
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
10,246 | 8 个很棒的 pytest 插件 | https://opensource.com/article/18/6/pytest-plugins | 2018-11-19T11:41:53 | [
"pytest",
"测试",
"Python"
] | https://linux.cn/article-10246-1.html |
>
> Python 测试工具最好的一方面是其强大的生态系统。这里列出了八个最好的插件。
>
>
>

我们是 [pytest](https://docs.pytest.org/en/latest/) 的忠实粉丝,并将其作为工作和开源项目的默认 Python 测试工具。在本月的 Python 专栏中,我们分享了为什么我们喜欢 `pytest` 以及一些让 `pytest` 测试工作更有趣的插件。
### 什么是 pytest?
正如该工具的网站所说,“pytest 框架可以轻松地编写小型测试,也能进行扩展以支持应用和库的复杂功能测试。”
`pytest` 允许你在任何名为 `test_*.py` 的文件中定义测试,并将其定义为以 `test_*` 开头的函数。然后,pytest 将在整个项目中查找所有测试,并在控制台中运行 `pytest` 时自动运行这些测试。pytest 接受[标志和参数](https://docs.pytest.org/en/latest/usage.html),它们可以在测试运行器停止时更改,这些包含如何输出结果,运行哪些测试以及输出中包含哪些信息。它还包括一个 `set_trace()` 函数,它可以进入到你的测试中。它会暂停您的测试, 并允许你与变量进行交互,不然你只能在终端中“四处翻弄”来调试你的项目。
`pytest` 最好的一方面是其强大的插件生态系统。因为 `pytest` 是一个非常流行的测试库,所以多年来创建了许多插件来扩展、定制和增强其功能。这八个插件是我们的最爱。
### 8 个很棒的插件
#### 1、pytest-sugar
[pytest-sugar](https://github.com/Frozenball/pytest-sugar) 改变了 `pytest` 的默认外观,添加了一个进度条,并立即显示失败的测试。它不需要配置,只需 `pip install pytest-sugar`,用 `pytest` 运行测试,来享受更漂亮、更有用的输出。
#### 2、pytest-cov
[pytest-cov](https://github.com/pytest-dev/pytest-cov) 在 `pytest` 中增加了覆盖率支持,来显示哪些代码行已经测试过,哪些还没有。它还将包括项目的测试覆盖率。
#### 3、pytest-picked
[pytest-picked](https://github.com/anapaulagomes/pytest-picked) 对你已经修改但尚未提交 `git` 的代码运行测试。安装库并运行 `pytest --picked` 来仅测试自上次提交后已更改的文件。
#### 4、pytest-instafail
[pytest-instafail](https://github.com/pytest-dev/pytest-instafail) 修改 `pytest` 的默认行为来立即显示失败和错误,而不是等到 `pytest` 完成所有测试。
#### 5、pytest-tldr
一个全新的 `pytest` 插件,可以将输出限制为你需要的东西。`pytest-tldr`(`tldr` 代表 “too long, didn’t read” —— 太长,不想读),就像 pytest-sugar 一样,除基本安装外不需要配置。不像 pytest 的默认输出那么详细,[pytest-tldr](https://github.com/freakboy3742/pytest-tldr) 将默认输出限制为失败测试的回溯信息,并忽略了一些令人讨厌的颜色编码。添加 `-v` 标志会为喜欢它的人返回更详细的输出。
#### 6、pytest-xdist
[pytest-xdist](https://github.com/pytest-dev/pytest-xdist) 允许你通过 `-n` 标志并行运行多个测试:例如,`pytest -n 2` 将在两个 CPU 上运行你的测试。这可以显著加快你的测试速度。它还包括 `--looponfail` 标志,它将自动重新运行你的失败测试。
#### 7、pytest-django
[pytest-django](https://pytest-django.readthedocs.io/en/latest/) 为 Django 应用和项目添加了 `pytest` 支持。具体来说,`pytest-django` 引入了使用 pytest fixture 测试 Django 项目的能力,而省略了导入 `unittest` 和复制/粘贴其他样板测试代码的需要,并且比标准的 Django 测试套件运行得更快。
#### 8、django-test-plus
[django-test-plus](https://django-test-plus.readthedocs.io/en/latest/) 并不是专门为 `pytest` 开发,但它现在支持 `pytest`。它包含自己的 `TestCase` 类,你的测试可以继承该类,并使你能够使用较少的按键来输出频繁的测试案例,例如检查特定的 HTTP 错误代码。
我们上面提到的库绝不是你扩展 `pytest` 的唯一选择。有用的 pytest 插件的前景是广阔的。查看 [pytest 插件兼容性](https://plugincompat.herokuapp.com/)页面来自行探索。你最喜欢哪些插件?
---
via: <https://opensource.com/article/18/6/pytest-plugins>
作者:[Jeff Triplett](https://opensource.com/users/jefftriplett), [Lacery Williams Henschel](https://opensource.com/users/laceynwilliams) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We are big fans of [pytest](https://docs.pytest.org/en/latest/) and use it as our default Python testing tool for work and open source projects. For this month's Python column, we're sharing why we love pytest and some of the plugins that make testing with pytest so much fun.
## What is pytest?
As the tool's website says, "The pytest framework makes it easy to write small tests, yet scales to support complex functional testing for applications and libraries."
Pytest allows you to define your tests in any file called `test_*.py`
and as functions that begin with `test_*`
. Pytest will then find all your tests, across your whole project, and run them automatically when you run `pytest`
in your console. Pytest accepts [flags and arguments](https://docs.pytest.org/en/latest/usage.html) that can change when the testrunner stops, how it outputs results, which tests are run, and what information is included in the output. It also includes a `set_trace()`
function that can be entered into your test; this will pause your tests and allow you to interact with your variables and otherwise "poke around" in the console to debug your project.
One of the best aspects of pytest is its robust plugin ecosystem. Because pytest is such a popular testing library, over the years many plugins have been created to extend, customize, and enhance its capabilities. These eight plugins are among our favorites.
## Great 8
**1. pytest-sugar**
`pytest-sugar`
changes the default look and feel of pytest, adds a progress bar, and shows failing tests instantly. It requires no configuration; just `pip install pytest-sugar`
, run your tests with `pytest`
, and enjoy the prettier, more useful output.**2. pytest-cov**
`pytest-cov`
adds coverage support for pytest to show which lines of code have been tested and which have not. It will also include the percentage of test coverage for your project.**3. pytest-picked**
`pytest-picked`
runs tests based on code that you have modified but not committed to `git`
yet. Install the library and run your tests with `pytest --picked`
to test only files that have been changed since your last commit.**4. pytest-instafail**
`pytest-instafail`
modifies pytest's default behavior to show failures and errors immediately instead of waiting until pytest has finished running every test.**5. pytest-tldr**
A brand-new pytest plugin that limits the output to just the things you need.
`pytest-tldr`
(the `tldr`
stands for "too long, didn't read"), like `pytest-sugar`
, requires no configuration other than basic installation. Instead of pytest's default output, which is pretty verbose, `pytest-tldr`
's default limits the output to only tracebacks for failing tests and omits the color-coding that some find annoying. Adding a `-v`
flag returns the more verbose output for those who prefer it.**6. pytest-xdist**
`pytest-xdist`
allows you to run multiple tests in parallel via the `-n`
flag: `pytest -n 2`
, for example, would run your tests on two CPUs. This can significantly speed up your tests. It also includes the `--looponfail`
flag, which will automatically re-run your failing tests.**7. pytest-django**
`pytest-django`
adds pytest support to Django applications and projects. Specifically, `pytest-django`
introduces the ability to test Django projects using pytest fixtures, omits the need to import `unittest`
and copy/paste other boilerplate testing code, and runs faster than the standard Django test suite.**8. django-test-plus **
`django-test-plus`
isn't specific to pytest, but it now supports pytest. It includes its own `TestCase`
class that your tests can inherit from and enables you to use fewer keystrokes to type out frequent test cases, like checking for specific HTTP error codes.The libraries we mentioned above are by no means your only options for extending your pytest usage. The landscape for useful pytest plugins is vast. Check out the [Pytest Plugins Compatibility](https://plugincompat.herokuapp.com/) page to explore on your own. Which ones are your favorites?
## Comments are closed. |
10,247 | COPR 仓库中 4 个很酷的新软件(2018.10) | https://fedoramagazine.org/4-cool-new-projects-try-copr-october-2018/ | 2018-11-19T12:01:00 | [
"COPR"
] | https://linux.cn/article-10247-1.html | 
COPR 是软件的个人存储库的[集合](https://copr.fedorainfracloud.org/),它包含那些不在标准的 Fedora 仓库中的软件。某些软件不符合允许轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是自由开源的。COPR 可以在标准的 Fedora 包之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己背书的。但是,它是尝试新的或实验性软件的一种很好的方法。
这是 COPR 中一组新的有趣项目。
[编者按:这些项目里面有一个并不适合通过 COPR 分发,所以从本文中 也删除了。相关的评论也删除了,以免误导读者。对此带来的不便,我们深表歉意。]
(LCTT 译注:本文后来移除了对“GitKraken”项目的介绍。)
### Music On Console
[Music On Console](http://moc.daper.net/) 播放器(简称 mocp)是一个简单的控制台音频播放器。它有一个类似于 “Midnight Commander” 的界面,并且很容易使用。你只需进入包含音乐的目录,然后选择要播放的文件或目录。此外,mocp 提供了一组命令,允许直接从命令行进行控制。

#### 安装说明
该仓库目前为 Fedora 28 和 29 提供 Music On Console 播放器。要安装 mocp,请使用以下命令:
```
sudo dnf copr enable Krzystof/Moc
sudo dnf install moc
```
### cnping
[Cnping](https://github.com/cnlohr/cnping) 是小型的图形化 ping IPv4 工具,可用于可视化显示 RTT 的变化。它提供了一个选项来控制每个数据包之间的间隔以及发送的数据大小。除了显示的图表外,cnping 还提供 RTT 和丢包的基本统计数据。

#### 安装说明
该仓库目前为 Fedora 27、28、29 和 Rawhide 提供 cnping。要安装 cnping,请使用以下命令:
```
sudo dnf copr enable dreua/cnping
sudo dnf install cnping
```
### Pdfsandwich
[Pdfsandwich](http://www.tobias-elze.de/pdfsandwich/) 是将文本添加到图像形式的文本 PDF 文件 (如扫描书籍) 的工具。它使用光学字符识别 (OCR) 创建一个额外的图层, 包含了原始页面已识别的文本。这对于复制和处理文本很有用。
#### 安装说明
该仓库目前为 Fedora 27、28、29、Rawhide 以及 EPEL 7 提供 pdfsandwich。要安装 pdfsandwich,请使用以下命令:
```
sudo dnf copr enable merlinm/pdfsandwich
sudo dnf install pdfsandwich
```
---
via: <https://fedoramagazine.org/4-cool-new-projects-try-copr-october-2018/>
作者:[Dominik Turecek](https://fedoramagazine.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | COPR is a [collection](https://copr.fedorainfracloud.org/) of personal repositories for software that isn’t carried in the standard Fedora repositories. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the standard set of Fedora Fedora packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
Here’s a set of new and interesting projects in COPR.
**[Editors’ Note:** One of these projects was unsuitable for distribution through COPR and has been removed from this article. Pursuant comments have also been removed to prevent confusion for additional readers. We apologize for any inconvenience.]
### Music On Console
[Music On Console](http://moc.daper.net/) player, or mocp, is a simple console audio player. It has an interface similar to the Midnight Commander and is easy use. You simply navigate to a directory with music files and select a file or directory to play. In addition, mocp provides a set of commands, allowing it to be controlled directly from command line.
#### Installation instructions
The repo currently provides Music On Console player for Fedora 28 and 29. To install mocp, use these commands:
sudo dnf copr enable krzysztof/Moc sudo dnf install moc
### cnping
[Cnping](https://github.com/cnlohr/cnping) is a small graphical ping tool for IPv4, useful for visualization of changes in round-trip time. It offers an option to control the time period between each packet as well as the size of data sent. In addition to the graph shown, cnping provides basic statistics on round-trip times and packet loss.
#### Installation instructions
The repo currently provides cnping for Fedora 27, 28, 29 and Rawhide. To install cnping, use these commands:
sudo dnf copr enable dreua/cnping sudo dnf install cnping
### Pdfsandwich
[Pdfsandwich](http://www.tobias-elze.de/pdfsandwich/) is a tool for adding text to PDF files which contain text in an image form — such as scanned books. It uses optical character recognition (OCR) to create an additional layer with the recognized text behind the original page. This can be useful for copying and working with the text.
#### Installation instructions
The repo currently provides pdfsandwich for Fedora 27, 28, 29 and Rawhide, and for EPEL 7. To install pdfsandwich, use these commands:
sudo dnf copr enable merlinm/pdfsandwich sudo dnf install pdfsandwich
## wk
The last one didn’t work:
dnf copr enable merlinm/pdfsandwich
(blah blah blah)
Do you want to continue? [y/N]: y
Repository successfully enabled.
[root@localhost bot]# dnf install pdfsandwich
Failed to synchronize cache for repo ‘merlinm-pdfsandwich’, disabling.
Last metadata expiration check: 0:21:56 ago on Wed 24 Oct 2018 11:52:22 AM PDT.
No match for argument: pdfsandwich
Error: Unable to find a match
#
## Paul W. Frields
Whatever problem you were encountering, it doesn’t seem to still be there. Works OK here.
## wk
I tried it again. Still gives the same error.
## Chris Moller
[1] ~/Downloads >sudo dnf copr enable Krzystof/Moc
You are about to enable a Copr repository. Please note that this
repository is not part of the main distribution, and quality may vary.
The Fedora Project does not exercise any power over the contents of
this repository beyond the rules outlined in the Copr FAQ at
https://docs.pagure.org/copr.copr/user_documentation.html#what-i-can-build-in-copr,
and packages are not held to any quality or security level.
Please do not file bug reports about these packages in Fedora
Bugzilla. In case of problems, contact the owner of this repository.
Do you want to continue? [y/N]: y
Error: Such repository does not exist.
[1] ~/Downloads >
## Guus
I have the same problem with the Krzystof/Moc repo. It does not seem to exist. Maybe the machine is offline now and again?
## Fred Weigel
The copr for moc should be:
krzysztof/Moc
## Guus
I can confirm this modification is correct. krzysztof/Moc is the right name. Remark the lowercase for krzysztof. This appears to be significant.
## Fred Weigel
: fred@tara ~ $; mocp
FATAL_ERROR: TiMidity-Plugin: Error processing TiMidity-Configuration!
Configuration file is:
## Dan Čermák
You can work around that issue by creating an empty timidity.conf file in your home directory (just touch it, it needn’t have any contents).
## Fred Weigel
Thanks! Using strace, the file name should be timidity.cfg.
## Nazar
Seems like I’m unable to count up to 4…
## Clément Verna
@Nazar please have a look at the Editor’s Note.
## Vaibhav Singh
[student@localhost-localdomain ~]$ sudo dnf copr enable Krzystof/Moc
[sudo] password for student:
You are about to enable a Copr repository. Please note that this
repository is not part of the main distribution, and quality may vary.
The Fedora Project does not exercise any power over the contents of
this repository beyond the rules outlined in the Copr FAQ at
https://docs.pagure.org/copr.copr/user_documentation.html#what-i-can-build-in-copr,
and packages are not held to any quality or security level.
Please do not file bug reports about these packages in Fedora
Bugzilla. In case of problems, contact the owner of this repository.
Do you want to continue? [y/N]: y
Error: Such repository does not exist.
[student@localhost-localdomain ~]$ sudo dnf install moc
Last metadata expiration check: 4:32:04 ago on Thu 25 Oct 2018 07:10:44 PM IST.
No match for argument: moc
Error: Unable to find a match
Please Help
Give a solution
## ddrfr
moc is ideal
## Vaibhav Singh
These two does’t work
sudo dnf copr enable Krzystof/Moc
sudo dnf install mocg
[work@localhost-localdomain ~]$ sudo dnf copr enable Krzystof/Moc
[sudo] password for work :
You are about to enable a Copr repository. Please note that this
repository is not part of the main distribution, and quality may vary.
The Fedora Project does not exercise any power over the contents of
this repository beyond the rules outlined in the Copr FAQ at
https://docs.pagure.org/copr.copr/user_documentation.html#what-i-can-build-in-copr,
and packages are not held to any quality or security level.
Please do not file bug reports about these packages in Fedora
Bugzilla. In case of problems, contact the owner of this repository.
Do you want to continue? [y/N]: y
Error: Such repository does not exist.
[work@localhost-localdomain ~]$ sudo dnf install moc
Last metadata expiration check: 0:33:37 ago on Fri 26 Oct 2018 10:47:51 AM IST.
No match for argument: moc
Error: Unable to find a match
## Larry
Let me get this straight, third party software that doesn’t conform to Fedora standards……Isn’t that one of the issues with Windoze, is “downloading software from other places,” or a far as that goes apps on Android not from the “play store.” Better yet when I used Ubuntu installing PPA’s from outside Ubuntu’s repositories, very unwise move. I don’t see a problem with installing software from outside repositories.
## Nick
For those that get an error which says “Error: Such repository does not exist.” on the first one, it is because the command is “sudo dnf copr enable krzysztof/Moc” not “sudo dnf copr enable krzystof/Moc”. Hope that helps.
## Clément Verna
Thanks I have edited the article to reflect this change
## Brenton Horne
I’ve created my own Copr for the application menu, window switch and dmenu replacement, Rofi (https://copr.fedorainfracloud.org/coprs/fusion809/Rofi/). Why am I mentioning this? Partly because I was surprised I had to package it, I would have thought it’d be in Fedora’s rather large and comprehensive repos. Also because it goes exceptionally well with i3 as a replacement for dmenu, but with a larger feature set. Might be worthwhile covering in a future article. |
10,249 | gitbase:用 SQL 查询 Git 仓库 | https://opensource.com/article/18/11/gitbase | 2018-11-19T13:14:50 | [
"Git",
"SQL"
] | https://linux.cn/article-10249-1.html |
>
> gitbase 是一个使用 go 开发的的开源项目,它实现了在 Git 仓库上执行 SQL 查询。
>
>
>

Git 已经成为了代码版本控制的事实标准,但尽管 Git 相当普及,对代码仓库的深入分析的工作难度却没有因此而下降;而 SQL 在大型代码库的查询方面则已经是一种久经考验的语言,因此诸如 Spark 和 BigQuery 这样的项目都采用了它。
所以,source{d} 很顺理成章地将这两种技术结合起来,就产生了 gitbase(LCTT 译注:source{d} 是一家开源公司,本文作者是该公司开发者关系副总裁)。gitbase 是一个<ruby> 代码即数据 <rt> code-as-data </rt></ruby>的解决方案,可以使用 SQL 对 git 仓库进行大规模分析。
[gitbase](https://github.com/src-d/gitbase) 是一个完全开源的项目。它站在了很多巨人的肩上,因此得到了足够的发展竞争力。下面就来介绍一下其中的一些“巨人”。

