
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
10,132 | 在 Linux 手册页中查看整个 Arch Linux Wiki | https://www.ostechnix.com/how-to-browse-and-read-entire-arch-wiki-as-linux-man-pages/ | 2018-10-19T23:23:02 | [
"Wiki",
"man"
] | https://linux.cn/article-10132-1.html | 
不久之前,我写了篇关于一个名叫 [arch-wiki-cli](https://www.ostechnix.com/search-arch-wiki-website-commandline/) 的命令行脚本的文章,使用它可以在终端命令行中查看 Arch Linux Wiki。使用这个脚本,你可以很轻松的用你喜欢的文本浏览器查看整个 Arch Wiki 网站。显然,使用这个脚本需要你有网络连接。我今天偶然发现了一个名为 Arch-wiki-man 的程序,与其有着相同的功能。就跟名字说的一样,它可以让你在命令行查看 Arch Wiki,但是无需联网。它可以以手册页的形式为你显示来自 Arch Wiki 的任何文章。它会下载整个 Arch Wiki 到本地,并每两天自动推送一次。因此,你的系统上总能有一份 Arch Wiki 最新的副本。
### 安装 Arch-wiki-man
Arch-wiki-man 在 [AUR](https://aur.archlinux.org/packages/arch-wiki-man/) 中可用,所以你可以通过类似[Yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/) 的 AUR 帮助程序安装它。
```
$ yay -S arch-wiki-man
```
另外,它也可以使用 NPM 安装。首先确保你已经[安装了 NoodJS](https://www.ostechnix.com/install-node-js-linux/),然后使用以下命令安装它。
```
$ npm install -g arch-wiki-man
```
### 以手册页的形式查看整个 Arch Wiki
Arch-wiki-man 的典型语法如下:
```
$ awman <search-query>
```
下面看一些具体的例子:
#### 搜索一个或多个匹配项
只需要下面的命令,就可以搜索 [Arch Linux 安装指南](https://www.ostechnix.com/install-arch-linux-latest-version/)。
```
$ awman Installation guide
```
上面的命令将会从 Arch Wiki 中搜索所有包含 “Installation guide” 的条目。如果对于给出的搜索条目有很多的匹配项,将会展示为一个选择菜单。使用上下方向键或是 Vim 风格的方向键(`j`/`k`),移动到你想查看的指南上,点击回车打开。然后就会像下面这样,以手册页的形式展示指南的内容。

awman 指的是 arch wiki man 的首字母组合。
它支持手册页的所有操作,所以你可以像使用手册页一样使用它。按 `h` 查看帮助选项。

要退出选择菜单而不显示手册页,只需要按 `Ctrl+c`。
输入 `q` 返回或者/并且退出手册页。
#### 在标题或者概述中搜索匹配项
awman 默认只会在标题中搜索匹配项。但是你也可以指定它同时在标题和概述中搜索匹配项。
```
$ awman -d vim
```
或者,
```
$ awman --desc-search vim
```
#### 在目录中搜索匹配项
不同于在标题和概述中搜索匹配项,它也能够扫描整个内容以匹配。不过请注意,这样将会使搜索进程明显变慢。
```
$ awman -k emacs
```
或者,
```
$ awman --apropos emacs
```
#### 在 web 浏览器中打开搜索结果
如果你不想以手册页的形式查看 Arch Wiki 指南,你也可以像下面这样在 web 浏览器中打开它。
```
$ awman -w pacman
```
或者,
```
$ awman --web pacman
```
这条命令将会在 web 浏览器中打开匹配结果。请注意,使用这个选项需要网络连接。
#### 在其他语言中搜索
awman 默认打开的是英文的 Arch Wiki 页面。如果你想用其他的语言查看搜索结果,例如西班牙语,只需要像这样做:
```
$ awman -l spanish codecs
```

使用以下命令查看可用的语言:
```
$ awman --list-languages
```
#### 升级本地的 Arch Wiki 副本
就像我已经说过的,更新会每两天自动推送一次。或者你也可以使用以下命令手动更新。
```
$ awman-update
[email protected] /usr/lib/node_modules/arch-wiki-man
└── [email protected]
arch-wiki-md-repo has been successfully updated or reinstalled.
```
:)
---
via: <https://www.ostechnix.com/how-to-browse-and-read-entire-arch-wiki-as-linux-man-pages/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,133 | 一个简单而美观的跨平台播客应用程序 | https://www.ostechnix.com/cpod-a-simple-beautiful-and-cross-platform-podcast-app/ | 2018-10-19T23:40:08 | [
"pod"
] | https://linux.cn/article-10133-1.html | 
播客在过去几年中变得非常流行。 播客就是所谓的“<ruby> 信息娱乐 <rt> infotainment </rt></ruby>”,它们通常是轻松的,但也会为你提供有价值的信息。 播客在过去几年中已经非常火爆了,如果你喜欢某些东西,就很可能有个相关的播客。 Linux 桌面版上有很多播客播放器,但是如果你想要一些视觉上美观、有顺滑的动画并且可以在每个平台上运行的东西,那就并没有很多替代品可以替代 CPod 了。 CPod(以前称为 Cumulonimbus)是一个开源而成熟的播客应用程序,适用于 Linux、MacOS 和 Windows。
CPod 运行在一个名为 Electron 的东西上 —— 这个工具允许开发人员构建跨平台(例如 Windows、MacOS 和 Linux)的桌面图形化应用程序。 在本简要指南中,我们将讨论如何在 Linux 中安装和使用 CPod 播客应用程序。
### 安装 CPod
转到 CPod 的[发布页面](https://github.com/z-------------/CPod/releases)。 下载并安装所选平台的二进制文件。 如果你使用 Ubuntu / Debian,你只需从发布页面下载并安装 .deb 文件,如下所示。
```
$ wget https://github.com/z-------------/CPod/releases/download/v1.25.7/CPod_1.25.7_amd64.deb
$ sudo apt update
$ sudo apt install gdebi
$ sudo gdebi CPod_1.25.7_amd64.deb
```
如果你使用其他发行版,你可能需要使用发布页面中的 AppImage。
从发布页面下载 AppImage 文件。
打开终端,然后转到存储 AppImage 文件的目录。 更改权限以允许执行:
```
$ chmod +x CPod-1.25.7-x86_64.AppImage
```
执行 AppImage 文件:
```
$ ./CPod-1.25.7-x86_64.AppImage
```
你将看到一个对话框询问是否将应用程序与系统集成。 如果要执行此操作,请单击“yes”。
### 特征
#### 探索标签页

CPod 使用 Apple iTunes 数据库查找播客。 这很好,因为 iTunes 数据库是最大的这类数据库。 如果某个播客存在,那么很可能就在 iTunes 上。 要查找播客,只需使用探索部分中的顶部搜索栏即可。 探索部分还展示了一些受欢迎的播客。
#### 主标签页

主标签页在打开应用程序时是默认打开的。 主标签页显示你已订阅的所有播客的所有剧集的时间顺序列表。
在主页选项卡中,你可以:
1. 标记剧集阅读。
2. 下载它们进行离线播放
3. 将它们添加到播放队列中。

#### 订阅标签页

你当然可以订阅你喜欢的播客。 你可以在订阅标签页中执行的其他一些操作是:
1. 刷新播客艺术作品
2. 导出订阅到 .OPML 文件中,从 .OPML 文件中导入订阅。
#### 播放器

播放器可能是 CPod 最美观的部分。 该应用程序根据播客的横幅更改整体外观。 底部有一个声音可视化器。 在右侧,你可以查看和搜索此播客的其他剧集。
#### 缺点/缺失功能
虽然我喜欢这个应用程序,但 CPod 确实有一些特性和缺点:
1. 糟糕的 MPRIS 集成 —— 你可以从桌面环境的媒体播放器对话框中播放或者暂停播客,但这是不够的。 播客的名称未显示,你可以转到下一个或者上一个剧集。
2. 不支持章节。
3. 没有自动下载 —— 你必须手动下载剧集。
4. 使用过程中的 CPU 使用率非常高(即使对于 Electron 应用程序而言)。
### 总结
虽然它确实有它的缺点,但 CPod 显然是最美观的播客播放器应用程序,并且它具有最基本的功能。 如果你喜欢使用视觉上美观的应用程序,并且不需要高级功能,那么这就是你的完美应用。我知道我肯定会使用它。
你喜欢 CPod 吗? 请将你的意见发表在下面的评论中。
**资源**
* [CPod GitHub 仓库](https://github.com/z-------------/CPod)
---
via: <https://www.ostechnix.com/cpod-a-simple-beautiful-and-cross-platform-podcast-app/>
作者:[EDITOR](https://www.ostechnix.com/author/editor/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,134 | 介绍 Fedora 上的 Swift | https://fedoramagazine.org/introducing-swift-fedora/ | 2018-10-20T09:35:21 | [
"Swift"
] | https://linux.cn/article-10134-1.html | 
Swift 是一种使用现代方法构建安全性、性能和软件设计模式的通用编程语言。它旨在成为各种编程项目的最佳语言,从系统编程到桌面应用程序,以及扩展到云服务。继续阅读了解它以及如何在 Fedora 中尝试它。
### 安全、快速、富有表现力
与许多现代编程语言一样,Swift 被设计为比基于 C 的语言更安全。例如,变量总是在使用之前初始化。检查数组和整数是否溢出。内存自动管理。
Swift 将意图放在语法中。要声明变量,请使用 `var` 关键字。要声明常量,请使用 `let`。
Swift 还保证对象永远不会是 `nil`。实际上,尝试使用已知为 `nil` 的对象将导致编译时错误。当使用 `nil` 值时,它支持一种称为 **optional** 的机制。optional 可能包含 `nil`,但使用 `?` 运算符可以安全地解包。
更多的功能包括:
* 与函数指针统一的闭包
* 元组和多个返回值
* 泛型
* 对范围或集合进行快速而简洁的迭代
* 支持方法、扩展和协议的结构体
* 函数式编程模式,例如 `map` 和 `filter`
* 内置强大的错误处理
* 拥有 `do`、`guard`、`defer` 和 `repeat` 关键字的高级控制流
### 尝试 Swift
Swift 在 Fedora 28 中可用,包名为 **swift-lang**。安装完成后,运行 `swift` 并启动 REPL 控制台。
```
$ swift
Welcome to Swift version 4.2 (swift-4.2-RELEASE). Type :help for assistance.
1> let greeting="Hello world!"
greeting: String = "Hello world!"
2> print(greeting)
Hello world!
3> greeting = "Hello universe!"
error: repl.swift:3:10: error: cannot assign to value: 'greeting' is a 'let' constant
greeting = "Hello universe!"
~~~~~~~~ ^
3>
```
Swift 有一个不断发展的社区,特别的,有一个[工作组](https://swift.org/server/)致力于使其成为一种高效且有力的服务器端编程语言。请访问其[主页](http://swift.org)了解更多参与方式。
图片由 [Uillian Vargas](https://unsplash.com/photos/7oJpVR1inGk?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 发布在 [Unsplash](https://unsplash.com/search/photos/fast?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 上。
---
via: <https://fedoramagazine.org/introducing-swift-fedora/>
作者:[Link Dupont](https://fedoramagazine.org/author/linkdupont/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Swift is a general-purpose programming language built using a modern approach to safety, performance, and software design patterns. It aims to be the best language for a variety of programming projects, ranging from systems programming to desktop applications and scaling up to cloud services. Read more about it and how to try it out in Fedora.
## Safe, Fast, Expressive
Like many modern programming languages, Swift was designed to be safer than C-based languages. For example, variables are always initialized before they can be used. Arrays and integers are checked for overflow. Memory is automatically managed.
Swift puts intent right in the syntax. To declare a variable, use the *var* keyword. To declare a constant, use *let*.
Swift also guarantees that objects can never be *nil*; in fact, trying to use an object known to be *nil* will cause a compile-time error. When using a *nil* value is appropriate, it supports a mechanism called **optionals**. An optional may contain *nil*, but is safely unwrapped using the **?** operator.
Some additional features include:
- Closures unified with function pointers
- Tuples and multiple return values
- Generics
- Fast and concise iteration over a range or collection
- Structs that support methods, extensions, and protocols
- Functional programming patterns, e.g., map and filter
- Powerful error handling built-in
- Advanced control flow with do, guard, defer, and repeat keywords
## Try Swift out
Swift is available in Fedora 28 under then package name **swift-lang**. Once installed, run *swift* and the REPL console starts up.
$ swift Welcome to Swift version 4.2 (swift-4.2-RELEASE). Type :help for assistance. 1> let greeting="Hello world!" greeting: String = "Hello world!" 2> print(greeting) Hello world! 3> greeting = "Hello universe!" error: repl.swift:3:10: error: cannot assign to value: 'greeting' is a 'let' constant greeting = "Hello universe!" ~~~~~~~~ ^ 3>
Swift has a growing community, and in particular, a [work group](https://swift.org/server/) dedicated to making it an efficient and effective server-side programming language. Be sure to visit [its home page](http://swift.org) for more ways to get involved.
Photo by [Uillian Vargas](https://unsplash.com/photos/7oJpVR1inGk?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/search/photos/fast?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText).
## Lan
Swift is almost useless on linux-based operating system without a way to create iOS and macOS applications. 🙁
## Paul W. Frields
@Lan: Swift is used in scientific applications as well, independently of iOS and MacOS.
## Cris
What are the benefits of Swift over Julia? It was a rhetorical question. I understand that it’s good to have alternatives but I don’t see this expanding beyond the Apple ecosystem. Just another FireWire®
## Tpk
Swift is a first class language for Tensorflow for example
## Ray Scott
I don’t think Apple have ever had the intention of porting their frameworks to Linux. I believe Swift support on Linux is intended to be used for writing backend services, but even that’s not possible I imagine without Apple’s Foundation module.
## Link Dupont
The Swift binary distribution from swift.org and the source code distribution available on GitHub include an implementation of the Foundation module. From the README:
Fedora’s swift-lang package includes this module.
## Ray Scott
Thanks for informing me. I might actually give it a try! 🙂
## Robb
Do you know if SourceKittenDaemon is included, or might be in the future?
## Ron Olson
It isn’t included as it’s not officially part of Apple’s toolchain. I’d never heard of it until now; I’ll take a look to see how difficult it would be to package.
## Robb
Thanks! It’s the equivalent of Rust Racer – the editor plugin that really brings home the benefits of working with an inferencing, statically typed language.
## Ron Olson
The Linux version of Swift includes the Foundation framework, along with Dispatch (GCD on MacOS) and, specifically for Linux, Glibc.
## Ron Olson
My use of Swift on Linux has been to test out code, algorithms, etc.; I can log into a powerful 16-core Linux box and use multithreaded Swift code without dealing with my much older, and much slower, Mac.
## M Leslie Satenstein
As far as I know from what I read about recent C compilers, uninitialized pointers and arrays are Nulled. Numbers (int, a char, float, are set to zero at function prologue.
My gcc C compiler tells me about a variable’s first use before being set.
If not C, I would still use C. The human brain knows better how to manage memory allocations.
## Andi
So, Fedora opens up the possibility to use Swift in order to develop Apps on Fedora? Is it right? Normally, I have to do it with my iMac.
## Robb
Really happy to see support for Fedora!
IMO there’s one piece of the puzzle remaining, to develop Swift on Linux: autocomplete and other code intelligence support. And
thatwill only arrive if “SourceKittenDaemon” is ported to Linux:https://github.com/terhechte/SourceKittenDaemon/issues/74
Without this part of the picture, we can’t get a lot of the benefits from working with Swift: the smart development environment that helps out with documentation and more as we go.
So personally, I switched to Rust as my compiled, modern, friendly Linux development language. But I’d like to see Swift give it some competition.
## Robb
Really happy to see this support for Swift.
I gave Swift dev on Fedora a try, but the lack of an intelligent code plugin held me back:
https://github.com/terhechte/SourceKittenDaemon/issues/74
No, I don’t NEED autocompletion and in-place documentation to code, but it makes my life so much more pleasant. I gave Rust a try, and it’s pretty much fulfilling the Swift promise, on Linux. Rust’s “Racer” code intelligence app compiles fine.
I’d love to give Swift a real shot on Fedora, but without IDE/editor support, we don’t get the full benefits.
## Paul W. Frields
I believe one can get Swift plugins for VS Code, which is available on Fedora, if you want to use that.
## Robb
Thanks, yep – that’s the path I followed, which led me to the SourceKittenDaemon dependency. If I’m right, that’s the piece which actually does the heavy lifting for the Swift plugins in VSC, Emacs, etc.
## Ray
I tried that this afternoon, but the plugin complained about a missing SourceKit dependency. I think the VSCode plugins are only expected to work on macOS, and won’t work on Linux until the SourceKit related issues are resolved.
## ANDRE GOMPEL
For assertive programming, from C, to Erlang, Julia, Go, Rust, Swift (and more), so many “me too languages” who do almost the same thing as C (C99) !
For system low level, the differences are so minor, that rather than a yet another language (YAL), I would much prefer as “a pragma statement” at the beginning of the source file, a choice for “YAFC” (yet another flavor of C).
So in most case (I know it is not always easy) theses file could be linked together.
In most cases it is doable.
Noe that many years ago, DEC (Digital Equipment Corporation) almost achieved the same goal on VAX/VMS.
The main issues are :
* “multi-core” processing (Like in Erlang).
Memory management (Automatic garbage collection is rarely suitable for system low level, i.e self contained , without O/S resources).
Object Oriented (when available) name mangling.
In line assembly code (Often necessary for system low level).
I am not sure thought, that a language adequate for system low level, which include device drivers, scheduler, semaphores, access to memory, and I/O mapped, embedded system (without an OS)…) will be the same for “a great application level” programming language, which in most cases run on top of an O/S and all its resources.
Microsoft Visual Studio:
I know, many people love IDE’s (I still prefer the UNIX philosophy of separate solutions: compiler, linker, debugger, Makefiles or similar).
I see a danger for the Open Source, to leave the control wide open to a large corporation (Microsoft) for the much appreciated “Visual Studio”, for which there seem to be no great “pure open source” equivalent.
GTK+ and Qt provide decent GUI frameworks. (Not KDE, bloated, never finished). Wondering if it ever will be a great FOSS, IDE build with either one?
Please comment.
Andre Gompel
## Frederik
For C++, the combination of Gnome builder and glade works pretty well. You’re buying into the entire glib ecosystem which is a no-go for some — personally that was the case, but I’ve realize that you simply can’t get anything real done without buying into one ecosystem or another. I personally like how glib does things, more than I like how Qt does things (lot of legacy cruft that hasn’t been dumped). I use the C-API of Glib, not the C++ API, which loses a lot of values over the C API on it’s insistence on using classes.
Gnome builder lacks a few integrations out of the box. I’d love to see a glade plugin that will at least allow me to launch glade from the IDE; at the moment I have to open my UI files from somewhere outside of Gnome builder. The git plugin seems to be hidden somewhere on the internet, that I can’t find (please provide a link if you know where to find it).
Given it’s dependency on meson (which is awesome), I would love to see a better integration with the Gnome builder.
## Michael J. Ryan
FYI: Visual Studio Code is completely Open-Source with an MIT license [1]. Not to be confused with the Visual Studio IDE. It’s quickly become one of the best developer environments on the planet imho. I use it on Windows, Linux and Mac regularly, as I tend to prefer the same tools everywhere as much as possible.
[1] https://github.com/Microsoft/vscode
## Ron Olson
I can also confirm that VS Code has syntax highlighting for Swift under Linux; I’m using it right now. 🙂
## Elmmur
Actually, the VS Code application that Microsoft provides is closed source.
License, see 5. :
http://code.visualstudio.com/license
If you would like to use actually FOSS VS code, you have to build it yourself:
https://github.com/Microsoft/vscode/wiki/How-to-Contribute
Or use flatpak OSS version with MS marketplace integrated:
https://flathub.org/apps/details/com.visualstudio.code.oss
More details:
https://github.com/flathub/com.visualstudio.code.oss/issues/6#issuecomment-380152999
## Elmmur
Give KDevelop a chance.
GomeBuilder is deeply tied to gnome projects. They even pin gnome projects at the front page, which will be wholey dowloaded if you click on them. That actually holds me back from it. But yeah maybe that’s why it’s called Gnome Builder. Anyway, KDevelop looks more like a general purpouse IDE to me.
## Thomas An
Can we use the kind of libraries with swift in Fedora? For examples, GLib, Gtk, DBus and so on. If so, it would be nice 🙂
## Ron Olson
You can interact with native libraries/headers, etc. Take a look at this (now old) project I wrote to learn how to do this very thing: https://github.com/tachoknight/Crazy8sBot. You could just as well work with any other library via the ‘unsafe’ bindings.
## Van
We can do server side on linux with Vapor (https://github.com/vapor/vapor) or Kitura (https://github.com/IBM-Swift/Kitura), Perfect. Apple also developed SwiftNIO for supporting server side frameworks (https://github.com/apple/swift-nio)
## steve
I downloaded and tried it. sorry to be so selective but there is no gui? modern programming languages have good editors, gui and graphical design of the screens. this looks like it runs in vi and is terminal based only. useless in today’s world. Unless i am doing something wrong in which case please tell me what it is.
## Ron Olson
Turning it around, good editors know about languages; gcc does not come with its own editor, but most (all?) Linux-based editors know how to highlight C/C++ code (though sometimes there’s a disconnect between the editor highlighting and the language features
coughC++20 experimental features).Visual Studio Code provides syntax highlighting for Swift; there is no Linux-based XCode (yet!)
## Ron Olson
I mentioned this elsewhere, but in case you didn’t see it, you can use Visual Studio Code, Microsoft’s free editor, on Linux with Swift syntax highlighting. Because it has a built-in terminal, you can use the Swift REPL in the editor whilst writing Swift code; I do this all the time.
## Paul Dufresne
hum… tried:
import Glibc
at line 1 of swift, and it seems to generate a few errors.
## Ron Olson
This happens when the REPL can’t find its Linux headers; this isn’t unique to Fedora (I’ve seen it happen with the official Ubuntu versions as well) and the solution for me is to add:
alias swift=”swift -I /usr/lib/swift-lldb/swift/clang/include/”
in my shell configuration of choice (I use both bash and fish so in .bashrc or config.fish, respectively)
## Paul Dufresne
Works fine. Thanks! |
10,136 | 命令行小技巧:读取文件的不同方式 | https://fedoramagazine.org/commandline-quick-tips-reading-files-different-ways/ | 2018-10-21T00:05:18 | [
"文件"
] | https://linux.cn/article-10136-1.html | 
作为图形操作系统,Fedora 的使用是令人愉快的。你可以轻松地点击完成任何任务。但你可能已经看到了,在底层还有一个强大的命令行。想要在 shell 下体验,只需要在 Fedora 系统中打开你的终端应用。这篇文章是向你展示常见的命令行使用方法的系列文章之一。
在这部分,你将学习如何以不同的方式读取文件,如果你在系统中打开一个终端完成一些工作,你就有可能需要读取一两个文件。
### 一应俱全的大餐
对命令行终端的用户来说, `cat` 命令众所周知。 当你 `cat` 一个文件,你很容易的把整个文件内容展示在你的屏幕上。而真正发生在底层的是文件一次读取一行,然后一行一行写入屏幕。
假设你有一个文件,叫做 `myfile`, 这个文件每行只有一个单词。为了简单起见,每行的单词就是这行的行号,就像这样:
```
one
two
three
four
five
```
所以如果你 `cat` 这个文件,你就会看到如下输出:
```
$ cat myfile
one
two
three
four
five
```
并没有太惊喜,不是吗? 但是有个有趣的转折,只要使用 `tac` 命令,你可以从后往前 `cat` 这个文件。(请注意, Fedora 对这种有争议的幽默不承担任何责任!)
```
$ tac myfile
five
four
three
two
one
```
`cat` 命令允许你以不同的方式装饰输出,比如,你可以输出行号:
```
$ cat -n myfile
1 one
2 two
3 three
4 four
5 five
```
还有其他选项可以显示特殊字符和其他功能。要了解更多, 请运行 `man cat` 命令, 看完之后,按 `q` 即可退出回到 shell。
### 挑选你的食物
通常,文件太长会无法全部显示在屏幕上,您可能希望能够像文档一样查看它。 这种情况下,可以试试 `less` 命令:
```
$ less myfile
```
你可以用方向键,也可以用 `PgUp`/`PgDn` 来查看文件, 按 `q` 就可以退回到 shell。
实际上,还有一个 `more` 命令,其基于老式的 UNIX 系统命令。如果在退回 shell 后仍想看到该文件的内容,则可能需要使用它。而 `less` 命令则让你回到你离开 shell 之前的样子,并且清除屏幕上你看到的所有的文件内容。
### 一点披萨或甜点
有时,你所需的输出只是文件的开头。 比如,有一个非常长的文件,当你使用 `cat` 命令时,会显示这个文件所有内容,前几行的内容很容易滚动过去,导致你看不到。`head` 命令会帮你获取文件的前几行:
```
$ head -n 2 myfile
one
two
```
同样,你会用 `tail` 命令来查看文件的末尾几行:
```
$ tail -n 3 myfile
three
four
five
```
当然,这些只是在这个领域的几个简单的命令。但它们可以让你在阅读文件时容易入手。
---
via: <https://fedoramagazine.org/commandline-quick-tips-reading-files-different-ways/>
作者:[Paul W. Frields](https://fedoramagazine.org/author/pfrields/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[distant1219](https://github.com/distant1219) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fedora is delightful to use as a graphical operating system. You can point and click your way through just about any task easily. But you’ve probably seen there is a powerful command line under the hood. To try it out in a shell, just open the Terminal application in your Fedora system. This article is one in a series that will show you some common command line utilities.
In this installment you’ll learn how to read files in different ways. If you open a Terminal to do some work on your system, chances are good that you’ll need to read a file or two.
## The whole enchilada
The **cat** command is well known to terminal users. When you **cat** a file, you’re simply displaying the whole file to the screen. Really what’s happening under the hood is the file is read one line at a time, then each line is written to the screen.
Imagine you have a file with one word per line, called *myfile*. To make this clear, the file will contain the word equivalent for a number on each line, like this:
one two three four five
So if you **cat** that file, you’ll see this output:
$cat myfileone two three four five
Nothing too surprising there, right? But here’s an interesting twist. You can also **cat** that file backward. For this, use the **tac** command. (Note that Fedora takes no blame for this debatable humor!)
$tac myfilefive four three two one
The **cat** file also lets you ornament the file in different ways, in case that’s helpful. For instance, you can number lines:
$cat -n myfile1 one 2 two 3 three 4 four 5 five
There are additional options that will show special characters and other features. To learn more, run the command **man cat**, and when done just hit **q** to exit back to the shell.
## Picking over your food
Often a file is too long to fit on a screen, and you may want to be able to go through it like a document. In that case, try the **less** command:
$less myfile
You can use your arrow keys as well as **PgUp/PgDn** to move around the file. Again, you can use the **q** key to quit back to the shell.
There’s actually a **more** command too, based on an older UNIX command. If it’s important to you to still see the file when you’re done, you might want to use it. The **less** command brings you back to the shell the way you left it, and clears the display of any sign of the file you looked at.
## Just the appetizer (or dessert)
Sometimes the output you want is just the beginning of a file. For instance, the file might be so long that when you **cat** the whole thing, the first few lines scroll past before you can see them. The **head** command will help you grab just those lines:
$head -n 2 myfileone two
In the same way, you can use **tail** to just grab the end of a file:
$tail -n 3 myfilethree four five
Of course these are only a few simple commands in this area. But they’ll get you started when it comes to reading files.
## jun.zhou
thankyou.The article is very simple,but userfull.
## João Rodrigues
The name cat comes from the word concatenate (and not from the animal).
Another useful uses of head and tail (that I always mix-up) are the signed “-n” arguments.
tail -n +NUM makes tail start outputting at line NUM
So, if you would want to print all the lines except the first one, you’d use
$ tail -n +2 myfile
two
three
four
five
head -n -NUM outputs every line except the last NUM lines.
So, if you want to output everything but the last line:
$ head -n -1 myfile
one
two
three
four
## Paul W. Frields
Great additional tips, João! We were hoping these short articles would invite helpful comments like this.
## svsv sarma
Very educative and informative indeed. Different moods of the same command is interesting. With GUI, Terminal has lost its importance. But in Linux, particularly in Fedora, Terminal has its own significance, for use with DNF, APT and Dracut etc. I am beginning and trying hard to understand its power now.
However, with the command $ cat or $ tac, the Terminal stuns and no output is shown!
## Paul W. Frields
The reason no output is shown is that, if you don’t include a file name, both
catandtacexpect to be fed data from the standard input (usually provided by a pipe). We’ll definitely cover using the pipe in a future article.## ryuuy
better way is using Ruby
https://github.com/tombenner/ru
https://www.sitepoint.com/ru-ruby-shell/
$ru ‘map(:to_i).sum’ myfile
sum of numbers in file
## Rich
Launching an entire interpreted language to apply line numbers to text files is not a great use of the Unix commandline; especially when atomic Unix commands provide the functionality that’s sought.
That becomes particularly important when using shell built-in commands, like “printf” or “read”. One of the goals of scripting should be to do as much as possible in one process, without loading up external commands, or deferring to other interpreters. This is why you’ll often see forum applause when someone solves a tricky regex using only bash built-in string manipulation and matching; or using a minimum of external atomic commands like “tr”, “cat” and “tac”, etc.
## peter p
i also like using sed for printing lines of a file.
sed 25q
will print the first 25 lines.
while
sed -n 7,10p
prints lines 7 thru 10.
## Declan McNulty
My favourite is “tail -f “. The f stands for “follow”. As the file changes on disk, any additional lines appended to the end are immediately displayed.
Very useful for following a log file in real time for troubleshooting.
For example you could run:
tail -f /var/log/messages
…while asking a user to repeat some action that did not complete as expected last time.
## Rich
…or uppercase, “tail -F /path/to/file” which is useful for following a logfile that either doesn’t exist yet, or you expect to be rotated.
## Daniel
a very useful flag for tail is:
tail -f myfile
to output appended data as the file grows.
## John G
I had not noticed that
will keep the file output in the terminal after you exit, where
will not.
Thanks for this interesting fact!
## Mehdi
Nice article!
Also, one useful of tail that I learned from our network guy is the following:
tail -f filename
This shows the end content of the file real-time; very useful for observing log files for example on a development system.
## Ralph
You mentioned that less does clear the screen on quit, while more leaves the last viewed screen visible, and recommended to use the more pager if one wanted the last screen still visible on return to the shell prompt.
Although this is true for less’es default behaviour there is no need to use more any more (no pun intended) and one should ditch it, unless one is forced to view text files on legacy Unices like e.g. AIX, HP-UX or Solaris, where less per se isn’t available.
For the folks who are only out and about on Linux less should almost always be preferred.
If you want less to not clear the screen on quit simply use the -X option.
e.g.
less -X /etc/fstab
Now when you press q you will be returned to the shell prompt, but still see above it the last viewed screen page of the file you viewed.
If you require this behaviour in general and you are tired of always typing extra options that you need (also others besides -X), you could either set an alias (e.g. in your ~/.bashrc and export BASH_ENV=$HOME/.bashrc),
or export the environment variable LESS and assign it any numer of options that you could read about in man less (e.g. also in .bashrc or .bash_profile).
Or simply pass LESS=”-X” as environment to the immediately to the issued command.
e.g.
LESS=-X man less
## João Rodrigues
A less known fact about man is that you can render man pages in postscript format.
$ man -t bash > bash.ps
$ xdg-open bash.ps
It’s great if you need a printed version of a man page.
You can also read man pages in html
$ man –html=firefox bash
or
$ export BROWSER=$(which firefox)
$ man -H bash
## fmatejic
while read line; do printf “$line\n”; done < /etc/fstab
Without calling extend command 😉
## Barry
It’s interesting to me as someone who has used UNIX (since BSD 4.2) and Linux since the kernel version was less than 1! That newcomers see Linux as a GUI OS with an add-on command line! The history of UNIX/Linux is that it is a command line OS with a bolt-on GUI!
The power of the command line is incredible and no effort spent learning it is a waste. You can achieve lots, quickly and easily.
If you use Linux, learn something about the command line, don’t fear it! Its not difficult and could make you more productive.
As an example imagine you have 1000 photos in a directory with names like IMG0001.PNG and you wanted to rename them to img-.png where was replaced with the creation date… Could you do this from the GUI? I could (given a hot cup of coffee and a few mins) craft a command or script to do this.
## Ivan
Why not using awk? 🙂
1) Print the line from 3 to end:
awk ‘{if (NR>=3 ) {print $0}}’ filename
2) Print the line between 2 and 30:
awk ‘{if (NR>=2 && NR <=30 ) {print $0}}’ filename
3) print the lines from 1 to 10:
awk ‘{if (NR<=10) {print $0}}’ filename
## Rahul Karkhanis
Wonderfully written article …
My favourite is “nl”
The “nl ” also lets you ornament the file in different ways, in case that’s helpful. For instance, you can number lines:
$ nl myfile
1 one
2 two
3 three
4 four
5 five
do refer man page for much more interesting options |
10,137 | 如何在双系统引导下替换 Linux 发行版 | https://itsfoss.com/replace-linux-from-dual-boot/ | 2018-10-21T00:22:39 | [
"双引导"
] | https://linux.cn/article-10137-1.html |
>
> 在双系统引导的状态下,你可以将已安装的 Linux 发行版替换为另一个发行版,同时还可以保留原本的个人数据。
>
>
>

假设你的电脑上已经[以双系统的形式安装了 Ubuntu 和 Windows](https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/),但经过[将 Linux Mint 与 Ubuntu 比较](https://itsfoss.com/linux-mint-vs-ubuntu/)之后,你又觉得 [Linux Mint](https://www.linuxmint.com/) 会更适合自己的时候,你会怎样做?又该如何在[删除 Ubuntu](https://itsfoss.com/uninstall-ubuntu-linux-windows-dual-boot/) 的同时[在双系统中安装 Mint](https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/) 呢?
你或许觉得应该首先从在双系统中卸载 [Ubuntu](https://www.ubuntu.com/),然后使用 Linux Mint 重新安装成双系统。但实际上并不需要这么麻烦。
如果你已经在双系统引导中安装了一种 Linux 发行版,就可以轻松替换成另一个发行版了,而且也不必卸载已有的 Linux 发行版,只需要删除其所在的分区,然后在腾出的磁盘空间上安装另一个 Linux 发行版就可以了。
与此同时,更换 Linux 发行版后,仍然会保留原本 home 目录中包含所有文件。
下面就来详细介绍一下。
### 在双系统引导中替换 Linux 发行版
<https://youtu.be/ptF2RUehbKs>
这是我的演示范例。我使用双系统引导同时安装了 Windows 10 和 Linux Mint 19,然后我会把 Linux Mint 19 替换成 Elementary OS 5,同时在替换后保留我的个人文件(包括音乐、图片、视频和 home 目录中的文件)。
你需要做好以下这些准备:
* 使用 Linux 和 Windows 双系统引导
* 需要安装的 Linux 发行版的 USB live 版
* 在外部磁盘备份 Windows 和 Linux 中的重要文件(并非必要,但建议备份一下)
#### 在替换 Linux 发行版时要记住保留你的 home 目录
如果想让个人文件在安装新 Linux 系统的过程中不受影响,原有的 Linux 系统必须具有单独的 root 目录和 home 目录。你可能会发现我的[双系统引导教程](https://itsfoss.com/guide-install-elementary-os-luna/)在安装过程中不选择“与 Windows 共存”选项,而选择“其它”选项,然后手动创建 root 和 home 分区。所以,手动创建单独的 home 分区也算是一个磨刀不误砍柴工的操作。因为如果要在不丢失文件的情况下,将现有的 Linux 发行版替换为另一个发行版,需要将 home 目录存放在一个单独的分区上。
不过,你必须记住现有 Linux 系统的用户名和密码才能使用与新系统中相同的 home 目录。
如果你没有单独的 home 分区,也可以后续再进行创建。但这并不是推荐做法,因为这个过程会比较复杂,有可能会把你的系统搞乱。
下面来看看如何替换到另一个 Linux 发行版。
#### 步骤 1:为新的 Linux 发行版创建一个 USB live 版
尽管上文中已经提到了它,但我还是要重复一次以免忽略。
你可以使用 Windows 或 Linux 中的启动盘创建器(例如 [Etcher](https://etcher.io/))来创建 USB live 版,这个过程比较简单,这里不再详细叙述。
#### 步骤 2:启动 USB live 版并安装 Linux
你应该已经使用过双系统启动,对这个过程不会陌生。使用 USB live 版重新启动系统,在启动时反复按 F10 或 F12 进入 BIOS 设置。选择从 USB 启动,就可以看到进入 live 环境或立即安装的选项。
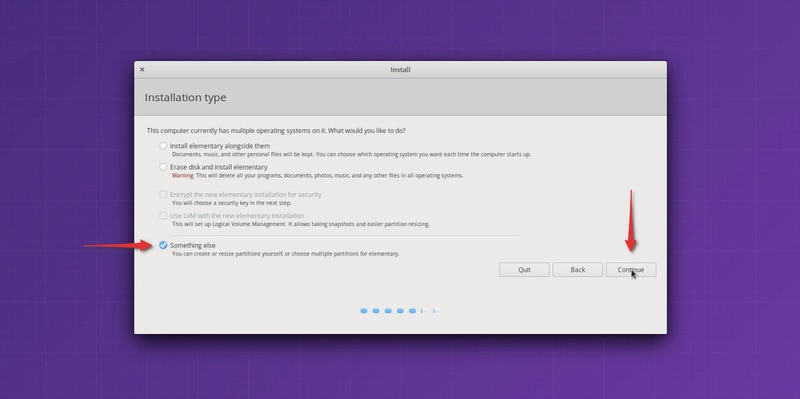
在安装过程中,进入“安装类型”界面时,选择“其它”选项。

*在这里选择“其它”选项*
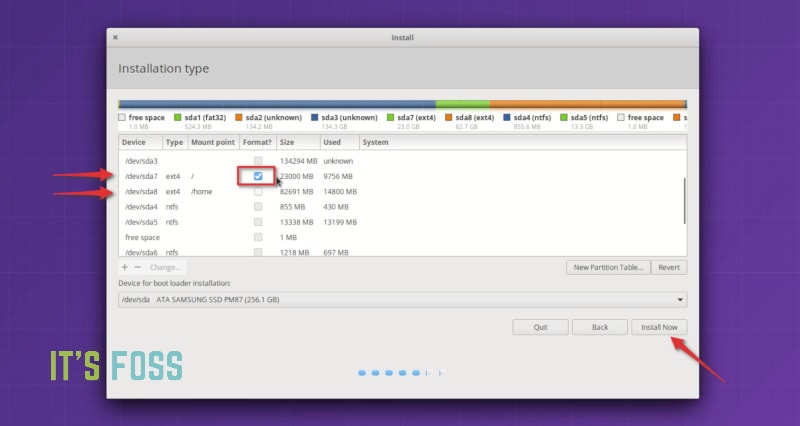
#### 步骤 3:准备分区操作
下图是分区界面。你会看到使用 Ext4 文件系统类型来安装 Linux。

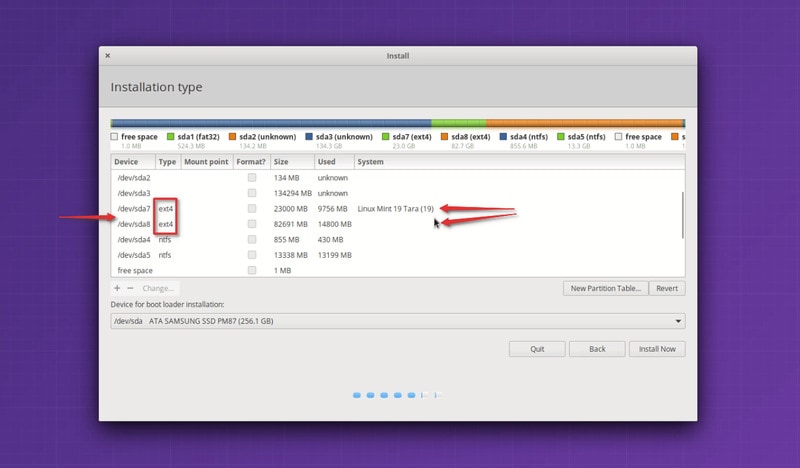
*确定 Linux 的安装位置*
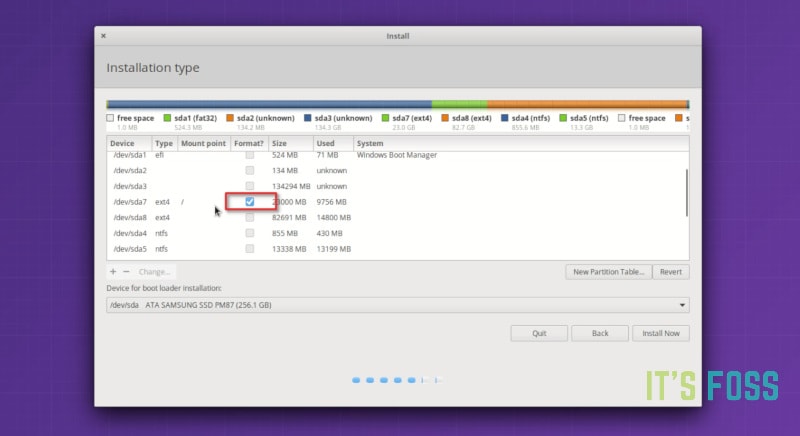
在上图中,标记为 Linux Mint 19 的 Ext4 分区是 root 分区,大小为 82691 MB 的第二个 Ext4 分区是 home 分区。在这里我这里没有使用[交换空间](https://itsfoss.com/swap-size/)。
如果你只有一个 Ext4 分区,就意味着你的 home 目录与 root 目录位于同一分区。在这种情况下,你就无法保留 home 目录中的文件了,这个时候我建议将重要文件复制到外部磁盘,否则这些文件将不会保留。
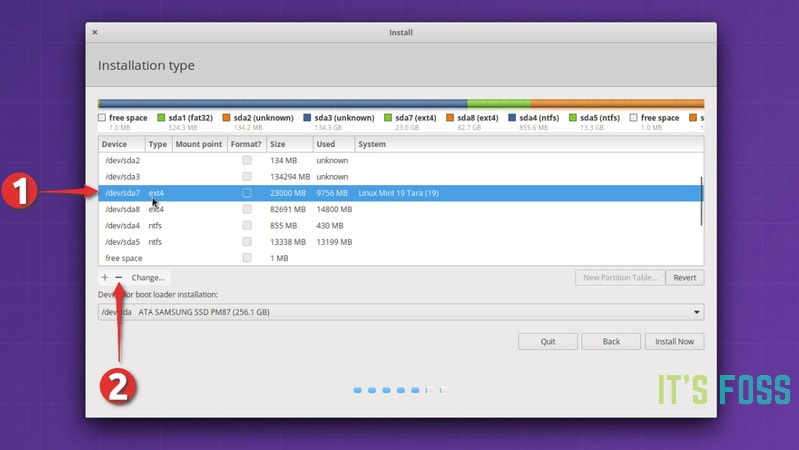
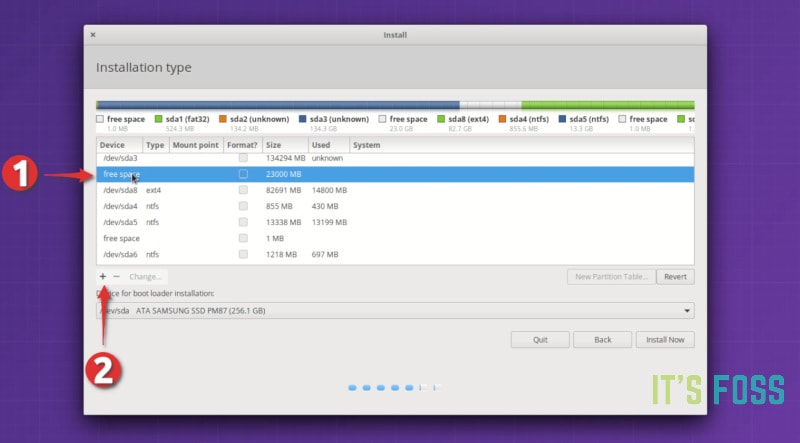
然后是删除 root 分区。选择 root 分区,然后点击 `-` 号,这个操作释放了一些磁盘空间。

*删除 root 分区*
磁盘空间释放出来后,点击 `+` 号。

*创建新的 root 分区*
现在已经在可用空间中创建一个新分区。如果你之前的 Linux 系统中只有一个 root 分区,就应该在这里创建 root 分区和 home 分区。如果需要,还可以创建交换分区。
如果你之前已经有 root 分区和 home 分区,那么只需要从已删除的 root 分区创建 root 分区就可以了。

*创建 root 分区*
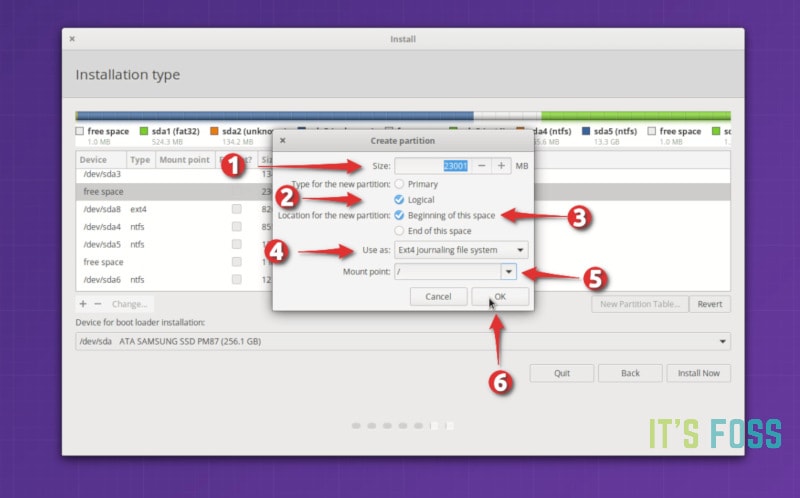
你可能有疑问,为什么要经过“删除”和“添加”两个过程,而不使用“更改”选项。这是因为以前使用“更改”选项好像没有效果,所以我更喜欢用 `-` 和 `+`。这是迷信吗?也许是吧。
这里有一个重要的步骤,对新创建的 root 分区进行格式化。在没有更改分区大小的情况下,默认是不会对分区进行格式化的。如果分区没有被格式化,之后可能会出现问题。

*格式化 root 分区很重要*
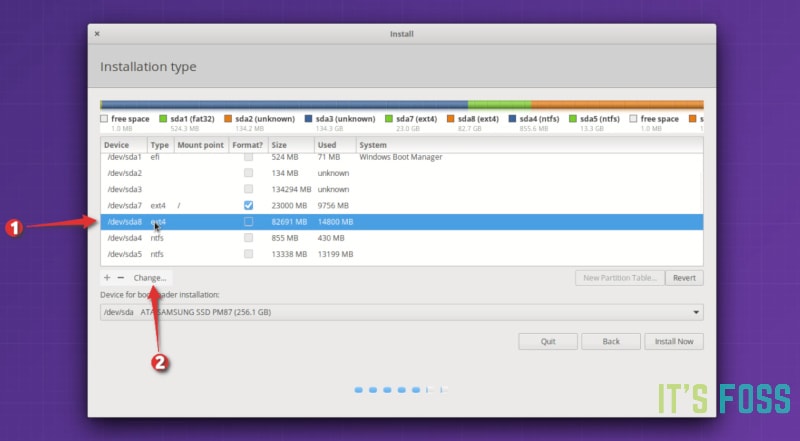
如果你在新的 Linux 系统上已经划分了单独的 home 分区,选中它并点击更改。

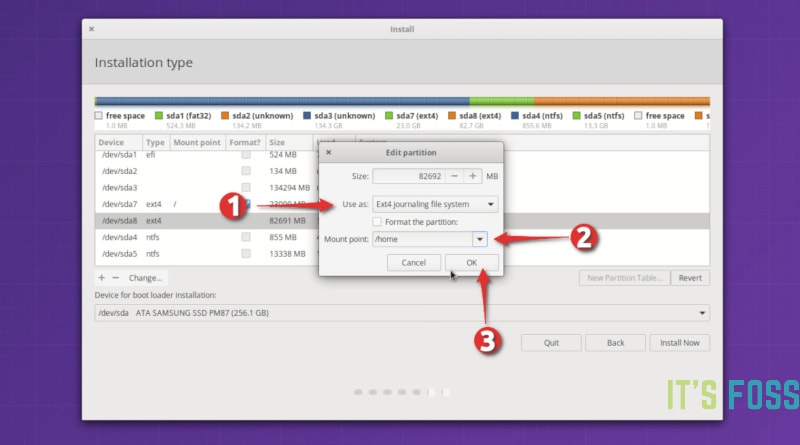
*修改已有的 home 分区*
然后指定将其作为 home 分区挂载即可。

*指定 home 分区的挂载点*
如果你还有交换分区,可以重复与 home 分区相同的步骤,唯一不同的是要指定将空间用作交换空间。
现在的状态应该是有一个 root 分区(将被格式化)和一个 home 分区(如果需要,还可以使用交换分区)。点击“立即安装”可以开始安装。

*检查分区情况*
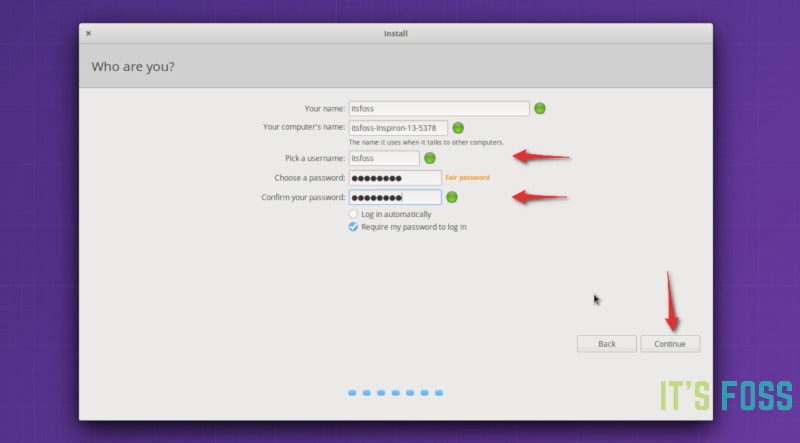
接下来的几个界面就很熟悉了,要重点注意的是创建用户和密码的步骤。如果你之前有一个单独的 home 分区,并且还想使用相同的 home 目录,那你必须使用和之前相同的用户名和密码,至于设备名称则可以任意指定。

*要保持 home 分区不变,请使用之前的用户名和密码*
接下来只要静待安装完成,不需执行任何操作。

*等待安装完成*
安装完成后重新启动系统,你就能使用新的 Linux 发行版。
在以上的例子中,我可以在新的 Linux Mint 19 中使用原有的 Elementary OS 中的整个 home 目录,并且其中所有视频和图片都原封不动。岂不美哉?
---
via: <https://itsfoss.com/replace-linux-from-dual-boot/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Suppose you managed to [successfully dual boot Ubuntu and Windows](https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/). But after reading the [Linux Mint versus Ubuntu discussion](https://itsfoss.com/linux-mint-vs-ubuntu/), you realized that [Linux Mint](https://www.linuxmint.com/?ref=itsfoss.com) is more suited for your needs. What would you do now? How would you [remove Ubuntu](https://itsfoss.com/uninstall-ubuntu-linux-windows-dual-boot/) and [install Mint in dual boot](https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/)?
You might think that you need to uninstall [Ubuntu](https://www.ubuntu.com/?ref=itsfoss.com) from dual boot first and then repeat the dual booting steps with Linux Mint. Let me tell you something. You don’t need to do all of that.
If you already have a Linux distribution installed in dual boot, you can easily replace it with another. You simply delete its partition and install the new distribution on the disk space vacated by the previous distribution.
Another good news is that you *may* be able to keep your Home directory with all your documents and pictures while switching the Linux distributions.
Let me show you how to switch Linux distributions.
## Replace one Linux with another from dual boot
Let me describe the scenario I am going to use here. I have Linux Mint 19 installed on my system in dual boot mode with Windows 10. I am going to replace it with elementary OS 5. I’ll also keep my personal files (music, pictures, videos, documents from my home directory) while switching distributions.
Let’s first take a look at the requirements:
- A system with Linux and Windows dual boot
- Live USB of Linux you want to install
- Backup of your important files in Windows and in Linux on an external disk (optional yet recommended)
### Things to keep in mind for keeping your home directory while changing Linux distribution
If you want to keep your files from existing Linux install as it is, you must have a separate root and home directory. You might have noticed that in my [dual boot tutorials](https://itsfoss.com/guide-install-elementary-os-luna/), I always go for ‘Something Else’ option and then manually create root and home partitions instead of choosing ‘Install alongside Windows’ option. This is where all the troubles in manually creating separate home partition pay off.
Keeping Home on a separate partition is helpful in situations when you want to replace your existing Linux install with another without losing your files.
Note: You must remember the exact username and password of your existing Linux install in order to use the same home directory as it is in the new distribution.
If you don’t have a separate Home partition, you may create it later as well BUT I won’t recommend that. That process is slightly complicated and I don’t want you to mess up your system.
With that much background information, it’s time to see how to replace a Linux distribution with another.
### Step 1: Create a live USB of the new Linux distribution
Alright! I already mentioned it in the requirements but I still included it in the main steps to avoid confusion.
You can create a live USB using a start up disk creator like [Etcher](https://etcher.io/?ref=itsfoss.com) in Windows or Linux. The process is simple so I am not going to list the steps here.
### Step 2: Boot into live USB and proceed to installing Linux
Since you have already dual booted before, you probably know the drill. Plugin the live USB, restart your system and at the boot time, press F10 or F12 repeatedly to enter BIOS settings.
In here, choose to boot from the USB. And then you’ll see the option to try the live environment or installing it immediately.
You should start the installation procedure. When you reach the ‘Installation type’ screen, choose the ‘Something else’ option.
### Step 3: Prepare the partition
You’ll see the partitioning screen now. Look closely and you’ll see your Linux installation with Ext4 file system type.
In the above picture, the Ext4 partition labeled as Linux Mint 19 is the root partition. The second Ext4 partition of 82691 MB is the Home partition. I [haven’t used any swap space](https://itsfoss.com/swap-size/) here.
Now, if you have just one Ext4 partition, that means that your home directory is on the same partition as root. In this case, you won’t be able to keep your Home directory. I suggest that you copy the important files to an external disk else you’ll lose them forever.
It’s time to delete the root partition. Select the root partition and click the – sign. This will create some free space.
When you have the free space, click on + sign.
Now you should create a new partition out of this free space. If you had just one root partition in your previous Linux install, you should create root and home partitions here. You can also create the swap partition if you want to.
If you had root and home partition separately, just create a root partition from the deleted root partition.
You may ask why did I use delete and add instead of using the ‘change’ option. It’s because a few years ago, using change didn’t work for me. So I prefer to do a – and +. Is it superstition? Maybe.
One important thing to do here is to mark the newly created partition for format. f you don’t change the size of the partition, it won’t be formatted unless you explicitly ask it to format. And if the partition is not formatted, you’ll have issues.
Now if you already had a separate Home partition on your existing Linux install, you should select it and click on change.
You just have to specify that you are mounting it as home partition.
If you had a swap partition, you can repeat the same steps as the home partition. This time specify that you want to use the space as swap.
At this stage, you should have a root partition (with format option selected) and a home partition (and a swap if you want to). Hit the install now button to start the installation.
The next few screens would be familiar to you. What matters is the screen where you are asked to create user and password.
If you had a separate home partition previously and you want to use the same home directory, you MUST use the same username and password that you had before. Computer name doesn’t matter.
Your struggle is almost over. You don’t have to do anything else other than waiting for the installation to finish.
Once the installation is over, restart your system. You’ll have a new Linux distribution or version.
In my case, I had the entire home directory of Linux Mint 19 as it is in the elementary OS. All the videos, pictures I had remained as it is. Isn’t that nice? |
10,139 | 在 Linux 命令行中使用 ls 列出文件的技巧 | https://opensource.com/article/18/10/ls-command | 2018-10-22T08:27:00 | [
"ls"
] | https://linux.cn/article-10139-1.html |
>
> 学习一些 Linux `ls` 命令最有用的变化。
>
>
>

我在 Linux 中最先学到的命令之一就是 `ls`。了解系统中文件所在目录中的内容非常重要。能够查看和修改不仅仅是一些文件还有所有文件也很重要。
我的第一个 Linux 备忘录是[单页 Linux 手册](http://hackerspace.cs.rutgers.edu/library/General/One_Page_Linux_Manual.pdf),它于 1999 年发布,成了我的首选参考资料。当我开始探索 Linux 时,我把它贴在桌子上并经常参考它。它在第一页第一列的底部介绍了 `ls -l` 列出文件的命令。
之后,我将学习这个最基本命令的其它迭代。通过 `ls` 命令,我开始了解 Linux 文件权限的复杂性,以及哪些是我的文件,哪些需要 root 或者 sudo 权限来修改。随着时间的推移,我习惯了使用命令行,虽然我仍然使用 `ls -l` 来查找目录中的文件,但我经常使用 `ls -al`,这样我就可以看到可能需要更改的隐藏文件,比如那些配置文件。
根据 Eric Fischer 在 [Linux 文档项目](http://www.tldp.org/LDP/LG/issue48/fischer.html)中关于 `ls` 命令的文章,该命令的起源可以追溯到 1961 年 MIT 的<ruby> 相容分时系统 <rt> Compatible Time-Sharing System </rt></ruby>(CTSS)上的 `listf` 命令。当 CTSS 被 [Multics](https://en.wikipedia.org/wiki/Multics) 代替时,命令变为 `list`,并有像 `list -all` 的开关。根据[维基百科](https://en.wikipedia.org/wiki/Ls),`ls` 出现在 AT&T Unix 的原始版本中。我们今天在 Linux 系统上使用的 `ls` 命令来自 [GNU Core Utilities](http://www.gnu.org/s/coreutils/)。
大多数时候,我只使用几个迭代的命令。我通常用 `ls` 或 `ls -al` 查看目录内容,但是你还应该熟悉许多其它选项。
`ls -l` 提供了一个简单的目录列表:

在我的 Fedora 28 系统的手册页中,我发现 `ls` 还有许多其它选项,所有这些选项都提供了有关 Linux 文件系统的有趣且有用的信息。通过在命令提示符下输入 `man ls`,我们可以开始探索其它一些选项:

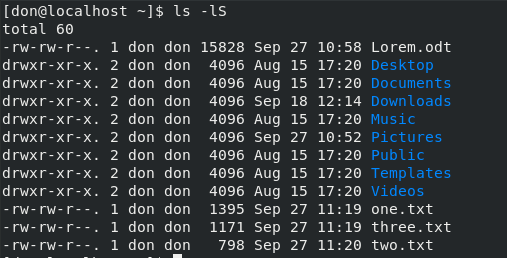
要按文件大小对目录进行排序,请使用 `ls -lS`:

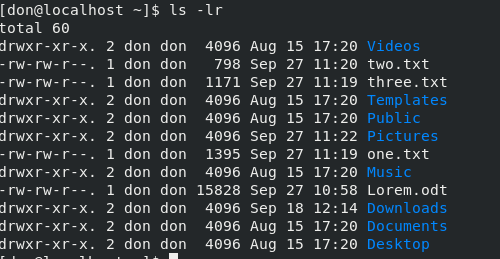
要以相反的顺序列出内容,请使用 `ls -lr`:

要按列列出内容,请使用 `ls -c`:

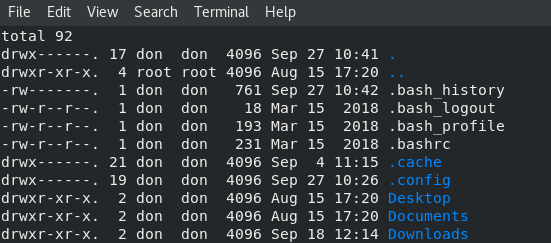
`ls -al` 提供了同一目录中所有文件的列表:

以下是我认为有用且有趣的一些其它选项:
* 仅列出目录中的 .txt 文件:`ls *.txt`
* 按文件大小列出:`ls -s`
* 按时间和日期排序:`ls -t`
* 按扩展名排序:`ls -X`
* 按文件大小排序:`ls -S`
* 带有文件大小的长格式:`ls -ls`
要生成指定格式的目录列表并将其定向到文件供以后查看,请输入 `ls -al > mydirectorylist`。最后,我找到的一个更奇特的命令是 `ls -R`,它提供了计算机上所有目录及其内容的递归列表。
有关 `ls` 命令的所有迭代的完整列表,请参阅 [GNU Core Utilities](https://www.gnu.org/software/coreutils/manual/html_node/ls-invocation.html#ls-invocation)。
---
via: <https://opensource.com/article/18/10/ls-command>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[pityonline](https://github.com/pityonline)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the first commands I learned in Linux was `ls`
. Knowing what’s in a directory where a file on your system resides is important. Being able to see and modify not just some but *all* of the files is also important.
My first LInux cheat sheet was the [One Page Linux Manual](http://hackerspace.cs.rutgers.edu/library/General/One_Page_Linux_Manual.pdf), which was released in1999 and became my go-to reference. I taped it over my desk and referred to it often as I began to explore Linux. Listing files with `ls -l`
is introduced on the first page, at the bottom of the first column.
Later, I would learn other iterations of this most basic command. Through the `ls`
command, I began to learn about the complexity of the Linux file permissions and what was mine and what required root or sudo permission to change. I became very comfortable on the command line over time, and while I still use `ls -l`
to find files in the directory, I frequently use `ls -al`
so I can see hidden files that might need to be changed, like configuration files.
According to an article by Eric Fischer about the `ls`
command in the [Linux Documentation Project](http://www.tldp.org/LDP/LG/issue48/fischer.html), the command's roots go back to the `listf`
command on MIT’s Compatible Time Sharing System in 1961. When CTSS was replaced by [Multics](https://en.wikipedia.org/wiki/Multics), the command became `list`
, with switches like `list -all`
. According to [Wikipedia](https://en.wikipedia.org/wiki/Ls), `ls`
appeared in the original version of AT&T Unix. The `ls`
command we use today on Linux systems comes from the [GNU Core Utilities](http://www.gnu.org/s/coreutils/).
Most of the time, I use only a couple of iterations of the command. Looking inside a directory with `ls`
or `ls -al`
is how I generally use the command, but there are many other options that you should be familiar with.
`$ ls -l`
provides a simple list of the directory:
Using the man pages of my Fedora 28 system, I find that there are many other options to `ls`
, all of which provide interesting and useful information about the Linux file system. By entering `man ls`
at the command prompt, we can begin to explore some of the other options:
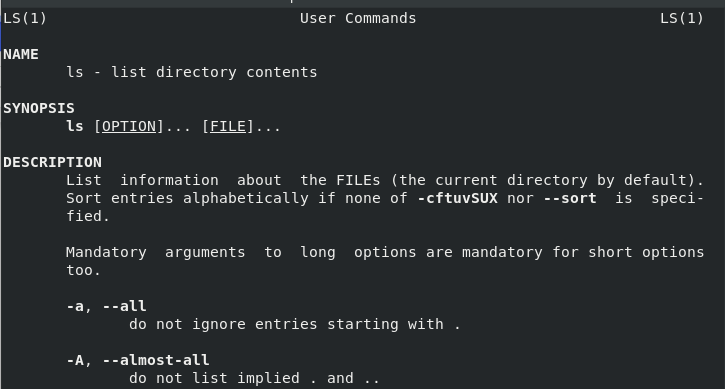
To sort the directory by file sizes, use `ls -lS`
:
To list the contents in reverse order, use `ls -lr`
:
To list contents by columns, use `ls -c`
:

`ls -al`
provides a list of all the files in the same directory:
Here are some additional options that I find useful and interesting:
- List only the .txt files in the directory:
`ls *.txt`
- List by file size:
`ls -s`
- Sort by time and date:
`ls -d`
- Sort by extension:
`ls -X`
- Sort by file size:
`ls -S`
- Long format with file size:
`ls -ls`
- List only the .txt files in a directory:
`ls *.txt`
To generate a directory list in the specified format and send it to a file for later viewing, enter `ls -al > mydirectorylist`
. Finally, one of the more exotic commands I found is `ls -R`
, which provides a recursive list of all the directories on your computer and their contents.
For a complete list of the all the iterations of the `ls`
command, refer to the [GNU Core Utilities](https://www.gnu.org/software/coreutils/manual/html_node/ls-invocation.html#ls-invocation).
## 4 Comments |
10,140 | PyTorch 1.0 预览版发布:Facebook 最新 AI 开源框架 | https://itsfoss.com/pytorch-open-source-ai-framework/ | 2018-10-22T08:44:30 | [] | https://linux.cn/article-10140-1.html | Facebook 在人工智能项目中广泛使用自己的开源 AI 框架 PyTorch,最近,他们已经发布了 PyTorch 1.0 的预览版本。
如果你尚不了解,[PyTorch](https://pytorch.org/) 是一个基于 Python 的科学计算库。
PyTorch 利用 [GPU 超强的运算能力](https://en.wikipedia.org/wiki/General-purpose_computing_on_graphics_processing_units) 来实现复杂的 [张量](https://en.wikipedia.org/wiki/Tensor) 计算 和 [深度神经网络](https://www.techopedia.com/definition/32902/deep-neural-network)。 因此, 它被世界各地的研究人员和开发人员广泛使用。
这一新的可以投入使用的 [预览版](https://code.fb.com/ai-research/facebook-accelerates-ai-development-with-new-partners-and-production-capabilities-for-pytorch-1-0) 已于 2018 年 10 月 2 日周二在旧金山 [The Midway](https://www.themidwaysf.com/) 举办的 [PyTorch 开发人员大会](https://pytorch.fbreg.com/) 宣布。
### PyTorch 1.0 候选版本的亮点

候选版本中的一些主要新功能包括:
#### 1、 JIT
JIT 是一个编译工具集,使研究和生产更加接近。 它包含一个基于 Python 语言的叫做 Torch Script 的脚本语言,也有能使现有代码与它自己兼容的方法。
#### 2、 全新的 torch.distributed 库: “C10D”
“C10D” 能够在不同的后端上启用异步操作, 并在较慢的网络上提高性能。
#### 3、 C++ 前端 (实验性功能)
虽然它被特别提到是一个不稳定的 API (估计是在预发行版中), 这是一个 PyTorch 后端的纯 C++ 接口, 遵循 API 和建立的 Python 前端的体系结构,以实现高性能、低延迟的研究和开发直接安装在硬件上的 C++ 应用程序。
想要了解更多,可以在 GitHub 上查看完整的 [更新说明](https://github.com/pytorch/pytorch/releases/tag/v1.0rc0)。
第一个 PyTorch 1.0 的稳定版本将在夏季发布。(LCTT 译注:此信息可能有误)
### 在 Linux 上安装 PyTorch
为了安装 PyTorch v1.0rc0, 开发人员建议使用 [conda](https://conda.io/), 同时也可以按照[本地安装页面](https://pytorch.org/get-started/locally/)所示,使用其他方法可以安装,所有必要的细节详见文档。
#### 前提
* Linux
* Pip
* Python
* [CUDA](https://www.pugetsystems.com/labs/hpc/How-to-install-CUDA-9-2-on-Ubuntu-18-04-1184/) (对于使用 Nvidia GPU 的用户)
我们已经知道[如何安装和使用 Pip](https://itsfoss.com/install-pip-ubuntu/),那就让我们来了解如何使用 Pip 安装 PyTorch。
请注意,PyTorch 具有 GPU 和仅限 CPU 的不同安装包。你应该安装一个适合你硬件的安装包。
#### 安装 PyTorch 的旧版本和稳定版
如果你想在 GPU 机器上安装稳定版(0.4 版本),使用:
```
pip install torch torchvision
```
使用以下两个命令,来安装仅用于 CPU 的稳定版:
```
pip install http://download.pytorch.org/whl/cpu/torch-0.4.1-cp27-cp27mu-linux_x86_64.whl
pip install torchvision
```
#### 安装 PyTorch 1.0 候选版本
使用如下命令安装 PyTorch 1.0 RC GPU 版本:
```
pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cu92/torch_nightly.html
```
如果没有GPU,并且更喜欢使用 仅限 CPU 版本,使用如下命令:
```
pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
```
#### 验证 PyTorch 安装
使用如下简单的命令,启动终端上的 python 控制台:
```
python
```
现在,按行输入下面的示例代码以验证您的安装:
```
from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
```
你应该得到如下输出:
```
tensor([[0.3380, 0.3845, 0.3217],
[0.8337, 0.9050, 0.2650],
[0.2979, 0.7141, 0.9069],
[0.1449, 0.1132, 0.1375],
[0.4675, 0.3947, 0.1426]])
```
若要检查是否可以使用 PyTorch 的 GPU 功能, 可以使用以下示例代码:
```
import torch
torch.cuda.is_available()
```
输出结果应该是:
```
True
```
支持 PyTorch 的 AMD GPU 仍在开发中, 因此, 尚未按[报告](https://github.com/pytorch/pytorch/issues/10657#issuecomment-415067478)提供完整的测试覆盖,如果您有 AMD GPU ,请在[这里](https://rocm.github.io/install.html#installing-from-amd-rocm-repositories)提出建议。
现在让我们来看看一些广泛使用 PyTorch 的研究项目:
### 基于 PyTorch 的持续研究项目
* [Detectron](https://github.com/facebookresearch/Detectron): Facebook AI 研究院的软件系统, 可以智能地进行对象检测和分类。它之前是基于 Caffe2 的。今年早些时候,Caffe2 和 PyTorch [合力](https://caffe2.ai/blog/2018/05/02/Caffe2_PyTorch_1_0.html)创建了一个研究 + 生产的 PyTorch 1.0
* [Unsupervised Sentiment Discovery](https://github.com/NVIDIA/sentiment-discovery): 广泛应用于社交媒体的一些算法
* [vid2vid](https://github.com/NVIDIA/vid2vid): 逼真的视频到视频的转换
* [DeepRecommender](https://github.com/NVIDIA/DeepRecommender/) 我们在过去的[网飞的 AI 文章](https://itsfoss.com/netflix-open-source-ai/)中介绍了这些系统是如何工作的
领先的 GPU 制造商英伟达在[更新](https://news.developer.nvidia.com/pytorch-1-0-accelerated-on-nvidia-gpus/)这方面最近的发展,你也可以阅读正在进行的合作的研究。
### 我们应该如何应对这种 PyTorch 的能力?
想到 Facebook 在社交媒体算法中应用如此令人惊叹的创新项目, 我们是否应该感激这一切或是感到惊恐?这几乎是[天网](https://en.wikipedia.org/wiki/Skynet_(Terminator))! 这一新改进的发布的 PyTorch 肯定会推动事情进一步向前! 在下方评论,随时与我们分享您的想法!
---
via: <https://itsfoss.com/pytorch-open-source-ai-framework/>
作者:[Avimanyu Bandyopadhyay](https://itsfoss.com/author/avimanyu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[distant1219](https://github.com/distant1219) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Facebook already uses its own Open Source AI,
For those who are not familiar, [PyTorch](https://pytorch.org/) is a Python-based library for Scientific Computing.
PyTorch harnesses the [superior computational power of Graphical Processing Units (GPUs)](https://en.wikipedia.org/wiki/General-purpose_computing_on_graphics_processing_units) for carrying out complex [Tensor](https://en.wikipedia.org/wiki/Tensor) computations and implementing [deep neural networks](https://www.techopedia.com/definition/32902/deep-neural-network). So, it is used widely across the world by numerous researchers and developers.
This new ready-to-use [Preview Release](https://code.fb.com/ai-research/facebook-accelerates-ai-development-with-new-partners-and-production-capabilities-for-pytorch-1-0) was announced at the [PyTorch Developer Conference](https://pytorch.fbreg.com/) at [The Midway](https://www.themidwaysf.com/), San Francisco, CA on Tuesday, October 2, 2018.
## Highlights of PyTorch 1.0 Release Candidate

Some of the main new features in the release candidate are:
### 1. JIT
JIT is a set of compiler tools to bring research close to production. It includes a Python-based language called Torch Script and also ways to make existing code compatible with itself.
### 2. New torch.distributed library: “C10D”
“C10D” enables asynchronous operation on different backends with performance improvements on slower networks and more.
### 3. C++ frontend (experimental)
Though it has been specifically mentioned as an unstable API (expected in a pre-release), this is a pure C++ interface to the PyTorch backend that follows the API and architecture of the established Python frontend to enable research in high performance, low latency and C++ applications installed directly on hardware.
To know more, you can take a look at the complete [update notes](https://github.com/pytorch/pytorch/releases/tag/v1.0rc0) on GitHub.
The first stable version PyTorch 1.0 will be released in summer.
## Installing PyTorch on Linux
To install PyTorch v1.0rc0, the developers recommend [using Conda](https://learnubuntu.com/install-conda/) while there also other ways to do that as shown on their [local installation page](https://pytorch.org/get-started/locally/) where they have documented everything necessary in detail.
### Prerequisites
- Linux
- Pip
- Python
[CUDA](https://www.pugetsystems.com/labs/hpc/How-to-install-CUDA-9-2-on-Ubuntu-18-04-1184/)(For Nvidia GPU owners)
As we recently showed you [how to install and use Pip](https://itsfoss.com/install-pip-ubuntu/), let’s get to know how we can install PyTorch with it.
Note that PyTorch has GPU and CPU-only variants. You should install the one that suits your hardware.
### Installing old and stable version of PyTorch
If you want the stable release (version 0.4) for your GPU, use:
`pip install torch torchvision`
Use these two commands in succession for a CPU-only stable release:
```
pip install http://download.pytorch.org/whl/cpu/torch-0.4.1-cp27-cp27mu-linux_x86_64.whl
pip install torchvision
```
### Installing PyTorch 1.0 Release Candidate
You install PyTorch 1.0 RC GPU version with this command:
`pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cu92/torch_nightly.html`
If you do not have a GPU and would prefer a CPU-only version, use:
`pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html`
### Verifying your PyTorch installation
Startup the python console on a terminal with the following simple command:
`python`
Now enter the following sample code line by line to verify your installation:
```
from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
```
You should get an output like:
```
tensor([[0.3380, 0.3845, 0.3217],
[0.8337, 0.9050, 0.2650],
[0.2979, 0.7141, 0.9069],
[0.1449, 0.1132, 0.1375],
[0.4675, 0.3947, 0.1426]])
```
To check whether you can use PyTorch’s GPU capabilities, use the following sample code:
```
import torch
torch.cuda.is_available()
```
The resulting output should be:
`True`
Support for AMD GPUs for PyTorch is still under development, so complete test coverage is not yet provided as reported [here](https://github.com/pytorch/pytorch/issues/10657#issuecomment-415067478), suggesting this [resource](https://rocm.github.io/install.html#installing-from-amd-rocm-repositories) in case you have an AMD GPU.
Lets now look into some research projects that extensively use PyTorch:
## Ongoing Research Projects based on PyTorch
[Detectron](https://github.com/facebookresearch/Detectron): Facebook AI Research’s software system to intelligently detect and classify objects. It is based on Caffe2. Earlier this year, Caffe2 and PyTorch[joined forces](https://caffe2.ai/blog/2018/05/02/Caffe2_PyTorch_1_0.html)to create a Research + Production enabled PyTorch 1.0 we talk about.[Unsupervised Sentiment Discovery](https://github.com/NVIDIA/sentiment-discovery): Such methods are extensively used with social media algorithms.[vid2vid](https://github.com/NVIDIA/vid2vid): Photorealistic video-to-video translation[DeepRecommender](https://github.com/NVIDIA/DeepRecommender/)(We covered how such systems work on our past[Netflix AI article](https://itsfoss.com/netflix-open-source-ai/))
Nvidia, leading GPU manufacturer covered more on this with their own [update](https://news.developer.nvidia.com/pytorch-1-0-accelerated-on-nvidia-gpus/) on this recent development where you can also read about ongoing collaborative research endeavours.
## How should we react to such PyTorch capabilities?
To think Facebook applies such amazingly innovative projects and more in its social media algorithms, should we appreciate all this or get alarmed? This is almost [Skynet](https://en.wikipedia.org/wiki/Skynet_(Terminator))! This newly improved production-ready pre-release of PyTorch will certainly push things further ahead! Feel free to share your thoughts with us in the comments below! |
10,143 | 如何在 Arch Linux(UEFI)上安装 GRUB | http://fasterland.net/how-to-install-grub-on-arch-linux-uefi.html | 2018-10-22T22:15:28 | [
"UEFI",
"GRUB"
] | https://linux.cn/article-10143-1.html | 
前段时间,我写了一篇在安装 Windows 后在 Arch Linux 上[如何重新安装 Grub](http://fasterland.net/reinstall-grub-arch-linux.html)的教程。
几周前,我不得不在我的笔记本上从头开始重新安装 Arch Linux,同时我发现安装 Grub 并不像我想的那么简单。
出于这个原因,由于在新安装 Arch Linux 时在 UEFI bios 中安装 Grub 并不容易,所以我要写这篇教程。
### 定位 EFI 分区
在 Arch Linux 上安装 Grub 的第一件重要事情是定位 EFI 分区。让我们运行以下命令以找到此分区:
```
# fdisk -l
```
我们需要检查标记为 EFI System 的分区,我这里是 `/dev/sda2`。
之后,我们需要在例如 `/boot/efi` 上挂载这个分区:
```
# mkdir /boot/efi
# mount /dev/sdb2 /boot/efi
```
另一件重要的事情是将此分区添加到 `/etc/fstab` 中。
#### 安装 Grub
现在我们可以在我们的系统中安装 Grub:
```
# grub-mkconfig -o /boot/grub/grub.cfg
# grub-install --target=x86_64-efi --efi-directory=/boot/efi --bootloader-id=GRUB
```
#### 自动将 Windows 添加到 Grub 菜单中
为了自动将 Windows 条目添加到 Grub 菜单,我们需要安装 os-prober:
```
# pacman -Sy os-prober
```
要添加它,让我们运行以下命令:
```
# os-prober
# grub-mkconfig -o /boot/grub/grub.cfg
# grub-install --target=x86_64-efi --efi-directory=/boot/efi --bootloader-id=GRUB
```
你可以在[这里](https://wiki.archlinux.org/index.php/GRUB)找到更多关于在 Arch Linux 上 Grub 的信息。
---
via: <http://fasterland.net/how-to-install-grub-on-arch-linux-uefi.html>
作者:[Francesco Mondello](http://fasterland.net/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,144 | 系统管理员需知的 16 个 iptables 使用技巧 | https://opensource.com/article/18/10/iptables-tips-and-tricks | 2018-10-22T22:48:44 | [
"iptables"
] | /article-10144-1.html |
>
> iptables 是一款控制系统进出流量的强大配置工具。
>
>
>

现代 Linux 内核带有一个叫 [Netfilter](https://en.wikipedia.org/wiki/Netfilter) 的数据包过滤框架。Netfilter 提供了允许、丢弃以及修改等操作来控制进出系统的流量数据包。基于 Netfilter 框架的用户层命令行工具 `iptables` 提供了强大的防火墙配置功能,允许你添加规则来构建防火墙策略。[iptables](https://en.wikipedia.org/wiki/Iptables) 丰富复杂的功能以及其巴洛克式命令语法可能让人难以驾驭。我们就来探讨一下其中的一些功能,提供一些系统管理员解决某些问题需要的使用技巧。
### 避免封锁自己
应用场景:假设你将对公司服务器上的防火墙规则进行修改,你需要避免封锁你自己以及其他同事的情况(这将会带来一定时间和金钱的损失,也许一旦发生马上就有部门打电话找你了)
#### 技巧 #1: 开始之前先备份一下 iptables 配置文件。
用如下命令备份配置文件:
```
/sbin/iptables-save > /root/iptables-works
```
#### 技巧 #2: 更妥当的做法,给文件加上时间戳。
用如下命令加时间戳:
```
/sbin/iptables-save > /root/iptables-works-`date +%F`
```
然后你就可以生成如下名字的文件:
```
/root/iptables-works-2018-09-11
```
这样万一使得系统不工作了,你也可以很快的利用备份文件恢复原状:
```
/sbin/iptables-restore < /root/iptables-works-2018-09-11
```
#### 技巧 #3: 每次创建 iptables 配置文件副本时,都创建一个指向最新的文件的链接。
```
ln –s /root/iptables-works-`date +%F` /root/iptables-works-latest
```
#### 技巧 #4: 将特定规则放在策略顶部,底部放置通用规则。
避免在策略顶部使用如下的一些通用规则:
```
iptables -A INPUT -p tcp --dport 22 -j DROP
```
你在规则中指定的条件越多,封锁自己的可能性就越小。不要使用上面非常通用的规则,而是使用如下的规则:
```
iptables -A INPUT -p tcp --dport 22 –s 10.0.0.0/8 –d 192.168.100.101 -j DROP
```
此规则表示在 `INPUT` 链尾追加一条新规则,将源地址为 `10.0.0.0/8`、 目的地址是 `192.168.100.101`、目的端口号是 `22` (`--dport 22` ) 的 TCP(`-p tcp` )数据包通通丢弃掉。
还有很多方法可以设置更具体的规则。例如,使用 `-i eth0` 将会限制这条规则作用于 `eth0` 网卡,对 `eth1` 网卡则不生效。
#### 技巧 #5: 在策略规则顶部将你的 IP 列入白名单。
这是一个有效地避免封锁自己的设置:
```
iptables -I INPUT -s <your IP> -j ACCEPT
```
你需要将该规则添加到策略首位置。`-I` 表示则策略首部插入规则,`-A` 表示在策略尾部追加规则。
#### 技巧 #6: 理解现有策略中的所有规则。
不犯错就已经成功了一半。如果你了解 iptables 策略背后的工作原理,使用起来更为得心应手。如果有必要,可以绘制流程图来理清数据包的走向。还要记住:策略的预期效果和实际效果可能完全是两回事。
### 设置防火墙策略
应用场景:你希望给工作站配置具有限制性策略的防火墙。
#### 技巧 #1: 设置默认规则为丢弃
```
# Set a default policy of DROP
*filter
:INPUT DROP [0:0]
:FORWARD DROP [0:0]
:OUTPUT DROP [0:0]
```
#### 技巧 #2: 将用户完成工作所需的最少量服务设置为允许
该策略需要允许工作站能通过 DHCP(`-p udp --dport 67:68 -sport 67:68`)来获取 IP 地址、子网掩码以及其他一些信息。对于远程操作,需要允许 SSH 服务(`-dport 22`),邮件服务(`--dport 25`),DNS 服务(`--dport 53`),ping 功能(`-p icmp`),NTP 服务(`--dport 123 --sport 123`)以及 HTTP 服务(`-dport 80`)和 HTTPS 服务(`--dport 443`)。
```
# Set a default policy of DROP
*filter
:INPUT DROP [0:0]
:FORWARD DROP [0:0]
:OUTPUT DROP [0:0]
# Accept any related or established connections
-I INPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT
-I OUTPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT
# Allow all traffic on the loopback interface
-A INPUT -i lo -j ACCEPT
-A OUTPUT -o lo -j ACCEPT
# Allow outbound DHCP request
-A OUTPUT –o eth0 -p udp --dport 67:68 --sport 67:68 -j ACCEPT
# Allow inbound SSH
-A INPUT -i eth0 -p tcp -m tcp --dport 22 -m state --state NEW -j ACCEPT
# Allow outbound email
-A OUTPUT -i eth0 -p tcp -m tcp --dport 25 -m state --state NEW -j ACCEPT
# Outbound DNS lookups
-A OUTPUT -o eth0 -p udp -m udp --dport 53 -j ACCEPT
# Outbound PING requests
-A OUTPUT –o eth0 -p icmp -j ACCEPT
# Outbound Network Time Protocol (NTP) requests
-A OUTPUT –o eth0 -p udp --dport 123 --sport 123 -j ACCEPT
# Outbound HTTP
-A OUTPUT -o eth0 -p tcp -m tcp --dport 80 -m state --state NEW -j ACCEPT
-A OUTPUT -o eth0 -p tcp -m tcp --dport 443 -m state --state NEW -j ACCEPT
COMMIT
```
### 限制 IP 地址范围
应用场景:贵公司的 CEO 认为员工在 Facebook 上花费过多的时间,需要采取一些限制措施。CEO 命令下达给 CIO,CIO 命令 CISO,最终任务由你来执行。你决定阻止一切到 Facebook 的访问连接。首先你使用 `host` 或者 `whois` 命令来获取 Facebook 的 IP 地址。
```
host -t a www.facebook.com
www.facebook.com is an alias for star.c10r.facebook.com.
star.c10r.facebook.com has address 31.13.65.17
whois 31.13.65.17 | grep inetnum
inetnum: 31.13.64.0 - 31.13.127.255
```
然后使用 [CIDR 到 IPv4 转换](http://www.ipaddressguide.com/cidr) 页面来将其转换为 CIDR 表示法。然后你得到 `31.13.64.0/18` 的地址。输入以下命令来阻止对 Facebook 的访问:
```
iptables -A OUTPUT -p tcp -i eth0 –o eth1 –d 31.13.64.0/18 -j DROP
```
### 按时间规定做限制 - 场景1
应用场景:公司员工强烈反对限制一切对 Facebook 的访问,这导致了 CEO 放宽了要求(考虑到员工的反对以及他的助理提醒说她负责更新他的 Facebook 页面)。然后 CEO 决定允许在午餐时间访问 Facebook(中午 12 点到下午 1 点之间)。假设默认规则是丢弃,使用 iptables 的时间功能便可以实现。
```
iptables –A OUTPUT -p tcp -m multiport --dport http,https -i eth0 -o eth1 -m time --timestart 12:00 –timestop 13:00 –d 31.13.64.0/18 -j ACCEPT
```
该命令中指定在中午12点(`--timestart 12:00`)到下午 1 点(`--timestop 13:00`)之间允许(`-j ACCEPT`)到 Facebook.com (`-d [31.13.64.0/18][5]`)的 http 以及 https (`-m multiport --dport http,https`)的访问。
### 按时间规定做限制 - 场景2
应用场景:在计划系统维护期间,你需要设置凌晨 2 点到 3 点之间拒绝所有的 TCP 和 UDP 访问,这样维护任务就不会受到干扰。使用两个 iptables 规则可实现:
```
iptables -A INPUT -p tcp -m time --timestart 02:00 --timestop 03:00 -j DROP
iptables -A INPUT -p udp -m time --timestart 02:00 --timestop 03:00 -j DROP
```
该规则禁止(`-j DROP`)在凌晨2点(`--timestart 02:00`)到凌晨3点(`--timestop 03:00`)之间的 TCP 和 UDP (`-p tcp and -p udp`)的数据进入(`-A INPUT`)访问。
### 限制连接数量
应用场景:你的 web 服务器有可能受到来自世界各地的 DoS 攻击,为了避免这些攻击,你可以限制单个 IP 地址到你的 web 服务器创建连接的数量:
```
iptables –A INPUT –p tcp –syn -m multiport -–dport http,https –m connlimit -–connlimit-above 20 –j REJECT -–reject-with-tcp-reset
```
分析一下上面的命令。如果单个主机在一分钟之内新建立(`-p tcp -syn`)超过 20 个(`-connlimit-above 20`)到你的 web 服务器(`--dport http,https`)的连接,服务器将拒绝(`-j REJECT`)建立新的连接,然后通知对方新建连接被拒绝(`--reject-with-tcp-reset`)。
### 监控 iptables 规则
应用场景:由于数据包会遍历链中的规则,iptables 遵循 “首次匹配获胜” 的原则,因此经常匹配的规则应该靠近策略的顶部,而不太频繁匹配的规则应该接近底部。 你怎么知道哪些规则使用最多或最少,可以在顶部或底部附近监控?
#### 技巧 #1: 查看规则被访问了多少次
使用命令:
```
iptables -L -v -n –line-numbers
```
用 `-L` 选项列出链中的所有规则。因为没有指定具体哪条链,所有链规则都会被输出,使用 `-v` 选项显示详细信息,`-n` 选项则显示数字格式的数据包和字节计数器,每个规则开头的数值表示该规则在链中的位置。
根据数据包和字节计数的结果,你可以将访问频率最高的规则放到顶部,将访问频率最低的规则放到底部。
#### 技巧 #2: 删除不必要的规则
哪条规则从来没有被访问过?这些可以被清除掉。用如下命令查看:
```
iptables -nvL | grep -v "0 0"
```
注意:两个数字 0 之间不是 Tab 键,而是 **5** 个空格。
#### 技巧 #3: 监控正在发生什么
可能你也想像使用 `top` 命令一样来实时监控 iptables 的情况。使用如下命令来动态监视 iptables 中的活动,并仅显示正在遍历的规则:
```
watch --interval=5 'iptables -nvL | grep -v "0 0"'
```
`watch` 命令通过参数 `iptables -nvL | grep -v “0 0“` 每隔 5 秒输出 iptables 的动态。这条命令允许你查看数据包和字节计数的变化。
### 输出日志
应用场景:经理觉得你这个防火墙员工的工作质量杠杠的,但如果能有网络流量活动日志最好了。有时候这比写一份有关工作的报告更有效。
使用工具 [FWLogwatch](http://fwlogwatch.inside-security.de/) 基于 iptables 防火墙记录来生成日志报告。FWLogwatch 工具支持很多形式的报告并且也提供了很多分析功能。它生成的日志以及月报告使得管理员可以节省大量时间并且还更好地管理网络,甚至减少未被注意的潜在攻击。
这里是一个 FWLogwatch 生成的报告示例:

### 不要满足于允许和丢弃规则
本文中已经涵盖了 iptables 的很多方面,从避免封锁自己、配置 iptables 防火墙以及监控 iptables 中的活动等等方面介绍了 iptables。你可以从这里开始探索 iptables 甚至获取更多的使用技巧。
---
via: <https://opensource.com/article/18/10/iptables-tips-and-tricks>
作者:[Gary Smith](https://opensource.com/users/greptile) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jrg](https://github.com/jrglinux) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,145 | 5 个很酷的平铺窗口管理器 | https://fedoramagazine.org/5-cool-tiling-window-managers/ | 2018-10-23T22:13:31 | [
"窗口管理器"
] | https://linux.cn/article-10145-1.html | 
Linux 桌面生态中有多种窗口管理器(WM)。有些是作为桌面环境的一部分开发的。有的则被用作独立程序。平铺窗口管理器就是这种情况,它提供了一个更轻量级的自定义环境。本文介绍了五种这样的平铺窗口管理器供你试用。
### i3
[i3](https://i3wm.org/) 是最受欢迎的平铺窗口管理器之一。与大多数其他此类 WM 一样,i3 专注于低资源消耗和用户可定制性。
您可以参考 [Magazine 上的这篇文章](https://fedoramagazine.org/getting-started-i3-window-manager/)了解 i3 安装细节以及如何配置它。
### sway
[sway](https://swaywm.org/) 是一个平铺 Wayland 合成器。它有与现有 i3 配置兼容的优点,因此你可以使用它来替换 i3 并使用 Wayland 作为显示协议。
您可以使用 `dnf` 从 Fedora 仓库安装 sway:
```
$ sudo dnf install sway
```
如果你想从 i3 迁移到 sway,这里有一个[迁移指南](https://github.com/swaywm/sway/wiki/i3-Migration-Guide)。
### Qtile
[Qtile](http://www.qtile.org/) 是另一个平铺管理器,也恰好是用 Python 编写的。默认情况下,你在位于 `~/.config/qtile/config.py` 下的 Python 脚本中配置 Qtile。当此脚本不存在时,Qtile 会使用默认[配置](https://github.com/qtile/qtile/blob/develop/libqtile/resources/default_config.py)。
Qtile 使用 Python 的一个好处是你可以编写脚本来控制 WM。例如,以下脚本打印屏幕详细信息:
```
> from libqtile.command import Client
> c = Client()
> print(c.screen.info)
{'index': 0, 'width': 1920, 'height': 1006, 'x': 0, 'y': 0}
```
要在 Fedora 上安装 Qlite,请使用以下命令:
```
$ sudo dnf install qtile
```
### dwm
[dwm](https://dwm.suckless.org/) 窗口管理器更侧重于轻量级。该项目的一个目标是保持 dwm 最小。例如,整个代码库从未超过 2000 行代码。另一方面,dwm 不容易定制和配置。实际上,改变 dwm 默认配置的唯一方法是[编辑源代码并重新编译程序](https://dwm.suckless.org/customisation/)。
如果你想尝试默认配置,你可以使用 `dnf` 在 Fedora 中安装 dwm:
```
$ sudo dnf install dwm
```
对于那些想要改变 dwm 配置的人,Fedora 中有一个 dwm-user 包。该软件包使用用户主目录中 `~/.dwm/config.h` 的配置自动重新编译 dwm。
### awesome
[awesome](https://awesomewm.org/) 最初是作为 dwm 的一个分支开发,使用外部配置文件提供 WM 的配置。配置通过 Lua 脚本完成,这些脚本允许你编写脚本以自动执行任务或创建 widget。
你可以使用这个命令在 Fedora 上安装 awesome:
```
$ sudo dnf install awesome
```
---
via: <https://fedoramagazine.org/5-cool-tiling-window-managers/>
作者:[Clément Verna](https://fedoramagazine.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Linux desktop ecosystem offers multiple window managers (WMs). Some are developed as part of a desktop environment. Others are meant to be used as standalone application. This is the case of tiling WMs, which offer a more lightweight, customized environment. This article presents five such tiling WMs for you to try out.
### i3
[i3](https://i3wm.org/) is one of the most popular tiling window managers. Like most other such WMs, i3 focuses on low resource consumption and customizability by the user.
You can refer to [this previous article in the Magazine](https://fedoramagazine.org/getting-started-i3-window-manager/) to get started with i3 installation details and how to configure it.
### sway
[sway](https://swaywm.org/) is a tiling Wayland compositor. It has the advantage of compatibility with an existing i3 configuration, so you can use it to replace i3 and use Wayland as the display protocol.
You can use *dnf* to install *sway* from Fedora repository:
$sudo dnf install sway
If you want to migrate from i3 to sway, there’s a small [migration guide](https://github.com/swaywm/sway/wiki/i3-Migration-Guide) available.
### Qtile
[Qtile](http://www.qtile.org/) is another tiling manager that also happens to be written in Python. By default, you configure Qtile in a Python script located under *~/.config/qtile/config.py.* When this script is not available, Qtile uses a default [configuration](https://github.com/qtile/qtile/blob/develop/libqtile/resources/default_config.py).
One of the benefits of Qtile being in Python is you can write scripts to control the WM. For example, the following script prints the screen details:
> from libqtile.command import Client > c = Client() > print(c.screen.info) {'index': 0, 'width': 1920, 'height': 1006, 'x': 0, 'y': 0}
To install Qlite on Fedora, use the following command:
$sudo dnf install qtile
### dwm
The [dwm](https://dwm.suckless.org/) window manager focuses more on being lightweight. One goal of the project is to keep dwm minimal and small. For example, the entire code base never exceeded 2000 lines of code. On the other hand, dwm isn’t as easy to customize and configure. Indeed, the only way to change dwm default configuration is to [edit the source code and recompile the application](https://dwm.suckless.org/customisation/).
If you want to try the default configuration, you can install dwm in Fedora using *dnf:*
$sudo dnf install dwm
For those who wand to change their dwm configuration, the *dwm-user *package is available in Fedora. This package automatically recompiles dwm using the configuration stored in the user home directory at *~/.dwm/config.h.*
### awesome
[awesome](https://awesomewm.org/) originally started as a fork of dwm, to provide configuration of the WM using an external configuration file. The configuration is done via Lua scripts, which allow you to write scripts to automate tasks or create widgets.
You can check out awesome on Fedora by installing it like this:
$sudo dnf install awesome
## Mark McIntyre
you have
for Qtile. it should be
.
## Clément Verna
Thanks updated
## Emiliano
Great article, thanks! (current awesome user :-P). I’ll try Sway, thanks!
## Hendrik
Note sway will soon release 1.0 version (https://github.com/swaywm/sway/issues/1735) backing up its own Wayland compositor library.
If you are a Awesome user you might want to check out Way Cooler which is a Wayland compositor implementing the Awesome api.
## John
Great article, but some screenshots would be nice, I think.
## freegoat
Why didn’t gTile get mentioned?
## Dann Griggs
i3 looks interesting, but I can reliably break it on my Fedora 28 install. Just install the basic i3 packages, log out of Gnome, and try it. Works fine, neat. Now exit i3 and do: ‘cp /etc/i3/config ~/.i3/config’. Try to start i3 again, it hangs during start up, no keystrokes work, and you have to switch to a VT to kill it. This makes customizing/configuring i3 a problem. Basically, if ~/.i3/config exists, you can’t start i3.
Anyone else run into this?
## Marian Šámal
Not sure, but I think the path should he ~/.config/i3/config
## Jens Petersen
There is also good ol’ xmonad, which is still well alive and kicking 🙂
waymonad is also under development.
## Sharlatan
How about StumpWM (CommonLisp base) so any configuration could load withing current session without lo-gout.
## svsv sarma
In the beginning, while learning, I used to tinker with WMs. But now I prefer the default GNOME and trust it to be memory friendly. So, forget about WMs and get on with the work.
## Nick
Pro-tip:
i3wm works very well when combined with the XFCE desktop environment.
Due to the modularity of XFCE you can easily replace the default window manager with i3 while retaining all the other niceties of a DE.
## Bill O
how about Xmonad?
## Bill O
I’ve tried a few times, moving from xmonad to i3, but never successfully.
## dg
I didn’t like i3 that much. I would love some detailed qtile and sway tutorial. Which is the most modern tiling manager? |
10,146 | 2018 年最好的 Linux 发行版 | https://www.linux.com/blog/learn/intro-to-linux/2018/1/best-linux-distributions-2018 | 2018-10-24T09:43:14 | [
"发行版",
"Linux"
] | https://linux.cn/article-10146-1.html | 
>
> Jack Wallen 分享他挑选的 2018 年最好的 Linux 发行版。
>
>
>
这是新的一年,Linux 仍有无限可能。而且许多 Linux 发行版在 2017 年都带来了许多重大的改变,我相信在 2018 年它在服务器和桌面上将会带来更加稳定的系统和市场份额的增长。
对于那些期待迁移到开源平台(或是那些想要切换到)的人对于即将到来的一年,什么是最好的选择?如果你去 [Distrowatch](https://distrowatch.com/) 找一下,你可能会因为众多的发行版而感到头晕,其中一些的排名在上升,而还有一些则恰恰相反。
因此,哪个 Linux 发行版将在 2018 年得到偏爱?我有我的看法。事实上,我现在就要和你们分享它。
跟我做的 [去年清单](https://www.linux.com/news/learn/sysadmin/best-linux-distributions-2017) 相似,我将会打破那张清单,使任务更加轻松。普通的 Linux 用户,至少包含以下几个类别:系统管理员,轻量级发行版,桌面,为物联网和服务器发行的版本。
根据这些,让我们开始 2018 年最好的 Linux 发行版清单吧。
### 对系统管理员最好的发行版
[Debian](https://www.debian.org/) 不常出现在“最好的”列表中。但它应该出现,为什么呢?如果了解到 Ubuntu 是基于 Debian 构建的(其实有很多的发行版都基于 Debian),你就很容易理解为什么这个发行版应该在许多“最好”清单中。但为什么是对管理员最好的呢?我想这是由于两个非常重要的原因:
* 容易使用
* 非常稳定
因为 Debain 使用 dpkg 和 apt 包管理,它使得使用该环境非常简单。而且因为 Debian 提供了最稳定的 Linux 平台之一,它为许多事物提供了理想的环境:桌面、服务器、测试、开发。虽然 Debian 可能不包括去年本分类的优胜者 [Parrot Linux](https://www.parrotsec.org/) 所带有的大量应用程序,但添加完成任务所需的任何或全部必要的应用程序都非常容易。而且因为 Debian 可以根据你的选择安装不同的桌面(Cinnamon、GNOME、KDE、LXDE、Mate 或者 Xfce),肯定可以满足你对桌面的需求。

*图 1:在 Debian 9.3 上运行的 GNOME 桌面。*
同时,Debain 在 Distrowatch 上名列第二。下载、安装,然后让它为你的工作而服务吧。Debain 尽管不那么华丽,但是对于管理员的工作来说十分有用。
### 最轻量级的发行版
轻量级的发行版有其特殊的用途:给予一些老旧或是性能低下的机器以新生。但是这不意味着这些特别的发行版仅仅只为了老旧的硬件机器而生。如果你想要的是运行速度,你可能会想知道在你的现代机器上这类发行版的运行速度能有多快。
在 2018 年上榜的最轻量级的发行版是 [Lubuntu](http://lubuntu.me/)。尽管在这个类别里还有很多选择,而且尽管 Lubuntu 的资源占用与 Puppy Linux 一样小,但得益于它是 Ubuntu 家庭的一员,其易用性为它加了分。但是不要担心,Lubuntu 对于硬件的要求并不高:
* CPU:奔腾 4 或者奔腾 M 或者 AMD K8 以上
* 对于本地应用,512 MB 的内存就可以了,对于网络使用(Youtube、Google+、Google Drive、Facebook),建议 1 GB 以上。
Lubuntu 使用的是 LXDE 桌面(图 2),这意味着新接触 Linux 的用户在使用这个发行版时不会有任何问题。这份简短清单中包含的应用(例如:Abiword、Gnumeric 和 Firefox)都是非常轻量的,且对用户友好的。

*图 2:LXDE桌面。*
Lubuntu 能让十年以上的电脑如获新生。
### 最好的桌面发行版
[Elementary OS](https://elementary.io/) 连续两年都是我清单中最好的桌面发行版。对于许多人,[Linux Mint](https://linuxmint.com/) (也是一个非常棒的分支)都是桌面发行版的领袖。但是,于我来说,它在易用性和稳定性上很难打败 Elementary OS。例如,我确信是 [Ubuntu](https://www.ubuntu.com/) 17.10 的发布让我迁移回了 Canonical 的发行版。迁移到新的使用 GNOME 桌面的 Ubuntu 不久之后,我发现我缺少了 Elementary OS 外观、可用性和感觉(图 3)。在使用 Ubuntu 两周以后,我又换回了 Elementary OS。

*图 3:Pantheon 桌面是一件像艺术品一样的桌面。*
使用 Elementary OS 的任何一个人都会觉得宾至如归。Pantheon 桌面是将操作顺滑和用户友好结合的最完美的桌面。每次更新,它都会变得更好。
尽管 Elementary OS 在 Distrowatch 页面访问量中排名第六,但我预计到 2018 年末,它将至少上升至第三名。Elementary 开发人员非常关注用户的需求。他们倾听并且改进,这个发行版目前的状态是如此之好,似乎他们一切都可以做的更好。 如果您需要一个具有出色可靠性和易用性的桌面,Elementary OS 就是你的发行版。
### 能够证明自己的最好的发行版
很长一段时间内,[Gentoo](https://www.gentoo.org/) 都稳坐“展现你技能”的发行版的首座。但是,我认为现在 Gentoo 是时候让出“证明自己”的宝座给 [Linux From Scratch(LFS)](http://www.linuxfromscratch.org/)。你可能认为这不公平,因为 LFS 实际上不是一个发行版,而是一个帮助用户创建自己的 Linux 发行版的项目。但是,有什么能比你自己创建一个自己的发行版更能证明自己所学的 Linux 知识的呢?在 LFS 项目中,你可以从头开始构建自定义的 Linux 系统,而且是从源代码开始。 所以,如果你真的想证明些什么,请下载 [Linux From Scratch Book](http://www.linuxfromscratch.org/lfs/download.html) 并开始构建。
### 对于物联网最好的发行版
[Ubuntu Core](https://www.ubuntu.com/core) 已经是第二年赢得了该项的冠军。Ubuntu Core 是 Ubuntu 的一个小型的、事务型版本,专为嵌入式和物联网设备而构建。使 Ubuntu Core 如此完美支持物联网的原因在于它将重点放在 snap 包上 —— 这种通用包可以安装到一个平台上而不会干扰其基本系统。这些 snap 包包含它们运行所需的所有内容(包括依赖项),因此不必担心安装它会破坏操作系统(或任何其他已安装的软件)。 此外,snap 包非常容易升级,并运行在隔离的沙箱中,这使它们成为物联网的理想解决方案。
Ubuntu Core 内置的另一个安全领域是登录机制。Ubuntu Core 使用Ubuntu One ssh密钥,这样登录系统的唯一方法是通过上传的 ssh 密钥到 [Ubuntu One帐户](https://login.ubuntu.com/)(图 4)。这为你的物联网设备提供了更高的安全性。

*图 4:Ubuntu Core屏幕指示通过Ubuntu One用户启用远程访问。*
### 最好的服务器发行版
这里有点意见不统一。主要原因是支持。如果你需要商业支持,乍一看,你最好的选择可能是 [Red Hat Enterprise Linux](https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux)。红帽年复一年地证明了自己不仅是全球最强大的企业服务器平台之一,而且是单一最赚钱的开源业务(年收入超过 20 亿美元)。
但是,Red Hat 并不是唯一的服务器发行版。 实际上,Red Hat 甚至并不能垄断企业服务器计算的各个方面。如果你关注亚马逊 Elastic Compute Cloud 上的云统计数据,Ubuntu 就会打败红帽企业 Linux。根据[云市场](http://thecloudmarket.com/stats#/by_platform_definition)的报告,EC2 统计数据显示 RHEL 的部署率低于 10 万,而 Ubuntu 的部署量超过 20 万。
最终的结果是,Ubuntu 几乎已经成为云计算的领导者。如果你将它与 Ubuntu 对容器的易用性和可管理性结合起来,就会发现 Ubuntu Server 是服务器类别的明显赢家。而且,如果你需要商业支持,Canonical 将为你提供 [Ubuntu Advantage](https://buy.ubuntu.com/?_ga=2.177313893.113132429.1514825043-1939188204.1510782993)。
对使用 Ubuntu Server 的一个警告是它默认为纯文本界面(图 5)。如果需要,你可以安装 GUI,但使用 Ubuntu Server 命令行非常简单(每个 Linux 管理员都应该知道)。

*图 5:Ubuntu 服务器登录,通知更新。*
### 你怎么看
正如我之前所说,这些选择都非常主观,但如果你正在寻找一个好的开始,那就试试这些发行版。每一个都可以用于非常特定的目的,并且比大多数做得更好。虽然你可能不同意我的个别选择,但你可能会同意 Linux 在每个方面都提供了惊人的可能性。并且,请继续关注下周更多“最佳发行版”选秀。
通过 Linux 基金会和 edX 的免费[“Linux 简介”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)课程了解有关Linux的更多信息。
---
via: <https://www.linux.com/blog/learn/intro-to-linux/2018/1/best-linux-distributions-2018>
作者:[JACK WALLEN](https://www.linux.com/users/jlwallen) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,147 | 写作是如何帮助技能拓展和事业成长的 | https://www.linux.com/blog/2018/9/how-writing-can-help-you-learn-new-skills-and-grow-your-career | 2018-10-24T10:30:00 | [
"写作"
] | https://linux.cn/article-10147-1.html |
>
> 了解为什么写作可以帮助学习新技能和事业成长
>
>
>

在最近的[温哥华开源峰会](https://events.linuxfoundation.org/events/open-source-summit-north-america-2018/)上,我参加了一个小组讨论,叫做“写作是如何改变你的职业生涯的(即使你不是个作家)”。主持人是 Opensource.com 的社区经理兼编辑 Rikki Endsley,成员有开源策略顾问 VM (Vicky) Brasseur,The New Stack 的创始人兼主编 Alex Williams,还有 The Scale Factory 的顾问 Dawn Foster。
Rikki 在她的[这篇文章](https://opensource.com/article/18/2/career-changing-magic-writing)中总结了一些令人愉快的,并且能以意想不到的方式改善你职业生涯的写作方法,我在峰会上的发言是受她这篇文章的启发。透露一下,我认识 Rikki 很久了,我们在同一家公司共事了很多年,一起带过孩子,到现在还是很亲密的朋友。
### 写作和学习
正如 Rikki 对这个小组讨论的描述,“即使你自认为不是一个‘作家’,你也应该考虑写一下对开源的贡献,还有你的项目或者社区”。写作是一种很好的方式,来分享自己的知识并让别人参与到你的工作中来,当然它对个人也有好处。写作能帮助你结识新人,学习新技能,还能改善你的沟通。
我发现写作能让我搞清楚自己对某个主题有哪些不懂的地方。写作的过程会让知识体系的空白很突出,这激励了我通过进一步的研究、阅读和提问来填补这些空白。
Rikki 说:“写那些你不知道的东西会更加困难也更加耗时,但是也更有成就感,更有益于你的事业。我发现写我不知道的东西有助于自己学习,因为得研究透彻才能给读者解释清楚。”
把你刚学到的东西写出来对其他也在学习这些知识的人是很有价值的。[Julia Evans](https://jvns.ca/) 经常在她的博客里写有关学习新技能的文章。她能把主题分解成一个个小的部分,这种方法对读者很友好,容易上手。Evans 在自己的博客中带领读者了解她的学习过程,指出在这个过程中哪些是对她有用的,哪些是没用的,基本消除了读者的学习障碍,为新手清扫了道路。
### 更明确的沟通
写作有助于思维训练和准确表达,尤其是面向国际受众写作(或演讲)时。例如,在[这篇文章中](https://www.linux.com/blog/event/open-source-summit-eu/2017/12/technical-writing-international-audience),Isabel Drost-Fromm 为那些母语不是英语的演讲者提供了几个技巧来消除歧义。不管是在会议上还是在自己团队内发言,写作还能帮你在演示幻灯片之前理清思路。
Rikki 说:“写文章的过程有助于我组织整理自己的发言和演示稿,也是一个给参会者提供笔记的好方式,还可以分享给没有参加活动的更多国际观众。”
如果你有兴趣,我鼓励你去写作。我强烈建议你参考这里提到的文章,开始思考你要写的内容。不幸的是,我们在开源峰会上的讨论没有记录下来,但我希望将来能再做一次讨论,分享更多的想法。
---
via: <https://www.linux.com/blog/2018/9/how-writing-can-help-you-learn-new-skills-and-grow-your-career>
作者:[Amber Ankerholz](https://www.linux.com/users/aankerholz) 选题:[lujun9972](https://github.com/lujun9972) 译者:[belitex](https://github.com/belitex) 校对:[pityonline](https://github.com/pityonline)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,148 | 你从不知道的 11 个 KDE 应用 | https://opensource.com/article/18/10/kde-applications | 2018-10-24T15:19:44 | [
"KDE"
] | https://linux.cn/article-10148-1.html |
>
> 你今天需要哪种有趣或奇特的应用?
>
>
>

Linux 桌面环境 KDE 于今年 10 月 14 日庆祝诞生 22 周年。KDE 社区用户创建了海量应用(并没有很多,但[也有不少](https://www.kde.org/applications/)),它们很多都提供有趣和奇特的服务。我们仔细看了该列表,并挑选出了你可能想了解的 11 个应用。
### 11 个你从没了解的 KDE 应用
1. [KTeaTime](https://www.kde.org/applications/games/kteatime/) 是一个泡茶计时器。选择你正在饮用的茶的类型 —— 绿茶、红茶、凉茶等 —— 当可以取出茶包来饮用时,计时器将会响。
2. [KTux](https://userbase.kde.org/KTux) 就是一个屏保程序……是么?Tux 用它的绿色飞船在外太空飞行。
3. [Blinken](https://www.kde.org/applications/education/blinken) 是一款基于 Simon Says 的记忆游戏,这是一个 1978 年发布的电子游戏。玩家们在记住长度增加的序列时会有挑战。
4. [Tellico](http://tellico-project.org/) 是一个收集管理器,用于组织你最喜欢的爱好。也许你还在收集棒球卡。也许你是红酒俱乐部的一员。也许你是一个严肃的书虫。也许三个都是!
5. [KRecipes](https://www.kde.org/applications/utilities/krecipes/) **不是** 简单的食谱管理器。它还有很多其他功能!购物清单、营养素分析、高级搜索、菜谱评级、导入/导出各种格式等。
6. [KHangMan](https://edu.kde.org/khangman/) 基于经典游戏 Hangman,你可以按逐个字母猜测单词。这个游戏有多种语言版本,这可以用来改善你学习另一种语言。它有四个分类,其中一个是“动物”,非常适合孩子。
7. [KLettres](https://edu.kde.org/klettres/) 是另一款可以帮助你学习新语言的应用。它教授字母表并挑战用户阅读和发音音节。
8. [KDiamond](https://games.kde.org/game.php?game=kdiamond) 类似于宝石迷阵或其他单人益智游戏,其中游戏的目标是搭建一定数量的相同类型的宝石或物体的行。这里是钻石。
9. [KolourPaint](https://www.kde.org/applications/graphics/kolourpaint/) 是一个非常简单的图像编辑工具,也可以用于创建简单的矢量图形。
10. [Kiriki](https://www.kde.org/applications/games/kiriki/) 是一款类似于 Yahtzee 的 2-6 名玩家的骰子游戏。
11. [RSIBreak](https://userbase.kde.org/RSIBreak) 居然没有以 K 开头!?它以“RSI”开头代表“<ruby> 重复性劳损 <rt> Repetitive Strain Injury </rt></ruby>” ,这会在日复一日长时间使用鼠标和键盘后发生。这个应用会提醒你休息,并可以个性化定制,以满足你的需求。
---
via: <https://opensource.com/article/18/10/kde-applications>
作者:[Opensource.com](https://opensource.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Linux desktop environment KDE celebrates its 22nd anniversary on October 14 this year. There are a gazillion* applications created by the KDE community of users, many of which provide fun and quirky services. We perused the list and picked out 11 applications you might like to know exist.
*Not really, but [there are a lot](https://www.kde.org/applications/).
## 11 KDE applications you never knew existed
1. [KTeaTime](https://www.kde.org/applications/games/kteatime/) is a timer for steeping tea. Set it by choosing the type of tea you are drinking—green, black, herbal, etc.—and the timer will ding when it's ready to remove the tea bag and drink.
2. [KTux](https://userbase.kde.org/KTux) is just a screensaver... or is it? Tux is flying in outer space in his green spaceship.
3. [Blinken](https://www.kde.org/applications/education/blinken) is a memory game based on Simon Says, an electronic game released in 1978. Players are challenged to remember sequences of increasing length.
4. [Tellico](http://tellico-project.org/) is a collection manager for organizing your favorite hobby. Maybe you still collect baseball cards. Maybe you're part of a wine club. Maybe you're a serious bookworm. Maybe all three!
5. [KRecipes](https://www.kde.org/applications/utilities/krecipes/) is **not** a simple recipe manager. It's got a lot going on! Shopping lists, nutrient analysis, advanced search, recipe ratings, import/export various formats, and more.
6. [KHangMan](https://edu.kde.org/khangman/) is based on the classic game Hangman where you guess the word letter by letter. This game is available in several languages, and it can be used to improve your learning of another language. It has four categories, one of which is "animals" which is great for kids.
7. [KLettres](https://edu.kde.org/klettres/) is another app that may help you learn a new language. It teaches the alphabet and challenges the user to read and pronounce syllables.
8. [KDiamond](https://games.kde.org/game.php?game=kdiamond) is similar to Bejeweled or other single player puzzle games where the goal of the game is to build lines of a certain number of the same type of jewel or object. In this case, diamonds.
9. [KolourPaint](https://www.kde.org/applications/graphics/kolourpaint/) is a very simple editing tool for your images or app for creating simple vectors.
10. [Kiriki](https://www.kde.org/applications/games/kiriki/) is a dice game for 2-6 players similar to Yahtzee.
11. [RSIBreak](https://userbase.kde.org/RSIBreak) doesn't start with a K. What!? It starts with an "RSI" for "Repetitive Strain Injury," which can occur from working for long hours, day in and day out, with a mouse and keyboard. This app reminds you to take breaks and can be personalized to meet your needs.
## 3 Comments |
10,151 | CPU 电源管理器:Linux 系统中 CPU 主频的控制和管理 | https://www.ostechnix.com/cpu-power-manager-control-and-manage-cpu-frequency-in-linux/ | 2018-10-24T23:07:26 | [
"CPU",
"电源管理"
] | https://linux.cn/article-10151-1.html | 
你使用笔记本的话,可能知道 Linux 系统的电源管理做的很不好。虽然有 **TLP**、[**Laptop Mode Tools** 和 **powertop**](https://www.ostechnix.com/improve-laptop-battery-performance-linux/) 这些工具来辅助减少电量消耗,但跟 Windows 和 Mac OS 系统比较起来,电池的整个使用周期还是不尽如意。此外,还有一种降低功耗的办法就是限制 CPU 的频率。这是可行的,然而却需要编写很复杂的终端命令来设置,所以使用起来不太方便。幸好,有一款名为 **CPU Power Manager** 的 GNOME 扩展插件,可以很容易的就设置和管理你的 CPU 主频。GNOME 桌面系统中,CPU Power Manager 使用名为 **intel\_pstate** 的频率调整驱动程序(几乎所有的 Intel CPU 都支持)来控制和管理 CPU 主频。
使用这个扩展插件的另一个原因是可以减少系统的发热量,因为很多系统在正常使用中的发热量总让人不舒服,限制 CPU 的主频就可以减低发热量。它还可以减少 CPU 和其他组件的磨损。
### 安装 CPU Power Manager
首先,进入[扩展插件主页面](https://extensions.gnome.org/extension/945/cpu-power-manager/),安装此扩展插件。
安装好插件后,在 GNOME 顶部栏的右侧会出现一个 CPU 图标。点击图标,会出现安装此扩展一个选项提示,如下示:

点击“尝试安装”按纽,会弹出输入密码确认框。插件需要 root 权限来添加 policykit 规则,进而控制 CPU 主频。下面是弹出的提示框样子:

输入密码,点击“认证”按纽,完成安装。最后在 `/usr/share/polkit-1/actions` 目录下添加了一个名为 `mko.cpupower.setcpufreq.policy` 的 policykit 文件。
都安装完成后,如果点击右上脚的 CPU 图标,会出现如下所示:

### 功能特性
* **查看 CPU 主频:** 显然,你可以通过这个提示窗口看到 CPU 的当前运行频率。
* **设置最大、最小主频:** 使用此扩展,你可以根据列出的最大、最小频率百分比进度条来分别设置其频率限制。一旦设置,CPU 将会严格按照此设置范围运行。
* **开/关 Turbo Boost:** 这是我最喜欢的功能特性。大多数 Intel CPU 都有 “Turbo Boost” 特性,为了提高额外性能,其中的一个内核为自动进行超频。此功能虽然可以使系统获得更高的性能,但也大大增加功耗。所以,如果不做 CPU 密集运行的话,为节约电能,最好关闭 Turbo Boost 功能。事实上,在我电脑上,我大部分时间是把 Turbo Boost 关闭的。
* **生成配置文件:** 可以生成最大和最小频率的配置文件,就可以很轻松打开/关闭,而不是每次手工调整设置。
### 偏好设置
你也可以通过偏好设置窗口来自定义扩展插件显示形式:

如你所见,你可以设置是否显示 CPU 主频,也可以设置是否以 **Ghz** 来代替 **Mhz** 显示。
你也可以编辑和创建/删除配置文件:

可以为每个配置文件分别设置最大、最小主频及开/关 Turbo boost。
### 结论
正如我在开始时所说的,Linux 系统的电源管理并不是最好的,许多人总是希望他们的 Linux 笔记本电脑电池能多用几分钟。如果你也是其中一员,就试试此扩展插件吧。为了省电,虽然这是非常规的做法,但有效果。我确实喜欢这个插件,到现在已经使用了好几个月了。
你对此插件有何看法呢?请把你的观点留在下面的评论区吧。
祝贺!
---
via: <https://www.ostechnix.com/cpu-power-manager-control-and-manage-cpu-frequency-in-linux/>
作者:[EDITOR](https://www.ostechnix.com/author/editor/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[runningwater](https://github.com/runningwater) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,152 | 万维网的创建者正在创建一个新的去中心化网络 | https://itsfoss.com/solid-decentralized-web/ | 2018-10-24T23:34:56 | [
"WWW",
"去中心化"
] | https://linux.cn/article-10152-1.html |
>
> 万维网(WWW)的创建者 Tim Berners-Lee 公布了他计划创建一个新的去中心化网络,该网络中的数据将由用户控制。
>
>
>
[Tim Berners-Lee](https://en.wikipedia.org/wiki/Tim_Berners-Lee) 以创建万维网而闻名,万维网就是你现在所知的互联网。二十多年之后,Tim 致力于将互联网从企业巨头的掌控中解放出来,并通过<ruby> 去中心化网络 <rt> Decentralized Web </rt></ruby>将权力交回给人们。
Berners-Lee 对互联网“强权”们处理用户数据的方式感到不满。所以他[开始致力于他自己的开源项目](https://medium.com/@timberners_lee/one-small-step-for-the-web-87f92217d085) Solid “来将在网络上的权力归还给人们”。
>
> Solid 改变了当前用户必须将个人数据交给数字巨头以换取可感知价值的模型。正如我们都已发现的那样,这不符合我们的最佳利益。Solid 是我们如何驱动网络进化以恢复平衡 —— 以一种革命性的方式,让我们每个人完全地控制数据,无论数据是否是个人数据。
>
>
>

基本上,[Solid](https://solid.inrupt.com/) 是一个使用现有网络构建的平台,在这里你可以创建自己的 “pod” (个人数据存储)。你决定这个 “pod” 将被托管在哪里,谁将访问哪些数据元素以及数据将如何通过这个 pod 分享。
Berners-Lee 相信 Solid “将以一种全新的方式,授权个人、开发者和企业来构思、构建和寻找创新、可信和有益的应用和服务。”
开发人员需要将 Solid 集成进他们的应用程序和网站中。 Solid 仍在早期阶段,所以目前没有相关的应用程序。但是项目网站宣称“第一批 Solid 应用程序正在开发当中”。
Berners-Lee 已经创立一家名为 [Inrupt](https://www.inrupt.com/) 的初创公司,并已从麻省理工学院休学术假来全职工作在 Solid,来将其”从少部分人的愿景带到多数人的现实“。
如果你对 Solid 感兴趣,可以[学习如何开发应用程序](https://solid.inrupt.com/docs/getting-started)或者以自己的方式[给项目做贡献](https://solid.inrupt.com/community)。当然,建立和推动 Solid 的广泛采用将需要大量的努力,所以每一点的贡献都将有助于去中心化网络的成功。
你认为[去中心化网络](https://tech.co/decentralized-internet-guide-2018-02)会成为现实吗?你是如何看待去中心化网络,特别是 Solid 项目的?
---
via: <https://itsfoss.com/solid-decentralized-web/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ypingcn](https://github.com/ypingcn) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Creator of the world wide web, Tim Berners-Lee has unveiled his plans to create a new decentralized web where the data will be controlled by the users.**
[Tim Berners-Lee](https://en.wikipedia.org/wiki/Tim_Berners-Lee) is known for creating the world wide web, i.e., the internet you know today. More than two decades later, Tim is working to free the internet from the clutches of corporate giants and give the power back to the people via a decentralized web.
Berners-Lee was unhappy with the way ‘powerful forces’ of the internet handle data of the users for their own agenda. So he [started working on his own open source project](https://medium.com/@timberners_lee/one-small-step-for-the-web-87f92217d085) Solid “to restore the power and agency of individuals on the web.”
Solid changes the current model where users have to hand over personal data to digital giants in exchange for perceived value. As we’ve all discovered, this hasn’t been in our best interests. Solid is how we evolve the web in order to restore balance — by giving every one of us complete control over data, personal or not, in a revolutionary way.

Basically, [Solid](https://solid.inrupt.com/) is a platform built using the existing web where you create own ‘pods’ (personal data store). You decide where this pod will be hosted, who will access which data element and how the data will be shared through this pod.
Berners-Lee believes that Solid “will empower individuals, developers and businesses with entirely new ways to conceive, build and find innovative, trusted and beneficial applications and services.”
Developers need to integrate Solid into their apps and sites. Solid is still in the early stages so there are no apps for now but the project website claims that “the first wave of Solid apps are being created now.”
Berners-Lee has created a startup called [Inrupt](https://www.inrupt.com/) and has taken a sabbatical from MIT to work full-time on Solid and to take it “from the vision of a few to the reality of many.”
If you are interested in Solid, [learn how to create apps](https://solid.inrupt.com/docs/getting-started) or [contribute to the project](https://solid.inrupt.com/community) in your own way. Of course, it will take a lot of effort to build and drive the broad adoption of Solid so every bit of contribution will count to the success of a decentralized web.
Do you think a [decentralized web](https://tech.co/decentralized-internet-guide-2018-02) will be a reality? What do you think of decentralized web in general and project Solid in particular? |
10,153 | 6 个托管 git 仓库的地方 | https://opensource.com/article/18/8/github-alternatives | 2018-10-25T14:35:51 | [
"Git",
"GitHub"
] | https://linux.cn/article-10153-1.html |
>
> GitHub 被收购导致一些用户去寻找这个流行的代码仓库的替代品。这里有一些你可以考虑一下。
>
>
>

也许你是少数一些没有注意到的人之一,就在之前,[微软收购了 GitHub](https://www.theverge.com/2018/6/4/17422788/microsoft-github-acquisition-official-deal)。两家公司达成了共识。微软在近些年已经变成了开源的有力支持者,而 GitHub 从成立起,就已经成为了大量的开源项目的实际代码库。
然而,最近发生的这次收购可能会带给你一些苦恼。毕竟公司的收购让你意识到了你的开源代码放在了一个商业平台上。可能你现在还没准备好迁移到其他的平台上去,但是至少这可以给你提供一些可选项。让我们找找网上现在都有哪些可用的平台。
### 选择之一: GitHub
严格来说,这是一个合格的选项。[GitHub](https://github.com/) 历史上没有什么失信的地方,而且微软后来也一直笑对开源。把你的项目继续放在 GitHub 上,保持观望没有什么不可以。它现在依然是最大的软件开发的网络社区,同时还有许多对于问题追踪、代码审查、持续集成、通用的代码管理等很有用的工具。而且它还是基于 Git 的,这是每个人都喜欢的开源版本控制系统。你的代码还是你的代码。如果没有出现什么问题,那保持原状是没错的。
### 选择之二: GitLab
[GitLab](https://gitlab.com) 是考虑替代代码库平台时的主要竞争者。它是完全开源的。你可以像在 GitHub 一样把你的代码托管在 GitLab,但你也可以选择在你自己的服务器上自行托管自己的 GitLab 实例,并完全控制谁可以访问那里的所有内容以及如何访问和管理。GitLab 与 GitHub 功能几乎相同,有些人甚至可能会说它的持续集成和测试工具更优越。尽管 GitLab 上的开发者社区肯定比 GitHub 上的开发者社区要小,但这并没有什么。你可能会在那里的人群中找到更多志同道合的开发者。
### 选择之三: Bitbucket
[Bitbucket](https://bitbucket.org) 已经存在很多年了。在某些方面,它可以作为 GitHub 未来的一面镜子。Bitbucket 八年前被一家大公司(Atlassian)收购,并且已经经历了一些变化。它仍然是一个像 GitHub 这样的商业平台,但它远不是一个创业公司,而且从组织上说它的基础相当稳定。Bitbucket 具有 GitHub 和 GitLab 上的大部分功能,以及它自己的一些新功能,如对 [Mercurial](https://www.mercurial-scm.org/wiki/Repository) 仓库的原生支持。
### 选择之四: SourceForge
[SourceForge](https://sourceforge.net) 是开源代码库的鼻祖。如果你曾经有一个开源项目,Sourceforge 就是那个托管你的代码并向其他人分享你的发布版本的地方。它迁移到 Git 版本控制用了一段时间,它有一些商业收购和再次收购的历史,以及一些对某些开源项目糟糕的捆绑决策。也就是说,SourceForge 从那时起似乎已经恢复,该网站仍然是一个有着不少开源项目的地方。然而,很多人仍然感到有点受伤,而且有些人并不是很支持它的平台货币化的各种尝试,所以一定要睁大眼睛。
### 选择之五: 自己管理
如果你想自己掌握自己项目的命运(除了你自己没人可以指责你),那么一切都由自己来做可能对你来说是最佳的选择。无论对于大项目还是小项目,都是好的选择。Git 是开源的,所以自己托管也很容易。如果你想要问题追踪和代码审查功能,你可以运行一个 GitLab 或者 [Phabricator](https://phacility.com/phabricator/) 的实例。对于持续集成,你可以设置自己的 [Jenkins](https://jenkins.io) 自动化服务实例。是的,你需要对自己的基础架构开销和相关的安全要求负责。但是,这个设置过程并不是很困难。所以如果你不想自己的代码被其他人的平台所吞没,这就是一种很好的方法。
### 选择之六:以上全部
以下是所有这些的美妙之处:尽管这些平台上有一些专有的选项,但它们仍然建立在坚实的开源技术之上。而且不仅仅是开源,而是明确设计为分布在大型网络(如互联网)上的多个节点上。你不需要只使用一个。你可以使用一对……或者全部。使用 GitLab 将你自己的设施作为保证的基础,并在 GitHub 和 Bitbucket 上安装克隆存储库,以进行问题跟踪和持续集成。将你的主代码库保留在 GitHub 上,但是出于你自己的考虑,可以在 GitLab 上安装“备份”克隆。
关键在于你可以选择。我们能有这么多选择,都是得益于那些非常有用而强大的项目之上的开源许可证。未来一片光明。
当然,在这个列表中我肯定忽略了一些开源平台。方便的话请补充给我们。你是否使用了多个平台?哪个是你最喜欢的?你都可以在这里说出来!
---
via: <https://opensource.com/article/18/8/github-alternatives>
作者:[Jason van Gumster](https://opensource.com/users/mairin) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Perhaps you're one of the few people who didn't notice, but a few months back, [Microsoft bought GitHub](https://www.theverge.com/2018/6/4/17422788/microsoft-github-acquisition-official-deal). Nothing against either company. Microsoft has become a vocal supporter of open source in recent years, and GitHub has been the de facto code repository for a heaping large number of open source projects almost since its inception.
However, the recent(-ish) purchase may have gotten you a little itchy. After all, there's nothing quite like a corporate buy-out to make you realize you've had your open source code sitting on a commercial platform. Maybe you're not quite ready to jump ship just yet, but it would at least be helpful to know your options. Let's have a look around the web and see what's available.
## Option 1: GitHub
Seriously, this is a valid option. [GitHub](https://github.com/) doesn't have a history of acting in bad faith, and Microsoft certainly has been smiling on open source of late. There's nothing wrong with keeping your project on GitHub and taking a wait-and-see perspective. It's still the largest community website for software development, and it still has some of the best tools for issue tracking, code review, continuous integration, and general code management. And its underpinnings are still on Git, everyone's favorite open source distributed version control system. Your code is still your code. There's nothing wrong with leaving things where they are if nothing is broken.
## Option 2: GitLab
[GitLab](https://gitlab.com) is probably the leading contender when it comes to alternative code platforms. It's fully open source. You can host your code right on GitLab's site much like you would on GitHub, but you can also choose to self-host a GitLab instance of your own on your own server and have full control over who has access to everything there and how things are managed. GitLab pretty much has feature parity with GitHub, and some folks might even say its continuous integration and testing tools are superior. Although the community of developers on GitLab is certainly smaller than the one on GitHub, it's still nothing to sneeze at. And it's possible that you'll find more like-minded developers among the population there.
## Option 3: Bitbucket
[Bitbucket](https://bitbucket.org) has been around for many years. In some ways, it could serve as a looking glass into the future of GitHub. Bitbucket was acquired by a larger corporation (Atlassian) eight years ago and has already been through some of that change-over process. It's still a commercial platform like GitHub, but it's far from being a startup, and it's on pretty stable footing, organizationally speaking. Bitbucket shares most of the features available on GitHub and GitLab, plus a few novel features of its own, like native support for [Mercurial](https://www.mercurial-scm.org/wiki/Repository) repositories.
## Option 4: SourceForge
The granddaddy of open source code repository sites is [SourceForge](https://sourceforge.net). It used to be that if you had an open source project, SourceForge was *the* place to host your code and share your releases. It took a little while to migrate to Git for version control, and it had its own rash of commercial acquiring and re-acquiring events, coupled with a few unfortunate bundling decisions for a few open source projects. That said, SourceForge seems to have recovered since then, and the site is still a place where quite a few open source projects live. A lot of folks still feel a bit burned, though, and some people aren't huge fans of its various attempts to monetize the platform, so be sure you go in with open eyes.
## Option 5: Roll your own
If you want full control of your project's destiny (and no one to blame but yourself), then doing it all yourself may be the best option for you. It is a good alternative for both large and small projects. Git is open source, so it's easily self-hosted. If you want issue tracking and code review, you can run an instance of GitLab or [Phabricator](https://phacility.com/phabricator/). For continuous integration, you can set up your own instance of the [Jenkins](https://jenkins.io) automation server. Yes, you'll need to take responsibility for your own infrastructure overhead and the associated security requirements. However, it's not that hard to get yourself set up. And if you want a sure-fire way to avoid being beholden to the whims of anyone else's platform, this is the way to do it.
## Option 6: All of the above
Here's the beauty of all of this: Despite the proprietary drapery strewn over some of these platforms, they're still built on top of solid open source technology. And not just open source, but explicitly designed to be distributed across multiple nodes on a large network (like the internet). You're not required to use just one. You can use a couple… or all of them. Roll your own setup as a guaranteed home base using GitLab and have clone repositories on GitHub and Bitbucket for issue tracking and continuous integration. Keep your main codebase on GitHub but have "backup" clones sitting on GitLab for your own piece of mind.
The key thing is you have options. And we have those options thanks to open source licensing on very useful and powerful projects. The future is bright.
Of course, I'm bound to have missed some of the open source options available out there. Feel free to pipe up with your favorites. Are you using multiple platforms? What's your setup? Let everyone know in the comments!
## 18 Comments |
10,154 | 如何使用 Apache Web 服务器配置多个站点 | https://opensource.com/article/18/3/configuring-multiple-web-sites-apache | 2018-10-25T15:38:35 | [
"Apache",
"HTTP"
] | https://linux.cn/article-10154-1.html |
>
> 如何在流行而强大的 Apache Web 服务器上托管两个或多个站点。
>
>
>

在我的[上一篇文章](/article-9506-1.html)中,我解释了如何为单个站点配置 Apache Web 服务器,事实证明这很容易。在这篇文章中,我将向你展示如何使用单个 Apache 实例来服务多个站点。
注意:我写这篇文章的环境是 Fedora 27 虚拟机,配置了 Apache 2.4.29。如果你用另一个发行版或不同的 Fedora 版本,那么你使用的命令以及配置文件的位置和内容可能会有所不同。
正如我之前的文章中提到的,Apache 的所有配置文件都位于 `/etc/httpd/conf` 和 `/etc/httpd/conf.d`。默认情况下,站点的数据位于 `/var/www` 中。对于多个站点,你需要提供多个位置,每个位置对应托管的站点。
### 基于名称的虚拟主机
使用基于名称的虚拟主机,你可以为多个站点使用一个 IP 地址。现代 Web 服务器,包括 Apache,使用指定 URL 的 `hostname` 部分来确定哪个虚拟 Web 主机响应页面请求。这仅仅需要比一个站点更多的配置。
即使你只从单个站点开始,我也建议你将其设置为虚拟主机,这样可以在以后更轻松地添加更多站点。在本文中,我将从上一篇文章中我们停止的地方开始,因此你需要设置原来的站点,即基于名称的虚拟站点。
### 准备原来的站点
在设置第二个站点之前,你需要为现有网站提供基于名称的虚拟主机。如果你现在没有站点,[请返回并立即创建一个](/article-9506-1.html)。
一旦你有了站点,将以下内容添加到 `/etc/httpd/conf/httpd.conf` 配置文件的底部(添加此内容是你需要对 `httpd.conf` 文件进行的唯一更改):
```
<VirtualHost 127.0.0.1:80>
DocumentRoot /var/www/html
ServerName www.site1.org
</VirtualHost>
```
这将是第一个虚拟主机配置节,它应该保持为第一个,以使其成为默认定义。这意味着通过 IP 地址或解析为此 IP 地址但没有特定命名主机配置节的其它名称对服务器的 HTTP 访问将定向到此虚拟主机。所有其它虚拟主机配置节都应跟在此节之后。
你还需要使用 `/etc/hosts` 中的条目设置你的网站以提供名称解析。上次,我们只使用了 `localhost` 的 IP 地址。通常,这可以使用你使用的任何名称服务来完成,例如 Google 或 Godaddy。对于你的测试网站,通过在 `/etc/hosts` 中的 `localhost` 行添加一个新名称来完成此操作。添加两个网站的条目,方便你以后不需再次编辑此文件。结果如下:
```
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 www.site1.org www.site2.org
```
让我们将 `/var/www/html/index.html` 文件改变得更加明显一点。它应该看起来像这样(带有一些额外的文本来识别这是站点 1):
```
<h1>Hello World</h1>
Web site 1.
```
重新启动 HTTPD 服务器,已启用对 `httpd` 配置的更改。然后,你可以从命令行使用 Lynx 文本模式查看网站。
```
[root@testvm1 ~]# systemctl restart httpd
[root@testvm1 ~]# lynx www.site1.org
Hello World
Web site 1.
<snip>
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
```
你可以看到原始网站的修改内容,没有明显的错误,先按下 `Q` 键,然后按 `Y` 退出 Lynx Web 浏览器。
### 配置第二个站点
现在你已经准备好建立第二个网站。使用以下命令创建新的网站目录结构:
```
[root@testvm1 html]# mkdir -p /var/www/html2
```
注意,第二个站点只是第二个 `html` 目录,与第一个站点位于同一 `/var/www` 目录下。
现在创建一个新的索引文件 `/var/www/html2/index.html`,其中包含以下内容(此索引文件稍有不同,以区别于原来的网站):
```
<h1>Hello World -- Again</h1>
Web site 2.
```
在 `httpd.conf` 中为第二个站点创建一个新的配置节,并将其放在上一个虚拟主机配置节下面(这两个应该看起来非常相似)。此节告诉 Web 服务器在哪里可以找到第二个站点的 HTML 文件。
```
<VirtualHost 127.0.0.1:80>
DocumentRoot /var/www/html2
ServerName www.site2.org
</VirtualHost>
```
重启 HTTPD,并使用 Lynx 来查看结果。
```
[root@testvm1 httpd]# systemctl restart httpd
[root@testvm1 httpd]# lynx www.site2.org
Hello World -- Again
Web site 2.
<snip>
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
```
在这里,我压缩了输出结果以适应这个空间。页面的差异表明这是第二个站点。要同时显示两个站点,请打开另一个终端会话并使用 Lynx Web 浏览器查看另一个站点。
### 其他考虑
这个简单的例子展示了如何使用 Apache HTTPD 服务器的单个实例来服务于两个站点。当考虑其他因素时,配置虚拟主机会变得有点复杂。
例如,你可能希望为这些网站中的一个或全部使用一些 CGI 脚本。为此,你可能为 CGI 程序在 `/var/www` 目录下创建一些目录:`/var/www/cgi-bin` 和 `/var/www/cgi-bin2`,以与 HTML 目录命名一致。然后,你需要将配置指令添加到虚拟主机节,以指定 CGI 脚本的目录位置。每个站点可以有下载文件的目录。这还需要相应虚拟主机节中的条目。
[Apache 网站](https://httpd.apache.org/docs/2.4/)描述了管理多个站点的其他方法,以及从性能调优到安全性的配置选项。
Apache 是一个强大的 Web 服务器,可以用来管理从简单到高度复杂的网站。尽管其总体市场份额在缩小,但它仍然是互联网上最常用的 HTTPD 服务器。
---
via: <https://opensource.com/article/18/3/configuring-multiple-web-sites-apache>
作者:[David Both](https://opensource.com/users/dboth) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my [last post](https://opensource.com/article/18/2/how-configure-apache-web-server), I explained how to configure an Apache web server for a single website. It turned out to be very easy. In this post, I will show you how to serve multiple websites using a single instance of Apache.
Note: I wrote this article on a virtual machine using Fedora 27 with Apache 2.4.29. If you have another distribution or release of Fedora, the commands you will use and the locations and content of the configuration files may be different.
As my previous article mentioned, all of the configuration files for Apache are located in `/etc/httpd/conf`
and `/etc/httpd/conf.d`
. The data for the websites is located in `/var/www`
by default. With multiple websites, you will need to provide multiple locations, one for each site you host.
## Name-based virtual hosting
With name-based virtual hosting, you can use a single IP address for multiple websites. Modern web servers, including Apache, use the `hostname`
portion of the specified URL to determine which virtual web host responds to the page request. This requires only a little more configuration than for a single site.
Even if you are starting with only a single website, I recommend that you set it up as a virtual host, which will make it easier to add more sites later. In this article, I'll pick up where we left off in the previous article, so you'll need to set up the original website, a name-based virtual website.
## Preparing the original website
Before you set up a second website, you need to get name-based virtual hosting working for the existing site. If you do not have an existing website, [go back and create one now](https://opensource.com/article/18/2/how-configure-apache-web-server).
Once you have your site, add the following stanza to the bottom of its `/etc/httpd/conf/httpd.conf`
configuration file (adding this stanza is the only change you need to make to the `httpd.conf`
file):
```
``````
<VirtualHost 127.0.0.1:80>
DocumentRoot /var/www/html
ServerName www.site1.org
</VirtualHost>
```
This will be the first virtual host stanza, and it should remain first, to make it the default definition. That means that HTTP access to the server by IP address, or by another name that resolves to this IP address but that does not have a specific named host configuration stanza, will be directed to this virtual host. All other virtual host configuration stanzas should follow this one.
You also need to set up your websites with entries in `/etc/hosts`
to provide name resolution. Last time, we just used the IP address for `localhost`
. Normally, this would be done using whichever name service you use; for example, Google or Godaddy. For your test website, do this by adding a new name to the `localhost`
line in `/etc/hosts`
. Add the entries for both websites so you don't need to edit this file again later. The result looks like this:
```
``````
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 www.site1.org www.site2.org
```
Let’s also change the `/var/www/html/index.html`
file to be a little more explicit. It should look like this (with some additional text to identify this as website number 1):
```
``````
<h1>Hello World</h1>
Web site 1.
```
Restart the HTTPD server to enable the changes to the `httpd`
configuration. You can then look at the website using the Lynx text mode browser from the command line.
```
``````
[root@testvm1 ~]# systemctl restart httpd
[root@testvm1 ~]# lynx www.site1.org
Hello World
Web site 1.
<snip>
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
```
You can see that the revised content for the original website is displayed and that there are no obvious errors. Press the “Q” key, followed by “Y” to exit the Lynx web browser.
## Configuring the second website
Now you are ready to set up the second website. Create a new website directory structure with the following command:
```
````[root@testvm1 html]# mkdir -p /var/www/html2`
Notice that the second website is simply a second `html`
directory in the same `/var/www`
directory as the first site.
Now create a new index file, `/var/www/html2/index.html`
, with the following content (this index file is a bit different, to distinguish it from the one for the original website):
```
``````
<h1>Hello World -- Again</h1>
Web site 2.
```
Create a new configuration stanza in `httpd.conf`
for the second website and place it below the previous virtual host stanza (the two should look very similar). This stanza tells the web server where to find the HTML files for the second site.
```
``````
<VirtualHost 127.0.0.1:80>
DocumentRoot /var/www/html2
ServerName www.site2.org
</VirtualHost>
```
Restart HTTPD again and use Lynx to view the results.
```
``````
[root@testvm1 httpd]# systemctl restart httpd
[root@testvm1 httpd]# lynx www.site2.org
Hello World -- Again
Web site 2.
<snip>
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
```
Here I have compressed the resulting output to fit this space. The difference in the page indicates that this is the second website. To show both websites at the same time, open another terminal session and use the Lynx web browser to view the other site.
## Other considerations
This simple example shows how to serve up two websites with a single instance of the Apache HTTPD server. Configuring the virtual hosts becomes a bit more complex when other factors are considered.
For example, you may want to use some CGI scripts for one or both of these websites. To do this, you would create directories for the CGI programs in `/var/www`
: `/var/www/cgi-bin`
and `/var/www/cgi-bin2`
, to be consistent with the HTML directory naming. You would then need to add configuration directives to the virtual host stanzas to specify the directory location for the CGI scripts. Each website could also have directories from which files could be downloaded; this would also require entries in the appropriate virtual host stanza.
The [Apache website](https://httpd.apache.org/docs/2.4/) describes other methods for managing multiple websites, as well as configuration options from performance tuning to security.
Apache is a powerful web server that can be used to manage websites ranging from simple to highly complex. Although its overall share is shrinking, Apache remains the single most commonly used HTTPD server on the Internet.
## 2 Comments |
10,155 | 用 GNOME Boxes 下载一个操作系统镜像 | https://fedoramagazine.org/download-os-gnome-boxes/ | 2018-10-25T16:48:02 | [
"虚拟机",
"Boxes"
] | https://linux.cn/article-10155-1.html | 
Boxes 是 GNOME 上的虚拟机应用。最近 Boxes 添加了一个新的特性,使得它在运行不同的 Linux 发行版时更加容易。你现在可以在 Boxes 中自动安装那些发行版以及像 FreeBSD 和 FreeDOS 这样的操作系统,甚至还包括红帽企业 Linux。红帽开发者计划包括了一个[红帽企业版 Linux 的免费订阅](https://developers.redhat.com/blog/2016/03/31/no-cost-rhel-developer-subscription-now-available/)。 使用[红帽开发者](http://developers.redhat.com)帐户,Boxes 可以自动设置一个名为 Developer Suite 订阅的 RHEL 虚拟机。 下面是它的工作原理。
### 红帽企业版 Linux
要创建一个红帽企业版 Linux 的虚拟机,启动 Boxes,点击“新建”。从源选择列表中选择“下载一个镜像”。在顶部,点击“红帽企业版 Linux”。这将会打开网址为 [developers.redhat.com](http://developers.redhat.com) 的一个 Web 表单。使用已有的红帽开发者账号登录,或是新建一个。

如果这是一个新帐号,Boxes 在继续之前需要一些额外的信息。这一步需要在账户中开启开发者订阅。还要确保 [接受条款和条件](https://www.redhat.com/wapps/tnc/termsack?event%5B%5D=signIn),这样可以在之后的注册中节省一步。

点击“提交”,然后就会开始下载安装磁盘镜像。下载需要的时间取决于你的网络状况。在这期间你可以去喝杯茶或者咖啡歇息一下。

等介质下载完成(一般位于 `~/Downloads` ),Boxes 会有一个“快速安装”的显示。填入账号和密码然后点击“继续”,当你确认了虚拟机的信息之后点击“创建”。“快速安装”会自动完成接下来的整个安装!(现在你可以去享受你的第二杯茶或者咖啡了)



等到安装结束,虚拟机会直接重启并登录到桌面。在虚拟机里,在应用菜单的“系统工具”一栏启动“红帽订阅管理”。这一步需要输入 root 密码。

单击“注册”按钮,然后按照注册助手中的步骤操作。 出现提示时,使用你的红帽开发者帐户登录。


现在你可以通过任何一种更新方法,像是 `yum` 或是 GNOME Software 进行下载和更新了。

### FreeDOS 或是其他
Boxes 可以安装很多操作系统,而不仅仅只是红帽企业版。 作为 KVM 和 qemu 的前端,Boxes 支持各种操作系统。使用 [libosinfo](https://libosinfo.org),Boxes 可以自动下载(在某些情况下安装)相当多不同操作系统。

要从列表中安装一个操作系统,只需选择并完成创建一个新的虚拟机。一些操作系统,比如 FreeDOS,并不支持快速安装。这些操作系统需要虚拟机从安装介质中引导。之后你可以手动安装。


### Boxes 上流行的操作系统
这里仅仅是一些目前在它上面比较受欢迎的选择。






Fedora 会定期更新它的操作系统信息数据库(osinfo-db)。确保你会经常检查是否有新的操作系统选项。
---
via: <https://fedoramagazine.org/download-os-gnome-boxes/>
作者:[Link Dupont](https://fedoramagazine.org/author/linkdupont/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Boxes is the GNOME application for running virtual machines. Recently Boxes added a new feature that makes it easier to run different Linux distributions. You can now automatically install these distros in Boxes, as well as operating systems like FreeBSD and FreeDOS. The list even includes Red Hat Enterprise Linux. The Red Hat Developer Program includes a [no-cost subscription to Red Hat Enterprise Linux](https://developers.redhat.com/blog/2016/03/31/no-cost-rhel-developer-subscription-now-available/). With a [Red Hat Developer](http://developers.redhat.com) account, Boxes can automatically set up a RHEL virtual machine entitled to the Developer Suite subscription. Here’s how it works.
## Red Hat Enterprise Linux
To create a Red Hat Enterprise Linux virtual machine, launch *Boxes* and click *New*. Select *Download an OS* from the source selection list. At the top, pick *Red Hat Enterprise Linux.* This opens a web form at [developers.redhat.com](http://developers.redhat.com). Sign in with an existing Red Hat Developer Account, or create a new one.
If this is a new account, Boxes requires some additional information before continuing. This step is required to enable the Developer Subscription on the account. Be sure to [accept the Terms & Conditions](https://www.redhat.com/wapps/tnc/termsack?event[]=signIn) now too. This saves a step later during registration.
Click *Submit* and the installation disk image starts to download. The download can take a while, depending on your Internet connection. This is a great time to go fix a cup of tea or coffee!
Once the media has downloaded (conveniently to *~/Downloads*), Boxes offers to perform an *Express Install*. Fill in the account and password information and click *Continue*. Click *Create* after you verify the virtual machine details. The *Express Install* automatically performs the entire installation! (Now is a great time to enjoy a second cup of tea or coffee, if so inclined.)
Once the installation is done, the virtual machine reboots and logs directly into the desktop. Inside the virtual machine, launch the *Red Hat Subscription Manager* via the *Applications* menu, under *System Tools*. Enter the root password to launch the utility.
Click the *Register* button and follow the steps through the registration assistant. Log in with your Red Hat Developers account when prompted.
Now you can download and install updates through any normal update method, such as *yum* or *GNOME Software*.
## FreeDOS anyone?
Boxes can install a lot more than just Red Hat Enterprise Linux, too. As a front end to KVM and *qemu*, Boxes supports a wide variety of operating systems. Using [libosinfo](https://libosinfo.org), Boxes can automatically download (and in some cases, install) quite a few different ones.
To install an OS from the list, select it and finish creating the new virtual machine. Some OSes, like FreeDOS, do not support an *Express Install. *In those cases the virtual machine boots from the installation media. You can then manually install.
## Popular operating systems on Boxes
These are just a few of the popular choices available in Boxes today.
Ubuntu 17.10

Pop!_OS 17.10
EndlessOS 3
Fedora 28
openSUSE Tumbleweed
Debian 9
Fedora updates its *osinfo-db* package regularly. Be sure to check back frequently for new OS options.
## Shelmed
First it was floppies then it was CDs, then DVDs then USBs and now it’s Gnome Boxes for me!…..Works a treat – ideal for the distro junkie 😉
## Udai Bhan Kashyap
Is there a limit on number of USB devices that can be shared with Guest OS?
I have usb keyboard and mouse and when I enable my usb webcam for the guest host, it looses the mouse.
## Udai Bhan Kashyap
Is there a limit on number of usb devices which can be shared with guest OS?
I am running RedHat 7.5 as host OS and windows 10 as guest OS.
I have usb mouse and keyboard and when I enable usb webcam , the windows 10 loosed mouse.
## Mat Selmeci
Under “Available to Download”, I only see “Red Hat Enterprise Linux”, “Enter URL”, and “Import 3 boxes from system broker” (which imports some Vagrant VMs I made a while back). How can I find images for the other OSs mentioned on this page?
Here are my versions of osinfo:
osinfo-db-tools-1.1.0-4.fc27.x86_64
libosinfo-1.1.0-1.fc27.x86_64
osinfo-db-20180514-1.fc27.noarch
## Paul W. Frields
@Mat: I think there’s a newer version of Boxes in Fedora 28. Try that.
## Wun Dei
I cant complain, however it’d be cool if it supported other OS’s a la Virtualbox e.g. fortran, Opensolaris, FreeBSD, and well, if last but not least, Mac and Windows. Perhaps one day x86 and Virtualbox will be unnecessary, all running on ARM?
## OppaErich
Hmm,
I tried making a FreeDOS one. Clicked new, chose the iso, booted, ran fdisk and rebooted. – “Running box FreeDOS was deleted”.
WTH ? Just one shot allowed ? |
10,156 | 使用 Podman 以非 root 用户身份运行 Linux 容器 | https://fedoramagazine.org/running-containers-with-podman/ | 2018-10-26T08:28:43 | [
"Docker",
"容器"
] | https://linux.cn/article-10156-1.html | 
Linux 容器是由 Linux 内核所提供的具有特定隔离功能的进程 —— 包括文件系统、进程和网络的隔离。容器有助于实现可移植性 —— 应用可以在容器镜像中与其依赖项一起分发,并可在几乎任何有容器运行时环境的 Linux 系统上运行。
虽然容器技术存在了很长时间,但 Linux 容器是由 Docker 而得到了广泛推广。 “Docker” 这个词可以指几个不同的东西,包括容器技术和工具,周围的社区,或者 Docker Inc. 公司。但是,在本文中,我将用来指管理 Linux 容器的技术和工具。
### 什么是 Docker
[Docker](https://docs.docker.com/) 是一个以 root 身份在你的系统上运行的守护程序,它利用 Linux 内核的功能来管理正在运行的容器。除了运行容器之外,它还可以轻松管理容器镜像 —— 与容器注册库交互、存储映像、管理容器版本等。它基本上支持运行单个容器所需的所有操作。
但即使 Docker 是管理 Linux 容器的一个非常方便的工具,它也有两个缺点:它是一个需要在你的系统上运行的守护进程,并且需要以 root 权限运行,这可能有一定的安全隐患。然而,Podman 在解决这两个问题。
### Podman 介绍
[Podman](https://podman.io/) 是一个容器运行时环境,提供与 Docker 非常相似的功能。正如已经提示的那样,它不需要在你的系统上运行任何守护进程,并且它也可以在没有 root 权限的情况下运行。让我们看看使用 Podman 运行 Linux 容器的一些示例。
#### 使用 Podman 运行容器
其中一个最简单的例子可能是运行 Fedora 容器,在命令行中打印 “Hello world!”:
```
$ podman run --rm -it fedora:28 echo "Hello world!"
```
使用通用 Dockerfile 构建镜像的方式与 Docker 相同:
```
$ cat Dockerfile
FROM fedora:28
RUN dnf -y install cowsay
$ podman build . -t hello-world
... output omitted ...
$ podman run --rm -it hello-world cowsay "Hello!"
```
为了构建容器,Podman 在后台调用另一个名为 Buildah 的工具。你可以阅读最近一篇[关于使用 Buildah 构建容器镜像的文章](https://fedoramagazine.org/daemon-less-container-management-buildah/) —— 它不仅仅是使用典型的 Dockerfile。
除了构建和运行容器外,Podman 还可以与容器托管进行交互。要登录容器注册库,例如广泛使用的 Docker Hub,请运行:
```
$ podman login docker.io
```
为了推送我刚刚构建的镜像,我只需打上标记来代表特定的容器注册库,然后直接推送它。
```
$ podman -t hello-world docker.io/asamalik/hello-world
$ podman push docker.io/asamalik/hello-world
```
顺便说一下,你是否注意到我如何以非 root 用户身份运行所有内容?此外,我的系统上没有运行又大又重的守护进程!
#### 安装 Podman
Podman 默认在 [Silverblue](https://silverblue.fedoraproject.org/) 上提供 —— 一个基于容器的工作流的新一代 Linux 工作站。要在任何 Fedora 版本上安装它,只需运行:
```
$ sudo dnf install podman
```
---
via: <https://fedoramagazine.org/running-containers-with-podman/>
作者:[Adam Šamalík](https://fedoramagazine.org/author/asamalik/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux containers are processes with certain isolation features provided by a Linux kernel — including filesystem, process, and network isolation. Containers help with portability — applications can be distributed in container images along with their dependencies, and run on virtually any Linux system with a container runtime.
Although container technologies exist for a very long time, Linux containers were widely popularized by Docker. The word “Docker” can refer to several different things, including the container technology and tooling, the community around that, or the Docker Inc. company. However, in this article, I’ll be using it to refer to the technology and the tooling that manages Linux containers.
## What is Docker
[Docker](https://docs.docker.com/) is a daemon that runs on your system as root, and manages running containers by leveraging features of the Linux kernel. Apart from running containers, it also makes it easy to manage container images — interacting with container registries, storing images, managing container versions, etc. It basically supports all the operations you need to run individual containers.
But even though Docker is very a handy tool for managing Linux containers, it has two drawbacks: it is a daemon that needs to run on your system, and it needs to run with root privileges which might have certain security implications. Both of those, however, are being addressed by Podman.
## Introducing Podman
[Podman](https://podman.io/) is a container runtime providing a very similar features as Docker. And as already hinted, it doesn’t require any daemon to run on your system, and it can also run without root privileges. So let’s have a look at some examples of using Podman to run Linux containers.
### Running containers with Podman
One of the simplest examples could be running a Fedora container, printing “Hello world!” in the command line:
$podman run --rm -it fedora:28 echo "Hello world!"
Building an image using the common Dockerfile works the same way as it does with Docker:
$cat DockerfileFROM fedora:28 RUN dnf -y install cowsay $podman build . -t hello-world... output omitted ... $podman run --rm -it hello-world cowsay "Hello!"
To build containers, Podman calls another tool called Buildah in the background. You can read a recent [post about building container images with Buildah](https://fedoramagazine.org/daemon-less-container-management-buildah/) — not just using the typical Dockerfile.
Apart from building and running containers, Podman can also interact with container registries. To log in to a container registry, for example the widely used Docker Hub, run:
$podman login docker.io
To push the image I just built, I just need to tag so it refers to the specific container registry and my personal namespace, and then simply push it.
$podman -t hello-world docker.io/asamalik/hello-world$podman push docker.io/asamalik/hello-world
By the way, have you noticed how I run everything as a non-root user? Also, there is no big fat daemon running on my system!
### Installing Podman
Podman is available by default on [Silverblue](https://silverblue.fedoraproject.org/) — a new generation of Linux Workstation for container-based workflows. To install it on any Fedora release, simply run:
$ sudo dnf install podman
## Dragnucs
Thank you for the explanation.
Can podman be used with tools like Docker-compose or similar?
## Dragnucs
After some research it turns out that Compose and Swarm are not supported, but Kubernetes is.
## Blaise Pabon
Hi @dragnucs, I have found that the atomic host commands are comparable to
and
, whereas podman is more comparable to openshift and kubectl.
## Steven Miano
It feels like something is broken with this example:
$ podman run –rm -it hello-world cowsay “Hello!”
As it pulls down an image from docker.io/library/hello-world
But that image isn’t in the right state. Whereas if you do a podman images and find the ‘IMAGE ID’ of the image just created:
$ podman run ${NEW_IMAGE_ID} cowsay “hello!”
Will work…not sure if this might be a bit more clear for folks not used to what’s going on or not….
…..great introduction to how podman works/functions though! Thanks much!
## Sascha
Looks like “-t ” needs to be specified before the directory reference:
podman build -t hello-world:latest .
instead of
podman build -t . hello-world:latest
Kind regards,
Sascha
## Blaise Pabon
Yes,
expects the name of the tag to follow it. It’s like saying
## Thomas
why does this work now? when did it start to work? can you give some pointers?
and “non-root” ? 😉
root
## Drakkai
Root is inside container, the container itself is run as a non-root user.
## Thomas
what are the limitations of non-root containers?
how can i access my $HOME content? i suspect is some uid/gid mapping is happening because adding a user with same uid in the container isnt enough to access my
mounted volume in the container.
## Drakkai
You can try to map user/group with –uidmap and –gidmap.
## Joe
This looks neat. I’m looking forward to port forwarding support.
## eee
when translate to Polish?
documentation and examples
## Bradley D. Thornton
Podman works great as a containerization method for those working with shared webhosting infrastructure; for example, with cPanel or Plesk accounts where the user does not have root access, and needs to run a few containers.
## Mahesh Hegde
Does it require
feature to run? |
10,157 | 为什么 Linux 用户应该试一试 Rust | https://www.networkworld.com/article/3308162/linux/why-you-should-try-rust.html | 2018-10-26T09:08:00 | [
"Rust"
] | https://linux.cn/article-10157-1.html |
>
> 在 Linux 系统上安装 Rust 编程语言可能是你近年来所做的最有价值的事情之一。
>
>
>

Rust 是一种相当年轻和现代的编程语言,具有许多使其非常灵活而及其安全的功能。数据显示它正在变得非常受欢迎,连续三年([2016](https://insights.stackoverflow.com/survey/2016#technology-most-loved-dreaded-and-wanted)、[2017](https://insights.stackoverflow.com/survey/2017#technology-most-loved-dreaded-and-wanted-languages) 和 [2018](https://insights.stackoverflow.com/survey/2018#technology-most-loved-dreaded-and-wanted-languages))在 Stack Overflow 开发者调查中获得“最受喜爱的编程语言”的第一名。
Rust 也是开源语言的一种,它具有一系列特殊的功能,使得它可以适应许多不同的编程项目。 它最初源于 2006 年 Mozilla 员工的个人项目,几年后(2009 年)被 Mozilla 选为特别项目,然后在 2010 年宣布供公众使用。
Rust 程序运行速度极快,可防止段错误,并能保证线程安全。这些属性使该语言极大地吸引了专注于应用程序安全性的开发人员。Rust 也是一种非常易读的语言,可用于从简单程序到非常大而复杂的项目。
Rust 优点:
* 内存安全 —— Rust 不会受到悬空指针、缓冲区溢出或其他与内存相关的错误的影响。它提供内存安全,无回收垃圾。
* 通用 —— Rust 是适用于任何类型编程的语言
* 快速 —— Rust 在性能上与 C / C++ 相当,但具有更好的安全功能。
* 高效 —— Rust 是为了便于并发编程而构建的。
* 面向项目 —— Rust 具有内置的依赖关系和构建管理系统 Cargo。
* 得到很好的支持 —— Rust 有一个令人印象深刻的[支持社区](https://www.rust-lang.org/en-US/community.html)。
Rust 还强制执行 RAII(<ruby> 资源获取初始化 <rt> Resource Acquisition Is Initialization </rt></ruby>)。这意味着当一个对象超出范围时,将调用其析构函数并释放其资源,从而提供防止资源泄漏的屏蔽。它提供了功能抽象和一个很棒的[类型系统](https://doc.rust-lang.org/reference/type-system.html),并具有速度和数学健全性。
简而言之,Rust 是一种令人印象深刻的系统编程语言,具有其它大多数语言所缺乏的功能,使其成为 C、C++ 和 Objective-C 等多年来一直被使用的语言的有力竞争者。
### 安装 Rust
安装 Rust 是一个相当简单的过程。
```
$ curl https://sh.rustup.rs -sSf | sh
```
安装 Rust 后,使用 `rustc --version` 或 `which` 命令显示版本信息。
```
$ which rustc
rustc 1.27.2 (58cc626de 2018-07-18)
$ rustc --version
rustc 1.27.2 (58cc626de 2018-07-18)
```
### Rust 入门
Rust 即使是最简单的代码也与你之前使用过的语言输入的完全不同。
```
$ cat hello.rs
fn main() {
// Print a greeting
println!("Hello, world!");
}
```
在这些行中,我们正在设置一个函数(`main`),添加一个描述该函数的注释,并使用 `println` 语句来创建输出。您可以使用下面显示的命令编译然后运行程序。
```
$ rustc hello.rs
$ ./hello
Hello, world!
```
另外,你也可以创建一个“项目”(通常仅用于比这个更复杂的程序!)来保持代码的有序性。
```
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
```
请注意,即使是简单的程序,一旦编译,就会变成相当大的可执行文件。
```
$ ./hello
Hello, world!
$ ls -l hello*
-rwxrwxr-x 1 shs shs 5486784 Sep 23 19:02 hello <== executable
-rw-rw-r-- 1 shs shs 68 Sep 23 15:25 hello.rs
```
当然,这只是一个开始且传统的“Hello, world!” 程序。 Rust 语言具有一系列可帮助你快速进入高级编程技能的功能。
### 学习 Rust

*No Starch Press*
Steve Klabnik 和 Carol Nichols 的《[Rust 编程语言](https://nostarch.com/Rust)》 (2018)一书提供了学习 Rust 的最佳方法之一。 这本书由核心开发团队的两名成员撰写,可从 [No Starch Press](https://nostarch.com/Rust) 出版社获得纸制书或者从 [rust-lang.org](https://doc.rust-lang.org/book/2018-edition/index.html) 获得电子书。它已经成为 Rust 开发者社区中的参考书。
在所涉及的众多主题中,你将了解这些高级主题:
* 所有权和 borrowing
* 安全保障
* 测试和错误处理
* 智能指针和多线程
* 高级模式匹配
* 使用 Cargo(内置包管理器)
* 使用 Rust 的高级编译器
#### 目录
* 前言(Nicholas Matsakis 和 Aaron Turon 编写)
* 致谢
* 介绍
* 第 1 章:新手入门
* 第 2 章:猜谜游戏
* 第 3 章:通用编程概念
* 第 4 章:了解所有权
* 第 5 章:结构
* 第 6 章:枚举和模式匹配
* 第 7 章:模块
* 第 8 章:常见集合
* 第 9 章:错误处理
* 第 10 章:通用类型、特征和生命周期
* 第 11 章:测试
* 第 12 章:输入/输出项目
* 第 13 章:迭代器和闭包
* 第 14 章:关于货物和 Crates.io 的更多信息
* 第 15 章:智能指针
* 第 16 章:并发
* 第 17 章:Rust 是面向对象的吗?
* 第 18 章:模式
* 第 19 章:关于生命周期的更多信息
* 第 20 章:高级类型系统功能
* 附录 A:关键字
* 附录 B:运算符和符号
* 附录 C:可衍生的特征
* 附录 D:宏
* 索引
《[Rust 编程语言](https://nostarch.com/Rust)》 将你从基本安装和语言语法带到复杂的主题,例如模块、错误处理、crates(与其他语言中的 “library” 或“package”同义),模块(允许你将你的代码分配到 crate 本身),生命周期等。
可能最重要的是,本书可以让您从基本的编程技巧转向构建和编译复杂、安全且非常有用的程序。
### 结束
如果你已经准备好用一种非常值得花时间和精力学习并且越来越受欢迎的语言进行一些严肃的编程,那么 Rust 是一个不错的选择!
加入 [Facebook](https://www.facebook.com/NetworkWorld/) 和 [LinkedIn](https://www.linkedin.com/company/network-world) 上的 Network World 社区,评论最重要的话题。
---
via: <https://www.networkworld.com/article/3308162/linux/why-you-should-try-rust.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[way-ww](https://github.com/way-ww) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,158 | 使用 Lakka Linux 将你的旧 PC 变成复古游戏主机 | https://itsfoss.com/lakka-retrogaming-linux/ | 2018-10-26T09:58:00 | [
"游戏"
] | https://linux.cn/article-10158-1.html |
>
> 如果你有一台吃灰的旧计算机,你可以用 Lakka Linux 将它变成像 PlayStation 那样的复古游戏主机。
>
>
>
你可能已经了解[专门用于复活旧计算机的 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/)。但是你知道有个 Linux 发行版专门是为了将旧电脑变成复古游戏主机创建的么?

