
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
10,350 | 在 Linux 中使用 SoundConverter 轻松转换音频文件格式 | https://itsfoss.com/sound-converter-linux/ | 2018-12-15T15:05:10 | [
"音乐",
"格式"
] | https://linux.cn/article-10350-1.html |
>
> 如果你正在寻找将音频文件格式转换为 wav、mp3、ogg 或任何其他格式,SoundConverter 是你在 Linux 中需要的工具。
>
>
>

最近我购买了一些没有 DRM 的音乐。我是从 [SaReGaMa](https://en.wikipedia.org/wiki/Saregama) 那里买的,这是一家印度历史最悠久,规模最大的音乐品牌。下载的文件采用高清质量的 WAV 格式。
不幸的是,Rhythmbox 无法播放 WAV。最重要的是,单个文件大小约为 70MB。想象一下,将这么大的音乐传输到智能手机。它会不必要地占用大量空间。
所以我认为是时候将 WAV 文件转换为 MP3 —— 这个长青且最流行的音乐文件格式。
为此,我需要一个在 Linux 中的音频转换器。在这个教程中,我将向你展示如何使用名为 SoundCoverter 的 GUI 工具轻松地将音频文件从一种格式转换为另一种格式。
### 在 Linux 中安装 SoundConverter
[SoundConverter](http://soundconverter.org/) 是一款流行的自由开源软件。它应该可以在大多数 Linux 发行版的官方仓库中找到。
Ubuntu/Linux Mint 用户只需在软件中心搜索 SoundConverter 并从那里安装即可。

*SoundConverter 可以从软件中心安装*
或者,你可以使用命令行方式。在基于 Debian 和 Ubuntu 的系统中,你可以使用以下命令:
```
sudo apt install soundconverter
```
在 Arch、Fedora 和其他非基于 Debian 的发行版中,你可以使用你的发行版的软件中心或软件包管理器。
### 在 Linux 中使用 SoundConverter 转换音频文件格式
安装完 SoundConverter 后,在菜单中搜索并启动它。
默认界面看起来像这样,它不能比这简单:

*简单的界面*
转换音频文件格式只要选择文件并单击转换。
但是,我建议你至少在第一次运行时检查下默认设置。默认情况下,它会将音频文件转换为 OGG 文件格式,你可能不希望这样。

*可以在“首选项”中更改默认输出设置*
要更改默认输出设置,请单击界面上的“首选项”图标。你会在这里看到很多可更改的选择。
你可以更改默认输出格式、比特率、质量等。你还可以选择是否要将转换后的文件保存在与原始文件相同的文件夹中。
转换后还可以选择自动删除原始文件。我不认为你应该使用那个选项。
你还可以更改输出文件名。默认情况下,它只会更改后缀,但你也可以选择根据曲目编号、标题、艺术家等进行命名。为此,原始文件中应包含适当的元数据。
说到元数据,你听说过 [MusicBrainz Picard](https://itsfoss.com/musicbrainz-picard/) 吗?此工具可帮助你自动更新本地音乐文件的元数据。
### 总结
我之前用讨论过用一个小程序 [在 Linux 中录制音频](https://itsfoss.com/record-streaming-audio/)。这些很棒的工具通过专注某个特定的任务使得生活更轻松。你可以使用成熟和更好的音频编辑工具,如 [Audacity](https://www.audacityteam.org/),但对于较小的任务,如转换音频文件格式,它可能用起来很复杂。
我希望你喜欢 SoundConverter。如果你使用其他工具,请在评论中提及,我会在 FOSS 中提及。使用开心!
---
via: <https://itsfoss.com/sound-converter-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

So recently I purchased some DRM-free music. I got it from [SaReGaMa](https://en.wikipedia.org/wiki/Saregama?ref=itsfoss.com), the oldest and the largest music label in India. The downloaded files were in HD quality and in WAV format.
Unfortunately, Rhythmbox doesn’t play the WAV files. On top of that, a single file was around 70 MB in size. Imagine transferring such large music files to smartphones. It would eat up a lot of space unnecessarily.
So I thought it was time to convert the WAV files to MP3, the evergreen and the most popular music file format.
And for this task, I needed an audio converter in Linux. There are plenty of [audio editors for Linux](https://itsfoss.com/best-audio-editors-linux/) but I needed a simple tool for this task.
In this quick tutorial, I’ll show you how can you convert your audio files from one format to another easily with a GUI tool called SoundConverter.
## Installing SoundConverter in Linux
If you prefer videos, you can watch this video from our YouTube channel.
[SoundConverter](http://soundconverter.org/?ref=itsfoss.com) is a popular free and open source software. It should be available in the official repository of most Linux distributions.
Ubuntu/Linux Mint users can simply search for SoundConverter in the software center and install it from there.
Alternatively, you can use the command line way. In Debian and Ubuntu-based systems, you can use the following command:
`sudo apt install soundconverter`
For Arch, Fedora and other non-Debian based distributions, you can use the software centre or the package manager of your distribution.
## Using SoundConverter to convert audio file formats in Linux
Once you have installed SoundConverter, search for it in the menu and start it.
The default interface looks like this and it cannot be more simple than this:
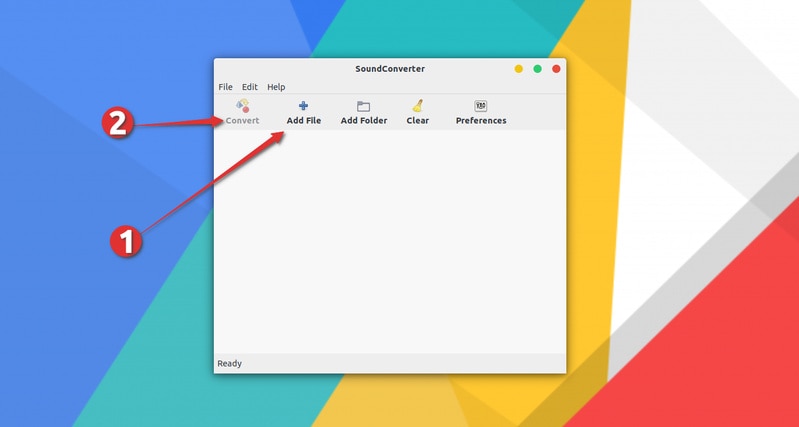
Converting audio file format is as easy as selecting the file and clicking on convert.
However, I would advise you to check the default settings at least on the first run. By default it converts the audio file to OGG file format and you may not want that.
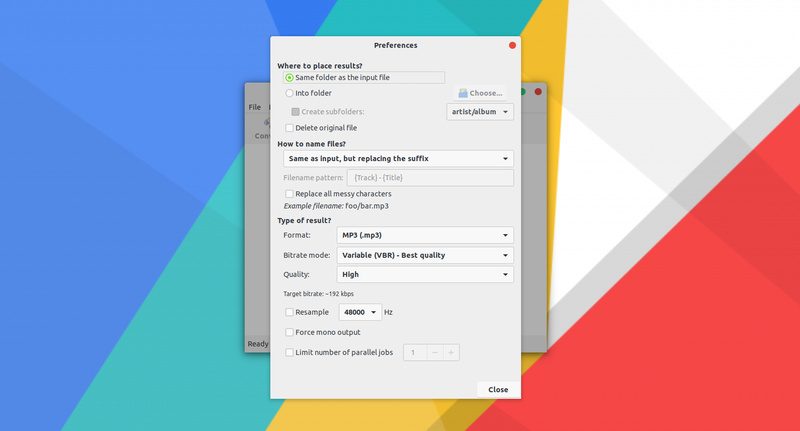
To change the default output settings, click on the Preferences icon visible on the interface. You’ll see plenty of options to change here.
You can change the default output format, bitrate, quality etc. You can also choose if you want to keep the converted files in the same folder as the original or not.
There is also an option of automatically deleting the original file after conversion. I don’t think you should use that option.
You can also change the output file name. By default, it will just change the suffix but you can also choose to name it based on track number, title, artist etc. For that to happen, you should have proper metadata on the original file.
Speaking of metadata, have you heard of [MusicBrainz Picard](https://itsfoss.com/musicbrainz-picard/)? This tool helps you automatically updates the metadata of your local music files.
**Conclusion**
I have discussed [recording audio in Linux](https://itsfoss.com/record-streaming-audio/) previously with a similar tiny application. Such nifty tools actually make life easier with their focused aim of completing a certain task. You may use full-fledged and a lot better [audio editing tool like Audacity](https://itsfoss.com/audacity-recording/) but that may be complicated to use for smaller tasks like converting audio file formats.
I hope you like SoundConverter. If you use some other tool, do mention that in the comments and I may cover it here on It’s FOSS. Enjoy! |
10,351 | Caffeinated 6.828:实验 4:抢占式多任务处理 | https://pdos.csail.mit.edu/6.828/2018/labs/lab4/ | 2018-12-16T12:58:17 | [
"6.828",
"多任务"
] | https://linux.cn/article-10351-1.html | 
### 简介
在本实验中,你将在多个同时活动的用户模式环境之间实现抢占式多任务处理。
在 Part A 中,你将在 JOS 中添加对多处理器的支持,以实现循环调度。并且添加基本的环境管理方面的系统调用(创建和销毁环境的系统调用、以及分配/映射内存)。
在 Part B 中,你将要实现一个类 Unix 的 `fork()`,它将允许一个用户模式中的环境去创建一个它自已的副本。
最后,在 Part C 中,你将在 JOS 中添加对进程间通讯(IPC)的支持,以允许不同用户模式环境之间进行显式通讯和同步。你也将要去添加对硬件时钟中断和优先权的支持。
#### 预备知识
使用 git 去提交你的实验 3 的源代码,并获取课程仓库的最新版本,然后创建一个名为 `lab4` 的本地分支,它跟踪我们的名为 `origin/lab4` 的远程 `lab4` 分支:
```
athena% cd ~/6.828/lab
athena% add git
athena% git pull
Already up-to-date.
athena% git checkout -b lab4 origin/lab4
Branch lab4 set up to track remote branch refs/remotes/origin/lab4.
Switched to a new branch "lab4"
athena% git merge lab3
Merge made by recursive.
...
athena%
```
实验 4 包含了一些新的源文件,在开始之前你应该去浏览一遍:
```
kern/cpu.h Kernel-private definitions for multiprocessor support
kern/mpconfig.c Code to read the multiprocessor configuration
kern/lapic.c Kernel code driving the local APIC unit in each processor
kern/mpentry.S Assembly-language entry code for non-boot CPUs
kern/spinlock.h Kernel-private definitions for spin locks, including the big kernel lock
kern/spinlock.c Kernel code implementing spin locks
kern/sched.c Code skeleton of the scheduler that you are about to implement
```
#### 实验要求
本实验分为三部分:Part A、Part B 和 Part C。我们计划为每个部分分配一周的时间。
和以前一样,你需要完成实验中出现的、所有常规练习和至少一个挑战问题。(不是每个部分做一个挑战问题,是整个实验做一个挑战问题即可。)另外,你还要写出你实现的挑战问题的详细描述。如果你实现了多个挑战问题,你只需写出其中一个即可,虽然我们的课程欢迎你完成越多的挑战越好。在动手实验之前,请将你的挑战问题的答案写在一个名为 `answers-lab4.txt` 的文件中,并把它放在你的 `lab` 目录的根下。
### Part A:多处理器支持和协调多任务处理
在本实验的第一部分,将去扩展你的 JOS 内核,以便于它能够在一个多处理器的系统上运行,并且要在 JOS 内核中实现一些新的系统调用,以便于它允许用户级环境创建附加的新环境。你也要去实现协调的循环调度,在当前的环境自愿放弃 CPU(或退出)时,允许内核将一个环境切换到另一个环境。稍后在 Part C 中,你将要实现抢占调度,它允许内核在环境占有 CPU 一段时间后,从这个环境上重新取回对 CPU 的控制,那怕是在那个环境不配合的情况下。
#### 多处理器支持
我们继续去让 JOS 支持 “对称多处理器”(SMP),在一个多处理器的模型中,所有 CPU 们都有平等访问系统资源(如内存和 I/O 总线)的权力。虽然在 SMP 中所有 CPU 们都有相同的功能,但是在引导进程的过程中,它们被分成两种类型:引导程序处理器(BSP)负责初始化系统和引导操作系统;而在操作系统启动并正常运行后,应用程序处理器(AP)将被 BSP 激活。哪个处理器做 BSP 是由硬件和 BIOS 来决定的。到目前为止,你所有的已存在的 JOS 代码都是运行在 BSP 上的。
在一个 SMP 系统上,每个 CPU 都伴有一个本地 APIC(LAPIC)单元。这个 LAPIC 单元负责传递系统中的中断。LAPIC 还为它所连接的 CPU 提供一个唯一的标识符。在本实验中,我们将使用 LAPIC 单元(它在 `kern/lapic.c` 中)中的下列基本功能:
* 读取 LAPIC 标识符(APIC ID),去告诉那个 CPU 现在我们的代码正在它上面运行(查看 `cpunum()`)。
* 从 BSP 到 AP 之间发送处理器间中断(IPI) `STARTUP`,以启动其它 CPU(查看 `lapic_startap()`)。
* 在 Part C 中,我们设置 LAPIC 的内置定时器去触发时钟中断,以便于支持抢占式多任务处理(查看 `apic_init()`)。
一个处理器使用内存映射的 I/O(MMIO)来访问它的 LAPIC。在 MMIO 中,一部分物理内存是硬编码到一些 I/O 设备的寄存器中,因此,访问内存时一般可以使用相同的 `load/store` 指令去访问设备的寄存器。正如你所看到的,在物理地址 `0xA0000` 处就是一个 IO 入口(就是我们写入 VGA 缓冲区的入口)。LAPIC 就在那里,它从物理地址 `0xFE000000` 处(4GB 减去 32MB 处)开始,这个地址对于我们在 KERNBASE 处使用直接映射访问来说太高了。JOS 虚拟内存映射在 `MMIOBASE` 处,留下一个 4MB 的空隙,以便于我们有一个地方,能像这样去映射设备。由于在后面的实验中,我们将介绍更多的 MMIO 区域,你将要写一个简单的函数,从这个区域中去分配空间,并将设备的内存映射到那里。
>
> **练习 1**、实现 `kern/pmap.c` 中的 `mmio_map_region`。去看一下它是如何使用的,从 `kern/lapic.c` 中的 `lapic_init` 开始看起。在 `mmio_map_region` 的测试运行之前,你还要做下一个练习。
>
>
>
##### 引导应用程序处理器
在引导应用程序处理器之前,引导程序处理器应该会首先去收集关于多处理器系统的信息,比如总的 CPU 数、它们的 APIC ID 以及 LAPIC 单元的 MMIO 地址。在 `kern/mpconfig.c` 中的 `mp_init()` 函数,通过读取内存中位于 BIOS 区域里的 MP 配置表来获得这些信息。
`boot_aps()` 函数(在 `kern/init.c` 中)驱动 AP 的引导过程。AP 们在实模式中开始,与 `boot/boot.S` 中启动引导加载程序非常相似。因此,`boot_aps()` 将 AP 入口代码(`kern/mpentry.S`)复制到实模式中的那个可寻址内存地址上。不像使用引导加载程序那样,我们可以控制 AP 将从哪里开始运行代码;我们复制入口代码到 `0x7000`(`MPENTRY_PADDR`)处,但是复制到任何低于 640KB 的、未使用的、页对齐的物理地址上都是可以运行的。
在那之后,通过发送 IPI `STARTUP` 到相关 AP 的 LAPIC 单元,以及一个初始的 `CS:IP` 地址(AP 将从那儿开始运行它的入口代码,在我们的案例中是 `MPENTRY_PADDR` ),`boot_aps()` 将一个接一个地激活 AP。在 `kern/mpentry.S` 中的入口代码非常类似于 `boot/boot.S`。在一些简短的设置之后,它启用分页,使 AP 进入保护模式,然后调用 C 设置程序 `mp_main()`(它也在 `kern/init.c` 中)。在继续唤醒下一个 AP 之前, `boot_aps()` 将等待这个 AP 去传递一个 `CPU_STARTED` 标志到它的 `struct CpuInfo` 中的 `cpu_status` 字段中。
>
> **练习 2**、阅读 `kern/init.c` 中的 `boot_aps()` 和 `mp_main()`,以及在 `kern/mpentry.S` 中的汇编代码。确保你理解了在 AP 引导过程中的控制流转移。然后修改在 `kern/pmap.c` 中的、你自己的 `page_init()`,实现避免在 `MPENTRY_PADDR` 处添加页到空闲列表上,以便于我们能够在物理地址上安全地复制和运行 AP 引导程序代码。你的代码应该会通过更新后的 `check_page_free_list()` 的测试(但可能会在更新后的 `check_kern_pgdir()` 上测试失败,我们在后面会修复它)。
>
>
>
.
>
> **问题 1**、比较 `kern/mpentry.S` 和 `boot/boot.S`。记住,那个 `kern/mpentry.S` 是编译和链接后的,运行在 `KERNBASE` 上面的,就像内核中的其它程序一样,宏 `MPBOOTPHYS` 的作用是什么?为什么它需要在 `kern/mpentry.S` 中,而不是在 `boot/boot.S` 中?换句话说,如果在 `kern/mpentry.S` 中删掉它,会发生什么错误? 提示:回顾链接地址和加载地址的区别,我们在实验 1 中讨论过它们。
>
>
>
##### 每个 CPU 的状态和初始化
当写一个多处理器操作系统时,区分每个 CPU 的状态是非常重要的,而每个 CPU 的状态对其它处理器是不公开的,而全局状态是整个系统共享的。`kern/cpu.h` 定义了大部分每个 CPU 的状态,包括 `struct CpuInfo`,它保存了每个 CPU 的变量。`cpunum()` 总是返回调用它的那个 CPU 的 ID,它可以被用作是数组的索引,比如 `cpus`。或者,宏 `thiscpu` 是当前 CPU 的 `struct CpuInfo` 缩略表示。
下面是你应该知道的每个 CPU 的状态:
* **每个 CPU 的内核栈**
因为内核能够同时捕获多个 CPU,因此,我们需要为每个 CPU 准备一个单独的内核栈,以防止它们运行的程序之间产生相互干扰。数组 `percpu_kstacks[NCPU][KSTKSIZE]` 为 NCPU 的内核栈资产保留了空间。
在实验 2 中,你映射的 `bootstack` 所引用的物理内存,就作为 `KSTACKTOP` 以下的 BSP 的内核栈。同样,在本实验中,你将每个 CPU 的内核栈映射到这个区域,而使用保护页做为它们之间的缓冲区。CPU 0 的栈将从 `KSTACKTOP` 处向下增长;CPU 1 的栈将从 CPU 0 的栈底部的 `KSTKGAP` 字节处开始,依次类推。在 `inc/memlayout.h` 中展示了这个映射布局。
* **每个 CPU 的 TSS 和 TSS 描述符**
为了指定每个 CPU 的内核栈在哪里,也需要有一个每个 CPU 的任务状态描述符(TSS)。CPU i 的任务状态描述符是保存在 `cpus[i].cpu_ts` 中,而对应的 TSS 描述符是定义在 GDT 条目 `gdt[(GD_TSS0 >> 3) + i]` 中。在 `kern/trap.c` 中定义的全局变量 `ts` 将不再被使用。
* **每个 CPU 当前的环境指针**
由于每个 CPU 都能同时运行不同的用户进程,所以我们重新定义了符号 `curenv`,让它指向到 `cpus[cpunum()].cpu_env`(或 `thiscpu->cpu_env`),它指向到当前 CPU(代码正在运行的那个 CPU)上当前正在运行的环境上。
* **每个 CPU 的系统寄存器**
所有的寄存器,包括系统寄存器,都是一个 CPU 私有的。所以,初始化这些寄存器的指令,比如 `lcr3()`、`ltr()`、`lgdt()`、`lidt()`、等待,必须在每个 CPU 上运行一次。函数 `env_init_percpu()` 和 `trap_init_percpu()` 就是为此目的而定义的。
>
> **练习 3**、修改 `mem_init_mp()`(在 `kern/pmap.c` 中)去映射每个 CPU 的栈从 `KSTACKTOP` 处开始,就像在 `inc/memlayout.h` 中展示的那样。每个栈的大小是 `KSTKSIZE` 字节加上未映射的保护页 `KSTKGAP` 的字节。你的代码应该会通过在 `check_kern_pgdir()` 中的新的检查。
>
>
>
.
>
> **练习 4**、在 `trap_init_percpu()`(在 `kern/trap.c` 文件中)的代码为 BSP 初始化 TSS 和 TSS 描述符。在实验 3 中它就运行过,但是当它运行在其它的 CPU 上就会出错。修改这些代码以便它能在所有 CPU 上都正常运行。(注意:你的新代码应该还不能使用全局变量 `ts`)
>
>
>
在你完成上述练习后,在 QEMU 中使用 4 个 CPU(使用 `make qemu CPUS=4` 或 `make qemu-nox CPUS=4`)来运行 JOS,你应该看到类似下面的输出:
```
...
Physical memory: 66556K available, base = 640K, extended = 65532K
check_page_alloc() succeeded!
check_page() succeeded!
check_kern_pgdir() succeeded!
check_page_installed_pgdir() succeeded!
SMP: CPU 0 found 4 CPU(s)
enabled interrupts: 1 2
SMP: CPU 1 starting
SMP: CPU 2 starting
SMP: CPU 3 starting
```
##### 锁定
在 `mp_main()` 中初始化 AP 后我们的代码快速运行起来。在你更进一步增强 AP 之前,我们需要首先去处理多个 CPU 同时运行内核代码的争用状况。达到这一目标的最简单的方法是使用大内核锁。大内核锁是一个单个的全局锁,当一个环境进入内核模式时,它将被加锁,而这个环境返回到用户模式时它将释放锁。在这种模型中,在用户模式中运行的环境可以同时运行在任何可用的 CPU 上,但是只有一个环境能够运行在内核模式中;而任何尝试进入内核模式的其它环境都被强制等待。
`kern/spinlock.h` 中声明大内核锁,即 `kernel_lock`。它也提供 `lock_kernel()` 和 `unlock_kernel()`,快捷地去获取/释放锁。你应该在以下的四个位置应用大内核锁:
* 在 `i386_init()` 时,在 BSP 唤醒其它 CPU 之前获取锁。
* 在 `mp_main()` 时,在初始化 AP 之后获取锁,然后调用 `sched_yield()` 在这个 AP 上开始运行环境。
* 在 `trap()` 时,当从用户模式中捕获一个<ruby> 陷阱 <rt> trap </rt></ruby>时获取锁。在检查 `tf_cs` 的低位比特,以确定一个陷阱是发生在用户模式还是内核模式时。
* 在 `env_run()` 中,在切换到用户模式之前释放锁。不能太早也不能太晚,否则你将可能会产生争用或死锁。
>
> **练习 5**、在上面所描述的情况中,通过在合适的位置调用 `lock_kernel()` 和 `unlock_kernel()` 应用大内核锁。
>
>
> 如果你的锁定是正确的,如何去测试它?实际上,到目前为止,还无法测试!但是在下一个练习中,你实现了调度之后,就可以测试了。
>
>
>
.
>
> **问题 2**、看上去使用一个大内核锁,可以保证在一个时间中只有一个 CPU 能够运行内核代码。为什么每个 CPU 仍然需要单独的内核栈?描述一下使用一个共享内核栈出现错误的场景,即便是在它使用了大内核锁保护的情况下。
>
>
> **小挑战!**大内核锁很简单,也易于使用。尽管如此,它消除了内核模式的所有并发。大多数现代操作系统使用不同的锁,一种称之为细粒度锁定的方法,去保护它们的共享的栈的不同部分。细粒度锁能够大幅提升性能,但是实现起来更困难并且易出错。如果你有足够的勇气,在 JOS 中删除大内核锁,去拥抱并发吧!
>
>
> 由你来决定锁的粒度(一个锁保护的数据量)。给你一个提示,你可以考虑在 JOS 内核中使用一个自旋锁去确保你独占访问这些共享的组件:
>
>
> * 页分配器
> * 控制台驱动
> * 调度器
> * 你将在 Part C 中实现的进程间通讯(IPC)的状态
>
>
>
#### 循环调度
本实验中,你的下一个任务是去修改 JOS 内核,以使它能够在多个环境之间以“循环”的方式去交替。JOS 中的循环调度工作方式如下:
* 在新的 `kern/sched.c` 中的 `sched_yield()` 函数负责去选择一个新环境来运行。它按顺序以循环的方式在数组 `envs[]` 中进行搜索,在前一个运行的环境之后开始(或如果之前没有运行的环境,就从数组起点开始),选择状态为 `ENV_RUNNABLE` 的第一个环境(查看 `inc/env.h`),并调用 `env_run()` 去跳转到那个环境。
* `sched_yield()` 必须做到,同一个时间在两个 CPU 上绝对不能运行相同的环境。它可以判断出一个环境正运行在一些 CPU(可能是当前 CPU)上,因为,那个正在运行的环境的状态将是 `ENV_RUNNING`。
* 我们已经为你实现了一个新的系统调用 `sys_yield()`,用户环境调用它去调用内核的 `sched_yield()` 函数,并因此将自愿把对 CPU 的控制禅让给另外的一个环境。
>
> **练习 6**、像上面描述的那样,在 `sched_yield()` 中实现循环调度。不要忘了去修改 `syscall()` 以派发 `sys_yield()`。
>
>
> 确保在 `mp_main` 中调用了 `sched_yield()`。
>
>
> 修改 `kern/init.c` 去创建三个(或更多个!)运行程序 `user/yield.c`的环境。
>
>
> 运行 `make qemu`。在它终止之前,你应该会看到像下面这样,在环境之间来回切换了五次。
>
>
> 也可以使用几个 CPU 来测试:`make qemu CPUS=2`。
>
>
>
> ```
> ...
> Hello, I am environment 00001000.
> Hello, I am environment 00001001.
> Hello, I am environment 00001002.
> Back in environment 00001000, iteration 0.
> Back in environment 00001001, iteration 0.
> Back in environment 00001002, iteration 0.
> Back in environment 00001000, iteration 1.
> Back in environment 00001001, iteration 1.
> Back in environment 00001002, iteration 1.
> ...
> ```
>
> 在程序 `yield` 退出之后,系统中将没有可运行的环境,调度器应该会调用 JOS 内核监视器。如果它什么也没有发生,那么你应该在继续之前修复你的代码。
>
>
> **问题 3**、在你实现的 `env_run()` 中,你应该会调用 `lcr3()`。在调用 `lcr3()` 的之前和之后,你的代码引用(至少它应该会)变量 `e`,它是 `env_run` 的参数。在加载 `%cr3` 寄存器时,MMU 使用的地址上下文将马上被改变。但一个虚拟地址(即 `e`)相对一个给定的地址上下文是有意义的 —— 地址上下文指定了物理地址到那个虚拟地址的映射。为什么指针 `e` 在地址切换之前和之后被解除引用?
>
>
>
.
>
> **问题 4**、无论何时,内核从一个环境切换到另一个环境,它必须要确保旧环境的寄存器内容已经被保存,以便于它们稍后能够正确地还原。为什么?这种事件发生在什么地方?
>
>
>
.
>
> 小挑战!给内核添加一个小小的调度策略,比如一个固定优先级的调度器,它将会给每个环境分配一个优先级,并且在执行中,较高优先级的环境总是比低优先级的环境优先被选定。如果你想去冒险一下,尝试实现一个类 Unix 的、优先级可调整的调度器,或者甚至是一个彩票调度器或跨步调度器。(可以在 Google 中查找“彩票调度”和“跨步调度”的相关资料)
>
>
> 写一个或两个测试程序,去测试你的调度算法是否工作正常(即,正确的算法能够按正确的次序运行)。如果你实现了本实验的 Part B 和 Part C 部分的 `fork()` 和 IPC,写这些测试程序可能会更容易。
>
>
>
.
>
> 小挑战!目前的 JOS 内核还不能应用到使用了 x87 协处理器、MMX 指令集、或流式 SIMD 扩展(SSE)的 x86 处理器上。扩展数据结构 `Env` 去提供一个能够保存处理器的浮点状态的地方,并且扩展上下文切换代码,当从一个环境切换到另一个环境时,能够保存和还原正确的状态。`FXSAVE` 和 `FXRSTOR` 指令或许对你有帮助,但是需要注意的是,这些指令在旧的 x86 用户手册上没有,因为它是在较新的处理器上引入的。写一个用户级的测试程序,让它使用浮点做一些很酷的事情。
>
>
>
#### 创建环境的系统调用
虽然你的内核现在已经有了在多个用户级环境之间切换的功能,但是由于内核初始化设置的原因,它在运行环境时仍然是受限的。现在,你需要去实现必需的 JOS 系统调用,以允许用户环境去创建和启动其它的新用户环境。
Unix 提供了 `fork()` 系统调用作为它的进程创建原语。Unix 的 `fork()` 通过复制调用进程(父进程)的整个地址空间去创建一个新进程(子进程)。从用户空间中能够观察到它们之间的仅有的两个差别是,它们的进程 ID 和父进程 ID(由 `getpid` 和 `getppid` 返回)。在父进程中,`fork()` 返回子进程 ID,而在子进程中,`fork()` 返回 0。默认情况下,每个进程得到它自己的私有地址空间,一个进程对内存的修改对另一个进程都是不可见的。
为创建一个用户模式下的新的环境,你将要提供一个不同的、更原始的 JOS 系统调用集。使用这些系统调用,除了其它类型的环境创建之外,你可以在用户空间中实现一个完整的类 Unix 的 `fork()`。你将要为 JOS 编写的新的系统调用如下:
* `sys_exofork`:
这个系统调用创建一个新的空白的环境:在它的地址空间的用户部分什么都没有映射,并且它也不能运行。这个新的环境与 `sys_exofork` 调用时创建它的父环境的寄存器状态完全相同。在父进程中,`sys_exofork` 将返回新创建进程的 `envid_t`(如果环境分配失败的话,返回的是一个负的错误代码)。在子进程中,它将返回 0。(因为子进程从一开始就被标记为不可运行,在子进程中,`sys_exofork` 将并不真的返回,直到它的父进程使用 …. 显式地将子进程标记为可运行之前。)
* `sys_env_set_status`:
设置指定的环境状态为 `ENV_RUNNABLE` 或 `ENV_NOT_RUNNABLE`。这个系统调用一般是在,一个新环境的地址空间和寄存器状态已经完全初始化完成之后,用于去标记一个准备去运行的新环境。
* `sys_page_alloc`:
分配一个物理内存页,并映射它到一个给定的环境地址空间中、给定的一个虚拟地址上。
* `sys_page_map`:
从一个环境的地址空间中复制一个页映射(不是页内容!)到另一个环境的地址空间中,保持一个内存共享,以便于新的和旧的映射共同指向到同一个物理内存页。
* `sys_page_unmap`:
在一个给定的环境中,取消映射一个给定的已映射的虚拟地址。
上面所有的系统调用都接受环境 ID 作为参数,JOS 内核支持一个约定,那就是用值 “0” 来表示“当前环境”。这个约定在 `kern/env.c` 中的 `envid2env()` 中实现的。
在我们的 `user/dumbfork.c` 中的测试程序里,提供了一个类 Unix 的 `fork()` 的非常原始的实现。这个测试程序使用了上面的系统调用,去创建和运行一个复制了它自己地址空间的子环境。然后,这两个环境像前面的练习那样使用 `sys_yield` 来回切换,父进程在迭代 10 次后退出,而子进程在迭代 20 次后退出。
>
> **练习 7**、在 `kern/syscall.c` 中实现上面描述的系统调用,并确保 `syscall()` 能调用它们。你将需要使用 `kern/pmap.c` 和 `kern/env.c` 中的多个函数,尤其是要用到 `envid2env()`。目前,每当你调用 `envid2env()` 时,在 `checkperm` 中传递参数 1。你务必要做检查任何无效的系统调用参数,在那个案例中,就返回了 `-E_INVAL`。使用 `user/dumbfork` 测试你的 JOS 内核,并在继续之前确保它运行正常。
>
>
>
.
>
> **小挑战!**添加另外的系统调用,必须能够读取已存在的、所有的、环境的重要状态,以及设置它们。然后实现一个能够 fork 出子环境的用户模式程序,运行它一小会(即,迭代几次 `sys_yield()`),然后取得几张屏幕截图或子环境的检查点,然后运行子环境一段时间,然后还原子环境到检查点时的状态,然后从这里继续开始。这样,你就可以有效地从一个中间状态“回放”了子环境的运行。确保子环境与用户使用 `sys_cgetc()` 或 `readline()` 执行了一些交互,这样,那个用户就能够查看和突变它的内部状态,并且你可以通过给子环境给定一个选择性遗忘的状况,来验证你的检查点/重启动的有效性,使它“遗忘”了在某些点之前发生的事情。
>
>
>
到此为止,已经完成了本实验的 Part A 部分;在你运行 `make grade` 之前确保它通过了所有的 Part A 的测试,并且和以往一样,使用 `make handin` 去提交它。如果你想尝试找出为什么一些特定的测试是失败的,可以运行 `run ./grade-lab4 -v`,它将向你展示内核构建的输出,和测试失败时的 QEMU 运行情况。当测试失败时,这个脚本将停止运行,然后你可以去检查 `jos.out` 的内容,去查看内核真实的输出内容。
### Part B:写时复制 Fork
正如在前面提到过的,Unix 提供 `fork()` 系统调用作为它主要的进程创建原语。`fork()` 系统调用通过复制调用进程(父进程)的地址空间来创建一个新进程(子进程)。
xv6 Unix 的 `fork()` 从父进程的页上复制所有数据,然后将它分配到子进程的新页上。从本质上看,它与 `dumbfork()` 所采取的方法是相同的。复制父进程的地址空间到子进程,是 `fork()` 操作中代价最高的部分。
但是,一个对 `fork()` 的调用后,经常是紧接着几乎立即在子进程中有一个到 `exec()` 的调用,它使用一个新程序来替换子进程的内存。这是 shell 默认去做的事,在这种情况下,在复制父进程地址空间上花费的时间是非常浪费的,因为在调用 `exec()` 之前,子进程使用的内存非常少。
基于这个原因,Unix 的最新版本利用了虚拟内存硬件的优势,允许父进程和子进程去共享映射到它们各自地址空间上的内存,直到其中一个进程真实地修改了它们为止。这个技术就是众所周知的“写时复制”。为实现这一点,在 `fork()` 时,内核将复制从父进程到子进程的地址空间的映射,而不是所映射的页的内容,并且同时设置正在共享中的页为只读。当两个进程中的其中一个尝试去写入到它们共享的页上时,进程将产生一个页故障。在这时,Unix 内核才意识到那个页实际上是“虚拟的”或“写时复制”的副本,然后它生成一个新的、私有的、那个发生页故障的进程可写的、页的副本。在这种方式中,个人的页的内容并不进行真实地复制,直到它们真正进行写入时才进行复制。这种优化使得一个`fork()` 后在子进程中跟随一个 `exec()` 变得代价很低了:子进程在调用 `exec()` 时或许仅需要复制一个页(它的栈的当前页)。
在本实验的下一段中,你将实现一个带有“写时复制”的“真正的”类 Unix 的 `fork()`,来作为一个常规的用户空间库。在用户空间中实现 `fork()` 和写时复制有一个好处就是,让内核始终保持简单,并且因此更不易出错。它也让个别的用户模式程序在 `fork()` 上定义了它们自己的语义。一个有略微不同实现的程序(例如,代价昂贵的、总是复制的 `dumbfork()` 版本,或父子进程真实共享内存的后面的那一个),它自己可以很容易提供。
#### 用户级页故障处理
一个用户级写时复制 `fork()` 需要知道关于在写保护页上的页故障相关的信息,因此,这是你首先需要去实现的东西。对用户级页故障处理来说,写时复制仅是众多可能的用途之一。
它通常是配置一个地址空间,因此在一些动作需要时,那个页故障将指示去处。例如,主流的 Unix 内核在一个新进程的栈区域中,初始的映射仅是单个页,并且在后面“按需”分配和映射额外的栈页,因此,进程的栈消费是逐渐增加的,并因此导致在尚未映射的栈地址上发生页故障。在每个进程空间的区域上发生一个页故障时,一个典型的 Unix 内核必须对它的动作保持跟踪。例如,在栈区域中的一个页故障,一般情况下将分配和映射新的物理内存页。一个在程序的 BSS 区域中的页故障,一般情况下将分配一个新页,然后用 0 填充它并映射它。在一个按需分页的系统上的一个可执行文件中,在文本区域中的页故障将从磁盘上读取相应的二进制页并映射它。
内核跟踪有大量的信息,与传统的 Unix 方法不同,你将决定在每个用户空间中关于每个页故障应该做的事。用户空间中的 bug 危害都较小。这种设计带来了额外的好处,那就是允许程序员在定义它们的内存区域时,会有很好的灵活性;对于映射和访问基于磁盘文件系统上的文件时,你应该使用后面的用户级页故障处理。
##### 设置页故障服务程序
为了处理它自己的页故障,一个用户环境将需要在 JOS 内核上注册一个页故障服务程序入口。用户环境通过新的 `sys_env_set_pgfault_upcall` 系统调用来注册它的页故障入口。我们给结构 `Env` 增加了一个新的成员 `env_pgfault_upcall`,让它去记录这个信息。
>
> **练习 8**、实现 `sys_env_set_pgfault_upcall` 系统调用。当查找目标环境的环境 ID 时,一定要确认启用了权限检查,因为这是一个“危险的”系统调用。 “`
>
>
>
##### 在用户环境中的正常和异常栈
在正常运行期间,JOS 中的一个用户环境运行在正常的用户栈上:它的 `ESP` 寄存器开始指向到 `USTACKTOP`,而它所推送的栈数据将驻留在 `USTACKTOP-PGSIZE` 和 `USTACKTOP-1`(含)之间的页上。但是,当在用户模式中发生页故障时,内核将在一个不同的栈上重新启动用户环境,运行一个用户级页故障指定的服务程序,即用户异常栈。其它,我们将让 JOS 内核为用户环境实现自动的“栈切换”,当从用户模式转换到内核模式时,x86 处理器就以大致相同的方式为 JOS 实现了栈切换。
JOS 用户异常栈也是一个页的大小,并且它的顶部被定义在虚拟地址 `UXSTACKTOP` 处,因此用户异常栈的有效字节数是从 `UXSTACKTOP-PGSIZE` 到 `UXSTACKTOP-1`(含)。尽管运行在异常栈上,用户页故障服务程序能够使用 JOS 的普通系统调用去映射新页或调整映射,以便于去修复最初导致页故障发生的各种问题。然后用户级页故障服务程序通过汇编语言 `stub` 返回到原始栈上的故障代码。
每个想去支持用户级页故障处理的用户环境,都需要为它自己的异常栈使用在 Part A 中介绍的 `sys_page_alloc()` 系统调用去分配内存。
##### 调用用户页故障服务程序
现在,你需要去修改 `kern/trap.c` 中的页故障处理代码,以能够处理接下来在用户模式中发生的页故障。我们将故障发生时用户环境的状态称之为捕获时状态。
如果这里没有注册页故障服务程序,JOS 内核将像前面那样,使用一个消息来销毁用户环境。否则,内核将在异常栈上设置一个陷阱帧,它看起来就像是来自 `inc/trap.h` 文件中的一个 `struct UTrapframe` 一样:
```
<-- UXSTACKTOP
trap-time esp
trap-time eflags
trap-time eip
trap-time eax start of struct PushRegs
trap-time ecx
trap-time edx
trap-time ebx
trap-time esp
trap-time ebp
trap-time esi
trap-time edi end of struct PushRegs
tf_err (error code)
fault_va <-- %esp when handler is run
```
然后,内核安排这个用户环境重新运行,使用这个栈帧在异常栈上运行页故障服务程序;你必须搞清楚为什么发生这种情况。`fault_va` 是引发页故障的虚拟地址。
如果在一个异常发生时,用户环境已经在用户异常栈上运行,那么页故障服务程序自身将会失败。在这种情况下,你应该在当前的 `tf->tf_esp` 下,而不是在 `UXSTACKTOP` 下启动一个新的栈帧。
去测试 `tf->tf_esp` 是否已经在用户异常栈上准备好,可以去检查它是否在 `UXSTACKTOP-PGSIZE` 和 `UXSTACKTOP-1`(含)的范围内。
>
> **练习 9**、实现在 `kern/trap.c` 中的 `page_fault_handler` 的代码,要求派发页故障到用户模式故障服务程序上。在写入到异常栈时,一定要采取适当的预防措施。(如果用户环境运行时溢出了异常栈,会发生什么事情?)
>
>
>
##### 用户模式页故障入口点
接下来,你需要去实现汇编程序,它将调用 C 页故障服务程序,并在原始的故障指令处恢复程序运行。这个汇编程序是一个故障服务程序,它由内核使用 `sys_env_set_pgfault_upcall()` 来注册。
>
> **练习 10**、实现在 `lib/pfentry.S` 中的 `_pgfault_upcall` 程序。最有趣的部分是返回到用户代码中产生页故障的原始位置。你将要直接返回到那里,不能通过内核返回。最难的部分是同时切换栈和重新加载 EIP。
>
>
>
最后,你需要去实现用户级页故障处理机制的 C 用户库。
>
> **练习 11**、完成 `lib/pgfault.c` 中的 `set_pgfault_handler()`。 ”`
>
>
>
##### 测试
运行 `user/faultread`(make run-faultread)你应该会看到:
```
...
[00000000] new env 00001000
[00001000] user fault va 00000000 ip 0080003a
TRAP frame ...
[00001000] free env 00001000
```
运行 `user/faultdie` 你应该会看到:
```
...
[00000000] new env 00001000
i faulted at va deadbeef, err 6
[00001000] exiting gracefully
[00001000] free env 00001000
```
运行 `user/faultalloc` 你应该会看到:
```
...
[00000000] new env 00001000
fault deadbeef
this string was faulted in at deadbeef
fault cafebffe
fault cafec000
this string was faulted in at cafebffe
[00001000] exiting gracefully
[00001000] free env 00001000
```
如果你只看到第一个 “this string” 行,意味着你没有正确地处理递归页故障。
运行 `user/faultallocbad` 你应该会看到:
```
...
[00000000] new env 00001000
[00001000] user_mem_check assertion failure for va deadbeef
[00001000] free env 00001000
```
确保你理解了为什么 `user/faultalloc` 和 `user/faultallocbad` 的行为是不一样的。
>
> **小挑战!**扩展你的内核,让它不仅是页故障,而是在用户空间中运行的代码能够产生的所有类型的处理器异常,都能够被重定向到一个用户模式中的异常服务程序上。写出用户模式测试程序,去测试各种各样的用户模式异常处理,比如除零错误、一般保护故障、以及非法操作码。
>
>
>
#### 实现写时复制 Fork
现在,你有个内核功能要去实现,那就是在用户空间中完整地实现写时复制 `fork()`。
我们在 `lib/fork.c` 中为你的 `fork()` 提供了一个框架。像 `dumbfork()`、`fork()` 应该会创建一个新环境,然后通过扫描父环境的整个地址空间,并在子环境中设置相关的页映射。重要的差别在于,`dumbfork()` 复制了页,而 `fork()` 开始只是复制了页映射。`fork()` 仅当在其中一个环境尝试去写入它时才复制每个页。
`fork()` 的基本控制流如下:
1. 父环境使用你在上面实现的 `set_pgfault_handler()` 函数,安装 `pgfault()` 作为 C 级页故障服务程序。
2. 父环境调用 `sys_exofork()` 去创建一个子环境。
3. 在它的地址空间中,低于 UTOP 位置的、每个可写入页、或写时复制页上,父环境调用 `duppage` 后,它应该会映射页写时复制到子环境的地址空间中,然后在它自己的地址空间中重新映射页写时复制。[ 注意:这里的顺序很重要(即,在父环境中标记之前,先在子环境中标记该页为 COW)!你能明白是为什么吗?尝试去想一个具体的案例,将顺序颠倒一下会发生什么样的问题。] `duppage` 把两个 PTE 都设置了,致使那个页不可写入,并且在 “avail” 字段中通过包含 `PTE_COW` 来从真正的只读页中区分写时复制页。
然而异常栈是不能通过这种方式重映射的。对于异常栈,你需要在子环境中分配一个新页。因为页故障服务程序不能做真实的复制,并且页故障服务程序是运行在异常栈上的,异常栈不能进行写时复制:那么谁来复制它呢?
`fork()` 也需要去处理存在的页,但不能写入或写时复制。
4. 父环境为子环境设置了用户页故障入口点,让它看起来像它自己的一样。
5. 现在,子环境准备去运行,所以父环境标记它为可运行。
每次其中一个环境写一个还没有写入的写时复制页时,它将产生一个页故障。下面是用户页故障服务程序的控制流:
1. 内核传递页故障到 `_pgfault_upcall`,它调用 `fork()` 的 `pgfault()` 服务程序。
2. `pgfault()` 检测到那个故障是一个写入(在错误代码中检查 `FEC_WR`),然后将那个页的 PTE 标记为 `PTE_COW`。如果不是一个写入,则崩溃。
3. `pgfault()` 在一个临时位置分配一个映射的新页,并将故障页的内容复制进去。然后,故障服务程序以读取/写入权限映射新页到合适的地址,替换旧的只读映射。
对于上面的几个操作,用户级 `lib/fork.c` 代码必须查询环境的页表(即,那个页的 PTE 是否标记为 `PET_COW`)。为此,内核在 `UVPT` 位置精确地映射环境的页表。它使用一个 [聪明的映射技巧](https://pdos.csail.mit.edu/6.828/2018/labs/lab4/uvpt.html) 去标记它,以使用户代码查找 PTE 时更容易。`lib/entry.S` 设置 `uvpt` 和 `uvpd`,以便于你能够在 `lib/fork.c` 中轻松查找页表信息。
>
> **练习 12**、在 `lib/fork.c` 中实现 `fork`、`duppage` 和 `pgfault`。
>
>
> 使用 `forktree` 程序测试你的代码。它应该会产生下列的信息,在信息中会有 ‘new env'、'free env'、和 'exiting gracefully’ 这样的字眼。信息可能不是按如下的顺序出现的,并且环境 ID 也可能不一样。
>
>
>
> ```
> 1000: I am ''
> 1001: I am '0'
> 2000: I am '00'
> 2001: I am '000'
> 1002: I am '1'
> 3000: I am '11'
> 3001: I am '10'
> 4000: I am '100'
> 1003: I am '01'
> 5000: I am '010'
> 4001: I am '011'
> 2002: I am '110'
> 1004: I am '001'
> 1005: I am '111'
> 1006: I am '101'
> ```
>
>
.
>
> **小挑战!**实现一个名为 `sfork()` 的共享内存的 `fork()`。这个版本的 `sfork()` 中,父子环境共享所有的内存页(因此,一个环境中对内存写入,就会改变另一个环境数据),除了在栈区域中的页以外,它应该使用写时复制来处理这些页。修改 `user/forktree.c` 去使用 `sfork()` 而是不常见的 `fork()`。另外,你在 Part C 中实现了 IPC 之后,使用你的 `sfork()` 去运行 `user/pingpongs`。你将找到提供全局指针 `thisenv` 功能的一个新方式。
>
>
>
.
>
> **小挑战!**你实现的 `fork` 将产生大量的系统调用。在 x86 上,使用中断切换到内核模式将产生较高的代价。增加系统调用接口,以便于它能够一次发送批量的系统调用。然后修改 `fork` 去使用这个接口。
>
>
> 你的新的 `fork` 有多快?
>
>
> 你可以用一个分析来论证,批量提交对你的 `fork` 的性能改变,以它来(粗略地)回答这个问题:使用一个 `int 0x30` 指令的代价有多高?在你的 `fork` 中运行了多少次 `int 0x30` 指令?访问 `TSS` 栈切换的代价高吗?等待 …
>
>
> 或者,你可以在真实的硬件上引导你的内核,并且真实地对你的代码做基准测试。查看 `RDTSC`(读取时间戳计数器)指令,它的定义在 IA32 手册中,它计数自上一次处理器重置以来流逝的时钟周期数。QEMU 并不能真实地模拟这个指令(它能够计数运行的虚拟指令数量,或使用主机的 TSC,但是这两种方式都不能反映真实的 CPU 周期数)。
>
>
>
到此为止,Part B 部分结束了。在你运行 `make grade` 之前,确保你通过了所有的 Part B 部分的测试。和以前一样,你可以使用 `make handin` 去提交你的实验。
### Part C:抢占式多任务处理和进程间通讯(IPC)
在实验 4 的最后部分,你将修改内核去抢占不配合的环境,并允许环境之间显式地传递消息。
#### 时钟中断和抢占
运行测试程序 `user/spin`。这个测试程序 fork 出一个子环境,它控制了 CPU 之后,就永不停歇地运转起来。无论是父环境还是内核都不能回收对 CPU 的控制。从用户模式环境中保护系统免受 bug 或恶意代码攻击的角度来看,这显然不是个理想的状态,因为任何用户模式环境都能够通过简单的无限循环,并永不归还 CPU 控制权的方式,让整个系统处于暂停状态。为了允许内核去抢占一个运行中的环境,从其中夺回对 CPU 的控制权,我们必须去扩展 JOS 内核,以支持来自硬件时钟的外部硬件中断。
##### 中断规则
外部中断(即:设备中断)被称为 IRQ。现在有 16 个可能出现的 IRQ,编号 0 到 15。从 IRQ 号到 IDT 条目的映射是不固定的。在 `picirq.c` 中的 `pic_init` 映射 IRQ 0 - 15 到 IDT 条目 `IRQ_OFFSET` 到 `IRQ_OFFSET+15`。
在 `inc/trap.h` 中,`IRQ_OFFSET` 被定义为十进制的 32。所以,IDT 条目 32 - 47 对应 IRQ 0 - 15。例如,时钟中断是 IRQ 0,所以 IDT[IRQ\_OFFSET+0](即:IDT[32])包含了内核中时钟中断服务程序的地址。这里选择 `IRQ_OFFSET` 是为了处理器异常不会覆盖设备中断,因为它会引起显而易见的混淆。(事实上,在早期运行 MS-DOS 的 PC 上, `IRQ_OFFSET` 事实上是 0,它确实导致了硬件中断服务程序和处理器异常处理之间的混淆!)
在 JOS 中,相比 xv6 Unix 我们做了一个重要的简化。当处于内核模式时,外部设备中断总是被关闭(并且,像 xv6 一样,当处于用户空间时,再打开外部设备的中断)。外部中断由 `%eflags` 寄存器的 `FL_IF` 标志位来控制(查看 `inc/mmu.h`)。当这个标志位被设置时,外部中断被打开。虽然这个标志位可以使用几种方式来修改,但是为了简化,我们只通过进程所保存和恢复的 `%eflags` 寄存器值,作为我们进入和离开用户模式的方法。
处于用户环境中时,你将要确保 `FL_IF` 标志被设置,以便于出现一个中断时,它能够通过处理器来传递,让你的中断代码来处理。否则,中断将被屏蔽或忽略,直到中断被重新打开后。我们使用引导加载程序的第一个指令去屏蔽中断,并且到目前为止,还没有去重新打开它们。
>
> **练习 13**、修改 `kern/trapentry.S` 和 `kern/trap.c` 去初始化 IDT 中的相关条目,并为 IRQ 0 到 15 提供服务程序。然后修改 `kern/env.c` 中的 `env_alloc()` 的代码,以确保在用户环境中,中断总是打开的。
>
>
> 另外,在 `sched_halt()` 中取消注释 `sti` 指令,以便于空闲的 CPU 取消屏蔽中断。
>
>
> 当调用一个硬件中断服务程序时,处理器不会推送一个错误代码。在这个时候,你可能需要重新阅读 [80386 参考手册](https://pdos.csail.mit.edu/6.828/2018/labs/readings/i386/toc.htm) 的 9.2 节,或 [IA-32 Intel 架构软件开发者手册 卷 3](https://pdos.csail.mit.edu/6.828/2018/labs/readings/ia32/IA32-3A.pdf) 的 5.8 节。
>
>
> 在完成这个练习后,如果你在你的内核上使用任意的测试程序去持续运行(即:`spin`),你应该会看到内核输出中捕获的硬件中断的捕获帧。虽然在处理器上已经打开了中断,但是 JOS 并不能处理它们,因此,你应该会看到在当前运行的用户环境中每个中断的错误属性并被销毁,最终环境会被销毁并进入到监视器中。
>
>
>
##### 处理时钟中断
在 `user/spin` 程序中,子环境首先运行之后,它只是进入一个高速循环中,并且内核再无法取得 CPU 控制权。我们需要对硬件编程,定期产生时钟中断,它将强制将 CPU 控制权返还给内核,在内核中,我们就能够将控制权切换到另外的用户环境中。
我们已经为你写好了对 `lapic_init` 和 `pic_init`(来自 `init.c` 中的 `i386_init`)的调用,它将设置时钟和中断控制器去产生中断。现在,你需要去写代码来处理这些中断。
>
> **练习 14**、修改内核的 `trap_dispatch()` 函数,以便于在时钟中断发生时,它能够调用 `sched_yield()` 去查找和运行一个另外的环境。
>
>
> 现在,你应该能够用 `user/spin` 去做测试了:父环境应该会 fork 出子环境,`sys_yield()` 到它许多次,但每次切换之后,将重新获得对 CPU 的控制权,最后杀死子环境后优雅地终止。
>
>
>
这是做回归测试的好机会。确保你没有弄坏本实验的前面部分,确保打开中断能够正常工作(即: `forktree`)。另外,尝试使用 `make CPUS=2 target` 在多个 CPU 上运行它。现在,你应该能够通过 `stresssched` 测试。可以运行 `make grade` 去确认。现在,你的得分应该是 65 分了(总分为 80)。
#### 进程间通讯(IPC)
(严格来说,在 JOS 中这是“环境间通讯” 或 “IEC”,但所有人都称它为 IPC,因此我们使用标准的术语。)
我们一直专注于操作系统的隔离部分,这就产生了一种错觉,好像每个程序都有一个机器完整地为它服务。一个操作系统的另一个重要服务是,当它们需要时,允许程序之间相互通讯。让程序与其它程序交互可以让它的功能更加强大。Unix 的管道模型就是一个权威的示例。
进程间通讯有许多模型。关于哪个模型最好的争论从来没有停止过。我们不去参与这种争论。相反,我们将要实现一个简单的 IPC 机制,然后尝试使用它。
##### JOS 中的 IPC
你将要去实现另外几个 JOS 内核的系统调用,由它们共同来提供一个简单的进程间通讯机制。你将要实现两个系统调用,`sys_ipc_recv` 和 `sys_ipc_try_send`。然后你将要实现两个库去封装 `ipc_recv` 和 `ipc_send`。
用户环境可以使用 JOS 的 IPC 机制相互之间发送 “消息” 到每个其它环境,这些消息有两部分组成:一个单个的 32 位值,和可选的一个单个页映射。允许环境在消息中传递页映射,提供了一个高效的方式,传输比一个仅适合单个的 32 位整数更多的数据,并且也允许环境去轻松地设置安排共享内存。
##### 发送和接收消息
一个环境通过调用 `sys_ipc_recv` 去接收消息。这个系统调用将取消对当前环境的调度,并且不会再次去运行它,直到消息被接收为止。当一个环境正在等待接收一个消息时,任何其它环境都能够给它发送一个消息 — 而不仅是一个特定的环境,而且不仅是与接收环境有父子关系的环境。换句话说,你在 Part A 中实现的权限检查将不会应用到 IPC 上,因为 IPC 系统调用是经过慎重设计的,因此可以认为它是“安全的”:一个环境并不能通过给它发送消息导致另一个环境发生故障(除非目标环境也存在 Bug)。
尝试去发送一个值时,一个环境使用接收者的 ID 和要发送的值去调用 `sys_ipc_try_send` 来发送。如果指定的环境正在接收(它调用了 `sys_ipc_recv`,但尚未收到值),那么这个环境将去发送消息并返回 0。否则将返回 `-E_IPC_NOT_RECV` 来表示目标环境当前不希望来接收值。
在用户空间中的一个库函数 `ipc_recv` 将去调用 `sys_ipc_recv`,然后,在当前环境的 `struct Env` 中查找关于接收到的值的相关信息。
同样,一个库函数 `ipc_send` 将去不停地调用 `sys_ipc_try_send` 来发送消息,直到发送成功为止。
##### 转移页
当一个环境使用一个有效的 `dstva` 参数(低于 `UTOP`)去调用 `sys_ipc_recv` 时,环境将声明愿意去接收一个页映射。如果发送方发送一个页,那么那个页应该会被映射到接收者地址空间的 `dstva` 处。如果接收者在 `dstva` 已经有了一个页映射,那么已存在的那个页映射将被取消映射。
当一个环境使用一个有效的 `srcva` 参数(低于 `UTOP`)去调用 `sys_ipc_try_send` 时,意味着发送方希望使用 `perm` 权限去发送当前映射在 `srcva` 处的页给接收方。在 IPC 成功之后,发送方在它的地址空间中,保留了它最初映射到 `srcva` 位置的页。而接收方也获得了最初由它指定的、在它的地址空间中的 `dstva` 处的、映射到相同物理页的映射。最后的结果是,这个页成为发送方和接收方共享的页。
如果发送方和接收方都没有表示要转移这个页,那么就不会有页被转移。在任何 IPC 之后,内核将在接收方的 `Env` 结构上设置新的 `env_ipc_perm` 字段,以允许接收页,或者将它设置为 0,表示不再接收。
##### 实现 IPC
>
> **练习 15**、实现 `kern/syscall.c` 中的 `sys_ipc_recv` 和 `sys_ipc_try_send`。在实现它们之前一起阅读它们的注释信息,因为它们要一起工作。当你在这些程序中调用 `envid2env` 时,你应该去设置 `checkperm` 的标志为 0,这意味着允许任何环境去发送 IPC 消息到另外的环境,并且内核除了验证目标 envid 是否有效外,不做特别的权限检查。
>
>
> 接着实现 `lib/ipc.c` 中的 `ipc_recv` 和 `ipc_send` 函数。
>
>
> 使用 `user/pingpong` 和 `user/primes` 函数去测试你的 IPC 机制。`user/primes` 将为每个质数生成一个新环境,直到 JOS 耗尽环境为止。你可能会发现,阅读 `user/primes.c` 非常有趣,你将看到所有的 fork 和 IPC 都是在幕后进行。
>
>
>
.
>
> **小挑战!**为什么 `ipc_send` 要循环调用?修改系统调用接口,让它不去循环。确保你能处理多个环境尝试同时发送消息到一个环境上的情况。
>
>
>
.
>
> **小挑战!**质数筛选是在大规模并发程序中传递消息的一个很巧妙的用法。阅读 C. A. R. Hoare 写的 《Communicating Sequential Processes》,Communications of the ACM\_ 21(8) (August 1978), 666-667,并去实现矩阵乘法示例。
>
>
>
.
>
> **小挑战!**控制消息传递的最令人印象深刻的一个例子是,Doug McIlroy 的幂序列计算器,它在 [M. Douglas McIlroy,《Squinting at Power Series》,Software–Practice and Experience, 20(7) (July 1990),661-683](https://swtch.com/%7Ersc/thread/squint.pdf) 中做了详细描述。实现了它的幂序列计算器,并且计算了 sin ( x + x <sup> 3)</sup> 的幂序列。
>
>
>
.
>
> **小挑战!**通过应用 Liedtke 的论文([通过内核设计改善 IPC 性能](http://dl.acm.org/citation.cfm?id=168633))中的一些技术、或你可以想到的其它技巧,来让 JOS 的 IPC 机制更高效。为此,你可以随意修改内核的系统调用 API,只要你的代码向后兼容我们的评级脚本就行。
>
>
>
**Part C 到此结束了。**确保你通过了所有的评级测试,并且不要忘了将你的小挑战的答案写入到 `answers-lab4.txt` 中。
在动手实验之前, 使用 `git status` 和 `git diff` 去检查你的更改,并且不要忘了去使用 `git add answers-lab4.txt` 添加你的小挑战的答案。在你全部完成后,使用 `git commit -am 'my solutions to lab 4’` 提交你的更改,然后 `make handin` 并关注它的动向。
---
via: <https://pdos.csail.mit.edu/6.828/2018/labs/lab4/>
作者:[csail.mit](https://pdos.csail.mit.edu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **
Part A due Thursday, October 18, 2018
Part B due Thursday, October 25, 2018
Part C due Thursday, November 1, 2018
**
In this lab you will implement preemptive multitasking among multiple simultaneously active user-mode environments.
In part A you will add multiprocessor support to JOS, implement round-robin scheduling, and add basic environment management system calls (calls that create and destroy environments, and allocate/map memory).
In part B, you will implement a Unix-like `fork()`
,
which allows a user-mode environment to create copies of
itself.
Finally, in part C you will add support for inter-process communication (IPC), allowing different user-mode environments to communicate and synchronize with each other explicitly. You will also add support for hardware clock interrupts and preemption.
Use Git to commit your Lab 3 source, fetch the latest version of the course
repository, and then create a local branch called `lab4` based on our
lab4 branch, `origin/lab4`:
athena%Lab 4 contains a number of new source files, some of which you should browse before you start:cd ~/6.828/labathena%add gitathena%git pullAlready up-to-date. athena%git checkout -b lab4 origin/lab4Branch lab4 set up to track remote branch refs/remotes/origin/lab4. Switched to a new branch "lab4" athena%git merge lab3Merge made by recursive. ... athena%
kern/cpu.h |
Kernel-private definitions for multiprocessor support |
kern/mpconfig.c |
Code to read the multiprocessor configuration |
kern/lapic.c |
Kernel code driving the local APIC unit in each processor |
kern/mpentry.S |
Assembly-language entry code for non-boot CPUs |
kern/spinlock.h |
Kernel-private definitions for spin locks, including the big kernel lock |
kern/spinlock.c |
Kernel code implementing spin locks |
kern/sched.c |
Code skeleton of the scheduler that you are about to implement |
This lab is divided into three parts, A, B, and C. We have allocated one week in the schedule for each part.
As before,
you will need to do all of the regular exercises described in the lab
and *at least one* challenge problem.
(You do not need to do one challenge problem per part,
just one for the whole lab.)
Additionally, you will need to write up a brief
description of the challenge problem that you implemented.
If you implement more than one challenge problem,
you only need to describe one of them in the write-up,
though of course you are welcome to do more.
Place the write-up in a file called `answers-lab4.txt`
in the top level of your `lab` directory
before handing in your work.
In the first part of this lab,
you will first extend JOS to run on a multiprocessor system,
and then implement some new JOS kernel system calls
to allow user-level environments to create
additional new environments.
You will also implement *cooperative* round-robin scheduling,
allowing the kernel to switch from one environment to another
when the current environment voluntarily relinquishes the CPU (or exits).
Later in part C you will implement *preemptive* scheduling,
which allows the kernel to re-take control of the CPU from an environment
after a certain time has passed even if the environment does not cooperate.
We are going to make JOS support "symmetric multiprocessing" (SMP), a multiprocessor model in which all CPUs have equivalent access to system resources such as memory and I/O buses. While all CPUs are functionally identical in SMP, during the boot process they can be classified into two types: the bootstrap processor (BSP) is responsible for initializing the system and for booting the operating system; and the application processors (APs) are activated by the BSP only after the operating system is up and running. Which processor is the BSP is determined by the hardware and the BIOS. Up to this point, all your existing JOS code has been running on the BSP.
In an SMP system, each CPU has an accompanying local APIC (LAPIC) unit.
The LAPIC units are responsible for delivering interrupts throughout
the system. The LAPIC also provides its connected CPU with a unique
identifier. In this lab, we make use of the following basic
functionality of the LAPIC unit (in `kern/lapic.c`):
`cpunum()`
). `STARTUP`
interprocessor interrupt (IPI) from
the BSP to the APs to bring up other CPUs (see
`lapic_startap()`
).`apic_init()`
).
A processor accesses its LAPIC using memory-mapped I/O (MMIO).
In MMIO, a portion of *physical* memory is hardwired to the
registers of some I/O devices, so the same load/store instructions
typically used to access memory can be used to access device
registers. You've already seen one IO hole at physical address
`0xA0000` (we use this to write to the VGA display buffer).
The LAPIC lives in a hole starting at physical address
`0xFE000000` (32MB short of 4GB), so it's too high for us to
access using our usual direct map at KERNBASE. The JOS virtual memory
map leaves a 4MB gap at `MMIOBASE` so we have a place to map
devices like this. Since later labs introduce more MMIO regions,
you'll write a simple function to allocate space from this region and
map device memory to it.
Exercise 1.
Implement `mmio_map_region`
in `kern/pmap.c`. To
see how this is used, look at the beginning of
`lapic_init`
in `kern/lapic.c`. You'll have to do
the next exercise, too, before the tests for
`mmio_map_region`
will run.
Before booting up APs, the BSP should first collect information
about the multiprocessor system, such as the total number of
CPUs, their APIC IDs and the MMIO address of the LAPIC unit.
The `mp_init()`
function in `kern/mpconfig.c`
retrieves this information by reading the MP configuration
table that resides in the BIOS's region of memory.
The `boot_aps()`
function (in `kern/init.c`) drives
the AP bootstrap process. APs start in real mode, much like how the
bootloader started in `boot/boot.S`, so `boot_aps()`
copies the AP entry code (`kern/mpentry.S`) to a memory
location that is addressable in the real mode. Unlike with the
bootloader, we have some control over where the AP will start
executing code; we copy the entry code to `0x7000`
(`MPENTRY_PADDR`
), but any unused, page-aligned
physical address below 640KB would work.
After that, `boot_aps()`
activates APs one after another, by
sending `STARTUP`
IPIs to the LAPIC unit of the corresponding
AP, along with an initial `CS:IP`
address at which the AP
should start running its entry code (`MPENTRY_PADDR`
in our
case). The entry code in `kern/mpentry.S` is quite similar to
that of `boot/boot.S`. After some brief setup, it puts the AP
into protected mode with paging enabled, and then calls the C setup
routine `mp_main()`
(also in `kern/init.c`).
`boot_aps()`
waits for the AP to signal a
`CPU_STARTED`
flag in `cpu_status`
field of
its `struct CpuInfo`
before going on to wake up the next one.
Exercise 2.
Read `boot_aps()`
and `mp_main()`
in
`kern/init.c`, and the assembly code in
`kern/mpentry.S`. Make sure you understand the control flow
transfer during the bootstrap of APs. Then modify your implementation
of `page_init()`
in `kern/pmap.c` to avoid adding
the page at `MPENTRY_PADDR`
to the free list, so that we
can safely copy and run AP bootstrap code at that physical address.
Your code should pass the updated `check_page_free_list()`
test (but might fail the updated `check_kern_pgdir()`
test, which we will fix soon).
Question
`KERNBASE`
just like
everything else in the kernel, what is the purpose of macro
`MPBOOTPHYS`
? Why is it
necessary in
When writing a multiprocessor OS, it is important to distinguish
between per-CPU state that is private to each processor, and global
state that the whole system shares. `kern/cpu.h` defines most
of the per-CPU state, including `struct CpuInfo`
, which stores
per-CPU variables. `cpunum()`
always returns the ID of the
CPU that calls it, which can be used as an index into arrays like
`cpus`
. Alternatively, the macro `thiscpu`
is
shorthand for the current CPU's `struct CpuInfo`
.
Here is the per-CPU state you should be aware of:
**Per-CPU kernel stack**.
Because multiple CPUs can trap into the kernel simultaneously,
we need a separate kernel stack for each processor to prevent them from
interfering with each other's execution. The array
`percpu_kstacks[NCPU][KSTKSIZE]`
reserves space for NCPU's
worth of kernel stacks.
In Lab 2, you mapped the physical memory that `bootstack`
refers to as the BSP's kernel stack just below
`KSTACKTOP`
.
Similarly, in this lab, you will map each CPU's kernel stack into this
region with guard pages acting as a buffer between them. CPU 0's
stack will still grow down from `KSTACKTOP`
; CPU 1's stack
will start `KSTKGAP`
bytes below the bottom of CPU 0's
stack, and so on. `inc/memlayout.h` shows the mapping layout.
**Per-CPU TSS and TSS descriptor**.
A per-CPU task state segment (TSS) is also needed in order to specify
where each CPU's kernel stack lives. The TSS for CPU *i* is stored
in `cpus[i].cpu_ts`
, and the corresponding TSS descriptor is
defined in the GDT entry `gdt[(GD_TSS0 >> 3) + i]`
. The
global `ts`
variable defined in `kern/trap.c` will
no longer be useful.
**Per-CPU current environment pointer**.
Since each CPU can run different user process simultaneously, we
redefined the symbol `curenv`
to refer to
`cpus[cpunum()].cpu_env`
(or `thiscpu->cpu_env`
), which
points to the environment *currently* executing on the
*current* CPU (the CPU on which the code is running).
**Per-CPU system registers**.
All registers, including system registers, are private to a
CPU. Therefore, instructions that
initialize these registers, such as `lcr3()`
,
`ltr()`
, `lgdt()`
, `lidt()`
, etc., must
be executed once on each CPU. Functions `env_init_percpu()`
and `trap_init_percpu()`
are defined for this purpose.
In addition to this, if you have added any extra per-CPU state or performed any additional CPU-specific initialization (by say, setting new bits in the CPU registers) in your solutions to challenge problems in earlier labs, be sure to replicate them on each CPU here!
Exercise 3.
Modify `mem_init_mp()`
(in `kern/pmap.c`) to map
per-CPU stacks starting
at `KSTACKTOP`
, as shown in
`inc/memlayout.h`. The size of each stack is
`KSTKSIZE`
bytes plus `KSTKGAP`
bytes of
unmapped guard pages. Your code should pass the new check in
`check_kern_pgdir()`
.
Exercise 4.
The code in `trap_init_percpu()`
(`kern/trap.c`)
initializes the TSS and
TSS descriptor for the BSP. It worked in Lab 3, but is incorrect
when running on other CPUs. Change the code so that it can work
on all CPUs. (Note: your new code should not use the global
`ts`
variable any more.)
When you finish the above exercises, run JOS in QEMU with 4 CPUs using
`make qemu CPUS=4` (or `make qemu-nox CPUS=4`), you
should see output like this:
... Physical memory: 66556K available, base = 640K, extended = 65532K check_page_alloc() succeeded! check_page() succeeded! check_kern_pgdir() succeeded! check_page_installed_pgdir() succeeded! SMP: CPU 0 found 4 CPU(s) enabled interrupts: 1 2 SMP: CPU 1 starting SMP: CPU 2 starting SMP: CPU 3 starting
Our current code spins after initializing the AP in
`mp_main()`
. Before letting the AP get any further, we need
to first address race conditions when multiple CPUs run kernel code
simultaneously. The simplest way to achieve this is to use a *big
kernel lock*.
The big kernel lock is a single global lock that is held whenever an
environment enters kernel mode, and is released when the environment
returns to user mode. In this model, environments in user mode can run
concurrently on any available CPUs, but no more than one environment can
run in kernel mode; any other environments that try to enter kernel mode
are forced to wait.
`kern/spinlock.h` declares the big kernel lock, namely
`kernel_lock`
. It also provides `lock_kernel()`
and `unlock_kernel()`
, shortcuts to acquire and
release the lock. You should apply the big kernel lock at four locations:
`i386_init()`
, acquire the lock before the BSP wakes up the
other CPUs.
`mp_main()`
, acquire the lock after initializing the AP,
and then call `sched_yield()`
to start running environments
on this AP.
`trap()`
, acquire the lock when trapped from user mode.
To determine whether a trap happened in user mode or in kernel mode,
check the low bits of the `tf_cs`
.
`env_run()`
, release the lock Exercise 5.
Apply the big kernel lock as described above, by calling
`lock_kernel()`
and `unlock_kernel()`
at
the proper locations.
How to test if your locking is correct? You can't at this moment! But you will be able to after you implement the scheduler in the next exercise.
Question
Challenge!
The big kernel lock is simple and easy to use. Nevertheless, it
eliminates all concurrency in kernel mode. Most
modern operating systems use different locks to protect different
parts of their shared state, an
approach called *fine-grained locking*.
Fine-grained locking can increase performance significantly, but is
more difficult to implement and error-prone. If you are brave
enough, drop the big kernel lock and embrace concurrency in JOS!
It is up to you to decide the locking granularity (the amount of data that a lock protects). As a hint, you may consider using spin locks to ensure exclusive access to these shared components in the JOS kernel:
Your next task in this lab is to change the JOS kernel so that it can alternate between multiple environments in "round-robin" fashion. Round-robin scheduling in JOS works as follows:
`sched_yield()`
in the new `envs[]`
array
in circular fashion,
starting just after the previously running environment
(or at the beginning of the array
if there was no previously running environment),
picks the first environment it finds
with a status of `ENV_RUNNABLE`
(see `env_run()`
to jump into that environment. `sched_yield()`
must never run the same environment
on two CPUs at the same time. It can tell that an environment
is currently running on some CPU (possibly the current CPU)
because that environment's status will be `ENV_RUNNING`
.`sys_yield()`
,
which user environments can call
to invoke the kernel's `sched_yield()`
function
and thereby voluntarily give up the CPU to a different environment. Exercise 6.
Implement round-robin scheduling in `sched_yield()`
as described above. Don't forget to modify
`syscall()`
to dispatch `sys_yield()`
.
Make sure to invoke `sched_yield()`
in `mp_main`
.
Modify `kern/init.c` to create three (or more!) environments
that all run the program `user/yield.c`.
Run `make qemu`.
You should see the environments
switch back and forth between each other
five times before terminating, like below.
Test also with several CPUS: `make qemu CPUS=2`.
... Hello, I am environment 00001000. Hello, I am environment 00001001. Hello, I am environment 00001002. Back in environment 00001000, iteration 0. Back in environment 00001001, iteration 0. Back in environment 00001002, iteration 0. Back in environment 00001000, iteration 1. Back in environment 00001001, iteration 1. Back in environment 00001002, iteration 1. ...
After the `yield` programs exit, there will be no runnable
environment in the system, the scheduler should
invoke the JOS kernel monitor.
If any of this does not happen,
then fix your code before proceeding.
Question
`env_run()`
you should have
called `lcr3()`
. Before and after the call to
`lcr3()`
, your code makes references (at least it should)
to the variable `e`
, the argument to `env_run`
.
Upon loading the `%cr3`
register, the addressing context
used by the MMU is instantly changed. But a virtual
address (namely `e`
) has meaning relative to a given
address context--the address context specifies the physical address to
which the virtual address maps. Why can the pointer `e`
be
dereferenced both before and after the addressing switch?
Challenge! Add a less trivial scheduling policy to the kernel, such as a fixed-priority scheduler that allows each environment to be assigned a priority and ensures that higher-priority environments are always chosen in preference to lower-priority environments. If you're feeling really adventurous, try implementing a Unix-style adjustable-priority scheduler or even a lottery or stride scheduler. (Look up "lottery scheduling" and "stride scheduling" in Google.)
Write a test program or two
that verifies that your scheduling algorithm is working correctly
(i.e., the right environments get run in the right order).
It may be easier to write these test programs
once you have implemented `fork()`
and IPC
in parts B and C of this lab.
Challenge!
The JOS kernel currently does not allow applications
to use the x86 processor's x87 floating-point unit (FPU),
MMX instructions, or Streaming SIMD Extensions (SSE).
Extend the `Env`
structure
to provide a save area for the processor's floating point state,
and extend the context switching code
to save and restore this state properly
when switching from one environment to another.
The `FXSAVE`
and `FXRSTOR`
instructions may be useful,
but note that these are not in the old i386 user's manual
because they were introduced in more recent processors.
Write a user-level test program
that does something cool with floating-point.
Although your kernel is now capable of running and switching between
multiple user-level environments,
it is still limited to running environments
that the *kernel* initially set up.
You will now implement the necessary JOS system calls
to allow *user* environments to create and start
other new user environments.
Unix provides the `fork()`
system call
as its process creation primitive.
Unix `fork()`
copies
the entire address space of calling process (the parent)
to create a new process (the child).
The only differences between the two observable from user space
are their process IDs and parent process IDs
(as returned by `getpid`
and `getppid`
).
In the parent,
`fork()`
returns the child's process ID,
while in the child, `fork()`
returns 0.
By default, each process gets its own private address space, and
neither process's modifications to memory are visible to the other.
You will provide a different, more primitive
set of JOS system calls
for creating new user-mode environments.
With these system calls you will be able to implement
a Unix-like `fork()`
entirely in user space,
in addition to other styles of environment creation.
The new system calls you will write for JOS are as follows:
`sys_exofork`
:`sys_exofork`
call.
In the parent, `sys_exofork`
will return the `envid_t`
of the newly created
environment
(or a negative error code if the environment allocation failed).
In the child, however, it will return 0.
(Since the child starts out marked as not runnable,
`sys_exofork`
will not actually return in the child
until the parent has explicitly allowed this
by marking the child runnable using....)`sys_env_set_status`
:`ENV_RUNNABLE`
or `ENV_NOT_RUNNABLE`
.
This system call is typically used
to mark a new environment ready to run,
once its address space and register state
has been fully initialized.`sys_page_alloc`
:`sys_page_map`
:`sys_page_unmap`
:
For all of the system calls above that accept environment IDs,
the JOS kernel supports the convention
that a value of 0 means "the current environment."
This convention is implemented by `envid2env()`
in `kern/env.c`.
We have provided a very primitive implementation
of a Unix-like `fork()`
in the test program `user/dumbfork.c`.
This test program uses the above system calls
to create and run a child environment
with a copy of its own address space.
The two environments
then switch back and forth using `sys_yield`
as in the previous exercise.
The parent exits after 10 iterations,
whereas the child exits after 20.
Exercise 7.
Implement the system calls described above
in `kern/syscall.c` and make sure `syscall()` calls
them.
You will need to use various functions
in `kern/pmap.c` and `kern/env.c`,
particularly `envid2env()`
.
For now, whenever you call `envid2env()`
,
pass 1 in the `checkperm`
parameter.
Be sure you check for any invalid system call arguments,
returning `-E_INVAL`
in that case.
Test your JOS kernel with `user/dumbfork`
and make sure it works before proceeding.
Challenge!
Add the additional system calls necessary
to *read* all of the vital state of an existing environment
as well as set it up.
Then implement a user mode program that forks off a child environment,
runs it for a while (e.g., a few iterations of `sys_yield()`
),
then takes a complete snapshot or *checkpoint*
of the child environment,
runs the child for a while longer,
and finally restores the child environment to the state it was in
at the checkpoint
and continues it from there.
Thus, you are effectively "replaying"
the execution of the child environment from an intermediate state.
Make the child environment perform some interaction with the user
using `sys_cgetc()`
or `readline()`
so that the user can view and mutate its internal state,
and verify that with your checkpoint/restart
you can give the child environment a case of selective amnesia,
making it "forget" everything that happened beyond a certain point.
This completes Part A of the lab;
make sure it passes all of the Part A tests when you run
`make grade`, and hand it in using `make
handin` as usual. If you are trying to figure out why a particular
test case is failing, run `./grade-lab4 -v`, which will
show you the output of the kernel builds and QEMU runs for each
test, until a test fails. When a test fails, the script will stop,
and then you can inspect `jos.out` to see what the
kernel actually printed.
As mentioned earlier,
Unix provides the `fork()`
system call
as its primary process creation primitive.
The `fork()`
system call
copies the address space of the calling process (the parent)
to create a new process (the child).
xv6 Unix implements `fork()`
by copying all data from the
parent's pages into new pages allocated for the child.
This is essentially the same approach
that `dumbfork()`
takes.
The copying of the parent's address space into the child is
the most expensive part of the `fork()`
operation.
However, a call to `fork()`
is frequently followed almost immediately
by a call to `exec()`
in the child process,
which replaces the child's memory with a new program.
This is what the the shell typically does, for example.
In this case,
the time spent copying the parent's address space is largely wasted,
because the child process will use
very little of its memory before calling `exec()`
.
For this reason,
later versions of Unix took advantage
of virtual memory hardware
to allow the parent and child to *share*
the memory mapped into their respective address spaces
until one of the processes actually modifies it.
This technique is known as *copy-on-write*.
To do this,
on `fork()`
the kernel would
copy the address space *mappings*
from the parent to the child
instead of the contents of the mapped pages,
and at the same time mark the now-shared pages read-only.
When one of the two processes tries to write to one of these shared pages,
the process takes a page fault.
At this point, the Unix kernel realizes that the page
was really a "virtual" or "copy-on-write" copy,
and so it makes a new, private, writable copy of the page for the
faulting process.
In this way, the contents of individual pages aren't actually copied
until they are actually written to.
This optimization makes a `fork()`
followed by
an `exec()`
in the child much cheaper:
the child will probably only need to copy one page
(the current page of its stack)
before it calls `exec()`
.
In the next piece of this lab, you will implement a "proper"
Unix-like `fork()`
with copy-on-write,
as a user space library routine.
Implementing `fork()`
and copy-on-write support in user space
has the benefit that the kernel remains much simpler
and thus more likely to be correct.
It also lets individual user-mode programs
define their own semantics for `fork()`
.
A program that wants a slightly different implementation
(for example, the expensive always-copy version like `dumbfork()`
,
or one in which the parent and child actually share memory afterward)
can easily provide its own.
A user-level copy-on-write `fork()`
needs to know about
page faults on write-protected pages, so that's what you'll
implement first.
Copy-on-write is only one of many possible uses
for user-level page fault handling.
It's common to set up an address space so that page faults indicate when some action needs to take place. For example, most Unix kernels initially map only a single page in a new process's stack region, and allocate and map additional stack pages later "on demand" as the process's stack consumption increases and causes page faults on stack addresses that are not yet mapped. A typical Unix kernel must keep track of what action to take when a page fault occurs in each region of a process's space. For example, a fault in the stack region will typically allocate and map new page of physical memory. A fault in the program's BSS region will typically allocate a new page, fill it with zeroes, and map it. In systems with demand-paged executables, a fault in the text region will read the corresponding page of the binary off of disk and then map it.
This is a lot of information for the kernel to keep track of. Instead of taking the traditional Unix approach, you will decide what to do about each page fault in user space, where bugs are less damaging. This design has the added benefit of allowing programs great flexibility in defining their memory regions; you'll use user-level page fault handling later for mapping and accessing files on a disk-based file system.
In order to handle its own page faults,
a user environment will need to register
a *page fault handler entrypoint* with the JOS kernel.
The user environment registers its page fault entrypoint
via the new `sys_env_set_pgfault_upcall`
system call.
We have added a new member to the `Env`
structure,
`env_pgfault_upcall`
,
to record this information.
Exercise 8.
Implement the `sys_env_set_pgfault_upcall`
system call.
Be sure to enable permission checking
when looking up the environment ID of the target environment,
since this is a "dangerous" system call.
During normal execution,
a user environment in JOS
will run on the *normal* user stack:
its `ESP` register starts out pointing at `USTACKTOP`
,
and the stack data it pushes resides on the page
between `USTACKTOP-PGSIZE`
and `USTACKTOP-1`
inclusive.
When a page fault occurs in user mode,
however,
the kernel will restart the user environment
running a designated user-level page fault handler
on a different stack,
namely the *user exception* stack.
In essence, we will make the JOS kernel
implement automatic "stack switching"
on behalf of the user environment,
in much the same way that the x86 *processor*
already implements stack switching on behalf of JOS
when transferring from user mode to kernel mode!
The JOS user exception stack is also one page in size,
and its top is defined to be at virtual address `UXSTACKTOP`
,
so the valid bytes of the user exception stack
are from `UXSTACKTOP-PGSIZE`
through `UXSTACKTOP-1`
inclusive.
While running on this exception stack,
the user-level page fault handler
can use JOS's regular system calls to map new pages or adjust mappings
so as to fix whatever problem originally caused the page fault.
Then the user-level page fault handler returns,
via an assembly language stub,
to the faulting code on the original stack.
Each user environment that wants to support user-level page fault handling
will need to allocate memory for its own exception stack,
using the `sys_page_alloc()`
system call introduced in part A.
You will now need to
change the page fault handling code in `kern/trap.c`
to handle page faults from user mode as follows.
We will call the state of the user environment at the time of the
fault the *trap-time* state.
If there is no page fault handler registered,
the JOS kernel destroys the user environment with a message as before.
Otherwise,
the kernel sets up a trap frame on the exception stack that looks like
a `struct UTrapframe`
from `inc/trap.h`:
<-- UXSTACKTOP trap-time esp trap-time eflags trap-time eip trap-time eax start of struct PushRegs trap-time ecx trap-time edx trap-time ebx trap-time esp trap-time ebp trap-time esi trap-time edi end of struct PushRegs tf_err (error code) fault_va <-- %esp when handler is run
The kernel then arranges for the user environment to resume execution
with the page fault handler
running on the exception stack with this stack frame;
you must figure out how to make this happen.
The `fault_va` is the virtual address
that caused the page fault.
If the user environment is *already* running on the user exception stack
when an exception occurs,
then the page fault handler itself has faulted.
In this case,
you should start the new stack frame just under the current
`tf->tf_esp`
rather than at `UXSTACKTOP`
.
You should first push an empty 32-bit word, then a `struct UTrapframe`
.
To test whether `tf->tf_esp`
is already on the user
exception stack, check whether it is in the range
between `UXSTACKTOP-PGSIZE`
and `UXSTACKTOP-1`
, inclusive.
Exercise 9.
Implement the code in `page_fault_handler`
in
`kern/trap.c`
required to dispatch page faults to the user-mode handler.
Be sure to take appropriate precautions
when writing into the exception stack.
(What happens if the user environment runs out of space
on the exception stack?)
Next, you need to implement the assembly routine that will
take care of calling the C page fault handler and resume
execution at the original faulting instruction.
This assembly routine is the handler that will be registered
with the kernel using `sys_env_set_pgfault_upcall()`
.
Exercise 10.
Implement the `_pgfault_upcall`
routine
in `lib/pfentry.S`.
The interesting part is returning to the original point in
the user code that caused the page fault.
You'll return directly there, without going back through
the kernel.
The hard part is simultaneously switching stacks and
re-loading the EIP.
Finally, you need to implement the C user library side of the user-level page fault handling mechanism.
Exercise 11.
Finish `set_pgfault_handler()`
in `lib/pgfault.c`.
Run `user/faultread` (`make run-faultread`). You should see:
... [00000000] new env 00001000 [00001000] user fault va 00000000 ip 0080003a TRAP frame ... [00001000] free env 00001000
Run `user/faultdie`. You should see:
... [00000000] new env 00001000 i faulted at va deadbeef, err 6 [00001000] exiting gracefully [00001000] free env 00001000
Run `user/faultalloc`. You should see:
... [00000000] new env 00001000 fault deadbeef this string was faulted in at deadbeef fault cafebffe fault cafec000 this string was faulted in at cafebffe [00001000] exiting gracefully [00001000] free env 00001000
If you see only the first "this string" line, it means you are not handling recursive page faults properly.
Run `user/faultallocbad`. You should see:
... [00000000] new env 00001000 [00001000] user_mem_check assertion failure for va deadbeef [00001000] free env 00001000
Make sure you understand why `user/faultalloc` and
`user/faultallocbad` behave differently.
Challenge!
Extend your kernel so that not only page faults,
but *all* types of processor exceptions
that code running in user space can generate,
can be redirected to a user-mode exception handler.
Write user-mode test programs
to test user-mode handling of various exceptions
such as divide-by-zero, general protection fault,
and illegal opcode.
You now have the kernel facilities
to implement copy-on-write `fork()`
entirely in user space.
We have provided a skeleton for your `fork()`
in `lib/fork.c`.
Like `dumbfork()`
,
`fork()`
should create a new environment,
then scan through the parent environment's entire address space
and set up corresponding page mappings in the child.
The key difference is that,
while `dumbfork()`
copied *pages*,
`fork()`
will initially only copy page *mappings*.
`fork()`
will
copy each page only when one of the environments tries to write it.
The basic control flow for `fork()`
is as follows:
`pgfault()`
as the C-level page fault handler,
using the `set_pgfault_handler()`
function
you implemented above.`sys_exofork()`
to create
a child environment.`duppage`
, which should
map the page copy-on-write into the address
space of the child and then `duppage`
sets both PTEs so that
the page is not writeable, and to contain `PTE_COW`
in the
"avail" field to distinguish copy-on-write pages from genuine
read-only pages.
The exception stack is *not* remapped this way, however.
Instead you need to allocate a fresh page in the child for
the exception stack. Since the page fault handler will be
doing the actual copying and the page fault handler runs
on the exception stack, the exception stack cannot be made
copy-on-write: who would copy it?
`fork()`
also needs to handle pages that are
present, but not writable or copy-on-write.
Each time one of the environments writes a copy-on-write page that it hasn't yet written, it will take a page fault. Here's the control flow for the user page fault handler:
`_pgfault_upcall`
,
which calls `fork()`
's `pgfault()`
handler.`pgfault()`
checks that the fault is a write
(check for `FEC_WR`
in the error code) and that the
PTE for the page is marked `PTE_COW`
.
If not, panic.`pgfault()`
allocates a new page mapped
at a temporary location and copies
the contents of the faulting page into it.
Then the fault handler maps the new page at the
appropriate address with read/write permissions,
in place of the old read-only mapping.The user-level `lib/fork.c` code must consult the environment's page
tables for several of the operations above (e.g., that the PTE for a page is
marked `PTE_COW`
). The kernel maps the environment's page tables at
`UVPT`
exactly for this purpose. It uses a [clever mapping trick](uvpt.html) to make it to make it easy to lookup
PTEs for user code. `lib/entry.S` sets up `uvpt`
and
`uvpd`
so that you can easily lookup page-table information in
`lib/fork.c`.
Exercise 12.
Implement `fork`
, `duppage`
and
`pgfault`
in `lib/fork.c`.
Test your code with the `forktree` program.
It should produce the following messages,
with interspersed 'new env', 'free env',
and 'exiting gracefully' messages.
The messages may not appear in this order, and the
environment IDs may be different.
1000: I am '' 1001: I am '0' 2000: I am '00' 2001: I am '000' 1002: I am '1' 3000: I am '11' 3001: I am '10' 4000: I am '100' 1003: I am '01' 5000: I am '010' 4001: I am '011' 2002: I am '110' 1004: I am '001' 1005: I am '111' 1006: I am '101'
Challenge!
Implement a shared-memory `fork()`
called `sfork()`
. This version should have the parent
and child *share* all their memory pages
(so writes in one environment appear in the other)
except for pages in the stack area,
which should be treated in the usual copy-on-write manner.
Modify `user/forktree.c`
to use `sfork()`
instead of regular `fork()`
.
Also, once you have finished implementing IPC in part C,
use your `sfork()`
to run `user/pingpongs`.
You will have to find a new way to provide the functionality
of the global `thisenv`
pointer.
Challenge!
Your implementation of `fork`
makes a huge number of system calls. On the x86, switching into
the kernel using interrupts has non-trivial cost. Augment the
system call interface
so that it is possible to send a batch of system calls at once.
Then change `fork`
to use this interface.
How much faster is your new `fork`
?
You can answer this (roughly) by using analytical
arguments to estimate how much of an improvement batching
system calls will make to the performance of your
`fork`
: How expensive is an `int 0x30`
instruction? How many times do you execute `int 0x30`
in your `fork`
? Is accessing the `TSS` stack
switch also expensive? And so on...
Alternatively, you can boot your kernel on real hardware
and *really* benchmark your code. See the `RDTSC`
(read time-stamp counter) instruction, defined in the IA32
manual, which counts the number of clock cycles that have
elapsed since the last processor reset. QEMU doesn't emulate
this instruction faithfully (it can either count the number of
virtual instructions executed or use the host TSC, neither of
which reflects the number of cycles a real CPU would
require).
This ends part B. Make sure you pass all of the Part B tests when you run
`make grade`.
As usual, you can hand in your submission
with `make handin`.
In the final part of lab 4 you will modify the kernel to preempt uncooperative environments and to allow environments to pass messages to each other explicitly.
Run the `user/spin` test program.
This test program forks off a child environment,
which simply spins forever in a tight loop
once it receives control of the CPU.
Neither the parent environment nor the kernel ever regains the CPU.
This is obviously not an ideal situation
in terms of protecting the system from bugs or malicious code
in user-mode environments,
because any user-mode environment can bring the whole system to a halt
simply by getting into an infinite loop and never giving back the CPU.
In order to allow the kernel to *preempt* a running environment,
forcefully retaking control of the CPU from it,
we must extend the JOS kernel to support external hardware interrupts
from the clock hardware.
External interrupts (i.e., device interrupts) are referred to as IRQs.
There are 16 possible IRQs, numbered 0 through 15.
The mapping from IRQ number to IDT entry is not fixed.
`pic_init`
in `picirq.c` maps IRQs 0-15
to IDT entries `IRQ_OFFSET`
through `IRQ_OFFSET+15`
.
In `inc/trap.h`,
`IRQ_OFFSET`
is defined to be decimal 32.
Thus the IDT entries 32-47 correspond to the IRQs 0-15.
For example, the clock interrupt is IRQ 0.
Thus, IDT[IRQ_OFFSET+0] (i.e., IDT[32]) contains the address of
the clock's interrupt handler routine in the kernel.
This `IRQ_OFFSET`
is chosen so that the device interrupts
do not overlap with the processor exceptions,
which could obviously cause confusion.
(In fact, in the early days of PCs running MS-DOS,
the `IRQ_OFFSET`
effectively *was* zero,
which indeed caused massive confusion between handling hardware interrupts
and handling processor exceptions!)
In JOS, we make a key simplification compared to xv6 Unix.
External device interrupts are *always* disabled
when in the kernel (and, like xv6, enabled when in user space).
External interrupts are controlled by the `FL_IF`
flag bit
of the `%eflags`
register
(see `inc/mmu.h`).
When this bit is set, external interrupts are enabled.
While the bit can be modified in several ways,
because of our simplification, we will handle it solely
through the process of saving and restoring `%eflags`
register
as we enter and leave user mode.
You will have to ensure that the `FL_IF`
flag is set in
user environments when they run so that when an interrupt arrives, it
gets passed through to the processor and handled by your interrupt code.
Otherwise, interrupts are *masked*,
or ignored until interrupts are re-enabled.
We masked interrupts with the very first instruction of the bootloader,
and so far we have never gotten around to re-enabling them.
Exercise 13.
Modify `kern/trapentry.S` and `kern/trap.c` to
initialize the appropriate entries in the IDT and provide
handlers for IRQs 0 through 15. Then modify the code
in `env_alloc()`
in `kern/env.c` to ensure
that user environments are always run with interrupts enabled.
Also uncomment the `sti` instruction in `sched_halt()` so
that idle CPUs unmask interrupts.
The processor never pushes an error code
when invoking a hardware interrupt handler.
You might want to re-read section 9.2 of the
[
80386 Reference Manual](../../readings/i386/toc.htm),
or section 5.8 of the
[
IA-32 Intel Architecture Software Developer's Manual, Volume 3](../../readings/ia32/IA32-3A.pdf),
at this time.
After doing this exercise,
if you run your kernel with any test program
that runs for a non-trivial length of time
(e.g., `spin`),
you should see the kernel print trap frames for hardware
interrupts. While interrupts are now enabled in the
processor, JOS isn't yet handling them, so you should see it
misattribute each interrupt to the currently running user
environment and destroy it. Eventually it should run out of
environments to destroy and drop into the monitor.
In the `user/spin` program,
after the child environment was first run,
it just spun in a loop,
and the kernel never got control back.
We need to program the hardware to generate clock interrupts periodically,
which will force control back to the kernel
where we can switch control to a different user environment.
The calls to `lapic_init`
and `pic_init`
(from `i386_init`
in `init.c`),
which we have written for you,
set up the clock and the interrupt controller to generate interrupts.
You now need to write the code to handle these interrupts.
Exercise 14.
Modify the kernel's `trap_dispatch()`
function
so that it calls `sched_yield()`
to find and run a different environment
whenever a clock interrupt takes place.
You should now be able to get the `user/spin` test to work:
the parent environment should fork off the child,
`sys_yield()`
to it a couple times
but in each case regain control of the CPU after one time slice,
and finally kill the child environment and terminate gracefully.
This is a great time to do some *regression testing*. Make sure that you
haven't broken any earlier part of that lab that used to work (e.g.
`forktree`) by enabling interrupts. Also, try running with
multiple CPUs using `make CPUS=2 target`. You should
also be able to
pass
(Technically in JOS this is "inter-environment communication" or "IEC", but everyone else calls it IPC, so we'll use the standard term.)
We've been focusing on the isolation aspects of the operating system, the ways it provides the illusion that each program has a machine all to itself. Another important service of an operating system is to allow programs to communicate with each other when they want to. It can be quite powerful to let programs interact with other programs. The Unix pipe model is the canonical example.
There are many models for interprocess communication. Even today there are still debates about which models are best. We won't get into that debate. Instead, we'll implement a simple IPC mechanism and then try it out.
You will implement a few additional JOS kernel system calls
that collectively provide a simple interprocess communication mechanism.
You will implement two
system calls, `sys_ipc_recv`
and
`sys_ipc_try_send`
.
Then you will implement two library wrappers
`ipc_recv`
and `ipc_send`
.
The "messages" that user environments can send to each other using JOS's IPC mechanism consist of two components: a single 32-bit value, and optionally a single page mapping. Allowing environments to pass page mappings in messages provides an efficient way to transfer more data than will fit into a single 32-bit integer, and also allows environments to set up shared memory arrangements easily.
To receive a message, an environment calls
`sys_ipc_recv`
.
This system call de-schedules the current
environment and does not run it again until a message has
been received.
When an environment is waiting to receive a message,
*any* other environment can send it a message -
not just a particular environment,
and not just environments that have a parent/child arrangement
with the receiving environment.
In other words, the permission checking that you implemented in Part A
will not apply to IPC,
because the IPC system calls are carefully designed so as to be "safe":
an environment cannot cause another environment to malfunction
simply by sending it messages
(unless the target environment is also buggy).
To try to send a value, an environment calls
`sys_ipc_try_send`
with both the receiver's
environment id and the value to be sent. If the named
environment is actually receiving (it has called
`sys_ipc_recv`
and not gotten a value yet),
then the send delivers the message and returns 0. Otherwise
the send returns `-E_IPC_NOT_RECV`
to indicate
that the target environment is not currently expecting
to receive a value.
A library function `ipc_recv`
in user space will take care
of calling `sys_ipc_recv`
and then looking up
the information about the received values in the current
environment's `struct Env`
.
Similarly, a library function `ipc_send`
will
take care of repeatedly calling `sys_ipc_try_send`
until the send succeeds.
When an environment calls `sys_ipc_recv`
with a valid `dstva`
parameter (below `UTOP`
),
the environment is stating that it is willing to receive a page mapping.
If the sender sends a page,
then that page should be mapped at `dstva`
in the receiver's address space.
If the receiver already had a page mapped at `dstva`
,
then that previous page is unmapped.
When an environment calls `sys_ipc_try_send`
with a valid `srcva`
(below `UTOP`
),
it means the sender wants to send the page
currently mapped at `srcva`
to the receiver,
with permissions `perm`
.
After a successful IPC,
the sender keeps its original mapping
for the page at `srcva`
in its address space,
but the receiver also obtains a mapping for this same physical page
at the `dstva`
originally specified by the receiver,
in the receiver's address space.
As a result this page becomes shared between the sender and receiver.
If either the sender or the receiver does not indicate
that a page should be transferred,
then no page is transferred.
After any IPC
the kernel sets the new field `env_ipc_perm`
in the receiver's `Env`
structure
to the permissions of the page received,
or zero if no page was received.
Exercise 15.
Implement `sys_ipc_recv`
and
`sys_ipc_try_send`
in `kern/syscall.c`.
Read the comments on both before implementing them, since they
have to work together.
When you call `envid2env`
in these routines, you should
set the `checkperm`
flag to 0,
meaning that any environment is allowed to send
IPC messages to any other environment,
and the kernel does no special permission checking
other than verifying that the target envid is valid.
Then implement
the `ipc_recv`
and `ipc_send`
functions
in `lib/ipc.c`.
Use the `user/pingpong` and `user/primes`
functions to test your IPC mechanism. `user/primes`
will generate for each prime number a new environment until
JOS runs out of environments. You might find it interesting
to read `user/primes.c` to see all the forking and IPC
going on behind the scenes.
Challenge!
Why does `ipc_send`
have to loop? Change the system call interface so it
doesn't have to. Make sure you can handle multiple
environments trying to send to one environment at the
same time.
Challenge!
The prime sieve is only one neat use of
message passing between a large number of concurrent programs.
Read C. A. R. Hoare, ``Communicating Sequential Processes,''
*Communications of the ACM* 21(8) (August 1978), 666-667,
and implement the matrix multiplication example.
Challenge!
One of the most impressive examples of
the power of message passing is Doug McIlroy's power series
calculator, described in
[M. Douglas McIlroy, ``Squinting at
Power Series,'' Software--Practice and Experience, 20(7)
(July 1990), 661-683](https://swtch.com/~rsc/thread/squint.pdf). Implement his
power series calculator and compute the power series for
Challenge!
Make JOS's IPC mechanism more efficient
by applying some of the techniques from Liedtke's paper,
[Improving IPC by Kernel Design](http://dl.acm.org/citation.cfm?id=168633),
or any other tricks you may think of.
Feel free to modify the kernel's system call API for this purpose,
as long as your code is backwards compatible
with what our grading scripts expect.
**This ends part C.**
Make sure you pass all of the `make grade` tests and
don't forget to write up your answers to the questions and a
description of your challenge exercise solution in
`answers-lab4.txt`.
Before handing in, use `git status` and `git diff`
to examine your changes and don't forget to `git add
answers-lab4.txt`. When you're ready, commit your changes with
`git commit -am 'my solutions to lab 4'`, then `make
handin` and follow the directions. |
10,352 | 神奇的 Linux 命令行字符形状工具 boxes | https://opensource.com/article/18/12/linux-toy-boxes | 2018-12-16T19:36:28 | [
"boxes",
"命令行"
] | https://linux.cn/article-10352-1.html |
>
> 本文将教你如何在 Linux 命令行终端中使用 boxes 工具绘制字符形状图形来包装你的文字让其更突出。
>
>
>

现在正值假期,每个 Linux 终端用户都该得到一点礼物。无论你是庆祝圣诞节还是庆祝其他节日,或者什么节日也没有,都没有关系。我将在接下来的几周内介绍 24 个 Linux 命令行小玩具,供你把玩或者与朋友分享。让我们享受乐趣,让这个月过得快乐一点,因为对于北半球来说,这个月有点冷并且沉闷。
对于我要讲述的内容,可能你之前就有些了解。但是,我还是希望我们都有机会学到一些新的东西(我做了一点研究,确保可以分享 24 个小玩具)。
24 个 Linux 终端小玩具中的第一个是叫做 `boxes` 的小程序。为何从 `boxes` 说起呢?因为在没有它的情况下很难将所有其他命令礼物包装起来!
在我的 Fedora 机器上,默认没有安装 `boxes` 程序,但它在我的普通仓库中可以获取到,所以用如下命令就可安装:
```
$ sudo dnf install boxes -y
```
如果你在使用其他 Linux 发行版,一般也都可以在默认仓库中找到 `boxes`。
`boxes` 是我真正希望在高中和大学计算机课程中就使用的实用程序,因为善意的老师要求我在每个源文件、函数、代码块等开头添加一些特定外观的备注信息。
```
/***************/
/* Hello World */
/***************/
```
事实证明,一旦你需要在框内添加几行文字,并且格式化的将它们统一风格就会变得很乏味。而 `boxes` 是一个简单实用程序,它使用 ASCII 艺术风格的字符形状框来包围文本。其字符形状默认风格是源代码注释风格,但也提供了一些其他选项。
它真的很容易使用。使用管道,便可以将一个简短问候语塞进字符形状盒子里。
```
$ cat greeting.txt | boxes -d diamonds -a c
```
上面的命令输出结果如下:
```
/\ /\ /\
/\//\\/\ /\//\\/\ /\//\\/\
/\//\\\///\\/\//\\\///\\/\//\\\///\\/\
//\\\//\/\\///\\\//\/\\///\\\//\/\\///\\
\\//\/ \/\\//
\/ \/
/\ I'm wishing you all a /\
//\\ joyous holiday season //\\
\\// and a Happy Gnu Year! \\//
\/ \/
/\ /\
//\\/\ /\//\\
\\///\\/\//\\\///\\/\//\\\///\\/\//\\\//
\/\\///\\\//\/\\///\\\//\/\\///\\\//\/
\/\\//\/ \/\\//\/ \/\\//\/
\/ \/ \/
```
或者玩点更有趣的,比如:
```
echo "I am a dog" | boxes -d dog -a c
```
不要惊讶,它将会输出如下:
```
__ _,--="=--,_ __
/ \." .-. "./ \
/ ,/ _ : : _ \/` \
\ `| /o\ :_: /o\ |\__/
`-'| :="~` _ `~"=: |
\` (_) `/
.-"-. \ | / .-"-.
.---{ }--| /,.-'-.,\ |--{ }---.
) (_)_)_) \_/`~-===-~`\_/ (_(_(_) (
( I am a dog )
) (
'---------------------------------------'
```
`boxes` 程序提供了[很多选项](http://boxes.thomasjensen.com/examples.html) 用于填充、定位甚至处理正则表达式。你可以在其 [项目主页](https://boxes.thomasjensen.com/) 上了解更多有关 `boxes` 的信息,或者转到 [GitHub](https://github.com/ascii-boxes/boxes) 去下载源代码或者贡献你自己的盒子形状。说到此,如果你想给你的提交找个好点子,我已经有了一个想法:为什么不能是一个节日礼物盒子?
```
_ _
/_\/_\
_______\_\/_/_______
| ///\\\ |
| /// \\\ |
| |
| "Happy pull |
| request!" |
|____________________|
```
`boxes` 是基于 GPLv2 许可证的开源项目。
你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经落实,但还预留了几个空位置。如果你有特别想了解的可以评论留言,我会查看的。如果还有空位置,我会考虑介绍它的。即使要介绍的小玩具已经有 24 个了,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
你可以通过 [Drive a locomotive through your Linux terminal](https://opensource.com/article/18/12/linux-toy-sl) 来查看明天会介绍的命令行小玩具。
---
via: <https://opensource.com/article/18/12/linux-toy-boxes>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jrg](https://github.com/jrglinux) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's the holiday season, and every Linux terminal user deserves a little gift. It doesn't matter whether you celebrate Christmas, another holiday, or nothing at all. So I'm gathering together a collection of 24 Linux command-line toys over the next few weeks for you to enjoy and share with your friends. Let's have a little fun and add a little joy to a month that, at least here in the northern hemisphere, can be a little bit cold and dreary.
Chances are, there will be a few that you've heard of before. But, hopefully, we'll all have a chance to learn something new. (I know I did when doing some research to make sure I could make it to 24.)
The first of our 24 Linux terminal toys is a program called boxes. Why start with boxes? Because it's going to be hard to wrap up all of our other command-line presents to you without it!
On my Fedora machine, boxes wasn't installed by default, but it was in my normal repositories, so installing it was as simple as
`$ sudo dnf install boxes`
If you're on a different distribution, there's a good chance you'll find it in your default repositories as well.
Boxes a utility I really wish I had in my high school and college computer science courses, where well-intentioned teachers insisted I provide very specific looking comment at the beginning of every source file, function, code block, etc.
```
/***************/
/* Hello World */
/***************/
```
It turns out, once you add a few lines of text inside, formatting them can get, well, tedious. Enter boxes. Boxes is a simple utility for surrounding a block of text with an ASCII art-style box. It comes with defaults for source code commenting, as well as other options.
It's really easy to use. Using pipes, I can push a short greeting into a box.
`$ cat greeting.txt | boxes -d diamonds -a c`
Which will give us the output as follows:
```
/\ /\ /\
/\//\\/\ /\//\\/\ /\//\\/\
/\//\\\///\\/\//\\\///\\/\//\\\///\\/\
//\\\//\/\\///\\\//\/\\///\\\//\/\\///\\
\\//\/ \/\\//
\/ \/
/\ I'm wishing you all a /\
//\\ joyous holiday season //\\
\\// and a Happy Gnu Year! \\//
\/ \/
/\ /\
//\\/\ /\//\\
\\///\\/\//\\\///\\/\//\\\///\\/\//\\\//
\/\\///\\\//\/\\///\\\//\/\\///\\\//\/
\/\\//\/ \/\\//\/ \/\\//\/
\/ \/ \/
```
Or perhaps something more fun, like:
`echo "I am a dog" | boxes -d dog -a c`
Which will, unsurprisingly, give you the following:
```
__ _,--="=--,_ __
/ \." .-. "./ \
/ ,/ _ : : _ \/` \
\ `| /o\ :_: /o\ |\__/
`-'| :="~` _ `~"=: |
\` (_) `/
.-"-. \ | / .-"-.
.---{ }--| /,.-'-.,\ |--{ }---.
) (_)_)_) \_/`~-===-~`\_/ (_(_(_) (
( I am a dog )
) (
'---------------------------------------'
```
Boxes comes with [lots of options](http://boxes.thomasjensen.com/examples.html) for padding, position, and even processing regular expressions. You can learn more about boxes on the [project's homepage](https://boxes.thomasjensen.com/), or head over to [GitHub](https://github.com/ascii-boxes/boxes) to download the source code or contribute your own box. In fact, if you're looking for an idea to submit, I've got an idea for you: why not a holiday present?
```
_ _
/_\/_\
_______\_\/_/_______
| ///\\\ |
| /// \\\ |
| |
| "Happy pull |
| request!" |
|____________________|
```
Boxes is open source under a GPLv2 license.
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Or check out tomorrow's command-line toy, [Drive a locomotive through your Linux terminal](https://opensource.com/article/18/12/linux-toy-sl).
## 8 Comments |
10,353 | 从 Linux 终端查看笔记本电池状态和等级的 5 个方法 | https://www.2daygeek.com/check-laptop-battery-status-and-charging-state-in-linux-terminal/ | 2018-12-16T20:12:36 | [
"电池"
] | https://linux.cn/article-10353-1.html | 
我们可以轻松地通过图形化界面查看当前电量百分比、是否在充电以及当前电量还可以使用多长时间等电池状态,但是却无法查看电池健康度等相关信息。
在这篇文章就是为了解决这些问题。
在 Linux 上有很多这样的实用工具,而且可以在命令行使用。
这篇文章今天就要探讨这个主题,我会尽我所能的覆盖尽可能多的信息。
每月检查一次你的电池健康度是一个很好的想法。它可以帮你检查你当前遇到的问题是否与电池或者充电相关。
同时,我们也可以查看电池模组名称、电源、厂商以及电池规格等。
电源管理是在不使用时关闭电源或者切换系统的组件到低耗模式的一种功能。
### 几种在 Linux 下检查电池状态的实用工具
* `upower`:是一个命令行工具,其提供了罗列系统中电源的接口。
* `acpi`:显示来自 `/proc` 或者 `/sys` 文件系统中的一些信息,例如电池状态或者热量信息。
* `batstat`:是一个为 Linux 打印电池状态的命令行工具。
* `tlp`:可以为你带来更高级的电源管理,而无需修改任何配置。
* `class file`:这个 sysfs 文件系统是一个提供了内核数据结构接口的伪文件系统。
### 如何使用 upower 命令检查笔记本电池状态
[upower](https://upower.freedesktop.org/) 是一个命令行工具,其提供了罗列系统中电源的接口。它在你的电脑上可以控制不同操作的延迟,这可以为你节省很大一部分电量。
只需要在 Linux 中运行以下命令获取电池以及它所依赖的其他信息。
```
$ upower -i /org/freedesktop/UPower/devices/battery_BAT0
native-path: BAT0
vendor: SMP
model: L14M4P23
serial: 756
power supply: yes
updated: Monday 03 December 2018 07:56:18 PM IST (95 seconds ago)
has history: yes
has statistics: yes
battery
present: yes
rechargeable: yes
state: discharging
warning-level: none
energy: 28.23 Wh
energy-empty: 0 Wh
energy-full: 52.26 Wh
energy-full-design: 60 Wh
energy-rate: 10.714 W
voltage: 14.819 V
time to empty: 2.6 hours
percentage: 54%
capacity: 87.1%
technology: lithium-ion
icon-name: 'battery-good-symbolic'
History (charge):
1543847178 54.000 discharging
History (rate):
1543847178 10.714 discharging
```
使用下面的格式检查电池的特定信息。
```
$ upower -i /org/freedesktop/UPower/devices/battery_BAT0 | grep -i "state\|percentage\|time to empty"
state: discharging
time to empty: 2.1 hours
percentage: 43%
```
这个类似于上面的那个,但是是在充电线缆的插入后运行,这也就是为什么下面会显示正在充电状态的原因。
```
$ upower -i /org/freedesktop/UPower/devices/battery_BAT0 | grep -i "state\|percentage\|time to empty"
state: charging
percentage: 41%
```
### 如何使用 TLP 命令检查笔记本电池状态
TLP 是一个自由开源的多功能的命令行工具,它可以优化笔记本电池而无需修改任何配置。
TLP 可以为你的 Linux 带来更高级的电源管理,而无需理解任何技术细节。TLP 默认附带了一个已经为你的电池优化好的配置,所以你可以安装好后就不再管它了。尽管 TLP 是一个可以根据你的需求高度可定制的工具。
TLP 在绝大多数 Linux 发行版,例如 Arch、Debian、Fedora、Gentoo、openSUSE 等的官方库中都可用。使用你的 Linux 发行版的包管理安装 TLP 即可。
只需要在 Linux 中运行以下命令获取电池以及其他所依赖的信息。
```
$ sudo tlp-stat -b
--- TLP 1.1 --------------------------------------------
+++ Battery Status
/sys/class/power_supply/BAT0/manufacturer = SMP
/sys/class/power_supply/BAT0/model_name = L14M4P23
/sys/class/power_supply/BAT0/cycle_count = (not supported)
/sys/class/power_supply/BAT0/energy_full_design = 60000 [mWh]
/sys/class/power_supply/BAT0/energy_full = 52260 [mWh]
/sys/class/power_supply/BAT0/energy_now = 21950 [mWh]
/sys/class/power_supply/BAT0/power_now = 10923 [mW]
/sys/class/power_supply/BAT0/status = Discharging
Charge = 42.0 [%]
Capacity = 87.1 [%]
```
也可以查看其他的信息。
```
$ sudo tlp-stat -s
--- TLP 1.1 --------------------------------------------
+++ System Info
System = LENOVO Lenovo ideapad Y700-15ISK 80NV
BIOS = CDCN35WW
Release = "Manjaro Linux"
Kernel = 4.19.6-1-MANJARO #1 SMP PREEMPT Sat Dec 1 12:21:26 UTC 2018 x86_64
/proc/cmdline = BOOT_IMAGE=/boot/vmlinuz-4.19-x86_64 root=UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f rw quiet resume=UUID=a2092b92-af29-4760-8e68-7a201922573b
Init system = systemd
Boot mode = BIOS (CSM, Legacy)
+++ TLP Status
State = enabled
Last run = 07:16:12 IST, 4362 sec(s) ago
Mode = battery
Power source = battery```
### 如何使用 ACPI 命令检查电池状态
ACPI 代表<ruby>高级配置和电源接口<rt>Advanced Configuration and Power Interface</rt></ruby>模块,它们是不同 ACPI 部件的内核模块。它们启用特殊的 ACPI 函数向 `/proc` 或者 `/sys` 中添加信息。这些信息可以通过事件或者其他监控程序的 acpid 进行解析。
```
$ acpi Battery 0: Charging, 43%, 01:05:11 until charged “`
查看电池容量。
```
$ acpi -i
Battery 0: Charging, 43%, 01:05:07 until charged
Battery 0: design capacity 3817 mAh, last full capacity 3324 mAh = 87%
```
查看更多有关电池及其相关的信息。
```
$ acpi -V
Battery 0: Charging, 43%, 01:05:07 until charged
Battery 0: design capacity 3815 mAh, last full capacity 3323 mAh = 87%
Adapter 0: on-line
Cooling 0: Processor 0 of 10
Cooling 1: Processor 0 of 10
Cooling 2: Processor 0 of 10
Cooling 3: iwlwifi 0 of 19
Cooling 4: Processor 0 of 10
Cooling 5: iwlwifi no state information available
Cooling 6: Processor 0 of 10
Cooling 7: Processor 0 of 10
Cooling 8: Processor 0 of 10
Cooling 9: intel_powerclamp no state information available
Cooling 10: x86_pkg_temp no state information available
Cooling 11: Processor 0 of 10
```
### 如何使用 Batstat 命令查看笔记本电池状态
`batstat` 是一个在 Linux 终端打印电池信息的命令行工具。
```
Status: Charging
Max energy: 50.00 Wh
Energy left: 24.50 Wh
Power Consumption: 26.40 W
Percentage left: 49.00%
Average power Consumption: 0.00 W
Time elapsed: 0: 0:12 since 49.00%
= Time ======== Percent ============================================
0: 0: 0 49.00%
```
### 如何使用 sysfs 文件系统查看笔记本电池状态
sysfs 文件系统是一个提供了内核数据结构接口的伪文件系统。sysfs 下的文件提供有关设备、内核模块、文件系统和其他内核组件的信息。
sysfs 文件系统通常挂载在 `/sys`。通常来说,它会被系统自动挂载,但是也可以使用例如 `mount -t sysfs sysfs /sys` 命令进行手动挂载。
在 sysfs 文件系统中的很多文件都是只读的,但也有一些是可写的,允许更改内核变量。为了避免冗余,符号链接被大量用于连接文件系统数中的条目。
```
$ cat /sys/class/power_supply/BAT0/*
0
51
Normal
0
cat: /sys/class/power_supply/BAT0/device: Is a directory
52260000
60000000
26660000
SMP
L14M4P23
cat: /sys/class/power_supply/BAT0/power: Is a directory
27656000
1
756
Charging
cat: /sys/class/power_supply/BAT0/subsystem: Is a directory
Li-ion
Battery
POWER_SUPPLY_NAME=BAT0
POWER_SUPPLY_STATUS=Charging
POWER_SUPPLY_PRESENT=1
POWER_SUPPLY_TECHNOLOGY=Li-ion
POWER_SUPPLY_CYCLE_COUNT=0
POWER_SUPPLY_VOLTAGE_MIN_DESIGN=14800000
POWER_SUPPLY_VOLTAGE_NOW=15840000
POWER_SUPPLY_POWER_NOW=27656000
POWER_SUPPLY_ENERGY_FULL_DESIGN=60000000
POWER_SUPPLY_ENERGY_FULL=52260000
POWER_SUPPLY_ENERGY_NOW=26660000
POWER_SUPPLY_CAPACITY=51
POWER_SUPPLY_CAPACITY_LEVEL=Normal
POWER_SUPPLY_MODEL_NAME=L14M4P23
POWER_SUPPLY_MANUFACTURER=SMP
POWER_SUPPLY_SERIAL_NUMBER= 756
14800000
15840000
```
---
via: <https://www.2daygeek.com/check-laptop-battery-status-and-charging-state-in-linux-terminal/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,354 | 制定开源战略的免费指南 | https://www.linux.com/blog/2018/11/free-guide-setting-your-open-source-strategy | 2018-12-16T20:38:03 | [
"开源",
"战略"
] | https://linux.cn/article-10354-1.html |
>
> 了解如何使用 TODO Group 的成熟实践,使您的组织的开源软件目标与您的业务目标保持一致。
>
>
>

大多数使用开源的公司都了解其商业价值,但他们可能缺乏战略性地实施开源计划和获得全部回报的工具。根据 [The New Stack](https://thenewstack.io/open-source-culture-starts-with-programs-and-policies/) 最近的一项调查,“开源计划的三大好处是 1)提高了对开源的认识,2)提高了开发周期的速度和灵活性,以及 3)更好的许可证合规性。”
运作一个开源计划办公室涉及到创建策略来帮助你定义和实施你的方法,并衡量你的进度。由 Linux 基金会与 TODO Group 合作开发的[企业开源指南](https://www.linuxfoundation.org/resources/open-source-guides/)基于多年的经验和实践提供了专业开源知识。
最新的指南中,[设置开源战略](https://www.linuxfoundation.org/resources/open-source-guides/setting-an-open-source-strategy/)详细介绍了制定战略和确保成功之路的基本步骤。根据该指南,“你的开源战略将管理、参与和创建开源软件的计划与计划所服务的业务目标联系起来。这可以开辟许多机会并促进创新。”该指南涵盖以下主题:
1. 为什么制定战略?
2. 你的战略文件
3. 战略方法
4. 关键考虑因素
5. 其他组成
6. 确定投资回报率
7. 投资目标
这里关键的第一步是创建和将你的开源策略形成文字,该策略将“帮助你最大限度地提高组织从开源中获得的利益。”同时,你详细的策略可以帮助你避免因错误而导致的困难,例如:选择错误的许可证或不正确地维护代码。根据指南,该文件还可以:
* 让领导者感到兴奋并参与
* 帮助在公司内获得支持
* 促进分散的多部门组织的决策
* 帮助建立一个健康的社区
* 解释贵公司的开源方式和对其使用的支持
* 明确贵公司在社区驱动的外部研发中投资的地方,以及贵公司将重点放在增值差异化的地方
Salesforce 的软件架构师兼本指南的撰稿人 Ian Varley 说:“在 Salesforce 内,我们有内部文件,我们将这些围绕开源战略指导和鼓励的文件分发给我们的工程团队。其中鼓励创建和使用开源,这让他们毫不含糊地知道公司的战略领导者完全支持它。此外,如果有某些我们不希望工程师使用的许可证或有其他开源指南,我们的内部文档需要明确。”
开源计划有助于促进企业文化,使企业更高效,并且根据指南,强有力的战略文档可以“帮助你的团队了解开源计划背后的业务目标,确保更好的决策,并最大限度地降低风险。”
了解如何使用[设置开源策略](https://www.linuxfoundation.org/resources/open-source-guides/setting-an-open-source-strategy/)新指南中的提示和经过验证的实践,将管理和创建开源软件的目标与组织的业务目标保持一致。然后,查看所有 12 个[企业开源指南](https://www.linuxfoundation.org/resources/open-source-guides/),了解有关使用开源获得成功的更多信息。
本文最初发表在 [Linux基金会](https://www.linuxfoundation.org/blog/2018/11/a-free-guide-for-setting-your-open-source-strategy/)。
---
via: <https://www.linux.com/blog/2018/11/free-guide-setting-your-open-source-strategy>
作者:[Amber Ankerholz](https://www.linux.com/users/aankerholz) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,355 | TLDR 页:Linux 手册页的简化替代品 | https://fossbytes.com/tldr-pages-linux-man-pages-alternative/ | 2018-12-17T18:22:00 | [
"TLDR",
"man"
] | https://linux.cn/article-10355-1.html | 
在终端上使用各种命令执行重要任务是 Linux 桌面体验中不可或缺的一部分。Linux 这个开源操作系统拥有[丰富的命令](https://fossbytes.com/a-z-list-linux-command-line-reference/),任何用户都无法全部记住所有这些命令。而使事情变得更复杂的是,每个命令都有自己的一组带来丰富的功能的选项。
为了解决这个问题,人们创建了<ruby> <a href="https://fossbytes.com/linux-lexicon-man-pages-navigation/"> 手册页 </a> <rt> man page </rt></ruby>,(手册 —— man 是 manual 的缩写)。首先,它是用英文写成的,包含了大量关于不同命令的深入信息。有时候,当你在寻找命令的基本信息时,它就会显得有点庞杂。为了解决这个问题,人们创建了[TLDR 页](https://github.com/tldr-pages/tldr)。
### 什么是 TLDR 页?
TLDR 页的 GitHub 仓库将其描述为简化的、社区驱动的手册页集合。在实际示例的帮助下,努力让使用手册页的体验变得更简单。如果还不知道,TLDR 取自互联网的常见俚语:<ruby> 太长没读 <rt> Too Long Didn’t Read </rt></ruby>。
如果你想比较一下,让我们以 `tar` 命令为例。 通常,手册页的篇幅会超过 1000 行。`tar` 是一个归档实用程序,经常与 `bzip` 或 `gzip` 等压缩方法结合使用。看一下它的手册页:
[](https://fossbytes.com/wp-content/uploads/2017/11/tar-man-page.jpg)
而另一方面,TLDR 页面让你只是浏览一下命令,看看它是如何工作的。 `tar` 的 TLDR 页面看起来像这样,并带有一些方便的例子 —— 你可以使用此实用程序完成的最常见任务:
[](https://fossbytes.com/wp-content/uploads/2017/11/tar-tldr-page.jpg)
让我们再举一个例子,向你展示 TLDR 页面为 `apt` 提供的内容:
[](https://fossbytes.com/wp-content/uploads/2017/11/tldr-page-of-apt.jpg)
如上,它向你展示了 TLDR 如何工作并使你的生活更轻松,下面让我们告诉你如何在基于 Linux 的操作系统上安装它。
### 如何在 Linux 上安装和使用 TLDR 页?
最成熟的 TLDR 客户端是基于 Node.js 的,你可以使用 NPM 包管理器轻松安装它。如果你的系统上没有 Node 和 NPM,请运行以下命令:
```
sudo apt-get install nodejs
sudo apt-get install npm
```
如果你使用的是 Debian、Ubuntu 或 Ubuntu 衍生发行版以外的操作系统,你可以根据自己的情况使用`yum`、`dnf` 或 `pacman`包管理器。
现在,通过在终端中运行以下命令,在 Linux 机器上安装 TLDR 客户端:
```
sudo npm install -g tldr
```
一旦安装了此终端实用程序,最好在尝试之前更新其缓存。 为此,请运行以下命令:
```
tldr --update
```
执行此操作后,就可以阅读任何 Linux 命令的 TLDR 页面了。 为此,只需键入:
```
tldr <commandname>
```
[](https://fossbytes.com/wp-content/uploads/2017/11/tldr-kill-command.jpg)
你还可以运行其[帮助命令](https://github.com/tldr-pages/tldr-node-client),以查看可与 TLDR 一起使用的各种参数,以获取所需输出。 像往常一样,这个帮助页面也附有例子。
### TLDR 的 web、Android 和 iOS 版本
你会惊喜地发现 TLDR 页不仅限于你的 Linux 桌面。 相反,它也可以在你的 Web 浏览器中使用,可以从任何计算机访问。
要使用 TLDR Web 版本,请访问 [tldr.ostera.io](https://tldr.ostera.io/) 并执行所需的搜索操作。
或者,你也可以下载 [iOS](https://itunes.apple.com/us/app/tldt-pages/id1071725095?ls=1&mt=8) 和 [Android](https://play.google.com/store/apps/details?id=io.github.hidroh.tldroid) 应用程序,并随时随地学习新命令。
[](https://fossbytes.com/wp-content/uploads/2017/11/tldr-app-ios.jpg)
你觉得这个很酷的 Linux 终端技巧很有意思吗? 请尝试一下,让我们知道您的反馈。
---
via: <https://fossbytes.com/tldr-pages-linux-man-pages-alternative/>
作者:[Adarsh Verma](https://fossbytes.com/author/adarsh/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,356 | 学习人工智能如何入门 | https://opensource.com/article/18/12/how-get-started-ai | 2018-12-17T19:31:24 | [
"AI",
"机器学习",
"人工智能"
] | https://linux.cn/article-10356-1.html |
>
> 在你开始从事人工智能之前,你需要先了解人类的智能。
>
>
>

我曾经问过别人、也被别人问过关于学习人工智能(AI)最好的方式是什么?我应该去阅读什么书?我应该去看什么视频?后面我将讲到这些,但是,考虑到人工智能涉及很多领域,我把这个问题分开来讲可能更好理解。
学习人工智能很重要的一点是区别开研究方面和应用方面。Google 的 Cassie Kozyrkov 在近日于伦敦举行的 O'Reilly 人工智能会议的一个演讲中 [描述了这个区别](https://www.youtube.com/watch?v=RLtI7r3QUyY),并且这是一个很好的演讲。
人工智能研究在本质上是学术性的,在你能够获得人工智能的某些细节之前,需要大量的跨各类学科的数学知识。这部分的人工智能关注于算法和驱动人工智能发展的工具。比如,什么样的神经网络结构能够改善视觉识别的结果?我们如何使无监督学习成为更有用的方法?我们能否找到一个更好的方法,去理解深度学习流水线是如何得出答案的?
另一方面,人工智能应用更多是关于使用现有工具去获取有用的结果。开源在这里发挥了一个重要的作用,那就是免费提供了易于使用的、各种语言的软件。公有云提供商也致力于提供大量的机器学习、模型、以及数据集,这使得人工智能的入门比其它的要简单的多。
在这个问题上我想补充一点,那就是人工智能的从业者不应该将他们的工具视为神秘地输出答案的黑匣子。至少,他们应该去了解不同技术、模型、和数据采集方法的限制和潜在偏差。只是不需要去深入研究他们工具链中每个部分的理论基础。
虽然在日常工作中人工智能可能并不那么重要,但理解人工智能的大量的背景知识还是很有用的。人工智能已经超越了神经网络上深度学习的狭窄范围,目前神经网络上的强化学习和监督学习已经取得重要成就。例如,人工智能经常被视为是增强(而不是替代)人类判断和决策的一种方法。但是在机器和人类之间交换信息还有其自身的缺陷。
有了这些背景知识,下面是的一些研究领域和资源,你可能发现会很有用。
### 研究人工智能
在很多方面,用于人工智能研究的一个资源清单,可以反映出本科(甚至是研究生)的计算机科学项目都是专注于人工智能。最主要的区别是,你起草的教学大纲比起传统的大纲更关注于跨学科。
你的计算机科学和数学背景知识决定了你的起点。
如果你的计算机科学和数据背景知识很差或已经荒芜了,但你还希望能够深入了解人工智能的基本原理,那么从一些数学课程开始将会让你受益。MOOC 上像非盈利的 [edX](https://www.edx.org/) 平台和 [Coursera](https://www.coursera.org/) 上都有许多可供你选择的课程(这两个平台都对认证收费,但 edX 上所有的课程,对旁听者是全免费的)。
典型的基础课程包括:
* [MIT 的微积分课程](https://www.edx.org/course/calculus-1a-differentiation),从微分开始学习
* [线性代数](https://www.edx.org/course/linear-algebra-foundations-to-frontiers) (德克萨斯大学)
* 概率与统计,比如 MIT 的 [概率 —— 不确定性与数据科学](https://courses.edx.org/courses/course-v1:MITx+6.431x+3T2018/course/)
从一个研究的角度去深入人工智能,你可能需要深入所有的这些数据领域,甚至更多。但是上面的内容应该让您在深入研究机器学习和AI之前大致了解可能是最重要的研究分支。
除了 MOOC 之外,像 [MIT OpenCourseWare](https://ocw.mit.edu/index.htm) 这样的资源也提供了大量的数学和计算机科学课程的大纲和各种支持材料。
有了这些基础,你就可以学习更专业的人工智能课程了。吴恩达从他在斯坦福大学时教的 “AI MOOC” 就是整个在线课程领域中最早流行起来的课程之一。今天,他的 [神经网络和深度学习](https://www.coursera.org/learn/neural-networks-deep-learning) 也是 Coursera 深度学习专业的一部分。在 edX 上也有相关的一些项目,比如,哥伦比亚大学提供的一个 [人工智能 MicroMasters](https://www.edx.org/micromasters/columbiax-artificial-intelligence)。
除了课程之外,也可以在网上找到各种范例和其它学习材料。这些包括:
* [神经网络和深度学习](http://neuralnetworksanddeeplearning.com/)
* MIT 出版的 Ian Goodfellow、Yoshua Bengio、Aaron Courville 的《[深度学习](http://www.deeplearningbook.org/)》
### 应用人工智能
人工智能应用更关注于使用可用的工具,而不是去构建新工具。对一些底层的数学,尤其是统计学的了解仍然是非常有用的 —— 甚至可以说是必需的 —— 但对这些知识的了解程度不像研究人工智能的要求那么高。
在这里编程是核心技能。虽然可以使用不同的编程语言去做,但是一些库和工具集 —— 比如 Python 的 [PyTorch](https://pytorch.org/),依赖于 Python,所以这是一个应该掌握的好技能。尤其是,如果你有某种程度上的编程背景,MIT 的 [计算机科学入门和使用 Python 编程](https://www.edx.org/course/introduction-to-computer-science-and-programming-using-python),它是基于 MIT 的 6.001 在校课程,是一个非常好的启蒙课程。如果你编程零基础,来自密歇根大学的 Charles Severance 的 [人人学编程(Python 使用入门)](https://www.coursera.org/learn/python) 是个很好的开端,它不会像 MIT 的课程那样,把你一下子扔进代码的汪洋大海。
[R 编程语言](https://www.r-project.org/about.html) 也是一个应该增加到你的技能库中的很有用的技能。虽然它在机器学习(ML)中使用的很少,但它在其它数据科学任务中很常见,并且经常与人工智能/机器学习和数据科学的应用实践结合在一起。例如,与组织和清理数据相关的许多任务同样适用于您最终使用的任何分析技术。像哈佛的 [数据科学认证](https://www.edx.org/professional-certificate/harvardx-data-science) 这样的一个 MOOC 系列就是一整套课程的一个例子,这些课程介绍了如何去很好地处理数据。
如果你从事人工智能方面的工作,那么你很可能会遇到的另一个开源软件库就是 [TensorFlow](https://www.tensorflow.org/)。它最初是由 Google 人工智能团队中的 Google 大脑团队的研发工程师开发的。[Google 提供了许多教程](https://www.tensorflow.org/tutorials/) 让你通过高级 Keras API 去开始使用 TensorFlow。你既可以在 Google 云上也可以在本地运行 TensorFlow。
通常,大的公有云提供商都提供在线数据集和易于使用的机器学习服务。但是,在你开始去 “玩” 数据集和应用之前,你需要考虑清楚,一旦开始选定一个提供商,你将被它们 “锁定” 的程度。
你的探索学习项目所需的数据集可以从许多不同的源获得。除了公有云提供商之外,[Kaggle](https://www.kaggle.com/) 是另一个受欢迎的源,总体来看,它也是一个比较好的学习源。以数字形式提供的政府数据也越来越多了。美国联邦政府的 [Data.gov](https://www.data.gov/) 声称它提供超过 300,000 个数据集。各州和地方政府也发布从餐馆健康评级到狗的名字的所有数据。
### 研究和应用人工智能兼而有之
最后我想说明的一点是,人工智能不仅是与数学、编程、数据有关的一个宽泛主题。人工智能作为一个综合体涉及到了许多其它的领域,包括心理学、语言学、博弈论、运筹学和控制系统。确实,现在有一些人工智能研究者担心,由于处理能力和大数据的结合,使得该领域过于关注最近才变得强大和有趣的少数几个技术。在了解人类如何学习和推理方面,许多长期存在的问题仍未解决。不管怎样,对这些广泛存在的问题有一个了解,将更好地让你在更广泛的背景中评估人工智能。
我比较喜欢的其中一个示例是杜克大学的 [人类和自治实验室](https://hal.pratt.duke.edu/)。这个实验室的工作涉及人机协同所面临的各种挑战,比如,如果自动化设备失效,自动驾驶仪如何设计才能让那些[“洋红色的孩子“](https://99percentinvisible.org/episode/children-of-the-magenta-automation-paradox-pt-1/) 快速取得控制。有一个基础的大脑科学课程,比如 MIT 的 [心理学导论](https://ocw.mit.edu/courses/brain-and-cognitive-sciences/9-00sc-introduction-to-psychology-fall-2011/),它提供了关于人类智能和机器智能之间关系的一些很有用的内容。另一个类似的课程是,MIT 电子工程与计算机科学系已故教授 Marvin Minsky 的 [心灵的社会](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-868j-the-society-of-mind-fall-2011/)。
关于学习人工智能,假如说有一个最重要的挑战,那它不是原材料和工具不易获得,因为它们有如此之多。我的目标并不是给你一个全面的指导,相反,而是指出了你可以去学习的不同路径,以及为你提供一些可能的起点。祝你学习愉快!
---
via: <https://opensource.com/article/18/12/how-get-started-ai>
作者:[Gordon Haff](https://opensource.com/users/ghaff) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I've both asked and been asked about the best way to learn more about artificial intelligence (AI). What should I read? What should I watch? I'll get to that. But, first, it's useful to break down this question, given that AI covers a lot of territory.
One important distinction to draw is between the research side of AI and the applied side. Cassie Kozyrkov of Google [drew this distinction](https://www.youtube.com/watch?v=RLtI7r3QUyY) in a talk at the recent O'Reilly Artificial Intelligence Conference in London, and it's a good one.
Research AI is rather academic in nature and requires a heavy dose of math across a variety of disciplines before you even get to those parts that are specific to AI. This aspect of AI focuses on the algorithms and tools that drive the state of AI forward. For example, what neural network structures might improve vision recognition results? How might we make unsupervised learning a more generally useful approach? Can we find ways to understand better how deep learning pipelines come up with the answers they do?
Applied AI, on the other hand, is more about using existing tools to obtain useful results. Open source has played a big role here in providing free and often easy-to-use software in a variety of languages. Public cloud providers have also devoted a lot of attention to providing machine learning services, models, and datasets that make the onramp to getting started with AI much simpler than it would be otherwise.
I'll add at this point that applied AI practitioners shouldn't treat their tools as some sort of black box that spits out answers for mysterious reasons. At a minimum, they need to understand the limits and potential biases of different techniques, models, and data collection approaches. It's just that they don't necessarily need to delve deeply into all the theory underpinning every part of their toolchain.
Although it's probably less important for working in AI on a day-to-day basis, it's also useful to understand the broader context of AI. It goes beyond the narrow scope of deep learning on neural networks that have been so important to the gains made in reinforcement learning and supervised learning to date. For example, AI is often viewed as a way to *augment* (rather than replace) human judgment and decisions. But the handoff between machine and human has its own pitfalls.
With that background, here are some study areas and resources you may find useful.
## Research AI
In a lot of respects, a list of resources for research AI mirror those in an undergraduate (or even graduate) computer science program that's focused on AI. The main difference is that the syllabus you draw up may be more interdisciplinary than more traditionally focused university curricula.
Where you start will depend on your computer science and math background.
If it's minimal or rusty, but you still want to develop a deep understanding of AI fundamentals, you'll benefit from taking some math courses to start. There are many options on massive online open courses (MOOCs) like the nonprofit [edX](https://www.edx.org/) platform and [Coursera](https://www.coursera.org/). (Both platforms charge for certifications, but edX makes all the content available for free to people just auditing the course.)
Typical foundational courses could include:
[MIT's Calculus courses](https://www.edx.org/course/calculus-1a-differentiation), starting with differentiation[Linear Algebra](https://www.edx.org/course/linear-algebra-foundations-to-frontiers)(University of Texas)- Probability and statistics, such as MIT's
[Probability—The Science of Uncertainty and Data](https://courses.edx.org/courses/course-v1:MITx+6.431x+3T2018/course/)
To get deeper into AI from a research perspective, you'll probably want to get into all these areas of mathematics and more. But the above should give you an idea of the general branches of study that are probably most important before delving into machine learning and AI proper.
In addition to MOOCs, resources such as [MIT OpenCourseWare](https://ocw.mit.edu/index.htm) provide the syllabus and various supporting materials for a wide range of mathematics and computer science courses.
With the foundations in place, you can move onto more specialized courses in AI proper. Andrew Ng's AI MOOC, from when he was teaching at Stanford, was one of the early courses to popularize the whole online course space. Today, his [Neural Networks and Deep Learning](https://www.coursera.org/learn/neural-networks-deep-learning) is part of the Deep Learning specialization at Coursera. There are corresponding programs on edX. For example, Columbia offers an [Artificial Intelligence MicroMasters](https://www.edx.org/micromasters/columbiax-artificial-intelligence).
In addition to courses, a variety of textbooks and other learning material are also available online. These include:
[Neural Networks and Deep Learning](http://neuralnetworksanddeeplearning.com/)from MIT Press by Ian Goodfellow and Yoshua Bengio and Aaron Courville[Deep Learning](http://www.deeplearningbook.org/)
## Applied AI
Applied AI is much more focused on using available tools than building new ones. Some appreciation of the mathematical underpinnings, especially statistics, is still useful—arguably even necessary—but you won't be majoring in that aspect of AI to the same degree you would in a research mode.
Programming is a core skill here. While different programming languages can come into play, a lot of libraries and toolsets—such as [PyTorch](https://pytorch.org/)—rely on Python, so that's a good skill to have. Especially if you have some level of programming background, MIT's [Introduction to Computer Science and Programming Using Python](https://www.edx.org/course/introduction-to-computer-science-and-programming-using-python), based on its on-campus 6.001 course, is a good primer. If you're truly new to programming, Charles Severance's [Programming for Everybody (Getting Started with Python)](https://www.coursera.org/learn/python) from the University of Michigan doesn't toss you into the deep end of the pool the way the MIT course does.
[The R programming language](https://www.r-project.org/about.html) is also a useful skill to add to your toolbox. While it's less used in machine learning (ML) per se, it's common for a variety of other data science tasks, and applied AI/ML and data science often blend in practice. For example, many tasks associated with organizing and cleaning data apply equally whatever analysis techniques you'll eventually use. A MOOC sequence like Harvard's [Data Science certificate](https://www.edx.org/professional-certificate/harvardx-data-science) is an example of a set of courses that provide a good introduction to working with data.
Another open source software library you're likely to encounter if you do any work with AI is [TensorFlow](https://www.tensorflow.org/). It was originally developed by researchers and engineers from the Google Brain team within Google's AI organization. [Google offers a variety of tutorials](https://www.tensorflow.org/tutorials/) to get started with TensorFlow using the high-level Keras API. You can run TensorFlow locally as well as online in Google Cloud.
In general, all of the big public cloud providers offer online datasets and ML services that can be an easy way to get started. However, especially as you move beyond "play" datasets and applications, you need to start thinking seriously about the degree to which you want to be locked into a single provider.
Datasets for your exploratory learning projects are available from many different sources. In addition to the public cloud providers, [Kaggle](https://www.kaggle.com/) is another popular source and also a good learning resource more broadly. Government data is also increasingly available in digital form. The US Federal Government's [Data.gov](https://www.data.gov/) claims over 300,000 datasets. State and local governments also publish data on everything from restaurant health ratings to dogs' names.
## Miscellany
I'll close by noting that AI is a broad topic that isn't just about math, programming, and data. AI as a whole touches many other fields, including cognitive psychology, linguistics, game theory, operations research, and control systems. Indeed, a concern among at least some AI researchers today is that the field has become too fixated on a small number of techniques that have become powerful and interesting only quite recently because of the intersection of processing power and big data. Many longstanding problems in understanding how humans learn and reason remain largely unsolved. Developing at least some appreciation for these broader problem spaces will better enable you to place AI within a broader context.
One of my favorite examples is the [Humans and Autonomy Lab](https://hal.pratt.duke.edu/) at Duke. The work in this lab touches on all the challenges of humans working with machines, such as how autopilots can create ["Children of the Magenta"](https://99percentinvisible.org/episode/children-of-the-magenta-automation-paradox-pt-1/) who are unable to take control quickly if the automation fails. A basic brain-science course, such as MIT's [Introduction to Psychology](https://ocw.mit.edu/courses/brain-and-cognitive-sciences/9-00sc-introduction-to-psychology-fall-2011/), provides some useful context for the relationship between human intelligence and machine intelligence. Another course in a similar vein, but taught by the late Marvin Minsky from MIT's Electrical Engineering and Computer Science department, is [The Society of Mind](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-868j-the-society-of-mind-fall-2011/).
If there's one key challenge to learning about AI, it's not that raw materials and tools aren't readily available. It's that there are so many of them. My objective hasn't been to give you a comprehensive set of pointers. Rather, it's been to both point out the different paths you can take and provide you with some possible starting points. Happy learning!
## 3 Comments |
10,357 | 在 Linux 终端中开火车 | https://opensource.com/article/18/12/linux-toy-sl | 2018-12-17T21:41:54 | [
"sl"
] | https://linux.cn/article-10357-1.html |
>
> 使用 sl 命令,你可以让自己驾驶火车,带来一个有趣的命令行体验。
>
>
>

现在是 12 月,每个 Linux 终端用户都值得这一年的奖励。因此,我们将为你带来一个 Linux 命令行玩具的日历。什么是命令行玩具?它可能是一个游戏、一个小的无意义的打发时间的东西,或者为你在终端带来快乐的东西。
今天的 Linux 命令行玩具来自 Opensource.com 社区版主 [Ben Cotton](https://opensource.com/users/bcotton) 的建议。Ben 建议 `sl`,它是<ruby> 蒸汽机车 <rt> steam locomotive </rt></ruby>的简称。
而对于 Linux `ls` 命令来说,`sl` 也是一个常见的拼写错误,这并不是巧合(LCTT 译注:意即 `sl` 是专门用来设计提醒 `ls` 打错的)。想要不再打错吗?尝试安装 `sl`。它可能已经在默认仓库中打包。对我而言,在 Fedora 中,这意味着安装起来很简单:
```
$ sudo dnf install sl -y
```
现在,只需键入 `sl` 即可测试。

你可能会像我一样注意到,`Ctrl+C` 不会让你的火车脱轨,所以你必须等待整列火车通过。这会让你知道打错了 `ls`!
想查看 `sl` 源码?它已经在[在 GitHub 上](https://github.com/mtoyoda/sl)。
`sl` 也是分享我个人关于开源许可证的见解的绝佳机会。虽然它的[许可证](https://github.com/mtoyoda/sl/blob/master/LICENSE)“足够开源”能够打包到我的发行版,但技术上而言,它并不是 [OSI 批准](https://opensource.org/licenses)的许可证。在其版权行之后,许可证的内容很简单:
>
> 每个人都可以在这个程序上做任何事情,包括复制,修改和改进,除非你试图假装你写了它。
>
>
> 即,上述版权声明必须出现在所有副本中。
>
>
> 作者对本软件不承担任何责任。
>
>
>
遗憾的是,当你选择未经 OSI 批准的许可证时,你可能会意外地为你的用户带来额外的工作,因为他们必须要弄清楚你的许可证是否适用于他们的情况。他们的公司政策是否允许他们做贡献?甚至他们可以合法地使用该程序吗?许可证是否与他们希望与之集成的其他程序的许可证相匹配?
除非你是律师(也许,即使你是律师),否则在非标准许可证范围内选择可能会很棘手。因此,如果你仍在寻找新年的方案,为什么不把仅 OSI 批准的许可证作为你 2019 年新项目的选择呢。
这并不是对作者的不尊重。`sl` 仍然是一个很棒的小命令行玩具。
你有一个你认为我应该介绍的最喜欢的命令行玩具吗?这个系列的日历大部分已经完成,但我还剩下几个空余。请在下面的评论中告诉我,我会了解一下。如果有空间,我会尝试包含它。如果没有,但我得到了一些好的投稿,我会在最后做一些荣誉介绍。
了解昨天的玩具,[在 Linux 命令行中装饰字符](https://opensource.com/article/18/12/linux-toy-boxes),还有记得明天再来!
---
via: <https://opensource.com/article/18/12/linux-toy-sl>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's December, and every Linux terminal user deserves a reward just for making through the year. So we're bringing you a sort of advent calendar of Linux command-line toys. What's a command-line toy? It might be a game, a pointless little time waster, or just something to bring you joy at the terminal.
Today's Linux command-line toy is a suggestion from Opensource.com community moderator [Ben Cotton](https://opensource.com/users/bcotton). Ben suggested **sl**, which is short for *steam** locomotive*.
It's also, conveniently and not coincidentally, a common typo for the Linux **ls** command. Want to stop mistyping ls? Try installing **sl**. It's probably packaged for your default repos. For me, in Fedora, that means it was as simple to install as:
`$ sudo dnf install sl`
Now, just type **sl** to try it out.