*[gitbase playground](https://github.com/src-d/gitbase-web) 为 gitbase 提供了一个可视化的操作环境。*
### 用 Vitess 解析 SQL
gitbase 通过 SQL 与用户进行交互,因此需要能够遵循 MySQL 协议来对通过网络传入的 SQL 请求作出解析和理解,万幸由 YouTube 建立的 [Vitess](https://github.com/vitessio/vitess) 项目已经在这一方面给出了解决方案。Vitess 是一个横向扩展的 MySQL 数据库集群系统。
我们只是使用了这个项目中的部分重要代码,并将其转化为一个可以让任何人在数分钟以内编写出一个 MySQL 服务器的[开源程序](https://github.com/src-d/go-mysql-server),就像我在 [justforfunc](http://justforfunc.com/) 视频系列中展示的 [CSVQL](https://youtu.be/bcRDXAraprk) 一样,它可以使用 SQL 操作 CSV 文件。
### 用 go-git 读取 git 仓库
在成功解析 SQL 请求之后,还需要对数据集中的 git 仓库进行查询才能返回结果。因此,我们还结合使用了 source{d} 最成功的 [go-git](https://github.com/src-d/go-git) 仓库。go-git 是使用纯 go 语言编写的具有高度可扩展性的 git 实现。
借此我们就可以很方便地将存储在磁盘上的代码仓库保存为 [siva](https://github.com/src-d/siva) 文件格式(这同样是 source{d} 的一个开源项目),也可以通过 `git clone` 来对代码仓库进行复制。
### 使用 enry 检测语言、使用 babelfish 解析文件
gitbase 集成了我们开源的语言检测项目 [enry](https://github.com/src-d/enry) 以及代码解析项目 [babelfish](https://github.com/bblfsh/bblfshd),因此在分析 git 仓库历史代码的能力也相当强大。babelfish 是一个自托管服务,普适于各种源代码解析,并将代码文件转换为<ruby> 通用抽象语法树 <rt> Universal Abstract Syntax Tree </rt></ruby>(UAST)。
这两个功能在 gitbase 中可以被用户以函数 `LANGUAGE` 和 `UAST` 调用,诸如“查找上个月最常被修改的函数的名称”这样的请求就需要通过这两个功能实现。
### 提高性能
gitbase 可以对非常大的数据集进行分析,例如来自 GitHub 高达 3 TB 源代码的 Public Git Archive([公告](https://blog.sourced.tech/post/announcing-pga/))。面临的工作量如此巨大,因此每一点性能都必须运用到极致。于是,我们也使用到了 Rubex 和 Pilosa 这两个项目。
#### 使用 Rubex 和 Oniguruma 优化正则表达式速度
[Rubex](https://github.com/moovweb/rubex) 是 go 的正则表达式标准库包的一个准替代品。之所以说它是准替代品,是因为它没有在 `regexp.Regexp` 类中实现 `LiteralPrefix` 方法,直到现在都还没有。
Rubex 的高性能是由于使用 [cgo](https://golang.org/cmd/cgo/) 调用了 [Oniguruma](https://github.com/kkos/oniguruma),它是一个高度优化的 C 代码库。
#### 使用 Pilosa 索引优化查询速度
索引几乎是每个关系型数据库都拥有的特性,但 Vitess 由于不需要用到索引,因此并没有进行实现。
于是我们引入了 [Pilosa](https://github.com/pilosa/pilosa) 这个开源项目。Pilosa 是一个使用 go 实现的分布式位图索引,可以显著提升跨多个大型数据集的查询的速度。通过 Pilosa,gitbase 才得以在巨大的数据集中进行查询。
### 总结
我想用这一篇文章来对开源社区表达我衷心的感谢,让我们能够不负众望的在短时间内完成 gitbase 的开发。我们 source{d} 的每一位成员都是开源的拥护者,github.com/src-d 下的每一行代码都是见证。
你想使用 gitbase 吗?最简单快捷的方式是从 sourced.tech/engine 下载 source{d} 引擎,就可以通过单个命令运行 gitbase 了。
想要了解更多,可以听听我在 [Go SF 大会](https://www.meetup.com/golangsf/events/251690574/)上的演讲录音。
本文在 [Medium](https://medium.com/sourcedtech/gitbase-exploring-git-repos-with-sql-95ec0986386c) 首发,并经许可在此发布。
---
via: <https://opensource.com/article/18/11/gitbase>
作者:[Francesc Campoy](https://opensource.com/users/francesc) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Git has become the de-facto standard for code versioning, but its popularity didn't remove the complexity of performing deep analyses of the history and contents of source code repositories.
SQL, on the other hand, is a battle-tested language to query large codebases as its adoption by projects like Spark and BigQuery shows.
So it is just logical that at source{d} we chose these two technologies to create gitbase: the code-as-data solution for large-scale analysis of git repositories with SQL.
[Gitbase](https://github.com/src-d/gitbase) is a fully open source project that stands on the shoulders of a series of giants which made its development possible, this article aims to point out the main ones.
*The gitbase playground provides a visual way to use gitbase.*
## Parsing SQL with Vitess
Gitbase's user interface is SQL. This means we need to be able to parse and understand the SQL requests that arrive through the network following the MySQL protocol. Fortunately for us, this was already implemented by our friends at YouTube and their [Vitess](https://github.com/vitessio/vitess) project. Vitess is a database clustering system for horizontal scaling of MySQL.
We simply grabbed the pieces of code that mattered to us and made it into an [open source project ](https://github.com/src-d/go-mysql-server)that allows anyone to write a MySQL server in minutes (as I showed in my [justforfunc](http://justforfunc.com/) episode [CSVQL—serving CSV with SQL](https://youtu.be/bcRDXAraprk)).
## Reading git repositories with go-git
Once we've parsed a request we still need to find how to answer it by reading the git repositories in our dataset. For this, we integrated source{d}'s most successful repository [go-git](https://github.com/src-d/go-git). Go-git is a* *highly extensible Git implementation in pure Go.
This allowed us to easily analyze repositories stored on disk as [siva](https://github.com/src-d/siva) files (again an open source project by source{d}) or simply cloned with *git clone*.
## Detecting languages with enry and parsing files with babelfish
Gitbase does not stop its analytic power at the git history. By integrating language detection with our (obviously) open source project [enry](https://github.com/src-d/enry) and program parsing with [babelfish](https://github.com/bblfsh/bblfshd). Babelfish is a self-hosted server for universal source code parsing, turning code files into Universal Abstract Syntax Trees (UASTs)
These two features are exposed in gitbase as the user functions *LANGUAGE *and *UAST*. Together they make requests like *"find the name of the function that was most often modified during the last month" *possible.
## Making it go fast
Gitbase analyzes really large datasets—e.g. Public Git Archive, with 3TB of source code from GitHub ([announcement](https://blog.sourced.tech/post/announcing-pga/)) and in order to do so every CPU cycle counts.
This is why we integrated two more projects into the mix: Rubex and Pilosa.
### Speeding up regular expressions with Rubex and Oniguruma
[Rubex](https://github.com/moovweb/rubex) is a quasi-drop-in replacement for Go's *regexp *standard library package. I say quasi because they do not implement the *LiteralPrefix* method on the *regexp.Regexp* type, but I also had never heard about that method until right now.
Rubex gets its performance from the highly optimized C library [Oniguruma](https://github.com/kkos/oniguruma) which it calls using [cgo](https://golang.org/cmd/cgo/).
### Speeding up queries with Pilosa indexes
Indexes are a well-known feature of basically every relational database, but Vitess does not implement them since it doesn't really need to.
But again open source came to the rescue with [Pilosa](https://github.com/pilosa/pilosa), a distributed bitmap index implemented in Go which made gitbase usable on massive datasets. Pilosa is an open source, distributed bitmap index that dramatically accelerates queries across multiple, massive datasets.
## Conclusion
I'd like to use this blog post to personally thank the open source community that made it possible for us to create gitbase in such a shorter period that anyone would have expected. At source{d} we are firm believers in open source and every single line of code under github.com/src-d (including our OKRs and investor board) is a testament to that.
Would you like to give gitbase a try? The fastest and easiest way is with source{d} Engine. Download it from sourced.tech/engine and get gitbase running with a single command!
Want to know more? Check out the recording of my talk at the [Go SF meetup](https://www.meetup.com/golangsf/events/251690574/).
*The article was originally published on Medium and is republished here with permission.*
## Comments are closed. |
10,250 | Chrony:一个类 Unix 系统上 NTP 客户端和服务器替代品 | https://www.ostechnix.com/chrony-an-alternative-ntp-client-and-server-for-unix-like-systems/ | 2018-11-19T14:34:07 | [
"NTP",
"时间"
] | https://linux.cn/article-10250-1.html | 
在这个教程中,我们会讨论如何安装和配置 **Chrony**,一个类 Unix 系统上 NTP 客户端和服务器的替代品。Chrony 可以更快的同步系统时钟,具有更好的时钟准确度,并且它对于那些不是一直在线的系统很有帮助。Chrony 是自由开源的,并且支持 GNU/Linux 和 BSD 衍生版(比如 FreeBSD、NetBSD)、macOS 和 Solaris 等。
### 安装 Chrony
Chrony 可以从大多数 Linux 发行版的默认软件库中获得。如果你使用的是 Arch Linux,运行下面的命令来安装它:
```
$ sudo pacman -S chrony
```
在 Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt-get install chrony
```
在 Fedora 上:
```
$ sudo dnf install chrony
```
当安装完成后,如果之前没有启动过的话需启动 `chronyd.service` 守护进程:
```
$ sudo systemctl start chronyd.service
```
使用下面的命令让它每次重启系统后自动运行:
```
$ sudo systemctl enable chronyd.service
```
为了确认 `chronyd.service` 已经启动,运行:
```
$ sudo systemctl status chronyd.service
```
如果一切正常,你将看到类似下面的输出:
```
● chrony.service - chrony, an NTP client/server
Loaded: loaded (/lib/systemd/system/chrony.service; enabled; vendor preset: ena
Active: active (running) since Wed 2018-10-17 10:34:53 UTC; 3min 15s ago
Docs: man:chronyd(8)
man:chronyc(1)
man:chrony.conf(5)
Main PID: 2482 (chronyd)
Tasks: 1 (limit: 2320)
CGroup: /system.slice/chrony.service
└─2482 /usr/sbin/chronyd
Oct 17 10:34:53 ubuntuserver systemd[1]: Starting chrony, an NTP client/server...
Oct 17 10:34:53 ubuntuserver chronyd[2482]: chronyd version 3.2 starting (+CMDMON
Oct 17 10:34:53 ubuntuserver chronyd[2482]: Initial frequency -268.088 ppm
Oct 17 10:34:53 ubuntuserver systemd[1]: Started chrony, an NTP client/server.
Oct 17 10:35:03 ubuntuserver chronyd[2482]: Selected source 85.25.84.166
Oct 17 10:35:03 ubuntuserver chronyd[2482]: Source 85.25.84.166 replaced with 2403
Oct 17 10:35:03 ubuntuserver chronyd[2482]: Selected source 91.189.89.199
Oct 17 10:35:06 ubuntuserver chronyd[2482]: Selected source 106.10.186.200
```
可以看到,Chrony 服务已经启动并且正在工作!
### 配置 Chrony
NTP 客户端需要知道它要连接到哪个 NTP 服务器来获取当前时间。我们可以直接在该 NTP 配置文件中的 `server` 或者 `pool` 项指定 NTP 服务器。通常,默认的配置文件位于 `/etc/chrony/chrony.conf` 或者 `/etc/chrony.conf`,取决于 Linux 发行版版本。为了更可靠的同步时间,建议指定至少三个服务器。
下面几行是我的 Ubuntu 18.04 LTS 服务器上的一个示例。
```
[...]
# About using servers from the NTP Pool Project in general see (LP: #104525).
# Approved by Ubuntu Technical Board on 2011-02-08.
# See http://www.pool.ntp.org/join.html for more information.
pool ntp.ubuntu.com iburst maxsources 4
pool 0.ubuntu.pool.ntp.org iburst maxsources 1
pool 1.ubuntu.pool.ntp.org iburst maxsources 1
pool 2.ubuntu.pool.ntp.org iburst maxsources 2
[...]
```
从上面的输出中你可以看到,[NTP 服务器池项目](https://www.ntppool.org/en/) 已经被设置成为了默认的时间服务器。对于那些好奇的人,NTP 服务器池项目是一个时间服务器集群,用来为全世界千万个客户端提供 NTP 服务。它是 Ubuntu 以及其他主流 Linux 发行版的默认时间服务器。
在这里, \* `iburst` 选项用来加速初始的同步过程 \* `maxsources` 代表 NTP 源的最大数量
请确保你选择的 NTP 服务器是同步的、稳定的、离你的位置较近的,以便使用这些 NTP 源来提升时间准确度。
### 在命令行中管理 Chronyd
chrony 有一个命令行工具叫做 `chronyc` 用来控制和监控 chrony 守护进程(`chronyd`)。
为了检查是否 chrony 已经同步,我们可以使用下面展示的 `tracking` 命令。
```
$ chronyc tracking
Reference ID : 6A0ABAC8 (t1.time.sg3.yahoo.com)
Stratum : 3
Ref time (UTC) : Wed Oct 17 11:48:51 2018
System time : 0.000984587 seconds slow of NTP time
Last offset : -0.000912981 seconds
RMS offset : 0.007983995 seconds
Frequency : 23.704 ppm slow
Residual freq : +0.006 ppm
Skew : 1.734 ppm
Root delay : 0.089718960 seconds
Root dispersion : 0.008760406 seconds
Update interval : 515.1 seconds
Leap status : Normal
```
我们可以使用命令确认现在 chrony 使用的时间源:
```
$ chronyc sources
210 Number of sources = 8
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^- chilipepper.canonical.com 2 10 377 296 +102ms[ +104ms] +/- 279ms
^- golem.canonical.com 2 10 377 302 +105ms[ +107ms] +/- 290ms
^+ pugot.canonical.com 2 10 377 297 +36ms[ +38ms] +/- 238ms
^- alphyn.canonical.com 2 10 377 279 -43ms[ -42ms] +/- 238ms
^- dadns.cdnetworks.co.kr 2 10 377 1070 +40ms[ +42ms] +/- 314ms
^* t1.time.sg3.yahoo.com 2 10 377 169 -13ms[ -11ms] +/- 80ms
^+ sin1.m-d.net 2 10 275 567 -9633us[-7826us] +/- 115ms
^- ns2.pulsation.fr 2 10 377 311 -75ms[ -73ms] +/- 250ms
```
`chronyc` 工具可以对每个源进行统计,比如使用 `sourcestats` 命令获得漂移速率和进行偏移估计。
```
$ chronyc sourcestats
210 Number of sources = 8
Name/IP Address NP NR Span Frequency Freq Skew Offset Std Dev
==============================================================================
chilipepper.canonical.com 32 16 89m +6.293 14.345 +30ms 24ms
golem.canonical.com 32 17 89m +0.312 18.887 +20ms 33ms
pugot.canonical.com 32 18 89m +0.281 11.237 +3307us 23ms
alphyn.canonical.com 31 20 88m -4.087 8.910 -58ms 17ms
dadns.cdnetworks.co.kr 29 16 76m -1.094 9.895 -83ms 14ms
t1.time.sg3.yahoo.com 32 16 91m +0.153 1.952 +2835us 4044us
sin1.m-d.net 29 13 83m +0.049 6.060 -8466us 9940us
ns2.pulsation.fr 32 17 88m +0.784 9.834 -62ms 22ms
```
如果你的系统没有连接到互联网,你需要告知 Chrony 系统没有连接到 互联网。为了这样做,运行:
```
$ sudo chronyc offline
[sudo] password for sk:
200 OK
```
为了确认你的 NTP 源的状态,只需要运行:
```
$ chronyc activity
200 OK
0 sources online
8 sources offline
0 sources doing burst (return to online)
0 sources doing burst (return to offline)
0 sources with unknown address
```
可以看到,我的所有源此时都是离线状态。
一旦你连接到互联网,只需要使用命令告知 Chrony 你的系统已经回到在线状态:
```
$ sudo chronyc online
200 OK
```
为了查看 NTP 源的状态,运行:
```
$ chronyc activity
200 OK
8 sources online
0 sources offline
0 sources doing burst (return to online)
0 sources doing burst (return to offline)
0 sources with unknown address
```
所有选项和参数的详细解释,请参考其帮助手册。
```
$ man chronyc
$ man chronyd
```
这就是文章的所有内容。希望对你有所帮助。在随后的教程中,我们会看到如何使用 Chrony 启动一个本地的 NTP 服务器并且配置客户端来使用这个服务器同步时间。
保持关注!
---
via: <https://www.ostechnix.com/chrony-an-alternative-ntp-client-and-server-for-unix-like-systems/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zianglei](https://github.com/zianglei) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,252 | 设计更快的网页(三):字体和 CSS 调整 | https://fedoramagazine.org/design-faster-web-pages-part-3-font-css-tweaks/ | 2018-11-19T22:54:41 | [
"CSS"
] | https://linux.cn/article-10252-1.html | 
欢迎回到我们为了构建更快网页所写的系列文章。本系列的[第一部分](/article-10166-1.html)和[第二部分](/article-10217-1.html)讲述了如何通过优化和替换图片来减少浏览器脂肪。本部分会着眼于在 CSS([层叠式样式表](https://en.wikipedia.org/wiki/Cascading_Style_Sheets))和字体中减掉更多的脂肪。
### 调整 CSS
首先,我们先来看看问题的源头。CSS 的出现曾是技术的一大进步。你可以用一个集中式的样式表来装饰多个网页。如今很多 Web 开发者都会使用 Bootstrap 这样的框架。
这些框架当然方便,可是很多人都会将整个框架直接复制粘贴走。Bootstrap 非常大:目前 Bootstrap 4.0 的“最小”版本也有 144.9 KB. 在这个以 TB 来计数据的时代,它可能不算多。但就像所说的那样,一头小牛也能搞出大麻烦。
我们回头来看 [getfedora.org](https://getfedora.org) 的例子。我们在[第一部分](/article-10166-1.html)中提过,第一个分析结果显示 CSS 文件占用的空间几乎比 HTML 本身还要大十倍。这里显示了所有用到的样式表:

那是九个不同的样式表。其中的很多样式在这个页面中并没有用上。
#### 移除、合并、以及压缩/缩小化
Font-awesome CSS 代表了包含未使用样式的极端。这个页面中只用到了这个字体的三个字形。如果以 KB 为单位,getfedora.org 用到的 font-awesome CSS 最初有 25.2 KB. 在清理掉所有未使用的样式后,它只有 1.3 KB 了。这只有原来体积的 4% 左右!对于 Bootstrap CSS,原来它有 118.3 KB,清理掉无用的样式后只有 13.2 KB,这就是差异。
下一个问题是,我们必须要这样一个 `bootstrap.css` 和 `font-awesome.css` 吗?或者,它们能不能合起来呢?没错,它们可以。这样虽然不会节省更多的文件空间,但浏览器成功渲染页面所需要发起的请求更少了。
最后,在合并 CSS 文件后,尝试去除无用样式并缩小它们。这样,它们只有 4.3 KB 大小,而你省掉了 10.1 KB.
不幸的是,在 Fedora 软件仓库中,还没有打包好的缩小工具。不过,有几百种在线服务可以帮到你。或者,你也可以使用 [CSS-HTML-JS Minify](https://github.com/juancarlospaco/css-html-js-minify),它用 Python 编写,所以容易安装。现在没有一个可用的工具来净化 CSS,不过我们有 [UnCSS](https://uncss-online.com/) 这样的 Web 服务。
### 字体改进
[CSS3](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS3) 带来了很多开发人员喜欢的东西。它可以定义一些渲染页面所用的字体,并让浏览器在后台下载。此后,很多 Web 设计师都很开心,尤其是在他们发现了 Web 设计中图标字体的用法之后。像 [Font Awesome](https://fontawesome.com/) 这样的字体集现在非常流行,也被广泛使用。这是这个字体集的大小:
```
current free version 912 glyphs/icons, smallest set ttf 30.9KB, woff 14.7KB, woff2 12.2KB, svg 107.2KB, eot 31.2
```
所以问题是,你需要所有的字形吗?很可能不需要。你可以通过 [FontForge](https://fontforge.github.io/en-US/) 来去除这些无用字形,但这需要很大的工作量。你还可以用 [Fontello](http://fontello.com/). 你可以使用公共实例,也可以配置你自己的版本,因为它是自由软件,可以在 [Github](https://github.com/fontello/fontello) 上找到。
这种自定义字体集的缺点在于,你必须自己来托管字体文件。你也没法使用其它在线服务来提供更新。但与更快的性能相比,这可能算不上一个缺点。
### 总结
现在,你已经做完了所有对内容本身的操作,来最大限度地减少浏览器加载和解释的内容。从现在开始,只有服务器的管理技巧才才能帮到你了。
有一个很简单,但很多人都做错了的事情,就是使用一些智能缓存。比如,CSS 或者图片文件可以缓存一周。但无论如何,如果你用了 Cloudflare 这样的代理服务或者自己构建了代理,首先要做的都应该是缩小页面。用户喜欢可以快速加载的页面。他们会(默默地)感谢你,服务器的负载也会更小。
---
via: <https://fedoramagazine.org/design-faster-web-pages-part-3-font-css-tweaks/>
作者:[Sirko Kemter](https://fedoramagazine.org/author/gnokii/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[StdioA](https://github.com/StdioA) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Welcome back to this series of articles on designing faster web pages. [Part 1](https://fedoramagazine.org/design-faster-web-pages-part-1-image-compression/) and [part 2](https://fedoramagazine.org/design-faster-web-pages-part-2-image-replacement/) of this series covered how to lose browser fat through optimizing and replacing images. This part looks at how to lose additional fat in CSS ([Cascading Style Sheets](https://en.wikipedia.org/wiki/Cascading_Style_Sheets)) and fonts.
## Tweaking CSS
First things first: let’s look at where the problem originates. CSS was once a huge step forward. You can use it to style several pages from a central style sheet. Nowadays, many web developers use frameworks like Bootstrap.
While these frameworks are certainly helpful, many people simply copy and paste the whole framework. Bootstrap is huge; the “minimal” version of 4.0 is currently 144.9 KB. Perhaps in the era of terabytes of data, this isn’t much. But as they say, even small cattle makes a mess.
Look back at the [getfedora.org](https://getfedora.org) example. Recall in [part 1](https://fedoramagazine.org/design-faster-web-pages-part-1-image-compression/), the first analysis showed the CSS files used nearly ten times more space than the HTML itself. Here’s a display of the stylesheets used:
That’s nine different stylesheets. Many styles in them that are also unused on the page.
### Remove, merge, and compress/minify
The font-awesome CSS inhabits the extreme end of included, unused styles. There are only three glyphs of the font used on the page. To make that up in KB, the font-awesome CSS used at getfedora.org is originally 25.2 KB. After cleaning out all unused styles, it’s only 1.3 KB. This is only about 4% of its original size! For Bootstrap CSS, the difference is 118.3 KB original, and 13.2 KB after removing unused styles.
The next question is, must there be a bootstrap.css and a font-awesome.css? Or can they be combined? Yes, they can. That doesn’t save much file space, but the browser now requests fewer files to succesfully render the page.
Finally, after merging the CSS files, try to remove unused styles and minify them. In this way, you save 10.1 KB for a final size of 4.3 KB.
Unfortunately, there’s no packaged “minifier” tool in Fedoras repositories yet. However, there are hundreds of online services to do that for you. Or you can use [CSS-HTML-JS Minify](https://github.com/juancarlospaco/css-html-js-minify), which is Python, and therefore easy to isntall. There’s not an available tool to purify CSS, but there are web services like [UnCSS](https://uncss-online.com/).
## Font improvement
[CSS3](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS3) came with something a lot of web developer like. They could define fonts the browser downloads in the background to render the page. Since then, a lot of web designers are very happy, especially after they discovered the usage of icon fonts for web design. Font sets like [Font Awesome](https://fontawesome.com/) are quiet popular today and widely used. Here’s the size of that content:
current free version 912 glyphs/icons, smallest set ttf 30.9KB, woff 14.7KB, woff2 12.2KB, svg 107.2KB, eot 31.2
So the question is, do you need all the glyphs? In all probability, no. You can get rid of them with [FontForge](https://fontforge.github.io/en-US/), but that’s a lot of work. You could also use [Fontello](http://fontello.com/). Use the public instance, or set up your own, as it’s free software and available on [Github](https://github.com/fontello/fontello).
The downside of such customized font sets is you must host the font by yourself. You can’t use other online font services to provide updates. But this may not really be a downside, compared to faster performance.
## Conclusion
Now you’ve done everything you can to the content itself, to minimize what the browser loads and interprets. From now on, only tricks with the administration of the server can help.
One easy to do, but which many people do wrong, is decide on some intelligent caching. For instance, a CSS or picture file can be cached for a week. Whatever you do, if you use a proxy service like Cloudflare or build your own proxy, minimze the pages first. Users like fast loading pages. They’ll (silently) thank you for it, and the server will have a smaller load, too.
## W
Critical Path CSS And render blocking should be mentioned.
## Sirko Kemter
could not should
## Maimela
this was an interesting topic. i will put it to good use (still a noob when it comes to web development) i don’t even have my own website running
## Afan Haqul Fadillah
Really Helpful,, keep it up????
## John
Most of the time I am not interested in stories in front-end development, but this whole series by Sirko blow my mind. I happened to open the link the today, and spent half a hour to read all three posts. Everything about this post, the story telling, open source tools used … is just so awesome. Good work! I hope to see more of your stories here on Fedora magazine.
## Sirko Kemter
thx for the feedback. More posts lets see
## Dave Cooper
I’ve really enjoyed this series. Tackling the amazing bloat in online content is massively overdue – even it involve the current generation of web developers in writing actual code 😉 ! |
10,253 | more、less 和 most 的区别 | https://www.ostechnix.com/the-difference-between-more-less-and-most-commands/ | 2018-11-19T23:21:23 | [
"more",
"less",
"most",
"分页"
] | https://linux.cn/article-10253-1.html | 
如果你是一个 Linux 方面的新手,你可能会在 `more`、`less`、`most` 这三个命令行工具之间产生疑惑。在本文当中,我会对这三个命令行工具进行对比,以及展示它们各自在 Linux 中的一些使用例子。总的来说,这几个命令行工具之间都有相通和差异,而且它们在大部分 Linux 发行版上都有自带。
我们首先来看看 `more` 命令。
### more 命令
`more` 是一个老式的、基础的终端分页阅读器,它可以用于打开指定的文件并进行交互式阅读。如果文件的内容太长,在一屏以内无法完整显示,就会逐页显示文件内容。使用回车键或者空格键可以滚动浏览文件的内容,但有一个限制,就是只能够单向滚动。也就是说只能按顺序往下翻页,而不能进行回看。

**更正**
有的 Linux 用户向我指出,在 `more` 当中是可以向上翻页的。不过,最原始版本的 `more` 确实只允许向下翻页,在后续出现的较新的版本中也允许了有限次数的向上翻页,只需要在浏览过程中按 `b` 键即可向上翻页。唯一的限制是 `more` 不能搭配管道使用(如 `ls | more`)。(LCTT 译注:此处原作者疑似有误,译者使用 `more` 是可以搭配管道使用的,或许与不同 `more` 版本有关)
按 `q` 即可退出 `more`。
**更多示例**
打开 `ostechnix.txt` 文件进行交互式阅读,可以执行以下命令:
```
$ more ostechnix.txt
```
在阅读过程中,如果需要查找某个字符串,只需要像下面这样输入斜杠(`/`)之后接着输入需要查找的内容:
```
/linux
```
按 `n` 键可以跳转到下一个匹配的字符串。
如果需要在文件的第 `10` 行开始阅读,只需要执行:
```
$ more +10 file
```
就可以从文件的第 `10` 行开始显示文件的内容了。
如果你需要让 `more` 提示你按空格键来翻页,可以加上 `-d` 参数:
```
$ more -d ostechnix.txt
```

如上图所示,`more` 会提示你可以按空格键翻页。
如果需要查看所有选项以及对应的按键,可以按 `h` 键。
要查看 `more` 的更多详细信息,可以参考手册:
```
$ man more
```
### less 命令
`less` 命令也是用于打开指定的文件并进行交互式阅读,它也支持翻页和搜索。如果文件的内容太长,也会对输出进行分页,因此也可以翻页阅读。比 `more` 命令更好的一点是,`less` 支持向上翻页和向下翻页,也就是可以在整个文件中任意阅读。

在使用功能方面,`less` 比 `more` 命令具有更多优点,以下列出其中几个:
* 支持向上翻页和向下翻页
* 支持向上搜索和向下搜索
* 可以跳转到文件的末尾并立即从文件的开头开始阅读
* 在编辑器中打开指定的文件
**更多示例**
打开文件:
```
$ less ostechnix.txt
```
按空格键或回车键可以向下翻页,按 `b` 键可以向上翻页。
如果需要向下搜索,在输入斜杠(`/`)之后接着输入需要搜索的内容:
```
/linux
```
按 `n` 键可以跳转到下一个匹配的字符串,如果需要跳转到上一个匹配的字符串,可以按 `N` 键。
如果需要向上搜索,在输入问号(`?`)之后接着输入需要搜索的内容:
```
?linux
```
同样是按 `n` 键或 `N` 键跳转到下一个或上一个匹配的字符串。
只需要按 `v` 键,就会将正在阅读的文件在默认编辑器中打开,然后就可以对文件进行各种编辑操作了。
按 `h` 键可以查看 `less` 工具的选项和对应的按键。
按 `q` 键可以退出阅读。
要查看 `less` 的更多详细信息,可以参考手册:
```
$ man less
```
### most 命令
`most` 同样是一个终端阅读工具,而且比 `more` 和 `less` 的功能更为丰富。`most` 支持同时打开多个文件。你可以在打开的文件之间切换、编辑当前打开的文件、迅速跳转到文件中的某一行、分屏阅读、同时锁定或滚动多个屏幕等等功能。在默认情况下,对于较长的行,`most` 不会将其截断成多行显示,而是提供了左右滚动功能以在同一行内显示。
**更多示例**
打开文件:
```
$ most ostechnix1.txt
```

按 `e` 键可以编辑当前文件。
如果需要向下搜索,在斜杠(`/`)或 `S` 或 `f` 之后输入需要搜索的内容,按 `n` 键就可以跳转到下一个匹配的字符串。

如果需要向上搜索,在问号(`?`)之后输入需要搜索的内容,也是通过按 `n` 键跳转到下一个匹配的字符串。
同时打开多个文件:
```
$ most ostechnix1.txt ostechnix2.txt ostechnix3.txt
```
在打开了多个文件的状态下,可以输入 `:n` 切换到下一个文件,使用 `↑` 或 `↓` 键选择需要切换到的文件,按回车键就可以查看对应的文件。

要打开文件并跳转到某个字符串首次出现的位置(例如 linux),可以执行以下命令:
```
$ most file +/linux
```
按 `h` 键可以查看帮助。
**按键操作列表**
移动:
* 空格键或 `D` 键 – 向下滚动一屏
* `DELETE` 键或 `U` 键 – 向上滚动一屏
* `↓` 键 – 向下移动一行
* `↑` 键 – 向上移动一行
* `T` 键 – 移动到文件开头
* `B` 键 – 移动到文件末尾
* `>` 键或 `TAB` 键 – 向右滚动屏幕
* `<` 键 – 向左滚动屏幕
* `→` 键 – 向右移动一列
* `←` 键 – 向左移动一列
* `J` 键或 `G` 键 – 移动到某一行,例如 `10j` 可以移动到第 10 行
* `%` 键 – 移动到文件长度某个百分比的位置
窗口命令:
* `Ctrl-X 2`、`Ctrl-W 2` – 分屏
* `Ctrl-X 1`、`Ctrl-W 1` – 只显示一个窗口
* `O` 键、`Ctrl-X O` – 切换到另一个窗口
* `Ctrl-X 0` – 删除窗口
文件内搜索:
* `S` 键或 `f` 键或 `/` 键 – 向下搜索
* `?` 键 – 向上搜索
* `n` 键 – 跳转到下一个匹配的字符串
退出:
* `q` 键 – 退出 `most` ,且所有打开的文件都会被关闭
* `:N`、`:n` – 退出当前文件并查看下一个文件(使用 `↑` 键、`↓` 键选择下一个文件)
要查看 `most` 的更多详细信息,可以参考手册:
```
$ man most
```
### 总结
`more` – 传统且基础的分页阅读工具,仅支持向下翻页和有限次数的向上翻页。
`less` – 比 `more` 功能丰富,支持向下翻页和向上翻页,也支持文本搜索。在打开大文件的时候,比 `vi` 这类文本编辑器启动得更快。
`most` – 在上述两个工具功能的基础上,还加入了同时打开多个文件、同时锁定或滚动多个屏幕、分屏等等大量功能。
以上就是我的介绍,希望能让你通过我的文章对这三个工具有一定的认识。如果想了解这篇文章以外的关于这几个工具的详细功能,请参阅它们的 `man` 手册。
---
via: <https://www.ostechnix.com/the-difference-between-more-less-and-most-commands/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,254 | 写直白的代码 | http://matthewrocklin.com/blog/work/2018/01/27/write-dumb-code | 2018-11-20T00:08:38 | [
"编程"
] | https://linux.cn/article-10254-1.html | 
为开源项目作贡献最好的方式是为它减少代码,我们应致力于写出让新手程序员无需注释就容易理解的代码,让维护者也无需花费太多精力就能着手维护。
在学生时代,我们会更多地用复杂巧妙的技术去挑战新的难题。首先我们会学习循环,然后是函数啊,类啊,等等。当我们到达一定高的程度,能用更高级的技术写更长的程序,我们会因此受到称赞。此刻我们发现老司机们用 monads 而新手们用 loop 作循环。
之后我们毕业找了工作,或者和他人合作开源项目。我们用在学校里学到的各种炫技寻求并骄傲地给出解决方案的代码实现。
*哈哈,我能扩展这个项目,并实现某牛 X 功能啦,我这里能用继承啦,我太聪明啦!*
我们实现了某个小的功能,并以充分的理由觉得自己做到了。现实项目中的编程却不是针对某某部分的功能而言。以我个人的经验而言,以前我很开心的去写代码,并骄傲地向世界展示我所知道的事情。有例为证,作为对某种编程技术的偏爱,这是用另一种元编程语言构建的一个 [线性代数语言](https://github.com/mrocklin/matrix-algebra),注意,这么多年以来一直没人愿意碰它。
在维护了更多的代码后,我的观点发生了变化。
1. 我们不应去刻意探求如何构建软件。软件是我们为解决问题所付出的代价,那才是我们真实的目的。我们应努力为了解决问题而构建较小的软件。
2. 我们应使用尽可能简单的技术,那么更多的人就越可能会使用,并且无需理解我们所知的高级技术就能扩展软件的功能。当然,在我们不知道如何使用简单技术去实现时,我们也可以使用高级技术。
所有的这些例子都不是听来的故事。我遇到的大部分人会认同某些部分,但不知为什么,当我们向一个新项目贡献代码时又会忘掉这个初衷。直觉里用复杂技术去构建的念头往往会占据上风。
### 软件是种投入
你写的每行代码都要花费人力。写代码当然是需要时间的,也许你会认为只是你个人在奉献,然而这些代码在被审阅的时候也需要花时间理解,对于未来维护和开发人员来说,他们在维护和修改代码时同样要花费时间。否则他们完全可以用这时间出去晒晒太阳,或者陪伴家人。
所以,当你向某个项目贡献代码时,请心怀谦恭。就像是,你正和你的家人进餐时,餐桌上却没有足够的食物,你只索取你所需的部分,别人对你的自我约束将肃然起敬。以更少的代码去解决问题是很难的,你肩负重任的同时自然减轻了别人的重负。
### 技术越复杂越难维护
作为学生,逐渐使用高端技术证明了自己的价值。这体现在,首先我们有能力在开源项目中使用函数,接着是类,然后是高阶函数,monads 等等。我们向同行显示自己的解决方案时,常因自己所用技术高低而感到自豪或卑微。
而在现实中,和团队去解决问题时,情况发生了逆转。现在,我们致力于尽可能使用简单的代码去解决问题。简单方式解决问题使新手程序员能够以此扩展并解决其他问题。简单的代码让别人容易上手,效果立竿见影。我们藉以只用简单的技术去解决难题,从而展示自己的价值。
*看,我用循环替代了递归函数并且一样达到了我们的需求。当然我明白这是不够聪明的做法,不过我注意到新手同事在这里会遇上麻烦,我觉得这种改变将有所帮助吧。*
如果你是个好的程序员,你不需要证明你知道很多炫技。相应的,你可以通过用一个简单的方法解决一个问题来显示你的价值,并激发你的团队在未来的时间里去完善它。
### 当然,也请保持节制
话虽如此,过于遵循 “用简单的工具去构建” 的教条也会降低生产力。通常用递归会比用循环解决问题更简单,用类或 monad 才是正确的途径。还有两种情况另当别论,一是只是只为满足自我而创建的系统,或者是别人毫无构建经验的系统。
---
via: <http://matthewrocklin.com/blog/work/2018/01/27/write-dumb-code>
作者:[Matthew Rocklin](http://matthewrocklin.com) 译者:[plutoid](https://github.com/plutoid) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,255 | Lisp 是怎么成为上帝的编程语言的 | https://twobithistory.org/2018/10/14/lisp.html | 2018-11-20T17:15:00 | [
"Lisp"
] | https://linux.cn/article-10255-1.html | 
当程序员们谈论各类编程语言的相对优势时,他们通常会采用相当平淡的措词,就好像这些语言是一条工具带上的各种工具似的 —— 有适合写操作系统的,也有适合把其它程序黏在一起来完成特殊工作的。这种讨论方式非常合理;不同语言的能力不同。不声明特定用途就声称某门语言比其他语言更优秀只能导致侮辱性的无用争论。
但有一门语言似乎受到和用途无关的特殊尊敬:那就是 Lisp。即使是恨不得给每个说出形如“某某语言比其他所有语言都好”这类话的人都来一拳的键盘远征军们,也会承认 Lisp 处于另一个层次。 Lisp 超越了用于评判其他语言的实用主义标准,因为普通程序员并不使用 Lisp 编写实用的程序 —— 而且,多半他们永远也不会这么做。然而,人们对 Lisp 的敬意是如此深厚,甚至于到了这门语言会时而被加上神话属性的程度。
大家都喜欢的网络漫画合集 xkcd 就至少在两组漫画中如此描绘过 Lisp:[其中一组漫画](https://xkcd.com/224/)中,某人得到了某种 Lisp 启示,而这好像使他理解了宇宙的基本构架。

在[另一组漫画](https://xkcd.com/297/)中,一个穿着长袍的老程序员给他的徒弟递了一沓圆括号,说这是“文明时代的优雅武器”,暗示着 Lisp 就像原力那样拥有各式各样的神秘力量。

另一个绝佳例子是 Bob Kanefsky 的滑稽剧插曲,《上帝就在人间》。这部剧叫做《永恒之火》,撰写于 1990 年代中期;剧中描述了上帝必然是使用 Lisp 创造世界的种种原因。完整的歌词可以在 [GNU 幽默合集](https://www.gnu.org/fun/jokes/eternal-flame.en.html)中找到,如下是一段摘抄:
>
> 因为上帝用祂的 Lisp 代码
>
>
> 让树叶充满绿意。
>
>
> 分形的花儿和递归的根:
>
>
> 我见过的奇技淫巧之中没什么比这更可爱。
>
>
> 当我对着雪花深思时,
>
>
> 从未见过两片相同的,
>
>
> 我知道,上帝偏爱那一门
>
>
> 名字是四个字母的语言。
>
>
>
(LCTT 译注:“四个字母”,参见:[四字神名](https://zh.wikipedia.org/wiki/%E5%9B%9B%E5%AD%97%E7%A5%9E%E5%90%8D),致谢 [no1xsyzy](https://github.com/LCTT/TranslateProject/issues/11320))
以下这句话我实在不好在人前说;不过,我还是觉得,这样一种 “Lisp 是奥术魔法”的文化模因实在是有史以来最奇异、最迷人的东西。Lisp 是象牙塔的产物,是人工智能研究的工具;因此,它对于编程界的俗人而言总是陌生的,甚至是带有神秘色彩的。然而,当今的程序员们[开始怂恿彼此,“在你死掉之前至少试一试 Lisp”](https://www.reddit.com/r/ProgrammerHumor/comments/5c14o6/xkcd_lisp/d9szjnc/),就像这是一种令人恍惚入迷的致幻剂似的。尽管 Lisp 是广泛使用的编程语言中第二古老的(只比 Fortran 年轻一岁)<sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup> ,程序员们也仍旧在互相怂恿。想象一下,如果你的工作是为某种组织或者团队推广一门新的编程语言的话,忽悠大家让他们相信你的新语言拥有神力难道不是绝佳的策略吗?—— 但你如何能够做到这一点呢?或者,换句话说,一门编程语言究竟是如何变成人们口中“隐晦知识的载体”的呢?
Lisp 究竟是怎么成为这样的?

*Byte 杂志封面,1979年八月。*
### 理论 A :公理般的语言
Lisp 的创造者<ruby> 约翰·麦卡锡 <rt> John McCarthy </rt></ruby>最初并没有想过把 Lisp 做成优雅、精炼的计算法则结晶。然而,在一两次运气使然的深谋远虑和一系列优化之后,Lisp 的确变成了那样的东西。 <ruby> 保罗·格雷厄姆 <rt> Paul Graham </rt></ruby>(我们一会儿之后才会聊到他)曾经这么写道, 麦卡锡通过 Lisp “为编程作出的贡献就像是欧几里得对几何学所做的贡献一般” <sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup>。人们可能会在 Lisp 中看出更加隐晦的含义 —— 因为麦卡锡创造 Lisp 时使用的要素实在是过于基础,基础到连弄明白他到底是创造了这门语言、还是发现了这门语言,都是一件难事。
最初, 麦卡锡产生要造一门语言的想法,是在 1956 年的<ruby> 达特茅斯人工智能夏季研究项目 <rt> Darthmouth Summer Research Project on Artificial Intelligence </rt></ruby>上。夏季研究项目是个持续数周的学术会议,直到现在也仍旧在举行;它是此类会议之中最早开始举办的会议之一。 麦卡锡当初还是个达特茅斯的数学助教,而“<ruby> 人工智能 <rt> artificial intelligence </rt></ruby>(AI)”这个词事实上就是他建议举办该会议时发明的 <sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup>。在整个会议期间大概有十人参加 <sup id="fnref4"> <a href="#fn4" rel="footnote"> 4 </a></sup>。他们之中包括了<ruby> 艾伦·纽厄尔 <rt> Allen Newell </rt></ruby>和<ruby> 赫伯特·西蒙 <rt> Herbert Simon </rt></ruby>,两名隶属于<ruby> 兰德公司 <rt> RAND Corporation </rt></ruby>和<ruby> 卡内基梅隆大学 <rt> Carnegie Mellon </rt></ruby>的学者。这两人不久之前设计了一门语言,叫做 IPL。
当时,纽厄尔和西蒙正试图制作一套能够在命题演算中生成证明的系统。两人意识到,用电脑的原生指令集编写这套系统会非常困难;于是他们决定创造一门语言——他们的原话是“<ruby> 伪代码 <rt> pseudo-code </rt></ruby>”,这样,他们就能更加轻松自然地表达这台“<ruby> 逻辑理论机器 <rt> Logic Theory Machine </rt></ruby>”的底层逻辑了 <sup id="fnref5"> <a href="#fn5" rel="footnote"> 5 </a></sup>。这门语言叫做 IPL,即“<ruby> 信息处理语言 <rt> Information Processing Language </rt></ruby>”;比起我们现在认知中的编程语言,它更像是一种高层次的汇编语言方言。 纽厄尔和西蒙提到,当时人们开发的其它“伪代码”都抓着标准数学符号不放 —— 也许他们指的是 Fortran <sup id="fnref6"> <a href="#fn6" rel="footnote"> 6 </a></sup>;与此不同的是,他们的语言使用成组的符号方程来表示命题演算中的语句。通常,用 IPL 写出来的程序会调用一系列的汇编语言宏,以此在这些符号方程列表中对表达式进行变换和求值。
麦卡锡认为,一门实用的编程语言应该像 Fortran 那样使用代数表达式;因此,他并不怎么喜欢 IPL <sup id="fnref7"> <a href="#fn7" rel="footnote"> 7 </a></sup>。然而,他也认为,在给人工智能领域的一些问题建模时,符号列表会是非常好用的工具 —— 而且在那些涉及演绎的问题上尤其有用。麦卡锡的渴望最终被诉诸行动;他要创造一门代数的列表处理语言 —— 这门语言会像 Fortran 一样使用代数表达式,但拥有和 IPL 一样的符号列表处理能力。
当然,今日的 Lisp 可不像 Fortran。在会议之后的几年中,麦卡锡关于“理想的列表处理语言”的见解似乎在逐渐演化。到 1957 年,他的想法发生了改变。他那时候正在用 Fortran 编写一个能下国际象棋的程序;越是长时间地使用 Fortran ,麦卡锡就越确信其设计中存在不当之处,而最大的问题就是尴尬的 `IF` 声明 <sup id="fnref8"> <a href="#fn8" rel="footnote"> 8 </a></sup>。为此,他发明了一个替代品,即条件表达式 `true`;这个表达式会在给定的测试通过时返回子表达式 `A` ,而在测试未通过时返回子表达式 `B` ,*而且*,它只会对返回的子表达式进行求值。在 1958 年夏天,当麦卡锡设计一个能够求导的程序时,他意识到,他发明的 `true` 条件表达式让编写递归函数这件事变得更加简单自然了 <sup id="fnref9"> <a href="#fn9" rel="footnote"> 9 </a></sup>。也是这个求导问题让麦卡锡创造了 `maplist` 函数;这个函数会将其它函数作为参数并将之作用于指定列表的所有元素 <sup id="fnref10"> <a href="#fn10" rel="footnote"> 10 </a></sup>。在给项数多得叫人抓狂的多项式求导时,它尤其有用。
然而,以上的所有这些,在 Fortran 中都是没有的;因此,在 1958 年的秋天,麦卡锡请来了一群学生来实现 Lisp。因为他那时已经成了一名麻省理工助教,所以,这些学生可都是麻省理工的学生。当麦卡锡和学生们最终将他的主意变为能运行的代码时,这门语言得到了进一步的简化。这之中最大的改变涉及了 Lisp 的语法本身。最初,麦卡锡在设计语言时,曾经试图加入所谓的 “M 表达式”;这是一层语法糖,能让 Lisp 的语法变得类似于 Fortran。虽然 M 表达式可以被翻译为 S 表达式 —— 基础的、“用圆括号括起来的列表”,也就是 Lisp 最著名的特征 —— 但 S 表达式事实上是一种给机器看的低阶表达方法。唯一的问题是,麦卡锡用方括号标记 M 表达式,但他的团队在麻省理工使用的 IBM 026 键盘打孔机的键盘上根本没有方括号 <sup id="fnref11"> <a href="#fn11" rel="footnote"> 11 </a></sup>。于是 Lisp 团队坚定不移地使用着 S 表达式,不仅用它们表示数据列表,也拿它们来表达函数的应用。麦卡锡和他的学生们还作了另外几样改进,包括将数学符号前置;他们也修改了内存模型,这样 Lisp 实质上就只有一种数据类型了 <sup id="fnref12"> <a href="#fn12" rel="footnote"> 12 </a></sup>。
到 1960 年,麦卡锡发表了他关于 Lisp 的著名论文,《用符号方程表示的递归函数及它们的机器计算》。那时候,Lisp 已经被极大地精简,而这让麦卡锡意识到,他的作品其实是“一套优雅的数学系统”,而非普通的编程语言 <sup id="fnref13"> <a href="#fn13" rel="footnote"> 13 </a></sup>。他后来这么写道,对 Lisp 的许多简化使其“成了一种描述可计算函数的方式,而且它比图灵机或者一般情况下用于递归函数理论的递归定义更加简洁” <sup id="fnref14"> <a href="#fn14" rel="footnote"> 14 </a></sup>。在他的论文中,他不仅使用 Lisp 作为编程语言,也将它当作一套用于研究递归函数行为方式的表达方法。
通过“从一小撮规则中逐步实现出 Lisp”的方式,麦卡锡将这门语言介绍给了他的读者。后来,保罗·格雷厄姆在短文《<ruby> <a href="http://languagelog.ldc.upenn.edu/myl/llog/jmc.pdf"> Lisp 之根 </a> <rt> The Roots of Lisp </rt></ruby>》中用更易读的语言回顾了麦卡锡的步骤。格雷厄姆只用了七种原始运算符、两种函数写法,以及使用原始运算符定义的六个稍微高级一点的函数来解释 Lisp。毫无疑问,Lisp 的这种只需使用极少量的基本规则就能完整说明的特点加深了其神秘色彩。格雷厄姆称麦卡锡的论文为“使计算公理化”的一种尝试 <sup id="fnref15"> <a href="#fn15" rel="footnote"> 15 </a></sup>。我认为,在思考 Lisp 的魅力从何而来时,这是一个极好的切入点。其它编程语言都有明显的人工构造痕迹,表现为 `While`,`typedef`,`public static void` 这样的关键词;而 Lisp 的设计却简直像是纯粹计算逻辑的鬼斧神工。Lisp 的这一性质,以及它和晦涩难懂的“递归函数理论”的密切关系,使它具备了获得如今声望的充分理由。
### 理论 B:属于未来的机器
Lisp 诞生二十年后,它成了著名的《<ruby> <a href="https://en.wikipedia.org/wiki/Jargon_File"> 黑客词典 </a> <rt> Hacker’s Dictionary </rt></ruby>》中所说的,人工智能研究的“母语”。Lisp 在此之前传播迅速,多半是托了语法规律的福 —— 不管在怎么样的电脑上,实现 Lisp 都是一件相对简单直白的事。而学者们之后坚持使用它乃是因为 Lisp 在处理符号表达式这方面有巨大的优势;在那个时代,人工智能很大程度上就意味着符号,于是这一点就显得十分重要。在许多重要的人工智能项目中都能见到 Lisp 的身影。这些项目包括了 [SHRDLU 自然语言程序](https://hci.stanford.edu/winograd/shrdlu/)、[Macsyma 代数系统](https://en.wikipedia.org/wiki/Macsyma) 和 [ACL2 逻辑系统](https://en.wikipedia.org/wiki/ACL2)。
然而,在 1970 年代中期,人工智能研究者们的电脑算力开始不够用了。PDP-10 就是一个典型。这个型号在人工智能学界曾经极受欢迎;但面对这些用 Lisp 写的 AI 程序,它的 18 位地址空间一天比一天显得吃紧 <sup id="fnref16"> <a href="#fn16" rel="footnote"> 16 </a></sup>。许多的 AI 程序在设计上可以与人互动。要让这些既极度要求硬件性能、又有互动功能的程序在分时系统上优秀发挥,是很有挑战性的。麻省理工的<ruby> 彼得·杜奇 <rt> Peter Deutsch </rt></ruby>给出了解决方案:那就是针对 Lisp 程序来特别设计电脑。就像是我那[关于 Chaosnet 的上一篇文章](https://twobithistory.org/2018/09/30/chaosnet.html)所说的那样,这些<ruby> Lisp 计算机 <rt> Lisp machines </rt></ruby>会给每个用户都专门分配一个为 Lisp 特别优化的处理器。到后来,考虑到硬核 Lisp 程序员的需求,这些计算机甚至还配备上了完全由 Lisp 编写的开发环境。在当时那样一个小型机时代已至尾声而微型机的繁盛尚未完全到来的尴尬时期,Lisp 计算机就是编程精英们的“高性能个人电脑”。
有那么一会儿,Lisp 计算机被当成是未来趋势。好几家公司雨后春笋般出现,追着赶着要把这项技术商业化。其中最成功的一家叫做 Symbolics,由麻省理工 AI 实验室的前成员创立。上世纪八十年代,这家公司生产了所谓的 3600 系列计算机,它们当时在 AI 领域和需要高性能计算的产业中应用极广。3600 系列配备了大屏幕、位图显示、鼠标接口,以及[强大的图形与动画软件](https://youtu.be/gV5obrYaogU?t=201)。它们都是惊人的机器,能让惊人的程序运行起来。例如,之前在推特上跟我聊过的机器人研究者 Bob Culley,就能用一台 1985 年生产的 Symbolics 3650 写出带有图形演示的寻路算法。他向我解释说,在 1980 年代,位图显示和面向对象编程(能够通过 [Flavors 扩展](https://en.wikipedia.org/wiki/Flavors_(programming_language))在 Lisp 计算机上使用)都刚刚出现。Symbolics 站在时代的最前沿。

*Bob Culley 的寻路程序。*
而以上这一切导致 Symbolics 的计算机奇贵无比。在 1983 年,一台 Symbolics 3600 能卖 111,000 美金 <sup id="fnref16:1"> <a href="#fn16" rel="footnote"> 16 </a></sup>。所以,绝大部分人只可能远远地赞叹 Lisp 计算机的威力和操作员们用 Lisp 编写程序的奇妙技术。不止他们赞叹,从 1979 年到 1980 年代末,Byte 杂志曾经多次提到过 Lisp 和 Lisp 计算机。在 1979 年八月发行的、关于 Lisp 的一期特别杂志中,杂志编辑激情洋溢地写道,麻省理工正在开发的计算机配备了“大坨大坨的内存”和“先进的操作系统” <sup id="fnref17"> <a href="#fn17" rel="footnote"> 17 </a></sup>;他觉得,这些 Lisp 计算机的前途是如此光明,以至于它们的面世会让 1978 和 1977 年 —— 诞生了 Apple II、Commodore PET 和 TRS-80 的两年 —— 显得黯淡无光。五年之后,在 1985 年,一名 Byte 杂志撰稿人描述了为“复杂精巧、性能强悍的 Symbolics 3670”编写 Lisp 程序的体验,并力劝读者学习 Lisp,称其为“绝大数人工智能工作者的语言选择”,和将来的通用编程语言 <sup id="fnref18"> <a href="#fn18" rel="footnote"> 18 </a></sup>。
我问过<ruby> 保罗·麦克琼斯 <rt> Paul McJones </rt></ruby>(他在<ruby> 山景城 <rt> Mountain View </rt> <rt> </rt></ruby>的<ruby> 计算机历史博物馆 <rt> Computer History Museum </rt></ruby>做了许多 Lisp 的[保护工作](http://www.softwarepreservation.org/projects/LISP/)),人们是什么时候开始将 Lisp 当作高维生物的赠礼一样谈论的呢?他说,这门语言自有的性质毋庸置疑地促进了这种现象的产生;然而,他也说,Lisp 上世纪六七十年代在人工智能领域得到的广泛应用,很有可能也起到了作用。当 1980 年代到来、Lisp 计算机进入市场时,象牙塔外的某些人由此接触到了 Lisp 的能力,于是传说开始滋生。时至今日,很少有人还记得 Lisp 计算机和 Symbolics 公司;但 Lisp 得以在八十年代一直保持神秘,很大程度上要归功于它们。
### 理论 C:学习编程
1985 年,两位麻省理工的教授,<ruby> 哈尔·阿伯尔森 <rt> Harold <q> Hal </q> Abelson </rt></ruby>和<ruby> 杰拉尔德·瑟斯曼 <rt> Gerald Sussman </rt></ruby>,外加瑟斯曼的妻子<ruby> 朱莉·瑟斯曼 <rt> Julie Sussman </rt></ruby>,出版了一本叫做《<ruby> 计算机程序的构造和解释 <rt> Structure and Interpretation of Computer Programs </rt></ruby>》的教科书。这本书用 Scheme(一种 Lisp 方言)向读者们示范了如何编程。它被用于教授麻省理工入门编程课程长达二十年之久。出于直觉,我认为 SICP(这本书的名字通常缩写为 SICP)倍增了 Lisp 的“神秘要素”。SICP 使用 Lisp 描绘了深邃得几乎可以称之为哲学的编程理念。这些理念非常普适,可以用任意一种编程语言展现;但 SICP 的作者们选择了 Lisp。结果,这本阴阳怪气、卓越不凡、吸引了好几代程序员(还成了一种[奇特的模因](https://knowyourmeme.com/forums/meme-research/topics/47038-structure-and-interpretation-of-computer-programs-hugeass-image-dump-for-evidence))的著作臭名远扬之后,Lisp 的声望也顺带被提升了。Lisp 已不仅仅是一如既往的“麦卡锡的优雅表达方式”;它现在还成了“向你传授编程的不传之秘的语言”。
SICP 究竟有多奇怪这一点值得好好说;因为我认为,时至今日,这本书的古怪之处和 Lisp 的古怪之处是相辅相成的。书的封面就透着一股古怪。那上面画着一位朝着桌子走去,准备要施法的巫师或者炼金术士。他的一只手里抓着一副测径仪 —— 或者圆规,另一只手上拿着个球,上书“eval”和“apply”。他对面的女人指着桌子;在背景中,希腊字母 λ (lambda)漂浮在半空,释放出光芒。

*SICP 封面上的画作。*
说真的,这上面画的究竟是怎么一回事?为什么桌子会长着动物的腿?为什么这个女人指着桌子?墨水瓶又是干什么用的?我们是不是该说,这位巫师已经破译了宇宙的隐藏奥秘,而所有这些奥秘就蕴含在 eval/apply 循环和 Lambda 演算之中?看似就是如此。单单是这张图片,就一定对人们如今谈论 Lisp 的方式产生了难以计量的影响。
然而,这本书的内容通常并不比封面正常多少。SICP 跟你读过的所有计算机科学教科书都不同。在引言中,作者们表示,这本书不只教你怎么用 Lisp 编程 —— 它是关于“现象的三个焦点:人的心智、复数的计算机程序,和计算机”的作品 <sup id="fnref19"> <a href="#fn19" rel="footnote"> 19 </a></sup>。在之后,他们对此进行了解释,描述了他们对如下观点的坚信:编程不该被当作是一种计算机科学的训练,而应该是“<ruby> 程序性认识论 <rt> procedural epistemology </rt></ruby>”的一种新表达方式 <sup id="fnref20"> <a href="#fn20" rel="footnote"> 20 </a></sup>。程序是将那些偶然被送入计算机的思想组织起来的全新方法。这本书的第一章简明地介绍了 Lisp,但是之后的绝大部分都在讲述更加抽象的概念。其中包括了对不同编程范式的讨论,对于面向对象系统中“时间”和“一致性”的讨论;在书中的某一处,还有关于通信的基本限制可能会如何带来同步问题的讨论 —— 而这些基本限制在通信中就像是光速不变在相对论中一样关键 <sup id="fnref21"> <a href="#fn21" rel="footnote"> 21 </a></sup>。都是些高深难懂的东西。
以上这些并不是说这是本糟糕的书;这本书其实棒极了。在我读过的所有作品中,这本书对于重要的编程理念的讨论是最为深刻的;那些理念我琢磨了很久,却一直无力用文字去表达。一本入门编程教科书能如此迅速地开始描述面向对象编程的根本缺陷,和函数式语言“将可变状态降到最少”的优点,实在是一件让人印象深刻的事。而这种描述之后变为了另一种震撼人心的讨论:某种(可能类似于今日的 [RxJS](https://rxjs-dev.firebaseapp.com/) 的)流范式能如何同时具备两者的优秀特性。SICP 用和当初麦卡锡的 Lisp 论文相似的方式提纯出了高级程序设计的精华。你读完这本书之后,会立即想要将它推荐给你的程序员朋友们;如果他们找到这本书,看到了封面,但最终没有阅读的话,他们就只会记住长着动物腿的桌子上方那神秘的、根本的、给予魔法师特殊能力的、写着 eval/apply 的东西。话说回来,书上这两人的鞋子也让我印象颇深。
然而,SICP 最重要的影响恐怕是,它将 Lisp 由一门怪语言提升成了必要的教学工具。在 SICP 面世之前,人们互相推荐 Lisp,以学习这门语言为提升编程技巧的途径。1979 年的 Byte 杂志 Lisp 特刊印证了这一事实。之前提到的那位编辑不仅就麻省理工的新 Lisp 计算机大书特书,还说,Lisp 这门语言值得一学,因为它“代表了分析问题的另一种视角” <sup id="fnref22"> <a href="#fn22" rel="footnote"> 22 </a></sup>。但 SICP 并未只把 Lisp 作为其它语言的陪衬来使用;SICP 将其作为*入门*语言。这就暗含了一种论点,那就是,Lisp 是最能把握计算机编程基础的语言。可以认为,如今的程序员们彼此怂恿“在死掉之前至少试试 Lisp”的时候,他们很大程度上是因为 SICP 才这么说的。毕竟,编程语言 [Brainfuck](https://en.wikipedia.org/wiki/Brainfuck) 想必同样也提供了“分析问题的另一种视角”;但人们学习 Lisp 而非学习 Brainfuck,那是因为他们知道,前者的那种 Lisp 视角在二十年中都被看作是极其有用的,有用到麻省理工在给他们的本科生教其它语言之前,必然会先教 Lisp。
### Lisp 的回归
在 SICP 出版的同一年,<ruby> 本贾尼·斯特劳斯特卢普 <rt> Bjarne Stroustrup </rt></ruby>发布了 C++ 语言的首个版本,它将面向对象编程带到了大众面前。几年之后,Lisp 计算机的市场崩盘,AI 寒冬开始了。在下一个十年的变革中, C++ 和后来的 Java 成了前途无量的语言,而 Lisp 被冷落,无人问津。
理所当然地,确定人们对 Lisp 重新燃起热情的具体时间并不可能;但这多半是保罗·格雷厄姆发表他那几篇声称 Lisp 是首选入门语言的短文之后的事了。保罗·格雷厄姆是 Y-Combinator 的联合创始人和《Hacker News》的创始者,他这几篇短文有很大的影响力。例如,在短文《<ruby> <a href="http://www.paulgraham.com/avg.html"> 胜于平庸 </a> <rt> Beating the Averages </rt></ruby>》中,他声称 Lisp 宏使 Lisp 比其它语言更强。他说,因为他在自己创办的公司 Viaweb 中使用 Lisp,他得以比竞争对手更快地推出新功能。至少,[一部分程序员](https://web.archive.org/web/20061004035628/http://wiki.alu.org/Chris-Perkins)被说服了。然而,庞大的主流程序员群体并未换用 Lisp。
实际上出现的情况是,Lisp 并未流行,但越来越多 Lisp 式的特性被加入到广受欢迎的语言中。Python 有了列表推导式。C# 有了 Linq。Ruby……嗯,[Ruby 是 Lisp 的一种](http://www.randomhacks.net/2005/12/03/why-ruby-is-an-acceptable-lisp/)。就如格雷厄姆之前在 2001 年提到的那样,“在一系列常用语言中所体现出的‘默认语言’正越发朝着 Lisp 的方向演化” <sup id="fnref23"> <a href="#fn23" rel="footnote"> 23 </a></sup>。尽管其它语言变得越来越像 Lisp,Lisp 本身仍然保留了其作为“很少人了解但是大家都该学的神秘语言”的特殊声望。在 1980 年,Lisp 的诞生二十周年纪念日上,麦卡锡写道,Lisp 之所以能够存活这么久,是因为它具备“编程语言领域中的某种近似局部最优” <sup id="fnref24"> <a href="#fn24" rel="footnote"> 24 </a></sup>。这句话并未充分地表明 Lisp 的真正影响力。Lisp 能够存活超过半个世纪之久,并非因为程序员们一年年地勉强承认它就是最好的编程工具;事实上,即使绝大多数程序员根本不用它,它还是存活了下来。多亏了它的起源和它的人工智能研究用途,说不定还要多亏 SICP 的遗产,Lisp 一直都那么让人着迷。在我们能够想象上帝用其它新的编程语言创造世界之前,Lisp 都不会走下神坛。
---
via: <https://twobithistory.org/2018/10/14/lisp.html>
作者:[Two-Bit History](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Northurland](https://github.com/Northurland) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
---
1. John McCarthy, “History of Lisp”, 14, Stanford University, February 12, 1979, accessed October 14, 2018, <http://jmc.stanford.edu/articles/lisp/lisp.pdf> [↩](#fnref1)
2. Paul Graham, “The Roots of Lisp”, 1, January 18, 2002, accessed October 14, 2018, <http://languagelog.ldc.upenn.edu/myl/llog/jmc.pdf>. [↩](#fnref2)
3. Martin Childs, “John McCarthy: Computer scientist known as the father of AI”, The Independent, November 1, 2011, accessed on October 14, 2018, <https://www.independent.co.uk/news/obituaries/john-mccarthy-computer-scientist-known-as-the-father-of-ai-6255307.html>. [↩](#fnref3)
4. Lisp Bulletin History. <http://www.artinfo-musinfo.org/scans/lb/lb3f.pdf> [↩](#fnref4)
5. Allen Newell and Herbert Simon, “Current Developments in Complex Information Processing,” 19, May 1, 1956, accessed on October 14, 2018, <http://bitsavers.org/pdf/rand/ipl/P-850_Current_Developments_In_Complex_Information_Processing_May56.pdf>. [↩](#fnref5)
6. ibid. [↩](#fnref6)
7. Herbert Stoyan, “Lisp History”, 43, Lisp Bulletin #3, December 1979, accessed on October 14, 2018, <http://www.artinfo-musinfo.org/scans/lb/lb3f.pdf> [↩](#fnref7)
8. McCarthy, “History of Lisp”, 5. [↩](#fnref8)
9. ibid. [↩](#fnref9)
10. McCarthy “History of Lisp”, 6. [↩](#fnref10)
11. Stoyan, “Lisp History”, 45 [↩](#fnref11)
12. McCarthy, “History of Lisp”, 8. [↩](#fnref12)
13. McCarthy, “History of Lisp”, 2. [↩](#fnref13)
14. McCarthy, “History of Lisp”, 8. [↩](#fnref14)
15. Graham, “The Roots of Lisp”, 11. [↩](#fnref15)
16. Guy Steele and Richard Gabriel, “The Evolution of Lisp”, 22, History of Programming Languages 2, 1993, accessed on October 14, 2018, <http://www.dreamsongs.com/Files/HOPL2-Uncut.pdf>. [↩](#fnref16) [↩<sup> 1</sup>](#fnref16:1)
17. Carl Helmers, “Editorial”, Byte Magazine, 154, August 1979, accessed on October 14, 2018, <https://archive.org/details/byte-magazine-1979-08/page/n153>. [↩](#fnref17)
18. Patrick Winston, “The Lisp Revolution”, 209, April 1985, accessed on October 14, 2018, <https://archive.org/details/byte-magazine-1985-04/page/n207>. [↩](#fnref18)
19. Harold Abelson, Gerald Jay. Sussman, and Julie Sussman, Structure and Interpretation of Computer Programs (Cambridge, Mass: MIT Press, 2010), xiii. [↩](#fnref19)
20. Abelson, xxiii. [↩](#fnref20)
21. Abelson, 428. [↩](#fnref21)
22. Helmers, 7. [↩](#fnref22)
23. Paul Graham, “What Made Lisp Different”, December 2001, accessed on October 14, 2018, <http://www.paulgraham.com/diff.html>. [↩](#fnref23)
24. John McCarthy, “Lisp—Notes on its past and future”, 3, Stanford University, 1980, accessed on October 14, 2018, <http://jmc.stanford.edu/articles/lisp20th/lisp20th.pdf>. [↩](#fnref24)
| 200 | OK | When programmers discuss the relative merits of different programming languages, they often talk about them in prosaic terms as if they were so many tools in a tool belt—one might be more appropriate for systems programming, another might be more appropriate for gluing together other programs to accomplish some ad hoc task. This is as it should be. Languages have different strengths and claiming that a language is better than other languages without reference to a specific use case only invites an unproductive and vitriolic debate.
But there is one language that seems to inspire a peculiar universal reverence:
Lisp. Keyboard crusaders that would otherwise pounce on anyone daring to
suggest that some language is better than any other will concede that Lisp is
on another level. Lisp transcends the utilitarian criteria used to judge other
languages, because the median programmer has never used Lisp to build anything
practical and probably never will, yet the reverence for Lisp runs so deep that
Lisp is often ascribed mystical properties. Everyone’s favorite webcomic,
*xkcd*, has depicted Lisp this way at least twice: In [one
comic](https://xkcd.com/224/), a character reaches some sort of Lisp
enlightenment, which appears to allow him to comprehend the fundamental
structure of the universe. In [another comic](https://xkcd.com/297/), a robed,
senescent programmer hands a stack of parentheses to his padawan, saying that
the parentheses are “elegant weapons for a more civilized age,” suggesting that
Lisp has all the occult power of the Force.
Another great example is Bob Kanefsky’s parody of a
song called “God Lives on Terra.” His parody, written in the mid-1990s and
called “Eternal Flame”, describes how God must have created the world using
Lisp. The following is an excerpt, but the full set of lyrics can be found in
the [GNU Humor
Collection](https://www.gnu.org/fun/jokes/eternal-flame.en.html):
For God wrote in Lisp code
When he filled the leaves with green.
The fractal flowers and recursive roots:
The most lovely hack I’ve seen.
And when I ponder snowflakes,
never finding two the same,
I know God likes a language
with its own four-letter name.
I can only speak for myself, I suppose, but I think this “Lisp Is Arcane Magic”
cultural meme is the most bizarre and fascinating thing ever. Lisp was
concocted in the ivory tower as a tool for artificial intelligence research, so
it was always going to be unfamiliar and maybe even a bit mysterious to the
programming laity. But programmers now [urge each other to “try Lisp before you
die”](https://www.reddit.com/r/ProgrammerHumor/comments/5c14o6/xkcd_lisp/d9szjnc/)
as if it were some kind of mind-expanding psychedelic. They do this even though
Lisp is now the second-oldest programming language in widespread use, younger
only than Fortran, and even then by just one year. 1 Imagine if your job were
to promote some new programming language on behalf of the organization or team
that created it. Wouldn’t it be great if you could convince everyone that your
new language had divine powers? But how would you even do that? How does a
programming language come to be known as a font of hidden knowledge?
How did Lisp get to be this way?
*The cover of Byte Magazine, August, 1979.*
## Theory A: The Axiomatic Language
John McCarthy, Lisp’s creator, did not originally intend for Lisp to be an
elegant distillation of the principles of computation. But, after one or two
fortunate insights and a series of refinements, that’s what Lisp became. Paul
Graham—we will talk about him some more later—has written that, with Lisp,
McCarthy “did for programming something like what Euclid did for geometry.” 2
People might see a deeper meaning in Lisp because McCarthy built Lisp out of
parts so fundamental that it is hard to say whether he invented it or
discovered it.
McCarthy began thinking about creating a language during the 1956 Darthmouth
Summer Research Project on Artificial Intelligence. The Summer Research Project
was in effect an ongoing, multi-week academic conference, the very first in the
field of artificial intelligence. McCarthy, then an assistant professor of
Mathematics at Dartmouth, had actually coined the term “artificial
intelligence” when he proposed the event. 3 About ten or so people attended
the conference for its entire duration.
Among them were Allen Newell and Herbert Simon, two researchers affiliated with the RAND Corporation and Carnegie Mellon that had just designed a language called IPL.
[4](#fn:4)Newell and Simon had been trying to build a system capable of generating proofs
in propositional calculus. They realized that it would be hard to do this while
working at the level of the computer’s native instruction set, so they decided
to create a language—or, as they called it, a “pseudo-code”—that would help
them more naturally express the workings of their “Logic Theory Machine.” 5
Their language, called IPL for “Information Processing Language”, was more of a
high-level assembly dialect then a programming language in the sense we mean
today. Newell and Simon, perhaps referring to Fortran, noted that other
“pseudo-codes” then in development were “preoccupied” with representing
equations in standard mathematical notation.
Their language focused instead on representing sentences in propositional calculus as lists of symbolic expressions. Programs in IPL would basically leverage a series of assembly-language macros to manipulate and evaluate expressions within one or more of these lists.
[6](#fn:6)McCarthy thought that having algebraic expressions in a language,
Fortran-style, would be useful. So he didn’t like IPL very much. 7 But he
thought that symbolic lists were a good way to model problems in artificial
intelligence, particularly problems involving deduction. This was the germ of
McCarthy’s desire to create an algebraic list processing language, a language
that would resemble Fortran but also be able to process symbolic lists like
IPL.
Of course, Lisp today does not resemble Fortran. Over the next few years,
McCarthy’s ideas about what an ideal list processing language should look like
evolved. His ideas began to change in 1957, when he started writing routines
for a chess-playing program in Fortran. The prolonged exposure to Fortran
convinced McCarthy that there were several infelicities in its design, chief
among them the awkward `IF`
statement. 8 McCarthy invented an alternative,
the “true” conditional expression, which returns sub-expression A if the
supplied test succeeds and sub-expression B if the supplied test fails and
which
*also*only evaluates the sub-expression that actually gets returned. During the summer of 1958, when McCarthy worked to design a program that could perform differentiation, he realized that his “true” conditional expression made writing recursive functions easier and more natural.
The differentiation problem also prompted McCarthy to devise the
[9](#fn:9)*maplist*function, which takes another function as an argument and applies it to all the elements in a list.
This was useful for differentiating sums of arbitrarily many terms.
[10](#fn:10)None of these things could be expressed in Fortran, so, in the fall of 1958,
McCarthy set some students to work implementing Lisp. Since McCarthy was now an
assistant professor at MIT, these were all MIT students. As McCarthy and his
students translated his ideas into running code, they made changes that further
simplified the language. The biggest change involved Lisp’s syntax. McCarthy
had originally intended for the language to include something called
“M-expressions,” which would be a layer of syntactic sugar that made Lisp’s
syntax resemble Fortran’s. Though M-expressions could be translated to
S-expressions—the basic lists enclosed by parentheses that Lisp is known for—
S-expressions were really a low-level representation meant for the machine. The
only problem was that McCarthy had been denoting M-expressions using square
brackets, and the IBM 026 keypunch that McCarthy’s team used at MIT did not
have any square bracket keys on its keyboard. 11 So the Lisp team stuck with
S-expressions, using them to represent not just lists of data but function
applications too. McCarthy and his students also made a few other
simplifications, including a switch to prefix notation and a memory model
change that meant the language only had one real type.
[12](#fn:12)In 1960, McCarthy published his famous paper on Lisp called “Recursive
Functions of Symbolic Expressions and Their Computation by Machine.” By that
time, the language had been pared down to such a degree that McCarthy realized
he had the makings of “an elegant mathematical system” and not just another
programming language. 13 He later wrote that the many simplifications that
had been made to Lisp turned it “into a way of describing computable functions
much neater than the Turing machines or the general recursive definitions used
in recursive function theory.”
In his paper, he therefore presented Lisp both as a working programming language and as a formalism for studying the behavior of recursive functions.
[14](#fn:14)McCarthy explained Lisp to his readers by building it up out of only a very
small collection of rules. Paul Graham later retraced McCarthy’s steps, using
more readable language, in his essay [“The Roots of
Lisp”](http://languagelog.ldc.upenn.edu/myl/llog/jmc.pdf). Graham is able to
explain Lisp using only seven primitive operators, two different notations for
functions, and a half-dozen higher-level functions defined in terms of the
primitive operators. That Lisp can be specified by such a small sequence of
basic rules no doubt contributes to its mystique. Graham has called McCarthy’s
paper an attempt to “axiomatize computation.” 15 I think that is a great way
to think about Lisp’s appeal. Whereas other languages have clearly artificial
constructs denoted by reserved words like
`while`
or `typedef`
or ```
public
static void
```
, Lisp’s design almost seems entailed by the very logic of
computing. This quality and Lisp’s original connection to a field as esoteric
as “recursive function theory” should make it no surprise that Lisp has so much
prestige today.## Theory B: Machine of the Future
Two decades after its creation, Lisp had become, according to the famous
[ Hacker’s Dictionary](https://en.wikipedia.org/wiki/Jargon_File), the “mother
tongue” of artificial intelligence research. Early on, Lisp spread quickly,
probably because its regular syntax made implementing it on new machines
relatively straightforward. Later, researchers would keep using it because of
how well it handled symbolic expressions, important in an era when so much of
artificial intelligence was symbolic. Lisp was used in seminal artificial
intelligence projects like the
[SHRDLU natural language program](https://hci.stanford.edu/winograd/shrdlu/), the
[Macsyma algebra system](https://en.wikipedia.org/wiki/Macsyma), and the
[ACL2 logic system](https://en.wikipedia.org/wiki/ACL2).
By the mid-1970s, though, artificial intelligence researchers were running out
of computer power. The PDP-10, in particular—everyone’s favorite machine for
artificial intelligence work—had an 18-bit address space that increasingly was
insufficient for Lisp AI programs. 16 Many AI programs were also supposed to
be interactive, and making a demanding interactive program perform well on a
time-sharing system was challenging. The solution, originally proposed by Peter
Deutsch at MIT, was to engineer a computer specifically designed to run Lisp
programs. These Lisp machines, as I described in
[my last post on Chaosnet](/2018/09/30/chaosnet.html), would give each user a dedicated processor optimized for Lisp. They would also eventually come with development environments written entirely in Lisp for hardcore Lisp programmers. Lisp machines, devised in an awkward moment at the tail of the minicomputer era but before the full flowering of the microcomputer revolution, were high-performance personal computers for the programming elite.
For a while, it seemed as if Lisp machines would be the wave of the future.
Several companies sprang into existence and raced to commercialize the
technology. The most successful of these companies was called Symbolics,
founded by veterans of the MIT AI Lab. Throughout the 1980s, Symbolics produced
a line of computers known as the 3600 series, which were popular in the AI
field and in industries requiring high-powered computing. The 3600 series
computers featured large screens, bit-mapped graphics, a mouse interface, and
[powerful graphics and animation software](https://youtu.be/gV5obrYaogU?t=201).
These were impressive machines that enabled impressive programs. For example,
Bob Culley, who worked in robotics research and contacted me via Twitter, was
able to implement and visualize a path-finding algorithm on a Symbolics 3650
in 1985. He explained to me that bit-mapped graphics and object-oriented
programming (available on Lisp machines via [the Flavors
extension](https://en.wikipedia.org/wiki/Flavors_(programming_language))) were
very new in the 1980s. Symbolics was the cutting edge.
*Bob Culley’s path-finding program.*
As a result, Symbolics machines were outrageously expensive. The Symbolics 3600
cost $110,000 in 1983. 16 So most people could only marvel at the power of
Lisp machines and the wizardry of their Lisp-writing operators from afar. But
marvel they did.
*Byte Magazine*featured Lisp and Lisp machines several times from 1979 through to the end of the 1980s. In the August, 1979 issue, a special on Lisp, the magazine’s editor raved about the new machines being developed at MIT with “gobs of memory” and “an advanced operating system.”
He thought they sounded so promising that they would make the two prior years—which saw the launch of the Apple II, the Commodore PET, and the TRS-80—look boring by comparison. A half decade later, in 1985, a
[17](#fn:17)*Byte Magazine*contributor described writing Lisp programs for the “sophisticated, superpowerful Symbolics 3670” and urged his audience to learn Lisp, claiming it was both “the language of choice for most people working in AI” and soon to be a general-purpose programming language as well.
[18](#fn:18)I asked Paul McJones, who has done lots of Lisp [preservation
work](http://www.softwarepreservation.org/projects/LISP/) for the Computer
History Museum in Mountain View, about when people first began talking about
Lisp as if it were a gift from higher-dimensional beings. He said that the
inherent properties of the language no doubt had a lot to do with it, but he
also said that the close association between Lisp and the powerful artificial
intelligence applications of the 1960s and 1970s probably contributed too. When
Lisp machines became available for purchase in the 1980s, a few more people
outside of places like MIT and Stanford were exposed to Lisp’s power and the
legend grew. Today, Lisp machines and Symbolics are little remembered, but they
helped keep the mystique of Lisp alive through to the late 1980s.
## Theory C: Learn to Program
In 1985, MIT professors Harold Abelson and Gerald Sussman, along with Sussman’s
wife, Julie Sussman, published a textbook called *Structure and Interpretation
of Computer Programs*. The textbook introduced readers to programming using the
language Scheme, a dialect of Lisp. It was used to teach MIT’s introductory
programming class for two decades. My hunch is that SICP (as the title is
commonly abbreviated) about doubled Lisp’s “mystique factor.” SICP took Lisp
and showed how it could be used to illustrate deep, almost philosophical
concepts in the art of computer programming. Those concepts were general enough
that any language could have been used, but SICP’s authors chose Lisp. As a
result, Lisp’s reputation was augmented by the notoriety of this bizarre and
brilliant book, which has intrigued generations of programmers (and also become
[a very strange
meme](https://knowyourmeme.com/forums/meme-research/topics/47038-structure-and-interpretation-of-computer-programs-hugeass-image-dump-for-evidence)).
Lisp had always been “McCarthy’s elegant formalism”; now it was also “that
language that teaches you the hidden secrets of programming.”
It’s worth dwelling for a while on how weird SICP really is, because I think the book’s weirdness and Lisp’s weirdness get conflated today. The weirdness starts with the book’s cover. It depicts a wizard or alchemist approaching a table, prepared to perform some sort of sorcery. In one hand he holds a set of calipers or a compass, in the other he holds a globe inscribed with the words “eval” and “apply.” A woman opposite him gestures at the table; in the background, the Greek letter lambda floats in mid-air, radiating light.
*The cover art for SICP.*
Honestly, what is going on here? Why does the table have animal feet? Why is the woman gesturing at the table? What is the significance of the inkwell? Are we supposed to conclude that the wizard has unlocked the hidden mysteries of the universe, and that those mysteries consist of the “eval/apply” loop and the Lambda Calculus? It would seem so. This image alone must have done an enormous amount to shape how people talk about Lisp today.
But the text of the book itself is often just as weird. SICP is unlike most
other computer science textbooks that you have ever read. Its authors explain
in the foreword to the book that the book is not merely about how to program in
Lisp—it is instead about “three foci of phenomena: the human mind, collections
of computer programs, and the computer.” 19 Later, they elaborate, describing
their conviction that programming shouldn’t be considered a discipline of
computer science but instead should be considered a new notation for “procedural
epistemology.”
Programs are a new way of structuring thought that only incidentally get fed into computers. The first chapter of the book gives a brief tour of Lisp, but most of the book after that point is about much more abstract concepts. There is a discussion of different programming paradigms, a discussion of the nature of “time” and “identity” in object-oriented systems, and at one point a discussion of how synchronization problems may arise because of fundamental constraints on communication that play a role akin to the fixed speed of light in the theory of relativity.
[20](#fn:20)It’s heady stuff.
[21](#fn:21)All this isn’t to say that the book is bad. It’s a wonderful book. It discusses
important programming concepts at a higher level than anything else I have
read, concepts that I had long wondered about but didn’t quite have the
language to describe. It’s impressive that an introductory programming textbook
can move so quickly to describing the fundamental shortfalls of object-oriented
programming and the benefits of functional languages that minimize mutable
state. It’s mind-blowing that this then turns into a discussion of how a stream
paradigm, perhaps something like today’s
[RxJS](https://rxjs-dev.firebaseapp.com/), can give you the best of both
worlds. SICP distills the essence of high-level program design in a way
reminiscent of McCarthy’s original Lisp paper. The first thing you want to do
after reading it is get your programmer friends to read it; if they look it
up, see the cover, but then don’t read it, all they take away is that some
mysterious, fundamental “eval/apply” thing gives magicians special powers over
tables with animal feet. I would be deeply impressed in their shoes too.
But maybe SICP’s most important contribution was to elevate Lisp from
curious oddity to pedagogical must-have. Well before SICP, people told each
other to learn Lisp as a way of getting better at programming. The 1979 Lisp
issue of *Byte Magazine* is testament to that fact. The same editor that raved
about MIT’s new Lisp machines also explained that the language was worth
learning because it “represents a different point of view from which to analyze
problems.” 22 But SICP presented Lisp as more than just a foil for other
languages; SICP used Lisp as an
*introductory*language, implicitly making the argument that Lisp is the best language in which to grasp the fundamentals of computer programming. When programmers today tell each other to try Lisp before they die, they arguably do so in large part because of SICP. After all, the language
[Brainfuck](https://en.wikipedia.org/wiki/Brainfuck)presumably offers “a different point of view from which to analyze problems.” But people learn Lisp instead because they know that, for twenty years or so, the Lisp point of view was thought to be so useful that MIT taught Lisp to undergraduates before anything else.
## Lisp Comes Back
The same year that SICP was released, Bjarne Stroustrup published the first
edition of *The C++ Programming Language*, which brought object-oriented
programming to the masses. A few years later, the market for Lisp machines
collapsed and the AI winter began. For the next decade and change, C++ and then
Java would be the languages of the future and Lisp would be left out in the
cold.
It is of course impossible to pinpoint when people started getting excited
about Lisp again. But that may have happened after Paul Graham, Y-Combinator
co-founder and Hacker News creator, published a series of influential essays
pushing Lisp as the best language for startups. In his essay [“Beating the
Averages,”](http://www.paulgraham.com/avg.html) for example, Graham argued that
Lisp macros simply made Lisp more powerful than other languages. He claimed
that using Lisp at his own startup, Viaweb, helped him develop features faster
than his competitors were able to. [Some programmers at
least](https://web.archive.org/web/20061004035628/http://wiki.alu.org/Chris-Perkins)
were persuaded. But the vast majority of programmers did not switch to Lisp.
What happened instead is that more and more Lisp-y features have been
incorporated into everyone’s favorite programming languages. Python got list
comprehensions. C# got Linq. Ruby got… well, Ruby [is a
Lisp](http://www.randomhacks.net/2005/12/03/why-ruby-is-an-acceptable-lisp/).
As Graham noted even back in 2001, “the default language, embodied in a
succession of popular languages, has gradually evolved toward Lisp.” 23
Though other languages are gradually becoming like Lisp, Lisp itself somehow
manages to retain its special reputation as that mysterious language that few
people understand but everybody should learn. In 1980, on the occasion of
Lisp’s 20th anniversary, McCarthy wrote that Lisp had survived as long as it
had because it occupied “some kind of approximate local optimum in the space of
programming languages.”
That understates Lisp’s real influence. Lisp hasn’t survived for over half a century because programmers have begrudgingly conceded that it is the best tool for the job decade after decade; in fact, it has survived even though most programmers do not use it at all. Thanks to its origins and use in artificial intelligence research and perhaps also the legacy of SICP, Lisp continues to fascinate people. Until we can imagine God creating the world with some newer language, Lisp isn’t going anywhere.
[24](#fn:24)*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
*
*Previously on TwoBitHistory…*
This week's post: A look at Chaosnet, the network that gave us the "CH" DNS class.
— TwoBitHistory (@TwoBitHistory)[https://t.co/dC7xqPYzi5][September 30, 2018]
-
John McCarthy, “History of Lisp”, 14, Stanford University, February 12, 1979, accessed October 14, 2018,
[http://jmc.stanford.edu/articles/lisp/lisp.pdf](http://jmc.stanford.edu/articles/lisp/lisp.pdf).[↩](#fnref:1) -
Paul Graham, “The Roots of Lisp”, 1, January 18, 2002, accessed October 14, 2018,
[http://languagelog.ldc.upenn.edu/myl/llog/jmc.pdf](http://languagelog.ldc.upenn.edu/myl/llog/jmc.pdf).[↩](#fnref:2) -
Martin Childs, “John McCarthy: Computer scientist known as the father of AI”, The Independent, November 1, 2011, accessed on October 14, 2018,
[https://www.independent.co.uk/news/obituaries/john-mccarthy-computer-scientist-known-as-the-father-of-ai-6255307.html](https://www.independent.co.uk/news/obituaries/john-mccarthy-computer-scientist-known-as-the-father-of-ai-6255307.html).[↩](#fnref:3) -
Lisp Bulletin History.
[http://www.artinfo-musinfo.org/scans/lb/lb3f.pdf](http://www.artinfo-musinfo.org/scans/lb/lb3f.pdf)[↩](#fnref:4) -
Allen Newell and Herbert Simon, “Current Developments in Complex Information Processing,” 19, May 1, 1956, accessed on October 14, 2018,
[http://bitsavers.org/pdf/rand/ipl/P-850_Current_Developments_In_Complex_Information_Processing_May56.pdf](http://bitsavers.org/pdf/rand/ipl/P-850_Current_Developments_In_Complex_Information_Processing_May56.pdf).[↩](#fnref:5) -
ibid.
[↩](#fnref:6) -
Herbert Stoyan, “Lisp History”, 43, Lisp Bulletin #3, December 1979, accessed on October 14, 2018,
[http://www.artinfo-musinfo.org/scans/lb/lb3f.pdf](http://www.artinfo-musinfo.org/scans/lb/lb3f.pdf)[↩](#fnref:7) -
McCarthy, “History of Lisp”, 5.
[↩](#fnref:8) -
ibid.
[↩](#fnref:9) -
McCarthy “History of Lisp”, 6.
[↩](#fnref:10) -
Stoyan, “Lisp History”, 45
[↩](#fnref:11) -
McCarthy, “History of Lisp”, 8.
[↩](#fnref:12) -
McCarthy, “History of Lisp”, 2.
[↩](#fnref:13) -
McCarthy, “History of Lisp”, 8.
[↩](#fnref:14) -
Graham, “The Roots of Lisp”, 11.
[↩](#fnref:15) -
Guy Steele and Richard Gabriel, “The Evolution of Lisp”, 22, History of Programming Languages 2, 1993, accessed on October 14, 2018,
[http://www.dreamsongs.com/Files/HOPL2-Uncut.pdf](http://www.dreamsongs.com/Files/HOPL2-Uncut.pdf).[↩](#fnref:16)[↩](#fnref:16:1)2 -
Carl Helmers, “Editorial”, Byte Magazine, 154, August 1979, accessed on October 14, 2018,
[https://archive.org/details/byte-magazine-1979-08/page/n153](https://archive.org/details/byte-magazine-1979-08/page/n153).[↩](#fnref:17) -
Patrick Winston, “The Lisp Revolution”, 209, April 1985, accessed on October 14, 2018,
[https://archive.org/details/byte-magazine-1985-04/page/n207](https://archive.org/details/byte-magazine-1985-04/page/n207).[↩](#fnref:18) -
Harold Abelson, Gerald Jay. Sussman, and Julie Sussman, Structure and Interpretation of Computer Programs (Cambridge, Mass: MIT Press, 2010), xiii.
[↩](#fnref:19) -
Abelson, xxiii.
[↩](#fnref:20) -
Abelson, 428.
[↩](#fnref:21) -
Helmers, 7.
[↩](#fnref:22) -
Paul Graham, “What Made Lisp Different”, December 2001, accessed on October 14, 2018,
[http://www.paulgraham.com/diff.html](http://www.paulgraham.com/diff.html).[↩](#fnref:23) -
John McCarthy, “Lisp—Notes on its past and future”, 3, Stanford University, 1980, accessed on October 14, 2018,
[http://jmc.stanford.edu/articles/lisp20th/lisp20th.pdf](http://jmc.stanford.edu/articles/lisp20th/lisp20th.pdf).[↩](#fnref:24) |
10,256 | Dropbox 在 Linux 上终止除了 Ext4 之外所有文件系统的同步支持 | https://itsfoss.com/dropbox-linux-ext4-only/ | 2018-11-20T21:22:30 | [
"Dropbox",
"Ext4"
] | https://linux.cn/article-10256-1.html |
>
> Dropbox 正考虑将同步支持限制为少数几种文件系统类型:Windows 的 NTFS、macOS 的 HFS+/APFS 和 Linux 的 Ext4。
>
>
>