认识下 [Lakka](http://www.lakka.tv/),它是一个轻量级 Linux 发行版,可以将旧的或低端的计算机(如 Raspberry Pi)变成一个完整的复古游戏主机,
当我说复古游戏主机时,我对主机部分很认真。如果你曾经使用过 Xbox 和 PlayStation,你就会知道典型的主机界面是什么样的。
Lakka 提供类似的界面和类似的体验。我稍后会谈到“体验”。先看一下界面。

*Lakka 复古游戏界面*
### Lakka:为复古游戏而生的 Linux 发行版
Lakka 是 [RetroArch](https://www.retroarch.com/) 和 [Libretro](https://www.libretro.com/) 生态系统的官方 Linux 发行版。
RetroArch 是复古游戏模拟器和游戏引擎的前端。你在上面的视频中看到的界面只是 RetroArch。如果你是只想玩复古游戏,只需在当前的 Linux 发行版中安装 RetroArch 即可。
Lakka 提供了带有 Libretro 核心的 RetroArch。因此,你会获得一个预先配置完的操作系统,你可以安装或插入 live USB 并开始玩游戏。
Lakka 是轻量级的,你可以将它安装在大多数老系统或单板计算机上,如 Raspberry Pi 上。
它支持大量的模拟器。你只需要在系统上下载 ROM,Lakka 将从这些 ROM 运行游戏。你可以在[这里](http://www.lakka.tv/powerful/)找到支持的模拟器和硬件列表。
它通过其顺滑的图形界面让你能够在许多计算机和主机上运行经典游戏。设置也是统一的,因此可以一劳永逸地完成配置。
让我总结一下 Lakka 的主要特点:
* RetroArch 中与 PlayStation 类似的界面
* 支持许多复古游戏模拟器
* 支持最多 5 名玩家在同一系统上玩游戏
* 存档允许你随时保存游戏中的进度
* 你可以使用各种图形过滤器改善旧游戏的外表
* 你可以通过网络加入多人游戏
* 开箱即用支持 XBOX360、Dualshock 3 和 8bitdo 等多种游戏手柄
* 连接到 [RetroAchievements](https://retroachievements.org/) 获取奖杯和徽章
### 获取 Lakka
在你继续安装 Lakka 之前,你应该了解它仍在开发中,因此会有一些 bug。
请记住,Lakka 仅支持 MBR 分区。因此,如果在安装时没有读到你的硬盘,这可能是一个原因。
[项目的 FAQ 部分](http://www.lakka.tv/doc/FAQ/)回答了常见的疑问,所以如有任何其他的问题,请参考它。
* [获取 Lakka](http://www.lakka.tv/disclaimer/)
你喜欢复古游戏吗?你使用什么模拟器?你以前用过 Lakka 吗?在评论区与我们分享你的观点。
---
via: <https://itsfoss.com/lakka-retrogaming-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[9]; <http://www.lakka.tv/disclaimer/>
| 200 | OK | **If you have an old computer gathering dust, you can turn it into a PlayStation like retrogaming console with Lakka Linux distribution. **
You probably already know that there are [Linux distributions specially crafted for reviving older computers](https://itsfoss.com/lightweight-linux-beginners/). But did you know about a Linux distribution that is created for the sole purpose of turning your old computer into a retro-gaming console?

Meet [Lakka](http://www.lakka.tv/), a lightweight Linux distribution that will transform your old or low-end computer (like Raspberry Pi) into a complete retrogaming console,
When I say retrogaming console, I am serious about the console part. If you have ever used a PlayStation
Lakka provides a similar interface and a similar experience. I’ll talk about the ‘experience’ later. Have a look at the interface first.
## Lakka: Linux distributions for retrogaming
Lakka is the official Linux distribution of [RetroArch](https://www.retroarch.com/) and the [Libretro](https://www.libretro.com/) ecosystem.
RetroArch is a frontend for retro game emulators and game engines. The interface you saw in the video above is nothing but RetroArch. If you just want to play retro games, you can simply install RetroArch in your current Linux distribution.
Lakka provides Libretro core with RetroArch. So you get a preconfigured operating system that you can install or plug in the live USB and start playing games.
Lakka is lightweight and you can install it on most old systems or [single board computers like Raspberry Pi](https://itsfoss.com/raspberry-pi-alternatives/).
It supports a huge number of emulators. You just need to download the ROMs on your system and Lakka will play the games from these ROMs. You can find the list supported emulators and hardware [here](http://www.lakka.tv/powerful/).
It enables you to run classic games on a wide range of computers and consoles through its slick graphical interface. Settings are also unified so configuration is done once and for all.
Let me summarize the main features of Lakka:
- PlayStation like interface with RetroArch
- Support for a number of retro game emulators
- Supports up to 5 players gaming on the same system
- Savestates allow you to save your progress at any moment in the game
- You can improve the look of your old games with various graphical filters
- You can join multiplayer games over the network
- Out of the box support for a number of joypads like XBOX360, Dualshock 3, and 8bitdo
- Unlike trophies and badges by connecting to
[RetroAchievements](https://retroachievements.org/)
[irp posts=12868]
## Getting Lakka
Before you go on installing Lakka you should know that it is still under development so expect a few bugs here and there.
Keep in mind that Lakka only supports MBR partitioning. So if it doesn’t
The [FAQ section of the project](http://www.lakka.tv/doc/FAQ/) answers the common doubts, so please refer to it for any further questions.
Do you like playing retro games? What emulators do you use? Have you ever used Lakka before? Share your views with us in the comments section. |
10,159 | 使用 Argbash 来改进你的 Bash 脚本 | https://fedoramagazine.org/improve-bash-scripts-argbash/ | 2018-10-27T09:28:50 | [
"脚本",
"参数"
] | https://linux.cn/article-10159-1.html | 
你编写或维护过有意义的 bash 脚本吗?如果回答是,那么你可能希望它们以标准且健壮的方式接收命令行参数。Fedora 最近得到了[一个很好的附加组件](https://argbash.readthedocs.io/),它可以帮助你生成更好的脚本。不用担心,它不会花费你很多时间或精力。
### 为什么需要 Argbash?
Bash 是一种解释性的命令行语言,没有标准库。因此,如果你编写 bash 脚本并希望命令行界面符合 [POSIX](http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap12.html) 和 [GNU CLI](https://www.gnu.org/prep/standards/html_node/Command_002dLine-Interfaces.html) 标准,那么你一般只有两种选择:
1. 直接编写为脚本量身定制的参数解析功能(可使用内置的 `getopts`)。
2. 使用外部 bash 模块。
第一个选项看起来非常愚蠢,因为正确实现接口并非易事。但是,从 [Stack Overflow](https://stackoverflow.com/questions/192249/how-do-i-parse-command-line-arguments-in-bash) 到 [Bash Hackers](http://wiki.bash-hackers.org/howto/getopts_tutorial) wiki 的各种站点上,它却被认为是最佳选择。
第二个选项看起来更聪明,但使用模块有它自己的问题。最大的问题是你必须将其代码与脚本捆绑在一起。这可能意味着:
* 要么,你将库作为单独的文件分发
* 或者,在脚本的开头包含库代码
有两个文件而不是一个是愚蠢的;但采用一个文件的话,会让一堆上千行的复杂代码污染了你的脚本。
这是 Argbash [项目诞生](https://argbash.readthedocs.io/)的主要原因。Argbash 是一个代码生成器,它为你的脚本生成一个量身定制的解析库。与其他 bash 模块的通用代码不同,它生成你的脚本所需的最少代码。此外,如果你不需要 100% 符合那些 CLI 标准的话,你可以生成更简单的代码。
### 示例
#### 分析
假设你要实现一个脚本,它可以在终端窗口中[绘制条形图](http://wiki.bash-hackers.org/snipplets/print_horizontal_line),你可以通过重复一个字符选定的次数来做到这一点。这意味着你需要从命令行获取以下信息:
* 哪个字符是组成该行的元素。如果未指定,使用破折号 `-`。 在命令行上,这是个单值定位参数 `character`,其默认值为 `-`。(LCTT 译注:定位参数是指确定位置的参数,此处 `character` 需是命令行的第一个参数)
* 直线的长度。如果未指定,会选择 `80`。 这是一个单值可选参数 `length`,默认值为 `80`。
* Verbose 模式(用于调试)。 这是一个布尔型参数 `verbose`,默认情况下关闭。
由于脚本的主体非常简单,因此本文主要关注从命令行获取用户的输入到合适的脚本变量。Argbash 生成的代码会将参数解析结果保存到 shell 变量 `_arg_character`、`_arg_length` 和 `_arg_verbose` 当中。
#### 执行
接下来,你还需要 `argbash-init` 和 `argbash` bash 脚本,它们是 argbash 包的一部分。因此,运行以下命令:
```
sudo dnf install argbash
```
然后,使用 `argbash-init` 来为 `argbash` 生成模板,它会生成可执行脚本。你需要三个参数:一个名为 `character` 的定位参数,一个可选的 `length` 参数以及一个可选的布尔 `verbose`。将这些传递给 `argbash-init`,然后将输出传递给 `argbash` : `argbash-init --pos character --opt length --opt-bool verbose script-template.sh
argbash script-template.sh -o script
./script`
看到帮助信息了吗?看起来该脚本不知道字符参数的默认选项。因此,看一下 [Argbash API](http://argbash.readthedocs.io/en/stable/guide.html#argbash-api),然后通过编辑脚本的模板部分来解决问题:
```
# ...
# ARG_OPTIONAL_SINGLE([length],[l],[Length of the line],[80])
# ARG_OPTIONAL_BOOLEAN([verbose],[V],[Debug mode])
# ARG_POSITIONAL_SINGLE([character],[The element of the line],[-])
# ARG_HELP([The line drawer])
# ...
```
Argbash 非常智能,它试图让每个生成的脚本都成为自己的模板,这意味着你不需要存储源模版以供进一步使用,你也不要丢掉生成的 bash 脚本。现在,尝试重新生成如你所预期的下一个线条绘图脚本:
```
argbash script -o script
./script
```
如你所见,一切正常。剩下要做的唯一事情就是完成线条绘图功能。
### 结论
你可能会发现包含解析代码的部分很长,但考虑到它允许你以 `./script.sh x -Vl50` 的方式调用,并且能像 `./script -V -l 50 x` 一样工作。确实需要一些代码才能做到这一点。
但是,通过调用 `argbash-init` 并将参数 `-mode` 设置为 `minimal`,你可以平衡生成的代码复杂度和解析能力,而转向更简单的代码。这个选项将脚本的大小减少了大约 20 行,这相当于生成的解析代码大小减少了大约 25%。另一方面,`full` 模式使脚本更加智能。
如果你想要检查生成的代码,请给 `argbash` 提供参数 `-commented`,它会将注释放入解析代码中,从而揭示各个部分背后的意图。与其他参数解析库相比较,如 [shflags](https://raw.githubusercontent.com/Anvil/bash-argsparse/master/argsparse.sh), [argsparse](https://raw.githubusercontent.com/Anvil/bash-argsparse/master/argsparse.sh) 或 [bash-modules/arguments](https://raw.githubusercontent.com/vlisivka/bash-modules/master/main/bash-modules/src/bash-modules/arguments.sh),你将看到 Argbash 强大的简单性。如果出现了严重的错误,你需要快速修复解析功能中的一个故障,Argbash 也允许你这样做。
由于你很有可能是 Fedora 用户,因此你可以享受从官方仓库安装命令行 Argbash 的便利。不过,也有一个[在线解析代码生成器](https://argbash.io/generate)服务可以使用。此外,如果你在服务器上使用 Docker 工作,你可以试试 [Argbash Docker 镜像](https://hub.docker.com/r/matejak/argbash/)。
这样你可以让你的脚本具有令用户满意的命令行界面。Argbash 随时为你提供帮助,你只需付出很少的努力。
---
via: <https://fedoramagazine.org/improve-bash-scripts-argbash/>
作者:[Matěj Týč](https://fedoramagazine.org/author/bubla/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Do you write or maintain non-trivial bash scripts? If so, you probably want them to accept command-line arguments in a standard and robust way. Fedora recently got [a nice addition](https://argbash.readthedocs.io) which can help you produce better scripts. And don’t worry, it won’t cost you much of your time or energy.
## Why Argbash?
Bash is an interpreted command-line language with no standard library. Therefore, if you write bash scripts and want command-line interfaces that conform to [POSIX](http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap12.html) and [GNU CLI](https://www.gnu.org/prep/standards/html_node/Command_002dLine-Interfaces.html) standards, you’re used to only two options:
- Write the argument-parsing functionality tailored to your script yourself (possibly using the
getopts
builtin).
- Use an external bash module.
The first option looks incredibly silly as implementing the interface properly is not trivial. However, it is suggested as the best choice on various sites ranging from [Stack Overflow](https://stackoverflow.com/questions/192249/how-do-i-parse-command-line-arguments-in-bash) to the [Bash Hackers](http://wiki.bash-hackers.org/howto/getopts_tutorial) wiki.
The second option looks smarter, but using a module has its issues. The biggest is you have to bundle its code with your script. This may mean either:
- You distribute the library as a separate file, or
- You include the library code at the beginning of your script.
Having two files instead of one is awkward. So is polluting your bash scripts with a chunk of complex code over thousand lines long.
This was the main reason why the Argbash [project came to life](https://argbash.readthedocs.io). Argbash is a code generator, so it generates a tailor-made parsing library for your script. Unlike the generic code of other bash modules, it produces minimal code your script needs. Moreover, you can request even simpler code if you don’t need 100% conformance to these CLI standards.
## Example
### Analysis
Let’s say you want to implement a script that [draws a bar](http://wiki.bash-hackers.org/snipplets/print_horizontal_line) across the terminal window. You do that by repeating a single character of your choice multiple times. This means you need to get the following information from the command-line:
*The character which is the element of the line. If not specified, use a dash.*On the command-line, this would be a single-valued positional argument*character*with a default value of -.*Length of the line. If not specified, go for 80.*This is a single-valued optional argument*–length*with a default of 80.*Verbose mode (for debugging).*This is a boolean argument*verbose*, off by default.
As the body of the script is really simple, this article focuses on getting the input of the user from the command-line to appropriate script variables. Argbash generates code that saves parsing results to shell variables *_arg_character*, *_arg_length* and *_arg_verbose*.
### Execution
In order to proceed, you need the *argbash-init* and *argbash* bash scripts that are parts of the *argbash* package. Therefore, run this command:
sudo dnf install argbash
Then, use *argbash-init* to generate a template for *argbash*, which generates the executable script. You want three arguments: a positional one called *character*, an optional *length* and an optional boolean *verbose*. Tell this to *argbash-init*, and then pass the output to *argbash*:
argbash-init --pos character --opt length --opt-bool verbose script-template.sh argbash script-template.sh -o script ./script
See the help message? Looks like the script doesn’t know about the default option for the character argument. So take a look at the [Argbash API](http://argbash.readthedocs.io/en/stable/guide.html#argbash-api), and then fix the issue by editing the template section of the script:
# ... # ARG_OPTIONAL_SINGLE([length],[l],[Length of the line],[80]) # ARG_OPTIONAL_BOOLEAN([verbose],[V],[Debug mode]) # ARG_POSITIONAL_SINGLE([character],[The element of the line],[-]) # ARG_HELP([The line drawer]) # ...
Argbash is so smart that it tries to make every generated script a template of itself. This means you don’t have to worry about storing source templates for further use. You just shouldn’t lose your generated bash scripts. Now, try to regenerate the future line drawer to work as expected:
argbash script -o script ./script
As you can see, everything is working all right. The only thing left to do is fill in the line drawing functionality itself.
## Conclusion
You might find the section containing parsing code quite long, but consider that it allows you to call *./script.sh x -Vl50* and it will be understood the same way as *./script -V -l 50 x. I*t does require some code to get this right.
However, you can shift the balance between generated code complexity and parsing abilities towards more simple code by calling *argbash-init* with argument *–mode* set to *minimal*. This option reduces the size of the script by about 20 lines, which corresponds to a roughly 25% decrease of the generated parsing code size. On the other hand, the *full* mode makes the script even smarter.
If you want to examine the generated code, give *argbash* the argument *–commented*, which puts comments into the parsing code that reveal the intent behind various sections. Compare that to other argument parsing libraries such as [shflags](https://raw.githubusercontent.com/Anvil/bash-argsparse/master/argsparse.sh), [argsparse](https://raw.githubusercontent.com/Anvil/bash-argsparse/master/argsparse.sh) or [bash-modules/arguments](https://raw.githubusercontent.com/vlisivka/bash-modules/master/main/bash-modules/src/bash-modules/arguments.sh), and you’ll see the powerful simplicity of Argbash. If something goes horribly wrong and you need to fix a glitch in the parsing functionality quickly, Argbash allows you to do that as well.
As you’re most likely a Fedora user, you can enjoy the luxury of having command-line Argbash installed from the official repositories. However, there is also an [online parsing code generator](https://argbash.io/generate) at your service. Furthermore, if you’re working on a server with Docker, you can appreciate the [Argbash Docker image](https://hub.docker.com/r/matejak/argbash/).
So enjoy and make sure that your scripts have a command-line interface that pleases your users. Argbash is here to help, with minimal effort required from your side.
## aaa
Where are the times where shell scripts had to be POSIX compatible and people were avoiding bahsizms?
## rexxor
strict posix ? But it is a small parody for posix standard in Bash, then I use Shellcheck + Dash to write scripts without HERE DOC and double brackets in TEST etc. 😉
## taikedz
I must say, this seems horribly unwieldy… My personal take is that the way to better bash scripting is to start providing tooling that helps reduce its idiosyncrasies, not compound them…
Generating templates that need post-processing, and generating heaps of caps’d variables to hunt down before they can be used, does not strike me as particularly friendly…
I’ve been working on a tool to try to make bash more usable, in similar manner as any other scripting language, by means of a build tool… My bash scripts really have started looking like normal code since…!
https://github.com/taikedz/bash-builder/
## Folkert M.
Did you forgot to activate the copr or was it already enabled?
[a@b ~]$ sudo dnf install argbash
Failed to synchronize cache for repo ‘home_zhonghuaren’, wird deaktiviert.
Letzte Prüfung auf abgelaufene Metadaten: vor 0:00:04 am Thu Dec 14 07:58:30 2017.
Kein Paket argbash verfügbar.
Fehler: Es konnte kein Treffer gefunden werden.
[a@b ~]$ sudo dnf copr enable sgallagh/argbash
[a@b ~]$ sudo dnf install argbash
Copr repo for argbash owned by sgallagh 1.1 kB/s | 1.4 kB 00:01
Failed to synchronize cache for repo ‘home_zhonghuaren’, wird deaktiviert.
Abhängigkeiten sind aufgelöst.
Package Arch Version Paketquelle Größe
Installieren:
argbash noarch 2.3.0-0.1.fc25 sgallagh-argbash 37 k
Transaktionsübersicht
Installieren 1 Paket
Gesamte Downloadgröße: 37 k
Installationsgröße: 100 k
Ist dies in Ordnung? [j/N]: |
10,160 | 一窥你安装的 Linux 软件包 | https://www.networkworld.com/article/3242808/linux/peeking-into-your-linux-packages.html | 2018-10-27T09:56:17 | [
"软件包"
] | https://linux.cn/article-10160-1.html |
>
> 这些最有用的命令可以让你了解安装在你的 Debian 类的 Linux 系统上的包的情况。
>
>
>

你有没有想过你的 Linux 系统上安装了几千个软件包? 是的,我说的是“千”。 即使是相当一般的 Linux 系统也可能安装了上千个软件包。 有很多方法可以获得这些包到底是什么包的详细信息。
首先,要在基于 Debian 的发行版(如 Ubuntu)上快速得到已安装的软件包数量,请使用 `apt list --installed`, 如下:
```
$ apt list --installed | wc -l
2067
```
这个数字实际上多了一个,因为输出中包含了 “Listing …” 作为它的第一行。 这个命令会更准确:
```
$ apt list --installed | grep -v "^Listing" | wc -l
2066
```
要获得所有这些包的详细信息,请按以下方式浏览列表:
```
$ apt list --installed | more
Listing...
a11y-profile-manager-indicator/xenial,now 0.1.10-0ubuntu3 amd64 [installed]
account-plugin-aim/xenial,now 3.12.11-0ubuntu3 amd64 [installed]
account-plugin-facebook/xenial,xenial,now 0.12+16.04.20160126-0ubuntu1 all [installed]
account-plugin-flickr/xenial,xenial,now 0.12+16.04.20160126-0ubuntu1 all [installed]
account-plugin-google/xenial,xenial,now 0.12+16.04.20160126-0ubuntu1 all [installed]
account-plugin-jabber/xenial,now 3.12.11-0ubuntu3 amd64 [installed]
account-plugin-salut/xenial,now 3.12.11-0ubuntu3 amd64 [installed]
```
这需要观察很多细节 —— 特别是让你的眼睛在所有 2000 多个文件中徘徊。 它包含包名称、版本等,以及更多但并不是以最易于我们人类解析的显示信息。 `dpkg-query` 使得描述更容易理解,但这些描述会塞满你的命令窗口,除非窗口非常宽。 因此,为了让此篇文章更容易阅读,下面的数据显示已经分成了左右两侧。
左侧:
```
$ dpkg-query -l | more
Desired=Unknown/Install/Remove/Purge/Hold
| Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
||/ Name Version
+++-==============================================-=================================-
ii a11y-profile-manager-indicator 0.1.10-0ubuntu3
ii account-plugin-aim 3.12.11-0ubuntu3
ii account-plugin-facebook 0.12+16.04.20160126-0ubuntu1
ii account-plugin-flickr 0.12+16.04.20160126-0ubuntu1
ii account-plugin-google 0.12+16.04.20160126-0ubuntu1
ii account-plugin-jabber 3.12.11-0ubuntu3
ii account-plugin-salut 3.12.11-0ubuntu3
ii account-plugin-twitter 0.12+16.04.20160126-0ubuntu1
rc account-plugin-windows-live 0.11+14.04.20140409.1-0ubuntu2
```
右侧:
```
Architecture Description
============-=====================================================================
amd64 Accessibility Profile Manager - Unity desktop indicator
amd64 Messaging account plugin for AIM
all GNOME Control Center account plugin for single signon - facebook
all GNOME Control Center account plugin for single signon - flickr
all GNOME Control Center account plugin for single signon
amd64 Messaging account plugin for Jabber/XMPP
amd64 Messaging account plugin for Local XMPP (Salut)
all GNOME Control Center account plugin for single signon - twitter
all GNOME Control Center account plugin for single signon - windows live
```
每行开头的 `ii` 和 `rc` 名称(见上文“左侧”)是包状态指示符。 第一个字母表示包的预期状态:
* `u` – 未知
* `i` – 安装
* `r` – 移除/反安装
* `p` – 清除(也包括配置文件)
* `h` – 保留
第二个代表包的当前状态:
* `n` – 未安装
* `i` – 已安装
* `c` – 配置文件(只安装了配置文件)
* `U` – 未打包
* `F` – 半配置(出于某些原因配置失败)
* `h` – 半安装(出于某些原因配置失败)
* `W` – 等待触发(该包等待另外一个包的触发器)
* `t` – 待定触发(该包被触发)
在通常的双字符字段末尾添加的 `R` 表示需要重新安装。 你可能永远不会碰到这些。
快速查看整体包状态的一种简单方法是计算在不同状态中包含的包的数量:
```
$ dpkg-query -l | tail -n +6 | awk '{print $1}' | sort | uniq -c
2066 ii
134 rc
```
我从上面的 `dpkg-query` 输出中排除了前五行,因为这些是标题行,会混淆输出。
这两行基本上告诉我们,在这个系统上,应该安装了 2066 个软件包,而 134 个其他的软件包已被删除,但留下了配置文件。 你始终可以使用以下命令删除程序包的剩余配置文件:
```
$ sudo dpkg --purge xfont-mathml
```
请注意,如果程序包二进制文件和配置文件都已经安装了,则上面的命令将两者都删除。
---
via: <https://www.networkworld.com/article/3242808/linux/peeking-into-your-linux-packages.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,161 | 为什么 Python 这么慢? | https://hackernoon.com/why-is-python-so-slow-e5074b6fe55b | 2018-10-27T11:41:00 | [
"Python"
] | https://linux.cn/article-10161-1.html | Python 现在越来越火,已经迅速扩张到包括 DevOps、数据科学、Web 开发、信息安全等各个领域当中。
然而,相比起 Python 扩张的速度,Python 代码的运行速度就显得有点逊色了。

>
> 在代码运行速度方面,Java、C、C++、C# 和 Python 要如何进行比较呢?并没有一个放之四海而皆准的标准,因为具体结果很大程度上取决于运行的程序类型,而<ruby> 语言基准测试 <rt> Computer Language Benchmarks Games </rt></ruby>可以作为[衡量的一个方面](http://algs4.cs.princeton.edu/faq/)。
>
>
>
根据我这些年来进行语言基准测试的经验来看,Python 比很多语言运行起来都要慢。无论是使用 [JIT](https://en.wikipedia.org/wiki/Just-in-time_compilation) 编译器的 C#、Java,还是使用 [AOT](https://en.wikipedia.org/wiki/Ahead-of-time_compilation) 编译器的 C、C++,又或者是 JavaScript 这些解释型语言,Python 都[比它们运行得慢](https://benchmarksgame-team.pages.debian.net/benchmarksgame/faster/python.html)。
注意:对于文中的 “Python” ,一般指 CPython 这个官方的实现。当然我也会在本文中提到其它语言的 Python 实现。
>
> 我要回答的是这个问题:对于一个类似的程序,Python 要比其它语言慢 2 到 10 倍不等,这其中的原因是什么?又有没有改善的方法呢?
>
>
>
主流的说法有这些:
* “是<ruby> 全局解释器锁 <rt> Global Interpreter Lock </rt></ruby>(GIL)的原因”
* “是因为 Python 是解释型语言而不是编译型语言”
* “是因为 Python 是一种动态类型的语言”
哪一个才是是影响 Python 运行效率的主要原因呢?
### 是全局解释器锁的原因吗?
现在很多计算机都配备了具有多个核的 CPU ,有时甚至还会有多个处理器。为了更充分利用它们的处理能力,操作系统定义了一个称为线程的低级结构。某一个进程(例如 Chrome 浏览器)可以建立多个线程,在系统内执行不同的操作。在这种情况下,CPU 密集型进程就可以跨核心分担负载了,这样的做法可以大大提高应用程序的运行效率。
例如在我写这篇文章时,我的 Chrome 浏览器打开了 44 个线程。需要提及的是,基于 POSIX 的操作系统(例如 Mac OS、Linux)和 Windows 操作系统的线程结构、API 都是不同的,因此操作系统还负责对各个线程的调度。
如果你还没有写过多线程执行的代码,你就需要了解一下线程锁的概念了。多线程进程比单线程进程更为复杂,是因为需要使用线程锁来确保同一个内存地址中的数据不会被多个线程同时访问或更改。
CPython 解释器在创建变量时,首先会分配内存,然后对该变量的引用进行计数,这称为<ruby> 引用计数 <rt> reference counting </rt></ruby>。如果变量的引用数变为 0,这个变量就会从内存中释放掉。这就是在 for 循环代码块内创建临时变量不会增加内存消耗的原因。
而当多个线程内共享一个变量时,CPython 锁定引用计数的关键就在于使用了 GIL,它会谨慎地控制线程的执行情况,无论同时存在多少个线程,解释器每次只允许一个线程进行操作。
#### 这会对 Python 程序的性能有什么影响?
如果你的程序只有单线程、单进程,代码的速度和性能不会受到全局解释器锁的影响。
但如果你通过在单进程中使用多线程实现并发,并且是 IO 密集型(例如网络 IO 或磁盘 IO)的线程,GIL 竞争的效果就很明显了。

*由 David Beazley 提供的 GIL 竞争情况图<http://dabeaz.blogspot.com/2010/01/python-gil-visualized.html>*
对于一个 web 应用(例如 Django),同时还使用了 WSGI,那么对这个 web 应用的每一个请求都运行一个**单独**的 Python 解释器,而且每个请求只有一个锁。同时因为 Python 解释器的启动比较慢,某些 WSGI 实现还具有“守护进程模式”,[可以使 Python 进程一直就绪](https://www.slideshare.net/GrahamDumpleton/secrets-of-a-wsgi-master)。
#### 其它的 Python 解释器表现如何?
[PyPy 也是一种带有 GIL 的解释器](http://doc.pypy.org/en/latest/faq.html#does-pypy-have-a-gil-why),但通常比 CPython 要快 3 倍以上。
[Jython 则是一种没有 GIL 的解释器](http://www.jython.org/jythonbook/en/1.0/Concurrency.html#no-global-interpreter-lock),这是因为 Jython 中的 Python 线程使用 Java 线程来实现,并且由 JVM 内存管理系统来进行管理。
#### JavaScript 在这方面又是怎样做的呢?
所有的 Javascript 引擎使用的都是 [mark-and-sweep 垃圾收集算法](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Memory_Management),而 GIL 使用的则是 CPython 的内存管理算法。
JavaScript 没有 GIL,而且它是单线程的,也不需要用到 GIL, JavaScript 的事件循环和 Promise/Callback 模式实现了以异步编程的方式代替并发。在 Python 当中也有一个类似的 asyncio 事件循环。
### 是因为 Python 是解释型语言吗?
我经常会听到这个说法,但是这过于粗陋地简化了 Python 所实际做的工作了。其实当终端上执行 `python myscript.py` 之后,CPython 会对代码进行一系列的读取、语法分析、解析、编译、解释和执行的操作。
如果你对这一系列过程感兴趣,也可以阅读一下我之前的文章:[在 6 分钟内修改 Python 语言](https://hackernoon.com/modifying-the-python-language-in-7-minutes-b94b0a99ce14) 。
`.pyc` 文件的创建是这个过程的重点。在代码编译阶段,Python 3 会将字节码序列写入 `__pycache__/` 下的文件中,而 Python 2 则会将字节码序列写入当前目录的 `.pyc` 文件中。对于你编写的脚本、导入的所有代码以及第三方模块都是如此。
因此,绝大多数情况下(除非你的代码是一次性的……),Python 都会解释字节码并本地执行。与 Java、C#.NET 相比:
>
> Java 代码会被编译为“中间语言”,由 Java 虚拟机读取字节码,并将其即时编译为机器码。.NET CIL 也是如此,.NET CLR(Common-Language-Runtime)将字节码即时编译为机器码。
>
>
>
既然 Python 像 Java 和 C# 那样都使用虚拟机或某种字节码,为什么 Python 在基准测试中仍然比 Java 和 C# 慢得多呢?首要原因是,.NET 和 Java 都是 JIT 编译的。
<ruby> 即时 <rt> Just-in-time </rt></ruby>(JIT)编译需要一种中间语言,以便将代码拆分为多个块(或多个帧)。而<ruby> 提前 <rt> ahead of time </rt></ruby>(AOT)编译器则需要确保 CPU 在任何交互发生之前理解每一行代码。
JIT 本身不会使执行速度加快,因为它执行的仍然是同样的字节码序列。但是 JIT 会允许在运行时进行优化。一个优秀的 JIT 优化器会分析出程序的哪些部分会被多次执行,这就是程序中的“热点”,然后优化器会将这些代码替换为更有效率的版本以实现优化。
这就意味着如果你的程序是多次重复相同的操作时,有可能会被优化器优化得更快。而且,Java 和 C# 是强类型语言,因此优化器对代码的判断可以更为准确。
PyPy 使用了明显快于 CPython 的 JIT。更详细的结果可以在这篇性能基准测试文章中看到:[哪一个 Python 版本最快?](https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b)。
#### 那为什么 CPython 不使用 JIT 呢?
JIT 也不是完美的,它的一个显著缺点就在于启动时间。 CPython 的启动时间已经相对比较慢,而 PyPy 比 CPython 启动还要慢 2 到 3 倍。Java 虚拟机启动速度也是出了名的慢。.NET CLR 则通过在系统启动时启动来优化体验,而 CLR 的开发者也是在 CLR 上开发该操作系统。
因此如果你有个长时间运行的单一 Python 进程,JIT 就比较有意义了,因为代码里有“热点”可以优化。
不过,CPython 是个通用的实现。设想如果使用 Python 开发命令行程序,但每次调用 CLI 时都必须等待 JIT 缓慢启动,这种体验就相当不好了。
CPython 试图用于各种使用情况。有可能实现[将 JIT 插入到 CPython 中](https://www.slideshare.net/AnthonyShaw5/pyjion-a-jit-extension-system-for-cpython),但这个改进工作的进度基本处于停滞不前的状态。
>
> 如果你想充分发挥 JIT 的优势,请使用 PyPy。
>
>
>
### 是因为 Python 是一种动态类型的语言吗?
在 C、C++、Java、C#、Go 这些静态类型语言中,必须在声明变量时指定变量的类型。而在动态类型语言中,虽然也有类型的概念,但变量的类型是可改变的。
```
a = 1
a = "foo"
```
在上面这个示例里,Python 将变量 `a` 一开始存储整数类型变量的内存空间释放了,并创建了一个新的存储字符串类型的内存空间,并且和原来的变量同名。
静态类型语言这样的设计并不是为了为难你,而是为了方便 CPU 运行而这样设计的。因为最终都需要将所有操作都对应为简单的二进制操作,因此必须将对象、类型这些高级的数据结构转换为低级数据结构。
Python 也实现了这样的转换,但用户看不到这些转换,也不需要关心这些转换。
不用必须声明类型并不是为了使 Python 运行慢,Python 的设计是让用户可以让各种东西变得动态:可以在运行时更改对象上的方法,也可以在运行时动态添加底层系统调用到值的声明上,几乎可以做到任何事。
但也正是这种设计使得 Python 的优化异常的难。
为了证明我的观点,我使用了一个 Mac OS 上的系统调用跟踪工具 DTrace。CPython 发布版本中没有内置 DTrace,因此必须重新对 CPython 进行编译。以下以 Python 3.6.6 为例:
```
wget https://github.com/python/cpython/archive/v3.6.6.zip
unzip v3.6.6.zip
cd v3.6.6
./configure --with-dtrace
make
```
这样 `python.exe` 将使用 DTrace 追踪所有代码。[Paul Ross 也作过关于 DTrace 的闪电演讲](https://github.com/paulross/dtrace-py#the-lightning-talk)。你可以下载 Python 的 DTrace 启动文件来查看函数调用、执行时间、CPU 时间、系统调用,以及各种其它的内容。
```
sudo dtrace -s toolkit/<tracer>.d -c ‘../cpython/python.exe script.py’
```
`py_callflow` 追踪器[显示](https://cdn-images-1.medium.com/max/1600/1*Lz4UdUi4EwknJ0IcpSJ52g.gif)了程序里调用的所有函数。
那么,Python 的动态类型会让它变慢吗?
* 类型比较和类型转换消耗的资源是比较多的,每次读取、写入或引用变量时都会检查变量的类型
* Python 的动态程度让它难以被优化,因此很多 Python 的替代品能够如此快都是为了提升速度而在灵活性方面作出了妥协
* 而 [Cython](http://cython.org/) 结合了 C 的静态类型和 Python 来优化已知类型的代码,它[可以将](http://notes-on-cython.readthedocs.io/en/latest/std_dev.html)性能提升 **84 倍**。
### 总结
>
> 由于 Python 是一种动态、多功能的语言,因此运行起来会相对缓慢。对于不同的实际需求,可以使用各种不同的优化或替代方案。
>
>
>
例如可以使用异步,引入分析工具或使用多种解释器来优化 Python 程序。
对于不要求启动时间且代码可以充分利用 JIT 的程序,可以考虑使用 PyPy。
而对于看重性能并且静态类型变量较多的程序,不妨使用 [Cython](http://cython.org/)。
#### 延伸阅读
Jake VDP 的优秀文章(略微过时) <https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/>
Dave Beazley 关于 GIL 的演讲 <http://www.dabeaz.com/python/GIL.pdf>
JIT 编译器的那些事 <https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/>
---
via: <https://hackernoon.com/why-is-python-so-slow-e5074b6fe55b>
作者:[Anthony Shaw](https://hackernoon.com/@anthonypjshaw?source=post_header_lockup) 选题:[oska874](https://github.com/oska874) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Python is booming in popularity. It is used in DevOps, Data Science, Web Development and Security.
It does not, however, win any medals for speed.
How does Java compare in terms of speed to C or C++ or C# or Python? The answer depends greatly on the type of application you’re running. No benchmark is perfect, but The Computer Language Benchmarks Game is
[a good starting point].
I’ve been referring to the Computer Language Benchmarks Game for over a decade; compared with other languages like Java, C#, Go, JavaScript, C++, Python is [one of the slowest](https://benchmarksgame-team.pages.debian.net/benchmarksgame/faster/python.html?ref=hackernoon.com). This includes [JIT](https://en.wikipedia.org/wiki/Just-in-time_compilation?ref=hackernoon.com) (C#, Java) and [AOT](https://en.wikipedia.org/wiki/Ahead-of-time_compilation?ref=hackernoon.com) (C, C++) compilers, as well as interpreted languages like JavaScript.
*NB: When I say “Python”, I’m talking about the reference implementation of the language, CPython. I will refer to other runtimes in this article.*
I want to answer this question:
When Python completes a comparable application 2–10x slower than another language,?why is it slowand can’t wemake it faster
Here are the top theories:
Which one of these reasons has the biggest impact on performance?
Modern computers come with CPU’s that have multiple cores, and sometimes multiple processors. In order to utilise all this extra processing power, the Operating System defines a low-level structure called a thread, where a process (e.g. Chrome Browser) can spawn multiple threads and have instructions for the system inside. That way if one process is particularly CPU-intensive, that load can be shared across the cores and this effectively makes most applications complete tasks faster.
My Chrome Browser, as I’m writing this article, has **44** threads open. Keep in mind that the structure and API of threading are different between POSIX-based (e.g. Mac OS and Linux) and Windows OS. The operating system also handles the scheduling of threads.
IF you haven’t done multi-threaded programming before, a concept you’ll need to quickly become familiar with locks. Unlike a single-threaded process, you need to ensure that when changing variables in memory, multiple threads don’t try and access/change the same memory address at the same time.
When CPython creates variables, it allocates the memory and then counts how many references to that variable exist, this is a concept known as reference counting. If the number of references is 0, then it frees that piece of memory from the system. This is why creating a “temporary” variable within say, the scope of a for loop, doesn’t blow up the memory consumption of your application.
The challenge then becomes when variables are shared within multiple threads, how CPython locks the reference count. There is a “global interpreter lock” that carefully controls thread execution. The interpreter can only execute one operation at a time, regardless of how many threads it has.
If you have a single-threaded, single interpreter application. **It will make no difference to the speed**. Removing the GIL would have no impact on the performance of your code.
If you wanted to implement concurrency within a single interpreter (Python process) by using threading, and your threads were IO intensive (e.g. Network IO or Disk IO), you would see the consequences of GIL-contention.
From David Beazley’s GIL visualised post [http://dabeaz.blogspot.com/2010/01/python-gil-visualized.html](http://dabeaz.blogspot.com/2010/01/python-gil-visualized.html?ref=hackernoon.com)
If you have a web-application (e.g. Django) and you’re using WSGI, then each request to your web-app is a **separate** Python interpreter, so there is only 1 lock *per* request. Because the Python interpreter is slow to start, some WSGI implementations have a “Daemon Mode” [which keep Python process(es) on the go for you.](https://www.slideshare.net/GrahamDumpleton/secrets-of-a-wsgi-master?ref=hackernoon.com)
[PyPy has a GIL](http://doc.pypy.org/en/latest/faq.html?ref=hackernoon.com#does-pypy-have-a-gil-why) and it is typically >3x faster than CPython.
[Jython does not have a GIL](http://www.jython.org/jythonbook/en/1.0/Concurrency.html?ref=hackernoon.com#no-global-interpreter-lock) because a Python thread in Jython is represented by a Java thread and benefits from the JVM memory-management system.
Well, firstly all Javascript engines [use mark-and-sweep Garbage Collection](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Memory_Management?ref=hackernoon.com). As stated, the primary need for the GIL is CPython’s memory-management algorithm.
JavaScript does not have a GIL, but it’s also **single**-threaded so it doesn’t require one. JavaScript’s event-loop and Promise/Callback pattern are how asynchronous-programming is achieved in place of concurrency. Python has a similar thing with the asyncio event-loop.
I hear this a lot and I find it a gross-simplification of the way CPython actually works. If at a terminal you wrote `python myscript.py`
then CPython would start a long sequence of reading, lexing, parsing, compiling, interpreting and executing that code.
If you’re interested in how that process works, I’ve written about it before:
**Modifying the Python language in 6 minutes**_This week I raised my first pull-request to the CPython core project, which was declined :-( but as to not completely…_hackernoon.com
An important point in that process is the creation of a `.pyc`
file, at the compiler stage, the bytecode sequence is written to a file inside `__pycache__/`
on Python 3 or in the same directory in Python 2. This doesn’t just apply to your script, but all of the code you imported, including 3rd party modules.
So most of the time (unless you write code which you only ever run once?), Python is interpreting bytecode and executing it locally. Compare that with Java and C#.NET:
Java compiles to an “Intermediate Language” and the Java Virtual Machine reads the bytecode and
just-in-timecompiles it to machine code. The .NET CIL is the same, the .NET Common-Language-Runtime, CLR, uses just-in-time compilation to machine code.
So, why is Python so much slower than both Java and C# in the benchmarks if they all use a virtual machine and some sort of Bytecode? Firstly, .NET and Java are JIT-Compiled.
JIT or Just-in-time compilation requires an intermediate language to allow the code to be split into chunks (or frames). Ahead of time (AOT) compilers are designed to ensure that the CPU can understand every line in the code before any interaction takes place.
The JIT itself does not make the execution any faster, because it is still executing the same bytecode sequences. However, JIT enables optimizations to be made at runtime. A good JIT optimizer will see which parts of the application are being executed a lot, call these “hot spots”. It will then make optimizations to those bits of code, by replacing them with more efficient versions.
This means that when your application does the same thing again and again, it can be significantly faster. Also, keep in mind that Java and C# are strongly-typed languages so the optimiser can make many more assumptions about the code.
**PyPy has a JIT** and as mentioned in the previous section, is significantly faster than CPython. This performance benchmark article goes into more detail —
**Which is the fastest version of Python?**_Of course, “it depends”, but what does it depend on and how can you assess which is the fastest version of Python for…_hackernoon.com
There are downsides to JITs: one of those is startup time. CPython startup time is already comparatively slow, PyPy is 2–3x slower to start than CPython. The Java Virtual Machine is notoriously slow to boot. The .NET CLR gets around this by starting at system-startup, but the developers of the CLR also develop the Operating System on which the CLR runs.
If you have a single Python process running for a long time, with code that can be optimized because it contains “hot spots”, then a JIT makes a lot of sense.
However, CPython is a **general-purpose** implementation. So if you were developing command-line applications using Python, having to wait for a JIT to start every time the CLI was called would be horribly slow.
CPython has to try and serve as many use cases as possible. There was the possibility of [plugging a JIT into CPython](https://www.slideshare.net/AnthonyShaw5/pyjion-a-jit-extension-system-for-cpython?ref=hackernoon.com) but this project has largely stalled.
If you want the benefits of a JIT and you have a workload that suits it, use PyPy.
In a “Statically-Typed” language, you have to specify the type of a variable when it is declared. Those would include C, C++, Java, C#, Go.
In a dynamically-typed language, there are still the concept of types, but the type of a variable is dynamic.
a = 1a = "foo"
In this toy-example, Python creates a second variable with the same name and a type of `str`
and deallocates the memory created for the first instance of `a`
Statically-typed languages aren’t designed as such to make your life hard, they are designed that way because of the way the CPU operates. If everything eventually needs to equate to a simple binary operation, you have to convert objects and types down to a low-level data structure.
Python does this for you, you just never see it, nor do you need to care.
Not having to declare the type isn’t what makes Python slow, the design of the Python language enables you to make almost anything dynamic. You can replace the methods on objects at runtime, you can monkey-patch low-level system calls to a value declared at runtime. Almost anything is possible.
It’s this design that makes it **incredibly hard** to optimise Python.
To illustrate my point, I’m going to use a syscall tracing tool that works in Mac OS called Dtrace. CPython distributions do not come with DTrace builtin, so you have to recompile CPython. I’m using 3.6.6 for my demo
wget [https://github.com/python/cpython/archive/v3.6.6.zip](https://github.com/python/cpython/archive/v3.6.6.zip?ref=hackernoon.com)unzip v3.6.6.zipcd v3.6.6./configure --with-dtracemake
Now `python.exe`
will have Dtrace tracers throughout the code. [Paul Ross wrote an awesome Lightning Talk on Dtrace](https://github.com/paulross/dtrace-py?ref=hackernoon.com#the-lightning-talk). You can [download DTrace starter files](https://github.com/paulross/dtrace-py/tree/master/toolkit?ref=hackernoon.com) for Python to measure function calls, execution time, CPU time, syscalls, all sorts of fun. e.g.
`sudo dtrace -s toolkit/<tracer>.d -c ‘../cpython/python.exe script.py’`
The `py_callflow`
tracer shows all the function calls in your application
So, does Python’s dynamic typing make it slow?
Python is primarily slow because of its dynamic nature and versatility. It can be used as a tool for all sorts of problems, where more optimised and faster alternatives are probably available.
There are, however, ways of optimising your Python applications by leveraging async, understanding the profiling tools, and consider using multiple-interpreters.
For applications where startup time is unimportant and the code would benefit a JIT, consider PyPy.
For parts of your code where performance is critical and you have more statically-typed variables, consider using [Cython](http://cython.org/?ref=hackernoon.com).
Jake VDP’s excellent article (although slightly dated) [https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/](https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/?ref=hackernoon.com)
Dave Beazley’s talk on the GIL [http://www.dabeaz.com/python/GIL.pdf](http://www.dabeaz.com/python/GIL.pdf?ref=hackernoon.com)
All about JIT compilers [https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/](https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/?ref=hackernoon.com) |
10,162 | 坚实的 React 基础:初学者指南 | https://medium.freecodecamp.org/rock-solid-react-js-foundations-a-beginners-guide-c45c93f5a923 | 2018-10-28T10:46:00 | [
"React"
] | https://linux.cn/article-10162-1.html | 
在过去的几个月里,我一直在使用 React 和 React-Native。我已经发布了两个作为产品的应用, [Kiven Aa](https://kivenaa.com/)(React)和 [Pollen Chat](https://play.google.com/store/apps/details?id=com.pollenchat.android)(React Native)。当我开始学习 React 时,我找了一些不仅仅是教我如何用 React 写应用的东西(一个博客,一个视频,一个课程,等等),我也想让它帮我做好面试准备。
我发现的大部分资料都集中在某一单一方面上。所以,这篇文章针对的是那些希望理论与实践完美结合的观众。我会告诉你一些理论,以便你了解幕后发生的事情,然后我会向你展示如何编写一些 React.js 代码。
如果你更喜欢视频形式,我在 [YouTube][<https://youtu.be/WJ6PgzI16I4>] 上传了整个课程,请去看看。
让我们开始……
>
> React.js 是一个用于构建用户界面的 JavaScript 库
>
>
>
你可以构建各种单页应用程序。例如,你希望在用户界面上实时显示变化的聊天软件和电子商务门户。
### 一切都是组件
React 应用由组件组成,数量繁多且互相嵌套。你或许会问:”可什么是组件呢?“
组件是可重用的代码段,它定义了某些功能在 UI 上的外观和行为。 比如,按钮就是一个组件。
让我们看看下面的计算器,当你尝试计算 2 + 2 = 4 -1 = 3(简单的数学题)时,你会在 Google 上看到这个计算器。

*红色标记表示组件*
如上图所示,这个计算器有很多区域,比如展示窗口和数字键盘。所有这些都可以是许多单独的组件或一个巨大的组件。这取决于在 React 中分解和抽象出事物的程度。你为所有这些组件分别编写代码,然后合并这些组件到一个容器中,而这个容器又是一个 React 组件。这样你就可以创建可重用的组件,最终的应用将是一组协同工作的单独组件。
以下是一个你践行了以上原则并可以用 React 编写计算器的方法。
```
<Calculator>
<DisplayWindow />
<NumPad>
<Key number={1}/>
<Key number={2}/>
.
.
.
<Key number={9}/>
</NumPad>
</Calculator>
```
没错!它看起来像HTML代码,然而并不是。我们将在后面的部分中详细探讨它。
### 设置我们的 Playground
这篇教程专注于 React 的基础部分。它没有偏向 Web 或 React Native(开发移动应用)。所以,我们会用一个在线编辑器,这样可以在学习 React 能做什么之前避免 web 或 native 的具体配置。
我已经为读者在 [codepen.io](https://codepen.io/raynesax/pen/MrNmBM) 设置好了开发环境。只需点开[该链接](https://codepen.io/raynesax/pen/MrNmBM)并且阅读 HTML 和 JavaScript 中的所有注释。
### 控制组件
我们已经了解到 React 应用是各种组件的集合,结构为嵌套树。因此,我们需要某种机制来将数据从一个组件传递到另一个组件。
#### 进入 “props”
我们可以使用 `props` 对象将任意数据传递给我们的组件。 React 中的每个组件都会获取 `props` 对象。在学习如何使用 `props` 之前,让我们学习函数式组件。
#### a) 函数式组件
在 React 中,一个函数式组件通过 `props` 对象使用你传递给它的任意数据。它返回一个对象,该对象描述了 React 应渲染的 UI。函数式组件也称为无状态组件。
让我们编写第一个函数式组件。
```
function Hello(props) {
return <div>{props.name}</div>
}
```
就这么简单。我们只是将 `props` 作为参数传递给了一个普通的 JavaScript 函数并且有返回值。嗯?返回了什么?那个 `<div>{props.name}</div>`。它是 JSX(JavaScript Extended)。我们将在后面的部分中详细了解它。
上面这个函数将在浏览器中渲染出以下 HTML。
```
<!-- If the "props" object is: {name: 'rajat'} -->
<div>
rajat
</div>
```
>
> 阅读以下有关 JSX 的部分,这一部分解释了如何从我们的 JSX 代码中得到这段 HTML 。
>
>
>
如何在 React 应用中使用这个函数式组件? 很高兴你问了! 它就像下面这么简单。
```
<Hello name='rajat' age={26}/>
```
属性 `name` 在上面的代码中变成了 `Hello` 组件里的 `props.name` ,属性 `age` 变成了 `props.age` 。
>
> 记住! 你可以将一个 React 组件嵌套在其他 React 组件中。
>
>
>
让我们在 codepen playground 使用 `Hello` 组件。用我们的 `Hello` 组件替换 `ReactDOM.render()` 中的 `div`,并在底部窗口中查看更改。
```
function Hello(props) {
return <div>{props.name}</div>
}
ReactDOM.render(<Hello name="rajat"/>, document.getElementById('root'));
```
>
> 但是如果你的组件有一些内部状态怎么办?例如,像下面的计数器组件一样,它有一个内部计数变量,它在 `+` 和 `-` 键按下时发生变化。
>
>
>

*具有内部状态的 React 组件*
#### b) 基于类的组件
基于类的组件有一个额外属性 `state` ,你可以用它存放组件的私有数据。我们可以用 `class` 表示法重写我们的 `Hello` 。由于这些组件具有状态,因此这些组件也称为有状态组件。
```
class Counter extends React.Component {
// this method should be present in your component
render() {
return (
<div>
{this.props.name}
</div>
);
}
}
```
我们继承了 React 库的 `React.Component` 类以在 React 中创建基于类的组件。在[这里](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes)了解更多有关 JavaScript 类的东西。
`render()` 方法必须存在于你的类中,因为 React 会查找此方法,用以了解它应在屏幕上渲染的 UI。为了使用这种内部状态,我们首先要在组件
要使用这种内部状态,我们首先必须按以下方式初始化组件类的构造函数中的状态对象。
```
class Counter extends React.Component {
constructor() {
super();
// define the internal state of the component
this.state = {name: 'rajat'}
}
render() {
return (
<div>
{this.state.name}
</div>
);
}
}
// Usage:
// In your react app: <Counter />
```
类似地,可以使用 `this.props` 对象在我们基于类的组件内访问 `props`。
要设置 `state`,请使用 `React.Component` 的 `setState()`。 在本教程的最后一部分中,我们将看到一个这样的例子。
>
> 提示:永远不要在 `render()` 函数中调用 `setState()`,因为 `setState` 会导致组件重新渲染,这将导致无限循环。
>
>
>

*基于类的组件具有可选属性 “state”。*
除了 `state` 以外,基于类的组件有一些声明周期方法比如 `componentWillMount()`。你可以利用这些去做初始化 `state`这样的事, 可是那将超出这篇文章的范畴。
### JSX
JSX 是 JavaScript Extended 的缩写,它是一种编写 React 组件的方法。使用 JSX,你可以在类 XML 标签中获得 JavaScript 的全部力量。
你把 JavaScript 表达式放在 `{}` 里。下面是一些有效的 JSX 例子。
```
<button disabled={true}>Press me!</button>
<button disabled={true}>Press me {3+1} times!</button>;
<div className='container'><Hello /></div>
```
它的工作方式是你编写 JSX 来描述你的 UI 应该是什么样子。像 Babel 这样的转码器将这些代码转换为一堆 `React.createElement()` 调用。然后,React 库使用这些 `React.createElement()` 调用来构造 DOM 元素的树状结构。对于 React 的网页视图或 React Native 的 Native 视图,它将保存在内存中。
React 接着会计算它如何在展示给用户的 UI 的内存中有效地模仿这个树。此过程称为 [reconciliation](https://reactjs.org/docs/reconciliation.html)。完成计算后,React 会对屏幕上的真正 UI 进行更改。

*React 如何将你的 JSX 转化为描述应用 UI 的树。*
你可以使用 [Babel 的在线 REPL](https://babeljs.io/repl) 查看当你写一些 JSX 的时候,React 的真正输出。

*使用Babel REPL 转换 JSX 为普通 JavaScript*
>
> 由于 JSX 只是 `React.createElement()` 调用的语法糖,因此可以在没有 JSX 的情况下使用 React。
>
>
>
现在我们了解了所有的概念,所以我们已经准备好编写我们之前看到之前的 GIF 图中的计数器组件。
代码如下,我希望你已经知道了如何在我们的 playground 上渲染它。
```
class Counter extends React.Component {
constructor(props) {
super(props);
this.state = {count: this.props.start || 0}
// the following bindings are necessary to make `this` work in the callback
this.inc = this.inc.bind(this);
this.dec = this.dec.bind(this);
}
inc() {
this.setState({
count: this.state.count + 1
});
}
dec() {
this.setState({
count: this.state.count - 1
});
}
render() {
return (
<div>
<button onClick={this.inc}>+</button>
<button onClick={this.dec}>-</button>
<div>{this.state.count}</div>
</div>
);
}
}
```
以下是关于上述代码的一些重点。
1. JSX 使用 `驼峰命名` ,所以 `button` 的 属性是 `onClick`,不是我们在HTML中用的 `onclick`。
2. 绑定 `this` 是必要的,以便在回调时工作。 请参阅上面代码中的第8行和第9行。
最终的交互式代码位于[此处](https://codepen.io/raynesax/pen/QaROqK)。
有了这个,我们已经到了 React 速成课程的结束。我希望我已经阐明了 React 如何工作,以及如何使用 React 来构建更大的应用程序,使用更小和可重用的组件。
---
via: <https://medium.freecodecamp.org/rock-solid-react-js-foundations-a-beginners-guide-c45c93f5a923>
作者:[Rajat Saxena](https://medium.freecodecamp.org/@rajat1saxena) 译者:[GraveAccent](https://github.com/GraveAccent) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,163 | 面向系统管理员的容器手册 | https://opensource.com/article/18/8/sysadmins-guide-containers | 2018-10-28T11:15:26 | [
"容器"
] | https://linux.cn/article-10163-1.html |
>
> 你所需了解的容器如何工作的知识。
>
>
>

现在人们严重过度使用了“容器”这个术语。另外,对不同的人来说,它可能会有不同的含义,这取决于上下文。
传统的 Linux 容器只是系统上普通的进程。一组进程与另外一组进程是相互隔离的,实现方法包括:资源限制(控制组 [cgoups])、Linux 安全限制(文件权限,基于 Capability 的安全模块、SELinux、AppArmor、seccomp 等)还有名字空间(进程 ID、网络、挂载等)。
如果你启动一台现代 Linux 操作系统,使用 `cat /proc/PID/cgroup` 命令就可以看到该进程是属于一个控制组的。还可以从 `/proc/PID/status` 文件中查看进程的 Capability 信息,从 `/proc/self/attr/current` 文件中查看进程的 SELinux 标签信息,从 `/proc/PID/ns` 目录下的文件查看进程所属的名字空间。因此,如果把容器定义为带有资源限制、Linux 安全限制和名字空间的进程,那么按照这个定义,Linux 操作系统上的每一个进程都在一个容器里。因此我们常说 [Linux 就是容器,容器就是 Linux](https://www.redhat.com/en/blog/containers-are-linux)。而**容器运行时**是这样一种工具,它调整上述资源限制、安全限制和名字空间,并启动容器。
Docker 引入了**容器镜像**的概念,镜像是一个普通的 TAR 包文件,包含了:
* **rootfs(容器的根文件系统)**:一个目录,看起来像是操作系统的普通根目录(`/`),例如,一个包含 `/usr`, `/var`, `/home` 等的目录。
* **JSON 文件(容器的配置)**:定义了如何运行 rootfs;例如,当容器启动的时候要在 rootfs 里运行什么命令(`CMD`)或者入口(`ENTRYPOINT`),给容器定义什么样的环境变量(`ENV`),容器的工作目录(`WORKDIR`)是哪个,以及其他一些设置。
Docker 把 rootfs 和 JSON 配置文件打包成**基础镜像**。你可以在这个基础之上,给 rootfs 安装更多东西,创建新的 JSON 配置文件,然后把相对于原始镜像的不同内容打包到新的镜像。这种方法创建出来的是**分层的镜像**。
<ruby> <a href="https://www.opencontainers.org/"> 开放容器计划 </a> <rt> Open Container Initiative </rt></ruby>(OCI)标准组织最终把容器镜像的格式标准化了,也就是 <ruby> <a href="https://github.com/opencontainers/image-spec/blob/master/spec.md"> 镜像规范 </a> <rt> OCI Image Specification </rt></ruby>(OCI)。
用来创建容器镜像的工具被称为**容器镜像构建器**。有时候容器引擎做这件事情,不过可以用一些独立的工具来构建容器镜像。
Docker 把这些容器镜像(**tar 包**)托管到 web 服务中,并开发了一种协议来支持从 web 拉取镜像,这个 web 服务就叫<ruby> 容器仓库 <rt> container registry </rt></ruby>。
**容器引擎**是能从镜像仓库拉取镜像并装载到**容器存储**上的程序。容器引擎还能启动**容器运行时**(见下图)。

容器存储一般是<ruby> 写入时复制 <rt> copy-on-write </rt></ruby>(COW)的分层文件系统。从容器仓库拉取一个镜像时,其中的 rootfs 首先被解压到磁盘。如果这个镜像是多层的,那么每一层都会被下载到 COW 文件系统的不同分层。 COW 文件系统保证了镜像的每一层独立存储,这最大化了多个分层镜像之间的文件共享程度。容器引擎通常支持多种容器存储类型,包括 `overlay`、`devicemapper`、`btrfs`、`aufs` 和 `zfs`。
容器引擎将容器镜像下载到容器存储中之后,需要创建一份**容器运行时配置**,这份配置是用户/调用者的输入和镜像配置的合并。例如,容器的调用者可能会调整安全设置,添加额外的环境变量或者挂载一些卷到容器中。
容器运行时配置的格式,和解压出来的 rootfs 也都被开放容器计划 OCI 标准组织做了标准化,称为 [OCI 运行时规范](https://github.com/opencontainers/runtime-spec)。
最终,容器引擎启动了一个**容器运行时**来读取运行时配置,修改 Linux 控制组、安全限制和名字空间,并执行容器命令来创建容器的 **PID 1** 进程。至此,容器引擎已经可以把容器的标准输入/标准输出转给调用方,并控制容器了(例如,`stop`、`start`、`attach`)。
值得一提的是,现在出现了很多新的容器运行时,它们使用 Linux 的不同特性来隔离容器。可以使用 KVM 技术来隔离容器(想想迷你虚拟机),或者使用其他虚拟机监视器策略(例如拦截所有从容器内的进程发起的系统调用)。既然我们有了标准的运行时规范,这些工具都能被相同的容器引擎来启动。即使在 Windows 系统下,也可以使用 OCI 运行时规范来启动 Windows 容器。
容器编排器是一个更高层次的概念。它是在多个不同的节点上协调容器执行的工具。容器编排工具通过和容器引擎的通信来管理容器。编排器控制容器引擎做容器的启动和容器间的网络连接,它能够监控容器,在负载变高的时候进行容器扩容。
---
via: <https://opensource.com/article/18/8/sysadmins-guide-containers>
作者:[Daniel J Walsh](https://opensource.com/users/rhatdan) 选题:[lujun9972](https://github.com/lujun9972) 译者:[belitex](https://github.com/belitex) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The term "containers" is heavily overused. Also, depending on the context, it can mean different things to different people.
Traditional Linux containers are really just ordinary processes on a Linux system. These groups of processes are isolated from other groups of processes using resource constraints (control groups [cgroups]), Linux security constraints (Unix permissions, capabilities, SELinux, AppArmor, seccomp, etc.), and namespaces (PID, network, mount, etc.).
If you boot a modern Linux system and took a look at any process with `cat /proc/PID/cgroup`
, you see that the process is in a cgroup. If you look at `/proc/PID/status`
, you see capabilities. If you look at `/proc/self/attr/current`
, you see SELinux labels. If you look at `/proc/PID/ns`
, you see the list of namespaces the process is in. So, if you define a container as a process with resource constraints, Linux security constraints, and namespaces, by definition every process on a Linux system is in a container. This is why we often say [Linux is containers, containers are Linux](https://www.redhat.com/en/blog/containers-are-linux). **Container runtimes** are tools that modify these resource constraints, security, and namespaces and launch the container.
Docker introduced the concept of a **container image**, which is a standard TAR file that combines:
**Rootfs (container root filesystem):**A directory on the system that looks like the standard root (`/`
) of the operating system. For example, a directory with`/usr`
,`/var`
,`/home`
, etc.**JSON file (container configuration):**Specifies how to run the rootfs; for example, what**command**or**entrypoint**to run in the rootfs when the container starts;**environment variables**to set for the container; the container's**working directory**; and a few other settings.
Docker "`tar`
's up" the rootfs and the JSON file to create the **base image**. This enables you to install additional content on the rootfs, create a new JSON file, and `tar`
the difference between the original image and the new image with the updated JSON file. This creates a **layered image**.
The definition of a container image was eventually standardized by the [Open Container Initiative (OCI)](https://www.opencontainers.org/) standards body as the [OCI Image Specification](https://github.com/opencontainers/image-spec/blob/master/spec.md).
Tools used to create container images are called **container image builders**. Sometimes container engines perform this task, but several standalone tools are available that can build container images.
Docker took these container images (**tarballs**) and moved them to a web service from which they could be pulled, developed a protocol to pull them, and called the web service a **container registry**.
**Container engines** are programs that can pull container images from container registries and reassemble them onto **container storage**. Container engines also launch **container runtimes** (see below).
Linux container internals. Illustration by Scott McCarty. [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)
Container storage is usually a **copy-on-write** (COW) layered filesystem. When you pull down a container image from a container registry, you first need to untar the rootfs and place it on disk. If you have multiple layers that make up your image, each layer is downloaded and stored on a different layer on the COW filesystem. The COW filesystem allows each layer to be stored separately, which maximizes sharing for layered images. Container engines often support multiple types of container storage, including `overlay`
, `devicemapper`
, `btrfs`
, `aufs`
, and `zfs`
.
After the container engine downloads the container image to container storage, it needs to create a **container runtime configuration.** The runtime configuration combines input from the caller/user along with the content of the container image specification. For example, the caller might want to specify modifications to a running container's security, add additional environment variables, or mount volumes to the container.
The layout of the container runtime configuration and the exploded rootfs have also been standardized by the OCI standards body as the [OCI Runtime Specification](https://github.com/opencontainers/runtime-spec).
Finally, the container engine launches a **container runtime** that reads the container runtime specification; modifies the Linux cgroups, Linux security constraints, and namespaces; and launches the container command to create the container's **PID 1**. At this point, the container engine can relay `stdin`
/`stdout`
back to the caller and control the container (e.g., stop, start, attach).
Note that many new container runtimes are being introduced to use different parts of Linux to isolate containers. People can now run containers using KVM separation (think mini virtual machines) or they can use other hypervisor strategies (like intercepting all system calls from processes in containers). Since we have a standard runtime specification, these tools can all be launched by the same container engines. Even Windows can use the OCI Runtime Specification for launching Windows containers.
At a much higher level are **container orchestrators.** Container orchestrators are tools used to coordinate the execution of containers on multiple different nodes. Container orchestrators talk to container engines to manage containers. Orchestrators tell the container engines to start containers and wire their networks together. Orchestrators can monitor the containers and launch additional containers as the load increases.
## 2 Comments |
10,164 | 如何构建 RPM 包 | https://opensource.com/article/18/9/how-build-rpm-packages | 2018-10-28T12:54:50 | [
"RPM",
"软件包"
] | /article-10164-1.html |
>
> 节省跨多个主机安装文件和脚本的时间和精力。
>
>
>

自20多年前我开始使用 Linux 以来,我已经使用过基于 rpm 的软件包管理器在 Red Hat 和 Fedora Linux 系统上安装软件。我使用过 `rpm` 程序本身,还有 `yum` 和 `dnf` ,用于在我的 Linux 主机上安装和更新软件包,`dnf` 是 `yum` 的一个近亲。 `yum` 和 `dnf` 工具是 `rpm` 实用程序的包装器,它提供了其他功能,例如查找和安装包依赖项的功能。
多年来,我创建了许多 Bash 脚本,其中一些脚本具有单独的配置文件,我希望在大多数新计算机和虚拟机上安装这些脚本。这也能解决安装所有这些软件包需要花费大量时间的难题,因此我决定通过创建一个 rpm 软件包来自动执行该过程,我可以将其复制到目标主机并将所有这些文件安装在适当的位置。虽然 `rpm` 工具以前用于构建 rpm 包,但该功能已被删除,并且创建了一个新工具来构建新的 rpm。
当我开始这个项目时,我发现很少有关于创建 rpm 包的信息,但我找到了一本书,名为《Maximum RPM》,这本书才帮我弄明白了。这本书现在已经过时了,我发现的绝大多数信息都是如此。它也已经绝版,用过的副本也需要花费数百美元。[Maximum RPM](http://ftp.rpm.org/max-rpm/) 的在线版本是免费提供的,并保持最新。该 [RPM 网站](http://rpm.org/index.html)还有其他网站的链接,这些网站上有很多关于 rpm 的文档。其他的信息往往是简短的,显然都是假设你已经对该过程有了很多了解。
此外,我发现的每个文档都假定代码需要在开发环境中从源代码编译。我不是开发人员。我是一个系统管理员,我们系统管理员有不同的需求,因为我们不需要或者我们不应该为了管理任务而去编译代码;我们应该使用 shell 脚本。所以我们没有源代码,因为它需要被编译成二进制可执行文件。我们拥有的源代码也应该是可执行的。
在大多数情况下,此项目应作为非 root 用户执行。 rpm 包永远不应该由 root 用户构建,而只能由非特权普通用户构建。我将指出哪些部分应该以 root 身份执行,哪些部分应由非 root,非特权用户执行。
### 准备
首先,打开一个终端会话,然后 `su` 到 root 用户。 请务必使用 `-` 选项以确保启用完整的 root 环境。 我不认为系统管理员应该使用 `sudo` 来执行任何管理任务。 在我的个人博客文章中可以找出为什么:[真正的系统管理员不要使用 sudo](http://www.both.org/?p=960)。
```
[student@testvm1 ~]$ su -
Password:
[root@testvm1 ~]#
```
创建可用于此项目的普通用户 student,并为该用户设置密码。
```
[root@testvm1 ~]# useradd -c "Student User" student
[root@testvm1 ~]# passwd student
Changing password for user student.
New password: <Enter the password>
Retype new password: <Enter the password>
passwd: all authentication tokens updated successfully.
[root@testvm1 ~]#
```
构建 rpm 包需要 `rpm-build` 包,该包可能尚未安装。 现在以 root 身份安装它。 请注意,此命令还将安装多个依赖项。 数量可能会有所不同,具体取决于主机上已安装的软件包; 它在我的测试虚拟机上总共安装了 17 个软件包,这是非常小的。
```
dnf install -y rpm-build
```
除非另有明确指示,否则本项目的剩余部分应以普通用户用户 student 来执行。 打开另一个终端会话并使用 `su` 切换到该用户以执行其余步骤。 使用以下命令从 GitHub 下载我准备好的开发目录结构 utils.tar 这个<ruby> tar 包 <rt> tarball </rt></ruby>(LCTT 译注:tarball 是以 tar 命令来打包和压缩的文件的统称):
```
wget https://github.com/opensourceway/how-to-rpm/raw/master/utils.tar
```
此 tar 包包含将由最终 `rpm` 程序安装的所有文件和 Bash 脚本。 还有一个完整的 spec 文件,你可以使用它来构建 rpm。 我们将详细介绍 spec 文件的每个部分。
作为普通学生 student,使用你的家目录作为当前工作目录(`pwd`),解压缩 tar 包。
```
[student@testvm1 ~]$ cd ; tar -xvf utils.tar
```
使用 `tree` 命令验证 `~/development` 的目录结构和包含的文件,如下所示:
```
[student@testvm1 ~]$ tree development/
development/
├── license
│ ├── Copyright.and.GPL.Notice.txt
│ └── GPL_LICENSE.txt
├── scripts
│ ├── create_motd
│ ├── die
│ ├── mymotd
│ └── sysdata
└── spec
└── utils.spec
3 directories, 7 files
[student@testvm1 ~]$
```
`mymotd` 脚本创建一个发送到标准输出的“当日消息”数据流。 `create_motd` 脚本运行 `mymotd` 脚本并将输出重定向到 `/etc/motd` 文件。 此文件用于向使用 SSH 远程登录的用户显示每日消息。
`die` 脚本是我自己的脚本,它将 `kill` 命令包装在一些代码中,这些代码可以找到与指定字符串匹配的运行程序并将其终止。 它使用 `kill -9` 来确保 `kill` 命令一定会执行。
`sysdata` 脚本可以显示有关计算机硬件,还有已安装的 Linux 版本,所有已安装的软件包以及硬盘驱动器元数据等数万行数据。 我用它来记录某个时间点的主机状态。 我以后可以用它作为参考。 我曾经这样做是为了维护我为客户安装的主机记录。
你可能需要将这些文件和目录的所有权更改为 `student:student` 。 如有必要,使用以下命令执行此操作:
```
chown -R student:student development
```
此文件树中的大多数文件和目录将通过你在此项目期间创建的 rpm 包安装在 Fedora 系统上。
### 创建构建目录结构
`rpmbuild` 命令需要非常特定的目录结构。 你必须自己创建此目录结构,因为没有提供自动方式。 在家目录中创建以下目录结构:
```
~ ─ rpmbuild
├── RPMS
│ └── noarch
├── SOURCES
├── SPECS
└── SRPMS
```
我们不会创建 `rpmbuild/RPMS/X86_64` 目录,因为它是特定于体系结构编译的 64 位二进制文件。 我们有 shell 脚本,不是特定于体系结构的。 实际上,我们也不会使用 `SRPMS` 目录,它将包含编译器的源文件。
### 检查 spec 文件
每个 spec 文件都有许多部分,其中一些部分可能会被忽视或省略,取决于 rpm 构建的具体情况。 这个特定的 spec 文件不是工作所需的最小文件的示例,但它是一个包含不需要编译的文件的中等复杂 spec 文件的很好例子。 如果需要编译,它将在 `%build` 部分中执行,该部分在此 spec 文件中省略掉了,因为它不是必需的。
#### 前言
这是 spec 文件中唯一没有标签的部分。 它包含运行命令 `rpm -qi [Package Name]` 时看到的大部分信息。 每个数据都是一行,由标签和标签值的文本数据组成。
```
###############################################################################
# Spec file for utils
################################################################################
# Configured to be built by user student or other non-root user
################################################################################
#
Summary: Utility scripts for testing RPM creation
Name: utils
Version: 1.0.0
Release: 1
License: GPL
URL: http://www.both.org
Group: System
Packager: David Both
Requires: bash
Requires: screen
Requires: mc
Requires: dmidecode
BuildRoot: ~/rpmbuild/
# Build with the following syntax:
# rpmbuild --target noarch -bb utils.spec
```
`rpmbuild` 程序会忽略注释行。我总是喜欢在本节中添加注释,其中包含创建包所需的 `rpmbuild` 命令的确切语法。
`Summary` 标签是包的简短描述。
`Name`、`Version` 和 `Release` 标签用于创建 rpm 文件的名称,如 `utils-1.00-1.rpm`。通过增加发行版号码和版本号,你可以创建 rpm 包去更新旧版本的。
`License` 标签定义了发布包的许可证。我总是使用 GPL 的一个变体。指定许可证对于澄清包中包含的软件是开源的这一事实非常重要。这也是我将 `License` 和 `GPL` 语句包含在将要安装的文件中的原因。
`URL` 通常是项目或项目所有者的网页。在这种情况下,它是我的个人网页。
`Group` 标签很有趣,通常用于 GUI 应用程序。 `Group` 标签的值决定了应用程序菜单中的哪一组图标将包含此包中可执行文件的图标。与 `Icon` 标签(我们此处未使用)一起使用时,`Group` 标签允许在应用程序菜单结构中添加用于启动程序的图标和所需信息。
`Packager` 标签用于指定负责维护和创建包的人员或组织。
`Requires` 语句定义此 rpm 包的依赖项。每个都是包名。如果其中一个指定的软件包不存在,DNF 安装实用程序将尝试在 `/etc/yum.repos.d` 中定义的某个已定义的存储库中找到它,如果存在则安装它。如果 DNF 找不到一个或多个所需的包,它将抛出一个错误,指出哪些包丢失并终止。
`BuildRoot` 行指定顶级目录,`rpmbuild` 工具将在其中找到 spec 文件,并在构建包时在其中创建临时目录。完成的包将存储在我们之前指定的 `noarch` 子目录中。
注释显示了构建此程序包的命令语法,包括定义了目标体系结构的 `–target noarch` 选项。因为这些是 Bash 脚本,所以它们与特定的 CPU 架构无关。如果省略此选项,则构建将选用正在执行构建的 CPU 的体系结构。
`rpmbuild` 程序可以针对许多不同的体系结构,并且使用 `--target` 选项允许我们在不同的体系结构主机上构建特定体系结构的包,其具有与执行构建的体系结构不同的体系结构。所以我可以在 x86\_64 主机上构建一个用于 i686 架构的软件包,反之亦然。
如果你有自己的网站,请将打包者的名称更改为你自己的网站。
#### 描述部分(`%description`)
spec 文件的 `%description` 部分包含 rpm 包的描述。 它可以很短,也可以包含许多信息。 我们的 `%description` 部分相当简洁。
```
%description
A collection of utility scripts for testing RPM creation.
```
#### 准备部分(`%prep`)
`%prep` 部分是在构建过程中执行的第一个脚本。 在安装程序包期间不会执行此脚本。
这个脚本只是一个 Bash shell 脚本。 它准备构建目录,根据需要创建用于构建的目录,并将相应的文件复制到各自的目录中。 这将包括作为构建的一部分的完整编译所需的源代码。
`$RPM_BUILD_ROOT` 目录表示已安装系统的根目录。 在 `$RPM_BUILD_ROOT` 目录中创建的目录是真实文件系统中的绝对路径,例如 `/user/local/share/utils`、`/usr/local/bin` 等。
对于我们的包,我们没有预编译源,因为我们的所有程序都是 Bash 脚本。 因此,我们只需将这些脚本和其他文件复制到已安装系统的目录中。
```
%prep
################################################################################
# Create the build tree and copy the files from the development directories #
# into the build tree. #
################################################################################
echo "BUILDROOT = $RPM_BUILD_ROOT"
mkdir -p $RPM_BUILD_ROOT/usr/local/bin/
mkdir -p $RPM_BUILD_ROOT/usr/local/share/utils
cp /home/student/development/utils/scripts/* $RPM_BUILD_ROOT/usr/local/bin
cp /home/student/development/utils/license/* $RPM_BUILD_ROOT/usr/local/share/utils
cp /home/student/development/utils/spec/* $RPM_BUILD_ROOT/usr/local/share/utils
exit
```
请注意,本节末尾的 `exit` 语句是必需的。
#### 文件部分(`%files`)
spec 文件的 `%files` 这一部分定义了要安装的文件及其在目录树中的位置。 它还指定了要安装的每个文件的文件属性(`%attr`)以及所有者和组所有者。 文件权限和所有权是可选的,但我建议明确设置它们以消除这些属性在安装时不正确或不明确的任何可能性。 如果目录尚不存在,则会在安装期间根据需要创建目录。
```
%files
%attr(0744, root, root) /usr/local/bin/*
%attr(0644, root, root) /usr/local/share/utils/*
```
#### 安装前(`%pre`)
在我们的实验室项目的 spec 文件中,此部分为空。 这应该放置那些需要 rpm 中的文件安装前执行的脚本。
#### 安装后(`%post`)
spec 文件的这一部分是另一个 Bash 脚本。 这个在文件安装后运行。 此部分几乎可以是你需要或想要的任何内容,包括创建文件、运行系统命令以及重新启动服务以在进行配置更改后重新初始化它们。 我们的 rpm 包的 `%post` 脚本执行其中一些任务。
```
%post
################################################################################
# Set up MOTD scripts #
################################################################################
cd /etc
# Save the old MOTD if it exists
if [ -e motd ]
then
cp motd motd.orig
fi
# If not there already, Add link to create_motd to cron.daily
cd /etc/cron.daily
if [ ! -e create_motd ]
then
ln -s /usr/local/bin/create_motd
fi
# create the MOTD for the first time
/usr/local/bin/mymotd > /etc/motd
```
此脚本中包含的注释应明确其用途。
#### 卸载后(`%postun`)
此部分包含将在卸载 rpm 软件包后运行的脚本。 使用 `rpm` 或 `dnf` 删除包会删除文件部分中列出的所有文件,但它不会删除安装后部分创建的文件或链接,因此我们需要在本节中处理。
此脚本通常由清理任务组成,只是清除以前由 `rpm` 安装的文件,但 rpm 本身无法完成清除。 对于我们的包,它包括删除 `%post` 脚本创建的链接并恢复 motd 文件的已保存原件。
```
%postun
# remove installed files and links
rm /etc/cron.daily/create_motd
# Restore the original MOTD if it was backed up
if [ -e /etc/motd.orig ]
then
mv -f /etc/motd.orig /etc/motd
fi
```
#### 清理(`%clean`)
这个 Bash 脚本在 rpm 构建过程之后开始清理。 下面 `%clean` 部分中的两行删除了 `rpm-build` 命令创建的构建目录。 在许多情况下,可能还需要额外的清理。
```
%clean
rm -rf $RPM_BUILD_ROOT/usr/local/bin
rm -rf $RPM_BUILD_ROOT/usr/local/share/utils
```
#### 变更日志(`%changelog`)
此可选的文本部分包含 rpm 及其包含的文件的变更列表。最新的变更记录在本部分顶部。
```
%changelog
* Wed Aug 29 2018 Your Name <[email protected]>
- The original package includes several useful scripts. it is
primarily intended to be used to illustrate the process of
building an RPM.
```
使用你自己的姓名和电子邮件地址替换标题行中的数据。
### 构建 rpm
spec 文件必须位于 `rpmbuild` 目录树的 `SPECS` 目录中。 我发现最简单的方法是创建一个指向该目录中实际 spec 文件的链接,以便可以在开发目录中对其进行编辑,而无需将其复制到 `SPECS` 目录。 将 `SPECS` 目录设为当前工作目录,然后创建链接。
```
cd ~/rpmbuild/SPECS/
ln -s ~/development/spec/utils.spec
```
运行以下命令以构建 rpm。 如果没有错误发生,只需要花一点时间来创建 rpm。
```
rpmbuild --target noarch -bb utils.spec
```
检查 `~/rpmbuild/RPMS/noarch` 目录以验证新的 rpm 是否存在。
```
[student@testvm1 ~]$ cd rpmbuild/RPMS/noarch/
[student@testvm1 noarch]$ ll
total 24
-rw-rw-r--. 1 student student 24364 Aug 30 10:00 utils-1.0.0-1.noarch.rpm
[student@testvm1 noarch]$
```
### 测试 rpm
以 root 用户身份安装 rpm 以验证它是否正确安装并且文件是否安装在正确的目录中。 rpm 的确切名称将取决于你在前言部分中标签的值,但如果你使用了示例中的值,则 rpm 名称将如下面的示例命令所示:
```
[root@testvm1 ~]# cd /home/student/rpmbuild/RPMS/noarch/
[root@testvm1 noarch]# ll
total 24
-rw-rw-r--. 1 student student 24364 Aug 30 10:00 utils-1.0.0-1.noarch.rpm
[root@testvm1 noarch]# rpm -ivh utils-1.0.0-1.noarch.rpm
Preparing... ################################# [100%]
Updating / installing...
1:utils-1.0.0-1 ################################# [100%]
```
检查 `/usr/local/bin` 以确保新文件存在。 你还应验证是否已创建 `/etc/cron.daily` 中的 `create_motd` 链接。
使用 `rpm -q --changelog utils` 命令查看更改日志。 使用 `rpm -ql utils` 命令(在 `ql` 中为小写 `L` )查看程序包安装的文件。
```
[root@testvm1 noarch]# rpm -q --changelog utils
* Wed Aug 29 2018 Your Name <[email protected]>
- The original package includes several useful scripts. it is
primarily intended to be used to illustrate the process of
building an RPM.
[root@testvm1 noarch]# rpm -ql utils
/usr/local/bin/create_motd
/usr/local/bin/die
/usr/local/bin/mymotd
/usr/local/bin/sysdata
/usr/local/share/utils/Copyright.and.GPL.Notice.txt
/usr/local/share/utils/GPL_LICENSE.txt
/usr/local/share/utils/utils.spec
[root@testvm1 noarch]#
```
删除包。
```
rpm -e utils
```
### 试验
现在,你将更改 spec 文件以要求一个不存在的包。 这将模拟无法满足的依赖关系。 在现有依赖行下立即添加以下行:
```
Requires: badrequire
```
构建包并尝试安装它。 显示什么消息?
我们使用 `rpm` 命令来安装和删除 `utils` 包。 尝试使用 `yum` 或 `dnf` 安装软件包。 你必须与程序包位于同一目录中,或指定程序包的完整路径才能使其正常工作。
### 总结
在这篇对创建 rpm 包的基础知识的概览中,我们没有涉及很多标签和很多部分。 下面列出的资源可以提供更多信息。 构建 rpm 包并不困难;你只需要正确的信息。 我希望这对你有所帮助——我花了几个月的时间来自己解决问题。
我们没有涵盖源代码构建,但如果你是开发人员,那么从这一点开始应该是一个简单的步骤。
创建 rpm 包是另一种成为懒惰系统管理员的好方法,可以节省时间和精力。 它提供了一种简单的方法来分发和安装那些我们作为系统管理员需要在许多主机上安装的脚本和其他文件。
### 资料
* Edward C. Baily,《Maximum RPM》,Sams 出版于 2000 年,ISBN 0-672-31105-4
* Edward C. Baily,《[Maximum RPM](http://ftp.rpm.org/max-rpm/)》,更新在线版本
* [RPM 文档](http://rpm.org/documentation.html):此网页列出了 rpm 的大多数可用在线文档。 它包括许多其他网站的链接和有关 rpm 的信息。
---
via: <https://opensource.com/article/18/9/how-build-rpm-packages>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,165 | 24 个必备的 Linux 应用程序 | https://itsfoss.com/essential-linux-applications/ | 2018-10-28T19:01:00 | [
"Linux",
"应用"
] | https://linux.cn/article-10165-1.html | 
>
> 提要:Linux 上必备的应用程序是什么呢?这个答案具有主观性并取决于你使用 Linux 桌面的目的是什么。但确实存在一些必备的并且大部分 Linux 用户都会安装的应用程序。接下来我们会列举出那些在所有 Linux 发行版上你都会安装的最优秀的 Linux 应用程序。
>
>
>
在 Linux 的世界中,所有东西都由你选择。你要选择一个发行版?你能找到一大把。你想要找到一个称心的音乐播放器?同样会有许多选择。
但它们并非全部遵循相同的设计理念 —— 其中一些可能追求极致轻量化而另一些会提供数不清的特性。因此想要找到正中需求的应用程序会成为相当令人头疼的繁重任务。那就让我们来缓解你的头疼吧。
### 对于 Linux 用户来说最优秀的自由软件
接下来我将罗列一系列在不同应用场景下我偏爱的必备 Linux 自由软件。当然此处我并非在说它们是最好的,但确实是在特定类别下我尝试的一系列软件中最喜欢的。也同样欢迎你在评论区介绍你最喜欢的应用程序。
同时我们也制作了关于此次应用清单的[视频](https://youtu.be/awawJnkUbWs)。在 YouTube 上订阅我们的频道获取更多的 Linux 视频。
### 网页浏览器

*网页浏览器*
#### Google Chrome
[Google Chrome](https://www.google.com/chrome/browser) 是一个强大并且功能完善的浏览器解决方案,它拥有完美的同步功能以及丰富的扩展。如果你喜欢 Google 的生态系统那么 Google Chrome 毫无疑问会是你的菜。如果你想要更加开源的解决方案,你可以尝试 [Chromium](https://www.chromium.org/Home),它是 Google Chrome 的上游项目。
#### Firefox
如果你不是 Google Chrome 的粉丝,你可以尝试 [Firefox](https://www.mozilla.org/en-US/firefox)。它一直以来都是一个非常稳定并且健壮的网页浏览器。
#### Vivaldi
当然,如果你想要尝试点不同的新东西,你可以尝试 [Vivaldi](https://vivaldi.com)。Vivaldi 是一个完全重新设计的网页浏览器,它由 Opera 浏览器项目的前成员基于 Chromium 项目而创建。Vivaldi 轻量并且可定制,虽然它还非常年轻并且在某些特性上仍不完善,但它仍能让你眼前一亮并且优雅地工作。
* [推荐阅读:[回顾] Otter 浏览器为 Opera 爱好者带来了希望](https://itsfoss.com/otter-browser-review/)
### 下载管理器

*下载管理器*
#### uGet
[uGet](http://ugetdm.com/) 是我遇到过最棒的下载管理器,它是开源的并且能满足你对于一款下载管理器的一切期许。uGet 提供一系列便于管理下载的高级设置。你能够管理下载队列并且断点续传,针对大文件使用多连接下载,根据不同列表将文件下载至不同路径,等等。
#### XDM
Xtreme 下载管理器([XDM](http://xdman.sourceforge.net/))是一个 Java 开发的强大并且开源的下载工具。它拥有下载管理器的所有基本特性,包括视频抓取、智能计划任务以及浏览器集成。
* [推荐阅读:Linux 下最好的 4 个下载管理器](https://itsfoss.com/4-best-download-managers-for-linux/)
### BitTorrent 客户端

*BitTorrent 客户端*
#### Deluge
[Deluge](http://deluge-torrent.org/) 是一个拥有漂亮用户界面的开源 BitTorrent 客户端。如果你习惯在 Windows 上使用 uTorrent,那么 Deluge 的界面会让你倍感亲切。它拥有丰富的设置项和针对不同任务的插件支持。
#### Transmission
[Transmission](https://transmissionbt.com/) 力求精简,它是用户界面最精简的 BitTorrent 客户端之一。Transmission 是许多 Linux 发行版的预装软件。
* [推荐阅读:Ubuntu Linux 上前 5 名的 Torrent 客户端](https://itsfoss.com/best-torrent-ubuntu/)
### 云存储

*云存储*
#### Dropbox
[Dropbox](https://www.dropbox.com) 是目前最流行的云存储服务之一,它为新用户提供了 2GB 的免费存储空间,以及一个健壮并且易于使用的 Linux 客户端。
#### MEGA
[MEGA](https://mega.nz/) 提供了 50GB 的免费存储,但这还并不是它最大的优点,MEGA 还为你的文件提供了端到端的加密支持。MEGA 提供一个名为 MEGAsync 的可靠的 Linux 客户端。
* [推荐阅读:2017 年 Linux 上最优秀的免费云服务](https://itsfoss.com/cloud-services-linux/)
### 通讯工具

*通讯工具*
#### Pidgin
[Pidgin](https://www.pidgin.im/) 是一款开源的即时通讯工具,它支持许多聊天平台,包括 Google Talk、Yahoo 甚至 IRC。Pidgin 可通过第三方插件进行扩展,能提供许多附加功能。
你也可以使用 [Franz](https://itsfoss.com/franz-messaging-app/) 或 [Rambox](http://rambox.pro/) 来在一个应用中使用多个通讯服务。
#### Skype
我们都知道 [Skype](https://www.skype.com) 是最流行的视频聊天平台之一,它[发布了全新的 Linux 桌面客户端](https://itsfoss.com/skpe-alpha-linux/)。
* [推荐阅读:2017 年 Linux 平台上最优秀的 6 款消息应用](https://itsfoss.com/best-messaging-apps-linux/)
### 办公套件

*办公套件*
#### LibreOffice
[LibreOffice](https://www.libreoffice.org) 是 Linux 平台上开发最为活跃的开源办公套件,主要包括 Writer、Calc、Impress、Draw、Math、Base 六个主要模块,并且每个模块都提供广泛的文件格式支持。同时 LibreOffice 也支持第三方的扩展,以上优势使它成为许多 Linux 发行版的默认办公套件。
#### WPS Office
如果你想要尝试除 LibreOffice 以外的办公套件,[WPS Office](https://www.wps.com) 值得一试。WPS Office 套件包括了写作、演示和数据表格支持。
* [推荐阅读:Linux 平台 6 款最优秀的 Microsoft Office 替代品](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/)
### 音乐播放器

*音乐播放器*
#### Lollypop
[Lollypop](http://gnumdk.github.io/lollypop-web/) 是一款相对较新的开源音乐播放器,拥有漂亮又不失简洁的用户界面。它提供优秀的音乐管理、歌曲推荐、在线广播和派对模式支持。虽然它是一款不具有太多特性的简洁音乐播放器,但仍值得我们去尝试。
#### Rhythmbox
[Rhythmbox](https://wiki.gnome.org/Apps/Rhythmbox) 是一款主要为 GNOME 桌面环境开发的音乐播放器,当然它也可以在其他桌面环境运行。它能完成所有作为一款音乐播放器的基础功能,包括 CD 抓取和烧制、乱序播放,等等。它也提供了 iPod 支持。
#### cmus
如果你想要最轻量,并且喜欢命令行的话,[cmus](https://cmus.github.io/) 适合你。个人来讲,我是它的粉丝用户。cmus 是一款面向类 Unix 平台的小巧、快速并且强大的命令音乐播放器。它包含所有基础的音乐播放器特性,并且你能够通过扩展和脚本来增强它的功能。
* [推荐阅读:如何在 Ubuntu 14.04 和 Linux Mint 17 上安装 Tomahawk 播放器](https://itsfoss.com/install-tomahawk-ubuntu-1404-linux-mint-17/)
(LCTT 译注:好了好了,大家不要提醒我了,我这次补充上深受国内 Linux 和开源爱好者喜爱的[网易云音乐](https://music.163.com/#/download)。:D )
### 视频播放器

*视频播放器*
#### VLC
[VLC](http://www.videolan.org) 是一款简洁、快速、轻量并且非常强大的开源媒体播放器,它能够直接播放几乎所有格式的媒体文件,同时也能够播放在线的流媒体。它也能够安装一些时髦的扩展来完成不同的任务,比如直接在播放器内下载字幕。
#### Kodi
[Kodi](https://kodi.tv) 是一款成熟并且开源的媒体中心,在它的用户群中非常受欢迎。它能够处理来自本地或者网络媒体存储的视频、音乐、图片、播客甚至游戏,更强大的是你还能用它来录制电视节目。Kodi 可由附加组件和皮肤进行定制。
* [推荐阅读:Linux 平台上的 4 款格式工厂替代品](https://itsfoss.com/format-factory-alternative-linux/)
### 照片编辑器

*照片编辑器*
#### GIMP
[GIMP](https://www.gimp.org/) 是 Linux 平台上 Photoshop 的替代品,它是一款开源、全功能并且专业的照片编辑软件。它打包了各式各样的工具用来编辑图片,更强大的是,它包含丰富的自定义设置以及第三方插件来增强体验。
#### Krita
[Krita](https://krita.org/en/) 主要是作为一款绘图工具,但也可以作为照片编辑软件。它是开源的并且打包了非常多复杂的高级工具。
* [推荐阅读:Linux 平台最好的照片应用](https://itsfoss.com/image-applications-ubuntu-linux/)
### 文字编辑器
每个 Linux 发行版都拥有自己的文字编缉器解决方案,当然大体上它们都非常简洁并且没有太多功能。但是也有一些文字编辑器具有更强大的功能。

*文字编辑器*
#### Atom
[Atom](https://atom.io/) 是由 GitHub 开发的一款现代高度可配置的文字编辑器,它是完全开源的并且能够提供所有你能想到的文字编辑器功能。你可以开箱即用,也可以将其配置成你想要的样子。并且你可以从它的社区安装大量的扩展和主题。
#### Sublime Text
[Sublime Text](http://www.sublimetext.com/) 是最受欢迎的文字编辑器之一,虽然它并不是免费的,但你可以无限地试用该款软件。Sublime Text 是一款特性丰富并且高度模块化的软件,当然它也提供插件和主题支持。
* [推荐阅读:Linux 平台最优秀的 4 款现代开源代码编辑器](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/)
(LCTT 译注:当然,我知道你们也忘记不了 [VSCode](https://code.visualstudio.com/download)。)
### 启动器

*启动器*
#### Albert
[Albert](https://github.com/ManuelSchneid3r/albert) 是一款快速、可扩展、可定制的生产力工具,受 Alfred(Mac 平台上一个非常好的生产力工具)启发并且仍处于开发阶段,它的目标是“使所有触手可及”。它能够与你的 Linux 发行版非常好的集成,帮助你提高生产力。
#### Synapse
[Synapse](https://launchpad.net/synapse-project) 已经有些年头了,它是一个能够搜索和运行程序的简单启动器。它也同时能够加速一些工作流,譬如音乐控制、文件搜索、路径切换、书签、运行命令,等等。
正如 Abhishek 所考虑的,我们将根据读者的(也就是你的)反馈更新最佳 Linux 应用程序清单。那么,你最爱的 Linux 应用程序是什么呢?分享给我们或者为这个清单增加新的软件分类吧。
---
via: <https://itsfoss.com/essential-linux-applications/>
作者:[Munif Tanjim](https://itsfoss.com/author/munif/) 译者:[cycoe](https://github.com/cycoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

In the world of Linux, there are alternatives to everything. Choosing a distro? There are dozens of them. Trying to find a decent music player? Plenty of alternatives there too.
But not all of them are built with the same thing in mind – some of them might target minimalism, while others might offer tons of features. Finding the right application for your needs can be quite a confusing and boring task.
Let’s make it a bit easier 😉
## ⭐ Essential applications for Linux users
I have put together a list of the **essential Linux applications** that I prefer to use in different categories.
I’m not saying that they are the best, but I’ve tried many applications in each category and these are the ones I liked the most. So, you are more than welcome to mention your favorite applications in the comments section, too.
In addition, we’ve categorized the apps as well to get you started!
**Some of the applications mentioned here are not open source. They have been included in the context of Linux usage.**
**Non-FOSS Warning!**## Image Editors

We’ve already discussed some of the [best photo applications for Linux](https://itsfoss.com/image-applications-ubuntu-linux/). Here we shall mention two essential tools for every user.
**1. GIMP **🖌️🎨
GIMP is the holy grail of image editors for casual users and professionals. It offers almost every type of tool you will ever require manipulating an image, scaling it, cropping it, or simply adding a layer to it.
Allowing plugins that extend its functionality while being an open-source solution is impressive.
You can install it from your Software Center or follow our [GIMP installation guide](https://itsfoss.com/gimp-2-10-release/).
**2. Inkscape **🖋️
One of the [best Linux tools for digital artists](https://itsfoss.com/best-linux-graphic-design-software/), Inkscape is certainly an impressive image editor as well.
Unlike GIMP, [Inkscape](https://inkscape.org/?ref=itsfoss.com) comes pre-installed on many major Linux distros. It offers a bunch of drawing tools and vector graphics editing capabilities, making it a powerful choice for manipulating images as well.
**3. Conjure **➰
If you are looking for a tool to help you with quick tasks like Blur, Emboss, Sharpen, etc, [Conjure](https://github.com/nate-xyz/conjure?ref=news.itsfoss.com) can help you transform images.
It is a fairly new GUI tool as a front end to ImageMagick.
## Audio Editors

**1. Audacity **🎧
We’ve mentioned several [audio editors](https://itsfoss.com/best-audio-editors-linux/) in the past, but Audacity is the most popular tool for basic editing tasks. You can try to experiment and pull off something interesting as well. For instance, [reducing noise from your recording](https://itsfoss.com/audacity-recording/).
It supports plugins to extend its functionality. If you’re wondering: it is an open-source software and available for free. You can install it directly from the Software Center, or explore other options on its [official download page](https://www.audacityteam.org/?ref=itsfoss.com).
**Suggested Read 📖**
[How to Record Audio in Linux With Audacity (and Reduce Noise)Audacity is a free and open source cross-platform audio editor. Professionals use it for the tone of features it provides in such a small package. You don’t have to be a professional and use all of its features. You can use it to record audio from your microphone and](https://itsfoss.com/audacity-recording/)

**2. LMMS 🎸**⏺️
LMMS is a free and open-source Digital Audio Workstation (DAW) available cross-platform. Undoubtedly, it is one of the [best DAWs for Linux](https://itsfoss.com/best-daw-linux/).
It is a feature-rich alternative to premium audio editors (or DAWs) for creating, editing, and recording music. If you have a MIDI device, you can just plug it into your machine and get started with LMMS. It also supports VST plugins, to say the least.
You can find it listed in the Software Center or explore other options on its official website.
## Email Clients

**1. Evolution **📧
Evolution is the default mail app for GNOME desktop users, and it is quickly replacing Thunderbird as a pre-installed mail client on numerous Linux distributions.
It offers a nice user interface and also supports Microsoft Exchange using an extension.
You can check out its [GNOME wiki page](https://wiki.gnome.org/Apps/Evolution/?ref=itsfoss.com) to find links to Flatpak and other installation options.
**2. Thunderbird **✉️⚡
A simple and free email client developed by Mozilla. You may find it pre-installed on some Linux distributions – if not, you can easily install it using your Software Center or package manager. One of the oldest and reliable email applications with an evolving user experience.
You can also download it from their [website](https://www.thunderbird.net/en-GB/?ref=itsfoss.com) and then install it.
## Personal Communication

**1. Signal **💬🔒
[Signal](https://www.signal.org) is a popular open-source instant messaging app as one of the [alternatives to WhatsApp](https://itsfoss.com/private-whatsapp-alternatives/).
We also have a guide to help you [install Signal in Li](https://itsfoss.com/install-signal-ubuntu/)[n](https://itsfoss.com/install-signal-ubuntu/)[ux](https://itsfoss.com/install-signal-ubuntu/) to get started.
**2. Element **💬🛡️
[Element](https://element.io/?ref=itsfoss.com) is a secure open-source collaboration platform built on the Matrix network.
It may not be a popular choice, but it offers plenty of features as a replacement for many other proprietary options for personal or work communication.
## Screen Recording and Streaming Tools

Are you a Blogger, YouTuber, or work in similar industries? Here are a few tools for you.
**1. Kazam **📷
If you’ve been following us, you might have already read about the [best screen recorders available for Linux](https://itsfoss.com/best-linux-screen-recorders/).
Kazam is the simplest solution among them. It lets you record your screen and includes several essential features like giving you the ability to select the area/window, hiding/showing the cursor, and enabling the sound from your mic/speaker.
For installation instructions, its [GitHub page](https://github.com/hzbd/kazam?ref=itsfoss.com) would be your best bet.
**Suggested Read 📖**
[Record Screen in Ubuntu Linux With Kazam [Beginner’s Guide]This tutorial shows you how to install Kazam screen recorder and explains how to record the screen in Ubuntu. The guide also lists useful shortcuts and handy tips for using Kazam. Kazam is one of the best screen recorders for Linux even though it is not being actively developed anymore.](https://itsfoss.com/kazam-screen-recorder/)

**2. OBS **🎥
[Open Broadcaster Software](https://obsproject.com/?ref=itsfoss.com) is a pretty popular and robust screen recorder and streaming app. Many professional streamers use it.
You can heavily customize it, add your template, etc. So, there are a lot of things you can do once you start exploring it. OBS is suitable for both personal and professional users – it’s not the easiest, but it’s really useful.
**3. Flameshot **📸
[Flameshot](https://github.com/flameshot-org/flameshot) is yet one of the nicest options to take screenshots and annotate them.
You can even directly upload your images to Imgur without needing to save them on your PC. Regardless of what Linux distro you use, you could find it handy.
**4. Ksnip **✂️
A simple Qt-based cross-platform screenshot tool that offers more annotation features.
We’ve discussed [multiple ways to take screenshots in Linux, ](https://itsfoss.com/take-screenshot-linux/)and using Ksnip is one of them.
It’s fairly new, and not the most popular screenshot tool out there, but it works as expected. Refer to its [GitHub page](https://github.com/ksnip/ksnip) for information on installation and more.
## System Optimizers/Task Managers

**1. Stacer **⚙️
Stacer is my favorite system optimizer and [task manager on Linux](https://itsfoss.com/task-manager-linux/), with a beautiful user interface.
You get not only a pretty UI, but also a solid set of features to help you in the best way possible. You can manage startup tasks, clean temporary/cache files, manage running services, uninstall packages, and monitor your system resources easily.
Check out its [GitHub page](https://github.com/oguzhaninan/Stacer?ref=itsfoss.com) for installation instructions, or follow our [Stacer guide](https://itsfoss.com/optimize-ubuntu-stacer/) to learn more.
**Suggested Read 📖**
[Optimize Ubuntu System With StacerWindows users often look for CCleaner alternatives for Linux. CCleaner is a popular Windows application that lets you easily free up space by removing unnecessary files and completely uninstalling software. Stacer is a new application for Ubuntu that functions similar to CCleaner, i.e., to opti…](https://itsfoss.com/optimize-ubuntu-stacer/)

**2. htop **🖥️
You probably know about the default “top” CLI tool to monitor processes in your system. It is still useful – but not the best out there.
So if you’re looking for a better command-line based tool, [htop](https://github.com/hishamhm/htop?ref=itsfoss.com) is the perfect replacement. You no longer need to type in the process number to kill it, just navigate to it and end it. It is way easier and faster than the traditional top CLI tool.
You can also take a look at our list of [top alternatives](https://itsfoss.com/linux-system-monitoring-tools/) to find more utilities for system monitoring.
## Apps for Gamers

While I recommend going through our [gaming guide](https://itsfoss.com/essential-linux-applications/) to get better insights on what you need to game on Linux. These are the absolute best apps to have:
**1. Steam **🎮
Yes, [Steam](https://store.steampowered.com/?ref=itsfoss.com) is a proprietary client or marketplace to purchase/install/manage your Linux games.
However, it is the best game client with a massive library of free and paid games to offer (both native Linux games and Windows exclusives).
To install it, you can download the .deb file from its [official download page](https://store.steampowered.com/about/?ref=itsfoss.com) or find the installer on Software Center. We also have a quick [Steam installation guide](https://itsfoss.com/install-steam-ubuntu-linux/) for help.
**2. Discord **🎮🕹️
Without a second thought, if you’re a gamer, you have to install this one right away. Do note that it’s **not an open-source application**.
Yes, there are alternatives to it. But nothing beats Discord when it comes to the ability to manage a server room where fellow gamers can interact and communicate on voice channels in-game.
You can easily [install Discord on Linux](https://itsfoss.com/install-discord-linux/).
[Epic Games Store on Linux](https://itsfoss.com/epic-games-linux/).
**Suggested Read 📖**
[How to Play GOG Games on LinuxWant to access and play GOG games on Linux? Here’s how to do that.](https://itsfoss.com/play-gog-games-linux/)

## Media Players

**1. Audacious **💿
Audacious is a simple music player that is low on resources while being an open-source solution. One of the [best music players for Linux](https://itsfoss.com/best-music-players-linux/).
You can customize the interface to give it a different look. To add songs, just drag and drop the folder you want. You can install it from the Software Center or visit the [official download page](https://audacious-media-player.org/download?ref=itsfoss.com).
Go on, get started!
**2. VLC **💽
I’ve tried a lot of video players on my Windows machine and on Linux systems as well – but I keep going back to VLC pretty much every time. VLC is a simple media player that’s open-source and free as well. It supports almost every type of file format.
You can download it from their [website](https://www.videolan.org/vlc/index.html?ref=itsfoss.com) or find it on your Software Center.
**3. MusicPod**
A Flutter-based app, [MusicPod](https://snapcraft.io/musicpod?ref=news.itsfoss.com) offers an excellent user experience.
It provides all the essentials and yet manages to stand out from some of the other options.
**Suggested Read 📖**
[Top 10 Best Music Players for LinuxIt isn’t rocket science to play music on Linux, but you should have a great experience with a good music player!](https://itsfoss.com/best-music-players-linux/)

## Media Server Software

Let’s have a look at some [media server software for Linux](https://itsfoss.com/best-linux-media-server/).
**1. Kodi **🎥💿
[Kodi](https://kodi.tv) is definitely one of the best media server programs available for Linux. Many of the other [best media server tools](https://itsfoss.com/best-linux-media-server/) are based on Kodi as well.
**2. Plex **👨 💻
[Plex](https://www.plex.tv/?ref=itsfoss.com) is not entirely open-source media server software, but it offers an option to create a free account. A nice UI with all the basic features you need included. You can easily [install Plex on Ubuntu](https://itsfoss.com/install-plex-ubuntu/).
## Video Editors

If I had to choose the top two [best video editors for Linux](https://itsfoss.com/best-video-editing-software-linux/), these would be my picks.
**1. Kdenlive **📹✂️
Kdenlive is one of the [best free video editing programs](https://itsfoss.com/best-video-editing-software-linux/) available for Linux. It’s an open-source solution and also offers support for dual monitors. It includes most of the necessary features, like basic transition effects, layout customization, multi-track editing, and so on.
**2. OpenShot **🎥✂️
OpenShot is an open source video editor is easy to use and robust as well. It includes 3D effects, basic video transitions, drag and drop support, and so on.
If you want to use it for professional-grade editing, you be the judge.
## Open-Source Media Converters

**1. Handbrake **📺
[Handbrake](https://handbrake.fr) is an impressive video converter. It supports a wide range of video codecs and quickly converts your videos. Of course, you get to decide the quality or resolution, frame rate, and plenty of other things like subtitles while converting the video.
**2. SoundConverter **🔊
Fret not if you’re a fan of audio instead of video. We’ve got you.
[SoundConverter](http://soundconverter.org/?ref=itsfoss.com) is a powerful audio conversion tool that supports almost all file formats and converts audio files pretty fast.
## Backup Tools

Backup is one of the essential parts of not only Linux, but any operating system. Here are two options for you.
**1. Timeshift **📁☁️
Yes, we often keep a backup of our files. But what about the driver updates and configuration changes that you perform? What if these break your entire system?
In such a case, [Timeshift](https://github.com/linuxmint/timeshift) will help you take a backup (or a snapshot) of your entire OS along with all its configurations. You can easily restore it when something goes wrong. We have a guide on how to use [Timeshift on Linux](https://itsfoss.com/backup-restore-linux-timeshift/) as well.
**2. Bacula **📁🔁
[Bacula](https://www.bacula.org/?ref=itsfoss.com) is a feature-rich open-source backup tool available for Linux.
It’s not just a single program but includes several tools for every specific option. Furthermore, it’s somewhat developer-oriented, so if you maintain a network of computers, you can definitely make use of Bacula.
## PDF Editing Tools

**1. LibreOffice Draw **📄
For basic PDF editing tasks, LibreOffice Draw is the go-to solution for users who prefer FOSS. It has its limitations – but works like a charm for most use-cases.
If it doesn’t fit your needs, you can check out the [best Linux PDF editors](https://itsfoss.com/pdf-editors-linux/) available.
**2. PDF Studio **📃
[PDF Studio](https://www.qoppa.com/pdfstudio/?ref=itsfoss.com) is a wonderful PDF editor by Qoppa software.
It’s **not an open-source offering** – in fact, it’s a paid solution for users looking to edit PDF files. You get features like annotate, edit, optimize, sign, watermark, etc. for manipulating PDF files easily.
## Code and Text Editors

**1. VS Code **👨💻
Even though we’re Linux users, I’ve noticed that many people like the [Visual Studio Code editor](https://code.visualstudio.com/?ref=itsfoss.com). It includes a smart feature to autocomplete what you write based on variable type or function definition. It’s highly recommended if you’re working with Git, because the relevant commands are built-in. And as you start exploring, you’ll discover so much more to it.
There’s also an unofficial open-source version, i.e., [VS Codium](https://vscodium.com/?ref=itsfoss.com).
Follow our [Visual Studio Code installation](https://itsfoss.com/install-visual-studio-code-ubuntu/) article to get started.
In addition to VS Code, you can look at some of the [best modern code editors](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/) for your work.
**2. Lyx 💻👨💻**
Lyx is an open-source editor with numerous features. If you’re writing scientific documents or a thesis, this can be helpful with its formula editor to make things easier.
You can download it right from the Software Center. More information can be found on its [website](https://www.lyx.org/?ref=itsfoss.com).
**3. Texmaker **✍️
Even though we’ve already discussed [some of the best LaTeX editors](https://itsfoss.com/latex-editors-linux/), I’ll mention this as one of the essential additions to your Linux system.
It is specifically tailored for the GNOME environment but works everywhere. Its PDF conversion is blazing fast. Try it by downloading it from the Software Center or the [official site](http://www.xm1math.net/texmaker/?ref=itsfoss.com).
## Note-Taking Apps
**1. Simplenote **📝
[Simplenote](https://simplenote.com/?ref=itsfoss.com) is one of the best Evernote alternatives available for Linux. The organization behind WordPress ([Automattic](https://automattic.com/?ref=itsfoss.com)) is responsible for developing Simplenote. So, it’s actively maintained and offers all the basic note-taking features (and syncing capabilities) across multiple devices for free.
In addition to this, you can also try some of the [best note taking apps for Linux](https://itsfoss.com/note-taking-apps-linux/).
**Suggested Read 📖**
[Looking for Some Good Note Taking Apps on Linux? Here are the Best Notes Apps we Found for YouNo matter what you do — taking notes is always a good habit. Yes, there are a lot of note taking apps to help you achieve that. But, what about some open-source note taking apps for Linux? Fret not, you don’t need to endlessly search the Internet to find the](https://itsfoss.com/note-taking-apps-linux/)

**2. Standard Notes **📋🔒
[Standard Notes](https://standardnotes.com) is a simple and flexible take on secure notes.
It offers end-to-end encrypting by default (for free) while offering cloud sync. You can opt for its premium to unlock more features and extensions.
## Team Communication & Productivity

**1. Slack **💬
Even at It’s FOSS, we used [Slack](https://slack.com/?ref=itsfoss.com) before moving to other chat platforms for team communication. This is **not an open-source solution**.
[Slack on Linux](https://itsfoss.com/slack-use-linux/) is available for free, and you can opt to upgrade it to the premium version for more features. You won’t be needing a premium plan unless you’re an enterprise user with many users to manage. Free or premium, it’s an essential addition.
You can also look for open-source [Slack alternatives](https://itsfoss.com/open-source-slack-alternative/) if you don’t like it.
**2. Franz **💬💭
With this app, you no longer have to switch between different browser tabs or applications while working on something. [Franz](https://meetfranz.com) combines almost all the essential messaging/email services under one roof. You just have to launch a single application (and sign in to multiple services) to keep up with all the communication you need without switching to different applications.
If you don’t like it, there are alternatives like [Rambox](https://rambox.pro/?ref=itsfoss.com).
## Virtualization Apps
**1. Oracle VM VirtualBox **🖥️
[VirtualBox](https://www.virtualbox.org/?ref=itsfoss.com) is a wonderful free and open-source virtualization solution for those who want to try different distros (or experiment with stuff) without affecting your host system. There are numerous uses for it – go explore!
## Authenticators
**Auth**🔒🔑
Almost everyone uses 2-factor authentication to secure their online accounts. But usually, you require your smartphone along with an authentication app for the codes, right?
Fret not, with [Auth](https://ente.io/auth/) by Ente.io, an open-source authenticator, you will be able to sync 2FA codes across devices without the risk of losing them. It is available for Android, iOS, Linux, Windows, and macOS as well.
**Wrapping Up**
We’ve tried to list all the essential applications for a Linux user here. But then again, you might have a favorite that we’ve missed.
*💭 Please let us know your thoughts in the comments below.* |
10,166 | 设计更快的网页(一):图片压缩 | https://fedoramagazine.org/design-faster-web-pages-part-1-image-compression/ | 2018-10-28T21:37:57 | [
"网页"
] | https://linux.cn/article-10166-1.html | 
很多 Web 开发者都希望做出加载速度很快的网页。在移动设备浏览占比越来越大的背景下,使用响应式设计使得网站在小屏幕下看起来更漂亮只是其中一个方面。Browser Calories 可以展示网页的加载时间 —— 这不单单关系到用户,还会影响到通过加载速度来进行评级的搜索引擎。这个系列的文章介绍了如何使用 Fedora 提供的工具来给网页“瘦身”。
### 准备工作
在你开始缩减网页之前,你需要明确核心问题所在。为此,你可以使用 [Browserdiet](https://browserdiet.com/calories/). 这是一个浏览器插件,适用于 Firefox、Opera、 Chrome 和其它浏览器。它会对打开的网页进行性能分析,这样你就可以知道应该从哪里入手来缩减网页。
然后,你需要一些用来处理的页面。下面的例子是针对 [getferoda.org](http://getfedora.org) 的测试截图。一开始,它看起来非常简单,也符合响应式设计。

然而,BroserDiet 的网页分析表明,这个网页需要加载 1.8MB 的文件。所以,我们现在有活干了!
### Web 优化
网页中包含 281 KB 的 JavaScript 文件、203 KB 的 CSS 文件,还有 1.2 MB 的图片。我们先从最严重的问题 —— 图片开始入手。为了解决问题,你需要的工具集有 GIMP、ImageMagick 和 optipng. 你可以使用如下命令轻松安装它们:
```
sudo dnf install gimp imagemagick optipng
```
比如,我们先拿到这个 6.4 KB 的[文件](https://getfedora.org/static/images/cinnamon.png):

首先,使用 `file` 命令来获取这张图片的一些基本信息:
```
$ file cinnamon.png
cinnamon.png: PNG image data, 60 x 60, 8-bit/color RGBA, non-interlaced
```
这张只由白色和灰色构成的图片使用 8 位 / RGBA 模式来存储。这种方式并没有那么高效。
使用 GIMP,你可以为这张图片设置一个更合适的颜色模式。在 GIMP 中打开 `cinnamon.png`。然后,在“图片 > 模式”菜单中将其设置为“灰度模式”。将这张图片以 PNG 格式导出。导出时使用压缩因子 9,导出对话框中的其它配置均使用默认选项。
```
$ file cinnamon.png
cinnamon.png: PNG image data, 60 x 60, 8-bit gray+alpha, non-interlaced
```
输出显示,现在这个文件现在处于 8 位 / 灰阶 + aplha 模式。文件大小从 6.4 KB 缩小到了 2.8 KB. 这已经是原来大小的 43.75% 了。但是,我们能做的还有很多!
你可以使用 ImageMagick 工具来查看这张图片的更多信息。
```
$ identify cinnamon2.png
cinnamon.png PNG 60x60 60x60+0+0 8-bit Grayscale Gray 2831B 0.000u 0:00.000
```
它告诉你,这个文件的大小为 2831 字节。我们回到 GIMP,重新导出文件。在导出对话框中,取消存储时间戳和 alpha 通道色值,来让文件更小一点。现在文件输出显示:
```
$ identify cinnamon.png
cinnamon.png PNG 60x60 60x60+0+0 8-bit Grayscale Gray 2798B 0.000u 0:00.000
```
下面,用 `optipng` 来无损优化你的 PNG 图片。具有相似功能的工具有很多,包括 `advdef`(这是 advancecomp 的一部分),`pngquant` 和 `pngcrush`。
对你的文件运行 `optipng`。 注意,这个操作会覆盖你的原文件:
```
$ optipng -o7 cinnamon.png
** Processing: cinnamon.png
60x60 pixels, 2x8 bits/pixel, grayscale+alpha
Reducing image to 8 bits/pixel, grayscale
Input IDAT size = 2720 bytes
Input file size = 2812 bytes
Trying:
zc = 9 zm = 8 zs = 0 f = 0 IDAT size = 1922
zc = 9 zm = 8 zs = 1 f = 0 IDAT size = 1920
Selecting parameters:
zc = 9 zm = 8 zs = 1 f = 0 IDAT size = 1920
Output IDAT size = 1920 bytes (800 bytes decrease)
Output file size = 2012 bytes (800 bytes = 28.45% decrease)
```
`-o7` 选项处理起来最慢,但最终效果最好。于是你又将文件缩小了 800 字节,现在它只有 2012 字节了。
要压缩文件夹下的所有 PNG,可以使用这个命令:
```
$ optipng -o7 -dir=<directory> *.png
```
`-dir` 选项用来指定输出文件夹。如果不加这个选项,`optipng` 会覆盖原文件。
### 选择正确的文件格式
当涉及到在互联网中使用的图片时,你可以选择:
* [JPG 或 JPEG](https://en.wikipedia.org/wiki/JPEG)
* [GIF](https://en.wikipedia.org/wiki/GIF)
* [PNG](https://en.wikipedia.org/wiki/Portable_Network_Graphics)
* [aPNG](https://en.wikipedia.org/wiki/APNG)
* [JPG-LS](https://en.wikipedia.org/wiki/JPEG_2000)
* [JPG 2000 或 JP2](https://en.wikipedia.org/wiki/JPEG_2000)
* [SVG](https://en.wikipedia.org/wiki/Scalable_Vector_Graphics)
JPG-LS 和 JPG 2000 没有得到广泛使用。只有一部分数码相机支持这些格式,所以我们可以忽略它们。aPNG 是动态的 PNG 格式,也没有广泛使用。
可以通过更改压缩率或者使用其它文件格式来节省下更多字节。我们无法在 GIMP 中应用第一种方法,因为现在的图片已经使用了最高的压缩率了。因为我们的图片中不再包含 [aplha 通道](https://www.webopedia.com/TERM/A/alpha_channel.html),你可以使用 JPG 类型来替代 PNG。 现在,使用默认值:90% 质量 —— 你可以将它减小至 85%,但这样会导致可见的叠影。这样又省下一些字节:
```
$ identify cinnamon.jpg
cinnamon.jpg JPEG 60x60 60x60+0+0 8-bit sRGB 2676B 0.000u 0:00.000
```
只将这张图转成正确的色域,并使用 JPG 作为文件格式,就可以将它从 23 KB 缩小到 12.3 KB,减少了近 50%.
#### PNG vs JPG: 质量和压缩率
那么,剩下的文件我们要怎么办呢?除了 Fedora “风味”图标和四个特性图标之外,此方法适用于所有其他图片。我们能够处理的图片都有一个白色的背景。
PNG 和 JPG 的一个主要区别在于,JPG 没有 alpha 通道。所以,它没有透明度选项。如果你使用 JPG 并为它添加白色背景,你可以将文件从 40.7 KB 缩小至 28.3 KB.
现在又有了四个可以处理的图片:背景图。对于灰色背景,你可以再次使用灰阶模式。对更大的图片,我们就可以节省下更多的空间。它从 216.2 KB 缩小到了 51 KB —— 基本上只有原图的 25% 了。整体下来,你把这些图片从 481.1 KB 缩小到了 191.5 KB —— 只有一开始的 39.8%.
#### 质量 vs 大小
PNG 和 JPG 的另外一个区别在于质量。PNG 是一种无损压缩光栅图形格式。但是 JPG 虽然使用压缩来缩小体积,可是这会影响到质量。不过,这并不意味着你不应该使用 JPG,只是你需要在文件大小和质量中找到一个平衡。
### 成就
这就是第一部分的结尾了。在使用上述技术后,得到的结果如下:

你将一开始 1.2 MB 的图片体积缩小到了 488.9 KB. 只需通过 `optipng` 进行优化,就可以达到之前体积的三分之一。这可能使得页面更快地加载。不过,要是使用蜗牛到超音速来对比,这个速度还没到达赛车的速度呢!
最后,你可以在 [Google Insights](https://developers.google.com/speed/pagespeed/insights/?url=getfedora.org&tab=mobile) 中查看结果,例如:

在移动端部分,这个页面的得分提升了 10 分,但它依然处于“中等”水平。对于桌面端,结果看起来完全不同,从 62/100 分提升至了 91/100 分,等级也达到了“好”的水平。如我们之前所说的,这个测试并不意味着我们的工作就做完了。通过参考这些分数可以让你朝着正确的方向前进。请记住,你正在为用户体验来进行优化,而不是搜索引擎。
---
via: <https://fedoramagazine.org/design-faster-web-pages-part-1-image-compression/>
作者:[Sirko Kemter](https://fedoramagazine.org/author/gnokii/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[StdioA](https://github.com/StdioA) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Lots of web developers want to achieve fast loading web pages. As more page views come from mobile devices, making websites look better on smaller screens using responsive design is just one side of the coin. *Browser Calories* can make the difference in loading times, which satisfies not just the user but search engines that rank on loading speed. This article series covers how to slim down your web pages with tools Fedora offers.
## Preparation
Before you sart to slim down your web pages, you need to identify the core issues. For this, you can use [Browserdiet](https://browserdiet.com/calories/). It’s a browser add-on available for Firefox, Opera and Chrome and other browsers. It analyzes the performance values of the actual open web page, so you know where to start slimming down.
Next you’ll need some pages to work on. The example screenshot shows a test of [getfedora.org](http://getfedora.org). At first it looks very simple and responsive.
Browser Diet – values of getfedora.org
However, BrowserDiet’s page analysis shows there are 1.8MB in files downloaded. Therefore, there’s some work to do!
## Web optimization
There are over 281 KB of JavaScript files, 203 KB more in CSS files, and 1.2 MB in images. Start with the biggest issue — the images. The tool set you need for this is GIMP, ImageMagick, and optipng. You can easily install them using the following command:
sudo dnf install gimp imagemagick optipng
For example, take the [following file](https://getfedora.org/static/images/cinnamon.png) which is 6.4 KB:
First, use the *file* command to get some basic information about this image:
$file cinnamon.pngcinnamon.png: PNG image data, 60 x 60, 8-bit/color RGBA, non-interlaced
The image — which is only in grey and white — is saved in 8-bit/color RGBA mode. That’s not as efficient as it could be.
Start GIMP so you can set a more appropriate color mode. Open *cinnamon.png* in GIMP. Then go to *Image>Mode* and set it to *greyscale*. Export the image as PNG with compression factor 9. All other settings in the export dialog should be the default.
$file cinnamon.pngcinnamon.png: PNG image data, 60 x 60, 8-bit gray+alpha, non-interlaced
The output shows the file’s now in *8bit gray+alpha* mode. The file size has shrunk from 6.4 KB to 2.8 KB. That’s already only 43.75% of the original size. But there’s more you can do!
You can also use the ImageMagick tool *identify* to provide more information about the image.
$identify cinnamon2.pngcinnamon.png PNG 60x60 60x60+0+0 8-bit Grayscale Gray 2831B 0.000u 0:00.000
This tells you the file is 2831 bytes. Jump back into GIMP, and export the file. In the export dialog disable the storing of the time stamp and the alpha channel color values to reduce this a little more. Now the *file* output shows:
$identify cinnamon.pngcinnamon.png PNG 60x60 60x60+0+0 8-bit Grayscale Gray 2798B 0.000u 0:00.000
Next, use *optipng* to losslessly optimize your PNG images. There are other tools that do similar things, including **advdef** (which is part of advancecomp), **pngquant **and** pngcrush.**
Run* optipng* on your file. Note that this will replace your original:
$optipng -o7 cinnamon.png** Processing: cinnamon.png 60x60 pixels, 2x8 bits/pixel, grayscale+alpha Reducing image to 8 bits/pixel, grayscale Input IDAT size = 2720 bytes Input file size = 2812 bytes Trying: zc = 9 zm = 8 zs = 0 f = 0 IDAT size = 1922 zc = 9 zm = 8 zs = 1 f = 0 IDAT size = 1920 Selecting parameters: zc = 9 zm = 8 zs = 1 f = 0 IDAT size = 1920 Output IDAT size = 1920 bytes (800 bytes decrease) Output file size = 2012 bytes (800 bytes = 28.45% decrease)
The option *-o7* is the slowest to process, but provides the best end results. You’ve knocked 800 more bytes off the file size, which is now 2012 bytes.
To resize all of the PNGs in a directory, use this command:
$optipng -o7 -dir=<directory>*.png
The option *-dir* lets you give a target directory for the output. If this option is not used, *optipng* would overwrite the original images.
## Choosing the right file format
When it comes to pictures for the usage in the internet, you have the choice between:
JPG-LS and JPG 2000 are not widely used. Only a few digital cameras support these formats, so they can be ignored. aPNG is an animated PNG, and not widely used either.
You could save a few bytes more through changing the compression rate or choosing another file format. The first option you can’t do in GIMP, as it’s already using the highest compression rate. As there are no [alpha channels](https://www.webopedia.com/TERM/A/alpha_channel.html) in the picture, you can choose JPG as file format instead. For now use the default value of 90% quality — you could change it down to 85%, but then alias effects become visible. This saves a few bytes more:
$identify cinnamon.jpgcinnamon.jpg JPEG 60x60 60x60+0+0 8-bit sRGB 2676B 0.000u 0:00.000
Alone this conversion to the right color space and choosing JPG as file format brought down the file size from 23 KB to 12.3 KB, a reduction of nearly 50%.
### PNG vs. JPG: quality and compression rate
So what about the rest of the images? This method would work for all the other pictures, except the Fedora “flavor” logos and the logos for the four foundations. Those are presented on a white background.
One of the main differences between PNG and JPG is that JPG has no alpha channel. Therefore it can’t handle transparency. If you rework these images by using a JPG on a white background, you can reduce the file size from 40.7 KB to 28.3 KB.
Now there are four more images you can rework: the backgrounds. For the grey background, set the mode to greyscale again. With this bigger picture, the savings also is bigger. It shrinks from 216.2 KB to 51.0 KB — it’s now barely 25% of its original size. All in all, you’ve shrunk 481.1 KB down to 191.5 KB — only 39.8% of the starting size.
### Quality vs. Quantity
Another difference between PNG and JPG is the quality. PNG is a lossless compressed raster graphics format. But JPG loses size through compression, and thus affects quality. That doesn’t mean you shouldn’t use JPG, though. But you have to find a balance between file size and quality.
## Achievement
This is the end of Part 1. After following the techniques described above, here are the results:
You brought image size down to 488.9 KB versus 1.2MB at the start. That’s only about a third of the size, just through optimizing with *optipng*. This page can probably be made to load faster still. On the scale from snail to hypersonic, it’s not reached racing car speed yet!
Finally you can check the results in [Google Insights](https://developers.google.com/speed/pagespeed/insights/?url=getfedora.org&tab=mobile), for example:
In the Mobile area the page gathered 10 points on scoring, but is still in the *Medium* sector. It looks totally different for the Desktop, which has gone from 62/100 to 91/100 and went up to *Good*. As mentioned before, this test isn’t the be all and end all. Consider scores such as these to help you go in the right direction. Keep in mind you’re optimizing for the user experience, and not for a search engine.
## Leandro Boari
Good job!
tinypng.com provides excellent compression as well.
## Sirko Kemter
true it does a good job but the difference to optipng and other featured tools, it doesnt work locally. So optipng I can script and automate it in my workflow. With tinypng I cant do that and need an internet connection and cause traffic
## TH301
Excellent start on the series, hope the following will be just as detailed! Maybe dip into Static Site Generators like Hugo and certainly CSS Grid as it’s now well supported and finally makes it possible to make responsive easily maintained superminimalistic code without the help of CSS frameworks, hacks and other nuances that was a necessity of the past.
Ruthlessly spamming some links to get headstarted…
Can I use it? (Yes you can!):
https://caniuse.com/#search=CSS%20Grid%20Layout
Amazingly good talk by Rachel Andrew:
https://www.youtube.com/watch?v=8ti7o-sQuYs
Mozilla docs:
https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Grid_Layout
25 videos by Wes Bos (all free!)
https://cssgrid.io/
Learn CSS Grid by Jonathan Suh:
https://learncssgrid.com/
The specs itself (yeah I know… partly written by Microsoft, but this is actually very good):
https://www.w3.org/TR/css-grid-1/
OK, I need to stop this linkspamming now! 🙂
## Sirko Kemter
no, we will not talk about CSS Grid and site frameworks like Hugo (But if you think thats something to talk about go ahead submit). Actually the title was changed by the editors, so “design” doesnt fit for what we do because we just make a “diet” on what we have, to save “calories” and speed up the loading time.
If you look to the page which we using as example http://getfedora.org. You see, that the changes we did in this part not really make sense as there are better options for the pictures, so we will throw them away and use something what makes more sense… 😉
## TH301
Maybe not SSG, but I still think CSS Grid makes a lot of sense for taking getfedora.org on a diet and reducing its CSS calories, which is the highest % load in your screenshot. Getfedora.org are currently using the CSS framework Bootstrap. CSS Grid is kind of like a framework, but built directly into the browsers itself so you could get rid of Bootstrap altogether and more. Looking at the html source there’s a lot of div’s and bootstrap-classes that would no longer be needed as well and thereby reducing the overall load even further. It’s your series and I’m sure I will enjoy the read however it expands, but I do hope you will reconsider here.
## Sirko Kemter
I am sure the web team takes every help they can get
## TH301
I have to admit that when writing my first comment I thought the series was just just using getfedora.org to give some general advises and not actually be applied on getfedora.org. Applying grid would require a lot more work and testing so I totally understand why grid would be out of the scope for this series. That’s cool.
Moving to grid however is still something I think would be beneficial for the future, so if I want to get my hands dirty (no promises), then were…
1. Do I start a start a proper discussion with the web team?
2. Do I submit patches against the website? Maybe there’s are a GitLab/Hub repo for this?
I’m not familiar with how Fedora is organized so any direction would be helpful.
PS: Also out of scope for this series, but when first speaking to a member I would strongly advice to get rid of all
inlineJavaScript and CSS so that CSP can be applied: https://infosec.mozilla.org/guidelines/web_security#content-security-policyAnd fedoramagazine.org is loading external JavaScript with no integrity check (SRI), that’s very easy and takes no time to apply: https://infosec.mozilla.org/guidelines/web_security#subresource-integrity
Thanks for the improvements you make and all the best wishes for this series my friend. 🙂
## Clément Verna
Hi you can get in contact with the website team here (https://pagure.io/fedora-websites), help and suggestions are always welcome 🙂
## Sirko Kemter
Pagure would be if you want to opening a conversation just via filing a bug. For all other we have this wonderful overview page under http://join.fedoraproject.org , where you find the ways how to join the different teams. For websites you have then a link to https://fedoraproject.org/wiki/Websites where you find, how to communicate with the team and what steps to do to become part of them.
## Martin
Good to see this series!
## Manuel Cabrera Caballero
Great, I’ll start to apply it.
## Linux Creative
My Tips for a ‘Site-Diet’ use “Save For Web” in GIMP for Graphics and ‘Ditch Bloated CSS/JavaScript Frameworks’ use custom CSS & Vanilla JS, modern browsers desktop/mobile has no problem with them. Also Dump all the Social Media and other Third-Party Junk Code slowing down sites. MSIE is Dead – It’s time to ‘Code Normal Again’ 8)
## Sirko Kemter
of course a binary plugin for GIMP that for his newer versions not exist anymore and still you had to know what you do
## D
The advise here seems very outdated. Guetzli (near-lossless) and Zopfli (lossless) yields much better compression ratios for JPEG and PNG than traditional compactor tools. New image file formats like WebP yields even smaller files still and works with all major browsers (sans Firefox).
## W
Thank you for your guetzli tip !
Optimized content downloaded from pagespeed insights provided me from 100kb 33kb image, but guetzli at 84% created 19kb image.
Although my site has 100/100 of pagespeed insights ( tips here https://dev.daanvandenbergh.com/wordpress/quick-guide-pagespeed-insights-pingdom/ )
## Sirko Kemter
to sad but guetzli isnt packaged for Fedora yet. WebP as long FF supports it, it would be crazy to use it. But the next version shall support it lets see.
## Rene Reichenbach
Its crucial to say that it mainly depends on the color count what format is the one to head for.
rule of thumbs is:
icons or graphics (low color count) png
pictures or fotos (high color count) jpg
and you could explain a bit more about vector graphics (svg)
Besides this its a nice topic and i am looking forward to the next articles.
## Sirko Kemter
a) what has the “color count” to do with the format?
b) its a series, so I would wait for SVG
## Marcio
Muito bom, o artigo é foi muito útil para melhor o desempenho do meu site, entretanto oi maior gargalo está por conta do JavaScript e o CSS!
## Sirko Kemter
as you comment to me in your mother tongue, I will answer in mine:
In der Ueberschrift steht, Part I was am Ende meint, es wird weitere Teile geben auch solche, die sich mit der Problematik von zu viel JS und CSS auseinandersetzen
## Kitty
Any ideas on how to compress an animated JPEG?
## Sirko Kemter
jpeg is already compressed 😉 You might improve the compression rate. But the question is, how is it animated 😉
## Laurie
Hi there, hearing a lot of buzz about the new animated JPEG format, any way to double compress these? |
10,167 | 使用开源同步工具 Syncthing 控制你的数据 | https://opensource.com/article/18/9/take-control-your-data-syncthing | 2018-10-28T22:10:00 | [
"同步",
"隐私"
] | https://linux.cn/article-10167-1.html |
>
> 决定如何存储和共享您的个人信息。
>
>
>

如今,我们的一些最重要的财产 —— 从家人和朋友的照片和视频到财务和医疗文件 —— 都是数据。即便是云存储服务的迅猛发展,我们仍有对隐私和个人数据缺乏控制的担忧。从棱镜监控计划到谷歌[让 APP 开发者扫描你的个人邮件](https://gizmodo.com/google-says-it-doesnt-go-through-your-inbox-anymore-bu-1827299695),这些新闻的报道应该会让我们对我们个人信息的安全性有所顾虑。
[Syncthing](https://syncthing.net/) 可以让你放下心来。它是一款开源的点对点文件同步工具,可以运行在 Linux、Windows、Mac、Android 和其他(抱歉,没有iOS)。Syncthing 使用自定的协议,叫[块交换协议](3)。简而言之,Syncting 能让你无需拥有服务器来跨设备同步数据。
在这篇文章中,我将解释如何在 Linux 电脑和安卓手机之间安装和同步文件。
### Linux
Syncting 在大多数流行的发行版都能下载。Fedora 28 包含其最新版本。
要在 Fedora 上安装 Syncthing,你能在软件中心搜索,或者执行以下命令:
```
sudo dnf install syncthing syncthing-gtk
```
一旦安装好后,打开它。你将会看到一个助手帮你配置 Syncthing。点击 “Next” 直到它要求配置 WebUI。最安全的选项是选择“Listen on localhost”。那将会禁止 Web 界面并且阻止未经授权的用户。

*Syncthing 安装时的 WebUI 对话框*
关闭对话框。现在 Syncthing 安装好了。现在可以分享文件夹,连接一台设备开始同步了。但是,让我们用你其它的客户端继续。
### Android
Syncthing 在 Google Play 和 F-Droid 应用商店都能下载。

安装应用程序后,会显示欢迎界面。给 Syncthing 授予你设备存储的权限。你可能会被要求为了此应用程序而禁用电池优化。这样做是安全的,因为我们将优化应用程序,使其仅在插入电源并连接到无线网络时同步。
点击主菜单图标来到“Settings”,然后是“Run Conditions”(运行条件)。点击“Always run in the background, Run only when charging”(总是在后台运行,仅在充电时运行)和“Run only on wifi”(仅在 WIFI 下运行)。现在你的安卓客户端已经准备好与你的设备交换文件。
Syncting 中有两个重要的概念需要记住:文件夹和设备。文件夹是你想要分享的,但是你必须有一台设备来分享。 Syncthing 允许你用不同的设备分享独立的文件夹。设备是通过交换设备的 ID 来添加的。设备 ID 是在 Syncting 首次启动时创建的一个唯一的密码安全标识符。
### 连接设备
现在让我们连接你的 Linux 机器和你的 Android 客户端。
在您的 Linux 计算机中,打开 Syncting,单击“Settings”图标,然后单击“Show ID”,就会显示一个二维码。
在你的安卓手机上,打开 Syncthing。在主界面上,点击“Devices”页后点击 “+” 。在第一个区域内点击二维码符号来启动二维码扫描。
将你手机的摄像头对准电脑上的二维码。设备 ID 字段将由您的桌面客户端设备 ID 填充。起一个适合的名字并保存。因为添加设备有两种方式,现在你需要在电脑客户端上确认你想要添加安卓手机。你的电脑客户端可能会花上好几分钟来请求确认。当提示确认时,点击“Add”。

在“New Device”窗口,你能确认并配置一些关于你设备的选项,像是“Device Name”和“Addresses”。如果你在地址那一栏选择 “dynamic” (动态),客户端将会自动探测设备的 IP 地址,但是你想要保持住某一个 IP 地址,你能将该地址填进这一栏里。如果你已经创建了文件夹(或者在这之后),你也能与新设备分享这个文件夹。

你的电脑和安卓设备已经配对,可以交换文件了。(如果你有多台电脑或手机,只需重复这些步骤。)
### 分享文件夹
既然您想要同步的设备之间已经连接,现在是时候共享一个文件夹了。您可以在电脑上共享文件夹,添加了该文件夹中的设备将获得一份副本。
若要共享文件夹,请转至“Settings”并单击“Add Shared Folder”(添加共享文件夹):

在下一个窗口中,输入要共享的文件夹的信息:

你可以使用任何你想要的标签。“Folder ID”将随机生成,用于识别客户端之间的文件夹。在“Path”里,点击“Browse”就能定位到你想要分享的文件夹。如果你想 Syncthing 监控文件夹的变化(例如删除、新建文件等),点击“Monitor filesystem for changes”(监控文件系统变化)。
记住,当你分享一个文件夹,在其他客户端的任何改动都将会反映到每一台设备上。这意味着如果你在其他电脑和手机设备之间分享了一个包含图片的文件夹,在这些客户端上的改动都会同步到每一台设备。如果这不是你想要的,你能让你的文件夹“Send Only”(只是发送)给其他客户端,但是其他客户端的改动都不会被同步。
完成后,转至“Share with Devices”(与设备共享)页并选择要与之同步文件夹的主机。
您选择的所有设备都需要接受共享请求;您将在设备上收到通知。
正如共享文件夹时一样,您必须配置新的共享文件夹:

同样,在这里您可以定义任何标签,但是 ID 必须匹配每个客户端。在文件夹选项中,选择文件夹及其文件的位置。请记住,此文件夹中所做的任何更改都将反映到文件夹所允许同步的每个设备上。
这些是连接设备和与 Syncting 共享文件夹的步骤。开始复制可能需要几分钟时间,这取决于您的网络设置或您是否不在同一网络上。
Syncting 提供了更多出色的功能和选项。试试看,并把握你数据的控制权。
---
via: <https://opensource.com/article/18/9/take-control-your-data-syncthing>
作者:[Michael Zamot](https://opensource.com/users/mzamot) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ypingcn](https://github.com/ypingcn) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | These days, some of our most important possessions—from pictures and videos of family and friends to financial and medical documents—are data. And even as cloud storage services are booming, so there are concerns about privacy and lack of control over our personal data. From the PRISM surveillance program to Google [letting app developers scan your personal emails](https://gizmodo.com/google-says-it-doesnt-go-through-your-inbox-anymore-bu-1827299695), the news is full of reports that should give us all pause regarding the security of our personal information.
[Syncthing](https://syncthing.net/) can help put your mind at ease. An open source peer-to-peer file synchronization tool that runs on Linux, Windows, Mac, Android, and others (sorry, no iOS), Syncthing uses its own protocol, called [Block Exchange Protocol](https://docs.syncthing.net/specs/bep-v1.html). In brief, Syncthing lets you synchronize your data across many devices without owning a server.
In this post, I will explain how to install and synchronize files between a Linux computer and an Android phone.
## Linux
Syncthing is readily available for most popular distributions. Fedora 28 includes the latest version.
To install Syncthing in Fedora, you can either search for it in Software Center or execute the following command:
`sudo dnf install syncthing syncthing-gtk`
Once it’s installed, open it. You’ll be welcomed by an assistant to help configure Syncthing. Click **Next** until it asks to configure the WebUI. The safest option is to keep the option **Listen on localhost**. That will disable the web interface and keep unauthorized users away.
Syncthing
Close the dialog. Now that Syncthing is installed, it’s time to share a folder, connect a device, and start syncing. But first, let’s continue with your other client.
## Android
Syncthing is available in Google Play and in F-Droid app stores.
Syncthing for F-Droid
Once the application is installed, you’ll be welcomed by a wizard. Grant Syncthing permissions to your storage. You might be asked to disable battery optimization for this application. It is safe to do so as we will optimize the app to synchronize only when plugged in and connected to a wireless network.
Click on the main menu icon and go to **Settings**, then **Run Conditions**. Tick **Always run in ****the background**, **Run only when charging**, and **Run only on wifi**. Now your Android client is ready to exchange files with your devices.
There are two important concepts to remember in Syncthing: folders and devices. Folders are what you want to share, but you must have a device to share with. Syncthing allows you to share individual folders with different devices. Devices are added by exchanging device IDs. A device ID is a unique, cryptographically secure identifier that is created when Syncthing starts for the first time.
## Connecting devices
Now let’s connect your Linux machine and your Android client.
In your Linux computer, open Syncthing, click on the **Settings** icon and click **Show ID**. A QR code will show up.
In your Android mobile, open Syncthing. In the main screen, click the **Devices** tab and press the **+** symbol. In the first field, press the QR code symbol to open the QR scanner.
Point your mobile camera to the computer QR code. The Device ID** **field will be populated with your desktop client Device ID. Give it a friendly name and save. Because adding a device goes two ways, you now need to confirm on the computer client that you want to add the Android mobile. It might take a couple of minutes for your computer client to ask for confirmation. When it does, click **Add**.