You may notice, as I did, that **Ctrl+C** doesn't derail your train, so you have to wait for the entire train to pass. That'll teach you to mistype **ls**!
Want to check out the source to **sl**? It's over [on GitHub](https://github.com/mtoyoda/sl).
**sl** is also a great opportunity to share a personal PSA about open source licensing. While its [license](https://github.com/mtoyoda/sl/blob/master/LICENSE) was "open source enough" to be packaged for my distribution, it's not technically an [OSI-approved](https://opensource.org/licenses) license. After the copyright line, the license reads simply:
```
Everyone is permitted to do anything on this program including copying,
modifying, and improving, unless you try to pretend that you wrote it.
i.e., the above copyright notice has to appear in all copies.
THE AUTHOR DISCLAIMS ANY RESPONSIBILITY WITH REGARD TO THIS SOFTWARE.
```
Unfortunately, when you chose a license that's not OSI-approved, you may accidentally be creating extra work for your users, as they must figure out whether your license will work for their situation. Do their corporate policies allow them to contribute? Can they even legally use the program? Does the license mesh with the license of another program they wish to integrate with it?
Unless you're a lawyer (and perhaps, even if you are), navigating the space of non-standard licenses can be tricky. So if you're still looking for a New Year's Resolution, why not resolve to choose only OSI-approved licenses for any new projects you start in 2019.
No disrespect to the creator, though. **sl** is still a great little command-line toy.
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Check out yesterday's toy, [Box yourself in on the Linux command line](https://opensource.com/article/18/12/linux-toy-boxes), and check back tomorrow for another!
## 3 Comments |
10,358 | 在 Linux 下交换 Ctrl 与大写锁定键 | https://opensource.com/article/18/11/how-swap-ctrl-and-caps-lock-your-keyboard | 2018-12-17T22:38:55 | [
"键盘"
] | https://linux.cn/article-10358-1.html |
>
> Linux 桌面环境使你可以根据需要轻松设置键盘。下面来演示如何去做。
>
>
>

对于许多使用计算机很多年的用户来说,自从第一批 PC 键盘从生产线上下线后不久,Ctrl 和大写锁定键就已经在错误的位置上了。对我来说,这张 1995 年 Sun 工作站的老式键盘照片上的两个键的位置才是正确的。(原谅我放了一张模糊的图片,它是在昏暗的光线下使用 Minox 间谍相机拍摄的。)

感兴趣的话,可以读一下维基百科上对于 [Ctrl 键位置的历史](https://en.wikipedia.org/wiki/Control_key) 的介绍。我不打算讨论将 Ctrl 键放在“a”旁边而不是 Shift 键下方的各种理由,也不评论大写锁定键的无用性,也没有打算与那些主张使用手掌根来触发 Ctrl 键的人争论,即使在一些笔记本电脑键盘上不可能这样做到,因为有的键会位于腕托以下。
相反,我将假设我不是唯一喜欢把 Ctrl 键放在“a”旁边的人,并说明如何使用 Linux 自带的灵活性在各种桌面环境中交换 Ctrl 和大写锁定键的位置。请注意,下面的演示可能只有有限的有效期,因为调整桌面设置的方法经常发生变化,但我希望这为你开了一个好头。
### GNOME 3
[GNOME 3](https://www.gnome.org/gnome-3/) 桌面环境用户可以使用 [Tweaks](https://wiki.gnome.org/Apps/Tweaks) 工具交换大写锁定和 Ctrl 键,如下所示。

具体步骤如下:
1. 从你的 Linux 发行版的软件仓库安装 Tweaks 工具。
2. 启动 Tweaks 程序。
3. 从左侧菜单中选择 “Keyboard & Mouse”。
4. 单击 “Additional Layout Options”。
5. 在打开的窗口中单击 “Ctrl position”,然后选择 “Swap Ctrl and Caps Lock”。
完成!顺便说一句,你可以使用 Tweaks 工具做很多很酷的事情。例如,我将我的右 Ctrl 键设置为 Compose 键,这让我可以使用键盘快捷键打出各种字符,例如通过 `Compose+c+,`、`Compose+e+'`、`Compose+o+^` 以及 `Compose+n+~` 分别键入 ç、é、ô 和 ñ。(LCTT 译注:可参考 [Special characters listed by extended compose sequence](https://www.ibm.com/support/knowledgecenter/en/SSKTWP_9.0.0/com.ibm.notes900.help.doc/acc_spec_characters_r.html))
### KDE
我不使用 [KDE](https://www.kde.org/),但我的同事 Seth Kenlon 写的 [将改变你的生命的 KDE tweaks](https://opensource.com/article/17/5/7-cool-kde-tweaks-will-improve-your-life) 这篇文章的第 5 项演示了如何重新映射按键。
### Xfce
据我所知,[Xfce](https://www.xfce.org/) 桌面环境没有一个方便的工具来管理这些(指交换按键)设置。 但是,`setxkbmap` 命令的 `ctrl:swapcaps` 选项可以帮助你完成交换按键的修改。这个修改包含两部分:
1. 弄清楚命令的用法;
2. 找出调用命令的位置,以便在桌面启动时激活它。
第一部分非常简单,命令是:
```
/usr/bin/setxkbmap -option "ctrl:nocaps"
```
在终端窗口中执行此命令,以确保结果符合你的预期。
假设上述命令有效,应该在哪里调用此命令呢?这需要一些实验。一种可能是在用户主目录的 `.profile` 文件中;另一个可能是将命令添加到 Xfce 的自启动配置(在设置管理器中查找 “Session and Startup”)里。
还有一种可能性是在文件 `/etc/default/keyboard` 中使用相同的选项,最终可能看起来像这样:
```
# KEYBOARD CONFIGURATION FILE
# Consult the keyboard(5) manual page.
XKBMODEL="pc105"
XKBLAYOUT="us"
XKBVARIANT=""
XKBOPTIONS="ctrl:swapcaps"
BACKSPACE="guess"
```
注意,这个更改将影响所有用户,因此如果你和其他人共享计算机,请准备好进行一些说明。此外,系统更新可能会覆盖此文件,因此如果你的设置失效了,就需要再次编辑它。将相同的信息放在用户主目录中的 `.keyboard` 文件内,可以为每个用户进行设置。
最后请注意,这些更改需要重新启动 Xfce(除非在终端窗口中的命令行上运行,但这在会话结束之后便会失效)。
### LXQt 和其他桌面环境
我没有用过 [LXQt](https://lxqt.org/),但根据我使用 [LXDE](https://lxde.org/) 的经验,我会尝试上面用于 Xfce 的方法。我也希望适用于 Xfce 的方法可以用于其他 Linux 桌面环境。当然了,在其他桌面环境上遇到问题的时候,可以通过你最喜欢的搜索引擎来查找解决办法。
### 控制台
我没有在控制台上进行过尝试,因为我很少有机会与控制台(你在服务器上看到的或你的窗口系统没有正确显示时出现的界面)进行交互。上面给出的方法以人们希望的方式(即与其他应用程序一致)调整终端窗口。
但是,如果像上面一样已经编辑了 `/etc/default/keyboard` 文件或 `〜/.keyboard`,则实用程序 `setupcon` 可以用于更改控制台的键盘设置,以便实现相同的功能。[链接 1](https://askubuntu.com/questions/485454/how-to-remap-keys-on-a-user-level-both-with-and-without-x)、[链接 2](https://unix.stackexchange.com/questions/198791/how-do-i-permanently-change-the-console-tty-font-type-so-it-holds-after-reboot) 和 [链接 3](https://superuser.com/questions/290115/how-to-change-console-keymap-in-linux) 给出了一些关于如何从这两个文件实现这些更改的想法。第三个链接还讨论了使用 `dumpkeys` 和 `loadkeys` 来实现想要的效果。[setupcon 的手册](http://man.he.net/man1/setupcon) 简短而重要,值得阅读,再结合上面 StackExchange 问题的一些评论,应该足以得到一个解决办法。
### 其他环境
最后,上面 StackExchange 的链接中提到的这一点值得强调 —— 配置控制台与配置终端窗口不同;如前所述,后者是通过桌面管理器进行配置的。
`setxkbmap`、`xkeyboard-config`、`keyboard`、`console-setup` 和 `setupcon` 命令的手册都是有用的参考资料。或者,如果你不喜欢阅读手册,可以看一下 [这篇极好的文章](http://www.noah.org/wiki/CapsLock_Remap_Howto)。
---
via: <https://opensource.com/article/18/11/how-swap-ctrl-and-caps-lock-your-keyboard>
作者:[Chris Hermansen](https://opensource.com/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jlztan](https://github.com/jlztan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
For many people who've been computer users for (let's just say) "quite some time now," the Ctrl and Caps Lock keys have been in the wrong place since shortly after the first PC keyboards rolled off the production line. For me, the correct positioning appears in this image of a vintage 1995 Sun Workstation keyboard. (Forgive me for the blurriness of the image; it was taken with a Minox spy camera in low light.)
If you're interested, you can read about the [history of the Ctrl key location](https://en.wikipedia.org/wiki/Control_key). I'm not going to discuss the various rationales for placing the Ctrl key next to the "a" key versus below the Shift key; I'm not going to comment on the overall uselessness of the Caps Lock key (whoops); and I'm not going to argue with those who advocate using the heel of the hand to activate the Ctrl key, even though it's impossible to do on some laptop keyboards where the keys are inset below the level of the wrist rest (whoops).
Rather, I'm going to assume I'm not the only one who prefers the Ctrl key next to the "a" and describe how to use the wonderful flexibility that comes with Linux to swap the Ctrl and Caps Lock keys on various desktop environments. Note that this kind of advice seems to have a limited shelf life, as tools for tweaking desktop settings change fairly often. But I hope this offers a good place for you to start.
## With GNOME 3
[GNOME 3](https://www.gnome.org/gnome-3/) desktop environment users can use the [Tweaks](https://wiki.gnome.org/Apps/Tweaks) tool to swap their Caps Lock and Ctrl keys, as you can see below.
Here's how to do it:
- Install the Tweaks tool from your distribution's repositories.
- Start the Tweaks application.
- Select "Keyboard & Mouse" from the left-hand menu.
- Click "Additional Layout Options".
- Click "Ctrl position" on the window that opens and choose "Swap Ctrl and Caps Lock."
That's it! By the way, you can do lots of cool stuff with the Tweaks tool. For example, I set my right Ctrl key to be a Compose key, which allows me to type all sorts of characters with keyboard shortcuts—such as ç, é, ô, and ñ and with the keystrokes Compose+c+Comma; Compose+e+Right quote; Compose+o+Circumflex; and Compose+n+Tilde.
## With KDE
I don't use [KDE](https://www.kde.org/), but item 5 in this article about [KDE tweaks that will change your life](https://opensource.com/article/17/5/7-cool-kde-tweaks-will-improve-your-life) by my colleague Seth Kenlon will show you how to remap your keys.
## With Xfce
As far as I can tell, the [Xfce](https://www.xfce.org/) desktop environment doesn't have a handy tool for managing these kinds of settings. However, the **ctrl:swapcaps** option to the **setxkbmap** command will help you make these changes. This type of modification has two parts:
- Figuring out the command's usage;
- Figuring out where to invoke the command so it is activated as the desktop comes up.
The first part is pretty straightforward: the command is:
`/usr/bin/setxkbmap -option "ctrl:nocaps"`
It's worth executing this in a terminal window to make sure the results are what you expect.
Assuming it works, where should you invoke the command? That requires some experimentation; one possibility is in the file **.profile** in the user's home directory. Another option is to add the command to the autostart facility in Xfce (look for "Session and Startup" in the Settings Manager).
Another possibility is to use the same option in the file /**etc/default/keyboard**, which might end up looking like this:
```
# KEYBOARD CONFIGURATION FILE
# Consult the keyboard(5) manual page.
XKBMODEL="pc105"
XKBLAYOUT="us"
XKBVARIANT=""
XKBOPTIONS="ctrl:swapcaps"
BACKSPACE="guess"
```
Note that this kind of change will affect *all* users, so if you share your computer, be prepared to do some explaining. Also, system updates may overwrite this file, so you'll need to edit it again if your setup stops working. Putting the same information in the file **.keyboard** in the user's home directory might accomplish the same task on the user's behalf.
Finally, note that these kinds of changes require you to restart Xfce (except when running the command on the command line in the terminal window, but that won't stick past the end of the session).
## With LXQt and other desktop environments
I haven't tried [LXQt](https://lxqt.org/), but if my memory serves from [LXDE](https://lxde.org/), I would try the same recipe used above for Xfce. I'd also expect that the Xfce recipe could work for other Linux desktop environments, but, of course, your favorite search engine is always your friend.
## The console
I haven't tried this, as I have very few opportunities to interact with the console (what you see on a server or when your window system doesn't come up properly). The recipes presented above affect the terminal window in the way one would hope, i.e., consistently with other applications.
However, if the file **/etc/default/keyboard** or **~/.keyboard** has already been edited (as described above), the utility **setupcon** is intended to change the console keyboard setup so it functions the same way.** **This [StackExchange article](https://askubuntu.com/questions/485454/how-to-remap-keys-on-a-user-level-both-with-and-without-x), [this other one](https://unix.stackexchange.com/questions/198791/how-do-i-permanently-change-the-console-tty-font-type-so-it-holds-after-reboot), and [this third one](https://superuser.com/questions/290115/how-to-change-console-keymap-in-linux) give some ideas on how to effect these changes from both of these files. The third article also talks about using **dumpkeys** and **loadkeys**. It's also worthwhile to read [the setupcon man page](http://man.he.net/man1/setupcon) — it's short and to the point, and combined with the comments from the StackExchange articles, should be enough to get a solution in place.
Finally, it's worth emphasizing here the point mentioned in the StackExchange articles - configuring the console IS NOT THE SAME as configuring terminal windows; the latter are configured through the desktop manager as described previously.
## When all else fails
The manual pages for **setxkbmap**, **xkeyboard-config**, **keyboard**, **console-setup**, and **setupcon** are all useful references. Or, if you don't like reading manual pages, there's [this great article](http://www.noah.org/wiki/CapsLock_Remap_Howto).
## 12 Comments |
10,359 | 90 年代的大学网管如何使用 Linux | https://opensource.com/article/18/5/my-linux-story-student | 2018-12-18T11:08:41 | [
"Linux"
] | https://linux.cn/article-10359-1.html | 
在上世纪 90 年代中期,我报名了计算机科学课。我大学的计算机科学系为学生提供了一台 SunOS 服务器,它是一个多用户、多任务的 Unix 系统。我们登录它并编写我们学习的编程语言代码,例如 C、C++ 和 ADA。在那时,在社交网络和 IM 出现之前,我们还使用该系统发送电子邮件和使用诸如 `write` 和 `talk` 之类的程序来相互通信。我们每个人被允许托管一个个人网站。我很高兴能够使用它完成我的作业并联系其他用户。
这是我第一次体验这种类型的操作环境,但我很快就了解了另一个可以做同样事情的操作系统:Linux。
那会我还是学生,我在大学找了份兼职工作。我的第一个职位是住房和住宅部(H&R)的网络安装人员。这工作涉及到将学生宿舍与校园网络连接起来。由于这是该大学的第一个宿舍网络服务,因此只有两幢楼和大约 75 名学生连上了网。
在第二年,该网络扩展到另外两幢楼。H&R 决定让该大学的信息技术办公室(OIT)管理这不断增长的业务。我进入 OIT 并开始担任 OIT 网络经理的学生助理。这就是我发现 Linux 的方式。我的新职责之一是管理防火墙系统,它为宿舍提供网络和互联网访问。
每个学生都注册了他们硬件的 MAC 地址。注册的学生可以连接到宿舍网络并获得 IP 地址及访问互联网。与大学使用的其他昂贵的 SunOS 和 VMS 服务器不同,这些防火墙使用运行着自由开源的 Linux 操作系统的低成本计算机。截至年底,该系统已注册近 500 名学生。

OIT 网络工作人员使用 Linux 运行 HTTP、FTP 和其他服务。他们还在个人桌面上使用 Linux。就在那时,我意识到我手上的计算机看起来和运行起来就像 CS 系昂贵的 SunOS 机器一样,但没有高昂的成本。Linux 可以在商用 x86 硬件上运行,例如有 8 MB RAM 和 133Mhz Intel Pentium CPU 的 Dell Latitude。那对我来说是个卖点!我在从一个存货仓库中清理出来的机器上安装了 Red Hat Linux 5.2,并给了我的朋友登录帐户。
我使用我的新 Linux 服务器来托管我的网站并向我的朋友提供帐户,同时它还提供 CS 系服务器没有的图形功能。它使用了 X Windows 系统,我可以使用 Netscape Navigator 浏览网页,使用 [XMMS](http://www.xmms.org/) 播放音乐,并尝试不同的窗口管理器。我也可以下载并编译其他开源软件并编写自己的代码。
我了解到 Linux 提供了一些非常先进的功能,其中许多功能比更主流的操作系统更方便或更优越。例如,许多操作系统尚未提供应用更新的简单方法。在 Linux 中,这很简单,感谢 [autoRPM](http://www.ccp14.ac.uk/solution/linux/autorpm_redhat7_3.html),一个由 Kirk Bauer 编写的更新管理器,它向 root 用户每日发送邮件,其中包含可用的更新。它有一个直观的界面,用于审查和选择要安装的软件更新 —— 这对于 90 年代中期来说非常了不起。
当时 Linux 可能并不为人所知,而且它经常受到怀疑,但我确信它会存活下来。而它确实生存下来了!
---
via: <https://opensource.com/article/18/5/my-linux-story-student>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the mid-1990s, I was enrolled in computer science classes. My university’s computer science department provided a SunOS server—a multi-user, multitasking Unix system—for its students. We logged into it and wrote source code for the programming languages we were learning, such as C, C++, and ADA. In those days, well before social networks and instant messaging, we also used the system to communicate with each other, sending emails and using utilities such as `write`
and `talk`
. We were each also allowed to host a personal website. I enjoyed being able to complete my assignments and contact other users.
It was my first experience with this type of operating environment, but I soon learned about another operating system that could do the same thing: Linux.
While I was a student, I also worked part-time at the university. My first position was as a network installer in the Department of Housing and Residence (H&R). This involved connecting student dormitories to the campus network. As this was the university's first dormitory network service, only two buildings and about 75 students had been connected.
In my second year, the network expanded to cover an additional two buildings. H&R decided to let the university’s Office of Information Technology (OIT) manage this growing operation. I transferred to OIT and started the position of Student Assistant to the OIT Network Manager. That is how I discovered Linux. One of my new responsibilities was to manage the firewall systems that provided network and internet access to the dormitories.
Each student was registered with their hardware MAC address. Registered students could connect to the dorm network and receive an IP address and a route to the internet. Unlike the other expensive SunOS and VMS servers used by the university, these firewalls used low-cost computers running the free and open source Linux operating system. By the end of the year, the system had registered nearly 500 students.
The OIT network staff members were using Linux for HTTP, FTP, and other services. They also used Linux on their personal desktops. That's when I realized I had my hands on a computer system that looked and acted just like the expensive SunOS box in the CS department but without the high cost. Linux could run on commodity x86 hardware, such as a Dell Latitude with 8 MB of RAM and a 133Mhz Intel Pentium CPU. That was the selling point for me! I installed Red Hat Linux 5.2 on a box scavenged from the surplus warehouse and gave my friends login accounts.
While I used my new Linux server to host my website and provide accounts to my friends, it also offered graphics capabilities over the CS department server. Using the X Windows system, I could browse the web with Netscape Navigator, play music with [XMMS](http://www.xmms.org/), and try out different window managers. I could also download and compile other open source software and write my own code.
I learned that Linux offered some pretty advanced features, many of which were more convenient than or superior to more mainstream operating systems. For example, many operating systems did not yet offer simple ways to apply updates. In Linux, this was easy, thanks to [autoRPM](http://www.ccp14.ac.uk/solution/linux/autorpm_redhat7_3.html), an update manager written by Kirk Bauer, which sent the root user a daily email with available updates. It had an intuitive interface for reviewing and selecting software updates to install—pretty amazing for the mid-'90s.
Linux may not have been well-known back then, and it was often received with skepticism, but I was convinced it would survive. And survive it did!
## 4 Comments |
10,360 | 极客漫画:TCP 兄弟 | https://turnoff.us/geek/tcp-buddies/ | 2018-12-18T11:15:20 | [
"TCP",
"漫画"
] | https://linux.cn/article-10360-1.html | 
这幅漫画展示了 TCP 协议的沟通过程。首先是构建一个层(TCP 工作于传输层),然后向要通信的人发送建立联系的信号(SYN),接受到信息的人回复确认信息(ACK),确认已经收到,同时,发送建立联系的信息(SYN),这时,它发送的信息就是(SYN-ACK),当最初发送信息的人收到信息后,再回复了确认信息(ACK)。在回复了确认信息后,他们可以正常的交流,就开始说话了。
TCP 协议规定,在传输数据之前,要进行三次“握手”,来保证数据传输的可靠性。上面这幅漫画就展示了这样的内容。
如果你有兴趣查看更多信息,可以参看 [https://zh.wikipedia.org/wiki/传输控制协议](https://zh.wikipedia.org/wiki/%E4%BC%A0%E8%BE%93%E6%8E%A7%E5%88%B6%E5%8D%8F%E8%AE%AE)。
---
via: <https://turnoff.us/geek/tcp-buddies/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者:[Bestony](https://github.com/bestony) 校对:[wxy](https://github.com/wxy) 合成&点评:[Bestony](https://github.com/Bestony)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # tcp buddies


### Comics Related
-
[Blue Screen of Death](/geek/bsod/) -
[don't share a pipe with cut](/geek/linux-cut-command/) -
[wc](/geek/linux-wc/) -
[permission issue](/geek/permission-issue/) -
[world backup day 2024](/geek/world-backup-day-2024/) -
[xz backdoor](/geek/xz-backdoor/) -
[pid 1](/geek/pid1/) -
[tar.gz](/geek/tar.gz/) -
[at malloc room](/geek/at-malloc-room/) -
[just compile it](/geek/just-compile-it/) -
[highest score](/geek/highest-score/) -
[chroot](/geek/chroot/) -
[full table scan](/geek/full-table-scan/) -
[shutdown!](/geek/linux-shutdown-2024/) -
[just touch it](/geek/just-touch-it/) -
[market driven humor](/geek/market-driven-humor/) -
[the real reason not to use sigkill (revamp)](/geek/the-real-reason-not-to-use-sigkill/) -
[linux free command](/geek/linux-free-command/) -
[linux top explained](/geek/linux-top-explained/) -
[hackerman](/geek/hackerman/) -
[signals](/geek/signals/) -
[mtu](/geek/mtu/) -
[unzip](/geek/unzip/) -
[skype for linux](/geek/skype-for-linux/) -
[bad malloc](/geek/bad-malloc/) -
[to save the devops world](/geek/linux-containers/) -
[beware of dog](/geek/beware-of-dog/) -
[sudo prank](/geek/sudo-prank/) -
[checksum](/geek/file-checksum/) -
[sysadmin](/geek/sysadmin/) -
[hello world!](/geek/hello-world/) -
[valentine's day at the kernel](/geek/valentines-day/) -
[what processes do when they're idle](/geek/idle/) -
[first time](/geek/first-time/) -
[kernel economics](/geek/kernel-economics/) -
[disney buys linux](/geek/disney-buys-linux/) -
[terminal transparency](/geek/terminal-transparency/) -
[the war for port 80 - epilogue](/geek/apache-vs-nginx-epilogue/) -
[terminal password typing](/geek/terminal-password-typing/) -
[forked!](/geek/forked/) -
[the chroot case](/geek/the-chroot-case/) -
[smart windows](/geek/smart-windows/) -
[windows update](/geek/windows-update/) -
[super power](/geek/super-power/) -
[escape room](/geek/escape-room/) -
[when you tail -f but forget to grep](/geek/tail-no-grep/) -
[we need to talk about ssl](/geek/we-need-to-talk-about-ssl/) -
[chown - chmod](/geek/chown-chmod/) -
[solution escalation](/geek/solution-escalation/) -
[when you hire the wrong architect](/geek/wrong-architect/) -
[ghost in the shell](/geek/ghost-in-the-shell/) -
[linus torvald's house](/geek/linus-torvalds-house/) -
[sudo (board game)](/geek/sudo-board-game/) -
[the jealous process](/geek/the-jealous-process/) -
[#!s](/geek/shebang/) -
[user space election](/geek/user-space-election/) -
[the war for port 80](/geek/apache-vs-nginx/) -
[adopt a good cause, don't sigkill](/geek/dont-sigkill-2/) -
[bash history](/geek/bash-history/) -
[the real reason not to share a mutable state](/geek/dont-share-mutable-state/) -
[one last question](/geek/one-last-question/) -
[protocols](/geek/protocols/) -
[life of embedded processes](/geek/ubuntu-core-2/) -
[ubuntu core](/geek/ubuntu-core/) -
[inside the linux kernel](/geek/inside-the-linux-kernel/) -
[zombie processes](/geek/zombie-processes/) -
[poprocks and coke](/geek/poprocks-and-coke/) -
[stranger things - in the sysadmin's world](/geek/stranger-things-sysadmin-world/) -
[who killed mysql? - epilogue](/geek/who-killed-mysql-epilogue/) -
[dotnet on linux](/geek/dotnet-on-linux/) -
[who killed mysql?](/geek/who-killed-mysql/) -
[to vi or not to vi](/geek/to-vi-or-not-to-vi/) -
[brothers conflict (at linux kernel)](/geek/brothers-conflict/) -
[introducing the oom killer](/geek/oom-killer/) -
[how i met your mother](/geek/how-i-met-your-mother/) -
[bash on windows](/geek/bash-on-windows/) -
[ubuntu updates](/geek/ubuntu-updates/) -
[sql server on linux part 2](/geek/sql-server-on-linux-2/) -
[the real reason to not use sigkill](/geek/dont-sigkill/) -
[sql server on linux](/geek/sql-server-on-linux/) -
[i love windows powershell](/geek/love-powershell/) -
[linux master hero](/geek/linux-master-hero/) |
10,361 | 使用 lolcat 为你的 Linux 终端带来彩虹 | https://opensource.com/article/18/12/linux-toy-lolcat | 2018-12-18T16:03:47 | [
"颜色",
"彩虹"
] | https://linux.cn/article-10361-1.html |
>
> 使用这个简单的工具,你可以为所需的任何程序的输出变成七彩。
>
>
>

今天是 Linux 命令行玩具日历的第五天。如果这是你第一次访问该系列,你可能会问自己,什么是命令行玩具。即使我不太确定,但一般来说,它可能是一个游戏,或任何简单的可以帮助你在终端玩得开心的东西。
很可能你们中的一些人之前已经看过我们日历中的各种玩具,但我们希望每个人至少见到一件新事物。
今日的选择,`lolcat`,是我选择的第一个没有在我的 Linux 发行版中打包的程序,但它安装仍然很简单。它是一个 Ruby 程序,你应该可以使用下面的命令轻松地添加到系统中。
```
$ gem install lolcat
```
之后,只需将一些文本传送给它,就可以看到彩色的输出。例如,尝试几个之前在我们的日历中出现的程序,使用以下命令:
```
$ fortune | boxes -a c -d parchment | lolcat
```
根据你的运气,你可能会看到这样:

你可以传递给 `lolcat` 一些参数。这里不再赘述,我建议你访问 `lolcat` 的 [GitHub 页面](https://github.com/busyloop/lolcat) 或者在终端输入 `lolcat --help` 了解。但一般来说,它们能设置彩虹的传递和频率,以及我个人最喜欢的动画。谁不喜欢终端的彩色动画输出呢?让我们再试一次,用一个不同的边框(当然是以猫为主题)和一句在我的格言列表中的适合猫的句子。
```
fortune -m "nine tails" | boxes -a c -d cat | lolcat -a
```

`lolcat` 是一个 BSD 许可下的开源软件。
你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。如果你有特别想了解的可以评论留言,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
了解一下昨天的玩具,[在 Linux 命令行中拥有一头牛](https://opensource.com/article/18/12/linux-toy-cowsay),还有记得明天再来!
---
via: <https://opensource.com/article/18/12/linux-toy-lolcat>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Today marks the fifth day of the Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself, what’s a command-line toy. Even I'm not quite sure, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
It's quite possible that some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
Today's selection, **lolcat**, is the first utility I'm including that wasn't packaged for my Linux distribution, but it was still an easy install. It's a Ruby program that you ought to be able to easily add to your system with the following.
`$ gem install lolcat`
After that, simply pipe some text to it to see the output in the colors of the rainbow. For example, using a couple of utilities from earlier days in our advent calendar, try the following:
`$ fortune | boxes -a c -d parchment | lolcat`
Depending on what good fortune you have, you'll likely get something like this:

There are a few parameters you can pass to **lolcat**, and rather than repeat them all here, I'd suggest you either visit the** lolcat **[GitHub page](https://github.com/busyloop/lolcat) or just see them at the terminal by typing **lolcat --help**. But generally, they're helpful to set the spread and frequency of your rainbow, and my personal favorite, enabling animation. Who doesn't like animated rainbow printing at the terminal? Let's try the above again, with a different box (cat-themed, of course) and a cat-appropriate fortune that was in my fortunes list, with the following.
`fortune -m "nine tails" | boxes -a c -d cat | lolcat -a`

**lolcat** is open source under a BSD license.
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Check out yesterday's toy, [Have a cow at the Linux command line](https://opensource.com/article/18/12/linux-toy-cowsay), and check back tomorrow for another!
## Comments are closed. |
10,362 | 搜索 Linux 中的文件和文件夹的四种简单方法 | https://www.2daygeek.com/four-easy-ways-to-search-or-find-files-and-folders-in-linux/ | 2018-12-18T23:23:56 | [
"find",
"搜索"
] | https://linux.cn/article-10362-1.html | 
Linux 管理员一天都不能离开搜索文件,因为这是他们的日常活动。了解一些搜索的东西是不错的,因为这能帮助你在命令行服务器中工作。这些命令记忆起来不复杂,因为它们使用的是标准语法。
可以通过四个 Linux 命令啦执行此操作,每个命令都有自己独特的功能。
### 方法 1:使用 find 命令在 Linux 中搜索文件和文件夹
`find` 命令被广泛使用,并且是在 Linux 中搜索文件和文件夹的著名命令。它搜索当前目录中的给定文件,并根据搜索条件递归遍历其子目录。
它允许用户根据大小、名称、所有者、组、类型、权限、日期和其他条件执行所有类型的文件搜索。
运行以下命令以在系统中查找给定文件。
```
# find / -iname "sshd_config"
/etc/ssh/sshd_config
```
运行以下命令以查找系统中的给定文件夹。要在 Linux 中搜索文件夹,我们需要使用 `-type` 参数。
```
# find / -type d -iname "ssh"
/usr/lib/ssh
/usr/lib/go/src/cmd/vendor/golang.org/x/crypto/ssh
/usr/lib/go/pkg/linux_amd64/cmd/vendor/golang.org/x/crypto/ssh
/etc/ssh
```
使用通配符搜索系统上的所有文件。我们将搜索系统中所有以 `.config` 为扩展名的文件。
```
# find / -name "*.config"
/usr/lib/mono/gac/avahi-sharp/1.0.0.0__4d116c78973743f5/avahi-sharp.dll.config
/usr/lib/mono/gac/avahi-ui-sharp/0.0.0.0__4d116c78973743f5/avahi-ui-sharp.dll.config
/usr/lib/python2.7/config/Setup.config
/usr/share/git/mw-to-git/t/test.config
/var/lib/lightdm/.config
/home/daygeek/.config
/root/.config
/etc/skel/.config
```
使用以下命令格式在系统中查找空文件和文件夹。
```
# find / -empty
```
使用以下命令组合查找 Linux 上包含特定文本的所有文件。
```
# find / -type f -exec grep "Port 22" '{}' \; -print
# find / -type f -print | xargs grep "Port 22"
# find / -type f | xargs grep 'Port 22'
# find / -type f -exec grep -H 'Port 22' {} \;
```
### 方法 2:使用 locate 命令在 Linux 中搜索文件和文件夹
`locate` 命令比 `find` 命令运行得更快,因为它使用 `updatedb` 数据库,而 `find` 命令在真实系统中搜索。
它使用数据库而不是搜索单个目录路径来获取给定文件。
`locate` 命令未在大多数发行版中预安装,因此,请使用你的包管理器进行安装。
数据库通过 cron 任务定期更新,但我们可以通过运行以下命令手动更新它。
```
$ sudo updatedb
```
只需运行以下命令即可列出给定的文件或文件夹。在 `locate` 命令中不需要指定特定选项来打印文件或文件夹。
在系统中搜索 `ssh` 文件夹。
```
# locate --basename '\ssh'
/etc/ssh
/usr/bin/ssh
/usr/lib/ssh
/usr/lib/go/pkg/linux_amd64/cmd/vendor/golang.org/x/crypto/ssh
/usr/lib/go/src/cmd/go/testdata/failssh/ssh
/usr/lib/go/src/cmd/vendor/golang.org/x/crypto/ssh
```
在系统中搜索 `ssh_config` 文件。
```
# locate --basename '\sshd_config'
/etc/ssh/sshd_config
```
### 方法 3:在 Linux 中搜索文件使用 which 命令
`which` 返回在终端输入命令时执行的可执行文件的完整路径。
当你想要为可执行文件创建桌面快捷方式或符号链接时,它非常有用。
`which` 命令搜索当前用户而不是所有用户的 `$PATH` 环境变量中列出的目录。我的意思是,当你登录自己的帐户时,你无法搜索 root 用户文件或目录。
运行以下命令以打印 `vim` 可执行文件的完整路径。
```
# which vi
/usr/bin/vi
```
或者,它允许用户一次执行多个文件搜索。
```
# which -a vi sudo
/usr/bin/vi
/bin/vi
/usr/bin/sudo
/bin/sudo
```
### 方法 4:使用 whereis 命令在 Linux 中搜索文件
`whereis` 命令用于搜索给定命令的二进制、源码和手册页文件。
```
# whereis vi
vi: /usr/bin/vi /usr/share/man/man1/vi.1p.gz /usr/share/man/man1/vi.1.gz
```
---
via: <https://www.2daygeek.com/four-easy-ways-to-search-or-find-files-and-folders-in-linux/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,363 | 迁移到 Linux:网络和系统设置 | https://www.linux.com/blog/learn/2018/4/migrating-linux-network-and-system-settings | 2018-12-19T00:44:19 | [
"迁移"
] | https://linux.cn/article-10363-1.html |
>
> 这个系列我们提供了基础知识的概述,以帮助您成功地从另一个操作系统过渡到 Linux;这篇中我们涉及到 Linux 桌面系统上的一些常见设置。
>
>
>

在这个系列中,我们提供了基础知识的概述,以帮助您成功地从另一个操作系统过渡到 Linux。如果你错过了以前的文章,可以从这访问:
* [第1部分 - 入门介绍](/article-9212-1.html)
* [第2部分 - 磁盘、文件和文件系统](/article-9213-1.html)
* [第3部分 - 图形操作环境](/article-9293-1.html)
* [第4部分 - 命令行](/article-9565-1.html)
* [第5部分 - 使用 sudo](/article-9819-1.html)
* [第5部分 - 安装软件](/article-9823-1.html)
Linux 提供了一系列网络和系统设置。在你的桌面计算机上,Linux 允许您调整系统上的任何内容。大多数这些设置都出现在 `/etc` 目录下的纯文本文件中。这里我将介绍你使用桌面 Linux 操作系统的过程中最常用的设置。
大多数设置都能够在“设置”程序里面找到,这些设置可能对于不同的 Linux 发行版有所不同。通常来说,你可以修改背景、调整音量、连接打印机、进行显示设置等。对于这些设置尽管我不会全部谈论,但你可以自己探索。
### 连接互联网
在 Linux 中连接到互联网通常非常简单。如果您通过以太网电缆连接,Linux 通常会在插入电缆时或启动时(如果电缆已连接)获得 IP 地址并自动连接。
如果您使用无线网络,则在大多数发行版中都有一个菜单,可以在指示器面板中或在“设置”中(取决于您的发行版),您可以在其中选择无线网络的 SSID。如果网络受密码保护,它通常会提示您输入密码。然后连接,这个过程相当顺利。
在图形界面您可以通过进入设置来调整网络设置。通常称为“系统设置”或者是“设置”。通常可以轻松找到设置程序,因为它的图标是齿轮或工具图片(图1)。

*图1: Gnome 桌面网络设置指示器图标。*
### 网络接口名称
在 Linux 下,网络设备有名称。 从历史上看,它们的名称分别为 eth0 和 wlan0 —— 或“以太网”和“无线网络”。 较新的 Linux 系统一直使用看起来更深奥的不同名称,如 enp4s0 和 wlp5s0 。 如果名称以 en 开头,则它是有线以太网接口。 如果它以 wl 开头,那么它就是一个无线接口。 其余的字母和数字反映了设备如何连接到硬件。
### 通过命令行进行网络管理
如果您希望更好地控制网络设置,或者如果您在没有图形桌面的情况下管理网络连接,则还可以从命令行管理网络。
请注意,用于在图形桌面中管理网络的最常用服务是“<ruby> 网络管理器 <rt> Network Manager </rt></ruby>”,而网络管理器通常会覆盖在命令行上进行的设置更改。如果您正在使用网络管理器,最好在其界面中更改您的设置,以防止撤消您从命令行或其他位置所做的更改。
在图形环境中的更改设置与在网络管理器中很类似,您还可以使用名为 `nmtui` 的工具从命令行更改网络管理器设置。`nmtui` 工具提供了您在图形环境中找到的所有设置,但是是在基于文本的半图形界面中提供了该设置,该界面可在命令行上运行(图 2)。

*图 2:nmtui 界面*
在命令行上,有一个名为 `ifconfig` 的旧工具来管理网络,还有一个名为 `ip` 的新工具。在某些发行版中,`ifconfig` 被认为是不推荐使用的,默认情况下甚至没有安装。在其他发行版上,`ifconfig` 仍可以使用。
以下是一些允许您显示和更改网络设置的命令:

### 进程和系统信息
在 Windows 系统中,你可以使用任务管理器来查看所有正在运行的程序和服务的列表。你可以停止运行中的程序,并且可以在其中显示的某些选项卡中查看系统性能。
在 Linux 系统下你可以使用命令行或者图形界面中做同样的事情。Linux 系统中根据你的发行版本会有不同的几个可用的图形工具。大多数所共有的工具是“系统监视器”和 KSysGuard。在这些工具中,你可以查看系统性能,查看进程列表甚至是杀死进程(图 3)。

*图 3:NetHogs 截图*
在这些工具中,你也可以查看系统全局网络流量(图 4)。

*图 4:Gnome System Monitor 的截图*
### 管理进程和系统使用
您还可以从命令行使用相当多的工具。使用 `ps` 命令可以查看系统中的进程列表。默认情况下,这个命令的结果是显示当前终端会话下的所有进程列表。但是你也可以通过使用各种命令行参数显示其他进程。如果 `ps` 命令不会使用,可以使用命令 `info ps` 或者 `man ps` 获取帮助。
大多数人都希望得到一个进程列表,因为他们想要停止占用过多内存或 CPU 时间的进程。这种情况下有两个非常简单的命令,分别是 `top` 和 `htop` 命令(图 5)。

*图 5:top 截屏*
`top` 和 `htop` 工具使用效果非常相似。两个命令每秒或者两秒会更新重新排序,这样会把占用 CPU 资源最多的放置在列表顶部。你也可以根据其他资源的使用情况比如内存使用情况来排序。
使用这两个命令时(`top` 和 `htop`),你可以输入 `?` 来获取使用帮助,输入 `q` 来退出程序。使用 `top` 命令你可以按 `k` 键然后输入进程 ID 来杀死某个进程。
使用 `htop` 命令时你可以使用 `↑` `↓` 键来将列表中的一条记录进行高亮显示,按下 `F9` 键会杀死进程(需要回车确认)。
本系列中提供的信息和工具将帮助您开始使用 Linux。 只需一点时间和耐心,您就会感到这非常舒服。
想学习更多 Linux 内容可访问免费的 [Linux 简介](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)课程,此课程来自 Linux 基金会和 edx。
---
via: <https://www.linux.com/blog/learn/2018/4/migrating-linux-network-and-system-settings>
作者:[John Bonesio](https://www.linux.com/users/johnbonesio) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ScarboroughCoral](https://github.com/ScarboroughCoral) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,364 | 认识存储:块、文件和对象 | https://www.linux.com/blog/2018/9/know-your-storage-block-file-object | 2018-12-19T15:45:17 | [
"存储"
] | https://linux.cn/article-10364-1.html |
>
> 今天产生的大量数据带来了新的存储挑战。在本文中了解各种存储类型以及它们的使用方式。
>
>
>

现在,对于那些创建或消费数据的公司来说,处理数量巨大的生成数据是个非常大的挑战。而对于那些解决存储相关问题的科技公司来说,也是一个挑战。
Red Hat 存储首席产品营销经理 Michael St. Jean 说,“数据每年呈几何级增长,而我们发现数据大量增长的主要原因是由于消费增长和为拓展价值而进行的产业转型,毫无疑问,物联网对数据增长的贡献很大,但对软件定义存储来说最重要的挑战是,如何处理用户场景相关的数据增长。“
任何挑战都意味着机遇。Azure 存储、介质和边缘计算总经理 Tad Brockway 说,“今天,新旧数据源产生的海量数据为我们满足客户在规模、性能、灵活性、治理方面急剧增长的需求提供了一个机遇。”
### 现代软件定义存储的三种类型
这里有三个不同类型的存储解决方案 —— 块、文件、和对象 —— 虽然它们每个都可以与其它的共同工作,但它们每个都有不同的用途。
块存储是数据存储的最古老形式,数据都存储在固定长度的块或多个块中。块存储适用于企业存储环境,并且通常使用光纤通道或 iSCSI 接口。根据 SUSE 的软件定义存储高级产品经理 Larry Morris 的说法,“块存储要求一个应用去映射存储设备上存储数据块的位置。”
块存储在存储区域网和软件定义存储系统中是虚拟的,它是处于一个共享的硬件基础设施上的抽象逻辑设备,其创建和存在于服务器、虚拟服务器、或运行在基于像 SCSI、SATA、SAS、FCP、FCoE、或 iSCSI 这样的协议的系统管理程序上。
St. Jean 说“块存储将单个的存储卷(如一个虚拟或云存储节点、或一个老式硬盘)分割成单独的被称为块的实体。”
每个块独立存在,并且能够用它自己的数据传输协议和操作系统格式化 —— 给用户完全的配置自主权。由于块存储系统并不负责像文件存储系统那样的文件查找职责,所以,块存储是一个非常快的存储系统。由于同时具备速度和配置灵活性,使得块存储非常适合原始服务器存储或富媒体数据库。
块存储适合于宿主机操作系统、应用程序、数据库、完整虚拟机和容器。传统上,块存储仅能够被独立的机器访问,或呈现给集群中的机器访问。
### 基于文件的存储
基于文件的存储使用一个文件系统去映射存储设备上数据的存储位置。这种技术在直连或网络附加存储系统应用领域中处于支配地位。它需要做两件事情:组织数据并呈现给用户。St. Jean 说,”使用文件存储时,数据在服务器侧的存储方式与客户端用户所看到的是完全相同的。这就允许用户通过一些唯一标识符(像文件名、位置、或 URL)去请求一个文件,使用特定的数据传输协议与存储系统沟通。
其结果就是一种能够从上到下进行浏览的分层的文件结构。文件存储处于块存储之上,允许用户去查看和访问文件、文件夹这样的数据,但是被限制访问处于这些文件和文件夹之下的数据块。
Brockway 解释说,“文件存储一般用于像 NFS 和 CIFS/SMB 这种很多服务器基于 IP 网络进行访问的共享文件系统上。访问控制通过用户和组的权限实现在文件、目录和导出级别上。基于文件的存储可用于被多个用户和机器、二进制应用程序、数据库、虚拟机所需要的文件的存储上,以及容器上。“
### 对象存储
对象存储是最新的数据存储形式,它为非结构化数据提供一个仓库,它将内容从索引中分离出来,并允许多个文件连接到一个对象上。一个对象就是与任何相关元数据配对的一个数据块,这些元数据提供对象中包含的字节的上下文(比如数据创建时间和数据大小等)。也就是说这两样东西 —— 数据和元数据 —— 构成了一个对象。
对象存储的一个好处是每个数据块都关联了一个唯一标识符。访问数据需要唯一标识符,并且不需要应用程序或用户知道数据的真实存储位置。对象数据是通过 API 来访问的。
St. Jean 说,“对象中存储的数据是没有压缩和加密的,对象本身被组织在对象存储(一个填满其它对象的中心库)中或容器(包含应用程序运行所需要的所有文件的一个包)中。与文件存储系统的层次结构相比,对象、对象存储和容器在本质上是平面的 —— 这使得它们在存储规模巨大时访问速度很快。”
对象存储可以扩展到很多 PB 字节大小,以适应巨大的数据集,因此它是图像、音频、视频、日志、备份、和分析服务所使用的数据存储的最佳选择。
### 结论
现在你已经知道了各种类型的存储以及它们的用处。后面我们将继续研究这个主题的更多内容,敬请关注。
---
via: <https://www.linux.com/blog/2018/9/know-your-storage-block-file-object>
作者:[Swapnil Bhartiya](https://www.linux.com/users/arnieswap) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,365 | SMPlayer:增强版的媒体播放器 | https://itsfoss.com/smplayer/ | 2018-12-19T17:44:55 | [
"媒体播放器"
] | https://linux.cn/article-10365-1.html | 
当你要播放视频时,你会在[全新安装的 Ubuntu](https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/),或其他许多发行版中,会注意到一个消息:

*默认媒体播放器没有适合的编解码器*
这意味着系统上没有安装播放媒体的[所需编解码器](https://packages.ubuntu.com/trusty/ubuntu-restricted-extras)。现在,由于某些版权问题,某些基于 Linux 的操作系统无法在安装介质中预先打包编解码器。但是它们能让你只需点击即可下载和安装编解码器,或者你可以安装拥有所有媒体编解码器的媒体播放器。让我们了解一下 [SMPlayer](https://www.smplayer.info/)。
### 认识 SMPlayer:适用于 Linux 的更好的媒体播放器
SMPlayer 是一款自由开源媒体播放器,它基于强大的 [MPlayer](http://www.mplayerhq.hu/design7/news.html) 媒体引擎。SMPlayer 能够播放 avi、mp4、mkv、mpeg、mov、divx、h.264 以及其他任何主要媒体格式。锦上添花的是,它也可以播放 [YouTube](https://www.youtube.com/) 视频,并且无广告。
SMPlayer 是一个完整的媒体解决方案。它是跨平台的,因此可在所有操作系统上使用。如果你是双启动系统,则可以将其安装在 Windows 和 Linux 操作系统上,以便在两个系统上获得统一的体验。它还支持带触摸的可变形笔记本。
你也可以在 SMPlayer 上播放 YouTube。我知道每次复制粘贴视频 URL 并在外部播放器上播放是不切实际的。但是当你观看相对较长的视频时,SMPlayer 特别有用。SMPlayer 以相当好的质量播放 YouTube 视频,我觉得比在浏览器中播放得更好。通过在 SMPlayer 上播放较长的视频,你可以远离视频中间弹出的插播广告。
如果你在观看没有字幕的电影,你可以直接通过 SMPlayer 下载字幕。它集成了 [opensubtitles.org](https://www.opensubtitles.org/en/search)。所以,打开浏览器,搜索字幕,下载相应的字幕,解压缩,将它们放在视频文件夹中并将字幕连接到电影,这些都不需要!SMPlayer 会为你服务。

SMPlayer 支持 30 多种语言,并可高度自定义。它还有应用主题和大量的图标集。
如果你觉得 SMPlayer 的默认界面看起来不太好,只需点击几下,它就可以看起来像这样:

SMPlayer 为高级用户提供了许多工具和功能。它有均衡器、视频速度控制、宽高比和缩放控制、视频过滤器、屏幕截图等等。
总而言之,我真的很喜欢 SMPlayer。它在一个小巧轻量级的安装包中提供了很多功能。我认为它是 Linux PC 上必备的视频播放器。除了轻松播放所有媒体格式外,它还提供了大量的控制。
### 在 Linux 上安装 SMPlayer
SMPlayer 应该可在所有主要 Linux 发行版的软件中心获取。你可以搜索它并从那里安装它。
在 Ubuntu/ Linux Mint/ Elementary OS 上,你还可以通过在终端中运行以下命令来安装 SMPlayer
```
sudo apt install smplayer
```
或者,你可以在[这里](https://software.opensuse.org/download.html?project=home%3Asmplayerdev&package=smplayer)下载 Fedora、Arch Linux、OpenSUSE 和 Debian 的软件包。
### 总结
有很多像 VLC 媒体播放器那样成熟的播放器。SMPlayer 是拥有完整功能和插件优势的最佳产品之一。我认为它是[必备 Linux 应用](https://itsfoss.com/essential-linux-applications/)之一。
请尝试一下并在下面的评论栏与我们分享你的想法。
---
via: <https://itsfoss.com/smplayer/>
作者:[Aquil Roshan;Abhishek Prakash](https://itsfoss.com/author/aquil/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the [things you’ll notice after a fresh install of Ubuntu](https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/), or pretty much any other Linux distribution, is this message when you try to play certain video files.
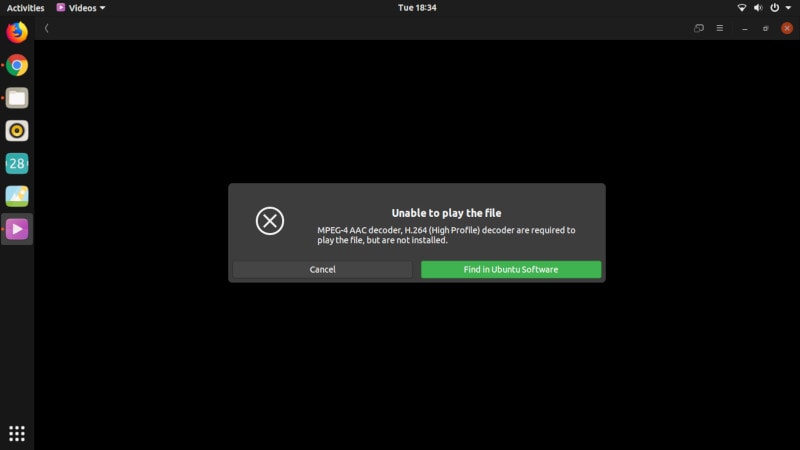
It means that the [codecs needed ](https://packages.ubuntu.com/trusty/ubuntu-restricted-extras)to play the media are not installed on the system. Now, due to some copyright issues, some Linux based operating systems cannot pre-pack the codecs in the installation media. But they do allow you to download and [install the codecs with just a click](https://itsfoss.com/install-media-codecs-ubuntu/), or you could just install a media player which has all the multimedia codecs, to begin with. Checkout [SMPlayer](https://www.smplayer.info/).
## Meet SMPlayer: A Better Media Player for Linux
SMPlayer is a free and open-source media player built on the powerful [MPlayer](http://www.mplayerhq.hu/design7/news.html) media engine. SMPlayer is capable of playing [YouTube](https://www.youtube.com/) videos too, ad-free.
SMPlayer is a complete media solution. It is cross-platform, so available on all the operating systems. If you have a dual boot, you can install it on your Windows and Linux OS to get a uniform experience on both the systems. It also supports convertible laptops with touch support.
You can play YouTube on SMPlayer too. I know it’s impractical to copy-paste the video URL and play on an external player every time. But SMPlayer is particularly useful when you are watching comparatively lengthy videos. SMPlayer plays YouTube videos in a very good quality and I felt the videos play out much better than the in-browser videos. And by playing the lengthier videos on SMPlayer, you can stay clear of the mid-roll ads that pop up on the lengthier videos.
If you’re watching a movie which doesn’t have subtitles, You can directly download the subtitles through SMPlayer. It comes with [opensubtitles.org](https://www.opensubtitles.org/en/search) integration. So none of that, open the browser, search for subtitles, download the appropriate ones, unzip, place them in the video folder and connect the subtitles to the movie. No Sir! SMPlayer at your service.
SMPlayer is available in more than 30 languages and it is highly customizable. It has both applications theming and a ton of icon sets in it.
If you feel that the default interface of SMPlayer doesn’t look good, in a few clicks you can make it look like this:
SMPlayer comes with a lot of tools and features for the power users. It has an equalizer, video speed controls, aspect ratio and zoom controls, video filters, screenshot ripping and lot more.
All in all, I really liked SMPlayer. It has a lot to offer in a small and lightweight package. I think it is a must have video player on your Linux PC. Along with playing all the media formats easily it also provides a ton of power controls.
## Installing SMPlayer on Linux
SMPlayer should be available in the software center of all major Linux distributions. You can search for it and install it from there itself.
On Ubuntu/ Linux Mint/ Elementary OS, you can also install SMPlayer by running the following command in the terminal
sudo apt install smplayer
Alternatively, you can download the package for Fedora, Arch Linux, OpenSUSE and Debian [here.](https://software.opensuse.org/download.html?project=home%3Asmplayerdev&package=smplayer)
## Wrapping Up
There are a good number of full-fledged media players out there like the VLC media player. SMPlayer is one of the [best video players for Linux](https://itsfoss.com/video-players-linux/) with a full functionality and great add-on benefits. I’ll consider it one of the [must-have applications for Linux](https://itsfoss.com/essential-linux-applications/).
Do give it a try and share your thoughts with us in the comments section below. |
10,366 | 极客漫画:聊天机器人 | http://turnoff.us/geek/chatbot/ | 2018-12-19T18:27:50 | [
"漫画",
"聊天机器人"
] | https://linux.cn/article-10366-1.html | 
现在聊天机器人技术使用的越来越多了,无论是 Slack 机器人还是 QQ 机器人,甚至还有图灵式的,比如 Siri、微软小冰。很多时候,群里面突然跑来一个机器人,那笨拙而无聊的话术,让人看了令人发噱。有时候,昨天我朋友表示,他的机器人被另外一个机器人搭讪了,然后由于本方的机器人太笨,对方色诱失败,哈哈。
前段时间听说,现在你接到的广告电话都不是人打的了,是自动语音机器人程序了 —— 而在几年前,国外就有一个人开发了一个语音对答机器人,以一个老人的角色和无数的电话销售人员(真人)聊得十分投入,有人到最后也没发现对方是个对答机器人。
所以,对面和你聊天的甚至不是一条狗,而是一段代码。
---
via: <http://turnoff.us/geek/chatbot/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者&点评:[wxy](https://github.com/wxy) 校对&合成:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,367 | 如何不重装修复损坏的 Ubuntu 系统 | https://www.ostechnix.com/how-to-fix-broken-ubuntu-os-without-reinstalling-it/ | 2018-12-20T22:14:02 | [
"Ubuntu"
] | https://linux.cn/article-10367-1.html | 
今天,我在升级我的 Ubuntu 18.04 LTS 系统。不幸的是,在更新 Ubuntu 时中途断电,系统关机。电源恢复后,我再次启动系统。在登录页面输入密码后,它变成空白并且没有响应。键盘和鼠标也没有作用。我只看到一个空白的屏幕!值得庆幸的是,它只是一台测试机,并且没有重要的数据。我可以直接擦除整个系统然后重新安装。但是,我不想这样做。由于我没有什么可失去的,我只是想不重装修复我损坏的 Ubuntu 系统,并且我成功了!如果你发现自己处于像我这样的境地,不要惊慌。这个简短的教程描述了如何在不丢失数据的情况下轻松修复损坏的 Ubuntu 系统,而无需重新安装。
### 修复损坏的 Ubuntu 系统
首先,尝试使用 live cd 登录并**在外部驱动器中备份数据**。以防这个方法没用,你仍然可以获取数据并重新安装系统!
在登录页上,按下 `CTRL+ALT+F1` 切换到 tty1。你可以在[此处](https://www.ostechnix.com/how-to-switch-between-ttys-without-using-function-keys-in-linux/)了解有关在 TTY 之间切换的更多信息。
现在,逐个输入以下命令来修复损坏的 Ubuntu Linux。
```
$ sudo rm /var/lib/apt/lists/lock
$ sudo rm /var/lib/dpkg/lock
$ sudo rm /var/lib/dpkg/lock-frontend
$ sudo dpkg --configure -a
$ sudo apt clean
$ sudo apt update --fix-missing
$ sudo apt install -f
$ sudo dpkg --configure -a
$ sudo apt upgrade
$ sudo apt dist-upgrade
```
最后,使用命令重启系统:
```
$ sudo reboot
```
你现在可以像往常一样登录到你的 Ubuntu 系统。
我做完这些步骤后,我 Ubuntu 18.04 测试系统中的所有数据都还在,一切都之前的一样。此方法可能不适用于所有人。但是,这个小小的技巧对我有用,并且比重装节省了一些时间。如果你了解其他更好的方法,请在评论区告诉我。我也会在本指南中添加它们。
这是这些了。希望这篇文章有用。
还有更多好东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-fix-broken-ubuntu-os-without-reinstalling-it/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,368 | 在命令行中步入黑客帝国 | https://opensource.com/article/18/12/linux-toy-cmatrix | 2018-12-20T22:25:05 | [
"黑客帝国"
] | https://linux.cn/article-10368-1.html |
>
> 使用 cmatrix 重建每个人都喜欢的 20 世纪 90 年代科幻电影中滚动代码的经典外观。
>
>
>

这是今天的命令行玩具日历推荐项目。如果这是你第一次访问该系列,你可能想知道什么是命令行玩具?它可以是在命令行中任何可以娱乐的东西,可以是一个游戏,一个有趣的工具,或者一个消遣的东西。
其中一些是经典,有些是全新的(至少对我而言),但我希望你们所有人都能在这个系列中找到你喜欢的东西。
在我们在接近下一年的时候,现在是回顾和期待的好时机。2019 年会为你带来什么?2019 年意味着什么?
我想起 2019 年将是我青少年时期最喜欢的科幻电影之一[黑客帝国](https://en.wikipedia.org/wiki/The_Matrix)的二十周年纪念日,它当时让我思考了未来将会发生什么。对于像我这样的痴迷计算机小孩来说,这是一个电脑程序员通过利用自己思维的力量崛起并成为虚拟宇宙中的动作英雄的终极故事。
当时,对我来说没有比这部电影更具未来感了。无论是故事本身,还是迷人的特效。即使意识到它是在二十多年前拍摄的也并没有改变我的想法。
今天将它带回我们的命令行玩具,让我们在终端用 `cmatrix` 重建黑客帝国中那向下滚动的代码流。 `cmatrix` 很容易安装,它在 Fedora 中被打包了,所以安装它只需:
```
$ dnf install cmatrix
```
接着,只需在你的终端输入 `cmatrix` 即可运行。

你可以在 [GitHub](https://github.com/abishekvashok/cmatrix) 上找到使用 GPL 许可的 `cmatrix` 的源代码。
你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。评论留言让我知道,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
了解一下昨天的玩具,[在 Linux 中让 Bash 提示符变得像冬天](https://github.com/abishekvashok/cmatrix),还有记得明天再来!
---
via: <https://opensource.com/article/18/12/linux-toy-cmatrix>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You've found your way to today's entry from the Linux command-line toys advent calendar. If this is your first visit to the series, you might be wondering what a command-line toy even is? It's anything that's an entertaining diversion at the terminal, be it a game, a fun utility, or a simple distraction.
Some of these are classics, and some are completely new (at least to me), but I hope all of you find something you enjoy in this series.
As we come to the close of another year, it's a good time for looking back, and looking forward. What will 2019 hold for you? What does it mean to be 2019?
I'm reminded that 2019 will mark the twentieth anniversary of one of my favorite science fiction movies from my teenage years, that at the time had me thinking a lot about what the future would hold: [The Matrix](https://en.wikipedia.org/wiki/The_Matrix). For a computer nerd kid like me, it was the ultimate story of a computer programmer rising up and becoming an action hero in a virtual universe by tapping into the power of his mind.
At the time, there was no movie that seemed more futuristic to me; both in the story itself, and in the mesmerizing special effects. Realizing that it was filmed over twenty years ago doesn't change that in my mind.
Bringing it back to our command-line toy for today, let's recreate the downward flowing code of the Matrix at our terminal with **cmatrix**. **cmatrix** was an easy install for me, packaged for Fedora, so installing it took simply:
`$ dnf install cmatrix`
Then, just type **cmatrix**** **at your terminal to run.
You can find the source code for** ****cmatrix** [on GitHub](https://github.com/abishekvashok/cmatrix) under a GPL license.
Do you have a favorite command-line toy that you think I ought to include? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Check out yesterday's toy, [Winterize your Bash prompt in Linux](https://opensource.com/article/18/12/linux-toy-bash-prompt), and check back tomorrow for another!
## 8 Comments |
10,369 | 我的个人电子邮件系统设置:notmuch、mbsync、Postfix 和 dovecot | https://copyninja.info/blog/email_setup.html | 2018-12-21T07:12:41 | [
"邮件服务",
"邮件"
] | https://linux.cn/article-10369-1.html | 
我使用个人电子邮件系统已经相当长的时间了,但是一直没有记录过文档。最近我换了我的笔记本电脑(职业变更导致的变动),我在试图重新创建本地邮件系统时迷茫了。所以这篇文章是一个给自己看的文档,这样我不用费劲就能再次搭建出来。
### 服务器端
我运行自己的邮件服务器,并使用 Postfix 作为 SMTP 服务器,用 Dovecot 实现 IMAP。我不打算详细介绍如何配置这些设置,因为我的设置主要是通过使用 Jonas 为 Redpill 基础架构创建的脚本完成的。什么是 Redpill?(用 Jonas 自己的话说):
>
> <jonas> Redpill 是一个概念:一种设置 Debian hosts 去跨组织协作的方式
>
>
> <jonas> 我发展了这个概念,并将其首次用于 Redpill 网中网:redpill.dk,其中涉及到了我自己的网络(jones.dk),我的主要客户的网络(homebase.dk),一个包括 Skolelinux Germany(free-owl.de)的在德国的网络,和 Vasudev 的网络(copyninja.info)
>
>
>
除此之外, 我还有一个 dovecot sieve 过滤,根据邮件的来源,对邮件进行高级分类,将其放到各种文件夹中。所有的规则都存在于每个有邮件地址的账户下的 `~/dovecot.sieve` 文件中。
再次,我不会详细介绍如何设置这些东西,因为这不是我这个帖子的目标。
### 在我的笔记本电脑上
在我的笔记本电脑上,我已经按照 4 个部分设置
1. 邮件同步:使用 `mbsync` 命令完成
2. 分类:使用 notmuch 完成
3. 阅读:使用 notmuch-emacs 完成
4. 邮件发送:使用作为中继服务器和 SMTP 客户端运行的 Postfix 完成。
### 邮件同步
邮件同步是使用 `mbsync` 工具完成的, 我以前是 OfflineIMAP 的用户,最近切换到 `mbsync`,因为我觉得它比 OfflineIMAP 的配置更轻量、更简单。该命令是由 isync 包提供的。
配置文件是 `~/.mbsyncrc`。下面是我的例子与一些个人设置。
```
IMAPAccount copyninja
Host imap.copyninja.info
User vasudev
PassCmd "gpg -q --for-your-eyes-only --no-tty --exit-on-status-write-error --batch --passphrase-file ~/path/to/passphrase.txt -d ~/path/to/mailpass.gpg"
SSLType IMAPS
SSLVersion TLSv1.2
CertificateFile /etc/ssl/certs/ca-certificates.crt
IMAPAccount gmail-kamathvasudev
Host imap.gmail.com
User [email protected]
PassCmd "gpg -q --for-your-eyes-only --no-tty --exit-on-status-write-error --batch --passphrase-file ~/path/to/passphrase.txt -d ~/path/to/mailpass.gpg"
SSLType IMAPS
SSLVersion TLSv1.2
CertificateFile /etc/ssl/certs/ca-certificates.crt
IMAPStore copyninja-remote
Account copyninja
IMAPStore gmail-kamathvasudev-remote
Account gmail-kamathvasudev
MaildirStore copyninja-local
Path ~/Mail/vasudev-copyninja.info/
Inbox ~/Mail/vasudev-copyninja.info/INBOX
MaildirStore gmail-kamathvasudev-local
Path ~/Mail/Gmail-1/
Inbox ~/Mail/Gmail-1/INBOX
Channel copyninja
Master :copyninja-remote:
Slave :copyninja-local:
Patterns *
Create Both
SyncState *
Sync All
Channel gmail-kamathvasudev
Master :gmail-kamathvasudev-remote:
Slave :gmail-kamathvasudev-local:
# Exclude everything under the internal [Gmail] folder, except the interesting folders
Patterns * ![Gmail]*
Create Both
SyncState *
Sync All
```
对上述配置中的一些有趣部分进行一下说明。一个是 PassCmd,它允许你提供 shell 命令来获取帐户的密码。这样可以避免在配置文件中填写密码。我使用 gpg 的对称加密,并在我的磁盘上存储密码。这当然是由 Unix ACL 保护安全的。
实际上,我想使用我的公钥来加密文件,但当脚本在后台或通过 systemd 运行时,解锁文件看起来很困难 (或者说几乎不可能)。如果你有更好的建议,我洗耳恭听:-)。
下一个指令部分是 Patterns。这使你可以有选择地同步来自邮件服务器的邮件。这对我来说真的很有帮助,可以排除所有的 “[Gmail]/ folders” 垃圾目录。
### 邮件分类
一旦邮件到达你的本地设备,我们需要一种方法来轻松地在邮件读取器中读取邮件。我最初的设置使用本地 dovecot 实例提供同步的 Maildir,并在 Gnus 中阅读。这种设置相比于设置所有的服务器软件是有点大题小作,但 Gnus 无法很好地应付 Maildir 格式,这是最好的方法。这个设置也有一个缺点,那就是在你快速搜索邮件时,要搜索大量邮件。而这就是 notmuch 的用武之地。
notmuch 允许我轻松索引上千兆字节的邮件档案而找到我需要的东西。我已经创建了一个小脚本,它结合了执行 `mbsync` 和 `notmuch`。我使用 dovecot sieve 来基于实际上创建在服务器端的 Maildirs 标记邮件。下面是我的完整 shell 脚本,它执行同步分类和删除垃圾邮件的任务。
```
#!/bin/sh
MBSYNC=$(pgrep mbsync)
NOTMUCH=$(pgrep notmuch)
if [ -n "$MBSYNC" -o -n "$NOTMUCH" ]; then
echo "Already running one instance of mail-sync. Exiting..."
exit 0
fi
echo "Deleting messages tagged as *deleted*"
notmuch search --format=text0 --output=files tag:deleted |xargs -0 --no-run-if-empty rm -v
echo "Moving spam to Spam folder"
notmuch search --format=text0 --output=files tag:Spam and \
to:[email protected] | \
xargs -0 -I {} --no-run-if-empty mv -v {} ~/Mail/vasudev-copyninja.info/Spam/cur
notmuch search --format=text0 --output=files tag:Spam and
to:[email protected] | \
xargs -0 -I {} --no-run-if-empty mv -v {} ~/Mail/vasudev-copyninja.info/Spam/cur
MDIR="vasudev-copyninja.info vasudev-debian Gmail-1"
mbsync -Va
notmuch new
for mdir in $MDIR; do
echo "Processing $mdir"
for fdir in $(ls -d /home/vasudev/Mail/$mdir/*); do
if [ $(basename $fdir) != "INBOX" ]; then
echo "Tagging for $(basename $fdir)"
notmuch tag +$(basename $fdir) -inbox -- folder:$mdir/$(basename $fdir)
fi
done
done
```
因此,在运行 `mbsync` 之前,我搜索所有标记为“deleted”的邮件,并将其从系统中删除。接下来,我在我的帐户上查找标记为“Spam”的邮件,并将其移动到“Spam”文件夹。你没看错,这些邮件逃脱了垃圾邮件过滤器进入到我的收件箱,并被我亲自标记为垃圾邮件。
运行 `mbsync` 后,我基于它们的文件夹标记邮件(搜索字符串 `folder:`)。这让我可以很容易地得到一个邮件列表的内容,而不需要记住列表地址。
### 阅读邮件
现在,我们已经实现同步和分类邮件,是时候来设置阅读部分。我使用 notmuch-emacs 界面来阅读邮件。我使用 emacs 的 Spacemacs 风格,所以我花了一些时间写了一个私有层,它将我所有的快捷键和分类集中在一个地方,而不会扰乱我的整个 `.spacemacs` 文件。你可以在 [notmuch-emacs-layer 仓库](https://source.copyninja.info/notmuch-emacs-layer.git/) 找到我的私有层的代码。
### 发送邮件
能阅读邮件这还不够,我们也需要能够回复邮件。而这是最近是我感到迷茫的一个略显棘手的部分,以至于不得不写这篇文章,这样我就不会再忘记了。(当然也不必在网络上参考一些过时的帖子。)
我的系统发送邮件使用 Postfix 作为 SMTP 客户端,使用我自己的 SMTP 服务器作为它的中继主机。中继的问题是,它不能是具有动态 IP 的主机。有两种方法可以允许具有动态 IP 的主机使用中继服务器, 一种是将邮件来源的 IP 地址放入 `my_network` 或第二个使用 SASL 身份验证。
我的首选方法是使用 SASL 身份验证。为此,我首先要为每台机器创建一个单独的账户,它将把邮件中继到我的主服务器上。想法是不使用我的主帐户 SASL 进行身份验证。(最初我使用的是主账户,但 Jonas 给出了可行的按账户的想法)
```
adduser <hostname>_relay
```
这里替换 `<hostname>` 为你的笔记本电脑的名称或任何你正在使用的设备。现在我们需要调整 Postfix 作为中继服务器。因此,在 Postfix 配置中添加以下行:
```
# SASL authentication
smtp_sasl_auth_enable = yes
smtp_tls_security_level = encrypt
smtp_sasl_tls_security_options = noanonymous
relayhost = [smtp.copyninja.info]:submission
smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd
```
因此, 这里的 `relayhost` 是用于将邮件转发到互联网的 Postfix 实例的服务器名称。`submission` 的部分 Postfix 将邮件转发到端口 587(安全端口)。`smtp_sasl_tls_security_options` 设置为不允许匿名连接。这是必须的,以便中继服务器信任你的移动主机,并同意为你转发邮件。
`/etc/postfix/sasl_passwd` 是你需要存储用于服务器 SASL 身份验证的帐户密码的文件。将以下内容放入其中。
```
[smtp.example.com]:submission user:password
```
用你已放入 `relayhost` 配置的 SMTP 服务器名称替换 `smtp.example.com`。用你创建的 `<hostname>_relay` 用户及其密码替换 `user` 和 `passwd`。
若要保护 `sasl_passwd` 文件,并为 Postfix 创建它的哈希文件,使用以下命令。
```
chown root:root /etc/postfix/sasl_passwd
chmod 0600 /etc/postfix/sasl_passwd
postmap /etc/postfix/sasl_passwd
```
最后一条命令将创建 `/etc/postfix/sasl_passwd.db` 文件,它是你的文件的 `/etc/postfix/sasl_passwd` 的哈希文件,具有相同的所有者和权限。现在重新加载 Postfix,并使用 `mail` 命令检查邮件是否从你的系统中发出。
### Bonus 的部分
好吧,因为我有一个脚本创建以上结合了邮件的同步和分类。我继续创建了一个 systemd 计时器,以定期同步后台的邮件。就我而言,每 10 分钟一次。下面是 `mailsync.timer` 文件。
```
[Unit]
Description=Check Mail Every 10 minutes
RefuseManualStart=no
RefuseManualStop=no
[Timer]
Persistent=false
OnBootSec=5min
OnUnitActiveSec=10min
Unit=mailsync.service
[Install]
WantedBy=default.target
```
下面是 mailsync.service 服务,这是 mailsync.timer 执行我们的脚本所需要的。
```
[Unit]
Description=Check Mail
RefuseManualStart=no
RefuseManualStop=yes
[Service]
Type=oneshot
ExecStart=/usr/local/bin/mail-sync
StandardOutput=syslog
StandardError=syslog
```
将这些文件置于 `/etc/systemd/user` 目录下并运行以下代码去开启它们:
```
systemctl enable --user mailsync.timer
systemctl enable --user mailsync.service
systemctl start --user mailsync.timer
```
这就是我从系统同步和发送邮件的方式。我从 Jonas Smedegaard 那里了解到了 afew,他审阅了这篇帖子。因此, 下一步, 我将尝试使用 afew 改进我的 notmuch 配置,当然还会有一个后续的帖子:-)。
---
via: <https://copyninja.info/blog/email_setup.html>
作者:[copyninja](https://copyninja.info) 译者:[lixinyuxx](https://github.com/lixinyuxx) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 410 | Gone | null |
10,370 | 用户、组及其它 Linux 特性 | https://www.linux.com/learn/intro-to-linux/2018/7/users-groups-and-other-linux-beasts | 2018-12-22T00:20:52 | [
"用户",
"用户组"
] | https://linux.cn/article-10370-1.html |
>
> Linux 和其他类 Unix 操作系统依赖于用户组,而不是逐个为用户分配权限和特权。一个组就是你想象的那样:一群在某种程度上相关的用户。
>
>
>

到这个阶段,[在看到如何操作目录或文件夹之后](/article-10066-1.html),但在让自己一头扎进文件之前,我们必须重新审视 权限、用户 和 组。幸运的是,[有一个网站上已经有了一个优秀而全面的教程,讲到了权限](https://www.linux.com/learn/understanding-linux-file-permissions),所以你应该去立刻阅读它。简而言之,你使用权限来确定谁可以对文件和目录执行操作,以及他们可以对每个文件和目录执行什么操作 —— 从中读取、写入、移动、擦除等等。
要尝试本教程涵盖的所有内容,你需要在系统上创建新用户。让我们实践起来,为每一个需要借用你电脑的人创建一个用户,我们称之为 `guest` 账户。
**警告:** 例如,如果你错误地删除了自己的用户和目录,那么创建用户,特别是删除用户以及主目录会严重损坏系统。你可能不想在你日常的工作机中练习,那么请在另一台机器或者虚拟机上练习。无论你是否想要安全地练习,经常备份你的东西总是一个好主意。检查备份是否正常工作,为你自己以后避免很多咬牙切齿的事情。
### 一个新用户
你可以使用 `useradd` 命令来创建一个新用户。使用超级用户或 root 权限运行 `useradd`,即使用 `sudo` 或 `su`,这具体取决于你的系统,你可以:
```
sudo useradd -m guest
```
然后输入你的密码。或者也可以这样:
```
su -c "useradd -m guest"
```
然后输入 root 或超级用户的密码。
( 为了简洁起见,我们将从现在开始假设你使用 `sudo` 获得超级用户或 root 权限。 )
通过使用 `-m` 参数,`useradd` 将为新用户创建一个主目录。你可以通过列出 `/home/guest` 来查看其内容。
然后你可以使用以下命令来为新用户设置密码:
```
sudo passwd guest
```
或者你也可以使用 `adduser`,这是一个交互式的命令,它会询问你一些问题,包括你要为用户分配的 shell(是的,shell 有不止一种),你希望其主目录在哪里,你希望他们属于哪些组(有关这点稍后会讲到)等等。在运行 `adduser` 结束时,你可以设置密码。注意,默认情况下,在许多发行版中都没有安装 `adduser`,但安装了 `useradd`。
顺便说一下,你可以使用 `userdel` 来移除一个用户:
```
sudo userdel -r guest
```
使用 `-r` 选项,`userdel` 不仅删除了 `guest` 用户,还删除了他们的主目录和邮件中的条目(如果有的话)。
### 主目录中的内容
谈到用户的主目录,它依赖于你所使用的发行版。你可能已经注意到,当你使用 `-m` 选项时,`useradd` 使用子目录填充用户的目录,包括音乐、文档和诸如此类的内容以及各种各样的隐藏文件。要查看 `guest` 主目录中的所有内容,运行 `sudo ls -la /home/guest`。
进入新用户目录的内容通常是由 `/etc/skel` 架构目录确定的。有时它可能是一个不同的目录。要检查正在使用的目录,运行:
```
useradd -D
GROUP=100
HOME=/home
INACTIVE=-1
EXPIRE=
SHELL=/bin/bash
SKEL=/etc/skel
CREATE_MAIL_SPOOL=no
```
这会给你一些额外的有趣信息,但你现在感兴趣的是 `SKEL=/etc/skel` 这一行,在这种情况下,按照惯例,它指向 `/etc/skel/`。
由于 Linux 中的所有东西都是可定制的,因此你可以更改那些放入新创建的用户目录的内容。试试这样做:在 `/etc/skel/` 中创建一个新目录:
```
sudo mkdir /etc/skel/Documents
```
然后创建一个包含欢迎消息的文件,并将其复制过来:
```
sudo cp welcome.txt /etc/skel/Documents
```
现在删除 `guest` 账户:
```
sudo userdel -r guest
```
再次创建:
```
sudo useradd -m guest
```
嘿!你的 `Documents/` 目录和 `welcome.txt` 文件神奇地出现在了 `guest` 的主目录中。
你还可以在创建用户时通过编辑 `/etc/default/useradd` 来修改其他内容。我的看起来像这样:
```
GROUP=users
HOME=/home
INACTIVE=-1
EXPIRE=
SHELL=/bin/bash
SKEL=/etc/skel
CREATE_MAIL_SPOOL=no
```
这些选项大多数都是不言自明的,但让我们仔细看看 `GROUP` 选项。
### 群组心态
Linux 和其他类 Unix 操作系统依赖于用户组,而不是逐个为用户分配权限和特权。一个组就是你想象的那样:一群在某种程度上相关的用户。在你的系统上可能有一组允许使用打印机的用户,他们属于 `lp`(即 “line printer”)组。传统上 `wheel` 组的成员是唯一可以通过使用 `su` 成为超级用户或 root 的成员。`network` 用户组可以启动或关闭网络。还有许多诸如此类的。
不同的发行版有不同的组,具有相同或相似名称的组具有不同的权限,这也取决于你使用的发行版。因此,如果你在前一段中读到的内容与你系统中的内容不匹配,不要感到惊讶。
不管怎样,要查看系统中有哪些组,你可以使用:
```
getent group
```
`getent` 命令列出了某些系统数据库的内容。
要查找当前用户所属的组,尝试:
```
groups
```
当你使用 `useradd` 创建新用户时,除非你另行指定,否则用户将只属于一个组:他们自己。`guest` 用户属于 `guest` 组。组使用户有权管理自己的东西,仅此而已。
你可以使用 `groupadd` 命令创建新组,然后添加用户:
```
sudo groupadd photos
```
例如,这将创建 `photos` 组。下一次,我们将使用它来构建一个共享目录,该组的所有成员都可以读取和写入,我们将更多地了解权限和特权。敬请关注!
---
via: <https://www.linux.com/learn/intro-to-linux/2018/7/users-groups-and-other-linux-beasts>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,371 | 持续集成与部署的 3 个最佳实践 | https://opensource.com/article/18/11/best-practices-cicd | 2018-12-22T09:51:35 | [
"CI",
"CD"
] | https://linux.cn/article-10371-1.html |
>
> 了解自动化,使用 Git 存储库以及参数化 Jenkins 管道。
>
>
>

本文涵盖了三个关键主题:自动化 CI/CD 配置、使用 Git 存储库处理常见的 CI/CD 工件、参数化 Jenkins 管道。
### 术语
首先,我们定义一些术语。**CI/CD** 是允许团队快速自动化测试、打包、部署其应用程序的实践。它通常通过利用名为 [Jenkins](https://jenkins.io/) 的服务器来实现,该服务器充当 CI/CD 协调器。Jenkins 侦听特定输入(通常是代码签入后的 Git 挂钩),并在触发时启动一个管道。
<ruby> 管道 <rt> pipeline </rt></ruby> 由开发和/或运营团队编写的代码组成,这些代码指导 Jenkins 在 CI/CD 过程中采取哪些操作。这个流水线通常类似于“构建我的代码,然后测试我的代码,如果这些测试通过,则把我的应用程序部署到下一个最高环境(通常是开发、测试或生产环境)”。组织通常具有更复杂的管道,并入了诸如工件存储库和代码分析器之类的工具,这里提供了一个高级示例。
现在我们了解了关键术语,让我们深入研究一些最佳实践。
### 1、自动化是关键
要在 PaaS 上运行 CI/CD,需要在集群上配置适当的基础设施。在这个例子中,我将使用 [OpenShift](https://www.openshift.com/)。
“Hello, World” 的实现很容易实现。简单地运行 `oc new-app jenkins-<persistent/ephemeral>`,然后,你就有了一个已经就绪的运行中的 Jenkins 服务器了。然而,在企业中的使用要复杂得多。除了 Jenkins 服务器之外,管理员通常还需要部署代码分析工具(如 SonarQube)和工件库(如 Nexus)。然后,它们必须创建管道来执行 CI/CD 和 Jenkins 从服务器,以减少主服务器的负载。这些实体中的大多数都由 OpenShift 资源支持,需要创建这些资源来部署所需的 CI/CD 基础设施。
最后,部署 CI/CD 组件所需要的手动步骤可能是需要重复进行的,而且你可能不想成为执行那些重复步骤的人。为了确保结果能够像以前一样快速、无错误和准确地产生,应该在创建基础设施的方式中结合自动化方法。这可以是一个 Ansible 剧本、一个 Bash 脚本,或者任何您希望自动化 CI/CD 基础设施部署的其它方式。我已经使用 [Ansible](https://docs.ansible.com/) 和 [OpenShift-Applier](https://github.com/redhat-cop/openshift-applier) 角色来自动化我的实现。您可能会发现这些工具很有价值,或者您可能会发现其他一些对您和组织更有效的工具。无论哪种方式,您都将发现自动化显著地减少了重新创建 CI/CD 组件所需的工作量。
#### 配置 Jenkins 主服务器
除了一般的“自动化”之外,我想单独介绍一下 Jenkins 主服务器,并讨论管理员如何利用 OpenShift 来自动化配置 Jenkins。来自 [Red Hat Container Catalog](https://access.redhat.com/containers/?tab=overview#/registry.access.redhat.com/openshift3/jenkins-2-rhel7) 的 Jenkins 镜像已经安装了 [OpenShift-Sync plugin](https://github.com/openshift/jenkins-sync-plugin)。在 [该视频](https://www.youtube.com/watch?v=zlL7AFWqzfw) 中,我们将讨论如何使用这个插件来创建 Jenkins 管道和从设备。
要创建 Jenkins 管道,请创建一个类似于下面的 OpenShift BuildConfig:
```
apiVersion: v1
kind: BuildConfig
...
spec:
source:
git:
ref: master
uri: <repository-uri>
...
strategy:
jenkinsPipelineStrategy:
jenkinsfilePath: Jenkinsfile
type: JenkinsPipeline
```
OpenShift-Sync 插件将注意到已经创建了带有 `jenkinsPipelineStrategy` 策略的 BuildConfig,并将其转换为 Jenkins 管道,从 Git 源指定的 Jenkinsfile 中提取。也可以使用内联 Jenkinsfile,而不是从 Git 存储库中提取。有关更多信息,请参阅[文档](https://docs.openshift.com/container-platform/3.11/dev_guide/dev_tutorials/openshift_pipeline.html#the-pipeline-build-config)。
要创建 Jenkins 从站,请创建一个 OpenShift ImageStream,它从以下定义开始:
```
apiVersion: v1
kind: ImageStream
metadata:
annotations:
slave-label: jenkins-slave
labels:
role: jenkins-slave
...
```
注意在这个 ImageStream 中定义的元数据。OpenShift-Sync 插件将把带有标签 `role: jenkins-slave` 的任何 ImageStream 转换为 Jenkins 从站。Jenkins 从站将以 `slave-label` 注释中的值命名。
ImageStreams 对于简单的 Jenkins 从属配置工作得很好,但是一些团队会发现有必要配置一些细节详情,比如资源限制、准备就绪和活动性探测,以及实例上限。这就是 ConfigMap 发挥作用的地方:
```
apiVersion: v1
kind: ConfigMap
metadata:
labels:
role: jenkins-slave
...
data:
template1: |-
<Kubernetes pod template>
```
注意,仍然需要角色:`jenkins-slave` 标签来将 ConfigMap 转换为 Jenkins 从站。Kubernetes pod 模板由一长段 XML 组成,它将根据组织的喜好配置每个细节。要查看此 XML,以及有关将 ImageStreams 和 ConfigMaps 转换为 Jenkins 从站的更多信息,请参阅[文档](https://docs.openshift.com/container-platform/3.11/using_images/other_images/jenkins.html#configuring-the-jenkins-kubernetes-plug-in)。
请注意上面所示的三个示例,其中没有一个操作需要管理员对 Jenkins 控制台进行手动更改。通过使用 OpenShift 资源,可以简单的自动化方式配置 Jenkins。
### 2、分享就是关爱
第二个最佳实践是维护一个公共 CI/CD 工件的 Git 存储库。主要思想是防止团队重新发明轮子。假设您的团队需要执行到 OpenShift 环境的蓝/绿部署,作为管道 CD 阶段的一部分。负责编写管道的团队成员可能不是 OpenShift 专家,也不可能具有从头开始编写此功能的能力。幸运的是,有人已经编写了一个将此功能合并到一个公共 CI/CD 存储库中的函数,因此您的团队可以使用该函数而不是花时间编写一个函数。
为了更进一步,您的组织可能决定维护整个管道。您可能会发现团队正在编写具有相似功能的管道。对于那些团队来说,使用来自公共存储库的参数化管道要比从头开始编写自己的管道更有效。
### 3、少即是多
正如我在前一节中提到的,第三个也是最后一个最佳实践是参数化您的 CI/CD 管道。参数化将防止过多的管道,使您的 CI/CD 系统更容易维护。假设我有多个区域可以部署应用程序。如果没有参数化,我需要为每个区域设置单独的管道。
要参数化一个作为 OpenShift 构建配置编写的管道,请将 `env` 节添加到配置:
```
...
spec:
...
strategy:
jenkinsPipelineStrategy:
env:
- name: REGION
value: US-West
jenkinsfilePath: Jenkinsfile
type: JenkinsPipeline
```
使用此配置,我可以传递 `REGION` 参数给管道以将我的应用程序部署到指定区域。
这有一个[视频](https://www.youtube.com/watch?v=zlL7AFWqzfw)提供了一个更实质性的情况,其中参数化是必须的。一些组织决定把他们的 CI/CD 管道分割成单独的 CI 和 CD 管道,通常是因为在部署之前有一些审批过程。假设我有四个镜像和三个不同的环境要部署。如果没有参数化,我需要 12 个 CD 管道来允许所有部署可能性。这会很快失去控制。为了使 CD 流水线的维护更容易,组织会发现将镜像和环境参数化以便允许一个流水线执行多个流水线的工作会更好。
### 总结
企业级的 CI/CD 往往比许多组织预期的更加复杂。幸运的是,对于 Jenkins,有很多方法可以无缝地提供设置的自动化。维护一个公共 CI/CD 工件的 Git 存储库也会减轻工作量,因为团队可以从维护的依赖项中提取而不是从头开始编写自己的依赖项。最后,CI/CD 管道的参数化将减少必须维护的管道的数量。
如果您找到了其他不可或缺的做法,请在评论中分享。
---
via: <https://opensource.com/article/18/11/best-practices-cicd>
作者:[Austin Dewey](https://opensource.com/users/adewey) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChiZelin](https://github.com/ChiZelin) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The article covers three key topics: automating CI/CD configuration, using a Git repository for common CI/CD artifacts, and parameterizing Jenkins pipelines.
## Terminology
First things first; let's define a few terms. **CI/CD** is a practice that allows teams to quickly and automatically test, package, and deploy their applications. It is often achieved by leveraging a server called ** Jenkins**, which serves as the CI/CD orchestrator. Jenkins listens to specific inputs (often a Git hook following a code check-in) and, when triggered, kicks off a pipeline.
A **pipeline** consists of code written by development and/or operations teams that instructs Jenkins which actions to take during the CI/CD process. This pipeline is often something like "build my code, then test my code, and if those tests pass, deploy my application to the next highest environment (usually a development, test, or production environment)." Organizations often have more complex pipelines, incorporating tools such as artifact repositories and code analyzers, but this provides a high-level example.
Now that we understand the key terminology, let's dive into some best practices.
## 1. Automation is key
To run CI/CD on a PaaS, you need the proper infrastructure to be configured on the cluster. In this example, I will use [OpenShift](https://www.openshift.com/).
"Hello, World" implementations of this are quite simple to achieve. Simply run **oc new-app jenkins-<persistent/ephemeral>** and *voilà*, you have a running Jenkins server ready to go. Uses in the enterprise, however, are much more complex. In addition to the Jenkins server, admins will often need to deploy a code analysis tool such as SonarQube and an artifact repository such as Nexus. They will then have to create pipelines to perform CI/CD and Jenkins slaves to reduce the load on the master. Most of these entities are backed by OpenShift resources that need to be created to deploy the desired CI/CD infrastructure.
Eventually, the manual steps required to deploy your CI/CD components may need to be replicated, and you might not be the person to perform those steps. To ensure the outcome is produced quickly, error-free, and exactly as it was before, an automation method should be incorporated in the way your infrastructure is created. This can be an Ansible playbook, a Bash script, or any other way you would like to automate the deployment of CI/CD infrastructure. I have used [Ansible](https://docs.ansible.com/) and the [OpenShift-Applier](https://github.com/redhat-cop/openshift-applier) role to automate my implementations. You may find these tools valuable, or you may find something else that works better for you and your organization. Either way, you'll find that automation significantly reduces the workload required to recreate CI/CD components.
### Configuring the Jenkins master
Outside of general "automation," I'd like to single out the Jenkins master and talk about a few ways admins can take advantage of OpenShift to automate Jenkins configuration. The Jenkins image from the [Red Hat Container Catalog](https://access.redhat.com/containers/?tab=overview#/registry.access.redhat.com/openshift3/jenkins-2-rhel7) comes packaged with the [OpenShift-Sync plugin](https://github.com/openshift/jenkins-sync-plugin) installed. In the [video](https://www.youtube.com/watch?v=zlL7AFWqzfw), we discuss how this plugin can be used to create Jenkins pipelines and slaves.
To create a Jenkins pipeline, create an OpenShift BuildConfig similar to this:
```
apiVersion: v1
kind: BuildConfig
...
spec:
source:
git:
ref: master
uri: <repository-uri>
...
strategy:
jenkinsPipelineStrategy:
jenkinsfilePath: Jenkinsfile
type: JenkinsPipeline
```
The OpenShift-Sync plugin will notice that a BuildConfig with the strategy **jenkinsPipelineStrategy** has been created and will convert it into a Jenkins pipeline, pulling from the Jenkinsfile specified by the Git source. An inline Jenkinsfile can also be used instead of pulling from one from a Git repository. See the [documentation](https://docs.openshift.com/container-platform/3.11/dev_guide/dev_tutorials/openshift_pipeline.html#the-pipeline-build-config) for more information.
To create a Jenkins slave, create an OpenShift ImageStream that starts with the following definition:
```
apiVersion: v1
kind: ImageStream
metadata:
annotations:
slave-label: jenkins-slave
labels:
role: jenkins-slave
…
```
Notice the metadata defined in this ImageStream. The OpenShift-Sync plugin will convert any ImageStream with the label **role: jenkins-slave** into a Jenkins slave. The Jenkins slave will be named after the value from the **slave-label** annotation.
ImageStreams work just fine for simple Jenkins slave configurations, but some teams will find it necessary to configure nitty-gritty details such as resource limits, readiness and liveness probes, and instance caps. This is where ConfigMaps come into play:
```
apiVersion: v1
kind: ConfigMap
metadata:
labels:
role: jenkins-slave
...
data:
template1: |-
<Kubernetes pod template>
```
Notice that the **role: jenkins-slave** label is still required to convert the ConfigMap into a Jenkins slave. The **Kubernetes pod template** consists of a lengthy bit of XML that will configure every detail to your organization's liking. To view this XML, as well as more information on converting ImageStreams and ConfigMaps into Jenkins slaves, see the [documentation](https://docs.openshift.com/container-platform/3.11/using_images/other_images/jenkins.html#configuring-the-jenkins-kubernetes-plug-in).
Notice with the three examples shown above that none of the operations required an administrator to make manual changes to the Jenkins console. By using OpenShift resources, Jenkins can be configured in a way that is easily automated.
## 2. Sharing is caring
The second best practice is maintaining a Git repository of common CI/CD artifacts. The main idea is to prevent teams from reinventing the wheel. Imagine your team needs to perform a blue/green deployment to an OpenShift environment as part of the pipeline's CD phase. The members of your team responsible for writing the pipeline may not be OpenShift experts, nor may they have the bandwidth to write this functionality from scratch. Luckily, somebody has already written a function that incorporates that functionality in a common CI/CD repository, so your team can use that function instead of spending time writing one.
To take this a step further, your organization may decide to maintain entire pipelines. You may find that teams are writing pipelines with similar functionality. It would be more efficient for those teams to use a parameterized pipeline from a common repository as opposed to writing their own from scratch.
## 3. Less is more
As I hinted in the previous section, the third and final best practice is to parameterize your CI/CD pipelines. Parameterization will prevent an over-abundance of pipelines, making your CI/CD system easier to maintain. Imagine I have multiple regions where I can deploy my application. Without parameterization, I would need a separate pipeline for each region.
To parameterize a pipeline written as an OpenShift build config, add the **env** stanza to the configuration:
```
...
spec:
...
strategy:
jenkinsPipelineStrategy:
env:
- name: REGION
value: US-West
jenkinsfilePath: Jenkinsfile
type: JenkinsPipeline
```
With this configuration, I can pass the **REGION** parameter the pipeline to deploy my application to the specified region.
The [video](https://www.youtube.com/watch?v=zlL7AFWqzfw) provides a more substantial case where parameterization is a must. Some organizations decide to split up their CI/CD pipelines into separate CI and CD pipelines, usually, because there is some sort of approval process that happens before deployment. Imagine I have four images and three different environments to deploy to. Without parameterization, I would need 12 CD pipelines to allow all deployment possibilities. This can get out of hand very quickly. To make maintenance of the CD pipeline easier, organizations would find it better to parameterize the image and environment to allow one pipeline to perform the work of many.
## Summary
CI/CD at the enterprise level tends to become more complex than many organizations anticipate. Luckily, with Jenkins, there are many ways to seamlessly provide automation of your setup. Maintaining a Git repository of common CI/CD artifacts will also ease the effort, as teams can pull from maintained dependencies instead of writing their own from scratch. Finally, parameterization of your CI/CD pipelines will reduce the number of pipelines that will have to be maintained.
If you've found other practices you can't do without, please share them in the comments.
## Comments are closed. |
10,372 | 极客漫画:密室逃脱 | http://turnoff.us/geek/escape-room/ | 2018-12-22T09:55:24 | [
"Vim",
"漫画"
] | https://linux.cn/article-10372-1.html | 
“密室逃脱”是近年来流行的益智解密游戏。我们的主人公就进入了这样的一个游戏,然而,发现谜题是——如何退出 Vim!!!
“如何退出 Vim”这个话题,已经成了众多 Linux 初学者经常听说的一个梗了,比如说,“如何制造乱码?——新手退出 Vim”。
甚至在国外著名的问答网站 Stack Overflow 上,从 2012 年 8 月 6 日,jclancy 发了“[如何退出 Vim 编辑器](https://stackoverflow.com/questions/11828270/how-to-exit-the-vim-editor)”求救。6 年过去了,这个帖子已经有 170 万的阅读了。(2017 年 5 月 24 日,Stack Overflow 官方博客还专门发文纪念了该贴阅读量突破 100 百万次)
---
via: <http://turnoff.us/geek/escape-room/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者 & 点评:[wxy](https://github.com/wxy) 校对 & 合成:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,373 | 如何在 Ubuntu 和其他 Linux 发行版上安装 Putty | https://itsfoss.com/putty-linux/ | 2018-12-22T18:16:07 | [
"putty",
"ssh"
] | https://linux.cn/article-10373-1.html | 如果我没弄错,[Putty](https://www.putty.org/) 可能是 Windows 最受欢迎的 SSH 客户端。
在 IT 公司中,开发环境通常在远程 Linux 系统上,而开发人员则使用 Windows 作为本地系统。Putty 用于从 Windows 机器连接到远程 Linux 系统。
Putty 不是限定于 Windows 的。你也可以在 Linux 和 macOS 上使用此开源软件。
但是等等!当你已经拥有“真正的” Linux 终端时,为什么要在 Linux 上使用单独的 SSH 客户端?这有几个想在 Linux 上使用 Putty 的原因。
* 你在 Windows 上使用 Putty 已经很久了,你觉得它更舒服。
* 你发现很难手动编辑 SSH 配置文件以保存各种 SSH 会话。你更喜欢 Putty 图形化保存 SSH 连接的方式。
* 你想通过连接到原始套接字和串口进行调试。
无论是什么原因,如果你想在 Ubuntu 或任何其他 Linux 上使用 Putty,你当然可以这样做。让我告诉你如何做到。
### 在 Ubuntu Linux 上安装 Putty

对于 Ubuntu 用户来说,好消息是 Putty 可以在 Ubuntu 的 universe 仓库中找到。
要在 Ubuntu上安装 Putty,首先应确保已启用 universe 仓库。
```
sudo add-apt-repository universe
```
启用 universe 仓库后,应使用以下命令更新 Ubuntu:
```
sudo apt update
```
之后,你可以使用以下命令安装 Putty:
```
sudo apt install putty
```
安装后,你可以在菜单中找到它来启动 Putty。
正如你在下面的截图中看到的,Putty 的 Linux 版本看起来与 Windows 版本相同。这让你松了一口气, 因为你不必再尝试新的设置。

当你输入远程系统的[主机名](https://itsfoss.com/change-hostname-ubuntu/)或 IP 地址并连接到它时,Putty 将使用你已保存在主目录中的 SSH 密钥。

### 在其他 Linux 发行版上安装 Putty
[Putty 可用于 Debian](https://packages.debian.org/jessie/putty),所以你只需要使用 `apt-get` 或 `aptitude` 来安装它。
```
sudo apt-get install putty
```
Putty 也适用于 Fedora/Red Hat,并可以使用默认的包管理器进行安装。
```
sudo dnf install putty
```
你还可以在基于 Arch Linux 的发行版中轻松安装 Putty。
```
sudo pacman -S putty
```
请记住,Putty 是一款开源软件。如果你真的想要,你也可以通过源代码安装它。你可以从下面的链接获取 Putty 的源代码。
* [下载 Putty 源代码](https://www.chiark.greenend.org.uk/%7Esgtatham/putty/latest.html)
我一直喜欢原生 Linux 终端而不是像 Putty 这样的 SSH 客户端。我觉得 GNOME 终端或 [Terminator](https://launchpad.net/terminator) 更有家的感觉。但是,在 Linux 中使用默认终端或 Putty 是个人选择。
你在 Linux 上管理多个 SSH 连接时使用了什么?
---
via: <https://itsfoss.com/putty-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If I am not wrong, [Putty](https://www.putty.org/?ref=itsfoss.com) is perhaps the most popular SSH client for Windows operating systems.
In IT companies, the development environment is usually on a remote Linux system while the developers use Windows as their local system. Putty is used for connecting to the remote Linux system from the Windows machine.
Putty is not limited to Windows only. You can also use this open source software on Linux and macOS.
But wait! Why would you use a separate SSH client on Linux when you already have plenty of ‘real’ [Linux terminals](https://itsfoss.com/linux-terminal-emulators/) with you? There are several reasons why you would want to use Putty on Linux.
- You have used Putty for so long on Windows that you are more comfortable with it.
- You find it difficult to manually edit
[SSH config file](https://linuxhandbook.com/ssh-config-file/?ref=itsfoss.com)to save the various SSH sessions. You prefer Putty’s graphical way of storing SSH connection. - You want to debug by connecting to raw sockets and serial ports.
Whatever may be the reason, if you want to **use Putty on Ubuntu** or any other Linux, you can certainly do so. Let me show you how to do that.
## Installing Putty on Ubuntu Linux

The good news for Ubuntu users is that Putty is available in the universe repository of Ubuntu.
To install Putty on Ubuntu, you should first make sure that the [universe repository is enabled](https://itsfoss.com/ubuntu-repositories/).
`sudo add-apt-repository universe`
Once you have the universe repository enabled, you should update Ubuntu with this command:
`sudo apt update`
After this, you can install Putty with this command:
`sudo apt install putty`
Once installed, you can start Putty by finding it in the menu.
As you can see in the screenshot below, the Linux version of Putty looks the same as the Windows version. That’s a relief because you won’t have to fiddle around trying to find your way through new and changed settings.
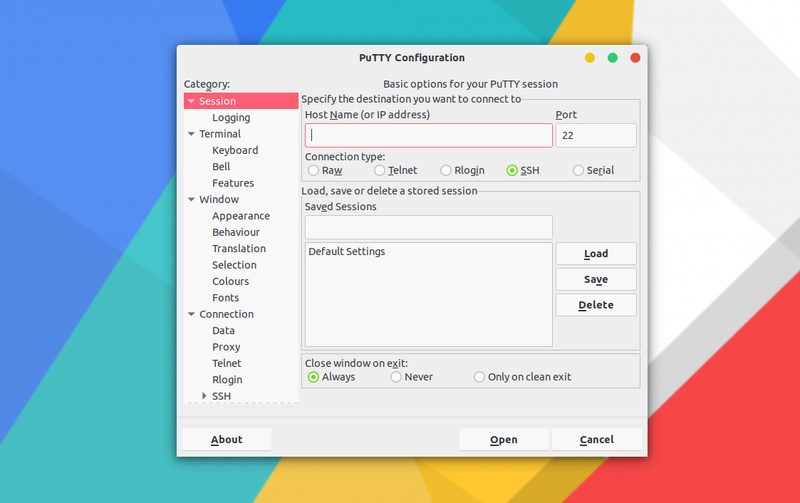
When you enter the remote system’s [hostname](https://itsfoss.com/change-hostname-ubuntu/) or IP address and connect to it, Putty will utilize the already saved SSH keys in your home directory. It’s quite good at SSH key management.
## Installing Putty on other Linux distributions
[Putty is available for Debian](https://packages.debian.org/jessie/putty?ref=itsfoss.com) so you just need to use apt-get or aptitude for installing it.
`sudo apt install putty`
Putty is also available for Fedora/Red Hat and can be installed using the default package manager.
`sudo dnf install putty`
You can also easily install Putty in Arch Linux based distributions.
`sudo pacman -S putty`
Remember that Putty is an open source software. You can also install it via source code if you really want to. You can download its source code from the link below.
## Learn the extra bits
If you are new to the whole terminal thing, I highly recommend reading this guide. You'll learn many useful things.
[19 Basic But Essential Linux Terminal Tips You Must KnowLearn some small, basic but often ignored things about the terminal. With the small tips, you should be able to use the terminal with slightly more efficiency.](https://itsfoss.com/basic-terminal-tips-ubuntu/)

Knowing the [essential Linux commands](https://itsfoss.com/essential-ubuntu-commands/) will also help you a great deal.
[31 Basic Yet Essential Ubuntu CommandsAn extensive list of essential Linux commands that every Ubuntu user will find helpful in their Linux journey.](https://itsfoss.com/essential-ubuntu-commands/)

I would always prefer the native Linux terminal over an SSH client like Putty. I feel more at home with the GNOME terminal or [Terminator](https://launchpad.net/terminator?ref=itsfoss.com). However, it’s up to an individual’s choice to use the default terminal or Putty in Linux.
What do you use for managing multiple SSH connections on Linux? |
10,374 | Bash 环境变量的那些事 | https://www.linux.com/blog/learn/2018/12/bash-variables-environmental-and-otherwise | 2018-12-23T15:12:49 | [
"环境变量",
"Bash",
"shell"
] | https://linux.cn/article-10374-1.html |
>
> 初学者可以在此教程中了解环境变量。
>
>
>

bash 变量,尤其是讨厌的*环境变量*,已经是一个老生常谈的话题了。我们也更应该对它有一个详细的了解,让它为我们所用。
下面就打开终端,开始吧。
### 环境变量
`HOME` (LCTT 译注:双关语)除了是你脱下帽子惬意休息的地方,同时也是 Linux 中的一个变量,它是当前用户主目录的路径:
```
echo $HOME
```
以上这个命令会显示当前用户的主目录路径,通常都在 `/home/<your username>` 下。
顾名思义,变量的值是可以根据上下文变化的。实际上,Linux 系统中每一个用户的 `HOME` 变量都是不一样的,当然你也可以这样自行更改 `HOME` 变量的值:
```
HOME=/home/<your username>/Documents
```
以上这个命令将会把 `HOME` 变量设置为你的 `Documents` 目录。
其中有三点需要留意:
1. `=` 符号和其两侧的内容之间不加空格。空格在 shell 中有专门的意义,不能随意地在任何地方添加空格。
2. 如果你需要对变量进行赋值,只需要使用变量名称就可以了。但如果需要读取或者使用变量的值,需要在变量前面加上一个 `$` 号。
3. 更改 `HOME` 变量具有一定的风险。有很多程序是依赖于 `HOME` 变量的,更改 `HOME` 变量可能会导致一些不可预见的结果。例如,如果按照上面的方式更改了 `HOME` 变量,然后执行不带有任何参数的 `cd` 命令,在通常情况下,会跳转到用户的主目录下,但在这个时候,会跳转到 `HOME` 变量指定的目录下。
上面第 3 点中环境变量的更改并不是持久有效的,在终端关闭后重新打开终端,又或者是新建一个终端,执行 `echo $HOME` 命令输出的仍然会是初始的值,而不是重新自定义的值。
在讨论如何持久地更改一个环境变量之前,我们先来看一下另一个比较重要的环境变量。
### PATH 变量
在 `PATH` 变量中存放了一系列目录,而且是放置了可执行程序的目录。正是由于 `PATH` 变量的存在,让你不需要知道应用程序具体安装到了什么目录,而 shell 却可以正确地找到这些应用程序。
如果你查看 `PATH` 变量的值,大概会是以下这样:
```
$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/bin:/usr/sbin:/bin:/sbin
```
每两个目录之间使用冒号 `:` 分隔。如果某个应用程序的所在目录不在 `PATH` 变量中,那么运行的时候就需要声明应用程序的目录让 shell 能够找到。
```
/home/<user name>/bin/my_program.sh
```
例如以上命令就会执行当前用户 `bin/` 目录下的 `my_program.sh` 文件。
有一个常见的问题:如果你不希望弄乱系统的 `bin/` 目录,同时也不希望你自己的文件被其它人运行,还不想每次运行的时候都要输入完整的路径,那么,你可以在你的主目录中创建一个独立的 `bin/` 目录:
```
mkdir $HOME/bin
```
然后将这个目录添加到 `PATH` 变量中:
```
PATH=$PATH:$HOME/bin
```
然后 `/home/<user name>/bin/` 目录就会出现在 `PATH` 变量中了。但正如之前所说,这个变更只会在当前的 shell 生效,当前的 shell 一旦关闭,环境变量的值就又恢复原状了。
如果要让变更对当前用户持续生效,就不能在 shell 中直接执行对应的变更,而是应该将这些变更操作写在每次启动 shell 时都会运行的文件当中。这个文件就是当前用户主目录中的 `.bashrc` 文件。文件名前面的点号表明这是一个隐藏文件,执行普通的 `ls` 命令是不会将这个文件显示出来的,但只要在 `ls` 命令中加入 `-a` 参数就可以看到这个文件了。
你可以使用诸如 [kate](https://www.kde.org/applications/utilities/kate/)、[gedit](https://help.gnome.org/users/gedit/stable/)、[nano](https://www.nano-editor.org/) 或者 [vim](https://www.vim.org/) 这些文本编辑器来打开 `.bashrc` 文件(但不要用 LibreOffice Writer,它是一个文字处理软件,跟前面几个文字编辑器完全不同)。打开 `.bashrc` 文件之后,你会看见里面放置了一些 shell 命令,是用于为当前用户设置环境的。
在文件的末尾添加新行并输入以下内容:
```
export PATH=$PATH:$HOME/bin
```
保存并关闭 `.bashrc` 文件,接下来你就会看到 `export` 语句的效果。执行以下的命令让刚才的修改立即生效:
```
source .bashrc
```
刚才执行的 `source` 命令让 `.bashrc` 文件在当前的 shell 立即生效,并且对于之后打开的 shell 都会有效。因此另一个等效的方法是退出并重新进入 shell,但这样也太麻烦了。
现在,你的 shell 就能自动寻找到 `/home/<user name>/bin/` 下的程序了,执行这个目录下的程序也不需要完整地写出程序的路径。
### 自定义变量
当然,你也可以定义自己的变量。刚才我们看到的变量名称都是全大写的,实际上[变量名称的定义还是比较灵活的](https://bash.cyberciti.biz/guide/Rules_for_Naming_variable_name)。
定义新变量的过程非常直观,直接对它赋值就可以了:
```
new_variable="Hello"
```
然后可以用以下的方式读取到已定义变量的值:
```
echo $new_variable
```
程序的正常工作离不开各种变量,例如要将某个选项设置为打开,又或者让程序找到所需的代码库,都需要使用变量。在 bash 中运行程序的时候会生成一个子 shell,这个子 shell 和执行原程序的父 shell 并不是完全一样的,只是继承了父 shell 的部分内容,而且默认是不继承父 shell 中的变量的。因为变量默认情况下是局部变量,出于安全原因,一个 shell 中的局部变量不会被另一个 shell 读取到,即使是子 shell 也不可以。
下面举一个例子。首先定义一个变量:
```
robots="R2D2 & C3PO"
```
然后执行:
```
bash
```
现在是在 bash shell 中创建了一个子 shell。
执行这个命令看看还能不能读取到刚才定义的变量:
```
echo $robots
```
你会发现读取不到。
还是在这个子 shell 中,为 `robots` 变量赋一个不同的值:
```
robots="These aren't the ones you are looking for"
```
再读取一次:
```
$ echo $robots
These aren't the ones you are looking for
```
退出这个子 shell:
```
exit
```
然后再看一下现在 `robots` 变量的值:
```
$ echo $robots
R2D2 & C3P0
```
这一个特性可以有效避免配置过程中产生混乱,同时也会导致一个问题:如果程序中需要设置变量,但却由于子 shell 的原因无法正常访问到这个变量,该如何解决呢?这个时候就需要用到 `export` 了。
重复一次刚才的过程,但这一次不是通过 `robots="R2D2 & C3PO"` 方式来设置变量,而是使用 `export` 命令:
```
export robots="R2D2 & C3PO"
```
现在你会发现,在进入子 shell 之后,`robots` 变量的值仍然是最初赋予的值。
要注意的是,尽管子 shell 会继承通过 `export` 导出的变量,但如果在子 shell 中对这个变量重新赋值,是不会影响到父 shell 中对应变量的。
如果要查看所有通过 `export` 导出的变量,可以执行以下命令:
```
export -p
```
自定义的变量会显示在这个列表的末尾。这个列表中还有一些常见的变量:例如 `USER` 的值是当前用户的用户名,`PWD` 的值是当前用户当前所在的目录,而 `OLDPWD` 的值则是当前用户上一个访问过的目录。因此如果执行:
```
cd -
```
就会切换到上一个访问过的目录,那是因为 `cd` 命令读取到了 `OLDPWD` 变量的值。
你也可以使用 `env` 命令查看所有环境变量。
如果要取消导出一个变量,可以加上 `-n` 参数:
```
export -n robots
```
### 接下来
了解过环境变量的知识之后,你已经到达了可能对自己和他人造成危险的水平,接下来就需要了解如何通过使用别名来让环境变得更安全、更友好以保护自己了。
---
via: <https://www.linux.com/blog/learn/2018/12/bash-variables-environmental-and-otherwise>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,375 | 树莓派在办公室的 11 种用法 | https://blog.dxmtechsupport.com.au/11-uses-for-a-raspberry-pi-around-the-office/ | 2018-12-23T15:36:36 | [
"树莓派",
"办公室"
] | /article-10375-1.html | 
我知道你在想什么:树莓派只能用在修修补补、原型设计和个人爱好中。它实际不能用在业务中。
毫无疑问,这台电脑的处理能力相对较低、易损坏的 SD 卡、缺乏电池备份以及支持的 DIY 性质,这意味着它不会是一个能在任何时候执行最关键的操作的[专业的、已安装好、配置好的商业服务器](https://dxmtechsupport.com.au/server-configuration)的可行替代品。
但是它电路板便宜、功耗很小、小到几乎适合任何地方、无限灵活 —— 这实际上是处理办公室一些基本任务的好方法。
而且,更好的是,已经有一些人完成了这些项目并很乐意分享他们是如何做到的。
### DNS 服务器
每次在浏览器中输入网站地址或者点击链接时,都需要将域名转换为数字 IP 地址,然后才能显示内容。
通常这意味着向互联网上某处 DNS 服务器发出请求 —— 但你可以通过本地处理来加快浏览速度。
你还可以分配自己的子域,以便本地访问办公室中的计算机。
[这里了解它是如何工作的。](https://www.1and1.com/digitalguide/server/configuration/how-to-make-your-raspberry-pi-into-a-dns-server/)
### 厕所占用标志
在厕所排过队吗?
这对于那些等待的人来说很烦人,花在处理它上面的时间会耗费你在办公室的工作效率。
我想你希望在办公室里也悬挂飞机上那个厕所有人的标志。
[Occu-pi](https://blog.usejournal.com/occu-pi-the-bathroom-of-the-future-ed69b84e21d5) 是一个非常简单的解决方案,使用磁性开关和树莓派来判断螺栓何时关闭,并在 Slack 频道中更新“厕所在使用中” —— 这意味着整个办公室的人都可以看一眼电脑或者移动设备知道是否有空闲的隔间。
### 针对黑客的蜜罐陷阱
黑客破坏了网络的第一个线索是一些事情变得糟糕,这应该会吓到大多数企业主。
这就是可以用到蜜罐的地方:一台没有任何服务的计算机位于你的网络,将特定端口打开,伪装成黑客喜欢的目标。
安全研究人员经常在网络外部部署蜜罐,以收集攻击者正在做的事情的数据。
但对于普通的小型企业来说,这些作为一种绊脚石部署在内部更有用。因为普通用户没有真正的理由想要连接到蜜罐,所以任何发生的登录尝试都是正在进行捣乱的非常好的指示。
这可以提供对外部人员入侵的预警,并且也可以提供对值得信赖的内部人员的预警。
在较大的客户端/服务器网络中,将它作为虚拟机运行可能更为实用。但是在无线路由器上运行的点对点的小型办公室/家庭办公网络中,[HoneyPi](https://trustfoundry.net/honeypi-easy-honeypot-raspberry-pi/) 之类的东西是一个很小的防盗报警器。
### 打印服务器
联网打印机更方便。
但更换所有打印机可能会很昂贵 —— 特别是如果你对现有的打印机感到满意的话。
[将树莓派设置为打印服务器](https://opensource.com/article/18/3/print-server-raspberry-pi)可能会更有意义。
### 网络附加存储(NAS)
将硬盘变为 NAS 是树莓派最早的实际应用之一,并且它仍然是最好的之一。
[这是如何使用树莓派创建 NAS。](https://howtoraspberrypi.com/create-a-nas-with-your-raspberry-pi-and-samba/)
### 工单服务器
想要在预算不足的情况下在服务台中支持工单?
有一个名为 osTicket 的完全开源的工单程序,它可以安装在你的树莓派上,它甚至还有[随时可用的 SD 卡镜像](https://everyday-tech.com/a-raspberry-pi-ticketing-system-image-with-osticket/)。
### 数字标牌
无论是用于活动、广告、菜单还是其他任何东西,许多企业都需要一种显示数字标牌的方式 —— 而树莓派的廉价和省电使其成为一个非常有吸引力的选择。
[这有很多可供选择的选项。](https://blog.capterra.com/7-free-and-open-source-digital-signage-software-options-for-your-next-event/)
### 目录和信息亭
[FullPageOS](https://github.com/guysoft/FullPageOS) 是一个基于 Raspbian 的 Linux 发行版,它直接引导到 Chromium 的全屏版本 —— 这非常适合导购、图书馆目录等。
### 基本的内联网 Web 服务器
对于托管一个面向公众的网站,你最好有一个托管帐户。树莓派不适合面对真正的网络流量。
但对于小型办公室,它可以托管内部业务维基或基本的公司内网。它还可以用作沙箱环境,用于试验代码和服务器配置。
[这里是如何在树莓派上运行 Apache、MySQL 和 PHP。](https://maker.pro/raspberry-pi/projects/raspberry-pi-web-server)
### 渗透测试器
Kali Linux 是专为探测网络安全漏洞而构建的操作系统。通过将其安装在树莓派上,你就拥有了一个超便携式穿透测试器,其中包含 600 多种工具。
[你可以在这里找到树莓派镜像的种子链接。](https://www.offensive-security.com/kali-linux-arm-images/)
绝对要小心只在你自己的网络或你有权对它安全审计的网络中使用它 —— 使用此方法来破解其他网络是严重的犯罪行为。
### VPN 服务器
当你外出时,依靠的是公共无线互联网,你无法控制还有谁在网络中、谁在窥探你的所有流量。这就是为什么通过 VPN 连接加密所有内容可以让人放心。
你可以订阅任意数量的商业 VPN 服务,并且你可以在云中安装自己的服务,但是在办公室运行一个 VPN,这样你也可以从任何地方访问本地网络。
对于轻度使用 —— 比如偶尔的商务旅行 —— 树莓派是一种强大的,节约能源的设置 VPN 服务器的方式。(首先要检查一下你的路由器是不是不支持这个功能,许多路由器是支持的。)
[这是如何在树莓派上安装 OpenVPN。](https://medium.freecodecamp.org/running-your-own-openvpn-server-on-a-raspberry-pi-8b78043ccdea)
### 无线咖啡机
啊,美味:好喝的饮料是神赐之物,也是公司内工作效率的支柱。
那么,为什么不[将办公室的咖啡机变成可以精确控制温度和无线连接的智能咖啡机呢?](https://www.techradar.com/au/how-to/how-to-build-your-own-smart-coffee-machine)
---
via: <https://blog.dxmtechsupport.com.au/11-uses-for-a-raspberry-pi-around-the-office/>
作者:[James Mawson](https://blog.dxmtechsupport.com.au/author/james-mawson/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='blog.dxmtechsupport.com.au', port=443): Max retries exceeded with url: /11-uses-for-a-raspberry-pi-around-the-office/ (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x7b83409d2f20>: Failed to resolve 'blog.dxmtechsupport.com.au' ([Errno -2] Name or service not known)")) | null |
10,376 | 量子计算的开源框架 Cirq 介绍 | https://itsfoss.com/qunatum-computing-cirq-framework/ | 2018-12-24T12:34:00 | [
"量子计算",
"Cirq"
] | https://linux.cn/article-10376-1.html | 
我们即将讨论的内容正如标题所示,本文通过使用 Cirq 的一个开源视角,尝试去了解我们已经在量子计算领域取得多大的成就,和该领域的发展方向,以加快科学和技术研究。
首先,我们将引领你进入量子计算的世界。在我们深入了解 Cirq 在未来的量子计算中扮演什么样的重要角色之前,我们将尽量向你解释其背后的基本概念。你最近可能听说过,在这个领域中有件重大新闻,就是 Cirq。在这篇开放科学栏目的文章中,我们将去尝试找出答案。
在我们开始了解量子计算之前,必须先去了解“量子”这个术语,量子是已知的 [亚原子粒子](https://en.wikipedia.org/wiki/Subatomic_particle) 中最小的物质。<ruby> <a href="https://en.wikipedia.org/wiki/Quantum"> 量子 </a> <rt> Quantum </rt></ruby> 这个词来自拉丁语 Quantus,意思是 “有多小”,在下面的短视频链接中有描述:
为了易于我们理解量子计算,我们将<ruby> 量子计算 <rt> Quantum Computing </rt></ruby>与<ruby> 经典计算 <rt> Classical Computing </rt></ruby>(LCTT 译注:也有译做“传统计算”)进行比较。经典计算是指今天的传统计算机如何设计工作的,正如你现在用于阅读本文的设备,就是我们所谓的经典计算设备。
### 经典计算
经典计算只是描述计算机如何工作的另一种方式。它们通过一个二进制系统工作,即信息使用 1 或 0 来存储。经典计算机不会理解除 1 或 0 之外的任何其它东西。
直白来说,在计算机内部一个晶体管只能是开(1)或关(0)。我们输入的任何信息都被转换为无数个 1 和 0,以便计算机能理解和存储。所有的东西都只能用无数个 1 和 0 的组合来表示。
### 量子计算
然而,量子计算不再像经典计算那样遵循 “开或关” 的模式。而是,借助量子的名为 [叠加和纠缠](https://www.clerro.com/guide/491/quantum-superposition-and-entanglement-explained) 的两个现象,能同时处理信息的多个状态,因此能以更快的速率加速计算,并且在信息存储方面效率更高。
请注意,叠加和纠缠 [不是同一个现象](https://physics.stackexchange.com/questions/148131/can-quantum-entanglement-and-quantum-superposition-be-considered-the-same-phenom)。

就像在经典计算中,我们有<ruby> 比特 <rt> bit </rt></ruby>,在量子计算中,我们相应也有<ruby> 量子比特 <rt> qubit </rt></ruby>(即 Quantum bit)。想了解它们二者之间的巨大差异之处,请查看这个 [页面](http://www.rfwireless-world.com/Terminology/Difference-between-Bit-and-Qubit.html),从那里的图片中可以得到答案。
量子计算机并不是来替代我们的经典计算机的。但是,有一些非常巨大的任务用我们的经典计算机是无法完成的,而那些正是量子计算机大显身手的好机会。下面链接的视频详细描述了上述情况,同时也描述了量子计算机的原理。
下面的视频全面描述了量子计算领域到目前为止的最新进展:
### 嘈杂中型量子
根据最新更新的(2018 年 7 月 31 日)研究论文,术语 “<ruby> 嘈杂 <rt> Noisy </rt></ruby>” 是指由于对量子比特未能完全控制所产生的不准确性。正是这种不准确性在短期内严重制约了量子设备实现其目标。
“中型” 指的是在接下来的几年中,量子计算机将要实现的量子规模大小,届时,量子比特的数目将可能从 50 到几百个不等。50 个量子比特是一个重大的量程碑,因为它将超越现有的最强大的 [超级计算机](https://www.explainthatstuff.com/how-supercomputers-work.html) 的 [暴力破解](https://en.wikipedia.org/wiki/Proof_by_exhaustion) 所能比拟的计算能力。更多信息请阅读 [这里的](https://arxiv.org/abs/1801.00862) 论文。
随着 Cirq 出现,许多事情将会发生变化。
### Cirq 是什么?
Cirq 是一个 Python 框架,它用于创建、编辑和调用我们前面讨论的嘈杂中型量子(NISQ)。换句话说,Cirq 能够解决挑战,去改善精确度和降低量子计算中的噪声。
Cirq 并不需要必须有一台真实的量子计算机。Cirq 能够使用一个类似模拟器的界面去执行量子电路模拟。
Cirq 的前进步伐越来越快了,[Zapata](https://www.xconomy.com/san-francisco/2018/07/19/google-partners-with-zapata-on-open-source-quantum-computing-effort/) 是使用它的首批用户之一,Zapata 是由来自哈佛大学的专注于量子计算的[一群科学家](https://www.zapatacomputing.com/about/)在去年成立的。
### Linux 上使用 Cirq 入门
开源的 [Cirq 库](https://github.com/quantumlib/Cirq) 开发者建议将它安装在像 [virtualenv](https://virtualenv.pypa.io) 这样的一个 [虚拟 Python 环境](https://itsfoss.com/python-setup-linux/) 中。在 Linux 上的开发者安装指南可以在 [这里](https://cirq.readthedocs.io/en/latest/install.html#installing-on-linux) 找到。
但我们在 Ubuntu 16.04 的系统上成功地安装和测试了 Python3 的 Cirq 库,安装步骤如下:
#### 在 Ubuntu 上安装 Cirq

首先,我们需要 `pip` 或 `pip3` 去安装 Cirq。[Pip](https://pypi.org/project/pip/) 是推荐用于安装和管理 Python 包的工具。
对于 Python 3.x 版本,Pip 能够用如下的命令来安装:
```
sudo apt-get install python3-pip
```
Python3 包能够通过如下的命令来安装:
```
pip3 install <package-name>
```
我们继续去使用 Pip3 为 Python3 安装 Cirq 库:
```
pip3 install cirq
```
#### 启用 Plot 和 PDF 生成(可选)
可选系统的依赖没有被 Pip 安装的,可以使用如下命令去安装它:
```
sudo apt-get install python3-tk texlive-latex-base latexmk
```
* python3-tk 是 Python 自有的启用了绘图功能的图形库
* texlive-latex-base 和 latexmk 启动了 PDF 输出功能。
最后,我们使用如下的命令和代码成功测试了 Cirq:
```
python3 -c 'import cirq; print(cirq.google.Foxtail)'
```
我们得到的输出如下图:

#### 为 Cirq 配置 Pycharm IDE
我们也配置了一个 Python IDE [PyCharm](https://itsfoss.com/install-pycharm-ubuntu/) 去测试同样的结果:
因为在我们的 Linux 系统上为 Python3 安装了 Cirq,我们在 IDE 中配置项目解释器路径为:
```
/usr/bin/python3
```

在上面的输出中,你可能注意到我们刚设置的项目解释器路径与测试程序文件(`test.py`)的路径显示在一起。退出代码 0 表示程序已经成功退出,没有错误。
因此,那是一个已经就绪的 IDE 环境,你可以导入 Cirq 库去开始使用 Python 去编程和模拟量子电路。
#### Cirq 使用入门
Criq 入门的一个好的开端就是它 GitHub 页面上的 [示例](https://github.com/quantumlib/Cirq/tree/master/examples)。
Cirq 的开发者在 GitHub 上已经放置了学习 [教程](https://github.com/quantumlib/Cirq/blob/master/docs/tutorial.md)。如果你想认真地学习量子计算,他们推荐你去看一本非常好的书,它是[由 Nielsen 和 Chuang 写的名为 《量子计算和量子信息》](http://mmrc.amss.cas.cn/tlb/201702/W020170224608149940643.pdf)。
#### OpenFermion-Cirq
[OpenFermion](http://openfermion.org) 是一个开源库,它是为了在量子计算机上模拟获取和操纵代表的费米系统(包含量子化学)。根据 [粒子物理学](https://en.wikipedia.org/wiki/Particle_physics) 理论,按照 [费米—狄拉克统计](https://en.wikipedia.org/wiki/Fermi-Dirac_statistics),费米系统与 [费米子](https://en.wikipedia.org/wiki/Fermion) 的产生相关。
OpenFermion 被称为从事 [量子化学](https://en.wikipedia.org/wiki/Quantum_chemistry) 的化学家和研究人员的 [一个极好的实践工具](https://phys.org/news/2018-03-openfermion-tool-quantum-coding.html)。量子化学主要专注于 [量子力学](https://en.wikipedia.org/wiki/Quantum_mechanics) 在物理模型和化学系统实验中的应用。量子化学也被称为 [分子量子力学](https://ocw.mit.edu/courses/chemical-engineering/10-675j-computational-quantum-mechanics-of-molecular-and-extended-systems-fall-2004/lecture-notes/)。
Cirq 的出现使 OpenFermion 通过提供程序和工具去扩展功能成为了可能,通过使用 Cirq 可以去编译和构造仿真量子电路。
#### Google Bristlecone
2018 年 3 月 5 日,在洛杉矶举行的一年一度的 [美国物理学会会议](http://meetings.aps.org/Meeting/MAR18/Content/3475) 上,Google 发布了 [Bristlecone](https://techcrunch.com/2018/03/05/googles-new-bristlecone-processor-brings-it-one-step-closer-to-quantum-supremacy/),这是他们的最新的量子处理器。这个 [基于门的超导系统](https://en.wikipedia.org/wiki/Superconducting_quantum_computing) 为 Google 提供了一个测试平台,用以研究 [量子比特技术](https://research.googleblog.com/2015/03/a-step-closer-to-quantum-computation.html) 的 [系统错误率](https://en.wikipedia.org/wiki/Quantum_error_correction) 和 [扩展性](https://en.wikipedia.org/wiki/Scalability) ,以及在量子 [仿真](https://research.googleblog.com/2017/10/announcing-openfermion-open-source.html)、[优化](https://research.googleblog.com/2016/06/quantum-annealing-with-digital-twist.html) 和 [机器学习](https://arxiv.org/abs/1802.06002) 方面的应用。
Google 希望在不久的将来,能够制造出它的 [云可访问](https://www.computerworld.com.au/article/644051/google-launches-quantum-framework-cirq-plans-bristlecone-cloud-move/) 的 72 个量子比特的 Bristlecone 量子处理器。Bristlecone 将越来越有能力完成一个经典超级计算机无法在合理时间内完成的任务。
Cirq 将让研究人员直接在云上为 Bristlecone 写程序变得很容易,它提供了一个非常方便的、实时的、量子编程和测试的接口。
Cirq 将允许我们去:
* 量子电路的微调管理
* 使用原生门去指定 [门](https://en.wikipedia.org/wiki/Logic_gate) 行为
* 在设备上放置适当的门
* 并调度这个门的时刻
### 开放科学关于 Cirq 的观点
我们知道 Cirq 是在 GitHub 上开源的,在开源科学社区之外,特别是那些专注于量子研究的人们,都可以通过高效率地合作,通过开发新方法,去降低现有量子模型中的错误率和提升精确度,以解决目前在量子计算中所面临的挑战。
如果 Cirq 不走开源模型的路线,事情可能变得更具挑战。一个伟大的创举可能就此错过,我们可能在量子计算领域止步不前。
### 总结
最后我们总结一下,我们首先通过与经典计算相比较,介绍了量子计算的概念,然后是一个非常重要的视频来介绍了自去年以来量子计算的最新发展。接着我们简单讨论了嘈杂中型量子,也就是为什么要特意构建 Cirq 的原因所在。
我们看了如何在一个 Ubuntu 系统上安装和测试 Cirq。我们也在一个更好用的 IDE 环境中做了安装测试,并使用一些资源去开始学习有关概念。
最后,我们看了两个示例 OpenFermion 和 Bristlecone,介绍了在量子计算中,Cirq 在开发研究中具有什么样的基本优势。最后我们以 Open Science 社区的视角对 Cirq 进行了一些精彩的思考,结束了我们的话题。
我们希望能以一种易于理解的方式向你介绍量子计算框架 Cirq 的使用。如果你有与此相关的任何反馈,请在下面的评论区告诉我们。感谢阅读,希望我们能在开放科学栏目的下一篇文章中再见。
---
via: <https://itsfoss.com/qunatum-computing-cirq-framework/>
作者:[Avimanyu Bandyopadhyay](https://itsfoss.com/author/avimanyu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,377 | 命令别名:定义自己的命令 | https://www.linux.com/blog/learn/2018/12/aliases-diy-shell-commands | 2018-12-24T12:53:53 | [
"别名",
"alias"
] | https://linux.cn/article-10377-1.html |
>
> 学习如何创建别名:你可以将太长或难以记忆的命令打包成你自己构建的命令。
>
>
>

<ruby> 命令别名 <rt> Alias </rt></ruby>在 Linux shell 中指的是将一些太长或者太难记的多个命令组合起来,成为一个由用户自己构建的命令。
可以通过 `alias` 命令来创建命令别名。在 `alias` 后面跟上想要创建的别名名称、一个等号(`=`),以及希望使用这个别名来执行的命令,这样一个命令别名就创建好了。举个例子,`ls` 命令在默认情况下是不会对输出的内容进行着色的,这样就不能让用户一眼分辨出目录、文件和连接了。对此,可以创建这样一个命令别名,在输出目录内容的时候为输出内容着色:
```
alias lc='ls --color=auto'
```
其中 `lc` 是自定义的命令别名,代表 “list with color” 的意思。在创建命令别名的时候,需要先确认使用的别名是不是已经有对应的命令了,如果有的话,原本的命令就会被覆盖掉了。注意,定义命令别名的时候,`=` 两端是没有空格的。当运行 `lc` 的时候,就相当于执行了 `ls --color` 命令。
此后,执行 `lc` 列出目录内容的时候,就会输出带有着色的内容了。
你可能会发现你在执行 `ls` 的时候,本来就是输出带有着色的内容。那是因为大部分 Linux 发行版都已经将 `ls` 设定为带有着色的命令别名了。
### 可以直接使用的命令别名
实际上,执行不带任何内容的 `alias` 命令就可以看到当前已经设定的所有命令别名。对于不同的发行版,包含的命令别名不尽相同,但普遍都会有以下这些命令别名:
* `alias ls='ls --color=auto'`:这个命令别名在前面已经提到过了。`--color=auto` 参数会让 `ls` 命令在通过标准输出在终端中显示内容时进行着色,而其它情况(例如通过管道输出到文件)下则不进行着色。`--color` 这个参数还可以设置为 `always` 或`never`。
* `alias cp='cp -i'`:`-i` 参数代表“<ruby> 交互 <rt> interactive </rt></ruby>”。在使用 `cp` 命令复制文件的时候,可能会无意中覆盖现有的文件,在使用了 `-i` 参数之后,`cp` 命令会在一些关键操作前向用户发出询问。
* `alias free='free -m'`:在 `free` 命令后面加上 `-m` 参数,就可以将输出的内存信息以 MiB 这个更方面阅读和计算的单位输出,而不是默认的 Byte 单位。
你使用的发行版自带的命令别名可能多多少少和上面有些差别。但你都可以在命令前面加上 `\` 修饰符来使用命令的最基本形式(而不是别名)。例如:
```
\free
```
就是直接执行 `free`,而不是 `free -m`。还有:
```
\ls
```
执行的就是不带有`--color=auto` 参数的 `ls`。
如果想要持久地保存命令别名,可以在 `.bashrc` 文件中进行修改,而它[来源于我们的 /etc/skel 目录](/article-10370-1.html)。
### 使用命令别名纠正错误
各种发行版的设计者都会尽量设置用户可能需要用到的命令别名。但是不同的用户的习惯各不相同,一些用户可能刚从其它操作系统迁移到 Linux,而不同操作系统的基本命令又因 shell 而异。因此,对于刚从 Windows/MS-DOS 系统迁移到 Linux 系统的用户,不妨使用
```
alias dir='ls'
```
这个命令别名来列出目录内容。
类似地,
```
alias copy='cp'
alias move='mv'
```
也可以在尚未完全熟悉 Linux 的时候用得顺手。
还有一种情况,就是在经常出现输入错误的场合中做出容错,例如,对于我来说, Administration 这个单词就很难快速正确地输入,因此很多用户都会设置类似这样的别名:
```
alias sl='ls'
```
以及
```
alias gerp='echo "You did it *again*!"; grep'
```
`grep` 命令最基本的用途就是在文件中查找字符串,在熟悉这个命令之后,它一定是最常用的命令之一,因此输入错误导致不得不重输命令就很令人抓狂。
在上面 `gerp` 的例子中,包含的不只是一条命令,而是两条。第一条命令 `echo "You did it *again*!"` 输出了一条提醒用户拼写错误的消息,然后使用分号(`;`)把两条命令隔开,再往后才是 `grep` 这一条正确的命令。
在我的系统上使用 `gerp` 来搜索 `/etc/skel/.bashrc` 中包含“alias”这个单词的行,就会输出以下内容:
```
$ gerp -R alias /etc/skel/.bashrc
You did it *again*!
alias ls='ls --color=auto'
alias grep='grep --colour=auto'
alias egrep='egrep --colour=auto'
alias fgrep='fgrep --colour=auto'
alias cp="cp -i"
alias df='df -h'
alias free='free -m'
alias np='nano -w PKGBUILD'
alias more=less
shopt -s expand_aliases
```
在命令别名中以固定的顺序执行多个命令,甚至更进一步,把多个命令串连起来,让后面的命令可以使用到前面的命令的执行结果。这样的做法已经非常接近 bash 脚本了。这篇文章已经接近尾声,我们将在下一篇文章中详细介绍。
如果想要删除在终端中临时设置的别名,可以使用 `unalias` 命令。
```
unalias gerp
```
如果想要持久保存命令别名,可以将命令别名放在用户主目录的 `.bashrc` 文件中,具体的方法在[上一篇文章](/article-10374-1.html)中已经介绍过。
---
via: <https://www.linux.com/blog/learn/2018/12/aliases-diy-shell-commands>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,378 | 通过询问-响应身份认证提高桌面登录安全 | https://fedoramagazine.org/login-challenge-response-authentication/ | 2018-12-24T13:42:58 | [
"登录",
"OTP",
"Yubikey"
] | https://linux.cn/article-10378-1.html | 
### 介绍
今天,Fedora 提供了多种方式来提高我们账户的身份认证的安全性。当然,它有我们熟悉的用户名密码登录方式,它也同样提供了其他的身份认证选项,比如生物识别、指纹、智能卡、一次性密码,甚至是<ruby> 询问-响应 <rt> challenge-response </rt></ruby>身份认证。
每种认证方式都有明确的优缺点。这点本身就可以成为一篇相当冗长的文章的主题。Fedora 杂志之前就已经介绍过了这其中的一些选项:
* [在 Fedora 中使用 YubiKey4](https://fedoramagazine.org/using-the-yubikey4-with-fedora/)
* [Fedora 28:在 OpenSSH 中更好的支持智能卡](https://fedoramagazine.org/fedora-28-better-smart-card-support-openssh/)
在现在的 Fedora 版本中,最安全的方法之一就是离线硬件询问-响应。它也同样是最容易部署的方法之一。下面是具体方法。
### 询问-响应认证
从技术上来讲,当你输入密码的时候,你就正在响应用户名询问。离线的询问、响应包含了这些部分:首先是需要你的用户名,接下来,Fedora 会要你提供一个加密的物理硬件的令牌。令牌会把另一个其存储的加密密钥通过<ruby> 可插入式身份认证 <rt> Pluggable Authentication Module </rt></ruby>模块(PAM)框架来响应询问。最后,Fedora 才会提示你输入密码。这可以防止其他人仅仅使用了找到的硬件令牌,或是只使用了账户名密码而没有正确的加密密钥。
这意味着除了你的账户名密码之外,你必须事先在你的操作系统中注册了一个或多个加密硬件令牌。你必须保证你的物理硬件令牌能够匹配你的用户名。
一些询问-响应的方法,比如一次性密码(OTP),在硬件令牌上获取加密的代码密钥,然后将这个密钥通过网络传输到远程身份认证服务器。然后这个服务器会告诉 Fedora 的 PAM 框架,这是否是该用户的一个有效令牌。如果身份认证服务器在本地网络上,这个方法非常好。但它的缺点是如果网络连接断开或是你在没有网的远程端工作。你会被锁在系统之外,直到你能通过网络连接到身份认证服务器。
有时候,生产环境会采用通过 Yubikey 使用一次性密码(OTP)的设置,然而,在家庭或个人的系统上,你可能更喜欢询问-响应设置。一切都是本地的,这种方法不需要通过远程网络调用。下面这些过程适用于 Fedora 27、28 和 29.
### 准备
#### 硬件令牌密钥
首先,你需要一个安全的硬件令牌密钥。具体来说,这个过程需要一个 Yubikey 4、Yubikey NEO,或者是最近发布的、同样支持 FIDO2 的 Yubikey 5 系列设备。你应该购买它们中的两个,一个做备份,以避免其中一个丢失或遭到损坏。你可以在不同的工作地点使用这些密钥。较为简单的 FIDO 和 FIDO U2F 版本不适用于这个过程,但是非常适合使用 FIDO 的在线服务。
#### 备份、备份,以及备份
接下来,为你所有的重要数据制作备份,你可能想在克隆在 VM 里的 Fedora 27/28/29 里测试配置,来确保你在设置你自己的个人工作环境之前理解这个过程。
#### 升级,然后安装
现在,确定你的 Fedora 是最新的,然后通过 `dnf` 命令安装所需要的 Fedora Yubikey 包。
```
$ sudo dnf upgrade
$ sudo dnf install ykclient* ykpers* pam_yubico*
```
如果你使用的是 VM 环境,例如 Virtual Box,确保 Yubikey 设备已经插进了 USB 口,然后允许 VM 控制的 USB 访问 Yubikey。
### 配置 Yubikey
确认你的账户访问到了 USB Yubikey:
```
$ ykinfo -v
version: 3.5.0
```
如果 Yubikey 没有被检测到,会出现下面这些错误信息:
```
Yubikey core error: no yubikey present
```
接下来,通过下面这些 `ykpersonalize` 命令初始化你每个新的 Yubikey。这将设置 Yubikey 配置插槽 2 使用 HMAC-SHA1 算法(即使少于 64 个字符)进行询问响应。如果你已经为询问响应设置好了你的 Yubikey。你就不需要再次运行 `ykpersonalize` 了。
```
ykpersonalize -2 -ochal-resp -ochal-hmac -ohmac-lt64 -oserial-api-visible
```
一些用户在使用的时候将 YubiKey 留在了他们的工作站上,甚至用于对虚拟机进行询问-响应。然而,为了更好的安全性,你可能会更愿意使用手动触发 YubiKey 来响应询问。
要添加手动询问按钮触发器,请添加 `-ochal-btn-trig` 选项,这个选项可以使得 Yubikey 在请求中闪烁其 LED。等待你在 15 秒内按下硬件密钥区域上的按钮来生成响应密钥。
```
$ ykpersonalize -2 -ochal-resp -ochal-hmac -ohmac-lt64 -ochal-btn-trig -oserial-api-visible
```
为你的每个新的硬件密钥执行此操作。每个密钥执行一次。完成编程之后,使用下面的命令将 Yubikey 配置存储到 `~/.yubico`:
```
$ ykpamcfg -2 -v
debug: util.c:222 (check_firmware_version): YubiKey Firmware version: 4.3.4
Sending 63 bytes HMAC challenge to slot 2
Sending 63 bytes HMAC challenge to slot 2
Stored initial challenge and expected response in '/home/chuckfinley/.yubico/challenge-9992567'.
```
如果你要设置多个密钥用于备份,请将所有的密钥设置为相同,然后使用 `ykpamcfg` 工具存储每个密钥的询问-响应。如果你在一个已经存在的注册密钥上运行 `ykpersonalize` 命令,你就必须再次存储配置信息。
### 配置 /etc/pam.d/sudo
现在要去验证配置是否有效,**在同一个终端窗口中**,你需要设置 `sudo` 来要求使用 Yubikey 的询问-响应。将下面这几行插入到 `/etc/pam.d/sudo` 文件中。
```
auth required pam_yubico.so mode=challenge-response
```
将上面的 `auth` 行插入到文件中的 `auth include system-auth` 行的上面,然后保存并退出编辑器。在默认的 Fedora 29 设置中,`/etc/pam.d/sudo` 应该像下面这样:
```
#%PAM-1.0
auth required pam_yubico.so mode=challenge-response
auth include system-auth
account include system-auth
password include system-auth
session optional pam_keyinit.so revoke
session required pam_limits.so
session include system-auth
```
**保持这个初始的终端窗口打开**,然后打开一个新的终端窗口进行测试,在新的终端窗口中输入:
```
$ sudo echo testing
```
你应该注意到了 Yubikey 上的 LED 在闪烁。点击 Yubikey 按钮,你应该会看见一个输入 `sudo` 密码的提示。在你输入你的密码之后,你应该会在终端屏幕上看见 “testing” 的字样。
现在去测试确保失败也正常,启动另一个终端窗口,并从 USB 插口中拔掉 Yubikey。使用下面这条命令验证,在没有 Yubikey 的情况下,`sudo` 是否会不再正常工作。
```
$ sudo echo testing fail
```
你应该立刻被提示输入 `sudo` 密码,但即使你输入了正确密码,登录也应该失败。
### 设置 Gnome 桌面管理器(GDM)
一旦你的测试完成后,你就可以为图形登录添加询问-响应支持了。将你的 Yubikey 再次插入进 USB 插口中。然后将下面这几行添加到 `/etc/pam.d/gdm-password` 文件中:
```
auth required pam_yubico.so mode=challenge-response
```
打开一个终端窗口,然后运行下面这些命令。如果需要,你可以使用其他的编辑器:
```
$ sudo vi /etc/pam.d/gdm-password
```
你应该看到 Yubikey 上的 LED 在闪烁,按下 Yubikey 按钮,然后在提示符处输入密码。
修改 `/etc/pam.d/gdm-password` 文件,在已有的 `auth substack password-auth` 行上添加新的行。这个文件的顶部应该像下面这样:
```
auth [success=done ignore=ignore default=bad] pam_selinux_permit.so
auth required pam_yubico.so mode=challenge-response
auth substack password-auth
auth optional pam_gnome_keyring.so
auth include postlogin
account required pam_nologin.so
```
保存更改并退出编辑器,如果你使用的是 vi,输入键是按 `Esc` 键,然后在提示符处输入 `wq!` 来保存并退出。
### 结论
现在注销 GNOME。将 Yubikey 插入到 USB 口,在图形登录界面上点击你的用户名。Yubikey LED 会开始闪烁。触摸那个按钮,你会被提示输入你的密码。
如果你丢失了 Yubikey,除了重置密码之外,你还可以使用备份的 Yubikey。你还可以给你的账户增加额外的 Yubikey 配置。
如果有其他人获得了你的密码,他们在没有你的物理硬件 Yubikey 的情况下,仍然不能登录。恭喜!你已经显著提高了你的工作环境登录的安全性了。
---
via: <https://fedoramagazine.org/login-challenge-response-authentication/>
作者:[nabooengineer](https://fedoramagazine.org/author/nabooengineer/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ## Introduction
Today, Fedora offers multiple ways to improve the secure authentication of our user accounts. Of course it has the familiar user name and password to login. It also offers additional authentication options such as biometric, fingerprint, smart card, one-time password, and even challenge-response authentication.
Each authentication method has clear pros and cons. That, in itself, could be a topic for a rather lengthy article. Fedora Magazine has covered a few of these options previously:
One of the most secure methods in modern Fedora releases is offline hardware challenge-response. It’s also one of the easiest to deploy. Here’s how.
## Challenge-response authentication
Technically, when you provide a password, you’re responding to a user name challenge. The offline challenge response covered here requires your user name first. Next, Fedora challenges you to provide an encrypted physical hardware token. The token responds to the challenge with another encrypted key it stores via the Pluggable Authentication Modules (PAM) framework. Finally, Fedora prompts you for the password. This prevents someone from just using a found hardware token, or just using a user name and password without the correct encrypted key.
This means that in addition to your user name and password, you must have previously registered one or more encrypted hardware tokens with the OS. And you have to provide that physical hardware token to be able to authenticate with your user name.
Some challenge-response methods, like one time passwords (OTP), take an encrypted code key on the hardware token, and pass that key across the network to a remote authentication server. The server then tells Fedora’s PAM framework if it’s is a valid token for that user name. This is great if the authentication server(s) are on the local network. The downside is if the network connection is down or you’re working remote without a network connection, you can’t use this remote authentication method. You could be locked out of the system until you can connect through the network to the server.
Sometimes a workplace requires use of Yubikey One Time Passwords (OTP) configuration. However, on home or personal systems you may prefer a local challenge-response configuration. Everything is local, and the method requires no remote network calls. The following process works on Fedora 27, 28, and 29.
## Preparation
### Hardware token keys
First you need a secure hardware token key. Specifically, this process requires a Yubikey 4, Yubikey NEO, or a recently released Yubikey 5 series device which also supports FIDO2. You should purchase two of them to provide a backup in case one becomes lost or damaged. You can use these keys on numerous workstations. The simpler FIDO or FIDO U2F only versions don’t work for this process, but are great for online services that use FIDO.
### Backup, backup, and backup
Next, make a backup of all your important data. You may want to test the configuration in a Fedora 27/28/29 cloned VM to make sure you understand the process before setting up your personal workstation.
### Updating and installing
Now make sure Fedora is up to date. Then install the required Fedora Yubikey packages via these *dnf* commands:
$sudo dnf upgrade$sudo dnf install ykclient* ykpers* pam_yubico*$cd
If you’re in a VM environment, such as Virtual Box, make sure the Yubikey device is inserted in a USB port, and enable USB access to the Yubikey in the VM control.
## Configuring Yubikey
Verify that your user account has access to the USB Yubikey:
$ykinfo -vversion: 3.5.0
If the YubiKey is not detected, the following error message appears:
Yubikey core error: no yubikey present
Next, initialize each of your new Yubikeys with the following *ykpersonalize* command. This sets up the Yubikey configuration slot 2 with a Challenge Response using the HMAC-SHA1 algorithm, even with less than 64 characters. If you have already setup your Yubikeys for challenge-response, you don’t need to run *ykpersonalize* again.
ykpersonalize -2 -ochal-resp -ochal-hmac -ohmac-lt64 -oserial-api-visible
Some users leave the YubiKey in their workstation while using it, and even use challenge-response for virtual machines. However, for more security you may prefer to manually trigger the Yubikey to respond to challenge.
To add that manual challenge button trigger, add the *-ochal-btn-trig* flag. This flag causes the Yubikey to flash the yubikey LED on a request. It waits for you to press the button on the hardware key area within 15 seconds to produce the response key.
$ykpersonalize -2 -ochal-resp -ochal-hmac -ohmac-lt64 -ochal-btn-trig -oserial-api-visible
Do this for each of your new hardware keys, only once per key. Once you have programmed your keys, store the Yubikey configuration to *~/.yubico* with the following command:
$ykpamcfg -2 -vdebug: util.c:222 (check_firmware_version): YubiKey Firmware version: 4.3.4 Sending 63 bytes HMAC challenge to slot 2 Sending 63 bytes HMAC challenge to slot 2 Stored initial challenge and expected response in '/home/chuckfinley/.yubico/challenge-9992567'.
If you are setting up multiple keys for backup purposes, configure all the keys the same, and store each key’s challenge-response using the *ykpamcfg* utility. If you run the command *ykpersonalize* on an existing registered key, you must store the configuration again.
## Configuring /etc/pam.d/sudo
Now to verify this configuration worked, **in the same terminal window** you’ll setup sudo to require the use of the Yubikey challenge-response. Insert the following line into the */etc/pam.d/sudo* file:
auth required pam_yubico.so mode=challenge-response
Insert the above auth line into the file above the *auth include system-auth* line. Then save the file and exit the editor. In a default Fedora 29 setup, */etc/pam.d/sudo* should now look like this:
#%PAM-1.0 auth required pam_yubico.so mode=challenge-response auth include system-auth account include system-auth password include system-auth session optional pam_keyinit.so revoke session required pam_limits.so session include system-auth
**Keep this original terminal window open**, and test by opening another new terminal window. In the new terminal window type:
$sudo echo testing
You should notice the LED blinking on the key. Tap the Yubikey button and you should see a prompt for your *sudo* password. After you enter your password, you should see “testing” echoed in the terminal screen.
Now test to ensure a correct failure. Start another terminal window and remove the Yubikey from the USB port. Verify that *sudo* no longer works without the Yubikey with this command:
$ sudo echo testing fail
You should immediately be prompted for the sudo password. Even if you enter the password, it should fail.
## Configuring Gnome Desktop Manager
Once your testing is complete, now you can add challenge-response support for the graphical login. Re-insert your Yubikey into the USB port. Next you’ll add the following line to the */etc/pam.d/gdm-password* file:
auth required pam_yubico.so mode=challenge-response
Open a terminal window, and issue the following command. You can use another editor if desired:
$sudo vi /etc/pam.d/gdm-password
You should see the yubikey LED blinking. Press the yubikey button, then enter the password at the prompt.
Modify the */etc/pam.d/gdm-password* file to add the new *auth* line above the existing line *auth substack password-auth*. The top of the file should now look like this:
auth [success=done ignore=ignore default=bad] pam_selinux_permit.so auth required pam_yubico.so mode=challenge-response auth substack password-auth auth optional pam_gnome_keyring.so auth include postlogin account required pam_nologin.so
Save the changes and exit the editor. If you use *vi*, the key sequence is to hit the **Esc** key, then type *wq!* at the prompt to save and exit.
## Conclusion
Now log out of GNOME. With the Yubikey inserted into the USB port, click on your user name in the graphical login. The Yubikey LED begins to flash. Touch the button, and you will be prompted for your password.
If you lose the Yubikey, you can still use the secondary backup Yubikey in addition to your set password. You can also add additional Yubikey configurations to your user account.
If someone gains access to your password, they still can’t login without your physical hardware Yubikey. Congratulations! You’ve now dramatically increased the security of your workstation login.
## wk
While I appreciate the nuts and bolts of establishing such authentication, it would help me dramatically to grasp the details if there were a higher level description of what is going on.
## AquaL1te
When you do this I assume you also have to lock down the TTY’s, otherwise you can still circumvent the 2FA if you have obtained a user’s password.
## nabooengineer
If you wish to add the challenge-response to the virtual console logins, add the following line to /etc/pam.d/login immediately after #%PAM-1.0 :
auth required pam_yubico.so mode=challenge-response
The top of the /etc/pam.d/login file should now look like:
#%PAM-1.0
auth required pam_yubico.so mode=challenge-response
auth substack system-auth
auth include postlogin
account required pam_nologin.so
account include system-auth
…
## AquaL1te
I prefer to use U2F for this, then you don’t have to spend one of your 2 slots for this. I disabled the TTY’s as a whole.
## Blake
Hey,
Great write up! I think you may have meant FIDO2 in reference to the Yubikey 5 in the hardware token keys paragraph.
Thanks again for the article ????
## nabooengineer
Good catch Blake! You are correct that should read FIDO2.
## Edgar Hoch
“If someone gains access to your password, they still can’t login without your physical hardware Yubikey. Congratulations! You’ve now dramatically increased the security of your workstation login.”
I think this is not true. There are still other access options that are not protected by Yubikey. ssh, text console for example.
## nabooengineer
Hi Edgar, you are correct. I should have explained that additional items can be further secured or even disabled; like the virtual consoles and ssh. If readers are interested, I can discuss with the editors and pitch a part 2 of the article.
## Stuart D Gathman
My favorite “hardware device” is a sheet of paper with one time passwords as a second factor. Is there a Fedora how to on setting that up? … both printing the sheet and configuring pam to consult the list and check them off when used.
## cmurf
Or even Grid Multifactor, and then in effect it’s an unlimited list.
## Vlad Klevtsov
In the Updating and installing section:
$ sudo dnf upgrade
$ sudo dnf install ykclient* ykpers* pam_yubico*
$ cd
What is with the last “cd” command? Where was it supposed to change directory, or it was unnecessary?
## Michael
without a parameter set your current working directory to
## Bruno Vernay
It would be kool to support the OpenSource Solo Key too https://www.kickstarter.com/projects/conorpatrick/solo-the-first-open-source-fido2-security-key-usb
## james miller
The opensource solo key was funded to the tune of $123 thousand in 20 minutes… I suspect we will see it soon… lol.
However, one still has to purchase a key. I have been thinking about writing a python program to interact with dbus to run when a usb key is plugged in that retrieves and displays your generated password when plugged in, which you can then type directly or copy and paste (if secure). That would allow any usb key to be used, although not quite as securely. The app could then generate and store passwords that are complex hex or hash type keys that are more secure than standard passwords and that can be renewed automatically at time intervals if necessary. This way the user wouldn’t have to rely on memory.
It might require that the user plugin their key each time, and there would have to be a udev rule installed on the computer, or however windows manages things (a batch file?), but it might complement a two factor authentication process that uses solo or yubikey.
## eddycaban3
Great to see that the project is still active! |
10,379 | 如何构建一台网络引导服务器(一) | https://fedoramagazine.org/how-to-build-a-netboot-server-part-1/ | 2018-12-24T23:49:49 | [
"网络引导"
] | https://linux.cn/article-10379-1.html | 
有些计算机网络需要在各个物理机器上维护相同的软件和配置。学校的计算机实验室就是这样的一个环境。 [网络引导](https://en.wikipedia.org/wiki/Network_booting) 服务器能够被配置为基于网络去提供一个完整的操作系统,以便于客户端计算机从一个中央位置获取配置。本教程将向你展示构建一台网络引导服务器的一种方法。
本教程的第一部分将包括创建一台网络引导服务器和镜像。第二部分将展示如何去添加 Kerberos 验证的家目录到网络引导配置中。
### 初始化配置
首先去下载 Fedora 服务器的 [netinst](https://dl.fedoraproject.org/pub/fedora/linux/releases/28/Server/x86_64/iso/) 镜像,将它刻录到一张光盘上,然后用它引导服务器来重新格式化。我们只需要一个典型的 Fedora Server 的“最小化安装”来作为我们的开端,安装完成后,我们可以使用命令行去添加我们需要的任何额外的包。

