an async web app, a To-Do List isn't the way.
But hey, that's what we're building, so let's see how our method takes advantage of that `@coroutine`
decorator. The `SessionMixin`
that was, well, mixed into the `BaseView`
declaration added two handy, database-aware attributes to our view class: `session`
and `make_session`
. They're similarly named and accomplish fairly similar goals.
The `self.session`
attribute is a session with an eye on the database. At the end of the request-response cycle, just before the view sends a response back to the client, any changes that have been made to the database are committed, and the session is closed.
`self.make_session`
is a context manager and generator, building and returning a brand new session object on the fly. That first `self.session`
object still exists; `make_session`
creates a new one anyway. The `make_session`
generator also has baked into itself the logic for committing and closing the session it creates as soon as its context (i.e., indentation level) ends.
If you inspect the source code, there is *no difference* between the type of object assigned to `self.session`
and the type of object generated by `self.make_session`
. The difference is in how they're managed.
With the `make_session`
context manager, the generated session belongs only to the context, beginning and ending within that context. You can open, modify, commit, and close multiple database sessions within the same view with the `make_session`
context manager.
`self.session`
is much simpler, with the session already opened by the time you get to your view method and committing before the response is sent back to the client.
Although the [read the docs snippet](https://tornado-sqlalchemy.readthedocs.io/en/latest/#usage) and the [the PyPI example](https://pypi.org/project/tornado-sqlalchemy/#description) both specify the use of the context manager, there's nothing about either the `self.session`
object or the `session`
generated by `self.make_session`
that is inherently asynchronous. The point where we start thinking about the async behavior built into `tornado-sqlalchemy`
comes when we initiate a query.
The `tornado-sqlalchemy`
package provides us with the `as_future`
function. The job of `as_future`
is to wrap the query constructed by the `tornado-sqlalchemy`
session and yield its return value. If the view method is decorated with `@coroutine`
, then using this `yield as_future(query)`
pattern will now make your wrapped query an asynchronous background process. The I/O loop takes over, awaiting the return value of the query and the resolution of the `future`
object created by `as_future`
.
To have access to the result from `as_future(query)`
, you must `yield`
from it. Otherwise, you get only an unresolved generator object and can do nothing with the query.
Everything else in this view method is pretty much par for the course, mirroring what we've already seen in Flask and Pyramid.
The `post`
method will look fairly similar. For the sake of consistency, let's see how the `post`
method looks and how it handles the `self.form_data`
that was constructed with the `BaseView`
.
```
@coroutine
def post(self, username):
"""Create a new task."""
with self.make_session() as session:
profile = yield as_future(session.query(Profile).filter(Profile.username == username).first)
if profile:
due_date = self.form_data['due_date'][0]
task = Task(
name=self.form_data['name'][0],
note=self.form_data['note'][0],
creation_date=datetime.now(),
due_date=datetime.strptime(due_date, '%d/%m/%Y %H:%M:%S') if due_date else None,
completed=self.form_data['completed'][0],
profile_id=profile.id,
profile=profile
)
session.add(task)
self.send_response({'msg': 'posted'}, status=201)
```
As I said, it's about what we'd expect:
- The same query pattern as we saw with the
`get`
method - The construction of an instance of a new
`Task`
object, populated with data from`form_data`
- The adding (but not committing because it's handled by the context manager!) of the new
`Task`
object to the database session - The sending of a response back to the client
And thus we have the basis for our Tornado web app. Everything else (e.g., database management and more views for a more complete app) is effectively the same as what we've already seen in the Flask and Pyramid apps.
## Thoughts about using the right tool for the right job
What we're starting to see as we continue to move through these web frameworks is that they can all effectively handle the same problems. For something like this To-Do List, any framework can do the job. However, some web frameworks are more appropriate for certain jobs than other ones, depending on what "more appropriate" means for you and your needs.
While Tornado is clearly capable of handling the same job that Pyramid or Flask can handle, to use it for an app like this is effectively a waste. It's like using a car to travel one block from home. Yes it can do the job of "travel," but short trips aren't why you choose to use a car over a bike or just your feet.
Per the documentation, Tornado is billed as "a Python web framework and asynchronous networking library." There are few like it in the Python web framework ecosystem. If the job you're trying to accomplish requires (or would benefit significantly from) asynchronicity in any way, shape, or form, use Tornado. If your application needs to handle multiple, long-lived connections while not sacrificing much in performance, choose Tornado. If your application is many applications in one and needs to be thread-aware for the accurate handling of data, reach for Tornado. That's where it works best.
Use your car to do "car things." Use other modes of transportation to do everything else.
## Going forward and a little perspective check
Speaking of using the right tool for the right job, keep in mind the scope and scale, both present and future, of your application when choosing your framework. Up to this point we've only looked at frameworks meant for small to midsized web applications. The next and final installment of this series will cover one of the most popular Python frameworks, Django, meant for big applications that might grow bigger. Again, while it technically can and will handle the To-Do List problem, keep in mind that it's not really what the framework is for. We'll still put it through its paces to show how an application can be built with it, but we have to keep in mind the intent of the framework and how that's reflected in its architecture:
**Flask:**Meant for small, simple projects; makes it easy for us to construct views and connect them to routes quickly; can be encapsulated in a single file without much fuss**Pyramid:**Meant for projects that may grow; contains a fair bit of configuration to get up and running; separate realms of application components can easily be divided and built out to arbitrary depth without losing sight of the central application**Tornado:**Meant for projects benefiting from precise and deliberate I/O control; allows for co-routines and easily exposes methods that can control how requests are received/responses are sent and when those operations occur**Django:**(As we'll see) meant for big things that may get bigger; large ecosystem of add-ons and mods; very opinionated in its configuration and management in order to keep all the disparate parts in line
Whether you've been reading since the first post in this series or joined a little later, thanks for reading! Please feel free to leave questions or comments. I'll see you next time with hands full of Django.
## Huge shout-out to the Python BDFL
I must give credit where credit is due. *Massive* thanks are owed to [Guido van Rossum](https://www.twitter.com/gvanrossum) for more than just creating my favorite programming language.
During [PyCascades 2018](https://www.pycascades.com), I was fortunate not only to give the talk this article series is based on, but also to be invited to the speakers' dinner. I got to sit next to Guido the whole night and pepper him with questions. One of those questions was how in the world async worked in Python, and he, without a bit of fuss, spent time explaining it to me in a way that I could start to grasp the concept. He later [tweeted to me](https://twitter.com/gvanrossum/status/956186585493458944) a spectacular resource for learning async with Python that I subsequently read three times over three months, then wrote this post. You're an awesome guy, Guido!
## 10 Comments |
10,523 | Linux 上最好的五款音乐播放器 | https://www.linux.com/learn/intro-to-linux/2017/12/top-5-linux-music-players | 2019-02-09T23:20:00 | [
"音乐",
"播放器"
] | https://linux.cn/article-10523-1.html |
>
> Jack Wallen 盘点他最爱的五款 Linux 音乐播放器。
>
>
>

不管你做什么,你都有时会来一点背景音乐。不管你是开发、运维或是一个典型的电脑用户,享受美妙的音乐都可能是你在电脑上最想做的事情之一。同时随着即将到来的假期,你可能收到一些能让你买几首新歌的礼物卡。如果你所选的音乐是数字形式(我的恰好是唱片形式)而且你的平台是 Linux 的话,你会想要一个好的图形用户界面播放器来享受音乐。
幸运的是,Linux 不缺好的数字音乐播放器。事实上,Linux 上有不少播放器,大部分是开源并且可以免费获得的。让我们看看其中的几款,看哪个能满足你的需要。
### Clementine
我想从我用来许多年的默认选项的播放器开始。[Clementine](https://www.clementine-player.org/) 可能是最好的平衡了易用性与灵活性的播放器。Clementine 是新停摆的 [Amarok](https://en.wikipedia.org/wiki/Amarok_(software)) 音乐播放器的复刻,但它不仅限于 Linux; Clementine 在 Mac OS 和 Windows 平台上也可以获得。它的一系列特性十分惊艳,包括:
* 內建的均衡器
* 可定制的界面(将现在的专辑封面显示成背景,见图一)
* 播放本地音乐或者从 Spotify、Last.fm 等播放音乐
* 便于库导航的侧边栏
* 內建的音频转码(转成 MP3、OGG、Flac 等)
* 通过 [安卓应用](https://play.google.com/store/apps/details?id=de.qspool.clementineremote) 远程控制
* 便利的搜索功能
* 选项卡式播放列表
* 简单创建常规和智能化的播放列表
* 支持 CUE 文件
* 支持标签

*图一:Clementine 界面可能有一点老派,但是它不可思议得灵活好用。*
在所有我用过的音乐播放器中,Clementine 是目前为止功能最多也是最容易使用的。它同时也包含了你能在 Linux 音乐播放器中找到的最好的均衡器(有十个频带可以调)。尽管它的界面不够时髦,但它创建、操控播放列表的能力是无与伦比的。如果你的音乐集很大,同时你想完全操控你的音乐集的话,这就是你想要的播放器。
Clementine 可以在标准仓库中找到。它可以从你的发行版的软件中心或通过命令行来安装。
### Rhythmbox
[Rhythmbox](https://wiki.gnome.org/Apps/Rhythmbox) 是 GNOME 桌面的默认播放器,但是它在其它桌面工作得也很好。Rhythmbox 的界面比 Clementine 的界面稍微时尚一点,它的设计遵循极简的理念。这并不意味着它缺乏特性,相反 Rhythmbox 提供无间隔回放、支持 Soundcloud、专辑封面显示、从 Last.fm 和 Libre.fm 导入音频、支持 Jamendo、播客订阅(从 [Apple iTunes](https://www.apple.com/itunes/))、从网页远程控制等特性。
在 Rhythmbox 中发现的一个很好的特性是支持插件,这使得你可以使用像 DAAP 音乐分享、FM 电台、封面查找、通知、ReplayGain、歌词等特性。
Rhythmbox 播放列表特性不像 Clementine 的那么强大,但是将你的音乐整理进任何形式的快速播放列表还是很简单的。尽管 Rhythmbox 的界面(图二)比 Clementine 要时髦一点,但是它不像 Clementine 那样灵活。

*图二:Rhythmbox 界面简单直接。*
### VLC Media Player
对于部分人来说,[VLC](https://www.videolan.org/vlc/index.html) 在视频播放方面是无懈可击的。然而 VLC 不仅限于视频播放。事实上,VLC在播放音频文件方面做得也很好。对于 [KDE Neon](https://neon.kde.org/) 用户来说,VLC 既是音乐也是视频的默认播放器。尽管 VLC 是 Linux 市场最好的视频播放器的之一(它是我的默认播放器),它在音频方面确实略有瑕疵 —— 缺少播放列表以及不能够连接到你网络中的远程仓库。但如果你是在寻找一种播放本地文件或者网络 mms/rtsp 的简单可靠的方式,VLC 是上佳之选。VLC 包括一个均衡器(图三)、一个压缩器以及一个空间音响。它同样也能够从捕捉到的设备录音。

*图三:运转中的 VLC 均衡器。*
### Audacious
如果你在寻找一个轻量级的音乐播放器,Audacious 完美地满足要求。这个音乐播放器相当的专一,但是它包括了一个均衡器和一小部分能够改善许多音频的声效(比如回声、消除默音、调节速度和音调、去除人声等,见图四)。

*图四:Audacious 均衡器和插件。*
Audacious 也包括了一个十分简便的闹铃功能。它允许你设置一个能在用户选定的时间点和持续的时间段内播放选定乐段的闹铃。
### Spotify
我必须承认,我每天都用 Spotify。我是一个 Spotify 的订阅者并用它去发现、购买新的音乐 —— 这意味着我在不停地探索发现。幸运的是,Spotify 有一个我能按照 [Spotify官方 Linux 平台安装指导](https://www.spotify.com/us/download/linux/) 轻松安装的桌面客户端。在桌面客户端与 [安卓应用](https://play.google.com/store/apps/details?id=com.spotify.music) 间无缝转换对我来说也大有帮助,这样我就永远不会错过我喜欢的音乐了。

*图五:Linux 上的 Spotify 官方客户端。*
Spotify 界面十分易于使用,事实上它完胜网页端的播放器。不要在 Linux 上装 [Spotify 网页播放器](https://open.spotify.com/browse/featured) 因为桌面客户端在创建管理你的播放列表方面简便得多。如果你是 Spotify 重度用户,甚至没必要用其他桌面应用的內建流传输客户端支持 —— 一旦你用过 Spotify 桌面客户端,其它应用就根本没可比性。
### 选择在你
其它选择也是有的(查看你的桌面软件中心),但这五款客户端(在我看来)是最好的了。对我来说,Clementine 和 Spotify 的组合拳就已经让我美好得唱赞歌了。尝试它们看看哪个能更好地满足你的需要。
### 额外奖品
虽然这篇文章翻译于国外作者,但作为给中国的 Linux 用户看的文章,如果在一篇分享音乐播放器的文章中**不提及**网易云音乐,那一定会被猛烈吐槽(事实上,我们曾经被吐槽过好多次了,哈哈)。
网易云音乐是我见过的最好的音乐播放器之一,不只是在 Linux 上,它甚至还支持包括 Windows、Mac、 iOS、安卓等在内的 8 个操作系统平台。当前的 Linux 版本是 1.1.0 版,支持 64 位的深度 Linux 15 和 Ubuntu 16.04 及之后的版本。下载地址和截图就不在这里安利了,大家想必自己能找到的。
通过 edX 和 Linux Foundation 上免费的 [Introduction to Linux](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 课程学习更多有关 Linux 的知识。
---
via: <https://www.linux.com/learn/intro-to-linux/2017/12/top-5-linux-music-players>
作者:[JACK WALLEN](https://www.linux.com/users/jlwallen) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,524 | 极客漫画:增强现实(AR) 2.0 | http://turnoff.us/geek/augmented-reality-2/ | 2019-02-10T09:28:00 | [
"VR",
"极客漫画",
"AR"
] | https://linux.cn/article-10524-1.html | 
最近这几年我们一直听到虚拟现实(VR)和增强现实(AR),可很多人并不了解它们是什么。<ruby> 增强现实技术 <rt> Augmented Reality </rt></ruby>,简称 AR,是一种实时地计算摄影机影像的位置及角度并加上相应图像、视频、3D 模型的技术,这种技术的目标是在屏幕上把虚拟世界套在现实世界并进行互动。
这种技术可以让你将现实世界和虚拟世界结合起来,从而创造非常有趣的互动效果。可是,有一天 AR 里面的小鬼们真的出来了!
---
via: <http://turnoff.us/geek/augmented-reality-2/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者 & 点评:[wxy](https://github.com/wxy) 校对 & 合成:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,525 | 开始使用 eDEX-UI 吧,一款受《电子世界争霸战》影响的终端程序 | https://opensource.com/article/19/1/productivity-tool-edex-ui | 2019-02-10T22:28:15 | [
"终端"
] | https://linux.cn/article-10525-1.html |
>
> 使用 eDEX-UI 让你的工作更有趣,这是我们开源工具系列中的第 15 个工具,它将使你在 2019 年更高效。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 15 个工具来帮助你在 2019 年更有效率。
### eDEX-UI
当[《电子世界争霸战》](https://en.wikipedia.org/wiki/Tron)上映时我才 11 岁。我不能否认,尽管这部电影充满幻想,但它对我后来的职业选择产生了影响。

[eDEX-UI](https://github.com/GitSquared/edex-ui) 是一款专为平板电脑和台式机设计的跨平台终端程序,它的用户界面受到《电子世界争霸战》的启发。它在选项卡式界面中有五个终端,因此可以轻松地在任务之间切换,以及显示有用的系统信息。
在启动时,eDEX-UI 会启动一系列的东西,其中包含它所基于的 ElectronJS 系统的信息。启动后,eDEX-UI 会显示系统信息、文件浏览器、键盘(用于平板电脑)和主终端选项卡。其他四个选项卡(被标记为 EMPTY)没有加载任何内容,并且当你单击它时将启动一个 shell。eDEX-UI 中的默认 shell 是 Bash(如果在 Windows 上,则可能需要将其更改为 PowerShell 或 cmd.exe)。

更改文件浏览器中的目录也将更改活动终端中的目录,反之亦然。文件浏览器可以执行你期望的所有操作,包括在单击文件时打开关联的应用。唯一的例外是 eDEX-UI 的 `settings.json` 文件(默认在 `.config/eDEX-UI`),它会打开配置编辑器。这允许你为终端设置 shell 命令、更改主题以及修改用户界面的其他几个设置。主题也保存在配置目录中,因为它们也是 JSON 文件,所以创建自定义主题非常简单。

eDEX-UI 允许你使用完全仿真运行五个终端。默认终端类型是 xterm-color,这意味着它支持全色彩。需要注意的一点是,输入时键会亮起,因此如果你在平板电脑上使用 eDEX-UI,键盘可能会在人们看见屏幕的环境中带来安全风险。因此最好在这些设备上使用没有键盘的主题,尽管在打字时看起来确实很酷。

虽然 eDEX-UI 仅支持五个终端窗口,但这对我来说已经足够了。在平板电脑上,eDEX-UI 给了我网络空间感而不会影响我的效率。在桌面上,eDEX-UI 支持所有功能,并让我在我的同事面前显得很酷。
---
via: <https://opensource.com/article/19/1/productivity-tool-edex-ui>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the 15th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## eDEX-UI
I was 11 years old when [ Tron](https://en.wikipedia.org/wiki/Tron) was in movie theaters. I cannot deny that, despite the fantastical nature of the film, it had an impact on my career choice later in life.
[eDEX-UI](https://github.com/GitSquared/edex-ui) is a cross-platform terminal program designed for tablets and desktops that was inspired by the user interface in *Tron*. It has five terminals in a tabbed interface, so it is easy to switch between tasks, as well as useful displays of system information.
At launch, eDEX-UI goes through a boot sequence with information about the ElectronJS system it is based on. After the boot, eDEX-UI shows system information, a file browser, a keyboard (for tablets), and the main terminal tab. The other four tabs (labeled EMPTY) don't have anything loaded and will start a shell when you click on one. The default shell in eDEX-UI is Bash (if you are on Windows, you will likely have to change it to either PowerShell or cmd.exe).
Changing directories in the file browser will change directories in the active terminal and vice-versa. The file browser does everything you'd expect, including opening associated applications when you click on a file. The one exception is eDEX-UI's settings.json file (in .config/eDEX-UI by default), which opens the configuration editor instead. This allows you to set the shell command for the terminals, change the theme, and modify several other settings for the user interface. Themes are also stored in the configuration directory and, since they are also JSON files, creating a custom theme is pretty straightforward.
eDEX-UI allows you to run five terminals with full emulation. The default terminal type is xterm-color, meaning it has full-color support. One thing to be aware of is that the keys light up on the keyboard while you type, so if you're using eDEX-UI on a tablet, the keyboard could present a security risk in environments where people can see the screen. It is better to use a theme without the keyboard on those devices, although it does look pretty cool when you are typing.
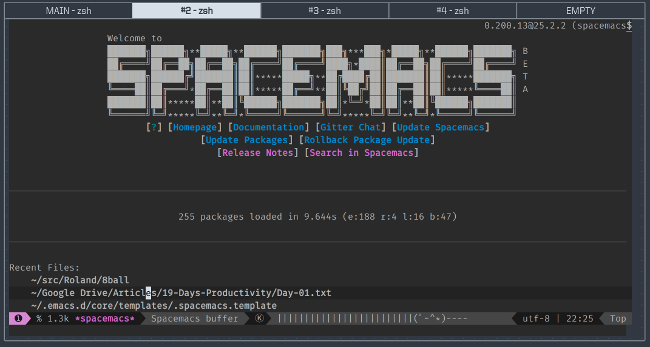
While eDEX-UI supports only five terminal windows, that has been more than enough for me. On a tablet, eDEX-UI gives me that cyberspace feel without impacting my productivity. On a desktop, eDEX-UI allows all of that and lets me look cool in front of my co-workers.
## 1 Comment |
10,526 | 计算机实验室之树莓派:课程 4 OK04 | https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html | 2019-02-10T23:42:00 | [
"树莓派",
"计时器"
] | https://linux.cn/article-10526-1.html | 
OK04 课程在 OK03 的基础上进行构建,它教你如何使用定时器让 OK 或 ACT LED 灯按精确的时间间隔来闪烁。假设你已经有了 [课程 3:OK03](/article-10519-1.html) 的操作系统,我们将以它为基础来构建。
### 1、一个新设备
>
> 定时器是树莓派保持时间的唯一方法。大多数计算机都有一个电池供电的时钟,这样当计算机关机后仍然能保持时间。
>
>
>
到目前为止,我们仅看了树莓派硬件的一小部分,即 GPIO 控制器。我只是简单地告诉你做什么,然后它会发生什么事情。现在,我们继续看定时器,并继续带你去了解它的工作原理。
和 GPIO 控制器一样,定时器也有地址。在本案例中,定时器的基地址在 20003000<sub> 16</sub>。阅读手册我们可以找到下面的表:
表 1.1 GPIO 控制器寄存器
| 地址 | 大小 / 字节 | 名字 | 描述 | 读或写 |
| --- | --- | --- | --- | --- |
| 20003000 | 4 | Control / Status | 用于控制和清除定时器通道比较器匹配的寄存器 | RW |
| 20003004 | 8 | Counter | 按 1 MHz 的频率递增的计数器 | R |
| 2000300C | 4 | Compare 0 | 0 号比较器寄存器 | RW |
| 20003010 | 4 | Compare 1 | 1 号比较器寄存器 | RW |
| 20003014 | 4 | Compare 2 | 2 号比较器寄存器 | RW |
| 20003018 | 4 | Compare 3 | 3 号比较器寄存器 | RW |

这个表只告诉我们一部分内容,在手册中描述了更多的字段。手册上解释说,定时器本质上是按每微秒将计数器递增 1 的方式来运行。每次它是这样做的,它将计数器的低 32 位(4 字节)与 4 个比较器寄存器进行比较,如果匹配它们中的任何一个,它更新 `Control/Status` 以反映出其中有一个是匹配的。
关于<ruby> 位 <rt> bit </rt></ruby>、<ruby> 字节 <rt> byte </rt></ruby>、<ruby> 位字段 <rt> bit field </rt></ruby>、以及数据大小的更多内容如下:
>
> 一个位是一个单个的二进制数的名称。你可能还记得,一个单个的二进制数既可能是一个 1,也可能是一个 0。
>
>
> 一个字节是一个 8 位集合的名称。由于每个位可能是 1 或 0 这两个值的其中之一,因此,一个字节有 2<sup> 8</sup> = 256 个不同的可能值。我们一般解释一个字节为一个介于 0 到 255(含)之间的二进制数。
>
>
> 
>
>
> 一个位字段是解释二进制的另一种方式。二进制可以解释为许多不同的东西,而不仅仅是一个数字。一个位字段可以将二进制看做为一系列的 1(开) 或 0(关)的开关。对于每个小开关,我们都有一个意义,我们可以使用它们去控制一些东西。我们已经遇到了 GPIO 控制器使用的位字段,使用它设置一个针脚的开或关。位为 1 时 GPIO 针脚将准确地打开或关闭。有时我们需要更多的选项,而不仅仅是开或关,因此我们将几个开关组合到一起,比如 GPIO 控制器的函数设置(如上图),每 3 位为一组控制一个 GPIO 针脚的函数。
>
>
>
我们的目标是实现一个函数,这个函数能够以一个时间数量为输入来调用它,这个输入的时间数量将作为等待的时间,然后返回。想一想如何去做,想想我们都拥有什么。
我认为这将有两个选择:
1. 从计数器中读取一个值,然后保持分支返回到相同的代码,直到计数器的等待时间数量大于它。
2. 从计数器中读取一个值,加上要等待的时间数量,将它保存到比较器寄存器,然后保持分支返回到相同的代码处,直到 `Control / Status` 寄存器更新。
这两种策略都工作的很好,但在本教程中,我们将只实现第一个。原因是比较器寄存器更容易出错,因为在增加等待时间并保存它到比较器的寄存器期间,计数器可能已经增加了,并因此可能会不匹配。如果请求的是 1 微秒(或更糟糕的情况是 0 微秒)的等待,这样可能导致非常长的意外延迟。
>
> 像这样存在被称为“并发问题”的问题,并且几乎无法解决。
>
>
>
### 2、实现
我将把这个创建完美的等待方法的挑战基本留给你。我建议你将所有与定时器相关的代码都放在一个名为 `systemTimer.s` 的文件中(理由很明显)。关于这个方法的复杂部分是,计数器是一个 8 字节值,而每个寄存器仅能保存 4 字节。所以,计数器值将分到 2 个寄存器中。
>
> 大型的操作系统通常使用等待函数来抓住机会在后台执行任务。
>
>
>
下列的代码块是一个示例。
```
ldrd r0,r1,[r2,#4]
```
>
> `ldrd regLow,regHigh,[src,#val]` 从 `src` 中的数加上 `val` 之和的地址加载 8 字节到寄存器 `regLow` 和 `regHigh` 中。
>
>
>
上面的代码中你可以发现一个很有用的指令是 `ldrd`。它加载 8 字节的内存到两个寄存器中。在本案例中,这 8 字节内存从寄存器 `r2` 中的地址 + 4 开始,将被复制进寄存器 `r0` 和 `r1`。这种安排的稍微复杂之处在于 `r1` 实际上只持有了高位 4 字节。换句话说就是,如果如果计数器的值是 999,999,999,999<sub> 10</sub> = 1110100011010100101001010000111111111111<sub> 2</sub> ,那么寄存器 `r1` 中只有 11101000<sub> 2</sub>,而寄存器 `r0` 中则是 11010100101001010000111111111111<sub> 2</sub>。
实现它的更明智的方式应该是,去计算当前计数器值与来自方法启动后的那一个值的差,然后将它与要求的等待时间数量进行比较。除非恰好你希望的等待时间是占用 8 字节的,否则上面示例中寄存器 `r1` 中的值将会丢弃,而计数器仅需要使用低位 4 字节。
当等待开始时,你应该总是确保使用大于比较,而不是使用等于比较,因为如果你尝试去等待一个时间,而这个时间正好等于方法开始的时间与结束的时间之差,那么你就错过这个值而永远等待下去。
如果你不明白如何编写等待函数的代码,可以参考下面的指南。
>
> 借鉴 GPIO 控制器的创意,第一个函数我们应该去写如何取得系统定时器的地址。示例如下:
>
>
>
> ```
> .globl GetSystemTimerBase
> GetSystemTimerBase:
> ldr r0,=0x20003000
> mov pc,lr
> ```
>
> 另一个被证明非常有用的函数是返回在寄存器 `r0` 和 `r1` 中的当前计数器值:
>
>
>
> ```
> .globl GetTimeStamp
> GetTimeStamp:
> push {lr}
> bl GetSystemTimerBase
> ldrd r0,r1,[r0,#4]
> pop {pc}
> ```
>
> 这个函数简单地使用了 `GetSystemTimerBase` 函数,并像我们前面学过的那样,使用 `ldrd` 去加载当前计数器值。
>
>
> 现在,我们可以去写我们的等待方法的代码了。首先,在该方法启动后,我们需要知道计数器值,我们可以使用 `GetTimeStamp` 来取得。
>
>
>
> ```
> delay .req r2
> mov delay,r0
> push {lr}
> bl GetTimeStamp
> start .req r3
> mov start,r0
> ```
>
> 这个代码复制了我们的方法的输入,将延迟时间的数量放到寄存器 `r2` 中,然后调用 `GetTimeStamp`,这个函数将会返回寄存器 `r0` 和 `r1` 中的当前计数器值。接着复制计数器值的低位 4 字节到寄存器 `r3` 中。
>
>
> 接下来,我们需要计算当前计数器值与读入的值的差,然后持续这样做,直到它们的差至少是 `delay` 的大小为止。
>
>
>
> ```
> loop$:
>
> bl GetTimeStamp
> elapsed .req r1
> sub elapsed,r0,start
> cmp elapsed,delay
> .unreq elapsed
> bls loop$
> ```
>
> 这个代码将一直等待,一直到等待到传递给它的时间数量为止。它从计数器中读取数值,减去最初从计数器中读取的值,然后与要求的延迟时间进行比较。如果过去的时间数量小于要求的延迟,它切换回 `loop$`。
>
>
>
> ```
> .unreq delay
> .unreq start
> pop {pc}
> ```
>
> 代码完成后,函数返回。
>
>
>
### 3、另一个闪灯程序
你一旦明白了等待函数的工作原理,修改 `main.s` 去使用它。修改各处 `r0` 的等待设置值为某个很大的数量(记住它的单位是微秒),然后在树莓派上测试。如果函数不能正常工作,请查看我们的排错页面。
如果正常工作,恭喜你学会控制另一个设备了,会使用它,则时间由你控制。在下一节课程中,我们将完成 OK 系列课程的最后一节 [课程 5:OK05](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html),我们将使用我们已经学习过的知识让 LED 按我们的模式进行闪烁。
---
via: <https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html>
作者:[Robert Mullins](http://www.cl.cam.ac.uk/%7Erdm34) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Raspberry Pi
# Lesson 4 OK04
The OK04 lesson builds on OK03 by teaching how to use the timer to flash the 'OK' or 'ACT'
LED at precise intervals. It is assumed you have the code for the [
Lesson 3: OK03](ok03.html) operating system as a basis.
## 1 A New Device
The timer is the only way the Pi can keep time. Most computers have a battery powered clock to keep time when off.
So far, we've only looked at one piece of hardware on the Raspberry Pi, namely the GPIO Controller. I've simply told you what to do, and it happened. Now we're going to look at the timer, and I'm going to lead you through understanding how it works.
Just like the GPIO Controller, the timer has an address. In this case, the timer
is based at 2000300016. Reading the manual, we find the following table:
Address | Size / Bytes | Name | Description | Read or Write |
---|---|---|---|---|
20003000 | 4 | Control / Status | Register used to control and clear timer channel comparator matches. | RW |
20003004 | 8 | Counter | A counter that increments at 1MHz. | R |
2000300C | 4 | Compare 0 | 0th Comparison register. | RW |
20003010 | 4 | Compare 1 | 1st Comparison register. | RW |
20003014 | 4 | Compare 2 | 2nd Comparison register. | RW |
20003018 | 4 | Compare 3 | 3rd Comparison register. | RW |

This table tells us a lot, but the descriptions in the manual of the various fields tell us the most. The manual explains that the timer fundamentally just increments the value in Counter by 1 every 1 micro second. Each time it does so, it compares the lowest 32 bits (4 bytes) of the counter's value with the 4 comparison registers, and if it matches any of them, it updates Control / Status to reflect which ones matched.
For more information about bits, bytes, bit fields, and data sizes expand the box below.
Our goal is to implement a function that we can call with an amount of time as an input that will wait for that amount of time and then return. Think for a moment about how we could do this, given what we have.
I see there being two options:
- Read a value from the counter, and then keep branching back into the same code until the counter is the amount of time to wait more than it was.
- Read a value from the counter, add the amount of time to wait, store this in one of the comparison registers and then keep branching back into the same code until the Control / Status register updates.
Issues like these are called concurrency problems, and can be almost impossible to fix.
Both of these strategies would work fine, but in this tutorial we will only implement the first. The reason is because the comparison registers are more likely to go wrong, as during the time it takes to add the wait time and store it in the comparison register, the counter may have increased, and so it would not match. This could lead to very long unintentional delays if a 1 micro second wait is requested (or worse, a 0 microsecond wait).
## 2 Implementation
Large Operating Systems normally use the Wait function as an opportunity to perform background tasks.
I will largely leave the challenge of creating the ideal wait method to you. I suggest you put all code related to the timer in a file called 'systemTimer.s' (for hopefully obvious reasons). The complicated part about this method, is that the counter is an 8 byte value, but each register only holds 4 bytes. Thus, the counter value will span two registers.
The following code blocks are examples.
ldrd r0,r1,[r2,#4]
ldrd regLow,regHigh,[src,#val] loads 8 bytes from the address given by the number in src plus val into regLow and regHigh .
An instruction you may find useful is the ldrd
instruction above. It loads 8 bytes of memory across 2 registers. In this case,
the 8 bytes of memory starting at the address in r2
would be copied into r0 and
r1. What is slightly complicated about this arrangement is that
r1 actually holds the highest 4 bytes. In other words, if the counter
had a value of 999,999,999,99910 = 11101000110101001010010100001111111111112,
r1 would contain 111010002 and r0 would contain 110101001010010100001111111111112.
The most sensible way to implement this would be to compute the difference between the current counter value and the one from when the method started, and then to compare this with the requested amount of time to wait. Conveniently, unless you wish to support wait times that were 8 bytes, the value in r1 in the example above could be discarded, and only the low 4 bytes of the counter need be used.
When waiting you should always be sure to use higher comparisons not equality comparisons, as if you try to wait for the gap between the time the method started and the time it ends to be exactly the amount requested, you could miss the value, and wait forever.
If you cannot figure out how to code the wait function, expand the box below for a guide.
## 3 Another Blinking Light
Once you have what you believe to be a working wait function, change 'main.s' to use it. Alter everywhere you wait to set the value of r0 to some big number (remember it is in microseconds) and then test it on the Raspberry Pi. If it does not function correctly please see our troubleshooting page.
Once it is working, congratulations you have now mastered another device, and with
it, time itself. In the next and final lesson in the OK series, [
Lesson 5: OK05](ok05.html) we shall use all we have learned to flash out a pattern on
the LED. |
10,527 | 将 Python 结合到数学教育中 | https://opensource.com/article/19/1/hacking-math | 2019-02-11T15:12:41 | [
"Python",
"数学"
] | https://linux.cn/article-10527-1.html |
>
> 身兼教师、开发者、作家数职的 Peter Farrell 来讲述为什么使用 Python 来讲数学课会比传统方法更加好。
>
>
>

数学课一直都是很讨厌的一件事情,尤其对于在传统教学方法上吃过苦头的人(例如我)来说。传统教学方法强调的是死记硬背和理论知识,这种形式与学生们的现实世界似乎相去甚远。
[Peter Farrell](https://twitter.com/hackingmath) 作为一位 Python 开发者和数学教师,发现学生在数学课程中遇到了困难,于是决定尝试使用 Python 来帮助介绍数学概念。
Peter 的灵感来源于 Logo 语言之父 [Seymour Papert](https://en.wikipedia.org/wiki/Seymour_Papert),他的 Logo 语言现在还存在于 Python 的 [Turtle 模块](https://en.wikipedia.org/wiki/Turtle_graphics)中。Logo 语言中的海龟形象让 Peter 喜欢上了 Python,并且进一步将 Python 应用到数学教学中。
Peter 在他的新书《<ruby> <a href="https://nostarch.com/mathadventures"> Python 数学奇遇记 </a> <rt> Math Adventures with Python </rt></ruby>》中分享了他的方法:“图文并茂地指导如何用代码探索数学”。因此我最近对他进行了一次采访,向他了解更多这方面的情况。
**Don Watkins(LCTT 译注:本文作者):** 你的教学背景是什么?
**Peter Farrell:** 我曾经当过八年的数学老师,之后又做了十年的数学私教。我还在当老师的时候,就阅读过 Papert 的 《<ruby> <a href="https://en.wikipedia.org/wiki/Mindstorms_(book)"> 头脑风暴 </a> <rt> Mindstorms </rt></ruby>》并从中受到了启发,将 Logo 语言和海龟引入到了我所有的数学课上。
**DW:** 你为什么开始使用 Python 呢?
**PF:** 在我当家教的时候,需要教学一门枯燥刻板的数学课程,这是一个痛苦的过程。后来我引入了 Logo 语言和海龟,我的学生刚好是一个编程爱好者,他非常喜欢这样的方式。在接触到函数和实际的编程之后,他还提议改用 Python。尽管当时我还不了解 Python,但看起来好像和 Logo 语言差别不大,我就同意了。后来我甚至坚持在 Python 上一条道走到黑了!
我还曾经寻找过 3D 图形方面的软件包,用来模拟太阳系行星的运动轨迹,让学生们理解行星是如何在牛顿的万有引力定律作用下运动的。很多图形软件包都需要用到 C 语言编程或者其它一些很复杂的内容,后来我发现了一个叫做 VisualPython 的软件包,它非常方便使用。于是在那之后的几年里,我就一直在用 [Vpython](http://vpython.org/) 这个软件包。
所以,我是在和学生一起学习数学的时候被介绍使用 Python 的。在那段时间里,他是我的编程老师,而我则是他的数学老师。
**DW:** 是什么让你对数学感兴趣?
**PF:** 我是通过传统的方法学习数学的,那时候都是用手写、用纸记、在黑板上计算。我擅长代数和几何,在大学的时候也接触过 Basic 和 Fortran 编程,但那个时候也没有从中获取到灵感。直到后来在从编程中收到了启发,编程可以让你将数学课上一些晦涩难懂的内容变得简单直观,也能让你轻松地绘图、调整、探索,进而发现更多乐趣。
**DW:** 是什么启发了你使用 Python 教学?
**PF:** 还是在我当家教的时候,我惊奇地发现可以通过循环来计算对同一个函数输入不同参数的结果。如果用人手计算,可能要花半个小时的时间,但计算机瞬间就完成了。在这样的基础上,我们只要将一些计算的过程抽象成一个函数,再对其进行一些适当的扩展,就可以让计算机来计算了。
**DW:** 你的教学方法如何帮助学生,特别是在数学上感觉吃力的学生?如何将 Python 编程和数学结合起来
**PF:** 很多学生,尤其是高中生,都认为通过手工计算和画图来解决问题的方式在当今已经没有必要了,我并不反对这样的观点。例如,使用 Excel 来处理数据确实应该算是办公室工作的基本技能。学习任何一种编程语言,对公司来说都是一项非常有价值的技能。因此,使用计算机计算确实是有实际意义的。
而使用代码来为数学课创造艺术,则是一项革命性的改变。例如,仅仅是把某个形状显示到屏幕上,就需要使用到数学,因为位置需要用 x-y 坐标去表示,而尺寸、颜色等等都是数字。如果想要移动或者更改某些内容,会需要用到变量。更特殊地,如果需要改变位置,就需要更有效的向量来实现。这样的最终结果是,类似向量、矩阵这些难以捉摸的空洞概念会转变成实打实有意义的数学工具。
那些看起来在数学上吃力的学生,或许只是不太容易接受“书本上的数学”。因为“书本上的数学”过分强调了死记硬背和循规蹈矩,而有些忽视了创造力和实际应用能力。有些学生其实擅长数学,但并不适应学校的教学方式。我的方法会让父母们看到他们的孩子通过代码画出了很多有趣的图形,然后说:“我从来不知道正弦和余弦还能这样用!”
**DW:** 你的教学方法是如何在学校里促进 STEM 教育的呢?
**PF:** 我喜欢将这几个学科统称为 STEM(<ruby> 科学、技术、工程、数学 <rt> Science, Technology, Engineering and Mathematics </rt></ruby>) 或 STEAM(<ruby> 科学、技术、工程、艺术、数学 <rt> Science, Technology, Engineering, Art and Mathematics </rt></ruby>)。但作为数学工作者,我很不希望其中的 M 被忽视。我经常看到很多很小的孩子在 STEM 实验室里参与一些有趣的项目,这表明他们已经在接受科学、技术和工程方面的教育。与此同时,我发现数学方面的材料和项目却很少。因此,我和[机电一体化](https://en.wikipedia.org/wiki/Mechatronics)领域的优秀教师 Ken Hawthorn 正在着手解决这个问题。
希望我的书能够帮助鼓励学生们在技术上有所创新,无论在形式上是切实的还是虚拟的。同时书中还有很多漂亮的图形,希望能够激励大家去体验编程的过程,并且应用到实际中来。我使用的软件([Python Processing](https://processing.org/))是免费的,在树莓派等系统上都可以轻松安装。因为我认为,个人或者学校的成本问题不应该成为学生进入 STEM 世界的门槛。
**DW:** 你有什么想要跟其他的数学老师分享?
**PF:** 如果数学教学机构决定要向学生教导数字推理、逻辑、分析、建模、几何、数据解释这些内容,那么它们应该承认,可以通过编程来实现这些目标。正如我上面所说的,我的教学方法是在尝试使传统枯燥的方法变得直观,我认为任何一位老师都可以做到这一点。他们只需要知道其中的本质做法,就可以使用代码来完成大量重复的工作了。
我的教学方法依赖于一些免费的图形软件,因此只需要知道在哪里找到这些软件包,以及如何使用这些软件包,就可以开始引导学生使用 21 世纪的技术来解决实际问题,将整个过程和结果可视化,并找到更多可以以此实现的模式。
---
via: <https://opensource.com/article/19/1/hacking-math>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Mathematics instruction has a bad reputation, especially with people (like me) who've had trouble with the traditional approach, which emphasizes rote memorization and theory that seems far removed from students' real world.
While teaching a student who was baffled by his math lessons, [Peter Farrell](https://twitter.com/hackingmath), a Python developer and mathematics teacher, decided to try using Python to teach the boy the math concepts he was having trouble learning.
Peter was inspired by the work of [Seymour Papert](https://en.wikipedia.org/wiki/Seymour_Papert), the father of the Logo programming language, which lives on in Python's [Turtle module](https://en.wikipedia.org/wiki/Turtle_graphics). The Turtle metaphor hooked Peter on Python and using it to teach math, much like [I was drawn to Python](https://opensource.com/life/15/8/python-turtle-graphics).
Peter shares his approach in his new book, * Math Adventures with Python: An Illustrated Guide to Exploring Math with Code*. And, I recently interviewed him to learn more about it.
**Don Watkins:** What is your background?
**Peter Farrell:** I was a math teacher for eight years, and I tutored math for 10 years after that. When I was a teacher, I read Papert's * Mindstorms* and was inspired to introduce all my math classes to Logo and Turtles.
**DW:** Why did you start using Python?
**PF:** I was working with a homeschooled boy on a very dry, textbook-driven math curriculum, which at the time seemed like a curse to me. But I found ways to sneak in the Logo Turtles, and he was a programming fan, so he liked that. Once we got into functions and real programming, he asked if we could continue in Python. I didn't know any Python but it didn't seem that different from Logo, so I agreed. And I never looked back!
I was also looking for a 3D graphics package I could use to model a solar system and lead students through making planets move and get pulled by the force of attraction between the bodies, according to Newton's formula. Many graphics packages required programming in C or something hard, but I found an excellent package called Visual Python that was very easy to use. I used [VPython](http://vpython.org/) for years after that.
So, I was introduced to Python in the context of working with a student on math. For some time after that, he was my programming tutor while I was his math tutor!
**DW:** What got you interested in math?
**PF:** I learned it the old-fashioned way: by hand, on paper and blackboards. I was good at manipulating symbols, so algebra was never a problem, and I liked drawing and graphing, so geometry and trig could be fun, too. I did some programming in BASIC and Fortran in college, but it never inspired me. Later on, programming inspired me greatly! I'm still tickled by the way programming makes easy work of the laborious stuff you have to do in math class, freeing you up to do the more fun of exploring, graphing, tweaking, and discovering.
**DW:** What inspired you to consider your Python approach to math?
**PF:** When I was teaching the homeschooled student, I was amazed at what we could do by writing a simple function and then calling it a bunch of times with different values using a loop. That would take a half an hour by hand, but the computer spit it out instantly! Then we could look for patterns (which is what a math student should be doing), express the pattern as a function, and extend it further.
**DW:** How does your approach to teaching help students—especially those who struggle with math? How does it make math more relevant?
**PF:** Students, especially high-schoolers, question the need to be doing all this calculating, graphing, and solving by hand in the 21st century, and I don't disagree with them. Learning to use Excel, for example, to crunch numbers should be seen as a basic necessity to work in an office. Learning to code, in any language, is becoming a very valuable skill to companies. So, there's a real-world appeal to me.
But the idea of making art with code can revolutionize math class. Just putting a shape on a screen requires math—the position (x-y coordinates), the dimensions, and even the color are all numbers. If you want something to move or change, you'll need to use variables, and not the "guess what *x* equals" kind of variable. You'll vary the position using a variable or, more efficiently, using a vector. [This makes] math topics like vectors and matrices seen as helpful tools you can use, rather than required information you'll never use.
Students who struggle with math might just be turned off to "school math," which is heavy on memorization and following rules and light on creativity and real applications. They might find they're actually good at math, just not the way it was taught in school. I've had parents see the cool graphics their kids have created with code and say, "I never knew that's what sines and cosines were used for!"
**DW:** How do you see your approach to math and programming encouraging STEM in schools?
**PF:** I love the idea of combining previously separated topics into an idea like STEM or STEAM! Unfortunately for us math folks, the "M" is very often neglected. I see lots of fun projects being done in STEM labs, even by very young children, and they're obviously getting an education in technology, engineering, and science. But I see precious little math material in the projects. STEM/[mechatronics](https://en.wikipedia.org/wiki/Mechatronics) teacher extraordinaire Ken Hawthorn and I are creating projects to try to remedy that.
Hopefully, my book helps encourage students, girls and boys, to get creative with technology, real and virtual. There are a lot of beautiful graphics in the book, which I hope will inspire people to go through the coding adventure and make them. All the software I use ([Python Processing](https://processing.org/)) is available for free and can be easily installed, or is already installed, on the Raspberry Pi. Entry into the STEM world should not be cost-prohibitive to schools or individuals.
**DW:** What would you like to share with other math teachers?
**PF:** If the math establishment is really serious about teaching students the standards they have agreed upon, like numerical reasoning, logic, analysis, modeling, geometry, interpreting data, and so on, they're going to have to admit that coding can help with every single one of those goals. My approach was born, as I said before, from just trying to enrich a dry, traditional approach, and I think any teacher can do that. They just need somebody who can show them how to do everything they're already doing, just using code to automate the laborious stuff.
My graphics-heavy approach is made possible by the availability of free graphics software. Folks might need to be shown where to find these packages and how to get started. But a math teacher can soon be leading students through solving problems using 21st-century technology and visualizing progress or results and finding more patterns to pursue.
## 5 Comments |
10,529 | Bash 中尖括号的更多用法 | https://www.linux.com/blog/learn/2019/1/more-about-angle-brackets-bash | 2019-02-12T11:58:46 | [
"尖括号"
] | https://linux.cn/article-10529-1.html |
>
> 在这篇文章,我们继续来深入探讨尖括号的更多其它用法。
>
>
>