In the **New Device** window, you can verify and configure some options about your new device, like the **Device Name** and **Addresses**. If you keep dynamic, it will try to auto-discover the device IP, but if you want to force one, you can add it in this field. If you already created a folder (more on this later), you can also share it with this new device.
Your computer and Android are now paired and ready to exchange files. (If you have more than one computer or mobile phone, simply repeat these steps.)
## Sharing folders
Now that the devices you want to sync are already connected, it’s time to share a folder. You can share folders on your computer and the devices you add to that folder will get a copy.
To share a folder, go to **Settings** and click **Add Shared Folder**:
In the next window, enter the information of the folder you want to share:
You can use any label you want. **Folder ID** will be generated randomly and will be used to identify the folder between the clients. In **Path**, click **Browse** and locate the folder you want to share. If you want Syncthing to monitor the folder for changes (such as deletes, new files, etc.), click **Monitor filesystem for changes**.
Remember, when you share a folder, any change that happens on the other clients will be reflected on every single device. That means that if you share a folder containing pictures with other computers or mobile devices, changes in these other clients will be reflected everywhere. If this is not what you want, you can make your folder “Send Only” so it will send files to the clients, but the other clients’ changes won’t be synced.
When this is done, go to **Share with Devices** and select the hosts you want to sync with your folder:
All the devices you select will need to accept the share request; you will get a notification from the devices:
Just as when you shared the folder, you must configure the new shared folder:
Again, here you can define any label, but the ID must match each client. In the folder option, select the destination for the folder and its files. Remember that any change done in this folder will be reflected with every device allowed in the folder.
These are the steps to connect devices and share folders with Syncthing. It might take a few minutes to start copying, depending on your network settings or if you are not on the same network.
Syncthing offers many more great features and options. Try it—and take control of your data.
## 2 Comments |
10,168 | 如何列出在 Linux 上已启用/激活的仓库 | https://www.2daygeek.com/how-to-list-the-enabled-active-repositories-in-linux/ | 2018-10-28T23:53:14 | [
"仓库"
] | https://linux.cn/article-10168-1.html | 
有很多方法可以列出在 Linux 已启用的仓库。我们将在下面展示给你列出已激活仓库的简便方法。这有助于你知晓你的系统上都启用了哪些仓库。一旦你掌握了这些信息,你就可以添加任何之前还没有准备启用的仓库了。
举个例子,如果你想启用 epel 仓库,你需要先检查它是否已经启用了。这篇教程将会帮助你做这件事情。
### 什么是仓库?
存储特定程序软件包的中枢位置就是一个软件仓库。
所有的 Linux 发行版都在维护自己的仓库,而且允许用户下载并安装这些软件包到他们的机器上。
每个仓库提供者都提供了一套包管理工具,用以管理他们的仓库,比如搜索、安装、更新、升级、移除等等。
大多数 Linux 发行版都作为免费软件,除了 RHEL 和 SUSE,要访问他们的仓库你需要先购买订阅。
**建议阅读:**
* [在 Linux 上,如何通过 DNF/YUM 设置管理命令添加、启用、关闭一个仓库](https://www.2daygeek.com/how-to-add-enable-disable-a-repository-dnf-yum-config-manager-on-linux/)
* [在 Linux 上如何按大小列出已安装的包](https://www.2daygeek.com/how-to-list-installed-packages-by-size-largest-on-linux/)
* [在 Linux 上如何列出升级的包](https://www.2daygeek.com/how-to-view-list-the-available-packages-updates-in-linux/)
* [在 Linux 上如何查看一个特定包安装/升级/更新/移除/清除的日期](https://www.2daygeek.com/how-to-view-a-particular-package-installed-updated-upgraded-removed-erased-date-on-linux/)
* [在 Linux 上如何查看一个包的详细信息](https://www.2daygeek.com/how-to-view-detailed-information-about-a-package-in-linux/)
* [在你的 Linux 发行版上如何查看一个包是否可用](https://www.2daygeek.com/how-to-search-if-a-package-is-available-on-your-linux-distribution-or-not/)
* [在 Linux 如何列出可用的软件包组](https://www.2daygeek.com/how-to-list-an-available-package-groups-in-linux/)
* [Newbies corner —— 一个图形化的 Linux 包管理的前端工具](https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/)
* [Linux 专家须知,命令行包管理 & 使用列表](https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/)
### 在 RHEL/CentOS 上列出已启用的库
RHEL 和 CentOS 系统使用的是 RPM 包管理,所以我们可以使用 Yum 包管理器查看这些信息。
YUM 意即 “Yellowdog Updater,Modified”,它是一个开源的包管理器的命令行前端,用于基于 RPM 的系统上,例如 RHEL 和 CentOS。
YUM 是获取、安装、删除、查询和管理来自发行版仓库和其他第三方库的 RPM 包的主要工具。
**建议阅读:** [在 RHEL/CentOS 系统上用 YUM 命令管理包](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/)
基于 RHEL 的系统主要提供以下三个主要的仓库。这些仓库是默认启用的。
* **base**:它包含了所有的核心包和基础包。
* **extras**:它向 CentOS 提供了不破坏上游兼容性或更新基本组件的额外功能。这是一个上游仓库,还有额外的 CentOS 包。
* **updates**:它提供了 bug 修复包、安全包和增强包。
```
# yum repolist
或者
# yum repolist enabled
```
```
Loaded plugins: fastestmirror
Determining fastest mirrors
* epel: ewr.edge.kernel.org
repo id repo name status
!base/7/x86_64 CentOS-7 - Base 9,911
!epel/x86_64 Extra Packages for Enterprise Linux 7 - x86_64 12,687
!extras/7/x86_64 CentOS-7 - Extras 403
!updates/7/x86_64 CentOS-7 - Updates 1,348
repolist: 24,349
```
### 如何列出 Fedora 上已启用的包
DNF 意即 “Dandified yum”。我们可以说 DNF 是下一代的 yum 包管理器,使用了 hawkey/libsolv 作为后端。自从 Fedroa 18 开始,Aleš Kozumplík 就开始开发 DNF,最终在 Fedora 22 上实现/发布。
Fedora 22 及之后的系统上都使用 DNF 安装、升级、搜索和移除包。它可以自动解决依赖问题,并使包的安装过程平顺没有任何麻烦。
因为 Yum 许多长时间未解决的问题,现在 Yum 已经被 DNF 所替代。你问为什么他没有给 Yum 打补丁。Aleš Kozumplík 解释说修补在技术上太困难了,而 YUM 团队无法立即承受这些变更,还有其他的问题,YUM 是 56k 行代码,而 DNF 是 29k 行代码。因此,除了分叉之外,别无选择。
**建议阅读:** [在 Fedora 上使用 DNF 管理软件](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/)
Fedora 主要提供下面两个主仓库。这些库将被默认启用。
* **fedora**:它包括所有的核心包和基础包。
* **updates**:它提供了来自稳定发行版的 bug 修复包、安全包和增强包。
```
# dnf repolist
或者
# dnf repolist enabled
```
```
Last metadata expiration check: 0:02:56 ago on Wed 10 Oct 2018 06:12:22 PM IST.
repo id repo name status
docker-ce-stable Docker CE Stable - x86_64 6
*fedora Fedora 26 - x86_64 53,912
home_mhogomchungu mhogomchungu's Home Project (Fedora_25) 19
home_moritzmolch_gencfsm Gnome Encfs Manager (Fedora_25) 5
mystro256-gnome-redshift Copr repo for gnome-redshift owned by mystro256 6
nodesource Node.js Packages for Fedora Linux 26 - x86_64 83
rabiny-albert Copr repo for albert owned by rabiny 3
*rpmfusion-free RPM Fusion for Fedora 26 - Free 536
*rpmfusion-free-updates RPM Fusion for Fedora 26 - Free - Updates 278
*rpmfusion-nonfree RPM Fusion for Fedora 26 - Nonfree 202
*rpmfusion-nonfree-updates RPM Fusion for Fedora 26 - Nonfree - Updates 95
*updates Fedora 26 - x86_64 - Updates
```
### 如何列出 Debian/Ubuntu 上已启用的仓库
基于 Debian 的系统使用的是 APT/APT-GET 包管理,因此我们可以使用 APT/APT-GET 包管理器去获取该信息。
APT 意即 “Advanced Packaging Tool”,它取代了 `apt-get`,就像 DNF 取代 Yum 一样。 它具有丰富的命令行工具,在一个命令(`apt`)中包含了所有功能,如 `apt-cache`、`apt-search`、`dpkg`、`apt-cdrom`、`apt-config`、`apt-key` 等,还有其他几个独特的功能。 例如,我们可以通过 APT 轻松安装 .dpkg 软件包,而我们无法通过 APT-GET 获得和包含在 APT 命令中类似的功能。 由于 APT-GET 中未能解决的问题,APT 取代了 APT-GET。
apt-get 是一个强大的命令行工具,它用以自动下载和安装新的软件包、升级已存在的软件包、更新包索引列表、还有升级整个基于 Debian 的系统。
```
# apt-cache policy
Package files:
100 /var/lib/dpkg/status
release a=now
500 http://ppa.launchpad.net/peek-developers/stable/ubuntu artful/main amd64 Packages
release v=17.10,o=LP-PPA-peek-developers-stable,a=artful,n=artful,l=Peek stable releases,c=main,b=amd64
origin ppa.launchpad.net
500 http://ppa.launchpad.net/notepadqq-team/notepadqq/ubuntu artful/main amd64 Packages
release v=17.10,o=LP-PPA-notepadqq-team-notepadqq,a=artful,n=artful,l=Notepadqq,c=main,b=amd64
origin ppa.launchpad.net
500 http://dl.google.com/linux/chrome/deb stable/main amd64 Packages
release v=1.0,o=Google, Inc.,a=stable,n=stable,l=Google,c=main,b=amd64
origin dl.google.com
500 https://download.docker.com/linux/ubuntu artful/stable amd64 Packages
release o=Docker,a=artful,l=Docker CE,c=stable,b=amd64
origin download.docker.com
500 http://security.ubuntu.com/ubuntu artful-security/multiverse amd64 Packages
release v=17.10,o=Ubuntu,a=artful-security,n=artful,l=Ubuntu,c=multiverse,b=amd64
origin security.ubuntu.com
500 http://security.ubuntu.com/ubuntu artful-security/universe amd64 Packages
release v=17.10,o=Ubuntu,a=artful-security,n=artful,l=Ubuntu,c=universe,b=amd64
origin security.ubuntu.com
500 http://security.ubuntu.com/ubuntu artful-security/restricted i386 Packages
release v=17.10,o=Ubuntu,a=artful-security,n=artful,l=Ubuntu,c=restricted,b=i386
origin security.ubuntu.com
.
.
origin in.archive.ubuntu.com
500 http://in.archive.ubuntu.com/ubuntu artful/restricted amd64 Packages
release v=17.10,o=Ubuntu,a=artful,n=artful,l=Ubuntu,c=restricted,b=amd64
origin in.archive.ubuntu.com
500 http://in.archive.ubuntu.com/ubuntu artful/main i386 Packages
release v=17.10,o=Ubuntu,a=artful,n=artful,l=Ubuntu,c=main,b=i386
origin in.archive.ubuntu.com
500 http://in.archive.ubuntu.com/ubuntu artful/main amd64 Packages
release v=17.10,o=Ubuntu,a=artful,n=artful,l=Ubuntu,c=main,b=amd64
origin in.archive.ubuntu.com
Pinned packages:
```
### 如何在 openSUSE 上列出已启用的仓库
openSUSE 使用 zypper 包管理,因此我们可以使用 zypper 包管理获得更多信息。
Zypper 是 suse 和 openSUSE 发行版的命令行包管理。它用于安装、更新、搜索、移除包和管理仓库,执行各种查询等。Zypper 以 ZYpp 系统管理库(libzypp)作为后端。
**建议阅读:** [在 openSUSE 和 suse 系统上使用 Zypper 命令管理包](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/)
```
# zypper repos
# | Alias | Name | Enabled | GPG Check | Refresh
--+-----------------------+-----------------------------------------------------+---------+-----------+--------
1 | packman-repository | packman-repository | Yes | (r ) Yes | Yes
2 | google-chrome | google-chrome | Yes | (r ) Yes | Yes
3 | home_lazka0_ql-stable | Stable Quod Libet / Ex Falso Builds (openSUSE_42.1) | Yes | (r ) Yes | No
4 | repo-non-oss | openSUSE-leap/42.1-Non-Oss | Yes | (r ) Yes | Yes
5 | repo-oss | openSUSE-leap/42.1-Oss | Yes | (r ) Yes | Yes
6 | repo-update | openSUSE-42.1-Update | Yes | (r ) Yes | Yes
7 | repo-update-non-oss | openSUSE-42.1-Update-Non-Oss | Yes | (r ) Yes | Yes
```
列出仓库及 URI。
```
# zypper lr -u
# | Alias | Name | Enabled | GPG Check | Refresh | URI
--+-----------------------+-----------------------------------------------------+---------+-----------+---------+---------------------------------------------------------------------------------
1 | packman-repository | packman-repository | Yes | (r ) Yes | Yes | http://ftp.gwdg.de/pub/linux/packman/suse/openSUSE_Leap_42.1/
2 | google-chrome | google-chrome | Yes | (r ) Yes | Yes | http://dl.google.com/linux/chrome/rpm/stable/x86_64
3 | home_lazka0_ql-stable | Stable Quod Libet / Ex Falso Builds (openSUSE_42.1) | Yes | (r ) Yes | No | http://download.opensuse.org/repositories/home:/lazka0:/ql-stable/openSUSE_42.1/
4 | repo-non-oss | openSUSE-leap/42.1-Non-Oss | Yes | (r ) Yes | Yes | http://download.opensuse.org/distribution/leap/42.1/repo/non-oss/
5 | repo-oss | openSUSE-leap/42.1-Oss | Yes | (r ) Yes | Yes | http://download.opensuse.org/distribution/leap/42.1/repo/oss/
6 | repo-update | openSUSE-42.1-Update | Yes | (r ) Yes | Yes | http://download.opensuse.org/update/leap/42.1/oss/
7 | repo-update-non-oss | openSUSE-42.1-Update-Non-Oss | Yes | (r ) Yes | Yes | http://download.opensuse.org/update/leap/42.1/non-oss/
```
通过优先级列出仓库。
```
# zypper lr -p
# | Alias | Name | Enabled | GPG Check | Refresh | Priority
--+-----------------------+-----------------------------------------------------+---------+-----------+---------+---------
1 | packman-repository | packman-repository | Yes | (r ) Yes | Yes | 99
2 | google-chrome | google-chrome | Yes | (r ) Yes | Yes | 99
3 | home_lazka0_ql-stable | Stable Quod Libet / Ex Falso Builds (openSUSE_42.1) | Yes | (r ) Yes | No | 99
4 | repo-non-oss | openSUSE-leap/42.1-Non-Oss | Yes | (r ) Yes | Yes | 99
5 | repo-oss | openSUSE-leap/42.1-Oss | Yes | (r ) Yes | Yes | 99
6 | repo-update | openSUSE-42.1-Update | Yes | (r ) Yes | Yes | 99
7 | repo-update-non-oss | openSUSE-42.1-Update-Non-Oss | Yes | (r ) Yes | Yes | 99
```
### 如何列出 Arch Linux 上已启用的仓库
基于 Arch Linux 的系统使用 pacman 包管理,因此我们可以使用 pacman 包管理获取这些信息。
pacman 意即 “package manager utility”。pacman 是一个命令行实用程序,用以安装、构建、移除和管理 Arch Linux 包。pacman 使用 libalpm (Arch Linux 包管理库)作为后端去进行这些操作。
**建议阅读:** [在基于 Arch Linux的系统上使用 Pacman命令管理包](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/)
```
# pacman -Syy
:: Synchronizing package databases...
core 132.6 KiB 1524K/s 00:00 [############################################] 100%
extra 1859.0 KiB 750K/s 00:02 [############################################] 100%
community 3.5 MiB 149K/s 00:24 [############################################] 100%
multilib 182.7 KiB 1363K/s 00:00 [############################################] 100%
```
### 如何使用 INXI Utility 列出 Linux 上已启用的仓库
inix 是 Linux 上检查硬件信息非常有用的工具,还提供很多的选项去获取 Linux 上的所有硬件信息,我从未在 Linux 上发现其他有如此效用的程序。它由 locsmif 分叉自古老而古怪的 infobash。
inix 是一个可以快速显示硬件信息、CPU、硬盘、Xorg、桌面、内核、GCC 版本、进程、内存使用和很多其他有用信息的程序,还使用于论坛技术支持和调试工具上。
这个实用程序将会显示所有发行版仓库的数据信息,例如 RHEL、CentOS、Fedora、Debain、Ubuntu、LinuxMint、ArchLinux、openSUSE、Manjaro等。
**建议阅读:** [inxi – 一个在 Linux 上检查硬件信息的好工具](https://www.2daygeek.com/inxi-system-hardware-information-on-linux/)
```
# inxi -r
Repos: Active apt sources in file: /etc/apt/sources.list
deb http://in.archive.ubuntu.com/ubuntu/ yakkety main restricted
deb http://in.archive.ubuntu.com/ubuntu/ yakkety-updates main restricted
deb http://in.archive.ubuntu.com/ubuntu/ yakkety universe
deb http://in.archive.ubuntu.com/ubuntu/ yakkety-updates universe
deb http://in.archive.ubuntu.com/ubuntu/ yakkety multiverse
deb http://in.archive.ubuntu.com/ubuntu/ yakkety-updates multiverse
deb http://in.archive.ubuntu.com/ubuntu/ yakkety-backports main restricted universe multiverse
deb http://security.ubuntu.com/ubuntu yakkety-security main restricted
deb http://security.ubuntu.com/ubuntu yakkety-security universe
deb http://security.ubuntu.com/ubuntu yakkety-security multiverse
Active apt sources in file: /etc/apt/sources.list.d/arc-theme.list
deb http://download.opensuse.org/repositories/home:/Horst3180/xUbuntu_16.04/ /
Active apt sources in file: /etc/apt/sources.list.d/snwh-ubuntu-pulp-yakkety.list
deb http://ppa.launchpad.net/snwh/pulp/ubuntu yakkety main
```
---
via: <https://www.2daygeek.com/how-to-list-the-enabled-active-repositories-in-linux/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,169 | 如何在 Linux 上锁定虚拟控制台会话 | https://www.ostechnix.com/how-to-lock-virtual-console-sessions-on-linux/ | 2018-10-29T18:49:14 | [
"控制台"
] | https://linux.cn/article-10169-1.html | 
当你在共享的系统上工作时,你可能不希望其他用户偷窥你的控制台中看你在做什么。如果是这样,我知道有个简单的技巧来锁定自己的会话,同时仍然允许其他用户在其他虚拟控制台上使用该系统。要感谢 **Vlock**(**V**irtual Console **lock**),这是一个命令行程序,用于锁定 Linux 控制台上的一个或多个会话。如有必要,你可以锁定整个控制台并完全禁用虚拟控制台切换功能。Vlock 对于有多个用户访问控制台的共享 Linux 系统特别有用。
### 安装 Vlock
在基于 Arch 的系统上,Vlock 软件包被替换为默认预安装的 **kpd** 包,因此你无需为安装烦恼。
在 Debian、Ubuntu、Linux Mint 上,运行以下命令来安装 Vlock:
```
$ sudo apt-get install vlock
```
在 Fedora 上:
```
$ sudo dnf install vlock
```
在 RHEL、CentOS 上:
```
$ sudo yum install vlock
```
### 在 Linux 上锁定虚拟控制台会话
Vlock 的一般语法是:
```
vlock [ -acnshv ] [ -t <timeout> ] [ plugins... ]
```
这里:
* `a` —— 锁定所有虚拟控制台会话,
* `c` —— 锁定当前虚拟控制台会话,
* `n` —— 在锁定所有会话之前切换到新的空控制台,
* `s` —— 禁用 SysRq 键机制,
* `t` —— 指定屏保插件的超时时间,
* `h` —— 显示帮助,
* `v` —— 显示版本。
让我举几个例子。
#### 1、 锁定当前控制台会话
在没有任何参数的情况下运行 Vlock 时,它默认锁定当前控制台会话 (TYY)。要解锁会话,你需要输入当前用户的密码或 root 密码。
```
$ vlock
```

你还可以使用 `-c` 标志来锁定当前的控制台会话。
```
$ vlock -c
```
请注意,此命令仅锁定当前控制台。你可以按 `ALT+F2` 切换到其他控制台。有关在 TTY 之间切换的更多详细信息,请参阅以下指南。
此外,如果系统有多个用户,则其他用户仍可以访问其各自的 TTY。
#### 2、 锁定所有控制台会话
要同时锁定所有 TTY 并禁用虚拟控制台切换功能,请运行:
```
$ vlock -a
```
同样,要解锁控制台会话,只需按下回车键并输入当前用户的密码或 root 用户密码。
请记住,**root 用户可以随时解锁任何 vlock 会话**,除非在编译时禁用。
#### 3、 在锁定所有控制台之前切换到新的虚拟控制台
在锁定所有控制台之前,还可以使 Vlock 从 X 会话切换到新的空虚拟控制台。为此,请使用 `-n` 标志。
```
$ vlock -n
```
#### 4、 禁用 SysRq 机制
你也许知道,魔术 SysRq 键机制允许用户在系统死机时执行某些操作。因此,用户可以使用 SysRq 解锁控制台。为了防止这种情况,请传递 `-s` 选项以禁用 SysRq 机制。请记住,这个选项只适用于有 `-a` 选项的时候。
```
$ vlock -sa
```
有关更多选项及其用法,请参阅帮助或手册页。
```
$ vlock -h
$ man vlock
```
Vlock 可防止未经授权的用户获得控制台访问权限。如果你在为 Linux 寻找一个简单的控制台锁定机制,那么 Vlock 值得一试!
就是这些了。希望这篇文章有用。还有更多好东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-lock-virtual-console-sessions-on-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,170 | 如何移除或禁用 Ubuntu Dock | https://www.linuxuprising.com/2018/08/how-to-remove-or-disable-ubuntu-dock.html | 2018-10-29T19:36:00 | [
"Dock"
] | https://linux.cn/article-10170-1.html | 
>
> 如果你想用其它 dock(例如 Plank dock)或面板来替换 Ubuntu 18.04 中的 Dock,或者你想要移除或禁用 Ubuntu Dock,本文会告诉你如何做。
>
>
>
Ubuntu Dock - 屏幕左侧栏,可用于固定应用程序或访问已安装的应用程序。使用默认的 Ubuntu 会话时,[无法](https://bugs.launchpad.net/ubuntu/+source/gnome-tweak-tool/+bug/1713020)使用 Gnome Tweaks 禁用它(禁用无效)。但是如果你需要,还是有几种方法来摆脱它的。下面我将列出 4 种方法可以移除或禁用 Ubuntu Dock,以及每个方法的缺点(如果有的话),还有如何撤销每个方法的更改。本文还包括在没有 Ubuntu Dock 的情况下访问<ruby> 活动概览 <rt> Activities Overview </rt></ruby>和已安装应用程序列表的其它方法。
### 如何在没有 Ubuntu Dock 的情况下访问活动概览
如果没有 Ubuntu Dock,你可能无法访问活动的或已安装的应用程序列表(可以通过单击 Dock 底部的“显示应用程序”按钮从 Ubuntu Dock 访问)。例如,如果你想使用 Plank Dock 就是这样。
显然,如果你安装了 Dash to Panel 扩展来替代 Ubuntu Dock,那么还好。因为 Dash to Panel 提供了一个按钮来访问活动概览或已安装的应用程序。
根据你计划用来替代 Ubuntu Dock 的软件,如果无法访问活动概览,那么你可以启用“活动概览热角”选项,只需将鼠标移动到屏幕的左上角即可打开活动概览。访问已安装的应用程序列表的另一种方法是使用快捷键:`Super + A`。
如果要启用“活动概览热角”,使用以下命令:
```
gsettings set org.gnome.shell enable-hot-corners true
```
如果以后要撤销此操作并禁用该热角,那么你需要使用以下命令:
```
gsettings set org.gnome.shell enable-hot-corners false
```
你可以使用 Gnome Tweaks 应用程序(该选项位于 Gnome Tweaks 的 “Top Bar” 部分)启用或禁用“活动概览热角” 选项,可以使用以下命令进行安装它:
```
sudo apt install gnome-tweaks
```
### 如何移除或禁用 Ubuntu Dock
下面你将找到 4 种摆脱 Ubuntu Dock 的方法,环境在 Ubuntu 18.04 下。
#### 方法 1: 移除 Gnome Shell Ubuntu Dock 包
摆脱 Ubuntu Dock 的最简单方法就是删除包。
这将会从你的系统中完全移除 Ubuntu Dock 扩展,但同时也移除了 `ubuntu-desktop` 元数据包。如果你移除 `ubuntu-desktop` 元数据包,不会马上出现问题,因为它本身没有任何作用。`ubuntu-desktop` 元数据包依赖于组成 Ubuntu 桌面的大量包。它的依赖关系不会被删除,也不会被破坏。问题是如果你以后想升级到新的 Ubuntu 版本,那么将不会安装任何新的 `ubuntu-desktop` 依赖项。
为了解决这个问题,你可以在升级到较新的 Ubuntu 版本之前安装 `ubuntu-desktop` 元数据包(例如,如果你想从 Ubuntu 18.04 升级到 18.10)。
如果你对此没有意见,并且想要从系统中删除 Ubuntu Dock 扩展包,使用以下命令:
```
sudo apt remove gnome-shell-extension-ubuntu-dock
```
如果以后要撤消更改,只需使用以下命令安装扩展:
```
sudo apt install gnome-shell-extension-ubuntu-dock
```
或者重新安装 `ubuntu-desktop` 元数据包(这将会安装你可能已删除的任何 `ubuntu-desktop` 依赖项,包括 Ubuntu Dock),你可以使用以下命令:
```
sudo apt install ubuntu-desktop
```
#### 方法 2:安装并使用 vanilla Gnome 会话而不是默认的 Ubuntu 会话
摆脱 Ubuntu Dock 的另一种方法是安装和使用原生 Gnome 会话。安装 原生 Gnome 会话还将安装此会话所依赖的其它软件包,如 Gnome 文档、地图、音乐、联系人、照片、跟踪器等。
通过安装原生 Gnome 会话,你还将获得默认 Gnome GDM 登录和锁定屏幕主题,而不是 Ubuntu 默认的 Adwaita Gtk 主题和图标。你可以使用 Gnome Tweaks 应用程序轻松更改 Gtk 和图标主题。
此外,默认情况下将禁用 AppIndicators 扩展(因此使用 AppIndicators 托盘的应用程序不会显示在顶部面板上),但你可以使用 Gnome Tweaks 启用此功能(在扩展中,启用 Ubuntu appindicators 扩展)。
同样,你也可以从原生 Gnome 会话启用或禁用 Ubuntu Dock,这在 Ubuntu 会话中是不可能的(使用 Ubuntu 会话时无法从 Gnome Tweaks 禁用 Ubuntu Dock)。
如果你不想安装原生 Gnome 会话所需的这些额外软件包,那么这个移除 Ubuntu Dock 的这个方法不适合你,请查看其它方法。
如果你对此没有意见,以下是你需要做的事情。要在 Ubuntu 中安装原生的 Gnome 会话,使用以下命令:
```
sudo apt install vanilla-gnome-desktop
```
安装完成后,重启系统。在登录屏幕上,单击用户名,单击 “Sign in” 按钮旁边的齿轮图标,然后选择 “GNOME” 而不是 “Ubuntu”,之后继续登录。

如果要撤销此操作并移除原生 Gnome 会话,可以使用以下命令清除原生 Gnome 软件包,然后删除它安装的依赖项(第二条命令):
```
sudo apt purge vanilla-gnome-desktop
sudo apt autoremove
```
然后重新启动,并以相同的方式从 GDM 登录屏幕中选择 Ubuntu。
#### 方法 3:从桌面上永久隐藏 Ubuntu Dock,而不是将其移除
如果你希望永久隐藏 Ubuntu Dock,不让它显示在桌面上,但不移除它或使用原生 Gnome 会话,你可以使用 Dconf 编辑器轻松完成此操作。这样做的缺点是 Ubuntu Dock 仍然会使用一些系统资源,即使你没有在桌面上使用它,但你也可以轻松恢复它而无需安装或移除任何包。
Ubuntu Dock 只对你的桌面隐藏,当你进入叠加模式(活动)时,你仍然可以看到并从那里使用 Ubuntu Dock。
要永久隐藏 Ubuntu Dock,使用 Dconf 编辑器导航到 `/org/gnome/shell/extensions/dash-to-dock` 并禁用以下选项(将它们设置为 `false`):`autohide`、`dock-fixed` 和 `intellihide`。
如果你愿意,可以从命令行实现此目的,运行以下命令:
```
gsettings set org.gnome.shell.extensions.dash-to-dock autohide false
gsettings set org.gnome.shell.extensions.dash-to-dock dock-fixed false
gsettings set org.gnome.shell.extensions.dash-to-dock intellihide false
```
如果你改变主意了并想撤销此操作,你可以使用 Dconf 编辑器从 `/org/gnome/shell/extensions/dash-to-dock` 中启动 `autohide`、 `dock-fixed` 和 `intellihide`(将它们设置为 `true`),或者你可以使用以下这些命令:
```
gsettings set org.gnome.shell.extensions.dash-to-dock autohide true
gsettings set org.gnome.shell.extensions.dash-to-dock dock-fixed true
gsettings set org.gnome.shell.extensions.dash-to-dock intellihide true
```
#### 方法 4:使用 Dash to Panel 扩展
[Dash to Panel](https://www.linuxuprising.com/2018/05/gnome-shell-dash-to-panel-v14-brings.html) 是 Gnome Shell 的一个高度可配置面板,是 Ubuntu Dock 或 Dash to Dock 的一个很好的替代品(Ubuntu Dock 是从 Dash to Dock 分叉而来的)。安装和启动 Dash to Panel 扩展会禁用 Ubuntu Dock,因此你无需执行其它任何操作。
你可以从 [extensions.gnome.org](https://extensions.gnome.org/extension/1160/dash-to-panel/) 来安装 Dash to Panel。
如果你改变主意并希望重新使用 Ubuntu Dock,那么你可以使用 Gnome Tweaks 应用程序禁用 Dash to Panel,或者通过单击以下网址旁边的 X 按钮完全移除 Dash to Panel: <https://extensions.gnome.org/local/> 。
---
via: <https://www.linuxuprising.com/2018/08/how-to-remove-or-disable-ubuntu-dock.html>
作者:[Logix](https://plus.google.com/118280394805678839070) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # How To Remove Or Disable Ubuntu Dock
**If you want to replace the Ubuntu Dock in Ubuntu 21.10, 21.04, 20.10, 20.04, 19.10 or 18.04 with some other dock (like Plank dock for example) or panel, and you want to remove or disable the Ubuntu Dock, here's what you can do and how.**
Ubuntu Dock - the bar on the left-hand side of the screen which can be used to pin applications and access installed applications -
[can't](https://bugs.launchpad.net/ubuntu/+source/gnome-tweak-tool/+bug/1713020)be disabled using Gnome Tweaks (disabling it does nothing) when using the default ubuntu session, but there are a few ways you can get rid of it if you need this. Below I'll list 4 ways you can remove or disable Ubuntu Dock, as well as the drawbacks (if any) of each option, and how to undo the changes for each option.
The 4 options are: remove the Ubuntu Dock package, use the vanilla Gnome session, permanently hide Ubuntu Dock without removing it, and use Dash to Panel extension instead of Ubuntu Dock (which automatically disables Ubuntu Dock).
The article also includes alternative ways to access the Activities Overview / list of installed applications without Ubuntu Dock.
## How to access the Activities Overview without Ubuntu Dock
Without Ubuntu Dock, you may have no way of accessing the Activities / installed application list (which can be accessed from Ubuntu Dock by clicking on Show Applications button at the bottom of the dock). For example if you want to use Plank dock.
Obviously, that's not the case if you install Dash to Panel extension to use it instead Ubuntu Dock, because Dash to Panel provides a button to access the Activities Overview / installed applications.
Depending on what you plan to use instead of Ubuntu Dock, if there's no way of accessing the Activities Overview, you can enable the Activities Overview Hot Corner option and simply move your mouse to the upper left corner of the screen to open the Activities. Another way of accessing the installed application list is using a keyboard shortcut:
`Super + A`
.If you want to enable the Activities Overview hot corner, use this command:
`gsettings set org.gnome.shell enable-hot-corners true`
If later you want to undo this and disable the hot corners, you need to use this command:
`gsettings set org.gnome.shell enable-hot-corners false`
You can also enable or disable the Activities Overview Hot Corner option by using the Gnome Tweaks application (the option is in the
`Top Bar`
section of Gnome Tweaks), which can be installed by using this command:`sudo apt install gnome-tweaks`
## How to remove or disable Ubuntu Dock
Below you'll find 4 ways of getting rid of Ubuntu Dock which work in Ubuntu 21.10, 21.04, 20.10, 20.04, 19.10 and 18.04.
### Option 1: Remove the Gnome Shell Ubuntu Dock package.
The easiest way of getting rid of the Ubuntu Dock is to remove the package.
This completely removes the Ubuntu Dock extension from your system, but it also removes the
`ubuntu-desktop`
meta package. There's no immediate issue if you remove the `ubuntu-desktop`
meta package because does nothing by itself. The `ubuntu-meta`
package depends on a large number of packages which make up the Ubuntu Desktop. Its dependencies won't be removed and nothing will break. The issue is that if you want to upgrade to a newer Ubuntu version, any new `ubuntu-desktop`
dependencies won't be installed.As a way around this, you can simply install the
`ubuntu-desktop`
meta package before upgrading to a newer Ubuntu version (for example if you want to upgrade from Ubuntu 18.04 to 20.04).If you're ok with this and want to remove the Ubuntu Dock extension package from your system, use the following command:
`sudo apt remove gnome-shell-extension-ubuntu-dock`
If later you want to undo the changes, simply install the extension back using this command:
`sudo apt install gnome-shell-extension-ubuntu-dock`
Or to install the
`ubuntu-desktop`
meta package back (this will install any ubuntu-desktop dependencies you may have removed, including Ubuntu Dock), you can use this command:`sudo apt install ubuntu-desktop`
### Option 2: Install and use the vanilla Gnome session instead of the default Ubuntu session.
Another way to get rid of Ubuntu Dock is to install and use the vanilla Gnome session. Installing the vanilla Gnome session will also install other packages this session depends on, like Gnome Documents, Maps, Music, Contacts, Photos, Tracker and more.
By installing the vanilla Gnome session, you'll also get the default Gnome GDM login / lock screen theme instead of the Ubuntu defaults as well as Adwaita Gtk theme and icons. You can easily change the Gtk and icon theme though, by using the Gnome Tweaks application.
Furthermore, the AppIndicators extension will be disabled by default (so applications that make use of the AppIndicators tray won't show up on the top panel), but you can enable this by using Gnome Tweaks (under Extensions, enable the Ubuntu appindicators extension).
In the same way, you can also enable or disable Ubuntu Dock from the vanilla Gnome session, which is not possible if you use the Ubuntu session (disabling Ubuntu Dock from Gnome Tweaks when using the Ubuntu session does nothing).
If you don't want to install these extra packages required by the vanilla Gnome session, this option of removing Ubuntu Dock is not for you so check out the other options.
If you are ok with this though, here's what you need to do. To install the vanilla Gnome session in Ubuntu, use this command:
`sudo apt install vanilla-gnome-desktop`
After the installation finishes, reboot your system and on the login screen, after you click on your username, click the gear icon next to the
`Sign in`
button, and select `GNOME`
instead of `Ubuntu`
, then proceed to login:In case you want to undo this and remove the vanilla Gnome session, you can purge the vanilla Gnome package and then remove the dependencies it installed (second command) using the following commands:
```
sudo apt purge vanilla-gnome-desktop
sudo apt autoremove
```
Then reboot and select Ubuntu in the same way, from the GDM login screen.
### Option 3: Permanently hide the Ubuntu Dock from your desktop instead of removing it.
If you prefer to permanently hide the Ubuntu Dock from showing up on your desktop instead of uninstalling it or using the vanilla Gnome session, you can easily do this using Dconf Editor. The drawback to this is that Ubuntu Dock will still use some system resources even though you're not using in on your desktop, but you'll also be able to easily revert this without installing or removing any packages.
Ubuntu Dock is only hidden from your desktop though. When you go in overlay mode (Activities), you'll still see and be able to use Ubuntu Dock from there.
To permanently hide Ubuntu Dock, use Dconf Editor to navigate to
`/org/gnome/shell/extensions/dash-to-dock`
and disable (set them to false) the following options: `autohide`
, `dock-fixed`
and `intellihide`
.You can achieve this from the command line if you wish, buy running the commands below:
```
gsettings set org.gnome.shell.extensions.dash-to-dock autohide false
gsettings set org.gnome.shell.extensions.dash-to-dock dock-fixed false
gsettings set org.gnome.shell.extensions.dash-to-dock intellihide false
```
In case you change your mind and you want to undo this, you can either use Dconf Editor and re-enable (set them to true) autohide, dock-fixed and intellihide from
`/org/gnome/shell/extensions/dash-to-dock`
, or you can use these commands:```
gsettings set org.gnome.shell.extensions.dash-to-dock autohide true
gsettings set org.gnome.shell.extensions.dash-to-dock dock-fixed true
gsettings set org.gnome.shell.extensions.dash-to-dock intellihide true
```
### Option 4: Use Dash to Panel extension.
[Dash to Panel](https://www.linuxuprising.com/2018/05/gnome-shell-dash-to-panel-v14-brings.html)is a highly configurable panel for Gnome Shell, and a great replacement for Ubuntu Dock / Dash to Dock (Ubuntu Dock is forked from Dash to Dock). It can replace not only Ubuntu Dock, but also the top panel, since it can show the tray/AppIndicators and the clock/calendar menu on a single panel.
Installing and enabling the Dash to Panel extension disables Ubuntu Dock so there's nothing else you need to do.
You can install Dash to Panel from
[extensions.gnome.org](https://extensions.gnome.org/extension/1160/dash-to-panel/).
If you change your mind and you want Ubuntu Dock back, you can either disable Dash to Panel by using Gnome Tweaks app, or completely remove Dash to Panel by clicking the X button next to it from here:
[https://extensions.gnome.org/local/](https://extensions.gnome.org/local/). |
10,171 | 命令行:增强版 | https://remysharp.com/2018/08/23/cli-improved | 2018-10-29T20:46:00 | [
"命令行",
"终端"
] | https://linux.cn/article-10171-1.html | 
我不确定有多少 Web 开发者能完全避免使用命令行。就我来说,我从 1997 年上大学就开始使用命令行了,那时的 l33t-hacker 让我着迷,同时我也觉得它很难掌握。
过去这些年我的命令行本领在逐步加强,我经常会去搜寻工作中能用的更好的命令行工具。下面就是我现在使用的用于增强原有命令行工具的列表。
### 怎么忽略我所做的命令行增强
通常情况下我会用别名将新的增强的命令行工具覆盖原来的命令(如 `cat` 和 `ping`)。
如果我需要运行原来的命令的话(有时我确实需要这么做),我会像下面这样来运行未加修改的原始命令。(我用的是 Mac,你的用法可能不一样)
```
$ \cat # 忽略叫 "cat" 的别名 - 具体解释: https://stackoverflow.com/a/16506263/22617
$ command cat # 忽略函数和别名
```
### bat > cat
`cat` 用于打印文件的内容,如果你平时用命令行很多的话,例如语法高亮之类的功能会非常有用。我首先发现了 [ccat](https://github.com/jingweno/ccat) 这个有语法高亮功能的工具,然后我发现了 [bat](https://github.com/sharkdp/bat),它的功能有语法高亮、分页、行号和 git 集成。
`bat` 命令也能让我在(多于一屏的)输出里使用 `/` 搜索(和用 `less` 搜索功能一样)。

我将别名 `cat` 指到了 `bat` 命令:
```
alias cat='bat'
```
* [安装指引](https://github.com/sharkdp/bat)
### prettyping > ping
`ping` 非常有用,当我碰到“糟了,是不是 X 挂了?/我的网不通了?”这种情况下我最先想到的工具就是它了。但是 `prettyping`(“prettyping” 可不是指“pre typing”)在 `ping` 的基础上加了友好的输出,这可让我感觉命令行友好了很多呢。

我也将 `ping` 用别名链接到了 `prettyping` 命令:
```
alias ping='prettyping --nolegend'
```
* [安装指引](http://denilson.sa.nom.br/prettyping/)
### fzf > ctrl+r
在终端里,使用 `ctrl+r` 将允许你在命令历史里[反向搜索](https://lifehacker.com/278888/ctrl%252Br-to-search-and-other-terminal-history-tricks)使用过的命令,这是个挺好的小技巧,尽管它有点麻烦。
`fzf` 这个工具相比于 `ctrl+r` 有了**巨大的**进步。它能针对命令行历史进行模糊查询,并且提供了对可能的合格结果进行全面交互式预览。
除了搜索命令历史,`fzf` 还能预览和打开文件,我在下面的视频里展示了这些功能。
为了这个预览的效果,我创建了一个叫 `preview` 的别名,它将 `fzf` 和前文提到的 `bat` 组合起来完成预览功能,还给上面绑定了一个定制的热键 `ctrl+o` 来打开 VS Code:
```
alias preview="fzf --preview 'bat --color \"always\" {}'"
# 支持在 VS Code 里用 ctrl+o 来打开选择的文件
export FZF_DEFAULT_OPTS="--bind='ctrl-o:execute(code {})+abort'"
```
* [安装指引](https://github.com/junegunn/fzf)
### htop > top
`top` 是当我想快速诊断为什么机器上的 CPU 跑的那么累或者风扇为什么突然呼呼大做的时候首先会想到的工具。我在生产环境也会使用这个工具。讨厌的是 Mac 上的 `top` 和 Linux 上的 `top` 有着极大的不同(恕我直言,应该是差的多)。
不过,`htop` 是对 Linux 上的 `top` 和 Mac 上蹩脚的 `top` 的极大改进。它增加了包括颜色输出,键盘热键绑定以及不同的视图输出,这对理解进程之间的父子关系有极大帮助。
一些很容易上手的热键:
* `P` —— 按 CPU 使用率排序
* `M` —— 按内存使用排序
* `F4` —— 用字符串过滤进程(例如只看包括 node 的进程)
* `space` —— 锚定一个单独进程,这样我能观察它是否有尖峰状态

在 Mac Sierra 上 htop 有个奇怪的 bug,不过这个 bug 可以通过以 root 运行来绕过(我实在记不清这个 bug 是什么,但是这个别名能搞定它,有点讨厌的是我得每次都输入 root 密码。):
```
alias top="sudo htop" # 给 top 加上别名并且绕过 Sierra 上的 bug
```
* [安装指引](http://hisham.hm/htop/)
### diff-so-fancy > diff
我非常确定我是几年前从 Paul Irish 那儿学来的这个技巧,尽管我很少直接使用 `diff`,但我的 git 命令行会一直使用 `diff`。`diff-so-fancy` 给了我代码语法颜色和更改字符高亮的功能。

在我的 `~/.gitconfig` 文件里我用了下面的选项来打开 `git diff` 和 `git show` 的 `diff-so-fancy` 功能。
```
[pager]
diff = diff-so-fancy | less --tabs=1,5 -RFX
show = diff-so-fancy | less --tabs=1,5 -RFX
```
* [安装指引](https://github.com/so-fancy/diff-so-fancy)
### fd > find
尽管我使用 Mac,但我绝不是 Spotlight 的粉丝,我觉得它的性能很差,关键字也难记,加上更新它自己的数据库时会拖慢 CPU,简直一无是处。我经常使用 [Alfred](https://www.alfredapp.com/),但是它的搜索功能也不是很好。
我倾向于在命令行中搜索文件,但是 `find` 的难用在于很难去记住那些合适的表达式来描述我想要的文件。(而且 Mac 上的 `find` 命令和非 Mac 的 `find` 命令还有些许不同,这更加深了我的失望。)
`fd` 是一个很好的替代品(它的作者和 `bat` 的作者是同一个人)。它非常快而且对于我经常要搜索的命令非常好记。
几个上手的例子:
```
$ fd cli # 所有包含 "cli" 的文件名
$ fd -e md # 所有以 .md 作为扩展名的文件
$ fd cli -x wc -w # 搜索 "cli" 并且在每个搜索结果上运行 `wc -w`
```

* [安装指引](https://github.com/sharkdp/fd/)
### ncdu > du
对我来说,知道当前磁盘空间被什么占用了非常重要。我用过 Mac 上的 [DaisyDisk](https://daisydiskapp.com/),但是我觉得那个程序产生结果有点慢。
`du -sh` 命令是我经常会运行的命令(`-sh` 是指结果以“汇总”和“人类可读”的方式显示),我经常会想要深入挖掘那些占用了大量磁盘空间的目录,看看到底是什么在占用空间。
`ncdu` 是一个非常棒的替代品。它提供了一个交互式的界面并且允许快速的扫描那些占用了大量磁盘空间的目录和文件,它又快又准。(尽管不管在哪个工具的情况下,扫描我的 home 目录都要很长时间,它有 550G)
一旦当我找到一个目录我想要“处理”一下(如删除,移动或压缩文件),我会使用 `cmd` + 点击 [iTerm2](https://www.iterm2.com/) 顶部的目录名字的方法在 Finder 中打开它。

还有另外[一个叫 nnn 的替代选择](https://github.com/jarun/nnn),它提供了一个更漂亮的界面,它也提供文件尺寸和使用情况,实际上它更像一个全功能的文件管理器。
我的 `du` 是如下的别名:
```
alias du="ncdu --color dark -rr -x --exclude .git --exclude node_modules"
```
选项说明:
* `--color dark` 使用颜色方案
* `-rr` 只读模式(防止误删和运行新的 shell 程序)
* `--exclude` 忽略不想操作的目录
* [安装指引](https://dev.yorhel.nl/ncdu)
### tldr > man
几乎所有的命令行工具都有一个相伴的手册,它可以被 `man <命令名>` 来调出,但是在 `man` 的输出里找到东西可有点让人困惑,而且在一个包含了所有的技术细节的输出里找东西也挺可怕的。
这就是 TL;DR 项目(LCTT 译注:英文里“文档太长,没空去读”的缩写)创建的初衷。这是一个由社区驱动的文档系统,而且可以用在命令行上。就我现在使用的经验,我还没碰到过一个命令没有它相应的文档,你[也可以做贡献](https://github.com/tldr-pages/tldr#contributing)。

一个小技巧,我将 `tldr` 的别名链接到 `help`(这样输入会快一点……)
```
alias help='tldr'
```
* [安装指引](http://tldr-pages.github.io/)
### ack || ag > grep
`grep` 毫无疑问是一个强力的命令行工具,但是这些年来它已经被一些工具超越了,其中两个叫 `ack` 和 `ag`。
我个人对 `ack` 和 `ag` 都尝试过,而且没有非常明显的个人偏好,(也就是说它们都很棒,并且很相似)。我倾向于默认只使用 `ack`,因为这三个字符就在指尖,很好打。并且 `ack` 有大量的 `ack --bar` 参数可以使用!(你一定会体会到这一点。)
`ack` 和 `ag` 默认都使用正则表达式来搜索,这非常契合我的工作,我能使用类似于 `--js` 或 `--html` 这种标识指定文件类型搜索。(尽管 `ag` 比 `ack` 在文件类型过滤器里包括了更多的文件类型。)
两个工具都支持常见的 `grep` 选项,如 `-B` 和 `-A` 用于在搜索的上下文里指代“之前”和“之后”。

因为 `ack` 不支持 markdown(而我又恰好写了很多 markdown),我在我的 `~/.ackrc` 文件里加了以下定制语句:
```
--type-set=md=.md,.mkd,.markdown
--pager=less -FRX
```
* 安装指引:[ack](https://beyondgrep.com),[ag](https://github.com/ggreer/the_silver_searcher)
* [关于 ack & ag 的更多信息](http://conqueringthecommandline.com/book/ack_ag)
### jq > grep 及其它
我是 [jq](https://stedolan.github.io/jq) 的忠实粉丝之一。当然一开始我也在它的语法里苦苦挣扎,好在我对查询语言还算有些使用心得,现在我对 `jq` 可以说是每天都要用。(不过从前我要么使用 `grep` 或者使用一个叫 [json](http://trentm.com/json/) 的工具,相比而言后者的功能就非常基础了。)
我甚至开始撰写一个 `jq` 的教程系列(有 2500 字并且还在增加),我还发布了一个[网页工具](https://jqterm.com)和一个 Mac 上的应用(这个还没有发布。)
`jq` 允许我传入一个 JSON 并且能非常简单的将其转变为一个使用 JSON 格式的结果,这正是我想要的。下面这个例子允许我用一个命令更新我的所有 node 依赖。(为了阅读方便,我将其分成为多行。)
```
$ npm i $(echo $(\
npm outdated --json | \
jq -r 'to_entries | .[] | "\(.key)@\(.value.latest)"' \
))
```
上面的命令将使用 npm 的 JSON 输出格式来列出所有过期的 node 依赖,然后将下面的源 JSON 转换为:
```
{
"node-jq": {
"current": "0.7.0",
"wanted": "0.7.0",
"latest": "1.2.0",
"location": "node_modules/node-jq"
},
"uuid": {
"current": "3.1.0",
"wanted": "3.2.1",
"latest": "3.2.1",
"location": "node_modules/uuid"
}
}
```
转换结果为:
```
[email protected]
[email protected]
```
上面的结果会被作为 `npm install` 的输入,你瞧,我的升级就这样全部搞定了。(当然,这里有点小题大做了。)
### 很荣幸提及一些其它的工具
我也在开始尝试一些别的工具,但我还没有完全掌握它们。(除了 `ponysay`,当我打开一个新的终端会话时,它就会出现。)
* [ponysay](https://github.com/erkin/ponysay) > `cowsay`
* [csvkit](https://csvkit.readthedocs.io/en/1.0.3/) > `awk 及其它`
* [noti](https://github.com/variadico/noti) > `display notification`
* [entr](http://www.entrproject.org/) > `watch`
### 你有什么好点子吗?
上面是我的命令行清单。你的呢?你有没有试着去增强一些你每天都会用到的命令呢?请告诉我,我非常乐意知道。
---
via: <https://remysharp.com/2018/08/23/cli-improved>
作者:[Remy Sharp](https://remysharp.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[DavidChenLiang](https://github.com/DavidChenLiang) 校对:[pityonline](https://github.com/pityonline), [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
10,172 | 用这个漂亮的工具将方程式截图迅速转换为 LaTeX | https://itsfoss.com/mathpix/ | 2018-10-29T22:27:15 | [
"LaTeX"
] | https://linux.cn/article-10172-1.html |
>
> Mathpix 是一个漂亮的小工具,它允许你截取复杂数学方程式的截图,并立即将其转换为 LaTeX 可编辑文本。
>
>
>

[LaTeX 编辑器](https://itsfoss.com/latex-editors-linux/)在撰写学术和科学文献时非常出色。
当然它还有一个陡峭的学习曲线。如果你不得不要写复杂的数学方程式,这种学习曲线会变得更加陡峭。
[Mathpix](https://mathpix.com/) 是一个在这方面可以帮助你的小工具。
假设你正在阅读带有数学方程式的文档。如果你想在 [LaTeX 文档](https://www.latex-project.org/)中使用这些方程,你需要使用你的 LaTeX 技能,并且得有充足的时间。
但是 Mathpix 为您解决了这个问题。使用 Mathpix,你可以截取数学方程式的截图,它会立即为你提供 LaTeX 代码。然后,你可以在你[最喜欢的 LaTeX 编辑器](https://itsfoss.com/latex-editors-linux/)中使用此代码。
请参阅[该视频](https://itsfoss.com/wp-content/uploads/2018/10/mathpix.mp4)中的 Mathpix 使用方式。
*[视频来源](https://g.redditmedia.com/b-GL1rQwNezQjGvdlov9U_6vDwb1A7kEwGHYcQ1Ogtg.gif?fm=mp4&mp4-fragmented=false&s=39fd1816b43e2b544986d629f75a7a8e):Reddit 用户 [kaitlinmcunningham](https://www.reddit.com/user/kaitlinmcunningham)*
不是超酷吗?我想编写 LaTeX 文档最困难的部分是那些复杂的方程式。对于像我这样懒人,Mathpix 是天赐之物。
### 获取 Mathpix
Mathpix 适用于 Linux、macOS、Windows 和 iOS。暂时还没有 Android 应用。
注意:Mathpix 是一个免费使用的工具,但它不是开源的。
在 Linux 上,[Mathpix 有一个 Snap 包](https://snapcraft.io/mathpix-snipping-tool)。这意味着[如果你在 Linux 发行版上启用了 Snap 支持](https://itsfoss.com/install-snap-linux/),你可以用这个简单命令安装 Mathpix:
```
sudo snap install mathpix-snipping-tool
```
使用 Mathpix 很简单。安装后,打开该工具。你会在顶部面板中找到它。你可以使用键盘快捷键 `Ctrl+Alt+M` 开始使用 Mathpix 截图。
它会立即将方程图片转换为 LaTeX 代码。代码将被复制到剪贴板中,然后你可以将其粘贴到 LaTeX 编辑器中。
Mathpix 的光学字符识别技术[正在被](https://mathpix.com/api.html)像 [WolframAlpha](https://www.wolframalpha.com/)、微软、谷歌等许多公司用于在处理数学符号时提升工具的图像识别能力。
总而言之,它对学生和学者来说是一个很棒的工具。它是免费使用的,我非常希望它是一个开源工具。但我们无法在生活中得到一切,不是么?
在 LaTeX 中处理数学符号时,你是否使用 Mathpix 或其他类似工具?你如何看待 Mathpix?在评论区与我们分享你的观点。
---
via: <https://itsfoss.com/mathpix/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Mathpix is a nifty little tool that allows you to take screenshots of complex mathematical equations and instantly converts it into LaTeX editable text.**
[LaTeX editors](https://itsfoss.com/latex-editors-linux/) are excellent when it comes to
There is a steep learning curved involved of course. And this learning curve becomes
[Mathpix](https://mathpix.com/) is a nifty little tool that helps you in this regard.
Suppose you are reading a document that has mathematical equations. If you want to use those equations in your [LaTeX document](https://www.latex-project.org/), you need to use your ninja LaTeX skills and plenty of time.
But Mathpix solves this problem for you. With Mathpix, you take the screenshot of the mathematical equations, and it will instantly give you the LaTeX code. You can then use this code in your [favorite LaTeX editor](https://itsfoss.com/latex-editors-linux/).
See Mathpix in action in the video below:
[Video credit](https://g.redditmedia.com/b-GL1rQwNezQjGvdlov9U_6vDwb1A7kEwGHYcQ1Ogtg.gif?fm=mp4&mp4-fragmented=false&s=39fd1816b43e2b544986d629f75a7a8e): Reddit User
[kaitlinmcunningham](https://www.reddit.com/user/kaitlinmcunningham)
Isn’t it super-cool? I guess the hardest part of writing LaTeX documents are those complicated equations. For
## Getting Mathpix
Mathpix is available for Linux, macOS, Windows and iOS. There is no Android app for the moment.
Note: Mathpix is a free to use tool but it’s not open source.
On Linux, [Mathpix is available as a Snap package](https://snapcraft.io/mathpix-snipping-tool). Which means [if you have Snap support enabled on your Linux distribution](https://itsfoss.com/install-snap-linux/), you can install Mathpix with this simple command:
`sudo snap install mathpix-snipping-tool`
Using Mathpix is simple. Once installed, open the tool. You’ll find it in the top panel. You can start taking the screenshot with Mathpix using the keyboard shortcut Ctrl+Alt+M.
It will instantly translate the image of equation into a LaTeX code. The code will be copied into clipboard and you can then paste it in a LaTeX editor.
Mathpix’s optical character recognition technology is [ being used](https://mathpix.com/api.html) by
[WolframAlpha](https://www.wolframalpha.com/), Microsoft, Google, etc. to improve their tools’ image recognition capability while dealing with math symbols.
Altogether, it’s an awesome
Do you use Mathpix or some other similar tool while dealing with mathematical symbols in LaTeX? What do you think of Mathpix? Share your views with us in the comment section. |
10,173 | 理解 Linux 链接(一) | https://www.linux.com/blog/intro-to-linux/2018/10/linux-links-part-1 | 2018-10-30T23:56:00 | [
"链接"
] | https://linux.cn/article-10173-1.html |
>
> 链接是可以将文件和目录放在你希望它们放在的位置的另一种方式。
>
>
>

除了 `cp` 和 `mv` 这两个我们在[本系列的前一部分](https://www.linux.com/blog/2018/8/linux-beginners-moving-things-around)中详细讨论过的,链接是可以将文件和目录放在你希望它们放在的位置的另一种方式。它的优点是可以让你同时在多个位置显示一个文件或目录。
如前所述,在物理磁盘这个级别上,文件和目录之类的东西并不真正存在。文件系统是为了方便人类使用,将它们虚构出来。但在磁盘级别上,有一个名为<ruby> 分区表 <rt> partition table </rt></ruby>的东西,它位于每个分区的开头,然后数据分散在磁盘的其余部分。
虽然有不同类型的分区表,但是在分区开头的那个表包含的数据将映射每个目录和文件的开始和结束位置。分区表的就像一个索引:当从磁盘加载文件时,操作系统会查找表中的条目,分区表会告诉文件在磁盘上的起始位置和结束位置。然后磁盘头移动到起点,读取数据,直到它到达终点,您看:这就是你的文件。
### 硬链接
硬链接只是分区表中的一个条目,它指向磁盘上的某个区域,表示该区域**已经被分配给文件**。换句话说,硬链接指向已经被另一个条目索引的数据。让我们看看它是如何工作的。
打开终端,创建一个实验目录并进入:
```
mkdir test_dir
cd test_dir
```
使用 [touch](https://www.linux.com/blog/2018/8/linux-beginners-moving-things-around) 创建一个文件:
```
touch test.txt
```
为了获得更多的体验(?),在文本编辑器中打开 `test.txt` 并添加一些单词。
现在通过执行以下命令来建立硬链接:
```
ln test.txt hardlink_test.txt
```
运行 `ls`,你会看到你的目录现在包含两个文件,或者看起来如此。正如你之前读到的那样,你真正看到的是完全相同的文件的两个名称: `hardlink_test.txt` 包含相同的内容,没有填充磁盘中的任何更多空间(可以尝试使用大文件来测试),并与 `test.txt` 使用相同的 inode:
```
$ ls -li *test*
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 hardlink_test.txt
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 test.txt
```
`ls` 的 `-i` 选项显示一个文件的 “inode 数值”。“inode” 是分区表中的信息块,它包含磁盘上文件或目录的位置、上次修改的时间以及其它数据。如果两个文件使用相同的 inode,那么无论它们在目录树中的位置如何,它们在实际上都是相同的文件。
### 软链接
软链接,也称为<ruby> 符号链接 <rt> symlink </rt></ruby>,它与硬链接是不同的:软链接实际上是一个独立的文件,它有自己的 inode 和它自己在磁盘上的小块地方。但它只包含一小段数据,将操作系统指向另一个文件或目录。
你可以使用 `ln` 的 `-s` 选项来创建一个软链接:
```
ln -s test.txt softlink_test.txt
```
这将在当前目录中创建软链接 `softlink_test.txt`,它指向 `test.txt`。
再次执行 `ls -li`,你可以看到两种链接的不同之处:
```
$ ls -li
total 8
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 hardlink_test.txt
16515855 lrwxrwxrwx 1 paul paul 8 oct 12 09:50 softlink_test.txt -> test.txt
16515846 -rw-r--r-- 2 paul paul 14 oct 12 09:50 test.txt
```
`hardlink_test.txt` 和 `test.txt` 包含一些文本并且*字面上*占据相同的空间。它们使用相同的 inode 数值。与此同时,`softlink_test.txt` 占用少得多,并且具有不同的 inode 数值,将其标记为完全不同的文件。使用 `ls` 的 `-l` 选项还会显示软链接指向的文件或目录。
### 为什么要用链接?
它们适用于**带有自己环境的应用程序**。你的 Linux 发行版通常不会附带你需要应用程序的最新版本。以优秀的 [Blender 3D](https://www.blender.org/) 设计软件为例,Blender 允许你创建 3D 静态图像以及动画电影,人人都想在自己的机器上拥有它。问题是,当前版本的 Blender 至少比任何发行版中的自带的高一个版本。
幸运的是,[Blender 提供可以开箱即用的下载](https://www.blender.org/download/)。除了程序本身之外,这些软件包还包含了 Blender 需要运行的复杂的库和依赖框架。所有这些数据和块都在它们自己的目录层次中。
每次你想运行 Blender,你都可以 `cd` 到你下载它的文件夹并运行:
```
./blender
```
但这很不方便。如果你可以从文件系统的任何地方,比如桌面命令启动器中运行 `blender` 命令会更好。
这样做的方法是将 `blender` 可执行文件链接到 `bin/` 目录。在许多系统上,你可以通过将其链接到文件系统中的任何位置来使 `blender` 命令可用,就像这样。
```
ln -s /path/to/blender_directory/blender /home/<username>/bin
```
你需要链接的另一个情况是**软件需要过时的库**。如果你用 `ls -l` 列出你的 `/usr/lib` 目录,你会看到许多软链接文件一闪而过。仔细看看,你会看到软链接通常与它们链接到的原始文件具有相似的名称。你可能会看到 `libblah` 链接到 `libblah.so.2`,你甚至可能会注意到 `libblah.so.2` 相应链接到原始文件 `libblah.so.2.1.0`。
这是因为应用程序通常需要安装比已安装版本更老的库。问题是,即使新版本仍然与旧版本(通常是)兼容,如果程序找不到它正在寻找的版本,程序将会出现问题。为了解决这个问题,发行版通常会创建链接,以便挑剔的应用程序**相信**它找到了旧版本,实际上它只找到了一个链接并最终使用了更新的库版本。
有些是和**你自己从源代码编译的程序**相关。你自己编译的程序通常最终安装在 `/usr/local` 下,程序本身最终在 `/usr/local/bin` 中,它在 `/usr/local/bin` 目录中查找它需要的库。但假设你的新程序需要 `libblah`,但 `libblah` 在 `/usr/lib` 中,这就是所有其它程序都会寻找到它的地方。你可以通过执行以下操作将其链接到 `/usr/local/lib`:
```
ln -s /usr/lib/libblah /usr/local/lib
```
或者如果你愿意,可以 `cd` 到 `/usr/local/lib`:
```
cd /usr/local/lib
```
然后使用链接:
```
ln -s ../lib/libblah
```
还有几十个案例证明软链接是有用的,当你使用 Linux 更熟练时,你肯定会发现它们,但这些是最常见的。下一次,我们将看一些你需要注意的链接怪异。
通过 Linux 基金会和 edX 的免费 [“Linux 简介”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)课程了解有关 Linux 的更多信息。
---
via: <https://www.linux.com/blog/intro-to-linux/2018/10/linux-links-part-1>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,174 | 如何在 Linux 中一次重命名多个文件 | https://www.ostechnix.com/how-to-rename-multiple-files-at-once-in-linux/ | 2018-10-31T09:27:56 | [
"mmv",
"mv"
] | https://linux.cn/article-10174-1.html | 
你可能已经知道,我们使用 `mv` 命令在类 Unix 操作系统中重命名或者移动文件和目录。 但是,`mv` 命令不支持一次重命名多个文件。 不用担心。 在本教程中,我们将学习使用 Linux 中的 `mmv` 命令一次重命名多个文件。 此命令用于在类 Unix 操作系统中使用标准通配符批量移动、复制、追加和重命名文件。
### 在 Linux 中一次重命名多个文件
`mmv` 程序可在基于 Debian 的系统的默认仓库中使用。 要想在 Debian、Ubuntu、Linux Mint 上安装它,请运行以下命令:
```
$ sudo apt-get install mmv
```
我们假设你在当前目录中有以下文件。
```
$ ls
a1.txt a2.txt a3.txt
```
现在,你想要将所有以字母 “a” 开头的文件重命名为以 “b” 开头的。 当然,你可以在几秒钟内手动执行此操作。 但是想想你是否有数百个文件想要重命名? 这是一个非常耗时的过程。 这时候 `mmv` 命令就很有帮助了。
要将所有以字母 “a” 开头的文件重命名为以字母 “b” 开头的,只需要运行:
```
$ mmv a\* b\#1
```
让我们检查一下文件是否都已经重命名了。
```
$ ls
b1.txt b2.txt b3.txt
```
如你所见,所有以字母 “a” 开头的文件(即 `a1.txt`、`a2.txt`、`a3.txt`)都重命名为 `b1.txt`、`b2.txt`、`b3.txt`。
**解释**
在上面的例子中,第一个参数(`a\*`)是 “from” 模式,第二个参数是 “to” 模式(`b\#1`)。根据上面的例子,`mmv` 将查找任何以字母 “a” 开头的文件名,并根据第二个参数重命名匹配的文件,即 “to” 模式。我们可以使用通配符,例如用 `*`、`?` 和 `[]` 来匹配一个或多个任意字符。请注意,你必须转义使用通配符,否则它们将被 shell 扩展,`mmv` 将无法理解。
“to” 模式中的 `#1` 是通配符索引。它匹配 “from” 模式中的第一个通配符。 “to” 模式中的 `#2` 将匹配第二个通配符(如果有的话),依此类推。在我们的例子中,我们只有一个通配符(星号),所以我们写了一个 `#1`。并且,`#` 符号也应该被转义。此外,你也可以用引号括起模式。
你甚至可以将具有特定扩展名的所有文件重命名为其他扩展名。例如,要将当前目录中的所有 `.txt` 文件重命名为 `.doc` 文件格式,只需运行:
```
$ mmv \*.txt \#1.doc
```
这是另一个例子。 我们假设你有以下文件。
```
$ ls
abcd1.txt abcd2.txt abcd3.txt
```
你希望在当前目录下的所有文件中将第一次出现的 “abc” 替换为 “xyz”。 你会怎么做呢?
很简单。
```
$ mmv '*abc*' '#1xyz#2'
```
请注意,在上面的示例中,模式被单引号括起来了。
让我们检查下 “abc” 是否实际上被替换为 “xyz”。
```
$ ls
xyzd1.txt xyzd2.txt xyzd3.txt
```
看到没? 文件 `abcd1.txt`、`abcd2.txt` 和 `abcd3.txt` 已经重命名为 `xyzd1.txt`、`xyzd2.txt` 和 `xyzd3.txt`。
`mmv` 命令的另一个值得注意的功能是你可以使用 `-n` 选项打印输出而不是重命名文件,如下所示。
```
$ mmv -n a\* b\#1
a1.txt -> b1.txt
a2.txt -> b2.txt
a3.txt -> b3.txt
```
这样,你可以在重命名文件之前简单地验证 `mmv` 命令实际执行的操作。
有关更多详细信息,请参阅 man 页面。
```
$ man mmv
```
### 更新:Thunar 文件管理器
**Thunar 文件管理器**默认具有内置**批量重命名**选项。 如果你正在使用 Thunar,那么重命名文件要比使用 `mmv` 命令容易得多。
Thunar 在大多数 Linux 发行版的默认仓库库中都可用。
要在基于 Arch 的系统上安装它,请运行:
```
$ sudo pacman -S thunar
```
在 RHEL、CentOS 上:
```
$ sudo yum install thunar
```
在 Fedora 上:
```
$ sudo dnf install thunar
```
在 openSUSE 上:
```
$ sudo zypper install thunar
```
在 Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt-get install thunar
```
安装后,你可以从菜单或应用程序启动器中启动批量重命名程序。 要从终端启动它,请使用以下命令:
```
$ thunar -B
```
批量重命名方式如下。

单击“+”,然后选择要重命名的文件列表。 批量重命名可以重命名文件的名称、文件的后缀或者同时重命名文件的名称和后缀。 Thunar 目前支持以下批量重命名:
* 插入日期或时间
* 插入或覆盖
* 编号
* 删除字符
* 搜索和替换
* 大写或小写
当你从选项列表中选择其中一个条件时,你将在“新名称”列中看到更改的预览,如下面的屏幕截图所示。

选择条件后,单击“重命名文件”选项来重命名文件。
你还可以通过选择两个或更多文件从 Thunar 中打开批量重命名器。 选择文件后,按 F2 或右键单击并选择“重命名”。
嗯,这就是本次的所有内容了。希望有所帮助。更多干货即将到来。敬请关注!
祝快乐!
---
via: <https://www.ostechnix.com/how-to-rename-multiple-files-at-once-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,175 | MidnightBSD 发布 1.0! | https://itsfoss.com/midnightbsd-1-0-release/ | 2018-10-31T09:38:05 | [
"BSD"
] | https://linux.cn/article-10175-1.html | 几天前,Lucas Holt 宣布发布 MidnightBSD 1.0。让我们快速看一下这个新版本中包含的内容。
### 什么是 MidnightBSD?

[MidnightBSD](https://www.midnightbsd.org/) 是 FreeBSD 的一个分支。Lucas 创建了 MightnightBSD,这成为桌面用户和 BSD 新手的一个选择。他想创造一个能让人们快速体验 BSD 桌面的东西。他认为其他发行版过于关注服务器市场。
### MidnightBSD 1.0 中有什么?
根据[发布说明](https://www.midnightbsd.org/notes/)([视频](https://www.youtube.com/embed/-rlk2wFsjJ4)),1.0 中的大部分工作都是更新基础系统,改进包管理器和更新工具。新版本与 FreeBSD 10-Stable 兼容。
Mports(MidnightBSD 的包管理系统)已经升级支持使用一个命令安装多个包。`mport upgrade` 命令已经修复。Mports 现在会跟踪已弃用和过期的包。它还引入了新的包格式。
其他变化包括:
* 现在支持 [ZFS](https://itsfoss.com/what-is-zfs/) 作为启动文件系统。以前,ZFS 只能用于附加存储。 \* 支持 NVME SSD。 \* AMD Ryzen 和 Radeon 的支持得到了改善。 \* Intel、Broadcom 和其他驱动程序已更新。 \* 已从 FreeBSD 移植 bhyve 支持。 \* 传感器框架已被删除,因为它导致锁定问题。 \* 删除了 Sudo 并用 OpenBSD 中的 [doas](https://man.openbsd.org/doas) 替换。 \* 增加了对 Microsoft hyper-v 的支持。
### 升级之前
如果你当前是 MidnightBSD 的用户或正在考虑尝试新版本,那么还是再等一会。Lucas 目前正在重建软件包以支持新的软件包格式和工具。他还计划在未来几个月内升级软件包和移植桌面环境。他目前正致力于移植 Firefox 52 ESR,因为它是最后一个不需要 Rust 的版本。他还希望将更新版本的 Chromium 移植到 MidnightBSD。我建议关注 MidnightBSD 的 [Twitter](https://twitter.com/midnightbsd)。
### 0.9 怎么回事?
你可能注意到 MidnightBSD 的先前版本是 0.8.6。你现在可能想知道“为什么跳到 1.0”?根据 Lucas 的说法,他在开发 0.9 时遇到了几个问题。事实上,他重试好几次。他最终采用与 0.9 分支不同的方式,并变成了 1.0。有些软件包在 0.\* 系列也有问题。
### 需要帮助
目前,MidnightBSD 项目几乎是 Lucas Holt 一个人的作品。这是其发展缓慢的主要原因。如果你有兴趣帮忙,可以通过 [Twitter](https://twitter.com/midnightbsd) 与他联系。
在[发布公告视频](https://www.youtube.com/watch?v=-rlk2wFsjJ4)中。Lucas 说他遇到了上游项目接受补丁的问题。他们似乎认为 MidnightBSD 太小了。这通常意味着他必须从头开始移植应用。
### 想法
我对劣势者有一个想法。在我接触的所有 BSD 中,这个外号最适合 MidnightBSD。一个人想要创建一个轻松的桌面体验。当前只有一个其他的 BSD 在尝试做相似的事情:Project Trident。我想这是 BSD 成功的真正的阻碍。Linux 成功是因为人们可以快速容易地安装它。希望 MidnightBSD 为 BSD 做到这一点,但是还有很长的路要走。
你有没有用过 MidnightBSD?如果没有,你最喜欢的 BSD 是什么?我们应该涵盖哪些其他 BSD 主题?请在下面的评论中告诉我们。
如果你觉得这篇文章有趣,请花一点时间在社交媒体,Hacker News 或 [Reddit](http://reddit.com/r/linuxusersgroup) 上分享它。
---
via: <https://itsfoss.com/midnightbsd-1-0-release/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A couple days ago, Lucas Holt announced the release of MidnightBSD 1.0. Let’s take a quick look at what is included in this new release.
## What is MidnightBSD?

[MidnightBSD](https://www.midnightbsd.org/) is a fork of FreeBSD. Lucas created MightnightBSD to be an option for desktop users and for BSD newbies. He wanted to create something that would allow people to quickly get a desktop experience on BSD. He believed that other options had too much of a focus on the server market.
## What is in MidnightBSD 1.0?
According to the [release notes](https://www.midnightbsd.org/notes/), most of the work in 1.0 went towards updating the base system, improving the package manager and updating tools. The new release is compatible with FreeBSD 10-Stable.
Mports (MidnightBSD’s package management system) has been upgraded to support installing multiple packages with one command. The `mport upgrade`
command has been fixed. Mports now tracks deprecated and expired packages. A new package format was also introduced.
Other changes include:
[ZFS](https://itsfoss.com/what-is-zfs/)is now supported as a boot file system. Previously, ZFS could only be used for additional storage.- Support for NVME SSDs
- AMD Ryzen and Radeon support have been improved.
- Intel, Broadcom, and other drivers updated.
- bhyve support has been ported from FreeBSD
- The sensors framework was removed because it was causing locking issues.
- Sudo was removed and replaced with
[doas](https://man.openbsd.org/doas)from OpenBSD. - Added support for Microsoft hyper-v
[irp posts=27379]
## Before you upgrade…
If you are a current MidnightBSD user or are thinking of trying out the new release, it would be a good idea to wait. Lucas is currently rebuilding packages to support the new package format and tooling. He also plans to upgrade packages and ports for the desktop environment over the next couple of months. He is currently working on porting Firefox 52 ESR because it is the last release that does not require Rust. He also hopes to get a newer version of Chromium ported to MidnightBSD. I would recommend keeping an eye on the MidnightBSD [Twi](https://twitter.com/midnightbsd)[t](https://twitter.com/midnightbsd)[ter](https://twitter.com/midnightbsd) feed.
## What happened to 0.9?
You might notice that the previous release of MidnightBSD was 0.8.6. Now, you might be wondering “Why the jump to 1.0”? According to Lucas, he ran into several issues while developing 0.9. In fact, he restarted it several times. He ending up taking CURRENT in a different direction than the 0.9 branch and it became 1.0. Some packages also had an issue with the 0.* numbering system.
## Help Needed
Currently, the MidnightBSD project is the work of pretty much one guy, Lucas Holt. This is the main reason why development has been slow. If you are interested in helping out, you can contact him on [Twitter](https://twitter.com/midnightbsd).
In the [release announcement video](https://www.youtube.com/watch?v=-rlk2wFsjJ4). Lucas said that he had encountered problems with upstream projects accepting patches. They seem to think that MidnightBSD is too small. This often means that he has to port an application from scratch.
## Thoughts
I have a thing for the underdog. Of all the BSDs that I have interacted with, that monicker fits MidnightBSD the most. One guy trying to create an easy desktop experience. Currently, there is only one other BSD trying to do something similar: Project Trident. I think that this is a real barrier to BSDs success. Linux succeeds because people can quickly and easily install it. Hopefully, MidnightBSD does that for BSD, but right now it has a long way to go.
Have you ever used MidnightBSD? If not, what is your favorite BSD? What other BSD topics should we cover? Let us know in the comments below.
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit](http://reddit.com/r/linuxusersgroup). |
10,176 | 用 350 行代码从零开始,将 Lisp 编译成 JavaScript | https://gilmi.me/blog/post/2016/10/14/lisp-to-js | 2018-10-31T10:18:10 | [
"编译器"
] | https://linux.cn/article-10176-1.html | 
我们将会在本篇文章中看到从零开始实现的编译器,将简单的类 LISP 计算语言编译成 JavaScript。完整的源代码在 [这里](https://gist.github.com/soupi/d4ff0727ccb739045fad6cdf533ca7dd)。
我们将会:
1. 自定义语言,并用它编写一个简单的程序
2. 实现一个简单的解析器组合器
3. 为该语言实现一个解析器
4. 为该语言实现一个美观的打印器
5. 为我们的用途定义 JavaScript 的一个子集
6. 实现代码转译器,将代码转译成我们定义的 JavaScript 子集
7. 把所有东西整合在一起
开始吧!
### 1、定义语言
Lisp 族语言最迷人的地方在于,它们的语法就是树状表示的,这就是这门语言很容易解析的原因。我们很快就能接触到它。但首先让我们把自己的语言定义好。关于我们语言的语法的范式(BNF)描述如下:
```
program ::= expr
expr ::= <integer> | <name> | ([<expr>])
```
基本上,我们可以在该语言的最顶层定义表达式并对其进行运算。表达式由一个整数(比如 `5`)、一个变量(比如 `x`)或者一个表达式列表(比如 `(add x 1)`)组成。
整数对应它本身的值,变量对应它在当前环境中绑定的值,表达式列表对应一个函数调用,该列表的第一个参数是相应的函数,剩下的表达式是传递给这个函数的参数。
该语言中,我们保留一些内建的特殊形式,这样我们就能做一些更有意思的事情:
* `let` 表达式使我们可以在它的 `body` 环境中引入新的变量。语法如下:
```
let ::= (let ([<letarg>]) <body>)
letargs ::= (<name> <expr>)
body ::= <expr>
```
* `lambda` 表达式:也就是匿名函数定义。语法如下:
```
lambda ::= (lambda ([<name>]) <body>)
```
还有一些内建函数: `add`、`mul`、`sub`、`div` 和 `print`。
让我们看看用我们这门语言编写的入门示例程序:
```
(let
((compose
(lambda (f g)
(lambda (x) (f (g x)))))
(square
(lambda (x) (mul x x)))
(add1
(lambda (x) (add x 1))))
(print ((compose square add1) 5)))
```
这个程序定义了 3 个函数:`compose`、`square` 和 `add1`。然后将计算结果的值 `((compose square add1) 5)` 输出出来。
我相信了解这门语言,这些信息就足够了。开始实现它吧。
在 Haskell 中,我们可以这样定义语言:
```
type Name = String
data Expr
= ATOM Atom
| LIST [Expr]
deriving (Eq, Read, Show)
data Atom
= Int Int
| Symbol Name
deriving (Eq, Read, Show)
```
我们可以解析用该语言用 `Expr` 定义的程序。而且,这里我们添加了新数据类型 `Eq`、`Read` 和 `Show` 等实例用于测试和调试。你能够在 REPL 中使用这些数据类型,验证它们确实有用。
我们不在语法中定义 `lambda`、`let` 或其它的内建函数,原因在于,当前情况下我们没必要用到这些东西。这些函数仅仅是 `LIST` (表达式列表)的更加特殊的用例。所以我决定将它放到后面的部分。
一般来说你想要在抽象语法中定义这些特殊用例 —— 用于改进错误信息、禁用静态分析和优化等等,但在这里我们不会这样做,对我们来说这些已经足够了。
另一件你想做的事情可能是在语法中添加一些注释信息。比如定位:`Expr` 是来自哪个文件的,具体到这个文件的哪一行哪一列。你可以在后面的阶段中使用这一特性,打印出错误定位,即使它们不是处于解析阶段。
* 练习 1:添加一个 `Program` 数据类型,可以按顺序包含多个 `Expr`
* 练习 2:向语法树中添加一个定位注解。
### 2、实现一个简单的解析器组合库
我们要做的第一件事情是定义一个<ruby> 嵌入式领域专用语言 <rt> Embedded Domain Specific Language </rt></ruby>(EDSL),我们会用它来定义我们的语言解析器。这常常被称为解析器组合库。我们做这件事完全是出于学习的目的,Haskell 里有很好的解析库,在实际构建软件或者进行实验时,你应该使用它们。[megaparsec](https://mrkkrp.github.io/megaparsec/) 就是这样的一个库。
首先我们来谈谈解析库的实现的思路。本质上,我们的解析器就是一个函数,接受一些输入,可能会读取输入的一些或全部内容,然后返回解析出来的值和无法解析的输入部分,或者在解析失败时抛出异常。我们把它写出来。
```
newtype Parser a
= Parser (ParseString -> Either ParseError (a, ParseString))
data ParseString
= ParseString Name (Int, Int) String
data ParseError
= ParseError ParseString Error
type Error = String
```
这里我们定义了三个主要的新类型。
第一个,`Parser a` 是之前讨论的解析函数。
第二个,`ParseString` 是我们的输入或携带的状态。它有三个重要的部分:
* `Name`: 这是源的名字
* `(Int, Int)`: 这是源的当前位置
* `String`: 这是等待解析的字符串
第三个,`ParseError` 包含了解析器的当前状态和一个错误信息。
现在我们想让这个解析器更灵活,我们将会定义一些常用类型的实例。这些实例让我们能够将小巧的解析器和复杂的解析器结合在一起(因此它的名字叫做 “解析器组合器”)。
第一个是 `Functor` 实例。我们需要 `Functor` 实例,因为我们要能够对解析值应用函数从而使用不同的解析器。当我们定义自己语言的解析器时,我们将会看到关于它的示例。
```
instance Functor Parser where
fmap f (Parser parser) =
Parser (\str -> first f <$> parser str)
```
第二个是 `Applicative` 实例。该实例的常见用例是在多个解析器中实现一个纯函数。
```
instance Applicative Parser where
pure x = Parser (\str -> Right (x, str))
(Parser p1) <*> (Parser p2) =
Parser $
\str -> do
(f, rest) <- p1 str
(x, rest') <- p2 rest
pure (f x, rest')
```
(注意:我们还会实现一个 Monad 实例,这样我们才能使用符号)
第三个是 `Alternative` 实例。万一前面的解析器解析失败了,我们要能够提供一个备用的解析器。
```
instance Alternative Parser where
empty = Parser (`throwErr` "Failed consuming input")
(Parser p1) <|> (Parser p2) =
Parser $
\pstr -> case p1 pstr of
Right result -> Right result
Left _ -> p2 pstr
```
第四个是 `Monad` 实例。这样我们就能链接解析器。
```
instance Monad Parser where
(Parser p1) >>= f =
Parser $
\str -> case p1 str of
Left err -> Left err
Right (rs, rest) ->
case f rs of
Parser parser -> parser rest
```
接下来,让我们定义一种的方式,用于运行解析器和防止失败的助手函数:
```
runParser :: String -> String -> Parser a -> Either ParseError (a, ParseString)
runParser name str (Parser parser) = parser $ ParseString name (0,0) str
throwErr :: ParseString -> String -> Either ParseError a
throwErr ps@(ParseString name (row,col) _) errMsg =
Left $ ParseError ps $ unlines
[ "*** " ++ name ++ ": " ++ errMsg
, "* On row " ++ show row ++ ", column " ++ show col ++ "."
]
```
现在我们将会开始实现组合器,这是 EDSL 的 API,也是它的核心。
首先,我们会定义 `oneOf`。如果输入列表中的字符后面还有字符的话,`oneOf` 将会成功,否则就会失败。
```
oneOf :: [Char] -> Parser Char
oneOf chars =
Parser $ \case
ps@(ParseString name (row, col) str) ->
case str of
[] -> throwErr ps "Cannot read character of empty string"
(c:cs) ->
if c `elem` chars
then Right (c, ParseString name (row, col+1) cs)
else throwErr ps $ unlines ["Unexpected character " ++ [c], "Expecting one of: " ++ show chars]
```
`optional` 将会抛出异常,停止解析器。失败时它仅仅会返回 `Nothing`。
```
optional :: Parser a -> Parser (Maybe a)
optional (Parser parser) =
Parser $
\pstr -> case parser pstr of
Left _ -> Right (Nothing, pstr)
Right (x, rest) -> Right (Just x, rest)
```
`many` 将会试着重复运行解析器,直到失败。当它完成的时候,会返回成功运行的解析器列表。`many1` 做的事情是一样的,但解析失败时它至少会抛出一次异常。
```
many :: Parser a -> Parser [a]
many parser = go []
where go cs = (parser >>= \c -> go (c:cs)) <|> pure (reverse cs)
many1 :: Parser a -> Parser [a]
many1 parser =
(:) <$> parser <*> many parser
```
下面的这些解析器通过我们定义的组合器来实现一些特殊的解析器:
```
char :: Char -> Parser Char
char c = oneOf [c]
string :: String -> Parser String
string = traverse char
space :: Parser Char
space = oneOf " \n"
spaces :: Parser String
spaces = many space
spaces1 :: Parser String
spaces1 = many1 space
withSpaces :: Parser a -> Parser a
withSpaces parser =
spaces *> parser <* spaces
parens :: Parser a -> Parser a
parens parser =
(withSpaces $ char '(')
*> withSpaces parser
<* (spaces *> char ')')
sepBy :: Parser a -> Parser b -> Parser [b]
sepBy sep parser = do
frst <- optional parser
rest <- many (sep *> parser)
pure $ maybe rest (:rest) frst
```
现在为该门语言定义解析器所需要的所有东西都有了。
* 练习 :实现一个 EOF(end of file/input,即文件或输入终止符)解析器组合器。
### 3、为我们的语言实现解析器
我们会用自顶而下的方法定义解析器。
```
parseExpr :: Parser Expr
parseExpr = fmap ATOM parseAtom <|> fmap LIST parseList
parseList :: Parser [Expr]
parseList = parens $ sepBy spaces1 parseExpr
parseAtom :: Parser Atom
parseAtom = parseSymbol <|> parseInt
parseSymbol :: Parser Atom
parseSymbol = fmap Symbol parseName
```
注意到这四个函数是在我们这门语言中属于高阶描述。这解释了为什么 Haskell 执行解析工作这么棒。在定义完高级部分后,我们还需要定义低级别的 `parseName` 和 `parseInt`。
我们能在这门语言中用什么字符作为名字呢?用小写的字母、数字和下划线吧,而且名字的第一个字符必须是字母。
```
parseName :: Parser Name
parseName = do
c <- oneOf ['a'..'z']
cs <- many $ oneOf $ ['a'..'z'] ++ "0123456789" ++ "_"
pure (c:cs)
```
整数是一系列数字,数字前面可能有负号 `-`:
```
parseInt :: Parser Atom
parseInt = do
sign <- optional $ char '-'
num <- many1 $ oneOf "0123456789"
let result = read $ maybe num (:num) sign of
pure $ Int result
```
最后,我们会定义用来运行解析器的函数,返回值可能是一个 `Expr` 或者是一条错误信息。
```
runExprParser :: Name -> String -> Either String Expr
runExprParser name str =
case runParser name str (withSpaces parseExpr) of
Left (ParseError _ errMsg) -> Left errMsg
Right (result, _) -> Right result
```
* 练习 1 :为第一节中定义的 `Program` 类型编写一个解析器
* 练习 2 :用 Applicative 的形式重写 `parseName`
* 练习 3 :`parseInt` 可能出现溢出情况,找到处理它的方法,不要用 `read`。
### 4、为这门语言实现一个更好看的输出器
我们还想做一件事,将我们的程序以源代码的形式打印出来。这对完善错误信息很有用。
```
printExpr :: Expr -> String
printExpr = printExpr' False 0
printAtom :: Atom -> String
printAtom = \case
Symbol s -> s
Int i -> show i
printExpr' :: Bool -> Int -> Expr -> String
printExpr' doindent level = \case
ATOM a -> indent (bool 0 level doindent) (printAtom a)
LIST (e:es) ->
indent (bool 0 level doindent) $
concat
[ "("
, printExpr' False (level + 1) e
, bool "\n" "" (null es)
, intercalate "\n" $ map (printExpr' True (level + 1)) es
, ")"
]
indent :: Int -> String -> String
indent tabs e = concat (replicate tabs " ") ++ e
```
* 练习 :为第一节中定义的 `Program` 类型编写一个美观的输出器
好,目前为止我们写了近 200 行代码,这些代码一般叫做编译器的前端。我们还要写大概 150 行代码,用来执行三个额外的任务:我们需要根据需求定义一个 JS 的子集,定义一个将我们的语言转译成这个子集的转译器,最后把所有东西整合在一起。开始吧。
### 5、根据需求定义 JavaScript 的子集
首先,我们要定义将要使用的 JavaScript 的子集:
```
data JSExpr
= JSInt Int
| JSSymbol Name
| JSBinOp JSBinOp JSExpr JSExpr
| JSLambda [Name] JSExpr
| JSFunCall JSExpr [JSExpr]
| JSReturn JSExpr
deriving (Eq, Show, Read)
type JSBinOp = String
```
这个数据类型表示 JavaScript 表达式。我们有两个原子类型 `JSInt` 和 `JSSymbol`,它们是由我们这个语言中的 `Atom` 转译来的,我们用 `JSBinOp` 来表示二元操作,比如 `+` 或 `*`,用 `JSLambda` 来表示匿名函数,和我们语言中的 `lambda expression(lambda 表达式)` 一样,我们将会用 `JSFunCall` 来调用函数,用 `let` 来引入新名字,用 `JSReturn` 从函数中返回值,在 JavaScript 中是需要返回值的。
`JSExpr` 类型是对 JavaScript 表达式的 **抽象表示**。我们会把自己语言中表达式的抽象表示 `Expr` 转译成 JavaScript 表达式的抽象表示 `JSExpr`。但为了实现这个功能,我们需要实现 `JSExpr` ,并从这个抽象表示中生成 JavaScript 代码。我们将通过递归匹配 `JSExpr` 实现,将 JS 代码当作 `String` 来输出。这和我们在 `printExpr` 中做的基本上是一样的。我们还会追踪元素的作用域,这样我们才可以用合适的方式缩进生成的代码。
```
printJSOp :: JSBinOp -> String
printJSOp op = op
printJSExpr :: Bool -> Int -> JSExpr -> String
printJSExpr doindent tabs = \case
JSInt i -> show i
JSSymbol name -> name
JSLambda vars expr -> (if doindent then indent tabs else id) $ unlines
["function(" ++ intercalate ", " vars ++ ") {"
,indent (tabs+1) $ printJSExpr False (tabs+1) expr
] ++ indent tabs "}"
JSBinOp op e1 e2 -> "(" ++ printJSExpr False tabs e1 ++ " " ++ printJSOp op ++ " " ++ printJSExpr False tabs e2 ++ ")"
JSFunCall f exprs -> "(" ++ printJSExpr False tabs f ++ ")(" ++ intercalate ", " (fmap (printJSExpr False tabs) exprs) ++ ")"
JSReturn expr -> (if doindent then indent tabs else id) $ "return " ++ printJSExpr False tabs expr ++ ";"
```
* 练习 1 :添加 `JSProgram` 类型,它可以包含多个 `JSExpr` ,然后创建一个叫做 `printJSExprProgram` 的函数来生成代码。
* 练习 2 :添加 `JSExpr` 的新类型:`JSIf`,并为其生成代码。
### 6、实现到我们定义的 JavaScript 子集的代码转译器
我们快做完了。这一节将会创建函数,将 `Expr` 转译成 `JSExpr`。
基本思想很简单,我们会将 `ATOM` 转译成 `JSSymbol` 或者 `JSInt`,然后会将 `LIST` 转译成一个函数调用或者转译的特例。
```
type TransError = String
translateToJS :: Expr -> Either TransError JSExpr
translateToJS = \case
ATOM (Symbol s) -> pure $ JSSymbol s
ATOM (Int i) -> pure $ JSInt i
LIST xs -> translateList xs
translateList :: [Expr] -> Either TransError JSExpr
translateList = \case
[] -> Left "translating empty list"
ATOM (Symbol s):xs
| Just f <- lookup s builtins ->
f xs
f:xs ->
JSFunCall <$> translateToJS f <*> traverse translateToJS xs
```
`builtins` 是一系列要转译的特例,就像 `lambada` 和 `let`。每一种情况都可以获得一系列参数,验证它是否合乎语法规范,然后将其转译成等效的 `JSExpr`。
```
type Builtin = [Expr] -> Either TransError JSExpr
type Builtins = [(Name, Builtin)]
builtins :: Builtins
builtins =
[("lambda", transLambda)
,("let", transLet)
,("add", transBinOp "add" "+")
,("mul", transBinOp "mul" "*")
,("sub", transBinOp "sub" "-")
,("div", transBinOp "div" "/")
,("print", transPrint)
]
```
我们这种情况,会将内建的特殊形式当作特殊的、非第一类的进行对待,因此不可能将它们当作第一类函数。
我们会把 Lambda 表达式转译成一个匿名函数:
```
transLambda :: [Expr] -> Either TransError JSExpr
transLambda = \case
[LIST vars, body] -> do
vars' <- traverse fromSymbol vars
JSLambda vars' <$> (JSReturn <$> translateToJS body)
vars ->
Left $ unlines
["Syntax error: unexpected arguments for lambda."
,"expecting 2 arguments, the first is the list of vars and the second is the body of the lambda."
,"In expression: " ++ show (LIST $ ATOM (Symbol "lambda") : vars)
]
fromSymbol :: Expr -> Either String Name
fromSymbol (ATOM (Symbol s)) = Right s
fromSymbol e = Left $ "cannot bind value to non symbol type: " ++ show e
```
我们会将 `let` 转译成带有相关名字参数的函数定义,然后带上参数调用函数,因此会在这一作用域中引入变量:
```
transLet :: [Expr] -> Either TransError JSExpr
transLet = \case
[LIST binds, body] -> do
(vars, vals) <- letParams binds
vars' <- traverse fromSymbol vars
JSFunCall . JSLambda vars' <$> (JSReturn <$> translateToJS body) <*> traverse translateToJS vals
where
letParams :: [Expr] -> Either Error ([Expr],[Expr])
letParams = \case
[] -> pure ([],[])
LIST [x,y] : rest -> ((x:) *** (y:)) <$> letParams rest
x : _ -> Left ("Unexpected argument in let list in expression:\n" ++ printExpr x)
vars ->
Left $ unlines
["Syntax error: unexpected arguments for let."
,"expecting 2 arguments, the first is the list of var/val pairs and the second is the let body."
,"In expression:\n" ++ printExpr (LIST $ ATOM (Symbol "let") : vars)
]
```
我们会将可以在多个参数之间执行的操作符转译成一系列二元操作符。比如:`(add 1 2 3)` 将会变成 `1 + (2 + 3)`。
```
transBinOp :: Name -> Name -> [Expr] -> Either TransError JSExpr
transBinOp f _ [] = Left $ "Syntax error: '" ++ f ++ "' expected at least 1 argument, got: 0"
transBinOp _ _ [x] = translateToJS x
transBinOp _ f list = foldl1 (JSBinOp f) <$> traverse translateToJS list
```
然后我们会将 `print` 转换成对 `console.log` 的调用。
```
transPrint :: [Expr] -> Either TransError JSExpr
transPrint [expr] = JSFunCall (JSSymbol "console.log") . (:[]) <$> translateToJS expr
transPrint xs = Left $ "Syntax error. print expected 1 arguments, got: " ++ show (length xs)
```
注意,如果我们将这些代码当作 `Expr` 的特例进行解析,那我们就可能会跳过语法验证。
* 练习 1 :将 `Program` 转译成 `JSProgram`
* 练习 2 :为 `if Expr Expr Expr` 添加一个特例,并将它转译成你在上一次练习中实现的 `JSIf` 条件语句。
### 7、把所有东西整合到一起
最终,我们将会把所有东西整合到一起。我们会:
1. 读取文件
2. 将文件解析成 `Expr`
3. 将文件转译成 `JSExpr`
4. 将 JavaScript 代码发送到标准输出流
我们还会启用一些用于测试的标志位:
* `--e` 将进行解析并打印出表达式的抽象表示(`Expr`)
* `--pp` 将进行解析,美化输出
* `--jse` 将进行解析、转译、并打印出生成的 JS 表达式(`JSExpr`)的抽象表示
* `--ppc` 将进行解析,美化输出并进行编译
```
main :: IO ()
main = getArgs >>= \case
[file] ->
printCompile =<< readFile file
["--e",file] ->
either putStrLn print . runExprParser "--e" =<< readFile file
["--pp",file] ->
either putStrLn (putStrLn . printExpr) . runExprParser "--pp" =<< readFile file
["--jse",file] ->
either print (either putStrLn print . translateToJS) . runExprParser "--jse" =<< readFile file
["--ppc",file] ->
either putStrLn (either putStrLn putStrLn) . fmap (compile . printExpr) . runExprParser "--ppc" =<< readFile file
_ ->
putStrLn $ unlines
["Usage: runghc Main.hs [ --e, --pp, --jse, --ppc ] <filename>"
,"--e print the Expr"
,"--pp pretty print Expr"
,"--jse print the JSExpr"
,"--ppc pretty print Expr and then compile"
]
printCompile :: String -> IO ()
printCompile = either putStrLn putStrLn . compile
compile :: String -> Either Error String
compile str = printJSExpr False 0 <$> (translateToJS =<< runExprParser "compile" str)
```
大功告成。将自己的语言编译到 JS 子集的编译器已经完成了。再说一次,你可以在 [这里](https://gist.github.com/soupi/d4ff0727ccb739045fad6cdf533ca7dd) 看到完整的源文件。
用我们的编译器运行第一节的示例,产生的 JavaScript 代码如下:
```
$ runhaskell Lisp.hs example.lsp
(function(compose, square, add1) {
return (console.log)(((compose)(square, add1))(5));
})(function(f, g) {
return function(x) {
return (f)((g)(x));
};
}, function(x) {
return (x * x);
}, function(x) {
return (x + 1);
})
```
如果你在自己电脑上安装了 node.js,你可以用以下命令运行这段代码:
```
$ runhaskell Lisp.hs example.lsp | node -p
36
undefined
```
* 最终练习 : 编译有多个表达式的程序而非仅编译一个表达式。
---
via: <https://gilmi.me/blog/post/2016/10/14/lisp-to-js>
作者:[Gil Mizrahi](https://gilmi.me/home) 选题:[oska874](https://github.com/oska874) 译者:[BriFuture](https://github.com/BriFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [- 2016-10-14 -](/blog/post/2016/10/14/lisp-to-js)
## Compiling Lisp to JavaScript from scratch in 350 LOC
In this article we will look at a from-scratch implementation of a compiler from a simple LISP-like calculator language to JavaScript.
The complete source code can be found [here](https://gist.github.com/soupi/d4ff0727ccb739045fad6cdf533ca7dd).
We will:
[Define our language and write a simple program in it](#1.-defining-the-language)[Implement a simple parser combinator library](#2.-implement-a-simple-parser-combinator-library)[Implement a parser for our language](#3.-implementing-a-parser-for-our-language)[Implement a prettyprinter for our language](#4.-implement-a-prettyprinter-for-our-language)[Define a subset of JavaScript for our usage](#5.-define-a-subset-of-javascript-for-our-usage)[Implement a prettyprinter for our subset of JavaScript](#6.-implement-a-prettyprinter-for-our-subset-of-javascript)[Implement a code translator to the JavaScript subset we defined](#7.-implement-a-code-translator-to-the-javascript-subset-we-defined)[Glue it all together](#8.-glue-it-all-together)
Let's start!
## 1. Defining the language
The main attraction of lisps is that their syntax already represent a tree, this is why they are so easy to parse. We'll see that soon. But first let's define our language. Here's a BNF description of our language's syntax:
```
program ::= expr
expr ::= <integer> | <name> | ([<expr>])
```
Basically, our language let's us define one expression at the top level which it will evaluate.
An expression is composed of either an integer, for example `5`
,
a variable, for example `x`
, or a list of expressions, for example `(add x 1)`
.
An integer evaluate to itself, a variable evaluates to what it's bound in the current environment, and a list evaluates to a function call where the first argument is the function and the rest are the arguments to the function.
We have some built-in special forms in our language so we can do more interesting stuff:
let expression let's us introduce new variables in the environment of the body of the let. The syntax is:
```
let ::= (let ([<letarg>]) <body>)
letargs ::= (<name> <expr>)
body ::= <expr>
```
lambda expression: evaluates to an anonymous function definition. The syntax is:
`lambda ::= (lambda ([<name>]) <body>)`
We also have a few built in functions: `add`
, `mul`
, `sub`
, `div`
and `print`
.
Let's see a quick example of a program written in our language:
```
(let
((compose
(lambda (f g)
(lambda (x) (f (g x)))))
(square
(lambda (x) (mul x x)))
(add1
(lambda (x) (add x 1))))
(print ((compose square add1) 5)))
```
This program defines 3 functions: `compose`
, `square`
and `add1`
. And then prints the result of the computation:
`((compose square add1) 5)`
I hope this is enough information about the language. Let's start implementing it!
We can define the language in Haskell like this:
```
type Name = String
data Expr
= ATOM Atom
| LIST [Expr]
deriving (Eq, Read, Show)
data Atom
= Int Int
| Symbol Name
deriving (Eq, Read, Show)
```
We can parse programs in the language we defined to an `Expr`
.
Also, we are giving the new data types `Eq`
, `Read`
and `Show`
instances to aid in testing and debugging. You'll be able to use
those in the REPL for example to verify all this actually works.
The reason we did not define `lambda`
, `let`
and the other built-in functions as part of the syntax
is because we can get away with it in this case. These functions are just a more specific case of
a `LIST`
. So I decided to leave this to a later phase.
Usually, you would like to define these special cases in the abstract syntax - to improve error messages, to unable static analysis and optimizations and such, but we won't do that here so this is enough for us.
Another thing you would like to do usually is add some annotation to the syntax. For example the location:
Which file did this `Expr`
come from and which row and col in the file. You can use this in later stages
to print the location of errors, even if they are not in the parser stage.
*Exercise 1*: Add a`Program`
data type to include multiple`Expr`
sequentially*Exercise 2*: Add location annotation to the syntax tree.
## 2. Implement a simple parser combinator library
First thing we are going to do is define an Embedded Domain Specific Language (or EDSL)
which we will use to define our languages' parser. This is often referred to as
parser combinator library.
The reason we are doing it is strictly for learning purposes, Haskell has great parsing
libraries and you should definitely use them when building real software, or even when just
experimenting. One such library is [megaparsec](https://mrkkrp.github.io/megaparsec/).
First let's talk about the idea behind our parser library implementation. In it's essence, our parser is a function that takes some input, might consume some or all of the input, and returns the value it managed to parse and the rest of the input it didn't parse yet, or throws an error if it failed. Let's write that down.
```
newtype Parser a
= Parser (ParseString -> Either ParseError (a, ParseString))
data ParseString
= ParseString Name (Int, Int) String
data ParseError
= ParseError ParseString Error
type Error = String
```
Here we defined three main new types.
First, `Parser a`
, is the parsing function we described before.
Second, `ParseString`
is our input or state we carry along. It has three significant parts:
`Name`
: This is the name of the source`(Int, Int)`
: This is the current location in the source`String`
: This is the remaining string left to parse
Third, `ParseError`
contains the current state of the parser and an error message.
Now we want our parser to be flexible, so we will define a few instances for common type classes for it. These instances will allow us to combine small parsers to make bigger parsers (hence the name 'parser combinators').
The first one is a `Functor`
instance. We want a `Functor`
instance because we want to be able to define
a parser using another parser simply by applying a function on the parsed value. We will see an example
of this when we define the parser for our language.
```
instance Functor Parser where
fmap f (Parser parser) =
Parser (\str -> first f <$> parser str)
```
The second instance is an `Applicative`
instance. One common use case for this instance instance
is to lift a pure function on multiple parsers.
```
instance Applicative Parser where
pure x = Parser (\str -> Right (x, str))
(Parser p1) <*> (Parser p2) =
Parser $
\str -> do
(f, rest) <- p1 str
(x, rest') <- p2 rest
pure (f x, rest')
```
(Note: *We will also implement a Monad instance so we can use do notation here.*)
The third instance is an `Alternative`
instance. We want to be able to supply an alternative parser in case one fails.
```
instance Alternative Parser where
empty = Parser (`throwErr` "Failed consuming input")
(Parser p1) <|> (Parser p2) =
Parser $
\pstr -> case p1 pstr of
Right result -> Right result
Left _ -> p2 pstr
```
The fourth instance is a `Monad`
instance. So we'll be able to chain parsers.
```
instance Monad Parser where
(Parser p1) >>= f =
Parser $
\str -> case p1 str of
Left err -> Left err
Right (rs, rest) ->
case f rs of
Parser parser -> parser rest
```
Next, let's define a way to run a parser and a utility function for failure:
```
runParser :: String -> String -> Parser a -> Either ParseError (a, ParseString)
runParser name str (Parser parser) = parser $ ParseString name (0,0) str
throwErr :: ParseString -> String -> Either ParseError a
throwErr ps@(ParseString name (row,col) _) errMsg =
Left $ ParseError ps $ unlines
[ "*** " ++ name ++ ": " ++ errMsg
, "* On row " ++ show row ++ ", column " ++ show col ++ "."
]
```
Now we'll start implementing the combinators which are the API and heart of the EDSL.
First, we'll define `oneOf`
. `oneOf`
will succeed if one of the characters in the list
supplied to it is the next character of the input and will fail otherwise.
```
oneOf :: [Char] -> Parser Char
oneOf chars =
Parser $ \case
ps@(ParseString name (row, col) str) ->
case str of
[] -> throwErr ps "Cannot read character of empty string"
(c:cs) ->
if c `elem` chars
then
let
(row', col')
| c == '\n' = (row + 1, 0)
| otherwise = (row, col + 1)
in
Right (c, ParseString name (row', col') cs)
else
throwErr ps $ unlines ["Unexpected character " ++ [c], "Expecting one of: " ++ show chars]
```
`optional`
will stop a parser from throwing an error. It will just return `Nothing`
on failure.
```
optional :: Parser a -> Parser (Maybe a)
optional (Parser parser) =
Parser $
\pstr -> case parser pstr of
Left _ -> Right (Nothing, pstr)
Right (x, rest) -> Right (Just x, rest)
```
`many`
will try to run a parser repeatedly until it fails. When it does, it'll return a list of successful parses.
`many1`
will do the same, but will throw an error if it fails to parse at least once.
```
many :: Parser a -> Parser [a]
many parser = go []
where go cs = (parser >>= \c -> go (c:cs)) <|> pure (reverse cs)
many1 :: Parser a -> Parser [a]
many1 parser =
(:) <$> parser <*> many parser
```
These next few parsers use the combinators we defined to make more specific parsers:
```
char :: Char -> Parser Char
char c = oneOf [c]
string :: String -> Parser String
string = traverse char
space :: Parser Char
space = oneOf " \n"
spaces :: Parser String
spaces = many space
spaces1 :: Parser String
spaces1 = many1 space
withSpaces :: Parser a -> Parser a
withSpaces parser =
spaces *> parser <* spaces
parens :: Parser a -> Parser a
parens parser =
(withSpaces $ char '(')
*> withSpaces parser
<* (spaces *> char ')')
sepBy :: Parser a -> Parser b -> Parser [b]
sepBy sep parser = do
frst <- optional parser
rest <- many (sep *> parser)
pure $ maybe rest (:rest) frst
```
Now we have everything we need to start defining a parser for our language.
*Exercise*: implement an EOF (end of file/input) parser combinator.
## 3. Implementing a parser for our language
To define our parser, we'll use the top-bottom method.
```
parseExpr :: Parser Expr
parseExpr = fmap ATOM parseAtom <|> fmap LIST parseList
parseList :: Parser [Expr]
parseList = parens $ sepBy spaces1 parseExpr
parseAtom :: Parser Atom
parseAtom = parseSymbol <|> parseInt
parseSymbol :: Parser Atom
parseSymbol = fmap Symbol parseName
```
Notice that these four function are a very high-level description of our language. This demonstrate why Haskell is so nice for parsing.
Still, after defining the high-level parts, we still need to define
the lower-level `parseName`
and `parseInt`
.
What characters can we use as names in our language? Let's decide to use lowercase letters, digits and underscores, where the first character must be a letter.
```
parseName :: Parser Name
parseName = do
c <- oneOf ['a'..'z']
cs <- many $ oneOf $ ['a'..'z'] ++ "0123456789" ++ "_"
pure (c:cs)
```
For integers, we want a sequence of digits optionally preceding by '-':
```
parseInt :: Parser Atom
parseInt = do
sign <- optional $ char '-'
num <- many1 $ oneOf "0123456789"
let result = read $ maybe num (:num) sign
pure $ Int result
```
Lastly, we'll define a function to run a parser and get back an `Expr`
or an error message.
```
runExprParser :: Name -> String -> Either String Expr
runExprParser name str =
case runParser name str (withSpaces parseExpr) of
Left (ParseError _ errMsg) -> Left errMsg
Right (result, _) -> Right result
```
*Exercise 1*: Write a parser for the`Program`
type you defined in the first section*Exercise 2*: Rewrite`parseName`
in Applicative style*Exercise 3*: Find a way to handle the overflow case in`parseInt`
instead of using`read`
.
## 4. Implement a prettyprinter for our language
One more thing we'd like to do is be able to print our programs as source code.
This is useful for better error messages. We want to write functions that take
an expression and produces a `String`
of source code.
This is usually something that is easier to do with a proper library,
such as [prettyprinter](https://hackage.haskell.org/package/prettyprinter).
```
printExpr :: Expr -> String
printExpr = printExpr' False 0
printAtom :: Atom -> String
printAtom = \case
Symbol s -> s
Int i -> show i
printExpr' :: Bool -> Int -> Expr -> String
printExpr' doindent level = \case
ATOM a -> indent (bool 0 level doindent) (printAtom a)
LIST (e:es) ->
indent (bool 0 level doindent) $
concat
[ "("
, printExpr' False (level + 1) e
, bool "\n" "" (null es)
, intercalate "\n" $ map (printExpr' True (level + 1)) es
, ")"
]
indent :: Int -> String -> String
indent tabs e = concat (replicate tabs " ") ++ e
```
*Exercise*: Write a prettyprinter for the`Program`
type you defined in the first section
Okay, we wrote around 200 lines so far of what's typically called the front-end of the compiler. We have around 150 more lines to go and three more tasks: We need to define a subset of JS for our usage, define the translator from our language to that subset, and glue the whole thing together. Let's go!
## 5. Define a subset of JavaScript for our usage
First, we'll define the subset of JavaScript we are going to use:
```
data JSExpr
= JSInt Int
| JSSymbol Name
| JSBinOp JSBinOp JSExpr JSExpr
| JSLambda [Name] JSExpr
| JSFunCall JSExpr [JSExpr]
| JSReturn JSExpr
deriving (Eq, Show, Read)
type JSBinOp = String
```
This data type represent a JavaScript expression. We have two atoms - `JSInt`
and `JSSymbol`
to which we'll translate our languages' `Atom`
,
We have `JSBinOp`
to represent a binary operation such as `+`
or `*`
, we have `JSLambda`
for anonymous functions same as our `lambda expression`
,
We have `JSFunCall`
which we'll use both for calling functions and introducing new names as in `let`
, and we have
`JSReturn`
to return values from functions as that's required in JavaScript.
This `JSExpr`
type is an **abstract representation** of a JavaScript expression. We will translate our own `Expr`
which is an
abstract representation of our languages' expression to `JSExpr`
and from there to JavaScript code.
## 6. Implement a prettyprinter for our subset of JavaScript
In order to generate JavaScript code we'll pattern matching on `JSExpr`
recursively and emitting JavaScript code as a `String`
.
This is basically the same thing we did in `printExpr`
.
We'll also track the scoping of elements so we can indent the generated code in a nice way.
```
printJSOp :: JSBinOp -> String
printJSOp op = op
printJSExpr :: Bool -> Int -> JSExpr -> String
printJSExpr doindent tabs = \case
JSInt i -> show i
JSSymbol name -> name
JSLambda vars expr -> (if doindent then indent tabs else id) $ unlines
["function(" ++ intercalate ", " vars ++ ") {"
,indent (tabs+1) $ printJSExpr False (tabs+1) expr
] ++ indent tabs "}"
JSBinOp op e1 e2 -> "(" ++ printJSExpr False tabs e1 ++ " " ++ printJSOp op ++ " " ++ printJSExpr False tabs e2 ++ ")"
JSFunCall f exprs -> "(" ++ printJSExpr False tabs f ++ ")(" ++ intercalate ", " (fmap (printJSExpr False tabs) exprs) ++ ")"
JSReturn expr -> (if doindent then indent tabs else id) $ "return " ++ printJSExpr False tabs expr ++ ";"
```
*Exercise 1*: Add a`JSProgram`
type that will hold multiple`JSExpr`
and create a function`printJSExprProgram`
to generate code for it.*Exercise 2*: Add a new type of`JSExpr`
-`JSIf`
, and generate code for it.
## 7. Implement a code translator to the JavaScript subset we defined
We are almost there. In this section we'll create a function to translate `Expr`
to `JSExpr`
.
The basic idea is simple, we'll translate `ATOM`
to `JSSymbol`
or `JSInt`
and `LIST`
to either a function call
or a special case we'll translate later.
```
type TransError = String
translateToJS :: Expr -> Either TransError JSExpr
translateToJS = \case
ATOM (Symbol s) -> pure $ JSSymbol s
ATOM (Int i) -> pure $ JSInt i
LIST xs -> translateList xs
translateList :: [Expr] -> Either TransError JSExpr
translateList = \case
[] -> Left "translating empty list"
ATOM (Symbol s):xs
| Just f <- lookup s builtins ->
f xs
f:xs ->
JSFunCall <$> translateToJS f <*> traverse translateToJS xs
```
`builtins`
is a list of special cases to translate, like `lambda`
and `let`
. Every case gets
the list of arguments for it, verify that its syntactically valid and translates it to the
equivalent `JSExpr`
.
```
type Builtin = [Expr] -> Either TransError JSExpr
type Builtins = [(Name, Builtin)]
builtins :: Builtins
builtins =
[("lambda", transLambda)
,("let", transLet)
,("add", transBinOp "add" "+")
,("mul", transBinOp "mul" "*")
,("sub", transBinOp "sub" "-")
,("div", transBinOp "div" "/")
,("print", transPrint)
]
```
In our case, we treat built-in special forms as special and not first class, so will not be able to use them as first class functions and such.
We'll translate a Lambda to an anonymous function:
```
transLambda :: [Expr] -> Either TransError JSExpr
transLambda = \case
[LIST vars, body] -> do
vars' <- traverse fromSymbol vars
JSLambda vars' <$> (JSReturn <$> translateToJS body)
vars ->
Left $ unlines
["Syntax error: unexpected arguments for lambda."
,"expecting 2 arguments, the first is the list of vars and the second is the body of the lambda."
,"In expression: " ++ show (LIST $ ATOM (Symbol "lambda") : vars)
]
fromSymbol :: Expr -> Either String Name
fromSymbol (ATOM (Symbol s)) = Right s
fromSymbol e = Left $ "cannot bind value to non symbol type: " ++ show e
```
We'll translate let to a definition of a function with the relevant named arguments and call it with the values, Thus introducing the variables in that scope:
```
transLet :: [Expr] -> Either TransError JSExpr
transLet = \case
[LIST binds, body] -> do
(vars, vals) <- letParams binds
vars' <- traverse fromSymbol vars
JSFunCall . JSLambda vars' <$> (JSReturn <$> translateToJS body) <*> traverse translateToJS vals
where
letParams :: [Expr] -> Either Error ([Expr],[Expr])
letParams = \case
[] -> pure ([],[])
LIST [x,y] : rest -> ((x:) *** (y:)) <$> letParams rest
x : _ -> Left ("Unexpected argument in let list in expression:\n" ++ printExpr x)
vars ->
Left $ unlines
["Syntax error: unexpected arguments for let."
,"expecting 2 arguments, the first is the list of var/val pairs and the second is the let body."
,"In expression:\n" ++ printExpr (LIST $ ATOM (Symbol "let") : vars)
]
```
We'll translate an operation that can work on multiple arguments to a chain of binary operations.
For example: `(add 1 2 3)`
will become `1 + (2 + 3)`
```
transBinOp :: Name -> Name -> [Expr] -> Either TransError JSExpr
transBinOp f _ [] = Left $ "Syntax error: '" ++ f ++ "' expected at least 1 argument, got: 0"
transBinOp _ _ [x] = translateToJS x
transBinOp _ f list = foldl1 (JSBinOp f) <$> traverse translateToJS list
```
And we'll translate a `print`
as a call to `console.log`
```
transPrint :: [Expr] -> Either TransError JSExpr
transPrint [expr] = JSFunCall (JSSymbol "console.log") . (:[]) <$> translateToJS expr
transPrint xs = Left $ "Syntax error. print expected 1 arguments, got: " ++ show (length xs)
```
Notice that we could have skipped verifying the syntax if we'd parse those as special cases of `Expr`
.
*Exercise 1*: Translate`Program`
to`JSProgram`
*Exercise 2*: add a special case for`if Expr Expr Expr`
and translate it to the`JSIf`
case you implemented in the last exercise
## 8. Glue it all together
Finally, we are going to glue this all together. We'll:
- Read a file
- Parse it to
`Expr`
- Translate it to
`JSExpr`
- Emit JavaScript code to the standard output
We'll also enable a few flags for testing:
`--e`
will parse and print the abstract representation of the expression (`Expr`
)`--pp`
will parse and prettyprint`--jse`
will parse, translate and print the abstract representation of the resulting JS (`JSExpr`
)`--ppc`
will parse, prettyprint and compile
```
main :: IO ()
main = getArgs >>= \case
[file] ->
printCompile =<< readFile file
["--e",file] ->
either putStrLn print . runExprParser "--e" =<< readFile file
["--pp",file] ->
either putStrLn (putStrLn . printExpr) . runExprParser "--pp" =<< readFile file
["--jse",file] ->
either print (either putStrLn print . translateToJS) . runExprParser "--jse" =<< readFile file
["--ppc",file] ->
either putStrLn (either putStrLn putStrLn) . fmap (compile . printExpr) . runExprParser "--ppc" =<< readFile file
_ ->
putStrLn $ unlines
["Usage: runghc Main.hs [ --e, --pp, --jse, --ppc ] <filename>"
,"--e print the Expr"
,"--pp prettyprint Expr"
,"--jse print the JSExpr"
,"--ppc prettyprint Expr and then compile"
]
printCompile :: String -> IO ()
printCompile = either putStrLn putStrLn . compile
compile :: String -> Either Error String
compile str = printJSExpr False 0 <$> (translateToJS =<< runExprParser "compile" str)
```
That's it. We have a compiler from our language to JS. Again, you can view the full source file [here](https://gist.github.com/soupi/d4ff0727ccb739045fad6cdf533ca7dd).
Running our compiler with the example from the first section yields this JavaScript code:
```
$ runhaskell Lisp.hs example.lsp
(function(compose, square, add1) {
return (console.log)(((compose)(square, add1))(5));
})(function(f, g) {
return function(x) {
return (f)((g)(x));
};
}, function(x) {
return (x * x);
}, function(x) {
return (x + 1);
})
```
If you have node.js installed on your computer, you can run this code by running:
```
$ runhaskell Lisp.hs example.lsp | node -p
36
undefined
```
*Final exercise*: instead of compiling an expression, compile a program of multiple expressions. |
10,177 | 重启和关闭 Linux 系统的 6 个终端命令 | https://www.2daygeek.com/6-commands-to-shutdown-halt-poweroff-reboot-the-linux-system/ | 2018-10-31T20:55:05 | [
"重启",
"关机"
] | https://linux.cn/article-10177-1.html | 
在 Linux 管理员的日程当中,有很多需要执行的任务,其中就有系统的重启和关闭。
对于 Linux 管理员来说,重启和关闭系统是其诸多风险操作中的一例,有时候,由于某些原因,这些操作可能无法挽回,他们需要更多的时间来排查问题。
在 Linux 命令行模式下我们可以执行这些任务。很多时候,由于熟悉命令行,Linux 管理员更倾向于在命令行下完成这些任务。
重启和关闭系统的 Linux 命令并不多,用户需要根据需要,选择合适的命令来完成任务。
以下所有命令都有其自身特点,并允许被 Linux 管理员使用.
**建议阅读:**
* [查看系统/服务器正常运行时间的 11 个方法](https://www.2daygeek.com/11-methods-to-find-check-system-server-uptime-in-linux/)
* [Tuptime 一款为 Linux 系统保存历史记录、统计运行时间工具](https://www.2daygeek.com/tuptime-a-tool-to-report-the-historical-and-statistical-running-time-of-linux-system/)
系统重启和关闭之始,会通知所有已登录的用户和进程。当然,如果使用了时间参数,系统将拒绝新的用户登入。
执行此类操作之前,我建议您坚持复查,因为您只能得到很少的提示来确保这一切顺利。
下面陈列了一些步骤:
* 确保您拥有一个可以处理故障的控制台,以防之后可能会发生的问题。 VMWare 可以访问虚拟机,而 IPMI、iLO 和 iDRAC 可以访问物理服务器。
* 您需要通过公司的流程,申请修改或故障的执行权直到得到许可。
* 为安全着想,备份重要的配置文件,并保存到其他服务器上.
* 验证日志文件(提前检查)
* 和相关团队交流,比如数据库管理团队,应用团队等。
* 通知数据库和应用服务人员关闭服务,并得到确定答复。
* 使用适当的命令复盘操作,验证工作。
* 最后,重启系统。
* 验证日志文件,如果一切顺利,执行下一步操作,如果发现任何问题,对症排查。
* 无论是回退版本还是运行程序,通知相关团队提出申请。
* 对操作做适当守候,并将预期的一切正常的反馈给团队
使用下列命令执行这项任务。
* `shutdown`、`halt`、`poweroff`、`reboot` 命令:用来停机、重启或切断电源
* `init` 命令:是 “initialization” 的简称,是系统启动的第一个进程。
* `systemctl` 命令:systemd 是 Linux 系统和服务器的管理程序。
### 方案 1:如何使用 shutdown 命令关闭和重启 Linux 系统
`shutdown` 命令用于断电或重启本地和远程的 Linux 机器。它为高效完成作业提供多个选项。如果使用了时间参数,系统关闭的 5 分钟之前,会创建 `/run/nologin` 文件,以确保后续的登录会被拒绝。
通用语法如下:
```
# shutdown [OPTION] [TIME] [MESSAGE]
```
运行下面的命令来立即关闭 Linux 机器。它会立刻杀死所有进程,并关闭系统。
```
# shutdown -h now
```
* `-h`:如果不特指 `-halt` 选项,这等价于 `-poweroff` 选项。
另外我们可以使用带有 `-halt` 选项的 `shutdown` 命令来立即关闭设备。
```
# shutdown --halt now
或者
# shutdown -H now
```
* `-H, --halt`:停止设备运行
另外我们可以使用带有 `poweroff` 选项的 `shutdown` 命令来立即关闭设备。
```
# shutdown --poweroff now
或者
# shutdown -P now
```
* `-P, --poweroff`:切断电源(默认)。
如果您没有使用时间选项运行下面的命令,它将会在一分钟后执行给出的命令。
```
# shutdown -h
Shutdown scheduled for Mon 2018-10-08 06:42:31 EDT, use 'shutdown -c' to cancel.
[email protected]#
Broadcast message from [email protected] (Mon 2018-10-08 06:41:31 EDT):
The system is going down for power-off at Mon 2018-10-08 06:42:31 EDT!
```
其他的登录用户都能在中断中看到如下的广播消息:
```
[[email protected] ~]$
Broadcast message from [email protected] (Mon 2018-10-08 06:41:31 EDT):
The system is going down for power-off at Mon 2018-10-08 06:42:31 EDT!
```
对于使用了 `-halt` 选项:
```
# shutdown -H
Shutdown scheduled for Mon 2018-10-08 06:37:53 EDT, use 'shutdown -c' to cancel.
[email protected]#
Broadcast message from [email protected] (Mon 2018-10-08 06:36:53 EDT):
The system is going down for system halt at Mon 2018-10-08 06:37:53 EDT!
```
对于使用了 `-poweroff` 选项:
```
# shutdown -P
Shutdown scheduled for Mon 2018-10-08 06:40:07 EDT, use 'shutdown -c' to cancel.
[email protected]#
Broadcast message from [email protected] (Mon 2018-10-08 06:39:07 EDT):
The system is going down for power-off at Mon 2018-10-08 06:40:07 EDT!
```
可以在您的终端上敲击 `shutdown -c` 选项取消操作。
```
# shutdown -c
Broadcast message from [email protected] (Mon 2018-10-08 06:39:09 EDT):
The system shutdown has been cancelled at Mon 2018-10-08 06:40:09 EDT!
```
其他的登录用户都能在中断中看到如下的广播消息:
```
[[email protected] ~]$
Broadcast message from [email protected] (Mon 2018-10-08 06:41:35 EDT):
The system shutdown has been cancelled at Mon 2018-10-08 06:42:35 EDT!
```
添加时间参数,如果你想在 `N` 秒之后执行关闭或重启操作。这里,您可以为所有登录用户添加自定义广播消息。例如,我们将在五分钟后重启设备。
```
# shutdown -r +5 "To activate the latest Kernel"
Shutdown scheduled for Mon 2018-10-08 07:13:16 EDT, use 'shutdown -c' to cancel.
[root@vps138235 ~]#
Broadcast message from [email protected] (Mon 2018-10-08 07:08:16 EDT):
To activate the latest Kernel
The system is going down for reboot at Mon 2018-10-08 07:13:16 EDT!
```
运行下面的命令立即重启 Linux 机器。它会立即杀死所有进程并且重新启动系统。
```
# shutdown -r now
```
* `-r, --reboot`: 重启设备。
### 方案 2:如何通过 reboot 命令关闭和重启 Linux 系统
`reboot` 命令用于关闭和重启本地或远程设备。`reboot` 命令拥有两个实用的选项。
它能够优雅的关闭和重启设备(就好像在系统菜单中惦记重启选项一样简单)。
执行不带任何参数的 `reboot` 命令来重启 Linux 机器。
```
# reboot
```
执行带 `-p` 参数的 `reboot` 命令来关闭 Linux 机器电源。
```
# reboot -p
```
* `-p, --poweroff`:调用 `halt` 或 `poweroff` 命令,切断设备电源。
执行带 `-f` 参数的 `reboot` 命令来强制重启 Linux 设备(这类似按压机器上的电源键)。
```
# reboot -f
```
* `-f, --force`:立刻强制中断,切断电源或重启。
### 方案 3:如何通过 init 命令关闭和重启 Linux 系统
`init`(“initialization” 的简写)是系统启动的第一个进程。
它将会检查 `/etc/inittab` 文件并决定 linux 运行级别。同时,允许用户在 Linux 设备上执行关机或重启操作. 这里存在从 `0` 到 `6` 的七个运行等级。
**建议阅读:**
* [如何检查 Linux 上所有运行的服务](https://www.2daygeek.com/how-to-check-all-running-services-in-linux/)
执行以下 `init` 命令关闭系统。
```
# init 0
```
* `0`: 停机 – 关闭系统。
运行下面的 `init` 命令重启设备:
```
# init 6
```
* `6`:重启 – 重启设备。
### 方案 4:如何通过 halt 命令关闭和重启 Linux 系统
`halt` 命令用来切断电源或关闭远程 Linux 机器或本地主机。 中断所有进程并关闭 cpu。
```
# halt
```
### 方案 5:如何通过 poweroff 命令关闭和重启 Linux 系统
`poweroff` 命令用来切断电源或关闭远程 Linux 机器或本地主机。 `poweroff` 很像 `halt`,但是它可以关闭设备硬件(灯和其他 PC 上的其它东西)。它会给主板发送 ACPI 指令,然后信号发送到电源,切断电源。
```
# poweroff
```
### 方案 6:如何通过 systemctl 命令关闭和重启 Linux 系统
systemd 是一款适用于所有主流 Linux 发型版的全新 init 系统和系统管理器,而不是传统的 SysV init 系统。
systemd 兼容与 SysV 和 LSB 初始化脚本。它能够替代 SysV init 系统。systemd 是内核启动的第一个进程,并持有序号为 1 的进程 PID。
**建议阅读:**
* [chkservice – 一款终端下系统单元管理工具](https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/)
它是一切进程的父进程,Fedora 15 是第一个适配安装 systemd (替代了 upstart)的发行版。
`systemctl` 是命令行下管理 systemd 守护进程和服务的主要工具(如 `start`、`restart`、`stop`、`enable`、`disable`、`reload` & `status`)。
systemd 使用 .service 文件而不是 SysV init 使用的 bash 脚本。 systemd 将所有守护进程归与自身的 Linux cgroups 用户组下,您可以浏览 `/cgroup/systemd` 文件查看该系统层次等级。
```
# systemctl halt
# systemctl poweroff
# systemctl reboot
# systemctl suspend
# systemctl hibernate
```
---
via: <https://www.2daygeek.com/6-commands-to-shutdown-halt-poweroff-reboot-the-linux-system/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[cyleft](https://github.com/cyleft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,179 | 用 Pandoc 生成一篇调研论文 | https://opensource.com/article/18/9/pandoc-research-paper | 2018-11-01T13:04:10 | [
"Markdown",
"LaTeX",
"Pandoc"
] | https://linux.cn/article-10179-1.html |
>
> 学习如何用 Markdown 管理章节引用、图像、表格以及更多。
>
>
>