[Dropbox](https://www.dropbox.com/) 是最受欢迎的 [Linux 中的云服务](https://itsfoss.com/cloud-services-linux/)之一。很多人都在使用 Linux 下的 Dropbox 同步客户端。但是,最近,一些用户在他们的 Dropbox Linux 桌面客户端上收到一条警告说:
>
> “移动 Dropbox 文件夹位置, Dropbox 将在 11 月停止同步“
>
>
>
### Dropbox 将仅支持少量文件系统
一个 [Reddit 主题](https://www.reddit.com/r/linux/comments/966xt0/linux_dropbox_client_will_stop_syncing_on_any/)强调了一位用户在 [Dropbox 论坛](https://www.dropboxforum.com/t5/Syncing-and-uploads/)上查询了该消息后的公告,该消息被社区管理员标记为意外新闻。这是[回复](https://www.dropboxforum.com/t5/Syncing-and-uploads/Linux-Dropbox-client-warn-me-that-it-ll-stop-syncing-in-Nov-why/m-p/290065/highlight/true#M42255)中的内容:
>
> “大家好,在 2018 年 11 月 7 日,我们会结束 Dropbox 在某些不常见文件系统的同步支持。支持的文件系统是 Windows 的 NTFS、macOS 的 HFS+ 或 APFS,以及Linux 的 Ext4。
>
>
> [Dropbox 官方论坛](https://www.dropboxforum.com/t5/Syncing-and-uploads/Linux-Dropbox-client-warn-me-that-it-ll-stop-syncing-in-Nov-why/m-p/290065/highlight/true#M42255)
>
>
>

*Dropbox 官方确认支持文件系统的限制*
此举旨在提供稳定和一致的体验。Dropbox 还更新了其[桌面要求](https://www.dropbox.com/help/desktop-web/system-requirements#desktop)。
### 那你该怎么办?
如果你在不受支持的文件系统上使用 Dropbox 进行同步,那么应该考虑更改位置。
Linux 仅支持 Ext4 文件系统。但这并不是一个令人担忧的新闻,因为你可能已经在使用 Ext4 文件系统了。
在 Ubuntu 或其他基于 Ubuntu 的发行版上,打开磁盘应用并查看 Linux 系统所在分区的文件系统。

*检查 Ubuntu 上的文件系统类型*
如果你的系统上没有安装磁盘应用,那么可以[使用命令行了解文件系统类型](https://www.thegeekstuff.com/2011/04/identify-file-system-type/)。
如果你使用的是 Ext4 文件系统并仍然收到来自 Dropbox 的警告,请检查你是否有可能收到通知的非活动计算机/设备。如果是,[将该系统与你的 Dropbox 帐户取消连接](https://www.dropbox.com/help/mobile/unlink-relink-computer-mobile)。
### Dropbox 也不支持加密的 Ext4 吗?
一些用户还报告说他们在加密 Ext4 文件系统同步时也收到了警告。那么,这是否意味着 Linux 的 Dropbox 客户端只支持未加密的 Ext4 文件系统?这方面 Dropbox 没有官方声明。
你使用的是什么文件系统?你也收到了警告吗?如果你在收到警告后仍不确定该怎么做,你应该前往该方案的[官方帮助中心页面](https://www.dropbox.com/help/desktop-web/cant-establish-secure-connection#location)。
请在下面的评论中告诉我们你的想法。
---
via: <https://itsfoss.com/dropbox-linux-ext4-only/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Dropbox is thinking of limiting the synchronization support to only a handful of file system types: NTFS for Windows, HFS+/APFS for macOS and Ext4 for Linux.

[Dropbox](https://www.dropbox.com/) is one of the most popular [cloud services for Linux](https://itsfoss.com/cloud-services-linux/). A lot of folks happen to utilize the Dropbox sync client for Linux. However, recently, some of the users received a warning on their Dropbox Linux desktop client that said:
“
Move Dropbox locationDropbox will stop syncing in November“
Important Update!
After almost a year, [Dropbox decided to bring back support for these filesystems](https://itsfoss.com/dropbox-brings-back-linux-filesystem-support/).
### Dropbox will only support a handful of file systems
A [Reddit thread](https://www.reddit.com/r/linux/comments/966xt0/linux_dropbox_client_will_stop_syncing_on_any/) highlighted the announcement where one of the users inquired about it on [Dropbox forums](https://www.dropboxforum.com/t5/Syncing-and-uploads/), which was addressed by a community moderator with an unexpected news. Here’s what the[ reply](https://www.dropboxforum.com/t5/Syncing-and-uploads/Linux-Dropbox-client-warn-me-that-it-ll-stop-syncing-in-Nov-why/m-p/290065/highlight/true#M42255) was:
“Hi everyone, on Nov. 7, 2018, we’re ending support for Dropbox syncing to drives with certain uncommon file systems. The supported file systems are NTFS for Windows, HFS+ or APFS for Mac, and Ext4 for Linux.[Official Dropbox Forum]
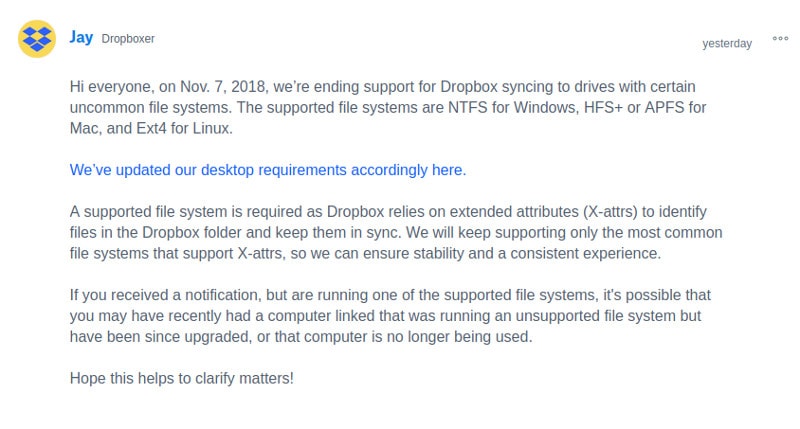
The move is *intended* to provide a stable and consistent experience. Dropbox has also updated its [desktop requirements.](https://www.dropbox.com/help/desktop-web/system-requirements#desktop)
### So, what should you do?
If you are using Dropbox on an unsupported filesystem to sync with, you should consider changing the location.
Only Ext4 file system will be supported for Linux. And that’s not entirely a worrying news because chances are that you are already using Ext4 file system.
On Ubuntu or other Ubuntu based distributions, open the Disks application and see the file system for the partition where you have installed your Linux system.

If you don’t have this Disk utility installed on your system, you can always [use the command line to find out file system type](https://www.thegeekstuff.com/2011/04/identify-file-system-type/).
If you are using Ext4 file system and still getting the warning from Dropbox, check if you have an inactive computer/device linked for which you might be getting the notification. If yes, [unlink that system from your Dropbox account](https://www.dropbox.com/help/mobile/unlink-relink-computer-mobile).
### Dropbox won’t support encrypted Ext4 as well?
Some users are also reporting that they received the warning while they have an *encrypted* *Ext4* filesystem synced with. So, does this mean that the Dropbox client for Linux will only support unencrypted Ext4 filesystem? There is no official statement from Dropbox in this regard.
What filesystem are you using? Did you receive the warning as well? If you’re still not sure what to do after receiving the warning, you should head to the [official help center page](https://www.dropbox.com/help/desktop-web/cant-establish-secure-connection#location) which mentions the solution.
Let us know your thoughts in the comments below. |
10,257 | 服务器的 LinuxBoot:告别 UEFI、拥抱开源 | https://itsfoss.com/linuxboot-uefi/ | 2018-11-20T22:20:25 | [
"LinuxBoot",
"UEFI",
"固件"
] | https://linux.cn/article-10257-1.html | [LinuxBoot](https://www.linuxboot.org/) 是私有的 [UEFI](https://itsfoss.com/check-uefi-or-bios/) 固件的开源 [替代品](https://www.phoronix.com/scan.php?page=news_item&px=LinuxBoot-OSFC-2018-State)。它发布于去年,并且现在已经得到主流的硬件生产商的认可成为他们产品的默认固件。去年,LinuxBoot 已经被 Linux 基金会接受并[纳入](https://www.linuxfoundation.org/blog/2018/01/system-startup-gets-a-boost-with-new-linuxboot-project/)开源家族。
这个项目最初是由 Ron Minnich 在 2017 年 1 月提出,它是 LinuxBIOS 的创造人,并且在 Google 领导 [coreboot](https://en.wikipedia.org/wiki/Coreboot) 的工作。
Google、Facebook、[Horizon Computing Solutions](http://www.horizon-computing.com/)、和 [Two Sigma](https://www.twosigma.com/) 共同合作,在运行 Linux 的服务器上开发 [LinuxBoot 项目](https://trmm.net/LinuxBoot_34c3)(以前叫 [NERF](https://trmm.net/NERF))。
它的开放性允许服务器用户去很容易地定制他们自己的引导脚本、修复问题、构建他们自己的 [运行时环境](https://trmm.net/LinuxBoot_34c3#Runtimes) 和用他们自己的密钥去 [刷入固件](http://www.tech-faq.com/flashing-firmware.html),而不需要等待供应商的更新。
下面是第一次使用 NERF BIOS 去引导 [Ubuntu Xenial](https://itsfoss.com/features-ubuntu-1604/) 的视频:
我们来讨论一下它与 UEFI 相比在服务器硬件方面的其它优势。
### LinuxBoot 超越 UEFI 的优势

下面是一些 LinuxBoot 超越 UEFI 的主要优势:
#### 启动速度显著加快
它能在 20 秒钟以内完成服务器启动,而 UEFI 需要几分钟的时间。
#### 显著的灵活性
LinuxBoot 可以用在 Linux 支持的各种设备、文件系统和协议上。
#### 更加安全
相比 UEFI 而言,LinuxBoot 在设备驱动程序和文件系统方面进行更加严格的检查。
我们可能争辩说 UEFI 是使用 [EDK II](https://www.tianocore.org/) 而部分开源的,而 LinuxBoot 是部分闭源的。但有人[提出](https://media.ccc.de/v/34c3-9056-bringing_linux_back_to_server_boot_roms_with_nerf_and_heads),即便有像 EDK II 这样的代码,但也没有做适当的审查级别和像 [Linux 内核](https://medium.com/@bhumikagoyal/linux-kernel-development-cycle-52b4c55be06e) 那样的正确性检查,并且在 UEFI 的开发中还大量使用闭源组件。
另一方面,LinuxBoot 有非常小的二进制文件,它仅用了大约几百 KB,相比而言,而 UEFI 的二进制文件有 32 MB。
严格来说,LinuxBoot 与 UEFI 不一样,更适合于[可信计算基础](https://en.wikipedia.org/wiki/Trusted_computing_base)。
LinuxBoot 有一个基于 [kexec](https://en.wikipedia.org/wiki/Kexec) 的引导加载器,它不支持启动 Windows/非 Linux 内核,但这影响并不大,因为主流的云都是基于 Linux 的服务器。
### LinuxBoot 的采用者
自 2011 年, [Facebook](https://github.com/facebook) 发起了[开源计算项目(OCP)](https://en.wikipedia.org/wiki/Open_Compute_Project),它的一些服务器是基于[开源](https://github.com/opencomputeproject)设计的,目的是构建的数据中心更加高效。LinuxBoot 已经在下面列出的几个开源计算硬件上做了测试:
* Winterfell
* Leopard
* Tioga Pass
更多 [OCP](https://www.networkworld.com/article/3266293/lan-wan/what-is-the-open-compute-project.html) 硬件在[这里](http://hyperscaleit.com/ocp-server-hardware/)有一个简短的描述。OCP 基金会通过[开源系统固件](https://www.opencompute.org/projects/open-system-firmware)运行一个专门的固件项目。
支持 LinuxBoot 的其它一些设备有:
* [QEMU](https://en.wikipedia.org/wiki/QEMU) 仿真的 [Q35](https://wiki.qemu.org/Features/Q35) 系统
* [Intel S2600wf](https://trmm.net/S2600)
* [Dell R630](https://trmm.net/NERF#Installing_on_a_Dell_R630)
上个月底(2018 年 9 月 24 日),[Equus 计算解决方案](https://www.equuscs.com/) [宣布](http://www.dcvelocity.com/products/Software_-_Systems/20180924-equus-compute-solutions-introduces-whitebox-open-m2660-and-m2760-servers/) 发行它的 [白盒开放式™](https://www.equuscs.com/servers/whitebox-open/) M2660 和 M2760 服务器,作为它们的定制的、成本优化的、开放硬件服务器和存储平台的一部分。它们都支持 LinuxBoot 灵活定制服务器的 BIOS,以提升安全性和设计一个非常快的纯净的引导体验。
### 你认为 LinuxBoot 怎么样?
LinuxBoot 在 [GitHub](https://github.com/linuxboot/linuxboot) 上有很丰富的文档。你喜欢它与 UEFI 不同的特性吗?由于 LinuxBoot 的开放式开发和未来,你愿意使用 LinuxBoot 而不是 UEFI 去启动你的服务器吗?请在下面的评论区告诉我们吧。
---
via: <https://itsfoss.com/linuxboot-uefi/>
作者:[Avimanyu Bandyopadhyay](https://itsfoss.com/author/avimanyu/) 选题:[oska874](https://github.com/oska874) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [LinuxBoot](https://www.linuxboot.org/) is an Open Source [alternative](https://www.phoronix.com/scan.php?page=news_item&px=LinuxBoot-OSFC-2018-State) to Proprietary [UEFI](https://itsfoss.com/check-uefi-or-bios/) firmware. It was released last year and is now being increasingly preferred by leading hardware manufacturers as default firmware. Last year, LinuxBoot was warmly [welcomed](https://www.linuxfoundation.org/blog/2018/01/system-startup-gets-a-boost-with-new-linuxboot-project/) into the Open Source family by The Linux Foundation.
This project was an initiative by Ronald Minnich, author of LinuxBIOS and lead of [ coreboot](https://en.wikipedia.org/wiki/Coreboot) at Google, in January 2017.
Google, Facebook, [Horizon Computing Solutions](http://www.horizon-computing.com/), and [Two Sigma](https://www.twosigma.com/) collaborated together to develop the [LinuxBoot project](https://trmm.net/LinuxBoot_34c3) (formerly called [NERF](https://trmm.net/NERF)) for server machines based on Linux.
Its openness allows Server users to easily customize their own boot scripts, fix issues, build their own [runtimes](https://trmm.net/LinuxBoot_34c3#Runtimes) and [reflash their firmware](http://www.tech-faq.com/flashing-firmware.html) with their own keys. They do not need to wait for vendor updates.
LinuxBoot works fine on UEFI systems, and the developers are always happy to help people get it working on their system. It is not just restricted to servers either. It works fine on systems that run UEFI, coreboot, or u-boot.
Following is a video of [Ubuntu Xenial](https://itsfoss.com/features-ubuntu-1604/) booting for the first time with NERF BIOS:
Let’s talk about some other advantages by comparing it to UEFI in terms of Server hardware.
## Advantages of LinuxBoot over UEFI

Here are some of the major advantages of LinuxBoot over UEFI:
### Significantly faster startup
It can boot up Server boards in less than twenty seconds, versus multiple minutes on UEFI.
### Significantly more flexible
LinuxBoot can make use of any devices, filesystems and protocols that Linux supports.
### Potentially more secure
Linux device drivers and filesystems have significantly more scrutiny than through UEFI.
We can argue that UEFI is partly open with [EDK II](https://www.tianocore.org/) and LinuxBoot is partly closed. But it has been [addressed](https://media.ccc.de/v/34c3-9056-bringing_linux_back_to_server_boot_roms_with_nerf_and_heads) that even such EDK II code does not have the proper level of inspection and correctness as the [Linux Kernel](https://medium.com/@bhumikagoyal/linux-kernel-development-cycle-52b4c55be06e) goes through, while there is a huge amount of other Closed Source components within UEFI development.
On the other hand, LinuxBoot has a significantly smaller amount of binaries with only a few hundred KB, compared to the 32 MB of UEFI binaries.
To be precise, LinuxBoot fits a whole lot better into the [Trusted Computing Base](https://en.wikipedia.org/wiki/Trusted_computing_base), unlike UEFI.
LinuxBoot has a [kexec](https://en.wikipedia.org/wiki/Kexec) based bootloader which does not support startup on Windows/non-Linux kernels, but that is insignificant since most clouds are Linux-based Servers.
## LinuxBoot adoption
In 2011, the [Open Compute Project](https://en.wikipedia.org/wiki/Open_Compute_Project) was started by [Facebook](https://github.com/facebook) who [open-sourced](https://github.com/opencomputeproject) designs of some of their Servers, built to make its data
- Winterfell
- Leopard
- Tioga Pass
More [OCP](https://www.networkworld.com/article/3266293/lan-wan/what-is-the-open-compute-project.html) hardware are described [here](http://hyperscaleit.com/ocp-server-hardware/) in brief. The OCP Foundation runs a dedicated project on firmware through [Open System Firmware](https://www.opencompute.org/projects/open-system-firmware).
Some other devices that support LinuxBoot are:
[QEMU](https://en.wikipedia.org/wiki/QEMU)emulated[Q35](https://wiki.qemu.org/Features/Q35)systems[Intel S2600wf](https://trmm.net/S2600)[Dell R630](https://trmm.net/NERF#Installing_on_a_Dell_R630)
Last month end, [Equus Compute Solutions](https://www.equuscs.com/) [announced](http://www.dcvelocity.com/products/Software_-_Systems/20180924-equus-compute-solutions-introduces-whitebox-open-m2660-and-m2760-servers/) the release of its [WHITEBOX OPEN™](https://www.equuscs.com/servers/whitebox-open/) M2660 and M2760 Servers, as a part of their custom, cost-optimized Open-Hardware Servers and storage platforms. Both of them support LinuxBoot to customize the Server BIOS for flexibility, improved security, and create a blazingly fast booting experience.
## What do you think of LinuxBoot?
LinuxBoot is quite well documented [on GitHub](https://github.com/linuxboot/linuxboot). Do you like the features that set it apart from UEFI? Would you prefer using LinuxBoot rather than UEFI for starting up Servers, owing to the former’s open-ended development and future? Let us know in the comments below. |
10,258 | 命令行快速技巧:如何定位一个文件 | https://fedoramagazine.org/commandline-quick-tips-locate-file/ | 2018-11-20T22:57:00 | [
"ls",
"tree"
] | https://linux.cn/article-10258-1.html | 
我们都会有文件存储在电脑里 —— 目录、相片、源代码等等。它们是如此之多。也无疑超出了我的记忆范围。要是毫无目标,找到正确的那一个可能会很费时间。在这篇文章里我们来看一下如何在命令行里找到需要的文件,特别是快速找到你想要的那一个。
好消息是 Linux 命令行专门设计了很多非常有用的命令行工具在你的电脑上查找文件。下面我们看一下它们其中三个:`ls`、`tree` 和 `find`。
### ls
如果你知道文件在哪里,你只需要列出它们或者查看有关它们的信息,`ls` 就是为此而生的。
只需运行 `ls` 就可以列出当下目录中所有可见的文件和目录:
```
$ ls
Documents Music Pictures Videos notes.txt
```
添加 `-l` 选项可以查看文件的相关信息。同时再加上 `-h` 选项,就可以用一种人们易读的格式查看文件的大小:
```
$ ls -lh
total 60K
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Documents
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Music
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:13 Pictures
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Videos
-rw-r--r-- 1 adam adam 43K Nov 2 13:12 notes.txt
```
`ls` 也可以搜索一个指定位置:
```
$ ls Pictures/
trees.png wallpaper.png
```
或者一个指定文件 —— 即便只跟着名字的一部分:
```
$ ls *.txt
notes.txt
```
少了点什么?想要查看一个隐藏文件?没问题,使用 `-a` 选项:
```
$ ls -a
. .bash_logout .bashrc Documents Pictures notes.txt
.. .bash_profile .vimrc Music Videos
```
`ls` 还有很多其他有用的选项,你可以把它们组合在一起获得你想要的效果。可以使用以下命令了解更多:
```
$ man ls
```
### tree
如果你想查看你的文件的树状结构,`tree` 是一个不错的选择。可能你的系统上没有默认安装它,你可以使用包管理 DNF 手动安装:
```
$ sudo dnf install tree
```
如果不带任何选项或者参数地运行 `tree`,将会以当前目录开始,显示出包含其下所有目录和文件的一个树状图。提醒一下,这个输出可能会非常大,因为它包含了这个目录下的所有目录和文件:
```
$ tree
.
|-- Documents
| |-- notes.txt
| |-- secret
| | `-- christmas-presents.txt
| `-- work
| |-- project-abc
| | |-- README.md
| | |-- do-things.sh
| | `-- project-notes.txt
| `-- status-reports.txt
|-- Music
|-- Pictures
| |-- trees.png
| `-- wallpaper.png
|-- Videos
`-- notes.txt
```
如果列出的太多了,使用 `-L` 选项,并在其后加上你想查看的层级数,可以限制列出文件的层级:
```
$ tree -L 2
.
|-- Documents
| |-- notes.txt
| |-- secret
| `-- work
|-- Music
|-- Pictures
| |-- trees.png
| `-- wallpaper.png
|-- Videos
`-- notes.txt
```
你也可以显示一个指定目录的树状图:
```
$ tree Documents/work/
Documents/work/
|-- project-abc
| |-- README.md
| |-- do-things.sh
| `-- project-notes.txt
`-- status-reports.txt
```
如果使用 `tree` 列出的是一个很大的树状图,你可以把它跟 `less` 组合使用:
```
$ tree | less
```
再一次,`tree` 有很多其他的选项可以使用,你可以把他们组合在一起发挥更强大的作用。man 手册页有所有这些选项:
```
$ man tree
```
### find
那么如果不知道文件在哪里呢?就让我们来找到它们吧!
要是你的系统中没有 `find`,你可以使用 DNF 安装它:
```
$ sudo dnf install findutils
```
运行 `find` 时如果没有添加任何选项或者参数,它将会递归列出当前目录下的所有文件和目录。
```
$ find
.
./Documents
./Documents/secret
./Documents/secret/christmas-presents.txt
./Documents/notes.txt
./Documents/work
./Documents/work/status-reports.txt
./Documents/work/project-abc
./Documents/work/project-abc/README.md
./Documents/work/project-abc/do-things.sh
./Documents/work/project-abc/project-notes.txt
./.bash_logout
./.bashrc
./Videos
./.bash_profile
./.vimrc
./Pictures
./Pictures/trees.png
./Pictures/wallpaper.png
./notes.txt
./Music
```
但是 `find` 真正强大的是你可以使用文件名进行搜索:
```
$ find -name do-things.sh
./Documents/work/project-abc/do-things.sh
```
或者仅仅是名字的一部分 —— 像是文件后缀。我们来找一下所有的 .txt 文件:
```
$ find -name "*.txt"
./Documents/secret/christmas-presents.txt
./Documents/notes.txt
./Documents/work/status-reports.txt
./Documents/work/project-abc/project-notes.txt
./notes.txt
```
你也可以根据大小寻找文件。如果你的空间不足的时候,这种方法也许特别有用。现在来列出所有大于 1 MB 的文件:
```
$ find -size +1M
./Pictures/trees.png
./Pictures/wallpaper.png
```
当然也可以搜索一个具体的目录。假如我想在我的 Documents 文件夹下找一个文件,而且我知道它的名字里有 “project” 这个词:
```
$ find Documents -name "*project*"
Documents/work/project-abc
Documents/work/project-abc/project-notes.txt
```
除了文件它还显示目录。你可以限制仅搜索查询文件:
```
$ find Documents -name "*project*" -type f
Documents/work/project-abc/project-notes.txt
```
最后再一次,`find` 还有很多供你使用的选项,要是你想使用它们,man 手册页绝对可以帮到你:
```
$ man find
```
---
via: <https://fedoramagazine.org/commandline-quick-tips-locate-file/>
作者:[Adam Šamalík](https://fedoramagazine.org/author/asamalik/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We all have files on our computers — documents, photos, source code, you name it. So many of them. Definitely more than I can remember. And if not challenging, it might be time consuming to find the right one you’re looking for. In this post, we’ll have a look at how to make sense of your files on the command line, and especially how to quickly find the ones you’re looking for.
Good news is there are few quite useful utilities in the Linux commandline designed specifically to look for files on your computer. We’ll have a look at three of those: ls, tree, and find.
## ls
If you know where your files are, and you just need to list them or see information about them, ls is here for you.
Just running ls lists all visible files and directories in the current directory:
$ ls Documents Music Pictures Videos notes.txt
Adding the **-l** option shows basic information about the files. And together with the **-h** option you’ll see file sizes in a human-readable format:
$ ls -lh total 60K drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Documents drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Music drwxr-xr-x 2 adam adam 4.0K Nov 2 13:13 Pictures drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Videos -rw-r--r-- 1 adam adam 43K Nov 2 13:12 notes.txt
**Is** can also search a specific place:
$ ls Pictures/ trees.png wallpaper.png
Or a specific file — even with just a part of the name:
$ ls *.txt notes.txt
Something missing? Looking for a hidden file? No problem, use the** -a** option:
$ ls -a . .bash_logout .bashrc Documents Pictures notes.txt .. .bash_profile .vimrc Music Videos
There are many other useful options for **ls**, and you can combine them together to achieve what you need. Learn about them by running:
$ man ls
## tree
If you want to see, well, a tree structure of your files, tree is a good choice. It’s probably not installed by default which you can do yourself using the package manager DNF:
$ sudo dnf install tree
Running tree without any options or parameters shows the whole tree starting at the current directory. Just a warning, this output might be huge, because it will include all files and directories:
$ tree . |-- Documents | |-- notes.txt | |-- secret | | `-- christmas-presents.txt | `-- work | |-- project-abc | | |-- README.md | | |-- do-things.sh | | `-- project-notes.txt | `-- status-reports.txt |-- Music |-- Pictures | |-- trees.png | `-- wallpaper.png |-- Videos `-- notes.txt
If that’s too much, I can limit the number of levels it goes using the -L option followed by a number specifying the number of levels I want to see:
$ tree -L 2 . |-- Documents | |-- notes.txt | |-- secret | `-- work |-- Music |-- Pictures | |-- trees.png | `-- wallpaper.png |-- Videos `-- notes.txt
You can also display a tree of a specific path:
$ tree Documents/work/ Documents/work/ |-- project-abc | |-- README.md | |-- do-things.sh | `-- project-notes.txt `-- status-reports.txt
To browse and search a huge tree, you can use it together with less:
$ tree | less
Again, there are other options you can use with three, and you can combine them together for even more power. The manual page has them all:
$ man tree
## find
And what about files that live somewhere in the unknown? Let’s find them!
In case you don’t have find on your system, you can install it using DNF:
$ sudo dnf install findutils
Running find without any options or parameters recursively lists all files and directories in the current directory.
$ find . ./Documents ./Documents/secret ./Documents/secret/christmas-presents.txt ./Documents/notes.txt ./Documents/work ./Documents/work/status-reports.txt ./Documents/work/project-abc ./Documents/work/project-abc/README.md ./Documents/work/project-abc/do-things.sh ./Documents/work/project-abc/project-notes.txt ./.bash_logout ./.bashrc ./Videos ./.bash_profile ./.vimrc ./Pictures ./Pictures/trees.png ./Pictures/wallpaper.png ./notes.txt ./Music
But the true power of find is that you can search by name:
$ find -name do-things.sh ./Documents/work/project-abc/do-things.sh
Or just a part of a name — like the file extension. Let’s find all .txt files:
$ find -name "*.txt" ./Documents/secret/christmas-presents.txt ./Documents/notes.txt ./Documents/work/status-reports.txt ./Documents/work/project-abc/project-notes.txt ./notes.txt
You can also look for files by size. That might be especially useful if you’re running out of space. Let’s list all files larger than 1 MB:
$ find -size +1M ./Pictures/trees.png ./Pictures/wallpaper.png
Searching a specific directory is also possible. Let’s say I want to find a file in my Documents directory, and I know it has the word “project” in its name:
$ find Documents -name "*project*" Documents/work/project-abc Documents/work/project-abc/project-notes.txt
Ah! That also showed the directory. One thing I can do is to limit the search query to files only:
$ find Documents -name "*project*" -type f Documents/work/project-abc/project-notes.txt
And again, find have many more options you can use, the man page might definitely help you:
$ man find
## Ellis
If you want to find files by content:
## Lukas
You forgot the most important tool in my opinion: locate. I quote from the Arch wiki:
locate is a common Unix tool for quickly finding files by name. It offers speed improvements over the find tool by searching a pre-constructed database file, rather than the filesystem directly. The downside of this approach is that changes made since the construction of the database file cannot be detected by locate. This problem can be minimised by scheduled database updates.
## WLBI
That’s right. My most used tool is
locate
In combination with
updatedb
## nolty
+1
## Robert Brady
$ locate -b ‘\cat’
## Florian
If you find yourself often in the position to find specific files by their name, index based tools might give you a significant edge over the usage of ‘find -name’. Take a look at locate/slocate.
## Fred Weigel
How about the venerable locate? (updatedb/locate)
sudo dnf install locate
queries like
locate –all yellow ball
which returns all filenames that contain yellow and ball.
## RM
Thanks for your comment. I knew about “locate” but did not know about the “all” switch!
## Mark Orchard
Very useful, thanks for the information. I keep forgetting the “Tree” function.
Is there an option with find to automatically cd to a file or directory once located?
## Fred Weigel
Look at the -exec action in the man page
## Spike
I don’t think so. How could it know which to cd if there are multiple matches?!
You could write a function that uses the first result and cd into it, if it’s a directory,
## Elliott S
You might want to try installing
. In Fedora by default, only the tab completion is enabled, so you would type cd ** then press Tab, and it will open a list of directories from which you can start typing to pick one by pressing Enter.
If you follow the instructions in the
in the package, you can enable keyboard shortcuts as well. Then you can just type cd and press Ctrl+T to open the completion list directly.
## Nathan D
Find all text files in all subdirectories where the phrase foo is used:
[Editor’s note: fixed an unclosed double-quote-pair]
## Ray McCaffity
There is also “which”
which bash
/usr/bin/bash
## Bartosz
I recommend “silver searcher” (ag) for searching content of text files (code mainly), “fasd” for fast finding already used files/folders and completing other commands with it and fzf for great fuzzy searching.
## Julian
When mentioning fzf one could also mention rip grep (rg) as an very fast grep alternative and fd instead of find. With these tools one then can also navigate to files and directories.
## JdeH
For file content, I find searchodt.sh and searchods.sh very useful for Open/LibreOffice document and spreadsheet files, respectively.
For pdf files, pdfgrep is really good.
## Szymon
Possible to find files by photo exif ? i.e. camera model ?
## EraZor
Definately +1 for Julian’s tip of ripgrep. Ultra high performant, multithreaded search tool for grepping or finding files. Totally upped my searching experiance!
If you have not: Take a look at it right now! |
10,259 | CPod:一个开源、跨平台播客应用 | https://itsfoss.com/cpod-podcast-app/ | 2018-11-21T10:07:56 | [
"播客"
] | https://linux.cn/article-10259-1.html | 播客是一个很好的娱乐和获取信息的方式。事实上,我会听十几个不同的播客,包括技术、神秘事件、历史和喜剧。当然,[Linux 播客](https://itsfoss.com/linux-podcasts/)也在此列表中。
今天,我们将看一个简单的跨平台应用来收听你的播客。

### 应用程序
[CPod](https://github.com/z-------------/CPod) 是 [Zack Guard(z————-)](https://github.com/z-------------) 的作品。**它是一个 [Election](https://electronjs.org/) 程序**,这使它能够在大多数操作系统(Linux、Windows、Mac OS)上运行。
>
> 一个小事:CPod 最初被命名为 Cumulonimbus。
>
>
>
应用的大部分被两个面板占用,来显示内容和选项。屏幕左侧的小条让你可以使用应用的不同功能。CPod 的不同栏目包括主页、队列、订阅、浏览和设置。

*设置*
### CPod 的功能
以下是 CPod 提供的功能列表:
* 简洁,干净的设计
* 可在主流计算机平台上使用
* 有 Snap 包
* 搜索 iTunes 的播客目录
* 可下载也可无需下载就播放节目
* 查看播客信息和节目
* 搜索播客的个别节目
* 深色模式
* 改变播放速度
* 键盘快捷键
* 将你的播客订阅与 gpodder.net 同步
* 导入和导出订阅
* 根据长度、日期、下载状态和播放进度对订阅进行排序
* 在应用启动时自动获取新节目
* 多语言支持

*搜索 ZFS 节目*
### 在 Linux 上体验 CPod
我最后在两个系统上安装了 CPod:ArchLabs 和 Windows。[Arch 用户仓库](https://aur.archlinux.org/packages/?O=0&K=cpod) 中有两个版本的 CPod。但是,它们都已过时,一个是版本 1.14.0,另一个是 1.22.6。最新版本的 CPod 是 1.27.0。由于 ArchLabs 和 Windows 之间的版本差异,我的体验有所不同。在本文中,我将重点关注 1.27.0,因为它是最新且功能最多的。
我马上能够找到我最喜欢的播客。我可以粘贴 RSS 源的 URL 来添加 iTunes 列表中没有的那些播客。
找到播客的特定节目也很容易。例如,我最近在寻找 [Late Night Linux](https://latenightlinux.com/) 中的一集,这集中他们在谈论 [ZFS](https://itsfoss.com/what-is-zfs/)。我点击播客,在搜索框中输入 “ZFS” 然后找到了它。
我很快发现播放一堆播客节目的最简单方法是将它们添加到队列中。一旦它们进入队列,你可以流式传输或下载它们。你也可以通过拖放重新排序它们。每集在播放时,它会显示可视化的声波以及节目摘要。
### 安装 CPod
在 [GitHub](https://github.com/z-------------/CPod/releases) 上,你可以下载适用于 Linux 的 AppImage 或 Deb 文件,适用于 Windows 的 .exe 文件或适用于 Mac OS 的 .dmg 文件。
你可以使用 [Snap](https://snapcraft.io/cumulonimbus) 安装 CPod。你需要做的就是使用以下命令:
```
sudo snap install cpod
```
就像我之前说的那样,CPod 的 [Arch 用户仓库](https://aur.archlinux.org/packages/?O=0&K=cpod)的版本已经过时了。我已经给其中一个打包者发了消息。如果你使用 Arch(或基于 Arch 的发行版),我建议你这样做。

*播放其中一个我最喜欢的播客*
### 最后的想法
总的来说,我喜欢 CPod。它外观漂亮,使用简单。事实上,我更喜欢原来的名字(Cumulonimbus),但是它有点拗口。
我刚刚在程序中遇到两个问题。首先,我希望每个播客都有评分。其次,在打开黑暗模式后,根据长度、日期、下载状态和播放进度对剧集进行排序的菜单不起作用。
你有没有用过 CPod?如果没有,你最喜欢的播客应用是什么?你最喜欢的播客有哪些?请在下面的评论中告诉我们。
如果你发现这篇文章很有意思,请花一点时间在社交媒体、Hacker News 或 [Reddit](http://reddit.com/r/linuxusersgroup) 上分享它。
---
via: <https://itsfoss.com/cpod-podcast-app/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Podcasts are a great way to be entertained and informed. In fact, I listen to about ten different podcasts covering technology, mysteries, history, and comedy. Of course, [Linux podcasts](https://itsfoss.com/linux-podcasts/) are also on this list.
Today, we will take a look at a simple cross-platform application for handling your podcasts.

Recommended podcasts and podcast search
## The Application
[ CPod](https://github.com/z-------------/CPod) is the creation of
[Zack Guard (z————-)](https://github.com/z-------------).
*, which gives it the ability to run on the largest operating systems (Linux, Windows, Mac OS).*
**It is an**[Election](https://electronjs.org/)appTrivia: CPod was originally named Cumulonimbus.
The majority of the application is taken up by two large panels to display content and options. A small bar along the left side of the screen gives you access to the different parts of the application. The different sections of CPod include Home, Queue, Subscriptions, Explore and Settings.