>
> 注意:本教程中我们将使用 Fedora 28。其它版本在“最小化安装”中包含的包可能略有不同。如果你使用的是不同的 Fedora 版本,如果一个预期的文件或命令不可用,你可能需要做一些调试。
>
>
>
最小化安装的 Fedora Server 运行起来之后,以 root 用户登入:
```
$ sudo -i
```
并设置主机名字:
```
$ MY_HOSTNAME=server-01.example.edu
$ hostnamectl set-hostname $MY_HOSTNAME
```
>
> 注意:Red Hat 建议静态和临时名字应都要与这个机器在 DNS 中的完全合格域名相匹配,比如 host.example.com([了解主机名字](https://docs.fedoraproject.org/en-US/Fedora/25/html/Networking_Guide/ch-Configure_Host_Names.html#sec_Understanding_Host_Names))。
>
>
> 注意:本指南为了方便“复制粘贴”。需要自定义的任何值都声明为一个 `MY_*` 变量,在你运行剩余命令之前,你可能需要调整它。如果你注销之后,变量的赋值将被清除。
>
>
> 注意:Fedora 28 Server 在默认情况下往往会转储大量的日志到控制台上。你可以通过运行命令:`sysctl -w kernel.printk=0` 去禁用控制台日志输出。
>
>
>
接下来,我们需要在我们的服务器上配置一个静态网络地址。运行下面的一系列命令将找到并重新配置你的默认网络连接:
```
$ MY_DNS1=192.0.2.91
$ MY_DNS2=192.0.2.92
$ MY_IP=192.0.2.158
$ MY_PREFIX=24
$ MY_GATEWAY=192.0.2.254
$ DEFAULT_DEV=$(ip route show default | awk '{print $5}')
$ DEFAULT_CON=$(nmcli d show $DEFAULT_DEV | sed -n '/^GENERAL.CONNECTION:/s!.*:\s*!! p')
$ nohup bash << END
nmcli con mod "$DEFAULT_CON" connection.id "$DEFAULT_DEV"
nmcli con mod "$DEFAULT_DEV" connection.interface-name "$DEFAULT_DEV"
nmcli con mod "$DEFAULT_DEV" ipv4.method disabled
nmcli con up "$DEFAULT_DEV"
nmcli con add con-name br0 ifname br0 type bridge
nmcli con mod br0 bridge.stp no
nmcli con mod br0 ipv4.dns $MY_DNS1,$MY_DNS2
nmcli con mod br0 ipv4.addresses $MY_IP/$MY_PREFIX
nmcli con mod br0 ipv4.gateway $MY_GATEWAY
nmcli con mod br0 ipv4.method manual
nmcli con up br0
nmcli con add con-name br0-slave0 ifname "$DEFAULT_DEV" type bridge-slave master br0
nmcli con up br0-slave0
END
```
>
> 注意:上面最后的一组命令被封装到一个 `nohup` 脚本中,因为它将临时禁用网络。这个 `nohup` 命令可以让 `nmcli` 命令运行完成,即使你的 SSH 连接断开。注意,连接恢复可能需要 10 秒左右的时间,如果你改变了服务器 IP 地址,你将需要重新启动一个新的 SSH 连接。
>
>
> 注意:上面的网络配置在默认的连接之上创建了一个 [网桥](https://en.wikipedia.org/wiki/Bridging_(networking)),这样我们在后面的测试中就可以直接运行一个虚拟机实例。如果你不想在这台服务器上去直接测试网络引导镜像,你可以跳过创建网桥的命令,并直接在你的默认网络连接上配置静态 IP 地址。
>
>
>
### 安装和配置 NFS4
从安装 nfs-utils 包开始:
```
$ dnf install -y nfs-utils
```
为发布 NFS 去创建一个顶级的 [伪文件系统](https://www.centos.org/docs/5/html/5.1/Deployment_Guide/s3-nfs-server-config-exportfs-nfsv4.html),然后在你的网络上共享它:
```
$ MY_SUBNET=192.0.2.0
$ mkdir /export
$ echo "/export -fsid=0,ro,sec=sys,root_squash $MY_SUBNET/$MY_PREFIX" > /etc/exports
```
SELinux 会干扰网络引导服务器的运行。为它配置例外规则超出了本教程中,因此我们这里直接禁用它:
```
$ sed -i '/GRUB_CMDLINE_LINUX/s/"$/ audit=0 selinux=0"/' /etc/default/grub
$ grub2-mkconfig -o /boot/grub2/grub.cfg
$ sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
$ setenforce 0
```
>
> 注意:应该不需要编辑 grub 命令行,但我们在测试过程中发现,直接编辑 `/etc/sysconfig/selinux` 被证明重启后是无效的,因此这样做再次确保设置了 `selinux=0` 标志。
>
>
>
现在,在本地防火墙中为 NFS 服务添加一个例外规则,然后启动 NFS 服务:
```
$ firewall-cmd --add-service nfs
$ firewall-cmd --runtime-to-permanent
$ systemctl enable nfs-server.service
$ systemctl start nfs-server.service
```
### 创建网络引导镜像
现在我们的 NFS 服务器已经启动运行了,我们需要为它提供一个操作系统镜像,以便于它提供给客户端计算机。我们将从一个非常小的镜像开始,等一切顺利之后再添加。
首先,创建一个存放我们镜像的新目录:
```
$ mkdir /fc28
```
使用 `dnf` 命令在新目录下用几个基础包去构建镜像:
```
$ dnf -y --releasever=28 --installroot=/fc28 install fedora-release systemd passwd rootfiles sudo dracut dracut-network nfs-utils vim-minimal dnf
```
在上面的命令中省略了很重要的 `kernel` 包。在它们被安装完成之前,我们需要去调整一下 `initramfs` 镜像中包含的驱动程序集,`kernel` 首次安装时将自动构建这个镜像。尤其是,我们需要禁用 `hostonly` 模式,以便于 `initramfs` 镜像能够在各种硬件平台上正常工作,并且我们还需要添加对网络和 NFS 的支持:
```
$ echo 'hostonly=no' > /fc28/etc/dracut.conf.d/hostonly.conf
$ echo 'add_dracutmodules+=" network nfs "' > /fc28/etc/dracut.conf.d/netboot.conf
```
现在,安装 `kernel` 包:
```
$ dnf -y --installroot=/fc28 install kernel
```
设置一个阻止 `kernel` 包被更新的规则:
```
$ echo 'exclude=kernel-*' >> /fc28/etc/dnf/dnf.conf
```
设置 locale:
```
$ echo 'LANG="en_US.UTF-8"' > /fc28/etc/locale.conf
```
>
> 注意:如果 locale 没有正确配置,一些程序(如 GNOME Terminal)将无法正常工作。
>
>
>
设置客户端的主机名字:
```
$ MY_CLIENT_HOSTNAME=client-01.example.edu
$ echo $MY_CLIENT_HOSTNAME > /fc28/etc/hostname
```
禁用控制台日志输出:
```
$ echo 'kernel.printk = 0 4 1 7' > /fc28/etc/sysctl.d/00-printk.conf
```
定义网络引导镜像中的本地 `liveuser` 用户:
```
$ echo 'liveuser:x:1000:1000::/home/liveuser:/bin/bash' >> /fc28/etc/passwd
$ echo 'liveuser::::::::' >> /fc28/etc/shadow
$ echo 'liveuser:x:1000:' >> /fc28/etc/group
$ echo 'liveuser:!::' >> /fc28/etc/gshadow
```
允许 `liveuser` 使用 `sudo`:
```
$ echo 'liveuser ALL=(ALL) NOPASSWD: ALL' > /fc28/etc/sudoers.d/liveuser
```
启用自动创建家目录:
```
$ dnf install -y --installroot=/fc28 authselect oddjob-mkhomedir
$ echo 'dirs /home' > /fc28/etc/rwtab.d/home
$ chroot /fc28 authselect select sssd with-mkhomedir --force
$ chroot /fc28 systemctl enable oddjobd.service
```
由于多个客户端将会同时挂载我们的镜像,我们需要去配置镜像工作在只读模式中:
```
$ sed -i 's/^READONLY=no$/READONLY=yes/' /fc28/etc/sysconfig/readonly-root
```
配置日志输出到内存而不是持久存储中:
```
$ sed -i 's/^#Storage=auto$/Storage=volatile/' /fc28/etc/systemd/journald.conf
```
配置 DNS:
```
$ MY_DNS1=192.0.2.91
$ MY_DNS2=192.0.2.92
$ cat << END > /fc28/etc/resolv.conf
nameserver $MY_DNS1
nameserver $MY_DNS2
END
```
绕开编写本教程时存在的根目录只读挂载的 bug([BZ1542567](https://bugzilla.redhat.com/show_bug.cgi?id=1542567)):
```
$ echo 'dirs /var/lib/gssproxy' > /fc28/etc/rwtab.d/gssproxy
$ cat << END > /fc28/etc/rwtab.d/systemd
dirs /var/lib/systemd/catalog
dirs /var/lib/systemd/coredump
END
```
最后,为我们镜像创建 NFS 文件系统,并将它共享到我们的子网中:
```
$ mkdir /export/fc28
$ echo '/fc28 /export/fc28 none bind 0 0' >> /etc/fstab
$ mount /export/fc28
$ echo "/export/fc28 -ro,sec=sys,no_root_squash $MY_SUBNET/$MY_PREFIX" > /etc/exports.d/fc28.exports
$ exportfs -vr
```
### 创建引导加载器
现在,我们已经有了可以进行网络引导的操作系统,我们需要一个引导加载器去从客户端系统上启动它。在本教程中我们使用的是 [iPXE](https://ipxe.org/)。
>
> 注意:本节和接下来的节使用 QEMU 测试,也能在另外一台单独的计算机上来完成;它们并不需要在网络引导服务器上来运行。
>
>
>
安装 `git` 并使用它去下载 iPXE:
```
$ dnf install -y git
$ git clone http://git.ipxe.org/ipxe.git $HOME/ipxe
```
现在我们需要去为我们的引导加载器创建一个指定的启动脚本:
```
$ cat << 'END' > $HOME/ipxe/init.ipxe
#!ipxe
prompt --key 0x02 --timeout 2000 Press Ctrl-B for the iPXE command line... && shell ||
dhcp || exit
set prefix file:///linux
chain ${prefix}/boot.cfg || exit
END
```
启动 “file” 下载协议:
```
$ echo '#define DOWNLOAD_PROTO_FILE' > $HOME/ipxe/src/config/local/general.h
```
安装 C 编译器以及相关的工具和库:
```
$ dnf groupinstall -y "C Development Tools and Libraries"
```
构建引导加载器:
```
$ cd $HOME/ipxe/src
$ make clean
$ make bin-x86_64-efi/ipxe.efi EMBED=../init.ipxe
```
记下新编译的引导加载器的存储位置。我们将在接下来的节中用到它:
```
$ IPXE_FILE="$HOME/ipxe/src/bin-x86_64-efi/ipxe.efi"
```
### 用 QEMU 测试
这一节是可选的,但是你需要去复制下面显示在物理机器上的 [EFI 系统分区](https://en.wikipedia.org/wiki/EFI_system_partition) 的布局,在网络引导时需要去配置它们。
>
> 注意:如果你想实现一个完全的无盘系统,你也可以复制那个文件到一个 TFTP 服务器,然后从 DHCP 上指向那台服务器。
>
>
>
为了使用 QEMU 去测试我们的引导加载器,我们继续去创建一个仅包含一个 EFI 系统分区和我们的启动文件的、很小的磁盘镜像。
从创建 EFI 系统分区所需要的目录布局开始,然后把我们在前面节中创建的引导加载器复制进去:
```
$ mkdir -p $HOME/esp/efi/boot
$ mkdir $HOME/esp/linux
$ cp $IPXE_FILE $HOME/esp/efi/boot/bootx64.efi
```
下面的命令将识别我们的引导加载器镜像正在使用的内核版本,并将它保存到一个变量中,以备后续的配置命令去使用它:
```
$ DEFAULT_VER=$(ls -c /fc28/lib/modules | head -n 1)
```
定义我们的客户端计算机将使用的引导配置:
```
$ MY_DNS1=192.0.2.91
$ MY_DNS2=192.0.2.92
$ MY_NFS4=server-01.example.edu
$ cat << END > $HOME/esp/linux/boot.cfg
#!ipxe
kernel --name kernel.efi \${prefix}/vmlinuz-$DEFAULT_VER initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=$MY_DNS1 nameserver=$MY_DNS2 root=nfs4:$MY_NFS4:/fc28 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet
initrd --name initrd.img \${prefix}/initramfs-$DEFAULT_VER.img
boot || exit
END
```
>
> 注意:上面的引导脚本展示了如何使用 iPXE 去网络引导 Linux 的最小示例。还可以做更多更复杂的配置。值得注意的是,iPXE 支持交互式引导菜单,它可以让你配置默认选项和超时时间。比如,一个更高级一点 iPXE 脚本可以默认从本地磁盘引导一个操作系统,如果在倒计时结束之前用户按下了一个键,才会去网络引导一个操作系统。
>
>
>
复制 Linux 内核并分配 initramfs 给 EFI 系统分区:
```
$ cp $(find /fc28/lib/modules -maxdepth 2 -name 'vmlinuz' | grep -m 1 $DEFAULT_VER) $HOME/esp/linux/vmlinuz-$DEFAULT_VER
$ cp $(find /fc28/boot -name 'init*' | grep -m 1 $DEFAULT_VER) $HOME/esp/linux/initramfs-$DEFAULT_VER.img
```
我们最终的目录布局应该看起来像下面的样子:
```
esp
├── efi
│ └── boot
│ └── bootx64.efi
└── linux
├── boot.cfg
├── initramfs-4.18.18-200.fc28.x86_64.img
└── vmlinuz-4.18.18-200.fc28.x86_64
```
要让 QEMU 去使用我们的 EFI 系统分区,我们需要去创建一个小的 `uefi.img` 磁盘镜像来包含它,然后将它连接到 QEMU 作为主引导驱动器。
开始安装必需的工具:
```
$ dnf install -y parted dosfstools
```
现在创建 `uefi.img` 文件,并将 `esp` 目录中的文件复制进去:
```
$ ESP_SIZE=$(du -ks $HOME/esp | cut -f 1)
$ dd if=/dev/zero of=$HOME/uefi.img count=$((${ESP_SIZE}+5000)) bs=1KiB
$ UEFI_DEV=$(losetup --show -f $HOME/uefi.img)
$ parted ${UEFI_DEV} -s mklabel gpt mkpart EFI FAT16 1MiB 100% toggle 1 boot
$ mkfs -t msdos ${UEFI_DEV}p1
$ mkdir -p $HOME/mnt
$ mount ${UEFI_DEV}p1 $HOME/mnt
$ cp -r $HOME/esp/* $HOME/mnt
$ umount $HOME/mnt
$ losetup -d ${UEFI_DEV}
```
>
> 注意:在物理计算机上,你只需要从 `esp` 目录中复制文件到计算机上已存在的 EFI 系统分区中。你不需要使用 `uefi.img` 文件去引导物理计算机。
>
>
> 注意:在一个物理计算机上,如果文件名已存在,你可以重命名 `bootx64.efi` 文件,如果你重命名了它,就需要去编辑计算机的 BIOS 设置,并添加重命令后的 efi 文件到引导列表中。
>
>
>
接下来我们需要去安装 qemu 包:
```
$ dnf install -y qemu-system-x86
```
允许 QEMU 访问我们在本教程“初始化配置”一节中创建的网桥:
```
$ echo 'allow br0' > /etc/qemu/bridge.conf
```
创建一个 `OVMF_VARS.fd` 镜像的副本去保存我们虚拟机的持久 BIOS 配置:
```
$ cp /usr/share/edk2/ovmf/OVMF_VARS.fd $HOME
```
现在,启动虚拟机:
```
$ qemu-system-x86_64 -machine accel=kvm -nographic -m 1024 -drive if=pflash,format=raw,unit=0,file=/usr/share/edk2/ovmf/OVMF_CODE.fd,readonly=on -drive if=pflash,format=raw,unit=1,file=$HOME/OVMF_VARS.fd -drive if=ide,format=raw,file=$HOME/uefi.img -net bridge,br=br0 -net nic,model=virtio
```
如果一切顺利,你将看到类似下图所示的结果:

你可以使用 `shutdown` 命令关闭虚拟机回到我们的服务器上:
```
$ sudo shutdown -h now
```
>
> 注意:如果出现了错误或虚拟机挂住了,你可能需要启动一个新的 SSH 会话去连接服务器,使用 `kill` 命令去终止 `qemu-system-x86_64` 进程。
>
>
>
### 镜像中添加包
镜像中添加包应该是一个很简单的问题,在服务器上 `chroot` 进镜像,然后运行 `dnf install <package_name>`。
在网络引导镜像中并不限制你能安装什么包。一个完整的图形化安装应该能够完美地工作。
下面是一个如何将最小化安装的网络引导镜像变成完整的图形化安装的示例:
```
$ for i in dev dev/pts dev/shm proc sys run; do mount -o bind /$i /fc28/$i; done
$ chroot /fc28 /usr/bin/bash --login
$ dnf -y groupinstall "Fedora Workstation"
$ dnf -y remove gnome-initial-setup
$ systemctl disable sshd.service
$ systemctl enable gdm.service
$ systemctl set-default graphical.target
$ sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
$ logout
$ for i in run sys proc dev/shm dev/pts dev; do umount /fc28/$i; done
```
可选地,你可能希望去启用 `liveuser` 用户的自动登录:
```
$ sed -i '/daemon/a AutomaticLoginEnable=true' /fc28/etc/gdm/custom.conf
$ sed -i '/daemon/a AutomaticLogin=liveuser' /fc28/etc/gdm/custom.conf
```
---
via: <https://fedoramagazine.org/how-to-build-a-netboot-server-part-1/>
作者:[Gregory Bartholomew](https://fedoramagazine.org/author/glb/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Some computer networks need to maintain identical software installations and configurations on several physical machines. One such environment would be a school computer lab. A [netboot](https://en.wikipedia.org/wiki/Network_booting) server can be set up to serve an entire operating system over a network so that the client computers can be configured from one central location. This tutorial will show one method of building a netboot server.
Part 1 of this tutorial will cover creating a netboot server and image. Part 2 will show how to add Kerberos-authenticated home directories to the netboot configuration.
## Initial Configuration
Start by downloading one of Fedora Server’s [netinst](https://dl.fedoraproject.org/pub/fedora/linux/releases/28/Server/x86_64/iso/) images, burning it to a CD, and booting the server that will be reformatted from it. We just need a typical “Minimal Install” of Fedora Server for our starting point and we will use the command line to add any additional packages that are needed after the installation is finished.
NOTE: For this tutorial we will be using Fedora 28. Other versions may include a slightly different set of packages in their “Minimal Install”. If you start with a different version of Fedora, then you may need to do some troubleshooting if an expected file or command is not available.
Once you have your minimal installation of Fedora Server up and running, log in and then become *root* using this command:
$ sudo -i
Set the hostname:
# MY_HOSTNAME=server-01.example.edu # hostnamectl set-hostname $MY_HOSTNAME
NOTE: Red Hat recommends that both static and transient names match the fully-qualified domain name (FQDN) used for the machine in DNS, such as host.example.com (
[Understanding Host Names]).NOTE: This guide is meant to be copy-and-paste friendly. Any value that you might need to customize will be stated as a MY_* variable that you can tweak before running the remaining commands. Beware that if you log out, the variable assignments will be cleared.
NOTE: Fedora 28 Server tends to dump a lot of logging output to the console by default. You may want to disable the console logging temporarily by running: sysctl -w kernel.printk=0
Next, we need a static network address on our server. The following sequence of commands should find and reconfigure your default network connection appropriately:
# MY_DNS1=192.0.2.91 # MY_DNS2=192.0.2.92 # MY_IP=192.0.2.158 # MY_PREFIX=24 # MY_GATEWAY=192.0.2.254 # DEFAULT_DEV=$(ip route show default | awk '{print $5}') # DEFAULT_CON=$(nmcli d show $DEFAULT_DEV | sed -n '/^GENERAL.CONNECTION:/s!.*:\s*!! p') # nohup bash << END nmcli con mod "$DEFAULT_CON" connection.id "$DEFAULT_DEV" nmcli con mod "$DEFAULT_DEV" connection.interface-name "$DEFAULT_DEV" nmcli con mod "$DEFAULT_DEV" ipv4.method disabled nmcli con up "$DEFAULT_DEV" nmcli con add con-name br0 ifname br0 type bridge nmcli con mod br0 bridge.stp no nmcli con mod br0 ipv4.dns $MY_DNS1,$MY_DNS2 nmcli con mod br0 ipv4.addresses $MY_IP/$MY_PREFIX nmcli con mod br0 ipv4.gateway $MY_GATEWAY nmcli con mod br0 ipv4.method manual nmcli con up br0 nmcli con add con-name br0-slave0 ifname "$DEFAULT_DEV" type bridge-slave master br0 nmcli con up br0-slave0 END
NOTE: The last set of commands above is wrapped in a “nohup” script because it will disable networking temporarily. The nohup command should allow the nmcli commands to finish running even while your ssh connection is down. Beware that it may take 10 or so seconds for the connection to come back up and that you will have to start a new ssh connection if you changed the server’s IP address.
NOTE: The above network configuration creates a
[network bridge]on top of the default connection so that we can run a virtual machine instance directly on the server for testing later. If you do not want to test the netboot image directly on the server, you can skip creating the bridge and set the static IP address directly on your default network connection.
## Install and Configure NFS4
Start by installing the nfs-utils package:
# dnf install -y nfs-utils
Create a top-level [pseudo filesystem](https://www.centos.org/docs/5/html/5.1/Deployment_Guide/s3-nfs-server-config-exportfs-nfsv4.html) for the NFS exports and share it out to your network:
# MY_SUBNET=192.0.2.0 # mkdir /export # echo "/export -fsid=0,ro,sec=sys,root_squash $MY_SUBNET/$MY_PREFIX" > /etc/exports
SELinux will interfere with the netboot server’s operation. Configuring exceptions for it is beyond the scope of this tutorial, so we will disable it:
# sed -i '/GRUB_CMDLINE_LINUX/s/"$/ audit=0 selinux=0"/' /etc/default/grub # grub2-mkconfig -o /boot/grub2/grub.cfg # sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux # setenforce 0
NOTE: Editing the grub command line should not be necessary, but simply editing /etc/sysconfig/selinux proved ineffective across reboots of Fedora Server 28 during testing, so the “selinux=0” flag has been set here to be doubly sure.
Now, add an exception for the NFS service to the local firewall and start the NFS service:
# firewall-cmd --add-service nfs # firewall-cmd --runtime-to-permanent # systemctl enable nfs-server.service # systemctl start nfs-server.service
## Create the Netboot Image
Now that our NFS server is up and running, we need to supply it with an operating system image to serve to the client computers. We will start with a very minimal image and add to it after everything is working.
First, create a new directory where our image will be stored:
# mkdir /fc28
Use the “dnf” command to build the image under the new directory with only a few base packages:
# dnf -y --releasever=28 --installroot=/fc28 install fedora-release systemd passwd rootfiles sudo dracut dracut-network nfs-utils vim-minimal dnf
It is important that the “kernel” packages were omitted from the above command. Before they are installed, we need to tweak the set of drivers that will be included in the “initramfs” image that is built automatically when the kernel is first installed. In particular, we need to disable “hostonly” mode so that the initramfs image will work on a wider set of hardware platforms and we need to add support for networking and NFS:
# echo 'hostonly=no' > /fc28/etc/dracut.conf.d/hostonly.conf # echo 'add_dracutmodules+=" network nfs "' > /fc28/etc/dracut.conf.d/netboot.conf
Now, install the kernel:
# dnf -y --installroot=/fc28 install kernel
Set a rule to prevent the kernel from being updated:
# echo 'exclude=kernel-*' >> /fc28/etc/dnf/dnf.conf
Set the locale:
# echo 'LANG="en_US.UTF-8"' > /fc28/etc/locale.conf
NOTE: Some programs (e.g. GNOME Terminal) will not function if the locale is not properly configured.
Set the client’s hostname:
# MY_CLIENT_HOSTNAME=client-01.example.edu # echo $MY_CLIENT_HOSTNAME > /fc28/etc/hostname
Disable logging to the console:
# echo 'kernel.printk = 0 4 1 7' > /fc28/etc/sysctl.d/00-printk.conf
Define a local “liveuser” in the netboot image:
# echo 'liveuser:x:1000:1000::/home/liveuser:/bin/bash' >> /fc28/etc/passwd # echo 'liveuser::::::::' >> /fc28/etc/shadow # echo 'liveuser:x:1000:' >> /fc28/etc/group # echo 'liveuser:::' >> /fc28/etc/gshadow
Allow “liveuser” to sudo:
# echo 'liveuser ALL=(ALL) NOPASSWD: ALL' > /fc28/etc/sudoers.d/liveuser
Enable automatic home directory creation:
# dnf install -y --installroot=/fc28 authselect oddjob-mkhomedir # echo 'dirs /home' > /fc28/etc/rwtab.d/home # chroot /fc28 authselect select sssd with-mkhomedir --force # chroot /fc28 systemctl enable oddjobd.service
Since multiple clients will be mounting our image concurrently, we need to configure the image so that it will operate in read-only mode:
# sed -i 's/^READONLY=no$/READONLY=yes/' /fc28/etc/sysconfig/readonly-root
Configure logging to go to RAM rather than permanent storage:
# sed -i 's/^#Storage=auto$/Storage=volatile/' /fc28/etc/systemd/journald.conf
Configure DNS:
# MY_DNS1=192.0.2.91 # MY_DNS2=192.0.2.92 # cat << END > /fc28/etc/resolv.conf nameserver $MY_DNS1 nameserver $MY_DNS2 END
Work-around a few bugs that exist for read-only root mounts at the time this tutorial is being written ([BZ1542567](https://bugzilla.redhat.com/show_bug.cgi?id=1542567)):
# echo 'dirs /var/lib/gssproxy' > /fc28/etc/rwtab.d/gssproxy # cat << END > /fc28/etc/rwtab.d/systemd dirs /var/lib/systemd/catalog dirs /var/lib/systemd/coredump END
Finally, we can create the NFS filesystem for our image and share it out to our subnet:
# mkdir /export/fc28 # echo '/fc28 /export/fc28 none bind 0 0' >> /etc/fstab # mount /export/fc28 # echo "/export/fc28 -ro,sec=sys,no_root_squash $MY_SUBNET/$MY_PREFIX" > /etc/exports.d/fc28.exports # exportfs -vr
## Create the Boot Loader
Now that we have an operating system available to netboot, we need a boot loader to kickstart it on the client systems. For this setup, we will be using [iPXE](https://ipxe.org/). Note you should be logged in to your user account here, not *root*.
NOTE: This section and the following section — Testing with QEMU — can be done on a separate computer; they do not have to be run on the netboot server.
Install git and use it to download iPXE:
$ sudo dnf install -y git $ git clone http://git.ipxe.org/ipxe.git $HOME/ipxe
Now we need to create a special startup script for our bootloader:
$ cat << 'END' > $HOME/ipxe/init.ipxe #!ipxe prompt --key 0x02 --timeout 2000 Press Ctrl-B for the iPXE command line... && shell || dhcp || exit set prefix file:///linux chain ${prefix}/boot.cfg || exit END
Enable the “file” download protocol:
$ echo '#define DOWNLOAD_PROTO_FILE' > $HOME/ipxe/src/config/local/general.h
Install the C compiler and related tools and libraries:
$ sudo dnf groupinstall -y "C Development Tools and Libraries"
Build the boot loader:
$ cd $HOME/ipxe/src $ make clean $ make bin-x86_64-efi/ipxe.efi EMBED=../init.ipxe
Make note of where the where the newly-compiled boot loader is. We will need it for the next section:
$ IPXE_FILE="$HOME/ipxe/src/bin-x86_64-efi/ipxe.efi"
## Testing with QEMU
This section is optional, but you will need to duplicate the file layout of the [EFI system partition](https://en.wikipedia.org/wiki/EFI_system_partition) that is shown below on your physical machines to configure them for netbooting.
NOTE: You could also copy the files to a TFTP server and reference that server from DHCP if you wanted a fully diskless system.
In order to test our boot loader with QEMU, we are going to create a small disk image containing only an EFI system partition and our startup files.
Start by creating the required directory layout for the EFI system partition and copying the boot loader that we created in the previous section to it:
$ mkdir -p $HOME/esp/efi/boot $ mkdir $HOME/esp/linux $ cp $IPXE_FILE $HOME/esp/efi/boot/bootx64.efi
The below command should identify the kernel version that our netboot image is using and store it in a variable for use in the remaining configuration directives:
$ DEFAULT_VER=$(ls -c /fc28/lib/modules | head -n 1)
Define the boot configuration that our client computers will be using:
$ MY_DNS1=192.0.2.91 $ MY_DNS2=192.0.2.92 $ MY_NFS4=server-01.example.edu $ cat << END > $HOME/esp/linux/boot.cfg #!ipxe kernel --name kernel.efi \${prefix}/vmlinuz-$DEFAULT_VER initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=$MY_DNS1 nameserver=$MY_DNS2 root=nfs4:$MY_NFS4:/fc28 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet initrd --name initrd.img \${prefix}/initramfs-$DEFAULT_VER.img boot || exit END
NOTE: The above boot script shows a minimal example of how to get iPXE to netboot Linux. Much more complex configurations are possible. Most notably, iPXE has support for interactive boot menus which can be configured with a default selection and a timeout. A more advanced iPXE script could, for example, default to booting an operation system from the local disk and only go to the netboot operation if a user pressed a key before a countdown timer reached zero.
Copy the Linux kernel and its associated initramfs to the EFI system partition:
$ cp $(find /fc28/lib/modules -maxdepth 2 -name 'vmlinuz' | grep -m 1 $DEFAULT_VER) $HOME/esp/linux/vmlinuz-$DEFAULT_VER $ cp $(find /fc28/boot -name 'init*' | grep -m 1 $DEFAULT_VER) $HOME/esp/linux/initramfs-$DEFAULT_VER.img
Our resulting directory layout should look like this:
esp ├── efi │ └── boot │ └── bootx64.efi └── linux ├── boot.cfg ├── initramfs-4.18.18-200.fc28.x86_64.img └── vmlinuz-4.18.18-200.fc28.x86_64
To use our EFI system partition with QEMU, we need to create a small “uefi.img” disk image containing it and then connect that to QEMU as the primary boot drive.
Begin by installing the necessary tools:
$ sudo dnf install -y parted dosfstools
Now create the “uefi.img” file and copy the files from the “esp” directory into it:
$ ESP_SIZE=$(du -ks $HOME/esp | cut -f 1) $ dd if=/dev/zero of=$HOME/uefi.img count=$((${ESP_SIZE}+5000)) bs=1KiB $ UEFI_DEV=$(sudo losetup --show -f $HOME/uefi.img) $ sudo parted ${UEFI_DEV} -s mklabel gpt mkpart EFI FAT16 1MiB 100% toggle 1 boot $ mkfs -t msdos ${UEFI_DEV}p1 $ mkdir -p $HOME/mnt $ sudo mount ${UEFI_DEV}p1 $HOME/mnt $ cp -r $HOME/esp/* $HOME/mnt $ sudo umount $HOME/mnt $ sudo losetup -d ${UEFI_DEV}
NOTE: On a physical computer, you need only copy the files from the “esp” directory to the computer’s existing EFI system partition. You do not need the “uefi.img” file to boot a physical computer.
NOTE: On a physical computer you can rename the “bootx64.efi” file if a file by that name already exists, but if you do so, you will probably have to edit the computer’s BIOS settings and add the renamed efi file to the boot list.
Next we need to install the qemu package:
$ sudo dnf install -y qemu-system-x86
Allow QEMU to access the bridge that we created in the “Initial Configuration” section of this tutorial:
$ sudo su - # echo 'allow br0' > /etc/qemu/bridge.conf # exit
Create a copy of the “OVMF_VARS.fd” image to store our virtual machine’s persistent BIOS settings:
$ cp /usr/share/edk2/ovmf/OVMF_VARS.fd $HOME
Now, start the virtual machine:
$ qemu-system-x86_64 -machine accel=kvm -nographic -m 1024 -drive if=pflash,format=raw,unit=0,file=/usr/share/edk2/ovmf/OVMF_CODE.fd,readonly=on -drive if=pflash,format=raw,unit=1,file=$HOME/OVMF_VARS.fd -drive if=ide,format=raw,file=$HOME/uefi.img -net bridge,br=br0 -net nic,model=virtio
If all goes well, you should see results similar to what is shown in the below image:
You can use the “shutdown” command to get out of the virtual machine and back to the server:
$ sudo shutdown -h now
NOTE: If something goes wrong and the virtual machine hangs, you may need to start a new ssh session to the server and use the “kill” command to terminate the “qemu-system-x86_64” process.
## Adding to the Image
Adding to the image should be a simple matter of chroot’ing into the image on the server and running “dnf install <package_name>”.
There is no limit to what can be installed on the netboot image. A full graphical installation should function perfectly.
Here is an example of how to bring our minimal netboot image up to a complete graphical installation:
# for i in dev dev/pts dev/shm proc sys run; do mount -o bind /$i /fc28/$i; done # chroot /fc28 /usr/bin/bash --login # dnf -y groupinstall "Fedora Workstation" # dnf -y remove gnome-initial-setup # systemctl disable sshd.service # systemctl enable gdm.service # systemctl set-default graphical.target # sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux # logout # for i in run sys proc dev/shm dev/pts dev; do umount /fc28/$i; done
Optionally, you may want to enable automatic login for the “liveuser” account:
# sed -i '/daemon/a AutomaticLoginEnable=true' /fc28/etc/gdm/custom.conf # sed -i '/daemon/a AutomaticLogin=liveuser' /fc28/etc/gdm/custom.conf
## Milos
Oh no. Another reason to spend money on a small server cluster 🙁
## Gregory Bartholomew
Yeah, actually, I probably should have made some mention of the server requirements in the article. I’m using a 16-core server with a 8Gbps xor-bonded network connection (https://en.wikipedia.org/wiki/Link_aggregation). This setup will netboot 50 clients in parallel in about 3 minutes. You can netboot your workstations with a much smaller server, but it might take a bit longer to boot the clients. Also, I mentioned that you
couldput the kernel and initramfs on a TFTP server, but I wouldn’t recommend it unless you have a fairly big server because the files are so big. Having the kernel and initramfs on the workstations’ local disk significantly reduces the load on the netboot server and speeds up the boot time for the clients.## Milos
In regards to link aggregation: In 2011 worked as a sysadmin where we got fresh new HPservers and 3 racks full of them to manage.
Each rack with redundant power and switches. Each server had 2 NICs with 4 gbit interfaces per NIC. Our idea was to bond the ETH1_x to ETH2_x, but we couldn’t use any aggregating protocol with the switches/firewalls we had. We had to settle for a bonding protocol that does failover rather than get the full speed of combined interfaces.
What I’m planning in the next few years is to have a small cluster most likely running OpenStack or some such. I don’t expect to have very powerful machines in that cluster. Probably something along the lines of Odroid machines + a decent storage unit.
I also definitely won’t have 50 clients running in parallel, but it’s nice to hear how this works for you!
Looking forward to part 2.
## Gregory Bartholomew
The xor load balancing protocol should work with any brand of switch and no special configuration on the switch should be required. If you have a router between your server and your clients though, then that could create a bottleneck.
## Thijs
I work at a high school, where everyone is hating the very slow windows 10 computers. It’s not the computers, they are not very fast, but not too slow either. It’s the system. I will not be able to convince our system administrator to use linux. But if I could set this up, maybe I could convince some other colleagues to use it. If it works flawlessly, we still won’t switch to linux, but I could maybe create some linux mind share 🙂
## Gregory Bartholomew
I have a similar problem — the general purpose (shared) labs at our university must run windows and the central IT department for our university was unwilling to re-partition all the computers for “dual boot” operation or to allocate space on them for a linux virtual machine. That is why I looked into how to set this up.
I might write a “Part 3” to this series at some point to show how to configure iPXE to present the user with a menu for choosing which OS to load (local or netboot).
BTW: If you use SCCM to manage your windows systems, it can also be used to copy the netboot startup files out to the EFI partition on all your client systems — just use “mountvol s: /s” to mount the EFI partition before running the copy command and then “mountvol s: /d” to un-mount it after the copy is complete.
## fmiz
My original question was something like “Why did you prefer this route instead of using a configuration manager like ansible?”, then I read your answer. So, if you could have space allocated for dual boot, would you still have gone with netbooting?
## Gregory Bartholomew
There are pros and cons to every option. I guess the main trade-off between net-boot versus dual-boot would be the performance of the local storage versus the manageability and consistency of the centralized storage. So, as long as the net-boot performance is adequate for our needs, I’d say the centralized storage is a benefit. If you are trying to maintain multiple copies of the OS, there is always a chance that some copies are not identical to others which, in our case, might leave some student scratching his head during a course assignment walk-through and wondering what he is doing wrong when in actuality, it is just a problem with the workstation that he happened to sit down at. I kind of think consistency is better in that situation — even if they are consistently wrong — for the sake of fairness. There are scalability problems though — a server can only churn out so much IO.
## Cesar
Will this work for Fedora 29?
## Gregory Bartholomew
I did start to setup Fedora 29 to test that, but I quickly discovered that the “read-only root” config file was missing. If you want it to work on Fedora 29, you’ll either have to figure out which packages are missing or — what I would probably do if I really needed Fedora 29 at this point — setup everything with Fedora 28 and then run “dnf distro-sync –releasever=29” to upgrade it.
## Cesar
Great suggestion Gregory!
Many thanks.
## Cristian Gherman
network/hostname settings can be done much easier on calameres installer
## Michael Charissis
IPXE should support http and ftp delivery of the kernel and initramfs. Removing all local storage may be a requirement in certain environments. Thank you for taking the time to share this article.
## Juan Antonio
¿What about Linux Terminal Server Project?
¿What about solutions like little vnc clients and a on-demand virtual machine server?
We currently have 200+ computers in an student lab
with net booting and an NBD (Network Block Device) as root filesystem configured as Fat Clients with LTSP and LDAP as auth method
No problems at all, booting fast, and really enjoy it… but need to upgrade (using Ubuntu16.04) and we are studying alternatives like virtual machine cloud server and so
Frankly: this tutorial is very interesting, but not sure about how easily scale up to 200+ simultaneous clients…. ¿What about K12Linux project?¿Is still alive?
## Gregory Bartholomew
200 simultaneous clients does sound like quite a challenge! I’m not sure that a terminal server solution would be any better though. With netbooting, the RAM and CPU of the clients are being utilized and only the storage is centralized. With a terminal server, the server would have to handle all three — RAM, processing, and disk IO. I guess it all depends on exactly what you have your clients running though.
NBD or iSCSI or AoE are all fine alternatives to NFS. As I stated in the first paragraph of the article — this is
onemethod of building a netboot server. There are many alternatives though; each with their trade-offs.Sorry, I don’t know anything about K12Linux.
## Oscar
IsardVDI (https://github.com/isard-vdi/isard) could be an option (it’s done by mates from Barcelona). Another one much more “famous” is Guacamole (https://guacamole.apache.org)
## Drew
Great instructions! It is somewhat over my head, but how else am I going to learn?
Is the entire image served read-only? If so, can you make the client image mount a location to store local configurations, like /home?
I’m sorry if you already mentioned this.
## Gregory Bartholomew
Yes, the entire image is served read-only. I’m currently working on a “Part 2” that will show how to add writable home directories, but I want to show how to do it with kerberos authentication and that is making the article
verylong, so it looks like it will be broken up into more posts — one on how to configure the home directories on the server and then another on how to reconfigure the netboot client to mount them.BTW: It is possible to make a writable version of the image, but you would have to set up a system that “cloned” a common template on the server for each user and the user would have to authenticate through iPXE before it attempts to mount the image.
## Justin
We have a setup similar to this at my work for thinclients which also run Fedora 28. The clients boot over dhcp and pxe. An issue we’ve encountered is running out of RAM space since some of the problems do a lot of logging and eventually the thinclient crashes. We experimented with utilizing the overlay kernel parameter with a directory on a local disk that all the clients have but couldn’t get it to work. Any guides for this sort of setup?
## Gregory Bartholomew
I had a quick look at the overlayfs documentation (https://www.kernel.org/doc/Documentation/filesystems/overlayfs.txt). It looks like it has some caveats about using it with NFS. Personally, if I wanted a client-side overlay for a read-only netboot target like that, I’d probably switch to using iSCSI for serving the image and write a custom dracut hook (http://man7.org/linux/man-pages/man7/dracut.modules.7.html) to setup the cow overlay at the block level with dmsetup (https://linuxgazette.net/114/kapil.html).
Or, alternatively, you could setup multiple cow overlays server-side on a per-user or per-computer bases before exporting them.
Or, if you can use NBD, it has a “copyonwrite” option that can create temporary COWs (see “man 5 nbd-server” if you have the “nbd” package installed).
Like the PERL folks say — There’s more than one way to do it. |
10,380 | 如何使用 Fedora IoT 点亮 LED 灯 | https://fedoramagazine.org/turnon-led-fedora-iot/ | 2018-12-25T00:24:54 | [
"IoT",
"LED"
] | https://linux.cn/article-10380-1.html | 
如果你喜欢 Fedora、容器,而且有一块树莓派,那么这三者结合操控 LED 会怎么样?本文介绍的是 Fedora IoT,将展示如何在树莓派上安装预览镜像。还将学习如何与 GPIO 交互以点亮 LED。
### 什么是 Fedora IoT?
Fedora IoT 是当前 Fedora 项目的目标之一,计划成为一个完整的 Fedora 版本。Fedora IoT 将是一个在 ARM(目前仅限 aarch64)设备上(例如树莓派),以及 x86\_64 架构上运行的系统。

Fedora IoT 基于 OSTree 开发,就像 [Fedora Silverblue](https://teamsilverblue.org/) 和以往的 [Atomic Host](https://www.projectatomic.io/)。
### 下载和安装 Fedora IoT
官方 Fedora IoT 镜像将和 Fedora 29 一起发布。但是在此期间你可以下载 [基于 Fedora 28 的镜像](https://kojipkgs.fedoraproject.org/compose/iot/latest-Fedora-IoT-28/compose/IoT/) 来进行这个实验。(LCTT 译注:截止至本译文发布,[Fedora 29 已经发布了](https://fedoramagazine.org/announcing-fedora-29/),但是 IoT 版本并未随同发布,或许会在 Fedora 30 一同发布?)
你有两种方法来安装这个系统:要么使用 `dd` 命令烧录 SD 卡,或者使用 `fedora-arm-installer` 工具。Fedora 的 Wiki 里面提供了为 IoT [设置物理设备](https://fedoraproject.org/wiki/InternetOfThings/GettingStarted#Setting_up_a_Physical_Device) 的更多信息。另外,你可能需要调整第三个分区的大小。
把 SD 卡插入到设备后,你需要创建一个用户来完成安装。这个步骤需要串行连接或一个 HDMI 显示器和键盘来与设备进行交互。
当系统安装完成后,下一步就是要设置网络连接。使用你刚才创建的用户登录系统,可以使用下列方式之一完成网络连接设置:
* 如果你需要手动配置你的网络,可能需要执行类似如下命令,需要保证设置正确的网络地址:
```
$ nmcli connection add con-name cable ipv4.addresses \
192.168.0.10/24 ipv4.gateway 192.168.0.1 \
connection.autoconnect true ipv4.dns "8.8.8.8,1.1.1.1" \
type ethernet ifname eth0 ipv4.method manual
```
* 如果你网络上运行着 DHCP 服务,可能需要类似如下命令:
```
$ nmcli con add type ethernet con-name cable ifname eth0
```
### Fedora 中的 GPIO 接口
许多关于 Linux 上 GPIO 的教程都关注传统的 GPIO sysfis 接口。这个接口已经不推荐使用了,并且上游 Linux 内核社区由于安全和其他问题的缘故打算完全删除它。
Fedora 已经不将这个传统的接口编译到内核了,因此在系统上没有 `/sys/class/gpio` 这个文件。此教程使用一个上游内核提供的一个新的字符设备 `/dev/gpiochipN` 。这是目前和 GPIO 交互的方式。
为了和这个新设备进行交互,你需要使用一个库和一系列命令行界面的工具。常用的命令行工具比如说 `echo` 和 `cat` 在此设备上无法正常工作。
你可以通过安装 libgpiod-utils 包来安装命令行界面工具。python3-libgpiod 包提供了相应的 Python 库。
### 使用 Podman 来创建一个容器
[Podman](https://github.com/containers/libpod) 是一个容器运行环境,其命令行界面类似于 Docker。Podman 的一大优势是它不会在后台运行任何守护进程。这对于资源有限的设备尤其有用。Podman 还允许您使用 systemd 单元文件启动容器化服务。此外,它还有许多其他功能。
我们使用如下两步来创建一个容器:
1. 创建包含所需包的分层镜像。
2. 使用分层镜像创建一个新容器。
首先创建一个 Dockerfile 文件,内容如下。这些内容告诉 Podman 基于可使用的最新 Fedora 镜像来构建我们的分层镜像。然后就是更新系统和安装一些软件包:
```
FROM fedora:latest
RUN dnf -y update
RUN dnf -y install libgpiod-utils python3-libgpiod
```
这样你就完成了镜像的生成前的配置工作,这个镜像基于最新的 Fedora,而且包含了和 GPIO 交互的软件包。
现在你就可以运行如下命令来构建你的基本镜像了:
```
$ sudo podman build --tag fedora:gpiobase -f ./Dockerfile
```
你已经成功创建了你的自定义镜像。这样以后你就可以不用每次都重新搭建环境了,而是基于你创建的镜像来完成工作。
### 使用 Podman 完成工作
为了确认当前的镜像是否就绪,可以运行如下命令:
```
$ sudo podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
localhost/fedora gpiobase 67a2b2b93b4b 10 minutes ago 488MB
docker.io/library/fedora latest c18042d7fac6 2 days ago 300MB
```
现在,启动容器并进行一些实际的实验。容器通常是隔离的,无法访问主机系统,包括 GPIO 接口。因此需要在启动容器时将其挂载在容器内。可以使用以下命令中的 `-device` 选项来解决:
```
$ sudo podman run -it --name gpioexperiment --device=/dev/gpiochip0 localhost/fedora:gpiobase /bin/bash
```
运行之后就进入了正在运行的容器中。在继续之前,这里有一些容器命令。输入 `exit` 或者按下 `Ctrl+D` 来退出容器。
显示所有存在的容器可以运行如下命令,这包括当前没有运行的,比如你刚刚创建的那个:
```
$ sudo podman container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
64e661d5d4e8 localhost/fedora:gpiobase /bin/bash 37 seconds ago Exited (0) Less than a second ago gpioexperiment
```
使用如下命令创建一个新的容器:
```
$ sudo podman run -it --name newexperiment --device=/dev/gpiochip0 localhost/fedora:gpiobase /bin/bash
```
如果想删除容器可以使用如下命令:
```
$ sudo podman rm newexperiment
```
### 点亮 LED 灯
现在可以使用已创建的容器。如果已经从容器退出,请使用以下命令再次启动它:
```
$ sudo podman start -ia gpioexperiment
```
如前所述,可以使用 Fedora 中 libgpiod-utils 包提供的命令行工具。要列出可用的 GPIO 芯片可以使用如下命令:
```
$ gpiodetect
gpiochip0 [pinctrl-bcm2835] (54 lines)
```
要获取特定芯片的连线列表,请运行:
```
$ gpioinfo gpiochip0
```
请注意,物理引脚数与前一个命令所打印的连线数之间没有相关性。重要的是 BCM 编号,如 [pinout.xyz](https://pinout.xyz/) 所示。建议不要使用没有相应 BCM 编号的连线。
现在,将 LED 连接到物理引脚 40,也就是 BCM 21。请记住:LED 的短腿(负极,称为阴极)必须连接到带有 330 欧姆电阻的树莓派的 GND 引脚, 并且长腿(阳极)到物理引脚 40。
运行以下命令点亮 LED,按下 `Ctrl + C` 关闭:
```
$ gpioset --mode=wait gpiochip0 21=1
```
要点亮一段时间,请添加 `-b`(在后台运行)和 `-s NUM`(多少秒)参数,如下所示。 例如,要点亮 LED 5 秒钟,运行如下命令:
```
$ gpioset -b -s 5 --mode=time gpiochip0 21=1
```
另一个有用的命令是 `gpioget`。 它可以获得引脚的状态(高或低),可用于检测按钮和开关。

### 总结
你也可以使用 Python 操控 LED —— [这里有一些例子](https://github.com/brgl/libgpiod/tree/master/bindings/python/examples)。 也可以在容器内使用 i2c 设备。 此外,Podman 与此 Fedora 版本并不严格相关。你可以在任何现有的 Fedora 版本上安装它,或者在 Fedora 中使用两个基于 OSTree 的新系统进行尝试:[Fedora Silverblue](https://teamsilverblue.org/) 和 [Fedora CoreOS](https://coreos.fedoraproject.org/)。
---
via: <https://fedoramagazine.org/turnon-led-fedora-iot/>
作者:[Alessio Ciregia](http://alciregi.id.fedoraproject.org/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ScarboroughCoral](https://github.com/ScarboroughCoral) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Do you enjoy running Fedora, containers, and have a Raspberry Pi? What about using all three together to play with LEDs? This article introduces Fedora IoT and shows you how to install a preview image on a Raspberry Pi. You’ll also learn how to interact with GPIO in order to light up an LED.
## What is Fedora IoT?
Fedora IoT is one of the current Fedora Project objectives, with a plan to become a full Fedora Edition. The result will be a system that runs on ARM (aarch64 only at the moment) devices such as the Raspberry Pi, as well as on the x86_64 architecture.
Fedora IoT is based on OSTree, like [Fedora Silverblue](https://teamsilverblue.org/) and the former [Atomic Host](https://www.projectatomic.io/).
## Download and install Fedora IoT
The official Fedora IoT images are coming with the Fedora 29 release. However, in the meantime you can download a [Fedora 28-based image](https://kojipkgs.fedoraproject.org/compose/iot/latest-Fedora-IoT-28/compose/IoT/) for this experiment.
You have two options to install the system: either flash the SD card using a dd command, or use a *fedora-arm-installer* tool. The Fedora Wiki offers more information about [setting up a physical device](https://fedoraproject.org/wiki/InternetOfThings/GettingStarted#Setting_up_a_Physical_Device) for IoT. Also, remember that you might need to resize the third partition.
Once you insert the SD card into the device, you’ll need to complete the installation by creating a user. This step requires either a serial connection, or a HDMI display with a keyboard to interact with the device.
When the system is installed and ready, the next step is to configure a network connection. Log in to the system with the user you have just created choose one of the following options:
- If you need to configure your network manually, run a command similar to the following. Remember to use the right addresses for your network:
$
**nmcli connection add con-name cable ipv4.addresses \ 192.168.0.10/24 ipv4.gateway 192.168.0.1 \ connection.autoconnect true ipv4.dns "8.8.8.8,1.1.1.1" \ type ethernet ifname eth0 ipv4.method manual** - If there’s a DHCP service on your network, run a command like this:
$
**nmcli con add type ethernet con-name cable ifname eth0**
**The GPIO interface in Fedora**
Many tutorials about GPIO on Linux focus on a legacy GPIO sysfis interface. This interface is deprecated, and the upstream Linux kernel community plan to remove it completely, due to security and other issues.
The Fedora kernel is already compiled without this legacy interface, so there’s no */sys/class/gpio* on the system. This tutorial uses a new character device */dev/gpiochipN* provided by the upstream kernel. This is the current way of interacting with GPIO.
To interact with this new device, you need to use a library and a set of command line interface tools. The common command line tools such as *echo* or *cat* won’t work with this device.
You can install the CLI tools by installing the *libgpiod-utils* package. A corresponding Python library is provided by the *python3-libgpiod* package.
**Creating a container with Podman**
[Podman](https://github.com/containers/libpod) is a container runtime with a command line interface similar to Docker. The big advantage of Podman is it doesn’t run any daemon in the background. That’s especially useful for devices with limited resources. Podman also allows you to start containerized services with systemd unit files. Plus, it has many additional features.
We’ll create a container in these two steps:
- Create a layered image containing the required packages.
- Create a new container starting from our image.
First, create a file *Dockerfile* with the content below. This tells podman to build an image based on the latest Fedora image available in the registry. Then it updates the system inside and installs some packages:
FROM fedora:latest RUN dnf -y update RUN dnf -y install libgpiod-utils python3-libgpiod
You have created a build recipe of a container image based on the latest Fedora with updates, plus packages to interact with GPIO.
Now, run the following command to build your base image:
$sudo podman build --tag fedora:gpiobase -f ./Dockerfile
You have just created your custom image with all the bits in place. You can play with this base container images as many times as you want without installing the packages every time you run it.
## Working with Podman
To verify the image is present, run the following command:
$sudo podman imagesREPOSITORY TAG IMAGE ID CREATED SIZE localhost/fedora gpiobase 67a2b2b93b4b 10 minutes ago 488MB docker.io/library/fedora latest c18042d7fac6 2 days ago 300MB
Now, start the container and do some actual experiments. Containers are normally isolated and don’t have an access to the host system, including the GPIO interface. Therefore, you need to mount it inside while starting the container. To do this, use the *–device* option in the following command:
$sudo podman run -it --name gpioexperiment --device=/dev/gpiochip0 localhost/fedora:gpiobase /bin/bash
You are now inside the running container. Before you move on, here are some more container commands. For now, exit the container by typing *exit* or pressing **Ctrl+D**.
To list the the existing containers, including those not currently running, such as the one you just created, run:
$sudo podman container ls -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 64e661d5d4e8 localhost/fedora:gpiobase /bin/bash 37 seconds ago Exited (0) Less than a second ago gpioexperiment
To create a new container, run this command:
$sudo podman run -it --name newexperiment --device=/dev/gpiochip0 localhost/fedora:gpiobase /bin/bash
Delete it with the following command:
$sudo podman rm newexperiment
**Turn on an LED**
Now you can use the container you already created. If you exited from the container, start it again with this command:
$sudo podman start -ia gpioexperiment
As already discussed, you can use the CLI tools provided by the *libgpiod-utils* package in Fedora. To list the available GPIO chips, run:
$gpiodetectgpiochip0 [pinctrl-bcm2835] (54 lines)
To get the list of the lines exposed by a specific chip, run:
$gpioinfo gpiochip0
Notice there’s no correlation between the number of physical pins and the number of lines printed by the previous command. What’s important is the BCM number, as shown on [pinout.xyz](https://pinout.xyz/). It is not advised to play with the lines that don’t have a corresponding BCM number.
Now, connect an LED to the physical pin 40, that is BCM 21. Remember: the shorter leg of the LED (the negative leg, called the cathode) must be connected to a GND pin of the Raspberry Pi with a 330 ohm resistor, and the long leg (the anode) to the physical pin 40.
To turn the LED on, run the following command. It will stay on until you press **Ctrl+C**:
$gpioset --mode=wait gpiochip0 21=1
To light it up for a certain period of time, add the *-b* (run in the background) and *-s NUM* (how many seconds) parameters, as shown below. For example, to light the LED for 5 seconds, run:
$gpioset -b -s 5 --mode=time gpiochip0 21=1
Another useful command is *gpioget*. It gets the status of a pin (high or low), and can be useful to detect buttons and switches.
**Conclusion**
You can also play with LEDs using Python — [there are some examples here](https://github.com/brgl/libgpiod/tree/master/bindings/python/examples). And you can also use the i2c devices inside the container as well. In addition, Podman is not strictly related to this Fedora edition. You can install it on any existing Fedora Edition, or try it on the two new OSTree-based systems in Fedora: [Fedora Silverblue](https://teamsilverblue.org/) and [Fedora CoreOS](https://coreos.fedoraproject.org/).
## Mace Moneta
I’ve used SBCs (running Fedora), Arduino SDK, Arduinos, and esp8266. This article is a great example of why it’s important to use the right tool for a job. In this case, Fedora on an aarch64 device was very much the wrong choice. Highest complexity, highest cost. If you want to showcase Fedora IoT, it should be with something that can’t be done (simpler and for lower cost) on an under $2 device.
## Alessio Ciregia
Well, if your goal is a blinking LED, you are right, you don’t even need any SBC: a couple of transistors should be enough.
Obviously the aim of this article was to introduce Fedora IoT, what technologies are in place, and how to interact with the GPIO using Fedora.
## qoheniac
Thanks for this! Just one question: As someone who never worked with containers, what’s the purpose of running the CLI tools inside a container?
## Alessio Ciregia
Because, in an OSTree system, the base system is read only, immutable. It is true that on Fedora, that uses rpm-ostree, you can “layer” packages, or in other words, you can install RPMs more or less in the traditional way. But in an OSTree system, the core concept is that the base OS is composed by essential tools, and the rest of the workflow (developement, services, etc.) should be made by using containers (where you can install as many packages you want, and tinker with them, without messing the base OS).
Anyway, if you want a traditional system, you can go with the Fedora ARM images, that are “traditional” operating systems: here you can play with the GPIO in the same way, also without using containers.
## qoheniac
So what is this about? Is it mainly about security, so that if one application fucks up its container it won’t hurt the rest of the system? Or is it about running multiple applications that were designed for different environments at the same time on the same machine? Or do I totally misunderstand what this is about? Is there an introduction explaining the motivation behind these kind of operating systems available online?
## Kjetil BM
When it comes to working with LED’s, there are some really nice modules for python around already, like the Gpiozero.
https://www.raspberrypi.org/blog/gpio-zero-a-friendly-python-api-for-physical-computing/ |
10,381 | 以 Linux 的方式庆祝圣诞节 | https://itsfoss.com/christmas-linux-wallpaper/ | 2018-12-25T01:14:00 | [
"圣诞节"
] | https://linux.cn/article-10381-1.html | 
当前正是假日季,很多人可能已经在庆祝圣诞节了。祝你圣诞快乐,新年快乐。
为了延续节日氛围,我将向你展示一些非常棒的圣诞主题的 [Linux 壁纸](https://itsfoss.com/beautiful-linux-wallpapers/)。在呈现这些壁纸之前,先来看一棵 Linux 终端下的圣诞树。
### 让你的桌面飘雪(针对 GNOME 用户)
如果您在 Ubuntu 18.04 或任何其他 Linux 发行版中使用 GNOME 桌面,您可以使用一个小的 [GNOME 扩展](https://itsfoss.com/gnome-shell-extensions/)并在桌面上飘雪。
您可以从软件中心或 GNOME 扩展网站获取此 gsnow 扩展。我建议您阅读一些关于[使用 GNOME 扩展](https://itsfoss.com/gnome-shell-extensions/)的内容。
安装此扩展程序后,您会在顶部面板上看到一个小雪花图标。 如果您单击一次,您会看到桌面屏幕上的小絮状物掉落。

你可以再次点击该图标来禁止雪花落下。
### 在 Linux 终端下显示圣诞树

如果你想要在终端里显示一个动画的圣诞树,你可以使用如下命令:
```
curl https://raw.githubusercontent.com/sergiolepore/ChristBASHTree/master/tree-EN.sh | bash
```
要是不想一直从互联网上获取这棵圣诞树,也可以从它的 [GitHub 仓库](https://github.com/sergiolepore/ChristBASHTree) 中获取对应的 shell 脚本,更改权限之后按照运行普通 shell 脚本的方式运行它。
### 使用 Perl 在 Linux 终端下显示圣诞树
[](https://itsfoss.com/christmas-linux-wallpaper/perl-tree/)
这个技巧最初由 [NixCraft](https://www.cyberciti.biz/open-source/command-line-hacks/linux-unix-desktop-fun-christmas-tree-for-your-terminal/) 分享,你需要为此安装 Perl 模块。
说实话,我不喜欢使用 Perl 模块,因为卸载它们真的很痛苦。所以使用这个 Perl 模块时需谨记,你必须手动移除它。
```
perl -MCPAN -e 'install Acme::POE::Tree'
```
你可以阅读 [原文](https://www.cyberciti.biz/open-source/command-line-hacks/linux-unix-desktop-fun-christmas-tree-for-your-terminal/) 来了解更多信息。
### 下载 Linux 圣诞主题壁纸
所有这些 Linux 圣诞主题壁纸都是由 Mark Riedesel 制作的,你可以在 [他的网站](http://www.klowner.com/) 上找到很多其他艺术品。
自 2002 年以来,他几乎每年都在制作这样的壁纸。可以理解的是,最早的一些壁纸不具有现代的宽高比。我把它们按时间倒序排列。
注意一个小地方,这里显示的图片都是高度压缩的,因此你要通过图片下方提供的链接进行下载。

*[下载此壁纸](http://www.klowner.com/wallery/christmas_tux_2018/download/ChristmasTux2018_4K_3840x2160.png)*

*[下载此壁纸](http://klowner.com/wallery/christmas_tux_2017/download/ChristmasTux2017_3840x2160.png)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2016_3840x2160_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2016/)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2015_2560x1920_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2015/)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2014_2560x1440_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2014/)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2013_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2013/)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2012_2560x1440_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2012/)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2011_2560x1440_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2011/)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2010_5120x2880_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2010/)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2009_1600x1200_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2009/)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2008_2560x1600_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2008/)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2007_2560x1600_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2007/)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2006_1024x768_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2006/)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2005_1600x1200_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2005/)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2004_1600x1200_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2004/)*
[](https://itsfoss.com/christmas-linux-wallpaper/christmastux2002_1600x1200_result/)
*[下载此壁纸](http://www.klowner.com/wallpaper/christmas_tux_2002/)*
### 福利:Linux 圣诞颂歌
这是给你的一份福利,给像我们一样的 Linux 爱好者的关于 Linux 的圣诞颂歌。
在 [《计算机世界》的一篇文章](http://www.computerworld.com/article/3151076/linux/merry-linux-to-you.html) 中,[Sandra Henry-Stocker](https://twitter.com/bugfarm) 分享了这些圣诞颂歌。摘录片段如下:
这一段用的 [Chestnuts Roasting on an Open Fire](https://www.youtube.com/watch?v=dhzxQCTCI3E) 的曲调:
>
> Running merrily on open source
>
>
> With users happy as can be
>
>
> We’re using Linux and getting lots done
>
>
> And happy everything is free
>
>
>
这一段用的 [The Twelve Days of Christmas](https://www.youtube.com/watch?v=oyEyMjdD2uk) 的曲调:
>
> On my first day with Linux, my admin gave to me a password and a login ID
>
>
> On my second day with Linux my admin gave to me two new commands and a password and a login ID
>
>
>
在 [这里](http://www.computerworld.com/article/3151076/linux/merry-linux-to-you.html) 阅读完整的颂歌。
Linux 快乐!
---
via: <https://itsfoss.com/christmas-linux-wallpaper/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jlztan](https://github.com/jlztan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

It’s the holiday season, and many of you might be celebrating Christmas already.
From the team of It’s FOSS, I would like to wish you a Merry Christmas and a happy new year.
To continue the festive mood, I’ll show you some really awesome [Linux wallpapers](https://itsfoss.com/beautiful-linux-wallpapers/) on Christmas theme. I’ll share a few tips to give your Linux system a Christmas touch.
## Let it snow on your Linux desktop [for GNOME users]
Nothing makes Christmas more “Christmasy” than the snow flurries. If you are using GNOME, you can let it snow on your desktop as well.
Check [which desktop environment you use](https://itsfoss.com/find-desktop-environment/). If it is GNOME, then you can use extensions to drop snowflakes on your desktop.
If you are not familiar with it, please read my detailed [guide on using GNOME Extensions](https://itsfoss.com/gnome-shell-extensions/) first. Repeating the steps here will derail the topic.
There are three GNOME Extensions that make snow flurries on your desktop.
[Snow](https://extensions.gnome.org/extension/3912/snow/?ref=itsfoss.com)(last updated with GNOME Shell 4.42)[Let it Snow](https://extensions.gnome.org/extension/1547/let-it-snow/?ref=itsfoss.com)(Last updated with GNOME 4.44)[gsnow](https://extensions.gnome.org/extension/1156/gsnow/?ref=itsfoss.com)(last updated with GNOME 3.10)
While ‘Let it Snow’ has more features where you can control the number of snowflakes or make it not snow on the active window, the Snow extension doesn’t have any configuration options.
You just have to activate this extension and enable it to make the snow fall on your desktop.
[keep an eye on the system stats with the task manager in Linux](https://itsfoss.com/task-manager-linux/). Disable the extension if you see high CPU usage with the extension. You don't want the snow to melt with the hot computer, do you? 😉
## Change terminal prompts with Christmas goodies [For expert users]
Here’s another way for Christmas makeover. Change the prompt with Christmas tree, snowflake and gifts.
Now, **if you are not too comfortable with the terminal, I suggest skipping it**. If you are a regular Linux command line pro who knows what’s .bashrc file and how to edit these files in the terminal, here’s what you need to do.
Copy this code:
```
# print the git branch name if in a git project
parse_git_branch() {
git branch 2> /dev/null | sed -e '/^[^*]/d' -e 's/* \(.*\)//'
}
# set the input prompt symbol
ARROW="❯"
# define text formatting
PROMPT_BOLD="$(tput bold)"
PROMPT_UNDERLINE="$(tput smul)"
PROMPT_FG_GREEN="$(tput setaf 2)"
PROMPT_FG_CYAN="$(tput setaf 6)"
PROMPT_FG_YELLOW="$(tput setaf 3)"
PROMPT_FG_MAGENTA="$(tput setaf 5)"
PROMPT_RESET="$(tput sgr0)"
# save each section prompt section in variable
PROMPT_SECTION_SHELL="\[$PROMPT_BOLD$PROMPT_FG_GREEN\]\s\[$PROMPT_RESET\]"
PROMPT_SECTION_DIRECTORY="\[$PROMPT_UNDERLINE$PROMPT_FG_CYAN\]\W\[$PROMPT_RESET\]"
PROMPT_SECTION_GIT_BRANCH="\[$PROMPT_FG_YELLOW\]\`parse_git_branch\`\[$PROMPT_RESET\]"
PROMPT_SECTION_ARROW="\[$PROMPT_FG_MAGENTA\]$ARROW\[$PROMPT_RESET\]"
# set the prompt string using each section variable
PS1="
🎄 $PROMPT_SECTION_SHELL ❄️ $PROMPT_SECTION_DIRECTORY 🎁 $PROMPT_SECTION_GIT_BRANCH 🌟
$PROMPT_SECTION_ARROW "
```
And add it to the end of your ~/.bashrc file. Save the file, close it and then open another terminal window or shell. You should have a changed command line prompt now.
To get back to normal, delete those lines you added from the ~/.bashrc file.
## Display Christmas Tree in Linux Terminal (Bash script)
If you want to display an animated Christmas tree in the terminal, you can use the command below:
```
curl https://raw.githubusercontent.com/sergiolepore/ChristBASHTree/master/tree-EN.sh | bash
```
If you don’t want to get it from the internet all the time, you can get the shell script from its GitHub repository, change the permission and run it like a normal shell script.
[Download Christmas Bash Tree Script](https://github.com/sergiolepore/ChristBASHTree?ref=itsfoss.com)
## Display Christmas Tree in terminal using Python script
Another similar CLI tool but written in Python this time.
Download or clone the project's GitHub repository. You'll have a `terminal_tree.py`
file here.
Open a terminal, switch to the directory where you have cloned/downloaded the repository.
Run the Python script:
`python terminal_tree.py`
You'll have the Christmas Tree animation running in the terminal. **Press Ctrl+C to stop it**.
## Display Christmas Tree in Linux terminal using Perl script

This trick was originally shared by [NixCraft](https://www.cyberciti.biz/open-source/command-line-hacks/linux-unix-desktop-fun-christmas-tree-for-your-terminal/?ref=itsfoss.com). You’ll need to install a Perl module for this.
To be honest, I don’t like using Perl modules because uninstalling them is a real pain. So **use this Perl module knowing that you’ll have to manually remove it**.
`perl -MCPAN -e 'install Acme::POE::Tree'`
You can read the original article [here](https://www.cyberciti.biz/open-source/command-line-hacks/linux-unix-desktop-fun-christmas-tree-for-your-terminal/?ref=itsfoss.com) to know more about it.
## Treefetch: Like Neoftech but with Christmas Tree
You are probably familiar with the [Neofetch](https://itsfoss.com/using-neofetch/) command line tool. It shows the ASCII logo of your distro along with some details about the currently installed system.
Treefetch is similar. Only, you display a Christmas tree instead of distro logo. And the colors are also more into Christmas spirit.
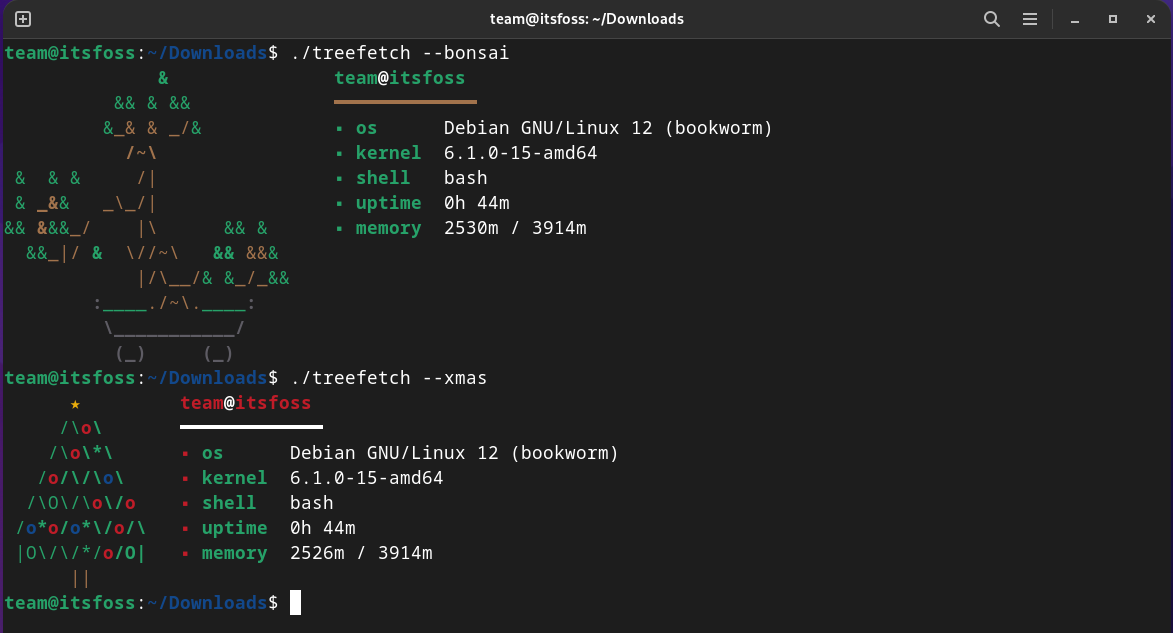
Some distributions have the treefetch package available from their repository. You can get more information on project's GitHub repository page.
## Download Linux Christmas Wallpapers
All these Linux Christmas wallpapers are created by Mark Riedesel and you can find plenty of other artwork on [his website](http://www.klowner.com/?ref=itsfoss.com).
He has been making such wallpapers almost every year since 2002. Quite understandably, some of the earliest wallpapers don’t have modern aspect ratio. I have put them up in reverse chronological order.
One tiny note. ** The images displayed here are highly compressed, so download the wallpapers from the provided link only**.

















## Bonus: Linux Christmas carols
Here is a bonus for you. Christmas carols Linuxified for Linux lovers like us.
In [an article on Computer World](http://www.computerworld.com/article/3151076/linux/merry-linux-to-you.html?ref=itsfoss.com), [Sandra Henry-Stocker](https://twitter.com/bugfarm?ref=itsfoss.com) shared such Christmas carols. An excerpt:
To the tune of: [Chestnuts Roasting on an Open Fire](https://www.youtube.com/watch?v=dhzxQCTCI3E&ref=itsfoss.com)
Running merrily on open source
With users happy as can be
We’re using Linux and getting lots done
And happy everything is free
To the tune of: [The Twelve Days of Christmas](https://www.youtube.com/watch?v=oyEyMjdD2uk&ref=itsfoss.com)
On my first day with Linux, my admin gave to me a password and a login ID
On my second day with Linux my admin gave to me two new commands and a password and a login ID
You can read full carols [here](http://www.computerworld.com/article/3151076/linux/merry-linux-to-you.html?ref=itsfoss.com). If you want Tux avatar in the reindeer format, check out [this repository](https://github.com/karinkasweet/linux-penguin-tux?ref=itsfoss.com).
Merry Linux to you!! |
10,382 | IBM 029 型打孔机 | https://twobithistory.org/2018/06/23/ibm-029-card-punch.html | 2018-12-25T14:45:00 | [
"打孔卡"
] | https://linux.cn/article-10382-1.html | 我知道这很学院派,可一行超过 80 个字符的代码还是让我抓狂。我也在网上见过不少人认为即使在现代的视网膜屏幕下也应当采用行长度为 80 个字符的标准,可他们都不理解我对破坏这一标准的怒火,就算多 1 个字符也不行。
在这一标准的黄金时期,一行代码的长度几乎不会超过 80 个字符的限制。在那时,这一限制是物理的,没有第 81 列用于存放第 81 个字符。每一个试图把函数名起的又长又臭的程序员都会在短暂的愉悦后迎来更多的麻烦,而这仅仅是因为没有足够的空间放下整个函数的声明。
这一黄金时期也是<ruby> 打孔卡 <rt> punch card </rt></ruby>编程时期。在 20 世纪 60 年代,IBM 打孔卡设立了标准,这个标准就是打孔卡的宽度为 80 列。这个 80 列标准在后来的电传打字机和哑终端时期得以延续,并逐渐成为操作系统中隐藏的细节。时至今日,即使我们用上了更大、更好的屏幕,偏向于使用更长的标识符而不是类似 `iswcntrl()` 这样令人难以猜测的函数名,可当你打开新的终端模拟器窗口时,默认的宽度依然是 80 个字符。
从 Quora 上的很多问题中可以发现,很多人并不能想象如何使用打孔卡给计算机编程。我承认,在很长的一段时间里我也不能理解打孔卡编程是如何工作的,因为这让我想到就像劳工一样不停的给这些打孔卡打孔。当然,这是一个误解,程序员不需要亲自给打孔卡打孔,就像是火车调度员不用亲自扳道岔。程序员们有<ruby> 打孔机 <rt> card punch machines </rt></ruby>(也被称为<ruby> 键控打孔机 <rt> key punches </rt></ruby>),这让他们可以使用打字机式的键盘给打孔卡打孔。这样的设备在 19 世纪 90 年代时就已经不是什么新技术了。
那时,最为广泛使用的打孔机之一便是 IBM 029 型打孔机。就算在今天,它也许是最棒的打孔机。

IBM 029 型打孔机在 1964 年作为 IBM 的 System/360 大型电脑的配件发售的。System/360 是计算系统与外设所组成的一个系列,在 20 世纪 60 年代晚期,它几乎垄断了整个大型计算机市场。就像其它 System/360 外设一样,029 型打孔机也是个大块头。那时,计算机和家具的界限还很模糊,但 029 型打孔机可不是那种会占领你的整张桌子的机器。它改进自 026 型打孔机,增加了新的字符支持,如括号,总体上也更加安静。与前辈 026 型所展出 20 世纪 40 年代的圆形按钮与工业化的样貌相比,029 型的按键方正扁平、功能按键还有酷炫的蓝色高亮提示。它的另一个重要买点是它能够在<ruby> 数字区 <rt> numeric field </rt></ruby>左侧自动的填充 0 ,这证明了 JavaScript 程序员不是第一批懒得自己做<ruby> 左填充 <rt> left-padding </rt></ruby>的程序员。(LCTT 译注:这项功能需要额外的 4 张 <ruby> <a href="https://en.wikipedia.org/wiki/IBM_Standard_Modular_System"> 标准模块系统卡 </a> <rt> SMS card </rt></ruby>才能使用。例如设置数字区域长度为 6 列时,操作员只需要输入 73 ,打孔机会自动填充起始位置上的 4 个 0 ,故最终输出 000073。[更多信息](https://en.wikipedia.org/wiki/Keypunch#IBM_029_Card_Punch))
等等!你说的是 IBM 在 1964 年发布了全新的打孔机?你知道那张在贝尔实验室拍摄的 Unix 之父正在使用电传打字机的照片吗?那是哪一年的来着?1970?打孔机不是应该在 20 世纪 60 年代中期到晚期时就过时了吗?是的,你也许会奇怪,为什么直到 1984 年,IBM 的产品目录中还会出现 029 型打孔机的身影 <sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup>。事实上,直到 20 世纪 70 年代,大多数程序员仍然在使用打孔卡编程。其实二战期间就已经有人在用电传打字机了,可那时并没能普及。客观的讲,电传打字机几乎和打孔卡一样古老。也许和你想象的恰恰相反,并不是电传打字机本身限制了它的普及,而是计算时间。人们拒绝使用电传打字机的原因是,它是可交互的,它和计算机使用<ruby> “在线”的传输方式 <rt> <q> online </q> mode of communication </rt></ruby>。在以 Unix 为代表的分时操作系统被发明前,你和电脑的交互会被任何人的使用而打断,而这一点延迟通常意味着几千美元的损失。所以程序员们普遍选择离线地使用打孔机编程,再将打孔卡放入大型计算机中,作为<ruby> 批任务 <rt> batch job </rt></ruby>执行。在那时,还没有即廉价又可靠的存储设备,可打孔卡的廉价优势已经足够让它成为那时最流行的数据存储方式了。那时的程序是书架上一摞打孔卡而不是硬盘里的一堆文件。
那么实际使用 IBM 029 型打孔机是个什么样子呢?这很难向没有实际看过打孔卡的人解释。一张打孔卡通常有 12 行 80 列。打孔卡下面是从 1 到 9 的<ruby> 数字行 <rt> digit rows </rt></ruby>,打孔卡上的每一列都有这些行所对应的数字。最上面的三行是<ruby> 空间行 <rt> <q> zone </q> rows </rt></ruby>,通常由两行空白行和一行 0 行组成。第 12 行是打孔卡最顶部的行,接下来是 11 行,随后是从数字 0 到 9 所在的行。这个有点让人感到困惑的顺序的原因是打孔卡的上边缘被称为<ruby> 12 边 <rt> 12 edge </rt></ruby>、下边缘被称为 <ruby> 9 边 <rt> 9 edge </rt></ruby>。那时,为了让打孔卡便于整理,常常会剪去打孔卡的一个角。

(LCTT 译注:可参考[EBCDIC 编码](https://zh.wikipedia.org/wiki/EBCDIC))
在打孔卡发明之初,孔洞的形状是圆形的,但是 IBM 最终意识到如果使用窄长方形作为孔洞,一张卡就可以放下更多的列了。每一列中孔洞的不同组合就可以表达不同的字符。像 029 型这样的拥有人性化设计的打孔机除了完成本质的打孔任务外,还会在打孔卡最上方打印出每一列所对应的字符。输入是数字就在对应的数字行上打孔。输入的是字母或符号就用一个在空间列的孔和一或俩个在数字列的孔的组合表示,例如字母 A 就用一个在第 12 空间行的空和一个数字 1 所在行的孔表示。这是一种顺序编码,在第一台打孔机被发明后,也叫 Hollerith 编码。这种编码只能表示相对较小的一套字符集,小写字母就没有包含在这套字符集中。如今一些聪明的工程师可能想知道为什么打卡不干脆使用二进制编码 —— 毕竟,有 12 行,你可以编码超过 4000 个字符。 使用 Hollerith 编码是因为它确保在单个列中出现不超过三个孔。这保留了卡的结构强度。二进制编码会带来太多的孔,会因为孔洞过于密集而断裂。
打孔卡也有不同。在 20 世纪 60 年代,80 列虽然是标准,但表达的方式不一定相同。基础打孔卡是无标注的,但用于 COBOL 编程的打孔卡会把最后的 8 列保留,供标识数保存使用。这一标识数可以在打孔卡被打乱 (例如一叠打孔卡掉在地上了) 后用于自动排序。此外,第 7 列被用于表示本张打孔卡上的是否与上一张打孔卡一起构成一条语句。也就是说当你真的对 80 字符的限制感到绝望的时候,还可以用两张卡甚至更多的卡拼接成一条长语句。用于 FORTRAN 编程的打孔卡和 COBOL 打孔卡类似,但是定义的列不同。大学里使用的打孔卡通常会由其计算机中心加上水印,其它的设计则会在如 [1976 年美国独立 200 周年](http://www.jkmscott.net/data/Punched%20card%20013.jpg) 的特殊场合才会加入。
最终,这些打孔卡都要被计算机读取和计算。IBM 出售的 System/360 大型计算机的外设 IBM 2540 可以以每分钟 1000 张打孔卡的速度读取这些卡片<sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup> 。IBM 2540 使用电刷扫过每张打孔卡,电刷通过孔洞就可以接触到卡片后面的金属板完成一次读取。一旦读取完毕,System/360 大型计算机就会把每张打孔卡上的数据使用一种定长的 8 位编码保存,这种编码是<ruby> 扩增二进式十进交换码 <rt> Extended Binary Coded Decimal Interchange Code </rt></ruby>,简写为 EBCDIC 编码。它是一种二进制编码,可以追溯自早期打孔卡所使用的 BCDIDC 编码 —— 其 6 位编码使用低 4 位表示数字行,高 2 位表示空间行。程序员们在打孔卡上编写完程序后,会把卡片们交给计算机操作员,操作员们会把这些卡片放入 IBM 2540 ,再把打印结果交给程序员。那时的程序员大多都没有见过计算机长什么样。
程序员们真正能见到的是很多打孔机。029 型打孔机虽然不是计算机,但这并不意味着它不是一台复杂的机器。看看这个由<ruby> 密歇根大学 <rt> University of Michigan </rt></ruby>计算机中心在 1967 年制作的[教学视频](https://www.youtube.com/watch?v=kaQmAybWn-w),你就能更好的理解使用一台 029 型打孔机是什么情形了。我会尽可能在这里总结这段视频,但如果你不去亲自看看的话,你会错过许多惊奇和感叹。
029 型打孔机的结构围绕着一个打孔卡穿过机器的 U 形轨道开始。使用打孔机时,右手边也就是 U 形轨道的右侧顶部是<ruby> 进卡卡槽 <rt> hopper </rt></ruby>,使用前通常在里面放入一叠未使用的打孔卡。虽然 029 型打孔机主要使用 80 列打孔卡,但在需要的情况下也可以使用更小号的打孔卡。在打孔机的使用过程中,打孔卡离开轨道右上端的进卡卡槽,顺着 U 形轨道移动并最终进入左上端的<ruby> 出卡卡槽 <rt> stacker </rt></ruby>。这一流程可以保证出卡卡槽中的打孔卡按打孔时的先后顺序排列。
029 型打孔机的开关在桌面下膝盖高度的位置。在开机后,连按两次 “<ruby> 装入 <rt> FEED </rt></ruby>” 键让机器自动将打孔卡从进卡卡槽中取出并移动到机器内。 U 形轨道的底部是打孔机的核心区域,它由三个部分组成:右侧是等待区,中间是打孔操作区,左侧是阅读区。连按两次 “装入” 键,机器就会把一张打孔卡装入打孔机的打孔操作区,另一张打孔卡进入等待区。在打孔操作区上方有一个列数指示器来显示当前打孔所在的列的位置。这时,每按下一个按键,机器就会在打孔卡对应的位置打孔并在卡片的顶部打印按键对应的字符,随后将打孔卡向左移动一列。如果一张卡片的 80 列全部被打上了数据,这张卡片会被打孔操作区自动释放并进入阅读区,同时,一张新的打孔卡会被装入打孔操作区。如果没有打完全部的 80 列,可以使用 “<ruby> 释放 <rt> REL </rt></ruby>” 键完成上面的操作。
在打孔卡上打印对应的字符这一设计让人很容易分辨出错误。但就像密歇根大学的视频中警告的那样,打孔卡上修正一个错误可不像擦掉一个打印的字符然后再写上一个新的那样容易,因为计算机只会根据卡片上的孔来读取信息。因为被打出的孔不能被<ruby> 复原 <rt> unpunched </rt></ruby>,所以并不能直接退回一列然后再打上一个新的字符。打出更多的孔也只能让这一列的组合变成一个无效字符。IBM 029 型打孔机上虽然有一个可以让打孔卡回退一列的退格按键,但这个按键被放置在机器上而非在键盘上。这样的设计也许是为了阻止这个按键的使用,因为实际上很少有用户需要这个功能。
实际上,只有废弃错误的打孔卡再在新的打孔卡上重新打孔这一种修正错误的方式。这就是阅读区的用武之处了。当你发现打孔卡上的第 68 列出错时,你需要在新的打孔卡上小心的给前 67 列重新打孔,然后给第 68 列打上正确的字母。另一种操作方式是把带有错误信息的打孔卡放在阅读区,同时在打孔操作区载入一张新的打孔卡,然后按下 “<ruby> 重复 <rt> DUP </rt></ruby>” 按键直到列数指示器显示 68 列。这时按下正确的字符来修正错误。阅读区和重复按键使得 029 型打孔机很容易复制打孔卡上的内容。当然,这一功能的使用可能有各种各样的原因,但改错是最常见的。
(LCTT 译注:有一种说法是“补丁”这个用于对已经发布的软件进行修复的术语来源于对打孔纸带或打孔卡上打错的孔贴上补丁的做法。可能对于长长的一卷打孔纸带来说,由于个别字母的错误而整个废弃成本过高,会采用“补丁”的方式;而对于这种单张式的打孔卡来说,重新打印一张正确的更为方便。)
“重复”按键允许 029 型打孔机的操作员手动调用重复的函数。但是 029 型打孔机还可以设置为自动重复。当用于记录数据而不是编程时,这项功能十分有效。举个例子,当用打孔卡来记录大学生的信息时,每张卡片上都需要输入学生的宿舍楼的名字,如果发现所输入信息的学生都在同一栋楼,就可以使用 029 型打孔机的自动重复功能来完成宿舍楼名称的填写。
像这样的自动化操作可以通过<ruby> 程序鼓 <rt> program drum </rt></ruby>编程到 029 型打孔机里面。程序鼓就安装在打孔操作区上方的 U 形轨道中间部分的右上角。通过在打孔卡上写下程序,然后把打孔卡装入程序鼓中,就完成了一次给 029 型打孔机的编程任务。用户可以通过这种方式对打孔卡的每一列都按需要定义不同的自动化操作。029 型打孔机允许指定某些列重复上一张打孔卡相同位置的字符,这就是它能更快的输入学生信息的理由。它还允许指定某些列只能输入数字或者字母,指定特定的列为空或者到某一列时就直接跳过一整张打孔卡。编程鼓使它在打孔特定列有特殊含义的固定模式卡片时很容易。密歇根大学制作的另一个[进阶教学视频](https://www.youtube.com/watch?v=SWD1PwNxpoU)包括了给 029 型打孔机编程的过程,如果你已经掌握了它的基础操作,就快去看看吧。
这会儿,无论你是否看了密歇根大学制作的视频,都会感叹打孔机的操作之简便。虽然修正错误的过程很乏味,但除此之外,操作一台打孔机并不像想象的那样复杂。我甚至可以想象打孔卡之间的无缝切换让 COBOL 和 FORTRAN 程序员忘记了他们的程序是打在不同的打孔卡上而不是写在一个连续的文本文件内。另一方面,思考一下打孔机是如何影响编程语言的发展也是很有趣的,虽然它仅仅是一台输入设备。结构化编程最终会出现并鼓励程序员把整个代码块视为一个整体,但可以想象打孔卡程序员们强调每一行的作用且难以认同结构化编程的场景。同时你能够理解他们为什么不把代码块闭合所使用的括号放在单独的一行,只是因为这样会浪费打孔卡。
现在,虽然没有人再使用打孔卡编程了,每个程序员都该试试[这个](http://www.masswerk.at/keypunch/),哪怕一次也好。或许你因此能够更好的理解 COBOL 和 FORTRAN 的历史,或许你就能体会到为什么每个人把 80 个字符作为长度限制的标注。
喜欢吗?这里每两周都会发表一篇这样的文章。请在推特上关注我们 [@TwoBitHistory](https://twitter.com/TwoBitHistory) 或者订阅我们的 [RSS](https://twobithistory.org/feed.xml),这样你就能在第一时间收到新文章的通知。
---
via: <https://twobithistory.org/2018/06/23/ibm-029-card-punch.html>
作者:[Two-Bit History](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wwhio](https://github.com/wwhio) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
---
1. “IBM 29 Card Punch,” IBM Archives, accessed June 23, 2018, <https://www-03.ibm.com/ibm/history/exhibits/vintage/vintage_4506VV4002.html>. [↩](#fnref1)
2. IBM, IBM 2540 Component Description and Operation Procedures (Rochester, MN: IBM Product Publications, 1965), September 06, 2009, accessed June 23, 2018, <http://bitsavers.informatik.uni-stuttgart.de/pdf/ibm/25xx/A21-9033-1_2540_Card_Punch_Component_Description_1965.pdf>. [↩](#fnref2)
| 200 | OK | Lines of code longer than 80 characters drive me crazy. I appreciate that this is pedantic. I’ve seen people on the internet make good arguments for why the 80-character limit ought to be respected even on our modern Retina-display screens, but those arguments hardly justify the visceral hatred I feel for even that one protruding 81st character.
There was once a golden era in which it was basically impossible to go over the 80-character limit. The 80-character limit was a physical reality, because there was no 81st column for an 81st character to fit in. Any programmers attempting to name a function something horrendously long and awful would discover, in a moment of delicious, slow-dawning horror, that there literally isn’t room for their whole declaration.
This golden era was the era of punch card programming. By the 1960s, IBM’s
punch cards had set the standard and the standard was that punch cards had 80
columns. The 80-column standard survived into the teletype and dumb terminal
era and from there embedded itself into the nooks and crannies of our operating
systems. Today, when you launch your terminal emulator and open a new window,
odds are it will be 80 characters wide, even though we now have plenty of
screen real estate and tend to favor longer identifiers over inscrutable
nonsense like `iswcntrl()`
.
If questions on Quora are any indication, many people have trouble imagining what it must have been like to program computers using punch cards. I will admit that for a long time I also didn’t understand how punch card programming could have worked, because it struck me as awfully labor-intensive to punch all those holes. This was a misunderstanding; programmers never punched holes in cards the same way a train conductor does. They had card punch machines (also known as key punches), which allowed them to punch holes in cards using a typewriter-style keyboard. And card punches were hardly new technology—they were around as early as the 1890s.
One of the most widely used card punch machines was the IBM 029. It is perhaps the best remembered card punch today.
The IBM 029 was released in 1964 as part of IBM’s System/360 rollout. System/360 was a family of computing systems and peripherals that would go on to dominate the mainframe computing market in the late 1960s. Like many of the other System/360 machines, the 029 was big. This was an era when the distinction between computing machinery and furniture was blurry—the 029 was not something you put on a table but an entire table in itself. The 029 improved upon its predecessor, the 026, by supporting new characters like parentheses and by generally being quieter. It had cool electric blue highlights and was flat and angular whereas the 026 had a 1940s rounded, industrial look. Another of its big selling points was that it could automatically left-pad numeric fields with zeros, demonstrating that JavaScript programmers were not the first programmers too lazy to do their own left-padding.
But wait, you might say—IBM released a brand-new card punch in 1964? What about
that photograph of the Unix gods at Bell Labs using teletype machines in, like,
1970? Weren’t card punching machines passé by the mid- to late-1960s? Well, it
might surprise you to know that the 029 was available in IBM’s catalog until as
late as 1984. 1 In fact, most programmers programmed using punch cards until
well into the 1970s. This doesn’t make much sense given that there were people
using teletype machines during World War II. Indeed, the teletype is almost of
the same vintage as the card punch. The limiting factor, it turns out, was not
the availability of teletypes but the availability of computing time. What kept
people from using teletypes was that teletypes assumed an interactive, “online”
model of communication with the computer. Before Unix and the invention of
timesharing operating systems, your interactive session with a computer would
have stopped everyone else from using it, a delay potentially costing thousands
of dollars. So programmers instead wrote their programs offline using card
punch machines and then fed them into mainframe computers later as batch jobs.
Punch cards had the added benefit of being a cheap data store in an era where
cheap, reliable data storage was hard to come by. Your programs lived in stacks
of cards on your shelves rather than in files on your hard drive.
So what was it actually like using an IBM 029 card punch? That’s hard to explain without first taking a look at the cards themselves. A typical punch card had 12 rows and 80 columns. The bottom nine rows were the digit rows, numbered one through nine. These rows had the appropriate digit printed in each column. The top three rows, called the “zone” rows, consisted of two blank rows and usually a zero row. Row 12 was at the very top of the card, followed by row 11, then rows zero through nine. This somewhat confusing ordering meant that the top edge of the card was called the 12 edge while the bottom was called the nine edge. A corner of each card was usually clipped to make it easier to keep a stack of cards all turned around the right way.
When they were first invented, punch cards were meant to be punched with circular holes, but IBM eventually realized that they could fit more columns on a card if the holes were narrow rectangles. Different combinations of holes in a column represented different characters. For human convenience, card punches like the 029 would print each column’s character at the top of the card at the same time as punching the necessary holes. Digits were represented by one punched hole in the appropriate digit row. Alphabetical and symbolic characters were represented by a hole in a zone row and then a combination of one or two holes in the digit rows. The letter A, for example, was represented by a hole in the 12 zone row and another hole in the one row. This was an encoding of sorts, sometimes called the Hollerith code, after the original inventor of the punch card machine. The encoding allowed for only a relatively small character set; lowercase letters, for example, were not represented. Some clever engineer today might wonder why punch cards didn’t just use a binary encoding—after all, with 12 rows, you could encode over 4000 characters. The Hollerith code was used instead because it ensured that no more than three holes ever appeared in a single column. This preserved the structural integrity of the card. A binary encoding would have entailed so many holes that the card would have fallen apart.
Cards came in different flavors. By the 1960s, 80 columns was the standard, but
those 80 columns could be used to represent different things. The basic punch
card was unlabeled, but cards meant for COBOL programming, for example, divided
the 80 columns into fields. On a COBOL card, the last eight columns were
reserved for an identification number, which could be used to automatically
sort a stack of cards if it were dropped (apparently a perennial hazard).
Another column, column seven, could be used to indicate that the statement on
this card was a continuation of a statement on a previous card. This meant that
if you were truly desperate you *could* circumvent the 80-character limit,
though whether a two-card statement counts as one long line or just two is
unclear. FORTRAN cards were similar but had different fields. Universities
often watermarked the punch cards handed out by their computing centers, while
other kinds of designs were introduced for special occasions like the [1976
bicentennial](http://www.jkmscott.net/data/Punched%20card%20013.jpg).
Ultimately the cards had to be read and understood by a computer. IBM sold a
System/360 peripheral called the IBM 2540 which could read up to 1000 cards per
minute. 2 The IBM 2540 ran electrical brushes across the surface of each card
which made contact with a plate behind the cards wherever there was a hole.
Once read, the System/360 family of computers represented the characters on
each punch card using an 8-bit encoding called EBCDIC, which stood for Extended
Binary Coded Decimal Interchange Code. EBCDIC was a proper binary encoding, but
it still traced its roots back to the punch card via an earlier encoding called
BCDIC, a 6-bit encoding which used the low four bits to represent a punch
card’s digit rows and the high two bits to represent the zone rows. Punch card
programmers would typically hand their cards to the actual computer operators,
who would feed the cards into the IBM 2540 and then hand the printed results
back to the programmer. The programmer usually didn’t see the computer at all.
What the programmer did see a lot of was the card punch. The 029 was not a
computer, but that doesn’t mean that it wasn’t a complicated machine. The best
way to understand what it was like using the 029 is to watch [this
instructional video](https://www.youtube.com/watch?v=kaQmAybWn-w) made by the
computing center at the University of Michigan in 1967. I’m going to do my best
to summarize it here, but if you don’t watch the video you will miss out on all
the wonderful clacking and whooshing.
The 029 was built around a U-shaped track that the punch cards traveled along. On the right-hand side, at the top of the U, was the card hopper, which you would typically load with a fresh stack of cards before using the machine. The IBM 029 worked primarily with 80-column cards, but the card hopper could accommodate smaller cards if needed. Your punch cards would start in the card hopper, travel along the line of the U, and then end up in the stacker, at the top of the U on the left-hand side. The cards would accumulate there in the order that you punched them.
To turn the machine on, you flipped a switch under the desk at about the height of your knees. You then pressed the “FEED” key twice to get cards loaded into the machine. The business part of the card track, the bottom of the U, was made up of three separate stations: On the right was a kind of waiting area, in the middle was the punching station, and on the left was the reading station. Pressing the “FEED” key twice loaded one card into the punching station and one card into the waiting area behind it. A column number indicator right above the punching station told you which column you were currently punching. With every keystroke, the machine would punch the requisite holes, print the appropriate character at the top of the card, and then advance the card through the punching station by one column. If you punched all 80 columns, the card would automatically be released to the reading station and a new card would be loaded into the punching station. If you wanted this to happen before you reached the 80th column, you could press the “REL” key (for “release”).
The printed characters made it easy to spot a mistake. But fixing a mistake, as the University of Michigan video warns, is not as easy as whiting out the printed character at the top of the card and writing in a new one. The holes are all that the computer will read. Nor is it as easy as backspacing one space and typing in a new character. The holes have already been punched in the column, after all, and cannot be unpunched. Punching more holes will only produce an invalid combination not associated with any character. The IBM 029 did have a backspace button that moved the punched card backward one column, but the button was placed on the face of the machine instead of on the keyboard. This was probably done to discourage its use, since backspacing was so seldom what the user actually wanted to do.
Instead, the only way to correct a mistake was scrap the incorrect card and punch a new one. This is where the reading station came in handy. Say you made a mistake in the 68th column of a card. To fix your mistake, you could carefully repunch the first 67 columns of a new card and then punch the correct character in the 68th column. Alternatively, you could release the incorrect card to the reading station, load a new card into the punching station, and hold down the “DUP” key (for duplicate) until the column number indicator reads 68. You could then correct your mistake by punching the correct character. The reading station and the “DUP” key together allowed IBM 029 operators to easily copy the contents of one card to the next. There were all sorts of reasons to do this, but correcting mistakes was the most common.
The “DUP” key allowed the 029’s operator to invoke the duplicate functionality manually. But the 029 could also duplicate automatically where necessary. This was particularly useful when punched cards were used to record data rather than programs. For example, you might be using each card to record information about a single undergraduate university student. On each card, you might have a field that contains the name of that student’s residence hall. Perhaps you find yourself entering data for all the students in one residence hall at one time. In that case, you’d want the 029 to automatically copy over the previous card’s residence hall field every time you reached the first column of the field.
Automated behavior like this could be programmed into the 029 by using the
program drum. The drum sat upright in the middle of the U above the punching
station. You programmed the 029 by punching holes in a card and wrapping that
card around the program drum. The punched card allowed you to specify the
automatic behavior you expected from the machine at each column of the card
currently in the punching station. You could specify that a column should
automatically be copied from the previous card, which is how an 029 operator
might more quickly enter student records. You could also specify, say, that a
particular field should contain numeric or alphabetic characters, or that a
given field should be left blank and skipped altogether. The program drum made
it much easier to punch schematized cards where certain column ranges had
special meanings. There is another [“advanced” instructional
video](https://www.youtube.com/watch?v=SWD1PwNxpoU) produced by the University
of Michigan that covers the program drum that is worth watching, provided, of
course, that you have already mastered the basics.
Watching either of the University of Michigan videos today, what’s surprising is how easy the card punch is to operate. Correcting mistakes is tedious, but otherwise the machine seems to be less of an obstacle than I would have expected. Moving from one card to the next is so seamless that I can imagine COBOL or FORTRAN programmers forgetting that they are creating separate cards rather than one long continuous text file. On the other hand, it’s interesting to consider how card punches, even though they were only an input tool, probably limited how early programming languages evolved. Structured programming would eventually come along and encourage people to think of entire blocks of code as one unit, but I can see how punch card programming’s emphasis on each line made structured programming hard to conceive of. It’s no wonder that punch card programmers were not the ones that decided to enclose blocks with single curly braces entirely on their own lines. How wasteful that would have seemed!
So even though nobody programs using punch cards anymore, every programmer
ought to [try it](http://www.masswerk.at/keypunch/) at least once—if only to
understand why COBOL and FORTRAN look the way they do, or how 80 characters
somehow became everybody’s favorite character limit.
*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
*
-
“IBM 29 Card Punch,” IBM Archives, accessed June 23, 2018,
[https://www-03.ibm.com/ibm/history/exhibits/vintage/vintage_4506VV4002.html](https://www-03.ibm.com/ibm/history/exhibits/vintage/vintage_4506VV4002.html).[↩](#fnref:1) -
IBM, IBM 2540 Component Description and Operation Procedures (Rochester, MN: IBM Product Publications, 1965), September 06, 2009, accessed June 23, 2018,
[http://bitsavers.informatik.uni-stuttgart.de/pdf/ibm/25xx/A21-9033-1_2540_Card_Punch_Component_Description_1965.pdf](http://bitsavers.informatik.uni-stuttgart.de/pdf/ibm/25xx/A21-9033-1_2540_Card_Punch_Component_Description_1965.pdf).[↩](#fnref:2) |
10,383 | 7 个最佳 Linux 电子书阅读器 | https://itsfoss.com/best-ebook-readers-linux/ | 2018-12-25T22:17:00 | [
"电子书",
"Calibre"
] | https://linux.cn/article-10383-1.html | **摘要:** 本文中我们涉及一些 Linux 最佳电子书阅读器。这些应用提供更佳的阅读体验甚至可以管理你的电子书。

最近,随着人们发现在手持设备、Kindle 或者 PC 上阅读更加舒适,对电子图书的需求有所增加。至于 Linux 用户,也有各种电子书应用满足你阅读和整理电子书的需求。
在本文中,我们选出了七个最佳 Linux 电子书阅读器。这些电子书阅读器最适合 pdf、epub 和其他电子书格式。
我提供的是 Ubuntu 安装说明,因为我现在使用它。如果你使用的是[非 Ubuntu 发行版](https://itsfoss.com/non-ubuntu-beginner-linux/),你能在你的发行版软件仓库中找到大多数这些电子书应用。
### 1. Calibre
[Calibre](https://www.calibre-ebook.com) 是 Linux 最受欢迎的电子书应用。老实说,这不仅仅是一个简单的电子书阅读器。它是一个完整的电子书解决方案。你甚至能[通过 Calibre 创建专业的电子书](https://itsfoss.com/create-ebook-calibre-linux/)。
通过强大的电子书管理和易用的界面,它提供了创建和编辑电子书的功能。Calibre 支持多种格式和与其它电子书阅读器同步。它也可以让你轻松转换一种电子书格式到另一种。
Calibre 最大的缺点是,资源消耗太多,因此作为一个独立的电子阅读器来说是一个艰难的选择。

#### 特性
* 管理电子书:Calibre 通过管理元数据来排序和分组电子书。你能从各种来源下载一本电子书的元数据或创建和编辑现有的字段。
* 支持所有主流电子书格式:Calibre 支持所有主流电子书格式并兼容多种电子阅读器。
* 文件转换:在转换时,你能通过改变电子书风格,创建内容表和调整边距的选项来转换任何一种电子书格式到另一种。你也能转换个人文档为电子书。
* 从 web 下载杂志期刊:Calibre 能从各种新闻源或者通过 RSS 订阅源传递故事。
* 分享和备份你的电子图书馆:它提供了一个选项,可以托管你电子书集合到它的服务端,从而你能与好友共享或用任何设备从任何地方访问。备份和导入/导出特性可以确保你的收藏安全和方便携带。
#### 安装
你能在主流 Linux 发行版的软件库中找到它。对于 Ubuntu,在软件中心搜索它或者使用下面的命令:
```
sudo apt-get install calibre
```
### 2. FBReader

[FBReader](https://fbreader.org) 是一个开源的轻量级多平台电子书阅读器,它支持多种格式,比如 ePub、fb2、mobi、rtf、html 等。它包括了一些可以访问的流行网络电子图书馆,那里你能免费或付费下载电子书。
#### 特性
* 支持多种文件格式和设备比如 Android、iOS、Windows、Mac 和更多。
* 同步书集、阅读位置和书签。
* 在线管理你图书馆,可以从你的 Linux 桌面添加任何书到所有设备。
* 支持 Web 浏览器访问你的书集。
* 支持将书籍存储在 Google Drive ,可以通过作者,系列或其他属性整理书籍。
#### 安装
你能从官方库或者在终端中输入以下命令安装 FBReader 电子阅读器。
```
sudo apt-get install fbreader
```
或者你能从[这里](https://fbreader.org/content/fbreader-beta-linux-desktop)抓取一个以 .deb 包,并在你的基于 Debian 发行版的系统上安装它。
### 3. Okular
[Okular](https://okular.kde.org/) 是另一个开源的基于 KDE 开发的跨平台文档查看器,它已经作为 KDE 应用发布的一部分了。

#### 特性
* Okular 支持多种文档格式像 PDF、Postscript、DjVu、CHM、XPS、ePub 和其他。
* 支持在 PDF 文档中评论、高亮和绘制不同的形状等。
* 无需修改原始 PDF 文件,分别保存上述这些更改。
* 电子书中的文本能被提取到一个文本文件,并且有个名为 Jovie 的内置文本阅读服务。
备注:查看这个应用的时候,我发现这个应用在 Ubuntu 和它的衍生系统中不支持 ePub 文件格式。其他发行版用户仍然可以发挥它全部的潜力。
#### 安装
Ubuntu 用户可以在终端中键入下面的命令来安装它:
```
sudo apt-get install okular
```
### 4. Lucidor
Lucidor 是一个易用的、支持 epub 文件格式和在 OPDS 格式中编目的电子阅读器。它也具有在本地书架里组织电子书集、从互联网搜索和下载,和将 Web 订阅和网页转换成电子书的功能。
Lucidor 是 XULRunner 应用程序,它向您展示了具有类似火狐的选项卡式布局,和存储数据和配置时的行为。它是这个列表中最简单的电子阅读器,包括诸如文本说明和滚动选项之类的配置。

你可以通过选择单词并右击“查找单词”来查找该单词在 Wiktionary.org 的定义。它也包含 web 订阅或 web 页面作为电子书的选项。
你能从[这里](http://lucidor.org/lucidor/download.php)下载和安装 deb 或者 RPM 包。
### 5. Bookworm

Bookworm 是另一个支持多种文件格式诸如 epub、pdf、mobi、cbr 和 cbz 的自由开源的电子阅读器。我写了一篇关于 Bookworm 应用程序的特性和安装的专题文章,到这里阅读:[Bookworm:一个简单而强大的 Linux 电子阅读器](https://itsfoss.com/bookworm-ebook-reader-linux/)
#### 安装
```
sudo apt-add-repository ppa:bookworm-team/bookworm
sudo apt-get update
sudo apt-get install bookworm
```
### 6. Easy Ebook Viewer
[Easy Ebook Viewer](https://github.com/michaldaniel/Ebook-Viewer) 是又一个用于读取 ePub 文件的很棒的 GTK Python 应用。具有基本章节导航、从上次阅读位置继续、从其他电子书文件格式导入、章节跳转等功能,Easy Ebook Viewer 是一个简单而简约的 ePub 阅读器.

这个应用仍然处于初始阶段,只支持 ePub 文件。
#### 安装
你可以从 [GitHub](https://github.com/michaldaniel/Ebook-Viewer.git) 下载源代码,并自己编译它及依赖项来安装 Easy Ebook Viewer。或者,以下终端命令将执行完全相同的工作。
```
sudo apt install git gir1.2-webkit-3.0 libwebkitgtk-3.0-0 gir1.2-gtk-3.0 python3-gi
git clone https://github.com/michaldaniel/Ebook-Viewer.git
cd Ebook-Viewer/
sudo make install
```
成功完成上述步骤后,你可以从 Dash 启动它。
### 7. Buka
Buka 主要是一个具有简单而清爽的用户界面的电子书管理器。它目前支持 PDF 格式,旨在帮助用户更加关注内容。拥有 PDF 阅读器的所有基本特性,Buka 允许你通过箭头键导航,具有缩放选项,并且能并排查看两页。
你可以创建单独的 PDF 文件列表并轻松地在它们之间切换。Buka 也提供了一个内置翻译工具,但是你需要有效的互联网连接来使用这个特性。

#### 安装
你能从[官方下载页面](https://github.com/oguzhaninan/Buka/releases)下载一个 AppImage。如果你不知道如何做,请阅读[如何在 Linux 下使用 AppImage](https://itsfoss.com/use-appimage-linux/)。或者,你可以通过命令行安装它:
```
sudo snap install buka
```
### 结束语
就我个人而言,我发现 Calibre 最适合我的需要。当然,Bookworm 看起来很有前途,这几天我经常使用它。不过,电子书应用的选择完全取决于你的喜好。
你使用哪个电子书应用呢?在下面的评论中让我们知道。
---
via: <https://itsfoss.com/best-ebook-readers-linux/>
作者:[Ambarish Kumar](https://itsfoss.com/author/ambarish/) 译者:[zjon](https://github.com/zjon) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Lately, the demand for digital books has increased as people find it more comfortable to reading a book on their handheld devices, Kindle or PC. When it comes to Linux users, there are various ebook apps that will serve your purpose in reading and organizing your collections.
In this article, I have compiled some of the best ebook readers for Linux. These ebook readers are best suited for PDFs, epubs, and other e-book formats.
## 1. Calibre
[Calibre](https://www.calibre-ebook.com/?ref=itsfoss.com) is one of the most popular eBook apps for Linux. To be honest, it’s a lot more than just a simple eBook reader. It’s a complete eBook solution. You can even [create professional eBooks with Calibre](https://itsfoss.com/create-ebook-calibre-linux/) or even [remove DRM from Kindle books](https://itsfoss.com/calibre-remove-drm-kindle/).
With a powerful eBook manager and easy-to-use interface, it features the creation and editing of an eBook. Calibre supports various formats and syncing with other eBook readers. It also lets you convert one eBook format to another with ease.
The biggest drawback of Calibre is that it can be heavy on system resources, and that makes it a difficult choice as a standalone eBook reader. Of course, that depends on what kind of system you’re rocking.
**Features**
- Calibre allows sorting and grouping eBooks by managing the metadata. You can download the metadata for an eBook from various sources, or create and edit the existing field.
- Calibre supports all major eBook formats and is compatible with various e-readers.
- You can convert any ebook format to another one with the option of changing the book style, creating a table of content, or improving margins while converting. You can also convert your personal documents to an ebook.
- Calibre can deliver stories from various news sources or through the RSS feed.
- It gives an option of hosting your eBook collection on its server, which you can share with your friends or access from anywhere, using any device. The backup and import/export features allow you to keep your collection safe and easy portability.
- Available cross-platform (Linux, Android, iOS, Windows, and macOS)
**Installation**
You can find it in the software repository of all major Linux distributions. For Ubuntu, search for it in the Software Center or use the command below:
`sudo apt install calibre`
This will install a dated version of the app. So, if you want to install the latest version of Calibre, you can use the binary install method using the following command:
`sudo -v && wget -nv -O- https://download.calibre-ebook.com/linux-installer.sh | sudo sh /dev/stdin`
If you encounter an untrusted certificate error, you can use the command below to install it successfully:
`sudo -v && wget --no-check-certificate -nv -O- https://download.calibre-ebook.com/linux-installer.sh | sudo sh /dev/stdin`
## 2. FBReader (Not FOSS anymore)
[FBReader](https://fbreader.org/?ref=itsfoss.com) is a free, lightweight, multi-platform ebook reader, that is not open-source. It supports various formats like *epub*, *fb2*, *mobi*, *RTF*, *HTML*, etc. It also includes access to popular network libraries from where you can download ebooks for free or buy one.
FBReader is highly customizable with options to choose colors, fonts, page-turning animations, bookmarks, and dictionaries.
**Features**
- Supports various file formats and devices like Android, iOS, Windows, Mac, and more.
- Synchronize book collection, reading positions, and bookmarks.
- Manage your library online by adding any book from your Linux desktop to all your devices.
- Web browser access to your stored collection.
- Supports storage of books in Google Drive and organizing of books by authors, series, or other attributes.
**Installation**
You can install the FBReader ebook reader from the official repository or by typing the below command in the terminal.
`sudo apt install fbreader`
They also have a snap version on [Snapcraft](https://snapcraft.io/fbreader?ref=itsfoss.com) that you can get for your Ubuntu system.
## 3. Okular
[Okular](https://okular.kde.org/?ref=itsfoss.com) is an open-source and cross-platform document viewer developed by KDE that is shipped as part of the KDE Application release.
**Features**
- Okular supports various document formats like
*PDF*,*Postscript*,*DjVu*,*CHM*,*XPS*,*epub*, and others. - Supports features like commenting on PDF documents, highlighting and drawing different shapes, etc.
- These changes are saved separately without modifying the original PDF file.
- Text from an eBook can be extracted to a text file and has an inbuilt text reading service called Jovie.
**Installation**
Ubuntu users can install it by typing the below command in the Terminal:
`sudo apt install okular`
You can also get it from the [Flathub store](https://flathub.org/apps/org.kde.okular), and for more details you can refer to the [official website](https://okular.kde.org/?ref=itsfoss.com).
## 4. Lucidor
[Lucidor](https://lucidor.org/lucidor/?ref=itsfoss.com) is a handy e-book reader supporting *epub* file formats and catalogs in OPDS formats. It also features organizing the collection of e-books in local bookcases, searching and downloading from the internet, and converting web feeds and web pages into e-books.
Lucidor is a [XULRunner](https://wiki.mozilla.org/XULRunner) application, giving you a classic look of Firefox with a tabbed layout that behaves like it while storing data and configurations. It’s the simplest ebook reader on the list and includes configurations like text justifications and scrolling options.

You can also look up the meaning of a word from [Wiktionary.org](https://www.wiktionary.org) by selecting a word and *right-click *> *lookup word options*. It also includes options for converting web feeds or web pages into e-books.
**Features**
- Firefox-like Interface.
- Low storage footprint.
- Not heavy on system resources.
**Installation**
You can download and install it using the deb or RPM packages from their [official download page](https://lucidor.org/lucidor/?ref=itsfoss.com).
## 5. Bookworm
Bookworm is another free and open-source ebook reader supporting different file formats like *epub*, *pdf*, *mobi*, *cbr*, and *cbz*.
You can also refer to our separate article on [Bookworm](https://itsfoss.com/bookworm-ebook-reader-linux/) if you’re curious to learn some more details about it.
**Features**
- Intuitive reader layout.
- Support for ebook metadata editing.
- Different reading profiles for comfortable reading.
**Installation**
For Ubuntu or Ubuntu-based distros, you can run the following commands to install it using the official PPA:
```
sudo add-apt-repository ppa:bookworm-team/bookworm
sudo apt-get update
sudo apt-get install com.github.babluboy.bookworm
```
For other Linux distros, head over to its [website](https://babluboy.github.io/bookworm/?ref=itsfoss.com) to find more details on the installation.
## 6. Thorium Reader
From the house of EDRLab, [Thorium Reader](https://thorium.edrlab.org) is an open-source e-book reader that has been tailored for viewing digital books, comics, PDFs, and even audiobooks. It is available in many languages, with a special focus on accessibility features for visually impaired and dyslexic people.
**Features**
- Built from scratch.
- Many accessibility features.
- Support for
[Readium LCP](https://www.edrlab.org/readium-lcp/)DRM
**Installation**
You can install Thorium Reader by downloading the AppImage or DEB packages from the official [GitHub repo](https://github.com/edrlab/thorium-reader/releases).
## 7. Koodo Reader
Pitched as** **a minimalist ebook reader, [Koodo Reader](https://www.koodoreader.com/en) is a cross-platform, open-source ebook reader app that features extensive format support with the option to save your data on OneDrive, Google Drive, or other options such as FTP, SFTP, WebDAV, etc.
As you can see above, the user interface is pretty straightforward to get used to, and new users should feel right at home when using Koodo Reader.
**Features**
- Intuitive User Interface.
- Easy Library Management.
- Hassle-free Reading Experience.
**Installation**
You can download an AppImage from the [GitHub releases section](https://github.com/koodo-reader/koodo-reader/releases). If you are unsure how to install it, then you can read our guide on [how to use AppImage in Linux](https://itsfoss.com/use-appimage-linux/).
Alternatively, you can install it from the command line as well, using the flatpak package. If you don’t know how to do that, follow our resource on [how to install Flatpak apps](https://itsfoss.com/flatpak-guide/) on Linux and type in the following commands:
```
flatpak install flathub io.github.troyeguo.koodo-reader
flatpak run io.github.troyeguo.koodo-reader
```
## 8. Foliate
[Foliate](https://johnfactotum.github.io/foliate/) is an eBook reader that is actively developed, which already provides the most essential features while also providing a great user experience.
It is an impressive alternative to the rest of the eBook readers mentioned above.
**Features**
- Ability to tweak the text.
- Many pre-installed themes.
- Support for bookmarks and annotations.
**Installation**
The most straightforward way you can install Foliate on your Linux system is by opting for either the [Flatpak](https://flathub.org/apps/details/com.github.johnfactotum.Foliate?ref=itsfoss.com) or the [Snap](https://snapcraft.io/foliate?ref=itsfoss.com) version.
You can also head over to its [GitHub release section](https://github.com/johnfactotum/foliate/releases?ref=itsfoss.com) to get the source code.
### Final Words
Personally, I find Calibre best suited for my needs. Moreover, Bookworm looks promising to me and I use it often. Though, Foliate can be worth a try if you’re looking for something modern.
At the end of the day, choosing an eBook application totally depends on your preference and use cases.
*💬 Which eBook app do you use? Let me know in the comments below.* |
10,384 | 在 Linux 终端上玩俄罗斯方块 | https://opensource.com/article/18/12/linux-toy-tetris | 2018-12-25T23:43:00 | [
"俄罗斯方块"
] | https://linux.cn/article-10384-1.html |
>
> 用每个人最喜欢的砖块配对游戏“俄罗斯方块”重新创造 20 世纪 80 年代的魔力。
>
>
>

感谢你来浏览我们今天的 Linux 命令行玩具日历。如果这是你第一次访问该系列,你可能会问自己,什么是命令行玩具。即使我不太确定,但一般来说,它可能是一个游戏或任何消遣,可以帮助你在终端获得乐趣。
很可能你们中的一些人之前会看到过我们日历中的各种推荐,但我们希望每个人至少遇到一件新事物。
我承诺在我开始这个系列时,我会介绍游戏,但到目前为止,我忽略了它,所以我们今天的选择就是游戏:俄罗斯方块。
俄罗斯方块和我差不多年纪,都在 1984 年夏天来到世界。不过,俄罗斯方块不是来自北卡罗来纳州的农村地区,而是来自当时苏联的莫斯科。
在风靡世界之后,俄罗斯方块被克隆过很多次。我怀疑你可以找到任何你想找的任何语言、操作系统的俄罗斯方块的克隆。说真的,去看看吧。会有一些有趣的。
我今天带来的命令行[版本](https://github.com/samtay/tetris)是[用 Haskell 编写](https://github.com/samtay/tetris)的,它是我见过的做得更好的版本之一,有屏幕预览、得分、帮助、干净的外观。
如果你愿意从不受信任的来源运行已编译的二进制文件(我不推荐它),你可以直接获取它,但有个更安全的方法,使用 [dex](https://github.com/dockerland/dex) 的容器化版本也很容易,或者使用 [stack](https://docs.haskellstack.org/en/stable/README/#how-to-install) 从源代码安装。
这个俄罗斯方块克隆版是由 Sam Tay 编写的,并且在 BSD 许可证下发布。[请看这里获取](https://github.com/samtay/tetris)!

如果你有自己喜欢的俄罗斯方块克隆版(或者你自己写的?),请告诉我们!
你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。如果你有特别想了解的可以评论留言,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
查看昨天的玩具,[在 Linux 命令行中计划你自己的假期日历](https://opensource.com/article/18/12/linux-toy-cal),明天再回来查看!
---
via: <https://opensource.com/article/18/12/linux-toy-tetris>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Thanks for joining us for today's installment of the Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself, what’s a command-line toy. Even I'm not quite sure, but generally, it could be a game or any simple diversion that helps you have fun at the terminal.
It's quite possible that some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
I promised when I started this series I'd be including games, but so far I've neglected to, so let's fix that with today's selection: Tetris.
Tetris and I are almost exactly the same age, having first come into the world in the summer of 1984. Instead of rural North Carolina, though, Tetris originated in Moscow in what was at the time the Soviet Union.
After taking the world by storm, Tetris was cloned many, many times. I would suspect you could find a Tetris clone for just about any operating system in any language you looked for. Seriously, go look. There are some fun ones out there.
The [version](https://github.com/samtay/tetris) I'm bringing you for today's command-line toy is [written in Haskell, ](https://github.com/samtay/tetris)and it's one of the better-done versions I've seen, with on-screen preview, score, help, and a clean look.
If you're willing to run a compiled binary from an untrusted source (I wouldn't recommend it), you can grab that directly, but for a safer approach, it's also easy to use a containerized version with [dex](https://github.com/dockerland/dex), or to install from source with [stack](https://docs.haskellstack.org/en/stable/README/#how-to-install).
This particular Tetris clone is by Sam Tay and available under a BSD license. [Check it out](https://github.com/samtay/tetris)!
If you've got your own favorite Tetris clone (or maybe you've written your own?), let us know!
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Check out yesterday's toy, [Plan your own holiday calendar at the Linux command line](https://opensource.com/article/18/12/linux-toy-cal), and check back tomorrow for another!
## 3 Comments |
10,385 | 如何在 VirtualBox 上安装并使用 FreeDOS? | https://itsfoss.com/install-freedos/ | 2018-12-26T00:41:00 | [
"VirtualBox",
"FreeDOS"
] | https://linux.cn/article-10385-1.html |
>
> 这份指南将带你如何一步一步在 Linux 平台下利用 VirtualBox 安装 FreeDOS。
>
>
>

### Linux 下借助 VirtualBox 安装 FreeDOS
2017 年的 11 月份,我[采访了 Jim Hall](https://itsfoss.com/interview-freedos-jim-hall/) 关于 [FreeDOS 项目](http://www.freedos.org/) 背后的历史故事。今天,我将告诉你如何安装并使用 FreeDOS。需要注意到是:我将在 [Solus](https://solus-project.com/home/)(一种针对家庭用户的 Linux 桌面发行版)下使用 5.2.14 版本的 [VirtualBox](https://www.virtualbox.org/) 来完成这些操作。
>
> 注意:在本教程我将使用 Solus 作为主机系统因为它很容易设置。另一个你需要注意的事情是 Solus 的软件中心有两个版本的 VirtualBox:`virtualbox` 和 `virtualbox-current`。Solus 会让你选择是使用 linux-lts 内核还是 linux-current 内核。最终区别就是,`virtualbox` 适用于 linux-lts 而 `virtualbx-current` 适用于 linux-current。
>
>
>
#### 第一步 – 创建新的虚拟机

当你打开 VirtualBox,点击 “New” 按钮来新建一个虚拟机。你可以自定义这台虚拟机的名字,我将它命名为 “FreeDOS”。你也可以在标注栏内指明你正在安装的 FreeDOS 的版本。你还需要选择你将要安装的操作系统的类型和版本。选择 “Other” 下的 “DOS”。
#### 第二步 – 设置内存大小

下一个对话框会问你要给 FreeDOS 主机分配多少可用的内存空间。默认分配 32 MB。不必更改它。在 DOS 系统盛行的年代,32 MB 大小的内存对于一台搭载 FreeDOS 的机器已经很足够了。如果你有需要,你可以通过对你针对 FreeDOS 新建的虚拟机右键并选择 “Setting -> Symtem” 来增加内存。

#### 第三步 – 创建虚拟硬盘

下一步,你会被要求创建一个虚拟硬盘用来存储 FreeDOS 和它的文件。如果你还没有创建,只需要点击 “Create”。
下一个对话框会问你想用什么磁盘文件类型。默认的类型 (VirtualBox Disk Image) 效果就挺好。点击 “Next”。
下一个你遇到的问题是你想虚拟硬盘以何种方式创建。你是否希望虚拟硬盘占据的空间刚开始很小然后会随着你创建文件和安装软件逐渐增加直至达到你设置的上限?那么选择动态分配。如果你更喜欢虚拟硬盘 (VHD) 按照既定大小直接创建,选择固定大小即可。如果你不打算使用整个 VHD 或者你的硬盘空余空间不是太足够,那么动态分配是个很不错的分配方式。(需要注意的是,动态分配的虚拟硬盘占据的空间会随着你增加文件而增加,但不会因为你删除文件而变小) 我个人更喜欢动态分配,但你可以根据实际需要来选择最合适你的分配类型然后点击 “Next”。

现在,你可以选择虚拟磁盘的大小和位置。500 MB 已经很足够了。需要注意的是很多你之后用到的程序都是基于文本的,这意味着它们占据的空间非常小。在你做好这些调整后,点击 “Create”。
#### 第四步 – 关联 .iso 文件
在我们继续之前,你需要[下载](http://www.freedos.org/download/) FreeDOS 的 .iso 文件。你需要选择 CDROM 格式的 “standard” 安装程序。

当文件下载完毕后,返回到 VirtualBox。选中你的虚拟机并打开设置。你可以通过对虚拟机右键并选中 “Setting” 或者选中虚拟机并点击 “Setting” 按钮。
接下来,点击 “Storage” 选项卡。在 “Storage Devices” 下面,选中 CD 图标。(它应该会在图标旁边显示 “Empty”。) 在右边的 “Attribute” 面板,点中 CD 图标然后在对应路径选中你刚下载的 .iso 文件。
>
> 提示:通常,在你通过 VirtualBox 安装完一个操作系统后你就可以删除对应的 .iso 文件了。但这并不适合 FreeDOS 。如果你想通过 FreeDOS 的包管理器来安装应用程序,你需要这个 .iso 文件。我通常会让这个 .iso 文件连接到虚拟机以便我安装一些程序。如果你也这么做了,你必须要确认下你让 FreeDOS 虚拟机每次启动的时候是从硬盘启动因为虚拟机的默认设置是从已关联的 .iso 文件启动。如果你忘了关联 .iso 文件,也不用担心。你可以通过选择 FreeDOS 虚拟机窗口上方的 “Devices” 来关联。然后就会发现 .iso 文件列在 “Optical Drives”。
>
>
>
#### 第五步 – 安装 FreeDOS

既然我们已经完成了所有的准备工作,让我们来开始安装 FreeDOS 吧。
首先,你需要知道关于最新版本的 VirtualBox 的一个 bug。当我们创建好虚拟硬盘然后选中 “Install to harddisk” 后,如果你开启虚拟机你会发现在 FreeDOS 的欢迎界面出现过后就是不断滚动无群无尽的机器代码。我最近就遇到过这个问题而且不管是 Linux 还是 Windows 平台的 VirtualBox 都会碰到这个问题。(我知道解决办法。)
为了避开这个问题,你需要做一个简单的修改。当你看到 FreeDOS 的欢迎界面的时候,按下 Tab 键。(确认 “Install to harddrive” 已经选中。)在 “fdboot.img” 之后输入 `raw` 然后按下回车键。接下来就会启动 FreeDOS 的安装程序。

安装程序会首先处理你的虚拟磁盘的格式化。当格式化完成后,安装程序会重启。当 FreeDOS 的欢迎界面再次出现的时候,你必须重新输入 `raw` 就像你之前输入的内容那样。
要确保在安装过程中你遇到的所有问题你选的都是 “Yes”。但也要注意有一个很重要的问题:“What FreeDOS packages do you want to install?” 的答案并不是 “Yes” 或者 “No”。答案有两个选择分别是 “Base packages” 和 “Full installation”。“Base packages” 针对的是想体验类似原始的 MS-DOS 环境的人群。“Full installation” 则包括了一系列工具和实用的程序来提升 DOS。
在整个安装过程的最后,你可以选择重启或者继续停留在 DOS。选择“reboot”。
#### 第六步 – 设置网络
不同于原始的 DOS,FreeDOS 可以访问互联网。你可以安装新的软件包或者更新你已经安装的软件包。要想使用网络,你还需要在 FreeDOS 安装些应用程序。

首先,启动进入你新创建的 FreeDOS 虚拟机。在 FreeDOS 的选择界面,选中 “Boot from System harddrive”。

现在,你可以通过输入 `fdimples` 来访问 FreeDOS 的软件包管理工具。你也可以借助方向键来浏览软件包管理器,然后用空格键选择类别或者软件包。在 “Networking” 类别中,你需要选中 `fdnet`。FreeDOS project 推荐也安装 `mtcp` 和 `wget`。多次点击 Tab 键直到选中 “OK” 然后在按下回车键。安装完成后,输入 `reboot` 并按下回车键确认执行。系统重启后,引导你的系统驱动。如果网络安装成功的话,你会在终端看到一些关于你的网络信息的新消息。

注意:
有时候 VirtualBox 的默认设置并没有生效。如果遇到这种情况,先关闭你的 FreeDOS 虚拟机窗口。在 VirtualBox 主界面右键你的虚拟机并选中 “Setting”。VirtualBox 默认的网络设置是 “NAT”。将它改为 “Bridged Adapter” 后再尝试安装 FreeDOS 的软件包。现在就应该能正常运作了。
#### 第七步 – FreeDOS 的基本使用
##### 常见命令
既然你已经成功安装了 FreeDOS,让我们来看些基础命令。如果你已经在 Windows 平台使用过命令提示符,那么你会发现有很多命令都是相似的。
* `DIR`– 显示当前目录的内容
* `CD` – 改变当前所在的目录
* `COPY OLD.TXT NEW.TXT`– 复制文件
* `TYPE TEST.TXT` – 显示文件内容
* `DEL TEST.TXT` – 删除文件
* `XCOPY DIR NEWDIR` – 复制目录及目录下的所有内容
* `EDIT TEST.TXT`– 编辑一个文件
* `MKDIR NEWDIR` – 创建一个新目录
* `CLS` – 清除屏幕
你可以借助互联网或者 Jim Hall 所创建的 [方便的速查表](https://opensource.com/article/18/6/freedos-commands-cheat-sheet) 来找到更多基本的 DOS 命令。
##### 运行一个程序
在 FreeDOS 上运行程序相当简单。需要注意的是当你借助 `fdimples` 软件包管理器来安装一个应用程序的时候,要确保你指定了待安装程序的 .EXE 文件的路径。这个路径会在应用程序的详细信息中显示。要想运行程序,通常你还需要进入到程序所在文件夹并输入该程序的名字。
例如,FreeDOS 中你可以安装一个叫 `FED` 的编辑器。安装完成后,你还需要做的就是进入 `C:\FED` 这个文件夹下并输入 `FED`。
对于位于 `\bin` 这个文件夹的程序,比如 Pico。这些程序可以在任意文件夹中被调用。
对于游戏通常会有一个或者两个 .EXE 程序,你玩游戏之前不得不先运行它们。这些设置文件通常能够修复你遇到的声音,视频,或者控制问题。
如果你遇到一些本教程中没指出的问题,别忘记访问 [FreeDOS 主站](http://www.freedos.org/) 来寻求解决办法。他们有一个 wiki 和一些其他的支持选项。
你使用过 FreeDOS 吗?你还想看关于 FreeDOS 哪些方面的教程?请在下面的评论区告诉我们。
如果你觉得本篇文章很有趣,请花一分钟的时间将它分享在你的社交媒体,Hacker News 或者 [Reddit](http://reddit.com/r/linuxusersgroup)。
---
via: <https://itsfoss.com/install-freedos/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[WangYueScream](https://github.com/WangYueScream) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This step-by-step guide shows you how to install FreeDOS on VirtualBox in Linux.
## Installing FreeDOS on VirtualBox in Linux
In November of 2017, I [interviewed Jim Hall](https://itsfoss.com/interview-freedos-jim-hall/) about the history behind the [FreeDOS project](http://www.freedos.org/). Today, I’m going to tell you how to install and use FreeDOS. Please note: I will be using [VirtualBox](https://www.virtualbox.org/) 5.2.14 on [Solus](https://solus-project.com/home/).
Note: I used Solus as the host operating system for this tutorial because it is very easy to setup. One thing you should keep in mind is that Solus’ Software Center contains two versions of VirtualBox: `virtualbox`
and `virtualbox-current`
. Solus gives you the option to use the linux-lts kernel and the linux-current kernel. `virtualbox`
is modified for linux-lts and `virtualbox-current`
is for linux-current.
### Step 1 – Create New Virtual Machine
Once you open VirtualBox, press the “New” button to create a new virtual machine. You can name it whatever you want, I just use “FreeDOS”. You can use the label to specify what version of FreeDOS you are installing. You also need to select the type and version of the operating system you will be installing. Select “Other” and “DOS”.
### Step 2 – Select Memory Size
The next dialog box will ask you how much of the host computer’s memory you want to make available to FreeDOS. The default is 32MB. Don’t change it. Back in the day, this would be a huge amount of RAM for a DOS machine. If you need to, you can increase it later by right-clicking on the virtual machine you created for FreeDOS and selecting Settings -> System.
### Step 3 – Create Virtual Hard Disk
Next, you will be asked to create a virtual hard drive where FreeDOS and its files will be stored. Since you haven’t created one yet, just click “Create”.
The next dialog box will ask you what hard disk file type you want to use. This default (VirtualBox Disk Image) works just fine. Click “Next”.
The next question you will encounter is how you want the virtual disk to act. Do you want it to start small and gradually grow to its full size as you create files and install programs? Then choose dynamically allocated. If you prefer that the virtual hard drive (vhd) is created at full size, then choose fixed size. Dynamically allocated is nice if you don’t plan to use the whole vhd or if you don’t have very much free space on your hard drive. (Keep in mind that while the size of a dynamically allocated vhd increases as you add files, it will not drop when you remove files.) I prefer dynamically allocated, but you can choose the option that serves your needs best and click “Next”.
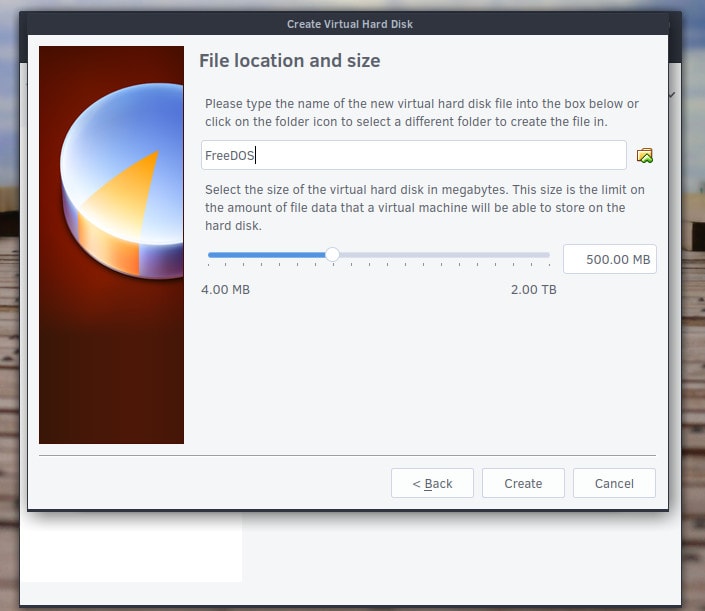
Now, you can choose the size and location of the vhd. 500 MB should be plenty of space. Remember most of the programs you will be using will be text-based, thus fairly small. Once you make your adjustments, click Create,
### Step 4 – Attach .iso file
Before we continue, you will need to [download](http://www.freedos.org/download/) the FreeDOS .iso file. You will need to choose the CDROM “standard” installer.
Once the file has been downloaded, return to VirtualBox. Select your virtual machine and open the settings. You can do this by either right-clicking on the virtual machine and selecting “Settings” or highlight the virtual machine and click the “Settings” button.
Now, click the “Storage” tab. Under “Storage Devices”, select the CD icon. (It should say “Empty” next to it.) In the “Attributes” panel on the right, click on the CD icon and select the location of the .iso file you just downloaded.
Note: Typically, after you install an operating system on VirtualBox you can delete the original .iso file. Not with FreeDOS. You need the .iso file if you want to install applications via the FreeDOS package manager. I generally keep the ,iso file attached the virtual machine in case I want to install something. If you do that, you have to make sure that you tell FreeDOS you want to boot from the hard drive each time you boot it up because it defaults to the attached CD/iso. If you forget to attach the .iso, don’t worry. You can do so by selecting “Devices” on the top of your FreeDOS virtual machine window. The .iso files are listed under “Optical Drives”.
### Step 5 – Install FreeDOS
Now that we’ve completed all of the preparations, let’s install FreeDOS.
First, you need to be aware of a bug in the most recent version of VirtualBox. If you start the virtual machine that we just created and select “Install to harddisk” when the FreeDOS welcome screen appears, you will see an unending, scrolling mass of machine code. I’ve only run into this issue recently and it affects both the Linux and Windows versions of VirtualBox. (I know first hand.)
To get around this, you need to make a simple edit. When you see the FreeDOS welcome screen, press Tab. (Make sure that the “Install to harddrive” option is selected.) Type the word `raw`
after “fdboot.img” and hit Enter. The FreeDOS installer will then start.
The first part of the installer will handle formatting your virtual drive. Once formatting is completed, the installer will reboot. When the FreeDOS welcome screen appears again, you will have to re-enter the `raw`
comment you used earlier.
Make sure that you select “Yes” on all of the questions in the installer. One important question that doesn’t have a “Yes” or “No” answer is: “What FreeDOS packages do you want to install?. The two options are “Base packages” or “Full installation”. Base packages are for those who want a DOS experience most like the original MS-DOS. The Full installation includes a bunch of tools and utilities to improve DOS.
At the end of the installation, you will be given the option to reboot or stay on DOS. Select “reboot”.
### Step 6 – Setup Networking
Unlike the original DOS, FreeDOS can access the internet. You can install new packages and update the ones already you have installed. In order to use networking, you need to install several applications in FreeDOS.
First, boot into your newly created FreeDOS virtual machine. At the FreeDOS selection screen, select “Boot from System harddrive”.
Now, to access the FreeDOS package manager, type `fdimples`
. You can navigate around the package manager with the arrow keys and select categories or packages with the space bar. From the “Networking” category, you need to select `fdnet`
. The FreeDOS Project also recommends installing `mtcp`
and `wget`
. Hit “Tab” several times until “OK” is selected and press “Enter”. Once the installation is complete, type `reboot`
and hit enter. After the system reboots, boot to your system drive. If the network installation was successful, you will see several new messages at the terminal listing your network information.
#### Note
Sometimes the default VirtualBox setup doesn’t work. If that happens, close your FreeDOS VirtualBox window. Right-click your virtual machine from the main VirtualBox screen and select “Settings”. The default VirtualBox network setting is “NAT”. Change it to “Bridged Adapter” and retry installing the FreeDOS packages. It should work now.
### Step 7 – Basic Usage of FreeDOS
#### Commons Commands
Now that you have installed FreeDOS, let’s look at a few basic commands. If you have ever used the Command Prompt on Windows, you will be familiar with some of these commands.
`DIR`
– display the contents of the current directory`CD`
– change the directory you are currently in`COPY OLD.TXT NEW.TXT`
– copy files`TYPE TEST.TXT`
– display content of file`DEL TEST.TXT`
– delete file`XCOPY DIR NEWDIR`
– copy directory and all of its contents`EDIT TEST.TXT`
– edit a file`MKDIR NEWDIR`
– create a new directory`CLS`
– clear the screen
You can find more basic DOS commands on the web or the [handy cheat sheet](https://opensource.com/article/18/6/freedos-commands-cheat-sheet) created by Jim Hall.
#### Running a Program
Running program on FreeDos is fairly easy. When you install an application with the `fdimples`
package manager, be sure to note where the .EXE file of the application is located. This is shown in the application’s details. To run the application, you generally need to navigate to the application folder and type the application’s name.
For example, FreeDOS has an editor named `FED`
that you can install. After installing it, all you need to do is navigate to `C:\FED`
and type `FED`
.
Sometimes a program, such as Pico, is stored in the `\bin`
folder. These programs can be called up from any folder.
Games usually have an .EXE program or two that you have to run before you can play the game. These setup file usually fix sound, video, or control issues.
If you run into problems that this tutorial didn’t cover, don’t forget to visit the [home of FreeDOS](http://www.freedos.org/). They have a wiki and several other support options.
Have you ever used FreeDOS? What tutorials would you like to see in the future? Please let us know in the comments below.
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit](http://reddit.com/r/linuxusersgroup). |
10,386 | 所有人的 DevOps | https://opensource.com/article/18/11/how-non-engineer-got-devops | 2018-12-26T19:46:00 | [
"DevOps"
] | /article-10386-1.html |
>
> 让一名非工程师来解释为什么你不必成为一位开发者或运维就能爱上 DevOps。
>
>
>

我从未做过开发或运维的工作 —— 那怎么我在写一篇关于 [DevOps](https://opensource.com/resources/devops) 的文章?我一直都对计算机和技术有兴趣。我还对社群、心理学以及帮助他人充满热情。当我第一次听到 DevOps 时,这个概念激起了我的兴趣,因为它看起来融合了很多我感兴趣的东西,即便我是不写代码的。
我的第一台电脑是 TRS-80,我喜欢在上面编写 BASIC 程序。我只上过两门我的高中开设的计算机编程课程。若干年后,我创办了一家计算机公司。我定制邮件标签和信纸,并建立了一个数据库来存储地址。
问题是我并不能从写代码中获得享受。我想要教育和帮助人们,我没法将写代码看作这样的一个机会。是的,技术可以帮助人们并改变生活,但是写代码没有点燃我的热情。我需要对我的工作感到兴奋并做我喜欢的事情。
我发现我爱 DevOps。对我而言,DevOps 指的是:
* 文化,而不是代码
* 过程,而不是结果
* 建立一个所有人可以持续提升的环境
* 沟通与合作,而不是独立工作
归根结底,DevOps 是指成为社区工作的一部分,实现共同的目标。DevOps 融合了心理学、社群、技术。DevOps 不是一个职位名称,它是一种生活和工作的哲学。
### 找到我的社群
快四年前,我在西雅图参加了我的第一个 [DevOps 日](https://www.devopsdays.org/) 会议。我感觉我找到了我的社群。我觉得受到了欢迎和接受,尽管我从事营销工作而且没有计算机科学文凭。我可以从心理学和技术中寻找乐趣。
在 DevOps 日,我学到了 [DevOps“三步工作法”](https://itrevolution.com/the-three-ways-principles-underpinning-devops/) —— 流动、反馈、持续实验和学习 —— 以及新(对我而言)的概念,如 Kaizen(改善)和 Kaikaku(改革)。随着我的学习深入,我发现我在说这样的话,“我是这样做的!我都不知道这样做还有个名字!”
[Kaizen(改善)](https://en.wikipedia.org/wiki/Kaizen)是持续改进和学习的实践。小的量变积累随着时间的推移可以引起质变。我发现它和卡罗尔·德韦克的[成长型思维](https://en.wikipedia.org/wiki/Mindset#Fixed_and_growth)的想法很相似。人们不是生来就是专家。在某方面拥有经验需要花费时间、练习,以及常常还有失败。承认增量的改善对确保我们不会放弃是很有必要的。
另一方面,[Kaikaku(改革)](https://en.wikipedia.org/wiki/Kaikaku)的概念是指,长时间的小的改变有时不能起作用,你需要做一些完全的或破坏性的改变。在没有找到下份工作前就辞职或移居新城市就足够有破坏性 —— 是的,两者我都做过。但这些彻底的改变收获巨大。如果我没有辞职并休息一段时间,我也许不会接触到 DevOps。等我决定继续工作的时候,我一直听到 DevOps,我开始研究它。这引导我参加了我的第一个 DevOps 日,从那里我开始看到我的所有热情开始聚集。从那时起,我已经参加了五次 DevOps 日活动,并且定期撰写关于 DevOps 话题的文章。
### 将三步工作法用到工作中
改变是困难的,学习新事物可以听起来很吓人。DevOps 的三步工作法提供了一个管理改变的框架。比如:信息流动是怎样的?是什么驱动着你做出改变?一旦你认为一个改变是必需的,你如何获得这个改变是否正确的反馈?你如何知道你在取得进展?反馈是必要的,并且应该包含积极和有建设性的要素。困难的地方在于保证建设性的要素不要重于积极要素。
对我而言,第三步 —— 持续实验和学习 —— 是 DevOps 最重要的部分。有一个可以自由地实验和冒险的环境,人们可以获得意想不到的结果。有时这些结果是好的,有时不是太好 —— 但这没事。创建一个可以接受失败结果的环境可以鼓励人们冒险。我们都应该力争定期的持续实验和学习。
DevOps 的三步工作法提供了一个尝试,获得反馈,以及从错误中获取经验的方法。几年前,我的儿子告诉我,“我从来就没想做到最好,因为那样我就没法从我的错误中学到东西了。”我们都会犯错,从中获得经验帮助我们成长和改善。如果我们的文化不支持尝试和学习,我们就不会愿意去犯错。
### 成为社区的一部分
我已经在技术领域工作了超过 20 年,直到我发现 DevOps 社区前,我还经常感觉自己是个外行。如果你像我一样——对技术充满热情,但不是工程和运维那方面——你仍然可以成为 DevOps 的一部分,即便你从事的是销售、营销、产品营销、技术写作、支持或其他工作。DevOps 是属于所有人的。
---
via: <https://opensource.com/article/18/11/how-non-engineer-got-devops>
作者:[Dawn Parych](https://opensource.com/users/dawnparzych) 选题:[lujun9972](https://github.com/lujun9972) 译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,387 | 在 Linux 终端中观看火焰 | https://opensource.com/article/18/12/linux-toy-aafire | 2018-12-26T20:03:00 | [
"命令行"
] | https://linux.cn/article-10387-1.html |
>
> 何不在命令行中进行一次“烧烤”呢?
>
>
>

这里是《24 天了解 Linux 命令行小玩意》。如果你未曾读过本系列的文章,可以在本文的结尾部分获取上一篇文章的链接,以了解本系列的大概内容。我们所介绍的命令行小玩意可供你消遣无聊时光。
你或许知道它们其中的一些,也可能不曾知晓它们。无论如何,我们都希望你能度过一段愉快的时光。
如果你住在北半球的非热带地区,可能冬季来临时你会被冻得满脸通红。住在这里的我,最喜欢的事情便是在火炉旁惬意地边喝茶边读书。
不幸的是,我家刚好缺个放火炉的地方。不过,多亏了今天我要介绍的 `aafire` ,我仍然可以假装我坐在火炉旁。
在我所使用的系统里, `aafire` 被打包进了 aalib 。 aalib 是一个受人喜爱的库,它可以很方便地将图像转换成 ASCII 图并输出到终端(或其它任何地方)。 aalib 将多种多样的图像带入了 Linux 终端。你可以看看本系列的其它文章,了解一下其它小程序,以便配合使用并充分利用它们。在 Fedora 中,你可以通过以下命令来安装 aalib :
```
$ sudo dnf install aalib
```
接着,试着运行 `aafire` 命令。 `aalib` 默认会使用 GUI 模式,我们要进行一些操作来让它在终端中运行(毕竟这一系列文章都讲的是命令行)。十分幸运的是,仅需安装 [curses](https://en.wikipedia.org/wiki/Curses_(programming_library)) 就能实现我们想要的效果。请执行:
```
$ aafire -driver curses
```

如果你觉得 aalib 挺有意思,可以在 [Sourceforge](http://aa-project.sourceforge.net/aalib/) 上找到它的源码(以 LGPLv2 许可证开源)。
欢迎将你觉得有意思的命令行小程序投稿到原作者处,只需在原文下留言即可。
如果有兴趣,可以查看原作者的上一篇文章: [在命令行中步入黑客帝国](https://opensource.com/article/18/12/linux-toy-cmatrix) 。
---
via: <https://opensource.com/article/18/12/linux-toy-aafire>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zhs852](https://github.com/zhs852) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Welcome back. Here we are, just past the halfway mark at day 13 of our 24 days of Linux command-line toys. If this is your first visit to the series, see the link to the previous article at the bottom of this one, and take a look back to learn what it's all about. In short, our command-line toys are anything that's a fun diversion at the terminal.
Maybe some are familiar, and some aren't. Either way, we hope you have fun.
If you're in the northern hemisphere outside of the tropics, perhaps winter is starting to rear its frigid face outside. At least it is where I live. And some I'd love nothing more than to curl up by the fire with a cup of tea and my favorite book (or a digital equivalent).
The bad news is my house lacks a fireplace. The good news is that I can still pretend, thanks to the Linux terminal and today's command-line toy, **aafire**.
On my system, I found **aafire** packed with **aalib**, a delightful library for converting visual images into the style of ASCII art and making it available at your terminal (or elsewhere). **aalib** enables all sorts of fun graphics at the Linux terminal, so we may revisit a toy or two that make use of it before the end of our series. On Fedora, this meant installation was as simple as:
`$ sudo dnf install aalib`
Then, it was simple to launch with the **aafire** command. By default, **aalib** attempted to draw to my GUI, so I had to manually override it to keep my fire in the terminal (this is a command-line series, after all). Fortunately, it comes with a [curses](https://en.wikipedia.org/wiki/Curses_(programming_library)) driver, so this meant I just had to run the following to get my fire going:
`$ aafire -driver curses`

You can find out more about the **aa-lib** library and download the source on [Sourceforge](http://aa-project.sourceforge.net/aalib/), under an LGPLv2 license.
Do you have a favorite command-line toy that you think I ought to include? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Check out yesterday's toy,
[Patch into The Matrix at the Linux command line](https://opensource.com/article/18/12/linux-toy-cmatrix) , and check back tomorrow for another!
## 1 Comment |
10,388 | 27 个全方位的开放式教育解决方案 | https://opensource.com/article/18/1/best-open-education | 2018-12-26T21:17:00 | [
"教育",
"开放"
] | https://linux.cn/article-10388-1.html |
>
> 阅读这些 2017 年 Opensource.com 发布的开放如何改进教育和学习的好文章。
>
>
>