这篇文章对于使用 [Markdown](https://en.wikipedia.org/wiki/Markdown) 语法做一篇调研论文进行了一个深度体验。覆盖了如何创建和引用章节、图像(用 Markdown 和 [LaTeX](https://www.latex-project.org/))和参考书目。我们也讨论了一些棘手的案例和为什么使用 LaTex 是一个正确的做法。
### 调研
调研论文一般包括对章节、图像、表格和参考书目的引用。[Pandoc](https://pandoc.org/) 本身并不能交叉引用这些,但是它能够利用 [pandoc-crossref](http://lierdakil.github.io/pandoc-crossref/) 过滤器来完成自动编号和章节、图像、表格的交叉引用。
让我们从重写原本以 LaTax 撰写的 [一个教育调研报告的例子](https://dl.acm.org/citation.cfm?id=3270118) 开始,然后用 Markdown(和一些 LaTax)、Pandoc 和 Pandoc-crossref 重写。
#### 添加并引用章节
要想章节被自动编号,必须使用 Markdown H1 标题编写。子章节使用 H2-H4 子标题编写(通常不需要更多级别了)。例如一个章节的标题是 “Implementation”,写作 `# Implementation {#sec: implementation}`,然后 Pandoc 会把它转化为 `3. Implementation`(或者转换为相应的章节编号)。`Implementation` 这个标题使用了 H1 并且声明了一个 `{#sec: implementation}` 的标签,这是作者用于引用该章节的标签。要想引用一个章节,输入 `@` 符号并跟上对应章节标签,使用方括号括起来即可: `[@ sec:implementation]`
[在这篇论文中](https://dl.acm.org/citation.cfm?id=3270118), 我们发现了下面这个例子:
```
we lack experience (consistency between TAs, [@sec:implementation]).
```
Pandoc 转换:
```
we lack experience (consistency between TAs, Section 4).
```
章节被自动编号(这在本文最后的 `Makefile` 当中说明)。要创建无编号的章节,输入章节的标题并在最后添加 `{-}`。例如:`### Designing a game for maintainability {-}` 就以标题 “Designing a game for maintainability”,创建了一个无标号的章节。
#### 添加并引用图像
添加并引用一个图像,跟添加并引用一个章节和添加一个 Markdown 图片很相似:
```
{#fig:scatter-matrix}
```
上面这一行是告诉 Pandoc,有一个标有 Scatterplot matrix 的图像以及这张图片路径是 `data/scatterplots/RScatterplotMatrix2.png`。`{#fig:scatter-matrix}` 表明了用于引用该图像的名字。
这里是从一篇论文中进行图像引用的例子:
```
The boxes "Enjoy", "Grade" and "Motivation" ([@fig:scatter-matrix]) ...
```
Pandoc 产生如下输出:
```
The boxes "Enjoy", "Grade" and "Motivation" (Fig. 1) ...
```
#### 添加及引用参考书目
大多数调研报告都把引用放在一个 BibTeX 的数据库文件中。在这个例子中,该文件被命名为 [biblio.bib](https://github.com/kikofernandez/pandoc-examples/blob/master/research-paper/biblio.bib),它包含了论文中所有的引用。下面是这个文件的样子:
```
@inproceedings{wrigstad2017mastery,
Author = {Wrigstad, Tobias and Castegren, Elias},
Booktitle = {SPLASH-E},
Title = {Mastery Learning-Like Teaching with Achievements},
Year = 2017
}
@inproceedings{review-gamification-framework,
Author = {A. Mora and D. Riera and C. Gonzalez and J. Arnedo-Moreno},
Publisher = {IEEE},
Booktitle = {2015 7th International Conference on Games and Virtual Worlds
for Serious Applications (VS-Games)},
Doi = {10.1109/VS-GAMES.2015.7295760},
Keywords = {formal specification;serious games (computing);design
framework;formal design process;game components;game design
elements;gamification design frameworks;gamification-based
solutions;Bibliographies;Context;Design
methodology;Ethics;Games;Proposals},
Month = {Sept},
Pages = {1-8},
Title = {A Literature Review of Gamification Design Frameworks},
Year = 2015,
Bdsk-Url-1 = {http://dx.doi.org/10.1109/VS-GAMES.2015.7295760}
}
...
```
第一行的 `@inproceedings{wrigstad2017mastery,` 表明了出版物 的类型(`inproceedings`),以及用来指向那篇论文的标签(`wrigstad2017mastery`)。
引用这篇题为 “Mastery Learning-Like Teaching with Achievements” 的论文, 输入:
```
the achievement-driven learning methodology [@wrigstad2017mastery]
```
Pandoc 将会输出:
```
the achievement- driven learning methodology [30]
```
这篇论文将会产生像下面这样被标号的参考书目:

引用文章的集合也很容易:只要引用使用分号 `;` 分隔开被标记的参考文献就可以了。如果一个引用有两个标签 —— 例如: `SEABORN201514` 和 `gamification-leaderboard-benefits`—— 像下面这样把它们放在一起引用:
```
Thus, the most important benefit is its potential to increase students' motivation
and engagement [@SEABORN201514;@gamification-leaderboard-benefits].
```
Pandoc 将会产生:
```
Thus, the most important benefit is its potential to increase students’ motivation
and engagement [26, 28]
```
### 问题案例
一个常见的问题是所需项目与页面不匹配。不匹配的部分会自动移动到它们认为合适的地方,即便这些位置并不是读者期望看到的位置。因此在图像或者表格接近于它们被提及的地方时,我们需要调节一下那些元素放置的位置,使得它们更加易于阅读。为了达到这个效果,我建议使用 `figure` 这个 LaTeX 环境参数,它可以让用户控制图像的位置。
我们看一个上面提到的图像的例子:
```
{#fig:scatter-matrix}
```
然后使用 LaTeX 重写:
```
\begin{figure}[t]
\includegraphics{data/scatterplots/RScatterplotMatrix2.png}
\caption{\label{fig:matrix}Scatterplot matrix}
\end{figure}
```
在 LaTeX 中,`figure` 环境参数中的 `[t]` 选项表示这张图用该位于该页的最顶部。有关更多选项,参阅 [LaTex/Floats, Figures, and Captions](https://en.wikibooks.org/wiki/LaTeX/Floats,_Figures_and_Captions#Figures) 这篇 Wikibooks 的文章。
### 产生一篇论文
到目前为止,我们讲了如何添加和引用(子)章节、图像和参考书目,现在让我们重温一下如何生成一篇 PDF 格式的论文。要生成 PDF,我们将使用 Pandoc 生成一篇可以被构建成最终 PDF 的 LaTeX 文件。我们还会讨论如何以 LaTeX,使用一套自定义的模板和元信息文件生成一篇调研论文,以及如何将 LaTeX 文档编译为最终的 PDF 格式。
很多会议都提供了一个 .cls 文件或者一套论文应有样式的模板;例如,它们是否应该使用两列的格式以及其它的设计风格。在我们的例子中,会议提供了一个名为 `acmart.cls` 的文件。
作者通常想要在他们的论文中包含他们所属的机构,然而,这个选项并没有包含在默认的 Pandoc 的 LaTeX 模板(注意,可以通过输入 `pandoc -D latex` 来查看 Pandoc 模板)当中。要包含这个内容,找一个 Pandoc 默认的 LaTeX 模板,并添加一些新的内容。将这个模板像下面这样复制进一个名为 `mytemplate.tex` 的文件中:
```
pandoc -D latex > mytemplate.tex
```
默认的模板包含以下代码:
```
$if(author)$
\author{$for(author)$$author$$sep$ \and $endfor$}
$endif$
$if(institute)$
\providecommand{\institute}[1]{}
\institute{$for(institute)$$institute$$sep$ \and $endfor$}
$endif$
```
因为这个模板应该包含作者的联系方式和电子邮件地址,在其他一些选项之间,我们更新这个模板以添加以下内容(我们还做了一些其他的更改,但是因为文件的长度,就没有包含在此处):
```
latex
$for(author)$
$if(author.name)$
\author{$author.name$}
$if(author.affiliation)$
\affiliation{\institution{$author.affiliation$}}
$endif$
$if(author.email)$
\email{$author.email$}
$endif$
$else$
$author$
$endif$
$endfor$
```
要让这些更改起作用,我们还应该有下面的文件:
* `main.md` 包含调研论文
* `biblio.bib` 包含参考书目数据库
* `acmart.cls` 我们使用的文档的集合
* `mytemplate.tex` 是我们使用的模板文件(代替默认的)
让我们添加论文的元信息到一个 `meta.yaml` 文件:
```
---
template: 'mytemplate.tex'
documentclass: acmart
classoption: sigconf
title: The impact of opt-in gamification on `\\`{=latex} students' grades in a software design course
author:
- name: Kiko Fernandez-Reyes
affiliation: Uppsala University
email: [email protected]
- name: Dave Clarke
affiliation: Uppsala University
email: [email protected]
- name: Janina Hornbach
affiliation: Uppsala University
email: [email protected]
bibliography: biblio.bib
abstract: |
An achievement-driven methodology strives to give students more control over their learning with enough flexibility to engage them in deeper learning. (more stuff continues)
include-before: |
\` ``{=latex}
\copyrightyear{2018}
\acmYear{2018}
\setcopyright{acmlicensed}
\acmConference[MODELS '18 Companion]{ACM/IEEE 21th International Conference on Model Driven Engineering Languages and Systems}{October 14--19, 2018}{Copenhagen, Denmark}
\acmBooktitle{ACM/IEEE 21th International Conference on Model Driven Engineering Languages and Systems (MODELS '18 Companion), October 14--19, 2018, Copenhagen, Denmark}
\acmPrice{XX.XX}
\acmDOI{10.1145/3270112.3270118}
\acmISBN{978-1-4503-5965-8/18/10}
\begin{CCSXML}
<ccs2012>
<concept>
<concept_id>10010405.10010489</concept_id>
<concept_desc>Applied computing~Education</concept_desc>
<concept_significance>500</concept_significance>
</concept>
</ccs2012>
\end{CCSXML}
\ccsdesc[500]{Applied computing~Education}
\keywords{gamification, education, software design, UML}
\` ``
figPrefix:
- "Fig."
- "Figs."
secPrefix:
- "Section"
- "Sections"
...
```
这个元信息文件使用 LaTeX 设置下列参数:
* `template` 指向使用的模板(`mytemplate.tex`)
* `documentclass` 指向使用的 LaTeX 文档集合(`acmart`)
* `classoption` 是在 `sigconf` 的案例中,指向这个类的选项
* `title` 指定论文的标题
* `author` 是一个包含例如 `name`、`affiliation` 和 `email` 的地方
* `bibliography` 指向包含参考书目的文件(`biblio.bib`)
* `abstract` 包含论文的摘要
* `include-before` 是这篇论文的具体内容之前应该被包含的信息;在 LaTeX 中被称为 [前言](https://www.sharelatex.com/learn/latex/Creating_a_document_in_LaTeX#The_preamble_of_a_document)。我在这里包含它去展示如何产生一篇计算机科学的论文,但是你可以选择跳过
* `figPrefix` 指向如何引用文档中的图像,例如:当引用图像的 `[@fig:scatter-matrix]` 时应该显示什么。例如,当前的 `figPrefix` 在这个例子 `The boxes "Enjoy", "Grade" and "Motivation" ([@fig:scatter-matrix])`中,产生了这样的输出:`The boxes "Enjoy", "Grade" and "Motivation" (Fig. 3)`。如果这里有很多图像,目前的设置表明它应该在图像号码旁边显示 `Figs.`
* `secPrefix` 指定如何引用文档中其他地方提到的部分(类似之前的图像和概览)
现在已经设置好了元信息,让我们来创建一个 `Makefile`,它会产生你想要的输出。`Makefile` 使用 Pandoc 产生 LaTeX 文件,`pandoc-crossref` 产生交叉引用,`pdflatex` 构建 LaTeX 为 PDF,`bibtex` 处理引用。
`Makefile` 已经展示如下:
```
all: paper
paper:
@pandoc -s -F pandoc-crossref --natbib meta.yaml --template=mytemplate.tex -N \
-f markdown -t latex+raw_tex+tex_math_dollars+citations -o main.tex main.md
@pdflatex main.tex &> /dev/null
@bibtex main &> /dev/null
@pdflatex main.tex &> /dev/null
@pdflatex main.tex &> /dev/null
clean:
rm main.aux main.tex main.log main.bbl main.blg main.out
.PHONY: all clean paper
```
Pandoc 使用下面的标记:
* `-s` 创建一个独立的 LaTeX 文档
* `-F pandoc-crossref` 利用 `pandoc-crossref` 进行过滤
* `--natbib` 用 `natbib` (你也可以选择 `--biblatex`)对参考书目进行渲染
* `--template` 设置使用的模板文件
* `-N` 为章节的标题编号
* `-f` 和 `-t` 指定从哪个格式转换到哪个格式。`-t` 通常包含格式和 Pandoc 使用的扩展。在这个例子中,我们标明的 `raw_tex+tex_math_dollars+citations` 允许在 Markdown 中使用 `raw_tex` LaTeX。 `tex_math_dollars` 让我们能够像在 LaTeX 中一样输入数学符号,`citations` 让我们可以使用 [这个扩展](http://pandoc.org/MANUAL.html#citations)。
要从 LaTeX 产生 PDF,按 [来自bibtex](http://www.bibtex.org/Using/) 的指导处理参考书目:
```
@pdflatex main.tex &> /dev/null
@bibtex main &> /dev/null
@pdflatex main.tex &> /dev/null
@pdflatex main.tex &> /dev/null
```
脚本用 `@` 忽略输出,并且重定向标准输出和错误到 `/dev/null` ,因此我们在使用这些命令的可执行文件时不会看到任何的输出。
最终的结果展示如下。这篇文章的库可以在 [GitHub](https://github.com/kikofernandez/pandoc-examples/tree/master/research-paper) 找到:

### 结论
在我看来,研究的重点是协作、思想的传播,以及在任何一个恰好存在的领域中改进现有的技术。许多计算机科学家和工程师使用 LaTeX 文档系统来写论文,它对数学提供了完美的支持。来自社会科学的研究人员似乎更喜欢 DOCX 文档。
当身处不同社区的研究人员一同写一篇论文时,他们首先应该讨论一下他们将要使用哪种格式。然而如果包含太多的数学符号,DOCX 对于工程师来说不会是最简便的选择,LaTeX 对于缺乏编程经验的研究人员来说也有一些问题。就像这篇文章中展示的,Markdown 是一门工程师和社会科学家都很轻易能够使用的语言。
---
via: <https://opensource.com/article/18/9/pandoc-research-paper>
作者:[Kiko Fernandez-Reyes](https://opensource.com/users/kikofernandez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This article takes a deep dive into how to produce a research paper using (mostly) [Markdown](https://en.wikipedia.org/wiki/Markdown) syntax. We'll cover how to create and reference sections, figures (in Markdown and [LaTeX](https://www.latex-project.org/)) and bibliographies. We'll also discuss troublesome cases and why writing them in LaTeX is the right approach.
## Research
Research papers usually contain references to sections, figures, tables, and a bibliography. [Pandoc](https://pandoc.org/) by itself cannot easily cross-reference these, but it can leverage the [pandoc-crossref](http://lierdakil.github.io/pandoc-crossref/) filter to do the automatic numbering and cross-referencing of sections, figures, and tables.
Let’s start by rewriting [an example of an educational research paper](https://dl.acm.org/citation.cfm?id=3270118) originally written in LaTeX and rewrites it in Markdown (and some LaTeX) with Pandoc and pandoc-crossref.
### Adding and referencing sections
Sections are automatically numbered and must be written using the Markdown heading H1. Subsections are written with subheadings H2-H4 (it is uncommon to need more than that). For example, to write a section titled “Implementation”, write `# Implementation {#sec:implementation}`
, and Pandoc produces `3. Implementation`
(or the corresponding numbered section). The title “Implementation” uses heading H1 and declares a label `{#sec:implementation}`
that authors can use to refer to that section. To reference a section, type the `@`
symbol followed by the label of the section and enclose it in square brackets: `[@sec:implementation]`
.
[In this paper](https://dl.acm.org/citation.cfm?id=3270118), we find the following example:
`we lack experience (consistency between TAs, [@sec:implementation]).`
Pandoc produces:
`we lack experience (consistency between TAs, Section 4).`
Sections are numbered automatically (this is covered in the `Makefile`
at the end of the article). To create unnumbered sections, type the title of the section, followed by `{-}`
. For example, `### Designing a game for maintainability {-}`
creates an unnumbered subsection with the title “Designing a game for maintainability”.
### Adding and referencing figures
Adding and referencing a figure is similar to referencing a section and adding a Markdown image:
`{#fig:scatter-matrix}`
The line above tells Pandoc that there is a figure with the caption *Scatterplot matrix* and the path to the image is `data/scatterplots/RScatterplotMatrix2.png`
. `{#fig:scatter-matrix}`
declares the name that should be used to reference the figure.
Here is an example of a figure reference from the example paper:
`The boxes "Enjoy", "Grade" and "Motivation" ([@fig:scatter-matrix]) ...`
Pandoc produces the following output:
`The boxes "Enjoy", "Grade" and "Motivation" (Fig. 1) ...`
### Adding and referencing a bibliography
Most research papers keep references in a BibTeX database file. In this example, this file is named [biblio.bib](https://github.com/kikofernandez/pandoc-examples/blob/master/research-paper/biblio.bib) and it contains all the references of the paper. Here is what this file looks like:
```
@inproceedings{wrigstad2017mastery,
Author = {Wrigstad, Tobias and Castegren, Elias},
Booktitle = {SPLASH-E},
Title = {Mastery Learning-Like Teaching with Achievements},
Year = 2017
}
@inproceedings{review-gamification-framework,
Author = {A. Mora and D. Riera and C. Gonzalez and J. Arnedo-Moreno},
Publisher = {IEEE},
Booktitle = {2015 7th International Conference on Games and Virtual Worlds
for Serious Applications (VS-Games)},
Doi = {10.1109/VS-GAMES.2015.7295760},
Keywords = {formal specification;serious games (computing);design
framework;formal design process;game components;game design
elements;gamification design frameworks;gamification-based
solutions;Bibliographies;Context;Design
methodology;Ethics;Games;Proposals},
Month = {Sept},
Pages = {1-8},
Title = {A Literature Review of Gamification Design Frameworks},
Year = 2015,
Bdsk-Url-1 = {http://dx.doi.org/10.1109/VS-GAMES.2015.7295760}
}
...
```
The first line, `@inproceedings{wrigstad2017mastery,`
, declares the type of publication (`inproceedings`
) and the label used to refer to that paper (`wrigstad2017mastery`
).
To cite the paper with its title, *Mastery Learning-Like Teaching with Achievements*, type:
`the achievement-driven learning methodology [@wrigstad2017mastery]`
Pandoc will output:
`the achievement- driven learning methodology [30]`
The paper we will produce includes a bibliography section with numbered references like these:

Citing a collection of articles is easy: Simply cite each article, separating the labeled references using a semi-colon: `;`
. If there are two labeled references—i.e., `SEABORN201514`
and `gamification-leaderboard-benefits`
—cite them together, like this:
```
Thus, the most important benefit is its potential to increase students' motivation
and engagement [@SEABORN201514;@gamification-leaderboard-benefits].
```
Pandoc will produce:
```
Thus, the most important benefit is its potential to increase students’ motivation
and engagement [26, 28]
```
## Problematic cases
A common problem involves objects that do not fit in the page. They then float to wherever they fit best, even if that position is not where the reader expects to see it. Since papers are easier to read when figures or tables appear close to where they are mentioned, we need to have some control over where these elements are placed. For this reason, I recommend the use of the `figure`
LaTeX environment, which enables users to control the positioning of figures.
Let’s take the figure example shown above:
`{#fig:scatter-matrix}`
And rewrite it in LaTeX:
```
\begin{figure}[t]
\includegraphics{data/scatterplots/RScatterplotMatrix2.png}
\caption{\label{fig:matrix}Scatterplot matrix}
\end{figure}
```
In LaTeX, the `[t]`
option in the `figure`
environment declares that the image should be placed at the top of the page. For more options, refer to the Wikibooks article [LaTex/Floats, Figures, and Captions](https://en.wikibooks.org/wiki/LaTeX/Floats,_Figures_and_Captions#Figures).
## Producing the paper
So far, we've covered how to add and reference (sub-)sections and figures and cite the bibliography—now let's review how to produce the research paper in PDF format. To generate the PDF, we will use Pandoc to generate a LaTeX file that can be compiled to the final PDF. We will also discuss how to generate the research paper in LaTeX using a customized template and a meta-information file, and how to compile the LaTeX document into its final PDF form.
Most conferences provide a **.cls** file or a template that specifies how papers should look; for example, whether they should use a two-column format and other design treatments. In our example, the conference provided a file named **acmart.cls**.
Authors are generally expected to include the institution to which they belong in their papers. However, this option was not included in the default Pandoc’s LaTeX template (note that the Pandoc template can be inspected by typing `pandoc -D latex`
). To include the affiliation, take the default Pandoc’s LaTeX template and add a new field. The Pandoc template was copied into a file named `mytemplate.tex`
as follows:
`pandoc -D latex > mytemplate.tex`
The default template contains the following code:
```
$if(author)$
\author{$for(author)$$author$$sep$ \and $endfor$}
$endif$
$if(institute)$
\providecommand{\institute}[1]{}
\institute{$for(institute)$$institute$$sep$ \and $endfor$}
$endif$
```
Because the template should include the author’s affiliation and email address, among other things, we updated it to include these fields (we made other changes as well but did not include them here due to the file length):
```
latex
$for(author)$
$if(author.name)$
\author{$author.name$}
$if(author.affiliation)$
\affiliation{\institution{$author.affiliation$}}
$endif$
$if(author.email)$
\email{$author.email$}
$endif$
$else$
$author$
$endif$
$endfor$
```
With these changes in place, we should have the following files:
`main.md`
contains the research paper`biblio.bib`
contains the bibliographic database`acmart.cls`
is the class of the document that we should use`mytemplate.tex`
is the template file to use (instead of the default)
Let’s add the meta-information of the paper in a `meta.yaml`
file:
```
---
template: 'mytemplate.tex'
documentclass: acmart
classoption: sigconf
title: The impact of opt-in gamification on `\\`{=latex} students' grades in a software design course
author:
- name: Kiko Fernandez-Reyes
affiliation: Uppsala University
email: [email protected]
- name: Dave Clarke
affiliation: Uppsala University
email: [email protected]
- name: Janina Hornbach
affiliation: Uppsala University
email: [email protected]
bibliography: biblio.bib
abstract: |
An achievement-driven methodology strives to give students more control over their learning with enough flexibility to engage them in deeper learning. (more stuff continues)
include-before: |
```{=latex}
\copyrightyear{2018}
\acmYear{2018}
\setcopyright{acmlicensed}
\acmConference[MODELS '18 Companion]{ACM/IEEE 21th International Conference on Model Driven Engineering Languages and Systems}{October 14--19, 2018}{Copenhagen, Denmark}
\acmBooktitle{ACM/IEEE 21th International Conference on Model Driven Engineering Languages and Systems (MODELS '18 Companion), October 14--19, 2018, Copenhagen, Denmark}
\acmPrice{XX.XX}
\acmDOI{10.1145/3270112.3270118}
\acmISBN{978-1-4503-5965-8/18/10}
\begin{CCSXML}
<ccs2012>
<concept>
<concept_id>10010405.10010489</concept_id>
<concept_desc>Applied computing~Education</concept_desc>
<concept_significance>500</concept_significance>
</concept>
</ccs2012>
\end{CCSXML}
\ccsdesc[500]{Applied computing~Education}
\keywords{gamification, education, software design, UML}
```
figPrefix:
- "Fig."
- "Figs."
secPrefix:
- "Section"
- "Sections"
...
```
This meta-information file sets the following variables in LaTeX:
`template`
refers to the template to use (‘mytemplate.tex’)`documentclass`
refers to the LaTeX document class to use (`acmart`
)`classoption`
refers to the options of the class, in this case`sigconf`
`title`
specifies the title of the paper`author`
is an object that contains other fields, such as`name`
,`affiliation`
, and`email`
.`bibliography`
refers to the file that contains the bibliography (biblio.bib)`abstract`
contains the abstract of the paper`include-before`
is information that should be included before the actual content of the paper; this is known as the[preamble](https://www.sharelatex.com/learn/latex/Creating_a_document_in_LaTeX#The_preamble_of_a_document)in LaTeX. I have included it here to show how to generate a computer science paper, but you may choose to skip it`figPrefix`
specifies how to refer to figures in the document, i.e., what should be displayed when one refers to the figure`[@fig:scatter-matrix]`
. For example, the current`figPrefix`
produces in the example`The boxes "Enjoy", "Grade" and "Motivation" ([@fig:scatter-matrix])`
this output:`The boxes "Enjoy", "Grade" and "Motivation" (Fig. 3)`
. If there are multiple figures, the current setup declares that it should instead display`Figs.`
next to the figure numbers.`secPrefix`
specifies how to refer to sections mentioned elsewhere in the document (similar to figures, described above)
Now that the meta-information is set, let’s create a `Makefile`
that produces the desired output. This `Makefile`
uses Pandoc to produce the LaTeX file, `pandoc-crossref`
to produce the cross-references, `pdflatex`
to compile the LaTeX to PDF, and `bibtex `
to process the references.
The `Makefile`
is shown below:
```
all: paper
paper:
@pandoc -s -F pandoc-crossref --natbib meta.yaml --template=mytemplate.tex -N \
-f markdown -t latex+raw_tex+tex_math_dollars+citations -o main.tex main.md
@pdflatex main.tex &> /dev/null
@bibtex main &> /dev/null
@pdflatex main.tex &> /dev/null
@pdflatex main.tex &> /dev/null
clean:
rm main.aux main.tex main.log main.bbl main.blg main.out
.PHONY: all clean paper
```
Pandoc uses the following flags:
`-s`
to create a standalone LaTeX document`-F pandoc-crossref`
to make use of the filter`pandoc-crossref`
`--natbib`
to render the bibliography with`natbib`
(you can also choose`--biblatex`
)`--template`
sets the template file to use`-N`
to number the section headings`-f`
and`-t`
specify the conversion*from*and*to*which format.`-t`
usually contains the format and is followed by the Pandoc extensions used. In the example, we declared`raw_tex+tex_math_dollars+citations`
to allow use of`raw_tex`
LaTeX in the middle of the Markdown file.`tex_math_dollars`
enables us to type math formulas as in LaTeX, and`citations`
enables us to use[this extension](http://pandoc.org/MANUAL.html#citations).
To generate a PDF from LaTeX, follow the guidelines [from bibtex](http://www.bibtex.org/Using/) to process the bibliography:
```
@pdflatex main.tex &> /dev/null
@bibtex main &> /dev/null
@pdflatex main.tex &> /dev/null
@pdflatex main.tex &> /dev/null
```
The script contains `@`
to ignore the output, and we redirect the file handle of the standard output and error to `/dev/null`
so that we don’t see the output generated from the execution of these commands.
The final result is shown below. The repository for the article can be found [on GitHub](https://github.com/kikofernandez/pandoc-examples/tree/master/research-paper):

## Conclusion
In my opinion, research is all about collaboration, dissemination of ideas, and improving the state of the art in whatever field one happens to be in. Most computer scientists and engineers write papers using the LaTeX document system, which provides excellent support for math. Researchers from the social sciences seem to stick to DOCX documents.
When researchers from different communities write papers together, they should first discuss which format they will use. While DOCX may not be convenient for engineers if there is math involved, LaTeX may be troublesome for researchers who lack a programming background. As this article shows, Markdown is an easy-to-use language that can be used by both engineers and social scientists.
## 3 Comments |
10,180 | Flameshot:一个简洁但功能丰富的截图工具 | https://www.ostechnix.com/flameshot-a-simple-yet-powerful-feature-rich-screenshot-tool/ | 2018-11-01T13:19:34 | [
"截图",
"Flameshot"
] | https://linux.cn/article-10180-1.html | 
截图是我工作的一部分,我先前使用深度截图工具来截图,深度截图是一个简单、轻量级且非常简洁的截图工具。它自带许多功能例如窗口识别、快捷键支持、图片编辑、延时截图、社交分享、智能存储以及图片清晰度调整等功能。今天我碰巧发现了另一个具备多种功能的截图工具,它就是 **Flameshot** ,一个简单但功能丰富的针对类 Unix 系统的截图工具。它简单易用,可定制并且有选项可以支持上传截图到在线图片分享网站 **imgur** 上。同时 Flameshot 有一个 CLI 版本,所以你也可以从命令行来进行截图。Flameshot 是一个完全免费且开源的工具。在本教程中,我们将看到如何安装 Flameshot 以及如何使用它来截图。
### 安装 Flameshot
**在 Arch Linux 上:**
Flameshot 可以从 Arch LInux 的 [community] 仓库中获取。确保你已经启用了 community 仓库,然后就可以像下面展示的那样使用 pacman 来安装 Flameshot :
```
$ sudo pacman -S flameshot
```
它也可以从 [**AUR**](https://aur.archlinux.org/packages/flameshot-git) 中获取,所以你还可以使用任意一个 AUR 帮助程序(例如 [**Yay**](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/))来在基于 Arch 的系统中安装它:
```
$ yay -S flameshot-git
```
**在 Fedora 中:**
```
$ sudo dnf install flameshot
```
在 **Debian 10+** 和 **Ubuntu 18.04+** 中,可以使用 APT 包管理器来安装它:
```
$ sudo apt install flameshot
```
**在 openSUSE 上:**
```
$ sudo zypper install flameshot
```
在其他的 Linux 发行版中,可以从源代码编译并安装它。编译过程中需要 **Qt version 5.3** 以及 **GCC 4.9.2** 或者它们的更高版本。
### 使用
可以从菜单或者应用启动器中启动 Flameshot。在 MATE 桌面环境,它通常可以在 “Applications -> Graphics” 下找到。
一旦打开了它,你就可以在系统面板中看到 Flameshot 的托盘图标。
**注意:**
假如你使用 Gnome 桌面环境,为了能够看到系统托盘图标,你需要安装 [TopIcons](https://extensions.gnome.org/extension/1031/topicons/) 扩展。
在 Flameshot 托盘图标上右击,你便会看到几个菜单项,例如打开配置窗口、信息窗口以及退出该应用。
要进行截图,只需要点击托盘图标就可以了。接着你将看到如何使用 Flameshot 的帮助窗口。选择一个截图区域,然后敲回车键便可以截屏了,点击右键便可以看到颜色拾取器,再敲空格键便可以查看屏幕侧边的面板。你可以使用鼠标的滚轮来增加或者减少指针的宽度。
Flameshot 自带一系列非常好的功能,例如:
* 可以进行手写
* 可以划直线
* 可以画长方形或者圆形框
* 可以进行长方形区域选择
* 可以画箭头
* 可以对要点进行标注
* 可以添加文本
* 可以对图片或者文字进行模糊处理
* 可以展示图片的尺寸大小
* 在编辑图片是可以进行撤销和重做操作
* 可以将选择的东西复制到剪贴板
* 可以保存选区
* 可以离开截屏
* 可以选择另一个 app 来打开图片
* 可以上传图片到 imgur 网站
* 可以将图片固定到桌面上
下面是一个示例的视频:
<http://www.ostechnix.com/wp-content/uploads/2018/09/Flameshot-demo.mp4>
### 快捷键
Frameshot 也支持快捷键。在 Flameshot 的托盘图标上右击并点击 “Information” 窗口便可以看到在 GUI 模式下所有可用的快捷键。下面是在 GUI 模式下可用的快捷键清单:
| 快捷键 | 描述 |
| --- | --- |
| `←`、`↓`、`↑`、`→` | 移动选择区域 1px |
| `Shift` + `←`、`↓`、`↑`、`→` | 将选择区域大小更改 1px |
| `Esc` | 退出截图 |
| `Ctrl` + `C` | 复制到粘贴板 |
| `Ctrl` + `S` | 将选择区域保存为文件 |
| `Ctrl` + `Z` | 撤销最近的一次操作 |
| 鼠标右键 | 展示颜色拾取器 |
| 鼠标滚轮 | 改变工具的宽度 |
边按住 `Shift` 键并拖动选择区域的其中一个控制点将会对它相反方向的控制点做类似的拖放操作。
### 命令行选项
Flameshot 也支持一系列的命令行选项来延时截图和保存图片到自定义的路径。
要使用 Flameshot GUI 模式,运行:
```
$ flameshot gui
```
要使用 GUI 模式截屏并将你选取的区域保存到一个自定义的路径,运行:
```
$ flameshot gui -p ~/myStuff/captures
```
要延时 2 秒后打开 GUI 模式可以使用:
```
$ flameshot gui -d 2000
```
要延时 2 秒并将截图保存到一个自定义的路径(无 GUI)可以使用:
```
$ flameshot full -p ~/myStuff/captures -d 2000
```
要截图全屏并保存到自定义的路径和粘贴板中使用:
```
$ flameshot full -c -p ~/myStuff/captures
```
要在截屏中包含鼠标并将图片保存为 PNG 格式可以使用:
```
$ flameshot screen -r
```
要对屏幕 1 进行截屏并将截屏复制到粘贴板中可以运行:
```
$ flameshot screen -n 1 -c
```
你还需要什么功能呢?Flameshot 拥有几乎截屏的所有功能:添加注释、编辑图片、模糊处理或者对要点做高亮等等功能。我想:在我找到它的最佳替代品之前,我将一直使用 Flameshot 来作为我当前的截图工具。请尝试一下它,你不会失望的。
好了,这就是今天的全部内容了。后续将有更多精彩内容,请保持关注!
Cheers!
---
via: <https://www.ostechnix.com/flameshot-a-simple-yet-powerful-feature-rich-screenshot-tool/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,181 | 模拟 Altair 8800 计算机 | https://twobithistory.org/2017/12/02/simulating-the-altair.html | 2018-11-01T21:19:00 | [
"模拟器",
"Altair"
] | https://linux.cn/article-10181-1.html | 
[Altair 8800](https://en.wikipedia.org/wiki/Altair_8800) 是 1975 年发布的自建家用电脑套件。Altair 基本上是第一台个人电脑(PC),虽然 PC 这个名词好几年前就出现了。对 Dell、HP 或者 Macbook 而言它是亚当(或者夏娃)。
有些人认为为 Z80(与 Altair 的 Intel 8080 密切相关的处理器)编写仿真器真是太棒了,并认为它需要一个模拟 Altair 的控制面板。所以如果你想知道 1975 年使用电脑是什么感觉,你可以在你的 Macbook 上运行 Altair:

### 安装它
你可以从[这里](http://www.autometer.de/unix4fun/z80pack/ftp/)的 FTP 服务器下载 Z80 包。你要查找最新的 Z80 包版本,例如 `z80pack-1.26.tgz`。
首先解压文件:
```
$ tar -xvf z80pack-1.26.tgz
```
进入解压目录:
```
$ cd z80pack-1.26
```
控制面板模拟基于名为 `frontpanel` 的库。你必须先编译该库。如果你进入 `frontpanel` 目录,你会发现 `README` 文件列出了这个库自己的依赖项。你在这里的体会几乎肯定会与我的不同,但也许我的痛苦可以作为例子。我安装了依赖项,但是是通过 [Homebrew](http://brew.sh/) 安装的。为了让库能够编译,我必须确保在 `Makefile.osx` 中将 `/usr/local/include`添加到 Clang 的 include 路径中。
如果你觉得依赖没有问题,那么你应该就能编译这个库(我们现在位于 `z80pack-1.26/frontpanel`):
```
$ make -f Makefile.osx ...
$ make -f Makefile.osx clean
```
你应该会得到 `libfrontpanel.so`。我把它拷贝到 `libfrontpanel.so`。
Altair 模拟器位于 `z80pack-1.26/altairsim` 下。你现在需要编译模拟器本身。进入 `z80pack-1.26/altairsim/srcsim` 并再次运行 `make`:
```
$ make -f Makefile.osx ...
$ make -f Makefile.osx clean
```
该过程将在 `z80pack-1.26/altairsim` 中创建一个名为 `altairsim` 的可执行文件。运行该可执行文件,你应该会看到标志性的 Altair 控制面板!
如果你想要探究,请阅读原始的 [Altair 手册](http://www.classiccmp.org/dunfield/altair/d/88opman.pdf)
如果你喜欢这篇文章,我们每两周更新一次!在 Twitter 上关注 [@TwoBitHistory][6](https://twitter.com/TwoBitHistory) 或订阅 [RSS 源](https://twobithistory.org/feed.xml)了解什么时候有新文章。
---
via: <https://twobithistory.org/2017/12/02/simulating-the-altair.html>
作者:[Two-Bit History](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [Altair 8800](https://en.wikipedia.org/wiki/Altair_8800) was a
build-it-yourself home computer kit released in 1975. The Altair was basically
the first personal computer, though it predated the advent of that term by
several years. It is Adam (or Eve) to every Dell, HP, or Macbook out there.
Some people thought it’d be awesome to write an emulator for the Z80—a processor closely related to the Altair’s Intel 8080—and then thought it needed a simulation of the Altair’s control panel on top of it. So if you’ve ever wondered what it was like to use a computer in 1975, you can run the Altair on your Macbook:
### Installing it
You can download Z80 pack from the FTP server available
[here](http://www.autometer.de/unix4fun/z80pack/ftp/). You’re looking for the
latest Z80 pack release, something like `z80pack-1.26.tgz`
.
First unpack the file:
```
$ tar -xvf z80pack-1.26.tgz
```
Move into the unpacked directory:
```
$ cd z80pack-1.26
```
The control panel simulation is based on a library called `frontpanel`
. You’ll
have to compile that library first. If you move into the `frontpanel`
directory, you will find a `README`
file listing the libraries own
dependencies. Your experience here will almost certainly differ from mine, but
perhaps my travails will be illustrative. I had the dependencies installed, but
via [Homebrew](http://brew.sh/). To get the library to compile I just had to
make sure that `/usr/local/include`
was added to Clang’s include path in
`Makefile.osx`
.
If you’ve satisfied the dependencies, you should be able to compile the library
(we’re now in `z80pack-1.26/frontpanel`
:
```
$ make -f Makefile.osx ...
$ make -f Makefile.osx clean
```
You should end up with `libfrontpanel.so`
. I copied this to `/usr/local/lib`
.
The Altair simulator is under `z80pack-1.26/altairsim`
. You now need to compile
the simulator itself. Move into `z80pack-1.26/altairsim/srcsim`
and run `make`
once more:
```
$ make -f Makefile.osx ...
$ make -f Makefile.osx clean
```
That process will create an executable called `altairsim`
one level up in
`z80pack-1.26/altairsim`
. Run that executable and you should see that iconic
Altair control panel!
And if you really want to nerd out, read through the original [Altair
manual](http://www.classiccmp.org/dunfield/altair/d/88opman.pdf).
*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
* |
10,182 | 在 Linux 上使用 systemd 设置定时器 | https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux | 2018-11-01T22:13:50 | [
"systemd",
"定时器"
] | https://linux.cn/article-10182-1.html |
>
> 学习使用 systemd 创建启动你的游戏服务器的定时器。
>
>
>

之前,我们看到了如何[手动的](/article-9700-1.html)、[在开机与关机时](/article-9703-1.html)、[在启用某个设备时](https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change)、[在文件系统发生改变时](https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories) 启用与禁用 systemd 服务。
定时器增加了另一种启动服务的方式,基于……时间。尽管与定时任务很相似,但 systemd 定时器稍微地灵活一些。让我们看看它是怎么工作的。
### “定时运行”
让我们展开[本系列前两篇文章](/article-9703-1.html)中[你所设置的](/article-9700-1.html) [Minetest](https://www.minetest.net/) 服务器作为如何使用定时器单元的第一个例子。如果你还没有读过那几篇文章,可以现在去看看。
你将通过创建一个定时器来“改进” Minetest 服务器,使得在服务器启动 1 分钟后运行游戏服务器而不是立即运行。这样做的原因可能是,在启动之前可能会用到其他的服务,例如发邮件给其他玩家告诉他们游戏已经准备就绪,你要确保其他的服务(例如网络)在开始前完全启动并运行。
最终,你的 `minetest.timer` 单元看起来就像这样:
```
# minetest.timer
[Unit]
Description=Runs the minetest.service 1 minute after boot up
[Timer]
OnBootSec=1 m
Unit=minetest.service
[Install]
WantedBy=basic.target
```
一点也不难吧。
如以往一般,开头是 `[Unit]` 和一段描述单元作用的信息,这儿没什么新东西。`[Timer]` 这一节是新出现的,但它的作用不言自明:它包含了何时启动服务,启动哪个服务的信息。在这个例子当中,`OnBootSec` 是告诉 systemd 在系统启动后运行服务的指令。
其他的指令有:
* `OnActiveSec=`,告诉 systemd 在定时器启动后多长时间运行服务。
* `OnStartupSec=`,同样的,它告诉 systemd 在 systemd 进程启动后多长时间运行服务。
* `OnUnitActiveSec=`,告诉 systemd 在上次由定时器激活的服务启动后多长时间运行服务。
* `OnUnitInactiveSec=`,告诉 systemd 在上次由定时器激活的服务停用后多长时间运行服务。
继续 `minetest.timer` 单元,`basic.target` 通常用作<ruby> 后期引导服务 <rt> late boot services </rt></ruby>的<ruby> 同步点 <rt> synchronization point </rt></ruby>。这就意味着它可以让 `minetest.timer` 单元运行在安装完<ruby> 本地挂载点 <rt> local mount points </rt></ruby>或交换设备,套接字、定时器、路径单元和其他基本的初始化进程之后。就像在[第二篇文章中 systemd 单元](/article-9703-1.html)里解释的那样,`targets` 就像<ruby> 旧的运行等级 <rt> old run levels </rt></ruby>一样,可以将你的计算机置于某个状态,或像这样告诉你的服务在达到某个状态后开始运行。
在前两篇文章中你配置的 `minetest.service` 文件[最终](/article-9703-1.html)看起来就像这样:
```
# minetest.service
[Unit]
Description= Minetest server
Documentation= https://wiki.minetest.net/Main_Page
[Service]
Type= simple
User=
ExecStart= /usr/games/minetest --server
ExecStartPost= /home//bin/mtsendmail.sh "Ready to rumble?" "Minetest Starting up"
TimeoutStopSec= 180
ExecStop= /home//bin/mtsendmail.sh "Off to bed. Nightie night!" "Minetest Stopping in 2 minutes"
ExecStop= /bin/sleep 120
ExecStop= /bin/kill -2 $MAINPID
[Install]
WantedBy= multi-user.target
```
这儿没什么需要修改的。但是你需要将 `mtsendmail.sh`(发送你的 email 的脚本)从:
```
#!/bin/bash
# mtsendmail
sleep 20
echo $1 | mutt -F /home/<username>/.muttrc -s "$2" my_minetest@mailing_list.com
sleep 10
```
改成:
```
#!/bin/bash
# mtsendmail.sh
echo $1 | mutt -F /home/paul/.muttrc -s "$2" [email protected]
```
你做的事是去除掉 Bash 脚本中那些蹩脚的停顿。Systemd 现在来做等待。
### 让它运行起来
确保一切运作正常,禁用 `minetest.service`:
```
sudo systemctl disable minetest
```
这使得系统启动时它不会一同启动;然后,相反地,启用 `minetest.timer`:
```
sudo systemctl enable minetest.timer
```
现在你就可以重启服务器了,当运行 `sudo journalctl -u minetest.*` 后,你就会看到 `minetest.timer` 单元执行后大约一分钟,`minetest.service` 单元开始运行。

*图 1:minetest.timer 运行大约 1 分钟后 minetest.service 开始运行*
### 时间的问题
`minetest.timer` 在 systemd 的日志里显示的启动时间为 09:08:33 而 `minetest.service` 启动时间是 09:09:18,它们之间少于 1 分钟,关于这件事有几点需要说明一下:首先,请记住我们说过 `OnBootSec=` 指令是从引导完成后开始计算服务启动的时间。当 `minetest.timer` 的时间到来时,引导已经在几秒之前完成了。
另一件事情是 systemd 给自己设置了一个<ruby> 误差幅度 <rt> margin of error </rt></ruby>(默认是 1 分钟)来运行东西。这有助于在多个<ruby> 资源密集型进程 <rt> resource-intensive processes </rt></ruby>同时运行时分配负载:通过分配 1 分钟的时间,systemd 可以等待某些进程关闭。这也意味着 `minetest.service` 会在引导完成后的 1~2 分钟之间启动。但精确的时间谁也不知道。
顺便一提,你可以用 `AccuracySec=` 指令[修改误差幅度](https://www.freedesktop.org/software/systemd/man/systemd.timer.html#AccuracySec=)。
你也可以检查系统上所有的定时器何时运行或是上次运行的时间:
```
systemctl list-timers --all
```

*图 2:检查定时器何时运行或上次运行的时间*
最后一件值得思考的事就是你应该用怎样的格式去表示一段时间。Systemd 在这方面非常灵活:`2 h`,`2 hours` 或 `2hr` 都可以用来表示 2 个小时。对于“秒”,你可以用 `seconds`,`second`,`sec` 和 `s`。“分”也是同样的方式:`minutes`,`minute`,`min` 和 `m`。你可以检查 `man systemd.time` 来查看 systemd 能够理解的所有时间单元。
### 下一次
下次你会看到如何使用日历中的日期和时间来定期运行服务,以及如何通过组合定时器与设备单元在插入某些硬件时运行服务。
回头见!
在 Linux 基金会和 edx 上通过免费课程 [“Introduction to Linux”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 学习更多关于 Linux 的知识。
---
via: <https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LuuMing](https://github.com/LuuMing) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,183 | 正确选择开源数据库的 5 个技巧 | https://opensource.com/article/18/10/tips-choosing-right-open-source-database | 2018-11-01T23:21:21 | [
"数据库"
] | https://linux.cn/article-10183-1.html |
>
> 对关键应用的选择不容许丝毫错误。
>
>
>

你或许会遇到需要选择合适的开源数据库的情况。但这无论对于开源方面的老手或是新手,都是一项艰巨的任务。
在过去的几年中,采用开源技术的企业越来越多。面对这样的趋势,众多开源应用公司都纷纷承诺自己提供的解决方案能够各种问题、适应各种负载。但这些承诺不能轻信,在开源应用上的选择是重要而艰难的,尤其是数据库这种关键的应用。
凭借我在 [Percona](https://www.percona.com/) 和其它公司担任 IT 专家的经验,我很幸运能够指导其他人在开源技术的选择上做出正确的决策,因为需要考虑的重要因素太多了。希望通过这篇文章能够向大家分享这方面的一些技巧。
### 有一个明确的目标
这一点看似简单,但在和很多人聊过 MySQL、MongoDB、PostgreSQL 之后,我觉得这一点才是最重要的。
面对繁杂的开源数据库,更需要明确自己的目标。无论这个数据库是作为开发用的标准化数据库后端,抑或是用于替换遗留代码中的原有数据库,这都是一个明确的目标。
目标一旦确定,就可以集中精力与开源软件的提供方商讨更多细节了。
### 了解你的工作负载
尽管开源数据库技术的功能越来越丰富,但这些新加入的功能都不太具有普适性。譬如 MongoDB 新增了事务的支持、MySQL 新增了 JSON 存储的功能等等。目前开源数据库的普遍趋势是不断加入新的功能,但很多人的误区却在于没有选择最适合的工具来完成自己的工作 —— 这样的人或许是一个自大的开发者,又或许是一个视野狭窄的主管 —— 最终导致公司业务上的损失。最致命的是,在业务初期,使用了不适合的工具往往也可以顺利地完成任务,但随着业务的增长,很快就会到达瓶颈,尽管这个时候还可以替换更合适的工具,但成本就比较高了。
例如,如果你需要的是数据分析仓库,关系数据库可能不是一个适合的选择;如果你处理事务的应用要求严格的数据完整性和一致性,就不要考虑 NoSQL 了。
### 不要重新发明轮子
在过去的数十年,开源数据库技术迅速发展壮大。开源数据库从新生,到受到质疑,再到受到认可,现在已经成为很多企业生产环境的数据库。企业不再需要担心选择开源数据库技术会产生风险,因为开源数据库通常都有活跃的社区,可以为越来越多的初创公司、中型企业甚至 500 强公司提供开源数据库领域的支持和第三方工具。
Battery Ventures 是一家专注于技术的投资公司,最近推出了一个用于跟踪最受欢迎开源项目的 [BOSS 指数](https://techcrunch.com/2017/04/07/tracking-the-explosive-growth-of-open-source-software/) 。它提供了对一些被广泛采用的开源项目和活跃的开源项目的详细情况。其中,数据库技术毫无悬念地占据了榜单的主导地位,在前十位之中占了一半。这个 BOSS 指数对于刚接触开源数据库领域的人来说,这是一个很好的切入点。当然,开源技术的提供者也会针对很多常见的典型问题给出对应的解决方案。
我认为,你想要做的事情很可能已经有人解决过了。即使这些先行者的解决方案不一定完全契合你的需求,但也可以从他们成功或失败的案例中根据你自己的需求修改得出合适的解决方案。
如果你采用了一个最前沿的技术,这就是你探索的好机会了。如果你的工作负载刚好适合新的开源数据库技术,放胆去尝试吧。第一个吃螃蟹的人总是会得到意外的挑战和收获。
### 先从简单开始
你的数据库实际上需要达到多少个 [9](https://en.wikipedia.org/wiki/Five_nines) 的可用性?对许多公司来说,“实现高可用性”仅仅只是一个模糊的目标。当然,最常见的答案都会是“它是关键应用,我们无论多短的停机时间都是无法忍受的”。
数据库环境越复杂,管理的难度就越大,成本也会越高。理论上你总可以将数据库的可用性提得更高,但代价将会是大大增加的管理难度和性能下降。所以,先从简单开始,直到有需要时再逐步扩展。
例如,Booking.com 是一个有名的旅游预订网站。但少有人知的是,它使用 MySQL 作为数据库后端。 Booking.com 高级系统架构师 Nicolai Plum 曾经发表过一次[演讲](https://www.percona.com/live/mysql-conference-2015/sessions/bookingcom-evolution-mysql-system-design),讲述了他们公司使用 MySQL 数据库的历程。其中一个重点就是,在初始阶段数据库可以被配置得很简单,然后逐渐变得复杂。对于早期的数据库需求,一个简单的主从架构就足够了,但随着工作负载和数据量的增加,数据库引入了负载均衡、多个读取副本,还使用 Hadoop 进行分析。尽管如此,早期的架构仍然是非常简单的。

### 有疑问,找专家
如果你仍然不确定数据库选择的是否合适,可以在论坛、网站或者与软件的提供者处商讨。研究各种开源数据库是否满足自己的需求是一件很有意义的事,因为总会发现你从不知道的技术。而开源社区就是分享这些信息的地方。
当你接触到开源软件和软件提供者时,有一件重要的事情需要注意。很多公司都有开放的核心业务模式,鼓励采用他们的数据库软件。你可以只接受他们的部分建议和指导,然后用你自己的能力去研究和探索替代方案。
### 总结
选择正确的开源数据库是一个重要的过程。很多时候,人们都会在真正理解需求之前就做出决定,这是本末倒置的。
---
via: <https://opensource.com/article/18/10/tips-choosing-right-open-source-database>
作者:[Barrett Chambers](https://opensource.com/users/barrettc) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | So, your company has a directive to adopt more open source database technologies, and they've recruited you to select the right direction. Whether you are an open source technology veteran or a newcomer, this is a daunting and overwhelming task.
Over the past several years, open source technology adoption has steadily increased in the enterprise space. With its popularity comes a crowded marketplace with open source software companies promising that their solution will solve every problem and fit every workload. Be wary of these promises. Choosing the right open source technology—especially a database—is an important and difficult decision you can't make lightly.
In my experience as an IT professional at [Percona](https://www.percona.com/) and other companies, I've been fortunate to work hands-on in adopting open source technologies and guiding others in making the right decisions. There are many important factors to consider; hopefully, this article will shine a light on a few.
## 1. Have a goal.
This may seem simple, but based on my many conversations with people exploring MySQL, MongoDB, or PostgreSQL, it is top of the list in importance.
To avoid getting overwhelmed by the unlimited combinations of open source database software in the market, have a specific goal in mind. Maybe your goal is to provide your internal developers with a standardized, open source database backend that is managed by your internal database team. Perhaps your goal is to rip and replace the entire functionality of a legacy application and database backend with new open source technology.
Once you have defined a goal, you can focus your efforts. This will lead to better conversations internally as well as externally with open source database software vendors and advocates.
## 2. Understand your workload.
Despite the increasing ability of database technologies to wear many hats, each specializes in certain areas, e.g., MongoDB is now transactional, MySQL now has JSON storage. A growing trend in open source databases involves providing check boxes claiming certain features are available. One of the biggest mistakes is not using the right tool for the right job. Something leads a company down the wrong path—perhaps an overzealous developer or a manager with tunnel vision. The unfortunate thing is that the wrong tool can work fine for smaller volumes of transactions and data, but later there will be bottlenecks that can be solved only by using a different tool.
If you want a data analytics warehouse, an open source relational database is probably not the right choice. If you want a transaction-processing app with rigid data integrity and consistency, NoSQL options may not be the right option.
## 3. Don't reinvent the wheel.
Open source database technologies have rapidly grown, expanded, and hardened over the past several decades. We've seen a transformation from new, questionably production-ready databases to proven, enterprise-grade database backends. It's no longer necessary to be a bleeding edge, early adopter to choose open source database technologies. Organizations have grown around these communities to provide production support and tooling in the open source database space for a growing number of startups, midsized businesses, and Fortune 500 companies.
Battery Ventures, a tech-focused investment firm, recently introduced its [BOSS Index](https://techcrunch.com/2017/04/07/tracking-the-explosive-growth-of-open-source-software/) for tracking the most popular open source projects. It's not perfect, but it provides great insight into some of the most widely adopted and active open source projects. Not surprisingly, database technologies dominate the list, comprising five of the top 10 technologies. This is a great starting point for someone new to the open source database space. A lot of times, vendors have already produced suitable architectures for solving specific problems.
My point is that someone has probably already done what you are trying to do. Learn from their successes and failures. Even if it is not a perfect fit, a solution can likely be modified to suit your needs. For example, Amazon provides a [CloudFormation script](https://docs.aws.amazon.com/quickstart/latest/mongodb/welcome.html) for deploying MongoDB in its EC2 environment.
If you are a bleeding-edge early adopter, that doesn't mean you can't explore. If you have a unique challenge or workload that seems to fit a new open source database technology, go for it. Keep in mind that there are inherent risks (and rewards!) to being an early adopter.
## 4. Start simple
How many[nines](https://en.wikipedia.org/wiki/Five_nines)does your database truly need? "Achieving high availability" is often a nebulous goal for many companies. Of course, the most common answer is "it's mission-critical, and we cannot afford any downtime."
The more complicated your database environment, the more difficult and costly it is to manage. You can theoretically achieve higher uptime, but the tradeoffs will be the feasibility of management and performance. When in doubt, start simple. There are always options to scale out when the need arises.
For example, Booking.com is a widely known travel reservation site. It might be less widely known that it uses MySQL as a database backend. Nicolai Plum, a Booking.com senior systems architect, gave [a talk](https://www.percona.com/live/mysql-conference-2015/sessions/bookingcom-evolution-mysql-system-design) outlining the evolution of the company's MySQL database. One of the takeaways was that the database started simple. It had to evolve over time, but in the beginning, simple master–replica architecture sufficed. As the workload and dataset increased, it introduced load balancers, multiple read replicas, archiving to Hadoop for analytics, etc. However, the early architecture was extremely simple.
## 5. When in doubt, ask an expert.
If you're unsure whether a database would be a good fit, reach out on forums, websites, or to vendors and strike up a conversation. This can be exciting as you research which database technologies meet your requirements and which do not. Often there are suitable alternatives that you haven't considered. The open source community is all about sharing knowledge.
There is one important thing to be aware of when reaching out to open source software and services vendors. Many have open-core business models that incentivize adopting their database software. Take their advice or guidance with a grain of salt and use your own ability to research, create proofs of concept, and explore alternatives.
## Conclusion
Choosing the right open source database is an important decision. Start by asking the right questions. All too often, people put the cart before the horse, making decisions before really understanding their needs.
*Barrett Chambers will present Choosing the Right Open Source Database at All Things Open, October 21-23 in Raleigh, N.C.*
## 2 Comments |
10,184 | 四个开源的 Android 邮件客户端 | https://opensource.com/article/18/10/open-source-android-email-clients | 2018-11-02T06:13:21 | [
"邮件",
"Android"
] | https://linux.cn/article-10184-1.html |
>
> Email 现在还没有绝迹,而且现在大部分邮件都来自于移动设备。
>
>
>

现在一些年轻人正将邮件称之为“老年人的交流方式”,然而事实却是邮件绝对还没有消亡。虽然[协作工具](https://opensource.com/alternatives/trello)、社交媒体,和短信很常用,但是它们还没做好取代邮件这种必要的商业(和社交)通信工具的准备。
考虑到邮件还没有消失,并且(很多研究表明)人们都是在移动设备上阅读邮件,拥有一个好的移动邮件客户端就变得很关键。如果你是一个想使用开源的邮件客户端的 Android 用户,事情就变得有点棘手了。
我们提供了四个开源的 Andorid 邮件客户端供选择。其中两个可以通过 Andorid 官方应用商店 [Google Play](https://play.google.com/store) 下载。你也可以在 [Fossdroid](https://fossdroid.com/) 或者 [F-Droid](https://f-droid.org/) 这些开源 Android 应用库中找到他们。(下方有每个应用的具体下载方式。)
### K-9 Mail
[K-9 Mail](https://k9mail.github.io/) 拥有几乎和 Android 一样长的历史——它起源于 Android 1.0 邮件客户端的一个补丁。它支持 IMAP 和 WebDAV、多用户、附件、emoji 和其它经典的邮件客户端功能。它的[用户文档](https://k9mail.github.io/documentation.html)提供了关于安装、启动、安全、阅读和发送邮件等等的帮助。
K-9 基于 [Apache 2.0](http://www.apache.org/licenses/LICENSE-2.0) 协议开源,[源码](https://github.com/k9mail/k-9)可以从 GitHub 上获得. 应用可以从 [Google Play](https://play.google.com/store/apps/details?id=com.fsck.k9)、[Amazon](https://www.amazon.com/K-9-Dog-Walkers-Mail/dp/B004JK61K0/) 和 [F-Droid](https://f-droid.org/packages/com.fsck.k9/) 上下载。
### p≡p
正如它的全称,”Pretty Easy Privacy”说的那样,[p≡p](https://www.pep.security/android.html.en) 主要关注于隐私和安全通信。它提供自动的、端到端的邮件和附件加密(但要求你的收件人也要能够加密邮件——否则,p≡p 会警告你的邮件将不加密发出)。
你可以从 GitLab 获得[源码](https://pep-security.lu/gitlab/android/pep)(基于 [GPLv3](https://pep-security.lu/gitlab/android/pep/blob/feature/material/LICENSE) 协议),并且可以从应用的官网上找到相应的[文档](https://www.pep.security/docs/)。应用可以在 [Fossdroid](https://fossdroid.com/a/p%E2%89%A1p.html) 上免费下载或者在 [Google Play](https://play.google.com/store/apps/details?id=security.pEp) 上支付一点儿象征性的费用下载。
### InboxPager
[InboxPager](https://github.com/itprojects/InboxPager) 允许你通过 SSL/TLS 协议收发邮件信息,这也表明如果你的邮件提供商(比如 Gmail )没有默认开启这个功能的话,你可能要做一些设置。(幸运的是, InboxPager 提供了 Gmail 的[设置教程](https://github.com/itprojects/InboxPager/blob/HEAD/README.md#gmail-configuration)。)它同时也支持通过 OpenKeychain 应用进行 OpenPGP 加密。
InboxPager 基于 [GPLv3](https://github.com/itprojects/InboxPager/blob/c5641a6d644d001bd4cec520b5a96d7e588cb6ad/LICENSE) 协议,其源码可从 GitHub 获得,并且应用可以从 [F-Droid](https://f-droid.org/en/packages/net.inbox.pager/) 下载。
### FairEmail
[FairEmail](https://email.faircode.eu/) 是一个极简的邮件客户端,它的功能集中于读写信息,没有任何多余的可能拖慢客户端的功能。它支持多个帐号和用户、消息线索、加密等等。
它基于 [GPLv3](https://github.com/M66B/open-source-email/blob/master/LICENSE) 协议开源,[源码](https://github.com/M66B/open-source-email)可以从 GitHub 上获得。你可以在 [Fossdroid](https://fossdroid.com/a/fairemail.html) 上下载 FairEamil;对 Google Play 版本感兴趣的人可以从 [testing the software](https://play.google.com/apps/testing/eu.faircode.email) 获得应用。
肯定还有更多的开源 Android 客户端(或者上述软件的加强版本)——活跃的开发者们可以关注一下。如果你知道还有哪些优秀的应用,可以在评论里和我们分享。
---
via: <https://opensource.com/article/18/10/open-source-android-email-clients>
作者:[Opensource.com](https://opensource.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zianglei](https://github.com/zianglei) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Even though members of the younger generations are trying to bury email as "communication for old people," the reality is email isn't anywhere near its deathbed. While [collaboration tools](https://opensource.com/alternatives/trello), social media, and texting are important, they aren't ready to replace email as an essential business (and social) communications tool.
Given that email isn't going away and most of it is now read on mobile devices (according to a host of studies), having a good mobile email client is critical. If you're an Android user who wants an *open source* email client, things get a little bit tricky.
We've uncovered four open source email clients for Android for you to consider. Two are available in the official Android app store, [Google Play](https://play.google.com/store), and you can find them in one of the open source Android app repositories, [Fossdroid](https://fossdroid.com/) or [F-Droid](https://f-droid.org/). (See below for specific download details for each.)
## K-9 Mail
[K-9 Mail](https://k9mail.github.io/) has been around almost as long as Android has—it originated out of a patch to the Android 1.0 email client. It has support for IMAP and WebDAV, multiple identities, attachments, emojis, and other typical email client features. Its [user documentation](https://k9mail.github.io/documentation.html) offers help on installation, setup, security, reading and sending email, and much more.
K-9 is open sourced under the [Apache 2.0](http://www.apache.org/licenses/LICENSE-2.0) License with [source code](https://github.com/k9mail/k-9) available on GitHub. It's available for download on [Google Play](https://play.google.com/store/apps/details?id=com.fsck.k9), [Amazon](https://www.amazon.com/K-9-Dog-Walkers-Mail/dp/B004JK61K0/), and [F-Droid](https://f-droid.org/packages/com.fsck.k9/).
## p≡p
As its full name, "Pretty Easy Privacy" suggests, [p≡p](https://www.pep.security/android.html.en) is focused on privacy and secure communications. It provides automatic, end-to-end encryption of emails and attachments (provided your recipient also has an encryption solution installed—if not, p≡p warns that your email will be sent without encryption).
You can access the [source code](https://pep-security.lu/gitlab/android/pep) (licensed under [GPLv3](https://pep-security.lu/gitlab/android/pep/blob/feature/material/LICENSE)) from GitLab and find [documentation](https://www.pep.security/docs/) on the app's website. Download p≡p for free on [Fossdroid](https://fossdroid.com/a/p%E2%89%A1p.html) or for a nominal fee on [Google Play](https://play.google.com/store/apps/details?id=security.pEp).
## InboxPager
[InboxPager](https://github.com/itprojects/InboxPager) allows you to send and read email messages over the SSL/TLS protocol, which means you may need to do some tweaking if your email provider (e.g., Gmail) doesn't turn that on by default. (Fortunately, InboxPager offers Gmail [instructions](https://github.com/itprojects/InboxPager/blob/HEAD/README.md#gmail-configuration).) It also supports OpenPGP encryption through the OpenKeychain application.
InboxPager is licensed under [GPLv3](https://github.com/itprojects/InboxPager/blob/c5641a6d644d001bd4cec520b5a96d7e588cb6ad/LICENSE) with [source code](https://github.com/itprojects/InboxPager) available on GitHub, and it can be installed via [F-Droid](https://f-droid.org/en/packages/net.inbox.pager/).
## FairEmail
[FairEmail](https://email.faircode.eu/) takes a minimalistic approach to mobile email, focusing on reading and writing messages—without all the bells and whistles that risk slowing your email client. It supports multiple accounts and identities, message threading, encryption, and more.
It's licensed under [GPLv3](https://github.com/M66B/open-source-email/blob/master/LICENSE) with [source code](https://github.com/M66B/open-source-email) available on GitHub. You can download FairEmail on [Fossdroid](https://fossdroid.com/a/fairemail.html); a Google Play version is available for people interested in [testing the software](https://play.google.com/apps/testing/eu.faircode.email).
There's certainly room for other entries into the open source Android email client space (or for improving the ones above)—motivated developers, take notice. And, if you know of an application we missed, please share it in the comments.
## 1 Comment |
10,185 | Linux 上最好的 9 个免费视频编辑软件(2018) | https://itsfoss.com/best-video-editing-software-linux/ | 2018-11-02T20:43:43 | [
"视频编辑"
] | https://linux.cn/article-10185-1.html |
>
> 概要:这里介绍 Linux 上几个最好的视频编辑器,介绍它们的特性、利与弊,以及如何在你的 Linux 发行版上安装它们。
>
>
>

我们曾经在一篇短文中讨论过 [Linux 上最好的照片管理应用](https://itsfoss.com/linux-photo-management-software/),[Linux 上最好的代码编辑器](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/)。今天我们将讨论 **Linux 上最好的视频编辑软件**。
当谈到免费视频编辑软件,Windows Movie Maker 和 iMovie 是大部分人经常推荐的。
很不幸,上述两者在 GNU/Linux 上都不可用。但是不必担心,我们为你汇集了一个**最好的视频编辑器**清单。
### Linux 上最好的视频编辑器
接下来让我们一起看看这些最好的视频编辑软件。如果你觉得文章读起来太长,这里有一个快速摘要。
| 视频编辑器 | 主要用途 | 类型 |
| --- | --- | --- |
| Kdenlive | 通用视频编辑 | 自由开源 |
| OpenShot | 通用视频编辑 | 自由开源 |
| Shotcut | 通用视频编辑 | 自由开源 |
| Flowblade | 通用视频编辑 | 自由开源 |
| Lightworks | 专业级视频编辑 | 免费增值 |
| Blender | 专业级三维编辑 | 自由开源 |
| Cinelerra | 通用视频编辑 | 自由开源 |
| DaVinci | 专业级视频处理编辑 | 免费增值 |
| VidCutter | 简单视频拆分合并 | 自由开源 |
### 1、 Kdenlive

[Kdenlive](https://kdenlive.org/) 是 [KDE](https://www.kde.org/) 上的一个自由且[开源](https://itsfoss.com/tag/open-source/)的视频编辑软件,支持双视频监控、多轨时间线、剪辑列表、自定义布局、基本效果,以及基本过渡效果。
它支持多种文件格式和多种摄像机、相机,包括低分辨率摄像机(Raw 和 AVI DV 编辑)、mpeg2、mpeg4 和 h264 AVCHD(小型相机和便携式摄像机)、高分辨率摄像机文件(包括 HDV 和 AVCHD 摄像机)、专业摄像机(包括 XDCAM-HD™ 流、IMX™ (D10) 流、DVCAM (D10)、DVCAM、DVCPRO™、DVCPRO50™ 流以及 DNxHD™ 流)。
如果你正寻找 Linux 上 iMovie 的替代品,Kdenlive 会是你最好的选择。
Kdenlive 特性:
* 多轨视频编辑
* 多种音视频格式支持
* 可配置的界面和快捷方式
* 使用文本或图像轻松创建切片
* 丰富的效果和过渡
* 音频和视频示波器可确保镜头绝对平衡
* 代理编辑
* 自动保存
* 广泛的硬件支持
* 关键帧效果
优点:
* 通用视频编辑器
* 对于那些熟悉视频编辑的人来说并不太复杂
缺点:
* 如果你想找的是极致简单的编辑软件,它可能还是令你有些困惑
* KDE 应用程序以臃肿而臭名昭著
#### 安装 Kdenlive
Kdenlive 适用于所有主要的 Linux 发行版。你只需在软件中心搜索即可。[Kdenlive 网站的下载部分](https://kdenlive.org/download/)提供了各种软件包。
命令行爱好者可以通过在 Debian 和基于 Ubuntu 的 Linux 发行版中运行以下命令从终端安装它:
```
sudo apt install kdenlive
```
### 2、 OpenShot

[OpenShot](http://www.openshot.org/) 是 Linux 上的另一个多用途视频编辑器。OpenShot 可以帮助你创建具有过渡和效果的视频。你还可以调整声音大小。当然,它支持大多数格式和编解码器。
你还可以将视频导出至 DVD,上传至 YouTube、Vimeo、Xbox 360 以及许多常见的视频格式。OpenShot 比 Kdenlive 要简单一些。因此,如果你需要界面简单的视频编辑器,OpenShot 是一个不错的选择。
它还有个简洁的[开始使用 Openshot](http://www.openshot.org/user-guide/) 文档。
OpenShot 特性:
* 跨平台,可在 Linux、macOS 和 Windows 上使用
* 支持多种视频,音频和图像格式
* 强大的基于曲线的关键帧动画
* 桌面集成与拖放支持
* 不受限制的音视频轨道或图层
* 可剪辑调整大小、缩放、修剪、捕捉、旋转和剪切
* 视频转换可实时预览
* 合成,图像层叠和水印
* 标题模板,标题创建,子标题
* 利用图像序列支持2D动画
* 3D 动画标题和效果
* 支持保存为 SVG 格式以及矢量标题和可信证
* 滚动动态图片
* 帧精度(逐步浏览每一帧视频)
* 剪辑的时间映射和速度更改
* 音频混合和编辑
* 数字视频效果,包括亮度,伽玛,色调,灰度,色度键等
优点:
* 用于一般视频编辑需求的通用视频编辑器
* 可在 Windows 和 macOS 以及 Linux 上使用
缺点:
* 软件用起来可能很简单,但如果你对视频编辑非常陌生,那么肯定需要一个曲折学习的过程
* 你可能仍然没有达到专业级电影制作编辑软件的水准
#### 安装 OpenShot
OpenShot 也可以在所有主流 Linux 发行版的软件仓库中使用。你只需在软件中心搜索即可。你也可以从[官方页面](http://www.openshot.org/download/)中获取它。
在 Debian 和基于 Ubuntu 的 Linux 发行版中,我最喜欢运行以下命令来安装它:
```
sudo apt install openshot
```
### 3、 Shotcut

[Shotcut](https://www.shotcut.org/) 是 Linux 上的另一个编辑器,可以和 Kdenlive 与 OpenShot 归为同一联盟。虽然它确实与上面讨论的其他两个软件有类似的功能,但 Shotcut 更先进的地方是支持 4K 视频。
支持许多音频、视频格式,过渡和效果是 Shotcut 的众多功能中的一部分。它也支持外部监视器。
这里有一系列视频教程让你[轻松上手 Shotcut](https://www.shotcut.org/tutorials/)。它也可在 Windows 和 macOS 上使用,因此你也可以在其他操作系统上学习。
Shotcut 特性:
* 跨平台,可在 Linux、macOS 和 Windows 上使用
* 支持各种视频,音频和图像格式
* 原生时间线编辑
* 混合并匹配项目中的分辨率和帧速率
* 音频滤波、混音和效果
* 视频转换和过滤
* 具有缩略图和波形的多轨时间轴
* 无限制撤消和重做播放列表编辑,包括历史记录视图
* 剪辑调整大小、缩放、修剪、捕捉、旋转和剪切
* 使用纹波选项修剪源剪辑播放器或时间轴
* 在额外系统显示/监视器上的外部监察
* 硬件支持
你可以在[这里](https://www.shotcut.org/features/)阅它的更多特性。
优点:
* 用于常见视频编辑需求的通用视频编辑器
* 支持 4K 视频
* 可在 Windows,macOS 以及 Linux 上使用
缺点:
* 功能太多降低了软件的易用性
#### 安装 Shotcut
Shotcut 以 [Snap](https://itsfoss.com/use-snap-packages-ubuntu-16-04/) 格式提供。你可以在 Ubuntu 软件中心找到它。对于其他发行版,你可以从此[下载页面](https://www.shotcut.org/download/)获取可执行文件来安装。
### 4、 Flowblade

[Flowblade](http://jliljebl.github.io/flowblade/) 是 Linux 上的一个多轨非线性视频编辑器。与上面讨论的一样,这也是一个自由开源的软件。它具有时尚和现代化的用户界面。
用 Python 编写,它的设计初衷是快速且准确。Flowblade 专注于在 Linux 和其他自由平台上提供最佳体验。所以它没有在 Windows 和 OS X 上运行的版本。Linux 用户专享其实感觉也不错的。
你也可以查看这个不错的[文档](https://jliljebl.github.io/flowblade/webhelp/help.html)来帮助你使用它的所有功能。
Flowblade 特性:
* 轻量级应用
* 为简单的任务提供简单的界面,如拆分、合并、覆盖等
* 大量的音视频效果和过滤器
* 支持[代理编辑](https://jliljebl.github.io/flowblade/webhelp/proxy.html)
* 支持拖拽
* 支持多种视频、音频和图像格式
* 批量渲染
* 水印
* 视频转换和过滤器
* 具有缩略图和波形的多轨时间轴
你可以在 [Flowblade 特性](https://jliljebl.github.io/flowblade/features.html)里阅读关于它的更多信息。
优点:
* 轻量
* 适用于通用视频编辑
缺点:
* 不支持其他平台
#### 安装 Flowblade
Flowblade 应当在所有主流 Linux 发行版的软件仓库中都可以找到。你可以从软件中心安装它。也可以在[下载页面](https://jliljebl.github.io/flowblade/download.html)查看更多信息。
另外,你可以在 Ubuntu 和基于 Ubuntu 的系统中使用一下命令安装 Flowblade:
```
sudo apt install flowblade
```
### 5、 Lightworks

如果你在寻找一个具有更多特性的视频编辑器,这就是你想要的。[Lightworks](https://www.lwks.com/) 是一个跨平台的专业视频编辑器,可以在 Linux、Mac OS X 以及 Windows上使用。
它是一款屡获殊荣的专业[非线性编辑](https://en.wikipedia.org/wiki/Non-linear_editing_system)(NLE)软件,支持高达 4K 的分辨率以及 SD 和 HD 格式的视频。
Lightworks 可以在 Linux 上使用,然而它不开源。
Lightwokrs 有两个版本:
* Lightworks 免费版
* Lightworks 专业版
专业版有更多功能,比如支持更高的分辨率,支持 4K 和蓝光视频等。
这个[页面](https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206&tab=4)有广泛的可用文档。你也可以参考 [Lightworks 视频向导页](https://www.lwks.com/videotutorials)的视频。
Lightworks 特性:
* 跨平台
* 简单直观的用户界面
* 简明的时间线编辑和修剪
* 实时可用的音频和视频FX
* 可用精彩的免版税音频和视频内容
* 适用于 4K 的 Lo-Res 代理工作流程
* 支持导出 YouTube/Vimeo,SD/HD视频,最高可达4K
* 支持拖拽
* 各种音频和视频效果和滤镜
优点:
* 专业,功能丰富的视频编辑器
缺点:
* 免费版有使用限制
#### 安装 Lightworks
Lightworks 为 Debian 和基于 Ubuntu 的 Linux 提供了 DEB 安装包,为基于 Fedora 的 Linux 发行版提供了RPM 安装包。你可以在[下载页面](https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206&tab=1)找到安装包。
### 6、 Blender

[Blender](https://www.blender.org/) 是一个专业的,工业级的开源跨平台视频编辑器。它在制作 3D 作品的工具当中较为流行。Blender 已被用于制作多部好莱坞电影,包括蜘蛛侠系列。
虽然最初设计用于制作 3D 模型,但它也具有多种格式视频的编辑功能。
Blender 特性:
* 实时预览、亮度波形、色度矢量显示和直方图显示
* 音频混合、同步、擦洗和波形可视化
* 最多32个轨道,用于添加视频、图像、音频、场景、面具和效果
* 速度控制、调整图层、过渡、关键帧、过滤器等
你可以在[这里](https://www.blender.org/features/)阅读更多相关特性。
优点:
* 跨平台
* 专业级视频编辑
缺点:
* 复杂
* 主要用于制作 3D 动画,不专门用于常规视频编辑
#### 安装 Blender
Blender 的最新版本可以从[下载页面](https://www.blender.org/download/)下载。
### 7、 Cinelerra

[Cinelerra](http://cinelerra.org/) 从 1998 年发布以来,已被下载超过 500 万次。它是 2003 年第一个在 64 位系统上提供非线性编辑的视频编辑器。当时它是 Linux 用户的首选视频编辑器,但随后一些开发人员丢弃了此项目,它也随之失去了光彩。
好消息是它正回到正轨并且良好地再次发展。
如果你想了解关于 Cinelerra 项目是如何开始的,这里有些[有趣的背景故事](http://cinelerra.org/our-story)。
Cinelerra 特性:
* 非线性编辑
* 支持 HD 视频
* 内置框架渲染器
* 各种视频效果
* 不受限制的图层数量
* 拆分窗格编辑
优点:
* 通用视频编辑器
缺点:
* 不适用于新手
* 没有可用的安装包
#### 安装 Cinelerra
你可以从 [SourceForge](https://sourceforge.net/projects/heroines/files/cinelerra-6-src.tar.xz/download) 下载源码。更多相关信息请看[下载页面](http://cinelerra.org/download)。
### 8、 DaVinci Resolve

如果你想要好莱坞级别的视频编辑器,那就用好莱坞正在使用的专业工具。来自 Blackmagic 公司的 [DaVinci Resolve](https://www.blackmagicdesign.com/products/davinciresolve/) 就是专业人士用于编辑电影和电视节目的专业工具。
DaVinci Resolve 不是常规的视频编辑器。它是一个成熟的编辑工具,在这一个应用程序中提供编辑,色彩校正和专业音频后期制作功能。
DaVinci Resolve 不开源。类似于 LightWorks,它也为 Linux 提供一个免费版本。专业版售价是 $300。
DaVinci Resolve 特性:
* 高性能播放引擎
* 支持所有类型的编辑类型,如覆盖、插入、波纹覆盖、替换、适合填充、末尾追加
* 高级修剪
* 音频叠加
* Multicam Editing 可实现实时编辑来自多个摄像机的镜头
* 过渡和过滤效果
* 速度效果
* 时间轴曲线编辑器
* VFX 的非线性编辑
优点:
* 跨平台
* 专业级视频编辑器
缺点:
* 不适用于通用视频编辑
* 不开源
* 免费版本中有些功能无法使用
#### 安装 DaVinci Resolve
你可以从[这个页面](https://www.blackmagicdesign.com/products/davinciresolve/)下载 DaVinci Resolve。你需要注册,哪怕仅仅下载免费版。
### 9、 VidCutter

不像这篇文章讨论的其他视频编辑器,[VidCutter](https://itsfoss.com/vidcutter-video-editor-linux/) 非常简单。除了分割和合并视频之外,它没有其他太多功能。但有时你正好需要 VidCutter 提供的这些功能。
VidCutter 特性:
* 适用于Linux、Windows 和 MacOS 的跨平台应用程序
* 支持绝大多数常见视频格式,例如:AVI、MP4、MPEG 1/2、WMV、MP3、MOV、3GP、FLV 等等
* 界面简单
* 修剪和合并视频,仅此而已
优点:
* 跨平台
* 很适合做简单的视频分割和合并
缺点:
* 不适合用于通用视频编辑
* 经常崩溃
#### 安装 VidCutter
如果你使用的是基于 Ubuntu 的 Linux 发行版,你可以使用这个官方 PPA(LCTT 译注:PPA,个人软件包档案,PersonalPackageArchives):
```
sudo add-apt-repository ppa:ozmartian/apps
sudo apt-get update
sudo apt-get install vidcutter
```
Arch Linux 用户可以轻松的使用 AUR 安装它。对于其他 Linux 发行版的用户,你可以从这个 [Github 页面](https://github.com/ozmartian/vidcutter/releases)上查找安装文件。
### 哪个是 Linux 上最好的视频编辑软件?
文章里提到的一些视频编辑器使用 [FFmpeg](https://www.ffmpeg.org/)。你也可以自己使用 FFmpeg。它只是一个命令行工具,所以我没有在上文的列表中提到,但一句也不提又不公平。
如果你需要一个视频编辑器来简单的剪切和拼接视频,请使用 VidCutter。
如果你需要的不止这些,**OpenShot** 或者 **Kdenlive** 是不错的选择。他们有规格标准的系统,适用于初学者。
如果你拥有一台高端计算机并且需要高级功能,可以使用 **Lightworks** 或者 **DaVinci Resolve**。如果你在寻找更高级的工具用于制作 3D 作品,你肯定会支持选择 **Blender**。
这就是在 Ubuntu、Linux Mint、Elementary,以及其它发行版等 **Linux 上最好的视频编辑软件**的全部内容。向我们分享你最喜欢的视频编辑器。
---
via: <https://itsfoss.com/best-video-editing-software-linux/>
作者:[itsfoss](https://itsfoss.com/author/itsfoss/) 译者:[fuowang](https://github.com/fuowang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Looking for the **best video editing software for Linux? **You're at the perfect place.
We have focused on listing some of the **best free video editors** suitable for beginners and professionals.
**Some of the applications mentioned here are not open source. They have been included in the context of Linux usage.**
**Non-FOSS Warning!**If you want FOSS-only, please refer to this list of [open source video editors](https://itsfoss.com/open-source-video-editors/).
## 1. Kdenlive
- Cross-platform
- Multi-track video editing
- A wide range of audio and video format supported
- Configurable interface and shortcuts
- Plenty of effects and transitions
- Proxy editing
- Automatic save
- Good hardware support
- Keyframeable effects
[Kdenlive](https://kdenlive.org/) is a free and open-source video editing software from KDE that provides support for **dual video monitors, a multi-track timeline, clip list, customizable layout support, basic effects, and basic transitions.**
It supports a wide variety of file formats from a wide range of camcorders and cameras, including *raw, avi, dv, mpeg2, mpeg4, h.264, AVCHD, HDV*, and more.
It may not be the most modern user experience, but it offers **most of the essential features fit for beginners and professionals**.
**Pros**
- All-purpose video editor
- Not too complicated for those who are familiar with video editing
**Cons**
- It may still be confusing if you are looking for something basic
- KDE applications are infamous for being bloated
**Installing Kdenlive**
Kdenlive is available for all major Linux distributions. You can simply search for it in your software center. Various packages including **AppImage **and** Flatpak** are available in the [download section of Kdenlive website](https://kdenlive.org/download/).
You can also install it from the terminal for Debian and Ubuntu-based Linux distributions using the command below:
`sudo apt install kdenlive`
**Suggested Read 📖**
[7 Best Linux Photo Management SoftwareLooking for a replacement for the good-old Picasa on Linux? Take a look at best photo management applications available for Linux.](https://itsfoss.com/linux-photo-management-software/)

## 2. OpenShot
- Cross-platform support
- Support for a wide range of video, audio, and image formats
- Powerful curve-based Keyframe animations
- Desktop integration with drag and drop support
- Unlimited tracks or layers
- Video transitions with real-time previews
- 3D animated titles and effects
- Time-mapping and speed changes on clips
[OpenShot](https://www.openshot.org/) is another multipurpose video editor for Linux. OpenShot can help you create videos with transitions and effects, and adjust audio levels. Of course, it supports most formats and codecs.
OpenShot is a tad bit simpler than Kdenlive. So if you need **a video editor with a simple UI**, OpenShot is a good choice.
There is also a neat documentation to [get you started with OpenShot](https://www.openshot.org/user-guide/).
**Pros**
- All-purpose video editor for average video editing needs
**Cons**
- The user interface is simple, but it may take a bit of a learning curve if you are extremely new
- It may not be suitable for all kinds of professionals.
**Installing OpenShot**
OpenShot is also available in the repositories of all major Linux distributions. You can simply search for it in your software center. You can also get it from its [official website](https://www.openshot.org/download/).
My favorite way to install OpenShot is to use the following command on Debian and Ubuntu-based Linux distributions:
`sudo apt install openshot-qt`
## 3. Shotcut
- Cross-platform support
- Support for a wide range of video, audio, and image formats
- Native timeline editing
- Mix and match resolutions and frame rates within a project
- Multitrack timeline with thumbnails and waveforms
- Unlimited undo and redo for playlist edits, including a history view
- External monitoring on an extra system display/monitor
- Good hardware support
[Shotcut](https://www.shotcut.org/) is another video editor for Linux that can be put in the same league as Kdenlive and OpenShot. While it does provide similar features as the other two discussed above, Shotcut is a **bit more advanced, with support for 4K videos**.
Support for a number of audio and video formats, transitions, and effects are some of the numerous features of Shotcut. An external monitor is also supported here.
The user interface may not be easy to navigate around for new users. But, there is a collection of official video tutorials available to [get you started with Shotcut](https://www.shotcut.org/tutorials/).
**Pros**
- All-purpose video editor for common video editing needs
- Support for 4K videos
**Cons**
- Too many features reduce the simplicity of the software
**Installing Shotcut**
Shotcut is available as an AppImage, Snap, and as a Flatpak. You may not be able to get it from the official repositories, so those are your best options.
For other platforms, you can explore its [download page](https://www.shotcut.org/download/).
## 4. Flowblade
- Lightweight application
- Supports
[proxy editing](https://jliljebl.github.io/flowblade/webhelp/proxy.html) - Drag and drop support
- Support for a wide range of video, audio, and image formats
- Video transitions and filters
- Multitrack timeline with thumbnails and waveforms
[Flowblade](https://jliljebl.github.io/flowblade/) is a multitrack non-linear video editor for Linux. Like the above-discussed ones, this too is free and open-source software. It comes with a **stylish and modern user interface.**
Written in Python, it is designed to be fast and precise. Flowblade has focused on providing the **best possible experience on Linux as an exclusive**.
You also get a decent [documentation](https://jliljebl.github.io/flowblade/webhelp/help.html) to help you use all of its features.
**Pros**
- Lightweight
- Good for general purpose video editing
**Cons**
- Not available on other platforms
**Installing Flowblade**
Flowblade should be available in the repositories of all major Linux distributions. You can install it from the software center. More information is available on its [download page](https://jliljebl.github.io/flowblade/download.html).
To install Flowblade in Ubuntu and Ubuntu-based systems, use the command below:
`sudo apt install flowblade`
**Suggested Read 📖**
[8 Best Open Source Code Editors for LinuxLooking for the best text editors in Linux for coding? Here’s a list of the best code open source code editors for Linux.](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/)

## 5. Lightworks
- Cross-platform
- Simple & intuitive User Interface
- Easy timeline editing & trimming
- Real-time ready to use audio & video FX
- Access amazing royalty-free audio & video content
- Lo-Res Proxy workflows for 4K
- Export video for YouTube/Vimeo, SD/HD, up to 4K
- Drag and drop support
- Wide variety of audio and video effects and filters
If you looking for video editing software that has more features, and fit for professional work, this is the answer. [Lightworks](https://www.lwks.com/) is a cross-platform professional video editor, available for Linux, macOS, and Windows.
It is a [non-linear editing](https://en.wikipedia.org/wiki/Non-linear_editing_system) (NLE) software that supports resolutions up to 4K as well as video in SD and HD formats.
Lightworks is available for Linux, however it is **not open source**.
This application has three versions:
**Lightworks Free****Lightworks Create****Lightworks Pro**
Pro version has more features, such as higher resolution support, 4K and Blue Ray support, etc.
Extensive documentation is available on its [website](https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206&tab=4). You can also refer to videos at [Lightworks video tutorials page](https://www.lwks.com/videotutorials) to learn more.
**Pros**
- Professional, feature-rich video editor
**Cons**
- Limited free version
**Installing Lightworks**
You need to sign up for a free account to get started using Lightworks. It provides a DEB package to download and install.
You should follow its [official installation instructions](https://lwks.com/guides/how-to-install-and-uninstall-lightworks-for-linux/) to proceed.
## 6. Blender
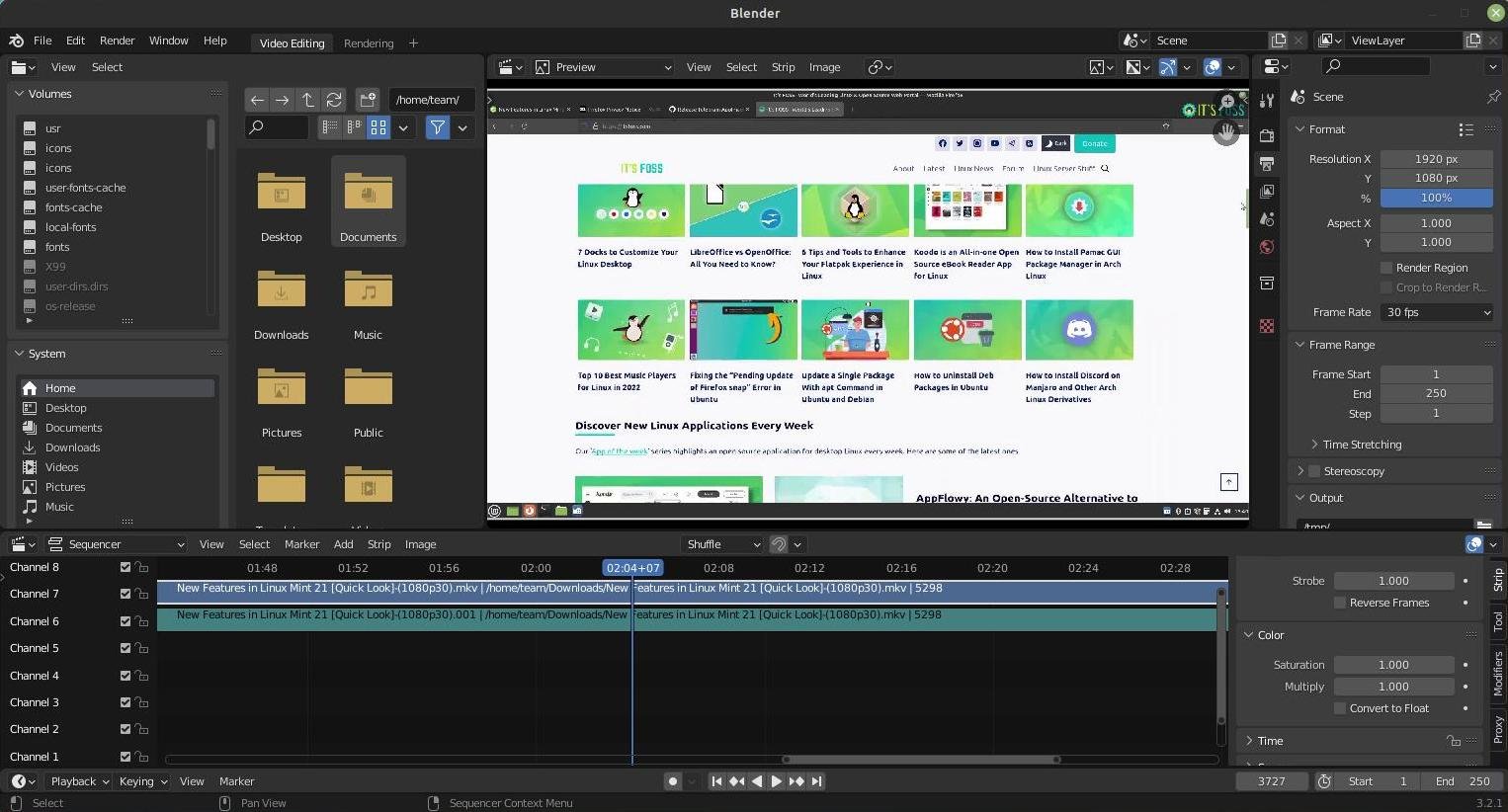
[Blender](https://www.blender.org/) is a **professional, industry-grade, open source, cross-platform video editor**. It is popular for 3D works. Blender has been used in several Hollywood movies, including the Spider-Man series.
Although originally designed for 3D modeling, it can also be used for video editing and has input capabilities with a variety of formats.
**Pros**
- Cross-platform
- Professional grade editing
**Cons**
- Complicated
- Mainly for 3D animation, not focused on regular video editing
**Installing Blender**
You can find it on the official repositories. But, to get the latest version you should opt for Flatpak or other packages available from its [download page](https://www.blender.org/download/).
**Suggested Read 📖**
[Using Flatpak on Ubuntu and Other Linux Distributions [Complete Guide]Flatpak is a universal packaging format from Fedora. Enabling Flatpak will give you access to the easy installation of many Linux applications. Here’s how to use Flatpak in Ubuntu and other Linux distributions.](https://itsfoss.com/flatpak-guide/)

## 7. Cinelerra GG Infinity
- Advanced timeline.
- Motion tracking support.
- Video stabilization.
- Hardware acceleration.
- Allows background rendering over a network with several connected computers.
- HiDPI 4K Monitor Support.
- Keyframe Support.
Cinelerra is a decade-old popular open-source video editor. However, it has several branches (in other words – different versions). I am not sure if that is a good thing, but you get different features (and abilities) on each of them.
[Cinelerra GG](https://www.cinelerra-gg.org/) is the most actively maintained edition with modern features, with new features constantly added. The original edition is an ancient video editor which is no longer being maintained.
**Install Cinelerra GG**
You will not find this in the repositories. So, head to its official website to download the AppImage or any other supported package.
## 8. DaVinci Resolve
- High-performance playback engine
- Advanced Trimming
- Audio Overlays
- Multicam Editing allows editing footage from multiple cameras in real-time
- Timeline curve editor
- Non-linear editing for VFX
If you want film-grade video editing, use the tool the professionals use. [DaVinci Resolve](https://www.blackmagicdesign.com/products/davinciresolve/) from Blackmagic is what professionals are using for editing movies and tv shows.
Unlike the Adobe suite, this is one excellent option that is truly cross-platform.
DaVinci Resolve is not your regular video editor. It’s a full-fledged editing tool that provides editing, color correction, and professional audio post-production in a single application.
DaVinci Resolve is **not open sourc**e. Like LightWorks, it provides a free version for Linux and the pro version costs **$300.**
**Pros**
- Cross-platform
- Professional grade video editor
**Cons**
- Not suitable for average editing
- Not open source
- Some features are not available in the free version
**Installing DaVinci Resolve**
You can download DaVinci Resolve for Linux from [its website](https://www.blackmagicdesign.com/products/davinciresolve/). You’ll have to register, even for the free version.
## 9. VidCutter

- Cross-platform app
- Supports most of the common video formats such as: AVI, MP4, MPEG 1/2, WMV, MP3, MOV, 3GP, FLV, etc.
- Simple interface
- Trims and merges the videos
Unlike all the other video editors discussed here, [VidCutter](https://github.com/ozmartian/vidcutter) is utterly simple. It doesn’t do much except splitting and merging videos. But sometimes that’s what you need and VidCutter gives you just that.
**Pros**
- Cross-platform
- Good for simple split and merge
**Cons**
- Not suitable for regular video editing
- Crashes often
**Installing VidCutter**
It is available as a Flatpak, Snap, AppImage and can be installed using a PPA.
If you want to use the PPA, you can get it using the following command:
```
sudo add-apt-repository ppa:ozmartian/apps
sudo apt-get update
sudo apt-get install vidcutter
```
For other Linux distributions and packages, you can head to its [GitHub page](https://github.com/ozmartian/vidcutter/releases).
## Which is the best video editing software for Linux?
There are some [online video editing tools](https://www.veed.io/tools/video-editor) available that could be used from your web browser in Linux. However, the comfort of a native tool is a different thing altogether.
If you require an editor for simply cutting and joining videos, go with **VidCutter**.
If you require something more than that, **OpenShot** or **Kdenlive** is a good choice. These are suitable for beginners and are systems with standard specifications.
If you have a high-end computer and need advanced features you can go out with **Lightworks** or **DaVinci Resolve**. If you are looking for more advanced features for 3D works, **Blender** has got your back.
💬 *What do you think is the best video editing software for Linux? Share your thoughts in the comments down below.* |
10,186 | Gifski:一个跨平台的高质量 GIF 编码器 | https://www.ostechnix.com/gifski-a-cross-platform-high-quality-gif-encoder/ | 2018-11-02T21:11:00 | [
"gif",
"动画"
] | https://linux.cn/article-10186-1.html | 
作为一名文字工作者,我需要在我的文章中添加图片。有时为了更容易讲清楚某个概念,我还会添加视频或者 gif 动图,相比于文字,通过视频或者 gif 格式的输出,读者可以更容易地理解我的指导。前些天,我已经写了篇文章来介绍针对 Linux 的功能丰富的强大截屏工具 [Flameshot](/article-10180-1.html)。今天,我将向你展示如何从一段视频或者一些图片来制作高质量的 gif 动图。这个工具就是 **Gifski**,一个跨平台、开源、基于 **Pngquant** 的高质量命令行 GIF 编码器。
对于那些好奇 pngquant 是什么的读者,简单来说 pngquant 是一个针对 PNG 图片的无损压缩命令行工具。相信我,pngquant 是我使用过的最好的 PNG 无损压缩工具。它可以将 PNG 图片最高压缩 **70%** 而不会损失图片的原有质量并保存了所有的阿尔法透明度。经过压缩的图片可以在所有的网络浏览器和系统中使用。而 Gifski 是基于 Pngquant 的,它使用 pngquant 的功能来创建高质量的 GIF 动图。Gifski 能够创建每帧包含上千种颜色的 GIF 动图。Gifski 也需要 **ffmpeg** 来将视频转换为 PNG 图片。
### 安装 Gifski
首先需要确保你安装了 FFMpeg 和 Pngquant。
FFmpeg 在大多数的 Linux 发行版的默认软件仓库中都可以获取到,所以你可以使用默认的包管理器来安装它。具体的安装过程,请参考下面链接中的指导。
* [在 Linux 中如何安装 FFmpeg](https://www.ostechnix.com/install-ffmpeg-linux/)
Pngquant 可以从 [AUR](https://aur.archlinux.org/packages/pngquant/) 中获取到。要在基于 Arch 的系统安装它,使用任意一个 AUR 帮助程序即可,例如下面示例中的 [Yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/):
```
$ yay -S pngquant
```
在基于 Debian 的系统中,运行:
```
$ sudo apt install pngquant
```
假如在你使用的发行版中没有 pngquant,你可以从源码编译并安装它。为此你还需要安装 `libpng-dev` 包。
```
$ git clone --recursive https://github.com/kornelski/pngquant.git
$ make
$ sudo make install
```
安装完上述依赖后,再安装 Gifski。假如你已经安装了 [Rust](https://www.ostechnix.com/install-rust-programming-language-in-linux/) 编程语言,你可以使用 **cargo** 来安装它:
```
$ cargo install gifski
```
另外,你还可以使用 [Linuxbrew](https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/) 包管理器来安装它:
```
$ brew install gifski
```
假如你不想安装 cargo 或 Linuxbrew,可以从它的 [发布页面](https://github.com/ImageOptim/gifski/releases) 下载最新的二进制程序,或者手动从源码编译并安装 gifski 。
### 使用 Gifski 来创建高质量的 GIF 动图
进入你保存 PNG 图片的目录,然后运行下面的命令来从这些图片创建 GIF 动图:
```
$ gifski -o file.gif *.png
```
上面的 `file.gif` 为最后输出的 gif 动图。
Gifski 还有其他的特性,例如:
* 创建特定大小的 GIF 动图
* 在每秒钟展示特定数目的动图
* 以特定的质量编码
* 更快速度的编码
* 以给定顺序来编码图片,而不是以排序的结果来编码
为了创建特定大小的 GIF 动图,例如宽为 800,高为 400,可以使用下面的命令:
```
$ gifski -o file.gif -W 800 -H 400 *.png
```
你可以设定 GIF 动图在每秒钟展示多少帧,默认值是 **20**。为此,可以运行下面的命令:
```
$ gifski -o file.gif --fps 1 *.png
```
在上面的例子中,我指定每秒钟展示 1 帧。
我们还能够以特定质量(1-100 范围内)来编码。显然,更低的质量将生成更小的文件,更高的质量将生成更大的 GIF 动图文件。
```
$ gifski -o file.gif --quality 50 *.png
```
当需要编码大量图片时,Gifski 将会花费更多时间。如果想要编码过程加快到通常速度的 3 倍左右,可以运行:
```
$ gifski -o file.gif --fast *.png
```
请注意上面的命令产生的 GIF 动图文件将减少 10% 的质量,并且文件大小也会更大。
如果想让图片以某个给定的顺序(而不是通过排序)精确地被编码,可以使用 `--nosort` 选项。
```
$ gifski -o file.gif --nosort *.png
```
假如你不想让 GIF 循环播放,只需要使用 `--once` 选项即可:
```
$ gifski -o file.gif --once *.png
```
### 从视频创建 GIF 动图
有时或许你想从一个视频创建 GIF 动图。这也是可以做到的,这时候 FFmpeg 便能提供帮助。首先像下面这样,将视频转换成一系列的 PNG 图片:
```
$ ffmpeg -i video.mp4 frame%04d.png
```
上面的命令将会从 `video.mp4` 这个视频文件创建名为 “frame0001.png”、“frame0002.png”、“frame0003.png” 等等形式的图片(其中的 `%04d` 代表帧数),然后将这些图片保存在当前的工作目录。
转换好图片后,只需要运行下面的命令便可以制作 GIF 动图了:
```
$ gifski -o file.gif *.png
```
想知晓更多的细节,请参考它的帮助部分:
```
$ gifski -h
```
[这是](https://gif.ski/jazz-chromecast-ultra.gif)使用 Gifski 创建的示例 GIF 动图文件。
正如你看到的那样,GIF 动图的质量看起来是非常好的。
好了,这就是全部内容了。希望这篇指南对你有所帮助。更多精彩内容即将呈现,请保持关注!
干杯吧!
---
```
via: https://www.ostechnix.com/gifski-a-cross-platform-high-quality-gif-encoder/
```
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,187 | 6 个用于写书的开源工具 | https://opensource.com/article/18/9/writing-book-open-source-tools | 2018-11-02T21:45:36 | [
"书籍"
] | https://linux.cn/article-10187-1.html |
>
> 这些多能、免费的工具可以满足你撰写、编辑和生成你自己的书籍的全部需求。
>
>
>

我在 1993 年首次使用并贡献了免费和开源软件,从那时起我一直是一名开源软件的开发人员和布道者。尽管我被记住的一个项目是 [FreeDOS 项目](http://www.freedos.org/),这是一个 DOS 操作系统的开源实现,但我已经编写或者贡献了数十个开源软件项目。
我最近写了一本关于 FreeDOS 的书。《[使用 FreeDOS](http://www.freedos.org/ebook/)》是我庆祝 FreeDOS 出现 24 周年而撰写的。它是关于安装和使用 FreeDOS、关于我最喜欢的 DOS 程序,以及 DOS 命令行和 DOS 批处理编程的快速参考指南的集合。在一位出色的专业编辑的帮助下,我在过去的几个月里一直在编写这本书。
《使用 FreeDOS》 可在知识共享署名(cc-by)国际公共许可证下获得。你可以从 [FreeDOS 电子书](http://www.freedos.org/ebook/)网站免费下载 EPUB 和 PDF 版本。(我也计划为那些喜欢纸质的人提供印刷版本。)
这本书几乎完全是用开源软件制作的。我想分享一下对用来创建、编辑和生成《使用 FreeDOS》的工具的看法。
### Google 文档
[Google 文档](https://www.google.com/docs/about/)是我使用的唯一不是开源软件的工具。我将我的第一份草稿上传到 Google 文档,这样我就能与编辑器进行协作。我确信有开源协作工具,但 Google 文档能够让两个人同时编辑同一个文档、发表评论、编辑建议和更改跟踪 —— 更不用说它使用段落样式和能够下载完成的文档 —— 这使其成为编辑过程中有价值的一部分。
### LibreOffice
我开始使用的是 [LibreOffice](https://www.libreoffice.org/) 6.0,但我最终使用 LibreOffice 6.1 完成了这本书。我喜欢 LibreOffice 对样式的丰富支持。段落样式可以轻松地为标题、页眉、正文、示例代码和其他文本应用样式。字符样式允许我修改段落中文本的外观,例如内联示例代码或用不同的样式代表文件名。图形样式让我可以将某些样式应用于截图和其他图像。页面样式允许我轻松修改页面的布局和外观。
### GIMP
我的书包括很多 DOS 程序截图、网站截图和 FreeDOS 的 logo。我用 [GIMP](https://www.gimp.org/) 修改这本书的图像。通常,只是裁剪或调整图像大小,但在我准备本书的印刷版时,我使用 GIMP 创建了一些更适于打印布局的图像。
### Inkscape
大多数 FreeDOS 的 logo 和小鱼吉祥物都是 SVG 格式,我使用 [Inkscape](https://inkscape.org/) 来调整它们。在准备电子书的 PDF 版本时,我想在页面顶部放置一个简单的蓝色横幅,角落里有 FreeDOS 的 logo。实验后,我发现在 Inkscape 中创建一个我想要的横幅 SVG 图案更容易,然后我将其粘贴到页眉中。
### ImageMagick
虽然使用 GIMP 来完成这项工作也很好,但有时在一组图像上运行 [ImageMagick](https://www.imagemagick.org/) 命令会更快,例如转换为 PNG 格式或调整图像大小。
### Sigil
LibreOffice 可以直接导出到 EPUB 格式,但它不是个好的转换器。我没有尝试使用 LibreOffice 6.1 创建 EPUB,但在 LibreOffice 6.0 中没有包含我的图像。它还以奇怪的方式添加了样式。我使用 [Sigil](https://sigil-ebook.com/) 来调整 EPUB 并使一切看起来正常。Sigil 甚至还有预览功能,因此你可以看到 EPUB 的样子。
### QEMU
因为本书是关于安装和运行 FreeDOS 的,所以我需要实际运行 FreeDOS。你可以在任何 PC 模拟器中启动 FreeDOS,包括 VirtualBox、QEMU、GNOME Boxes、PCem 和 Bochs。但我喜欢 [QEMU](https://www.qemu.org/) 的简单性。QEMU 控制台允许你以 PPM 格式转储屏幕,这非常适合抓取截图来包含在书中。
当然,我不得不提到在 [Linux](https://www.kernel.org/) 上运行 [GNOME](https://www.gnome.org/)。我使用 Linux 的 [Fedora](https://getfedora.org/) 发行版。
---
via: <https://opensource.com/article/18/9/writing-book-open-source-tools>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I first used and contributed to free and open source software in 1993, and since then I've been an open source software developer and evangelist. I've written or contributed to dozens of open source software projects, although the one that I'll be remembered for is the [FreeDOS Project](http://www.freedos.org/), an open source implementation of the DOS operating system.
I recently wrote a book about FreeDOS. [ Using FreeDOS](http://www.freedos.org/ebook/) is my celebration of the 24
thanniversary of FreeDOS. It is a collection of how-to's about installing and using FreeDOS, essays about my favorite DOS applications, and quick-reference guides to the DOS command line and DOS batch programming. I've been working on this book for the last few months, with the help of a great professional editor.
*Using FreeDOS* is available under the Creative Commons Attribution (cc-by) International Public License. You can download the EPUB and PDF versions at no charge from the [FreeDOS e-books](http://www.freedos.org/ebook/) website. (I'm also planning a print version, for those who prefer a bound copy.)
The book was produced almost entirely with open source software. I'd like to share a brief insight into the tools I used to create, edit, and produce *Using FreeDOS*.
## Google Docs
[Google Docs](https://www.google.com/docs/about/) is the only tool I used that isn't open source software. I uploaded my first drafts to Google Docs so my editor and I could collaborate. I'm sure there are open source collaboration tools, but Google Doc's ability to let two people edit the same document at the same time, make comments, edit suggestions, and change tracking—not to mention its use of paragraph styles and the ability to download the finished document—made it a valuable part of the editing process.
## LibreOffice
I started on [LibreOffice](https://www.libreoffice.org/) 6.0 but I finished the book using LibreOffice 6.1. I love LibreOffice's rich support of styles. Paragraph styles made it easy to apply a style for titles, headers, body text, sample code, and other text. Character styles let me modify the appearance of text within a paragraph, such as inline sample code or a different style to indicate a filename. Graphics styles let me apply certain styling to screenshots and other images. And page styles allowed me to easily modify the layout and appearance of the page.
## GIMP
My book includes a lot of DOS program screenshots, website screenshots, and FreeDOS logos. I used [GIMP](https://www.gimp.org/) to modify these images for the book. Usually, this was simply cropping or resizing an image, but as I prepare the print edition of the book, I'm using GIMP to create a few images that will be simpler for print layout.
## Inkscape
Most of the FreeDOS logos and fish mascots are in SVG format, and I used [Inkscape](https://inkscape.org/) for any image tweaking here. And in preparing the PDF version of the ebook, I wanted a simple blue banner at top of the page, with the FreeDOS logo in the corner. After some experimenting, I found it easier to create an SVG image in Inkscape that looked like the banner I wanted, and I pasted that into the header.
## ImageMagick
While it's great to use GIMP to do the fine work, sometimes it's faster to run an [ImageMagick](https://www.imagemagick.org/) command over a set of images, such as to convert into PNG format or to resize images.
## Sigil
LibreOffice can export directly to EPUB format, but it wasn't a great transfer. I haven't tried creating an EPUB with LibreOffice 6.1, but LibreOffice 6.0 didn't include my images. It also added styles in a weird way. I used [Sigil](https://sigil-ebook.com/) to tweak the EPUB file and make everything look right. Sigil even has a preview function so you can see what the EPUB will look like.
## QEMU
Because this book is about installing and running FreeDOS, I needed to actually run FreeDOS. You can boot FreeDOS inside any PC emulator, including VirtualBox, QEMU, GNOME Boxes, PCem, and Bochs. But I like the simplicity of [QEMU](https://www.qemu.org/). And the QEMU console lets you issue a screen dump in PPM format, which is ideal for grabbing screenshots to include in the book.
Of course, I have to mention running [GNOME](https://www.gnome.org/) on [Linux](https://www.kernel.org/). I use the [Fedora](https://getfedora.org/) distribution of Linux.
## 12 Comments |
10,188 | 10 个最值得关注的树莓派博客 | https://opensource.com/article/18/8/top-10-raspberry-pi-blogs-follow | 2018-11-02T23:14:05 | [
"树莓派"
] | /article-10188-1.html |
>
> 如果你正在计划你的下一个树莓派项目,那么这些博客或许有帮助。
>
>
>

网上有很多很棒的树莓派爱好者网站、教程、代码仓库、YouTube 频道和其他资源。以下是我最喜欢的十大树莓派博客,排名不分先后。
### 1、Raspberry Pi Spy
树莓派粉丝 Matt Hawkins 从很早开始就在他的网站 [Raspberry Pi Spy](https://www.raspberrypi-spy.co.uk/) 上撰写了大量全面且信息丰富的教程。我从这个网站上直接学到了很多东西,而且 Matt 似乎也总是涵盖到众多主题的第一个人。在我学习使用树莓派的前三年里,多次在这个网站得到帮助。
值得庆幸的是,这个不断采用新技术的网站仍然很强大。我希望看到它继续存在下去,让新社区成员在需要时得到帮助。
### 2、Adafruit
[Adafruit](https://blog.adafruit.com/category/raspberry-pi/) 是硬件黑客中知名品牌之一。该公司制作和销售漂亮的硬件,并提供由员工、社区成员,甚至 Lady Ada 女士自己编写的优秀教程。
除了网上商店,Adafruit 还经营一个博客,这个博客充满了来自世界各地的精彩内容。在博客上可以查看树莓派的类别,特别是在工作日的最后一天,会在 Adafruit Towers 举办名为 [Friday is Pi Day](https://blog.adafruit.com/category/raspberry-pi/) 的活动。
### 3、Recantha 的 Raspberry Pi Pod
Mike Horne(Recantha)是英国一位重要的树莓派社区成员,负责 [CamJam 和 Potton Pi&Pint](https://camjam.me/?page_id=753)(剑桥的两个树莓派社团)以及 [Pi Wars](https://piwars.org/) (一年一度的树莓派机器人竞赛)。他为其他人建立树莓派社团提供建议,并且总是有时间帮助初学者。Horne 和他的共同组织者 Tim Richardson 一起开发了 CamJam Edu Kit (一系列小巧且价格合理的套件,适合初学者使用 Python 学习物理计算)。
除此之外,他还运营着 [Pi Pod](https://www.recantha.co.uk/blog/),这是一个包含了世界各地树莓派相关内容的博客。它可能是这个列表中更新最频繁的树莓派博客,所以这是一个把握树莓派社区动向的极好方式。
### 4. Raspberry Pi 官方博客
必须提一下[树莓派基金会](https://www.raspberrypi.org/blog/)的官方博客,这个博客涵盖了基金会的硬件、软件、教育、社区、慈善和青年编码俱乐部的一系列内容。博客上的大型主题是家庭数字化、教育授权,以及硬件版本和软件更新的官方新闻。
该博客自 [2011 年](https://www.raspberrypi.org/blog/first-post/) 运行至今,并提供了自那时以来所有 1800 多个帖子的 [存档](https://www.raspberrypi.org/blog/archive/) 。你也可以在 Twitter 上关注[@raspberrypi\_otd](https://twitter.com/raspberrypi_otd),这是我用 [Python](https://github.com/bennuttall/rpi-otd-bot/blob/master/src/bot.py) 创建的机器人(教程在这里:[Opensource.com](https://opensource.com/article/17/8/raspberry-pi-twitter-bot))。Twitter 机器人推送来自博客存档的过去几年同一天的树莓派帖子。
### 5、RasPi.tv
另一位开创性的树莓派社区成员是 Alex Eames,通过他的博客和 YouTube 频道 [RasPi.tv](https://rasp.tv/),他很早就加入了树莓派社区。他的网站为很多创客项目提供高质量、精心制作的视频教程和书面指南。
Alex 的网站 [RasP.iO](https://rasp.io/) 制作了一系列树莓派附加板和配件,包括方便的 GPIO 端口引脚、电路板测量尺等等。他的博客也拓展到了 [Arduino](https://www.arduino.cc/)、[WEMO](http://community.wemo.com/) 以及其他小网站。
### 6、pyimagesearch
虽然不是严格的树莓派博客(名称中的“py”是“Python”,而不是“树莓派”),但该网站的 [树莓派栏目](https://www.pyimagesearch.com/category/raspberry-pi/) 有着大量内容。 Adrian Rosebrock 获得了计算机视觉和机器学习领域的博士学位,他的博客旨在分享他在学习和制作自己的计算机视觉项目时所学到的机器学习技巧。
如果你想使用树莓派的相机模块学习面部或物体识别,来这个网站就对了。Adrian 在图像识别领域的深度学习和人工智能知识和实际应用是首屈一指的,而且他编写了自己的项目,这样任何人都可以进行尝试。
### 7、Raspberry Pi Roundup
这个[博客](https://thepihut.com/blogs/raspberry-pi-roundup)由英国官方树莓派经销商之一 The Pi Hut 进行维护,会有每周的树莓派新闻。这是另一个很好的资源,可以紧跟树莓派社区的最新资讯,而且之前的文章也值得回顾。
### 8、Dave Akerman
[Dave Akerman](http://www.daveakerman.com/) 是研究高空热气球的一流专家,他分享使用树莓派以最低的成本进行热气球发射方面的知识和经验。他会在一张由热气球拍摄的平流层照片下面对本次发射进行评论,也会对个人发射树莓派热气球给出自己的建议。
查看 Dave 的[博客](http://www.daveakerman.com/),了解精彩的临近空间摄影作品。
### 9、Pimoroni
[Pimoroni](https://blog.pimoroni.com/) 是一家世界知名的树莓派经销商,其总部位于英国谢菲尔德。这家经销商制作了著名的 [树莓派彩虹保护壳](https://shop.pimoroni.com/products/pibow-for-raspberry-pi-3-b-plus),并推出了许多极好的定制附加板和配件。
Pimoroni 的博客布局与其硬件设计和品牌推广一样精美,博文内容非常适合创客和业余爱好者在家进行创作,并且可以在有趣的 YouTube 频道 [Bilge Tank](https://www.youtube.com/channel/UCuiDNTaTdPTGZZzHm0iriGQ) 上找到。
### 10、Stuff About Code
Martin O'Hanlon 以树莓派社区成员的身份转为了树莓派基金会的员工,他起初出于乐趣在树莓派上开发“我的世界”作弊器,最近作为内容编辑加入了树莓派基金会。幸运的是,马丁的新工作并没有阻止他更新[博客](https://www.stuffaboutcode.com/)并与世界分享有益的趣闻。
除了“我的世界”的很多内容,你还可以在 Python 库、[Blue Dot](https://bluedot.readthedocs.io/en/latest/#) 和 [guizero](https://lawsie.github.io/guizero/) 上找到 Martin O'Hanlon 的贡献,以及一些总结性的树莓派技巧。
---
via: <https://opensource.com/article/18/8/top-10-raspberry-pi-blogs-follow>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jlztan](https://github.com/jlztan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,189 | 9 个提升开发者与设计师协作的方法 | https://opensource.com/article/18/5/9-ways-improve-collaboration-developers-designers | 2018-11-03T23:17:00 | [
"协作"
] | https://linux.cn/article-10189-1.html |
>
> 抛开成见,设计师和开发者的命运永远交织在一起。 以下是如何让每个人都在同一页面上。
>
>
>

在任何软件项目中,设计至关重要。设计师不像开发团队那样熟悉其内部工作,但迟早都要知道开发人员写代码的意图。
两边都有自己的成见。工程师经常认为设计师们古怪不理性,而设计师也认为工程师们死板要求高。在一天的工作快要结束时,情况会变得更加微妙。设计师和开发者们的命运永远交织在一起。
做到以下九件事,便可以改进他们之间的合作。
### 1. 首先,说实在的,打破壁垒
几乎每一个行业都有“<ruby> 迷墙 <rt> wall of confusion </rt></ruby>”的因子。无论你干什么工作,拆除这堵墙的第一步就是要双方都认同它需要拆除。一旦所有的人都认为现有的流程效率低下,你就可以从其它想法中获得灵感,然后解决问题。
### 2. 学会共情
在开始干之前,先等一下。这是团队建设的重要的交汇点,也是建立共同认知的时机:我们都是成人,我们都有自己的优点与缺点,更重要的是,我们是一个团队。围绕工作流程与工作效率的讨论会经常发生,因此在开始之前,建立一个信任与协作的基础至关重要。
### 3. 认识差异
设计师和开发者从不同的角度攻克问题。对于相同的问题,设计师会追求更好的效果,而开发者会寻求更高的效率。这两种观点不必互相排斥。谈判和妥协的余地很大,并且在二者之间必然存在一个用户满意度最佳的中点。
### 4. 拥抱共性
这一切都是与工作流程相关的。<ruby> 持续集成 <rt> Continuous Integration </rt></ruby>/<ruby> 持续交付 <rt> Continuous Delivery </rt></ruby>,scrum,agile 等等,都基本上说了一件事:构思,迭代,考察,重复。迭代和重复是两种工作的相同点。因此,不再让开发周期紧跟设计周期,而是同时并行地运行它们,这样会更有意义。<ruby> 同步周期 <rt> Syncing cycles </rt></ruby>允许团队在每个环节交流、协作、互相影响。
### 5. 管理期望
一切冲突的起因一言以蔽之:期望不符。因此,防止系统性分裂的简单办法就是通过确保团队成员在说之前先想、在做之前先说来管理期望。设定的期望往往会通过日常对话不断演变。强迫团队通过开会以达到其效果可能会适得其反。
### 6. 按需开会
只在工作开始和工作结束开一次会远远不够。但也不意味着每天或每周都要开会。定期开会也可能会适得其反。试着按需开会吧。即兴会议,即使是员工闲聊,也可能会发生很棒的事情。如果你的团队是分散式的或者甚至有一名远程员工,视频会议,文本聊天或者打电话都是开会的好方法。团队中的每人都有多种方式互相沟通,这一点非常重要。
### 7. 建立词库
设计师和开发者有时候对相似的想法有着不同的术语,就像把猫叫成喵。毕竟,比起术语的准确度和合适度来,大家统一说法才更重要。
### 8. 学会沟通
无论什么时候,团队中的每个人都有责任去维持一个有效的沟通。每个人都应该努力做到一字一板。
### 9. 不断改善
仅一名团队成员就能破坏整个进度。全力以赴。如果每个人都不关心产品或目标,继续项目或者做出改变的动机就会出现问题。
---
via: <https://opensource.com/article/18/5/9-ways-improve-collaboration-developers-designers>
作者:[Jason Brock](https://opensource.com/users/jkbrock), [Jason Porter](https://opensource.com/users/lightguardjp) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LuuMing](https://github.com/LuuMing) 校对:[pityonline](https://github.com/pityonline)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *This article was co-written with Jason Porter.*
Design is a crucial element in any software project. Sooner or later, the developers' reasons for writing all this code will be communicated to the designers, human beings who aren't as familiar with its inner workings as the development team.
Stereotypes exist on both side of the divide; engineers often expect designers to be flaky and irrational, while designers often expect engineers to be inflexible and demanding. The truth is considerably more nuanced and, at the end of the day, the fates of designers and developers are forever intertwined.
Here are nine things that can improve collaboration between the two.
## 1. First, knock down the wall. Seriously.
There are loads of memes about the "wall of confusion" in just about every industry. No matter what else you do, the first step toward tearing down this wall is getting both sides to agree it needs to be gone. Once everyone agrees the existing processes aren't functioning optimally, you can pick and choose from the rest of these ideas to begin fixing the problems.
## 2. Learn to empathize.
Before rolling up any sleeves to build better communication, take a break. This is a great junction point for team building. A time to recognize that we're all people, we all have strengths and weaknesses, and most importantly, we're all on the same team. Discussions around workflows and productivity can become feisty, so it's crucial to build a foundation of trust and cooperation before diving on in.
## 3. Recognize differences.
Designers and developers attack the same problem from different angles. Given a similar problem, designers will seek the solution with the biggest impact while developers will seek the solution with the least amount of waste. These two viewpoints do not have to be mutually exclusive. There is plenty of room for negotiation and compromise, and somewhere in the middle is where the end user receives the best experience possible.
## 4. Embrace similarities.
This is all about workflow. CI/CD, scrum, agile, etc., are all basically saying the same thing: Ideate, iterate, investigate, and repeat. Iteration and reiteration are common denominators for both kinds of work. So instead of running a design cycle followed by a development cycle, it makes much more sense to run them concurrently and in tandem. Syncing cycles allows teams to communicate, collaborate, and influence each other every step of the way.
## 5. Manage expectations.
All conflict can be distilled down to one simple idea: incompatible expectations. Therefore, an easy way to prevent systemic breakdowns is to manage expectations by ensuring that teams are thinking before talking and talking before doing. Setting expectations often evolves organically through everyday conversation. Forcing them to happen by having meetings can be counterproductive.
## 6. Meet early and meet often.
Meeting once at the beginning of work and once at the end simply isn't enough. This doesn't mean you need daily or even weekly meetings. Setting a cadence for meetings can also be counterproductive. Let them happen whenever they're necessary. Great things can happen with impromptu meetings—even at the watercooler! If your team is distributed or has even one remote employee, video conferencing, text chat, or phone calls are all excellent ways to meet. It's important that everyone on the team has multiple ways to communicate with each other.
## 7. Build your own lexicon.
Designers and developers sometimes have different terms for similar ideas. One person's card is another person's tile is a third person's box. Ultimately, the fit and accuracy of a term aren't as important as everyone's agreement to use the same term consistently.
## 8. Make everyone a communication steward.
Everyone in the group is responsible for maintaining effective communication, regardless of how or when it happens. Each person should strive to say what they mean and mean what they say.
## 9. Give a darn.
It only takes one member of a team to sabotage progress. Go all in. If every individual doesn't care about the product or the goal, there will be problems with motivation to make changes or continue the process.
This article is based on [Designers and developers: Finding common ground for effective collaboration](https://agenda.summit.redhat.com/SessionDetail.aspx?id=154267), a talk the authors will be giving at [Red Hat Summit 2018](https://www.redhat.com/en/summit/2018), which will be held May 8-10 in San Francisco. [Register by May 7](https://www.redhat.com/en/summit/2018) to save US$ 500 off of registration. Use discount code **OPEN18** on the payment page to apply the discount.
## 1 Comment |
10,190 | 如何分析并探索 Docker 容器镜像的内容 | https://www.ostechnix.com/how-to-analyze-and-explore-the-contents-of-docker-images/ | 2018-11-03T23:46:57 | [
"容器",
"镜像"
] | https://linux.cn/article-10190-1.html | 
或许你已经了解到 Docker 容器镜像是一个轻量、独立、含有运行某个应用所需全部软件的可执行包,这也是为什么容器镜像会经常被开发者用于构建和分发应用。假如你很好奇一个 Docker 镜像里面包含了什么东西,那么这篇简要的指南或许会帮助到你。今天,我们将学会使用一个名为 **Dive** 的工具来分析和探索 Docker 镜像每层的内容。
通过分析 Docker 镜像,我们可以发现在各个层之间可能重复的文件并通过移除它们来减小 Docker 镜像的大小。Dive 工具不仅仅是一个 Docker 镜像分析工具,它还可以帮助我们来构建镜像。Dive 是一个用 Go 编程语言编写的自由开源工具。
### 安装 Dive
首先从该项目的 [发布页](https://github.com/wagoodman/dive/releases) 下载最新版本,然后像下面展示的那样根据你所使用的发行版来安装它。
假如你正在使用 **Debian** 或者 **Ubuntu**,那么可以运行下面的命令来下载并安装它。
```
$ wget https://github.com/wagoodman/dive/releases/download/v0.0.8/dive_0.0.8_linux_amd64.deb
```
```
$ sudo apt install ./dive_0.0.8_linux_amd64.deb
```
**在 RHEL 或 CentOS 系统中**
```
$ wget https://github.com/wagoodman/dive/releases/download/v0.0.8/dive_0.0.8_linux_amd64.rpm
```
```
$ sudo rpm -i dive_0.0.8_linux_amd64.rpm
```
Dive 也可以使用 [Linuxbrew](https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/) 包管理器来安装。
```
$ brew tap wagoodman/dive
```
```
$ brew install dive
```
至于其他的安装方法,请参考 [Dive 项目的 GitHub 网页](https://github.com/wagoodman/dive)。
### 分析并探索 Docker 镜像的内容
要分析一个 Docker 镜像,只需要运行加上 Docker 镜像 ID 的 `dive` 命令就可以了。你可以使用 `sudo docker images` 来得到 Docker 镜像的 ID。
```
$ sudo dive ea4c82dcd15a
```
上面命令中的 `ea4c82dcd15a` 是某个镜像的 ID。
然后 `dive` 命令将快速地分析给定 Docker 镜像的内容并将它在终端中展示出来。

正如你在上面的截图中看到的那样,在终端的左边一栏列出了给定 Docker 镜像的各个层及其详细内容,浪费的空间大小等信息。右边一栏则给出了给定 Docker 镜像每一层的内容。你可以使用 `Ctrl+空格` 来在左右栏之间切换,使用 `UP`/`DOWN` 光标键来在目录树中进行浏览。
下面是 `dive` 的快捷键列表:
* `Ctrl+空格` —— 在左右栏之间切换
* `空格` —— 展开或收起目录树
* `Ctrl+A` —— 文件树视图:展示或隐藏增加的文件
* `Ctrl+R` —— 文件树视图:展示或隐藏被移除的文件
* `Ctrl+M` —— 文件树视图:展示或隐藏被修改的文件
* `Ctrl+U` —— 文件树视图:展示或隐藏未修改的文件
* `Ctrl+L` —— 层视图:展示当前层的变化
* `Ctrl+A` —— 层视图:展示总的变化
* `Ctrl+/` —— 筛选文件
* `Ctrl+C` —— 退出
在上面的例子中,我使用了 `sudo` 权限,这是因为我的 Docker 镜像存储在 `/var/lib/docker/` 目录中。假如你的镜像保存在你的家目录 (`$HOME`)或者在其他不属于 `root` 用户的目录,你就没有必要使用 `sudo` 命令。
你还可以使用下面的单个命令来构建一个 Docker 镜像并立刻分析该镜像:
```
$ dive build -t <some-tag>
```
Dive 工具仍处于 beta 阶段,所以可能会存在 bug。假如你遇到了 bug,请在该项目的 GitHub 主页上进行报告。
好了,这就是今天的全部内容。现在你知道如何使用 Dive 工具来探索和分析 Docker 容器镜像的内容以及利用它构建镜像。希望本文对你有所帮助。
更多精彩内容即将呈现,请保持关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-analyze-and-explore-the-contents-of-docker-images/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,191 | 在 Linux 命令行中使用 tcpdump 抓包 | https://opensource.com/article/18/10/introduction-tcpdump | 2018-11-04T00:20:35 | [
"tcpdump"
] | https://linux.cn/article-10191-1.html |
>
> `tcpdump` 是一款灵活、功能强大的抓包工具,能有效地帮助排查网络故障问题。
>
>
>