在[上一篇文章](/article-10502-1.html)当中,我们介绍了尖括号(`<>`)以及它们的一些用法。在这篇文章,我们继续来深入探讨尖括号的更多其它用法。
通过使用 `<`,可以实现“欺骗”的效果,让其它命令认为某个命令的输出是一个文件。
例如,在进行备份文件的时候不确定备份是否完整,就需要去确认某个目录是否已经包含从原目录中复制过去的所有文件。你可以试一下这样操作:
```
diff <(ls /original/dir/) <(ls /backup/dir/)
```
[diff](https://linux.die.net/man/1/diff) 命令是一个逐行比较两个文件之间差异的工具。在上面的例子中,就使用了 `<` 让 `diff` 认为两个 `ls` 命令输出的结果都是文件,从而能够比较它们之间的差异。
要注意,在 `<` 和 `(...)` 之间是没有空格的。
我尝试在我的图片目录和它的备份目录执行上面的命令,输出的是以下结果:
```
diff <(ls /My/Pictures/) <(ls /My/backup/Pictures/)
5d4 < Dv7bIIeUUAAD1Fc.jpg:large.jpg
```
输出结果中的 `<` 表示 `Dv7bIIeUUAAD1Fc.jpg:large.jpg` 这个文件存在于左边的目录(`/My/Pictures`)但不存在于右边的目录(`/My/backup/Pictures`)中。也就是说,在备份过程中可能发生了问题,导致这个文件没有被成功备份。如果 `diff` 没有显示出任何输出结果,就表明两个目录中的文件是一致的。
看到这里你可能会想到,既然可以通过 `<` 将一些命令行的输出内容作为一个文件提供给一个需要接受文件格式的命令,那么在上一篇文章的“最喜欢的演员排序”例子中,就可以省去中间的一些步骤,直接对输出内容执行 `sort` 操作了。
确实如此,这个例子可以简化成这样:
```
sort -r <(while read -r name surname films;do echo $films $name $surname ; done < CBactors)
```
### Here 字符串
除此以外,尖括号的重定向功能还有另一种使用方式。
使用 `echo` 和管道(`|`)来传递变量的用法,相信大家都不陌生。假如想要把一个字符串变量转换为全大写形式,你可以这样做:
```
myvar="Hello World" echo $myvar | tr '[:lower:]' '[:upper:]' HELLO WORLD
```
[tr](https://linux.die.net/man/1/tr) 命令可以将一个字符串转换为某种格式。在上面的例子中,就使用了 `tr` 将字符串中的所有小写字母都转换为大写字母。
要理解的是,这个传递过程的重点不是变量,而是变量的值,也就是字符串 `Hello World`。这样的字符串叫做 HERE 字符串,含义是“这就是我们要处理的字符串”。但对于上面的例子,还可以用更直观的方式的处理,就像下面这样:
```
tr '[:lower:]' '[:upper:]' <<< $myvar
```
这种简便方式并不需要使用到 `echo` 或者管道,而是使用了我们一直在说的尖括号。
### 总结
使用 `<` 和 `>` 这两个简单的符号,原来可以实现这么多功能,Bash 又一次为工作的灵活性提供了很多选择。
当然,我们的介绍还远远没有完结,因为还有很多别的符号可以为 Bash 命令带来更多便利。不过如果没有充分理解它们,充满符号的 Bash 命令看起来只会像是一堆乱码。接下来我会解读更多类似的 Bash 符号,下次见!
---
via: <https://www.linux.com/blog/learn/2019/1/more-about-angle-brackets-bash>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,530 | 计算机实验室之树莓派:课程 5 OK05 | https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html | 2019-02-12T12:30:11 | [
"树莓派",
"摩尔斯电码"
] | https://linux.cn/article-10530-1.html | 
OK05 课程构建于课程 OK04 的基础,使用它来闪烁摩尔斯电码的 SOS 序列(`...---...`)。这里假设你已经有了 [课程 4:OK04](/article-10526-1.html) 操作系统的代码作为基础。
### 1、数据
到目前为止,我们与操作系统有关的所有内容提供的都是指令。然而有时候,指令只是完成了一半的工作。我们的操作系统可能还需要数据。
>
> 一些早期的操作系统确实只允许特定文件中的特定类型的数据,但是这通常被认为限制太多了。现代方法确实可以使程序变得复杂的多。
>
>
>
通常,数据就是些很重要的值。你可能接受过培训,认为数据就是某种类型的,比如,文本文件包含文本,图像文件包含图片,等等。说实话,这只是你的想法而已。计算机上的全部数据都是二进制数字,重要的是我们选择用什么来解释这些数据。在这个例子中,我们会用一个闪灯序列作为数据保存下来。
在 `main.s` 结束处复制下面的代码:
```
.section .data %定义 .data 段
.align 2 %对齐
pattern: %定义整形变量
.int 0b11111111101010100010001000101010
```
>
> `.align num` 确保下一行代码的地址是 2<sup> num</sup> 的整数倍。
>
>
> `.int val` 输出数值 `val`。
>
>
>
要区分数据和代码,我们将数据都放在 `.data` 区域。我已经将该区域包含在操作系统的内存布局图。我选择将数据放到代码后面。将我们的指令和数据分开保存的原因是,如果最后我们在自己的操作系统上实现一些安全措施,我们就需要知道代码的那些部分是可以执行的,而那些部分是不行的。
我在这里使用了两个新命令 `.align` 和 `.int`。`.align` 保证接下来的数据是按照 2 的乘方对齐的。在这个里,我使用 `.align 2` ,意味着数据最终存放的地址是 2<sup> 2=4</sup> 的整数倍。这个操作是很重要的,因为我们用来读取内存的指令 `ldr` 要求内存地址是 4 的倍数。
命令 `.int` 直接复制它后面的常量到输出。这意味着 11111111101010100010001000101010<sub> 2</sub> 将会被存放到输出,所以该标签模式实际是将这段数据标识为模式。
>
> 关于数据的一个挑战是寻找一个高效和有用的展示形式。这种保存一个开、关的时间单元的序列的方式,运行起来很容易,但是将很难编辑,因为摩尔斯电码的 `-` 或 `.` 样式丢失了。
>
>
>
如我提到的,数据可以代表你想要的所有东西。在这里我编码了摩尔斯电码的 SOS 序列,对于不熟悉的人,就是 `...---...`。我使用 0 表示一个时间单元的 LED 灭灯,而 1 表示一个时间单元的 LED 亮。这样,我们可以像这样编写一些代码在数据中显示一个序列,然后要显示不同序列,我们所有需要做的就是修改这段数据。下面是一个非常简单的例子,操作系统必须一直执行这段程序,解释和展示数据。
复制下面几行到 `main.s` 中的标记 `loop$` 之前。
```
ptrn .req r4 %重命名 r4 为 ptrn
ldr ptrn,=pattern %加载 pattern 的地址到 ptrn
ldr ptrn,[ptrn] %加载地址 ptrn 所在内存的值
seq .req r5 %重命名 r5 为 seq
mov seq,#0 %seq 赋值为 0
```
这段代码加载 `pattrern` 到寄存器 `r4`,并加载 0 到寄存器 `r5`。`r5` 将是我们的序列位置,所以我们可以追踪我们已经展示了多少个 `pattern`。
如果 `pattern` 的当前位置是 1 且仅有一个 1,下面的代码将非零值放入 `r1`。
```
mov r1,#1 %加载1到 r1
lsl r1,seq %对r1 的值逻辑左移 seq 次
and r1,ptrn %按位与
```
这段代码对你调用 `SetGpio` 很有用,它必须有一个非零值来关掉 LED,而一个 0 值会打开 LED。
现在修改 `main.s` 中你的全部代码,这样代码中每次循环会根据当前的序列数设置 LED,等待 250000 毫秒(或者其他合适的延时),然后增加序列数。当这个序列数到达 32 就需要返回 0。看看你是否能实现这个功能,作为额外的挑战,也可以试着只使用一条指令。
### 2、当你玩得开心时,时间过得很快
你现在准备好在树莓派上实验。应该闪烁一串包含 3 个短脉冲,3 个长脉冲,然后 3 个短脉冲的序列。在一次延时之后,这种模式应该重复。如果这不工作,请查看我们的问题页。
一旦它工作,祝贺你已经抵达 OK 系列教程的结束点。
在这个系列我们学习了汇编代码,GPIO 控制器和系统定时器。我们已经学习了函数和 ABI,以及几个基础的操作系统原理,已经关于数据的知识。
你现在已经可以准备学习下面几个更高级的课程的某一个。
* [Screen](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html) 系列是接下来的,会教你如何通过汇编代码使用屏幕。
* [Input](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html) 系列教授你如何使用键盘和鼠标。
到现在,你已经有了足够的信息来制作操作系统,用其它方法和 GPIO 交互。如果你有任何机器人工具,你可能会想尝试编写一个通过 GPIO 管脚控制的机器人操作系统。
---
via: <https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html>
作者:[Robert Mullins](http://www.cl.cam.ac.uk/%7Erdm34) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ezio](https://github.com/oska874) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Raspberry Pi
# Lesson 5 OK05
The OK05 lesson builds on OK04 using it to flash the SOS Morse Code pattern (...---...).
It is assumed you have the code for the [Lesson 4: OK04](ok04.html) operating
system as a basis.
## 1 Data
So far, all we've had to do with our operating system is provide instructions to be followed. Sometimes however, instructions are only half the story. Our operating systems may need data.
Some early Operating Systems did only allow certain types of data in certain files, but this was generally found to be too restrictive. The modern way does make programs a lot more complicated however.
In general data is just values that are important. You are probably trained to think of data as being of a specific type, e.g. a text file contains text, an image file contains an image, etc. This is, in truth, just an idea. All data on a computer is just binary numbers, how we choose to interpret them is what counts. In this example we're going to store a light flashing sequence as data.
At the end of 'main.s' copy the following code:
.section .data
.align 2
pattern:
.int 0b11111111101010100010001000101010
.align num ensures the address of the next line
is a multiple of 2num
.
.int val outputs the number val .
To differentiate between data and code, we put all the data in the .data. I've included this on the operating system memory layout diagram here. I've just chosen to put the data after the end of the code. The reason for keeping our data and instructions separate is so that if we eventually implement some security on our operating system, we need to know what parts of the code can be executed, and what parts can't.
I've used two new commands here. .align and .int. .align
ensures alignment of the following data to a specified power of 2. In this case
I've used .align 2 which means that this data
will definitely be placed at an address which is a multiple of 22 = 4.
It is really important to do this, because the ldr
instruction we used to read memory only works at addresses that are multiples of
4.
The .int command copies the constant after it
into the output directly. That means that 111111111010101000100010001010102
will be placed into the output, and so the label pattern actually labels this piece
of data as pattern.
One challenge with data is finding an efficient and useful representation. This method of storing the sequence as on and off units of time is easy to run, but would be difficult to edit, as the concept of a Morse - or . is lost.
As I mentioned, data can mean whatever you want. In this case I've encoded the Morse Code SOS sequence, which is ...---... for those unfamiliar. I've used a 0 to represent a unit of time with the LED off, and a 1 to represent a unit of time with the LED on. That way, we can write some code which just displays a sequence in data like this one, and then all we have to do to make it display a different sequence is change the data. This is a very simple example of what operating systems must do all the time; interpret and display data.
Copy the following lines before the loop$ label in 'main.s'.
ptrn .req r4
ldr ptrn,=pattern
ldr ptrn,[ptrn]
seq .req r5
mov seq,#0
This code loads the pattern into r4, and loads 0 into r5. r5 will be our sequence position, so we can keep track of how much of the pattern we have displayed.
The following code puts a non-zero into r1 if and only if there is a 1 in the current part of the pattern.
mov r1,#1
lsl r1,seq
and r1,ptrn
This code is useful for your calls to SetGpio, which must have a non-zero value to turn the LED off, and a value of zero to turn the LED on.
Now modify all of your code in 'main.s' so that each loop the code sets the LED based on the current sequence number, waits for 250000 micro seconds (or any other appropriate delay), and then increments the sequence number. When the sequence number reaches 32, it needs to go back to 0. See if you can implement this, and for an extra challenge, try to do it using only 1 instruction (solution in the download).
## 2 Time Flies When You're Having Fun...
You're now ready to test this on the Raspberry Pi. It should flash out a sequence of 3 short pulses, 3 long pulses and then 3 more short pulses. After a delay, the pattern should repeat. If it doesn't work please see our troubleshooting page.
Once it works, congratulations you have reached the end of the OK series of tutorials.
In this series we've learnt about assembly code, the GPIO controller and the System Timer. We've learnt about functions and the ABI, as well as several basic Operating System concepts, and also about data.
You're now ready to move onto one of the more advanced series.
- The
[Screen](screen01.html)series is next and teaches you how to use the screen with assembly code. - The
[Input](input01.html)series teaches you how to use the keyboard and mouse.
By now you already have enough information to make Operating Systems that interact with the GPIO in other ways. If you have any robot kits, you may want to try writing a robot operating system controlled with the GPIO pins! |
10,531 | 在 Linux 命令行使用 more 查看文本文件 | https://opensource.com/article/19/1/more-text-files-linux | 2019-02-12T20:06:00 | [
"more",
"less"
] | /article-10531-1.html |
>
> 文本文件和 Linux 一直是携手并进的。或者说看起来如此。那你又是依靠哪些让你使用起来很舒服的工具来查看这些文本文件的呢?
>
>
>

Linux 下有很多实用工具可以让你在终端界面查看文本文件。其中一个就是 [more](https://en.wikipedia.org/wiki/More_(command))。
`more` 跟我之前另一篇文章里写到的工具 —— [less](https://opensource.com/article/18/4/using-less-view-text-files-command-line) 很相似。它们之间的主要不同点在于 `more` 只允许你向前查看文件。
尽管它能提供的功能看起来很有限,不过它依旧有很多有用的特性值得你去了解。下面让我们来快速浏览一下 `more` 可以做什么,以及如何使用它吧。
### 基础使用
假设你现在想在终端查看一个文本文件。只需打开一个终端,进入对应的目录,然后输入以下命令:
```
$ more <filename>
```
例如,
```
$ more jekyll-article.md
```

使用空格键可以向下翻页,输入 `q` 可以退出。
如果你想在这个文件中搜索一些文本,输入 `/` 字符并在其后加上你想要查找的文字。例如你要查看的字段是 “terminal”,只需输入:
```
/terminal
```

搜索的内容是区分大小写的,所以输入 `/terminal` 跟 `/Terminal` 会出现不同的结果。
### 和其他实用工具组合使用
你可以通过管道将其他命令行工具得到的文本传输到 `more`。你问为什么这样做?因为有时这些工具获取的文本会超过终端一页可以显示的限度。
想要做到这个,先输入你想要使用的完整命令,后面跟上管道符(`|`),管道符后跟 `more`。假设现在有一个有很多文件的目录。你就可以组合 `more` 跟 `ls` 命令完整查看这个目录当中的内容。
```
$ ls | more
```

你可以组合 `more` 和 `grep` 命令,从而实现在多个文件中找到指定的文本。下面是我在多篇文章的源文件中查找 “productivity” 的例子。
```
$ grep ‘productivity’ core.md Dict.md lctt2014.md lctt2016.md lctt2018.md README.md | more
```

另外一个可以和 `more` 组合的实用工具是 `ps`(列出你系统上正在运行的进程)。当你的系统上运行了很多的进程,你现在想要查看他们的时候,这个组合将会派上用场。例如你想找到一个你需要杀死的进程,只需输入下面的命令:
```
$ ps -u scott | more
```
注意用你的用户名替换掉 “scott”。

就像我文章开篇提到的, `more` 很容易使用。尽管不如它的双胞胎兄弟 `less` 那般灵活,但是仍然值得了解一下。
---
via: <https://opensource.com/article/19/1/more-text-files-linux>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,532 | PyGame Zero: 无需模板的游戏开发 | https://opensource.com/article/19/1/pygame-zero | 2019-02-12T22:59:22 | [
"游戏",
"PyGame"
] | https://linux.cn/article-10532-1.html |
>
> 在你的游戏开发过程中有了 PyGame Zero,和枯燥的模板说再见吧。
>
>
>

Python 是一个很好的入门级编程语言。并且,游戏是一个很好的入门项目:它们是可视化的,自驱动的,并且可以很愉快的与朋友和家人分享。虽然,绝大多数的 Python 写就的库,比如 [PyGame](https://www.pygame.org/news) ,会让初学者因为忘记微小的细节很容易导致什么都没渲染而感到困扰。
在理解所有部分的作用之前,他们会将其中的许多部分都视为“无意识的模板文件”——需要复制和粘贴到程序中才能使其工作的神奇段落。
[PyGame Zero](https://pygame-zero.readthedocs.io/en/stable/) 试图通过在 PyGame 上放置一个抽象层来弥合这一差距,因此它字面上并不需要模板。
我们在说的“字面”,就是在指字面。
这是一个合格的 PyGame Zero 文件:
```
# This comment is here for clarity reasons
```
我们可以将它放在一个 `game.py` 文件里,并运行:
```
$ pgzrun game.py
```
这将会展示一个窗口,并运行一个可以通过关闭窗口或按下 `CTRL-C` 中断的游戏循环。
遗憾的是,这将是一场无聊的游戏。什么都没发生。
为了让它更有趣一点,我们可以画一个不同的背景:
```
def draw():
screen.fill((255, 0, 0))
```
这将会把背景色从黑色换为红色。但是这仍是一个很无聊的游戏,什么都没发生。我们可以让它变的更有意思一点:
```
colors = [0, 0, 0]
def draw():
screen.fill(tuple(colors))
def update():
colors[0] = (colors[0] + 1) % 256
```
这将会让窗口从黑色开始,逐渐变亮,直到变为亮红色,再返回黑色,一遍一遍循环。
`update` 函数更新了参数的值,而 `draw` 基于这些参数渲染这个游戏。
即使是这样,这里也没有任何方式给玩家与这个游戏的交互的方式。让我们试试其他一些事情:
```
colors = [0, 0, 0]
def draw():
screen.fill(tuple(colors))
def update():
colors[0] = (colors[0] + 1) % 256
def on_key_down(key, mod, unicode):
colors[1] = (colors[1] + 1) % 256
```
现在,按下按键来提升亮度。
这些包括游戏循环的三个重要部分:响应用户输入,更新参数和重新渲染屏幕。
PyGame Zero 提供了更多功能,包括绘制精灵图和播放声音片段的功能。
试一试,看看你能想出什么类型的游戏!
---
via: <https://opensource.com/article/19/1/pygame-zero>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[bestony](https://github.com/bestony) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Python is a good beginner programming language. And games are a good beginner project: they are visual, self-motivating, and fun to show off to friends and family. However, the most common library to write games in Python, [PyGame](https://www.pygame.org/news), can be frustrating for beginners because forgetting seemingly small details can easily lead to nothing rendering.
Until people understand *why* all the parts are there, they treat many of them as "mindless boilerplate"—magic paragraphs that need to be copied and pasted into their program to make it work.
[PyGame Zero](https://pygame-zero.readthedocs.io/en/stable/) is intended to bridge that gap by putting a layer of abstraction over PyGame so it requires literally no boilerplate.
When we say *literally*, we mean it.
This is a valid PyGame Zero file:
`# This comment is here for clarity reasons`
We can run put it in a **game.py** file and run:
`$ pgzrun game.py`
This will show a window and run a game loop that can be shut down by closing the window or interrupting the program with **CTRL-C**.
This will, sadly, be a boring game. Nothing happens.
To make it slightly more interesting, we can draw a different background:
```
def draw():
screen.fill((255, 0, 0))
```
This will make the background red instead of black. But it is still a boring game. Nothing is happening. We can make it slightly more interesting:
```
colors = [0, 0, 0]
def draw():
screen.fill(tuple(colors))
def update():
colors[0] = (colors[0] + 1) % 256
```
This will make a window that starts black, becomes brighter and brighter red, then goes back to black, over and over again.
The **update** function updates parameters, while the **draw** function renders the game based on these parameters.
However, there is no way for the player to interact with the game! Let's try something else:
```
colors = [0, 0, 0]
def draw():
screen.fill(tuple(colors))
def update():
colors[0] = (colors[0] + 1) % 256
def on_key_down(key, mod, unicode):
colors[1] = (colors[1] + 1) % 256
```
Now pressing keys on the keyboard will increase the "greenness."
These comprise the three important parts of a *game loop*: respond to user input, update parameters, and re-render the screen.
PyGame Zero offers much more, including functions for drawing sprites and playing sound clips.
Try it out and see what type of game you can come up with!
## 1 Comment |
10,533 | DNS 和根证书 | https://lushka.al/dns-and-certificates/ | 2019-02-13T13:05:45 | [
"DNS",
"证书",
"隐私",
"安全"
] | https://linux.cn/article-10533-1.html |
>
> 关于 DNS 和根证书你需要了解的内容。
>
>
>

由于最近发生的一些事件,我们(Privacy Today 组织)感到有必要写一篇关于此事的短文。它适用于所有读者,因此它将保持简单 —— 技术细节可能会在稍后的文章发布。
### 什么是 DNS,为什么它与你有关?
DNS 的意思是<ruby> 域名系统 <rt> Domain Name System </rt></ruby>,你每天都会接触到它。每当你的 Web 浏览器或任何其他应用程序连接到互联网时,它就很可能会使用域名。简单来说,域名就是你键入的地址:例如 [duckduckgo.com](https://duckduckgo.com)。你的计算机需要知道它所导向的地方,会向 DNS 解析器寻求帮助。而它将返回类似 [176.34.155.23](http://176.34.155.23) 这样的 IP —— 这就是连接时所需要知道的公开网络地址。 此过程称为 DNS 查找。
这对你的隐私、安全以及你的自由都有一定的影响:
#### 隐私
由于你要求解析器获取域名的 IP,因此它会确切地知道你正在访问哪些站点,并且由于“物联网”(通常缩写为 IoT),甚至它还知道你在家中使用的是哪个设备。
#### 安全
你可以相信解析器返回的 IP 是正确的。有一些检查措施可以确保如此,在正常情况下这一般不是问题。但这些可能措施会被破坏,这就是写作本文的原因。如果返回的 IP 不正确,你可能会被欺骗引向了恶意的第三方 —— 甚至你都不会注意到任何差异。在这种情况下,你的隐私会受到更大的危害,因为不仅会被跟踪你访问了什么网站,甚至你访问的内容也会被跟踪。第三方可以准确地看到你正在查看的内容,收集你输入的个人信息(例如密码)等等。你的整个身份可以轻松接管。
#### 自由
审查通常是通过 DNS 实施的。这不是最有效的方法,但它非常普遍。即使在西方国家,它也经常被公司和政府使用。他们使用与潜在攻击者相同的方法;当你查询 IP 地址时,他们不会返回正确的 IP。他们可以表现得就好像某个域名不存在,或完全将访问指向别处。
### DNS 查询的方式
#### 由你的 ISP 提供的第三方 DNS 解析器
大多数人都在使用由其互联网接入提供商(ISP)提供的第三方解析器。当你连接调制解调器时(LCTT 译注:或宽带路由器),这些 DNS 解析器就会被自动取出,而你可能从来没注意过它。
#### 你自己选择的第三方 DNS 解析器
如果你已经知道 DNS 意味着什么,那么你可能会决定使用你选择的另一个 DNS 解析器。这可能会改善这种情况,因为它使你的 ISP 更难以跟踪你,并且你可以避免某些形式的审查。尽管追踪和审查仍然是可能的,但这种方法并没有被广泛使用。
#### 你自己(本地)的 DNS 解析器
你可以自己动手,避免使用别人的 DNS 解析器的一些危险。如果你对此感兴趣,请告诉我们。
### 根证书
#### 什么是根证书?
每当你访问以 https 开头的网站时,你都会使用它发送的证书与之通信。它使你的浏览器能够加密通信并确保没有人可以窥探。这就是为什么每个人都被告知在登录网站时要注意 https(而不是 http)。证书本身仅用于验证是否为某个域所生成。以及:
这就是根证书的来源。可以其视为一个更高的级别,用来确保其下的级别是正确的。它验证发送给你的证书是否已由证书颁发机构授权。此权限确保创建证书的人实际上是真正的运营者。
这也被称为信任链。默认情况下,你的操作系统包含一组这些根证书,以确保该信任链的存在。
#### 滥用
我们现在知道:
* DNS 解析器在你发送域名时向你发送 IP 地址
* 证书允许加密你的通信,并验证它们是否为你访问的域生成
* 根证书验证该证书是否合法,并且是由真实站点运营者创建的
**怎么会被滥用呢?**
* 如前所述,恶意 DNS 解析器可能会向你发送错误的 IP 以进行审查。它们还可以将你导向完全不同的网站。
* 这个网站可以向你发送假的证书。
* 恶意的根证书可以“验证”此假证书。
对你来说,这个网站看起来绝对没问题;它在网址中有 https,如果你点击它,它会说已经通过验证。就像你了解到的一样,对吗?**不对!**
它现在可以接收你要发送给原站点的所有通信。这会绕过想要避免被滥用而创建的检查。你不会收到错误消息,你的浏览器也不会发觉。
**而你所有的数据都会受到损害!**
### 结论
#### 风险
* 使用恶意 DNS 解析器总是会损害你的隐私,但只要你注意 https,你的安全性就不会受到损害。
* 使用恶意 DNS 解析程序和恶意根证书,你的隐私和安全性将完全受到损害。
#### 可以采取的动作
**不要安装第三方根证书!**只有非常少的例外情况才需要这样做,并且它们都不适用于一般最终用户。
**不要被那些“广告拦截”、“军事级安全”或类似的东西营销噱头所吸引**。有一些方法可以自行使用 DNS 解析器来增强你的隐私,但安装第三方根证书永远不会有意义。你正在将自己置身于陷阱之中。
### 实际看看
**警告**
有位友好的系统管理员提供了一个现场演示,你可以实时看到自己。这是真事。
**千万不要输入私人数据!之后务必删除证书和该 DNS!**
如果你不知道如何操作,那就不要安装它。虽然我们相信我们的朋友,但你不要随便安装随机和未知的第三方根证书。
#### 实际演示
链接在这里:<http://https-interception.info.tm/>
* 设置所提供的 DNS 解析器
* 安装所提供的根证书
* 访问 <https://paypal.com> 并输入随机登录数据
* 你的数据将显示在该网站上
### 延伸信息
如果你对更多技术细节感兴趣,请告诉我们。如果有足够多感兴趣的人,我们可能会写一篇文章,但是目前最重要的部分是分享基础知识,这样你就可以做出明智的决定,而不会因为营销和欺诈而陷入陷阱。请随时提出对你很关注的其他主题。
这篇文章来自 [Privacy Today 频道](https://t.me/privacytoday)。[Privacy Today](https://t.me/joinchat/Awg5A0UW-tzOLX7zMoTDog) 是一个关于隐私、开源、自由哲学等所有事物的组织!
所有内容均根据 CC BY-NC-SA 4.0 获得许可。([署名 - 非商业性使用 - 共享 4.0 国际](https://creativecommons.org/licenses/by-nc-sa/4.0/))。
---
via: <https://lushka.al/dns-and-certificates/>
作者:[Anxhelo Lushka](https://lushka.al/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
10,534 | 5 个用于开发工作的 Linux 发行版 | https://www.linux.com/blog/2019/1/top-5-linux-distributions-development-2019 | 2019-02-13T23:13:55 | [
"发行版",
"开发"
] | https://linux.cn/article-10534-1.html |
>
> 这五个发行版用于开发工作将不会让你失望。
>
>
>

Linux 上最受欢迎的任务之一肯定是开发。理由很充分:业务依赖于 Linux。没有 Linux,技术根本无法满足当今不断发展的世界的需求。因此,开发人员不断努力改善他们的工作环境。而进行此类改善的一种方法就是拥有合适的平台。值得庆幸的是,这就是 Linux,所以你总是有很多选择。
但有时候,太多的选择本身就是一个问题。哪种发行版适合你的开发需求?当然,这取决于你正在开发的工作,但某些发行版更适合作为你的工作任务的基础。我将重点介绍我认为 2019 年最适合开发人员的五个发行版。
### Ubuntu
无需赘言。虽然 Linux Mint 的忠实用户无疑是一个非常忠诚的群体(这是有充分的理由的,他们选择的发行版很棒),但 Ubuntu Linux 在这里更被认可。为什么?因为有像 [AWS](https://aws.amazon.com/) 这样的云服务商存在,Ubuntu 成了部署最多的服务器操作系统之一。这意味着在 Ubuntu 桌面发行版上进行开发可以更轻松地转换为 Ubuntu Server。而且因为 Ubuntu 使得开发、使用和部署容器非常容易,所以你想要使用这个平台是完全合理的。而 Ubuntu 与其包含的 Snap 软件包相结合,使得这个 Canonical(Ubuntu 发行版背后的公司)的操作系统如虎添翼。
但这不仅是你可以用 Ubuntu 做什么,而是你可以轻松做到。几乎对于所有的任务,Ubuntu 都是一个非常易用的发行版。而且因为 Ubuntu 如此受欢迎,所以你可以从 Ubuntu “软件” 应用的图形界面里轻松安装你想要使用的每个工具和 IDE(图 1)。

*图 1:可以在 Ubuntu “软件”工具里面找到开发者工具。*
如果你正在寻求易用、易于迁移,以及大量的工具,那么将 Ubuntu 作为开发平台就不会有错。
### openSUSE
我将 openSUSE 添加到此列表中有一个非常具体的原因。它不仅是一个出色的桌面发行版,它还是市场上最好的滚动发行版之一。因此,如果你希望用最新的软件开发、发布最新的软件,[openSUSE Tumbleweed](https://en.opensuse.org/Portal:Tumbleweed) 应该是你的首选之一。如果你想使用最喜欢的 IDE 的最新版本,如果你总是希望确保使用最新的库和工具包进行开发,那么 Tumbleweed 就是你的平台。
但 openSUSE 不仅提供滚动发布版本。如果你更愿意使用标准发行版,那么 [openSUSE Leap](https://en.opensuse.org/Portal:Leap) 就是你想要的。
当然,它不仅有标准版或滚动版,openSUSE 平台还有一个名为 [Kubic](https://software.opensuse.org/distributions/tumbleweed) 的 Kubernetes 特定版本,该版本基于 openSUSE MicroOS 上的 Kubernetes。但即使你没有为 Kubernetes 进行开发,你也会发现许多软件和工具可供使用。
openSUSE 还提供了选择桌面环境的能力,或者你也可以选择通用桌面或服务器(图 2)。

*图 2: 正在安装 openSUSE Tumbleweed。*
### Fedora
使用 Fedora 作为开发平台才有意义。为什么?这个发行版本身似乎是面向开发人员的。通过定期的六个月发布周期,开发人员可以确保他们不会一直使用过时的软件。当你需要最新的工具和库时,这很重要。如果你正在开发企业级业务,Fedora 是一个理想的平台,因为它是红帽企业 Linux(RHEL)的上游。这意味着向 RHEL 的过渡应该是无痛的。这一点很重要,特别是如果你希望将你的项目带到一个更大的市场(一个比以桌面为中心的目标更深的领域)。
Fedora 还提供了你将体验到的最佳 GNOME 体验之一(图 3)。换言之,这是非常稳定和快速的桌面。

*图 3:Fedora 上的 GNOME 桌面。*
但是如果 GNOME 不是你的菜,你还可以选择安装一个 [Fedora 花样版](https://spins.fedoraproject.org/)(包括 KDE、XFCE、LXQT、Mate-Compiz、Cinnamon、LXDE 和 SOAS 等桌面环境)。
### Pop!\_OS
如果这个列表中我没有包括 [System76](https://system76.com/) 平台专门为他们的硬件定制的操作系统(虽然它也在其他硬件上运行良好),那我算是失职了。为什么我要包含这样的发行版,尤其是它还并未远离其所基于的 Ubuntu 平台?主要是因为如果你计划从 System76 购买台式机或笔记本电脑,那它就是你想要的发行版。但是你为什么要这样做呢(特别是考虑到 Linux 几乎适用于所有现成的硬件)?因为 System76 销售的出色硬件。随着他们的 Thelio 桌面的发布,这是你可以使用的市场上最强大的台式计算机之一。如果你正在努力开发大型应用程序(特别是那些非常依赖于非常大的数据库或需要大量处理能力进行编译的应用程序),为什么不用最好的计算机呢?而且由于 Pop!\_OS 完全适用于 System76 硬件,因此这是一个明智的选择。
由于 Pop!\_OS 基于 Ubuntu,因此你可以轻松获得其所基于的 Ubuntu 可用的所有工具(图 4)。

*图 4:运行在 Pop!\_OS 上的 Anjunta IDE*
Pop!\_OS 也会默认加密驱动器,因此你可以放心你的工作可以避免窥探(如果你的硬件落入坏人之手)。
### Manjaro
对于那些喜欢在 Arch Linux 上开发,但不想经历安装和使用 Arch Linux 的所有环节的人来说,那选择就是 Manjaro。Manjaro 可以轻松地启动和运行一个基于 Arch Linux 的发行版(就像安装和使用 Ubuntu 一样简单)。
但是 Manjaro 对开发人员友好的原因(除了享受 Arch 式好处)是你可以下载好多种不同口味的桌面。从[Manjaro 下载页面](https://manjaro.org/download/) 中,你可以获得以下口味:
* GNOME
* XFCE
* KDE
* OpenBox
* Cinnamon
* I3
* Awesome
* Budgie
* Mate
* Xfce 开发者预览版
* KDE 开发者预览版
* GNOME 开发者预览版
* Architect
* Deepin
值得注意的是它的开发者版本(面向测试人员和开发人员),Architect 版本(适用于想要从头开始构建 Manjaro 的用户)和 Awesome 版本(图 5,适用于开发人员处理日常工作的版本)。使用 Manjaro 的一个警告是,与任何滚动版本一样,你今天开发的代码可能明天无法运行。因此,你需要具备一定程度的敏捷性。当然,如果你没有为 Manjaro(或 Arch)做开发,并且你正在进行工作更多是通用的(或 Web)开发,那么只有当你使用的工具被更新了且不再适合你时,才会影响你。然而,这种情况发生的可能性很小。和大多数 Linux 发行版一样,你会发现 Manjaro 有大量的开发工具。

*图 5:Manjaro Awesome 版对于开发者来说很棒。*
Manjaro 还支持 AUR(Arch User Repository —— Arch 用户的社区驱动软件库),其中包括最先进的软件和库,以及 [Unity Editor](https://unity3d.com/unity/editor) 或 yEd 等专有应用程序。但是,有个关于 AUR 的警告:AUR 包含的软件中被怀疑发现了恶意软件。因此,如果你选择使用 AUR,请谨慎操作,风险自负。
### 其实任何 Linux 都可以
说实话,如果你是开发人员,几乎任何 Linux 发行版都可以工作。如果从命令行执行大部分开发,则尤其如此。但是如果你喜欢在可靠的桌面上运行一个好的图形界面程序,试试这些发行版中的一个,它们不会令人失望。
通过 Linux 基金会和 edX 的免费[“Linux 简介”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)课程了解有关 Linux 的更多信息。
---
via: <https://www.linux.com/blog/2019/1/top-5-linux-distributions-development-2019>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,535 | 开始使用 Sandstorm 吧,一个开源 Web 应用平台 | https://opensource.com/article/19/1/productivity-tool-sandstorm | 2019-02-13T23:28:00 | [
"Web应用"
] | https://linux.cn/article-10535-1.html |
>
> 了解 Sandstorm,这是我们在开源工具系列中的第三篇,它将在 2019 年提高你的工作效率。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第三个工具来帮助你在 2019 年更有效率。
### Sandstorm
保持高效不仅仅需要待办事项以及让事情有组织。通常它需要一组工具以使工作流程顺利进行。

[Sandstorm](https://sandstorm.io/) 是打包的开源应用集合,它们都可从一个 Web 界面访问,也可在中央控制台进行管理。你可以自己托管或使用 [Sandstorm Oasis](https://oasis.sandstorm.io) 服务。它按用户收费。