开放式理念 (从开源软件到开放硬件,再到开放原则) 正在改变教育的范式。因此,为了庆祝今年发生的一切,我收集了 2017 年(译注:本文原发布于 2018 年初)在 Opensource.com 上发表的 27 篇关于这个主题的最好的文章。我把它们分成明确的主题,而不是按人气来分类。而且,如果这 27 个故事不能满足你对教育方面开源信息的胃口,那就看看我们的合作文章吧 “[教育如何借助 Linux 和树莓派](https://opensource.com/article/17/12/best-opensourcecom-linux-and-raspberry-pi-education)”。
### 开放对每个人都有好处
1. [书评:《OPEN》探讨了开放性的广泛文化含义](https://opensource.com/article/17/7/book-review-open):Scott Nesbitt 评价 David Price 的书 《OPEN》 ,该书探讨了 “开放” 不仅仅是技术转变的观点,而是 “我们未来将如何工作、生活和学习”。
2. [通过开源技能快速开始您的职业生涯](https://opensource.com/article/17/8/jump-start-your-career): VM (Vicky) Brasseur 指出了如何借助学习开源在工作群体中脱颖而出。这个建议不仅仅是针对程序员的;设计师、作家、营销人员和其他创意专业人士也对开源的成功至关重要。
3. [研究生学位可以让你跳槽到开源职位](https://opensource.com/article/17/1/grad-school-open-source-academic-lab):引用的研究表明会 Linux 技能会带来更高的薪水, Joshua Pearce 说对开源的熟练和研究生学位是无与伦比的职业技能组合。
4. [彻底改变了宾夕法尼亚的学校文化的三种实践](https://opensource.com/article/17/7/open-school-leadership):Charlie Reisinger 向我们展示了开放式实践是如何在宾夕法尼亚州的一个学区创造一种更具包容性、敏捷性和开放性的文化的。Charlie 说,这不仅仅是为了省钱;该区还受益于 “开放式领导原则,促进师生创新,帮助更好地吸引社区,创造一个更有活力和包容性的学习社区”。
5. [使用开源工具促使学生进步的 15 种方法](https://opensource.com/article/17/7/empower-students-open-source-tools):我写了开源是如何让学生自由探索、补拙和学习的,不管他们是在学习基本的数字化素养,还是通过有趣的项目来扩展这些技能。
6. [开发人员有机会编写好的代码](https://opensource.com/article/17/3/interview-anh-bui-benetech-labs):开源往往是对社会有益的项目的支柱。正如 Benetech Labs 副总裁 Ahn Bui 在这次采访中指出的那样:“建立开放数据标准是打破数据孤岛不可或缺的一步。这些开放标准将为互操作性提供基础,进而转化为更多的组织共同建设,往往更具成本效益。最终目标是以同样的成本甚至更低的成本为更多的人服务。”
### 用于再融合和再利用的开放式教育资源
1. [学术教员可以和维基百科一起教学吗?](https://opensource.com/article/17/1/Wiki-Education-Foundation):Wiki Ed 的项目总监 LiAnna Davis 讨论<ruby> 开放式教育资源 <rt> open educational resources </rt></ruby> (OER) ,如 Wiki Ed,是如何提供高质量且经济实惠的开源学习资源作为课堂教学工具。
2. [书本内外?开放教育资源的状态](https://opensource.com/article/17/2/future-textbooks-cable-green-creative-commons):Cable Green 是 Creative Common 开放教育主管,分享了高等教育中教育面貌是如何变化的,以及 Creative Common 正在采取哪些措施来促进教育。
3. [急需符合标准的课程的学校系统找到了希望](https://opensource.com/article/17/1/open-up-resources):Karen Vaites 是 Open Up Resources 社区布道师和首席营销官,谈论了非营利组织努力为 K-12 学校提供开放的、标准一致的课程。
4. [夏威夷大学如何解决当今高等教育的问题](https://opensource.com/article/17/2/interview-education-billy-meinke):夏威夷大学 Manoa 分校的教育技术专家 Billy Meinke 表示,在大学课程中过渡到 ORE 将 “使教师能够控制他们教授的内容,我们预计这将为他们节省学生的费用。”
5. [开放式课程如何削减高等教育成本](https://opensource.com/article/17/7/college-alternatives):塞勒学院的教育总监 Devon Ritter 报告了塞勒学院是如何建立以公开许可内容为基础的大学学分课程,目的是使更多的人能够负担得起和获得高等教育。
6. [开放教育资源运动在提速](https://opensource.com/article/17/10/open-educational-resources-alexis-clifton):Alexis Clifton 是纽约州立大学的 OER 服务的执行董事,描述了纽约 800 万美元的投资如何刺激开放教育的增长,并使大学更实惠。
7. [开放项目合作,从小学到大学教室](https://opensource.com/article/17/3/education-should-be-open-design):来自杜克大学的 Aria F. Chernik 探索 OSPRI (开源教育学的研究与创新), 这是杜克大学和红帽的合作,旨在建立一个 21 世纪的,开放设计的 preK-12 学习生态系统。
8. [Perma.cc 将阻止学术链接腐烂](https://opensource.com/article/17/9/stop-link-rot-permacc)::弗吉尼亚理工大学的 Phillip Young 写的关于 Perma.cc 的文章,这种一种“链接腐烂”的解决方案,在学术论文中的超链接随着时间的推移而消失或变化的概览很高。
9. [开放教育:学生如何通过创建开放教科书来节省资金](https://opensource.com/article/17/11/creating-open-textbooks):OER 先驱 Robin DeRosa 谈到 “引入公开许可教科书的自由,以及教育和学习应结合包容性生态系统,以增强公益的总体理念”。
### 课堂上的开源工具
1. [开源棋盘游戏如何拯救地球](https://opensource.com/article/17/7/save-planet-board-game):Joshua Pearce 写的关于拯救地球的一个棋盘游戏,这是一款让学生在玩乐和为创客社区做出贡献的同时解决环境问题的棋盘游戏。
2. [一个教孩子们如何阅读的新 Android 应用程序](https://opensource.com/article/17/4/phoenicia-education-software):Michael Hall 谈到了他在儿子被诊断为自闭症后为他开发的儿童识字应用 Phoenicia,以及良好编码的价值,和为什么用户测试比你想象的更重要。
3. [8 个用于教育的开源 Android 应用程序](https://opensource.com/article/17/8/8-open-source-android-apps-education):Joshua Allen Holm 推荐了 8 个来自 F-Droid 软件库的开源应用,使我们可以将智能手机用作学习工具。
4. [MATLA B的 3 种开源替代方案](https://opensource.com/alternatives/matlab):Jason Baker 更新了他 2016 年的开源数学计算软件调查报告,提供了 MATLAB 的替代方案,这是数学、物理科学、工程和经济学中几乎无处不在的昂贵的专用解决方案。
5. [SVG 与教孩子编码有什么关系?](https://opensource.com/article/17/5/coding-scalable-vector-graphics-make-steam):退休工程师 Jay Nick 谈论他如何使用艺术作为一种创新的方式,向学生介绍编码。他在学校做志愿者,使用 SVG 来教授一种结合数学和艺术原理的编码方法。
6. [5 个破灭的神话:在高等教育中使用开源](https://opensource.com/article/17/5/how-linux-higher-education): 拥有德克萨斯理工大学美术博士学位的 Kyle Conway 分享他在一个由专有解决方案统治的世界中使用开源工具的经验。 Kyle 说有一种偏见,反对在计算机科学以外的学科中使用开源:“很多人认为非技术专业的学生不能使用 Linux,他们对在高级学位课程中使用 Linux 的人做出了很多假设……嗯,这是有可能的,我就是证明。”
7. [大学开源工具列表](https://opensource.com/article/17/6/open-source-tools-university-student):Aaron Cocker 概述了他在攻读计算机科学本科学位时使用的开源工具 (包括演示、备份和编程软件)。
8. [5 个可帮助您学习优秀 KDE 应用程序](https://opensource.com/article/17/6/kde-education-software):Zsolt Szakács 提供五个 KDE 应用程序,可以帮助任何想要学习新技能或培养现有技能的人。
### 在教室编码
1. [如何尽早让下一代编码](https://opensource.com/article/17/8/teach-kid-code-change-life):Bryson Payne 说我们需要在高中前教孩子们学会编码: 到了九年级,80% 的女孩和 60% 的男孩已经从 STEM 职业中自选。但他建议,这不仅仅是就业和缩小 IT 技能差距的问题。“教一个年轻人编写代码可能是你能给他们的最改变生活的技能。而且这不仅仅是一个职业提升者。编码是关于解决问题,它是关于创造力,更重要的是,它是提升能力”。
2. [孩子们无法在没有计算机的情况下编码](https://opensource.com/article/17/9/floss-desktops-kids):Patrick Masson 推出了 FLOSS 儿童桌面计划, 该计划教授服务不足学校的学生使用开源软件 (如 Linux、LibreOffice 和 GIMP) 重新利用较旧的计算机。该计划不仅为破旧或退役的硬件注入新的生命,还为学生提供了重要的技能,而且还为学生提供了可能转化为未来职业生涯的重要技能。
3. [如今 Scratch 是否能像 80 年代的 LOGO 语言一样教孩子们编码?](https://opensource.com/article/17/3/logo-scratch-teach-programming-kids):Anderson Silva 提出使用 [Scratch](https://scratch.mit.edu/) 以激发孩子们对编程的兴趣,就像在 20 世纪 80 年代开始使用 LOGO 语言时一样。
4. [通过这个拖放框架学习Android开发](https://opensource.com/article/17/8/app-inventor-android-app-development):Eric Eslinger 介绍了 App Inventor,这是一个编程框架,用于构建 Android 应用程序使用可视块语言(类似 Scratch 或者 [Snap](http://snap.berkeley.edu/))。
在这一年里,我们了解到,教育领域的各个方面都有了开放的解决方案,我预计这一主题将在 2018 年及以后继续下去。在未来的一年里,你是否希望 Opensource.com 涵盖开放式的教育主题?如果是, 请在评论中分享你的想法。
---
via: <https://opensource.com/article/18/1/best-open-education>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 译者:[lixinyuxx](https://github.com/lixinyuxx) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Openness (from open source software, to open hardware, to open principles) is changing the paradigm of education. So, to celebrate all that's gone on this year, I collected 27 of the best articles published on Opensource.com in 2017 on the subject. I divided them into broad themes, rather than ordering them by popularity. And, if these 27 stories don't satisfy your appetite for information about open source in education, check out our companion article on how [education is leveraging Raspberry Pi and Linux](https://opensource.com/article/17/12/best-opensourcecom-linux-and-raspberry-pi-education).
## Open is better for everyone
[Book review: 'OPEN' explores broad cultural implications of openness](https://opensource.com/article/17/7/book-review-open): Scott Nesbitt reviews David Price's book*OPEN*, which explores the idea that "open" isn't just a technological shift, rather it's "how we'll work, live, and learn in the future."[Jump-start your career with open source skills](https://opensource.com/article/17/8/jump-start-your-career): VM (Vicky) Brasseur points out how to get ahead in the workforce by learning open source. This advice isn't just for programmers; designers, writers, marketers, and other creative professionals are also essential to the success of open source.[A graduate degree could springboard you into an open source job](https://opensource.com/article/17/1/grad-school-open-source-academic-lab): Citing research that shows that Linux skills lead to higher pay, Joshua Pearce makes the case that open source proficiency and a graduate degree are an unbeatable career combination.[These 3 practices revolutionized Penn Manor's school culture](https://opensource.com/article/17/7/open-school-leadership): Charlie Reisinger shows us how open practices are creating a more inclusive, agile, and open culture in a Pennsylvania school district. Charlie says it's not just about saving money; the district also gains from "open leadership principles that foster innovation among teachers and students, help to better engage the community, and create a more vibrant and inclusive learning community."[15 ways to empower students with open source tools](https://opensource.com/article/17/7/empower-students-open-source-tools): I write how open source gives students the freedom to explore, tinker, and learn, whether they're learning basic digital literacy or expanding on those skills with fun projects.[Developer opportunities to code for good](https://opensource.com/article/17/3/interview-anh-bui-benetech-labs): Open source is often the backbone of socially beneficial projects. As Ahn Bui, vice president of Benetech Labs, states in this interview: "Establishing open data standards is an integral step in breaking down data silos. Those open standards will provide the foundation for interoperability and in turn, translate to more organizations building together, often more cost effectively. The ultimate goal is to serve more people at the same cost or even less."
## Open education resources for remixing and reusing
[Can academic faculty members teach with Wikipedia?](https://opensource.com/article/17/1/Wiki-Education-Foundation)LiAnna Davis, director of programs for Wiki Ed, discusses how open educational resources (OERs), such as Wiki Ed, are providing high-quality and affordable open source learning resources as classroom teaching tools.[Are textbooks in or out? The state of open educational resources](https://opensource.com/article/17/2/future-textbooks-cable-green-creative-commons): Cable Green, director of open education for Creative Commons, shares how the face of education is changing in higher education and what Creative Commons is doing to facilitate it.[School systems desperate for standards-aligned curricula find hope](https://opensource.com/article/17/1/open-up-resources): Karen Vaites, community evangelist and chief marketing officer of Open Up Resources, talks about the nonprofit organization's efforts to provide open, standards-aligned curricula for K-12 schools.[How the University of Hawaii is solving today's higher ed problems](https://opensource.com/article/17/2/interview-education-billy-meinke): Billy Meinke, educational technologist at the University of Hawaii at Manoa, says that transitioning to OER in college courses will "empower faculty to take control of what content they teach with, which we expect will result in their saving students money."[How open courses are slashing the cost of higher education](https://opensource.com/article/17/7/college-alternatives): Saylor Academy's director of education Devon Ritter reports how Saylor is building its college credit-eligible courses on openly licensed content, with the goal of making higher education affordable and accessible to more people.[Open educational resources movement gains speed](https://opensource.com/article/17/10/open-educational-resources-alexis-clifton): Alexis Clifton, executive director of the State University of New York OER Services, describes how New York's US$ 8 million investment is spurring growth in open education and making college more affordable.[Open project collaboration from elementary to university classrooms](https://opensource.com/article/17/3/education-should-be-open-design): Aria F. Chernik from Duke University explores OSPRI (Open Source Pedagogy Research and Innovation), a collaboration between Duke and Red Hat that's building a 21st-century, preK-12 learning ecosystem that is open by design.[Perma.cc stops scholarly link rot](https://opensource.com/article/17/9/stop-link-rot-permacc): Virginia Tech's Phillip Young writes about Perma.cc, a solution to "link rot," which is the high probability that hyperlinks in academic papers will disappear or change over time.[Open education: How students save money by creating open textbooks](https://opensource.com/article/17/11/creating-open-textbooks): OER pioneer Robin DeRosa talks about "the freedom that the openly licensed textbook introduced, and the overarching idea that education and learning should be contextualized in inclusive ecosystems that enhance the public good."
## Open source tools in the classroom
[How an open source board game is saving the planet](https://opensource.com/article/17/7/save-planet-board-game): Joshua Pearce writes about*Save the Planet*, a board game that empowers students to solve environmental problems while having fun and contributing to the maker community.[A new Android app for teaching kids how to read](https://opensource.com/article/17/4/phoenicia-education-software): Michael Hall talks about Phoenicia, a children's literacy app he developed after his son was diagnosed with autism, the value of coding for good, and why user testing matters more than you think.[8 open source Android apps for education](https://opensource.com/article/17/8/8-open-source-android-apps-education): Joshua Allen Holm challenges us to use our smartphones as learning tools by recommending eight open source apps from the F-Droid repository to try.[3 open source alternatives to MATLAB](https://opensource.com/alternatives/matlab): Jason Baker's update to his 2016 survey of open source mathematical computing software presents alternatives to MATLAB, the expensive, proprietary solution nearly ubiquitous in mathematics, physical sciences, engineering, and economics.[What does SVG have to do with teaching kids to code?](https://opensource.com/article/17/5/coding-scalable-vector-graphics-make-steam)Retired engineer Jay Nick talks about how he uses art as a creative way to introduce students to coding. He volunteers in schools, using Scalable Vector Graphics (SVG) to teach an approach to coding that combines principles of mathematics and art.[5 myths busted: Using open source in higher education](https://opensource.com/article/17/5/how-linux-higher-education): Kyle Conway, who holds a PhD in fine arts from Texas Tech, shares his experience using open source tools in a world ruled by proprietary solutions. Kyle says there's a bias against using open source in disciplines outside of computer science: "Many people think non-technical students can't use Linux, and they make a lot of assumptions about people who use it in their advanced degree programs. … Well, it is possible, and I'm proof."[A list of open source tools for college](https://opensource.com/article/17/6/open-source-tools-university-student): Aaron Cocker outlines the open source tools (including presentation, backup, and programming software) he uses while working on his undergraduate degree in computer science.[5 great KDE apps to help you study](https://opensource.com/article/17/6/kde-education-software): Zsolt Szakács offers five KDE applications that help anyone who wants to learn new skills or cultivate existing ones.
## Coding in the classroom
[How to get the next generation coding early](https://opensource.com/article/17/8/teach-kid-code-change-life): Bryson Payne says we need to teach kids to code before high school: By ninth grade 80% of girls and 60% of boys have already self-selected out of a STEM career. But it's not only about jobs and closing the IT skills gap, he suggests. "Teaching a young person to code could be the single most life-changing skill you can give them. And it's not just a career-enhancer. Coding is about problem-solving, it's about creativity, and more importantly, it's about empowerment."[Kids can't code without computers](https://opensource.com/article/17/9/floss-desktops-kids): Patrick Masson introduces the FLOSS Desktops for Kids program, which teaches students at underserved schools to repurpose older computers with open source software, such as Linux, LibreOffice, and GIMP. Not only is the program breathing new life into broken or decommissioned hardware, it's also giving students important skills that may translate into future careers.[Is Scratch today like the Logo of the '80s for teaching kids to code?](https://opensource.com/article/17/3/logo-scratch-teach-programming-kids)Anderson Silva offers suggestions for using[Scratch](https://scratch.mit.edu/)to spark kids' interest in programming, just as LOGO did when he started using it in the 1980s.[Learn Android development with this drag-and-drop framework](https://opensource.com/article/17/8/app-inventor-android-app-development): Eric Eslinger describes App Inventor, a programming framework for building Android applications using a visual blocks language (similar to Scratch or[Snap](http://snap.berkeley.edu/)).
Throughout the year we learned that there is an open solution to everything in education, and I expect this theme to continue in 2018 and beyond. Are there open education topics you'd like Opensource.com to cover in the coming year? If so, please share your ideas in the comments.
## Comments are closed. |
10,389 | Caffeinated 6.828:实验 5:文件系统、Spawn 和 Shell | https://pdos.csail.mit.edu/6.828/2018/labs/lab5/ | 2018-12-27T12:54:44 | [
"6.828"
] | https://linux.cn/article-10389-1.html | 
### 简介
在本实验中,你将要去实现 `spawn`,它是一个加载和运行磁盘上可运行文件的库调用。然后,你接着要去充实你的内核和库,以使操作系统能够在控制台上运行一个 shell。而这些特性需要一个文件系统,本实验将引入一个可读/写的简单文件系统。
#### 预备知识
使用 Git 去获取最新版的课程仓库,然后创建一个命名为 `lab5` 的本地分支,去跟踪远程的 `origin/lab5` 分支:
```
athena% cd ~/6.828/lab
athena% add git
athena% git pull
Already up-to-date.
athena% git checkout -b lab5 origin/lab5
Branch lab5 set up to track remote branch refs/remotes/origin/lab5.
Switched to a new branch "lab5"
athena% git merge lab4
Merge made by recursive.
.....
athena%
```
在实验中这一部分的主要新组件是文件系统环境,它位于新的 `fs` 目录下。通过检查这个目录中的所有文件,我们来看一下新的文件都有什么。另外,在 `user` 和 `lib` 目录下还有一些文件系统相关的源文件。
* `fs/fs.c` 维护文件系统在磁盘上结构的代码
* `fs/bc.c` 构建在我们的用户级页故障处理功能之上的一个简单的块缓存
* `fs/ide.c` 极简的基于 PIO(非中断驱动的)IDE 驱动程序代码
* `fs/serv.c` 使用文件系统 IPC 与客户端环境交互的文件系统服务器
* `lib/fd.c` 实现一个常见的类 UNIX 的文件描述符接口的代码
* `lib/file.c` 磁盘上文件类型的驱动,实现为一个文件系统 IPC 客户端
* `lib/console.c` 控制台输入/输出文件类型的驱动
* `lib/spawn.c` spawn 库调用的框架代码
你应该再次去运行 `pingpong`、`primes` 和 `forktree`,测试实验 4 完成后合并到新的实验 5 中的代码能否正确运行。你还需要在 `kern/init.c` 中注释掉 `ENV_CREATE(fs_fs)` 行,因为 `fs/fs.c` 将尝试去做一些 I/O,而 JOS 到目前为止还不具备该功能。同样,在 `lib/exit.c` 中临时注释掉对 `close_all()` 的调用;这个函数将调用你在本实验后面部分去实现的子程序,如果现在去调用,它将导致 JOS 内核崩溃。如果你的实验 4 的代码没有任何 bug,将很完美地通过这个测试。在它们都能正常工作之前是不能继续后续实验的。在你开始做练习 1 时,不要忘记去取消这些行上的注释。
如果它们不能正常工作,使用 `git diff lab4` 去重新评估所有的变更,确保你在实验 4(及以前)所写的代码在本实验中没有丢失。确保实验 4 仍然能正常工作。
#### 实验要求
和以前一样,你需要做本实验中所描述的所有常规练习和至少一个挑战问题。另外,你需要写出你在本实验中问题的详细答案,和你是如何解决挑战问题的一个简短(即:用一到两个段落)的描述。如果你实现了多个挑战问题,你只需要写出其中一个即可,当然,我们欢迎你做的越多越好。在你动手实验之前,将你的问题答案写入到你的 `lab5` 根目录下的一个名为 `answers-lab5.txt` 的文件中。
### 文件系统的雏形
你将要使用的文件系统比起大多数“真正的”文件系统(包括 xv6 UNIX 的文件系统)要简单的多,但它也是很强大的,足够去提供基本的特性:创建、读取、写入和删除组织在层次目录结构中的文件。
到目前为止,我们开发的是一个单用户操作系统,它提供足够的保护并能去捕获 bug,但它还不能在多个不可信用户之间提供保护。因此,我们的文件系统还不支持 UNIX 的所有者或权限的概念。我们的文件系统目前也不支持硬链接、时间戳、或像大多数 UNIX 文件系统实现的那些特殊的设备文件。
### 磁盘上的文件系统结构
主流的 UNIX 文件系统将可用磁盘空间分为两种主要的区域类型:节点区域和数据区域。UNIX 文件系统在文件系统中为每个文件分配一个节点;一个文件的节点保存了这个文件重要的元数据,比如它的 `stat` 属性和指向数据块的指针。数据区域被分为更大的(一般是 8 KB 或更大)数据块,它在文件系统中存储文件数据和目录元数据。目录条目包含文件名字和指向到节点的指针;如果文件系统中的多个目录条目指向到那个文件的节点上,则称该文件是硬链接的。由于我们的文件系统不支持硬链接,所以我们不需要这种间接的级别,并且因此可以更方便简化:我们的文件系统将压根就不使用节点,而是简单地将文件的(或子目录的)所有元数据保存在描述那个文件的(唯一的)目录条目中。
文件和目录逻辑上都是由一系列的数据块组成,它或许是很稀疏地分散到磁盘上,就像一个环境的虚拟地址空间上的页,能够稀疏地分散在物理内存中一样。文件系统环境隐藏了块布局的细节,只提供文件中任意偏移位置读写字节序列的接口。作为像文件创建和删除操作的一部分,文件系统环境服务程序在目录内部完成所有的修改。我们的文件系统允许用户环境去直接读取目录元数据(即:使用 `read`),这意味着用户环境自己就能够执行目录扫描操作(即:实现 `ls` 程序),而不用另外依赖对文件系统的特定调用。用这种方法做目录扫描的缺点是,(也是大多数现代 UNIX 操作系统变体摒弃它的原因)使得应用程序依赖目录元数据的格式,如果不改变或至少要重编译应用程序的前提下,去改变文件系统的内部布局将变得很困难。
#### 扇区和块
大多数磁盘都不能执行以字节为粒度的读写操作,而是以扇区为单位执行读写。在 JOS 中,每个扇区是 512 字节。文件系统实际上是以块为单位来分配和使用磁盘存储的。要注意这两个术语之间的区别:扇区大小是硬盘硬件的属性,而块大小是使用这个磁盘的操作系统上的术语。一个文件系统的块大小必须是底层磁盘的扇区大小的倍数。
UNIX xv6 文件系统使用 512 字节大小的块,与它底层磁盘的扇区大小一样。而大多数现代文件系统使用更大尺寸的块,因为现在存储空间变得很廉价了,而使用更大的粒度在存储管理上更高效。我们的文件系统将使用 4096 字节的块,以更方便地去匹配处理器上页的大小。
#### 超级块

文件系统一般在磁盘上的“易于查找”的位置(比如磁盘开始或结束的位置)保留一些磁盘块,用于保存描述整个文件系统属性的元数据,比如块大小、磁盘大小、用于查找根目录的任何元数据、文件系统最后一次挂载的时间、文件系统最后一次错误检查的时间等等。这些特定的块被称为超级块。
我们的文件系统只有一个超级块,它固定为磁盘的 1 号块。它的布局定义在 `inc/fs.h` 文件里的 `struct Super` 中。而 0 号块一般是保留的,用于去保存引导加载程序和分区表,因此文件系统一般不会去使用磁盘上比较靠前的块。许多“真实的”文件系统都维护多个超级块,并将它们复制到间隔较大的几个区域中,这样即便其中一个超级块坏了或超级块所在的那个区域产生了介质错误,其它的超级块仍然能够被找到并用于去访问文件系统。
#### 文件元数据

元数据的布局是描述在我们的文件系统中的一个文件中,这个文件就是 `inc/fs.h` 中的 `struct File`。元数据包含文件的名字、大小、类型(普通文件还是目录)、指向构成这个文件的块的指针。正如前面所提到的,我们的文件系统中并没有节点,因此元数据是保存在磁盘上的一个目录条目中,而不是像大多数“真正的”文件系统那样保存在节点中。为简单起见,我们将使用 `File` 这一个结构去表示文件元数据,因为它要同时出现在磁盘上和内存中。
在 `struct File` 中的数组 `f_direct` 包含一个保存文件的前 10 个块(`NDIRECT`)的块编号的空间,我们称之为文件的直接块。对于最大 `10*4096 = 40KB` 的小文件,这意味着这个文件的所有块的块编号将全部直接保存在结构 `File` 中,但是,对于超过 40 KB 大小的文件,我们需要一个地方去保存文件剩余的块编号。所以我们分配一个额外的磁盘块,我们称之为文件的间接块,由它去保存最多 4096/4 = 1024 个额外的块编号。因此,我们的文件系统最多允许有 1034 个块,或者说不能超过 4MB 大小。为支持大文件,“真正的”文件系统一般都支持两个或三个间接块。
#### 目录与普通文件
我们的文件系统中的结构 `File` 既能够表示一个普通文件,也能够表示一个目录;这两种“文件”类型是由 `File` 结构中的 `type` 字段来区分的。除了文件系统根本就不需要解释的、分配给普通文件的数据块的内容之外,它使用完全相同的方式来管理普通文件和目录“文件”,文件系统将目录“文件”的内容解释为包含在目录中的一系列的由 `File` 结构所描述的文件和子目录。
在我们文件系统中的超级块包含一个结构 `File`(在 `struct Super` 中的 `root` 字段中),它用于保存文件系统的根目录的元数据。这个目录“文件”的内容是一系列的 `File` 结构所描述的、位于文件系统根目录中的文件和目录。在根目录中的任何子目录转而可以包含更多的 `File` 结构所表示的子目录,依此类推。
### 文件系统
本实验的目标并不是让你去实现完整的文件系统,你只需要去实现几个重要的组件即可。实践中,你将负责把块读入到块缓存中,并且刷新脏块到磁盘上;分配磁盘块;映射文件偏移量到磁盘块;以及实现读取、写入、和在 IPC 接口中打开。因为你并不去实现完整的文件系统,熟悉提供给你的代码和各种文件系统接口是非常重要的。
### 磁盘访问
我们的操作系统的文件系统环境需要能访问磁盘,但是我们在内核中并没有实现任何磁盘访问的功能。与传统的在内核中添加了 IDE 磁盘驱动程序、以及允许文件系统去访问它所必需的系统调用的“大一统”策略不同,我们将 IDE 磁盘驱动实现为用户级文件系统环境的一部分。我们仍然需要对内核做稍微的修改,是为了能够设置一些东西,以便于文件系统环境拥有实现磁盘访问本身所需的权限。
只要我们依赖轮询、基于 “编程的 I/O”(PIO)的磁盘访问,并且不使用磁盘中断,那么在用户空间中实现磁盘访问还是很容易的。也可以去实现由中断驱动的设备驱动程序(比如像 L3 和 L4 内核就是这么做的),但这样做的话,内核必须接收设备中断并将它派发到相应的用户模式环境上,这样实现的难度会更大。
x86 处理器在 EFLAGS 寄存器中使用 IOPL 位去确定保护模式中的代码是否允许执行特定的设备 I/O 指令,比如 `IN` 和 `OUT` 指令。由于我们需要的所有 IDE 磁盘寄存器都位于 x86 的 I/O 空间中而不是映射在内存中,所以,为了允许文件系统去访问这些寄存器,我们需要做的唯一的事情便是授予文件系统环境“I/O 权限”。实际上,在 EFLAGS 寄存器的 IOPL 位上规定,内核使用一个简单的“要么全都能访问、要么全都不能访问”的方法来控制用户模式中的代码能否访问 I/O 空间。在我们的案例中,我们希望文件系统环境能够去访问 I/O 空间,但我们又希望任何其它的环境完全不能访问 I/O 空间。
>
> **练习 1**、`i386_init` 通过将类型 `ENV_TYPE_FS` 传递给你的环境创建函数 `env_create` 来识别文件系统。修改 `env.c` 中的 `env_create` ,以便于它只授予文件系统环境 I/O 的权限,而不授予任何其它环境 I/O 的权限。
>
>
> 确保你能启动这个文件系统环境,而不会产生一般保护故障。你应该要通过在 `make grade` 中的 fs i/o 测试。
>
>
>
.
>
> **问题 1**、当你从一个环境切换到另一个环境时,你是否需要做一些操作来确保 I/O 权限设置能被保存和正确地恢复?为什么?
>
>
>
注意本实验中的 `GNUmakefile` 文件,它用于设置 QEMU 去使用文件 `obj/kern/kernel.img` 作为磁盘 0 的镜像(一般情况下表示 DOS 或 Windows 中的 “C 盘”),以及使用(新)文件 `obj/fs/fs.img` 作为磁盘 1 的镜像(”D 盘“)。在本实验中,我们的文件系统应该仅与磁盘 1 有交互;而磁盘 0 仅用于去引导内核。如果你想去恢复其中一个有某些错误的磁盘镜像,你可以通过输入如下的命令,去重置它们到最初的、”崭新的“版本:
```
$ rm obj/kern/kernel.img obj/fs/fs.img
$ make
```
或者:
```
$ make clean
$ make
```
小挑战!实现中断驱动的 IDE 磁盘访问,既可以使用也可以不使用 DMA 模式。由你来决定是否将设备驱动移植进内核中、还是与文件系统一样保留在用户空间中、甚至是将它移植到一个它自己的的单独的环境中(如果你真的想了解微内核的本质的话)。
### 块缓存
在我们的文件系统中,我们将在处理器虚拟内存系统的帮助下,实现一个简单的”缓冲区“(实际上就是一个块缓冲区)。块缓存的代码在 `fs/bc.c` 文件中。
我们的文件系统将被限制为仅能处理 3GB 或更小的磁盘。我们保留一个大的、尺寸固定为 3GB 的文件系统环境的地址空间区域,从 0x10000000(`DISKMAP`)到 0xD0000000(`DISKMAP+DISKMAX`)作为一个磁盘的”内存映射版“。比如,磁盘的 0 号块被映射到虚拟地址 0x10000000 处,磁盘的 1 号块被映射到虚拟地址 0x10001000 处,依此类推。在 `fs/bc.c` 中的 `diskaddr` 函数实现从磁盘块编号到虚拟地址的转换(以及一些完整性检查)。
由于我们的文件系统环境在系统中有独立于所有其它环境的虚拟地址空间之外的、它自己的虚拟地址空间,并且文件系统环境仅需要做的事情就是实现文件访问,以这种方式去保留大多数文件系统环境的地址空间是很明智的。如果在一台 32 位机器上的”真实的“文件系统上这么做是很不方便的,因为现在的磁盘都远大于 3 GB。而在一台有 64 位地址空间的机器上,这样的缓存管理方法仍然是明智的。
当然,将整个磁盘读入到内存中需要很长时间,因此,我们将它实现成”按需“分页的形式,那样我们只在磁盘映射区域中分配页,并且当在这个区域中产生页故障时,从磁盘读取相关的块去响应这个页故障。通过这种方式,我们能够假装将整个磁盘装进了内存中。
>
> **练习 2**、在 `fs/bc.c` 中实现 `bc_pgfault` 和 `flush_block` 函数。`bc_pgfault` 函数是一个页故障服务程序,就像你在前一个实验中编写的写时复制 fork 一样,只不过它的任务是从磁盘中加载页去响应一个页故障。在你编写它时,记住: (1) `addr` 可能并不会做边界对齐,并且 (2) 在扇区中的 `ide_read` 操作并不是以块为单位的。
>
>
> (如果需要的话)函数 `flush_block` 应该会将一个块写入到磁盘上。如果在块缓存中没有块(也就是说,页没有映射)或者它不是一个脏块,那么 `flush_block` 将什么都不做。我们将使用虚拟内存硬件去跟踪,磁盘块自最后一次从磁盘读取或写入到磁盘之后是否被修改过。查看一个块是否需要写入时,我们只需要去查看 `uvpt` 条目中的 `PTE_D` 的 ”dirty“ 位即可。(`PTE_D` 位由处理器设置,用于表示那个页被写入;具体细节可以查看 x386 参考手册的 [第 5 章](http://pdos.csail.mit.edu/6.828/2011/readings/i386/s05_02.htm) 的 5.2.4.3 节)块被写入到磁盘上之后,`flush_block` 函数将使用 `sys_page_map` 去清除 `PTE_D` 位。
>
>
> 使用 `make grade` 去测试你的代码。你的代码应该能够通过 check\_bc、check\_super、和 check\_bitmap 的测试。
>
>
>
在 `fs/fs.c` 中的函数 `fs_init` 是块缓存使用的一个很好的示例。在初始化块缓存之后,它简单地在全局变量 `super` 中保存指针到磁盘映射区。在这之后,如果块在内存中,或我们的页故障服务程序按需将它们从磁盘上读入后,我们就能够简单地从 `super` 结构中读取块了。
.
>
> **小挑战!**到现在为止,块缓存还没有清除策略。一旦某个块因为页故障被读入到缓存中之后,它将一直不会被清除,并且永远保留在内存中。给块缓存增加一个清除策略。在页表中使用 `PTE_A` 的 accessed 位来实现,任何环境访问一个页时,硬件就会设置这个位,你可以通过它来跟踪磁盘块的大致使用情况,而不需要修改访问磁盘映射区域的任何代码。使用脏块要小心。
>
>
>
### 块位图
在 `fs_init` 设置了 `bitmap` 指针之后,我们可以认为 `bitmap` 是一个装满比特位的数组,磁盘上的每个块就是数组中的其中一个比特位。比如 `block_is_free`,它只是简单地在位图中检查给定的块是否被标记为空闲。
>
> **练习 3**、使用 `free_block` 作为实现 `fs/fs.c` 中的 `alloc_block` 的一个模型,它将在位图中去查找一个空闲的磁盘块,并将它标记为已使用,然后返回块编号。当你分配一个块时,你应该立即使用 `flush_block` 将已改变的位图块刷新到磁盘上,以确保文件系统的一致性。
>
>
> 使用 `make grade` 去测试你的代码。现在,你的代码应该要通过 alloc\_block 的测试。
>
>
>
### 文件操作
在 `fs/fs.c` 中,我们提供一系列的函数去实现基本的功能,比如,你将需要去理解和管理结构 `File`、扫描和管理目录”文件“的条目、 以及从根目录开始遍历文件系统以解析一个绝对路径名。阅读 `fs/fs.c` 中的所有代码,并在你开始实验之前,确保你理解了每个函数的功能。
>
> **练习 4**、实现 `file_block_walk` 和 `file_get_block`。`file_block_walk` 从一个文件中的块偏移量映射到 `struct File` 中那个块的指针上或间接块上,它非常类似于 `pgdir_walk` 在页表上所做的事。`file_get_block` 将更进一步,将去映射一个真实的磁盘块,如果需要的话,去分配一个新的磁盘块。
>
>
> 使用 `make grade` 去测试你的代码。你的代码应该要通过 file\_open、filegetblock、以及 fileflush/filetruncated/file rewrite、和 testfile 的测试。
>
>
>
`file_block_walk` 和 `file_get_block` 是文件系统中的”劳动模范“。比如,`file_read` 和 `file_write` 或多或少都在 `file_get_block` 上做必需的登记工作,然后在分散的块和连续的缓存之间复制字节。
.
>
> **小挑战!**如果操作在中途实然被打断(比如,突然崩溃或重启),文件系统很可能会产生错误。实现软件更新或日志处理的方式让文件系统的”崩溃可靠性“更好,并且演示一下旧的文件系统可能会崩溃,而你的更新后的文件系统不会崩溃的情况。
>
>
>
### 文件系统接口
现在,我们已经有了文件系统环境自身所需的功能了,我们必须让其它希望使用文件系统的环境能够访问它。由于其它环境并不能直接调用文件系统环境中的函数,我们必须通过一个远程过程调用或 RPC、构建在 JOS 的 IPC 机制之上的抽象化来暴露对文件系统的访问。如下图所示,下图是对文件系统服务调用(比如:读取)的样子:
```
Regular env FS env
+---------------+ +---------------+
| read | | file_read |
| (lib/fd.c) | | (fs/fs.c) |
...|.......|.......|...|.......^.......|...............
| v | | | | RPC mechanism
| devfile_read | | serve_read |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| fsipc | | serve |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| ipc_send | | ipc_recv |
| | | | ^ |
+-------|-------+ +-------|-------+
| |
+-------------------+
```
圆点虚线下面的过程是一个普通的环境对文件系统环境请求进行读取的简单机制。从(我们提供的)在任何文件描述符上的 `read` 工作开始,并简单地派发到相关的设备读取函数上,在我们的案例中是 `devfile_read`(我们还有更多的设备类型,比如管道)。`devfile_read` 实现了对磁盘上文件指定的 `read`。它和 `lib/file.c` 中的其它的 `devfile_*` 函数实现了客户端侧的文件系统操作,并且所有的工作大致都是以相同的方式来完成的,把参数打包进一个请求结构中,调用 `fsipc` 去发送 IPC 请求以及解包并返回结果。`fsipc` 函数把发送请求到服务器和接收来自服务器的回复的普通细节做了简化处理。
在 `fs/serv.c` 中可以找到文件系统服务器代码。它是一个 `serve` 函数的循环,无休止地接收基于 IPC 的请求,并派发请求到相关的服务函数,并通过 IPC 来回送结果。在读取示例中,`serve` 将派发到 `serve_read` 函数上,它将去处理读取请求的 IPC 细节,比如,解包请求结构并最终调用 `file_read` 去执行实际的文件读取动作。
回顾一下 JOS 的 IPC 机制,它让一个环境发送一个单个的 32 位数字和可选的共享页。从一个客户端向服务器发送一个请求,我们为请求类型使用 32 位的数字(文件系统服务器 RPC 是有编号的,就像系统调用那样的编号),然后通过 IPC 在共享页上的一个 `union Fsipc` 中存储请求参数。在客户端侧,我们已经在 `fsipcbuf` 处共享了页;在服务端,我们在 `fsreq`(`0x0ffff000`)处映射入站请求页。
服务器也通过 IPC 来发送响应。我们为函数的返回代码使用 32 位的数字。对于大多数 RPC,这已经涵盖了它们全部的返回代码。`FSREQ_READ` 和 `FSREQ_STAT` 也返回数据,它们只是被简单地写入到客户端发送它的请求时的页上。在 IPC 的响应中并不需要去发送这个页,因为这个页是文件系统服务器和客户端从一开始就共享的页。另外,在它的响应中,`FSREQ_OPEN` 与客户端共享一个新的 “Fd page”。我们将快捷地返回到文件描述符页上。
>
> **练习 5**、实现 `fs/serv.c` 中的 `serve_read`。
>
>
> `serve_read` 的重任将由已经在 `fs/fs.c` 中实现的 `file_read` 来承担(它实际上不过是对 `file_get_block` 的一连串调用)。对于文件读取,`serve_read` 只能提供 RPC 接口。查看 `serve_set_size` 中的注释和代码,去大体上了解服务器函数的结构。
>
>
> 使用 `make grade` 去测试你的代码。你的代码通过 serveopen/filestat/file\_close 和 file\_read 的测试后,你得分应该是 70(总分为 150)。
>
>
>
.
>
> **练习 6**、实现 `fs/serv.c` 中的 `serve_write` 和 `lib/file.c` 中的 `devfile_write`。
>
>
> 使用 `make grade` 去测试你的代码。你的代码通过 file\_write、fileread after filewrite、open、和 large file 的测试后,得分应该是 90(总分为150)。
>
>
>
### 进程增殖
我们给你提供了 `spawn` 的代码(查看 `lib/spawn.c` 文件),它用于创建一个新环境、从文件系统中加载一个程序镜像并启动子环境来运行这个程序。然后这个父进程独立于子环境持续运行。`spawn` 函数的行为,在效果上类似于UNIX 中的 `fork`,然后同时紧跟着 `fork` 之后在子进程中立即启动执行一个 `exec`。
我们实现的是 `spawn`,而不是一个类 UNIX 的 `exec`,因为 `spawn` 是很容易从用户空间中、以”外内核式“ 实现的,它无需来自内核的特别帮助。为了在用户空间中实现 `exec`,想一想你应该做什么?确保你理解了它为什么很难。
>
> **练习 7**、`spawn` 依赖新的系统调用 `sys_env_set_trapframe` 去初始化新创建的环境的状态。实现 `kern/syscall.c` 中的 `sys_env_set_trapframe`。(不要忘记在 `syscall()` 中派发新系统调用)
>
>
> 运行来自 `kern/init.c` 中的 `user/spawnhello` 程序来测试你的代码`kern/init.c` ,它将尝试从文件系统中增殖 `/hello`。
>
>
> 使用 `make grade` 去测试你的代码。
>
>
>
.
>
> **小挑战!**实现 Unix 式的 `exec`。
>
>
>
.
>
> **小挑战!**实现 `mmap` 式的文件内存映射,并如果可能的话,修改 `spawn` 从 ELF 中直接映射页。
>
>
>
### 跨 fork 和 spawn 共享库状态
UNIX 文件描述符是一个通称的概念,它还包括管道、控制台 I/O 等等。在 JOS 中,每个这类设备都有一个相应的 `struct Dev`,使用指针去指向到实现读取/写入/等等的函数上。对于那个设备类型,`lib/fd.c` 在其上实现了类 UNIX 的文件描述符接口。每个 `struct Fd` 表示它的设备类型,并且大多数 `lib/fd.c` 中的函数只是简单地派发操作到 `struct Dev` 中相应函数上。
`lib/fd.c` 也在每个应用程序环境的地址空间中维护一个文件描述符表区域,开始位置在 `FDTABLE` 处。这个区域为应该程序能够一次最多打开 `MAXFD`(当前为 32)个文件描述符而保留页的地址空间值(4KB)。在任意给定的时刻,当且仅当相应的文件描述符处于使用中时,一个特定的文件描述符表才会被映射。在区域的 `FILEDATA` 处开始的位置,每个文件描述符表也有一个可选的”数据页“,如果它们被选定,相应的设备就能使用它。
我们想跨 `fork` 和 `spawn` 共享文件描述符状态,但是文件描述符状态是保存在用户空间的内存中。而现在,在 `fork` 中,内存是标记为写时复制的,因此状态将被复制而不是共享。(这意味着环境不能在它们自己无法打开的文件中去搜索,并且管道不能跨一个 `fork` 去工作)在 `spawn` 上,内存将被保留,压根不会去复制。(事实上,增殖的环境从使用一个不打开的文件描述符去开始。)
我们将要修改 `fork`,以让它知道某些被”库管理的系统“所使用的、和总是被共享的内存区域。而不是去”硬编码“一个某些区域的列表,我们将在页表条目中设置一个”这些不使用“的位(就像我们在 `fork` 中使用的 `PTE_COW` 位一样)。
我们在 `inc/lib.h` 中定义了一个新的 `PTE_SHARE` 位,在 Intel 和 AMD 的手册中,这个位是被标记为”软件可使用的“的三个 PTE 位之一。我们将创建一个约定,如果一个页表条目中这个位被设置,那么在 `fork` 和 `spawn` 中应该直接从父环境中复制 PTE 到子环境中。注意它与标记为写时复制的差别:正如在第一段中所描述的,我们希望确保能共享页更新。
>
> **练习 8**、修改 `lib/fork.c` 中的 `duppage`,以遵循最新约定。如果页表条目设置了 `PTE_SHARE` 位,仅直接复制映射。(你应该去使用 `PTE_SYSCALL`,而不是 `0xfff`,去从页表条目中掩掉有关的位。`0xfff` 仅选出可访问的位和脏位。)
>
>
> 同样的,在 `lib/spawn.c` 中实现 `copy_shared_pages`。它应该循环遍历当前进程中所有的页表条目(就像 `fork` 那样),复制任何设置了 `PTE_SHARE` 位的页映射到子进程中。
>
>
>
使用 `make run-testpteshare` 去检查你的代码行为是否正确。正确的情况下,你应该会看到像 `fork handles PTE_SHARE right` 和 ”`spawn handles PTE_SHARE right`” 这样的输出行。
使用 `make run-testfdsharing` 去检查文件描述符是否正确共享。正确的情况下,你应该会看到 `read in child succeeded` 和 “`read in parent succeeded`” 这样的输出行。
### 键盘接口
为了能让 shell 工作,我们需要一些方式去输入。QEMU 可以显示输出,我们将它的输出写入到 CGA 显示器上和串行端口上,但到目前为止,我们仅能够在内核监视器中接收输入。在 QEMU 中,我们从图形化窗口中的输入作为从键盘到 JOS 的输入,虽然键入到控制台的输入作为出现在串行端口上的字符的方式显现。在 `kern/console.c` 中已经包含了由我们自实验 1 以来的内核监视器所使用的键盘和串行端口的驱动程序,但现在你需要去把这些增加到系统中。
>
> **练习 9**、在你的 `kern/trap.c` 中,调用 `kbd_intr` 去处理捕获 `IRQ_OFFSET+IRQ_KBD` 和 `serial_intr`,用它们去处理捕获 `IRQ_OFFSET+IRQ_SERIAL`。
>
>
>
在 `lib/console.c` 中,我们为你实现了文件的控制台输入/输出。`kbd_intr` 和 `serial_intr` 将使用从最新读取到的输入来填充缓冲区,而控制台文件类型去排空缓冲区(默认情况下,控制台文件类型为 stdin/stdout,除非用户重定向它们)。
运行 `make run-testkbd` 并输入几行来测试你的代码。在你输入完成之后,系统将回显你输入的行。如果控制台和窗口都可以使用的话,尝试在它们上面都做一下测试。
### Shell
运行 `make run-icode` 或 `make run-icode-nox` 将运行你的内核并启动 `user/icode`。`icode` 又运行 `init`,它将设置控制台作为文件描述符 0 和 1(即:标准输入 stdin 和标准输出 stdout),然后增殖出环境 `sh`,就是 shell。之后你应该能够运行如下的命令了:
```
echo hello world | cat
cat lorem |cat
cat lorem |num
cat lorem |num |num |num |num |num
lsfd
```
注意用户库常规程序 `cprintf` 将直接输出到控制台,而不会使用文件描述符代码。这对调试非常有用,但是对管道连接其它程序却很不利。为将输出打印到特定的文件描述符(比如 1,它是标准输出 stdout),需要使用 `fprintf(1, "...", ...)`。`printf("...", ...)` 是将输出打印到文件描述符 1(标准输出 stdout) 的快捷方式。查看 `user/lsfd.c` 了解更多示例。
>
> **练习 10**、这个 shell 不支持 I/O 重定向。如果能够运行 `run sh <script` 就更完美了,就不用将所有的命令手动去放入一个脚本中,就像上面那样。为 `<` 在 `user/sh.c` 中添加重定向的功能。
>
>
> 通过在你的 shell 中输入 `sh <script` 来测试你实现的重定向功能。
>
>
> 运行 `make run-testshell` 去测试你的 shell。`testshell` 只是简单地给 shell ”喂“上面的命令(也可以在 `fs/testshell.sh` 中找到),然后检查它的输出是否与 `fs/testshell.key` 一样。
>
>
>
.
>
> **小挑战!**给你的 shell 添加更多的特性。最好包括以下的特性(其中一些可能会要求修改文件系统):
>
>
> * 后台命令 (`ls &`)
> * 一行中运行多个命令 (`ls; echo hi`)
> * 命令组 (`(ls; echo hi) | cat > out`)
> * 扩展环境变量 (`echo $hello`)
> * 引号 (`echo "a | b"`)
> * 命令行历史和/或编辑功能
> * tab 命令补全
> * 为命令行查找目录、cd 和路径
> * 文件创建
> * 用快捷键 `ctl-c` 去杀死一个运行中的环境
>
>
> 可做的事情还有很多,并不仅限于以上列表。
>
>
>
到目前为止,你的代码应该要通过所有的测试。和以前一样,你可以使用 `make grade` 去评级你的提交,并且使用 `make handin` 上交你的实验。
**本实验到此结束。** 和以前一样,不要忘了运行 `make grade` 去做评级测试,并将你的练习答案和挑战问题的解决方案写下来。在动手实验之前,使用 `git status` 和 `git diff` 去检查你的变更,并不要忘记使用 `git add answers-lab5.txt` 去提交你的答案。完成之后,使用 `git commit -am 'my solutions to lab 5’` 去提交你的变更,然后使用 `make handin` 去提交你的解决方案。
---
via: <https://pdos.csail.mit.edu/6.828/2018/labs/lab5/>
作者:[csail.mit](https://pdos.csail.mit.edu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **
Due Thursday, November 15, 2018
**
In this lab, you will implement `spawn`
, a library call
that loads and runs on-disk executables. You will then flesh out your
kernel and library operating system enough to run a shell on the
console. These features need a file system, and this lab introduces a
simple read/write file system.
Use Git to fetch the latest version of the course
repository, and then create a local branch called `lab5` based on our
lab5 branch, `origin/lab5`:
athena%cd ~/6.828/labathena%add gitathena%git pullAlready up-to-date. athena%git checkout -b lab5 origin/lab5Branch lab5 set up to track remote branch refs/remotes/origin/lab5. Switched to a new branch "lab5" athena%git merge lab4Merge made by recursive. ..... athena%
The main new component for this part of the lab is the file
system environment, located in the new `fs` directory. Scan
through all the files in this directory to get a feel for what all is
new. Also, there are some new file system-related source files in
the `user` and `lib` directories,
fs/fs.c |
Code that mainipulates the file system's on-disk structure. |
fs/bc.c |
A simple block cache built on top of our user-level page fault handling facility. |
fs/ide.c |
Minimal PIO-based (non-interrupt-driven) IDE driver code. |
fs/serv.c |
The file system server that interacts with client environments using file system IPCs. |
lib/fd.c |
Code that implements the general UNIX-like file descriptor interface. |
lib/file.c |
The driver for on-disk file type, implemented as a file system IPC client. |
lib/console.c |
The driver for console input/output file type. |
lib/spawn.c |
Code skeleton of the spawn library call. |
You should run the pingpong, primes, and forktree test cases from lab
4 again after merging in the new lab 5 code. You will need to comment
out the `ENV_CREATE(fs_fs)`
line in `kern/init.c`
because `fs/fs.c` tries to do some I/O, which JOS does not allow
yet.
Similarly, temporarily comment out the call to `close_all()`
in
`lib/exit.c`; this function calls subroutines that you will implement
later in the lab, and therefore will panic if called.
If your lab 4 code doesn't contain any bugs, the test cases should run
fine. Don't proceed until they work. Don't forget to un-comment
these lines when you start Exercise 1.
If they don't work, use ` git diff lab4` to review
all the changes, making sure there isn't any code you wrote for lab4
(or before) missing from lab 5. Make sure that lab 4 still works.
As before, you will need
to do all of the regular exercises described in the lab and *at
least one* challenge problem.
Additionally, you will
need to write up brief answers to the questions posed in the lab and a
short (e.g., one or two paragraph) description of what you did to
solve your chosen challenge problem. If you implement more than one
challenge problem, you only need to describe one of them in the
write-up, though of course you are welcome to do more. Place the
write-up in a file called `answers-lab5.txt` in the top level of
your `lab5` directory before handing in your work.
The file system you will work with is much simpler than most "real" file systems including that of xv6 UNIX, but it is powerful enough to provide the basic features: creating, reading, writing, and deleting files organized in a hierarchical directory structure.
We are (for the moment anyway) developing only a single-user operating system, which provides protection sufficient to catch bugs but not to protect multiple mutually suspicious users from each other. Our file system therefore does not support the UNIX notions of file ownership or permissions. Our file system also currently does not support hard links, symbolic links, time stamps, or special device files like most UNIX file systems do.
Most UNIX file systems divide available disk space into two main types
of regions:
*inode* regions and *data* regions.
UNIX file systems assign one *inode* to each file in the file system;
a file's inode holds critical meta-data about the file
such as its `stat`
attributes and pointers to its data blocks.
The data regions are divided into much larger (typically 8KB or more)
*data blocks*, within which the file system stores
file data and directory meta-data.
Directory entries contain file names and pointers to inodes;
a file is said to be *hard-linked*
if multiple directory entries in the file system
refer to that file's inode.
Since our file system will not support hard links,
we do not need this level of indirection
and therefore can make a convenient simplification:
our file system will not use inodes at all
and instead will simply store all of a file's (or sub-directory's) meta-data
within the (one and only) directory entry describing that file.
Both files and directories logically consist of a series of data blocks,
which may be scattered throughout the disk
much like the pages of an environment's virtual address space
can be scattered throughout physical memory.
The file system environment hides the details of block layout,
presenting interfaces for reading and writing sequences of bytes at
arbitrary offsets within files. The file system environment
handles all modifications to directories internally
as a part of performing actions such as file creation and deletion.
Our file system does allow user environments
to *read* directory meta-data directly
(e.g., with `read`
),
which means that user environments can perform directory scanning operations
themselves (e.g., to implement the `ls` program)
rather than having to rely on additional special calls to the file system.
The disadvantage of this approach to directory scanning,
and the reason most modern UNIX variants discourage it,
is that it makes application programs dependent
on the format of directory meta-data,
making it difficult to change the file system's internal layout
without changing or at least recompiling application programs as well.
The UNIX xv6 file system uses a block size of 512 bytes, the same as the sector size of the underlying disk. Most modern file systems use a larger block size, however, because storage space has gotten much cheaper and it is more efficient to manage storage at larger granularities. Our file system will use a block size of 4096 bytes, conveniently matching the processor's page size.
File systems typically reserve certain disk blocks
at "easy-to-find" locations on the disk
(such as the very start or the very end)
to hold meta-data describing properties of the file system as a whole,
such as the block size, disk size,
any meta-data required to find the root directory,
the time the file system was last mounted,
the time the file system was last checked for errors,
and so on.
These special blocks are called *superblocks*.
Our file system will have exactly one superblock,
which will always be at block 1 on the disk.
Its layout is defined by `struct Super`
in `inc/fs.h`.
Block 0 is typically reserved to hold boot loaders and partition tables,
so file systems generally do not use the very first disk block.
Many "real" file systems maintain multiple superblocks,
replicated throughout several widely-spaced regions of the disk,
so that if one of them is corrupted
or the disk develops a media error in that region,
the other superblocks can still be found and used to access the file system.
`struct File`
in `File`
structure to
represent file meta-data as it appears
The `f_direct`
array in `struct File`
contains space
to store the block numbers
of the first 10 (`NDIRECT`
) blocks of the file,
which we call the file's *direct* blocks.
For small files up to 10*4096 = 40KB in size,
this means that the block numbers of all of the file's blocks
will fit directly within the `File`
structure itself.
For larger files, however, we need a place
to hold the rest of the file's block numbers.
For any file greater than 40KB in size, therefore,
we allocate an additional disk block, called the file's *indirect block*,
to hold up to 4096/4 = 1024 additional block numbers.
Our file system therefore allows files to be up to 1034 blocks,
or just over four megabytes, in size.
To support larger files,
"real" file systems typically support
*double-* and *triple-indirect blocks* as well.
`File`
structure in our file system
can represent either a `type`
field
in the `File`
structure.
The file system manages regular files and directory-files
in exactly the same way,
except that it does not interpret the contents of the data blocks
associated with regular files at all,
whereas the file system interprets the contents
of a directory-file as a series of `File`
structures
describing the files and subdirectories within the directory.
The superblock in our file system
contains a `File`
structure
(the `root`
field in `struct Super`
)
that holds the meta-data for the file system's root directory.
The contents of this directory-file
is a sequence of `File`
structures
describing the files and directories located
within the root directory of the file system.
Any subdirectories in the root directory
may in turn contain more `File`
structures
representing sub-subdirectories, and so on.
The goal for this lab is not to have you implement the entire file system, but for you to implement only certain key components. In particular, you will be responsible for reading blocks into the block cache and flushing them back to disk; allocating disk blocks; mapping file offsets to disk blocks; and implementing read, write, and open in the IPC interface. Because you will not be implementing all of the file system yourself, it is very important that you familiarize yourself with the provided code and the various file system interfaces.
The file system environment in our operating system needs to be able to access the disk, but we have not yet implemented any disk access functionality in our kernel. Instead of taking the conventional "monolithic" operating system strategy of adding an IDE disk driver to the kernel along with the necessary system calls to allow the file system to access it, we instead implement the IDE disk driver as part of the user-level file system environment. We will still need to modify the kernel slightly, in order to set things up so that the file system environment has the privileges it needs to implement disk access itself.
It is easy to implement disk access in user space this way as long as we rely on polling, "programmed I/O" (PIO)-based disk access and do not use disk interrupts. It is possible to implement interrupt-driven device drivers in user mode as well (the L3 and L4 kernels do this, for example), but it is more difficult since the kernel must field device interrupts and dispatch them to the correct user-mode environment.
The x86 processor uses the IOPL bits in the EFLAGS register to determine whether protected-mode code is allowed to perform special device I/O instructions such as the IN and OUT instructions. Since all of the IDE disk registers we need to access are located in the x86's I/O space rather than being memory-mapped, giving "I/O privilege" to the file system environment is the only thing we need to do in order to allow the file system to access these registers. In effect, the IOPL bits in the EFLAGS register provides the kernel with a simple "all-or-nothing" method of controlling whether user-mode code can access I/O space. In our case, we want the file system environment to be able to access I/O space, but we do not want any other environments to be able to access I/O space at all.
Exercise 1.
`i386_init`
identifies the file system environment by
passing the type `ENV_TYPE_FS`
to your environment creation
function, `env_create`
.
Modify `env_create`
in `env.c`,
so that it gives the file system environment I/O privilege,
but never gives that privilege to any other environment.
Make sure you can start the file environment without causing a General
Protection fault. You should pass the "fs i/o" test in `make grade`.
Question
Note that the `GNUmakefile` file in this lab
sets up QEMU to use the file `obj/kern/kernel.img`
as the image for disk 0 (typically "Drive C" under DOS/Windows) as before,
and to use the (new) file `obj/fs/fs.img`
as the image for disk 1 ("Drive D").
In this lab our file system should only ever touch disk 1;
disk 0 is used only to boot the kernel.
If you manage to corrupt either disk image in some way,
you can reset both of them to their original, "pristine" versions
simply by typing:
$rm obj/kern/kernel.img obj/fs/fs.img$make
or by doing:
$make clean$make
Challenge! Implement interrupt-driven IDE disk access, with or without DMA. You can decide whether to move the device driver into the kernel, keep it in user space along with the file system, or even (if you really want to get into the micro-kernel spirit) move it into a separate environment of its own.
In our file system,
we will implement a simple "buffer cache" (really just a block cache)
with the help of the processor's virtual memory system.
The code for the block cache is in `fs/bc.c`.
Our file system will be limited to handling disks of size 3GB or less.
We reserve a large, fixed 3GB region
of the file system environment's address space,
from 0x10000000 (`DISKMAP`
)
up to 0xD0000000 (`DISKMAP+DISKMAX`
),
as a "memory mapped" version of the disk.
For example,
disk block 0 is mapped at virtual address 0x10000000,
disk block 1 is mapped at virtual address 0x10001000,
and so on. The `diskaddr`
function in `fs/bc.c`
implements this translation from disk block numbers to virtual
addresses (along with some sanity checking).
Since our file system environment has its own virtual address space independent of the virtual address spaces of all other environments in the system, and the only thing the file system environment needs to do is to implement file access, it is reasonable to reserve most of the file system environment's address space in this way. It would be awkward for a real file system implementation on a 32-bit machine to do this since modern disks are larger than 3GB. Such a buffer cache management approach may still be reasonable on a machine with a 64-bit address space.
Of course, it would take a long time to read the entire disk into
memory, so instead we'll implement a form of *demand paging*,
wherein we only allocate pages in the disk map region and read the
corresponding block from the disk in response to a page fault in this
region. This way, we can pretend that the entire disk is in memory.
Exercise 2.
Implement the `bc_pgfault`
and `flush_block`
functions in `fs/bc.c`.
`bc_pgfault`
is a page fault handler, just like the one
your wrote in the previous lab for copy-on-write fork, except that
its job is to load pages in from the disk in response to a page
fault. When writing this, keep in mind that (1) `addr`
may not be aligned to a block boundary and (2) `ide_read`
operates in sectors, not blocks.
The `flush_block`
function should write a block out to disk
*if necessary*. `flush_block`
shouldn't do anything
if the block isn't even in the block cache (that is, the page isn't
mapped) or if it's not dirty.
We will use the VM hardware to keep track of whether a disk
block has been modified since it was last read from or written to disk.
To see whether a block needs writing,
we can just look to see if the `PTE_D`
"dirty" bit
is set in the `uvpt`
entry.
(The `PTE_D`
bit is set by the processor in response to a
write to that page; see 5.2.4.3 in [chapter
5](http://pdos.csail.mit.edu/6.828/2011/readings/i386/s05_02.htm) of the 386 reference manual.)
After writing the block to disk, `flush_block`
should clear
the `PTE_D`
bit using `sys_page_map`
.
Use `make grade` to test your code. Your code should pass
"check_bc", "check_super", and "check_bitmap".
`fs_init`
function in `super`
global variable.
After this point, we can simply read from the `super`
structure as if they were in memory and our page fault handler will
read them from disk as necessary.
Challenge!
The block cache has no eviction policy. Once a block gets faulted in
to it, it never gets removed and will remain in memory forevermore.
Add eviction to the buffer cache. Using the `PTE_A`
"accessed" bits in the page tables, which the hardware sets on any
access to a page, you can track approximate usage of
disk blocks without the need to modify every place in the code that
accesses the disk map region. Be careful with dirty blocks.
`fs_init`
sets the `bitmap`
pointer, we
can treat `bitmap`
as a packed array of bits, one for each
block on the disk. See, for example, `block_is_free`
,
which simply checks whether a given block is marked free in the
bitmap.
Exercise 3.
Use `free_block`
as a model to
implement `alloc_block`
in `fs/fs.c`, which should find a
free disk
block in the bitmap, mark it used, and return the number of that
block.
When you allocate a block, you should immediately flush
the changed bitmap block to disk with `flush_block`
, to
help file system consistency.
Use `make grade` to test your code. Your code should now
pass "alloc_block".
We have provided a variety of functions in `fs/fs.c`
to implement the basic facilities you will need
to interpret and manage `File`
structures,
scan and manage the entries of directory-files,
and walk the file system from the root
to resolve an absolute pathname.
Read through *all* of the code in `fs/fs.c`
and make sure you understand what each function does
before proceeding.
Exercise 4. Implement
`file_block_walk`
and `file_get_block`
. `file_block_walk`
maps
from a block offset within a file to the pointer for that block in the
`struct File`
or the indirect block, very much like what
`pgdir_walk`
did for page tables.
`file_get_block`
goes one step further and maps to the
actual disk block, allocating a new one if necessary.
Use `make grade` to test your code. Your code should pass
"file_open", "file_get_block", and "file_flush/file_truncated/file
rewrite", and "testfile".
`file_block_walk`
and `file_get_block`
are the
workhorses of the file system. For example, `file_read`
and `file_write`
are little more than the bookkeeping atop
`file_get_block`
necessary to copy bytes between scattered
blocks and a sequential buffer.
Challenge! The file system is likely to be corrupted if it gets interrupted in the middle of an operation (for example, by a crash or a reboot). Implement soft updates or journalling to make the file system crash-resilient and demonstrate some situation where the old file system would get corrupted, but yours doesn't.
Now that we have the necessary functionality
within the file system environment itself,
we must make it accessible to other environments
that wish to use the file system.
Since other environments can't directly call functions in the file
system environment, we'll expose access to the file system
environment via a *remote procedure call*, or RPC, abstraction,
built atop JOS's IPC mechanism.
Graphically, here's what a call to the file system server (say, read)
looks like
Regular env FS env +---------------+ +---------------+ | read | | file_read | | (lib/fd.c) | | (fs/fs.c) | ...|.......|.......|...|.......^.......|............... | v | | | | RPC mechanism | devfile_read | | serve_read | | (lib/file.c) | | (fs/serv.c) | | | | | ^ | | v | | | | | fsipc | | serve | | (lib/file.c) | | (fs/serv.c) | | | | | ^ | | v | | | | | ipc_send | | ipc_recv | | | | | ^ | +-------|-------+ +-------|-------+ | | +-------------------+ |
Everything below the dotted line is simply the mechanics of getting a
read request from the regular environment to the file system
environment. Starting at the beginning, `read`
(which we
provide) works on any file descriptor and simply dispatches to the
appropriate device read function, in this case
`devfile_read`
(we can have more device types, like pipes).
`devfile_read`
implements `read`
specifically for on-disk files. This and
the other `devfile_*`
functions in `lib/file.c`
implement the client side of the FS operations and all work in roughly
the same way, bundling up arguments in a request structure, calling
`fsipc`
to send the IPC request, and unpacking and
returning the results. The `fsipc`
function simply handles
the common details of sending a request to the server and receiving
the reply.
The file system server code can be found in `fs/serv.c`. It
loops in the `serve`
function, endlessly receiving a
request over IPC, dispatching that request to the appropriate handler
function, and sending the result back via IPC. In the read example,
`serve`
will dispatch to `serve_read`
, which
will take care of the IPC details specific to read requests such as
unpacking the request structure and finally call
`file_read`
to actually perform the file read.
Recall that JOS's IPC mechanism lets an environment send a single
32-bit number and, optionally, share a page. To send a request from
the client to the server, we use the 32-bit number for the request
type (the file system server RPCs are numbered, just like how
syscalls were numbered) and store the arguments to the request in a
`union Fsipc`
on the page shared via the IPC. On the
client side, we always share the page at `fsipcbuf`
; on the
server side, we map the incoming request page at `fsreq`
(`0x0ffff000`
).
The server also sends the response back via IPC. We use the 32-bit
number for the function's return code. For most RPCs, this is all
they return. `FSREQ_READ`
and `FSREQ_STAT`
also
return data, which they simply write to the page that the client sent
its request on. There's no need to send this page in the response
IPC, since the client shared it with the file system server in the
first place. Also, in its response, `FSREQ_OPEN`
shares with
the client a new "Fd page". We'll return to the file descriptor
page shortly.
Exercise 5.
Implement `serve_read`
in `fs/serv.c`.
`serve_read`
's heavy lifting will be done by
the already-implemented `file_read`
in `fs/fs.c`
(which, in turn, is just a bunch of calls to
`file_get_block`
). `serve_read`
just has to
provide the RPC interface for file reading. Look at the comments and
code in `serve_set_size`
to get a general idea of how the
server functions should be structured.
Use `make grade` to test your code. Your code should pass
"serve_open/file_stat/file_close" and "file_read" for a score of 70/150.
Exercise 6.
Implement `serve_write`
in `fs/serv.c` and
`devfile_write`
in `lib/file.c`.
Use `make grade` to test your code. Your code should pass
"file_write", "file_read after file_write", "open", and "large file" for a
score of 90/150.
We have given you the code for `spawn`
(see `lib/spawn.c`)
which creates a new environment,
loads a program image from the file system into it,
and then starts the child environment running this program.
The parent process then continues running independently of the child.
The `spawn`
function effectively acts like a `fork`
in UNIX
followed by an immediate `exec`
in the child process.
We implemented `spawn`
rather than a
UNIX-style `exec`
because `spawn`
is easier to
implement from user space in "exokernel fashion", without special help
from the kernel. Think about what you would have to do in order to
implement `exec`
in user space, and be sure you understand
why it is harder.
Exercise 7.
`spawn`
relies on the new syscall
`sys_env_set_trapframe`
to initialize the state of the
newly created environment. Implement
`sys_env_set_trapframe`
in `kern/syscall.c` (don't forget to dispatch the new system call in `syscall()`
).
Test your code by running the
`user/spawnhello` program
from `kern/init.c`, which will attempt to
spawn `/hello` from the file system.
Use `make grade` to test your code.
Challenge!
Implement Unix-style `exec`
.
Challenge!
Implement `mmap`
-style memory-mapped files and
modify `spawn`
to map pages directly from the ELF
image when possible.
The UNIX file descriptors are a general notion that also
encompasses pipes, console I/O, etc. In JOS, each of these device
types has a corresponding `struct Dev`
,
with pointers to the functions that implement
read/write/etc. for that device type. `lib/fd.c` implements the
general UNIX-like file descriptor interface on top of this. Each
`struct Fd`
indicates its device type, and most of the
functions in `lib/fd.c` simply dispatch operations to functions
in the appropriate `struct Dev`
.
`lib/fd.c` also maintains the *file descriptor table*
region in each application environment's address space, starting at
`FDTABLE`
. This area reserves a page's worth (4KB) of
address space for each of the up to `MAXFD`
(currently 32)
file descriptors the application can have open at once. At any given
time, a particular file descriptor table page is mapped if and only if
the corresponding file descriptor is in use. Each file descriptor
also has an optional "data page" in the region starting at
`FILEDATA`
, which devices can use if they choose.
We would like to share file descriptor state across
`fork`
and `spawn`
, but file descriptor state is kept
in user-space memory. Right now, on `fork`
, the memory
will be marked copy-on-write,
so the state will be duplicated rather than shared.
(This means environments won't be able to seek in files they
didn't open themselves and that pipes won't work across a fork.)
On `spawn`
, the memory will be
left behind, not copied at all. (Effectively, the spawned environment
starts with no open file descriptors.)
We will change `fork`
to know that
certain regions of memory are used by the "library operating system" and
should always be shared. Rather than hard-code a list of regions somewhere,
we will set an otherwise-unused bit in the page table entries (just like
we did with the `PTE_COW`
bit in `fork`
).
We have defined a new `PTE_SHARE`
bit
in `inc/lib.h`.
This bit is one of the three PTE bits
that are marked "available for software use"
in the Intel and AMD manuals.
We will establish the convention that
if a page table entry has this bit set,
the PTE should be copied directly from parent to child
in both `fork`
and `spawn`
.
Note that this is different from marking it copy-on-write:
as described in the first paragraph,
we want to make sure to *share*
updates to the page.
Exercise 8.
Change `duppage`
in `lib/fork.c` to follow
the new convention. If the page table entry has the `PTE_SHARE`
bit set, just copy the mapping directly.
(You should use `PTE_SYSCALL`
, not `0xfff`
,
to mask out the relevant bits from the page table entry. `0xfff`
picks up the accessed and dirty bits as well.)
Likewise, implement `copy_shared_pages`
in
`lib/spawn.c`. It should loop through all page table
entries in the current process (just like `fork`
did), copying any page mappings that have the
`PTE_SHARE`
bit set into the child process.
Use `make run-testpteshare` to check that your code is
behaving properly.
You should see lines that say "`fork handles PTE_SHARE right`"
and "`spawn handles PTE_SHARE right`".
Use `make run-testfdsharing` to check that file descriptors are shared
properly.
You should see lines that say "`read in child succeeded`" and
"`read in parent succeeded`".
For the shell to work, we need a way to type at it.
QEMU has been displaying output we write to
the CGA display and the serial port, but so far we've only taken
input while in the kernel monitor.
In QEMU, input typed in the graphical window appear as input
from the keyboard to JOS, while input typed to the console
appear as characters on the serial port.
`kern/console.c` already contains the keyboard and serial
drivers that have been used by the kernel monitor since lab 1,
but now you need to attach these to the rest
of the system.
Exercise 9.
In your `kern/trap.c`, call `kbd_intr`
to handle trap
`IRQ_OFFSET+IRQ_KBD`
and `serial_intr`
to
handle trap `IRQ_OFFSET+IRQ_SERIAL`
.
We implemented the console input/output file type for you,
in `lib/console.c`. `kbd_intr`
and `serial_intr`
fill a buffer with the recently read input while the console file
type drains the buffer (the console file type is used for stdin/stdout by
default unless the user redirects them).
Test your code by running `make run-testkbd` and type
a few lines. The system should echo your lines back to you as you finish them.
Try typing in both the console and the graphical window, if you
have both available.
Run `make run-icode` or `make run-icode-nox`.
This will run your kernel and start `user/icode`.
`icode` execs `init`,
which will set up the console as file descriptors 0 and 1 (standard input and
standard output). It will then spawn `sh`, the shell.
You should be able to run the following
commands:
echo hello world | cat cat lorem |cat cat lorem |num cat lorem |num |num |num |num |num lsfd
Note that the user library routine `cprintf`
prints straight
to the console, without using the file descriptor code. This is great
for debugging but not great for piping into other programs.
To print output to a particular file descriptor (for example, 1, standard output),
use `fprintf(1, "...", ...)`
.
`printf("...", ...)`
is a short-cut for printing to FD 1.
See `user/lsfd.c` for examples.
Exercise 10.
The shell doesn't support I/O redirection. It would be nice to run
`sh <script` instead of having to type in all the
commands in the script by hand, as you did above. Add
I/O redirection for < to `user/sh.c`
.
Test your implementation by typing `sh <script` into
your shell
Run `make run-testshell` to test your shell.
`testshell` simply feeds the above commands (also found in
`fs/testshell.sh`) into the shell and then checks that the
output matches `fs/testshell.key`.
Challenge! Add more features to the shell. Possibilities include (a few require changes to the file system too):
`ls &`
)
`ls; echo hi`
)
`(ls; echo hi) | cat > out`
)
`echo $hello`
)
`echo "a | b"`
)
Your code should pass all tests at this point. As usual, you can
grade your submission with `make grade` and hand it in with
`make handin`.
**This completes the lab.**
As usual, don't forget to run `make grade` and to write up
your answers and a description of your challenge exercise solution.
Before handing in, use `git status` and `git diff`
to examine your changes and don't forget to `git add
answers-lab5.txt`. When you're ready, commit your changes with
`git commit -am 'my solutions to lab 5'`, then `make
handin` to submit your solution. |
10,390 | 在你的终端里探索海洋的秘密 | https://opensource.com/article/18/12/linux-toy-asciiquarium | 2018-12-27T19:19:59 | [
"鱼缸"
] | /article-10390-1.html |
>
> “亲爱的,当您的命令行变得更湿润的时候会更好。这多亏了 ASCII。”
>
>
>

现在,我们即将数完长达 24 天的 Linux 命令行玩具日历。离今天只剩一周了!如果这是您第一次访问本系列文章,那么您可能会问自己什么是命令行玩具。我们一边走,一边说,但一般来说,这可能是一个游戏,或者可以帮助你在终端玩得开心的任何简单的娱乐活动。
你们其中的一些人可能已经在以前的系列文章中看到了各种各样的命令行玩具。但是,我们希望每个人都能够获得一个新玩具。
今天的玩具有一点鱼的味道。先和 `asciiquarium` 打个招呼,一个在你终端里海底冒险的玩具。我是在我的 Fedora 仓库里发现 `asciiquarium` 的,因此安装它非常容易:
```
$ sudo dnf install asciiquarium
```
如果您正在运行不同的发行版,那么它也可能已经为您打包。 只需在您的终端中运行 `asciiquarium` 即可感受到蛤蜊的快乐。 该项目也在终端之外进行了“翻译”,所有水族伙伴的屏保都是为几个非 Linux 操作系统制作的,甚至还有一个 Android 动态壁纸版本。
访问 asciiquarium [主页](https://robobunny.com/projects/asciiquarium/html/)了解更多信息或下载 Perl 源代码。 该项目是 GPL 第 2 版许可证下的开源项目。 如果你想更多地了解开源,开放数据和开放科学如何在实际的海洋中发挥作用,请花点时间去了解[海洋健康指数](https://opensource.com/article/18/12/protecting-world-oceans)。

你觉得我应该介绍一下你最喜欢的命令行玩具吗?时间不多了,但我还是想听听你的建议。请在下面的评论中告诉我,我会查阅的。让我知道你对今天的娱乐有什么看法。
一定要看看昨天的玩具,[安排一次与 Emacs 精神病医生的访问](https://opensource.com/article/18/12/linux-toy-eliza),明天再来看另一个玩具!
---
via: <https://opensource.com/article/18/12/linux-toy-asciiquarium>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,391 | 糖尿病患者们是怎样使用开源造出自己的医疗设备的 | https://opensource.com/article/18/5/dana-lewis-women-open-source-community-award-winner-2018 | 2018-12-27T19:46:44 | [
"糖尿病",
"医疗"
] | https://linux.cn/article-10391-1.html |
>
> Red Hat 的 2018 女性开源社区奖获得者 Dana Lewis 的故事。
>
>
>

Dana Lewis 被评选为[开源社区 2018 年度最佳女性](https://www.redhat.com/en/about/women-in-open-source)!下面是开源怎样改善了她的健康的故事。
Dana 患有 I 型糖尿病,但当时市面上流通的药品和医疗设备都对她无效。她用来管理血糖的动态血糖监测(CGM)报警器的声音太小了,根本叫不醒熟睡的她,产品这样的设计无法保证她每天睡眠时间的生命安全。
“我和生产厂家见了一面商议提出意见,厂家的回复是‘我们产品的音量已经足够大了,很少有人叫不醒’,我被告知‘这不是普遍问题,我们正在改进,请期待我们的新产品。’听到这些时我真的很挫败,但我从没想象过我能做出什么改变,毕竟那是通过了 FDA 标准的医疗设备,不是我们能随意改变的。”
面临着这些阻碍,Dana 想着如果她能把自己的数据从设备里导出,就可以设置手机闹铃来叫醒自己。在 2013 年末,她看到的一条推特解决了她的疑问。那条推特的作者是一位糖尿病患儿的家长,他把动态血糖监测仪进行了逆向工程,这样就可以导出孩子的血糖数据进行远程监控了。
她意识到如果对方愿意把过程分享给她,她也可以用那些代码做一个自己的响亮的血糖监测仪了。
“我并不知道向别人要源代码是件稀松平常的事,那是我第一次接触开源。”
那个系统演化成一个响亮闹钟的代码,她也可以把代码在网页上分享给别人。和她的丈夫 Scott Leibrand 一起,她逐步向闹铃添加属性,最终形成了一个算法,这个算法不仅能监测实时血糖水平,还能主动预测未来血糖波动。
随着 Dana 与开源糖尿病患者社区的接触越来越深,她认识了 Ben West,他花了很多年才研究出与 Dana 使用的胰岛素泵沟通数据的方法,与血糖监测仪不同,胰岛素泵不是简单的报告血糖,它是个单独的设备,要按人体需要持续推注胰岛素,比血糖监测仪要复杂得多。
“老路行不通了,我们说‘哦,如果我们能用这段代码和胰岛素泵沟通,就像我们之前用算法和血糖监测仪沟通实时数据那样,我们就能获取两个设备的实时数据,创建一个闭路系统。’”
我们得到的是一个自制人工胰腺系统 (DIY APS)。
这个系统可以使用算法处理胰岛素泵和血糖监测仪的数据,来预测患者血糖水平,据此调整胰岛素的注射量,从而保持患者的血糖稳定。这个人工胰岛素系统取代了从前患者每日多次对胰岛素注射量的计算和调整,减轻了糖尿病患者的负担。
“正因为我们使用的是开源软件,在做出这个系统之后我们就把成果开源化了,这样可以造福更多的人。”开源人工胰腺系统 (OpenAPS) 由此诞生。
OpenAPS 社区已经拥有超过 600 名用户,大家都提供了各种各样的自制“闭路”系统代码。OpenAPS 贡献者们聚集到了 #WeAreNotWaiting 话题之下,以表达患者群体不该干等着医疗保健工厂制造出真正有效便捷产品的理念。
“你可以选择等待未来的商业解决方案,这无可厚非,选择等待是你的自由。等待可以是一种选择,但不能是无法改变的现状。对我来说,开源在医疗保健方面做出的这个举动让等待变成了一种选择。你可以选择不自行解决,你可以选择等待商业解决方案,但如果你不想等了,你无需再等。现在你有很多选择,开源社区的人们已经解决了很多问题。”
OpenAPS 社区由糖尿病患者、患者家属,还有想要合理利用这项技术的人们。在社区的帮助下,Dana 学会了很多种贡献开源项目的方式。她发现许多从 Facebook 或 [Gitter](https://gitter.im/) 上过来的非技术贡献者也对 OpenAPS 做出了很大贡献。
“贡献有很多方式,我们要认识到各种方式的贡献都是平等的。它们一般涉及不同的兴趣领域和技能组合,只有把这些综合起来,才能做成社区的项目。”
她亲身经历过,所以知道自己的贡献不被社区的其他成员认可是怎样难过的感受。对于人们习惯把女性的贡献打折的这一现象,她也不回避。在她的 [2014 年博客](https://diyps.org/2014/08/25/being-female-a-patient-and-co-designing-diyps-means-often-being-discounted/) 和 [反思](https://diyps.org/2018/02/01/women-in-open-source-make-a-difference/) 文章中她初次写到在入围开源年度最佳人物时所遭受到的区别待遇,这些待遇让她意识到身为女性的不同。
在她最初的博客中,她写道了自己和丈夫 Scott 同为开源社区成员,遭受到的区别待遇。他们都注意到,Dana 总是被提出一些细枝末节的要求,但 Scott 就不会。而 Scott 总被问道一些技术性问题,即使他向他们推荐 Dana,人们也更倾向于问身为男性的 Scott。大家都或多或少经历过这些行为,Dana 的博文在社区里引起了广泛的讨论。
“人们更愿意认为项目是‘Scott 发起的’而非‘Dana 和 Scott 一起发起的’。”这让我感受到千刀万剐般的痛苦和挫败,我写了博客把这个现象提到明面上,我说,‘看看这些行为,我知道你们有些是故意的,有些是无意的,但如果我们的社区想要得到多元化参与者的支持,想要发展壮大,我们就要规范自己的行为,有不妥之处也不要回避,直接摊开来交流。”值得赞扬的是,社区里的大部分成员都加入进来,认真地讨论这个问题。他们都说,‘好的,我知道有哪里需要改了,如果我再无意识这样做时提醒我一下。’这就是我们社区形成的风气。”
她还说如果没有 Scott 这位社区里活跃开发者的支持,还有社区里其他女性贡献者的鼓励,她可能就半途而废了。
“我想如果我就放弃努力了,可能开源世界里糖尿病患者们的现状会有很大不同。我知道别人不幸的遭遇,他们在开源社区中感受不到认同感和自身价值,最终离开了开源。我希望我们可以继续这种讨论,大家都能意识到如果我们不故意打击贡献者,我们可以变得更加温暖,成员们也能感受到认同感,大家的付出也能得到相应的认可。
OpenAPS 社区的交流和分享给我们提供了一个很好的例子,它说明非技术性的贡献者对于整个社区的成功都是至关重要的。Dana 在现实社会中的关系和交流经历对她为开源社区做出的宣传有着很大的贡献。她为社区在 [DIYPS 博客](https://diyps.org/) 上写了很多篇文章,她还在 [TEDx Talk](https://www.youtube.com/watch?v=kgu-AYSnyZ8) 做过一场演讲, 在 [开源大会 (OSCON)](https://www.youtube.com/watch?v=eQGWrdgu_fE) 上也演讲过很多次,诸如此类的还有很多。
“不是每个项目都像 OpenAPS 一样,对患者有那么大的影响,甚至成为患者中间的主流项目。糖尿病社区在项目的沟通中真的做了很多贡献,引来了很多糖尿病患者,也让需要帮助的人们知道了我们的存在。”
Dana 现在的目标是帮助其他疾病的患者社区创建项目。她尤其想要把社区成员们学到的工具和技术和其他的患者社区分享,特别是那些想要把项目进一步提升,进行深入研究,或者想和公司合作的社区。
“我听说很多参与项目的患者都听过这样的话,‘你应该申请个专利;你应该拿它开个公司;你应该成立个非营利组织。’但这些都是大事,它们太耗时间了,不仅占据你的工作时间,甚至强行改变你的专业领域。我这样的人并不想做那样的事,我们更倾向于把精力放在壮大其他项目上,以此帮助更多的人。”
在此之后,她开始寻找其他不那么占用时间的任务,比如给小孩们写一本书。Dana 在 2017 年进行了这项挑战,她写了本书给侄子侄女,讲解他们婶婶的糖尿病设备是怎样工作的。在她侄女问她“胳膊上的东西是什么”(那是她的血糖监测仪)时,她意识到她不知道怎么和一个小孩子解释糖尿病患者是什么,所以写了[《卡罗琳的机器人亲戚》](https://www.amazon.com/gp/product/1977641415/ref=as_li_tl?ie=UTF8&tag=diyps-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=1977641415&linkId=96bb65e21b5801901586e9fabd12c860)这本书。
“我想用我侄子侄女那个年纪的语言和他们交流,毕竟不同年龄的人说话方式也不同。我当时想,‘真希望有本这方面的儿童读物,那我为什么不自己写一本呢?’”
她写了书在亚马逊上出版,因为她想把开源的价值分享给更多的人。她还开了一个名为[“自己在亚马逊上出书”](https://diyps.org/2017/11/01/makers-gonna-make-a-book-about-diabetes-devices-kids-book-written-by-danamlewis/)的博客,希望大家也可以把自己的经历写进书里出版。
像《卡罗琳的机器人亲戚》这本书还有开源社区年度最佳女性这样的奖项都说明生活中包括开源在内的不同领域中,还有很多人的工作等待着大众的认知。
“社区越多元,事情越好办。”
---
via: <https://opensource.com/article/18/5/dana-lewis-women-open-source-community-award-winner-2018>
作者:[Taylor Greene](https://opensource.com/users/tgreene) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Valoniakim](https://github.com/Valoniakim) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Dana Lewis is the 2018 Women in [Open Source Community Award](https://www.redhat.com/en/about/women-in-open-source) winner! Here is her story about how open source improved her health in a big way.
Dana has Type 1 diabetes and commercially available medical devices were failing her. The continuous glucose monitor (CGM) alarm she was using to manage her blood sugar was not loud enough to wake her up. The product design put her in danger every time she went to sleep.
"I went to a bunch of manufacturers and asked what they could do, and I was told, 'It’s loud enough for most people.' I was told that 'it’s not a problem for most people, and we're working on it. It'll be out in a future version.’' That was all really frustrating to hear, but at the same time, I didn’t feel like I could do anything about it because it’s an FDA-approved medical device. You can’t change it."
These obstacles aside, Dana thought that if she could get her data from the device, she could use her phone to make a louder alarm. Toward the end of 2013, she saw a tweet that provided an answer to her problem. The author of the tweet, who is the parent of a child with diabetes, had reverse-engineered a CGM to get the data off his child’s device so that he could monitor his child’s blood sugar remotely.
She realized that if he was willing to share, she could use the same code to build a louder alarm system.
"I didn’t understand that it was perfectly normal to ask people to share code. That was my first introduction to open source."
The system evolved from a louder alarm to a web page where she could share data with her loved ones. Together with her now-husband, Scott Leibrand, she iteratively added features to the page, eventually including an algorithm that could not only monitor glucose levels in real time but also proactively predict future highs and lows.
As Dana got more involved with the open source diabetes community, she met Ben West. He had spent years figuring out how to communicate with the insulin pump Dana used. Unlike a CGM, which tells the user if their blood sugar is high or low, an insulin pump is a separate device used to continuously infuse insulin throughout the day.
"A light bulb went off. We said, 'Oh, if we take this code to communicate with the pump with what we’ve done to access the data from the CGM in real time and our algorithm, we can actually process data from both devices in real time and create a closed-loop system.'"
The result was a do-it-yourself artificial pancreas system (DIY APS).
Using the algorithm to process data from the insulin pump and CGM, the DIY APS forecasts predicted blood glucose levels and automates adjustments to the insulin delivery, making small changes to keep blood sugar within the target range. This makes life much easier for people with diabetes because they no longer have to calibrate insulin delivery manually several times per day.
"Because we had been using open source software, we knew that the right thing to do was to turn around and make what we had done open source as well so that other people could leverage it." And thus, OpenAPS (the Open Source Artificial Pancreas System) was born.
The OpenAPS community has since grown to more than 600 users of various DIY "closed-loop" systems. OpenAPS contributors have embraced the hashtag #WeAreNotWaiting as a mantra to express their belief that patient communities should not have to wait for the healthcare industry to create something that works for them.
"Yes, you may choose to adopt a commercial solution in the future—that’s totally fine, and you should have the freedom do to that. Waiting should be a choice and not the status quo. To me, what’s amazing about this movement of open source in healthcare is that waiting is now a choice. You can choose not to DIY. You can choose to wait for a commercial solution. But if you don’t want to wait, you don’t have to. There are a plethora of options to take advantage of. A lot of problems have been solved by people in the community."
The OpenAPS community is made up of people with diabetes, their loved ones, parents of children with diabetes, and people who want to use their skills for good. By helping lead the community, Dana has learned about the many ways of contributing to an open source project. She sees many valuable contributions to OpenAPS come from non-technical contributors on Facebook or [Gitter](https://gitter.im/).
"There are a lot of different ways that people contribute, and it’s important that we recognize all of those because they’re all equally valuable. And they often involve different interests and different skill sets, but together, that’s what makes a community project in open source succeed."
She knows firsthand how discouraging it can be for contributions to go unrecognized by others in a community. She also isn’t shy about discussing people’s tendency to discount the contributions of women. She first wrote about her experience being treated differently in a [2014 blog post](https://diyps.org/2014/08/25/being-female-a-patient-and-co-designing-diyps-means-often-being-discounted/) and [reflected on it again](https://diyps.org/2018/02/01/women-in-open-source-make-a-difference/) when she learned she was a Women in Open Source Award finalist.
In her first blog post, she and Scott shared the differences in the way they were treated by members of the community. They both noticed that, in subtle ways, Dana was constantly battling to be taken seriously. People often directed technical questions to him instead of her, even after Scott tried to redirect them to Dana. By calling out these behaviors, the post opened up a highly productive discussion in the community.
"People would talk about the project initially as 'Scott’s thing' instead of 'Dana and Scott’s thing.' It was death by a thousand paper cuts in terms of frustration. I wrote the blog post to call it out. I said, 'Look, for some of you it’s conscious, but for some of you, it’s unconscious. We need to think that if we want this community to grow and support and allow many diverse participants, we need to talk about how we’re behaving.' To their credit, a lot of people in the community stopped and had serious conversations. They said, 'OK, here’s what I’m going to do to change. Call me out if I do it unconsciously.' It was phenomenal."
She added that if it weren’t for the support of Scott as another active developer in the community, as well as that of other women in the community she could talk to and get encouragement from, she might have stopped.
"I think that might have totally changed what happened in diabetes in open source if I had just thrown up my hands. I know that happens to other people, and it’s unfortunate. They leave open source because they don’t feel welcome or valued. My hope is that we continue to have the conversation about it and recognize that even if you’re not consciously trying to discourage people, we can all always do better at being more welcoming and engaging and recognizing contributions."
Communication and sharing about OpenAPS are examples of non-technical contributions that have been critical to the success of the community. Dana’s background in public relations and communications certainly contributed to getting the word out. She has written and spoken extensively about the community on the [DIYPS blog](https://diyps.org/), in a [TEDx Talk](https://www.youtube.com/watch?v=kgu-AYSnyZ8), at [OSCON](https://www.youtube.com/watch?v=eQGWrdgu_fE), and more.
"Not every project that is really impactful to a patient community has made it into the mainstream the way OpenAPS has. The diabetes community has done a really good job communicating about various projects, which brings more people with diabetes in and also gets the attention of people who want to help."
Her goal now is to help bring to light to other patient community projects. Specifically, she wants to share tools or skills community members have learned with other patient communities looking to take projects to the next level, facilitate research, or work with companies.
"I also realize that a lot of patients in these projects are told, 'You should patent that. You should create a company. You should create a non-profit.' But all those are huge things. They’re very time-consuming. They take away from your day job or require you to totally switch professions. People like me, we don’t always want to do that, and we shouldn’t have to do that in order to scale projects like this and help other people."
To this end, she also wants to find other pathways people can take that aren’t all-consuming—for example, writing a children’s book. Dana took on this challenge in 2017 to help her nieces and nephews understand their aunt’s diabetes devices. When her niece asked her what "the thing on her arm was" (her CGM), she realized she didn’t have a point of reference to explain to a young child what it meant to be a person with diabetes. Her solution was [ Carolyn’s Robot Relative](https://www.amazon.com/gp/product/1977641415/ref=as_li_tl?ie=UTF8&tag=diyps-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=1977641415&linkId=96bb65e21b5801901586e9fabd12c860).
"I wanted to talk to my nieces and nephews in a way that was age-appropriate that also normalizes that people are different in different ways. I was like, 'I wish there was a kid’s book that talks about this. Well, why don’t I write my own?'"
She wrote the book and published it on Amazon because true to her open source values, she wanted it to be available to others. She followed up by also writing a [blog post about self-publishing a book on Amazon](https://diyps.org/2017/11/01/makers-gonna-make-a-book-about-diabetes-devices-kids-book-written-by-danamlewis/) in the hopes that others would publish books that speak to their own experiences.
Books like *Carolyn’s Robot Relative* and awards like the Women in Open Source Award speak to the greater need for representation of different kinds of people in many areas of life, including open source.
"Things are always better when the communities are more diverse."
## Comments are closed. |
10,392 | 如何在 Linux 中安装 Rust 编程语言 | https://www.2daygeek.com/how-to-install-rust-programming-language-in-linux/ | 2018-12-28T23:47:00 | [
"Rust"
] | https://linux.cn/article-10392-1.html | 
Rust 通常被称为 rust-lang。Rust 是一个由 Mozilla Research 赞助的通用的、多范式、现代的、跨平台和开源系统编程语言。
它旨在实现安全性、速度和并发性等目标。
Rust 在语法上与 C++ 相似,但它的设计者希望它在保持性能的同时提供更好的内存安全性。
Rust 目前在许多组织中使用,例如 Firefox、Chef、Dropbox、Oracle、GNOME 等。
### 如何在 Linux 中安装 Rust 语言?
我们可以通过多种方式安装 Rust,但以下是官方推荐的安装方式。
```
$ curl https://sh.rustup.rs -sSf | sh
info: downloading installer
Welcome to Rust!
This will download and install the official compiler for the Rust programming
language, and its package manager, Cargo.
It will add the cargo, rustc, rustup and other commands to Cargo's bin
directory, located at:
/home/daygeek/.cargo/bin
This path will then be added to your PATH environment variable by modifying the
profile files located at:
/home/daygeek/.profile
/home/daygeek/.bash_profile
You can uninstall at any time with rustup self uninstall and these changes will
be reverted.
Current installation options:
default host triple: x86_64-unknown-linux-gnu
default toolchain: stable
modify PATH variable: yes
1) Proceed with installation (default)
2) Customize installation
3) Cancel installation
>1
info: syncing channel updates for 'stable-x86_64-unknown-linux-gnu'
info: latest update on 2018-12-06, rust version 1.31.0 (abe02cefd 2018-12-04)
info: downloading component 'rustc'
77.7 MiB / 77.7 MiB (100 %) 1.2 MiB/s ETA: 0 s
info: downloading component 'rust-std'
54.2 MiB / 54.2 MiB (100 %) 1.2 MiB/s ETA: 0 s
info: downloading component 'cargo'
4.7 MiB / 4.7 MiB (100 %) 1.2 MiB/s ETA: 0 s
info: downloading component 'rust-docs'
8.5 MiB / 8.5 MiB (100 %) 1.2 MiB/s ETA: 0 s
info: installing component 'rustc'
info: installing component 'rust-std'
info: installing component 'cargo'
info: installing component 'rust-docs'
info: default toolchain set to 'stable'
stable installed - rustc 1.31.0 (abe02cefd 2018-12-04)
Rust is installed now. Great!
To get started you need Cargo's bin directory ($HOME/.cargo/bin) in your PATH
environment variable. Next time you log in this will be done automatically.
To configure your current shell run source $HOME/.cargo/env
```
运行以下命令配置当前 shell。
```
$ source $HOME/.cargo/env
```
运行以下命令验证已安装的 Rust 版本。
```
$ rustc --version
rustc 1.31.0 (abe02cefd 2018-12-04)
```
### 如何测试 Rust 编程语言?
安装 Rust 后,请按照以下步骤检查 Rust 语言是否正常工作。
```
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
```
创建一个文件并添加以下代码并保存。确保 Rust 文件始终以 .rs 扩展名结尾。
```
$ vi 2g.rs
fn main() {
println!("Hello, It's 2DayGeek.com - Best Linux Practical Blog!");
}
```
运行以下命令编译 rust 代码。
```
$ rustc 2g.rs
```
上面的命令将在同一目录中创建一个可执行的 Rust 程序。
```
$ ls -lh
total 3.9M
-rwxr-xr-x 1 daygeek daygeek 3.9M Dec 14 11:09 2g
-rw-r--r-- 1 daygeek daygeek 86 Dec 14 11:09 2g.rs
```
运行 Rust 可执行文件得到输出。
```
$ ./2g
Hello, It's 2DayGeek.com - Best Linux Practical Blog!
```
好了!正常工作了。
将 Rust 更新到最新版本。
```
$ rustup update
info: syncing channel updates for 'stable-x86_64-unknown-linux-gnu'
info: checking for self-updates
stable-x86_64-unknown-linux-gnu unchanged - rustc 1.31.0 (abe02cefd 2018-12-04)
```
运行以下命令从系统中删除 Rust 包。
```
$ rustup self uninstall
```
卸载 Rust 包后,删除 Rust 项目目录。
```
$ rm -fr ~/projects
```
---
via: <https://www.2daygeek.com/how-to-install-rust-programming-language-in-linux/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,393 | 在 Linux 终端收听广播 | https://opensource.com/article/18/12/linux-toy-mplayer | 2018-12-29T11:32:38 | [
"MPlayer"
] | https://linux.cn/article-10393-1.html |
>
> MPlayer 是一个多功能的开源媒体播放器,它在 Linux 命令行中非常有用。
>
>
>

你已经看到我们为期 24 天的 Linux 命令行玩具日历。如果这是你第一次访问该系列,你可能会问自己什么是命令行玩具。它可能是一个游戏或任何简单的消遣,可以帮助你在终端玩得开心。
你们中的一些人之前已经看过我们日历中的各种玩具,但我们希望每个人至少见到一件新玩具。
在命令行中有很多方法可以听音乐。如果你有本地存储的媒体,`cmus` 是一个很好的选择,但还有[很多其他选择](https://opensource.com/life/16/8/3-command-line-music-players-linux)。
不过,很多时候,当我在终端的时候,我会走神并且不会注意挑选每首歌,并让其他的来做。虽然为了这个我有很多播放列表,但过了一段时间,即使过时,我也会切换到互联网电台。
今天的玩具,MPlayer,是一个多功能的多媒体播放器,几乎可以支持任何你给它的媒体格式。如果尚未安装 MPlayer,你可能会发现它已在你的发行版中打包。在 Fedora 中,我在 [RPM Fusion](https://rpmfusion.org/) 中找到了它(请注意,这不是 Fedora 的“官方”仓库,因此请谨慎操作):
```
$ sudo dnf install mplayer
```
MPlayer 有一系列命令行选项可根据你的具体情况进行设置。我想听 Raleigh 当地的大学广播电台([88.1 WKN](https://wknc.org/index.php),这个很棒!),在它们的网站得到流媒体网址之后,像这样就可以让收音机运行了,不需要 GUI 或 Web 播放器:
```
$ mplayer -nocache -afm ffmpeg http://wknc.sma.ncsu.edu:8000/wknchd1.mp3
```
MPlayer 是 GPLv3 许可证下的开源软件,你可以从项目的[网站](http://www.mplayerhq.hu/)中找到更多关于项目的信息并下载源代码。
正如我在昨天的文章中提到的,我试图使用每个玩具的截图作为每篇文章的主图,但是当进入音频世界时,我不得不稍微改改。所以今天的图像是由 **libcaca** 包中的 **img2txt** 绘制的来自公共域的无线电塔图标。
你有特别喜欢的命令行小玩具需要我介绍的吗?我们的日历基本上是为这个系列剩余的玩具设置的,但我们仍然很想在新的一年里推出一些很酷的命令行玩具。评论告诉我,我会查看的。如果还有空位置,我会考虑介绍它的。并让我知道你对今天的玩具有何看法。
一定要看看昨天的玩具,[让你的 Linux 终端说出来](https://opensource.com/article/18/12/linux-toy-espeak),明天记得回来!
---
via: <https://opensource.com/article/18/12/linux-toy-mplayer>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You've found your way to our 24-day-long Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is. It could be a game or any simple diversion that helps you have fun at the terminal.
Some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
There are many ways to listen to music at the command line; if you've got media stored locally, **cmus** is a great option, but there are [plenty of others](https://opensource.com/life/16/8/3-command-line-music-players-linux) as well.
Lots of times when I'm at the terminal, though, I'd really rather just zone out and not pay close attention to picking each song, and let someone else do the work. While I've got plenty of playlists that work for just such a purpose, after a while, even though go stale, and I'll switch over to an internet radio station.
Today's toy, MPlayer, is a versatile multimedia player that will support just about any media format you throw at it. If MPlayer is not already installed, you can probably find it packaged for your distribution. On Fedora, I found it in [RPM Fusion](https://rpmfusion.org/) (be aware that this is not an "official" repository for Fedora, so exercise caution):
`$ sudo dnf install mplayer`
MPlayer has a slew of command-line options to set depending on your situation. I wanted to listen to the local college radio station here in Raleigh ([88.1 WKNC,](https://wknc.org/index.php) they're pretty good!), and so after grabbing the streaming URL from their website, all that took to get my radio up and running, no GUI or web player needed, was:
`$ mplayer -nocache -afm ffmpeg http://wknc.sma.ncsu.edu:8000/wknchd1.mp3`
MPlayer is open source under the GPLv3, and you can find out more about the project and download source code from the project's [website](http://www.mplayerhq.hu/).
As I mentioned in yesterday's article, I'm trying to use a screenshot of each toy as the lead image for each article, but as we moved into the world of audio, I had to fudge it a little. So today's image was created from a public domain icon of a radio tower using **img2txt**, which is provided by the **libcaca** package.
Do you have a favorite command-line toy that you we should have included? Our calendar is basically set for the remainder of the series, but we'd still love to feature some cool command-line toys in the new year. Let me know in the comments below, and I'll check it out. And let me know what you thought of today's amusement.
Be sure to check out yesterday's toy, [Let you Linux terminal speak its mind](https://opensource.com/article/18/12/linux-toy-espeak), and come back tomorrow for another!
## 5 Comments |
10,395 | 救命!我的电子邮件发不到 500 英里以外! | http://web.mit.edu/jemorris/humor/500-miles | 2018-12-29T16:41:00 | [
"邮件"
] | https://linux.cn/article-10395-1.html | 
这是一个听起来几乎不可能的事情……我甚至有点后悔将它发到网上,因为它在一个会议上成了一则著名的酒后故事。这个故事略有改动,以保护故事中的人物,以及忽略了一些无关的细节使之更有趣一些。
几年前,当我接到统计系主任的电话时,我正在从事维护校园电子邮件系统的工作。
“我们从部门发送电子邮件时遇到了问题。”
“有什么问题?” 我问。
“我们不能发送超过 500 英里的邮件,”主任解释说。
“咳咳”,我被我喝的拿铁呛了一口,“您再说一遍?”
“我们不能发送距这里超过 500 英里的邮件,”他重复道。 “实际上,更远一点,是 520 英里,但不能更远了。”
“嗯......电子邮件真的不会这样,通常,”我说,试着让我的声音听起来不那么慌乱。我不能和一个系主任说话时显得慌乱,即使是一个像统计系这样的相对没钱的院系。 “是什么让你觉得你不能发送邮件超过 500 英里?”
“这不是我**认为的**,”主任有点急躁地回答道。 “我们首先注意到了这种情况是几天前。”
“你等了**几天**?” 我打断他,带点颤音说道。 “这段时间你一直你不能发送电子邮件?”
“我们可以发送电子邮件。只是不超过 ——”
“—— 500 英里,我知道,”我接过他的话,“我知道了。但为什么没有你早点打电话呢?”
“好吧,我们没有收集到足够的数据来确定发生了什么,直到现在。”没错,这是**统计**系的主任。“不管怎么说,我请了一位地理统计学家研究它 ——”
“地理统计学家……”
“—— 是的,她制作了一张地图,显示了我们发送电子邮件能够达到的半径略超过 500 英里。在那个半径范围内有零星的几个无法到达的目的地,但我们永远不能发送比这半径更远的电子邮件。”
“我明白了,”我说,把头埋在我的手中。 “这是什么时候开始的?几天前,你说过,但是那时你的系统做了什么改变?”
“嗯,服务顾问来给我们的服务器打了补丁,并重新启动了它。但我打电话给他,他说他没有碰过邮件系统。”
“好的,让我来看看,我稍后会给你回电话,”我说。我简直觉得我在做梦,这不是愚人节。我试着回想是不是有人恶作剧报复我。
我登录了他们系的服务器,并发送了一些测试邮件。在北卡罗来纳州的<ruby> 三角研究园 <rp> ( </rp> <rt> Research Triangle Park </rt> <rp> ) </rp></ruby>,我自己的帐户的测试邮件顺利投递。发往里士满、亚特兰大和华盛顿的也是如此。发往普林斯顿(400 英里)的另一个邮件也正常。
但后来我尝试向孟菲斯(600 英里)发送电子邮件,失败了。波士顿,失败了。底特律,也失败了。我拿出了我的地址簿,开始试图缩小它的范围。纽约(420 英里)成功,但普罗维登斯(580 英里)失败了。
我开始怀疑自己是不是疯了。我试过给住在北卡罗来纳州的朋友发电子邮件,但他的 ISP 在西雅图。谢天谢地,它失败了。如果问题与收件人的地理位置有关,而不是他的邮件服务器,我想我要哭了。
已经确定!虽然令人难以置信,但所报告的问题是真实的、可重复的,我看了一下 `sendmail.cf` 文件。它看起来很正常。事实上,它看起来很熟悉。
我把它与我主目录中的 `sendmail.cf` 做了个对比。它没有被改过 —— 这是我写的 `sendmail.cf`。 而且我相当确定我没有启用某种 “`FAIL_MAIL_OVER_500_MILES`” 选项。我不知所措,我 telnet 到 SMTP 端口。 服务器愉快地回复了 SunOS sendmail 的横幅消息。
等一下……一个 SunOS sendmail 的横幅消息?当时,即使 Sendmail 8 已经相当成熟,Sun 公司在其操作系统中装的仍然是 Sendmail 5。作为一名优秀的系统管理员,我已经对 Sendmail 8 进行了标准化。并且作为一名优秀的系统管理员,我编写了一个 `sendmail.cf`,它使用了 Sendmail 8 中提供的很长的、具有自我描述意义的选项和变量,而不是 Sendmail 5 中使用的那种神秘的标点符号式配置选项。
这个细节一下子又回到了起点,我再次被我现在已经冷掉了的拿铁咖啡渣呛了。 当服务顾问“对服务器打补丁”时,他显然升级了 SunOS 的版本,并且这样做**降级了** Sendmail。这次升级会将 sendmail.cf 单独留下,即使它现在是错误的版本。
事实上,Sendmail 5 —— 至少是 Sun 所带的版本,是有一些调整的 —— 它可以处理 Sendmail 8 的 `sendmail.cf`,因为大多数规则在那时保持不变。但新的长配置选项 —— 它被视为垃圾,并跳过。 并且 `sendmail` 二进制文件编译时没有针对其中大多数设置默认值,因此,在 `sendmail.cf` 文件中找不到合适的配置,它们被设置为 0。
被设置为 **0** 的配置之一是连接到远程 SMTP 服务器的超时选项。 一些实验证明,在具有典型负载的特定机器上,**0** 超时将在稍微超过 **3 毫秒**的时间内中止连接调用。
当时我们校园网络的一个奇怪的特点是它是 100% 交换的。传出的数据包不会出现路由器延迟,直到命中 POP 服务器并到达远端的路由器。因此,连接到附近网络上的轻负载的远程主机的时间实际上主要取决于到目的地的光速的速度,而不是偶然的路由器延迟。
这让我有点晕,我在我的 shell 中输入:
```
$ units
1311 units, 63 prefixes
You have: 3 millilightseconds
You want: miles
* 558.84719
/ 0.0017893979
```
“500 英里,或者稍微多一点点。”
| 200 | OK | null |
10,396 | 如何构建一台网络引导服务器(二) | https://fedoramagazine.org/how-to-build-a-netboot-server-part-2/ | 2018-12-29T22:46:32 | [
"网络引导",
"NFS"
] | https://linux.cn/article-10396-1.html | 
在 [如何构建一台网络引导服务器(一)](/article-10379-1.html) 的文章中,我们展示了如何创建一个网络引导镜像,在那个镜像中使用了一个名为 `liveuser` 帐户,它的家目录位于内存中,重启后家目录中的内容将全部消失。然而很多用户都希望机器重启后保存他们的文件和设置。因此,在本系列的第二部分,我们将向你展示如何在第一部分的基础上,重新配置网络引导镜像,以便 [活动目录](https://en.wikipedia.org/wiki/Active_Directory) 中的用户帐户可以进行登录,然后从一个 NFS 服务器上自动挂载他们的家目录。
本系列的第三部分,我们将向你展示网络引导客户端如何与中心化配置的 iPXE 引导菜单进行交互。
### 设置使用 KRB5 认证的 NFS4 Home 目录
按以前的文章 “[使用 Kerberos 强化共享的 NFS Home 目录安全性](https://fedoramagazine.org/secure-nfs-home-directories-kerberos)” 的指导来做这个设置。
### 删除 Liveuser 帐户
删除本系列文章第一部分中创建的 `liveuser` 帐户:
```
$ sudo -i
# sed -i '/automaticlogin/Id' /fc28/etc/gdm/custom.conf
# rm -f /fc28/etc/sudoers.d/liveuser
# for i in passwd shadow group gshadow; do sed -i '/^liveuser:/d' /fc28/etc/$i; done
```
### 配置 NTP、KRB5 和 SSSD
接下来,我们需要将 NTP、KRB5 和 SSSD 的配置文件复制进客户端使用的镜像中,以便于它们能够使用同一个帐户:
```
# MY_HOSTNAME=$(</etc/hostname)
# MY_DOMAIN=${MY_HOSTNAME#*.}
# dnf -y --installroot=/fc28 install ntp krb5-workstation sssd
# cp /etc/ntp.conf /fc28/etc
# chroot /fc28 systemctl enable ntpd.service
# cp /etc/krb5.conf.d/${MY_DOMAIN%%.*} /fc28/etc/krb5.conf.d
# cp /etc/sssd/sssd.conf /fc28/etc/sssd
```
在已配置的识别服务的基础上,重新配置 sssd 提供认证服务:
```
# sed -i '/services =/s/$/, pam/' /fc28/etc/sssd/sssd.conf
```
另外,配置成确保客户端不能更改这个帐户密码:
```
# sed -i '/id_provider/a \ \ ad_maximum_machine_account_password_age = 0' /fc28/etc/sssd/sssd.conf
```
另外,复制 nfsnobody 的定义:
```
# for i in passwd shadow group gshadow; do grep "^nfsnobody:" /etc/$i >> /fc28/etc/$i; done
```
### 加入活动目录
接下来,你将执行一个 `chroot` 将客户端镜像加入到活动目录。从删除预置在网络引导镜像中同名的计算机帐户开始:
```
# MY_USERNAME=jsmith
# MY_CLIENT_HOSTNAME=$(</fc28/etc/hostname)
# adcli delete-computer "${MY_CLIENT_HOSTNAME%%.*}" -U "$MY_USERNAME"
```
在网络引导镜像中如果有 `krb5.keytab` 文件,也删除它:
```
# rm -f /fc28/etc/krb5.keytab
```
`chroot` 到网络引导镜像中:
```
# for i in dev dev/pts dev/shm proc sys run; do mount -o bind /$i /fc28/$i; done
# chroot /fc28 /usr/bin/bash --login
```
执行一个加入操作:
```
# MY_USERNAME=jsmith
# MY_HOSTNAME=$(</etc/hostname)
# MY_DOMAIN=${MY_HOSTNAME#*.}
# MY_REALM=${MY_DOMAIN^^}
# MY_OU="cn=computers,dc=${MY_DOMAIN//./,dc=}"
# adcli join $MY_DOMAIN --login-user="$MY_USERNAME" --computer-name="${MY_HOSTNAME%%.*}" --host-fqdn="$MY_HOSTNAME" --user-principal="host/$MY_HOSTNAME@$MY_REALM" --domain-ou="$MY_OU"
```
现在登出 chroot,并清除 root 用户的命令历史:
```
# logout
# for i in run sys proc dev/shm dev/pts dev; do umount /fc28/$i; done
# > /fc28/root/.bash_history
```
### 安装和配置 PAM 挂载
我们希望客户端登入后自动挂载用户家目录。为实现这个目的,我们将要使用 `pam_mount` 模块。安装和配置 `pam_mount`:
```
# dnf install -y --installroot=/fc28 pam_mount
# cat << END > /fc28/etc/security/pam_mount.conf.xml
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE pam_mount SYSTEM "pam_mount.conf.xml.dtd">
<pam_mount>
<debug enable="0" />
<volume uid="1400000000-1499999999" fstype="nfs4" server="$MY_HOSTNAME" path="/home/%(USER)" mountpoint="/home/%(USER)" options="sec=krb5" />
<mkmountpoint enable="1" remove="0" />
<msg-authpw>Password:</msg-authpw>
</pam_mount>
END
```
重新配置 PAM 去使用 `pam_mount`:
```
# dnf install -y patch
# cp -r /fc28/usr/share/authselect/default/sssd /fc28/etc/authselect/custom
# echo 'initgroups: files' >> /fc28/etc/authselect/custom/sssd/nsswitch.conf
# patch /fc28/etc/authselect/custom/sssd/system-auth << END
@@ -12 +12,2 @@
-auth sufficient pam_sss.so forward_pass
+auth requisite pam_mount.so {include if "with-pammount"}
+auth sufficient pam_sss.so {if "with-pammount":use_first_pass|forward_pass}
@@ -35,2 +36,3 @@
session required pam_unix.so
+session optional pam_mount.so {include if "with-pammount"}
session optional pam_sss.so
END
# patch /fc28/etc/authselect/custom/sssd/password-auth << END
@@ -9 +9,2 @@
-auth sufficient pam_sss.so forward_pass
+auth requisite pam_mount.so {include if "with-pammount"}
+auth sufficient pam_sss.so {if "with-pammount":use_first_pass|forward_pass}
@@ -32,2 +33,3 @@
session required pam_unix.so
+session optional pam_mount.so {include if "with-pammount"}
session optional pam_sss.so
END
# chroot /fc28 authselect select custom/sssd with-pammount --force
```
另外,要确保从客户端上总是可解析 NFS 服务器的主机名:
```
# MY_IP=$(host -t A $MY_HOSTNAME | awk '{print $4}')
# echo "$MY_IP $MY_HOSTNAME ${MY_HOSTNAME%%.*}" >> /fc28/etc/hosts
```
可选,允许所有用户可以使用 `sudo`:
```
# echo '%users ALL=(ALL) NOPASSWD: ALL' > /fc28/etc/sudoers.d/users
```
### 转换 NFS 根目录到一个 iSCSI 后备存储器
在一个 nfsroot 连接建立之后,目前版本的 nfs-utils 可能很难为家目录建立一个从客户端到 NFS 服务器的第二个连接。当尝试去访问家目录时,客户端将被挂起。因此,为了共享网络引导镜像,我们将使用一个不同的协议(iSCSI)来规避这个问题。
首先 `chroot` 到镜像中,重新配置它的 `initramfs`,让它从一个 iSCSI 根目录中去引导:
```
# for i in dev dev/pts dev/shm proc sys run; do mount -o bind /$i /fc28/$i; done
# chroot /fc28 /usr/bin/bash --login
# dnf install -y iscsi-initiator-utils
# sed -i 's/nfs/iscsi/' /etc/dracut.conf.d/netboot.conf
# echo 'omit_drivers+=" qedi "' > /etc/dracut.conf.d/omit-qedi.conf
# echo 'blacklist qedi' > /etc/modprobe.d/blacklist-qedi.conf
# KERNEL=$(ls -c /lib/modules | head -n 1)
# INITRD=$(find /boot -name 'init*' | grep -m 1 $KERNEL)
# dracut -f $INITRD $KERNEL
# logout
# for i in run sys proc dev/shm dev/pts dev; do umount /fc28/$i; done
# > /fc28/root/.bash_history
```
在测试时,qedi 驱动会破坏 iSCSI,因此我们将它禁用。
接着,创建一个 `fc28.img` [稀疏文件](https://en.wikipedia.org/wiki/Sparse_file)。这个稀疏文件代表 iSCSI 目标的后备存储器:
```
# FC28_SIZE=$(du -ms /fc28 | cut -f 1)
# dd if=/dev/zero of=/fc28.img bs=1MiB count=0 seek=$(($FC28_SIZE*2))
```
(如果你有一个可使用的独立分区或磁盘驱动器,也可以用它,而不用再去创建这个稀疏文件了。)
接着,使用一个文件系统去格式化镜像、挂载它、然后将网络引导镜像复制进去:
```
# mkfs -t xfs -L NETROOT /fc28.img
# TEMP_MNT=$(mktemp -d)
# mount /fc28.img $TEMP_MNT
# cp -a /fc28/* $TEMP_MNT
# umount $TEMP_MNT
```
在使用 SquashFS 测试时,客户端偶尔会出现小状况。似乎是因为 SquashFS 在多处理器客户端上没法执行随机 I/O。(更多内容见 [squashfs 读取卡顿的奇怪案例](https://chrisdown.name/2018/04/17/kernel-adventures-the-curious-case-of-squashfs-stalls.html))。如果你希望使用文件系统压缩来提升吞吐性能,[ZFS](https://en.wikipedia.org/wiki/ZFS) 或许是个很好的选择。
如果你对 iSCSI 服务器的吞吐性能要求非常高(比如,成百上千的客户端要连接它),可能需要使用带 [负载均衡](https://en.wikipedia.org/wiki/Load_balancing_(computing)) 的 [Ceph](http://docs.ceph.com/docs/mimic/rbd/iscsi-overview/) 集群了。更多相关内容,请查看 [使用 HAProxy 和 Keepalived 负载均衡的 Ceph 对象网关](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/load_balancer_administration/ceph_example)。
### 安装和配置 iSCSI
为了给我们的客户端提供网络引导镜像,安装 `scsi-target-utils` 包:
```
# dnf install -y scsi-target-utils
```
配置 iSCSI 守护程序去提供 `fc28.img` 文件:
```
# MY_REVERSE_HOSTNAME=$(echo $MY_HOSTNAME | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_HOSTNAME})
# cat << END > /etc/tgt/conf.d/fc28.conf
<target iqn.$MY_REVERSE_HOSTNAME:fc28>
backing-store /fc28.img
readonly 1
</target>
END
```
开头的 `iqn.` 是 `/usr/lib/dracut/modules.d/40network/net-lib.sh` 所需要的。
添加一个防火墙例外,并启用和启动这个服务:
```
# firewall-cmd --add-service=iscsi-target
# firewall-cmd --runtime-to-permanent
# systemctl enable tgtd.service
# systemctl start tgtd.service
```
你现在应该能够使用 `tatadm` 命令看到这个镜像共享了:
```
# tgtadm --mode target --op show
```
上述命令的输出应该类似如下的内容:
```
Target 1: iqn.edu.example.server-01:fc28
System information:
Driver: iscsi
State: ready
I_T nexus information:
LUN information:
LUN: 0
Type: controller
SCSI ID: IET 00010000
SCSI SN: beaf10
Size: 0 MB, Block size: 1
Online: Yes
Removable media: No
Prevent removal: No
Readonly: No
SWP: No
Thin-provisioning: No
Backing store type: null
Backing store path: None
Backing store flags:
LUN: 1
Type: disk
SCSI ID: IET 00010001
SCSI SN: beaf11
Size: 10488 MB, Block size: 512
Online: Yes
Removable media: No
Prevent removal: No
Readonly: Yes
SWP: No
Thin-provisioning: No
Backing store type: rdwr
Backing store path: /fc28.img
Backing store flags:
Account information:
ACL information:
ALL
```
现在,我们可以去删除本系列文章的第一部分中创建的 NFS 共享了:
```
# rm -f /etc/exports.d/fc28.exports
# exportfs -rv
# umount /export/fc28
# rmdir /export/fc28
# sed -i '/^\/fc28 /d' /etc/fstab
```
你也可以删除 `/fc28` 文件系统,但为了以后进一步更新,你可能需要保留它。
### 更新 ESP 去使用 iSCSI 内核
更新 ESP 去包含启用了 iSCSI 的 `initramfs`:
```
$ rm -vf $HOME/esp/linux/*.fc28.*
$ MY_KRNL=$(ls -c /fc28/lib/modules | head -n 1)
$ cp $(find /fc28/lib/modules -maxdepth 2 -name 'vmlinuz' | grep -m 1 $MY_KRNL) $HOME/esp/linux/vmlinuz-$MY_KRNL
$ cp $(find /fc28/boot -name 'init*' | grep -m 1 $MY_KRNL) $HOME/esp/linux/initramfs-$MY_KRNL.img
```
更新 `boot.cfg` 文件去传递新的 `root` 和 `netroot` 参数:
```
$ MY_NAME=server-01.example.edu
$ MY_EMAN=$(echo $MY_NAME | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_NAME})
$ MY_ADDR=$(host -t A $MY_NAME | awk '{print $4}')
$ sed -i "s! root=[^ ]*! root=/dev/disk/by-path/ip-$MY_ADDR:3260-iscsi-iqn.$MY_EMAN:fc28-lun-1 netroot=iscsi:$MY_ADDR::::iqn.$MY_EMAN:fc28!" $HOME/esp/linux/boot.cfg
```
现在,你只需要从 `$HOME/esp/linux` 目录中复制更新后的文件到所有客户端系统的 ESP 中。你应该会看到类似下面屏幕截图的结果:

### 更新镜像
首先,复制出一个当前镜像的副本:
```
# cp -a /fc28 /fc29
```
`chroot` 进入到镜像的新副本:
```
# for i in dev dev/pts dev/shm proc sys run; do mount -o bind /$i /fc29/$i; done
# chroot /fc29 /usr/bin/bash --login
```
允许更新内核:
```
# sed -i 's/^exclude=kernel-\*$/#exclude=kernel-*/' /etc/dnf/dnf.conf
```
执行升级:
```
# dnf distro-sync -y --releasever=29
```
阻止更新过的内核被再次更新:
```
# sed -i 's/^#exclude=kernel-\*$/exclude=kernel-*/' /etc/dnf/dnf.conf
```
上述命令是可选的,但是在以后,如果在镜像中添加和更新了几个包,在你的客户端之外保存有一个最新内核的副本,会在关键时刻对你非常有帮助。
清理 dnf 的包缓存:
```
# dnf clean all
```
退出 chroot 并清理 root 的命令历史:
```
# logout
# for i in run sys proc dev/shm dev/pts dev; do umount /fc29/$i; done
# > /fc29/root/.bash_history
```
创建 iSCSI 镜像:
```
# FC29_SIZE=$(du -ms /fc29 | cut -f 1)
# dd if=/dev/zero of=/fc29.img bs=1MiB count=0 seek=$(($FC29_SIZE*2))
# mkfs -t xfs -L NETROOT /fc29.img
# TEMP_MNT=$(mktemp -d)
# mount /fc29.img $TEMP_MNT
# cp -a /fc29/* $TEMP_MNT
# umount $TEMP_MNT
```
定义一个新的 iSCSI 目标,指向到新的镜像并导出它:
```
# MY_HOSTNAME=$(</etc/hostname)
# MY_REVERSE_HOSTNAME=$(echo $MY_HOSTNAME | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_HOSTNAME})
# cat << END > /etc/tgt/conf.d/fc29.conf
<target iqn.$MY_REVERSE_HOSTNAME:fc29>
backing-store /fc29.img
readonly 1
</target>
END
# tgt-admin --update ALL
```
添加新内核和 `initramfs` 到 ESP:
```
$ MY_KRNL=$(ls -c /fc29/lib/modules | head -n 1)
$ cp $(find /fc29/lib/modules -maxdepth 2 -name 'vmlinuz' | grep -m 1 $MY_KRNL) $HOME/esp/linux/vmlinuz-$MY_KRNL
$ cp $(find /fc29/boot -name 'init*' | grep -m 1 $MY_KRNL) $HOME/esp/linux/initramfs-$MY_KRNL.img
```
更新 ESP 的 `boot.cfg`:
```
$ MY_DNS1=192.0.2.91
$ MY_DNS2=192.0.2.92
$ MY_NAME=server-01.example.edu
$ MY_EMAN=$(echo $MY_NAME | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_NAME})
$ MY_ADDR=$(host -t A $MY_NAME | awk '{print $4}')
$ cat << END > $HOME/esp/linux/boot.cfg
#!ipxe
kernel --name kernel.efi \${prefix}/vmlinuz-$MY_KRNL initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=$MY_DNS1 nameserver=$MY_DNS2 root=/dev/disk/by-path/ip-$MY_ADDR:3260-iscsi-iqn.$MY_EMAN:fc29-lun-1 netroot=iscsi:$MY_ADDR::::iqn.$MY_EMAN:fc29 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet
initrd --name initrd.img \${prefix}/initramfs-$MY_KRNL.img
boot || exit
END
```
最后,从我的 `$HOME/esp/linux` 目录中复制文件到所有客户端系统的 ESP 中去使用它吧!
---
via: <https://fedoramagazine.org/how-to-build-a-netboot-server-part-2/>
作者:[Gregory Bartholomew](https://fedoramagazine.org/author/glb/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The article [How to Build a Netboot Server, Part 1](https://fedoramagazine.org/how-to-build-a-netboot-server-part-1/) showed you how to create a netboot image with a “liveuser” account whose home directory lives in volatile memory. Most users probably want to preserve files and settings across reboots, though. So this second part of the netboot series shows how to reconfigure the netboot image from part one so that [Active Directory](https://en.wikipedia.org/wiki/Active_Directory) user accounts can log in and their home directories can be automatically mounted from a NFS server.
Part 3 of this series will show how to make an interactive and centrally-configurable iPXE boot menu for the netboot clients.
## Setup NFS4 Home Directories with KRB5 Authentication
Follow the directions from the previous post “[Share NFS Home Directories Securely with Kerberos](https://fedoramagazine.org/secure-nfs-home-directories-kerberos),” then return here.
## Remove the Liveuser Account
Remove the “liveuser” account created in part one of this series:
$ sudo -i # sed -i '/automaticlogin/Id' /fc28/etc/gdm/custom.conf # rm -f /fc28/etc/sudoers.d/liveuser # for i in passwd shadow group gshadow; do sed -i '/^liveuser:/d' /fc28/etc/$i; done
## Configure NTP, KRB5 and SSSD
Next, we will need to duplicate the NTP, KRB5, and SSSD configuration that we set up on the server in the client image so that the same accounts will be available:
# MY_HOSTNAME=$(</etc/hostname) # MY_DOMAIN=${MY_HOSTNAME#*.} # dnf -y --installroot=/fc28 install ntp krb5-workstation sssd # cp /etc/ntp.conf /fc28/etc # chroot /fc28 systemctl enable ntpd.service # cp /etc/krb5.conf.d/${MY_DOMAIN%%.*} /fc28/etc/krb5.conf.d # cp /etc/sssd/sssd.conf /fc28/etc/sssd
Reconfigure sssd to provide authentication services, in addition to the identification service already configured:
# sed -i '/services =/s/$/, pam/' /fc28/etc/sssd/sssd.conf
Also, ensure none of the clients attempt to update the computer account password:
# sed -i '/id_provider/a \ \ ad_maximum_machine_account_password_age = 0' /fc28/etc/sssd/sssd.conf
Also, copy the *nfsnobody* definitions:
# for i in passwd shadow group gshadow; do grep "^nfsnobody:" /etc/$i >> /fc28/etc/$i; done
## Join Active Directory
Next, you’ll perform a chroot to join the client image to Active Directory. Begin by deleting any pre-existing computer account with the same name your netboot image will use:
# MY_USERNAME=jsmith # MY_CLIENT_HOSTNAME=$(</fc28/etc/hostname) # adcli delete-computer "${MY_CLIENT_HOSTNAME%%.*}" -U "$MY_USERNAME"
Also delete the *krb5.keytab* file from the netboot image if it exists:
# rm -f /fc28/etc/krb5.keytab
Perform a chroot into the netboot image:
# for i in dev dev/pts dev/shm proc sys run; do mount -o bind /$i /fc28/$i; done # chroot /fc28 /usr/bin/bash --login
Perform the join:
# MY_USERNAME=jsmith # MY_HOSTNAME=$(</etc/hostname) # MY_DOMAIN=${MY_HOSTNAME#*.} # MY_REALM=${MY_DOMAIN^^} # MY_OU="cn=computers,dc=${MY_DOMAIN//./,dc=}" # adcli join $MY_DOMAIN --login-user="$MY_USERNAME" --computer-name="${MY_HOSTNAME%%.*}" --host-fqdn="$MY_HOSTNAME" --user-principal="host/$MY_HOSTNAME@$MY_REALM" --domain-ou="$MY_OU"
Now log out of the chroot and clear the root user’s command history:
# logout # for i in run sys proc dev/shm dev/pts dev; do umount /fc28/$i; done # > /fc28/root/.bash_history
## Install and Configure PAM Mount
We want our clients to automatically mount the user’s home directory when they log in. To accomplish this, we’ll use the “pam_mount” module. Install and configure *pam_mount:*
# dnf install -y --installroot=/fc28 pam_mount # cat << END > /fc28/etc/security/pam_mount.conf.xml <?xml version="1.0" encoding="utf-8" ?> <!DOCTYPE pam_mount SYSTEM "pam_mount.conf.xml.dtd"> <pam_mount> <debug enable="0" /> <volume uid="1400000000-1499999999" fstype="nfs4" server="$MY_HOSTNAME" path="/home/%(USER)" mountpoint="/home/%(USER)" options="sec=krb5" /> <mkmountpoint enable="1" remove="0" /> <msg-authpw>Password:</msg-authpw> </pam_mount> END
Reconfigure PAM to use *pam_mount:*
# dnf install -y patch # cp -r /fc28/usr/share/authselect/default/sssd /fc28/etc/authselect/custom # echo 'initgroups: files' >> /fc28/etc/authselect/custom/sssd/nsswitch.conf # patch /fc28/etc/authselect/custom/sssd/system-auth << END @@ -12 +12,2 @@ -auth sufficient pam_sss.so forward_pass +auth requisite pam_mount.so {include if "with-pammount"} +auth sufficient pam_sss.so {if "with-pammount":use_first_pass|forward_pass} @@ -35,2 +36,3 @@ session required pam_unix.so +session optional pam_mount.so {include if "with-pammount"} session optional pam_sss.so END # patch /fc28/etc/authselect/custom/sssd/password-auth << END @@ -9 +9,2 @@ -auth sufficient pam_sss.so forward_pass +auth requisite pam_mount.so {include if "with-pammount"} +auth sufficient pam_sss.so {if "with-pammount":use_first_pass|forward_pass} @@ -32,2 +33,3 @@ session required pam_unix.so +session optional pam_mount.so {include if "with-pammount"} session optional pam_sss.so END # chroot /fc28 authselect select custom/sssd with-pammount --force
Also ensure the NFS server’s hostname is always resolvable from the client:
# MY_IP=$(host -t A $MY_HOSTNAME | awk '{print $4}') # echo "$MY_IP $MY_HOSTNAME ${MY_HOSTNAME%%.*}" >> /fc28/etc/hosts
Optionally, allow all users to run *sudo:*
# echo '%users ALL=(ALL) NOPASSWD: ALL' > /fc28/etc/sudoers.d/users
## Convert the NFS Root to an iSCSI Backing-Store
Current versions of *nfs-utils* may have difficulty establishing a second connection from the client back to the NFS server for home directories when an nfsroot connection is already established. The client hangs when attempting to access the home directory. So, we will work around the problem by using a different protocol (iSCSI) for sharing our netboot image.
First chroot into the image to reconfigure its initramfs for booting from an iSCSI root:
# for i in dev dev/pts dev/shm proc sys run; do mount -o bind /$i /fc28/$i; done # chroot /fc28 /usr/bin/bash --login # dnf install -y iscsi-initiator-utils # sed -i 's/nfs/iscsi/' /etc/dracut.conf.d/netboot.conf # sed -i '/^node.conn\[0\].timeo.noop_out_interval /s/=.*$/= 0/' /etc/iscsi/iscsid.conf # sed -i '/^node.conn\[0\].timeo.noop_out_timeout /s/=.*$/= 0/' /etc/iscsi/iscsid.conf # sed -i '/^node.session.timeo.replacement_timeout /s/=.*$/= 86400/' /etc/iscsi/iscsid.conf # echo 'omit_drivers+=" qedi "' > /etc/dracut.conf.d/omit-qedi.conf # echo 'blacklist qedi' > /etc/modprobe.d/blacklist-qedi.conf # KERNEL=$(ls -c /lib/modules | head -n 1) # INITRD=$(find /boot -name 'init*' | grep -m 1 $KERNEL) # dracut -f $INITRD $KERNEL # logout # for i in run sys proc dev/shm dev/pts dev; do umount /fc28/$i; done # > /fc28/root/.bash_history
The *qedi* driver broke iscsi during testing, so it’s been disabled here.
Next, create a fc28.img [sparse file](https://en.wikipedia.org/wiki/Sparse_file). This file serves as the iSCSI target’s backing store:
# FC28_SIZE=$(du -ms /fc28 | cut -f 1) # dd if=/dev/zero of=/fc28.img bs=1MiB count=0 seek=$(($FC28_SIZE*2))
(If you have one available, a separate partition or disk drive can be used instead of creating a file.)
Next, format the image with a filesystem, mount it, and copy the netboot image into it:
# mkfs -t xfs -L NETROOT /fc28.img # TEMP_MNT=$(mktemp -d) # mount /fc28.img $TEMP_MNT # cp -a /fc28/* $TEMP_MNT # umount $TEMP_MNT
During testing using SquashFS, the client would occasionally stutter. It seems that SquashFS does not perform well when doing random I/O from a multiprocessor client. (See also [The curious case of stalled squashfs reads](https://chrisdown.name/2018/04/17/kernel-adventures-the-curious-case-of-squashfs-stalls.html).) If you want to improve throughput performance with filesystem compression, [ZFS](https://en.wikipedia.org/wiki/ZFS) is probably a better option.
If you need extremely high throughput from the iSCSI server (say, for hundreds of clients), it might be possible to [load balance](https://en.wikipedia.org/wiki/Load_balancing_(computing)) a [Ceph](http://docs.ceph.com/docs/mimic/rbd/iscsi-overview/) cluster. For more information, see [Load Balancing Ceph Object Gateway Servers with HAProxy and Keepalived](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/load_balancer_administration/ceph_example).
## Install and Configure iSCSI
Install the *scsi-target-utils* package which will provide the iSCSI daemon for serving our image out to our clients:
# dnf install -y scsi-target-utils
Configure the iSCSI daemon to serve the *fc28.img* file:
# MY_REVERSE_HOSTNAME=$(echo $MY_HOSTNAME | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_HOSTNAME}) # cat << END > /etc/tgt/conf.d/fc28.conf <target iqn.$MY_REVERSE_HOSTNAME:fc28> backing-store /fc28.img readonly 1 </target> END
The leading *iqn.* is expected by */usr/lib/dracut/modules.d/40network/net-lib.sh.*
Add an exception to the firewall and enable and start the service:
# firewall-cmd --add-service=iscsi-target # firewall-cmd --runtime-to-permanent # systemctl enable tgtd.service # systemctl start tgtd.service
You should now be able to see the image being shared with the *tgtadm* command:
# tgtadm --mode target --op show
The above command should output something similar to the following:
Target 1: iqn.edu.example.server-01:fc28 System information: Driver: iscsi State: ready I_T nexus information: LUN information: LUN: 0 Type: controller SCSI ID: IET 00010000 SCSI SN: beaf10 Size: 0 MB, Block size: 1 Online: Yes Removable media: No Prevent removal: No Readonly: No SWP: No Thin-provisioning: No Backing store type: null Backing store path: None Backing store flags: LUN: 1 Type: disk SCSI ID: IET 00010001 SCSI SN: beaf11 Size: 10488 MB, Block size: 512 Online: Yes Removable media: No Prevent removal: No Readonly: Yes SWP: No Thin-provisioning: No Backing store type: rdwr Backing store path: /fc28.img Backing store flags: Account information: ACL information: ALL
We can now remove the NFS share that we created in part one of this series:
# rm -f /etc/exports.d/fc28.exports # exportfs -rv # umount /export/fc28 # rmdir /export/fc28 # sed -i '/^\/fc28 /d' /etc/fstab
You can also delete the */fc28* filesystem, but you may want to keep it for performing future updates.
## Update the ESP to use the iSCSI Kernel
Update the ESP to contain the iSCSI-enabled initramfs:
$ rm -vf $HOME/esp/linux/*.fc28.* $ MY_KRNL=$(ls -c /fc28/lib/modules | head -n 1) $ cp $(find /fc28/lib/modules -maxdepth 2 -name 'vmlinuz' | grep -m 1 $MY_KRNL) $HOME/esp/linux/vmlinuz-$MY_KRNL $ cp $(find /fc28/boot -name 'init*' | grep -m 1 $MY_KRNL) $HOME/esp/linux/initramfs-$MY_KRNL.img
Update the *boot.cfg* file to pass the new *root* and *netroot* parameters:
$ MY_NAME=server-01.example.edu $ MY_EMAN=$(echo $MY_NAME | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_NAME}) $ MY_ADDR=$(host -t A $MY_NAME | awk '{print $4}') $ sed -i "s! root=[^ ]*! root=/dev/disk/by-path/ip-$MY_ADDR:3260-iscsi-iqn.$MY_EMAN:fc28-lun-1 netroot=iscsi:$MY_ADDR::::iqn.$MY_EMAN:fc28!" $HOME/esp/linux/boot.cfg
Now you just need to copy the updated files from your *$HOME/esp/linux* directory out to the ESPs of all your client systems. You should see results similar to what is shown in the below screenshot:
## Upgrading the Image
First, make a copy of the current image:
# cp -a /fc28 /fc29
Chroot into the new copy of the image:
# for i in dev dev/pts dev/shm proc sys run; do mount -o bind /$i /fc29/$i; done # chroot /fc29 /usr/bin/bash --login
Allow updating the kernel:
# sed -i 's/^exclude=kernel-\*$/#exclude=kernel-*/' /etc/dnf/dnf.conf
Perform the upgrade:
# dnf distro-sync -y --releasever=29
Prevent the kernel from being updated:
# sed -i 's/^#exclude=kernel-\*$/exclude=kernel-*/' /etc/dnf/dnf.conf
The above command is optional, but saves you from having to copy a new kernel out to the clients if you add or update a few packages in the image at some future time.
Clean up dnf’s package cache:
# dnf clean all
Exit the chroot and clear root’s command history:
# logout # for i in run sys proc dev/shm dev/pts dev; do umount /fc29/$i; done # > /fc29/root/.bash_history
Create the iSCSI image:
# FC29_SIZE=$(du -ms /fc29 | cut -f 1) # dd if=/dev/zero of=/fc29.img bs=1MiB count=0 seek=$(($FC29_SIZE*2)) # mkfs -t xfs -L NETROOT /fc29.img # TEMP_MNT=$(mktemp -d) # mount /fc29.img $TEMP_MNT # cp -a /fc29/* $TEMP_MNT # umount $TEMP_MNT
Define a new iSCSI target that points to our new image and export it:
# MY_HOSTNAME=$(</etc/hostname) # MY_REVERSE_HOSTNAME=$(echo $MY_HOSTNAME | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_HOSTNAME}) # cat << END > /etc/tgt/conf.d/fc29.conf <target iqn.$MY_REVERSE_HOSTNAME:fc29> backing-store /fc29.img readonly 1 </target> END # tgt-admin --update ALL
Add the new kernel and initramfs to the ESP:
$ MY_KRNL=$(ls -c /fc29/lib/modules | head -n 1) $ cp $(find /fc29/lib/modules -maxdepth 2 -name 'vmlinuz' | grep -m 1 $MY_KRNL) $HOME/esp/linux/vmlinuz-$MY_KRNL $ cp $(find /fc29/boot -name 'init*' | grep -m 1 $MY_KRNL) $HOME/esp/linux/initramfs-$MY_KRNL.img
Update the *boot.cfg* in the ESP:
$ MY_DNS1=192.0.2.91 $ MY_DNS2=192.0.2.92 $ MY_NAME=server-01.example.edu $ MY_EMAN=$(echo $MY_NAME | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_NAME}) $ MY_ADDR=$(host -t A $MY_NAME | awk '{print $4}') $ cat << END > $HOME/esp/linux/boot.cfg #!ipxe kernel --name kernel.efi \${prefix}/vmlinuz-$MY_KRNL initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=$MY_DNS1 nameserver=$MY_DNS2 root=/dev/disk/by-path/ip-$MY_ADDR:3260-iscsi-iqn.$MY_EMAN:fc29-lun-1 netroot=iscsi:$MY_ADDR::::iqn.$MY_EMAN:fc29 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet initrd --name initrd.img \${prefix}/initramfs-$MY_KRNL.img boot || exit END
Finally, copy the files from your *$HOME/esp/linux* directory out to the ESPs of all your client systems and enjoy!
## Oscar
Thanks a lot for this very complete and informative post!
One question, though…Do you think using NBD (nbd-server, nbdkit…) instead of iSCSI would be a valid solution? Would there be any problem? Thanks!
## Gregory Bartholomew
Hi Oscar. You should be able to use NBD. I considered using it at one point myself, but I chose iSCSI after reading a comment saying that iSCSI was better at re-establishing connections in case of a temporary network interruption. I don’t know if the comment is valid to current versions of NBD, but it might be something to verify and consider when making your decision.
## fmiz
What made you choose Fedora for this setup?
## Gregory Bartholomew
Hi fmiz. The real reason that I use Fedora for most everything that I run is because the systems that I inherited when I started working here at Southern Illinois University Edwardsville in 1998 were already running Red Hat’s operating system. I found other BSD-based distros to be just different enough in their package management tools and config file locations to be frustrated when working on them. I would inevitably end up thinking, “I could do this in 5 seconds on Fedora” because I was already so familiar with Red Hat’s distros. So, it is really just because that is what I am familiar with. I can’t really comment as to which is “better” because I am not really that familiar with the BSD derivatives.
## fmiz
I asked because Fedora does not strike me as the first distro to run this kind of setup on. I think of fedora as somewhat less flexible in comparison to debian, but you just prove otherwise. Reading again your articles, this setup is a lot of work and there are a few details that seem to have required quite some time to troubleshoot, but it does not look like fedora gets in your way, the only default you had to change is selinux, everything else is just configuration.
Thanks for your answer and your interesting series.
## imsedgar
I think it’s not a good idea to use “firewall-cmd –runtime-to-permanent”, because it may save firewalls rules that the user may not be aware at that time.
Why not use just the same rule as in the previous line of your instruction, but with “–permanent” added? It is not so much longer than the other, but has a clear and clean result – it only add this rule to the permanent rules.
firewall-cmd –permanent –add-service=iscsi-target
There should be also checked if there should be used another firewall zone than the default zone. One may put some network devices in another zone, for example zone “work”, and apply the rules to that zone.
## Gregory Bartholomew
Hi imsedgar. Really, I’ve been using the “–runtime-to-permanent” parameter because another commenter recommended it in a previous post (see the Nov. 15th comment here: https://fedoramag.wpengine.com/never-leave-irc-znc/).
I kind of agree with you about the longer form being clearer about what it is doing. If the reader has been following this guide though, there shouldn’t be any unexpected things committed to the firewall. And if the reader has been doing other things or has started from a different base configuration, then they are really on their own to figure out what does and doesn’t need to be done (including using –permanent instead of –runtime-to-permanent).
“firewall-cmd –list-all” is a good thing to run every once in a while if you are worried about it. |
10,397 | Linux 求职建议 | http://reallylinux.com/docs/gettinglinuxjobs.shtml | 2018-12-30T10:37:00 | [
"面试",
"招聘"
] | https://linux.cn/article-10397-1.html | 
通过对招聘网站数据的仔细研究,我们发现,即使是非常有经验的 Linux 程序员,也会在面试中陷入困境。
这就导致了很多优秀并且有经验的人无缘无故地找不到合适的工作,因为如今的就业市场需要我们有一些手段来提高自己的竞争力。
我有两个同事和一个表哥,他们都有 RedHat 认证,管理过比较大的服务器机房,也都收到过前雇主的认真推荐。
可是,在他们应聘的时候,所有的这些证书、本身的能力、工作经验好像都没有起到任何作用,他们所面对的招聘广告是某人从技术词汇中临时挑选的一些“技能片段”所组成的。
现如今,礼貌变得过时了,**不回应**变成了发布招聘广告的公司的新沟通方式。
这同样也意味着大多公司的招聘或者人事可能会**错过**非常优秀的应聘者。
我之所以敢说的如此肯定,是因为现在招聘广告大多数看上去都非常的滑稽。
[Reallylinux.com](http://reallylinux.com) 另一位特约撰稿人 Walter ,发表过一篇关于 [招聘广告疯掉了](http://reallylinux.com/docs/wantadsmad.shtml) 的文章。
他说的也许是对的,可是我认为 Linux 工作应聘者可以通过注意招聘广告的**三个关键点**避免落入陷阱。
**首先**,很少会有 Linux 系统管理员的招聘广告只针对 Linux 有要求。
一定要注意很少有 Linux 系统管理员的职位是实际在服务器上跑 Linux的,反而,很多在搜索 “Linux 管理员” 得到的职位实际上是指大量的 \*NX 操作系统的。
举个例子,有一则关于 **Linux 管理员** 的招聘广告:
>
> 该职位需要为建立系统集成提供支持,尤其是 BSD 应用的系统安装…
>
>
>
或者有一些其他的要求:
>
> 有 Windows 系统管理经验的。
>
>
>
最为讽刺的是,如果你在应聘面试的时候表现出专注于 Linux 的话,你可能不会被聘用。
另外,如果你直接把 Linux 写在你的特长或者专业上,他们可能都不会仔细看你的简历,因为他们根本区分不了 UNIX、BSD、Linux。
最终的结果就是,如果你太老实,只在简历上写了 Linux,你可能会被直接过掉,但是如果你把 Linux 改成 UNIX/Linux 的话,可能会走得更远。
我有两个同事最后修改了他们的简历,然后获得了更好的面试机会,虽然依旧没有被聘用,因为大多数招聘广告其实已经内定人员了,这些招聘信息被放出来仅仅是为了表现出他们有招聘的想法。
**第二点**,公司里唯一在乎系统管理员职位的只有技术主管,其他人包括人事或管理层根本不关心这个。
我记得有一次开会旁听的时候,听见一个执行副总裁把服务器管理人员说成“一毛钱一打的人”,这种想法是多么的奇怪啊。
讽刺的是,等到邮件系统出故障,电话交换机连接时不时会断开,或者核心商业文件从企业内网中消失的时候,这些总裁又是最先打电话给系统管理员的。
或许如果他们不整天在电话留言中说那么多空话,或者不往邮件里塞满妻子的照片和旅行途中的照片的话,服务器可能就不会崩溃。
请注意,招聘 Linux 运维或者服务器管理员的广告被放出来是因为公司**技术层**认为有迫切的需求。你也不需要和人事或者公司高层聊什么,搞清楚谁是招聘的技术经理然后打电话给他们。
你需要直接联系他们因为“有些技术问题”是人事回答不了的,即使你只有 60 秒的时间可以和他们交流,你也必须抓住这个机会和真正有需求并且懂技术的人沟通。
那如果人事的漂亮 MM 不让你直接联系技术怎么办呢?
开始记得问人事一些技术性问题,比如说他们的 Linux 集群是如何建立的,它们运行在独立的虚拟机上吗?这些技术性的问题会让人事变得不耐烦,最后让你有机会问出“我能不能直接联系你们团队的技术人员”。
如果对方的回答是“应该可以”或者“稍后回复你”,那么他们可能已经在两周前就已经计划好了找一个人来填补这个空缺,比如说人事部员工的未婚夫。**他们只是不希望看起来太像裙带主义,而是带有一点利己主义的不确定主义。**
所以一定要记得花点时间弄清楚到底谁是发布招聘广告的直接**技术**负责人,然后和他们聊一聊,这可能会让你少一番胡扯并且让你更有可能应聘成功。
**第三点**,现在的招聘广告很少有完全真实的内容了。
我以前见过一个招聘具有高级别专家也不会有的专门知识的初级系统管理员的广告,他们的计划是列出公司的发展计划蓝图,然后找到应聘者。
在这种情况下,你应聘 Linux 管理员职位应该提供几个关键性信息,例如工作经验和相关证书。
诀窍在于,用这些关键词尽量装点你的简历,以匹配他们的招聘信息,这样他们几乎不可能发现你缺失了哪个关键词。
这并不一定会让你成功找到一份工作,但它可以让你获得一次面试机会,这也算是一个巨大的进步。
通过理解和应用以上三点,或许可以让那些寻求 Linux 管理员工作的人能够比那些只有一线地狱机会的人领先一步。
即使这些建议不能让你马上得到面试机会,你也可以利用这些经验和意识去参加贸易展或公司主办的技术会议等活动。
我强烈建议你们也经常参加这种活动,尤其是当它们比较近的话,可以给你一个扩展人脉的机会。
请记住,如今的职业人脉已经失去了原来的意义了,现在只是可以用来获取“哪些公司实际上在招聘、哪些公司只是为了给股东带来增长的表象而在职位方面撒谎”的小道消息。
---
via: <http://reallylinux.com/docs/gettinglinuxjobs.shtml>
作者:[Andrea W.Codingly](http://reallylinux.com) 译者:[Ryze-Borgia](https://github.com/Ryze-Borgia) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | |
10,398 | 在 Linux 命令行中观看彩虹猫来稍事休息 | https://opensource.com/article/18/12/linux-toy-nyancat | 2018-12-30T11:12:00 | [
"彩虹猫"
] | https://linux.cn/article-10398-1.html |
>
> 你甚至可以在终端里欣赏彩虹猫。
>
>
>

今天是《Linux 命令行小玩具介绍》的第六天。在本系列文章中,我们将会探索一些娱乐用途(甚至有时完全没用)的 Linux 命令行小玩具。所有我们介绍的小玩具都是开源的。
也许你会问,它们都很独特吗?是的。不过,它们对你是否独特,我就不知道了。但是,我们相信你应该能在这系列文章结束之前找到至少一个好玩的玩具。
从[昨天的选题](https://opensource.com/article/18/12/linux-toy-lolcat)继续:我们谈到了猫和彩虹。不过,在 Linux 命令行下有更有趣的彩虹和猫结合的程序吗?答案是肯定的。
我们不妨看看之前可以在命令行中使用彩虹猫的方式吧。意料之中,2011 年发布的 [彩虹猫](https://en.wikipedia.org/wiki/Nyan_Cat) 可以用 `nyancat` 呈现在终端中。你想念这只曾火遍网络的彩虹猫吗?看看下面这个视频记录吧,我会等你看完的。
现在,让我们在终端中重新感受这个令人惊奇的体验吧。`nyancat` 包正在很多发行版上(比如 Arch、Debian、Gentoo、Ubuntu 等等……)都有,不过我的系统(Fedora)没有,但是我们仍然可以很轻松地从源码编译它。
根据读者的一个很好的提醒,对于我来说,这应该在该系列中提及:要警惕从不受信任的来源安装应用程序,或者编译和运行你在网上找到的任何代码,就像你在这样的文章中找到这个一样。如果您不确定,请采取适当的预防措施,特别是如果您在生产机器上。
从这里克隆源代码:
```
git clone https://github.com/klange/nyancat.git
```
然后使用 `make` 编译,并用 `./nyancat` 来运行。
这直接为我带来了彩虹猫体验,甚至还有个计时器来显示我享受 “彩虹猫魔法”的时间。

你可以在 [GitHub](https://github.com/klange/nyancat) 上找到 `nyancat` 的源码,它正以 [NCSA 许可证](http://en.wikipedia.org/wiki/University_of_Illinois/NCSA_Open_Source_License) 开源。
命令行版本的彩虹猫可在[这个公共 Telnet 服务器上访问](http://nyancat.dakko.us/)(或者用另外一个猫 [netcat](http://netcat.sourceforge.net/) 也行),所以理论上来说你不必安装它。不过不幸的是,由于带宽限制,该服务器目前已经被关闭了。尽管如此,在各种老设备上连接老 Telnet 服务器上运行彩虹猫的[照片](http://nyancat.dakko.us/)还是值得一看的,说不准你还会萌生搭建一个能让大家连接的公共服务器的想法呢(如果你真的搭建了,请务必告知作者,万一他们可能会向公众分享呢?)。
你想让我介绍一下你最喜爱的命令行玩具吗?请在原文下留言,作者会考虑介绍的。
瞧瞧我们昨天介绍的小玩意:[用 lolcat 为你的 Linux 终端增添些许色彩](https://opensource.com/article/18/12/linux-toy-lolcat)。明天再来看我们的下一篇文章吧!
---
via: <https://opensource.com/article/18/12/linux-toy-nyancat>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zhs852](https://github.com/zhs852) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We're now on day six of the Linux command-line toys advent calendar, where we explore some of the fun, entertaining, and in some cases, utterly useless toys available for your Linux terminal. All are available under an open source license.
Will they all be unique? Yes. Will they all be unique to you? I don't know, but, chances are you'll find at least one new toy to play with by the time our advent calendar is done.
Today's selection is a continuation on the [theme](https://opensource.com/article/18/12/linux-toy-lolcat) we started yesterday: cats and rainbows. Wait, there's more cat-related rainbow fun to be had at the Linux command line? You bet there is.
So let's make a throwback all the way to 2011's [Nyan Cat](https://en.wikipedia.org/wiki/Nyan_Cat) with a command-line toy call, not surprisingly, **nyancat**. Did you miss the cultural phenomenon that was Nyan Cat? Watch the embed below, I'll wait.
Now, let's recreate that amazing experience in your terminal. **Nyancat** is packaged for many distributions (Arch, Debian, Gentoo, Ubuntu, etc.) but not for mine (Fedora), but compiling from source was simple.
Per a great reminder from a reader, this would be a good point in the series for me to mention: be careful about installing applications from untrusted sources or compiling and running any piece code you find online, just because you find them in an article like this one. If you're not sure, use appropriate precautions, especially if you're on a production machine.
I cloned the source with:
`git clone https://github.com/klange/nyancat.git`
Then I used **make**** **to compile, and ran the application with **./nyancat**.
This launched straight into a **nyancat** experience complete with a counter of how long I had been enjoying the **nyancat** magic for.