以我作为管理员的经验,在网络连接中经常遇到十分难以排查的故障问题。对于这类情况,`tcpdump` 便能派上用场。
`tcpdump` 是一个命令行实用工具,允许你抓取和分析经过系统的流量数据包。它通常被用作于网络故障分析工具以及安全工具。
`tcpdump` 是一款强大的工具,支持多种选项和过滤规则,适用场景十分广泛。由于它是命令行工具,因此适用于在远程服务器或者没有图形界面的设备中收集数据包以便于事后分析。它可以在后台启动,也可以用 cron 等定时工具创建定时任务启用它。
本文中,我们将讨论 `tcpdump` 最常用的一些功能。
### 1、在 Linux 中安装 tcpdump
`tcpdump` 支持多种 Linux 发行版,所以你的系统中很有可能已经安装了它。用下面的命令检查一下是否已经安装了 `tcpdump`:
```
$ which tcpdump
/usr/sbin/tcpdump
```
如果还没有安装 `tcpdump`,你可以用软件包管理器安装它。 例如,在 CentOS 或者 Red Hat Enterprise 系统中,用如下命令安装 `tcpdump`:
```
$ sudo yum install -y tcpdump
```
`tcpdump` 依赖于 `libpcap`,该库文件用于捕获网络数据包。如果该库文件也没有安装,系统会根据依赖关系自动安装它。
现在你可以开始抓包了。
### 2、用 tcpdump 抓包
使用 `tcpdump` 抓包,需要管理员权限,因此下面的示例中绝大多数命令都是以 `sudo` 开头。
首先,先用 `tcpdump -D` 命令列出可以抓包的网络接口:
```
$ sudo tcpdump -D
1.eth0
2.virbr0
3.eth1
4.any (Pseudo-device that captures on all interfaces)
5.lo [Loopback]
```
如上所示,可以看到我的机器中所有可以抓包的网络接口。其中特殊接口 `any` 可用于抓取所有活动的网络接口的数据包。
我们就用如下命令先对 `any` 接口进行抓包:
```
$ sudo tcpdump -i any
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
09:56:18.293641 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 3770820720:3770820916, ack 3503648727, win 309, options [nop,nop,TS val 76577898 ecr 510770929], length 196
09:56:18.293794 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 196, win 391, options [nop,nop,TS val 510771017 ecr 76577898], length 0
09:56:18.295058 IP rhel75.59883 > gateway.domain: 2486+ PTR? 1.64.168.192.in-addr.arpa. (43)
09:56:18.310225 IP gateway.domain > rhel75.59883: 2486 NXDomain* 0/1/0 (102)
09:56:18.312482 IP rhel75.49685 > gateway.domain: 34242+ PTR? 28.64.168.192.in-addr.arpa. (44)
09:56:18.322425 IP gateway.domain > rhel75.49685: 34242 NXDomain* 0/1/0 (103)
09:56:18.323164 IP rhel75.56631 > gateway.domain: 29904+ PTR? 1.122.168.192.in-addr.arpa. (44)
09:56:18.323342 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 196:584, ack 1, win 309, options [nop,nop,TS val 76577928 ecr 510771017], length 388
09:56:18.323563 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 584, win 411, options [nop,nop,TS val 510771047 ecr 76577928], length 0
09:56:18.335569 IP gateway.domain > rhel75.56631: 29904 NXDomain* 0/1/0 (103)
09:56:18.336429 IP rhel75.44007 > gateway.domain: 61677+ PTR? 98.122.168.192.in-addr.arpa. (45)
09:56:18.336655 IP gateway.domain > rhel75.44007: 61677* 1/0/0 PTR rhel75. (65)
09:56:18.337177 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 584:1644, ack 1, win 309, options [nop,nop,TS val 76577942 ecr 510771047], length 1060
---- SKIPPING LONG OUTPUT -----
09:56:19.342939 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 1752016, win 1444, options [nop,nop,TS val 510772067 ecr 76578948], length 0
^C
9003 packets captured
9010 packets received by filter
7 packets dropped by kernel
$
```
`tcpdump` 会持续抓包直到收到中断信号。你可以按 `Ctrl+C` 来停止抓包。正如上面示例所示,`tcpdump` 抓取了超过 9000 个数据包。在这个示例中,由于我是通过 `ssh` 连接到服务器,所以 `tcpdump` 也捕获了所有这类数据包。`-c` 选项可以用于限制 `tcpdump` 抓包的数量:
```
$ sudo tcpdump -i any -c 5
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
11:21:30.242740 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 3772575680:3772575876, ack 3503651743, win 309, options [nop,nop,TS val 81689848 ecr 515883153], length 196
11:21:30.242906 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 196, win 1443, options [nop,nop,TS val 515883235 ecr 81689848], length 0
11:21:30.244442 IP rhel75.43634 > gateway.domain: 57680+ PTR? 1.64.168.192.in-addr.arpa. (43)
11:21:30.244829 IP gateway.domain > rhel75.43634: 57680 NXDomain 0/0/0 (43)
11:21:30.247048 IP rhel75.33696 > gateway.domain: 37429+ PTR? 28.64.168.192.in-addr.arpa. (44)
5 packets captured
12 packets received by filter
0 packets dropped by kernel
$
```
如上所示,`tcpdump` 在抓取 5 个数据包后自动停止了抓包。这在有些场景中十分有用 —— 比如你只需要抓取少量的数据包用于分析。当我们需要使用过滤规则抓取特定的数据包(如下所示)时,`-c` 的作用就十分突出了。
在上面示例中,`tcpdump` 默认是将 IP 地址和端口号解析为对应的接口名以及服务协议名称。而通常在网络故障排查中,使用 IP 地址和端口号更便于分析问题;用 `-n` 选项显示 IP 地址,`-nn` 选项显示端口号:
```
$ sudo tcpdump -i any -c5 -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
23:56:24.292206 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 166198580:166198776, ack 2414541257, win 309, options [nop,nop,TS val 615664 ecr 540031155], length 196
23:56:24.292357 IP 192.168.64.1.35110 > 192.168.64.28.22: Flags [.], ack 196, win 1377, options [nop,nop,TS val 540031229 ecr 615664], length 0
23:56:24.292570 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 196:568, ack 1, win 309, options [nop,nop,TS val 615664 ecr 540031229], length 372
23:56:24.292655 IP 192.168.64.1.35110 > 192.168.64.28.22: Flags [.], ack 568, win 1400, options [nop,nop,TS val 540031229 ecr 615664], length 0
23:56:24.292752 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 568:908, ack 1, win 309, options [nop,nop,TS val 615664 ecr 540031229], length 340
5 packets captured
6 packets received by filter
0 packets dropped by kernel
```
如上所示,抓取的数据包中显示 IP 地址和端口号。这样还可以阻止 `tcpdump` 发出 DNS 查找,有助于在网络故障排查中减少数据流量。
现在你已经会抓包了,让我们来分析一下这些抓包输出的含义吧。
### 3、理解抓取的报文
`tcpdump` 能够抓取并解码多种协议类型的数据报文,如 TCP、UDP、ICMP 等等。虽然这里我们不可能介绍所有的数据报文类型,但可以分析下 TCP 类型的数据报文,来帮助你入门。更多有关 `tcpdump` 的详细介绍可以参考其 [帮助手册](http://www.tcpdump.org/manpages/tcpdump.1.html#lbAG)。`tcpdump` 抓取的 TCP 报文看起来如下:
```
08:41:13.729687 IP 192.168.64.28.22 > 192.168.64.1.41916: Flags [P.], seq 196:568, ack 1, win 309, options [nop,nop,TS val 117964079 ecr 816509256], length 372
```
具体的字段根据不同的报文类型会有不同,但上面这个例子是一般的格式形式。
第一个字段 `08:41:13.729687` 是该数据报文被抓取的系统本地时间戳。
然后,`IP` 是网络层协议类型,这里是 `IPv4`,如果是 `IPv6` 协议,该字段值是 `IP6`。
`192.168.64.28.22` 是源 ip 地址和端口号,紧跟其后的是目的 ip 地址和其端口号,这里是 `192.168.64.1.41916`。
在源 IP 和目的 IP 之后,可以看到是 TCP 报文标记段 `Flags [P.]`。该字段通常取值如下:
| 值 | 标志类型 | 描述 |
| --- | --- | --- |
| S | SYN | Connection Start |
| F | FIN | Connection Finish |
| P | PUSH | Data push |
| R | RST | Connection reset |
| . | ACK | Acknowledgment |
该字段也可以是这些值的组合,例如 `[S.]` 代表 `SYN-ACK` 数据包。
接下来是该数据包中数据的序列号。对于抓取的第一个数据包,该字段值是一个绝对数字,后续包使用相对数值,以便更容易查询跟踪。例如此处 `seq 196:568` 代表该数据包包含该数据流的第 196 到 568 字节。
接下来是 ack 值:`ack 1`。该数据包是数据发送方,ack 值为 1。在数据接收方,该字段代表数据流上的下一个预期字节数据,例如,该数据流中下一个数据包的 ack 值应该是 568。
接下来字段是接收窗口大小 `win 309`,它表示接收缓冲区中可用的字节数,后跟 TCP 选项如 MSS(最大段大小)或者窗口比例值。更详尽的 TCP 协议内容请参考 [Transmission Control Protocol(TCP) Parameters](https://www.iana.org/assignments/tcp-parameters/tcp-parameters.xhtml)。
最后,`length 372` 代表数据包有效载荷字节长度。这个长度和 seq 序列号中字节数值长度是不一样的。
现在让我们学习如何过滤数据报文以便更容易的分析定位问题。
### 4、过滤数据包
正如上面所提,`tcpdump` 可以抓取很多种类型的数据报文,其中很多可能和我们需要查找的问题并没有关系。举个例子,假设你正在定位一个与 web 服务器连接的网络问题,就不必关系 SSH 数据报文,因此在抓包结果中过滤掉 SSH 报文可能更便于你分析问题。
`tcpdump` 有很多参数选项可以设置数据包过滤规则,例如根据源 IP 以及目的 IP 地址,端口号,协议等等规则来过滤数据包。下面就介绍一些最常用的过滤方法。
#### 协议
在命令中指定协议便可以按照协议类型来筛选数据包。比方说用如下命令只要抓取 ICMP 报文:
```
$ sudo tcpdump -i any -c5 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
```
然后再打开一个终端,去 ping 另一台机器:
```
$ ping opensource.com
PING opensource.com (54.204.39.132) 56(84) bytes of data.
64 bytes from ec2-54-204-39-132.compute-1.amazonaws.com (54.204.39.132): icmp_seq=1 ttl=47 time=39.6 ms
```
回到运行 `tcpdump` 命令的终端中,可以看到它筛选出了 ICMP 报文。这里 `tcpdump` 并没有显示有关 `opensource.com` 的域名解析数据包:
```
09:34:20.136766 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 1, length 64
09:34:20.176402 IP ec2-54-204-39-132.compute-1.amazonaws.com > rhel75: ICMP echo reply, id 20361, seq 1, length 64
09:34:21.140230 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 2, length 64
09:34:21.180020 IP ec2-54-204-39-132.compute-1.amazonaws.com > rhel75: ICMP echo reply, id 20361, seq 2, length 64
09:34:22.141777 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 3, length 64
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
#### 主机
用 `host` 参数只抓取和特定主机相关的数据包:
```
$ sudo tcpdump -i any -c5 -nn host 54.204.39.132
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
09:54:20.042023 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [S], seq 1375157070, win 29200, options [mss 1460,sackOK,TS val 122350391 ecr 0,nop,wscale 7], length 0
09:54:20.088127 IP 54.204.39.132.80 > 192.168.122.98.39326: Flags [S.], seq 1935542841, ack 1375157071, win 28960, options [mss 1460,sackOK,TS val 522713542 ecr 122350391,nop,wscale 9], length 0
09:54:20.088204 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 122350437 ecr 522713542], length 0
09:54:20.088734 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 122350438 ecr 522713542], length 112: HTTP: GET / HTTP/1.1
09:54:20.129733 IP 54.204.39.132.80 > 192.168.122.98.39326: Flags [.], ack 113, win 57, options [nop,nop,TS val 522713552 ecr 122350438], length 0
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
如上所示,只抓取和显示与 `54.204.39.132` 有关的数据包。
#### 端口号
`tcpdump` 可以根据服务类型或者端口号来筛选数据包。例如,抓取和 HTTP 服务相关的数据包:
```
$ sudo tcpdump -i any -c5 -nn port 80
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
09:58:28.790548 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [S], seq 1745665159, win 29200, options [mss 1460,sackOK,TS val 122599140 ecr 0,nop,wscale 7], length 0
09:58:28.834026 IP 54.204.39.132.80 > 192.168.122.98.39330: Flags [S.], seq 4063583040, ack 1745665160, win 28960, options [mss 1460,sackOK,TS val 522775728 ecr 122599140,nop,wscale 9], length 0
09:58:28.834093 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 122599183 ecr 522775728], length 0
09:58:28.834588 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 122599184 ecr 522775728], length 112: HTTP: GET / HTTP/1.1
09:58:28.878445 IP 54.204.39.132.80 > 192.168.122.98.39330: Flags [.], ack 113, win 57, options [nop,nop,TS val 522775739 ecr 122599184], length 0
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
#### IP 地址/主机名
同样,你也可以根据源 IP 地址或者目的 IP 地址或者主机名来筛选数据包。例如抓取源 IP 地址为 `192.168.122.98` 的数据包:
```
$ sudo tcpdump -i any -c5 -nn src 192.168.122.98
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
10:02:15.220824 IP 192.168.122.98.39436 > 192.168.122.1.53: 59332+ A? opensource.com. (32)
10:02:15.220862 IP 192.168.122.98.39436 > 192.168.122.1.53: 20749+ AAAA? opensource.com. (32)
10:02:15.364062 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [S], seq 1108640533, win 29200, options [mss 1460,sackOK,TS val 122825713 ecr 0,nop,wscale 7], length 0
10:02:15.409229 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [.], ack 669337581, win 229, options [nop,nop,TS val 122825758 ecr 522832372], length 0
10:02:15.409667 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [P.], seq 0:112, ack 1, win 229, options [nop,nop,TS val 122825759 ecr 522832372], length 112: HTTP: GET / HTTP/1.1
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
注意此处示例中抓取了来自源 IP 地址 `192.168.122.98` 的 53 端口以及 80 端口的数据包,它们的应答包没有显示出来因为那些包的源 IP 地址已经变了。
相对的,使用 `dst` 就是按目的 IP/主机名来筛选数据包。
```
$ sudo tcpdump -i any -c5 -nn dst 192.168.122.98
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
10:05:03.572931 IP 192.168.122.1.53 > 192.168.122.98.47049: 2248 1/0/0 A 54.204.39.132 (48)
10:05:03.572944 IP 192.168.122.1.53 > 192.168.122.98.47049: 33770 0/0/0 (32)
10:05:03.621833 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [S.], seq 3474204576, ack 3256851264, win 28960, options [mss 1460,sackOK,TS val 522874425 ecr 122993922,nop,wscale 9], length 0
10:05:03.667767 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [.], ack 113, win 57, options [nop,nop,TS val 522874436 ecr 122993972], length 0
10:05:03.672221 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 522874437 ecr 122993972], length 642: HTTP: HTTP/1.1 302 Found
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
#### 多条件筛选
当然,可以使用多条件组合来筛选数据包,使用 `and` 以及 `or` 逻辑操作符来创建过滤规则。例如,筛选来自源 IP 地址 `192.168.122.98` 的 HTTP 数据包:
```
$ sudo tcpdump -i any -c5 -nn src 192.168.122.98 and port 80
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
10:08:00.472696 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [S], seq 2712685325, win 29200, options [mss 1460,sackOK,TS val 123170822 ecr 0,nop,wscale 7], length 0
10:08:00.516118 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [.], ack 268723504, win 229, options [nop,nop,TS val 123170865 ecr 522918648], length 0
10:08:00.516583 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [P.], seq 0:112, ack 1, win 229, options [nop,nop,TS val 123170866 ecr 522918648], length 112: HTTP: GET / HTTP/1.1
10:08:00.567044 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 123170916 ecr 522918661], length 0
10:08:00.788153 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [F.], seq 112, ack 643, win 239, options [nop,nop,TS val 123171137 ecr 522918661], length 0
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
你也可以使用括号来创建更为复杂的过滤规则,但在 shell 中请用引号包含你的过滤规则以防止被识别为 shell 表达式:
```
$ sudo tcpdump -i any -c5 -nn "port 80 and (src 192.168.122.98 or src 54.204.39.132)"
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
10:10:37.602214 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [S], seq 871108679, win 29200, options [mss 1460,sackOK,TS val 123327951 ecr 0,nop,wscale 7], length 0
10:10:37.650651 IP 54.204.39.132.80 > 192.168.122.98.39346: Flags [S.], seq 854753193, ack 871108680, win 28960, options [mss 1460,sackOK,TS val 522957932 ecr 123327951,nop,wscale 9], length 0
10:10:37.650708 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 123328000 ecr 522957932], length 0
10:10:37.651097 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 123328000 ecr 522957932], length 112: HTTP: GET / HTTP/1.1
10:10:37.692900 IP 54.204.39.132.80 > 192.168.122.98.39346: Flags [.], ack 113, win 57, options [nop,nop,TS val 522957942 ecr 123328000], length 0
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
该例子中我们只抓取了来自源 IP 为 `192.168.122.98` 或者 `54.204.39.132` 的 HTTP (端口号80)的数据包。使用该方法就很容易抓取到数据流中交互双方的数据包了。
### 5、检查数据包内容
在以上的示例中,我们只按数据包头部的信息来建立规则筛选数据包,例如源地址、目的地址、端口号等等。有时我们需要分析网络连接问题,可能需要分析数据包中的内容来判断什么内容需要被发送、什么内容需要被接收等。`tcpdump` 提供了两个选项可以查看数据包内容,`-X` 以十六进制打印出数据报文内容,`-A` 打印数据报文的 ASCII 值。
例如,HTTP 请求报文内容如下:
```
$ sudo tcpdump -i any -c10 -nn -A port 80
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
13:02:14.871803 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [S], seq 2546602048, win 29200, options [mss 1460,sackOK,TS val 133625221 ecr 0,nop,wscale 7], length 0
E..<..@[email protected].'[email protected]............
............................
13:02:14.910734 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [S.], seq 1877348646, ack 2546602049, win 28960, options [mss 1460,sackOK,TS val 525532247 ecr 133625221,nop,wscale 9], length 0
E..<..@./..a6.'...zb.P..o..&...A..q a..........
.R.W....... ................
13:02:14.910832 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 133625260 ecr 525532247], length 0
E..4..@[email protected].'....P...Ao..'...........
.....R.W................
13:02:14.911808 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 133625261 ecr 525532247], length 112: HTTP: GET / HTTP/1.1
E.....@[email protected].'....P...Ao..'...........
.....R.WGET / HTTP/1.1
User-Agent: Wget/1.14 (linux-gnu)
Accept: */*
Host: opensource.com
Connection: Keep-Alive
................
13:02:14.951199 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [.], ack 113, win 57, options [nop,nop,TS val 525532257 ecr 133625261], length 0
E..4.F@./.."6.'...zb.P..o..'.......9.2.....
.R.a....................
13:02:14.955030 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 525532258 ecr 133625261], length 642: HTTP: HTTP/1.1 302 Found
E....G@./...6.'...zb.P..o..'.......9.......
.R.b....HTTP/1.1 302 Found
Server: nginx
Date: Sun, 23 Sep 2018 17:02:14 GMT
Content-Type: text/html; charset=iso-8859-1
Content-Length: 207
X-Content-Type-Options: nosniff
Location: https://opensource.com/
Cache-Control: max-age=1209600
Expires: Sun, 07 Oct 2018 17:02:14 GMT
X-Request-ID: v-6baa3acc-bf52-11e8-9195-22000ab8cf2d
X-Varnish: 632951979
Age: 0
Via: 1.1 varnish (Varnish/5.2)
X-Cache: MISS
Connection: keep-alive
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>302 Found</title>
</head><body>
<h1>Found</h1>
<p>The document has moved <a href="https://opensource.com/">here</a>.</p>
</body></html>
................
13:02:14.955083 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 133625304 ecr 525532258], length 0
E..4..@[email protected].'....P....o..............
.....R.b................
13:02:15.195524 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [F.], seq 113, ack 643, win 239, options [nop,nop,TS val 133625545 ecr 525532258], length 0
E..4..@[email protected].'....P....o..............
.....R.b................
13:02:15.236592 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 525532329 ecr 133625545], length 0
E..4.H@./.. 6.'...zb.P..o..........9.I.....
.R......................
13:02:15.236656 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 644, win 239, options [nop,nop,TS val 133625586 ecr 525532329], length 0
E..4..@[email protected].'....P....o..............
.....R..................
10 packets captured
10 packets received by filter
0 packets dropped by kernel
```
这对定位一些普通 HTTP 调用 API 接口的问题很有用。当然如果是加密报文,这个输出也就没多大用了。
### 6、保存抓包数据
`tcpdump` 提供了保存抓包数据的功能以便后续分析数据包。例如,你可以夜里让它在那里抓包,然后早上起来再去分析它。同样当有很多数据包时,显示过快也不利于分析,将数据包保存下来,更有利于分析问题。
使用 `-w` 选项来保存数据包而不是在屏幕上显示出抓取的数据包:
```
$ sudo tcpdump -i any -c10 -nn -w webserver.pcap port 80
[sudo] password for ricardo:
tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
10 packets captured
10 packets received by filter
0 packets dropped by kernel
```
该命令将抓取的数据包保存到文件 `webserver.pcap`。后缀名 `pcap` 表示文件是抓取的数据包格式。
正如示例中所示,保存数据包到文件中时屏幕上就没有任何有关数据报文的输出,其中 `-c10` 表示抓取到 10 个数据包后就停止抓包。如果想有一些反馈来提示确实抓取到了数据包,可以使用 `-v` 选项。
`tcpdump` 将数据包保存在二进制文件中,所以不能简单的用文本编辑器去打开它。使用 `-r` 选项参数来阅读该文件中的报文内容:
```
$ tcpdump -nn -r webserver.pcap
reading from file webserver.pcap, link-type LINUX_SLL (Linux cooked)
13:36:57.679494 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [S], seq 3709732619, win 29200, options [mss 1460,sackOK,TS val 135708029 ecr 0,nop,wscale 7], length 0
13:36:57.718932 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [S.], seq 1999298316, ack 3709732620, win 28960, options [mss 1460,sackOK,TS val 526052949 ecr 135708029,nop,wscale 9], length 0
13:36:57.719005 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 135708068 ecr 526052949], length 0
13:36:57.719186 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 135708068 ecr 526052949], length 112: HTTP: GET / HTTP/1.1
13:36:57.756979 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [.], ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 0
13:36:57.760122 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 642: HTTP: HTTP/1.1 302 Found
13:36:57.760182 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 135708109 ecr 526052959], length 0
13:36:57.977602 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [F.], seq 113, ack 643, win 239, options [nop,nop,TS val 135708327 ecr 526052959], length 0
13:36:58.022089 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 526053025 ecr 135708327], length 0
13:36:58.022132 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 644, win 239, options [nop,nop,TS val 135708371 ecr 526053025], length 0
$
```
这里不需要管理员权限 `sudo` 了,因为此刻并不是在网络接口处抓包。
你还可以使用我们讨论过的任何过滤规则来过滤文件中的内容,就像使用实时数据一样。 例如,通过执行以下命令从源 IP 地址 `54.204.39.132` 检查文件中的数据包:
```
$ tcpdump -nn -r webserver.pcap src 54.204.39.132
reading from file webserver.pcap, link-type LINUX_SLL (Linux cooked)
13:36:57.718932 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [S.], seq 1999298316, ack 3709732620, win 28960, options [mss 1460,sackOK,TS val 526052949 ecr 135708029,nop,wscale 9], length 0
13:36:57.756979 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [.], ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 0
13:36:57.760122 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 642: HTTP: HTTP/1.1 302 Found
13:36:58.022089 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 526053025 ecr 135708327], length 0
```
### 下一步做什么?
以上的基本功能已经可以帮助你使用强大的 `tcpdump` 抓包工具了。更多的内容请参考 [tcpdump 网站](http://www.tcpdump.org/#) 以及它的 [帮助文件](http://www.tcpdump.org/manpages/tcpdump.1.html)。
`tcpdump` 命令行工具为分析网络流量数据包提供了强大的灵活性。如果需要使用图形工具来抓包请参考 [Wireshark](https://www.wireshark.org/)。
Wireshark 还可以用来读取 `tcpdump` 保存的 pcap 文件。你可以使用 `tcpdump` 命令行在没有 GUI 界面的远程机器上抓包然后在 Wireshark 中分析数据包。
---
via: <https://opensource.com/article/18/10/introduction-tcpdump>
作者:[Ricardo Gerardi](https://opensource.com/users/rgerardi) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jrg](https://github.com/jrglinux) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my experience as a sysadmin, I have often found network connectivity issues challenging to troubleshoot. For those situations, tcpdump is a great ally.
Tcpdump is a command line utility that allows you to capture and analyze network traffic going through your system. It is often used to help troubleshoot network issues, as well as a security tool.
A powerful and versatile tool that includes many options and filters, tcpdump can be used in a variety of cases. Since it's a command line tool, it is ideal to run in remote servers or devices for which a GUI is not available, to collect data that can be analyzed later. It can also be launched in the background or as a scheduled job using tools like cron.
In this article, we'll look at some of tcpdump's most common features.
## 1. Installation on Linux
Tcpdump is included with several Linux distributions, so chances are, you already have it installed. Check whether tcpdump is installed on your system with the following command:
```
$ which tcpdump
/usr/sbin/tcpdump
```
If tcpdump is not installed, you can install it but using your distribution's package manager. For example, on CentOS or Red Hat Enterprise Linux, like this:
`$ sudo dnf install -y tcpdump`
Tcpdump requires `libpcap`
, which is a library for network packet capture. If it's not installed, it will be automatically added as a dependency.
You're ready to start capturing some packets.
## 2. Capturing packets with tcpdump
To capture packets for troubleshooting or analysis, tcpdump requires elevated permissions, so in the following examples most commands are prefixed with `sudo`
.
To begin, use the command `tcpdump --list-interfaces `
(or `-D`
for short) to see which interfaces are available for capture:
```
$ sudo tcpdump -D
1.eth0
2.virbr0
3.eth1
4.any (Pseudo-device that captures on all interfaces)
5.lo [Loopback]
```
In the example above, you can see all the interfaces available in my machine. The special interface `any`
allows capturing in any active interface.
Let's use it to start capturing some packets. Capture all packets in any interface by running this command:
```
$ sudo tcpdump --interface any
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
09:56:18.293641 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 3770820720:3770820916, ack 3503648727, win 309, options [nop,nop,TS val 76577898 ecr 510770929], length 196
09:56:18.293794 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 196, win 391, options [nop,nop,TS val 510771017 ecr 76577898], length 0
09:56:18.295058 IP rhel75.59883 > gateway.domain: 2486+ PTR? 1.64.168.192.in-addr.arpa. (43)
09:56:18.310225 IP gateway.domain > rhel75.59883: 2486 NXDomain* 0/1/0 (102)
09:56:18.312482 IP rhel75.49685 > gateway.domain: 34242+ PTR? 28.64.168.192.in-addr.arpa. (44)
09:56:18.322425 IP gateway.domain > rhel75.49685: 34242 NXDomain* 0/1/0 (103)
09:56:18.323164 IP rhel75.56631 > gateway.domain: 29904+ PTR? 1.122.168.192.in-addr.arpa. (44)
09:56:18.323342 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 196:584, ack 1, win 309, options [nop,nop,TS val 76577928 ecr 510771017], length 388
09:56:18.323563 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 584, win 411, options [nop,nop,TS val 510771047 ecr 76577928], length 0
09:56:18.335569 IP gateway.domain > rhel75.56631: 29904 NXDomain* 0/1/0 (103)
09:56:18.336429 IP rhel75.44007 > gateway.domain: 61677+ PTR? 98.122.168.192.in-addr.arpa. (45)
09:56:18.336655 IP gateway.domain > rhel75.44007: 61677* 1/0/0 PTR rhel75. (65)
09:56:18.337177 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 584:1644, ack 1, win 309, options [nop,nop,TS val 76577942 ecr 510771047], length 1060
---- SKIPPING LONG OUTPUT -----
09:56:19.342939 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 1752016, win 1444, options [nop,nop,TS val 510772067 ecr 76578948], length 0
^C
9003 packets captured
9010 packets received by filter
7 packets dropped by kernel
$
```
Tcpdump continues to capture packets until it receives an interrupt signal. You can interrupt capturing by pressing `Ctrl+C`
. As you can see in this example, `tcpdump`
captured more than 9,000 packets. In this case, since I am connected to this server using `ssh`
, tcpdump captured all these packets. To limit the number of packets captured and stop `tcpdump`
, use the `-c`
(for *count*) option:
```
$ sudo tcpdump -i any -c 5
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
11:21:30.242740 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 3772575680:3772575876, ack 3503651743, win 309, options [nop,nop,TS val 81689848 ecr 515883153], length 196
11:21:30.242906 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 196, win 1443, options [nop,nop,TS val 515883235 ecr 81689848], length 0
11:21:30.244442 IP rhel75.43634 > gateway.domain: 57680+ PTR? 1.64.168.192.in-addr.arpa. (43)
11:21:30.244829 IP gateway.domain > rhel75.43634: 57680 NXDomain 0/0/0 (43)
11:21:30.247048 IP rhel75.33696 > gateway.domain: 37429+ PTR? 28.64.168.192.in-addr.arpa. (44)
5 packets captured
12 packets received by filter
0 packets dropped by kernel
$
```
In this case, `tcpdump`
stopped capturing automatically after capturing five packets. This is useful in different scenarios—for instance, if you're troubleshooting connectivity and capturing a few initial packets is enough. This is even more useful when we apply filters to capture specific packets (shown below).
By default, tcpdump resolves IP addresses and ports into names, as shown in the previous example. When troubleshooting network issues, it is often easier to use the IP addresses and port numbers; disable name resolution by using the option `-n`
and port resolution with `-nn`
:
```
$ sudo tcpdump -i any -c5 -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
23:56:24.292206 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 166198580:166198776, ack 2414541257, win 309, options [nop,nop,TS val 615664 ecr 540031155], length 196
23:56:24.292357 IP 192.168.64.1.35110 > 192.168.64.28.22: Flags [.], ack 196, win 1377, options [nop,nop,TS val 540031229 ecr 615664], length 0
23:56:24.292570 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 196:568, ack 1, win 309, options [nop,nop,TS val 615664 ecr 540031229], length 372
23:56:24.292655 IP 192.168.64.1.35110 > 192.168.64.28.22: Flags [.], ack 568, win 1400, options [nop,nop,TS val 540031229 ecr 615664], length 0
23:56:24.292752 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 568:908, ack 1, win 309, options [nop,nop,TS val 615664 ecr 540031229], length 340
5 packets captured
6 packets received by filter
0 packets dropped by kernel
```
As shown above, the capture output now displays the IP addresses and port numbers. This also prevents tcpdump from issuing DNS lookups, which helps to lower network traffic while troubleshooting network issues.
Now that you're able to capture network packets, let's explore what this output means.
## 3. Understanding the output format
Tcpdump is capable of capturing and decoding many different protocols, such as TCP, UDP, ICMP, and many more. While we can't cover all of them here, to help you get started, let's explore the TCP packet. You can find more details about the different protocol formats in tcpdump's [manual pages](http://www.tcpdump.org/manpages/tcpdump.1.html#lbAG). A typical TCP packet captured by tcpdump looks like this:
`08:41:13.729687 IP 192.168.64.28.22 > 192.168.64.1.41916: Flags [P.], seq 196:568, ack 1, win 309, options [nop,nop,TS val 117964079 ecr 816509256], length 372`
The fields may vary depending on the type of packet being sent, but this is the general format.
The first field, `08:41:13.729687,`
represents the timestamp of the received packet as per the local clock.
Next, `IP`
represents the network layer protocol—in this case, `IPv4`
. For `IPv6`
packets, the value is `IP6`
.
The next field, `192.168.64.28.22`
, is the source IP address and port. This is followed by the destination IP address and port, represented by `192.168.64.1.41916`
.
After the source and destination, you can find the TCP Flags `Flags [P.]`
. Typical values for this field include:
Value | Flag Type | Description |
S | SYN | Connection Start |
F | FIN | Connection Finish |
P | PUSH | Data push |
R | RST | Connection reset |
. | ACK | Acknowledgment |
This field can also be a combination of these values, such as `[S.]`
for a `SYN-ACK`
packet.
Next is the sequence number of the data contained in the packet. For the first packet captured, this is an absolute number. Subsequent packets use a relative number to make it easier to follow. In this example, the sequence is `seq 196:568,`
which means this packet contains bytes 196 to 568 of this flow.
This is followed by the Ack Number: `ack 1`
. In this case, it is 1 since this is the side sending data. For the side receiving data, this field represents the next expected byte (data) on this flow. For example, the Ack number for the next packet in this flow would be 568.
The next field is the window size `win 309`
, which represents the number of bytes available in the receiving buffer, followed by TCP options such as the MSS (Maximum Segment Size) or Window Scale. For details about TCP protocol options, consult [Transmission Control Protocol (TCP) Parameters](https://www.iana.org/assignments/tcp-parameters/tcp-parameters.xhtml).
Finally, we have the packet length, `length 372`
, which represents the length, in bytes, of the payload data. The length is the difference between the last and first bytes in the sequence number.
Now let's learn how to filter packets to narrow down results and make it easier to troubleshoot specific issues.
## 4. Filtering packets
As mentioned above, tcpdump can capture too many packets, some of which are not even related to the issue you're troubleshooting. For example, if you're troubleshooting a connectivity issue with a web server you're not interested in the SSH traffic, so removing the SSH packets from the output makes it easier to work on the real issue.
One of tcpdump's most powerful features is its ability to filter the captured packets using a variety of parameters, such as source and destination IP addresses, ports, protocols, etc. Let's look at some of the most common ones.
### Protocol
To filter packets based on protocol, specifying the protocol in the command line. For example, capture ICMP packets only by using this command:
```
$ sudo tcpdump -i any -c5 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
```
In a different terminal, try to ping another machine:
```
$ ping opensource.com
PING opensource.com (54.204.39.132) 56(84) bytes of data.
64 bytes from ec2-54-204-39-132.compute-1.amazonaws.com (54.204.39.132): icmp_seq=1 ttl=47 time=39.6 ms
```
Back in the tcpdump capture, notice that tcpdump captures and displays only the ICMP-related packets. In this case, tcpdump is not displaying name resolution packets that were generated when resolving the name `opensource.com`
:
```
09:34:20.136766 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 1, length 64
09:34:20.176402 IP ec2-54-204-39-132.compute-1.amazonaws.com > rhel75: ICMP echo reply, id 20361, seq 1, length 64
09:34:21.140230 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 2, length 64
09:34:21.180020 IP ec2-54-204-39-132.compute-1.amazonaws.com > rhel75: ICMP echo reply, id 20361, seq 2, length 64
09:34:22.141777 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 3, length 64
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
### Host
Limit capture to only packets related to a specific host by using the `host`
filter:
```
$ sudo tcpdump -i any -c5 -nn host 54.204.39.132
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
09:54:20.042023 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [S], seq 1375157070, win 29200, options [mss 1460,sackOK,TS val 122350391 ecr 0,nop,wscale 7], length 0
09:54:20.088127 IP 54.204.39.132.80 > 192.168.122.98.39326: Flags [S.], seq 1935542841, ack 1375157071, win 28960, options [mss 1460,sackOK,TS val 522713542 ecr 122350391,nop,wscale 9], length 0
09:54:20.088204 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 122350437 ecr 522713542], length 0
09:54:20.088734 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 122350438 ecr 522713542], length 112: HTTP: GET / HTTP/1.1
09:54:20.129733 IP 54.204.39.132.80 > 192.168.122.98.39326: Flags [.], ack 113, win 57, options [nop,nop,TS val 522713552 ecr 122350438], length 0
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
In this example, tcpdump captures and displays only packets to and from host `54.204.39.132`
.
### Port
To filter packets based on the desired service or port, use the `port`
filter. For example, capture packets related to a web (HTTP) service by using this command:
```
$ sudo tcpdump -i any -c5 -nn port 80
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
09:58:28.790548 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [S], seq 1745665159, win 29200, options [mss 1460,sackOK,TS val 122599140 ecr 0,nop,wscale 7], length 0
09:58:28.834026 IP 54.204.39.132.80 > 192.168.122.98.39330: Flags [S.], seq 4063583040, ack 1745665160, win 28960, options [mss 1460,sackOK,TS val 522775728 ecr 122599140,nop,wscale 9], length 0
09:58:28.834093 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 122599183 ecr 522775728], length 0
09:58:28.834588 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 122599184 ecr 522775728], length 112: HTTP: GET / HTTP/1.1
09:58:28.878445 IP 54.204.39.132.80 > 192.168.122.98.39330: Flags [.], ack 113, win 57, options [nop,nop,TS val 522775739 ecr 122599184], length 0
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
### Source IP/hostname
You can also filter packets based on the source or destination IP Address or hostname. For example, to capture packets from host `192.168.122.98`
:
```
$ sudo tcpdump -i any -c5 -nn src 192.168.122.98
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
10:02:15.220824 IP 192.168.122.98.39436 > 192.168.122.1.53: 59332+ A? opensource.com. (32)
10:02:15.220862 IP 192.168.122.98.39436 > 192.168.122.1.53: 20749+ AAAA? opensource.com. (32)
10:02:15.364062 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [S], seq 1108640533, win 29200, options [mss 1460,sackOK,TS val 122825713 ecr 0,nop,wscale 7], length 0
10:02:15.409229 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [.], ack 669337581, win 229, options [nop,nop,TS val 122825758 ecr 522832372], length 0
10:02:15.409667 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [P.], seq 0:112, ack 1, win 229, options [nop,nop,TS val 122825759 ecr 522832372], length 112: HTTP: GET / HTTP/1.1
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
Notice that tcpdumps captured packets with source IP address `192.168.122.98`
for multiple services such as name resolution (port 53) and HTTP (port 80). The response packets are not displayed since their source IP is different.
Conversely, you can use the `dst`
filter to filter by destination IP/hostname:
```
$ sudo tcpdump -i any -c5 -nn dst 192.168.122.98
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
10:05:03.572931 IP 192.168.122.1.53 > 192.168.122.98.47049: 2248 1/0/0 A 54.204.39.132 (48)
10:05:03.572944 IP 192.168.122.1.53 > 192.168.122.98.47049: 33770 0/0/0 (32)
10:05:03.621833 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [S.], seq 3474204576, ack 3256851264, win 28960, options [mss 1460,sackOK,TS val 522874425 ecr 122993922,nop,wscale 9], length 0
10:05:03.667767 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [.], ack 113, win 57, options [nop,nop,TS val 522874436 ecr 122993972], length 0
10:05:03.672221 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 522874437 ecr 122993972], length 642: HTTP: HTTP/1.1 302 Found
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
### Complex expressions
You can also combine filters by using the logical operators `and`
and `or`
to create more complex expressions. For example, to filter packets from source IP address `192.168.122.98`
and service HTTP only, use this command:
```
$ sudo tcpdump -i any -c5 -nn src 192.168.122.98 and port 80
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
10:08:00.472696 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [S], seq 2712685325, win 29200, options [mss 1460,sackOK,TS val 123170822 ecr 0,nop,wscale 7], length 0
10:08:00.516118 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [.], ack 268723504, win 229, options [nop,nop,TS val 123170865 ecr 522918648], length 0
10:08:00.516583 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [P.], seq 0:112, ack 1, win 229, options [nop,nop,TS val 123170866 ecr 522918648], length 112: HTTP: GET / HTTP/1.1
10:08:00.567044 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 123170916 ecr 522918661], length 0
10:08:00.788153 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [F.], seq 112, ack 643, win 239, options [nop,nop,TS val 123171137 ecr 522918661], length 0
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
You can create more complex expressions by grouping filter with parentheses. In this case, enclose the entire filter expression with quotation marks to prevent the shell from confusing them with shell expressions:
```
$ sudo tcpdump -i any -c5 -nn "port 80 and (src 192.168.122.98 or src 54.204.39.132)"
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
10:10:37.602214 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [S], seq 871108679, win 29200, options [mss 1460,sackOK,TS val 123327951 ecr 0,nop,wscale 7], length 0
10:10:37.650651 IP 54.204.39.132.80 > 192.168.122.98.39346: Flags [S.], seq 854753193, ack 871108680, win 28960, options [mss 1460,sackOK,TS val 522957932 ecr 123327951,nop,wscale 9], length 0
10:10:37.650708 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 123328000 ecr 522957932], length 0
10:10:37.651097 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 123328000 ecr 522957932], length 112: HTTP: GET / HTTP/1.1
10:10:37.692900 IP 54.204.39.132.80 > 192.168.122.98.39346: Flags [.], ack 113, win 57, options [nop,nop,TS val 522957942 ecr 123328000], length 0
5 packets captured
5 packets received by filter
0 packets dropped by kernel
```
In this example, we're filtering packets for HTTP service only (port 80) and source IP addresses `192.168.122.98`
or `54.204.39.132`
. This is a quick way of examining both sides of the same flow.
## 5. Checking packet content
In the previous examples, we're checking only the packets' headers for information such as source, destinations, ports, etc. Sometimes this is all we need to troubleshoot network connectivity issues. Sometimes, however, we need to inspect the content of the packet to ensure that the message we're sending contains what we need or that we received the expected response. To see the packet content, tcpdump provides two additional flags: `-X`
to print content in hex, and ASCII or `-A`
to print the content in ASCII.
For example, inspect the HTTP content of a web request like this:
```
$ sudo tcpdump -i any -c10 -nn -A port 80
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
13:02:14.871803 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [S], seq 2546602048, win 29200, options [mss 1460,sackOK,TS val 133625221 ecr 0,nop,wscale 7], length 0
E..<..@[email protected].'[email protected]............
............................
13:02:14.910734 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [S.], seq 1877348646, ack 2546602049, win 28960, options [mss 1460,sackOK,TS val 525532247 ecr 133625221,nop,wscale 9], length 0
E..<..@./..a6.'...zb.P..o..&...A..q a..........
.R.W....... ................
13:02:14.910832 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 133625260 ecr 525532247], length 0
E..4..@[email protected].'....P...Ao..'...........
.....R.W................
13:02:14.911808 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 133625261 ecr 525532247], length 112: HTTP: GET / HTTP/1.1
E.....@[email protected].'....P...Ao..'...........
.....R.WGET / HTTP/1.1
User-Agent: Wget/1.14 (linux-gnu)
Accept: */*
Host: opensource.com
Connection: Keep-Alive
................
13:02:14.951199 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [.], ack 113, win 57, options [nop,nop,TS val 525532257 ecr 133625261], length 0
E..4.F@./.."6.'...zb.P..o..'.......9.2.....
.R.a....................
13:02:14.955030 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 525532258 ecr 133625261], length 642: HTTP: HTTP/1.1 302 Found
E....G@./...6.'...zb.P..o..'.......9.......
.R.b....HTTP/1.1 302 Found
Server: nginx
Date: Sun, 23 Sep 2018 17:02:14 GMT
Content-Type: text/html; charset=iso-8859-1
Content-Length: 207
X-Content-Type-Options: nosniff
Location: https://opensource.com/
Cache-Control: max-age=1209600
Expires: Sun, 07 Oct 2018 17:02:14 GMT
X-Request-ID: v-6baa3acc-bf52-11e8-9195-22000ab8cf2d
X-Varnish: 632951979
Age: 0
Via: 1.1 varnish (Varnish/5.2)
X-Cache: MISS
Connection: keep-alive
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>302 Found</title>
</head><body>
<h1>Found</h1>
<p>The document has moved <a href="https://opensource.com/">here</a>.</p>
</body></html>
................
13:02:14.955083 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 133625304 ecr 525532258], length 0
E..4..@[email protected].'....P....o..............
.....R.b................
13:02:15.195524 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [F.], seq 113, ack 643, win 239, options [nop,nop,TS val 133625545 ecr 525532258], length 0
E..4..@[email protected].'....P....o..............
.....R.b................
13:02:15.236592 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 525532329 ecr 133625545], length 0
E..4.H@./.. 6.'...zb.P..o..........9.I.....
.R......................
13:02:15.236656 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 644, win 239, options [nop,nop,TS val 133625586 ecr 525532329], length 0
E..4..@[email protected].'....P....o..............
.....R..................
10 packets captured
10 packets received by filter
0 packets dropped by kernel
```
This is helpful for troubleshooting issues with API calls, assuming the calls are using plain HTTP. For encrypted connections, this output is less useful.
## 6. Saving captures to a file
Another useful feature provided by tcpdump is the ability to save the capture to a file so you can analyze the results later. This allows you to capture packets in batch mode overnight, for example, and verify the results in the morning. It also helps when there are too many packets to analyze since real-time capture can occur too fast.
To save packets to a file instead of displaying them on screen, use the option `-w`
(for *write*):
```
$ sudo tcpdump -i any -c10 -nn -w webserver.pcap port 80
[sudo] password for ricardo:
tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
10 packets captured
10 packets received by filter
0 packets dropped by kernel
```
This command saves the output in a file named `webserver.pcap`
. The `.pcap`
extension stands for "packet capture" and is the convention for this file format.
As shown in this example, nothing gets displayed on-screen, and the capture finishes after capturing 10 packets, as per the option `-c10`
. If you want some feedback to ensure packets are being captured, use the option `-v`
.
Tcpdump creates a file in binary format so you cannot simply open it with a text editor. To read the contents of the file, execute tcpdump with the `-r`
(for *read*) option:
```
$ tcpdump -nn -r webserver.pcap
reading from file webserver.pcap, link-type LINUX_SLL (Linux cooked)
13:36:57.679494 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [S], seq 3709732619, win 29200, options [mss 1460,sackOK,TS val 135708029 ecr 0,nop,wscale 7], length 0
13:36:57.718932 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [S.], seq 1999298316, ack 3709732620, win 28960, options [mss 1460,sackOK,TS val 526052949 ecr 135708029,nop,wscale 9], length 0
13:36:57.719005 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 135708068 ecr 526052949], length 0
13:36:57.719186 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 135708068 ecr 526052949], length 112: HTTP: GET / HTTP/1.1
13:36:57.756979 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [.], ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 0
13:36:57.760122 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 642: HTTP: HTTP/1.1 302 Found
13:36:57.760182 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 135708109 ecr 526052959], length 0
13:36:57.977602 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [F.], seq 113, ack 643, win 239, options [nop,nop,TS val 135708327 ecr 526052959], length 0
13:36:58.022089 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 526053025 ecr 135708327], length 0
13:36:58.022132 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 644, win 239, options [nop,nop,TS val 135708371 ecr 526053025], length 0
$
```
Since you're no longer capturing the packets directly from the network interface, `sudo`
is not required to read the file.
You can also use any of the filters we've discussed to filter the content from the file, just as you would with real-time data. For example, inspect the packets in the capture file from source IP address `54.204.39.132`
by executing this command:
```
$ tcpdump -nn -r webserver.pcap src 54.204.39.132
reading from file webserver.pcap, link-type LINUX_SLL (Linux cooked)
13:36:57.718932 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [S.], seq 1999298316, ack 3709732620, win 28960, options [mss 1460,sackOK,TS val 526052949 ecr 135708029,nop,wscale 9], length 0
13:36:57.756979 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [.], ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 0
13:36:57.760122 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 642: HTTP: HTTP/1.1 302 Found
13:36:58.022089 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 526053025 ecr 135708327], length 0
```
## What's next?
These basic features of tcpdump will help you get started with this powerful and versatile tool. To learn more, consult the [tcpdump website](http://www.tcpdump.org/#) and [man pages](http://www.tcpdump.org/manpages/tcpdump.1.html).
The tcpdump command line interface provides great flexibility for capturing and analyzing network traffic. If you need a graphical tool to understand more complex flows, look at [Wireshark](https://www.wireshark.org/).
One benefit of Wireshark is that it can read `.pcap`
files captured by tcpdump. You can use tcpdump to capture packets in a remote machine that does not have a GUI and analyze the result file with Wireshark, but that is a topic for another day.
*This article was originally published in October 2018 and has been updated by Seth Kenlon.*
## 5 Comments |
10,193 | 让决策更透明的三步 | https://opensource.com/open-organization/17/9/exercise-in-transparent-decisions | 2018-11-04T22:28:36 | [
"透明",
"决策"
] | https://linux.cn/article-10193-1.html |
>
> 当您使用这种决策技巧时,可以使你作为一个开源领导人做出决策时更透明。
>
>
>

要让你的领导工作更加透明,其中一个最有效的方法就是将一个现有的流程开放给你的团队进行反馈,然后根据反馈去改变流程。下面这些练习能让透明度更加切实,并且它有助于让你在持续评估并调整你的工作的透明度时形成“肌肉记忆”。
我想说,你可以通过任何流程来完成这项工作 —— 即使有些流程看起来像是“禁区”流程,比如晋升或者调薪。但是如果第一次它对于初步实践来说太大了,那么你可能需要从一个不那么敏感的流程开始,比如旅行批准流程或者为你的团队寻找空缺候选人的系统。(举个例子,我在我们的招聘和晋升流程中使用了这种方式)
开放流程并使其更加透明可以建立你的信誉并增强团队成员对你的信任。它会使你以一种可能超乎你设想和舒适程度的方式“走在透明的路上”。以这种方式工作确实会产生额外的工作,尤其是在过程的开始阶段 —— 但是,最终这种方法对于让管理者(比如我)对团队成员更具责任,而且它会更加相容。
### 阶段一:选择一个流程
**第一步** 想想你的团队使用的一个普通的或常规的流程,但是这个流程通常不需要仔细检查。下面有一些例子:
* 招聘:如何创建职位描述、如何挑选面试团队、如何筛选候选人以及如何做出最终的招聘决定。
* 规划:你的团队或组织如何确定年度或季度目标。
* 升职:你如何选择并考虑升职候选人,并决定谁升职。
* 经理绩效评估:谁有机会就经理绩效提供反馈,以及他们是如何反馈。
* 旅游:旅游预算如何分配,以及你如何决定是否批准旅行(或提名某人是否旅行)。
上面的某个例子可能会引起你的共鸣,或者你可能会发现一些你觉得更合适的流程。也许你已经收到了关于某个特定流程的问题,又或者你发现自己屡次解释某个特定决策的逻辑依据。选择一些你能够控制或影响的东西 —— 一些你认为你的成员所关心的东西。
**第二步** 现在回答以下关于这个流程的问题:
* 该流程目前是否记录在一个所有成员都知道并可以访问的地方?如果没有,现在就开始创建文档(不必太详细;只需要解释这个流程的不同步骤以及它是如何工作的)。你可能会发现这个过程不够清晰或一致,无法记录到文档。在这种情况下,用你*认为*理想情况下所应该的方式去记录它。
* 完成流程的文档是否说明了在不同的点上是如何做出决定?例如,在旅行批准流程中,它是否解释了如何批准或拒绝请求。
* 流程的*输入信息*是什么?例如,在确定部门年度目标时,哪些数据用于关键绩效指标,查找或者采纳谁的反馈,谁有机会审查或“签字”。
* 这个过程会做出什么*假设*?例如,在升职决策中,你是否认为所有的晋升候选人都会在适当的时间被他们的经理提出。
* 流程的*输出物*是什么?例如,在评估经理的绩效时,评估的结果是否会与经理共享,该审查报告的任何方面是否会与经理的直接报告更广泛地共享(例如,改进的领域)?
回答上述问题时,避免作出判断。如果这个流程不能清楚地解释一个决定是如何做出的,那也可以接受。这些问题只是评估现状的一个机会。
接下来,修改流程的文档,直到你对它充分说明了流程并预测潜在的问题感到满意。
### 阶段二:收集反馈
下一个阶段涉及到与你的成员分享这个流程并要求反馈。分享说起来容易做起来难。
**第一步** 鼓励人们提供反馈。考虑一下实现此目的的各种机制:
* 把这个流程公布在人们可以在内部找到的地方,并提示他们可以在哪里发表评论或提供反馈。谷歌文档可以很好地评论特定的文本或直接提议文本中的更改。
* 通过电子邮件分享过程文档,邀请反馈。
* 提及流程文档,在团队会议或一对一的谈话时要求反馈。
* 给人们一个他们可以提供反馈的时间窗口,并在此窗口内定期发送提醒。
如果你得不到太多的反馈,不要认为沉默就等于认可。你可以试着直接询问人们,他们为什么没有反馈。是因为他们太忙了吗?这个过程对他们来说不像你想的那么重要吗?你清楚地表达了你的要求吗?
**第二步** 迭代。当你获得关于流程的反馈时,鼓励团队对流程进行修改和迭代。加入改进的想法和建议,并要求确认预期的反馈已经被应用。如果你不同意某个建议,那就接受讨论,问问自己为什么不同意,以及一种方法和另一种方法的优点是什么。
设置一个收集反馈和迭代的时间窗口有助于向前推进。一旦收集和审查了反馈,你应当讨论和应用它,并且发布最终的流程供团队审查。
### 阶段三:实现
实现一个流程通常是计划中最困难的阶段。但如果你在修改过程中考虑了反馈意见,人们应该已经预料到了,并且可能会更支持你。从上面迭代过程中获得的文档是一个很好的工具,可以让你对实现负责。
**第一步** 审查实施需求。许多可以从提高透明度中获益的流程只需要做一点不同的事情,但是你确实需要检查你是否需要其他支持(例如工具)。
**第二步** 设置实现的时间表。与成员一起回顾时间表,这样他们就知道会发生什么。如果新流程需要对其他流程进行更改,请确保为人们提供足够的时间去适应新方式,并提供沟通和提醒。
**第三步** 跟进。在使用该流程 3-6 个月后,与你的成员联系,看看进展如何。新流程是否更加透明、更有效、更可预测?你有什么经验教训可以用来进一步改进这个流程吗?
### 关于作者
Sam Knuth —— 我有幸在 Red Hat 领导客户内容服务团队;我们生成提供给我们的客户的所有文档。我们的目标是为客户提供他们在企业中使用开源技术取得成功所需要的洞察力。在 Twitter 上与我 [@samfw](https://twitter.com/samfw) 联系。
---
via: <https://opensource.com/open-organization/17/9/exercise-in-transparent-decisions>
作者:[Sam Knuth](https://opensource.com/users/samfw) 译者:[MarineFish](https://github.com/MarineFish) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the most powerful ways to make your work as a leader more transparent is to take an existing process, open it up for feedback from your team, and then change the process to account for this feedback. The following exercise makes transparency more tangible, and it helps develop the "muscle memory" needed for continually evaluating and adjusting your work with transparency in mind.
I would argue that you can undertake this activity this with any process—even processes that might seem "off limits," like the promotion or salary adjustment processes. But if that's too big for a first bite, then you might consider beginning with a less sensitive process, such as the travel approval process or your system for searching for candidates to fill open positions on your team. (I've done this with our hiring process and promotion processes, for example.)
Opening up processes and making them more transparent builds your credibility and enhances trust with team members. It forces you to "walk the transparency walk" in ways that might challenge your assumptions or comfort level. Working this way does create additional work, particularly at the beginning of the process—but, ultimately, this works well for holding managers (like me) accountable to team members, and it creates more consistency.
## Phase 1: Pick a process
**Step 1.** Think of a common or routine process your team uses, but one that is not generally open for scrutiny. Some examples might include:
- Hiring: How are job descriptions created, interview teams selected, candidates screened and final hiring decisions made?
- Planning: How are your team or organizational goals determined for the year or quarter?
- Promotions: How do you select candidates for promotion, consider them, and decide who gets promoted?
- Manager performance appraisals: Who receives the opportunity to provide feedback on manager performance, and how are they able to do it?
- Travel: How is the travel budget apportioned, and how do you make decisions about whether to approval travel (or whether to nominate someone for travel)?
One of the above examples may resonate with you, or you may identify something else that you feel is more appropriate. Perhaps you've received questions about a particular process, or you find yourself explaining the rationale for a particular kind of decision frequently. Choose something that you are able to control or influence—and something you believe your constituents care about.
**Step 2.** Now answer the following questions about the process:
- Is the process currently documented in a place that all constituents know about and can access? If not, go ahead and create that documentation now (it doesn't have to be too detailed; just explain the different steps of the process and how it works). You may find that the process isn't clear or consistent enough to document. In that case, document it the way you
*think*it should work in the ideal case. - Does the completed process documentation explain how decisions are made at various points? For example, in a travel approval process, does it explain how a decision to approve or deny a request is made?
- What are the
*inputs*of the process? For example, when determining departmental goals for the year, what data is used for key performance indicators? Whose feedback is sought and incorporated? Who has the opportunity to review or "sign off"? - What
*assumptions*does this process make? For example, in promotion decisions, do you assume that all candidates for promotion will be put forward by their managers at the appropriate time? - What are the
*outputs*of the process? For example, in assessing the performance of the managers, is the result shared with the manager being evaluated? Are any aspects of the review shared more broadly with the manager's direct reports (areas for improvement, for example)?
Avoid making judgements when answering the above questions. If the process doesn't clearly explain how a decision is made, that might be fine. The questions are simply an opportunity to assess the current state.
Next, revise the documentation of the process until you are satisfied that it adequately explains the process and anticipates the potential questions.
## Phase 2: Gather feedback
The next phase involves sharing the process with your constituents and asking for feedback. Sharing is easier said than done.
**Step 1.** Encourage people to provide feedback. Consider a variety of mechanisms for doing this:
- Post the process somewhere people can find it internally and note where they can make comments or provide feedback. A Google document works great with the ability to comment on specific text or suggest changes directly in the text.
- Share the process document via email, inviting feedback
- Mention the process document and ask for feedback during team meetings or one-on-one conversations
- Give people a time window within which to provide feedback, and send periodic reminders during that window.
If you don't get much feedback, don't assume that silence is equal to endorsement. Try asking people directly if they have any idea why feedback is not coming in. Are people too busy? Is the process not as important to people as you thought? Have you effectively articulated what you're asking for?
**Step 2.** Iterate. As you get feedback about the process, engage the team in revising and iterating on the process. Incorporate ideas and suggestions for improvement, and ask for confirmation that the intended feedback has been applied. If you don't agree with a suggestion, be open to the discussion and ask yourself why you don't agree and what the merits are of one method versus another.
Setting a timebox for collecting feedback and iterating is helpful to move things forward. Once feedback has been collected and reviewed, discussed and applied, post the final process for the team to review.
## Phase 3: Implement
Implementing a process is often the hardest phase of the initiative. But if you've taken account of feedback when revising your process, people should already been anticipating it and will likely be more supportive. The documentation you have from the iterative process above is a great tool to keep you accountable on the implementation.
**Step 1.** Review requirements for implementation. Many processes that can benefit from increased transparency simply require doing things a little differently, but you do want to review whether you need any other support (tooling, for example).
**Step 2.** Set a timeline for implementation. Review the timeline with constituents so they know what to expect. If the new process requires a process change for others, be sure to provide enough time for people to adapt to the new behavior, and provide communication and reminders.
**Step 3.** Follow up. After using the process for 3-6 months, check in with your constituents to see how it's going. Is the new process more transparent? More effective? More predictable? Do you have any lessons learned that could be used to improve the process further?
## Comments are closed. |
10,194 | 如何在 Linux 中查看已挂载的文件系统类型 | https://www.ostechnix.com/how-to-find-the-mounted-filesystem-type-in-linux/ | 2018-11-04T23:00:44 | [
"文件系统",
"Ext4"
] | https://linux.cn/article-10194-1.html | 
如你所知,Linux 支持非常多的文件系统,例如 ext4、ext3、ext2、sysfs、securityfs、FAT16、FAT32、NTFS 等等,当前被使用最多的文件系统是 ext4。你曾经疑惑过你的 Linux 系统使用的是什么类型的文件系统吗?没有疑惑过?不用担心!我们将帮助你。本指南将解释如何在类 Unix 的操作系统中查看已挂载的文件系统类型。
### 在 Linux 中查看已挂载的文件系统类型
有很多种方法可以在 Linux 中查看已挂载的文件系统类型,下面我将给出 8 种不同的方法。那现在就让我们开始吧!
#### 方法 1 – 使用 findmnt 命令
这是查出文件系统类型最常使用的方法。`findmnt` 命令将列出所有已挂载的文件系统或者搜索出某个文件系统。`findmnt` 命令能够在 `/etc/fstab`、`/etc/mtab` 或 `/proc/self/mountinfo` 这几个文件中进行搜索。
`findmnt` 预装在大多数的 Linux 发行版中,因为它是 `util-linux` 包的一部分。如果 `findmnt` 命令不可用,你可以安装这个软件包。例如,你可以使用下面的命令在基于 Debian 的系统中安装 `util-linux` 包:
```
$ sudo apt install util-linux
```
下面让我们继续看看如何使用 `findmnt` 来找出已挂载的文件系统。
假如你只敲 `findmnt` 命令而不带任何的参数或选项,它将像下面展示的那样以树状图形式列举出所有已挂载的文件系统。
```
$ findmnt
```
示例输出:

正如你看到的那样,`findmnt` 展示出了目标挂载点(`TARGET`)、源设备(`SOURCE`)、文件系统类型(`FSTYPE`)以及相关的挂载选项(`OPTIONS`),例如文件系统是否是可读可写或者只读的。以我的系统为例,我的根(`/`)文件系统的类型是 EXT4 。
假如你不想以树状图的形式来展示输出,可以使用 `-l` 选项来以简单平凡的形式来展示输出:
```
$ findmnt -l
```

你还可以使用 `-t` 选项来列举出特定类型的文件系统,例如下面展示的 `ext4` 文件系统类型:
```
$ findmnt -t ext4
TARGET SOURCE FSTYPE OPTIONS
/ /dev/sda2 ext4 rw,relatime,commit=360
└─/boot /dev/sda1 ext4 rw,relatime,commit=360,data=ordered
```
`findmnt` 还可以生成 `df` 类型的输出,使用命令
```
$ findmnt --df
```
或
```
$ findmnt -D
```
示例输出:
```
SOURCE FSTYPE SIZE USED AVAIL USE% TARGET
dev devtmpfs 3.9G 0 3.9G 0% /dev
run tmpfs 3.9G 1.1M 3.9G 0% /run
/dev/sda2 ext4 456.3G 342.5G 90.6G 75% /
tmpfs tmpfs 3.9G 32.2M 3.8G 1% /dev/shm
tmpfs tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
bpf bpf 0 0 0 - /sys/fs/bpf
tmpfs tmpfs 3.9G 8.4M 3.9G 0% /tmp
/dev/loop0 squashfs 82.1M 82.1M 0 100% /var/lib/snapd/snap/core/4327
/dev/sda1 ext4 92.8M 55.7M 30.1M 60% /boot
tmpfs tmpfs 788.8M 32K 788.8M 0% /run/user/1000
gvfsd-fuse fuse.gvfsd-fuse 0 0 0 - /run/user/1000/gvfs
```
你还可以展示某个特定设备或者挂载点的文件系统类型。
查看某个特定的设备:
```
$ findmnt /dev/sda1
TARGET SOURCE FSTYPE OPTIONS
/boot /dev/sda1 ext4 rw,relatime,commit=360,data=ordered
```
查看某个特定的挂载点:
```
$ findmnt /
TARGET SOURCE FSTYPE OPTIONS
/ /dev/sda2 ext4 rw,relatime,commit=360
```
你甚至还可以查看某个特定标签的文件系统的类型:
```
$ findmnt LABEL=Storage
```
更多详情,请参考其 man 手册。
```
$ man findmnt
```
`findmnt` 命令已足够完成在 Linux 中查看已挂载文件系统类型的任务,这个命令就是为了这个特定任务而生的。然而,还存在其他方法来查看文件系统的类型,假如你感兴趣的话,请接着往下看。
#### 方法 2 – 使用 blkid 命令
`blkid` 命令被用来查找和打印块设备的属性。它也是 `util-linux` 包的一部分,所以你不必再安装它。
为了使用 `blkid` 命令来查看某个文件系统的类型,可以运行:
```
$ blkid /dev/sda1
```
#### 方法 3 – 使用 df 命令
在类 Unix 的操作系统中,`df` 命令被用来报告文件系统的磁盘空间使用情况。为了查看所有已挂载文件系统的类型,只需要运行:
```
$ df -T
```
示例输出:

关于 `df` 命令的更多细节,可以参考下面的指南。
* [针对新手的 df 命令教程](https://www.ostechnix.com/the-df-command-tutorial-with-examples-for-beginners/)
同样也可以参考其 man 手册:
```
$ man df
```
#### 方法 4 – 使用 file 命令
`file` 命令可以判读出某个特定文件的类型,即便该文件没有文件后缀名也同样适用。
运行下面的命令来找出某个特定分区的文件系统类型:
```
$ sudo file -sL /dev/sda1
[sudo] password for sk:
/dev/sda1: Linux rev 1.0 ext4 filesystem data, UUID=83a1dbbf-1e15-4b45-94fe-134d3872af96 (needs journal recovery) (extents) (large files) (huge files)
```
查看其 man 手册可以知晓更多细节:
```
$ man file
```
#### 方法 5 – 使用 fsck 命令
`fsck` 命令被用来检查某个文件系统是否健全或者修复它。你可以像下面那样通过将分区名字作为 `fsck` 的参数来查看该分区的文件系统类型:
```
$ fsck -N /dev/sda1
fsck from util-linux 2.32
[/usr/bin/fsck.ext4 (1) -- /boot] fsck.ext4 /dev/sda1
```
如果想知道更多的内容,请查看其 man 手册:
```
$ man fsck
```
#### 方法 6 – 使用 fstab 命令
`fstab` 是一个包含文件系统静态信息的文件。这个文件通常包含了挂载点、文件系统类型和挂载选项等信息。
要查看某个文件系统的类型,只需要运行:
```
$ cat /etc/fstab
```

更多详情,请查看其 man 手册:
```
$ man fstab
```
#### 方法 7 – 使用 lsblk 命令
`lsblk` 命令可以展示设备的信息。
要展示已挂载文件系统的信息,只需运行:
```
$ lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
loop0 squashfs /var/lib/snapd/snap/core/4327
sda
├─sda1 ext4 83a1dbbf-1e15-4b45-94fe-134d3872af96 /boot
├─sda2 ext4 4d25ddb0-5b20-40b4-ae35-ef96376d6594 /
└─sda3 swap 1f8f5e2e-7c17-4f35-97e6-8bce7a4849cb [SWAP]
sr0
```
更多细节,可以参考它的 man 手册:
```
$ man lsblk
```
#### 方法 8 – 使用 mount 命令
`mount` 被用来在类 Unix 系统中挂载本地或远程的文件系统。
要使用 `mount` 命令查看文件系统的类型,可以像下面这样做:
```
$ mount | grep "^/dev"
/dev/sda2 on / type ext4 (rw,relatime,commit=360)
/dev/sda1 on /boot type ext4 (rw,relatime,commit=360,data=ordered)
```
更多详情,请参考其 man 手册的内容:
```
$ man mount
```
好了,上面便是今天的全部内容了。现在你知道了 8 种不同的 Linux 命令来查看已挂载的 Linux 文件系统的类型。假如你知道其他的命令来完成同样的任务,请在下面的评论部分让我们知晓,我将确认并相应地升级本教程。
更过精彩内容即将呈现,请保持关注!
---
via: <https://www.ostechnix.com/how-to-find-the-mounted-filesystem-type-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,195 | 使用极简浏览器 Min 浏览网页 | https://opensource.com/article/18/10/min-web-browser | 2018-11-04T23:31:02 | [
"浏览器"
] | https://linux.cn/article-10195-1.html |
>
> 并非所有 web 浏览器都要做到无所不能,Min 就是一个极简主义风格的浏览器。
>
>
>

现在还有开发新的 Web 浏览器的需要吗?即使现在浏览器领域已经成为了寡头市场,但仍然不断涌现出各种前所未有的浏览器产品。
[Min](https://minbrowser.github.io/min/) 就是其中一个。顾名思义,Min 是一个小的浏览器,也是一个极简主义的浏览器。但它麻雀虽小五脏俱全,而且还是一个开源的浏览器,它的 Apache 2.0 许可证引起了我的注意。
让我们来看看 Min 有什么值得关注的方面。
### 开始
Min 基于 [Electron](http://electron.atom.io/apps/) 框架开发,值得一提的是,[Atom 文本编辑器](https://opensource.com/article/17/5/atom-text-editor-packages-writers)也是基于这个框架开发的。它提供 Linux、MacOS 和 Windows 的[安装程序](https://github.com/minbrowser/min/releases/),当然也可以[从 GitHub 获取它的源代码](https://github.com/minbrowser/min)自行编译安装。
我使用的 Linux 发行版是 Manjaro,但没有完全匹配这个发行版的安装程序。还好,我通过 Manjaro 的包管理器也能安装 Min。
安装完成后,在终端就可以直接启动 Min。

Min 号称是更智能、更快速的浏览器。经过尝试以后,我觉得它比我在其它电脑上使用过的 Firefox 和 Chrome 浏览器启动得更快。
而使用 Min 浏览网页的过程则和 Firefox 或 Chrome 一样,只要再地址栏输入 URL,回车,就好了。
### Min 的功能
尽管 Min 不可能带有 Firefox 或 Chrome 等浏览器得所有功能,但它也有可取之处。
Min 和其它浏览器一样,支持页面选项卡。它还有一个称为 Tasks 的功能,可以对打开的选项卡进行分组。
[DuckDuckGo](http://duckduckgo.com) 是我最喜欢的搜索引擎,而 Min 的默认搜索引擎恰好就是它,这正合我意。当然,如果你喜欢另一个搜索引擎,也可以在 Min 的偏好设置中配置你喜欢的搜索引擎作为默认搜索引擎。
Min 没有使用类似 AdBlock 这样的插件来过滤你不想看到的内容,而是使用了一个名为 [EasyList](https://easylist.to/) 的内置的广告拦截器,你可以使用它来屏蔽脚本和图片。另外 Min 还带有一个内置的防跟踪软件。
类似 Firefox,Min 有一个名为叫做 Reading List 的阅读模式。只需点击地址栏中的对应图标,就可以去除页面中的大部分无关内容,让你专注于正在阅读的内容。网页在阅读列表中可以保留 30 天。

Min 还有一个专注模式,可以隐藏其它选项卡并阻止你打开新的选项卡。在专注模式下,如果一个 web 页面中进行工作,需要多点击好几次才能打开一个新页面。
Min 也有很多快捷键让你快速使用某个功能。你可以[在 GitHub 上](https://github.com/minbrowser/min/wiki)找到这些这些快捷键的参考文档,也可以在 Min 的偏好设置中进行更改。
我发现 Min 可以在 YouTube、Vimeo、Dailymotion 等视频网站上播放视频,还可以在音乐网站 7Digital 上播放音乐。但由于我没有账号,所以没法测试是否能在 Spotify 或 Last.fm 等这些网站上播放音乐。

### Min 的弱点
Min 确实也有自己的缺点,例如它无法将网站添加为书签。替代方案要么是查看 Min 的搜索历史来找回你需要的链接,要么是使用一个第三方的书签服务。
最大的缺点是 Min 不支持插件。这对我来说不是一件坏事,因为浏览器启动速度和运行速度快的主要原因就在于此。当然也有一些人非常喜欢使用浏览器插件,Min 就不是他们的选择。
### 总结
Min 算是一个中规中矩的浏览器,它可以凭借轻量、快速的优点吸引很多极简主义的用户。但是对于追求多功能的用户来说,Min 就显得相当捉襟见肘了。
所以,如果你想摆脱当今多功能浏览器的束缚,我觉得可以试用一下 Min。
---
via: <https://opensource.com/article/18/10/min-web-browser>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Does the world need another web browser? Even though the days of having a multiplicity of browsers to choose from are long gone, there still are folks out there developing new applications that help us use the web.
One of those new-fangled browsers is [Min](https://minbrowser.github.io/min/). As its name suggests (well, suggests to me, anyway), Min is a minimalist browser. That doesn't mean it's deficient in any significant way, and its open source, Apache 2.0 license piques my interest.
But is Min worth a look? Let's find out.
## Getting going
Min is one of many applications written using a development framework called [Electron](http://electron.atom.io/apps/). (It's the same framework that brought us the [Atom text editor](https://opensource.com/article/17/5/atom-text-editor-packages-writers).) You can [get installers](https://github.com/minbrowser/min/releases/) for Linux, MacOS, and Windows. You can also grab the [source code from GitHub](https://github.com/minbrowser/min) and compile it if you're inclined.
I run Manjaro Linux, and there isn't an installer for that distro. Luckily, I was able to install Min from Manjaro's package manager.
Once that was done, I fired up Min by pressing Alt+F2, typing **min** in the run-application box, and pressing Enter, and I was ready to go.
Min is billed as *a smarter, faster web browser*. It definitely is fast—at the risk of drawing the ire of denizens of certain places on the web, I'll say that it starts faster than Firefox and Chrome on the laptops with which I tried it.
Browsing with Min is like browsing with Firefox or Chrome. Type a URL in the address bar, press Enter, and away you go.
## Min's features
While Min doesn't pack everything you'd find in browsers like Firefox or Chrome, it doesn't do too badly.
Like any other browser these days, Min supports multiple tabs. It also has a feature called Tasks, which lets you group your open tabs.
Min's default search engine is [DuckDuckGo](http://duckduckgo.com). I really like that touch because DuckDuckGo is one of my search engines of choice. If DuckDuckGo isn't your thing, you can set another search engine as the default in Min's preferences.
Instead of using tools like AdBlock to filter out content you don't want, Min has a built-in ad blocker. It uses the [EasyList filters](https://easylist.to/), which were created for AdBlock. You can block scripts and images, and Min also has a built-in tracking blocker.
Like Firefox, Min has a reading mode called Reading List. Flipping the Reading List switch (well, clicking the icon in the address bar) removes most of the cruft from a page so you can focus on the words you're reading. Pages stay in the Reading List for 30 days.
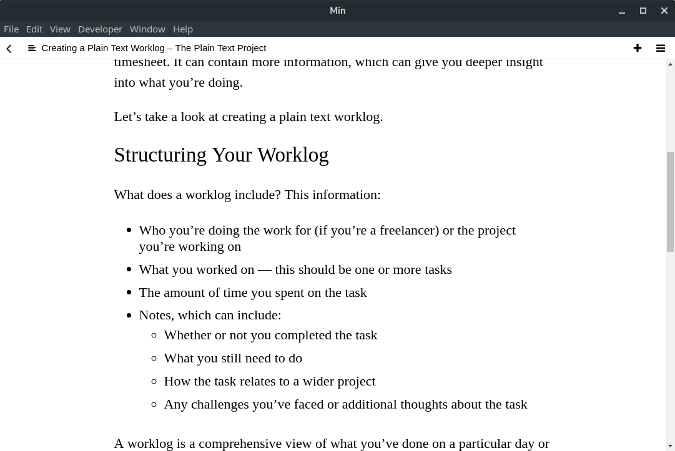
Speaking of focus, Min also has a Focus Mode that hides and prevents you from opening other tabs. So, if you're working in a web application, you'll need to click a few times if you feel like procrastinating.
Of course, Min has a number of keyboard shortcuts that can make using it a lot faster. You can find a reference for those shortcuts [on GitHub](https://github.com/minbrowser/min/wiki). You can also change a number of them in Min's preferences.
I was pleasantly surprised to find Min can play videos on YouTube, Vimeo, Dailymotion, and similar sites. I also played sample tracks at music retailer 7Digital. I didn't try playing music on popular sites like Spotify or Last.fm (because I don't have accounts with them).
## What's not there
The features that Min *doesn't* pack are as noticeable as the ones it does. There doesn't seem to be a way to bookmark sites. You either have to rely on Min's search history to find your favorite links, or you'll have to rely on a bookmarking service.
On top of that, Min doesn't support plugins. That's not a deal breaker for me—not having plugins is undoubtedly one of the reasons the browser starts and runs so quickly. I know a number of people who are … well, I wouldn't go so far to say junkies, but they really like their plugins. Min wouldn't cut it for them.
## Final thoughts
Min isn't a bad browser. It's light and fast enough to appeal to the minimalists out there. That said, it lacks features that hardcore web browser users clamor for.
If you want a zippy browser that isn't weighed down by all the features of so-called *modern* web browsers, I suggest giving Min a serious look.
## 7 Comments |
10,196 | 推动 DevOps 变革的三个方面 | https://opensource.com/article/18/10/tales-devops-transformation | 2018-11-05T10:22:39 | [
"DevOps"
] | https://linux.cn/article-10196-1.html |
>
> 推动大规模的组织变革是一个痛苦的过程。对于 DevOps 来说,尽管也有阵痛,但变革带来的价值则相当可观。
>
>
>

避免痛苦是一种强大的动力。一些研究表明,[植物也会通过遭受疼痛的过程](https://link.springer.com/article/10.1007%2Fs00442-014-2995-6)以采取措施来保护自己。我们人类有时也会刻意让自己受苦——在剧烈运动之后,身体可能会发生酸痛,但我们仍然坚持运动。那是因为当人认为整个过程利大于弊时,几乎可以忍受任何事情。
推动大规模的组织变革的过程确实是痛苦的。有人可能会因难以改变价值观和行为而感到痛苦,有人可能会因难以带领团队而感到痛苦,也有人可能会因难以开展工作而感到痛苦。但就 DevOps 而言,我可以说这些痛苦都是值得的。
我也曾经关注过一个团队耗费大量时间优化技术流程的过程,在这个过程中,团队逐渐将流程进行自动化改造,并最终获得了成功。

图片来源:Lee Eason. CC BY-SA 4.0
这张图表充分表明了变革的价值。一家公司在我主导实行了 DevOps 转型之后,60 多个团队每月提交了超过 900 个发布请求。这些工作量的原耗时高达每个月 350 人/天,而这么多的工作量对于任何公司来说都是不可忽视的。除此以外,他们每月的部署次数从 100 次增加到了 9000 次,高危 bug 减少了 24%,工程师们更轻松了,<ruby> 净推荐值 <rt> Net Promoter Score </rt></ruby>(NPS)也提高了,而 NPS 提高反过来也让团队的 DevOps 转型更加顺利。正如 [Puppet 发布的 DevOps 报告](https://puppet.com/resources/whitepaper/state-of-devops-report)所预测的,用在技术流程改进上的投入可以在业务成果上明显地体现出来。
而 DevOps 主导者在推动变革时必须关注这三个方面:团队管理,团队文化和团队活力。
### 团队管理
最重要的是,改进对技术流程的投入可以转化为更好的业务成果。
组织架构越大,业务领导与一线员工之间的距离就会越大,当然发生误解的可能性也会越大。而且各种技术工具和实际应用都在以日新月异的速度变化,这就导致业务领导几乎不可能对 DevOps 或敏捷开发的转型方向有一个亲身的了解。
DevOps 主导者必须和管理层密切合作,在进行决策的时候给出相关的意见,以帮助他们做出正确的决策。
公司的管理层只是知道 DevOps 会对产品部署的方式进行改进,而并不了解其中的具体过程。假设你正在帮助一个软件开发团队实现自动化部署,当管理层得知某次部署失败时(这种情况是有的),就会想要了解这件事情的细节。如果管理层了解到进行部署的是软件团队而不是专门的发布管理团队,就可能会坚持使用传统的变更流程来保证业务的正常运作。你可能会失去团队的信任,团队也可能不愿意做出进一步的改变。
如果没有和管理层做好心理上的预期,一旦发生意外的生产事件,重建管理层的信任并得到他们的支持比事先对他们进行教育需要更长的时间。所以,最好事先和管理层在各方面协调好,这会让你在后续的工作中避免很多麻烦。
对于和管理层之间的协调,这里有两条建议:
* 一是**重视所有规章制度**。如果管理层对合同、安全等各方面有任何疑问,你都可以向法务或安全负责人咨询,这样做可以避免犯下后果严重的错误。
* 二是**将管理层重点关注的方面输出为量化指标**。举个例子,如果公司的目标是减少客户流失,而你调查得出计划外的服务宕机是造成客户流失的主要原因,那么就可以让团队对故障的<ruby> 平均排查时间 <rt> Mean Time To Detection </rt></ruby>(MTTD)和<ruby> 平均解决时间 <rt> Mean Time To Resolution </rt></ruby>(MTTR)实行重点优化。你可以使用这些关键指标来量化团队的工作成果,而管理层对此也可以有一个直观的了解。
### 团队文化
DevOps 是一种专注于持续改进代码、构建、部署和操作流程的文化,而团队文化代表了团队的价值观和行为。从本质上说,团队文化是要塑造团队成员的行为方式,而这并不是一件容易的事。
我推荐一本叫做《[披着狼皮的 CIO](https://www.gartner.com/en/publications/wolf-cio)》的书。另外,研究心理学、阅读《[Drive](https://en.wikipedia.org/wiki/Drive:_The_Surprising_Truth_About_What_Motivates_Us)》、观看 Daniel Pink 的 [TED 演讲](https://www.ted.com/talks/dan_pink_on_motivation?language=en#t-2094)、阅读《[千面英雄](https://www.ted.com/talks/dan_pink_on_motivation?language=en#t-2094)》、了解每个人的心路历程,以上这些都是你推动公司技术变革所应该尝试去做的事情。如果这些你都没兴趣,说明你不是那个推动公司变革的人。如果你想成为那个人,那就开始学习吧!
从本质上说,改变一个人真不是件容易的事。
理性的人大多都按照自己的价值观工作,然而团队通常没有让每个人都能达成共识的明确价值观。因此,你需要明确团队目前的价值观,包括价值观的形成过程和价值观的目标导向。但不能将这些价值观强加到团队成员身上,只需要让团队成员在现有条件下力所能及地做到最好就可以了。
同时需要向团队成员阐明,公司正在发生组织和团队目标的变化,团队的价值观也随之改变,最好也厘清整个过程中将会作出什么变化。例如,公司以往或许是由于资金有限,一直将节约成本的原则放在首位,在研发新产品的时候,基础架构团队不得不共享数据库集群或服务器,从而导致了服务之间的紧密耦合。然而随着时间的推移,这种做法会产生难以维护的混乱,即使是一个小小的变化也可能造成无法预料的后果。这就导致交付团队难以执行变更控制流程,进而令变更停滞不前。
如果这种状况持续几年,最终的结果将会是毫无创新、技术老旧、问题繁多以及产品品质低下,公司的发展到达了瓶颈,原本的价值观已经不再适用。所以,工作效率的优先级必须高于节约成本。如果一个选择能让团队运作更好,另一个选择只是短期来看成本便宜,那你应该选择前者。
你必须反复强调团队的价值观。每当团队取得了一定的工作进展(即使探索创新时出现一些小的失误),都应该对团队作出激励。在团队部署出现失败时,鼓励他们承担风险、吸取教训,同时指导团队如何改进他们的工作并表示支持。长此下来,团队成员就会对你产生信任,不再顾虑为切合团队的价值观而做出改变。
### 团队活力
你有没有在会议上听过类似这样的话?“在张三度假回来之前,我们无法对这件事情做出评估。他是唯一一个了解代码的人”,或者是“我们完成不了这项任务,它在网络上需要跨团队合作,而防火墙管理员刚好请病假了”,又或者是“张三最清楚这个系统,他说是怎么样,通常就是怎么样”。那么如果团队在处理工作时,谁才是主力?就是张三。而且也一直会是他。
我们一直都认为这就是软件开发的自带属性。但是如果我们不作出改变,这种循环就会一直持续下去。
熵的存在会让团队自发地变得混乱和缺乏活力,团队的成员和主导者的都有责任控制这个熵并保持团队的活力。DevOps、敏捷开发、上云、代码重构这些行为都会令熵加速增长,这是因为转型让团队需要学习更多新技能和专业知识以开展新工作。
我们来看一个产品团队重构历史代码的例子。像往常一样,他们在 AWS 上构建新的服务。而传统的系统则在数据中心部署,并由 IT 部门进行监控和备份。IT 部门会确保在基础架构的层面上满足应用的安全需求、进行灾难恢复测试、系统补丁、安装配置了入侵检测和防病毒代理,而且 IT 部门还保留了年度审计流程所需的变更控制记录。
产品团队经常会犯一个致命的错误,就是认为 IT 是消耗资源的部门,是需要突破的瓶颈。他们希望脱离已有的 IT 部门并使用公有云,但实际上是他们忽视了 IT 部门提供的关键服务。迁移到云上只是以不同的方式实现这些关键服务,因为 AWS 也是一个数据中心,团队即使使用 AWS 也需要完成 IT 运维任务。
实际上,产品团队在向云迁移的时候也必须学习如何使用这些 IT 服务。因此,当产品团队开始重构历史代码并部署到云上时,也需要学习大量的技能才能正常运作。这些技能不会无师自通,必须自行学习或者聘用相关的人员,团队的主导者也必须积极进行管理。
在带领团队时,我找不到任何适合我的工具,因此我建立了 [Tekita.io](https://tekata.io/) 这个项目。Tekata 免费而且容易使用。但相比起来,把注意力集中在人员和流程上更为重要,你需要不断学习,持续关注团队的短板,因为它们会影响团队的交付能力,而弥补这些短板往往需要学习大量的新知识,这就需要团队成员之间有一个很好的协作。因此 76% 的年轻人都认为个人发展机会是公司文化[最重要的的一环](https://www.execu-search.com/%7E/media/Resources/pdf/2017_Hiring_Outlook_eBook)。
### 效果就是最好的证明
DevOps 转型会改变团队的工作方式和文化,这需要得到管理层的支持和理解。同时,工作方式的改变意味着新技术的引入,所以在管理上也必须谨慎。但转型的最终结果是团队变得更高效、成员变得更积极、产品变得更优质,客户也变得更满意。
免责声明:本文中的内容仅为 Lee Eason 的个人立场,不代表 Ipreo 或 IHS Markit。
---
via: <https://opensource.com/article/18/10/tales-devops-transformation>
作者:[Lee Eason](https://opensource.com/users/leeeason) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[pityonline](https://github.com/pityonline)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Pain avoidance is a powerful motivator. Some studies hint that even [plants experience a type of pain](https://link.springer.com/article/10.1007%2Fs00442-014-2995-6) and take steps to defend themselves. Yet we have plenty of examples of humans enduring pain on purpose—exercise often hurts, but we still do it. When we believe the payoff is worth the pain, we'll endure almost anything.
The truth is that driving large-scale organizational change is painful. It hurts for those having to change their values and behaviors, it hurts for leadership, and it hurts for the people just trying to do their jobs. In the case of DevOps, though, I can tell you the pain is worth it.
I've seen firsthand how teams learn they must spend time improving their technical processes, take ownership of their automation pipelines, and become masters of their fate. They gain the tools they need to be successful.
This chart shows the value of that change. In a company where I directed a DevOps transformation, its 60+ teams submitted more than 900 requests per month to release management. If you add up the time those tickets stayed open, it came to more than 350 days *per month*. What could your company do with an extra 350 person-days per month? In addition to the improvements seen above, they went from 100 to 9,000 deployments per month, a 24% decrease in high-severity bugs, happier engineers, and improved net promoter scores (NPS). The biggest NPS improvements link to the teams furthest along on their DevOps journey, as the [Puppet State of DevOps](https://puppet.com/resources/whitepaper/state-of-devops-report) report predicted. The bottom line is that investments into technical process improvement translate into better business outcomes.
DevOps leaders must focus on three main areas to drive this change: executives, culture, and team health.
## Executives
The larger your organization, the greater the distance (and opportunities for misunderstanding) between business leadership and the individuals delivering services to your customers. To make things worse, the landscape of tools and practices in technology is changing at an accelerating rate. This makes it practically impossible for business leaders to understand on their own how transformations like DevOps or agile work.DevOps leaders must help executives come along for the ride. Educating leaders gives them options when they're making decisions and makes it more likely they'll choose paths that help your company.
For example, let's say your executives believe DevOps is going to improve how you deploy your products into production, but they don't understand how. You've been working with a software team to help automate their deployment. When an executive hears about a deploy failure (and there will be failures), they will want to understand how it occurred. When they learn the software team did the deployment rather than the release management team, they may try to protect the business by decreeing all production releases must go through traditional change controls. You will lose credibility, and teams will be far less likely to trust you and accept further changes.
It takes longer to rebuild trust with executives and get their support *after* an incident than it would have taken to educate them in the first place. Put the time in upfront to build alignment, and it will pay off as you implement tactical changes.
Two pieces of advice when building that alignment:
- First,
**don't ignore any constraints**they raise. If they have worries about contracts or security, make the heads of legal and security your new best friends. By partnering with them, you'll build their trust and avoid making costly mistakes. - Second,
**use metrics to build a bridge**between what your delivery teams are doing and your executives' concerns. If the business has a goal to reduce customer churn, and you know from research that many customers leave because of unplanned downtime, reinforce that your teams are committed to tracking and improving Mean Time To Detection and Resolution (MTTD and MTTR). You can use those key metrics to show meaningful progress that teams and executives understand and get behind.
## Culture
DevOps is a culture of continuous improvement focused on code, build, deploy, and operational processes. Culture describes the organization's values and behaviors. Essentially, we're talking about changing how people behave, which is never easy.
I recommend reading * The Wolf in CIO's Clothing*. Spend time thinking about psychology and motivation. Read
*or at least watch Daniel Pink's excellent*
[Drive](https://en.wikipedia.org/wiki/Drive:_The_Surprising_Truth_About_What_Motivates_Us)[TED Talk](https://www.ted.com/talks/dan_pink_on_motivation?language=en#t-2094). Read
*and learn to identify the different journeys everyone is on. If none of these things sound interesting, you are not the right person to drive change in your company. Otherwise, read on!*
[The Hero with a Thousand Faces](https://en.wikipedia.org/wiki/The_Hero_with_a_Thousand_Faces)Explain that the company and its organizational goals are changing, and the team must alter its values. It's helpful to express this in terms of contrast. For example, your company may have historically valued cost savings above all else. That value is there for a reason—the company was cash-strapped. To get new products out, the infrastructure group had to tightly couple services by sharing database clusters or servers. Over time, those practices created a real mess that became hard to maintain. Simple changes started breaking things in unexpected ways. This led to tight change-control processes that were painful for delivery teams, so they stopped changing things.
Play that movie for five years, and you end up with little to no innovation, legacy technology, attraction and retention problems, and poor-quality products. You've grown the company, but you've hit a ceiling, and you can't continue to grow with those same values and behaviors. Now you must put engineering efficiency above cost saving. If one option will help teams maintain their service easier, but the other option is cheaper in the short term, you go with the first option.
You must tell this story again and again. Then you must celebrate any time a team expresses the new value through their behavior—even if they make a mistake. When a team has a deploy failure, congratulate them for taking the risk and encourage them to keep learning. Explain how their behavior is leading to the right outcome and support them. Over time, teams will see the message is real, and they'll feel safe altering their behavior.
## Team health
Have you ever been in a planning meeting and heard something like this: "We can't really estimate that story until John gets back from vacation. He's the only one who knows that area of the code well enough." Or: "We can't get this task done because it's got a cross-team dependency on network engineering, and the guy that set up the firewall is out sick." Or: "John knows that system best; if he estimated the story at a 3, then let's just go with that." When the team works on that story, who will most likely do the work? That's right, John will, and the cycle will continue.
For a long time, we've accepted that this is just the nature of software development. If we don't solve for it, we perpetuate the cycle.
Entropy will always drive teams naturally towards disorder and bad health. Our job as team members and leaders is to intentionally manage against that entropy and keep our teams healthy. Transformations like DevOps, agile, moving to the cloud, or refactoring a legacy application all amplify and accelerate that entropy. That's because transformations add new skills and expertise needed for the team to take on that new type of work.
Let's look at an example of a product team refactoring its legacy monolith. As usual, they build those new services in AWS. The legacy monolith was deployed to the data center, monitored, and backed up by IT. IT made sure the application's infosec requirements were met at the infrastructure layer. They conducted disaster recovery tests, patched the servers, and installed and configured required intrusion detection and antivirus agents. And they kept change control records, required for the annual audit process, of everything was done to the application's infrastructure.I often see product teams make the fatal mistake of thinking IT is all cost and bottleneck. They're hungry to shed the skin of IT and use the public cloud, but they never stop to appreciate the critical services IT provides. Moving to the cloud means you implement these things differently; they don't go away. AWS is still a data center, and any team utilizing it accepts the related responsibilities.
In practice, this means product teams must learn how to do those IT services when they move to the cloud. So, when our fictional product team starts refactoring its legacy application and putting new services in in the cloud, it will need a vastly expanded skillset to be successful. Those skills don't magically appear—they're learned or hired—and team leaders and managers must actively manage the process.
I built [Tekata.io](https://tekata.io/) because I couldn't find any tools to support me as I helped my teams evolve. Tekata is free and easy to use, but the tool is not as important as the people and process. Make sure you build continuous learning into your cadence and keep track of your team's weak spots. Those weak spots affect your ability to deliver, and filling them usually involves learning new things, so there's a wonderful synergy here. In fact, 76% of millennials think professional development opportunities are [one of the most important elements](https://www.execu-search.com/~/media/Resources/pdf/2017_Hiring_Outlook_eBook) of company culture.
## Proof is in the payoff
DevOps transformations involve altering the behavior, and therefore the culture, of your teams. That must be done with executive support and understanding. At the same time, those behavior changes mean learning new skills, and that process must also be managed carefully. But the payoff for pulling this off is more productive teams, happier and more engaged team members, higher quality products, and happier customers.
*Lee Eason will present Tales From A DevOps Transformation at All Things Open, October 21-23 in Raleigh, N.C.*
*Disclaimer: All opinions are statements in this article are exclusively those of Lee Eason and are not representative of Ipreo or IHS Markit.*
## 2 Comments |
10,198 | 在你开始使用 Kali Linux 之前必须知道的事情 | https://fosspost.org/articles/must-know-before-using-kali-linux | 2018-11-05T14:27:00 | [
"Kali"
] | https://linux.cn/article-10198-1.html | 
Kali Linux 在渗透测试和白帽子方面是业界领先的 Linux 发行版。默认情况下,该发行版附带了大量入侵和渗透的工具和软件,并且在全世界都得到了广泛认可。即使在那些甚至可能不知道 Linux 是什么的 Windows 用户中也是如此。
由于后者的原因(LCTT 译注:Windows 用户),许多人都试图单独使用 Kali Linux,尽管他们甚至不了解 Linux 系统的基础知识。原因可能各不相同,有的为了玩乐,有的是为了取悦女友而伪装成黑客,有的仅仅是试图破解邻居的 WiFi 网络以免费上网。如果你打算使用 Kali Linux,记住,所有的这些都是不好的事情。
在计划使用 Kali Linux 之前,你应该了解一些提示。
### Kali Linux 不适合初学者

*Kali Linux 默认 GNOME 桌面*
如果你是几个月前刚开始使用 Linux 的人,或者你认为自己的知识水平低于平均水平,那么 Kali Linux 就不适合你。如果你打算问“如何在 Kali 上安装 Steam?如何让我的打印机在 Kali 上工作?如何解决 Kali 上的 APT 源错误?”这些东西,那么 Kali Linux 并不适合你。
Kali Linux 主要面向想要运行渗透测试套件的专家或想要学习成为白帽子和数字取证的人。但即使你属于后者,普通的 Kali Linux 用户在日常使用时也会遇到很多麻烦。他还被要求以非常谨慎的方式使用工具和软件,而不仅仅是“让我们安装并运行一切”。每一个工具必须小心使用,你安装的每一个软件都必须仔细检查。
**建议阅读:** [Linux 系统的组件有什么?](https://fosspost.org/articles/what-are-the-components-of-a-linux-distribution)
普通 Linux 用户都无法自如地使用它。一个更好的方法是花几周时间学习 Linux 及其守护进程、服务、软件、发行版及其工作方式,然后观看几十个关于白帽子攻击的视频和课程,然后再尝试使用 Kali 来应用你学习到的东西。
### 它会让你被黑客攻击

*Kali Linux 入侵和测试工具*
在普通的 Linux 系统中,普通用户有一个账户,而 root 用户也有一个单独的账号。但在 Kali Linux 中并非如此。Kali Linux 默认使用 root 账户,不提供普通用户账户。这是因为 Kali 中几乎所有可用的安全工具都需要 root 权限,并且为了避免每分钟要求你输入 root 密码,所以这样设计。
当然,你可以简单地创建一个普通用户账户并开始使用它。但是,这种方式仍然不推荐,因为这不是 Kali Linux 系统设计的工作方式。使用普通用户在使用程序,打开端口,调试软件时,你会遇到很多问题,你会发现为什么这个东西不起作用,最终却发现它是一个奇怪的权限错误。另外每次在系统上做任何事情时,你会被每次运行工具都要求输入密码而烦恼。
现在,由于你被迫以 root 用户身份使用它,因此你在系统上运行的所有软件也将以 root 权限运行。如果你不知道自己在做什么,那么这很糟糕,因为如果 Firefox 中存在漏洞,并且你访问了一个受感染的网站,那么黑客能够在你的 PC 上获得全部 root 权限并入侵你。如果你使用的是普通用户账户,则会受到限制。此外,你安装和使用的某些工具可能会在你不知情的情况下打开端口并泄露信息,因此如果你不是非常小心,人们可能会以你尝试入侵他们的方式入侵你。
如果你曾经访问过与 Kali Linux 相关的 Facebook 群组,你会发现这些群组中几乎有四分之一的帖子是人们在寻求帮助,因为有人入侵了他们。
### 它可以让你入狱
Kali Linux 只是提供了软件。那么,如何使用它们完全是你自己的责任。
在世界上大多数发达国家,使用针对公共 WiFi 网络或其他设备的渗透测试工具很容易让你入狱。现在不要以为你使用了 Kali 就无法被跟踪,许多系统都配置了复杂的日志记录设备来简单地跟踪试图监听或入侵其网络的人,你可能无意间成为其中的一个,那么它会毁掉你的生活。
永远不要对不属于你的设备或网络使用 Kali Linux 系统,也不要明确允许对它们进行入侵。如果你说你不知道你在做什么,在法庭上它不会被当作借口来接受。
### 修改了的内核和软件
Kali [基于](https://www.kali.org/news/kali-linux-rolling-edition-2016-1/) Debian(“测试”分支,这意味着 Kali Linux 使用滚动发布模型),因此它使用了 Debian 的大部分软件体系结构,你会发现 Kali Linux 中的大部分软件跟 Debian 中的没什么区别。
但是,Kali 修改了一些包来加强安全性并修复了一些可能的漏洞。例如,Kali 使用的 Linux 内核被打了补丁,允许在各种设备上进行无线注入。这些补丁通常在普通内核中不可用。此外,Kali Linux 不依赖于 Debian 服务器和镜像,而是通过自己的服务器构建软件包。以下是最新版本中的默认软件源:
```
deb http://http.kali.org/kali kali-rolling main contrib non-free
deb-src http://http.kali.org/kali kali-rolling main contrib non-free
```
这就是为什么,对于某些特定的软件,当你在 Kali Linux 和 Fedora 中使用相同的程序时,你会发现不同的行为。你可以从 [git.kali.org](http://git.kali.org) 中查看 Kali Linux 软件的完整列表。你还可以在 Kali Linux(GNOME)上找到我们[自己生成的已安装包列表](https://paste.ubuntu.com/p/bctSVWwpVw/)。
更重要的是,Kali Linux 官方文档极力建议不要添加任何其他第三方软件仓库,因为 Kali Linux 是一个滚动发行版,并且依赖于 Debian 测试分支,由于依赖关系冲突和包钩子,所以你很可能只是添加一个新的仓库源就会破坏系统。
### 不要安装 Kali Linux

*使用 Kali Linux 在 fosspost.org 上运行 wpscan*
我在极少数情况下使用 Kali Linux 来测试我部署的软件和服务器。但是,我永远不敢安装它并将其用作主系统。
如果你要将其用作主系统,那么你必须保留自己的个人文件、密码、数据以及系统上的所有内容。你还需要安装大量日常使用的软件,以解放你的生活。但正如我们上面提到的,使用 Kali Linux 是非常危险的,应该非常小心地进行,如果你被入侵了,你将丢失所有数据,并且可能会暴露给更多的人。如果你在做一些不合法的事情,你的个人信息也可用于跟踪你。如果你不小心使用这些工具,那么你甚至可能会毁掉自己的数据。
即使是专业的白帽子也不建议将其作为主系统安装,而是通过 USB 使用它来进行渗透测试工作,然后再回到普通的 Linux 发行版。
### 底线
正如你现在所看到的,使用 Kali 并不是一个轻松的决定。如果你打算成为一个白帽子,你需要使用 Kali 来学习,那么在学习了基础知识并花了几个月的时间使用普通 Linux 系统之后再来学习 Kali。但是小心你正在做的事情,以避免遇到麻烦。
如果你打算使用 Kali,或者你需要任何帮助,我很乐意在评论中听到你的想法。
---
via: <https://fosspost.org/articles/must-know-before-using-kali-linux>
作者:[M.Hanny Sabbagh](https://fosspost.org/author/mhsabbagh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,199 | 如何禁用 Ubuntu 服务器中终端欢迎消息中的广告 | https://www.ostechnix.com/how-to-disable-ads-in-terminal-welcome-message-in-ubuntu-server/ | 2018-11-05T21:50:47 | [
"motd",
"Ubuntu"
] | https://linux.cn/article-10199-1.html | 如果你正在使用最新的 Ubuntu 服务器版本,你可能已经注意到欢迎消息中有一些与 Ubuntu 服务器平台无关的促销链接。你可能已经知道 **MOTD**,即 **M**essage **O**f **T**he **D**ay 的开头首字母,在 Linux 系统每次登录时都会显示欢迎信息。通常,欢迎消息包含操作系统版本,基本系统信息,官方文档链接以及有关最新安全更新等的链接。这些是我们每次通过 SSH 或本地登录时通常会看到的内容。但是,最近在终端欢迎消息中出现了一些其他链接。我已经几次注意到这些链接,但我并在意,也从未点击过。题图是我的 Ubuntu 18.04 LTS 服务器上显示的终端欢迎消息。

正如你在上面截图中所看到的,欢迎消息中有一个 bit.ly 链接和 Ubuntu wiki 链接。有些人可能会惊讶并想知道这是什么。其实欢迎信息中的链接无需担心。它可能看起来像广告,但并不是商业广告。链接实际上指向到了 [Ubuntu 官方博客](https://blog.ubuntu.com/) 和 [Ubuntu wiki](https://wiki.ubuntu.com/)。正如我之前所说,其中的一个链接是不相关的,没有任何与 Ubuntu 服务器相关的细节,这就是为什么我开头称它们为广告。
虽然我们大多数人都不会访问 bit.ly 链接,但是有些人可能出于好奇去访问这些链接,结果失望地发现它只是指向一个外部链接。你可以使用任何 URL 去短网址服务,例如 unshorten.it,在访问真正链接之前,查看它会指向哪里。或者,你只需在 bit.ly 链接的末尾输入加号(`+`)即可查看它们的实际位置以及有关链接的一些统计信息。

### 什么是 MOTD 以及它是如何工作的?
2009 年,来自 Canonical 的 Dustin Kirkland 在 Ubuntu 中引入了 MOTD 的概念。它是一个灵活的框架,使管理员或发行包能够在 `/etc/update-motd.d/` 位置添加可执行脚本,目的是生成在登录时显示有益的、有趣的消息。它最初是为 Landscape(Canonical 的商业服务)实现的,但是其它发行版维护者发现它很有用,并且在他们自己的发行版中也采用了这个特性。
如果你在 Ubuntu 系统中查看 `/etc/update-motd.d/`,你会看到一组脚本。一个是打印通用的 “欢迎” 横幅。下一个打印 3 个链接,显示在哪里可以找到操作系统的帮助。另一个计算并显示本地系统包可以更新的数量。另一个脚本告诉你是否需要重新启动等等。
从 Ubuntu 17.04 起,开发人员添加了 `/etc/update-motd.d/50-motd-news`,这是一个脚本用来在欢迎消息中包含一些附加信息。这些附加信息是:
1. 重要的关键信息,例如 ShellShock、Heartbleed 等
2. 生命周期(EOL)消息,新功能可用性等
3. 在 Ubuntu 官方博客和其他有关 Ubuntu 的新闻中发布的一些有趣且有益的帖子
另一个特点是异步,启动后约 60 秒,systemd 计时器运行 `/etc/update-motd.d/50-motd-news –force` 脚本。它提供了 `/etc/default/motd-news` 脚本中定义的 3 个配置变量。默认值为:`ENABLED=1, URLS="https://motd.ubuntu.com", WAIT="5"`。
以下是 `/etc/default/motd-news` 文件的内容:
```
$ cat /etc/default/motd-news
# Enable/disable the dynamic MOTD news service
# This is a useful way to provide dynamic, informative
# information pertinent to the users and administrators
# of the local system
ENABLED=1
# Configure the source of dynamic MOTD news
# White space separated list of 0 to many news services
# For security reasons, these must be https
# and have a valid certificate
# Canonical runs a service at motd.ubuntu.com, and you
# can easily run one too
URLS="https://motd.ubuntu.com"
# Specify the time in seconds, you're willing to wait for
# dynamic MOTD news
# Note that news messages are fetched in the background by
# a systemd timer, so this should never block boot or login
WAIT=5
```
好事情是 MOTD 是完全可定制的,所以你可以彻底禁用它(`ENABLED=0`)、根据你的意愿更改或添加脚本、以秒为单位更改等待时间等等。
如果启用了 MOTD,那么 systemd 计时器作业将循环遍历每个 URL,将它们的内容缩减到每行 80 个字符、最多 10 行,并将它们连接到 `/var/cache/motd-news` 中的缓存文件。此 systemd 计时器作业将每隔 12 小时运行并更新 `/var/cache/motd-news`。用户登录后,`/var/cache/motd-news` 的内容会打印到屏幕上。这就是 MOTD 的工作原理。
此外,`/etc/update-motd.d/50-motd-news` 文件中包含自定义的用户代理字符串,以报告有关计算机的信息。如果你查看 `/etc/update-motd.d/50-motd-news` 文件,你会看到:
```
# Piece together the user agent
USER_AGENT="curl/$curl_ver $lsb $platform $cpu $uptime"
```
这意味着,MOTD 检索器将向 Canonical 报告你的操作系统版本、硬件平台、CPU 类型和正常运行时间。
到这里,希望你对 MOTD 有了一个基本的了解。
现在让我们回到主题,我不想要这个功能。我该如何禁用它?如果欢迎消息中的促销链接仍然困扰你,并且你想永久禁用它们,则可以通过以下方法快速禁用它。
### 在 Ubuntu 服务器中禁用终端欢迎消息中的广告
要禁用这些广告,编辑文件:
```
$ sudo vi /etc/default/motd-news
```
找到以下行并将其值设置为 `0`(零)。
```
[...]
ENABLED=0
[...]
```
保存并关闭文件。现在,重新启动系统,看看欢迎消息是否仍然显示来自 Ubuntu 博客的链接。

看到没?现在没有来自 Ubuntu 博客和 Ubuntu wiki 的链接。
这就是全部内容了。希望这对你有所帮助。更多好东西要来了,敬请关注!
顺祝时祺!
---
via: <https://www.ostechnix.com/how-to-disable-ads-in-terminal-welcome-message-in-ubuntu-server/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,200 | 在 Linux 上使用 Lutries 管理你的游戏 | https://www.ostechnix.com/manage-games-using-lutris-linux/ | 2018-11-05T22:21:39 | [
"游戏"
] | https://linux.cn/article-10200-1.html | 
今天我们要讨论的是 **Lutris**,一个 Linux 上的开源游戏平台。你可以使用 Lutries 安装、移除、配置、启动和管理你的游戏。它可以在一个单一界面中帮你管理你的 Linux 游戏、Windows 游戏、仿真控制台游戏和浏览器游戏。它还包含社区编写的安装脚本,使得游戏的安装过程更加简单。
Lutries 自动安装(或者你可以单击点击安装)了超过 20 个模拟器,它提供了从七十年代到现在的大多数游戏系统。目前支持的游戏系统如下:
* Linux 原生
* Windows
* Steam (Linux 和 Windows)
* MS-DOS
* 街机
* Amiga 电脑
* Atari 8 和 16 位计算机和控制器
* 浏览器 (Flash 或者 HTML5 游戏)
* Commmodore 8 位计算机
* 基于 SCUMM 的游戏和其他点击式冒险游戏
* Magnavox Odyssey²、Videopac+
* Mattel Intellivision
* NEC PC-Engine Turbographx 16、Supergraphx、PC-FX
* Nintendo NES、SNES、Game Boy、Game Boy Advance、DS
* Game Cube 和 Wii
* Sega Master Sytem、Game Gear、Genesis、Dreamcast
* SNK Neo Geo、Neo Geo Pocket
* Sony PlayStation
* Sony PlayStation 2
* Sony PSP
* 像 Zork 这样的 Z-Machine 游戏
* 还有更多
### 安装 Lutris
就像 Steam 一样,Lutries 包含两部分:网站和客户端程序。从网站你可以浏览可用的游戏,添加最喜欢的游戏到个人库,以及使用安装链接安装他们。
首先,我们还是来安装客户端。它目前支持 Arch Linux、Debian、Fedroa、Gentoo、openSUSE 和 Ubuntu。
对于 **Arch Linux** 和它的衍生版本,像是 Antergos, Manjaro Linux,都可以在 [AUR](https://aur.archlinux.org/packages/lutris/) 中找到。因此,你可以使用 AUR 帮助程序安装它。
使用 [Pacaur](https://www.ostechnix.com/install-pacaur-arch-linux/):
```
pacaur -S lutris
```
使用 [Packer](https://www.ostechnix.com/install-packer-arch-linux-2/):
```
packer -S lutris
```
使用 [Yaourt](https://www.ostechnix.com/install-yaourt-arch-linux/):
```
yaourt -S lutris
```
使用 [Yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/):
```
yay -S lutris
```
**Debian:**
在 **Debian 9.0** 上以 **root** 身份运行以下命令:
```
echo 'deb http://download.opensuse.org/repositories/home:/strycore/Debian_9.0/ /' > /etc/apt/sources.list.d/lutris.list
wget -nv https://download.opensuse.org/repositories/home:strycore/Debian_9.0/Release.key -O Release.key
apt-key add - < Release.key
apt-get update
apt-get install lutris
```
在 **Debian 8.0** 上以 **root** 身份运行以下命令:
```
echo 'deb http://download.opensuse.org/repositories/home:/strycore/Debian_8.0/ /' > /etc/apt/sources.list.d/lutris.list
wget -nv https://download.opensuse.org/repositories/home:strycore/Debian_8.0/Release.key -O Release.key
apt-key add - < Release.key
apt-get update
apt-get install lutris
```
在 **Fedora 27** 上以 **root** 身份运行以下命令:
```
dnf config-manager --add-repo https://download.opensuse.org/repositories/home:strycore/Fedora_27/home:strycore.repo
dnf install lutris
```
在 **Fedora 26** 上以 **root** 身份运行以下命令:
```
dnf config-manager --add-repo https://download.opensuse.org/repositories/home:strycore/Fedora_26/home:strycore.repo
dnf install lutris
```
在 **openSUSE Tumbleweed** 上以 **root** 身份运行以下命令:
```
zypper addrepo https://download.opensuse.org/repositories/home:strycore/openSUSE_Tumbleweed/home:strycore.repo
zypper refresh
zypper install lutris
```
在 **openSUSE Leap 42.3** 上以 **root** 身份运行以下命令:
```
zypper addrepo https://download.opensuse.org/repositories/home:strycore/openSUSE_Leap_42.3/home:strycore.repo
zypper refresh
zypper install lutris
```
**Ubuntu 17.10**:
```
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/strycore/xUbuntu_17.10/ /' > /etc/apt/sources.list.d/lutris.list"
wget -nv https://download.opensuse.org/repositories/home:strycore/xUbuntu_17.10/Release.key -O Release.key
sudo apt-key add - < Release.key
sudo apt-get update
sudo apt-get install lutris
```
**Ubuntu 17.04**:
```
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/strycore/xUbuntu_17.04/ /' > /etc/apt/sources.list.d/lutris.list"
wget -nv https://download.opensuse.org/repositories/home:strycore/xUbuntu_17.04/Release.key -O Release.key
sudo apt-key add - < Release.key
sudo apt-get update
sudo apt-get install lutris
```
**Ubuntu 16.10**:
```
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/strycore/xUbuntu_16.10/ /' > /etc/apt/sources.list.d/lutris.list"
wget -nv https://download.opensuse.org/repositories/home:strycore/xUbuntu_16.10/Release.key -O Release.key
sudo apt-key add - < Release.key
sudo apt-get update
sudo apt-get install lutris
```
**Ubuntu 16.04**:
```
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/strycore/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/lutris.list"
wget -nv https://download.opensuse.org/repositories/home:strycore/xUbuntu_16.04/Release.key -O Release.key
sudo apt-key add - < Release.key
sudo apt-get update
sudo apt-get install lutris
```
对于其他平台,参考 [Lutris 下载链接](https://lutris.net/downloads/)。
### 使用 Lutris 管理你的游戏
安装完成后,从菜单或者应用启动器里打开 Lutries。首次启动时,Lutries 的默认界面像下面这样:

#### 登录你的 Lutris.net 账号
为了能同步你个人库中的游戏,下一步你需要在客户端中登录你的 Lutris.net 账号。如果你没有,先 [注册一个新的账号](https://lutris.net/user/register/)。然后点击 “Connecting to your Lutirs.net account to sync your library” 连接到 Lutries 客户端。
输入你的账号信息然后点击 “Connect”。

现在你已经连接到你的 Lutries.net 账号了。

#### 浏览游戏
点击工具栏里的浏览图标(游戏控制器图标)可以搜索任何游戏。它会自动定向到 Lutries 网站的游戏页。你可以以字母顺序查看所有可用的游戏。Lutries 现在已经有了很多游戏,而且还有更多的不断添加进来。

任选一个游戏,添加到你的库中。

然后返回到你的 Lutries 客户端,点击 “Menu -> Lutris -> Synchronize library”。现在你可以在本地的 Lutries 客户端中看到所有在库中的游戏了。

如果你没有看到游戏,只需要重启一次。
#### 安装游戏
安装游戏,只需要点击游戏,然后点击 “Install” 按钮。例如,我想在我的系统安装 [2048](https://www.ostechnix.com/let-us-play-2048-game-terminal/),就像你在底下的截图中看到的,它要求我选择一个版本去安装。因为它只有一个版本(例如,在线),它就会自动选择这个版本。点击 “Continue”。

点击“Install”:

安装完成之后,你可以启动新安装的游戏或是关闭这个窗口,继续从你的库中安装其他游戏。
#### 导入 Steam 库
你也可以导入你的 Steam 库。在你的头像处点击 “Sign in through Steam” 按钮。接下来你将被重定向到 Steam,输入你的账号信息。填写正确后,你的 Steam 账号将被连接到 Lutries 账号。请注意,为了同步库中的游戏,这里你的 Steam 账号将被公开。你可以在同步完成之后将其重新设为私密状态。
#### 手动添加游戏
Lutries 有手动添加游戏的选项。在工具栏中点击 “+” 号登录。

在下一个窗口,输入游戏名,在游戏信息栏选择一个运行器。运行器是指 Linux 上类似 wine、Steam 之类的程序,它们可以帮助你启动这个游戏。你可以从 “Menu -> Manage” 中安装运行器。

然后在下一栏中选择可执行文件或者 ISO。最后点击保存。有一个好消息是,你可以添加一个游戏的多个版本。
#### 移除游戏
移除任何已安装的游戏,只需在 Lutries 客户端的本地库中点击对应的游戏。选择 “Remove” 然后 “Apply”。

Lutries 就像 Steam。只是从网站向你的库中添加游戏,并在客户端中为你安装它们。
各位,这就是今天所有的内容了。我们将会在今年发表更多好的和有用的文章。敬请关注!
干杯!
:)
---
via: <https://www.ostechnix.com/manage-games-using-lutris-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,201 | Caffeinated 6.828:实验 2:内存管理 | https://sipb.mit.edu/iap/6.828/lab/lab2/ | 2018-11-06T16:17:31 | [
"内存管理"
] | https://linux.cn/article-10201-1.html | 
### 简介
在本实验中,你将为你的操作系统写内存管理方面的代码。内存管理由两部分组成。
第一部分是内核的物理内存分配器,内核通过它来分配内存,以及在不需要时释放所分配的内存。分配器以<ruby> 页 <rt> page </rt></ruby>为单位分配内存,每个页的大小为 4096 字节。你的任务是去维护那个数据结构,它负责记录物理页的分配和释放,以及每个分配的页有多少进程共享它。本实验中你将要写出分配和释放内存页的全套代码。
第二个部分是虚拟内存的管理,它负责由内核和用户软件使用的虚拟内存地址到物理内存地址之间的映射。当使用内存时,x86 架构的硬件是由内存管理单元(MMU)负责执行映射操作来查阅一组页表。接下来你将要修改 JOS,以根据我们提供的特定指令去设置 MMU 的页表。
#### 预备知识
在本实验及后面的实验中,你将逐步构建你的内核。我们将会为你提供一些附加的资源。使用 Git 去获取这些资源、提交自[实验 1](/article-9740-1.html) 以来的改变(如有需要的话)、获取课程仓库的最新版本、以及在我们的实验 2 (`origin/lab2`)的基础上创建一个称为 `lab2` 的本地分支:
```
athena% cd ~/6.828/lab
athena% add git
athena% git pull
Already up-to-date.
athena% git checkout -b lab2 origin/lab2
Branch lab2 set up to track remote branch refs/remotes/origin/lab2.
Switched to a new branch "lab2"
athena%
```
上面的 `git checkout -b` 命令其实做了两件事情:首先它创建了一个本地分支 `lab2`,它跟踪给我们提供课程内容的远程分支 `origin/lab2` ,第二件事情是,它改变你的 `lab` 目录的内容以反映 `lab2` 分支上存储的文件的变化。Git 允许你在已存在的两个分支之间使用 `git checkout *branch-name*` 命令去切换,但是在你切换到另一个分支之前,你应该去提交那个分支上你做的任何有意义的变更。
现在,你需要将你在 `lab1` 分支中的改变合并到 `lab2` 分支中,命令如下:
```
athena% git merge lab1
Merge made by recursive.
kern/kdebug.c | 11 +++++++++--
kern/monitor.c | 19 +++++++++++++++++++
lib/printfmt.c | 7 +++----
3 files changed, 31 insertions(+), 6 deletions(-)
athena%
```
在一些案例中,Git 或许并不知道如何将你的更改与新的实验任务合并(例如,你在第二个实验任务中变更了一些代码的修改)。在那种情况下,你使用 `git` 命令去合并,它会告诉你哪个文件发生了冲突,你必须首先去解决冲突(通过编辑冲突的文件),然后使用 `git commit -a` 去重新提交文件。
实验 2 包含如下的新源代码,后面你将逐个了解它们:
* `inc/memlayout.h`
* `kern/pmap.c`
* `kern/pmap.h`
* `kern/kclock.h`
* `kern/kclock.c`
`memlayout.h` 描述虚拟地址空间的布局,这个虚拟地址空间是通过修改 `pmap.c`、`memlayout.h` 和 `pmap.h` 所定义的 `PageInfo` 数据结构来实现的,这个数据结构用于跟踪物理内存页面是否被释放。`kclock.c` 和 `kclock.h` 维护 PC 上基于电池的时钟和 CMOS RAM 硬件,在此,BIOS 中记录了 PC 上安装的物理内存数量,以及其它的一些信息。在 `pmap.c` 中的代码需要去读取这个设备硬件,以算出在这个设备上安装了多少物理内存,但这部分代码已经为你完成了:你不需要知道 CMOS 硬件工作原理的细节。
特别需要注意的是 `memlayout.h` 和 `pmap.h`,因为本实验需要你去使用和理解的大部分内容都包含在这两个文件中。你或许还需要去看看 `inc/mmu.h` 这个文件,因为它也包含了本实验中用到的许多定义。
开始本实验之前,记得去添加 `exokernel` 以获取 QEMU 的 6.828 版本。
#### 实验过程
在你准备进行实验和写代码之前,先添加你的 `answers-lab2.txt` 文件到 Git 仓库,提交你的改变然后去运行 `make handin`。
```
athena% git add answers-lab2.txt
athena% git commit -am "my answer to lab2"
[lab2 a823de9] my answer to lab2 4 files changed, 87 insertions(+), 10 deletions(-)
athena% make handin
```
正如前面所说的,我们将使用一个评级程序来分级你的解决方案,你可以在 `lab` 目录下运行 `make grade`,使用评级程序来测试你的内核。为了完成你的实验,你可以改变任何你需要的内核源代码和头文件。但毫无疑问的是,你不能以任何形式去改变或破坏评级代码。
### 第 1 部分:物理页面管理
操作系统必须跟踪物理内存页是否使用的状态。JOS 以“页”为最小粒度来管理 PC 的物理内存,以便于它使用 MMU 去映射和保护每个已分配的内存片段。
现在,你将要写内存的物理页分配器的代码。它将使用 `struct PageInfo` 对象的链表来保持对物理页的状态跟踪,每个对象都对应到一个物理内存页。在你能够编写剩下的虚拟内存实现代码之前,你需要先编写物理内存页面分配器,因为你的页表管理代码将需要去分配物理内存来存储页表。
>
> **练习 1**
>
>
> 在文件 `kern/pmap.c` 中,你需要去实现以下函数的代码(或许要按给定的顺序来实现)。
>
>
> * `boot_alloc()`
> * `mem_init()`(只要能够调用 `check_page_free_list()` 即可)
> * `page_init()`
> * `page_alloc()`
> * `page_free()`
>
>
> `check_page_free_list()` 和 `check_page_alloc()` 可以测试你的物理内存页分配器。你将需要引导 JOS 然后去看一下 `check_page_alloc()` 是否报告成功即可。如果没有报告成功,修复你的代码直到成功为止。你可以添加你自己的 `assert()` 以帮助你去验证是否符合你的预期。
>
>
>
本实验以及所有的 6.828 实验中,将要求你做一些检测工作,以便于你搞清楚它们是否按你的预期来工作。这个任务不需要详细描述你添加到 JOS 中的代码的细节。查找 JOS 源代码中你需要去修改的那部分的注释;这些注释中经常包含有技术规范和提示信息。你也可能需要去查阅 JOS 和 Intel 的技术手册、以及你的 6.004 或 6.033 课程笔记的相关部分。
### 第 2 部分:虚拟内存
在你开始动手之前,需要先熟悉 x86 内存管理架构的保护模式:即分段和页面转换。
>
> **练习 2**
>
>
> 如果你对 x86 的保护模式还不熟悉,可以查看 [Intel 80386 参考手册](https://sipb.mit.edu/iap/6.828/readings/i386/toc.htm)的第 5 章和第 6 章。阅读这些章节(5.2 和 6.4)中关于页面转换和基于页面的保护。我们建议你也去了解关于段的章节;在虚拟内存和保护模式中,JOS 使用了分页、段转换、以及在 x86 上不能禁用的基于段的保护,因此你需要去理解这些基础知识。
>
>
>
#### 虚拟地址、线性地址和物理地址
在 x86 的专用术语中,一个<ruby> 虚拟地址 <rt> virtual address </rt></ruby>是由一个段选择器和在段中的偏移量组成。一个<ruby> 线性地址 <rt> linear address </rt></ruby>是在页面转换之前、段转换之后得到的一个地址。一个<ruby> 物理地址 <rt> physical address </rt></ruby>是段和页面转换之后得到的最终地址,它最终将进入你的物理内存中的硬件总线。

一个 C 指针是虚拟地址的“偏移量”部分。在 `boot/boot.S` 中我们安装了一个<ruby> 全局描述符表 <rt> Global Descriptor Table </rt></ruby>(GDT),它通过设置所有的段基址为 0,并且限制为 `0xffffffff` 来有效地禁用段转换。因此“段选择器”并不会生效,而线性地址总是等于虚拟地址的偏移量。在实验 3 中,为了设置权限级别,我们将与段有更多的交互。但是对于内存转换,我们将在整个 JOS 实验中忽略段,只专注于页转换。
回顾[实验 1](/article-9740-1.html) 中的第 3 部分,我们安装了一个简单的页表,这样内核就可以在 `0xf0100000` 链接的地址上运行,尽管它实际上是加载在 `0x00100000` 处的 ROM BIOS 的物理内存上。这个页表仅映射了 4MB 的内存。在实验中,你将要为 JOS 去设置虚拟内存布局,我们将从虚拟地址 `0xf0000000` 处开始扩展它,以映射物理内存的前 256MB,并映射许多其它区域的虚拟内存。
>
> **练习 3**
>
>
> 虽然 GDB 能够通过虚拟地址访问 QEMU 的内存,它经常用于在配置虚拟内存期间检查物理内存。在实验工具指南中复习 QEMU 的[监视器命令](https://sipb.mit.edu/iap/6.828/labguide/#qemu),尤其是 `xp` 命令,它可以让你去检查物理内存。要访问 QEMU 监视器,可以在终端中按 `Ctrl-a c`(相同的绑定返回到串行控制台)。
>
>
> 使用 QEMU 监视器的 `xp` 命令和 GDB 的 `x` 命令去检查相应的物理内存和虚拟内存,以确保你看到的是相同的数据。
>
>
> 我们的打过补丁的 QEMU 版本提供一个非常有用的 `info pg` 命令:它可以展示当前页表的一个具体描述,包括所有已映射的内存范围、权限、以及标志。原本的 QEMU 也提供一个 `info mem` 命令用于去展示一个概要信息,这个信息包含了已映射的虚拟内存范围和使用了什么权限。
>
>
>
在 CPU 上运行的代码,一旦处于保护模式(这是在 `boot/boot.S` 中所做的第一件事情)中,是没有办法去直接使用一个线性地址或物理地址的。所有的内存引用都被解释为虚拟地址,然后由 MMU 来转换,这意味着在 C 语言中的指针都是虚拟地址。
例如在物理内存分配器中,JOS 内存经常需要在不反向引用的情况下,去维护作为地址的一个很难懂的值或一个整数。有时它们是虚拟地址,而有时是物理地址。为便于在代码中证明,JOS 源文件中将它们区分为两种:类型 `uintptr_t` 表示一个难懂的虚拟地址,而类型 `physaddr_trepresents` 表示物理地址。这些类型其实不过是 32 位整数(`uint32_t`)的同义词,因此编译器不会阻止你将一个类型的数据指派为另一个类型!因为它们都是整数(而不是指针)类型,如果你想去反向引用它们,编译器将报错。
JOS 内核能够通过将它转换为指针类型的方式来反向引用一个 `uintptr_t` 类型。相反,内核不能反向引用一个物理地址,因为这是由 MMU 来转换所有的内存引用。如果你转换一个 `physaddr_t` 为一个指针类型,并反向引用它,你或许能够加载和存储最终结果地址(硬件将它解释为一个虚拟地址),但你并不会取得你想要的内存位置。
总结如下:
| C 类型 | 地址类型 |
| --- | --- |
| `T*` | 虚拟 |
| `uintptr_t` | 虚拟 |
| `physaddr_t` | 物理 |
>
> 问题:
>
>
> 1. 假设下面的 JOS 内核代码是正确的,那么变量 `x` 应该是什么类型?`uintptr_t` 还是 `physaddr_t` ?
>
>
> 
>
>
>
JOS 内核有时需要去读取或修改它只知道其物理地址的内存。例如,添加一个映射到页表,可以要求分配物理内存去存储一个页目录,然后去初始化它们。然而,内核也和其它的软件一样,并不能跳过虚拟地址转换,内核并不能直接加载和存储物理地址。一个原因是 JOS 将重映射从虚拟地址 `0xf0000000` 处的物理地址 `0` 开始的所有的物理地址,以帮助内核去读取和写入它知道物理地址的内存。为转换一个物理地址为一个内核能够真正进行读写操作的虚拟地址,内核必须添加 `0xf0000000` 到物理地址以找到在重映射区域中相应的虚拟地址。你应该使用 `KADDR(pa)` 去做那个添加操作。
JOS 内核有时也需要能够通过给定的内核数据结构中存储的虚拟地址找到内存中的物理地址。内核全局变量和通过 `boot_alloc()` 分配的内存是在内核所加载的区域中,从 `0xf0000000` 处开始的这个所有物理内存映射的区域。因此,要转换这些区域中一个虚拟地址为物理地址时,内核能够只是简单地减去 `0xf0000000` 即可得到物理地址。你应该使用 `PADDR(va)` 去做那个减法操作。
#### 引用计数
在以后的实验中,你将会经常遇到多个虚拟地址(或多个环境下的地址空间中)同时映射到相同的物理页面上。你将在 `struct PageInfo` 数据结构中的 `pp_ref` 字段来记录一个每个物理页面的引用计数器。如果一个物理页面的这个计数器为 0,表示这个页面已经被释放,因为它不再被使用了。一般情况下,这个计数器应该等于所有页表中物理页面出现在 `UTOP` 之下的次数(`UTOP` 之上的映射大都是在引导时由内核设置的,并且它从不会被释放,因此不需要引用计数器)。我们也使用它去跟踪放到页目录页的指针数量,反过来就是,页目录到页表页的引用数量。
使用 `page_alloc` 时要注意。它返回的页面引用计数总是为 0,因此,一旦对返回页做了一些操作(比如将它插入到页表),`pp_ref` 就应该增加。有时这需要通过其它函数(比如,`page_instert`)来处理,而有时这个函数是直接调用 `page_alloc` 来做的。
#### 页表管理
现在,你将写一套管理页表的代码:去插入和删除线性地址到物理地址的映射表,并且在需要的时候去创建页表。
>
> **练习 4**
>
>
> 在文件 `kern/pmap.c` 中,你必须去实现下列函数的代码。
>
>
> * pgdir\_walk()
> * bootmapregion()
> * page\_lookup()
> * page\_remove()
> * page\_insert()
>
>
> `check_page()`,调用自 `mem_init()`,测试你的页表管理函数。在进行下一步流程之前你应该确保它成功运行。
>
>
>
### 第 3 部分:内核地址空间
JOS 分割处理器的 32 位线性地址空间为两部分:用户环境(进程),(我们将在实验 3 中开始加载和运行),它将控制其上的布局和低位部分的内容;而内核总是维护对高位部分的完全控制。分割线的定义是在 `inc/memlayout.h` 中通过符号 `ULIM` 来划分的,它为内核保留了大约 256MB 的虚拟地址空间。这就解释了为什么我们要在实验 1 中给内核这样的一个高位链接地址的原因:如是不这样做的话,内核的虚拟地址空间将没有足够的空间去同时映射到下面的用户空间中。
你可以在 `inc/memlayout.h` 中找到一个图表,它有助于你去理解 JOS 内存布局,这在本实验和后面的实验中都会用到。
#### 权限和故障隔离
由于内核和用户的内存都存在于它们各自环境的地址空间中,因此我们需要在 x86 的页表中使用权限位去允许用户代码只能访问用户所属地址空间的部分。否则,用户代码中的 bug 可能会覆写内核数据,导致系统崩溃或者发生各种莫名其妙的的故障;用户代码也可能会偷窥其它环境的私有数据。
对于 `ULIM` 以上部分的内存,用户环境没有任何权限,只有内核才可以读取和写入这部分内存。对于 `[UTOP,ULIM]` 地址范围,内核和用户都有相同的权限:它们可以读取但不能写入这个地址范围。这个地址范围是用于向用户环境暴露某些只读的内核数据结构。最后,低于 `UTOP` 的地址空间是为用户环境所使用的;用户环境将为访问这些内核设置权限。
#### 初始化内核地址空间
现在,你将去配置 `UTOP` 以上的地址空间:内核部分的地址空间。`inc/memlayout.h` 中展示了你将要使用的布局。我将使用函数去写相关的线性地址到物理地址的映射配置。
>
> **练习 5**
>
>
> 完成调用 `check_page()` 之后在 `mem_init()` 中缺失的代码。
>
>
>
现在,你的代码应该通过了 `check_kern_pgdir()` 和 `check_page_installed_pgdir()` 的检查。
>
> 问题:
>
>
> 1、在这个时刻,页目录中的条目(行)是什么?它们映射的址址是什么?以及它们映射到哪里了?换句话说就是,尽可能多地填写这个表:
>
>
>
>
> | 条目 | 虚拟地址基址 | 指向(逻辑上): |
> | --- | --- | --- |
> | 1023 | ? | 物理内存顶部 4MB 的页表 |
> | 1022 | ? | ? |
> | . | ? | ? |
> | . | ? | ? |
> | . | ? | ? |
> | 2 | 0x00800000 | ? |
> | 1 | 0x00400000 | ? |
> | 0 | 0x00000000 | [参见下一问题] |
>
>
> 2、(来自课程 3) 我们将内核和用户环境放在相同的地址空间中。为什么用户程序不能去读取和写入内核的内存?有什么特殊机制保护内核内存?
>
>
> 3、这个操作系统能够支持的最大的物理内存数量是多少?为什么?
>
>
> 4、如果我们真的拥有最大数量的物理内存,有多少空间的开销用于管理内存?这个开销可以减少吗?
>
>
> 5、复习在 `kern/entry.S` 和 `kern/entrypgdir.c` 中的页表设置。一旦我们打开分页,EIP 仍是一个很小的数字(稍大于 1MB)。在什么情况下,我们转而去运行在 KERNBASE 之上的一个 EIP?当我们启用分页并开始在 KERNBASE 之上运行一个 EIP 时,是什么让我们能够一个很低的 EIP 上持续运行?为什么这种转变是必需的?
>
>
>
#### 地址空间布局的其它选择
在 JOS 中我们使用的地址空间布局并不是我们唯一的选择。一个操作系统可以在低位的线性地址上映射内核,而为用户进程保留线性地址的高位部分。然而,x86 内核一般并不采用这种方法,因为 x86 向后兼容模式之一(被称为“虚拟 8086 模式”)“不可改变地”在处理器使用线性地址空间的最下面部分,所以,如果内核被映射到这里是根本无法使用的。
虽然很困难,但是设计这样的内核是有这种可能的,即:不为处理器自身保留任何固定的线性地址或虚拟地址空间,而有效地允许用户级进程不受限制地使用整个 4GB 的虚拟地址空间 —— 同时还要在这些进程之间充分保护内核以及不同的进程之间相互受保护!
将内核的内存分配系统进行概括类推,以支持二次幂为单位的各种页大小,从 4KB 到一些你选择的合理的最大值。你务必要有一些方法,将较大的分配单位按需分割为一些较小的单位,以及在需要时,将多个较小的分配单位合并为一个较大的分配单位。想一想在这样的一个系统中可能会出现些什么样的问题。
这个实验做完了。确保你通过了所有的等级测试,并记得在 `answers-lab2.txt` 中写下你对上述问题的答案。提交你的改变(包括添加 `answers-lab2.txt` 文件),并在 `lab` 目录下输入 `make handin` 去提交你的实验。
---
via: <https://sipb.mit.edu/iap/6.828/lab/lab2/>
作者:[Mit](https://sipb.mit.edu/iap/6.828/lab/lab2/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
10,202 | 对 C++ 的忧虑?C++ 创始人警告:关于 C++ 的某些未来计划十分危险 | https://www.theregister.co.uk/2018/06/18/bjarne_stroustrup_c_plus_plus/ | 2018-11-06T16:47:00 | [
"编程语言"
] | https://linux.cn/article-10202-1.html | 
今年早些时候,我们对 Bjarne Stroustrup 进行了采访。他是 C++ 语言的创始人,摩根士丹利技术部门的董事总经理,美国哥伦比亚大学计算机科学的客座教授。他写了[一封信](http://open-std.org/JTC1/SC22/WG21/docs/papers/2018/p0977r0.pdf),请那些关注编程语言进展的人去“想想瓦萨号!”
这句话对于丹麦人来说,毫无疑问,很容易理解。而那些对于 17 世纪的斯堪的纳维亚历史了解不多的人,还需要详细说明一下。瓦萨号是一艘瑞典军舰,由国王 Gustavus Adolphus 定做。它是当时波罗的海国家中最强大的军舰,但在 1628 年 8 月 10 日首航没几分钟之后就沉没了。

巨大的瓦萨号有一个难以解决的设计缺陷:头重脚轻,以至于它被[一阵狂风刮翻了](https://www.vasamuseet.se/en/vasa-history/disaster)。通过援引这艘沉船的历史,Stroustrup 警示了 C++ 所面临的风险 —— 现在越来越多的特性被添加到了 C++ 中。
我们现在已经发现了好些能导致头重脚轻的特性。Stroustrup 在他的信中引用了 43 个提议。他认为那些参与 C++ 语言 ISO 标准演进的人(即所谓的 [WG21 小组](http://open-std.org/JTC1/SC22/WG21/))正在努力推进语言发展,但成员们的努力方向却并不一致。
在他的信中,他写道:
>
> 分开来看,许多提议都很有道理。但将它们综合到一起,这些提议是很愚蠢的,将危害 C++ 的未来。
>
>
>
他明确表示,他用瓦萨号作为比喻并不是说他认为不断提升会带来毁灭。我们应该吸取瓦萨号的教训,构建一个坚实的基础,从错误中学习并对新版本做彻底的测试。
在瑞士<ruby> 拉普斯威尔 <rt> Rapperswill </rt></ruby>召开 C++ 标准化委员会会议之后,本月早些时候,Stroustrup 接受了 *The Register* 的采访,回答了有关 C++ 语言下一步发展方向的几个问题。(最新版是去年刚发布的 C++17;下一个版本是 C++20,预计于 2020 年发布。)
*Register:*在您的信件《想想瓦萨号!》中,您写道:
>
> 在 C++11 开始的基础建设尚未完成,而 C++17 基本没有在使基础更加稳固、规范和完整方面做出改善。相反,却增加了重要接口的复杂度(原文为 surface complexity,直译“表面复杂度”),让人们需要学习的特性数量越来越多。C++ 可能在这种不成熟的提议的重压之下崩溃。我们不应该花费大量的时间为专家级用户们(比如我们自己)去创建越来越复杂的东西。~~(还要考虑普通用户的学习曲线,越复杂的东西越不易普及。)~~
>
>
>
**对新人来说,C++ 过难了吗?如果是这样,您认为怎样的特性让新人更易理解?**
*Stroustrup:*C++ 的有些东西对于新人来说确实很具有挑战性。
另一方面而言,C++ 中有些东西对于新人来说,比起 C 或上世纪九十年代的 C++ 更容易理解了。而难点是让大型社区专注于这些部分,并且帮助新手和非专业的 C++ 用户去规避那些对高级库实现提供支持的部分。
我建议使用 [C++ 核心准则](https://github.com/isocpp/CppCoreGuidelines/blob/master/CppCoreGuidelines.md)作为实现上述目标的一个辅助。
此外,我的“C++ 教程”也可以帮助人们在使用现代 C++ 时走上正确的方向,而不会迷失在自上世纪九十年代以来的复杂性中,或困惑于只有专家级用户才能理解的东西中。这本即将出版的第二版的“C++ 教程”涵盖了 C++17 和部分 C++20 的内容。
我和其他人给没有编程经验的大一新生教过 C++,只要你不去深入编程语言的每个晦涩难懂的角落,把注意力集中到 C++ 中最主流的部分,就可以在三个月内学会 C++。
“让简单的东西保持简单”是我长期追求的目标。比如 C++11 的 `range-for` 循环:
```
for (int& x : v) ++x; // increment each element of the container v
```
`v` 的位置可以是任何容器。在 C 和 C 风格的 C++ 中,它可能看起来是这样:
```
for (int i=0; i<MAX; i++) ++v[i]; // increment each element of the array v
```
一些人抱怨说添加了 `range-for` 循环让 C++ 变得更复杂了,很显然,他们是正确的,因为它添加了一个新特性。但它却让 C++ 用起来更简单,而且同时它还消除了使用传统 `for` 循环时会出现的一些常见错误。
另一个例子是 C++11 的<ruby> 标准线程库 <rt> standard thread library </rt></ruby>。它比起使用 POSIX 或直接使用 Windows 的 C API 来说更简单,并且更不易出错。
*Register:***您如何看待 C++ 现在的状况?**
*Stroustrup:*C++11 中作出了许多重大改进,并且我们在 C++14 上全面完成了改进工作。C++17 添加了相当多的新特性,但是没有提供对新技术的很多支持。C++20 目前看上去可能会成为一个重大改进版。编译器的状况非常好,标准库实现得也很优秀,非常接近最新的标准。C++17 现在已经可以使用,对于工具的支持正在逐步推进。已经有了许多第三方的库和好些新工具。然而,不幸的是,这些东西不太好找到。
我在《想想瓦萨号!》一文中所表达的担忧与标准化过程有关,对新东西的过度热情与完美主义的组合推迟了重大改进。“追求完美往往事与愿违”。在六月份拉普斯威尔的会议上有 160 人参与;在这样一个数量庞大且多样化的人群中很难取得一致意见。专家们也本来就有只为自己设计语言的倾向,这让他们不会时常在设计时考虑整个社区的需求。
*Register:***C++ 是否有一个理想的状态,或者与之相反,您只是为了程序员们的期望而努力,随时适应并且努力满足程序员们的需要?**
*Stroustrup:*二者都有。我很乐意看到 C++ 支持彻底保证<ruby> 类型安全 <rt> type-safe </rt></ruby>和<ruby> 资源安全 <rt> resource-safe </rt></ruby>的编程方式。这不应该通过限制适用性或增加性能损耗来实现,而是应该通过改进的表达能力和更好的性能来实现。通过让程序员使用更好的(和更易用的)语言工具可以达到这个目标,我们可以做到的。
终极目标不会马上实现,也不会单靠语言设计来实现。为了实现这一目标,我们需要改进语言特性、提供更好的库和静态分析,并且设立提升编程效率的规则。C++ 核心准则是我为了提升 C++ 代码质量而实行的广泛而长期的计划的一部分。
*Register:***目前 C++ 是否面临着可以预见的风险?如果有,它是以什么形式出现的?(如,迭代过于缓慢,新兴低级语言,等等……据您的观点来看,似乎是提出的提议过多。)**
*Stroustrup:*就是这样。今年我们已经收到了 400 篇文章。当然了,它们并不都是新提议。许多提议都与规范语言和标准库这一必需而乏味的工作相关,但是量大到难以管理。你可以在 [WG21 网站](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/)上找到所有这些文章。
我写了《想想瓦萨号!》这封信作为一个呼吁,因为这种为了解决即刻需求(或者赶时髦)而不断增添语言特性,却对巩固语言基础(比如,改善<ruby> 静态类型系统 <rt> static type system </rt></ruby>)不管不问的倾向让我感到震惊。增加的任何新东西,无论它多小都会产生成本,比如实现、学习、工具升级。重大的特性改变能够改变我们对编程的想法,而它们才是我们必须关注的东西。
委员会已经设立了一个“指导小组”,这个小组由在语言、标准库、实现、以及工程实践领域中拥有不错履历的人组成。我是其中的成员之一。我们负责为重点领域写[一些关于发展方向、设计理念和建议重点发展领域的东西](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p0939r0.pdf)。
对于 C++20,我们建议去关注:
* 概念
* 模块(适度地模块化并带来编译时的显著改进)
* Ranges(包括一些无限序列的扩展)
* 标准库中的网络概念
在拉普斯威尔会议之后,这些都有了实现的机会,虽然模块和网络化都不是会议的重点讨论对象。我是一个乐观主义者,并且委员会的成员们都非常努力。
我并不担心其它语言或新语言会取代它。我喜欢编程语言。如果一门新的语言提供了独一无二的、非常有用的东西,那它就是我们的榜样,我们可以向它学习。当然,每门语言本身都有一些问题。C++ 的许多问题都与它广泛的应用领域、大量的使用人群和过度的热情有关。大多数语言的社区都会有这样的问题。
*Register:***关于 C++ 您是否重新考虑过任何架构方面的决策?**
*Stroustrup:*当我着手规划新版本时,我经常反思原来的决策和设计。关于这些,可以看我的《编程的历史》论文第 [1](http://www.stroustrup.com/hopl-almost-final.pdf)、[2](http://www.stroustrup.com/hopl2.pdf) 部分。
并没有让我觉得很后悔的重大决策。如果我必须重新做一次,我觉得和以前做的不会有太大的不同。
与以前一样,能够直接处理硬件加上零开销的抽象是设计的指导思想。使用<ruby> 构造函数 <rt> constructor </rt></ruby>和<ruby> 析构函数 <rt> destructor </rt></ruby>去处理资源是关键(<ruby> 资源获取即初始化 <rt> Resource Acquisition Is Initialization </rt> <ruby> ,RAII); <ruby> 标准模板库 <rt> Standard Template Library </rt> </ruby> (STL) 就是解释 C++ 库能够做什么的一个很好的例子。 </ruby></ruby>
*Register:***在 2011 年被采纳的每三年发布一个新版本的节奏是否仍然有效?我之所以这样问是因为 Java 已经决定更快地迭代。**
*Stroustrup:*我认为 C++20 将会按时发布(就像 C++14 和 C++17 那样),并且主流的编译器也会立即采用它。我也希望 C++20 基于 C++17 能有重大的改进。
对于其它语言如何管理它们的版本,我并不十分关心。C++ 是由一个遵循 ISO 规则的委员会来管理的,而不是由某个大公司或某种“<ruby> 终生的仁慈独裁者 <rt> Beneficial Dictator Of Life </rt></ruby>(BDOL)”来管理。这一点不会改变。C++ 每三年发布一次的周期在 ISO 标准中是一个引人注目的创举。通常而言,周期应该是 5 或 10 年。
*Register:***在您的信中您写道:**
>
> 我们需要一个能够被“普通程序员”使用的,条理还算清楚的编程语言。他们主要关心的是,能否按时高质量地交付他们的应用程序。
>
>
>
改进语言能够解决这个问题吗?或者,我们还需要更容易获得的工具和教育支持?
*Stroustrup:*我尽力宣传我关于 C++ 的实质和使用方式的[理念](http://www.stroustrup.com/papers.html),并且我鼓励其他人也和我采取相同的行动。
特别是,我鼓励讲师和作者们向 C++ 程序员们提出有用的建议,而不是去示范复杂的示例和技术来展示他们自己有多高明。我在 2017 年的 CppCon 大会上的演讲主题就是“学习和传授 C++”,并且也指出,我们需要更好的工具。
我在演讲中提到了构建技术支持和包管理器,这些历来都是 C++ 的弱项。标准化委员会现在有一个工具研究小组,或许不久的将来也会组建一个教育研究小组。
C++ 的社区以前是十分无组织性的,但是在过去的五年里,为了满足社区对新闻和技术支持的需要,出现了很多集会和博客。CppCon、isocpp.org、以及 Meeting++ 就是一些例子。
在一个庞大的委员会中做语言标准设计是很困难的。但是,对于所有的大型项目来说,委员会又是必不可少的。我很忧虑,但是关注它们并且面对问题是成功的必要条件。
*Register:***您如何看待 C++ 社区的流程?在沟通和决策方面你希望看到哪些变化?**
*Stroustrup:*C++ 并没有企业管理一般的“社区流程”;它所遵循的是 ISO 标准流程。我们不能对 ISO 的条例做大的改变。理想的情况是,我们设立一个小型的、全职的“秘书处”来做最终决策和方向管理,但这种理想情况是不会出现的。相反,我们有成百上千的人在线讨论,大约有 160 人在技术问题上进行投票,大约有 70 组织和 11 个国家的人在最终提议上正式投票。这样很混乱,但是有些时候它的确能发挥作用。
*Register:***在最后,您认为那些即将推出的 C++ 特性中,对 C++ 用户最有帮助的是哪些?**
*Stroustrup:*
* 那些能让编程显著变简单的概念。
* <ruby> 并行算法 <rt> Parallel algorithms </rt></ruby> —— 如果要使用现代硬件的并发特性的话,这方法再简单不过了。
* <ruby> 协程 <rt> Coroutines </rt></ruby>,如果委员会能够确定在 C++20 上推出。
* 改进了组织源代码方式的,并且大幅改善了编译时间的模块。我希望能有这样的模块,但是还没办法确定我们能不能在 C++20 上推出。
* 一个标准的网络库,但是还没办法确定我们能否在 C++20 上推出。
此外:
* Contracts(运行时检查的先决条件、后置条件、和断言)可能对许多人都非常重要。
* date 和 time-zone 支持库可能对许多人(行业)非常重要。
*Register:***您还有想对读者们说的话吗?**
*Stroustrup:*如果 C++ 标准化委员会能够专注于重大问题,去解决重大问题,那么 C++20 将会非常优秀。但是在 C++20 推出之前,我们还有 C++17;无论如何,它仍然远超许多人对 C++ 的旧印象。®
---
via: <https://www.theregister.co.uk/2018/06/18/bjarne_stroustrup_c_plus_plus/>
作者:[Thomas Claburn](http://www.theregister.co.uk/Author/3190) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[thecyanbird](https://github.com/thecyanbird)、[Northurland](https://github.com/Northurland)、[pityonline](https://github.com/pityonline)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,203 | Python 数据科学入门 | https://opensource.com/article/18/3/getting-started-data-science | 2018-11-06T19:50:28 | [
"数据科学",
"Python"
] | https://linux.cn/article-10203-1.html |
>
> 不需要昂贵的工具即可领略数据科学的力量,从这些开源工具起步即可。
>
>
>

无论你是一个具有数学或计算机科学背景的资深数据科学爱好者,还是一个其它领域的专家,数据科学提供的可能性都在你力所能及的范围内,而且你不需要昂贵的,高度专业化的企业级软件。本文中讨论的开源工具就是你入门时所需的全部内容。
[Python](https://www.python.org/),其机器学习和数据科学库([pandas](https://pandas.pydata.org/)、 [Keras](https://keras.io/)、 [TensorFlow](https://www.tensorflow.org/)、 [scikit-learn](http://scikit-learn.org/stable/)、 [SciPy](https://www.scipy.org/)、 [NumPy](http://www.numpy.org/) 等),以及大量可视化库([Matplotlib](https://matplotlib.org/)、[pyplot](https://matplotlib.org/api/pyplot_api.html)、 [Plotly](https://plot.ly/) 等)对于初学者和专家来说都是优秀的自由及开源软件工具。它们易于学习,很受欢迎且受到社区支持,并拥有为数据科学而开发的最新技术和算法。它们是你在开始学习时可以获得的最佳工具集之一。
许多 Python 库都是建立在彼此之上的(称为依赖项),其基础是 [NumPy](http://www.numpy.org/) 库。NumPy 专门为数据科学设计,经常被用于在其 ndarray 数据类型中存储数据集的相关部分。ndarray 是一种方便的数据类型,用于将关系表中的记录存储为 `cvs` 文件或其它任何格式,反之亦然。将 scikit 函数应用于多维数组时,它特别方便。SQL 非常适合查询数据库,但是对于执行复杂和资源密集型的数据科学操作,在 ndarray 中存储数据可以提高效率和速度(但请确保在处理大量数据集时有足够的 RAM)。当你使用 pandas 进行知识提取和分析时,pandas 中的 DataFrame 数据类型和 NumPy 中的 ndarray 之间的无缝转换分别为提取和计算密集型操作创建了一个强大的组合。
作为快速演示,让我们启动 Python shell 并在 pandas DataFrame 变量中加载来自巴尔的摩的犯罪统计数据的开放数据集,并查看加载的一部分 DataFrame:
```
>>> import pandas as pd
>>> crime_stats = pd.read_csv('BPD_Arrests.csv')
>>> crime_stats.head()
```

我们现在可以在这个 pandas DataFrame 上执行大多数查询,就像我们可以在数据库中使用 SQL 一样。例如,要获取 `Description` 属性的所有唯一值,SQL 查询是:
```
$ SELECT unique(“Description”) from crime_stats;
```
利用 pandas DataFrame 编写相同的查询如下所示:
```
>>> crime_stats['Description'].unique()
['COMMON ASSAULT' 'LARCENY' 'ROBBERY - STREET' 'AGG. ASSAULT'
'LARCENY FROM AUTO' 'HOMICIDE' 'BURGLARY' 'AUTO THEFT'
'ROBBERY - RESIDENCE' 'ROBBERY - COMMERCIAL' 'ROBBERY - CARJACKING'
'ASSAULT BY THREAT' 'SHOOTING' 'RAPE' 'ARSON']
```
它返回的是一个 NumPy 数组(ndarray 类型):
```
>>> type(crime_stats['Description'].unique())
<class 'numpy.ndarray'>
```
接下来让我们将这些数据输入神经网络,看看它能多准确地预测使用的武器类型,给出的数据包括犯罪事件,犯罪类型以及发生的地点:
```
>>> from sklearn.neural_network import MLPClassifier
>>> import numpy as np
>>>
>>> prediction = crime_stats[[‘Weapon’]]
>>> predictors = crime_stats['CrimeTime', ‘CrimeCode’, ‘Neighborhood’]
>>>
>>> nn_model = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5,
2), random_state=1)
>>>
>>>predict_weapon = nn_model.fit(prediction, predictors)
```
现在学习模型准备就绪,我们可以执行一些测试来确定其质量和可靠性。对于初学者,让我们输入一个训练集数据(用于训练模型的原始数据集的一部分,不包括在创建模型中):
```
>>> predict_weapon.predict(training_set_weapons)
array([4, 4, 4, ..., 0, 4, 4])
```
如你所见,它返回一个列表,每个数字预测训练集中每个记录的武器。我们之所以看到的是数字而不是武器名称,是因为大多数分类算法都是用数字优化的。对于分类数据,有一些技术可以将属性转换为数字表示。在这种情况下,使用的技术是标签编码,使用 sklearn 预处理库中的 `LabelEncoder` 函数:`preprocessing.LabelEncoder()`。它能够对一个数据和其对应的数值表示来进行变换和逆变换。在这个例子中,我们可以使用 `LabelEncoder()` 的 `inverse_transform` 函数来查看武器 0 和 4 是什么:
```
>>> preprocessing.LabelEncoder().inverse_transform(encoded_weapons)
array(['HANDS', 'FIREARM', 'HANDS', ..., 'FIREARM', 'FIREARM', 'FIREARM']
```
这很有趣,但为了了解这个模型的准确程度,我们将几个分数计算为百分比:
```
>>> nn_model.score(X, y)
0.81999999999999995
```
这表明我们的神经网络模型准确度约为 82%。这个结果似乎令人印象深刻,但用于不同的犯罪数据集时,检查其有效性非常重要。还有其它测试来做这个,如相关性、混淆、矩阵等。尽管我们的模型有很高的准确率,但它对于一般犯罪数据集并不是非常有用,因为这个特定数据集具有不成比例的行数,其列出 `FIREARM` 作为使用的武器。除非重新训练,否则我们的分类器最有可能预测 `FIREARM`,即使输入数据集有不同的分布。
在对数据进行分类之前清洗数据并删除异常值和畸形数据非常重要。预处理越好,我们的见解准确性就越高。此外,为模型或分类器提供过多数据(通常超过 90%)以获得更高的准确度是一个坏主意,因为它看起来准确但由于[过度拟合](https://www.kdnuggets.com/2014/06/cardinal-sin-data-mining-data-science.html)而无效。
[Jupyter notebooks](http://jupyter.org/) 相对于命令行来说是一个很好的交互式替代品。虽然 CLI 对于大多数事情都很好,但是当你想要运行代码片段以生成可视化时,Jupyter 会很出色。它比终端更好地格式化数据。
[这篇文章](https://machinelearningmastery.com/best-machine-learning-resources-for-getting-started/) 列出了一些最好的机器学习免费资源,但是还有很多其它的指导和教程。根据你的兴趣和爱好,你还会发现许多开放数据集可供使用。作为起点,由 [Kaggle](https://www.kaggle.com/) 维护的数据集,以及在州政府网站上提供的数据集是极好的资源。
---
via: <https://opensource.com/article/18/3/getting-started-data-science>
作者:[Payal Singh](https://opensource.com/users/payalsingh) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Whether you're a budding data science enthusiast with a math or computer science background or an expert in an unrelated field, the possibilities data science offers are within your reach. And you don't need expensive, highly specialized enterprise software—the open source tools discussed in this article are all you need to get started.
[Python](https://www.python.org/), its machine-learning and data science libraries ([pandas](https://pandas.pydata.org/), [Keras](https://keras.io/), [TensorFlow](https://www.tensorflow.org/), [scikit-learn](http://scikit-learn.org/stable/), [SciPy](https://www.scipy.org/), [NumPy](http://www.numpy.org/), etc.), and its extensive list of visualization libraries ([Matplotlib](https://matplotlib.org/), [pyplot](https://matplotlib.org/api/pyplot_api.html), [Plotly](https://plot.ly/), etc.) are excellent FOSS tools for beginners and experts alike. Easy to learn, popular enough to offer community support, and armed with the latest emerging techniques and algorithms developed for data science, these comprise one of the best toolsets you can acquire when starting out.
Many of these Python libraries are built on top of each other (known as *dependencies*), and the basis is the [NumPy](http://www.numpy.org/) library. Designed specifically for data science, NumPy is often used to store relevant portions of datasets in its ndarray datatype, which is a convenient datatype for storing records from relational tables as `csv`
files or in any other format, and vice-versa. It is particularly convenient when scikit functions are applied to multidimensional arrays. SQL is great for querying databases, but to perform complex and resource-intensive data science operations, storing data in ndarray boosts efficiency and speed (but make sure you have ample RAM when dealing with large datasets). When you get to using pandas for knowledge extraction and analysis, the almost seamless conversion between DataFrame datatype in pandas and ndarray in NumPy creates a powerful combination for extraction and compute-intensive operations, respectively.
For a quick demonstration, let’s fire up the Python shell and load an open dataset on crime statistics from the city of Baltimore in a pandas DataFrame variable, and view a portion of the loaded frame:
```
``````
>>> import pandas as pd
>>> crime_stats = pd.read_csv('BPD_Arrests.csv')
>>> crime_stats.head()
```
We can now perform most of the queries on this pandas DataFrame that we can with SQL in databases. For instance, to get all the unique values of the "Description" attribute, the SQL query is:
```
````$ SELECT unique(“Description”) from crime_stats;`
This same query written for a pandas DataFrame looks like this:
```
``````
>>> crime_stats['Description'].unique()
['COMMON ASSAULT' 'LARCENY' 'ROBBERY - STREET' 'AGG. ASSAULT'
'LARCENY FROM AUTO' 'HOMICIDE' 'BURGLARY' 'AUTO THEFT'
'ROBBERY - RESIDENCE' 'ROBBERY - COMMERCIAL' 'ROBBERY - CARJACKING'
'ASSAULT BY THREAT' 'SHOOTING' 'RAPE' 'ARSON']
```
which returns a NumPy array (ndarray):
```
``````
>>> type(crime_stats['Description'].unique())
<class 'numpy.ndarray'>
```
Next let’s feed this data into a neural network to see how accurately it can predict the type of weapon used, given data such as the time the crime was committed, the type of crime, and the neighborhood in which it happened:
```
``````
>>> from sklearn.neural_network import MLPClassifier
>>> import numpy as np
>>>
>>> prediction = crime_stats[[‘Weapon’]]
>>> predictors = crime_stats['CrimeTime', ‘CrimeCode’, ‘Neighborhood’]
>>>
>>> nn_model = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5,
2), random_state=1)
>>>
>>>predict_weapon = nn_model.fit(prediction, predictors)
```
Now that the learning model is ready, we can perform several tests to determine its quality and reliability. For starters, let’s feed a training set data (the portion of the original dataset used to train the model and not included in creating the model):
```
``````
>>> predict_weapon.predict(training_set_weapons)
array([4, 4, 4, ..., 0, 4, 4])
```
As you can see, it returns a list, with each number predicting the weapon for each of the records in the training set. We see numbers rather than weapon names, as most classification algorithms are optimized with numerical data. For categorical data, there are techniques that can reliably convert attributes into numerical representations. In this case, the technique used is Label Encoding, using the LabelEncoder function in the sklearn preprocessing library: `preprocessing.LabelEncoder()`
. It has a function to transform and inverse transform data and their numerical representations. In this example, we can use the `inverse_transform`
function of LabelEncoder() to see what Weapons 0 and 4 are:
```
``````
>>> preprocessing.LabelEncoder().inverse_transform(encoded_weapons)
array(['HANDS', 'FIREARM', 'HANDS', ..., 'FIREARM', 'FIREARM', 'FIREARM']
```
This is fun to see, but to get an idea of how accurate this model is, let's calculate several scores as percentages:
```
``````
>>> nn_model.score(X, y)
0.81999999999999995
```
This shows that our neural network model is ~82% accurate. That result seems impressive, but it is important to check its effectiveness when used on a different crime dataset. There are other tests, like correlations, confusion, matrices, etc., to do this. Although our model has high accuracy, it is not very useful for general crime datasets as this particular dataset has a disproportionate number of rows that list ‘FIREARM’ as the weapon used. Unless it is re-trained, our classifier is most likely to predict ‘FIREARM’, even if the input dataset has a different distribution.
It is important to clean the data and remove outliers and aberrations before we classify it. The better the preprocessing, the better the accuracy of our insights. Also, feeding the model/classifier with too much data to get higher accuracy (generally over ~90%) is a bad idea because it looks accurate but is not useful due to [overfitting](https://www.kdnuggets.com/2014/06/cardinal-sin-data-mining-data-science.html).
[Jupyter notebooks](http://jupyter.org/) are a great interactive alternative to the command line. While the CLI is fine for most things, Jupyter shines when you want to run snippets on the go to generate visualizations. It also formats data better than the terminal.
[This article](https://machinelearningmastery.com/best-machine-learning-resources-for-getting-started/) has a list of some of the best free resources for machine learning, but plenty of additional guidance and tutorials are available. You will also find many open datasets available to use, based on your interests and inclinations. As a starting point, the datasets maintained by [Kaggle](https://www.kaggle.com/), and those available at state government websites are excellent resources.
*Payal Singh will be presenting at SCaLE16x this year, March 8-11 in Pasadena, California. To attend and get 50% of your ticket, register using promo code OSDC*
## 2 Comments |
10,204 | 在 Ubuntu 和 Debian 上启用双因子身份验证的三种备选方案 | https://bash-prompt.net/guides/ssh-2fa/ | 2018-11-06T20:47:58 | [
"2FA",
"SSH"
] | https://linux.cn/article-10204-1.html |
>
> 如何为你的 SSH 服务器安装三种不同的双因子身份验证方案。
>
>
>