Sandstorm 有一个市场,在这里可以轻松安装应用。应用包括效率类、财务、笔记、任务跟踪、聊天、游戏等等。你还可以按照[开发人员文档](https://docs.sandstorm.io/en/latest/developing/)中的应用打包指南打包自己的应用并上传它们。

安装后,用户可以创建 [grain](https://sandstorm.io/how-it-works) - 容器化后的应用数据实例。默认情况下,grain 是私有的,它可以与其他 Sandstorm 用户共享。这意味着它们默认是安全的,用户可以选择与他人共享的内容。

Sandstorm 可以从几个不同的外部源进行身份验证,也可以使用无需密码的基于电子邮件的身份验证。使用外部服务意味着如果你已使用其中一种受支持的服务,那么就无需管理另一组凭据。
最后,Sandstorm 使安装和使用支持的协作应用变得快速,简单和安全。
---
via: <https://opensource.com/article/19/1/productivity-tool-sandstorm>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the third of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## Sandstorm
Being productive isn't just about to-do lists and keeping things organized. Often it requires a suite of tools linked to make a workflow go smoothly.
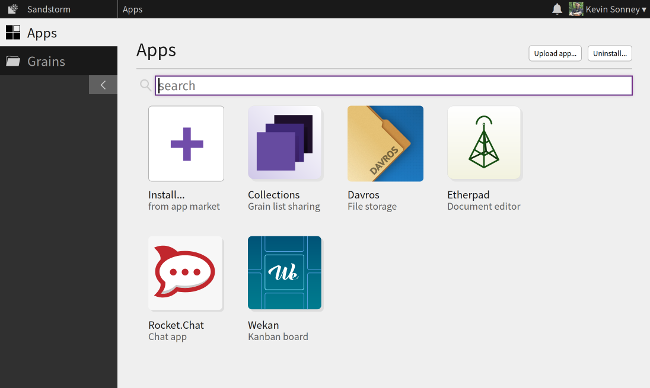
[Sandstorm](https://sandstorm.io/) is an open source collection of packaged apps, all accessible from a single web interface and managed from a central console. You can host it yourself or use the [Sandstorm Oasis](https://oasis.sandstorm.io) service—for a per-user fee.
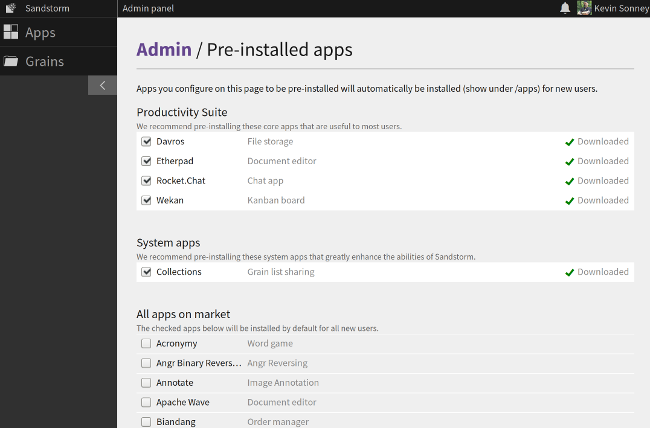
Sandstorm has a marketplace that makes it simple to install the apps that are available. It includes apps for productivity, finance, note taking, task tracking, chat, games, and a whole lot more. You can also package your own apps and upload them by following the application-packaging guidelines in the [developer documentation](https://docs.sandstorm.io/en/latest/developing/).
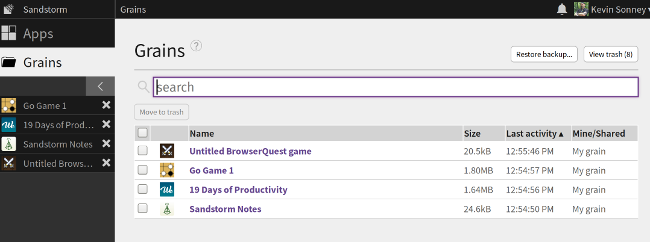
Once installed, a user can create [grains](https://sandstorm.io/how-it-works)—basically containerized instances of app data. Grains are private by default and can be shared with other Sandstorm users. This means they are secure by default, and users can chose what to share with others.
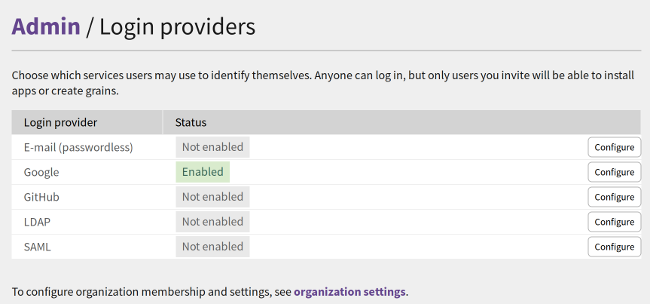
Sandstorm can authenticate from several different external sources as well as use a "passwordless" email-based authentication. Using an external service means you don't have to manage yet another set of credentials if you already use one of the supported services.
In the end, Sandstorm makes installing and using supported collaborative apps quick, easy, and secure.
## Comments are closed. |
10,536 | 3 个简单实用的 GNOME Shell 扩展 | https://fedoramagazine.org/3-simple-and-useful-gnome-shell-extensions/ | 2019-02-13T23:47:35 | [
"GNOME",
"扩展"
] | https://linux.cn/article-10536-1.html | 
Fedora 工作站的默认桌面 GNOME Shell,因其极简、整洁的用户界面而闻名,并深受许多用户的喜爱。它还以可使用扩展添加到 stock 界面的能力而闻名。在本文中,我们将介绍 GNOME Shell 的 3 个简单且有用的扩展。这三个扩展为你的桌面提供了更多的行为,可以完成你可能每天都会做的简单任务。
### 安装扩展程序
安装 GNOME Shell 扩展的最快捷、最简单的方法是使用“软件”应用。有关详细信息,请查看 Magazine [以前的文章](https://fedoramagazine.org/install-extensions-via-software-application/):

### 可移动驱动器菜单

*Fedora 29 中的 Removable Drive Menu 扩展*
首先是 [Removable Drive Menu](https://extensions.gnome.org/extension/7/removable-drive-menu/) 扩展。如果你的计算机中有可移动驱动器,它是一个可在系统托盘中添加一个 widget 的简单工具。它可以使你轻松打开可移动驱动器中的文件,或者快速方便地弹出驱动器以安全移除设备。

*软件应用中的 Removable Drive Menu*
### 扩展之扩展

如果你一直在安装和尝试新扩展,那么 [Extensions](https://extensions.gnome.org/extension/1036/extensions/) 扩展非常有用。它提供了所有已安装扩展的列表,允许你启用或禁用它们。此外,如果该扩展有设置,那么可以快速打开每个扩展的设置对话框。

*软件中的 Extensions 扩展*
### 无用的时钟移动

最后的是列表中最简单的扩展。[Frippery Move Clock](https://extensions.gnome.org/extension/2/move-clock/),只是将时钟位置从顶部栏的中心向右移动,位于状态区旁边。

---
via: <https://fedoramagazine.org/3-simple-and-useful-gnome-shell-extensions/>
作者:[Ryan Lerch](https://fedoramagazine.org/introducing-flatpak/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The default desktop of Fedora Workstation — GNOME Shell — is known and loved by many users for its minimal, clutter-free user interface. It is also known for the ability to add to the stock interface using extensions. In this article, we cover 3 simple, and useful extensions for GNOME Shell. These three extensions provide a simple extra behaviour to your desktop; simple tasks that you might do every day.
### Installing Extensions
The quickest and easiest way to install GNOME Shell extensions is with the Software Application. Check out the previous post here on the Magazine for more details:
## Removable Drive Menu

First up is the [Removable Drive Menu](https://extensions.gnome.org/extension/7/removable-drive-menu/) extension. It is a simple tool that adds a small widget in the system tray if you have a removable drive inserted into your computer. This allows you easy access to open Files for your removable drive, or quickly and easily eject the drive for safe removal of the device.
## Extensions Extension.

The [Extensions](https://extensions.gnome.org/extension/1036/extensions/) extension is super useful if you are always installing and trying out new extensions. It provides a list of all the installed extensions, allowing you to enable or disable them. Additionally, if an extension has settings, it allows quick access to the settings dialog for each one.
## Frippery Move Clock

Finally, there is the simplest extension in the list. [Frippery Move Clock](https://extensions.gnome.org/extension/2/move-clock/), simply moves the position of the clock from the center of the top bar to the right, next to the status area.
## Steven
The layout of this post is a bit odd, if someone doesn’t notice the pages they’d miss all of the content…you may want to advertise that in the body of the first page?
## Clément Verna
That should be fixed now 🙂
## Steven
Yep, looks great and seems to show the content on a single page.
Great content. I’d also propose the multi-monitors-add-on, TopIcons, dash-to-dock, and audio-output-switcher as great utilitarian extensions for those that have a Fedora/Gnome workstations.
The multi-monitors-add-on allows you to have a top bar (with a clock) on your secondary/ancillary displays.
The dash-to-dock allows for a MacOS type of dock on the bottom of the screen that is really nice for those who may use both Mac OS and Gnome in their day to day routines.
The audio-output-switcher makes it a really quick and seamless way to transition from a headset to speakers for when you’re playing games, or joining online meetings and would rather confine your audio input/output.
## Ryan Lerch
We recently did a post on Dash to Dock here on the magazine:
https://fedoramag.wpengine.com/dash-dock-extenstion/
The other ones would be awesome too for standalone articles! The Fedora Magazine is by the Fedora Community for the Fedora Community, so if you are feeling keen, we are always looking for new writers and content 😀
## Ryan Lerch
Thanks for fixing that! 😀
## Erick White
You know, it’s a pretty bare document with just the paragraph up in my e-mail. :p Either the page didn’t publish or an accidently early publish. It was funny.
## Stuart Gathman
All of those come “out of the box” with Cinnamon spin!
## Saif
same for KDE
## Jorge
“Is known and loved by many users for its minimal, clutter-free user interface…” so minimal that after installation you will lost a lot of time to choose and parameterize the poor extensions to make Gnome useful.
## Fabio
Perfect!
## Pawa
Thank you, this is helpful!
## archuser
Why isn’t drop-down terminal mentioned here?
## Ryan Lerch
what a nifty extension! that is a great idea for a future post!
we are always looking for new writers here at the Magazine, so if you are feeling writer-y, jump in and pitch!
https://fedoramag.wpengine.com/writing-an-article-for-the-fedora-magazine/
## Fabio
If you guys know that these are useful extensions, so why dont they come enabled? Until when will we have to keep installing extensions to have basic functions like eject a usb drive?
## Ryan Lerch
To be honest, I rarely use USB drives, so having this feature in the top bar is not really something that i use every day. So i understand the assumption here to not clutter up the top bar all the time with every shortcut and feature in an OS. Ejecting a USB is available out-of-the-box on Fedora with the files app, so it really isn’t a missing feature.
The Workstation Working Group is responsible for decisions like this for Fedora Workstation, so feel free to file a feature request in their ticket queue for discussion:
https://pagure.io/fedora-workstation/issues
## Yury
When Gnome 3 came out, there was some discussion about how the desktop metaphor was dead and the minimal “tablet-style” the new norm. Then Windows 8 dropped and people felt justified in the direction Gnome was heading. Except, Windows 8 had a nifty button called “Desktop”. Click it, and you’re in the original Windows interface. You could use the Tiles, sure, but it also had a full desktop experience. When’s that extension coming to Gnome?
## Thomas
Not sure what you are asking for. By default the windows desktop doesn’t force tiling. In fact you must install extensions to get a tiling wm like interface.
## AsciiWolf
Another must-have extension for me is (K)StatusNotifierItem/AppIndicator Support for tray icon support.
## jesse
Do we have anything like these “tips and tricks” but for the KDE side of the house?
I love both Gnome and KDE, but am currently using KDE. I like the look of KDE but enjoy the ease of Gnome.
KDE has the same functionality and in some way a little more polished for advance users. Gnome is very minimalist and that is good for new users.
Anyways, I was just wondering if we have these same type of articles for KDE on Fedora. They have their own distribution now, but I still like KDE + Fedora.
thanks,
## jakfrost
The differences of the two are evident. The fundamental difference being that Gnome uses Wayland, and KDE is only available by using Xorg. Wayland is a better windowing compositor than Xorg, but Xorg is still more ubiquitous.
## Leslie Satenstein
The bqckground prior to the first extension, appears to be the Manjaro Linux background.
It may be too late to change the background to something flat/unicolor. |
10,537 | 在 Linux 终端上进行冒险 | https://opensource.com/article/18/12/linux-toy-adventure | 2019-02-14T23:36:07 | [
"命令行"
] | https://linux.cn/article-10537-1.html |
>
> 我们的 Linux 命令行玩具日历的最后一天以一场盛大冒险结束。
>
>
>

今天是我们为期 24 天的 Linux 命令行玩具日历的最后一天。希望你一直有在看,但如果没有,请[从头开始](https://opensource.com/article/18/12/linux-toy-boxes),继续努力。你会发现 Linux 终端有很多游戏、消遣和奇怪之处。
虽然你之前可能已经看过我们日历中的一些玩具,但我们希望对每个人而言至少有一件新东西。
今天的玩具是由 Opensource.com 管理员 [Joshua Allen Holm](https://opensource.com/users/holmja) 提出的:
>
> “如果你的冒险日历的最后一天不是 ESR(Eric S. Raymond)的[开源版的 Adventure 游戏](https://gitlab.com/esr/open-adventure "https://gitlab.com/esr/open-adventure") —— 它仍然使用经典的 `advent` 命令(在 BSD 游戏包中的 `adventure`) ,我会非常非常非常失望 ;-)“
>
>
>
这是结束我们这个系列的完美方式。
<ruby> 巨洞冒险 <rt> Colossal Cave Adventure </rt></ruby>(通常简称 Adventure),是一款来自 20 世纪 70 年代的基于文本的游戏,它引领产生了冒险游戏这个类型的游戏。尽管它很古老,但是当探索幻想世界时,Adventure 仍然是一种轻松消耗时间的方式,就像龙与地下城那样,地下城主可能会引导你穿过一个充满想象的地方。
与其带你了解 Adventure 的历史,我鼓励你去阅读 Joshua 的[该游戏的历史](https://opensource.com/article/17/6/revisit-colossal-cave-adventure-open-adventure)这篇文章,以及为什么它几年前会重新复活,并且被重新移植。接着,[克隆它的源码](https://gitlab.com/esr/open-adventure)并按照[安装说明](https://gitlab.com/esr/open-adventure/blob/master/INSTALL.adoc)在你的系统上使用 `advent` 启动游戏。或者,像 Joshua 提到的那样,可以从 bsd-games 包中获取该游戏的另一个版本,该软件包可能存在于你的发行版中的默认仓库。
你有喜欢的命令行玩具认为我们应该介绍么?今天我们的系列结束了,但我们仍然乐于在新的一年中介绍一些很酷的命令行玩具。请在下面的评论中告诉我,我会查看一下。让我知道你对今天玩具的看法。
一定要看看昨天的玩具,[能从远程获得乐趣的 Linux 命令](https://opensource.com/article/18/12/linux-toy-remote),明年再见!
---
via: <https://opensource.com/article/18/12/linux-toy-adventure>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Today is the final day of our 24-day-long Linux command-line toys advent calendar. Hopefully, you've been following along, but if not, start back at [the beginning](https://opensource.com/article/18/12/linux-toy-boxes) and work your way through. You'll find plenty of games, diversions, and oddities for your Linux terminal.
And while you may have seen some toys from our calendar before, we hope there’s at least one new thing for everyone.
Today's toy was suggested by Opensource.com moderator [Joshua Allen Holm](https://opensource.com/users/holmja):
*"If the last day of your advent calendar is not ESR's [Eric S. Raymond's] open source release of Adventure, which retains use of the classic 'advent' command (Adventure in the BSD Games package uses 'adventure), I will be very, very, very disappointed. ;-)"*
What a perfect way to end our series.
Colossal Cave Adventure (often just called Adventure), is a text-based game from the 1970s that gave rise to the entire adventure game genre. Despite its age, Adventure is still an easy way to lose hours as you explore a fantasy world, much like a Dungeons and Dragons dungeon master might lead you through an imaginary place.
Rather than take you through the history of Adventure here, I encourage you to go read Joshua's [history of the game](https://opensource.com/article/17/6/revisit-colossal-cave-adventure-open-adventure) itself and why it was resurrected and re-ported a few years ago. Then, go [clone the source](https://gitlab.com/esr/open-adventure) and follow the [installation instructions](https://gitlab.com/esr/open-adventure/blob/master/INSTALL.adoc) to launch the game with **advent**** **on your system. Or, as Joshua mentions, another version of the game can be obtained from the **bsd****-games **package, which is probably available from your default repositories in your distribution of choice.
Do you have a favorite command-line toy that you we should have included? Our series concludes today, but we'd still love to feature some cool command-line toys in the new year. Let me know in the comments below, and I'll check it out. And let me know what you thought of today's amusement.
Be sure to check out yesterday's toy, [The Linux command line can fetch fun from afar](https://opensource.com/article/18/12/linux-toy-remote), and I'll see you next year!
## 8 Comments |
10,538 | 如何在终端显示图像缩略图 | https://www.ostechnix.com/how-to-display-thumbnail-images-in-terminal/ | 2019-02-15T10:05:00 | [
"图像",
"终端"
] | https://linux.cn/article-10538-1.html | 
不久前,我们讨论了 [Fim](https://www.ostechnix.com/how-to-display-images-in-the-terminal/),这是一个轻量级的命令行图像查看器应用程序,用于从命令行显示各种类型的图像,如 bmp、gif、jpeg 和 png 等。今天,我偶然发现了一个名为 `lsix` 的类似工具。它类似于类 Unix 系统中的 `ls` 命令,但仅适用于图像。`lsix` 是一个简单的命令行实用程序,旨在使用 Sixel 图形格式在终端中显示缩略图。对于那些想知道的人来说,Sixel 是<ruby> 六像素 <rt> six pixels </rt></ruby>的缩写,是一种位图图形格式。它使用 ImageMagick,因此几乎所有 imagemagick 支持的文件格式都可以正常工作。
### 功能
关于 `lsix` 的功能,我们可以列出如下:
* 自动检测你的终端是否支持 Sixel 图形格式。如果你的终端不支持 Sixel,它会通知你启用它。
* 自动检测终端背景颜色。它使用终端转义序列来试图找出终端应用程序的前景色和背景色,并清楚地显示缩略图。
* 如果目录中有更多图像(通常大于 21 个),`lsix` 将一次显示这些图像,因此你无需等待创建整个蒙太奇图像(LCTT 译注:拼贴图)。
* 可以通过 SSH 工作,因此你可以轻松操作存储在远程 Web 服务器上的图像。
* 它支持非位图图形,例如 .svg、.eps、.pdf、.xcf 等。
* 用 Bash 编写,适用于几乎所有 Linux 发行版。
### 安装 lsix
由于 `lsix` 使用 ImageMagick,请确保已安装它。它在大多数 Linux 发行版的默认软件库中都可用。 例如,在 Arch Linux 及其变体如 Antergos、Manjaro Linux 上,可以使用以下命令安装ImageMagick:
```
$ sudo pacman -S imagemagick
```
在 Debian、Ubuntu、Linux Mint:
```
$ sudo apt-get install imagemagick
```
`lsix` 并不需要安装,因为它只是一个 Bash 脚本。只需要下载它并移动到你的 `$PATH` 中。就这么简单。
从该项目的 GitHub 主页下载最新的 `lsix` 版本。我使用如下命令下载 `lsix` 归档包:
```
$ wget https://github.com/hackerb9/lsix/archive/master.zip
```
提取下载的 zip 文件:
```
$ unzip master.zip
```
此命令将所有内容提取到名为 `lsix-master` 的文件夹中。将 `lsix` 二进制文件从此目录复制到 `$PATH` 中,例如 `/usr/local/bin/`。
```
$ sudo cp lsix-master/lsix /usr/local/bin/
```
最后,使 `lsix` 二进制文件可执行:
```
$ sudo chmod +x /usr/local/bin/lsix
```
如此,现在是在终端本身显示缩略图的时候了。
在开始使用 `lsix` 之前,请确保你的终端支持 Sixel 图形格式。
开发人员在 vt340 仿真模式下的 Xterm 上开发了 `lsix`。 然而,他声称 `lsix` 应该适用于任何Sixel 兼容终端。
Xterm 支持 Sixel 图形格式,但默认情况下不启用。
你可以从另外一个终端使用命令来启动一个启用了 Sixel 模式的 Xterm:
```
$ xterm -ti vt340
```
或者,你可以使 vt340 成为 Xterm 的默认终端类型,如下所述。
编辑 `.Xresources` 文件(如果它不可用,只需创建它):
```
$ vi .Xresources
```
添加如下行:
```
xterm*decTerminalID : vt340
```
按下 `ESC` 并键入 `:wq` 以保存并关闭该文件。
最后,运行如下命令来应用改变:
```
$ xrdb -merge .Xresources
```
现在,每次启动 Xterm 就会默认启用 Sixel 图形支持。
### 在终端中显示缩略图
启动 Xterm(不要忘记以 vt340 模式启动它)。以下是 Xterm 在我的系统中的样子。

就像我已经说过的那样,`lsix` 非常简单实用。它没有任何命令行选项或配置文件。你所要做的就是将文件的路径作为参数传递,如下所示。
```
$ lsix ostechnix/logo.png
```

如果在没有路径的情况下运行它,它将显示在当前工作目录中的缩略图图像。我在名为 `ostechnix` 的目录中有几个文件。
要显示此目录中的缩略图,只需运行:
```
$ lsix
```

看到了吗?所有文件的缩略图都显示在终端里。
如果使用 `ls` 命令,则只能看到文件名,而不是缩略图。

你还可以使用通配符显示特定类型的指定图像或一组图像。
例如,要显示单个图像,只需提及图像的完整路径,如下所示。
```
$ lsix girl.jpg
```

要显示特定类型的所有图像,例如 PNG,请使用如下所示的通配符。
```
$ lsix *.png
```

对于 JEPG 类型,命令如下:
```
$ lsix *jpg
```
缩略图的显示质量非常好。我以为 `lsix` 会显示模糊的缩略图。但我错了,缩略图清晰可见,就像在图形图像查看器上一样。
而且,这一切都是唾手可得。如你所见,`lsix` 与 `ls` 命令非常相似,但它仅用于显示缩略图。如果你在工作中处理很多图像,`lsix` 可能会非常方便。试一试,请在下面的评论部分告诉我们你对此实用程序的看法。如果你知道任何类似的工具,也请提出建议。我将检查并更新本指南。
更多好东西即将到来。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-display-thumbnail-images-in-terminal/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,539 | 开始使用 TaskBoard 吧,一款轻量级看板 | https://opensource.com/article/19/1/productivity-tool-taskboard | 2019-02-15T10:26:00 | [
"看板"
] | https://linux.cn/article-10539-1.html |
>
> 了解我们在开源工具系列中的第九个工具,它将帮助你在 2019 年提高工作效率。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第九个工具来帮助你在 2019 年更有效率。
### TaskBoard
正如我在本系列的[第二篇文章](/article-10454-1.html)中所写的那样,[看板](https://en.wikipedia.org/wiki/Kanban)现在非常受欢迎。但并非所有的看板都是相同的。[TaskBoard](https://taskboard.matthewross.me/) 是一个易于在现有 Web 服务器上部署的 PHP 应用,它有一些易于使用和管理的功能。

[安装](https://taskboard.matthewross.me/docs/)它只需要解压 Web 服务器上的文件,运行一两个脚本,并确保目录可正常访问。第一次启动时,你会看到一个登录页面,然后可以就可以添加用户和制作看板了。看板创建选项包括添加要使用的列以及设置卡片的默认颜色。你还可以将用户分配给指定看板,这样每个人都只能看到他们需要查看的看板。
用户管理是轻量级的,所有帐户都是服务器的本地帐户。你可以为服务器上的每个用户设置默认看板,用户也可以设置自己的默认看板。当有人在多个看板上工作时,这个选项非常有用。

TaskBoard 还允许你创建自动操作,包括更改用户分配、列或卡片类别这些操作。虽然 TaskBoard 不如其他一些看板应用那么强大,但你可以设置自动操作,使看板用户更容易看到卡片、清除截止日期,并根据需要自动为人们分配新卡片。例如,在下面的截图中,如果将卡片分配给 “admin” 用户,那么它的颜色将更改为红色,并且当将卡片分配给我的用户时,其颜色将更改为蓝绿色。如果项目已添加到“待办事项”列,我还添加了一个操作来清除项目的截止日期,并在发生这种情况时自动将卡片分配给我的用户。

卡片非常简单。虽然它们没有开始日期,但它们确实有结束日期和点数字段。点数可用于估计所需的时间、所需的工作量或仅是一般优先级。使用点数是可选的,但如果你使用 TaskBoard 进行 scrum 规划或其他敏捷技术,那么这是一个非常方便的功能。你还可以按用户和类别过滤视图。这对于正在进行多个工作流的团队非常有用,因为它允许团队负责人或经理了解进度状态或人员工作量。