[irp posts=30477]
## Features of CPod
Here is a list of features that CPod has to offer:
- Simple, clean design
- Available on the top computer platforms
- Available as a Snap
- Search iTunes’ podcast directory
- Download and play episodes without downloading
- View podcast information and episode
- Search for an individual episode of a podcast
- Dark mode
- Change playback speed
- Keyboard shortcuts
- Sync your podcast subscriptions with gpodder.net
- Import and export subscriptions
- Sort subscriptions based on length, date, download status, and play progress
- Auto-fetch new episodes on application startup
- Multiple language support

[irp posts=7157]
## Experiencing CPod on Linux
I ended up installing CPod on two systems: ArchLabs and Windows. There are two versions of CPod in the [Arch User Repository](https://aur.archlinux.org/packages/?O=0&K=cpod). However, they are both out of date, one is version 1.14.0 and the other was 1.22.6. The most recent version of CPod is 1.27.0. Because of the version difference between ArchLabs and Windows, I had to different experiences. For this article, I will focus on 1.27.0, since that is the most current and has the most features.
Right out of the gate, I was able to find most of my favorite podcasts. I was able to add the ones that were not on the iTunes’ list by pasting in the URL for the RSS feed.
It was also very easy to find a particular episode of a podcast. for example, I was recently looking for an episode of [Late Night Linux](https://latenightlinux.com/) where they were talking about [ZFS](https://itsfoss.com/what-is-zfs/). I clicked on the podcast, typed “ZFS” in the search box and found it.
I quickly discovered that the easiest way to play a bunch of podcast episodes was to add them to the queue. Once they are in the queue, you can either stream them or download them. You can also reorder them by dragging and dropping. As each episode played, it displayed a visualization of the sound wave, along with the episode summary.
[irp posts=9745]
Installating CPod
On [GitHub](https://github.com/z-------------/CPod/releases), you can download an AppImage or Deb file for Linux, a .exe file for Windows or a .dmg file for Mac OS.
You can also install CPod as a [Snap](https://snapcraft.io/cumulonimbus). All you need to do is use the following command:
`sudo snap install cpod`
Like I said earlier, the [Arch User Repository](https://aur.archlinux.org/packages/?O=0&K=cpod) version of CPod is old. I already messaged one of the packagers. If you use Arch (or an Arch-based distro), I would recommend doing the same.
## Final Thoughts
Overall, I liked CPod. It was nice looking and simple to use. In fact, I like the original name (Cumulonimbus) better, but it is a bit of a mouthful.
I just had two problems with the application. First, I wish that the ratings were available for each podcast. Second, the menus that allow you to sort episodes based on length, date, download status, and play progress don’t work when the dork mode is turned on.
Have you ever used CPod? If not, what is your favorite podcast app? What are some of your favorite podcasts? Let us know in the comments below.
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Red](http://reddit.com/r/linuxusersgroup)[d](http://reddit.com/r/linuxusersgroup)[it](http://reddit.com/r/linuxusersgroup). |
10,260 | 使用 Docker 企业版搭建自己的私有注册服务器 | https://blog.docker.com/2018/01/dtr/ | 2018-11-21T15:17:15 | [
"Docker"
] | https://linux.cn/article-10260-1.html | 
Docker 真的很酷,特别是和使用虚拟机相比,转移 Docker 镜像十分容易。如果你已准备好使用 Docker,那你肯定已从 [Docker Hub](https://hub.docker.com/) 上拉取过完整的镜像。Docker Hub 是 Docker 的云端注册服务器服务,它包含成千上万个供选择的 Docker 镜像。如果你开发了自己的软件包并创建了自己的 Docker 镜像,那么你会想有自己私有的注册服务器。如果你有搭配着专有许可的镜像,或想为你的构建系统提供复杂的持续集成(CI)过程,则更应该拥有自己的私有注册服务器。
Docker 企业版包括 <ruby> Docker 可信注册服务器 <rt> Docker Trusted Registry </rt></ruby>(DTR)。这是一个具有安全镜像管理功能的高可用的注册服务器,为在你自己的数据中心或基于云端的架构上运行而构建。在接下来,我们将了解到 DTR 是提供安全、可重用且连续的[软件供应链](https://blog.docker.com/2016/08/securing-enterprise-software-supply-chain-using-docker/)的一个关键组件。你可以通过我们的[免费托管小样](https://www.docker.com/trial)立即开始使用,或者通过下载安装进行 30 天的免费试用。下面是开始自己安装的步骤。
### 配置 Docker 企业版
DTR 运行于通用控制面板(UCP)之上,所以开始前要安装一个单节点集群。如果你已经有了自己的 UCP 集群,可以跳过这一步。在你的 docker 托管主机上,运行以下命令:
```
# 拉取并安装 UCP
docker run -it -rm -v /var/run/docker.sock:/var/run/docker.sock -name ucp docker/ucp:latest install
```
当 UCP 启动并运行后,在安装 DTR 之前你还有几件事要做。针对刚刚安装的 UCP 实例,打开浏览器。在日志输出的末尾应该有一个链接。如果你已经有了 Docker 企业版的许可证,那就在这个界面上输入它吧。如果你还没有,可以访问 [Docker 商店](https://store.docker.com/search?offering=enterprise&page=1&q=&type=edition)获取 30 天的免费试用版。
准备好许可证后,你可能会需要改变一下 UCP 运行的端口。因为这是一个单节点集群,DTR 和 UCP 可能会以相同的端口运行它们的 web 服务。如果你拥有不只一个节点的 UCP 集群,这就不是问题,因为 DTR 会寻找有所需空闲端口的节点。在 UCP 中,点击“管理员设置 -> 集群配置”并修改控制器端口,比如 5443。
### 安装 DTR
我们要安装一个简单的、单节点的 DTR 实例。如果你要安装实际生产用途的 DTR,那么你会将其设置为高可用(HA)模式,即需要另一种存储介质,比如基于云端的对象存储或者 NFS(LCTT 译注:Network File System,网络文件系统)。因为目前安装的是一个单节点实例,我们依然使用默认的本地存储。
首先我们需要拉取 DTR 的 bootstrap 镜像。boostrap 镜像是一个微小的独立安装程序,包括了连接到 UCP 以及设置和启动 DTR 所需的所有容器、卷和逻辑网络。
使用命令:
```
# 拉取并运行 DTR 引导程序
docker run -it -rm docker/dtr:latest install -ucp-insecure-tls
```
注意:默认情况下,UCP 和 DTR 都有自己的证书,系统无法识别。如果你已使用系统信任的 TLS 证书设置 UCP,则可以省略 `-ucp-insecure-tls` 选项。另外,你可以使用 `-ucp-ca` 选项来直接指定 UCP 的 CA 证书。
然后 DTR bootstrap 镜像会让你确定几项设置,比如 UCP 安装的 URL 地址以及管理员的用户名和密码。从拉取所有的 DTR 镜像到设置全部完成,只需要一到两分钟的时间。
### 保证一切安全
一切都准备好后,就可以向注册服务器推送或者从中拉取镜像了。在做这一步之前,让我们设置 TLS 证书,以便与 DTR 安全地通信。
在 Linux 上,我们可以使用以下命令(只需确保更改了 `DTR_HOSTNAME` 变量,来正确映射我们刚刚设置的 DTR):
```
# 从 DTR 拉取 CA 证书(如果 curl 不可用,你可以使用 wget)
DTR_HOSTNAME=< DTR 主机名>
curl -k https://$(DTR_HOSTNAME)/ca > $(DTR_HOSTNAME).crt
sudo mkdir /etc/docker/certs.d/$(DTR_HOSTNAME)
sudo cp $(DTR_HOSTNAME) /etc/docker/certs.d/$(DTR_HOSTNAME)
# 重启 docker 守护进程(在 Ubuntu 14.04 上,使用 `sudo service docker restart` 命令)
sudo systemctl restart docker
```
对于 Mac 和 Windows 版的 Docker,我们会以不同的方式安装客户端。转入“设置 -> 守护进程”,在“不安全的注册服务器”部分,输入你的 DTR 主机名。点击“应用”,docker 守护进程应在重启后可以良好使用。
### 推送和拉取镜像
现在我们需要设置一个仓库来存放镜像。这和 Docker Hub 有一点不同,如果你做的 docker 推送仓库中不存在,它会自动创建一个。要创建一个仓库,在浏览器中打开 `https://<Your DTR hostname>` 并在出现登录提示时使用你的管理员凭据登录。如果你向 UCP 添加了许可证,则 DTR 会自动获取该许可证。如果没有,请现在确认上传你的许可证。
进入刚才的网页之后,点击“新建仓库”按钮来创建新的仓库。
我们会创建一个用于存储 Alpine linux 的仓库,所以在名字输入处键入 “alpine”,点击“保存”(在 DTR 2.5 及更高版本中叫“创建”)。
现在我们回到 shell 界面输入以下命令:
```
# 拉取 Alpine Linux 的最新版
docker pull alpine:latest
# 登入新的 DTR 实例
docker login <Your DTR hostname>
# 标记上 Alpine 使能推送其至你的 DTR
docker tag alpine:latest <Your DTR hostname>/admin/alpine:latest
# 向 DTR 推送镜像
docker push <Your DTR hostname>/admin/alpine:latest
```
就是这样!我们刚刚推送了最新的 Alpine Linux 的一份拷贝,重新打了标签以便将其存储到 DTR 中,并将其推送到我们的私有注册服务器。如果你想将镜像拉取至不同的 Docker 引擎中,按如上所示设置你的 DTR 证书,然后执行以下命令:
```
# 从 DTR 中拉取镜像
docker pull <Your DTR hostname>/admin/alpine:latest
```
DTR 具有许多优秀的镜像管理功能,例如镜像的缓存、映像、扫描、签名甚至自动化供应链策略。这些功能我们在后期的博客文章中更详细的探讨。
---
via: <https://blog.docker.com/2018/01/dtr/>
作者:[Patrick Devine](https://blog.docker.com/author/pdevine/) 译者:[fuowang](https://github.com/fuowang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,261 | 在 Linux 中如何查找一个命令或进程的执行时间 | https://www.ostechnix.com/how-to-find-the-execution-time-of-a-command-or-process-in-linux/ | 2018-11-21T15:59:10 | [
"time",
"时间"
] | https://linux.cn/article-10261-1.html | 
在类 Unix 系统中,你可能知道一个命令或进程开始执行的时间,以及[一个进程运行了多久](https://www.ostechnix.com/find-long-process-running-linux/)。 但是,你如何知道这个命令或进程何时结束或者它完成运行所花费的总时长呢? 在类 Unix 系统中,这是非常容易的! 有一个专门为此设计的程序名叫 **GNU time**。 使用 `time` 程序,我们可以轻松地测量 Linux 操作系统中命令或程序的总执行时间。 `time` 命令在大多数 Linux 发行版中都有预装,所以你不必去安装它。
### 在 Linux 中查找一个命令或进程的执行时间
要测量一个命令或程序的执行时间,运行:
```
$ /usr/bin/time -p ls
```
或者,
```
$ time ls
```
输出样例:
```
dir1 dir2 file1 file2 mcelog
real 0m0.007s
user 0m0.001s
sys 0m0.004s
```
```
$ time ls -a
. .bash_logout dir1 file2 mcelog .sudo_as_admin_successful
.. .bashrc dir2 .gnupg .profile .wget-hsts
.bash_history .cache file1 .local .stack
real 0m0.008s
user 0m0.001s
sys 0m0.005s
```
以上命令显示出了 `ls` 命令的总执行时间。 你可以将 `ls` 替换为任何命令或进程,以查找总的执行时间。
输出详解:
1. `real` —— 指的是命令或程序所花费的总时间
2. `user` —— 指的是在用户模式下程序所花费的时间
3. `sys` —— 指的是在内核模式下程序所花费的时间
我们也可以将命令限制为仅运行一段时间。参考如下教程了解更多细节:
* [在 Linux 中如何让一个命令运行特定的时长](https://www.ostechnix.com/run-command-specific-time-linux/)
### time 与 /usr/bin/time
你可能注意到了, 我们在上面的例子中使用了两个命令 `time` 和 `/usr/bin/time` 。 所以,你可能会想知道他们的不同。
首先, 让我们使用 `type` 命令看看 `time` 命令到底是什么。对于那些我们不了解的 Linux 命令,`type` 命令用于查找相关命令的信息。 更多详细信息,[请参阅本指南](https://www.ostechnix.com/the-type-command-tutorial-with-examples-for-beginners/)。
```
$ type -a time
time is a shell keyword
time is /usr/bin/time
```
正如你在上面的输出中看到的一样,`time` 是两个东西:
* 一个是 BASH shell 中内建的关键字
* 一个是可执行文件,如 `/usr/bin/time`
由于 shell 关键字的优先级高于可执行文件,当你没有给出完整路径只运行 `time` 命令时,你运行的是 shell 内建的命令。 但是,当你运行 `/usr/bin/time` 时,你运行的是真正的 **GNU time** 命令。 因此,为了执行真正的命令你可能需要给出完整路径。
在大多数 shell 中如 BASH、ZSH、CSH、KSH、TCSH 等,内建的关键字 `time` 是可用的。 `time` 关键字的选项少于该可执行文件,你可以使用的唯一选项是 `-p`。
你现在知道了如何使用 `time` 命令查找给定命令或进程的总执行时间。 想进一步了解 GNU time 工具吗? 继续阅读吧!
### 关于 GNU time 程序的简要介绍
GNU time 程序运行带有给定参数的命令或程序,并在命令完成后将系统资源使用情况汇总到标准输出。 与 `time` 关键字不同,GNU time 程序不仅显示命令或进程的执行时间,还显示内存、I/O 和 IPC 调用等其他资源。
`time` 命令的语法是:
```
/usr/bin/time [options] command [arguments...]
```
上述语法中的 `options` 是指一组可以与 `time` 命令一起使用去执行特定功能的选项。 下面给出了可用的选项:
* `-f, –format` —— 使用此选项可以根据需求指定输出格式。
* `-p, –portability` —— 使用简要的输出格式。
* `-o file, –output=FILE` —— 将输出写到指定文件中而不是到标准输出。
* `-a, –append` —— 将输出追加到文件中而不是覆盖它。
* `-v, –verbose` —— 此选项显示 `time` 命令输出的详细信息。
* `–quiet` – 此选项可以防止 `time` 命令报告程序的状态.
当不带任何选项使用 GNU time 命令时,你将看到以下输出。
```
$ /usr/bin/time wc /etc/hosts
9 28 273 /etc/hosts
0.00user 0.00system 0:00.00elapsed 66%CPU (0avgtext+0avgdata 2024maxresident)k
0inputs+0outputs (0major+73minor)pagefaults 0swaps
```
如果你用 shell 关键字 `time` 运行相同的命令, 输出会有一点儿不同:
```
$ time wc /etc/hosts
9 28 273 /etc/hosts
real 0m0.006s
user 0m0.001s
sys 0m0.004s
```
有时,你可能希望将系统资源使用情况输出到文件中而不是终端上。 为此, 你可以使用 `-o` 选项,如下所示。
```
$ /usr/bin/time -o file.txt ls
dir1 dir2 file1 file2 file.txt mcelog
```
正如你看到的,`time` 命令不会显示到终端上。因为我们将输出写到了`file.txt` 的文件中。 让我们看一下这个文件的内容:
```
$ cat file.txt
0.00user 0.00system 0:00.00elapsed 66%CPU (0avgtext+0avgdata 2512maxresident)k
0inputs+0outputs (0major+106minor)pagefaults 0swaps
```
当你使用 `-o` 选项时, 如果你没有一个名为 `file.txt` 的文件,它会创建一个并把输出写进去。如果文件存在,它会覆盖文件原来的内容。
你可以使用 `-a` 选项将输出追加到文件后面,而不是覆盖它的内容。
```
$ /usr/bin/time -a file.txt ls
```
`-f` 选项允许用户根据自己的喜好控制输出格式。 比如说,以下命令的输出仅显示用户,系统和总时间。
```
$ /usr/bin/time -f "\t%E real,\t%U user,\t%S sys" ls
dir1 dir2 file1 file2 mcelog
0:00.00 real, 0.00 user, 0.00 sys
```
请注意 shell 中内建的 `time` 命令并不具有 GNU time 程序的所有功能。
有关 GNU time 程序的详细说明可以使用 `man` 命令来查看。
```
$ man time
```
想要了解有关 Bash 内建 `time` 关键字的更多信息,请运行:
```
$ help time
```
就到这里吧。 希望对你有所帮助。
会有更多好东西分享哦。 请关注我们!
加油哦!
---
via: <https://www.ostechnix.com/how-to-find-the-execution-time-of-a-command-or-process-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[caixiangyue](https://github.com/caixiangyue) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,262 | 监测数据库的健康和行为:有哪些重要指标? | https://opensource.com/article/18/10/database-metrics-matter | 2018-11-21T21:51:27 | [
"数据库",
"监测"
] | https://linux.cn/article-10262-1.html |
>
> 对数据库的监测可能过于困难或者没有找到关键点。本文将讲述如何正确的监测数据库。
>
>
>

我们没有对数据库讨论过多少。在这个充满监测仪器的时代,我们监测我们的应用程序、基础设施、甚至我们的用户,但有时忘记我们的数据库也值得被监测。这很大程度是因为数据库表现的很好,以至于我们单纯地信任它能把任务完成的很好。信任固然重要,但能够证明它的表现确实如我们所期待的那样就更好了。

### 为什么监测你的数据库?
监测数据库的原因有很多,其中大多数原因与监测系统的任何其他部分的原因相同:了解应用程序的各个组件中发生的什么,会让你成为更了解情况的,能够做出明智决策的开发人员。

更具体地说,数据库是系统健康和行为的重要标志。数据库中的异常行为能够指出应用程序中出现问题的区域。另外,当应用程序中有异常行为时,你可以利用数据库的指标来迅速完成排除故障的过程。
### 问题
最轻微的调查揭示了监测数据库的一个问题:数据库有很多指标。说“很多”只是轻描淡写,如果你是<ruby> 史高治 <rt> Scrooge McDuck </rt></ruby>(LCTT 译注:史高治,唐老鸭的舅舅,以一毛不拔著称),你不会放过任何一个可用的指标。如果这是<ruby> 摔角狂热 <rt> Wrestlemania </rt></ruby> 比赛,那么指标就是折叠椅。监测所有指标似乎并不实用,那么你如何决定要监测哪些指标?

### 解决方案
开始监测数据库的最好方式是认识一些基础的数据库指标。这些指标为理解数据库的行为创造了良好的开端。
### 吞吐量:数据库做了多少?
开始检测数据库的最好方法是跟踪它所接到请求的数量。我们对数据库有较高期望;期望它能稳定的存储数据,并处理我们抛给它的所有查询,这些查询可能是一天一次大规模查询,或者是来自用户一天到晚的数百万次查询。吞吐量可以告诉我们数据库是否如我们期望的那样工作。
你也可以将请求按照类型(读、写、服务器端、客户端等)分组,以开始分析流量。
### 执行时间:数据库完成工作需要多长时间?
这个指标看起来很明显,但往往被忽视了。你不仅想知道数据库收到了多少请求,还想知道数据库在每个请求上花费了多长时间。 然而,参考上下文来讨论执行时间非常重要:像 InfluxDB 这样的时间序列数据库中的慢与像 MySQL 这样的关系型数据库中的慢不一样。InfluxDB 中的慢可能意味着毫秒,而 MySQL 的 `SLOW_QUERY` 变量的默认值是 10 秒。

监测执行时间和提高执行时间不一样,所以如果你的应用程序中有其他问题需要修复,那么请注意在优化上花费时间的诱惑。
### 并发性:数据库同时做了多少工作?
一旦你知道数据库正在处理多少请求以及每个请求需要多长时间,你就需要添加一层复杂性以开始从这些指标中获得实际值。
如果数据库接收到十个请求,并且每个请求需要十秒钟来完成,那么数据库是忙碌了 100 秒、10 秒,还是介于两者之间?并发任务的数量改变了数据库资源的使用方式。当你考虑连接和线程的数量等问题时,你将开始对数据库指标有更全面的了解。
并发性还能影响延迟,这不仅包括任务完成所需的时间(执行时间),还包括任务在处理之前需要等待的时间。
### 利用率:数据库繁忙的时间百分比是多少?
利用率是由吞吐量、执行时间和并发性的峰值所确定的数据库可用的频率,或者数据库太忙而不能响应请求的频率。

该指标对于确定数据库的整体健康和性能特别有用。如果只能在 80% 的时间内响应请求,则可以重新分配资源、进行优化工作,或者进行更改以更接近高可用性。
### 好消息
监测和分析似乎非常困难,特别是因为我们大多数人不是数据库专家,我们可能没有时间去理解这些指标。但好消息是,大部分的工作已经为我们做好了。许多数据库都有一个内部性能数据库(Postgres:`pg_stats`、CouchDB:`Runtime_Statistics`、InfluxDB:`_internal` 等),数据库工程师设计该数据库来监测与该特定数据库有关的指标。你可以看到像慢速查询的数量一样广泛的内容,或者像数据库中每个事件的平均微秒一样详细的内容。
### 结论
数据库创建了足够的指标以使我们需要长时间研究,虽然内部性能数据库充满了有用的信息,但并不总是使你清楚应该关注哪些指标。从吞吐量、执行时间、并发性和利用率开始,它们为你提供了足够的信息,使你可以开始了解你的数据库中的情况。

你在监视你的数据库吗?你发现哪些指标有用?告诉我吧!
---
via: <https://opensource.com/article/18/10/database-metrics-matter>
作者:[Katy Farmer](https://opensource.com/users/thekatertot) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChiZelin](https://github.com/ChiZelin) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We don’t talk about our databases enough. In this age of instrumentation, we monitor our applications, our infrastructure, and even our users, but we sometimes forget that our database deserves monitoring, too. That’s largely because most databases do their job so well that we simply trust them to do it. Trust is great, but confirmation of our assumptions is even better.

## Why monitor your databases?
There are plenty of reasons to monitor your databases, most of which are the same reasons you'd monitor any other part of your systems: Knowing what’s going on in the various components of your applications makes you a better-informed developer who makes smarter decisions.

More specifically, databases are great indicators of system health and behavior. Odd behavior in the database can point to problem areas in your applications. Alternately, when there’s odd behavior in your application, you can use database metrics to help expedite the debugging process.
## The problem
The slightest investigation reveals one problem with monitoring databases: Databases have a *lot* of metrics. "A lot" is an understatement—if you were Scrooge McDuck, you could swim through all of the metrics available. If this were Wrestlemania, the metrics would be folding chairs. Monitoring them all doesn’t seem practical, so how do you decide which metrics to monitor?

## The solution
The best way to start monitoring databases is to identify some foundational, database-agnostic metrics. These metrics create a great start to understanding the lives of your databases.
## Throughput: How much is the database doing?
The easiest way to start monitoring a database is to track the number of requests the database receives. We have high expectations for our databases; we expect them to store data reliably and handle all of the queries we throw at them, which could be one massive query a day or millions of queries from users all day long. Throughput can tell you which of those is true.
You can also group requests by type (reads, writes, server-side, client-side, etc.) to begin analyzing the traffic.
## Execution time: How long does it take the database to do its job?
This metric seems obvious, but it often gets overlooked. You don’t just want to know *how many* requests the database received, but also *how long* the database spent on each request. It’s important to approach execution time with context, though: What's slow for a time-series database like InfluxDB isn’t the same as what's slow for a relational database like MySQL. Slow in InfluxDB might mean milliseconds, whereas MySQL’s default value for its `SLOW_QUERY`
variable is ten seconds.

Monitoring execution time is not the same thing as *improving *execution time, so beware of the temptation to spend time on optimizations if you have other problems in your app to fix.
## Concurrency: How many jobs is the database doing at the same time?
Once you know how many requests the database is handling and how long each one takes, you need to add a layer of complexity to start getting real value from these metrics.
If the database receives ten requests and each one takes ten seconds to complete, is the database busy for 100 seconds, ten seconds—or somewhere in between? The number of concurrent tasks changes the way the database’s resources are used. When you consider things like the number of connections and threads, you’ll start to get a fuller picture of your database metrics.
Concurrency can also affect latency, which includes not only the time it takes for the task to be completed (execution time) but also the time the task needs to wait before it’s handled.
## Utilization: What percentage of the time was the database busy?
Utilization is a culmination of throughput, execution time, and concurrency to determine how often the database was available—or alternatively, how often the database was too busy to respond to a request.

This metric is particularly useful for determining the overall health and performance of your database. If it’s available to respond to requests only 80% of the time, you can reallocate resources, work on optimization, or otherwise make changes to get closer to high availability.
## The good news
It can seem overwhelming to monitor and analyze, especially because most of us aren’t database experts and we may not have time to devote to understanding these metrics. But the good news is that most of this work is already done for us. Many databases have an internal performance database (Postgres: pg_stats, CouchDB: Runtime_Statistics, InfluxDB: _internal, etc.), which is designed by database engineers to monitor the metrics that matter for that particular database. You can see things as broad as the number of slow queries or as detailed as the average microseconds each event in the database takes.
## Conclusion
Databases create enough metrics to keep us all busy for a long time, and while the internal performance databases are full of useful information, it’s not always clear which metrics you should care about. Start with throughput, execution time, concurrency, and utilization, which provide enough information for you to start understanding the patterns in your database.

Are you monitoring your databases? Which metrics have you found to be useful? Tell me about it!
## Comments are closed. |
10,263 | 顶级 Linux 开发者推荐的编程书籍 | https://www.hpe.com/us/en/insights/articles/top-linux-developers-recommended-programming-books-1808.html | 2018-11-22T16:59:00 | [
"书籍"
] | /article-10263-1.html | 
>
> 毫无疑问,Linux 是由那些拥有深厚计算机知识背景而且才华横溢的程序员发明的。让那些大名鼎鼎的 Linux 程序员向如今的开发者分享一些曾经带领他们登堂入室的好书和技术参考资料吧,你会不会也读过其中几本呢?
>
>
>
Linux,毫无争议的属于 21 世纪的操作系统。虽然 Linus Torvalds 在建立开源社区这件事上做了很多工作和社区决策,不过那些网络专家和开发者愿意接受 Linux 的原因还是因为它卓越的代码质量和高可用性。Torvalds 是个编程天才,同时必须承认他还是得到了很多其他同样极具才华的开发者的无私帮助。
就此我咨询了 Torvalds 和其他一些顶级 Linux 开发者,有哪些书籍帮助他们走上了成为顶级开发者的道路,下面请听我一一道来。
### 熠熠生辉的 C 语言
Linux 是在大约上世纪 90 年代开发出来的,与它一起问世的还有其他一些完成基础功能的开源软件。与此相应,那时的开发者使用的工具和语言反映了那个时代的印记,也就是说 C 语言。可能 [C 语言不再流行了](https://www.codingdojo.com/blog/7-most-in-demand-programming-languages-of-2018/),可对于很多已经建功立业的开发者来说,C 语言是他们的第一个在实际开发中使用的语言,这一点也在他们推选的对他们有着深远影响的书单中反映出来。
Torvalds 说,“你不应该再选用我那个时代使用的语言或者开发方式”,他的开发道路始于 BASIC,然后转向机器码(“甚至都不是汇编语言,而是真真正正的‘二进制’机器码”,他解释道),再然后转向汇编语言和 C 语言。
“任何人都不应该再从这些语言开始进入开发这条路了”,他补充道。“这些语言中的一些今天已经没有什么意义(如 BASIC 和机器语言)。尽管 C 还是一个主流语言,我也不推荐你从它开始。”
并不是他不喜欢 C。不管怎样,Linux 是用 [GNU C 语言](https://www.gnu.org/software/gnu-c-manual/)写就的。“我始终认为 C 是一个伟大的语言,它有着非常简单的语法,对于很多方向的开发都很合适,但是我怀疑你会遇到重重挫折,从你的第一个‘Hello World’程序开始到你真正能开发出能用的东西当中有很大一步要走”。他认为,用现在的标准,如果作为入门语言的话,从 C 语言开始的代价太大。
在他那个时代,Torvalds 的唯一选择的书就只能是 Brian W. Kernighan 和 Dennis M. Ritchie 合著的《<ruby> <a href="https://amzn.to/2nhyjEO"> C 编程语言,第二版 </a> <rt> C Programming Language, 2nd Edition </rt></ruby>》,它在编程圈内也被尊称为 K&R。“这本书简单精炼,但是你要先有编程的背景才能欣赏它”,Torvalds 说到。
Torvalds 并不是唯一一个推荐 K&R 的开源开发者。以下几位也同样引用了这本他们认为值得推荐的书籍,他们有:Linux 和 Oracle 虚拟化开发副总裁 Wim Coekaerts;Linux 开发者 Alan Cox;Google 云 CTO Brian Stevens;Canonical 技术运营部副总裁 Pete Graner。
如果你今日还想同 C 语言较量一番的话,Samba 的共同创始人 Jeremy Allison 推荐《<ruby> <a href="https://amzn.to/2vsL8k9"> C 程序设计新思维 </a> <rt> 21st Century C: C Tips from the New School </rt></ruby>》。他还建议,同时也去阅读一本比较旧但是写的更详细的《<ruby> <a href="https://amzn.to/2KBbWn9"> C 专家编程 </a> <rt> Expert C Programming: Deep C Secrets </rt></ruby>》和有着 20 年历史的《<ruby> <a href="https://amzn.to/2M0rfeR"> POSIX 多线程编程 </a> <rt> Programming with POSIX Threads </rt></ruby>》。
### 如果不选 C 语言, 那选什么?
Linux 开发者推荐的书籍自然都是他们认为适合今时今日的开发项目的语言工具。这也折射了开发者自身的个人偏好。例如,Allison 认为年轻的开发者应该在《<ruby> <a href="https://amzn.to/2nhyrnMe"> Go 编程语言 </a> <rt> The Go Programming Language </rt></ruby>》和《<ruby> <a href="http://shop.oreilly.com/product/0636920040385.do"> Rust 编程 </a> <rt> Rust with Programming Rust </rt></ruby>》的帮助下去学习 Go 语言和 Rust 语言。
但是超越编程语言来考虑问题也不无道理(尽管这些书传授了你编程技巧)。今日要做些有意义的开发工作的话,要从那些已经完成了 99% 显而易见工作的框架开始,然后你就能围绕着它开始写脚本了, Torvalds 推荐了这种做法。
“坦率来说,语言本身远远没有围绕着它的基础架构重要”,他继续道,“可能你会从 Java 或者 Kotlin 开始,但那是因为你想为自己的手机开发一个应用,因此安卓 SDK 成为了最佳的选择,又或者,你对游戏开发感兴趣,你选择了一个游戏开发引擎来开始,而通常它们有着自己的脚本语言”。
这里提及的基础架构包括那些和操作系统本身相关的编程书籍。 Garner 在读完了大名鼎鼎的 K&R 后又拜读了 W. Richard Steven 的《<ruby> <a href="https://amzn.to/2MfpbyC"> Unix 网络编程 </a> <rt> Unix Network Programming </rt></ruby>》。特别是,Steven 的《<ruby> <a href="https://amzn.to/2MpgrTn"> TCP/IP 详解,卷1:协议 </a> <rt> TCP/IP Illustrated, Volume 1: The Protocols </rt></ruby>》在出版了 30 年之后仍然被认为是必读之书。因为 Linux 开发很大程度上和[和网络基础架构有关](https://www.hpe.com/us/en/insights/articles/how-to-see-whats-going-on-with-your-linux-system-right-now-1807.html),Garner 也推荐了很多 O'Reilly 在 [Sendmail](http://shop.oreilly.com/product/9780596510299.do)、[Bash](http://shop.oreilly.com/product/9780596009656.do)、[DNS](http://shop.oreilly.com/product/9780596100575.do) 以及 [IMAP/POP](http://shop.oreilly.com/product/9780596000127.do) 等方面的书。
Coekaerts 也是 Maurice Bach 的《<ruby> <a href="https://amzn.to/2vsCJgF"> UNIX 操作系统设计 </a> <rt> The Design of the Unix Operation System </rt></ruby>》的书迷之一。James Bottomley 也是这本书的推崇者,作为一个 Linux 内核开发者,当 Linux 刚刚问世时 James 就用 Bach 的这本书所传授的知识将它研究了个底朝天。
### 软件设计知识永不过时
尽管这样说有点太局限在技术领域。Stevens 还是说到,“所有的开发者都应该在开始钻研语法前先研究如何设计,《<ruby> <a href="https://amzn.to/2APzt3Z"> 设计心理学 </a> <rt> The Design of Everyday Things </rt></ruby>》是我的最爱”。
Coekaerts 喜欢 Kernighan 和 Rob Pike 合著的《<ruby> <a href="https://www.amazon.com/Practice-Programming-Addison-Wesley-Professional-Computing/dp/020161586X/ref=as_li_ss_tl?ie=UTF8&linkCode=sl1&tag=thegroovycorpora&linkId=e6bbdb1ca2182487069bf9089fc8107e&language=en_US"> 程序设计实践 </a> <rt> The Practic of Programming </rt></ruby>》。这本关于设计实践的书当 Coekaerts 还在学校念书的时候还未出版,他说道,“但是我把它推荐给每一个人”。
不管何时,当你问一个长期从事于开发工作的开发者他最喜欢的计算机书籍时,你迟早会听到一个名字和一本书:Donald Knuth 和他所著的《<ruby> <a href="https://amzn.to/2OknFsJ"> 计算机程序设计艺术(1-4A) </a> <rt> The Art of Computer Programming, Volumes 1-4A </rt></ruby>》。VMware 首席开源官 Dirk Hohndel,认为这本书尽管有永恒的价值,但他也承认,“今时今日并非极其有用”。(LCTT 译注:不代表译者观点)
### 读代码。大量的读。
编程书籍能教会你很多,也请别错过另外一个在开源社区特有的学习机会:《<ruby> <a href="https://amzn.to/2M4VVL3"> 代码阅读方法与实践 </a> <rt> Code Reading: The Open Source Perspective </rt></ruby>》。那里有不可计数的代码例子阐述如何解决编程问题(以及如何让你陷入麻烦……)。Stevens 说,谈到磨炼编程技巧,在他的书单里排名第一的“书”是 Unix 的源代码。
“也请不要忽略从他人身上学习的各种机会。” Cox 道,“我是在一个计算机俱乐部里和其他人一起学的 BASIC,在我看来,这仍然是一个学习的最好办法”,他从《<ruby> <a href="https://amzn.to/2OjccJA"> 精通 ZX81 机器码 </a> <rt> Mastering machine code on your ZX81 </rt></ruby>》这本书和 Honeywell L66 B 编译器手册里学习到了如何编写机器码,但是学习技术这点来说,单纯阅读和与其他开发者在工作中共同学习仍然有着很大的不同。
Cox 说,“我始终认为最好的学习方法是和一群人一起试图去解决你们共同关心的一些问题并从中找到快乐,这和你是 5 岁还是 55 岁无关”。
最让我吃惊的是这些顶级 Linux 开发者都是在非常底层级别开始他们的开发之旅的,甚至不是从汇编语言或 C 语言,而是从机器码开始开发。毫无疑问,这对帮助开发者理解计算机在非常微观的底层级别是怎么工作的起了非常大的作用。
那么现在你准备好尝试一下硬核 Linux 开发了吗?Greg Kroah-Hartman,这位 Linux 内核稳定分支的维护者,推荐了 Steve Oualline 的《<ruby> <a href="http://shop.oreilly.com/product/9781565923065.do"> 实用 C 语言编程 </a> <rt> Practical C Programming </rt></ruby>》和 Samuel harbison 与 Guy Steels 合著的《<ruby> <a href="https://amzn.to/2OjzgrT"> C 语言参考手册 </a> <rt> C: A Reference Manual </rt></ruby>》。接下来请阅读<ruby> <a href="https://www.kernel.org/doc/html/v4.16/process/howto.html"> 如何进行 Linux 内核开发 </a> <rt> HOWTO do Linux kernel development </rt></ruby>,到这时,就像 Kroah-Hartman 所说,你已经准备好启程了。
于此同时,还请你刻苦学习并大量编码,最后祝你在跟随顶级 Linux 开发者脚步的道路上好运相随。
---
via: <https://www.hpe.com/us/en/insights/articles/top-linux-developers-recommended-programming-books-1808.html>
作者:[Steven Vaughan-Nichols](https://www.hpe.com/us/en/insights/contributors/steven-j-vaughan-nichols.html) 选题:[lujun9972](https://github.com/lujun9972) 译者:[DavidChenLiang](https://github.com/DavidChenLiang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='www.hpe.com', port=443): Read timed out. (read timeout=10) | null |
10,264 | 为 Linux 选择打印机 | https://opensource.com/article/18/11/choosing-printer-linux | 2018-11-22T20:28:42 | [
"打印机"
] | /article-10264-1.html |
>
> Linux 为打印机提供了广泛的支持。学习如何利用它。
>
>
>

我们在传闻已久的无纸化社会方面取得了重大进展,但我们仍需要不时打印文件。如果你是 Linux 用户,并有一台没有 Linux 安装盘的打印机,或者你正准备在市场上购买新设备,那么你很幸运。因为大多数 Linux 发行版(以及 MacOS)都使用通用 Unix 打印系统([CUPS](https://www.cups.org/)),它包含了当今大多数打印机的驱动程序。这意味着 Linux 为打印机提供了比 Windows 更广泛的支持。
### 选择打印机
如果你需要购买新打印机,了解它是否支持 Linux 的最佳方法是查看包装盒或制造商网站上的文档。你也可以搜索 [Open Printing](http://www.openprinting.org/printers) 数据库。它是检查各种打印机与 Linux 兼容性的绝佳资源。
以下是与 Linux 兼容的佳能打印机的一些 Open Printing 结果。

下面的截图是 Open Printing 的 Hewlett-Packard LaserJet 4050 的结果 —— 根据数据库,它应该可以“完美”工作。这里列出了建议驱动以及通用说明,让我了解它适用于 CUPS、行式打印守护程序(LPD)、LPRng 等。

在任何情况下,最好在购买打印机之前检查制造商的网站并询问其他 Linux 用户。
### 检查你的连接
有几种方法可以将打印机连接到计算机。如果你的打印机是通过 USB 连接的,那么可以在 Bash 提示符下输入 `lsusb` 来轻松检查连接。
```
$ lsusb
```
该命令返回 “Bus 002 Device 004: ID 03f0:ad2a Hewlett-Packard” —— 这没有太多价值,但可以得知打印机已连接。我可以通过输入以下命令获得有关打印机的更多信息:
```
$ dmesg | grep -i usb
```
结果更加详细。

如果你尝试将打印机连接到并口(假设你的计算机有并口 —— 如今很少见),你可以使用此命令检查连接:
```
$ dmesg | grep -i parport
```
返回的信息可以帮助我为我的打印机选择正确的驱动程序。我发现,如果我坚持使用流行的名牌打印机,大部分时间我都能获得良好的效果。
### 设置你的打印机软件
Fedora Linux 和 Ubuntu Linux 都包含简单的打印机设置工具。[Fedora](https://fedoraproject.org/wiki/Printing) 为打印问题的答案维护了一个出色的 wiki。可以在 GUI 中的设置轻松启动这些工具,也可以在命令行上调用 `system-config-printer`。

HP 支持 Linux 打印的 [HP Linux 成像和打印](https://developers.hp.com/hp-linux-imaging-and-printing) (HPLIP) 软件可能已安装在你的 Linux 系统上。如果没有,你可以为你的发行版[下载](https://developers.hp.com/hp-linux-imaging-and-printing/gethplip)最新版本。打印机制造商 [Epson](https://epson.com/Support/wa00821) 和 [Brother](https://support.brother.com/g/s/id/linux/en/index.html?c=us_ot&lang=en&comple=on&redirect=on) 也有带有 Linux 打印机驱动程序和信息的网页。
你最喜欢的 Linux 打印机是什么?请在评论中分享你的意见。
---
via: <https://opensource.com/article/18/11/choosing-printer-linux>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,266 | 我们如何得知安装的包来自哪个仓库? | https://www.2daygeek.com/how-do-we-find-out-the-installed-packages-came-from-which-repository/ | 2018-11-22T21:42:19 | [
"仓库",
"软件包"
] | https://linux.cn/article-10266-1.html | 
有时候你可能想知道安装的软件包来自于哪个仓库。这将帮助你在遇到包冲突问题时进行故障排除。因为[第三方仓库](https://www.2daygeek.com/category/repository/)拥有最新版本的软件包,所以有时候当你试图安装一些包的时候会出现兼容性的问题。在 Linux 上一切都是可能的,因为你可以安装一个即使在你的发行版系统上不能使用的包。你也可以安装一个最新版本的包,即使你的发行版系统仓库还没有这个版本,怎么做到的呢?这就是为什么出现了第三方仓库。它们允许用户从库中安装所有可用的包。
几乎所有的发行版系统都允许第三方软件库。一些发行版还会官方推荐一些不会取代基础仓库的第三方仓库,例如 CentOS 官方推荐安装 [EPEL 库](https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/)。
下面是常用的仓库列表和它们的详细信息。
* CentOS: [EPEL](https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/)、[ELRepo](https://www.2daygeek.com/install-enable-elrepo-on-rhel-centos-scientific-linux/) 等是 [Centos 社区认证仓库](4)。
* Fedora: [RPMfusion 仓库](https://www.2daygeek.com/install-enable-rpm-fusion-repository-on-centos-fedora-rhel/) 是经常被很多 [Fedora](https://fedoraproject.org/wiki/Third_party_repositories) 用户使用的仓库。
* ArchLinux: ArchLinux 社区仓库包含了来自于 Arch 用户仓库的可信用户审核通过的软件包。
* openSUSE: [Packman 仓库](https://www.2daygeek.com/install-enable-packman-repository-on-opensuse-leap/) 为 openSUSE 提供了各种附加的软件包,特别是但不限于那些在 openSUSE Build Service 应用黑名单上的与多媒体相关的应用和库。它是 openSUSE 软件包的最大外部软件库。
* Ubuntu:个人软件包归档(PPA)是一种软件仓库。开发者们可以创建这种仓库来分发他们的软件。你可以在 PPA 导航页面找到相关信息。同时,你也可以启用 Cananical 合作伙伴软件仓库。
### 仓库是什么?
软件仓库是存储特定的应用程序的软件包的集中场所。
所有的 Linux 发行版都在维护他们自己的仓库,并允许用户在他们的机器上获取和安装包。
每个厂商都提供了各自的包管理工具来管理它们的仓库,例如搜索、安装、更新、升级、删除等等。
除了 RHEL 和 SUSE 以外大部分 Linux 发行版都是自由软件。要访问付费的仓库,你需要购买其订阅服务。
### 为什么我们需要启用第三方仓库?
在 Linux 里,并不建议从源代码安装包,因为这样做可能会在升级软件和系统的时候产生很多问题,这也是为什么我们建议从库中安装包而不是从源代码安装。
### 在 RHEL/CentOS 系统上我们如何得知安装的软件包来自哪个仓库?
这可以通过很多方法实现。我们会给你所有可能的选择,你可以选择一个对你来说最合适的。
#### 方法-1:使用 yum 命令
RHEL 和 CentOS 系统使用 RPM 包,因此我们能够使用 [Yum 包管理器](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 来获得信息。
YUM 即 “Yellodog Updater, Modified” 是适用于基于 RPM 的系统例如 RHEL 和 CentOS 的一个开源命令行前端包管理工具。
`yum` 是从发行版仓库和其他第三方库中获取、安装、删除、查询和管理 RPM 包的一个主要工具。
```
# yum info apachetop
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* epel: epel.mirror.constant.com
Installed Packages
Name : apachetop
Arch : x86_64
Version : 0.15.6
Release : 1.el7
Size : 65 k
Repo : installed
From repo : epel
Summary : A top-like display of Apache logs
URL : https://github.com/tessus/apachetop
License : BSD
Description : ApacheTop watches a logfile generated by Apache (in standard common or
: combined logformat, although it doesn't (yet) make use of any of the extra
: fields in combined) and generates human-parsable output in realtime.
```
`apachetop` 包来自 EPEL 仓库。
#### 方法-2:使用 yumdb 命令
`yumdb info` 提供了类似于 `yum info` 的信息但是它又提供了包校验和数据、类型、用户信息(谁安装的软件包)。从 yum 3.2.26 开始,yum 已经开始在 rpmdatabase 之外存储额外的信息(user 表示软件是用户安装的,dep 表示它是作为依赖项引入的)。
```
# yumdb info lighttpd
Loaded plugins: fastestmirror
lighttpd-1.4.50-1.el7.x86_64
checksum_data = a24d18102ed40148cfcc965310a516050ed437d728eeeefb23709486783a4d37
checksum_type = sha256
command_line = --enablerepo=epel install lighttpd apachetop aria2 atop axel
from_repo = epel
from_repo_revision = 1540756729
from_repo_timestamp = 1540757483
installed_by = 0
origin_url = https://epel.mirror.constant.com/7/x86_64/Packages/l/lighttpd-1.4.50-1.el7.x86_64.rpm
reason = user
releasever = 7
var_contentdir = centos
var_infra = stock
var_uuid = ce328b07-9c0a-4765-b2ad-59d96a257dc8
```
`lighttpd` 包来自 EPEL 仓库。
#### 方法-3:使用 rpm 命令
[RPM 命令](https://www.2daygeek.com/rpm-command-examples/) 即 “Red Hat Package Manager” 是一个适用于基于 Red Hat 的系统(例如 RHEL、CentOS、Fedora、openSUSE & Mageia)的强大的命令行包管理工具。
这个工具允许你在你的 Linux 系统/服务器上安装、更新、移除、查询和验证软件。RPM 文件具有 .rpm 后缀名。RPM 包是用必需的库和依赖关系构建的,不会与系统上安装的其他包冲突。
```
# rpm -qi apachetop
Name : apachetop
Version : 0.15.6
Release : 1.el7
Architecture: x86_64
Install Date: Mon 29 Oct 2018 06:47:49 AM EDT
Group : Applications/Internet
Size : 67020
License : BSD
Signature : RSA/SHA256, Mon 22 Jun 2015 09:30:26 AM EDT, Key ID 6a2faea2352c64e5
Source RPM : apachetop-0.15.6-1.el7.src.rpm
Build Date : Sat 20 Jun 2015 09:02:37 PM EDT
Build Host : buildvm-22.phx2.fedoraproject.org
Relocations : (not relocatable)
Packager : Fedora Project
Vendor : Fedora Project
URL : https://github.com/tessus/apachetop
Summary : A top-like display of Apache logs
Description :
ApacheTop watches a logfile generated by Apache (in standard common or
combined logformat, although it doesn't (yet) make use of any of the extra
fields in combined) and generates human-parsable output in realtime.
```
`apachetop` 包来自 EPEL 仓库。
#### 方法-4:使用 repoquery 命令
`repoquery` 是一个从 YUM 库查询信息的程序,类似于 rpm 查询。
```
# repoquery -i httpd
Name : httpd
Version : 2.4.6
Release : 80.el7.centos.1
Architecture: x86_64
Size : 9817285
Packager : CentOS BuildSystem
Group : System Environment/Daemons
URL : http://httpd.apache.org/
Repository : updates
Summary : Apache HTTP Server
Source : httpd-2.4.6-80.el7.centos.1.src.rpm
Description :
The Apache HTTP Server is a powerful, efficient, and extensible
web server.
```
`httpd` 包来自 CentOS updates 仓库。
### 在 Fedora 系统上我们如何得知安装的包来自哪个仓库?
DNF 是 “Dandified yum” 的缩写。DNF 是使用 hawkey/libsolv 库作为后端的下一代 yum 包管理器(yum 的分支)。从 Fedora 18 开始 Aleš Kozumplík 开始开发 DNF,并最终在 Fedora 22 上得以应用/启用。
[dnf 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 用于在 Fedora 22 以及之后的系统上安装、更新、搜索和删除包。它会自动解决依赖并使安装包的过程变得顺畅,不会出现任何问题。
```
$ dnf info tilix
Last metadata expiration check: 27 days, 10:00:23 ago on Wed 04 Oct 2017 06:43:27 AM IST.
Installed Packages
Name : tilix
Version : 1.6.4
Release : 1.fc26
Arch : x86_64
Size : 3.6 M
Source : tilix-1.6.4-1.fc26.src.rpm
Repo : @System
From repo : updates
Summary : Tiling terminal emulator
URL : https://github.com/gnunn1/tilix
License : MPLv2.0 and GPLv3+ and CC-BY-SA
Description : Tilix is a tiling terminal emulator with the following features:
:
: - Layout terminals in any fashion by splitting them horizontally or vertically
: - Terminals can be re-arranged using drag and drop both within and between
: windows
: - Terminals can be detached into a new window via drag and drop
: - Input can be synchronized between terminals so commands typed in one
: terminal are replicated to the others
: - The grouping of terminals can be saved and loaded from disk
: - Terminals support custom titles
: - Color schemes are stored in files and custom color schemes can be created by
: simply creating a new file
: - Transparent background
: - Supports notifications when processes are completed out of view
:
: The application was written using GTK 3 and an effort was made to conform to
: GNOME Human Interface Guidelines (HIG).
```
`tilix` 包来自 Fedora updates 仓库。
### 在 openSUSE 系统上我们如何得知安装的包来自哪个仓库?
Zypper 是一个使用 libzypp 的命令行包管理器。[Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 提供了存储库访问、依赖处理、包安装等功能。
```
$ zypper info nano
Loading repository data...
Reading installed packages...
Information for package nano:
-----------------------------
Repository : Main Repository (OSS)
Name : nano
Version : 2.4.2-5.3
Arch : x86_64
Vendor : openSUSE
Installed Size : 1017.8 KiB
Installed : No
Status : not installed
Source package : nano-2.4.2-5.3.src
Summary : Pico editor clone with enhancements
Description :
GNU nano is a small and friendly text editor. It aims to emulate
the Pico text editor while also offering a few enhancements.
```
`nano` 包来自于 openSUSE Main 仓库(OSS)。
### 在 ArchLinux 系统上我们如何得知安装的包来自哪个仓库?
[Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 即包管理器工具(package manager utility ),是一个简单的用来安装、构建、删除和管理 Arch Linux 软件包的命令行工具。Pacman 使用 libalpm 作为后端来执行所有的操作。
```
# pacman -Ss chromium
extra/chromium 48.0.2564.116-1
The open-source project behind Google Chrome, an attempt at creating a safer, faster, and more stable browser
extra/qt5-webengine 5.5.1-9 (qt qt5)
Provides support for web applications using the Chromium browser project
community/chromium-bsu 0.9.15.1-2
A fast paced top scrolling shooter
community/chromium-chromevox latest-1
Causes the Chromium web browser to automatically install and update the ChromeVox screen reader extention. Note: This
package does not contain the extension code.
community/fcitx-mozc 2.17.2313.102-1
Fcitx Module of A Japanese Input Method for Chromium OS, Windows, Mac and Linux (the Open Source Edition of Google Japanese
Input)
```
`chromium` 包来自 ArchLinux extra 仓库。
或者,我们可以使用以下选项获得关于包的详细信息。
```
# pacman -Si chromium
Repository : extra
Name : chromium
Version : 48.0.2564.116-1
Description : The open-source project behind Google Chrome, an attempt at creating a safer, faster, and more stable browser
Architecture : x86_64
URL : http://www.chromium.org/
Licenses : BSD
Groups : None
Provides : None
Depends On : gtk2 nss alsa-lib xdg-utils bzip2 libevent libxss icu libexif libgcrypt ttf-font systemd dbus
flac snappy speech-dispatcher pciutils libpulse harfbuzz libsecret libvpx perl perl-file-basedir
desktop-file-utils hicolor-icon-theme
Optional Deps : kdebase-kdialog: needed for file dialogs in KDE
gnome-keyring: for storing passwords in GNOME keyring
kwallet: for storing passwords in KWallet
Conflicts With : None
Replaces : None
Download Size : 44.42 MiB
Installed Size : 172.44 MiB
Packager : Evangelos Foutras
Build Date : Fri 19 Feb 2016 04:17:12 AM IST
Validated By : MD5 Sum SHA-256 Sum Signature
```
`chromium` 包来自 ArchLinux extra 仓库。
### 在基于 Debian 的系统上我们如何得知安装的包来自哪个仓库?
在基于 Debian 的系统例如 Ubuntu、LinuxMint 上可以使用两种方法实现。
#### 方法-1:使用 apt-cache 命令
[apt-cache 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 可以显示存储在 APT 内部数据库的很多信息。这些信息是一种缓存,因为它们是从列在 `source.list` 文件里的不同的源中获得的。这个过程发生在 apt 更新操作期间。
```
$ apt-cache policy python3
python3:
Installed: 3.6.3-0ubuntu2
Candidate: 3.6.3-0ubuntu3
Version table:
3.6.3-0ubuntu3 500
500 http://in.archive.ubuntu.com/ubuntu artful-updates/main amd64 Packages
*** 3.6.3-0ubuntu2 500
500 http://in.archive.ubuntu.com/ubuntu artful/main amd64 Packages
100 /var/lib/dpkg/status
```
`python3` 包来自 Ubuntu updates 仓库。
#### 方法-2:使用 apt 命令
[APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 即 “Advanced Packaging Tool”,是 `apt-get` 命令的替代品,就像 DNF 是如何取代 YUM 一样。它是具有丰富功能的命令行工具并将所有的功能例如 `apt-cache`、`apt-search`、`dpkg`、`apt-cdrom`、`apt-config`、`apt-ket` 等包含在一个命令(APT)中,并且还有几个独特的功能。例如我们可以通过 APT 轻松安装 .dpkg 包,但我们不能使用 `apt-get` 命令安装,更多类似的功能都被包含进了 APT 命令。`apt-get` 因缺失了很多未被解决的特性而被 `apt` 取代。
```
$ apt -a show notepadqq
Package: notepadqq
Version: 1.3.2-1~artful1
Priority: optional
Section: editors
Maintainer: Daniele Di Sarli
Installed-Size: 1,352 kB
Depends: notepadqq-common (= 1.3.2-1~artful1), coreutils (>= 8.20), libqt5svg5 (>= 5.2.1), libc6 (>= 2.14), libgcc1 (>= 1:3.0), libqt5core5a (>= 5.9.0~beta), libqt5gui5 (>= 5.7.0), libqt5network5 (>= 5.2.1), libqt5printsupport5 (>= 5.2.1), libqt5webkit5 (>= 5.6.0~rc), libqt5widgets5 (>= 5.2.1), libstdc++6 (>= 5.2)
Download-Size: 356 kB
APT-Sources: http://ppa.launchpad.net/notepadqq-team/notepadqq/ubuntu artful/main amd64 Packages
Description: Notepad++-like editor for Linux
Text editor with support for multiple programming
languages, multiple encodings and plugin support.
Package: notepadqq
Version: 1.2.0-1~artful1
Status: install ok installed
Priority: optional
Section: editors
Maintainer: Daniele Di Sarli
Installed-Size: 1,352 kB
Depends: notepadqq-common (= 1.2.0-1~artful1), coreutils (>= 8.20), libqt5svg5 (>= 5.2.1), libc6 (>= 2.14), libgcc1 (>= 1:3.0), libqt5core5a (>= 5.9.0~beta), libqt5gui5 (>= 5.7.0), libqt5network5 (>= 5.2.1), libqt5printsupport5 (>= 5.2.1), libqt5webkit5 (>= 5.6.0~rc), libqt5widgets5 (>= 5.2.1), libstdc++6 (>= 5.2)
Homepage: http://notepadqq.altervista.org
Download-Size: unknown
APT-Manual-Installed: yes
APT-Sources: /var/lib/dpkg/status
Description: Notepad++-like editor for Linux
Text editor with support for multiple programming
languages, multiple encodings and plugin support.
```
`notepadqq` 包来自 Launchpad PPA。
---
via: <https://www.2daygeek.com/how-do-we-find-out-the-installed-packages-came-from-which-repository/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zianglei](https://github.com/zianglei) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,267 | 容器技术对 DevOps 的一些启发 | https://opensource.com/article/18/9/containers-can-teach-us-devops | 2018-11-23T09:37:07 | [
"DevOps",
"容器"
] | https://linux.cn/article-10267-1.html |
>
> 容器技术的使用支撑了目前 DevOps 三大主要实践:工作流、及时反馈、持续学习。
>
>
>