如今,安全比以往更加重要,保护 SSH 服务器是作为系统管理员可以做的最为重要的事情之一。传统地,这意味着禁用密码身份验证而改用 SSH 密钥。无疑这是你首先应该做的,但这并不意味着 SSH 无法变得更加安全。
双因子身份验证就是指需要两种身份验证才能登录。可以是密码和 SSH 密钥,也可以是密钥和第三方服务,比如 Google。这意味着单个验证方法的泄露不会危及服务器。
以下指南是为 SSH 启用双因子验证的三种方式。
当你修改 SSH 配置时,总是要确保有一个连接到服务器的第二终端。第二终端意味着你可以修复你在 SSH 配置中犯的任何错误。打开的终端将一直保持,即便 SSH 服务重启。
### SSH 密钥和密码
SSH 支持对登录要求不止一个身份验证方法。
在 `/etc/sh/sshd_config` 中的 SSH 服务器配置文件中的 `AuthenticationMethods` 选项中设置了身份验证方法。
当在 `/etc/ssh/sshd_config` 中添加下一行时,SSH 需要提交一个 SSH 密钥,然后提示输入密码:
```
AuthenticationMethods "publickey,password"
```
如果你想要根据使用情况设置这些方法,那么请使用以下附加配置:
```
Match User jsmith
AuthenticationMethods "publickey,password"
```
当你已经编辑或保存了新的 `sshd_config` 文件,你应该通过运行以下程序来确保你没有犯任何错误:
```
sshd -t
```
任何导致 SSH 不能启动的语法或其他错误都将在这里标记出来。当 `ssh-t` 运行时没有错误,使用 `systemctl` 重新启动 SSH:
```
systemctl restart sshd
```
现在,你可以使用新终端登录,以核实你会被提示输入密码并需要 SSH 密钥。如果你用 `ssh-v`,例如:
```
ssh -v [email protected]
```
你将可以看到登录的每一步。
注意,如果你确实将密码设置成必需的身份验证方法,你要确保将 `PasswordAuthentication` 选项设置成 `yes`。
### 使用 Google Authenticator 的 SSH
Google 在 Google 自己的产品上使用的双因子身份验证系统可以集成到你的 SSH 服务器中。如果你已经使用了Google Authenticator,那么此方法将非常方便。
虽然 libpam-google-authenticator 是由 Google 编写的,但它是[开源](https://github.com/google/google-authenticator-libpam)的。此外,Google Authenticator 是由 Google 编写的,但并不需要 Google 帐户才能工作。多亏了 [Sitaram Chamarty](https://plus.google.com/115609618223925128756) 的贡献。
如果你还没有在手机上安装和配置 Google Authenticator,请参阅 [这里](https://support.google.com/accounts/answer/1066447?hl=en)的说明。
首先,我们需要在服务器上安装 Google Authenticatior 安装包。以下命令将更新你的系统并安装所需的软件包:
```
apt-get update
apt-get upgrade
apt-get install libpam-google-authenticator
```
现在,我们需要在你的手机上使用 Google Authenticatior APP 注册服务器。这是通过首先运行我们刚刚安装的程序完成的:
```
google-authenticator
```
运行这个程序时,会问到几个问题。你应该以适合你的设置的方式回答,然而,最安全的选项是对每个问题回答 `y`。如果以后需要更改这些选项,您可以简单地重新运行 `google-authenticator` 并选择不同的选项。
当你运行 `google-authenticator` 时,一个二维码会被打印到终端上,有些代码看起来像这样:
```
Your new secret key is: VMFY27TYDFRDNKFY
Your verification code is 259652
Your emergency scratch codes are:
96915246
70222983
31822707
25181286
28919992
```
你应该将所有这些代码记录到一个像密码管理器一样安全的位置。“scratch codes” 是单一的使用代码,即使你的手机不可用,它总是允许你访问。
要将服务器注册到 Authenticator APP 中,只需打开应用程序并点击右下角的红色加号即可。然后选择扫描条码选项,扫描打印到终端的二维码。你的服务器和应用程序现在连接。
回到服务器上,我们现在需要编辑用于 SSH 的 PAM (可插入身份验证模块),以便它使用我们刚刚安装的身份验证器安装包。PAM 是独立系统,负责 Linux 服务器上的大多数身份验证。
需要修改的 SSH PAM 文件位于 `/etc/pam.d/sshd` ,用以下命令编辑:
```
nano /etc/pam.d/sshd
```
在文件顶部添加以下行:
```
auth required pam_google_authenticator.so
```
此外,我们还需要注释掉一行,这样 PAM 就不会提示输入密码。改变这行:
```
# Standard Un*x authentication.
@include common-auth
```
为如下:
```
# Standard Un*x authentication.
# @include common-auth
```
接下来,我们需要编辑 SSH 服务器配置文件:
```
nano /etc/ssh/sshd\_config “`
改变这一行:
```
ChallengeResponseAuthentication no
```
为:
```
ChallengeResponseAuthentication yes
```
接下来,添加以下代码行来启用两个身份验证方案:SSH 密钥和谷歌认证器(键盘交互):
```
AuthenticationMethods "publickey,keyboard-interactive"
```
在重新加载 SSH 服务器之前,最好检查一下在配置中没有出现任何错误。执行以下命令:
```
sshd -t
```
如果没有标识出任何错误,用新的配置重载 SSH:
```
systemctl reload sshd.service
```
现在一切都应该开始工作了。现在,当你登录到你的服务器时,你将需要使用 SSH 密钥,并且当你被提示输入:
```
Verification code:
```
打开 Authenticator APP 并输入为您的服务器显示的 6 位代码。
### Authy
[Authy](https://authy.com/) 是一个双重身份验证服务,与 Google 一样,它提供基于时间的代码。然而,Authy 不需要手机,因为它提供桌面和平板客户端。它们还支持离线身份验证,不需要 Google 帐户。
你需要从应用程序商店安装 Authy 应用程序,或 Authy [下载页面](https://authy.com/download/)所链接的桌面客户端。
安装完应用程序后,需要在服务器上使用 API 密钥。这个过程需要几个步骤:
1. 在[这里](https://www.authy.com/signup)注册一个账户。
2. 向下滚动到 “Authy” 部分。
3. 在帐户上启用双因子认证(2FA)。
4. 回 “Authy” 部分。
5. 为你的服务器创建一个新的应用程序。
6. 从新应用程序的 “General Settings” 页面顶部获取 API 密钥。你需要 “PRODUCTION API KEY”旁边的眼睛符号来显示密钥。如图:

在某个安全的地方记下 API 密钥。
现在,回到服务器,以 root 身份运行以下命令:
```
curl -O 'https://raw.githubusercontent.com/authy/authy-ssh/master/authy-ssh'
bash authy-ssh install /usr/local/bin
```
当提示时输入 API 键。如果输入错误,你始终可以编辑 `/usr/local/bin/authy-ssh` 再添加一次。
Authy 现已安装。但是,在为用户启用它之前,它不会开始工作。启用 Authy 的命令有以下形式:
```
/usr/local/bin/authy-ssh enable <system-user> <your-email> <your-phone-country-code> <your-phone-number>
```
root 登录的一些示例细节:
```
/usr/local/bin/authy-ssh enable root [email protected] 44 20822536476
```
如果一切顺利,你会看到:
```
User was registered
```
现在可以通过运行以下命令来测试 Authy:
```
authy-ssh test
```
最后,重载 SSH 实现新的配置:
```
systemctl reload sshd.service
```
Authy 现在正在工作,SSH 需要它才能登录。
现在,当你登录时,你将看到以下提示:
```
Authy Token (type 'sms' to request a SMS token):
```
你可以输入手机或桌面客户端的 Authy APP 上的代码。或者你可以输入 `sms`, Authy 会给你发送一条带有登录码的短信。
可以通过运行以下命令卸载 Authy:
```
/usr/local/bin/authy-ssh uninstall
```
---
via: <https://bash-prompt.net/guides/ssh-2fa/>
作者:[Elliot Cooper](https://bash-prompt.net) 译者:[cielllll](https://github.com/cielllll) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Security is now more important than ever and securing your SSH server is one of the most important things that you can do as a systems administrator. Traditionally this has meant disabling password authentication and instead using SSH keys. Whilst this is absolutely the first thing you should do that doesn’t mean that SSH can’t be made even more secure.
Two-factor authentication simply means that two means of identification are required to log in. These could be a password and an SSH key, or a key and a 3rd party service like Google. It means that the compromise of a single authentication method does not compromise the server.
The following guides are three ways to enable two-factor authentication for SSH.
Whenever you are modifying the configuration of SSH always ensure that you have a second terminal open to the server. The second terminal means that you will be able to fix any mistakes you make with the SSH configuration. Open terminals will stay open even through SSH restarts.
## SSH Key and Password
SSH supports the ability to require more than a single authentication method for logins.
The authentication methods are set with the `AuthenticationMethods`
option in the SSH server’s configuration file at `/etc/ssh/sshd_config`
.
When the following line is added into `/etc/ssh/sshd_config`
SSH requires an SSH key to be submitted and then a password is prompted for:
```
AuthenticationMethods "publickey,password"
```
If you want to set these methods on a per use basis then use the following additional configuration:
```
Match User jsmith
AuthenticationMethods "publickey,password"
```
When you have edited and saved the new `sshd_config`
file you should check that you did not make any errors by running this command:
```
sshd -t
```
Any syntax or other errors that would stop SSH from starting will be flagged here. When `ssh -t`
runs without error use `systemctl`
to restart SSH"
```
systemctl restart sshd
```
Now you can log in with a new terminal to check that you are prompted for a password and your SSH key is required. If you use `ssh -v`
e.g.:
```
ssh -v [email protected]
```
you will be able to see every step of the login.
Note, if you do set `password`
as a required authentication method then you will need to ensure that `PasswordAuthentication`
option is set to `yes`
.
## SSH With Google Authenticator
Google’s two-factor authentication system that is used on Google’s own products can be integrated into your SSH server. This makes this method very convenient if you already have use the Google Authenticator app.
Although the `libpam-google-authenticator`
is written by Google it is [open source](https://github.com/google/google-authenticator-libpam). Also, the Google Authenticator app is written by Google but does not require a Google account to work. Thanks to [Sitaram Chamarty](https://plus.google.com/115609618223925128756) for the heads up on that.
If you don’t already have the Google Authenticator app installed and configured on your phone please see the instructions [here](https://support.google.com/accounts/answer/1066447?hl=en).
First, we need to install the Google Authenticator package on the server. The following commands will update your system and install the needed packages:
```
apt-get update
apt-get upgrade
apt-get install libpam-google-authenticator
```
Now, we need to register the server with the Google Authenticator app on your phone. This is done by first running the program we just installed:
```
google-authenticator
```
You will be asked a few questions when you run this. You should answer in the way that suits your setup, however, the most secure options are to answer `y`
to every question. If you need to change these later you can simply re-run `google-authenticator`
and select different options.
When you run `google-authenticator`
a QR code will be printed to the terminal and some codes that look like:
```
Your new secret key is: VMFY27TYDFRDNKFY
Your verification code is 259652
Your emergency scratch codes are:
96915246
70222983
31822707
25181286
28919992
```
You should record all of these codes to a secure location like a password manager. The scratch codes are single use codes that will always allow you access even if your phone is unavailable.
All you need to do to register your server with the Authenticator app is to open the app and hit the red plus symbol on the bottom right. Then select the **Scan a barcode** option and scan the QR code that was printed to the terminal. Your server and the app are now linked.
Back on the server, we now need to edit the PAM (Pluggable Authentication Module) for SSH so that it uses the authenticator package we just installed. PAM is the standalone system that takes care of most authentication on a Linux server.
The PAM file for SSH that needs modifying is located at `/etc/pam.d/sshd`
and edited with the following command:
```
nano /etc/pam.d/sshd
```
Add the following line to the top of the file:
```
auth required pam_google_authenticator.so
```
In addition, we also need to comment out a line so that PAM will not prompt for a password. Change this line:
```
# Standard Un*x authentication.
@include common-auth
```
To this:
```
# Standard Un*x authentication.
# @include common-auth
```
Next, we need to edit the SSH server configuration file:
```
nano /etc/ssh/sshd_config
```
And change this line:
```
ChallengeResponseAuthentication no
```
To:
```
ChallengeResponseAuthentication yes
```
Next, add the following line to enable two authentication schemes; SSH keys and Google Authenticator (keyboard-interactive):
```
AuthenticationMethods "publickey,keyboard-interactive"
```
Before we reload the SSH server it is a good idea to check that we did not make any errors in the configuration. This is done with the following command:
```
sshd -t
```
If this does not flag any errors, reload SSH with the new configuration:
```
systemctl reload sshd.service
```
Everything should now be working. Now, when you log into to your server you will need to use your SSH keys and when you are prompted for the:
```
Verification code:
```
open the Authenticator app and enter the 6 digit code that is displaying for your server.
## Authy
[Authy](https://authy.com/) is a two-factor authentication service that, like Google, offers time-based codes. However, Authy does not require a phone as they provide desktop and tables clients. They also enable offline authentication and do not require a Google account.
You will need to install the Authy app from your app store, or the desktop client all of which are linked to from the Authy [download page](https://authy.com/download/).
After you have installed the app you will need an API key that will be used on the server. This process requires a few steps:
- Sign up for an account
[here](https://www.authy.com/signup). - Scroll down to the
**Authy**section. - Enable 2FA on the account.
- Return to the
**Authy**section. - Create a new Application for your server.
- Obtain the API key from the top of the
`General Settings`
page for the new Application. You need to click the eye symbol next to the`PRODUCTION API KEY`
line to reveal the key. Shown here:
Take a note of the API key somewhere secure.
Now, go back to your server and run the following commands as root:
```
curl -O 'https://raw.githubusercontent.com/authy/authy-ssh/master/authy-ssh'
bash authy-ssh install /usr/local/bin
```
Enter the API key when prompted. If you input it incorrectly you can always edit `/usr/local/bin/authy-ssh.conf`
and add it again.
Authy is now installed. However, it will not start working until it is enabled for a user. The command to enable Authy has the form:
```
/usr/local/bin/authy-ssh enable <system-user> <your-email> <your-phone-country-code> <your-phone-number>
```
With some example details for **root** logins:
```
/usr/local/bin/authy-ssh enable root [email protected] 44 20822536476
```
If everything was successful you will see:
```
User was registered
```
You can test Authy now by running the command:
```
authy-ssh test
```
Finally, reload SSH to implement the new configuration:
```
systemctl reload sshd.service
```
Authy is now working and will be required for SSH logins.
Now, when you log in you will see the following prompt:
```
Authy Token (type 'sms' to request a SMS token):
```
You can either enter the code from the Authy app on your phone or desktop client. Or you can type `sms`
and Authy will send you an SMS message with a login code.
Authy is uninstalled by running the following:
```
/usr/local/bin/authy-ssh uninstall
``` |
10,205 | 如何在 Linux 中快速地通过 HTTP 提供文件访问服务 | https://www.ostechnix.com/how-to-quickly-serve-files-and-folders-over-http-in-linux/ | 2018-11-07T13:22:37 | [
"文件服务",
"http"
] | https://linux.cn/article-10205-1.html | 
如今,我有很多方法来通过 Web 浏览器为局域网中的其他系统提供单个文件或整个目录的访问。我在我的 Ubuntu 测试机上测试了这些方法,它们如下面描述的那样运行正常。如果你想知道如何在类 Unix 操作系统中通过 HTTP 轻松快速地提供文件和文件夹的访问服务,以下方法之一肯定会有所帮助。
### 在 Linux 中通过 HTTP 访问文件和文件夹
**免责声明:**此处给出的所有方法适用于安全的局域网。由于这些方法没有任何安全机制,因此**不建议在生产环境中使用它们**。你注意了!
#### 方法 1 - 使用 simpleHTTPserver(Python)
我们写了一篇简要的指南来设置一个简单的 http 服务器,以便在以下链接中即时共享文件和目录。如果你有一个安装了 Python 的系统,这个方法非常方便。
* [如何使用 simpleHTTPserver 设置一个简单的文件服务器](https://www.ostechnix.com/how-to-setup-a-file-server-in-minutes-using-python/)
#### 方法 2 - 使用 Quickserve(Python)
此方法针对 Arch Linux 及其衍生版。有关详细信息,请查看下面的链接。
* [如何在 Arch Linux 中即时共享文件和文件夹](https://www.ostechnix.com/instantly-share-files-folders-arch-linux/)
#### 方法 3 - 使用 Ruby
在此方法中,我们使用 Ruby 在类 Unix 系统中通过 HTTP 提供文件和文件夹访问。按照以下链接中的说明安装 Ruby 和 Rails。
* [在 CentOS 和 Ubuntu 中安装 Ruby on Rails](https://www.ostechnix.com/install-ruby-rails-ubuntu-16-04/)
安装 Ruby 后,进入要通过网络共享的目录,例如 ostechnix:
```
$ cd ostechnix
```
并运行以下命令:
```
$ ruby -run -ehttpd . -p8000
[2018-08-10 16:02:55] INFO WEBrick 1.4.2
[2018-08-10 16:02:55] INFO ruby 2.5.1 (2018-03-29) [x86_64-linux]
[2018-08-10 16:02:55] INFO WEBrick::HTTPServer#start: pid=5859 port=8000
```
确保在路由器或防火墙中打开端口 8000。如果该端口已被其他一些服务使用,那么请使用不同的端口。
现在你可以使用 URL 从任何远程系统访问此文件夹的内容 - `http:// <ip-address>:8000`。

要停止共享,请按 `CTRL+C`。
#### 方法 4 - 使用 Http-server(NodeJS)
[Http-server](https://www.npmjs.com/package/http-server) 是一个用 NodeJS 编写的简单的可用于生产环境的命令行 http 服务器。它不需要配置,可用于通过 Web 浏览器即时共享文件和目录。
按如下所述安装 NodeJS。
* [如何在 Linux 上安装 NodeJS](https://www.ostechnix.com/install-node-js-linux/)
安装 NodeJS 后,运行以下命令安装 http-server。
```
$ npm install -g http-server
```
现在进入任何目录并通过 HTTP 共享其内容,如下所示。
```
$ cd ostechnix
$ http-server -p 8000
Starting up http-server, serving ./
Available on:
http://127.0.0.1:8000
http://192.168.225.24:8000
http://192.168.225.20:8000
Hit CTRL-C to stop the server
```
现在你可以使用 URL 从任何远程系统访问此文件夹的内容 - `http:// <ip-address>:8000`。

要停止共享,请按 `CTRL+C`。
#### 方法 5 - 使用 Miniserve(Rust)
[**Miniserve**](https://github.com/svenstaro/miniserve) 是另一个命令行程序,它允许你通过 HTTP 快速访问文件。它是一个非常快速、易于使用的跨平台程序,它用 Rust 编程语言编写。与上面的程序/方法不同,它提供身份验证支持,因此你可以为共享设置用户名和密码。
按下面的链接在 Linux 系统中安装 Rust。
* [在 Linux 上安装 Rust 编程语言](https://www.ostechnix.com/install-rust-programming-language-in-linux/)
安装 Rust 后,运行以下命令安装 miniserve:
```
$ cargo install miniserve
```
或者,你可以在其[发布页](https://github.com/svenstaro/miniserve/releases)下载二进制文件并使其可执行。
```
$ chmod +x miniserve-linux
```
然后,你可以使用命令运行它(假设 miniserve 二进制文件下载到当前的工作目录中):
```
$ ./miniserve-linux <path-to-share>
```
**用法**
要提供目录访问:
```
$ miniserve <path-to-directory>
```
**示例:**
```
$ miniserve /home/sk/ostechnix/
miniserve v0.2.0
Serving path /home/sk/ostechnix at http://[::]:8080, http://localhost:8080
Quit by pressing CTRL-C
```
现在,你可以在本地系统使用 URL – `http://localhost:8080` 访问共享,或者在远程系统使用 URL – `http://<ip-address>:8080` 访问。
要提供单个文件访问:
```
$ miniserve <path-to-file>
```
**示例:**
```
$ miniserve ostechnix/file.txt
```
带用户名和密码提供文件/文件夹访问:
```
$ miniserve --auth joe:123 <path-to-share>
```
绑定到多个接口:
```
$ miniserve -i 192.168.225.1 -i 10.10.0.1 -i ::1 -- <path-to-share>
```
如你所见,我只给出了 5 种方法。但是,本指南末尾附带的链接中还提供了几种方法。也去测试一下它们。此外,收藏并时不时重新访问它来检查将来是否有新的方法。
今天就是这些。希望这篇文章有用。还有更多的好东西。敬请期待!
干杯!
### 资源
* [单行静态 http 服务器大全](https://gist.github.com/willurd/5720255)
---
via: <https://www.ostechnix.com/how-to-quickly-serve-files-and-folders-over-http-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,206 | SDKMAN:轻松管理多个软件开发套件 (SDK) 的命令行工具 | https://www.ostechnix.com/sdkman-a-cli-tool-to-easily-manage-multiple-software-development-kits/ | 2018-11-07T16:04:51 | [
"SDK"
] | https://linux.cn/article-10206-1.html | 
你是否是一个经常在不同的 SDK 下安装和测试应用的开发者?我有一个好消息要告诉你!给你介绍一下 **SDKMAN**,一个可以帮你轻松管理多个 SDK 的命令行工具。它为安装、切换、列出和移除 SDK 提供了一个简便的方式。有了 SDKMAN,你可以在任何类 Unix 的操作系统上轻松地并行管理多个 SDK 的多个版本。它允许开发者为 JVM 安装不同的 SDK,例如 Java、Groovy、Scala、Kotlin 和 Ceylon、Ant、Gradle、Grails、Maven、SBT、Spark、Spring Boot、Vert.x,以及许多其他支持的 SDK。SDKMAN 是免费、轻量、开源、使用 **Bash** 编写的程序。
### 安装 SDKMAN
安装 SDKMAN 很简单。首先,确保你已经安装了 `zip` 和 `unzip` 这两个应用。它们在大多数的 Linux 发行版的默认仓库中。
例如,在基于 Debian 的系统上安装 unzip,只需要运行:
```
$ sudo apt-get install zip unzip
```
然后使用下面的命令安装 SDKMAN:
```
$ curl -s "https://get.sdkman.io" | bash
```
在安装完成之后,运行以下命令:
```
$ source "$HOME/.sdkman/bin/sdkman-init.sh"
```
如果你希望自定义安装到其他位置,例如 `/usr/local/`,你可以这样做:
```
$ export SDKMAN_DIR="/usr/local/sdkman" && curl -s "https://get.sdkman.io" | bash
```
确保你的用户有足够的权限访问这个目录。
最后,在安装完成后使用下面的命令检查一下:
```
$ sdk version
==== BROADCAST =================================================================
* 01/08/18: Kotlin 1.2.60 released on SDKMAN! #kotlin
* 31/07/18: Sbt 1.2.0 released on SDKMAN! #sbt
* 31/07/18: Infrastructor 0.2.1 released on SDKMAN! #infrastructor
================================================================================
SDKMAN 5.7.2+323
```
恭喜你!SDKMAN 已经安装完成了。让我们接下来看如何安装和管理 SDKs 吧。
### 管理多个 SDK
查看可用的 SDK 清单,运行:
```
$ sdk list
```
将会输出:
```
================================================================================
Available Candidates
================================================================================
q-quit /-search down
j-down ?-search up
k-up h-help
--------------------------------------------------------------------------------
Ant (1.10.1) https://ant.apache.org/
Apache Ant is a Java library and command-line tool whose mission is to drive
processes described in build files as targets and extension points dependent
upon each other. The main known usage of Ant is the build of Java applications.
Ant supplies a number of built-in tasks allowing to compile, assemble, test and
run Java applications. Ant can also be used effectively to build non Java
applications, for instance C or C++ applications. More generally, Ant can be
used to pilot any type of process which can be described in terms of targets and
tasks.
: $ sdk install ant
```
就像你看到的,SDK 每次列出众多 SDK 中的一个,以及该 SDK 的描述信息、官方网址和安装命令。按回车键继续下一个。
安装一个新的 SDK,例如 Java JDK,运行:
```
$ sdk install java
```
将会输出:
```
Downloading: java 8.0.172-zulu
In progress...
######################################################################################## 100.0%
Repackaging Java 8.0.172-zulu...
Done repackaging...
Installing: java 8.0.172-zulu
Done installing!
Setting java 8.0.172-zulu as default.
```
如果你安装了多个 SDK,它将会提示你是否想要将当前安装的版本设置为 **默认版本**。回答 `Yes` 将会把当前版本设置为默认版本。
使用以下命令安装一个 SDK 的其他版本:
```
$ sdk install ant 1.10.1
```
如果你之前已经在本地安装了一个 SDK,你可以像下面这样设置它为本地版本。
```
$ sdk install groovy 3.0.0-SNAPSHOT /path/to/groovy-3.0.0-SNAPSHOT
```
列出一个 SDK 的多个版本:
```
$ sdk list ant
```
将会输出:
```
================================================================================
Available Ant Versions
================================================================================
> * 1.10.1
1.10.0
1.9.9
1.9.8
1.9.7
================================================================================
+ - local version
* - installed
> - currently in use
================================================================================
```
像我之前说的,如果你安装了多个版本,SDKMAN 会提示你是否想要设置当前安装的版本为 **默认版本**。你可以回答 Yes 设置它为默认版本。当然,你也可以在稍后使用下面的命令设置:
```
$ sdk default ant 1.9.9
```
上面的命令将会设置 Apache Ant 1.9.9 为默认版本。
你可以根据自己的需要选择使用任何已安装的 SDK 版本,仅需运行以下命令:
```
$ sdk use ant 1.9.9
```
检查某个具体 SDK 当前的版本号,例如 Java,运行:
```
$ sdk current java
Using java version 8.0.172-zulu
```
检查所有当下在使用的 SDK 版本号,运行:
```
$ sdk current
Using:
ant: 1.10.1
java: 8.0.172-zulu
```
升级过时的 SDK,运行:
```
$ sdk upgrade scala
```
你也可以检查所有的 SDK 中还有哪些是过时的。
```
$ sdk upgrade
```
SDKMAN 有离线模式,可以让 SDKMAN 在离线时也正常运作。你可以使用下面的命令在任何时间开启或者关闭离线模式:
```
$ sdk offline enable
$ sdk offline disable
```
要移除已安装的 SDK,运行:
```
$ sdk uninstall ant 1.9.9
```
要了解更多的细节,参阅帮助章节。
```
$ sdk help
Usage: sdk <command> [candidate] [version]
sdk offline <enable|disable>
commands:
install or i <candidate> [version]
uninstall or rm <candidate> <version>
list or ls [candidate]
use or u <candidate> [version]
default or d <candidate> [version]
current or c [candidate]
upgrade or ug [candidate]
version or v
broadcast or b
help or h
offline [enable|disable]
selfupdate [force]
update
flush <broadcast|archives|temp>
candidate : the SDK to install: groovy, scala, grails, gradle, kotlin, etc.
use list command for comprehensive list of candidates
eg: $ sdk list
version : where optional, defaults to latest stable if not provided
eg: $ sdk install groovy
```
### 更新 SDKMAN
如果有可用的新版本,可以使用下面的命令安装:
```
$ sdk selfupdate
```
SDKMAN 会定期检查更新,并给出让你了解如何更新的指令。
```
WARNING: SDKMAN is out-of-date and requires an update.
$ sdk update
Adding new candidates(s): scala
```
### 清除缓存
建议时不时的清理缓存(包括那些下载的 SDK 的二进制文件)。仅需运行下面的命令就可以了:
```
$ sdk flush archives
```
它也可以用于清理空的文件夹,节省一点空间:
```
$ sdk flush temp
```
### 卸载 SDKMAN
如果你觉得不需要或者不喜欢 SDKMAN,可以使用下面的命令删除。
```
$ tar zcvf ~/sdkman-backup_$(date +%F-%kh%M).tar.gz -C ~/ .sdkman
$ rm -rf ~/.sdkman
```
最后打开你的 `.bashrc`、`.bash_profile` 和/或者 `.profile`,找到并删除下面这几行。
```
#THIS MUST BE AT THE END OF THE FILE FOR SDKMAN TO WORK!!!
export SDKMAN_DIR="/home/sk/.sdkman"
[[ -s "/home/sk/.sdkman/bin/sdkman-init.sh" ]] && source "/home/sk/.sdkman/bin/sdkman-init.sh"
```
如果你使用的是 ZSH,就从 `.zshrc` 中删除上面这一行。
这就是所有的内容了。我希望 SDKMAN 可以帮到你。还有更多的干货即将到来。敬请期待!
祝近祺!
:)
---
via: <https://www.ostechnix.com/sdkman-a-cli-tool-to-easily-manage-multiple-software-development-kits/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,208 | 如何在树莓派上搭建 WordPress | https://opensource.com/article/18/10/setting-wordpress-raspberry-pi | 2018-11-07T21:35:17 | [
"WordPress",
"树莓派"
] | https://linux.cn/article-10208-1.html |
>
> 这篇简单的教程可以让你在树莓派上运行你的 WordPress 网站。
>
>
>

WordPress 是一个非常受欢迎的开源博客平台和内容管理平台(CMS)。它很容易搭建,而且还有一个活跃的开发者社区构建网站、创建主题和插件供其他人使用。
虽然通过一键式 WordPress 设置获得托管包很容易,但也可以简单地通过命令行在 Linux 服务器上设置自己的托管包,而且树莓派是一种用来尝试它并顺便学习一些东西的相当好的途径。
一个经常使用的 Web 套件的四个部分是 Linux、Apache、MySQL 和 PHP。这里是你对它们每一个需要了解的。
### Linux
树莓派上运行的系统是 Raspbian,这是一个基于 Debian,为运行在树莓派硬件上而优化的很好的 Linux 发行版。你有两个选择:桌面版或是精简版。桌面版有一个熟悉的桌面还有很多教育软件和编程工具,像是 LibreOffice 套件、Mincraft,还有一个 web 浏览器。精简版本没有桌面环境,因此它只有命令行以及一些必要的软件。
这篇教程在两个版本上都可以使用,但是如果你使用的是精简版,你必须要有另外一台电脑去访问你的站点。
### Apache
Apache 是一个受欢迎的 web 服务器应用,你可以安装在你的树莓派上伺服你的 web 页面。就其自身而言,Apache 可以通过 HTTP 提供静态 HTML 文件。使用额外的模块,它也可以使用像是 PHP 的脚本语言提供动态网页。
安装 Apache 非常简单。打开一个终端窗口,然后输入下面的命令:
```
sudo apt install apache2 -y
```
Apache 默认放了一个测试文件在一个 web 目录中,你可以从你的电脑或是你网络中的其他计算机进行访问。只需要打开 web 浏览器,然后输入地址 `<http://localhost>`。或者(特别是你使用的是 Raspbian Lite 的话)输入你的树莓派的 IP 地址代替 `localhost`。你应该会在你的浏览器窗口中看到这样的内容:

这意味着你的 Apache 已经开始工作了!
这个默认的网页仅仅是你文件系统里的一个文件。它在你本地的 `/var/www/html/index/html`。你可以使用 [Leafpad](https://en.wikipedia.org/wiki/Leafpad) 文本编辑器写一些 HTML 去替换这个文件的内容。
```
cd /var/www/html/
sudo leafpad index.html
```
保存并关闭 Leafpad 然后刷新网页,查看你的更改。
### MySQL
MySQL(读作 “my S-Q-L” 或者 “my sequel”)是一个很受欢迎的数据库引擎。就像 PHP,它被非常广泛的应用于网页服务,这也是为什么像 WordPress 一样的项目选择了它,以及这些项目是为何如此受欢迎。
在一个终端窗口中输入以下命令安装 MySQL 服务(LCTT 译注:实际上安装的是 MySQL 分支 MariaDB):
```
sudo apt-get install mysql-server -y
```
WordPress 使用 MySQL 存储文章、页面、用户数据、还有许多其他的内容。
### PHP
PHP 是一个预处理器:它是在服务器通过网络浏览器接受网页请求是运行的代码。它解决那些需要展示在网页上的内容,然后发送这些网页到浏览器上。不像静态的 HTML,PHP 能在不同的情况下展示不同的内容。PHP 是一个在 web 上非常受欢迎的语言;很多像 Facebook 和 Wikipedia 的项目都使用 PHP 编写。
安装 PHP 和 MySQL 的插件:
```
sudo apt-get install php php-mysql -y
```
删除 `index.html`,然后创建 `index.php`:
```
sudo rm index.html
sudo leafpad index.php
```
在里面添加以下内容:
```
<?php phpinfo(); ?>
```
保存、退出、刷新你的网页。你将会看到 PHP 状态页:

### WordPress
你可以使用 `wget` 命令从 [wordpress.org](http://wordpress.org/) 下载 WordPress。最新的 WordPress 总是使用 [wordpress.org/latest.tar.gz](https://wordpress.org/latest.tar.gz) 这个网址,所以你可以直接抓取这些文件,而无需到网页里面查看,现在的版本是 4.9.8。
确保你在 `/var/www/html` 目录中,然后删除里面的所有内容:
```
cd /var/www/html/
sudo rm *
```
使用 `wget` 下载 WordPress,然后提取里面的内容,并移动提取的 WordPress 目录中的内容移动到 `html` 目录下:
```
sudo wget http://wordpress.org/latest.tar.gz
sudo tar xzf latest.tar.gz
sudo mv wordpress/* .
```
现在可以删除压缩包和空的 `wordpress` 目录了:
```
sudo rm -rf wordpress latest.tar.gz
```
运行 `ls` 或者 `tree -L 1` 命令显示 WordPress 项目下包含的内容:
```
.
├── index.php
├── license.txt
├── readme.html
├── wp-activate.php
├── wp-admin
├── wp-blog-header.php
├── wp-comments-post.php
├── wp-config-sample.php
├── wp-content
├── wp-cron.php
├── wp-includes
├── wp-links-opml.php
├── wp-load.php
├── wp-login.php
├── wp-mail.php
├── wp-settings.php
├── wp-signup.php
├── wp-trackback.php
└── xmlrpc.php
3 directories, 16 files
```
这是 WordPress 的默认安装源。在 `wp-content` 目录中,你可以编辑你的自定义安装。
你现在应该把所有文件的所有权改为 Apache 的运行用户 `www-data`:
```
sudo chown -R www-data: .
```
### WordPress 数据库
为了搭建你的 WordPress 站点,你需要一个数据库。这里使用的是 MySQL。
在终端窗口运行 MySQL 的安全安装命令:
```
sudo mysql_secure_installation
```
你将会被问到一系列的问题。这里原来没有设置密码,但是在下一步你应该设置一个。确保你记住了你输入的密码,后面你需要使用它去连接你的 WordPress。按回车确认下面的所有问题。
当它完成之后,你将会看到 “All done!” 和 “Thanks for using MariaDB!” 的信息。
在终端窗口运行 `mysql` 命令:
```
sudo mysql -uroot -p
```
输入你创建的 root 密码(LCTT 译注:不是 Linux 系统的 root 密码,是 MySQL 的 root 密码)。你将看到 “Welcome to the MariaDB monitor.” 的欢迎信息。在 “MariaDB [(none)] >” 提示处使用以下命令,为你 WordPress 的安装创建一个数据库:
```
create database wordpress;
```
注意声明最后的分号,如果命令执行成功,你将看到下面的提示:
```
Query OK, 1 row affected (0.00 sec)
```
把数据库权限交给 root 用户在声明的底部输入密码:
```
GRANT ALL PRIVILEGES ON wordpress.* TO 'root'@'localhost' IDENTIFIED BY 'YOURPASSWORD';
```
为了让更改生效,你需要刷新数据库权限:
```
FLUSH PRIVILEGES;
```
按 `Ctrl+D` 退出 MariaDB 提示符,返回到 Bash shell。
### WordPress 配置
在你的 树莓派 打开网页浏览器,地址栏输入 `http://localhost`。选择一个你想要在 WordPress 使用的语言,然后点击“Continue”。你将会看到 WordPress 的欢迎界面。点击 “Let’s go!” 按钮。
按照下面这样填写基本的站点信息:
```
Database Name: wordpress
User Name: root
Password: <YOUR PASSWORD>
Database Host: localhost
Table Prefix: wp_
```
点击 “Submit” 继续,然后点击 “Run the install”。

按下面的格式填写:为你的站点设置一个标题、创建一个用户名和密码、输入你的 email 地址。点击 “Install WordPress” 按钮,然后使用你刚刚创建的账号登录,你现在已经登录,而且你的站点已经设置好了,你可以在浏览器地址栏输入 `http://localhost/wp-admin` 查看你的网站。
### 永久链接
更改你的永久链接设置,使得你的 URL 更加友好是一个很好的想法。
要这样做,首先登录你的 WordPress ,进入仪表盘。进入 “Settings”,“Permalinks”。选择 “Post name” 选项,然后点击 “Save Changes”。接着你需要开启 Apache 的 `rewrite` 模块。
```
sudo a2enmod rewrite
```
你还需要告诉虚拟托管服务,站点允许改写请求。为你的虚拟主机编辑 Apache 配置文件:
```
sudo leafpad /etc/apache2/sites-available/000-default.conf
```
在第一行后添加下面的内容:
```
<Directory "/var/www/html">
AllowOverride All
</Directory>
```
确保其中有像这样的内容 `<VirtualHost *:80>`:
```
<VirtualHost *:80>
<Directory "/var/www/html">
AllowOverride All
</Directory>
...
```
保存这个文件,然后退出,重启 Apache:
```
sudo systemctl restart apache2
```
### 下一步?
WordPress 是可以高度自定义的。在网站顶部横幅处点击你的站点名,你就会进入仪表盘。在这里你可以修改主题、添加页面和文章、编辑菜单、添加插件、以及许多其他的事情。
这里有一些你可以在树莓派的网页服务上尝试的有趣的事情:
* 添加页面和文章到你的网站
* 从外观菜单安装不同的主题
* 自定义你的网站主题或是创建你自己的
* 使用你的网站服务向你的网络上的其他人显示有用的信息
不要忘记,树莓派是一台 Linux 电脑。你也可以使用相同的结构在运行着 Debian 或者 Ubuntu 的服务器上安装 WordPress。
---
via: <https://opensource.com/article/18/10/setting-wordpress-raspberry-pi>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | WordPress is a popular open source blogging platform and content management system (CMS). It's easy to set up and has a thriving community of developers building websites and creating themes and plugins for others to use.
Although getting hosting packages with a "one-click WordPress setup" is easy, it's also simple to set up your own on a Linux server with only command-line access, and the [Raspberry Pi](https://opensource.com/sitewide-search?search_api_views_fulltext=raspberry%20pi) is a perfect way to try it out and learn something along the way.
The four components of a commonly used web stack are Linux, Apache, MySQL, and PHP. Here's what you need to know about each.
## Linux
The Raspberry Pi runs Raspbian, which is a Linux distribution based on Debian and optimized to run well on Raspberry Pi hardware. It comes with two options to start: Desktop or Lite. The Desktop version boots to a familiar-looking desktop and comes with lots of educational software and programming tools, as well as the LibreOffice suite, Minecraft, and a web browser. The Lite version has no desktop environment, so it's command-line only and comes with only the essential software.
This tutorial will work with either version, but if you use the Lite version you'll have to use another computer to access your website.
## Apache
Apache is a popular web server application you can install on the Raspberry Pi to serve web pages. On its own, Apache can serve static HTML files over HTTP. With additional modules, it can serve dynamic web pages using scripting languages such as PHP.
Installing Apache is very simple. Open a terminal window and type the following command:
`sudo apt install apache2 -y`
By default, Apache puts a test HTML file in a web folder you can view from your Pi or another computer on your network. Just open the web browser and enter the address ** http://localhost**. Alternatively (particularly if you're using Raspbian Lite), enter the Pi's IP address instead of
**localhost**. You should see this in your browser window:
This means you have Apache working!
This default webpage is just an HTML file on the filesystem. It is located at **/var/www/html/index.html**. You can try replacing this file with some HTML of your own using the [Leafpad](https://en.wikipedia.org/wiki/Leafpad) text editor:
```
cd /var/www/html/
sudo leafpad index.html
```
Save and close Leafpad then refresh the browser to see your changes.
## MySQL
MySQL (pronounced "my S-Q-L" or "my sequel") is a popular database engine. Like PHP, it's widely used on web servers, which is why projects like WordPress use it and why those projects are so popular.
Install MySQL Server by entering the following command into the terminal window:
`sudo apt-get install mysql-server -y`
WordPress uses MySQL to store posts, pages, user data, and lots of other content.
## PHP
PHP is a preprocessor: it's code that runs when the server receives a request for a web page via a web browser. It works out what needs to be shown on the page, then sends that page to the browser. Unlike static HTML, PHP can show different content under different circumstances. PHP is a very popular language on the web; huge projects like Facebook and Wikipedia are written in PHP.
Install PHP and the MySQL extension:
`sudo apt-get install php php-mysql -y`
Delete the **index.html** file and create **index.php**:
```
sudo rm index.html
sudo leafpad index.php
```
Add the following line:
`<?php phpinfo(); ?>`
Save, exit, and refresh your browser. You'll see the PHP status page:
## WordPress
You can download WordPress from [wordpress.org](http://wordpress.org/) using the **wget** command. Helpfully, the latest version of WordPress is always available at [wordpress.org/latest.tar.gz](https://wordpress.org/latest.tar.gz), so you can grab it without having to look it up on the website. As I'm writing, this is version 4.9.8.
Make sure you're in **/var/www/html** and delete everything in it:
```
cd /var/www/html/
sudo rm *
```
Download WordPress using **wget**, then extract the contents and move the WordPress files to the **html** directory:
```
sudo wget http://wordpress.org/latest.tar.gz
sudo tar xzf latest.tar.gz
sudo mv wordpress/* .
```
Tidy up by removing the tarball and the now-empty **wordpress** directory:
`sudo rm -rf wordpress latest.tar.gz`
Running the **ls** or **tree -L 1** command will show the contents of a WordPress project:
```
.
├── index.php
├── license.txt
├── readme.html
├── wp-activate.php
├── wp-admin
├── wp-blog-header.php
├── wp-comments-post.php
├── wp-config-sample.php
├── wp-content
├── wp-cron.php
├── wp-includes
├── wp-links-opml.php
├── wp-load.php
├── wp-login.php
├── wp-mail.php
├── wp-settings.php
├── wp-signup.php
├── wp-trackback.php
└── xmlrpc.php
3 directories, 16 files
```
This is the source of a default WordPress installation. The files you edit to customize your installation belong in the **wp-content** folder.
You should now change the ownership of all these files to the Apache user:
`sudo chown -R www-data: .`
## WordPress database
To get your WordPress site set up, you need a database. This is where MySQL comes in!
Run the MySQL secure installation command in the terminal window:
`sudo mysql_secure_installation`
You will be asked a series of questions. There's no password set up initially, but you should set one in the second step. Make sure you enter a password you will remember, as you'll need it to connect to WordPress. Press Enter to say Yes to each question that follows.
When it's complete, you will see the messages "All done!" and "Thanks for using MariaDB!"
Run **mysql** in the terminal window:
`sudo mysql -uroot -p`
Enter the root password you created. You will be greeted by the message "Welcome to the MariaDB monitor." Create the database for your WordPress installation at the **MariaDB [(none)]>** prompt using:
`create database wordpress;`
Note the semicolon at the end of the statement. If the command is successful, you should see this:
`Query OK, 1 row affected (0.00 sec)`
Grant database privileges to the root user, entering your password at the end of the statement:
`GRANT ALL PRIVILEGES ON wordpress.* TO 'root'@'localhost' IDENTIFIED BY 'YOURPASSWORD';`
For the changes to take effect, you will need to flush the database privileges:
`FLUSH PRIVILEGES;`
Exit the MariaDB prompt with **Ctrl+D** to return to the Bash shell.
## WordPress configuration
Open the web browser on your Raspberry Pi and open ** http://localhost**. You should see a WordPress page asking you to pick your language. Select your language and click
**Continue**. You will be presented with the WordPress welcome screen. Click the
**Let's go!**button.
Fill out the basic site information as follows:
```
Database Name: wordpress
User Name: root
Password: <YOUR PASSWORD>
Database Host: localhost
Table Prefix: wp_
```
Click **Submit** to proceed, then click **Run the install**.
Fill in the form: Give your site a title, create a username and password, and enter your email address. Hit the **Install WordPress** button, then log in using the account you just created. Now that you're logged in and your site is set up, you can see your website by visiting ** http://localhost/wp-admin**.
## Permalinks
It's a good idea to change your permalink settings to make your URLs more friendly.
To do this, log into WordPress and go to the dashboard. Go to **Settings**, then **Permalinks**. Select the **Post name** option and click **Save Changes**. You'll need to enable Apache's **rewrite** module:
`sudo a2enmod rewrite`
You'll also need to tell the virtual host serving the site to allow requests to be overwritten. Edit the Apache configuration file for your virtual host:
`sudo leafpad /etc/apache2/sites-available/000-default.conf`
Add the following lines after line 1:
```
<Directory "/var/www/html">
AllowOverride All
</Directory>
```
Ensure it's within the **<VirtualHost *:80>** like so:
```
<VirtualHost *:80>
<Directory "/var/www/html">
AllowOverride All
</Directory>
...
```
Save the file and exit, then restart Apache:
`sudo systemctl restart apache2`
## What's next?
WordPress is very customizable. By clicking your site name in the WordPress banner at the top of the page (when you're logged in), you'll be taken to the Dashboard. From there, you can change the theme, add pages and posts, edit the menu, add plugins, and do lots more.
Here are some interesting things you can try on the Raspberry Pi's web server.
- Add pages and posts to your website
- Install different themes from the Appearance menu
- Customize your website's theme or create your own
- Use your web server to display useful information for people on your network
Don't forget, the Raspberry Pi is a Linux computer. You can also follow these instructions to install WordPress on a server running Debian or Ubuntu.
## 1 Comment |
10,209 | 在 Fedora 上使用 Pitivi 编辑视频 | https://fedoramagazine.org/edit-your-videos-with-pitivi-on-fedora/ | 2018-11-07T22:51:33 | [
"视频"
] | https://linux.cn/article-10209-1.html | 
想制作一部你本周末冒险的视频吗?视频编辑有很多选择。但是,如果你在寻找一个容易上手的视频编辑器,并且也可以在官方 Fedora 仓库中找到,请尝试一下 [Pitivi](http://www.pitivi.org/)。
Pitivi 是一个使用 GStreamer 框架的开源非线性视频编辑器。在 Fedora 下开箱即用,Pitivi 支持 OGG、WebM 和一系列其他格式。此外,通过 GStreamer 插件可以获得更多视频格式支持。Pitivi 也与 GNOME 桌面紧密集成,因此相比其他新的程序,它的 UI 在 Fedora Workstation 上会感觉很熟悉。
### 在 Fedora 上安装 Pitivi
Pitivi 可以在 Fedora 仓库中找到。在 Fedora Workstation 上,只需在应用中心搜索并安装 Pitivi。

或者,使用以下命令在终端中安装 Pitivi:
```
sudo dnf install pitivi
```
### 基本编辑
Pitivi 内置了多种工具,可以快速有效地编辑剪辑。只需将视频、音频和图像导入 Pitivi 媒体库,然后将它们拖到时间线上即可。此外,除了时间线上的简单淡入淡出过渡之外,Pitivi 还允许你轻松地将剪辑的各个部分分割、修剪和分组。

### 过渡和效果
除了两个剪辑之间的基本淡入淡出外,Pitivi 还具有一系列不同的过渡和擦除功能。此外,有超过一百种效果可应用于视频或音频,以更改媒体元素在最终演示中的播放或显示方式。

Pitivi 还具有一系列其他强大功能,因此请务必查看其网站上的[教程](http://www.pitivi.org/?go=tour)来获得 Pitivi 功能的完整描述。
---
via: <https://fedoramagazine.org/edit-your-videos-with-pitivi-on-fedora/>
作者:[Ryan Lerch](https://fedoramagazine.org/introducing-flatpak/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Looking to produce a video of your adventures this weekend? There are many different options for editing videos out there. However, if you are looking for a video editor that is simple to pick up, and also available in the official Fedora Repositories, give [Pitivi](http://www.pitivi.org/) a go.
Pitivi is an open source, non-linear video editor that uses the GStreamer framework. Out of the box on Fedora, Pitivi supports OGG Video, WebM, and a range of other formats. Additionally, more support for for video formats is available via gstreamer plugins. Pitivi is also tightly integrated with the GNOME Desktop, so the UI will feel at home among the other newer applications on Fedora Workstation.
### Installing Pitivi on Fedora
Pitivi is available in the Fedora Repositories. On Fedora Workstation, simply search and install Pitivi from the Software application.
Alternatively, install Pitivi using the following command in the Terminal:
sudo dnf install pitivi
### Basic Editing
Pitivi has a wide range of tools built-in to allow quick and effective editing of your clips. Simply import videos, audio, and images into the Pitivi media library, then drag them onto the timeline. Additionally, pitivi allows you to easily split, trim, and group parts of clips together, in addition to simple fade transitions on the timeline.
### Transitions and Effects
In addition to a basic fade between two clips, Pitivi also features a range of different transitions and wipes. Additionally, there are over a hundred effects that can be applied to either videos or audio to change how the media elements are played or displayed in your final presentation
Pitivi also features a range of other great features, so be sure to check out the [tour](http://www.pitivi.org/?go=tour) on their website for a full description of the features of the awesome Pitivi.
## Dimitri V
Btw, Pitivi is available also as a flatpak; to install via command line:
sudo flatpak install flathub org.pitivi.Pitivi
## Thibault Saunier
Also note that the recommended way to install is using the official flatpak: https://flathub.org/apps/details/org.pitivi.Pitivi
## Dimitri V
I think you mean “note” instead of “not”; could confuse some people… 🙂
## Clément Verna
I have edited the original comment 🙂
## Tim Lauridsen
Other great alternatives for video editing is Shortcut, Openshot and Kdelive all exists as flatpaks
## mythcat
Read more about: https://en.wikipedia.org/wiki/FFmpeg
All software use the FFmpeg library!
## Jack
If I try to install pitivi it seems I have to install a lot of dependencies including texlive. It’ quite odd, isn’t it?
## Alex
Do you have a screenshot?
## Jack
https://i.postimg.cc/GmVScn8z/Schermata-da-2018-10-26-21-21-37.png
As you can see there are a lot of dependecies including three texlive packages
## Alex
Indeed. Could you please get in touch with the “point of contact” person for the “pitivi” package in Fedora about this: https://apps.fedoraproject.org/packages/pitivi#
## Paul W. Frields
@Jack: @Alex: I see no cause for concern here. The python3-matplotlib library, required by pitivi, brings in these dependencies. The matplotlib library is useful in other contexts beyond pitivi and this isn’t an error. I imagine if a few extra MB of disk space is a problem, running pitivi will present other difficulties. 🙂
## Jack
Of course it’s not a problem to install few mb of packages (also because I have already install the entire texlive suite from tug site). I didn’t know that texlive is a dependence of python3-matplotlib (at least in fedora, I didn’t found the same with other distro), maybe it’s a recommended package. I’m quite new with fedora, I’ll try to understand if in Fedora there’s difference between dependencies and recommended package
## Peter Braet
i use qwinff (rpmfusion-free repository) to convert the “videos.MTS” from my camera to another format for Pitivi to work with.
## Alex
You should be able to use MTS files as they are, make sure you installed all the optional dependencies of the pitivi package. Another option is to install pitivi with flatpak: https://flathub.org/apps/details/org.pitivi.Pitivi
For the best video editing experience, right-click the imported files and choose “proxy” to create optimized media. |
10,210 | Python 机器学习的必备技巧 | https://opensource.com/article/18/10/machine-learning-python-essential-hacks-and-tricks | 2018-11-08T09:57:00 | [
"机器学习"
] | https://linux.cn/article-10210-1.html |
>
> 尝试使用 Python 掌握机器学习、人工智能和深度学习。
>
>
>

想要入门机器学习并不难。除了<ruby> 大规模网络公开课 <rt> Massive Open Online Courses </rt></ruby>(MOOC)之外,还有很多其它优秀的免费资源。下面我分享一些我觉得比较有用的方法。
1. 从一些 YouTube 上的好视频开始,阅览一些关于这方面的文章或者书籍,例如 《[主算法:终极学习机器的探索将如何重塑我们的世界](https://www.goodreads.com/book/show/24612233-the-master-algorithm)》,而且我觉得你肯定会喜欢这些[关于机器学习的很酷的互动页面](http://www.r2d3.us/visual-intro-to-machine-learning-part-1/)。
2. 对于“<ruby> 机器学习 <rt> machine learning </rt></ruby>”、“<ruby> 人工智能 <rt> artificial intelligence </rt></ruby>”、“<ruby> 深度学习 <rt> deep learning </rt></ruby>”、“<ruby> 数据科学 <rt> data science </rt></ruby>”、“<ruby> 计算机视觉 <rt> computer vision </rt></ruby>”和“<ruby> 机器人技术 <rt> robotics </rt></ruby>”这一堆新名词,你需要知道它们之间的区别。你可以阅览或聆听这些领域的专家们的演讲,例如这位有影响力的[数据科学家 Brandon Rohrer 的精彩视频](https://www.youtube.com/watch?v=tKa0zDDDaQk)。或者这个讲述了数据科学相关的[各种角色之间的区别](https://www.youtube.com/watch?v=Ura_ioOcpQI)的视频。
3. 明确你自己的学习目标,并选择合适的 [Coursera 课程](https://www.coursera.org/learn/machine-learning),或者参加高校的网络公开课,例如[华盛顿大学的课程](https://www.coursera.org/specializations/machine-learning)就很不错。
4. 关注优秀的博客:例如 [KDnuggets](https://www.kdnuggets.com/) 的博客、[Mark Meloon](http://www.markmeloon.com/) 的博客、[Brandon Rohrer](https://brohrer.github.io/blog.html) 的博客、[Open AI](https://blog.openai.com/) 的研究博客,这些都值得推荐。
5. 如果你热衷于在线课程,后文中会有如何[正确选择 MOOC 课程](https://towardsdatascience.com/how-to-choose-effective-moocs-for-machine-learning-and-data-science-8681700ed83f)的指导。
6. 最重要的是,培养自己对这些技术的兴趣。加入一些优秀的社交论坛,不要被那些耸人听闻的头条和新闻所吸引,专注于阅读和了解,将这些技术的背景知识和发展方向理解透彻,并积极思考在日常生活和工作中如何应用机器学习或数据科学的原理。例如建立一个简单的回归模型来预测下一次午餐的成本,又或者是从电力公司的网站上下载历史电费数据,在 Excel 中进行简单的时序分析以发现某种规律。在你对这些技术产生了浓厚兴趣之后,可以观看以下这个视频。
### Python 是机器学习和人工智能方面的最佳语言吗?
除非你是一名专业的研究一些复杂算法纯理论证明的研究人员,否则,对于一个机器学习的入门者来说,需要熟悉至少一种高级编程语言。因为大多数情况下都是需要考虑如何将现有的机器学习算法应用于解决实际问题,而这需要有一定的编程能力作为基础。
哪一种语言是数据科学的最佳语言?这个讨论一直没有停息过。对于这方面,你可以提起精神来看一下 FreeCodeCamp 上这一篇关于[数据科学语言](https://medium.freecodecamp.org/which-languages-should-you-learn-for-data-science-e806ba55a81f)的文章,又或者是 KDnuggets 关于 [Python 和 R 之争](https://www.kdnuggets.com/2017/09/python-vs-r-data-science-machine-learning.html)的深入探讨。
目前人们普遍认为 Python 在开发、部署、维护各方面的效率都是比较高的。与 Java、C 和 C++ 这些较为传统的语言相比,Python 的语法更为简单和高级。而且 Python 拥有活跃的社区群体、广泛的开源文化、数百个专用于机器学习的优质代码库,以及来自业界巨头(包括 Google、Dropbox、Airbnb 等)的强大技术支持。
### 基础 Python 库
如果你打算使用 Python 实施机器学习,你必须掌握一些 Python 包和库的使用方法。
#### NumPy
NumPy 的完整名称是 [Numerical Python](http://numpy.org/),它是 Python 生态里高性能科学计算和数据分析都需要用到的基础包,几乎所有高级工具(例如 [Pandas](https://pandas.pydata.org/) 和 [scikit-learn](http://scikit-learn.org/))都依赖于它。[TensorFlow](https://www.tensorflow.org/) 使用了 NumPy 数组作为基础构建块以支持 Tensor 对象和深度学习的图形流。很多 NumPy 操作的速度都非常快,因为它们都是通过 C 实现的。高性能对于数据科学和现代机器学习来说是一个非常宝贵的优势。

#### Pandas
Pandas 是 Python 生态中用于进行通用数据分析的最受欢迎的库。Pandas 基于 NumPy 数组构建,在保证了可观的执行速度的同时,还提供了许多数据工程方面的功能,包括:
* 对多种不同数据格式的读写操作
* 选择数据子集
* 跨行列计算
* 查找并补充缺失的数据
* 将操作应用于数据中的独立分组
* 按照多种格式转换数据
* 组合多个数据集
* 高级时间序列功能
* 通过 Matplotlib 和 Seaborn 进行可视化

#### Matplotlib 和 Seaborn
数据可视化和数据分析是数据科学家的必备技能,毕竟仅凭一堆枯燥的数据是无法有效地将背后蕴含的信息向受众传达的。这两项技能对于机器学习来说同样重要,因为首先要对数据集进行一个探索性分析,才能更准确地选择合适的机器学习算法。
[Matplotlib](https://matplotlib.org/) 是应用最广泛的 2D Python 可视化库。它包含海量的命令和接口,可以让你根据数据生成高质量的图表。要学习使用 Matplotlib,可以参考这篇详尽的[文章](https://realpython.com/python-matplotlib-guide/)。

[Seaborn](https://seaborn.pydata.org/) 也是一个强大的用于统计和绘图的可视化库。它在 Matplotlib 的基础上提供样式灵活的 API、用于统计和绘图的常见高级函数,还可以和 Pandas 提供的功能相结合。要学习使用 Seaborn,可以参考这篇优秀的[教程](https://www.datacamp.com/community/tutorials/seaborn-python-tutorial)。

#### Scikit-learn
Scikit-learn 是机器学习方面通用的重要 Python 包。它实现了多种[分类](https://en.wikipedia.org/wiki/Statistical_classification)、[回归](https://en.wikipedia.org/wiki/Regression_analysis)和[聚类](https://en.wikipedia.org/wiki/Cluster_analysis)算法,包括[支持向量机](https://en.wikipedia.org/wiki/Support_vector_machine)、[随机森林](https://en.wikipedia.org/wiki/Random_forests)、[梯度增强](https://en.wikipedia.org/wiki/Gradient_boosting)、[k-means 算法](https://en.wikipedia.org/wiki/K-means_clustering)和 [DBSCAN 算法](https://en.wikipedia.org/wiki/DBSCAN),可以与 Python 的数值库 NumPy 和科学计算库 [SciPy](https://en.wikipedia.org/wiki/SciPy) 结合使用。它通过兼容的接口提供了有监督和无监督的学习算法。Scikit-learn 的强壮性让它可以稳定运行在生产环境中,同时它在易用性、代码质量、团队协作、文档和性能等各个方面都有良好的表现。可以参考[这篇基于 Scikit-learn 的机器学习入门](http://scikit-learn.org/stable/tutorial/basic/tutorial.html),或者[这篇基于 Scikit-learn 的简单机器学习用例演示](https://towardsdatascience.com/machine-learning-with-python-easy-and-robust-method-to-fit-nonlinear-data-19e8a1ddbd49)。
本文使用 [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/) 许可,在 [Heartbeat](https://heartbeat.fritz.ai/some-essential-hacks-and-tricks-for-machine-learning-with-python-5478bc6593f2) 上首发。
---
via: <https://opensource.com/article/18/10/machine-learning-python-essential-hacks-and-tricks>
作者:[Tirthajyoti Sarkar](https://opensource.com/users/tirthajyoti) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's never been easier to get started with machine learning. In addition to structured massive open online courses (MOOCs), there are a huge number of incredible, free resources available around the web. Here are a few that have helped me.
- Start with some cool videos on YouTube. Read a couple of good books or articles, such as
. And I guarantee you'll fall in love with[The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World](https://www.goodreads.com/book/show/24612233-the-master-algorithm)[this cool, interactive page about machine learning](http://www.r2d3.us/visual-intro-to-machine-learning-part-1/).
- Learn to clearly differentiate between the buzzwords—for example, machine learning, artificial intelligence, deep learning, data science, computer vision, and robotics. Read or listen to talks by experts on each of them. Watch this
[amazing video by Brandon Rohrer](https://www.youtube.com/watch?v=tKa0zDDDaQk), an influential data scientist. Or this video about the[clear differences between various roles](https://www.youtube.com/watch?v=Ura_ioOcpQI)associated with data science.
- Clearly set a goal for what you want to learn. Then go and take
[that Coursera course](https://www.coursera.org/learn/machine-learning). Or take the one[from the University of Washington](https://www.coursera.org/specializations/machine-learning), which is pretty good too.
- Follow some good blogs:
[KDnuggets](https://www.kdnuggets.com/),[Mark Meloon](http://www.markmeloon.com/)'s blog about data science careers,[Brandon Rohrer](https://brohrer.github.io/blog.html)'s blog,[Open AI](https://blog.openai.com/)'s research blog.
- If you are enthusiastic about taking online courses, check out this article for guidance on
[choosing the right MOOC](https://towardsdatascience.com/how-to-choose-effective-moocs-for-machine-learning-and-data-science-8681700ed83f).
- Most of all, develop a feel for it. Join some good social forums, but resist the temptation to latch onto sensationalized headlines and news. Do your own reading to understand what it is and what it is not, where it might go, and what possibilities it can open up. Then sit back and think about how you can apply machine learning or imbue data science principles into your daily work. Build a simple regression model to predict the cost of your next lunch or download your electricity usage data from your energy provider and do a simple time-series plot in Excel to discover some pattern of usage. And after you are thoroughly enamored with machine learning, you can watch this video.
## Is Python a good language for machine learning/AI?
Familiarity and moderate expertise in at least one high-level programming language is useful for beginners in machine learning. Unless you are a Ph.D. researcher working on a purely theoretical proof of some complex algorithm, you are expected to mostly use the existing machine learning algorithms and apply them in solving novel problems. This requires you to put on a programming hat.
There's a lot of talk about the best language for data science. While the debate rages, grab a coffee and read this insightful FreeCodeCamp article to learn about [data science languages](https://medium.freecodecamp.org/which-languages-should-you-learn-for-data-science-e806ba55a81f). Or, check out this post on KDnuggets to dive directly into the [Python vs. R debate](https://www.kdnuggets.com/2017/09/python-vs-r-data-science-machine-learning.html).
For now, it's widely believed that Python helps developers be more productive from development to deployment and maintenance. Python's syntax is simpler and at a higher level when compared to Java, C, and C++. It has a vibrant community, open source culture, hundreds of high-quality libraries focused on machine learning, and a huge support base from big names in the industry (e.g., Google, Dropbox, Airbnb, etc.).
## Fundamental Python libraries
Assuming you go with the widespread opinion that Python is the best language for machine learning, there are a few core Python packages and libraries you need to master.
### NumPy
Short for [Numerical Python](http://numpy.org/), NumPy is the fundamental package required for high-performance scientific computing and data analysis in the Python ecosystem. It's the foundation on which nearly all of the higher-level tools, such as [Pandas](https://pandas.pydata.org/) and [scikit-learn](http://scikit-learn.org/), are built. [TensorFlow](https://www.tensorflow.org/) uses NumPy arrays as the fundamental building blocks underpinning Tensor objects and graphflow for deep learning tasks. Many NumPy operations are implemented in C, making them super fast. For data science and modern machine learning tasks, this is an invaluable advantage.

### Pandas
Pandas is the most popular library in the scientific Python ecosystem for doing general-purpose data analysis. Pandas is built upon a NumPy array, thereby preserving fast execution speed and offering many data engineering features, including:
- Reading/writing many different data formats
- Selecting subsets of data
- Calculating across rows and down columns
- Finding and filling missing data
- Applying operations to independent groups within the data
- Reshaping data into different forms
- Combing multiple datasets together
- Advanced time-series functionality
- Visualization through Matplotlib and Seaborn

### Matplotlib and Seaborn
Data visualization and storytelling with data are essential skills for every data scientist because it's crtitical to be able to communicate insights from analyses to any audience effectively. This is an equally critical part of your machine learning pipeline, as you often have to perform an exploratory analysis of a dataset before deciding to apply a particular machine learning algorithm.
[Matplotlib](https://matplotlib.org/) is the most widely used 2D Python visualization library. It's equipped with a dazzling array of commands and interfaces for producing publication-quality graphics from your data. This amazingly detailed and rich article will help you [get started with Matplotlib](https://realpython.com/python-matplotlib-guide/).
[Seaborn](https://seaborn.pydata.org/) is another great visualization library focused on statistical plotting. It provides an API (with flexible choices for plot style and color defaults) on top of Matplotlib, defines simple high-level functions for common statistical plot types, and integrates with functionality provided by Pandas. You can start with this great tutorial on [Seaborn for beginners](https://www.datacamp.com/community/tutorials/seaborn-python-tutorial).
### Scikit-learn
Scikit-learn is the most important general machine learning Python package to master. It features various [classification](https://en.wikipedia.org/wiki/Statistical_classification), [regression](https://en.wikipedia.org/wiki/Regression_analysis), and [clustering](https://en.wikipedia.org/wiki/Cluster_analysis) algorithms, including [support vector machines](https://en.wikipedia.org/wiki/Support_vector_machine), [random forests](https://en.wikipedia.org/wiki/Random_forests), [gradient boosting](https://en.wikipedia.org/wiki/Gradient_boosting), [ k-means](https://en.wikipedia.org/wiki/K-means_clustering), and
[DBSCAN](https://en.wikipedia.org/wiki/DBSCAN), and is designed to interoperate with the Python numerical and scientific libraries NumPy and
[SciPy](https://en.wikipedia.org/wiki/SciPy). It provides a range of supervised and unsupervised learning algorithms via a consistent interface. The library has a level of robustness and support required for use in production systems. This means it has a deep focus on concerns such as ease of use, code quality, collaboration, documentation, and performance. Look at this
[gentle introduction to machine learning vocabulary](http://scikit-learn.org/stable/tutorial/basic/tutorial.html)used in the Scikit-learn universe or this article demonstrating
[a simple machine learning pipeline](https://towardsdatascience.com/machine-learning-with-python-easy-and-robust-method-to-fit-nonlinear-data-19e8a1ddbd49)method using Scikit-learn.
*This article was originally published on Heartbeat under CC BY-SA 4.0.*
## 3 Comments |
10,211 | KeeWeb:一个开源且跨平台的密码管理工具 | https://www.ostechnix.com/keeweb-an-open-source-cross-platform-password-manager/ | 2018-11-08T20:07:03 | [
"KeePass",
"密码"
] | https://linux.cn/article-10211-1.html | 
如果你长时间使用互联网,那很可能在很多网站上都有很多帐户。所有这些帐户都必须有密码,而且必须记住所有的密码,或者把它们写下来。在纸上写下密码可能不安全,如果有多个密码,记住它们实际上是不可能的。这就是密码管理工具在过去几年中大受欢迎的原因。密码管理工具就像一个中央存储库,你可以在其中存储所有帐户的所有密码,并为它设置一个主密码。使用这种方法,你唯一需要记住的只有主密码。
**KeePass** 就是一个这样的开源密码管理工具,它有一个官方客户端,但功能非常简单。也有许多 PC 端和手机端的其他密码管理工具,并且与 KeePass 存储加密密码的文件格式兼容。其中一个就是 **KeeWeb**。
KeeWeb 是一个开源、跨平台的密码管理工具,具有云同步,键盘快捷键和插件等功能。KeeWeb使用 Electron 框架,这意味着它可以在 Windows、Linux 和 Mac OS 上运行。
### KeeWeb 的使用
有两种方式可以使用 KeeWeb。第一种无需安装,直接在网页上使用,第二中就是在本地系统中安装 KeeWeb 客户端。
#### 在网页上使用 KeeWeb
如果不想在系统中安装应用,可以去 <https://app.keeweb.info/> 使用KeeWeb。

网页端具有桌面客户端的所有功能,当然也需要联网才能进行使用。
#### 在计算机中安装 KeeWeb
如果喜欢客户端的舒适性和离线可用性,也可以将其安装在系统中。
如果使用 Ubuntu/Debian,你可以去 [发布页](https://github.com/keeweb/keeweb/releases/latest) 下载 KeeWeb 最新的 .deb 文件,然后通过下面的命令进行安装:
```
$ sudo dpkg -i KeeWeb-1.6.3.linux.x64.deb
```
如果用的是 Arch,在 [AUR](https://aur.archlinux.org/packages/keeweb/) 上也有 KeeWeb,可以使用任何 AUR 助手进行安装,例如 [Yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/):
```
$ yay -S keeweb
```
安装后,从菜单中或应用程序启动器启动 KeeWeb。默认界面如下:

### 总体布局
KeeWeb 界面主要显示所有密码的列表,在左侧展示所有标签。单击标签将对密码进行筛选,只显示带有那个标签的密码。在右侧,显示所选帐户的所有字段。你可以设置用户名、密码、网址,或者添加自定义的备注。你甚至可以创建自己的字段并将其标记为安全字段,这在存储信用卡信息等内容时非常有用。你只需单击即可复制密码。 KeeWeb 还显示账户的创建和修改日期。已删除的密码会保留在回收站中,可以在其中还原或永久删除。

### KeeWeb 功能
#### 云同步
KeeWeb 的主要功能之一是支持各种远程位置和云服务。除了加载本地文件,你可以从以下位置打开文件:
1. WebDAV Servers
2. Google Drive
3. Dropbox
4. OneDrive
这意味着如果你使用多台计算机,就可以在它们之间同步密码文件,因此不必担心某台设备无法访问所有密码。
#### 密码生成器

除了对密码进行加密之外,为每个帐户创建新的强密码也很重要。这意味着,如果你的某个帐户遭到入侵,攻击者将无法使用相同的密码进入其他帐户。
为此,KeeWeb 有一个内置密码生成器,可以生成特定长度、包含指定字符的自定义密码。
#### 插件

你可以使用插件扩展 KeeWeb 的功能。其中一些插件用于更改界面语言,而其他插件则添加新功能,例如访问 <https://haveibeenpwned.com> 以查看密码是否暴露。
#### 本地备份

无论密码文件存储在何处,你都应该在计算机上保留一份本地备份。幸运的是,KeeWeb 内置了这个功能。你可以备份到特定路径,并将其设置为定期备份,或者只在文件更改时进行备份。
### 结论
我实际使用 KeeWeb 已经好几年了,它完全改变了我存储密码的方式。云同步是我长期使用 KeeWeb 的主要功能,这样我不必担心在多个设备上保存多个不同步的文件。如果你想要一个具有云同步功能的密码管理工具,KeeWeb 就是你应该关注的东西。
---
via: <https://www.ostechnix.com/keeweb-an-open-source-cross-platform-password-manager/>
作者:[EDITOR](https://www.ostechnix.com/author/editor/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jlztan](https://github.com/jlztan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,212 | 理解 Linux 链接(二) | https://www.linux.com/blog/2018/10/understanding-linux-links-part-2 | 2018-11-08T20:37:00 | [
"链接"
] | https://linux.cn/article-10212-1.html |
>
> 我们继续这个系列,来看一些你所不知道的微妙之处。
>
>
>

在[本系列的第一篇文章中](/article-10173-1.html),我们认识了硬链接、软链接,知道在很多时候链接是非常有用的。链接看起来比较简单,但是也有一些不易察觉的奇怪的地方需要注意。这就是我们这篇文章中要讲的。例如,像一下我们在前一篇文章中创建的指向 `libblah` 的链接。请注意,我们是如何从目标文件夹中创建链接的。
```
cd /usr/local/lib
ln -s /usr/lib/libblah
```
这样是可以工作的,但是下面的这个例子却是不行的。
```
cd /usr/lib
ln -s libblah /usr/local/lib
```
也就是说,从原始文件夹内到目标文件夹之间的链接将不起作用。
出现这种情况的原因是 `ln` 会把它当作是你在 `/usr/local/lib` 中创建一个到 `/usr/local/lib` 的链接,并在 `/usr/local/lib` 中创建了从 `libblah` 到 `libblah` 的一个链接。这是因为所有链接文件获取的是文件的名称(`libblah),而不是文件的路径,最终的结果将会产生一个坏的链接。
然而,请看下面的这种情况。
```
cd /usr/lib
ln -s /usr/lib/libblah /usr/local/lib
```
是可以工作的。奇怪的事情又来了,不管你在文件系统的任何位置执行这个指令,它都可以好好的工作。使用绝对路径,也就是说,指定整个完整的路径,从根目录(`/`)开始到需要的文件或者是文件夹,是最好的实现方式。
其它需要注意的事情是,只要 `/usr/lib` 和 `/usr/local/lib` 在一个分区上,做一个如下的硬链接:
```
cd /usr/lib
ln libblah /usr/local/lib
```
也是可以工作的,因为硬链接不依赖于指向文件系统内的文件来工作。
如果硬链接不起作用,那么可能是你想跨分区之间建立一个硬链接。就比如说,你有分区 A 上有文件 `fileA` ,并且把这个分区挂载到 `/path/to/partitionA/directory` 目录,而你又想从 `fileA` 链接到分区 B 上 `/path/to/partitionB/directory` 目录,这样是行不通的。
```
ln /path/to/partitionA/directory/file /path/to/partitionB/directory
```
正如我们之前说的一样,硬链接是分区表中指向的是同一个分区的数据的条目,你不能把一个分区表的条目指向另一个分区上的数据,这种情况下,你只能选择创建一个软链接:
```
ln -s /path/to/partitionA/directory/file /path/to/partitionB/directory
```
另一个软链接能做到,而硬链接不能的是链接到一个目录。
```
ln -s /path/to/some/directory /path/to/some/other/directory
```
这将在 `/path/to/some/other/directory` 中创建 `/path/to/some/directory` 的链接,没有任何问题。
当你使用硬链接做同样的事情的时候,会提示你一个错误,说不允许那么做。而不允许这么做的原因量会导致无休止的递归:如果你在目录 A 中有一个目录 B,然后你在目录 B 中链接 A,就会出现同样的情况,在目录 A 中,目录 A 包含了目录 B,而在目录 B 中又包含了 A,然后又包含了 B,等等无穷无尽。
当然你可以在递归中使用软链接,但你为什么要那样做呢?
### 我应该使用硬链接还是软链接呢?
通常,你可以在任何地方使用软链接做任何事情。实际上,在有些情况下你只能使用软链接。话说回来,硬链接的效率要稍高一些:它们占用的磁盘空间更少,访问速度更快。在大多数的机器上,你可以忽略这一点点的差异,因为:在磁盘空间越来越大,访问速度越来越快的今天,空间和速度的差异可以忽略不计。不过,如果你是在一个有小存储和低功耗的处理器上使用嵌入式系统上使用 Linux, 则可能需要考虑使用硬链接。
另一个使用硬链接的原因是硬链接不容易损坏。假设你有一个软链接,而你意外的移动或者删除了它指向的文件,那么你的软链接将会损坏,并指向了一个不存在的东西。这种情况是不会发生在硬链接中的,因为硬链接直接指向的是磁盘上的数据。实际上,磁盘上的空间不会被标记为空闲,除非最后一个指向它的硬链接把它从文件系统中擦除掉。
软链接,在另一方面比硬链接可以做更多的事情,而且可以指向任何东西,可以是文件或目录。它也可以指向不在同一个分区上的文件和目录。仅这两个不同,我们就可以做出唯一的选择了。
### 下期
现在我们已经介绍了文件和目录以及操作它们的工具,你是否已经准备好转到这些工具,可以浏览目录层次结构,可以查找文件中的数据,也可以检查目录。这就是我们下一期中要做的事情。下期见。
你可以通过 Linux 基金会和 edX “[Linux 简介](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)”了解更多关于 Linux 的免费课程。
---
via: <https://www.linux.com/blog/2018/10/understanding-linux-links-part-2>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Jamkr](https://github.com/Jamkr) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,213 | 使用 Ultimate Plumber 即时预览管道命令结果 | https://www.ostechnix.com/ultimate-plumber-writing-linux-pipes-with-instant-live-preview/ | 2018-11-08T21:27:00 | [
"管道"
] | https://linux.cn/article-10213-1.html | 
管道命令的作用是将一个命令/程序/进程的输出发送给另一个命令/程序/进程,以便将输出结果进行进一步的处理。我们可以通过使用管道命令把多个命令组合起来,使一个命令的标准输入或输出重定向到另一个命令。两个或多个 Linux 命令之间的竖线字符(`|`)表示在命令之间使用管道命令。管道命令的一般语法如下所示:
```
Command-1 | Command-2 | Command-3 | …| Command-N
```
Ultimate Plumber(简称 UP)是一个命令行工具,它可以用于即时预览管道命令结果。如果你在使用 Linux 时经常会用到管道命令,就可以通过它更好地运用管道命令了。它可以预先显示执行管道命令后的结果,而且是即时滚动地显示,让你可以轻松构建复杂的管道。
下文将会介绍如何安装 UP 并用它将复杂管道命令的编写变得简单。
**重要警告:**
在生产环境中请谨慎使用 UP!在使用它的过程中,有可能会在无意中删除重要数据,尤其是搭配 `rm` 或 `dd` 命令时需要更加小心。勿谓言之不预。
### 使用 Ultimate Plumber 即时预览管道命令
下面给出一个简单的例子介绍 `up` 的使用方法。如果需要将 `lshw` 命令的输出传递给 `up`,只需要在终端中输入以下命令,然后回车:
```
$ lshw |& up
```
你会在屏幕顶部看到一个输入框,如下图所示。

在输入命令的过程中,输入管道符号并回车,就可以立即执行已经输入了的命令。Ultimate Plumber 会在下方的可滚动窗口中即时显示管道命令的输出。在这种状态下,你可以通过 `PgUp`/`PgDn` 键或 `ctrl + ←`/`ctrl + →` 组合键来查看结果。
当你满意执行结果之后,可以使用 `ctrl + x` 组合键退出 `UP`。而退出前编写的管道命令则会保存在当前工作目录的文件中,并命名为 `up1.sh`。如果这个文件名已经被占用,就会命名为 `up2.sh`、`up3.sh` 等等以此类推,直到第 1000 个文件。如果你不需要将管道命令保存输出,只需要使用 `ctrl + c` 组合键退出即可。
通过 `cat` 命令可以查看 `upX.sh` 文件的内容。例如以下是我的 `up2.sh` 文件的输出内容:
```
$ cat up2.sh
#!/bin/bash
grep network -A5 | grep : | cut -d: -f2- | paste - -
```
如果通过管道发送到 `up` 的命令运行时间太长,终端窗口的左上角会显示一个波浪号(~)字符,这就表示 `up` 在等待前一个命令的输出结果作为输入。在这种情况下,你可能需要使用 `ctrl + s` 组合键暂时冻结 `up` 的输入缓冲区大小。在需要解冻的时候,使用 `ctrl + q` 组合键即可。Ultimate Plumber 的输入缓冲区大小一般为 40 MB,到达这个限制之后,屏幕的左上角会显示一个加号。
以下是 `up` 命令的一个简单演示:

### 安装 Ultimate Plumber
喜欢这个工具的话,你可以在你的 Linux 系统上安装使用。安装过程也相当简单,只需要在终端里执行以下两个命令就可以安装 `up` 了。
首先从 Ultimate Plumber 的[发布页面](https://github.com/akavel/up/releases)下载最新的二进制文件,并将放在你系统的某个路径下,例如 `/usr/local/bin/`。
```
$ sudo wget -O /usr/local/bin/up wget https://github.com/akavel/up/releases/download/v0.2.1/up
```
然后向 `up` 二进制文件赋予可执行权限:
```
$ sudo chmod a+x /usr/local/bin/up
```
至此,你已经完成了 `up` 的安装,可以开始编写你的管道命令了。
---
via: <https://www.ostechnix.com/ultimate-plumber-writing-linux-pipes-with-instant-live-preview/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,215 | 8 个出没于终端中的吓人命令 | https://opensource.com/article/18/10/spookier-side-unix-linux | 2018-11-09T19:59:26 | [
"万圣节"
] | https://linux.cn/article-10215-1.html |
>
> 欢迎来到 Linux 令人毛骨悚然的一面。
>
>
>

又是一年中的这个时候:天气变冷了、树叶变色了,各处的孩子都化妆成了小鬼、妖精和僵尸。(LCTT 译注:本文原发表于万圣节)但你知道吗, Unix (和 Linux) 和它们的各个分支也充满了令人毛骨悚然的东西?让我们来看一下我们所熟悉和喜爱的操作系统的一些令人毛骨悚然的一面。
### 半神(守护进程)
如果没有潜伏于系统中的各种<ruby> 守护进程 <rt> daemon </rt></ruby>,那么 Unix 就没什么不同。守护进程是运行在后台的进程,并为用户和操作系统本身提供有用的服务,比如 SSH、FTP、HTTP 等等。
### 僵尸(僵尸进程)
不时出现的僵尸进程是一种被杀死但是拒绝离开的进程。当它出现时,无疑你只能选择你有的工具来赶走它。僵尸进程通常表明产生它的进程出现了问题。
### 杀死(kill)
你不仅可以使用 `kill` 来干掉一个僵尸进程,你还可以用它杀死任何对你系统产生负面影响的进程。有一个使用太多 RAM 或 CPU 周期的进程?使用 `kill` 命令杀死它。
### 猫(cat)
`cat` 和猫科动物无关,但是与文件操作有关:`cat` 是 “concatenate” 的缩写。你甚至可以使用这个方便的命令来查看文件的内容。
### 尾巴(tail)
当你想要查看文件中最后 n 行时,`tail` 命令很有用。当你想要监控一个文件时,它也很棒。
### 巫师(which)
哦,不,它不是巫师(witch)的一种。而是打印传递给它的命令所在的文件位置的命令。例如,`which python` 将在你系统上打印每个版本的 Python 的位置。
### 地下室(crypt)
`crypt` 命令,以前称为 `mcrypt`,当你想要加密(encrypt)文件的内容时,它是很方便的,这样除了你之外没有人可以读取它。像大多数 Unix 命令一样,你可以单独使用 `crypt` 或在系统脚本中调用它。
### 切碎(shred)
当你不仅要删除文件还想要确保没有人能够恢复它时,`shred` 命令很方便。使用 `rm` 命令删除文件是不够的。你还需要覆盖该文件以前占用的空间。这就是 `shred` 的用武之地。
这些只是你会在 Unix 中发现的一部分令人毛骨悚然的东西。你还知道其他诡异的命令么?请随时告诉我。
万圣节快乐!(LCTT:可惜我们翻译晚了,只能将恐怖的感觉延迟了 :D)
---
via: <https://opensource.com/article/18/10/spookier-side-unix-linux>
作者:[Patrick H.Mullins](https://opensource.com/users/pmullins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It’s that time of year again: The weather gets chilly, the leaves change colors, and kids everywhere transform into tiny ghosts, goblins, and zombies. But did you know that Unix (and Linux) and its various offshoots are also chock-full of creepy crawly things? Let’s take a quick look at some of the spookier aspects of the operating system we all know and love.
## daemon
Unix just wouldn’t be the same without all the various daemons that haunt the system. A `daemon`
is a process that runs in the background and provides useful services to both the user and the operating system itself. Think SSH, FTP, HTTP, etc.
## zombie
Every now and then a zombie, a process that has been killed but refuses to go away, shows up. When this happens, you have no choice but to dispatch it using whatever tools you have available. A zombie usually indicates that something is wrong with the process that spawned it.
## kill
Not only can you use the `kill`
command to dispatch a zombie, but you can also use it to kill any process that’s adversely affecting your system. Have a process that’s using too much RAM or CPU cycles? Dispatch it with the `kill`
command.
## cat
The `cat`
command has nothing to do with felines and everything to do with combining files: `cat`
is short for "concatenate." You can even use this handy command to view the contents of a file.
## tail
The `tail`
command is useful when you want to see last *n* number of lines in a file. It’s also great when you want to monitor a file.
## which
No, not that kind of witch, but the command that prints the location of the files associated with any command passed to it. `which python`
, for example, will print the locations of every version of Python on your system.
## crypt
The `crypt`
command, known these days as `mcrypt`
, is handy when you want to scramble (encrypt) the contents of a file so that no one but you can read it. Like most Unix commands, you can use `crypt`
standalone or within a system script.
## shred
The `shred`
command is handy when you not only want to delete a file but you also want to ensure that no one will ever be able to recover it. Using the `rm`
command to delete a file isn’t enough. You also need to overwrite the space that the file previously occupied. That’s where `shred`
comes in.
These are just a few of the spooky things you’ll find hiding inside Unix. Do you know more creepy commands? Feel free to let me know.
Happy Halloween!
## 1 Comment |
10,216 | 适用于小型企业的 4 个开源发票工具 | https://opensource.com/article/18/10/open-source-invoicing-tools | 2018-11-09T21:32:00 | [
"发票"
] | https://linux.cn/article-10216-1.html |
>
> 用基于 web 的发票软件管理你的账单,轻松完成收款,十分简单。
>
>
>

无论您开办小型企业的原因是什么,保持业务发展的关键是可以盈利。收款也就意味着向客户提供发票。
使用 LibreOffice Writer 或 LibreOffice Calc 提供发票很容易,但有时候你需要的不止这些。从更专业的角度看,一种跟进发票的方法,可以提醒你何时跟进你发出的发票。
在这里有各种各样的商业闭源的发票管理工具。但是开源的产品和相对应的闭源商业工具比起来,并不差,没准还更灵活。
让我们一起了解这 4 款基于 web 的开源发票工具,它们很适用于预算紧张的自由职业者和小型企业。2014 年,我在本文的[早期版本](https://opensource.com/business/14/9/4-open-source-invoice-tools)中提到了其中两个工具。这 4 个工具用起来都很简单,并且你可以在任何设备上使用它们。
### Invoice Ninja
我不是很喜欢 ninja (忍者)这个词。尽管如此,我喜欢 [Invoice Ninja](https://www.invoiceninja.org/)。非常喜欢。它将功能融合在一个简单的界面,其中包含一组可让你创建、管理和向客户、消费者发送发票的功能。
您可以轻松配置多个客户端,跟进付款和未结清的发票,生成报价并用电子邮件发送发票。Invoice Ninja 与其竞争对手不同,它[集成](https://www.invoiceninja.com/integrations/)了超过 40 个流行支付方式,包括 PayPal、Stripe、WePay 以及 Apple Pay。
[下载](https://github.com/invoiceninja/invoiceninja)一个可以安装到自己服务器上的版本,或者获取一个[托管版](https://www.invoiceninja.com/invoicing-pricing-plans/)的账户,都可以使用 Invoice Ninja。它有免费版,也有每月 8 美元的收费版。
### InvoicePlane
以前,有一个叫做 FusionInvoice 的漂亮的开源发票工具。有一天,FusionInvoice 的开发者将最新版本的代码设为了专有。这件事结局并不完美,因为 FusionInvoice 从 2018 年起再也不开源了。但这不代表这个工具完蛋了。它旧版本的代码依然是开源的,并且再次开发为包括 FusionInvoice 所有优点的新工具 [InvoicePlane](https://invoiceplane.com/)。
只需点几下鼠标即可制作发票。你可以根据需要将它们设为最简或者最详细。一切准备就绪时,你可以用电子邮件发送发票或者输出为 PDF 文件。你还可以为经常开发票的客户或消费者制作定期发票。
InvoicePlane 不仅可以生成或跟进发票。你还可以为任务或商品创制报价,跟进你销售的产品,查看确认付款,并在发票上生成报告。
[获取代码](https://wiki.invoiceplane.com/en/1.5/getting-started/installation)并将其安装在你的 Web 服务器上。或者,如果你还没准备好安装它,可以[拿小样](https://demo.invoiceplane.com/)试用以下。
### OpenSourceBilling
[OpenSourceBilling](http://www.opensourcebilling.org/) 被它的开发者称赞为“非常简单的计费软件”,当之无愧。它拥有最简洁的交互界面,配置使用起来轻而易举。
OpenSourceBilling 因它的商业智能仪表盘脱颖而出,它可以跟进你当前和以前的发票,以及任何没有支付的款项。它以图表的形式整理信息,使之很容易阅读。
你可以在发票上配置很多信息。只需点几下鼠标按几下键盘,即可添加项目、税率、客户名称以及付款条件。OpenSourceBilling 将这些信息保存在你所有的发票当中,不管新发票还是旧发票。
与我们之前讨论过的工具一样,OpenSourceBilling 也有可以试用的[程序小样](http://demo.opensourcebilling.org/)。
### BambooInvoice
当我是一个全职自由作家和顾问时,我通过 [BambooInvoice](https://www.bambooinvoice.net/) 向客户收费。当它最初的开发者停止维护此软件时,我有点失望。但是 BambooInvoice 又回来了,并一如既往的好。
BambooInvoice 的简洁很吸引我。它只做一件事并做的很好。你可以创建并修改发票,BambooInvoice 会根据客户和分配的发票编号负责跟进。它会告诉你哪些发票是开放的或过期的。你可以在程序中通过电子邮件发送发票或者导出为 PDF 文件。你还可以生成报告密切关注收入。
要[安装](https://sourceforge.net/projects/bambooinvoice/)并使用 BambooInvoice,你需要一个运行 PHP 5 或更高版本的 web 服务器,并运行 MySQL 数据库。机会就在你面前,所以你很乐意去用它。
你又最喜欢的开源发票工具吗?请自由分享评论。
---
via: <https://opensource.com/article/18/10/open-source-invoicing-tools>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[fuowang](https://github.com/fuowang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | No matter what your reasons for starting a small business, the key to keeping that business going is getting paid. Getting paid usually means sending a client an invoice.
It's easy enough to whip up an invoice using LibreOffice Writer or LibreOffice Calc, but sometimes you need a bit more. A more professional look. A way of keeping track of your invoices. Reminders about when to follow up on the invoices you've sent.
There's a wide range of commercial and closed-source invoicing tools out there. But the offerings on the open source side of the fence are just as good, and maybe even more flexible, than their closed source counterparts.
Let's take a look at four web-based open source invoicing tools that are great choices for freelancers and small businesses on a tight budget. I reviewed two of them in 2014, in an [earlier version](https://opensource.com/business/14/9/4-open-source-invoice-tools) of this article. These four picks are easy to use and you can use them on just about any device.
## Invoice Ninja
I've never been a fan of the term *ninja*. Despite that, I like [Invoice Ninja](https://www.invoiceninja.org/). A lot. It melds a simple interface with a set of features that let you create, manage, and send invoices to clients and customers.
You can easily configure multiple clients, track payments and outstanding invoices, generate quotes, and email invoices. What sets Invoice Ninja apart from its competitors is its [integration with](https://www.invoiceninja.com/integrations/) over 40 online popular payment gateways, including PayPal, Stripe, WePay, and Apple Pay.
[Download](https://github.com/invoiceninja/invoiceninja) a version that you can install on your own server or get an account with the [hosted version](https://www.invoiceninja.com/invoicing-pricing-plans/) of Invoice Ninja. There's a free version and a paid tier that will set you back US$ 8 a month.
## InvoicePlane
Once upon a time, there was a nifty open source invoicing tool called FusionInvoice. One day, its creators took the latest version of the code proprietary. That didn't end happily, as FusionInvoice's doors were shut for good in 2018. But that wasn't the end of the application. An old version of the code stayed open source and morphed into [InvoicePlane](https://invoiceplane.com/), which packs all of FusionInvoice's goodness.
Creating an invoice takes just a couple of clicks. You can make them as minimal or detailed as you need. When you're ready, you can email your invoices or output them as PDFs. You can also create recurring invoices for clients or customers you regularly bill.
InvoicePlane does more than generate and track invoices. You can also create quotes for jobs or goods, track products you sell, view and enter payments, and run reports on your invoices.
[Grab the code](https://wiki.invoiceplane.com/en/1.5/getting-started/installation) and install it on your web server. Or, if you're not quite ready to do that, [take the demo](https://demo.invoiceplane.com/) for a spin.
## OpenSourceBilling
Described by its developer as "beautifully simple billing software," [OpenSourceBilling](http://www.opensourcebilling.org/) lives up to the description. It has one of the cleanest interfaces I've seen, which makes configuring and using the tool a breeze.
OpenSourceBilling stands out because of its dashboard, which tracks your current and past invoices, as well as any outstanding amounts. Your information is broken up into graphs and tables, which makes it easy to follow.
You do much of the configuration on the invoice itself. You can add items, tax rates, clients, and even payment terms with a click and a few keystrokes. OpenSourceBilling saves that information across all of your invoices, both new and old.
As with some of the other tools we've looked at, OpenSourceBilling has a [demo](http://demo.opensourcebilling.org/) you can try.
## BambooInvoice
When I was a full-time freelance writer and consultant, I used [BambooInvoice](https://www.bambooinvoice.net/) to bill my clients. When its original developer stopped working on the software, I was a bit disappointed. But BambooInvoice is back, and it's as good as ever.
What attracted me to BambooInvoice is its simplicity. It does one thing and does it well. You can create and edit invoices, and BambooInvoice keeps track of them by client and by the invoice numbers you assign to them. It also lets you know which invoices are open or overdue. You can email the invoices from within the application or generate PDFs. You can also run reports to keep tabs on your income.
To [install](https://sourceforge.net/projects/bambooinvoice/) and use BambooInvoice, you'll need a web server running PHP 5 or newer as well as a MySQL database. Chances are you already have access to one, so you're good to go.
Do you have a favorite open source invoicing tool? Feel free to share it by leaving a comment.
## 1 Comment |
10,217 | 设计更快的网页(二):图片替换 | https://fedoramagazine.org/design-faster-web-pages-part-2-image-replacement/ | 2018-11-09T22:00:11 | [
"网页"
] | https://linux.cn/article-10217-1.html | 
欢迎回到我们为了构建更快网页所写的系列文章。上一篇[文章](/article-10166-1.html)讨论了只通过图片压缩实现这个目标的方法。这个例子从一开始有 1.2MB 的“浏览器脂肪”,然后它减轻到了 488.9KB 的大小。但这还不够快!那么本文继续来给浏览器“减肥”。你可能在这个过程中会认为我们所做的事情有点疯狂,但一旦完成,你就会明白为什么要这么做了。
### 准备工作
本文再次从对网页的分析开始。使用 Firefox 内置的截图功能来对整个页面进行截图。你还需要[用 sudo](https://fedoramagazine.org/howto-use-sudo/) 来安装 Inkscape:
```
$ sudo dnf install inkscape
```
如果你想了解 Inkscape 的用法,Fedora 杂志上有几篇现成的[文章](https://fedoramagazine.org/?s=Inkscape)。本文仅会介绍一些基本的 SVG 优化方法以供 Web 使用。
### 分析
我们再来用 [getfedora.org](https://getfedora.org) 的网页来举例。

这次分析以图形方式完成更好,这也就是它从屏幕截图开始的原因。上面的截图标记了页面中的所有图形元素。Fedora 网站团队已经针对两种情况措施(也有可能是四种,这样更好)来替换图像了。社交媒体的图标变成了字体的字形,而语言选择器变成了 SVG.
我们有几个可以替换的选择:
* CSS3
* 字体
* SVG
* HTML5 Canvas
#### HTML5 Canvas
简单来说,HTML5 Canvas 是一种 HTML 元素,它允许你借助脚本语言(通常是 JavaScript)在上面绘图,不过它现在还没有被广泛使用。因为它可以使用脚本语言来绘制,所以这个元素也可以用来做动画。这里有一些使用 HTML Canvas 实现的实例,比如[三角形模式](https://codepen.io/Cthulahoop/pen/umcvo)、[动态波浪](https://codepen.io/jackrugile/pen/BvLHg)和[字体动画](https://codepen.io/tholman/pen/lDLhk)。不过,在这种情况下,似乎这也不是最好的选择。
#### CSS3
使用层叠式样式表,你可以绘制图形,甚至可以让它们动起来。CSS 常被用来绘制按钮等元素。然而,使用 CSS 绘制的更复杂的图形通常只能在技术演示页面中看到。这是因为使用视觉来制作图形依然要比使用代码来的更快一些。
#### 字体
另外一种方式是使用字体来装饰网页,[Fontawesome](https://fontawesome.com/) 在这方面很流行。比如,在这个例子中你可以使用字体来替换“Flavor”和“Spin”的图标。这种方法有一个负面影响,但解决起来很容易,我们会在本系列的下一部分中来介绍。
#### SVG
这种图形格式已经存在了很长时间,而且它总是在浏览器中被使用。有很长一段时间并非所有浏览器都支持它,不过现在这已经成为历史了。所以,本例中图形替换的最佳方法是使用 SVG.
### 为网页优化 SVG
优化 SVG 以供互联网使用,需要几个步骤。
SVG 是一种 XML 方言。它用节点来描述圆形、矩形或文本路径等组件。每个节点都是一个 XML 元素。为了保证代码简洁,SVG 应该包含尽可能少的元素。
我们选用的 SVG 实例是带有一个咖啡杯的圆形图标。你有三种选项来用 SVG 描述它。
#### 一个圆形元素,上面有一个咖啡杯
```
<circle
style="opacity:1;fill:#717d82;fill-opacity:1;stroke:none;stroke-width:9.51950836;stroke-linecap:round;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;paint-order:markers fill stroke"
id="path36"
cx="68.414307"
cy="130.71523"
r="3.7620001" />
```
#### 一个圆形路径,上面有一个咖啡杯
```
<path
style="opacity:1;fill:#717d82;fill-opacity:1;stroke:none;stroke-width:1.60968435;stroke-linecap:round;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;paint-order:markers fill stroke"
d="m 68.414044,126.95318 a 3.7618673,3.7618673 0 0 0 -3.76153,3.76204 3.7618673,3.7618673 0 0 0 3.76153,3.76205 3.7618673,3.7618673 0 0 0 3.76206,-3.76205 3.7618673,3.7618673 0 0 0 -3.76206,-3.76204 z"
id="path20" />
```
#### 单一路径
```
<path
style="opacity:1;fill:#717d82;fill-opacity:1;stroke:none;stroke-width:1.60968435;stroke-linecap:round;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;paint-order:markers fill stroke"
d="m 68.414044,126.95318 a 3.7618673,3.7618673 0 0 0 -3.76153,3.76204 3.7618673,3.7618673 0 0 0 3.76153,3.76205 3.7618673,3.7618673 0 0 0 3.76206,-3.76205 3.7618673,3.7618673 0 0 0 -3.76206,-3.76204 z m -1.21542,0.92656 h 2.40554 c 0.0913,0.21025 0.18256,0.42071 0.27387,0.63097 h 0.47284 v 0.60099 h -0.17984 l -0.1664,1.05989 h 0.24961 l -0.34779,1.96267 -0.21238,-0.003 -0.22326,1.41955 h -2.12492 l -0.22429,-1.41955 -0.22479,0.003 -0.34829,-1.96267 h 0.26304 l -0.16692,-1.05989 h -0.1669 v -0.60099 h 0.44752 c 0.0913,-0.21026 0.18206,-0.42072 0.27336,-0.63097 z m 0.12608,0.19068 c -0.0614,0.14155 -0.12351,0.28323 -0.185,0.42478 h 2.52336 c -0.0614,-0.14155 -0.12248,-0.28323 -0.18397,-0.42478 z m -0.65524,0.63097 v 0.21911 l 0.0594,5.2e-4 h 3.35844 l 0.0724,-5.2e-4 v -0.21911 z m 0.16846,0.41083 0.1669,1.05937 h 2.80603 l 0.16693,-1.05937 -1.57046,0.008 z m -0.061,1.25057 0.27956,1.5782 1.34411,-0.0145 1.34567,0.0145 0.28059,-1.5782 z m 1.62367,1.75441 -1.08519,0.0124 0.19325,1.2299 h 1.79835 l 0.19328,-1.2299 z"
id="path2714"
inkscape:connector-curvature="0" />
```
你应该可以看出,代码变得越来越复杂,需要更多的字符来描述它。当然,文件中包含更多的字符,就会导致更大的尺寸。
#### 节点清理
如果你在 Inkscape 中打开了实例 SVG 按下 F2,就会激活一个节点工具。你应该看到这样的界面:

这个例子中有五个不必要的节点——就是直线中间的那些。要删除它们,你可以使用已激活的节点工具依次选中它们,并按下 `Del` 键。然后,选中这条线的定义节点,并使用工具栏的工具把它们重新做成角。

如果不修复这些角,我们还有方法可以定义这条曲线,这条曲线会被保存,也就会增加文件体积。你可以手动清理这些节点,因为它无法有效的自动完成。现在,你已经为下一阶段做好了准备。
使用“另存为”功能,并选择“优化的 SVG”。这会弹出一个窗口,你可以在里面选择移除或保留哪些成分。

虽然这个 SVG 实例很小,但它还是从 3.2KB 减小到了 920 字节,不到原有的三分之一。
回到 getfedora 的页面:页面主要部分的背景中的灰色沃罗诺伊图,在经过本系列第一篇文章中的优化处理之后,从原先的 211.12 KB 减小到了 164.1 KB.
页面中导出的原始 SVG 有 1.9 MB 大小。经过这些 SVG 优化步骤后,它只有 500.4 KB 了。太大了?好吧,现在的蓝色背景的体积是 564.98 KB。SVG 和 PNG 之间只有很小的差别。
#### 压缩文件
```
$ ls -lh
insgesamt 928K
-rw-r--r--. 1 user user 161K 19. Feb 19:44 grey-pattern.png
-rw-rw-r--. 1 user user 160K 18. Feb 12:23 grey-pattern.png.gz
-rw-r--r--. 1 user user 489K 19. Feb 19:43 greyscale-pattern-opti.svg
-rw-rw-r--. 1 user user 112K 19. Feb 19:05 greyscale-pattern-opti.svg.gz
```
这是我为可视化这个主题所做的一个小测试的输出。你可能应该看到光栅图形——PNG——已经被压缩,不能再被压缩了。而 SVG,它是一个 XML 文件正相反。它是文本文件,所以可被压缩至原来的四分之一不到。因此,现在它的体积要比 PNG 小 50 KB 左右。
现代浏览器可以以原生方式处理压缩文件。所以,许多 Web 服务器都打开了 mod\_deflate (Apache) 和 gzip (Nginx) 模式。这样我们就可以在传输过程中节省空间。你可以在[这儿](https://checkgzipcompression.com/?url=http%3A%2F%2Fgetfedora.org)看看你的服务器是不是启用了它。
### 生产工具
首先,没有人希望每次都要用 Inkscape 来优化 SVG. 你可以在命令行中脱离 GUI 来运行 Inkscape,但你找不到选项来将 Inkscape SVG 转换成优化的 SVG. 用这种方式只能导出光栅图像。但是我们替代品:
* SVGO (看起来开发过程已经不活跃了)
* Scour
本例中我们使用 `scour` 来进行优化。先来安装它:
```
$ sudo dnf install scour
```
要想自动优化 SVG 文件,请运行 `scour`,就像这样:
```
[user@localhost ]$ scour INPUT.svg OUTPUT.svg -p 3 --create-groups --renderer-workaround --strip-xml-prolog --remove-descriptive-elements --enable-comment-stripping --disable-embed-rasters --no-line-breaks --enable-id-stripping --shorten-ids
```
这就是第二部分的结尾了。在这部分中你应该学会了如何将光栅图像替换成 SVG,并对它进行优化以供使用。请继续关注 Feroda 杂志,第三篇即将出炉。
---
via: <https://fedoramagazine.org/design-faster-web-pages-part-2-image-replacement/>
作者:[Sirko Kemter](https://fedoramagazine.org/author/gnokii/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[StdioA](https://github.com/StdioA) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Welcome back to this series on building faster web pages. The last [article](https://wp.me/p3XX0v-5fJ) talked about what you can achieve just through image compression. The example started with 1.2MB of browser fat, and reduced down to a weight of 488.9KB. That’s still not fast enough! This article continues the browser diet to lose more fat. You might think that partway through this process things are a bit crazy, but once finished, you’ll understand why.
## Preparation
Once again this article starts with an analysis of the web pages. Use the built-in screenshot function of Firefox to make a screenshot of the entire page. You’ll also want to install Inkscape [using sudo](https://fedoramagazine.org/howto-use-sudo/):
$sudo dnf install inkscape
If you want to know how to use Inkscape, there are already several [articles](https://fedoramagazine.org/?s=Inkscape) in Fedora Magazine. This article will only explain some basic tasks for optimizing an SVG for web use.
## Analysis
Once again, this example uses the [getfedora.org](https://getfedora.org) web page.
Getfedora page with graphics marked
This analysis is better done graphically, which is why it starts with a screenshot. The screenshot above marks all graphical elements of the page. In two cases or better in four cases, the Fedora websites team already used measures to replace images. The icons for social media are glyphs from a font and the language selector is an SVG.
There are several options for replacing:
### HTML5 Canvas
Briefly, HTML5 Canvas is an HTML element that allows you to draw with the help of scripts, mostly JavaScript, although it’s not widely used yet. As you draw with the help of scripts, the element can also be animated. Some examples of what you can achieve with HTML Canvas include this [triangle pattern,](https://codepen.io/Cthulahoop/pen/umcvo) [animated wave](https://codepen.io/jackrugile/pen/BvLHg), and [text animation](https://codepen.io/tholman/pen/lDLhk). In this case, though, it seems not to be the right choice.
### CSS3
With Cascading Style Sheets you can draw shapes and even animate them. CSS is often used for drawing elements like buttons. However, more complicated graphics via CSS are usually only seen in technical demonstration pages. This is because graphics are still better done visually as with coding.
### Fonts
The usage of fonts for styling web pages is another way, and [Fontawesome](https://fontawesome.com/) is quiet popular. For instance, you could replace the Flavor and the Spin icons with a font in this example. There is a negative side to using this method, which will be covered in the next part of this series, but it can be done easily.
### SVG
This graphics format has existed for a long time and was always supposed to be used in the browser. For a long time not all browsers supported it, but that’s history. So the best way to replace pictures in this example is with SVG.
## Optimizing SVG for the web
To optimize an SVG for internet use requires several steps.
SVG is an XML dialect. Components like circle, rectangle, or text paths are described with nodes. Each node is an XML element. To keep the code clean, an SVG should use as few nodes as possible.
The SVG example is a circular icon with a coffee mug on it. You have 3 options to describe it with SVG.
#### Circle element with the mug on top
<circle style="opacity:1;fill:#717d82;fill-opacity:1;stroke:none;stroke-width:9.51950836;stroke-linecap:round;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;paint-order:markers fill stroke" id="path36" cx="68.414307" cy="130.71523" r="3.7620001" />
#### Circular path with the mug on top
<path style="opacity:1;fill:#717d82;fill-opacity:1;stroke:none;stroke-width:1.60968435;stroke-linecap:round;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;paint-order:markers fill stroke" d="m 68.414044,126.95318 a 3.7618673,3.7618673 0 0 0 -3.76153,3.76204 3.7618673,3.7618673 0 0 0 3.76153,3.76205 3.7618673,3.7618673 0 0 0 3.76206,-3.76205 3.7618673,3.7618673 0 0 0 -3.76206,-3.76204 z" id="path20" />
#### single path
<path style="opacity:1;fill:#717d82;fill-opacity:1;stroke:none;stroke-width:1.60968435;stroke-linecap:round;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;paint-order:markers fill stroke" d="m 68.414044,126.95318 a 3.7618673,3.7618673 0 0 0 -3.76153,3.76204 3.7618673,3.7618673 0 0 0 3.76153,3.76205 3.7618673,3.7618673 0 0 0 3.76206,-3.76205 3.7618673,3.7618673 0 0 0 -3.76206,-3.76204 z m -1.21542,0.92656 h 2.40554 c 0.0913,0.21025 0.18256,0.42071 0.27387,0.63097 h 0.47284 v 0.60099 h -0.17984 l -0.1664,1.05989 h 0.24961 l -0.34779,1.96267 -0.21238,-0.003 -0.22326,1.41955 h -2.12492 l -0.22429,-1.41955 -0.22479,0.003 -0.34829,-1.96267 h 0.26304 l -0.16692,-1.05989 h -0.1669 v -0.60099 h 0.44752 c 0.0913,-0.21026 0.18206,-0.42072 0.27336,-0.63097 z m 0.12608,0.19068 c -0.0614,0.14155 -0.12351,0.28323 -0.185,0.42478 h 2.52336 c -0.0614,-0.14155 -0.12248,-0.28323 -0.18397,-0.42478 z m -0.65524,0.63097 v 0.21911 l 0.0594,5.2e-4 h 3.35844 l 0.0724,-5.2e-4 v -0.21911 z m 0.16846,0.41083 0.1669,1.05937 h 2.80603 l 0.16693,-1.05937 -1.57046,0.008 z m -0.061,1.25057 0.27956,1.5782 1.34411,-0.0145 1.34567,0.0145 0.28059,-1.5782 z m 1.62367,1.75441 -1.08519,0.0124 0.19325,1.2299 h 1.79835 l 0.19328,-1.2299 z" id="path2714" inkscape:connector-curvature="0" />
You probably can see the code becomes more complex and needs more characters to describe it. More characters in a file result, of course, in a larger size.
### Node cleaning
If you open an example SVG in Inkscape and press F2, that activates the Node tool. You should see something like this:
Inkscape – Node tool activated
There are 5 nodes that aren’t necessary in this example — the ones in the middle of the lines. To remove them, select them one by one with the activated Node tool and press the **Del** key. After this, select the nodes which define this lines and make them corners again using the toolbar tool.
Inkscape – Node tool make node a corner
Without fixing the corners, handles are used that define the curve, which gets saved and will increase file size. You have to do this node cleaning by hand, as it can’t be effectively automated. Now you’re ready for the next stage.
Use the *Save as* function and choose *Optimized svg.* A dialogue window opens where you can select what to remove or keep.
Inkscape – Dialog window for save as optimized SVG
Even the little SVG in this example got down from 3.2 KB to 920 bytes, less than a third of its original size.
Back to the *getfedora* page: The grey voronoi pattern used in the background of the main section, after our optimization from Part 1 of this series, is down to 164.1 KB versus the original 211.12 KB size.
The original SVG it was exported from is 1.9 MB in size. After these SVG optimization steps, it’s only 500.4KB. Too big? Well, the current blue background is 564.98 KB in size. But there’s only a small difference between the SVG and the PNG.
### Compressed files
$ls -lhinsgesamt 928K -rw-r--r--. 1 user user 161K 19. Feb 19:44 grey-pattern.png -rw-rw-r--. 1 user user 160K 18. Feb 12:23 grey-pattern.png.gz -rw-r--r--. 1 user user 489K 19. Feb 19:43 greyscale-pattern-opti.svg -rw-rw-r--. 1 user user 112K 19. Feb 19:05 greyscale-pattern-opti.svg.gz
This is the output of a small test I did to visualize this topic. You should probably see that the raster graphic — the PNG — is already compressed and can’t be anymore. The opposite is the SVG, an XML file. This is just text and can compressed, to less then a fourth of its size. As a result it is now around 50 KB smaller in size than the PNG.
Modern browsers can handle compressed files natively. Therefore, a lot of web servers have switched on *mod_deflate* (Apache) and *gzip* (nginx). That’s how we save space during delivery. Check out if it’s enabled at your server [here](https://checkgzipcompression.com/?url=http%3A%2F%2Fgetfedora.org).
## Tooling for production
First of all, nobody wants to always optimize SVG in Inkscape. You can run Inkscape without a GUI in batch mode, but there’s no option to convert from Inkscape SVG to optimized SVG. You can only export raster graphics this way. But there are alternatives:
- SVGO (which seems not actively developed)
- Scour
This example will use scour for optimization. To install it:
$sudo dnf install scour
To automatically optimize an SVG file, run *scour* similarly to this:
[user@localhost ]$ scourINPUT.svgOUTPUT.svg-p 3 --create-groups --renderer-workaround --strip-xml-prolog --remove-descriptive-elements --enable-comment-stripping --disable-embed-rasters --no-line-breaks --enable-id-stripping --shorten-ids
This is the end of part two, in which you learned how to replace raster images with SVG and how to optimize it for usage. Stay tuned to the Fedora Magazine for part three, coming soon.
## KerstinW
Thanks Part 1 and Part 2 are both awesome.
## Sam
Great stuff. Thanks.
## rugk
Why is SVGO not developed anymore? On GitHub you still see commits and such stuff. I’ve asked the author for clarification: https://github.com/svg/svgo/issues/1055
## Sirko Kemter
thats strange, you should have asked me instead of the developer, as it is my personal opinion. There is a difference between “not actively developed” and “unmaintained” and the developer has given you now the answer, he just develops it from time to time and in the time I wrote this article (what was unfortunately long time ago) there was for nearly a year no movement in the repositories and that is what I call then not actively developed
## Chester Friesen
Good article. Thanks.
I had to install it as “python3-scour” on my Fedora 28. “python2-scour” was also available.
## Sirko Kemter
yes, I wrote this article still on F27, my fault I should have checked all articles for the changes during the versions
## JoKalliauer
This blog only names scour and SVGO, but you missed a third important one:
svgcleaner is much faster than SVGO or scour, and is activly developed. In my personal opinion svgcleaner has much less issues than SVGO and if it is a serious bug it is often fixed on the same day.
I’m a Wikipedian who optimized more than 1000 Buggy-SVG-files from Wikimedia.
## Sirko Kemter
Not forgotten, I know it very well. I wrote in my personal blog a few years back about it. The thing is, its not packaged for Fedora 😉 |
10,218 | 最棒的免费 Roguelike 游戏 | https://www.linuxlinks.com/excellent-free-roguelike-games/ | 2018-11-10T20:53:00 | [
"游戏",
"Rogue"
] | https://linux.cn/article-10218-1.html | 
Roguelike 属于角色扮演游戏的一个子流派,它从字面上理解就是“类 Rogue 游戏”。Rogue 是一个地牢探索视频游戏,第一个版本由开发者 Michel Toy、Glenn Wichman 和 Ken Arnold 在 1980 年发布,由于其极易上瘾使得它从一众游戏中脱颖而出。整个游戏的目标是深入第 26 层,取回 Yendor 的护身符并回到地面,所有设定都基于龙与地下城的世界观。
Rogue 被认为是一个经典、极其困难并且让人废寝忘食的游戏。虽然它在大学校园中非常受欢迎,但并不十分畅销。在 Rogue 发布时,它并没有使用开源许可证,导致了爱好者们开发了许多克隆版本。
对于 Roguelike 游戏并没有一个明确的定义,但是此类游戏会拥有下述的典型特征:
* 高度魔幻的叙事背景;
* 程序化生成关卡。游戏世界中的大部分地图在每次开始游戏时重新生成,也就意味着鼓励多周目;
* 回合制的地牢探险和战斗;
* 基于图块随机生成的图形;
* 随机的战斗结果;
* 永久死亡——死亡实际起作用,一旦死亡你就需要重新开始
* 高难度
此篇文章收集了大量 Linux 平台可玩的 Roguelike 游戏。如果你享受提供真实紧张感的上瘾游戏体验,我衷心推荐你下载这些游戏。不要被其中很多游戏的原始画面吓退,一旦你沉浸其中你会很快忽略简陋的画面。记住,在 Roguelike 游戏中应是游戏机制占主导,画面只是一个加分项而不是必需项。
此处推荐 16 款游戏。所有的游戏都可免费下载,并且大部分采用开源许可证发布。
| Roguelike 游戏 | |
| --- | --- |
| [Dungeon Crawl Stone Soup](https://www.linuxlinks.com/dungeoncrawlstonesoup/) | Linley 的 Dungeon Crawl 的续作 |
| [Prospector](https://www.linuxlinks.com/Prospector-roguelike/) | 基于科幻小说世界观的 Roguelike 游戏 |
| [Dwarf Fortress](https://www.linuxlinks.com/dwarffortress/) | 冒险和侏儒塔防 |
| [NetHack](https://www.linuxlinks.com/nethack/) | 非常怪诞并且令人上瘾的龙与地下城风格冒险游戏 |
| [Angband](https://www.linuxlinks.com/angband/) | 沿着 Rogue 和 NetHack 的路线,它源于游戏 Moria 和 Umoria |
| [Ancient Domains of Mystery](https://www.linuxlinks.com/ADOM/) | 非常成熟的 Roguelike 游戏 |
| [Tales of Maj’Eyal](https://www.linuxlinks.com/talesofmajeyal/) | 特色的策略回合制战斗与先进的角色培养系统 |
| [UnNetHack](https://www.linuxlinks.com/unnethack/) | NetHack 的创新复刻 |
| [Hydra Slayer](https://www.linuxlinks.com/hydra-slayer/) | 基于数学谜题的 Roguelike 游戏 |
| [Cataclysm DDA](https://www.linuxlinks.com/cataclysmdda/) | 后启示录风格 Roguelike 游戏,设定于虚构的新英格兰乡下 |
| [Brogue](https://www.linuxlinks.com/brogue/) | Rogue 的正统续作 |
| [Goblin Hack](https://www.linuxlinks.com/goblin-hack/) | 受 NetHack 启发的游戏, 但密钥更少游戏流程更快 |
| [Ascii Sector](https://www.linuxlinks.com/asciisector/) | 拥有 Roguelike 动作系统的 2D 版贸易和太空飞行模拟器 |
| [SLASH'EM](https://www.linuxlinks.com/slashem/) | Super Lotsa Added Stuff Hack - Extended Magic |
| [Everything Is Fodder](https://www.linuxlinks.com/everything-is-fodder/) | Seven Day Roguelike 比赛入口 |
| [Woozoolike](https://www.linuxlinks.com/Woozoolike/) | 7DRL 2017 比赛中一款简单的太空探索 Roguelike 游戏 |
---
via: <https://www.linuxlinks.com/excellent-free-roguelike-games/>
作者:[Steve Emms](https://www.linuxlinks.com/author/linuxlinks/) 译者:[cycoe](https://github.com/cycoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last Updated on December 10, 2018
Roguelike is a sub-genre of role-playing games. It literally means “a game like Rogue”. Rogue is a dungeon crawling video game, first released in 1980 by developers Michel Toy, Glenn Wichman and Ken Arnold. The game stood out from the crowd by being fiendishly addictive. The game’s goal was to retrieve the Amulet of Yendor, hidden deep in the 26th level, and ascend back to the top, all set in a world based on Dungeons & Dragons.
The game is rightly considered to be a classic, formidably difficult yet compelling addictive. While it was popular in college and university campuses, it wasn’t a big seller. At the time of its release, Rogue wasn’t published under an open source license, which led to many clones being developed.
There is no exact definition of a roguelike, but this type of game typically has the following characteristics:
- High fantasy narrative background
- Procedural level generation. Most of the game world is generated by the game for every new gameplay session. This is meant to encourage replayability
- Turn-based dungeon exploration and combat
- Tile-based graphics that are randomly generated
- Random conflict outcomes
- Permanent death – death works realistically, once you’re gone, you’re gone
- High difficulty
This article compiles a wide selection of roguelike games available for Linux. If you enjoy addictive gameplay with real intensity, I heartily recommended downloading these games. Don’t be put off by the primitive graphics offered by many of the games, you’ll soon forget the visuals once you get immersed in playing. Remember, in roguelikes game mechanics tend to be the primary focus, with graphics being a welcome, but not essential, addition.
There are 16 games recommended here. All of the games are available to download without charge, and almost all are released under an open source license.
Roguelike Games |
|
---|---|
| A continuation of Linley’s Dungeon Crawl |
| Roguelike game set in a science fiction universe |
| Adventure and Dwarf Fortress modes |
| Wonderfully silly, and addictive Dungeons and Dragons-style adventure game |
| Along the lines of Rogue and NetHack. It is derived from the games Moria and Umoria |
| Very mature Roguelike game |
| Features tactical turn-based combat and advanced character building |
| Inspired fork of NetHack |
| Roguelike game based on mathematical puzzles |
| Post-apocalyptic roguelike, set in the countryside of fictional New England |
| A direct descendant of Rogue |
| Inspired by the likes of NetHack, but faster with fewer keys |
| 2D trading and space flight simulator with roguelike action |
| Super Lotsa Added Stuff Hack - Extended Magic |
| Seven Day Roguelike competition entry |
| A simple space exploration roguelike for 7DRL 2017. |
![]() |
**. Our curated compilation covers all categories of software.**
[recommended free and open source software](/best-free-open-source-software/)The software collection forms part of our
**for Linux enthusiasts. There are hundreds of in-depth reviews, open source alternatives to proprietary software from large corporations like Google, Microsoft, Apple, Adobe, IBM, Cisco, Oracle, and Autodesk.**
[series of informative articles](/linuxlinks-home-linux/)There are also fun things to try, hardware, free programming books and tutorials, and much more.
Also Pixel Dungeon, Isleward, those two are really well-made and quite popular too, perfectly playable on Linux. |
10,219 | 如何在 CentOS 中添加、启用和禁用一个仓库 | https://www.2daygeek.com/how-to-add-enable-disable-a-repository-dnf-yum-config-manager-on-linux/ | 2018-11-10T22:14:02 | [
"仓库"
] | https://linux.cn/article-10219-1.html | 
在基于 RPM 的系统上,例如 RHEL、CentOS 等,我们中的许多人使用 yum 包管理器来管理软件的安装、删除、更新、搜索等。
Linux 发行版的大部分软件都来自发行版官方仓库。官方仓库包含大量免费和开源的应用和软件。它很容易安装和使用。
由于一些限制和专有问题,基于 RPM 的发行版在其官方仓库中没有提供某些包。另外,出于稳定性考虑,它不会提供最新版本的核心包。
为了克服这种情况,我们需要安装或启用需要的第三方仓库。对于基于 RPM 的系统,有许多第三方仓库可用,但所建议使用的仓库很少,因为这些不会替换大量的基础包。
建议阅读:
* [在 RHEL/CentOS 系统中使用 YUM 命令管理包](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/)
* [在 Fedora 系统中使用 DNF (YUM 的分支) 命令来管理包](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/)
* [命令行包管理器和用法列表](https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/)
* [Linux 包管理器的图形化工具](https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/)
这可以在基于 RPM 的系统上完成,比如 RHEL, CentOS, OEL, Fedora 等。
* Fedora 系统使用 `dnf config-manager [options] [section …]`
* 其它基于 RPM 的系统使用 `yum-config-manager [options] [section …]`
### 如何列出启用的仓库
只需运行以下命令即可检查系统上启用的仓库列表。
对于 CentOS/RHEL/OLE 系统:
```
# yum repolist
Loaded plugins: fastestmirror, security
Loading mirror speeds from cached hostfile
repo id repo name status
base CentOS-6 - Base 6,706
extras CentOS-6 - Extras 53
updates CentOS-6 - Updates 1,255
repolist: 8,014
```
对于 Fedora 系统:
```
# dnf repolist
```
### 如何在系统中添加一个新仓库
每个仓库通常都提供自己的 `.repo` 文件。要将此类仓库添加到系统中,使用 root 用户运行以下命令。在我们的例子中将添加 EPEL 仓库 和 IUS 社区仓库,见下文。
但是没有 `.repo` 文件可用于这些仓库。因此,我们使用以下方法进行安装。
对于 EPEL 仓库,因为它可以从 CentOS 额外仓库获得,所以运行以下命令来安装它。
```
# yum install epel-release -y
```
对于 IUS 社区仓库,运行以下 bash 脚本来安装。
```
# curl 'https://setup.ius.io/' -o setup-ius.sh
# sh setup-ius.sh
```
如果你有 `.repo` 文件,在 RHEL/CentOS/OEL 中,只需运行以下命令来添加一个仓库。
```
# yum-config-manager --add-repo http://www.example.com/example.repo
Loaded plugins: product-id, refresh-packagekit, subscription-manager
adding repo from: http://www.example.com/example.repo
grabbing file http://www.example.com/example.repo to /etc/yum.repos.d/example.repo
example.repo | 413 B 00:00
repo saved to /etc/yum.repos.d/example.repo
```
对于 Fedora 系统,运行以下命令来添加一个仓库:
```
# dnf config-manager --add-repo http://www.example.com/example.repo
adding repo from: http://www.example.com/example.repo
```
如果在添加这些仓库之后运行 `yum repolist` 命令,你就可以看到新添加的仓库了。Yes,我看到了。
注意:每当运行 `yum repolist` 命令时,该命令会自动从相应的仓库获取更新,并将缓存保存在本地系统中。
```
# yum repolist
Loaded plugins: fastestmirror, security
Loading mirror speeds from cached hostfile
epel/metalink | 6.1 kB 00:00
* epel: epel.mirror.constant.com
* ius: ius.mirror.constant.com
ius | 2.3 kB 00:00
repo id repo name status
base CentOS-6 - Base 6,706
epel Extra Packages for Enterprise Linux 6 - x86_64 12,505
extras CentOS-6 - Extras 53
ius IUS Community Packages for Enterprise Linux 6 - x86_64 390
updates CentOS-6 - Updates 1,255
repolist: 20,909
```
每个仓库都有多个渠道,比如测试(Testing)、开发(Dev)和存档(Archive)等。通过导航到仓库文件位置,你可以更好地理解这一点。
```
# ls -lh /etc/yum.repos.d
total 64K
-rw-r--r-- 1 root root 2.0K Apr 12 02:44 CentOS-Base.repo
-rw-r--r-- 1 root root 647 Apr 12 02:44 CentOS-Debuginfo.repo
-rw-r--r-- 1 root root 289 Apr 12 02:44 CentOS-fasttrack.repo
-rw-r--r-- 1 root root 630 Apr 12 02:44 CentOS-Media.repo
-rw-r--r-- 1 root root 916 May 18 11:07 CentOS-SCLo-scl.repo
-rw-r--r-- 1 root root 892 May 18 10:36 CentOS-SCLo-scl-rh.repo
-rw-r--r-- 1 root root 6.2K Apr 12 02:44 CentOS-Vault.repo
-rw-r--r-- 1 root root 7.9K Apr 12 02:44 CentOS-Vault.repo.rpmnew
-rw-r--r-- 1 root root 957 May 18 10:41 epel.repo
-rw-r--r-- 1 root root 1.1K Nov 4 2012 epel-testing.repo
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-archive.repo
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-dev.repo
-rw-r--r-- 1 root root 1.1K May 18 10:41 ius.repo
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-testing.repo
```
### 如何在系统中启用一个仓库
当你在默认情况下添加一个新仓库时,它将启用它们的稳定仓库,这就是为什么我们在运行 `yum repolist` 命令时获取了仓库信息。在某些情况下,如果你希望启用它们的测试、开发或存档仓库,使用以下命令。另外,我们还可以使用此命令启用任何禁用的仓库。
为了验证这一点,我们将启用 `epel-testing.repo`,运行下面的命令:
```
# yum-config-manager --enable epel-testing
Loaded plugins: fastestmirror
==================================================================================== repo: epel-testing =====================================================================================
[epel-testing]
bandwidth = 0
base_persistdir = /var/lib/yum/repos/x86_64/6
baseurl =
cache = 0
cachedir = /var/cache/yum/x86_64/6/epel-testing
cost = 1000
enabled = 1
enablegroups = True
exclude =
failovermethod = priority
ftp_disable_epsv = False
gpgcadir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgcadir
gpgcakey =
gpgcheck = True
gpgdir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgdir
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
hdrdir = /var/cache/yum/x86_64/6/epel-testing/headers
http_caching = all
includepkgs =
keepalive = True
mdpolicy = group:primary
mediaid =
metadata_expire = 21600
metalink =
mirrorlist = https://mirrors.fedoraproject.org/metalink?repo=testing-epel6&arch=x86_64
mirrorlist_expire = 86400
name = Extra Packages for Enterprise Linux 6 - Testing - x86_64
old_base_cache_dir =
password =
persistdir = /var/lib/yum/repos/x86_64/6/epel-testing
pkgdir = /var/cache/yum/x86_64/6/epel-testing/packages
proxy = False
proxy_dict =
proxy_password =
proxy_username =
repo_gpgcheck = False
retries = 10
skip_if_unavailable = False
ssl_check_cert_permissions = True
sslcacert =
sslclientcert =
sslclientkey =
sslverify = True
throttle = 0
timeout = 30.0
username =
```
运行 `yum repolist` 命令来检查是否启用了 “epel-testing”。它被启用了,我可以从列表中看到它。
```
# yum repolist
Loaded plugins: fastestmirror, security
Determining fastest mirrors
epel/metalink | 18 kB 00:00
epel-testing/metalink | 17 kB 00:00
* epel: mirror.us.leaseweb.net
* epel-testing: mirror.us.leaseweb.net
* ius: mirror.team-cymru.com
base | 3.7 kB 00:00
centos-sclo-sclo | 2.9 kB 00:00
epel | 4.7 kB 00:00
epel/primary_db | 6.0 MB 00:00
epel-testing | 4.7 kB 00:00
epel-testing/primary_db | 368 kB 00:00
extras | 3.4 kB 00:00
ius | 2.3 kB 00:00
ius/primary_db | 216 kB 00:00
updates | 3.4 kB 00:00
updates/primary_db | 8.1 MB 00:00 ...
repo id repo name status
base CentOS-6 - Base 6,706
centos-sclo-sclo CentOS-6 - SCLo sclo 495
epel Extra Packages for Enterprise Linux 6 - x86_64 12,509
epel-testing Extra Packages for Enterprise Linux 6 - Testing - x86_64 809
extras CentOS-6 - Extras 53
ius IUS Community Packages for Enterprise Linux 6 - x86_64 390
updates CentOS-6 - Updates 1,288
repolist: 22,250
```
如果你想同时启用多个仓库,使用以下格式。这个命令将启用 epel、epel-testing 和 ius 仓库:
```
# yum-config-manager --enable epel epel-testing ius
```
对于 Fedora 系统,运行下面的命令来启用仓库:
```
# dnf config-manager --set-enabled epel-testing
```
### 如何在系统中禁用一个仓库
无论何时你在默认情况下添加一个新的仓库,它都会启用它们的稳定仓库,这就是为什么我们在运行 `yum repolist` 命令时获取了仓库信息。如果你不想使用仓库,那么可以通过下面的命令来禁用它。
为了验证这点,我们将要禁用 `epel-testing.repo` 和 `ius.repo`,运行以下命令:
```
# yum-config-manager --disable epel-testing ius
Loaded plugins: fastestmirror
==================================================================================== repo: epel-testing =====================================================================================
[epel-testing]
bandwidth = 0
base_persistdir = /var/lib/yum/repos/x86_64/6
baseurl =
cache = 0
cachedir = /var/cache/yum/x86_64/6/epel-testing
cost = 1000
enabled = 0
enablegroups = True
exclude =
failovermethod = priority
ftp_disable_epsv = False
gpgcadir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgcadir
gpgcakey =
gpgcheck = True
gpgdir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgdir
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
hdrdir = /var/cache/yum/x86_64/6/epel-testing/headers
http_caching = all
includepkgs =
keepalive = True
mdpolicy = group:primary
mediaid =
metadata_expire = 21600
metalink =
mirrorlist = https://mirrors.fedoraproject.org/metalink?repo=testing-epel6&arch=x86_64
mirrorlist_expire = 86400
name = Extra Packages for Enterprise Linux 6 - Testing - x86_64
old_base_cache_dir =
password =
persistdir = /var/lib/yum/repos/x86_64/6/epel-testing
pkgdir = /var/cache/yum/x86_64/6/epel-testing/packages
proxy = False
proxy_dict =
proxy_password =
proxy_username =
repo_gpgcheck = False
retries = 10
skip_if_unavailable = False
ssl_check_cert_permissions = True
sslcacert =
sslclientcert =
sslclientkey =
sslverify = True
throttle = 0
timeout = 30.0
username =
========================================================================================= repo: ius =========================================================================================
[ius]
bandwidth = 0
base_persistdir = /var/lib/yum/repos/x86_64/6
baseurl =
cache = 0
cachedir = /var/cache/yum/x86_64/6/ius
cost = 1000
enabled = 0
enablegroups = True
exclude =
failovermethod = priority
ftp_disable_epsv = False
gpgcadir = /var/lib/yum/repos/x86_64/6/ius/gpgcadir
gpgcakey =
gpgcheck = True
gpgdir = /var/lib/yum/repos/x86_64/6/ius/gpgdir
gpgkey = file:///etc/pki/rpm-gpg/IUS-COMMUNITY-GPG-KEY
hdrdir = /var/cache/yum/x86_64/6/ius/headers
http_caching = all
includepkgs =
keepalive = True
mdpolicy = group:primary
mediaid =
metadata_expire = 21600
metalink =
mirrorlist = https://mirrors.iuscommunity.org/mirrorlist?repo=ius-centos6&arch=x86_64&protocol=http
mirrorlist_expire = 86400
name = IUS Community Packages for Enterprise Linux 6 - x86_64
old_base_cache_dir =
password =
persistdir = /var/lib/yum/repos/x86_64/6/ius
pkgdir = /var/cache/yum/x86_64/6/ius/packages
proxy = False
proxy_dict =
proxy_password =
proxy_username =
repo_gpgcheck = False
retries = 10
skip_if_unavailable = False
ssl_check_cert_permissions = True
sslcacert =
sslclientcert =
sslclientkey =
sslverify = True
throttle = 0
timeout = 30.0
username =
```
运行 `yum repolist` 命令检查 “epel-testing” 和 “ius” 仓库是否被禁用。它被禁用了,我不能看到那些仓库,除了 “epel”。
```
# yum repolist
Loaded plugins: fastestmirror, security
Loading mirror speeds from cached hostfile
* epel: mirror.us.leaseweb.net
repo id repo name status
base CentOS-6 - Base 6,706
centos-sclo-sclo CentOS-6 - SCLo sclo 495
epel Extra Packages for Enterprise Linux 6 - x86_64 12,505
extras CentOS-6 - Extras 53
updates CentOS-6 - Updates 1,288
repolist: 21,051
```
或者,我们可以运行以下命令查看详细信息:
```
# yum repolist all | grep "epel*\|ius*"
* epel: mirror.steadfast.net
epel Extra Packages for Enterprise Linux 6 enabled: 12,509
epel-debuginfo Extra Packages for Enterprise Linux 6 disabled
epel-source Extra Packages for Enterprise Linux 6 disabled
epel-testing Extra Packages for Enterprise Linux 6 disabled
epel-testing-debuginfo Extra Packages for Enterprise Linux 6 disabled
epel-testing-source Extra Packages for Enterprise Linux 6 disabled
ius IUS Community Packages for Enterprise disabled
ius-archive IUS Community Packages for Enterprise disabled
ius-archive-debuginfo IUS Community Packages for Enterprise disabled
ius-archive-source IUS Community Packages for Enterprise disabled
ius-debuginfo IUS Community Packages for Enterprise disabled
ius-dev IUS Community Packages for Enterprise disabled
ius-dev-debuginfo IUS Community Packages for Enterprise disabled
ius-dev-source IUS Community Packages for Enterprise disabled
ius-source IUS Community Packages for Enterprise disabled
ius-testing IUS Community Packages for Enterprise disabled
ius-testing-debuginfo IUS Community Packages for Enterprise disabled
ius-testing-source IUS Community Packages for Enterprise disabled
```
对于 Fedora 系统,运行以下命令来启用一个仓库:
```
# dnf config-manager --set-disabled epel-testing
```
或者,可以通过手动编辑适当的 repo 文件来完成。为此,打开相应的 repo 文件并将值从 `enabled=0` 改为 `enabled=1`(启用仓库)或从 `enabled=1` 变为 `enabled=0`(禁用仓库)。
即从:
```
[epel]
name=Extra Packages for Enterprise Linux 6 - $basearch
#baseurl=http://download.fedoraproject.org/pub/epel/6/$basearch
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-6&arch=$basearch
failovermethod=priority
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
```
改为:
```
[epel]
name=Extra Packages for Enterprise Linux 6 - $basearch
#baseurl=http://download.fedoraproject.org/pub/epel/6/$basearch
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-6&arch=$basearch
failovermethod=priority
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
```
---
via: <https://www.2daygeek.com/how-to-add-enable-disable-a-repository-dnf-yum-config-manager-on-linux/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,220 | Joplin:开源加密笔记及待办事项应用 | https://www.linuxuprising.com/2018/08/joplin-encrypted-open-source-note.html | 2018-11-11T10:27:00 | [
"加密",
"笔记"
] | https://linux.cn/article-10220-1.html |
>
> [Joplin](https://joplin.cozic.net/) 是一个自由开源的笔记和待办事项应用,可用于 Linux、Windows、macOS、Android 和 iOS。它的主要功能包括端到端加密,Markdown 支持以及通过 NextCloud、Dropbox、OneDrive 或 WebDAV 等第三方服务进行同步。
>
>
>

在 Joplin 中你可以用 Markdown 格式(支持数学符号和复选框)记笔记,桌面程序有 3 种视图:Markdown 代码、Markdown 预览或两者并排。你可以在笔记中添加附件(使用图像预览)或在外部 Markdown 编辑器中编辑它们并在每次保存文件时自动在 Joplin 中更新它们。
这个应用应该可以很好地处理大量笔记,它允许你将笔记组织到笔记本中、添加标签和搜索。你还可以按更新日期、创建日期或标题对笔记进行排序。每个笔记本可以包含笔记、待办事项或两者,你可以轻松添加其他笔记的链接(在桌面应用中右键单击笔记并选择 “Copy Markdown link”,然后在笔记中添加链接)。
Joplin 中的待办事项支持警报,但在 Ubuntu 18.04 上,此功能我无法使用。
其他 Joplin 功能包括:
* Firefox 和 Chrome 中可选的 Web Clipper 扩展(在 Joplin 桌面应用中进入 “Tools > Web clipper options” 以启用剪切服务并找到 Chrome/Firefox 扩展程序的下载链接),它可以剪切简单或完整的页面、剪切选中的区域或者截图。
* 可选命令行客户端。
* 导入 Enex 文件(Evernote 导出格式)和 Markdown 文件。
* 导出 JEX 文件(Joplin 导出格式)、PDF 和原始文件。
* 离线优先,因此即使没有互联网连接,所有数据也始终可在设备上查看。
* 地理位置支持。

*Joplin 带有显示复选框和指向另一个笔记链接的隐藏侧边栏*
虽然它没有提供与 Evernote 一样多的功能,但 Joplin 是一个强大的开源 Evernote 替代品。Joplin 包含所有基本功能,除了它是开源软件之外,它还包括加密支持,你还可以选择用于同步的服务。
该应用实际上被设计为 Evernote 替代品,因此它可以导入完整的 Evernote 笔记本、笔记、标签、附件和笔记元数据,如作者、创建和更新时间或地理位置。
Joplin 开发重点关注的另一个方面是避免与特定公司或服务挂钩。这就是为什么该应用提供多种同步方案,如 NextCloud、Dropbox、oneDrive 和 WebDav,同时也容易支持新的服务。如果你改变主意,也很容易从一种服务切换到另一种服务。
我注意到 Joplin 默认情况下不使用加密,你必须在设置中启用此功能。进入 “Tools> Encryption options” 并在这里启用 Joplin 端到端加密。
### 下载 Joplin
* [下载 Joplin](https://joplin.cozic.net/#installation)
Joplin 适用于 Linux、Windows、macOS、Android 和 iOS。在 Linux 上,还有 AppImage 和 Aur 包。
要在 Linux 上运行 Joplin AppImage,请双击它并选择 “Make executable and run”(如果文件管理器支持这个)。如果不支持,你需要使用你的文件管理器使它可执行(应该类似这样:“右键单击>属性>权限>允许作为程序执行”,但这可能会因你使用的文件管理器而有所不同),或者从命令行:
```
chmod +x /path/to/Joplin-*-x86_64.AppImage
```
用你下载 Joplin 的路径替换 `/path/to/`。现在,你可以双击 Joplin Appimage 文件来启动它。
提示:如果你将 Joplin 集成到你的菜单中,而它的图标没有显示在你 dock 或应用切换器中,你可以打开 Joplin 的桌面文件(如果你使用 appimagekit 集成,它应该在 `~/.local/share/applications/appimagekit-joplin.desktop`)并在文件末尾添加 `StartupWMClass=Joplin` 其他不变来修复。
Joplin 有一个命令行客户端,它可以[使用 npm 安装](https://joplin.cozic.net/terminal/)(对于 Debian、Ubuntu 或 Linux Mint,请参阅[如何安装和配置 Node.js 和 npm](https://www.linuxuprising.com/2018/04/how-to-install-and-configure-nodejs-and.html))。
---
via: <https://www.linuxuprising.com/2018/08/joplin-encrypted-open-source-note.html>
作者:[Logix](https://plus.google.com/118280394805678839070) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Joplin: Encrypted Open Source Note Taking And To-Do Application
[Joplin](https://joplin.cozic.net/)is a free and open source note taking and to-do application available for Linux, Windows, macOS, Android and iOS. Its key features include end-to-end encryption, Markdown support, and synchronization via third-party services like NextCloud, Dropbox, OneDrive or WebDAV.With Joplin you can write your notes in the
**Markdown format**(with support for math notations and checkboxes) and the desktop app comes with 3 views: Markdown code, Markdown preview, or both side by side.
**You can add attachments to your notes (with image previews) or edit them in an external Markdown editor**and have them automatically updated in Joplin each time you save the file.
The application should handle a large number of notes pretty well by allowing you to
**organizing notes into notebooks, add tags, and search in notes**. You can also sort notes by updated date, creation date or title.
**Each notebook can contain notes, to-do items, or both**, and you can easily add links to other notes (in the desktop app right click on a note and select
`Copy Markdown link`
, then paste the link in a note).**To-do items in Joplin support alarms**, but this feature didn't work for me on Ubuntu 18.04.
**Other Joplin features include:**
**Optional Web Clipper extension**for Firefox and Chrome (in the Joplin desktop application go to`Tools > Web clipper options`
to enable the clipper service and find download links for the Chrome / Firefox extension) which can clip simplified or complete pages, clip a selection or screenshot.**Optional command line client**.**Import Enex files (Evernote export format) and Markdown files**.**Export JEX files (Joplin Export format), PDF and raw files**.**Offline first, so the entire data is always available on the device even without an internet connection**.**Geolocation support**.
|
**Related:**
[EncryptPad: Encrypted Text Editor For Your Secrets](https://www.linuxuprising.com/2018/07/encryptpad-encrypted-text-editor-for.html)While it doesn't offer as many features as Evernote, Joplin is a robust open source Evernote alternative. Joplin includes all the basic features, and on top of that it's open source software, it includes encryption support, and you also get to choose the service you want to use for synchronization.
The application was actually designed as an Evernote alternative so it can import complete Evernote notebooks, notes, tags, attachments, and note metadata like the author, creation and updated time, or geolocation.
Another aspect on which the Joplin development was focused was to avoid being tied to a particular company or service. This is why the application offers multiple synchronization solutions, like NextCloud, Dropbox, oneDrive and WebDav, while also making it easy to support new services. It's also easy to switch from one service to another if you change your mind.
**I should note that Joplin doesn't use encryption by default and you must enable this from its settings. Go to**
`Tools > Encryption options`
and enable the Joplin end-to-end encryption from there.## Download Joplin
**Joplin is available for Linux, Windows, macOS, Android and iOS. On Linux, there's an AppImage as well as an Aur package available.**
To run the Joplin AppImage on Linux, double click it and select
`Make executable and run`
if your file manager supports this. If not, you'll need to make it executable either using your file manager (should be something like: `right click > Properties > Permissions > Allow executing file as program`
, but this may vary depending on the file manager you use), or from the command line:`chmod +x /path/to/Joplin-*-x86_64.AppImage`
Replacing
`/path/to/`
with the path to where you downloaded Joplin. Now you can double click the Joplin Appimage file to launch it.**TIP:**If you integrate Joplin to your menu and
[its icon doesn't show up](https://github.com/laurent22/joplin/issues/338)in whatever dock / application switcher you're using, you can fix it by opening the the Joplin desktop file (if you've integrated it using appimagekit it should be
`~/.local/share/applications/appimagekit-joplin.desktop`
) and adding `StartupWMClass=Joplin`
at the end of the file on a new line, without modifying anything else.Joplin has a
**command line client**that can be
[installed using npm](https://joplin.cozic.net/terminal/)(for Debian, Ubuntu or Linux Mint, see
[how to install and configure Node.js and npm](https://www.linuxuprising.com/2018/04/how-to-install-and-configure-nodejs-and.html)). |
10,221 | 5 个适合系统管理员使用的告警可视化工具 | https://opensource.com/article/18/10/alerting-and-visualization-tools-sysadmins | 2018-11-11T17:41:00 | [
"可视化",
"告警"
] | https://linux.cn/article-10221-1.html |
>
> 这些开源的工具能够通过输出帮助用户了解系统的运行状况,并对可能发生的潜在问题作出告警。
>
>
>

你大概已经知道(或猜到)<ruby> 告警可视化 <rt> alerting and visualization </rt></ruby>工具是用来做什么的了。下面我们就要来说一下,为什么要讨论这样的工具,甚至某些系统专门将可视化作为特有的功能。
<ruby> 可观察性 <rt> Observability </rt></ruby>的概念来自<ruby> 控制理论 <rt> control theory </rt></ruby>,这个概念描述了我们通过对系统的输入和输出来了解其的能力。本文将重点介绍具有可观察性的输出组件。
告警可视化工具可以对其它系统的输出进行分析,进而对输出的信息进行结构化表示。告警实际上是对系统异常状态的描述,而可视化则是让用户能够直观理解的结构化表示。
### 常见的可视化告警
#### 告警
首先要明确一下<ruby> 告警 <rt> alert </rt></ruby>的含义。在人员无法响应告警内容情况下,不应该发送告警 —— 包括那些发给多个人但只有其中少数人可以响应的告警,以及系统中的每个异常都触发的告警。因为这样会产生告警疲劳,告警接收者也往往会对这些过多的告警采取忽视的态度 —— 直到系统恶化到以少见的方式告警。
例如,如果管理员每天都会收到告警系统发来的数百封告警邮件,他就很容易会忽略告警系统的所有邮件。除非他真的看到问题发生,或者受到了客户或上级的询问时,管理员才会重新重视告警信息。在这种情况下,告警已经失去了原有的意义和用途。
告警不是一个持续的信息流或者状态更新。告警的目的在于暴露系统无法自动恢复的问题,而且告警应该只发送给最有可能解决问题的人员。超出这个定义的内容都不应该作为告警,否则将会对实际工作造成不良的影响。
不同的告警体系都会有各自的告警类型,因此不能用优先级(P1-P5)或者诸如“信息”、“警告”、“严重”之类的字眼来一概而论,下面我会介绍一些新兴的复杂系统的事件响应中出现的通用分类方式。
刚才我提到了一个“信息”这个告警类型,但实际上告警不应该是一个信息,尽管有些人可能会不这样认为。但我觉得如果一个告警没有发送给任何一个人,它就不应该是警报,而只是一些在许多系统中被视为警报的数据点,代表了一些应该知晓但不需要响应的事件。它更应该作为告警可视化工具的一部分,而不是会导致触发告警的事件。《[实用监控](https://www.practicalmonitoring.com/)》是这个领域的必读书籍,其作者 Mike Julian 在书中就介绍了他自己关于告警的看法。
而非信息警报则代表告警需要被响应以及需要相关的操作。我将这些告警大致分为内部故障和外部故障两种类型,而对于大多数公司来说,通常会有两个以上的级别来确定响应告警的优先级。系统性能下降就是一种故障,因为其对用户的影响通常都是未知的。
内部故障比外部故障的优先级低,但也需要快速响应。内部故障通常包括公司员工使用的内部系统或仅对公司员工可见的应用故障。
外部故障则包括任何马上会产生业务影响的系统故障,但不包括影响系统更新的故障。外部故障一般包括客户所面临的应用故障、数据库故障和导致系统可用性或一致性失效的网络故障,这些都会影响用户的正常使用。对于不直接影响用户的依赖组件故障也属于外部故障,随着应用程序的不断运行,一旦依赖组件发生故障,系统的性能也会受到波及。这种情况对于使用某些外部服务或数据源的系统来说很常见,尽管这些外部服务或数据源对于可能不涉及到系统的主要功能,但是当系统在处理相关依赖组件的错误时可能会出现较明显的延迟。
### 可视化
可视化的种类有很多,我就不一一赘述了。这是一个有趣的研究领域,在我这些年的数据分析经历当中,学习和应用可视化方面的知识可以说是相当有挑战性。我们需要将复杂的系统输出通过直观的方式来向他人展示,才能有效地把信息传播出去。[Google Charts](https://developers.google.com/chart/interactive/docs/gallery) 和 [Tableau](https://libguides.libraries.claremont.edu/c.php?g=474417&p=3286401) 都提供了很多可视化方面的工具。下面将会介绍一些最常见的可视化创新解决方案。
#### 折线图
折线图可能是最常见的可视化方式了,它可以让用户很直观地按照时间维度了解系统的情况。系统中每个单一或聚合的指标都会以一条折线在图表中体现。但当同一个图表中同时存在多条折线时,就可能会对阅读有所影响(如下图所示),所以大多数情况下都可以选择仅查看其中的少数几条折线,而不是让所有折线同时显示。如果某个指标的数值产生了大于正常范围的波动,就会很容易发现。例如下图中异常的紫线、黄线、浅蓝线。

折线图的另一个用法是可以将多条折线堆叠起来以显示它们之间的关系。例如对于通过折线图反映服务器的请求数量,可以单独看到每台服务器上的请求,也可以聚合在一起看。这就可以在同一个图表中灵活查看整个系统以及每个实例的情况了。

#### 热力图
另一种常见的可视化方式是热力图。热力图与条形图比较类似,还可以在条形图的基础上显示某部分在整体中占比的变化情况。例如在查看网络请求延时的时候,就可以使用热力图快速查看到所有网络请求的总体趋势和分布情况,另外,它可以使用不同颜色来表示不同部分的数值。
在以下这个热力图中,通过竖直方向上每个时间段的色块数量分布,可以清楚地看到大部分数据集中在整个范围的中心位置。我们还可以发现,大多数时间段的色块分布都是比较宽松的,而 14:00 到 15:00 这一段则分布得很密集,这样的分布有可能意味着一种不健康的状态。

#### 仪表图
还有一种常见的可视化方式是仪表图,用户可以通过仪表图快速了解单个指标。仪表一般用于单个指标的显示,例如车速表代表汽车的行驶速度、油量表代表油箱中的汽油量等等。大多数的仪表图都有一个共通点,就是会划分出所示指标的对应状态。如下图所示,绿色表示正常的状态,橙色表示不良的状态,而红色则表示极差的状态。下图中间一行模拟了真实仪表的显示情况。

上面图表中,除了常规仪表样式的显示方式之外,还有较为直接的数据显示方式,配合相同的配色方案,一眼就可以看出各个指标所处的状态,这一点与和仪表的特点类似。所以,最下面一行可能是仪表图的最佳显示方式,用户不需要仔细阅读,就可以大致了解各个指标的不同状态。这种类型的可视化是我最常用的类型,在数秒钟之间,我就可以全面地总览系统各方面地运行情况。
#### 火焰图
由 [Netflix 的 Brendan Gregg](http://www.brendangregg.com/flamegraphs.html) 在 2011 年开始使用的火焰图是一种较为少见地可视化方式。它不像仪表图那样可以从图表中快速得到关键信息,通常只会在需要解决某个应用的问题的时候才会用到这种图表。火焰图主要用于 CPU、内存和相关帧方面的表示,X 轴按字母顺序将帧一一列出,而 Y 轴则表示堆栈的深度。图中每个矩形都是一个标明了调用的函数的堆栈帧。矩形越宽,就表示它在堆栈中出现越频繁。在分析系统性能问题的时候,火焰图能够起到很大的作用,大家不妨尝试一下。

### 工具的选择
在告警工具方面,有几个商用的工具相当不错。但由于这是一篇介绍开源技术的文章,我只会介绍那些已经被广泛使用的免费工具。希望你也能够为这些工具贡献你自己的代码,让它们更加完善。
### 告警工具
#### Bosun
如果你的电脑出现问题,得多亏 Stack Exchange 你才能在网上查到解决办法。Stack Exchange 以众包问答的模式运营着很多不同类型的网站。其中就有广受开发者欢迎的 [Stack Overflow](https://stackoverflow.com/),以及运维方面有名的 [Super User](https://superuser.com/)。除此以外,从育儿经验到科幻小说、从哲学讨论到单车论坛,Stack Exchange 都有涉猎。
Stack Exchange 开源了它的告警管理系统 [Bosun](http://bosun.org/),同时也发布了 Prometheus 及其 [AlertManager](https://prometheus.io/docs/alerting/alertmanager/) 系统。这两个系统有共通点。Bosun 和 Prometheus 一样使用 Golang 开发,但 Bosun 比 Prometheus 更为强大,因为它可以使用<ruby> 指标聚合 <rt> metrics aggregation </rt></ruby>以外的方式与系统交互。Bosun 还可以从日志和事件收集系统中提取数据,并且支持 Graphite、InfluxDB、OpenTSDB 和 Elasticsearch。
Bosun 的架构包括一个单一的服务器的二进制文件,一个诸如 OpenTSDB 的后端、Redis 以及 [scollector 代理](https://bosun.org/scollector/)。 scollector 代理会自动检测主机上正在运行的服务,并反馈这些进程和其它的系统资源的情况。这些数据将发送到后端。随后 Bosun 的二进制服务文件会向后端发起查询,确定是否需要触发告警。也可以通过 [Grafana](https://grafana.com/) 这些工具通过一个通用接口查询 Bosun 的底层后端。而 Redis 则用于存储 Bosun 的状态信息和元数据。
Bosun 有一个非常巧妙的功能,就是可以根据历史数据来测试告警。这是我几年前在使用 Prometheus 的时候就非常需要的功能,当时我有一个异常的数据需要产生告警,但没有一个可以用于测试的简便方法。为了确保告警能够正常触发,我不得不造出对应的数据来进行测试。而 Bosun 让这个步骤的耗时大大缩短。
Bosun 更是涵盖了所有常用过的功能,包括简单的图形化表示和告警的创建。它还带有强大的用于编写告警规则的表达式语言。但 Bosun 默认只带有电子邮件通知配置和 HTTP 通知配置,因此如果需要连接到 Slack 或其它工具,就需要对配置作出更大程度的定制化([其文档中有](https://bosun.org/notifications))。类似于 Prometheus,Bosun 还可以使用模板通知,你可以使用 HTML 和 CSS 来创建你所需要的电子邮件通知。
#### Cabot
[Cabot](https://cabotapp.com/) 由 [Arachnys](https://www.arachnys.com/) 公司开发。你或许对 Arachnys 公司并不了解,但它很有影响力:Arachnys 公司构建了一个基于云的先进解决方案,用于防范金融犯罪。在之前的公司时,我也曾经参与过类似“[了解你的客户](https://en.wikipedia.org/wiki/Know_your_customer)(KYC)”的工作。大多数公司都认为与恐怖组织产生联系会造成相当不好的影响,因为恐怖组织可能会利用自己的系统来筹集资金。而这些解决方案将有助于防范欺诈类犯罪,尽管这类犯罪情节相对较轻,但仍然也会对机构产生风险。
Arachnys 公司为什么要开发 Cabot 呢?其实只是因为 Arachnys 的开发人员对 [Nagios](https://www.nagios.org/) 不太熟悉。Cabot 的出现对很多人来说都是一个好消息,它基于 Django 和 Bootstrap 开发,因此如果想对这个项目做出自己的贡献,门槛并不高。(另外值得一提的是,Cabot 这个名字来源于开发者的狗。)
与 Bosun 类似,Cabot 也不对数据进行收集,而是使用监控对象的 API 提供的数据。因此,Cabot 告警的模式是拉取而不是推送。它通过访问每个监控对象的 API,根据特定的指标检索所需的数据,然后将告警数据使用 Redis 缓存,进而持久化存储到 Postgres 数据库。
Cabot 的一个较为少见的特点是,它原生支持 [Graphite](https://graphiteapp.org/),同时也支持 [Jenkins](https://jenkins.io/)。Jenkins 在这里被视为一个集中式的定时任务,它会以对待故障的方式去对待构建失败的状况。构建失败当然没有系统故障那么紧急,但一旦出现构建失败,还是需要团队采取措施去处理,毕竟并不是每个人在收到构建失败的电子邮件时都会亲自去检查 Jenkins。
Cabot 另一个有趣的功能是它可以接入 Google 日历安排值班人员,这个称为 Rota 的功能用处很大,希望其它告警系统也能加入类似的功能。Cabot 目前仅支持安排主备联系人,但还有继续改进的空间。它自己的文档也提到,如果需要全面的功能,更应该考虑付费的解决方案。
#### StatsAgg
[Pearson](https://www.pearson.com/us/) 作为一家开发了 [StatsAgg](https://github.com/PearsonEducation/StatsAgg) 告警平台的出版公司,这是极为罕见的,当然也很值得敬佩。除此以外,Pearson 还运营着另外几个网站以及和 [O'Reilly Media](https://www.oreilly.com/) 合资的企业。但我仍然会将它视为出版教学书籍的公司。
StatsAgg 除了是一个告警平台,还是一个指标聚合平台,甚至也有点类似其它系统的代理。StatsAgg 支持通过 Graphite、StatsD、InfluxDB 和 OpenTSDB 输入数据,也支持将其转发到各种平台。但随着中心服务的负载不断增加,风险也不断增大。尽管如此,如果 StatsAgg 的基础架构足够强壮,即使后端存储平台出现故障,也不会对它产生告警的过程造成影响。
StatsAgg 是用 Java 开发的,为了尽可能降低复杂性,它仅包括主服务和一个 UI。StatsAgg 支持基于正则表达式匹配来发送告警,而且它更注重于服务方面的告警,而不是服务器基础告警。我认为它填补了开源监控工具方面的空白,而这正式它自己的目标。
### 可视化工具
#### Grafana
[Grafana](https://grafana.com/) 的知名度很高,它也被广泛采用。每当我需要用到数据面板的时候,我总是会想到它,因为它比我使用过的任何一款类似的产品都要好。Grafana 由 Torkel Ödegaard 开发的,像 Cabot 一样,也是在圣诞节期间开发的,并在 2014 年 1 月发布。在短短几年之间,它已经有了长足的发展。Grafana 基于 Kibana 开发,Torkel 开启了新的分支并将其命名为 Grafana。
Grafana 着重体现了实用性以及数据呈现的美观性。它天生就可以从 Graphite、Elasticsearch、OpenTSDB、Prometheus 和 InfluxDB 收集数据。此外有一个 Grafana 商用版插件可以从更多数据源获取数据,但是其他数据源插件也并非没有开源版本,Grafana 的插件生态系统已经提供了各种数据源。
Grafana 能做什么呢?Grafana 提供了一个中心化的了解系统的方式。它通过 web 来展示数据,任何人都有机会访问到相关信息,当然也可以使用身份验证来对访问进行限制。Grafana 使用各种可视化方式来提供对系统一目了然的了解。Grafana 还支持不同类型的可视化方式,包括集成告警可视化的功能。
现在你可以更直观地设置告警了。通过 Grafana,可以查看图表,还可以查看由于系统性能下降而触发告警的位置,单击要触发报警的位置,并告诉 Grafana 将告警发送何处。这是一个对告警平台非常强大的补充。告警平台不一定会因此而被取代,但告警系统一定会由此得到更多启发和发展。
Grafana 还引入了很多团队协作的功能。不同用户之间能够共享数据面板,你不再需要为 [Kubernetes](https://opensource.com/resources/what-is-kubernetes) 集群创建独立的数据面板,因为由 Kubernetes 开发者和 Grafana 开发者共同维护的一些数据面板已经可用了。
团队协作过程中一个重要的功能是注释。注释功能允许用户将上下文添加到图表当中,其他用户就可以通过上下文更直观地理解图表。当团队成员在处理某个事件,并且需要沟通和理解时,这个功能就十分重要了。将所有相关信息都放在需要的位置,可以让整个团队中快速达成共识。在团队需要调查故障原因和定位事件责任时,这个功能就可以发挥作用了。
#### Vizceral
[Vizceral](https://github.com/Netflix/vizceral) 由 Netflix 开发,用于在故障发生时更有效地了解流量的情况。Grafana 是一种通用性更强的工具,而 Vizceral 则专用于某些领域。 尽管 Netflix 表示已经不再在内部使用 Vizceral,也不再主动对其展开维护,但 Vizceral 仍然会定期更新。我在这里介绍这个工具,主要是为了介绍它的的可视化机制,以及如何利用它来协助解决问题。你可以在样例环境中用它来更好地掌握这一类系统的特性。
---
via: <https://opensource.com/article/18/10/alerting-and-visualization-tools-sysadmins>
作者:[Dan Barker](https://opensource.com/users/barkerd427) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You probably know (or can guess) what alerting and visualization tools are used for. Why would we discuss them as observability tools, especially since some systems include visualization as a feature?
Observability comes from control theory and describes our ability to understand a system based on its inputs and outputs. This article focuses on the output component of observability.
Alerting and visualization tools analyze the outputs of other systems and provide structured representations of these outputs. Alerts are basically a synthesized understanding of negative system outputs, and visualizations are disambiguated structured representations that facilitate user comprehension.
## Common types of alerts and visualizations
### Alerts
Let’s first cover what alerts are *not*. Alerts should not be sent if the human responder can’t do anything about the problem. This includes alerts that are sent to multiple individuals with only a few who can respond, or situations where every anomaly in the system triggers an alert. This leads to alert fatigue and receivers ignoring all alerts within a specific medium until the system escalates to a medium that isn’t already saturated.
For example, if an operator receives hundreds of emails a day from the alerting system, that operator will soon ignore all emails from the alerting system. The operator will respond to a real incident only when he or she is experiencing the problem, emailed by a customer, or called by the boss. In this case, alerts have lost their meaning and usefulness.
Alerts are not a constant stream of information or a status update. They are meant to convey a problem from which the system can’t automatically recover, and they are sent only to the individual most likely to be able to recover the system. Everything that falls outside this definition isn’t an alert and will only damage your employees and company culture.
Everyone has a different set of alert types, so I won't discuss things like priority levels (P1-P5) or models that use words like "Informational," "Warning," and "Critical." Instead, I’ll describe the generic categories emergent in complex systems’ incident response.
You might have noticed I mentioned an “Informational” alert type right after I wrote that alerts shouldn’t be informational. Well, not everyone agrees, but I don’t consider something an alert if it isn’t sent to anyone. It is a data point that many systems refer to as an alert. It represents some event that should be known but not responded to. It is generally part of the visualization system of the alerting tool and not an event that triggers actual notifications. Mike Julian covers this and other aspects of alerting in his book [Practical Monitoring](https://www.practicalmonitoring.com/). It's a must read for work in this area.
Non-informational alerts consist of types that can be responded to or require action. I group these into two categories: internal outage and external outage. (Most companies have more than two levels for prioritizing their response efforts.) Degraded system performance is considered an outage in this model, as the impact to each user is usually unknown.
Internal outages are a lower priority than external outages, but they still need to be responded to quickly. They often include internal systems that company employees use or components of applications that are visible only to company employees.
External outages consist of any system outage that would immediately impact a customer. These don’t include a system outage that prevents releasing updates to the system. They do include customer-facing application failures, database outages, and networking partitions that hurt availability or consistency if either can impact a user. They also include outages of tools that may not have a direct impact on users, as the application continues to run but this transparent dependency impacts performance. This is common when the system uses some external service or data source that isn’t necessary for full functionality but may cause delays as the application performs retries or handles errors from this external dependency.
## Visualizations
There are many visualization types, and I won’t cover them all here. It’s a fascinating area of research. On the data analytics side of my career, learning and applying that knowledge is a constant challenge. We need to provide simple representations of complex system outputs for the widest dissemination of information. [Google Charts](https://developers.google.com/chart/interactive/docs/gallery) and [Tableau](https://libguides.libraries.claremont.edu/c.php?g=474417&p=3286401) have a wide selection of visualization types. We’ll cover the most common visualizations and some innovative solutions for quickly understanding systems.
### Line chart
The line chart is probably the most common visualization. It does a pretty good job of producing an understanding of a system over time. A line chart in a metrics system would have a line for each unique metric or some aggregation of metrics. This can get confusing when there are a lot of metrics in the same dashboard (as shown below), but most systems can select specific metrics to view rather than having all of them visible. Also, anomalous behavior is easy to spot if it’s significant enough to escape the noise of normal operations. Below we can see purple, yellow, and light blue lines that might indicate anomalous behavior.
Image source: [Stackoverflow.com](https://stackoverflow.com/questions/48604283/metrics-for-top-n-load-memory-cpu-uage-by-host-in-grafana) ([Creative Commons BY SA 3.0](https://creativecommons.org/licenses/by-sa/3.0/))
Another feature of a line chart is that you can often stack them to show relationships. For example, you might want to look at requests on each server individually, but also in aggregate. This allows you to understand the overall system as well as each instance in the same graph.
Image source: [Grafana](https://github.com/grafana/grafana) (© Grafana Labs)
### Heatmaps
Another common visualization is the heatmap. It is useful when looking at histograms. This type of visualization is similar to a bar chart but can show gradients within the bars representing the different percentiles of the overall metric. For example, suppose you’re looking at request latencies and you want to quickly understand the overall trend as well as the distribution of all requests. A heatmap is great for this, and it can use color to disambiguate the quantity of each section with a quick glance.
The heatmap below shows the higher concentration around the centerline of the graph with an easy-to-understand visualization of the distribution vertically for each time bucket. We might want to review a couple of points in time where the distribution gets wide while the others are fairly tight like at 14:00. This distribution might be a negative performance indicator.
Image source: [Grafana.org](http://docs.grafana.org/img/docs/v43/heatmap_histogram_over_time.png) (© Grafana Labs)
### Gauges
The last common visualization I’ll cover here is the gauge, which helps users understand a single metric quickly. Gauges can represent a single metric, like your speedometer represents your driving speed or your gas gauge represents the amount of gas in your car. Similar to the gas gauge, most monitoring gauges clearly indicate what is good and what isn’t. Often (as is shown below), good is represented by green, getting worse by orange, and “everything is breaking” by red. The middle row below shows traditional gauges.
Image source: [Grafana.org](http://docs.grafana.org/img/docs/v45/singlestat-panel.png) (© Grafana Labs)
This image shows more than just traditional gauges. The other gauges are single stat representations that are similar to the function of the classic gauge. They all use the same color scheme to quickly indicate system health with just a glance. Arguably, the bottom row is probably the best example of a gauge that allows you to glance at a dashboard and know that everything is healthy (or not). This type of visualization is usually what I put on a top-level dashboard. It offers a full, high-level understanding of system health in seconds.
### Flame graphs
A less common visualization is the flame graph, introduced by [Netflix’s Brendan Gregg ](http://www.brendangregg.com/flamegraphs.html) in 2011. It’s not ideal for dashboarding or quickly observing high-level system concerns; it’s normally seen when trying to understand a specific application problem. This visualization focuses on CPU and memory and the associated frames. The X-axis lists the frames alphabetically, and the Y-axis shows stack depth. Each rectangle is a stack frame and includes the function being called. The wider the rectangle, the more it appears in the stack. This method is invaluable when trying to diagnose system performance at the application level and I urge everyone to give it a try.
Image source: [Wikimedia.org](https://upload.wikimedia.org/wikipedia/commons/b/b5/MediaWiki_flame_graph_screenshot_2014-12-15_22.png) ([Creative Commons BY SA 3.0](https://creativecommons.org/licenses/by-sa/3.0/))
## Tool options
There are several commercial options for alerting, but since this is Opensource.com, I’ll cover only systems that are being used at scale by real companies that you can use at no cost. Hopefully, you’ll be able to contribute new and innovative features to make these systems even better.
## Alerting tools
### Bosun
If you’ve ever done anything with computers and gotten stuck, the help you received was probably thanks to a Stack Exchange system. Stack Exchange runs many different websites around a crowdsourced question-and-answer model. [Stack Overflow](https://stackoverflow.com/) is very popular with developers, and [Super User](https://superuser.com/) is popular with operations. However, there are now hundreds of sites ranging from parenting to sci-fi and philosophy to bicycles.
Stack Exchange open-sourced its alert management system, [Bosun](http://bosun.org/), around the same time Prometheus and its [AlertManager](https://prometheus.io/docs/alerting/alertmanager/) system were released. There were many similarities in the two systems, and that’s a really good thing. Like Prometheus, Bosun is written in Golang. Bosun’s scope is more extensive than Prometheus’ as it can interact with systems beyond metrics aggregation. It can also ingest data from log and event aggregation systems. It supports Graphite, InfluxDB, OpenTSDB, and Elasticsearch.
Bosun’s architecture consists of a single server binary, a backend like OpenTSDB, Redis, and [scollector agents](https://bosun.org/scollector/). The scollector agents automatically detect services on a host and report metrics for those processes and other system resources. This data is sent to a metrics backend. The Bosun server binary then queries the backends to determine if any alerts need to be fired. Bosun can also be used by tools like [Grafana](https://grafana.com/) to query the underlying backends through one common interface. Redis is used to store state and metadata for Bosun.
A really neat feature of Bosun is that it lets you test your alerts against historical data. This was something I missed in Prometheus several years ago, when I had data for an issue I wanted alerts on but no easy way to test it. To make sure my alerts were working, I had to create and insert dummy data. This system alleviates that very time-consuming process.
Bosun also has the usual features like showing simple graphs and creating alerts. It has a powerful expression language for writing alerting rules. However, it only has email and HTTP notification configurations, which means connecting to Slack and other tools requires a bit more customization ([which its documentation covers](https://bosun.org/notifications)). Similar to Prometheus, Bosun can use templates for these notifications, which means they can look as awesome as you want them to. You can use all your HTML and CSS skills to create the baddest email alert anyone has ever seen.
### Cabot
[Cabot](https://cabotapp.com/) was created by a company called [Arachnys](https://www.arachnys.com/). You may not know who Arachnys is or what it does, but you have probably felt its impact: It built the leading cloud-based solution for fighting financial crimes. That sounds pretty cool, right? At a previous company, I was involved in similar functions around [“know your customer"](https://en.wikipedia.org/wiki/Know_your_customer) laws. Most companies would consider it a very bad thing to be linked to a terrorist group, for example, funneling money through their systems. These solutions also help defend against less-atrocious offenders like fraudsters who could also pose a risk to the institution.
So why did Arachnys create Cabot? Well, it is kind of a Christmas present to everyone, as it was a Christmas project built because its developers couldn’t wrap their heads around [Nagios](https://www.nagios.org/). And really, who can blame them? Cabot was written with Django and Bootstrap, so it should be easy for most to contribute to the project. (Another interesting factoid: The name comes from the creator’s dog.)
The Cabot architecture is similar to Bosun in that it doesn’t collect any data. Instead, it accesses data through the APIs of the tools it is alerting for. Therefore, Cabot uses a pull (rather than a push) model for alerting. It reaches out into each system’s API and retrieves the information it needs to make a decision based on a specific check. Cabot stores the alerting data in a Postgres database and also has a cache using Redis.
Cabot natively supports [Graphite](https://graphiteapp.org/), but it also supports [Jenkins](https://jenkins.io/), which is rare in this area. [Arachnys](https://www.arachnys.com/) uses Jenkins like a centralized cron, but I like this idea of treating build failures like outages. Obviously, a build failure isn’t as critical as a production outage, but it could still alert the team and escalate if the failure isn’t resolved. Who actually checks Jenkins every time an email comes in about a build failure? Yeah, me too!
Another interesting feature is that Cabot can integrate with Google Calendar for on-call rotations. Cabot calls this feature Rota, which is a British term for a roster or rotation. This makes a lot of sense, and I wish other systems would take this idea further. Cabot doesn’t support anything more complex than primary and backup personnel, but there is certainly room for additional features. The docs say if you want something more advanced, you should look at a commercial option.
### StatsAgg
[StatsAgg](https://github.com/PearsonEducation/StatsAgg)? How did that make the list? Well, it’s not every day you come across a publishing company that has created an alerting platform. I think that deserves recognition. Of course, [Pearson](https://www.pearson.com/us/) isn’t just a publishing company anymore; it has several web presences and a joint venture with [O’Reilly Media](https://www.oreilly.com/). However, I still think of it as the company that published my schoolbooks and tests.
StatsAgg isn’t just an alerting platform; it’s also a metrics aggregation platform. And it’s kind of like a proxy for other systems. It supports Graphite, StatsD, InfluxDB, and OpenTSDB as inputs, but it can also forward those metrics to their respective platforms. This is an interesting concept, but potentially risky as loads increase on a central service. However, if the StatsAgg infrastructure is robust enough, it can still produce alerts even when a backend storage platform has an outage.
StatsAgg is written in Java and consists only of the main server and UI, which keeps complexity to a minimum. It can send alerts based on regular expression matching and is focused on alerting by service rather than host or instance. Its goal is to fill a void in the open source observability stack, and I think it does that quite well.
## Visualization tools
### Grafana
Almost everyone knows about [Grafana](https://grafana.com/), and many have used it. I have used it for years whenever I need a simple dashboard. The tool I used before was deprecated, and I was fairly distraught about that until Grafana made it okay. Grafana was gifted to us by Torkel Ödegaard. Like Cabot, Grafana was also created around Christmastime, and released in January 2014. It has come a long way in just a few years. It started life as a Kibana dashboarding system, and Torkel forked it into what became Grafana.
Grafana’s sole focus is presenting monitoring data in a more usable and pleasing way. It can natively gather data from Graphite, Elasticsearch, OpenTSDB, Prometheus, and InfluxDB. There’s an Enterprise version that uses plugins for more data sources, but there’s no reason those other data source plugins couldn’t be created as open source, as the Grafana plugin ecosystem already offers many other data sources.
What does Grafana do for me? It provides a central location for understanding my system. It is web-based, so anyone can access the information, although it can be restricted using different authentication methods. Grafana can provide knowledge at a glance using many different types of visualizations. However, it has started integrating alerting and other features that aren’t traditionally combined with visualizations.
Now you can set alerts visually. That means you can look at a graph, maybe even one showing where an alert should have triggered due to some degradation of the system, click on the graph where you want the alert to trigger, and then tell Grafana where to send the alert. That’s a pretty powerful addition that won’t necessarily replace an alerting platform, but it can certainly help augment it by providing a different perspective on alerting criteria.
Grafana has also introduced more collaboration features. Users have been able to share dashboards for a long time, meaning you don’t have to create your own dashboard for your [Kubernetes](https://opensource.com/resources/what-is-kubernetes) cluster because there are several already available—with some maintained by Kubernetes developers and others by Grafana developers.
The most significant addition around collaboration is annotations. Annotations allow a user to add context to part of a graph. Other users can then use this context to understand the system better. This is an invaluable tool when a team is in the middle of an incident and communication and common understanding are critical. Having all the information right where you’re already looking makes it much more likely that knowledge will be shared across the team quickly. It’s also a nice feature to use during blameless postmortems when the team is trying to understand how the failure occurred and learn more about their system.
### Vizceral
Netflix created [Vizceral](https://github.com/Netflix/vizceral) to understand its traffic patterns better when performing a traffic failover. Unlike Grafana, which is a more general tool, Vizceral serves a very specific use case. Netflix no longer uses this tool internally and says it is no longer actively maintained, but it still updates the tool periodically. I highlight it here primarily to point out an interesting visualization mechanism and how it can help solve a problem. It’s worth running it in a demo environment just to better grasp the concepts and witness what’s possible with these systems.
## Comments are closed. |
10,222 | Python 函数式编程:不可变数据结构 | https://opensource.com/article/18/10/functional-programming-python-immutable-data-structures | 2018-11-11T22:41:16 | [
"不可变",
"函数式编程"
] | https://linux.cn/article-10222-1.html |
>
> 不可变性可以帮助我们更好地理解我们的代码。下面我将讲述如何在不牺牲性能的条件下来实现它。
>
>
>

在这个由两篇文章构成的系列中,我将讨论如何将函数式编程方法论中的思想引入至 Python 中,来充分发挥这两个领域的优势。
本文(也就是第一篇文章)中,我们将探讨不可变数据结构的优势。第二部分会探讨如何在 `toolz` 库的帮助下,用 Python 实现高层次的函数式编程理念。
为什么要用函数式编程?因为变化的东西更难推理。如果你已经确信变化会带来麻烦,那很棒。如果你还没有被说服,在文章结束时,你会明白这一点的。
我们从思考正方形和矩形开始。如果我们抛开实现细节,单从接口的角度考虑,正方形是矩形的子类吗?
子类的定义基于[里氏替换原则](https://en.wikipedia.org/wiki/Liskov_substitution_principle)。一个子类必须能够完成超类所做的一切。
如何为矩形定义接口?
```
from zope.interface import Interface
class IRectangle(Interface):
def get_length(self):
"""正方形能做到"""
def get_width(self):
"""正方形能做到"""
def set_dimensions(self, length, width):
"""啊哦"""
```
如果我们这么定义,那正方形就不能成为矩形的子类:如果长度和宽度不等,它就无法对 `set_dimensions` 方法做出响应。
另一种方法,是选择将矩形做成不可变对象。
```
class IRectangle(Interface):
def get_length(self):
"""正方形能做到"""
def get_width(self):
"""正方形能做到"""
def with_dimensions(self, length, width):
"""返回一个新矩形"""
```
现在,我们可以将正方形视为矩形了。在调用 `with_dimensions` 时,它可以返回一个新的矩形(它不一定是个正方形),但它本身并没有变,依然是一个正方形。
这似乎像是个学术问题 —— 直到我们认为正方形和矩形可以在某种意义上看做一个容器的侧面。在理解了这个例子以后,我们会处理更传统的容器,以解决更现实的案例。比如,考虑一下随机存取数组。
我们现在有 `ISquare` 和 `IRectangle`,而且 `ISequere` 是 `IRectangle` 的子类。
我们希望把矩形放进随机存取数组中:
```
class IArrayOfRectangles(Interface):
def get_element(self, i):
"""返回一个矩形"""
def set_element(self, i, rectangle):
"""'rectangle' 可以是任意 IRectangle 对象"""
```
我们同样希望把正方形放进随机存取数组:
```
class IArrayOfSquare(Interface):
def get_element(self, i):
"""返回一个正方形"""
def set_element(self, i, square):
"""'square' 可以是任意 ISquare 对象"""
```
尽管 `ISquare` 是 `IRectangle` 的子集,但没有任何一个数组可以同时实现 `IArrayOfSquare` 和 `IArrayOfRectangle`.
为什么不能呢?假设 `bucket` 实现了这两个类的功能。
```
>>> rectangle = make_rectangle(3, 4)
>>> bucket.set_element(0, rectangle) # 这是 IArrayOfRectangle 中的合法操作
>>> thing = bucket.get_element(0) # IArrayOfSquare 要求 thing 必须是一个正方形
>>> assert thing.height == thing.width
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AssertionError
```
无法同时实现这两类功能,意味着这两个类无法构成继承关系,即使 `ISquare` 是 `IRectangle` 的子类。问题来自 `set_element` 方法:如果我们实现一个只读的数组,那 `IArrayOfSquare` 就可以是 `IArrayOfRectangle` 的子类了。
在可变的 `IRectangle` 和可变的 `IArrayOf*` 接口中,可变性都会使得对类型和子类的思考变得更加困难 —— 放弃变换的能力,意味着我们的直觉所希望的类型间关系能够成立了。
可变性还会带来作用域方面的影响。当一个共享对象被两个地方的代码改变时,这种问题就会发生。一个经典的例子是两个线程同时改变一个共享变量。不过在单线程程序中,即使在两个相距很远的地方共享一个变量,也是一件简单的事情。从 Python 语言的角度来思考,大多数对象都可以从很多位置来访问:比如在模块全局变量,或在一个堆栈跟踪中,或者以类属性来访问。
如果我们无法对共享做出约束,那我们可能要考虑对可变性来进行约束了。
这是一个不可变的矩形,它利用了 [attr](https://www.attrs.org/en/stable/) 库:
```
@attr.s(frozen=True)
class Rectange(object):
length = attr.ib()
width = attr.ib()
@classmethod
def with_dimensions(cls, length, width):
return cls(length, width)
```
这是一个正方形:
```
@attr.s(frozen=True)
class Square(object):
side = attr.ib()
@classmethod
def with_dimensions(cls, length, width):
return Rectangle(length, width)
```
使用 `frozen` 参数,我们可以轻易地使 `attrs` 创建的类成为不可变类型。正确实现 `__setitem__` 方法的工作都交给别人完成了,对我们是不可见的。
修改对象仍然很容易;但是我们不可能改变它的本质。
```
too_long = Rectangle(100, 4)
reasonable = attr.evolve(too_long, length=10)
```
[Pyrsistent](https://pyrsistent.readthedocs.io/en/latest/) 能让我们拥有不可变的容器。
```
# 由整数构成的向量
a = pyrsistent.v(1, 2, 3)
# 并非由整数构成的向量
b = a.set(1, "hello")
```
尽管 `b` 不是一个由整数构成的向量,但没有什么能够改变 `a` 只由整数构成的性质。
如果 `a` 有一百万个元素呢?`b` 会将其中的 999999 个元素复制一遍吗?`Pyrsistent` 具有“大 O”性能保证:所有操作的时间复杂度都是 `O(log n)`. 它还带有一个可选的 C 语言扩展,以在“大 O”性能之上进行提升。
修改嵌套对象时,会涉及到“变换器”的概念:
```
blog = pyrsistent.m(
title="My blog",
links=pyrsistent.v("github", "twitter"),
posts=pyrsistent.v(
pyrsistent.m(title="no updates",
content="I'm busy"),
pyrsistent.m(title="still no updates",
content="still busy")))
new_blog = blog.transform(["posts", 1, "content"],
"pretty busy")
```
`new_blog` 现在将是如下对象的不可变等价物:
```
{'links': ['github', 'twitter'],
'posts': [{'content': "I'm busy",
'title': 'no updates'},
{'content': 'pretty busy',
'title': 'still no updates'}],
'title': 'My blog'}
```
不过 `blog` 依然不变。这意味着任何拥有旧对象引用的人都没有受到影响:转换只会有局部效果。
当共享行为猖獗时,这会很有用。例如,函数的默认参数:
```
def silly_sum(a, b, extra=v(1, 2)):
extra = extra.extend([a, b])
return sum(extra)
```
在本文中,我们了解了为什么不可变性有助于我们来思考我们的代码,以及如何在不带来过大性能负担的条件下实现它。下一篇,我们将学习如何借助不可变对象来实现强大的程序结构。
---
via: <https://opensource.com/article/18/10/functional-programming-python-immutable-data-structures>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[StdioA](https://github.com/StdioA) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this two-part series, I will discuss how to import ideas from the functional programming methodology into Python in order to have the best of both worlds.
This first post will explore how immutable data structures can help. The second part will explore higher-level functional programming concepts in Python using the **toolz** library.
Why functional programming? Because mutation is hard to reason about. If you are already convinced that mutation is problematic, great. If you're not convinced, you will be by the end of this post.
Let's begin by considering squares and rectangles. If we think in terms of interfaces, neglecting implementation details, are squares a subtype of rectangles?
The definition of a subtype rests on the [Liskov substitution principle](https://en.wikipedia.org/wiki/Liskov_substitution_principle). In order to be a subtype, it must be able to do everything the supertype does.
How would we define an interface for a rectangle?
```
from zope.interface import Interface
class IRectangle(Interface):
def get_length(self):
"""Squares can do that"""
def get_width(self):
"""Squares can do that"""
def set_dimensions(self, length, width):
"""Uh oh"""
```
If this is the definition, then squares cannot be a subtype of rectangles; they cannot respond to a `set_dimensions`
method if the length and width are different.
A different approach is to choose to make rectangles *immutable*.
```
class IRectangle(Interface):
def get_length(self):
"""Squares can do that"""
def get_width(self):
"""Squares can do that"""
def with_dimensions(self, length, width):
"""Returns a new rectangle"""
```
Now, a square can be a rectangle. It can return a *new* rectangle (which would not usually be a square) when `with_dimensions`
is called, but it would not stop being a square.
This might seem like an academic problem—until we consider that squares and rectangles are, in a sense, a container for their sides. After we understand this example, the more realistic case this comes into play with is more traditional containers. For example, consider random-access arrays.
We have `ISquare`
and `IRectangle`
, and `ISquare`
is a subtype of `IRectangle`
.
We want to put rectangles in a random-access array:
```
class IArrayOfRectangles(Interface):
def get_element(self, i):
"""Returns Rectangle"""
def set_element(self, i, rectangle):
"""'rectangle' can be any IRectangle"""
```
We want to put squares in a random-access array too:
```
class IArrayOfSquare(Interface):
def get_element(self, i):
"""Returns Square"""
def set_element(self, i, square):
"""'square' can be any ISquare"""
```
Even though `ISquare`
is a subtype of `IRectangle`
, no array can implement both `IArrayOfSquare`
and `IArrayOfRectangle`
.
Why not? Assume `bucket`
implements both.
```
>>> rectangle = make_rectangle(3, 4)
>>> bucket.set_element(0, rectangle) # This is allowed by IArrayOfRectangle
>>> thing = bucket.get_element(0) # That has to be a square by IArrayOfSquare
>>> assert thing.height == thing.width
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AssertionError
```
Being unable to implement both means that neither is a subtype of the other, even though `ISquare`
is a subtype of `IRectangle`
. The problem is the `set_element`
method: If we had a read-only array, `IArrayOfSquare`
would be a subtype of `IArrayOfRectangle`
.
Mutability, in both the mutable `IRectangle`
interface and the mutable `IArrayOf*`
interfaces, has made thinking about types and subtypes much more difficult—and giving up on the ability to mutate meant that the intuitive relationships we expected to have between the types actually hold.
Mutation can also have *non-local* effects. This happens when a shared object between two places is mutated by one. The classic example is one thread mutating a shared object with another thread, but even in a single-threaded program, sharing between places that are far apart is easy. Consider that in Python, most objects are reachable from many places: as a module global, or in a stack trace, or as a class attribute.
If we cannot constrain the sharing, we might think about constraining the mutability.
Here is an immutable rectangle, taking advantage of the [attrs](https://www.attrs.org/en/stable/) library:
```
@attr.s(frozen=True)
class Rectange(object):
length = attr.ib()
width = attr.ib()
@classmethod
def with_dimensions(cls, length, width):
return cls(length, width)
```
Here is a square:
```
@attr.s(frozen=True)
class Square(object):
side = attr.ib()
@classmethod
def with_dimensions(cls, length, width):
return Rectangle(length, width)
```
Using the `frozen`
argument, we can easily have `attrs`
-created classes be immutable. All the hard work of writing `__setitem__`
correctly has been done by others and is completely invisible to us.
It is still easy to *modify* objects; it's just nigh impossible to *mutate* them.
```
too_long = Rectangle(100, 4)
reasonable = attr.evolve(too_long, length=10)
```
The [Pyrsistent](https://pyrsistent.readthedocs.io/en/latest/) package allows us to have immutable containers.
```
# Vector of integers
a = pyrsistent.v(1, 2, 3)
# Not a vector of integers
b = a.set(1, "hello")
```
While `b`
is not a vector of integers, nothing will ever stop `a`
from being one.
What if `a`
was a million elements long? Is `b`
going to copy 999,999 of them? Pyrsistent comes with "big O" performance guarantees: All operations take `O(log n)`
time. It also comes with an optional C extension to improve performance beyond the big O.
For modifying nested objects, it comes with a concept of "transformers:"
```
blog = pyrsistent.m(
title="My blog",
links=pyrsistent.v("github", "twitter"),
posts=pyrsistent.v(
pyrsistent.m(title="no updates",
content="I'm busy"),
pyrsistent.m(title="still no updates",
content="still busy")))
new_blog = blog.transform(["posts", 1, "content"],
"pretty busy")
```
`new_blog`
will now be the immutable equivalent of
```
{'links': ['github', 'twitter'],
'posts': [{'content': "I'm busy",
'title': 'no updates'},
{'content': 'pretty busy',
'title': 'still no updates'}],
'title': 'My blog'}
```
But `blog`
is still the same. This means anyone who had a reference to the old object has not been affected: The transformation had only *local* effects.
This is useful when sharing is rampant. For example, consider default arguments:
```
def silly_sum(a, b, extra=v(1, 2)):
extra = extra.extend([a, b])
return sum(extra)
```
In this post, we have learned why immutability can be useful for thinking about our code, and how to achieve it without an extravagant performance price. Next time, we will learn how immutable objects allow us to use powerful programming constructs.
## Comments are closed. |
10,223 | KRS:一个收集 Kubernetes 资源统计数据的新工具 | https://opensource.com/article/18/11/kubernetes-resource-statistics | 2018-11-12T00:05:45 | [
"Kubernetes"
] | https://linux.cn/article-10223-1.html |
>
> 零配置工具简化了信息收集,例如在某个命名空间中运行了多少个 pod。
>
>
>

最近我在纽约的 O'Reilly Velocity 就 [Kubernetes 应用故障排除](http://troubleshooting.kubernetes.sh/)的主题发表了演讲,并且在积极的反馈和讨论的推动下,我决定重新审视这个领域的工具。结果,除了 [kubernetes-incubator/spartakus](https://github.com/kubernetes-incubator/spartakus) 和 [kubernetes/kube-state-metrics](https://github.com/kubernetes/kube-state-metrics) 之外,我们还没有太多的轻量级工具来收集资源统计数据(例如命名空间中的 pod 或服务的数量)。所以,我在回家的路上开始编写一个小工具 —— 创造性地命名为 `krs`,它是 Kubernetes Resource Stats 的简称 ,它允许你收集这些统计数据。
你可以通过两种方式使用 [mhausenblas/krs](https://github.com/mhausenblas/krs):
* 直接在命令行(有 Linux、Windows 和 MacOS 的二进制文件),以及
* 在集群中使用 [launch.sh](https://github.com/mhausenblas/krs/blob/master/launch.sh) 脚本部署,该脚本动态创建适当的基于角色的访问控制(RBAC) 权限。
提醒你,它还在早期,并且还在开发中。但是,`krs` 的 0.1 版本提供以下功能:
* 在每个命名空间的基础上,它定期收集资源统计信息(支持 pod、部署和服务)。
* 它以 [OpenMetrics 格式](https://openmetrics.io/)公开这些统计。
* 它可以直接通过二进制文件使用,也可以在包含所有依赖项的容器化设置中使用。
目前,你需要安装并配置 `kubectl`,因为 `krs` 依赖于执行 `kubectl get all` 命令来收集统计数据。(另一方面,谁会使用 Kubernetes 但没有安装 `kubectl` 呢?)
使用 `krs` 很简单。[下载](https://github.com/mhausenblas/krs/releases)适合你平台的二进制文件,并按如下方式执行:
```
$ krs thenamespacetowatch
# HELP pods Number of pods in any state, for example running
# TYPE pods gauge
pods{namespace="thenamespacetowatch"} 13
# HELP deployments Number of deployments
# TYPE deployments gauge
deployments{namespace="thenamespacetowatch"} 6
# HELP services Number of services
# TYPE services gauge
services{namespace="thenamespacetowatch"} 4
```
这将在前台启动 `krs`,从名称空间 `thenamespacetowatch` 收集资源统计信息,并分别在标准输出中以 OpenMetrics 格式输出它们,以供你进一步处理。

*krs 实战截屏*
也许你会问,Michael,为什么它不能做一些有用的事(例如将指标存储在 S3 中)?因为 [Unix 哲学](http://harmful.cat-v.org/cat-v/)。
对于那些想知道他们是否可以直接使用 Prometheus 或 [kubernetes/kube-state-metrics](https://github.com/kubernetes/kube-state-metrics) 来完成这项任务的人:是的,你可以,为什么不行呢? `krs` 的重点是作为已有工具的轻量级且易于使用的替代品 —— 甚至可能在某些方面略微互补。
本文最初发表在 [Medium 的 ITNext](https://itnext.io/kubernetes-resource-statistics-e8247f92b45c) 上,并获得授权转载。
---
via: <https://opensource.com/article/18/11/kubernetes-resource-statistics>
作者:[Michael Hausenblas](https://opensource.com/users/mhausenblas) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Recently I was in New York giving a talk at O'Reilly Velocity on the topic of [troubleshooting Kubernetes apps](http://troubleshooting.kubernetes.sh/) and, motivated by the positive feedback and great discussions on the topic, I decided to revisit tooling in the space. It turns out that, besides [kubernetes-incubator/spartakus](https://github.com/kubernetes-incubator/spartakus) and [kubernetes/kube-state-metrics](https://github.com/kubernetes/kube-state-metrics), we don't really have much lightweight tooling available to collect resource stats (such as the number of pods or services in a namespace). So, I sat down on my way home and started coding on a little tool—creatively named **krs**, which is short for Kubernetes Resource Stats—that allows you to gather these stats.
You can use [mhausenblas/krs](https://github.com/mhausenblas/krs) in two ways:
- directly from the command line (binaries for Linux, Windows, and MacOS are available); and
- in cluster, as a deployment, using the
[launch.sh](https://github.com/mhausenblas/krs/blob/master/launch.sh)script, which creates the appropriate role-based access control (RBAC) permissions on the fly.
Mind you, it's very early days, and this is heavily a work in progress. However, the 0.1 release of **krs** offers the following features:
- In a per-namespace basis, it periodically gathers resource stats (supporting pods, deployments, and services).
- It exposes these stats as metrics in the
[OpenMetrics format](https://openmetrics.io/). - It can be used directly via binaries or in a containerized setup with all dependencies included.
In its current form, you need to have **kubectl** installed and configured for **krs** to work, because **krs** relies on a **kubectl get all** command to be executed to gather the stats. (On the other hand, who's using Kubernetes and doesn't have **kubectl** installed?)
Using **krs** is simple; [Download](https://github.com/mhausenblas/krs/releases) the binary for your platform and execute it like this:
```
$ krs thenamespacetowatch
# HELP pods Number of pods in any state, for example running
# TYPE pods gauge
pods{namespace="thenamespacetowatch"} 13
# HELP deployments Number of deployments
# TYPE deployments gauge
deployments{namespace="thenamespacetowatch"} 6
# HELP services Number of services
# TYPE services gauge
services{namespace="thenamespacetowatch"} 4
```
This will launch **krs** in the foreground, gathering resource stats from the namespace **thenamespacetowatch** and outputting them respectively in the OpenMetrics format on **stdout** for you to further process.
Screenshot of krs in action.
*But Michael, you may ask, why isn't it doing something useful (such as storing 'em in S3) with the metrics? Because Unix philosophy.*
For those wondering if they can directly use Prometheus or [kubernetes/kube-state-metrics](https://github.com/kubernetes/kube-state-metrics) for this task: Well, sure you can, why not? The emphasis of **krs** is on being a lightweight and easy-to-use alternative to already available tooling—and maybe even being slightly complementary in certain aspects.
*This was originally published on Medium's ITNext and is reprinted with permission.*
## Comments are closed. |
10,224 | Bash 脚本中如何使用 here 文档将数据写入文件 | https://www.cyberciti.biz/faq/using-heredoc-rediection-in-bash-shell-script-to-write-to-file/ | 2018-11-12T09:51:20 | [
"here",
"bash"
] | https://linux.cn/article-10224-1.html | <ruby> here 文档 <rt> here document </rt></ruby> (LCTT 译注:here 文档又称作 heredoc )不是什么特殊的东西,只是一种 I/O 重定向方式,它告诉 bash shell 从当前源读取输入,直到读取到只有分隔符的行。

这对于向 ftp、cat、echo、ssh 和许多其他有用的 Linux/Unix 命令提供指令很有用。 此功能适用于 bash 也适用于 Bourne、Korn、POSIX 这三种 shell。
### here 文档语法
语法是:
```
command <<EOF
cmd1
cmd2 arg1
EOF
```
或者允许 shell 脚本中的 here 文档使用 `EOF<<-` 以自然的方式缩进:
```
command <<-EOF
msg1
msg2
$var on line
EOF
```
或者
```
command <<'EOF'
cmd1
cmd2 arg1
$var won't expand as parameter substitution turned off
by single quoting
EOF
```
或者 **重定向并将其覆盖** 到名为 `my_output_file.txt` 的文件中:
```
command <<EOF > my_output_file.txt
mesg1
msg2
msg3
$var on $foo
EOF
```
或**重定向并将其追加**到名为 `my_output_file.txt` 的文件中:
```
command <<EOF >> my_output_file.txt
mesg1
msg2
msg3
$var on $foo
EOF
```
### 示例
以下脚本将所需内容写入名为 `/tmp/output.txt` 的文件中:
```
#!/bin/bash
OUT=/tmp/output.txt
echo "Starting my script..."
echo "Doing something..."
cat <<EOF >$OUT
Status of backup as on $(date)
Backing up files $HOME and /etc/
EOF
echo "Starting backup using rsync..."
```
你可以使用[cat命令](https//www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/)查看/tmp/output.txt文件:
```
$ cat /tmp/output.txt
```
示例输出:
```
Status of backup as on Thu Nov 16 17:00:21 IST 2017
Backing up files /home/vivek and /etc/
```
### 禁用路径名/参数/变量扩展、命令替换、算术扩展
像 `$HOME` 这类变量和像 `$(date)` 这类命令在脚本中会被解释为替换。 要禁用它,请使用带有 `'EOF'` 这样带有单引号的形式,如下所示:
```
#!/bin/bash
OUT=/tmp/output.txt
echo "Starting my script..."
echo "Doing something..."
# No parameter and variable expansion, command substitution, arithmetic expansion, or pathname expansion is performed on word.
# If any part of word is quoted, the delimiter is the result of quote removal on word, and the lines in the here-document
# are not expanded. So EOF is quoted as follows
cat <<'EOF' >$OUT
Status of backup as on $(date)
Backing up files $HOME and /etc/
EOF
echo "Starting backup using rsync..."
```
你可以使用 [cat 命令](https//www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/)查看 `/tmp/output.txt` 文件:
```
$ cat /tmp/output.txt
```
示例输出:
```
Status of backup as on $(date)
Backing up files $HOME and /etc/
```
### 关于 tee 命令的使用
语法是:
```
tee /tmp/filename <<EOF >/dev/null
line 1
line 2
line 3
$(cmd)
$var on $foo
EOF
```
或者通过在单引号中引用 `EOF` 来禁用变量替换和命令替换:
```
tee /tmp/filename <<'EOF' >/dev/null
line 1
line 2
line 3
$(cmd)
$var on $foo
EOF
```
这是我更新的脚本:
```
#!/bin/bash
OUT=/tmp/output.txt
echo "Starting my script..."
echo "Doing something..."
tee $OUT <<EOF >/dev/null
Status of backup as on $(date)
Backing up files $HOME and /etc/
EOF
echo "Starting backup using rsync..."
```
### 关于内存 here 文档的使用
这是我更新的脚本:
```
#!/bin/bash
OUT=/tmp/output.txt
## in memory here docs
## thanks https://twitter.com/freebsdfrau
exec 9<<EOF
Status of backup as on $(date)
Backing up files $HOME and /etc/
EOF
## continue
echo "Starting my script..."
echo "Doing something..."
## do it
cat <&9 >$OUT
echo "Starting backup using rsync..."
```
---
via: <https://www.cyberciti.biz/faq/using-heredoc-rediection-in-bash-shell-script-to-write-to-file/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,226 | 在 Linux 中怎么运行 MS-DOS 游戏和程序 | https://www.ostechnix.com/how-to-run-ms-dos-games-and-programs-in-linux/ | 2018-11-12T23:51:12 | [
"DOSBox",
"DOS",
"模拟器"
] | https://linux.cn/article-10226-1.html | 
你是否想过尝试一些经典的 MS-DOS 游戏和像 Turbo C++ 这样的废弃的 C++ 编译器?这篇教程将会介绍如何使用 DOSBox 在 Linux 环境下运行 MS-DOS 的游戏和程序。DOSBox 是一个 x86 平台的 DOS 模拟器,可以用来运行经典的 DOS 游戏和程序。 DOSBox 可以模拟带有声音、图形、鼠标、操纵杆和调制解调器等的因特尔 x86 电脑,它允许你运行许多旧的 MS-DOS 游戏和程序,这些游戏和程序根本无法在任何现代 PC 和操作系统上运行,例如 Microsoft Windows XP 及更高版本、Linux 和FreeBSD。 DOSBox 是免费的,使用 C++ 编程语言编写并在 GPL 下分发。
### 在 Linux 上安装 DOSBox
DOSBox 在大多数 Linux 发行版的默认仓库中都能找的到。
在 Arch Linux 及其衍生版如 Antergos、Manjaro Linux 上:
```
$ sudo pacman -S dosbox
```
在 Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt-get install dosbox
```
在 Fedora 上:
```
$ sudo dnf install dosbox
```
### 配置 DOSBox
DOSBox 是一个开箱即用的软件,它不需要进行初始化配置。它的配置文件位于 `~/.dosbox` 文件夹中,名为 `dosbox-x.xx.conf`。 在此配置文件中,你可以编辑/修改各种设置,例如以全屏模式启动 DOSBox,全屏使用双缓冲,设置首选分辨率,鼠标灵敏度,启用或禁用声音,扬声器,操纵杆等等。如前所述,默认设置即可正常工作。你可以不用进行任何更改。
### 在 Linux 中运行 MS-DOS 上的游戏和程序
在终端运行以下命令启动 DOSBox:
```
$ dosbox
```
下图就是 DOSBox 的界面