如果你需要一个相当轻便的看板,请看下 TaskBoard。它安装快速,有一些很好的功能,且非常、非常容易使用。它还足够的灵活性,可用于开发团队,个人任务跟踪等等。
---
via: <https://opensource.com/article/19/1/productivity-tool-taskboard>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the ninth of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## TaskBoard
As I wrote in the [second article](https://opensource.com/article/19/1/productivity-tool-wekan) in this series, [kanban boards](https://en.wikipedia.org/wiki/Kanban) are pretty popular these days. And not all kanban boards are created equal. [TaskBoard](https://taskboard.matthewross.me/) is a PHP application that is easy to set up on an existing web server and has a set of functions that make it easy to use and manage.
[Installation](https://taskboard.matthewross.me/docs/) is as simple as unzipping the files on your web server, running a script or two, and making sure the correct directories are accessible. The first time you start it up, you're presented with a login form, and then it's time to start adding users and making boards. Board creation options include adding the columns you want to use and setting the default color of the cards. You can also assign users to boards so everyone sees only the boards they need to see.
User management is lightweight, and all accounts are local to the server. You can set a default board for everyone on the server, and users can set their own default boards, too. These options can be useful when someone works on one board more than others.
TaskBoard also allows you to create automatic actions, which are actions taken upon changes to user assignment, columns, or card categories. Although TaskBoard is not as powerful as some other kanban apps, you can set up automatic actions to make cards more visible for board users, clear due dates, and auto-assign new cards to people as needed. For example, in the screenshot below, if a card is assigned to the "admin" user, its color is changed to red, and when a card is assigned to my user, its color is changed to teal. I've also added an action to clear an item's due date if it's added to the "To-Do" column and to auto-assign cards to my user when that happens.
The cards are very straightforward. While they don't have a start date, they do have end dates and a points field. Points can be used for estimating the time needed, effort required, or just general priority. Using points is optional, but if you are using TaskBoard for scrum planning or other agile techniques, it is a really handy feature. You can also filter the view by users and categories. This can be helpful on a team with multiple work streams going on, as it allows a team lead or manager to get status information about progress or a person's workload.
If you need a reasonably lightweight kanban board, check out TaskBoard. It installs quickly, has some nice features, and is very, very easy to use. It's also flexible enough to be used for development teams, personal task tracking, and a whole lot more.
## Comments are closed. |
10,540 | 计算机实验室之树莓派:课程 6 屏幕01 | https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html | 2019-02-16T14:52:00 | [
"树莓派",
"屏幕"
] | https://linux.cn/article-10540-1.html | 
欢迎来到屏幕系列课程。在本系列中,你将学习在树莓派中如何使用汇编代码控制屏幕,从显示随机数据开始,接着学习显示一个固定的图像和显示文本,然后格式化数字为文本。假设你已经完成了 OK 系列课程的学习,所以在本系列中出现的有些知识将不再重复。
第一节的屏幕课程教你一些关于图形的基础理论,然后用这些理论在屏幕或电视上显示一个图案。
### 1、入门
预期你已经完成了 OK 系列的课程,以及那个系列课程中在 `gpio.s` 和 `systemTimer.s` 文件中调用的函数。如果你没有完成这些,或你喜欢完美的实现,可以去下载 `OK05.s` 解决方案。在这里也要使用 `main.s` 文件中从开始到包含 `mov sp,#0x8000` 的这一行之前的代码。请删除这一行以后的部分。
### 2、计算机图形
正如你所认识到的,从根本上来说,计算机是非常愚蠢的。它们只能执行有限数量的指令,仅仅能做一些数学,但是它们也能以某种方式来做很多很多的事情。而在这些事情中,我们目前想知道的是,计算机是如何将一个图像显示到屏幕上的。我们如何将这个问题转换成二进制?答案相当简单;我们为每个颜色设计一些编码方法,然后我们为在屏幕上的每个像素保存一个编码。一个像素就是你的屏幕上的一个非常小的点。如果你离屏幕足够近,你或许能够辨别出你的屏幕上的单个像素,能够看到每个图像都是由这些像素组成的。
>
> 将颜色表示为数字有几种方法。在这里我们专注于 RGB 方法,但 HSL 也是很常用的另一种方法。
>
>
>
随着计算机时代的进步,人们希望显示越来越复杂的图形,于是发明了图形卡的概念。图形卡是你的计算机上用来在屏幕上专门绘制图像的第二个处理器。它的任务就是将像素值信息转换成显示在屏幕上的亮度级别。在现代计算机中,图形卡已经能够做更多更复杂的事情了,比如绘制三维图形。但是在本系列教程中,我们只专注于图形卡的基本使用;从内存中取得像素然后把它显示到屏幕上。
不管使用哪种方法,现在马上出现的一个问题就是我们使用的颜色编码。这里有几种选择,每个产生不同的输出质量。为了完整起见,我在这里只是简单概述它们。
| 名字 | 唯一颜色数量 | 描述 | 示例 |
| --- | --- | --- | --- |
| 单色 | 2 | 每个像素使用 1 位去保存,其中 1 表示白色,0 表示黑色。 | Monochrome image of a bird |
| 灰度 | 256 | 每个像素使用 1 个字节去保存,使用 255 表示白色,0 表示黑色,介于这两个值之间的所有值表示这两个颜色的一个线性组合。 | Geryscale image of a bird |
| 8 色 | 8 | 每个像素使用 3 位去保存,第一位表示红色通道,第二位表示绿色通道,第三位表示蓝色通道。 | 8 colour image of a bird |
| 低色值 | 256 | 每个像素使用 8 位去保存,前三位表示红色通道的强度,接下来的三位表示绿色通道的强度,最后两位表示蓝色通道的强度。 | Low colour image of a bird |
| 高色值 | 65,536 | 每个像素使用 16 位去保存,前五位表示红色通道的强度,接下来的六位表示绿色通道的强度,最后的五位表示蓝色通道的强度。 | High colour image of a bird |
| 真彩色 | 16,777,216 | 每个像素使用 24 位去保存,前八位表示红色通道,第二个八位表示绿色通道,最后八位表示蓝色通道。 | True colour image of a bird |
| RGBA32 | 16,777,216 带 256 级透明度 | 每个像素使用 32 位去保存,前八位表示红色通道,第二个八位表示绿色通道,第三个八位表示蓝色通道。只有一个图像绘制在另一个图像的上方时才考虑使用透明通道,值为 0 时表示下面图像的颜色,值为 255 时表示上面这个图像的颜色,介于这两个值之间的所有值表示这两个图像颜色的混合。 |
>
> 不过这里的一些图像只用了很少的颜色,因为它们使用了一个叫空间抖动的技术。这允许它们以很少的颜色仍然能表示出非常好的图像。许多早期的操作系统就使用了这种技术。
>
>
>
在本教程中,我们将从使用高色值开始。这样你就可以看到图像的构成,它的形成过程清楚,图像质量好,又不像真彩色那样占用太多的空间。也就是说,显示一个比较小的 800x600 像素的图像,它只需要小于 1 MiB 的空间。它另外的好处是它的大小是 2 次幂的倍数,相比真彩色这将极大地降低了获取信息的复杂度。
树莓派和它的图形处理器有一种特殊而奇怪的关系。在树莓派上,首先运行的事实上是图形处理器,它负责启动主处理器。这是很不常见的。最终它不会有太大的差别,但在许多交互中,它经常给人感觉主处理器是次要的,而图形处理器才是主要的。在树莓派上这两者之间依靠一个叫 “邮箱” 的东西来通讯。它们中的每一个都可以为对方投放邮件,这个邮件将在未来的某个时刻被对方收集并处理。我们将使用这个邮箱去向图形处理器请求一个地址。这个地址将是一个我们在屏幕上写入像素颜色信息的位置,我们称为帧缓冲,图形卡将定期检查这个位置,然后更新屏幕上相应的像素。
>
> 保存<ruby> 帧缓冲 <rt> frame buffer </rt></ruby>给计算机带来了很大的内存负担。基于这种原因,早期计算机经常作弊,比如,保存一屏幕文本,在每次单独刷新时,它只绘制刷新了的字母。
>
>
>
### 3、编写邮差程序
接下来我们做的第一件事情就是编写一个“邮差”程序。它有两个方法:`MailboxRead`,从寄存器 `r0` 中的邮箱通道读取一个消息。而 `MailboxWrite`,将寄存器 `r0` 中的头 28 位的值写到寄存器 `r1` 中的邮箱通道。树莓派有 7 个与图形处理器进行通讯的邮箱通道。但仅第一个对我们有用,因为它用于协调帧缓冲。
>
> 消息传递是组件间通讯时使用的常见方法。一些操作系统在程序之间使用虚拟消息进行通讯。
>
>
>
下列的表和示意图描述了邮箱的操作。
表 3.1 邮箱地址
| 地址 | 大小 / 字节 | 名字 | 描述 | 读 / 写 |
| --- | --- | --- | --- | --- |
| 2000B880 | 4 | Read | 接收邮件 | R |
| 2000B890 | 4 | Poll | 不检索接收 | R |
| 2000B894 | 4 | Sender | 发送者信息 | R |
| 2000B898 | 4 | Status | 信息 | R |
| 2000B89C | 4 | Configuration | 设置 | RW |
| 2000B8A0 | 4 | Write | 发送邮件 | W |
为了给指定的邮箱发送一个消息:
1. 发送者等待,直到 `Status` 字段的头一位为 0。
2. 发送者写入到 `Write`,低 4 位是要发送到的邮箱,高 28 位是要写入的消息。
为了读取一个消息:
1. 接收者等待,直到 `Status` 字段的第 30 位为 0。
2. 接收者读取消息。
3. 接收者确认消息来自正确的邮箱,否则再次重试。
如果你觉得有信心,你现在已经有足够的信息去写出我们所需的两个方法。如果没有信心,请继续往下看。
与以前一样,我建议你实现的第一个方法是获取邮箱区域的地址。
```
.globl GetMailboxBase
GetMailboxBase:
ldr r0,=0x2000B880
mov pc,lr
```
发送程序相对简单一些,因此我们将首先去实现它。随着你的方法越来越复杂,你需要提前去规划它们。规划它们的一个好的方式是写出一个简单步骤列表,详细地列出你需要做的事情,像下面一样。
1. 我们的输入将要写什么(`r0`),以及写到什么邮箱(`r1`)。我们必须验证邮箱的真实性,以及它的低 4 位的值是否为 0。不要忘了验证输入。
2. 使用 `GetMailboxBase` 去检索地址。
3. 读取 `Status` 字段。
4. 检查头一位是否为 0。如果不是,回到第 3 步。
5. 将写入的值和邮箱通道组合到一起。
6. 写入到 `Write`。
我们来按顺序写出它们中的每一步。
1、这将实现我们验证 `r0` 和 `r1` 的目的。`tst` 是通过计算两个操作数的逻辑与来比较两个操作数的函数,然后将结果与 0 进行比较。在本案例中,它将检查在寄存器 `r0` 中的输入的低 4 位是否为全 0。
```
.globl MailboxWrite
MailboxWrite:
tst r0,#0b1111
movne pc,lr
cmp r1,#15
movhi pc,lr
```
>
> `tst reg,#val` 计算寄存器 `reg` 和 `#val` 的逻辑与,然后将计算结果与 0 进行比较。
>
>
>
2、这段代码确保我们不会覆盖我们的值,或链接寄存器,然后调用 `GetMailboxBase`。
```
channel .req r1
value .req r2
mov value,r0
push {lr}
bl GetMailboxBase
mailbox .req r0
```
3、这段代码加载当前状态。
```
wait1$:
status .req r3
ldr status,[mailbox,#0x18]
```
4、这段代码检查状态字段的头一位是否为 0,如果不为 0,循环回到第 3 步。
```
tst status,#0x80000000
.unreq status
bne wait1$
```
5、这段代码将通道和值组合到一起。
```
add value,channel
.unreq channel
```
6、这段代码保存结果到写入字段。
```
str value,[mailbox,#0x20]
.unreq value
.unreq mailbox
pop {pc}
```
`MailboxRead` 的代码和它非常类似。
1. 我们的输入将从哪个邮箱读取(`r0`)。我们必须要验证邮箱的真实性。不要忘了验证输入。
2. 使用 `GetMailboxBase` 去检索地址。
3. 读取 `Status` 字段。
4. 检查第 30 位是否为 0。如果不为 0,返回到第 3 步。
5. 读取 `Read` 字段。
6. 检查邮箱是否是我们所要的,如果不是返回到第 3 步。
7. 返回结果。
我们来按顺序写出它们中的每一步。
1、这一段代码来验证 `r0` 中的值。
```
.globl MailboxRead
MailboxRead:
cmp r0,#15
movhi pc,lr
```
2、这段代码确保我们不会覆盖掉我们的值,或链接寄存器,然后调用 `GetMailboxBase`。
```
channel .req r1
mov channel,r0
push {lr}
bl GetMailboxBase
mailbox .req r0
```
3、这段代码加载当前状态。
```
rightmail$:
wait2$:
status .req r2
ldr status,[mailbox,#0x18]
```
4、这段代码检查状态字段第 30 位是否为 0,如果不为 0,返回到第 3 步。
```
tst status,#0x40000000
.unreq status
bne wait2$
```
5、这段代码从邮箱中读取下一条消息。
```
mail .req r2
ldr mail,[mailbox,#0]
```
6、这段代码检查我们正在读取的邮箱通道是否为提供给我们的通道。如果不是,返回到第 3 步。
```
inchan .req r3
and inchan,mail,#0b1111
teq inchan,channel
.unreq inchan
bne rightmail$
.unreq mailbox
.unreq channel
```
7、这段代码将答案(邮件的前 28 位)移动到寄存器 `r0` 中。
```
and r0,mail,#0xfffffff0
.unreq mail
pop {pc}
```
### 4、我心爱的图形处理器
通过我们新的邮差程序,我们现在已经能够向图形卡上发送消息了。我们应该发送些什么呢?这对我来说可能是个很难找到答案的问题,因为它不是任何线上手册能够找到答案的问题。尽管如此,通过查找有关树莓派的 GNU/Linux,我们能够找出我们需要发送的内容。
消息很简单。我们描述我们想要的帧缓冲区,而图形卡要么接受我们的请求,给我们返回一个 0,然后用我们写的一个小的调查问卷来填充屏幕;要么发送一个非 0 值,我们知道那表示很遗憾(出错了)。不幸的是,我并不知道它返回的其它数字是什么,也不知道它意味着什么,但我们知道仅当它返回一个 0,才表示一切顺利。幸运的是,对于合理的输入,它总是返回一个 0,因此我们不用过于担心。
>
> 由于在树莓派的内存是在图形处理器和主处理器之间共享的,我们能够只发送可以找到我们信息的位置即可。这就是 DMA,许多复杂的设备使用这种技术去加速访问时间。
>
>
>
为简单起见,我们将提前设计好我们的请求,并将它保存到 `framebuffer.s` 文件的 `.data` 节中,它的代码如下:
```
.section .data
.align 4
.globl FrameBufferInfo
FrameBufferInfo:
.int 1024 /* #0 物理宽度 */
.int 768 /* #4 物理高度 */
.int 1024 /* #8 虚拟宽度 */
.int 768 /* #12 虚拟高度 */
.int 0 /* #16 GPU - 间距 */
.int 16 /* #20 位深 */
.int 0 /* #24 X */
.int 0 /* #28 Y */
.int 0 /* #32 GPU - 指针 */
.int 0 /* #36 GPU - 大小 */
```
这就是我们发送到图形处理器的消息格式。第一对两个关键字描述了物理宽度和高度。第二对关键字描述了虚拟宽度和高度。帧缓冲的宽度和高度就是虚拟的宽度和高度,而 GPU 按需要伸缩帧缓冲去填充物理屏幕。如果 GPU 接受我们的请求,接下来的关键字将是 GPU 去填充的参数。它们是帧缓冲每行的字节数,在本案例中它是 `2 × 1024 = 2048`。下一个关键字是每个像素分配的位数。使用了一个 16 作为值意味着图形处理器使用了我们上面所描述的高色值模式。值为 24 是真彩色,而值为 32 则是 RGBA32。接下来的两个关键字是 x 和 y 偏移量,它表示当将帧缓冲复制到屏幕时,从屏幕左上角跳过的像素数目。最后两个关键字是由图形处理器填写的,第一个表示指向帧缓冲的实际指针,第二个是用字节数表示的帧缓冲大小。
在这里我非常谨慎地使用了一个 `.align 4` 指令。正如前面所讨论的,这样确保了下一行地址的低 4 位是 0。所以,我们可以确保将被放到那个地址上的帧缓冲(`FrameBufferInfo`)是可以发送到图形处理器上的,因为我们的邮箱仅发送低 4 位全为 0 的值。
>
> 当设备使用 DMA 时,对齐约束变得非常重要。GPU 预期该消息都是 16 字节对齐的。
>
>
>
到目前为止,我们已经有了待发送的消息,我们可以写代码去发送它了。通讯将按如下的步骤进行:
1. 写入 `FrameBufferInfo + 0x40000000` 的地址到邮箱 1。
2. 从邮箱 1 上读取结果。如果它是非 0 值,意味着我们没有请求一个正确的帧缓冲。
3. 复制我们的图像到指针,这时图像将出现在屏幕上!
我在步骤 1 中说了一些以前没有提到的事情。我们在发送之前,在帧缓冲地址上加了 `0x40000000`。这其实是一个给 GPU 的特殊信号,它告诉 GPU 应该如何写到结构上。如果我们只是发送地址,GPU 将写到它的回复上,这样不能保证我们可以通过刷新缓存看到它。缓存是处理器使用的值在它们被发送到存储之前保存在内存中的片段。通过加上 `0x40000000`,我们告诉 GPU 不要将写入到它的缓存中,这样将确保我们能够看到变化。
因为在那里发生很多事情,因此最好将它实现为一个函数,而不是将它以代码的方式写入到 `main.s` 中。我们将要写一个函数 `InitialiseFrameBuffer`,由它来完成所有协调和返回指向到上面提到的帧缓冲数据的指针。为方便起见,我们还将帧缓冲的宽度、高度、位深作为这个方法的输入,这样就很容易地修改 `main.s` 而不必知道协调的细节了。
再一次,来写下我们要做的详细步骤。如果你有信心,可以略过这一步直接尝试去写函数。
1. 验证我们的输入。
2. 写输入到帧缓冲。
3. 发送 `frame buffer + 0x40000000` 的地址到邮箱。
4. 从邮箱中接收回复。
5. 如果回复是非 0 值,方法失败。我们应该返回 0 去表示失败。
6. 返回指向帧缓冲信息的指针。
现在,我们开始写更多的方法。以下是上面其中一个实现。
1、这段代码检查宽度和高度是小于或等于 4096,位深小于或等于 32。这里再次使用了条件运行的技巧。相信自己这是可行的。
```
.section .text
.globl InitialiseFrameBuffer
InitialiseFrameBuffer:
width .req r0
height .req r1
bitDepth .req r2
cmp width,#4096
cmpls height,#4096
cmpls bitDepth,#32
result .req r0
movhi result,#0
movhi pc,lr
```
2、这段代码写入到我们上面定义的帧缓冲结构中。我也趁机将链接寄存器推入到栈上。
```
fbInfoAddr .req r3
push {lr}
ldr fbInfoAddr,=FrameBufferInfo
str width,[fbInfoAddr,#0]
str height,[fbInfoAddr,#4]
str width,[fbInfoAddr,#8]
str height,[fbInfoAddr,#12]
str bitDepth,[fbInfoAddr,#20]
.unreq width
.unreq height
.unreq bitDepth
```
3、`MailboxWrite` 方法的输入是写入到寄存器 `r0` 中的值,并将通道写入到寄存器 `r1` 中。
```
mov r0,fbInfoAddr
add r0,#0x40000000
mov r1,#1
bl MailboxWrite
```
4、`MailboxRead` 方法的输入是写入到寄存器 `r0` 中的通道,而输出是值读数。
```
mov r0,#1
bl MailboxRead
```
5、这段代码检查 `MailboxRead` 方法的结果是否为 0,如果不为 0,则返回 0。
```
teq result,#0
movne result,#0
popne {pc}
```
6、这是代码结束,并返回帧缓冲信息地址。
```
mov result,fbInfoAddr
pop {pc}
.unreq result
.unreq fbInfoAddr
```
### 5、在一帧中一行之内的一个像素
到目前为止,我们已经创建了与图形处理器通讯的方法。现在它已经能够给我们返回一个指向到帧缓冲的指针去绘制图形了。我们现在来绘制一个图形。
第一示例中,我们将在屏幕上绘制连续的颜色。它看起来并不漂亮,但至少能说明它在工作。我们如何才能在帧缓冲中设置每个像素为一个连续的数字,并且要持续不断地这样做。
将下列代码复制到 `main.s` 文件中,并放置在 `mov sp,#0x8000` 行之后。
```
mov r0,#1024
mov r1,#768
mov r2,#16
bl InitialiseFrameBuffer
```
这段代码使用了我们的 `InitialiseFrameBuffer` 方法,简单地创建了一个宽 1024、高 768、位深为 16 的帧缓冲区。在这里,如果你愿意可以尝试使用不同的值,只要整个代码中都一样就可以。如果图形处理器没有给我们创建好一个帧缓冲区,这个方法将返回 0,我们最好检查一下返回值,如果出现返回值为 0 的情况,我们打开 OK LED 灯。
```
teq r0,#0
bne noError$
mov r0,#16
mov r1,#1
bl SetGpioFunction
mov r0,#16
mov r1,#0
bl SetGpio
error$:
b error$
noError$:
fbInfoAddr .req r4
mov fbInfoAddr,r0
```
现在,我们已经有了帧缓冲信息的地址,我们需要取得帧缓冲信息的指针,并开始绘制屏幕。我们使用两个循环来做实现,一个走行,一个走列。事实上,树莓派中的大多数应用程序中,图片都是以从左到右然后从上到下的顺序来保存的,因此我们也按这个顺序来写循环。
```
render$:
fbAddr .req r3
ldr fbAddr,[fbInfoAddr,#32]
colour .req r0
y .req r1
mov y,#768
drawRow$:
x .req r2
mov x,#1024
drawPixel$:
strh colour,[fbAddr]
add fbAddr,#2
sub x,#1
teq x,#0
bne drawPixel$
sub y,#1
add colour,#1
teq y,#0
bne drawRow$
b render$
.unreq fbAddr
.unreq fbInfoAddr
```
>
> `strh reg,[dest]` 将寄存器中的低位半个字保存到给定的 `dest` 地址上。
>
>
>
这是一个很长的代码块,它嵌套了三层循环。为了帮你理清头绪,我们将循环进行缩进处理,这就有点类似于高级编程语言,而汇编器会忽略掉这些用于缩进的 `tab` 字符。我们看到,在这里它从帧缓冲信息结构中加载了帧缓冲的地址,然后基于每行来循环,接着是每行上的每个像素。在每个像素上,我们使用一个 `strh`(保存半个字)命令去保存当前颜色,然后增加地址继续写入。每行绘制完成后,我们增加绘制的颜色号。在整个屏幕绘制完成后,我们跳转到开始位置。
### 6、看到曙光
现在,你已经准备好在树莓派上测试这些代码了。你应该会看到一个渐变图案。注意:在第一个消息被发送到邮箱之前,树莓派在它的四个角上一直显示一个渐变图案。如果它不能正常工作,请查看我们的排错页面。
如果一切正常,恭喜你!你现在可以控制屏幕了!你可以随意修改这些代码去绘制你想到的任意图案。你还可以做更精彩的渐变图案,可以直接计算每个像素值,因为每个像素包含了一个 Y 坐标和 X 坐标。在下一个 [课程 7:Screen 02](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html) 中,我们将学习一个更常用的绘制任务:行。
---
via: <https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html>
作者:[Alex Chadwick](https://www.cl.cam.ac.uk) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Raspberry Pi
# Lesson 6 Screen01
Welcome to the Screen lesson series. In this series, you will learn how to control the screen using the Raspberry Pi in assembly code, starting at just displaying random data, then moving up to displaying a fixed image, displaying text and then formatting numbers into text. It is assumed that you have already completed the OK series, and so things covered in this series will not be repeated here.
This first screen lesson teaches some basic theory about graphics, and then applies it to display a gradient pattern to the screen or TV.
Contents |
## 1 Getting Started
It is expected that you have completed the OK series, and so functions in the 'gpio.s' file and 'systemTimer.s' file from that series will be called. If you do not have these files, or prefer to use a correct implementation, download the solution to OK05.s. The 'main.s' file from here will also be useful, up to and including mov sp,#0x8000. Please delete anything after that line.
## 2 Computer Graphics
There are a few systems for representing colours as numbers. Here we focus on RGB systems, but HSL is another common system used.
As you're hopefully beginning to appreciate, at a fundamental level, computers are very stupid. They have a limited number of instructions, almost exclusively to do with maths, and yet somehow they are capable of doing many things. The thing we currently wish to understand is how a computer could possibly put an image on the screen. How would we translate this problem into binary? The answer is relatively straightforward; we devise some system of numbering each colour, and then we store one number for every pixel on the screen. A pixel is a small dot on your screen. If you move very close, you will probably be able to make out individual pixels on your screen, and be able to see that everything image is just made out of these pixels in combination.
As the computer age advanced, people wanted more and more complicated graphics, and so the concept of a graphics card was invented. The graphics card is a secondary processor on your computer which only exists to draw images to the screen. It has the job of turning the pixel value information into light intensity levels to be transmitted to the screen. On modern computers, graphics cards can also do a lot more than that, such as drawing 3D graphics. In this tutorial however, we will just concentrate on the first use of graphics cards; getting pixel colours from memory out to the screen.
One issue that is raised immediately by all this is the system we use for numbering colours. There are several choices, each producing outputs of different quality. I will outline a few here for completeness.
Although some images here have few colours they use a technique called spatial dithering. This allows them to still show a good representation of the image, with very few colours. Many early Operating Systems used this technique.
Name | Unique Colours | Description | Examples | |
---|---|---|---|---|
Monochrome | 2 | Use 1 bit to store each pixel, with a 1 being white, and a 0 being black. |
![]() |
|
Greyscale | 256 | Use 1 byte to store each pixel, with 255 representing white, 0 representing black, and all values in between representing a linear combination of the two. |
![]() |
|
8 Colour | 8 | Use 3 bits to store each pixel, the first bit representing the presence of a red channel, the second representing a green channel and the third a blue channel. |
![]() |
|
Low Colour | 256 | Use 8 bits to store each pixel, the first 3 bit representing the intensity of the red channel, the next 3 bits representing the intensity of the green channel and the final 2 bits representing the intensity of the blue channel. |
![]() |
|
High Colour | 65,536 | Use 16 bits to store each pixel, the first 5 bit representing the intensity of the red channel, the next 6 bits representing the intensity of the green channel and the final 5 bits representing the intensity of the blue channel. |
![]() |
|
True Colour | 16,777,216 | Use 24 bits to store each pixel, the first 8 bits representing the intensity of the red channel, the second 8 representing the green channel and the final 8 bits the blue channel. |
![]() |
|
RGBA32 | 16,777,216 with 256 transparency levels | Use 32 bits to store each pixel, the first 8 bits representing the intensity of the red channel, the second 8 representing the green channel, the third 8 bits the blue channel, and the final 8 bits a transparency channel. The transparency channel is only considered when drawing one image on top of another and is stored such that a value of 0 indicates the image behind's colour, a value of 255 represents this image's colour, and all values between represent a mix. |
In this tutorial we shall use High Colour initially. As you can see form the image, it is produces clear, good quality images, but it doesn't take up as much space as True Colour. That said, for quite a small display of 800x600 pixels, it would still take just under 1 megabyte of space. It also has the advantage that the size is a multiple of a power of 2, which greatly reduces the complexity of getting information compared with True Colour.
Storing the frame buffer places a heavy memory burden on a computer. For this reason, early computers often cheated, by, for example, storing a screens worth of text, and just drawing each letter to the screen every time it is refreshed separately.
The Raspberry Pi has a very special and rather odd relationship with it's graphics processor. On the Raspberry Pi, the graphics processor actually runs first, and is responsible for starting up the main processor. This is very unusual. Ultimately it doesn't make too much difference, but in many interactions, it often feels like the processor is secondary, and the graphics processor is the most important. The two communicate on the Raspberry Pi by what is called the 'mailbox'. Each can deposit mail for the other, which will be collected at some future point and then dealt with. We shall use the mailbox to ask the graphics processor for an address. The address will be a location to which we can write the pixel colour information for the screen, called a frame buffer, and the graphics card will regularly check this location, and update the pixels on the screen appropriately.
## 3 Programming the Postman
Message passing is quite a common way for components to communicate. Some Operating Systems use virtual message passing to allow programs to communicate.
The first thing we are going to need to program is a 'postman'. This is just two methods: MailboxRead, reading one message from the mailbox channel in r0. and MailboxWrite, writing the value in the top 28 bits of r0 to the mailbox channel in r1. The Raspberry Pi has 7 mailbox channels for communication with the graphics processor, only the first of which is useful to us, as it is for negotiating the frame buffer.
The following table and diagrams describe the operation of the mailbox.
Address | Size / Bytes | Name | Description | Read / Write |
---|---|---|---|---|
2000B880 | 4 | Read | Receiving mail. | R |
2000B890 | 4 | Poll | Receive without retrieving. | R |
2000B894 | 4 | Sender | Sender information. | R |
2000B898 | 4 | Status | Information. | R |
2000B89C | 4 | Configuration | Settings. | RW |
2000B8A0 | 4 | Write | Sending mail. | W |
In order to send a message to a particular mailbox:
- The sender waits until the Status field has a 0 in the top bit.
- The sender writes to Write such that the lowest 4 bits are the mailbox to write to, and the upper 28 bits are the message to write.
In order to read a message:
- The receiver waits until the Status field has a 0 in the 30th bit.
- The receiver reads from Read.
- The receiver confirms the message is for the correct mailbox, and tries again if not.
If you're feeling particularly confident, you now have enough information to write the two methods we need. If not, read on.
As always the first method I recommend you implement is one to get the address of the mailbox region.
.globl GetMailboxBase
GetMailboxBase:
ldr r0,=0x2000B880
mov pc,lr
The sending procedure is least complicated, so we shall implement this first. As your methods become more and more complicated, you will need to start planning them in advance. A good way to do this might be to write out a simple list of the steps that need to be done, in a fair amount of detail, like below.
- Our input will be what to write (r0), and what mailbox to write it to (r1). We must validate this is by checking it is a real mailbox, and that the low 4 bits of the value are 0. Never forget to validate inputs.
- Use GetMailboxBase to retrieve the address.
- Read from the Status field.
- Check the top bit is 0. If not, go back to 3.
- Combine the value to write and the channel.
- Write to the Write.
Let's handle each of these in order.
-
.globl MailboxWrite
MailboxWrite:
tst r0,#0b1111
movne pc,lr
cmp r1,#15
movhi pc,lr
tst reg,#val computes and reg,#val and compares the result with 0.
This achieves our validation on r0 and r1. tst is a function that compares two numbers by computing the logical and operation of the numbers, and then comparing the result with 0. In this case it checks that the lowest 4 bits of the input in r0 are all 0.
-
channel .req r1
value .req r2
mov value,r0
push {lr}
bl GetMailboxBase
mailbox .req r0
This code ensures we will not overwrite our value, or link register and calls GetMailboxBase.
-
wait1$:
status .req r3
ldr status,[mailbox,#0x18]
This code loads in the current status.
-
tst status,#0x80000000
.unreq status
bne wait1$
This code checks that the top bit of the status field is 0, and loops back to 3. if it is not.
-
add value,channel
.unreq channel
This code combines the channel and value together.
-
str value,[mailbox,#0x20]
.unreq value
.unreq mailbox
pop {pc}
This code stores the result to the write field.
The code for MailboxRead is quite similar.
- Our input will be what mailbox to read from (r0). We must validate this is by checking it is a real mailbox. Never forget to validate inputs.
- Use GetMailboxBase to retrieve the address.
- Read from the Status field.
- Check the 30th bit is 0. If not, go back to 3.
- Read from the Read field.
- Check the mailbox is the one we want, if not go back to 3.
- Return the result.
Let's handle each of these in order.
-
.globl MailboxRead
MailboxRead:
cmp r0,#15
movhi pc,lr
This achieves our validation on r0.
-
channel .req r1
mov channel,r0
push {lr}
bl GetMailboxBase
mailbox .req r0
This code ensures we will not overwrite our value, or link register and calls GetMailboxBase.
-
rightmail$:
wait2$:
status .req r2
ldr status,[mailbox,#0x18]
This code loads in the current status.
-
tst status,#0x40000000
.unreq status
bne wait2$
This code checks that the 30th bit of the status field is 0, and loops back to 3. if it is not.
-
mail .req r2
ldr mail,[mailbox,#0]
This code reads the next item from the mailbox.
-
inchan .req r3
and inchan,mail,#0b1111
teq inchan,channel
.unreq inchan
bne rightmail$
.unreq mailbox
.unreq channel
This code checks that the channel of the mail we just read is the one we were supplied. If not it loops back to 3.
-
and r0,mail,#0xfffffff0
.unreq mail
pop {pc}
This code moves the answer (the top 28 bits of mail) to r0.
## 4 My Dearest Graphics Processor
Through our new postman, we now have the ability to send a message to the graphics card. What should we send though? This was certainly a difficult question for me to find the answer to, as it isn't in any online manual that I have found. Nevertheless, by looking at the GNU/Linux for the Raspberry Pi, we are able to work out what we needed to send.
Since the RAM is shared between the graphics processor and the processor on the Pi, we can just send where to find our message. This is called DMA, many complicated devices use this to speed up access times.
The message is very simple. We describe the framebuffer we would like, and the graphics card either agrees to our request, in which case it sends us back a 0, and fills in a small questionnaire we make, or it sends back a non-zero number, in which case we know it is unhappy. Unfortunately, I have no idea what any of the other numbers it can send back are, nor what they mean, but only when it sends a zero it is happy. Fortunately it always seems to send a zero for sensible inputs, so we don't need to worry too much.
For simplicity we shall design our request in advance, and store it in the .data section. In a file called 'framebuffer.s' place the following code:
.section .data
.align 4
.globl FrameBufferInfo
FrameBufferInfo:
.int 1024 /* #0 Physical Width */
.int 768 /* #4 Physical Height */
.int 1024 /* #8 Virtual Width */
.int 768 /* #12 Virtual Height */
.int 0 /* #16 GPU - Pitch */
.int 16 /* #20 Bit Depth */
.int 0 /* #24 X */
.int 0 /* #28 Y */
.int 0 /* #32 GPU - Pointer */
.int 0 /* #36 GPU - Size */
This is the format of our messages to the graphics processor. The first two words describe the physical width and height. The second pair is the virtual width and height. The framebuffer's width and height are the virtual width and height, and the GPU scales the framebuffer as need to fit the physical screen. The next word is one of the ones the GPU will fill in if it grants our request. It will be the number of bytes on each row of the frame buffer, in this case 2 × 1024 = 2048. The next word is how many bits to allocate to each pixel. Using a value of 16 means that the graphics processor uses High Colour mode described above. A value of 24 would use True Colour, and 32 would use RGBA32. The next two words are x and y offsets, which mean the number of pixels to skip in the top left corner of the screen when copying the framebuffer to the screen. Finally, the last two words are filled in by the graphics processor, the first of which is the actual pointer to the frame buffer, and the second is the size of the frame buffer in bytes.
When working with devices using DMA, alignment constraints become very important. The GPU expects the message to be 16 byte aligned.
I was very careful to include a .align 4 here. As discussed before, this ensures the lowest 4 bits of the address of the next line are 0. Thus, we know for sure that FrameBufferInfo will be placed at an address we can send to the graphics processor, as our mailbox only sends values with the low 4 bits all 0.
So, now that we have our message, we can write code to send it. The communication will go as follows:
- Write the address of FrameBufferInfo + 0x40000000 to mailbox 1.
- Read the result from mailbox 1. If it is not zero, we didn't ask for a proper frame buffer.
- Copy our images to the pointer, and they will appear on screen!
I've said something that I've not mentioned before in step 1. We have to add 0x40000000 to the address of FrameBufferInfo before sending it. This is actually a special signal to the GPU of how it should write to the structure. If we just send the address, the GPU will write its response, but will not make sure we can see it by flushing its cache. The cache is a piece of memory where a processor stores values its working on before sending them to the RAM. By adding 0x40000000, we tell the GPU not to use its cache for these writes, which ensures we will be able to see the change.
Since there is quite a lot going on there, it would be best to implement this as a function, rather than just putting the code into main.s. We shall write a function InitialiseFrameBuffer which does all this negotiation and returns the pointer to the frame buffer info data above, once it has a pointer in it. For ease, we should also make it so that the width, height and bit depth of the frame buffer are inputs to this method, so that it is easy to change in main.s without having to get into the details of the negotiation.
Once again, let's write down in detail the steps we will have to take. If you're feeling confident, try writing the function straight away.
- Validate our inputs.
- Write the inputs into the frame buffer.
- Send the address of the frame buffer + 0x40000000 to the mailbox.
- Receive the reply from the mailbox.
- If the reply is not 0, the method has failed. We should return 0 to indicate failure.
- Return a pointer to the frame buffer info.
Now we're getting into much bigger methods than before. Below is one implementation of the above.
-
.section .text
.globl InitialiseFrameBuffer
InitialiseFrameBuffer:
width .req r0
height .req r1
bitDepth .req r2
cmp width,#4096
cmpls height,#4096
cmpls bitDepth,#32
result .req r0
movhi result,#0
movhi pc,lr
This code checks that the width and height are less than or equal to 4096, and that the bit depth is less than or equal to 32. This is once again using a trick with conditional execution. Convince yourself that this works.
-
fbInfoAddr .req r3
push {lr}
ldr fbInfoAddr,=FrameBufferInfo
str width,[fbInfoAddr,#0]
str height,[fbInfoAddr,#4]
str width,[fbInfoAddr,#8]
str height,[fbInfoAddr,#12]
str bitDepth,[fbInfoAddr,#20]
.unreq width
.unreq height
.unreq bitDepth
This code simply writes into our frame buffer structure defined above. I also take the opportunity to push the link register onto the stack.
-
mov r0,fbInfoAddr
add r0,#0x40000000
mov r1,#1
bl MailboxWrite
The inputs to the MailboxWrite method are the value to write in r0, and the channel to write to in r1.
-
mov r0,#1
bl MailboxRead
The inputs to the MailboxRead method is the channel to write to in r0, and the output is the value read.
-
teq result,#0
movne result,#0
popne {pc}
This code checks if the result of the MailboxRead method is 0, and returns 0 if not.
-
mov result,fbInfoAddr
pop {pc}
.unreq result
.unreq fbInfoAddr
This code finishes off and returns the frame buffer info address.
## 5 A Pixel Within a Row Within a Frame
So, we've now created our methods to communicate with the graphics processor. It should now be capable of giving us the pointer to a frame buffer we can draw graphics to. Let's draw something now.
In this first example, we'll just draw consecutive colours to the screen. It won't look pretty, but at least it will be working. How we will do this is by setting each pixel in the framebuffer to a consecutive number, and continually doing so.
Copy the following code to 'main.s' after mov sp,#0x8000
mov r0,#1024
mov r1,#768
mov r2,#16
bl InitialiseFrameBuffer
This code simply uses our InitialiseFrameBuffer method to create a frame buffer with width 1024, height 768, and bit depth 16. You can try different values in here if you wish, as long as you are consistent throughout the code. Since it's possible that this method can return 0 if the graphics processor did not give us a frame buffer, we had better check for this, and turn the OK LED on if it happens.
teq r0,#0
bne noError$
mov r0,#16
mov r1,#1
bl SetGpioFunction
mov r0,#16
mov r1,#0
bl SetGpio
error$:
b error$
noError$:
fbInfoAddr .req r4
mov fbInfoAddr,r0
Now that we have the frame buffer info address, we need to get the frame buffer pointer from it, and start drawing to the screen. We will do this using two loops, one going down the rows, and one going along the columns. On the Raspberry Pi, indeed in most applications, pictures are stored left to right then top to bottom, so we have to do the loops in the order I have said.
render$:
fbAddr .req r3
ldr fbAddr,[fbInfoAddr,#32]
colour .req r0
y .req r1
mov y,#768
drawRow$:
x .req r2
mov x,#1024
drawPixel$:
strh colour,[fbAddr]
add fbAddr,#2
sub x,#1
teq x,#0
bne drawPixel$
sub y,#1
add colour,#1
teq y,#0
bne drawRow$
b render$
.unreq fbAddr
.unreq fbInfoAddr
strh reg,[dest] stores the low half word number in reg at the address given by dest.
This is quite a large chunk of code, and has a loop within a loop within a loop. To help get your head around the looping, I've indented the code which is looped, depending on which loop it is in. This is quite common in most high level programming languages, and the assembler simply ignores the tabs. We see here that I load in the frame buffer address from the frame buffer information structure, and then loop over every row, then every pixel on the row. At each pixel, I use an strh (store half word) command to store the current colour, then increment the address we're writing to. After drawing each row, we increment the colour that we are drawing. After drawing the full screen, we branch back to the beginning.
## 6 Seeing the Light
Now you're ready to test this code on the Raspberry Pi. You should see a changing gradient pattern. Be careful: until the first message is sent to the mailbox, the Raspberry Pi displays a still gradient pattern between the four corners. If it doesn't work, please see our troubleshooting page.
If it does work, congratulations! You can now control the screen! Feel free to alter
this code to draw whatever pattern you like. You can do some very nice gradient
patterns, and can compute the value of each pixel directly, since
y contains a y-coordinate for the pixel, and x
contains an x-coordinate. In the next lesson, [Lesson 7: Screen
02](screen02.html), we will look at one of the most common drawing tasks, lines. |
10,541 | Pony 编程语言简介 | https://opensource.com/article/18/5/pony | 2019-02-16T15:39:16 | [
"Pony",
"并发"
] | /article-10541-1.html |
>
> Pony,一种“Rust 遇上 Erlang”的语言,让开发快捷、安全、高效、高并发的程序更简单。
>
>
>

在 [Wallaroo Labs](http://www.wallaroolabs.com/),我是工程副总裁,我们正在构建一个用 [Pony](https://www.ponylang.org/) 编程语言编写的 [高性能分布式流处理器](https://github.com/wallaroolabs/wallaroo)。大多数人没有听说过 Pony,但它一直是 Wallaroo 的最佳选择,它也可能成为你的下一个项目的最佳选择。
>
> “一门编程语言只是另一种工具。与语法无关,与表达性无关,与范式或模型无关,仅与解决难题有关。” —Sylvan Clebsch,Pony 的创建者
>
>
>
我是 Pony 项目的贡献者,但在这里我要谈谈为什么 Pony 对于像 Wallaroo 这样的应用是个好选择,并分享我使用 Pony 的方式。如果你对我们为什么使用 Pony 来编写 Wallaroo 甚感兴趣,我们有一篇关于它的 [博文](https://blog.wallaroolabs.com/2017/10/why-we-used-pony-to-write-wallaroo/)。
### Pony 是什么?
你可以把 Pony 想象成某种“Rust 遇上 Erlang”的东西。Pony 有着最引人注目的特性,它们是:
* 类型安全
* 存储安全
* 异常安全
* 无数据竞争
* 无死锁
此外,它可以被编译为高效的本地代码,它是在开放的情况下开发的,在两句版 BSD 许可证下发布。
以上说的功能不少,但在这里我将重点关注那些对我们公司来说采用 Pony 至关重要的功能。
### 为什么使用 Pony?
使用大多数我们现有的工具编写快速、安全、高效、高并发的程序并非易事。“快速、高效、高并发”是可实现的目标,但加入“安全”之后,就困难了许多。对于 Wallaroo,我们希望同时实现四个目标,而 Pony 让实现它们更加简单。
#### 高并发
Pony 让并发变得简单。部分是通过提供一个固执的并发方式实现的。在 Pony 语言中,所有的并发都是通过 [Actor 模型](https://en.wikipedia.org/wiki/Actor_model) 进行的。
Actor 模型以在 Erlang 和 Akka 中的实现最为著名。Actor 模型出现于上世纪 70 年代,细节因实现方式而异。不变的是,所有计算都由通过异步消息进行通信的 actor 来执行。
你可以用这种方式来看待 Actor 模型:面向对象中的对象是状态 + 同步方法,而 actor 是状态 + 异步方法。
当一个 actor 收到一个消息时,它执行相应的方法。该方法可以在只有该 actor 可访问的状态下运行。Actor 模型允许我们以并发安全的方式使用可变状态。每个 actor 都是单线程的。一个 actor 中的两个方法绝不会并发运行。这意味着,在给定的 actor 中,数据更新不会引起数据竞争或通常与线程和可变状态相关的其他问题。
#### 快速高效
Pony actor 通过一个高效的工作窃取调度程序来调度。每个可用的 CPU 都有一个单独 Pony 调度程序。这种每个核心一个线程的并发模型是 Pony 尝试与 CPU 协同工作以尽可能高效运行的一部分。Pony 运行时尝试尽可能利用 CPU 缓存。代码越少干扰缓存,运行得越好。Pony 意在帮你的代码与 CPU 缓存友好相处。
Pony 的运行时还会有每个 actor 的堆,因此在垃圾收集期间,没有 “停止一切” 的垃圾收集步骤。这意味着你的程序总是至少能做一点工作。因此 Pony 程序最终具有非常一致的性能和可预测的延迟。
#### 安全
Pony 类型系统引入了一个新概念:引用能力,它使得数据安全成为类型系统的一部分。Pony 语言中每种变量的类型都包含了有关如何在 actor 之间分享数据的信息。Pony 编译器用这些信息来确认,在编译时,你的代码是无数据竞争和无死锁的。
如果这听起来有点像 Rust,那是因为本来就是这样的。Pony 的引用功能和 Rust 的借用检查器都提供数据安全性;它们只是以不同的方式来接近这个目标,并有不同的权衡。
### Pony 适合你吗?
决定是否要在一个非业余爱好的项目上使用一门新的编程语言是困难的。与其他方法想比,你必须权衡工具的适当性和不成熟度。那么,Pony 和你搭不搭呢?
如果你有一个困难的并发问题需要解决,那么 Pony 可能是一个好选择。解决并发应用问题是 Pony 之所以存在的理由。如果你能用一个单线程的 Python 脚本就完成所需操作,那你大概不需要它。如果你有一个困难的并发问题,你应该考虑 Pony 及其强大的无数据竞争、并发感知类型系统。
你将获得一个这样的编译器,它将阻止你引入许多与并发相关的错误,并在运行时为你提供出色的性能特征。
### 开始使用 Pony
如果你准备好开始使用 Pony,你需要先在 Pony 的网站上访问 [学习部分](https://www.ponylang.org/learn/)。在这里你会找到安装 Pony 编译器的步骤和学习这门语言的资源。
如果你愿意为你正在使用的这个语言做出贡献,我们会在 GitHub 上为你提供一些 [初学者友好的问题](https://github.com/ponylang/ponyc/issues?q=is%3Aissue+is%3Aopen+label%3A%22complexity%3A+beginner+friendly%22)。
同时,我迫不及待地想在 [我们的 IRC 频道](https://webchat.freenode.net/?channels=%23ponylang) 和 [Pony 邮件列表](https://pony.groups.io/g/user) 上与你交谈。
要了解更多有关 Pony 的消息,请参阅 Sean Allen 2018 年 7 月 16 日至 19 日在俄勒冈州波特兰举行的 [第 20 届 OSCON 会议](https://conferences.oreilly.com/oscon/oscon-or) 上的演讲: [Pony,我如何学会停止担心并拥抱未经证实的技术](https://conferences.oreilly.com/oscon/oscon-or/public/schedule/speaker/213590)。
---
via: <https://opensource.com/article/18/5/pony>
作者:[Sean T Allen](https://opensource.com/users/seantallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[beamrolling](https://github.com/beamrolling) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,542 | 如何从 Linux 上连接到远程桌面 | https://opensource.com/article/18/6/linux-remote-desktop | 2019-02-16T16:01:15 | [
"远程桌面"
] | https://linux.cn/article-10542-1.html |
>
> Remmina 的极简用户界面使得远程访问 Linux / Windows 10 变得轻松。
>
>
>

根据维基百科,[远程桌面](https://en.wikipedia.org/wiki/Remote_desktop_software) 是一种“软件或者操作系统特性,它可以让个人电脑上的桌面环境在一个系统(通常是电脑,但是也可以是服务器)上远程运行,但在另一个分开的客户端设备显示”。
换句话说,远程桌面是用来访问在另一台电脑上运行的环境的。比如说 [ManageIQ/Integration tests](https://github.com/ManageIQ/integration_tests) 仓库的拉取请求 (PR) 测试系统开放了一个虚拟网络计算 (VNC) 连接端口,使得我能够远程浏览正被实时测试的拉取请求。远程桌面也被用于帮助客户解决电脑问题:在客户的许可下,你可以远程建立 VNC 或者远程桌面协议(RDP)连接来查看或者交互式地访问该电脑以寻找并解决问题。
运用远程桌面连接软件可以建立这些连接。可供选择的软件有很多,我用 [Remmina](https://www.remmina.org/wp/),因为我喜欢它极简、好用的用户界面 (UI)。它是用 GTK+ 编写的,在 GNU GPL 许可证开源。
在这篇文章里,我会解释如何使用 Remmina 客户端从一台 Linux 电脑上远程连接到 Windows 10 系统 和 Red Hat 企业版 Linux 7 系统。
### 在 Linux 上安装 Remmina
首先,你需要在你用来远程访问其它电脑的的主机上安装 Remmina。如果你用的是 Fedora,你可以运行如下的命令来安装 Remmina:
```
sudo dnf install -y remmina
```
如果你想在一个不同的 Linux 平台上安装 Remmina,跟着 [安装教程](https://www.tecmint.com/remmina-remote-desktop-sharing-and-ssh-client/) 走。然后你会发现 Remmina 正和你其它软件出现在一起(在这张图片里选中了 Remmina)。

点击图标运行 Remmina,你应该能看到像这样的屏幕:

Remmina 提供不同种类的连接,其中包括用来连接到 Windows 系统的 RDP 和用来连接到 Linux 系统的 VNC。如你在上图左上角所见的,Remmina 的默认设置是 RDP。
### 连接到 Windows 10
在你通过 RDP 连接到一台 Windows 10 电脑之前,你必须修改权限以允许分享远程桌面并通过防火墙建立连接。
* [注意: Windows 10 家庭版没有列入 RDP 特性](https://superuser.com/questions/1019203/remote-desktop-settings-missing#1019212)
要许可远程桌面分享,在“文件管理器”界面右击“我的电脑 → 属性 → 远程设置”,接着在跳出的窗口中,勾选“在这台电脑上允许远程连接”,再点击“应用”。

然后,允许远程连接通过你的防火墙。首先在“开始菜单”中查找“防火墙设置”,选择“允许应用通过防火墙”。

在打开的窗口中,在“允许的应用和特性”下找到“远程桌面”。根据你用来访问这个桌面的网络酌情勾选“隐私”和/或“公开”列的选框。点击“确定”。

回到你用来远程访问 Windows 主机的 Linux 电脑,打开 Remmina。输入你的 Windows 主机的 IP 地址,敲击回车键。(我怎么在 [Linux](https://opensource.com/article/18/5/how-find-ip-address-linux) 和 [Windws](https://www.groovypost.com/howto/find-windows-10-device-ip-address/) 中确定我的 IP 地址?)看到提示后,输入你的用户名和密码,点击“确定”。

如果你被询问是否接受证书,点击“确定”。

你此时应能看到你的 Windows 10 主机桌面。

### 连接到 Red Hat 企业版 Linux 7
要在你的 RHEL7 电脑上允许远程访问,在 Linux 桌面上打开“所有设置”。

点击分享图标会打开如下的窗口:

如果“屏幕分享”处于关闭状态,点击一下。一个窗口会弹出,你可以滑动到“打开”的位置。如果你想允许远程控制桌面,将“允许远程控制”调到“打开”。你同样也可以在两种访问选项间选择:一个能够让电脑的主要用户接受或者否绝连接要求,另一个能用密码验证连接。在窗口底部,选择被允许连接的网络界面,最后关闭窗口。
接着,从“应用菜单 → 其它 → 防火墙”打开“防火墙设置”。

勾选 “vnc-server”旁边的选框(如下图所示)关闭窗口。接着直接到你远程电脑上的 Remmina,输入你想连接到的 Linux 桌面的 IP 地址,选择 VNC 作为协议,点击回车键。

如果你之前选择的验证选项是“新连接必须询问访问许可”,RHEL 系统用户会看到这样的一个弹窗:

点击“接受”以成功进行远程连接。
如果你选择用密码验证连接,Remmina 会向你询问密码。

输入密码然后“确认”,你应该能连接到远程电脑。

### 使用 Remmina
Remmina 提供如上图所示的标签化的 UI,就好像一个浏览器一样。在上图所示的左上角你可以看到两个标签:一个是之前建立的 WIndows 10 连接,另一个新的是 RHEL 连接。
在窗口的左侧,有一个有着“缩放窗口”、“全屏模式”、“偏好”、“截屏”、“断开连接”等选项的工具栏。你可以自己探索看那种适合你。
你也可以通过点击左上角的“+”号创建保存过的连接。根据你的连接情况填好表单点击“保存”。以下是一个 Windows 10 RDP 连接的示例:

下次你打开 Remmina 时连接就在那了。

点击一下它,你不用补充细节就可以建立连接了。
### 补充说明
当你使用远程桌面软件时,你所有的操作都在远程桌面上消耗资源 —— Remmina(或者其它类似软件)仅仅是一种与远程桌面交互的方式。你也可以通过 SSH 远程访问一台电脑,但那将会让你在那台电脑上局限于仅能使用文字的终端。
你也应当注意到当你允许你的电脑远程连接时,如果一名攻击者用这种方法获得你电脑的访问权同样会给你带来严重损失。因此当你不频繁使用远程桌面时,禁止远程桌面连接以及其在防火墙中相关的服务是很明智的做法。
---
via: <https://opensource.com/article/18/6/linux-remote-desktop>
作者:[Kedar Vijay Kulkarni](https://opensource.com/users/kkulkarn) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A [remote desktop](https://en.wikipedia.org/wiki/Remote_desktop_software), according to Wikipedia, is "a software or operating system feature that allows a personal computer's desktop environment to be run remotely on one system (usually a PC, but the concept applies equally to a server), while being displayed on a separate client device."
In other words, a remote desktop is used to access an environment running on another computer. For example, the [ManageIQ/Integration tests](https://github.com/ManageIQ/integration_tests) repository's pull request (PR) testing system exposes a Virtual Network Computing (VNC) connection port so I can remotely view my PRs being tested in real time. Remote desktops are also used to help customers solve computer problems: with the customer's permission, you can establish a VNC or Remote Desktop Protocol (RDP) connection to see or interactively access the computer to troubleshoot or repair the problem.
These connections are made using remote desktop connection software, and there are many options available. I use [Remmina](https://www.remmina.org/wp/) because I like its minimal, easy-to-use user interface (UI). It's written in GTK+ and is open source under the GNU GPL license.
In this article, I'll explain how to use the Remmina client to connect remotely from a Linux computer to a Windows 10 system and a Red Hat Enterprise Linux 7 system.
## Install Remmina on Linux
First, you need to install Remmina on the computer you'll use to access the other computer(s) remotely. If you're using Fedora, you can run the following command to install Remmina:
`sudo dnf install -y remmina`
If you want to install Remmina on a different Linux platform, follow these [installation instructions](https://www.tecmint.com/remmina-remote-desktop-sharing-and-ssh-client/). You should then find Remmina with your other apps (Remmina is selected in this image).
Launch Remmina by clicking on the icon. You should see a screen that resembles this:
Remmina offers several types of connections, including RDP, which is used to connect to Windows-based computers, and VNC, which is used to connect to Linux machines. As you can see in the top-left corner above, Remmina's default setting is RDP.
## Connecting to Windows 10
According to Microsoft['](https://www.microsoft.com/en-us/WindowsForBusiness/Compare)s product matrix, Windows 10 Home edition does not include the ability to connect over RDP, so you must be running Pro or Enterprise editions to connect over RDP.
Before you can connect to a Windows 10 computer through RDP, you must change some permissions to allow remote desktop sharing and connections through your firewall.
To enable remote desktop sharing, in **File Explorer** right-click on **My Computer → Properties → Remote Settings** and, in the pop-up that opens, check **Allow remote connections to this computer**, then select **Apply**.
Next, enable remote desktop connections through your firewall. First, search for **firewall settings** in the **Start** menu and select **Allow an app through Windows Firewall**.
In the window that opens, look for **Remote Desktop** under **Allowed apps and features**. Check the box(es) in the **Private **and/or** Public** columns, depending on the type of network(s) you will use to access this desktop. Click **OK**.
Go to the Linux computer you use to remotely access the Windows PC and launch Remmina. Enter the IP address of your Windows computer and hit the Enter key. (How do I locate my IP address [in Linux](https://opensource.com/article/18/5/how-find-ip-address-linux) and [Windows 10](https://www.groovypost.com/howto/find-windows-10-device-ip-address/)?) When prompted, enter your username and password and click OK.
If you're asked to accept the certificate, select OK.
You should be able to see your Windows 10 computer's desktop.
## Connecting to Red Hat Enterprise Linux
To set permissions to enable remote access on your Linux computer, open **Settings** from the **Activities** menu in the top left corner of the [GNOME desktop](https://opensource.com/article/19/12/gnome-linux-desktop).
Click on the **Sharing** category.
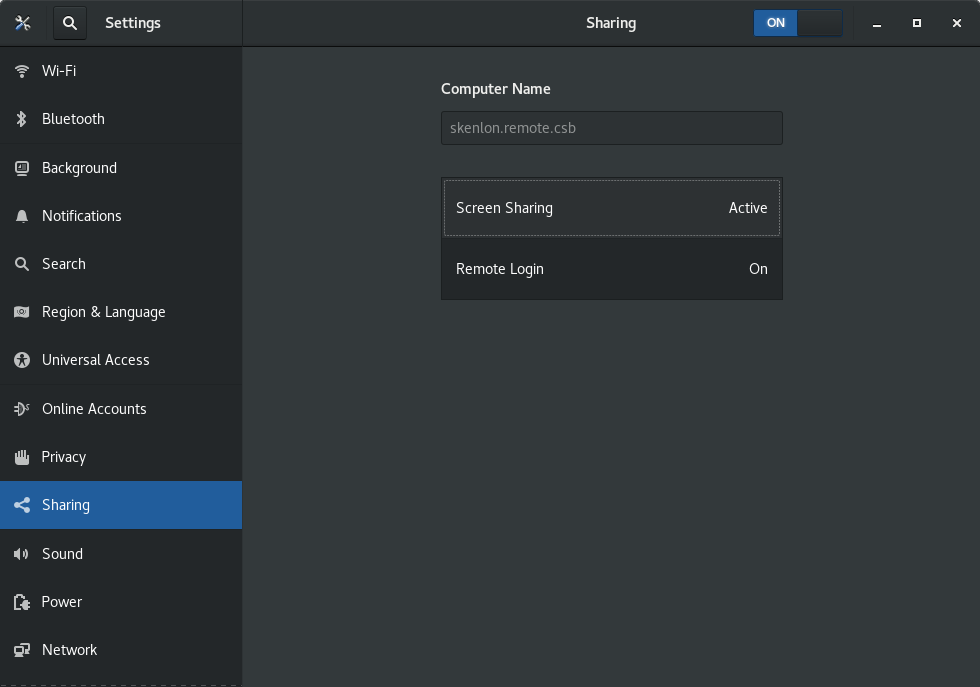
Enable **Screen Sharing** (and **Allow connections to control screen**, when prompted). You can also select between two access options: one that prompts the computer's primary user to accept or deny the connection request, and another that allows connection authentication with a password. At the bottom of the window, select the network interface where connections are allowed, then close the window.
Next, open **Firewall Settings** from **Applications Menu → Sundry → Firewall**.
Next, head to Remmina on your remote computer, enter the IP address of the Linux desktop you want to connect with, select **VNC** as the protocol, and hit the **Enter** key.
If you previously chose the authentication option **New connections must ask for access**, the RHEL system's user will see a prompt like this:
Select **Accept** for the remote connection to succeed.
If you chose the option to authenticate the connection with a password, Remmina will prompt you for the password.
Enter the password and hit **OK**, and you should be connected to the remote computer.
## Using Remmina
Remmina offers a tabbed UI, as shown in above picture, much like a web browser. In the top-left corner, as shown in the screenshot above, you can see two tabs: one for the previously established Windows 10 connection and a new one for the RHEL connection.
On the left-hand side of the window, there is a toolbar with options such as **Resize Window**, **Full-Screen Mode**, **Preferences**, **Screenshot**, **Disconnect**, and more. Explore them and see which ones work best for you.
You can also create saved connections in Remmina by clicking on the **+** (plus) sign in the top-left corner. Fill in the form with details specific to your connection and click **Save**. Here is an example Windows 10 RDP connection:
The next time you open Remmina, the connection will be available.
Just click on it, and your connection will be established without re-entering the details.
## Additional info
When you use remote desktop software, all the operations you perform take place on the remote desktop and use its resources—Remmina (or similar software) is just a way to interact with that desktop. You can also access a computer remotely through SSH, but it usually limits you to a text-only terminal to that computer.
You should also note that enabling remote connections with your computer could cause serious damage if an attacker uses this method to gain access to your computer. Therefore, it is wise to disallow remote desktop connections and block related services in your firewall when you are not actively using Remote Desktop.
*This article originally published in June 2018 and has been updated by the editor.*
## 4 Comments |
10,543 | 丰田汽车的 Linux 之旅 | https://itsfoss.com/toyota-motors-linux-journey | 2019-02-17T09:32:12 | [
"AGL",
"汽车"
] | https://linux.cn/article-10543-1.html | 我之前跟丰田汽车北美分公司的 Brian.R.Lyons(丰田发言人)聊了聊,话题是关于 Linux 在丰田和雷克萨斯汽车的信息娱乐系统上的实施方案。我了解到一些汽车制造商使用了 Automotive Grade Linux(AGL)。
然后我写了一篇短文,记录了我和 Brian 的讨论内容,谈及了丰田和 Linux 的一些渊源。希望 Linux 的狂热粉丝们能够喜欢这次对话。
全部的[丰田和雷克萨斯汽车都将会使用 Automotive Grade Linux(AGL)](https://www.linuxfoundation.org/press-release/2018/01/automotive-grade-linux-hits-road-globally-toyota-amazon-alexa-joins-agl-support-voice-recognition/),主要是用于车载信息娱乐系统。这项措施对于丰田集团来说是至关重要的,因为据 Lyons 先生所说:“作为技术的引领者之一,丰田认识到,赶上科技快速进步最好的方法就是接受开源发展的理念。”
丰田和众多汽车制造公司都认为,与使用非自由软件相比,采用基于 Linux 的操作系统在更新和升级方面会更加廉价和快捷。
这简直太棒了! Linux 终于跟汽车结合起来了。我每天都在电脑上使用 Linux;能看到这个优秀的软件在一个完全不同的产业领域里大展拳脚真是太好了。
我很好奇丰田是什么时候开始使用 [Automotive Grade Linux(AGL)](https://www.automotivelinux.org/)的。按照 Lyons 先生的说法,这要追溯到 2011 年。
>
> “自 AGL 项目在五年前启动之始,作为活跃的会员和贡献者,丰田与其他顶级制造商和供应商展开合作,着手开发一个基于 Linux 的强大平台,并不断地增强其功能和安全性。”
>
>
>

[丰田于 2011 年加入了 Linux 基金会](https://www.linuxfoundation.org/press-release/2011/07/toyota-joins-linux-foundation/),与其他汽车制造商和软件公司就 IVI(车内信息娱乐系统)展开讨论,最终在 2012 年,Linux 基金会内部成立了 Automotive Grade Linux 工作组。
丰田在 AGL 工作组里首先提出了“代码优先”的策略,这在开源领域是很常见的做法。然后丰田和其他汽车制造商、IVI 一线厂家,软件公司等各方展开对话,根据各方的技术需求详细制定了初始方向。
在加入 Linux 基金会的时候,丰田就已经意识到,在一线公司之间共享软件代码将会是至关重要的。因为要维护如此复杂的软件系统,对于任何一家顶级厂商都是一笔不小的开销。丰田和它的一级供货商想把更多的资源用在开发新功能和新的用户体验上,而不是用在维护各自的代码上。
各个汽车公司联合起来深入合作是一件大事。许多公司都达成了这样的共识,因为他们都发现开发维护私有软件其实更费钱。
今天,在全球市场上,丰田和雷克萨斯的全部车型都使用了 AGL。
身为雷克萨斯的销售人员,我认为这是一大进步。我和其他销售顾问都曾接待过很多回来找技术专员的客户,他们想更多的了解自己车上的信息娱乐系统到底都能做些什么。
这件事本身对于 Linux 社区和用户是个重大利好。虽然那个我们每天都在使用的操作系统变了模样,被推到了更广阔的舞台上,但它仍然是那个 Linux,简单、包容而强大。
未来将会如何发展呢?我希望它能少出差错,为消费者带来更佳的用户体验。
---
via: <https://itsfoss.com/toyota-motors-linux-journey>
作者:[Malcolm Dean](https://itsfoss.com/toyota-motors-linux-journey) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jdh8383](https://github.com/jdh8383) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,544 | 4 个独特的 Linux 终端模拟器 | https://www.linux.com/blog/learn/2018/12/4-unique-terminals-linux | 2019-02-17T09:57:48 | [
"终端"
] | https://linux.cn/article-10544-1.html |
>
> 这四个不同的终端模拟器 —— 不仅可以完成工作,还可以增加一些乐趣。
>
>
>

让我们面对现实,如果你是 Linux 管理员,那么你要用命令行来工作。为此,你将使用终端模拟器(LCTT 译注:常简称为“终端”,与终端本身的原意不同)。最有可能的是,你选择的发行版预先安装了一个可以完成工作的默认终端模拟器。但这是有很多选择可供选择的 Linux,所以这种思想自然也适用于终端模拟器。实际上,如果你打开发行版的图形界面的包管理器(或从命令行搜索),你将找到大量可能的选择。其中许多是非常简单的工具;然而,有些是真正独特的。
在本文中,我将重点介绍四个这样的终端模拟器,它们不仅可以完成工作,而且可以使工作变得更有趣或更好玩。那么,让我们来看看这些终端。
### Tilda
[Tilda](http://tilda.sourceforge.net/tildadoc.php) 是为 Gtk 设计的,是一种酷炫的下拉终端。这意味着该终端始终运行在后台,可以随时从显示器顶部拉下来(就像 Guake 和 Yakuake)。让 Tilda 超越许多其他产品的原因是该终端可用的配置选项数量(图 1)。

可以从标准的软件库安装 Tilda。在基于 Ubuntu(或 Debian)的发行版上,安装非常简单:
```
sudo apt-get install tilda -y
```
安装完成后,从桌面菜单中打开 Tilda,这也将打开其配置窗口。根据你的喜好配置应用程序,然后关闭配置窗口。然后,你可以通过点击 `F1` 热键来打开和关闭 Tilda。对使用 Tilda 的一个警告是,在第一次运行后,你将找不到有关如何打开配置向导的任何提示。别担心。只要运行命令 `tilda -C`,它将打开配置窗口,同时仍会保留你之前设置的选项。
可用选项包括:
* 终端大小和位置
* 字体和颜色配置
* 自动隐藏
* 标题
* 自定义命令
* URL 处理
* 透明度
* 动画
* 滚动
* 等等
我喜欢这些类型的终端是因为当你不需要时它们很容易就会消失,只需按一下按钮即可。对于那些不断进出于终端的人来说,像 Tilda 这样的工具是理想的选择。
### Aterm
Aterm 在我心中占有特殊的位置,因为它是我第一次使用的终端之一,它让我意识到 Linux 的灵活性。 这要回到 AfterStep 成为我选择的窗口管理器时(没用了太久),而且那时我是命令行新手。Aterm 提供的是一个高度可定制的终端仿真器,同时帮助我了解了使用终端的细节(如何给命令添加选项和开关)。或许你会问:“你觉得怎么样?”。因为 Aterm 从未有过用于定制选项的图形界面。要使用任何特殊选项运行 Aterm,必须以命令选项的方式运行。例如,假设你要启用透明度、绿色文本、白色高亮和无滚动条。为此,请运行以下命令:
```
aterm -tr -fg green -bg white +xb
```
最终结果(`top` 命令运行用于说明)看起来如图 2 所示。

*图 2:使用了一些定制选项的 Aterm*
当然,你必须先安装 Aterm。幸运的是,这个应用程序仍然可以在标准软件库中找到,因此在 Ubuntu 上安装就像下面这样简单:
```
sudo apt-get install aterm -y
```
如果你想总是用这些选项打开 Aterm,最好的办法是在 `~/.bashrc` 文件中创建一个别名,如下所示:
```
alias=”aterm -tr -fg green -bg white +sb”
```
保存该文件,当你运行命令 `aterm` 时,它将始终打开这些选项。有关创建别名的更多信息,请查看[这个教程](https://www.linux.com/blog/learn/2018/12/aliases-diy-shell-commands)。
### Eterm
Eterm 是第二个真正告诉我 Linux 命令行可以带来多少乐趣的终端。Eterm 是 Enlightenment 桌面的默认终端模拟器。当我最终从 AfterStep 迁移到 Enlightenment 时(那时早在 20 世纪初),我担心我会失去所有那些很酷的美学选择。结果并非如此。实际上,Eterm 提供了许多独特的选项,同时使用终端工具栏使任务变得更容易。使用 Eterm,你可以通过从 “Background > Pixmap” 菜单条目中轻松地从大量背景图像中选择一个背景(如果你需要一个的话,图 3)。

*图 3:从大量的背景图中为 Eterm 选择一个。*
还有许多其他配置选项(例如字体大小、映射警报、切换滚动条、亮度、对比度和背景图像的透明度等)。 你要确定的一件事是,在你配置 Eterm 以满足你的口味后,需要单击 “Eterm > Save User Settings”(否则,关闭应用程序时所有设置都将丢失)。
可以从标准软件库安装 Eterm,其命令如下:
```
sudo apt-get install eterm
```
### Extraterm
[Extraterm](http://extraterm.org) 应该可以赢得当今终端窗口项目最酷功能集的一些奖项。Extraterm 最独特的功能是能够以彩色框来包装命令(蓝色表示成功命令,红色表示失败命令。图 4)。

*图 4:Extraterm 显示有两个失败的命令框。*
在运行命令时,Extraterm 会将命令包装在一个单独的颜色框中。如果该命令成功,则该颜色框将以蓝色轮廓显示。如果命令失败,框将以红色标出。
无法通过标准软件库安装 Extraterm。事实上,在 Linux 上运行 Extraterm(目前)的唯一方法是从该项目的 GitHub 页面[下载预编译的二进制文件](https://github.com/sedwards2009/extraterm/releases),解压缩文件,切换到新创建的目录,然后运行命令 `./extraterm`。
当该应用程序运行后,要启用颜色框,你必须首先启用 Bash 集成功能。为此,请打开 Extraterm,然后右键单击窗口中的任意位置以显示弹出菜单。滚动,直到看到 “Inject Bash shell Integration” 的条目(图 5)。选择该条目,然后你可以开始使用这个颜色框选项。

*图 5:为 Extraterm 插入 Bash 集成。。*
如果你运行了一个命令,并且看不到颜色框,则可能必须为该命令创建一个新的颜色框(因为 Extraterm 仅附带一些默认颜色框)。为此,请单击 “Extraterm” 菜单按钮(窗口右上角的三条水平线),选择 “Settings”,然后单击 “Frames” 选项卡。在此窗口中,向下滚动并单击 “New Rule” 按钮。 然后,你可以添加要使用颜色框的命令(图 6)。

*图 6:为颜色框添加新规则。*
如果在此之后仍然没有看到颜色框出现,请从[下载页面](https://github.com/sedwards2009/extraterm/releases)下载 `extraterm-commands` 文件,解压缩该文件,切换到新创建的目录,然后运行命令 `sh setup_extraterm_bash.sh`。这应该可以为 Extraterm 启用颜色框。
还有更多可用于 Extraterm 的选项。我相信,一旦你开始在终端窗口上玩这个新花招,你就不会想回到标准终端了。希望开发人员可以尽快将这个应用程序提供给标准软件库(因为它很容易就可以成为最流行的终端窗口之一)。
### 更多
正如你可能预期的那样,Linux 有很多可用的终端。这四个代表四个独特的终端(至少对我来说),每个都可以帮助你运行 Linux 管理员需要运行的命令。如果你对其中一个不满意,用你的包管理器找找有什么可用的软件包。你一定会找到适合你的东西。
---
via: <https://www.linux.com/blog/learn/2018/12/4-unique-terminals-linux>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,545 | 极客漫画:Windows 更新 | http://turnoff.us/geek/windows-update/ | 2019-02-17T10:50:00 | [
"Windows",
"极客漫画"
] | https://linux.cn/article-10545-1.html | 
嗨,还在使用 Windows 的兄弟们,你是不是又更新了?
那么,拿起手机,去喝杯咖啡吧,请稍………………候……………再…………回………来……吧…
---
via: <http://turnoff.us/geek/windows-update/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者 & 点评:[wxy](https://github.com/wxy) 校对 & 合成:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,546 | 14 个依然很棒的 Linux ASCII 游戏 | https://itsfoss.com/best-ascii-games/ | 2019-02-17T21:02:18 | [
"ASCII",
"游戏"
] | https://linux.cn/article-10546-1.html | 基于文本的(或者我应该说是[基于终端的](https://itsfoss.com/best-command-line-games-linux/))游戏在十年前非常流行 —— 当时还没有像<ruby> 战神 <rt> God Of War </rt></ruby>、<ruby> 荒野大镖客:救赎 2 <rt> Red Dead Redemption 2 </rt></ruby>或<ruby> 蜘蛛侠 <rt> Spiderman </rt></ruby>这样的视觉游戏大作。
当然,Linux 平台有很多好游戏 —— 虽然并不总是“最新和最好”。但是,有一些 ASCII 游戏,却是你永远不会玩腻的。
你或许不相信,有一些 ASCII 游戏被证明是非常容易上瘾的(所以,我可能需要一段时间才能继续写下一篇文章,或者我可能会被解雇? —— 帮帮我!)
哈哈,开个玩笑。让我们来看看最好的 ASCII 游戏吧。
**注意:**安装 ASCII 游戏可能要花费不少时间(有些可能会要求你安装其他依赖项或根本不起作用)。你甚至可能会遇到一些需要你从源代码构建的 ASCII 游戏。因此,我们只筛选出那些易于安装和运行的产品 —— 不用费劲。
### 在运行和安装 ASCII 游戏之前需要做的事情
如果你没有安装的话,某些 ASCII 游戏可能需要你安装 [Simple DirectMedia Layer](https://www.libsdl.org/)。因此,以防万一,你应该先尝试安装它,然后再尝试运行本文中提到的任何游戏。
要安装它,你需要键入如下命令:
```
sudo apt install libsdl2-2.0
sudo apt install libsdl2_mixer-2.0
```
### Linux 上最好的 ASCII 游戏

如下列出的游戏排名不分先后。
#### 1、战争诅咒

<ruby> <a href="http://a-nikolaev.github.io/curseofwar/"> 战争诅咒 </a> <rt> Curse of War </rt></ruby>是一个有趣的策略游戏。一开始你可能会发现它有点令人困惑,但一旦你掌握了,就会喜欢上它。在启动游戏之前,我建议你在其 [主页](http://a-nikolaev.github.io/curseofwar/) 上查看该游戏规则。
你将建设基础设施、保护资源并指挥你的军队进行战斗。你所要做的就是把你的旗帜放在一个合适的位置,让你的军队来完成其余的任务。不仅仅是攻击敌人,你还需要管理和保护资源以帮助赢得战斗。
如果你之前从未玩过任何 ASCII 游戏,请耐心花一些时间来学习它、体验它的全部潜力。
##### 如何安装?
你可以在官方软件库里找到它。键入如下命令来安装它:
```
sudo apt install curseofwar
```
#### 2、ASCII 领域

讨厌策略游戏?不用担心,<ruby> ASCII 领域 <rt> ASCII Sector </rt></ruby>是一款具有空间环境的游戏,可让你进行大量探索。
此外,不仅仅局限于探索,你还想要采取一些行动吗?也是可以的。当然,虽然战斗体验不是最好的,但它也很有趣。当你看到各种基地、任务和探索时,会让你更加兴奋。你会在这个小小的游戏中遇到一个练级系统,你必须赚取足够的钱或进行交易才能升级你的宇宙飞船。
而这个游戏最好的地方是你可以创建自己的任务,也可以玩其他人的任务。
##### 如何安装?
你需要先从其 [官方网站](http://www.asciisector.net/download/) 下载并解压缩归档包。完成后,打开终端并输入这些命令(将 “Downloads” 文件夹替换为你解压缩文件夹所在的位置,如果解压缩文件夹位于你的主目录中,则忽略它):
```
cd Downloads
cd asciisec
chmod +x asciisec
./asciisec
```
#### 3、DoomRL

你肯定知道经典游戏“<ruby> 毁灭战士 <rt> DOOM </rt></ruby>”,所以,如果你想把它像 Rogue 类游戏一样略微体验一下,DoomRL 就是适合你的游戏。它是一个基于 ASCII 的游戏,这或许让你想不到。
这是一个非常小的游戏,但是可以玩很久。
##### 如何安装?
与你对 “ASCII 领域”所做的类似,你需要从其 [下载页面](https://drl.chaosforge.org/downloads) 下载官方归档文件,然后将其解压缩到一个文件夹。
解压缩后,输入以下命令:
```
cd Downloads // navigating to the location where the unpacked folder exists
cd doomrl-linux-x64-0997
chmod +x doomrl
./doomrl
```
#### 4、金字塔建造者

<ruby> 金字塔建造者 <rt> Pyramid Builder </rt></ruby> 是一款创新的 ASCII 游戏,你可以通过帮助建造金字塔来提升你的文明。
你需要指导工人耕种、卸载货物、并移动巨大的石头,以成功建造金字塔。
这确实是一个值得下载的 ASCII 游戏。
##### 如何安装?
只需前往其官方网站并下载包以解压缩。提取后,导航到该文件夹并运行可执行文件。
```
cd Downloads
cd pyramid_builder_linux
chmod +x pyramid_builder_linux.x86_64
./pyramid_builder_linux.x86_64
```
#### 5、DiabloRL

如果你是一位狂热的游戏玩家,你一定听说过暴雪的<ruby> 暗黑破坏神 <rt> Diablo </rt></ruby> 1 代,毫无疑问这是一个精彩的游戏。
现在你有机会玩一个该游戏的独特演绎版本 —— 一个 ASCII 游戏。DiabloRL 是一款非常棒的基于回合制的 Rogue 类的游戏。你可以从各种职业(战士、巫师或盗贼)中进行选择。每个职业都具有一套不同的属性,可以带来不同游戏体验。
当然,个人偏好会有所不同,但它是一个不错的暗黑破坏神“降级版”。你觉得怎么样?
#### 6、Ninvaders

Ninvaders 是最好的 ASCII 游戏之一,因为它是如此简单,且可以消磨时间的街机游戏。
你必须防御入侵者,需要在它们到达之前击败它们。这听起来很简单,但它极具挑战性。
##### 如何安装?
与“战争诅咒”类似,你可以在官方软件库中找到它。所以,只需输入此命令即可安装它:
```
sudo apt install ninvaders
```
#### 7、帝国

<ruby> 帝国 <rt> Empire </rt></ruby>这是一款即时战略游戏,你需要互联网连接。我个人不是实时战略游戏的粉丝,但如果你是这类游戏的粉丝,你可以看看他们的 [指南](http://www.wolfpackempire.com/infopages/Guide.html) 来玩这个游戏,因为学习起来非常具有挑战性。
游戏区域包含城市、土地和水。你需要用军队、船只、飞机和其他资源扩展你的城市。通过快速扩张,你可以通过在对方动作之前摧毁它们来捕获其他城市。
##### 如何安装?
安装很简单,只需输入以下命令:
```
sudo apt install empire
```
#### 8、Nudoku

喜欢数独游戏?好吧,你也有个 Nudoku 游戏,这是它的克隆。这是当你想放松时的一个完美的消磨时间的 ASCII 游戏。
它为你提供三个难度级别:简单、正常和困难。如果你想要挑战电脑,其难度会非常难!如果你只是想放松一下,那么就选择简单难度吧。
##### 如何安装?
安装它很容易,只需在终端输入以下命令:
```
sudo apt install nudoku
```
#### 9、Nethack
最好的地下城式 ASCII 游戏之一。如果你已经知道一些 Linux 的 ASCII 游戏,我相信这是你的最爱之一。
它具有许多不同的层(约 45 个),并且包含一堆武器、卷轴、药水、盔甲、戒指和宝石。你也可以选择“永久死亡”模式来玩试试。
在这里可不仅仅是杀戮,你还有很多需要探索的地方。
##### 如何安装?
只需按照以下命令安装它:
```
sudo apt install nethack
```
#### 10、ASCII 滑雪

<ruby> ASCII 滑雪 <rt> ASCII Jump </rt></ruby> 是一款简单易玩的游戏,你必须沿着各种轨道滑动,同时跳跃、改变位置,并尽可能长时间地移动以达到最大距离。
即使看起来很简单,但是看看这个 ASCII 游戏视觉上的表现也是很神奇的。你可以从训练模式开始,然后进入世界杯比赛。你还可以选择你的竞争对手以及你想要开始游戏的山丘。
##### 如何安装?
只需按照以下命令安装它:
```
sudo apt install asciijump
```
#### 11、Bastet

不要被这个名字误导,它实际上是俄罗斯方块游戏的一个有趣的克隆。
你不要觉得它只是另一个普通的俄罗斯方块游戏,它会为你丢下最糟糕的砖块。祝你玩得开心!
##### 如何安装?
打开终端并键入如下命令:
```
sudo apt install bastet
```
#### 12、Bombardier

Bombardier 是另一个简单的 ASCII 游戏,它会让你迷上它。
在这里,你有一架直升机(或许你想称之为飞机),每一圈它都会降低,你需要投掷炸弹才能摧毁你下面的街区/建筑物。当你摧毁一个街区时,游戏还会在它显示的消息里面添加一些幽默。很好玩。
##### 如何安装?
Bombardier 可以在官方软件库中找到,所以只需在终端中键入以下内容即可安装它:
```
sudo apt install bombardier
```
#### 13、Angband

一个很酷的地下城探索游戏,界面整洁。在探索该游戏时,你可以在一个屏幕上看到所有重要信息。
它包含不同种类的种族可供选择角色。你可以是精灵、霍比特人、矮人或其他什么,有十几种可供选择。请记住,你需要在最后击败黑暗之王,所以尽可能升级你的武器并做好准备。
##### 如何安装?
直接键入如下命令:
```
sudo apt install angband
```
#### 14、GNU 国际象棋

为什么不下盘棋呢?这是我最喜欢的策略游戏了!
但是,除非你知道如何使用代表的符号来描述下一步行动,否则 GNU 国际象棋可能很难玩。当然,作为一个 ASCII 游戏,它不太好交互,所以它会要求你记录你的移动并显示输出(当它等待计算机思考它的下一步行动时)。
##### 如何安装?
如果你了解国际象棋的代表符号,请输入以下命令从终端安装它:
```
sudo apt install gnuchess
```
#### 一些荣誉奖
正如我之前提到的,我们试图向你推荐最好的(也是最容易在 Linux 机器上安装的那些) ASCII 游戏。
然而,有一些标志性的 ASCII 游戏值得关注,它们需要更多的安装工作(你可以获得源代码,但需要构建它/安装它)。
其中一些游戏是:
* [Cataclysm: Dark Days Ahead](https://github.com/CleverRaven/Cataclysm-DDA)
* [Brogue](https://sites.google.com/site/broguegame/)
* [Dwarf Fortress](http://www.bay12games.com/dwarves/index.html)
你可以按照我们的 [从源代码安装软件的完全指南](/article-9172-1.html) 来进行。
### 总结
我们提到的哪些 ASCII 游戏适合你?我们错过了你最喜欢的吗?
请在下面的评论中告诉我们你的想法。
---
via: <https://itsfoss.com/best-ascii-games/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Text-based or should I say [terminal-based games](https://itsfoss.com/best-command-line-games-linux/) were very popular more than a decade back – when you didn’t have visual masterpieces like God Of War, Red Dead Redemption 2 or Spider-Man.
Of course, the Linux platform has its share of good games – but not always the “latest and greatest”. But, there are some ASCII games out there – to which you can never turn your back on.
I’m uncertain if you’d believe me, but some ASCII games on this list proved to be very addictive (So, it might take a while for me to resume work on the next article, or I might just get fired? — Help me!😂)
Jokes apart, let's take a look at the best ASCII games.
## Things to do before Running or Installing an ASCII Game
Before we begin, some ASCII games might require you to install [Simple DirectMedia Layer](https://www.libsdl.org/?ref=itsfoss.com), unless you already have it installed. I suggest you install it before trying to run any of the games mentioned in this article.
For that, you need to type in these commands:
`sudo apt install libsdl2-2.0-0 libsdl2-mixer-2.0-0 libsdl2-image-2.0-0 libsmpeg0 lua5.4`
## 1. Curse of War
[Curse of War](https://a-nikolaev.github.io/curseofwar/) is an interesting strategy game. You might find it a bit confusing at first, but once you get to know it – you’ll love it. I’ll recommend you to take a look at the rules of the game on their homepage before launching the game.
You will be building infrastructure, securing resources and directing your army to fight. All you have to do is place your flag in a good position to let your army take care of the rest. It’s not just about attacking – you need to manage and secure the resources to help win the fight.
If you’ve never played any ASCII game before, be patient and spend some time learning it – to experience it to its fullest potential.
**How to install?**
You will find it in the official repository. So, type in the following command to install it:
`sudo apt install curseofwar`
## 2. ASCII Sector

Hate strategy games? Fret not, [ASCII sector](https://asciisector.fandom.com/wiki/Ascii_Sector_Wiki) is a game that has a space-setting and lets you explore a lot.
Also, the game isn’t just limited to exploration, you need some action? You got that here as well. Of course, not the best combat experience- but it is fun. It gets even more exciting when you see a variety of bases, missions, and quests.
You’ll encounter a leveling system in this tiny game, where you have to earn enough money or trade to upgrade your spaceship.
The best part about this game is – you can create your own quests or play other’s.
**How to install?**
You need to first download and unpack the archived package from [here](https://web.archive.org/web/20230630162623/https://www.asciisector.net/download/). After it’s done, open up your terminal and type these commands:
```
cd Downloads
cd asciisec
chmod +x asciisec
./asciisec
```
## 3. DRL
You may know the classic game “Doom”. So, if you want a scaled down experience of it, [DRL](https://drl.chaosforge.org/?ref=itsfoss.com) is for you. It's an ASCII-based game that is very small in size, with lots of gameplay.
**How to install?**
Before you begin, ensure to install these additional packages:
`sudo apt install libsdl-image1.2 libsdl-mixer1.2 libsdl1.2debian libsmpeg0 lua5.1 timidity libpng16-16`
After that, you need to download the archive from their [download page](https://drl.chaosforge.org/downloads?ref=itsfoss.com) and extract it to a folder. Then type these commands:
```
cd Downloads // navigating to the location where the unpacked folder exists
cd doomrl-linux-x64-0997
chmod +x doomrl
./doomrl
```
## 4. Pyramid Builder
[Pyramid Builder](https://standardcombo.itch.io/pyramid-builder?ref=itsfoss.com) is an innovative take as an ASCII game where you get to improve your civilization by helping build pyramids.
You need to direct the workers to farm, unload cargo, and move the gigantic stones to successfully build the pyramid.
It is indeed a beautiful ASCII game to play.
**How to install?**
Simply head over to the [official site](https://standardcombo.itch.io/pyramid-builder?ref=itsfoss.com), and grab the package. After extracting it, navigate to the folder and run the executable file.
```
cd Downloads
cd pyramid_builder_linux
chmod +x pyramid_builder_linux.x86_64
./pyramid_builder_linux.x86_64
```
## 5. DiabloRL
If you’re an avid gamer, then you must have heard about Blizzard’s Diablo 1. It is undoubtedly one of the good ones.
With [DiabloRL](https://diablo.chaosforge.org) you get the chance to play a unique rendition of the game in an ASCII format. It is a turn-based rogue-like game that is insanely good.
You get to choose from a variety of classes (Warrior, Sorcerer, or Rogue). Every class would result in a different gameplay experience with a set of different stats.
Of course, personal preference will differ – but it’s a decent “unmake” of Diablo. What do you think?
**How to install?**
You can grab the archive from the official [downloads page](https://diablo.chaosforge.org/downloads). To run it, simply go into the extracted folder and run this command:
`./rl`
## 6. Ninvaders
[Ninvaders](https://ninvaders.sourceforge.net) is one of the best ASCII games just because it’s so simple to learn, and also acts an arcade game to kill time.
In this, you have to defend against a horde of invaders, and have to finish them off before they get to you. It sounds basic, but it's a challenging game.
**How to install?**
Similar to Curse of War, you can find this in the official repository. So, just type in this command to install it:
`sudo apt install ninvaders`
## 7. Empire
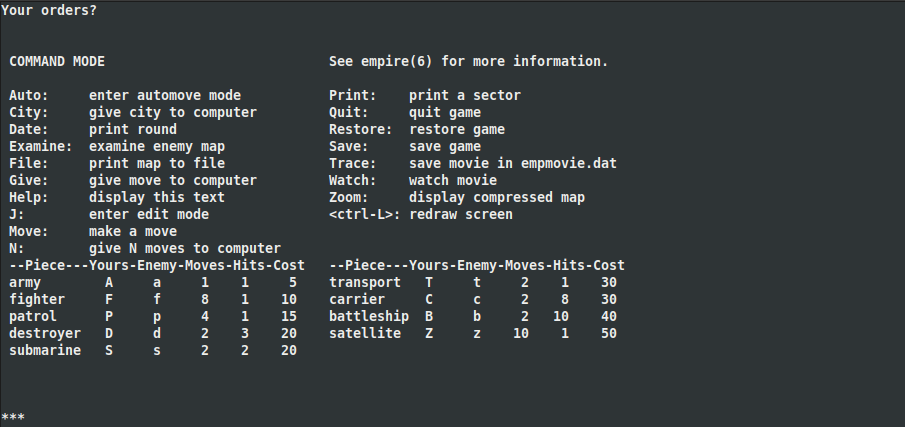
[Empire](http://www.wolfpackempire.com/?ref=itsfoss.com) is a real-time strategy game that requires an active Internet connection.
The rectangle contains cities, land, and water. You need to expand your city with an army, ships, planes and other resources. By expanding quickly, you will be able to capture other cities by destroying them before they make a move.
I’m personally not a fan of Real-Time strategy games, but if you are a fan of such games. You should check out their [guide](http://www.wolfpackempire.com/infopages/Guide.html?ref=itsfoss.com) for playing this game – because it can be challenging to learn.
**How to install?**
Installing this is very simple, just type in the following command:
`sudo apt install empire`
## 8. Nudoku
Love Sudoku? Well, you have [Nudoku](https://jubalh.github.io/nudoku/) – a clone for it. A perfect time-killing ASCII game while you relax.
It presents you with three difficulty levels – Easy, normal, and hard. If you want to put up a challenge with the computer, the hard difficulty will be perfect! If you just want to chill, go for the easy one.
**How to install?**
It’s straightforward to get it installed, just type in the following command in the terminal:
`sudo apt install nudoku`
## 9. NetHack
[NetHack](https://www.nethack.org) is a dungeons and dragon-style ASCII game which might be one of the best out there. I think it’s one of your favorites already, if you know about ASCII games for Linux – in general.
It features plenty of different levels (40+) and comes packed in with many weapons, scrolls, potions, armor, rings, and gems. You can also choose a perma-death mode to play it.
It’s not just about killing here – you get a lot to explore around.
**How to install?**
Simply follow the command below to install it:
`sudo apt install nethack-x11`
## 10. ASCII Jump
[ASCII Jump](https://launchpad.net/ubuntu/jammy/+package/asciijump) is a dead simple Ski-jumping game where you have to slide along a variety of tracks – while jumping, changing position, and moving as long as you can to cover the maximum distance.
It’s really amazing to see how this ASCII game looks (visually) even though it seems so simple.
You can start with the training mode and then proceed to the world cup. You also get to pick your competitors and the hills on which you want to start the game.
**How to install?**
To install the game, just type the following command:
`sudo apt install asciijump`
## 11. Bastet
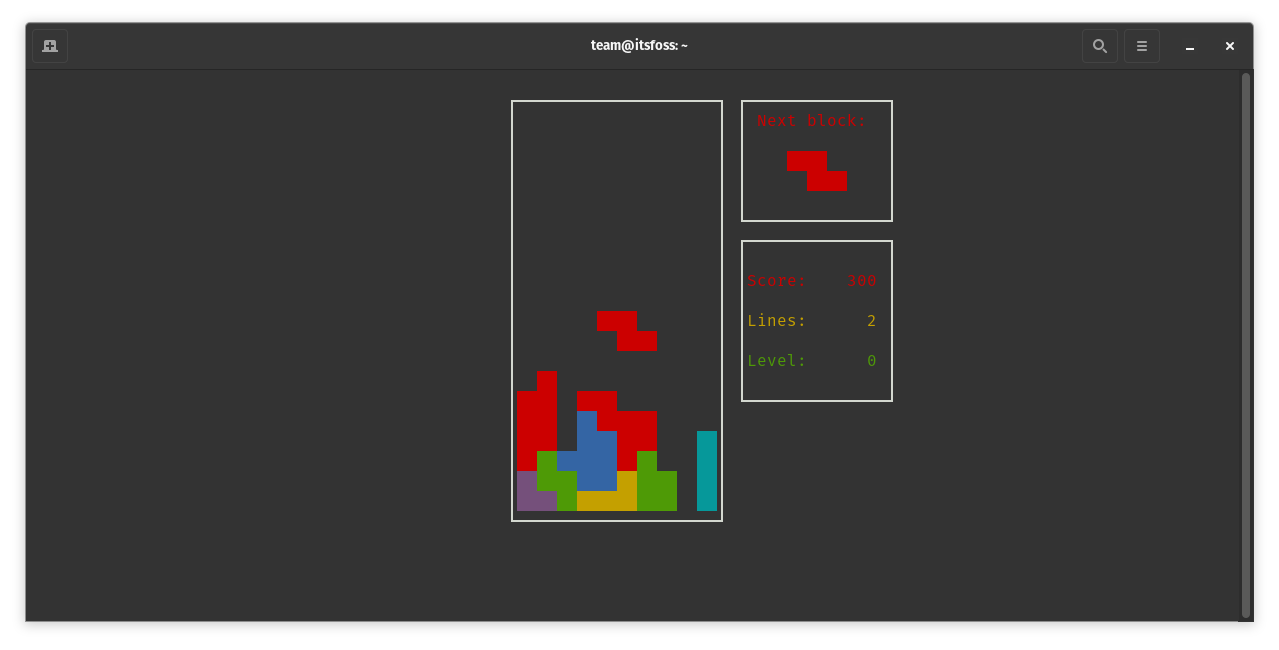
Let’s just not pay any attention to the name – [Bastet](https://github.com/fph/bastet) is actually a fun clone of the good old Tetris game.
You shouldn’t expect it to be just another ordinary Tetris game – but it will present you the worst possible bricks to play with. Have fun!
**How to install?**
Open the terminal and type in the following command:
`sudo apt install bastet`
## 12. Bombardier
[Bombardier](https://launchpad.net/ubuntu/+source/bombardier) is yet another simple ASCII game which will keep you hooked on to it.
Here, you have a helicopter (or whatever you’d like to call your aircraft) which lowers down every cycle, and you need to throw bombs to destroy the blocks/buildings under you.
The game also puts a pinch of humor in the messages it displays when you destroy a block. It's fun.
**How to install?**
Bombardier is available in the official repository, so just type in the following in the terminal to install it:
`sudo apt install bombardier`
## 13. Angband
[Angband](https://rephial.org) is a cool dungeon exploration game with a neat interface. You can see all the vital information in a single screen while you explore the game.
It contains different kinds of character races. You can either be an Elf, Hobbit, Dwarf, or something else – there’s nearly a dozen to choose from.
Remember, that you need to defeat the lord of darkness at the end – so make every upgrade possible to your weapon and get ready.
**How to install?**
You can head over to the [official documentation](https://angband.readthedocs.io/en/latest/hacking/compiling.html) site to learn how to compile it using the source code found in its [GitHub repo](https://github.com/angband/angband).
For a simpler approach, type in the following command:
`sudo apt install angband`
## 14. GNU Chess
How can you not play chess? It is my favorite strategy game!
But, [GNU Chess](https://www.gnu.org/software/chess/) can be tough to play with unless you know the Algebraic notation to describe the next move. Of course, being an ASCII game – it isn’t quite possible to interact – so it asks you the notation to detect your move and displays the output (while it waits for the computer to think its next move).
**How to install?**
If you’re aware of the algebraic notations of Chess, enter the following command to install it from the terminal:
`sudo apt install gnuchess`
## Some Honorable Mentions
As I mentioned earlier, we’ve tried to recommend you the best (but also the ones that are the easiest to install on your Linux machine).
However, there are some iconic ASCII games which deserve your attention. But, these require a tad more effort to install (* You will get the source code, and you need to build it / install it*).
Some of those games are:
You may follow [our guide](https://itsfoss.com/install-software-from-source-code/) on how to install software from source code.
So, wrapping up.
*💬 Which of the ASCII games sounds good to you? Did we miss any of your favorites? Let us know in the comments below!* |
10,547 | 开始使用 Budgie 吧,一款 Linux 桌面环境 | https://opensource.com/article/19/1/productivity-tool-budgie-desktop | 2019-02-17T21:27:37 | [
"Budgie"
] | https://linux.cn/article-10547-1.html |
>
> 使用 Budgie 按需配置你的桌面,这是我们开源工具系列中的第 18 个工具,它将在 2019 年提高你的工作效率。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 18 个工具来帮助你在 2019 年更有效率。
### Budgie 桌面
Linux 中有许多桌面环境。从易于使用并有令人惊叹图形界面的 [GNOME 桌面](https://www.gnome.org/)(在大多数主要 Linux 发行版上是默认桌面)和 [KDE](https://www.kde.org/),到极简主义的 [Openbox](http://openbox.org/wiki/Main_Page),再到高度可配置的平铺化的 [i3](https://i3wm.org/),有很多选择。我要寻找的桌面环境需要速度、不引人注目和干净的用户体验。当桌面不适合你时,很难会有高效率。
[Budgie 桌面](https://getsol.us/solus/experiences/)是 [Solus](https://getsol.us/home/) Linux 发行版的默认桌面,它在大多数主要 Linux 发行版的附加软件包中提供。它基于 GNOME,并使用了许多你可能已经在计算机上使用的相同工具和库。
其默认桌面非常简约,只有面板和空白桌面。Budgie 包含一个集成的侧边栏(称为 Raven),通过它可以快速访问日历、音频控件和设置菜单。Raven 还包含一个集成的通知区域,其中包含与 MacOS 类似的统一系统消息显示。