有人说容器技术与 DevOps 二者在发展的过程中是互相促进的关系。得益于 DevOps 设计理念的流行,容器生态系统在设计上与组件选择上也有相应发展。同时,由于容器技术在生产环境中的使用,反过来也促进了 DevOps 三大主要实践:[支撑 DevOps 的三个实践](https://itrevolution.com/the-three-ways-principles-underpinning-devops/)。
### 工作流
#### 容器中的工作流
每个容器都可以看成一个独立的运行环境,对于容器内部,不需要考虑外部的宿主环境、集群环境,以及其它基础设施。在容器内部,每个功能看起来都是以传统的方式运行。从外部来看,容器内运行的应用一般作为整个应用系统架构的一部分:比如 web API、web app 用户界面、数据库、任务执行、缓存系统、垃圾回收等。运维团队一般会限制容器的资源使用,并在此基础上建立完善的容器性能监控服务,从而降低其对基础设施或者下游其他用户的影响。
#### 现实中的工作流
那些跟“容器”一样业务功能独立的团队,也可以借鉴这种容器思维。因为无论是在现实生活中的工作流(代码发布、构建基础设施,甚至制造 [《杰森一家》中的斯贝斯利太空飞轮](https://en.wikipedia.org/wiki/The_Jetsons) 等),还是技术中的工作流(开发、测试、运维、发布)都使用了这样的线性工作流,一旦某个独立的环节或者工作团队出现了问题,那么整个下游都会受到影响,虽然使用这种线性的工作流有效降低了工作耦合性。
#### DevOps 中的工作流
DevOps 中的第一条原则,就是掌控整个执行链路的情况,努力理解系统如何协同工作,并理解其中出现的问题如何对整个过程产生影响。为了提高流程的效率,团队需要持续不断的找到系统中可能存在的性能浪费以及问题,并最终修复它们。
>
> 践行这样的工作流后,可以避免将一个已知缺陷带到工作流的下游,避免局部优化导致可能的全局性能下降,要不断探索如何优化工作流,持续加深对于系统的理解。
>
>
> —— Gene Kim,《[支撑 DevOps 的三个实践](http://itrevolution.com/the-three-ways-principles-underpinning-devops)》,IT 革命,2017.4.25
>
>
>
### 反馈
#### 容器中的反馈
除了限制容器的资源,很多产品还提供了监控和通知容器性能指标的功能,从而了解当容器工作不正常时,容器内部处于什么样的状态。比如目前[流行的](https://opensource.com/article/18/9/prometheus-operational-advantage) [Prometheus](https://prometheus.io/),可以用来收集容器和容器集群中相应的性能指标数据。容器本身特别适用于分隔应用系统,以及打包代码和其运行环境,但同时也带来了不透明的特性,这时,从中快速收集信息来解决其内部出现的问题就显得尤为重要了。
#### 现实中的反馈
在现实中,从始至终同样也需要反馈。一个高效的处理流程中,及时的反馈能够快速地定位事情发生的时间。反馈的关键词是“快速”和“相关”。当一个团队被淹没在大量不相关的事件时,那些真正需要快速反馈的重要信息很容易被忽视掉,并向下游传递形成更严重的问题。想象下[如果露西和埃塞尔](https://www.youtube.com/watch?v=8NPzLBSBzPI)能够很快地意识到:传送带太快了,那么制作出的巧克力可能就没什么问题了(尽管这样就不那么搞笑了)。(LCTT 译注:露西和埃塞尔是上世纪 50 年代的著名黑白情景喜剧《我爱露西》中的主角)
#### DevOps 中的反馈
DevOps 中的第二条原则,就是快速收集所有相关的有用信息,这样在问题影响到其它开发流程之前就可以被识别出。DevOps 团队应该努力去“优化下游”,以及快速解决那些可能会影响到之后团队的问题。同工作流一样,反馈也是一个持续的过程,目标是快速的获得重要的信息以及当问题出现后能够及时地响应。
>
> 快速的反馈对于提高技术的质量、可用性、安全性至关重要。
>
>
> —— Gene Kim 等人,《DevOps 手册:如何在技术组织中创造世界级的敏捷性,可靠性和安全性》,IT 革命,2016
>
>
>
### 持续学习
#### 容器中的持续学习
践行第三条原则“持续学习”是一个不小的挑战。在不需要掌握太多边缘的或难以理解的东西的情况下,容器技术让我们的开发工程师和运营团队依然可以安全地进行本地和生产环境的测试,这在之前是难以做到的。即便是一些激进的实验,容器技术仍然让我们轻松地进行版本控制、记录和分享。
#### 现实中的持续学习
举个我自己的例子:多年前,作为一个年轻、初出茅庐的系统管理员(仅仅工作三周),我被安排对一个运行着某个大学核心 IT 部门网站的 Apache 虚拟主机配置进行更改。由于没有方便的测试环境,我直接在生产站点上修改配置,当时觉得配置没问题就发布了,几分钟后,我无意中听到了隔壁同事说:
“等会,网站挂了?”
“没错,怎么回事?”
很多人蒙圈了……
在被嘲讽之后(真实的嘲讽),我一头扎在工作台上,赶紧撤销我之前的更改。当天下午晚些时候,部门主管 —— 我老板的老板的老板 —— 来到我的工位询问发生了什么事。“别担心,”她告诉我。“我们不会责怪你,这是一个错误,现在你已经学会了。”
而在容器中,这种情形在我的笔记本上就很容易测试了,并且也很容易在部署生产环境之前,被那些经验老道的团队成员发现。
#### DevOps 中的持续学习
持续学习文化的一部分是我们每个人都希望通过一些改变从而能够提高一些东西,并勇敢地通过实验来验证我们的想法。对于 DevOps 团队来说,失败无论对团队还是个人来说都是成长而不是惩罚,所以不要畏惧失败。团队中的每个成员不断学习、共享,也会不断提升其所在团队与组织的水平。
随着系统越来越被细分,我们更需要将注意力集中在具体的点上:上面提到的两条原则主要关注整体流程,而持续学习关注的则是整个项目、人员、团队、组织的未来。它不仅对流程产生了影响,还对流程中的每个人产生影响。
>
> 实验和冒险让我们能够不懈地改进我们的工作,但也要求我们尝试之前未用过的工作方式。
>
>
> —— Gene Kim 等人,《[凤凰计划:让你了解 IT、DevOps 以及如何取得商业成功》](https://itrevolution.com/book/the-phoenix-project/),IT 革命,2013
>
>
>
### 容器技术带给 DevOps 的启迪
有效地应用容器技术可以学习 DevOps 的三条原则:工作流,反馈以及持续学习。从整体上看应用程序和基础设施,而不是对容器外的东西置若罔闻,教会我们考虑到系统的所有部分,了解其上游和下游影响,打破隔阂,并作为一个团队工作,以提升整体表现和深度了解整个系统。通过努力提供及时准确的反馈,我们可以在组织内部创建有效的反馈机制,以便在问题发生影响之前发现问题。最后,提供一个安全的环境来尝试新的想法并从中学习,教会我们创造一种文化,在这种文化中,失败一方面促进了我们知识的增长,另一方面通过有根据的猜测,可以为复杂的问题带来新的、优雅的解决方案。
---
via: <https://opensource.com/article/18/9/containers-can-teach-us-devops>
作者:[Chris Hermansen](https://opensource.com/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[littleji](https://github.com/littleji) 校对:[pityonline](https://github.com/pityonline), [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One can argue that containers and DevOps were made for one another. Certainly, the container ecosystem benefits from the skyrocketing popularity of DevOps practices, both in design choices and in DevOps’ use by teams developing container technologies. Because of this parallel evolution, the use of containers in production can teach teams the fundamentals of DevOps and its three pillars: [The Three Ways](https://itrevolution.com/the-three-ways-principles-underpinning-devops/).
## Principles of flow
**Container flow**
A container can be seen as a silo, and from inside, it is easy to forget the rest of the system: the host node, the cluster, the underlying infrastructure. Inside the container, it might appear that everything is functioning in an acceptable manner. From the outside perspective, though, the application inside the container is a part of a larger ecosystem of applications that make up a service: the web API, the web app user interface, the database, the workers, and caching services and garbage collectors. Teams put constraints on the container to limit performance impact on infrastructure, and much has been done to provide metrics for measuring container performance because overloaded or slow container workloads have downstream impact on other services or customers.
**Real-world flow**
This lesson can be applied to teams functioning in a silo as well. Every process (be it code release, infrastructure creation or even, say, manufacturing of [ Spacely’s Sprockets](https://en.wikipedia.org/wiki/The_Jetsons)), follows a linear path from conception to realization. In technology, this progress flows from development to testing to operations and release. If a team working alone becomes a bottleneck or introduces a problem, the impact is felt all along the entire pipeline. A defect passed down the line destroys productivity downstream. While the broken process within the scope of the team itself may seem perfectly correct, it has a negative impact on the environment as a whole.
**DevOps and flow**
The first way of DevOps, *principles of flow*, is about approaching the process as a whole, striving to comprehend how the system works together and understanding the impact of issues on the entire process. To increase the efficiency of the process, pain points and waste are identified and removed. This is an ongoing process; teams must continually strive to increase visibility into the process and find and fix trouble spots and waste.
“The outcomes of putting the First Way into practice include never passing a known defect to downstream work centers, never allowing local optimization to create global degradation, always seeking to increase flow, and always seeking to achieve a profound understanding of the system (as per Deming).”
–Gene Kim, [The Three Ways: The Principles Underpinning DevOps](http://itrevolution.com/the-three-ways-principles-underpinning-devops), IT Revolution, 25 Apr. 2017
## Principles of feedback
**Container feedback**
In addition to limiting containers to prevent impact elsewhere, many products have been created to monitor and trend container metrics in an effort to understand what they are doing and notify when they are misbehaving. [Prometheus](https://prometheus.io/), for example, is [all the rage](https://opensource.com/article/18/9/prometheus-operational-advantage) for collecting metrics from containers and clusters. Containers are excellent at separating applications and providing a way to ship an environment together with the code, sometimes at the cost of opacity, so much is done to try to provide rapid feedback so issues can be addressed promptly within the silo.
**Real-world feedback**
The same is necessary for the flow of the system. From inception to realization, an efficient process quickly provides relevant feedback to identify when there is an issue. The key words here are “quick” and “relevant.” Burying teams in thousands of irrelevant notifications make it difficult or even impossible to notice important events that need immediate action, and receiving even relevant information too late may allow small, easily solved issues to move downstream and become bigger problems. Imagine [if Lucy and Ethel](https://www.youtube.com/watch?v=8NPzLBSBzPI) had provided immediate feedback that the conveyor belt was too fast—there would have been no problem with the chocolate production (though that would not have been nearly as funny).
**DevOps and feedback**
The Second Way of DevOps, *principles of feedback*, is all about getting relevant information quickly. With immediate, useful feedback, problems can be identified as they happen and addressed before impact is felt elsewhere in the development process. DevOps teams strive to “optimize for downstream” and immediately move to fix problems that might impact other teams that come after them. As with flow, feedback is a continual process to identify ways to quickly get important data and act on problems as they occur.
“Creating fast feedback is critical to achieving quality, reliability, and safety in the technology value stream.”
–Gene Kim, et al., *The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations*, IT Revolution Press, 2016
## Principles of continual experimentation and learning
**Container continual experimentation and learning**
It is a bit more challenging applying operational learning to the Third Way of DevOps:*continual experimentation and learning*. Trying to salvage what we can grasp of the very edges of the metaphor, containers make development easy, allowing developers and operations teams to test new code or configurations locally and safely outside of production and incorporate discovered benefits into production in a way that was difficult in the past. Changes can be radical and still version-controlled, documented, and shared quickly and easily.
**Real-world continual experimentation and learning**
For example, consider this anecdote from my own experience: Years ago, as a young, inexperienced sysadmin (just three weeks into the job), I was asked to make changes to an Apache virtual host running the website of the central IT department for a university. Without an easy-to-use test environment, I made a configuration change to the production site that I thought would accomplish the task and pushed it out. Within a few minutes, I overheard coworkers in the next cube:
“Wait, is the website down?”
“Hrm, yeah, it looks like it. What the heck?”
There was much eye-rolling involved.
Mortified (the shame is real, folks), I sunk down as far as I could into my seat and furiously tried to back out the changes I’d introduced. Later that same afternoon, the director of the department—the boss of my boss’s boss—appeared in my cube to talk about what had happened. “Don’t worry,” she told me. “We’re not mad at you. It was a mistake and now you have learned.”
In the world of containers, this could have been easily changed and tested on my own laptop and the broken configuration identified by more skilled team members long before it ever made it into production.
**DevOps continual experimentation and learning**
A real culture of experimentation promotes the individual’s ability to find where a change in the process may be beneficial, and to test that assumption without the fear of retaliation if they fail. For DevOps teams, failure becomes an educational tool that adds to the knowledge of the individual and organization, rather than something to be feared or punished. Individuals in the DevOps team dedicate themselves to continuous learning, which in turn benefits the team and wider organization as that knowledge is shared.
As the metaphor completely falls apart, focus needs to be given to a specific point: The other two principles may appear at first glance to focus entirely on process, but continual learning is a human task—important for the future of the project, the person, the team, and the organization. It has an impact on the process, but it also has an impact on the individual and other people.
“Experimentation and risk-taking are what enable us to relentlessly improve our system of work, which often requires us to do things very differently than how we’ve done it for decades.”
–Gene Kim, et al., * The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win*, IT Revolution Press, 2013
## Containers can teach us DevOps
Learning to work effectively with containers can help teach DevOps and the Three Ways: principles of flow, principles of feedback, and principles of continuous experimentation and learning. Looking holistically at the application and infrastructure rather than putting on blinders to everything outside the container teaches us to take all parts of the system and understand their upstream and downstream impacts, break out of silos, and work as a team to increase global performance and deep understanding of the entire system. Working to provide timely and accurate feedback teaches us to create effective feedback patterns within our organizations to identify problems before their impact grows. Finally, providing a safe environment to try new ideas and learn from them teaches us to create a culture where failure represents a positive addition to our knowledge and the ability to take big chances with educated guesses can result in new, elegant solutions to complex problems.
## 3 Comments |
10,268 | 在 Grails 中使用 jQuery 和 DataTables | https://opensource.com/article/18/9/using-grails-jquery-and-datatables | 2018-11-24T10:24:47 | [
"Grails",
"Groovy"
] | https://linux.cn/article-10268-1.html |
>
> 本文介绍如何构建一个基于 Grails 的数据浏览器来可视化复杂的表格数据。
>
>
>

我是 [Grails](https://grails.org/) 的忠实粉丝。当然,我主要是热衷于利用命令行工具来探索和分析数据的数据从业人员。数据从业人员经常需要*查看*数据,这也意味着他们通常拥有优秀的数据浏览器。利用 Grails、[jQuery](https://jquery.com/),以及 [DataTables jQuery 插件](https://datatables.net/),我们可以制作出非常友好的表格数据浏览器。
[DataTables 网站](https://datatables.net/)提供了许多“食谱式”的教程文档,展示了如何组合一些优秀的示例应用程序,这些程序包含了完成一些非常漂亮的东西所必要的 JavaScript、HTML,以及偶尔出现的 [PHP](http://php.net/)。但对于那些宁愿使用 Grails 作为后端的人来说,有必要进行一些说明示教。此外,样本程序中使用的数据是一个虚构公司的员工的单个平面表格数据,因此处理这些复杂的表关系可以作为读者的一个练习项目。
本文中,我们将创建具有略微复杂的数据结构和 DataTables 浏览器的 Grails 应用程序。我们将介绍 Grails 标准,它是 [Groovy](http://groovy-lang.org/) 式的 Java Hibernate 标准。我已将代码托管在 [GitHub](https://github.com/monetschemist/grails-datatables) 上方便大家访问,因此本文主要是对代码细节的解读。
首先,你需要配置 Java、Groovy、Grails 的使用环境。对于 Grails,我倾向于使用终端窗口和 [Vim](https://www.vim.org/),本文也使用它们。为获得现代的 Java 环境,建议下载并安装 Linux 发行版提供的 [Open Java Development Kit](http://openjdk.java.net/) (OpenJDK)(应该是 Java 8、9、10 或 11 之一,撰写本文时,我正在使用 Java 8)。从我的角度来看,获取最新的 Groovy 和 Grails 的最佳方法是使用 [SDKMAN!](http://sdkman.io/)。
从未尝试过 Grails 的读者可能需要做一些背景资料阅读。作为初学者,推荐文章 [创建你的第一个 Grails 应用程序](http://guides.grails.org/creating-your-first-grails-app/guide/index.html)。
### 获取员工信息浏览器应用程序
正如上文所提,我将本文中员工信息浏览器的源代码托管在 [GitHub](https://github.com/monetschemist/grails-datatables)上。进一步讲,应用程序 **embrow** 是在 Linux 终端中用如下命令构建的:
```
cd Projects
grails create-app com.nuevaconsulting.embrow
```
域类和单元测试创建如下:
```
grails create-domain-class com.nuevaconsulting.embrow.Position
grails create-domain-class com.nuevaconsulting.embrow.Office
grails create-domain-class com.nuevaconsulting.embrow.Employeecd embrowgrails createdomaincom.grails createdomaincom.grails createdomaincom.
```
这种方式构建的域类没有属性,因此必须按如下方式编辑它们:
`Position` 域类:
```
package com.nuevaconsulting.embrow
class Position {
String name
int starting
static constraints = {
name nullable: false, blank: false
starting nullable: false
}
}com.Stringint startingstatic constraintsnullableblankstarting nullable
```
`Office` 域类:
```
package com.nuevaconsulting.embrow
class Office {
String name
String address
String city
String country
static constraints = {
name nullable: false, blank: false
address nullable: false, blank: false
city nullable: false, blank: false
country nullable: false, blank: false
}
}
```
`Enployee` 域类:
```
package com.nuevaconsulting.embrow
class Employee {
String surname
String givenNames
Position position
Office office
int extension
Date hired
int salary
static constraints = {
surname nullable: false, blank: false
givenNames nullable: false, blank: false
: false
office nullable: false
extension nullable: false
hired nullable: false
salary nullable: false
}
}
```
请注意,虽然 `Position` 和 `Office` 域类使用了预定义的 Groovy 类型 `String` 以及 `int`,但 `Employee` 域类定义了 `Position` 和 `Office` 字段(以及预定义的 `Date`)。这会导致创建数据库表,其中存储的 `Employee` 实例中包含了指向存储 `Position` 和 `Office` 实例表的引用或者外键。
现在你可以生成控制器,视图,以及其他各种测试组件:
```
-all com.nuevaconsulting.embrow.Position
grails generate-all com.nuevaconsulting.embrow.Office
grails generate-all com.nuevaconsulting.embrow.Employeegrails generateall com.grails generateall com.grails generateall com.
```
此时,你已经准备好了一个基本的增删改查(CRUD)应用程序。我在 `grails-app/init/com/nuevaconsulting/BootStrap.groovy` 中包含了一些基础数据来填充表格。
如果你用如下命令来启动应用程序:
```
grails run-app
```
在浏览器输入 `http://localhost:8080/`,你将会看到如下界面:

*Embrow 应用程序主界面。*
单击 “OfficeController” 链接,会跳转到如下界面:

*Office 列表*
注意,此表由 `OfficeController` 的 `index` 方式生成,并由视图 `office/index.gsp` 显示。
同样,单击 “EmployeeController” 链接 跳转到如下界面:

*employee 控制器*
好吧,这很丑陋: Position 和 Office 链接是什么?
上面的命令 `generate-all` 生成的视图创建了一个叫 `index.gsp` 的文件,它使用 Grails `<f:table/>` 标签,该标签默认会显示类名(`com.nuevaconsulting.embrow.Position`)和持久化示例标识符(`30`)。这个操作可以自定义用来产生更好看的东西,并且自动生成链接,自动生成分页以及自动生成可排序列的一些非常简洁直观的东西。
但该员工信息浏览器功能也是有限的。例如,如果想查找 “position” 信息中包含 “dev” 的员工该怎么办?如果要组合排序,以姓氏为主排序关键字,“office” 为辅助排序关键字,该怎么办?或者,你需要将已排序的数据导出到电子表格或 PDF 文档以便通过电子邮件发送给无法访问浏览器的人,该怎么办?
jQuery DataTables 插件提供了这些所需的功能。允许你创建一个完成的表格数据浏览器。
### 创建员工信息浏览器视图和控制器的方法
要基于 jQuery DataTables 创建员工信息浏览器,你必须先完成以下两个任务:
1. 创建 Grails 视图,其中包含启用 DataTable 所需的 HTML 和 JavaScript
2. 给 Grails 控制器增加一个方法来控制新视图。
#### 员工信息浏览器视图
在目录 `embrow/grails-app/views/employee` 中,首先复制 `index.gsp` 文件,重命名为 `browser.gsp`:
```
cd Projects
cd embrow/grails-app/views/employee
cp gsp browser.gsp
```
此刻,你自定义新的 `browser.gsp` 文件来添加相关的 jQuery DataTables 代码。
通常,在可能的时候,我喜欢从内容提供商处获得 JavaScript 和 CSS;在下面这行后面:
```
<title><g:message code="default.list.label" args="[entityName]" /></title>
```
插入如下代码:
```
<script src="https://code.jquery.com/jquery-2.2.4.min.js" integrity="sha256-BbhdlvQf/xTY9gja0Dq3HiwQF8LaCRTXxZKRutelT44=" crossorigin="anonymous"></script>
<link rel="stylesheet" type="text/css" href="https://cdn.datatables.net/1.10.16/css/jquery.dataTables.css">
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/1.10.16/js/jquery.dataTables.js"></script>
<link rel="stylesheet" type="text/css" href="https://cdn.datatables.net/scroller/1.4.4/css/scroller.dataTables.min.css">
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/scroller/1.4.4/js/dataTables.scroller.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/dataTables.buttons.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.flash.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/jszip/3.1.3/jszip.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/pdfmake.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/vfs_fonts.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.html5.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.print.min.js "></script>
```
然后删除 `index.gsp` 中提供数据分页的代码:
```
<div id="list-employee" class="content scaffold-list" role="main">
<h1><g:message code="default.list.label" args="[entityName]" /></h1>
<g:if test="${flash.message}">
<div class="message" role="status">${flash.message}</div>
</g:if>
<f:table collection="${employeeList}" />
<div class="pagination">
<g:paginate total="${employeeCount ?: 0}" />
</div>
</div>
```
并插入实现 jQuery DataTables 的代码。
要插入的第一部分是 HTML,它将创建浏览器的基本表格结构。DataTables 与后端通信的应用程序来说,它们只提供表格页眉和页脚;DataTables JavaScript 则负责表中内容。
```
<div id="employee-browser" class="content" role="main">
<h1>Employee Browser</h1>
<table id="employee_dt" class="display compact" style="width:99%;">
<thead>
<tr>
<th>Surname</th>
<th>Given name(s)</th>
<th>Position</th>
<th>Office</th>
<th>Extension</th>
<th>Hired</th>
<th>Salary</th>
</tr>
</thead>
<tfoot>
<tr>
<th>Surname</th>
<th>Given name(s)</th>
<th>Position</th>
<th>Office</th>
<th>Extension</th>
<th>Hired</th>
<th>Salary</th>
</tr>
</tfoot>
</table>
</div>
```
接下来,插入一个 JavaScript 块,它主要提供三个功能:它设置页脚中显示的文本框的大小,以进行列过滤,建立 DataTables 表模型,并创建一个处理程序来进行列过滤。
```
<g:javascript>
$('#employee_dt tfoot th').each( function() {javascript
```
下面的代码处理表格列底部的过滤器框的大小:
```
var title = $(this).text();
if (title == 'Extension' || title == 'Hired')
$(this).html('<input type="text" size="5" placeholder="' + title + '?" />');
else
$(this).html('<input type="text" size="15" placeholder="' + title + '?" />');
});titletitletitletitletitle
```
接下来,定义表模型。这是提供所有表选项的地方,包括界面的滚动,而不是分页,根据 DOM 字符串提供的装饰,将数据导出为 CSV 和其他格式的能力,以及建立与服务器的 AJAX 连接。 请注意,使用 Groovy GString 调用 Grails `createLink()` 的方法创建 URL,在 `EmployeeController` 中指向 `browserLister` 操作。同样有趣的是表格列的定义。此信息将发送到后端,后端查询数据库并返回相应的记录。
```
var table = $('#employee_dt').DataTable( {
"scrollY": 500,
"deferRender": true,
"scroller": true,
"dom": "Brtip",
"buttons": [ 'copy', 'csv', 'excel', 'pdf', 'print' ],
"processing": true,
"serverSide": true,
"ajax": {
"url": "${createLink(controller: 'employee', action: 'browserLister')}",
"type": "POST",
},
"columns": [
{ "data": "surname" },
{ "data": "givenNames" },
{ "data": "position" },
{ "data": "office" },
{ "data": "extension" },
{ "data": "hired" },
{ "data": "salary" }
]
});
```
最后,监视过滤器列以进行更改,并使用它们来应用过滤器。
```
table.columns().every(function() {
var that = this;
$('input', this.footer()).on('keyup change', function(e) {
if (that.search() != this.value && 8 < e.keyCode && e.keyCode < 32)
that.search(this.value).draw();
});
```
这就是 JavaScript,这样就完成了对视图代码的更改。
```
});
</g:javascript>
```
以下是此视图创建的UI的屏幕截图:

这是另一个屏幕截图,显示了过滤和多列排序(寻找 “position” 包括字符 “dev” 的员工,先按 “office” 排序,然后按姓氏排序):

这是另一个屏幕截图,显示单击 CSV 按钮时会发生什么:

最后,这是一个截图,显示在 LibreOffice 中打开的 CSV 数据:

好的,视图部分看起来非常简单;因此,控制器必须做所有繁重的工作,对吧? 让我们来看看……
#### 控制器 browserLister 操作
回想一下,我们看到过这个字符串:
```
"${createLink(controller: 'employee', action: 'browserLister')}"
```
对于从 DataTables 模型中调用 AJAX 的 URL,是在 Grails 服务器上动态创建 HTML 链接,其 Grails 标记背后通过调用 [createLink()](https://gsp.grails.org/latest/ref/Tags/createLink.html) 的方法实现的。这会最终产生一个指向 `EmployeeController` 的链接,位于:
```
embrow/grails-app/controllers/com/nuevaconsulting/embrow/EmployeeController.groovy
```
特别是控制器方法 `browserLister()`。我在代码中留了一些 `print` 语句,以便在运行时能够在终端看到中间结果。
```
def browserLister() {
// Applies filters and sorting to return a list of desired employees
```
首先,打印出传递给 `browserLister()` 的参数。我通常使用此代码开始构建控制器方法,以便我完全清楚我的控制器正在接收什么。
```
println "employee browserLister params $params"
println()
```
接下来,处理这些参数以使它们更加有用。首先,jQuery DataTables 参数,一个名为 `jqdtParams` 的 Groovy 映射:
```
def jqdtParams = [:]
params.each { key, value ->
def keyFields = key.replace(']','').split(/\[/)
def table = jqdtParams
for (int f = 0; f < keyFields.size() - 1; f++) {
def keyField = keyFields[f]
if (!table.containsKey(keyField))
table[keyField] = [:]
table = table[keyField]
}
table[keyFields[-1]] = value
}
println "employee dataTableParams $jqdtParams"
println()
```
接下来,列数据,一个名为 `columnMap` 的 Groovy 映射:
```
def columnMap = jqdtParams.columns.collectEntries { k, v ->
def whereTerm = null
switch (v.data) {
case 'extension':
case 'hired':
case 'salary':
if (v.search.value ==~ /\d+(,\d+)*/)
whereTerm = v.search.value.split(',').collect { it as Integer }
break
default:
if (v.search.value ==~ /[A-Za-z0-9 ]+/)
whereTerm = "%${v.search.value}%" as String
break
}
[(v.data): [where: whereTerm]]
}
println "employee columnMap $columnMap"
println()
```
接下来,从 `columnMap` 中检索的所有列表,以及在视图中应如何排序这些列表,Groovy 列表分别称为 `allColumnList` 和 `orderList` :
```
def allColumnList = columnMap.keySet() as List
println "employee allColumnList $allColumnList"
def orderList = jqdtParams.order.collect { k, v -> [allColumnList[v.column as Integer], v.dir] }
println "employee orderList $orderList"
```
我们将使用 Grails 的 Hibernate 标准实现来实际选择要显示的元素以及它们的排序和分页。标准要求过滤器关闭;在大多数示例中,这是作为标准实例本身的创建的一部分给出的,但是在这里我们预先定义过滤器闭包。请注意,在这种情况下,“date hired” 过滤器的相对复杂的解释被视为一年并应用于建立日期范围,并使用 `createAlias` 以允许我们进入相关类别 `Position` 和 `Office`:
```
def filterer = {
createAlias 'position', 'p'
createAlias 'office', 'o'
if (columnMap.surname.where) ilike 'surname', columnMap.surname.where
if (columnMap.givenNames.where) ilike 'givenNames', columnMap.givenNames.where
if (columnMap.position.where) ilike 'p.name', columnMap.position.where
if (columnMap.office.where) ilike 'o.name', columnMap.office.where
if (columnMap.extension.where) inList 'extension', columnMap.extension.where
if (columnMap.salary.where) inList 'salary', columnMap.salary.where
if (columnMap.hired.where) {
if (columnMap.hired.where.size() > 1) {
or {
columnMap.hired.where.each {
between 'hired', Date.parse('yyyy/MM/dd',"${it}/01/01" as String),
Date.parse('yyyy/MM/dd',"${it}/12/31" as String)
}
}
} else {
between 'hired', Date.parse('yyyy/MM/dd',"${columnMap.hired.where[0]}/01/01" as String),
Date.parse('yyyy/MM/dd',"${columnMap.hired.where[0]}/12/31" as String)
}
}
}
```
是时候应用上述内容了。第一步是获取分页代码所需的所有 `Employee` 实例的总数:
```
def recordsTotal = Employee.count()
println "employee recordsTotal $recordsTotal"
```
接下来,将过滤器应用于 `Employee` 实例以获取过滤结果的计数,该结果将始终小于或等于总数(同样,这是针对分页代码):
```
def c = Employee.createCriteria()
def recordsFiltered = c.count {
filterer.delegate = delegate
filterer()
}
println "employee recordsFiltered $recordsFiltered"
```
获得这两个计数后,你还可以使用分页和排序信息获取实际过滤的实例。
```
def orderer = Employee.withCriteria {
filterer.delegate = delegate
filterer()
orderList.each { oi ->
switch (oi[0]) {
case 'surname': order 'surname', oi[1]; break
case 'givenNames': order 'givenNames', oi[1]; break
case 'position': order 'p.name', oi[1]; break
case 'office': order 'o.name', oi[1]; break
case 'extension': order 'extension', oi[1]; break
case 'hired': order 'hired', oi[1]; break
case 'salary': order 'salary', oi[1]; break
}
}
maxResults (jqdtParams.length as Integer)
firstResult (jqdtParams.start as Integer)
}
```
要完全清楚,JTable 中的分页代码管理三个计数:数据集中的记录总数,应用过滤器后得到的数字,以及要在页面上显示的数字(显示是滚动还是分页)。 排序应用于所有过滤的记录,并且分页应用于那些过滤的记录的块以用于显示目的。
接下来,处理命令返回的结果,在每行中创建指向 `Employee`、`Position` 和 `Office` 实例的链接,以便用户可以单击这些链接以获取相关实例的所有详细信息:
```
def dollarFormatter = new DecimalFormat('$##,###.##')
def employees = orderer.collect { employee ->
['surname': "<a href='${createLink(controller: 'employee', action: 'show', id: employee.id)}'>${employee.surname}</a>",
'givenNames': employee.givenNames,
'position': "<a href='${createLink(controller: 'position', action: 'show', id: employee.position?.id)}'>${employee.position?.name}</a>",
'office': "<a href='${createLink(controller: 'office', action: 'show', id: employee.office?.id)}'>${employee.office?.name}</a>",
'extension': employee.extension,
'hired': employee.hired.format('yyyy/MM/dd'),
'salary': dollarFormatter.format(employee.salary)]
}
```
最后,创建要返回的结果并将其作为 JSON 返回,这是 jQuery DataTables 所需要的。
```
def result = [draw: jqdtParams.draw, recordsTotal: recordsTotal, recordsFiltered: recordsFiltered, data: employees]
render(result as JSON)
}
```
大功告成。
如果你熟悉 Grails,这可能看起来比你原先想象的要多,但这里没有火箭式的一步到位方法,只是很多分散的操作步骤。但是,如果你没有太多接触 Grails(或 Groovy),那么需要了解很多新东西 - 闭包,代理和构建器等等。
在那种情况下,从哪里开始? 最好的地方是了解 Groovy 本身,尤其是 [Groovy closures](http://groovy-lang.org/closures.html) 和 [Groovy delegates and builders](http://groovy-lang.org/dsls.html)。然后再去阅读上面关于 Grails 和 Hibernate 条件查询的建议阅读文章。
### 结语
jQuery DataTables 为 Grails 制作了很棒的表格数据浏览器。对视图进行编码并不是太棘手,但 DataTables 文档中提供的 PHP 示例提供的功能仅到此位置。特别是,它们不是用 Grails 程序员编写的,也不包含探索使用引用其他类(实质上是查找表)的元素的更精细的细节。
我使用这种方法制作了几个数据浏览器,允许用户选择要查看和累积记录计数的列,或者只是浏览数据。即使在相对适度的 VPS 上的百万行表中,性能也很好。
一个警告:我偶然发现了 Grails 中暴露的各种 Hibernate 标准机制的一些问题(请参阅我的其他 GitHub 代码库),因此需要谨慎和实验。如果所有其他方法都失败了,另一种方法是动态构建 SQL 字符串并执行它们。在撰写本文时,我更喜欢使用 Grails 标准,除非我遇到杂乱的子查询,但这可能只反映了我在 Hibernate 中对子查询的相对缺乏经验。
我希望 Grails 程序员发现本文的有趣性。请随时在下面留下评论或建议。
---
via: <https://opensource.com/article/18/9/using-grails-jquery-and-datatables>
作者:[Chris Hermansen](https://opensource.com/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jrg](https://github.com/jrglinux) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I’m a huge fan of [Grails](https://grails.org/). Granted, I’m mostly a data person who likes to explore and analyze data using command-line tools. But even data people sometimes need to *look at* the data, and sometimes using data means having a great data browser. With Grails, [jQuery](https://jquery.com/), and the [DataTables jQuery plugin](https://datatables.net/), we can make really nice tabular data browsers.
The [DataTables website](https://datatables.net/) offers a lot of decent “recipe-style” documentation that shows how to put together some fine sample applications, and it includes the necessary JavaScript, HTML, and occasional [PHP](http://php.net/) to accomplish some pretty spiffy stuff. But for those who would rather use Grails as their backend, a bit of interpretation is necessary. Also, the sample application data used is a single flat table of employees of a fictional company, so the complexity of dealing with table relations serves as an exercise for the reader.
In this article, we’ll fill those two gaps by creating a Grails application with a slightly more complex data structure and a DataTables browser. In doing so, we’ll cover Grails criteria, which are [Groovy](http://groovy-lang.org/)-fied Java Hibernate criteria. I’ve put the code for the application on [GitHub](https://github.com/monetschemist/grails-datatables), so this article is oriented toward explaining the nuances of the code.
For prerequisites, you will need Java, Groovy, and Grails environments set up. With Grails, I tend to use a terminal window and [Vim](https://www.vim.org/), so that’s what’s used here. To get a modern Java, I suggest downloading and installing the [Open Java Development Kit](http://openjdk.java.net/) (OpenJDK) provided by your Linux distro (which should be Java 8, 9, 10 or 11; at the time of writing, I’m working with Java 8). From my point of view, the best way to get up-to-date Groovy and Grails is to use [SDKMAN!](http://sdkman.io/).
Readers who have never tried Grails will probably need to do some background reading. As a starting point, I recommend [Creating Your First Grails Application](http://guides.grails.org/creating-your-first-grails-app/guide/index.html).
## Getting the employee browser application
As mentioned above, I’ve put the source code for this sample employee browser application on [GitHub](https://github.com/monetschemist/grails-datatables). For further explanation, the application **embrow** was built using the following commands in a Linux terminal window:
```
cd Projects
grails create-app com.nuevaconsulting.embrow
```
The domain classes and unit tests are created as follows:
```
cd embrow
grails create-domain-class com.nuevaconsulting.embrow.Position
grails create-domain-class com.nuevaconsulting.embrow.Office
grails create-domain-class com.nuevaconsulting.embrow.Employee
```
The domain classes built this way have no attributes, so they must be edited as follows:
The Position domain class:
```
package com.nuevaconsulting.embrow
class Position {
String name
int starting
static constraints = {
name nullable: false, blank: false
starting nullable: false
}
}
```
The Office domain class:
```
package com.nuevaconsulting.embrow
class Office {
String name
String address
String city
String country
static constraints = {
name nullable: false, blank: false
address nullable: false, blank: false
city nullable: false, blank: false
country nullable: false, blank: false
}
}
```
And the Employee domain class:
```
package com.nuevaconsulting.embrow
class Employee {
String surname
String givenNames
Position position
Office office
int extension
Date hired
int salary
static constraints = {
surname nullable: false, blank: false
givenNames nullable: false, blank: false
position nullable: false
office nullable: false
extension nullable: false
hired nullable: false
salary nullable: false
}
}
```
Note that whereas the Position and Office domain classes use predefined Groovy types String and int, the Employee domain class defines fields that are of type Position and Office (as well as the predefined Date). This causes the creation of the database table in which instances of Employee are stored to contain references, or foreign keys, to the tables in which instances of Position and Office are stored.
Now you can generate the controllers, views, and various other test components:
```
grails generate-all com.nuevaconsulting.embrow.Position
grails generate-all com.nuevaconsulting.embrow.Office
grails generate-all com.nuevaconsulting.embrow.Employee
```
At this point, you have a basic create-read-update-delete (CRUD) application ready to go. I’ve included some base data in the **grails-app/init/com/nuevaconsulting/BootStrap.groovy** to populate the tables.
If you run the application with the command:
`grails run-app`
you will see the following screen in the browser at [http://localhost:8080/:](http://localhost:8080/:)
The Embrow application home screen
Clicking on the link for the OfficeController gives you a screen that looks like this:
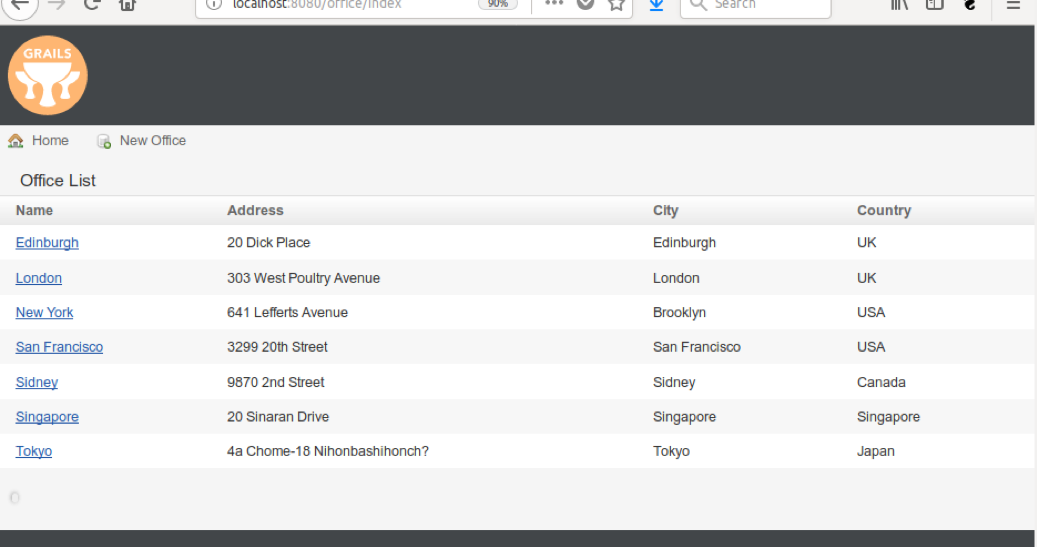
The office list
Note that this list is generated by the **OfficeController index** method and displayed by the view `office/index.gsp`
.
Similarly, clicking on the **EmployeeController** gives a screen that looks like this:
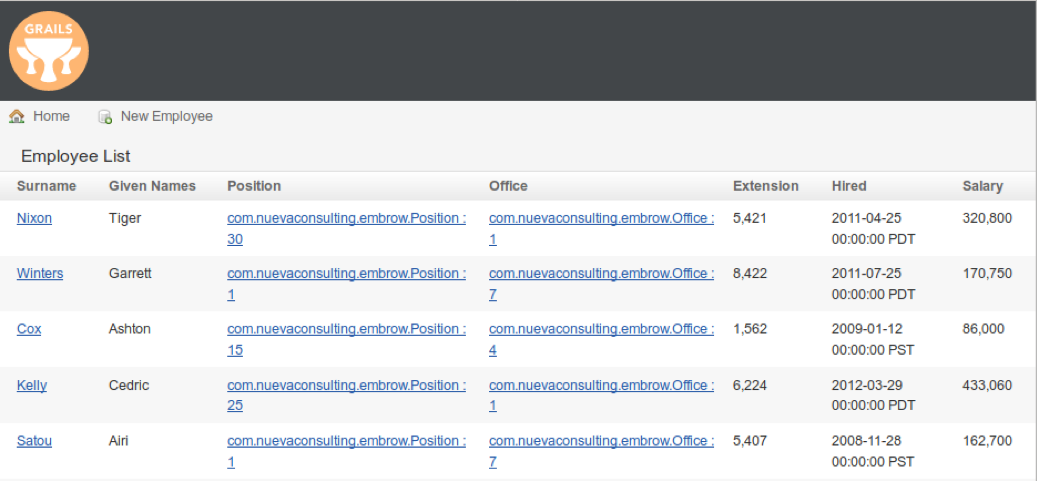
The employee controller
Ok, that’s pretty ugly—what’s with the Position and Office links?
Well, the views generated by the `generate-all`
commands above create an **index.****gsp** file that uses the Grails <f:table/> tag that by default shows the class name (**com.nuevaconsulting.embrow.Position**) and the persistent instance identifier (**30**). This behavior can be customized to yield something better looking, and there is some pretty neat stuff with the autogenerated links, the autogenerated pagination, and the autogenerated sortable columns.
But even when it's fully cleaned up, this employee browser offers limited functionality. For example, what if you want to find all employees whose position includes the text “dev”? What if you want to combine columns for sorting so that the primary sort key is a surname and the secondary sort key is an office name? Or what if you want to export a sorted subset to a spreadsheet or PDF to email to someone who doesn’t have access to the browser?
The jQuery DataTables plugin provides this kind of extra functionality and allows you to create a full-fledged tabular data browser.
## Creating the employee browser view and controller methods
In order to create an employee browser based on jQuery DataTables, you must complete two tasks:
-
Create a Grails view that incorporates the HTML and JavaScript required to enable the DataTables
-
Add a method to the Grails controller to handle the new view
### The employee browser view
In the directory **embrow****/grails-app/views/employee**, start by making a copy of the **index.****gsp** file, calling it **browser.gsp**:
```
cd Projects
cd embrow/grails-app/views/employee
cp index.gsp browser.gsp
```
At this point, you want to customize the new **browser.****gsp** file to add the relevant jQuery DataTables code.
As a rule, I like to grab my JavaScript and CSS from a content provider when feasible; to do so in this case, after the line:
`<title><g:message code="default.list.label" args="[entityName]" /></title>`
insert the following lines:
```
<script src="https://code.jquery.com/jquery-2.2.4.min.js" integrity="sha256-BbhdlvQf/xTY9gja0Dq3HiwQF8LaCRTXxZKRutelT44=" crossorigin="anonymous"></script>
<link rel="stylesheet" type="text/css" href="https://cdn.datatables.net/1.10.16/css/jquery.dataTables.css">
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/1.10.16/js/jquery.dataTables.js"></script>
<link rel="stylesheet" type="text/css" href="https://cdn.datatables.net/scroller/1.4.4/css/scroller.dataTables.min.css">
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/scroller/1.4.4/js/dataTables.scroller.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/dataTables.buttons.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.flash.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/jszip/3.1.3/jszip.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/pdfmake.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/vfs_fonts.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.html5.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.print.min.js "></script>
```
Next, remove the code that provided the data pagination in **index.gsp**:
```
<div id="list-employee" class="content scaffold-list" role="main">
<h1><g:message code="default.list.label" args="[entityName]" /></h1>
<g:if test="${flash.message}">
<div class="message" role="status">${flash.message}</div>
</g:if>
<f:table collection="${employeeList}" />
<div class="pagination">
<g:paginate total="${employeeCount ?: 0}" />
</div>
</div>
```
and insert the code that materializes the jQuery DataTables.
The first part to insert is the HTML that creates the basic tabular structure of the browser. For the application where DataTables talks to a database backend, provide only the table headers and footers; the DataTables JavaScript takes care of the table contents.
```
<div id="employee-browser" class="content" role="main">
<h1>Employee Browser</h1>
<table id="employee_dt" class="display compact" style="width:99%;">
<thead>
<tr>
<th>Surname</th>
<th>Given name(s)</th>
<th>Position</th>
<th>Office</th>
<th>Extension</th>
<th>Hired</th>
<th>Salary</th>
</tr>
</thead>
<tfoot>
<tr>
<th>Surname</th>
<th>Given name(s)</th>
<th>Position</th>
<th>Office</th>
<th>Extension</th>
<th>Hired</th>
<th>Salary</th>
</tr>
</tfoot>
</table>
</div>
```
Next, insert a JavaScript block, which serves three primary functions: It sets the size of the text boxes shown in the footer for column filtering, it establishes the DataTables table model, and it creates a handler to do the column filtering.
```
<g:javascript>
$('#employee_dt tfoot th').each( function() {
```
The code below handles sizing the filter boxes at the bottoms of the table columns:
```
var title = $(this).text();
if (title == 'Extension' || title == 'Hired')
$(this).html('<input type="text" size="5" placeholder="' + title + '?" />');
else
$(this).html('<input type="text" size="15" placeholder="' + title + '?" />');
});
```
Next, define the table model. This is where all the table options are provided, including the scrolling, rather than paginated, nature of the interface, the cryptic decorations to be provided according to the dom string, the ability to export data to CSV and other formats, as well as where the Ajax connection to the server is established. Note that the URL is created with a Groovy GString call to the Grails **createLink()** method, referring to the **browserLister** action in the **EmployeeController**. Also of interest is the definition of the columns of the table. This information is sent across to the back end, which queries the database and returns the appropriate records.
```
var table = $('#employee_dt').DataTable( {
"scrollY": 500,
"deferRender": true,
"scroller": true,
"dom": "Brtip",
"buttons": [ 'copy', 'csv', 'excel', 'pdf', 'print' ],
"processing": true,
"serverSide": true,
"ajax": {
"url": "${createLink(controller: 'employee', action: 'browserLister')}",
"type": "POST",
},
"columns": [
{ "data": "surname" },
{ "data": "givenNames" },
{ "data": "position" },
{ "data": "office" },
{ "data": "extension" },
{ "data": "hired" },
{ "data": "salary" }
]
});
```
Finally, monitor the filter columns for changes and use them to apply the filter(s).
```
table.columns().every(function() {
var that = this;
$('input', this.footer()).on('keyup change', function(e) {
if (that.search() != this.value && 8 < e.keyCode && e.keyCode < 32)
that.search(this.value).draw();
});
```
And that’s it for the JavaScript. This completes the changes to the view code.
```
});
</g:javascript>
```
Here’s a screenshot of the UI this view creates:
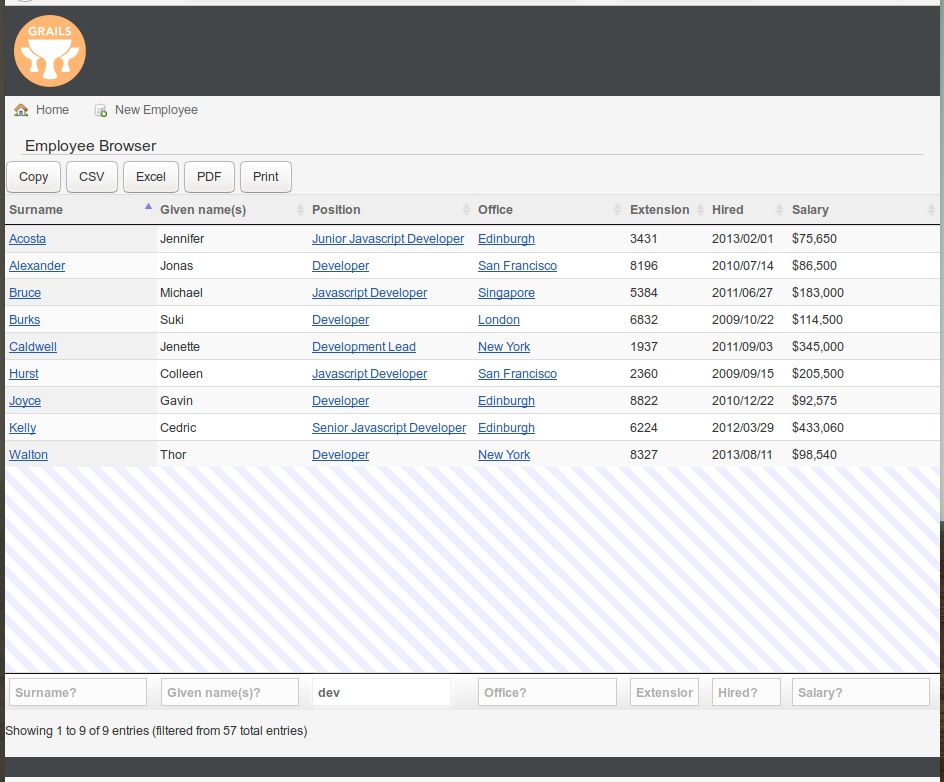
Here’s another screenshot showing the filtering and multi-column sorting at work (looking for employees whose positions include the characters “dev”, ordering first by office, then by surname):
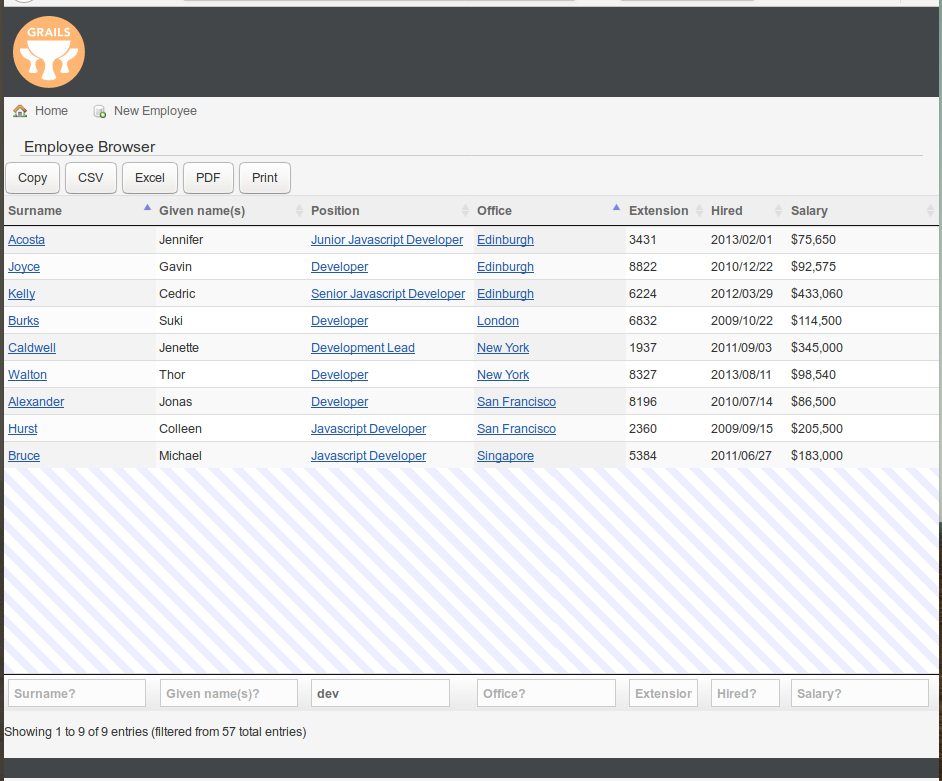
Here’s another screenshot, showing what happens when you click on the CSV button:
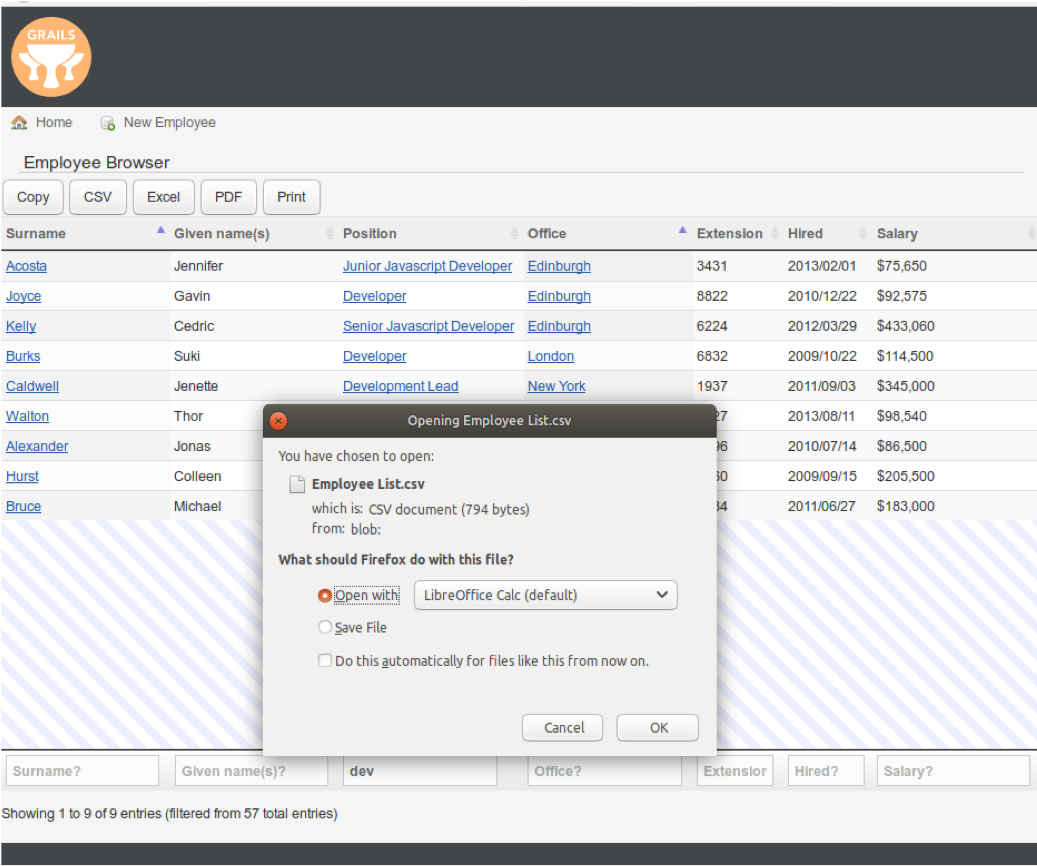
And finally, here’s a screenshot showing the CSV data opened in LibreOffice:
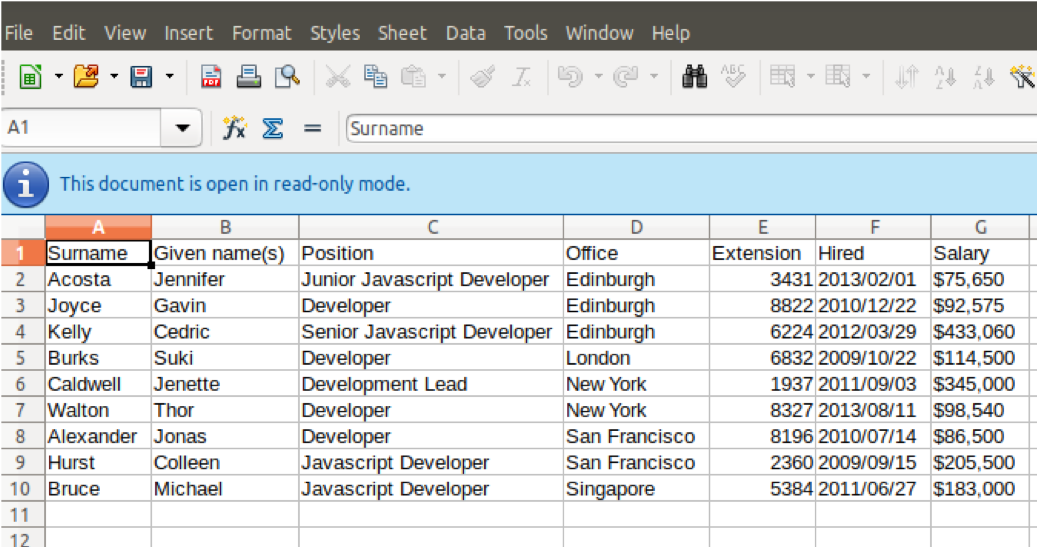
Ok, so the view part looked pretty straightforward; therefore, the controller action must do all the heavy lifting, right? Let’s see…
### The employee controller browserLister action
Recall that we saw this string
`"${createLink(controller: 'employee', action: 'browserLister')}"`
as the URL used for the Ajax calls from the DataTables table model. [createLink() is the method](https://gsp.grails.org/latest/ref/Tags/createLink.html) behind a Grails tag that is used to dynamically generate a link as the HTML is preprocessed on the Grails server. This ends up generating a link to the **EmployeeController**, located in
`embrow/grails-app/controllers/com/nuevaconsulting/embrow/EmployeeController.groovy`
and specifically to the controller method **browserLister()**. I’ve left some print statements in the code so that the intermediate results can be seen in the terminal window where the application is running.
```
def browserLister() {
// Applies filters and sorting to return a list of desired employees
```
First, print out the parameters passed to **browserLister()**. I usually start building controller methods with this code so that I’m completely clear on what my controller is receiving.
```
println "employee browserLister params $params"
println()
```
Next, process those parameters to put them in a more usable shape. First, the jQuery DataTables parameters, a Groovy map called **jqdtParams**:
```
def jqdtParams = [:]
params.each { key, value ->
def keyFields = key.replace(']','').split(/\[/)
def table = jqdtParams
for (int f = 0; f < keyFields.size() - 1; f++) {
def keyField = keyFields[f]
if (!table.containsKey(keyField))
table[keyField] = [:]
table = table[keyField]
}
table[keyFields[-1]] = value
}
println "employee dataTableParams $jqdtParams"
println()
```
Next, the column data, a Groovy map called **columnMap**:
```
def columnMap = jqdtParams.columns.collectEntries { k, v ->
def whereTerm = null
switch (v.data) {
case 'extension':
case 'hired':
case 'salary':
if (v.search.value ==~ /\d+(,\d+)*/)
whereTerm = v.search.value.split(',').collect { it as Integer }
break
default:
if (v.search.value ==~ /[A-Za-z0-9 ]+/)
whereTerm = "%${v.search.value}%" as String
break
}
[(v.data): [where: whereTerm]]
}
println "employee columnMap $columnMap"
println()
```
Next, a list of all column names, retrieved from **columnMap**, and a corresponding list of how those columns should be ordered in the view, Groovy lists called **allColumnList** and **orderList**, respectively:
```
def allColumnList = columnMap.keySet() as List
println "employee allColumnList $allColumnList"
def orderList = jqdtParams.order.collect { k, v -> [allColumnList[v.column as Integer], v.dir] }
println "employee orderList $orderList"
```
We’re going to use Grails’ implementation of Hibernate criteria to actually carry out the selection of elements to be displayed as well as their ordering and pagination. Criteria requires a filter closure; in most examples, this is given as part of the creation of the criteria instance itself, but here we define the filter closure beforehand. Note in this case the relatively complex interpretation of the “date hired” filter, which is treated as a year and applied to establish date ranges, and the use of **createAlias** to allow us to reach into related classes Position and Office:
```
def filterer = {
createAlias 'position', 'p'
createAlias 'office', 'o'
if (columnMap.surname.where) ilike 'surname', columnMap.surname.where
if (columnMap.givenNames.where) ilike 'givenNames', columnMap.givenNames.where
if (columnMap.position.where) ilike 'p.name', columnMap.position.where
if (columnMap.office.where) ilike 'o.name', columnMap.office.where
if (columnMap.extension.where) inList 'extension', columnMap.extension.where
if (columnMap.salary.where) inList 'salary', columnMap.salary.where
if (columnMap.hired.where) {
if (columnMap.hired.where.size() > 1) {
or {
columnMap.hired.where.each {
between 'hired', Date.parse('yyyy/MM/dd',"${it}/01/01" as String),
Date.parse('yyyy/MM/dd',"${it}/12/31" as String)
}
}
} else {
between 'hired', Date.parse('yyyy/MM/dd',"${columnMap.hired.where[0]}/01/01" as String),
Date.parse('yyyy/MM/dd',"${columnMap.hired.where[0]}/12/31" as String)
}
}
}
```
At this point, it’s time to apply the foregoing. The first step is to get a total count of all the Employee instances, required by the pagination code:
```
def recordsTotal = Employee.count()
println "employee recordsTotal $recordsTotal"
```
Next, apply the filter to the Employee instances to get the count of filtered results, which will always be less than or equal to the total number (again, this is for the pagination code):
```
def c = Employee.createCriteria()
def recordsFiltered = c.count {
filterer.delegate = delegate
filterer()
}
println "employee recordsFiltered $recordsFiltered"
```
Once you have those two counts, you can get the actual filtered instances using the pagination and ordering information as well.
```
def orderer = Employee.withCriteria {
filterer.delegate = delegate
filterer()
orderList.each { oi ->
switch (oi[0]) {
case 'surname': order 'surname', oi[1]; break
case 'givenNames': order 'givenNames', oi[1]; break
case 'position': order 'p.name', oi[1]; break
case 'office': order 'o.name', oi[1]; break
case 'extension': order 'extension', oi[1]; break
case 'hired': order 'hired', oi[1]; break
case 'salary': order 'salary', oi[1]; break
}
}
maxResults (jqdtParams.length as Integer)
firstResult (jqdtParams.start as Integer)
}
```
To be completely clear, the pagination code in JTables manages three counts: the total number of records in the data set, the number resulting after the filters are applied, and the number to be displayed on the page (whether the display is scrolling or paginated). The ordering is applied to all the filtered records and the pagination is applied to chunks of those filtered records for display purposes.
Next, process the results returned by the orderer, creating links to the Employee, Position, and Office instance in each row so the user can click on these links to get all the detail on the relevant instance:
```
def dollarFormatter = new DecimalFormat('$##,###.##')
def employees = orderer.collect { employee ->
['surname': "<a href='${createLink(controller: 'employee', action: 'show', id: employee.id)}'>${employee.surname}</a>",
'givenNames': employee.givenNames,
'position': "<a href='${createLink(controller: 'position', action: 'show', id: employee.position?.id)}'>${employee.position?.name}</a>",
'office': "<a href='${createLink(controller: 'office', action: 'show', id: employee.office?.id)}'>${employee.office?.name}</a>",
'extension': employee.extension,
'hired': employee.hired.format('yyyy/MM/dd'),
'salary': dollarFormatter.format(employee.salary)]
}
```
And finally, create the result you want to return and give it back as JSON, which is what jQuery DataTables requires.
```
def result = [draw: jqdtParams.draw, recordsTotal: recordsTotal, recordsFiltered: recordsFiltered, data: employees]
render(result as JSON)
}
```
That’s it.
If you’re familiar with Grails, this probably seems like more work than you might have originally thought, but there’s no rocket science here, just a lot of moving parts. However, if you haven’t had much exposure to Grails (or to Groovy), there’s a lot of new stuff to understand—closures, delegates, and builders, among other things.
In that case, where to start? The best place is to learn about Groovy itself, especially [Groovy closures](http://groovy-lang.org/closures.html) and [Groovy delegates and builders](http://groovy-lang.org/dsls.html). Then go back to the reading suggested above on Grails and Hibernate criteria queries.
## Conclusions
jQuery DataTables make awesome tabular data browsers for Grails. Coding the view isn’t too tricky, but the PHP examples provided in the DataTables documentation take you only so far. In particular, they aren’t written with Grails programmers in mind, nor do they explore the finer details of using elements that are references to other classes (essentially lookup tables).
I’ve used this approach to make a couple of data browsers that allow the user to select which columns to view and accumulate record counts, or just to browse the data. The performance is good even in million-row tables on a relatively modest VPS.
One caveat: I have stumbled upon some problems with the various Hibernate criteria mechanisms exposed in Grails (see my other GitHub repositories), so care and experimentation is required. If all else fails, the alternative approach is to build SQL strings on the fly and execute them instead. As of this writing, I prefer to work with Grails criteria, unless I get into messy subqueries, but that may just reflect my relative lack of experience with subqueries in Hibernate.
I hope you Grails programmers out there find this interesting. Please feel free to leave comments or suggestions below.
## Comments are closed. |
10,269 | 如何使用 Emacs 创建 LaTeX 文档 | https://opensource.com/article/18/4/how-create-latex-documents-emacs | 2018-11-24T10:52:00 | [
"LaTex",
"Emacs"
] | https://linux.cn/article-10269-1.html |
>
> 这篇教程将带你遍历在 Emacs 使用强大的开源排版系统 LaTex 来创建文档的全过程。
>
>
>