正如你所看到的,DOSBox 带有自己的类似 DOS 的命令提示符和一个虚拟的 `Z:\` 的驱动器,如果你熟悉 MS-DOS 的话,你会发现在 DOSBox 环境下工作不会有任何问题。
这是 `dir` 命令(在 Linux 中等同于 `ls` 命令)的输出:

如果你是第一次使用 DOSBox,你可以通过在 DOSBox 提示符中输入以下命令来查看关于 DOSBox 的简介:
```
intro
```
在介绍部分按回车进入下一页。
要查看 DOS 中最常用命令的列表,请使用此命令:
```
help
```
要查看 DOSBox 中所有支持的命令的列表,请键入:
```
help /all
```
记好了这些命令应该在 DOSBox 提示符中使用,而不是在 Linux 终端中使用。
DOSBox 还支持一些实用的键盘组合键。下图是能有效使用 DOSBox 的默认键盘快捷键。

要退出 DOSBox,只需键入如下命令并按回车:
```
exit
```
默认情况下,DOSBox 开始运行时的正常屏幕窗口大小如上所示。
要直接在全屏启动 DOSBox,请编辑 `dosbox-x.xx.conf` 文件并将`fullscreen` 变量的值设置为 `enable`。 之后,DOSBox 将以全屏模式启动。 如果要返回正常屏幕,请按 `ALT+ENTER`。
希望你掌握了 DOSBox 的这些基本用法。
让我们继续安装一些 DOS 程序和游戏。
首先,我们需要在 Linux 系统中创建目录来保存程序和游戏。我将创建两个名为 `~/dosprograms` 和 `~/dosgames` 的目录,第一个用于存储程序,后者用于存储游戏。
```
$ mkdir ~/dosprograms ~/dosgames
```
出于本指南的目的,我将向你展示如何安装 Turbo C++ 程序和 Mario 游戏。我们首先将看到如何安装 Turbo。
下载最后版本的 Turbo C++ 编译器并将其解压到 `~/dosprograms` 目录中。 我已经将 Turbo C++ 保存在在我的 `~/dosprograms/TC/` 目录中了。
```
$ ls dosprograms/tc/
BGI BIN CLASSLIB DOC EXAMPLES FILELIST.DOC INCLUDE LIB README README.COM
```
运行 DOSBox:
```
$ dosbox
```
将 `~/dosprograms` 目录挂载为 DOSBox 中的虚拟驱动器 `C:\`
```
Z:\>mount c ~/dosprograms
```
你会看到类似下面的输出:
```
Drive C is mounted as local directory /home/sk/dosprograms.
```

现在,使用命令切换到 C 盘:
```
Z:\>c:
```
然后切换到 `tc/bin` 目录:
```
Z:\>cd tc/bin
```
最后,运行 Turbo C++ 可执行文件:
```
Z:\>tc.exe
```
**备注:**只需输入前几个字母,然后按回车键可以自动填充文件名。

你现在将进入 Turbo C++ 控制台。

创建新文件(`ATL + F`)并开始编程:

你可以同样安装和运行其他经典 DOS 程序。
**故障排除:**
运行 Turbo C++ 或其他任何 DOS 程序时,你可能会遇到以下错误:
```
DOSBox switched to max cycles, because of the setting: cycles=auto. If the game runs too fast try a fixed cycles amount in DOSBox's options. Exit to error: DRC64:Unhandled memory reference
```
要解决此问题,编辑 `~/.dosbox/dosbox-x.xx.conf` 文件:
```
$ nano ~/.dosbox/dosbox-0.74.conf
```
找到以下变量:
```
core=auto
```
并更改其值为:
```
core=normal
```
现在,让我们看看如何运行基于DOS的游戏,例如 **Mario Bros VGA**。
从 [这里](https://www.dosgames.com/game/mario-bros-vga) 下载 Mario 游戏,并将其解压到 Linux 中的 `~/dosgames` 目录。
运行 DOSBox:
```
$ dosbox
```
我们刚才使用了虚拟驱动器 `C:` 来运行 DOS 程序。现在让我们使用 `D:` 作为虚拟驱动器来运行游戏。
在 DOSBox 提示符下,运行以下命令将 `~/dosgames` 目录挂载为虚拟驱动器 `D`:
```
Z:\>mount d ~/dosgames
```
进入驱动器 `D:`:
```
Z:\>d:
```
然后进入 mario 游戏目录并运行 `mario.exe` 文件来启动游戏。
```
D:\>cd mario
D:\>mario.exe
```

开始玩游戏:

你可以同样像上面所说的那样运行任何基于 DOS 的游戏。 [点击这里](https://www.dosbox.com/comp_list.php)查看可以使用 DOSBox 运行的游戏的完整列表。
### 总结
尽管 DOSBox 并不能作为 MS-DOS 的完全替代品,并且还缺少 MS-DOS 中的许多功能,但它足以安装和运行大多数的 DOS 游戏和程序。
有关更多详细信息,请参阅官方 [DOSBox手册](https://www.dosbox.com/DOSBoxManual.html)。
这就是全部内容。希望这对你有用。更多优秀指南即将到来。 敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-run-ms-dos-games-and-programs-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[way-ww](https://github.com/way-ww) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,227 | 如何弄清 Linux 系统运行何种系统管理程序 | https://www.2daygeek.com/how-to-determine-which-init-system-manager-is-running-on-linux-system/ | 2018-11-13T00:37:01 | [
"初始化"
] | https://linux.cn/article-10227-1.html | 
虽然我们经常听到<ruby> 系统管理器 <rt> System Manager </rt></ruby>这词,但很少有人深究其确切意义。现在我们将向你展示其区别。
我会尽自己所能来解释清楚一切。我们大多都知道 System V 和 systemd 两种系统管理器。 System V (简写 SysV) 是老式系统所使用的古老且传统的初始化系统及系统管理器。
Systemd 是全新的初始化系统及系统管理器,并且已被大部分主流 Linux 发行版所采用。
Linux 系统中主要有三种有名而仍在使用的初始化系统。大多数 Linux 发行版都使用其中之一。
### 什么是初始化系统管理器?
在基于 Linux/Unix 的操作系统中,`init` (初始化的简称) 是内核启动系统时开启的第一个进程。
它持有的进程 ID(PID)号为 1,其在后台一直运行着,直到关机。
`init` 会查找 `/etc/inittab` 文件中相应配置信息来确定系统的运行级别,然后根据运行级别在后台启动所有的其它进程和应用。
作为 Linux 启动过程的一部分,BIOS、MBR、GRUB 和内核进程在此进程之前就被激活了。
下面列出的是 Linux 的可用运行级别(存在七个运行级别,从 0 到 6)。
* `0`:停机
* `1`:单用户模式
* `2`:多用户,无 NFS(LCTT 译注:NFS 即 Network File System,网络文件系统)
* `3`:全功能多用户模式
* `4`:未使用
* `5`:X11(GUI – 图形用户界面)
* `6`:重启
下面列出的是 Linux 系统中广泛使用的三种初始化系统。
* System V (Sys V):是类 Unix 操作系统传统的也是首款初始化系统。
* Upstart:基于事件驱动,是 `/sbin/init` 守护进程的替代品。
* Systemd:是一款全新的初始化系统及系统管理器,它被所有主流的 Linux 发行版实现/采用,以替代传统的 SysV 初始化系统。
### 什么是 System V (Sys V)?
System V(Sys V)是类 Unix 操作系统传统的也是首款初始化系统。`init` 是系统由内核启动期间启动的第一个进程,它是所有进程的父进程。
起初,大多数 Linux 发行版都使用名为 System V(SysV)的传统的初始化系统。多年来,为了解决标准版本中的设计限制,发布了几个替代的初始化系统,例如 launchd、Service Management Facility、systemd 和 Upstart。
但只有 systemd 最终被几个主流 Linux 发行版所采用,以替代传统的 SysV。
### 什么是 Upstart?
Upstart 基于事件驱动,是 `/sbin/init` 守护进程的替代品。用来在启动期间控制任务和服务的启动,在关机期间停止它们,及在系统运行过程中监视它们。
它最初是为 Ubuntu 发行版开发的,但也可以在所有的 Linux 发行版中部署运行,以替代古老的 System V 初始化系统。
它用于 Ubuntu 9.10 到 14.10 版本和基于 RHEL 6 的系统中,之后的被 systemd 取代了。
### 什么是 systemd?
systemd 是一款全新的初始化系统及系统管理器,它被所有主流的 Linux 发行版实现/采用,以替代传统的 SysV 初始化系统。
systemd 与 SysV 和 LSB(LCTT 译注:Linux Standards Base) 初始化脚本兼容。它可以作为 SysV 初始化系统的直接替代品。其是内核启动的第一个进程并占有数字 1 的 PID,它是所有进程的父进程。
Fedora 15 是第一个采用 systemd 而不是 upstart 的发行版。[systemctl](https://www.2daygeek.com/how-to-check-all-running-services-in-linux/) 是一款命令行工具,它是管理 systemd 守护进程/服务(如 `start`、`restart`、`stop`、`enable`、`disable`、`reload` 和 `status`)的主要工具。
systemd 使用 `.service` 文件而不是(SysV 初始化系统使用的) bash 脚本。systemd 把所有守护进程按顺序排列到自己 Cgroups (LCTT 译注:Cgroups 是 control groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组所使用的物理资源,如:cpu、memory、IO 等的机制。最初由 Google 的工程师提出,后来被整合进 Linux 内核。Cgroups 也是 LXC 为实现虚拟化所使用的资源管理手段,可以说没有 cgroups 就没有 LXC)中,所以通过查看 `/cgroup/systemd` 文件就可以查看系统层次结构。
### 在 Linux 上如何识别出系统管理器
在系统上运行如下命令来查看运行着什么系统管理器:
(LCTT 译注:原文繁冗啰嗦,翻译时进行了裁剪整理。)
#### 方法 1:使用 ps 命令
`ps` – 显示当前进程快照。`ps` 会显示选定的活动进程的信息。其输出不能确切区分出是 System V(SysV) 还是 upstart,所以我建议使用其它方法。
```
# ps -p1 | grep "init\|upstart\|systemd"
1 ? 00:00:00 init
```
#### 方法 2:使用 rpm 命令
RPM 即 Red Hat Package Manager (红帽包管理),是一款功能强大的[安装包管理](https://www.2daygeek.com/category/package-management/)命令行工具,在基于 Red Hat 的发行版中使用,如 RHEL、CentOS、Fedora、openSUSE 和 Mageia。此工具可以在系统/服务上对软件进行安装、更新、删除、查询及验证等操作。通常 RPM 文件都带有 `.rpm` 后缀。
RPM 会使用必要的库和依赖库来构建软件,并且不会与系统上安装的其它包冲突。
```
# rpm -qf /sbin/init
SysVinit-2.86-17.el5
```
#### 方法 3:使用 /sbin/init 文件
`/sbin/init` 程序会将根文件系统从内存加载或切换到磁盘。
这是启动过程的主要部分。这个进程开始时的运行级别为 “N”(无)。`/sbin/init` 程序会按照 `/etc/inittab` 配制文件的描述来初始化系统。
```
# /sbin/init --version
init (upstart 0.6.5)
Copyright (C) 2010 Canonical Ltd.
This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
```
---
via: <https://www.2daygeek.com/how-to-determine-which-init-system-manager-is-running-on-linux-system/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[runningwater](https://github.com/runningwater) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,228 | 在命令行使用 Pandoc 进行文件转换 | https://opensource.com/article/18/9/intro-pandoc | 2018-11-13T11:52:00 | [
"Markdown",
"PDF",
"Pandoc",
"LaTex"
] | https://linux.cn/article-10228-1.html |
>
> 这篇指南介绍如何使用 Pandoc 将文档转换为多种不同的格式。
>
>
>

Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为另一种标记语言。标记语言使用标签来标记文档的各个部分。常用的标记语言包括 Markdown、ReStructuredText、HTML、LaTex、ePub 和 Microsoft Word DOCX。
简单来说,[Pandoc](https://pandoc.org/) 允许你将一些文件从一种标记语言转换为另一种标记语言。典型的例子包括将 Markdown 文件转换为演示文稿、LaTeX,PDF 甚至是 ePub。
本文将解释如何使用 Pandoc 从单一标记语言(在本文中为 Markdown)生成多种格式的文档,引导你完成从 Pandoc 安装,到展示如何创建多种类型的文档,再到提供有关如何编写易于移植到其他格式的文档的提示。
文中还将解释使用元信息文件对文档内容和元信息(例如,作者姓名、使用的模板、书目样式等)进行分离的意义。
### Pandoc 安装和要求
Pandoc 默认安装在大多数 Linux 发行版中。本教程使用 pandoc-2.2.3.2 和 pandoc-citeproc-0.14.3。如果不打算生成 PDF,那么这两个包就足够了。但是,我建议也安装 texlive,这样就可以选择生成 PDF 了。
通过以下命令在 Linux 上安装这些程序:
```
sudo apt-get install pandoc pandoc-citeproc texlive
```
您可以在 Pandoc 的网站上找到其他平台的 [安装说明](http://pandoc.org/installing.html)。
我强烈建议安装 [pandoc-crossref](https://hackage.haskell.org/package/pandoc-crossref),这是一个“用于对图表,方程式,表格和交叉引用进行编号的过滤器”。最简单的安装方式是下载 [预构建的可执行文件](https://github.com/lierdakil/pandoc-crossref/releases/tag/v0.3.2.1),但也可以通过以下命令从 Haskell 的软件包管理器 cabal 安装它:
```
cabal update
cabal install pandoc-crossref
```
如果需要额外的 Haskell [安装信息](https://github.com/lierdakil/pandoc-crossref#installation),请参考 pandoc-crossref 的 GitHub 仓库。
### 几个例子
我将通过解释如何生成三种类型的文档来演示 Pandoc 的工作原理:
* 由包含数学公式的 LaTeX 文件创建的网页
* 由 Markdown 文件生成的 Reveal.js 幻灯片
* 混合 Markdown 和 LaTeX 的合同文件
#### 创建一个包含数学公式的网站
Pandoc 的优势之一是以不同的输出文件格式显示数学公式。例如,我们可以从包含一些数学符号(用 LaTeX 编写)的 LaTeX 文档(名为 `math.tex`)生成一个网页。
`math.tex` 文档如下所示:
```
% Pandoc math demos
$a^2 + b^2 = c^2$
$v(t) = v_0 + \frac{1}{2}at^2$
$\gamma = \frac{1}{\sqrt{1 - v^2/c^2}}$
$\exists x \forall y (Rxy \equiv Ryx)$
$p \wedge q \models p$
$\Box\diamond p\equiv\diamond p$
$\int_{0}^{1} x dx = \left[ \frac{1}{2}x^2 \right]_{0}^{1} = \frac{1}{2}$
$e^x = \sum_{n=0}^\infty \frac{x^n}{n!} = \lim_{n\rightarrow\infty} (1+x/n)^n$
```
通过输入以下命令将 LaTeX 文档转换为名为 `mathMathML.html` 的网站:
```
pandoc math.tex -s --mathml -o mathMathML.html
```
参数 `-s` 告诉 Pandoc 生成一个独立的网页(而不是网页片段,因此它将包括 HTML 中的 head 和 body 标签),`-mathml` 参数强制 Pandoc 将 LaTeX 中的数学公式转换成 MathML,从而可以由现代浏览器进行渲染。

看一下 [网页效果](http://pandoc.org/demo/mathMathML.html) 和 [代码](https://github.com/kikofernandez/pandoc-examples/tree/master/math),代码仓库中的 Makefile 使得运行更加简单。
#### 制作一个 Reveal.js 幻灯片
使用 Pandoc 从 Markdown 文件生成简单的演示文稿很容易。幻灯片包含顶级幻灯片和下面的嵌套幻灯片。可以通过键盘控制演示文稿,从一个顶级幻灯片跳转到下一个顶级幻灯片,或者显示顶级幻灯片下面的嵌套幻灯片。 这种结构在基于 HTML 的演示文稿框架中很常见。
创建一个名为 `SLIDES` 的幻灯片文档(参见 [代码仓库](https://github.com/kikofernandez/pandoc-examples/tree/master/slides))。首先,在 `%` 后面添加幻灯片的元信息(例如,标题、作者和日期):
```
% Case Study
% Kiko Fernandez Reyes
% Sept 27, 2017
```
这些元信息同时也创建了第一张幻灯片。要添加更多幻灯片,使用 Markdown 的一级标题(在下面例子中的第5行,参考 [Markdown 的一级标题](https://daringfireball.net/projects/markdown/syntax#header) )生成顶级幻灯片。
例如,可以通过以下命令创建一个标题为 “Case Study”、顶级幻灯片名为 “Wine Management System” 的演示文稿:
```
% Case Study
% Kiko Fernandez Reyes
% Sept 27, 2017
# Wine Management System
```
使用 Markdown 的二级标题将内容(比如包含一个新管理系统的说明和实现的幻灯片)放入刚刚创建的顶级幻灯片。下面添加另外两张幻灯片(在下面例子中的第 7 行和 14 行 ,参考 [Markdown 的二级标题](https://daringfireball.net/projects/markdown/syntax#header) )。
* 第一个二级幻灯片的标题为 “Idea”,并显示瑞士国旗的图像
* 第二个二级幻灯片的标题为 “Implementation”
```
% Case Study
% Kiko Fernandez Reyes
% Sept 27, 2017
# Wine Management System
## <img src="img/SwissFlag.png" style="vertical-align:middle"/> Idea
## Implementation
```
我们现在有一个顶级幻灯片(`#Wine Management System`),其中包含两张幻灯片(`## Idea` 和 `## Implementation`)。
通过创建一个由符号 `>` 开头的 Markdown 列表,在这两张幻灯片中添加一些内容。在上面代码的基础上,在第一张幻灯片中添加两个项目(第 9-10 行),第二张幻灯片中添加五个项目(第 16-20 行):
```
% Case Study
% Kiko Fernandez Reyes
% Sept 27, 2017
# Wine Management System
## <img src="img/SwissFlag.png" style="vertical-align:middle"/> Idea
>- Swiss love their **wine** and cheese
>- Create a *simple* wine tracker system

## Implementation
>- Bottles have a RFID tag
>- RFID reader (emits and read signal)
>- **Raspberry Pi**
>- **Server (online shop)**
>- Mobile app
```
上面的代码添加了马特洪峰的图像,也可以使用纯 Markdown 语法或添加 HTML 标签来改进幻灯片。
要生成幻灯片,Pandoc 需要引用 Reveal.js 库,因此它必须与 `SLIDES` 文件位于同一文件夹中。生成幻灯片的命令如下所示:
```
pandoc -t revealjs -s --self-contained SLIDES \
-V theme=white -V slideNumber=true -o index.html
```

上面的 Pandoc 命令使用了以下参数:
* `-t revealjs` 表示将输出一个 revealjs 演示文稿
* `-s` 告诉 Pandoc 生成一个独立的文档
* `--self-contained` 生成没有外部依赖关系的 HTML 文件
* `-V` 设置以下变量:
+ `theme=white` 将幻灯片的主题设为白色
+ `slideNumber=true` 显示幻灯片编号
* `-o index.html` 在名为 `index.html` 的文件中生成幻灯片
为了简化操作并避免键入如此长的命令,创建以下 Makefile:
```
all: generate
generate:
pandoc -t revealjs -s --self-contained SLIDES \
-V theme=white -V slideNumber=true -o index.html
clean: index.html
rm index.html
.PHONY: all clean generate
```
可以在 [这个仓库](https://github.com/kikofernandez/pandoc-examples/tree/master/slides) 中找到所有代码。
#### 制作一份多种格式的合同
假设你正在准备一份文件,并且(这样的情况现在很常见)有些人想用 Microsoft Word 格式,其他人使用自由软件,想要 ODT 格式,而另外一些人则需要 PDF。你不必使用 OpenOffice 或 LibreOffice 来生成 DOCX 或 PDF 格式的文件,可以用 Markdown 创建一份文档(如果需要高级格式,可以使用一些 LaTeX 语法),并生成任何这些文件类型。
和以前一样,首先声明文档的元信息(标题、作者和日期):
```
% Contract Agreement for Software X
% Kiko Fernandez-Reyes
% August 28th, 2018
```
然后在 Markdown 中编写文档(如果需要高级格式,则添加 LaTeX)。例如,创建一个固定间隔的表格(在 LaTeX 中用 `\hspace{3cm}` 声明)以及客户端和承包商应填写的行(在 LaTeX 中用 `\hrulefill` 声明)。之后,添加一个用 Markdown 编写的表格。
创建的文档如下所示:

创建此文档的代码如下:
```
% Contract Agreement for Software X
% Kiko Fernandez-Reyes
% August 28th, 2018
...
### Work Order
\begin{table}[h]
\begin{tabular}{ccc}
The Contractor & \hspace{3cm} & The Customer \\
& & \\
& & \\
\hrulefill & \hspace{3cm} & \hrulefill \\
%
Name & \hspace{3cm} & Name \\
& & \\
& & \\
\hrulefill & \hspace{3cm} & \hrulefill \\
...
\end{tabular}
\end{table}
\vspace{1cm}
+--------------------------------------------|----------|-------------+
| Type of Service | Cost | Total |
+:===========================================+=========:+:===========:+
| Game Engine | 70.0 | 70.0 |
| | | |
+--------------------------------------------|----------|-------------+
| | | |
+--------------------------------------------|----------|-------------+
| Extra: Comply with defined API functions | 10.0 | 10.0 |
| and expected returned format | | |
+--------------------------------------------|----------|-------------+
| | | |
+--------------------------------------------|----------|-------------+
| **Total Cost** | | **80.0** |
+--------------------------------------------|----------|-------------+
```
要生成此文档所需的三种不同输出格式,编写如下的 Makefile:
```
DOCS=contract-agreement.md
all: $(DOCS)
pandoc -s $(DOCS) -o $(DOCS:md=pdf)
pandoc -s $(DOCS) -o $(DOCS:md=docx)
pandoc -s $(DOCS) -o $(DOCS:md=odt)
clean:
rm *.pdf *.docx *.odt
.PHONY: all clean
```
4 到 7 行是生成三种不同输出格式的具体命令:
如果有多个 Markdown 文件并想将它们合并到一个文档中,需要按照希望它们出现的顺序编写命令。例如,在撰写本文时,我创建了三个文档:一个介绍文档、三个示例和一些高级用法。以下命令告诉 Pandoc 按指定的顺序将这些文件合并在一起,并生成一个名为 document.pdf 的 PDF 文件。
```
pandoc -s introduction.md examples.md advanced-uses.md -o document.pdf
```
### 模板和元信息
编写复杂的文档并非易事,你需要遵循一系列独立于内容的规则,例如使用特定的模板、编写摘要、嵌入特定字体,甚至可能要声明关键字。所有这些都与内容无关:简单地说,它就是元信息。
Pandoc 使用模板生成不同的输出格式。例如,有一个 LaTeX 的模板,还有一个 ePub 的模板,等等。这些模板的元信息中有未赋值的变量。使用以下命令找出 Pandoc 模板中可用的元信息:
```
pandoc -D FORMAT
```
例如,LaTex 的模版是:
```
pandoc -D latex
```
按照以下格式输出:
```
$if(title)$
\title{$title$$if(thanks)$\thanks{$thanks$}$endif$}
$endif$
$if(subtitle)$
\providecommand{\subtitle}[1]{}
\subtitle{$subtitle$}
$endif$
$if(author)$
\author{$for(author)$$author$$sep$ \and $endfor$}
$endif$
$if(institute)$
\providecommand{\institute}[1]{}
\institute{$for(institute)$$institute$$sep$ \and $endfor$}
$endif$
\date{$date$}
$if(beamer)$
$if(titlegraphic)$
\titlegraphic{\includegraphics{$titlegraphic$}}
$endif$
$if(logo)$
\logo{\includegraphics{$logo$}}
$endif$
$endif$
\begin{document}
```
如你所见,输出的内容中有标题、致谢、作者、副标题和机构模板变量(还有许多其他可用的变量)。可以使用 YAML 元区块轻松设置这些内容。 在下面例子的第 1-5 行中,我们声明了一个 YAML 元区块并设置了一些变量(使用上面合同协议的例子):
```
---
title: Contract Agreement for Software X
author: Kiko Fernandez-Reyes
date: August 28th, 2018
---
(continue writing document as in the previous example)
```
这样做非常奏效,相当于以前的代码:
```
% Contract Agreement for Software X
% Kiko Fernandez-Reyes
% August 28th, 2018
```
然而,这样做将元信息与内容联系起来,也即 Pandoc 将始终使用此信息以新格式输出文件。如果你将要生成多种文件格式,最好要小心一点。例如,如果你需要以 ePub 和 HTML 的格式生成合同,并且 ePub 和 HTML 需要不同的样式规则,该怎么办?
考虑一下这些情况:
* 如果你只是尝试嵌入 YAML 变量 `css:style-epub.css`,那么将从 HTML 版本中移除该变量。这不起作用。
* 复制文档显然也不是一个好的解决方案,因为一个版本的更改不会与另一个版本同步。
* 你也可以像下面这样将变量添加到 Pandoc 命令中:
```
pandoc -s -V css=style-epub.css document.md document.epub
pandoc -s -V css=style-html.css document.md document.html
```
我的观点是,这样做很容易从命令行忽略这些变量,特别是当你需要设置数十个变量时(这可能出现在编写复杂文档的情况中)。现在,如果将它们放在同一文件中(`meta.yaml` 文件),则只需更新或创建新的元信息文件即可生成所需的输出格式。然后你会编写这样的命令:
```
pandoc -s meta-pub.yaml document.md document.epub
pandoc -s meta-html.yaml document.md document.html
```
这是一个更简洁的版本,你可以从单个文件更新所有元信息,而无需更新文档的内容。
### 结语
通过以上的基本示例,我展示了 Pandoc 在将 Markdown 文档转换为其他格式方面是多么出色。
---
via: <https://opensource.com/article/18/9/intro-pandoc>
作者:[Kiko Fernandez-Reyes](https://opensource.com/users/kikofernandez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jlztan](https://github.com/jlztan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Pandoc is a command-line tool for converting files from one markup language to another. Markup languages use tags to annotate sections of a document. Commonly used markup languages include Markdown, ReStructuredText, HTML, LaTex, ePub, and Microsoft Word DOCX.
In plain English, [Pandoc](https://pandoc.org/) allows you to convert a bunch of files from one markup language into another one. Typical examples include converting a Markdown file into a presentation, LaTeX, PDF, or even ePub.
This article will explain how to produce documentation in multiple formats from a single markup language (in this case Markdown) using Pandoc. It will guide you through Pandoc installation, show how to create several types of documents, and offer tips on how to write documentation that is easy to port to other formats. It will also explain the value of using meta-information files to create a separation between the content and the meta-information (e.g., author name, template used, bibliographic style, etc.) of your documentation.
## Installation and requirements
Pandoc is installed by default in most Linux distributions. This tutorial uses pandoc-2.2.3.2 and pandoc-citeproc-0.14.3. If you don't intend to generate PDFs, those two packages are enough. However, I recommend installing texlive as well, so you have the option to generate PDFs.
To install these programs on Linux, type the following on the command line:
`sudo apt-get install pandoc pandoc-citeproc texlive`
You can find [installation instructions](http://pandoc.org/installing.html) for other platforms on Pandoc's website.
I highly recommend installing [pandoc](https://hackage.haskell.org/package/pandoc-crossref)[-crossref](https://hackage.haskell.org/package/pandoc-crossref), a "filter for numbering figures, equations, tables, and cross-references to them." The easiest option is to download a [prebuilt executable](https://github.com/lierdakil/pandoc-crossref/releases/tag/v0.3.2.1), but you can install it from Haskell's package manager, cabal, by typing:
```
cabal update
cabal install pandoc-crossref
```
Consult pandoc-crossref's GitHub repository if you need additional Haskell [installation information](https://github.com/lierdakil/pandoc-crossref#installation).
## Some examples
I'll demonstrate how Pandoc works by explaining how to produce three types of documents:
- A website from a LaTeX file containing math formulas
- A Reveal.js slideshow from a Markdown file
- A contract agreement document that mixes Markdown and LaTeX
### Create a website with math formulas
One of the ways Pandoc excels is displaying math formulas in different output file formats. For instance, let's generate a website from a LaTeX document (named math.tex) containing some math symbols (written in LaTeX).
The math.tex document looks like:
```
% Pandoc math demos
$a^2 + b^2 = c^2$
$v(t) = v_0 + \frac{1}{2}at^2$
$\gamma = \frac{1}{\sqrt{1 - v^2/c^2}}$
$\exists x \forall y (Rxy \equiv Ryx)$
$p \wedge q \models p$
$\Box\diamond p\equiv\diamond p$
$\int_{0}^{1} x dx = \left[ \frac{1}{2}x^2 \right]_{0}^{1} = \frac{1}{2}$
$e^x = \sum_{n=0}^\infty \frac{x^n}{n!} = \lim_{n\rightarrow\infty} (1+x/n)^n$
```
Convert the LaTeX document into a website named mathMathML.html by entering the following command:
`pandoc math.tex -s --mathml -o mathMathML.html`
The flag **-s** tells Pandoc to generate a standalone website (instead of a fragment, so it will include the head and body HTML tags), and the **–mathml** flag forces Pandoc to convert the math in LaTeX to MathML, which can be rendered by modern browsers.
Take a look at the [website result](http://pandoc.org/demo/mathMathML.html) and the [code](https://github.com/kikofernandez/pandoc-examples/tree/master/math); the code repository contains a Makefile to make things even simpler.
### Make a Reveal.js slideshow
It's easy to generate simple presentations from a Markdown file using Pandoc. The slides contain top-level slides and nested slides underneath. The presentation can be controlled from the keyboard, and you can jump from one top-level slide to the next top-level slide or show the nested slides on a per-top-level basis. This structure is typical in HTML-based presentation frameworks.
Let's create a slide document named SLIDES (see the [code repository](https://github.com/kikofernandez/pandoc-examples/tree/master/slides)). First, add the slides' meta-information (e.g., title, author, and date) prepended by the **%** symbol:
```
% Case Study
% Kiko Fernandez Reyes
% Sept 27, 2017
```
This meta-information also creates the first slide. To add more slides, declare top-level slides using Markdown heading H1 (line 5 in the example below, [heading 1 in Markdown](https://daringfireball.net/projects/markdown/syntax#header), designated by **#**).
For example, if we want to create a presentation with the title *Case Study* that starts with a top-level slide titled *Wine Management System*, write:
```
% Case Study
% Kiko Fernandez Reyes
% Sept 27, 2017
# Wine Management System
```
To put content (such as slides that explain a new management system and its implementation) inside this top-level section, use a Markdown header H2. Let's add two more slides (lines 7 and 14 below, [heading 2 in Markdown](https://daringfireball.net/projects/markdown/syntax#header), designated by **##**):
- The first second-level slide has the title
*Idea*and shows an image of the Swiss flag - The second second-level slide has the title
*Implementation*
```
% Case Study
% Kiko Fernandez Reyes
% Sept 27, 2017
# Wine Management System
## <img src="https://opensource.com/img/SwissFlag.png" style="vertical-align:middle"/> Idea
## Implementation
```
We now have a top-level slide (**# Wine Management System**) that contains two slides (**## Idea** and **## Implementation**).
Let's put some content in these two slides using incremental bulleted lists by creating a Markdown list prepended by the symbol **>**. Continuing from above, add two items in the first slide (lines 9–10 below) and five items in the second slide (lines 16–20):
```
% Case Study
% Kiko Fernandez Reyes
% Sept 27, 2017
# Wine Management System
## <img src="https://opensource.com/img/SwissFlag.png" style="vertical-align:middle"/> Idea
>- Swiss love their **wine** and cheese
>- Create a *simple* wine tracker system

## Implementation
>- Bottles have a RFID tag
>- RFID reader (emits and read signal)
>- **Raspberry Pi**
>- **Server (online shop)**
>- Mobile app
```
We added an image of the Matterhorn mountain. Your slides can be improved by using plain Markdown or adding plain HTML.
To generate the slides, Pandoc needs to point to the Reveal.js library, so it must be in the same folder as the SLIDES file. The command to generate the slides is:
```
pandoc -t revealjs -s --self-contained SLIDES \
-V theme=white -V slideNumber=true -o index.html
```

The above Pandoc command uses the following flags:
**-t revealjs**specifies we are going to output a**revealjs**presentation**-s**tells Pandoc to generate a standalone document**--self-contained**produces HTML with no external dependencies**-V**sets the following variables:
–**theme=white**sets the theme of the slideshow to**white**
–**slideNumber=true**shows the slide number**-o index.html**generates the slides in the file named**index.html**
To make things simpler and avoid typing this long command, create the following Makefile:
```
all: generate
generate:
pandoc -t revealjs -s --self-contained SLIDES \
-V theme=white -V slideNumber=true -o index.html
clean: index.html
rm index.html
.PHONY: all clean generate
```
You can find all the code in [this repository](https://github.com/kikofernandez/pandoc-examples/tree/master/slides).
### Make a multi-format contract
Let's say you are preparing a document and (as things are nowadays) some people want it in Microsoft Word format, others use free software and would like an ODT, and others need a PDF. You do not have to use OpenOffice nor LibreOffice to generate the DOCX or PDF file. You can create your document in Markdown (with some bits of LaTeX if you need advanced formatting) and generate any of these file types.
As before, begin by declaring the document's meta-information (title, author, and date):
```
% Contract Agreement for Software X
% Kiko Fernandez-Reyes
% August 28th, 2018
```
Then write the document in Markdown (and add LaTeX if you require advanced formatting). For example, create a table that needs fixed separation space (declared in LaTeX with **\hspace{3cm}**) and a line where a client and a contractor should sign (declared in LaTeX with **\hrulefill**). After that, add a table written in Markdown.
Here's what the document will look like:
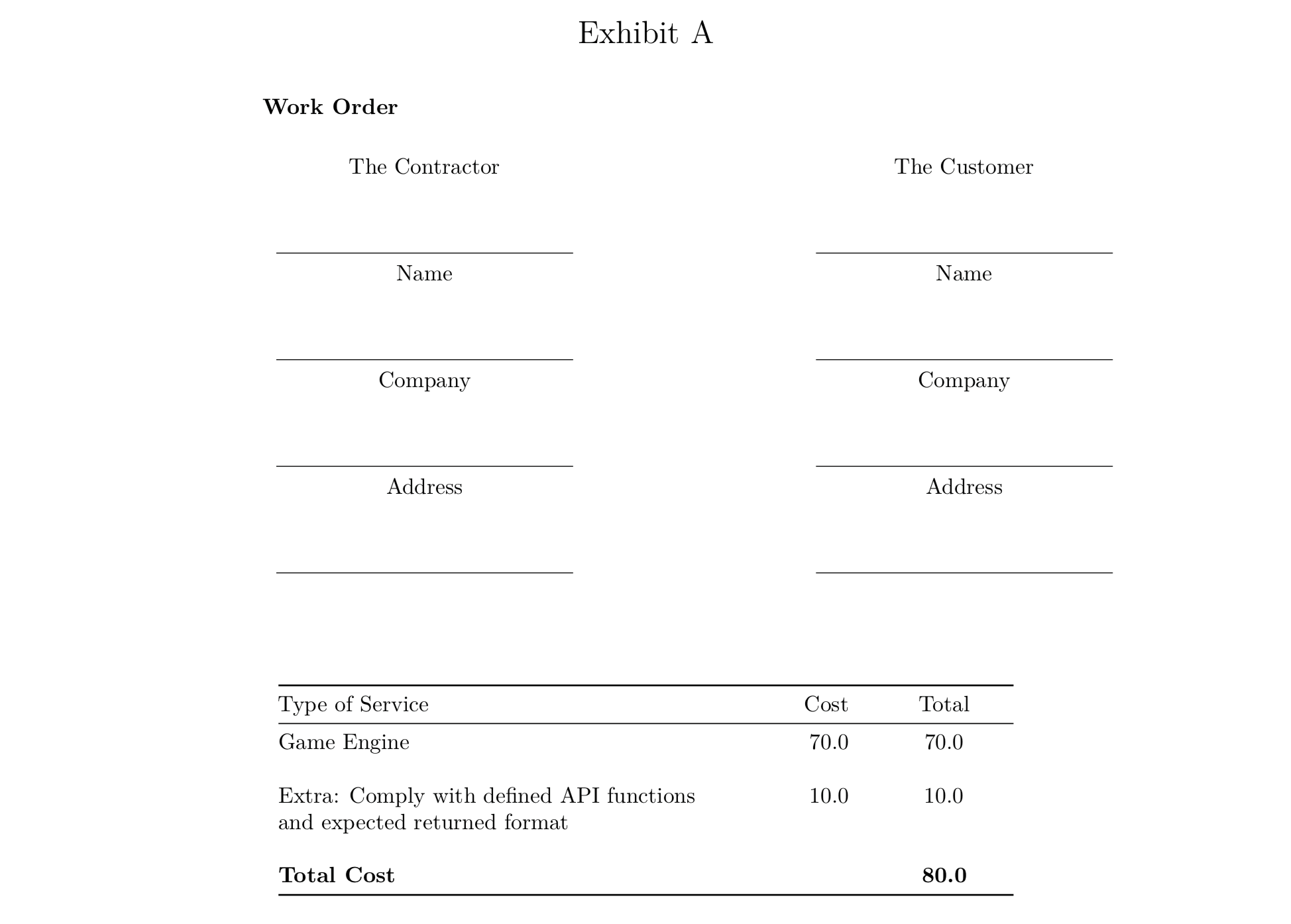
The code to create this document is:
```
% Contract Agreement for Software X
% Kiko Fernandez-Reyes
% August 28th, 2018
...
### Work Order
\begin{table}[h]
\begin{tabular}{ccc}
The Contractor & \hspace{3cm} & The Customer \\
& & \\
& & \\
\hrulefill & \hspace{3cm} & \hrulefill \\
%
Name & \hspace{3cm} & Name \\
& & \\
& & \\
\hrulefill & \hspace{3cm} & \hrulefill \\
...
\end{tabular}
\end{table}
\vspace{1cm}
+--------------------------------------------+----------+-------------+
| Type of Service | Cost | Total |
+:===========================================+=========:+:===========:+
| Game Engine | 70.0 | 70.0 |
| | | |
+--------------------------------------------+----------+-------------+
| | | |
+--------------------------------------------+----------+-------------+
| Extra: Comply with defined API functions | 10.0 | 10.0 |
| and expected returned format | | |
+--------------------------------------------+----------+-------------+
| | | |
+--------------------------------------------+----------+-------------+
| **Total Cost** | | **80.0** |
+--------------------------------------------+----------+-------------+
```
To generate the three different output formats needed for this document, write a Makefile:
```
DOCS=contract-agreement.md
all: $(DOCS)
pandoc -s $(DOCS) -o $(DOCS:md=pdf)
pandoc -s $(DOCS) -o $(DOCS:md=docx)
pandoc -s $(DOCS) -o $(DOCS:md=odt)
clean:
rm *.pdf *.docx *.odt
.PHONY: all clean
```
Lines 4–7 contain the commands to generate the different outputs.
If you have several Markdown files and want to merge them into one document, issue a command with the files in the order you want them to appear. For example, when writing this article, I created three documents: an introduction document, three examples, and some advanced uses. The following tells Pandoc to merge these files together in the specified order and produce a PDF named document.pdf.
`pandoc -s introduction.md examples.md advanced-uses.md -o document.pdf`
## Templates and meta-information
Writing a complex document is no easy task. You need to stick to a set of rules that are independent from your content, such as using a specific template, writing an abstract, embedding specific fonts, and maybe even declaring keywords. All of this has nothing to do with your content: simply put, it is meta-information.
Pandoc uses templates to generate different output formats. There is a template for LaTeX, another for ePub, etc. These templates have unfulfilled variables that are set with the meta-information given to Pandoc. To find out what meta-information is available in a Pandoc template, type:
`pandoc -D FORMAT`
For example, the template for LaTeX would be:
`pandoc -D latex`
Which outputs something along these lines:
```
$if(title)$
\title{$title$$if(thanks)$\thanks{$thanks$}$endif$}
$endif$
$if(subtitle)$
\providecommand{\subtitle}[1]{}
\subtitle{$subtitle$}
$endif$
$if(author)$
\author{$for(author)$$author$$sep$ \and $endfor$}
$endif$
$if(institute)$
\providecommand{\institute}[1]{}
\institute{$for(institute)$$institute$$sep$ \and $endfor$}
$endif$
\date{$date$}
$if(beamer)$
$if(titlegraphic)$
\titlegraphic{\includegraphics{$titlegraphic$}}
$endif$
$if(logo)$
\logo{\includegraphics{$logo$}}
$endif$
$endif$
\begin{document}
```
As you can see, there are **title**, **thanks**, **author**, **subtitle**, and **institute** template variables (and many others are available). These are easily set using YAML metablocks. In lines 1–5 of the example below, we declare a YAML metablock and set some of those variables (using the contract agreement example above):
```
---
title: Contract Agreement for Software X
author: Kiko Fernandez-Reyes
date: August 28th, 2018
---
(continue writing document as in the previous example)
```
This works like a charm and is equivalent to the previous code:
```
% Contract Agreement for Software X
% Kiko Fernandez-Reyes
% August 28th, 2018
```
However, this ties the meta-information to the content; i.e., Pandoc will always use this information to output files in the new format. If you know you need to produce multiple file formats, you better be careful. For example, what if you need to produce the contract in ePub and in HTML, and the ePub and HTML need specific and different styling rules?
Let's consider the cases:
- If you simply try to embed the YAML variable
**css: style-epub.css**, you would be excluding the one from the HTML version.*This does not work*. - Duplicating the document is obviously
*not a good solution*either, as changes in one version would not be in sync with the other copy. - You can add variables to the Pandoc command line as follows:
```
pandoc -s -V css=style-epub.css document.md document.epub
pandoc -s -V css=style-html.css document.md document.html
```
My opinion is that it is easy to overlook these variables from the command line, especially when you need to set tens of these (which can happen in complex documents). Now, if you put them all together under the same roof (a meta.yaml file), you only need to update or create a new meta-information file to produce the desired output. You would then write:
```
pandoc -s meta-pub.yaml document.md document.epub
pandoc -s meta-html.yaml document.md document.html
```
This is a much cleaner version, and you can update all the meta-information from a single file without ever having to update the content of your document.
## Wrapping up
With these basic examples, I have shown how Pandoc can do a really good job at converting Markdown documents into other formats.
## Comments are closed. |
10,230 | 使用 SonarQube 追踪代码问题 | https://opensource.com/article/17/10/sonarqube | 2018-11-14T09:28:00 | [
"代码质量",
"DevOps"
] | https://linux.cn/article-10230-1.html |
>
> 通过不断分析代码以了解潜在的质量问题,开源的 SonarQube 项目支持了 DevOps 的“尽早发布和经常发布” 的思维模式。
>
>
>

越来越多的组织正在实施 [DevOps](https://en.wikipedia.org/wiki/DevOps) 以便在通过中间开发和测试环境以后更快更好的将新代码引入到生产环境。虽然版本控制、持续集成和部署以及自动化测试都属于 DevOps 的范畴,但仍然存在一个关键问题:组织如何量化代码质量,而不仅仅是部署的速度?
[SonarQube](https://www.sonarqube.org/) 是用来填补这个空隙的一种选择。它是一个开源平台,通过代码的自动化静态分析不断的检查代码质量。 SonarQube 支持 20 多种语言的分析,并在各种类型的项目中输出和存储问题。
SonarQube 同时也提供了一个可同时维护和管理不同项目、不同代码的集中的环境。可以为每个项目定制规则。持续的检查和分析代码的健康轨迹。
SonarQube 还可以集成到可持续集成和开发(CI/CD)流程中,协助和自动确定代码是否为生产环境做好了准备的过程。
### 它可以衡量什么
开箱即用,SonarQube 可以测量的关键指标,包括代码错误、<ruby> 代码异味 <rt> code smells </rt></ruby>、安全漏洞和重复的代码。
* **代码错误** 是代码中的一部分不正确或无法正常运行、可能会导致错误的结果,是指那些在代码发布到生产环境之前应该被修复的明显的错误。
* [代码异味](https://en.wikipedia.org/wiki/Code_smell) 不同于代码错误,被检测到的代码是可能能正确执行并符合预期。然而,它不容易被修复,也不能被单元测试覆盖,却可能会导致一些未知的错误,或是一些其它的问题。从长期的可维护性来讲,立即修复代码异味是明智之举。通常在编写代码的时候,代码异味并不容易被发现,而 SonarQube 的静态分析是一种发现它们的很好的方式。
* **安全漏洞** 正如听起来的一样:指的是现在的代码中可能存在的安全问题的缺陷。这些缺陷应该立即修复来防止黑客利用它们。
* **重复的代码** 也和听起来的一样:指的是源代码中重复的部分。代码重复在软件设计中是一种很不好的做法。总的来说,如果对一部分代码进行更改而另一部分没有,则会导致一些维护性的问题。例如,识别重复的代码可以很容易的将重复的代码打包成一个库来重复的使用。
### 可自定义的选项
因为它是开源的,所以 SonarQube 鼓励用户开发和提供可定制的选项。目前有超过 60 个[插件](https://docs.sonarqube.org/display/PLUG/Plugin+Library) 可用于增强 SonarQube 开箱即用的分析功能。
大多数的插件是为了增加 SonarQube 可以分析的编程语言的数量。另一些插件可以分析一些额外的指标甚至包括一些显示的仪表盘视图。实际上,如果组织需要检查一些自定义指标,或是想要在自己的仪表盘和以特定的方式查看分析数据,或使用 SonarQube 不支持的编程语言,则可能存在一些自定义的选项可以使用。如果你想要的功能并不支持,SonarQube 源码的开放也为你自己开发新的功能提供了可能性。
用户还可以定制适用于每种特定编程语言分析器的规则。通过 SonarQube 用户界面,可以按语言和按项目选择和取消规则。这些为特定的项目指定的规则,可以很好的在一个集中的位置维护所有的数据和配置。
### 为什么它那么重要
SonarQube 为组织提供了一个集中的位置来管理和跟踪多个项目代码中的问题。它还可以把持续的检查与质量门限相结合。一旦项目分析过一次以后,更进一步的分析会参考软件最新的修改来更新原始的统计信息,以反映最新的变化。这些跟踪可以让用户看到问题解决的程度和速度。这与 “尽早发布并经常发布”不谋而合。
另外,SonarQube 可使用 [可持续集成流程](https://jenkins.io/blog/2017/04/18/continuousdelivery-devops-sonarqube/),比如像 [Hudson](https://en.wikipedia.org/wiki/Hudson_(software)) 和 [Jenkins](https://en.wikipedia.org/wiki/Jenkins_(software)) 这样的工具。这个质量门限可以很好的反映代码的整体运行状况,并且通过 Jenkins 等集成工具,在发布代码到生产环境时担任一个重要的角色。
本着 DevOps 的精神, SonarQube 可以量化代码质量,来达到组织内部的要求。为了加快代码生产和发布的周期,组织必须意识到它们自己的技术债务和软件问题。通过发现这些信息, SonarQube 可以帮助组织更快的生成高质量的软件。
### 想要了解更多吗?
SonarQube 基于 GUN 通用公共许可证发布,它的源码可以在 [GitHub](https://github.com/SonarSource/sonarqube) 上查看。越来越多的用户对 SonarQube 的特性和功能感兴趣。 [Twitter](https://twitter.com/SonarQube) 和 [Google](https://groups.google.com/forum/#!forum/sonarqube) 上有活跃的社区。这些社区以及 [SonarQube 博客](https://blog.sonarsource.com/) 对任何有兴趣开始和使用 SonarQube 的人有很有帮助。
---
via: <https://opensource.com/article/17/10/sonarqube>
作者:[Sophie Polson](https://opensource.com/users/sophiepolson) 译者:[Jamkr](https://github.com/Jamkr) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | More and more organizations are implementing [DevOps](https://en.wikipedia.org/wiki/DevOps) to make it faster to get quality code into the production environment after passing through the intermediate development and testing environments. Although things such as version control, continuous integration and deployment, and automated testing all fall under the scope of DevOps, one critical question remains: How can an organization quantify code *quality*, not just deployment speed?
[SonarQube](https://www.sonarqube.org/) is one option to fill this gap. It is an open source platform that continually inspects code quality via automatic static analysis of the source code. SonarQube can analyze more than 20 coding languages and store issues on all sorts of project types.
SonarQube also offers a centralized location for maintaining and managing code issues within multiple, multi-language projects simultaneously. Custom rules can be implemented per project. Continuous inspection permits the analysis of the overall trajectory of the code's health.
SonarQube can also be integrated into continuous integration and development (CI/CD) pipelines, assisting in and automating the process of determining the code's readiness for the production environment.
## What it can measure
Out of the box, SonarQube can measure key metrics, including bugs, code smells, security vulnerabilities, and duplicated code.
**Bugs**are portions of code that are incorrect or likely functioning improperly, thus producing potentially erroneous results. These are obvious errors that should be fixed before the code is released to production.differ from bugs in that the detected code likely functions correctly and as intended. However, it may be hard to maintain, lead to future bugs, be uncovered by unit tests, or have other problems. For long-term maintainability, it's smart to fix code smells right away. It's generally hard to detect code smells when writing code, but SonarQube's static analysis is one way to discover them.[Code smells](https://en.wikipedia.org/wiki/Code_smell)**Security vulnerabilities**are exactly as they sound: a flaw somewhere in the code that may present a security issue. These vulnerabilities should be fixed to prevent hackers from exploiting them.**Duplicated code**is also exactly as it sounds: portions of code that are repeated in the source code. Code duplication is a bad practice in software design. On the whole, it leads to maintainability problems if changes are made to one portion but not another. Identifying code duplication makes it easier to package the duplicated code into a library for repeated use, for example.
## What customization options exist
Because it is open source, SonarQube encourages users to develop and offer customization options. Currently there are more than 60 [plugins](https://docs.sonarqube.org/display/PLUG/Plugin+Library) available to augment SonarQube's out-of-the-box analysis functionality.
The majority of the plugins were created to increase the number of coding languages SonarQube can analyze. Other plugins enable analysis of extra metrics or include other views for the displayed dashboards. Essentially, if an organization needs to examine a custom metric, wants to view its analyzed data in specific ways on its own dashboard, or uses a coding language that SonarQube doesn't support, there are probably customization options available. If the needed functionality doesn't yet exist, the openness of SonarQube's source code makes it possible to develop custom solutions.
Users can also customize the rules applied for each specific coding language analyzer. Rules can be selected and deselected per language and per project through SonarQube's user interface. These options recognize the need for project-specific rules, as well as maintaining all data and configurations in a central location.
## Why it's important
SonarQube provides a centralized location for organizations to manage and track issues in their code throughout multiple projects. It also allows continuous inspection combined with a quality gate. Once a project has been analyzed, further analyses update the original statistics, as the software is modified, to reflect the latest changes. This tracking allows users to view how well and how quickly code issues are being resolved, consistent with a "release early and release often" mentality.
Additionally, SonarQube can be utilized in a [continuous integration pipeline](https://jenkins.io/blog/2017/04/18/continuousdelivery-devops-sonarqube/), such as those run on tools like [Hudson](https://en.wikipedia.org/wiki/Hudson_(software)) and [Jenkins](https://en.wikipedia.org/wiki/Jenkins_(software)). The quality gate will reflect the overall health of the code and, by integrating with tools like Jenkins, can play an important role in deciding when to release code to the production environment.
In the spirit of DevOps, SonarQube can quantify code quality to help organizations meet internal requirements. In order to speed the cycle of code production and release, organizations must be aware of their technical debt and software issues. By uncovering this information, SonarQube can help organizations more rapidly produce the highest quality software possible.
## Want to learn more?
SonarQube is licensed under the GNU Lesser General Public License, and its source code is available on [GitHub](https://github.com/SonarSource/sonarqube). There is a growing community of users interested in SonarQube, its features, and its capabilities. There are active communities on [Twitter](https://twitter.com/SonarQube) and [Google](https://groups.google.com/forum/#!forum/sonarqube); these as well as the [SonarQube blog](https://blog.sonarsource.com/) are helpful for anyone interested in getting started with SonarQube.
## 2 Comments |
10,231 | 使用 Redis 和 Python 构建一个共享单车的应用程序 | https://opensource.com/article/18/2/building-bikesharing-application-open-source-tools | 2018-11-14T11:21:26 | [
"Redis",
"地理位置"
] | /article-10231-1.html |
>
> 学习如何使用 Redis 和 Python 构建一个位置感知的应用程序。
>
>
>

我经常出差。但不是一个汽车狂热分子,所以当我有空闲时,我更喜欢在城市中散步或者骑单车。我参观过的许多城市都有共享单车系统,你可以租个单车用几个小时。大多数系统都有一个应用程序来帮助用户定位和租用他们的单车,但对于像我这样的用户来说,在一个地方可以获得可租赁的城市中所有单车的信息会更有帮助。
为了解决这个问题并且展示开源的强大还有为 Web 应用程序添加位置感知的功能,我组合了可用的公开的共享单车数据、[Python](https://www.python.org/) 编程语言以及开源的 [Redis](https://redis.io/) 内存数据结构服务,用来索引和查询地理空间数据。
由此诞生的共享单车应用程序包含来自很多不同的共享系统的数据,包括纽约市的 [Citi Bike](https://www.citibikenyc.com/) 共享单车系统(LCTT 译注:Citi Bike 是纽约市的一个私营公共单车系统。在 2013 年 5 月 27 日正式营运,是美国最大的公共单车系统。Citi Bike 的名称有两层意思。Citi 是计划赞助商花旗银行(CitiBank)的名字。同时,Citi 和英文中“城市(city)”一词的读音相同)。它利用了花旗单车系统提供的 <ruby> 通用共享单车数据流 <rt> General Bikeshare Feed </rt></ruby>,并利用其数据演示了一些使用 Redis 地理空间数据索引的功能。 花旗单车数据可按照 [花旗单车数据许可协议](https://www.citibikenyc.com/data-sharing-policy) 提供。
### 通用共享单车数据流规范
<ruby> 通用共享单车数据流规范 <rt> General Bikeshare Feed Specification </rt></ruby>(GBFS)是由 [北美共享单车协会](http://nabsa.net/) 开发的 [开放数据规范](https://github.com/NABSA/gbfs),旨在使地图程序和运输程序更容易的将共享单车系统添加到对应平台中。 目前世界上有 60 多个不同的共享系统使用该规范。
Feed 流由几个简单的 [JSON](https://www.json.org/) 数据文件组成,其中包含系统状态的信息。 Feed 流以一个顶级 JSON 文件开头,其引用了子数据流的 URL:
```
{
"data": {
"en": {
"feeds": [
{
"name": "system_information",
"url": "https://gbfs.citibikenyc.com/gbfs/en/system_information.json"
},
{
"name": "station_information",
"url": "https://gbfs.citibikenyc.com/gbfs/en/station_information.json"
},
. . .
]
}
},
"last_updated": 1506370010,
"ttl": 10
}
```
第一步是使用 `system_information` 和 `station_information` 的数据将共享单车站的信息加载到 Redis 中。
`system_information` 提供系统 ID,系统 ID 是一个简短编码,可用于为 Redis 键名创建命名空间。 GBFS 规范没有指定系统 ID 的格式,但确保它是全局唯一的。许多共享单车数据流使用诸如“coastbikeshare”,“boisegreenbike” 或者 “topekametro\_bikes” 这样的短名称作为系统 ID。其他的使用常见的有地理缩写,例如 NYC 或者 BA,并且使用通用唯一标识符(UUID)。 这个共享单车应用程序使用该标识符作为前缀来为指定系统构造唯一键。
`station_information` 数据流提供组成整个系统的共享单车站的静态信息。车站由具有多个字段的 JSON 对象表示。车站对象中有几个必填字段,用于提供物理单车站的 ID、名称和位置。还有几个可选字段提供有用的信息,例如最近的十字路口、可接受的付款方式。这是共享单车应用程序这一部分的主要信息来源。
### 建立数据库
我编写了一个示例应用程序 [loadstationdata.py](https://gist.github.com/tague/5a82d96bcb09ce2a79943ad4c87f6e15),它模仿后端进程中从外部源加载数据时会发生什么。
### 查找共享单车站
从 [GitHub 上 GBFS 仓库](https://github.com/NABSA/gbfs)中的 [systems.csv](https://github.com/NABSA/gbfs/blob/master/systems.csv) 文件开始加载共享单车数据。
仓库中的 [systems.csv](https://github.com/NABSA/gbfs/blob/master/systems.csv) 文件提供已注册的共享单车系统及可用的 GBFS 数据流的<ruby> 发现 URL <rt> discovery URL </rt></ruby>。 这个发现 URL 是处理共享单车信息的起点。
`load_station_data` 程序获取系统文件中找到的每个发现 URL,并使用它来查找两个子数据流的 URL:系统信息和车站信息。 系统信息提供提供了一条关键信息:系统的唯一 ID。 (注意:系统 ID 也在 `systems.csv` 文件中提供,但文件中的某些标识符与数据流中的标识符不匹配,因此我总是从数据流中获取标识符。)系统上的详细信息,比如共享单车 URL、电话号码和电子邮件, 可以在程序的后续版本中添加,因此使用 `${system_id}:system_info` 这个键名将数据存储在 Redis 中。
### 载入车站数据
车站信息提供系统中每个车站的数据,包括该系统的位置。`load_station_data` 程序遍历车站数据流中的每个车站,并使用 `${system_id}:station:${station_id}` 形式的键名将每个车站的数据存储到 Redis 中。 使用 `GEOADD` 命令将每个车站的位置添加到共享单车的地理空间索引中。
### 更新数据
在后续运行中,我不希望代码从 Redis 中删除所有 Feed 数据并将其重新加载到空的 Redis 数据库中,因此我仔细考虑了如何处理数据的原地更新。
代码首先加载所有需要系统在内存中处理的共享单车站的信息数据集。 当加载了一个车站的信息时,该站就会按照 Redis 键名从内存中的车站集合中删除。 加载完所有车站数据后,我们就剩下一个包含该系统所有必须删除的车站数据的集合。
程序迭代处理该数据集,并创建一个事务删除车站的信息,从地理空间索引中删除该车站的键名,并从系统的车站列表中删除该车站。
### 代码重点
在[示例代码](https://gist.github.com/tague/5a82d96bcb09ce2a79943ad4c87f6e15)中有一些值得注意的地方。 首先,使用 `GEOADD` 命令将所有数据项添加到地理空间索引中,而使用 `ZREM` 命令将其删除。 由于地理空间类型的底层实现使用了有序集合,因此需要使用 ZREM 删除数据项。 需要注意的是:为简单起见,示例代码演示了如何在单个 Redis 节点工作; 为了在集群环境中运行,需要重新构建事务块。
如果你使用的是 Redis 4.0(或更高版本),则可以在代码中使用 `DELETE` 和 `HMSET` 命令。 Redis 4.0 提供 `UNLINK` 命令作为 `DELETE` 命令的异步版本的替代。 `UNLINK` 命令将从键空间中删除键,但它会在另外的线程中回收内存。 在 Redis 4.0 中 [HMSET 命令已经被弃用了而且 HSET 命令现在接收可变参数](https://raw.githubusercontent.com/antirez/redis/4.0/00-RELEASENOTES)(即,它接受的参数个数不定)。
### 通知客户端
处理结束时,会向依赖我们数据的客户端发送通知。 使用 Redis 发布/订阅机制,通知将通过 `geobike:station_changed` 通道和系统 ID 一起发出。
### 数据模型
在 Redis 中构建数据时,最重要的考虑因素是如何查询信息。 共享单车程序需要支持的两个主要查询是:
* 找到我们附近的车站
* 显示车站相关的信息
Redis 提供了两种主要数据类型用于存储数据:哈希和有序集。 [哈希类型](https://redis.io/topics/data-types#Hashes)很好地映射到表示车站的 JSON 对象;由于 Redis 哈希不使用固定的数据结构,因此它们可用于存储可变的车站信息。
当然,在地理位置上寻找站点需要地理空间索引来搜索相对于某些坐标的站点。 Redis 提供了[几个](https://redis.io/commands#geo)使用[有序集](https://redis.io/topics/data-types-intro#redis-sorted-sets)数据结构构建地理空间索引的命令。
我们使用 `${system_id}:station:${station_id}` 这种格式的键名存储车站相关的信息,使用 `${system_id}:stations:location` 这种格式的键名查找车站的地理空间索引。
### 获取用户位置
构建应用程序的下一步是确定用户的当前位置。 大多数应用程序通过操作系统提供的内置服务来实现此目的。 操作系统可以基于设备内置的 GPS 硬件为应用程序提供定位,或者从设备的可用 WiFi 网络提供近似的定位。
### 查找车站
找到用户的位置后,下一步是找到附近的共享单车站。 Redis 的地理空间功能可以返回用户当前坐标在给定距离内的所有车站信息。 以下是使用 Redis 命令行界面的示例。

想象一下,我正在纽约市第五大道的苹果零售店,我想要向市中心方向前往位于西 37 街的 MOOD 布料店,与我的好友 [Swatch](https://twitter.com/swatchthedog) 相遇。 我可以坐出租车或地铁,但我更喜欢骑单车。 附近有没有我可以使用的单车共享站呢?
苹果零售店位于 40.76384,-73.97297。 根据地图显示,在零售店 500 英尺半径范围内(地图上方的蓝色)有两个单车站,分别是陆军广场中央公园南单车站和东 58 街麦迪逊单车站。
我可以使用 Redis 的 `GEORADIUS` 命令查询 500 英尺半径范围内的车站的 `NYC` 系统索引:
```
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft
1) "NYC:station:3457"
2) "NYC:station:281"
```
Redis 使用地理空间索引中的元素作为特定车站的元数据的键名,返回在该半径内找到的两个共享单车站。 下一步是查找两个站的名称:
```
127.0.0.1:6379> hget NYC:station:281 name
"Grand Army Plaza & Central Park S"
127.0.0.1:6379> hget NYC:station:3457 name
"E 58 St & Madison Ave"
```
这些键名对应于上面地图上标识的车站。 如果需要,可以在 `GEORADIUS` 命令中添加更多标志来获取元素列表,每个元素的坐标以及它们与当前点的距离:
```
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft WITHDIST WITHCOORD ASC
1) 1) "NYC:station:281"
2) "289.1995"
3) 1) "-73.97371262311935425"
2) "40.76439830559216659"
2) 1) "NYC:station:3457"
2) "383.1782"
3) 1) "-73.97209256887435913"
2) "40.76302702144496237"
```
查找与这些键名关联的名称会生成一个我可以从中选择的车站的有序列表。 Redis 不提供方向和路线的功能,因此我使用设备操作系统的路线功能绘制从当前位置到所选单车站的路线。
`GEORADIUS` 函数可以很轻松的在你喜欢的开发框架的 API 里实现,这样就可以向应用程序添加位置功能了。
### 其他的查询命令
除了 `GEORADIUS` 命令外,Redis 还提供了另外三个用于查询索引数据的命令:`GEOPOS`、`GEODIST` 和 `GEORADIUSBYMEMBER`。
`GEOPOS` 命令可以为 <ruby> 地理哈希 <rt> geohash </rt></ruby> 中的给定元素提供坐标(LCTT 译注:geohash 是一种将二维的经纬度编码为一位的字符串的一种算法,常用于基于距离的查找算法和推荐算法)。 例如,如果我知道西 38 街 8 号有一个共享单车站,ID 是 523,那么该站的元素名称是 `NYC:station:523`。 使用 Redis,我可以找到该站的经度和纬度:
```
127.0.0.1:6379> geopos NYC:stations:location NYC:station:523
1) 1) "-73.99138301610946655"
2) "40.75466497634030105"
```
`GEODIST` 命令提供两个索引元素之间的距离。 如果我想找到陆军广场中央公园南单车站与东 58 街麦迪逊单车站之间的距离,我会使用以下命令:
```
127.0.0.1:6379> GEODIST NYC:stations:location NYC:station:281 NYC:station:3457 ft
"671.4900"
```
最后,`GEORADIUSBYMEMBER` 命令与 `GEORADIUS` 命令类似,但该命令不是采用一组坐标,而是采用索引的另一个成员的名称,并返回以该成员为中心的给定半径内的所有成员。 要查找陆军广场中央公园南单车站 1000 英尺范围内的所有车站,请输入以下内容:
```
127.0.0.1:6379> GEORADIUSBYMEMBER NYC:stations:location NYC:station:281 1000 ft WITHDIST
1) 1) "NYC:station:281"
2) "0.0000"
2) 1) "NYC:station:3132"
2) "793.4223"
3) 1) "NYC:station:2006"
2) "911.9752"
4) 1) "NYC:station:3136"
2) "940.3399"
5) 1) "NYC:station:3457"
2) "671.4900"
```
虽然此示例侧重于使用 Python 和 Redis 来解析数据并构建共享单车系统位置的索引,但可以很容易地衍生为定位餐馆、公共交通或者是开发人员希望帮助用户找到的任何其他类型的场所。
本文基于今年我在北卡罗来纳州罗利市的开源 101 会议上的[演讲](http://opensource101.com/raleigh/talks/building-location-aware-apps-open-source-tools/)。
---
via: <https://opensource.com/article/18/2/building-bikesharing-application-open-source-tools>
作者:[Tague Griffith](https://opensource.com/users/tague) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,232 | Sed 命令完全指南 | https://linuxhandbook.com/sed-reference-guide/ | 2018-11-14T19:06:00 | [
"sed"
] | https://linux.cn/article-10232-1.html | 在前面的文章中,我展示了 [Sed 命令的基本用法](https://linuxhandbook.com/sed-command-basics/), Sed 是一个实用的流编辑器。今天,我们准备去了解关于 Sed 更多的知识,深入了解 Sed 的运行模式。这将是你全面了解 Sed 命令的一个机会,深入挖掘它的运行细节和精妙之处。因此,如果你已经做好了准备,那就打开终端吧,[下载测试文件](https://gist.github.com/s-leroux/5cb36435bac46c10cfced26e4bf5588c) 然后坐在电脑前:开始我们的探索之旅吧!

### 关于 Sed 的一点点理论知识
#### 首先我们看一下 sed 的运行模式
要准确理解 Sed 命令,你必须先了解工具的运行模式。
当处理数据时,Sed 从输入源一次读入一行,并将它保存到所谓的<ruby> 模式空间 <rt> pattern space </rt></ruby>中。所有 Sed 的变换都发生在模式空间。变换都是由命令行上或外部 Sed 脚本文件提供的单字母命令来描述的。大多数 Sed 命令都可以由一个地址或一个地址范围作为前导来限制它们的作用范围。
默认情况下,Sed 在结束每个处理循环后输出模式空间中的内容,也就是说,输出发生在输入的下一个行覆盖模式空间之前。我们可以将这种运行模式总结如下:
1. 尝试将下一个行读入到模式空间中
2. 如果读取成功:
1. 按脚本中的顺序将所有命令应用到与那个地址匹配的当前输入行上
2. 如果 sed 没有以静默模式(`-n`)运行,那么将输出模式空间中的所有内容(可能会是修改过的)。
3. 重新回到 1。
因此,在每个行被处理完毕之后,模式空间中的内容将被丢弃,它并不适合长时间保存内容。基于这种目的,Sed 有第二个缓冲区:<ruby> 保持空间 <rt> hold space </rt></ruby>。除非你显式地要求它将数据置入到保持空间、或从保持空间中取得数据,否则 Sed 从不清除保持空间的内容。在我们后面学习到 `exchange`、`get`、`hold` 命令时将深入研究它。
#### Sed 的抽象机制
你将在许多的 Sed 教程中都会看到上面解释的模式。的确,这是充分正确理解大多数基本 Sed 程序所必需的。但是当你深入研究更多的高级命令时,你将会发现,仅这些知识还是不够的。因此,我们现在尝试去了解更深入的一些知识。
的确,Sed 可以被视为是[抽象机制](http://mathworld.wolfram.com/AbstractMachine.html)的实现,它的[状态](https://en.wikipedia.org/wiki/State_(computer_science))由三个[缓冲区](https://en.wikipedia.org/wiki/Data_buffer) 、两个[寄存器](https://en.wikipedia.org/wiki/Processor_register#Categories_of_registers)和两个[标志](https://www.computerhope.com/jargon/f/flag.htm)来定义的:
* **三个缓冲区**用于去保存任意长度的文本。是的,是三个!在前面的基本运行模式中我们谈到了两个:模式空间和保持空间,但是 Sed 还有第三个缓冲区:<ruby> 追加队列 <rt> append queue </rt></ruby>。从 Sed 脚本的角度来看,它是一个只写缓冲区,Sed 将在它运行时的预定义阶段来自动刷新它(一般是在从输入源读入一个新行之前,或仅在它退出运行之前)。
* Sed 也维护**两个寄存器**:<ruby> 行计数器 <rt> line counter </rt></ruby>(LC)用于保存从输入源读取的行数,而<ruby> 程序计数器 <rt> program counter </rt></ruby>(PC)总是用来保存下一个将要运行的命令的索引(就是脚本中的位置),Sed 将它作为它的主循环的一部分来自动增加 PC。但在使用特定的命令时,脚本也可以直接修改 PC 去跳过或重复执行程序的一部分。这就像使用 Sed 实现的一个循环或条件语句。更多内容将在下面的专用分支一节中描述。
* 最后,**两个标志**可以修改某些 Sed 命令的行为:<ruby> 自动输出 <rt> auto-print </rt></ruby>(AP)标志和<ruby替换 substitution(SF)标志。当自动输出标志 AP 被设置时,Sed 将在模式空间的内容被覆盖前自动输出(尤其是,包括但不限于,在从输入源读入一个新行之前)。当自动输出标志被清除时(即:没有设置),Sed 在脚本中没有显式命令的情况下,将不会输出模式空间中的内容。你可以通过在“静默模式”(使用命令行选项 `-n` 或者在第一行或脚本中使用特殊注释 `#n`)运行 Sed 命令来清除自动输出标志。当它的地址和查找模式与模式空间中的内容都匹配时,替换标志 SF 将被替换命令(`s` 命令)设置。替换标志在每个新的循环开始时、或当从输入源读入一个新行时、或获得条件分支之后将被清除。我们将在分支一节中详细研究这一话题。
另外,Sed 维护一个进入到它的地址范围(关于地址范围的更多知识将在地址范围一节详细描述)的命令列表,以及用于读取和写入数据的两个文件句柄(你将在读取和写入命令的描述中获得更多有关文件句柄的内容)。
#### 一个更精确的 Sed 运行模式
一图胜千言,所以我画了一个流程图去描述 Sed 的运行模式。我将两个东西放在了旁边,像处理多个输入文件或错误处理,但是我认为这足够你去理解任何 Sed 程序的行为了,并且可以避免你在编写你自己的 Sed 脚本时浪费在摸索上的时间。

你可能已经注意到,在上面的流程图上我并没有描述特定的命令动作。对于命令,我们将逐个详细讲解。因此,不用着急,我们马上开始!
### 打印命令
打印命令(`p`)是用于输出在它运行那一刻模式空间中的内容。它并不会以任何方式改变 Sed 抽象机制中的状态。

示例:
```
sed -e 'p' inputfile
```
上面的命令将输出输入文件中每一行的内容……两次,因为你一旦显式地要求使用 `p` 命令时,将会在每个处理循环结束时再隐式地输出一次(因为在这里我们不是在“静默模式”中运行 Sed)。
如果我们不想每个行看到两次,我们可以用两种方式去解决它:
```
sed -n -e 'p' inputfile # 在静默模式中显式输出
sed -e '' inputfile # 空的“什么都不做的”程序,隐式输出
```
注意:`-e` 选项是引入一个 Sed 命令。它被用于区分命令和文件名。由于一个 Sed 表达式必须包含至少一个命令,所以对于第一个命令,`-e` 标志不是必需的。但是,由于我个人使用习惯问题,为了与在这里的大多数的一个命令行上给出多个 Sed 表达式的更复杂的案例保持一致性,我添加了它。你自己去判断这是一个好习惯还是坏习惯,并且在本文的后面部分还将延用这一习惯。
### 地址
显而易见,`print` 命令本身并没有太多的用处。但是,如果你在它之前添加一个地址,这样它就只输出输入文件的一些行,这样它就突然变得能够从一个输入文件中过滤一些不希望的行。那么 Sed 的地址又是什么呢?它是如何来辨别输入文件的“行”呢?
#### 行号
Sed 的地址既可以是一个行号(`$` 表示“最后一行”)也可以是一个正则表达式。在使用行号时,你需要记住 Sed 中的行数是从 1 开始的 —— 并且需要注意的是,它**不是**从 0 行开始的。
```
sed -n -e '1p' inputfile # 仅输出文件的第一行
sed -n -e '5p' inputfile # 仅输出第 5 行
sed -n -e '$p' inputfile # 输出文件的最后一行
sed -n -e '0p' inputfile # 结果将是报错,因为 0 不是有效的行号
```
根据 [POSIX 规范](http://pubs.opengroup.org/onlinepubs/9699919799/utilities/sed.html),如果你指定了几个输出文件,那么它的行号是累加的。换句话说,当 Sed 打开一个新输入文件时,它的行计数器是不会被重置的。因此,以下的两个命令所做的事情是一样的。仅输出一行文本:
```
sed -n -e '1p' inputfile1 inputfile2 inputfile3
cat inputfile1 inputfile2 inputfile3 | sed -n -e '1p'
```
实际上,确实在 POSIX 中规定了多个文件是如何处理的:
>
> 如果指定了多个文件,将按指定的文件命名顺序进行读取并被串联编辑。
>
>
>
但是,一些 Sed 的实现提供了命令行选项去改变这种行为,比如, GNU Sed 的 `-s` 标志(在使用 GNU Sed `-i` 标志时,它也被隐式地应用):
```
sed -sn -e '1p' inputfile1 inputfile2 inputfile3
```
如果你的 Sed 实现支持这种非标准选项,那么关于它的具体细节请查看 `man` 手册页。
#### 正则表达式
我前面说过,Sed 地址既可以是行号也可以是正则表达式。那么正则表达式是什么呢?
正如它的名字,一个[正则表达式](https://www.regular-expressions.info/)是描述一个字符串集合的方法。如果一个指定的字符串符合一个正则表达式所描述的集合,那么我们就认为这个字符串与正则表达式匹配。
正则表达式可以包含必须完全匹配的文本字符。例如,所有的字母和数字,以及大部分可以打印的字符。但是,一些符号有特定意义:
* 它们相当于锚,像 `^` 和 `$` 它们分别表示一个行的开始和结束;
* 能够做为整个字符集的占位符的其它符号(比如圆点 `.` 可以匹配任意单个字符,或者方括号 `[]` 用于定义一个自定义的字符集);
* 另外的是表示重复出现的数量(像 [克莱尼星号(`*`)](https://chortle.ccsu.edu/FiniteAutomata/Section07/sect07_16.html) 表示前面的模式出现 0、1 或多次);
这篇文章的目的不是给大家讲正则表达式。因此,我只粘几个示例。但是,你可以在网络上随便找到很多关于正则表达式的教程,正则表达式的功能非常强大,它可用于许多标准的 Unix 命令和编程语言中,并且是每个 Unix 用户应该掌握的技能。
下面是使用 Sed 地址的几个示例:
```
sed -n -e '/systemd/p' inputfile # 仅输出包含字符串“systemd”的行
sed -n -e '/nologin$/p' inputfile # 仅输出以“nologin”结尾的行
sed -n -e '/^bin/p' inputfile # 仅输出以“bin”开头的行
sed -n -e '/^$/p' inputfile # 仅输出空行(即:开始和结束之间什么都没有的行)
sed -n -e '/./p' inputfile # 仅输出包含字符的行(即:非空行)
sed -n -e '/^.$/p' inputfile # 仅输出只包含一个字符的行
sed -n -e '/admin.*false/p' inputfile # 仅输出包含字符串“admin”后面有字符串“false”的行(在它们之间有任意数量的任意字符)
sed -n -e '/1[0,3]/p' inputfile # 仅输出包含一个“1”并且后面是一个“0”或“3”的行
sed -n -e '/1[0-2]/p' inputfile # 仅输出包含一个“1”并且后面是一个“0”、“1”、“2”或“3”的行
sed -n -e '/1.*2/p' inputfile # 仅输出包含字符“1”后面是一个“2”(在它们之间有任意数量的字符)的行
sed -n -e '/1[0-9]*2/p' inputfile # 仅输出包含字符“1”后面跟着“0”、“1”、或更多数字,最后面是一个“2”的行
```
如果你想在正则表达式(包括正则表达式分隔符)中去除字符的特殊意义,你可以在它前面使用一个反斜杠:
```
# 输出所有包含字符串“/usr/sbin/nologin”的行
sed -ne '/\/usr\/sbin\/nologin/p' inputfile
```
并不限制你只能使用斜杠作为地址中正则表达式的分隔符。你可以通过在第一个分隔符前面加上反斜杠(`\`)的方式,来使用任何你认为适合你需要和偏好的其它字符作为正则表达式的分隔符。当你用地址与带文件路径的字符一起来匹配的时,是非常有用的:
```
# 以下两个命令是完全相同的
sed -ne '/\/usr\/sbin\/nologin/p' inputfile
sed -ne '\=/usr/sbin/nologin=p' inputfile
```
#### 扩展的正则表达式
默认情况下,Sed 的正则表达式引擎仅理解 [POSIX 基本正则表达式](https://www.regular-expressions.info/posix.html#bre) 的语法。如果你需要用到 [扩展正则表达式](https://www.regular-expressions.info/posix.html#ere),你必须在 Sed 命令上添加 `-E` 标志。扩展正则表达式在基本正则表达式基础上增加了一组额外的特性,并且很多都是很重要的,它们所要求的反斜杠要少很多。我们来比较一下:
```
sed -n -e '/\(www\)\|\(mail\)/p' inputfile
sed -En -e '/(www)|(mail)/p' inputfile
```
#### 花括号量词
正则表达式之所以强大的一个原因是[范围量词](https://www.regular-expressions.info/repeat.html#limit) `{,}`。事实上,当你写一个不太精确匹配的正则表达式时,量词 `*` 就是一个非常完美的符号。但是,(用花括号量词)你可以显式在它边上添加一个下限和上限,这样就有了很好的灵活性。当量词范围的下限省略时,下限被假定为 0。当上限被省略时,上限被假定为无限大:
| 括号 | 速记词 | 解释 |
| --- | --- | --- |
| `{,}` | `*` | 前面的规则出现 0、1、或许多遍 |
| `{,1}` | `?` | 前面的规则出现 0 或 1 遍 |
| `{1,}` | `+` | 前面的规则出现 1 或许多遍 |
| `{n,n}` | `{n}` | 前面的规则精确地出现 n 遍 |
花括号在基本正则表达式中也是可以使用的,但是它要求使用反斜杠。根据 POSIX 规范,在基本正则表达式中可以使用的量词仅有星号(`*`)和花括号(使用反斜杠,如 `\{m,n\}`)。许多正则表达式引擎都扩展支持 `\?` 和 `\+`。但是,为什么魔鬼如此有诱惑力呢?因为,如果你需要这些量词,使用扩展正则表达式将不但易于写而且可移植性更好。
为什么我要花点时间去讨论关于正则表达式的花括号量词,这是因为在 Sed 脚本中经常用这个特性去计数字符。
```
sed -En -e '/^.{35}$/p' inputfile # 输出精确包含 35 个字符的行
sed -En -e '/^.{0,35}$/p' inputfile # 输出包含 35 个字符或更少字符的行
sed -En -e '/^.{,35}$/p' inputfile # 输出包含 35 个字符或更少字符的行
sed -En -e '/^.{35,}$/p' inputfile # 输出包含 35 个字符或更多字符的行
sed -En -e '/.{35}/p' inputfile # 你自己指出它的输出内容(这是留给你的测试题)
```
#### 地址范围
到目前为止,我们使用的所有地址都是唯一地址。在我们使用一个唯一地址时,命令是应用在与那个地址匹配的行上。但是,Sed 也支持地址范围。Sed 命令可以应用到那个地址范围中从开始到结束的所有地址中的所有行上:
```
sed -n -e '1,5p' inputfile # 仅输出 1 到 5 行
sed -n -e '5,$p' inputfile # 从第 5 行输出到文件结尾
sed -n -e '/www/,/systemd/p' inputfile # 输出与正则表达式 /www/ 匹配的第一行到与接下来匹配正则表达式 /systemd/ 的行为止
```
(LCTT 译注:下面用的一个生成的列表例子,如下供参考:)
```
printf "%s\n" {a,b,c}{d,e,f} | cat -n
1 ad
2 ae
3 af
4 bd
5 be
6 bf
7 cd
8 ce
9 cf
```
如果在开始和结束地址上使用了同一个行号,那么范围就缩小为那个行。事实上,如果第二个地址的数字小于或等于地址范围中选定的第一个行的数字,那么仅有一个行被选定:
```
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '4,4p'
4 bd
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '4,3p'
4 bd
```
下面有点难了,但是在前面的段落中给出的规则也适用于起始地址是正则表达式的情况。在那种情况下,Sed 将对正则表达式匹配的第一个行的行号和给定的作为结束地址的显式的行号进行比较。再强调一次,如果结束行号小于或等于起始行号,那么这个范围将缩小为一行:
(LCTT 译注:此处作者陈述有误,Sed 会在处理以正则表达式表示的开始行时,并不会同时测试结束表达式:从匹配开始行的正则表达式开始,直到不匹配时,才会测试结束行的表达式——无论是否是正则表达式——并在结束的表达式测试不通过时停止,并循环此测试。)
```
# 这个 /b/,4 地址将匹配三个单行
# 因为每个匹配的行有一个行号 >= 4
#(LCTT 译注:结果正确,但是说明不正确。4、5、6 行都会因为匹配开始正则表达式而通过,第 7 行因为不匹配开始正则表达式,所以开始比较行数: 7 > 4,遂停止。)
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '/b/,4p'
4 bd
5 be
6 bf
# 你自己指出匹配的范围是多少
# 第二个例子:
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '/d/,4p'
1 ad
2 ae
3 af
4 bd
7 cd
```
但是,当结束地址是一个正则表达式时,Sed 的行为将不一样。在那种情况下,地址范围的第一行将不会与结束地址进行检查,因此地址范围将至少包含两行(当然,如果输入数据不足的情况除外):
(LCTT 译注:如上译注,当满足开始的正则表达式时,并不会测试结束的表达式;仅当不满足开始的表达式时,才会测试结束表达式。)
```
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '/b/,/d/p'
4 bd
5 be
6 bf
7 cd
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '4,/d/p'
4 bd
5 be
6 bf
7 cd
```
(LCTT 译注:对地址范围的总结,当满足开始的条件时,从该行开始,并不测试该行是否满足结束的条件;从下一行开始测试结束条件,并在结束条件不满足时结束;然后对剩余的行,再从开始条件开始匹配,以此循环——也就是说,匹配结果可以是非连续的单/多行。大家可以调整上述命令行的条件以理解。)
#### 补集
在一个地址选择行后面添加一个感叹号(`!`)表示不匹配那个地址。例如:
```
sed -n -e '5!p' inputfile # 输出除了第 5 行外的所有行
sed -n -e '5,10!p' inputfile # 输出除了第 5 到 10 之间的所有行
sed -n -e '/sys/!p' inputfile # 输出除了包含字符串“sys”的所有行
```
#### 交集
(LCTT 译注:原文标题为“合集”,应为“交集”)
Sed 允许在一个块中使用花括号 `{…}` 组合命令。你可以利用这个特性去组合几个地址的交集。例如,我们来比较下面两个命令的输出:
```
sed -n -e '/usb/{
/daemon/p
}' inputfile
sed -n -e '/usb.*daemon/p' inputfile
```
通过在一个块中嵌套命令,我们将在任意顺序中选择包含字符串 “usb” 和 “daemon” 的行。而正则表达式 “usb.\*daemon” 将仅匹配在字符串 “daemon” 前面包含 “usb” 字符串的行。
离题太长时间后,我们现在重新回去学习各种 Sed 命令。
### 退出命令
退出命令(`q`)是指在当前的迭代循环处理结束之后停止 Sed。

`q` 命令是在到达输入文件的尾部之前停止处理输入的方法。为什么会有人想去那样做呢?
很好的问题,如果你还记得,我们可以使用下面的命令来输出文件中第 1 到第 5 的行:
```
sed -n -e '1,5p' inputfile
```
对于大多数 Sed 的实现方式,工具将循环读取输入文件的所有行,那怕是你只处理结果中的前 5 行。如果你的输入文件包含了几百万行(或者更糟糕的情况是,你从一个无限的数据流,比如像 `/dev/urandom` 中读取)将有重大影响。
使用退出命令,相同的程序可以被修改的更高效:
```
sed -e '5q' inputfile
```
由于我在这里并不使用 `-n` 选项,Sed 将在每个循环结束后隐式输出模式空间的内容。但是在你处理完第 5 行后,它将退出,并且因此不会去读取更多的数据。
我们能够使用一个类似的技巧只输出文件中一个特定的行。这也是从命令行中提供多个 Sed 表达式的几种方法。下面的三个变体都可以从 Sed 中接受几个命令,要么是不同的 `-e` 选项,要么是在相同的表达式中新起一行,或用分号(`;`)隔开:
```
sed -n -e '5p' -e '5q' inputfile
sed -n -e '
5p
5q
' inputfile
sed -n -e '5p;5q' inputfile
```
如果你还记得,我们在前面看到过能够使用花括号将命令组合起来,在这里我们使用它来防止相同的地址重复两次:
```
# 组合命令
sed -e '5{
p
q
}' inputfile
# 可以简写为:
sed '5{p;q;}' inputfile
# 作为 POSIX 扩展,有些实现方式可以省略闭花括号之前的分号:
sed '5{p;q}' inputfile
```
### 替换命令
你可以将替换命令(`s`)想像为 Sed 的“查找替换”功能,这个功能在大多数的“所见即所得”的编辑器上都能找到。Sed 的替换命令与之类似,但比它们更强大。替换命令是 Sed 中最著名的命令之一,在网上有大量的关于这个命令的文档。

[在前一篇文章](https://linuxhandbook.com/?p=128)中我们已经讲过它了,因此,在这里就不再重复了。但是,如果你对它的使用不是很熟悉,那么你需要记住下面的这些关键点:
* 替换命令有两个参数:查找模式和替换字符串:`sed s/:/-----/ inputfile`
* `s` 命令和它的参数是用任意一个字符来分隔的。这主要看你的习惯,在 99% 的时间中我都使用斜杠,但也会用其它的字符:`sed s%:%-----% inputfile`、`sed sX:X-----X inputfile` 或者甚至是 `sed 's : ----- ' inputfile`
* 默认情况下,替换命令仅被应用到模式空间中匹配到的第一个字符串上。你可以通过在命令之后指定一个匹配指数作为标志来改变这种情况:`sed 's/:/-----/1' inputfile`、`sed 's/:/-----/2' inputfile`、`sed 's/:/-----/3' inputfile`、…
* 如果你想执行一个全局替换(即:在模式空间上的每个非重叠匹配上进行),你需要增加 `g` 标志:`sed 's/:/-----/g' inputfile`
* 在字符串替换中,出现的任何一个 `&` 符号都将被与查找模式匹配的子字符串替换:`sed 's/:/-&&&-/g' inputfile`、`sed 's/.../& /g' inputfile`
* 圆括号(在扩展的正则表达式中的 `(...)` ,或者基本的正则表达式中的 `\(...\)`)被当做<ruby> 捕获组 <rt> capturing group </rt></ruby>。那是匹配字符串的一部分,可以在替换字符串中被引用。`\1` 是第一个捕获组的内容,`\2` 是第二个捕获组的内容,依次类推:`sed -E 's/(.)(.)/\2\1/g' inputfile`、`sed -E 's/(.):x:(.):(.*)/\1:\3/' inputfile`(后者之所能正常工作是因为 [正则表达式中的量词星号表示尽可能多的匹配,直到不匹配为止](https://www.regular-expressions.info/repeat.html#greedy),并且它可以匹配许多个字符)
* 在查找模式或替换字符串时,你可以通过使用一个反斜杠来去除任何字符的特殊意义:`sed 's/:/--\&--/g' inputfile`,`sed 's/\//\\/g' inputfile`
所有的这些看起来有点抽象,下面是一些示例。首先,我想去显示我的测试输入文件的第一个字段并给它在右侧附加 20 个空格字符,我可以这样写:
```
sed < inputfile -E -e '
s/:/ / # 用 20 个空格替换第一个字段的分隔符
s/(.{20}).*/\1/ # 只保留一行的前 20 个字符
s/.*/| & |/ # 为了输出好看添加竖条
'
```
第二个示例是,如果我想将用户 sonia 的 UID/GID 修改为 1100,我可以这样写:
```
sed -En -e '
/sonia/{
s/[0-9]+/1100/g
p
}' inputfile
```
注意在替换命令结束部分的 `g` 选项。这个选项改变了它的行为,因此它将查找全部的模式空间并替换,如果没有那个选项,它只替换查找到的第一个。
顺便说一下,这也是使用前面讲过的输出(`p`)命令的好机会,可以在命令运行时输出修改前后的模式空间的内容。因此,为了获得替换前后的内容,我可以这样写:
```
sed -En -e '
/sonia/{
p
s/[0-9]+/1100/g
p
}' inputfile
```
事实上,替换后输出一个行是很常见的用法,因此,替换命令也接受 `p` 选项:
```
sed -En -e '/sonia/s/[0-9]+/1100/gp' inputfile
```
最后,我就不详细讲替换命令的 `w` 选项了,我们将在稍后的学习中详细介绍。
### 删除命令
删除命令(`d`)用于清除模式空间的内容,然后立即开始下一个处理循环。这样它将会跳过隐式输出模式空间内容的行为,即便是你设置了自动输出标志(AP)也不会输出。

只输出一个文件前五行的一个很低效率的方法将是:
```
sed -e '6,$d' inputfile
```
你猜猜看,我为什么说它很低效率?如果你猜不到,建议你再次去阅读前面的关于退出命令的章节,答案就在那里!
当你组合使用正则表达式和地址,从输出中删除匹配的行时,删除命令将非常有用:
```
sed -e '/systemd/d' inputfile
```
### 次行命令
如果 Sed 命令没有运行在静默模式中,这个命令(`n`)将输出当前模式空间的内容,然后,在任何情况下它将读取下一个输入行到模式空间中,并使用新的模式空间中的内容来运行当前循环中剩余的命令。

用次行命令去跳过行的一个常见示例:
```
cat -n inputfile | sed -n -e 'n;n;p'
```
在上面的例子中,Sed 将隐式地读取输入文件的第一行。但是次行命令将丢弃对模式空间中的内容的输出(不输出是因为使用了 `-n` 选项),并从输入文件中读取下一行来替换模式空间中的内容。而第二个次行命令做的事情和前一个是一模一样的,这就实现了跳过输入文件 2 行的目的。最后,这个脚本显式地输出包含在模式空间中的输入文件的第三行的内容。然后,Sed 将启动一个新的循环,由于次行命令,它会隐式地读取第 4 行的内容,然后跳过它,同样地也跳过第 5 行,并输出第 6 行。如此循环,直到文件结束。总体来看,这个脚本就是读取输入文件然后每三行输出一行。
使用次行命令,我们也可以找到一些显示输入文件的前五行的几种方法:
```
cat -n inputfile | sed -n -e '1{p;n;p;n;p;n;p;n;p}'
cat -n inputfile | sed -n -e 'p;n;p;n;p;n;p;n;p;q'
cat -n inputfile | sed -e 'n;n;n;n;q'
```
更有趣的是,如果你需要根据一些地址来处理行时,次行命令也非常有用:
```
cat -n inputfile | sed -n '/pulse/p' # 输出包含 “pulse” 的行
cat -n inputfile | sed -n '/pulse/{n;p}' # 输出包含 “pulse” 之后的行
cat -n inputfile | sed -n '/pulse/{n;n;p}' # 输出包含 “pulse” 的行的下一行的下一行
```
### 使用保持空间
到目前为止,我们所看到的命令都是仅使用了模式空间。但是,我们在文章的开始部分已经提到过,还有第二个缓冲区:保持空间,它完全由用户管理。它就是我们在第二节中描述的目标。
#### 交换命令
正如它的名字所表示的,交换命令(`x`)将交换保持空间和模式空间的内容。记住,你只要没有把任何东西放入到保持空间中,那么保持空间就是空的。