点击 Raven 中的齿轮图标会显示 Budgie 的控制面板及其配置。由于 Budgie 仍处于开发阶段,与 GNOME 或 KDE 相比,它的选项有点少,我希望随着时间的推移它会有更多的选项。顶部面板选项允许用户配置顶部面板的排序、位置和内容,这很不错。

Budgie 的 Welcome 应用(首次登录时展示)包含安装其他软件、面板小程序、截图和 Flatpack 软件包的选项。这些小程序有处理网络、截图、额外的时钟和计时器等等。

Budgie 提供干净稳定的桌面。它响应迅速,有许多选项,允许你根据需要自定义它。
---
via: <https://opensource.com/article/19/1/productivity-tool-budgie-desktop>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the 18th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## Budgie Desktop
There are many, many desktop environments for Linux. From the easy to use and graphically stunning [GNOME desktop](https://www.gnome.org/) (default on most major Linux distributions) and [KDE](https://www.kde.org/), to the minimalist [Openbox](http://openbox.org/wiki/Main_Page), to the highly configurable tiling [i3](https://i3wm.org/), there are a lot of options. What I look for in a good desktop environment is speed, unobtrusiveness, and a clean user experience. It is hard to be productive when a desktop works against you, not with or for you.
opensource.com
[Budgie Desktop](https://getsol.us/solus/experiences/) is the default desktop on the [Solus](https://getsol.us/home/) Linux distribution and is available as an add-on package for most of the major Linux distributions. It is based on GNOME and uses many of the same tools and libraries you likely already have on your computer.
The default desktop is exceptionally minimalistic, with just the panel and a blank desktop. Budgie includes an integrated sidebar (called Raven) that gives quick access to the calendar, audio controls, and settings menu. Raven also contains an integrated notification area with a unified display of system messages similar to MacOS's.
Clicking on the gear icon in Raven brings up Budgie's control panel with its configuration settings. Since Budgie is still in development, it is a little bare-bones compared to GNOME or KDE, and I hope it gets more options over time. The Top Panel option, which allows the user to configure the ordering, positioning, and contents of the top panel, is nice.
The Budgie Welcome application (presented at first login) contains options to install additional software, panel applets, snaps, and Flatpack packages. There are applets to handle networking, screenshots, additional clocks and timers, and much, much more.
Budgie provides a desktop that is clean and stable. It responds quickly and has many options that allow you to customize it as you see fit.
## 1 Comment |
10,549 | 在 Linux 上创建文件的 10 个方法 | https://www.2daygeek.com/linux-command-to-create-a-file/ | 2019-02-18T21:38:41 | [
"文件"
] | https://linux.cn/article-10549-1.html | 
我们都知道,在 Linux 上,包括设备在内的一切都是文件。Linux 管理员每天应该会多次执行文件创建活动(可能是 20 次,50 次,甚至是更多,这依赖于他们的环境)。如果你想 [在Linux上创建一个特定大小的文件](https://www.2daygeek.com/create-a-file-in-specific-certain-size-linux/),查看前面的这个链接。
高效创建一个文件是非常重要的能力。为什么我说高效?如果你了解一些高效进行你当前活动的方式,你就可以事半功倍。这将会节省你很多的时间。你可以把这些有用的时间用到到其他重要的事情上。
我下面将会介绍多个在 Linux 上创建文件的方法。我建议你选择几个简单高效的来辅助你的工作。你不必安装下列的任何一个命令,因为它们已经作为 Linux 核心工具的一部分安装到你的系统上了。
创建文件可以通过以下六个方式来完成。
* `>`:标准重定向符允许我们创建一个 0KB 的空文件。
* `touch`:如果文件不存在的话,`touch` 命令将会创建一个 0KB 的空文件。
* `echo`:通过一个参数显示文本的某行。
* `printf`:用于显示在终端给定的文本。
* `cat`:它串联并打印文件到标准输出。
* `vi`/`vim`:Vim 是一个向上兼容 Vi 的文本编辑器。它常用于编辑各种类型的纯文本。
* `nano`:是一个简小且用户友好的编辑器。它复制了 `pico` 的外观和优点,但它是自由软件。
* `head`:用于打印一个文件开头的一部分。
* `tail`:用于打印一个文件的最后一部分。
* `truncate`:用于缩小或者扩展文件的尺寸到指定大小。
### 在 Linux 上使用重定向符(>)创建一个文件
标准重定向符允许我们创建一个 0KB 的空文件。它通常用于重定向一个命令的输出到一个新文件中。在没有命令的情况下使用重定向符号时,它会创建一个文件。
但是它不允许你在创建文件时向其中输入任何文本。然而它对于不是很勤劳的管理员是非常简单有用的。只需要输入重定向符后面跟着你想要的文件名。
```
$ > daygeek.txt
```
使用 `ls` 命令查看刚刚创建的文件。
```
$ ls -lh daygeek.txt
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:00 daygeek.txt
```
### 在 Linux 上使用 touch 命令创建一个文件
`touch` 命令常用于将每个文件的访问和修改时间更新为当前时间。
如果指定的文件名不存在,将会创建一个新的文件。`touch` 不允许我们在创建文件的同时向其中输入一些文本。它默认创建一个 0KB 的空文件。
```
$ touch daygeek1.txt
```
使用 `ls` 命令查看刚刚创建的文件。
```
$ ls -lh daygeek1.txt
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:02 daygeek1.txt
```
### 在 Linux 上使用 echo 命令创建一个文件
`echo` 内置于大多数的操作系统中。它常用于脚本、批处理文件,以及作为插入文本的单个命令的一部分。
它允许你在创建一个文件时就向其中输入一些文本。当然也允许你在之后向其中输入一些文本。
```
$ echo "2daygeek.com is a best Linux blog to learn Linux" > daygeek2.txt
```
使用 `ls` 命令查看刚刚创建的文件。
```
$ ls -lh daygeek2.txt
-rw-rw-r-- 1 daygeek daygeek 49 Feb 4 02:04 daygeek2.txt
```
可以使用 `cat` 命令查看文件的内容。
```
$ cat daygeek2.txt
2daygeek.com is a best Linux blog to learn Linux
```
你可以使用两个重定向符 (`>>`) 添加其他内容到同一个文件。
```
$ echo "It's FIVE years old blog" >> daygeek2.txt
```
你可以使用 `cat` 命令查看添加的内容。
```
$ cat daygeek2.txt
2daygeek.com is a best Linux blog to learn Linux
It's FIVE years old blog
```
### 在 Linux 上使用 printf 命令创建一个新的文件
`printf` 命令也可以以类似 `echo` 的方式执行。
`printf` 命令常用来显示在终端窗口给出的字符串。`printf` 可以有格式说明符、转义序列或普通字符。
```
$ printf "2daygeek.com is a best Linux blog to learn Linux\n" > daygeek3.txt
```
使用 `ls` 命令查看刚刚创建的文件。
```
$ ls -lh daygeek3.txt
-rw-rw-r-- 1 daygeek daygeek 48 Feb 4 02:12 daygeek3.txt
```
使用 `cat` 命令查看文件的内容。
```
$ cat daygeek3.txt
2daygeek.com is a best Linux blog to learn Linux
```
你可以使用两个重定向符 (`>>`) 添加其他的内容到同一个文件中去。
```
$ printf "It's FIVE years old blog\n" >> daygeek3.txt
```
你可以使用 `cat` 命令查看这个文件中添加的内容。
```
$ cat daygeek3.txt
2daygeek.com is a best Linux blog to learn Linux
It's FIVE years old blog
```
### 在 Linux 中使用 cat 创建一个文件
`cat` 表示<ruby> 串联 <rt> concatenate </rt></ruby>。在 Linux 经常用于读取一个文件中的数据。
`cat` 是在类 Unix 系统中最常使用的命令之一。它提供了三个与文本文件相关的功能:显示一个文件的内容、组合多个文件的内容到一个输出以及创建一个新的文件。(LCTT 译注:如果 `cat` 命令后如果不带任何文件的话,下面的命令在回车后也不会立刻结束,回车后的操作可以按 `Ctrl-C` 或 `Ctrl-D` 来结束。)
```
$ cat > daygeek4.txt
2daygeek.com is a best Linux blog to learn Linux
It's FIVE years old blog
```
使用 `ls` 命令查看创建的文件。
```
$ ls -lh daygeek4.txt
-rw-rw-r-- 1 daygeek daygeek 74 Feb 4 02:18 daygeek4.txt
```
使用 `cat` 命令查看文件的内容。
```
$ cat daygeek4.txt
2daygeek.com is a best Linux blog to learn Linux
It's FIVE years old blog
```
如果你想向同一个文件中添加其他内容,使用两个连接的重定向符(`>>`)。
```
$ cat >> daygeek4.txt
This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
```
你可以使用 `cat` 命令查看添加的内容。
```
$ cat daygeek4.txt
2daygeek.com is a best Linux blog to learn Linux
It's FIVE years old blog
This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
```
### 在 Linux 上使用 vi/vim 命令创建一个文件
`vim` 是一个向上兼容 `vi` 的文本编辑器。它通常用来编辑所有种类的纯文本。在编辑程序时特别有用。
`vim` 中有很多功能可以用于编辑单个文件。
```
$ vi daygeek5.txt
2daygeek.com is a best Linux blog to learn Linux
It's FIVE years old blog
```
使用 `ls` 查看刚才创建的文件。
```
$ ls -lh daygeek5.txt
-rw-rw-r-- 1 daygeek daygeek 75 Feb 4 02:23 daygeek5.txt
```
使用 `cat` 命令查看文件的内容。
```
$ cat daygeek5.txt
2daygeek.com is a best Linux blog to learn Linux
It's FIVE years old blog
```
### 在 Linux 上使用 nano 命令创建一个文件
`nano` 是一个编辑器,它是一个自由版本的 `pico` 克隆。`nano` 是一个小且用户友好的编辑器。它复制了 `pico` 的外观及优点,并且是一个自由软件,它添加了 `pico` 缺乏的一系列特性,像是打开多个文件、逐行滚动、撤销/重做、语法高亮、行号等等。
```
$ nano daygeek6.txt
2daygeek.com is a best Linux blog to learn Linux
It's FIVE years old blog
This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
```
使用 `ls` 命令查看创建的文件。
```
$ ls -lh daygeek6.txt
-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:26 daygeek6.txt
```
使用 `cat` 命令来查看一个文件的内容。
```
$ cat daygeek6.txt
2daygeek.com is a best Linux blog to learn Linux
It's FIVE years old blog
This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
```
### 在 Linux 上使用 head 命令创建一个文件
`head` 命令通常用于输出一个文件开头的一部分。它默认会打印一个文件的开头 10 行到标准输出。如果有多个文件,则每个文件前都会有一个标题,用来表示文件名。
```
$ head -c 0K /dev/zero > daygeek7.txt
```
使用 `ls` 命令查看创建的文件。
```
$ ls -lh daygeek7.txt
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:30 daygeek7.txt
```
### 在 Linux 上使用 tail 创建一个文件
`tail` 命令通常用来输出一个文件最后的一部分。它默认会打印每个文件的最后 10 行到标准输出。如果有多个文件,则每个文件前都会有一个标题,用来表示文件名。
```
$ tail -c 0K /dev/zero > daygeek8.txt
```
使用 `ls` 命令查看创建的文件。
```
$ ls -lh daygeek8.txt
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:31 daygeek8.txt
```
### 在 Linux 上使用 truncate 命令创建一个文件
`truncate` 命令通常用作将一个文件的尺寸缩小或者扩展为某个指定的尺寸。
```
$ truncate -s 0K daygeek9.txt
```
使用 `ls` 命令检查创建的文件。
```
$ ls -lh daygeek9.txt
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:37 daygeek9.txt
```
在这篇文章中,我使用这十个命令分别创建了下面的这十个文件。
```
$ ls -lh daygeek*
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:02 daygeek1.txt
-rw-rw-r-- 1 daygeek daygeek 74 Feb 4 02:07 daygeek2.txt
-rw-rw-r-- 1 daygeek daygeek 74 Feb 4 02:15 daygeek3.txt
-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:20 daygeek4.txt
-rw-rw-r-- 1 daygeek daygeek 75 Feb 4 02:23 daygeek5.txt
-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:26 daygeek6.txt
-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:32 daygeek7.txt
-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:32 daygeek8.txt
-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:38 daygeek9.txt
-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:00 daygeek.txt
```
---
via: <https://www.2daygeek.com/linux-command-to-create-a-file/>
作者:[Vinoth Kumar](https://www.2daygeek.com/author/vinoth/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,550 | 在 VirtualBox 上安装 Kali Linux 的最安全快捷的方式 | https://itsfoss.com/install-kali-linux-virtualbox | 2019-02-18T23:28:47 | [
"VirtualBox"
] | https://linux.cn/article-10550-1.html |
>
> 本教程将向你展示如何以最快的方式在运行于 Windows 和 Linux 上的 VirtualBox 上安装 Kali Linux。
>
>
>
[Kali Linux](https://www.kali.org/) 是最好的[黑客](https://itsfoss.com/linux-hacking-penetration-testing/) 和安全爱好者的 Linux 发行版之一。
由于它涉及像黑客这样的敏感话题,它就像一把双刃剑。我们过去在一篇详细的 [Kali Linux 点评](/article-10198-1.html)中对此进行了讨论,所以我不会再次赘述。
虽然你可以通过替换现有的操作系统来安装 Kali Linux,但通过虚拟机使用它将是一个更好、更安全的选择。
使用 Virtual Box,你可以将 Kali Linux 当做 Windows / Linux 系统中的常规应用程序一样,几乎就和在系统中运行 VLC 或游戏一样简单。
在虚拟机中使用 Kali Linux 也是安全的。无论你在 Kali Linux 中做什么都不会影响你的“宿主机系统”(即你原来的 Windows 或 Linux 操作系统)。你的实际操作系统将不会受到影响,宿主机系统中的数据将是安全的。

### 如何在 VirtualBox 上安装 Kali Linux
我将在这里使用 [VirtualBox](https://www.virtualbox.org/)。它是一个很棒的开源虚拟化解决方案,适用于任何人(无论是专业或个人用途)。它可以免费使用。
在本教程中,我们将特指 Kali Linux 的安装,但你几乎可以安装任何其他已有 ISO 文件的操作系统或预先构建好的虚拟机存储文件。
**注意:**这些相同的步骤适用于运行在 Windows / Linux 上的 VirtualBox。
正如我已经提到的,你可以安装 Windows 或 Linux 作为宿主机。但是,在本文中,我安装了 Windows 10(不要讨厌我!),我会尝试在 VirtualBox 中逐步安装 Kali Linux。
而且,最好的是,即使你碰巧使用 Linux 发行版作为主要操作系统,相同的步骤也完全适用!
想知道怎么样做吗?让我们来看看…
### 在 VirtualBox 上安装 Kali Linux 的逐步指导
我们将使用专为 VirtualBox 制作的定制 Kali Linux 镜像。当然,你还可以下载 Kali Linux 的 ISO 文件并创建一个新的虚拟机,但是为什么在你有一个简单的替代方案时还要这样做呢?
#### 1、下载并安装 VirtualBox
你需要做的第一件事是从 Oracle 官方网站下载并安装 VirtualBox。
* [下载 VirtualBox](https://www.virtualbox.org/wiki/Downloads)
下载了安装程序后,只需双击它即可安装 VirtualBox。在 Ubuntu / Fedora Linux 上安装 VirtualBox 也是一样的。
#### 2、下载就绪的 Kali Linux 虚拟镜像
VirtualBox 成功安装后,前往 [Offensive Security 的下载页面](https://www.offensive-security.com/kali-linux-vm-vmware-virtualbox-image-download/) 下载用于 VirtualBox 的虚拟机镜像。如果你改变主意想使用 [VMware](https://itsfoss.com/install-vmware-player-ubuntu-1310/),也有用于它的。

如你所见,文件大小远远超过 3 GB,你应该使用 torrent 方式或使用 [下载管理器](https://itsfoss.com/4-best-download-managers-for-linux/) 下载它。
#### 3、在 VirtualBox 上安装 Kali Linux
一旦安装了 VirtualBox 并下载了 Kali Linux 镜像,你只需将其导入 VirtualBox 即可使其正常工作。
以下是如何导入 Kali Linux 的 VirtualBox 镜像:
**步骤 1**:启动 VirtualBox。你会注意到有一个 “Import” 按钮,点击它。

*点击 “Import” 按钮*
**步骤 2**:接着,浏览找到你刚刚下载的文件并选择它导入(如你在下图所见)。文件名应该以 “kali linux” 开头,并以 “.ova” 扩展名结束。

*导入 Kali Linux 镜像*
选择好之后,点击 “Next” 进行处理。
**步骤 3**:现在,你将看到要导入的这个虚拟机的设置。你可以自定义它们,这是你的自由。如果你想使用默认设置,也没关系。
你需要选择具有足够存储空间的路径。我永远不会在 Windows 上推荐使用 C:驱动器。

*以 VDI 方式导入硬盘驱动器*
这里,VDI 方式的硬盘驱动器是指通过分配其存储空间设置来实际挂载该硬盘驱动器。
完成设置后,点击 “Import” 并等待一段时间。
**步骤 4**:你现在将看到这个虚拟机已经列出了。所以,只需点击 “Start” 即可启动它。
你最初可能会因 USB 端口 2.0 控制器支持而出现错误,你可以将其禁用以解决此问题,或者只需按照屏幕上的说明安装其他软件包进行修复即可。现在就完成了!

*运行于 VirtualBox 中的 Kali Linux*
我希望本指南可以帮助你在 VirtualBox 上轻松安装 Kali Linux。当然,Kali Linux 有很多有用的工具可用于渗透测试 —— 祝你好运!
**提示**:Kali Linux 和 Ubuntu 都是基于 Debian 的。如果你在使用 Kali Linux 时遇到任何问题或错误,可以按照互联网上针对 Ubuntu 或 Debian 的教程进行操作。
### 赠品:免费的 Kali Linux 指南手册
如果你刚刚开始使用 Kali Linux,那么了解如何使用 Kali Linux 是一个好主意。
Kali Linux 背后的公司 Offensive Security 已经创建了一本指南,介绍了 Linux 的基础知识,Kali Linux 的基础知识、配置和设置。它还有一些关于渗透测试和安全工具的章节。
基本上,它拥有你开始使用 Kali Linux 时所需知道的一切。最棒的是这本书可以免费下载。
* [免费下载 Kali Linux 揭秘](https://kali.training/downloads/Kali-Linux-Revealed-1st-edition.pdf)
如果你遇到问题或想分享在 VirtualBox 上运行 Kali Linux 的经验,请在下面的评论中告诉我们。
---
via: <https://itsfoss.com/install-kali-linux-virtualbox>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,551 | 计算机实验室之树莓派:课程 7 屏幕02 | https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html | 2019-02-19T21:38:08 | [
"树莓派"
] | https://linux.cn/article-10551-1.html | 
屏幕02 课程在屏幕01 的基础上构建,它教你如何绘制线和一个生成伪随机数的小特性。假设你已经有了 [课程 6:屏幕01](/article-10540-1.html) 的操作系统代码,我们将以它为基础来构建。
### 1、点
现在,我们的屏幕已经正常工作了,现在开始去创建一个更实用的图像,是水到渠成的事。如果我们能够绘制出更实用的图形那就更好了。如果我们能够在屏幕上的两点之间绘制一条线,那我们就能够组合这些线绘制出更复杂的图形了。
我们将尝试用汇编代码去实现它,但在开始时,我们确实需要使用一些其它的函数去辅助。我们需要一个这样的函数,我将调用 `SetPixel` 去修改指定像素的颜色,而在寄存器 `r0` 和 `r1` 中提供输入。如果我们写出的代码可以在任意内存中而不仅仅是屏幕上绘制图形,这将在以后非常有用,因此,我们首先需要一些控制真实绘制位置的方法。我认为实现上述目标的最好方法是,能够有一个内存片段用于保存将要绘制的图形。我应该最终得到的是一个存储地址,它通常指向到自上次的帧缓存结构上。我们将一直在我们的代码中使用这个绘制方法。这样,如果我们想在我们的操作系统的另一部分绘制一个不同的图像,我们就可以生成一个不同结构的地址值,而使用的是完全相同的代码。为简单起见,我们将使用另一个数据片段去控制我们绘制的颜色。
>
> 为了绘制出更复杂的图形,一些方法使用一个着色函数而不是一个颜色去绘制。每个点都能够调用着色函数来确定在那里用什么颜色去绘制。
>
>
>
复制下列代码到一个名为 `drawing.s` 的新文件中。
```
.section .data
.align 1
foreColour:
.hword 0xFFFF
.align 2
graphicsAddress:
.int 0
.section .text
.globl SetForeColour
SetForeColour:
cmp r0,#0x10000
movhs pc,lr
ldr r1,=foreColour
strh r0,[r1]
mov pc,lr
.globl SetGraphicsAddress
SetGraphicsAddress:
ldr r1,=graphicsAddress
str r0,[r1]
mov pc,lr
```
这段代码就是我上面所说的一对函数以及它们的数据。我们将在 `main.s` 中使用它们,在绘制图像之前去控制在何处绘制什么内容。
我们的下一个任务是去实现一个 `SetPixel` 方法。它需要带两个参数,像素的 x 和 y 轴,并且它应该要使用 `graphicsAddress` 和 `foreColour`,我们只定义精确控制在哪里绘制什么图像即可。如果你认为你能立即实现这些,那么去动手实现吧,如果不能,按照我们提供的步骤,按示例去实现它。
>
> 构建一个通用方法,比如 `SetPixel`,我们将在它之上构建另一个方法是一个很好的想法。但我们必须要确保这个方法很快,因为我们要经常使用它。
>
>
>
1. 加载 `graphicsAddress`。
2. 检查像素的 x 和 y 轴是否小于宽度和高度。
3. 计算要写入的像素地址(提示:`frameBufferAddress +(x + y * 宽度)* 像素大小`)
4. 加载 `foreColour`。
5. 保存到地址。
上述步骤实现如下:
1、加载 `graphicsAddress`。
```
.globl DrawPixel
DrawPixel:
px .req r0
py .req r1
addr .req r2
ldr addr,=graphicsAddress
ldr addr,[addr]
```
2、记住,宽度和高度被各自保存在帧缓冲偏移量的 0 和 4 处。如有必要可以参考 `frameBuffer.s`。
```
height .req r3
ldr height,[addr,#4]
sub height,#1
cmp py,height
movhi pc,lr
.unreq height
width .req r3
ldr width,[addr,#0]
sub width,#1
cmp px,width
movhi pc,lr
```
3、确实,这段代码是专用于高色值帧缓存的,因为我使用一个逻辑左移操作去计算地址。你可能希望去编写一个不需要专用的高色值帧缓冲的函数版本,记得去更新 `SetForeColour` 的代码。它实现起来可能更复杂一些。
```
ldr addr,[addr,#32]
add width,#1
mla px,py,width,px
.unreq width
.unreq py
add addr, px,lsl #1
.unreq px
```
>
> `mla dst,reg1,reg2,reg3` 将寄存器 `reg1` 和 `reg2` 中的值相乘,然后将结果与寄存器 `reg3` 中的值相加,并将结果的低 32 位保存到 `dst` 中。
>
>
>
4、这是专用于高色值的。
```
fore .req r3
ldr fore,=foreColour
ldrh fore,[fore]
```
5、这是专用于高色值的。
```
strh fore,[addr]
.unreq fore
.unreq addr
mov pc,lr
```
### 2、线
问题是,线的绘制并不是你所想像的那么简单。到目前为止,你必须认识到,编写一个操作系统时,几乎所有的事情都必须我们自己去做,绘制线条也不例外。我建议你们花点时间想想如何在任意两点之间绘制一条线。
我估计大多数的策略可能是去计算线的梯度,并沿着它来绘制。这看上去似乎很完美,但它事实上是个很糟糕的主意。主要问题是它涉及到除法,我们知道在汇编中,做除法很不容易,并且还要始终记录小数,这也很困难。事实上,在这里,有一个叫布鲁塞姆的算法,它非常适合汇编代码,因为它只使用加法、减法和位移运算。
>
> 在我们日常编程中,我们对像除法这样的运算通常懒得去优化。但是操作系统不同,它必须高效,因此我们要始终专注于如何让事情做的尽可能更好。
>
>
>
>
> 我们从定义一个简单的直线绘制算法开始,代码如下:
>
>
>
> ```
> /* 我们希望从 (x0,y0) 到 (x1,y1) 去绘制一条线,只使用一个函数 setPixel(x,y),它的功能是在给定的 (x,y) 上绘制一个点。 */
>
> if x1 > x0 then
>
> set deltax to x1 - x0
> set stepx to +1
>
> otherwise
>
> set deltax to x0 - x1
> set stepx to -1
>
> end if
>
> if y1 > y0 then
>
> set deltay to y1 - y0
> set stepy to +1
>
> otherwise
>
> set deltay to y0 - y1
> set stepy to -1
>
> end if
>
> if deltax > deltay then
>
> set error to 0
> until x0 = x1 + stepx
>
> setPixel(x0, y0)
> set error to error + deltax ÷ deltay
> if error ≥ 0.5 then
>
> set y0 to y0 + stepy
> set error to error - 1
>
> end if
> set x0 to x0 + stepx
>
> repeat
>
> otherwise
>
> end if
> ```
>
> 这个算法用来表示你可能想像到的那些东西。变量 `error` 用来记录你离实线的距离。沿着 x 轴每走一步,这个 `error` 的值都会增加,而沿着 y 轴每走一步,这个 `error` 值就会减 1 个单位。`error` 是用于测量距离 y 轴的距离。
>
>
> 虽然这个算法是有效的,但它存在一个重要的问题,很明显,我们使用了小数去保存 `error`,并且也使用了除法。所以,一个立即要做的优化将是去改变 `error` 的单位。这里并不需要用特定的单位去保存它,只要我们每次使用它时都按相同数量去伸缩即可。所以,我们可以重写这个算法,通过在所有涉及 `error` 的等式上都简单地乘以 `deltay`,从面让它简化。下面只展示主要的循环:
>
>
>
> ```
> set error to 0 × deltay
> until x0 = x1 + stepx
>
> setPixel(x0, y0)
> set error to error + deltax ÷ deltay × deltay
> if error ≥ 0.5 × deltay then
>
> set y0 to y0 + stepy
> set error to error - 1 × deltay
>
> end if
> set x0 to x0 + stepx
>
> repeat
> ```
>
> 它将简化为:
>
>
>
> ```
> cset error to 0
> until x0 = x1 + stepx
>
> setPixel(x0, y0)
> set error to error + deltax
> if error × 2 ≥ deltay then
>
> set y0 to y0 + stepy
> set error to error - deltay
>
> end if
> set x0 to x0 + stepx
>
> repeat
> ```
>
> 突然,我们有了一个更好的算法。现在,我们看一下如何完全去除所需要的除法运算。最好保留唯一的被 2 相乘的乘法运算,我们知道它可以通过左移 1 位来实现!现在,这是非常接近布鲁塞姆算法的,但还可以进一步优化它。现在,我们有一个 `if` 语句,它将导致产生两个代码块,其中一个用于 x 差异较大的线,另一个用于 y 差异较大的线。对于这两种类型的线,如果审查代码能够将它们转换成一个单语句,还是很值得去做的。
>
>
> 困难之处在于,在第一种情况下,`error` 是与 y 一起变化,而第二种情况下 `error` 是与 x 一起变化。解决方案是在一个变量中同时记录它们,使用负的 `error` 去表示 x 中的一个 `error`,而用正的 `error` 表示它是 y 中的。
>
>
>
> ```
> set error to deltax - deltay
> until x0 = x1 + stepx or y0 = y1 + stepy
>
> setPixel(x0, y0)
> if error × 2 > -deltay then
>
> set x0 to x0 + stepx
> set error to error - deltay
>
> end if
> if error × 2 < deltax then
>
> set y0 to y0 + stepy
> set error to error + deltax
>
> end if
>
> repeat
> ```
>
> 你可能需要一些时间来搞明白它。在每一步中,我们都认为它正确地在 x 和 y 中移动。我们通过检查来做到这一点,如果我们在 x 或 y 轴上移动,`error` 的数量会变低,那么我们就继续这样移动。
>
>
>
>
> 布鲁塞姆算法是在 1962 年由 Jack Elton Bresenham 开发,当时他 24 岁,正在攻读博士学位。
>
>
>
用于画线的布鲁塞姆算法可以通过以下的伪代码来描述。以下伪代码是文本,它只是看起来有点像是计算机指令而已,但它却能让程序员实实在在地理解算法,而不是为机器可读。
```
/* 我们希望从 (x0,y0) 到 (x1,y1) 去绘制一条线,只使用一个函数 setPixel(x,y),它的功能是在给定的 (x,y) 上绘制一个点。 */
if x1 > x0 then
set deltax to x1 - x0
set stepx to +1
otherwise
set deltax to x0 - x1
set stepx to -1
end if
set error to deltax - deltay
until x0 = x1 + stepx or y0 = y1 + stepy
setPixel(x0, y0)
if error × 2 ≥ -deltay then
set x0 to x0 + stepx
set error to error - deltay
end if
if error × 2 ≤ deltax then
set y0 to y0 + stepy
set error to error + deltax
end if
repeat
```
与我们目前所使用的编号列表不同,这个算法的表示方式更常用。看看你能否自己实现它。我在下面提供了我的实现作为参考。
```
.globl DrawLine
DrawLine:
push {r4,r5,r6,r7,r8,r9,r10,r11,r12,lr}
x0 .req r9
x1 .req r10
y0 .req r11
y1 .req r12
mov x0,r0
mov x1,r2
mov y0,r1
mov y1,r3
dx .req r4
dyn .req r5 /* 注意,我们只使用 -deltay,因此为了速度,我保存它的负值。(因此命名为 dyn)*/
sx .req r6
sy .req r7
err .req r8
cmp x0,x1
subgt dx,x0,x1
movgt sx,#-1
suble dx,x1,x0
movle sx,#1
cmp y0,y1
subgt dyn,y1,y0
movgt sy,#-1
suble dyn,y0,y1
movle sy,#1
add err,dx,dyn
add x1,sx
add y1,sy
pixelLoop$:
teq x0,x1
teqne y0,y1
popeq {r4,r5,r6,r7,r8,r9,r10,r11,r12,pc}
mov r0,x0
mov r1,y0
bl DrawPixel
cmp dyn, err,lsl #1
addle err,dyn
addle x0,sx
cmp dx, err,lsl #1
addge err,dx
addge y0,sy
b pixelLoop$
.unreq x0
.unreq x1
.unreq y0
.unreq y1
.unreq dx
.unreq dyn
.unreq sx
.unreq sy
.unreq err
```
### 3、随机性
到目前,我们可以绘制线条了。虽然我们可以使用它来绘制图片及诸如此类的东西(你可以随意去做!),我想应该借此机会引入计算机中随机性的概念。我将这样去做,选择一对随机的坐标,然后从上一对坐标用渐变色绘制一条线到那个点。我这样做纯粹是认为它看起来很漂亮。
那么,总结一下,我们如何才能产生随机数呢?不幸的是,我们并没有产生随机数的一些设备(这种设备很罕见)。因此只能利用我们目前所学过的操作,需要我们以某种方式来发明“随机数”。你很快就会意识到这是不可能的。各种操作总是给出定义好的结果,用相同的寄存器运行相同的指令序列总是给出相同的答案。而我们要做的是推导出一个伪随机序列。这意味着数字在外人看来是随机的,但实际上它是完全确定的。因此,我们需要一个生成随机数的公式。其中有人可能会想到很垃圾的数学运算,比如:4x<sup> 2</sup>! / 64,而事实上它产生的是一个低质量的随机数。在这个示例中,如果 x 是 0,那么答案将是 0。看起来很愚蠢,我们需要非常谨慎地选择一个能够产生高质量随机数的方程式。
>
> 硬件随机数生成器很少用在安全中,因为可预测的随机数序列可能影响某些加密的安全。
>
>
>
我将要教给你的方法叫“二次同余发生器”。这是一个非常好的选择,因为它能够在 5 个指令中实现,并且能够产生一个从 0 到 232-1 之间的看似很随机的数字序列。
不幸的是,对为什么使用如此少的指令能够产生如此长的序列的原因的研究,已经远超出了本课程的教学范围。但我还是鼓励有兴趣的人去研究它。它的全部核心所在就是下面的二次方程,其中 `xn` 是产生的第 `n` 个随机数。
>
> 这类讨论经常寻求一个问题,那就是我们所谓的随机数到底是什么?通常从统计学的角度来说的随机性是:一组没有明显模式或属性能够概括它的数的序列。
>
>
>