You can find the source for **nyancat** [on GitHub](https://github.com/klange/nyancat) under an [NCSA open source license](http://en.wikipedia.org/wiki/University_of_Illinois/NCSA_Open_Source_License).
The command-line version of Nyan Cat used to be [accessible by a public Telnet server](http://nyancat.dakko.us/) (or, for even more pun, with [netcat](http://netcat.sourceforge.net/)) so that you didn't even have to install it, but sadly was shut down due to bandwidth limitations. Nevertheless, the [gallery](http://nyancat.dakko.us/) from the old Telnet server running Nyan Cat on a variety of old devices is well-worth checking out, and maybe you'd like to do the community a favor by launching your own public mirror and letting the author know so that they may share it with the public yet again?
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Check out yesterday's toy, [Bring some color to your Linux terminal with lolcat](https://opensource.com/article/18/12/linux-toy-lolcat), and check back tomorrow for another!
## Comments are closed. |
10,399 | 用户、组及其它 Linux 特性(二) | https://www.linux.com/blog/learn/intro-to-linux/2018/7/users-groups-and-other-linux-beasts-part-2 | 2018-12-30T19:33:35 | [
"用户",
"用户组"
] | https://linux.cn/article-10399-1.html |
>
> 我们继续创建和管理用户和组的 Linux 教程之旅。
>
>
>

在正在进行的 Linux 之旅中,我们了解了[如何操作文件夹或目录](/article-10066-1.html),现在我们继续讨论 权限、用户 和 组,这对于确定谁可以操作哪些文件和目录是必要的。[上次](/article-10370-1.html),我们展示了如何创建新用户,现在我们将重新起航:
你可以使用 `groupadd` 命令创建新组,然后随意添加用户。例如,使用:
```
sudo groupadd photos
```
这将会创建 `photos` 组。
你需要在根目录下[创建一个目录](/article-10066-1.html):
```
sudo mkdir /photos
```
如果你运行 `ls -l /`,结果中会有如下这一行:
```
drwxr-xr-x 1 root root 0 jun 26 21:14 photos
```
输出中的第一个 `root` 是所属的用户,第二个 `root` 是所属的组。
要将 `/photos` 目录的所有权转移到 `photos` 组,使用:
```
chgrp photos /photos
```
`chgrp` 命令通常采用两个参数,第一个参数是将要获得文件或目录所有权的组,第二个参数是希望交给组的文件或目录。
接着,运行 `ls -l /`,你会发现刚才那一行变了:
```
drwxr-xr-x 1 root photos 0 jun 26 21:14 photos
```
你已成功将新目录的所有权转移到了 `photos` 组。
然后,将你自己的用户和 `guest` 用户添加到 `photos` 组:
```
sudo usermod <你的用户名> -a -G photos
sudo usermod guest -a -G photos
```
你可能必须注销并重新登录才能看到更改,但是当你这样做时,运行 `groups` 会将 `photos` 显示为你所属的组之一。
关于上面提到的 `usermod` 命令,需要指明几点。第一:注意要使用 `-G` 选项而不是 `-g` 选项。`-g` 选项更改你的主要组,如果你意外地使用它,它可能会锁定你的一些东西。另一方面,`-G` 将你添加到列出的组中,并没有干扰主要组。如果要将用户添加到多个组中,在 `-G` 之后逐个列出它们,用逗号分隔,不要有空格:
```
sudo usermod <your username> -a -G photos,pizza,spaceforce
```
第二点:小心点不要忘记 `-a` 参数。`-a` 参数代表追加,将你传递给 `-G` 的组列表附加到你已经属于的组。这意味着,如果你不包含 `-a`,那么你之前所属的组列表将被覆盖,再次将你拒之门外。
这些都不是灾难性问题,但这意味着你必须手动将用户添加回你所属的所有组,这可能是个麻烦,特别是如果你失去了对 `sudo` 和 `wheel` 组的访问权限。
### 权限
在将图像复制到 `/photos` 目录之前,还要做一件事情。注意,当你执行上面的 `ls -l /` 时,该文件夹的权限将以 `drwxr-xr-x` 形式返回。
如果你阅读[我在本文开头推荐的文章](https://www.linux.com/learn/understanding-linux-file-permissions),你将知道第一个 `d` 表示文件系统中的条目是一个目录,接着你有三组三个字符(`rwx`、`r-x`、`r-x`),它们表示目录的所属用户(`rwx`)的权限,然后是所属组(`r-x`)的权限,最后是其他用户(`r-x`)的权限。这意味着到目前为止唯一具有写权限的人,即能够在 `/photos` 目录中复制或创建文件的唯一人员是 `root` 用户。
但是[我提到的那篇文章也告诉你如何更改目录或文件的权限](https://www.linux.com/learn/understanding-linux-file-permissions):
```
sudo chmod g+w /photos
```
运行 `ls -l /`,你会看到 `/photos` 权限变为了 `drwxrwxr-x`。这就是你希望的:组成员现在可以对目录进行写操作了。
现在你可以尝试将图像或任何其他文件复制到目录中,它应该没有问题:
```
cp image.jpg /photos
```
`guest` 用户也可以从目录中读取和写入。他们也可以读取和写入,甚至移动或删除共享目录中其他用户创建的文件。
### 总结
Linux 中的权限和特权系统已经磨练了几十年,它继承自昔日的旧 Unix 系统。就其本身而言,它工作的非常好,而且经过了深思熟虑。熟悉它对于任何 Linux 系统管理员都是必不可少的。事实上,除非你理解它,否则你根本就无法做很多事情。但是,这并不难。
下一次,我们将深入研究文件,并以一个创新的方式查看创建,操作和销毁文件的不同方法。最后一个总是很有趣。
回头见!
*通过 Linux 基金会和 edX 的免费[“Linux 简介”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)课程了解有关 Linux 的更多信息。*
---
via: <https://www.linux.com/blog/learn/intro-to-linux/2018/7/users-groups-and-other-linux-beasts-part-2>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,400 | 用于游戏开发的图形和音乐工具 | https://opensource.com/article/18/1/graphics-music-tools-game-dev | 2018-12-31T00:17:01 | [
"游戏",
"开发"
] | https://linux.cn/article-10400-1.html |
>
> 要在三天内打造一个可玩的游戏,你需要一些快速而稳定的好工具。
>
>
>

在十月初,我们的俱乐部马歇尔大学的 [Geeks and Gadgets](http://mugeeks.org/) 参加了首次 [Open Jam](https://itch.io/jam/open-jam-1),这是一个庆祝最佳开源工具的游戏 Jam。游戏 Jam 是一种活动,参与者以团队协作的方式来开发有趣的计算机游戏。Jam 一般都很短,仅有三天,并且非常累。Opensource.com 在八月下旬[发布了](https://opensource.com/article/17/8/open-jam-announcement) Open Jam 活动,足有 [45 支游戏](https://opensource.com/article/17/11/open-jam) 进入到了竞赛中。
我们的俱乐部希望在我们的项目中创建和使用开放源码软件,所以 Open Jam 自然是我们想要参与的 Jam 了。我们提交的游戏是一个实验性的游戏,名为 [Mark My Words](https://mugeeksalpha.itch.io/mark-omy-words)。我们使用了多种自由和开放源码 (FOSS) 工具来开发它;在这篇文章中,我们将讨论一些我们使用的工具和我们注意到可能有潜在阻碍的地方。
### 音频工具
#### MilkyTracker
[MilkyTracker](http://milkytracker.titandemo.org/) 是一个可用于编曲老式视频游戏中的音乐的软件包。它是一种<ruby> <a href="https://en.wikipedia.org/wiki/Music_tracker"> 音乐声道器 </a> <rt> music tracker </rt></ruby>,是一个强大的 MOD 和 XM 文件创建器,带有基于特征网格的模式编辑器。在我们的游戏中,我们使用它来编曲大多数的音乐片段。这个程序最好的地方是,它比我们其它的大多数工具消耗更少的硬盘空间和内存。虽然如此,MilkyTracker 仍然非常强大。

其用户界面需要一会来习惯,这里有对一些想试用 MilkyTracker 的音乐家的一些提示:
* 转到 “Config > Misc.” ,设置编辑模式的控制风格为 “MilkyTracker”,这将给你提供几乎全部现代键盘快捷方式。
* 用 `Ctrl+Z` 撤销
* 用 `Ctrl+Y` 重做
* 用空格键切换模式编辑方式
* 用退格键删除先前的音符
* 用插入键来插入一行
* 默认情况下,一个音符将持续作用,直到它在该频道上被替换。你可以明确地结束一个音符,通过使用一个反引号(`)键来插入一个 KeyOff 音符
* 在你开始谱写乐曲前,你需要创建或查找采样。我们建议在诸如 [Freesound](https://freesound.org/) 或 [ccMixter](http://ccmixter.org/view/media/home) 这样的网站上查找采用 [Creative Commons](https://creativecommons.org/) 协议的采样,
另外,把 [MilkyTracker 文档页面](http://milkytracker.titandemo.org/documentation/) 放在手边。它含有数不清的教程和手册的链接。一个好的起点是在该项目 wiki 上的 [MilkyTracker 指南](https://github.com/milkytracker/MilkyTracker/wiki/MilkyTracker-Guide)。
#### LMMS
我们的两个音乐家使用多用途的现代音乐创建工具 [LMMS](https://lmms.io/)。它带有一个绝妙的采样和效果库,以及多种多样的灵活的插件来生成独特的声音。LMMS 的学习曲线令人吃惊的低,在某种程度上是因为其好用的节拍/低音线编辑器。

我们对于想试试 LMMS 的音乐家有一个建议:使用插件。对于 [chiptune](https://en.wikipedia.org/wiki/Chiptune)式音乐,我们推荐 [sfxr](https://github.com/grimfang4/sfxr)、[BitInvader](https://lmms.io/wiki/index.php?title=BitInvader) 和 [FreeBoy](https://lmms.io/wiki/index.php?title=FreeBoy)。对于其它风格,[ZynAddSubFX](http://zynaddsubfx.sourceforge.net/) 是一个好的选择。它配备了各种合成仪器,可以根据您的需要进行更改。
### 图形工具
#### Tiled
在开放源码游戏开发中,[Tiled](http://www.mapeditor.org/) 是一个流行的贴片地图编辑器。我们使用它为来为我们在游戏场景中组合连续的、复古式的背景。

Tiled 可以导出地图为 XML、JSON 或普通的图片。它是稳定的、跨平台的。
Tiled 的功能之一允许你在地图上定义和放置随意的游戏对象,例如硬币和提升道具,但在 jam 期间我们没有使用它。你需要做的全部是以贴片集的方式加载对象的图像,然后使用“插入平铺”来放置它们。
一般来说,对于需要一个地图编辑器的项目,Tiled 是我们所推荐的软件中一个不可或缺的部分。
#### Piskel
[Piskel](https://www.piskelapp.com/) 是一个像素艺术编辑器,它的源文件代码以 [Apache 2.0 协议](https://github.com/piskelapp/piskel/blob/master/LICENSE) 发布。在这次 Jam 期间,们的大多数的图像资源都使用 Piskel 来处理,我们当然也将在未来的工程中使用它。
在这个 Jam 期间,Piskel 极大地帮助我们的两个功能是<ruby> 洋葱皮 <rt> Onion skin </rt></ruby>和<ruby> 精灵序列图 <rt> spritesheet </rt></ruby>导出。
##### 洋葱皮
洋葱皮功能将使 Piskel 以虚影显示你编辑的动画的前一帧和后一帧的,像这样:

洋葱皮是很方便的,因为它适合作为一个绘制指引和帮助你在整个动画进程中保持角色的一致形状和体积。 要启用它,只需单击屏幕右上角预览窗口下方的洋葱形图标即可。

##### 精灵序列图导出
Piskel 将动画导出为精灵序列图的能力也非常有用。精灵序列图是一个包含动画所有帧的光栅图像。例如,这是我们从 Piskel 导出的精灵序列图:

该精灵序列图包含两帧。一帧位于图像的上半部分,另一帧位于图像的下半部分。精灵序列图通过从单个文件加载整个动画,大大简化了游戏的代码。这是上面精灵序列图的动画版本:

##### Unpiskel.py
在 Jam 期间,我们很多次想批量转换 Piskel 文件到 PNG 文件。由于 Piskel 文件格式基于 JSON,我们写一个基于 GPLv3 协议的名为 [unpiskel.py](https://raw.githubusercontent.com/MUGeeksandGadgets/MarkMyWords/master/tools/unpiskel.py) 的 Python 小脚本来做转换。
它像这样被调用的:
```
python unpiskel.py input.piskel
```
这个脚本将从一个 Piskel 文件(这里是 `input.piskel`)中提取 PNG 数据帧和图层,并将它们各自存储。这些文件采用模式 `NAME_XX_YY.png` 命名,在这里 `NAME` 是 Piskel 文件的缩减名称,`XX` 是帧的编号,`YY` 是层的编号。
因为脚本可以从一个 shell 中调用,它可以用在整个文件列表中。
```
for f in *.piskel; do python unpiskel.py "$f"; done
```
### Python、Pygame 和 cx\_Freeze
#### Python 和 Pygame
我们使用 [Python](https://www.python.org/) 语言来制作我们的游戏。它是一个脚本语言,通常被用于文本处理和桌面应用程序开发。它也可以用于游戏开发,例如像 [Angry Drunken Dwarves](https://www.sacredchao.net/%7Epiman/angrydd/) 和 [Ren'Py](https://renpy.org/) 这样的项目所展示的。这两个项目都使用一个称为 [Pygame](https://www.Pygame.org/) 的 Python 库来显示图形和产生声音,所以我们也决定在 Open Jam 中使用这个库。
Pygame 被证明是既稳定又富有特色,并且它对我们创建的街机式游戏来说是很棒的。在低分辨率时,库的速度足够快的,但是在高分辨率时,它只用 CPU 的渲染开始变慢。这是因为 Pygame 不使用硬件加速渲染。然而,开发者可以充分利用 OpenGL 基础设施的优势。
如果你正在寻找一个好的 2D 游戏编程库,Pygame 是值得密切注意的一个。它的网站有 [一个好的教程](http://Pygame.org/docs/tut/PygameIntro.html) 可以作为起步。务必看看它!
#### cx\_Freeze
准备发行我们的游戏是有趣的。我们知道,Windows 用户不喜欢装一套 Python,并且要求他们来安装它可能很过分。除此之外,他们也可能必须安装 Pygame,在 Windows 上,这不是一个简单的工作。
很显然:我们必须放置我们的游戏到一个更方便的格式中。很多其他的 Open Jam 参与者使用专有的游戏引擎 Unity,它能够使他们的游戏在网页浏览器中来玩。这使得它们非常方便地来玩。便利性是一个我们的游戏中根本不存在的东西。但是,感谢生机勃勃的 Python 生态系统,我们有选择。已有的工具可以帮助 Python 程序员将他们的游戏做成 Windows 上的发布版本。我们考虑过的两个工具是 [cx\_Freeze](https://anthony-tuininga.github.io/cx_Freeze/) 和 [Pygame2exe](https://Pygame.org/wiki/Pygame2exe)(它使用 [py2exe](http://www.py2exe.org/))。我们最终决定用 cx\_Freeze,因为它是跨平台的。
在 cx\_Freeze 中,你可以把一个单脚本游戏打包成发布版本,只要在 shell 中运行一个命令,像这样:
```
cxfreeze main.py --target-dir dist
```
`cxfreeze` 的这个调用将把你的脚本(这里是 `main.py`)和在你系统上的 Python 解释器捆绑到到 `dist` 目录。一旦完成,你需要做的是手动复制你的游戏的数据文件到 `dist` 目录。你将看到,`dist` 目录包含一个可以运行来开始你的游戏的可执行文件。
这里有使用 cx\_Freeze 的更复杂的方法,允许你自动地复制数据文件,但是我们发现简单的调用 `cxfreeze` 足够满足我们的需要。感谢这个工具,我们使我们的游戏玩起来更便利一些。
### 庆祝开源
Open Jam 是庆祝开源模式的软件开发的重要活动。这是一个分析开源工具的当前状态和我们在未来工作中需求的一个机会。对于游戏开发者探求其工具的使用极限,学习未来游戏开发所必须改进的地方,游戏 Jam 或许是最好的时机。
开源工具使人们能够在不损害自由的情况下探索自己的创造力,而无需预先投入资金。虽然我们可能不会成为专业的游戏开发者,但我们仍然能够通过我们的简短的实验性游戏 [Mark My Words](https://mugeeksalpha.itch.io/mark-omy-words) 获得一点点体验。它是一个以语言学为主题的游戏,描绘了虚构的书写系统在其历史中的演变。还有很多其他不错的作品提交给了 Open Jam,它们都值得一试。 真的,[去看看](https://itch.io/jam/open-jam-1/entries)!
在本文结束前,我们想要感谢所有的 [参加俱乐部的成员](https://github.com/MUGeeksandGadgets/MarkMyWords/blob/3e1e8aed12ebe13acccf0d87b06d4f3bd124b9db/README.md#credits),使得这次经历真正的有价值。我们也想要感谢 [Michael Clayton](https://twitter.com/mwcz)、[Jared Sprague](https://twitter.com/caramelcode) 和 [Opensource.com](https://opensource.com/) 主办 Open Jam。简直酷毙了。
现在,我们对读者提出了一些问题。你是一个 FOSS 游戏开发者吗?你选择的工具是什么?务必在下面留下一个评论!
---
via: <https://opensource.com/article/18/1/graphics-music-tools-game-dev>
作者:[Charlie Murphy](https://opensource.com/users/rsg167) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In early October, our club, [Geeks and Gadgets](http://mugeeks.org/) from Marshall University, participated in the inaugural [Open Jam](https://itch.io/jam/open-jam-1), a game jam that celebrated the best of open source tools. Game jams are events where participants work as teams to develop computer games for fun. Jams tend to be very short—only three days long—and very exhausting. Opensource.com [announced](https://opensource.com/article/17/8/open-jam-announcement) Open Jam in late August, and more than [three dozen games](https://opensource.com/article/17/11/open-jam) were entered into the competition.
Our club likes to create and use open source software in our projects, so Open Jam was naturally the jam we wanted to participate in. Our submission was an experimental game called [Mark My Words](https://mugeeksalpha.itch.io/mark-omy-words). We used a variety of free and open source (FOSS) tools to develop it; in this article we'll discuss some of the tools we used and potential stumbling blocks to be aware of.
## Audio tools
### MilkyTracker
[MilkyTracker](http://milkytracker.titandemo.org/) is one of the best software packages available for composing old-style video game music. It is an example of a [music tracker](https://en.wikipedia.org/wiki/Music_tracker), a powerful MOD and XM file creator with a characteristic grid-based pattern editor. We used it to compose most of the musical pieces in our game. One of the great things about this program is that it consumed much less disk space and RAM than most of our other tools. Even so, MilkyTracker is still extremely powerful.
opensource.com
The user interface took a while to get used to, so here are some pointers for any musician who wants to try out MilkyTracker:
- Go to Config > Misc. and set the edit mode control style to "MilkyTracker." This will give you modern keyboard shortcuts for almost everything
- Undo with Ctrl+Z
- Redo with Ctrl+Y
- Toggle pattern-edit mode with the Spacebar
- Delete the previous note with the Backspace key
- Insert a row with the Insert key
- By default, a note will continue playing until it is replaced on that channel. You can end a note explicitly by inserting a KeyOff note with the backquote (`) key
- You will have to create or find samples before you can start composing. We recommend finding
[Creative Commons](https://creativecommons.org/)licensed samples at websites such as[Freesound](https://freesound.org/)or[ccMixter](http://ccmixter.org/view/media/home)
In addition, keep the [MilkyTracker documentation page](http://milkytracker.titandemo.org/documentation/) handy. It contains links to numerous tutorials and manuals. A good starting point is the [MilkyTracker Guide](https://github.com/milkytracker/MilkyTracker/wiki/MilkyTracker-Guide) on the project's wiki.
### LMMS
Two of our musicians used the versatile and modern music creation tool [LMMS](https://lmms.io/). It comes with a library of cool samples and effects, plus a variety of flexible plugins for generating unique sounds. The learning curve for LMMS was surprisingly low, in part due to the nice beat/bassline editor.
opensource.com
We have one suggestion for musicians trying out LMMS: Use the plugins. For [chiptune](https://en.wikipedia.org/wiki/Chiptune)-style music, we recommend [sfxr](https://github.com/grimfang4/sfxr), [BitInvader](https://lmms.io/wiki/index.php?title=BitInvader), and [FreeBoy](https://lmms.io/wiki/index.php?title=FreeBoy). For other styles, [ZynAddSubFX](http://zynaddsubfx.sourceforge.net/) is a good choice. It comes with a wide range of synthesized instruments that can be altered however you see fit.
## Graphics tools
### Tiled
[Tiled](http://www.mapeditor.org/) is a popular tilemap editor in open source game development. We used it to assemble consistent, retro-looking backgrounds for our in-game scenes.
opensource.com
Tiled can export maps as XML, JSON, or as flattened images. It is stable and cross-platform.
One of Tiled's features, which we did not use during the jam, allows you to define and place arbitrary game objects, such as coins and powerups, onto the map. All you have to do is load the object's graphics as a tileset, then place them using Insert Tile.
Overall, Tiled is a stellar piece of software that we recommend for any project that needs a map editor.
### Piskel
[Piskel](https://www.piskelapp.com/) is a pixel art editor whose source code is licensed under the [Apache License, Version 2.0](https://github.com/piskelapp/piskel/blob/master/LICENSE). We used Piskel for almost all our graphical assets during the jam, and we will certainly be using it in future projects as well.
Two features of Piskel that helped us immensely during the jam are onion skin and spritesheet exporting.
#### Onion skin
The onion skin feature will make Piskel show a ghostly overlay of the previous and next frames of your animation as you edit, like this:
opensource.com
Onion skin is handy because it serves as a drawing guide and helps you maintain consistent shapes and volumes on your characters throughout the animation process. To enable it, just click the onion-shaped icon underneath the preview window on the top-right of the screen.
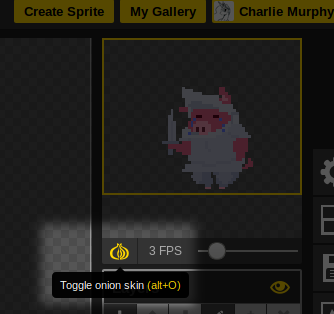
opensource.com
#### Spritesheet exporting
Piskel's ability to export animations as a spritesheet was also very helpful. A spritesheet is a single raster image that contains all the frames of an animation. For example, here is a spritesheet we exported from Piskel:

opensource.com
The spritesheet consists of two frames. One frame is in the top half of the image and the other frame is in the bottom half of the image. Spritesheets greatly simplify a game's code by enabling an entire animation to be loaded from a single file. Here is an animated version of the above spritesheet:

opensource.com
#### Unpiskel.py
There were several times during the jam when we wanted to batch convert Piskel files into PNGs. Since the Piskel file format is based on JSON, we wrote a small GPLv3-licensed Python script called [unpiskel.py](https://raw.githubusercontent.com/MUGeeksandGadgets/MarkMyWords/master/tools/unpiskel.py) to do the conversion.
It is invoked like this:
```
``````
python unpiskel.py input.piskel
```
The script will extract the PNG data frames and layers from a Piskel file (here `input.piskel`
) and store them in their own files. The files follow the pattern `NAME_XX_YY.png`
where `NAME`
is the truncated name of the Piskel file, `XX`
is the frame number, and `YY`
is the layer number.
Because the script can be invoked from a shell, it can be used on a whole list of files.
```
``````
for f in *.piskel; do python unpiskel.py "$f"; done
```
## Python, Pygame, and cx_Freeze
### Python and Pygame
We used the [Python](https://www.python.org/) language to make our game. It is a scripting language that is commonly used for text processing and desktop app development. It can also be used for game development, as projects like [Angry Drunken Dwarves](https://www.sacredchao.net/~piman/angrydd/) and [Ren'Py](https://renpy.org/) have shown. Both of these projects use a Python library called [Pygame](https://www.Pygame.org/) to display graphics and produce sound, so we decided to use this library in Open Jam, too.
Pygame turned out to be both stable and featureful, and it was great for the arcade-style game we were creating. The library's speed was fast enough at low resolutions, but its CPU-only rendering starts to slow down at higher resolutions. This is because Pygame does not use hardware-accelerated rendering. However, the infrastructure is there for developers to take full advantage of OpenGL.
If you're looking for a good 2D game programming library, Pygame is one to keep your eye on. Its website has [a good tutorial](http://Pygame.org/docs/tut/PygameIntro.html) to get started. Be sure to check it out!
### cx_Freeze
Prepping our game for distribution was interesting. We knew that Windows users were unlikely to have a Python installation, and asking them to install it would have been too much. On top of that, they would have had to also install Pygame, which is not an intuitive task on Windows.
One thing was clear: We had to put our game into a more convenient form. Many of the other Open Jam participants used the proprietary game engine Unity, which enabled their games to be played in the web browser. This made them extremely convenient to play. Convenience was one thing our game didn't have even a sliver of. But, thanks to a vibrant Python ecosystem, we had options. Tools exist to help Python programmers prepare their programs for distribution on Windows. The two that we considered were [cx_Freeze](https://anthony-tuininga.github.io/cx_Freeze/) and [Pygame2exe](https://Pygame.org/wiki/Pygame2exe) (which uses [py2exe](http://www.py2exe.org/)). We decided on cx_Freeze because it was cross-platform.
In cx_Freeze, you can pack a single-script game for distribution just by running a command like this in the shell:
```
``````
cxfreeze main.py --target-dir dist
```
This invocation of `cxfreeze`
will take your script (here `main.py`
) and the Python interpreter on your system and bundle them up into the `dist`
directory. Once this is done, all you have to do is manually copy your game's data files into the `dist`
directory. You will find that the `dist`
directory contains an executable file that can be run to start your game.
There is a more involved way to use cx_Freeze that allows you to automate the copying of data files, but we found the straightforward invocation of `cxfreeze`
to be good enough for our needs. Thanks to this tool, we made our game a little more convenient to play.
## Celebrating open source
Open Jam is important because it celebrates the open source model of software development. This is an opportunity to analyze the current state of open source tools and what we need to work on in the future. Game jams are perhaps the best time for game devs to try to push their tools to the limit, to learn what must be improved for the good of future game devs.
Open source tools enable people to explore their creativity without compromising their freedom and without investing money upfront. Although we might not become professional game developers, we were still able to get a small taste of it with our short, experimental game called [Mark My Words](https://mugeeksalpha.itch.io/mark-omy-words). It is a linguistically themed game that depicts the evolution of a fictional writing system throughout its history. There were many other delightful submissions to Open Jam, and they are all worth checking out. Really, [go look](https://itch.io/jam/open-jam-1/entries)!
Before closing, we would like to thank all the [club members who participated](https://github.com/MUGeeksandGadgets/MarkMyWords/blob/3e1e8aed12ebe13acccf0d87b06d4f3bd124b9db/README.md#credits) and made this experience truly worthwhile. We would also like to thank [Michael Clayton](https://twitter.com/mwcz), [Jared Sprague](https://twitter.com/caramelcode), and [Opensource.com](https://opensource.com/) for hosting Open Jam. It was a blast.
Now, we have some questions for readers. Are you a FOSS game developer? What are your tools of choice? Be sure to leave a comment below!
## 3 Comments |
10,401 | CEO 的 Emacs 秘籍 | https://blog.fugue.co/2015-11-11-guide-to-emacs.html | 2018-12-31T20:16:00 | [
"Emacs"
] | /article-10401-1.html | 
几年前,不,是几十年前,我就在用 Emacs。不论是码代码、编写文档,还是管理邮件和日程,我都用这个编辑器,或者是说操作系统,而且我还乐此不疲。许多年过去了,我也转向了其他更新、更好的工具。结果,就连最基本的文件浏览,我都已经忘了在不用鼠标的情况下该怎么操作。大约三个月前,我意识到我在应用程序和计算机之间切换上耗费了大量的时间,于是我决定再次使用 Emacs。这是个很正确的决定,原因有以下几个。其中包括用 `.emacs` 和 Dropbox 来搭建一个良好的、可移植的环境的一些技巧。
对于那些还没用过 Emacs 的人来说,Emacs 会让你爱恨交加。它有点像一个房子大小的<ruby> 鲁布·戈德堡机械 <rt> Rube Goldberg machine </rt></ruby>,乍一看,它具备烤面包机的所有功能。这听起来不像是一种认可,但关键词是“乍一看”。一旦你了解了 Emacs,你就会意识到它其实是一台可以当发动机用的热核烤面包机……好吧,只是指文本处理的所有事情。当考虑到你计算机的使用周期在很大程度上都是与文本有关时,这是一个相当大胆的声明。大胆,但却是真的。
也许对我来说更重要的是,Emacs 是我曾经使用过的一个应用,并让我觉得我真正的拥有它,而不是把我塑造成一个匿名的“用户”,就好像位于 [Soma](http://www.huffingtonpost.com/zachary-ehren/soma-isnt-a-drug-san-fran_b_987841.html)(LCTT 译注:旧金山的一个街区)或雷蒙德(LCTT 译注:微软总部所在地)附近某个高档办公室的产品营销部门把钱作为明确的目标一样。现代生产力和创作应用程序(如 Pages 或 IDE)就像碳纤维赛车,它们装备得很好,也很齐全。而 Emacs 就像一盒经典的 [Campagnolo](http://www.campagnolo.com/US/en) (LCTT 译注:世界上最好的三个公路自行车套件系统品牌之一)零件和一个漂亮的自行车牵引式钢框架,但缺少曲柄臂和刹车杆,你必须在网上某个小众文化中找到它们。前者更快而且很完整,后者是无尽的快乐或烦恼的源泉,当然这取决于你自己,而且这种快乐或烦恼会伴随到你死。我就是那种在找到一堆老古董或用 `Emacs Lisp` 配置编辑器时会感到高兴的人,具体情况因人而异。

*一辆我还在骑的 1933 年产的钢制自行车。你可以看看框架管差别: <https://www.youtube.com/watch?v=khJQgRLKMU0>*
这可能给人一种 Emacs 已经过气或过时的印象。然而并不是,Emacs 是强大和永恒的,只要你耐心地去理解它的一些规则。Emacs 的规则很另类,也很奇怪,但其中的逻辑却引人注目,且魅力十足。对于我来说, Emacs 更像是未来而不是过去。就像牵引式钢框架在未来几十年里将会变得好用和舒适,而神奇的碳纤维自行车将会被扔进垃圾场,在撞击中粉碎一样,Emacs 也将会作为一种在最新的流行应用早已被遗忘的时候的好用的工具继续存在这里。
使用 Lisp 代码来构建个人工作环境,并将这个恰到好处的环境移植到任何计算机,如果这种想法打动了你,那么你将会爱上 Emacs。如果你喜欢很潮、很炫的,又不想投入太多时间和精力的情况下就能直接工作的话,那么 Emacs 可能不适合你。我已经不再写代码了(除了 Ludwig 和 Emacs Lisp),但是 Fugue 公司的很多工程师都使用 Emacs 来提高码代码的效率。我公司有 30% 的工程师用 Emacs,40% 用 IDE 和 30% 的用 vim。但这篇文章是写给 CEO 和其他<ruby> <a href="http://www.businessinsider.com/best-pointy-haired-boss-moments-from-dilbert-2013-10"> 精英 </a> <rt> Pointy-Haired Bosses </rt></ruby>(PHB<sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup> )(以及对 Emacs 感兴趣的人)的,所以我将解释或者说辩解我为什么喜欢它以及我如何使用它。同时我也希望我能介绍清楚,从而让你有个良好的体验,而不是花上几个小时去 Google。
### 恒久优势
使用 Emacs 带来的长期优势是让生活更轻松。与最后的收获相比,最开始的付出完全值得。想想这些:
#### 简单高效
Org 模式本身就值得花时间,但如果你像我一样,你通常要处理十几份左右的文件 —— 从博客帖子到会议事务清单,再到员工评估。在现代计算世界中,这通常意味着要使用多个应用程序,所有这些程序都有不同的用户界面、保存方式、排序和搜索方式。结果就是你需要不断转换思维环境,记住各种细节。我讨厌在程序间切换,这是在强人所难,因为这是个不完整界面模型<sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup> ,并且我讨厌记住本该由计算机记住的东西。在单个环境下,Emacs 对 PHB 甚至比对于程序员更高效,因为程序员更多时候只需要专注于一个程序。转换思维环境的成本比表面上的要更高。操作系统和应用程序厂商已经构建了各种界面,以分散我们对这一现实的注意力。如果你是技术人员,通过快捷键(`M-:`)来访问功能强大的[语言解释器](http://www.webopedia.com/TERM/I/interpreter.html)会方便的多<sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup> 。
许多应用程序可以全天全屏地用于编辑文本。但Emacs 是唯一的,因为它既是编辑器也是 Emacs Lisp 解释器。从本质上来说,你工作时只要用电脑上的一两个键就能完成。如果你略懂编程的话,就会发现这代表着你可以在 Emacs 中做 任何事情。一旦你在内存中存储了这些指令,你的电脑就可以在工作时几乎实时地为你提供高效的运转。你不会想用 Emacs Lisp 来重建 Excel,因为只要用简单的一两行代码就能实现 Excel 中大多数的功能。比如说我要处理数字,我更有可能转到 scratch 缓冲区,编写一些代码,而不是打开电子表格。即便是要写一封比较大的邮件时,我通常也会先在 Emacs 中写完,然后再复制粘贴到邮件客户端中。当你可以流畅的书写时,为什么要去切换呢?你可以先从一两个简单的算术开始,随着时间的推移,你可以很容易的在 Emacs 中添加你所需要处理的计算。这在应用程序中可能是独一无二的,同时还提供了让为其他的人创造的丰富特性。还记得艾萨克·阿西莫夫书中那些神奇的终端吗? Emacs 是我所遇到的最接近它们的东西<sup id="fnref4"> <a href="#fn4" rel="footnote"> 4 </a></sup> 。我决定不再用什么应用程序来做这个或那个。相反,我只是工作。拥有一个伟大的工具并致力于此,这才是真正的动力和效率。
#### 静中造物
拥有所发现的最好的文本编辑功能的最终结果是什么?有一群人在做各种各样有用的补充吗?发挥了 Lisp 键盘的全部威力了吗?我用 Emacs 来完成所有的创作性工作,音乐和图片除外。
我办公桌上有两个显示器。其中一块竖屏是将 Emacs 全天全屏显示,另一个显示浏览器,用来搜索和阅读,我通常也会打开一个终端。我将日历、邮件等放在 OS X 的另一个桌面上,当我使用 Emacs 时,这个桌面会隐藏起来,同时我也会关掉所有通知。这样就能让我专注于我手头上在做的事了。我发现,越是先进的 UI 应用程序,消除干扰越是不可能,因为这些应用程序致力于提供帮助和易用性。我不需要经常被提醒该如何操作,我已经做了成千上万次了,我真正需要的是一张干净整洁的白纸用来思考。也许因为年龄和自己的“恶习”,我不太喜欢处在嘈杂的环境中,但我认为这值得一试。看看在你电脑环境中有一些真正的宁静是怎样的。当然,现在很多应用程序都有隐藏界面的模式,谢天谢地,苹果和微软现在都有了真正意义上的全屏模式。但是,没有并没有应用程序可以强大到足以“处理”大多数事务。除非你整天写代码,或者像出书一样,处理很长的文档,否则你仍然会面临其他应用程序的干扰。而且,大多数现代应用程序似乎同时显得自视甚高,缺乏功能和可用性<sup id="fnref5"> <a href="#fn5" rel="footnote"> 5 </a></sup> 。比起 office 桌面版,我更讨厌它的在线版。

*我的桌面布局, Emacs 在左边*
但是沟通呢?创造和沟通之间的差别很大。当我将这两件事在不同时间段处理时,我的效率会更高。我们 Fugue 公司使用 Slack,痛并快乐着。我把 Slack 和我的日历、电子邮件放在一个即时通讯的桌面上,这样,当我正在做事时,我就能够忽略所有的聊天信息了。虽然只要一个 Slackstorm 或一封风投或董事会董事的电子邮件,就能让我立刻丢掉手头工作。但是,大多数事情通常可以等上一两个小时。
#### 普适恒久
第三个原因是,我发现 Emacs 比其它的环境更有优势的是,你可以很容易地用它来处理事务。我的意思是,你所需要的只是通过类似于 Dropbox 的网站同步一两个目录,而不是让大量的应用程序以它们自己的方式进行交互和同步。然后,你可以在任何你已经精心打造了适合你的目的的套件的环境中工作了。我在 OS X、Windows,或有时在 Linux 都是这样做的。它非常简单可靠。这种功能很有用,以至于我害怕处理 Pages、Google Docs、Office 或其他类型的文件和应用程序,这些文件和应用程序会迫使我回到文件系统或云中的某个地方去寻找。
限制在计算机上永久存储的因素是文件格式。假设人类已经解决了存储问题<sup id="fnref6"> <a href="#fn6" rel="footnote"> 6 </a></sup> ,随着时间的推移,我们面临的问题是我们能否够继续访问我们创建的信息。文本文件是保存时间最久的格式。你可以用 Emacs 轻松地打开 1970 年的文本文件。然而对于 Office 应用程序却并非如此。同时文本文件要比 Office 应用程序数据文件小得多,也要好的多。作为一个数码背包迷,作为一个在脑子里一闪而过就会做很多小笔记的人,拥有一个简单、轻便、永久、随时可用的东西对我来说很重要。
如果你准备尝试 Emacs,请继续读下去!下面的部分不是完整的教程,但是在读完后,就可以动手操作了。
### 驾驭之道 —— 专业定制
所有这些强大、精神上的平静和安宁的代价是,Emacs 有一个陡峭的学习曲线,它的一切都与你以前所习惯的不同。一开始,这会让你觉得你是在浪费时间在一个过时和奇怪的应用程序上,就好像穿越到过去。这有点像你只开过车,却要你去学骑自行车<sup id="fnref7"> <a href="#fn7" rel="footnote"> 7 </a></sup> 。
#### 类型抉择
我用的是来自 GNU 的 OS X 和 Windows 的通用版本的 Emacs。你可以在 [http://emacsformacos.com/](http://emacsformacosx.com/) 获取 OS X 版本,在 <http://www.gnu.org/software/emacs/> 获取 Windows 版本。市面上还有很多其他版本,尤其是 Mac 版本,但我发现,要做一些功能强大的东西(涉及到 Lisp 和许多模式),学习曲线要比实际操作低得多。下载,然后我们就可以开始了<sup id="fnref8"> <a href="#fn8" rel="footnote"> 8 </a></sup> !
#### 驾驭之始
在本文中,我将使用 Emacs 的按键和组合键约定。`C` 表示 `Control` 键,`M` 表示 `meta`(通常是 `Alt` 或 `Option` 键),以及用于组合键的连字符。因此,`C-h t` 表示同时按下 `Control` 和 `h` 键,然后释放,再按下 `t`。这个组合快捷键会指向一个教程,这是你首先要做的一件事。
不要使用方向键或鼠标。它们可以工作,但是你应该给自己一周的时间来使用 Emacs 教程中的原生的导航命令。一旦你这些命令变为了肌肉记忆,你可能就会乐在其中,无论到哪里,你都会非常想念它们。这个 Emacs 教程在介绍它们方面做得很好,但是我将进行总结,所以你不需要阅读全部内容。最无聊的是,不用方向键,用 `C-b` 向前移动,用 `C-f` 向后移动,上一行用 `C-p`,下一行用 `C-n`。你可能会想:“我用方向键就很好,为什么还要这样做?” 有几个原因。首先,你不需要从主键盘区将你的手移开。第二,使用 `Alt`(或用 Emacs 的说法 `Meta`)键来向前或向后在单词间移动。显而易见这样更方便。第三,如果想重复某个命令,可以在命令前面加上一个数字。在编辑文档时,我经常使用这种方法,通过估计向后移动多少个单词或向上或向下移动多少行,然后按下 `C-9 C-p` 或 `M-5 M-b` 之类的快捷键。其它真正重要的导航命令基于开头用 `a` 和结尾用 `e`。在行中使用 `C-a|e`,在句中使用 `M-a|e`。为了让句中的命令正常工作,需要在句号后增加两个空格,这同时提供了一个有用的特性,并消除了脑中一个过时的[观点](http://www.huffingtonpost.com/2015/05/29/two-spaces-after-period-debate_n_7455660.html)。如果需要将文档导出到单个空间[发布环境](http://practicaltypography.com/one-space-between-sentences.html),可以编写一个宏来执行此操作。
Emacs 所附带的教程很值得去看。对于真正缺乏耐心的人,我将介绍一些重要的命令,但那个教程非常有用。记住:用 `C-h t` 进入教程。
#### 驾驭之复制粘贴
你可以把 Emacs 设为 CUA 模式,这将会以熟悉的方式工作来操作复制粘贴,但是原生的 Emacs 方法更好,而且你一旦学会了它,就很容易。你可以使用 `Shift` 和导航命令来标记区域(如同选择)。所以 `C-F` 是选中光标前的一个字符,等等。亦可以用 `M-w` 来复制,用 `C-w` 剪切,然后用 `C-y` 粘贴。这些实际上叫做<ruby> 删除 <rt> killing </rt></ruby>和<ruby> 召回 <rt> yanking </rt></ruby>,但它非常类似于剪切和粘贴。在删除中还有一些小技巧,但是现在,你只需要关注剪切、复制和粘贴。如果你开始尝试了,那么 `C-x u` 是撤销。
#### 驾驭之 Ido 模式
相信我,Ido 会让文件的工作变得很简单。通常,你在 Emacs 中处理文件不需要使用一个单独的访达或文件资源管理器的窗口。相反,你可以用编辑器的命令来创建、打开和保存文件。如果没有 Ido 的话,这将有点麻烦,所以我建议你在学习其他之前安装好它。 Ido 是 Emacs 的 22 版时开始出现的,但是需要对你的 `.emacs` 文件做一些调整,来确保它一直开启着。这是个配置环境的好理由。
Emacs 中的大多数功能都表现在模式上。要安装指定的模式,需要做两件事。嗯,一开始你需要做一些额外的事情,但这些只需要做一次,然后再做这两件事。那么,这件额外的事情是你需要一个单独的位置来放置所有 Emacs Lisp 文件,并且你需要告诉 Emacs 这个位置在哪。我建议你在 Dropbox 上创建一个单独的目录,那是你 Emacs 主目录。在这里,你需要创建一个 `.emacs` 文件和 `.emacs.d` 目录。在 `.emacs.d` 目录下,创建一个 `lisp` 的目录。就像这样:
```
home
|
+.emacs
|
-.emacs.d
|
-lisp
```
你可以将 `.el` 文件,比如说模式文件,放到 `home/.emacs.d/lisp` 目录下,然后在你的 `.emacs` 文件中添加以下代码来指明该路径:
```
(add-to-list 'load-path "~/.emacs.d/lisp/")
```
Ido 模式是 Emacs 自带的,所以你不需要在你的 `lisp` 目录中放这个 `.el` 文件,但你仍然需要添加上面代码,因为下面的介绍会使用到它.
#### 驾驭之符号链接
等等,这里写的 `.emacs` 和 `.emacs.d` 都是存放在你的主目录下,但我们把它们放到了 Dropbox 的某些愚蠢的文件夹!对,这就让你的环境在任何地方都很容易使用。把所有东西都保存在 Dropbox 上,并做符号链接到 `~` 下的 `.emacs` 、`.emacs.d` 和你的主要存放文档的目录。在 OS X 上,使用 `ln -s` 命令非常简单,但在 Windows 上却很麻烦。幸运的是,Emacs 提供了一种简单的方法来替代 Windows 上的符号链接,Windows 的 `HOME` 环境变量。转到 Windows 的环境变量(Windows 10,你可以按 Windows 键然后输入 “环境变量” 来搜索,这是 Windows 10 最好的地方了),在你的帐户下创建一个指向你在 Dropbox 中 Emacs 的文件夹的 `HOME` 环境变量。如果你想方便地浏览 Dropbox 之外的本地文件,你可能想在你的实际主目录下建立一个到 Dropbox 下 Emacs 主目录的符号链接。
至此,你已经完成了在任意机器上指向你的 Emacs 配置和文件所需的技巧。如果你买了一台新电脑,或者用别人的电脑一小时或一天,你就可以得到你的整个工作环境。第一次操作起来似乎有点难,但是一旦你知道你在做什么,就(最多)只需要 10 分钟。
但我们现在是在配置 Ido ……
按下 `C-x` `C-f` 然后输入 `~/.emacs` 和两次回车来创建 `.emacs` 文件,将下面几行添加进去:
```
;; set up ido mode
(require `ido)
(setq ido-enable-flex-matching t)
(setq ido-everywhere t)
(ido-mode 1)
```
在 `.emacs` 窗口开着的时候,执行 `M-x evaluate-buffer` 命令。如果某处弄错了的话,将得到一个错误,或者你将得到 Ido。Ido 改变了在 minibuffer 中操作文件操方式。关于这个有一篇比较好的文档,但是我也会指出一些技巧。有效地使用 `~/`;你可以在 minibuffer 的任何地方输入 `~/`,它就会跳转到主目录。这就意味着,你应该让你的大部分东西就近的放在主目录下。我用 `~/org` 目录来保存所有非代码的东西,用 `~/code` 保存代码。一旦你进入到正确的目录,通常会拥有一组具有不同扩展名的文件,特别是当你使用 Org 模式并从中发布的话。你可以输入 `.` 和想要的扩展名,无论你的在文件名的什么位置,Ido 都会将选择限制在具有该扩展名的文件中。例如,我在 Org 模式下写这篇博客,所以该文件是:
```
~/org/blog/emacs.org
```
我偶尔也会用 Org 模式发布成 HTML 格式,所以我将在同一目录下得到 `emacs.html` 文件。当我想打开该 Org 文件时,我会输入:
```
C-x C-f ~/o[RET]/bl[RET].or[RET]
```
其中 `[RET]` 是我使用 `Ido` 模式的自动补全而按下的回车键。所以,这只需要按 12 个键,如果你习惯了的话, 这将比打开访达或文件资源管理器再用鼠标点要节省 很 多时间。 Ido 模式很有用,而这只是操作 Emacs 的一种实用模式而已。下面让我们去探索一些其它对完成工作很有帮助的模式吧。
#### 驾驭之字体风格
我推荐在 Emacs 中使用漂亮的字体族。它们可以使用不同的括号、0 和其他字符进行自定义。你可以在字体文件本身中构建额外的行间距。我推荐 1.5 倍的行间距,并在代码和数据中使用不等宽字体。写作中我用 `Serif` 字体,它有一种紧凑但时髦的感觉。你可以在 <http://input.fontbureau.com/> 上找到它们,在那里你可以根据自己的喜好进行定制。你可以使用 Emacs 中的菜单手动设置字体,但这会将代码保存到你的 `.emacs` 文件中,如果你使用多个设备,你可能需要一些不同的设置。我将我的 `.emacs` 设置为根据使用的机器的名称来相应配置屏幕。代码如下:
```
;; set up fonts for different OSes. OSX toggles to full screen.
(setq myfont "InputSerif")
(cond
((string-equal system-name "Sampo.local")
(set-face-attribute 'default nil :font myfont :height 144)
(toggle-frame-fullscreen))
((string-equal system-name "Morpheus.local")
(set-face-attribute 'default nil :font myfont :height 144))
((string-equal system-name "ILMARINEN")
(set-face-attribute 'default nil :font myfont :height 106))
((string-equal system-name "UKKO")
(set-face-attribute 'default nil :font myfont :height 104)))
```
你应该将 Emacs 中的 `system-name` 的值替换成你通过 `(system-name)` 得到的值。注意,在 Sampo (我的 MacBook)上,我还将 Emacs 设置为全屏。我也想在 Windows 实现这个功能,但是 Windows 和 Emacs 好像互相嫌弃对方,当我尝试配置时,它总是不稳定。相反,我只能在启动后手动全屏。
我还建议去掉 Emacs 中的上世纪 90 年代出现的难看工具栏,当时比较流行在应用程序中使用工具栏。我还去掉了一些其它的“电镀层”,这样我就有了一个简单、高效的界面。把这些加到你的 `.emacs` 的文件中来去掉工具栏和滚动条,但要保留菜单(在 OS X 上,它将被隐藏,除非你将鼠标到屏幕顶部):
```
(if (fboundp 'scroll-bar-mode) (scroll-bar-mode -1))
(if (fboundp 'tool-bar-mode) (tool-bar-mode -1))
(if (fboundp 'menu-bar-mode) (menu-bar-mode 1))
```
#### 驾驭之 Org 模式
我基本上是在 Org 模式下处理工作的。它是我创作文档、记笔记、列任务清单以及 90% 其他工作的首选环境。Org 模式是笔记和待办事项列表的组合工具,最初是由一个在会议中使用笔记本电脑的人构想出来的。我反对在会议中使用笔记本电脑,自己也不使用,所以我的用法与他的有些不同。对我来说,Org 模式主要是一种处理结构中内容的方式。在 Org 模式中有标题和副标题等,它们的作用就像一个大纲。Org 模式允许你展开或隐藏大纲树,还可以重新排列该树。这正合我意,并且我发现用这种方式使用它是一种乐趣。
Org 模式也有很多让生活愉快的小功能。例如,脚注处理非常好,LaTeX/PDF 输出也很好。Org 模式能够根据所有文档中的待办事项生成议程,并能很好地将它们与日期/时间联系起来。我不把它用在任何形式的外部任务上,这些任务都是在一个共享的日历上处理的,但是在创建事物和跟踪我未来需要创建的东西时,它是无价的。安装它,你只要将 `org-mode.el` 放到你的 `lisp` 目录下。如果你想要它基于文档的结构进行缩进并在打开时全部展开的话,在你的 `.emacs` 文件中添加如下代码:
```
;; set up org mode
(setq org-startup-indented t)
(setq org-startup-folded "showall")
(setq org-directory "~/org")
```
最后一行是让 Org 模式知道在哪里查找要包含在议程和其他事情中的文件。我把 Org 模式保存在我的主目录中,也就是说,像前面介绍的一样,它是 Dropbox 目录的一个符号链接。
我有一个总是在缓冲区中打开的 `stuff.org` 文件。我把它当作记事本。Org 模式使得提取待办事项和有期限的事情变得很容易。当你能够内联 Lisp 代码并在需要计算它时,它特别有用。拥有包含内容的代码非常方便。同样,你可以使用 Emacs 访问实际的计算机,这是一种解放。
##### 用 Org 模式进行发布
我关心的是文档的外观及格式。我刚开始工作时是个设计师,而且我认为信息可以,也应该表现得清晰和美丽。Org 模式对将 LaTeX 生成 PDF 支持的很好,LaTeX 虽然也有学习曲线,但是很容易处理一些简单的事务。
如果你想使用字体和样式,而不是典型的 LaTeX 字体和样式,你需要做些事。首先,你要用到 XeLaTeX,这样就可以使用普通的系统字体,而不是 LaTeX 的特殊字体。接下来,你需要将以下代码添加到 `.emacs` 中:
```
(setq org-latex-pdf-process
'("xelatex -interaction nonstopmode %f"
"xelatex -interaction nonstopmode %f"))
```
我把这个放在 `.emacs` 中 Org 模式配置部分的末尾,使文档变得更整洁。这让你在从 Org 模式发布时可以使用更多格式化选项。例如,我经常使用:
```
#+LaTeX_HEADER: \usepackage{fontspec}
#+LATEX_HEADER: \setmonofont[Scale=0.9]{Input Mono}
#+LATEX_HEADER: \setromanfont{Maison Neue}
#+LATEX_HEADER: \linespread{1.5}
#+LATEX_HEADER: \usepackage[margin=1.25in]{geometry}
#+TITLE: Document Title Here
```
这些都可以在 `.org` 文件中找到。我们的公司规定的正文字体是 `Maison Neue`,但你也可以在这写上任何适当的东西。我很是抵制 `Maison Neue`,因为这是一种糟糕的字体,任何人都不应该使用它。
这个文件是一个使用该配置输出为 PDF 的实例。这就是开箱即用的 LaTeX 一样。在我看来这还不错,但是字体很平淡,而且有点奇怪。此外,如果你使用标准格式,人们会觉得他们正在阅读的东西是、或者假装是一篇学术论文。别怪我没提醒你。
#### 驾驭之 Ace Jump 模式
这只是一个辅助模式,而不是一个主模式,但是你也需要它。其工作原理有点像之前提到的 Jef Raskin 的 Leap 功能<sup id="fnref9"> <a href="#fn9" rel="footnote"> 9 </a></sup> 。 按下 `C-c C-SPC`,然后输入要跳转到单词的第一个字母。它会高亮显示所有以该字母开头的单词,并将其替换为字母表中的字母。你只需键入所需位置的字母,光标就会跳转到该位置。我常将它作为导航键或是用来检索。将 `.el` 文件下到你的 `lisp` 目录下,并在 `.emacs` 文件添加如下代码:
```
;; set up ace-jump-mode
(add-to-list 'load-path "which-folder-ace-jump-mode-file-in/")
(require 'ace-jump-mode)
(define-key global-map (kbd "C-c C-SPC" ) 'ace-jump-mode)
```
### 待续
本文已经够详细了,你能在其中得到你所想要的。我很想知道除编程之外(或用于编程)Emacs 的使用情况,及其是否高效。在我使用 Emacs 的过程中,可能存在一些自作聪明的老板式想法,如果你能指出来,我将不胜感激。之后,我可能会写一些更新来介绍其它特性或模式。我很确定我将会向你展示如何在 Emacs 和 Ludwig 模式下使用 Fugue,因为我会将它发展成比代码高亮更有用的东西。更多想法,请在 Twitter 上 [@fugueHQ](https://twitter.com/fugueHQ) 。
### 脚注
---
1. 如果你是位精英,但从没涉及过技术方面,那么 Emacs 并不适合你。对于少数的人来说,Emacs 可能会为他们开辟一条通往计算机技术方面的道路,但这只是极少数。如果你知道怎么使用 Unix 或 Windows 的终端,或者曾编辑过 dotfile,或者说你曾写过一点代码的话,这对使用 Emacs 有很大的帮助。 [↩](#fnref1)
2. 参考链接: <http://archive.wired.com/wired/archive/2.08/tufte.html> [↩](#fnref2)
3. 我主要是在写作时使用这个模式来进行一些运算。比如说,当我在给一个新雇员写一封入职信时,我想要算这封入职信中有多少个选项。由于我在我的 `.emacs` 为 outstanding-shares 定义了一个变量,所以我只要按下 `M-:` 然后输入 `(* .001 outstanding-shares)` 就能再无需打开计算器或电子表格的情况下得到精度为 0.001 的结果。我使用了 大量 的变量来避免程序间切换。 [↩](#fnref3)
4. 缺少的部分是 web。有个名为 eww 的 Emacs 网页浏览器能够让你在 Emacs 中浏览网页。我用的就是这个,因为它既能拦截广告(LCTT 译注:实质上是无法显示,/laugh),同时也在可读性方面为 web 开发者消除了大多数差劲的选项。这个其实有点类似于 Safari 的阅读模式。不幸的是,大部分网站都有很多令人讨厌的繁琐的东西以及难以转换为文本的导航, [↩](#fnref4)
5. 易用性和易学性这两者经常容易被搞混。易学性是指学习使用工具的难易程度。而易用性是指工具高效的程度。通常来说,这是要差别的,就想鼠标和菜单栏的差别一样。菜单栏很容易学会,但是却不怎么高效,以致于早期会存在一些键盘的快捷键。除了在 GUI 方面上,Raskin 在很多方面上的观点都很正确。如今,操作系统正在将一些合适的搜索映射到键盘的快捷键上。比如说在 OS X 和 Windows 上,我默认的导航方式就是搜索。Ubuntu 的搜索做的很差劲,如同它的 GUI 一样差劲。 [↩](#fnref5)
6. 在有网的情况下,[AWS S3](https://baike.baidu.com/item/amazon%20s3/10809744?fr=aladdin) 是解决文件存储问题的有效方案。数万亿个对象存在 S3 中,但是从来没有遗失过。大部分提供云存储的服务都是在 S3 上或是模拟 S3 构建的。没人能够拥有 S3 一样的规模,所以我将重要的文件通过 Dropbox 存储在上面。 [↩](#fnref6)
7. 目前,你可能会想:“这个人和自行车有什么关系?”……我在各个层面上都喜欢自行车。自行车是迄今为止发明的最具机械效率的交通工具。自行车可以是真正美丽的事物。而且,只要注意点的话,自行车可以用一辈子。早在 2001 年,我曾向 Rivendell Bicycle Works 订购了一辆自行车,现在我每次看到那辆自行车依然很高兴,自行车和 Unix 是我接触过的最好的两个发明。对了,还有 Emacs。 [↩](#fnref7)
8. 这个网站有一个很棒的 Emacs 教程,但不是这个。当我浏览这个页面时,我确实得到了一些对获取高效的 Emacs 配置很重要的知识,但无论怎么说,这都不是个替代品。 [↩](#fnref8)
9. 20 世纪 80 年代,Jef Raskin 与 Steve Jobs 在 Macintosh 项目上闹翻后, Jef Raskin 又设计了 [Canon Cat 计算机](https://en.wikipedia.org/wiki/Canon_Cat)。这台 Cat 计算机是以文档为中心的界面(所有的计算机都应如此),并以一种全新的方式使用键盘,你现在可以用 Emacs 来模仿这种键盘。如果现在有一台现代的,功能强大的 Cat 计算机并配有一个高分辨的显示器和 Unix 系统的话,我立马会用 Mac 来换。[https://youtu.be/oTlEU\_X3c?t=19s](https://youtu.be/o_TlE_U_X3c?t=19s) [↩](#fnref9)
###
---
via: <https://blog.fugue.co/2015-11-11-guide-to-emacs.html>
作者:[Josh Stella](https://blog.fugue.co/authors/josh.html) 译者:[oneforalone](https://github.com/oneforalone) 校对:[wxy](https://github.com/wxy), [oneforalone](https://github.com/oneforalone)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='blog.fugue.co', port=443): Max retries exceeded with url: /2015-11-11-guide-to-emacs.html (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x7b83409d3040>: Failed to resolve 'blog.fugue.co' ([Errno -2] Name or service not known)")) | null |
10,402 | 用 PGP 保护代码完整性(四):将主密钥移到离线存储中 | https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage | 2019-01-01T00:35:38 | [
"pgp"
] | https://linux.cn/article-10402-1.html |
>
> 如果开发者的 PGP 密钥被偷了,危害非常大。了解一下如何更安全。
>
>
>

在本系列教程中,我们为使用 PGP 提供了一个实用指南。你可以从下面的链接中查看前面的文章:
* [第一部分:基本概念和工具](/article-9524-1.html)
* [第二部分:生成你的主密钥](/article-9529-1.html)
* [第三部分:生成 PGP 子密钥](/article-9607-1.html)
这是本系列教程的第四部分,我们继续本教程,我们将谈一谈如何及为什么要将主密钥从你的家目录移到离线存储中。现在开始我们的教程。
#### 清单
* 准备一个加密的可移除的存储(必要)
* 备份你的 GnuPG 目录(必要)
* 从你的家目录中删除主密钥(推荐)
* 从你的家目录中删除吊销证书(推荐)
#### 考虑事项
为什么要从你的家目录中删除你的主 [C] 密钥 ?这样做的主要原因是防止你的主密钥失窃或意外泄露。对于心怀不轨的人来说,私钥对他们具有很大的诱惑力 —— 我们知道有几个恶意软件成功地实现了扫描用户的家目录并将发现的私钥内容上传。
对于开发者来说,私钥失窃是非常危险的事情 —— 在自由软件的世界中,这无疑是身份证明失窃。从你的家目录中删除私钥将帮你防范这类事件的发生。
#### 备份你的 GnuPG 目录
**!!!绝对不要跳过这一步!!!**
备份你的 PGP 密钥将让你在需要的时候很容易地恢复它们,这很重要!(这与我们做的使用 paperkey 的灾难级备份是不一样的)。
#### 准备可移除的加密存储
我们从取得一个(最好是两个)小型的 USB “拇指“ 驱动器(可加密 U 盘)开始,我们将用它来做备份。你首先需要去加密它们:
加密密码可以使用与主密钥相同的密码。
#### 备份你的 GnuPG 目录
加密过程结束之后,重新插入 USB 驱动器并确保它能够正常挂载。你可以通过运行 `mount` 命令去找到设备挂载点的完全路径。(在 Linux 下,外置介质一般挂载在 `/media/disk` 下,Mac 一般在它的 `/Volumes` 下)
你知道了挂载点的全路径后,将你的整个 GnuPG 的目录复制进去:
```
$ cp -rp ~/.gnupg [/media/disk/name]/gnupg-backup
```
(注意:如果出现任何套接字不支持的错误,没有关系,直接忽略它们。)
现在,用如下的命令去测试一下,确保它们能够正常地工作:
```
$ gpg --homedir=[/media/disk/name]/gnupg-backup --list-key [fpr]
```
如果没有出现任何错误,说明一切正常。弹出这个 USB 驱动器并给它粘上一个明确的标签,以便于你下次需要它时能够很快找到它。接着,将它放到一个安全的 —— 但不要太远 —— 的地方,因为从现在起,你需要偶尔使用它来做一些像编辑身份信息、添加或吊销子证书、或签署其它人的密钥这样的事情。
#### 删除主密钥
我们家目录中的文件并没有像我们所想像的那样受到保护。它们可能会通过许多不同的方式被泄露或失窃:
* 通过快速复制来配置一个新工作站时的偶尔事故
* 通过系统管理员的疏忽或恶意操作
* 通过安全性欠佳的备份
* 通过桌面应用中的恶意软件(浏览器、pdf 查看器等等)
* 通过跨境胁迫
使用一个很好的密码来保护你的密钥是降低上述风险的一个很好方法,但是密码能够通过键盘记录器、背后窥视、或其它方式被发现。基于以上原因,我们建议去配置一个从你的家目录上可移除的主密钥,将它保存在一个离线存储中。
##### 删除你的主密钥
**请查看前面的节,确保你有完整的你的 GnuPG 目录的一个备份。如果你没有一个可用的备份,下面所做的操作将会使你的主密钥失效!!!**
首先,识别你的主密钥的 keygrip:
```
$ gpg --with-keygrip --list-key [fpr]
```
它的输出应该像下面这样:
```
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
111122223333444455556666AAAABBBBCCCCDDDD
Keygrip = AAAA999988887777666655554444333322221111
uid [ultimate] Alice Engineer <[email protected]>
uid [ultimate] Alice Engineer <[email protected]>
sub rsa2048 2017-12-06 [E]
Keygrip = BBBB999988887777666655554444333322221111
sub rsa2048 2017-12-06 [S]
Keygrip = CCCC999988887777666655554444333322221111
```
找到 `pub` 行下方的 `Keygrip` 条目(就在主密钥指纹的下方)。它与你的家目录下 `.gnupg` 目录下的一个文件是一致的:
```
$ cd ~/.gnupg/private-keys-v1.d
$ ls
AAAA999988887777666655554444333322221111.key
BBBB999988887777666655554444333322221111.key
CCCC999988887777666655554444333322221111.key
```
现在你做的全部操作就是简单地删除与主密钥 keygrip 一致的 `.key` 文件:
```
$ cd ~/.gnupg/private-keys-v1.d
$ rm AAAA999988887777666655554444333322221111.key
```
现在,如果运行 `--list-secret-keys` 命令将出现问题,它将显示主密钥丢失(`#` 表示不可用):
```
$ gpg --list-secret-keys
sec# rsa4096 2017-12-06 [C] [expires: 2019-12-06]
111122223333444455556666AAAABBBBCCCCDDDD
uid [ultimate] Alice Engineer <[email protected]>
uid [ultimate] Alice Engineer <[email protected]>
ssb rsa2048 2017-12-06 [E]
ssb rsa2048 2017-12-06 [S]
```
#### 删除吊销证书
你应该去删除的另一个文件是吊销证书(**删除之前,确保你的备份中有它**),它是使用你的主密钥自动创建的。吊销证书允许一些人去永久标记你的证书为吊销状态,这意味着它无论在任何用途中将不再被使用或信任。一般是使用它来吊销由于某些原因不再受控的一个密钥 —— 比如,你丢失了密钥密码。
与使用主密钥一样,如果一个吊销证书泄露到恶意者手中,他们能够使用它去破坏你的开发者数字身份,因此,最好是从你的家目录中删除它。
```
cd ~/.gnupg/openpgp-revocs.d
rm [fpr].rev
```
在下一篇文章中,你将学习如何保护你的子密钥。敬请期待。
从来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 中学习更多 Linux 知识。
---
via: <https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage>
作者:[Konstantin Ryabitsev](https://www.linux.com/users/mricon) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,403 | 极客漫画:呃,70 后 | http://turnoff.us/geek/oh-the-70s/ | 2019-01-01T10:40:51 | [
"编程语言"
] | https://linux.cn/article-10403-1.html | 
70 后的老程序员已经对层出不穷的编程语言感到了厌烦,虽然这已经距离上一个编程语言出现已经十年了。
虽然老程序员依旧很潮——扎着马尾,穿着花裤子——但是不能掩饰其秃顶和肥胖的腰身。
IT 行业,是一个日新月异的行业,老程序员们如何跟上时代呢?十年,快吗?
---
via: <http://turnoff.us/geek/oh-the-70s/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者 & 校对:[wxy](https://github.com/wxy) 校对 & 合成:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,404 | 一个 HTTP/2 的故事 | https://veronneau.org/a-tale-of-http2.html | 2019-01-01T16:57:00 | [
"HTTP/2"
] | https://linux.cn/article-10404-1.html | 大约一个月前,有人在我所在的 IRC 频道中提到了 [HTTP/2](https://en.wikipedia.org/wiki/HTTP/2)。由于某种原因,我从未听说过它,而且新协议的一些功能(比如无需打开多个 TCP 连接就能复用请求)似乎很酷。
说实话,我刚刚重写了管理我们备份程序的 Puppet 代码,启用 HTTP/2 似乎是一种转向另一个大型项目之前有效的拖延方式。这有多难?
结果我花了大约 25 个小时来完成。坐下来穿上舒适的拖鞋,听听这个 HTTP/2 的故事!

### 被诅咒的 HTTP/1.1
当我第一次看到如何在 Apache 上启用 HTTP/2 时,这似乎是一项非常简单的任务。文档提到加载 `http2` 模块并通过如下配置文件确保新协议优先:
```
Protocols h2 h2c http/1.1
H2Push on
H2PushPriority * after
H2PushPriority text/css before
H2PushPriority image/jpeg after 32
H2PushPriority image/png after 32
H2PushPriority application/javascript interleaved
```
这当然很容易。即使 Apache 中的所有内容都已正确设置,网站仍然使用的是 HTTP/1.1。不过,显然我做得没错,因为我的网站现在发送了一个新的 HTTP 头:`Upgrade: h2, h2c`。
在浪费了大量时间调试 TLS 密钥(HTTP/2 [与 TLS 1.1 不兼容](https://http2.github.io/http2-spec/#TLSUsage))之后,我终于发现问题是没有使用正确的 Apache 多进程处理模块。
事实证明,在使用 `mpm_prefork`(默认 MPM)时,Apache 不会使用 HTTP/2,因为 `mod_http2` 不支持它。尽管 Apache 还有两个其他的 MPM,但只有 `mpm_prefork` 支持 `mod_php`。突然之间,添加对 HTTP/2 的支持意味着我们将要把所有的 PHP 网站切换到 PHP-FPM。
### 掉进兔子洞
在很长一段时间里,一位好友一直试图让我相信 [PHP-FPM](https://wiki.apache.org/httpd/PHP-FPM) 的优点。虽然表面上看起来很好,但我从来没有真正试过。它看起来很复杂。常规的 `mod_php` 做得很好,还有其他事情需要我注意。
事实上,这次的 HTTP/2 事件是让我钻研它的一个契机。在我理解了 FPM 池的工作原理后,它实际上很容易设置。由于我不得不重写我们用于部署网站的 Puppet 配置文件,我也借此机会巩固了一堆东西。
PHP-FPM 允许你在不同的 Unix 用户下运行网站来增加隔离性。最重要的是,我决定是时候让我们服务器上的 PHP 代码以只读模式运行,并且不得不为我们的 Wordpress、Nextcloud、KanBoard 和 Drupal 实例调整一些东西来减少报错。
过了很长时间通过 Puppet 的自动任务后,我终于能够全部关闭 `mod_php` 和 `mpm_prefork` 并启用 `mpm_event` 和 `mod_http2`。PHP-FPM 和 HTTP/2 带来的速度提升不错,但更让我感到高兴的是这次磨练增强了我们的 Apache 处理 PHP 的能力。

---
via: <https://veronneau.org/a-tale-of-http2.html>
作者:[Louis-Philippe Véronneau](https://veronneau.org/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
10,405 | 如何构建一台网络引导服务器(三) | https://fedoramagazine.org/how-to-build-a-netboot-server-part-3/ | 2019-01-01T17:18:00 | [
"网络引导"
] | https://linux.cn/article-10405-1.html | 
在 [如何构建一台网络引导服务器(一)](/article-10379-1.html) 中,我们提供了一个极简的 [iPXE](https://ipxe.org/) 引导脚本来引导你的网络引导镜像。许多用户除了使用网络引导镜像外,可能在机器本地也有一个操作系统。但是使用常见的工作站的 BIOS 去切换引导加载器是很笨拙的。在本系列文件的第三部分,我们将向你展示如何设置一个更复杂的 iPXE 配置。它将允许终端用户以更容易的方式去选择引导哪个操作系统。它也可以配置为让系统管理员从一台中央服务器来统一管理引导菜单。
### 一个交互式 iPXE 引导菜单
下面这些命令重定义了网络引导镜像的 `boot.cfg` 来作为一个交互式的 iPXE 引导菜单,并使用了一个 5 秒倒计时的定时器:
```
$ MY_FVER=29
$ MY_KRNL=$(ls -c /fc$MY_FVER/lib/modules | head -n 1)
$ MY_DNS1=192.0.2.91
$ MY_DNS2=192.0.2.92
$ MY_NAME=server-01.example.edu
$ MY_EMAN=$(echo $MY_NAME | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_NAME})
$ MY_ADDR=$(host -t A $MY_NAME | awk '{print $4}')
$ cat << END > $HOME/esp/linux/boot.cfg
#!ipxe
set timeout 5000
:menu
menu iPXE Boot Menu
item --key 1 lcl 1. Microsoft Windows 10
item --key 2 f$MY_FVER 2. RedHat Fedora $MY_FVER
choose --timeout \${timeout} --default lcl selected || goto shell
set timeout 0
goto \${selected}
:failed
echo boot failed, dropping to shell...
goto shell
:shell
echo type 'exit' to get the back to the menu
set timeout 0
shell
goto menu
:lcl
exit
:f$MY_FVER
kernel --name kernel.efi \${prefix}/vmlinuz-$MY_KRNL initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=$MY_DNS1 nameserver=$MY_DNS2 root=/dev/disk/by-path/ip-$MY_ADDR:3260-iscsi-iqn.$MY_EMAN:fc$MY_FVER-lun-1 netroot=iscsi:$MY_ADDR::::iqn.$MY_EMAN:fc$MY_FVER console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet
initrd --name initrd.img \${prefix}/initramfs-$MY_KRNL.img
boot || goto failed
END
```
上述菜单有五个节:
* `menu` 定义了显示在屏幕上的实际菜单内容。
* `failed` 提示用户发生了错误,并将用户带到 shell 以错误错误。
* `shell` 提供了交互式命令提示符。你可以在引导菜单出现时按下 `Esc` 键进入,或者是 `boot` 命令失败时也会进入到命令提示符。
* `lcl` 包含一个提供给 iPXE 退出的简单命令,以及返还控制权给 BIOS。在 iPXE 之后,无论你希望缺省引导的设备(即:工作站的本地硬件)是什么,都必须在你的工作站的 BIOS 中正确地作为下一个引导设备列出来。
* `f29` 包含前面文章提到同一个网络引导代码,但使用最终的退出代码来替换掉 `goto failed`。
从你的 `$HOME/esp/linux` 目录中复制更新后的 `boot.cfg` 到所有客户端系统的 ESP 中。如果一切顺利,你应该会看到类似下面图片的结果:

### 一个服务器托管的引导菜单
你可以添加到网络引导服务器的另一个特性是,能够从一台中央位置去管理所有客户端的引导菜单。这个特性尤其适用于批量安装(升级)一个新版本的操作系统。在你将新内核和新的 `initramfs` 复制到所有客户端的 ESP 之后,这个特性可以让你执行一种 [原子事务](https://en.wikipedia.org/wiki/Atomicity_(database_systems)) 去切换所有客户端到新操作系统。
安装 Mojolicious:
```
$ sudo -i
# dnf install -y perl-Mojolicious
```
定义 “bootmenu” 应用程序:
```
# mkdir /opt/bootmenu
# cat << END > /opt/bootmenu/bootmenu.pl
#!/usr/bin/env perl
use Mojolicious::Lite;
use Mojolicious::Plugins;
plugin 'Config';
get '/menu';
app->start;
END
# chmod 755 /opt/bootmenu/bootmenu.pl
```
为 “bootmenu” 应用程序定义配置文件:
```
# cat << END > /opt/bootmenu/bootmenu.conf
{
hypnotoad => {
listen => ['http://*:80'],
pid_file => '/run/bootmenu/bootmenu.pid',
}
}
END
```
这是一个非常简单的 Mojolicious 应用程序,它监听 80 端口,并且只回应对 `/menu` 的请求。如果你想快速了解 Mojolicious 能做什么,运行 `man Mojolicious::Guides::Growing` 去查看手册。按 `Q` 键退出手册。
将 `boot.cfg` 移到我们的网络引导应用程序中作为一个名为 `menu.html.ep` 的模板:
```
# mkdir /opt/bootmenu/templates
# mv $HOME/esp/linux/boot.cfg /opt/bootmenu/templates/menu.html.ep
```
定义一个 systemd 服务去管理引导菜单应用程序:
```
# cat << END > /etc/systemd/system/bootmenu.service
[Unit]
Description=Serves iPXE Menus over HTTP
After=network-online.target
[Service]
Type=forking
DynamicUser=true
RuntimeDirectory=bootmenu
PIDFile=/run/bootmenu/bootmenu.pid
ExecStart=/usr/bin/hypnotoad /opt/bootmenu/bootmenu.pl
ExecReload=/usr/bin/hypnotoad /opt/bootmenu/bootmenu.pl
AmbientCapabilities=CAP_NET_BIND_SERVICE
KillMode=process
[Install]
WantedBy=multi-user.target
END
```
在本地防火墙中为 HTTP 服务添加一个例外规则,并启动 bootmenu 服务:
```
# firewall-cmd --add-service http
# firewall-cmd --runtime-to-permanent
# systemctl enable bootmenu.service
# systemctl start bootmenu.service
```
用 `wget` 测试它:
```
$ sudo dnf install -y wget
$ MY_BOOTMENU_SERVER=server-01.example.edu
$ wget -q -O - http://$MY_BOOTMENU_SERVER/menu
```
以上的命令应该会输出类似下面的内容:
```
#!ipxe
set timeout 5000
:menu
menu iPXE Boot Menu
item --key 1 lcl 1. Microsoft Windows 10
item --key 2 f29 2. RedHat Fedora 29
choose --timeout ${timeout} --default lcl selected || goto shell
set timeout 0
goto ${selected}
:failed
echo boot failed, dropping to shell...
goto shell
:shell
echo type 'exit' to get the back to the menu
set timeout 0
shell
goto menu
:lcl
exit
:f29
kernel --name kernel.efi ${prefix}/vmlinuz-4.19.4-300.fc29.x86_64 initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=192.0.2.91 nameserver=192.0.2.92 root=/dev/disk/by-path/ip-192.0.2.158:3260-iscsi-iqn.edu.example.server-01:fc29-lun-1 netroot=iscsi:192.0.2.158::::iqn.edu.example.server-01:fc29 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet
initrd --name initrd.img ${prefix}/initramfs-4.19.4-300.fc29.x86_64.img
boot || goto failed
```
现在,引导菜单服务器已经正常工作了,重新构建 `ipxe.efi` 引导加载器,使用一个初始化脚本指向它。
第一步,先更新我们在本系列文章的第一部分中创建的 `init.ipxe` 脚本:
```
$ MY_BOOTMENU_SERVER=server-01.example.edu
$ cat << END > $HOME/ipxe/init.ipxe
#!ipxe
dhcp || exit
set prefix file:///linux
chain http://$MY_BOOTMENU_SERVER/menu || exit
END
```
现在,重新构建引导加载器:
```
$ cd $HOME/ipxe/src
$ make clean
$ make bin-x86_64-efi/ipxe.efi EMBED=../init.ipxe
```
将更新后的引导加载器复制到你的 ESP 中:
```
$ cp $HOME/ipxe/src/bin-x86_64-efi/ipxe.efi $HOME/esp/efi/boot/bootx64.efi
```
将更新后的引导加载器复制到所有的客户端中之后,以后更新引导菜单只需要简单地编辑 `/opt/bootmenu/templates/menu.html.ep` 文件,然后再运行如下命令:
```
$ sudo systemctl restart bootmenu.service
```
### 做一步的改变
如果引导菜单服务器工作正常,在你的客户端系统上的 `boot.cfg` 文件将更长。
比如,重新添加 Fedora 28 镜像到引导菜单中:
```
$ sudo -i
# MY_FVER=28
# MY_KRNL=$(ls -c /fc$MY_FVER/lib/modules | head -n 1)
# MY_DNS1=192.0.2.91
# MY_DNS2=192.0.2.92
# MY_NAME=$(</etc/hostname)
# MY_EMAN=$(echo $MY_NAME | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_NAME})
# MY_ADDR=$(host -t A $MY_NAME | awk '{print $4}')
# cat << END >> /opt/bootmenu/templates/menu.html.ep
:f$MY_FVER
kernel --name kernel.efi \${prefix}/vmlinuz-$MY_KRNL initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=$MY_DNS1 nameserver=$MY_DNS2 root=/dev/disk/by-path/ip-$MY_ADDR:3260-iscsi-iqn.$MY_EMAN:fc$MY_FVER-lun-1 netroot=iscsi:$MY_ADDR::::iqn.$MY_EMAN:fc$MY_FVER console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet
initrd --name initrd.img \${prefix}/initramfs-$MY_KRNL.img
boot || goto failed
END
# sed -i "/item --key 2/a item --key 3 f$MY_FVER 3. RedHat Fedora $MY_FVER" /opt/bootmenu/templates/menu.html.ep
# systemctl restart bootmenu.service
```
如果一切顺利,你的客户端下次引导时,应该看到如下图所示的结果:

---
via: <https://fedoramagazine.org/how-to-build-a-netboot-server-part-3/>
作者:[Gregory Bartholomew](https://fedoramagazine.org/author/glb/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [How to Build a Netboot Server, Part 1](https://fedoramagazine.org/how-to-build-a-netboot-server-part-1/) article provided a minimal [iPXE](https://ipxe.org/) boot script for your netboot image. Many users probably have a local operating system that they want to use in addition to the netboot image. But switching bootloaders using the typical workstation’s BIOS can be cumbersome. This part of the series shows how to set up some more complex iPXE configurations. These allow the end user to easily choose which operating system they want to boot. They also let the system administrator manage the boot menus from a central server.
## An interactive iPXE boot menu
The commands below redefine the netboot image’s *boot.cfg* as an interactive iPXE boot menu with a 5 second countdown timer:
$ MY_FVER=29 $ MY_KRNL=$(ls -c /fc$MY_FVER/lib/modules | head -n 1) $ MY_DNS1=192.0.2.91 $ MY_DNS2=192.0.2.92 $ MY_NAME=server-01.example.edu $ MY_EMAN=$(echo $MY_NAME | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_NAME}) $ MY_ADDR=$(host -t A $MY_NAME | awk '{print $4}') $ cat << END > $HOME/esp/linux/boot.cfg #!ipxe set timeout 5000 :menu menu iPXE Boot Menu item --key 1 lcl 1. Microsoft Windows 10 item --key 2 f$MY_FVER 2. RedHat Fedora $MY_FVER choose --timeout \${timeout} --default lcl selected || goto shell set timeout 0 goto \${selected} :failed echo boot failed, dropping to shell... goto shell :shell echo type 'exit' to get the back to the menu set timeout 0 shell goto menu :lcl exit :f$MY_FVER kernel --name kernel.efi \${prefix}/vmlinuz-$MY_KRNL initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=$MY_DNS1 nameserver=$MY_DNS2 root=/dev/disk/by-path/ip-$MY_ADDR:3260-iscsi-iqn.$MY_EMAN:fc$MY_FVER-lun-1 netroot=iscsi:$MY_ADDR::::iqn.$MY_EMAN:fc$MY_FVER console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet initrd --name initrd.img \${prefix}/initramfs-$MY_KRNL.img boot || goto failed END
The above menu has five sections:
**menu**defines the actual menu that will be shown on the screen.**failed**notifies the user that something went wrong and drops the user to a shell so they can troubleshot the problem.**shell**provides an interactive command prompt. You can reach it either by pressing the**Esc**key while at the boot menu or if the “boot” command returns with a failure code.**lcl**contains a single command that tells iPXE to*exit*and return control back to the BIOS. Whatever you want to boot by default (e.g. the workstation’s local hard drive)**must**be listed as the next boot item right after iPXE in your workstation’s BIOS.**f29**contains the same netboot code used earlier but with the final*exit*replaced with*goto failed*.
Copy the updated *boot.cfg* from your *$HOME/esp/linux* directory out to the ESPs of all your client systems. If all goes well, you should see results similar to the image below:
## A server hosted boot menu
Another feature you can add to the netboot server is the ability to manage all the client boot menus from one central location. This feature can be especially useful when rolling out a new version of the OS. It lets you perform a sort of [atomic transaction](https://en.wikipedia.org/wiki/Atomicity_(database_systems)) to switch all clients over to the new OS after you’ve copied the new kernel and initramfs out to the ESPs of all the clients.
Install Mojolicious:
$ sudo -i # dnf install -y perl-Mojolicious
Define the “bootmenu” app:
# mkdir /opt/bootmenu # cat << END > /opt/bootmenu/bootmenu.pl #!/usr/bin/env perl use Mojolicious::Lite; use Mojolicious::Plugins; plugin 'Config'; get '/menu'; app->start; END # chmod 755 /opt/bootmenu/bootmenu.pl
Define the configuration file for the bootmenu app:
# cat << END > /opt/bootmenu/bootmenu.conf { hypnotoad => { listen => ['http://*:80'], pid_file => '/run/bootmenu/bootmenu.pid', } } END
This is an extremely simple Mojolicious application that listens on port 80 and only answers to */menu* requests. If you want a quick introduction to what Mojolicious can do, run *man Mojolicious::Guides::Growing* to view the manual. Use the **Q** key to quit the manual.
Move *boot.cfg* over to our netboot app as a template named *menu.html.ep:*
# mkdir /opt/bootmenu/templates # mv $HOME/esp/linux/boot.cfg /opt/bootmenu/templates/menu.html.ep
Define a systemd service to manage the bootmenu app:
# cat << END > /etc/systemd/system/bootmenu.service [Unit] Description=Serves iPXE Menus over HTTP After=network-online.target [Service] Type=forking DynamicUser=true RuntimeDirectory=bootmenu PIDFile=/run/bootmenu/bootmenu.pid ExecStart=/usr/bin/hypnotoad /opt/bootmenu/bootmenu.pl ExecReload=/usr/bin/hypnotoad /opt/bootmenu/bootmenu.pl AmbientCapabilities=CAP_NET_BIND_SERVICE KillMode=process [Install] WantedBy=multi-user.target END
Add an exception for the HTTP service to the local firewall and start the bootmenu service:
# firewall-cmd --add-service http # firewall-cmd --runtime-to-permanent # systemctl enable bootmenu.service # systemctl start bootmenu.service
Test it with *wget*:
$ sudo dnf install -y wget $ MY_BOOTMENU_SERVER=server-01.example.edu $ wget -q -O - http://$MY_BOOTMENU_SERVER/menu
The above command should output something similar to the following:
#!ipxe set timeout 5000 :menu menu iPXE Boot Menu item --key 1 lcl 1. Microsoft Windows 10 item --key 2 f29 2. RedHat Fedora 29 choose --timeout ${timeout} --default lcl selected || goto shell set timeout 0 goto ${selected} :failed echo boot failed, dropping to shell... goto shell :shell echo type 'exit' to get the back to the menu set timeout 0 shell goto menu :lcl exit :f29 kernel --name kernel.efi ${prefix}/vmlinuz-4.19.4-300.fc29.x86_64 initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=192.0.2.91 nameserver=192.0.2.92 root=/dev/disk/by-path/ip-192.0.2.158:3260-iscsi-iqn.edu.example.server-01:fc29-lun-1 netroot=iscsi:192.0.2.158::::iqn.edu.example.server-01:fc29 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet initrd --name initrd.img ${prefix}/initramfs-4.19.4-300.fc29.x86_64.img boot || goto failed
Now that the boot menu server is working, rebuild the *ipxe.efi* bootloader with an init script that points to it.
First, update the *init.ipxe* script created in part one of this series:
$ MY_BOOTMENU_SERVER=server-01.example.edu $ cat << END > $HOME/ipxe/init.ipxe #!ipxe dhcp || exit set prefix file:///linux chain http://$MY_BOOTMENU_SERVER/menu || exit END
Now, rebuild the boot loader:
$ cd $HOME/ipxe/src $ make clean $ make bin-x86_64-efi/ipxe.efi EMBED=../init.ipxe
Copy the updated bootloader to your ESP:
$ cp $HOME/ipxe/src/bin-x86_64-efi/ipxe.efi $HOME/esp/efi/boot/bootx64.efi
After you’ve copied the updated bootloader to all your clients, you can make future updates to the boot menu simply by editing */opt/bootmenu/templates/menu.html.ep* and running:
$ sudo systemctl restart bootmenu.service
## Making further changes
If the boot menu server is working properly, you’ll longer need the the *boot.cfg* file on your client systems.
For example, re-add the Fedora 28 image to the boot menu:
$ sudo -i # MY_FVER=28 # MY_KRNL=$(ls -c /fc$MY_FVER/lib/modules | head -n 1) # MY_DNS1=192.0.2.91 # MY_DNS2=192.0.2.92 # MY_NAME=$(</etc/hostname) # MY_EMAN=$(echo $MY_NAME | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_NAME}) # MY_ADDR=$(host -t A $MY_NAME | awk '{print $4}') # cat << END >> /opt/bootmenu/templates/menu.html.ep :f$MY_FVER kernel --name kernel.efi \${prefix}/vmlinuz-$MY_KRNL initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=$MY_DNS1 nameserver=$MY_DNS2 root=/dev/disk/by-path/ip-$MY_ADDR:3260-iscsi-iqn.$MY_EMAN:fc$MY_FVER-lun-1 netroot=iscsi:$MY_ADDR::::iqn.$MY_EMAN:fc$MY_FVER console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet initrd --name initrd.img \${prefix}/initramfs-$MY_KRNL.img boot || goto failed END # sed -i "/item --key 2/a item --key 3 f$MY_FVER 3. RedHat Fedora $MY_FVER" /opt/bootmenu/templates/menu.html.ep # systemctl restart bootmenu.service
If all goes well, your clients should see results similar to the image below the next time they boot:
## Sinan
Why “Redhat” Fedora 2x ??
## Gregory Bartholomew
I was going for ” “. It is true though that Fedora is the product of many companies and individuals; not just Red Hat. See https://getfedora.org/en/sponsors for a partial list of companies that contribute to Fedora.
## Gregory Bartholomew
WordPress mutilated my reply — Between the quotes should have been “<company> <product> <version>”.
## Gregory Bartholomew
TIP:
If you need iPXE to provide different options depending on the machine type, you can use the
iseqcommand to test the value of the${product:hex}variable like so:...
set initrd initramfs-4.19.4-300.fc29.x86_64.img
iseq ${product:hex} 50:72:65:63:69:73:69:6f:6e:20:54:31:36:35:30 && set initrd initramfs-4.16.3-301.fc28.x86_64.img
...
initrd --name initrd.img ${prefix}/${initrd}
In the example above, a different initramfs is provided if the client is a “Precision T1650” computer.
You can get the hex value either by echoing the ${product:hex} variable at an iPXE command prompt:
Or by piping the string through the xxd command in a bash shell:
## Gregory Bartholomew
Oops, the “iseq …” line needs a “||” at the end or else the script will stop if the equality fails. That line should have been: |
10,406 | 初级:如何在终端及图形界面中更新 Ubuntu | https://itsfoss.com/update-ubuntu/ | 2019-01-01T21:29:04 | [
"Ubuntu",
"升级",
"更新"
] | https://linux.cn/article-10406-1.html |
>
> 这篇教程将向你展示如何更新服务器版本或者桌面版本的 Ubuntu。它还解释了更新和升级之间的区别以及你应该了解的有关于 Ubuntu Linux 中的更新的一些其他内容。
>
>
>
如果你是一个新手并已经体验 Ubuntu 数天或几周,你可能想知道如何更新你的 [Ubuntu](https://www.ubuntu.com/) 系统以获取安全补丁,错误修复和应用升级。
更新 Ubuntu 非常简单。我并不是瞎说。它简单得只要运行两个命令。让我来告诉你这两个命令的更多细节。
请注意,本教程适用于 Ubuntu 18.04、16.04 或任何其他版本。命令行方式也适用于基于 Ubuntu 的发行版如 Linux Mint、Linux Lite、elementary OS 等。
### 通过命令行更新 Ubuntu

在桌面上,打开终端。你可以在菜单里找到它或者使用 `Ctrl+Alt+T` [快捷键](https://itsfoss.com/ubuntu-shortcuts/)。如果你是登录到一台 [Ubuntu 服务器](https://www.ubuntu.com/download/server),那你已经在访问一个终端了。
在终端里,你只需要使用以下命令:
```
sudo apt update && sudo apt upgrade -y
```
它将询问你密码,而你可以使用你的账号密码。输入时,你将不会看到任何内容在屏幕上,所以请继续输入你的密码并按回车键。
现在,我来解释下上面的命令。
事实上,这不是一条命令。它由两条命令组成。符号 `&&` 是合并两条命令的一个方法,第二条命令仅在前一条命令执行成功时执行。
当命令 `apt upgrade` 要求你在安装更新前确认时,末尾的参数 `-y` 会自动输入 `yes`。
请注意,你也可以逐条使用这两条命令:
```
sudo apt update
sudo apt upgrade
```
这将花费更长的时间,因为你必须等待第一条命令执行完成后才能输入第二条命令。
#### 说明:sudo apt update
这条命令更新了可用软件包的本地数据库。如果你没运行这条命令,本地数据库将不会被更新,而你的系统将不会知道是否有可用的新版本。
这就是为什么当你运行 `sudo apt update`,你会在输出中看到大量的 URL。这条命令会从对应的储存库(你在输出中看到的 URL)中获取软件包信息。

在命令的末尾,它告诉你有多少个软件包可以被更新。你可以使用下列命令查看这些软件包:
```
apt list --upgradable
```
**补充阅读:** 阅读这篇文章了解[命令 apt update 的输出中的 Ign、Hit 和 Get 是什么](https://itsfoss.com/apt-get-linux-guide/)。
#### 说明:sudo apt upgrade
这条命令将已安装的软件包版本与本地数据库进行匹配。它收集全部信息,然后列出所有具有更新版本的软件包。此时,它会询问您是否要升级(已安装的软件包更新到新版本)。

你可以键入 `yes`、`y` 或者只敲回车键去确认安装这些更新。
所以总的来说,`sudo apt update` 会检查可用的新版本,而 `sudo apt upgrade` 实际上会执行更新。
命令 `update` 可能会令人困惑,因为你可能期望通过命令 `apt update` 安装更新来更新系统,但这并不会发生。
### 通过 GUI 更新 Ubuntu(适用于桌面用户)
如果你使用桌面版 Ubuntu,你并不需要为了更新系统而打开终端。你可以仍可以使用命令行更新,但这只是一个选择。
在菜单里,找到 “软件更新” 并运行它。

它将检查你的系统是否有可用的更新。

如果有可用的更新,它将给你提供安装更新的选择。

现在,点击 “安装”,它可能会向你询问密码。

一旦你输入你的密码,它将开始安装更新。

在某些情况下,你可能需要重启系统才能使已安装的更新正常工作。如果需要重启系统,你将在更新结束时收到通知。

如果你不希望马上重启你的系统,可以选择稍后重启。

提示:如果“软件更新”返回一个错误,你需要在终端是使用命令 `sudo apt update`。输出的最后几行将包含真正的错误信息。你可以在因特网上搜索该错误并解决问题。
### 更新 Ubuntu 时要记住几件事
你刚学习了如何更新你的 Ubuntu 系统。如果你感兴趣,你还需要了解一些关于 Ubuntu 更新的内容。
#### 更新后清理
你的系统将会有一些更新后不再需要的软件包。你可用使用这条命令删除这些软件包并[释放空间](https://itsfoss.com/free-up-space-ubuntu-linux/):
```
sudo apt autoremove
```
#### 在 Ubuntu Server 中内核热修复以避免重启
如果是 Linux 内核更新,你将需要在系统更新后重启。当你不希望服务器停机时,这将会是一个问题。
[热修复](https://www.ubuntu.com/livepatch)功能允许 Linux 内核在持续运行时打补丁。换句话说就是你不需要重启你的系统。
如果你在管理服务器,你可能需要[在 Ubuntu 中启用热修复](https://www.cyberciti.biz/faq/howto-live-patch-ubuntu-linux-server-kernel-without-rebooting/)。
#### 版本升级是不同的
本文讨论的更新是使你安装的 Ubuntu 保持最新。但它不包括[版本升级](https://itsfoss.com/upgrade-ubuntu-version/)(例如从 Ubuntu 16.04 升级到 18.04)。
[Ubuntu 版本](https://itsfoss.com/how-to-know-ubuntu-unity-version/) 升级完全是另一回事。它更新整个操作系统核心。你需要在这个漫长的过程开始前做好备份。
### 总结
我希望你喜欢这个关于 Ubuntu 系统更新的教程并学到一些新东西。
如果你有其他问题,请随时提出。如果你是一位经验丰富的 Linux 用户并且有些更好的技巧,请同我们分享。
---
via: <https://itsfoss.com/update-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LazyWolfLin](https://github.com/LazyWolfLin) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you are a new user and have been using Ubuntu for a few days or weeks, you might be wondering how to update your [Ubuntu](https://www.ubuntu.com/?ref=itsfoss.com) system for security patches, bug fixes and application upgrades.
Updating Ubuntu is incredibly simple. I am not exaggerating. It’s as simple as running two commands:
```
sudo apt update
sudo apt upgrade
```
Actually, there are two ways you can update your Ubuntu system:
- Update Ubuntu via the command line
- Update Ubuntu using the Software Updater GUI tool
Let me give you more details. Please note that this tutorial is valid for Ubuntu 20.04, 22.04, or any other version. The command line method is also valid for Ubuntu-based Linux distributions, like Linux Mint, Linux Lite, elementary OS, etc.
[upgrading Ubuntu version](https://itsfoss.com/upgrade-ubuntu-version/).
## Method 1: Update Ubuntu via the Command Line
First, [open the terminal in Ubuntu desktop](https://itsfoss.com/open-terminal-ubuntu/). You can find it in the menu, or use the Ctrl+Alt+T [keyboard shortcut](https://itsfoss.com/ubuntu-shortcuts/). If you are logged on to an [Ubuntu server](https://www.ubuntu.com/download/server?ref=itsfoss.com), you already have access to a terminal.
In the terminal, you have to use the following command:
`sudo apt update && sudo apt upgrade -y`
**, so keep on typing your password and hit enter. This will update the packages in Ubuntu.**
*You won’t see characters on the screen while typing the password in the terminal*
See, how easy it is to update Ubuntu from the terminal? Now let me explain the above command.
It’s actually not a single command; it’s a combination of two commands. The && is a way to [run multiple commands in Linux](https://itsfoss.com/run-multiple-commands-linux/) in a way such that the second command runs only when the previous command ran successfully.
**The “-y” in the end automatically enters “yes” when the command “apt upgrade” ask for your confirmation before installing updates.**
Note that you can also use the two commands separately, one by one:
```
sudo apt update
sudo apt upgrade
```
It will take a little longer because you have to wait for one command to finish and then enter the second command.
**More than just OS updates**: Unlike Windows,
[Linux works with a package manager](https://itsfoss.com/package-manager/). When you run the updates, it updates all the packages installed via apt. This means updating Ubuntu will update the core operating system, Linux kernels, and the applications installed from the software center (if they were apt packages) or installed using apt command.
### Explanation: sudo apt update
This command updates the local database of available packages. If you don’t run this command, the local database won’t be updated and your system will not know if there are any new versions of packages available.
This is why, when you run the “sudo apt update” command, you’ll see lots of URLs in the output. The command fetches the package information from the respective repositories (the URLs you see in the output).
At the end of the command, it tells you how many packages can be upgraded. You can see these packages by running the following command:
`apt list --upgradable`
### Explanation: sudo apt upgrade
This command matches the versions of installed packages with the local database. It collects all of them, and then it will list those packages that have a newer version available. At this point, it will ask if you want to upgrade the installed packages to the newer version.
You can type “yes,” or “y,” or just press enter to confirm the installation of updates.
So the bottom line is that “sudo apt update” checks for the availability of new package versions, while “sudo apt upgrade” actually installs the new versions.
The term update might be confusing, as you might expect the “apt update” command to update the system by installing new software, but that’s not how it works.
## Method 2: Update Ubuntu via the GUI [For Desktop Users]
If you are using Ubuntu as a desktop, you don’t have to go to the terminal to update the system. You can still use the command line, but it’s optional for you.
In the menu, look for “Software Updater” and run it.
It will check if there are updates available for your system.
If there are updates available, it will give you the option to install the updates.
Click on “Install Now.” It may ask for your password.
Once you enter your password, it will start installing the updates.
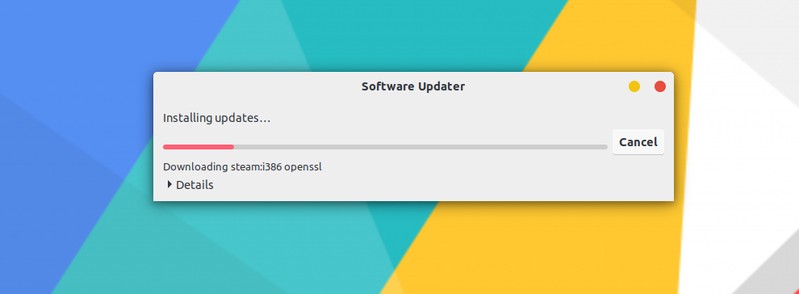
In some cases, you may need to [reboot your Ubuntu system](https://itsfoss.com/schedule-shutdown-ubuntu/) for the installed updates to work properly. You’ll be notified at the end of the update if you need to restart the system.

You can choose to restart later if you don’t want to reboot your system straightaway.
Tip: If the software updater returns an error, you should use the command “sudo apt update” in the terminal. The last few lines of the output will contain the actual error message. You can then search on the internet for that error and fix the problem.
## A few things to keep in mind about updating Ubuntu
You just learned how to update your Ubuntu system. If you are interested, you should also know these few things relating to Ubuntu updates.
### Cleaning up after an update
After an update, your system may have some unnecessary packages that are no longer required. You can remove such packages and [free up some space](https://itsfoss.com/free-up-space-ubuntu-linux/) by using this command:
`sudo apt autoremove`
### Live patching the kernel in Ubuntu Server to avoid rebooting
In the case of Linux kernel updates, you’ll have to restart the system after the update. This can be a problem if you don’t want downtime for your server.
The [live patching](https://www.ubuntu.com/livepatch?ref=itsfoss.com) feature allows for the patching of the Linux kernel while it is still running. In other words, you don’t have to reboot your system.
If you manage servers, you may want to [enable live patching in Ubuntu](https://www.cyberciti.biz/faq/howto-live-patch-ubuntu-linux-server-kernel-without-rebooting/?ref=itsfoss.com).
### Ubuntu version upgrades are different from package upgrades
The update methods discussed here keep your Ubuntu install fresh and updated. It doesn’t cover OS [version upgrades](https://itsfoss.com/upgrade-ubuntu-version/) (for example, upgrading Ubuntu 16.04 to 18.04).
[Ubuntu version](https://itsfoss.com/how-to-know-ubuntu-unity-version/) upgrades are an entirely different thing. They involve updating the entire operating system core. You’ll need to make proper backups before starting this lengthy process.
## Conclusion
I hope you liked this tutorial on updating the Ubuntu system and that you learned a few new things.
If you have any questions, please feel free to ask. If you are an experienced Linux user and have some tips that can make this tutorial more useful, please share them with the rest of us. |
10,407 | Linux 下最棒的 11 个图片查看器 | https://itsfoss.com/image-viewers-linux/ | 2019-01-02T14:05:21 | [
"图片",
"图像"
] | https://linux.cn/article-10407-1.html | 如果不是因为系统自带的图片查看器没有你想要的功能,或者你想要更棒的体验,你大概不会想切换到其它图片查看器吧。
不过,如果你喜欢折腾,你可能就会想用不同的图片查看器了吧。我猜最终你会被新图片查看器的全新用户体验或特色功能所吸引的。
在本篇文章中,无论是简单的还是复杂的、无论是为 Ubuntu 准备的还是其它 Linux 发行版准备的,我们都有提到。
### Linux 下最棒的图片查看器

**注意:** 在准备安装一个图片查看器时,请前往您系统中预先安装的软件商店中查找。如果您没有任何软件商店或无法在软件商店中找到它,请手动执行我们给出的命令。
#### 1. Nomacs

**它有什么特点?**
* 轻快
* 内建图像调整工具(可以调整色彩和大小)
* 拍摄位置信息
* 元数据调节器
* 局域网同步
* 全屏模式
Nomacs 是一款自由软件。虽然没有什么出众的功能,但是它的兼容性还不错,可以支持许多常见格式。
它的界面超级简单,但是提供了简单的图片编辑功能(可以调整色彩、亮度、大小和裁剪)。除此之外,它还支持全屏模式、直方图,以及可以切换显示元数据、编辑历史等信息的许多面板。
**我该如何安装它?**
简单起见,你可以在各种软件中心中安装它。如果你想通过终端安装它,请参见它的 [GitHub 页](https://github.com/nomacs/nomacs) 。或者,在使用 APT 包管理的系统中使用如下命令安装:
```
sudo apt install nomacs
```
#### 2. Gnome 之眼

**它有什么特点?**
* 极其简单的图像查看器
* 幻灯片视图
* 为 GNOME 量身打造的图片查看器
这是一款经典的图片查看器,它在数年前作为 GNOME 项目的一部分被开发出来。不过需要注意的是,对它的维护目前已经不是很活跃了。不过它仍能在最新版 Ubuntu LTS 和部分 Linux 发行版中正常工作。
如果你需要一个简单、有幻灯片视图并可以在侧栏看到元数据的图像查看器,Gnome 之眼是最佳选择。
**我该如何安装它?**
若要在 Ubuntu 及基于 Ubuntu 的 Linux 发行版上安装它,仅需一条命令:
```
sudo apt install eog
```
如果你想在其它发行版中安装它,请参见 [该项目的 GitHub 页面](https://github.com/GNOME/eog) 。
#### 3. EOM

**它有什么特点?**
* 简洁
* 可扩展
* 为 MATE 量身打造的图片查看器
另一个基本功能齐全,支持幻灯片视图和图像旋转的查看器。
虽然它没什么特色功能,但它支持大部分的图像格式,并且还能处理大体积的图像。
**我该如何安装它?**
若要在 Ubuntu 及基于 Ubuntu 的 Linux 发行版上安装它,仅需一条命令:
```
sudo apt install eom
```
如果你想在其它发行版中安装它,请参见 [该项目的 GitHub 页面](https://github.com/mate-desktop/eom) 。
#### 4. Geeqie

**它有什么特点?**
* 可扩展的灵活的图像查看器(其它的图像查看器支持它)
* 可以显示色彩信息
Geeqie 是一个令用户印象深刻的图片管理/查看器。它支持将其它查看器作为扩展使用,不过它并不提供任何对图像操作的工具。
如果你希望获取图像的颜色信息、元数据,或是查看/管理一组图片,它将会是一个不错的选择。
**我该如何安装它?**
在终端输入:
```
sudo apt install geeqie
```
若想查看它的源代码,请前往 [它的 GitHub 主页](https://github.com/BestImageViewer/geeqie)。
#### 5. gThumb

**它有什么特点?**
* 全功能(查看、编辑和管理)
* 可清除 EXIF 信息
* 图像格式转换
* 查找重复的图像
gThumb 会让你眼前一亮,因为它有很多功能。它的查看/管理界面和编辑工具(裁剪、缩放、颜色编辑等等)将会给你留下很深的印象。
你甚至可以为图像添加评论或清除它的 EXIF 信息。它使得你可以方便地找到重复的图像或转码图像。
**我该如何安装它?**
你可以在终端中输入这条命令:
```
sudo apt install gthumb
```
输了没用?请参阅 [项目 GitHub 主页](https://github.com/GNOME/gthumb) 来获取帮助。
#### 6. Gwenview

**它有什么特点?**
* 简单,有基础图像编辑功能(旋转、调整大小)
* 可使用 KIPI 插件扩展
Gwenview 又是一个基本的图像查看器,它为 KDE 量身定做。不过这并不影响你在其它桌面环境中使用它。
如果你使用 Konqueror 浏览器,你可以将 Gwenview 作为它的内嵌图片浏览器。你也可以为图片添加评论。此外,它还支持 [KIPI](https://en.wikipedia.org/wiki/KDE_Image_Plugin_Interface) 插件。
**我该如何安装它?**
你可以在终端中输入这条命令:
```
sudo apt install gwenview
```
若想查看它的源代码,请前往 [它的 GitHub 主页](https://github.com/KDE/gwenview)。
#### 7. Mirage

**它有什么特点?**
* 可定制的基本用户界面
* 基本图像编辑工具
* 可在命令行使用
如果你想要一个可在命令行中访问、支持全屏和幻灯片视图、带有基础编辑工具以及可定制 UI 的普通查看器,Mirage 是个不二之选。
它是一个非常快速且兼容性优良的查看器。它支持包括 png、jpg、svg、xpm、gif、bmp 和 tiff 在内的多种图像格式。
**我该如何安装它?**
你需要执行:
```
sudo apt install mirage
```
访问 [该项目 GitHub 页面](https://github.com/xiongchiamiov/Mirage) 来获取更多信息。
#### 8. KPhotoAlbum

**它有什么特点?**
* 为图像添加标签
* 数据库支持
* 图片压缩
* 将图像合并到一组图像,或移除
确切地说,KPhotoAlbum 其实不仅仅是一款图像查看器,它还能为图像添加标签并管理图像。
你可以用它来压缩图片以及使用标签搜索你的图片。你还可以使用幻灯片视图来观看图片。
**我该如何安装它?**
在终端中输入:
```
sudo apt kphotoalbum
```
跟从 [官网上的指引](https://www.kphotoalbum.org/download/) 来在其它 Linux 发行版中安装它。
#### 9. Shotwell

**它有什么特点?**
* 红眼消除工具
* 将照片上传到 Facebook 或 Flickr 等社交网络中
* 支持原始格式(RAW)的图片
Shotwell 是一个多功能照片管理器。在此,你能查看或管理你的照片。虽然它没带有许多图像编辑工具,但是你还是可以裁剪和调整亮度的。
**我该如何安装它?**
在终端中执行以下命令 (Ubuntu 及其衍生版本):
```
sudo apt install shotwell
```
若想获取更多信息,请 [前往它的 GitHub 页面](https://github.com/GNOME/shotwell)。
#### 10. Ristretto

**它有什么特点?**
* 极其简单
* 全屏模式
* 幻灯片视图
简易的图像查看器。它能查看、全屏查看、缩放查看或以幻灯片视图查看图片。
它是为 Xfce 定制的,但你仍然可以在其它任何地方安装它。
**我该如何安装它?**
即使它是为 Xfce 桌面环境构建的,你仍能在其它地方安装它。对 Ubuntu 及其衍生发行版,请执行:
```
sudo apt install ristretto
```
#### 11. digiKam

**它有什么特点?**
* 带有高级图像管理功能(查看/管理/编辑)的多合一查看器
* 可以进行批处理
* 带有 [Light Table 功能](https://docs.kde.org/trunk5/en/extragear-graphics/digikam/using-lighttable.html)
digiKam 是一个带有多种图像编辑功能的高级照片管理器。你可以使用 SQLite 或 MySQL 来配置它的数据库。
为了提升你的看图体验,你可以在预览图片时加载低画质的图片。这样一来,即使你有一大堆图片,它也丝滑般流畅。不仅如此,你还可以通过 Google、Facebook、Imgur 等来导入/导出图片。如果你希望使用一个超多功能的查看器,请务必试试这个 digiKam。
**我该如何安装它?**
执行这条命令:
```
sudo apt install digikam
```
访问 [项目 GitHub 页面](https://github.com/KDE/digikam) 来获取更多信息。
### 尾声
总的来说,无论你想要不同的用户体验、丰富的功能还是强大的管理工具,上面总有适合你的工具。
你更喜欢哪个图像查看器呢?它是系统自带的吗?
欢迎前往原文的评论区留下你的答案。
---
via: <https://itsfoss.com/image-viewers-linux/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zhs852](https://github.com/zhs852) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

It is probably a good idea to stick with the default system image viewer unless you want a specific feature (that’s missing) or if you crave for better user experience.
However, you may try out different image viewers if you like to experiment. You could end up loving the new user experience of viewing the images or get hooked on the extra features offered.
This article has mentioned every kind of image viewer ranging from the simplest to the most advanced tool available for Ubuntu or any other Linux distro.
## Best Image Viewers for Linux

## 1. Nomacs
**What’s good about it?**
- Simple & Fast UI
- Image adjustment tools (color & size)
- Geolocation of the image
- Metadata information panel
- LAN Synchronization
- Fullscreen mode
[Nomacs](https://nomacs.org/?ref=itsfoss.com) is a free and open source image viewer that does not come baked with any fancy features. However, Nomacs does support most of the common image file formats if you want to use it.
The user interface is very simple but it does offer some essential features for image adjustment (color, brightness, resize, crop, & cut). In addition to that, it also supports fullscreen mode, histogram, and a lot of different panels that you can toggle for metadata, edit history, and more such information.
**How do I install it?**
You can find it listed in the software center/AppCenter for easy installation. If you want to install it via terminal, you can take a look at their [GitHub page](https://github.com/nomacs/nomacs?ref=itsfoss.com) or type in the command below:
`sudo apt install nomacs`
## 2. Eye Of Gnome
**What’s good about it?**
- A dead simple image viewer
- Slideshow style (if that’s what you like)
- An image viewer tailored for the GNOME desktop environment
[eog](https://projects-old.gnome.org/eog/?ref=itsfoss.com) is a classic image viewer developed as a part of The GNOME Project a lot of years ago. Do note that this isn’t actively maintained anymore. But it still works on Ubuntu’s latest LTS release and several other Linux distros.
If you want a dead simple image viewer where you browse through the images in a slideshow-type UI and get the meta info in the sidebar, Eye of GNOME should be your choice. One of the best for GNOME desktop environment!
**How do I install it?**
To manually install it on Ubuntu (or Ubuntu-based Linux distros), type in the following command:
`sudo apt install eog`
For other distros and sources, you should follow the [GitHub page.](https://github.com/GNOME/eog?ref=itsfoss.com)
## 3. Eye Of MATE Image Viewer
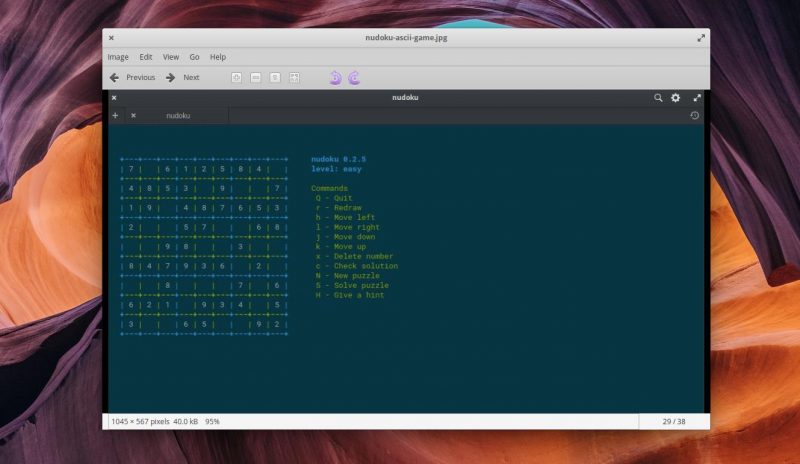
**What’s good about it?**
- A simple image viewer
- Plugins supported
- An image viewer tailored for MATE desktop environment
Yet another simple image viewer with the basic functionalities of slideshow view and rotating images.
Even if doesn’t support any image manipulation feature, it does support numerous image file formats and can handle big image files.
**How do I install it?**
For Ubuntu/Ubuntu-based distros, type in the following command:
`sudo apt install eom`
If you need help with other distros and the source, follow their [GitHub page](https://github.com/mate-desktop/eom?ref=itsfoss.com).
## 4. Geeqie
**What’s good about it?**
- A flexible image manager that supports plugins (you’ll find other image viewers supported as well)
- Information about the color profile
[Geeqie](http://geeqie.org/?ref=itsfoss.com) is an impressive image manager and viewer. It supports other image viewers as plugins but does not offer any image manipulation tools.
If you need to know the color profile, image info, and manage/view a collection of images. It should be a good choice for that.
**How do I install it?**
Type in the terminal:
`sudo apt install geeqie`
For the source, you can refer to the [GitHub page](https://github.com/BestImageViewer/geeqie?ref=itsfoss.com).
## 5. gThumb Image Viewer
**What’s good about it?**
- An all-in-one image viewer with the ability to manage, edit and view the images
- Reset EXIF orientation
- Convert image formats
- Find duplicate images
[gThumb](https://github.com/GNOME/gthumb?ref=itsfoss.com) is an amazing image viewer with a lot of features. You get an impressive user interface to view/manage your images along with the basic image manipulation tools (crop, resize, color, and so on.)
You can also add comments to an image or reset the EXIF orientation info. It also gives you the ability to find duplicate images and convert image formats.
**How do I install it?**
You can enter this command in the terminal:
`sudo apt install gthumb`
If that doesn’t work, head to the [GitHub page](https://github.com/GNOME/gthumb?ref=itsfoss.com) for more info.
## 6. Gwenview
**What’s good about it?**
- A basic image viewer with common image manipulation tools to rotate and resize
- Feature extension using KIPI plugins
[Gwenview](https://www.kde.org/applications/graphics/gwenview/?ref=itsfoss.com) is just another basic image viewer tailored for KDE desktop environment. However, you can install it on other desktop environments as well.
If you utilize the Konqueror web browser, you can use it as an embedded image viewer. Here, you can add comments/description to the image as well. In addition, it supports [KIPI](https://en.wikipedia.org/wiki/KDE_Image_Plugin_Interface?ref=itsfoss.com) plugins.
**How do I install it?**
Type the following in the terminal to install it:
`sudo apt install gwenview`
For the source, check out their [GitHub page](https://github.com/KDE/gwenview?ref=itsfoss.com).
## 7. Loupe
**What’s good about it?**
- Simple and minimal
- Gesture support for touch/laptop users
- Modern user interface
Loupe is a potential successor to the Eye of GNOME app at the time of updating this. It is a straightforward image viewer app with the essentials like metadata view and buttons to navigate images.
**How do I install it?**
You can [set up Flatpak](https://itsfoss.com/flatpak-guide/) on your system and then type in the following to install it:
`flatpak install flathub org.gnome.Loupe`
For the source code and other installation instructions, refer to its [GitLab page](https://gitlab.gnome.org/GNOME/Incubator/loupe/).
## 8. KPhotoAlbum
**What’s good about it?**
- Perfect image manager to tag and manage the pictures
- Demo databases
- Image compression
- Merge/Remove images to/from Stack
KPhotoAlbum is not exactly a dedicated image viewer but a photo manager to tag and manage the pictures you’ve got.
You can opt for slideshows to view the image along with the ability to compress images and search them using the labels/tags.
**How do I install it?**
You can install it via the terminal by typing in:
`sudo apt install kphotoalbum`
In either case, you can check for the [official instructions on their website](https://www.kphotoalbum.org/download/?ref=itsfoss.com) to get it installed on your Linux distro.
## 9. Shotwell
**What’s good about it?**
- Red-eye correction tool
- Upload photos to Facebook, Flickr, etc.
- Supports RAW file formats as well
[Shotwell](https://wiki.gnome.org/Apps/Shotwell?ref=itsfoss.com) is a feature-rich photo manager. You can view and manage your photos. Although you do not get all the basic image manipulation tools baked in it – you can easily crop and enhance your photos in a single click (auto brightness/contrast adjustments).
**How do I install it?**
Go to the terminal and enter the following (Ubuntu/Ubuntu-based distros):
`sudo apt install shotwell`
For more information, check out their [GitHub page](https://github.com/GNOME/shotwell?ref=itsfoss.com).
## 10. Ristretto
**What’s good about it?**
- A dead simple image viewer
- Fullscreen mode & Slideshow
A very straightforward image viewer where you get the ability to zoom, view in fullscreen mode, and view the images as a slideshow.
It is tailored for the Xfce desktop environment – but you can install it anywhere.
**How do I install it?**
Even though it’s built for Xfce desktop environment, you can install it on any Ubuntu/Ubuntu-based distro by typing the following command in the terminal:
`sudo apt install ristretto`
## 11. digiKam
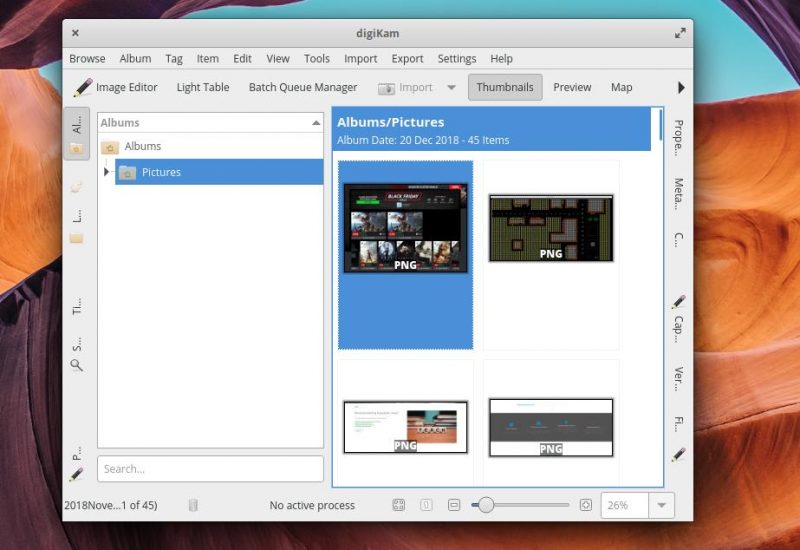
**What’s good about it?**
- An all-in-one image viewer with advanced photo management features (editing/managing/viewing)
- Batch Queue Manager
[Light Table](https://docs.kde.org/trunk5/en/extragear-graphics/digikam/using-lighttable.html?ref=itsfoss.com)
digiKam is an advanced photo manager with some additional image manipulation tools. You get the ability to configure the database using SQLite or MySQL.
To enhance your experience of viewing images, it lets you choose the reduced version of images while you preview them. So, that becomes super fast even if you have a lot of images. You get several import/export options via Google, Facebook, Imgur, and so on. If you want a feature-rich image viewer, this is the one you should have installed.
**How do I install it?**
Type in the following command:
`sudo apt install digikam`
For more information, visit their [GitHub page](https://github.com/KDE/digikam?ref=itsfoss.com).
## Wrapping Up
So, whether you want a different user experience or a rich set of features and powerful tools to manage your photos – there’s something for everyone.
💬 *Which image viewer do you prefer to use? Is it the system’s default viewer? Let us know in the comments below.* |
10,408 | 使用 Node.js 构建交互式命令行工具 | https://opensource.com/article/18/7/node-js-interactive-cli | 2019-01-02T23:25:54 | [
"Node.js"
] | https://linux.cn/article-10408-1.html |
>
> 使用 Node.js 构建一个根据询问创建文件的命令行工具。
>
>
>

当用于构建命令行界面(CLI)时,Node.js 十分有用。在这篇文章中,我将会教你如何使用 [Node.js](https://nodejs.org/en/) 来构建一个问一些问题并基于回答创建一个文件的命令行工具。
### 开始
首先,创建一个新的 [npm](https://www.npmjs.com/) 包(NPM 是 JavaScript 包管理器)。
```
mkdir my-script
cd my-script
npm init
```
NPM 将会问一些问题。随后,我们需要安装一些包。
```
npm install --save chalk figlet inquirer shelljs
```
这是我们需要的包:
* Chalk:正确设定终端的字符样式
* Figlet:使用普通字符制作大字母的程序(LCTT 译注:使用标准字符,拼凑出图片)
* Inquirer:通用交互式命令行用户界面的集合
* ShellJS:Node.js 版本的可移植 Unix Shell 命令行工具
### 创建一个 index.js 文件
现在我们要使用下述内容创建一个 `index.js` 文件。
```
#!/usr/bin/env node
const inquirer = require("inquirer");
const chalk = require("chalk");
const figlet = require("figlet");
const shell = require("shelljs");
```
### 规划命令行工具
在我们写命令行工具所需的任何代码之前,做计划总是很棒的。这个命令行工具只做一件事:**创建一个文件**。
它将会问两个问题:文件名是什么以及文件后缀名是什么?然后创建文件,并展示一个包含了所创建文件路径的成功信息。
```
// index.js
const run = async () => {
// show script introduction
// ask questions
// create the file
// show success message
};
run();
```
第一个函数只是该脚本的介绍。让我们使用 `chalk` 和 `figlet` 来把它完成。
```
const init = () => {
console.log(
chalk.green(
figlet.textSync("Node JS CLI", {
font: "Ghost",
horizontalLayout: "default",
verticalLayout: "default"
})
)
);
}
const run = async () => {
// show script introduction
init();
// ask questions
// create the file
// show success message
};
run();
```
然后,我们来写一个函数来问问题。
```
const askQuestions = () => {
const questions = [
{
name: "FILENAME",
type: "input",
message: "What is the name of the file without extension?"
},
{
type: "list",
name: "EXTENSION",
message: "What is the file extension?",
choices: [".rb", ".js", ".php", ".css"],
filter: function(val) {
return val.split(".")[1];
}
}
];
return inquirer.prompt(questions);
};
// ...
const run = async () => {
// show script introduction
init();
// ask questions
const answers = await askQuestions();
const { FILENAME, EXTENSION } = answers;
// create the file
// show success message
};
```
注意,常量 `FILENAME` 和 `EXTENSIONS` 来自 `inquirer` 包。
下一步将会创建文件。
```
const createFile = (filename, extension) => {
const filePath = `${process.cwd()}/${filename}.${extension}`
shell.touch(filePath);
return filePath;
};
// ...
const run = async () => {
// show script introduction
init();
// ask questions
const answers = await askQuestions();
const { FILENAME, EXTENSION } = answers;
// create the file
const filePath = createFile(FILENAME, EXTENSION);
// show success message
};
```
最后,重要的是,我们将展示成功信息以及文件路径。
```
const success = (filepath) => {
console.log(
chalk.white.bgGreen.bold(`Done! File created at ${filepath}`)
);
};
// ...
const run = async () => {
// show script introduction
init();
// ask questions
const answers = await askQuestions();
const { FILENAME, EXTENSION } = answers;
// create the file
const filePath = createFile(FILENAME, EXTENSION);
// show success message
success(filePath);
};
```
来让我们通过运行 `node index.js` 来测试这个脚本,这是我们得到的:

### 完整代码
下述代码为完整代码:
```
#!/usr/bin/env node
const inquirer = require("inquirer");
const chalk = require("chalk");
const figlet = require("figlet");
const shell = require("shelljs");
const init = () => {
console.log(
chalk.green(
figlet.textSync("Node JS CLI", {
font: "Ghost",
horizontalLayout: "default",
verticalLayout: "default"
})
)
);
};
const askQuestions = () => {
const questions = [
{
name: "FILENAME",
type: "input",
message: "What is the name of the file without extension?"
},
{
type: "list",
name: "EXTENSION",
message: "What is the file extension?",
choices: [".rb", ".js", ".php", ".css"],
filter: function(val) {
return val.split(".")[1];
}
}
];
return inquirer.prompt(questions);
};
const createFile = (filename, extension) => {
const filePath = `${process.cwd()}/${filename}.${extension}`
shell.touch(filePath);
return filePath;
};
const success = filepath => {
console.log(
chalk.white.bgGreen.bold(`Done! File created at ${filepath}`)
);
};
const run = async () => {
// show script introduction
init();
// ask questions
const answers = await askQuestions();
const { FILENAME, EXTENSION } = answers;
// create the file
const filePath = createFile(FILENAME, EXTENSION);
// show success message
success(filePath);
};
run();
```
### 使用这个脚本
想要在其它地方执行这个脚本,在你的 `package.json` 文件中添加一个 `bin` 部分,并执行 `npm link`:
```
{
"name": "creator",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node index.js"
},
"author": "",
"license": "ISC",
"dependencies": {
"chalk": "^2.4.1",
"figlet": "^1.2.0",
"inquirer": "^6.0.0",
"shelljs": "^0.8.2"
},
"bin": {
"creator": "./index.js"
}
}
```
执行 `npm link` 使得这个脚本可以在任何地方调用。
这就是是当你运行这个命令时的结果。
```
/usr/bin/creator -> /usr/lib/node_modules/creator/index.js
/usr/lib/node_modules/creator -> /home/hugo/code/creator
```
这会连接 `index.js` 作为一个可执行文件。这是完全可能的,因为这个 CLI 脚本的第一行是 `#!/usr/bin/env node`。
现在我们可以通过执行如下命令来调用。
```
$ creator
```
### 总结
正如你所看到的,Node.js 使得构建一个好的命令行工具变得非常简单。如果你希望了解更多内容,查看下列包。
* [meow](https://github.com/sindresorhus/meow):一个简单的命令行助手工具
* [yargs](https://github.com/yargs/yargs):一个命令行参数解析工具
* [pkg](https://github.com/zeit/pkg):将你的 Node.js 程序包装在一个可执行文件中。
在评论中留下你关于构建命令行工具的经验吧!
---
via: <https://opensource.com/article/18/7/node-js-interactive-cli>
作者:[Hugo Dias](https://opensource.com/users/hugodias) 选题:[lujun9972](https://github.com/lujun9972) 译者:[bestony](https://github.com/bestony) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Node.js can be very useful when it comes to building command-line interfaces (CLIs). In this post, I'll teach you how to use [Node.js](https://nodejs.org/en/) to build a CLI that asks some questions and creates a file based on the answers.
## Get started
Let's start by creating a brand new [npm](https://www.npmjs.com/) package. (Npm is the JavaScript package manager.)
```
mkdir my-script
cd my-script
npm init
```
Npm will ask some questions. After that, we need to install some packages.
`npm install --save chalk figlet inquirer shelljs`
Here's what these packages do:
**Chalk:**Terminal string styling done right**Figlet:**A program for making large letters out of ordinary text**Inquirer:**A collection of common interactive command-line user interfaces**ShellJS:**Portable Unix shell commands for Node.js
## Make an index.js file
Now we'll create an `index.js`
file with the following content:
```
#!/usr/bin/env node
const inquirer = require("inquirer");
const chalk = require("chalk");
const figlet = require("figlet");
const shell = require("shelljs");
```
## Plan the CLI
It's always good to plan what a CLI needs to do before writing any code. This CLI will do just one thing: **create a file**.
The CLI will ask two questions—what is the filename and what is the extension?—then create the file, and show a success message with the created file path.
```
// index.js
const run = async () => {
// show script introduction
// ask questions
// create the file
// show success message
};
run();
```
The first function is the script introduction. Let's use `chalk`
and `figlet`
to get the job done.
```
const init = () => {
console.log(
chalk.green(
figlet.textSync("Node JS CLI", {
font: "Ghost",
horizontalLayout: "default",
verticalLayout: "default"
})
)
);
}
const run = async () => {
// show script introduction
init();
// ask questions
// create the file
// show success message
};
run();
```
Second, we'll write a function that asks the questions.
```
const askQuestions = () => {
const questions = [
{
name: "FILENAME",
type: "input",
message: "What is the name of the file without extension?"
},
{
type: "list",
name: "EXTENSION",
message: "What is the file extension?",
choices: [".rb", ".js", ".php", ".css"],
filter: function(val) {
return val.split(".")[1];
}
}
];
return inquirer.prompt(questions);
};
// ...
const run = async () => {
// show script introduction
init();
// ask questions
const answers = await askQuestions();
const { FILENAME, EXTENSION } = answers;
// create the file
// show success message
};
```
Notice the constants FILENAME and EXTENSIONS that came from `inquirer`
.
The next step will create the file.
```
const createFile = (filename, extension) => {
const filePath = `${process.cwd()}/${filename}.${extension}`
shell.touch(filePath);
return filePath;
};
// ...
const run = async () => {
// show script introduction
init();
// ask questions
const answers = await askQuestions();
const { FILENAME, EXTENSION } = answers;
// create the file
const filePath = createFile(FILENAME, EXTENSION);
// show success message
};
```
And last but not least, we'll show the success message along with the file path.
```
const success = (filepath) => {
console.log(
chalk.white.bgGreen.bold(`Done! File created at ${filepath}`)
);
};
// ...
const run = async () => {
// show script introduction
init();
// ask questions
const answers = await askQuestions();
const { FILENAME, EXTENSION } = answers;
// create the file
const filePath = createFile(FILENAME, EXTENSION);
// show success message
success(filePath);
};
```
Let's test the script by running `node index.js`
. Here's what we get:

## The full code
Here is the final code:
```
#!/usr/bin/env node
const inquirer = require("inquirer");
const chalk = require("chalk");
const figlet = require("figlet");
const shell = require("shelljs");
const init = () => {
console.log(
chalk.green(
figlet.textSync("Node JS CLI", {
font: "Ghost",
horizontalLayout: "default",
verticalLayout: "default"
})
)
);
};
const askQuestions = () => {
const questions = [
{
name: "FILENAME",
type: "input",
message: "What is the name of the file without extension?"
},
{
type: "list",
name: "EXTENSION",
message: "What is the file extension?",
choices: [".rb", ".js", ".php", ".css"],
filter: function(val) {
return val.split(".")[1];
}
}
];
return inquirer.prompt(questions);
};
const createFile = (filename, extension) => {
const filePath = `${process.cwd()}/${filename}.${extension}`
shell.touch(filePath);
return filePath;
};
const success = filepath => {
console.log(
chalk.white.bgGreen.bold(`Done! File created at ${filepath}`)
);
};
const run = async () => {
// show script introduction
init();
// ask questions
const answers = await askQuestions();
const { FILENAME, EXTENSION } = answers;
// create the file
const filePath = createFile(FILENAME, EXTENSION);
// show success message
success(filePath);
};
run();
```
## Use the script anywhere
To execute this script anywhere, add a `bin`
section in your `package.json`
file and run `npm link`
.
```
{
"name": "creator",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node index.js"
},
"author": "",
"license": "ISC",
"dependencies": {
"chalk": "^2.4.1",
"figlet": "^1.2.0",
"inquirer": "^6.0.0",
"shelljs": "^0.8.2"
},
"bin": {
"creator": "./index.js"
}
}
```
Running `npm link`
makes this script available anywhere.
That's what happens when you run this command:
```
/usr/bin/creator -> /usr/lib/node_modules/creator/index.js
/usr/lib/node_modules/creator -> /home/hugo/code/creator
```
It links the `index.js`
file as an executable. This is only possible because of the first line of the CLI script: `#!/usr/bin/env node`
.
Now we can run this script by calling:
`$ creator`
## Wrapping up
As you can see, Node.js makes it very easy to build nice command-line tools! If you want to go even further, check this other packages:
[meow](https://github.com/sindresorhus/meow)– a simple command-line helper[yargs](https://github.com/yargs/yargs)– a command-line opt-string parser[pkg](https://github.com/zeit/pkg)– package your Node.js project into an executable
Tell us about your experience building a CLI in the comments.
## Comments are closed. |
10,409 | 如何在 Ubuntu 18.04 中启动到救援模式或紧急模式 | https://www.ostechnix.com/how-to-boot-into-rescue-mode-or-emergency-mode-in-ubuntu-18-04/ | 2019-01-02T23:34:00 | [
"救援模式",
"紧急模式"
] | https://linux.cn/article-10409-1.html | 
正如你可能已经知道的那样,**运行级别** 在许多最近的 Linux 发行版(如 RHEL 7 和 Ubuntu 16.04 LTS)中被 **systemd 的目标** 替换。有关它们的更多详细信息,请参阅[这个指南](https://www.ostechnix.com/check-runlevel-linux/)。在这个简短的教程中,我们将看到如何启动**救援模式**以及**紧急模式**。本指南在 Ubuntu 18.04 LTS 中进行了测试,但是下面给出的步骤适用于大多数使用 systemd 作为默认服务管理器的 Linux 发行版。在进一步讨论之前,让我澄清什么是救援模式和紧急模式以及这两种模式的目的是什么。
### 什么是救援模式?
**救援模式**相当于使用 **SysV** 作为默认的服务管理器的 Linux 发行版中的 **单用户模式**。在救援模式下,将挂载所有本地文件系统,仅启动一些重要服务。但是,不会启动正常服务(例如网络服务)。救援模式在系统无法正常启动的情况下很有用。此外,我们可以在救援模式下执行一些重要的救援操作,例如[重置 root 密码](https://www.ostechnix.com/how-to-reset-or-recover-root-user-password-in-linux/)。
### 什么是紧急模式?
与救援模式相比,在**紧急模式**中不启动任何东西。没有服务启动、没有挂载点、没有建立套接字,什么也没有。你所拥有的只是一个**原始的 shell**。紧急模式适用于调试目的。
### 在 Ubuntu 18.04 LTS 中进入救援模式
启动你的 Ubuntu 系统。出现 Grub 菜单时,选择第一条并按下 `e` 进行编辑。

如果你没有看到 Grub 菜单,只需在 BIOS 的 logo 消失后立即按下 `ESC` 键。
找到以单词 `linux` 开头的行,并在该行的末尾添加以下内容(要到达末尾,只需按下 `CTRL+e` 或使用 `END` 键或左右箭头键):
```
systemd.unit=rescue.target
```

添加完成后,只需按下 `CTRL+x` 或 `F10` 即可继续启动救援模式。几秒钟后,你将以 root 用户身份进入救援模式(单用户模式)。以下是 Ubuntu 18.04 LTS 服务器版中救援模式的样子:

接下来,输入以下命令将根 (`/`) 文件系统重新挂载成读/写模式。
```
mount -n -o remount,rw /
```
### 启动到紧急模式
将 Ubuntu 引导到紧急模式与上述方法相同。你只需在编辑 Grub 菜单时将 `systemd.unit=rescue.target` 替换为 `systemd.unit=emergency.target` 即可。

添加 `systemd.unit=emergency.target` 后,按下 `Ctrl+x` 或 `F10` 继续启动到紧急模式。

最后,你可以使用以下命令将根文件系统重新挂载成读/写模式:
```
mount -n -o remount,rw /
```
### 在救援模式和紧急模式之间切换
如果你处于救援模式,则不必像上面提到的那样编辑 Grub 条目。相反,只需输入以下命令即可立即切换到紧急模式:
```
systemctl emergency
```
同样,要从紧急模式切换到救援模式,请输入:
```
systemctl rescue
```
你现在知道了什么是救援模式和紧急模式以及如何在 Ubuntu 18.04 中启动这些模式。就像我已经提到的,这里提供的步骤将适用于许多使用 systemd 的 Linux 版本。
就是这些了。希望这篇文章有用。
还有更多好东西。敬请期待!
干杯!
---
via: <https://www.ostechnix.com/how-to-boot-into-rescue-mode-or-emergency-mode-in-ubuntu-18-04/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,410 | dbxfs:在 Linux 中本地挂载 Dropbox 文件夹 | https://www.ostechnix.com/dbxfs-mount-dropbox-folder-locally-as-virtual-file-system-in-linux/ | 2019-01-03T13:44:55 | [
"Dropbox",
"FUSE"
] | https://linux.cn/article-10410-1.html | 
不久前,我们总结了所有 [在本地挂载 Google Drive](https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/) 作为虚拟文件系统,并从 Linux 系统访问存储在 Google Drive 中的文件的方法。今天,我们将学习使用 `dbxfs` 将 Dropbox 文件夹挂载到本地文件系统中。`dbxfs` 用于在类 Unix 操作系统中本地挂载 Dropbox 文件夹作为虚拟文件系统。虽然在 Linux 中很容易[安装 Dropbox 客户端](https://www.ostechnix.com/install-dropbox-in-ubuntu-18-04-lts-desktop/),但这种方法与官方方法略有不同。它是一个命令行 dropbox 客户端,且无需磁盘空间即可访问。`dbxfs` 是自由开源的,并且是用 Python 3.5+ 编写的。
### 安装 dbxfs
`dbxfs` 官方支持 Linux 和 Mac OS。但是,它应该适用于任何提供 **FUSE 兼容库**或能够挂载 SMB 共享的 POSIX 系统。由于它是用 Python 3.5 编写的,因此可以使用 pip3 包管理器进行安装。如果尚未安装 pip,请参阅以下指南。
* [如何使用 pip 管理 Python 包](https://www.ostechnix.com/manage-python-packages-using-pip/)
并且也要安装 FUSE 库。
在基于 Debian 的系统上,运行以下命令以安装 FUSE:
```
$ sudo apt install libfuse2
```
在 Fedora 上:
```
$ sudo dnf install fuse
```
安装完所有必需的依赖项后,运行以下命令以安装 `dbxfs`:
```
$ pip3 install dbxfs
```
### 在本地挂载 Dropbox 文件夹
创建一个挂载点以将 Dropbox 文件夹挂载到本地文件系统中。
```
$ mkdir ~/mydropbox
```
然后,使用 `dbxfs` 在本地挂载 dropbox 文件夹,如下所示:
```
$ dbxfs ~/mydropbox
```
你将被要求生成一个访问令牌:

要生成访问令牌,只需在 Web 浏览器中输入上面输出的 URL,然后单击 **允许** 以授权 Dropbox 访问。你需要登录 Dropbox 帐户才能完成授权过程。
下一个页面将生成新的授权码。复制代码并返回终端将其粘贴到 cli-dbxfs 提示符中以完成该过程。
然后,系统会要求你保存凭据以供将来访问。根据你是要保存还是拒绝,输入 `Y` 或 `N`。然后,你需要为新的访问令牌输入两次密码。
最后,输入 `Y` 接受 `/home/username/mydropbox` 作为默认挂载点。如果你要设置不同的路径,输入 `N` 并输入你选择的位置。

完成了!从现在开始,你可以看到你的 Dropbox 文件夹已挂载到本地文件系统中。

### 更改访问令牌存储路径
默认情况下,`dbxfs` 会将 Dropbox 访问令牌存储在系统密钥环或加密文件中。但是,你可能希望将其存储在 gpg 加密文件或其他地方。如果是这样,请在 [Dropbox 开发者应用控制台](https://dropbox.com/developers/apps)上创建个人应用来获取访问令牌。

创建应用后,单击下一步中的**生成**按钮。此令牌可用于通过 API 访问你的 Dropbox 帐户。不要与任何人共享你的访问令牌。

创建访问令牌后,使用任何你选择的加密工具对其进行加密,例如 [Cryptomater](https://www.ostechnix.com/cryptomator-open-source-client-side-encryption-tool-cloud/)、[Cryptkeeper](https://www.ostechnix.com/how-to-encrypt-your-personal-foldersdirectories-in-linux-mint-ubuntu-distros/)、[CryptGo](https://www.ostechnix.com/cryptogo-easy-way-encrypt-password-protect-files/)、[Cryptr](https://www.ostechnix.com/cryptr-simple-cli-utility-encrypt-decrypt-files/)、[Tomb](https://www.ostechnix.com/tomb-file-encryption-tool-protect-secret-files-linux/)、[Toplip](https://www.ostechnix.com/toplip-strong-file-encryption-decryption-cli-utility/) 和 [\*\*GnuPG](https://www.ostechnix.com/an-easy-way-to-encrypt-and-decrypt-files-from-commandline-in-linux/) 等,并在你喜欢的位置保存。
接下来编辑 dbxfs 配置文件并添加以下行:
```
"access_token_command": ["gpg", "--decrypt", "/path/to/access/token/file.gpg"]
```
你可以通过运行以下命令找到 dbxfs 配置文件:
```
$ dbxfs --print-default-config-file
```
有关更多详细信息,请参阅 dbxfs 帮助:
```
$ dbxfs -h
```
如你所见,使用 `dbxfs` 在你的文件系统中本地挂载 Dropfox 文件夹并不复杂。经过测试,`dbxfs` 如常工作。如果你有兴趣了解它是如何工作的,请尝试一下,并在下面的评论栏告诉我们你的体验。
就是这些了。希望这篇文章有用。还有更多好东西。敬请期待!
干杯!
---
via: <https://www.ostechnix.com/dbxfs-mount-dropbox-folder-locally-as-virtual-file-system-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,411 | 下载 Linux 游戏的最佳网站 | https://itsfoss.com/download-linux-games/ | 2019-01-03T14:36:57 | [
"游戏"
] | https://linux.cn/article-10411-1.html |
>
> 新接触 Linux 游戏并想知道从哪里来 下载 Linux 游戏?我们列出了最好的资源,在这里你既能 下载免费的 Linux 游戏 ,也能购买优质的 Linux 游戏。
>
>
>
Linux 和游戏?从前,很难想象这两者走到一起。然而随着时间流逝,很多事情都在变化。到如今,有成千上万在 Linux 上可以玩的游戏,而大公司和独立开发者们正在开发更多的游戏。
[在 Linux 上玩游戏](/article-7316-1.html) 现在已经是现实。今天我们将去看看,你在哪里可以找到 Linux 平台游戏、搜索到你喜欢的游戏。
### 在哪里来下载 Linux 游戏?

首先,看看你的 Linux 发行版的软件中心(如果有的话)。在这里你也能找到大量的游戏。
但是,这不意味着你应该将自己的视野局限于软件中心上。让我们来为你列出一些可以下载 Linux 游戏网站。
#### 1. Steam
如果你是老练的玩家,你应该听过 Steam。如果你还不知道的话,没错,Steam 在 Linux 上也是可用的。Steam 推荐运行在 Ubuntu 上,但是它也能运行在其它主要的发行版上。如果你真的对 Steam 很狂热,这里甚至还有一个玩 Steam 游戏的专用操作系统:[SteamOS](http://store.steampowered.com/steamos/)。我们在上一年 [最佳的 Linux 游戏发行版](https://itsfoss.com/linux-gaming-distributions/) 文章中提及了它。

Steam 有最大的 Linux 游戏商店。当写这篇文章的时候,在 Linux 平台上,确切地说有 3487 款游戏,这真的是很多了。你可以从宽广的类型中寻找游戏。至于 [数字版权管理(DRM)](https://www.wikiwand.com/en/Digital_rights_management),大多数的 Steam 游戏都有某种 DRM 。
对于使用 Steam ,要么你必须在你的 Linux 系统上安装 [Steam 客户端](http://store.steampowered.com/about/),要么使用 SteamOS。Steam 的一个优势是,在初始化安装后,对于大多数的游戏,你不需要担心依赖关系和复杂的安装过程。 Steam 客户端将为你做这些繁重的任务。
* [Steam 商店](http://store.steampowered.com/linux)
#### 2. GOG
如果你只对免 DRM 的游戏感兴趣,GOG 收集了相当多的这种游戏。此刻,GOG 在它们的库中有 1978 种免 DRM 游戏。GOG 因它大量收集了免 DRM 游戏而闻名。

GOG 游戏官方支持 Ubuntu LTS 版本和 Linux Mint。所以,Ubuntu 和它的衍生版在安装它们时将没有问题。在其他发行版上安装它们时可能需要一些额外的工作,例如,你需要安装正确的依赖关系。
从 GOG 中下载游戏,你不需要额外的客户端。所有购买的游戏都可在你的账户区内找到。你可以使用你最爱的下载管理器直接下载它们。
* [GOG 商店](https://www.gog.com/games?system=lin_mint,lin_ubuntu)
#### 3. Humble 商店
Humble 商店是另一个你可以查找各种各样 Linux 游戏的地方。在 Humble 商店中有免 DRM 和非免 DRM 的游戏。非免 DRM 游戏通常来自 Steam。在 Humble 商店中,当前有超过 1826 款 Linux 游戏。

Humble 商店因另一个原因而著名。它们有一个被称为 [Humble 独立包](https://www.humblebundle.com/?partner=itsfoss)的活动,其中打包提供了一批游戏,带有令人不可抗拒的限时优惠。关于 Humble 的另一件事是,当你购买时,你的购买金额的 10% 将捐给慈善机构。
Humble 不需要额外的客户端来下载它们的游戏。
* [Humble 商店](https://www.humblebundle.com/store?partner=itsfoss)
#### 4. itch.io 商店
itch.io 是给独立数字创作者的一个开放市场,其致力于独立视频游戏。itch.io 有一些你能找到的最有趣、最独特的游戏。在 itch.io 的大多数游戏是免 DRM 的。

现今,itch.io 在它的商店中有 9514 款 Linux 平台的游戏。
itch.io 有它自己的 [客户端](https://itch.io/app),可以轻松地下载、安装、更新和玩它们的游戏。
* [itch.io 商店](https://itch.io/games/platform-linux)
#### 5. LGDB
LGDB 是 <ruby> Linux 游戏数据库 <rt> Linux Game DataBase </rt></ruby>的缩写。虽然从技术上说它不是一个游戏商店,它收集有大量的 Linux 游戏,以及关于它们的各种各样的信息。每一款游戏都有你可以在哪里找到它们的链接。

如今,在该数据库中有 2046 款游戏。它们也有很长的关于 [模拟器](https://lgdb.org/emulators)、[工具](https://lgdb.org/tools) 和 [游戏引擎](https://lgdb.org/engines) 的列表。
* [LGDB](https://lgdb.org/games)
#### 6. Game Jolt 商店
Game Jolt 有一个非常可观的集合,在它的库藏中大约有 5000 个 Linux 独立游戏。

Game Jolt 有一个(预览版)[客户端](http://gamejolt.com/client),可用于轻松地下载、安装、更新和玩游戏。
* [Game Jolt 商店](http://gamejolt.com/games/best?os=linux)
### 其他
有很多其他的销售 Linux 游戏的商店。也有很多你能找到免费游戏的地方。这是它们中的两个:
* [Bundle Stars](https://www.bundlestars.com/en/games?page=1&platforms=Linux):当前有 814 个 Linux 游戏和 31 个游戏包。
* [GamersGate](https://www.gamersgate.com/games?state=available):现在有 595 个 Linux 游戏。既有免 DRM 的,也有非免 DRM 的。
#### 应用商店、软件中心 & 软件库
Linux 发行版有它们自己的应用商店或软件库。尽管不是很多,但是在这里你也能找到各种各样的游戏。
今天到此为止。你知道这里有这么多 Linux 上可玩的游戏吗?你使用一些其他的网站来下载 Linux 游戏吗?与我们分享你的收藏。
---
via: <https://itsfoss.com/download-linux-games/>
作者:[Munif Tanjim](https://itsfoss.com/author/munif/) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linux and Games?
Once upon a time, it was hard to imagine these two going together. Then time passed, and a lot of things happened.
Fast-forward to the present, there are thousands of games available for Linux. Not to forget, there are always new games developed by major game studios and indie publishers with native Linux support.
Even though Linux isn’t an AAA (triple-A)-first platform, [Steam Play](https://itsfoss.com/steam-play/), and the Steam Deck has made it possible to enjoy some of the latest and greatest games.
[Gaming on Linux](https://itsfoss.com/linux-gaming-guide/) is now a reality, and here we are going to see where you can find games for the Linux platform and hunt down the games you like.
**Where to download Linux games?**
First and foremost, look into your Linux distribution’s **software center**. You should find plenty of games there already. Of course, you will not find any major video game titles but some classics and fun games.
If you want to explore further, these websites should give you a collection of exciting games to play on Linux:
## 1. Steam
If you are a seasoned gamer, you already know about Steam.
If you didn’t know, **Steam is the biggest PC gaming portal **that lets you purchase, install, and play games you like. From free to paid, the latest to classic/indie, you will find a massive collection of games here.
We also have a [list of the best games on steam to play on Linux and Windows](https://itsfoss.com/best-linux-games-steam/#strategy) if you are looking for recommendations.
Steam's parent company, **Valve** is known for making impactful efforts to improve the gaming scene for Linux users. Whether it is SteamOS (that powers Steam Deck) or [Steam Play](https://itsfoss.com/steam-play/) (that lets you play Windows games on Linux), it is safe to say that Steam is a popular website for every Linux gamer.
**Steam has been available for Linux** for a long time now.
So, you can install and run it on any major Linux distribution without hassle. You can find the package to install on its [official website](https://store.steampowered.com/about/) or search for it in your software center.
**Suggested Read 📖**
[Best Distributions for Gaming on LinuxIf you are a hardcore PC gamer, Linux might not be your first choice. That’s fair because Linux isn’t treated as a first-class citizen when it comes to gaming. You won’t find the most awaited games of the year available on Linux natively. Not to forget that](https://itsfoss.com/linux-gaming-distributions/)

## 2. GOG
If you are solely interested in **DRM-free games**, GOG has a large collection. **GOG** is famous for its vast collection of DRM-free games.
Officially, GOG games support **Ubuntu LTS versions and Linux Mint**. So, Ubuntu and its derivatives will have no problem installing them. Installing them on other distributions might need extra work, such as — installing the correct dependencies.
You will not need any extra clients to download games from GOG. All the purchased games will be available in your accounts section. You can download them directly with your favorite download manager.
## 3. Humble Bundle Store
As the name suggests, the Humble Bundle store is famous for its bundled offers. Not just limited to games, you will also find great resources like e-books at affordable prices. Another thing about Humble is that when you make a purchase, some revenue from your purchase goes to charities.
Humble Bundle doesn’t offer any native clients for downloading games. You will have to redeem the games in Steam for the most part.
[Humble BundlePay what you want. Support charity. Get awesome games.](https://www.humblebundle.com/?partner=itsfoss)

## 4. itch.io
itch.io is an open marketplace for independent digital creators focusing on indie video games. itch.io has some of the most exciting and unique games you can find. Most games available on itch.io are **DRM-free**.
You will now find many games available in their store for the Linux platform.
itch.io has its [client](https://itch.io/app) for effortlessly downloading, installing, updating, and playing their games. You can [easily install Itch on Linux](https://itsfoss.com/install-itch-linux/).
**Suggested Read 📖**
[10 Best Indie RPG Games for Linux in 2022Whether it is Windows, Linux, or macOS, you will find plenty of Indie games to play. There are chances to find incredibly exciting games that are often underrated, which makes it exciting to explore Indie games. But, here, I focus only on the best Indie RPG games (i.e. developed](https://itsfoss.com/best-indie-rpg-games-linux/)

### 5. Game Jolt
Game Jolt has a very impressive collection of indie games for Linux under its belt.
Game Jolt has a pre-release [client](http://gamejolt.com/client) for downloading, installing, updating, and playing games with ease.
### 6. Portable Linux Games
If you’re someone who wants to have fun playing some games tailored for 32-bit systems, you can download a great deal of games along with their dependencies here.
You’ll find a list of interesting games — so do take a look!
## Others
Many other stores sell Linux Games. Also, there are places you can find free games too. Here are a couple of them:
: Fanatical features a lot of games tailored for Linux and offers great deals as well. You have to redeem the games on Steam — but it’s a decent website to look for Linux games.**Fanatical**: GamersGate is yet another interesting store to list Linux games, you cannot download it here but have to redeem the game on Steam.**GamersGate**
There's also the "** Epic Games Store**", a
**competitor to**
**Steam**, that you can use on Linux. However, it does not officially support Linux yet. So, if you have purchased or want to purchase a game offered at a good deal from them, you can follow our guide to access it on Linux:
[The Ultimate Guide to Epic Games Store on LinuxEpic Games Store is gaining more attention than ever, with some exclusive releases, and attractive discounts for PC gamers. While I still prefer Steam to Epic Games Store (or EGS) because the client is superior, and it officially works on Linux without any workarounds. Unfortunately, games…](https://itsfoss.com/epic-games-linux/)

💬 *How do you prefer to get games for your Linux system? Did we miss your favorite websites to purchase or download Linux games? Let me know in the comments below.* |
10,412 | 在 Linux 终端上观看 YouTube 视频 | https://opensource.com/article/18/12/linux-toy-youtube-dl | 2019-01-04T09:48:37 | [
"终端",
"视频"
] | /article-10412-1.html |
>
> 视频只能在 GUI 下看么?再想想。
>
>
>

我们即将结束为期 24 天的 Linux 命令行玩具日历。希望你一直在看,如果没有,请回到[这里](https://opensource.com/article/18/12/linux-toy-boxes)开始,自己试试。你会发现 Linux 终端有很多游戏,消遣和奇怪的东西。
虽然你之前可能已经看过我们日历中的一些玩具,但我们希望对每个人至少有一个新事物。
今天我们要在昨天的玩具 [MPlayer](/article-10393-1.html) 上再加上一个 [youtube-dl](https://rg3.github.io/youtube-dl/)。
正如其名称所暗示的那样,`youtube-dl` 是一个用于下载 YouTube 视频的命令行程序,但它也可以从其他许多站点下载视频,而且它是一个有着[丰富文档](https://github.com/rg3/youtube-dl/blob/master/README.md#readme)的功能齐全的程序,从而使视频获取变得容易。注意:请勿在任何违反你所在司法辖区的版权法的情况下使用 `youtube-dl`。
`youtube-dl` 使用的是 [Unlicense](https://unlicense.org/) 这个公共领域许可,类似于 Creative Common 的 [CC0](https://creativecommons.org/share-your-work/public-domain/cc0/)。这里还有哪些公共领域贡献适用于开源领域的[法律意见](https://opensource.org/faq#public-domain),但它通常被认为与现有的开源许可证兼容,即使是不推荐使用它的组织也是如此。
最简单地,我们将使用 `youtube-dl` 来获取视频以便在终端中播放。首先,使用适用于你发行版的方法[安装](https://github.com/rg3/youtube-dl/blob/master/README.md#installation)它。对我来说,在 Fedora 中,它被打包在我的仓库中,因此安装非常简单:
```
$ sudo dnf install youtube-dl
```
然后,获取一个视频。YouTube 允许你按照许可证进行搜索,所以今天我们将根据知识共享署名许可证查看来自 [Gemmy’s Videos](https://www.youtube.com/channel/UCwwaepmpWZVDd605MIRC20A) 中的壁炉[视频](https://www.youtube.com/watch?v=pec8P5K4s8c)。对于 YouTube 视频,你可以像这样用文件 ID 下载,我们也可以指定输出文件名。我故意选择了一个短片,因为长视频会变得很大!
```
$ youtube-dl pec8P5K4s8c -o fireplace.mp4
```
如果你昨天没有安装 [MPlayer](/article-10393-1.html),请继续安装好,如果你之前没有安装 libcaca 则需要安装它。如果你直接用 MPlayer 在命令行中播放视频 ( `$ mplayer fireplace.webm` ),它能够播放,但是会在一个自己的窗口中,这不是我们想要的。
首先,我设置将 libcaca 强制使用 ncurses 作为显示驱动,使输出保持在我的终端:
```
$ export CACA_DRIVER=ncurses
```
然后,我放大了终端(“像素”越多越好),并使用以下命令播放文件(强制使用 libcaca 并静默 MPlayer 的文本输出):
```
$ mplayer -really-quiet -vo caca fireplace.mp4
```
这就完成了!

你有特别喜欢的命令行小玩具需要我介绍的吗?提交今年的建议有点晚了,但我们仍然希望在新的一年里有一些很酷的命令行玩具。请在下面的评论中告诉我,我会查看的。让我知道你对今天的玩具有何看法。
一定要看看昨天的玩具,[在 Linux 终端收听广播](/article-10393-1.html),明天还要再来!
---
via: <https://opensource.com/article/18/12/linux-toy-youtube-dl>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,413 | 使用 Xfce Linux 桌面环境的 8 个理由 | https://opensource.com/article/18/6/xfce-desktop | 2019-01-04T22:48:00 | [
"桌面",
"Xfce"
] | /article-10413-1.html |
>
> 整体上很优雅的 Xfce 桌面所具备的足够轻巧和快速的特性能够让它很容易都知道如何做好一件事。
>
>
>

由于某些原因(也包括好奇),几周前我开始使用 [Xfce](https://xfce.org/) 作为我的 Linux 桌面。促使我更换 Linux 桌面环境的原因之一是桌面相关的守护进程占据了我的性能非常强大的主工作站的绝大部分 CPU 资源和 I/O 带宽。当然,有些不稳定性可能是因为我删除了提供这些守护进程的 RPM 包。然而,事实是在我删除这些 RPM 包之前,KDE 就已经很不稳定了而且还导致了一系列其他方面的性能和稳定性问题。所以我需要换一个桌面来避免这些问题。
在回顾了我为 Linux 桌面所写的一系列文章后我才意识到我忽略了 Xfce。这篇文章也是力图能够纠正弥补这个疏忽。我非常喜欢 Xfce 也很享受它所带给我超乎预期的快速、轻量的体验。
作为研究的一部分,我有尝试过在 Google 上查询 Xfce 对应什么意思。有个历史参考是它对应着 “XForms Common Environment”,但 Xfce 早已不在使用 XForms 工具。几年前,我找到另一个参考是 “Xtra fine computing environment” 而且我也很喜欢这个解释。我将会用它作为 Xfce 的全称(尽管再也找不到这个参考页面)。
### 推荐 Xfce 的 8 个理由
#### 1、轻量级架构
Xfce 相对于其他的桌面如 KDE 和 GNOME,不管是内存还是 CPU 的占用率都非常小。在我的系统中,组成 Xfce 桌面的程序仅占用了少量内存就构成一个如此强大的桌面。超低的 CPU 占用率也是 Xfce 桌面的一个特点。了解到 Xfce 内存占用特别低后,我对它的 CPU 占用率也非常低这个特性自然而言也就不感到奇怪了。
#### 2、简洁
Xfce 桌面很简单,就像绒毛整洁的动物让人一目了然、赏心悦目。基础的桌面有两个面板和一条在左边垂直的图标行。面板 0 在底部,并由一些基础的应用启动程序和能访问到系统里对应程序的图标组成。面板 1 在顶部,由一个应用程序启动器和一个能够允许用户在多个工作区之间来回切换的工作区切换器组成。面板可以通过补充项自定义修改,比如增加个新的应用启动器或者更改它们的宽高。
桌面左侧的图标对应是家目录和垃圾桶。它也可以显示其他的图标,如完整的文件系统目录树和已连接上系统的可插拔的任意 USB 存储设备。这些图标可以用来挂载和卸载设备,也可以用来打开默认的文件管理器。如果你愿意,它们都可以被隐藏,同时文件系统、垃圾箱、家目录对应的图标都可以逐个控制管理。所有的可移动设备也可以被隐藏或作为一个组显示。
#### 3、文件管理
作为 Xfce 的默认文件管理器 Thunar,它很简单,既易于使用和配置也非常容易学习。尽管它并不像其他的文件管理器比如 Konqueror 或者 Dolphin 那样效果华丽,但它很强大也很快。Thunar 并不能在一个窗口里面打开多个面板,但它提供了选项卡来支持多个目录的同时打开。Thunar 也有一个非常漂亮的侧边栏,其上同样的图标就像桌面那样能够显示完整的文件系统目录树和所有已连接的 USB 存储设备。设备能够被挂载和卸载,可移动媒介如 CD 也能够被弹出。Thunar 也可以使用类似 Ark 这种帮助软件来在你点击归档文件的时候打开它们。比如 ZIP、TAR、RPM 这种归档文件都可以被浏览也可以从中复制单个文件。

*Xfce 桌面及 Thunar 和 Xfce 下的终端模拟器。*
在我的[文件管理器系列](https://opensource.com/sitewide-search?search_api_views_fulltext=David%20Both%20File%20managers)文章中,我已经使用体验过很多不同的文件管理器软件,我不得不说 Thunar 的简单易用让你无法不喜欢上它。它可以让你通过使用侧边栏来很容易地浏览文件系统。
#### 4、稳定
Xfce 桌面非常稳定。新版本的发布周期似乎是三年,但也会根据需要发布相关更新。最新的版本是于 2015 年 2 月发布的 4.12。在使用 KDE 遇到一系列问题后,稳如磐石的 Xfce 桌面环境显得让人格外放心。在我使用 Xfce 的过程中,它从来没有崩溃过,也不会产生额外的守护进程占据过多的系统资源。这正是我想要的:它安安静静地工作,不会给你带来额外的困扰。
#### 5、优雅
Xfce 简单优雅。在我的今年秋天将面世的新书《系统管理员的 Linux 哲学》中我谈到了关于简单的一系列好处,包括简单事实上也是优雅的诸多标志之一。很明确能够确定的就是 Xfce 及相关组件程序的开发者和维护者也是极力推崇简单至上。这种简单特性很可能也是 Xfce 如此稳定的主要原因,但它也给用户带来了一个整洁的桌面外观,一个反应灵敏的操作界面,一个会让人感觉很自然也很易用的导航结构,而且 Xfce 整体上的优雅特性也会让用户的使用过程中充满愉悦感。
#### 6、终端仿真程序
Xfce4 的终端仿真程序非常强大,而且和其他很多终端仿真程序一样可以允许你使用多个选项卡来让多个终端在一个单独窗口里共存。尽管它与 Tilix、Terminator、Konsole 这种终端仿真程序比起来相对简陋,但它也能很好的完成工作。选项卡的名字可以更改,而且选项卡也可以通过拖放或者工具栏的箭头图标或者菜单栏的选项重新排列。我特别喜欢 Xfce 的终端仿真程序的一点就是不管你连接了多少主机,相对应的选项卡都会显示对应的主机名,比如,从 host1=>host2=>host3=>host4,会准确地在选项卡显示了 “host4”。但其他的终端仿真程序最多也就显示 “host2”。
至于这个终端仿真程序功能和外观的其他方面都可以根据你的需要很容易配置成你想要的。当然同 Xfce 的其他组件一样,这款终端仿真程序占用了系统资源的很少一部分。
#### 7、可配置性
Xfce 能够配置的范围极大。虽然 Xfce 桌面的可配置性比不上 KDE,但依旧远超 GNOME,而且比它更容易配置。比如,我发现设置管理器是 Xfce 配置一切的入口。虽然每个配置程序都可以单独使用,但是设置管理器把他们都放在一个窗口里以便快速访问。关于 Xfce 桌面很多重要的部分都可以通过配置来满足我的需求。
#### 8、模块化
Xfce 是由一系列单个的项目组成的整体,而且在你的 Linux 桌面发行版中也未必安装了 Xfce 的所有组件。[Xfce 项目](https://xfce.org/projects) 的主页列出了主要的项目,所以你可以根据需要安装你想安装的附加组件。比如在我的 Fedora 28 workstation 版本上我安装的 Xfce 组时就没有 [Xfce 项目](https://xfce.org/projects) 主页最下面的说明的一些程序。
这里还有个关于 Xfce 的 [文档页面](https://docs.xfce.org/) 和 一个被称为 [Xfce 超值项目](https://goodies.xfce.org/) 的 wiki 列举了其他的 Xfce 相关的项目,它们为 Xfce 的面板及 Thunar 提供了很多不错的应用程序、精美的插图、好用的插件。
### 总结
整体上很优雅的 Xfce 桌面所具备的足够轻巧和快速的特性能够让它很容易都知道如何做好一件事。它的轻量级的结构也节省了大量的 CPU 和内存资源。这也使得 Xfce 非常适合那种由于硬件有限而无法分配给桌面太多资源的旧主机。然而,Xfce 又是足够的灵活和强大的,能够满足高级用户的需要。
我知道,更换到一个新的 Linux 桌面环境需要你自己按照你想要的做些对应的自定义设置:比如面板上显示你最爱用的程序对应的启动器,设置下你最喜欢的桌面背景壁纸等一系列工作。这些年来我已经在切换到新桌面环境或更新旧桌面环境折腾很多次了。这需要时间也需要耐心。
我觉得切换 Linux 的桌面环境就像我在工作中换个办公工位或者办公室一样。别人把我的东西装箱从旧办公室搬到新办公室,然后我在我的新办公室里组装连接好我的电脑,打开箱子再把里面的东西放在合适的位置。而切换到 Xfce 桌面大概就是我做过的最简单省事容易的桌面环境更换了。
---
via: <https://opensource.com/article/18/6/xfce-desktop>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[WangYueScream](https://github.com/WangYueScream) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,414 | McFly:利用神经网络为 Bash 提供历史命令搜索功能 | https://www.ostechnix.com/mcfly-a-replacement-to-ctrlr-bash-history-search-feature/ | 2019-01-04T23:25:03 | [
"McFly",
"命令历史"
] | https://linux.cn/article-10414-1.html | 
假如你在命令行模式下渡过了很长时间,那么你必定使用过或者听说过 BASH 的 **反向搜索** 功能,在 Bash 中执行反向搜索功能的快捷键是 `Ctrl+r`。通过使用这个特性,我们可以找到我们执行过的命令而无需再次输入它们。当然,你可以使用上下键来搜索你的 bash 命令记录,但使用 `Ctrl+r` 快捷键可以让这个搜索过程更简单快速。今天我找寻到了 Bash 历史命令搜索特性 `Ctrl+r` 的一个替代品,它就是 McFly。McFly 是一个使用 Rust 编程语言写就的简洁工具,自带一个智能的搜索引擎,用来替换默认的 `Ctrl+r` 这个 Bash 历史命令搜索功能。 McFly 提供的命令建议都是通过一个小巧的 **神经网络** 来实时排序给出的。
McFly 重新绑定了 `Ctrl+r` 快捷键,可以从你的 Bash 历史命令中找到所有最近执行过的命令。它通过追溯下面的信息来增强你的 shell 历史命令搜索特性:
* 命令结束状态
* 当你运行命令时的时间戳
* 以及你运行命令的执行目录
它将所有追溯的信息保存在一个 SQLite 数据库中。由于它追溯了命令的历史结束状态,所以你可以很轻易地忽略掉失败的命令。听起来很酷,对吧?
在给出一个命令建议时,它将考虑如下因素:
* 你在哪个目录执行的这个命令,将来你很有可能在相同的目录重复这个命令
* 在你执行这个命令之前,执行过什么命令
* 你执行这个命令有多频繁
* 你最后执行该命令的时间
* 你是否在 McFly 中选择过这个命令
* 以及这个命令的历史结束状态。因为你很有可能不会去执行失败过的命令,对吧?
McFly 维护着你的默认 Bash 历史文件,所以你可以随时停止使用它。McFly 也并不只服务于 BASH, 它也可以扩展到其他 shell 程序。
### 安装 McFly
在 Linux 中,McFly 可以使用 Linuxbrew 来安装。如若你还没有安装过 Linuxbrew,那么你可以参考下面的这个链接。(LCTT 译注:从其 [GitHub 主页](https://github.com/cantino/mcfly)了解到也可以下载其二进制来使用。)
* [Linuxbrew:一个用于 Linux 和 Mac OS X 的通用包管理](https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/)
一旦安装好了 Linuxbrew,运行下面的命令来安装 McFly:
```
$ brew tap cantino/mcfly https://github.com/cantino/mcfly
$ brew install mcfly
```
在安装完成后,你将看到下面的输出:
```
==> Installing mcfly from cantino/mcfly
==> Downloading https://github.com/cantino/mcfly/releases/download/v0.2.5/mcfly-v0
==> Downloading from https://github-production-release-asset-2e65be.s3.amazonaws.c
######################################################################## 100.0%
==> ONE MORE STEP! Edit ~/.bashrc and add the following:
if [ -f $(brew --prefix)/opt/mcfly/mcfly.bash ]; then
. $(brew --prefix)/opt/mcfly/mcfly.bash
fi
/home/linuxbrew/.linuxbrew/Cellar/mcfly/v0.2.5: 4 files, 3.5MB, built in 33 seconds
```

正如你上面看到的那样,在使用 McFly 之前我们需要再做一些配置。
将下面几行添加到你的 `~/.bashrc` 文件中:
```
if [ -f $(brew --prefix)/opt/mcfly/mcfly.bash ]; then
. $(brew --prefix)/opt/mcfly/mcfly.bash
fi
```
最后,再运行下面的命令来让更改生效。
```
$ source ~/.bashrc
```
当你第一次执行上面的这个命令时,你的 BASH 历史将会被导入 McFly 的数据库。依据你的 bash 历史文件的大小,这个过程将花费一些时间。一旦导入完成,你讲看到下面的提示信息。
```
McFly: Importing Bash history for the first time. This may take a minute or two...done.
```
现在你就可以使用 McFly 了。
### 使用方法
要在你的命令历史中执行搜索,只需要键入 `mcfly search` 再加上命令名的一部分,最后敲击回车键即可。Mcfly 将会基于你刚才键入的搜索查询语句给出命令建议。
```
$ mcfly search <part-of-the-command>
```
例如我键入了下面的命令:
```
$ mcfly search mk
```
下面展示的是我 Ubuntu 机子上的示例输出:

如你所见,我已经使用过 `mkdir` 这个命令两次。假如你想从这些命令建议中执行其中之一,只需使用上下键来选择它,然后敲击**回车键**来执行它就可以了。假如你想编辑其中一个命令,则需要先选择它,然后敲 `TAB` 键将这个命令放置到终端中,最后在运行它之前更改它就行了。要从历史中删除已经选择的命令,按 `F2` 即可。
或者,输入下面的命令来打开历史搜索,然后输入任意一个命令或者命令的一部分来从你的历史命令中查看它提供的建议。
```
$ mcfly search
```
在你输入的同时, McFly 将会展示命令的提示。
下面是一个介绍 McFly 的简短演示视频:

你还可以使用下面的命令来查看帮助:
```
$ mcfly --help
```
### 移除 McFly
不喜欢 McFly,没问题!可以使用下面的命令来移除它:
```
$ brew uninstall mcfly
$ brew untap cantino/mcfly
```
最后,移除先前添加到 `~/.bashrc` 文件中的几行命令。
好了,这些就是所有了,更多精彩内容敬请期待,请保存关注!
干杯!
---
via: <https://www.ostechnix.com/mcfly-a-replacement-to-ctrlr-bash-history-search-feature/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,415 | 用 PGP 保护代码完整性(五):将子密钥移到一个硬件设备中 | https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-5-moving-subkeys-hardware-device | 2019-01-05T00:15:36 | [
"PGP"
] | https://linux.cn/article-10415-1.html |
>
> 在这个系列教程中,将为你提供使用 PGP 和保护你的私钥的最佳体验。
>
>
>

在本系列教程中,我们将提供一个使用 PGP 的实用指南。如果你没有看过前面的文章,你可以通过下面的链接去查看。在这篇文章中,我们将继续讨论如何保护你的密钥,谈一谈将你的子密钥移到一个专门的硬件设备中的一些技巧。
* [第一部分:基本概念和工具](/article-9524-1.html)
* [第二部分:生成你的主密钥](/article-9529-1.html)
* [第三部分:生成 PGP 子密钥](/article-9607-1.html)
* [第四部分:将主密钥移到离线存储中](/article-10402-1.html)
#### 清单
* 取得一个 GnuPG 兼容的硬件设备(必要)
* 配置 GnuPG 在设备上工作(必要)
* 设置用户和管理员的 PIN(必要)
* 移动子密钥到设备中(必要)
#### 考虑事项
虽然现在主密钥已经不用担心泄露或失窃了,但子密钥仍然在你的家目录中。任何得到它的人都能够解密你的通讯或假冒你的签名(如果他们知道密钥的密码)。并且,每次执行一个 GnuPG 操作都要将密钥加载到操作系统内存中,这将使一些更高级的恶意软件有机会得到你的密钥(想想 Meltdown 和 Spectre)。
完全保护密钥的最好方式就是,将它移到一个专门的硬件设备中,这种硬件设备是一个可操作的智能卡。
##### 智能卡的好处
一个智能卡包含一个加密芯片,它能够存储私钥,并且直接在智能卡内部执行秘密操作。因为密钥内容从来没有离开过智能卡,计算机操作系统并不能检索你插入的智能卡上的私钥。这与前面用于备份目的的加密 USB 存储是不同的 —— 虽然 USB 设备也是插入并解密的,但操作系统是能够去访问私钥内容的。使用外置的加密 USB 介质并不能代替智能卡设备的功能。
智能卡的一些其它好处:
* 它们很便宜且易于获得
* 它们小巧且易于携带
* 它们可以用于多种设备上
* 它们中的很多都具有防篡改功能(取决于制造商)
#### 可用的智能卡设备
智能卡最初是嵌入到真实钱包大小的卡中,故而得名智能卡。你肯定可以买到并使用 GnuPG 功能的智能卡,并且它们是你能得到的最便宜的可用设备之一。但是,事实上智能卡有一个很重要的缺点:它们需要一个智能卡读卡器,只有极小数的笔记本电脑上有这种读卡器。
由于这个原因,制造商开始推出小型 USB 设备,它的大小和 U 盘类似,内置有微型智能卡,并且在芯片上简单地实现了智能卡协议特性。下面推荐几个这样的设备:
* [Nitrokey Start](https://shop.nitrokey.com/shop/product/nitrokey-start-6):开源硬件和自由软件,可用于 GnuPG 的最便宜的选择之一,但是额外的安全特性很少。
* [Nitrokey Pro](https://shop.nitrokey.com/shop/product/nitrokey-pro-3):类似于 Nitrokey Start,它提供防篡改及更多的安全特性(但没有 U2F,具体查看指南的 U2F 节)。
* [Yubikey 4](https://www.yubico.com/product/yubikey-4-series/):专利硬件和软件,但比 Nitrokey Pro 便宜,并且可以用在最新的笔记本电脑上的 USB-C 接口;也提供像 U2F 这样的额外的安全特性。
我们推荐选一个同时具备智能卡功能和 U2F 的设备,在写这篇文章时,只能选择 Yubikey 4。
#### 配置智能卡设备
你的智能卡设备插入任何一台现代的 Linux 或 Mac 工作站上都应该能正常工作。你可以通过运行如下的命令去验证它:
```
$ gpg --card-status
```
如果你没有收到错误,有一个完整的卡列表,就表示一切正常。不幸的是,排除为什么设备不能正常工作的所有可能原因,已经超出了本指南的范围。如果你的智能卡使用 GnuPG 时有问题,请通过你的操作系统的常见支持通道寻求支持。
##### PIN 不一定是数字
注意,尽管名为 “PIN”(暗示你它必须是一个“数字”),不论是用户 PIN 还是管理员 PIN 都不必非要是数字。
当你收到一个新设备时,它可能设置有一个默认的用户和管理员 PIN,对于 Yubikey,它分别是 `123456` 和 `12345678`。如果它们的 PIN 不是默认的,请查看设备附带的说明书。
##### 快速设置
为配置你的智能卡,你需要使用 GnuPG 菜单系统,因此这里并没有更方便的命令行开关:
```
$ gpg --card-edit
[...omitted...]
gpg/card> admin
Admin commands are allowed
gpg/card> passwd
```
你应该去设置用户 PIN (1)、管理员 PIN (3)、和重置码 (4)。请确保把它们记录并保存到一个安全的地方 —— 尤其是管理员 PIN 和重置码(它允许你去擦除整个智能卡内容)。你很少使用到管理员 PIN,因此如果你不记录下来,很可能会忘掉它。
返回到智能卡主菜单,你也可以设置其它值(比如名字、性别、登入日期、等等),但是这些都不是必需的,一旦你的智能卡丢失了,将导致额外的信息泄露。
#### 将子密钥移到你的智能卡中
退出卡菜单(使用 `q` 命令)保存所有更改。接下来,我们将你的子密钥移到智能卡中。将需要用到你的 PGP 密钥的密码,在大多数的智能卡操作中都将用到管理员 PIN。记住,那个 `[fpr]` 表示你的密钥的完整的 40 个字符的指纹。
```
$ gpg --edit-key [fpr]
Secret subkeys are available.
pub rsa4096/AAAABBBBCCCCDDDD
created: 2017-12-07 expires: 2019-12-07 usage: C
trust: ultimate validity: ultimate
ssb rsa2048/1111222233334444
created: 2017-12-07 expires: never usage: E
ssb rsa2048/5555666677778888
created: 2017-12-07 expires: never usage: S
[ultimate] (1). Alice Engineer <[email protected]>
[ultimate] (2) Alice Engineer <[email protected]>
gpg>
```
使用 `--edit-key` 再次进入到菜单模式,你将注意到那个密钥清单有一点小差别。从现在开始,所有的命令都是在这个菜单模式下运行,它用 `gpg>` 提示符来表示。
首先,我们来选择移到智能卡中的密钥 —— 你可以通过键入 `key 1`(它表示选择清单中的第一个密钥)来实现:
```
gpg> key 1
```
这个输出会有一点细微的差别:
```
pub rsa4096/AAAABBBBCCCCDDDD
created: 2017-12-07 expires: 2019-12-07 usage: C
trust: ultimate validity: ultimate
ssb* rsa2048/1111222233334444
created: 2017-12-07 expires: never usage: E
ssb rsa2048/5555666677778888
created: 2017-12-07 expires: never usage: S
[ultimate] (1). Alice Engineer <[email protected]>
[ultimate] (2) Alice Engineer <[email protected]>
```
注意与密钥对应的 `ssb` 行旁边的 `*` —— 它表示这是当前选定的密钥。它是可切换的,意味着如果你再次输入 `key 1`,这个 `*` 将消失,这个密钥将不再被选中。
现在,我们来将密钥移到智能卡中:
```
gpg> keytocard
Please select where to store the key:
(2) Encryption key
Your selection? 2
```
由于它是我们的 [E] 密钥,把它移到加密区中是有很有意义的。当你提交了你的选择之后,将会被提示输入你的 PGP 密钥的保护密码,接下来输入智能卡的管理员 PIN。如果命令没有返回错误,表示你的密钥已经被移到智能卡中了。
**重要:** 现在再次输入 `key 1` 去取消选中第一个密钥,并输入 `key 2` 去选择 [S] 密钥:
```
gpg> key 1
gpg> key 2
gpg> keytocard
Please select where to store the key:
(1) Signature key
(3) Authentication key
Your selection? 1
```
你可以使用 [S] 密钥同时做签名和验证,但是我们希望确保它在签名区,因此,我们选择 (`1`)。完成后,如果你的命令没有返回错误,表示操作已成功。
最后,如果你创建了一个 [A](https://www.linux.com/users/mricon) 密钥,你也可以将它移到智能卡中,但是你需要先取消选中 `key 2`。完成后,选择 `q`:
```
gpg> q
Save changes? (y/N) y
```
保存变更将把你的子密钥移到智能卡后,把你的家目录中的相应子密钥删除(没有关系,因为我们的备份中还有,如果更换了智能卡,你需要再做一遍)。
##### 验证移动后的密钥
现在,如果你执行一个`--list-secret-keys` 操作,你将看到一个稍有不同的输出:
```
$ gpg --list-secret-keys
sec# rsa4096 2017-12-06 [C] [expires: 2019-12-06]
111122223333444455556666AAAABBBBCCCCDDDD
uid [ultimate] Alice Engineer <[email protected]>
uid [ultimate] Alice Engineer <[email protected]>
ssb> rsa2048 2017-12-06 [E]
ssb> rsa2048 2017-12-06 [S]
```
在 `ssb>` 的输出中的 `>` 表示子密钥仅在智能卡上有效。如果你进入到你的密钥目录中,查看目录的内容,你将会看到那个 `.key` 文件已经被存根替换:
```
$ cd ~/.gnupg/private-keys-v1.d
$ strings *.key
```
这个输出将包含一个影子私钥,它表示那个文件仅是个存根,真正的内容在智能卡中。
#### 验证智能卡的功能
验证智能卡能否如期正常运行,你可以通过创建一个签名来验证:
```
$ echo "Hello world" | gpg --clearsign > /tmp/test.asc
$ gpg --verify /tmp/test.asc
```
首次运行这个命令时将询问你智能卡的 PIN,在你运行 `gpg —verify` 之后,它将显示 “Good signature”。
祝贺你,你已经成功将窃取你的开发者数字身份变得更加困难了!
#### 其它常见 GnuPG 操作
下面是使用你的 PGP 密钥需要做的一些常见操作的快速指南。
在下面的所有命令中,`[fpr]` 表示你的密钥指纹。
##### 挂载主密钥离线存储
下面的一些操作将需要你的主密钥,因此首先需要去挂载你的主密钥离线存储,并告诉 GnuPG 去使用它。首先,找出介质挂载路径,可以通过查看 `mount` 命令的输出找到它。接着,设置你的 GnuPG 目录为你的介质上备份的目录,并告诉 GnuPG 将那个目录做为它的家目录:
```
$ export GNUPGHOME=/media/disk/name/gnupg-backup
$ gpg --list-secret-keys
```
确保你在输出中看到的是 `sec` 而不是 `sec#`(这个 `#` 表示密钥不可用,仍然使用的是惯常的那个 Home 目录)。
##### 更新你惯常使用的那个 GnuPG 工作目录
在你的离线存储上做了任何更改之后,你应该将这些更改同步应用到你惯常使用的工作目录中:
```
$ gpg --export | gpg --homedir ~/.gnupg --import
$ unset GNUPGHOME
```
##### 延长密钥过期日期
我们创建的主密钥的默认过期日期是自创建之日起两年后。这样做都是为安全考虑,这样将使淘汰密钥最终从密钥服务器上消失。
延长你的密钥过期日期,从当前日期延长一年,只需要运行如下命令:
```
$ gpg --quick-set-expire [fpr] 1y
```
如果为了好记住,你也可以使用一个特定日期(比如,你的生日、1 月 1 日、或加拿大国庆日):
```
$ gpg --quick-set-expire [fpr] 2020-07-01
```
记得将更新后的密钥发送到密钥服务器:
```
$ gpg --send-key [fpr]
```
##### 吊销身份
如果你需要吊销一个身份(比如,你换了雇主并且旧的邮件地址不再有效了),你可以使用一行命令搞定:
```
$ gpg --quick-revoke-uid [fpr] 'Alice Engineer <[email protected]>'
```
你也可以通过使用 `gpg --edit-key [fpr]` 在菜单模式下完成同样的事情。
完成后,记得将更新后的密钥发送到密钥服务器上:
```
$ gpg --send-key [fpr]
```
下一篇文章中,我们将谈谈 Git 如何支持 PGP 的多级别集成。
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)学习更多 Linux 知识。
---
via: <https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-5-moving-subkeys-hardware-device>
作者:[KONSTANTIN RYABITSEV](https://www.linux.com/users/mricon) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,416 | 让 Linux 终端说出它的想法 | https://opensource.com/article/18/12/linux-toy-espeak | 2019-01-05T15:41:26 | [
"TTS",
"语音"
] | https://linux.cn/article-10416-1.html |
>
> eSpeak 是一个可在 Linux 命令行中使用的开源的 TTS 合成器。
>
>
>

欢迎回到《24 天介绍 Linux 命令行小玩具》。如果这是你首次阅读本系列文章,你可能不知道什么是 Linux 命令行小玩具。无需担心,你只需要边看边体会。通常来说,它有可能是游戏或其它能让你在终端中娱乐的小程序。
或许你已经对一些玩具有了解了,不过我们相信,在本系列文章中总有那么几个你没见过的玩意。
年轻读者可能不知道,在 Alexa、Siri 或 Google Assistant 问世之前,计算机就能说话了。
我们也许永远不会忘记来自 [2001 太空漫游](https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey_(film)) 中与机组人员交流的 HAL 9000。但是在 1960 年代到今天的时间里,是存在着许多能说话的计算机的。它们有些很出色,也有些不那么出色。
其中一个我最爱的是一个叫做 [eSpeak](http://espeak.sourceforge.net/) 的开源项目。它以多种形式发布,比如可以嵌入你自己项目中的库。与此同时,它也提供了可供你安装的命令行版本。在我所用的发行版中,安装十分简单,只需使用:
```
$ sudo dnf install espeak
```
你既可以与 eSpeak 交互,也可以用它来输出其它程序的信息,甚至通过简单的 `echo` 命令来使用它。[这里](http://espeak.sourceforge.net/voices.html) 有一些可供 eSpeak 使用的声音文件,你可以在无聊时切换他们。甚者你可以制作一个属于你自己的声音。
在 2015 年,一些希望继续 eSpeak 开发的开发者创建了一个名为 eSpeak NG (即 “Next Generation”,“下一代”的意思)的项目。eSpeak 目前在 GPL v3 许可证下开源,你可以在 [SourceForge](http://espeak.sourceforge.net/) 上详细了解这个项目或下载源代码。
别急,我今天还会介绍一个额外的小程序,它叫 [cava](https://github.com/karlstav/cava)。我经常希望用一张独一无二的截图作为我文章的头图,更何况今天的玩具主要是关于声音的,这就图片更少了。因此,我需要一些东西来填补这些空白。Cava 是<ruby> 基于 ALSA 的命令行音频可视化工具 <rt> console-based audio visualizer for ALSA </rt></ruby>的简写(尽管它现在支持的比 ALSA 更多),它是一个优秀的命令行音频可视化工具,并且它正以 MIT 许可证开源。下面是一个将 eSpeak 输出可视化的命令:
```
$ echo "Rudolph, the red-nosed reindeer, had a very shiny nose." | espeak
```

你想让作者介绍你喜欢的命令行玩具吗?请前往原文下留言,作者可能会考虑介绍的。同时,你也可以去原文下评论你对文章的看法。
欢迎去看看我们昨天介绍的玩具,[在 Linux 命令行中使用 nudoku 解决谜题](https://opensource.com/article/18/12/linux-toy-nudoku)。敬请期待我们明天的文章吧!
---
via: <https://opensource.com/article/18/12/linux-toy-espeak>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zhs852](https://github.com/zhs852) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Greetings from another day in our 24-day-long Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is. We’re figuring that out as we go, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
We hope that even if you've seen some of these before, there will be something new for everybody in our series.
Some of you may be too young to remember, but before there was Alexa, Siri, or the Google Assistant, computers still had voices.
Many of us will never forget HAL 9000 from [2001: A Space Odessey](https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey_(film)) helpfully conversing with the crew (sorry, Dave). But between 1960s science fiction and today, there was a whole generation of speaking computers. Some of them great, most of them, not so great.
One of my favorites is the open source project [eSpeak](http://espeak.sourceforge.net/). It's available in many forms, including a library version you can use to include speech technology in your own project, but it also coms as a command-line program that you can install and use easily. In my distribution, this was as simple as:
`$ sudo dnf install espeak`
Invoking eSpeak then can be invoked either interactively, or by piping text to it using the output of another program or a simple echo command. There are a number of [voice files](http://espeak.sourceforge.net/voices.html) available for eSpeak, and if you're especially bored over the holidays, you could even create your own.
A fork of eSpeak called eSpeak NG ("Next Generation") was created in 2015 from some developers who wanted to continue development of the otherwise lightly-updated eSpeak. eSpeak is made available as open source under a GPL version 3 license, and you can find out more about the project and download the source code [on SourceForge](http://espeak.sourceforge.net/).
I'll also throw in a bonus toy today, [cava](https://github.com/karlstav/cava). Because I've been eager to give each of these articles a unique screenshot as the lead image, and today's toy outputs sound rather than something visual, I needed to find something to fill the space. Short for "console-based audio visualizer for ALSA" (although it supports more than just ALSA now), cava is a nice MIT-licensed terminal audio visualization tool that's fun to watch. Below, is a visualization of eSpeak's output of the following:
`$ echo "Rudolph, the red-nosed reindeer, had a very shiny nose." | espeak`
Do you have a favorite command-line toy that you we should have included? Our calendar is basically set for the remainder of the series, but we'd still love to feature some cool command-line toys in the new year. Let me know in the comments below, and I'll check it out. And let me know what you thought of today's amusement.
Be sure to check out yesterday's toy, [Solve a puzzle at the Linux command line with nudoku](https://opensource.com/article/18/12/linux-toy-nudoku), and come back tomorrow for another!
## 3 Comments |
10,417 | 如何用 Gonimo 创建一个免费的婴儿监视系统 | https://opensource.com/article/17/9/gonimo | 2019-01-05T20:31:00 | [
"监视器",
"婴儿"
] | https://linux.cn/article-10417-1.html |
>
> 当你可以用两个设备、浏览器和网络连接就能免费搭建一个婴儿监视器时,谁还会花钱去买呢?
>
>
>

新父母和准父母很快就会知道将会有一个既长且昂贵的新生儿所需设备的清单,清单中的首位是一个婴儿监视器,借此他们可以在做其他事情时照看自己的婴儿,但这儿有一件不必消耗你的婴儿经费的设备,Gonimo 是一个可以将现有的设备转换成婴儿监控系统的自由开源解决方案,附近大型婴儿用品商店的过道中有数以千计的其他必备或时尚物品,就可以为其中某一个腾出一些婴儿的预算。
Gonimo 诞生时,它的开发者,一个有双胞胎的开源粉丝,发现现有选择存在问题:
* 现有硬件婴儿监视器价格昂贵,使用范围有限,需要您带着额外的设备。
* 虽然有移动监控应用程序,但大多数现有的 iOS / Android 婴儿监控应用程序都不可靠且不安全,不太容易找到开源产品。
* 如果您有两个小孩(例如双胞胎),您将需要两台监视器,使您的成本翻倍。
Gonimo 是作为一个解决典型的监视器的缺点的开源解决方案而创建的:
* 昂贵?不,它是免费的!
* 使用范围有限?不,它适用于互联网 / WiFi,无论您身在何处。
* 下载并安装应用程序?噢不,它适用于您现有的网络浏览器。
* 购买新设备?不用,你可以使用任何笔记本电脑、手机或平板电脑与网络浏览器和麦克风和/或相机。
(注意:遗憾的是,Apple iOS 设备尚不支持,但预计很快就会发生变化 —— 请继续阅读,了解如何帮实现这一目标。)
### 开始
将您的设备转换为婴儿监视器很容易。从您设备的浏览器(理想情况下为 Chrome),访问 [gonimo.com](https://gonimo.com/) 并单击 “Start baby monitor” 以访问该 Web 应用程序。
1、创建家庭:在首次启动的屏幕上,你会看到一只可爱的兔子在地球上奔跑。这是您创建新家庭的地方。单击 “+” 按钮并接受随机生成的姓氏或键入您自己的选择。

*从开始屏幕创建一个新家庭*
2、邀请设备:建立完家庭以后,下个屏幕将指示您邀请其他设备加入你的 Gonimo 家庭。您可以通过电子邮件直接发送一次性邀请链接,也可以将其复制并粘贴到消息中。对其他设备,只需打开该链接并接受邀请。对您要邀请的任何其他设备重复此过程。您的设备现在属于同一家庭,可以作为一个完全正常工作的婴儿监视器系统进行配合。

*邀请家庭成员*
3、启动婴儿站流:接下来,通过转到 [Gonimo 主屏](https://app.gonimo.com/),点击带有奶嘴的按钮,并允许网络浏览器访问设备的麦克风和摄像头,选择将婴儿的音频和视频流式传输到父母的设备。调整相机以指向宝宝的床,或关闭它以节省设备电池(音频仍将流式传输)。点击“Start”。该流现在处于活动状态。

*选择婴儿站*

*按“Start”开始以流式传输视频*
4、连接到父母站流:要查看婴儿站流,请转到 Gonimo 家族中的另外的设备 —— 即父母站。点击 Gonimo 主屏幕上的 “Parent” 按钮。您将看到该系列中所有设备的列表;旁边有一个闪动的“Connect”按钮的是活跃的婴儿站。选择“Connect”,您可以通过点对点音频/视频流看到和听到您的宝宝。音量条为传输的音频流提供可视化。

*选择父母站*

*按下“Connect”开始观看婴儿流。*
5、恭喜!您已成功将设备直接通过网络浏览器转换为婴儿监视器,无需下载或安装任何应用程序!
有关重命名设备,从系列中删除设备或删除系列的详细信息和详细说明,请查看 gonimo.com 的[视频教程](https://gonimo.com/index.php#intro)。
### 家庭系统的灵活性
Gonimo 的优势之一是其基于家庭的系统,它为即使在商业 Android 或 iOS 应用中也无法提供的各种情况提供了极大的灵活性。要深入了解这些功能,我们假设您创建了一个由三个设备组成的家庭系统。
* 多婴儿:如果你想留意你在两个不同房间睡觉的两个小孩怎么办?在每个孩子的房间放一个设备,并将其设置为婴儿站。第三个设备将充当父母站,您可以在其上连接到两个流并通过分屏查看您的幼儿。您甚至可以通过向该家庭系统提供更多设备,并将其设置为婴儿站来将此用例扩展到两个以上的婴儿站。只要您的父母站连接到第一个婴儿站,请单击左上角的后退箭头返回“设备概述”屏幕。现在您可以连接到第二个(以及依次为第三个、第四个、第五个和第五个等)设备,并自动建立分屏。酷!
* 多父母:如果爸爸想在他上班的时候看孩子怎么办?只需邀请第四个设备(例如,他的办公室 PC )到家庭并将其设置为父母站。父母双方都可以通过他们自己的设备同时检查他们的孩子,甚至可以独立地选择他们希望连接的孩子。
* 多家庭:单个设备也可以是几个家庭系统的一部分。当您的婴儿站与您一起时,如平板电脑,您经常访问亲戚或朋友时,这非常有用。为“奶奶的房子”或“约翰叔叔的房子”创建另一个家庭,其中包括您的婴儿站设备与奶奶或约翰叔叔的设备配对。您可以随时通过婴儿站设备的 Gonimo 主屏幕在这些家庭中切换婴儿站设备。
### 想要参加吗?
Gonimo 团队喜欢开源。代码来自社区,代码用于社区。Gonimo 的用户对我们非常重要,但它们只是 Gonimo 故事的一部分。幕后有创意的大脑是创造出色婴儿监视器体验的关键。
目前我们特别需要那些愿意成为 iOS 11 测试者的人的帮助,因为 Apple 在 iOS 11 中对 WebRTC 的支持意味着我们最终将能够支持 iOS 设备。如果可以,请帮助我们实现这个令人赞叹的里程碑。
如果您了解 Haskell 或想要了解它,您可以查看 [GitHub 上我们的代码](https://github.com/gonimo/gonimo)。欢迎发起拉取请求、审查代码以及提出问题。
最后,请通过向新父母和开源世界宣传 Gonimo 婴儿监视器是易于使用并且便携的。
### 关于作者
Robert Klotzner:我是双胞胎的父亲,一个程序员。当我听到普通人可以给计算机编程时,我买了一本 1200 页的关于 C++ 的书开始学习,我当时才十五岁。我坚持用 C++ 相当长的一段时间,学习了 Java 又回归到 C++,学习了 D、Python 等等,最终学习了 Haskell。我喜欢 Haskell 是因为它丰富的类型系统,这几乎可以避免我书写错误的代码。强壮的静态类型和性能让我爱上了 C++……
---
via: <https://opensource.com/article/17/9/gonimo>
作者:[Robert Klotzner](https://opensource.com/users/robert-klotzner) 译者:[lintaov587](https://github.com/lintaov587) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | New and expecting parents quickly learn that there is a long—and expensive—list of equipment that a new baby needs. High on that list is a baby monitor, so they can keep an eye (and an ear) on their infant while they're doing other things. But this is one piece of equipment that doesn't have to eat into your baby fund; Gonimo is a free and open source solution that turns existing devices into a baby monitoring system, freeing up some of your baby budget for any of the thousands of other must-have or trendy items lining the aisles of the nearby big-box baby store.
Gonimo was born when its developer, an open source fan, had twins and found problems with the existing options:
- Status-quo hardware baby monitors are expensive, have limited range, and require you to carry extra devices.
- There are mobile monitoring apps, but most of the existing iOS/Android baby monitoring apps are unreliable and unsecure, with no obvious open source product in sight.
- If you have two young children (e.g., twins), you'll need two monitors, doubling your costs.
Gonimo was created as an open source solution to the shortcomings of typical monitors:
- Expensive? Nope, it is free!
- Limited range? No, it works with internet/WiFi, wherever you are.
- Download and install apps? Uh-uh, it works in your existing web browser.
- Buy new devices? No way, you can use any laptop, mobile phone, or tablet with a web browser and a microphone and/or camera.
(Note: Apple iOS devices are unfortunately not yet supported, but that's expected to change very soon—read on for how you can help make that happen.)
## Get started
Transforming your devices into a baby monitor is easy. From your device's browser (ideally Chrome), visit [gonimo.com](https://gonimo.com/) and click *Start baby monitor* to get to the web app.
**Create family:**On the first-time startup screen, you will see a cute rabbit running on the globe. This is where you create a new family. Hit the**+**button and either accept the randomly generated family name or type in your own choice.
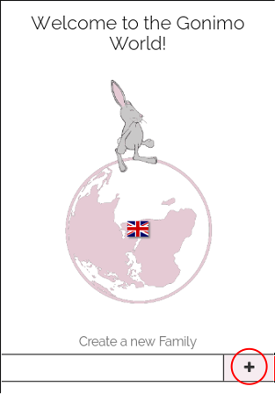
opensource.com
**Invite devices:**After you've set up your family, the next screen directs you to invite another device to join your Gonimo family. There is a one-time invitation link that you can directly send via email or copy and paste into a message. From the other device, simply open the link and accept the invitation. Repeat this process for any other devices you'd like to invite to your family. Your devices are now in the same family, ready to cooperate as a fully working baby monitor system.
opensource.com
**Start baby station stream:**Next, choose which device will stream the baby's audio and video to the parent station by going to the[Gonimo home screen](https://app.gonimo.com/), clicking on the button with the pacifier, and giving the web browser permission to access the device's microphone and camera. Adjust the camera to point at your baby's bed, or turn it off to save device battery (audio will still be streamed). Hit*Start*. The stream is now active.
![]() opensource.com |
![]() opensource.com |
**Connect to parent station stream:**To view the baby station stream, go to another device in your Gonimo family—this is the parent station. Hit the "parent" button on the Gonimo home screen. You will see a list of all the devices in the family; next to the one with the active baby station will be a pulsing*Connect*button. Select*Connect*, and you can see and hear your baby over a peer-to-peer audio/video stream. A volume bar provides visualization for the transmitted audio stream.
![]() opensource.com |
![]() opensource.com |
**Congratulations!**You have successfully transformed your devices into a baby monitor directly over a web browser without downloading or installing any apps!
For more information and detailed descriptions about renaming devices, removing devices from a family, or deleting a family, check out the [video tutorial](https://gonimo.com/index.php#intro) at gonimo.com.
## Flexibility of the family system
One of Gonimo's strengths is its family-based system, which offers enormous flexibility for different kinds of situations that aren't available even in commercial Android or iOS apps. To dive into these features, let's assume that you have created a family that consists of three devices.
**Multi-baby:**What if you want to keep an eye on your two young children who sleep in separate rooms? Put a device in each child's room and set them as baby stations. The third device will act as the parent station, on which you can connect to both streams and see your toddlers via split screen. You can even extend this use case to more than two baby stations by inviting more devices to your family and setting them up as baby stations. As soon as your parent station is connected to the first baby station, return to the Device Overview screen by clicking the back arrow in the top left corner. Now you can connect to the second (and, in turn, the third, and fourth, and fifth, and so on) device, and the split screen will be established automatically. Voila!
**Multi-parent:**What if daddy wants to watch the children while he's at work? Just invite a fourth device (e.g., his office PC) to the family and set it up as a parent station. Both parents can check in on their children simultaneously from their own devices, even independently choosing to which stream(s) they wish to connect.
**Multi-family:**A single device can also be part of several families. This is very useful when your baby station is something that's always with you, such as a tablet, and you frequently visit relatives or friends. Create another family for "Granny's house" or "Uncle John's house," which consists of your baby station device paired with Granny's or Uncle John's devices. You can switch the baby station device among those families, whenever you want, from the baby station device's Gonimo home screen.
## Want to participate?
The Gonimo team loves open source. Code from the community, for the community. Gonimo's users are very important to us, but they are only one part of the Gonimo story. Creative brains behind the scenes are the key to creating a great baby monitor experience.
Currently we especially need help from people who are willing to be iOS 11 testers, as Apple's support of WebRTC in iOS 11 means we will finally be able to support iOS devices. If you can, please help us realize this awesome milestone.
If you know Haskell or want to learn it, you can check out [our code at GitHub](https://github.com/gonimo/gonimo). Pull requests, code reviews, and issues are all welcome.
And, finally, please help by spreading the word to new parents and the open source world that the Gonimo baby monitor is simple to use and already in your pocket.
## 4 Comments |
10,418 | 在 Linux 上使用 tarball | https://www.networkworld.com/article/3328840/linux/working-with-tarballs-on-linux.html | 2019-01-05T21:52:00 | [
"tar",
"归档"
] | https://linux.cn/article-10418-1.html |
>
> Tarball 提供了一种在 Linux 系统上备份和管理一组文件的通用方法。请按照以下提示了解如何创建它们,以及从中提取和删除单个文件。
>
>
>

“tarball” (LCTT 译注:国内也常称为“tar 包”)一词通常用于描述备份一组选择的文件并将它们打包在一个文件中的一种文件格式。该名称来自 .tar 文件扩展名和 `tar` 命令,它用于将文件打包到一个文件中,有时还会压缩该文件,使其在移动到其它系统时更小。
tarball 通常用于备份个人或系统文件来创建存档,特别是在进行可能需要撤消的更改之前。例如,Linux 系统管理员通常会在更改应用之前创建包含一系列配置文件的 tarball,以防必须撤消这些更改。从 tarball 中解压文件通常比在备份中搜索文件快。
### 如何在 Linux 上创建 tarball
使用如下命令,你可以在单条命令中创建 tarball 并压缩它。
```
$ tar -cvzf PDFs.tar.gz *.pdf
```
其结果是一个压缩文件(gzip 压缩的),其中包含了当前目录中的所有 PDF 文件。当然,压缩是可选的。一个稍微简单的只是将 PDF 文件打包成未压缩 tarball 的命令:
```
$ tar -cvf PDFs.tar *.pdf
```
注意,选项中的 `z` 将文件变成压缩的。 `c` 表明创建文件,`v`(详细)表示你在命令运行时需要一些反馈。如果你不想查看列出的文件,请忽略 `v`。
另一个常见的命名约定是给压缩的 tarball 命名成 .tgz 而不是双扩展名 .tar.gz,如下所示:
```
$ tar cvzf MyPDFs.tgz *.pdf
```
### 如何从 tarball 中解压文件
要从 gzip 压缩包中解压所有文件,你可以使用如下命令:
```
$ tar -xvzf file.tar.gz
```
如果使用 .tgz 命名约定,该命令将如下所示:
```
$ tar -xvzf MyPDFs.tgz
```
要从 gzip 包中解压单个文件,你可以执行几乎相同的操作,只需添加文件名:
```
$ tar -xvzf PDFs.tar.gz ShenTix.pdf
ShenTix.pdf
ls -l ShenTix.pdf
-rw-rw-r-- 1 shs shs 122057 Dec 14 14:43 ShenTix.pdf
```
如果未压缩 tarball,你甚至可以从 tarball 中删除文件。例如,如果我们想从 PDFs.tar.gz 中删除我们上面解压过的文件,我们会这样做:
```
$ gunzip PDFs.tar.gz
$ ls -l PDFs.tar
-rw-rw-r-- 1 shs shs 10700800 Dec 15 11:51 PDFs.tar
$ tar -vf PDFs.tar --delete ShenTix.pdf
$ ls -l PDFs.tar
-rw-rw-r-- 1 shs shs 10577920 Dec 15 11:45 PDFs.tar
```
请注意,我们在删除 ShenTix.pdf 后,缩小了一点 tarball 文件占用的空间。如果我们想要,我们可以再次压缩文件:
```
$ gzip -f PDFs.tar
ls -l PDFs.tar.gz
-rw-rw-r-- 1 shs shs 10134499 Dec 15 11:51 PDFs.tar.gzFlickr / James St. John
```
丰富的命令行选项使得 tarball 使用起来简单方便。
---
via: <https://www.networkworld.com/article/3328840/linux/working-with-tarballs-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,419 | 如何成为一名懒惰的系统管理员 | https://opensource.com/article/18/7/how-be-lazy-sysadmin | 2019-01-06T22:50:00 | [
"系统管理员"
] | https://linux.cn/article-10419-1.html |
>
> 我们是聪明地工作,而不是刻苦工作,但仍能把工作做好。
>
>
>

Linux 的系统管理员的工作总是复杂的,并且总是伴随着各种陷阱和障碍。做每件事都没有足够时间,当你想完成那个半秃头老板(PHB)给的任务时,他(只会)不停在你的后面盯着,而最核心的服务器总是在最不合时宜的时间点崩溃,问题和挑战比比皆是。而我发现,成为一名<ruby> 懒惰的系统管理员 <rt> Lazy SysAdmin </rt></ruby>可以解决这一困境。
(LCTT 译注:<ruby> <a href="https://en.wikipedia.org/wiki/Pointy-haired_Boss"> 半秃头老板 </a> <rt> Pointy-Haired Boss </rt></ruby>(PHB),那是[呆伯特漫画](https://zh.wikipedia.org/wiki/%E5%91%86%E4%BC%AF%E7%89%B9)中的角色,缺乏一般知识常识及其职位所应具有的管理能力,爱说大话且富有向物理显示挑战的精神,大概长成下图这样。)

我在即将在 Apress 出版的新书 《The Linux Philosophy for SysAdmins》(LCTT 译注:暂译《系统管理员的 Linux 哲学》)中更详细地讨论如何成为一个懒惰的系统管理员,那书预计会在 9 月出版(LCTT 译注:已于 2018 年 8 月出版)。这本的部分内容摘录自该书,特别是第九章,“成为一名懒惰的系统管理员”。在我们讨论如何做到这点前,让我们简单了解一下成为一个名懒惰的系统管理员意味着什么。

### 真实生产力 vs. 虚假生产力
#### 虚假生产力
在我工作的地方,半秃头老板相信的管理风格叫“<ruby> 走动式管理 <rt> management by walking around </rt></ruby>”。通过判断某人在不在他的键盘上输入东西,或者至少要看看他们显示器上显示的东西,来判断他们的工作是否有效率。这是一个糟糕的工作场所。各部门间有道很高的行政墙,这会造就了许多的、微小的沟通壁垒,大量无用的文书工作,以及获得任何事情的许可都要等待漫长的时间。因为这样、那样的原因,不可能高效地做任何事情,如果真的是这样,那是非常低效。为了看起来很忙,我们都有自己的一套<ruby> “看起来很忙”的工具包 <rt> Look Busy Kits </rt></ruby>(LBK),可能是一些短小的、用来显示一些行为活动的 Bash 脚本,或者是 `top`、`htop`、`iotop` 之类的程序,或者是一些持续显示某些行为活动的监控工具。这种工作场所的风气让人不可能真正高效,我讨厌这种地方,也讨厌那个几乎不可能完成任何有价值的事情的事实。
这种糟糕场所对真实的系统管理员来讲是场噩梦。没有人会感到快乐。在那里花费四五个月才能完成的事,在其他地方只需的一个早晨。我们没有什么实际工作要做,却要花大量的时间干活来让自己看起来很忙。我们在默默地竞赛,看谁能创造最好的“看起来很忙”的工具包,这就是我们花费最多时间的地方了。那份工作我只做了几个月,但好像已经耗费了一生。如果你看到的这个监狱的表面,你可能会说我们是很懒,因为我们只完成了几乎为 0 的实际工作。
这是个极端的例子,它完全与我所说的“我是一个懒惰的系统管理员”的意思相反,而做一个懒惰的系统管理是件好事。
#### 真实生产力
我很幸运,曾为一些真正的管理者工作过 —— 他们明白,系统管理员的生产力并不是以每天花多少小时敲键盘来衡量。毕竟,即使一只猴子能敲击他们的键盘,但也不能说明结果的价值。
正如我书中所言:
>
> “我是一个懒惰的系统管理员,同时我也是一个高效的系统管理员。这两者看似矛盾的说法不是相互排斥的,而是会以一种非常积极的方式相辅相成……
>
>
> “系统管理员在思考的时候是最高效的 —— 思考关于如何解决现有问题和避免未来的问题;思考怎样监控 Linux 计算机,以便找到预测和预示这些未来的问题的线索;思考如何让他们的工作更有效率;思考如何自动化所有这些要执行的任务,无论是每天还是每年一次的任务。
>
>
> “系统管理员冥思苦想的那一面是不会被非系统管理员所熟知的,那些人包括很多管理着系统管理员的人,比如那个半秃头老板。系统管理员都会以不同的方式解决他们工作中苦思的部分。一些我认识的系统管理员会在沙滩、骑自行车、参加马拉松或者攀岩时找到最好的想法。另一些人会认为静坐或听音乐的时候思考得最好。还有一些会在阅读小说、学习不相关的学科、甚至在学习 Linux 系统的时候可以最佳思考。关键是我们都有不同的方式激发我们的创造力,而这些创造力的推进器中很多并不涉及键盘上的任何一个按键。我们真正的生产力对于系统管理员周围的人来说可能是完全看不见的。”
>
>
>
成为懒惰的系统管理员有一些简单的秘诀 —— 系统管理员要完成一切需要完成的事,而且更多的是,当所有人都处于恐慌的状态时要保持冷静和镇定。秘诀的一部分是高效工作,另一部分是把预防问题放在首位。
### 成为懒惰系统管理员的方法
#### 多思考
我相信关于懒惰系统管理员最重要的秘诀在于思考。正如上面的摘录所言,优秀的系统管理员会花大量的时候思考这些事情,如何更有效率地工作,在异常成为问题前如何定位,更聪明地工作,做其它事情的同时会考虑如何完成这些事情等等。
例如,除了撰写本文之外,我现在正在想一个项目,我打算在从亚马逊和本地计算机商店采购的新部件到达时才开始。我有一台不太关键的计算机上的主板坏了,最近它的崩溃更频率。但我的一台非常老的小服务器并没有出现故障,它负责处理我的电子邮件和外部网站,以及为我的网络的其余部分提供 DHCP 和 DNS 服务,但需要解决由于各种外部攻击而导致的间歇性过载。
我一开始想,我只要替换故障设备的主板及其直接部件:内存、CPU,可能还有电源。但是在考虑了一段时间之后,我决定将新部件放到服务器中,并将旧的(但仍然可用的)部件从服务器移到故障设备中。可以这样做的,只需一、两个小时就可以从服务器上移除旧部件并安装新的。然后我就可以花时间更换出故障的电脑里的部件了。太好了,所以我开始在脑海中列出要完成的任务。
然而,当我查看这个任务列表时,我意识到服务器中唯一不能替换的部件是机箱和硬盘驱动器,这两台计算机的机箱几乎完全相同。在有了这个小小的发现之后,我开始考虑用新的部件替换出了故障的计算机的部件,并将之作为我的服务器。经过一些测试之后,我只需从当前的服务器移除硬盘,并将它安装到用了新组件的机箱中,改下网络配置项,再更改 KVM 交换机端口上的主机名,并更改机箱上的主机名标签,就可以了。这将大大减少服务器停机时间,大大减少我的压力。此外,如果出现故障,我可以简单地将硬盘移回原来的服务器,直到我可以用新服务器解决问题为止。
所以,现在我在脑海中已经创建了一个完成这项工作我所需要做的任务清单。而且,我希望你能仔细观察,当我脑子里想着这一切的时候,我的手指从来没有碰过键盘。我新的心理行动计划风险很低,与我最初的计划相比,涉及的服务器停机时间要少得多。
当我在 IBM 工作的时候,我经常看到很多语言中都有写着“**思考**”的标语。思考可以节省时间和压力,是懒散的系统管理员的主要标志。
#### 做预防性维护
在 1970 年代中期,我被 IBM 聘为客户工程师,我的领地由相当多的[穿孔卡片设备](https://en.wikipedia.org/wiki/Unit_record_equipment)组成。这也就是说,它们是处理打孔卡的重型机械设备,其中一些可以追溯到 20 世纪 30 年代。因为这些机器主要是机械的,所以它们的部件经常磨损或失调。我的部分工作是在它们损坏时修复它们。我工作的主要部分,也是最重要的部分,是首先要防止它们损坏。预防性维护的目的是在磨损部件损坏之前进行更换,并对还在运行的部件进行润滑和调整,以确保它们工作正常。
正如我在《系统管理员的 Linux 哲学》中所言:
>
> “我在 IBM 的经理们明白这只是冰山一角;他们和我都知道,我的工作是让顾客满意。虽然这通常意味着修复损坏的硬件,但也意味着减少硬件损坏的次数。这对客户来说是好事,因为他们的机器在工作时工作效率更高。这对我有好处,因为我从那些快乐的客户那里接到的电话要少得多。我也睡了更多的觉,因为这样做的结果是更少的非工作时间的紧急电话。我是个懒惰的(客户工程师)。通过提前做额外的工作,从长远来看,我需要做的工作要少得多。
>
>
> “这一原则已成为系统管理员的 Linux 哲学的功能原则之一。作为系统管理员,我们的时间最好用在最大限度地减少未来工作量的任务上。”
>
>
>
在 Linux 计算机中查找要解决的问题相当于项目管理。我检查系统日志,寻找以后可能会变得非常危险的问题的迹象。如果出现了一些小问题,或者我注意到我的工作站、服务器没有做出该有的响应,或者如果日志显示了一些不寻常的东西,所有这些都可以暗示出潜在的问题,而对于用户或半秃头老板来说,这些问题并没有产生明显的症状。
我经常检查 `/var/log/` 中的文件,特别是 `messages` 和 `security` 文件。我最常见的问题之一是许多脚本小子在我的防火墙系统上尝试各种类型的攻击。而且,不,我不依赖 ISP 提供的调制解调器/路由器中的所谓的防火墙。这些日志包含了大量关于企图攻击来源的信息,非常有价值。但是要扫描不同主机上的日志并将解决方案部署到位,需要做大量的工作,所以我转向自动化。
#### 自动化
我发现我的工作有很大一部分可以通过某种形式的自动化来完成。系统管理员的 Linux 哲学的原则之一是 “自动化一切”,这包括每天扫描日志文件等枯燥乏味的任务。
像是 [Logwatch](https://www.techrepublic.com/article/how-to-install-and-use-logwatch-on-linux/) 这类的程序能够监控你的日志文件中的异常条目,并在异常条目发生时通知您。Logwatch 通常作为 cron 任务每天运行一次,并向本地主机上的 root 用户发送电子邮件。你可以从命令行运行 Logwatch,并立即在显示器上查看结果。现在我只需要每天查看 Logwatch 的电子邮件通知。
但现实是,仅仅收到通知是不够的,因为我们不能坐以待毙。有时需要立即作出反应。我喜欢的另一个程序是——它能为我做所有事(看,这就是懒惰的管理员)——它就是 [Fail2ban](https://www.fail2ban.org/wiki/index.php/Main_Page)。Fail2Ban 会扫描指定的日志文件,查找各种类型的黑客攻击和入侵尝试,如果它发现某个 IP 地址在持续做特定类型的活动,它会向防火墙添加一个条目,在指定的时间内阻止来自该 IP 地址的任何进一步的黑客尝试。默认值通常在 10 分钟左右,但我喜欢为大多数类型的攻击指定为 12 或 24 小时。每种类型的黑客攻击都是单独配置的,例如尝试通过 SSH 登录和那些 Web 服务器的攻击。
#### 写脚本
自动化是这种哲学的关键组成部分之一。一切可以自动化的东西都应该自动化的,其余的尽可能地自动化。所以,我也写了很多脚本来解决问题,也就是说我编写了脚本来完成我的大部分工作。
我的脚本帮我节省了大量时间,因为它们包含执行特定任务的命令,这大大减少了我需要输入的数量。例如,我经常重新启动我的电子邮件服务器和垃圾邮件过滤软件(当修改 SpamAssassin 的 `local.cf` 配置文件时,就需要重启)。必须按特定顺序停止并重新启动这些服务。因此,我用几个命令编写了一个简短的脚本,并将其存储在可访问的 `/usr/local/bin` 中。现在,不用键入几个命令并等待每个命令都完成,然后再键入下一个命令,更不用记住正确的命令顺序和每个命令的正确语法,我输入一个三个字符的命令,其余的留给我的脚本来完成。
#### 简化键入
另一种成为懒惰的系统管理员的方法是减少我们需要键入的数量。而且,我的打字技巧真的很糟糕(也就是说,我一点也没有,顶多是几个笨拙的手指)。导致错误的一个可能原因是我糟糕的打字技巧,所以我会尽量少打字。
绝大多数 GNU 和 Linux 核心实用程序都有非常短的名称。然而,它们都是有意义的名字。诸如用于更改目录的 `cd` 、用于列出目录内容的 `ls` 和用于磁盘转储的 `dd` 等工具都一目了然。短名字意味着更少的打字和更少的产生错误机会。我认为短的名字通常更容易记住。
当我编写 shell 脚本时,我喜欢保持名称简短而意义(至少对我来说是),比如用于 rsync 备份的 `rsbu`(LCTT 译注,Rsync Backup 的简写)。但在某些情况下,我喜欢使用更长的名称,比如 `doUpdates` 来执行系统更新。在后一种情况下,更长一点的名字让脚本的目的更明显。这可以节省时间,因为很容易记住脚本的名称。
其他减少键入的方法包括命令行别名、历史命令调回和编辑。别名只是你在 Bash shell 键入命令时才做的替换。键入 `alias` 命令会看到默认配置的别名列表。例如,当你输入命令 `ls` 时,会被条目 `alias ls='ls –color=auto'` 替成较长的命令,因此你只需键入 2 个字符而不是 14 个字符即可获得带有颜色的文件列表。还可以使用 `alias` 命令添加你自己定义的别名。
历史命令调回允许你使用键盘的向上和向下箭头键滚动浏览命令历史记录。如果需要再次使用相同的命令,只需在找到所需的命令时按回车键即可。如果在找到命令后需要更改该命令,则可以使用标准命令行编辑功能进行更改。
### 结束语
一名懒惰的系统管理员实际上也有很多的工作。但我们是聪明地工作,而不是刻苦工作。早在一堆小问题汇聚成大问题之前,我们就花时间探索我们负责的主机,并处理好所有的小问题。我们花了很多时间思考解决问题的最佳方法,我们也花了很多时间来发现新的方法,让自己更聪明地工作,成为懒惰的系统管理员。
除了这里描述的少数方法外,还有许多其他的方式可以成为懒惰的系统管理员。我相信你也有一些自己的方式;请在评论中和我们分享。
---
via: <https://opensource.com/article/18/7/how-be-lazy-sysadmin>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zgj1024](https://github.com/zgj1024) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The job of a Linux SysAdmin is always complex and often fraught with various pitfalls and obstacles. Ranging from never having enough time to do everything, to having the Pointy-Haired Boss (PHB) staring over your shoulder while you try to work on the task that she or he just gave you, to having the most critical server in your care crash at the most inopportune time, problems and challenges abound. I have found that becoming the Lazy Sysadmin can help.
I discuss how to be a lazy SysAdmin in detail in my forthcoming book, * The Linux Philosophy for SysAdmins*, (Apress), which is scheduled to be available in September. Parts of this article are taken from that book, especially Chapter 9, "Be a Lazy SysAdmin." Let's take a brief look at what it means to be a Lazy SysAdmin before we discuss how to do it.
## Real vs. fake productivity
### Fake productivity
At one place I worked, the PHB believed in the management style called "management by walking around," the supposition being that anyone who wasn't typing something on their keyboard, or at least examining something on their display, was not being productive. This was a horrible place to work. It had high administrative walls between departments that created many, tiny silos, a heavy overburden of useless paperwork, and excruciatingly long wait times to obtain permission to do anything. For these and other reasons, it was impossible to do anything efficiently—if at all—so we were incredibly non-productive. To look busy, we all had our Look Busy Kits (LBKs), which were just short Bash scripts that showed some activity, or programs like `top`
, `htop`
, `iotop`
, or any monitoring tool that constantly displayed some activity. The ethos of this place made it impossible to be truly productive, and I hated both the place and the fact that it was nearly impossible to accomplish anything worthwhile.
That horrible place was a nightmare for real SysAdmins. None of us was happy. It took four or five months to accomplish what took only a single morning in other places. We had little real work to do but spent a huge amount of time working to look busy. We had an unspoken contest going to create the best LBK, and that is where we spent most of our time. I only managed to last a few months at that job, but it seemed like a lifetime. If you looked only at the surface of that dungeon, you could say we were lazy because we accomplished almost zero real work.
This is an extreme example, and it is totally the opposite of what I mean when I say I am a Lazy SysAdmin and being a Lazy SysAdmin is a good thing.
### Real productivity
I am fortunate to have worked for some true managers—they were people who understood that the productivity of a SysAdmin is not measured by how many hours per day are spent banging on a keyboard. After all, even a monkey can bang on a keyboard, but that is no indication of the value of the results.
As I say in my book:
"I am a lazy SysAdmin and yet I am also a very productive SysAdmin. Those two seemingly contradictory statements are not mutually exclusive, rather they are complementary in a very positive way. …
"A SysAdmin is most productive when thinking—thinking about how to solve existing problems and about how to avoid future problems; thinking about how to monitor Linux computers in order to find clues that anticipate and foreshadow those future problems; thinking about how to make their work more efficient; thinking about how to automate all of those tasks that need to be performed whether every day or once a year.
"This contemplative aspect of the SysAdmin job is not well known or understood by those who are not SysAdmins—including many of those who manage the SysAdmins, the Pointy Haired Bosses. SysAdmins all approach the contemplative parts of their job in different ways. Some of the SysAdmins I have known found their best ideas at the beach, cycling, participating in marathons, or climbing rock walls. Others think best when sitting quietly or listening to music. Still others think best while reading fiction, studying unrelated disciplines, or even while learning more about Linux. The point is that we all stimulate our creativity in different ways, and many of those creativity boosters do not involve typing a single keystroke on a keyboard. Our true productivity may be completely invisible to those around the SysAdmin."
There are some simple secrets to being the Lazy SysAdmin—the SysAdmin who accomplishes everything that needs to be done and more, all the while keeping calm and collected while others are running around in a state of panic. Part of this is working efficiently, and part is about preventing problems in the first place.
## Ways to be the Lazy SysAdmin
### Thinking
I believe the most important secret about being the Lazy SysAdmin is thinking. As in the excerpt above, great SysAdmins spend a significant amount of time thinking about things we can do to work more efficiently, locate anomalies before they become problems, and work smarter, all while considering how to accomplish all of those things and more.
For example, right now—in addition to writing this article—I am thinking about a project I intend to start as soon as the new parts arrive from Amazon and the local computer store. The motherboard on one of my less critical computers is going bad, and it has been crashing more frequently recently. But my very old and minimal server—the one that handles my email and external websites, as well as providing DHCP and DNS services for the rest of my network—isn't failing but has to deal with intermittent overloads due to external attacks of various types.
I started by thinking I would just replace the motherboard and its direct components—memory, CPU, and possibly the power supply—in the failing unit. But after thinking about it for a while, I decided I should put the new components into the server and move the old (but still serviceable) ones from the server into the failing system. This would work and take only an hour, or perhaps two, to remove the old components from the server and install the new ones. Then I could take my time replacing the components in the failing computer. Great. So I started generating a mental list of tasks to do to accomplish this.
However, as I worked the list, I realized that about the only components of the server I wouldn't replace were the case and the hard drive, and the two computers' cases are almost identical. After having this little revelation, I started thinking about replacing the failing computer's components with the new ones and making it my server. Then, after some testing, I would just need to remove the hard drive from my current server and install it in the case with all the new components, change a couple of network configuration items, change the hostname on the KVM switch port, and change the hostname labels on the case, and it should be good to go. This will produce far less server downtime and significantly less stress for me. Also, if something fails, I can simply move the hard drive back to the original server until I can fix the problem with the new one.
So now I have created a mental list of the tasks I need to do to accomplish this. And—I hope you were watching closely—my fingers never once touched the keyboard while I was working all of this out in my head. My new mental action plan is low risk and involves a much smaller amount of server downtime compared to my original plan.
When I worked for IBM, I used to see signs all over that said "THINK" in many languages. Thinking can save time and stress and is the main hallmark of a Lazy SysAdmin.
### Doing preventative maintenance
In the mid-1970s, I was hired as a customer engineer at IBM, and my territory consisted of a fairly large number of [unit record machines](https://en.wikipedia.org/wiki/Unit_record_equipment). That just means that they were heavily mechanical devices that processed punched cards—a few dated from the 1930s. Because these machines were primarily mechanical, their parts often wore out or became maladjusted. Part of my job was to fix them when they broke. The main part of my job—the most important part—was to prevent them from breaking in the first place. The preventative maintenance was intended to replace worn parts before they broke and to lubricate and adjust the moving components to ensure that they were working properly.
As I say in *The Linux Philosophy for SysAdmins*:
"My managers at IBM understood that was only the tip of the iceberg; they—and I—knew my job was customer satisfaction. Although that usually meant fixing broken hardware, it also meant reducing the number of times the hardware broke. That was good for the customer because they were more productive when their machines were working. It was good for me because I received far fewer calls from those happier customers. I also got to sleep more due to the resultant fewer emergency off-hours callouts. I was being the Lazy [Customer Engineer]. By doing the extra work upfront, I had to do far less work in the long run.
"This same tenet has become one of the functional tenets of the Linux Philosophy for SysAdmins. As SysAdmins, our time is best spent doing those tasks that minimize future workloads."
Looking for problems to fix in a Linux computer is the equivalent of project management. I review the system logs looking for hints of problems that might become critical later. If something appears to be a little amiss, or I notice my workstation or a server is not responding as it should, or if the logs show something unusual—all of these can be indicative of an underlying problem that has not generated symptoms obvious to users or the PHB.
I do frequent checks of the files in `/var/log/`
, especially messages and security. One of my more common problems is the many script kiddies who try various types of attacks on my firewall system. And, no, I do not rely on the alleged firewall in the modem/router provided by my ISP. These logs contain a lot of information about the source of the attempted attack and can be very valuable. But it takes a lot of work to scan the logs on various hosts and put solutions into place. So I turn to automation.
### Automating
I have found that a very large percentage of my work can be performed by some form of automation. One of the tenets of the Linux Philosophy for SysAdmins is "automate everything," and this includes boring, drudge tasks like scanning logfiles every day.
Programs like [Logwatch](https://www.techrepublic.com/article/how-to-install-and-use-logwatch-on-linux/) can monitor your logfiles for anomalous entries and notify you when they occur. Logwatch usually runs as a cron job once a day and sends an email to root on the localhost. You can run Logwatch from the command line and view the results immediately on your display. Now I just need to look at the Logwatch email notification every day.
But the reality is just getting a notification is not enough, because we can't sit and watch for problems all the time. Sometimes an immediate response is required. Another program I like, one that does all of the work for me—see, this is the real Lazy Admin—is [Fail2Ban](https://www.fail2ban.org/wiki/index.php/Main_Page). Fail2Ban scans designated logfiles for various types of hacking and intrusion attempts, and if it sees enough sustained activity of a specific type from a particular IP address, it adds an entry to the firewall that blocks any further hacking attempts from that IP address for a specified time. The defaults tend to be around 10 minutes, but I like to specify 12 or 24 hours for most types of attacks. Each type of hacking attack is configured separately, such as those trying to log in via SSH and those attacking a web server.
### Writing scripts
Automation is one of the key components of the Philosophy. Everything that can be automated should be, and the rest should be automated as much as possible. So, I also write a lot of scripts to solve problems, which also means I write scripts to do most of my work for me.
My scripts save me huge amounts of time because they contain the commands to perform specific tasks, which significantly reduces the amount of typing I need to do. For example, I frequently restart my email server and my spam-fighting software (which needs restarted when configuration changes are made to SpamAssassin's `local.cf`
file). Those services must be stopped and restarted in a specific order. So, I wrote a short script with a few commands and stored it in `/usr/local/bin`
, where it is accessible. Now, instead of typing several commands and waiting for each to finish before typing the next one—not to mention remembering the correct sequence of commands and the proper syntax of each—I type in a three-character command and leave the rest to my script.
### Reducing typing
Another way to be the Lazy SysAdmin is to reduce the amount of typing we need to do. Besides, my typing skills are really horrible (that is to say I have none—a few clumsy fingers at best). One possible cause for errors is my poor typing, so I try to keep typing to a minimum.
The vast majority of GNU and Linux core utilities have very short names. They are, however, names that have some meaning. Tools like `cd`
for change directory, `ls`
for list (the contents of a directory), and `dd`
for disk dump are pretty obvious. Short names mean less typing and fewer opportunities for errors to creep in. I think the short names are usually easier to remember.
When I write shell scripts, I like to keep the names short but meaningful (to me at least) like `rsbu`
for Rsync BackUp. In some cases, I like the names a bit longer, such as `doUpdates`
to perform system updates. In the latter case, the longer name makes the script's purpose obvious. This saves time because it's easy to remember the script's name.
Other methods to reduce typing are command line aliases and command line recall and editing. Aliases are simply substitutions that are made by the Bash shell when you type a command. Type the `alias`
command and look at the list of aliases that are configured by default. For example, when you enter the command `ls`
, the entry `alias ls='ls –color=auto'`
substitutes the longer command, so you only need to type two characters instead of 14 to get a listing with colors. You can also use the `alias`
command to add your own aliases.
Command line recall allows you to use the keyboard's Up and Down arrow keys to scroll through your command history. If you need to use the same command again, you can just press the Enter key when you find the one you need. If you need to change the command once you have found it, you can use standard command line editing features to make the changes.
## Parting thoughts
It is actually quite a lot of work being the Lazy SysAdmin. But we work smart, rather than working hard. We spend time exploring the hosts we are responsible for and dealing with any little problems long before they become large problems. We spend a lot of time thinking about the best ways to resolve problems, and we think a lot about discovering new ways to work smarter at being the Lazy SysAdmin.
There are many other ways to be the Lazy SysAdmin besides the few described here. I'm sure you have some of your own; please share them with the rest of us in the comments.
## 2 Comments |
10,420 | COPR 仓库中 4 个很酷的新软件(2018.12) | https://fedoramagazine.org/4-try-copr-december-2018/ | 2019-01-06T23:22:47 | [
"COPR"
] | https://linux.cn/article-10420-1.html | 
COPR 是软件的个人存储库的[集合](https://copr.fedorainfracloud.org/),它包含那些不在标准的 Fedora 仓库中的软件。某些软件不符合允许轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是自由开源的。COPR 可以在标准的 Fedora 包之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己背书的。但是,它是尝试新的或实验性软件的一种很好的方法。
这是 COPR 中一组新的有趣项目。
### MindForger
[MindForger](https://www.mindforger.com/) 是一个 Markdown 编辑器和笔记本。除了你预期的 Markdown 编辑器的功能之外,MindForger 还允许你将单个文件拆分为多个笔记。组织笔记并在文件之间移动、搜索它们都很容易。我已经使用 MindForger 一段时间来记录学习笔记了,现在可以在 COPR 中找到它啦。

#### 安装说明
该仓库目前在 Fedora 29 和 Rawhide 中提供 MindForger。要安装 MindForger,请使用以下命令:
```
sudo dnf copr enable deadmozay/mindforger
sudo dnf install mindforger
```
### Clingo
[Clingo](https://potassco.org/clingo/) 是使用[回答集编程](https://en.wikipedia.org/wiki/Answer_set_programming)(ASP)建模语言解决逻辑问题的程序。使用 ASP,你可以将问题声明为一个逻辑程序,然后 Clingo 来解决。最后,Clingo 以逻辑模型的形式产生问题的解决方案,称为回答集。
#### 安装说明
该仓库目前为 Fedora 28 和 29 提供 Clingo。要安装 Clingo,请使用以下命令:
```
sudo dnf copr enable timn/clingo
sudo dnf install clingo
```
### SGVrecord
[SGVrecord](https://github.com/yucefsourani/sgvrecord) 是一个用于录制屏幕的简单工具。它允许你捕获整个屏幕或仅选择其中的一部分。此外,有没有声音都可以进行录制。SGVrecord 以 WebM 格式生成文件。

#### 安装说明
该仓库目前为 Fedora 28、29 和 Rawhide 提供 SGVrecord。要安装 SGVrecord,请使用以下命令:
```
sudo dnf copr enable youssefmsourani/sgvrecord
sudo dnf install sgvrecord
```
### Watchman
[Watchman](https://facebook.github.io/watchman/) 是一个对文件更改进行监视和记录的服务。你可以为指定 Watchman 监视的目录树,以及定义指定文件发生更改时触发的操作。
#### 安装说明
该仓库目前为 Fedora 29 和 Rawhide 提供 Watchman。要安装 Watchman,请使用以下命令:
```
sudo dnf copr enable eklitzke/watchman
sudo dnf install watchman
```
---
via: <https://fedoramagazine.org/4-try-copr-december-2018/>
作者:[Dominik Turecek](https://fedoramagazine.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | COPR is a [collection](https://copr.fedorainfracloud.org/) of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
Here’s a set of new and interesting projects in COPR.
### MindForger
[MindForger](https://www.mindforger.com/) is a Markdown editor and a notebook. In addition to features you’d expect from a Markdown editor, MindForger lets you split a single file into multiple notes. It’s easy to organize the notes and move them around between files, as well as search through them. I’ve been using MindForger for some time for my study notes, so it’s nice that it’s available through COPR now.
#### Installation instructions
The repo currently provides MindForger for Fedora 29 and Rawhide. To install MindForger, use these commands:
sudo dnf copr enable deadmozay/mindforger sudo dnf install mindforger
### Clingo
[Clingo](https://potassco.org/clingo/) is a program for solving logical problems using [answer set programming](https://en.wikipedia.org/wiki/Answer_set_programming) (ASP) modeling language. With ASP, you can declaratively describe a problem as a logical program that Clingo then solves. As a result, Clingo produces solutions to the problem in the form of logical models, called answer sets.
#### Installation instructions
The repo currently provides Clingo for Fedora 28 and 29. To install Clingo, use these commands:
sudo dnf copr enable timn/clingo sudo dnf install clingo
### SGVrecord
[SGVrecord](https://github.com/yucefsourani/sgvrecord) is a simple tool for recording your screen. It allows you to either capture the whole screen or select just a part of it. Furthermore, it is possible to make the record with or without sound. Sgvrecord produces files in WebM format.
#### Installation instructions
The repo currently provides SGVrecord for Fedora 28, 29, and Rawhide. To install SGVrecord, use these commands:
sudo dnf copr enable youssefmsourani/sgvrecord sudo dnf install sgvrecord
### Watchman
[Watchman](https://facebook.github.io/watchman/) is a service for monitoring and recording when changes are done to files.
You can specify directory trees for Watchman to monitor, as well as define actions
that are triggered when specified files are changed.
#### Installation instructions
The repo currently provides Watchman for Fedora 29 and Rawhide. To install Watchman, use these commands:
sudo dnf copr enable eklitzke/watchman sudo dnf install watchman
## cal
I’m excited about MindForger but I’m getting library errors right off the bat. It installed with no errors but it fails to launch. Running it from bash shows complaints about missing libQt5WebChannel. I found that library and installed it but now it’s complaining about libQt5Positioning. I haven’t gone beyond that yet, but I think there is a missing Qt package with all the qt libraries that need to be installed before the MindForger package.
## Nathan
I got it to run but it consumes 90% CPU while it’s running and causes my fans to go crazy, I ran strace on it and it’s apparently the RECVMSG syscall over and over again
$ strace -p 9879 -c
strace: Process 9879 attached
strace: [ Process PID=9879 runs in x32 mode. ]
strace: [ Process PID=9879 runs in 64 bit mode. ]
^Cstrace: Process 9879 detached
% time seconds usecs/call calls errors syscall
47.13 0.011296 1 10977 11 futex
14.19 0.003402 0 27444 poll
13.41 0.003215 0 16466 writev
9.77 0.002342 0 21954 21950 recvmsg
9.68 0.002319 0 16463 write
5.82 0.001394 0 10975 read
0.00 0.000000 0 2 recvfrom
100.00 0.023968 104281 21961 total
## svsv sarma
Why bother about CORP, when strictly forbidden by FEDORA? We can certainly do with out it! Why invite trouble by installing non recommended packages. There must be equally others in Fedora to consider. I like Fedora as it is. Long live FEDORA!
## Miroslav Suchý
@svs Copr does not contain packages forbidden by Fedora. It contains (mostly) packages where packager does not want to push it to Fedora. Usually because it does not meet Fedora packaging standard, packager do not want to dedicate much time for packaging, he does not want to react on security issues, he does not want to follow new releases, the software is too old or too new. There are plenty of reasons.
## Me
[ME@Atlas-Rise ~]$ sudo dnf copr enable eklitzke/watchman
You are about to enable a Copr repository. Please note that this
repository is not part of the main distribution, and quality may vary.
The Fedora Project does not exercise any power over the contents of
this repository beyond the rules outlined in the Copr FAQ at
https://docs.pagure.org/copr.copr/user_documentation.html#what-i-can-build-in-copr,
and packages are not held to any quality or security level.
Please do not file bug reports about these packages in Fedora
Bugzilla. In case of problems, contact the owner of this repository.
Do you want to continue? [y/N]: y
Repository successfully enabled.
[ME@Atlas-Rise ~]$ sudo dnf install watchman
Failed to synchronize cache for repo ‘deadmozay-mindforger’, disabling.
Failed to synchronize cache for repo ‘eklitzke-watchman’, disabling.
Last metadata expiration check: 0:01:05 ago on Fri 21 Dec 2018 10:21:19 AM EST.
No match for argument: watchman
Error: Unable to find a match
[ME@Atlas-Rise ~]$
## TD Stasio
MindForger is pretty cool but I installed from the RPM in their git downloads. I’ve had issues with COPR repos lately because the maintainers aren’t neglecting to keep them updated. 🙁 |
10,421 | 用 PGP 保护代码完整性(六):在 Git 上使用 PGP | https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-6-using-pgp-git | 2019-01-07T00:09:00 | [
"PGP",
"git"
] | https://linux.cn/article-10421-1.html |
>
> 我们继续我们的 PGP 实践系列,来看看签名标签的标签和提交,这可以帮你确保你的仓库没有被篡改。
>
>
>

在本系列教程中,我们提供了一个使用 PGP 的实用指南,包括基本概念和工具、生成和保护你的密钥。如果你错过了前面的文章,你可以查看下面的链接。在这篇文章中,我们谈一谈在 Git 中如何集成 PGP、使用签名的标签,然后介绍签名提交,最后添加签名推送的支持。
* [第一部分:基本概念和工具](/article-9524-1.html)
* [第二部分:生成你的主密钥](/article-9529-1.html)
* [第三部分:生成 PGP 子密钥](/article-9607-1.html)
* [第四部分:将主密钥移到离线存储中](/article-10402-1.html)
* [第五部分:将子密钥移到硬件设备中](/article-10415-1.html)
Git 的核心特性之一就是它的去中心化本质 —— 一旦仓库克隆到你的本地系统,你就拥有了项目的完整历史,包括所有的标签、提交和分支。然而由于存在着成百上千的克隆仓库,如何才能验证你下载的仓库没有被恶意的第三方做过篡改?你可以从 GitHub 或一些貌似官方的位置来克隆它们,但是如果有些人故意欺骗了你怎么办?
或者在你参与的一些项目上发现了后门,而 “Author” 行显示是你干的,然而你很确定 [不是你干的](https://github.com/jayphelps/git-blame-someone-else),会发生什么情况?
为解决上述问题,Git 添加了 PGP 集成。签名的标签通过确认它的内容与创建这个标签的开发者的工作站上的内容完全一致来证明仓库的完整性,而签名的提交几乎是不可能在不访问你的 PGP 密钥的情况下能够假冒你。
#### 清单
* 了解签名的标签、提交和推送(必要)
* 配置 git 使用你的密钥(必要)
* 学习标签如何签名和验证(必要)
* 配置 git 总是签名带注释标签(推荐)
* 学习提交如何签名和验证工作(必要)
* 配置 git 总是签名提交(推荐)
* 配置 gpg-agent 选项(必要)
#### 考虑事项
git 实现了 PGP 的多级集成,首先从签名标签开始,接着介绍签名提交,最后添加签名推送的支持。
##### 了解 Git 哈希
git 是一个复杂的东西,为了你能够更好地掌握它如何集成 PGP,你需要了解什么是”哈希“。我们将它归纳为两种类型的哈希:树哈希和提交哈希。
###### 树哈希
每次你向仓库提交一个变更,对于仓库中的每个子目录,git 都会记录它里面所有对象的校验和哈希 —— 内容(blobs)、目录(trees)、文件名和许可等等。它只对每次提交中发生变更的树和内容做此操作,这样在只变更树的一小部分时就不必去重新计算整个树的校验和。
然后再计算和存储处于顶级的树的校验和,这样如果仓库的任何一部分发生变化,校验和将不可避免地发生变化。
###### 提交哈希
一旦创建了树哈希,git 将计算提交哈希,它将包含有关仓库和变更的下列信息:
* 树哈希的校验和
* 变更前树哈希的校验和(父级)
* 有关作者的信息(名字、email、创作时间)
* 有关提交者的信息(名字、email、提交时间)
* 提交信息
###### 哈希函数
在写这篇文章时,虽然研究一种更强大的、抗碰撞的算法的工作正在进行,但 git 仍然使用的是 SHA1 哈希机制去计算校验和。注意,git 已经包含了碰撞防范程序,因此认为对 git 成功进行碰撞攻击仍然是不可行的。
#### 带注释标签和标签签名
在每个 Git 仓库中,标签允许开发者标记特定的提交。标签可以是 “轻量级的” —— 几乎只是一个特定提交上的指针,或者它们可以是 “带注释的”,它自己将成为 git 树中的项目。一个带注释标签对象包含所有下列的信息:
* 成为标签的提交的哈希的校验和
* 标签名字
* 关于打标签的人的信息(名字、email、打标签时间)
* 标签信息
一个 PGP 签名的标签是一个带有将所有这些条目封装进一个 PGP 签名的带注释标签。当开发者签名他们的 git 标签时,他们实际上是向你保证了如下的信息:
* 他们是谁(以及他们为什么应该被信任)
* 他们在签名时的仓库状态是什么样:
+ 标签包含的提交的哈希
- 提交的哈希包含了顶级树的哈希
- 顶级树哈希包含了所有文件、内容和子树的哈希
- 它也包含有关作者的所有信息
- 包含变更发生时的精确时间
当你克隆一个仓库并验证一个签名的标签时,就是向你以密码方式保证:仓库中的所有内容、包括所有它的历史,与开发者签名时在它的计算机上的仓库完全一致。
#### 签名的提交
签名的提交与签名的标签非常类似 —— PGP 签名的是提交对象的内容,而不是标签对象的内容。一个提交签名也给你提供了开发者签名时开发者树上的全部可验证信息。标签签名和提交的 PGP 签名提供了有关仓库和它的完整历史的完全一致的安全保证。
#### 签名的推送
为了完整起见,在这里包含了签名的推送这一功能,因为在你使用这个功能之前,需要在接收推送的服务器上先启用它。正如我们在上面所说过的,PGP 签名一个 git 对象就是提供了开发者的 git 树当时的可验证信息,但不提供开发者对那个树意图相关的信息。
比如,你可以在你自己复刻的 git 仓库的一个实验分支上尝试一个很酷的特性,为了评估它,你提交了你的工作,但是有人在你的代码中发现了一个恶意的 bug。由于你的提交是经过正确签名的,因此有人可能将包含有恶意 bug 的分支推入到 master 分支中,从而在生产系统中引入一个漏洞。由于提交是经过你的密钥正确签名的,所以一切看起来都是合理合法的,而当 bug 被发现时,你的声誉就会因此而受到影响。
在 `git push` 时,为了验证提交的意图而不仅仅是验证它的内容,添加了要求 PGP 推送签名的功能。
#### 配置 git 使用你的 PGP 密钥
如果在你的钥匙环上只有一个密钥,那么你就不需要再做额外的事了,因为它是你的默认密钥。
然而,如果你有多个密钥,那么你必须要告诉 git 去使用哪一个密钥。(`[fpr]` 是你的密钥的指纹):
```
$ git config --global user.signingKey [fpr]
```
注意:如果你有一个不同的 `gpg2` 命令,那么你应该告诉 git 总是去使用它,而不是传统的版本 1 的 `gpg`:
```
$ git config --global gpg.program gpg2
```
#### 如何使用签名标签
创建一个签名的标签,只要传递一个简单地 `-s` 开关给 `tag` 命令即可:
```
$ git tag -s [tagname]
```
我们建议始终对 git 标签签名,这样让其它的开发者确信他们使用的 git 仓库没有被恶意地修改过(比如,引入后门):
##### 如何验证签名的标签
验证一个签名的标签,只需要简单地使用 `verify-tag` 命令即可:
```
$ git verify-tag [tagname]
```
如果你要验证其他人的 git 标签,那么就需要你导入他的 PGP 公钥。请参考 “可信任的团队沟通” 一文中关于此主题的指导。
##### 在拉取时验证
如果你从项目仓库的其它复刻中拉取一个标签,git 将自动验证签名,并在合并操作时显示结果:
```
$ git pull [url] tags/sometag
```
合并信息将包含类似下面的内容:
```
Merge tag 'sometag' of [url]
[Tag message]
# gpg: Signature made [...]
# gpg: Good signature from [...]
```
#### 配置 git 始终签名带注释标签
很可能的是,你正在创建一个带注释标签,你应该去签名它。强制 git 始终签名带注释的标签,你可以设置一个全局配置选项:
```
$ git config --global tag.forceSignAnnotated true
```
或者,你始终记得每次都传递一个 `-s` 开关:
```
$ git tag -asm "Tag message" tagname
```
#### 如何使用签名的提交
创建一个签名的提交很容易,但是将它纳入到你的工作流中却很困难。许多项目使用签名的提交作为一种 “Committed-by:” 的等价行,它记录了代码来源 —— 除了跟踪项目历史外,签名很少有人去验证。在某种意义上,签名的提交用于 “篡改证据”,而不是 git 工作流的 “篡改证明”。
为创建一个签名的提交,你只需要 `git commit` 命令传递一个 `-S` 标志即可(由于它与另一个标志冲突,所以改为大写的 `-S`):
```
$ git commit -S
```
我们建议始终使用签名提交,并要求项目所有成员都这样做,这样其它人就可以验证它们(下面就讲到如何验证)。
##### 如何去验证签名的提交
验证签名的提交需要使用 `verify-commit` 命令:
```
$ git verify-commit [hash]
```
你也可以查看仓库日志,要求所有提交签名是被验证和显示的:
```
$ git log --pretty=short --show-signature
```
##### 在 git 合并时验证提交
如果项目的所有成员都签名了他们的提交,你可以在合并时强制进行签名检查(然后使用 `-S` 标志对合并操作本身进行签名):
```
$ git merge --verify-signatures -S merged-branch
```
注意,如果有一个提交没有签名或验证失败,将导致合并操作失败。通常情况下,技术是最容易的部分 —— 而人的因素使得项目中很难采用严格的提交验证。
##### 如果你的项目在补丁管理上采用邮件列表
如果你的项目在提交和处理补丁时使用一个邮件列表,那么一般很少使用签名提交,因为通过那种方式发送时,签名信息将会丢失。对提交进行签名仍然是非常有用的,这样其他人就能引用你托管在公开 git 树作为参考,但是上游项目接收你的补丁时,仍然不能直接使用 git 去验证它们。
尽管,你仍然可以签名包含补丁的电子邮件。
#### 配置 git 始终签名提交
你可以告诉 git 总是签名提交:
```
git config --global commit.gpgSign true
```
或者你每次都记得给 `git commit` 操作传递一个 `-S` 标志(包括 `—amend`)。
#### 配置 gpg-agent 选项
GnuPG agent 是一个守护工具,它能在你使用 gpg 命令时随时自动启动,并运行在后台来缓存私钥的密码。这种方式让你只需要解锁一次密钥就可以重复地使用它(如果你需要在一个自动脚本中签署一组 git 操作,而不想重复输入密钥,这种方式就很方便)。
为了调整缓存中的密钥过期时间,你应该知道这两个选项:
* `default-cache-ttl`(秒):如果在 TTL 过期之前再次使用同一个密钥,这个倒计时将重置成另一个倒计时周期。缺省值是 600(10 分钟)。
* `max-cache-ttl`(秒):自首次密钥输入以后,不论最近一次使用密钥是什么时间,只要最大值的 TTL 倒计时过期,你将被要求再次输入密码。它的缺省值是 30 分钟。
如果你认为这些缺省值过短(或过长),你可以编辑 `~/.gnupg/gpg-agent.conf` 文件去设置你自己的值:
```
# set to 30 minutes for regular ttl, and 2 hours for max ttl
default-cache-ttl 1800
max-cache-ttl 7200
```
##### 补充:与 ssh 一起使用 gpg-agent
如果你创建了一个 [A](https://www.linux.com/users/mricon)(验证)密钥,并将它移到了智能卡,你可以将它用到 ssh 上,为你的 ssh 会话添加一个双因子验证。为了与 agent 沟通你只需要告诉你的环境去使用正确的套接字文件即可。
首先,添加下列行到你的 `~/.gnupg/gpg-agent.conf` 文件中:
```
enable-ssh-support
```
接着,添加下列行到你的 `.bashrc` 文件中:
```
export SSH_AUTH_SOCK=$(gpgconf --list-dirs agent-ssh-socket)
```
为了让改变生效,你需要杀掉正在运行的 gpg-agent 进程,并重新启动一个新的登入会话:
```
$ killall gpg-agent
$ bash
$ ssh-add -L
```
最后的命令将列出代表你的 PGP Auth 密钥的 SSH(注释应该会在结束的位置显示: cardno:XXXXXXXX,表示它来自智能卡)。
为了启用 ssh 的基于密钥的登入,只需要在你要登入的远程系统上添加 `ssh-add -L` 的输出到 `~/.ssh/authorized_keys` 中。祝贺你,这将使你的 SSH 登入凭据更难以窃取。
此外,你可以从公共密钥服务器上下载其它人的基于 PGP 的 ssh 公钥,这样就可以赋予他登入 ssh 的权利:
```
$ gpg --export-ssh-key [keyid]
```
如果你有让开发人员通过 ssh 来访问 git 仓库的需要,这将让你非常方便。下一篇文章,我们将提供像保护你的密钥那样保护电子邮件帐户的小技巧。
---
via: <https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-6-using-pgp-git>
作者:[KONSTANTIN RYABITSEV](https://www.linux.com/users/mricon) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,422 | 10 个供管理员救急的杀手级工具 | https://opensource.com/article/18/7/tools-admin | 2019-01-07T22:27:01 | [
"系统管理"
] | https://linux.cn/article-10422-1.html |
>
> 可以让你赶快离开办公室的网络管理技巧和工具。
>
>
>

当工作任务堆积成山时,管理网络和系统就变得十分有压力了。没有人能真正意识到需要花费多长时间,每个人都希望在昨天就完成他们的工作。
所以难怪我们这么多人都被致力于找出有效的方法并与大家分享的开源精神所吸引。因为,当截止日期来临,并且当天没有足够多的时间时,如果你可以找到立刻施行的免费答案,那会非常有帮助。
因此,闲话少叙,下述是我的瑞士军刀,可以保证你在晚饭前离开办公室。
### 服务器配置和脚本
让我们看一看!
* [NixCraft](https://www.cyberciti.biz/)
使用该网站的搜索功能。经过十多年的定期更新,这里遍地是黄金!有用的脚本和方便的技巧可以立刻解决你的问题。这是我一般使用 Google 后的第二个选项。
* [Webmin](http://www.webmin.com/)
它提供给你了一个很好的 Web 界面来帮助你远程编辑配置文件。它减少了在处理目录路径和 `sudo nano` 上花费的大量时间,在你处理多个客户时,非常方便。
* [Windows 下的 Linux 子系统](http://wsl-guide.org/en/latest/)
现代工作场所的现实是大多数员工都运行着 Windows,而服务器机房中不断增长的设备则运行着 Linux 。因此,有些时候你会发现尝试在 Windows 桌面上执行管理任务。
你怎么做?装一个虚拟机?如果安装目前 Windows 10 中免费提供的 Linux 子系统的兼容层,实际上要快得多,配置要少的多。
这为你提供了一个 Bash 终端窗口,你可以在这个窗口中执行本地计算机上的 Bash 脚本和 Linux 二进制文件,可以完全访问 Windows 和 Linux 文件系统,以及安装网络驱动器。它包含 Ubuntu 、OpenSUSE、SLES、Debian 和 Kali 发行版。
* [mRemoteNG](https://mremoteng.org/)
当你有 100 多个服务器需要去管理时,这会是一个出色的 SSH 和远程桌面客户端。
### 设置网络,这样你就无需再这样做了。
一个设计不周的网络是厌恶加班的管理员的死敌。
* [可拓展的 IP 寻址方案](https://blog.dxmtechsupport.com.au/ip-addressing-for-a-small-business-that-might-grow/)
IP 地址耗尽的可怕之处在于,当 IP 地址耗尽时,网络已经变的足够大,而新的寻址方案是众所周知的昂贵、令人痛苦的耗时。
没有人有时间做这件事!
到了某个时候,IPv6 终将到来,来拯救这世界。但在那之前,无论世界向我们扔了多少可穿戴设备、平板电脑、智能锁、灯、安全摄像头、VoIP 耳机和浓缩咖啡机,这些以不变应万变的 IP 寻址方案都应该让我们继续前行。
* [Linux Chmod 权限备忘录](https://isabelcastillo.com/linux-chmod-permissions-cheat-sheet)
一个简短但是有用的 Bash 命令备忘录可以帮助你通过网络设置权限。所以,客户服务部的账单落入到勒索软件骗局时,你可以只恢复他们的文件,而不是整个公司的文件。
* [VLSM 子网计算器](http://www.vlsm-calc.net/)
只需要输入你想要从地址空间中创建的网络的数量,以及每个网络所需要的主机数量,它就可以计算出所有的子网掩码应该是什么。
### 单一用途的 Linux 发行版
需要一个只做一件事的 Linux 容器?如果其他人已经在一个操作系统上搞好了一个小东西,你就可以快速安装它并马上投入使用。
下面这些每一个都使得我的工作变得轻松了许多。
* [Porteus Kiosk](http://porteus-kiosk.org/)
这个工具用来帮你把一台电脑上锁定到一个浏览器上。通过稍稍一些调整,你甚至可以把浏览器锁定在一个特定的网站上。它对于公共访问机器来说非常方便。它可以与触摸屏或键盘鼠标配合使用。
* [Parted Magic](https://partedmagic.com/)
这是一个你可以从 USB 驱动器启动的,可以用来划分磁盘驱动器、恢复数据并运行基准测试工具的操作系统。
* [IPFire](https://www.ipfire.org/)
啊哈~我还是不敢相信有人把路由器/防火墙/代理组合成为“我尿火”(LCTT 译注:IPFire 和 “I pee Fire“ 同音)。这是我在这个 Linux 发行版中第二喜欢的东西。我最喜欢的是它是一个非常可靠的软件套件,设置和配置十分容易,而且有一系列的插件可以拓展它。
那么,你呢?你发现了哪些工具、资源和备忘录可以让我们的工作日更加的轻松?我很高兴知道,请在评论中分享您的工具。
---
via: <https://opensource.com/article/18/7/tools-admin>
作者:[Grant Hamono](https://opensource.com/users/grantdxm) 选题:[lujun9972](https://github.com/lujun9972) 译者:[bestony](https://github.com/bestony) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Administering networks and systems can get very stressful when the workload piles up. Nobody really appreciates how long anything takes, and everyone wants their specific thing done yesterday.
So it's no wonder so many of us are drawn to the open source spirit of figuring out what works and sharing it with everyone. Because, when deadlines are looming, and there just aren't enough hours in the day, it really helps if you can just find free answers you can implement immediately.
So, without further ado, here's my Swiss Army Knife of stuff to get you out of the office before dinner time.
## Server configuration and scripting
Let's jump right in.
[NixCraft](https://www.cyberciti.biz/)
Use the site's internal search function. With more than a decade of regular updates, there's gold to be found here—useful scripts and handy hints that can solve your problem straight away. This is often the second place I look after Google.
[Webmin](http://www.webmin.com/)
This gives you a nice web interface to remotely edit your configuration files. It cuts down on a lot of time spent having to juggle directory paths and `sudo nano`
, which is handy when you're handling several customers.
[Windows Subsystem for Linux](http://wsl-guide.org/en/latest/)
The reality of the modern workplace is that most employees are on Windows, while the grown-up gear in the server room is on Linux. So sometimes you find yourself trying to do admin tasks from (gasp) a Windows desktop.
What do you do? Install a virtual machine? It's actually much faster and far less work to configure if you install the Windows Subsystem for Linux compatibility layer, now available at no cost on Windows 10.
This gives you a Bash terminal in a window where you can run Bash scripts and Linux binaries on the local machine, have full access to both Windows and Linux filesystems, and mount network drives. It's available in Ubuntu, OpenSUSE, SLES, Debian, and Kali flavors.
[mRemoteNG](https://mremoteng.org/)
This is an excellent SSH and remote desktop client for when you have 100+ servers to manage.
## Setting up a network so you don't have to do it again
A poorly planned network is the sworn enemy of the admin who hates working overtime.
[IP Addressing Schemes that Scale](https://blog.dxmtechsupport.com.au/ip-addressing-for-a-small-business-that-might-grow/)
The diabolical thing about running out of IP addresses is that, when it happens, the network's grown large enough that a new addressing scheme is an expensive, time-consuming pain in the proverbial.
Ain't nobody got time for that!
At some point, IPv6 will finally arrive to save the day. Until then, these one-size-fits-most IP addressing schemes should keep you going, no matter how many network-connected wearables, tablets, smart locks, lights, security cameras, VoIP headsets, and espresso machines the world throws at us.
[Linux Chmod Permissions Cheat Sheet](https://isabelcastillo.com/linux-chmod-permissions-cheat-sheet)
A short but sweet cheat sheet of Bash commands to set permissions across the network. This is so when Bill from Customer Service falls for that ransomware scam, you're recovering just his files and not the entire company's.
[VLSM Subnet Calculator](http://www.vlsm-calc.net/)
Just put in the number of networks you want to create from an address space and the number of hosts you want per network, and it calculates what the subnet mask should be for everything.
## Single-purpose Linux distributions
Need a Linux box that does just one thing? It helps if someone else has already sweated the small stuff on an operating system you can install and have ready immediately.
Each of these has, at one point, made my work day so much easier.
[Porteus Kiosk](http://porteus-kiosk.org/)
This is for when you want a computer totally locked down to just a web browser. With a little tweaking, you can even lock the browser down to just one website. This is great for public access machines. It works with touchscreens or with a keyboard and mouse.
[Parted Magic](https://partedmagic.com/)
This is an operating system you can boot from a USB drive to partition hard drives, recover data, and run benchmarking tools.
[IPFire](https://www.ipfire.org/)
Hahahaha, I still can't believe someone called a router/firewall/proxy combo "I pee fire." That's my second favorite thing about this Linux distribution. My favorite is that it's a seriously solid software suite. It's so easy to set up and configure, and there is a heap of plugins available to extend it.
## What about your top tools and cheat sheets?
So, how about you? What tools, resources, and cheat sheets have you found to make the workday easier? I'd love to know. Please share in the comments.
## 5 Comments |
10,423 | YAML:可能并不是那么完美 | https://arp242.net/weblog/yaml_probably_not_so_great_after_all.html | 2019-01-07T23:51:00 | [
"YAML"
] | https://linux.cn/article-10423-1.html | 
我之前写过[为什么将 JSON 用于人类可编辑的配置文件是一个坏主意](http://arp242.net/weblog/JSON_as_configuration_files-_please_dont.html),今天我们将讨论 YAML 格式的一些常见问题。
### 默认情况下不安全
YAML 默认是不安全的。加载用户提供的(不可信的)YAML 字符串需要仔细考虑。
```
!!python/object/apply:os.system
args: ['ls /']
```
用 `print(yaml.load(open('a.yaml')))` 运行它,应该给你这样的东西:
```
bin etc lib lost+found opt root sbin tmp var sys
boot dev efi home lib64 mnt proc run srv usr
0
```
许多其他语言(包括 Ruby 和 PHP <sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup> )默认情况下也不安全(LCTT 译注:这里应该说的是解析 yaml)。[在 GitHub 上搜索 yaml.load](https://github.com/search?q=yaml.load&type=Code&utf8=%E2%9C%93) 会得到惊人的 280 万个结果,而 [yaml.safe\_load](https://github.com/search?q=yaml.safe_load&type=Code&utf8=%E2%9C%93) 只能得到 26000 个结果。
提个醒,很多这样的 `yaml.load()` 都工作的很好,在配置文件中加载 `yaml.load()` 通常没问题,因为它通常(虽然并不总是!)来自“可靠源”,而且很多都来自静态的 YAML 测试文件。但是,人们还是不禁怀疑在这 280 万个结果中隐藏了多少漏洞。
这不是一个理论问题。在 2013 年,[正是由于这个问题,所有的 Ruby on Rails 应用程序都被发现易受](https://www.sitepoint.com/anatomy-of-an-exploit-an-in-depth-look-at-the-rails-yaml-vulnerability/)远程代码执行攻击。
有人可能会反驳说这不是 YAML 格式的错误,而是那些库实现错误的的问题,但似乎大多数库默认不是安全的(特别是动态语言),所以事实上这是 YAML 的一个问题。
有些人可能会反驳认为修复它就像用 `safe_load()` 替换 `load()` 一样容易,但是很多人都没有意识到这个问题,即使你知道它,它也是很容易忘记的事情之一。这是非常糟糕的 API 设计。
### 可能很难编辑,特别是对于大文件
YAML 文件可能很难编辑,随着文件变大,这个难度会快速增大。
一个很好的例子是 Ruby on Rails 的本地化翻译文件。例如:
```
en:
formtastic:
labels:
title: "Title" # Default global value
article:
body: "Article content"
post:
new:
title: "Choose a title..."
body: "Write something..."
edit:
title: "Edit title"
body: "Edit body"
```
看起来不错,对吧?但是如果这个文件有 100 行怎么办?或者 1,000 行?在文件中很难看到 “where”,因为它可能在屏幕外。你需要向上滚动,但是你需要跟踪缩进,即使遵循缩进指南也很难,特别是因为 2 个空格缩进是常态而且 [制表符缩进被禁止](http://www.yaml.org/faq.html) <sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup> 。
不小心缩进出错通常不算错误,它通常只是反序列化为你不想要的东西。这样只能祝你调试快乐!
我已经愉快地编写 Python 长达十多年,所以我已经习惯了显眼的空白,但有时候我仍在和 YAML 抗争。在 Python 中,虽然没有那种长达几页的函数,但数据或配置文件的长度没有这种自然限制,这就带来了缺点和损失了清晰度。
对于小文件,这不是问题,但它确实无法很好地扩展到较大的文件,特别是如果你以后想编辑它们的话。
### 这非常复杂
在浏览一个基本的例子时,YAML 看似“简单”和“显而易见”,但事实证明并非如此。[YAML 规范](http://yaml.org/spec/1.2/spec.pdf)有 23449 个单词,为了比较,[TOML](https://github.com/toml-lang/toml) 有 3339 个单词,[Json](http://www.ecma-international.org/publications/files/ECMA-ST/ECMA-404.pdf) 有 1969 个单词,[XML](https://www.w3.org/TR/REC-xml/) 有 20603 个单词。
我们中有谁读过全部规范吗?有谁读过并理解了全部?谁阅读过,理解进而**记住**所有这些?
例如,你知道[在 YAML 中编写多行字符串有 9 种方法](http://stackoverflow.com/a/21699210/660921)吗?并且它们具有细微的不同行为。
是的 :-/
如果你看一下[那篇文章的修订历史](http://stackoverflow.com/posts/21699210/revisions),它就会变得更加有趣,因为文章的作者发现了越来越多的方法可以实现这一点,以及更多的细微之处。
它从预览开始告诉我们 YAML 规范,它表明(强调我的):
>
> 本节简要介绍了 YAML 的表达能力。**预计初次阅读的人不可能理解所有的例子**。相反,这些选择用作该规范其余部分的动机。
>
>
>
#### 令人惊讶的行为
以下会解析成什么([Colm O’Connor](https://github.com/crdoconnor/strictyaml/blob/master/FAQ.rst#what-is-wrong-with-implicit-typing) 提供的例子):
```
- Don Corleone: Do you have faith in my judgment?
- Clemenza: Yes
- Don Corleone: Do I have your loyalty?
```
结果为:
```
[
{'Don Corleone': 'Do you have faith in my judgment?'},
{'Clemenza': True},
{'Don Corleone': 'Do I have your loyalty?'}
]
```
那么这个呢:
```
python: 3.5.3
postgres: 9.3
```
`3.5.3` 被识别为字符串,但 `9.3` 被识别为数字而不是字符串:
```
{'python': '3.5.3', 'postgres': 9.3}
```
这个呢:
```
Effenaar: Eindhoven
013: Tilburg
```
`013` 是<ruby> 蒂尔堡 <rt> Tilburg </rt> <rt> </rt></ruby>的一个流行音乐场地,但 YAML 会告诉你错误答案,因为它被解析为八进制数字:
```
{11: 'Tilburg', 'Effenaar': 'Eindhoven'}
```
所有这一切,以及更多,就是为什么许多经验丰富的 YAMLer 经常会将所有字符串用引号引起来的原因,即使它不是严格要求。许多人不使用引号,而且很容易忘记,特别是如果文件的其余部分(可能由其他人编写)不使用引号。
### 它不方便
因为它太复杂了,它所声称的可移植性被夸大了。例如,考虑以下这个从 YAML 规范中获取的示例:
```
? - Detroit Tigers
- Chicago cubs
:
- 2001-07-23
? [ New York Yankees,
Atlanta Braves ]
: [ 2001-07-02, 2001-08-12,
2001-08-14 ]
```
抛开大多数读者可能甚至不知道这是在做什么之外,请尝试使用 PyYAML 在 Python 中解析它:
```
yaml.constructor.ConstructorError: while constructing a mapping
in "a.yaml", line 1, column 1
found unhashable key
in "a.yaml", line 1, column 3
```
在 Ruby 中,它可以工作:
```
{
["Detroit Tigers", "Chicago cubs"] => [
#<Date: 2001-07-23 ((2452114j,0s,0n),+0s,2299161j)>
],
["New York Yankees", "Atlanta Braves"] => [
#<Date: 2001-07-02 ((2452093j,0s,0n),+0s,2299161j)>,
#<Date: 2001-08-12 ((2452134j,0s,0n),+0s,2299161j)>,
#<Date: 2001-08-14 ((2452136j,0s,0n),+0s,2299161j)>
]
}
```
这个原因是你不能在 Python 中使用列表作为一个字典的键:
```
>>> {['a']: 'zxc'}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
```
而这种限制并不是 Python 特有的,PHP、JavaScript 和 Go 等常用语言都有此限制。
因此,在 YAML 文件中使用这种语法,你将无法在大多数语言中解析它。
这是另一个从 YAML 规范的示例部分中获取的:
```
# Ranking of 1998 home runs
---
- Mark McGwire
- Sammy Sosa
- Ken Griffey
# Team ranking
---
- Chicago Cubs
- St Louis Cardinals
```
Python 会输出:
```
yaml.composer.ComposerError: expected a single document in the stream
in "a.yaml", line 3, column 1
but found another document
in "a.yaml", line 8, column 1
```
然而 Ruby 输出:
```
["Mark McGwire", "Sammy Sosa", "Ken Griffey"]
```
原因是单个文件中有多个 YAML 文档(`---` 意味开始一个新文档)。在 Python 中,有一个 `load_all` 函数来解析所有文档,而 Ruby 的 `load()` 只是加载第一个文档,据我所知,它没有办法加载多个文档。
[在实现之间存在很多不兼容](https://github.com/cblp/yaml-sucks)。
### 目标实现了吗?
规范说明:
>
> YAML 的设计目标安装优先级降序排列如下:
>
>
> 1. YAML 很容易被人类阅读。
> 2. YAML 数据在编程语言之间是可移植的。
> 3. YAML 匹配敏捷语言的原生数据结构。
> 4. YAML 有一个一致的模型来支持通用工具。
> 5. YAML 支持一次性处理。
> 6. YAML 具有表现力和可扩展性。
> 7. YAML 易于实现和使用。
>
>
>
那么它做的如何呢?
>
> YAML 很容易被人类阅读。
>
>
>
只有坚持一小部分子集时才有效。完整的规则集很复杂 —— 远远超过 XML 或 JSON。
>
> YAML 数据在编程语言之间是可移植的。
>
>
>
事实并非如此,因为创建常见语言不支持的结构太容易了。
>
> YAML 匹配敏捷语言的原生数据结构。
>
>
>
参见上面。另外,为什么只支持敏捷(或动态)语言?其他语言呢?
>
> YAML 有一个一致的模型来支持通用工具。
>
>
>
我甚至不确定这意味着什么,我找不到任何详细说明。
>
> YAML 支持一次性处理。
>
>
>
这点我接受。
>
> YAML 具有表现力和可扩展性。
>
>
>
嗯,是的,但它太富有表现力(例如太复杂)。
>
> YAML 易于实现和使用。
>
>
>
```
$ cat `ls -1 ~/gocode/src/github.com/go-yaml/yaml/*.go | grep -v _test` | wc -l
9247
$ cat /usr/lib/python3.5/site-packages/yaml/*.py | wc -l
5713
```
### 结论
不要误解我的意思,并不是说 YAML 很糟糕 —— 它肯定不像[使用 JSON 那么多的问题](http://arp242.net/weblog/JSON_as_configuration_files-_please_dont.html) —— 但它也不是非常好。有一些一开始并不明显的缺点和惊喜,还有许多更好的替代品,如 [TOML](https://github.com/toml-lang/toml) 和其他更专业的格式。
就个人而言,当我有选择时,我不太可能再次使用它。
如果你必须使用 YAML,那么我建议你使用 [StrictYAML](https://github.com/crdoconnor/strictyaml),它会删除一些(虽然不是全部)比较麻烦的部分。
### 反馈
你可以发送电子邮件至 [[email protected]](mailto:[email protected]) 或[创建 GitHub issue](https://github.com/Carpetsmoker/arp242.net/issues/new) 以获取反馈、问题等。
### 脚注
1. 在 PHP 中你需要修改一个 INI 设置来获得安全的行为,不能只是调用像 `yaml_safe()` 这样的东西。PHP 想尽办法让愚蠢的东西越发愚蠢。干得漂亮! [↩](#fnref1)
2. 不要在这里做空格与制表符之争,如果这里可以用制表符的话,我可以(临时)增加制表符宽度来使它更易读——这是制表符的一种用途。 [↩](#fnref2)
---
via: <https://arp242.net/weblog/yaml_probably_not_so_great_after_all.html>
作者:[Martin Tournoij](https://arp242.net/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,424 | 极客漫画:当你雇佣了一个错误的架构师 | http://turnoff.us/geek/wrong-architect/ | 2019-01-08T10:43:00 | [
"漫画"
] | https://linux.cn/article-10424-1.html | 
这幅漫画讽刺了一些不懂架构的人,盲目使用复杂的、新的架构来尝试业务,建立了一堆无用的组件(灯/LAMP,即常见的 Linux+Apache+MySQL+PHP 网站架构),但却不知道该怎么用这些组件完成需求。
---
via: - <http://turnoff.us/geek/wrong-architect/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者&点评:[Besony](https://github.com/bestony) 校对:[wxy](https://github.com/wxy) 合成:[Bestony](https://github.com/bestony)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,425 | 怎样如软件工程师一样组织知识 | https://dev.to/brpaz/how-do-i-organize-my-knowledge-as-a-software-engineer-4387 | 2019-01-08T15:30:17 | [
"知识"
] | https://linux.cn/article-10425-1.html | 
总体上说,软件开发和技术是以非常快的速度发展的领域,所以持续学习是必不可少的。在互联网上花几分钟找一下,在 Twitter、媒体、RSS 订阅、Hacker News 和其它专业网站和社区等地方,就可以从文章、案例研究、教程、代码片段、新应用程序和信息中找到大量有用的信息。
保存和组织所有这些信息可能是一项艰巨的任务。在这篇文章中,我将介绍一些我用来组织信息的工具。
我认为在知识管理方面非常重要的一点就是避免锁定在特定平台。我使用的所有工具都允许以标准格式(如 Markdown 和 HTML)导出数据。
请注意,我的流程并不完美,我一直在寻找新工具和方法来优化它。每个人都不同,所以对我有用的东西可能不适合你。
### 用 NotionHQ 做知识库
对我来说,知识管理的基本部分是拥有某种个人知识库或维基。这是一个你可以以有组织的方式保存链接、书签、备注等的地方。
我使用 [NotionHQ](https://www.notion.so/) 做这件事。我使用它来记录各种主题,包括资源列表,如通过编程语言分组的优秀的库或教程,为有趣的博客文章和教程添加书签等等,不仅与软件开发有关,而且与我的个人生活有关。
我真正喜欢 NotionHQ 的是,创建新内容是如此简单。你可以使用 Markdown 编写它并将其组织为树状。
这是我的“开发”工作区的顶级页面:
[](https://res.cloudinary.com/practicaldev/image/fetch/s--uMbaRUtu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/http://i.imgur.com/kRnuvMV.png)
NotionHQ 有一些很棒的其他功能,如集成了电子表格/数据库和任务板。
如果您想认真使用 NotionHQ,您将需要订阅付费个人计划,因为免费计划有所限制。我觉得它物有所值。NotionHQ 允许将整个工作区导出为 Markdown 文件。导出功能存在一些重要问题,例如丢失页面层次结构,希望 Notion 团队可以改进这一点。
作为一个免费的替代方案,我可能会使用 [VuePress](https://vuepress.vuejs.org/) 或 [GitBook](https://www.gitbook.com/?t=1) 来托管我自己的知识库。
### 用 Pocket 保存感兴趣的文章
[Pocket](https://getpocket.com/) 是我最喜欢的应用之一!使用 Pocket,您可以创建一个来自互联网上的文章的阅读列表。每当我看到一篇看起来很有趣的文章时,我都会使用 Chrome 扩展程序将其保存到 Pocket。稍后,我会阅读它,如果我发现它足够有用,我将使用 Pocket 的“存档”功能永久保存该文章并清理我的 Pocket 收件箱。
我尽量保持这个阅读清单足够小,并存档我已经处理过的信息。Pocket 允许您标记文章,以便以后更轻松地搜索特定主题的文章。
如果原始网站消失,您还可以在 Pocket 服务器中保存文章的副本,但是您需要 Pocket Premium 订阅计划。
Pocket 还具有“发现”功能,根据您保存的文章推荐类似的文章。这是找到可以阅读的新内容的好方法。
### 用 SnippetStore 做代码片段管理
从 GitHub 到 Stack Overflow 的答案,到博客文章,经常能找到一些你想要保存备用的好代码片段。它可能是一些不错的算法实现、一个有用的脚本或如何在某种语言中执行某种操作的示例。
我尝试了很多应用程序,从简单的 GitHub Gists 到 [Boostnote](https://boostnote.io/),直到我发现 [SnippetStore](https://github.com/ZeroX-DG/SnippetStore)。
SnippetStore 是一个开源的代码片段管理应用。SnippetStore 与其他产品的区别在于其简单性。您可以按语言或标签整理片段,并且可以拥有多个文件片段。它不完美,但是可以用。例如,Boostnote 具有更多功能,但我更喜欢 SnippetStore 组织内容的简单方法。
对于我每天使用的缩写和片段,我更喜欢使用我的编辑器 / IDE 的代码片段功能,因为它更便于使用。我使用 SnippetStore 更像是作为编码示例的参考。
[Cacher](https://www.cacher.io/) 也是一个有趣的选择,因为它与许多编辑器进行了集成,他有一个命令行工具,并使用 GitHub Gists 作为后端,但其专业计划为 6 美元/月,我觉这有点太贵。
### 用 DevHints 管理速查表
[Devhints](https://devhints.io/) 是由 Rico Sta. Cruz 创建的一个速查表集合。它是开源的,是用 Jekyll 生成的,Jekyll 是最受欢迎的静态站点生成器之一。
这些速查表是用 Markdown 编写的,带有一些额外的格式化支持,例如支持列。
我非常喜欢其界面的外观,并且不像可以在 [Cheatography](https://cheatography.com/) 等网站上找到 PDF 或图像格式的速查表, Markdown 非常容易添加新内容并保持更新和进行版本控制。
因为它是开源,我创建了自己的分叉版本,删除了一些我不需要的速查表,并添加了更多。
我使用速查表作为如何使用某些库或编程语言或记住一些命令的参考。速查表的单个页面非常方便,例如,可以列出特定编程语言的所有基本语法。
我仍在尝试这个工具,但到目前为止它的工作很好。
### Diigo
[Diigo](https://www.diigo.com/index) 允许您注释和突出显示部分网站。我在研究新东西时使用它来注释重要信息,或者从文章、Stack Overflow 答案或来自 Twitter 的鼓舞人心的引语中保存特定段落!;)
---
就这些了。某些工具的功能方面可能存在一些重叠,但正如我在开始时所说的那样,这是一个不断演进的工作流程,因为我一直在尝试和寻找改进和提高工作效率的方法。
你呢?是如何组织你的知识的?请随时在下面发表评论。
谢谢你的阅读。
---
作者简介:Bruno Paz,Web 工程师,专精 #PHP 和 @Symfony 框架。热心于新技术。喜欢运动,@FCPorto 的粉丝!
---
via: <https://dev.to/brpaz/how-do-i-organize-my-knowledge-as-a-software-engineer-4387>
作者:[Bruno Paz](http://brunopaz.net/) 选题:[oska874](https://github.com/oska874) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Software Development and Technology in general are areas that evolve at a very fast pace and continuous learning is essential.
Some minutes navigating in the internet, in places like Twitter, Medium, RSS feeds, Hacker News and other specialized sites and communities, are enough to find lots of great pieces of information from articles, case studies, tutorials, code snippets, new applications and much more.
Saving and organizing all that information can be a daunting task. In this post I will present some tools tools that I use to do it.
One of the points I consider very important regarding knowledge management is to avoid lock-in in a particular platform. All the tools I use, allow to export your data in standard formats like Markdown and HTML.
Note that, My workflow is not perfect and I am constantly searching for new tools and ways to optimize it. Also everyone is different, so what works for me might not working well for you.
##
[
](#knowledge-base-with-notionhq)
Knowledge base with NotionHQ
For me, the fundamental piece of Knowledge management is to have some kind of personal Knowledge base / wiki. A place where you can save links, bookmarks, notes etc in an organized manner.
I use [NotionHQ](https://www.notion.so/) for that matter. I use it to keep notes on various topics, having lists of resources like great libraries or tutorials grouped by programming language, bookmarking interesting blog posts and tutorials, and much more, not only related to software development but also my personal life.
What I really like about Notion, is how simple it is to create new content. You write it using Markdown and it is organized as tree.
Here is my top level pages of my "Development" workspace:
Notion has some nice other features like integrated spreadsheets / databases and Task boards.
You will need to subscribe to paid Personal Plan, if you want to use Notion seriously as the free plan is somewhat limited. I think its worth the price. Notion allows to export your entire workspace to Markdown files. The export has some important problems, like loosing the page hierarchy, but hope Notion Team can improve that.
As a free alternative I would probably use [VuePress](https://vuepress.vuejs.org/) or [GitBook](https://www.gitbook.com/?t=1) to host my own.
##
[
](#save-interesting-articles-with-pocket)
Save interesting articles with Pocket
[Pocket](https://getpocket.com) is one of my favorite applications ever! With Pocket you can create a reading list of articles from the Internet.
Every time I see an article that looks interesting, I save it to Pocket using its Chrome Extension. Later on, I will read it and If I found it useful enough, I will use the "Archive" function of Pocket to permanently save that article and clean up my Pocket inbox.
I try to keep the Reading list small enough and keep archiving information that I have dealt with. Pocket allows you to tag articles which will make it simpler to search articles for a particular topic later in time.
You can also save a copy of the article in Pocket servers in case of the original site disappears, but you will need Pocket Premium for that.
Pocket also have a "Discover" feature which suggests similar articles based on the articles you have saved. This is a great way to find new content to read.
##
[
](#snippet-management-with-snippetstore)
Snippet Management with SnippetStore
From GitHub, to Stack Overflow answers, to blog posts, its common to find some nice code snippets that you want to save for later. It could be some nice algorithm implementation, an useful script or an example of how to do X in Y language.
I tried many apps from simple GitHub Gists to [Boostnote](https://boostnote.io/) until I discovered [SnippetStore](https://github.com/ZeroX-DG/SnippetStore).
SnippetStore is an open source snippet management app. What distinguish SnippetStore from others is its simplicity. You can organize snippets by Language or Tags and you can have multi file snippets. Its not perfect but it gets the job done. Boostnote, for example has more features, but I prefer the simpler way of organizing content of SnippetStore.
For abbreviations and snippets that I use on a daily basis, I prefer to use my Editor / IDE snippets feature as it is more convenient to use. I use SnippetStore more like a reference of coding examples.
[Cacher](https://www.cacher.io/) is also an interesting alternative, since it has integrations with many editors, have a cli tool and uses GitHub Gists as backend, but 6$/month for its pro plan, its too much IMO.
##
[
](#managing-cheat-sheets-with-devhints)
Managing cheat sheets with DevHints
[Devhints](https://devhints.io/) is a collection of cheat sheets created by Rico Sta. Cruz. Its open source and powered by Jekyll, one of the most popular static site generator.
The cheat sheets are written in Markdown with some extra formatting goodies like support for columns.
I really like the looks of the interface and being Markdown makes in incredibly easy to add new content and keep it updated and in version control, unlike cheat sheets in PDF or Image format, that you can find on sites like [Cheatography](https://cheatography.com).
As it is open source I have created my own fork, removed some cheat sheets that I dont need and add some more.
I use cheat sheets as reference of how to use some library or programming language or to remember some commands. Its very handy to have a single page, with all the basic syntax of a specific programming language for example.
I am still experimenting with this but its working great so far.
##
[
](#diigo)
Diigo
[Diigo](https://www.diigo.com/index) allows you to Annotate and Highlight parts of websites. I use it to annotate important information when studying new topics or to save particular paragraphs from articles, Stack Overflow answers or inspirational quotes from Twitter! ;)
And thats it. There might be some overlap in terms of functionality in some of the tools, but like I said in the beginning, this is an always evolving workflow, as I am always experimenting and searching for ways to improve and be more productive.
What about you? How to you organize your Knowledge?. Please feel free to comment below.
Thank you for reading.
## Top comments (9)
Thank you Bruno for sharing these tips!
I'm on a very similar quest of creating my own knowledge base and I relate a lot with your post :)
In my experience, I have really trouble with the snippets and cheatsheets parts. I never remember about which ones I have or store, and when I was using more than two or three softwares to keep different parts of knowledge, I lost track of where I keep what, and eventually give up. Can you talk a bit more how does it look like when you use your Snippets or Cheatsheets? And how does it look like to use so many different softwares?
Hello. Thank you for your comment.
Yes, Snippets and Cheatsheets is the most difficult part also for me and I am still trying to figure out the perfect workflow.
Right now I am trying to think like this:
I am very bad at memorizing shortcuts so I try to give clear abbreviations and make use of the editor autocomplete function to help me found what I want.
A tip, create your own snippets with sane abbreviations and avoid using third party snippets. You can take inspiration of course but I cant stand with some 3 or 4 letters abbreviations that most snippet packages you can find for popular editors like VSCode or Sublime use.
I use most VSCode and PHPStorm / Intelij but mostly in different contexts, so right now I dont feel the need to have snippets in sync between the two, but would be nice to have some kind of tool to do that.
For a more kind of reference cheat sheets that behaves like a resume of some language documentation, DevHints is working great so far. I like that its just Markdown, which make it kinda portable to other systems.
Same tip as before. Build your own, based on your needs.
For code that I might want to reference later, like interesting scripts or algorithms implementation I found on the internet, then it goes to SnippetStore.
There are some overlap in this for sure.
For example, I constantly search on Google the syntax for "create table" in MySQL. should I make it a snippet in my IDE or adding to the "MySQL" reference in DevHints? In the IDE works great if I am creating a database migration for example, but what if I want to run the query directly in the database? God, organizing snippets is hard!
Its a matter of trying and thinking well about how you want your workflow to be. Maybe you need to build your own tools. Who knows.
About the use of different softwares, I think its ok, If you are clear about the use of each one. It should be a no brainer to know when to use each of them and where to search for a specific piece of information.
In my case, besides snippets that like I said, still have some doubts, its very clear. Found an interesting article, archive to Pocket. All kinds of personal notes, NotionHQ.
Of course, the less software you have to use the better. For example I was using Evernote together with Pocket, and I completely ditched it now as Pocket can do everything I want.
I hope I answered your questions.
Btw, if you want inspiration about building a personal knowledge base take a look at this. Its simply amazing and an inspiration to me!
Thank you for the detailed explanation :)
Yes, we are on the same page about snippets and cheatsheet, it's plain hard. I will try to give a second chance with DevHints though... And yes, that knowledge base is the master of them all.
Hello, very nice tip for code snippets organize, mine are all lost in many locations. Pocket is the best utility for organizing the reading list, I'm using it for many years. I'm using Evernote instead of Notion+Diigo, works really nice for me.
Today are you using the same tools?
I love diigo too!
Nice suggestions! Thank you
Have you ever tried TiddlyWiki?
Nice Share and Good Advice! *Cheers
Can you share your resources, I mean the development workspace.
great article! nice advice ! |
10,426 | 在 Linux 命令行中使用 nudoku 解决谜题 | https://opensource.com/article/18/12/linux-toy-nudoku | 2019-01-08T18:36:29 | [
"数独"
] | https://linux.cn/article-10426-1.html |
>
> 数独是简单的逻辑游戏,它可以在任何地方玩,包括在 Linux 终端中。
>
>
>

欢迎回到我们为期 24 天的 Linux 命令行玩具日历。如果这是你第一次访问该系列,你甚至可能会问什么是命令行玩具。我们在考虑中,但一般来说,它可能是一个游戏,或任何简单的消遣,可以帮助你在终端玩得开心。
很可能你们中的一些人之前已经看过我们日历中的各种玩具,但我们希望每个人至少见到一件新事物。
每年圣诞节,我的岳母都会给我妻子一本数独日历。它接着会在我们的咖啡桌上呆上一年。每天都是一张单独的表格(星期六和星期日除外,它们合并在一页上),这样你每天都有一个新的谜题,同时还有一本能用的日历。
问题在于在实际中它是一本很好的谜题,但不是一本好的日历,因为事实证明有些日子的题目比其他日子更难,我们没有以每天一个的速度解决它们。然后,我们会在懒散的周日来解决这周堆积的谜题。
既然我在这个系列的一部分中介绍过[日历](https://opensource.com/article/18/12/linux-toy-cal),那么在这里介绍数独也是公平的,除了我们的命令行版本是解耦的,因此将来很容易就能完成它。
我在 Fedora 的默认仓库中找到了 `nudoku`,因此安装它就像下面这样简单:
```
$ sudo dnf install nudoku
```
安装完后,只需输入 `nudoku` 即可启动它,之后的操作就很明了。如果你以前从未玩过数独,它它很容易:你只需要确保每行、每列、每个 3x3 构成的方块里都包含了 1-9 的所有数字。
你可在 [Github](https://github.com/jubalh/nudoku) 中找到 GPLv3 许可的 `nudoku` 源码

你有特别喜欢的命令行小玩具需要我介绍的吗?我们的日历基本上满了,但我们仍然希望在新的一年中展示一些很酷的命令行玩具。请在评论中留言,我会查看的。记得让我知道你对今天玩具的看法。
一定要看看昨天的玩具,[使用 Linux 终端庆祝丰年](https://opensource.com/article/18/12/linux-toy-figlet),记得明天回来!
---
via: <https://opensource.com/article/18/12/linux-toy-nudoku>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Welcome back to another installment in our 24-day-long Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is. We’re figuring that out as we go, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
Some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
Every year for Christmas, my mother-in-law gives my wife a Sudoku calendar. It sits on our coffee table for the year to follow. Each day is a separate sheet (except for Saturday and Sunday, that are combined onto one page), with the idea being that you have a new puzzle every day while also having a functioning calendar.
The problem, in practice, is that it's a great pad of puzzles but not a great calendar because it turns out some days are harder than others and we just don't get through them at the necessary rate of one a day. Then, we may have a week's worth that gets batched on a lazy Sunday.
Since I've already given you a [calendar](https://opensource.com/article/18/12/linux-toy-cal) as a part of this series, I figure it's only fair to give you a Sudoku puzzle as well, except our command-line versions are decoupled so there's no pressure to complete exactly one a day.
I found **nudoku** in my default repositories on Fedora, so installing it was as simple as:
`$ sudo dnf install nudoku`
Once installed, just invoke **nudoku** by name to launch it, and it should be fairly self-explanatory from there. If you've never played Sudoku before, it's fairly simple: You need to make sure that each row, each column, and each of the nine 3x3 squares that make up the large square each have one of every digit, 1-9.
You can find **nudoku**'s c source code [on GitHub](https://github.com/jubalh/nudoku) under a GPLv3 license.

Do you have a favorite command-line toy that you we should have included? Our calendar is basically set for the remainder of the series, but we'd still love to feature some cool command-line toys in the new year. Let me know in the comments below, and I'll check it out. And let me know what you thought of today's amusement.
Be sure to check out yesterday's toy, [Use your Linux terminal to celebrate a banner ](https://opensource.com/article/18/12/linux-toy-figlet)[year](https://opensource.com/article/18/12/linux-toy-figlet), and come back tomorrow for another!
## Comments are closed. |
10,428 | 使用你的 Linux 终端庆祝新年 | https://opensource.com/article/18/12/linux-toy-figlet | 2019-01-09T18:50:06 | [
"终端"
] | /article-10428-1.html |
>
> 想让你的终端被记住么?将它打在横幅上,不要错过。
>
>
>

欢迎再次来到为期 24 天的 Linux 命令行玩具日历。如果这是你第一次访问该系列,你甚至可能会问自己什么是命令行玩具。我们也在思考,但一般来说,它可能是一个游戏,或任何简单的消遣,可以帮助你在终端玩得开心。
很可能你们中的一些人之前已经看过我们日历中的各种玩具,但我们希望每个人至少见到一件新事物。
今天的玩具是 `figlet`,一个在 Linux 终端上以横幅形式打印文本的程序。
你可能会再标准仓库中找到 `figlet`。在我的 Fedora 上,这意味着安装就像下面这样简单:
```
$ sudo dnf install figlet
```
之后,只需使用程序的名称来调用它。你可以以交互方式使用它,或者将一些文本通过管道输入,如下所示:
```
echo "Hello world" | figlet
_ _ _ _ _ _
| | | | ___| | | ___ __ _____ _ __| | __| |
| |_| |/ _ \ | |/ _ \ \ \ /\ / / _ \| '__| |/ _` |
| _ | __/ | | (_) | \ V V / (_) | | | | (_| |
|_| |_|\___|_|_|\___/ \_/\_/ \___/|_| |_|\__,_|
```
`figlet` 有许多不同的字体。要查看可用的字体,请尝试使用命令 `showfigfonts`。在我这里显示了十几个。我在下面复制了一些我的最爱。
```
block :
_| _| _|
_|_|_| _| _|_| _|_|_| _| _|
_| _| _| _| _| _| _|_|
_| _| _| _| _| _| _| _|
_|_|_| _| _|_| _|_|_| _| _|
bubble :
_ _ _ _ _ _
/ \ / \ / \ / \ / \ / \
( b | u | b | b | l | e )
\_/ \_/ \_/ \_/ \_/ \_/
lean :
_/
_/ _/_/ _/_/_/ _/_/_/
_/ _/_/_/_/ _/ _/ _/ _/
_/ _/ _/ _/ _/ _/
_/ _/_/_/ _/_/_/ _/ _/
script :
o
, __ ,_ _ _|_
/ \_/ / | | |/ \_|
\/ \___/ |_/|_/|__/ |_/
/|
\|
```
你可以在项目的[主页](http://www.figlet.org/)上找到有关 `figlet` 的更多信息。我下载的版本是以 MIT 许可开源的。
你会发现 `figlet` 不是唯一的 Linux 终端横幅打印机。另外一个你可以选择的是 [toilet](http://caca.zoy.org/wiki/toilet),它有一套自己的 ASCII 艺术风格的打印选项。
你有特别喜欢的命令行小玩具需要我介绍的吗?我们的日历基本上满了,但我们仍然希望在新的一年中展示一些很酷的命令行玩具。请在评论中留言,我会查看的。记得让我知道你对今天玩具的看法。
一定要看看昨天的玩具,[使用 asciiquarium 在终端中游泳](https://opensource.com/article/18/12/linux-toy-asciiquarium),记得明天回来!
---
via: <https://opensource.com/article/18/12/linux-toy-figlet>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,429 | 计算机实验室之树莓派:课程 0 简介 | https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/introduction.html | 2019-01-09T19:37:00 | [
"树莓派"
] | https://linux.cn/article-10429-1.html | 
这个课程简介不包含实践内容,但它解释了一个操作系统的基本概念、汇编代码、和其它很重要的一些基本原理。如果你想直接进入实践环节,跳过本课程并不会有什么问题。
### 1、操作系统
操作系统就是一个非常复杂的程序。它的任务就是组织安排计算机上的其它程序,包括共享计算机的时间、内存、硬件和其它资源。你可能听说过的一些比较大的桌面操作系统家族有 GNU/Linux、Mac OS X 和 Microsoft Windows。其它的设备比如电话,也需要操作系统,它可能使用的操作系统是 Android、iOS 和 Windows Phone。 <sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup>
由于操作系统是用来与计算机系统上的硬件进行交互的,所以它必须了解系统上硬件专有的信息。为了能让操作系统适用于各种类型的计算机,发明了 **驱动程序** 的概念。驱动程序是为了能够让操作系统与特定的硬件进行交互而添加(并可删除)到操作系统上的一小部分代码。在本课程中,我们并不涉及如何创建可删除的驱动程序,而是专注于特定的一个硬件:树莓派。
操作系统有各种不同的设计方式,在本课程中,我们只触及操作系统设计的皮毛。本课程中,我们主要专注于操作系统与各种硬件的交互部分,因为这经常是比较棘手的部分,并且也是在网络上文档和帮助最少的部分。
### 2、汇编代码
>
> 处理器每秒可以执行上百万的指令,但是这些指令必须要简单。
>
>
>
本课程几乎要完全靠汇编代码来写。汇编代码非常接近计算机的底层。计算机其实是靠一个叫处理器的设备来工作的,处理器能够执行像加法这样的简单任务,还有一组叫做 RAM 的芯片,它能够用来保存数字。当计算机通电后,处理器执行程序员给定的一系列指令,这将导致内存中的数字发生变化,以及与连接的硬件进行交互。汇编代码只是将这些机器命令转换为人类可读的文本。
常规的编程就是,程序员使用编程语言,比如 C++、Java、C#、Basic 等等来写代码,然后一个叫编译器的程序将程序员写的代码转换成汇编代码,然后进一步转换为二进制代码。<sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup> 二进制代码才是计算机真正能够理解的东西,但它是人类无法读取的东西。汇编代码比二进制代码好一点,至少它的命令是人类可读的,但它仍然让人很沮丧。请记住,你用汇编代码写的每个命令都是处理器可以直接认识的,因此这些命令设计的很简单,因为物理电路必须能够处理每个命令。

和普通编程一样,也有很多不同的汇编代码编程语言,但与普通编程不一样的是,每个汇编编程语言是面对不同的处理器的,每种处理器设计为去理解不同的语言。因此,用一个针对某种机器设计的汇编语言所写的汇编代码,是不能在其它种类的机器上运行的。很多情况下,这都是一个大灾难,因此每个程序都必须在使用它的不同种类的机器上重写一遍,但对于操作系统,这不是个问题,因为在不同的硬件上它必须得重写。尽管如此,大多数操作系统都是用 C++ 或 C 来写的,这样它们就可以很容易地在不同种类的硬件上使用,只需要重写那些必须用汇编代码来实现的部分即可。
现在,你已经准备好进入第一节课了,它是 [课程 1 OK01](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok01.html)。
---
1. 要查看更完整的操作系统列表,请参照:[操作系统列表 - Wikipedia](http://en.wikipedia.org/wiki/List_of_operating_systems) [↩](#fnref1)
2. 当然,我简化了普通编程的这种解释,实际上它在很大程度上取决于语言和机器。感兴趣的话,参见 [编译器 - Wikipedia](http://en.wikipedia.org/wiki/Compiler) [↩](#fnref2)
---
via: <https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/introduction.html>
作者:[Robert Mullins](http://www.cl.cam.ac.uk/%7Erdm34) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Raspberry Pi
# Lesson 0 Introduction
This introductory lesson does not contain a practical element, but exists to explain the basic concepts of what is an operating system, what is assembly code and other important basics. If you just want to get straight into practicals, it should be safe to skip this lesson.
Contents |
## 1 Operating Systems
Throughout these tutorials I will put interesting information in boxes like this one.
Throughout these tutorials I will put information about each command we learn in boxes like this one.
An operating system is just a very complicated program. It has the job of organising
other programs on a computer, including sharing the computer's time, memory, hardware
and other resources. Some big families of desktop operating systems that you may
have heard of include GNU/Linux, Mac OS X and Microsoft Windows. Other devices also
need operating systems such as phones, which may use operating systems such as Android,
iOS and Windows Phone.[1]
Since the operating system has to interact with the hardware on a computer system,
it also has to have specific knowledge of the hardware on a system. To allow operating
systems to be used on a variety of computers, the concept of **drivers**
was invented. Drivers are small bits of code that can be added and removed from
the operating system in order to allow the operating system to talk to a particular
piece of hardware. In this course, we do not cover how to create such removable
drivers, and instead focus on making specific ones for the Raspberry Pi.
There are all kinds of different designs of operating systems, and this course can only just scratch the surface. In this course we will mainly focus on getting the operating system to interact with a variety of bits of hardware, as this is often the trickiest bit, and the part for which the least documentation and help exists online.
## 2 Assembly Code
A processor can often perform millions of instructions per second, but they must be simple.
This course will be written almost exclusively in assembly code. Assembly code is
code that is *very* close to what the computer understands. How a computer
really works is that there is a small device called a processor which is capable
of performing simple jobs like adding numbers, and there is a set of one or more
microchips called the **RAM** which are
capable of storing numbers. When a computer has power, the processor works through
a sequence of instructions given to it by the programmer, which cause it to change
numbers in the RAM, and interact with connected hardware. Assembly code is a translation
into human readable text of those commands.
When programming normally, the programmer writes code in a programming language
such as C++, Java, C#, Basic, etc, and then a program called the compiler translates
what the programmer wrote into assembly code, which is the further reduced into
binary code[ [2]](#note2).
Binary code is what the computer actually understands, but it is almost impossible
for humans to read. Assembly code is much better, but it can be frustrating how
few commands are possible. Remember that every command you write in assembly code
is something that the processor understands directly, and so the commands are simple
by design, as a physical circuit must process each one.

Just like with ordinary programming, there are many different assembly code languages, however unlike ordinary programming, the reason these exist is due to the fact that there exists many different processors, each designed to understand a different language. Thus a program written in assembly code for one machine, will not work on a different one. For most things, this would be a disaster as each program would have to be rewritten for every system it was used on, but for operating systems this isn't so much of a problem, as it would have to be rewritten anyway due to differing hardware. Nevertheless, most operating systems are written in C++ or C, so that they can be converted more easily, and only the sections that absolutely have to be written in assembly are.
You're now ready to move on to the first lesson, [Lesson 1: OK01](ok01.html) |
10,431 | 区块链的生态系统 | https://www.myblockchainblog.com/blog/the-blockchain-ecosystem | 2019-01-10T12:40:00 | [
"区块链"
] | https://linux.cn/article-10431-1.html | ### 介绍
在这篇文章中,我们将讨论一个典型区块链的生态系统。这里说的生态系统,指的是不同的利益相关者及其相互之间,系统和外部世界间的相互作用。我们将要探索的不同利益相关者是:
1. 用户
2. 投资者
3. 矿工
4. 开发商
了解这些利益相关者如何融入区块链生态系统,不仅可以让您更好地了解区块链的运作方式,还可以让您更好地评估其增长潜力。区块链对于上述每个利益相关者来说越有吸引力,就越有可能健康的增长。所以,不多说了,下面介绍区块链生态系统的丰富的特色。

### 用户
用户是使用区块链或加密货币实现某些目的的普通人,而不仅仅是投资者。为维护用户,加密货币必须具有一些实用程序(用于花费你的钱币)。让我们快速浏览三个最受欢迎的区块链,以了解它们当前和潜在的效用。
#### 比特币
比特币只有一个功能,即用于货物和服务的付款。在撰写本文时,全球约有 48,000 家(编者注:截止到 2018 年 9 月)商家接受比特币为商品和服务付款([Coinbase](https://www.coinbase.com/clients?locale=en-US))。事实上,包括 PayPal、Expedia、微软、赛百味、彭博、Reddit、戴尔、Steam、Whole Foods、Shopify 和 Webjet 在内的几个家用品牌和主要电子商务公司都将自己的名字添加到了不断增长的比特币商家名单中。未来十年,这个名单将不可避免地继续增长,并且在不远的将来的某个时候,比特币完全有可能像 Visa、AMEX 或万事达卡那样被广泛接受。这可以说意味着比特币目前比任何其他区块链更具实用性。与传统支付方式相比,比特币支付的优势在于:
* 更快的国际支付和交易
* 交易费用非常低
* 伪匿名
* 没有第三方介入
商家的额外好处包括:
* 没有 chargeback(编者注:Chargeback 是信用卡中的一个术语,意思是顾客可以声明一笔交易并非本人发起的。根据国家法律,这种情况往往商家或银行要负责对顾客的全额退款,是一种保护顾客的机制,但也给商家和银行增加了支付处理中的风险。)
* 额外的客户群
由于比特币的高效用,其生态系统的相当大部分由用户组成。从长期投资的角度来看,这非常好,因为它可以提高价格稳定性,并为投资者提供有详实的数据(用户增长,商家采用,交易数量等)以便预测其价格。
#### 以太坊
以太坊区块链与比特币区块链根本不同,因为它能够将智能合约嵌入区块链(见前一篇区块链历史介绍)。因此,以太坊为其用户提供了两种不同类型的应用:
货币应用:虽然不是以太坊的主要目标,但用户可以使用 Ether(以太币,以太坊区块链的加密货币)来支付商品和服务。一些公司([TenX](https://www.tenx.tech/)、[Token Card](https://tokencard.io/)、[Monaco](https://mona.co/))正在竞相通过其加密货币借记卡和 Coinify 等在线支付平台获取市场份额,为在线商家提供即插即用解决方案,以接受像以太币这样的加密货币作为支付。然而,目前,比特币仍然是加密货币的王者,以太和其他加密货币可能不得不追赶几年。
常规应用:这是指用户与基于以太坊区块链的 dApp 交互。已有数百个 dApp 允许用户以各种方式与以太坊区块链进行交互。例如,Numerai 是一种独特的对冲基金,它为世界各地的数据科学家提供加密市场数据,激励他们超越当前的交易算法并提高对冲基金的整体表现。还有一些彩票 dApp,以公平透明的方式提供彩票服务。然而,这只是一个开始。新的 dApp 每天都在发布,将来必定会有人开发出一款真正吸引公众注意力并引领下一波以太坊用户浪潮的 dApp。
可以在[此处](https://dapps.ethercasts.com/)找到以太坊区块链上所有 dApp 的列表。
#### 瑞波
市值排名第三的区块链是<ruby> 瑞波 <rt> Ripple </rt></ruby>。 瑞波与比特币和以太坊的不同之处在于它的设计考虑了一个特定的目标:为金融机构提供任何规模的安全,即时和近乎免费的全球交易。瑞波也与大多数区块链不同,因为它的目标用户是金融机构而不是私人。瑞波已经宣布与渣打银行和 UniCredit 等世界上大型金融机构建立合作伙伴关系,已经在区块链市场排行榜上获得第三名。
### 投资者
几乎所有区块链生态系统中的大多数利益相关者仍然是投资者。因此,加密货币市场仍然具有高度投机性,一天内价格波动 +/- 30% 或更多并不罕见。区块链市场如此不稳定的部分原因是,评估加密货币或 dApp 的真正价值极其困难。该技术仍然年轻,由于实用性有限导致缺乏用户,因此很难预测在大规模采用时该技术将如何。
尽管投资区块链技术存在许多陷阱,但目前的市场条件实际上是一个有吸引力的投资机会:
* 专家、顾问和投资者几乎一致同意,区块链技术市场将在未来十年内继续快速增长([麦肯锡](http://www.mckinsey.com/industries/high-tech/our-insights/how-blockchains-could-change-the-world)、[世界经济论坛](https://www.weforum.org/whitepapers/realizing-the-potential-of-blockchain))
* 进入壁垒仍然很高,大多数人不愿意进入市场
* 虽然区块链在 2016 年和 2017 年都经历了令人难以置信的增长,但所有公共区块链的总市值仍然相对较小,约为 150 亿美元。为了更好地理解这一点,在撰写本文时,整个区块链行业的市值将只是世界第 50 大公司,位于荷兰的消费品公司联合利华之后。[HowMuch.net](https://howmuch.net/articles/worlds-money-in-perspective) 的这篇文章将加密货币的总市值与其他类型的资产进行了比较,并且展望了未来:

话虽如此,并非所有的区块链都是平等的……在接下来的几年里,我们无疑会看到很多初创公司倒闭或烧钱,导致投资者辛苦赚来的钱损失掉。我们将看到诈骗公司,其唯一目标是从愚蠢的投资者那里榨取资金。我们将看到来自成熟公司的激烈竞争,以开发自己的区块链应用程序。生活中没有任何东西是免费的。如果想把钱投入区块链,将不得不接受高风险。我们将有足够的时间在未来的博客文章中讨论投资策略,但现在我们将给您留下两个想法:
1. 在投资任何公司之前,请积极研究至少一周。向自己提出有关投资的一些棘手问题。如果您无法回答问题,请与社区和开发人员联系。如果他们采用某些主观信息来回答,要持怀疑态度。如果他们不能充分回答您的问题,那么不是说一定就要停止投资,但请注意它是一种风险,并在购买之前将其考虑在内。
2. 多样化。必须强调这一点。在接下来的几年里,很多公司都会陷入困境,如果你把所有的鸡蛋都放在一个篮子里,你不仅会冒失去钱的风险,还可能有失去对该行业中最终占据主导地位的公司投资机会的风险。
我认为在任何区块链生态系统中,有 4 种不同类型的投资者:
#### 新手
区块链市场的巨大增长和不断增加的宣传吸引了成千上万的新投资者。很大一部分投资者会被潜在的收益所吸引,而没有去充分了解这项技术。新手用自己的情绪做决定,而且没有比害怕这种情绪更强迫人行动的了。害怕失去钱,也害怕失去机会。因此,新手的买入价格经常过高。

同样,如果价格下跌超过其初始买入点 10-20%,由于害怕失去所有资金,新手经常会卖出。这在超级易变的区块链市场尤其危险。因此,新手经常会买高卖低卖。

[Vanguard](https://personal.vanguard.com/pdf/ISGPRINC.pdf) 的结论是:
1. 对于大多数私人非专业投资者来说,追求投机绩效常常影响回报率
2. 市场波动性越大,追逐绩效的负面影响就越大
在区块链市场上很难不扮演新手的角色。即使您有先前的投资经验,区块链市场的不确定性和极端波动性也将考验您的意志力和自制力。
#### 鲸鱼
鲸鱼是那些拥有庞大储备的大型投资者,他们可以使市场向某一个方向发展。
通常,订单约为 1-500 万美元或以上的人被视为鲸鱼。像这样的大订单足以显著影响大多数加密货币或区块链令牌。如果这种变化吸引了小玩家的注意,并对他们的钱进行相同的操作(如果价格上涨则买入,或者如果价格下降则卖出),鲸鱼可以在稍后的时间执行相反的操作以获取利润。
另一个深渊,即巨鲸。

巨鲸在这里指对冲基金和比特币投资基金,通常管理约 1 亿美元以上的投资组合。他们管理的资本过于庞大,一次下单市场常无法消化。他们通常会在一周或更长时间内将成千上万的比特币注入或流出市场,从而慢慢推动价格上涨或下跌,以满足他们自己的需求。
这些听起来可能令人难以置信,但区块链市场确实具有一些特征,使其成为具有正确手段和风险承受能力的高风险对冲基金的理想场所:
* 没有规定
* 相对较少的竞争
* 小市场给大型企业带来优势
* 大量缺乏经验的投资者
还有最后一个水下野兽,一个足以完全吞噬世界巨头并永远改变区块链市场的人。这里说的是政府投资者。政府可能有一天将加密货币作为一种多样化储备货币组合的方式,这种想法非常有趣,无疑会导致之前闻所未闻的价格水平 ([Coin Telegraph](https://cointelegraph.com/news/bitcoin-price-will-skyrocket-if-it-becomes-worlds-reserve-currency-by-2020))。
#### 套利者
套利者不断寻找并利用不同在线交易所之间的小价格差距。他们与数百家交易所相连,如果有机会,他们将在澳大利亚交易所买入低价并在瑞士交易所卖出高价。你可能认为套利者正在破坏区块链生态系统,但它们实际上发挥了一个非常特别和重要的功能。它们稳定了交易所的价格。他们就像大海的清洁工一样,总是在海底搜寻,以寻找市场上的不合理处。
#### 聪明的八爪鱼
这种投资者是你想成为的人!这种聪明的八足动物买得低,卖得很高。他们在做出决定之前进行了广泛的研究,并认识到风险和潜在的回报。这种聪明的八足动物认识到,利用加密货币的短期波动操作非常困难,要关注长期回报。他们避免情绪化决策,并通过价格波动坚持他们的投资,除非他们的投资有一些根本性的变化。这种聪明的八足动物认识到在区块链这样的新兴行业中识别赢家和输家是极其困难的。他们认识到总体行业风险,关注传统公司进入市场并密切关注他们的投资。

如果你发展出聪明的八爪鱼的特性,你将有很大机会在未来十年内为你的投资带来非常好的回报。
虽然很希望告诉你,我们属于最后一类,而且我们从未做过情绪化或恐惧驱动的决定,但事实并非如此。在这一点上,我们可能介于新手和聪明的八足动物之间。希望通过撰写此博客并继续获得区块链市场的经验,将在未来几年内把我们变成聪明的八足动物。我希望你能加入我们,成为这次旅程的积极参与者。我们可以共同学习和研究,做出更好的决策。
### 矿工
为了使区块链能够运行并保持其完整性,它需要世界各地的独立节点网络来持续维护它。在私有区块链中,中心组织拥有网络上的每个节点。而在公共区块链中,任何人都可以将其计算机设置为节点。这些计算机的所有者称为矿工。

由于区块链的完整性与网络上独立节点的数量直接相关,因此还需要一些挖矿激励。不同的区块链使用不同的采矿系统,但大多数采用以下形式:
* 激励系统:最常见的是微交易费用和块解决方案奖励的组合(比特币矿工每解决一个比特币块,获得 12.5 BTC 奖励。按照约定奖励着时间的推移逐渐减少)。
* 共识算法:所有区块链都需要一种验证广播到网络的块的方法。比特币区块链使用工作证明(PoW)。您将在下一篇文章中了解有关 PoW 如何工作的更多信息。以太坊也使用 PoW,但将更改为权益证明 (PoS)(以太坊区块链包含故意放置在代码中的 <ruby> 难度炸弹 <rt> difficulty bomb </rt></ruby>,以强制在某些时候更改为 PoS。之后将详细介绍)。
正如您将在下一篇文章中看到的那样,挖掘一个块是非常困难的,一台计算机需要多年来实现。因此,个体矿工组建了采矿行会,将他们的资源汇集在一起并分享回报。[blockchain.info](https://blockchain.info/pools?timespan=4days) 的资料显示了过去 4 天比特币区块链中每个采矿公会的相对哈希率(工作量)。

因为矿工需要保持区块链的完整性,所以他们拥有很大的权力。如果比特币社区想以这种或那种方式改变比特币协议,他们将不得不说服大多数矿工采用新代码。对现有区块链协议的更改称为分叉。潜在的分叉一直是采矿论坛上讨论的热门话题,没有中央权威就很难达成共识。
### 开发商
正如上一篇文章中所讨论的,区块链有可能变得不仅仅是加密货币。区块链世界中目前有两种类型的开发人员:
* 区块链开发人员
* dApp 开发人员

区块链开发人员构建具有不同功能级别的全新区块链。dApp 开发人员可以构建在区块链上运行的去中心化应用程序,从而为用户提供使用区块链(即实用程序)的理由。
以太坊推出的智能合约为渴望创造下一个重大事件的 dApp 开发者打开了大门。在评估区块链时,重要的是要考虑开发人员如何对其做出反应。有些问题要问自己,包括:
* 该平台允许开发人员使用哪些脚本语言?
* 社区是否有足够的活跃,能够说服开发人员花时间为该平台开发 dApp?
* 区块链中是否有一些特殊功能,当 dApp 开发人员无法在更受欢迎的区块链上创建其应用,而在这个区块链上可以?
* 区块链的可扩展性如何?如果它最终变得流行,代码是否能够处理大量的交易?
要充分利用区块链技术,您需要同时了解区块链和 dApp 开发中的最新消息。
### 结论
区块链生态系统复杂而充满活力。
了解这一点将使您能够做出更好的决策并充分利用这一新兴技术。你喜欢这篇博文吗?我们是否错过了任何利益相关者?您对不同的利益相关者及其对整个区块链生态系统的影响有何看法?你认为会看到政府在他们的储备中加入加密货币吗?
我们很乐意在下面的留言板上收到您的来信!如果您发现我们的内容有任何错误或错误,请随时通知我们,我们会及时更正。我们的下一篇文章将为您提供加密功能的概述,使区块链能够安全且伪匿名地工作。希望能在那里见到你!
---
via: <https://www.myblockchainblog.com/blog/the-blockchain-ecosystem>
作者:[Vegard Nordahl & Meghana Rao](https://www.myblockchainblog.com/blog/the-blockchain-ecosystem) 选题:[jasminepeng](https://github.com/jasminepeng) 译者:[jasminepeng](https://github.com/jasminepeng) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
10,432 | 用 PGP 保护代码完整性(七):保护在线帐户 | https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-7-protecting-online-accounts | 2019-01-10T23:12:00 | [
"PGP"
] | https://linux.cn/article-10432-1.html |
>
> 在这个系列的最后一篇当中,我们将为你展示如何用双因子认证保护你的在线账户。
>
>
>

到目前为止,本系列教程已经提供了 PGP 的实用指南,包括基本概念和工具、生成和保护你的密钥的步骤。如果你错过了前面的文章,可以通过下面的链接查看。在本系列的最后一篇文章中,我们将为你保护在线帐户提供一个额外的指南,保护在线帐户是当今非常重要的一件事情。
* [第一部分:基本概念和工具](/article-9524-1.html)
* [第二部分:生成你的主密钥](/article-9529-1.html)
* [第三部分:生成 PGP 子密钥](/article-9607-1.html)
* [第四部分:将主密钥移到离线存储中](/article-10402-1.html)
* [第五部分:将子密钥移到硬件设备中](/article-10415-1.html)
* [第六部分:在 Git 中使用 PGP](/article-10421-1.html)
#### 清单
* 取得一个具备 U2F 功能的设备(必要)
* 为你的在线帐户启用双因子认证(必要)
+ GitHub/GitLab
+ Google
+ 社交媒体
* 使用 U2F 作为主验证机制,使用 TOTP 作为备选(必要)
#### 考虑事项
你可能注意到,很多在线开发者身份是捆绑了 email 地址的。如果有人能够访问你的邮箱,他们就能够去做一些对你会产生危害的事情,进而会损害你作为自由软件开发者的声誉。应该像保护你的 PGP 密钥那样保护你的 email 地址。
##### 使用 Fido U2F 的双因子认证
[双因子认证](https://en.wikipedia.org/wiki/Multi-factor_authentication) 是一种提升帐户安全性的机制,它除了要求用户名和密码之外,还要求一个物理令牌。它的目标是即便在有人窃取了你的密码(通过按键记录器、肩窥攻击或其它方式)的情况下,仍然能确保你的帐户安全,他们在没有得到你的一个专用的物理设备(“必备”的那个因子)的情况下,始终不能获取你的帐户。
广为人知的双因子认证机制有:
* 基于 SMS 的验证
* 借助智能手机应用程序的基于时间的一次性令牌(TOTP),比如 Google Authenticator 或类似解决方案
* 支持 Fido U2F 的硬件令牌
基于 SMS 的验证很容易配置,但是它有如下的缺点:它在没有手机信号的地方无法使用(比如,建筑物的地下室),并且如果攻击者能够阻断或转向 SMS 信息,这种方式可能就会失败,比如通过克隆你的 SIM 卡。
基于 TOTP 的多因子认证提供了比 SMS 更好的安全保护,但它也有一些重要的缺点(你要在智能手机中添加的那么多令牌中找到正确的那个)。此外,还不能避免一个事实,那就是你的密钥最终还是保存在你的智能手机中 —— 它是一个复杂的、全球连接的设备,它有可能还没有及时从制造商那儿收到安全补丁。
更重要的是,不论是使用 TOTP 还是 SMS 的方法来保护你免受诱骗攻击 —— 如果诱骗攻击者能够窃取你的帐户密码和双因子令牌,他们就可以在合法的站点上使用它们,访问你的帐户。
[Fido U2F](https://en.wikipedia.org/wiki/Universal_2nd_Factor) 是一个按标准开发的专用设备,它能够提供双因子认证机制来对付诱骗攻击。U2F 协议在 USB 令牌中保存每个站点的的唯一密钥,如果你在任何合法站点以外的地方尝试使用它,它将阻止你,以防范偶然让攻击者获得你的密码和一次性令牌。
Chrome 和 Firefox 都支持 U2F 双因子认证,希望其它浏览器也能够提供对 U2F 的支持。
#### 获得一个支持 Fido U2F 功能的令牌
支持 U2F 的硬件令牌的 [可选目标很多](http://www.dongleauth.info/dongles/),但如果你已经订购了一个支持智能卡的物理设备,那么你最好的选择就是 Yubikey 4,它两者都支持。
#### 启用你的在线帐户的双因子认证
你要确定想启用双因子认证的在线账户,你的 email 提供商已经使用了(特别是 Google,它对 U2F 的支持非常好)。其它的站点这个功能应该是启用了:
* GitHub:当你上传你的 PGP 公钥时,你应该要想到,如果其他人能够获得访问你的帐户,他们可以用他们自己的 PGP 公钥替换掉你的 PGP 公钥。如果在 GitHub 上发布代码,你应该使用 U2F 认证来保护你的帐户安全。
* GitLab:理由同上
* Google:如果你有 google 帐户,你就惊奇地发现,许多帐户都允许以 Google 帐户来代替站点专用的认证来登入它们。
* Facebook:理由同上,许多在线站点都提供一个选择让你以 Facebook 的帐户来认证。即便你不使用 Facebook 也应该使用双因子认证来保护你的 Facebook 帐户。
* 你认为必要的其它站点。查看 [dongleauth.info](http://www.dongleauth.info/) 去找找灵感。
#### 如有可能,配置 TOTP 作为备选
许多站点都允许你配置多个双因子认证机制,推荐的设置是:
* U2F 令牌作为主认证机制
* TOTP 手机应用作为辅助认证机制
通过这种方式,即便你丢失了你的 U2F 令牌,你仍然能够重新获取对你的帐户的访问。或者,你可以注册多个 U2F 令牌(即:你可以用一个便宜的令牌仅用它做 U2F,并且将它用作备份)。
### 延伸阅读
到目前为止,你已经完成了下列的重要任务:
1. 创建你的开发者身份并使用 PGP 加密来保护它。
2. 通过将你的主密钥移到一个离线存储中并将子密钥移到一个外置硬件设备中的方式来配置你的环境,让窃取你的身份变得极为困难。
3. 配置你的 Git 环境去确保任何使用你项目的人都能够验证仓库的完整性和它的整个历史。
4. 使用双因子认证强化你的在线帐户。
在安全保护方面,你已经做的很好了,但是你还应该去阅读以下的主题:
* 如何去强化你的团队沟通。你的项目开发和治理决策的要求应该和保护提交代码那样去保护,如果不这样做,应该确保你的团队沟通是可信任的,并且所有决策的完整性是可验证的。
* 如何去强化你的工作站的安全。你的目标是尽可能减少导致项目代码被污染的危险或你的开发者身份被窃的行为。
* 如何写出安全的代码(查看相关编程语言和你项目所使用的库的各种文档)。即便引入它的提交代码上有一个 PGP 签名,糟糕的、不安全的代码仍然是糟糕的、不安全的代码!
---
via: <https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-7-protecting-online-accounts>
作者:[Konstantin Ryabitsev](https://www.linux.com/users/mricon) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,433 | 5 款 Linux 街机游戏 | https://opensource.com/article/18/1/arcade-games-linux | 2019-01-11T09:54:40 | [
"游戏",
"街机"
] | https://linux.cn/article-10433-1.html | 
长久以来,游戏都是 Linux 的软肋。近些年,Steam、GOG 等游戏发布平台上不少商业游戏都开始支持 Linux,这对于 Linux 的游戏生态来说是件好事,但是我们能在这些平台上玩到的游戏通常是不开源的商业作品。当然,这些游戏在一个开源的操作系统上运行,但对于一个开源提倡者来说这似乎还不够纯粹。
那么,我们能找到既自由开源又能给玩家带来完整游戏体验的优质游戏吗?当然!虽然绝大多数的开源游戏很难和 3A 商业游戏大作竞争,但仍然有不少各种类型的开源游戏,不仅内容有趣而且直接可以通过几大 Linux 发行版本库中直接安装。
本文首先介绍 Linux 开源游戏中的街机类型游戏,在之后的文章中,我将介绍桌面和卡牌游戏,解谜游戏,竞速游戏,以及策略模拟游戏。
### <ruby> 太空危机 <rt> AstroMenace </rt></ruby>

[太空危机](http://www.viewizard.com/) 是一个近现代太空背景下的滚动页面射击游戏。开发初期它是一个闭源游戏,但它的代码和素材而后以开源许可证发布了。游戏玩法和大多数此类游戏大同小异,但它有质量极高的 3D 画面。飞船和武器升级可以通过击杀敌人所获得的点数购买。游戏的难度可以选择,因此适合新手以及想要追求挑战的硬核玩家。
安装太空危机,你只需要在终端下运行以下指令:
* Fedora 用户: `dnf install astromenace`
* Debian/Ubuntu 用户: `apt install astromenace`
### <ruby> 坦克战役 <rt> Battle Tanks </rt></ruby>

[坦克战役](http://btanks.sourceforge.net/blog/about-game) 是一个俯瞰式视角的快节奏坦克战斗游戏。玩家可以选择三种不同的陆地坦克,操纵其在地图上前行,收集道具并且尝试炸飞敌军。它有四种游戏模式,死亡竞赛(又称“死斗”)、团队死斗、夺旗模式和合作模式。死斗和夺旗模式下,分别有 9 张地图可供玩家选择,合作模式则有 4 张。该游戏支持分屏本地双人游戏,以及在线多人竞技。游戏节奏很快,默认一次战役仅 5 分钟,因此,坦克战役十分适合想要利用零碎时间快速来一局的玩家。
安装坦克战役,你只需要在终端下运行以下指令:
* Fedora 用户: `dnf install btanks`
* Debian/Ubuntu 用户: `apt install btanks`
### <ruby> 火星 <rt> M.A.R.S. </rt></ruby>

[火星](http://mars-game.sourceforge.net/?page_id=10) 是一个自上而下的太空射击游戏,游戏机制类似传统街机游戏 “<ruby> 爆破彗星 <rt> Asteroids </rt></ruby>”。玩家在操控一个太空船的同时向敌方射击并躲避敌军的弹幕射击。游戏有标准的死斗和团体死斗模式,除此之外也有更新鲜的比赛形式 —— 例如在一个模式下,玩家需要控制一个球使其进入敌方母星。该游戏支持本地多人游戏,但遗憾的是不支持多人联机。该游戏的开发更新似乎已经停止,所以该游戏之后增加联机模式的几率很小,但就算没有联机支持,这个游戏仍然值得一试。
安装火星,你只需要在终端下运行以下指令:
* Fedora 用户: `dnf install marsshooter`
* Debian/Ubuntu 用户: `apt install marsshooter`
### <ruby> 不存在之球 <rt> Neverball </rt></ruby>

[不存在之球](https://neverball.org/index.php) 的游戏灵感来源自世嘉的 “<ruby> 超级猴子球 <rt> Super Monkey Ball </rt></ruby>” ,玩家需要将一个球在 3D 球场上运动起来,但是玩家控制的不是球,而是球场。游戏任务是在规定的时限内,收集足够多的金币从而打开该关卡的出口并且将小球落进该洞中。游戏可以调整难度,从休闲到难以超乎想象,可以适应不同的玩家需求。该游戏支持键盘/鼠标以及控制杆操作。
安装不存在之球,你只需要在终端下运行以下指令:
* Fedora 用户:`dnf install neverball`
* Debian/Ubuntu 用户:`apt install neverball`
### <ruby> 超级 Tux <rt> SuperTux </rt></ruby>

[超级 Tux](http://supertux.org/) 是继任天堂超级马里奥后的一款 2D 的平台跳跃游戏。Linux 的吉祥物企鹅 Tux 代替了马里奥,而鸡蛋对应着马里奥系列中的蘑菇能力提升。当 Tux 获得了鸡蛋得到了能力提升,它便可以收集花朵,而花朵可以带来新的附加特殊能力。火焰花在关卡中最为常见,收集了火焰花的 Tux 可以掷出火球。除此之外,冰冻花/空气花/土地花也在游戏的程序中。收集星星的能力提升能使 Tux 暂时变得隐形,就如同马里奥系列游戏。该游戏最基础的一组关卡,冰之岛也有 30 关之多,因此游戏的内容和流程和超级马里奥系列一般长。SuperTux 还有一些附加关卡,例如三个额外奖励小岛、一个森林之岛、一个万圣节岛、一个孵化处,以及很多测试关卡。SuperTux 有一个自带的关卡编辑器,所以玩家可以创建他们的原创关卡。
安装超级 Tux,你只需要在终端下运行以下指令:
* Fedora 用户:`dnf install supertux`
* Debian/Ubuntu 用户: `apt install supertux`
如果我没有在上文中提及你最喜欢的开源街机游戏,欢迎在评论中分享。
### 有关作者
Joshua Allen Holm - 是 Opensource.com 的社区协调者之一。他的主要兴趣有数字人文、学术开放以及公开教育资源。你可以在 GitHub、GitLab、LinkedIn 和 Zotero 上找到他。可以通过 [[email protected]](mailto:[email protected]) 联系到他。
---
via: <https://opensource.com/article/18/1/arcade-games-linux>
作者:[Joshua Allen Holm](https://opensource.com/users/holmja) 译者:[Scoutydren](https://github.com/Scoutydren) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Gaming has traditionally been one of Linux's weak points. That has changed somewhat in recent years thanks to Steam, GOG, and other efforts to bring commercial games to multiple operating systems, but those games often are not open source. Sure, the games can be played on an open source operating system, but that is not good enough for an open source purist.
So, can someone who uses only free and open source software find games that are polished enough to present a solid gaming experience without compromising their open source ideals? Absolutely! While most open source games are unlikely to rival some of the AAA commercial games developed with massive budgets, there are plenty of open source games, in many genres, that are fun to play and can be installed from the repositories of most major Linux distributions.
I am starting this series of articles on open source games for Linux by looking at arcade-style games. In future articles, I plan to cover board & card, puzzle, racing, role-playing, and strategy & simulation games.
## AstroMenace

opensource.com
[AstroMenace](http://www.viewizard.com/) is a scrolling space shooter for the modern era. It began as a closed source game, but the code and art assets have since been released under open licenses. Gameplay is fairly typical for the style of game, but it features nice, modern 3D graphics. Ship and weapon upgrades can be purchased using the points earned from shooting down enemies. The difficulty level can be tweaked by changing a wide variety of options, so the game is approachable to new players while still offering a challenge to experienced ones.
To install AstroMenace, run the following command:
- On Fedora:
`dnf install astromenace`
- On Debian/Ubuntu:
`apt install astromenace`
## Battle Tanks

opensource.com
[Battle Tanks](http://btanks.sourceforge.net/blog/about-game) is a fast-paced tank battle game with an overhead perspective. Players maneuver one of three different vehicle types around a map, collecting power-ups and trying to blow up their opponents. It has deathmatch, team deathmatch, capture the flag, and cooperative game modes. There are nine maps for the deathmatch and capture the flag modes and four maps for cooperative mode. The game supports split-screen local multiplayer for two players and local area network multiplayer for larger matches. Gameplay is fast-paced, and the default match length of five minutes is short, which makes Battle Tanks a nice choice for gamers who want something quick to play.
To install Battle Tanks, run the following command:
- On Fedora:
`dnf install btanks`
- On Debian/Ubuntu:
`apt install btanks`
## M.A.R.S.

opensource.com
[M.A.R.S.](http://mars-game.sourceforge.net/?page_id=10) is a top-down space shooter with physics similar to the classic Asteroids arcade game. Players control a spaceship while shooting at their opponents, maneuvering around the screen, and avoiding planets and opponents' incoming fire. The standard death match and team death match modes are available, but there are other modes, like one that requires pushing a ball into the opposing team's home planet, that provide some variety to the gameplay options. It supports local multiplayer, but unfortunately network multiplayer has not been implemented. Since development on the game appears to have stalled, network multiplayer is not likely to appear at any point in the near future, but the game is still fun and playable without it.
To install M.A.R.S., run the following command:
- On Fedora:
`dnf install marsshooter`
- On Debian/Ubuntu:
`apt install marsshooter`
## Neverball

opensource.com
With gameplay inspired by Sega's Super Monkey Ball, [Neverball](https://neverball.org/index.php) challenges the player to move a ball through a 3D playing field by moving the playing field, not the ball. The objective is to collect enough coins to open a level's exit and maneuver the ball to the exit before time runs out. There are seven different sets of levels, which range in difficulty from easy to impossible. The game can be played using the keyboard, mouse, or joystick.
To install Neverball, run the following command:
- On Fedora:
`dnf install neverball`
- On Debian/Ubuntu:
`apt install neverball`
## SuperTux

opensource.com
[SuperTux](http://supertux.org/) is a 2D platformer modeled after Nintendo's Super Mario Bros. games. Linux's mascot, Tux the Penguin, takes the place of Mario with eggs serving as the equivalent of Super Mario Bros.'s mushroom power-ups. When Tux is powered up with an egg, he can collect flowers that grant him extra abilities. The fire flower, which lets Tux throw fireballs, is the most common in the game's levels, but ice, air, and earth flowers are included in the game's code. Collecting star power-ups makes Tux temporarily invincible, just like in the Super Mario games. The default level set, Icy Island, is 30 levels, making the game approximately the same length as the original Super Mario Bros., but SuperTux also comes with several contributed level sets, including three bonus islands, a forest island, a Halloween island, and incubator and test levels. SuperTux has a built-in level editor, so users can create their own.
To install SuperTux, run the following command:
- On Fedora:
`dnf install supertux`
- On Debian/Ubuntu:
`apt install supertux`
Did I miss one of your favorite open source arcade games? Share it in the comments below.
## 7 Comments |
10,434 | 如何使用 Ansible 管理你的工作站配置 | https://opensource.com/article/18/3/manage-workstation-ansible | 2019-01-11T22:48:46 | [
"Ansible"
] | https://linux.cn/article-10434-1.html |
>
> 在这个系列的第一篇中,学习一下管理笔记本电脑和台式机配置的基础内容。
>
>
>

配置管理是服务器管理和 DevOps 的一个非常重要的方面。“<ruby> 基础架构即代码 <rt> infrastructure as code </rt></ruby>”方法可以轻松地以各种配置部署服务器,并动态扩展组织的资源以满足用户需求。但是,对于希望自动设置自己的笔记本电脑和台式机(工作站)的个人管理员的关注较少。
在本系列中,我将向你展示如何通过 [Ansible](https://www.ansible.com/) 自动化你的工作站设置,如果你想要或需要重新安装你的机器,这可以让你轻松恢复整个配置。此外,如果你有多个工作站,则可以使用相同的方法在每个工作站上进行相同的配置。在第一篇文章中,我们将为个人或工作计算机设置基本的配置管理,并为本系列的其余部分奠定基础。到本文结束时,你将会因此得到一个可以工作的环境。本系列之后的每篇文章都会自动化更多内容并增加复杂性。
### 为什么用 Ansible?
有许多配置管理解决方案,包括 Salt Stack、Chef 和 Puppet。我更喜欢 Ansible,因为它在资源利用方面更轻量级,语法更容易阅读,并且如果正确使用它可以彻底改变你的配置管理。Ansible 的轻量级特性与这个主题特别相关,因为我们可能不希望运行一整台服务器而只是为了自动化我们的笔记本电脑和台式机的设置。一般我们总是想要快一些;我们可以使用某些东西来快速启动和运行,以在我们需要恢复的工作站或在多台机器之间同步我们的配置。我使用 Ansible 的具体方法(我将在本文中演示)非常适用于此,而不需要维护服务器。你只需下载配置并运行它。
### 我的方法
通常,Ansible 运行于中央服务器。它使用一个<ruby> 库存清单 <rt> inventory </rt></ruby>文件,该文件是一个文本文件,其中包含我们希望 Ansible 管理的所有主机及其 IP 地址或域名的列表。这对于静态环境非常有用,但对于工作站来说并不理想。原因是我们真的不知道我们的工作站在某一时刻的状态。也许我关闭了台式电脑,或者笔记本电脑可能会被挂起并放在我的包里。在任何一种情况下,Ansible 服务器都会抱怨,因为如果它们处于脱机状态,Ansible 就无法联系到我的机器。我们更需要的是按需方式,我们通过利用 `ansible-pull` 来实现这一目标。`ansible-pull` 命令是 Ansible 的一个命令,允许你从 Git 仓库下载配置并立即应用它。你不需要维护服务器或库存清单;你只需运行 `ansible-pull` 命令,给它一个 Git 仓库 URL,它将为你完成剩下的工作。
### 起步
首先,在要管理的计算机上安装 Ansible。有一个问题是许多发行版都附带了旧版本的 Ansible。根据经验,你肯定希望获得最新版本。Ansible 中经常引入新功能,如果你运行的是旧版本,则你在网上找到的示例语法可能无法正常运行,因为它使用的功能未在你安装的版本中实现。甚至发布的小版本都有很多新功能。其中一个例子是 `dconf` 模块,它是从 Ansible 2.4 开始的新功能。如果你尝试使用使用此模块的语法,除非你使用 2.4 或更新版本,否则会失败。在 Ubuntu 及其衍生产品中,我们可以使用官方个人包存档([PPA](https://launchpad.net/ubuntu/+ppas))轻松安装最新版本的 Ansible。以下命令可以解决这个问题:
```
sudo apt-get install software-properties-common
sudo apt-add-repository ppa:ansible/ansible
sudo apt-get update
sudo apt-get install ansible
```
如果你没有使用 Ubuntu,请参阅 [Ansible 的文档](http://docs.ansible.com/ansible/latest/intro_installation.html) 了解如何为你的平台获取它。
接下来,我们需要一个 Git 仓库来保存我们的配置。满足此要求的最简单方法是在 GitHub 上创建一个空的仓库,或者如果有的话,也可以使用自己的 Git 服务器。为了简单起见,我假设你正在使用 GitHub,因此如果你正在使用其他仓库,请相应调整命令。在 GitHub 中创建一个仓库;你最终会得到一个与此类似的仓库 URL:
```
[email protected]:<your_user_name>/ansible.git
```
将该仓库克隆到你的本地工作目录(忽略任何抱怨仓库为空的消息):
```
git clone [email protected]:<your_user_name>/ansible.git
```
现在我们有了一个可以使用的空仓库。将你的工作目录切换到仓库(例如 `cd ./ansible`),并在你喜欢的文本编辑器中创建名为 `local.yml` 的文件。将以下配置放在该文件中:
```
- hosts: localhost
become: true
tasks:
- name: Install htop
apt: name=htop
```
你刚刚创建的文件被称为<ruby> 剧本 <rt> playbook </rt></ruby>,安装 `htop` 的指令(我任意选择的一个包作为例子)被称为<ruby> 动作 <rt> play </rt></ruby>。剧本本身是一个 YAML 格式的文件,它是一种易于阅读的标记语言。对 YAML 的完整讲述超出了本文的范围,但你无需专业理解即可熟练使用 Ansible。该配置易于阅读;只需查看此文件,你就可以轻松理解我们正在安装的 `htop` 软件包。要注意一下最后一行的 `apt` 模块,它只适用于基于 Debian 的系统。如果你使用的是 Red Hat 平台,你可以将其更改为 `yum` 而不是 `apt`,或者如果你正在使用 Fedora,则将其更改为 `dnf`。`name` 行只是提供有关我们任务的信息,并将显示在输出中。因此,你需要确保名称具有描述性,以便在需要对多个动作进行故障排除时很容易找到。
接下来,让我们将新文件提交到我们的仓库:
```
git add local.yml
git commit -m "initial commit"
git push origin master
```
现在我们的新剧本应该出现在我们的 GitHub 上的仓库中。我们可以使用以下命令应用我们创建的剧本:
```
sudo ansible-pull -U https://github.com/<your_user_name>/ansible.git
```
如果执行正确,`htop`包应该会安装在你的系统上。你可能会在开头附近看到一些警告,抱怨缺少库存清单文件。这很好,因为我们没有使用库存清单文件(我们也不需要这样做)。在输出结束时,它将概述它做的内容。如果 `htop` 安装正确,你应该在输出的最后一行看到 `changed = 1`。
它是如何工作的呢?`ansible-pull` 命令使用了 `-U` 选项,它需要一个仓库 URL。出于安全考虑,我给它提供了仓库 URL 的 https 版本,因为我不希望任何主机对仓库具有写访问权限(默认情况下 https 是只读的)。`local.yml` 是预设的剧本名称,因此我们不需要为剧本提供文件名:如果它在仓库的根目录中找到名为 `local.yml` 的剧本,它将自动运行它。接下来,我们在命令前面使用了 `sudo`,因为我们正在修改系统。
让我们继续为我们的剧本添加更多的包。我将添加两个包,使它看起来像这样:
```
- hosts: localhost
become: true
tasks:
- name: Install htop
apt: name=htop
- name: Install mc
apt: name=mc
- name: Install tmux
apt: name=tmux
```
我添加了更多的动作(任务)来安装另外两个包,`mc` 和 `tmux`。在此剧本中选择安装的哪些软件包并不重要;我只是随意挑选这些。你应该安装你希望所有的系统都具有的软件包。唯一需要注意的是,在你分发前,你必须知道那个包存在于软件仓库中。
在我们提交并应用这个更新的剧本之前,我们应该整理一下它。它可以很好地工作,但(说实话)它看起来有点混乱。让我们尝试在一个动作中安装所有三个包。用下面这个替换你的 `local.yml` 的内容:
```
- hosts: localhost
become: true
tasks:
- name: Install packages
apt: name={{item}}
with_items:
- htop
- mc
- tmux
```
现在看起来更干净、更有效率了。我们使用 `with_items` 将我们的包列表合并为一个动作。如果我们想要添加其他包,我们只需添加另一个带有连字符和包名称的行。可以把 `with_items` 看做类似于 `for` 循环。我们列出的每个包都将安装。
将我们的新更改提交回仓库:
```
git add local.yml
git commit -m "added additional packages, cleaned up formatting"
git push origin master
```
现在我们可以运行我们的剧本以接受新的新配置:
```
sudo ansible-pull -U https://github.com/<your_user_name>/ansible.git
```
不可否认,这个例子还没有做多少事情;它所做的就是安装一些软件包。你可以使用包管理器更快地安装这些包。然而,随着这个系列的继续,这些例子将变得更加复杂,我们将自动化更多的东西。最后,你创建的 Ansible 配置将自动执行越来越多的任务。例如,我自己使用的那个配置可以自动安装数百个软件包、设置cron 作业、处理桌面配置等等。
从我们迄今为止所取得的成就来看,你可能已经有了大概了解。我们所要做的就是创建一个仓库,在该仓库中放置一个剧本,然后利用 `ansible-pull` 命令拉取该仓库并将其应用到我们的机器上。我们不需要设置服务器。将来,如果我们想要更改配置,我们可以拉取该仓库、更新它,然后将其推回到我们的仓库并应用它。如果我们要设置新机器,我们只需要安装 Ansible 并应用配置。
在下一篇文章中,我们将通过 cron 和一些其他项目进一步自动化。与此同时,我已将本文的代码复制到 [我的 GitHub 仓库](https://github.com/jlacroix82/ansible_article) 中,以便你可以用你的语法对比一下我的。随着我们的进展,我会不断更新代码。
---
via: <https://opensource.com/article/18/3/manage-workstation-ansible>
作者:[Jay LaCroix](https://opensource.com/users/jlacroix) 译者:[wxy](https://github.com/) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Configuration management is a very important aspect of both server administration and DevOps. The "infrastructure as code" methodology makes it easy to deploy servers in various configurations and dynamically scale an organization's resources to keep up with user demands. But less attention is paid to individual administrators who want to automate the setup of their own laptops and desktops (workstations).
In this series, I'll show you how to automate your workstation setup via [Ansible](https://www.ansible.com/), which will allow you to easily restore your entire configuration if you want or need to reload your machine. In addition, if you have multiple workstations, you can use this same approach to make the configuration identical on each. In this first article, we'll set up basic configuration management for our personal or work computers and set the foundation for the rest of the series. By the end of this article, you'll have a working setup to benefit from right away. Each article will automate more things and grow in complexity.
[Read [part two](https://opensource.com/article/18/3/manage-your-workstation-configuration-ansible-part-2) of this series.]
## Why Ansible?
Many configuration management solutions are available, including Salt Stack, Chef, and Puppet. I prefer Ansible because it's lighter in terms of resource utilization, its syntax is easier to read, and when harnessed properly it can revolutionize your configuration management. Ansible's lightweight nature is especially relevant to the topic at hand, because we may not want to run an entire server just to automate the setup of our laptops and desktops. Ideally, we want something fast; something we can use to get up and running quickly should we need to restore our workstations or synchronize our configuration between multiple machines. My specific method for Ansible (which I'll demonstrate in this article) is perfect for this—there's no server to maintain. You just download your configuration and run it.
## My approach
Typically, Ansible is run from a central server. It utilizes an inventory file, which is a text file that contains a list of all the hosts and their IP addresses or domain names we want Ansible to manage. This is great for static environments, but it is not ideal for workstations. The reason being we really don't know what the status of our workstations will be at any one moment. Perhaps I powered down my desktop or my laptop may be suspended and stowed in my bag. In either case, the Ansible server would complain, as it can't reach my machines if they are offline. We need something that's more of an on-demand approach, and the way we'll accomplish that is by utilizing `ansible-pull`
. The `ansible-pull`
command, which is part of Ansible, allows you to download your configuration from a Git repository and apply it immediately. You won't need to maintain a server or an inventory list; you simply run the `ansible-pull`
command, feed it a Git repository URL, and it will do the rest for you.
## Getting started
First, install Ansible on the computer you want it to manage. One problem is that a lot of distributions ship with an older version. I can tell you from experience you'll definitely want the latest version available. New features are introduced into Ansible quite frequently, and if you're running an older version, example syntax you find online may not be functional because it's using features that aren't implemented in the version you have installed. Even point releases have quite a few new features. One example of this is the `dconf`
module, which is new to Ansible as of 2.4. If you try to utilize syntax that makes use of this module, unless you have 2.4 or newer it will fail. In Ubuntu and its derivatives, we can easily install the latest version of Ansible with the official personal package archive ([PPA](https://launchpad.net/ubuntu/+ppas)). The following commands will do the trick:
```
sudo apt-get install software-properties-common
sudo apt-add-repository ppa:ansible/ansible
sudo apt-get update
sudo apt-get install ansible
```
If you're not using Ubuntu, [consult Ansible's documentation](http://docs.ansible.com/ansible/latest/intro_installation.html) on how to obtain it for your platform.
Next, we'll need a Git repository to hold our configuration. The easiest way to satisfy this requirement is to create an empty repository, or you can utilize [your own Git server](https://gitlab.com/jsherman82/ansible_article.git) if you have one. To keep things simple, I'll assume you're using GitHub, so adjust the commands if you're using something else. Create a repository in GitHub; you'll end up with a repository URL that will be similar to this:
`[email protected]:<your_user_name>/ansible.git`
Clone that repository to your local working directory (ignore any message that complains that the repository is empty):
`git clone [email protected]:<your_user_name>/ansible.git`
Now we have an empty repository we can work with. Change your working directory to be inside the repository (`cd ./ansible`
for example) and create a file named `local.yml`
in your favorite text editor. Place the following configuration in that file:
```
- hosts: localhost
become: true
tasks:
- name: Install htop
apt: name=htop
```
The file you just created is known as a **playbook**, and the instruction to install `htop`
(a package I arbitrarily picked to serve as an example) is known as a **play**. The playbook itself is a file in the YAML format, which is a simple to read markup language. A full walkthrough of YAML is beyond the scope of this article, but you don't need to have an expert understanding of it to be proficient with Ansible. The configuration is easy to read; by simply looking at this file, you can easily glean that we're installing the `htop`
package. Pay special attention to the `apt`
module on the last line, which will only work on Debian-based systems. You can change this to `yum`
instead of `apt`
if you're using a Red Hat platform or change it to `dnf`
if you're using Fedora. The `name`
line simply gives information regarding our task and will be shown in the output. Therefore, you'll want to make sure the name is descriptive so it's easy to find if you need to troubleshoot multiple plays.
Next, let's commit our new file to our repository:
```
git add local.yml
git commit -m "initial commit"
git push origin master
```
Now our new playbook should be present in our repository on GitHub. We can apply the playbook we created with the following command:
`sudo ansible-pull -U https://github.com/<your_user_name>/ansible.git`
If executed properly, the `htop`
package should be installed on your system. You might've seen some warnings near the beginning that complain about the lack of an inventory file. This is fine, as we're not using an inventory file (nor do we need to for this use). At the end of the output, it will give you an overview of what it did. If `htop`
was installed properly, you should see `changed=1`
on the last line of the output.
How did this work? The `ansible-pull`
command uses the `-U`
option, which expects a repository URL. I gave it the `https`
version of the repository URL for security purposes because I don't want any hosts to have write access back to the repository (`https`
is read-only by default). The `local.yml`
playbook name is assumed, so we didn't need to provide a filename for the playbook—it will automatically run a playbook named `local.yml`
if it finds it in the repository's root. Next, we used `sudo`
in front of the command since we are modifying the system.
Let's go ahead and add additional packages to our playbook. I'll add two additional packages so that it looks like this:
```
- hosts: localhost
become: true
tasks:
- name: Install htop
apt: name=htop
- name: Install mc
apt: name=mc
- name: Install tmux
apt: name=tmux
```
I added additional plays (tasks) for installing two other packages, `mc`
and `tmux`
. It doesn't matter what packages you choose to have this playbook install; I just picked these arbitrarily. You should install whichever packages you want all your systems to have. The only caveat is that you have to know that the packages exist in the repository for your distribution ahead of time.
Before we commit and apply this updated playbook, we should clean it up. It will work fine as it is, but (to be honest) it looks kind of messy. Let's try installing all three packages in just one play. Replace the contents of your `local.yml`
with this:
```
- hosts: localhost
become: true
tasks:
- name: Install packages
apt: name={{item}}
with_items:
- htop
- mc
- tmux
```
Now *that* looks cleaner and more efficient. We used `with_items`
to consolidate our package list into one play. If we want to add additional packages, we simply add another line with a hyphen and a package name. Consider `with_items`
to be similar to a `for`
loop. Every package we list will be installed.
Commit our new changes back to the repository:
```
git add local.yml
git commit -m "added additional packages, cleaned up formatting"
git push origin master
```
Now we can run our playbook to benefit from the new configuration:
`sudo ansible-pull -U https://github.com/<your_user_name>/ansible.git`
Admittedly, this example doesn't do much yet; all it does is install a few packages. You could've installed these packages much faster just using your package manager. However, as this series continues, these examples will become more complex and we'll automate more things. By the end, the Ansible configuration you'll create will automate more and more tasks. For example, the one I use automates the installation of hundreds of packages, sets up `cron`
From what we've accomplished so far, you can probably already see the big picture. All we had to do was create a repository, put a playbook in that repository, then utilize the `ansible-pull`
command to pull down that repository and apply it to our machine. We didn't need to set up a server. In the future, if we want to change our config, we can pull down the repo, update it, then push it back to our repository and apply it. If we're setting up a new machine, we only need to install Ansible and apply the configuration.
In the next article, we'll automate this even further via `cron`
and some additional items. In the meantime, I've copied the code for this article into [my GitLab repository](https://gitlab.com/jsherman82/ansible_article.git) so you can check your syntax against mine. I'll update the code as we go along.
*Want more on Ansible? Learn how to automate your CI/CD pipeline with Ansible in this free whitepaper.*
## 4 Comments |
10,435 | 在 Linux 终端中玩贪吃蛇 | https://opensource.com/article/18/12/linux-toy-snake | 2019-01-12T10:42:59 | [
"贪吃蛇"
] | https://linux.cn/article-10435-1.html |
>
> 有了这个 20 世纪 70 年代的经典重制游戏,Python 将不再是你在 Linux 终端能发现的唯一的“蛇”。
>
>
>

欢迎回到 Linux 命令行玩具日历。如果这是你第一次访问该系列,你可能会问什么是命令行玩具。这很难确切地说,但我的定义是任何可以帮助你在终端玩得开心的东西。
我们这周都在介绍游戏,这很有趣,接着让我们看下今天的游戏,贪吃蛇!
贪吃蛇是一个古老又很好的游戏,这些年一直有各种版本。我记得我第一次玩得版本是 20 世纪 90 年代与 [QBasic](https://en.wikipedia.org/wiki/QBasic) 一起打包发布的 [Nibbles](https://en.wikipedia.org/wiki/Nibbles_(video_game)),它对我理解什么是编程语言起了很重要的作用。我有游戏的源码,我可以修改并查看会发生什么,并学习到一些组成这个编程语言的有趣词汇究竟是什么意思。
今天的[贪吃蛇](https://github.com/DyegoCosta/snake-game)是用 Go 写的,它很简单并且和原版的游戏一样有趣。像大多数简单的老游戏一样,它有很多版本可供选择。这今天的贪吃蛇中,甚至还有一个经典的 [bsdgames](https://github.com/vattam/BSDGames) 形式的包,它的发行版几乎一定有它。
但我喜欢的是用 Docker 打包的贪吃蛇,因为我可以轻松地在命令行中运行,而不用担心发行版相关的问题。这个版本使用 15 个随机的食物 emoji 图案让蛇来吃。我玩得不好。不管怎样,请试一下:
```
$ docker run -ti dyego/snake-game
```
这个贪吃蛇以 MIT 许可证开源,你可在 [Github](https://github.com/DyegoCosta/snake-game) 取得源码。

你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。请在评论区留言,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
请查看昨天的玩具,[数字 2 的力量,Linux 的力量:在命令行中玩 2048](https://opensource.com/article/18/12/linux-toy-2048),记得明天再来!
---
via: <https://opensource.com/article/18/12/linux-toy-snake>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Welcome back to the Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is. It's hard to say exactly, but my definition is anything that helps you have fun at the terminal.
We've been on a roll with games over the weekend, and it was fun, so let's look at one more game today, Snake!
Snake is an oldie but goodie; versions of it have been around seemingly forever. The first version I remember playing was one called [Nibbles](https://en.wikipedia.org/wiki/Nibbles_(video_game)) that came packaged with [QBasic](https://en.wikipedia.org/wiki/QBasic) in the 1990s, and was probably pretty important to my understanding of what a programming language even was. Here I had the source code to a game that I could modify and just see what happens, and maybe learn something about what all of those funny little words that made up a programming language were all about.
Today's [Snake](https://github.com/DyegoCosta/snake-game) is written in Go, and while it's simple, it's just as much fun as the original. Like most simple old games, there are a ton of versions to choose from. In Snake's case, there's even a version in the classic [bsdgames](https://github.com/vattam/BSDGames) package that's almost certainly packaged for your distribution.
But what I like about this version of Snake is that it's packaged for Docker so I can easily run it in one line from my terminal without worrying about anything disto-specific. That, and it makes use of 15 randomized food emojis for the snake to eat. I'm a sucker for food emojis. Anyway, give it a try using:
`$ docker run -ti dyego/snake-game`
This Snake is licensed as open source under an MIT license, and you can check out the source code [on GitHub](https://github.com/DyegoCosta/snake-game).

Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Check out yesterday's toy, [Powers of two, powers of Linux: 2048 at the command line](https://opensource.com/article/18/12/linux-toy-2048), and check back tomorrow for another!
## Comments are closed. |
10,437 | 能从远程获得乐趣的 Linux 命令 | https://opensource.com/article/18/12/linux-toy-remote | 2019-01-12T15:31:07 | [
"终端"
] | https://linux.cn/article-10437-1.html |
>
> 使用这些工具从远程了解天气、阅读资料等。
>
>
>

我们即将结束为期 24 天的 Linux 命令行玩具日历。希望你有一直在看,如果没有,请回到[开始](https://opensource.com/article/18/12/linux-toy-boxes),从头看过来。你会发现 Linux 终端有很多游戏、消遣和奇怪之处。
虽然你之前可能已经看过我们日历中的一些玩具,但我们希望每个人都遇见一个新事物。
今天的玩具(实际是玩具集合)有点不同。到目前为止,我主要是想把重点放在那些独立的玩具上,并且完全可在开源许可下使用。但是我从读者那里得到了一些很好的建议,利用开源工具远程访问一些开源或者不开源的东西。今天,我将介绍其中的一些。
第一个是经典之作:使用 Telnet 观看星球大战的 ASCII 演绎版本。你的系统可能已经安装了 Telnet,因此你只需运行:
```
$ telnet towel.blinkenlights.nl
```
我第一次看到它是十年之前,因此我对于它还存在有点惊奇。如果你还没看过,请留出一点时间看一下。你不会后悔的。

接下来,Opensource.com 的撰稿人 [Manuel Dewald](https://opensource.com/users/ntlx) 提出了一种从终端获取当地天气的方法。它很简单,你只需安装 `curl`(或者,`wget`)。
```
$ curl wttr.in
```

最后,在假期中虽然你可以从[命令行 Web 浏览器](https://opensource.com/article/16/12/web-browsers-linux-command-line)浏览你喜欢的网站(包括 Opensource.com),但有一些我最喜欢的网站可以通过专用客户端更轻松地浏览。其中两个是 Reddit 和 Hacker News,有人推荐给我一些它们的客户端,你可能也想尝试,它们都使用开源许可。我尝试过 [haxor-news](https://github.com/donnemartin/haxor-news) (Hacker News) 和 [rtv](https://github.com/michael-lazar/rtv) (Reddit),它们都还不错。
你有特别喜欢的命令行小玩具需要我介绍的吗?提交今年的建议有点晚了,但我们仍然希望在新的一年里有一些很酷的命令行玩具。请在下面的评论中告诉我,我会查看的。让我知道你对今天的玩具有何看法。
一定要看看昨天的玩具,[在 Linux 终端收看 Youtube 视频](https://opensource.com/users/ntlx),明天还要再来!
---
via: <https://opensource.com/article/18/12/linux-toy-remote>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We're almost to the end of our 24-day-long Linux command-line toys advent calendar. Hopefully, you've been following along, but if not, start back at [the beginning](https://opensource.com/article/18/12/linux-toy-boxes) and work your way through. You'll find plenty of games, diversions, and oddities for your Linux terminal.
And while you may have seen some toys from our calendar before, we hope there’s at least one new thing for everyone.
Today's toy (or actually, collection of toys) is a little different. So far I've mostly tried to focus on toys that are self-contained, and completely usable under an open source license. But I've gotten some great suggestions from readers which utilize an open source tool to access something remotely that may or may not be open source. Today, I'll round up a few of those.
The first one is a total classic: use Telnet to watch an ASCII-rendition of Star Wars. Chances are that Telnet is already installed on your system, so all you'll need to do is run:
`$ telnet towel.blinkenlights.nl`
I feel like I first saw this one over a decade ago, so it's a bit amazing to me that it's still alive and online. If you've never watched it, set aside some time and go check it out. You won't regret it.

Next, Opensource.com contributor [Manuel Dewald ](https://opensource.com/users/ntlx)suggested a way to fetch your local weather from the terminal. It's easy, and only requires that you have **curl **(or, well,** ****wget**) installed.
`$ curl wttr.in`
Finally, while you can spend the holidays reading your favorite sites (including Opensource.com) from your favorite [command-line web browser](https://opensource.com/article/16/12/web-browsers-linux-command-line), there are a few of my favorite sites that are more easily browsed with a dedicated client. Two of these include Reddit and Hacker News, for which there are clients that have been recommended to me that you may wish to try, mostly available under open source licenses. I've poked around with [haxor-news](https://github.com/donnemartin/haxor-news) (Hacker News) and [rtv](https://github.com/michael-lazar/rtv) (Reddit), and both seem pretty cool.
Do you have a favorite command-line toy that we should have included? It's a little late to submit a suggestion for this year, but we'd still love to feature some cool command-line toys in the new year. Let me know in the comments below, and I'll check it out. And let me know what you thought of today's amusement.
Be sure to check out yesterday's toy, [Watch YouTube videos at the Linux terminal](https://opensource.com/article/18/12/linux-toy-youtube-dl), and come back tomorrow for another!
## 1 Comment |
10,438 | 在 Linux 中移除从源代码安装的程序的一种简单的方法 | https://www.ostechnix.com/an-easy-way-to-remove-programs-installed-from-source-in-linux/ | 2019-01-12T23:54:00 | [
"源代码",
"安装"
] | https://linux.cn/article-10438-1.html | 
不是所有的程序都可以在官方或者第三方库中找到,因此你不能使用常规的包管理来安装它们。有时你不得不从源代码中手动构建这些程序。就如你已经知道的一样,当你从源代码中安装一个程序的时候,这个软件包所包含的文件将会复制到本地的多个位置,例如 `/usr/local/bin`、`/usr/local/etc/`。如果从源代码中安装的程序没有内置的卸载程序,当你不再需要这个程序的时候,卸载它就会很麻烦。你可能会花费双倍(甚至更多)的时间找出这些文件然后手动删除它们。我以前一直是这样做的,直到我发现了 GNU Stow。谢天谢地,Stow 有一个很棒的方法可以轻松管理从源代码安装的程序。
引用官方网站里的一段介绍,
>
> GNU Stow 是一个符号链接归集管理器,它可以收集文件系统上不同目录中的不同软件和/或数据包,使它们看起来像是一个整体。
>
>
>
简单来说,Stow 帮助你把这些程序文件以一种容易管理的方式组织在了一起。在这个方法中,文件将不会被复制到多个位置。所有的这些文件都会被保存在一个特定的文件夹中,通常是以程序名命名的,然后 Stow 会在一个合适的位置为所有的程序文件创建符号连接。比如 `/usr/local/bin` 中会包含 `/usr/local/stow/vim/bin`、`/usr/local/stow/python/bin` 中文件的符号链接。并且同样递归地用于其他的任何的子目录,例如 `.../share`、`.../man`,等等。在这篇教程中,我将会举例教你如何轻松地使用 Stow 管理从源中安装的程序。
### 安装 GNU Stow
GNU Stow 在流行 Linux 操作系统的默认库中都可用。
在 Arch Linux 及它的衍生版本中,运行下面的命令安装 Stow。
```
$ sudo pacman -S stow
```
在 Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt install stow
```
在 Fedora 上:
```
$ sudo dnf install stow
```
在 RHEL/CentOS 上:
```
$ sudo yum install epel-release
$ sudo yum install stow
```
### 在 Linux 上轻松移除从源代码安装的程序
就像我之前提到的,所有包的程序文件都将被保存在位于 `/usr/local/stow/` 的一个根文件夹。在这个根文件夹或者父目录之下,每个包都将保存在对应的子目录中。例如,如果我们从源代码中安装了 Vim 编辑器,所有关联到 Vim 的程序文件和目录都将保存在 `/usr/local/stow/vim` 文件夹之下。如果你从源代码中安装了 Python,所有关联到 python 的文件都会保存在 `/usr/local/stow/python` 之下。
我现在从源代码中来安装一个叫做 hello 的程序。
首先下载 hello 程序的压缩包。
```
$ wget http://ftp.gnu.org/gnu/hello/hello-2.10.tar.gz
```
使用下面的命令解压压缩包:
```
$ tar -zxvf hello-2.10.tar.gz
```
上面的命令将会在当前工作目录下创建一个叫做 `hello-2.10` 的目录,并且提取压缩包中的所有内容到其中去。
切换到这个目录当中:
```
$ cd hello-2.10/
```
运行下面的命令,并且添加 `-prefix` 选项。
```
$ ./configure --prefix=/usr/local/stow/hello
```
上面的命令将会保存构建文件到一个指定位置,在这个例子中是 `/usr/local/stow/hello`。
最后,使用下面的命令构建并安装 hello 这个程序:
```
$ make
$ sudo make install
```
就这样。hello 这个程序就已经安装在 `/usr/local/stow/hello/` 这个位置了。你可以使用下面的 `ls` 命令确认一下。
```
$ ls /usr/local/stow/hello/
bin share
```
最后,进入 `/usr/local/stow/` 目录,运行下面的命令来生成必要的符号链接。
```
$ cd /usr/local/stow/
$ sudo stow hello
```
大功告成!
刚才那一步是将包含在 hello 这个程序中的所有文件或者目录创建了链接到 `/usr/local/` 目录中。换一种说法, `/usr/local/stow/hello/bin` 链接到 `/usr/local/share`,以及 `/usr/local/stow/hello/share/man` 链接到 `/usr/local/share`,还有 `/usr/local/stow/hello/share/man` 链接到 `/usr/local/share/man`。
你可以使用 `ls` 命令来确认一下:
```
$ ls /usr/local/bin/
hello
```
可以使用下面的命令来确认 hello 这个程序是否可以正常工作了:
```
$ hello
Hello, world!
```
很好,它已经开始工作了!!
类似地,你可以像上面描述的那样安装程序到它对应的子目录下。
下面是 Stow 根目录包含的内容:
```
$ tree /usr/local/stow/
```