作为第一个示例,我们可使用交换命令去反序输出一个输入文件的前两行:
```
cat -n inputfile | sed -n -e 'x;n;p;x;p;q'
```
当然,在你设置保持空间之后你并没有立即使用它的内容,因为只要你没有显式地去修改它,保持空间中的内容就保持不变。在下面的例子中,我在输入一个文件的前五行后,使用它去删除第一行:
```
cat -n inputfile | sed -n -e '
1{x;n} # 交换保持和模式空间
# 保存第 1 行到保持空间中
# 然后读取第 2 行
5{
p # 输出第 5 行
x # 交换保持和模式空间
# 去取得第 1 行的内容放回到模式空间
}
1,5p # 输出第 2 到第 5 行
# (并没有输错!尝试找出这个规则
# 没有在第 1 行上运行的原因 ;)
'
```
#### 保持命令
保持命令(`h`)是用于将模式空间中的内容保存到保持空间中。但是,与交换命令不同的是,模式空间中的内容不会被改变。保持命令有两种用法:
* `h` 将复制模式空间中的内容到保持空间中,覆盖保持空间中任何已经存在的内容。
* `H` 将模式空间中的内容追加到保持空间中,使用一个新行作为分隔符。

上面使用交换命令的例子可以使用保持命令重写如下:
```
cat -n inputfile | sed -n -e '
1{h;n} # 保存第 1 行的内容到保持缓冲区并继续
5{ # 在第 5 行
x # 交换模式和保持空间
# (现在模式空间包含了第 1 行)
H # 在保持空间的第 5 行后追加第 1 行
x # 再次交换第 5 行和第 1 行,第 5 行回到模式空间
}
1,5p # 输出第 2 行到第 5 行
# (没有输错!尝试去找到为什么这个规则
# 不在第 1 行上运行 ;)
'
```
#### 获取命令
获取命令(`g`)与保持命令恰好相反:它从保持空间中取得内容并将它置入到模式空间中。同样它也有两种方式:
* `g` 将复制保持空间中的内容并将其放入到模式空间,覆盖模式空间中已存在的任何内容
* `G` 将保持空间中的内容追加到模式空间中,并使用一个新行作为分隔符

将保持命令和获取命令一起使用,可以允许你去存储并调回数据。作为一个小挑战,我让你重写前一节中的示例,将输入文件的第 1 行放置在第 5 行之后,但是这次必须使用获取和保持命令(使用大写或小写命令的版本)而不能使用交换命令。带点小运气,可以更简单!
同时,我可以给你展示另一个示例,它能给你一些灵感。目标是将拥有登录 shell 权限的用户与其它用户分开:
```
cat -n inputfile | sed -En -e '
\=(/usr/sbin/nologin|/bin/false)$= { H;d; }
# 追回匹配的行到保持空间
# 然后继续下一个循环
p # 输出其它行
$ { g;p } # 在最后一行上
# 获取并打印保持空间中的内容
'
```
### 复习打印、删除和次行命令
现在你已经更熟悉使用保持空间了,我们回到打印、删除和次行命令。我们已经讨论了小写的 `p`、`d` 和 `n` 命令了。而它们也有大写的版本。因为每个命令都有大小写版本,似乎是 Sed 的习惯,这些命令的大写版本将与多行缓冲区有关:
* `P` 将模式空间中第一个新行之前的内容输出
* `D` 删除模式空间中第一个新行之前的内容(包含新行),然后不读取任何新的输入而是使用剩余的文本去重启一个循环
* `N` 读取输入并追加一个新行到模式空间,用一个新行作为新旧数据的分隔符。继续运行当前的循环。


这些命令的使用场景主要用于实现队列([FIFO 列表](https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics)))。从一个输入文件中删除最后 5 行就是一个很权威的例子:
```
cat -n inputfile | sed -En -e '
1 { N;N;N;N } # 确保模式空间中包含 5 行
N # 追加第 6 行到队列中
P # 输出队列的第 1 行
D # 删除队列的第 1 行
'
```
作为第二个示例,我们可以在两个列上显示输入数据:
```
# 输出两列
sed < inputfile -En -e '
$!N # 追加一个新行到模式空间
# 除了输入文件的最后一行
# 当在输入文件的最后一行使用 N 命令时
# GNU Sed 和 POSIX Sed 的行为是有差异的
# 需要使用一个技巧去处理这种情况
# https://www.gnu.org/software/sed/manual/sed.html#N_005fcommand_005flast_005fline
# 用空间填充第 1 行的第 1 个字段
# 并丢弃其余行
s/:.*\n/ \n/
s/:.*// # 除了第 2 行上的第 1 个字段外,丢弃其余的行
s/(.{20}).*\n/\1/ # 修剪并连接行
p # 输出结果
'
```
### 分支
我们刚才已经看到,Sed 因为有保持空间所以有了缓存的功能。其实它还有测试和分支的指令。因为有这些特性使得 Sed 是一个[图灵完备](https://chortle.ccsu.edu/StructuredC/Chap01/struct01_5.html)的语言。虽然它可能看起来很傻,但意味着你可以使用 Sed 写任何程序。你可以实现任何你的目的,但并不意味着实现起来会很容易,而且结果也不一定会很高效。
不过不用担心。在本文中,我们将使用能够展示测试和分支功能的最简单的例子。虽然这些功能乍一看似乎很有限,但请记住,有些人用 Sed 写了 <http://www.catonmat.net/ftp/sed/dc.sed> [计算器]、<http://www.catonmat.net/ftp/sed/sedtris.sed> [俄罗斯方块] 或许多其它类型的应用程序!
#### 标签和分支
从某些方面,你可以将 Sed 看到是一个功能有限的汇编语言。因此,你不会找到在高级语言中常见的 “for” 或 “while” 循环,或者 “if … else” 语句,但是你可以使用分支来实现同样的功能。

如果你在本文开始部分看到了用流程图描述的 Sed 运行模型,那么你应该知道 Sed 会自动增加程序计数器(PC)的值,命令是按程序的指令顺序来运行的。但是,使用分支(`b`)指令,你可以通过选择执行程序中的任意命令来改变顺序运行的程序。跳转目的地是使用一个标签(`:`)来显式定义的。

这是一个这样的示例:
```
echo hello | sed -ne '
:start # 在程序的该行上放置一个 “start” 标签
p # 输出模式空间内容
b start # 继续在 :start 标签上运行
' | less
```
那个 Sed 程序的行为非常类似于 `yes` 命令:它获取一个字符串并产生一个包含那个字符串的无限流。
切换到一个标签就像我们绕开了 Sed 的自动化特性一样:它既不读取任何输入,也不输出任何内容,更不更新任何缓冲区。它只是跳转到源程序指令顺序中下一条的另外一个指令。
值得一提的是,如果在分支命令(`b`)上没有指定一个标签作为它的参数,那么分支将直接切换到程序结束的地方。因此,Sed 将启动一个新的循环。这个特性可以用于去跳过一些指令并且因此可以用于作为“块”的替代者:
```
cat -n inputfile | sed -ne '
/usb/!b
/daemon/!b
p
'
```
#### 条件分支
到目前为止,我们已经看到了无条件分支,这个术语可能有点误导嫌疑,因为 Sed 命令总是基于它们的可选地址来作为条件的。
但是,在传统意义上,一个无条件分支也是一个分支,当它运行时,将跳转到特定的目的地,而条件分支既有可能也或许不可能跳转到特定的指令,这取决于系统的当前状态。
Sed 只有一个条件指令,就是测试(`t`)命令。只有在当前循环的开始或因为前一个条件分支运行了替换,它才跳转到不同的指令。更多的情况是,只有替换标志被设置时,测试命令才会切换分支。

使用测试指令,你可以在一个 Sed 程序中很轻松地执行一个循环。作为一个特定的示例,你可以用它将一个行填充到某个长度(这是使用正则表达式无法实现的):
```
# 居中文本
cut -d: -f1 inputfile | sed -Ee '
:start
s/^(.{,19})$/ \1 / # 用一个空格填充少于 20 个字符的行的开始处
# 并在结束处添加另一个空格
t start # 如果我们已经添加了一个空格,则返回到 :start 标签
s/(.{20}).*/| \1 |/ # 只保留一个行的前 20 个字符
# 以修复由于奇数行引起的差一错误
'
```
如果你仔细读前面的示例,你可能注意到,在将要把数据“喂”给 Sed 之前,我通过 `cut` 命令做了一点小修正去预处理数据。
不过,我们也可以只使用 Sed 对程序做一些小修改来执行相同的任务:
```
cat inputfile | sed -Ee '
s/:.*// # 除第 1 个字段外删除剩余字段
t start
:start
s/^(.{,19})$/ \1 / # 用一个空格填充少于 20 个字符的行的开始处
# 并在结束处添加另一个空格
t start # 如果我们已经添加了一个空格,则返回到 :start 标签
s/(.{20}).*/| \1 |/ # 仅保留一个行的前 20 个字符
# 以修复由于奇数行引起的差一错误
'
```
在上面的示例中,你或许对下列的结构感到惊奇:
```
t start
:start
```
乍一看,在这里的分支并没有用,因为它只是跳转到将要运行的指令处。但是,如果你仔细阅读了测试命令的定义,你将会看到,如果在当前循环的开始或者前一个测试命令运行后发生了一个替换,分支才会起作用。换句话说就是,测试指令有清除替换标志的副作用。这也正是上面的代码片段的真实目的。这是一个在包含条件分支的 Sed 程序中经常看到的技巧,用于在使用多个替换命令时避免出现<ruby> 误报 <rt> false positive </rt></ruby>的情况。
通过它并不能绝对强制地清除替换标志,我同意这一说法。因为在将字符串填充到正确的长度时我使用的特定的替换命令是<ruby> 幂等 <rt> idempotent </rt></ruby>的。因此,一个多余的迭代并不会改变结果。不过,我们可以现在再次看一下第二个示例:
```
# 基于它们的登录程序来分类用户帐户
cat inputfile | sed -Ene '
s/^/login=/
/nologin/s/^/type=SERV /
/false/s/^/type=SERV /
t print
s/^/type=USER /
:print
s/:.*//p
'
```
我希望在这里根据用户默认配置的登录程序,为用户帐户打上 “SERV” 或 “USER” 的标签。如果你运行它,预计你将看到 “SERV” 标签。然而,并没有在输出中跟踪到 “USER” 标签。为什么呢?因为 `t print` 指令不论行的内容是什么,它总是切换,替换标志总是由程序的第一个替换命令来设置。一旦替换标志设置完成后,在下一个行被读取或直到下一个测试命令之前,这个标志将保持不变。下面我们给出修复这个程序的解决方案:
```
# 基于用户登录程序来分类用户帐户
cat inputfile | sed -Ene '
s/^/login=/
t classify # clear the "substitution flag"
:classify
/nologin/s/^/type=SERV /
/false/s/^/type=SERV /
t print
s/^/type=USER /
:print
s/:.*//p
'
```
### 精确地处理文本
Sed 是一个非交互式文本编辑器。虽然是非交互式的,但仍然是文本编辑器。而如果没有在输出中插入一些东西的功能,那它就不算一个完整的文本编辑器。我不是很喜欢它的文本编辑的特性,因为我发现它的语法太难用了(即便是以 Sed 的标准而言),但有时你难免会用到它。
采用严格的 POSIX 语法的只有三个命令:改变(`c`)、插入(`i`)或追加(`a`)一些文字文本到输出,都遵循相同的特定语法:命令字母后面跟着一个反斜杠,并且文本从脚本的下一行上开始插入:
```
head -5 inputfile | sed '
1i\
# List of user accounts
$a\
# end
'
```
插入多行文本,你必须每一行结束的位置使用一个反斜杠:
```
head -5 inputfile | sed '
1i\
# List of user accounts\
# (users 1 through 5)
$a\
# end
'
```
一些 Sed 实现,比如 GNU Sed,在初始的反斜杠后面的换行符是可选的,即便是在 `--posix` 模式下仍然如此。我在标准中并没有找到任何关于该替代语法的说明(如果是因为我没有在标准中找到那个特性,请在评论区留言告诉我!)。因此,如果对可移植性要求很高,请注意使用它的风险:
```
# 非 POSIX 语法:
head -5 inputfile | sed -e '
1i\# List of user accounts
$a\# end
'
```
也有一些 Sed 的实现,让初始的反斜杠完全是可选的。因此毫无疑问,它是一个厂商对 POSIX 标准进行扩展的特定版本,它是否支持那个语法,你需要去查看那个 Sed 版本的手册。
在简单概述之后,我们现在来回顾一下这些命令的更多细节,从我还没有介绍的改变命令开始。
#### 改变命令
改变命令(`c\`)就像 `d` 命令一样删除模式空间的内容并开始一个新的循环。唯一的不同在于,当命令运行之后,用户提供的文本是写往输出的。

```
cat -n inputfile | sed -e '
/systemd/c\
# :REMOVED:
s/:.*// # This will NOT be applied to the "changed" text
'
```
如果改变命令与一个地址范围关联,当到达范围的最后一行时,这个文本将仅输出一次。这在某种程度上成为 Sed 命令将被重复应用在地址范围内所有行这一惯例的一个例外情况:
```
cat -n inputfile | sed -e '
19,22c\
# :REMOVED:
s/:.*// # This will NOT be applied to the "changed" text
'
```
因此,如果你希望将改变命令重复应用到地址范围内的所有行上,除了将它封装到一个块中之外,你将没有其它的选择:
```
cat -n inputfile | sed -e '
19,22{c\
# :REMOVED:
}
s/:.*// # This will NOT be applied to the "changed" text
'
```
#### 插入命令
插入命令(`i\`)将立即在输出中给出用户提供的文本。它并不以任何方式修改程序流或缓冲区的内容。

```
# display the first five user names with a title on the first row
sed < inputfile -e '
1i\
USER NAME
s/:.*//
5q
'
```
#### 追加命令
当输入的下一行被读取时,追加命令(`a\`)将一些文本追加到显示队列。文本在当前循环的结束部分(包含程序结束的情况)或当使用 `n` 或 `N` 命令从输入中读取一个新行时被输出。

与上面相同的一个示例,但这次是插入到底部而不是顶部:
```
sed < inputfile -e '
5a\
USER NAME
s/:.*//
5q
'
```
#### 读取命令
这是插入一些文本内容到输出流的第四个命令:读取命令(`r`)。它的工作方式与追加命令完全一样,但不同的,它不从 Sed 脚本中取得硬编码到脚本中的文本,而是把一个文件的内容写入到一个输出上。
读取命令只调度要读取的文件。当清理追加队列时,后者才被高效地读取,而不是在读取命令运行时。如果这时候对这个文件有并发的访问读取,或那个文件不是一个普通的文件(比如,它是一个字符设备或命名管道),或文件在读取期间被修改,这时可能会产生严重的后果。
作为一个例证,如果你使用我们将在下一节详细讲述的写入命令,它与读取命令共同配合从一个临时文件中写入并重新读取,你可能会获得一些创造性的结果(使用法语版的 [Shiritori](https://en.wikipedia.org/wiki/Shiritori) 游戏作为一个例证):
```
printf "%s\n" "Trois p'tits chats" "Chapeau d' paille" "Paillasson" |
sed -ne '
r temp
a\
----
w temp
'
```
现在,在流输出中专门用于插入一些文本的 Sed 命令清单结束了。我的最后一个示例纯属好玩,但是由于我前面提到过有一个写入命令,这个示例将我们完美地带到下一节,在下一节我们将看到在 Sed 中如何将数据写入到一个外部文件。
### 替代的输出
Sed 的设计思想是,所有的文本转换都将写入到进程的标准输出上。但是,Sed 也有一些特性支持将数据发送到替代的目的地。你有两种方式去实现上述的输出目标替换:使用专门的写入命令(`w`),或者在一个替换命令(`s`)上添加一个写入标志。
#### 写入命令
写入命令(`w`)会追加模式空间的内容到给定的目标文件中。POSIX 要求在 Sed 处理任何数据之前,目标文件能够被 Sed 所创建。如果给定的目标文件已经存在,它将被覆写。

因此,即便是你从未真的写入到该文件中,但该文件仍然会被创建。例如,下列的 Sed 程序将创建/覆写这个 `output` 文件,那怕是这个写入命令从未被运行过:
```
echo | sed -ne '
q # 立刻退出
w output # 这个命令从未被运行
'
```
你可以将几个写入命令指向到同一个目标文件。指向同一个目标文件的所有写入命令将追加那个文件的内容(工作方式几乎与 shell 的重定向符 `>>` 相同):
```
sed < inputfile -ne '
/:\/bin\/false$/w server
/:\/usr\/sbin\/nologin$/w server
w output
'
cat server
```
#### 替换命令的写入标志
在前面,我们已经学习了替换命令(`s`),它有一个 `p` 选项用于在替换之后输出模式空间的内容。同样它也提供一个类似功能的 `w` 选项,用于在替换之后将模式空间的内容输出到一个文件中:
```
sed < inputfile -ne '
s/:.*\/nologin$//w server
s/:.*\/false$//w server
'
cat server
```
### 注释
我无数次使用过它们,但我从未花时间正式介绍过它们,因此,我决定现在来正式地介绍它们:就像大多数编程语言一样,注释是添加软件不去解析的自由格式文本的一种方法。Sed 的语法很晦涩,我不得不强调在脚本中需要的地方添加足够的注释。否则,除了作者外其他人将几乎无法理解它。

不过,和 Sed 的其它部分一样,注释也有它自己的微妙之处。首先并且是最重要的,注释并不是语法结构,但它是真正意义的 Sed 命令。注释虽然是一个“什么也不做”的命令,但它仍然是一个命令。至少,它是在 POSIX 中定义了的。因此,严格地说,它们只允许使用在其它命令允许使用的地方。
大多数 Sed 实现都通过允许行内命令来放松了那种要求,就像在那个文章中我到处都使用的那样。
结束那个主题之前,需要说一下 `#n` 注释(`#` 后面紧跟一个字母 `n`,中间没有空格)的特殊情况。如果在脚本的第一行找到这个精确注释,Sed 将切换到静默模式(即:清除自动输出标志),就像在命令行上指定了 `-n` 选项一样。
### 很少用得到的命令
现在,我们已经学习的命令能让你写出你所用到的 99.99% 的脚本。但是,如果我没有提到剩余的 Sed 命令,那么本教程就不能称为完全指南。我把它们留到最后是因为我们很少用到它。但或许你有实际使用案例,那么你就会发现它们很有用。如果是那样,请不要犹豫,在下面的评论区中把它分享给我们吧。
#### 行数命令
这个 `=` 命令将向标准输出上显示当前 Sed 正在读取的行数,这个行数就是行计数器(`LC`)的内容。没有任何方式从任何一个 Sed 缓冲区中捕获那个数字,也不能对它进行输出格式化。由于这两个限制使得这个命令的可用性大大降低。

请记住,在严格的 POSIX 兼容模式中,当在命令行上给定几个输入文件时,Sed 并不重置那个计数器,而是连续地增长它,就像所有的输入文件是连接在一起的一样。一些 Sed 实现,像 GNU Sed,它就有一个选项可以在每个输入文件读取结束后去重置计数器。
#### 明确打印命令
这个 `l`(小写的字母 `l`)作用类似于打印命令(`p`),但它是以精确的格式去输出模式空间的内容。以下引用自 [POSIX 标准](http://pubs.opengroup.org/onlinepubs/9699919799/utilities/sed.html):
>
> 在 XBD 转义序列中列出的字符和相关的动作(`\\`、`\a`、`\b`、`\f`、`\r`、`\t`、`\v`)将被写为相应的转义序列;在那个表中的 `\n` 是不适用的。不在那个表中的不可打印字符将被写为一个三位八进制数字(在前面使用一个反斜杠 `\`),表示字符中的每个字节(最重要的字节在前面)。长行应该被换行,通过写一个反斜杠后跟一个换行符来表示换行位置;发生换行时的长度是不确定的,但应该适合输出设备的具体情况。每个行应该以一个 `$` 标记结束。
>
>
>

我怀疑这个命令是在非 [8 位规则化信道](https://en.wikipedia.org/wiki/8-bit_clean) 上交换数据的。就我本人而言,除了调试用途以外,也从未使用过它。
#### 移译命令
<ruby> 移译 <rt> transliterate </rt></ruby>(`y`)命令允许从一个源集到一个目标集映射模式空间的字符。它非常类似于 `tr` 命令,但是限制更多。

```
# The `y` c0mm4nd 1s for h4x0rz only
sed < inputfile -e '
s/:.*//
y/abcegio/48<3610/
'
```
虽然移译命令语法与替换命令的语法有一些相似之处,但它在替换字符串之后不接受任何选项。这个移译总是全局的。
请注意,移译命令要求源集和目标集之间要一一对应地转换。这意味着下面的 Sed 程序可能所做的事情并不是你乍一看所想的那样:
```
# 注意:这可能并不如你想的那样工作!
sed < inputfile -e '
s/:.*//
y/[a-z]/[A-Z]/
'
```
### 写在最后的话
```
# 它要做什么?
# 提示:答案就在不远处...
sed -E '
s/.*\W(.*)/\1/
h
${ x; p; }
d' < inputfile
```
我们已经学习了所有的 Sed 命令,真不敢相信我们已经做到了!如果你也读到这里了,应该恭喜你,尤其是如果你花费了一些时间,在你的系统上尝试了所有的不同示例!
正如你所见,Sed 是非常复杂的,不仅因为它的语法比较零乱,也因为许多极端案例或命令行为之间的细微差别。毫无疑问,我们可以将这些归结于历史的原因。尽管它有这么多缺点,但是 Sed 仍然是一个非常强大的工具,甚至到现在,它仍然是 Unix 工具箱中为数不多的大量使用的命令之一。是时候总结一下这篇文章了,没有你们的支持我将无法做到:请节选你对喜欢的或最具创意的 Sed 脚本,并共享给我们。如果我收集到的你们共享出的脚本足够多了,我将会把这些 Sed 脚本结集发布!
---
via: <https://linuxhandbook.com/sed-reference-guide/>
作者:[Sylvain Leroux](https://linuxhandbook.com/author/sylvain/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Explain](https://linuxhandbook.com/tag/explain/)
# Complete Sed Command Guide [Explained with Practical Examples]
Sed is a must know command for Linux sysadmins. This detailed guide provides an in-depth look at all the Sed commands and the tool execution model.


In a previous article, I showed the [basic usage of Sed](https://linuxhandbook.com/sed-command-basics/), the stream editor, on a practical use case. Today, be prepared to gain more insight about Sed as we will take an in-depth tour of the sed execution model.
This will be also an opportunity to make an exhaustive review of all Sed commands and to dive into their details and subtleties.
So, if you are ready, launch a terminal, [download the test files](https://gist.github.com/s-leroux/5cb36435bac46c10cfced26e4bf5588c) and sit comfortably before your keyboard: we will start our exploration right now!
## A little bit of theory on Sed

### A first look at the sed execution model
To truly understand Sed you must first understand the tool execution model.
When processing data, Sed reads one line of input at a time and stores it into the so-called * pattern space*. All Sed’s transformations apply to the pattern space. Transformations are described by one-letter commands provided on the command line or in an external Sed script file. Most Sed commands can be preceded by an address, or an address range, to limit their scope.
By default, Sed prints the content of the pattern space at the end of each processing cycle, that is, just before overwriting the pattern space with the next line of input. We can summarize that model like that:
- Try to read the next input line into the pattern space
If the read was successful:
- Apply in the script order all commands whose address matches the current input line
- If sed was not launched in quiet mode (
`-n`
) print the content of the (potentially modified) pattern space - got back to 1.
Since the content of the pattern space is lost after each line is processed, it is not suitable for long-term storage. For that purpose, Sed has a second buffer, the * hold space*. Sed never clears, puts or gets data from the hold space unless you explicitly request it. We will investigate that more in depth later when studying the
[exchange](https://linuxhandbook.com/sed-reference-guide/#the-exchange-command),
[get](https://linuxhandbook.com/sed-reference-guide/#the-get-command)and
[hold](https://linuxhandbook.com/sed-reference-guide/#the-hold-commands)commands.
### The Sed abstract machine
The model explained above is what you will see described in many Sed tutorials. Indeed, it is correct enough to understand the most basic Sed programs. But when you start digging into more advanced commands, you will see it is not sufficient. So let’s try to be a little bit more formal now.
Actually, Sed can be viewed as implementing an [abstract machine](http://mathworld.wolfram.com/AbstractMachine.html) whose [state](https://en.wikipedia.org/wiki/State_(computer_science)) is defined by three [buffers](https://en.wikipedia.org/wiki/Data_buffer), two [registers](https://en.wikipedia.org/wiki/Processor_register#Categories_of_registers), and two [flags](https://www.computerhope.com/jargon/f/flag.htm):
**three buffers**to store arbitrary length text. Yes:! In the basic execution model we talked about the pattern- and hold-space, but Sed has a third buffer: the*three*. From the Sed script perspective, it is a write-only buffer that Sed will flush automatically at predefined moments of its execution (broadly speaking before reading a new line from the input, or just before quitting).*append queue*- Sed also maintains
**two registers**: the(LC) which holds the number of lines read from the input, and the*line counter*(PC) which always hold the index (“position” in the script) of the next command to execute. Sed automatically increments the PC as part of its main loop. But using specific commands, a script can also directly modify the PC to skip or repeat parts of the program. This is how loops or conditional statements can be implemented with Sed. More on that in the dedicated*program counter*[branches section](https://linuxhandbook.com/sed-reference-guide/#branching)below. - Finally
**two flags**can modify the behavior of certain Sed commands: the(AP) the*auto-print flag*(SF). When the auto-print flag is*substitution flag*, Sed will automatically print the content of the pattern space*set*overwriting it (notably before reading a new line of input but not only). When the auto-print flag is*before*(“not set”), Sed will never print the content of the pattern space without an explicit command in the script. You can clear the auto-print flag by running Sed in “quiet mode” (using the*clear*`-n`
command line option or by using the[special comment](https://linuxhandbook.com/sed-reference-guide/#comments)`#n`
on the very first line or the script). The “substitution flag” is set by the[substitution command](https://linuxhandbook.com/sed-reference-guide/#the-substitution-command)(the`s`
command) when both its address and search pattern match the content of the pattern space. The substitution flag is cleared at the start of each new cycle, or when a new line is read from input, or after a conditional branch is taken. Here again, we will revisit that topic in details in the[branches section](https://linuxhandbook.com/sed-reference-guide/#branching).
In addition, Sed maintains the list of commands having entered their address range (more on that of the [range addresses](https://linuxhandbook.com/sed-reference-guide/#range-addresses) section) as well as a couple of file handles to read and write data. You will find some more information on that in the [read](https://linuxhandbook.com/sed-reference-guide/#the-read-command) and [write](https://linuxhandbook.com/sed-reference-guide/#the-write-command) command description.
[Sylvain Leroux](https://linuxhandbook.com/author/sylvain/)
Engineer by Passion, Teacher by Vocation. My goal is to share my enthusiasm for what I teach and prepare my students to develop their skills by themselves.
[Website](http://www.yesik.it/)France |
10,233 | Caffeinated 6.828:使用的工具 | https://pdos.csail.mit.edu/6.828/2018/tools.html | 2018-11-15T09:20:00 | [] | https://linux.cn/article-10233-1.html | 
在这个课程中你将使用两套工具:一个是 x86 模拟器 QEMU,它用来运行你的内核;另一个是编译器工具链,包括汇编器、链接器、C 编译器,以及调试器,它们用来编译和测试你的内核。本文有你需要去下载和安装你自己的副本相关信息。本课程假定你熟悉所有出现的 Unix 命令的用法。
我们强烈推荐你使用一个 Debathena 机器去做你的实验,比如 athena.dialup.mit.edu。如果你使用运行在 Linux 上的 MIT Athena 机器,那么本课程所需要的所有软件工具都在 6.828 的存储中:只需要输入 `add -f 6.828` 就可以访问它们。
如果你不使用 Debathena 机器,我们建议你使用一台 Linux 虚拟机。如果是这样,你可以在你的 Linux 虚拟机上构建和安装工具。我们将在下面介绍如何在 Linux 和 MacOS 计算上来构建和安装工具。
在 [Cygwin](http://www.cygwin.com) 的帮助下,在 Windows 中运行这个开发环境也是可行的。安装 cygwin,并确保安装了 flex 和 bison 包(它们在开发 header 软件包分类下面)。
对于 6.828 中使用的工具中的有用的命令,请参考[实验工具指南](labguide.html)。
### 编译器工具链
“编译器工具链“ 是一套程序,包括一个 C 编译器、汇编器和链接器,使用它们来将代码转换成可运行的二进制文件。你需要一个能够生成在 32 位 Intel 架构(x86 架构)上运行的 ELF 二进制格式程序的编译器工具链。
#### 测试你的编译器工具链
现代的 Linux 和 BSD UNIX 发行版已经为 6.828 提供了一个合适的工具链。去测试你的发行版,可以输入如下的命令:
```
% objdump -i
```
第二行应该是 `elf32-i386`。
```
% gcc -m32 -print-libgcc-file-name
```
这个命令应该会输出如 `/usr/lib/gcc/i486-linux-gnu/version/libgcc.a` 或 `/usr/lib/gcc/x86_64-linux-gnu/version/32/libgcc.a` 这样的东西。
如果这些命令都运行成功,说明你的工具链都已安装,你不需要去编译你自己的工具链。
如果 `gcc` 命令失败,你可能需要去安装一个开发环境。在 Ubuntu Linux 上,输入如下的命令:
```
% sudo apt-get install -y build-essential gdb
```
在 64 位的机器上,你可能需要去安装一个 32 位的支持库。链接失败的表现是有一个类似于 “`__udivdi3` not found” 和 “`__muldi3` not found” 的错误信息。在 Ubuntu Linux 上,输入如下的命令去尝试修复这个问题:
```
% sudo apt-get install gcc-multilib
```
#### 使用一个虚拟机
获得一个兼容的工具链的最容易的另外的方法是,在你的计算机上安装一个现代的 Linux 发行版。使用虚拟化平台,Linux 可以与你正常的计算环境和平共处。安装一个 Linux 虚拟机共有两步。首先,去下载一个虚拟化平台。
* [VirtualBox](http://www.oracle.com/us/technologies/virtualization/oraclevm/)(对 Mac、Linux、Windows 免费)— [下载地址](http://www.oracle.com/us/technologies/virtualization/oraclevm/)
* [VMware Player](http://www.vmware.com/products/player/)(对 Linux 和 Windows 免费,但要求注册)
* [VMware Fusion](http://www.vmware.com/products/fusion/)(可以从 IS&T 免费下载)。
VirtualBox 有点慢并且灵活性欠佳,但它免费!
虚拟化平台安装完成后,下载一个你选择的 Linux 发行版的引导磁盘镜像。
* 我们使用的是 [Ubuntu 桌面版](http://www.ubuntu.com/download/desktop)。
这将下载一个命名类似于 `ubuntu-10.04.1-desktop-i386.iso` 的文件。启动你的虚拟化平台并创建一个新(32 位)的虚拟机。使用下载的 Ubuntu 镜像作为一个引导磁盘;安装过程在不同的虚拟机上有所不同,但都很简单。就像上面一样输入 `objdump -i`,去验证你的工具是否已安装。你将在虚拟机中完成你的工作。
#### 构建你自己的编译器工具链
你需要花一些时间来设置,但是比起一个虚拟机来说,它的性能要稍好一些,并且让你工作在你熟悉的环境中(Unix/MacOS)。对于 MacOS 命令,你可以快进到文章的末尾部分去看。
##### Linux
通过将下列行添加到 `conf/env.mk` 中去使用你自己的工具链:
```
GCCPREFIX=
```
我们假设你将工具链安装到了 `/usr/local` 中。你将需要大量的空间(大约 1 GB)去编译工具。如果你空间不足,在它的 `make install` 步骤之后删除它们的目录。
下载下列包:
* <ftp://ftp.gmplib.org/pub/gmp-5.0.2/gmp-5.0.2.tar.bz2>
* <https://www.mpfr.org/mpfr-3.1.2/mpfr-3.1.2.tar.bz2>
* <http://www.multiprecision.org/downloads/mpc-0.9.tar.gz>
* <http://ftpmirror.gnu.org/binutils/binutils-2.21.1.tar.bz2>
* <http://ftpmirror.gnu.org/gcc/gcc-4.6.4/gcc-core-4.6.4.tar.bz2>
* <http://ftpmirror.gnu.org/gdb/gdb-7.3.1.tar.bz2>
(你可能也在使用这些包的最新版本。)解包并构建。安装到 `/usr/local` 中,它是我们建议的。要安装到不同的目录,如 `$PFX`,注意相应修改。如果有问题,可以看下面。
```
export PATH=$PFX/bin:$PATH
export LD_LIBRARY_PATH=$PFX/lib:$LD_LIBRARY_PATH
tar xjf gmp-5.0.2.tar.bz2
cd gmp-5.0.2
./configure --prefix=$PFX
make
make install # This step may require privilege (sudo make install)
cd ..
tar xjf mpfr-3.1.2.tar.bz2
cd mpfr-3.1.2
./configure --prefix=$PFX --with-gmp=$PFX
make
make install # This step may require privilege (sudo make install)
cd ..
tar xzf mpc-0.9.tar.gz
cd mpc-0.9
./configure --prefix=$PFX --with-gmp=$PFX --with-mpfr=$PFX
make
make install # This step may require privilege (sudo make install)
cd ..
tar xjf binutils-2.21.1.tar.bz2
cd binutils-2.21.1
./configure --prefix=$PFX --target=i386-jos-elf --disable-werror
make
make install # This step may require privilege (sudo make install)
cd ..
i386-jos-elf-objdump -i
# Should produce output like:
# BFD header file version (GNU Binutils) 2.21.1
# elf32-i386
# (header little endian, data little endian)
# i386...
tar xjf gcc-core-4.6.4.tar.bz2
cd gcc-4.6.4
mkdir build # GCC will not compile correctly unless you build in a separate directory
cd build
../configure --prefix=$PFX --with-gmp=$PFX --with-mpfr=$PFX --with-mpc=$PFX \
--target=i386-jos-elf --disable-werror \
--disable-libssp --disable-libmudflap --with-newlib \
--without-headers --enable-languages=c MAKEINFO=missing
make all-gcc
make install-gcc # This step may require privilege (sudo make install-gcc)
make all-target-libgcc
make install-target-libgcc # This step may require privilege (sudo make install-target-libgcc)
cd ../..
i386-jos-elf-gcc -v
# Should produce output like:
# Using built-in specs.
# COLLECT_GCC=i386-jos-elf-gcc
# COLLECT_LTO_WRAPPER=/usr/local/libexec/gcc/i386-jos-elf/4.6.4/lto-wrapper
# Target: i386-jos-elf
tar xjf gdb-7.3.1.tar.bz2
cd gdb-7.3.1
./configure --prefix=$PFX --target=i386-jos-elf --program-prefix=i386-jos-elf- \
--disable-werror
make all
make install # This step may require privilege (sudo make install)
cd ..
```
**Linux 排错:**
Q:我不能运行 `make install`,因为我在这台机器上没有 root 权限。
A:我们的指令假定你是安装到了 `/usr/local` 目录中。但是,在你的环境中可能并不是这样做的。如果你仅能够在你的家目录中安装代码。那么在上面的命令中,使用 `--prefix=$HOME` 去替换 `--prefix=/usr/local`。你也需要修改你的 `PATH` 和 `LD_LIBRARY_PATH` 环境变量,以通知你的 shell 这个工具的位置。例如:
```
export PATH=$HOME/bin:$PATH
export LD_LIBRARY_PATH=$HOME/lib:$LD_LIBRARY_PATH
```
在你的 `~/.bashrc` 文件中输入这些行,以便于你登入后不需要每次都输入它们。
Q:我构建失败了,错误信息是 “library not found”。
A:你需要去设置你的 `LD_LIBRARY_PATH`。环境变量必须包含 `PREFIX/lib` 目录(例如 `/usr/local/lib`)。
##### MacOS
首先从 Mac OSX 上安装开发工具开始:`xcode-select --install` 。
你可以从 homebrew 上安装 qemu 的依赖,但是不能去安装 qemu,因为我们需要安装打了 6.828 补丁的 qemu。
```
brew install $(brew deps qemu)
```
gettext 工具并不能把它已安装的二进制文件添加到路径中,因此你需要去运行:
```
PATH=${PATH}:/usr/local/opt/gettext/bin make install
```
完成后,开始安装 qemu。
### QEMU 模拟器
[QEMU](http://www.nongnu.org/qemu/) 是一个现代化的、并且速度非常快的 PC 模拟器。QEMU 的 2.3.0 版本是设置在 Athena 上的 6.828 中的 x86 机器存储中的(`add -f 6.828`)。
不幸的是,QEMU 的调试功能虽然很强大,但是有点不成熟,因此我们强烈建议你使用我们打过 6.828 补丁的版本,而不是发行版自带的版本。这个安装在 Athena 上的 QEMU 版本已经打过补丁了。构建你自己的、打 6.828 补丁的 QEMU 版本的过程如下:
1. 克隆 IAP 6.828 QEMU 的 git 仓库:`git clone https://github.com/mit-pdos/6.828-qemu.git qemu`。
2. 在 Linux 上,你或许需要安装几个库。我们成功地在 Debian/Ubuntu 16.04 上构建 6.828 版的 QEMU 需要安装下列的库:libsdl1.2-dev、libtool-bin、libglib2.0-dev、libz-dev 和 libpixman-1-dev。
3. 配置源代码(方括号中是可选参数;用你自己的真实路径替换 `PFX`)
1. Linux:`./configure --disable-kvm --disable-werror [--prefix=PFX] [--target-list="i386-softmmu x86_64-softmmu"]`。
2. OS X:`./configure --disable-kvm --disable-werror --disable-sdl [--prefix=PFX] [--target-list="i386-softmmu x86_64-softmmu"]`。`prefix` 参数指定安装 QEMU 的位置;如果不指定,将缺省安装 QEMU 到 `/usr/local` 目录中。`target-list` 参数将简单地简化 QEMU 所支持的架构。
4. 运行 `make && make install`。
---
via: <https://pdos.csail.mit.edu/6.828/2018/tools.html>
作者:[csail.mit](https://pdos.csail.mit.edu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You'll use two sets of tools in this class: an x86 emulator, [QEMU](#qemu), for
running your kernel; and a [compiler toolchain](#chain), including assembler, linker, C
compiler, and debugger, for compiling and testing your kernel. This page has the
information you'll need to download and install your own copies. This class
assumes familiarity with Unix commands throughout.
We highly recommend using a Debathena machine, such as
athena.dialup.mit.edu, to work on the labs. If you use the MIT Athena machines
that run Linux, then all the software tools you will need for this course are
located in the 6.828 locker: just type '`add -f 6.828`' to get access
to them.
If you don't have access to a Debathena machine, we recommend you use a virtual machine with Linux. If you really want to, you can build and install the tools on your own machine. We have instructions below for Linux and MacOS computers.
It should be possible to get this development environment running
under windows with the help of
[Cygwin](http://www.cygwin.com). Install cygwin, and be
sure to install the `flex` and `bison` packages
(they are under the development header).
For an overview of useful commands in the tools used in 6.828, see the
[lab tools guide](labguide.html).
A "compiler toolchain" is the set of programs, including a C compiler, assemblers, and linkers, that turn code into executable binaries. You'll need a compiler toolchain that generates code for 32-bit Intel architectures ("x86" architectures) in the ELF binary format.
Modern Linux and BSD UNIX distributions already provide a toolchain suitable for 6.828. To test your distribution, try the following commands:
```
% objdump -i
```
The second line should say `elf32-i386`.
```
% gcc -m32 -print-libgcc-file-name
```
The command should print something like
`/usr/lib/gcc/i486-linux-gnu/ version/libgcc.a` or
If both these commands succeed, you're all set, and don't need to compile your own toolchain.
If the gcc command fails, you may need to install a development environment. On Ubuntu Linux, try this:
```
% sudo apt-get install -y build-essential gdb
```
On 64-bit machines, you may need to install a 32-bit support
library. The symptom is that linking fails with error messages
like "`__udivdi3` not found" and "`__muldi3` not
found". On Ubuntu Linux, try this to fix the problem:
```
% sudo apt-get install gcc-multilib
```
Otherwise, the easiest way to get a compatible toolchain is to install a modern Linux distribution on your computer. With platform virtualization, Linux can cohabitate with your normal computing environment. Installing a Linux virtual machine is a two step process. First, you download the virtualization platform.
VirtualBox is a little slower and less flexible, but free!
Once the virtualization platform is installed, download a boot disk image for the Linux distribution of your choice.
This will download a file named something like
`ubuntu-10.04.1-desktop-i386.iso`. Start up your
virtualization platform and create a new (32-bit) virtual machine.
Use the downloaded Ubuntu image as a boot disk; the
procedure differs among VMs but is pretty simple. Type `objdump -i`, as above, to verify that your
toolchain is now set up. You will do your work inside the VM.
This will take longer to set up, but give slightly better performance than a virtual machine, and lets you work in your own familiar environment (Unix/MacOS). Fast-forward to the end for MacOS instructions.
You can use your own tool chain by adding the following line to
`conf/env.mk`:
GCCPREFIX=
We assume that you are installing the toolchain into
`/usr/local`. You will need a fair amount of disk space to compile
the tools (around 1GiB). If you don't have that much space, delete
each directory after its `make install` step.
Download the following packages:
(You may also use newer versions of these packages.)
Unpack and build the packages. The `green bold`
text shows you how to install into `/usr/local`
, which is what
we recommend. To install into a different directory,
$PFX, [click here](javascript:unfoldinstrux(1))note the differences in lighter type ([hide](javascript:unfoldinstrux(0))). If you have problems, see below.
export PATH=$PFX/bin:$PATH export LD_LIBRARY_PATH=$PFX/lib:$LD_LIBRARY_PATHtar xjf gmp-5.0.2.tar.bz2 cd gmp-5.0.2 ./configure --prefix=/usr/local--prefix=$PFX make make install # This step may require privilege (sudo make install) cd .. tar xjf mpfr-3.1.2.tar.bz2 cd mpfr-3.1.2 ./configure --prefix=/usr/local--prefix=$PFX --with-gmp=$PFX make make install # This step may require privilege (sudo make install) cd .. tar xzf mpc-0.9.tar.gz cd mpc-0.9 ./configure --prefix=/usr/local--prefix=$PFX --with-gmp=$PFX --with-mpfr=$PFX make make install # This step may require privilege (sudo make install) cd .. tar xjf binutils-2.21.1.tar.bz2 cd binutils-2.21.1 ./configure --prefix=/usr/local--prefix=$PFX --target=i386-jos-elf --disable-werror make make install # This step may require privilege (sudo make install) cd .. i386-jos-elf-objdump -i # Should produce output like: # BFD header file version (GNU Binutils) 2.21.1 # elf32-i386 # (header little endian, data little endian) # i386... tar xjf gcc-core-4.6.4.tar.bz2 cd gcc-4.6.4 mkdir build # GCC will not compile correctly unless you build in a separate directory cd build ../configure --prefix=/usr/local--prefix=$PFX --with-gmp=$PFX --with-mpfr=$PFX --with-mpc=$PFX \ --target=i386-jos-elf --disable-werror \ --disable-libssp --disable-libmudflap --with-newlib \ --without-headers --enable-languages=c MAKEINFO=missing make all-gcc make install-gcc # This step may require privilege (sudo make install-gcc) make all-target-libgcc make install-target-libgcc # This step may require privilege (sudo make install-target-libgcc) cd ../.. i386-jos-elf-gcc -v # Should produce output like: # Using built-in specs. # COLLECT_GCC=i386-jos-elf-gcc # COLLECT_LTO_WRAPPER=/usr/local/libexec/gcc/i386-jos-elf/4.6.4/lto-wrapper # Target: i386-jos-elf tar xjf gdb-7.3.1.tar.bz2 cd gdb-7.3.1 ./configure --prefix=/usr/local--prefix=$PFX --target=i386-jos-elf --program-prefix=i386-jos-elf- \ --disable-werror make all make install # This step may require privilege (sudo make install) cd ..
export PATH=$HOME/bin:$PATH export LD_LIBRARY_PATH=$HOME/lib:$LD_LIBRARY_PATHEnter these lines in your
`xcode-select --install`
You can install the qemu dependencies from homebrew, however do not install qemu itself as you will need the 6.828 patched version.
`brew install $(brew deps qemu)`
The gettext utility does not add installed binaries to the path, so you will need to run
`PATH=${PATH}:/usr/local/opt/gettext/bin make install`
when installing qemu below.
[QEMU](http://www.nongnu.org/qemu/) is a modern and fast
PC emulator. QEMU version 2.3.0 is set up on Athena for x86 machines
in the 6.828 locker (`add -f 6.828`)
Unfortunately, QEMU's debugging facilities, while powerful, are somewhat immature, so we highly recommend you use our patched version of QEMU instead of the stock version that may come with your distribution. The version installed on Athena is already patched. To build your own patched version of QEMU:
`git clone https://github.com/mit-pdos/6.828-qemu.git qemu `
`./configure --disable-kvm --disable-werror [--prefix=PFX] [--target-list="i386-softmmu x86_64-softmmu"]`
`./configure --disable-kvm --disable-werror --disable-sdl [--prefix=PFX] [--target-list="i386-softmmu x86_64-softmmu"]`
The `prefix`
argument specifies where to install QEMU; without it
QEMU will install to `/usr/local`
by default. The `target-list`
argument simply slims down the architectures QEMU will build support
for.`make && make install`
Questions or comments regarding 6.828? Send e-mail to the TAs at
[ [email protected]](mailto:[email protected]).
** Top** // |
10,234 | 使用 Python 的 toolz 库开始函数式编程 | https://opensource.com/article/18/10/functional-programming-python-toolz | 2018-11-15T09:42:09 | [
"函数式编程"
] | https://linux.cn/article-10234-1.html |
>
> toolz 库允许你操作函数,使其更容易理解,更容易测试代码。
>
>
>

在这个由两部分组成的系列文章的第二部分中,我们将继续探索如何将函数式编程方法中的好想法引入到 Python中,以实现两全其美。
在上一篇文章中,我们介绍了[不可变数据结构](/article-10222-1.html)。 这些数据结构使得我们可以编写“纯”函数,或者说是没有副作用的函数,仅仅接受一些参数并返回结果,同时保持良好的性能。
在这篇文章中,我们使用 toolz 库来构建。 这个库具有操作此类函数的函数,并且它们在纯函数中表现得特别好。 在函数式编程世界中,它们通常被称为“高阶函数”,因为它们将函数作为参数,将函数作为结果返回。
让我们从这里开始:
```
def add_one_word(words, word):
return words.set(words.get(word, 0) + 1)
```
这个函数假设它的第一个参数是一个不可变的类似字典的对象,它返回一个新的类似字典的在相关位置递增的对象:这就是一个简单的频率计数器。
但是,只有将它应用于单词流并做*归纳*时才有用。 我们可以使用内置模块 `functools` 中的归纳器。
```
functools.reduce(function, stream, initializer)
```
我们想要一个函数,应用于流,并且能能返回频率计数。
我们首先使用 `toolz.curry` 函数:
```
add_all_words = curry(functools.reduce, add_one_word)
```
使用此版本,我们需要提供初始化程序。但是,我们不能只将 `pyrsistent.m` 函数添加到 `curry` 函数中; 因为这个顺序是错误的。
```
add_all_words_flipped = flip(add_all_words)
```
`flip` 这个高阶函数返回一个调用原始函数的函数,并且翻转参数顺序。
```
get_all_words = add_all_words_flipped(pyrsistent.m())
```
我们利用 `flip` 自动调整其参数的特性给它一个初始值:一个空字典。
现在我们可以执行 `get_all_words(word_stream)` 这个函数来获取频率字典。 但是,我们如何获得一个单词流呢? Python 文件是按行供流的。
```
def to_words(lines):
for line in lines:
yield from line.split()
```
在单独测试每个函数后,我们可以将它们组合在一起:
```
words_from_file = toolz.compose(get_all_words, to_words)
```
在这种情况下,组合只是使两个函数很容易阅读:首先将文件的行流应用于 `to_words`,然后将 `get_all_words` 应用于 `to_words` 的结果。 但是文字上读起来似乎与代码执行相反。
当我们开始认真对待可组合性时,这很重要。有时可以将代码编写为一个单元序列,单独测试每个单元,最后将它们全部组合。如果有几个组合元素时,组合的顺序可能就很难理解。
`toolz` 库借用了 Unix 命令行的做法,并使用 `pipe` 作为执行相同操作的函数,但顺序相反。
```
words_from_file = toolz.pipe(to_words, get_all_words)
```
现在读起来更直观了:将输入传递到 `to_words`,并将结果传递给 `get_all_words`。 在命令行上,等效写法如下所示:
```
$ cat files | to_words | get_all_words
```
`toolz` 库允许我们操作函数,切片、分割和组合,以使我们的代码更容易理解和测试。
---
via: <https://opensource.com/article/18/10/functional-programming-python-toolz>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the second of a two-part series, we continue to explore how we can import ideas from functional programming methodology into Python to have the best of both worlds.
In the previous post, we covered [immutable data structures](https://opensource.com/article/18/10/functional-programming-python-immutable-data-structures). Those allow us to write "pure" functions, or functions that have no side effects, merely accepting some arguments and returning a result while maintaining decent performance.
In this post, we build on that using the `toolz`
library. This library has functions that manipulate such functions, and they work especially well with pure functions. In the functional programming world, these are often referred to as "higher-order functions" since they take functions as arguments and return functions as results.
Let's start with this:
```
def add_one_word(words, word):
return words.set(words.get(word, 0) + 1)
```
This function assumes that its first argument is an immutable dict-like object, and it returns a new dict-like object with the relevant place incremented: It's a simple frequency counter.
However, it is useful only if we apply it to a stream of words and *reduce*. We have access to a reducer in the built-in module `functools`
. `functools.reduce(function, stream, initializer)`
.
We want a function that, applied to a stream, will return a frequency count.
We start by using `toolz.curry`
:
`add_all_words = curry(functools.reduce, add_one_word)`
With this version, we will need to supply the initializer. However, we can't just add `pyrsistent.m`
to the `curry`
; it is in the wrong order.
`add_all_words_flipped = flip(add_all_words)`
The `flip`
higher-level function returns a function that calls the original, with arguments flipped.
`get_all_words = add_all_words_flipped(pyrsistent.m())`
We take advantage of the fact that `flip`
auto-curries its argument to give it a starting value: an empty dictionary.
Now we can do `get_all_words(word_stream)`
and get a frequency dictionary. However, how do we get a word stream? Python files are by line streams.
```
def to_words(lines):
for line in lines:
yield from line.split()
```
After testing each function by itself, we can combine them:
`words_from_file = toolz.compose(get_all_words, to_words)`
In this case, the composition being of just being two functions was straightforward to read: Apply `to_words`
first, then apply `get_all_words`
to the result. The prose, it seems, is in the inverse of the code.
This matters when we start taking composability seriously. It is sometimes possible to write the code as a sequence of units, test each individually, and finally, compose them all. If there are several elements, the ordering of `compose`
can get tricky to understand.
The `toolz`
library borrows from the Unix command line and uses `pipe`
as a function that does the same, but in the reverse order.
`words_from_file = toolz.pipe(to_words, get_all_words)`
Now it reads more intuitively: Pipe the input into `to_words`
, and pipe the results into `get_all_words`
. On a command line, the equivalent would look like this:
`$ cat files | to_words | get_all_words`
The `toolz`
library allows us to manipulate functions, slicing, dicing, and composing them to make our code easier to understand and to test.
## 2 Comments |
10,235 | 17 种查看 Linux 物理内存的方法 | https://www.2daygeek.com/easy-ways-to-check-size-of-physical-memory-ram-in-linux/ | 2018-11-15T19:02:11 | [
"内存"
] | https://linux.cn/article-10235-1.html | 
大多数系统管理员在遇到性能问题时会检查 CPU 和内存利用率。Linux 中有许多实用程序可以用于检查物理内存。这些命令有助于我们检查系统中存在的物理内存,还允许用户检查各种方面的内存利用率。
我们大多数人只知道很少的命令,在本文中我们试图包含所有可能的命令。
你可能会想,为什么我想知道所有这些命令,而不是知道一些特定的和例行的命令呢。
不要觉得没用或对此有负面的看法,因为每个人都有不同的需求和看法,所以,对于那些在寻找其它目的的人,这对于他们非常有帮助。
### 什么是 RAM
计算机内存是能够临时或永久存储信息的物理设备。RAM 代表随机存取存储器,它是一种易失性存储器,用于存储操作系统,软件和硬件使用的信息。
有两种类型的内存可供选择:
* 主存
* 辅助内存
主存是计算机的主存储器。CPU 可以直接读取或写入此内存。它固定在电脑的主板上。
* **RAM**:随机存取存储器是临时存储。关闭计算机后,此信息将消失。
* **ROM**: 只读存储器是永久存储,即使系统关闭也能保存数据。
### 方法-1:使用 free 命令
`free` 显示系统中空闲和已用的物理内存和交换内存的总量,以及内核使用的缓冲区和缓存。它通过解析 `/proc/meminfo` 来收集信息。
**建议阅读:** [free – 在 Linux 系统中检查内存使用情况统计(空闲和已用)的标准命令](https://www.2daygeek.com/free-command-to-check-memory-usage-statistics-in-linux/)
```
$ free -m
total used free shared buff/cache available
Mem: 1993 1681 82 81 228 153
Swap: 12689 1213 11475
$ free -g
total used free shared buff/cache available
Mem: 1 1 0 0 0 0
Swap: 12 1 11
```
### 方法-2:使用 /proc/meminfo 文件
`/proc/meminfo` 是一个虚拟文本文件,它包含有关系统 RAM 使用情况的大量有价值的信息。
它报告系统上的空闲和已用内存(物理和交换)的数量。
```
$ grep MemTotal /proc/meminfo
MemTotal: 2041396 kB
$ grep MemTotal /proc/meminfo | awk '{print $2 / 1024}'
1993.55
$ grep MemTotal /proc/meminfo | awk '{print $2 / 1024 / 1024}'
1.94683
```
### 方法-3:使用 top 命令
`top` 命令是 Linux 中监视实时系统进程的基本命令之一。它显示系统信息和运行的进程信息,如正常运行时间、平均负载、正在运行的任务、登录的用户数、CPU 数量和 CPU 利用率,以及内存和交换信息。运行 `top` 命令,然后按下 `E` 来使内存利用率以 MB 为单位显示。
**建议阅读:** [TOP 命令示例监视服务器性能](https://www.2daygeek.com/top-command-examples-to-monitor-server-performance/)
```
$ top
top - 14:38:36 up 1:59, 1 user, load average: 1.83, 1.60, 1.52
Tasks: 223 total, 2 running, 221 sleeping, 0 stopped, 0 zombie
%Cpu(s): 48.6 us, 11.2 sy, 0.0 ni, 39.3 id, 0.3 wa, 0.0 hi, 0.5 si, 0.0 st
MiB Mem : 1993.551 total, 94.184 free, 1647.367 used, 252.000 buff/cache
MiB Swap: 12689.58+total, 11196.83+free, 1492.750 used. 306.465 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9908 daygeek 20 0 2971440 649324 39700 S 55.8 31.8 11:45.74 Web Content
21942 daygeek 20 0 2013760 308700 69272 S 35.0 15.1 4:13.75 Web Content
4782 daygeek 20 0 3687116 227336 39156 R 14.5 11.1 16:47.45 gnome-shell
```
### 方法-4:使用 vmstat 命令
`vmstat` 是一个漂亮的标准工具,它报告 Linux 系统的虚拟内存统计信息。`vmstat` 报告有关进程、内存、分页、块 IO、陷阱和 CPU 活动的信息。它有助于 Linux 管理员在故障检修时识别系统瓶颈。
**建议阅读:** [vmstat – 一个报告虚拟内存统计信息的标准且漂亮的工具](https://www.2daygeek.com/linux-vmstat-command-examples-tool-report-virtual-memory-statistics/)
```
$ vmstat -s | grep "total memory"
2041396 K total memory
$ vmstat -s -S M | egrep -ie 'total memory'
1993 M total memory
$ vmstat -s | awk '{print $1 / 1024 / 1024}' | head -1
1.94683
```
### 方法-5:使用 nmon 命令
`nmon` 是另一个很棒的工具,用于在 Linux 终端上监视各种系统资源,如 CPU、内存、网络、磁盘、文件系统、NFS、top 进程、Power 的微分区和资源(Linux 版本和处理器)。
只需按下 `m` 键,即可查看内存利用率统计数据(缓存、活动、非活动、缓冲、空闲,以 MB 和百分比为单位)。
**建议阅读:** [nmon – Linux 中一个监视系统资源的漂亮的工具](https://www.2daygeek.com/nmon-system-performance-monitor-system-resources-on-linux/)
```
┌nmon─14g──────[H for help]───Hostname=2daygeek──Refresh= 2secs ───07:24.44─────────────────┐
│ Memory Stats ─────────────────────────────────────────────────────────────────────────────│
│ RAM High Low Swap Page Size=4 KB │
│ Total MB 32079.5 -0.0 -0.0 20479.0 │
│ Free MB 11205.0 -0.0 -0.0 20479.0 │
│ Free Percent 34.9% 100.0% 100.0% 100.0% │
│ MB MB MB │
│ Cached= 19763.4 Active= 9617.7 │
│ Buffers= 172.5 Swapcached= 0.0 Inactive = 10339.6 │
│ Dirty = 0.0 Writeback = 0.0 Mapped = 11.0 │
│ Slab = 636.6 Commit_AS = 118.2 PageTables= 3.5 │
│───────────────────────────────────────────────────────────────────────────────────────────│
│ │
│ │
│ │
│ │
│ │
│ │
└───────────────────────────────────────────────────────────────────────────────────────────┘
```
### 方法-6:使用 dmidecode 命令
`dmidecode` 是一个读取计算机 DMI 表内容的工具,它以人类可读的格式显示系统硬件信息。(DMI 意即桌面管理接口,也有人说是读取的是 SMBIOS —— 系统管理 BIOS)
此表包含系统硬件组件的描述,以及其它有用信息,如序列号、制造商信息、发布日期和 BIOS 修改等。
**建议阅读:** [Dmidecode – 获取 Linux 系统硬件信息的简便方法](https://www.2daygeek.com/dmidecode-get-print-display-check-linux-system-hardware-information/)
```
# dmidecode -t memory | grep Size:
Size: 8192 MB
Size: No Module Installed
Size: No Module Installed
Size: 8192 MB
Size: No Module Installed
Size: No Module Installed
Size: No Module Installed
Size: No Module Installed
Size: No Module Installed
Size: No Module Installed
Size: No Module Installed
Size: No Module Installed
Size: 8192 MB
Size: No Module Installed
Size: No Module Installed
Size: 8192 MB
Size: No Module Installed
Size: No Module Installed
Size: No Module Installed
Size: No Module Installed
Size: No Module Installed
Size: No Module Installed
Size: No Module Installed
Size: No Module Installed
```
只打印已安装的 RAM 模块。
```
# dmidecode -t memory | grep Size: | grep -v "No Module Installed"
Size: 8192 MB
Size: 8192 MB
Size: 8192 MB
Size: 8192 MB
```
汇总所有已安装的 RAM 模块。
```
# dmidecode -t memory | grep Size: | grep -v "No Module Installed" | awk '{sum+=$2}END{print sum}'
32768
```
### 方法-7:使用 hwinfo 命令
`hwinfo` 意即硬件信息,它是另一个很棒的实用工具,用于探测系统中存在的硬件,并以人类可读的格式显示有关各种硬件组件的详细信息。
它报告有关 CPU、RAM、键盘、鼠标、图形卡、声音、存储、网络接口、磁盘、分区、BIOS 和网桥等的信息。
**建议阅读:** [hwinfo(硬件信息)– 一个在 Linux 系统上检测系统硬件信息的好工具](https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/)
```
$ hwinfo --memory
01: None 00.0: 10102 Main Memory
[Created at memory.74]
Unique ID: rdCR.CxwsZFjVASF
Hardware Class: memory
Model: "Main Memory"
Memory Range: 0x00000000-0x7a4abfff (rw)
Memory Size: 1 GB + 896 MB
Config Status: cfg=new, avail=yes, need=no, active=unknown
```
### 方法-8:使用 lshw 命令
`lshw`(代表 Hardware Lister)是一个小巧的工具,可以生成机器上各种硬件组件的详细报告,如内存配置、固件版本、主板配置、CPU 版本和速度、缓存配置、USB、网卡、显卡、多媒体、打印机、总线速度等。
它通过读取 `/proc` 目录和 DMI 表中的各种文件来生成硬件信息。
**建议阅读:** [LSHW (Hardware Lister) – 一个在 Linux 上获取硬件信息的好工具](https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/)
```
$ sudo lshw -short -class memory
[sudo] password for daygeek:
H/W path Device Class Description
==================================================
/0/0 memory 128KiB BIOS
/0/1 memory 1993MiB System memory
```
### 方法-9:使用 inxi 命令
`inxi` 是一个很棒的工具,它可以检查 Linux 上的硬件信息,并提供了大量的选项来获取 Linux 系统上的所有硬件信息,这些特性是我在 Linux 上的其它工具中从未发现的。它是从 locsmif 编写的古老的但至今看来都异常灵活的 infobash 演化而来的。
`inxi` 是一个脚本,它可以快速显示系统硬件、CPU、驱动程序、Xorg、桌面、内核、GCC 版本、进程、RAM 使用情况以及各种其它有用的信息,还可以用于论坛技术支持和调试工具。
**建议阅读:** [inxi – 一个检查 Linux 上硬件信息的好工具](https://www.2daygeek.com/inxi-system-hardware-information-on-linux/)
```
$ inxi -F | grep "Memory"
Info: Processes: 234 Uptime: 3:10 Memory: 1497.3/1993.6MB Client: Shell (bash) inxi: 2.3.37
```
### 方法-10:使用 screenfetch 命令
`screenfetch` 是一个 bash 脚本。它将自动检测你的发行版,并在右侧显示该发行版标识的 ASCII 艺术版本和一些有价值的信息。
**建议阅读:** [ScreenFetch – 以 ASCII 艺术标志在终端显示 Linux 系统信息](https://www.2daygeek.com/screenfetch-display-linux-systems-information-ascii-distribution-logo-terminal/)
```
$ screenfetch
./+o+- daygeek@ubuntu
yyyyy- -yyyyyy+ OS: Ubuntu 17.10 artful
://+//////-yyyyyyo Kernel: x86_64 Linux 4.13.0-37-generic
.++ .:/++++++/-.+sss/` Uptime: 44m
.:++o: /++++++++/:--:/- Packages: 1831
o:+o+:++.`..`` `.-/oo+++++/ Shell: bash 4.4.12
.:+o:+o/. `+sssoo+/ Resolution: 1920x955
.++/+:+oo+o:` /sssooo. DE: GNOME
/+++//+:`oo+o /::--:. WM: GNOME Shell
\+/+o+++`o++o ++////. WM Theme: Adwaita
.++.o+++oo+:` /dddhhh. GTK Theme: Azure [GTK2/3]
.+.o+oo:. `oddhhhh+ Icon Theme: Papirus-Dark
\+.++o+o``-````.:ohdhhhhh+ Font: Ubuntu 11
`:o+++ `ohhhhhhhhyo++os: CPU: Intel Core i7-6700HQ @ 2x 2.592GHz
.o:`.syhhhhhhh/.oo++o` GPU: llvmpipe (LLVM 5.0, 256 bits)
/osyyyyyyo++ooo+++/ RAM: 1521MiB / 1993MiB
````` +oo+++o\:
`oo++.
```
### 方法-11:使用 neofetch 命令
`neofetch` 是一个跨平台且易于使用的命令行(CLI)脚本,它收集你的 Linux 系统信息,并将其作为一张图片显示在终端上,也可以是你的发行版徽标,或者是你选择的任何 ascii 艺术。
**建议阅读:** [Neofetch – 以 ASCII 分发标志来显示 Linux 系统信息](https://www.2daygeek.com/neofetch-display-linux-systems-information-ascii-distribution-logo-terminal/)
```
$ neofetch
.-/+oossssoo+/-. daygeek@ubuntu
`:+ssssssssssssssssss+:` --------------
-+ssssssssssssssssssyyssss+- OS: Ubuntu 17.10 x86_64
.ossssssssssssssssssdMMMNysssso. Host: VirtualBox 1.2
/ssssssssssshdmmNNmmyNMMMMhssssss/ Kernel: 4.13.0-37-generic
+ssssssssshmydMMMMMMMNddddyssssssss+ Uptime: 47 mins
/sssssssshNMMMyhhyyyyhmNMMMNhssssssss/ Packages: 1832
.ssssssssdMMMNhsssssssssshNMMMdssssssss. Shell: bash 4.4.12
+sssshhhyNMMNyssssssssssssyNMMMysssssss+ Resolution: 1920x955
ossyNMMMNyMMhsssssssssssssshmmmhssssssso DE: ubuntu:GNOME
ossyNMMMNyMMhsssssssssssssshmmmhssssssso WM: GNOME Shell
+sssshhhyNMMNyssssssssssssyNMMMysssssss+ WM Theme: Adwaita
.ssssssssdMMMNhsssssssssshNMMMdssssssss. Theme: Azure [GTK3]
/sssssssshNMMMyhhyyyyhdNMMMNhssssssss/ Icons: Papirus-Dark [GTK3]
+sssssssssdmydMMMMMMMMddddyssssssss+ Terminal: gnome-terminal
/ssssssssssshdmNNNNmyNMMMMhssssss/ CPU: Intel i7-6700HQ (2) @ 2.591GHz
.ossssssssssssssssssdMMMNysssso. GPU: VirtualBox Graphics Adapter
-+sssssssssssssssssyyyssss+- Memory: 1620MiB / 1993MiB
`:+ssssssssssssssssss+:`
.-/+oossssoo+/-.
```
### 方法-12:使用 dmesg 命令
`dmesg`(代表显示消息或驱动消息)是大多数类 Unix 操作系统上的命令,用于打印内核的消息缓冲区。
```
$ dmesg | grep "Memory"
[ 0.000000] Memory: 1985916K/2096696K available (12300K kernel code, 2482K rwdata, 4000K rodata, 2372K init, 2368K bss, 110780K reserved, 0K cma-reserved)
[ 0.012044] x86/mm: Memory block size: 128MB
```
### 方法-13:使用 atop 命令
`atop` 是一个用于 Linux 的 ASCII 全屏系统性能监视工具,它能报告所有服务器进程的活动(即使进程在间隔期间已经完成)。
它记录系统和进程活动以进行长期分析(默认情况下,日志文件保存 28 天),通过使用颜色等来突出显示过载的系统资源。它结合可选的内核模块 netatop 显示每个进程或线程的网络活动。
**建议阅读:** [Atop – 实时监控系统性能,资源,进程和检查资源利用历史](https://www.2daygeek.com/atop-system-process-performance-monitoring-tool/)
```
$ atop -m
ATOP - ubuntu 2018/03/31 19:34:08 ------------- 10s elapsed
PRC | sys 0.47s | user 2.75s | | | #proc 219 | #trun 1 | #tslpi 802 | #tslpu 0 | #zombie 0 | clones 7 | | | #exit 4 |
CPU | sys 7% | user 22% | irq 0% | | | idle 170% | wait 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
cpu | sys 3% | user 11% | irq 0% | | | idle 85% | cpu001 w 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
cpu | sys 4% | user 11% | irq 0% | | | idle 85% | cpu000 w 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
CPL | avg1 1.98 | | avg5 3.56 | avg15 3.20 | | | csw 14894 | | intr 6610 | | | numcpu 2 | |
MEM | tot 1.9G | free 101.7M | cache 244.2M | dirty 0.2M | buff 6.9M | slab 92.9M | slrec 35.6M | shmem 97.8M | shrss 21.0M | shswp 3.2M | vmbal 0.0M | hptot 0.0M | hpuse 0.0M |
SWP | tot 12.4G | free 11.6G | | | | | | | | | vmcom 7.9G | | vmlim 13.4G |
PAG | scan 0 | steal 0 | | stall 0 | | | | | | | swin 3 | | swout 0 |
DSK | sda | busy 0% | | read 114 | write 37 | KiB/r 21 | KiB/w 6 | | MBr/s 0.2 | MBw/s 0.0 | avq 6.50 | | avio 0.26 ms |
NET | transport | tcpi 11 | tcpo 17 | udpi 4 | udpo 8 | tcpao 3 | tcppo 0 | | tcprs 3 | tcpie 0 | tcpor 0 | udpnp 0 | udpie 0 |
NET | network | ipi 20 | | ipo 33 | ipfrw 0 | deliv 20 | | | | | icmpi 5 | | icmpo 0 |
NET | enp0s3 0% | pcki 11 | pcko 28 | sp 1000 Mbps | si 1 Kbps | so 1 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
NET | lo ---- | pcki 9 | pcko 9 | sp 0 Mbps | si 0 Kbps | so 0 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
PID TID MINFLT MAJFLT VSTEXT VSLIBS VDATA VSTACK VSIZE RSIZE PSIZE VGROW RGROW SWAPSZ RUID EUID MEM CMD 1/1
2536 - 941 0 188K 127.3M 551.2M 144K 2.3G 281.2M 0K 0K 344K 6556K daygeek daygeek 14% Web Content
2464 - 75 0 188K 187.7M 680.6M 132K 2.3G 226.6M 0K 0K 212K 42088K daygeek daygeek 11% firefox
2039 - 4199 6 16K 163.6M 423.0M 132K 3.5G 220.2M 0K 0K 2936K 109.6M daygeek daygeek 11% gnome-shell
10822 - 1 0 4K 16680K 377.0M 132K 3.4G 193.4M 0K 0K 0K 0K root root 10% java
```
### 方法-14:使用 htop 命令
`htop` 是由 Hisham 用 ncurses 库开发的用于 Linux 的交互式进程查看器。与 `top` 命令相比,`htop` 有许多特性和选项。
**建议阅读:** [使用 Htop 命令监视系统资源](https://www.2daygeek.com/htop-command-examples-to-monitor-system-resources/)
```
$ htop
1 [||||||||||||| 13.0%] Tasks: 152, 587 thr; 1 running
2 [||||||||||||||||||||||||| 25.0%] Load average: 0.91 2.03 2.66
Mem[||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||1.66G/1.95G] Uptime: 01:14:53
Swp[|||||| 782M/12.4G]
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
2039 daygeek 20 0 3541M 214M 46728 S 36.6 10.8 22:36.77 /usr/bin/gnome-shell
2045 daygeek 20 0 3541M 214M 46728 S 10.3 10.8 3:02.92 /usr/bin/gnome-shell
2046 daygeek 20 0 3541M 214M 46728 S 8.3 10.8 3:04.96 /usr/bin/gnome-shell
6080 daygeek 20 0 807M 37228 24352 S 2.1 1.8 0:11.99 /usr/lib/gnome-terminal/gnome-terminal-server
2880 daygeek 20 0 2205M 164M 17048 S 2.1 8.3 7:16.50 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
6125 daygeek 20 0 1916M 159M 92352 S 2.1 8.0 2:09.14 /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
2536 daygeek 20 0 2335M 243M 26792 S 2.1 12.2 6:25.77 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
2653 daygeek 20 0 2237M 185M 20788 S 1.4 9.3 3:01.76 /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
```
### 方法-15:使用 corefreq 实用程序
CoreFreq 是为 Intel 64 位处理器设计的 CPU 监控软件,支持的架构有 Atom、Core2、Nehalem、SandyBridge 和 superior,AMD 家族 0F。
CoreFreq 提供了一个框架来以高精确度检索 CPU 数据。
**建议阅读:** [CoreFreq – 一个用于 Linux 系统的强大的 CPU 监控工具](https://www.2daygeek.com/corefreq-linux-cpu-monitoring-tool/)
```
$ ./corefreq-cli -k
Linux:
|- Release [4.13.0-37-generic]
|- Version [#42-Ubuntu SMP Wed Mar 7 14:13:23 UTC 2018]
|- Machine [x86_64]
Memory:
|- Total RAM 2041396 KB
|- Shared RAM 99620 KB
|- Free RAM 108428 KB
|- Buffer RAM 8108 KB
|- Total High 0 KB
|- Free High 0 KB
```
### 方法-16:使用 glances 命令
Glances 是用 Python 编写的跨平台基于 curses(LCTT 译注:curses 是一个 Linux/Unix 下的图形函数库)的系统监控工具。我们可以说它一应俱全,就像在最小的空间含有最大的信息。它使用 psutil 库从系统中获取信息。
Glances 可以监视 CPU、内存、负载、进程列表、网络接口、磁盘 I/O、Raid、传感器、文件系统(和文件夹)、Docker、监视器、警报、系统信息、正常运行时间、快速预览(CPU、内存、负载)等。
**建议阅读:** [Glances (一应俱全)– 一个 Linux 的高级的实时系 统性能监控工具](https://www.2daygeek.com/install-glances-advanced-real-time-linux-system-performance-monitoring-tool-on-centos-fedora-ubuntu-debian-opensuse-arch-linux/)
```
$ glances
ubuntu (Ubuntu 17.10 64bit / Linux 4.13.0-37-generic) - IP 192.168.1.6/24 Uptime: 1:08:40
CPU [|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 90.6%] CPU - 90.6% nice: 0.0% ctx_sw: 4K MEM \ 78.4% active: 942M SWAP - 5.9% LOAD 2-core
MEM [||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 78.0%] user: 55.1% irq: 0.0% inter: 1797 total: 1.95G inactive: 562M total: 12.4G 1 min: 4.35
SWAP [|||| 5.9%] system: 32.4% iowait: 1.8% sw_int: 897 used: 1.53G buffers: 14.8M used: 749M 5 min: 4.38
idle: 7.6% steal: 0.0% free: 431M cached: 273M free: 11.7G 15 min: 3.38
NETWORK Rx/s Tx/s TASKS 211 (735 thr), 4 run, 207 slp, 0 oth sorted automatically by memory_percent, flat view
docker0 0b 232b
enp0s3 12Kb 4Kb Systemd 7 Services loaded: 197 active: 196 failed: 1
lo 616b 616b
_h478e48e 0b 232b CPU% MEM% VIRT RES PID USER NI S TIME+ R/s W/s Command
63.8 18.9 2.33G 377M 2536 daygeek 0 R 5:57.78 0 0 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
DefaultGateway 83ms 78.5 10.9 3.46G 217M 2039 daygeek 0 S 21:07.46 0 0 /usr/bin/gnome-shell
8.5 10.1 2.32G 201M 2464 daygeek 0 S 8:45.69 0 0 /usr/lib/firefox/firefox -new-window
DISK I/O R/s W/s 1.1 8.5 2.19G 170M 2653 daygeek 0 S 2:56.29 0 0 /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
dm-0 0 0 1.7 7.2 2.15G 143M 2880 daygeek 0 S 7:10.46 0 0 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
sda1 9.46M 12K 0.0 4.9 1.78G 97.2M 6125 daygeek 0 S 1:36.57 0 0 /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
```
### 方法-17 : 使用 Gnome 系统监视器
Gnome 系统监视器是一个管理正在运行的进程和监视系统资源的工具。它向你显示正在运行的程序以及耗费的处理器时间,内存和磁盘空间。

---
via: <https://www.2daygeek.com/easy-ways-to-check-size-of-physical-memory-ram-in-linux/>
作者:[Ramya Nuvvula](https://www.2daygeek.com/author/ramya/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,236 | 我爱开源的 7 个理由 | https://opensource.com/article/18/11/reasons-love-open-source | 2018-11-15T23:21:56 | [
"社区"
] | https://linux.cn/article-10236-1.html |
>
> 成为开源社区的一员绝对是一个明智之举,原因有很多。
>
>
>

这就是我为什么包括晚上和周末在内花费非常多的时间待在 [GitHub](https://github.com/ColinEberhardt/) 上,成为开源社区的一个活跃成员。
我参加过各种规模的项目,从个人项目到几个人的协作项目,乃至有数百位贡献者的项目,每一个项目都让我有新的受益。

也就是说,这里有七个原因让我为开源做出贡献:
* **它让我的技能与时俱进。** 在咨询公司的管理职位工作,有时我觉得自己与创建软件的实际过程越来越远。参与开源项目使我可以重新回到我最热爱的编程之中。也使我能够体验新技术,学习新技术和语言,并且使我不被酷酷的孩子们落下。
* **它教我如何与人打交道。** 与一群素未谋面的人合作开源项目在与人交往方面能够教会你很多。你很快会发现每个人有他们自己的压力,他们自己的义务,以及不同的时间表。学习如何与一群陌生人合作是一种很好的生活技能。
* **它使我成为一个更好的沟通者。** 开源项目的维护者的时间有限。你很快就知道,要成功地贡献,你必须能够清楚、简明地表达你所做的改变、添加或修复,最重要的是,你为什么要这么做。
* **它使我成为一个更好的开发者。** 没有什么能像成百上千的其他开发者依赖你的代码一样 —— 它敦促你更加专注软件设计、测试和文档。
* **它使我的造物变得更好。** 可能开源背后最强大的观念是它允许你驾驭一个由有创造力、有智慧、有知识的个人组成的全球网络。我知道我自己一个人的能力是有限的,我不可能什么都知道,但与开源社区的合作有助于我改进我的创作。
* **它告诉我小事物的价值。** 如果一个项目的文档不清楚或不完整,我会毫不犹豫地把它做得更好。一个小小的更新或修复可能只节省开发人员几分钟的时间,但是随着用户数量的增加,您一个小小的更改可能产生巨大的价值。
* **它使我更好的营销。** 好的,这是一个奇怪的例子。有这么多伟大的开源项目在那里,感觉像一场争夺关注的拼搏。从事于开源让我学到了很多营销的价值。这不是关于讲述或创建一个华丽的网站。而是关于如何清楚地传达你所创造的,它是如何使用的,以及它带来的好处。
我可以继续讨论开源是如何帮助你发展伙伴、关系和朋友的,不过你应该都知道了。有许多原因让我乐于成为开源社区的一员。
你可能想知道这些如何用于大型金融服务机构的 IT 战略。简单来说:谁不想要一个擅长与人交流和工作,具有尖端的技能,并能够推销他们的成果的开发团队呢?
---
via: <https://opensource.com/article/18/11/reasons-love-open-source>
作者:[Colin Eberhardt](https://opensource.com/users/colineberhardt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChiZelin](https://github.com/ChiZelin) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Here's why I spend so much of my time—including evenings and weekends—[on GitHub](https://github.com/ColinEberhardt/), as an active member of the open source community.
I’ve worked on everything from solo projects to small collaborative group efforts to projects with hundreds of contributors. With each project, I’ve learned something new.
That said, here are seven reasons why I contribute to open source:
**It keeps my skills fresh.**As someone in a management position at a consultancy, I sometimes feel like I am becoming more and more distant from the physical process of creating software. Working on open source projects allows me to get back to what I love best: writing code. It also allows me to experiment with new technologies, learn new techniques and languages—and keep up with the cool kids!**It teaches me about people.**Working on an open source project with a group of people you’ve never met teaches you a lot about how to interact with people. You quickly discover that everyone has their own pressures, their own commitments, and differing timescales. Learning how to work collaboratively with a group of strangers is a great life skill.**It makes me a better communicator.**Maintainers of open source projects have a limited amount of time. You quickly learn that to successfully contribute, you must be able to communicate clearly and concisely what you are changing, adding, or fixing, and most importantly, why you are doing it.**It makes me a better developer**. There is nothing quite like having hundreds—or thousands—of other developers depend on your code. It motivates you to pay a lot more attention to software design, testing, and documentation.**It makes my own creations better**. Possibly the most powerful concept behind open source is that it allows you to harness a global network of creative, intelligent, and knowledgeable individuals. I know I have my limits, and I don’t know everything, but engaging with the open source community helps me improve my creations.**It teaches me the value of small things**. If the documentation for a project is unclear or incomplete, I don’t hesitate to make it better. One small update or fix might save a developer only a few minutes, but multiplied across all the users, your one small change can have a significant impact.**It makes me better at marketing**. Ok, this is an odd one. There are so many great open source projects out there that it can feel like a struggle to get noticed. Working in open source has taught me a lot about the value of marketing your creations. This isn’t about spin or creating a flashy website. It is about clearly communicating what you have created, how it is used, and the benefits it brings.
I could go on about how open source helps you build partnerships, connections, and friends, but you get the idea. There are a great many reasons why I thoroughly enjoy being part of the open source community.
You might be wondering how all this applies to the IT strategy for large financial services organizations. Simple: Who *wouldn’t* want a team of developers who are great at communicating and working with people, have cutting-edge skills, and are able to market their creations?
## 2 Comments |
10,237 | Terminalizer:一个记录您终端活动并且生成 Gif 图像的工具 | https://www.2daygeek.com/terminalizer-a-tool-to-record-your-terminal-and-generate-animated-gif-images/ | 2018-11-15T23:40:02 | [
"gif"
] | https://linux.cn/article-10237-1.html | 
今天我们要讨论一个广为人知的主题,我们也围绕这个主题写过许多的文章,因此我不会针对这个如何记录终端会话流程给出太多具体的资料。
我们可以使用脚本命令来记录 Linux 的终端会话,这也是大家公认的一种办法。不过今天我们将来介绍一个能起到相同作用的工具 — Terminalizer。
这个工具可以帮助我们记录用户的终端活动,以帮助我们从输出的文件中找到有用的信息。
### 什么是 Terminlizer
用户可以用 Terminlizer 记录他们的终端活动并且生成一个 Gif 图像。它是一个允许高度定制的 CLI 工具。用户可以在网络播放器、在线播放器上用链接分享他们记录下的文件。
**推荐阅读:**
* [Script – 一个记录您终端对话的简单工具](https://www.2daygeek.com/script-command-record-save-your-terminal-session-activity-linux/)
* [在 Linux 上自动记录/捕捉所有用户的终端对话](https://www.2daygeek.com/automatically-record-all-users-terminal-sessions-activity-linux-script-command/)
* [Teleconsole – 一个能立即与任何人分享您终端对话的工具](https://www.2daygeek.com/teleconsole-share-terminal-session-instantly-to-anyone-in-seconds/)
* [tmate – 立即与任何人分享您的终端对话](https://www.2daygeek.com/tmate-instantly-share-your-terminal-session-to-anyone-in-seconds/)
* [Peek – 在 Linux 里制造一个 Gif 记录器](https://www.2daygeek.com/peek-create-animated-gif-screen-recorder-capture-arch-linux-mint-fedora-ubuntu/)
* [Kgif – 一个能生成 Gif 图片,以记录窗口活动的简单 Shell 脚本](https://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/)
* [Gifine – 在 Ubuntu/Debian 里快速制造一个 Gif 视频](https://www.2daygeek.com/gifine-create-animated-gif-vedio-recorder-linux-mint-debian-ubuntu/)
目前没有发行版拥有官方软件包来安装此实用程序,不过我们可以用 Node.js 来安装它。
### 如何在 Linux 上安装 Node.js
安装 Node.js 有许多种方法。我们在这里将会教您一个常用的方法。
在 Ubuntu/LinuxMint 上可以使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或者 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 Node.js。
```
$ curl -sL https://deb.nodesource.com/setup_8.x | sudo -E bash -
$ sudo apt-get install -y nodejs
```
在 Debian 上使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或者 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 Node.js。
```
# curl -sL https://deb.nodesource.com/setup_8.x | bash -
# apt-get install -y nodejs
```
在 RHEL/CentOS 上,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 来安装。
```
$ sudo curl --silent --location https://rpm.nodesource.com/setup_8.x | sudo bash -
$ sudo yum install epel-release
$ sudo yum -y install nodejs
```
在 Fedora 上,用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 tmux。
```
$ sudo dnf install nodejs
```
在 Arch Linux 上,用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 tmux。
```
$ sudo pacman -S nodejs npm
```
在 openSUSE 上,用 [Zypper Command](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 来安装 tmux。
```
$ sudo zypper in nodejs6
```
### 如何安装 Terminalizer
您已经安装了 Node.js 这个先决软件包,现在是时候在您的系统上安装 Terminalizer 了。简单执行如下的 `npm` 命令即可安装。
```
$ sudo npm install -g terminalizer
```
### 如何使用 Terminalizer
您只需要执行如下的命令,即可使用 Terminalizer 记录您的终端会话活动。您可以敲击 `CTRL+D` 来结束并且保存记录。
```
# terminalizer record 2g-session
defaultConfigPath
The recording session is started
Press CTRL+D to exit and save the recording
```
这将会将您记录的会话保存成一个 YAML 文件,在这个例子里,我的文件名将会是 2g-session-activity.yml。

```
# logout
Successfully Recorded
The recording data is saved into the file:
/home/daygeek/2g-session.yml
You can edit the file and even change the configurations.
```

### 如何播放记录下来的文件
使用以下命令来播放您记录的 YAML 文件。在以下操作中,请确保您已经用了您的文件名来替换 “2g-session”。
```
# terminalizer play 2g-session
```
将记录的文件渲染成 Gif 图像。
```
# terminalizer render 2g-session
```
注意: 以下的两个命令在此版本尚且不可用,或许在下一版本这两个命令将会付诸使用。
如果您想要将记录的文件分享给其他人,您可以将您的文件上传到在线播放器,并且将链接分享给对方。
```
terminalizer share 2g-session
```
为记录的文件生成一个网络播放器。
```
# terminalizer generate 2g-session
```
---
via: <https://www.2daygeek.com/terminalizer-a-tool-to-record-your-terminal-and-generate-animated-gif-images/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[thecyanbird](https://github.com/thecyanbird) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,238 | 使用 Calcurse 在 Linux 命令行中组织任务 | https://opensource.com/article/18/10/calcurse | 2018-11-16T22:15:53 | [
"日历",
"行事历"
] | /article-10238-1.html |
>
> 使用 Calcurse 了解你的日历和待办事项列表。
>
>
>

你是否需要复杂、功能丰富的图形或 Web 程序才能保持井井有条?我不这么认为。合适的命令行工具可以完成工作并且做得很好。
当然,说出命令行这个词可能会让一些 Linux 用户感到害怕。对他们来说,命令行是未知领域。
使用 [Calcurse](http://www.calcurse.org/) 可以轻松地在命令行中进行组织任务。Calcurse 在基于文本的界面里带来了图形化外观。你可以得到简单、结合易用性的命令行和导航。
让我们仔细看看 Calcurse,它是在 BSD 许可证下开源的。
### 获取软件
如果你喜欢编译代码(我通常不喜欢),你可以从 [Calcurse 网站](http://www.calcurse.org/)获取源码。否则,根据你的 Linux 发行版获取[二进制安装程序](http://www.calcurse.org/downloads/#packages)。你甚至可以从 Linux 发行版的软件包管理器中获取 Calcurse。检查一下不会有错的。
编译或安装 Calcurse 后(两者都不用太长时间),你就可以开始使用了。
### 使用 Calcurse
打开终端并输入 `calcurse`。

Calcurse 的界面由三个面板组成:
* <ruby> 预约 <rt> Appointments </rt></ruby>(屏幕左侧) \* <ruby> 日历 <rt> Calendar </rt></ruby>(右上角) \* <ruby> 待办事项清单 <rt> TODO </rt></ruby>(右下角)
按键盘上的 `Tab` 键在面板之间移动。要在面板添加新项目,请按下 `a`。Calcurse 将指导你完成添加项目所需的操作。
一个有趣的地方地是预约和日历面板配合工作。你选中日历面板并添加一个预约。在那里,你选择一个预约的日期。完成后,你回到预约面板,你就看到了。
按下 `a` 设置开始时间、持续时间(以分钟为单位)和预约说明。开始时间和持续时间是可选的。Calcurse 在它们到期的那天显示预约。

一天的预约看起来像这样:

待办事项列表独立运作。选中待办面板并(再次)按下 `a`。输入任务的描述,然后设置优先级(1 表示最高,9 表示最低)。Calcurse 会在待办事项面板中列出未完成的任务。

如果你的任务有很长的描述,那么 Calcurse 会截断它。你可以使用键盘上的向上或向下箭头键浏览任务,然后按下 `v` 查看描述。

Calcurse 将其信息以文本形式保存在你的主目录下名为 `.calcurse` 的隐藏文件夹中,例如 `/home/scott/.calcurse`。如果 Calcurse 停止工作,那也很容易找到你的信息。
### 其他有用的功能
Calcurse 其他的功能包括设置重复预约的功能。要执行此操作,找出要重复的预约,然后在预约面板中按下 `r`。系统会要求你设置频率(例如,每天或每周)以及你希望重复预约的时间。
你还可以导入 [ICAL](https://tools.ietf.org/html/rfc2445) 格式的日历或以 ICAL 或 [PCAL](http://pcal.sourceforge.net/) 格式导出数据。使用 ICAL,你可以与其他日历程序共享数据。使用 PCAL,你可以生成日历的 Postscript 版本。
你还可以将许多命令行参数传递给 Calcurse。你可以[在文档中](http://www.calcurse.org/files/manual.chunked/ar01s04.html#_invocation)了解它们。
虽然很简单,但 Calcurse 可以帮助你保持井井有条。你需要更加关注自己的任务和预约,但是你将能够更好地关注你需要做什么以及你需要做的方向。
---
via: <https://opensource.com/article/18/10/calcurse>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,239 | 几个用于替代 du 命令的更好选择 | https://www.ostechnix.com/some-good-alternatives-to-du-command/ | 2018-11-16T23:08:16 | [
"du",
"磁盘"
] | https://linux.cn/article-10239-1.html | 
大家对 `du` 命令应该都不陌生,它可以在类 Unix 系统中对文件和目录的空间使用情况进行计算和汇总。如果你也经常需要使用 `du` 命令,你会对以下内容感兴趣的。我发现了五个可以替代原有的 `du` 命令的更好的工具。当然,如果后续有更多更好的选择,我会继续列出来。如果你有其它推荐,也欢迎在评论中留言。
### ncdu
`ncdu` 作为普通 `du` 的替代品,这在 Linux 社区中已经很流行了。`ncdu` 正是基于开发者们对 `du` 的性能不满意而被开发出来的。`ncdu` 是一个使用 C 语言和 ncurses 接口开发的简易快速的磁盘用量分析器,可以用来查看目录或文件在本地或远程系统上占用磁盘空间的情况。如果你有兴趣查看关于 `ncdu` 的详细介绍,可以浏览《[如何在 Linux 上使用 ncdu 查看磁盘占用量](https://www.ostechnix.com/check-disk-space-usage-linux-using-ncdu/)》这一篇文章。
### tin-summer
tin-summer 是使用 Rust 语言编写的自由开源工具,它可以用于查找占用磁盘空间的文件,它也是 `du` 命令的另一个替代品。由于使用了多线程,因此 tin-summer 在计算大目录的大小时会比 `du` 命令快得多。tin-summer 与 `du` 命令之间的区别是前者读取文件的大小,而后者则读取磁盘使用情况。
tin-summer 的开发者认为它可以替代 `du`,因为它具有以下优势:
* 在大目录的操作速度上比 `du` 更快;
* 在显示结果上默认采用易读格式;
* 可以使用正则表达式排除文件或目录;
* 可以对输出进行排序和着色处理;
* 可扩展,等等。
**安装 tin-summer**
要安装 tin-summer,只需要在终端中执行以下命令:
```
$ curl -LSfs https://japaric.github.io/trust/install.sh | sh -s -- --git vmchale/tin-summer
```
你也可以使用 `cargo` 软件包管理器安装 tin-summer,但你需要在系统上先安装 Rust。在 Rust 已经安装好的情况下,执行以下命令:
```
$ cargo install tin-summer
```
如果上面提到的这两种方法都不能成功安装 tin-summer,还可以从它的[软件发布页](https://github.com/vmchale/tin-summer/releases)下载最新版本的二进制文件编译,进行手动安装。
**用法**
(LCTT 译注:tin-summer 的命令名为 `sn`)
如果需要查看当前工作目录的文件大小,可以执行以下命令:
```
$ sn f
749 MB ./.rustup/toolchains
749 MB ./.rustup
147 MB ./.cargo/bin
147 MB ./.cargo
900 MB .
```
不需要进行额外声明,它也是默认以易读的格式向用户展示数据。在使用 `du` 命令的时候,则必须加上额外的 `-h` 参数才能得到同样的效果。
只需要按以下的形式执行命令,就可以查看某个特定目录的文件大小。
```
$ sn f <path-to-the-directory>
```
还可以对输出结果进行排序,例如下面的命令可以输出指定目录中最大的 5 个文件或目录:
```
$ sn sort /home/sk/ -n5
749 MB /home/sk/.rustup
749 MB /home/sk/.rustup/toolchains
147 MB /home/sk/.cargo
147 MB /home/sk/.cargo/bin
2.6 MB /home/sk/mcelog
900 MB /home/sk/
```
顺便一提,上面结果中的最后一行是指定目录 `/home/sk` 的总大小。所以不要惊讶为什么输入的是 5 而实际输出了 6 行结果。
在当前目录下查找带有构建工程的目录,可以使用以下命令:
```
$ sn ar
```
tin-summer 同样支持查找指定大小的带有构建工程的目录。例如执行以下命令可以查找到大小在 100 MB 以上的带有构建工程的目录:
```
$ sn ar -t100M
```
如上文所说,tin-summer 在操作大目录的时候速度比较快,因此在操作小目录的时候,速度会相对比较慢一些。不过它的开发者已经表示,将会在以后的版本中优化这个缺陷。
要获取相关的帮助,可以执行以下命令:
```
$ sn --help
```
如果想要更详尽的介绍,可以查看[这个项目的 GitHub 页面](https://github.com/vmchale/tin-summer)。
### dust
`dust` (含义是 `du` + `rust` = `dust`)使用 Rust 编写,是一个免费、开源的更直观的 `du` 工具。它可以在不需要 `head` 或`sort` 命令的情况下即时显示目录占用的磁盘空间。与 tin-summer 一样,它会默认情况以易读的格式显示每个目录的大小。
**安装 dust**
由于 `dust` 也是使用 Rust 编写,因此它也可以通过 `cargo` 软件包管理器进行安装:
```
$ cargo install du-dust
```
也可以从它的[软件发布页](https://github.com/bootandy/dust/releases)下载最新版本的二进制文件,并按照以下步骤安装。在写这篇文章的时候,最新的版本是 0.3.1。
```
$ wget https://github.com/bootandy/dust/releases/download/v0.3.1/dust-v0.3.1-x86_64-unknown-linux-gnu.tar.gz
```
抽取文件:
```
$ tar -xvf dust-v0.3.1-x86_64-unknown-linux-gnu.tar.gz
```
最后将可执行文件复制到你的 `$PATH`(例如 `/usr/local/bin`)下:
```
$ sudo mv dust /usr/local/bin/
```
**用法**
需要查看当前目录及所有子目录下的文件大小,可以执行以下命令:
```
$ dust
```
输出示例:

带上 `-p` 参数可以按照从当前目录起始的完整目录显示。
```
$ dust -p
```

如果需要查看多个目录的大小,只需要同时列出这些目录,并用空格分隔开即可:
```
$ dust <dir1> <dir2>
```
下面再多举几个例子,例如:
显示文件的长度:
```
$ dust -s
```
只显示 10 个目录:
```
$ dust -n 10
```
查看当前目录下最多 3 层子目录:
```
$ dust -d 3
```
查看帮助:
```
$ dust -h
```
如果想要更详尽的介绍,可以查看[这个项目的 GitHub 页面](https://github.com/bootandy/dust)。
### diskus
`diskus` 也是使用 Rust 编写的一个小型、快速的开源工具,它可以用于替代 `du -sh` 命令。`diskus` 将会计算当前目录下所有文件的总大小,它的效果相当于 `du -sh` 或 `du -sh --bytes`,但其开发者表示 `diskus` 的运行速度是 `du -sh` 的 9 倍。
**安装 diskus**
`diskus` 已经存放于 <ruby> Arch Linux 社区用户软件仓库 <rt> Arch Linux User-community Repository </rt></ruby>([AUR](https://aur.archlinux.org/packages/diskus-bin/))当中,可以通过任何一种 AUR 帮助工具(例如 [`yay`](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/))把它安装在基于 Arch 的系统上:
```
$ yay -S diskus
```
对于 Ubuntu 及其衍生发行版,可以在 `diskus` 的[软件发布页](https://github.com/sharkdp/diskus/releases)上下载最新版的软件包并安装:
```
$ wget "https://github.com/sharkdp/diskus/releases/download/v0.3.1/diskus_0.3.1_amd64.deb"
$ sudo dpkg -i diskus_0.3.1_amd64.deb
```
还可以使用 `cargo` 软件包管理器安装 `diskus`,但必须在系统上先安装 Rust 1.29+。
安装好 Rust 之后,就可以使用以下命令安装 `diskus`:
```
$ cargo install diskus
```
**用法**
在通常情况下,如果需要查看某个目录的大小,我会使用形如 `du -sh` 的命令。
```
$ du -sh dir
```
这里的 `-s` 参数表示显示总大小。
如果使用 `diskus`,直接就可以显示当前目录的总大小。
```
$ diskus
```

我使用 `diskus` 查看 Arch Linux 系统上各个目录的总大小,这个工具的速度确实比 `du -sh` 快得多。但是它目前只能显示当前目录的大小。
要获取相关的帮助,可以执行以下命令:
```
$ diskus -h
```
如果想要更详尽的介绍,可以查看[这个项目的 GitHub 页面](https://github.com/sharkdp/diskus)。
### duu
`duu` 是 Directory Usage Utility 的缩写。它是使用 Python 编写的查看指定目录大小的工具。它具有跨平台的特性,因此在 Windows、Mac OS 和 Linux 系统上都能够使用。
**安装 duu**
安装这个工具之前需要先安装 Python 3。不过目前很多 Linux 发行版的默认软件仓库中都带有 Python 3,所以这个依赖并不难解决。
Python 3 安装完成后,从 `duu` 的[软件发布页](https://github.com/jftuga/duu/releases)下载其最新版本。
```
$ wget https://github.com/jftuga/duu/releases/download/2.20/duu.py
```
**用法**
要查看当前目录的大小,只需要执行以下命令:
```
$ python3 duu.py
```
输出示例:

从上图可以看出,`duu` 会显示当前目录下文件的数量情况,按照 Byte、KB、MB 单位显示这些文件的总大小,以及每个文件的大小。
如果需要查看某个目录的大小,只需要声明目录的绝对路径即可:
```
$ python3 duu.py /home/sk/Downloads/
```
如果想要更详尽的介绍,可以查看[这个项目的 GitHub 页面](https://github.com/jftuga/duu)。
以上就是 `du` 命令的五种替代方案,希望这篇文章能够帮助到你。就我自己而言,我并不会在这五种工具之间交替使用,我更喜欢使用 `ncdu`。欢迎在下面的评论区发表你对这些工具的评论。
---
via: <https://www.ostechnix.com/some-good-alternatives-to-du-command/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,240 | 2018 年 5 款最好的 Linux 游戏 | https://www.maketecheasier.com/best-linux-games/ | 2018-11-17T10:06:00 | [
"游戏"
] | https://linux.cn/article-10240-1.html | 
Linux 可能不会很快成为游戏玩家选择的平台 —— Valve Steam Machines 的失败似乎是对这一点的深刻提醒 —— 但这并不意味着该平台没有稳定增长,并且拥有相当多的优秀游戏。
从独立单机到辉煌的 RPG(角色扮演),2018 年已经可以称得上是 Linux 游戏的丰收年,在这里,我们将列出迄今为止最喜欢的五款。
你是否在寻找优秀的 Linux 游戏却又不想挥霍金钱?来看看我们的最佳 [免费 Linux 游戏](https://www.maketecheasier.com/open-source-linux-games/) 名单吧!
### 1、<ruby> 永恒之柱 2:死亡之火 <rt> Pillars of Eternity II: Deadfire </rt></ruby>

其中一款最能代表近年来 cRPG 的复兴,它让传统的 Bethesda RPG 看起来更像是轻松的动作冒险游戏。在磅礴的《<ruby> 永恒之柱 <rt> Pillars of Eternity </rt></ruby>》系列的最新作品中,当你和船员在充满冒险和危机的岛屿周围航行时,你会发现自己更像是一个海盗。
在混合了海战元素的基础上,《死亡之火》延续了前作丰富的游戏剧情和出色的文笔,同时在美丽的画面和手绘背景的基础上更进一步。
这是一款毫无疑问的令人印象深刻的硬核 RPG ,可能会让一些人对它产生抵触情绪,不过那些接受它的人会投入几个月的时间沉迷其中。
### 2、<ruby> 杀戮尖塔 <rt> Slay the Spire </rt></ruby>

《杀戮尖塔》仍处于早期阶段,却已经成为年度最佳游戏之一,它是一款采用 deck-building 玩法的卡牌游戏,由充满活力的视觉风格和 rogue-like 机制加以点缀,即便在一次次令人愤怒的(但可能是应受的)死亡之后,你还会再次投入其中。
每次游戏都有无尽的卡牌组合和不同的布局,《杀戮尖塔》就像是近年来所有令人震撼的独立游戏的最佳具现 —— 卡牌游戏和永久死亡冒险模式合二为一。
再强调一次,它仍处于早期阶段,所以它只会变得越来越好!
### 3、<ruby> 战斗机甲 <rt> Battletech </rt></ruby>

这是我们榜单上像“大片”一样的游戏,《战斗机甲》是一款星际战争游戏(基于桌面游戏),你将装载一个机甲战队并引导它们进行丰富的回合制战斗。
战斗发生在一系列的地形上,从寒冷的荒地到阳光普照的地带,你将用巨大的热武器装备你的四人小队,与对手小队作战。如果你觉得这听起来有点“机械战士”的味道,那么你想的没错,只不过这次更注重战术安排而不是直接行动。
除了让你在宇宙冲突中指挥的战役外,多人模式也可能会耗费你数不清的时间。
### 4、<ruby> 死亡细胞 <rt> Dead Cells </rt></ruby>

这款游戏称得上是年度最佳平台动作游戏。Roguelike 游戏《死亡细胞》将你带入一个黑暗(却色彩绚丽)的世界,在那里进行攻击和躲避以通过程序生成的关卡。它有点像 2D 的《<ruby> 黑暗之魂 <rt> Dark Souls </rt></ruby>》,如果《黑暗之魂》也充满五彩缤纷的颜色的话。
《死亡细胞》是无情的,只有精确而灵敏的控制才会让你避开死亡,而在两次运行期间的升级系统又会确保你总是有一些进步的成就感。
《死亡细胞》的像素风、动画效果和游戏机制都达到了巅峰,它及时地提醒我们,在没有 3D 图形的过度使用下游戏可以制作成什么样子。
### 5、<ruby> 叛逆机械师 <rt> Iconoclasts </rt></ruby>

这款游戏不像上面提到的几款那样为人所知,它是一款可爱风格的游戏,可以看作是《死亡细胞》不那么惊悚、更可爱的替代品。玩家将扮演成罗宾,一个发现自己处于政治扭曲的外星世界后开始了逃亡的女孩。
尽管你的角色将在非线性的关卡中行动,游戏却有着扣人心弦的游戏剧情,罗宾会获得各种各样充满想象力的提升,其中最重要的是她的扳手,从发射炮弹到解决巧妙的环境问题,你几乎可以用它来做任何事。
《叛逆机械师》是一个充满快乐与活力的平台游戏,融合了《<ruby> 洛克人 <rt> Megaman </rt></ruby>》的战斗和《<ruby> 银河战士 <rt> Metroid </rt></ruby>》的探索。如果你借鉴了那两部伟大的作品,可能不会比它做得更好。
### 总结
以上就是我们选出的 2018 年最佳的 Linux 游戏。有哪些我们错过的游戏精华?请在评论区告诉我们!
---
via: <https://www.maketecheasier.com/best-linux-games/>
作者:[Robert Zak](https://www.maketecheasier.com/author/robzak/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[seriouszyx](https://github.com/seriouszyx) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
There have been many false dawns for Linux gaming, but in recent years things have been improving unabated. The launch of the Proton compatibility layer meant that thousands of DirectX-only games can now be translated to Vulkan and therefore work on Linux, while new Linux-compatible games continue to be released as well.
If you want to play Windows-only games on Linux, see our guide on [how to set up Proton and Steam Play](https://www.maketecheasier.com/steam-play-windows-games-linux/). If, however, you just want to check out all the best native Linux games in 2024 you can play, then read on below.
**Tip:** [Use a retro game emulator](https://www.maketecheasier.com/best-retro-gaming-emulators-for-linux/) to play old games on Linux.
## 1. SuperTuxKart
It might not feel like it due to its modest visuals and simple idea, but [SuperTuxKart](https://supertuxkart.net/Main_Page) is perhaps the most fun you’ll have in a multiplayer racing game. Think **open-source Mario Kart** with cheerful music and multiple game modes and characters.

[Wikimedia Commons](https://commons.wikimedia.org/wiki/File:SuperTuxKart_0.8_screenshot.jpg)
SuperTuxKart is not a new game – it first came out 16 years ago. But it has been under active development since then, with the latest version having come out last year. The game features mascots of many open-source projects such as the Mozilla Thunderbird. You have an actual story mode to complete, unlocking multiple characters and tracks along the way.

The game received a major visual upgrade in 2015 and looks pretty decent for an open-source title. Any modern Linux machine will have no trouble playing it, and you can even play it on the Steam Deck. The game is still not available on Steam but that might change soon, considering its popularity.
## 2. Friday Night Funkin’
It’s time to give a little love to the excellent indie scene over at Itch.io, which is a veritable treasure trove of free games. Some eventually make it over to Steam, but others become cult classics for the Itch community.

[Friday Night Funkin’](https://ninja-muffin24.itch.io/funkin) is one of the current big hitters on the Itch scene. It’s a rhythm-action game in the style of the PS1 classic Parappa the Rapper, with a cheeky sense of humor, catchy tunes, and a vicious retired rockstar dad who’s trying to kill you as you try to kiss your girlfriend.

[Wikimedia Commons](https://commons.wikimedia.org/wiki/File:1452635_mkmaffo_friday-night-funkin-2p.gif)
The gameplay here is pretty simple to grasp but hard to master. Accuracy and speed are equally important to defeat the various colorful foes in rap battles. Plenty of mods have cropped up, introducing new characters, tunes, and levels for players to sink their teeth into. Plus, Twitch and YouTube creators have taken notice and are further hyping the game up.
It’s super simple to play, but very addictive… and did we mention that it’s free?
## 3. Valheim
The Viking-themed survival game [Valheim](https://store.steampowered.com/app/892970/Valheim/) may still be in early access, but it’s already an undisputed success. In a lot of ways, Valheim does much the same things as every other survival game, but its co-op focus (allowing for up to 10 people to play together) and pretty PS2-style visuals make its randomly generated worlds a joy to explore.

The game runs perfectly on Linux, and is receiving a steady stream of updates as it slowly builds up toward a full release. Admittedly, its story and exploration aspects aren’t fully fleshed out yet, but you can already go through its main quest of hunting down several legendary beasts as you try to maintain order in the monster-beset purgatory of Valheim.

Valheim is probably one of the most standout and [most popular co-op games](https://www.maketecheasier.com/best-co-op-browser-games/) and considering the success it has garnered with a 5-person development team, it looks like the game will only get better from here.
## 4. RimWorld
Not only can you play this sci-fi colony simulator on Linux, but you can play it on a low-end Linux machine (probably even without a dedicated GPU, depending on how good your iGPU is). RimWorld’s stories are AI-generated and it’s fascinating to see how minute changes in variables affect the narrative and gameplay.

Don’t let the simple visuals fool you, [RimWorld](https://store.steampowered.com/app/294100/RimWorld/) is an incredibly deep game that was worked on in Early Access for years before maturing to a full release. It sees you manage a colony of people trying to survive on an Earth-like planet populated by other tribes.

Not only do you go through the basics of farming, building up your settlement, and raiding others, but each in-game character has their own complex personality, relationships, and needs, and it’s fascinating watching your little people chat, play with, and even marry each other while you deal with delegating tasks around your colony.
## 5. Life is Strange
[Life is Strange](https://store.steampowered.com/app/319630/Life_is_Strange__Episode_1/) became widely known for its emotionally charged narrative and top-notch music. It’s an award-winning episodic adventure with themes of young love and friendship at its core, powered by a unique time-travel gameplay mechanic.

The game repeatedly mentions that player choices have consequences. While you may or may not feel convinced about that based on your playthrough and preferences, the story definitely makes you feel like you have a say in the events that unfold. The simplistic point-and-click gameplay manages to deliver some heavy and gut-wrenching moments that form the highlights of the 5-episode narrative.

Despite a few patches of sub-par dialogue and common pitfalls of any media about teens and high-school drama, Life is Strange delivers one of the most satisfying and memorable gaming experiences in recent history. The first episode is free and there’s even a [remastered version](https://store.steampowered.com/app/1265920/Life_is_Strange_Remastered/) with improved visuals.
## 6. A Short Hike
Some games are just designed to make you feel good, and while we’ve got plenty of deep and challenging titles on this list, we thought it’d be nice to include this indie gem in the mix. [A Short Hike](https://store.steampowered.com/app/1055540/A_Short_Hike/) sees you wandering, flying, and base-jumping around a beautiful national park as an anthropomorphic hawk.

You explore the park at your own pace, traverse mountains, chat with other hikers, and generally have a wonderful time bounding around the bright and cheery landscape. It’s extremely relaxing, while also having some breathtaking moments as you can freely soar around the park on your birdy wings.

At a time when many of us want to escape into something that helps us relax and forget about the woes of reality, A Short Hike is the perfect getaway. Whether you’re looking for a change of pace or want to discover something new, this short and sweet dose of wholesomeness might get you started on an endless binge of the [best indie games](https://www.maketecheasier.com/best-indie-games/).
## 7. Total War: Warhammer 2
When people dream up which video-game franchise would match up well with movies, board games, or other IPs, the combo of Total War with Warhammer would surely rank high on many lists. A few years ago, this dream was realized, and the Total War: Warhammer bandwagon has plowed on unopposed ever since.

[Total War: Warhammer 2](https://store.steampowered.com/app/594570/Total_War_WARHAMMER_II/) stacks on top of the original game if you own it, letting you combine all the factions from both games into one super-campaign. Each faction feels completely unique to play, and watching thousands-strong armies of Skaven, Undead, Lizardmen, Chaos, and the other grimdark factions go at it is a sight to behold.

Several other Total War games, like [Three Kingdoms](https://store.steampowered.com/app/779340/Total_War_THREE_KINGDOMS/) and [Attila](https://store.steampowered.com/app/325610/Total_War_ATTILA/), are also available on Linux.
## 8. Desperados 3
A hotly-anticipated release that supported Linux from the get-go, Desperados 3 is a relentlessly old-school real-time tactics game in the vein of Commandos (or of course the older Desperados games). It’s tough, tactical, and will have your finger permanently hovering over the quick-save button as you try to execute your plans to perfection.

But [Desperados 3](https://store.steampowered.com/app/610370/Desperados_III/) (made by the devs behind the excellent Shadow Tactics) modernizes the formula, too. Showdown mode lets you pause and slow the game down to line up moves by your ragtag crew of vagabonds, and you can even play with a gamepad should you want to kick back on your couch.

It’s still a tough old game at heart but made more palatable for modern gamers. Fans of the genre can’t give this one a miss. For others, the ample variety in locations, flexible playstyles, and devilishly interesting characters might just make the game one of your favorites.
## 9. Dying Light: Enhanced Edition
Probably the best zombie game that people don’t talk about enough (but millions of people still play it), [Dying Light](https://store.steampowered.com/app/239140/Dying_Light/) has been around for a few years but is still top of the pile thanks to its frantic zombie hordes and excellent parkour mechanics. The Enhanced Edition bundles together a few years’ worth of DLC, including the excellent expansion, The Following.

Dying Light chucks you into an open-world city destroyed by a zombie pandemic, as you try to help out the enclaves of humanity that still live there. You refine your character with skills, leap between rooftops, and chop up zombies with crafted weapons.

It doubles as one of the best co-op experiences out there, too, as up to three friends can dash around the city with you (complete with new challenges and competitive modes like races). Despite the success of Dying Light 2, fans of the original still swear by its superior storytelling, nerve-wracking [horror experience](https://www.maketecheasier.com/free-steam-horror-games/), and overall feel of the grimy open world.
## 10. Sid Meier’s Civilization VI
There’s some debate around which Civilization game is truly the best (and the previous entry, Civilization V, is also available on Linux), but when it comes to accessibility and easing players into this strategy epic, the latest version is a good place to start.

[Civilization VI](https://store.steampowered.com/app/289070/Sid_Meiers_Civilization_VI/) has the same stone-age-to-space-age turn-based formula as its predecessors, but adds neat new ideas like de-stacked cities, combined arms units, and (in the DLC) climate change, golden ages, and dark ages. Civilization games have always struck a chord with lovers of deep strategy and turn-based mechanics, and Civilization VI does this better than ever.

Some say it lacks the depth of previous entries, but now that all the major expansion packs are out, it’s a worthy addition to Sid Meier’s legendary series.
This is a deep and unquestionably hardcore RPG that may cause some to bounce off of it, but those who take to it will be absorbed in its world for months.
## 11. Slay the Spire
Already one of the best games of the year, [Slay the Spire](https://store.steampowered.com/app/646570/Slay_the_Spire/) is a deck-building card game that’s embellished by a vibrant visual style and rogue-like mechanics that’ll leave you coming back for more after each infuriating (but probably deserved) death.

With endless card combinations and a different layout each time you play, Slay the Spire feels like the realization of all the best systems that have been rocking the indie scene in recent years – card games and a permadeath adventure rolled into one.

Like many roguelikes, Slay the Spire is easy to pick up but (you guessed it) hard to master. You have powerful relics to discover, hundreds of cards to build your deck, and four characters to try out. And we repeat that it’s still in early access, so it’s only going to get better!
## 12. Dead Cells
This one deserves highlighting as the combat platformer of the year. With its rogue-lite structure, [Dead Cells](https://store.steampowered.com/app/588650/Dead_Cells/) throws you into a dark (yet gorgeously colored) world where you slash and dodge your way through procedurally-generated levels. It’s a bit like a 2D Dark Souls, if Dark Souls were saturated in vibrant neon colors.

Dead Cells can be merciless, but its precise and responsive controls ensure that you only ever have yourself to blame for failure. Its upgrade system carries over between runs and ensures that you always have some sense of progress. If you’re itching to get your hands on a 2D platformer, this should be at the top of your list.

Dead Cells is the zenith of pixel-game graphics, animations, and mechanics – a timely reminder of just how much can be achieved without the excesses of 3D graphics.
## 13. Team Fortress 2
Everyone thought Valve was crazy to turn Team Fortress from a Half-life style realistic(ish) online shooter to a bold and bouncy [online shooter](https://www.maketecheasier.com/best-single-player-fps-games/) in 2007. But it worked, and incredibly well, too.

The bread-and-butter of [Team Fortress 2](https://store.steampowered.com/app/440/Team_Fortress_2/) are classic team-based modes, like Capture the Flag, Control Points, and the excellent Payload, where one team needs to escort a cart across a level (sound familiar, Overwatch fans?). You pick one of several distinct classes, specializing in either offense, defense, or support, and dive into one of its many meticulously designed vibrant maps.

It’s one of the best influential online shooters of all time, and it’s completely free these days unless you fancy splashing out on skins and other sillies.
## 14. Dota 2
Another Valve stalwart, [Dota 2](https://store.steampowered.com/app/570/Dota_2/) is a free-to-play MOBA phenomenon, rubbing shoulders with League of Legends as the most popular game of its kind. Fun fact: the original Dota is in fact a mod for the RTS classic Warcraft III.

So what makes Dota 2 special? It’s actually a little deeper than League of Legends in some ways (though I’m sure LoL fans will disagree). You can pick from one of over 100 heroes to take into battle, fighting alongside your team and your army of minions to push those lanes and destroy the other team’s base. Units range from healing support types to charging, head-down attackers. Whatever your play style, there will be one in there to suit you.

Dota 2 has a few interesting features as well, such as the option to eat up your own minions in exchange for gold and numerous ways of kitting out and upgrading your character. Be warned: Dota 2 isn’t for the faint-hearted.
## 15. Open-Source Games
As an open-source platform itself, it’s only right that Linux is home to plenty of great free open-source games as well. There’s [Brutal Doom](https://www.moddb.com/mods/brutal-doom) for example – a beefed-up version of [ZDoom](https://zdoom.org/index), the open-source port of Doom, Doom 2, Final Doom, and Master Levels. It features extra animations, gore, and weapons, as well as redesigned maps, modernized controls, and UIs.

OpenRA lets you play Westwood strategy games like Red Alert, Tiberian Dawn, and Dune 2000 online in high resolutions. There’s [0 AD](https://play0ad.com) – the seemingly endless project to make an Age-of-Empires strategy game, not to mention the brilliant [Dark Mod](https://www.thedarkmod.com), which is a Thief-style game in the Doom 3 engine with hundreds of brilliant player-created levels.
Other than these free Linux games, you can also [install DosBox to play old DOS games on Linux](https://www.maketecheasier.com/play-old-dos-games-in-linux/). Alternatively, you can also play [Windows](https://www.maketecheasier.com/4-ways-to-play-windows-game-on-linux/) or [Android](https://www.maketecheasier.com/play-android-games-on-linux/) games on Linux. If you’re a handheld gamer, the [best games for Steam Deck](https://www.maketecheasier.com/best-steam-deck-games/) might keep you hooked for months.
Our latest tutorials delivered straight to your inbox |
10,241 | 关于安全,开发人员需要知道的 | https://opensource.com/article/18/4/what-developers-need-know-about-security | 2018-11-17T11:00:10 | [
"安全",
"DevOps"
] | https://linux.cn/article-10241-1.html |
>
> 开发人员不需要成为安全专家, 但他们确实需要摆脱将安全视为一些不幸障碍的心态。
>
>
>

DevOps 并不意味着每个人都需要成为开发和运维方面的专家。尤其在大型组织中,其中角色往往更加专业化。相反,DevOps 思想在某种程度上更多地是关注问题的分离。在某种程度上,运维团队可以为开发人员(无论是在本地云还是在公共云中)部署平台,并且不受影响,这对两个团队来说都是好消息。开发人员可以获得高效的开发环境和自助服务,运维人员可以专注于保持基础管道运行和维护平台。
这是一种约定。开发者期望从运维人员那里得到一个稳定和实用的平台,运维人员希望开发者能够自己处理与开发应用相关的大部分任务。
也就是说,DevOps 还涉及更好的沟通、合作和透明度。如果它不仅仅是一种介于开发和运维之间的新型壁垒,它的效果会更好。运维人员需要对开发者想要和需要的工具类型以及他们通过监视和日志记录来编写更好应用程序所需的可见性保持敏感。另一方面,开发人员需要了解如何才能更有效地使用底层基础设施,以及什么能够使运维在夜间(字面上)保持运行。
同样的原则也适用于更广泛的 DevSecOps,这个术语明确地提醒我们,安全需要嵌入到整个 DevOps 管道中,从获取内容到编写应用程序、构建应用程序、测试应用程序以及在生产环境中运行它们。开发人员(和运维人员)除了他们已有的角色不需要突然成为安全专家。但是,他们通常可以从对安全最佳实践(这可能不同于他们已经习惯的)的更高认识中获益,并从将安全视为一些不幸障碍的心态中转变出来。
以下是一些观察结果。
<ruby> 开放式 Web 应用程序安全项目 <rt> Open Web Application Security Project </rt></ruby>([OWASP](https://www.owasp.org/index.php/Main_Page))[Top 10 列表]提供了一个窗口,可以了解 Web 应用程序中的主要漏洞。列表中的许多条目对 Web 程序员来说都很熟悉。跨站脚本(XSS)和注入漏洞是最常见的。但令人震惊的是,2007 年列表中的许多漏洞仍在 2017 年的列表中([PDF](https://www.owasp.org/images/7/72/OWASP_Top_10-2017_%28en%29.pdf.pdf))。无论是培训还是工具,都有问题,许多同样的编码漏洞一再出现。
新的平台技术加剧了这种情况。例如,虽然容器不一定要求应用程序以不同的方式编写,但是它们与新模式(例如[微服务](https://opensource.com/tags/microservices))相吻合,并且可以放大某些对于安全实践的影响。例如,我的同事 [Dan Walsh](https://opensource.com/users/rhatdan)([@rhatdan](https://twitter.com/rhatdan))写道:“计算机领域最大的误解是需要 root 权限来运行应用程序,问题是并不是所有开发者都认为他们需要 root,而是他们将这种假设构建到他们建设的服务中,即服务无法在非 root 情况下运行,而这降低了安全性。”
默认使用 root 访问是一个好的实践吗?并不是。但它可能(也许)是一个可以防御的应用程序和系统,否则就会被其它方法完全隔离。但是,由于所有东西都连接在一起,没有真正的边界,多用户工作负载,拥有许多不同级别访问权限的用户,更不用说更加危险的环境了,那么快捷方式的回旋余地就更小了。
[自动化](https://opensource.com/tags/automation)应该是 DevOps 不可分割的一部分。自动化需要覆盖整个过程中,包括安全和合规性测试。代码是从哪里来的?是否涉及第三方技术、产品或容器镜像?是否有已知的安全勘误表?是否有已知的常见代码缺陷?机密信息和个人身份信息是否被隔离?如何进行身份认证?谁被授权部署服务和应用程序?
你不是自己在写你的加密代码吧?
尽可能地自动化渗透测试。我提到过自动化没?它是使安全性持续的一个重要部分,而不是偶尔做一次的检查清单。
这听起来很难吗?可能有点。至少它是不同的。但是,一名 [DevOpsDays OpenSpaces](https://www.devopsdays.org/open-space-format/) 伦敦论坛的参与者对我说:“这只是技术测试。它既不神奇也不神秘。”他接着说,将安全作为一种更广泛地了解整个软件生命周期的方法(这是一种不错的技能)来参与进来并不难。他还建议参加事件响应练习或[夺旗练习](https://dev.to/_theycallmetoni/capture-the-flag-its-a-game-for-hacki-mean-security-professionals)。你会发现它们很有趣。
---
via: <https://opensource.com/article/18/4/what-developers-need-know-about-security>
作者:[Gordon Haff](https://opensource.com/users/ghaff) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | DevOps doesn't mean that everyone needs to be an expert in both development and operations. This is especially true in larger organizations in which roles tend to be more specialized. Rather, DevOps thinking has evolved in a way that makes it more about the separation of concerns. To the degree that operations teams can deploy platforms for developers (whether on-premises or in a public cloud) and get out of the way, that's good news for both teams. Developers get a productive development environment and self-service. Operations can focus on keeping the underlying plumbing running and maintaining the platform.
It's a contract of sorts. Devs expect a stable and functional platform from ops. Ops expects that devs will be able to handle most of the tasks associated with developing apps on their own.
That said, DevOps is also about better communication, collaboration, and transparency. It works better if it's not about merely a new type of wall between dev and ops. Ops needs to be sensitive to the type of tools developers want and need and the visibility they require, through monitoring and logging, to write better applications. Conversely, developers need some awareness of how the underlying infrastructure can be used most effectively and what can keep operations up at night (literally).The same principle applies more broadly to DevSecOps, a term that serves to explicitly remind us that security needs to be embedded throughout the entire DevOps pipeline from sourcing content to writing apps, building them, testing them, and running them in production. Developers (and operations) don't suddenly need to become security specialists in addition to the other hats they already wear. But they can often benefit from a greater awareness of security best practices (which may be different from what they've become accustomed to) and shifting away from a mindset that views security as some unfortunate obstacle.
Here are a few observations.
The Open Web Application Security Project ([OWASP](https://www.owasp.org/index.php/Main_Page)) [Top 10 list](https://www.owasp.org/index.php/Category:OWASP_Top_Ten_Project) provides a window into the top vulnerabilities in web applications. Many entries on the list will be familiar to web programmers. Cross-site scripting (XSS) and injection flaws are among the most common. What's striking though is that many of the flaws on the original 2007 list are still on 2017's list ([PDF](https://www.owasp.org/images/7/72/OWASP_Top_10-2017_%28en%29.pdf.pdf)). Whether it's training or tooling that's most at fault, many of the same coding flaws keep popping up.
The situation is exacerbated by new platform technologies. For example, while containers don't necessarily require applications to be written differently, they dovetail with new patterns (such as [microservices](https://opensource.com/tags/microservices)) and can amplify the effects of certain security practices. For example, as my colleague [Dan Walsh](https://opensource.com/users/rhatdan) ([@rhatdan](https://twitter.com/rhatdan)) writes, "The biggest misconception in computing [is] you need root to run applications. The problem is not so much that devs think they need root. It is that they build this assumption into the services that they build, i.e., the services cannot run without root, making us all less secure."
Was defaulting to root access ever a good practice? Not really. But it was arguably (maybe) a defensible one with applications and systems that were otherwise sufficiently isolated by other means. But with everything connected, no real perimeter, multi-tenant workloads, users with many different levels of access rights—to say nothing of an ever more dangerous threat environment—there's far less leeway for shortcuts.
[Automation](https://opensource.com/tags/automation) should be an integral part of DevOps anyway. That automation needs to include security and compliance testing throughout the process. Where did the code come from? Are third-party technologies, products, or container images involved? Are there known security errata? Are there known common code flaws? Are secrets and personally identifiable information kept isolated? How do we authenticate? Who is authorized to deploy services and applications?
You're not writing your own crypto, are you?
Automate penetration testing where possible. Did I mention automation? It's an essential part of making security continuous rather than a checklist item that's done once in a while.
Does this sound hard? It probably is a bit. At least it may be different. But as a participant in a [DevOpsDays OpenSpaces](https://www.devopsdays.org/open-space-format/) London said to me: "It's just technical testing. It's not magical or mysterious." He went on to say that it's not even that hard to get involved with security as a way to gain a broader understanding of the whole software lifecycle (which is not a bad skill to have). He also suggested taking part in incident response exercises or [capture the flag exercises](https://dev.to/_theycallmetoni/capture-the-flag-its-a-game-for-hacki-mean-security-professionals). You might even find they're fun.
This article is based on [a talk](https://agenda.summit.redhat.com/SessionDetail.aspx?id=154677) the author will be giving at [Red Hat Summit 2018](https://www.redhat.com/en/summit/2018), which will be held May 8-10 in San Francisco. [Register by May 7](https://www.redhat.com/en/summit/2018) to save US$ 500 off of registration. Use discount code **OPEN18** on the payment page to apply the discount.
## Comments are closed. |
10,243 | pydbgen:一个数据库随机生成器 | https://opensource.com/article/18/11/pydbgen-random-database-table-generator | 2018-11-17T23:11:42 | [
"数据库"
] | /article-10243-1.html |
>
> 用这个简单的工具生成带有多表的大型数据库,让你更好地用 SQL 研究数据科学。
>
>
>

在研究数据科学的过程中,最麻烦的往往不是算法或者技术,而是如何获取到一批原始数据。尽管网上有很多真实优质的数据集可以用于机器学习,然而在学习 SQL 时却不是如此。
对于数据科学来说,熟悉 SQL 的重要性不亚于了解 Python 或 R 编程。如果想收集诸如姓名、年龄、信用卡信息、地址这些信息用于机器学习任务,在 Kaggle 上查找专门的数据集比使用足够大的真实数据库要容易得多。
如果有一个简单的工具或库来帮助你生成一个大型数据库,表里还存放着大量你需要的数据,岂不美哉?
不仅仅是数据科学的入门者,即使是经验丰富的软件测试人员也会需要这样一个简单的工具,只需编写几行代码,就可以通过随机(但是是假随机)生成任意数量但有意义的数据集。
因此,我要推荐这个名为 [pydbgen](https://github.com/tirthajyoti/pydbgen) 的轻量级 Python 库。在后文中,我会简要说明这个库的相关内容,你也可以[阅读它的文档](http://pydbgen.readthedocs.io/en/latest/)详细了解更多信息。
### pydbgen 是什么
`pydbgen` 是一个轻量的纯 Python 库,它可以用于生成随机但有意义的数据记录(包括姓名、地址、信用卡号、日期、时间、公司名称、职位、车牌号等等),存放在 Pandas Dataframe 对象中,并保存到 SQLite 数据库或 Excel 文件。
### 如何安装 pydbgen
目前 1.0.5 版本的 pydbgen 托管在 PyPI(<ruby> Python 包索引存储库 <rt> Python Package Index repository </rt></ruby>)上,并且对 [Faker](https://faker.readthedocs.io/en/latest/index.html) 有依赖关系。安装 pydbgen 只需要执行命令:
```
pip install pydbgen
```
已经在 Python 3.6 环境下测试安装成功,但在 Python 2 环境下无法正常安装。
### 如何使用 pydbgen
在使用 `pydbgen` 之前,首先要初始化 `pydb` 对象。
```
import pydbgen
from pydbgen import pydbgen
myDB=pydbgen.pydb()
```
随后就可以调用 `pydb` 对象公开的各种内部函数了。可以按照下面的例子,输出随机的美国城市和车牌号码:
```
myDB.city_real()
>> 'Otterville'
for _ in range(10):
print(myDB.license_plate())
>> 8NVX937
6YZH485
XBY-564
SCG-2185
XMR-158
6OZZ231
CJN-850
SBL-4272
TPY-658
SZL-0934
```
另外,如果你输入的是 `city()` 而不是 `city_real()`,返回的将会是虚构的城市名。
```
print(myDB.gen_data_series(num=8,data_type='city'))
>>
New Michelle
Robinborough
Leebury
Kaylatown
Hamiltonfort
Lake Christopher
Hannahstad
West Adamborough
```
### 生成随机的 Pandas Dataframe
你可以指定生成数据的数量和种类,但需要注意的是,返回结果均为字符串或文本类型。
```
testdf=myDB.gen_dataframe(5,['name','city','phone','date'])
testdf
```
最终产生的 Dataframe 类似下图所示。

### 生成数据库表
你也可以指定生成数据的数量和种类,而返回结果是数据库中的文本或者变长字符串类型。在生成过程中,你可以指定对应的数据库文件名和表名。
```
myDB.gen_table(db_file='Testdb.DB',table_name='People',
fields=['name','city','street_address','email'])
```
上面的例子种生成了一个能被 MySQL 和 SQLite 支持的 `.db` 文件。下图则显示了这个文件中的数据表在 SQLite 可视化客户端中打开的画面。

### 生成 Excel 文件
和上面的其它示例类似,下面的代码可以生成一个具有随机数据的 Excel 文件。值得一提的是,通过将 `phone_simple` 参数设为 `False` ,可以生成较长较复杂的电话号码。如果你想要提高自己在数据提取方面的能力,不妨尝试一下这个功能。
```
myDB.gen_excel(num=20,fields=['name','phone','time','country'],
phone_simple=False,filename='TestExcel.xlsx')
```
最终的结果类似下图所示:

### 生成随机电子邮箱地址
`pydbgen` 内置了一个 `realistic_email` 方法,它基于种子来生成随机的电子邮箱地址。如果你不想在网络上使用真实的电子邮箱地址时,这个功能可以派上用场。
```
for _ in range(10):
print(myDB.realistic_email('Tirtha Sarkar'))
>>
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
```
### 未来的改进和用户贡献
目前的版本中并不完美。如果你发现了 pydbgen 的 bug 导致它在运行期间发生崩溃,请向我反馈。如果你打算对这个项目贡献代码,[也随时欢迎你](https://github.com/tirthajyoti/pydbgen)。当然现在也还有很多改进的方向:
* pydbgen 作为随机数据生成器,可以集成一些机器学习或统计建模的功能吗?
* pydbgen 是否会添加可视化功能?
一切皆有可能!
如果你有任何问题或想法想要分享,都可以通过 [[email protected]](mailto:[email protected]) 与我联系。如果你像我一样对机器学习和数据科学感兴趣,也可以添加我的 [LinkedIn](https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/) 或在 [Twitter](https://twitter.com/tirthajyotiS) 上关注我。另外,还可以在我的 [GitHub](https://github.com/tirthajyoti?tab=repositories) 上找到更多 Python、R 或 MATLAB 的有趣代码和机器学习资源。
本文以 [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/) 许可在 [Towards Data Science](https://towardsdatascience.com/introducing-pydbgen-a-random-dataframe-database-table-generator-b5c7bdc84be5) 首发。
---
via: <https://opensource.com/article/18/11/pydbgen-random-database-table-generator>
作者:[Tirthajyoti Sarkar](https://opensource.com/users/tirthajyoti) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,244 | 一个用于家庭项目的单用户、轻量级操作系统 | https://opensource.com/article/18/7/gentle-intro-risc-os | 2018-11-18T10:19:25 | [
"RISC",
"树莓派"
] | /article-10244-1.html |
>
> 业余爱好者应该了解一下 RISC OS 的五个原因。
>
>
>

究竟什么是 RISC OS?嗯,它不是一种新的 Linux。它也不是有些人认为的 Windows。事实上,它发布于 1987 年,它比它们任何一个都要古老。但你看到它时不一定会意识到这一点。
其点击式图形用户界面在底部为活动的程序提供一个固定面板和一个图标栏。因此,它看起来像 Windows 95,并且比它早了 8 年。
这个操作系统最初是为 [Acorn Archimedes](https://en.wikipedia.org/wiki/Acorn_Archimedes) 编写的。这台机器中的 Acorn RISC Machines CPU 是全新的硬件,因此需要在其上运行全新的软件。这是最早的 ARM 芯片上的系统,早于任何人想到的 Android 或 [Armbian](https://www.armbian.com/) 之前。
虽然 Acorn 桌面最终消失了,但 ARM 芯片继续征服世界。在这里,RISC OS 一直有一个优点 —— 通常在嵌入式设备中,你从来没有真正地意识到它。RISC OS 过去长期以来一直是一个完全专有的操作系统。但近年来,该抄系统的所有者已经开始将源代码发布到一个名为 [RISC OS Open](https://www.riscosopen.org/content/) 的项目中。
### 1、你可以将它安装在树莓派上
树莓派的官方操作系统 [Raspbian](https://www.raspbian.org/) 实际上非常棒(如果你对摆弄不同技术上新奇的东西不感兴趣,那么你可能最初也不会选择树莓派)。由于 RISC OS 是专门为 ARM 编写的,因此它可以在各种小型计算机上运行,包括树莓派的各个型号。
### 2、它超轻量级
我的树莓派上安装的 RISC 系统占用了几百兆 —— 这是在我加载了数十个程序和游戏之后。它们大多数时候不超过 1 兆。
如果你真的节俭,RISC OS Pico 可用在 16MB SD 卡上。如果你要在嵌入式系统或物联网项目中鼓捣某些东西,这是很完美的。当然,16MB 实际上比压缩到 512KB 的老 Archimedes 的 ROM 要多得多。但我想 30 年间内存技术的发展,我们可以稍微放宽一下了。
### 3、它非常适合复古游戏
当 Archimedes 处于鼎盛时期时,ARM CPU 的速度比 Apple Macintosh 和 Commodore Amiga 中的 Motorola 68000 要快几倍,它也完全吸了新的 386 技术。这使得它成为对游戏开发者有吸引力的一个平台,他们希望用这个星球上最强大的桌面计算机来支撑他们的东西。
那些游戏的许多拥有者都非常慷慨,允许业余爱好者免费下载他们的老作品。虽然 RISC OS 和硬件已经发展了,但只需要进行少量的调整就可以让它们运行起来。
如果你有兴趣探索这个,[这里有一个指南](https://www.riscosopen.org/wiki/documentation/show/Introduction%20to%20RISC%20OS)让这些游戏在你的树莓派上运行。
### 4、它有 BBC BASIC
就像过去一样,按下 `F12` 进入命令行,输入 `*BASIC`,就可以看到一个完整的 BBC BASIC 解释器。
对于那些在 80 年代没有接触过它的人,请让我解释一下:BBC BASIC 是当时我们很多人的第一个编程语言,因为它专门教孩子如何编码。当时有大量的书籍和杂志文章教我们编写自己的简单但高度可玩的游戏。
几十年后,对于一个想要在学校假期做点什么的有技术头脑的孩子而言,在 BBC BASIC 上编写自己的游戏仍然是一个很棒的项目。但很少有孩子在家里有 BBC micro。那么他们应该怎么做呢?
当然,你可以在每台家用电脑上运行解释器,但是当别人需要使用它时就不能用了。那么为什么不使用装有 RISC OS 的树莓派呢?
### 5、它是一个简单的单用户操作系统
RISC OS 不像 Linux 一样有自己的用户和超级用户访问权限。它有一个用户并可以完全访问整个机器。因此,它可能不是跨企业部署的最佳日常驱动,甚至不适合给老人家做银行业务。但是,如果你正在寻找可以用来修改和鼓捣的东西,那绝对是太棒了。你和机器之间没有那么多障碍,所以你可以直接闯进去。
### 扩展阅读
如果你想了解有关此操作系统的更多信息,请查看 [RISC OS Open](https://www.riscosopen.org/content/),或者将镜像烧到闪存到卡上并开始使用它。
---
via: <https://opensource.com/article/18/7/gentle-intro-risc-os>
作者:[James Mawson](https://opensource.com/users/dxmjames) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,245 | 如何使用 chkconfig 和 systemctl 命令启用或禁用 Linux 服务 | https://www.2daygeek.com/how-to-enable-or-disable-services-on-boot-in-linux-using-chkconfig-and-systemctl-command/ | 2018-11-18T10:59:12 | [
"systemd"
] | https://linux.cn/article-10245-1.html | 
对于 Linux 管理员来说这是一个重要(美妙)的话题,所以每个人都必须知道,并练习怎样才能更高效的使用它们。
在 Linux 中,无论何时当你安装任何带有服务和守护进程的包,系统默认会把这些服务的初始化及 systemd 脚本添加进去,不过此时它们并没有被启用。
我们需要手动的开启或者关闭那些服务。Linux 中有三个著名的且一直在被使用的初始化系统。
### 什么是初始化系统?
在以 Linux/Unix 为基础的操作系统上,`init` (初始化的简称) 是内核引导系统启动过程中第一个启动的进程。
`init` 的进程 id (pid)是 1,除非系统关机否则它将会一直在后台运行。
`init` 首先根据 `/etc/inittab` 文件决定 Linux 运行的级别,然后根据运行级别在后台启动所有其他进程和应用程序。
BIOS、MBR、GRUB 和内核程序在启动 `init` 之前就作为 Linux 的引导程序的一部分开始工作了。
下面是 Linux 中可以使用的运行级别(从 0~6 总共七个运行级别):
* `0`:关机
* `1`:单用户模式
* `2`:多用户模式(没有NFS)
* `3`:完全的多用户模式
* `4`:系统未使用
* `5`:图形界面模式
* `6`:重启
下面是 Linux 系统中最常用的三个初始化系统:
* System V(Sys V)
* Upstart
* systemd
### 什么是 System V(Sys V)?
System V(Sys V)是类 Unix 系统第一个也是传统的初始化系统。`init` 是内核引导系统启动过程中第一支启动的程序,它是所有程序的父进程。
大部分 Linux 发行版最开始使用的是叫作 System V(Sys V)的传统的初始化系统。在过去的几年中,已经发布了好几个初始化系统以解决标准版本中的设计限制,例如:launchd、Service Management Facility、systemd 和 Upstart。
但是 systemd 已经被几个主要的 Linux 发行版所采用,以取代传统的 SysV 初始化系统。
### 什么是 Upstart?
Upstart 是一个基于事件的 `/sbin/init` 守护进程的替代品,它在系统启动过程中处理任务和服务的启动,在系统运行期间监视它们,在系统关机的时候关闭它们。
它最初是为 Ubuntu 而设计,但是它也能够完美的部署在其他所有 Linux系统中,用来代替古老的 System-V。
Upstart 被用于 Ubuntu 从 9.10 到 Ubuntu 14.10 和基于 RHEL 6 的系统,之后它被 systemd 取代。
### 什么是 systemd?
systemd 是一个新的初始化系统和系统管理器,它被用于所有主要的 Linux 发行版,以取代传统的 SysV 初始化系统。
systemd 兼容 SysV 和 LSB 初始化脚本。它可以直接替代 SysV 初始化系统。systemd 是被内核启动的第一个程序,它的 PID 是 1。
systemd 是所有程序的父进程,Fedora 15 是第一个用 systemd 取代 upstart 的发行版。`systemctl` 用于命令行,它是管理 systemd 的守护进程/服务的主要工具,例如:(开启、重启、关闭、启用、禁用、重载和状态)
systemd 使用 .service 文件而不是 bash 脚本(SysVinit 使用的)。systemd 将所有守护进程添加到 cgroups 中排序,你可以通过浏览 `/cgroup/systemd` 文件查看系统等级。
### 如何使用 chkconfig 命令启用或禁用引导服务?
`chkconfig` 实用程序是一个命令行工具,允许你在指定运行级别下启动所选服务,以及列出所有可用服务及其当前设置。
此外,它还允许我们从启动中启用或禁用服务。前提是你有超级管理员权限(root 或者 `sudo`)运行这个命令。
所有的服务脚本位于 `/etc/rd.d/init.d`文件中
### 如何列出运行级别中所有的服务
`--list` 参数会展示所有的服务及其当前状态(启用或禁用服务的运行级别):
```
# chkconfig --list
NetworkManager 0:off 1:off 2:on 3:on 4:on 5:on 6:off
abrt-ccpp 0:off 1:off 2:off 3:on 4:off 5:on 6:off
abrtd 0:off 1:off 2:off 3:on 4:off 5:on 6:off
acpid 0:off 1:off 2:on 3:on 4:on 5:on 6:off
atd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
.
.
```
### 如何查看指定服务的状态
如果你想查看运行级别下某个服务的状态,你可以使用下面的格式匹配出需要的服务。
比如说我想查看运行级别中 `auditd` 服务的状态
```
# chkconfig --list| grep auditd
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
```
### 如何在指定运行级别中启用服务
使用 `--level` 参数启用指定运行级别下的某个服务,下面展示如何在运行级别 3 和运行级别 5 下启用 `httpd` 服务。
```
# chkconfig --level 35 httpd on
```
### 如何在指定运行级别下禁用服务
同样使用 `--level` 参数禁用指定运行级别下的服务,下面展示的是在运行级别 3 和运行级别 5 中禁用 `httpd` 服务。
```
# chkconfig --level 35 httpd off
```
### 如何将一个新服务添加到启动列表中
`-–add` 参数允许我们添加任何新的服务到启动列表中,默认情况下,新添加的服务会在运行级别 2、3、4、5 下自动开启。
```
# chkconfig --add nagios
```
### 如何从启动列表中删除服务
可以使用 `--del` 参数从启动列表中删除服务,下面展示的是如何从启动列表中删除 Nagios 服务。
```
# chkconfig --del nagios
```
### 如何使用 systemctl 命令启用或禁用开机自启服务?
`systemctl` 用于命令行,它是一个用来管理 systemd 的守护进程/服务的基础工具,例如:(开启、重启、关闭、启用、禁用、重载和状态)。
所有服务创建的 unit 文件位与 `/etc/systemd/system/`。
### 如何列出全部的服务
使用下面的命令列出全部的服务(包括启用的和禁用的)。
```
# systemctl list-unit-files --type=service
UNIT FILE STATE
arp-ethers.service disabled
auditd.service enabled
[email protected] enabled
blk-availability.service disabled
brandbot.service static
[email protected] static
chrony-wait.service disabled
chronyd.service enabled
cloud-config.service enabled
cloud-final.service enabled
cloud-init-local.service enabled
cloud-init.service enabled
console-getty.service disabled
console-shell.service disabled
[email protected] static
cpupower.service disabled
crond.service enabled
.
.
150 unit files listed.
```
使用下面的格式通过正则表达式匹配出你想要查看的服务的当前状态。下面是使用 `systemctl` 命令查看 `httpd` 服务的状态。
```
# systemctl list-unit-files --type=service | grep httpd
httpd.service disabled
```
### 如何让指定的服务开机自启
使用下面格式的 `systemctl` 命令启用一个指定的服务。启用服务将会创建一个符号链接,如下可见:
```
# systemctl enable httpd
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
```
运行下列命令再次确认服务是否被启用。
```
# systemctl is-enabled httpd
enabled
```
### 如何禁用指定的服务
运行下面的命令禁用服务将会移除你启用服务时所创建的符号链接。
```
# systemctl disable httpd
Removed symlink /etc/systemd/system/multi-user.target.wants/httpd.service.
```
运行下面的命令再次确认服务是否被禁用。
```
# systemctl is-enabled httpd
disabled
```
### 如何查看系统当前的运行级别
使用 `systemctl` 命令确认你系统当前的运行级别,`runlevel` 命令仍然可在 systemd 下工作,不过,运行级别对于 systemd 来说是一个历史遗留的概念。所以我建议你全部使用 `systemctl` 命令。
我们当前处于运行级别 3, 它等同于下面显示的 `multi-user.target`。
```
# systemctl list-units --type=target
UNIT LOAD ACTIVE SUB DESCRIPTION
basic.target loaded active active Basic System
cloud-config.target loaded active active Cloud-config availability
cryptsetup.target loaded active active Local Encrypted Volumes
getty.target loaded active active Login Prompts
local-fs-pre.target loaded active active Local File Systems (Pre)
local-fs.target loaded active active Local File Systems
multi-user.target loaded active active Multi-User System
network-online.target loaded active active Network is Online
network-pre.target loaded active active Network (Pre)
network.target loaded active active Network
paths.target loaded active active Paths
remote-fs.target loaded active active Remote File Systems
slices.target loaded active active Slices
sockets.target loaded active active Sockets
swap.target loaded active active Swap
sysinit.target loaded active active System Initialization
timers.target loaded active active Timers
```
---
via: <https://www.2daygeek.com/how-to-enable-or-disable-services-on-boot-in-linux-using-chkconfig-and-systemctl-command/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[way-ww](https://github.com/way-ww) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.