这个方程受到以下的限制:
1. a 是偶数
2. b = a + 1 mod 4
3. c 是奇数
如果你之前没有见到过 `mod` 运算,我来解释一下,它的意思是被它后面的数相除之后的余数。比如 `b = a + 1 mod 4` 的意思是 `b` 是 `a + 1` 除以 `4` 的余数,因此,如果 `a` 是 12,那么 `b` 将是 `1`,因为 `a + 1` 是 13,而 `13` 除以 4 的结果是 3 余 1。
复制下列代码到名为 `random.s` 的文件中。
```
.globl Random
Random:
xnm .req r0
a .req r1
mov a,#0xef00
mul a,xnm
mul a,xnm
add a,xnm
.unreq xnm
add r0,a,#73
.unreq a
mov pc,lr
```
这是随机函数的一个实现,使用一个在寄存器 `r0` 中最后生成的值作为输入,而接下来的数字则是输出。在我的案例中,我使用 a = EF00<sub> 16</sub>,b = 1, c = 73。这个选择是随意的,但是需要满足上述的限制。你可以使用任何数字代替它们,只要符合上述的规则就行。
### 4、Pi-casso
OK,现在我们有了所有我们需要的函数,我们来试用一下它们。获取帧缓冲信息的地址之后,按如下的要求修改 `main`:
1. 使用包含了帧缓冲信息地址的寄存器 `r0` 调用 `SetGraphicsAddress`。
2. 设置四个寄存器为 0。一个将是最后的随机数,一个将是颜色,一个将是最后的 x 坐标,而最后一个将是最后的 y 坐标。
3. 调用 `random` 去产生下一个 x 坐标,使用最后一个随机数作为输入。
4. 调用 `random` 再次去生成下一个 y 坐标,使用你生成的 x 坐标作为输入。
5. 更新最后的随机数为 y 坐标。
6. 使用 `colour` 值调用 `SetForeColour`,接着增加 `colour` 值。如果它大于 FFFF~16~,确保它返回为 0。
7. 我们生成的 x 和 y 坐标将介于 0 到 FFFFFFFF<sub> 16</sub>。通过将它们逻辑右移 22 位,将它们转换为介于 0 到 1023<sub> 10</sub> 之间的数。
8. 检查 y 坐标是否在屏幕上。验证 y 坐标是否介于 0 到 767<sub> 10</sub> 之间。如果不在这个区间,返回到第 3 步。
9. 从最后的 x 坐标和 y 坐标到当前的 x 坐标和 y 坐标之间绘制一条线。
10. 更新最后的 x 和 y 坐标去为当前的坐标。
11. 返回到第 3 步。
一如既往,你可以在下载页面上找到这个解决方案。
在你完成之后,在树莓派上做测试。你应该会看到一系列颜色递增的随机线条以非常快的速度出现在屏幕上。它一直持续下去。如果你的代码不能正常工作,请查看我们的排错页面。
如果一切顺利,恭喜你!我们现在已经学习了有意义的图形和随机数。我鼓励你去使用它绘制线条,因为它能够用于渲染你想要的任何东西,你可以去探索更复杂的图案了。它们中的大多数都可以由线条生成,但这需要更好的策略?如果你愿意写一个画线程序,尝试使用 `SetPixel` 函数。如果不是去设置像素值而是一点点地增加它,会发生什么情况?你可以用它产生什么样的图案?在下一节课 [课程 8:屏幕 03](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html) 中,我们将学习绘制文本的宝贵技能。
---
via: <https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html>
作者:[Alex Chadwick](https://www.cl.cam.ac.uk) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Raspberry Pi
# Lesson 7 Screen02
The Screen02 lesson builds on Screen01, by teaching how to draw lines and also
a small feature on generating pseudo random numbers. It is assumed you have the
code for the [Lesson 6: Screen01](screen01.html) operating system as a
basis.
Contents |
## 1 Dots
Now that we've got the screen working, it is only natural to start waiting to create sensible images. It would be very nice indeed if we were able to actually draw something. One of the most basic components in all drawings is a line. If we were able to draw a line between any two points on the screen, we could start creating more complicated drawings just using combinations of these lines.
To allow complex drawing, some systems use a colouring function rather than just one colour to draw things. Each pixel calls the colouring function to determine what colour to draw there.
We will attempt to implement this in assembly code, but first we could really use some other functions to help. We need a function I will call SetPixel that changes the colour of a particular pixel, supplied as inputs in r0 and r1. It will be helpful for future if we write code that could draw to any memory, not just the screen, so first of all, we need some system to control where we are actually going to draw to. I think that the best way to do this would be to have a piece of memory which stores where we are going to draw to. What we should end up with is a stored address which normally points to the frame buffer structure from last time. We will use this at all times in our drawing method. That way, if we want to draw to a different image in another part of our operating system, we could make this value the address of a different structure, and use the exact same code. For simplicity we will use another piece of data to control the colour of our drawings.
Copy the following code to a new file called 'drawing.s'.
.section .data
.align 1
foreColour:
.hword 0xFFFF
.align 2
graphicsAddress:
.int 0
.section .text
.globl SetForeColour
SetForeColour:
cmp r0,#0x10000
movhs pc,lr
ldr r1,=foreColour
strh r0,[r1]
mov pc,lr
.globl SetGraphicsAddress
SetGraphicsAddress:
ldr r1,=graphicsAddress
str r0,[r1]
mov pc,lr
This is just the pair of functions that I described above, along with their data. We will use them in 'main.s' before drawing anything to control where and what we are drawing.
Building generic methods like SetPixel which we can build other methods on top of is a useful idea. We have to make sure the method is fast though, since we will use it a lot.
Our next task is to implement a SetPixel method. This needs to take two parameters, the x and y co-ordinate of a pixel, and it should use the graphicsAddress and foreColour we have just defined to control exactly what and where it is drawing. If you think you can implement this immediately, do, if not I shall outline the steps to be taken, and then give an example implementation.
- Load in the graphicsAddress.
- Check that the x and y co-ordinates of the pixel are less than the width and height.
- Compute the address of the pixel to write. (hint: frameBufferAddress + (x + y * width) * pixel size)
- Load in the foreColour.
- Store it at the address.
An implementation of the above follows.
-
.globl DrawPixel
DrawPixel:
px .req r0
py .req r1
addr .req r2
ldr addr,=graphicsAddress
ldr addr,[addr]
-
height .req r3
ldr height,[addr,#4]
sub height,#1
cmp py,height
movhi pc,lr
.unreq height
width .req r3
ldr width,[addr,#0]
sub width,#1
cmp px,width
movhi pc,lr
Remember that the width and height are stored at offsets of 0 and 4 into the frame buffer description respectively. You can refer back to 'frameBuffer.s' if necessary.
-
ldr addr,[addr,#32]
add width,#1
mla px,py,width,px
.unreq width
.unreq py
add addr, px,lsl #1
.unreq px
mla dst,reg1,reg2,reg3 multiplies the values from reg1 and reg2, adds the value from reg3 and places the least significant 32 bits of the result in dst.
Admittedly, this code is specific to high colour frame buffers, as I use a bit shift directly to compute this address. You may wish to code a version of this function without the specific requirement to use high colour frame buffers, remembering to update the SetForeColour code. It may be significantly more complicated to implement.
-
fore .req r3
ldr fore,=foreColour
ldrh fore,[fore]
As above, this is high colour specific.
-
strh fore,[addr]
.unreq fore
.unreq addr
mov pc,lr
As above, this is high colour specific.
## 2 Lines
The trouble is, line drawing isn't quite as simple as you may expect. By now you must realise that when making operating system, we have to do almost everything ourselves, and line drawing is no exception. I suggest for a few minutes you have a think about how you would draw a line between any two points.
When programming normally, we tend to be lazy with things like division. Operating Systems must be incredibly efficient, and so we must focus on doing things as best as possible.
I expect the central idea of most strategies will involve computing the gradient of the line, and stepping along it. This sounds perfectly reasonable, but is actually a terrible idea. The problem with it is it involves division, which is something that we know can't easily be done in assembly, and also keeping track of decimal numbers, which is again difficult. There is, in fact, an algorithm called Bresenham's Algorithm, which is perfect for assembly code because it only involves addition, subtraction and bit shifts.
Bresenham's Line Algorithm was developed in 1962 by Jack Elton Bresenham, 24 at the time, whilst studying for a PhD.
Bresenham's Algorithm for drawing a line can be described by the following pseudo code. Pseudo code is just text which looks like computer instructions, but is actually intended for programmers to understand algorithms, rather than being machine readable.
/* We wish to draw a line from (x0,y0) to (x1,y1), using only
a function setPixel(x,y) which draws a dot in the pixel given by (x,y). */
if x1 > x0 then
set deltax to x1 - x0
set stepx to +1
otherwise
set deltax to x0 - x1
set stepx to -1
end if
set error to deltax -
deltay
until x0 = x1 + stepx or
y0 = y1 + stepy
setPixel(x0, y0)
if error × 2 ≥ -deltay then
set x0 to x0 + stepx
set error to error - deltay
end if
if error × 2 ≤ deltax then
set y0 to y0 + stepy
set error to error + deltax
end if
repeat
Rather than numbered lists as I have used so far, this representation of an algorithm is far more common. See if you can implement this yourself. For reference, I have provided my implementation below.
.globl DrawLine
DrawLine:
push {r4,r5,r6,r7,r8,r9,r10,r11,r12,lr}
x0 .req r9
x1 .req r10
y0 .req r11
y1 .req r12
mov x0,r0
mov x1,r2
mov y0,r1
mov y1,r3
dx .req r4
dyn .req r5 /* Note that we only ever use -deltay, so I store
its negative for speed. (hence dy**n**) */
sx .req r6
sy .req r7
err .req r8
cmp x0,x1
subgt dx,x0,x1
movgt sx,#-1
suble dx,x1,x0
movle sx,#1
cmp y0,y1
subgt dyn,y1,y0
movgt sy,#-1
suble dyn,y0,y1
movle sy,#1
add err,dx,dyn
add x1,sx
add y1,sy
pixelLoop$:
teq x0,x1
teqne y0,y1
popeq {r4,r5,r6,r7,r8,r9,r10,r11,r12,pc}
mov r0,x0
mov r1,y0
bl DrawPixel
cmp dyn, err,lsl #1
addle err,dyn
addle x0,sx
cmp dx, err,lsl #1
addge err,dx
addge y0,sy
b pixelLoop$
.unreq x0
.unreq x1
.unreq y0
.unreq y1
.unreq dx
.unreq dyn
.unreq sx
.unreq sy
.unreq err
## 3 Randomness
So, now we can draw lines. Although we could use this to draw pictures and whatnot (feel free to do so!), I thought I would take the opportunity to introduce the idea of computer randomness. What we will do is select a pair of random co-ordinates, and then draw a line from the last pair to that point in steadily incrementing colours. I do this purely because it looks quite pretty.
Hardware random number generators are occasionally used in security, where the predictability sequence of random numbers may affect the security of some encryption.
So, now it comes down to it, how do we be random? Unfortunately for us there isn't
some device which generates random numbers (such devices are very rare). So somehow
using only the operations we've learned so far we need to invent 'random numbers'.
It shouldn't take you long to realise this is impossible. The operations always
have well defined results, executing the same sequence of instructions with the
same registers yields the same answer. What we instead do is deduce a sequence that
is pseudo random. This means numbers that, to the outside observer, look random,
but in fact were completely determined. So, we need a formula to generate random
numbers. One might be tempted to just spam mathematical operators out for example:
4x2! / 64, but in actuality this generally produces low quality random
numbers. In this case for example, if x were 0, the answer would be 0. Stupid though
it sounds, we need a very careful choice of equation to produce high quality random
numbers.
This sort of discussion often begs the question what do we mean by a random number? We generally mean statistical randomness: A sequence of numbers that has no obvious patterns or properties that could be used to generalise it.
The method I'm going to teach you is called the quadratic congruence generator.
This is a good choice because it can be implemented in 5 instructions, and yet generates
a seemingly random order of the numbers from 0 to 232-1.
The reason why the generator can create such long sequence with so few instructions
is unfortunately a little beyond the scope of this course, but I encourage the interested
to research it. It all centralises on the following quadratic formula, where xn is the nth random number generated.
xn+1 = axn2 + bxn + c mod 232
Subject to the following constraints:
- a is even
- b = a + 1 mod 4
- c is odd
If you've not seen mod before, it means the remainder of a division by the number after it. For example b = a + 1 mod 4 means that b is the remainder of dividing a + 1 by 4, so if a were 12 say, b would be 1 as a + 1 is 13, and 13 divided by 4 is 3 remainder 1.
Copy the following code into a file called 'random.s'.
.globl Random
Random:
xnm .req r0
a .req r1
mov a,#0xef00
mul a,xnm
mul a,xnm
add a,xnm
.unreq xnm
add r0,a,#73
.unreq a
mov pc,lr
This is an implementation of the random function, with an input of the last value
generated in r0, and an output of the next number.
In my case, I've used a = EF0016, b = 1, c = 73. This choice was arbitrary
but meets the requirements above. Feel free to use any numbers you wish instead,
as long as they obey the rules.
## 4 Pi-casso
OK, now we have all the functions we're going to need, let's try it out. Alter main to do the following, after getting the frame buffer info address:
- Call SetGraphicsAddress with r0 containing the frame buffer info address.
- Set four registers to 0. One will be the last random number, one will be the colour, one will be the last x co-ordinate and one will be the last y co-ordinate.
- Call random to generate the next x-coordinate, using the last random number as the input.
- Call random again to generate the next y-coordinate, using the x-coordinate you generated as an input.
- Update the last random number to contain the y-coordinate.
- Call SetForeColour with the colour, then increment the colour. If it goes above
FFFF
16, make sure it goes back to 0. - The x and y coordinates we have generated are between 0 and FFFFFFFF
16. Convert them to a number between 0 and 102310by using a logical shift right of 22. - Check the y coordinate is on the screen. Valid y coordinates are between 0 and 767
10. If not, go back to 3. - Draw a line from the last x and y coordinates to the current x and y coordinates.
- Update the last x and y coordinates to contain the current ones.
- Go back to 3.
As always, a solution for this can be found on the downloads page.
Once you've finished, test it on the Raspberry Pi. You should see a very fast sequence of random lines being drawn on the screen, in steadily incrementing colours. This should never stop. If it doesn't work, please see our troubleshooting page.
When you have it working, congratulations! We've now learned about meaningful graphics,
and also about random numbers. I encourage you to play with line drawing, as it
can be used to render almost anything you want. You may also want to explore more
complicated shapes. Most can be made out of lines, but is this necessarily the best
strategy? If you like the line program, try experimenting with the SetPixel function.
What happens if instead of just setting the value of the pixel, you increase it
by a small amount? What other patterns can you make? In the next lesson, [
Lesson 8: Screen 03](screen03.html), we will look at the invaluable skill of drawing text. |
10,552 | 在 Linux 中安装并使用 PuTTY | https://www.ostechnix.com/how-to-install-and-use-putty-on-linux/ | 2019-02-20T10:02:24 | [
"PuTTY",
"SSH"
] | https://linux.cn/article-10552-1.html | 
PuTTY 是一个自由开源且支持包括 SSH、Telnet 和 Rlogin 在内的多种协议的 GUI 客户端。一般来说,Windows 管理员们会把 PuTTY 当成 SSH 或 Telnet 客户端来在本地 Windows 系统和远程 Linux 服务器之间建立连接。不过,PuTTY 可不是 Windows 的独占软件。它在 Linux 用户之中也是很流行的。本篇文章将会告诉你如何在 Linux 中安装并使用 PuTTY。
### 在 Linux 中安装 PuTTY
PuTTY 已经包含在了许多 Linux 发行版的官方源中。举个例子,在 Arch Linux 中,我们可以通过这个命令安装 PuTTY:
```
$ sudo pacman -S putty
```
在 Debian、Ubuntu 或是 Linux Mint 中安装它:
```
$ sudo apt install putty
```
### 使用 PuTTY 访问远程 Linux 服务器
在安装完 PuTTY 之后,你可以在菜单或启动器中打开它。如果你想用终端打开它,也是可以的:
```
$ putty
```
PuTTY 的默认界面长这个样子:

如你所见,许多选项都配上了说明。在左侧面板中,你可以配置许多项目,比如:
1. 修改 PuTTY 登录会话选项;
2. 修改终端模拟器控制选项,控制各个按键的功能;
3. 控制终端响铃的声音;
4. 启用/禁用终端的高级功能;
5. 设定 PuTTY 窗口大小;
6. 控制命令回滚长度(默认是 2000 行);
7. 修改 PuTTY 窗口或光标的外观;
8. 调整窗口边缘;
9. 调整字体;
10. 保存登录信息;
11. 设置代理;
12. 修改各协议的控制选项;
13. 以及更多。
所有选项基本都有注释,相信你理解起来不难。
### 使用 PuTTY 访问远程 Linux 服务器
请在左侧面板点击 “Session” 选项卡,输入远程主机名(或 IP 地址)。然后,请选择连接类型(比如 Telnet、Rlogin 以及 SSH 等)。根据你选择的连接类型,PuTTY 会自动选择对应连接类型的默认端口号(比如 SSH 是 22、Telnet 是 23),如果你修改了默认端口号,别忘了手动把它输入到 “Port” 里。在这里,我用 SSH 连接到远程主机。在输入所有信息后,请点击 “Open”。

如果这是你首次连接到这个远程主机,PuTTY 会显示一个安全警告,问你是否信任你连接到的远程主机。点击 “Accept” 即可将远程主机的密钥加入 PuTTY 的缓存当中:

接下来,输入远程主机的用户名和密码。然后你就成功地连接上远程主机啦。

#### 使用密钥验证访问远程主机
一些 Linux 管理员可能在服务器上配置了密钥认证。举个例子,在用 PuTTY 访问 AMS 实例的时候,你需要指定密钥文件的位置。PuTTY 可以使用它自己的格式(`.ppk` 文件)来进行公钥验证。
首先输入主机名或 IP。之后,在 “Category” 选项卡中,展开 “Connection”,再展开 “SSH”,然后选择 “Auth”,之后便可选择 `.ppk` 密钥文件了。

点击 “Accept” 来关闭安全提示。然后,输入远程主机的密码(如果密钥被密码保护)来建立连接。
#### 保存 PuTTY 会话
有些时候,你可能需要多次连接到同一个远程主机,你可以保存这些会话并在之后不输入信息访问他们。
请输入主机名(或 IP 地址),并提供一个会话名称,然后点击 “Save”。如果你有密钥文件,请确保你在点击 “Save” 按钮之前指定它们。

现在,你可以通过选择 “Saved sessions”,然后点击 “Load”,再点击 “Open” 来启动连接。
#### 使用 PuTTY 安全复制客户端(pscp)来将文件传输到远程主机中
通常来说,Linux 用户和管理员会使用 `scp` 这个命令行工具来从本地往远程主机传输文件。不过 PuTTY 给我们提供了一个叫做 <ruby> PuTTY 安全复制客户端 <rt> PuTTY Secure Copy Client </rt></ruby>(简写为 `pscp`)的工具来干这个事情。如果你的本地主机运行的是 Windows,你可能需要这个工具。PSCP 在 Windows 和 Linux 下都是可用的。
使用这个命令来将 `file.txt` 从本地的 Arch Linux 拷贝到远程的 Ubuntu 上:
```
pscp -i test.ppk file.txt [email protected]:/home/sk/
```
让我们来分析这个命令:
* `-i test.ppk`:访问远程主机所用的密钥文件;
* `file.txt`:要拷贝到远程主机的文件;
* `[email protected]`:远程主机的用户名与 IP;
* `/home/sk/`:目标路径。
要拷贝一个目录,请使用 `-r`(<ruby> 递归 <rt> Recursive </rt></ruby>)参数:
```
pscp -i test.ppk -r dir/ [email protected]:/home/sk/
```
要使用 `pscp` 传输文件,请执行以下命令:
```
pscp -i test.ppk c:\documents\file.txt.txt [email protected]:/home/sk/
```
你现在应该了解了 PuTTY 是什么,知道了如何安装它和如何使用它。同时,你也学习到了如何使用 `pscp` 程序在本地和远程主机上传输文件。
以上便是所有了,希望这篇文章对你有帮助。
干杯!
---
via: <https://www.ostechnix.com/how-to-install-and-use-putty-on-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zhs852](https://github.com/zhs852) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,553 | 5 个面向新手的 Linux 发行版 | https://www.linux.com/blog/learn/2019/2/top-5-linux-distributions-new-users | 2019-02-20T10:56:23 | [
"发行版",
"新手"
] | https://linux.cn/article-10553-1.html |
>
> 5 个可使用新用户有如归家般感觉的发行版。
>
>
>

从最初的 Linux 到现在,Linux 已经发展了很长一段路。但是,无论你曾经多少次听说过现在使用 Linux 有多容易,仍然会有表示怀疑的人。而要真的承担得其这份声明,桌面必须足够简单,以便不熟悉 Linux 的人也能够使用它。事实上大量的桌面发行版使这成为了现实。
### 无需 Linux 知识
将这个清单误解为又一个“最佳用户友好型 Linux 发行版”的清单可能很简单。但这不是我们要在这里看到的。这二者之间有什么不同?就我的目的而言,定义的界限是 Linux 是否真正起到了使用的作用。换句话说,你是否可以将这个桌面操作系统放在一个用户面前,并让他们应用自如而无需懂得 Linux 知识呢?
不管你相信与否,有些发行版就能做到。这里我将介绍给你 5 个这样的发行版。这些或许你全都听说过。它们或许不是你所选择的发行版,但可以向你保证它们无需过多关注,而是将用户放在眼前的。
我们来看看选中的几个。
### Elementary OS
[Elementary OS](https://elementary.io/) 的理念主要围绕人们如何实际使用他们的桌面。开发人员和设计人员不遗余力地创建尽可能简单的桌面。在这个过程中,他们致力于去 Linux 化的 Linux。这并不是说他们已经从这个等式中删除了 Linux。不,恰恰相反,他们所做的就是创建一个与你所发现的一样的中立的操作系统。Elementary OS 是如此流畅,以确保一切都完美合理。从单个 Dock 到每个人都清晰明了的应用程序菜单,这是一个桌面,而不用提醒用户说,“你正在使用 Linux!” 事实上,其布局本身就让人联想到 Mac,但附加了一个简单的应用程序菜单(图 1)。

*图 1:Elementary OS Juno 应用菜单*
将 Elementary OS 放在此列表中的另一个重要原因是它不像其他桌面发行版那样灵活。当然,有些用户会对此不以为然,但是如果桌面没有向用户扔出各种花哨的定制诱惑,那么就会形成一个非常熟悉的环境:一个既不需要也不允许大量修修补补的环境。操作系统在让新用户熟悉该平台这一方面还有很长的路要走。
与任何现代 Linux 桌面发行版一样,Elementary OS 包括了应用商店,称为 AppCenter,用户可以在其中安装所需的所有应用程序,而无需触及命令行。
### 深度操作系统
[深度操作系统](https://www.deepin.org/)不仅得到了市场上最漂亮的台式机之一的赞誉,它也像任何桌面操作系统一样容易上手。其桌面界面非常简单,对于毫无 Linux 经验的用户来说,它的上手速度非常快。事实上,你很难找到无法立即上手使用 Deepin 桌面的用户。而这里唯一可能的障碍可能是其侧边栏控制中心(图 2)。

*图 2:Deepin 的侧边栏控制编码*
但即使是侧边栏控制面板,也像市场上的任何其他配置工具一样直观。任何使用过移动设备的人对于这种布局都很熟悉。至于打开应用程序,Deepin 的启动器采用了 macOS Launchpad 的方式。此按钮位于桌面底座上通常最右侧的位置,因此用户立即就可以会意,知道它可能类似于标准的“开始”菜单。
与 Elementary OS(以及市场上大多数 Linux 发行版)类似,深度操作系统也包含一个应用程序商店(简称为“商店”),可以轻松安装大量应用程序。
### Ubuntu
你知道肯定有它。[Ubuntu](https://www.ubuntu.com/) 通常在大多数用户友好的 Linux 列表中占据首位。因为它是少数几个不需要懂得 Linux 就能使用的桌面之一。但在采用 GNOME(和 Unity 谢幕)之前,情况并非如此。因为 Unity 经常需要进行一些调整才能达到一点 Linux 知识都不需要的程度(图 3)。现在 Ubuntu 已经采用了 GNOME,并将其调整到甚至不需要懂得 GNOME 的程度,这个桌面使得对 Linux 的简单性和可用性的要求不再是迫切问题。

*图 3:Ubuntu 18.04 桌面可使用马上熟悉起来*
与 Elementary OS 不同,Ubuntu 对用户毫无阻碍。因此,任何想从桌面上获得更多信息的人都可以拥有它。但是,其开箱即用的体验对于任何类型的用户都是足够的。任何一个让用户不知道他们触手可及的力量有多少的桌面,肯定不如 Ubuntu。
### Linux Mint
我需要首先声明,我从来都不是 [Linux Mint](https://linuxmint.com/) 的忠实粉丝。但这并不是说我不尊重开发者的工作,而更多的是一种审美观点。我更喜欢现代化的桌面环境。但是,旧式的学校计算机桌面的隐喻(可以在默认的 Cinnamon 桌面中找到)可以让几乎每个人使用它的人都格外熟悉。Linux Mint 使用任务栏、开始按钮、系统托盘和桌面图标(图 4),提供了一个需要零学习曲线的界面。事实上,一些用户最初可能会被愚弄,以为他们正在使用 Windows 7 的克隆版。甚至是它的更新警告图标也会让用户感到非常熟悉。

*图 4:Linux Mint 的 Cinnamon 桌面非常像 Windows 7*
因为 Linux Mint 受益于其所基于的 Ubuntu,它不仅会让你马上熟悉起来,而且具有很高的可用性。无论你是否对底层平台有所了解,用户都会立即感受到宾至如归的感觉。
### Ubuntu Budgie
我们的列表将以这样一个发行版做结:它也能让用户忘记他们正在使用 Linux,并且使用常用工具变得简单、美观。使 Ubuntu 融合 Budgie 桌面可以构成一个令人印象深刻的易用发行版。虽然其桌面布局(图 5)可能不太一样,但毫无疑问,适应这个环境并不需要浪费时间。实际上,除了 Dock 默认居于桌面的左侧,[Ubuntu Budgie](https://ubuntubudgie.org/) 确实看起来像 Elementary OS。

*图 5:Budgie 桌面既漂亮又简单*
Ubuntu Budgie 中的系统托盘/通知区域提供了一些不太多见的功能,比如:快速访问 Caffeine(一种保持桌面清醒的工具)、快速笔记工具(用于记录简单笔记)、Night Lite 开关、原地下拉菜单(用于快速访问文件夹),当然还有 Raven 小程序/通知侧边栏(与深度操作系统中的控制中心侧边栏类似,但不太优雅)。Budgie 还包括一个应用程序菜单(左上角),用户可以访问所有已安装的应用程序。打开一个应用程序,该图标将出现在 Dock 中。右键单击该应用程序图标,然后选择“保留在 Dock”以便更快地访问。
Ubuntu Budgie 的一切都很直观,所以几乎没有学习曲线。这种发行版既优雅又易于使用,不能再好了。
### 选择一个吧
至此介绍了 5 个 Linux 发行版,它们各自以自己的方式提供了让任何用户都马上熟悉的桌面体验。虽然这些可能不是你对顶级发行版的选择,但对于那些不熟悉 Linux 的用户来说,却不能否定它们的价值。
---
via: <https://www.linux.com/blog/learn/2019/2/top-5-linux-distributions-new-users>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,554 | COPR 仓库中 4 个很酷的新软件(2019.2) | https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-february-2019/ | 2019-02-20T16:25:57 | [
"COPR",
"Fedora"
] | https://linux.cn/article-10554-1.html | 
COPR 是个人软件仓库[集合](https://copr.fedorainfracloud.org/),它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不被 Fedora 基础设施不支持或没有被该项目所签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
这是 COPR 中一组新的有趣项目。
### CryFS
[CryFS](https://www.cryfs.org/) 是一个加密文件系统。它设计与云存储一同使用,主要是 Dropbox,尽管它也可以与其他存储提供商一起使用。CryFS 不仅加密文件系统中的文件,还会加密元数据、文件大小和目录结构。
#### 安装说明
仓库目前为 Fedora 28 和 29 以及 EPEL 7 提供 CryFS。要安装 CryFS,请使用以下命令:
```
sudo dnf copr enable fcsm/cryfs
sudo dnf install cryfs
```
### Cheat
[Cheat](https://github.com/chrisallenlane/cheat) 是一个用于在命令行中查看各种备忘录的工具,用来提醒仅偶尔使用的程序的使用方法。对于许多 Linux 程序,`cheat` 提供了来自手册页的精简后的信息,主要关注最常用的示例。除了内置的备忘录,`cheat` 允许你编辑现有的备忘录或从头开始创建新的备忘录。

#### 安装说明
仓库目前为 Fedora 28、29 和 Rawhide 以及 EPEL 7 提供 `cheat`。要安装 `cheat`,请使用以下命令:
```
sudo dnf copr enable tkorbar/cheat
sudo dnf install cheat
```
### Setconf
[setconf](https://setconf.roboticoverlords.org/) 是一个简单的程序,作为 `sed` 的替代方案,用于对配置文件进行更改。`setconf` 唯一能做的就是找到指定文件中的密钥并更改其值。`setconf` 仅提供很少的选项来更改其行为 - 例如,取消更改行的注释。
#### 安装说明
仓库目前为 Fedora 27、28 和 29 提供 `setconf`。要安装 `setconf`,请使用以下命令:
```
sudo dnf copr enable jamacku/setconf
sudo dnf install setconf
```
### Reddit 终端查看器
[Reddit 终端查看器](https://github.com/michael-lazar/rtv),或称为 `rtv`,提供了从终端浏览 Reddit 的界面。它提供了 Reddit 的基本功能,因此你可以登录到你的帐户,查看 subreddits、评论、点赞和发现新主题。但是,rtv 目前不支持 Reddit 标签。

#### 安装说明
该仓库目前为 Fedora 29 和 Rawhide 提供 Reddit Terminal Viewer。要安装 Reddit Terminal Viewer,请使用以下命令:
```
sudo dnf copr enable tc01/rtv
sudo dnf install rtv
```
---
via: <https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-february-2019/>
作者:[Dominik Turecek](https://fedoramagazine.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | COPR is a [collection](https://copr.fedorainfracloud.org/) of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
Here’s a set of new and interesting projects in COPR.
### CryFS
[CryFS](https://www.cryfs.org/) is a cryptographic filesystem. It is designed for use with cloud storage, mainly Dropbox, although it works with other storage providers as well. CryFS encrypts not only the files in the filesystem, but also metadata, file sizes and directory structure.
#### Installation instructions
The repo currently provides CryFS for Fedora 28 and 29, and for EPEL 7. To install CryFS, use these commands:
sudo dnf copr enable fcsm/cryfs
sudo dnf install cryfs
### Cheat
[Cheat](https://github.com/chrisallenlane/cheat) is a utility for viewing various cheatsheets in command-line, aiming to help remind usage of programs that are used only occasionally. For many Linux utilities, *cheat* provides cheatsheets containing condensed information from man pages, focusing mainly on the most used examples. In addition to the built-in cheatsheets, *cheat* allows you to edit the existing ones or creating new ones from scratch.
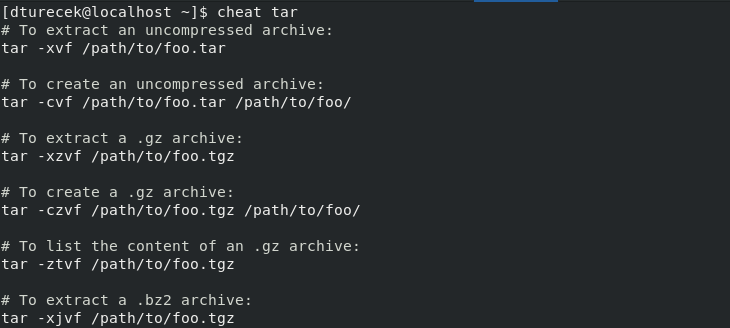
#### Installation instructions
The repo currently provides *cheat* for Fedora 28, 29 and Rawhide, and for EPEL 7. To install *cheat*, use these commands:
sudo dnf copr enable tkorbar/cheat
sudo dnf install cheat
### Setconf
[Setconf](https://setconf.roboticoverlords.org/) is a simple program for making changes in configuration files, serving as an alternative for sed. The only thing *setconf* does is that it finds the key in the specified file and changes its value. Setconf provides only a few options to change its behavior — for example, uncommenting the line that is being changed.
#### Installation instructions
The repo currently provides setconf for Fedora 27, 28 and 29. To install setconf, use these commands:
sudo dnf copr enable jamacku/setconf
sudo dnf install setconf
### Reddit Terminal Viewer
[Reddit Terminal Viewer](https://github.com/michael-lazar/rtv), or rtv, is an interface for browsing Reddit from terminal. It provides the basic functionality of Reddit, so you can log in to your account, view subreddits, comment, upvote and discover new topics. Rtv currently doesn’t, however, support Reddit tags.
#### Installation instructions
The repo currently provides Reddit Terminal Viewer for Fedora 29 and Rawhide. To install Reddit Terminal Viewer, use these commands:
sudo dnf copr enable tc01/rtv
sudo dnf install rtv
## Andrei
Can’t really agree with the Cheat one as it’s easier to curl on http://cheat.sh/term-here. Pretty sure that’s what they use in that package as well.
## Guus
Thank you for the tip! it is actually interesting to compare the two source repositories.
There are two github libraries: cheat/cheat (article) and chubin/cheat (curls version). I found both different authors and both using very different python programs and (with limited python knowledge) I found no links from one to the other.
In the ‘cheat/cheat’ github code I found the literal formulation of the cheats in the subdirectory ‘cheatsheets’.
In the ‘chubin/cheat’ github code I could find no reference to where the cheats come from.
But …. running both cheats in terminator in 2 side by side terminals, the output appears to be identical. Unless this has a link in common in the manpages, this is too much of a coincidence to be accidental.
About usage though, I would suspect that the following arguments apply:
cheat/cheat (article) provides local access to the cheats.
chubin/cheat (curl) provides remote access to the cheats.
So, if you are always connected, it really doesn’t matter which one you chose (the output appears to be the same). If you work offline as well, then the articles solution is the better as you always have access.
## Guus
Would it be possible for all
packages to specify why it was not included in Fedora? I am usually interested in the reason and for encryption I am especially interested in what is holding Fedora back.
## Baggypants
For all the things I put in copr, it’s just because I can’t be bothered becoming an official package manager. And given it’s lazyness that means I use copr to provide packages, then no, I’m not going to bother to write up why it’s not in the main repo either.
## Guus
I get your response from the perspective of a copr provider. My question is aimed at Fedora (the writer of this article), for recommending them. Not at copr providers.
What is the reason for not including them in Fedora? Maybe the only reason is availability of a packager. Maybe it’s some other reason. But if the package has license issues I would want to know. If there are issues between the software and the system software, I would want to know.
I chose Fedora for a set of reasons, one of which is reliability, the other is guaranteed getting free software. So, getting a copr that Fedora recommends, shouldn’t introduce problems in these respects. I just want to know why. |
10,555 | 用 AWK 喝咖啡 | https://opensource.com/article/19/2/drinking-coffee-awk | 2019-02-20T17:38:15 | [
"AWK"
] | https://linux.cn/article-10555-1.html |
>
> 用一个简单的 AWK 程序跟踪你的同事喝咖啡的欠款。
>
>
>

以下基于一个真实的故事,虽然一些名字和细节有所改变。
>
> 很久以前,在一个遥远的地方,有一间~~庙~~(划掉)办公室。由于各种原因,这个办公室没有购买速溶咖啡。所以那个办公室的一些人聚在一起决定建立“咖啡角”。
>
>
> 咖啡角的一名成员会购买一些速溶咖啡,而其他成员会付给他钱。有人喝咖啡比其他人多,所以增加了“半成员”的级别:半成员每周允许喝的咖啡限量,并可以支付其它成员支付的一半。
>
>
>
管理这事非常操心。而我刚读过《Unix 编程环境》这本书,想练习一下我的 [AWK](https://en.wikipedia.org/wiki/AWK) 编程技能,所以我自告奋勇创建了一个系统。
第 1 步:我用一个数据库来记录成员及其应支付给咖啡角的欠款。我是以 AWK 便于处理的格式记录的,其中字段用冒号分隔:
```
member:john:1:22
member:jane:0.5:33
member:pratyush:0.5:17
member:jing:1:27
```
上面的第一个字段标识了这是哪一种行(`member`)。第二个字段是成员的名字(即他们的电子邮件用户名,但没有 @ )。下一个字段是其成员级别(成员 = 1,或半会员 = 0.5)。最后一个字段是他们欠咖啡角的钱。正数表示他们欠咖啡角钱,负数表示咖啡角欠他们。
第 2 步:我记录了咖啡角的收入和支出:
```
payment:jane:33
payment:pratyush:17
bought:john:60
payback:john:50
```
Jane 付款 $33,Pratyush 付款 $17,John 买了价值 $60 的咖啡,而咖啡角还款给 John $50。
第 3 步:我准备写一些代码,用来处理成员和付款,并生成记录了新欠账的更新的成员文件。
```
#!/usr/bin/env --split-string=awk -F: -f
```
释伴行(`#!`)需要做一些调整,我使用 `env` 命令来允许从释伴行传递多个参数:具体来说,AWK 的 `-F` 命令行参数会告诉它字段分隔符是什么。
AWK 程序就是一个规则序列(也可以包含函数定义,但是对于这个咖啡角应用来说不需要)
第一条规则读取该成员文件。当我运行该命令时,我总是首先给它的是成员文件,然后是付款文件。它使用 AWK 关联数组来在 `members` 数组中记录成员级别,以及在 `debt` 数组中记录当前欠账。
```
$1 == "member" {
members[$2]=$3
debt[$2]=$4
total_members += $3
}
```
第二条规则在记录付款(`payment`)时减少欠账。
```
$1 == "payment" {
debt[$2] -= $3
}
```
还款(`payback`)则相反:它增加欠账。这可以优雅地支持意外地给了某人太多钱的情况。
```
$1 == "payback" {
debt[$2] += $3
}
```
最复杂的部分出现在有人购买(`bought`)速溶咖啡供咖啡角使用时。它被视为付款(`payment`),并且该人的债务减少了适当的金额。接下来,它计算每个会员的费用。它根据成员的级别对所有成员进行迭代并增加欠款
```
$1 == "bought" {
debt[$2] -= $3
per_member = $3/total_members
for (x in members) {
debt[x] += per_member * members[x]
}
}
```
`END` 模式很特殊:当 AWK 没有更多的数据要处理时,它会一次性执行。此时,它会使用更新的欠款数生成新的成员文件。
```
END {
for (x in members) {
printf "%s:%s:%s\n", x, members[x], debt[x]
}
}
```
再配合一个遍历成员文件,并向人们发送提醒电子邮件以支付他们的会费(积极清账)的脚本,这个系统管理咖啡角相当一段时间。
---
via: <https://opensource.com/article/19/2/drinking-coffee-awk>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The following is based on a true story, although some names and details have been changed.
A long time ago, in a place far away, there was an office. The office did not, for various reasons, buy instant coffee. Some workers in that office got together and decided to institute the "Coffee Corner."
A member of the Coffee Corner would buy some instant coffee, and the other members would pay them back. It came to pass that some people drank more coffee than others, so the level of a "half-member" was added: a half-member was allowed a limited number of coffees per week and would pay half of what a member paid.
Managing this was a huge pain. I had just read *The Unix Programming Environment* and wanted to practice my [AWK](https://en.wikipedia.org/wiki/AWK) programming. So I volunteered to create a system.
Step 1: I kept a database of members and their debt to the Coffee Corner. I did it in an AWK-friendly format, where fields are separated by colons:
```
member:john:1:22
member:jane:0.5:33
member:pratyush:0.5:17
member:jing:1:27
```
The first field above identifies what kind of row this is (member). The second field is the member's name (i.e., their email username without the @). The next field is their membership level (full=1 or half=0.5). The last field is their debt to the Coffee Corner. A positive number means they owe money, a negative number means the Coffee Corner owes them.
Step 2: I kept a log of inputs to and outputs from the Coffee Corner:
```
payment:jane:33
payment:pratyush:17
bought:john:60
payback:john:50
```
Jane paid $33, Pratyush paid $17, John bought $60 worth of coffee, and the Coffee Corner paid John $50.
Step 3: I was ready to write some code. The code would process the members and payments and spit out an updated *members* file with the new debts.
`#!/usr/bin/env --split-string=awk -F: -f`
The shebang (**#!**) line required some work! I used the **env** command to allow passing multiple arguments from the shebang: specifically, the **-F** command-line argument to AWK tells it what the field separator is.
An AWK program is a sequence of rules. (It can also contain function definitions, but I don't need any for the Coffee Corner.)
The first rule reads the *members* file. When I run the command, I always give it the *members* file first, and the *payments* file second. It uses AWK associative arrays to record membership levels in the **members** array and current debt in the **debt** array.
```
$1 == "member" {
members[$2]=$3
debt[$2]=$4
total_members += $3
}
```
The second rule reduces the debt when a **payment** is recorded.
```
$1 == "payment" {
debt[$2] -= $3
}
```
**Payback** is the opposite: it *increases* the debt. This elegantly supports the case of accidentally giving someone too much money.
```
$1 == "payback" {
debt[$2] += $3
}
```
The most complicated part happens when someone buys (**"bought"**) instant coffee for the Coffee Club's use. It is treated as a payment and the person's debt is reduced by the appropriate amount. Next, it calculates the per-member fee. It iterates over all members and increases their debt, according to their level of membership.
```
$1 == "bought" {
debt[$2] -= $3
per_member = $3/total_members
for (x in members) {
debt[x] += per_member * members[x]
}
}
```
The **END** pattern is special: it happens exactly once, when AWK has no more lines to process. At this point, it spits out the new *members* file with updated debt levels.
```
END {
for (x in members) {
printf "%s:%s:%s\n", x, members[x], debt[x]
}
}
```
Along with a script that iterates over the members and sends a reminder email to people to pay their dues (for positive debts), this system managed the Coffee Corner for quite a while.
## 8 Comments |
10,556 | 极客漫画:AI 会抢走我们的工作吗? | http://turnoff.us/geek/will-ai-take-our-jobs/ | 2019-02-20T21:40:26 | [
"AI"
] | https://linux.cn/article-10556-1.html | 
你不觉得现在的 AI 越来越厉害了么?会不会担心有一天你会失业?瞧瞧,很多工厂都用机器人换下了流水线上的工人们。你觉得你是一个白领,是一个会打字、会做 PPT、会编程的白领。别做梦了,电脑蓝领们,这些事情 AI 干的比你好多了。(还好,这篇漫画 Google 翻译的没有我翻译的好……)
---
via: <http://turnoff.us/geek/will-ai-take-our-jobs/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者 & 点评:[wxy](https://github.com/wxy) 校对 & 合成:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,557 | 开始使用 Go For It 吧,一个灵活的待办事项列表程序 | https://opensource.com/article/19/1/productivity-tool-go-for-it | 2019-02-20T22:06:00 | [
"todo"
] | https://linux.cn/article-10557-1.html |
>
> Go For It,是我们开源工具系列中的第十个工具,它将使你在 2019 年更高效,它在 Todo.txt 系统的基础上构建,以帮助你完成更多工作。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 10 个工具来帮助你在 2019 年更有效率。
### Go For It
有时,人们要高效率需要的不是一个花哨的看板或一组笔记,而是一个简单、直接的待办事项清单。像“将项目添加到列表中,在完成后检查”一样基本的东西。为此,[纯文本 Todo.txt 系统](http://todotxt.org/)可能是最容易使用的系统之一,几乎所有系统都支持它。

[Go For It](http://manuel-kehl.de/projects/go-for-it/) 是一个简单易用的 Todo.txt 图形界面。如果你已经在使用 Todo.txt,它可以与现有文件一起使用,如果还没有,那么可以同时创建待办事项和完成事项。它允许拖放任务排序,允许用户按照他们想要执行的顺序组织待办事项。它还支持 [Todo.txt 格式指南](https://github.com/todotxt/todo.txt)中所述的优先级、项目和上下文。而且,只需单击任务列表中的项目或者上下文就可通过它们过滤任务。

一开始,Go For It 可能看起来与任何其他 Todo.txt 程序相同,但外观可能是骗人的。将 Go For It 与其他程序真正区分开的功能是它包含一个内置的[番茄工作法](https://en.wikipedia.org/wiki/Pomodoro_Technique)计时器。选择要完成的任务,切换到“计时器”选项卡,然后单击“启动”。任务完成后,只需单击“完成”,它将自动重置计时器并选择列表中的下一个任务。你可以暂停并重新启动计时器,也可以单击“跳过”跳转到下一个任务(或中断)。在当前任务剩余 60 秒时,它会发出警告。任务的默认时间设置为 25 分钟,中断的默认时间设置为 5 分钟。你可以在“设置”页面中调整,同时还能调整 Todo.txt 和 done.txt 文件的目录的位置。

Go For It 的第三个选项卡是“已完成”,允许你查看已完成的任务并在需要时将其清除。能够看到你已经完成的可能是非常激励的,也是一种了解你在更长的过程中进度的好方法。

它还有 Todo.txt 的所有其他优点。Go For It 的列表可以被其他使用相同格式的程序访问,包括 [Todo.txt 的原始命令行工具](https://github.com/todotxt/todo.txt-cli)和任何已安装的[附加组件](https://github.com/todotxt/todo.txt-cli/wiki/Todo.sh-Add-on-Directory)。
Go For It 旨在成为一个简单的工具来帮助管理你的待办事项列表并完成这些项目。如果你已经使用过 Todo.txt,那么 Go For It 是你的工具箱的绝佳补充,如果你还没有,这是一个尝试最简单、最灵活系统之一的好机会。
---
via: <https://opensource.com/article/19/1/productivity-tool-go-for-it>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the tenth of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## Go For It
Sometimes what a person needs to be productive isn't a fancy kanban board or a set of notes, but a simple, straightforward to-do list. Something that is as basic as "add item to list, check it off when done." And for that, the [plain-text Todo.txt system](http://todotxt.org/) is possibly one of the easiest to use, and it's supported on almost every system out there.
[Go For It](http://manuel-kehl.de/projects/go-for-it/) is a simple, easy-to-use graphical interface for Todo.txt. It can be used with an existing file, if you are already using Todo.txt, and will create both a to-do and a done file if you aren't. It allows drag-and-drop ordering of tasks, allowing users to organize to-do items in the order they want to execute them. It also supports priorities, projects, and contexts, as outlined in the [Todo.txt format guidelines](https://github.com/todotxt/todo.txt). And, it can filter tasks by context or project simply by clicking on the project or context in the task list.
At first, Go For It may look the same as just about any other Todo.txt program, but looks can be deceiving. The real feature that sets Go For It apart is that it includes a built-in [Pomodoro Technique](https://en.wikipedia.org/wiki/Pomodoro_Technique) timer. Select the task you want to complete, switch to the Timer tab, and click Start. When the task is done, simply click Done, and it will automatically reset the timer and pick the next task on the list. You can pause and restart the timer as well as click Skip to jump to the next task (or break). It provides a warning when 60 seconds are left for the current task. The default time for tasks is set at 25 minutes, and the default time for breaks is set at five minutes. You can adjust this in the Settings screen, as well as the location of the directory containing your Todo.txt and done.txt files.
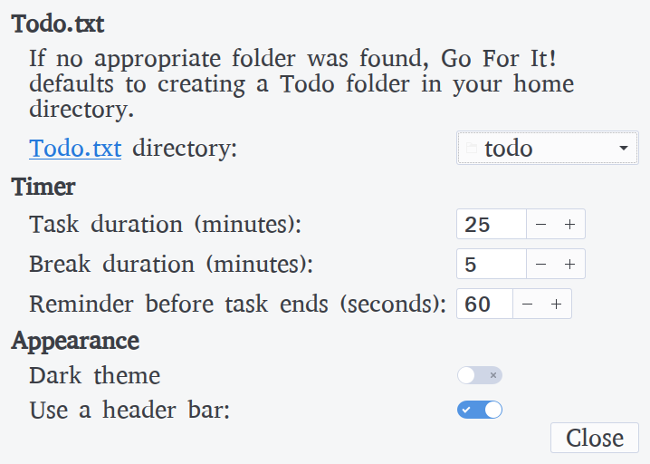
Go For It's third tab, Done, allows you to look at the tasks you've completed and clean them out when you want. Being able to look at what you've accomplished can be very motivating and a good way to get a feel for where you are in a longer process.
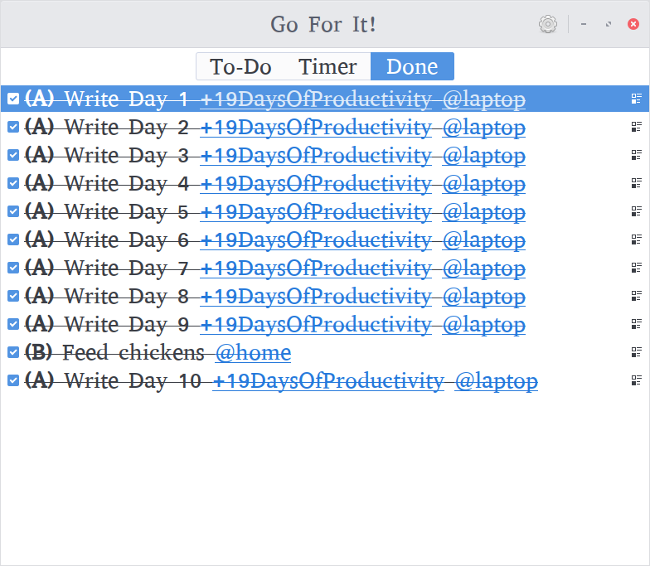
It also has all of Todo.txt's other advantages. Go For It's list is accessible by other programs that use the same format, including [Todo.txt's original command-line tool](https://github.com/todotxt/todo.txt-cli) and any [add-ons](https://github.com/todotxt/todo.txt-cli/wiki/Todo.sh-Add-on-Directory) you've installed.
Go For It seeks to be a simple tool to help manage your to-do list and get those items done. If you already use Todo.txt, Go For It is a fantastic addition to your toolkit, and if you don't, it's a really good way to start using one of the simplest and most flexible systems available.
## Comments are closed. |
10,559 | 3 个 Linux 上的 SSH 图形界面工具 | https://www.linux.com/blog/learn/intro-to-linux/2018/11/three-ssh-guis-linux | 2019-02-21T13:57:34 | [
"SSH",
"PuTTY"
] | https://linux.cn/article-10559-1.html |
>
> 了解一下这三个用于 Linux 上的 SSH 图形界面工具。
>
>
>