一篇由 Aaron Cocker 写的很棒的文章 “[在 LaTeX 中创建文件的介绍](https://opensource.com/article/17/6/introduction-latex)” 中,介绍了 [LaTeX 排版系统](https://www.latex-project.org) 并描述了如何使用 [TeXstudio](http://www.texstudio.org/) 来创建 LaTeX 文档。同时,他也列举了一些很多用户觉得创建 LaTeX 文档很方便的编辑器。
[Greg Pittman](https://opensource.com/users/greg-p) 对这篇文章的评论吸引了我:“当你第一次开始使用 LaTeX 时,他似乎是个很差劲的排版……” 事实也确实如此。LaTeX 包含了多种排版字体和调试,如果你漏了一个特殊的字符比如说感叹号,这会让很多用户感到沮丧,尤其是新手。在本文中,我将介绍如何使用 [GNU Emacs](https://www.gnu.org/software/emacs/) 来创建 LaTeX 文档。
### 创建你的第一个文档
启动 Emacs:
```
emacs -q --no-splash helloworld.org
```
参数 `-q` 确保 Emacs 不会加载其他的初始化配置。参数 `--no-splash-screen` 防止 Emacs 打开多个窗口,确保只打开一个窗口,最后的参数 `helloworld.org` 表示你要创建的文件名为 `helloworld.org` 。

*GNU Emacs 打开文件名为 helloworld.org 的窗口时的样子。*
现在让我们用 Emacs 添加一些 LaTeX 的标题吧:在菜单栏找到 “Org” 选项并选择 “Export/Publish”。

*导入一个默认的模板*
在下一个窗口中,Emacs 同时提供了导入和导出一个模板。输入 `#`(“[#] Insert template”)来导入一个模板。这将会使光标跳转到一个带有 “Options category:” 提示的 mini-buffer 中。第一次你可能不知道这个类型的名字,但是你可以使用 `Tab` 键来查看所有的补全。输入 “default” 然后按回车,之后你就能看到如下的内容被插入了:
```
#+TITLE: helloworld
#+DATE: <2018-03-12 Mon>
#+AUTHOR:
#+EMAIL: makerpm@nubia
#+OPTIONS: ':nil *:t -:t ::t <:t H:3 \n:nil ^:t arch:headline
#+OPTIONS: author:t c:nil creator:comment d:(not "LOGBOOK") date:t
#+OPTIONS: e:t email:nil f:t inline:t num:t p:nil pri:nil stat:t
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:t todo:t |:t
#+CREATOR: Emacs 25.3.1 (Org mode 8.2.10)
#+DESCRIPTION:
#+EXCLUDE_TAGS: noexport
#+KEYWORDS:
#+LANGUAGE: en
#+SELECT_TAGS: export
```
根据自己的需求修改标题、日期、作者和 email。我自己的话是下面这样的:
```
#+TITLE: Hello World! My first LaTeX document
#+DATE: \today
#+AUTHOR: Sachin Patil
#+EMAIL: [email protected]
```
我们目前还不想创建一个目录,所以要将 `toc` 的值由 `t` 改为 `nil`,具体如下:
```
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:nil todo:t |:t
```
现在让我们添加一个章节和段落吧。章节是由一个星号(`*`)开头。我们从 Aaron 的贴子(来自 [Lipsum Lorem Ipsum 生成器](https://www.lipsum.com/feed/html))复制一些文本过来:
```
* Introduction
\paragraph{}
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras lorem
nisi, tincidunt tempus sem nec, elementum feugiat ipsum. Nulla in
diam libero. Nunc tristique ex a nibh egestas sollicitudin.
\paragraph{}
Mauris efficitur vitae ex id egestas. Vestibulum ligula felis,
pulvinar a posuere id, luctus vitae leo. Sed ac imperdiet orci, non
elementum leo. Nullam molestie congue placerat. Phasellus tempor et
libero maximus commodo.
```

*helloworld.org 文件*
将内容修改好后,我们要把它导出为 PDF 格式。再次在 “Org” 的菜单选项中选择 “Export/Publish”,但是这次,要输入 `l`(“export to LaTeX”),紧跟着输入 `o`(“as PDF file and open”)。这次操作不止会打开 PDF 文件让你浏览,同时也会将文件保存为 `helloworld.pdf`,并保存在与 `helloworld.org` 的同一个目录下。

*将 helloworld.org 导出为 helloworld.pdf*

*打开 helloworld.pdf 文件*
你也可以按下 `Alt + x` 键,然后输入 `org-latex-export-to-pdf` 来将 org 文件导出为 PDF 文件。可以使用 `Tab` 键来自动补全命令。
Emacs 也会创建 `helloworld.tex` 文件来让你控制具体的内容。

*Emacs 在三个不同的窗口中分别打开 LaTeX,org 和 PDF 文档。*
你可以使用命令来将 `.tex` 文件转换为 `.pdf` 文件:
```
pdflatex helloworld.tex
```
你也可以将 `.org` 文件输出为 HTML 或是一个简单的文本格式的文件。我最喜欢 `.org` 文件的原因是他们可以被推送到 [GitHub](https://github.com) 上,然后同 markdown 一样被渲染。
### 创建一个 LaTeX 的 Beamer 简报
现在让我们更进一步,通过少量的修改上面的文档来创建一个 LaTeX [Beamer](https://www.sharelatex.com/learn/Beamer) 简报,如下所示:
```
#+TITLE: LaTeX Beamer presentation
#+DATE: \today
#+AUTHOR: Sachin Patil
#+EMAIL: [email protected]
#+OPTIONS: ':nil *:t -:t ::t <:t H:3 \n:nil ^:t arch:headline
#+OPTIONS: author:t c:nil creator:comment d:(not "LOGBOOK") date:t
#+OPTIONS: e:t email:nil f:t inline:t num:t p:nil pri:nil stat:t
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:nil todo:t |:t
#+CREATOR: Emacs 25.3.1 (Org mode 8.2.10)
#+DESCRIPTION:
#+EXCLUDE_TAGS: noexport
#+KEYWORDS:
#+LANGUAGE: en
#+SELECT_TAGS: export
#+LATEX_CLASS: beamer
#+BEAMER_THEME: Frankfurt
#+BEAMER_INNER_THEME: rounded
* Introduction
*** Programming
- Python
- Ruby
*** Paragraph one
Lorem ipsum dolor sit amet, consectetur adipiscing
elit. Cras lorem nisi, tincidunt tempus sem nec, elementum feugiat
ipsum. Nulla in diam libero. Nunc tristique ex a nibh egestas
sollicitudin.
*** Paragraph two
Mauris efficitur vitae ex id egestas. Vestibulum
ligula felis, pulvinar a posuere id, luctus vitae leo. Sed ac
imperdiet orci, non elementum leo. Nullam molestie congue
placerat. Phasellus tempor et libero maximus commodo.
* Thanks
*** Links
- Link one
- Link two
```
我们给标题增加了三行:
```
#+LATEX_CLASS: beamer
#+BEAMER_THEME: Frankfurt
#+BEAMER_INNER_THEME: rounded
```
导出为 PDF,按下 `Alt + x` 键后输入 `org-beamer-export-to-pdf`。