看,hello 这个程序已经安装在 `/usr/local/stow/hello/` 下。同样地,所有的包都将保存在它们对应的目录之下。
下面进入主要环节,移除 hello 这个程序。首先进入 `/usr/local/stow/` 目录:
```
$ cd /usr/local/stow/
```
然后运行下面的命令:
```
$ sudo stow --delete hello
```
hello 这个程序就会被移除了。你可以使用下面的命令确认它是否真的被移除了:
```
$ hello
-bash: /usr/local/bin/hello: No such file or directory
```

看, Hello 已经被移除了!
请注意 Stow 仅仅只移除了符号链接。所有与 hello 这个程序相关的文件或者目录还保存在 `/usr/local/stow/hello` 目录下。所以你无需再次下载源文件就可以再次安装 hello 这个程序。如果你不再需要它了,直接删除这个文件夹即可。
```
$ sudo rm -fr /usr/local/stow/hello/
```
想了解更多 Stow 的细节,请参阅 man 手册。
```
$ man stow
```
Stow 可以像安装程序一样轻松地帮你移除它。如果你想知道如何高效的管理很多从源代码中安装的程序,GNU Stow 就是一个使得这个任务更加轻松的一个选择,尝试一下,你一定不会失望的。
这就是所有的内容了,希望对你有所帮助。还有更多干活即将到来,可以期待一下的!
祝近祺!
---
via: <https://www.ostechnix.com/an-easy-way-to-remove-programs-installed-from-source-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,439 | 如何使用 Beamer 创建演示文稿 | https://opensource.com/article/19/1/create-presentations-beamer | 2019-01-13T11:39:13 | [
"Beamer",
"PPT"
] | https://linux.cn/article-10439-1.html |
>
> Beamer 将 LaTeX 强大的排版功能和生态系统带进创建幻灯片中。
>
>
>

[Beamer](https://www.overleaf.com/learn/latex/Beamer) 是用于生成幻灯片的 LaTeX 包。它最棒的功能之一是它可以利用 LaTeX 强大的排版系统和其生态系统中的所有其他软件包。例如,我经常在包含代码的 Beamer 演示文稿中使用 LaTeX 的 [listings](https://www.overleaf.com/learn/latex/Code_listing) 包。
### 创建演示文稿
要创建一个 Beamer 文档,输入:
```
\documentclass{beamer}
```
与任何其他 LaTeX 文档一样,添加你要使用的任何包。例如,要使用 `listings` 包,请输入:
```
\usepackage{listings}
```
将所有内容放在 `document` 环境中:
```
\begin{document}
```
Beamer 文档通常时是一系列的 `frame` 环境。包含代码的 `frame` 应该被标记为 `fragile`:
```
\begin{frame}[fragile]
```
使用标题开始你的 `frame`:
```
\frametitle{Function to Do Stuff}
```
### 开始演示前测试你的代码
世上最糟糕的感受之一你在演讲中说到代码时,突然发现了一个 bug —— 也许是拼错了关键词或者漏掉了括号。
解决方法之一就是测试演示的代码。在多数演示环境中,这意味着创建一个单独的文件、编写测试接着拷贝和粘贴。
然而,在 Beamer 中有一种更好的方法。想象一下,你有一个名为 `do_stuff.py` 的文件,其中包含代码。你可以在第二个文件中编写 `do_stuff.py` 代码的测试,你可以将其命名为 `test_do_stuff.py`,并且可以使用 [pytest](https://docs.pytest.org/en/latest/) 测试。但是,`do_stuff.py` 中的大多数行都缺乏教学价值,比如定义辅助函数。
要简化你受众看到的东西,你可在演示文稿中只导入你要讨论的行到 frame 中:
```
\lstinputlisting[
language=Python,
firstline=8,
lastline=15
]{do_stuff.py}
```
由于你会对这几行(从 8 到 15)进行讨论,因此幻灯片上不需要任何其他内容。结束 `frame`:
```
\end{frame}
```
在下一张幻灯片中,你想展示刚才的 `do_stuff()` 函数的用法示例:
```
\begin{frame}[fragile]
\frametitle{Calling Function to Do Stuff}
\lstinputlisting[
language=Python,
firstline=17,
lastline=19
]{do_stuff.py}
\end{frame}
```
你使用相同的文件,但这次显示调用该函数的行。最后,结束 `document`:
```
\end{document}
```
假设你在 `do_stuff.py` 中有一个合适的 Python 文件,这将生成一个含有 2 页的幻灯片。
Beamer 还支持必要的功能如渐进式演示,每次给观众展示一部分以免受到前面的打扰。在行中放入 `\pause` 会将页面分成不同的部分:
```
\begin{frame}
Remember:
\begin{itemize}
\item This will show up on the first slide. \pause
\item This will show up on the
second slide, as well as the preceding point. \pause
\item Finally, on the third slide,
all three bullets will show up.
\end{frame}
```
### 创建讲义
Beamer 中我最喜欢的功能是可以用 `\documentclass[ignorenonframetext]{beamer}` 设置忽略 `frame` 外的所有内容。当我准备演示文稿时,我离开顶部(声明文档类的位置)并自动生成它的两个版本:我的演示稿使用 Beamer 忽略任何 `frame` 之外的所有文本,另一个含有类似这样的头:
```
\documentclass{article}
\usepackage{beamerarticle}
```
这会生成一份讲义:一份含有所有 `frame` 和它们之间文字的 PDF。
当会议组织者要求我发布我的幻灯片时,我会包含原始幻灯片作为参考,但我希望人们拿到的是讲义,它包含了所有我不想在幻灯片上写的解释部分。
在创建幻灯片时,人们经常会考虑是为演讲优化讲稿还是为之后想要阅读它的人们优化。幸运的是,Beamer 提供了两全其美的办法。
---
via: <https://opensource.com/article/19/1/create-presentations-beamer>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Beamer](https://www.overleaf.com/learn/latex/Beamer) is a LaTeX package for generating presentation slide decks. One of its nicest features is that it can take advantage of LaTeX's powerful typesetting system and all the other packages in its ecosystem. For example, I often use LaTeX's [listings](https://www.overleaf.com/learn/latex/Code_listing) package in Beamer presentations that include code.
## Starting a presentation
To begin a Beamer document, enter:
`\documentclass{beamer}`
As you would with any other LaTeX document, add any packages you want to use. For example, to use the **listings** package, enter:
`\usepackage{listings}`
Place all content inside the **document **environment:
`\begin{document}`
Beamer documents are usually a sequence of **frame **environments. Frames that contain code should be marked **fragile**:
`\begin{frame}[fragile]`
Begin your frames with a title:
`\frametitle{Function to Do Stuff}`
## Testing your code before you present it
One of the worst feelings in the world is giving a talk and realizing, as you walk through the code, that there is a glaring bug in it—maybe a misspelled keyword or an unclosed brace.
The solution is to *test* code that is presented. In most presentation environments, this means creating a separate file, writing tests, then copying and pasting.
However, with Beamer, there is a better way. Imagine you have a file named **do_stuff.py** that contains code. You can write tests for the **do_stuff.py** code in a second file, which you call **test_do_stuff.py**, and can exercise it with, say, [pytest](https://docs.pytest.org/en/latest/). However, most of the lines in **do_stuff.py** lack pedagogic value, like defining helper functions.
To simplify things for your audience, you can import just the lines you want to talk about into the frame in your presentation :
```
\lstinputlisting[
language=Python,
firstline=8,
lastline=15
]{do_stuff.py}
```
Since you will be talking through those lines (from 8 to 15), you don't need any other content on the slide. Close the frame:
`\end{frame}`
On the next slide, you want to show a usage example for the **do_stuff()** function you just presented:
```
\begin{frame}[fragile]
\frametitle{Calling Function to Do Stuff}
\lstinputlisting[
language=Python,
firstline=17,
lastline=19
]{do_stuff.py}
\end{frame}
```
You use the same file, but this time you show the lines that *call* the function. Finally, close the document:
`\end{document}`
Assuming you have an appropriate Python file in **do_stuff.py**, this will produce a short two-slide presentation.
Beamer also supports necessary features such as progressive revelation, showing only one bullet at a time to prevent the audience from being distracted by reading ahead.": **\pause** inside a list will divide bullets into pages:
```
\begin{frame}
Remember:
\begin{itemize}
\item This will show up on the first slide. \pause
\item This will show up on the
second slide, as well as the preceding point. \pause
\item Finally, on the third slide,
all three bullets will show up.
\end{frame}
```
## Creating handouts
My favorite feature in Beamer is that you can set it to *ignore* everything outside a frame with **\documentclass[ignorenonframetext]{beamer}**. When I prepare a presentation, I leave off the top (where the document class is declared) and auto-generate two versions of it: one with Beamer that ignores all text outside any frame, which I use for my presentation, and one with a header like:
```
\documentclass{article}
\usepackage{beamerarticle}
```
which generates a handout—a PDF that has all the frames *and* all the text between them.
When a conference organizer asks me to publish my slides, I include the original slide deck as a reference, but the main thing I like people to have is the handout, which has all the explanatory text that I don't want to include on the slide deck itself.
When creating presentation slides, people often wonder whether it's better to optimize their materials for the presentation or for people who want to read them afterward. Fortunately, Beamer provides the best of both worlds.
## 4 Comments |
10,440 | JSON 的兴起与崛起 | https://twobithistory.org/2017/09/21/the-rise-and-rise-of-json.html | 2019-01-14T11:50:00 | [
"JavaScript",
"JSON",
"XML"
] | https://linux.cn/article-10440-1.html | 
JSON 已经占领了全世界。当今,任何两个应用程序彼此通过互联网通信时,可以打赌它们在使用 JSON。它已被所有大型企业所采用:十大最受欢迎的 web API 接口列表中(主要由 Google、Facebook 和 Twitter 提供),仅仅只有一个 API 接口是以 XML 的格式开放数据的。<sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup> 这个列表中的 Twitter API 为此做了一个鲜活的注脚:其对 XML 格式的支持到 2013 年结束,其时发布的新版本的 API 取消 XML 格式,转而仅使用 JSON。JSON 也在程序编码级别和文件存储上被广泛采用:在 Stack Overflow(LCTT 译注:一个面向程序员的问答网站)上,现在更多的是关于 JSON 的问题,而不是其他的数据交换格式。<sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup>

XML 仍然在很多地方存在。网络上它被用于 SVG 和 RSS / Atom 信息流。Android 开发者想要获得用户权限许可时,需要在其 APP 的 `manifest` 文件中声明 —— 此文件是 XML 格式的。XML 的替代品也不仅仅只有 JSON,现在有很多人在使用 YAML 或 Google 的 Protocol Buffers 等技术,但这些技术的受欢迎程度远不如 JSON。目前来看,JSON 是应用程序在网络之间通信的首选协议格式。
考虑到自 2005 年来 Web 编程世界就垂涎于 “异步 JavaScript 和 XML” 而非 “异步 JavaScript 和 JSON” 的技术潜力,你可以发现 JSON 的主导地位是如此的让人惊讶。当然了,这可能与这两种通信格式的受欢迎程度无关,而仅反映出缩写 “AJAX” 似乎比 “AJAJ” 更具吸引力。但是,即使在 2005 年有些人(实际上没有太多人)已经用 JSON 来取代 XML 了,我们不禁要问 XML 的噩运来的如此之快,以至于短短十来年,“异步 JavaScript 和 XML” 这个名称就成为一个很讽刺的误称。那这十来年发生了什么?JSON 怎么会在那么多应用程序中取代了 XML?现在被全世界工程师和系统所使用、依赖的这种数据格式是谁提出的?
### JSON 之诞生
2001 年 4 月,首个 JSON 格式的消息被发送出来。此消息是从旧金山湾区某车库的一台计算机发出的,这是计算机历史上重要的的时刻。Douglas Crockford 和 Chip Morningstar 是一家名为 State Software 的技术咨询公司的联合创始人,他们当时聚集在 Morningstar 的车库里测试某个想法,发出了此消息。
在 “AJAX” 这个术语被创造之前,Crockford 和 Morningstar 就已经在尝试构建好用的 AJAX 应用程序了,可是浏览器对其兼容性不好。他们想要在初始页面加载后就将数据传递给应用程序,但其目标要针对所有的浏览器,这就实现不了。
这在今天看来不太可信,但是要记得 2001 年的时候 Internet Explorer(IE)代表了网页浏览器的最前沿技术产品。早在 1999 年的时候,Internet Explorer 5 就支持了原始形式的 `XMLHttpRequest`,开发者可以使用名为 ActiveX 的框架来访问此对象。Crockford 和 Morningstar 能够使用此技术(在 IE 中)来获取数据,但是在 Netscape 4 中(这是他们想要支持的另一种浏览器)就无法使用这种解决方案。为此 Crockford 和 Morningstar 只得使用一套不同的系统以兼容不同的浏览器。
第一条 JSON 消息如下所示:
```
<html><head><script>
document.domain = 'fudco';
parent.session.receive(
{ to: "session", do: "test",
text: "Hello world" }
)
</script></head></html>
```
消息中只有一小部分类似于今天我们所知的 JSON,本身其实是一个包含有一些 JavaScript 的 HTML 文档。类似于 JSON 的部分只是传递给名为 `receive()` 的函数的 JavaScript 对象字面量。
Crockford 和 Morningstar 决定滥用 HTML 的帧(`<frame>`)以发送数据。他们可以让一个帧指向一个返回的上述 HTML 文档的 URL。当接收到 HTML 时,JavaScript 代码段就会运行,就可以把数据对象字面量如实地传递回应用程序。只要小心的回避浏览器保护策略(即子窗口不允许访问父窗口),这种技术就可以正常运行无误。可以看到 Crockford 和 Mornginstar 通过明确地设置文档域这种方法来达到其目的。(这种基于帧的技术,有时称为隐藏帧技术,通常在 90 年代后期,即在广泛使用 XMLHttpRequest 技术之前使用。<sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup> )
第一个 JSON 消息的惊人之处在于,它显然不是一种新的数据格式的首次使用。它就是 JavaScript!实际上,以此方式使用 JavaScript 的想法如此简单,Crockford 自己也说过他不是第一个这样做的人。他说 Netscape 公司的某人早在 1996 年就使用 JavaScript 数组字面量来交换信息。<sup id="fnref4"> <a href="#fn4" rel="footnote"> 4 </a></sup> 因为消息就是 JavaScript,其不需要任何特殊解析工作,JavaScript 解释器就可搞定一切。
最初的 JSON 信息实际上与 JavaScript 解释器发生了冲突。JavaScript 保留了大量的关键字(ECMAScript 6 版本就有 64 个保留字),Crockford 和 Morningstar 无意中在其 JSON 中使用了一个保留字。他们使用了 `do` 作为了键名,但 `do` 是解释器中的保留字。因为 JavaScript 使用的保留字太多了,Crockford 做了决定:既然不可避免的要使用到这些保留字,那就要求所有的 JSON 键名都加上引号。被引起来的键名会被 JavaScript 解释器识别成字符串,其意味着那些保留字也可以放心安全的使用。这就为什么今天 JSON 键名都要用引号引起来的原因。
Crockford 和 Morningstar 意识到这技术可以应用于各类应用系统。想给其命名为 “JSML”,即 <ruby> JavaScript 标记语言 <rt> JavaScript Markup Language </rt></ruby>的意思,但发现这个缩写已经被一个名为 Java Speech 标记语言的东西所使用了。因此他们决定采用 “JavaScript Object Notation”,缩写为 JSON。他们开始向客户推销,但很快发现客户不愿意冒险使用缺乏官方规范的未知技术。所以 Crockford 决定写一个规范。
2002 年,Crockford 买下了 [JSON.org](http://JSON.org) 域名,放上了 JSON 语法及一个解释器的实例例子。该网站仍然在运行,现在已经包含有 2013 年正式批准的 JSON ECMA 标准的显著链接。在该网站建立后,Crockford 并没有过多的推广,但很快发现很多人都在提交各种不同编程语言的 JSON 解析器实现。JSON 的血统显然与 JavaScript 相关联,但很明显 JSON 非常适合于不同语言之间的数据交换。
### AJAX 导致的误会
2005 年,JSON 有了一次大爆发。那一年,一位名叫 Jesse James Garrett 的网页设计师和开发者在博客文章中创造了 “AJAX” 一词。他很谨慎地强调:AJAX 并不是新技术,而是 “好几种蓬勃发展的技术以某种强大的新方式汇集在一起。<sup id="fnref5"> <a href="#fn5" rel="footnote"> 5 </a></sup> ” AJAX 是 Garrett 给这种正受到青睐的 Web 应用程序的新开发方法的命名。他的博客文章接着描述了开发人员如何利用 JavaScript 和 XMLHttpRequest 构建新型应用程序,这些应用程序比传统的网页更具响应性和状态性。他还以 Gmail 和 Flickr 网站已经使用 AJAX 技术作为了例子。
当然了,“AJAX” 中的 “X” 代表 XML。但在随后的问答帖子中,Garrett 指出,JSON 可以完全替代 XML。他写道:“虽然 XML 是 AJAX 客户端进行数据输入、输出的最完善的技术,但要实现同样的效果,也可以使用像 JavaScript Object Notation(JSON)或任何类似的结构数据方法等技术。 ”<sup id="fnref6"> <a href="#fn6" rel="footnote"> 6 </a></sup>
开发者确实发现在构建 AJAX 应用程序时可以很容易的使用 JSON,许多人更喜欢它而不是 XML。具有讽刺意味的是,对 AJAX 的兴趣逐渐的导致了 JSON 的普及。大约在这个时候,JSON 引起了博客圈的注意。
2006 年,Dave Winer,一位高产的博主,他也是许多基于 XML 的技术(如 RSS 和 XML-RPC)背后的开发工程师,他抱怨到 JSON 毫无疑问的正在重新发明 XML。尽管人们认为数据交换格式之间的竞争不会导致某一技术的消亡。其写到:
>
> 毫无疑问,我可以编写一个例程来解析 JSON,但来看看他们要重新发明一个东西有多大的意义,出于某种原因 XML 本身对他们来说还不够好(我很想听听原因)。谁想干这荒谬之事?查找一棵树然后把节点串起来。可以立马试试。<sup id="fnref7"> <a href="#fn7" rel="footnote"> 7 </a></sup>
>
>
>
我很理解 Winer 的挫败感。事实上并没有太多人喜欢 XML。甚至 Winer 也说过他不喜欢 XML。<sup id="fnref8"> <a href="#fn8" rel="footnote"> 8 </a></sup> 但 XML 已被设计成一个可供任何人使用,并且可以用于几乎能想象到的所有事情。归根到底,XML 实际上是一门元语言,允许你为特定应用程序自定义该领域特定的语言。如 Web 信息流技术 RSS 和 SOAP(简单对象访问协议)就是例子。Winer 认为由于通用交换格式所带来的好处,努力达成共识非常重要。XML 的灵活性应该能满足任何人的需求,然而 JSON 格式呢,其并没有比 XML 提供更多东西,除了它抛弃了使 XML 更灵活的那些繁琐的东西。
Crockford 阅读了 Winer 的这篇文章并留下了评论。为了回应 JSON 重新发明 XML 的指责,Crockford 写到:“重造轮子的好处是可以得到一个更好的轮子。”<sup id="fnref9"> <a href="#fn9" rel="footnote"> 9 </a></sup>
### JSON 与 XML 对比
到 2014 年,JSON 已经由 ECMA 标准和 RFC 官方正式认可。它有了自己的 MIME 类型。JSON 已经进入了大联盟时代。
为什么 JSON 比 XML 更受欢迎?
在 [JSON.org](http://JSON.org) 网站上,Crockford 总结了一些 JSON 的优势。他写到,JSON 的语法极少,其结构可预测,因此 JSON 更容易被人类和机器理解。<sup id="fnref10"> <a href="#fn10" rel="footnote"> 10 </a></sup> 其他博主一直关注 XML 的冗长啰嗦及“尖括号负担”。<sup id="fnref11"> <a href="#fn11" rel="footnote"> 11 </a></sup> XML 中每个开始标记都必须与结束标记匹配,这意味着 XML 文档包含大量的冗余信息。在未压缩时,XML 文档的体积比同等信息量 JSON 文档的体积大很多,但是,更重要的,这也使 XML 文档更难以阅读。
Crockford 还声称 JSON 的另一个巨大优势是其被设计为数据交换格式。<sup id="fnref12"> <a href="#fn12" rel="footnote"> 12 </a></sup> 从一开始,它的目的就是在应用程序间传递结构化信息的。而 XML 呢,虽然也可以使用来传递数据,但其最初被设计为文档标记语言。它演变自 SGML(通用标准标记语言),而它又是从被称为 Scribe 的标记语言演变而来,其旨在发展成类似于 LaTeX 一样的文字处理系统。XML 中,一个标签可以包含有所谓的“混合内容”,即带有围绕单词、短语的内嵌标签的文本。这会让人浮现出一副用红蓝笔记录的手稿画面,这是标记语言核心思想的形象比喻。另一方面,JSON 不支持对混合内容模型的清晰构建,但这也意味着它的结构足够简单。一份文档最好的建模就是一棵树,但 JSON 抛弃了这种文档的思想,Crockford 将 JSON 抽象限制为字典和数组,这是所有程序员构建程序时都会使用的最基本的、也最熟悉的元素。
最后,我认为人们不喜欢 XML 是因为它让人困惑。它让人迷惑的地方就是有很多不同的风格。乍一看,XML 本身及其子语言(如 RSS、ATOM、SOAP 或 SVG)之间的界限并不明显。典型的 XML 文档的第一行标识了该 XML 的版本,然后该 XML 文档应该符合特定的子语言。这就有变化需要考虑了,特别是跟 JSON 做比较,JSON 是如此简单,以至于永远不需要编写新版本的 JSON 规范。XML 的设计者试图将 XML 做为唯一的数据交换格式以支配所有格式,就会掉入那个经典的程序员陷阱:过度工程化。XML 非常笼统及概念化,所以很难于简单的使用。
在 2000 年的时候,发起了一场使 HTML 符合 XML 标准的活动,发布了一份符合 XML 标准的 HTML 开发规范,这就此后很出名的 XHTML。虽然一些浏览器厂商立即开始支持这个新标准,但也很明显,大部分基于 HTML 技术的开发者不愿意改变他们的习惯。新标准要求对 XHTML 文档进行严格的验证,而不是基于 HTML 的基准。但大多的网站都是依赖于 HTML 的宽容规则的。到 2009 年的时候,试图编写第二版本的 XHTML 标准的努力已经流产,因为未来已清晰可见,HTML 将会发展为 HTML5(一种不强制要求接受 XML 规则的标准)。
如果 XHTML 的努力取得了成功,那么 XML 可能会成为其设计者所希望的通用数据格式。想象一下,一个 HTML 文档和 API 响应具有完全相同结构的世界。在这样的世界中,JSON 可能不会像现在一样普遍存在。但我把 HTML 的失败看做是 XML 阵营的一种道义上的失败。如果 XML 不是 HTML 的最佳工具,那么对于其他应用程序,也许会有更好的工具出现。在这个世界,我们的世界,很容易看到像 JSON 格式这样的足够简单、量体裁衣的才能获得更大的成功。
如果你喜欢这博文,每两周会更新一次! 请在 Twitter 上关注 [@TwoBitHistory](https://twitter.com/TwoBitHistory) 或订阅 [RSS feed](https://twobithistory.org/feed.xml),以确保得到更新的通知。
---
1. <http://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html#software> [↩](#fnref1)
2. <https://insights.stackoverflow.com/trends?tags=json%2Cxml%2Cprotocol-buffers%2Cyaml%2Ccsv> [↩](#fnref2)
3. Zakas, Nicholas C., et al. “What Is Ajax?” Professional Ajax, 2nd ed., Wiley, 2007. [↩](#fnref3)
4. <https://youtu.be/-C-JoyNuQJs?t=32s> [↩](#fnref4)
5. <http://adaptivepath.org/ideas/ajax-new-approach-web-applications/> [↩](#fnref5)
6. 同上 [↩](#fnref6)
7. <http://scripting.com/2006/12/20.html> [↩](#fnref7)
8. <http://blogoscoped.com/archive/2009-03-05-n15.html> [↩](#fnref8)
9. <https://scripting.wordpress.com/2006/12/20/scripting-news-for-12202006/#comment-26383> [↩](#fnref9)
10. <http://www.json.org/xml.html> [↩](#fnref10)
11. <https://blog.codinghorror.com/xml-the-angle-bracket-tax> [↩](#fnref11)
12. <https://youtu.be/-C-JoyNuQJs?t=33m50sgg> [↩](#fnref12)
---
via: <https://twobithistory.org/2017/09/21/the-rise-and-rise-of-json.html>
作者:[Two-Bit History](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[runningwater](https://github.com/runningwater) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | JSON has taken over the world. Today, when any two applications communicate
with each other across the internet, odds are they do so using JSON. It has
been adopted by all the big players: Of the ten most popular web APIs, a list
consisting mostly of APIs offered by major companies like Google, Facebook, and
Twitter, only one API exposes data in XML rather than JSON. 1 Twitter, to
take an illustrative example from that list, supported XML until 2013, when it
released a new version of its API that dropped XML in favor of using JSON
exclusively. JSON has also been widely adopted by the programming rank and
file: According to Stack Overflow, a question and answer site for programmers,
more questions are now asked about JSON than about any other data interchange
format.
[2](#fn:2)XML still survives in many places. It is used across the web for SVGs and for RSS and Atom feeds. When Android developers want to declare that their app requires a permission from the user, they do so in their app’s manifest, which is written in XML. XML also isn’t the only alternative to JSON—some people now use technologies like YAML or Google’s Protocol Buffers. But these are nowhere near as popular as JSON. For the time being, JSON appears to be the go-to format for communicating with other programs over the internet.
JSON’s dominance is surprising when you consider that as recently as 2005 the
web world was salivating over the potential of “Asynchronous JavaScript and
XML” and *not* “Asynchronous JavaScript and JSON.” It is of course possible
that this had nothing to do with the relative popularity of the two formats at
the time and reflects only that “AJAX” must have seemed a more appealing
acronym than “AJAJ.” But even if some people were already using JSON instead of
XML in 2005 (and in fact not many people were yet), one still wonders how XML’s
fortunes could have declined so precipitously that a mere decade or so later
“Asynchronous JavaScript and XML” has become an ironic misnomer. What happened
in that decade? How did JSON supersede XML in so many applications? And who
came up with this data format now depended on by engineers and systems all over
the world?
## The Birth of JSON
The first JSON message was sent in April of 2001. Since this was a historically significant moment in computing, the message was sent from a computer in a Bay-Area garage. Douglas Crockford and Chip Morningstar, co-founders of a technology consulting company called State Software, had gathered in Morningstar’s garage to test out an idea.
Crockford and Morningstar were trying to build AJAX applications well before the term “AJAX” had been coined. Browser support for what they were attempting was not good. They wanted to pass data to their application after the initial page load, but they had not found a way to do this that would work across all the browsers they were targeting.
Though it’s hard to believe today, Internet Explorer represented the bleeding edge of web browsing in 2001. As early as 1999, Internet Explorer 5 supported a primordial form of XMLHttpRequest, which programmers could access using a framework called ActiveX. Crockford and Morningstar could have used this technology to fetch data for their application, but they could not have used the same solution in Netscape 4, another browser that they sought to support. So Crockford and Morningstar had to use a different system that worked in both browsers.
The first JSON message looked like this:
```
<html><head><script>
document.domain = 'fudco';
parent.session.receive(
{ to: "session", do: "test",
text: "Hello world" }
)
</script></head></html>
```
Only a small part of the message resembles JSON as we know it today. The
message itself is actually an HTML document containing some JavaScript. The
part that resembles JSON is just a JavaScript object literal being passed to a
function called `receive()`
.
Crockford and Morningstar had decided that they could abuse an HTML frame to
send themselves data. They could point a frame at a URL that would return an
HTML document like the one above. When the HTML was received, the JavaScript
would be run, passing the object literal back to the application. This worked
as long as you were careful to sidestep browser protections preventing a
sub-window from accessing its parent; you can see that Crockford and
Mornginstar did that by explicitly setting the document domain. (This
frame-based technique, sometimes called the hidden frame technique, was
commonly used in the late 90s before the widespread implementation of
XMLHttpRequest. 3)
The amazing thing about the first JSON message is that it’s not obviously the
first usage of a new kind of data format at all. It’s just JavaScript! In fact
the idea of using JavaScript this way is so straightforward that Crockford
himself has said that he wasn’t the first person to do it—he claims that
somebody at Netscape was using JavaScript array literals to communicate
information as early as 1996. 4 Since the message is just JavaScript, it
doesn’t require any kind of special parsing. The JavaScript interpreter can do
it all.
The first ever JSON message actually ran afoul of the JavaScript interpreter.
JavaScript reserves an enormous number of words—there are 64 reserved words as
of ECMAScript 6—and Crockford and Morningstar had unwittingly used one in their
message. They had used `do`
as a key, but `do`
is reserved. Since JavaScript
has so many reserved words, Crockford decided that, rather than avoid using all
those reserved words, he would just mandate that all JSON keys be quoted. A
quoted key would be treated as a string by the JavaScript interpreter, meaning
that reserved words could be used safely. This is why JSON keys are quoted to
this day.
Crockford and Morningstar realized they had something that could be used in all sorts of applications. They wanted to name their format “JSML”, for JavaScript Markup Language, but found that the acronym was already being used for something called Java Speech Markup Language. So they decided to go with “JavaScript Object Notation”, or JSON. They began pitching it to clients but soon found that clients were unwilling to take a chance on an unknown technology that lacked an official specification. So Crockford decided he would write one.
In 2002, Crockford bought the domain [JSON.org](http://JSON.org) and put up the
JSON grammar and an example implementation of a parser. The website is still
up, though it now includes a prominent link to the JSON ECMA standard ratified
in 2013. After putting up the website, Crockford did little more to promote
JSON, but soon found that lots of people were submitting JSON parser
implementations in all sorts of different programming languages. JSON’s lineage
clearly tied it to JavaScript, but it became apparent that JSON was well-suited
to data interchange between arbitrary pairs of languages.
## Doing AJAX Wrong
JSON got a big boost in 2005. That year, a web designer and developer named
Jesse James Garrett coined the term “AJAX” in a blog post. He was careful to
stress that AJAX wasn’t any one new technology, but rather “several
technologies, each flourishing in its own right, coming together in powerful
new ways.” 5 AJAX was the name that Garrett was giving to a new approach to
web application development that he had noticed gaining favor. His blog post
went on to describe how developers could leverage JavaScript and XMLHttpRequest
to build new kinds of applications that were more responsive and stateful than
the typical web page. He pointed to Gmail and Flickr as examples of websites
already relying on AJAX techniques.
The “X” in “AJAX” stood for XML, of course. But in a follow-up Q&A post,
Garrett pointed to JSON as an entirely acceptable alternative to XML. He wrote
that “XML is the most fully-developed means of getting data in and out of an
AJAX client, but there’s no reason you couldn’t accomplish the same effects
using a technology like JavaScript Object Notation or any similar means of
structuring data.”[6](#fn:6)
Developers indeed found that they could easily use JSON to build AJAX applications and many came to prefer it to XML. And so, ironically, the interest in AJAX led to an explosion in JSON’s popularity. It was around this time that JSON drew the attention of the blogosphere.
In 2006, Dave Winer, a prolific blogger and the engineer behind a number of XML-based technologies such as RSS and XML-RPC, complained that JSON was reinventing XML for no good reason. Though one might think that a contest between data interchange formats would be unlikely to engender death threats, Winer wrote:
No doubt I can write a routine to parse [JSON], but look at how deep they went to re-invent, XML itself wasn’t good enough for them, for some reason (I’d love to hear the reason). Who did this travesty? Let’s find a tree and string them up. Now.
[7]
It’s easy to understand Winer’s frustration. XML has never been widely loved.
Even Winer has said that he does not love XML. 8 But XML was designed to be a
system that could be used by everyone for almost anything imaginable. To that
end, XML is actually a meta-language that allows you to define domain-specific
languages for individual applications—RSS, the web feed technology, and SOAP
(Simple Object Access Protocol) are examples. Winer felt that it was important
to work toward consensus because of all the benefits a common interchange
format could bring. He felt that XML’s flexibility should be able to
accommodate everybody’s needs. And yet here was JSON, a format offering no
benefits over XML except those enabled by throwing out the cruft that made XML
so flexible.
Crockford saw Winer’s blog post and left a comment on it. In response to the
charge that JSON was reinventing XML, Crockford wrote, “The good thing about
reinventing the wheel is that you can get a round one.”[9](#fn:9)
## JSON vs XML
By 2014, JSON had been officially specified by both an ECMA standard and an RFC. It had its own MIME type. JSON had made it to the big leagues.
Why did JSON become so much more popular than XML?
On [JSON.org](http://JSON.org), Crockford summarizes some of JSON’s advantages
over XML. He writes that JSON is easier for both humans and machines to
understand, since its syntax is minimal and its structure is predictable. 10
Other bloggers have focused on XML’s verbosity and “the angle bracket
tax.”
Each opening tag in XML must be matched with a closing tag, meaning that an XML document contains a lot of redundant information. This can make an XML document much larger than an equivalent JSON document when uncompressed, but, perhaps more importantly, it also makes an XML document harder to read.
[11](#fn:11)Crockford has also claimed that another enormous advantage for JSON is that
JSON was designed as a data interchange format. 12 It was meant to carry
structured information between programs from the very beginning. XML, though it
has been used for the same purpose, was originally designed as a document
markup language. It evolved from SGML (Standard Generalized Markup Language),
which in turn evolved from a markup language called Scribe, intended as a word
processing system similar to LaTeX. In XML, a tag can contain what is called
“mixed content,” or text with inline tags surrounding words or phrases. This
recalls the image of an editor marking up a manuscript with a red or blue pen,
which is arguably the central metaphor of a markup language. JSON, on the other
hand, does not support a clear analogue to mixed content, but that means that
its structure can be simpler. A document is best modeled as a tree, but by
throwing out the document idea Crockford could limit JSON to dictionaries and
arrays, the basic and familiar elements all programmers use to build their
programs.
Finally, my own hunch is that people disliked XML because it was confusing, and it was confusing because it seemed to come in so many different flavors. At first blush, it’s not obvious where the line is between XML proper and its sub-languages like RSS, ATOM, SOAP, or SVG. The first lines of a typical XML document establish the XML version and then the particular sub-language the XML document should conform to. That is a lot of variation to account for already, especially when compared to JSON, which is so straightforward that no new version of the JSON specification is ever expected to be written. The designers of XML, in their attempt to make XML the one data interchange format to rule them all, fell victim to that classic programmer’s pitfall: over-engineering. XML was so generalized that it was hard to use for something simple.
In 2000, a campaign was launched to get HTML to conform to the XML standard. A specification was published for XML-compliant HTML, thereafter known as XHTML. Some browser vendors immediately started supporting the new standard, but it quickly became obvious that the vast HTML-producing public were unwilling to revise their habits. The new standard called for stricter validation of XHTML than had been the norm for HTML, but too many websites depended on HTML’s forgiving rules. By 2009, an attempt to write a second version of the XHTML standard was aborted when it became clear that the future of HTML was going to be HTML5, a standard that did not insist on XML compliance.
If the XHTML effort had succeeded, then maybe XML would have become the common data format that its designers hoped it would be. Imagine a world in which HTML documents and API responses had the exact same structure. In such a world, JSON might not have become as ubiquitous as it is today. But I read the failure of XHTML as a kind of moral defeat for the XML camp. If XML wasn’t the best tool for HTML, then maybe there were better tools out there for other applications also. In that world, our world, it is easy to see how a format as simple and narrowly tailored as JSON could find great success.
*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
*
-
[http://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html#software](http://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html#software)[↩](#fnref:1) -
[https://insights.stackoverflow.com/trends?tags=json%2Cxml%2Cprotocol-buffers%2Cyaml%2Ccsv](https://insights.stackoverflow.com/trends?tags=json%2Cxml%2Cprotocol-buffers%2Cyaml%2Ccsv)[↩](#fnref:2) -
Zakas, Nicholas C., et al. “What Is Ajax?” Professional Ajax, 2nd ed., Wiley, 2007.
[↩](#fnref:3) -
[http://adaptivepath.org/ideas/ajax-new-approach-web-applications/](http://adaptivepath.org/ideas/ajax-new-approach-web-applications/)[↩](#fnref:5) -
ibid.
[↩](#fnref:6) -
[https://scripting.wordpress.com/2006/12/20/scripting-news-for-12202006/#comment-26383](https://scripting.wordpress.com/2006/12/20/scripting-news-for-12202006/#comment-26383)[↩](#fnref:9) |
10,441 | Termtosvg:将你在 Linux 终端中操作录制成 SVG 动画 | https://www.2daygeek.com/termtosvg-record-your-terminal-sessions-as-svg-animations-in-linux/ | 2019-01-14T12:13:17 | [
"SVG",
"终端",
"动画"
] | https://linux.cn/article-10441-1.html | 
一般人喜欢使用历史命令功能来查看/再次调用之前在终端中输入的命令。不幸的是,那样做只会显示先前输入的命令,而不是之前输出的内容。
在 Linux 中,有许多可以用来记录终端活动的实用工具。这种工具将会帮助我们记录用户在终端中的活动,并帮助我们识别输出中有用的信息。
在这之前,我们已经介绍了一些这类实用工具了。今天,让我们接着讨论这类工具。
如果你希望尝试其它一些记录你终端活动的工具,我推荐你试试 [script](https://www.2daygeek.com/script-command-record-save-your-terminal-session-activity-linux/) 命令和 [Terminalizer](https://www.2daygeek.com/terminalizer-a-tool-to-record-your-terminal-and-generate-animated-gif-images/) 工具。`script` 是在无头服务器中记录终端活动的最佳方式之一。`script` 是一个记录在终端中输入过的 Unix 命令的实用工具(在某些终端中,它会记录显示在你终端中的所有东西)。它会在当前工作目录下以文本文件方式储存所有终端输出。
不过,如果你在寻找 [GIF 录制器](https://www.2daygeek.com/category/gif-recorder/) ,你可以尝试 [Gifine](https://www.2daygeek.com/gifine-create-animated-gif-vedio-recorder-linux-mint-debian-ubuntu/)、[Kgif](https://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/) 和 [Peek](https://www.2daygeek.com/peek-create-animated-gif-screen-recorder-capture-arch-linux-mint-fedora-ubuntu/)。
### 什么是 Termtosvg
Termtosvg 是一个用 Python 编写的 Unix 终端录制器,它可以将你的命令行会话保存为 SVG 动画。
### Termtosvg 的特点
* 可以制作嵌入于项目主页的简洁美观的动画。
* 可以在 SVG 模板中自定义配色、终端 UI 和动画。
* 兼容 asciinema 录制格式。
* 要求 Python 版本为 3.5 或更高。
### 如何在 Linux 中安装 Termtosvg
它是用 Python 编写的,所以我推荐使用 `pip` 来安装它。
请确保你已经安装了 python-pip 包。如果你还没安装,请输入下面的命令。 对于 Debian 或 Ubuntu 用户,请使用 [apt](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 或 [apt-get](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 `pip`。
```
sudo apt install python-pip
```
对于 Archlinux 用户,请使用 [pacman](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 `pip`。
```
sudo pacman -S python-pip
```
对于 Fedora 用户,请使用 [dnf](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 `pip`。
```
sudo dnf install python-pip
```
对于 CentOS 或 RHEL 用户,请使用 [yum](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 来安装 `pip`。
```
sudo yum install python-pip
```
对于 openSUSE 用户,请使用 [zypper](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 来安装 `pip`。
```
sudo zypper install python-pip
```
最后,请执行 [pip](https://www.2daygeek.com/install-pip-manage-python-packages-linux/) 来安装 Termtosvg。
```
sudo pip3 install termtosvg pyte python-xlib svgwrite
```
### 如何使用 Termtosvg
成功安装 Termtosvg 后,请使用以下命令来开始录制。
```
$ termtosvg
Recording started, enter "exit" command or Control-D to end
```
如果只是想测试它是否正常工作,随意输入几行命令即可。
```
$ uname -a
Linux daygeek-Y700 4.19.8-2-MANJARO #1 SMP PREEMPT Sat Dec 8 14:45:36 UTC 2018 x86_64 GNU/Linux
$ hostname
daygeek-Y700
$ cat /etc/*-release
Manjaro Linux
DISTRIB_ID=ManjaroLinux
DISTRIB_RELEASE=18.0
DISTRIB_CODENAME=Illyria
DISTRIB_DESCRIPTION="Manjaro Linux"
Manjaro Linux
NAME="Manjaro Linux"
ID=manjaro
ID_LIKE=arch
PRETTY_NAME="Manjaro Linux"
ANSI_COLOR="1;32"
HOME_URL="https://www.manjaro.org/"
SUPPORT_URL="https://www.manjaro.org/"
BUG_REPORT_URL="https://bugs.manjaro.org/"
$ free -g
free: Multiple unit options doesn't make sense.
$ free -m
free: Multiple unit options doesn't make sense.
$ pip3 --version
pip 18.1 from /usr/lib/python3.7/site-packages/pip (python 3.7)
```
完成后,你可以按下 `CTRL+D` 或输入 `exit` 来停止录制。录制完后,输出文件会以一个独一无二的名字被保存在 `/tmp` 文件夹中。
```
$ exit
exit
Recording ended, SVG animation is /tmp/termtosvg_5waorper.svg
```
我们可以在任意浏览器中打开 SVG 文件。
```
firefox /tmp/termtosvg_5waorper.svg
```

---
via: <https://www.2daygeek.com/termtosvg-record-your-terminal-sessions-as-svg-animations-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zhs852](https://github.com/zhs852) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,442 | 极客漫画:你准备好微服务了吗? | http://turnoff.us/geek/are-you-ready-for-microservices/ | 2019-01-14T12:34:38 | [
"微服务",
"极客漫画"
] | https://linux.cn/article-10442-1.html | 
微服务是个好东西,就像乐高积木一样,你可以拼成各种东西,当前,前提是你足够会玩。
从早些年的 SOA 和中间件,到现在的微服务和容器,但似乎历史总是螺旋式变化的。看起来笨拙而大而无当的独石应用,其实在很多场景,要比微服务更适合。
话说,微服务的锅该那只汤姆猫背吗?:->
---
via: <http://turnoff.us/geek/are-you-ready-for-microservices/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者&点评&校对:[wxy](https://github.com/wxy) 合成:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,443 | Linux 上查看系统/服务器运行时间的 11 种方法 | https://www.2daygeek.com/11-methods-to-find-check-system-server-uptime-in-linux/ | 2019-01-15T10:09:00 | [
"时间",
"启动",
"运行"
] | https://linux.cn/article-10443-1.html | 
你是否想知道自己的 Linux 系统正常运行了多长时间而没有宕机?系统是什么时候启动的?
Linux 上有多个查看服务器/系统运行时间的命令,大多数用户喜欢使用标准并且很有名的 `uptime` 命令获取这些具体的信息。
服务器的运行时间对一些用户来说不那么重要,但是当服务器运行诸如在线商城<ruby> 门户 <rt> portal </rt></ruby>、网上银行门户等<ruby> 关键任务应用 <rt> mission-critical applications </rt></ruby>时,它对于<ruby> 服务器管理员 <rt> server adminstrators </rt></ruby>来说就至关重要。
它必须做到零宕机,因为一旦停机就会影响到数百万用户。
正如我所说,许多命令都可以让用户看到 Linux 服务器的运行时间。在这篇教程里我会教你如何使用下面 11 种方式来查看。
<ruby> 正常运行时间 <rt> uptime </rt></ruby>指的是服务器自从上次关闭或重启以来经过的时间。
`uptime` 命令获取 `/proc` 文件中的详细信息并输出正常运行时间,而 `/proc` 文件并不适合人直接看。
以下这些命令会输出系统运行和启动的时间。也会显示一些额外的信息。
### 方法 1:使用 uptime 命令
`uptime` 命令会告诉你系统运行了多长时间。它会用一行显示以下信息。
当前时间、系统运行时间、当前登录用户的数量、过去 1 分钟/5 分钟/15 分钟系统负载的均值。
```
# uptime
08:34:29 up 21 days, 5:46, 1 user, load average: 0.06, 0.04, 0.00
```
### 方法 2:使用 w 命令
`w` 命令为每个登录进系统的用户,每个用户当前所做的事情,所有活动的负载对计算机的影响提供了一个快速的概要。这个单一命令结合了多个 Unix 程序:`who`、`uptime`,和 `ps -a` 的结果。
```
# w
08:35:14 up 21 days, 5:47, 1 user, load average: 0.26, 0.09, 0.02
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/1 103.5.134.167 08:34 0.00s 0.01s 0.00s w
```
### 方法 3:使用 top 命令
`top` 命令是 Linux 上监视实时系统进程的基础命令之一。它显示系统信息和运行进程的信息,例如正常运行时间、平均负载、运行的任务、登录用户数量、CPU 数量 & CPU 利用率、内存 & 交换空间信息。
**推荐阅读:**[TOP 命令监视服务器性能的例子](https://www.2daygeek.com/top-command-examples-to-monitor-server-performance/)
```
# top -c
top - 08:36:01 up 21 days, 5:48, 1 user, load average: 0.12, 0.08, 0.02
Tasks: 98 total, 1 running, 97 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.3%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1872888k total, 1454644k used, 418244k free, 175804k buffers
Swap: 2097148k total, 0k used, 2097148k free, 1098140k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 19340 1492 1172 S 0.0 0.1 0:01.04 /sbin/init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kthreadd]
3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 [migration/0]
4 root 20 0 0 0 0 S 0.0 0.0 0:34.32 [ksoftirqd/0]
5 root RT 0 0 0 0 S 0.0 0.0 0:00.00 [stopper/0]
```
### 方法 4:使用 who 命令
`who` 命令列出当前登录进计算机的用户。`who` 命令与 `w` 命令类似,但后者还包含额外的数据和统计信息。
```
# who -b
system boot 2018-04-12 02:48
```
### 方法 5:使用 last 命令
`last` 命令列出最近登录过的用户。`last` 回溯 `/var/log/wtmp` 文件并显示自从文件创建后登录进(出)的用户。
```
# last reboot -F | head -1 | awk '{print $5,$6,$7,$8,$9}'
Thu Apr 12 02:48:04 2018
```
### 方法 6:使用 /proc/uptime 文件
这个文件中包含系统上次启动后运行时间的详细信息。`/proc/uptime` 的输出相当精简。
第一个数字是系统自从启动的总秒数。第二个数字是总时间中系统空闲所花费的时间,以秒为单位。
```
# cat /proc/uptime
1835457.68 1809207.16
```
### 方法 7:使用 tuptime 命令
`tuptime` 是一个汇报系统运行时间的工具,输出历史信息并作以统计,保留重启之间的数据。和 `uptime` 命令很像,但输出更有意思一些。
```
$ tuptime
```
### 方法 8:使用 htop 命令
`htop` 是运行在 Linux 上的一个交互式进程查看器,是 Hisham 使用 ncurses 库开发的。`htop` 比起 `top` 有很多的特性和选项。
**推荐阅读:** [使用 Htop 命令监控系统资源](https://www.2daygeek.com/htop-command-examples-to-monitor-system-resources/)
```
# htop
CPU[| 0.5%] Tasks: 48, 5 thr; 1 running
Mem[||||||||||||||| 165/1828MB] Load average: 0.10 0.05 0.01
Swp[ 0/2047MB] Uptime: 21 days, 05:52:35
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
29166 root 20 0 110M 2484 1240 R 0.0 0.1 0:00.03 htop
29580 root 20 0 11464 3500 1032 S 0.0 0.2 55:15.97 /bin/sh ./OSWatcher.sh 10 1
1 root 20 0 19340 1492 1172 S 0.0 0.1 0:01.04 /sbin/init
486 root 16 -4 10780 900 348 S 0.0 0.0 0:00.07 /sbin/udevd -d
748 root 18 -2 10780 932 360 S 0.0 0.0 0:00.00 /sbin/udevd -d
```
### 方法 9:使用 glances 命令
`glances` 是一个跨平台的基于 curses 库的监控工具,它是使用 python 编写的。可以说它非常强大,仅用一点空间就能获得很多信息。它使用 psutil 库从系统中获取信息。
`glances` 可以监控 CPU、内存、负载、进程、网络接口、磁盘 I/O、<ruby> 磁盘阵列 <rt> RAID </rt></ruby>、传感器、文件系统(与文件夹)、容器、监视器、Alert 日志、系统信息、运行时间、<ruby> 快速查看 <rt> Quicklook </rt></ruby>(CPU,内存、负载)等。
**推荐阅读:** [Glances (集大成)– Linux 上高级的实时系统运行监控工具](https://www.2daygeek.com/install-glances-advanced-real-time-linux-system-performance-monitoring-tool-on-centos-fedora-ubuntu-debian-opensuse-arch-linux/)
```
glances
ubuntu (Ubuntu 17.10 64bit / Linux 4.13.0-37-generic) - IP 192.168.1.6/24 Uptime: 21 days, 05:55:15
CPU [||||||||||||||||||||| 90.6%] CPU - 90.6% nice: 0.0% ctx_sw: 4K MEM \ 78.4% active: 942M SWAP - 5.9% LOAD 2-core
MEM [|||||||||||||||| 78.0%] user: 55.1% irq: 0.0% inter: 1797 total: 1.95G inactive: 562M total: 12.4G 1 min: 4.35
SWAP [| 5.9%] system: 32.4% iowait: 1.8% sw_int: 897 used: 1.53G buffers: 14.8M used: 749M 5 min: 4.38
idle: 7.6% steal: 0.0% free: 431M cached: 273M free: 11.7G 15 min: 3.38
NETWORK Rx/s Tx/s TASKS 211 (735 thr), 4 run, 207 slp, 0 oth sorted automatically by memory_percent, flat view
docker0 0b 232b
enp0s3 12Kb 4Kb Systemd 7 Services loaded: 197 active: 196 failed: 1
lo 616b 616b
_h478e48e 0b 232b CPU% MEM% VIRT RES PID USER NI S TIME+ R/s W/s Command
63.8 18.9 2.33G 377M 2536 daygeek 0 R 5:57.78 0 0 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
DefaultGateway 83ms 78.5 10.9 3.46G 217M 2039 daygeek 0 S 21:07.46 0 0 /usr/bin/gnome-shell
8.5 10.1 2.32G 201M 2464 daygeek 0 S 8:45.69 0 0 /usr/lib/firefox/firefox -new-window
DISK I/O R/s W/s 1.1 8.5 2.19G 170M 2653 daygeek 0 S 2:56.29 0 0 /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
dm-0 0 0 1.7 7.2 2.15G 143M 2880 daygeek 0 S 7:10.46 0 0 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
sda1 9.46M 12K 0.0 4.9 1.78G 97.2M 6125 daygeek 0 S 1:36.57 0 0 /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
```
### 方法 10:使用 stat 命令
`stat` 命令显示指定文件或文件系统的详细状态。
```
# stat /var/log/dmesg | grep Modify
Modify: 2018-04-12 02:48:04.027999943 -0400
```
### 方法 11:使用 procinfo 命令
`procinfo` 从 `/proc` 文件夹下收集一些系统数据并将其很好的格式化输出在标准输出设备上。
```
# procinfo | grep Bootup
Bootup: Fri Apr 20 19:40:14 2018 Load average: 0.16 0.05 0.06 1/138 16615
```
---
via: <https://www.2daygeek.com/11-methods-to-find-check-system-server-uptime-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LuuMing](https://github.com/LuuMing) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,446 | 将旧的 Linux 台式机变成家庭媒体中心 | https://opensource.com/article/18/11/old-linux-desktop-new-home-media-center | 2019-01-16T08:39:25 | [
"媒体中心"
] | https://linux.cn/article-10446-1.html |
>
> 重新利用过时的计算机来浏览互联网并在大屏电视上观看视频。
>
>
>

我第一次尝试搭建一台“娱乐电脑”是在 20 世纪 90 年代后期,使用了一台带 Trident ProVidia 9685 PCI 显卡的普通旧台式电脑。我使用了所谓的“电视输出”卡,它有一个额外的输出可以连接到标准电视端子上。屏幕显示看起来不太好,而且没有音频输出。并且外观很丑:有一条 S-Video 线穿过了客厅地板连接到我的 19 英寸 Sony Trinitron CRT 电视机上。
我在 Linux 和 Windows 98 上得到了同样令人遗憾的结果。在和那些看起来不对劲的系统挣扎之后,我放弃了几年。值得庆幸的是,如今的 HDMI 拥有更好的性能和标准化的分辨率,这使得廉价的家庭媒体中心成为现实。
我的新媒体中心娱乐电脑实际上是我的旧 Ubuntu Linux 桌面,最近我用更快的电脑替换了它。这台电脑在工作中太慢,但是它的 3.4GHz 的 AMD Phenom II X4 965 处理器和 8GB 的 RAM 足以满足一般浏览和视频流的要求。
以下是我让旧系统在新角色中发挥最佳性能所采取的步骤。
### 硬件
首先,我移除了不必要的设备,包括读卡器、硬盘驱动器、DVD 驱动器和后置 USB 卡,我添加了一块 PCI-Express 无线网卡。我将 Ubuntu 安装到单个固态硬盘 (SSD) 上,这可以切实提高任何旧系统的性能。
### BIOS
在 BIOS 中,我禁用了所有未使用的设备,例如软盘和 IDE 驱动器控制器。我禁用了板载显卡,因为我安装了带 HDMI 输出的 NVidia GeForce GTX 650 PCI Express 显卡。我还禁用了板载声卡,因为 NVidia 显卡芯片组提供音频。
### 音频
Nvidia GeForce GTX 音频设备在 GNOME 控制中心的声音设置中被显示为 GK107 HDMI Audio Controller,因此单条 HDMI 线缆可同时处理音频和视频。无需将音频线连接到板载声卡的输出插孔。

*GNOME 音频设置中的 HDMI 音频控制器。*
### 键盘和鼠标
我有罗技的无线键盘和鼠标。当我安装它们时,我插入了两个外置 USB 接收器,它们可以使用,但我经常遇到信号反应问题。接着我发现其中一个被标记为联合接收器,这意味着它可以自己处理多个罗技输入设备。罗技不提供在 Linux 中配置联合接收器的软件。但幸运的是,有个开源程序 [Solaar](https://pwr.github.io/Solaar/) 能够做到。使用单个接收器解决了我的输入性能问题。

*Solaar 联合接收器界面。*
### 视频
最初很难在我的 47 英寸平板电视上阅读文字,所以我在 Universal Access 下启用了“大文字”。我下载了一些与电视 1920x1080 分辨率相匹配的壁纸,这看起来很棒!
### 最后处理
我需要在电脑的冷却需求和我对不受阻碍的娱乐的渴望之间取得平衡。由于这是一台标准的 ATX 微型塔式计算机,我确保我有足够的风扇转速,以及在 BIOS 中精心配置过的温度以减少噪音。我还把电脑放在我的娱乐控制台后面,以进一步减少风扇噪音,但同时我可以按到电源按钮。
最后得到一台简单的、没有巨大噪音的机器,而且只使用了两根线缆:交流电源线和 HDMI。它应该能够运行任何主流或专门的媒体中心 Linux 发行版。我不期望去玩高端的游戏,因为这可能需要更多的处理能力。

*Ubuntu Linux 的关于页面。*

*在大屏幕上测试 YouTube 视频。*
我还没安装像 [Kodi](https://kodi.tv/) 这样专门的媒体中心发行版。截至目前,它运行的是 Ubuntu Linux 18.04.1 LTS,而且很稳定。
这是一个有趣的挑战,可以充分利用我已经拥有的东西,而不是购买新的硬件。这只是开源软件的一个好处。最终,我可能会用一个更小,更安静的带有媒体中心的系统或其他小机顶盒替换它,但是现在,它很好地满足了我的需求。
---
via: <https://opensource.com/article/18/11/old-linux-desktop-new-home-media-center>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | My first attempt to set up an "entertainment PC" was back in the late 1990s, using a plain old desktop computer with a Trident ProVidia 9685 PCI graphics card. I used what was known as a "TV-out" card, which had an extra output to connect to a standard television set. The onscreen result didn't look very nice and there was no audio output. And it was ugly: I had an S-Video cable running across my living room floor to my 19" Sony Trinitron CRT TV set.
I had the same sad result from Linux and Windows 98. After struggling with systems that never looked right, I gave up for a few years. Thankfully, today we have HDMI with its vastly better performance and standardized resolution, which makes an inexpensive home media center a reality.
My new media center entertainment computer is actually my old Ubuntu Linux desktop, which I recently replaced with something faster. The computer became too slow for work, but its AMD Phenom II X4 965 processor at 3.4GHz and 8GB of RAM are good enough for general browsing and video streaming.
Here are the steps I took to get the best possible performance out of this old system for its new role.
## Hardware
First, I removed unnecessary devices including a card reader, hard drives, DVD drive, and a rear-mounted USB card, and I added a PCI-Express WiFi card. I installed Ubuntu to a single solid-state drive (SSD), which can really improve the performance of any older system.
## BIOS
In the BIOS, I disabled all unused devices, such as floppy and IDE drive controllers. I disabled onboard video because I installed an NVidia GeForce GTX 650 PCI Express graphics card with an HDMI output. I also disabled onboard audio because the NVidia graphics card chipset provides audio.
## Audio
The Nvidia GeForce GTX audio device is listed in the GNOME Control Center's sound settings as a GK107 HDMI Audio Controller, so a single HDMI cable handles both audio and video. There's no need for an audio cable connected to the onboard audio output jack.
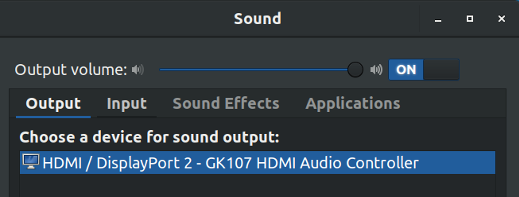
HDMI audio controller shown in GNOME sound settings.
## Keyboard and mouse
I have a wireless keyboard and mouse, both from Logitech. When I installed them, I plugged in both peripherals' USB receivers; they worked, but I often had signal-response problems. Then I discovered one was labeled a Unifying Receiver, which meant it can handle multiple Logitech input devices on its own. Logitech doesn't provide software to configure Unifying Receivers in Linux; fortunately, the open source utility [Solaar](https://pwr.github.io/Solaar/) does. Using a single receiver solved my input performance issues.
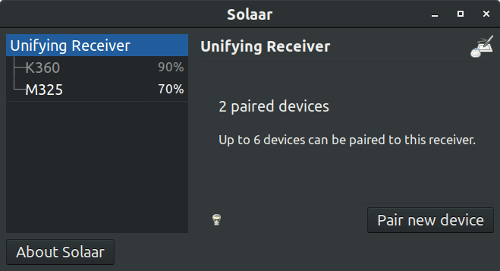
Solaar Unifying Receiver utility interface
## Video
It was initially hard to read fonts on my 47" flat-panel TV, so I enabled "Large Text" under Universal Access. I downloaded some wallpapers matching the TV's 1920x1080 resolution that look fantastic!
## Final touches
I needed to balance the computer's cooling needs with my desire for unimpeded entertainment. Since this is a standard ATX mini-tower computer, I made sure I had just enough fans with carefully configured temperature settings in the BIOS to reduce fan noise. I also placed the computer behind my entertainment console to further block fan noise but positioned so I can reach the power button.
The result is a simple machine that is not overly loud and uses only two cables—AC power and HDMI. It should be able to run any mainstream or specialized media center Linux distribution. I don't expect to do too much high-end gaming because that may require more processing horsepower.
Ubuntu Linux About page.
Testing a YouTube Video on the big screen.
I haven't yet installed a dedicated media center distribution of Linux like [Kodi](https://kodi.tv/). For now, it is running Ubuntu Linux 18.04.1 LTS and is very stable.
This was a fun challenge to make the best of what I already had rather than buying new hardware. This is just one benefit of open source software. Eventually, I will probably replace it with a smaller, quieter system with a media-center case or another small box, but for now, it meets my needs quite well.
## 7 Comments |
10,447 | 2 的威力,Linux 的威力:终端中的 2048 | https://opensource.com/article/18/12/linux-toy-2048 | 2019-01-16T08:53:24 | [
"2048"
] | https://linux.cn/article-10447-1.html |
>
> 正在寻找基于终端的游戏来打发时间么?来看看 2048-cli 吧。
>
>
>

你好,欢迎来到今天的 Linux 命令行玩具日历。每天,我们会为你的终端带来一个不同的玩具:它可能是一个游戏或任何简单的消遣,可以帮助你获得乐趣。
很可能你们中的一些人之前已经看过我们日历中的各种玩具,但我们希望每个人至少见到一件新事物。
今天的玩具是我最喜欢的休闲游戏之一 [2048](https://github.com/gabrielecirulli/2048) (它本身就是另外一个克隆品的克隆)的[命令行版本](https://github.com/tiehuis/2048-cli)。
要进行游戏,你只需将滑块向上、向下、向左、向右移动,组合成对的数字,并增加数值,直到你得到数字为 2048 的块。最吸引人的地方(以及挑战)是你不能只移动一个滑块,而是需要移动屏幕上的每一块。(LCTT 译注:不知道有没有人在我们 Linux 中国的网站上遇到过 [404](https://linux.cn/404) 页面?那就是一个 2048 游戏,经常我错误地打开一个不存在的页面时,本应该去修复这个问题,却不小心沉迷于其中……)
它简单、有趣,很容易在里面沉迷几个小时。这个 2048 的克隆 [2048-cli](https://github.com/tiehuis/2048-cli) 是 Marc Tiehuis 用 C 编写的,并在 MIT 许可下开源。你可以在 [GitHub](https://github.com/tiehuis/2048-cli) 上找到源代码,你也可在这找到适用于你的平台的安装说明。由于它已为 Fedora 打包,因此我来说,安装就像下面那样简单:
```
$ sudo dnf install 2048-cli
```
这是这样,玩得开心!

你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。如果你有特别想了解的可以评论留言,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
查看昨天的玩具,[在 Linux 终端中玩俄罗斯方块](https://opensource.com/article/18/12/linux-toy-tetris),记得明天再来!
---
via: <https://opensource.com/article/18/12/linux-toy-2048>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello and welcome to today's installment of the Linux command-line toys advent calendar. Every day, we look at a different toy for your terminal: it could be a game or any simple diversion that helps you have fun.
Maybe you have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
Today's toy is a [command-line version](https://github.com/tiehuis/2048-cli) of one of my all-time favorite casual games, [2048](https://github.com/gabrielecirulli/2048) (which itself is a clone of another clone).
To play, you just slide blocks up, down, left, and right to combine matching pairs and increment numbers, until you've made a block that is 2048 in size. The catch (and the challenge), is that you can't just move one block; instead, you move every block on the screen.
It's simple, fun, and easy to get lost in it for hours. This 2048 clone, [2048-](https://github.com/tiehuis/2048-cli)[cli](https://github.com/tiehuis/2048-cli), is by Marc Tiehuis and written in C, and made available as open source under an MIT license. You can find the source code [on GitHub](https://github.com/tiehuis/2048-cli), where you can also get installation instructions for your platform. Since it was packaged for Fedora, for me, installing it was as simple as:
`$ sudo dnf install 2048-cli`
That's it, have fun!
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Check out yesterday's toy, [Play Tetris at your Linux terminal](https://opensource.com/article/18/12/linux-toy-tetris), and check back tomorrow for another!
## Comments are closed. |
10,448 | 一位开源项目维护者的 5 个决心 | https://opensource.com/article/18/12/resolutions-open-source-project-maintainers | 2019-01-16T09:39:17 | [
"开源",
"贡献者"
] | https://linux.cn/article-10448-1.html |
>
> 不管怎么说,好的交流是一个活跃的开源社区的必备品。
>
>
>

我通常不会定下大的新年决心。当然,我在自我提升方面没有任何问题,这篇文章我希望锚定的是这个日历中的另外一部分。不过即使是这样,这里也有一些东西要从今年的免费日历上划掉,并将其替换为一些可以激发我的自省的新日历内容。
在 2017 年,我从不在社交媒体上分享我从未阅读过的文章。我一直保持这样的状态,我也认为它让我成为了一个更好的互联网公民。对于 2019 年,我正在考虑让我成为更好的开源软件维护者的决心。
下面是一些我在一些项目中担任维护者或共同维护者时坚持的决心:
### 1、包含行为准则
Jono Bacon 在他的文章“[7 个你可能犯的错误](https://opensource.com/article/17/8/mistakes-open-source-avoid)”中包含了一条“不强制执行行为准则”。当然,要强制执行行为准则,你首先需要有一个行为准则。我打算默认用[贡献者契约](https://www.contributor-covenant.org/),但是你可以使用其他你喜欢的。关于这个许可协议,最好的方法是使用别人已经写好的,而不是你自己写的。但是重要的是,要找到一些能够定义你希望你的社区执行的,无论它们是什么样子。一旦这些被记录下来并强制执行,人们就能自行决定是否成为他们想象中社区的一份子。
### 2、使许可证清晰且明确
你知道什么真的很烦么?不清晰的许可证。这个软件基于 GPL 授权,如果没有进一步提供更多信息的文字,我无法知道更多信息。基于哪个版本的[GPL](https://opensource.org/licenses/gpl-license)?我可以用它吗?对于项目的非代码部分,“根据知识共享许可证(CC)授权”更糟糕。我喜欢[知识共享许可证](https://creativecommons.org/share-your-work/licensing-types-examples/),但它有几个不同的许可证包含着不同的权利和义务。因此,我将非常清楚的说明哪个许可证的变种和版本适用于我的项目。我将会在仓库中包含许可的全文,并在其他文件中包含简明的注释。
与此相关的一类问题是使用 [OSI](https://opensource.org/) 批准的许可证。想出一个新的准确的说明了你想要表达什么的许可证是有可能的,但是如果你需要强制推行它,祝你好运。会坚持使用它么?使用您项目的人会理解么?
### 3、快速分类错误报告和问题
在技术领域, 很少有比开源维护者更贫乏的东西了。即使在小型项目中,也很难找到时间去回答每个问题并修复每个错误。但这并不意味着我不能哪怕回应一下,它没必要是多段的回复。即使只是给 GitHub 问题贴了个标签也表明了我看见它了。也许我马上就会处理它,也许一年后我会处理它。但是让社区看到它很重要,是的,这里还有人管。
### 4、如果没有伴随的文档,请不要推送新特性或错误修复
尽管多年来我的开源贡献都围绕着文档,但我的项目并没有反映出我对它的重视。我能推送的提交不多,并不不需要某种形式的文档。新的特性显然应该在他们被提交时甚至是在之前就编写文档。但即使是错误修复,也应该在发行说明中有一个条目提及。如果没有什么意外,推送提交也是很好的改善文档的机会。
### 5、放弃一个项目时,要说清楚
我很不擅长对事情说“不”,我告诉编辑我会为 [Opensource.com](http://Opensource.com) 写一到两篇文章,而现在我有了将近 60 篇文章。哎呀。但在某些时候,曾经我有兴趣的事情也会不再有兴趣。也许该项目是不必要的,因为它的功能被吸收到更大的项目中;也许只是我厌倦了它。但这对社区是不公平的(并且存在潜在的危险,正如最近的 [event-stream 恶意软件注入](https://arstechnica.com/information-technology/2018/11/hacker-backdoors-widely-used-open-source-software-to-steal-bitcoin/)所示),会让该项目陷入困境。维护者有权随时离开,但他们离开时应该说清楚。
无论你是开源维护者还是贡献者,如果你知道项目维护者应该作出的其他决心,请在评论中分享!
---
via: <https://opensource.com/article/18/12/resolutions-open-source-project-maintainers>
作者:[Ben Cotton](https://opensource.com/users/bcotton) 选题:[lujun9972](https://github.com/lujun9972) 译者:[bestony](https://github.com/bestony) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I'm generally not big on New Year's resolutions. I have no problem with self-improvement, of course, but I tend to anchor around other parts of the calendar. Even so, there's something about taking down this year's free calendar and replacing it with next year's that inspires some introspection.
In 2017, I resolved to not share articles on social media until I'd read them. I've kept to that pretty well, and I'd like to think it has made me a better citizen of the internet. For 2019, I'm thinking about resolutions to make me a better open source software maintainer.
Here are some resolutions I'll try to stick to on the projects where I'm a maintainer or co-maintainer.
## 1. Include a code of conduct
Jono Bacon included "not enforcing the code of conduct" in his article "[7 mistakes you're probably making](https://opensource.com/article/17/8/mistakes-open-source-avoid)." Of course, to *enforce* a code of conduct, you must first *have* a code of conduct. I plan on defaulting to the [Contributor Covenant](https://www.contributor-covenant.org/), but you can use whatever you like. As with licenses, it's probably best to use one that's already written instead of writing your own. But the important thing is to find something that defines how you want your community to behave, whatever that looks like. Once it's written down and enforced, people can decide for themselves if it looks like the kind of community they want to be a part of.
## 2. Make the license clear and specific
You know what really stinks? Unclear licenses. "This software is licensed under the GPL" with no further text doesn't tell me much. Which version of the [GPL](https://opensource.org/licenses/gpl-license)? Do I get to pick? For non-code portions of a project, "licensed under a Creative Commons license" is even worse. I love the [Creative Commons licenses](https://creativecommons.org/share-your-work/licensing-types-examples/), but there are several different licenses with significantly different rights and obligations. So, I will make it very clear which variant and version of a license applies to my projects. I will include the full text of the license in the repo and a concise note in the other files.
Sort of related to this is using an [OSI](https://opensource.org/)-approved license. It's tempting to come up with a new license that says exactly what you want it to say, but good luck if you ever need to enforce it. Will it hold up? Will the people using your project understand it?
## 3. Triage bug reports and questions quickly
Few things in technology scale as poorly as open source maintainers. Even on small projects, it can be hard to find the time to answer every question and fix every bug. But that doesn't mean I can't at least acknowledge the person. It doesn't have to be a multi-paragraph reply. Even just labeling the GitHub issue shows that I saw it. Maybe I'll get to it right away. Maybe I'll get to it a year later. But it's important for the community to see that, yes, there is still someone here.
## 4. Don't push features or bug fixes without accompanying documentation
For as much as my open source contributions over the years have revolved around documentation, my projects don't reflect the importance I put on it. There aren't many commits I can push that don't require some form of documentation. New features should obviously be documented at (or before!) the time they're committed. But even bug fixes should get an entry in the release notes. If nothing else, a push is a good opportunity to also make a commit to improving the docs.
## 5. Make it clear when I'm abandoning a project
I'm really bad at saying "no" to things. I told the editors I'd write one or two articles for [Opensource.com](http://Opensource.com) and here I am almost 60 articles later. Oops. But at some point, the things that once held my interests no longer do. Maybe the project is unnecessary because its functionality got absorbed into a larger project. Maybe I'm just tired of it. But it's unfair to the community (and potentially dangerous, as the recent [event-stream malware injection](https://arstechnica.com/information-technology/2018/11/hacker-backdoors-widely-used-open-source-software-to-steal-bitcoin/) showed) to leave a project in limbo. Maintainers have the right to walk away whenever and for whatever reason, but it should be clear that they have.
Whether you're an open source maintainer or contributor, if you know other resolutions project maintainers should make, please share them in the comments.
## 2 Comments |
10,449 | 使用 Ansible 来管理你的工作站:配置自动化 | https://opensource.com/article/18/3/manage-your-workstation-configuration-ansible-part-2 | 2019-01-16T16:25:20 | [
"Ansible",
"工作站"
] | https://linux.cn/article-10449-1.html |
>
> 学习如何使 Ansible 自动对一系列台式机和笔记本应用配置。
>
>
>

Ansible 是一个令人惊讶的自动化的配置管理工具。其主要应用在服务器和云部署上,但在工作站上的应用(无论是台式机还是笔记本)却鲜少得到关注,这就是本系列所要关注的。
在这个系列的[第一部分](/article-10434-1.html),我向你展示了 `ansible-pull` 命令的基本用法,我们创建了一个安装了少量包的剧本。它本身是没有多大的用处的,但是为后续的自动化做了准备。
在这篇文章中,将会达成闭环,而且在最后部分,我们将会有一个针对工作站自动配置的完整的工作解决方案。现在,我们将要设置 Ansible 的配置,这样未来将要做的改变将会自动的部署应用到我们的工作站上。现阶段,假设你已经完成了[第一部分](/article-10434-1.html)的工作。如果没有的话,当你完成的时候回到本文。你应该已经有一个包含第一篇文章中代码的 GitHub 库。我们将直接在之前创建的部分之上继续。
首先,因为我们要做的不仅仅是安装包文件,所以我们要做一些重新的组织工作。现在,我们已经有一个名为 `local.yml` 并包含以下内容的剧本:
```
- hosts: localhost
become: true
tasks:
- name: Install packages
apt: name={{item}}
with_items:
- htop
- mc
- tmux
```
如果我们仅仅想实现一个任务那么上面的配置就足够了。随着向我们的配置中不断的添加内容,这个文件将会变的相当的庞大和杂乱。最好能够根据不同类型的配置将我们的<ruby> 动作 <rt> play </rt></ruby>分为独立的文件。为了达到这个要求,创建一个名为<ruby> 任务手册 <rt> taskbook </rt></ruby>的东西,它和<ruby> 剧本 <rt> playbook </rt></ruby>很像但内容更加的流线型。让我们在 Git 库中为任务手册创建一个目录。
```
mkdir tasks
```
`local.yml` 剧本中的代码可以很好地过渡为安装包文件的任务手册。让我们把这个文件移动到刚刚创建好的 `task` 目录中,并重新命名。
```
mv local.yml tasks/packages.yml
```
现在,我们编辑 `packages.yml` 文件将它进行大幅的瘦身,事实上,我们可以精简除了独立任务本身之外的所有内容。让我们把 `packages.yml` 编辑成如下的形式:
```
- name: Install packages
apt: name={{item}}
with_items:
- htop
- mc
- tmux
```
正如你所看到的,它使用同样的语法,但我们去掉了对这个任务无用没有必要的所有内容。现在我们有了一个专门安装包文件的任务手册。然而我们仍然需要一个名为 `local.yml` 的文件,因为执行 `ansible-pull` 命令时仍然会去找这个文件。所以我们将在我们库的根目录下(不是在 `task` 目录下)创建一个包含这些内容的全新文件:
```
- hosts: localhost
become: true
pre_tasks:
- name: update repositories
apt: update_cache=yes
changed_when: False
tasks:
- include: tasks/packages.yml
```
这个新的 `local.yml` 扮演的是导入我们的任务手册的索引的角色。我已经在这个文件中添加了一些你在这个系列中还没见到的内容。首先,在这个文件的开头处,我添加了 `pre_tasks`,这个任务的作用是在其他所有任务运行之前先运行某个任务。在这种情况下,我们给 Ansible 的命令是让它去更新我们的发行版的软件库的索引,下面的配置将执行这个任务要求:
```
apt: update_cache=yes
```
通常 `apt` 模块是用来安装包文件的,但我们也能够让它来更新软件库索引。这样做的目的是让我们的每个动作在 Ansible 运行的时候能够以最新的索引工作。这将确保我们在使用一个老旧的索引安装一个包的时候不会出现问题。因为 `apt` 模块仅仅在 Debian、Ubuntu 及它们的衍生发行版下工作。如果你运行的一个不同的发行版,你要使用特定于你的发行版的模块而不是 `apt`。如果你需要使用一个不同的模块请查看 Ansible 的相关文档。
下面这行也需要进一步解释:
```
changed_when: False
```
在某个任务中的这行阻止了 Ansible 去报告动作改变的结果,即使是它本身在系统中导致的一个改变。在这里,我们不会去在意库索引是否包含新的数据;它几乎总是会的,因为库总是在改变的。我们不会去在意 `apt` 库的改变,因为索引的改变是正常的过程。如果我们删除这行,我们将在过程报告的后面看到所有的变动,即使仅仅库的更新而已。最好忽略这类的改变。
接下来是常规任务的阶段,我们将创建好的任务手册导入。我们每次添加另一个任务手册的时候,要添加下面这一行:
```
tasks:
- include: tasks/packages.yml
```
如果你现在运行 `ansible-pull` 命令,它应该基本上像上一篇文章中做的一样。不同的是我们已经改进了我们的组织方式,并且能够更有效的扩展它。为了节省你到上一篇文章中去寻找,`ansible-pull` 命令的语法参考如下:
```
sudo ansible-pull -U https://github.com/<github_user>/ansible.git
```
如果你还记得话,`ansible-pull` 的命令拉取一个 Git 仓库并且应用它所包含的配置。
既然我们的基础已经搭建好,我们现在可以扩展我们的 Ansible 并且添加功能。更特别的是,我们将添加配置来自动化的部署对工作站要做的改变。为了支撑这个要求,首先我们要创建一个特殊的账户来应用我们的 Ansible 配置。这个不是必要的,我们仍然能够在我们自己的用户下运行 Ansible 配置。但是使用一个隔离的用户能够将其隔离到不需要我们参与的在后台运行的一个系统进程中,
我们可以使用常规的方式来创建这个用户,但是既然我们正在使用 Ansible,我们应该尽量避开使用手动的改变。替代的是,我们将会创建一个任务手册来处理用户创建任务。这个任务手册目前将会仅仅创建一个用户,但你可以在这个任务手册中添加额外的动作来创建更多的用户。我将这个用户命名为 `ansible`,你可以按照自己的想法来命名(如果你做了这个改变要确保更新所有出现地方)。让我们来创建一个名为 `user.yml` 的任务手册并且将以下代码写进去:
```
- name: create ansible user
user: name=ansible uid=900
```
下一步,我们需要编辑 `local.yml` 文件,将这个新的任务手册添加进去,像如下这样写:
```
- hosts: localhost
become: true
pre_tasks:
- name: update repositories
apt: update_cache=yes
changed_when: False
tasks:
- include: tasks/users.yml
- include: tasks/packages.yml
```
现在当我们运行 `ansible-pull` 命令的时候,一个名为 `ansible` 的用户将会在系统中被创建。注意我特地通过参数 `uid` 为这个用户声明了用户 ID 为 900。这个不是必须的,但建议直接创建好 UID。因为在 1000 以下的 UID 在登录界面是不会显示的,这样是很棒的,因为我们根本没有需要去使用 `ansibe` 账户来登录我们的桌面。UID 900 是随便定的;它应该是在 1000 以下没有被使用的任何一个数值。你可以使用以下命令在系统中去验证 UID 900 是否已经被使用了:
```
cat /etc/passwd |grep 900
```
不过,你使用这个 UID 应该不会遇到什么问题,因为迄今为止在我使用的任何发行版中我还没遇到过它是被默认使用的。
现在,我们已经拥有了一个名为 `ansible` 的账户,它将会在之后的自动化配置中使用。接下来,我们可以创建实际的定时作业来自动操作。我们应该将其分开放到它自己的文件中,而不是将其放置到我们刚刚创建的 `users.yml` 文件中。在任务目录中创建一个名为 `cron.yml` 的任务手册并且将以下的代码写进去:
```
- name: install cron job (ansible-pull)
cron: user="ansible" name="ansible provision" minute="*/10" job="/usr/bin/ansible-pull -o -U https://github.com/<github_user>/ansible.git > /dev/null"
```
`cron` 模块的语法几乎不需加以说明。通过这个动作,我们创建了一个通过用户 `ansible` 运行的定时作业。这个作业将每隔 10 分钟执行一次,下面是它将要执行的命令:
```
/usr/bin/ansible-pull -o -U https://github.com/<github_user>/ansible.git > /dev/null
```
同样,我们也可以添加想要我们的所有工作站部署的额外的定时作业到这个文件中。我们只需要在新的定时作业中添加额外的动作即可。然而,仅仅是添加一个定时的任务手册是不够的,我们还需要将它添加到 `local.yml` 文件中以便它能够被调用。将下面的一行添加到末尾:
```
- include: tasks/cron.yml
```
现在当 `ansible-pull` 命令执行的时候,它将会以用户 `ansible` 每隔十分钟设置一个新的定时作业。但是,每个十分钟运行一个 Ansible 作业并不是一个好的方式,因为这个将消耗很多的 CPU 资源。每隔十分钟来运行对于 Ansible 来说是毫无意义的,除非我们已经在 Git 仓库中改变一些东西。
然而,我们已经解决了这个问题。注意我在定时作业中的命令 `ansible-pill` 添加的我们之前从未用到过的参数 `-o`。这个参数告诉 Ansible 只有在从上次 `ansible-pull` 被调用以后库有了变化后才会运行。如果库没有任何变化,它将不会做任何事情。通过这个方法,你将不会无端的浪费 CPU 资源。当然在拉取存储库的时候会使用一些 CPU 资源,但不会像再一次应用整个配置的时候使用的那么多。当 `ansible-pull` 执行的时候,它将会遍历剧本和任务手册中的所有任务,但至少它不会毫无目的的运行。
尽管我们已经添加了所有必须的配置要素来自动化 `ansible-pull`,它仍然还不能正常的工作。`ansible-pull` 命令需要 `sudo` 的权限来运行,这将允许它执行系统级的命令。然而我们创建的用户 `ansible` 并没有被设置为以 `sudo` 的权限来执行命令,因此当定时作业触发的时候,执行将会失败。通常我们可以使用命令 `visudo` 来手动的去设置用户 `ansible` 去拥有这个权限。然而我们现在应该以 Ansible 的方式来操作,而且这将会是一个向你展示 `copy` 模块是如何工作的机会。`copy` 模块允许你从库复制一个文件到文件系统的任何位置。在这个案列中,我们将会复制 `sudo` 的一个配置文件到 `/etc/sudoers.d/` 以便用户 `ansible` 能够以管理员的权限执行任务。
打开 `users.yml`,将下面的的动作添加到文件末尾。
```
- name: copy sudoers_ansible
copy: src=files/sudoers_ansible dest=/etc/sudoers.d/ansible owner=root group=root mode=0440
```
正如我们看到的,`copy`模块从我们的仓库中复制一个文件到其他任何位置。在这个过程中,我们正在抓取一个名为 `sudoers_ansible`(我们将在后续创建)的文件并将它复制为 `/etc/sudoers/ansible`,并且拥有者为 `root`。
接下来,我们需要创建我们将要复制的文件。在你的仓库的根目录下,创建一个名为 `files` 的目录:
```
mkdir files
```
然后,在我们刚刚创建的 `files` 目录里,创建名为 `sudoers_ansible` 的文件,包含以下内容:
```
ansible ALL=(ALL) NOPASSWD: ALL
```
就像我们正在这样做的,在 `/etc/sudoer.d` 目录里创建一个文件允许我们为一个特殊的用户配置 `sudo` 权限。现在我们正在通过 `sudo` 允许用户 `ansible` 不需要密码提示就拥有完全控制权限。这将允许 `ansible-pull` 以后台任务的形式运行而不需要手动去运行。
现在,你可以通过再次运行 `ansible-pull` 来拉取最新的变动:
```
sudo ansible-pull -U https://github.com/<github_user>/ansible.git
```
从这里开始,`ansible-pull` 的定时作业将会在后台每隔十分钟运行一次来检查你的仓库是否有变化,如果它发现有变化,将会运行你的剧本并且应用你的任务手册。
所以现在我们有了一个完整的可工作方案。当你第一次设置一台新的笔记本或者台式机的时候,你要去手动的运行 `ansible-pull` 命令,但仅仅是在第一次的时候。从第一次之后,用户 `ansible` 将会在后台接手后续的运行任务。当你想对你的机器做变动的时候,你只需要简单的去拉取你的 Git 仓库来做变动,然后将这些变化回传到库中。接着,当定时作业下次在每台机器上运行的时候,它将会拉取变动的部分并应用它们。你现在只需要做一次变动,你的所有工作站将会跟着一起变动。这方法尽管有一点不同寻常,通常,你会有一个包含你的机器列表和不同机器所属规则的清单文件。然而,`ansible-pull` 的方法,就像在文章中描述的,是管理工作站配置的非常有效的方法。
我已经在我的 [Github 仓库](https://github.com/jlacroix82/ansible_article.git)中更新了这篇文章中的代码,所以你可以随时去浏览来对比检查你的语法。同时我将前一篇文章中的代码移到了它自己的目录中。
在[第三部分](https://opensource.com/article/18/5/manage-your-workstation-ansible-part-3),我们将通过介绍使用 Ansible 来配置 GNOME 桌面设置来结束这个系列。我将会告诉你如何设置你的墙纸和锁屏壁纸、应用一个桌面主题以及更多的东西。
同时,到了布置一些作业的时候了,大多数人都有我们所使用的各种应用的配置文件。可能是 Bash、Vim 或者其他你使用的工具的配置文件。现在你可以尝试通过我们在使用的 Ansible 库来自动复制这些配置到你的机器中。在这篇文章中,我已将向你展示了如何去复制文件,所以去尝试以下看看你是都已经能应用这些知识。
---
via: <https://opensource.com/article/18/3/manage-your-workstation-configuration-ansible-part-2>
作者:[Jay LaCroix](https://opensource.com/users/jlacroix) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FelixYFZ](https://github.com/FelixYFZ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Ansible is an amazing automation and configuration management tool. It is mainly used for servers and cloud deployments, and it gets far less attention for its use in workstations, both desktops and laptops, which is the focus of this series.
In the [first part](https://opensource.com/article/18/3/manage-workstation-ansible) of this series, I showed you basic usage of the `ansible-pull`
command, and we created a playbook that installs a handful of packages. That wasn't extremely useful by itself, but it set the stage for further automation.
In this article, everything comes together full circle, and by the end we will have a fully working solution for automating workstation configuration. This time, we'll set up our Ansible configuration such that future changes we make will automatically be applied to our workstations. At this point, I'm assuming you already worked through part one. If you haven't, feel free to do that now and then return to this article when you're done. You should already have a GitHub repository with the code from the first article inside it. We're going to build directly on what we did before.
First, we need to do some reorganization because we're going to do more than just install packages. At this point, we currently have a playbook named `local.yml`
with the following content:
```
- hosts: localhost
become: true
tasks:
- name: Install packages
apt: name={{item}}
with_items:
- htop
- mc
- tmux
```
That's all well and good if we only want to perform one task. As we add new things to our configuration, this file will become quite large and get very cluttered. It's better to organize our plays into individual files with each responsible for a different type of configuration. To achieve this, create what's called a taskbook, which is very much like a playbook but the contents are more streamlined. Let's create a directory for our taskbooks inside our Git repository:
`mkdir tasks`
The code inside our current `local.yml`
playbook lends itself well to become a taskbook for installing packages. Let's move this file into the `tasks`
directory we just created with a new name:
`mv local.yml tasks/packages.yml`
Now, we can edit our `packages.yml`
taskbook and strip it down quite a bit. In fact, we can strip everything except for the individual task itself. Let's make `packages.yml`
look like this:
```
- name: Install packages
apt: name={{item}}
with_items:
- htop
- mc
- tmux
```
As you can see, it uses the same syntax, but we stripped out everything that isn't necessary to the task it's performing. Now we have a dedicated taskbook for installing packages. However, we still need a file named `local.yml`
, since `ansible-pull`
still expects to find a file with that name. So we'll create a fresh one with this content in the root of our repository (not in the `tasks`
directory):
```
- hosts: localhost
become: true
pre_tasks:
- name: update repositories
apt: update_cache=yes
changed_when: False
tasks:
- include: tasks/packages.yml
```
This new `local.yml`
acts as an index that will import all our taskbooks. I've added a few new things to this file that you haven't seen yet in this series. First, at the beginning of the file, I added `pre_tasks`
, which allows us to have Ansible perform a task before all the other tasks run. In this case, we're telling Ansible to update our distribution's repository index. This line does that for us:
`apt: update_cache=yes`
Normally the `apt`
module allows us to install packages, but we can also tell it to update our repository index. The idea is that we want all our individual plays to work with a fresh index each time Ansible runs. This will help ensure we don't have an issue with a stale index while attempting to install a package. Note that the `apt`
module works only with Debian, Ubuntu, and their derivatives. If you're running a different distribution, you'll want to use a module specific to your distribution rather than `apt`
. See the documentation for Ansible if you need to use a different module.
The following line is also worth further explanation:
`changed_when: False`
This line on an individual task stops Ansible from reporting the results of the play as changed even when it results in a change in the system. In this case, we don't care if the repository index contains new data; it almost always will, since repositories are always changing. We don't care about changes to `apt`
repositories, as index changes are par for the course. If we omit this line, we'll see the summary at the end of the process report that something has changed, even if it was merely about the repository being updated. It's better to ignore these types of changes.
Next is our normal tasks section, and we import the taskbook we created. Each time we add another taskbook, we add another line here:
```
tasks:
- include: tasks/packages.yml
```
If you were to run the `ansible-pull`
command here, it should essentially do the same thing as it did in the last article. The difference is that we have improved our organization and we can more efficiently expand on it. The `ansible-pull`
command syntax, to save you from finding the previous article, is this:
`sudo ansible-pull -U https://github.com/<github_user>/ansible.git`
If you recall, the `ansible-pull`
command pulls down a Git repository and applies the configuration it contains.
Now that our foundation is in place, we can expand upon our Ansible config and add features. Specifically, we'll add configuration to automate the deployment of future changes to our workstations. To support this goal, the first thing we should do is to create a user specifically to apply our Ansible configuration. This isn't required—we can continue to run our Ansible configuration under our own user. But using a separate user segregates this to a system process that will run in the background, without our involvement.
We could create this user with the normal method, but since we're using Ansible, we should shy away from manual changes. Instead, we'll create a taskbook to handle user creation. This taskbook will create just one user for now, but you can always add additional plays to this taskbook to add additional users. I'll call this user `ansible`
, but you can name it something else if you wish (if you do, make sure to update all occurrences). Let's create a taskbook named `users.yml`
and place this code inside of it:
```
- name: create ansible user
user: name=ansible uid=900
```
Next, we need to edit our `local.yml`
file and append this new taskbook to the file, so it will look like this:
```
- hosts: localhost
become: true
pre_tasks:
- name: update repositories
apt: update_cache=yes
changed_when: False
tasks:
- include: tasks/users.yml
- include: tasks/packages.yml
```
Now when we run our `ansible-pull`
command, a user named `ansible`
will be created on the system. Note that I specifically declared `User ID 900`
for this user by using the `UID`
option. This isn't required, but it's recommended. The reason is that UIDs under 1,000 are typically not shown on the login screen, which is great because there's no reason we would need to log into a desktop session as our `ansible`
user. UID 900 is arbitrary; it should be any number under 1,000 that's not already in use. You can find out if UID 900 is in use on your system with the following command:
`cat /etc/passwd |grep 900`
However, you shouldn't run into a problem with this UID because I've never seen it used by default in any distribution I've used so far.
Now, we have an `ansible`
user that will later be used to apply our Ansible configuration automatically. Next, we can create the actual cron job that will be used to automate this. Rather than place this in the `users.yml`
taskbook we just created, we should separate this into its own file. Create a taskbook named `cron.yml`
in the tasks directory and place the following code inside:
```
- name: install cron job (ansible-pull)
cron: user="ansible" name="ansible provision" minute="*/10" job="/usr/bin/ansible-pull -o -U https://github.com/<github_user>/ansible.git > /dev/null"
```
The syntax for the cron module should be fairly self-explanatory. With this play, we're creating a cron job to be run as the `ansible`
user. The job will execute every 10 minutes, and the command it will execute is this:
`/usr/bin/ansible-pull -o -U https://github.com/<github_user>/ansible.git > /dev/null`
Also, we can put additional cron jobs we want all our workstations to have into this one file. We just need to add additional plays to add new cron jobs. However, simply adding a new taskbook for cron isn't enough—we'll also need to add it to our `local.yml`
file so it will be called. Place the following line with the other includes:
`- include: tasks/cron.yml`
Now when `ansible-pull`
is run, it will set up a new cron job that will be run as the `ansible`
user every 10 minutes. But, having an Ansible job running every 10 minutes isn't ideal because it will take considerable CPU power. It really doesn't make sense for Ansible to run every 10 minutes unless we've changed something in the Git repository.
However, we've already solved this problem. Notice the `-o`
option I added to the `ansible-pull`
command in the cron job that we've never used before. This option tells Ansible to run only if the repository has changed since the last time `ansible-pull`
was called. If the repository hasn't changed, it won't do anything. This way, you're not wasting valuable CPU for no reason. Sure, some CPU will be used when it pulls down the repository, but not nearly as much as it would use if it were applying your entire configuration all over again. When `ansible-pull`
does run, it will go through all the tasks in the Playbook and taskbooks, but at least it won't run for no purpose.
Although we've added all the required components to automate `ansible-pull`
, it actually won't work properly yet. The `ansible-pull`
command will run with `sudo`
, which would give it access to perform system-level commands. However, our `ansible`
user is not set up to perform tasks as `sudo`
. Therefore, when the cron job triggers, it will fail. Normally we could just use `visudo`
and manually set the `ansible`
user up to have this access. However, we should do things the Ansible way from now on, and this is a great opportunity to show you how the `copy`
module works. The `copy`
module allows you to copy a file from your Ansible repository to somewhere else in the filesystem. In our case, we'll copy a config file for `sudo`
to `/etc/sudoers.d/`
so that the `ansible`
user can perform administrative tasks.
Open up the `users.yml`
taskbook, and add the following play to the bottom:
```
- name: copy sudoers_ansible
copy: src=files/sudoers_ansible dest=/etc/sudoers.d/ansible owner=root group=root mode=0440
```
The `copy`
module, as we can see, copies a file from our repository to somewhere else. In this case, we're grabbing a file named `sudoers_ansible`
(which we will create shortly) and copying it to `/etc/sudoers.d/ansible`
with `root`
as the owner.
Next, we need to create the file that we'll be copying. In the root of your Ansible repository, create a `files`
directory:
`mkdir files`
Then, in the `files`
directory we just created, create the `sudoers_ansible`
file with the following content:
`ansible ALL=(ALL) NOPASSWD: ALL`
Creating a file in `/etc/sudoers.d`
, like we're doing here, allows us to configure `sudo`
for a specific user. Here we're allowing the `ansible`
user full access to the system via `sudo`
without a password prompt. This will allow `ansible-pull`
to run as a background task without us needing to run it manually.
Now, you can run `ansible-pull`
again to pull down the latest changes:
`sudo ansible-pull -U https://github.com/<github_user>/ansible.git`
From this point forward, the cron job for `ansible-pull`
will run every 10 minutes in the background and check your repository for changes. If it finds changes, it will run your playbook and apply your taskbooks.
So now we have a fully working solution. When you first set up a new laptop or desktop, you'll run the `ansible-pull`
command manually, but only the first time. From that point forward, the `ansible`
user will take care of subsequent runs in the background. When you want to make a change to your workstation machines, you simply pull down your Git repository, make the changes, then push those changes back to the repository. Then, the next time the cron job fires on each machine, it will pull down those changes and apply them. You now only have to make changes once, and all your workstations will follow suit. This method may be a bit unconventional though. Normally, you'd have an `inventory`
file with your machines listed and several roles each machine could be a member of. However, the `ansible-pull`
method, as described in this article, is a very efficient way of managing workstation configuration.
I have updated the code in [my GitLab repository](https://gitlab.com/jsherman82/ansible_article.git) for this article, so feel free to browse the code there and check your syntax against mine. Also, I moved the code from the previous article into its own directory in that repository.
[In part 3](https://opensource.com/article/18/5/manage-your-workstation-ansible-part-3), we'll close out the series by using Ansible to configure GNOME desktop settings. I'll show you how to set your wallpaper and lock screen, apply a desktop theme, and more.
In the meantime, it's time for a little homework assignment. Most of us have configuration files we like to maintain for various applications we use. This could be configuration files for Bash, Vim, or whatever tools you use. I challenge you now to automate copying these configuration files to your machines via the Ansible repository we've been working on. In this article, I've shown you how to copy a file, so take a look at that and see if you can apply that knowledge to your personal files.
## 2 Comments |
10,450 | 在 Linux 中打扮你的冬季 Bash 提示符 | https://opensource.com/article/18/12/linux-toy-bash-prompt | 2019-01-16T18:40:00 | [
"提示符"
] | https://linux.cn/article-10450-1.html |
>
> 你的 Linux 终端可能支持 Unicode,那么为何不利用它在提示符中添加季节性的图标呢?
>
>
>