在你担任 Linux 管理员的职业生涯中,你会使用 Secure Shell(SSH)远程连接到 Linux 服务器或桌面。可能你曾经在某些情况下,会同时 SSH 连接到多个 Linux 服务器。实际上,SSH 可能是 Linux 工具箱中最常用的工具之一。因此,你应该尽可能提高体验效率。对于许多管理员来说,没有什么比命令行更有效了。但是,有些用户更喜欢使用 GUI 工具,尤其是在从台式机连接到远程并在服务器上工作时。
如果你碰巧喜欢好的图形界面工具,你肯定很乐于了解一些 Linux 上优秀的 SSH 图形界面工具。让我们来看看这三个工具,看看它们中的一个(或多个)是否完全符合你的需求。
我将在 [Elementary OS](https://elementary.io/) 上演示这些工具,但它们都可用于大多数主要发行版。
### PuTTY
已经有一些经验的人都知道 [PuTTY](https://www.chiark.greenend.org.uk/%7Esgtatham/putty/latest.html)。实际上,从 Windows 环境通过 SSH 连接到 Linux 服务器时,PuTTY 是事实上的标准工具。但 PuTTY 不仅适用于 Windows。事实上,通过标准软件库,PuTTY 也可以安装在 Linux 上。 PuTTY 的功能列表包括:
* 保存会话。
* 通过 IP 或主机名连接。
* 使用替代的 SSH 端口。
* 定义连接类型。
* 日志。
* 设置键盘、响铃、外观、连接等等。
* 配置本地和远程隧道。
* 支持代理。
* 支持 X11 隧道。
PuTTY 图形工具主要是一种保存 SSH 会话的方法,因此可以更轻松地管理所有需要不断远程进出的各种 Linux 服务器和桌面。一旦连接成功,PuTTY 就会建立一个到 Linux 服务器的连接窗口,你将可以在其中工作。此时,你可能会有疑问,为什么不在终端窗口工作呢?对于一些人来说,保存会话的便利确实使 PuTTY 值得使用。
在 Linux 上安装 PuTTY 很简单。例如,你可以在基于 Debian 的发行版上运行命令:
```
sudo apt-get install -y putty
```
安装后,你可以从桌面菜单运行 PuTTY 图形工具或运行命令 `putty`。在 PuTTY “Configuration” 窗口(图 1)中,在 “HostName (or IP address) ” 部分键入主机名或 IP 地址,配置 “Port”(如果不是默认值 22),从 “Connection type”中选择 SSH,然后单击“Open”。

*图 1:PuTTY 连接配置窗口*
建立连接后,系统将提示你输入远程服务器上的用户凭据(图2)。

*图 2:使用 PuTTY 登录到远程服务器*
要保存会话(以便你不必始终键入远程服务器信息),请填写主机名(或 IP 地址)、配置端口和连接类型,然后(在单击 “Open” 之前),在 “Saved Sessions” 部分的顶部文本区域中键入名称,然后单击 “Save”。这将保存会话的配置。若要连接到已保存的会话,请从 “Saved Sessions” 窗口中选择它,单击 “Load”,然后单击 “Open”。系统会提示你输入远程服务器上的远程凭据。
### EasySSH
虽然 [EasySSH](https://github.com/muriloventuroso/easyssh) 没有提供 PuTTY 中的那么多的配置选项,但它(顾名思义)非常容易使用。 EasySSH 的最佳功能之一是它提供了一个标签式界面,因此你可以打开多个 SSH 连接并在它们之间快速切换。EasySSH 的其他功能包括:
* 分组(出于更好的体验效率,可以对标签进行分组)。
* 保存用户名、密码。
* 外观选项。
* 支持本地和远程隧道。
在 Linux 桌面上安装 EasySSH 很简单,因为可以通过 Flatpak 安装应用程序(这意味着你必须在系统上安装 Flatpak)。安装 Flatpak 后,使用以下命令添加 EasySSH:
```
sudo flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
sudo flatpak install flathub com.github.muriloventuroso.easyssh
```
用如下命令运行 EasySSH:
```
flatpak run com.github.muriloventuroso.easyssh
```
将会打开 EasySSH 应用程序,你可以单击左上角的 “+” 按钮。 在结果窗口(图 3)中,根据需要配置 SSH 连接。

*图 3:在 EasySSH 中添加连接很简单*
添加连接后,它将显示在主窗口的左侧导航中(图 4)。

*图 4:EasySSH 主窗口*
要在 EasySSH 连接到远程服务器,请从左侧导航栏中选择它,然后单击 “Connect” 按钮(图 5)。

*图 5:用 EasySSH 连接到远程服务器*
对于 EasySSH 的一个警告是你必须将用户名和密码保存在连接配置中(否则连接将失败)。这意味着任何有权访问运行 EasySSH 的桌面的人都可以在不知道密码的情况下远程访问你的服务器。因此,你必须始终记住在你离开时锁定桌面屏幕(并确保使用强密码)。否则服务器容易受到意外登录的影响。
### Terminator
(LCTT 译注:这个选择不符合本文主题,本节删节)
### termius
(LCTT 译注:本节是根据网友推荐补充的)
termius 是一个商业版的 SSH、Telnet 和 Mosh 客户端,不是开源软件。支持包括 [Linux](https://www.termius.com/linux)、Windows、Mac、iOS 和安卓在内的各种操作系统。对于单一设备是免费的,支持多设备的白金账号需要按月付费。
### 很少(但值得)的选择
Linux 上没有很多可用的 SSH 图形界面工具。为什么?因为大多数管理员更喜欢简单地打开终端窗口并使用标准命令行工具来远程访问其服务器。但是,如果你需要图形界面工具,则有两个可靠选项,可以更轻松地登录多台计算机。虽然对于那些寻找 SSH 图形界面工具的人来说只有不多的几个选择,但那些可用的工具当然值得你花时间。尝试其中一个,亲眼看看。
---
via: <https://www.linux.com/blog/learn/intro-to-linux/2018/11/three-ssh-guis-linux>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,560 | PowerTOP:在 Linux 上监视电量使用和改善笔记本电池寿命 | https://www.2daygeek.com/powertop-monitors-laptop-battery-usage-linux/ | 2019-02-21T23:53:00 | [
"电池",
"电源"
] | https://linux.cn/article-10560-1.html | 
我们都知道,现在几乎都从 PC 机换到了笔记本电脑了。但是使用笔记本有个问题,我们希望电池耐用,我们可以使用到每一点电量。所以,我们需要知道电量都去哪里了,是不是浪费了。
你可以使用 PowerTOP 工具来查看没有接入电源线时电量都用在了何处。你需要在终端中使用超级用户权限来运行 PowerTOP 工具。它可以访问该电池硬件并测量电量使用情况。
### 什么是 PowerTOP
PowerTOP 是一个 Linux 工具,用于诊断电量消耗和电源管理的问题。
它是由 Intel 开发的,可以在内核、用户空间和硬件中启用各种节电模式。
除了作为一个一个诊断工具之外,PowerTop 还有一个交互模式,可以让你实验 Linux 发行版没有启用的各种电源管理设置。
它也能监控进程,并展示其中哪个正在使用 CPU,以及从休眠状态页将其唤醒,也可以找出电量消耗特别高的应用程序。
### 如何安装 PowerTOP
PowerTOP 软件包在大多数发行版的软件库中可用,使用发行版的 [包管理器](https://www.2daygeek.com/category/package-management/) 安装即可。
对于 Fedora 系统,使用 `dnf` 命令 来安装 PowerTOP。
```
$ sudo dnf install powertop
```
对于 Debian/Ubuntu 系统,使用 `apt-get` 命令 或 `apt` 命令 来安装 PowerTOP。
```
$ sudo apt install powertop
```
对于基于 Arch Linux 的系统,使用 `pacman` 命令 来安装 PowerTOP。
```
$ sudo pacman -S powertop
```
对于 RHEL/CentOS 系统,使用 `yum` 命令 来安装 PowerTOP。
```
$ sudo yum install powertop
```
对于 openSUSE Leap 系统,使用 `zypper` 命令 来安装 PowerTOP。
```
$ sudo zypper install powertop
```
### 如何使用 PowerTOP
PowerTOP 需要超级用户权限,所以在 Linux 系统中以 root 身份运行 PowerTOP 工具。
默认情况下其显示 “概览” 页,在这里我们可以看到所有设备的电量消耗情况,也可以看到系统的唤醒秒数。
```
$ sudo powertop
PowerTOP v2.9 Overview Idle stats Frequency stats Device stats Tunables
The battery reports a discharge rate of 12.6 W
The power consumed was 259 J
The estimated remaining time is 1 hours, 52 minutes
Summary: 1692.9 wakeups/second, 0.0 GPU ops/seconds, 0.0 VFS ops/sec and 54.9% CPU use
Usage Events/s Category Description
9.3 ms/s 529.4 Timer tick_sched_timer
378.5 ms/s 139.8 Process [PID 2991] /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -prefsLen 8314 -prefMapSize 173895 -schedulerPrefs 00
7.5 ms/s 141.7 Timer hrtimer_wakeup
3.3 ms/s 102.7 Process [PID 1527] /usr/lib/firefox/firefox --new-window
11.6 ms/s 69.1 Process [PID 1568] /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -prefsLen 1 -prefMapSize 173895 -schedulerPrefs 0001,
6.2 ms/s 59.0 Process [PID 1496] /usr/lib/firefox/firefox --new-window
2.1 ms/s 59.6 Process [PID 2466] /usr/lib/firefox/firefox -contentproc -childID 3 -isForBrowser -prefsLen 5814 -prefMapSize 173895 -schedulerPrefs 00
1.8 ms/s 52.3 Process [PID 2052] /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -prefsLen 5814 -prefMapSize 173895 -schedulerPrefs 00
1.8 ms/s 50.8 Process [PID 3034] /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -prefsLen 8314 -prefMapSize 173895 -schedulerPrefs 00
3.6 ms/s 48.4 Process [PID 3009] /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -prefsLen 8314 -prefMapSize 173895 -schedulerPrefs 00
7.5 ms/s 46.2 Process [PID 2996] /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -prefsLen 8314 -prefMapSize 173895 -schedulerPrefs 00
25.2 ms/s 33.6 Process [PID 1528] /usr/lib/firefox/firefox --new-window
5.7 ms/s 32.2 Interrupt [7] sched(softirq)
2.1 ms/s 32.2 Process [PID 1811] /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -prefsLen 5814 -prefMapSize 173895 -schedulerPrefs 00
19.7 ms/s 25.0 Process [PID 1794] /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -prefsLen 5814 -prefMapSize 173895 -schedulerPrefs 00
1.9 ms/s 31.5 Process [PID 1596] /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -prefsLen 1 -prefMapSize 173895 -schedulerPrefs 0001,
3.1 ms/s 29.9 Process [PID 1535] /usr/lib/firefox/firefox --new-window
7.1 ms/s 28.2 Process [PID 1488] /usr/lib/firefox/firefox --new-window
1.8 ms/s 29.5 Process [PID 1762] /usr/lib/firefox/firefox -contentproc -childID 3 -isForBrowser -prefsLen 5814 -prefMapSize 173895 -schedulerPrefs 00
8.8 ms/s 23.3 Process [PID 1121] /usr/bin/gnome-shell
1.2 ms/s 21.8 Process [PID 1657] /usr/lib/firefox/firefox -contentproc -childID 2 -isForBrowser -prefsLen 920 -prefMapSize 173895 -schedulerPrefs 000
13.3 ms/s 13.9 Process [PID 1746] /usr/lib/firefox/firefox -contentproc -childID 3 -isForBrowser -prefsLen 5814 -prefMapSize 173895 -schedulerPrefs 00
2.7 ms/s 11.1 Process [PID 3410] /usr/lib/gnome-terminal-server
3.8 ms/s 10.8 Process [PID 1057] /usr/lib/Xorg vt2 -displayfd 3 -auth /run/user/1000/gdm/Xauthority -nolisten tcp -background none -noreset -keeptty
3.1 ms/s 9.8 Process [PID 1629] /usr/lib/firefox/firefox -contentproc -childID 2 -isForBrowser -prefsLen 920 -prefMapSize 173895 -schedulerPrefs 000
0.9 ms/s 6.7 Interrupt [136] xhci_hcd
278.0 us/s 6.4 Process [PID 414] [irq/141-iwlwifi]
128.7 us/s 5.7 Process [PID 1] /sbin/init
118.5 us/s 5.2 Process [PID 10] [rcu_preempt]
49.0 us/s 4.7 Interrupt [0] HI_SOFTIRQ
459.3 us/s 3.1 Interrupt [142] i915
2.1 ms/s 2.3 Process [PID 3451] powertop
8.4 us/s 2.7 kWork intel_atomic_helper_free_state_
1.2 ms/s 1.8 kWork intel_atomic_commit_work
374.2 us/s 2.1 Interrupt [9] acpi
42.1 us/s 1.8 kWork intel_atomic_cleanup_work
3.5 ms/s 0.25 kWork delayed_fput
238.0 us/s 1.5 Process [PID 907] /usr/lib/upowerd
17.7 us/s 1.5 Timer intel_uncore_fw_release_timer
26.4 us/s 1.4 Process [PID 576] [i915/signal:0]
19.8 us/s 1.3 Timer watchdog_timer_fn
1.1 ms/s 0.00 Process [PID 206] [kworker/7:2]
2.4 ms/s 0.00 Interrupt [1] timer(softirq)
13.4 us/s 0.9 Process [PID 9] [ksoftirqd/0]
Exit | / Navigate |
```
PowerTOP 的输出类似如上截屏,在你的机器上由于硬件不同会稍有不同。它的显示有很多页,你可以使用 `Tab` 和 `Shift+Tab` 在它们之间切换。
### 空闲状态页
它会显示处理器的各种信息。
```
PowerTOP v2.9 Overview Idle stats Frequency stats Device stats Tunables
Package | Core | CPU 0 CPU 4
| | C0 active 6.7% 7.2%
| | POLL 0.0% 0.1 ms 0.0% 0.1 ms
| | C1E 1.2% 0.2 ms 1.6% 0.3 ms
C2 (pc2) 7.5% | |
C3 (pc3) 25.2% | C3 (cc3) 0.7% | C3 0.5% 0.2 ms 0.6% 0.1 ms
C6 (pc6) 0.0% | C6 (cc6) 7.1% | C6 6.6% 0.5 ms 6.3% 0.5 ms
C7 (pc7) 0.0% | C7 (cc7) 59.8% | C7s 0.0% 0.0 ms 0.0% 0.0 ms
C8 (pc8) 0.0% | | C8 33.9% 1.6 ms 32.3% 1.5 ms
C9 (pc9) 0.0% | | C9 2.1% 3.4 ms 0.7% 2.8 ms
C10 (pc10) 0.0% | | C10 39.5% 4.7 ms 41.4% 4.7 ms
| Core | CPU 1 CPU 5
| | C0 active 8.3% 7.2%
| | POLL 0.0% 0.0 ms 0.0% 0.1 ms
| | C1E 1.3% 0.2 ms 1.4% 0.3 ms
| |
| C3 (cc3) 0.5% | C3 0.5% 0.2 ms 0.4% 0.2 ms
| C6 (cc6) 6.0% | C6 5.3% 0.5 ms 4.7% 0.5 ms
| C7 (cc7) 59.3% | C7s 0.0% 0.8 ms 0.0% 1.0 ms
| | C8 27.2% 1.5 ms 23.8% 1.4 ms
| | C9 1.6% 3.0 ms 0.5% 3.0 ms
| | C10 44.5% 4.7 ms 52.2% 4.6 ms
| Core | CPU 2 CPU 6
| | C0 active 11.2% 8.4%
| | POLL 0.0% 0.0 ms 0.0% 0.0 ms
| | C1E 1.4% 0.4 ms 1.3% 0.3 ms
| |
| C3 (cc3) 0.3% | C3 0.2% 0.1 ms 0.4% 0.2 ms
| C6 (cc6) 4.0% | C6 3.7% 0.5 ms 4.3% 0.5 ms
| C7 (cc7) 54.2% | C7s 0.0% 0.0 ms 0.0% 1.0 ms
| | C8 20.0% 1.5 ms 20.7% 1.4 ms
| | C9 1.0% 3.4 ms 0.4% 3.8 ms
| | C10 48.8% 4.6 ms 52.3% 5.0 ms
| Core | CPU 3 CPU 7
| | C0 active 8.8% 8.1%
| | POLL 0.0% 0.1 ms 0.0% 0.0 ms
| | C1E 1.2% 0.2 ms 1.2% 0.2 ms
| |
| C3 (cc3) 0.6% | C3 0.6% 0.2 ms 0.4% 0.2 ms
| C6 (cc6) 7.0% | C6 7.5% 0.5 ms 4.4% 0.5 ms
| C7 (cc7) 56.8% | C7s 0.0% 0.0 ms 0.0% 0.9 ms
| | C8 29.4% 1.4 ms 23.8% 1.4 ms
| | C9 1.1% 2.7 ms 0.7% 3.9 ms
| | C10 41.0% 4.0 ms 50.0% 4.8 ms
Exit | / Navigate |
```
### 频率状态页
它会显示 CPU 的主频。
```
PowerTOP v2.9 Overview Idle stats Frequency stats Device stats Tunables
Package | Core | CPU 0 CPU 4
| | Average 930 MHz 1101 MHz
Idle | Idle | Idle
| Core | CPU 1 CPU 5
| | Average 1063 MHz 979 MHz
| Idle | Idle
| Core | CPU 2 CPU 6
| | Average 976 MHz 942 MHz
| Idle | Idle
| Core | CPU 3 CPU 7
| | Average 924 MHz 957 MHz
| Idle | Idle
```
### 设备状态页
它仅针对设备显示其电量使用信息。
```
PowerTOP v2.9 Overview Idle stats Frequency stats Device stats Tunables
The battery reports a discharge rate of 13.8 W
The power consumed was 280 J
Usage Device name
46.7% CPU misc
46.7% DRAM
46.7% CPU core
19.0% Display backlight
0.0% Audio codec hwC0D0: Realtek
0.0% USB device: Lenovo EasyCamera (160709000341)
100.0% PCI Device: Intel Corporation HD Graphics 530
100.0% Radio device: iwlwifi
100.0% PCI Device: O2 Micro, Inc. SD/MMC Card Reader Controller
100.0% PCI Device: Intel Corporation Xeon E3-1200 v5/E3-1500 v5/6th Gen Core Processor Host Bridge/DRAM Registers
100.0% USB device: Lenovo Wireless Optical Mouse N100
100.0% PCI Device: Intel Corporation Wireless 8260
100.0% PCI Device: Intel Corporation HM170/QM170 Chipset SATA Controller [AHCI Mode]
100.0% Radio device: btusb
100.0% PCI Device: Intel Corporation 100 Series/C230 Series Chipset Family PCI Express Root Port #4
100.0% USB device: xHCI Host Controller
100.0% PCI Device: Intel Corporation 100 Series/C230 Series Chipset Family USB 3.0 xHCI Controller
100.0% PCI Device: Realtek Semiconductor Co., Ltd. RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller
100.0% PCI Device: Intel Corporation 100 Series/C230 Series Chipset Family PCI Express Root Port #3
100.0% PCI Device: Samsung Electronics Co Ltd NVMe SSD Controller SM951/PM951
100.0% PCI Device: Intel Corporation 100 Series/C230 Series Chipset Family PCI Express Root Port #2
100.0% PCI Device: Intel Corporation 100 Series/C230 Series Chipset Family PCI Express Root Port #9
100.0% PCI Device: Intel Corporation 100 Series/C230 Series Chipset Family SMBus
26.1 pkts/s Network interface: wlp8s0 (iwlwifi)
0.0% USB device: usb-device-8087-0a2b
0.0% runtime-reg-dummy
0.0% Audio codec hwC0D2: Intel
0.0 pkts/s Network interface: enp9s0 (r8168)
0.0% PCI Device: Intel Corporation 100 Series/C230 Series Chipset Family Power Management Controller
0.0% PCI Device: Intel Corporation HM170 Chipset LPC/eSPI Controller
0.0% PCI Device: Intel Corporation Xeon E3-1200 v5/E3-1500 v5/6th Gen Core Processor PCIe Controller (x16)
0.0% PCI Device: Intel Corporation 100 Series/C230 Series Chipset Family MEI Controller #1
0.0% PCI Device: NVIDIA Corporation GM107M [GeForce GTX 960M]
0.0% I2C Adapter (i2c-8): nvkm-0000:01:00.0-bus-0005
0.0% runtime-PNP0C14:00
0.0% PCI Device: Intel Corporation 100 Series/C230 Series Chipset Family HD Audio Controller
0.0% runtime-PNP0C0C:00
0.0% USB device: xHCI Host Controller
0.0% runtime-ACPI000C:00
0.0% runtime-regulatory.0
0.0% runtime-PNP0C14:01
0.0% runtime-vesa-framebuffer.0
0.0% runtime-coretemp.0
0.0% runtime-alarmtimer
Exit | / Navigate |
```
### 可调整状态页
这个页面是个重要区域,可以为你的笔记本电池优化提供建议。
```
PowerTOP v2.9 Overview Idle stats Frequency stats Device stats Tunables
>> Bad Enable SATA link power management for host2
Bad Enable SATA link power management for host3
Bad Enable SATA link power management for host0
Bad Enable SATA link power management for host1
Bad VM writeback timeout
Bad Autosuspend for USB device Lenovo Wireless Optical Mouse N100 [1-2]
Good Bluetooth device interface status
Good Enable Audio codec power management
Good NMI watchdog should be turned off
Good Runtime PM for I2C Adapter i2c-7 (nvkm-0000:01:00.0-bus-0002)
Good Autosuspend for unknown USB device 1-11 (8087:0a2b)
Good Runtime PM for I2C Adapter i2c-3 (i915 gmbus dpd)
Good Autosuspend for USB device Lenovo EasyCamera [160709000341]
Good Runtime PM for I2C Adapter i2c-1 (i915 gmbus dpc)
Good Runtime PM for I2C Adapter i2c-12 (nvkm-0000:01:00.0-bus-0009)
Good Autosuspend for USB device xHCI Host Controller [usb1]
Good Runtime PM for I2C Adapter i2c-13 (nvkm-0000:01:00.0-aux-000a)
Good Runtime PM for I2C Adapter i2c-2 (i915 gmbus dpb)
Good Runtime PM for I2C Adapter i2c-8 (nvkm-0000:01:00.0-bus-0005)
Good Runtime PM for I2C Adapter i2c-15 (nvkm-0000:01:00.0-aux-000c)
Good Runtime PM for I2C Adapter i2c-16 (nvkm-0000:01:00.0-aux-000d)
Good Runtime PM for I2C Adapter i2c-5 (nvkm-0000:01:00.0-bus-0000)
Good Runtime PM for I2C Adapter i2c-0 (SMBus I801 adapter at 6040)
Good Runtime PM for I2C Adapter i2c-11 (nvkm-0000:01:00.0-bus-0008)
Good Runtime PM for I2C Adapter i2c-14 (nvkm-0000:01:00.0-aux-000b)
Good Autosuspend for USB device xHCI Host Controller [usb2]
Good Runtime PM for I2C Adapter i2c-9 (nvkm-0000:01:00.0-bus-0006)
Good Runtime PM for I2C Adapter i2c-10 (nvkm-0000:01:00.0-bus-0007)
Good Runtime PM for I2C Adapter i2c-6 (nvkm-0000:01:00.0-bus-0001)
Good Runtime PM for PCI Device Intel Corporation 100 Series/C230 Series Chipset Family HD Audio Controller
Good Runtime PM for PCI Device Intel Corporation 100 Series/C230 Series Chipset Family USB 3.0 xHCI Controller
Good Runtime PM for PCI Device Intel Corporation Xeon E3-1200 v5/E3-1500 v5/6th Gen Core Processor Host Bridge/DRAM Registers
Good Runtime PM for PCI Device Intel Corporation 100 Series/C230 Series Chipset Family PCI Express Root Port #9
Good Runtime PM for PCI Device Intel Corporation HD Graphics 530
Good Runtime PM for PCI Device Realtek Semiconductor Co., Ltd. RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller
Good Runtime PM for PCI Device Intel Corporation 100 Series/C230 Series Chipset Family PCI Express Root Port #3
Good Runtime PM for PCI Device O2 Micro, Inc. SD/MMC Card Reader Controller
Good Runtime PM for PCI Device Intel Corporation HM170 Chipset LPC/eSPI Controller
Good Runtime PM for PCI Device Intel Corporation 100 Series/C230 Series Chipset Family MEI Controller #1
Good Runtime PM for PCI Device Samsung Electronics Co Ltd NVMe SSD Controller SM951/PM951
Good Runtime PM for PCI Device Intel Corporation HM170/QM170 Chipset SATA Controller [AHCI Mode]
Good Runtime PM for PCI Device Intel Corporation 100 Series/C230 Series Chipset Family Power Management Controller
Good Runtime PM for PCI Device Intel Corporation 100 Series/C230 Series Chipset Family PCI Express Root Port #2
Good Runtime PM for PCI Device Intel Corporation Wireless 8260
Good Runtime PM for PCI Device Intel Corporation Xeon E3-1200 v5/E3-1500 v5/6th Gen Core Processor PCIe Controller (x16)
Good Runtime PM for PCI Device Intel Corporation 100 Series/C230 Series Chipset Family PCI Express Root Port #4
Good Runtime PM for PCI Device Intel Corporation 100 Series/C230 Series Chipset Family SMBus
Good Runtime PM for PCI Device NVIDIA Corporation GM107M [GeForce GTX 960M]
Exit | Toggle tunable | Window refresh
```
### 如何生成 PowerTop 的 HTML 报告
运行如下命令生成 PowerTop 的 HTML 报告。
```
$ sudo powertop --html=powertop.html
modprobe cpufreq_stats failedLoaded 100 prior measurements
Cannot load from file /var/cache/powertop/saved_parameters.powertop
File will be loaded after taking minimum number of measurement(s) with battery only
RAPL device for cpu 0
RAPL Using PowerCap Sysfs : Domain Mask f
RAPL device for cpu 0
RAPL Using PowerCap Sysfs : Domain Mask f
Devfreq not enabled
glob returned GLOB_ABORTED
Cannot load from file /var/cache/powertop/saved_parameters.powertop
File will be loaded after taking minimum number of measurement(s) with battery only
Preparing to take measurements
To show power estimates do 182 measurement(s) connected to battery only
Taking 1 measurement(s) for a duration of 20 second(s) each.
PowerTOP outputing using base filename powertop.html
```
打开 `file:///home/daygeek/powertop.html` 文件以访问生成的 PowerTOP 的 HTML 报告。

### 自动调整模式
这个功能可以将所有可调整选项从 BAD 设置为 GOOD,这可以提升 Linux 中的笔记本电池寿命。
```
$ sudo powertop --auto-tune
modprobe cpufreq_stats failedLoaded 210 prior measurements
Cannot load from file /var/cache/powertop/saved_parameters.powertop
File will be loaded after taking minimum number of measurement(s) with battery only
RAPL device for cpu 0
RAPL Using PowerCap Sysfs : Domain Mask f
RAPL device for cpu 0
RAPL Using PowerCap Sysfs : Domain Mask f
Devfreq not enabled
glob returned GLOB_ABORTED
Cannot load from file /var/cache/powertop/saved_parameters.powertop
File will be loaded after taking minimum number of measurement(s) with battery only
To show power estimates do 72 measurement(s) connected to battery only
Leaving PowerTOP
```
---
via: <https://www.2daygeek.com/powertop-monitors-laptop-battery-usage-linux/>
作者:[Vinoth Kumar](https://www.2daygeek.com/author/vinoth/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,561 | 开始使用 LogicalDOC 吧,一个开源文档管理系统 | https://opensource.com/article/19/1/productivity-tool-logicaldoc | 2019-02-22T22:39:25 | [
"文档"
] | https://linux.cn/article-10561-1.html |
>
> 使用 LogicalDOC 更好地跟踪文档版本,这是我们开源工具系列中的第 12 个工具,它将使你在 2019 年更高效。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 12 个工具来帮助你在 2019 年更有效率。
### LogicalDOC
高效部分表现在能够在你需要时找到你所需的东西。我们都看到过塞满名称类似的文件的目录,这是每次更改文档时为了跟踪所有版本而重命名这些文件而导致的。例如,我的妻子是一名作家,她在将文档发送给审稿人之前,她经常使用新名称保存文档修订版。

程序员对此一个自然的解决方案是 Git 或者其他版本控制器,但这个不适用于文档作者,因为用于代码的系统通常不能很好地兼容商业文本编辑器使用的格式。之前有人说,“改变格式就行”,[这不是适合每个人的选择](http://www.antipope.org/charlie/blog-static/2013/10/why-microsoft-word-must-die.html)。同样,许多版本控制工具对于非技术人员来说并不是非常友好。在大型组织中,有一些工具可以解决此问题,但它们还需要大型组织的资源来运行、管理和支持它们。

[LogicalDOC CE](https://www.logicaldoc.com/download-logicaldoc-community) 是为解决此问题而编写的开源文档管理系统。它允许用户签入、签出、查看版本、搜索和锁定文档,并保留版本历史记录,类似于程序员使用的版本控制工具。
LogicalDOC 可在 Linux、MacOS 和 Windows 上[安装](https://docs.logicaldoc.com/en/installation),使用基于 Java 的安装程序。在安装时,系统将提示你提供数据库存储位置,并提供只在本地文件存储的选项。你将获得访问服务器的 URL 和默认用户名和密码,以及保存用于自动安装脚本选项。
登录后,LogicalDOC 的默认页面会列出你已标记、签出的文档以及有关它们的最新说明。切换到“文档”选项卡将显示你有权访问的文件。你可以在界面中选择文件或使用拖放来上传文档。如果你上传 ZIP 文件,LogicalDOC 会解压它,并将其中的文件添加到仓库中。

右键单击文件将显示一个菜单选项,包括检出文件、锁定文件以防止更改,以及执行大量其他操作。签出文件会将其下载到本地计算机以便编辑。在重新签入之前,其他任何人都无法修改签出的文件。当重新签入文件时(使用相同的菜单),用户可以向版本添加标签,并且需要备注对其执行的操作。

查看早期版本只需在“版本”页面下载就行。对于某些第三方服务,它还有导入和导出选项,内置 [Dropbox](https://dropbox.com) 支持。
文档管理不仅仅是能够负担得起昂贵解决方案的大公司才能有的。LogicalDOC 可帮助你追踪文档的版本历史,并为难以管理的文档提供了安全的仓库。
---
via: <https://opensource.com/article/19/1/productivity-tool-logicaldoc>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the 12th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## LogicalDOC
Part of being productive is being able to find what you need when you need it. We've all seen directories full of similar files with similar names, a result of renaming them every time a document changes to keep track of all the versions. For example, my wife is a writer, and she often saves document revisions with new names before she sends them to reviewers.

A coder's natural solution to this problem—Git or another version control tool—won't work for document creators because the systems used for code often don't play nice with the formats used by commercial text editors. And before someone says, "just change formats," [that isn't an option for everyone](http://www.antipope.org/charlie/blog-static/2013/10/why-microsoft-word-must-die.html). Also, many version control tools are not very friendly for the less technically inclined. In large organizations, there are tools to solve this problem, but they also require the resources of a large organization to run, manage, and support them.
[LogicalDOC CE](https://www.logicaldoc.com/download-logicaldoc-community) is an open source document management system built to solve this problem. It allows users to check in, check out, version, search, and lock document files and keeps a history of versions, similar to the version control tools used by coders.
LogicalDOC can be [installed](https://docs.logicaldoc.com/en/installation) on Linux, MacOS, and Windows using a Java-based installer. During installation, you'll be prompted for details on the database where its data will be stored and have an option for a local-only file store. You'll get the URL and a default username and password to access the server as well as an option to save a script to automate future installations.
After you log in, LogicalDOC's default screen lists the documents you have tagged, checked out, and any recent notes on them. Switching to the Documents tab will show the files you have access to. You can upload documents by selecting a file through the interface or using drag and drop. If you upload a ZIP file, LogicalDOC will expand it and add its individual files to the repository.
Right-clicking on a file will bring up a menu of options to check out files, lock files against changes, and do a whole host of other things. Checking out a file downloads it to your local machine where it can be edited. A checked-out file cannot be modified by anyone else until it's checked back in. When the file is checked back in (using the same menu), the user can add tags to the version and is required to comment on what was done to it.
Going back and looking at earlier versions is as easy as downloading them from the Versions page. There are also import and export options for some third-party services, with [Dropbox](https://dropbox.com) support built-in.
Document management is not just for big companies that can afford expensive solutions. LogicalDOC helps you keep track of the documents you're using with a revision history and a safe repository for documents that are otherwise difficult to manage.
## 7 Comments |
10,562 | 如何列出 Ubuntu 和 Debian 上已安装的软件包 | https://itsfoss.com/list-installed-packages-ubuntu | 2019-02-23T00:27:16 | [
"软件包"
] | https://linux.cn/article-10562-1.html | 当你安装了 [Ubuntu 并想好好用一用](https://itsfoss.com/getting-started-with-ubuntu/)。但在将来某个时候,你肯定会遇到忘记曾经安装了那些软件包。
这个是完全正常。没有人要求你把系统里所有已安装的软件包都记住。但是问题是,如何才能知道已经安装了哪些软件包?如何查看安装过的软件包呢?
### 列出 Ubuntu 和 Debian 上已安装的软件包

如果你经常用 [apt 命令](https://itsfoss.com/apt-command-guide/),你可能觉得会有个命令像 `apt` 一样可以列出已安装的软件包。不算全错。
[apt-get 命令](https://itsfoss.com/apt-get-linux-guide/) 没有类似列出已安装软件包的简单的选项,但是 `apt` 有一个这样的命令:
```
apt list --installed
```
这个会显示使用 `apt` 命令安装的所有的软件包。同时也会包含由于依赖而被安装的软件包。也就是说不仅会包含你曾经安装的程序,而且会包含大量库文件和间接安装的软件包。

*用 atp 命令列出显示已安装的软件包*
由于列出出来的已安装的软件包太多,用 `grep` 过滤特定的软件包是一个比较好的办法。
```
apt list --installed | grep program_name
```
如上命令也可以检索出使用 .deb 软件包文件安装的软件。是不是很酷?
如果你阅读过 [apt 与 apt-get 对比](https://itsfoss.com/apt-vs-apt-get-difference/)的文章,你可能已经知道 `apt` 和 `apt-get` 命令都是基于 [dpkg](https://wiki.debian.org/dpkg)。也就是说用 `dpkg` 命令可以列出 Debian 系统的所有已经安装的软件包。
```
dpkg-query -l
```
你可以用 `grep` 命令检索指定的软件包。
!
*用 dpkg 命令列出显示已经安装的软件包*
现在你可以搞定列出 Debian 的软件包管理器安装的应用了。那 Snap 和 Flatpak 这个两种应用呢?如何列出它们?因为它们不能被 `apt` 和 `dpkg` 访问。
显示系统里所有已经安装的 [Snap 软件包](https://itsfoss.com/use-snap-packages-ubuntu-16-04/),可以这个命令:
```
snap list
```
Snap 可以用绿色勾号标出哪个应用来自经过认证的发布者。

*列出已经安装的 Snap 软件包*
显示系统里所有已安装的 [Flatpak 软件包](https://itsfoss.com/flatpak-guide/),可以用这个命令:
```
flatpak list
```
让我来个汇总:
用 `apt` 命令显示已安装软件包:
```
apt list –installed
```
用 `dpkg` 命令显示已安装软件包:
```
dpkg-query -l
```
列出系统里 Snap 已安装软件包:
```
snap list
```
列出系统里 Flatpak 已安装软件包:
```
flatpak list
```
### 显示最近安装的软件包
现在你已经看过以字母顺序列出的已经安装软件包了。如何显示最近已经安装的软件包?
幸运的是,Linux 系统保存了所有发生事件的日志。你可以参考最近安装软件包的日志。
有两个方法可以来做。用 `dpkg` 命令的日志或者 `apt` 命令的日志。
你仅仅需要用 `grep` 命令过滤已经安装的软件包日志。
```
grep " install " /var/log/dpkg.log
```
这会显示所有的软件安装包,其中包括最近安装的过程中所依赖的软件包。
```
2019-02-12 12:41:42 install ubuntu-make:all 16.11.1ubuntu1
2019-02-13 21:03:02 install xdg-desktop-portal:amd64 0.11-1
2019-02-13 21:03:02 install libostree-1-1:amd64 2018.8-0ubuntu0.1
2019-02-13 21:03:02 install flatpak:amd64 1.0.6-0ubuntu0.1
2019-02-13 21:03:02 install xdg-desktop-portal-gtk:amd64 0.11-1
2019-02-14 11:49:10 install qml-module-qtquick-window2:amd64 5.9.5-0ubuntu1.1
2019-02-14 11:49:10 install qml-module-qtquick2:amd64 5.9.5-0ubuntu1.1
2019-02-14 11:49:10 install qml-module-qtgraphicaleffects:amd64 5.9.5-0ubuntu1
```
你也可以查看 `apt` 历史命令日志。这个仅会显示用 `apt` 命令安装的的程序。但不会显示被依赖安装的软件包,详细的日志在日志里可以看到。有时你只是想看看对吧?
```
grep " install " /var/log/apt/history.log
```
具体的显示如下:
```
Commandline: apt install pinta
Commandline: apt install pinta
Commandline: apt install tmux
Commandline: apt install terminator
Commandline: apt install moreutils
Commandline: apt install ubuntu-make
Commandline: apt install flatpak
Commandline: apt install cool-retro-term
Commandline: apt install ubuntu-software
```

*显示最近已安装的软件包*
`apt` 的历史日志非常有用。因为他显示了什么时候执行了 `apt` 命令,哪个用户执行的命令以及安装的软件包名。
### 小技巧:在软件中心显示已安装的程序包名
如果你觉得终端和命令行交互不友好,还有一个方法可以查看系统的程序名。
可以打开软件中心,然后点击已安装标签。你可以看到系统上已经安装的程序包名

*在软件中心显示已安装的软件包*
这个不会显示库和其他命令行的东西,有可能你也不想看到它们,因为你的大量交互都是在 GUI。此外,你也可以用 Synaptic 软件包管理器。
### 结束语
我希望这个简易的教程可以帮你查看 Ubuntu 和基于 Debian 的发行版的已安装软件包。
如果你对本文有什么问题或建议,请在下面留言。
---
via: <https://itsfoss.com/list-installed-packages-ubuntu>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[guevaraya](https://github.com/guevaraya) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.