*用 Emacs 和 Org 模式创建的 Latex Beamer 简报*
希望你会爱上使用 Emacs 来创建 LaTex 和 Beamer 文档(注意:使用快捷键比用鼠标更快些)。Emacs 的 Org 模式提供了比我在这篇文章中说的更多的功能,你可以在 [orgmode.org](https://orgmode.org/worg/org-tutorials/org-latex-export.html) 获取更多的信息.
---
via: <https://opensource.com/article/18/4/how-create-latex-documents-emacs>
作者:[Sachin Patil](https://opensource.com/users/psachin) 选题:[lujun9972](https://github.com/lujun9972) 译者:[oneforalone](https://github.com/oneforalone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In his excellent article, * An introduction to creating documents in LaTeX*, author
[Aaron Cocker](https://opensource.com/users/aaroncocker)introduces the
[LaTeX typesetting system](https://www.latex-project.org)and explains how to create a LaTeX document using
[TeXstudio](http://www.texstudio.org/). He also lists a few LaTeX editors that many users find helpful in creating LaTeX documents.
This comment on the article by [Greg Pittman](https://opensource.com/users/greg-p) caught my attention: "LaTeX seems like an awful lot of typing when you first start...". This is true. LaTeX involves a lot of typing and debugging, if you missed a special character like an exclamation mark, which can discourage many users, especially beginners. In this article, I will introduce you to [GNU Emacs](https://www.gnu.org/software/emacs/) and describe how to use it to create LaTeX documents.
## Creating your first document
Launch Emacs by typing:
```
````emacs -q --no-splash helloworld.org`
The `-q`
flag ensures that no Emacs initializations will load. The `--no-splash-screen`
flag prevents splash screens to ensure that only one window is open, with the file `helloworld.org`
.
GNU Emacs with helloworld.org file opened in a buffer window.
Let's add some LaTeX headers the Emacs way: Go to **Org** in the menu bar and select **Export/Publish**.
How to insert a default template.
In the next window, Emacs offers options to either export or insert a template. Insert the template by entering **#** ([#] Insert template). This will move a cursor to a mini-buffer, where the prompt reads **Options category:**. At this time you may not know the category names; press Tab to see possible completions. Type "default" and press Enter. The following content will be inserted:
```
``````
#+TITLE: helloworld
#+DATE: <2018-03-12 Mon>
#+AUTHOR:
#+EMAIL: makerpm@nubia
#+OPTIONS: ':nil *:t -:t ::t <:t H:3 \n:nil ^:t arch:headline
#+OPTIONS: author:t c:nil creator:comment d:(not "LOGBOOK") date:t
#+OPTIONS: e:t email:nil f:t inline:t num:t p:nil pri:nil stat:t
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:t todo:t |:t
#+CREATOR: Emacs 25.3.1 (Org mode 8.2.10)
#+DESCRIPTION:
#+EXCLUDE_TAGS: noexport
#+KEYWORDS:
#+LANGUAGE: en
#+SELECT_TAGS: export
```
Change the title, date, author, and email as you wish. Mine looks like this:
```
``````
#+TITLE: Hello World! My first LaTeX document
#+DATE: \today
#+AUTHOR: Sachin Patil
#+EMAIL: [email protected]
```
We don't want to create a Table of Contents yet, so change the value of `toc`
from `t`
to `nil`
inline, as shown below:
```
````#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:nil todo:t |:t`
Let's add a section and paragraphs. A section starts with an asterisk (*). We'll copy the content of some paragraphs from Aaron's post (from the [Lipsum Lorem Ipsum generator](https://www.lipsum.com/feed/html)):
```
``````
* Introduction
\paragraph{}
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras lorem
nisi, tincidunt tempus sem nec, elementum feugiat ipsum. Nulla in
diam libero. Nunc tristique ex a nibh egestas sollicitudin.
\paragraph{}
Mauris efficitur vitae ex id egestas. Vestibulum ligula felis,
pulvinar a posuere id, luctus vitae leo. Sed ac imperdiet orci, non
elementum leo. Nullam molestie congue placerat. Phasellus tempor et
libero maximus commodo.
```
Helloworld.org file
With the content in place, we'll export the content as a PDF. Select **Export/Publish** from the **Org** menu again, but this time, type **l** (export to LaTeX), followed by **o** (as PDF file and open). This not only opens PDF file for you to view, but also saves the file as `helloworld.pdf`
in the same path as `helloworld.org`
.
Exporting helloworld.org to helloworld.pdf
The helloworld.pdf file opened at the bottom
You can also export org to PDF by pressing `Alt + x`
, then typing "org-latex-export-to-pdf". Use Tab to auto-complete.
Emacs also creates the `helloworld.tex`
file to give you control over the content.
Emacs with LaTeX, org, and PDF files open in three different windows
You can compile the `.tex`
file to `.pdf`
using the command:
```
````pdflatex helloworld.tex`
You can also export the `.org`
file to HTML or as a simple text file. What I like about .org files is they can be pushed to [GitHub](https://github.com), where they are rendered just like any other markdown formats.
## Creating a LaTeX Beamer presentation
Let's go a step further and create a LaTeX [Beamer](https://www.sharelatex.com/learn/Beamer) presentation using the same file with some modifications as shown below:
```
``````
#+TITLE: LaTeX Beamer presentation
#+DATE: \today
#+AUTHOR: Sachin Patil
#+EMAIL: [email protected]
#+OPTIONS: ':nil *:t -:t ::t <:t H:3 \n:nil ^:t arch:headline
#+OPTIONS: author:t c:nil creator:comment d:(not "LOGBOOK") date:t
#+OPTIONS: e:t email:nil f:t inline:t num:t p:nil pri:nil stat:t
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:nil todo:t |:t
#+CREATOR: Emacs 25.3.1 (Org mode 8.2.10)
#+DESCRIPTION:
#+EXCLUDE_TAGS: noexport
#+KEYWORDS:
#+LANGUAGE: en
#+SELECT_TAGS: export
#+LATEX_CLASS: beamer
#+BEAMER_THEME: Frankfurt
#+BEAMER_INNER_THEME: rounded
* Introduction
*** Programming
- Python
- Ruby
*** Paragraph one
Lorem ipsum dolor sit amet, consectetur adipiscing
elit. Cras lorem nisi, tincidunt tempus sem nec, elementum feugiat
ipsum. Nulla in diam libero. Nunc tristique ex a nibh egestas
sollicitudin.
*** Paragraph two
Mauris efficitur vitae ex id egestas. Vestibulum
ligula felis, pulvinar a posuere id, luctus vitae leo. Sed ac
imperdiet orci, non elementum leo. Nullam molestie congue
placerat. Phasellus tempor et libero maximus commodo.
* Thanks
*** Links
- Link one
- Link two
```
We have added three more lines to the header:
```
``````
#+LATEX_CLASS: beamer
#+BEAMER_THEME: Frankfurt
#+BEAMER_INNER_THEME: rounded
```
To export to PDF, press `Alt + x`
and type "org-beamer-export-to-pdf".
Latex Beamer presentation created using Emacs and Org mode
I hope you enjoyed creating this LaTeX and Beamer document using Emacs (note that it's faster to use keyboard shortcuts than a mouse). Emacs Org-mode offers much more than I can cover in this post; you can learn more at [orgmode.org](https://orgmode.org/worg/org-tutorials/org-latex-export.html).
## 14 Comments |
10,270 | 学习 Golang 的 4 个技巧 | https://opensource.com/article/18/11/learning-golang | 2018-11-24T12:21:37 | [
"Golang"
] | https://linux.cn/article-10270-1.html |
>
> 到达 Golang 大陆:一位资深开发者之旅。
>
>
>

2014 年夏天……
>
> IBM:“我们需要你弄清楚这个 Docker。”
>
>
> 我:“没问题。”
>
>
> IBM:“那就开始吧。”
>
>
> 我:“好的。”(内心声音):”Docker 是用 Go 编写的。是吗?“(Google 一下)“哦,一门编程语言。我在我的岗位上已经学习了很多了。这不会太难。”
>
>
>
我的大学新生编程课是使用 VAX 汇编程序教授的。在数据结构课上,我们使用 Pascal —— 在图书馆计算机中心的旧电脑上使用软盘加载。在一门更高一级的课程中,我的教授教授喜欢用 ADA 去展示所有的例子。在我们的 Sun 工作站上,我通过各种 UNIX 的实用源代码学到了一点 C。在 IBM,OS/2 源代码中我们使用了 C 和一些 x86 汇编程序;在一个与 Apple 合作的项目中我们大量使用 C++ 的面向对象功能。不久后我学到了 shell 脚本,开始是 csh,但是在 90 年代中期发现 Linux 后就转到了 Bash。在 90 年代后期,我在将 IBM 的定制的 JVM 代码中的即时(JIT)编译器移植到 Linux 时,我不得不开始学习 m4(与其说是编程语言,不如说是一种宏处理器)。
一晃 20 年……我从未因为学习一门新的编程语言而焦灼。但是 [Go](https://golang.org/) 让我感觉有些不同。我打算公开贡献,上传到 GitHub,让任何有兴趣的人都可以看到!作为一个 40 多岁的资深开发者的 Go 新手,我不想成为一个笑话。我们都知道程序员的骄傲,不想丢人,不论你的经验水平如何。
我早期的调研显示,Go 似乎比某些语言更 “地道”。它不仅仅是让代码可以编译;也需要让代码可以 “Go Go Go”。
现在,我的个人的 Go 之旅四年间有了几百个拉取请求(PR),我不是致力于成为一个专家,但是现在我觉得贡献和编写代码比我在 2014 年的时候更舒服了。所以,你该怎么教一个老人新的技能或者一门编程语言呢?以下是我自己在前往 Golang 大陆之旅的四个步骤。
### 1、不要跳过基础
虽然你可以通过复制代码来进行你早期的学习(谁还有时间阅读手册!?),Go 有一个非常易读的 [语言规范](https://golang.org/ref/spec),它写的很易于理解,即便你在语言或者编译理论方面没有取得硕士学位。鉴于 Go 的 **参数:类型** 顺序的特有习惯,以及一些有趣的语言功能,例如通道和 go 协程,搞定这些新概念是非常重要的是事情。阅读这个附属的文档 [高效 Go 编程](https://golang.org/doc/effective_go.html),这是 Golang 创造者提供的另一个重要资源,它将为你提供有效和正确使用语言的准备。
### 2、从最好的中学习
有许多宝贵的资源可供挖掘,可以将你的 Go 知识提升到下一个等级。最近在 [GopherCon](https://www.gophercon.com/) 上的所有讲演都可以在网上找到,如这个 [GopherCon US 2018](https://tqdev.com/2018-gophercon-2018-videos-online) 的详尽列表。这些讲演的专业知识和技术水平各不相同,但是你可以通过它们轻松地找到一些你所不了解的事情。[Francesc Campoy](https://twitter.com/francesc) 创建了一个名叫 [JustForFunc](https://www.youtube.com/channel/UC_BzFbxG2za3bp5NRRRXJSw) 的 Go 编程视频系列,其不断增多的剧集可以用来拓宽你的 Go 知识和理解。直接搜索 “Golang" 可以为那些想要了解更多信息的人们展示许多其它视频和在线资源。
想要看代码?在 GitHub 上许多受欢迎的云原生项目都是用 Go 写的:[Docker/Moby](https://github.com/moby/moby)、[Kubernetes](https://github.com/kubernetes/kubernetes)、[Istio](https://github.com/istio/istio)、[containerd](https://github.com/containerd/containerd)、[CoreDNS](https://github.com/coredns/coredns),以及许多其它的。语言纯粹主义者可能会认为一些项目比另外一些更地道,但这些都是很好的起点,可以看到在高度活跃的项目的大型代码库中使用 Go 的程度。
### 3、使用优秀的语言工具
你会很快了解到 [gofmt](https://blog.golang.org/go-fmt-your-code) 的宝贵之处。Go 最漂亮的一个地方就在于没有关于每个项目代码格式的争论 —— **gofmt** 内置在语言的运行环境中,并且根据一系列可靠的、易于理解的语言规则对 Go 代码进行格式化。我不知道有哪个基于 Golang 的项目会在持续集成中不坚持使用 **gofmt** 检查拉取请求。
除了直接构建于运行环境和 SDK 中的一系列有价值的工具之外,我强烈建议使用一个对 Golang 的特性有良好支持的编辑器或者 IDE。由于我经常在命令行中进行工作,我依赖于 Vim 加上强大的 [vim-go](https://github.com/fatih/vim-go) 插件。我也喜欢微软提供的 [VS Code](https://code.visualstudio.com/),特别是它的 [Go 语言](https://code.visualstudio.com/docs/languages/go) 插件。
想要一个调试器?[Delve](https://github.com/derekparker/delve) 项目在不断的改进和成熟,它是在 Go 二进制文件上进行 [gdb](https://www.gnu.org/software/gdb/) 式调试的强有力的竞争者。
### 4、写一些代码
你要是不开始尝试使用 Go 写代码,你永远不知道它有什么好的地方。找一个有 “需要帮助” 问题标签的项目,然后开始贡献代码。如果你已经使用了一个用 Go 编写的开源项目,找出它是否有一些可以用初学者方式解决的 Bug,然后开始你的第一个拉取请求。与生活中的大多数事情一样,实践出真知,所以开始吧。
事实证明,你可以教会一个资深的老开发者一门新的技能甚至编程语言。
---
via: <https://opensource.com/article/18/11/learning-golang>
作者:[Phill Estes](https://opensource.com/users/estesp) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the summer of 2014...
IBM: "We need you to go figure out this Docker thing."
Me: "OK."
IBM: "Start contributing and just get involved."
Me: "OK." (internal voice): "This is written in Go. What's that?" (Googles) "Oh, a programming language. I've learned a few of those in my career. Can't be that hard."
My university's freshman programming class was taught using VAX assembler. In data structures class, we used Pascal—loaded via diskette on tired, old PCs in the library's computer center. In one upper-level course, I had a professor that loved to show all examples in ADA. I learned a bit of C via playing with various Unix utilities' source code on our Sun workstations. At IBM we used C—and some x86 assembler—for the OS/2 source code, and we heavily used C++'s object-oriented features for a joint project with Apple. I learned shell scripting soon after, starting with csh, but moving to Bash after finding Linux in the mid-'90s. I was thrust into learning m4 (arguably more of a macro-processor than a programming language) while working on the just-in-time (JIT) compiler in IBM's custom JVM code when porting it to Linux in the late '90s.
Fast-forward 20 years... I'd never been *nervous* about learning a new programming language. But [Go](https://golang.org/) felt different. I was going to contribute publicly, upstream on GitHub, visible to anyone interested enough to look! I didn't want to be the laughingstock, the Go newbie as a 40-something-year-old senior developer! We all know that programmer pride that doesn't like to get bruised, no matter your experience level.
My early investigations revealed that Go seemed more committed to its "idiomatic-ness" than some languages. It wasn't just about getting the code to compile; I needed to be able to write code "the Go way."
Now that I'm four years and several hundred pull requests into my personal Go journey, I don't claim to be an expert, but I do feel a lot more comfortable contributing and writing Go code than I did in 2014. So, how do you teach an old guy new tricks—or at least a new programming language? Here are four steps that were valuable in my own journey to Golang land.
## 1. Don't skip the fundamentals
While you might be able to get by with copying code and hunting and pecking your way through early learnings (who has time to read the manual?!?), Go has a very readable [language spec](https://golang.org/ref/spec) that was clearly written to be read and understood, even if you don't have a master's in language or compiler theory. Given that Go made some unique decisions about the order of the **parameter:type** constructs and has interesting language features like channels and goroutines, it is important to get grounded in these new concepts. Reading this document alongside [Effective Go](https://golang.org/doc/effective_go.html), another great resource from the Golang creators, will give you a huge boost in readiness to use the language effectively and properly.
## 2. Learn from the best
There are many valuable resources for digging in and taking your Go knowledge to the next level. All the talks from any recent [GopherCon](https://www.gophercon.com/) can be found online, like this exhaustive list from [GopherCon US in 2018](https://tqdev.com/2018-gophercon-2018-videos-online). Talks range in expertise and skill level, but you can easily find something you didn't know about Go by watching the talks. [Francesc Campoy](https://twitter.com/francesc) created a Go programming video series called [JustForFunc](https://www.youtube.com/channel/UC_BzFbxG2za3bp5NRRRXJSw) that has an ever-increasing number of episodes to expand your Go knowledge and understanding. A quick search on "Golang" reveals many other video and online resources for those who want to learn more.
Want to look at code? Many of the most popular cloud-native projects on GitHub are written in Go: [Docker/Moby](https://github.com/moby/moby), [Kubernetes](https://github.com/kubernetes/kubernetes), [Istio](https://github.com/istio/istio), [containerd](https://github.com/containerd/containerd), [CoreDNS](https://github.com/coredns/coredns), and many others. Language purists might rate some projects better than others regarding idiomatic-ness, but these are all good starting points to see how large codebases are using Go in highly active projects.
## 3. Use good language tools
You will learn quickly about the value of [gofmt](https://blog.golang.org/go-fmt-your-code). One of the beautiful aspects of Go is that there is no arguing about code formatting guidelines per project—**gofmt** is built into the language runtime, and it formats Go code according to a set of stable, well-understood language rules. I don't know of any Golang-based project that doesn't insist on checking with **gofmt** for pull requests as part of continuous integration.
Beyond the wide, valuable array of useful tools built directly into the runtime/SDK, I strongly recommend using an editor or IDE with good Golang support features. Since I find myself much more often at a command line, I rely on Vim plus the great [vim-go](https://github.com/fatih/vim-go) plugin. I also like what Microsoft has offered with [VS Code](https://code.visualstudio.com/), especially with its [Go language](https://code.visualstudio.com/docs/languages/go) plugins.
Looking for a debugger? The [Delve](https://github.com/derekparker/delve) project has been improving and maturing and is a strong contender for doing [gdb](https://www.gnu.org/software/gdb/)-like debugging on Go binaries.
## 4. Jump in and write some Go!
You'll never get better at writing Go unless you start trying. Find a project that has some "help needed" issues flagged and make a contribution. If you are already using an open source project written in Go, find out if there are some bugs that have beginner-level solutions and make your first pull request. As with most things in life, the only real way to improve is through practice, so get going.
And, as it turns out, apparently you can teach an old senior developer new tricks—or languages at least.
## 4 Comments |
10,271 | 在 Fedora 上使用 Steam play 和 Proton 来玩 Windows 游戏 | https://fedoramagazine.org/play-windows-games-steam-play-proton/ | 2018-11-25T10:28:07 | [
"Steam",
"游戏"
] | https://linux.cn/article-10271-1.html | 
之前,Steam [宣布](https://steamcommunity.com/games/221410/announcements/detail/1696055855739350561)要给 Steam Play 增加一个新组件,用于支持在 Linux 平台上使用 Proton 来玩 Windows 的游戏,这个组件是 WINE 的一个分支。这个功能仍然处于测试阶段,且并非对所有游戏都有效。这里有一些关于 Steam 和 Proton 的细节。
据 Steam 网站称,测试版本中有以下这些新功能:
* 现在没有 Linux 版本的 Windows 游戏可以直接从 Linux 上的 Steam 客户端进行安装和运行,并且有完整、原生的 Steamworks 和 OpenVR 的支持。
* 现在 DirectX 11 和 12 的实现都基于 Vulkan,它可以提高游戏的兼容性并减小游戏性能收到的影响。
* 全屏支持已经得到了改进,全屏游戏时可以无缝扩展到所需的显示程度,而不会干扰到显示屏本身的分辨率或者说需要使用虚拟桌面。
* 改进了对游戏控制器的支持,游戏自动识别所有 Steam 支持的控制器,比起游戏的原始版本,能够获得更多开箱即用的控制器兼容性。
* 和 vanilla WINE 比起来,游戏的多线程性能得到了极大的提高。
### 安装
如果你有兴趣,想尝试一下 Steam 和 Proton。请按照下面这些简单的步骤进行操作。(请注意,如果你已经安装了最新版本的 Steam,可以忽略启用 Steam 测试版这个第一步。在这种情况下,你不再需要通过 Steam 测试版来使用 Proton。)
打开 Steam 并登陆到你的帐户,这个截屏示例显示的是在使用 Proton 之前仅支持 22 个游戏。

现在点击客户端顶部的 “Steam” 选项,这会显示一个下拉菜单。然后选择“设置”。

现在弹出了设置窗口,选择“账户”选项,并在 “参与 Beta 测试” 旁边,点击“更改”。

现在将 “None” 更改为 “Steam Beta Update”。

点击“确定”,然后系统会提示你重新启动。

让 Steam 下载更新,这会需要一段时间,具体需要多久这要取决于你的网络速度和电脑配置。

在重新启动之后,返回到上面的设置窗口。这次你会看到一个新选项。确定勾选了“为提供支持的游戏使用 Stream Play” 、“让所有的游戏都使用 Steam Play 运行”,“使用这个工具替代 Steam 中游戏特定的选项”。这个兼容性工具应该就是 Proton。

Steam 客户端会要求你重新启动,照做,然后重新登录你的 Steam 账户,你的 Linux 的游戏库就能得到扩展了。

### 使用 Steam Play 来安装一个 Windows 游戏
现在你已经启用 Proton,开始安装游戏,选择你想要安装的游戏,然后你会发现这个安装过程类似于在 Steam 上安装一个普通游戏,如下面这些截图所示。




在下载和安装完游戏后,你就可以开始玩了。


一些游戏可能会受到 Proton 测试性质的影响,在这个叫 Chantelise 游戏中,没有了声音并且帧率很低。请记住这个功能仍然在测试阶段,Fedora 不会对结果负责。如果你想要了解更多,社区已经创建了一个 Google 文档,这个文档里有已经测试过的游戏的列表。
---
via: <https://fedoramagazine.org/play-windows-games-steam-play-proton/>
作者:[Francisco J. Vergara Torres](https://fedoramagazine.org/author/patxi/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Some weeks ago, Steam [announced](https://steamcommunity.com/games/221410/announcements/detail/1696055855739350561) a new addition to Steam Play with Linux support for Windows games using Proton, a fork from WINE. This capability is still in beta, and not all games work. Here are some more details about Steam and Proton.
According to the Steam website, there are new features in the beta release:
- Windows games with no Linux version currently available can now be installed and run directly from the Linux Steam client, complete with native Steamworks and OpenVR support.
- DirectX 11 and 12 implementations are now based on Vulkan, which improves game compatibility and reduces performance impact.
- Fullscreen support has been improved. Fullscreen games seamlessly stretch to the desired display without interfering with the native monitor resolution or requiring the use of a virtual desktop.
- Improved game controller support. Games automatically recognize all controllers supported by Steam. Expect more out-of-the-box controller compatibility than even the original version of the game.
- Performance for multi-threaded games has been greatly improved compared to vanilla WINE.
## Installation
If you’re interested in trying Steam with Proton out, just follow these easy steps. (Note that you can ignore the first steps to enable the Steam Beta if you have the [latest updated version of Steam installed](https://fedoramagazine.org/third-party-repositories-fedora/). In that case you no longer need Steam Beta to use Proton.)
Open up Steam and log in to your account. This example screenshot shows support for only 22 games before enabling Proton.
Now click on *Steam* option on top of the client. This displays a drop down menu. Then select *Settings.*
Now the settings window pops up. Select the *Account* option and next to *Beta participation,* click on *change.*
Now change *None* to *Steam Beta Update.*
Click on *OK* and a prompt asks you to restart.
Let Steam download the update. This can take a while depending on your internet speed and computer resources.
After restarting, go back to the *Settings* window. This time you’ll see a new option. Make sure the check boxes for *Enable Steam Play for supported titles*, *Enable Steam Play for all titles* and *Use this tool instead of game-specific selections from Steam* are enabled. The compatibility tool should be Proton.
The Steam client asks you to restart. Do so, and once you log back into your Steam account, your game library for Linux should be extended.
## Installing a Windows game using Steam Play
Now that you have Proton enabled, install a game. Select the title you want and you’ll find the process is similar to installing a normal game on Steam, as shown in these screenshots.
After the game is done downloading and installing, you can play it.
Some games may be affected by the beta nature of Proton. The game in this example, Chantelise, had no audio and a low frame rate. Keep in mind this capability is still in beta and Fedora is not responsible for results. If you’d like to read further, the community has created a [Google doc](https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/edit#gid=1003113831) with a list of games that have been tested.
## Zlopez
There is also this page https://spcr.netlify.com/ for list of games compatible with Steam play. It is much nicer than google docs.
You can also use this page to submit new testing data for Steam play.
## Zlopez
Also there is no need for beta now. This is part of the standard Steam release now.
## TartareFR
An online database (wineHQ like) website exists at https://spcr.netlify.com/, there is a lot of tips for almost all running games with proton.
## DePingus
With Fedora you’re going to have to add your user to the input group or gamepads won’t work correctly.
Also, specific to Fedora, you should increase the open file limits or be prepared to disable ESYNC for proton. https://github.com/zfigura/wine/blob/esync/README.esync
## Brian
I didn’t see any entries in that database mentioning nouveau, as opposed to the Nvidia proprietary drivers. I’d given up on the proprietary drivers, since they tended to cause issues during kernel updates.
Is performance with Steam Play and Proton tested with nouveau drivers?
## Dman
You need the proprietary driver unfortunately. NVIDIA however is actually updating the Linux drivers to support Steam Play such as recent DXVK fixes.
## Steve Ebey
using dkms for kernel update of the nvidia drivers, currently running 410.57 on fedora 28, and every kernel update automatically recompiles the driver, during the kernel update. If you have a problem, it could mean some of the necessary components for dkms or gcc are not installed.
## Matthew Bunt
There is a cool little project on github that helps configure proton just like winetricks helps configure wine. You can use it to make changes for specific games so the configs wont overlap with other games (just like separate wine prefixes).
protontricks – https://github.com/Sirmentio/protontricks
## Greyson
Perfect! I am using Steam Play and is a gorgeous project
## andrei
Is this ever going to be implemented for games outside of steam?
## Luke
This is a specific feature of Steam Client that pulls a fork of WINE down and auto-configures it, essentially, to make Steam-based Windows games play easier.
You can use WINE directly for non-Steam games.
## Frederik
I think what Andrei is asking is if the Proton specific bits will be made available for regular Wine. Wine is LGPL, which should mean that the new bits needs to be released under LGPL as well (knowing nothing about the details about how stuff is implemented — it may not be requried).
## Dman
You dont mention the drivers required to run Steam Play properly in Linux. Obviously the latest NVIDIA proprietary drivers are required but Fedora 28 ships with an old version of Mesa. Therefore you need to update Mesa for AMD users from a compatible copr. Ideally version 18.2.2 which has a bunch of DXVK fixes. Hopefully Mesa is more up to date in Fedora 29…
## Dman
Here is the best copr to use with Fedora 28 for AMD users to get the updated Mesa drivers… https://copr.fedorainfracloud.org/coprs/jerbear64/mesa_dxvk/
## Peter
I believe this solution is far from being ready yet. I could’t find a game that would start on my machine even though they are listed as fully supported. Things like miss-identifying my graphics card are happening.
I’m on the latest Nvidia proprietary drivers, and native Linux games are working just fine. So we’re not there yet, but it’s a hopeful start.
## HesusFTW
Is there a chance to play games with Intel Graphics Drivers? (I’m currently playing Dota 2 on the integrated graphics of my Intel Core i7-7700). I already tried to play Age of Empires 2 but it doesn’t even start/crash/do something.
## Dman
Not supported. You can upgrade the Mesa drivers to help but I don’t think Intel have a strong focus here unlike the AMD driver stack. Unless the game supported Intel graphics natively & ideally uses OpenGL you’re going to struggle.
## Dman
HesusFTW, try the Mesa copr from here…
https://copr.fedorainfracloud.org/coprs/jerbear64/mesa_dxvk/
Age of Empires is a DirectX 9 game so you need the Gallium Nine compatibility layer.
This is now part of the updated Mesa stack. Hopefully this works for you.
## Przemek
I’m looking for some help.
I’m trying to run Rocksmith, which needs special cable (USB to guitar jack).
Game starts without the problem, but I have no luck with the recognition of the cable. Cable itself shows up correctly in the lsusb.
Any idea how to proceed? This is the only things which keeps me from removing windows dual boot partition.
## pac
@Przemek
You probably need to add your user to the input group, depending on your distribution. I’m guessing it might treat it like a gamepad, and without your user being in the group it refuses to work.
## Michel
Can someone recommend a good game to try this on that’s also cheap? None of my Windows-only titles (like Sid Meier’s Ace Patrol and Typing of the Dead) are well-supported, and I’m using the Steam flatpak so I want to check if that introduces additional issues or not.
## Zlopez
I’m using flatpak Steam with steam play and these games are working for me without issue: Warhammer End Times: Vermintide, The Walking Dead, Shortest Trip to Earth and Anachronox.
Didn’t noticed any additional issue when I switched from RPM Steam to Flatpak.
## Edward O'Callaghan
https://github.com/ValveSoftware/steam-for-linux/issues/5634
Because of this issue it is sometimes the case that the Steam client will SegFault on Fedora under certain Audio device configurations, depending if your HDMI audio adapters happen to come first or not. Possible other configuration variants will trigger the crash.
## AngryAnonymous
Yeah, if you just figured out how to install drivers on fedora then you can publish a post like this.
## Jatin
There are many games still, infact most of the games dont run using steam proton but they run on linux using DXVK via Lutris. Lutris is a great application it has pre tested scripts for the games to run using DXVK (Vulkan). Proton is still not that mature currently. In many cases Wine still does the better job. Proton is a folk of wine for steam and i hope it will be great in the future.
## John Harris
It’d be awesome if Fedora Magazine would stop supporting the use of proprietary software.
## ImFromPL
Shakes and Fidget working too good. |
10,272 | ProtectedText:一个免费的在线加密笔记 | https://www.ostechnix.com/protectedtext-a-free-encrypted-notepad-to-save-your-notes-online/ | 2018-11-25T10:41:56 | [
"加密",
"笔记"
] | https://linux.cn/article-10272-1.html | 
记录笔记是我们每个人必备的重要技能,它可以帮助我们把自己听到、读到、学到的内容长期地保留下来,也有很多的应用和工具都能让我们更好地记录笔记。下面我要介绍一个叫做 **ProtectedText** 的应用,这是一个可以将你的笔记在线上保存起来的免费的加密笔记。它是一个免费的 web 服务,在上面记录文本以后,它将会对文本进行加密,只需要一台支持连接到互联网并且拥有 web 浏览器的设备,就可以访问到记录的内容。
ProtectedText 不会向你询问任何个人信息,也不会保存任何密码,没有广告,没有 Cookies,更没有用户跟踪和注册流程。除了拥有密码能够解密文本的人,任何人都无法查看到笔记的内容。而且,使用前不需要在网站上注册账号,写完笔记之后,直接关闭浏览器,你的笔记也就保存好了。
### 在加密笔记本上记录笔记
访问 <https://www.protectedtext.com/> 这个链接,就可以打开 ProtectedText 页面了(LCTT 译注:如果访问不了,你知道的)。这个时候你将进入网站主页,接下来需要在页面上的输入框输入一个你想用的名称,或者在地址栏后面直接加上想用的名称。这个名称是一个自定义的名称(例如 <https://www.protectedtext.com/mysite>),是你查看自己保存的笔记的专有入口。

如果你选用的名称还没有被占用,你就会看到下图中的提示信息。点击 “Create” 键就可以创建你的个人笔记页了。

至此你已经创建好了你自己的笔记页面,可以开始记录笔记了。目前每个笔记页的最大容量是每页 750000+ 个字符。
ProtectedText 使用 AES 算法对你的笔记内容进行加密和解密,而计算散列则使用了 SHA512 算法。
笔记记录完毕以后,点击顶部的 “Save” 键保存。

按下保存键之后,ProtectedText 会提示你输入密码以加密你的笔记内容。按照它的要求输入两次密码,然后点击 “Save” 键。

尽管 ProtectedText 对你使用的密码没有太多要求,但毕竟密码总是一寸长一寸强,所以还是最好使用长且复杂的密码(用到数字和特殊字符)以避免暴力破解。由于 ProtectedText 不会保存你的密码,一旦密码丢失,密码和笔记内容就都找不回来了。因此,请牢记你的密码,或者使用诸如 [Buttercup](https://www.ostechnix.com/buttercup-a-free-secure-and-cross-platform-password-manager/)、[KeeWeb](https://www.ostechnix.com/keeweb-an-open-source-cross-platform-password-manager/) 这样的密码管理器来存储你的密码。
在使用其它设备时,可以通过访问之前创建的 URL 就可以访问你的笔记了。届时会出现如下的提示信息,只需要输入正确的密码,就可以查看和编辑你的笔记。

一般情况下,只有知道密码的人才能正常访问笔记的内容。如果你希望将自己的笔记公开,只需要以 <https://www.protectedtext.com/yourSite?yourPassword> 的形式访问就可以了,ProtectedText 将会自动使用 `yourPassword` 字符串解密你的笔记。
ProtectedText 还有配套的 [Android 应用](https://play.google.com/store/apps/details?id=com.protectedtext.android) 可以让你在移动设备上进行同步笔记、离线工作、备份笔记、锁定/解锁笔记等等操作。
**优点**
* 简单、易用、快速、免费
* ProtectedText.com 的客户端代码可以在[这里](https://www.protectedtext.com/js/main.js)免费获取,如果你想了解它的底层实现,可以自行学习它的源代码
* 存储的内容没有到期时间,只要你愿意,笔记内容可以一直保存在服务器上
* 可以让你的数据限制为私有或公开开放
**缺点**
* 尽管客户端代码是公开的,但服务端代码并没有公开,因此你无法自行搭建一个类似的服务。如果你不信任这个网站,请不要使用。
* 由于网站不存储你的任何个人信息,包括你的密码,因此如果你丢失了密码,数据将永远无法恢复。网站方还声称他们并不清楚谁拥有了哪些数据,所以一定要牢记密码。
如果你想通过一种简单的方式将笔记保存到线上,并且需要在不需要安装任何工具的情况下访问,那么 ProtectedText 会是一个好的选择。如果你还知道其它类似的应用程序,欢迎在评论区留言!
---
via: <https://www.ostechnix.com/protectedtext-a-free-encrypted-notepad-to-save-your-notes-online/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,273 | Caffeinated 6.828:实验工具指南 | https://pdos.csail.mit.edu/6.828/2018/labguide.html | 2018-11-25T12:02:04 | [
"GDB",
"6.828"
] | https://linux.cn/article-10273-1.html | 
熟悉你的环境对高效率的开发和调试来说是至关重要的。本文将为你简单概述一下 JOS 环境和非常有用的 GDB 和 QEMU 命令。话虽如此,但你仍然应该去阅读 GDB 和 QEMU 手册,来理解这些强大的工具如何使用。
### 调试小贴士
#### 内核
GDB 是你的朋友。使用 `qemu-gdb target`(或它的变体 `qemu-gdb-nox`)使 QEMU 等待 GDB 去绑定。下面在调试内核时用到的一些命令,可以去查看 GDB 的资料。
如果你遭遇意外的中断、异常、或三重故障,你可以使用 `-d` 参数要求 QEMU 去产生一个详细的中断日志。
调试虚拟内存问题时,尝试 QEMU 的监视命令 `info mem`(提供内存高级概述)或 `info pg`(提供更多细节内容)。注意,这些命令仅显示**当前**页表。
(在实验 4 以后)去调试多个 CPU 时,使用 GDB 的线程相关命令,比如 `thread` 和 `info threads`。
#### 用户环境(在实验 3 以后)
GDB 也可以去调试用户环境,但是有些事情需要注意,因为 GDB 无法区分开多个用户环境或区分开用户环境与内核环境。
你可以使用 `make run-name`(或编辑 `kern/init.c` 目录)来指定 JOS 启动的用户环境,为使 QEMU 等待 GDB 去绑定,使用 `run-name-gdb` 的变体。
你可以符号化调试用户代码,就像调试内核代码一样,但是你要告诉 GDB,哪个符号表用到符号文件命令上,因为它一次仅能够使用一个符号表。提供的 `.gdbinit` 用于加载内核符号表 `obj/kern/kernel`。对于一个用户环境,这个符号表在它的 ELF 二进制文件中,因此你可以使用 `symbol-file obj/user/name` 去加载它。不要从任何 `.o` 文件中加载符号,因为它们不会被链接器迁移进去(库是静态链接进 JOS 用户二进制文件中的,因此这些符号已经包含在每个用户二进制文件中了)。确保你得到了正确的用户二进制文件;在不同的二进制文件中,库函数被链接为不同的 EIP,而 GDB 并不知道更多的内容!
(在实验 4 以后)因为 GDB 绑定了整个虚拟机,所以它可以将时钟中断看作为一种控制转移。这使得从底层上不可能实现步进用户代码,因为一个时钟中断无形中保证了片刻之后虚拟机可以再次运行。因此可以使用 `stepi` 命令,因为它阻止了中断,但它仅可以步进一个汇编指令。断点一般来说可以正常工作,但要注意,因为你可能在不同的环境(完全不同的一个二进制文件)上遇到同一个 EIP。
### 参考
#### JOS makefile
JOS 的 GNUmakefile 包含了在各种方式中运行的 JOS 的许多假目标。所有这些目标都配置 QEMU 去监听 GDB 连接(`*-gdb` 目标也等待这个连接)。要在运行中的 QEMU 上启动它,只需要在你的实验目录中简单地运行 `gdb` 即可。我们提供了一个 `.gdbinit` 文件,它可以在 QEMU 中自动指向到 GDB、加载内核符号文件、以及在 16 位和 32 位模式之间切换。退出 GDB 将关闭 QEMU。
* `make qemu`
在一个新窗口中构建所有的东西并使用 VGA 控制台和你的终端中的串行控制台启动 QEMU。想退出时,既可以关闭 VGA 窗口,也可以在你的终端中按 `Ctrl-c` 或 `Ctrl-a x`。
* `make qemu-nox`
和 `make qemu` 一样,但仅使用串行控制台来运行。想退出时,按下 `Ctrl-a x`。这种方式在通过 SSH 拨号连接到 Athena 上时非常有用,因为 VGA 窗口会占用许多带宽。
* `make qemu-gdb`
和 `make qemu` 一样,但它与任意时间被动接受 GDB 不同,而是暂停第一个机器指令并等待一个 GDB 连接。
* `make qemu-nox-gdb`
它是 `qemu-nox` 和 `qemu-gdb` 目标的组合。
* `make run-nam`
(在实验 3 以后)运行用户程序 name。例如,`make run-hello` 运行 `user/hello.c`。
* `make run-name-nox`,`run-name-gdb`, `run-name-gdb-nox`
(在实验 3 以后)与 `qemu` 目标变量对应的 `run-name` 的变体。
makefile 也接受几个非常有用的变量:
* `make V=1 …`
详细模式。输出正在运行的每个命令,包括参数。
* `make V=1 grade`
在评级测试失败后停止,并将 QEMU 的输出放入 `jos.out` 文件中以备检查。
* `make QEMUEXTRA=' _args_ ' …`
指定传递给 QEMU 的额外参数。
#### JOS obj/
在构建 JOS 时,makefile 也产生一些额外的输出文件,这些文件在调试时非常有用:
* `obj/boot/boot.asm`、`obj/kern/kernel.asm`、`obj/user/hello.asm`、等等。
引导加载器、内核、和用户程序的汇编代码列表。
* `obj/kern/kernel.sym`、`obj/user/hello.sym`、等等。
内核和用户程序的符号表。
* `obj/boot/boot.out`、`obj/kern/kernel`、`obj/user/hello`、等等。
内核和用户程序链接的 ELF 镜像。它们包含了 GDB 用到的符号信息。
#### GDB
完整的 GDB 命令指南请查看 [GDB 手册](http://sourceware.org/gdb/current/onlinedocs/gdb/)。下面是一些在 6.828 课程中非常有用的命令,它们中的一些在操作系统开发之外的领域几乎用不到。
* `Ctrl-c`
在当前指令处停止机器并打断进入到 GDB。如果 QEMU 有多个虚拟的 CPU,所有的 CPU 都会停止。
* `c`(或 `continue`)
继续运行,直到下一个断点或 `Ctrl-c`。
* `si`(或 `stepi`)
运行一个机器指令。
* `b function` 或 `b file:line`(或 `breakpoint`)
在给定的函数或行上设置一个断点。
* `b * addr`(或 `breakpoint`)
在 EIP 的 addr 处设置一个断点。
* `set print pretty`
启用数组和结构的美化输出。
* `info registers`
输出通用寄存器 `eip`、`eflags`、和段选择器。更多更全的机器寄存器状态转储,查看 QEMU 自己的 `info registers` 命令。
* `x/ N x addr`
以十六进制显示虚拟地址 addr 处开始的 N 个词的转储。如果 N 省略,默认为 1。addr 可以是任何表达式。
* `x/ N i addr`
显示从 addr 处开始的 N 个汇编指令。使用 `$eip` 作为 addr 将显示当前指令指针寄存器中的指令。
* `symbol-file file`
(在实验 3 以后)切换到符号文件 file 上。当 GDB 绑定到 QEMU 后,它并不是虚拟机中进程边界内的一部分,因此我们要去告诉它去使用哪个符号。默认情况下,我们配置 GDB 去使用内核符号文件 `obj/kern/kernel`。如果机器正在运行用户代码,比如是 `hello.c`,你就需要使用 `symbol-file obj/user/hello` 去切换到 hello 的符号文件。
QEMU 将每个虚拟 CPU 表示为 GDB 中的一个线程,因此你可以使用 GDB 中所有的线程相关的命令去查看或维护 QEMU 的虚拟 CPU。
* `thread n`
GDB 在一个时刻只关注于一个线程(即:CPU)。这个命令将关注的线程切换到 n,n 是从 0 开始编号的。
* `info threads`
列出所有的线程(即:CPU),包括它们的状态(活动还是停止)和它们在什么函数中。
#### QEMU
QEMU 包含一个内置的监视器,它能够有效地检查和修改机器状态。想进入到监视器中,在运行 QEMU 的终端中按入 `Ctrl-a c` 即可。再次按下 `Ctrl-a c` 将切换回串行控制台。
监视器命令的完整参考资料,请查看 [QEMU 手册](http://wiki.qemu.org/download/qemu-doc.html#pcsys_005fmonitor)。下面是 6.828 课程中用到的一些有用的命令:
* `xp/ N x paddr`
显示从物理地址 paddr 处开始的 N 个词的十六进制转储。如果 N 省略,默认为 1。这是 GDB 的 `x` 命令模拟的物理内存。
* `info registers`
显示机器内部寄存器状态的一个完整转储。实践中,对于段选择器,这将包含机器的 隐藏 段状态和局部、全局、和中断描述符表加任务状态寄存器。隐藏状态是在加载段选择器后,虚拟的 CPU 从 GDT/LDT 中读取的信息。下面是实验 1 中 JOS 内核处于运行中时的 CS 信息和每个字段的含义:
```
CS =0008 10000000 ffffffff 10cf9a00 DPL=0 CS32 [-R-]
```
* `CS =0008`
代码选择器可见部分。我们使用段 0x8。这也告诉我们参考全局描述符表(0x8&4=0),并且我们的 CPL(当前权限级别)是 0x8&3=0。
* `10000000`
这是段基址。线性地址 = 逻辑地址 + 0x10000000。
* `ffffffff`
这是段限制。访问线性地址 0xffffffff 以上将返回段违规异常。
* `10cf9a00`
段的原始标志,QEMU 将在接下来的几个字段中解码这些对我们有用的标志。
* `DPL=0`
段的权限级别。一旦代码以权限 0 运行,它将就能够加载这个段。
* `CS32`
这是一个 32 位代码段。对于数据段(不要与 DS 寄存器混淆了),另外的值还包括 `DS`,而对于本地描述符表是 `LDT`。
* `[-R-]`
这个段是只读的。
* `info mem`
(在实验 2 以后)显示映射的虚拟内存和权限。比如:
```
ef7c0000-ef800000 00040000 urw
efbf8000-efc00000 00008000 -rw
```
这告诉我们从 0xef7c0000 到 0xef800000 的 0x00040000 字节的内存被映射为读取/写入/用户可访问,而映射在 0xefbf8000 到 0xefc00000 之间的内存权限是读取/写入,但是仅限于内核可访问。
* `info pg`
(在实验 2 以后)显示当前页表结构。它的输出类似于 `info mem`,但与页目录条目和页表条目是有区别的,并且为每个条目给了单独的权限。重复的 PTE 和整个页表被折叠为一个单行。例如:
```
VPN range Entry Flags Physical page
[00000-003ff] PDE[000] -------UWP
[00200-00233] PTE[200-233] -------U-P 00380 0037e 0037d 0037c 0037b 0037a ..
[00800-00bff] PDE[002] ----A--UWP
[00800-00801] PTE[000-001] ----A--U-P 0034b 00349
[00802-00802] PTE[002] -------U-P 00348
```
这里各自显示了两个页目录条目、虚拟地址范围 0x00000000 到 0x003fffff 以及 0x00800000 到 0x00bfffff。 所有的 PDE 都存在于内存中、可写入、并且用户可访问,而第二个 PDE 也是可访问的。这些页表中的第二个映射了三个页、虚拟地址范围 0x00800000 到 0x00802fff,其中前两个页是存在于内存中的、可写入、并且用户可访问的,而第三个仅存在于内存中,并且用户可访问。这些 PTE 的第一个条目映射在物理页 0x34b 处。
QEMU 也有一些非常有用的命令行参数,使用 `QEMUEXTRA` 变量可以将参数传递给 JOS 的 makefile。
* `make QEMUEXTRA='-d int' ...`
记录所有的中断和一个完整的寄存器转储到 `qemu.log` 文件中。你可以忽略前两个日志条目、“SMM: enter” 和 “SMM: after RMS”,因为这些是在进入引导加载器之前生成的。在这之后的日志条目看起来像下面这样:
```
4: v=30 e=0000 i=1 cpl=3 IP=001b:00800e2e pc=00800e2e SP=0023:eebfdf28 EAX=00000005
EAX=00000005 EBX=00001002 ECX=00200000 EDX=00000000
ESI=00000805 EDI=00200000 EBP=eebfdf60 ESP=eebfdf28
...
```
第一行描述了中断。`4:` 只是一个日志记录计数器。`v` 提供了十六进程的向量号。`e` 提供了错误代码。`i=1` 表示它是由一个 `int` 指令(相对一个硬件产生的中断而言)产生的。剩下的行的意思很明显。对于一个寄存器转储而言,接下来看到的就是寄存器信息。
注意:如果你运行的是一个 0.15 版本之前的 QEMU,日志将写入到 `/tmp` 目录,而不是当前目录下。
---
via: <https://pdos.csail.mit.edu/6.828/2018/labguide.html>
作者:[csail.mit](https://pdos.csail.mit.edu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # 6.828 lab tools guide
Familiarity with your environment is crucial for productive
development and debugging. This page gives a brief overview of the
JOS environment and useful GDB and QEMU commands. Don't take our word
for it, though. Read the GDB and QEMU manuals. These are powerful
tools that are worth knowing how to use.
## Debugging tips
### Kernel
GDB is your friend. Use the `qemu-gdb` target (or its `qemu-gdb-nox` variant) to make
QEMU wait for GDB to attach. See the [GDB](#gdb) reference
below for some commands that are useful when debugging kernels.
If you're getting unexpected interrupts, exceptions, or triple
faults, you can ask QEMU to generate a detailed log of interrupts
using the [-d](#qemu--d) argument.
To debug virtual memory issues, try the QEMU monitor commands `info mem` (for a high-level
overview) or `info pg` (for lots
of detail). Note that these commands only display the *current*
page table.
(Lab 4+) To debug multiple CPUs, use GDB's thread-related commands
like `thread` and `info threads`.
### User environments (lab 3+)
GDB also lets you debug user environments, but there are a few
things you need to watch out for, since GDB doesn't know that there's
a distinction between multiple user environments, or between user and
kernel.
You can start JOS with a specific user environment using `make run-`*name* (or you can edit
`kern/init.c` directly). To make QEMU wait for GDB to attach,
use the `run-`*name*-gdb
variant.
You can symbolically debug user code, just like you can kernel
code, but you have to tell GDB which [symbol
table](#obj-elf) to use with the `symbol-file` command, since it
can only use one symbol table at a time. The provided
`.gdbinit` loads the kernel symbol table,
`obj/kern/kernel`. The symbol table for a user environment is
in its ELF binary, so you can load it using `symbol-file
obj/user/`*name*. *Don't* load symbols from any
`.o` files, as those haven't been relocated by the linker
(libraries are statically linked into JOS user binaries, so those
symbols are already included in each user binary). Make sure you get
the *right* user binary; library functions will be linked at
different EIPs in different binaries and GDB won't know any
better!
(Lab 4+) Since GDB is attached to the virtual machine as a whole,
it sees clock interrupts as just another control transfer. This makes
it basically impossible to step through user code because a clock
interrupt is virtually guaranteed the moment you let the VM run again.
The `stepi` command works because it
suppresses interrupts, but it only steps one assembly instruction. [Breakpoints](#gdb-b) generally work, but watch out because
you can hit the same EIP in a different environment (indeed, a
different binary altogether!).
## Reference
### JOS makefile
The JOS GNUmakefile includes a number of phony targets for running JOS
in various ways. All of these targets configure QEMU to listen for
GDB connections (the
`*-gdb` targets also wait for this
connection). To start once QEMU is running, simply run
`gdb`
from your lab directory. We provide a
`.gdbinit` file that
automatically points GDB at QEMU, loads the kernel symbol file, and
switches between 16-bit and 32-bit mode. Exiting GDB will shut down
QEMU.
`make qemu`
- Build everything and start QEMU with the VGA console in a new
window and the serial console in your terminal. To exit, either
close the VGA window or press
`Ctrl-c` or `Ctrl-a x`
in your terminal.
`make qemu-nox`
- Like
`make qemu`, but run with only the serial console.
To exit, press `Ctrl-a x`. This is particularly useful over
SSH connections to Athena dialups because the VGA window consumes a
lot of bandwidth.
`make qemu-gdb`
- Like
`make qemu`, but rather than passively accepting GDB
connections at any time, this pauses at the first machine
instruction and waits for a GDB connection.
`make qemu-nox-gdb`
- A combination of the
`qemu-nox` and `qemu-gdb`
targets.
`make run-`*name*
- (Lab 3+) Run user program
*name*. For example, `make
run-hello` runs `user/hello.c`.
`make run-`*name*-nox,
`run-`*name*-gdb,
`run-`*name*-gdb-nox,
- (Lab 3+) Variants of
`run-`*name* that correspond to
the variants of the `qemu` target.
The makefile also accepts a few useful variables:
`make V=1 ...`
- Verbose mode. Print out every command being executed, including
arguments.
`make V=1 grade`
- Stop after any failed grade test and leave the QEMU output in
`jos.out` for inspection.
- Specify additional arguments to pass to QEMU.
### JOS obj/
When building JOS, the makefile also produces some additional
output files that may prove useful while debugging:
`obj/boot/boot.asm`,
`obj/kern/kernel.asm`, `obj/user/hello.asm`, etc.
- Assembly code listings for the bootloader, kernel, and user
programs.
`obj/kern/kernel.sym`,
`obj/user/hello.sym`, etc.
- Symbol tables for the kernel and user programs.
`obj/boot/boot.out`, `obj/kern/kernel`,
`obj/user/hello`, etc
- Linked ELF images of the kernel and user programs. These
contain symbol information that can be used by GDB.
### GDB
See the [GDB
manual](http://sourceware.org/gdb/current/onlinedocs/gdb/) for a full guide to GDB commands. Here are some
particularly useful commands for 6.828, some of which don't typically
come up outside of OS development.
`Ctrl-c`
- Halt the machine and break in to GDB at the current
instruction. If QEMU has multiple virtual CPUs, this halts all of
them.
`c` (or `continue`)
- Continue execution until the next breakpoint or
`Ctrl-c`.
`si` (or `stepi`)
- Execute one machine instruction.
`b function` or `b file:line` (or
`breakpoint`)
- Set a breakpoint at the given function or line.
`b *`*addr* (or `breakpoint`)
- Set a breakpoint at the EIP
*addr*.
`set print pretty`
- Enable pretty-printing of arrays and structs.
`info registers`
- Print the general purpose registers,
`eip`,
`eflags`, and the segment selectors. For a much more
thorough dump of the machine register state, see QEMU's own `info
registers` command.
`x/`*N*x *addr*
- Display a hex dump of
*N* words starting at virtual address
*addr*. If *N* is omitted, it defaults to 1. *addr*
can be any expression.
`x/`*N*i *addr*
- Display the
*N* assembly instructions starting at
*addr*. Using `$eip` as *addr* will display the
instructions at the current instruction pointer.
`symbol-file `*file*
- (Lab 3+) Switch to symbol file
*file*. When GDB attaches
to QEMU, it has no notion of the process boundaries within the
virtual machine, so we have to tell it which symbols to use. By
default, we configure GDB to use the kernel symbol file,
`obj/kern/kernel`. If the machine is running user code, say
`hello.c`, you can switch to the hello symbol file using
`symbol-file obj/user/hello`.
QEMU represents each virtual CPU as a thread in GDB, so you can use
all of GDB's thread-related commands to view or manipulate QEMU's
virtual CPUs.
`thread `*n*
- GDB focuses on one thread (i.e., CPU) at a time. This command
switches that focus to thread
*n*, numbered from zero.
`info threads`
- List all threads (i.e., CPUs), including their state (active or
halted) and what function they're in.
### QEMU
QEMU includes a built-in monitor that can inspect and modify the
machine state in useful ways. To enter the monitor, press `Ctrl-a
c` in the terminal running QEMU. Press `Ctrl-a c` again
to switch back to the serial console.
For a complete reference to the monitor commands, see the [QEMU
manual](http://wiki.qemu.org/download/qemu-doc.html#pcsys_005fmonitor). Here are some particularly useful commands:
`xp/`*N*x *paddr*
- Display a hex dump of
*N* words starting at *physical*
address *paddr*. If *N* is omitted, it defaults to 1.
This is the physical memory analogue of GDB's `x`
command.
`info registers`
- Display a full dump of the machine's internal register state.
In particular, this includes the machine's
*hidden* segment
state for the segment selectors and the local, global, and interrupt
descriptor tables, plus the task register. This hidden state is the
information the virtual CPU read from the GDT/LDT when the segment
selector was loaded. Here's the CS when running in the JOS kernel
in lab 1 and the meaning of each field:
CS =0008 10000000 ffffffff 10cf9a00 DPL=0 CS32 [-R-]
`CS =0008`
- The visible part of the code selector. We're using segment
0x8. This also tells us we're referring to the global descriptor
table (0x8&4=0), and our CPL (current privilege level) is
0x8&3=0.
`10000000`
- The base of this segment. Linear address = logical address +
0x10000000.
`ffffffff`
- The limit of this segment. Linear addresses above 0xffffffff
will result in segment violation exceptions.
`10cf9a00`
- The raw flags of this segment, which QEMU helpfully decodes
for us in the next few fields.
`DPL=0`
- The privilege level of this segment. Only code running with
privilege level 0 can load this segment.
`CS32`
- This is a 32-bit code segment. Other values include
`DS` for data segments (not to be confused with the DS
register), and `LDT` for local descriptor tables.
`[-R-]`
- This segment is read-only.
`info mem`
- (Lab 2+) Display mapped virtual memory and permissions. For
example,
ef7c0000-ef800000 00040000 urw
efbf8000-efc00000 00008000 -rw
tells us that the 0x00040000 bytes of memory from 0xef7c0000 to
0xef800000 are mapped read/write and user-accessible, while the
memory from 0xefbf8000 to 0xefc00000 is mapped read/write, but only
kernel-accessible.
`info pg`
- (Lab 2+) Display the current page table structure. The output
is similar to
`info mem`, but distinguishes page directory
entries and page table entries and gives the permissions for each
separately. Repeated PTE's and entire page tables are folded up
into a single line. For example,
VPN range Entry Flags Physical page
[00000-003ff] PDE[000] -------UWP
[00200-00233] PTE[200-233] -------U-P 00380 0037e 0037d 0037c 0037b 0037a ..
[00800-00bff] PDE[002] ----A--UWP
[00800-00801] PTE[000-001] ----A--U-P 0034b 00349
[00802-00802] PTE[002] -------U-P 00348
This shows two page directory entries, spanning virtual addresses
0x00000000 to 0x003fffff and 0x00800000 to 0x00bfffff, respectively.
Both PDE's are present, writable, and user and the second PDE is also
accessed. The second of these page tables maps three pages, spanning
virtual addresses 0x00800000 through 0x00802fff, of which the first
two are present, user, and accessed and the third is only present and
user. The first of these PTE's maps physical page 0x34b.
QEMU also takes some useful command line arguments, which can be
passed into the JOS makefile using the
[QEMUEXTRA](#make-qemuextra) variable.
`make QEMUEXTRA='-d int' ...`
- Log all interrupts, along with a full register dump, to
`qemu.log`. You can ignore the first two log entries, "SMM:
enter" and "SMM: after RMS", as these are generated before entering
the boot loader. After this, log entries look like
4: v=30 e=0000 i=1 cpl=3 IP=001b:00800e2e pc=00800e2e SP=0023:eebfdf28 EAX=00000005
EAX=00000005 EBX=00001002 ECX=00200000 EDX=00000000
ESI=00000805 EDI=00200000 EBP=eebfdf60 ESP=eebfdf28
...
The first line describes the interrupt. The `4:` is just a
log record counter. `v` gives the vector number in hex.
`e` gives the error code. `i=1` indicates that this
was produced by an `int`
instruction (versus a hardware
interrupt). The rest of the line should be self-explanatory. See
[info registers](#qemu-info-registers) for a description
of the register dump that follows.
- Note: If you're running a pre-0.15 version of QEMU, the log will
be written to
`/tmp` instead of the current directory.
Questions or comments regarding 6.828? Send e-mail to the TAs at
*[email protected]*.

[Top](#top) //
[6.828 home](index.html) //
[Accessibility](https://accessibility.mit.edu/) //
*Last updated Wednesday, 22-Sep-2021 12:14:47 EDT* |
10,274 | 让系统崩溃的黑天鹅分类 | https://opensource.com/article/18/10/taxonomy-black-swans | 2018-11-25T12:39:38 | [
"黑天鹅",
"故障"
] | https://linux.cn/article-10274-1.html |
>
> 在严重的故障发生之前,找到引起问题的异常事件,并修复它。
>
>
>

<ruby> 黑天鹅 <rt> Black swan </rt></ruby>用来比喻造成严重影响的小概率事件(比如 2008 年的金融危机)。在生产环境的系统中,黑天鹅是指这样的事情:它引发了你不知道的问题,造成了重大影响,不能快速修复或回滚,也不能用值班说明书上的其他标准响应来解决。它是事发几年后你还在给新人说起的事件。
从定义上看,黑天鹅是不可预测的,不过有时候我们能找到其中的一些模式,针对有关联的某一类问题准备防御措施。
例如,大部分故障的直接原因是变更(代码、环境或配置)。虽然这种方式触发的 bug 是独特的、不可预测的,但是常见的金丝雀发布对避免这类问题有一定的作用,而且自动回滚已经成了一种标准止损策略。
随着我们的专业性不断成熟,一些其他的问题也正逐渐变得容易理解,被归类到某种风险并有普适的预防策略。
### 公布出来的黑天鹅事件
所有科技公司都有生产环境的故障,只不过并不是所有公司都会分享他们的事故分析。那些公开讨论事故的公司帮了我们的忙。下列事故都描述了某一类问题,但它们绝对不是只一个孤例。我们的系统中都有黑天鹅在潜伏着,只是有些人还不知道而已。
#### 达到上限
达到任何类型的限制都会引发严重事故。这类问题的一个典型例子是 2017 年 2 月 [Instapaper 的一次服务中断](https://medium.com/making-instapaper/instapaper-outage-cause-recovery-3c32a7e9cc5f)。我把这份事故报告给任何一个运维工作者看,他们读完都会脊背发凉。Instapaper 生产环境的数据库所在的文件系统有 2 TB 的大小限制,但是数据库服务团队并不知情。在没有任何报错的情况下,数据库不再接受任何写入了。完全恢复需要好几天,而且还得迁移数据库。
资源限制有各式各样的触发场景。Sentry 遇到了 [Postgres 的最大事务 ID 限制](https://blog.sentry.io/2015/07/23/transaction-id-wraparound-in-postgres.html)。Platform.sh 遇到了[管道缓冲区大小限制](https://medium.com/@florian_7764/technical-post-mortem-of-the-august-incident-82ab4c3d6547)。SparkPost [触发了 AWS 的 DDoS 保护](https://www.usenix.org/conference/srecon18americas/presentation/blosser)。Foursquare 在他们的一个 [MongoDB 耗尽内存](https://groups.google.com/forum/#!topic/mongodb-user/UoqU8ofp134)时遭遇了性能骤降。
提前了解系统限制的一个办法是定期做测试。好的压力测试(在生产环境的副本上做)应该包含写入事务,并且应该把每一种数据存储都写到超过当前生产环境的容量。压力测试时很容易忽略的是次要存储(比如 Zookeeper)。如果你是在测试时遇到了资源限制,那么你还有时间去解决问题。鉴于这种资源限制问题的解决方案可能涉及重大的变更(比如数据存储拆分),所以时间是非常宝贵的。
说到云产品的使用,如果你的服务产生了异常的负载,或者你用的产品或功能还没有被广泛使用(比如老旧的或者新兴的),那么你遇到资源上限的风险很大。对这些云产品做一下压力测试是值得的。不过,做之前要提醒一下你的云服务提供商。
最后,知道了哪里有限制之后,要增加监控(和对应文档),这样你才能知道系统在什么时候接近了资源上限。不要寄希望于那些还在维护服务的人会记得。
#### 扩散的慢请求
>
> “这个世界的关联性远比我们想象中更大。所以我们看到了更多 Nassim Taleb 所说的‘黑天鹅事件’ —— 即罕见事件以更高的频率离谱地发生了,因为世界是相互关联的” —— [Richard Thaler](https://en.wikipedia.org/wiki/Richard_Thaler)
>
>
>
HostedGraphite 的负载均衡器并没有托管在 AWS 上,却[被 AWS 的服务中断给搞垮了](https://blog.hostedgraphite.com/2018/03/01/spooky-action-at-a-distance-how-an-aws-outage-ate-our-load-balancer/),他们关于这次事故原因的分析报告很好地诠释了分布式计算系统之间存在多么大的关联。在这个事件里,负载均衡器的连接池被来自 AWS 上的客户访问占满了,因为这些连接很耗时。同样的现象还会发生在应用的线程、锁、数据库连接上 —— 任何能被慢操作占满的资源。
这个 HostedGraphite 的例子中,慢速连接是外部系统施加的,不过慢速连接经常是由内部某个系统的饱和所引起的,饱和与慢操作的级联,拖慢了系统中的其他部分。[Spotify 的一个事故](https://labs.spotify.com/2013/06/04/incident-management-at-spotify/)就说明了这样的传播 —— 流媒体服务的前端被另一个微服务的饱和所影响,造成健康检查失败。强制给所有请求设置超时时间,以及限制请求队列的长度,可以预防这一类故障传播。这样即使有问题,至少你的服务还能承担一些流量,而且因为整体上你的系统里故障的部分更少了,恢复起来也会更快。
重试的间隔应该用指数退避来限制一下,并加入一些时间抖动。Square 有一次服务中断是 [Redis 存储的过载](https://medium.com/square-corner-blog/incident-summary-2017-03-16-2f65be39297),原因是有一段代码对失败的事务重试了 500 次,没有任何重试退避的方案,也说明了过度重试的潜在风险。另外,针对这种情况,[断路器](https://en.wikipedia.org/wiki/Circuit_breaker_design_pattern)设计模式也是有用的。
应该设计出监控仪表盘来清晰地展示所有资源的[使用率、饱和度和报错](http://www.brendangregg.com/usemethod.html),这样才能快速发现问题。
#### 突发的高负载
系统在异常高的负载下经常会发生故障。用户天然会引发高负载,不过也常常是由系统引发的。午夜突发的 cron 定时任务是老生常谈了。如果程序让移动客户端同时去获取更新,这些客户端也会造成突发的大流量(当然,给这种请求加入时间抖动会好很多)。
在预定时刻同时发生的事件并不是突发大流量的唯一原因。Slack 经历过一次短时间内的[多次服务中断](https://slackhq.com/this-was-not-normal-really),原因是非常多的客户端断开连接后立即重连,造成了突发的大负载。 CircleCI 也经历过一次[严重的服务中断](https://circleci.statuspage.io/incidents/hr0mm9xmm3x6),当时 Gitlab 从故障中恢复了,所以数据库里积累了大量的构建任务队列,服务变得饱和而且缓慢。
几乎所有的服务都会受突发的高负载所影响。所以对这类可能出现的事情做应急预案 —— 并测试一下预案能否正常工作 —— 是必须的。客户端退避和[减载](https://www.youtube.com/watch?v=XNEIkivvaV4)通常是这些方案的核心。
如果你的系统必须不间断地接收数据,并且数据不能被丢掉,关键是用可伸缩的方式把数据缓冲到队列中,后续再处理。
#### 自动化系统是复杂的系统
>
> “复杂的系统本身就是有风险的系统”
> —— [Richard Cook, MD](https://web.mit.edu/2.75/resources/random/How%20Complex%20Systems%20Fail.pdf)
>
>
>
过去几年里软件的运维操作趋势是更加自动化。任何可能降低系统容量的自动化操作(比如擦除磁盘、退役设备、关闭服务)都应该谨慎操作。这类自动化操作的故障(由于系统有 bug 或者有不正确的调用)能很快地搞垮你的系统,而且可能很难恢复。
谷歌的 Christina Schulman 和 Etienne Perot 在[用安全规约协助保护你的数据中心](https://www.usenix.org/conference/srecon18americas/presentation/schulman)的演讲中给了一些例子。其中一次事故是将谷歌整个内部的内容分发网络(CDN)提交给了擦除磁盘的自动化系统。
Schulman 和 Perot 建议使用一个中心服务来管理规约,限制破坏性自动化操作的速度,并能感知到系统状态(比如避免在最近有告警的服务上执行破坏性的操作)。
自动化系统在与运维人员(或其他自动化系统)交互时,也可能造成严重事故。[Reddit](https://www.reddit.com/r/announcements/comments/4y0m56/why_reddit_was_down_on_aug_11/) 遭遇过一次严重的服务中断,当时他们的自动化系统重启了一个服务,但是这个服务是运维人员停掉做维护的。一旦有了多个自动化系统,它们之间潜在的交互就变得异常复杂和不可预测。
所有的自动化系统都把日志输出到一个容易搜索的中心存储上,能帮助到对这类不可避免的意外情况的处理。自动化系统总是应该具备这样一种机制,即允许快速地关掉它们(完全关掉或者只关掉其中一部分操作或一部分目标)。
### 防止黑天鹅事件
可能在等着击垮系统的黑天鹅可不止上面这些。有很多其他的严重问题是能通过一些技术来避免的,像金丝雀发布、压力测试、混沌工程、灾难测试和模糊测试 —— 当然还有冗余性和弹性的设计。但是即使用了这些技术,有时候你的系统还是会有故障。
为了确保你的组织能有效地响应,在服务中断期间,请保证关键技术人员和领导层有办法沟通协调。例如,有一种你可能需要处理的烦人的事情,那就是网络完全中断。拥有故障时仍然可用的通信通道非常重要,这个通信通道要完全独立于你们自己的基础设施及对其的依赖。举个例子,假如你使用 AWS,那么把故障时可用的通信服务部署在 AWS 上就不明智了。在和你的主系统无关的地方,运行电话网桥或 IRC 服务器是比较好的方案。确保每个人都知道这个通信平台,并练习使用它。
另一个原则是,确保监控和运维工具对生产环境系统的依赖尽可能的少。将控制平面和数据平面分开,你才能在系统不健康的时候做变更。不要让数据处理和配置变更或监控使用同一个消息队列,比如,应该使用不同的消息队列实例。在 [SparkPost: DNS 挂掉的那一天](https://www.usenix.org/conference/srecon18americas/presentation/blosser) 这个演讲中,Jeremy Blosser 讲了一个这类例子,很关键的工具依赖了生产环境的 DNS 配置,但是生产环境的 DNS 出了问题。
### 对抗黑天鹅的心理学
处理生产环境的重大事故时会产生很大的压力。为这些场景制定结构化的事故管理流程确实是有帮助的。很多科技公司([包括谷歌](https://landing.google.com/sre/book/chapters/managing-incidents.html))成功地使用了联邦应急管理局事故指挥系统的某个版本。对于每一个值班的人,遇到了他们无法独立解决的重大问题时,都应该有一个明确的寻求协助的方法。
对于那些持续很长时间的事故,有一点很重要,要确保工程师不会连续工作到不合理的时长,确保他们不会不吃不睡(没有报警打扰的睡觉)。疲惫不堪的工程师很容易犯错或者漏掉了可能更快解决故障的信息。
### 了解更多
关于黑天鹅(或者以前的黑天鹅)事件以及应对策略,还有很多其他的事情可以说。如果你想了解更多,我强烈推荐你去看这两本书,它们是关于生产环境中的弹性和稳定性的:Susan Fowler 写的《[生产微服务](http://shop.oreilly.com/product/0636920053675.do)》,还有 Michael T. Nygard 的 《[Release It!](https://www.oreilly.com/library/view/release-it/9781680500264/)》。
---
via: <https://opensource.com/article/18/10/taxonomy-black-swans>
作者:[Laura Nolan](https://opensource.com/users/lauranolan) 选题:[lujun9972](https://github.com/lujun9972) 译者:[BeliteX](https://github.com/belitex) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Black swans are a metaphor for outlier events that are severe in impact (like the 2008 financial crash). In production systems, these are the incidents that trigger problems that you didn't know you had, cause major visible impact, and can't be fixed quickly and easily by a rollback or some other standard response from your on-call playbook. They are the events you tell new engineers about years after the fact.
Black swans, by definition, can't be predicted, but sometimes there are patterns we can find and use to create defenses against categories of related problems.
For example, a large proportion of failures are a direct result of changes (code, environment, or configuration). Each bug triggered in this way is distinctive and unpredictable, but the common practice of canarying all changes is somewhat effective against this class of problems, and automated rollbacks have become a standard mitigation.
As our profession continues to mature, other kinds of problems are becoming well-understood classes of hazards with generalized prevention strategies.