欢迎再次来到 Linux 命令行玩具日历的另一篇。如果这是你第一次访问该系列,你甚至可能会问自己什么是命令行玩具?我们对此比较随意:它会是终端上有任何有趣的消遣,对于任何节日主题相关的还有额外的加分。
也许你以前见过其中的一些,也许你没有。不管怎样,我们希望你玩得开心。
今天的玩具非常简单:它是你的 Bash 提示符。你的 Bash 提示符?是的!我们还有几个星期的假期可以盯着它看,在北半球冬天还会再多几周,所以为什么不玩玩它。
目前你的 Bash 提示符号可能是一个简单的美元符号( `$`),或者更有可能是一个更长的东西。如果你不确定你的 Bash 提示符是什么,你可以在环境变量 `$PS1` 中找到它。要查看它,请输入:
```
echo $PS1
```
对于我而言,它返回:
```
[\u@\h \W]\$
```
`\u`、`\h` 和 `\W` 分别是用户名、主机名和工作目录的特殊字符。你还可以使用其他一些符号。为了帮助构建你的 Bash 提示符,你可以使用 [EzPrompt](http://ezprompt.net/),这是一个 `PS1` 配置的在线生成器,它包含了许多选项,包括日期和时间、Git 状态等。
你可能还有其他变量来组成 Bash 提示符。对我来说,`$PS2` 包含了我命令提示符的结束括号。有关详细信息,请参阅 [这篇文章](https://access.redhat.com/solutions/505983)。
要更改提示符,只需在终端中设置环境变量,如下所示:
```
$ PS1='\u is cold: '
jehb is cold:
```
要永久设置它,请使用你喜欢的文本编辑器将相同的代码添加到 `/etc/bashrc` 中。
那么这些与冬季化有什么关系呢?好吧,你很有可能有现代一下的机器,你的终端支持 Unicode,所以你不仅限于标准的 ASCII 字符集。你可以使用任何符合 Unicode 规范的 emoji,包括雪花 ❄、雪人 ☃ 或一对滑雪板。你有很多冬季 emoji 可供选择。
* 圣诞树
* 外套
* 鹿手套
* 圣诞夫人
* 圣诞老人
* 围巾
* 滑雪者
* 滑雪板
* 雪花
* 雪人
* 没有雪的雪人
* 包装好的礼物
选择你最喜欢的,享受冬天的欢乐。有趣的事实:现代文件系统也支持文件名中的 Unicode 字符,这意味着技术上你可以将你下个程序命名为 `❄❄❄❄❄.py`。只是说说,不要这么做。
你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。如果你有特别想了解的可以评论留言,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
查看昨天的玩具,[在 Linux 终端玩贪吃蛇](https://opensource.com/article/18/12/linux-toy-snake),记得明天再来!
---
via: <https://opensource.com/article/18/12/linux-toy-bash-prompt>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello once again for another installment of the Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is? Really, we're keeping it pretty open-ended: It's anything that's a fun diversion at the terminal, and we're giving bonus points for anything holiday-themed.
Maybe you've seen some of these before, maybe you haven't. Either way, we hope you have fun.
Today's toy is super-simple: It's your Bash prompt. Your Bash prompt? Yep! We've got a few more weeks of the holiday season left to stare at it, and even more weeks of winter here in the northern hemisphere, so why not have some fun with it.
Your Bash prompt currently might be a simple dollar sign (**$**), or more likely, it's something a little longer. If you're not sure what makes up your Bash prompt right now, you can find it in an environment variable called $PS1. To see it, type:
`echo $PS1`
For me, this returns:
`[\u@\h \W]\$`
The **\u**, **\h**, and **\W** are special characters for username, hostname, and working directory. There are others you can use as well; for help building out your Bash prompt, you can use [EzPrompt](http://ezprompt.net/), an online generator of PS1 configurations that includes lots of options including date and time, Git status, and more.
You may have other variables that make up your Bash prompt set as well; **$PS2** for me contains the closing brace of my command prompt. See [this article](https://access.redhat.com/solutions/505983) for more information.
To change your prompt, simply set the environment variable in your terminal like this:
```
$ PS1='\u is cold: '
jehb is cold:
```
To set it permanently, add the same code to your **/etc/****bashrc**** **using your favorite text editor.
So what does this have to do with winterization? Well, chances are on a modern machine, your terminal support Unicode, so you're not limited to the standard ASCII character set. You can use any emoji that's a part of the Unicode specification, including a snowflake ❄, a snowman ☃, or a pair of skis ?. You've got plenty of wintery options to choose from.
```
? Christmas Tree
? Coat
? Deer
? Gloves
? Mrs. Claus
? Santa Claus
? Scarf
? Skis
? Snowboarder
❄ Snowflake
☃ Snowman
⛄ Snowman Without Snow
? Wrapped Gift
```
Pick your favorite, and enjoy some winter cheer. Fun fact: modern filesystems also support Unicode characters in their filenames, meaning you can technically name your next program **"❄❄❄❄❄.py"**. That said, please don't.
Do you have a favorite command-line toy that you think I ought to include? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Check out yesterday's toy, [Snake your way across your Linux terminal](https://opensource.com/article/18/12/linux-toy-snake), and check back tomorrow for another!
## 3 Comments |
10,452 | Caffeinated 6.828:实验 6:网络驱动程序 | https://pdos.csail.mit.edu/6.828/2018/labs/lab6/ | 2019-01-17T20:44:00 | [
"网卡",
"6.828"
] | https://linux.cn/article-10452-1.html | 
### 简介
这个实验是默认你能够自己完成的最终项目。
现在你已经有了一个文件系统,一个典型的操作系统都应该有一个网络栈。在本实验中,你将继续为一个网卡去写一个驱动程序。这个网卡基于 Intel 82540EM 芯片,也就是众所周知的 E1000 芯片。
#### 预备知识
使用 Git 去提交你的实验 5 的源代码(如果还没有提交的话),获取课程仓库的最新版本,然后创建一个名为 `lab6` 的本地分支,它跟踪我们的远程分支 `origin/lab6`:
```
athena% cd ~/6.828/lab
athena% add git
athena% git commit -am 'my solution to lab5'
nothing to commit (working directory clean)
athena% git pull
Already up-to-date.
athena% git checkout -b lab6 origin/lab6
Branch lab6 set up to track remote branch refs/remotes/origin/lab6.
Switched to a new branch "lab6"
athena% git merge lab5
Merge made by recursive.
fs/fs.c | 42 +++++++++++++++++++
1 files changed, 42 insertions(+), 0 deletions(-)
athena%
```
然后,仅有网卡驱动程序并不能够让你的操作系统接入互联网。在新的实验 6 的代码中,我们为你提供了网络栈和一个网络服务器。与以前的实验一样,使用 git 去拉取这个实验的代码,合并到你自己的代码中,并去浏览新的 `net/` 目录中的内容,以及在 `kern/` 中的新文件。
除了写这个驱动程序以外,你还需要去创建一个访问你的驱动程序的系统调用。你将要去实现那些在网络服务器中缺失的代码,以便于在网络栈和你的驱动程序之间传输包。你还需要通过完成一个 web 服务器来将所有的东西连接到一起。你的新 web 服务器还需要你的文件系统来提供所需要的文件。
大部分的内核设备驱动程序代码都需要你自己去从头开始编写。本实验提供的指导比起前面的实验要少一些:没有框架文件、没有现成的系统调用接口、并且很多设计都由你自己决定。因此,我们建议你在开始任何单独练习之前,阅读全部的编写任务。许多学生都反应这个实验比前面的实验都难,因此请根据你的实际情况计划你的时间。
#### 实验要求
与以前一样,你需要做实验中全部的常规练习和至少一个挑战问题。在实验中写出你的详细答案,并将挑战问题的方案描述写入到 `answers-lab6.txt` 文件中。
### QEMU 的虚拟网络
我们将使用 QEMU 的用户模式网络栈,因为它不需要以管理员权限运行。QEMU 的文档的[这里](http://wiki.qemu.org/download/qemu-doc.html#Using-the-user-mode-network-stack)有更多关于用户网络的内容。我们更新后的 makefile 启用了 QEMU 的用户模式网络栈和虚拟的 E1000 网卡。
缺省情况下,QEMU 提供一个运行在 IP 地址 10.2.2.2 上的虚拟路由器,它给 JOS 分配的 IP 地址是 10.0.2.15。为了简单起见,我们在 `net/ns.h` 中将这些缺省值硬编码到网络服务器上。
虽然 QEMU 的虚拟网络允许 JOS 随意连接互联网,但 JOS 的 10.0.2.15 的地址并不能在 QEMU 中的虚拟网络之外使用(也就是说,QEMU 还得做一个 NAT),因此我们并不能直接连接到 JOS 上运行的服务器,即便是从运行 QEMU 的主机上连接也不行。为解决这个问题,我们配置 QEMU 在主机的某些端口上运行一个服务器,这个服务器简单地连接到 JOS 中的一些端口上,并在你的真实主机和虚拟网络之间传递数据。
你将在端口 7(echo)和端口 80(http)上运行 JOS,为避免在共享的 Athena 机器上发生冲突,makefile 将为这些端口基于你的用户 ID 来生成转发端口。你可以运行 `make which-ports` 去找出是哪个 QEMU 端口转发到你的开发主机上。为方便起见,makefile 也提供 `make nc-7` 和 `make nc-80`,它允许你在终端上直接与运行这些端口的服务器去交互。(这些目标仅能连接到一个运行中的 QEMU 实例上;你必须分别去启动它自己的 QEMU)
#### 包检查
makefile 也可以配置 QEMU 的网络栈去记录所有的入站和出站数据包,并将它保存到你的实验目录中的 `qemu.pcap` 文件中。
使用 `tcpdump` 命令去获取一个捕获的 hex/ASCII 包转储:
```
tcpdump -XXnr qemu.pcap
```
或者,你可以使用 [Wireshark](http://www.wireshark.org/) 以图形化界面去检查 pcap 文件。Wireshark 也知道如何去解码和检查成百上千的网络协议。如果你在 Athena 上,你可以使用 Wireshark 的前辈:ethereal,它运行在加锁的保密互联网协议网络中。
#### 调试 E1000
我们非常幸运能够去使用仿真硬件。由于 E1000 是在软件中运行的,仿真的 E1000 能够给我们提供一个人类可读格式的报告、它的内部状态以及它遇到的任何问题。通常情况下,对祼机上做驱动程序开发的人来说,这是非常难能可贵的。
E1000 能够产生一些调试输出,因此你可以去打开一个专门的日志通道。其中一些对你有用的通道如下:
| 标志 | 含义 |
| --- | --- |
| tx | 包发送日志 |
| txerr | 包发送错误日志 |
| rx | 到 RCTL 的日志通道 |
| rxfilter | 入站包过滤日志 |
| rxerr | 接收错误日志 |
| unknown | 未知寄存器的读写日志 |
| eeprom | 读取 EEPROM 的日志 |
| interrupt | 中断和中断寄存器变更日志 |
例如,你可以使用 `make E1000_DEBUG=tx,txerr` 去打开 “tx” 和 “txerr” 日志功能。
注意:`E1000_DEBUG` 标志仅能在打了 6.828 补丁的 QEMU 版本上工作。
你可以使用软件去仿真硬件,来做进一步的调试工作。如果你使用它时卡壳了,不明白为什么 E1000 没有如你预期那样响应你,你可以查看在 `hw/e1000.c` 中的 QEMU 的 E1000 实现。
### 网络服务器
从头开始写一个网络栈是很困难的。因此我们将使用 lwIP,它是一个开源的、轻量级 TCP/IP 协议套件,它能做包括一个网络栈在内的很多事情。你能在 [这里](http://www.sics.se/%7Eadam/lwip/) 找到很多关于 lwIP 的信息。在这个任务中,对我们而言,lwIP 就是一个实现了一个 BSD 套接字接口和拥有一个包输入端口和包输出端口的黑盒子。
一个网络服务器其实就是一个有以下四个环境的混合体:
* 核心网络服务器环境(包括套接字调用派发器和 lwIP)
* 输入环境
* 输出环境
* 定时器环境
下图展示了各个环境和它们之间的关系。下图展示了包括设备驱动的整个系统,我们将在后面详细讲到它。在本实验中,你将去实现图中绿色高亮的部分。

#### 核心网络服务器环境
核心网络服务器环境由套接字调用派发器和 lwIP 自身组成的。套接字调用派发器就像一个文件服务器一样。用户环境使用 stubs(可以在 `lib/nsipc.c` 中找到它)去发送 IPC 消息到核心网络服务器环境。如果你看了 `lib/nsipc.c`,你就会发现核心网络服务器与我们创建的文件服务器 `i386_init` 的工作方式是一样的,`i386_init` 是使用 NSTYPENS 创建的 NS 环境,因此我们检查 `envs`,去查找这个特殊的环境类型。对于每个用户环境的 IPC,网络服务器中的派发器将调用相应的、由 lwIP 提供的、代表用户的 BSD 套接字接口函数。
普通用户环境不能直接使用 `nsipc_*` 调用。而是通过在 `lib/sockets.c` 中的函数来使用它们,这些函数提供了基于文件描述符的套接字 API。以这种方式,用户环境通过文件描述符来引用套接字,就像它们引用磁盘上的文件一样。一些操作(`connect`、`accept` 等等)是特定于套接字的,但 `read`、`write` 和 `close` 是通过 `lib/fd.c` 中一般的文件描述符设备派发代码的。就像文件服务器对所有的打开的文件维护唯一的内部 ID 一样,lwIP 也为所有的打开的套接字生成唯一的 ID。不论是文件服务器还是网络服务器,我们都使用存储在 `struct Fd` 中的信息去映射每个环境的文件描述符到这些唯一的 ID 空间上。
尽管看起来文件服务器的网络服务器的 IPC 派发器行为是一样的,但它们之间还有很重要的差别。BSD 套接字调用(像 `accept` 和 `recv`)能够无限期阻塞。如果派发器让 lwIP 去执行其中一个调用阻塞,派发器也将被阻塞,并且在整个系统中,同一时间只能有一个未完成的网络调用。由于这种情况是无法接受的,所以网络服务器使用用户级线程以避免阻塞整个服务器环境。对于每个入站 IPC 消息,派发器将创建一个线程,然后在新创建的线程上来处理请求。如果线程被阻塞,那么只有那个线程被置入休眠状态,而其它线程仍然处于运行中。
除了核心网络环境外,还有三个辅助环境。核心网络服务器环境除了接收来自用户应用程序的消息之外,它的派发器也接收来自输入环境和定时器环境的消息。
#### 输出环境
在为用户环境套接字调用提供服务时,lwIP 将为网卡生成用于发送的包。lwIP 将使用 `NSREQ_OUTPUT` 去发送在 IPC 消息页参数中附加了包的 IPC 消息。输出环境负责接收这些消息,并通过你稍后创建的系统调用接口来转发这些包到设备驱动程序上。
#### 输入环境
网卡接收到的包需要传递到 lwIP 中。输入环境将每个由设备驱动程序接收到的包拉进内核空间(使用你将要实现的内核系统调用),并使用 `NSREQ_INPUT` IPC 消息将这些包发送到核心网络服务器环境。
包输入功能是独立于核心网络环境的,因为在 JOS 上同时实现接收 IPC 消息并从设备驱动程序中查询或等待包有点困难。我们在 JOS 中没有实现 `select` 系统调用,这是一个允许环境去监视多个输入源以识别准备处理哪个输入的系统调用。
如果你查看了 `net/input.c` 和 `net/output.c`,你将会看到在它们中都需要去实现那个系统调用。这主要是因为实现它要依赖你的系统调用接口。在你实现了驱动程序和系统调用接口之后,你将要为这两个辅助环境写这个代码。
#### 定时器环境
定时器环境周期性发送 `NSREQ_TIMER` 类型的消息到核心服务器,以提醒它那个定时器已过期。lwIP 使用来自线程的定时器消息来实现各种网络超时。
### Part A:初始化和发送包
你的内核还没有一个时间概念,因此我们需要去添加它。这里有一个由硬件产生的每 10 ms 一次的时钟中断。每收到一个时钟中断,我们将增加一个变量值,以表示时间已过去 10 ms。它在 `kern/time.c` 中已实现,但还没有完全集成到你的内核中。
>
> **练习 1**、为 `kern/trap.c` 中的每个时钟中断增加一个到 `time_tick` 的调用。实现 `sys_time_msec` 并增加到 `kern/syscall.c` 中的 `syscall`,以便于用户空间能够访问时间。
>
>
>
使用 `make INIT_CFLAGS=-DTEST_NO_NS run-testtime` 去测试你的代码。你应该会看到环境计数从 5 开始以 1 秒为间隔减少。`-DTEST_NO_NS` 参数禁止在网络服务器环境上启动,因为在当前它将导致 JOS 崩溃。
#### 网卡
写驱动程序要求你必须深入了解硬件和软件中的接口。本实验将给你提供一个如何使用 E1000 接口的高度概括的文档,但是你在写驱动程序时还需要大量去查询 Intel 的手册。
>
> **练习 2**、为开发 E1000 驱动,去浏览 Intel 的 [软件开发者手册](https://pdos.csail.mit.edu/6.828/2018/readings/hardware/8254x_GBe_SDM.pdf)。这个手册涵盖了几个与以太网控制器紧密相关的东西。QEMU 仿真了 82540EM。
>
>
> 现在,你应该去浏览第 2 章,以对设备获得一个整体概念。写驱动程序时,你需要熟悉第 3 到 14 章,以及 4.1(不包括 4.1 的子节)。你也应该去参考第 13 章。其它章涵盖了 E1000 的组件,你的驱动程序并不与这些组件去交互。现在你不用担心过多细节的东西;只需要了解文档的整体结构,以便于你后面需要时容易查找。
>
>
> 在阅读手册时,记住,E1000 是一个拥有很多高级特性的很复杂的设备,一个能让 E1000 工作的驱动程序仅需要它一小部分的特性和 NIC 提供的接口即可。仔细考虑一下,如何使用最简单的方式去使用网卡的接口。我们强烈推荐你在使用高级特性之前,只去写一个基本的、能够让网卡工作的驱动程序即可。
>
>
>
##### PCI 接口
E1000 是一个 PCI 设备,也就是说它是插到主板的 PCI 总线插槽上的。PCI 总线有地址、数据、和中断线,并且 PCI 总线允许 CPU 与 PCI 设备通讯,以及 PCI 设备去读取和写入内存。一个 PCI 设备在它能够被使用之前,需要先发现它并进行初始化。发现 PCI 设备是 PCI 总线查找已安装设备的过程。初始化是分配 I/O 和内存空间、以及协商设备所使用的 IRQ 线的过程。
我们在 `kern/pci.c` 中已经为你提供了使用 PCI 的代码。PCI 初始化是在引导期间执行的,PCI 代码遍历PCI 总线来查找设备。当它找到一个设备时,它读取它的供应商 ID 和设备 ID,然后使用这两个值作为关键字去搜索 `pci_attach_vendor` 数组。这个数组是由像下面这样的 `struct pci_driver` 条目组成:
```
struct pci_driver {
uint32_t key1, key2;
int (*attachfn) (struct pci_func *pcif);
};
```
如果发现的设备的供应商 ID 和设备 ID 与数组中条目匹配,那么 PCI 代码将调用那个条目的 `attachfn` 去执行设备初始化。(设备也可以按类别识别,那是通过 `kern/pci.c` 中其它的驱动程序表来实现的。)
绑定函数是传递一个 PCI 函数 去初始化。一个 PCI 卡能够发布多个函数,虽然这个 E1000 仅发布了一个。下面是在 JOS 中如何去表示一个 PCI 函数:
```
struct pci_func {
struct pci_bus *bus;
uint32_t dev;
uint32_t func;
uint32_t dev_id;
uint32_t dev_class;
uint32_t reg_base[6];
uint32_t reg_size[6];
uint8_t irq_line;
};
```
上面的结构反映了在 Intel 开发者手册里第 4.1 节的表 4-1 中找到的一些条目。`struct pci_func` 的最后三个条目我们特别感兴趣的,因为它们将记录这个设备协商的内存、I/O、以及中断资源。`reg_base` 和 `reg_size` 数组包含最多六个基址寄存器或 BAR。`reg_base` 为映射到内存中的 I/O 区域(对于 I/O 端口而言是基 I/O 端口)保存了内存的基地址,`reg_size` 包含了以字节表示的大小或来自 `reg_base` 的相关基值的 I/O 端口号,而 `irq_line` 包含了为中断分配给设备的 IRQ 线。在表 4-2 的后半部分给出了 E1000 BAR 的具体涵义。
当设备调用了绑定函数后,设备已经被发现,但没有被启用。这意味着 PCI 代码还没有确定分配给设备的资源,比如地址空间和 IRQ 线,也就是说,`struct pci_func` 结构的最后三个元素还没有被填入。绑定函数将调用 `pci_func_enable`,它将去启用设备、协商这些资源、并在结构 `struct pci_func` 中填入它。
>
> **练习 3**、实现一个绑定函数去初始化 E1000。添加一个条目到 `kern/pci.c` 中的数组 `pci_attach_vendor` 上,如果找到一个匹配的 PCI 设备就去触发你的函数(确保一定要把它放在表末尾的 `{0, 0, 0}` 条目之前)。你在 5.2 节中能找到 QEMU 仿真的 82540EM 的供应商 ID 和设备 ID。在引导期间,当 JOS 扫描 PCI 总线时,你也可以看到列出来的这些信息。
>
>
> 到目前为止,我们通过 `pci_func_enable` 启用了 E1000 设备。通过本实验我们将添加更多的初始化。
>
>
> 我们已经为你提供了 `kern/e1000.c` 和 `kern/e1000.h` 文件,这样你就不会把构建系统搞糊涂了。不过它们现在都是空的;你需要在本练习中去填充它们。你还可能在内核的其它地方包含这个 `e1000.h` 文件。
>
>
> 当你引导你的内核时,你应该会看到它输出的信息显示 E1000 的 PCI 函数已经启用。这时你的代码已经能够通过 `make grade` 的 `pci attach` 测试了。
>
>
>
##### 内存映射的 I/O
软件与 E1000 通过内存映射的 I/O(MMIO)来沟通。你在 JOS 的前面部分可能看到过 MMIO 两次:CGA 控制台和 LAPIC 都是通过写入和读取“内存”来控制和查询设备的。但这些读取和写入不是去往内存芯片的,而是直接到这些设备的。
`pci_func_enable` 为 E1000 协调一个 MMIO 区域,来存储它在 BAR 0 的基址和大小(也就是 `reg_base[0]` 和 `reg_size[0]`),这是一个分配给设备的一段物理内存地址,也就是说你可以通过虚拟地址访问它来做一些事情。由于 MMIO 区域一般分配高位物理地址(一般是 3GB 以上的位置),因此你不能使用 `KADDR` 去访问它们,因为 JOS 被限制为最大使用 256MB。因此,你可以去创建一个新的内存映射。我们将使用 `MMIOBASE`(从实验 4 开始,你的 `mmio_map_region` 区域应该确保不能被 LAPIC 使用的映射所覆盖)以上的部分。由于在 JOS 创建用户环境之前,PCI 设备就已经初始化了,因此你可以在 `kern_pgdir` 处创建映射,并且让它始终可用。
>
> **练习 4**、在你的绑定函数中,通过调用 `mmio_map_region`(它就是你在实验 4 中写的,是为了支持 LAPIC 内存映射)为 E1000 的 BAR 0 创建一个虚拟地址映射。
>
>
> 你将希望在一个变量中记录这个映射的位置,以便于后面访问你映射的寄存器。去看一下 `kern/lapic.c` 中的 `lapic` 变量,它就是一个这样的例子。如果你使用一个指针指向设备寄存器映射,一定要声明它为 `volatile`;否则,编译器将允许缓存它的值,并可以在内存中再次访问它。
>
>
> 为测试你的映射,尝试去输出设备状态寄存器(第 12.4.2 节)。这是一个在寄存器空间中以字节 8 开头的 4 字节寄存器。你应该会得到 `0x80080783`,它表示以 1000 MB/s 的速度启用一个全双工的链路,以及其它信息。
>
>
>
提示:你将需要一些常数,像寄存器位置和掩码位数。如果从开发者手册中复制这些东西很容易出错,并且导致调试过程很痛苦。我们建议你使用 QEMU 的 [e1000\_hw.h](https://pdos.csail.mit.edu/6.828/2018/labs/lab6/e1000_hw.h) 头文件做为基准。我们不建议完全照抄它,因为它定义的值远超过你所需要,并且定义的东西也不见得就是你所需要的,但它仍是一个很好的参考。
##### DMA
你可能会认为是从 E1000 的寄存器中通过写入和读取来传送和接收数据包的,其实这样做会非常慢,并且还要求 E1000 在其中去缓存数据包。相反,E1000 使用直接内存访问(DMA)从内存中直接读取和写入数据包,而且不需要 CPU 参与其中。驱动程序负责为发送和接收队列分配内存、设置 DMA 描述符、以及配置 E1000 使用的队列位置,而在这些设置完成之后的其它工作都是异步方式进行的。发送包的时候,驱动程序复制它到发送队列的下一个 DMA 描述符中,并且通知 E1000 下一个发送包已就绪;当轮到这个包发送时,E1000 将从描述符中复制出数据。同样,当 E1000 接收一个包时,它从接收队列中将它复制到下一个 DMA 描述符中,驱动程序将能在下一次读取到它。
总体来看,接收队列和发送队列非常相似。它们都是由一系列的描述符组成。虽然这些描述符的结构细节有所不同,但每个描述符都包含一些标志和包含了包数据的一个缓存的物理地址(发送到网卡的数据包,或网卡将接收到的数据包写入到由操作系统分配的缓存中)。
队列被实现为一个环形数组,意味着当网卡或驱动到达数组末端时,它将重新回到开始位置。它有一个头指针和尾指针,队列的内容就是这两个指针之间的描述符。硬件就是从头开始移动头指针去消费描述符,在这期间驱动程序不停地添加描述符到尾部,并移动尾指针到最后一个描述符上。发送队列中的描述符表示等待发送的包(因此,在平静状态下,发送队列是空的)。对于接收队列,队列中的描述符是表示网卡能够接收包的空描述符(因此,在平静状态下,接收队列是由所有的可用接收描述符组成的)。正确的更新尾指针寄存器而不让 E1000 产生混乱是很有难度的;要小心!
指向到这些数组及描述符中的包缓存地址的指针都必须是物理地址,因为硬件是直接在物理内存中且不通过 MMU 来执行 DMA 的读写操作的。
#### 发送包
E1000 中的发送和接收功能本质上是独立的,因此我们可以同时进行发送接收。我们首先去攻克简单的数据包发送,因为我们在没有先去发送一个 “I’m here!” 包之前是无法测试接收包功能的。
首先,你需要初始化网卡以准备发送,详细步骤查看 14.5 节(不必着急看子节)。发送初始化的第一步是设置发送队列。队列的详细结构在 3.4 节中,描述符的结构在 3.3.3 节中。我们先不要使用 E1000 的 TCP offload 特性,因此你只需专注于 “传统的发送描述符格式” 即可。你应该现在就去阅读这些章节,并要熟悉这些结构。
##### C 结构
你可以用 C `struct` 很方便地描述 E1000 的结构。正如你在 `struct Trapframe` 中所看到的结构那样,C `struct` 可以让你很方便地在内存中描述准确的数据布局。C 可以在字段中插入数据,但是 E1000 的结构就是这样布局的,这样就不会是个问题。如果你遇到字段对齐问题,进入 GCC 查看它的 “packed” 属性。
查看手册中表 3-8 所给出的一个传统的发送描述符,将它复制到这里作为一个示例:
```
63 48 47 40 39 32 31 24 23 16 15 0
+---------------------------------------------------------------+
| Buffer address |
+---------------|-------|-------|-------|-------|---------------+
| Special | CSS | Status| Cmd | CSO | Length |
+---------------|-------|-------|-------|-------|---------------+
```
从结构右上角第一个字节开始,我们将它转变成一个 C 结构,从上到下,从右到左读取。如果你从右往左看,你将看到所有的字段,都非常适合一个标准大小的类型:
```
struct tx_desc
{
uint64_t addr;
uint16_t length;
uint8_t cso;
uint8_t cmd;
uint8_t status;
uint8_t css;
uint16_t special;
};
```
你的驱动程序将为发送描述符数组去保留内存,并由发送描述符指向到包缓冲区。有几种方式可以做到,从动态分配页到在全局变量中简单地声明它们。无论你如何选择,记住,E1000 是直接访问物理内存的,意味着它能访问的任何缓存区在物理内存中必须是连续的。
处理包缓存也有几种方式。我们推荐从最简单的开始,那就是在驱动程序初始化期间,为每个描述符保留包缓存空间,并简单地将包数据复制进预留的缓冲区中或从其中复制出来。一个以太网包最大的尺寸是 1518 字节,这就限制了这些缓存区的大小。主流的成熟驱动程序都能够动态分配包缓存区(即:当网络使用率很低时,减少内存使用量),或甚至跳过缓存区,直接由用户空间提供(就是“零复制”技术),但我们还是从简单开始为好。
>
> **练习 5**、执行一个 14.5 节中的初始化步骤(它的子节除外)。对于寄存器的初始化过程使用 13 节作为参考,对发送描述符和发送描述符数组参考 3.3.3 节和 3.4 节。
>
>
> 要记住,在发送描述符数组中要求对齐,并且数组长度上有限制。因为 TDLEN 必须是 128 字节对齐的,而每个发送描述符是 16 字节,你的发送描述符数组必须是 8 个发送描述符的倍数。并且不能使用超过 64 个描述符,以及不能在我们的发送环形缓存测试中溢出。
>
>
> 对于 TCTL.COLD,你可以假设为全双工操作。对于 TIPG、IEEE 802.3 标准的 IPG(不要使用 14.5 节中表上的值),参考在 13.4.34 节中表 13-77 中描述的缺省值。
>
>
>
尝试运行 `make E1000_DEBUG=TXERR,TX qemu`。如果你使用的是打了 6.828 补丁的 QEMU,当你设置 TDT(发送描述符尾部)寄存器时你应该会看到一个 “e1000: tx disabled” 的信息,并且不会有更多 “e1000” 信息了。
现在,发送初始化已经完成,你可以写一些代码去发送一个数据包,并且通过一个系统调用使它可以访问用户空间。你可以将要发送的数据包添加到发送队列的尾部,也就是说复制数据包到下一个包缓冲区中,然后更新 TDT 寄存器去通知网卡在发送队列中有另外的数据包。(注意,TDT 是一个进入发送描述符数组的索引,不是一个字节偏移量;关于这一点文档中说明的不是很清楚。)
但是,发送队列只有这么大。如果网卡在发送数据包时卡住或发送队列填满时会发生什么状况?为了检测这种情况,你需要一些来自 E1000 的反馈。不幸的是,你不能只使用 TDH(发送描述符头)寄存器;文档上明确说明,从软件上读取这个寄存器是不可靠的。但是,如果你在发送描述符的命令字段中设置 RS 位,那么,当网卡去发送在那个描述符中的数据包时,网卡将设置描述符中状态字段的 DD 位,如果一个描述符中的 DD 位被设置,你就应该知道那个描述符可以安全地回收,并且可以用它去发送其它数据包。
如果用户调用你的发送系统调用,但是下一个描述符的 DD 位没有设置,表示那个发送队列已满,该怎么办?在这种情况下,你该去决定怎么办了。你可以简单地丢弃数据包。网络协议对这种情况的处理很灵活,但如果你丢弃大量的突发数据包,协议可能不会去重新获得它们。可能需要你替代网络协议告诉用户环境让它重传,就像你在 `sys_ipc_try_send` 中做的那样。在环境上回推产生的数据是有好处的。
>
> **练习 6**、写一个函数去发送一个数据包,它需要检查下一个描述符是否空闲、复制包数据到下一个描述符并更新 TDT。确保你处理的发送队列是满的。
>
>
>
现在,应该去测试你的包发送代码了。通过从内核中直接调用你的发送函数来尝试发送几个包。在测试时,你不需要去创建符合任何特定网络协议的数据包。运行 `make E1000_DEBUG=TXERR,TX qemu` 去测试你的代码。你应该看到类似下面的信息:
```
e1000: index 0: 0x271f00 : 9000002a 0
...
```
在你发送包时,每行都给出了在发送数组中的序号、那个发送的描述符的缓存地址、`cmd/CSO/length` 字段、以及 `special/CSS/status` 字段。如果 QEMU 没有从你的发送描述符中输出你预期的值,检查你的描述符中是否有合适的值和你配置的正确的 TDBAL 和 TDBAH。如果你收到的是 “e1000: TDH wraparound @0, TDT x, TDLEN y” 的信息,意味着 E1000 的发送队列持续不断地运行(如果 QEMU 不去检查它,它将是一个无限循环),这意味着你没有正确地维护 TDT。如果你收到了许多 “e1000: tx disabled” 的信息,那么意味着你没有正确设置发送控制寄存器。
一旦 QEMU 运行,你就可以运行 `tcpdump -XXnr qemu.pcap` 去查看你发送的包数据。如果从 QEMU 中看到预期的 “e1000: index” 信息,但你捕获的包是空的,再次检查你发送的描述符,是否填充了每个必需的字段和位。(E1000 或许已经遍历了你的发送描述符,但它认为不需要去发送)
>
> **练习 7**、添加一个系统调用,让你从用户空间中发送数据包。详细的接口由你来决定。但是不要忘了检查从用户空间传递给内核的所有指针。
>
>
>
#### 发送包:网络服务器
现在,你已经有一个系统调用接口可以发送包到你的设备驱动程序端了。输出辅助环境的目标是在一个循环中做下面的事情:从核心网络服务器中接收 `NSREQ_OUTPUT` IPC 消息,并使用你在上面增加的系统调用去发送伴随这些 IPC 消息的数据包。这个 `NSREQ_OUTPUT` IPC 是通过 `net/lwip/jos/jif/jif.c` 中的 `low_level_output` 函数来发送的。它集成 lwIP 栈到 JOS 的网络系统。每个 IPC 将包含一个页,这个页由一个 `union Nsipc` 和在 `struct jif_pkt pkt` 字段中的一个包组成(查看 `inc/ns.h`)。`struct jif_pkt` 看起来像下面这样:
```
struct jif_pkt {
int jp_len;
char jp_data[0];
};
```
`jp_len` 表示包的长度。在 IPC 页上的所有后续字节都是为了包内容。在结构的结尾处使用一个长度为 0 的数组来表示缓存没有一个预先确定的长度(像 `jp_data` 一样),这是一个常见的 C 技巧(也有人说这是一个令人讨厌的做法)。因为 C 并不做数组边界的检查,只要你确保结构后面有足够的未使用内存即可,你可以把 `jp_data` 作为一个任意大小的数组来使用。
当设备驱动程序的发送队列中没有足够的空间时,一定要注意在设备驱动程序、输出环境和核心网络服务器之间的交互。核心网络服务器使用 IPC 发送包到输出环境。如果输出环境在由于一个发送包的系统调用而挂起,导致驱动程序没有足够的缓存去容纳新数据包,这时核心网络服务器将阻塞以等待输出服务器去接收 IPC 调用。
>
> **练习 8**、实现 `net/output.c`。
>
>
>
你可以使用 `net/testoutput.c` 去测试你的输出代码而无需整个网络服务器参与。尝试运行 `make E1000_DEBUG=TXERR,TX run-net_testoutput`。你将看到如下的输出:
```
Transmitting packet 0
e1000: index 0: 0x271f00 : 9000009 0
Transmitting packet 1
e1000: index 1: 0x2724ee : 9000009 0
...
```
运行 `tcpdump -XXnr qemu.pcap` 将输出:
```
reading from file qemu.pcap, link-type EN10MB (Ethernet)
-5:00:00.600186 [|ether]
0x0000: 5061 636b 6574 2030 30 Packet.00
-5:00:00.610080 [|ether]
0x0000: 5061 636b 6574 2030 31 Packet.01
...
```
使用更多的数据包去测试,可以运行 `make E1000_DEBUG=TXERR,TX NET_CFLAGS=-DTESTOUTPUT_COUNT=100 run-net_testoutput`。如果它导致你的发送队列溢出,再次检查你的 DD 状态位是否正确,以及是否告诉硬件去设置 DD 状态位(使用 RS 命令位)。
你的代码应该会通过 `make grade` 的 `testoutput` 测试。
>
> **问题 1**、你是如何构造你的发送实现的?在实践中,如果发送缓存区满了,你该如何处理?
>
>
>
### Part B:接收包和 web 服务器
#### 接收包
就像你在发送包中做的那样,你将去配置 E1000 去接收数据包,并提供一个接收描述符队列和接收描述符。在 3.2 节中描述了接收包的操作,包括接收队列结构和接收描述符、以及在 14.4 节中描述的详细的初始化过程。
>
> **练习 9**、阅读 3.2 节。你可以忽略关于中断和 offload 校验和方面的内容(如果在后面你想去使用这些特性,可以再返回去阅读),你现在不需要去考虑阈值的细节和网卡内部缓存是如何工作的。
>
>
>
除了接收队列是由一系列的等待入站数据包去填充的空缓存包以外,接收队列的其它部分与发送队列非常相似。所以,当网络空闲时,发送队列是空的(因为所有的包已经被发送出去了),而接收队列是满的(全部都是空缓存包)。
当 E1000 接收一个包时,它首先与网卡的过滤器进行匹配检查(例如,去检查这个包的目标地址是否为这个 E1000 的 MAC 地址),如果这个包不匹配任何过滤器,它将忽略这个包。否则,E1000 尝试从接收队列头部去检索下一个接收描述符。如果头(RDH)追上了尾(RDT),那么说明接收队列已经没有空闲的描述符了,所以网卡将丢弃这个包。如果有空闲的接收描述符,它将复制这个包的数据到描述符指向的缓存中,设置这个描述符的 DD 和 EOP 状态位,并递增 RDH。
如果 E1000 在一个接收描述符中接收到了一个比包缓存还要大的数据包,它将按需从接收队列中检索尽可能多的描述符以保存数据包的全部内容。为表示发生了这种情况,它将在所有的这些描述符上设置 DD 状态位,但仅在这些描述符的最后一个上设置 EOP 状态位。在你的驱动程序上,你可以去处理这种情况,也可以简单地配置网卡拒绝接收这种”长包“(这种包也被称为”巨帧“),你要确保接收缓存有足够的空间尽可能地去存储最大的标准以太网数据包(1518 字节)。
>
> **练习 10**、设置接收队列并按 14.4 节中的流程去配置 E1000。你可以不用支持 ”长包“ 或多播。到目前为止,我们不用去配置网卡使用中断;如果你在后面决定去使用接收中断时可以再去改。另外,配置 E1000 去除以太网的 CRC 校验,因为我们的评级脚本要求必须去掉校验。
>
>
> 默认情况下,网卡将过滤掉所有的数据包。你必须使用网卡的 MAC 地址去配置接收地址寄存器(RAL 和 RAH)以接收发送到这个网卡的数据包。你可以简单地硬编码 QEMU 的默认 MAC 地址 52:54:00:12:34:56(我们已经在 lwIP 中硬编码了这个地址,因此这样做不会有问题)。使用字节顺序时要注意;MAC 地址是从低位字节到高位字节的方式来写的,因此 52:54:00:12 是 MAC 地址的低 32 位,而 34:56 是它的高 16 位。
>
>
> E1000 的接收缓存区大小仅支持几个指定的设置值(在 13.4.22 节中描述的 RCTL.BSIZE 值)。如果你的接收包缓存够大,并且拒绝长包,那你就不用担心跨越多个缓存区的包。另外,要记住的是,和发送一样,接收队列和包缓存必须是连接的物理内存。
>
>
> 你应该使用至少 128 个接收描述符。
>
>
>
现在,你可以做接收功能的基本测试了,甚至都无需写代码去接收包了。运行 `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput`。`testinput` 将发送一个 ARP(地址解析协议)通告包(使用你的包发送的系统调用),而 QEMU 将自动回复它,即便是你的驱动尚不能接收这个回复,你也应该会看到一个 “e1000: unicast match[0]: 52:54:00:12:34:56” 的消息,表示 E1000 接收到一个包,并且匹配了配置的接收过滤器。如果你看到的是一个 “e1000: unicast mismatch: 52:54:00:12:34:56” 消息,表示 E1000 过滤掉了这个包,意味着你的 RAL 和 RAH 的配置不正确。确保你按正确的顺序收到了字节,并不要忘记设置 RAH 中的 “Address Valid” 位。如果你没有收到任何 “e1000” 消息,或许是你没有正确地启用接收功能。
现在,你准备去实现接收数据包。为了接收数据包,你的驱动程序必须持续跟踪希望去保存下一下接收到的包的描述符(提示:按你的设计,这个功能或许已经在 E1000 中的一个寄存器来实现了)。与发送类似,官方文档上表示,RDH 寄存器状态并不能从软件中可靠地读取,因为确定一个包是否被发送到描述符的包缓存中,你需要去读取描述符中的 DD 状态位。如果 DD 位被设置,你就可以从那个描述符的缓存中复制出这个数据包,然后通过更新队列的尾索引 RDT 来告诉网卡那个描述符是空闲的。
如果 DD 位没有被设置,表明没有接收到包。这就与发送队列满的情况一样,这时你可以有几种做法。你可以简单地返回一个 ”重传“ 错误来要求对端重发一次。对于满的发送队列,由于那是个临时状况,这种做法还是很好的,但对于空的接收队列来说就不太合理了,因为接收队列可能会保持好长一段时间的空的状态。第二个方法是挂起调用环境,直到在接收队列中处理了这个包为止。这个策略非常类似于 `sys_ipc_recv`。就像在 IPC 的案例中,因为我们每个 CPU 仅有一个内核栈,一旦我们离开内核,栈上的状态就会被丢弃。我们需要设置一个标志去表示那个环境由于接收队列下溢被挂起并记录系统调用参数。这种方法的缺点是过于复杂:E1000 必须被指示去产生接收中断,并且驱动程序为了恢复被阻塞等待一个包的环境,必须处理这个中断。
>
> **练习 11**、写一个函数从 E1000 中接收一个包,然后通过一个系统调用将它发布到用户空间。确保你将接收队列处理成空的。
>
>
>
.
>
> 小挑战!如果发送队列是满的或接收队列是空的,环境和你的驱动程序可能会花费大量的 CPU 周期是轮询、等待一个描述符。一旦完成发送或接收描述符,E1000 能够产生一个中断,以避免轮询。修改你的驱动程序,处理发送和接收队列是以中断而不是轮询的方式进行。
>
>
> 注意,一旦确定为中断,它将一直处于中断状态,直到你的驱动程序明确处理完中断为止。在你的中断服务程序中,一旦处理完成要确保清除掉中断状态。如果你不那样做,从你的中断服务程序中返回后,CPU 将再次跳转到你的中断服务程序中。除了在 E1000 网卡上清除中断外,也需要使用 `lapic_eoi` 在 LAPIC 上清除中断。
>
>
>
#### 接收包:网络服务器
在网络服务器输入环境中,你需要去使用你的新的接收系统调用以接收数据包,并使用 `NSREQ_INPUT` IPC 消息将它传递到核心网络服务器环境。这些 IPC 输入消息应该会有一个页,这个页上绑定了一个 `union Nsipc`,它的 `struct jif_pkt pkt` 字段中有从网络上接收到的包。
>
> **练习 12**、实现 `net/input.c`。
>
>
>
使用 `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput` 再次运行 `testinput`,你应该会看到:
```
Sending ARP announcement...
Waiting for packets...
e1000: index 0: 0x26dea0 : 900002a 0
e1000: unicast match[0]: 52:54:00:12:34:56
input: 0000 5254 0012 3456 5255 0a00 0202 0806 0001
input: 0010 0800 0604 0002 5255 0a00 0202 0a00 0202
input: 0020 5254 0012 3456 0a00 020f 0000 0000 0000
input: 0030 0000 0000 0000 0000 0000 0000 0000 0000
```
“input:” 打头的行是一个 QEMU 的 ARP 回复的十六进制转储。
你的代码应该会通过 `make grade` 的 `testinput` 测试。注意,在没有发送至少一个包去通知 QEMU 中的 JOS 的 IP 地址上时,是没法去测试包接收的,因此在你的发送代码中的 bug 可能会导致测试失败。
为彻底地测试你的网络代码,我们提供了一个称为 `echosrv` 的守护程序,它在端口 7 上设置运行 `echo` 的服务器,它将回显通过 TCP 连接发送给它的任何内容。使用 `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-echosrv` 在一个终端中启动 `echo` 服务器,然后在另一个终端中通过 `make nc-7` 去连接它。你输入的每一行都被这个服务器回显出来。每次在仿真的 E1000 上接收到一个包,QEMU 将在控制台上输出像下面这样的内容:
```
e1000: unicast match[0]: 52:54:00:12:34:56
e1000: index 2: 0x26ea7c : 9000036 0
e1000: index 3: 0x26f06a : 9000039 0
e1000: unicast match[0]: 52:54:00:12:34:56
```
做到这一点后,你应该也就能通过 `echosrv` 的测试了。
>
> **问题 2**、你如何构造你的接收实现?在实践中,如果接收队列是空的并且一个用户环境要求下一个入站包,你怎么办?
>
>
>
.
>
> 小挑战!在开发者手册中阅读关于 EEPROM 的内容,并写出从 EEPROM 中加载 E1000 的 MAC 地址的代码。目前,QEMU 的默认 MAC 地址是硬编码到你的接收初始化代码和 lwIP 中的。修复你的初始化代码,让它能够从 EEPROM 中读取 MAC 地址,和增加一个系统调用去传递 MAC 地址到 lwIP 中,并修改 lwIP 去从网卡上读取 MAC 地址。通过配置 QEMU 使用一个不同的 MAC 地址去测试你的变更。
>
>
>
.
>
> 小挑战!修改你的 E1000 驱动程序去使用 零复制 技术。目前,数据包是从用户空间缓存中复制到发送包缓存中,和从接收包缓存中复制回到用户空间缓存中。一个使用 ”零复制“ 技术的驱动程序可以通过直接让用户空间和 E1000 共享包缓存内存来实现。还有许多不同的方法去实现 ”零复制“,包括映射内容分配的结构到用户空间或直接传递用户提供的缓存到 E1000。不论你选择哪种方法,都要注意你如何利用缓存的问题,因为你不能在用户空间代码和 E1000 之间产生争用。
>
>
>
.
>
> 小挑战!把 “零复制” 的概念用到 lwIP 中。
>
>
> 一个典型的包是由许多头构成的。用户发送的数据被发送到 lwIP 中的一个缓存中。TCP 层要添加一个 TCP 包头,IP 层要添加一个 IP 包头,而 MAC 层有一个以太网头。甚至还有更多的部分增加到包上,这些部分要正确地连接到一起,以便于设备驱动程序能够发送最终的包。
>
>
> E1000 的发送描述符设计是非常适合收集分散在内存中的包片段的,像在 lwIP 中创建的包的帧。如果你排队多个发送描述符,但仅设置最后一个描述符的 EOP 命令位,那么 E1000 将在内部把这些描述符串成包缓存,并在它们标记完 EOP 后仅发送串起来的缓存。因此,独立的包片段不需要在内存中把它们连接到一起。
>
>
> 修改你的驱动程序,以使它能够发送由多个缓存且无需复制的片段组成的包,并且修改 lwIP 去避免它合并包片段,因为它现在能够正确处理了。
>
>
>
.
>
> 小挑战!增加你的系统调用接口,以便于它能够为多于一个的用户环境提供服务。如果有多个网络栈(和多个网络服务器)并且它们各自都有自己的 IP 地址运行在用户模式中,这将是非常有用的。接收系统调用将决定它需要哪个环境来转发每个入站的包。
>
>
> 注意,当前的接口并不知道两个包之间有何不同,并且如果多个环境去调用包接收的系统调用,各个环境将得到一个入站包的子集,而那个子集可能并不包含调用环境指定的那个包。
>
>
> 在 [这篇](http://pdos.csail.mit.edu/papers/exo:tocs.pdf) 外内核论文的 2.2 节和 3 节中对这个问题做了深度解释,并解释了在内核中(如 JOS)处理它的一个方法。用这个论文中的方法去解决这个问题,你不需要一个像论文中那么复杂的方案。
>
>
>
#### Web 服务器
一个最简单的 web 服务器类型是发送一个文件的内容到请求的客户端。我们在 `user/httpd.c` 中提供了一个非常简单的 web 服务器的框架代码。这个框架内码处理入站连接并解析请求头。
>
> **练习 13**、这个 web 服务器中缺失了发送一个文件的内容到客户端的处理代码。通过实现 `send_file` 和 `send_data` 完成这个 web 服务器。
>
>
>
在你完成了这个 web 服务器后,启动这个 web 服务器(`make run-httpd-nox`),使用你喜欢的浏览器去浏览 `http://host:port/index.html` 地址。其中 host 是运行 QEMU 的计算机的名字(如果你在 athena 上运行 QEMU,使用 `hostname.mit.edu`(其中 hostname 是在 athena 上运行 `hostname` 命令的输出,或者如果你在运行 QEMU 的机器上运行 web 浏览器的话,直接使用 `localhost`),而 port 是 web 服务器运行 `make which-ports` 命令报告的端口号。你应该会看到一个由运行在 JOS 中的 HTTP 服务器提供的一个 web 页面。
到目前为止,你的评级测试得分应该是 105 分(满分为 105)。
>
> 小挑战!在 JOS 中添加一个简单的聊天服务器,多个人可以连接到这个服务器上,并且任何用户输入的内容都被发送到其它用户。为实现它,你需要找到一个一次与多个套接字通讯的方法,并且在同一时间能够在同一个套接字上同时实现发送和接收。有多个方法可以达到这个目的。lwIP 为 `recv`(查看 `net/lwip/api/sockets.c` 中的 `lwip_recvfrom`)提供了一个 MSG\_DONTWAIT 标志,以便于你不断地轮询所有打开的套接字。注意,虽然网络服务器的 IPC 支持 `recv` 标志,但是通过普通的 `read` 函数并不能访问它们,因此你需要一个方法来传递这个标志。一个更高效的方法是为每个连接去启动一个或多个环境,并且使用 IPC 去协调它们。而且碰巧的是,对于一个套接字,在结构 Fd 中找到的 lwIP 套接字 ID 是全局的(不是每个环境私有的),因此,比如一个 `fork` 的子环境继承了它的父环境的套接字。或者,一个环境通过构建一个包含了正确套接字 ID 的 Fd 就能够发送到另一个环境的套接字上。
>
>
> **问题 3**、由 JOS 的 web 服务器提供的 web 页面显示了什么?
>
>
>
.
>
> **问题 4**、你做这个实验大约花了多长的时间?
>
>
>
**本实验到此结束了。**一如既往,不要忘了运行 `make grade` 并去写下你的答案和挑战问题的解决方案的描述。在你动手之前,使用 `git status` 和 `git diff` 去检查你的变更,并不要忘了去 `git add answers-lab6.txt`。当你完成之后,使用 `git commit -am 'my solutions to lab 6’` 去提交你的变更,然后 `make handin` 并关注它的动向。
---
via: <https://pdos.csail.mit.edu/6.828/2018/labs/lab6/>
作者:[csail.mit](https://pdos.csail.mit.edu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **
Due on Thursday, December 6, 2018
**
This lab is the default final project that you can do on your own.
Now that you have a file system, no self respecting OS should go without a network stack. In this the lab you are going to write a driver for a network interface card. The card will be based on the Intel 82540EM chip, also known as the E1000.
Use Git to commit your Lab 5 source (if you haven't already), fetch
the latest version of the course
repository, and then create a local branch called `lab6` based on our
lab6 branch, `origin/lab6`:
athena%cd ~/6.828/labathena%add gitathena%git commit -am 'my solution to lab5'nothing to commit (working directory clean) athena%git pullAlready up-to-date. athena%git checkout -b lab6 origin/lab6Branch lab6 set up to track remote branch refs/remotes/origin/lab6. Switched to a new branch "lab6" athena%git merge lab5Merge made by recursive. fs/fs.c | 42 +++++++++++++++++++ 1 files changed, 42 insertions(+), 0 deletions(-) athena%
The network card driver, however, will not be enough to get your OS hooked up to the
Internet. In the new lab6 code, we have provided you with a network stack
and a network server. As in previous labs, use git to grab the code for
this lab, merge in your own code, and explore the contents of the new
`net/` directory, as well as the new files in `kern/`.
In addition to writing the driver, you will need to create a system call interface to give access to your driver. You will implement missing network server code to transfer packets between the network stack and your driver. You will also tie everything together by finishing a web server. With the new web server you will be able to serve files from your file system.
Much of the kernel device driver code you will have to write yourself from scratch. This lab provides much less guidance than previous labs: there are no skeleton files, no system call interfaces written in stone, and many design decisions are left up to you. For this reason, we recommend that you read the entire assignment write up before starting any individual exercises. Many students find this lab more difficult than previous labs, so please plan your time accordingly.
As before, you will need
to do all of the regular exercises described in the lab and *at
least one* challenge problem. Write up brief answers to the
questions posed in the lab and a description of your challenge
exercise in `answers-lab6.txt`.
We will be using QEMU's user mode network stack since it requires no administrative
privileges to run. QEMU's documentation has more about user-net
[here](http://wiki.qemu.org/download/qemu-doc.html#Using-the-user-mode-network-stack).
We've updated the makefile to enable QEMU's user-mode network stack
and the virtual E1000 network card.
By default, QEMU provides a virtual router running on IP 10.0.2.2 and
will assign JOS the IP address 10.0.2.15. To keep things simple, we
hard-code these defaults into the network server in `net/ns.h`.
While QEMU's virtual network allows JOS to make arbitrary connections
out to the Internet, JOS's 10.0.2.15 address has no meaning outside
the virtual network running inside QEMU (that is, QEMU acts as a NAT),
so we can't connect directly to servers running inside JOS, even from
the host running QEMU. To address this, we configure QEMU to run a
server on some port on the *host* machine that simply connects
through to some port in JOS and shuttles data back and forth between
your real host and the virtual network.
You will run JOS servers on ports 7 (echo) and 80 (http). To avoid
collisions on shared Athena machines, the makefile generates
forwarding ports for these based on your user ID. To find out what
ports QEMU is forwarding to on your development host, run `make
which-ports`. For convenience, the makefile also provides
`make nc-7` and `make nc-80`, which allow you to
interact directly with servers running on these ports in your
terminal. (These targets only connect to a running QEMU instance; you
must start QEMU itself separately.)
The makefile also configures QEMU's network stack to record all
incoming and outgoing packets to `qemu.pcap` in your lab
directory.
To get a hex/ASCII dump of captured packets use `tcpdump` like this:
tcpdump -XXnr qemu.pcap
Alternatively, you can use [Wireshark](http://www.wireshark.org/) to graphically inspect
the pcap file. Wireshark also knows how to decode and inspect
hundreds of network protocols. If you're on Athena, you'll have to
use Wireshark's predecessor, ethereal, which is in the sipbnet locker.
We are very lucky to be using emulated hardware. Since the E1000 is running in software, the emulated E1000 can report to us, in a user readable format, its internal state and any problems it encounters. Normally, such a luxury would not be available to a driver developer writing with bare metal.
The E1000 can produce a lot of debug output, so you have to enable specific logging channels. Some channels you might find useful are:
Flag | Meaning |
---|---|
tx | Log packet transmit operations |
txerr | Log transmit ring errors |
rx | Log changes to RCTL |
rxfilter | Log filtering of incoming packets |
rxerr | Log receive ring errors |
unknown | Log reads and writes of unknown registers |
eeprom | Log reads from the EEPROM |
interrupt | Log interrupts and changes to interrupt registers. |
To enable "tx" and "txerr" logging, for example, use
`make E1000_DEBUG=tx,txerr ...`.
Note:
`E1000_DEBUG` flags only work in the 6.828 version of QEMU.
You can take debugging using software emulated hardware one step
further. If you are ever stuck and do not understand why the E1000 is
not responding the way you would expect, you can look at QEMU's E1000
implementation in `hw/net/e1000.c`.
Writing a network stack from scratch is hard work. Instead, we will be using
lwIP, an open source lightweight TCP/IP protocol suite that among many things
includes a network stack. You can find more information on lwIP
[here](https://savannah.nongnu.org/projects/lwip/). In this assignment, as far
as we are concerned, lwIP is a black box that implements a BSD socket interface
and has a packet input port and packet output port.
The network server is actually a combination of four environments:
The following diagram shows the different environments and their relationships. The diagram shows the entire system including the device driver, which will be covered later. In this lab, you will implement the parts highlighted in green.
The core network server environment is composed of the socket call dispatcher
and lwIP itself. The socket call dispatcher works exactly like the file server.
User environments use stubs (found in `lib/nsipc.c`) to send IPC
messages to the core network environment. If you look at
`lib/nsipc.c` you will see that we find the core network server
the same way we found the file server: `i386_init`
created
the NS environment with NS_TYPE_NS, so we scan `envs`
,
looking for this special environment type.
For each user environment IPC, the dispatcher in the network server
calls the appropriate BSD socket
interface function provided by lwIP on behalf of the user.
Regular user environments do not use the `nsipc_*`
calls
directly. Instead, they use the functions in `lib/sockets.c`,
which provides a file descriptor-based sockets API. Thus, user
environments refer to sockets via file descriptors, just
like how they referred to on-disk files. A number of operations
(`connect`
, `accept`
, etc.) are specific to
sockets, but `read`
, `write`
, and
`close`
go through the normal file descriptor
device-dispatch code in `lib/fd.c`. Much like how the file
server maintained internal unique ID's for all open files, lwIP also
generates unique ID's for all open sockets. In both the file server
and the network server, we
use information stored in `struct Fd`
to map
per-environment file descriptors to these unique ID spaces.
Even though it may seem that the IPC dispatchers of the file server and network
server act the same, there is a key difference. BSD socket calls like
`accept`
and `recv`
can block indefinitely. If the
dispatcher were to let lwIP execute one of these blocking calls, the dispatcher
would also block and there could only be one outstanding network call
at a time for the whole system. Since this is unacceptable, the network
server uses user-level threading to avoid blocking the entire server
environment. For every incoming IPC message, the dispatcher creates a
thread and processes the request in the newly created thread. If the thread
blocks, then only that thread is put to sleep while other threads continue
to run.
In addition to the core network environment there are three helper environments. Besides accepting messages from user applications, the core network environment's dispatcher also accepts messages from the input and timer environments.
When servicing user environment socket calls, lwIP will generate packets for
the network card to transmit. LwIP will send each packet to be transmitted to
the output helper environment using the `NSREQ_OUTPUT`
IPC message
with the packet attached in the page argument of the IPC message. The output
environment is responsible for accepting
these messages and forwarding the packet on to the device driver via the
system call interface that you will soon create.
Packets received by the network card
need to be injected into lwIP. For every packet received by the device driver,
the input environment pulls the packet out of kernel space (using kernel
system calls that you will implement) and sends the packet to the core
server environment using the `NSREQ_INPUT`
IPC message.
The packet input functionality is separated from the core network environment
because JOS makes it hard to simultaneously accept IPC messages and poll or wait
for a packet from the device driver. We do not have a `select`
system call in JOS that would allow environments to monitor multiple input
sources to identify which input is ready to be processed.
If you take a look at `net/input.c` and `net/output.c` you
will see that both need to be implemented. This is mainly because the
implementation depends on your system call interface. You will write the code
for the two helper environments after you implement the driver and system call
interface.
The timer
environment periodically sends messages of type `NSREQ_TIMER`
to the
core network server notifying it that a timer has expired. The timer messages
from this thread are used by lwIP to implement various network timeouts.
Your kernel does not have a notion of time, so we need to add
it. There is
currently a clock interrupt that is generated by the hardware every 10ms. On
every clock interrupt we can increment a variable to indicate that time has
advanced by 10ms. This is implemented in `kern/time.c`, but is not
yet fully integrated into your kernel.
Exercise 1.
Add a call to `time_tick`
for every clock interrupt in
`kern/trap.c`. Implement `sys_time_msec`
and add it
to `syscall`
in `kern/syscall.c` so that user space has
access to the time.
Use `make INIT_CFLAGS=-DTEST_NO_NS run-testtime` to test your time
code. You
should see the environment count down from 5 in 1 second intervals.
The "-DTEST_NO_NS" disables starting the network server environment
because it will panic at this point in the lab.
Writing a driver requires knowing in depth the hardware and the interface presented to the software. The lab text will provide a high-level overview of how to interface with the E1000, but you'll need to make extensive use of Intel's manual while writing your driver.
Exercise 2. Browse Intel's [Software Developer's
Manual](../../readings/hardware/8254x_GBe_SDM.pdf) for the E1000. This manual covers several closely related
Ethernet controllers. QEMU emulates the 82540EM.
You should skim over chapter 2 now to get a feel for the device. To write your driver, you'll need to be familiar with chapters 3 and 14, as well as 4.1 (though not 4.1's subsections). You'll also need to use chapter 13 as reference. The other chapters mostly cover components of the E1000 that your driver won't have to interact with. Don't worry about the details right now; just get a feel for how the document is structured so you can find things later.
While reading the manual, keep in mind that the E1000 is a sophisticated device with many advanced features. A working E1000 driver only needs a fraction of the features and interfaces that the NIC provides. Think carefully about the easiest way to interface with the card. We strongly recommend that you get a basic driver working before taking advantage of the advanced features.
The E1000 is a PCI device, which means it plugs into the PCI bus on the motherboard. The PCI bus has address, data, and interrupt lines, and allows the CPU to communicate with PCI devices and PCI devices to read and write memory. A PCI device needs to be discovered and initialized before it can be used. Discovery is the process of walking the PCI bus looking for attached devices. Initialization is the process of allocating I/O and memory space as well as negotiating the IRQ line for the device to use.
We have provided you with PCI code in `kern/pci.c`.
To perform PCI initialization during boot, the PCI code walks the PCI
bus looking for devices. When it finds
a device, it reads its vendor ID and device ID and uses these two values as a key
to search the `pci_attach_vendor`
array. The array is composed of
`struct pci_driver`
entries like this:
struct pci_driver { uint32_t key1, key2; int (*attachfn) (struct pci_func *pcif); };
If the discovered device's vendor ID and device ID match an entry in
the array, the PCI code calls that entry's `attachfn` to
perform device initialization.
(Devices can also be identified by class, which is
what the other driver table in `kern/pci.c` is for.)
The attach function is passed a *PCI function* to initialize. A
PCI card can expose multiple functions, though the E1000 exposes only
one. Here is how we represent a PCI function in JOS:
struct pci_func { struct pci_bus *bus; uint32_t dev; uint32_t func; uint32_t dev_id; uint32_t dev_class; uint32_t reg_base[6]; uint32_t reg_size[6]; uint8_t irq_line; };
The above structure reflects some of the entries found in Table
4-1 of Section 4.1 of the
developer manual. The last three entries of
`struct pci_func`
are of particular interest to us, as they
record the negotiated memory, I/O, and interrupt resources for the
device.
The `reg_base`
and `reg_size`
arrays contain
information for up to six Base Address Registers or BARs.
`reg_base`
stores the base memory addresses for
memory-mapped I/O regions (or base I/O ports for I/O port resources),
`reg_size`
contains the size in bytes or number of I/O
ports for the corresponding base values from `reg_base`
,
and `irq_line`
contains the IRQ line
assigned to the device for interrupts. The specific meanings of the
E1000 BARs are given in the second half of table 4-2.
When the attach function of a device is called, the
device has been found but not yet *enabled*. This means that the PCI code has
not yet determined the resources allocated to the device, such as address space and
an IRQ line, and, thus, the last three elements of the ```
struct
pci_func
```
structure are not yet filled in. The attach function should call
`pci_func_enable`
, which will enable the device,
negotiate these resources, and fill in the ```
struct
pci_func
```
.
Exercise 3.
Implement an attach function to initialize the E1000. Add an entry to the
`pci_attach_vendor`
array in `kern/pci.c` to trigger
your function if a matching PCI device is found (be sure to put it
before the `{0, 0, 0}`
entry that mark the end of the
table). You can find the
vendor ID and device ID of the 82540EM that QEMU emulates in section
5.2. You
should also see these listed when JOS scans the PCI bus while booting.
For now, just enable the E1000 device via
`pci_func_enable`
. We'll add more initialization
throughout the lab.
We have provided the `kern/e1000.c` and
`kern/e1000.h` files for you so that you do not need to mess with
the build system. They are currently blank; you need to fill them in for
this exercise. You may also need to include the `e1000.h` file in
other places in the kernel.
When you boot your kernel, you should see it print that the PCI
function of the E1000 card was enabled. Your code should now pass the
`pci attach` test of `make grade`.
Software communicates with the E1000 via *memory-mapped I/O*
(MMIO). You've seen this twice before in JOS: both the CGA console
and the LAPIC are devices that you control and query by writing to
and reading from "memory". But these reads and writes don't go to
DRAM; they go directly to these devices.
`pci_func_enable`
negotiates an MMIO region with the
E1000 and stores its base and size in BAR 0 (that is,
`reg_base[0]`
and `reg_size[0]`
). This is a
range of *physical memory addresses* assigned to the device,
which means you'll have to do something to access it via virtual
addresses. Since MMIO regions are assigned very high physical
addresses (typically above 3GB), you can't use `KADDR`
to
access it because of JOS's 256MB limit. Thus, you'll have to create
a new memory mapping. We'll use the area above MMIOBASE (your ```
mmio_map_region
```
from lab 4 will make sure we don't overwrite
the mapping used by the LAPIC). Since PCI device initialization
happens before JOS creates user environments, you can create the
mapping in `kern_pgdir`
and it will always be available.
Exercise 4. In your attach function,
create a virtual memory mapping for the E1000's BAR 0 by calling
`mmio_map_region`
(which you wrote in lab 4 to support
memory-mapping the LAPIC).
You'll want to record the location of this mapping in a variable
so you can later access the registers you just mapped. Take a look
at the `lapic`
variable in `kern/lapic.c` for an
example of one way to do this. If you do use a pointer to the
device register mapping, be sure to declare it
`volatile`
; otherwise, the compiler is allowed to cache
values and reorder accesses to this memory.
To test your mapping, try printing out the device status register
(section 13.4.2). This is a 4 byte register that starts at byte 8
of the register space. You should get `0x80080783`, which
indicates a full duplex link is up at 1000 MB/s, among other
things.
Hint: You'll need a lot of constants, like the locations of
registers and values of bit masks. Trying to copy these out of the
developer's manual is error-prone and mistakes can lead to painful
debugging sessions. We recommend instead using QEMU's [ e1000_hw.h](e1000_hw.h) header as a guideline. We
don't recommend copying it in verbatim, because it defines far more
than you actually need and may not define things in the way you
need, but it's a good starting point.
You could imagine transmitting and receiving packets by writing and
reading from the E1000's registers, but this would be slow and would
require the E1000 to buffer packet data internally. Instead, the
E1000 uses *Direct Memory Access* or DMA to read and write
packet data directly from memory without involving the CPU. The
driver is responsible for allocating memory for the transmit and
receive queues, setting up DMA descriptors, and configuring the
E1000 with the location of these queues, but everything after that
is asynchronous. To transmit a packet, the driver copies it into
the next DMA descriptor in the transmit queue and informs the E1000
that another packet is available; the E1000 will copy the data out
of the descriptor when there is time to send the packet. Likewise,
when the E1000 receives a packet, it copies it into the next DMA
descriptor in the receive queue, which the driver can read from at
its next opportunity.
The receive and transmit queues are very similar at a high level.
Both consist of a sequence of *descriptors*. While the exact
structure of these descriptors varies, each descriptor contains some
flags and the physical address of a buffer containing packet data
(either packet data for the card to send, or a buffer allocated by
the OS for the card to write a received packet to).
The queues are implemented as circular arrays, meaning that when the
card or the driver reach the end of the array, it wraps back around
to the beginning. Both have a *head pointer* and a *tail
pointer* and the contents of the queue are the descriptors
between these two pointers. The hardware always consumes
descriptors from the head and moves the head pointer, while the
driver always add descriptors to the tail and moves the tail
pointer. The descriptors in the transmit queue represent packets
waiting to be sent (hence, in the steady state, the transmit queue
is empty). For the receive queue, the descriptors in the queue are
free descriptors that the card can receive packets into (hence, in
the steady state, the receive queue consists of all available
receive descriptors). Correctly updating the tail register without confusing
the E1000 is tricky; be careful!
The pointers to these arrays as well as the addresses of the packet
buffers in the descriptors must all be *physical addresses*
because hardware performs DMA directly to and from physical RAM
without going through the MMU.
The transmit and receive functions of the E1000 are basically independent of each other, so we can work on one at a time. We'll attack transmitting packets first simply because we can't test receive without transmitting an "I'm here!" packet first.
First, you'll have to initialize the card to transmit, following the steps described in section 14.5 (you don't have to worry about the subsections). The first step of transmit initialization is setting up the transmit queue. The precise structure of the queue is described in section 3.4 and the structure of the descriptors is described in section 3.3.3. We won't be using the TCP offload features of the E1000, so you can focus on the "legacy transmit descriptor format." You should read those sections now and familiarize yourself with these structures.
You'll find it convenient to use C `struct`
s to describe
the E1000's structures. As you've seen with structures like the
`struct Trapframe`
, C `struct`
s let you
precisely layout data in memory. C can insert padding between
fields, but the E1000's structures are laid out such that this
shouldn't be a problem. If you do encounter field alignment
problems, look into GCC's "packed" attribute.
As an example, consider the legacy transmit descriptor given in table 3-8 of the manual and reproduced here:
63 48 47 40 39 32 31 24 23 16 15 0 +---------------------------------------------------------------+ | Buffer address | +---------------+-------+-------+-------+-------+---------------+ | Special | CSS | Status| Cmd | CSO | Length | +---------------+-------+-------+-------+-------+---------------+
The first byte of the structure starts at the top right, so to convert this into a C struct, read from right to left, top to bottom. If you squint at it right, you'll see that all of the fields even fit nicely into a standard-size types:
struct tx_desc { uint64_t addr; uint16_t length; uint8_t cso; uint8_t cmd; uint8_t status; uint8_t css; uint16_t special; };
Your driver will have to reserve memory for the transmit descriptor array and the packet buffers pointed to by the transmit descriptors. There are several ways to do this, ranging from dynamically allocating pages to simply declaring them in global variables. Whatever you choose, keep in mind that the E1000 accesses physical memory directly, which means any buffer it accesses must be contiguous in physical memory.
There are also multiple ways to handle the packet buffers. The simplest, which we recommend starting with, is to reserve space for a packet buffer for each descriptor during driver initialization and simply copy packet data into and out of these pre-allocated buffers. The maximum size of an Ethernet packet is 1518 bytes, which bounds how big these buffers need to be. More sophisticated drivers could dynamically allocate packet buffers (e.g., to reduce memory overhead when network usage is low) or even pass buffers directly provided by user space (a technique known as "zero copy"), but it's good to start simple.
Exercise 5. Perform the initialization steps described in section 14.5 (but not its subsections). Use section 13 as a reference for the registers the initialization process refers to and sections 3.3.3 and 3.4 for reference to the transmit descriptors and transmit descriptor array.
Be mindful of the alignment requirements on the transmit descriptor array and the restrictions on length of this array. Since TDLEN must be 128-byte aligned and each transmit descriptor is 16 bytes, your transmit descriptor array will need some multiple of 8 transmit descriptors. However, don't use more than 64 descriptors or our tests won't be able to test transmit ring overflow.
For the TCTL.COLD, you can assume full-duplex operation. For TIPG, refer to the default values described in table 13-77 of section 13.4.34 for the IEEE 802.3 standard IPG (don't use the values in the table in section 14.5).
Try running `make E1000_DEBUG=TXERR,TX qemu`. If you are using the
course qemu, you should
see an "e1000: tx disabled" message when you set the TDT register
(since this happens before you set TCTL.EN) and no further "e1000"
messages.
Now that transmit is initialized, you'll have to write the code to
transmit a packet and make it accessible to user space via a system
call. To transmit a packet, you have to add it to the tail of the
transmit queue, which means copying the packet data into the next
packet buffer and then updating the TDT (transmit descriptor tail)
register to inform the card that there's another packet in the
transmit queue. (Note that TDT is an *index* into the transmit
descriptor array, not a byte offset; the documentation isn't very
clear about this.)
However, the transmit queue is only so big. What happens if the card has fallen behind transmitting packets and the transmit queue is full? In order to detect this condition, you'll need some feedback from the E1000. Unfortunately, you can't just use the TDH (transmit descriptor head) register; the documentation explicitly states that reading this register from software is unreliable. However, if you set the RS bit in the command field of a transmit descriptor, then, when the card has transmitted the packet in that descriptor, the card will set the DD bit in the status field of the descriptor. If a descriptor's DD bit is set, you know it's safe to recycle that descriptor and use it to transmit another packet.
What if the user calls your transmit system call, but the DD bit of
the next descriptor isn't set, indicating that the transmit queue is
full? You'll have to decide what to do in this situation. You
could simply drop the packet. Network protocols are resilient to
this, but if you drop a large burst of packets, the protocol may not
recover. You could instead tell the user environment that it has to retry,
much like you did for `sys_ipc_try_send`
. This has the
advantage of pushing back on the environment generating the data.
Exercise 6. Write a function to transmit a packet by checking that the next descriptor is free, copying the packet data into the next descriptor, and updating TDT. Make sure you handle the transmit queue being full.
Now would be a good time to test your packet transmit code. Try
transmitting just a few packets by directly calling your transmit
function from the kernel. You don't have to create packets that
conform to any particular network protocol in order to test this.
Run `make E1000_DEBUG=TXERR,TX qemu` to run your test. You
should see something like
e1000: index 0: 0x271f00 : 9000002a 0 ...
as you transmit packets. Each line gives the index in the transmit array, the buffer address of that transmit descriptor, the cmd/CSO/length fields, and the special/CSS/status fields. If QEMU doesn't print the values you expected from your transmit descriptor, check that you're filling in the right descriptor and that you configured TDBAL and TDBAH correctly. If you get "e1000: TDH wraparound @0, TDT x, TDLEN y" messages, that means the E1000 ran all the way through the transmit queue without stopping (if QEMU didn't check this, it would enter an infinite loop), which probably means you aren't manipulating TDT correctly. If you get lots of "e1000: tx disabled" messages, then you didn't set the transmit control register right.
Once QEMU runs, you can then run `tcpdump -XXnr qemu.pcap`
to see the packet data that you transmitted. If you saw the
expected "e1000: index" messages from QEMU, but your packet capture
is empty, double check that you filled in every necessary field and
bit in your transmit descriptors (the E1000 probably went through
your transmit descriptors, but didn't think it had to send
anything).
Exercise 7. Add a system call that lets you transmit packets from user space. The exact interface is up to you. Don't forget to check any pointers passed to the kernel from user space.
Now that you have a system call interface to the transmit side of your device
driver, it's time to send packets. The output helper environment's goal is to
do the following in a loop:
accept `NSREQ_OUTPUT`
IPC messages from the core network server and
send the packets accompanying these IPC message to the network device driver
using the system call you added above. The `NSREQ_OUTPUT`
IPC's are sent by the `low_level_output`
function in
`net/lwip/jos/jif/jif.c`, which glues the lwIP stack to JOS's
network system. Each IPC will include a page consisting of a
`union Nsipc`
with the packet in its
`struct jif_pkt pkt`
field (see `inc/ns.h`).
`struct jif_pkt`
looks like
struct jif_pkt { int jp_len; char jp_data[0]; };
`jp_len`
represents the length of the packet. All
subsequent bytes on the IPC page are dedicated to the packet contents.
Using a zero-length array like `jp_data`
at the end of a
struct is a common C trick (some would say abomination) for
representing buffers without pre-determined lengths. Since C doesn't
do array bounds checking, as long as you ensure there's enough unused
memory following the struct, you can use `jp_data`
as if it
were an array of any size.
Be aware of the interaction between the device driver, the output environment and the core network server when there is no more space in the device driver's transmit queue. The core network server sends packets to the output environment using IPC. If the output environment is suspended due to a send packet system call because the driver has no more buffer space for new packets, the core network server will block waiting for the output server to accept the IPC call.
Exercise 8.
Implement `net/output.c`.
You can use `net/testoutput.c` to test your output code
without involving the whole network server. Try running
`make E1000_DEBUG=TXERR,TX run-net_testoutput`. You should
see something like
Transmitting packet 0 e1000: index 0: 0x271f00 : 9000009 0 Transmitting packet 1 e1000: index 1: 0x2724ee : 9000009 0 ...
and `tcpdump -XXnr qemu.pcap` should output
reading from file qemu.pcap, link-type EN10MB (Ethernet) -5:00:00.600186 [|ether] 0x0000: 5061 636b 6574 2030 30 Packet.00 -5:00:00.610080 [|ether] 0x0000: 5061 636b 6574 2030 31 Packet.01 ...
To test with a larger packet count, try
`make E1000_DEBUG=TXERR,TX
NET_CFLAGS=-DTESTOUTPUT_COUNT=100 run-net_testoutput`. If this
overflows your transmit ring, double check that you're handling the
DD status bit correctly and that you've told the hardware to set the
DD status bit (using the RS command bit).
Your code should pass the `testoutput` tests of `make
grade`.
Question
Just like you did for transmitting packets, you'll have to configure the E1000 to receive packets and provide a receive descriptor queue and receive descriptors. Section 3.2 describes how packet reception works, including the receive queue structure and receive descriptors, and the initialization process is detailed in section 14.4.
Exercise 9. Read section 3.2. You can ignore anything about interrupts and checksum offloading (you can return to these sections if you decide to use these features later), and you don't have to be concerned with the details of thresholds and how the card's internal caches work.
The receive queue is very similar to the transmit queue, except that it consists of empty packet buffers waiting to be filled with incoming packets. Hence, when the network is idle, the transmit queue is empty (because all packets have been sent), but the receive queue is full (of empty packet buffers).
When the E1000 receives a packet, it first checks if it matches the card's configured filters (for example, to see if the packet is addressed to this E1000's MAC address) and ignores the packet if it doesn't match any filters. Otherwise, the E1000 tries to retrieve the next receive descriptor from the head of the receive queue. If the head (RDH) has caught up with the tail (RDT), then the receive queue is out of free descriptors, so the card drops the packet. If there is a free receive descriptor, it copies the packet data into the buffer pointed to by the descriptor, sets the descriptor's DD (Descriptor Done) and EOP (End of Packet) status bits, and increments the RDH.
If the E1000 receives a packet that is larger than the packet buffer
in one receive descriptor, it will retrieve as many descriptors as
necessary from the receive queue to store the entire contents of the
packet. To indicate that this has happened, it will set the DD
status bit on all of these descriptors, but only set the EOP status
bit on the last of these descriptors. You can either deal with this
possibility in your driver, or simply configure the card to not
accept "long packets" (also known as *jumbo frames*) and make
sure your receive buffers are large enough to store the largest
possible standard Ethernet packet (1518 bytes).
Exercise 10. Set up the receive queue and configure the E1000 by following the process in section 14.4. You don't have to support "long packets" or multicast. For now, don't configure the card to use interrupts; you can change that later if you decide to use receive interrupts. Also, configure the E1000 to strip the Ethernet CRC, since the grade script expects it to be stripped.
By default, the card will filter out *all* packets. You
have to configure the Receive Address Registers (RAL and RAH) with
the card's own MAC address in order to accept packets addressed to
that card. You can simply hard-code QEMU's default MAC address of
52:54:00:12:34:56 (we already hard-code this in lwIP, so doing it
here too doesn't make things any worse). Be very careful with the
byte order; MAC addresses are written from lowest-order byte to
highest-order byte, so 52:54:00:12 are the low-order 32 bits of the
MAC address and 34:56 are the high-order 16 bits.
The E1000 only supports a specific set of receive buffer sizes (given in the description of RCTL.BSIZE in 13.4.22). If you make your receive packet buffers large enough and disable long packets, you won't have to worry about packets spanning multiple receive buffers. Also, remember that, just like for transmit, the receive queue and the packet buffers must be contiguous in physical memory.
You should use at least 128 receive descriptors
You can do a basic test of receive functionality now, even without
writing the code to receive packets. Run
`make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput`.
`testinput` will transmit an ARP (Address Resolution
Protocol) announcement packet (using your packet transmitting system call),
which QEMU will automatically reply
to. Even though your driver can't receive this reply yet, you
should see a "e1000: unicast match[0]: 52:54:00:12:34:56" message,
indicating that a packet was received by the E1000 and matched the
configured receive filter. If you see a "e1000: unicast mismatch:
52:54:00:12:34:56" message instead, the E1000 filtered out the
packet, which means you probably didn't configure RAL and RAH
correctly. Make sure you got the byte ordering right and didn't
forget to set the "Address Valid" bit in RAH. If you don't get any
"e1000" messages, you probably didn't enable receive correctly.
Now you're ready to implement receiving packets. To receive a packet, your driver will have to keep track of which descriptor it expects to hold the next received packet (hint: depending on your design, there's probably already a register in the E1000 keeping track of this). Similar to transmit, the documentation states that the RDH register cannot be reliably read from software, so in order to determine if a packet has been delivered to this descriptor's packet buffer, you'll have to read the DD status bit in the descriptor. If the DD bit is set, you can copy the packet data out of that descriptor's packet buffer and then tell the card that the descriptor is free by updating the queue's tail index, RDT.
If the DD bit isn't set, then no packet has been received. This is
the receive-side equivalent of when the transmit queue was full, and
there are several things you can do in this situation. You can
simply return a "try again" error and require the caller to retry.
While this approach works well for full transmit queues because
that's a transient condition, it is less justifiable for empty
receive queues because the receive queue may remain empty for long
stretches of time. A second approach is to suspend the calling
environment until there are packets in the receive queue to process.
This tactic is very similar to `sys_ipc_recv`
. Just like
in the IPC case, since we have only one kernel stack per CPU, as
soon as we leave the kernel the state on the stack will be lost. We
need to set a flag indicating that an environment has been suspended
by receive queue underflow and record the system call arguments.
The drawback of this approach is complexity: the E1000 must be
instructed to generate receive interrupts and the driver must handle
them in order to resume the environment blocked waiting for a
packet.
Exercise 11. Write a function to receive a packet from the E1000 and expose it to user space by adding a system call. Make sure you handle the receive queue being empty.
Challenge! If the transmit queue is full or the receive queue is empty, the environment and your driver may spend a significant amount of CPU cycles polling, waiting for a descriptor. The E1000 can generate an interrupt once it is finished with a transmit or receive descriptor, avoiding the need for polling. Modify your driver so that processing the both the transmit and receive queues is interrupt driven instead of polling.
Note that, once an interrupt is asserted, it will remain asserted until
the driver clears the interrupt. In your interrupt handler make sure to clear
the interrupt as soon as you handle it. If you don't, after returning from
your interrupt handler, the CPU will jump back into it again. In addition to
clearing the interrupts on the E1000 card, interrupts also need to be cleared
on the LAPIC. Use `lapic_eoi`
to do so.
In the network server input environment, you will need to use your new
receive system call to receive packets and pass them to the core
network server environment using the `NSREQ_INPUT`
IPC
message. These IPC input message should have a page
attached with a `union Nsipc`
with its ```
struct jif_pkt
pkt
```
field filled in with the packet received from the network.
Exercise 12.
Implement `net/input.c`.
Run `testinput` again with `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER
run-net_testinput`. You should see
Sending ARP announcement... Waiting for packets... e1000: index 0: 0x26dea0 : 900002a 0 e1000: unicast match[0]: 52:54:00:12:34:56 input: 0000 5254 0012 3456 5255 0a00 0202 0806 0001 input: 0010 0800 0604 0002 5255 0a00 0202 0a00 0202 input: 0020 5254 0012 3456 0a00 020f 0000 0000 0000 input: 0030 0000 0000 0000 0000 0000 0000 0000 0000
The lines beginning with "input:" are a hexdump of QEMU's ARP reply.
Your code should pass the `testinput` tests of `make
grade`. Note that there's no way to test packet receiving
without sending at least one ARP packet to inform QEMU of JOS' IP
address, so bugs in your transmitting code can cause this test to
fail.
To more thoroughly test your networking code, we have provided a daemon called
`echosrv` that sets up an echo server running on port 7
that will echo back anything sent over a TCP connection. Use
`make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-echosrv` to
start the echo server in one terminal and `make nc-7` in
another to connect to it. Every line you type should be echoed back
by the server.
Every time the emulated E1000 receives a packet, QEMU should print
something like the following to the console:
e1000: unicast match[0]: 52:54:00:12:34:56 e1000: index 2: 0x26ea7c : 9000036 0 e1000: index 3: 0x26f06a : 9000039 0 e1000: unicast match[0]: 52:54:00:12:34:56
At this point, you should also be able to pass the `echosrv`
test.
Question
Challenge! Read about the EEPROM in the developer's manual and write the code to load the E1000's MAC address out of the EEPROM. Currently, QEMU's default MAC address is hard-coded into both your receive initialization and lwIP. Fix your initialization to use the MAC address you read from the EEPROM, add a system call to pass the MAC address to lwIP, and modify lwIP to the MAC address read from the card. Test your change by configuring QEMU to use a different MAC address.
Challenge! Modify your E1000 driver to be "zero copy." Currently, packet data has to be copied from user-space buffers to transmit packet buffers and from receive packet buffers back to user-space buffers. A zero copy driver avoids this by having user space and the E1000 share packet buffer memory directly. There are many different approaches to this, including mapping the kernel-allocated structures into user space or passing user-provided buffers directly to the E1000. Regardless of your approach, be careful how you reuse buffers so that you don't introduce races between user-space code and the E1000.
Challenge! Take the zero copy concept all the way into lwIP.
A typical packet is composed of many headers. The user sends data to be transmitted to lwIP in one buffer. The TCP layer wants to add a TCP header, the IP layer an IP header and the MAC layer an Ethernet header. Even though there are many parts to a packet, right now the parts need to be joined together so that the device driver can send the final packet.
The E1000's transmit descriptor design is well-suited to collecting pieces of a packet scattered throughout memory, like the packet fragments created inside lwIP. If you enqueue multiple transmit descriptors, but only set the EOP command bit on the last one, then the E1000 will internally concatenate the packet buffers from these descriptors and only transmit the concatenated buffer when it reaches the EOP-marked descriptor. As a result, the individual packet pieces never need to be joined together in memory.
Change your driver to be able to send packets composed of many buffers without copying and modify lwIP to avoid merging the packet pieces as it does right now.
Challenge! Augment your system call interface to service more than one user environment. This will prove useful if there are multiple network stacks (and multiple network servers) each with their own IP address running in user mode. The receive system call will need to decide to which environment it needs to forward each incoming packet.
Note that the current interface cannot tell the difference between two packets and if multiple environments call the packet receive system call, each respective environment will get a subset of the incoming packets and that subset may include packets that are not destined to the calling environment.
Sections 2.2 and 3 in
[this](http://pdos.csail.mit.edu/papers/exo:tocs.pdf)
Exokernel paper have an in-depth explanation of the problem
and a method of addressing it in a kernel like JOS. Use the paper to
help you get a grip on the problem, chances are you do not need a
solution as complex as presented in the paper.
A web server in its simplest form sends the contents of a file to the
requesting client. We have provided skeleton code for a very simple web server
in `user/httpd.c`. The skeleton code deals with incoming connections
and parses the headers.
Exercise 13.
The web server is missing the code that deals with sending the
contents of a file back to the client. Finish the web server by
implementing `send_file`
and `send_data`
.
Once you've finished the web server, start the webserver (`make
run-httpd-nox`) and point your favorite browser at
http://*host*:*port*/index.html, where *host* is the
name of the computer running QEMU (If you're running QEMU on athena
use `hostname.mit.edu` (hostname is the output of the ```
hostname
```
command on athena, or `localhost` if you're
running the web browser and QEMU on the same computer) and *port*
is the port number reported for the web server by `make which-ports
`. You should see a web page served by the HTTP server running
inside JOS.
At this point, you should score 105/105 on `make grade`.
Challenge!
Add a simple chat server to JOS, where multiple people can
connect to the server and anything that any user types is
transmitted to the other users. To do this, you will have to
find a way to communicate with multiple sockets at once
*and* to send and receive on the same socket at the same
time. There are multiple ways to go about this. lwIP
provides a MSG_DONTWAIT flag for recv (see
`lwip_recvfrom` in `net/lwip/api/sockets.c`), so
you could constantly loop through all open sockets, polling
them for data. Note that, while `recv` flags are
supported by the network server IPC, they aren't accessible
via the regular `read` function, so you'll need a way
to pass the flags. A more efficient approach is to start one
or more environments for each connection
and to use IPC to coordinate them. Conveniently, the lwIP
socket ID found in the struct Fd for a socket is global (not
per-environment), so, for example, the child of a
`fork` inherits its parents sockets. Or, an
environment can even send on another environment's socket simply by
constructing an Fd containing the right socket ID.
Question
**This completes the lab.**
As usual, don't forget to run `make grade` and to write up
your answers and a description of your challenge exercise solution.
Before handing in, use `git status` and `git diff`
to examine your changes and don't forget to `git add
answers-lab6.txt`. When you're ready, commit your changes with
`git commit -am 'my solutions to lab 6'`, then `make
handin` and follow the directions. |
10,453 | 如何在 Linux 中安装微软的 .NET Core SDK | https://www.ostechnix.com/how-to-install-microsoft-net-core-sdk-on-linux/ | 2019-01-17T21:58:00 | [
".NET"
] | https://linux.cn/article-10453-1.html | 
**.NET Core** 是微软提供的免费、跨平台和开源的开发框架,可以构建桌面应用程序、移动端应用程序、网络应用程序、物联网应用程序和游戏应用程序等。如果你是 Windows 平台下的 dotnet 开发人员的话,使用 .NET core 可以很轻松就设置好任何 Linux 和类 Unix 操作系统下的开发环境。本分步操作指南文章解释了如何在 Linux 中安装 .NET Core SDK 以及如何使用 .NET 开发出第一个应用程序。
### Linux 中安装 .NET Core SDK
.NET Core 支持 GNU/Linux、Mac OS 和 Windows 系统,可以在主流的 GNU/Linux 操作系统上安装运行,包括 Debian、Fedora、CentOS、Oracle Linux、RHEL、SUSE/openSUSE 和 Ubuntu 。在撰写这篇教程时,其最新版本为 **2.2**。
**Debian 9** 系统上安装 .NET Core SDK,请按如下步骤进行。
首先,需要注册微软的密钥,接着把 .NET 源仓库地址添加进来,运行的命令如下:
```
$ wget -qO- https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor > microsoft.asc.gpg
$ sudo mv microsoft.asc.gpg /etc/apt/trusted.gpg.d/
$ wget -q https://packages.microsoft.com/config/debian/9/prod.list
$ sudo mv prod.list /etc/apt/sources.list.d/microsoft-prod.list
$ sudo chown root:root /etc/apt/trusted.gpg.d/microsoft.asc.gpg
$ sudo chown root:root /etc/apt/sources.list.d/microsoft-prod.list
```
注册好密钥及添加完仓库源后,就可以安装 .NET SDK 了,命令如下:
```
$ sudo apt-get update
$ sudo apt-get install dotnet-sdk-2.2
```
**Debian 8 系统上安装:**
增加微软密钥,添加 .NET 仓库源:
```
$ wget -qO- https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor > microsoft.asc.gpg
$ sudo mv microsoft.asc.gpg /etc/apt/trusted.gpg.d/
$ wget -q https://packages.microsoft.com/config/debian/8/prod.list
$ sudo mv prod.list /etc/apt/sources.list.d/microsoft-prod.list
$ sudo chown root:root /etc/apt/trusted.gpg.d/microsoft.asc.gpg
$ sudo chown root:root /etc/apt/sources.list.d/microsoft-prod.list
```
安装 .NET SDK:
```
$ sudo apt-get update
$ sudo apt-get install dotnet-sdk-2.2
```
**Fedora 28 系统上安装:**
增加微软密钥,添加 .NET 仓库源:
```
$ sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc
$ wget -q https://packages.microsoft.com/config/fedora/27/prod.repo
$ sudo mv prod.repo /etc/yum.repos.d/microsoft-prod.repo
$ sudo chown root:root /etc/yum.repos.d/microsoft-prod.repo
```
现在, 可以安装 .NET SDK 了:
```
$ sudo dnf update
$ sudo dnf install dotnet-sdk-2.2
```
**Fedora 27 系统下:**
增加微软密钥,添加 .NET 仓库源,命令如下:
```
$ sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc
$ wget -q https://packages.microsoft.com/config/fedora/27/prod.repo
$ sudo mv prod.repo /etc/yum.repos.d/microsoft-prod.repo
$ sudo chown root:root /etc/yum.repos.d/microsoft-prod.repo
```
接着安装 .NET SDK ,命令如下:
```
$ sudo dnf update
$ sudo dnf install dotnet-sdk-2.2
```
**CentOS/Oracle 版本的 Linux 系统上:**
增加微软密钥,添加 .NET 仓库源,使其可用:
```
$ sudo rpm -Uvh https://packages.microsoft.com/config/rhel/7/packages-microsoft-prod.rpm
```
更新源仓库,安装 .NET SDK:
```
$ sudo yum update
$ sudo yum install dotnet-sdk-2.2
```
**openSUSE Leap 版本的系统上:**
添加密钥,使仓库源可用,安装必需的依赖包,其命令如下:
```
$ sudo zypper install libicu
$ sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc
$ wget -q https://packages.microsoft.com/config/opensuse/42.2/prod.repo
$ sudo mv prod.repo /etc/zypp/repos.d/microsoft-prod.repo
$ sudo chown root:root /etc/zypp/repos.d/microsoft-prod.repo
```
更新源仓库,安装 .NET SDK,命令如下:
```
$ sudo zypper update
$ sudo zypper install dotnet-sdk-2.2
```
**Ubuntu 18.04 LTS 版本的系统上:**
注册微软的密钥和 .NET Core 仓库源,命令如下:
```
$ wget -q https://packages.microsoft.com/config/ubuntu/18.04/packages-microsoft-prod.deb
$ sudo dpkg -i packages-microsoft-prod.deb
```
使 Universe 仓库可用:
```
$ sudo add-apt-repository universe
```
然后,安装 .NET Core SDK ,命令如下:
```
$ sudo apt-get install apt-transport-https
$sudo apt-get update
$ sudo apt-get install dotnet-sdk-2.2
```
**Ubuntu 16.04 LTS 版本的系统上:**
注册微软的密钥和 .NET Core 仓库源,命令如下:
```
$ wget -q https://packages.microsoft.com/config/ubuntu/16.04/packages-microsoft-prod.deb
$ sudo dpkg -i packages-microsoft-prod.deb
```
然后安装 .NET core SDK:
```
$ sudo apt-get install apt-transport-https
$ sudo apt-get update
$ sudo apt-get install dotnet-sdk-2.2
```
### 创建你的第一个应用程序
我们已经成功的在 Linux 机器中安装了 .NET Core SDK。是时候使用 dotnet 创建第一个应用程序了。
接下来的目的,我们会创建一个名为 ostechnixApp 的应用程序。为此,可以简单的运行如下命令:
```
$ dotnet new console -o ostechnixApp
```
**示例输出:**
```
Welcome to .NET Core!
---------------------
Learn more about .NET Core: https://aka.ms/dotnet-docs
Use 'dotnet --help' to see available commands or visit: https://aka.ms/dotnet-cli-docs
Telemetry
---------
The .NET Core tools collect usage data in order to help us improve your experience. The data is anonymous and doesn't include command-line arguments. The data is collected by Microsoft and shared with the community. You can opt-out of telemetry by setting the DOTNET_CLI_TELEMETRY_OPTOUT environment variable to '1' or 'true' using your favorite shell.
Read more about .NET Core CLI Tools telemetry: https://aka.ms/dotnet-cli-telemetry
ASP.NET Core
------------
Successfully installed the ASP.NET Core HTTPS Development Certificate.
To trust the certificate run 'dotnet dev-certs https --trust' (Windows and macOS only). For establishing trust on other platforms refer to the platform specific documentation.
For more information on configuring HTTPS see https://go.microsoft.com/fwlink/?linkid=848054.
Getting ready...
The template "Console Application" was created successfully.
Processing post-creation actions...
Running 'dotnet restore' on ostechnixApp/ostechnixApp.csproj...
Restoring packages for /home/sk/ostechnixApp/ostechnixApp.csproj...
Generating MSBuild file /home/sk/ostechnixApp/obj/ostechnixApp.csproj.nuget.g.props.
Generating MSBuild file /home/sk/ostechnixApp/obj/ostechnixApp.csproj.nuget.g.targets.
Restore completed in 894.27 ms for /home/sk/ostechnixApp/ostechnixApp.csproj.
Restore succeeded.
```
正如上面的输出所示的,.NET 已经为我们创建一个控制台类型的应用程序。`-o` 参数创建了一个名为 “ostechnixApp” 的目录,其包含有存储此应用程序数据所必需的文件。
让我们切换到 ostechnixApp 目录,看看里面有些什么。
```
$ cd ostechnixApp/
$ ls
obj ostechnixApp.csproj Program.cs
```
可以看到有两个名为 `ostechnixApp.csproj` 和 `Program.cs` 的文件,以及一个名为 `obj` 的目录。默认情况下, `Program.cs` 文件包含有可以在控制台中运行的 “Hello World” 程序代码。可以看看此代码:
```
$ cat Program.cs
using System;
namespace ostechnixApp
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello World!");
}
}
}
```
要运行此应用程序,可以简单的使用如下命令:
```
$ dotnet run
Hello World!
```

很简单,对吧?是的,就是如此简单。现在你可以在 `Program.cs` 这文件中写上自己的代码,然后像上面所示的执行。
或者,你可以创建一个新的目录,如例子所示的 `mycode` 目录,命令如下:
```
$ mkdir ~/.mycode
$ cd mycode/
```
然后运行如下命令,使其成为你的新开发环境目录:
```
$ dotnet new console
```
示例输出:
```
The template "Console Application" was created successfully.
Processing post-creation actions...
Running 'dotnet restore' on /home/sk/mycode/mycode.csproj...
Restoring packages for /home/sk/mycode/mycode.csproj...
Generating MSBuild file /home/sk/mycode/obj/mycode.csproj.nuget.g.props.
Generating MSBuild file /home/sk/mycode/obj/mycode.csproj.nuget.g.targets.
Restore completed in 331.87 ms for /home/sk/mycode/mycode.csproj.
Restore succeeded.
```
上的命令会创建两个名叫 `mycode.csproj` 和 `Program.cs` 的文件及一个名为 `obj` 的目录。用你喜欢的编辑器打开 `Program.cs` 文件, 删除或修改原来的 “hello world” 代码段,然后编写自己的代码。
写完代码,保存,关闭 `Program.cs` 文件,然后运行此应用程序,命令如下:
```
$ dotnet run
```
想要查看安装的 .NET core SDK 的版本的话,可以简单的运行:
```
$ dotnet --version
2.2.101
```
要获得帮助,请运行:
```
$ dotnet --help
```
### 使用微软的 Visual Studio Code 编辑器
要编写代码,你可以任选自己喜欢的编辑器。同时微软自己也有一款支持 .NET 的编辑器,其名为 “Microsoft Visual Studio Code”。它是一款开源、轻量级、功能强大的源代码编辑器。其内置了对 JavaScript、TypeScript 和 Node.js 的支持,并为其它语言(如 C++、C#、Python、PHP、Go)和运行时态(如 .NET 和 Unity)提供了丰富的扩展,已经形成一个完整的生态系统。它是一款跨平台的代码编辑器,所以在微软的 Windows 系统、GNU/Linux 系统和 Mac OS X 系统都可以使用。如果对其感兴趣,就可以使用。
想了解如何在 Linux 上安装和使用,请参阅以下指南。
[Linux 中安装 Microsoft Visual Studio Code](https://www.ostechnix.com/install-microsoft-visual-studio-code-linux/)
关于 Visual Studio Code editor 中 .NET Core 和 .NET Core SDK 工具的使用,[此网页](https://docs.microsoft.com/en-us/dotnet/core/tutorials/index)有一些基础的教程。想了解更多就去看看吧。
### Telemetry
默认情况下,.NET core SDK 会采集用户使用情况数据,此功能被称为 Telemetry。采集数据是匿名的,并根据[知识共享署名许可](https://creativecommons.org/licenses/by/4.0/)分享给其开发团队和社区。因此 .NET 团队会知道这些工具的使用状况,然后根据统计做出决策,改进产品。如果你不想分享自己的使用信息的话,可以使用顺手的 shell 工具把名为 `DOTNET_CLI_TELEMETRY_OPTOUT` 的环境变量参数设置为 `1` 或 `true`,这样就简单的关闭此功能了。
就这样。你已经知道如何在各 Linux 平台上安装 .NET Core SDK 以及知道如何创建基本的应用程序了。想了解更多 .NET 使用知识的话,请参阅此文章末尾给出的链接。
会爆出更多干货的。敬请关注!
祝贺下!
### 资源
* [.NET Core](https://dotnet.microsoft.com/)
---
via: <https://www.ostechnix.com/how-to-install-microsoft-net-core-sdk-on-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[runningwater](https://github.com/runningwater) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,454 | 开始使用 Wekan 吧,一款开源看板软件 | https://opensource.com/article/19/1/productivity-tool-wekan | 2019-01-18T10:41:31 | [
"看板"
] | https://linux.cn/article-10454-1.html |
>
> 这是开源工具类软件推荐的第二期,本文将让你在 2019 年更具生产力。来,让我们一起看看 Wekan 吧。
>
>
>

每年年初,人们似乎都在想方设法地让自己更具生产力。对新年目标、期待,当然还有“新年新气象”这样的口号等等都促人上进。可大部分生产力软件的推荐都严重偏向闭源的专有软件,但事实上并不用这样。
这是我挑选的 19 款帮助你在 2019 年提升生产力的开源工具中的第 2 个。
### Wekan
[看板](https://en.wikipedia.org/wiki/Kanban)是当今敏捷开发流程中的重要组成部分。我们中的很多人使用它同时管理自己的工作和生活。有些人在用 [Trello](https://www.trello.com) 这样的 APP 来跟踪他们的项目,例如哪些事务正在处理,哪些事务已经完成。

但这些 APP 通常需要连接到一个工作账户或者商业服务中。而 [Wekan](https://wekan.github.io/) 作为一款开源看板工具,你可以让它完全在本地运行,或者使用你自己选择的服务运行它。其他的看板 APP 提供的功能在 Wekan 里几乎都有,例如创建看板、列表、泳道、卡片,在列表间拖放,给指定的用户安排任务,给卡片添加标签等等,基本上你对一款现代看板软件的功能需求它都能提供。

Wekan 的独到之处在于它的内置规则。虽然其他的看板软件支持<ruby> 邮件更新 <rt> emailing updates </rt></ruby>,但 Wekan 允许用户自行设定触发器,其触发条件可以是卡片变动、清单变动或标签变动等等。

当触发条件满足时, Wekan 可以自动执行如移动卡片、更新标签、添加清单或者发送邮件等操作。

Wekan 的本地搭建可以直接使用 snap 。如果你的桌面环境支持 [Snapcraft](https://snapcraft.io/) 构建的应用,那么只需要一条命令就能安装 Wekan :
```
sudo snap install wekan
```
此外 Wekan 还支持 Docker 安装,这使它在大部分服务器环境和桌面环境下的搭建变得相当容易。
最后,如果你想寻找一款能自建又好用的看板软件,你已经遇上了 Wekan 。
---
via: <https://opensource.com/article/19/1/productivity-tool-wekan>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[wwhio](https://github.com/wwhio) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the second of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## Wekan
[Kanban](https://en.wikipedia.org/wiki/Kanban) boards are a mainstay of today's agile processes. And many of us (myself included) use them to organize not just our work but also our personal lives. I know several artists who use apps like [Trello](https://www.trello.com) to keep track of their commision lists as well as what's in progress and what's complete.
Wekan rules list
But these apps are often linked to a work account or a commercial service. Enter [Wekan](https://wekan.github.io/), an open source kanban board you can run locally or on the service of your choice. Wekan offers much of the same functionality as other Kanban apps, such as creating boards, lists, swimlanes, and cards, dragging and dropping between lists, assigning to users, labeling cards, and doing pretty much everything else you'd expect in a modern kanban board.
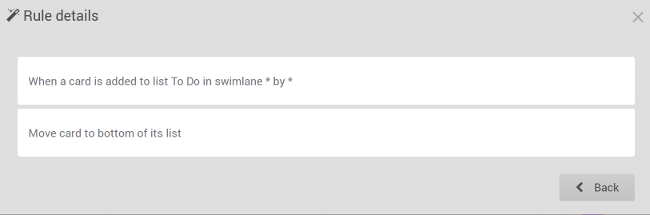
Rule triggers
The thing that distinguishes Wekan from most other kanban boards is the built-in rules. While most other boards support emailing updates, Wekan allows you to set up triggers when taking actions on cards, checklists, and labels.
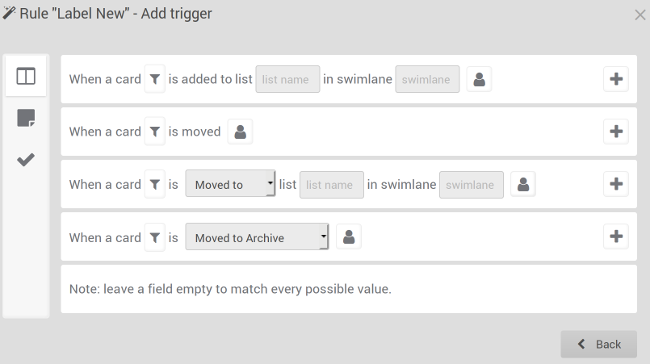
Rule actions
Wekan can then take actions like moving cards, updating labels, adding checklists, and sending emails.
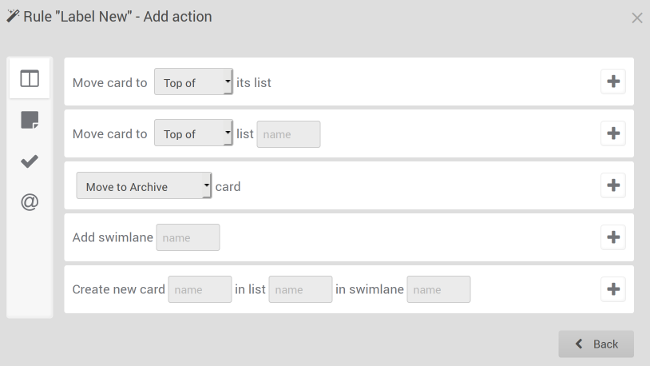
Rule actions
Setting up Wekan locally is a snap—literally. If your desktop supports [Snapcraft](https://snapcraft.io/) applications, installing is as easy as:
```
````sudo snap install wekan`
It also supports Docker, which means installing on a server is reasonably straightforward on most servers and desktops.
Overall, if you want a nice kanban board that you can run yourself, Wekan has you covered.
## Comments are closed. |
10,455 | 设计微服务架构前应该了解的 5 项指导原则 | https://opensource.com/article/18/4/guide-design-microservices | 2019-01-19T00:27:05 | [
"微服务"
] | https://linux.cn/article-10455-1.html |
>
> 顶级 CTO 基于五个简单的原则为精心设计的微服务提供建议。
>
>
>

对于从微服务开始的团队来说,最大的挑战之一就是坚持<ruby> 金发女孩原则 <rt> The Goldilocks principle </rt></ruby>(该典故来自于童话《金发姑娘和三只熊》):不要太大,不要太小,不能太紧密耦合。之所以是挑战的部分原因是会对究竟什么是设计良好的微服务感到疑惑。
数十位 CTO 通过采访分享了他们的经验,这些对话说明了设计良好的微服务的五个特点。本文将帮助指导团队设计微服务。(有关详细信息,请查看即将出版的书籍 [Microservices for Startups](https://buttercms.com/books/microservices-for-startups/),LCTT 译注:已可免费下载完整的电子版)。本文将简要介绍微服务的边界和主观的 “规则”,以避免在深入了解五个特征之前就开始指导您的微服务设计。
### 微服务边界
[使用微服务开发新系统的核心优势](https://buttercms.com/books/microservices-for-startups/should-you-always-start-with-a-monolith)之一是该体系结构允许开发人员独立构建和修改各个组件,但在最大限度地减少每个 API 之间的回调数量方面可能会出现问题。根据 [SparkPost](https://www.sparkpost.com/) 工程副总裁 Chris McFadden 所说,解决方案是应用适当的服务边界。
关于边界,与有时难以理解和抽象的领域驱动设计(DDD,一种微服务框架)形成鲜明对比,本文重点介绍了和我们行业的一些顶级 CTO 一同建立的明确定义的微服务边界的实用原则。
### 避免主观的 “规则”
如果您阅读了足够多的关于设计和创建微服务的建议,您一定会遇到下面的一些 “规则”。 尽管将它们用作创建微服务的指南很有吸引力,但加入这些主观规则并不是思考确定微服务的边界的原则性方式。
#### “微服务应该有 X 行代码”
让我们直说:微服务中有多少行代码没有限制。微服务不会因为您写了几行额外的代码而突然变成一个独石应用。关键是要确保服务中的代码具有很高的内聚性(稍后将对此进行更多介绍)。
#### “将每个功能转换为微服务”
如果函数基于三个输入值计算某些内容并返回结果,它是否是微服务的理想候选项?它是否应该是单独可部署应用程序?这确实取决于该函数是什么以及它是如何服务于整个系统。将每个函数转换为微服务在您的情景中可能根本没有意义。
其他主观规则包括不考虑整个情景的规则,例如团队的经验、DevOps 能力、服务正在执行的操作以及数据的可用性需求。
### 精心设计的服务的 5 个特点
如果您读过关于微服务的文章,您无疑会遇到有关设计良好的服务的建议。简单地说,高内聚和低耦合。如果您不熟悉这些概念,有[许多](https://thebojan.ninja/2015/04/08/high-cohesion-loose-coupling/)[文章](https://thebojan.ninja/2015/04/08/high-cohesion-loose-coupling/)关于这些概念的文章。虽然它们提供了合理的建议,但这些概念是相当抽象的。基于与经验丰富的 CTO 们的对话,下面是在创建设计良好的微服务时需要牢记的关键特征。
#### #1:不与其他服务共享数据库表
在 SparkPost 的早期,Chris McFadden 和他的团队必须解决每个 SaaS 业务需要面对的问题:它们需要提供基本服务,如身份验证、帐户管理和计费。
为了解决这个问题,他们创建了两个微服务:用户 API 和帐户 API。用户 API 将处理用户帐户、API 密钥和身份验证,而帐户 API 将处理所有与计费相关的逻辑。这是一个非常合乎逻辑的分离 —— 但没过多久,他们发现了一个问题。
McFadden 解释说,“我们有一个名为‘用户 API’的服务,还有一个名为‘帐户 API’的服务。问题是,他们之间实际上有几个来回的调用。因此,您会在帐户服务中执行一些操作,然后调用并终止于用户服务,反之亦然”
这两个服务的耦合太紧密了。
在设计微服务时,如果您有多个服务引用同一个表,则它是一个危险的信号,因为这可能意味着您的数据库是耦合的源头。
这确实是关于服务与数据的关系,这正是 [Swiftype SRE,Elastic](https://www.elastic.co/solutions/site-search) 的负责人 Oleksiy Kovrin 告诉我。他说,“我们在开发新服务时使用的主要基本原则之一是,它们不应跨越数据库边界。每个服务都应依赖于自己的一组底层数据存储。这使我们能够集中访问控制、审计日志记录、缓存逻辑等。”
Kovrin 接着解释说,如果数据库表的某个子集“与数据集的其余部分没有或很少连接,则这是一个强烈的信号,表明该组件可以被隔离到单独的 API 或单独的服务中”。
[Lead Honestly](https://leadhonestly.com/) 的联合创始人 Darby Frey 与此的观点相呼应:“每个服务都应该有自己的表并且永远不应该共享数据库表。”
#### #2:数据库表数量最小化
微服务的理想尺寸应该足够小,但不能太小。每个服务的数据库表的数量也是如此。
[Scaylr](https://www.scalyr.com/) 的工程主管 Steven Czerwinski 在接受采访时解释说 Scaylr 的最佳选择是“一个或两个服务的数据库表。”
SparkPost 的 Chris McFadden 表示同意:“我们有一个 suppression 微服务,它处理、跟踪数以百万计和数十亿围绕 suppression 的条目,但它们都非常专注于围绕 suppression,所以实际上只有一个或两个表。其他服务也是如此,比如 webhooks。
#### #3:考虑有状态和无状态
在设计微服务时,您需要问问自己它是否需要访问数据库,或者它是否是处理 TB 级数据 (如电子邮件或日志) 的无状态服务。
[Algolia](https://www.algolia.com/) 的 CTO Julien Lemoine 解释说:“我们通过定义服务的输入和输出来定义服务的边界。有时服务是网络 API,但它也可能是使用文件并在数据库中生成记录的进程 (这就是我们的日志处理服务)。”
事先要明确是否有状态,这将引导一个更好的服务设计。
#### #4:考虑数据可用性需求
在设计微服务时,请记住哪些服务将依赖于此新服务,以及在该数据不可用时的整个系统的影响。考虑到这一点,您可以正确地设计此服务的数据备份和恢复系统。
Steven Czerwinski 提到,在 Scaylr 由于关键客户行空间映射数据的重要性,它将以不同的方式复制和分离。
相比之下,他补充说,“每个分片信息,都在自己的小分区里。如果部分客户群体因为没有可用日志而停止服务那很糟糕,但它只影响 5% 的客户,而不是100% 的客户。”
#### #5:单一的真实来源
设计服务,使其成为系统中某些内容的唯一真实来源。
例如,当您从电子商务网站订购内容时,则会生成订单 ID,其他服务可以使用此订单 ID 来查询订单服务,以获取有关订单的完整信息。使用 [发布/订阅模式](https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern),在服务之间传递的数据应该是订单 ID ,而不是订单本身的属性信息。只有订单服务具有订单的完整信息,并且是给定订单信息的唯一真实来源。
### 大型团队的注意事项
考虑到上面列出的五个注意事项,较大的团队应了解其组织结构对微服务边界的影响。
对于较大的组织,整个团队可以专门拥有服务,在确定服务边界时,组织性就会发挥作用。还有两个需要考虑的因素:**独立的发布计划**和**不同的正常运行时间**的重要性。
[Cloud66.](https://www.cloud66.com/) 的 CEO Khash Sajadi 说:“我们所看到的微服务最成功的实现要么基于类似领域驱动设计这样的软件设计原则 (如面向服务的体系结构),要么基于反映组织方法的设计原则。”
“所以 (对于) 支付团队” Sajadi 说,“他们有支付服务或信用卡验证服务,这就是他们向外界提供的服务。所以这不一定是关于软件的。这主要是关于为外界提供更多服务的业务单位。”
### 双披萨原理
Amazon 是一个拥有多个团队的大型组织的完美示例。正如在一篇发表于 [API Evangelist](https://apievangelist.com/2012/01/12/the-secret-to-amazons-success-internal-apis/) 的文章中所提到的,Jeff Bezos 向所有员工发布一项要求,告知他们公司内的每个团队都必须通过 API 进行沟通。任何不这样做的人都会被解雇。
这样,所有数据和功能都通过该接口公开。Bezos 还设法让每个团队解耦,定义他们的资源,并通过 API 提供。Amazon 正在从头建立一个系统。这使得公司内的每一支团队都能成为彼此的合作伙伴。
我与 [Iron.io](https://www.iron.io/) 的 CTO Travis Reeder 谈到了 Bezos 的内部倡议。
“Jeff Bezos 规定所有团队都必须构建 API 才能与其他团队进行沟通,” Reeder 说。“他也是提出‘双披萨’规则的人:一支团队不应该比两个比萨饼能养活的大。”
“我认为这里也可以适用同样的方法:无论一个小型团队是否能够开发、管理和富有成效。如果它开始变得笨重或开始变慢,它可能变得太大了。” Reeder 告诉我。
### 最后注意事项: 您的服务是否具有合适的大小和正确的定义?
在微服务系统的测试和实施阶段,有一些指标需要记住。
#### 指标 #1: 服务之间是否存在过度依赖?
如果两个服务不断地相互回调,那么这就是强烈的耦合信号,也是它们可能更好地合并为一个服务的信号。
回到 Chris McFadden 的例子, 他有两个 API 服务,帐户服务和用户服务不断地相互通信, McFadden 提出了一个合并服务的想法,并决定将其称为 “账户用户 API”。事实证明,这是一项富有成效的战略。
“我们开始做的是消除这些内部 API 之间调用的链接,” McFadden 告诉我。“这有助于简化代码。”
#### 指标 #2: 设置服务的开销是否超过了服务独立的好处?
Darby Frey 解释说,“每个应用都需要将其日志聚合到某个位置,并需要进行监视。你需要设置它的警报。你需要有标准的操作程序,和在出现问题时的操作手册。您必须管理 SSH 对它的访问。只是为了让一个应用运行起来,就有大量的基础性工作必须存在。”
### 关键要点
设计微服务往往会让人感觉更像是一门艺术,而不是一门科学。对工程师来说,这可能并不顺利。有很多一般性的建议,但有时可能有点太抽象了。让我们回顾一下在设计下一组微服务时要注意的五个具体特征:
1. 不与其他服务共享数据库表
2. 数据库表数量最小化
3. 考虑有状态和无状态
4. 考虑数据可用性需求
5. 单一的真实来源
下次设计一组微服务并确定服务边界时,回顾这些原则应该会使任务变得更容易。
---
via: <https://opensource.com/article/18/4/guide-design-microservices>
作者:[Jake Lumetta](https://opensource.com/users/jakelumetta) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lixinyuxx](https://github.com/lixinyuxx) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the biggest challenges for teams starting off with microservices is adhering to the *Goldilocks Principle*: Not too big, not too small, and not too tightly coupled. Part of this challenge arises from confusion about what, exactly, constitutes a well-designed microservice.
Dozens of CTOs shared their experiences through interviews, and those conversations illuminated five characteristics of well-designed microservices. This article will help guide teams as they design microservices. (For more information, check out the upcoming book [ Microservices for Startups](https://buttercms.com/books/microservices-for-startups/)). This article will briefly touch on microservice boundaries and arbitrary "rules" to avoid before diving into the five characteristics to guide your design of microservices.
## Microservice boundaries
One of the [core benefits of developing new systems with microservices](https://buttercms.com/books/microservices-for-startups/should-you-always-start-with-a-monolith) is that the architecture allows developers to build and modify individual components independently—but problems can arise when it comes to minimizing the number of callbacks between each API. The solution, according to Chris McFadden, VP of engineering at [SparkPost](https://www.sparkpost.com/), is to apply the appropriate service boundaries.
With respect to boundaries, in contrast to the sometimes difficult-to-grasp and abstract concept of domain-driven design (DDD)—a framework for microservices—this article focuses on practical principles for creating well-defined microservice boundaries with some of our industry's top CTOs.
## Avoid arbitrary "rules"
If you read enough advice about designing and creating a microservice, you're bound to come across some of the "rules" below. Although it's tempting to use them as guideposts for creating microservices, adhesion to these arbitrary rules is not a principled way to determine thoughtful boundaries for microservices.
### "A microservice should have *X* lines of code"
Let's get one thing straight: There are no limitations on how many lines of code there are in a microservice. A microservice doesn't suddenly become a monolith just because you write a few lines of extra code. The key is ensuring there is high cohesion for the code within a service (more on this later).
### "Turn each function into a microservice"
If a function computes something based on three input values and returns a result, is it a good candidate for a microservice? Should it be a separately deployable application of its own? This really depends on what the function is and how it serves to the entire system. Turning each function into a microservice simply might not make sense in your context.
Other arbitrary rules include those that don't take into account your entire context, such as the team's experience, DevOps capacity, what the service is doing, and availability needs of the data.
## 5 characteristics of a well-designed service
If you've read about microservices, you've no doubt come across advice on what makes a well-designed service. Simply put, high cohesion and loose coupling. There are [many](https://thebojan.ninja/2015/04/08/high-cohesion-loose-coupling/) [articles](https://en.wikipedia.org/wiki/Single_responsibility_principle) on these concepts to review if you're not familiar with them. And while they offer sound advice, these concepts are quite abstract. Below, based on conversations with experienced CTOs, are key characteristics to keep in mind when creating well-designed microservices.
### #1: It doesn't share database tables with another service
In the early days of SparkPost, Chris McFadden and his team had to solve a problem that every SaaS business faces: They needed to provide basic services like authentication, account management, and billing.
To tackle this, they created two microservices: a Users API and an Accounts API. The Users API would handle user accounts, API keys, and authentication, while the Accounts API would handle all of the billing-related logic. A very logical separation—but before long, they spotted a problem.
"We had one service that was called the User API, and we had another one called the Account API. The problem was that they were actually having several calls back and forth between them. So you would do something in accounts and have a call and endpoint in users or vice versa," McFadden explained.
The two services were too tightly coupled.
When it comes to designing a microservice, it's a red flag if you have multiple services referencing the same table, as it likely means your DB is a source of coupling.
It is really about how the service relates to the data, which is exactly what Oleksiy Kovrin, head of [Swiftype SRE, Elastic](https://www.elastic.co/solutions/site-search), told me. "One of the main foundational principles we use when developing new services is that they should not cross database boundaries. Each service should rely on its own set of underlying data stores. This allows us to centralize access controls, audit logging, caching logic, etc.," he said.
Kovyrin went on to explain that if a subset of your database tables "have no or very little connections to the rest of the dataset, it is a strong signal that component could be isolated into a separate API or a separate service."
Darby Frey, co-founder of [Lead Honestly](https://leadhonestly.com/), echoed this sentiment: "Each service should have its own tables [and] should never share database tables."
### #2: It has a minimal amount of database tables
The ideal size of a microservice is *small enough, but no smaller*. And the same goes for the number of database tables per service.
Steven Czerwinski, head of engineering, [Scaylr](https://www.scalyr.com/), explained during an interview that the sweet spot for Scaylr is "one or two database tables for a service."
SparkPost's Chris McFadden agreed: "We have a suppression microservices, and it handles, keeps track of, millions and billions of entries around suppressions, but it's all very focused just around suppression, so there's really only one or two tables there. The same goes for other services like webhooks."
### #3: It's thoughtfully stateful or stateless
When designing your microservice, you need to ask yourself whether it requires access to a database or whether it's going to be a stateless service processing terabytes of data like emails or logs.
Julien Lemoine, CTO of [Algolia](https://www.algolia.com/), explained, "We define the boundaries of a service by defining its input and output. Sometimes a service is a network API, but it can also be a process consuming files and producing records in a database (this is the case of our log-processing service)."
Be clear about statefulness up front and it will lead to a better-designed service.
### #4: Its data availability needs are accounted for
When designing a microservice, keep in mind what services will rely on this new service and the system-wide impact if that data becomes unavailable. Taking that into account allows you to properly design data backup and recovery systems for this service
Steven Czerwinski mentioned that at Scaylr, critical customer row space mapping data is replicated and separated in different ways due to its importance.
In contrast, he added, "The per shard information, that's in its own little partition. It sucks if it goes down because that portion of the customer population is not going to have their logs available, but it's only impacting 5 percent of the customers rather than 100 percent of the customers."
### #5: It's a single source of truth
Design a service to be the single source of truth for something in your system
For example, when you order something from an e-commerce site, an order ID is generated. This order ID can be used by other services to query an order service for complete information about the order. Using the [publish/subscribe pattern](https://en.wikipedia.org/wiki/Publish–subscribe_pattern), the data that is passed around between services should be the order ID, not the attributes/information of the order itself. Only the order service has complete information and is the single source of truth for a given order.
## Considerations for larger teams
Keeping in mind the five considerations listed above, larger teams should be aware of the impacts of their organizational structure on microservice boundaries.
For larger organizations, where entire teams can be dedicated to owning a service, organizational consideration comes into play when determining service boundaries. And there are two considerations to consider: **independent release schedule** and **different uptime importance**.
"The most successful implementation of microservices we've seen is either based on a software design principle like domain-driven design, for example, and service-oriented architecture, or the ones that reflect an organizational approach," said Khash Sajadi, CEO of [Cloud66.](https://www.cloud66.com/)
"So [for the] payments team," Sajadi continued, "they have the payment service or credit card validation service, and that's the service they provide to the outside world. So it's not necessarily anything about software. It's mostly about the business unit [that] provides one more service to the outside world."
## The two-pizza principle
Amazon is a perfect example of a large organization with multiple teams. As mentioned in an article published in [API Evangelist](https://apievangelist.com/2012/01/12/the-secret-to-amazons-success-internal-apis/), Jeff Bezos issued a mandate to all employees informing them that every team within the company had to communicate via API. Anyone who didn't would be fired.
This way, all the data and functionality was exposed through the interface. Bezos also managed to get every team to decouple, define what their resources are, and make them available through the API. Amazon was building a system from the ground up. This allows every team within the company to become a partner of one another.
I spoke to Travis Reeder, CTO of [Iron.io](https://www.iron.io/), about Bezos' internal initiative.
"Jeff Bezos mandated that all teams had to build API's to communicate with other teams," Reeder said. "He's also the guy who came up with the 'two-pizza' rule: A team shouldn't be larger than what two pizzas can feed.
"I think the same could apply here: Whatever a small team can develop, manage, and be productive with. If it starts to get unwieldy or starts to slow down, it's probably getting too big," Reeder told me.
## Final considerations: Is your service the right size and properly defined?
During the testing and implementation phase of your microservice system, there are indicators to keep in mind.
### Indicator #1: Is there over-reliance between services?
If two services are constantly calling back to one another, then that's a strong indication of coupling and a signal that they might be better off combined into one service.
Going back to Chris McFadden's example where he had two API services, accounts, and users that were constantly communicating with one another, McFadden came up an idea to merge the services and decided to call it the Accuser's API. This turned out to be a fruitful strategy.
"What we started doing was eliminating these links [which were the] internal API calls between them," McFadden told me. "It's helped simplify the code."
### Indicator #2: Does the overhead of setting up the service outweigh the benefit of having the service be independent?
Darby Frey explained, "Every app needs to have its logs aggregated somewhere and needs to be monitored. You need to set up alerting for it. You need to have standard operating procedures and run books for when things break. You have to manage SSH access to that thing. There's a huge foundation of things that have to exist in order for an app to just run."
## Key takeaways
Designing microservices can often feel more like an art than a science. For engineers, that may not sit well. There's lots of general advice out there, but at times it can be a bit too abstract. Let's recap the five specific characteristics to look for when designing your next set of microservices:
- It doesn't share database tables with another service
- It has a minimal amount of database tables
- It's thoughtfully stateful or stateless
- Its data availability needs are accounted for
- It's a single source of truth
Next time you're designing a set of microservices and determining service boundaries, referring back to these principles should make the task easier.
**[See our related story, What are microservices?]**
## Comments are closed. |
10,456 | Ubuntu PPA 使用指南 | https://itsfoss.com/ppa-guide/ | 2019-01-19T11:02:47 | [
"PPA",
"Ubuntu"
] | https://linux.cn/article-10456-1.html |
>
> 一篇涵盖了在 Ubuntu 和其他 Linux 发行版中使用 PPA 的几乎所有问题的深入的文章。
>
>
>
如果你一直在使用 Ubuntu 或基于 Ubuntu 的其他 Linux 发行版,例如 Linux Mint、Linux Lite、Zorin OS 等,你可能会遇到以下三种神奇的命令:
```
sudo add-apt-repository ppa:dr-akulavich/lighttable
sudo apt-get update
sudo apt-get install lighttable-installer
```
许多网站推荐使用类似于以上几行的形式 [在 Ubuntu 中安装应用程序](https://itsfoss.com/remove-install-software-ubuntu/)。这就是所谓的使用 PPA 安装应用程序。
但什么是 PPA?为什么要用它?使用 PPA 安全吗?如何正确使用 PPA?如何删除 PPA?
我将在这个详细的指南中回答上述所有问题。即使你已经了解了一些关于 PPA 的事情,我相信这篇文章仍然会让你了解这方面的更多知识。
请注意我正在使用 Ubuntu 撰写本文。因此,我几乎在各个地方都使用了 Ubuntu 这个术语,但文中的说明和步骤也适用于其他基于 Debian/Ubuntu 的发行版。
### 什么是 PPA?为什么要使用 PPA?

PPA 表示<ruby> 个人软件包存档 <rt> Personal Package Archive </rt></ruby>。
这样说容易理解吗?可能不是很容易。
在了解 PPA 之前,你应该了解 Linux 中软件仓库的概念。关于软件仓库,在这里我不会详述。
#### 软件仓库和包管理的概念
软件仓库是一组文件,其中包含各种软件及其版本的信息,以及校验和等其他一些详细信息。每个版本的 Ubuntu 都有自己的四个官方软件仓库:
* Main - Canonical 支持的自由开源软件。
* Universe - 社区维护的自由开源软件。
* Restricted - 设备的专有驱动程序。
* Multiverse - 受版权或法律问题限制的软件。
你可以在 [这里](http://archive.ubuntu.com/ubuntu/dists/) 看到所有版本的 Ubuntu 的软件仓库。你可以浏览并转到各个仓库。例如,可以在 [这里](http://archive.ubuntu.com/ubuntu/dists/xenial/main/) 找到 Ubuntu 16.04 的主存储库(Main)。
所以,PPA 基本上是一个包含软件信息的网址。那你的系统又是如何知道这些仓库的位置的呢?
这些信息存储在 `/etc/apt` 目录中的 `sources.list` 文件中。如果查看此文件的内容,你就会看到里面有软件仓库的网址。`#` 开头的行将被忽略。
这样的话,当你运行 `sudo apt update` 命令时,你的系统将使用 [APT 工具](https://wiki.debian.org/Apt) 来检查软件仓库并将软件及其版本信息存储在缓存中。当你使用 `sudo apt install package_name` 命令时,它通过该信息从实际存储软件的网址获取该软件包。
如果软件仓库中没有关于某个包的信息,你将看到如下错误:
```
E: Unable to locate package
```
此时,建议阅读我的 [apt 命令使用指南](https://itsfoss.com/apt-command-guide/) 一文,这将帮你更好地理解 `apt`、`update` 等命令。
以上是关于软件仓库的内容。但什么是 PPA?PPA 和软件仓库又有什么关联呢?
#### 为什么要用 PPA?
如你所见,Ubuntu 对系统中的软件进行管理,更重要的是控制你在系统上获得哪个版本的软件。但想象一下开发人员发布了软件的新版本的情况。
Ubuntu 不会立即提供该新版本的软件。需要一个步骤来检查此新版本的软件是否与系统兼容,从而可以确保系统的稳定性。
但这也意味着它需要经过几周才能在 Ubuntu 上可用,在某些情况下,这可能需要几个月的时间。不是每个人都想等待那么长时间才能获得他们最喜欢的软件的新版本。
类似地,假设有人开发了一款软件,并希望 Ubuntu 将该软件包含在官方软件仓库中。在 Ubuntu 做出决定并将其包含在官方存软件仓库之前,还需要几个月的时间。
另一种情况是在 beta 测试阶段。即使官方软件仓库中提供了稳定版本的软件,软件开发人员也可能希望某些终端用户测试他们即将发布的版本。他们是如何使终端用户对即将发布的版本进行 beta 测试的呢?
通过 PPA!
### 如何使用 PPA?PPA 是怎样工作的?
正如我已经告诉过你的那样,[PPA](https://launchpad.net/ubuntu/+ppas) 代表<ruby> 个人软件包存档 <rt> Personal Package Archive </rt></ruby>。在这里注意 “个人” 这个词,它暗示了这是开发人员独有的东西,并没有得到分发的正式许可。
Ubuntu 提供了一个名为 Launchpad 的平台,使软件开发人员能够创建自己的软件仓库。终端用户,也就是你,可以将 PPA 仓库添加到 `sources.list` 文件中,当你更新系统时,你的系统会知道这个新软件的可用性,然后你可以使用标准的 `sudo apt install` 命令安装它。
```
sudo add-apt-repository ppa:dr-akulavich/lighttable
sudo apt-get update
sudo apt-get install lighttable-installer
```
概括一下上面三个命令:
* `sudo add-apt-repository <PPA_info>` <- 此命令将 PPA 仓库添加到列表中。
* `sudo apt-get update` <- 此命令更新可以在当前系统上安装的软件包列表。
* `sudo apt-get install <package_in_PPA>` <- 此命令安装软件包。
你会发现使用 `sudo apt update` 命令非常重要,否则你的系统将无法知道新软件包何时可用。
现在让我们更详细地看一下第一个命令。
```
sudo add-apt-repository ppa:dr-akulavich/lighttable
```
你会注意到此命令没有软件仓库的 URL。这是因为该工具被设计成将 URL 信息抽象之后再展示给你。
小小注意一下:如果你添加的是 `ppa:dr-akulavich/lighttable`,你会得到 Light Table。但是如果你添加 `ppa:dr-akulavich`,你将得到 “上层软件仓库” 中的所有仓库或软件包。它是按层级划分的。
基本上,当您使用 `add-apt-repository` 添加 PPA 时,它将执行与手动运行这些命令相同的操作:
```
deb http://ppa.launchpad.net/dr-akulavich/lighttable/ubuntu YOUR_UBUNTU_VERSION_HERE main
deb-src http://ppa.launchpad.net/dr-akulavich/lighttable/ubuntu YOUR_UBUNTU_VERSION_HERE main
```
以上两行是将任何软件仓库添加到你系统的 `sources.list` 文件的传统方法。但 PPA 会自动为你完成这些工作,无需考虑确切的软件仓库 URL 和操作系统版本。
此处不那么重要的一点是,当你使用 PPA 时,它不会更改原始的 `sources.list` 文件。相反,它在 `/etc/apt/sources.d` 目录中创建了两个文件,一个 `.list` 文件和一个带有 `.save` 后缀的备份文件。

*PPA 创建了单独的 `sources.list` 文件*
带有后缀 `.list` 的文件含有添加软件仓库的信息的命令。

*一个 PPA 的 `source.list` 文件的内容*
这是一种安全措施,可以确保添加的 PPA 不会和原始的 `sources.list` 文件弄混,它还有助于移除 PPA。
#### 为什么使用 PPA?为何不用 DEB 包
你可能会问为什么要使用 PPA,PPA 需要通过命令行使用,而不是每个人都喜欢用命令行。为什么不直接分发可以图形方式安装的 DEB 包呢?
答案在于更新的过程。如果使用 DEB 包安装软件,将无法保证在运行 `sudo apt update` 和 `sudo apt upgrade` 命令时,已安装的软件会被更新为较新的版本。
这是因为 `apt` 的升级过程依赖于 `sources.list` 文件。如果文件中没有相应的软件条目,则不会通过标准软件更新程序获得更新。
那么这是否意味着使用 DEB 安装的软件永远不会得到更新?不是的。这取决于 DEB 包的创建方式。
一些开发人员会自动在 `sources.list` 中添加一个条目,这样软件就可以像普通软件一样更新。谷歌 Chrome 浏览器就是这样一个例子。
某些软件会在运行时通知你有新版本可用。你必须下载新的 DEB 包并再次运行,来将当前软件更新为较新版本。Oracle Virtual Box 就是这样一个例子。
对于其余的 DEB 软件包,你必须手动查找更新,这很不方便,尤其是在你的软件面向 Beta 测试者时,你需要频繁的添加很多更新。这正是 PPA 要解决的问题。
#### 官方 PPA vs 非官方 PPA
你或许听过官方 PPA 或非官方 PPA 这个词,二者有什么不同呢?
开发人员为他们的软件创建的 PPA 称为官方 PPA。很明显,这是因为它来自项目开发者。
但有时,个人会创建由其他开发人员所创建的项目的 PPA。
为什么会有人这样做? 因为许多开发人员只提供软件的源代码,而且你也知道 [在 Linux 中从源代码安装软件](/article-9172-1.html) 是一件痛苦的事情,并不是每个人都可以或者会这样做。
这就是志愿者自己从这些源代码创建 PPA 以便其他用户可以轻松安装软件的原因。毕竟,使用这 3 行命令比从源代码安装要容易得多。
#### 确保你的 Linux 发行版本可以使用 PPA
当在 Ubuntu 或任何其他基于 Debian 的发行版中使用 PPA 时,你应该记住一些事情。
并非每个 PPA 都适用于你的特定版本。你应该知道正在使用 [哪个版本的 Ubuntu](https://itsfoss.com/how-to-know-ubuntu-unity-version/)。版本的开发代号很重要,因为当你访问某个 PPA 的页面时,你可以看到该 PPA 都支持哪些版本的 Ubuntu。
对于其他基于 Ubuntu 的发行版,你可以查看 `/etc/os-release` 的内容来 [找出 Ubuntu 版本](https://itsfoss.com/how-to-know-ubuntu-unity-version/) 的信息。

*检查 PPA 是否适用于你的 Ubuntu 版本*
如何知道 PPA 的网址呢?只需在网上搜索 PPA 的名称,如 `ppa:dr-akulavich/lighttable`,第一个搜索结果来自 [Launchpad](https://launchpad.net/),这是托管 PPA 的官方平台。你也可以转到 Launchpad 并直接在那里搜索所需的 PPA。
如果不验证是否适用当前的版本就添加 PPA,当尝试安装不适用于你的系统版本的软件时,可能会看到类似下面的错误。
```
E: Unable to locate package
```
更糟糕的是,因为它已经添加到你的 `source.list` 中,每次运行软件更新程序时,你都会看到 “[无法下载软件仓库信息](https://itsfoss.com/failed-to-download-repository-information-ubuntu-13-04/)” 的错误。

如果你在终端中运行 `sudo apt update`,错误提示将包含导致此问题的仓库的更多详细信息。你可以在 `sudo apt update` 的输出内容结尾看到类似的内容:
```
W: Failed to fetch http://ppa.launchpad.net/venerix/pkg/ubuntu/dists/raring/main/binary-i386/Packages 404 Not Found
E: Some index files failed to download. They have been ignored, or old ones used instead.
```
上面的错误提示说的很明白,是因为系统找不到当前版本对应的仓库。还记得我们之前看到的仓库结构吗?APT 将尝试在 `http://ppa.launchpad.net/<PPA_NAME>/ubuntu/dists/<Ubuntu_Version>` 中寻找软件信息。
如果特定版本的 PPA 不可用,它将永远无法打开 URL,你会看到著名的 404 错误。
#### 为什么 PPA 不适用于所有 Ubuntu 发行版?
这是因为 PPA 的作者必须编译软件并在特定版本上创建 PPA。考虑到每六个月发布一个新的 Ubuntu 版本,为每个版本的 Ubuntu 更新 PPA 是一项繁琐的任务,并非所有开发人员都有时间这样做。
#### 如果 PPA 不适用于你的系统版本,该如何安装应用程序?
尽管 PPA 不适用于你的 Ubuntu 版本,你仍然可以下载 DEB 文件并安装应用程序。
比如说,你访问 Light Table 的 PPA 页面,使用刚刚学到的有关 PPA 的知识,你会发现 PPA 不适用于你的特定 Ubuntu 版本。
你可以点击 “查看软件包详细信息”。

在这里,你可以单击软件包以显示更多详细信息,还可以在此处找到包的源代码和 DEB 文件。

我建议 [使用 Gdebi 安装这些 DEB 文件](https://itsfoss.com/gdebi-default-ubuntu-software-center/) 而不是通过软件中心,因为 Gdebi 在处理依赖项方面要好得多。
请注意,以这种方式安装的软件包可能无法获得任何将来的更新。
我认为你已经阅读了足够多的关于添加 PPA 的内容,那么如何删除 PPA 及其安装的软件呢?
### 如何删除 PPA?
我过去曾写过 [删除 PPA](https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/) 的教程,这里写的也是同样的方法。
我建议在删除 PPA 之前删除从 PPA 安装的软件。如果只是删除 PPA,则已安装的软件仍保留在系统中,但不会获得任何更新。这不是你想要的,不是吗?
那么,问题来了,如何知道是哪个 PPA 安装了哪个应用程序?
#### 查找 PPA 安装的软件包并将其移除
Ubuntu 软件中心无法移除 PPA 安装的软件包,你必须使用具有更多高级功能的 Synaptic 包管理器。
可以从软件中心安装 Synaptic 或使用以下命令进行安装:
```
sudo apt install synaptic
```
安装后,启动 Synaptic 包管理器并选择 “Origin”。你会看到添加到系统的各种软件仓库。PPA 条目将以前缀 PPA 进行标识,单击以查看 PPA 可用的包。已安装的软件前面会有恰当的符号进行标识。

*查找通过 PPA 安装的软件包*
找到包后,你可以从 Synaptic 删除它们。此外,也始终可以选择使用命令行进行移除:
```
sudo apt remove package_name
```
删除 PPA 安装的软件包后,你可以继续从 `sources.list` 中删除PPA。
#### 以图形界面的方式删除 PPA
在设置中打开 “软件和更新”,然后点击 “其他软件” 选项卡。查找要删除的 PPA:

此处你可以进项两项操作,可以取消选择 PPA 或选择 “删除” 选项。
区别在于,当你取消选择 PPA 条目时,系统将在 `/etc/apt/sources.list.d` 中的`ppa_name.list` 文件中注释掉仓库条目;但如果选择 “删除” 选项,将会删除 `/etc/apt/sources.list.d`目录中 `ppa_name.list` 文件里的仓库条目。
在这两种情况下,文件 `ppa_name.list` 都保留在所在的目录中,即使它是空的。
### 使用 PPA 安全吗?
这是一个主观问题。纯粹主义者厌恶 PPA,因为大多数时候 PPA 来自第三方开发者。但与此同时,PPA 在 Debian/Ubuntu 世界中很受欢迎,因为它们提供了更简单的安装选项。
就安全性而言,很少见到因为使用 PPA 之后你的 Linux 系统被黑客攻击或注入恶意软件。到目前为止,我不记得发生过这样的事件。
官方 PPA 可以不加考虑的使用,使用非官方 PPA 完全是你自己的决定。
根据经验,如果程序需要 sudo 权限,则应避免通过第三方 PPA 进行安装。
### 你如何看待使用 PPA?
我知道这篇文章需要挺长时间来阅读,但我想让你更好地了解 PPA。我希望这份详细指南能够回答你关于使用 PPA 的大部分问题。
如果你对 PPA 有更多疑问,请随时在评论区提问。
如果你发现任何技术或语法错误,或者有改进的建议,请告诉我。
---
via: <https://itsfoss.com/ppa-guide/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jlztan](https://github.com/jlztan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you have been using Ubuntu or some other Linux distribution based on Ubuntu such as Linux Mint, Linux Lite, Zorin OS etc, you may have come across three magical lines of this sort:
```
sudo add-apt-repository ppa:dr-akulavich/lighttable
sudo apt-get update
sudo apt-get install lighttable-installer
```
A number of websites suggest these kind of lines to [install applications in Ubuntu](https://itsfoss.com/remove-install-software-ubuntu/). This is what is called installing an application using PPA.
But what is PPA? Why is it used? Is it safe to use PPA? How to properly use PPA? How to delete a PPA?
I’ll answer all of the above questions in this detailed guide. Even if you already know a few things about PPAs, I am sure this article will still add to your knowledge.
Do note that I am writing this article using Ubuntu. Therefore I’ll use the term Ubuntu almost everywhere but the explanations and steps are also applicable to other Debian/Ubuntu based distributions.

## What is PPA?
PPA stands for Personal Package Archive. The PPA allows application developers and Linux users to create their own repositories to distribute software. With PPA, you can easily get newer software version or software that are not available via the official Ubuntu repositories.
Does that make sense? Probably not.
Before you understand PPA, you should know the concept of repositories in Linux. I won’t go into details here though.
### Concept of repositories and package management
A repository is a collection of files that has information about various software, their versions and some other details like the checksum. Each Ubuntu version has its own official set of four repositories:
**Main**– Canonical-supported free and open-source software.**Universe**– Community-maintained free and open-source software.**Restricted**– Proprietary drivers for devices.**Multiverse**– Software restricted by copyright or legal issues.
You can see such repositories for all Ubuntu versions [here](http://archive.ubuntu.com/ubuntu/dists/). You can browse through them and also go to the individual repositories. For example, Ubuntu 16.04 main repository can be found [here](http://archive.ubuntu.com/ubuntu/dists/xenial/main/).
So basically it’s a web URL that has information about the software. How does your system know where are these repositories?
This information is stored in the sources.list file in the directory /etc/apt. If you look at its content, you’ll see that it has the URL of the repositories. The lines with # at the beginning are ignored.
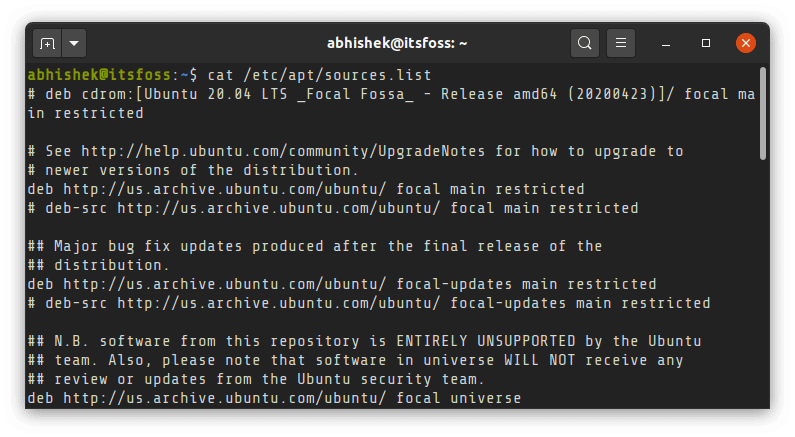
Now when you run the command sudo apt update, your system uses [APT tool](https://wiki.debian.org/Apt) to check against the repo and stores the information about the software and their version in a cache. When you use the command sudo apt install package_name, it uses the information to get that package from the URL where the actual software is stored.
If the repository doesn’t have the information about a certain package, you’ll see [unable to locate package error](https://itsfoss.com/unable-to-locate-package-error-ubuntu/):
`E: Unable to locate package`
At this point, I recommend reading my [guide to using apt commands](https://itsfoss.com/apt-command-guide/). This will give you a much better understanding of apt commands, update etc.
So this was about repositories. But what is PPA? How does it enter into the picture?
## Why is PPA used?
As you can see, Ubuntu controls what software and more importantly which version of a software you get on your system. But imagine if a software developer releases a new version of the software.
Ubuntu won’t make it available immediately. There is a procedure to check if the new version of the software is compatible with the system or not. This ensures the stability of the system.
But this also means that it will be some weeks or in some cases, some months before it is made available by Ubuntu. Not everyone would want to wait that long to get their hands on the new version of their favorite software.
Similarly, suppose someone develops a software and wants Ubuntu to include that software in the official repositories. It again will take months before Ubuntu makes a decision and includes it in the official repositories.
Another case would be during beta testing. Even if a stable version of the software is available in the official repositories, a software developer may want some end users to test their upcoming release. How do they enable the end user to beta test the upcoming release?
Enter PPA!
## How to use PPA? How does PPA work?
[PPA](https://launchpad.net/ubuntu/+ppas), as I already told you, means Personal Package Archive. Mind the word ‘Personal’ here. That gives the hint that this is something exclusive to a developer and is not officially endorsed by the distribution.
Ubuntu provides a platform called Launchpad that enables software developers to create their own repositories. An end user i.e. you can add the PPA repository to your sources.list and when you update your system, your system would know about the availability of this new software and you can install it using the standard sudo apt install command like this.
```
sudo add-apt-repository ppa:dr-akulavich/lighttable
sudo apt-get update
sudo apt-get install lighttable-installer
```
To summarize:
<– This command adds the PPA repository to the list.*sudo add-apt-repository <PPA_info>*<– This command updates the list of the packages that can be installed on the system.*sudo apt-get update*<– This command installs the package.*sudo*install <package_in_PPA>*apt-get*
You see that it is important to use the command sudo apt update or else your system will not know when a new package is available. Ubuntu 18.04 and higher versions automatically run the update to refresh the list of packages but I cannot vouch for other distributions. It’s a good practice to run this command.
Now let’s take a look at the first command in a bit more detail.
`sudo add-apt-repository ppa:dr-akulavich/lighttable`
You would notice that this command doesn’t have a URL to the repository. This is because the tool has been designed to abstract the information about URL from you.
Just a small note. If you add ppa:dr-akulavich/lighttable, you get Light Table. But if you add ppa:dr-akulavich, you’ll get all the repository or packages mentioned in the ‘upper repository’. It’s hierarchical.
Basically, when you add a PPA using add-apt-repository, it will do the same action as if you manually run these commands:
```
deb http://ppa.launchpad.net/dr-akulavich/lighttable/ubuntu YOUR_UBUNTU_VERSION_HERE main
deb-src http://ppa.launchpad.net/dr-akulavich/lighttable/ubuntu YOUR_UBUNTU_VERSION_HERE main
```
The above two lines are the traditional way to add any repositories to your sources.list. But PPA does it automatically for you, without wondering about the exact repository URL and operating system version.
One important thing to note here is that when you use PPA, it doesn’t change your original sources.list. Instead, it creates two files in /etc/apt/sources.list.d directory, a list and a back up file with suffix ‘save’.
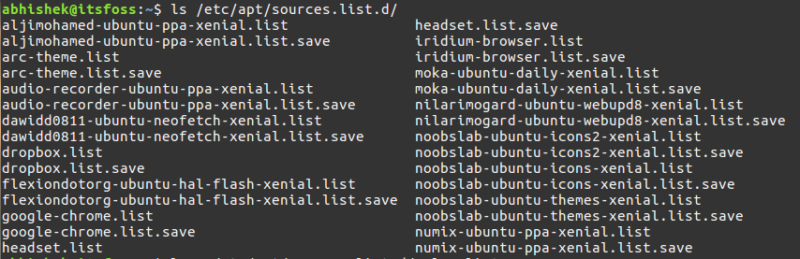
The files with suffix ‘list’ has the command that adds information about the repository.

This is a safety measure to ensure that adding PPAs doesn’t mess with the original [sources.list](https://itsfoss.com/sources-list-ubuntu/). It also helps in removing the PPA.
### Why PPA? Why not DEB packages?
You may ask why you should use PPA when it involves using the command line which might not be preferred by everyone. Why not just distribute a DEB package that can be installed graphically?
The answer lies in the update procedure. If you install software using a DEB package, there is no guarantee that the installed software will be updated to a newer version when you run sudo apt update && sudo apt upgrade.
It’s because the apt upgrade procedure relies on the sources.list. If there is no entry for software, it doesn’t get the update via the standard software updater.
So does it mean software installed using DEB never gets an update? No, not really. It depends on how the package was created.
Some developers automatically add an entry to the sources.list and then it is updated like regular software. Google Chrome is one such example.
Some software would notify you of the availability of a new version when you try to run it. You’ll have to download the new DEB package and run it again to update the current software to a newer version. Oracle Virtual Box is an example in this case.
For the rest of the DEB packages, you’ll have to manually look for an update and this is not convenient, especially if your software is meant for beta testers. You need to add more updates frequently. This is where PPA come to the rescue.
### Official PPA vs unofficial PPA
You may also hear the term official PPA or unofficial PPA. What’s the difference?
When developers create PPA for their software, it is called the official PPA. Quite obviously, because it is coming from none other than the project developers.
But at times, individuals create PPA of projects that were created by other developers.
Why would someone do that? Because many developers just provide the source code of the software and you know that [installing software from source code in Linux](https://itsfoss.com/install-software-from-source-code/) is a pain and not everyone could or would do that.
This is why volunteers take it upon themselves to create a PPA from those source code so that other users can install the software easily. After all, using those 3 lines is a lot easier than battling the source code installation.
How do you know if a PPA is official or not? Well, there is no straightforward way. Sometimes the developer's website mentions that they maintain a PPA. Sometimes the PPA page mentions that it is the official PPA.
### Make sure that a PPA is available for your distribution version
When it comes to using PPA in Ubuntu or any other Debian based distribution, there are a few things you should keep in mind.
Not every PPA is available for your particular version. You should know [which Ubuntu version](https://itsfoss.com/how-to-know-ubuntu-unity-version/) you are using. The codename of the release is important because when you go to the webpage of a certain PPA, you can see which Ubuntu versions are supported by the PPA.
For other Ubuntu-based distributions, you can check the content of /etc/os-release to [find out the Ubuntu version](https://itsfoss.com/how-to-know-ubuntu-unity-version/) information.
How to know the PPA url? Simply search on the internet with the PPA name like ppa:dr-akulavich/lighttable and you should get the first result from [Launchpad](https://launchpad.net/) website, the official platform for hosting PPA. You can also go to Launchpad and search for the required PPA directly there.
If you don’t verify and add the PPA, you may see an error like this when you try to install a software not available for your version.
`E: Unable to locate package`
What’s worse is that since it has been added to your source.list, each time you run software updater, you’ll see an error “[Failed to download repository information](https://itsfoss.com/failed-to-download-repository-information-ubuntu-13-04/)“.
If you run sudo apt update in the terminal, the error will have more details about which repository is causing the trouble. You can see something like this in the end of the output of sudo apt update:
```
W: Failed to fetch http://ppa.launchpad.net/venerix/pkg/ubuntu/dists/raring/main/binary-i386/Packages 404 Not Found
E: Some index files failed to download. They have been ignored, or old ones used instead.
```
Which is self-explanatory because the system cannot find the repository for your version. Remember what we saw earlier about repository structure? APT will try to look for software information in the place http://ppa.launchpad.net/<PPA_NAME>/ubuntu/dists/Ubuntu_Version
And if the PPA for the specific version is not available, it will never be able to open the URL and you get the famous 404 error.
### Why are PPAs not available for all the Ubuntu release versions?
It is because someone has to compile the software and create a PPA out of it on the specific versions. Considering that a new Ubuntu version is released every six months, it’s a tiresome task to update the PPA for every Ubuntu release. Not all developers have time to do that.
### How to install the application if PPA is not available for your version?
It is possible that though the PPA is not available for your Ubuntu version, you could still download the DEB file and install the application
Let’s say that you go to the Light Table PPA. Using the knowledge about PPA you just learned, you realize that the PPA is not available for your specific Ubuntu release.
What you can do is to click on the ‘View package details’.
And in here, you can click on a package to reveal more details. You’ll also find the source code and the DEB file of the package here.
I advise [using Gdebi to install these DEB files](https://itsfoss.com/gdebi-default-ubuntu-software-center/) instead of the Software Center because Gdebi is a lot better at handling dependencies.
Do note that the package installed this way might not get any future updates.
I think you have read enough about adding PPAs. How about removing a PPA and the software installed by it?
## How to delete PPA?
I have written about [deleting PPA](https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/) in the past. I am going to describe the same methods here as well.
I advise deleting the software that you installed from a PPA before removing the PPA. If you just remove the PPA, the installed software remains in the system but it won’t get any updates. You wouldn’t want that, would you?
So, the question comes, how to know which application was installed by which PPA?
### Find packages installed by a PPA and remove them
Ubuntu Software Center doesn’t help here. You’ll have to use Synaptic package manager here which has more advanced features.
You can [install Synaptic in Ubuntu](https://itsfoss.com/synaptic-package-manager/) from Software Center or use the command below:
`sudo apt install synaptic`
Once installed, start Synaptic package manager and select Origin. You’ll see various repositories added to the system. PPA entries will be labeled with prefix PPA. Click on them to see the packages that are available by the PPA. Installed software will have appropriate symbol before it.
Once you have found the packages, you can delete them from Synaptic itself. Otherwise, you always have the option to use the command line:
`sudo apt remove package_name`
Once you have removed the packages installed by a PPA, you can continue to remove the PPA from your sources.list.
### Remove a PPA graphically
Go to Software & Updates and then go to tab Other Software. Look for the PPA that you want to remove:
You have two options here. Either you deselect the PPA or you choose the Remove option.
The difference is that when you deselect a PPA entry, your system will comment out the repository entry in its ppa_name.list file in /etc/apt/sources.list.d but if you choose the Remove option, it will delete the repository entry from its ppa_name.list file in /etc/apt/sources.list.d directory.
In both cases, the files ppa_name.list remains in the said directory, even if it is empty.
## Is it safe to use PPA?
It is a subjective question. Purists abhor PPA because most of the time PPAs are from third-party developers. But at the same time, PPAs are popular in the Debian/Ubuntu world as they provide an easier installation option.
As far as security is concerned, it’s less likely that you use a PPA and your Linux system is hacked or injected with malware. I don’t recall such an incident ever happening so far.
Official PPAs can be used without thinking twice. Using unofficial PPA is entirely your decision.
As a rule of thumb, you should avoid installing a program via a third-party PPA if it the program requires sudo access to run.
## What do you think about using PPA?
I know it’s a long read but I wanted to give you a better understanding of PPA. I hope this detailed guide answered most of your questions about using PPA.
If you have more questions about PPA, please feel free to ask in the comment section.
If you notice any technical or grammatical errors or if you have suggestions for improving this article, please let me know. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.