## Black swans observed in the wild
All technology organizations have production problems, but not all of them share their analyses. The organizations that publicly discuss incidents are doing us all a service. The following incidents describe one class of a problem and are by no means isolated instances. We all have black swans lurking in our systems; it's just some of us don't know it yet.
### Hitting limits
Running headlong into any sort of limit can produce very severe incidents. A canonical example of this was [Instapaper's outage in February 2017](https://medium.com/making-instapaper/instapaper-outage-cause-recovery-3c32a7e9cc5f). I challenge any engineer who has carried a pager to read the outage report without a chill running up their spine. Instapaper's production database was on a filesystem that, unknown to the team running the service, had a 2TB limit. With no warning, it stopped accepting writes. Full recovery took days and required migrating its database.
[limits on maximum transaction IDs in Postgres](https://blog.sentry.io/2015/07/23/transaction-id-wraparound-in-postgres.html). Platform.sh hit
[size limits on a pipe buffer](https://medium.com/@florian_7764/technical-post-mortem-of-the-august-incident-82ab4c3d6547). SparkPost
[triggered AWS's DDoS protection](https://www.usenix.org/conference/srecon18americas/presentation/blosser). Foursquare hit a performance cliff when one of its
[datastores ran out of RAM](https://groups.google.com/forum/#!topic/mongodb-user/UoqU8ofp134).
One way to get advance knowledge of system limits is to test periodically. Good load testing (on a production replica) ought to involve write transactions and should involve growing each datastore beyond its current production size. It's easy to forget to test things that aren't your main datastores (such as Zookeeper). If you hit limits during testing, you have time to fix the problems. Given that resolution of limits-related issues can involve major changes (like splitting a datastore), time is invaluable.
When it comes to cloud services, if your service generates unusual loads or uses less widely used products or features (such as older or newer ones), you may be more at risk of hitting limits. It's worth load testing these, too. But warn your cloud provider first.
Finally, where limits are known, add monitoring (with associated documentation) so you will know when your systems are approaching those ceilings. Don't rely on people still being around to remember.
### Spreading slowness
"The world is much more correlated than we give credit to. And so we see more of what Nassim Taleb calls 'black swan events'—rare events happen more often than they should because the world is more correlated."
—[Richard Thaler]
HostedGraphite's postmortem on how an [AWS outage took down its load balancers](https://blog.hostedgraphite.com/2018/03/01/spooky-action-at-a-distance-how-an-aws-outage-ate-our-load-balancer/) (which are not hosted on AWS) is a good example of just how much correlation exists in distributed computing systems. In this case, the load-balancer connection pools were saturated by slow connections from customers that were hosted in AWS. The same kinds of saturation can happen with application threads, locks, and database connections—any kind of resource monopolized by slow operations.
HostedGraphite's incident is an example of externally imposed slowness, but often slowness can result from saturation somewhere in your own system creating a cascade and causing other parts of your system to slow down. An [incident at Spotify](https://labs.spotify.com/2013/06/04/incident-management-at-spotify/) demonstrates such spread—the streaming service's frontends became unhealthy due to saturation in a different microservice. Enforcing deadlines for all requests, as well as limiting the length of request queues, can prevent such spread. Your service will serve at least some traffic, and recovery will be easier because fewer parts of your system will be broken.
Retries should be limited with exponential backoff and some jitter. An outage at Square, in which its [Redis datastore became overloaded](https://medium.com/square-corner-blog/incident-summary-2017-03-16-2f65be39297) due to a piece of code that retried failed transactions up to 500 times with no backoff, demonstrates the potential severity of excessive retries. The [Circuit Breaker](https://en.wikipedia.org/wiki/Circuit_breaker_design_pattern) design pattern can be helpful here, too.
Dashboards should be designed to clearly show [utilization, saturation, and errors](http://www.brendangregg.com/usemethod.html) for all resources so problems can be found quickly.
### Thundering herds
Often, failure scenarios arise when a system is under unusually heavy load. This can arise organically from users, but often it arises from systems. A surge of cron jobs that starts at midnight is a venerable example. Mobile clients can also be a source of coordinated demand if they are programmed to fetch updates at the same time (of course, it is much better to jitter such requests).
Events occurring at pre-configured times aren't the only source of thundering herds. Slack experienced [multiple outages](https://slackhq.com/this-was-not-normal-really) over a short time due to large numbers of clients being disconnected and immediately reconnecting, causing large spikes of load. CircleCI saw a [severe outage](https://circleci.statuspage.io/incidents/hr0mm9xmm3x6) when a GitLab outage ended, leading to a surge of builds queued in its database, which became saturated and very slow.
Almost any service can be the target of a thundering herd. Planning for such eventualities—and testing that your plan works as intended—is therefore a must. Client backoff and [load shedding](https://www.youtube.com/watch?v=XNEIkivvaV4) are often core to such approaches.
If your systems must constantly ingest data that can't be dropped, it's key to have a scalable way to buffer this data in a queue for later processing.
### Automation systems are complex systems
The trend for the past several years has been strongly towards more automation of software operations. Automation of anything that can reduce your system's capacity (e.g., erasing disks, decommissioning devices, taking down serving jobs) needs to be done with care. Accidents (due to bugs or incorrect invocations) with this kind of automation can take down your system very efficiently, potentially in ways that are hard to recover from.
"Complex systems are intrinsically hazardous systems."
—[Richard Cook, MD]
Christina Schulman and Etienne Perot of Google describe some examples in their talk [Help Protect Your Data Centers with Safety Constraints](https://www.usenix.org/conference/srecon18americas/presentation/schulman). One incident sent Google's entire in-house content delivery network (CDN) to disk-erase.
Schulman and Perot suggest using a central service to manage constraints, which limits the pace at which destructive automation can operate, and being aware of system conditions (for example, avoiding destructive operations if the service has recently had an alert).
Automation systems can also cause havoc when they interact with operators (or with other automated systems). [Reddit](https://www.reddit.com/r/announcements/comments/4y0m56/why_reddit_was_down_on_aug_11/) experienced a major outage when its automation restarted a system that operators had stopped for maintenance. Once you have multiple automation systems, their potential interactions become extremely complex and impossible to predict.
It will help to deal with the inevitable surprises if all this automation writes logs to an easily searchable, central place. Automation systems should always have a mechanism to allow them to be quickly turned off (fully or only for a subset of operations or targets).
## Defense against the dark swans
These are not the only black swans that might be waiting to strike your systems. There are many other kinds of severe problem that can be avoided using techniques such as canarying, load testing, chaos engineering, disaster testing, and fuzz testing—and of course designing for redundancy and resiliency. Even with all that, at some point your system will fail.
To ensure your organization can respond effectively, make sure your key technical staff and your leadership have a way to coordinate during an outage. For example, one unpleasant issue you might have to deal with is a complete outage of your network. It's important to have a fail-safe communications channel completely independent of your own infrastructure and its dependencies. For instance, if you run on AWS, using a service that also runs on AWS as your fail-safe communication method is not a good idea. A phone bridge or an IRC server that runs somewhere separate from your main systems is good. Make sure everyone knows what the communications platform is and practices using it.
Another principle is to ensure that your monitoring and your operational tools rely on your production systems as little as possible. Separate your control and your data planes so you can make changes even when systems are not healthy. Don't use a single message queue for both data processing and config changes or monitoring, for example—use separate instances. In [SparkPost: The Day the DNS Died](https://www.usenix.org/conference/srecon18americas/presentation/blosser), Jeremy Blosser presents an example where critical tools relied on the production DNS setup, which failed.
## The psychology of battling the black swan
Dealing with major incidents in production can be stressful. It really helps to have a structured incident-management process in place for these situations. Many technology organizations ([including Google](https://landing.google.com/sre/book/chapters/managing-incidents.html)) successfully use a version of FEMA's Incident Command System. There should be a clear way for any on-call individual to call for assistance in the event of a major problem they can't resolve alone.
For long-running incidents, it's important to make sure people don't work for unreasonable lengths of time and get breaks to eat and sleep (uninterrupted by a pager). It's easy for exhausted engineers to make a mistake or overlook something that might resolve the incident faster.
## Learn more
There are many other things that could be said about black (or formerly black) swans and strategies for dealing with them. If you'd like to learn more, I highly recommend these two books dealing with resilience and stability in production: Susan Fowler's [ Production-Ready Microservices](http://shop.oreilly.com/product/0636920053675.do) and Michael T. Nygard's
[.](https://www.oreilly.com/library/view/release-it/9781680500264/)
*Release It!**Laura Nolan will present What Breaks Our Systems: A Taxonomy of Black Swans at LISA18, October 29-31 in Nashville, Tennessee, USA.*
## 2 Comments |
10,275 | DevOps 应聘者应该准备回答的 20 个问题 | https://opensource.com/article/18/3/questions-devops-employees-should-answer | 2018-11-25T21:09:00 | [
"招聘"
] | https://linux.cn/article-10275-1.html |
>
> 想要建立一个积极,富有成效的工作环境? 在招聘过程中要专注于寻找契合点。
>
>
>

聘请一个不合适的人[代价是很高的](https://www.shrm.org/resourcesandtools/hr-topics/employee-relations/pages/cost-of-bad-hires.aspx)。根据 Link 人力资源的首席执行官 Jörgen Sundberg 的统计,招聘、雇佣一名新员工将会花费公司$240,000 之多,当你进行了一次不合适的招聘:
* 你失去了他们的知识技能。
* 你失去了他们的人脉。
* 你的团队将可能进入到一个组织发展的震荡阶段
* 你的公司将会面临组织破裂的风险
当你失去一名员工的时候,你就像丢失了公司版图中的一块。同样值得一提的是另一端的痛苦。应聘到一个错误工作岗位的员工会感受到很大的压力以及整个身心的不满意,甚至是健康问题。
另外一方面,当你招聘到合适的人时,新的员工将会:
* 丰富公司现有的文化,使你的组织成为一个更好的工作场所。研究表明一个积极的工作文化能够帮助更长久推动财务业绩增长,而且如果你在一个欢快的环境中工作,你更有可能在生活中做的更好。
* 热爱和你的组织在一起工作。当人们热爱他们所在做的,他们会趋向于做的更好。
招聘以适合或加强现有的文化在 DevOps 和敏捷团多中是必不可少的。也就是说雇佣到一个能够鼓励积极合作的人,以便来自不同背景,有着不同目标和工作方式的团队能够在一起有效的工作。你新雇佣的员工应该能够帮助团队合作来充分发挥放大他们的价值,同时也能够增加员工的满意度以及平衡组织目标的冲突。他或者她应该能够通过明智的选择工具和工作流来促进你的组织,文化就是一切。
作为我们 2017 年 11 月发布的一篇文章 [DevOps 的招聘经理应该准备回答的 20 个问题](https://opensource.com/article/17/11/inclusive-workforce-takes-work) 的回应,这篇文章将会重点关注在如何招聘最适合的人。
### 为什么招聘走错了方向
很多公司现在用的典型的雇佣策略是基于人才过剩的基础上:
* 在职位公告栏发布招聘。
* 关注具有所需才能的应聘者。
* 尽可能找多的候选者。
* 通过面试淘汰弱者。
* 通过正式的面试淘汰更多的弱者。
* 评估,投票,选择。
* 渐渐接近补偿。

职位公告栏是有成千上万失业者人才过剩的经济大萧条时期发明的。在今天的求职市场上已经没有人才过剩了,然而我们仍然在使用基于此的招聘策略。

### 雇佣最合适的人员:运用文化和情感
在人才过剩雇佣策略背后的思想是设计工作岗位然后将人员安排进去。
反而应该反过来:寻找将会积极融入你的商业文化的人才,然后为他们寻找他们热爱的最合适的岗位。要想实现这样的目标,你必须能够围绕他们热情为他们创造工作岗位。
**谁正在寻找一份工作?** 根据一份 2016 年对美国 50000 名开发者的调查显示,[85.7% 的受访对象](https://insights.stackoverflow.com/survey/2016#work-job-discovery)要么对新的机会不感兴趣,要么对于寻找新工作没有积极性。在寻找工作的那部分中,有将近 [28.3% 的求职者](https://insights.stackoverflow.com/survey/2016#work-job-discovery)来自于朋友的推荐。如果你只是在那些在找工作的人中寻找人才,你将会错过高端的人才。
**运用团队力量去发现和寻找潜力的雇员**。例如,戴安娜是你的团队中的一名开发者,她所能提供的机会是,她已经[从事编程很多年](https://research.hackerrank.com/developer-skills/2018/)而且在期间已经结识了很多从事热爱他们所从事的工作的人。难道你不认为她所推荐的潜在员工在技能、知识和智慧上要比 HR 所寻找的要优秀吗?在要求戴安娜分享她同伴之前,通知她即将到来的使命任务,向她阐明你要雇佣潜在有探索精神的团队,描述在将来会需要的知识领域。
**雇员想要什么?**一份来自千禧年婴儿潮时期出生的人的对比综合性研究显示,20% 的人所想要的是相同的:
1. 对组织产生积极的影响
2. 帮助解决社交或者环境上的挑战
3. 和一群有动力的人一起工作
### 面试的挑战
面试应该是招聘者和应聘者双方为了寻找最合适的人才进行的一次双方之间的对话。将面试聚焦在企业文化和情感对话两个问题上:这个应聘者将会丰富你的企业文化并且会热爱和你在一起工作吗?你能够在工作中帮他们取得成功吗?
**对于招聘经理来说:** 每一次的面试都是你学习如何将自己的组织变得对未来的团队成员更有吸引力,并且每次积极的面试都可能是你发现人才(即使你不会雇佣)的机会。每个人都将会记得积极有效的面试的经历。即使他们不会被雇佣,他们将会和他们的朋友谈论这次经历,你会得到一个被推荐的机会。这有很大的好处:如果你无法吸引到这个人才,你也将会从中学习吸取经验并且改善。
**对面试者来说**:每次的面试都是你释放激情的机会。
### 助你释放潜在雇员激情的 20 个问题
1. 你热爱什么?
2. “今天早晨我已经迫不及待的要去工作”,你怎么看待这句话?
3. 你曾经最快乐的是什么?
4. 你曾经解决问题的最典型的例子是什么,你是如何解决的?
5. 你如何看待配对学习?
6. 你到达办公室和离开办公室心里最先想到的是什么?
7. 你如果你有一次改变你之前或者现在的工作中的一件事的机会,将会是什么事?
8. 当你在工作的时候,你最乐于去学习什么?
9. 你的梦想是什么,你如何去实现?
10. 你在学会如何去实现你的追求的时候想要或者需要什么?
11. 你的价值观是什么?
12. 你是如何坚守自己的价值观的?
13. 在你的生活中平衡意味着什么?
14. 你最引以为傲的工作交流能力是什么?为什么?
15. 你最喜欢营造什么样的环境?
16. 你喜欢别人怎样对待你?
17. 你信任我们什么,如何验证?
18. 告诉我们你在最近的一个项目中学习到什么?
19. 我们还能知道你的其他方面的什么?
20. 如果你正在雇佣我,你将会问我什么问题?
---
via: <https://opensource.com/article/18/3/questions-devops-employees-should-answer>
作者:[Catherine Louis](https://opensource.com/users/catherinelouis) 译者:[FelixYFZ](https://github.com/FelixYFZ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hiring the wrong person is [expensive](https://www.shrm.org/resourcesandtools/hr-topics/employee-relations/pages/cost-of-bad-hires.aspx). Recruiting, hiring, and onboarding a new employee can cost a company as much as $240,000, according to Jörgen Sundberg, CEO of Link Humans. When you make the wrong hire:
- You lose what they know.
- You lose
*who*they know. - Your team could go into the
[storming](https://en.wikipedia.org/wiki/Tuckman%27s_stages_of_group_development)phase of group development. - Your company risks disorganization.
When you lose an employee, you lose a piece of the fabric of the company. It's also worth mentioning the pain on the other end. The person hired into the wrong job may experience stress, feelings of overall dissatisfaction, and even health issues.
On the other hand, when you get it right, your new hire will:
- Enhance the existing culture, making your organization an even a better place to work. Studies show that a positive work culture helps
[drive long-term financial performance](http://www.forbes.com/sites/johnkotter/2011/02/10/does-corporate-culture-drive-financial-performance/)and that if you work in a happy environment, you’re more likely to do better in life. - Love working with your organization. When people love what they do, they tend to do it well.
Hiring to fit or enhance your existing culture is essential in DevOps and agile teams. That means hiring someone who can encourage effective collaboration so that individual contributors from varying backgrounds, and teams with different goals and working styles, can work together productively. Your new hire should help teams collaborate to maximize their value while also increasing employee satisfaction and balancing conflicting organizational goals. He or she should be able to choose tools and workflows wisely to complement your organization. Culture is everything.
As a follow-up to our November 2017 post, * 20 questions DevOps hiring managers should be prepared to answer*, this article will focus on how to hire for the best mutual fit.
## Why hiring goes wrong
The typical hiring strategy many companies use today is based on a talent surplus:
- Post on job boards.
- Focus on candidates with the skills they need.
- Find as many candidates as possible.
- Interview to weed out the weak.
- Conduct formal interviews to do more weeding.
- Assess, vote, and select.
- Close on compensation.

Job boards were invented during the Great Depression when millions of people were out of work and there was a talent surplus. There is no talent surplus in today's job market, yet we’re still using a hiring strategy that's based on one.

Image credit: Creative Commons
## Hire for mutual fit: Use culture and emotions
The idea behind the talent surplus hiring strategy is to design jobs and then slot people into them.
Instead, do the opposite: Find talented people who will positively add to your business culture, then find the best fit for them in a job they’ll love. To do this, you must be open to creating jobs around their passions.
**Who is looking for a job? **According to a 2016 survey of more than 50,000 U.S. developers, [85.7% of respondents](https://insights.stackoverflow.com/survey/2016#work-job-discovery) were either not interested in new opportunities or were not actively looking for them. And of those who were looking, a whopping [28.3% of job discoveries](https://insights.stackoverflow.com/survey/2016#work-job-discovery) came from referrals by friends. If you’re searching only for people who are looking for jobs, you’re missing out on top talent.
**Use your team to find and vet potential recruits**. For example, if Diane is a developer on your team, chances are she has [been coding for years](https://research.hackerrank.com/developer-skills/2018/) and has met fellow developers along the way who also love what they do. Wouldn’t you think her chances of vetting potential recruits for skills, knowledge, and intelligence would be higher than having someone from HR find and vet potential recruits? And before asking Diane to share her knowledge of fellow recruits, inform her of the upcoming mission, explain your desire to hire a diverse team of passionate explorers, and describe some of the areas where help will be needed in the future.
**What do employees want?** A comprehensive study comparing the wants and needs of Millennials, GenX’ers, and Baby Boomers shows that within two percentage points, we all [want the same things](http://www-935.ibm.com/services/us/gbs/thoughtleadership/millennialworkplace/):
- To make a positive impact on the organization
- To help solve social and/or environmental challenges
- To work with a diverse group of people
## The interview challenge
The interview should be a two-way conversation for finding a mutual fit between the person hiring and the person interviewing. Focus your interview on CQ ([Cultural Quotient](http://www-935.ibm.com/services/us/gbs/thoughtleadership/millennialworkplace/)) and EQ ([Emotional Quotient](https://en.wikipedia.org/wiki/Emotional_intelligence)): Will this person reinforce and add to your culture and love working with you? Can you help make them successful at their job?
**For the hiring manager:** Every interview is an opportunity to learn how your organization could become more irresistible to prospective team members, and every positive interview can be your best opportunity to finding talent, even if you don’t hire that person. Everyone remembers being interviewed if it is a positive experience. Even if they don’t get hired, they will talk about the experience with their friends, and you may get a referral as a result. There is a big upside to this: If you’re not attracting this talent, you have the opportunity to learn the reason and fix it.
**For the interviewee**: Each interview experience is an opportunity to unlock your passions.
## 20 questions to help you unlock the passions of potential hires
-
What are you passionate about?
-
What makes you think, "I can't wait to get to work this morning!”
-
What is the most fun you’ve ever had?
-
What is your favorite example of a problem you’ve solved, and how did you solve it?
-
How do you feel about paired learning?
-
What’s at the top of your mind when you arrive at, and leave, the office?
-
If you could have changed one thing in your previous/current job, what would it be?
-
What are you excited to learn while working here?
-
What do you aspire to in life, and how are you pursuing it?
-
What do you want, or feel you need, to learn to achieve these aspirations?
-
What values do you hold?
-
How do you live those values?
-
What does balance mean in your life?
-
What work interactions are you are most proud of? Why?
-
What type of environment do you like to create?
-
How do you like to be treated?
-
What do you trust vs. verify?
-
Tell me about a recent learning you had when working on a project.
-
What else should we know about you?
-
If you were hiring me, what questions would you ask me?
## Comments are closed. |
10,276 | 用 Python 和 Conu 测试容器 | https://fedoramagazine.org/test-containers-python-conu/ | 2018-11-25T21:51:20 | [
"容器",
"测试"
] | https://linux.cn/article-10276-1.html | 
越来越多的开发人员使用容器开发和部署他们的应用。这意味着可以轻松地测试容器也变得很重要。[Conu](https://github.com/user-cont/conu) (container utilities 的简写) 是一个 Python 库,让你编写容器测试变得简单。本文向你介绍如何使用它测试容器。
### 开始吧
首先,你需要一个容器程序来测试。为此,以下命令创建一个包含一个容器的 Dockerfile 和一个被容器伺服的 Flask 应用程序的文件夹。
```
$ mkdir container_test
$ cd container_test
$ touch Dockerfile
$ touch app.py
```
将以下代码复制到 `app.py` 文件中。这是惯常的基本 Flask 应用,它返回字符串 “Hello Container World!”。
```
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello Container World!'
if __name__ == '__main__':
app.run(debug=True,host='0.0.0.0')
```
### 创建和构建测试容器
为了构建测试容器,将以下指令添加到 Dockerfile。
```
FROM registry.fedoraproject.org/fedora-minimal:latest
RUN microdnf -y install python3-flask && microdnf clean all
ADD ./app.py /srv
CMD ["python3", "/srv/app.py"]
```
然后使用 Docker CLI 工具构建容器。
```
$ sudo dnf -y install docker
$ sudo systemctl start docker
$ sudo docker build . -t flaskapp_container
```
提示:只有在系统上未安装 Docker 时才需要前两个命令。
构建之后使用以下命令运行容器。
```
$ sudo docker run -p 5000:5000 --rm flaskapp_container
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 473-505-51
```
最后,使用 `curl` 检查 Flask 应用程序是否在容器内正确运行:
```
$ curl http://127.0.0.1:5000
Hello Container World!
```
现在,flaskapp\_container 正在运行并准备好进行测试,你可以使用 `Ctrl+C` 将其停止。
### 创建测试脚本
在编写测试脚本之前,必须安装 `conu`。在先前创建的 `container_test` 目录中,运行以下命令。
```
$ python3 -m venv .venv
$ source .venv/bin/activate
(.venv)$ pip install --upgrade pip
(.venv)$ pip install conu
$ touch test_container.py
```
然后将以下脚本复制并保存在 `test_container.py` 文件中。
```
import conu
PORT = 5000
with conu.DockerBackend() as backend:
image = backend.ImageClass("flaskapp_container")
options = ["-p", "5000:5000"]
container = image.run_via_binary(additional_opts=options)
try:
# Check that the container is running and wait for the flask application to start.
assert container.is_running()
container.wait_for_port(PORT)
# Run a GET request on / port 5000.
http_response = container.http_request(path="/", port=PORT)
# Check the response status code is 200
assert http_response.ok
# Get the response content
response_content = http_response.content.decode("utf-8")
# Check that the "Hello Container World!" string is served.
assert "Hello Container World!" in response_content
# Get the logs from the container
logs = [line for line in container.logs()]
# Check the the Flask application saw the GET request.
assert b'"GET / HTTP/1.1" 200 -' in logs[-1]
finally:
container.stop()
container.delete()
```
#### 测试设置
这个脚本首先设置 `conu` 使用 Docker 作为后端来运行容器。然后它设置容器镜像以使用你在本教程第一部分中构建的 flaskapp\_container。
下一步是配置运行容器所需的选项。在此示例中,Flask 应用在端口5000上提供内容。于是你需要暴露此端口并将其映射到主机上的同一端口。
最后,用这个脚本启动容器,现在可以测试了。
#### 测试方法
在测试容器之前,检查容器是否正在运行并准备就绪。示范脚本使用 `container.is_running` 和 `container.wait_for_port`。这些方法可确保容器正在运行,并且服务在预设端口上可用。
`container.http_request` 是 [request](http://docs.python-requests.org/en/master/) 库的包装器,可以方便地在测试期间发送 HTTP 请求。这个方法返回[requests.Responseobject](http://docs.python-requests.org/en/master/api/#requests.Response),因此可以轻松地访问响应的内容以进行测试。
`conu` 还可以访问容器日志。又一次,这在测试期间非常有用。在上面的示例中,`container.logs` 方法返回容器日志。你可以使用它们断言打印了特定日志,或者,例如在测试期间没有异常被引发。
`conu` 提供了许多与容器接合的有用方法。[文档](https://conu.readthedocs.io/en/latest/index.html)中提供了完整的 API 列表。你还可以参考 [GitHub](https://github.com/user-cont/conu/tree/master/docs/source/examples) 上提供的示例。
运行本教程所需的所有代码和文件也可以在 [GitHub](https://github.com/cverna/container_test_script) 上获得。 对于想要进一步采用这个例子的读者,你可以看看使用 [pytest](https://docs.pytest.org/en/latest/) 来运行测试并构建一个容器测试套件。
---
via: <https://fedoramagazine.org/test-containers-python-conu/>
作者:[Clément Verna](https://fedoramagazine.org/author/cverna/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[GraveAccent](https://github.com/GraveAccent) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | More and more developers are using containers to develop and deploy their applications. This means that easily testing containers is also becoming important. [Conu](https://github.com/user-cont/conu) (short for container utilities) is a Python library that makes it easy to write tests for your containers. This article shows you how to use it to test your containers.
## Getting started
First you need a container application to test. For that, the following commands create a new directory with a container *Dockerfile,* and a Flask application to be served by the container.
$mkdir container_test$cd container_test$touch Dockerfile$touch app.py
Copy the following code inside the *app.py *file. This is the customary basic Flask application that returns the string “Hello Container World!”
from flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello Container World!' if __name__ == '__main__': app.run(debug=True,host='0.0.0.0')
## Create and Build a Test Container
To build the test container, add the following instructions to the *Dockerfile*.
FROM registry.fedoraproject.org/fedora-minimal:latest RUN microdnf -y install python3-flask && microdnf clean all ADD ./app.py /srv CMD ["python3", "/srv/app.py"]
Then build the container using the Docker CLI tool.
$sudo dnf -y install docker$sudo systemctl start docker$sudo docker build . -t flaskapp_container
Note : The first two commands are only needed if Docker is not installed on your system.
After the build use the following command to run the container.
$sudo docker run -p 5000:5000 --rm flaskapp_container* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 473-505-51
Finally, use *curl* to check that the Flask application is correctly running inside the container:
$ curl http://127.0.0.1:5000 Hello Container World!
With the *flaskapp_container* now running and ready for testing, you can stop it using **Ctrl+C**.
## Create a test script
Before you write the test script, you must install *conu*. Inside the previously created *container_test* directory run the following commands.
$python3 -m venv .venv$source .venv/bin/activate(.venv)$pip install --upgrade pip(.venv)$pip install conu$touch test_container.py
Then copy and save the following script in the *test_container.py * file.
import conu PORT = 5000 with conu.DockerBackend() as backend: image = backend.ImageClass("flaskapp_container") options = ["-p", "5000:5000"] container = image.run_via_binary(additional_opts=options) try: # Check that the container is running and wait for the flask application to start. assert container.is_running() container.wait_for_port(PORT) # Run a GET request on / port 5000. http_response = container.http_request(path="/", port=PORT) # Check the response status code is 200 assert http_response.ok # Get the response content response_content = http_response.content.decode("utf-8") # Check that the "Hello Container World!" string is served. assert "Hello Container World!" in response_content # Get the logs from the container logs = [line for line in container.logs()] # Check the the Flask application saw the GET request. assert b'"GET / HTTP/1.1" 200 -' in logs[-1] finally: container.stop() container.delete()
### Test Setup
The script starts by setting *conu* to use Docker as a backend to run the container. Then it sets the container image to use the *flaskapp_container* you built in the first part of this tutorial.
The next step is to configure the options needed to run the container. In this example, the Flask application serves the content on port 5000. Therefore you need to expose this port and map it to the same port on the host.
Finally, the script starts the container, and it’s now ready to be tested.
### Testing methods
Before testing a container, check that the container is running and ready. The example script is using *container.is_running* and *container.wait_for_port.* These methods ensure the container is running and the service is available on the expected port.
The *container.**http_request * is a wrapper around the [ requests](http://docs.python-requests.org/en/master/) library which makes it convenient to send HTTP requests during the tests. This method returns a
[object, so it’s easy to access the content of the response for testing.](http://docs.python-requests.org/en/master/api/#requests.Response)
*requests.Response*Conu also gives access to the container logs. Once again, this can be useful during testing. In the example above, the *container.logs *method returns the container logs. You can use them to assert that a specific log was printed, or for example that no exceptions were raised during testing.
*Conu *provides many other useful methods to interface with containers. A full list of the APIs is available in the [documentation](https://conu.readthedocs.io/en/latest/index.html). You can also consult the examples available on [GitHub](https://github.com/user-cont/conu/tree/master/docs/source/examples).
All the code and files needed to run this tutorial are available on [GitHub](https://github.com/cverna/container_test_script) as well. For readers who want to take this example further, you can look at using [pytest](https://docs.pytest.org/en/latest/) to run the tests and build a container test suite.
## Pavan Sapkal
can we test other application using conu except container of docker ?
## Clément Verna
There are other backends available so you can test containers using a Kubernestes backend for example (see here https://github.com/user-cont/conu#kubernetes) |
10,277 | Greg Kroah-Hartman 解释内核社区是如何使 Linux 安全的 | https://www.linux.com/blog/2018/10/greg-kroah-hartman-explains-how-kernel-community-securing-linux-0 | 2018-11-25T22:27:48 | [
"内核",
"安全"
] | https://linux.cn/article-10277-1.html | 
>
> 内核维护者 Greg Kroah-Hartman 谈论内核社区如何保护 Linux 不遭受损害。
>
>
>
由于 Linux 使用量持续扩大,内核社区去提高这个世界上使用最广泛的技术 —— Linux 内核的安全性的重要性越来越高。安全不仅对企业客户很重要,它对消费者也很重要,因为 80% 的移动设备都使用了 Linux。在本文中,Linux 内核维护者 Greg Kroah-Hartman 带我们了解内核社区如何应对威胁。
### bug 不可避免

*Greg Kroah-Hartman [Linux 基金会](https://www.linux.com/licenses/category/linux-foundation)*
正如 Linus Torvalds 曾经说过的,大多数安全问题都是 bug 造成的,而 bug 又是软件开发过程的一部分。是软件就有 bug。
Kroah-Hartman 说:“就算是 bug,我们也不知道它是安全的 bug 还是不安全的 bug。我修复的一个著名 bug,在三年后才被 Red Hat 认定为安全漏洞“。
在消除 bug 方面,内核社区没有太多的办法,只能做更多的测试来寻找 bug。内核社区现在已经有了自己的安全团队,它们是由熟悉内核核心的内核开发者组成。
Kroah-Hartman 说:”当我们收到一个报告时,我们就让参与这个领域的核心开发者去修复它。在一些情况下,他们可能是同一个人,让他们进入安全团队可以更快地解决问题“。但他也强调,内核所有部分的开发者都必须清楚地了解这些问题,因为内核是一个可信环境,它必须被保护起来。
Kroah-Hartman 说:”一旦我们修复了它,我们就将它放到我们的栈分析规则中,以便于以后不再重新出现这个 bug。“
除修复 bug 之外,内核社区也不断加固内核。Kroah-Hartman 说:“我们意识到,我们需要一些主动的缓减措施,因此我们需要加固内核。”
Kees Cook 和其他一些人付出了巨大的努力,带来了一直在内核之外的加固特性,并将它们合并或适配到内核中。在每个内核发行后,Cook 都对所有新的加固特性做一个总结。但是只加固内核是不够的,供应商们必须要启用这些新特性来让它们充分发挥作用,但他们并没有这么做。
Kroah-Hartman [每周发布一个稳定版内核](https://www.kernel.org/category/releases.html),而为了长期的支持,公司们只从中挑选一个,以便于设备制造商能够利用它。但是,Kroah-Hartman 注意到,除了 Google Pixel 之外,大多数 Android 手机并不包含这些额外的安全加固特性,这就意味着,所有的这些手机都是有漏洞的。他说:“人们应该去启用这些加固特性”。
Kroah-Hartman 说:“我购买了基于 Linux 内核 4.4 的所有旗舰级手机,去查看它们中哪些确实升级了新特性。结果我发现只有一家公司升级了它们的内核。……我在整个供应链中努力去解决这个问题,因为这是一个很棘手的问题。它涉及许多不同的组织 —— SoC 制造商、运营商等等。关键点是,需要他们把我们辛辛苦苦设计的内核去推送给大家。”
好消息是,与消费电子产品不一样,像 Red Hat 和 SUSE 这样的大供应商,在企业环境中持续对内核进行更新。使用容器、pod 和虚拟化的现代系统做到这一点更容易了。无需停机就可以毫不费力地更新和重启。事实上,现在来保证系统安全相比过去容易多了。
### Meltdown 和 Spectre
没有任何一个关于安全的讨论能够避免提及 Meltdown 和 Spectre 缺陷。内核社区一直致力于修改新发现的和已查明的安全漏洞。不管怎样,Intel 已经因为这些事情改变了它们的策略。
Kroah-Hartman 说:“他们已经重新研究如何处理安全 bug,以及如何与社区合作,因为他们知道他们做错了。内核已经修复了几乎所有大的 Spectre 问题,但是还有一些小问题仍在处理中”。
好消息是,这些 Intel 漏洞使得内核社区正在变得更好。Kroah-Hartman 说:“我们需要做更多的测试。对于最新一轮的安全补丁,在它们被发布之前,我们自己花了四个月时间来测试它们,因为我们要防止这个安全问题在全世界扩散。而一旦这些漏洞在真实的世界中被利用,将让我们认识到我们所依赖的基础设施是多么的脆弱,我们多年来一直在做这种测试,这确保了其它人不会遭到这些 bug 的伤害。所以说,Intel 的这些漏洞在某种程度上让内核社区变得更好了”。
对安全的日渐关注也为那些有才华的人创造了更多的工作机会。由于安全是个极具吸引力的领域,那些希望在内核空间中有所建树的人,安全将是他们一个很好的起点。
Kroah-Hartman 说:“如果有人想从事这方面的工作,我们有大量的公司愿意雇佣他们。我知道一些开始去修复 bug 的人已经被他们雇佣了。”
你可以在下面链接的视频上查看更多的内容:
---
via: <https://www.linux.com/blog/2018/10/greg-kroah-hartman-explains-how-kernel-community-securing-linux-0>
作者:[SWAPNIL BHARTIYA](https://www.linux.com/users/arnieswap) 选题:[oska874](https://github.com/oska874) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,278 | 如何在 Linux 上安装设备驱动程序 | https://opensource.com/article/18/11/how-install-device-driver-linux | 2018-11-25T22:59:51 | [
"驱动"
] | https://linux.cn/article-10278-1.html |
>
> 学习 Linux 设备驱动如何工作,并知道如何使用它们。
>
>
>

对于一个熟悉 Windows 或者 MacOS 的人,想要切换到 Linux,它们都会面临一个艰巨的问题就是怎么安装和配置设备驱动。这是可以理解的,因为 Windows 和 MacOS 都有一套机制把这个过程做得非常的友好。比如说,当你插入一个新的硬件设备, Windows 能够自动检测并会弹出一个窗口询问你是否要继续驱动程序的安装。你也可以从网络上下载驱动程序,仅仅需要双击解压或者是通过设备管理器导入驱动程序即可。
而这在 Linux 操作系统上并非这么简单。第一个原因是, Linux 是一个开源的操作系统,所以有 [数百种 Linux 发行版的变体](https://en.wikipedia.org/wiki/List_of_Linux_distributions)。也就是说不可能做一个指南来适应所有的 Linux 发行版。因为每种 Linux 安装驱动程序的过程都有差异。
第二,大多数默认的 Linux 驱动程序也都是开源的,并被集成到了系统中,这使得安装一些并未包含的驱动程序变得非常复杂,即使已经可以检测大多数的硬件设备。第三,不同发行版的许可也有差异。例如,[Fedora 禁止事项](https://fedoraproject.org/wiki/Forbidden_items?rd=ForbiddenItems) 禁止包含专有的、受法律保护,或者是违反美国法律的驱动程序。而 Ubuntu 则让用户[避免使用受法律保护或闭源的硬件设备](https://www.ubuntu.com/licensing)。
为了更好的学习 Linux 驱动程序是如何工作的,我建议阅读 《Linux 设备驱动程序》一书中的 [设备驱动程序简介](https://www.xml.com/ldd/chapter/book/ch01.html)。
### 两种方式来寻找驱动程序
#### 1、 用户界面
如果是一个刚从 Windows 或 MacOS 转过来的 Linux 新手,那你会很高兴知道 Linux 也提供了一个通过向导式的程序来查看驱动程序是否可用的方法。 Ubuntu 提供了一个 [附加驱动程序](https://askubuntu.com/questions/47506/how-do-i-install-additional-drivers) 选项。其它的 Linux 发行版也提供了帮助程序,像 [GNOME 的包管理器](https://help.gnome.org/users/gnome-packagekit/stable/add-remove.html.en),你可以使用它来检查驱动程序是否可用。
#### 2、 命令行
如果你通过漂亮的用户界面没有找到驱动程序,那又该怎么办呢?或许你只能通过没有任何图形界面的 shell?甚至你可以使用控制台来展现你的技能。你有两个选择:
1. **通过一个仓库**
这和 MacOS 中的 [homebrew](https://brew.sh/) 命令行很像。通过使用 `yum`、 `dnf`、`apt-get` 等等。你基本可以通过添加仓库,并更新包缓存。
2. **下载、编译,然后自己构建**
这通常包括直接从网络,或通过 `wget` 命令下载源码包,然后运行配置和编译、安装。这超出了本文的范围,但是你可以在网络上找到很多在线指南,如果你选择的是这条路的话。
### 检查是否已经安装了这个驱动程序
在进一步学习安装 Linux 驱动程序之前,让我们来学习几条命令,用来检测驱动程序是否已经在你的系统上可用。
[lspci](https://en.wikipedia.org/wiki/Lspci) 命令显示了系统上所有 PCI 总线和设备驱动程序的详细信息。
```
$ lscpci
```
或者使用 `grep`:
```
$ lscpci | grep SOME_DRIVER_KEYWORD
```
例如,你可以使用 `lspci | grep SAMSUNG` 命令,如果你想知道是否安装过三星的驱动。
[dmesg](https://en.wikipedia.org/wiki/Dmesg) 命令显示了所有内核识别的驱动程序。
```
$ dmesg
```
或配合 `grep` 使用:
```
$ dmesg | grep SOME_DRIVER_KEYWORD
```
任何识别到的驱动程序都会显示在结果中。
如果通过 `dmesg` 或者 `lscpi` 命令没有识别到任何驱动程序,尝试下这两个命令,看看驱动程序至少是否加载到硬盘。
```
$ /sbin/lsmod
```
和
```
$ find /lib/modules
```
技巧:和 `lspci` 或 `dmesg` 一样,通过在上面的命令后面加上 `| grep` 来过滤结果。
如果一个驱动程序已经被识别到了,但是通过 `lscpi` 或 `dmesg` 并没有找到,这意味着驱动程序已经存在于硬盘上,但是并没有加载到内核中,这种情况,你可以通过 `modprobe` 命令来加载这个模块。
```
$ sudo modprobe MODULE_NAME
```
使用 `sudo` 来运行这个命令,因为这个模块要使用 root 权限来安装。
### 添加仓库并安装
可以通过 `yum`、`dnf` 和 `apt-get` 几种不同的方式来添加一个仓库;一个个介绍完它们并不在本文的范围。简单一点来说,这个示例将会使用 `apt-get` ,但是这个命令和其它的几个都是很类似的。
#### 1、删除存在的仓库,如果它存在
```
$ sudo apt-get purge NAME_OF_DRIVER*
```
其中 `NAME_OF_DRIVER` 是你的驱动程序的可能的名称。你还可以将模式匹配加到正则表达式中来进一步过滤。
#### 2、将仓库加入到仓库表中,这应该在驱动程序指南中有指定
```
$ sudo add-apt-repository REPOLIST_OF_DRIVER
```
其中 `REPOLIST_OF_DRIVER` 应该从驱动文档中有指定(例如:`epel-list`)。
#### 3、更新仓库列表
```
$ sudo apt-get update
```
#### 4、安装驱动程序
```
$ sudo apt-get install NAME_OF_DRIVER
```
#### 5、检查安装状态
像上面说的一样,通过 `lscpi` 命令来检查驱动程序是否已经安装成功。
---
via: <https://opensource.com/article/18/11/how-install-device-driver-linux>
作者:[Bryant Son](https://opensource.com/users/brson) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Jamskr](https://github.com/Jamskr) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the most daunting challenges for people switching from a familiar Windows or MacOS system to Linux is installing and configuring a driver. This is understandable, as Windows and MacOS have mechanisms that make this process user-friendly. For example, when you plug in a new piece of hardware, Windows automatically detects it and shows a pop-up window asking if you want to continue with the driver's installation. You can also download a driver from the internet, then just double-click it to run a wizard or import the driver through Device Manager.
This process isn't as easy on a Linux operating system. For one reason, Linux is an open source operating system, so there are [ hundreds of Linux distribution variations](https://en.wikipedia.org/wiki/List_of_Linux_distributions). This means it's impossible to create one how-to guide that works for all Linux distros. Each Linux operating system handles the driver installation process a different way.
Second, most default Linux drivers are open source and integrated into the system, which makes installing any drivers that are not included quite complicated, even though most hardware devices can be automatically detected. Third, license policies vary among the different Linux distributions. For example, [ Fedora prohibits](https://fedoraproject.org/wiki/Forbidden_items?rd=ForbiddenItems) including drivers that are proprietary, legally encumbered, or that violate US laws. And Ubuntu asks users to [avoid using proprietary or closed hardware](https://www.ubuntu.com/licensing).
To learn more about how Linux drivers work, I recommend reading [ An Introduction to Device Drivers](https://www.xml.com/ldd/chapter/book/ch01.html) in the book *Linux Device Drivers*.
## Two approaches to finding drivers
### 1. User interfaces
If you are new to Linux and coming from the Windows or MacOS world, you'll be glad to know that Linux offers ways to see whether a driver is available through wizard-like programs. Ubuntu offers the [ Additional Drivers](https://askubuntu.com/questions/47506/how-do-i-install-additional-drivers) option. Other Linux distributions provide helper programs, like [Package Manager for GNOME](https://help.gnome.org/users/gnome-packagekit/stable/add-remove.html.en), that you can check for available drivers.
### 2. Command line
What if you can't find a driver through your nice user interface application? Or you only have access through the shell with no graphic interface whatsoever? Maybe you've even decided to expand your skills by using a console. You have two options:
**Use a repository**
This is similar to thecommand in MacOS.**homebrew****yum**,**dnf**,**apt-get**, etc., you're basically adding a repository and updating the package cache.
**Download, compile, and build it yourself**
This usually involves downloading a package directly from a website or using the**wget**command and running the configuration file and Makefile to install it. This is beyond the scope of this article, but you should be able to find online guides if you choose to go this route.
## Check if a driver is already installed
Before jumping further into installing a driver in Linux, let's look at some commands that will determine whether the driver is already available on your system.
The [ lspci](https://en.wikipedia.org/wiki/Lspci) command shows detailed information about all PCI buses and devices on the system:
`$ lscpci`
Or with **grep**:
`$ lscpci | grep SOME_DRIVER_KEYWORD`
For example, you can type **lspci | grep SAMSUNG** if you want to know if a Samsung driver is installed.
The [ dmesg](https://en.wikipedia.org/wiki/Dmesg) command shows all device drivers recognized by the kernel:
`$ dmesg`
Or with **grep**:
`$ dmesg | grep SOME_DRIVER_KEYWORD`
Any driver that's recognized will show in the results.
If nothing is recognized by the **dmesg** or **lscpi** commands, try these two commands to see if the driver is at least loaded on the disk:
`$ /sbin/lsmod`
and
`$ find /lib/modules`
Tip: As with **lspci** or **dmesg**, append **| grep** to either command above to filter the results.
If a driver is recognized by those commands but not by **lscpi** or **dmesg**, it means the driver is on the disk but not in the kernel. In this case, load the module with the **modprobe** command:
`$ sudo modprobe MODULE_NAME`
Run as this command as **sudo** since this module must be installed as a root user.
## Add the repository and install
There are different ways to add the repository through **yum**, **dnf**, and **apt-get**; describing them all is beyond the scope of this article. To make it simple, this example will use **apt-get**, but the idea is similar for the other options.
**1. Delete the existing repository, if it exists.**
`$ sudo apt-get purge NAME_OF_DRIVER*`
where **NAME_OF_DRIVER** is the probable name of your driver. You can also add pattern match to your regular expression to filter further.
**2. Add the repository to the repolist, which should be specified in the driver guide.**
`$ sudo add-apt-repository REPOLIST_OF_DRIVER`
where **REPOLIST_OF_DRIVER** should be specified from the driver documentation (e.g., **epel-list**).
**3. Update the repository list.**
`$ sudo apt-get update`
**4. Install the package.**
`$ sudo apt-get install NAME_OF_DRIVER`
**5. Check the installation.**
Run the **lscpi** command (as above) to check that the driver was installed successfully.
## 1 Comment |
10,280 | 在 Linux 上自定义 bash 命令提示符 | https://www.ostechnix.com/hide-modify-usernamelocalhost-part-terminal/ | 2018-11-26T23:19:00 | [
"提示符",
"bash"
] | https://linux.cn/article-10280-1.html | 
众所周知,**bash**(the **B**ourne-**A**gain **Sh**ell)是目前绝大多数 Linux 发行版使用的默认 shell。本文将会介绍如何通过添加颜色和样式来自定义 bash 命令提示符的显示。尽管很多插件或工具都可以很轻易地满足这一需求,但我们也可以不使用插件和工具,自己手动自定义一些基本的显示方式,例如添加或者修改某些元素、更改前景色、更改背景色等等。
### 在 Linux 中自定义 bash 命令提示符
在 bash 中,我们可以通过更改 `$PS1` 环境变量的值来自定义 bash 命令提示符。
一般情况下,bash 命令提示符会是以下这样的形式:

在上图这种默认显示形式当中,“sk” 是我的用户名,而 “ubuntuserver” 是我的主机名。
只要插入一些以反斜杠开头的特殊转义字符串,就可以按照你的喜好修改命令提示符了。下面我来举几个例子。
在开始之前,我强烈建议你预先备份 `~/.bashrc` 文件。
```
$ cp ~/.bashrc ~/.bashrc.bak
```
#### 更改 bash 命令提示符中的 username@hostname 部分
如上所示,bash 命令提示符一般都带有 “username@hostname” 部分,这个部分是可以修改的。
只需要编辑 `~/.bashrc` 文件:
```
$ vi ~/.bashrc
```
在文件的最后添加一行:
```
PS1="ostechnix> "
```
将上面的 “ostechnix” 替换为任意一个你想使用的单词,然后按 `ESC` 并输入 `:wq` 保存、退出文件。
执行以下命令使刚才的修改生效:
```
$ source ~/.bashrc
```
你就可以看见 bash 命令提示符中出现刚才添加的 “ostechnix” 了。

再来看看另一个例子,比如将 “username@hostname” 替换为 “Hello@welcome>”。
同样是像刚才那样修改 `~/.bashrc` 文件。
```
export PS1="Hello@welcome> "
```
然后执行 `source ~/.bashrc` 让修改结果立即生效。
以下是我在 Ubuntu 18.04 LTS 上修改后的效果。

#### 仅显示用户名
如果需要仅显示用户名,只需要在 `~/.bashrc` 文件中加入以下这一行。
```
export PS1="\u "
```
这里的 `\u` 就是一个转义字符串。
下面提供了一些可以添加到 `$PS1` 环境变量中的用以改变 bash 命令提示符样式的转义字符串。每次修改之后,都需要执行 `source ~/.bashrc` 命令才能立即生效。
#### 显示用户名和主机名
```
export PS1="\u\h "
```
命令提示符会这样显示:
```
skubuntuserver
```
#### 显示用户名和完全限定域名
```
export PS1="\u\H "
```
#### 在用户名和主机名之间显示其它字符
如果你还需要在用户名和主机名之间显示其它字符(例如 `@`),可以使用以下格式:
```
export PS1="\u@\h "
```
命令提示符会这样显示:
```
sk@ubuntuserver
```
#### 显示用户名、主机名,并在末尾添加 $ 符号
```
export PS1="\u@\h\\$ "
```
#### 综合以上两种显示方式
```
export PS1="\u@\h> "
```
命令提示符最终会这样显示:
```
sk@ubuntuserver>
```
相似地,还可以添加其它特殊字符,例如冒号、分号、星号、下划线、空格等等。
#### 显示用户名、主机名、shell 名称
```
export PS1="\u@\h>\s "
```
#### 显示用户名、主机名、shell 名称以及 shell 版本
```
export PS1="\u@\h>\s\v "
```
bash 命令提示符显示样式:

#### 显示用户名、主机名、当前目录
```
export PS1="\u@\h\w "
```
如果当前目录是 `$HOME` ,会以一个波浪线(`~`)显示。
#### 在 bash 命令提示符中显示日期
除了用户名和主机名,如果还想在 bash 命令提示符中显示日期,可以在 `~/.bashrc` 文件中添加以下内容:
```
export PS1="\u@\h>\d "
```

#### 在 bash 命令提示符中显示日期及 12 小时制时间
```
export PS1="\u@\h>\d\@ "
```
#### 显示日期及 hh:mm:ss 格式时间
```
export PS1="\u@\h>\d\T "
```
#### 显示日期及 24 小时制时间
```
export PS1="\u@\h>\d\A "
```
#### 显示日期及 24 小时制 hh:mm:ss 格式时间
```
export PS1="\u@\h>\d\t "
```
以上是一些常见的可以改变 bash 命令提示符的转义字符串。除此以外的其它转义字符串,可以在 bash 的 man 手册 PROMPTING 章节中查阅。
你也可以随时执行以下命令查看当前的命令提示符样式。
```
$ echo $PS1
```
#### 在 bash 命令提示符中去掉 username@hostname 部分
如果我不想做任何调整,直接把 username@hostname 部分整个去掉可以吗?答案是肯定的。
如果你是一个技术方面的博主,你有可能会需要在网站或者博客中上传自己的 Linux 终端截图。或许你的用户名和主机名太拉风、太另类,不想让别人看到,在这种情况下,你就需要隐藏命令提示符中的 “username@hostname” 部分。
如果你不想暴露自己的用户名和主机名,只需要按照以下步骤操作。
编辑 `~/.bashrc` 文件:
```
$ vi ~/.bashrc
```
在文件末尾添加这一行:
```
PS1="\W> "
```
输入 `:wq` 保存并关闭文件。
执行以下命令让修改立即生效。
```
$ source ~/.bashrc
```
现在看一下你的终端,“username@hostname” 部分已经消失了,只保留了一个 `~>` 标记。

如果你想要尽可能简单的操作,又不想弄乱你的 `~/.bashrc` 文件,最好的办法就是在系统中创建另一个用户(例如 “user@example”、“admin@demo”)。用带有这样的命令提示符的用户去截图或者录屏,就不需要顾虑自己的用户名或主机名被别人看见了。
**警告:**在某些情况下,这种做法并不推荐。例如像 zsh 这种 shell 会继承当前 shell 的设置,这个时候可能会出现一些意想不到的问题。这个技巧只用于隐藏命令提示符中的 “username@hostname” 部分,仅此而已,如果把这个技巧挪作他用,也可能会出现异常。
### 为 bash 命令提示符着色
目前我们也只是变更了 bash 命令提示符中的内容,下面介绍一下如何对命令提示符进行着色。
通过向 `~/.bashrc` 文件写入一些配置,可以修改 bash 命令提示符的前景色(也就是文本的颜色)和背景色。
例如,下面这一行配置可以令某些文本的颜色变成红色:
```
export PS1="\u@\[\e[31m\]\h\[\e[m\] "
```
添加配置后,执行 `source ~/.bashrc` 立即生效。
你的 bash 命令提示符就会变成这样:

类似地,可以用这样的配置来改变背景色:
```
export PS1="\u@\[\e[31;46m\]\h\[\e[m\] "
```

### 添加 emoji
大家都喜欢 emoji。还可以按照以下配置把 emoji 插入到命令提示符中。
```
PS1="\W ♤ >"
```
需要注意的是,emoji 的显示取决于使用的字体,因此某些终端可能会无法正常显示 emoji,取而代之的是一些乱码或者单色表情符号。
### 自定义 bash 命令提示符有点难,有更简单的方法吗?
如果你是一个新手,编辑 `$PS1` 环境变量的过程可能会有些困难,因为命令提示符中的大量转义字符串可能会让你有点晕头转向。但不要担心,有一个在线的 bash `$PS1` 生成器可以帮助你轻松生成各种 `$PS1` 环境变量值。
就是这个[网站](http://ezprompt.net/):
[](http://ezprompt.net/)
只需要直接选择你想要的 bash 命令提示符样式,添加颜色、设计排序,然后就完成了。你可以预览输出,并将配置代码复制粘贴到 `~/.bashrc` 文件中。就这么简单。顺便一提,本文中大部分的示例都是通过这个网站制作的。
### 我把我的 ~/.bashrc 文件弄乱了,该如何恢复?
正如我在上面提到的,强烈建议在更改 `~/.bashrc` 文件前做好备份(在更改其它重要的配置文件之前也一定要记得备份)。这样一旦出现任何问题,你都可以很方便地恢复到更改之前的配置状态。当然,如果你忘记了备份,还可以按照下面这篇文章中介绍的方法恢复为默认配置。
* [如何将 `~/.bashrc` 文件恢复到默认配置](https://www.ostechnix.com/restore-bashrc-file-default-settings-ubuntu/)
这篇文章是基于 ubuntu 的,但也适用于其它的 Linux 发行版。不过事先声明,这篇文章的方法会将 `~/.bashrc` 文件恢复到系统最初时的状态,你对这个文件做过的任何修改都将丢失。
感谢阅读!
---
via: <https://www.ostechnix.com/hide-modify-usernamelocalhost-part-terminal/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,281 | 如何在 Anbox 上安装 Google Play 商店及启用 ARM 支持 | https://www.linuxuprising.com/2018/07/anbox-how-to-install-google-play-store.html | 2018-11-27T11:49:00 | [
"Android",
"安卓"
] | https://linux.cn/article-10281-1.html | 
[Anbox](https://anbox.io/) (Anroid in a Box)是一个自由开源工具,它允许你在 Linux 上运行 Android 应用程序。它的工作原理是在 LXC 容器中运行 Android 运行时环境,重新创建 Android 的目录结构作为可挂载的 loop 镜像,同时使用本机 Linux 内核来执行应用。
据其网站所述,它的主要特性是安全性、性能、集成和趋同(不同外形尺寸缩放)。
使用 Anbox,每个 Android 应用或游戏就像系统应用一样都在一个单独的窗口中启动,它们的行为或多或少类似于常规窗口,显示在启动器中,可以平铺等等。
默认情况下,Anbox 没有 Google Play 商店或 ARM 应用支持。要安装应用,你必须下载每个应用的 APK 并使用 `adb` 手动安装。此外,默认情况下不能使用 Anbox 安装 ARM 应用或游戏 —— 尝试安装 ARM 应用会显示以下错误:
```
Failed to install PACKAGE.NAME.apk: Failure [INSTALL_FAILED_NO_MATCHING_ABIS: Failed to extract native libraries, res=-113]
```
你可以在 Anbox 中手动设置 Google Play 商店和 ARM 应用支持(通过 libhoudini),但这是一个非常复杂的过程。为了更容易地在 Anbox 上安装 Google Play 商店和 Google Play 服务,并让它支持 ARM 应用程序和游戏(使用 libhoudini),[geeks-r-us.de](https://geeks-r-us.de/2017/08/26/android-apps-auf-dem-linux-desktop/)(文章是德语)上的人创建了一个自动执行这些任务的脚本。
在使用之前,我想明确指出,即使在集成 libhoudini 来支持 ARM 后,也并非所有 Android 应用和游戏都能在 Anbox 中运行。某些 Android 应用和游戏可能根本不会出现在 Google Play 商店中,而一些应用和游戏可能可以安装但无法使用。此外,某些应用可能无法使用某些功能。
### 安装 Google Play 商店并在 Anbox 上启用 ARM 应用/游戏支持
如果你的 Linux 桌面上尚未安装 Anbox,这些说明显然不起作用。如果你还没有,请按照[此处](https://github.com/anbox/anbox/blob/master/docs/install.md)的安装说明安装 Anbox。此外,请确保在安装 Anbox 之后,使用此脚本之前至少运行一次 `anbox.appmgr`,以避免遇到问题。另外,确保在执行下面的脚本时 Anbox 没有运行(我怀疑这是导致评论中提到的这个[问题](https://www.linuxuprising.com/2018/07/anbox-how-to-install-google-play-store.html?showComment=1533506821283#c4415289781078860898)的原因)。
1、 安装所需的依赖项(wget、lzip、unzip 和 squashfs-tools)。
在 Debian、Ubuntu 或 Linux Mint 中,使用此命令安装所需的依赖项:
```
sudo apt install wget lzip unzip squashfs-tools
```
2、 下载并运行脚本,在 Anbox 上自动下载并安装 Google Play 商店(和 Google Play 服务)和 libhoudini(用于 ARM 应用/游戏支持)。
**警告:永远不要在不知道它做什么的情况下运行不是你写的脚本。在运行此脚本之前,请查看其[代码](https://github.com/geeks-r-us/anbox-playstore-installer/blob/master/install-playstore.sh)。**
要下载脚本,使其可执行并在 Linux 桌面上运行,请在终端中使用以下命令:
```
wget https://raw.githubusercontent.com/geeks-r-us/anbox-playstore-installer/master/install-playstore.sh
chmod +x install-playstore.sh
sudo ./install-playstore.sh
```
3、要让 Google Play 商店在 Anbox 中运行,你需要启用 Google Play 商店和 Google Play 服务的所有权限
为此,请运行Anbox:
```
anbox.appmgr
```
然后进入“设置 > 应用 > Google Play 服务 > 权限”并启用所有可用权限。对 Google Play 商店也一样!

你现在应该可以使用 Google 帐户登录 Google Play 商店了。
如果未启用 Google Play 商店和 Google Play 服务的所有权限,你可能会在尝试登录 Google 帐户时可能会遇到问题,并显示以下错误消息:“Couldn’t sign in. There was a problem communicating with Google servers. Try again later“,如你在下面的截图中看到的那样:

登录后,你可以停用部分 Google Play 商店/Google Play 服务权限。
**如果你在 Anbox 上登录 Google 帐户时遇到一些连接问题**,请确保 `anbox-bride.sh` 正在运行:
启动它:
```
sudo /snap/anbox/current/bin/anbox-bridge.sh start
```
重启它:
```
sudo /snap/anbox/current/bin/anbox-bridge.sh restart
```
根据[此用户](https://github.com/anbox/anbox/issues/118#issuecomment-295270113)的说法,如果 Anbox 仍然存在连接问题,你可能还需要安装 dnsmasq 包。但是在我的 Ubuntu 18.04 桌面上不需要这样做。
---
via: <https://www.linuxuprising.com/2018/07/anbox-how-to-install-google-play-store.html>
作者:[Logix](https://plus.google.com/118280394805678839070) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Anbox: How To Install Google Play Store And Enable ARM (libhoudini) Support, The Easy Way
**It works by running the Android runtime environment in an LXC container, recreating the directory structure of Android as a mountable loop image, while using the native Linux kernel to execute applications.**
[Anbox](https://anbox.io/), or Android in a Box, is a free and open source tool that allows running Android applications on Linux.Its key features are security, performance, integration and convergence (scales across different form factors), according to its website.
**Using Anbox, each Android application or game is launched in a separate window, just like system applications**, and they behave more or less like regular windows, showing up in the launcher, can be tiled, etc.
By default, Anbox doesn't ship with the Google Play Store or support for ARM applications. To install applications you must download each app APK and install it manually using adb. Also, installing ARM applications or games doesn't work by default with Anbox - trying to install ARM apps results in the following error being displayed:
`Failed to install PACKAGE.NAME.apk: Failure [INSTALL_FAILED_NO_MATCHING_ABIS: Failed to extract native libraries, res=-113]`
You can set up both Google Play Store and support for ARM applications (through libhoudini) manually for Android in a Box, but it's a quite complicated process.
**To make it easier to install Google Play Store and Google Play Services on Anbox, and get it to support ARM applications and games (using libhoudini), the folks at**
[geeks-r-us.de](https://geeks-r-us.de/2017/08/26/android-apps-auf-dem-linux-desktop/)(linked article is in German) have created a[script](https://github.com/geeks-r-us/anbox-playstore-installer/)that automates these tasks.Before using this, I'd like to make it clear that not all Android applications and games work in Anbox, even after integrating libhoudini for ARM support. Some Android applications and games may not show up in the Google Play Store at all, while others may be available for installation but will not work. Also, some features may not be available in some applications.
## Install Google Play Store and enable ARM applications / games support on Anbox (Android in a Box)
**Update (February, 2019): The script to install Google Play Store and enable ARM (libhoudini) support for Anbox was updated to automatically download the latest open-gapps, fixing an issue that caused Google Play Store to close immediately after starting in some cases (when the Google Play Store version downloaded by the script was too old).**
**These instructions will obviously not work if Anbox is not already installed on your Linux desktop. If you haven't already, install Anbox by following the installation instructions found**Also, make sure you run
[here](https://github.com/anbox/anbox/blob/master/docs/install.md).`anbox.appmgr`
at least once after installing Anbox and before using this script, to avoid running into issues. Also, make sure Anbox is not running when executing the script below (I suspect this is what causes [this](https://www.linuxuprising.com/2018/07/anbox-how-to-install-google-play-store.html?showComment=1533506821283#c4415289781078860898)issue mentioned in the comments).
1. Install the required dependencies (
`wget`
, `lzip`
, `unzip`
and `squashfs-tools`
).In Debian, Ubuntu or Linux Mint, use this command to install the required dependencies:
`sudo apt install wget curl lzip tar unzip squashfs-tools`
2. Download and run the script that automatically downloads and installs Google Play Store (and Google Play Services) and libhoudini (for ARM apps / games support) on your Android in a Box installation.
**Warning: never run a script you didn't write without knowing what it does. Before running this script, check out its**
[code](https://github.com/geeks-r-us/anbox-playstore-installer/blob/master/install-playstore.sh).To download the script and make it executable, use these commands in a terminal:
```
wget https://raw.githubusercontent.com/geeks-r-us/anbox-playstore-installer/master/install-playstore.sh
chmod +x install-playstore.sh
```
Now you can run the script:
`./install-playstore.sh`
Initially the script needed to run with superuser privileges, but that's no longer the case. After it's done installing Google Play Store and libhoudini, you can clean the leftovers - remove the anbox-work folder created by the script.
4. To get Google Play Store to work in Anbox, you need to enable all the permissions for both Google Play Store and Google Play Services
To do this, run Anbox:
`anbox.appmgr`
Then go to
`Settings > Apps > Google Play Services > Permissions`
and enable all available permissions. Do the same for Google Play Store!You should now be able to login using a Google account into Google Play Store.
Without enabling all permissions for Google Play Store and Google Play Services, you may encounter an issue when trying to login to your Google account, with the following error message: "
*Couldn't sign in. There was a problem communicating with Google servers. Try again later*", as you can see in this screenshot:
After logging in, you can disable some of the Google Play Store / Google Play Services permissions.
**If you're encountering some connectivity issues when logging in to your Google account on Anbox,**make sure the
`anbox-bride.sh`
is running:- to start it:
`sudo /snap/anbox/current/bin/anbox-bridge.sh start`
- to restart it:
`sudo /snap/anbox/current/bin/anbox-bridge.sh restart`
You may also need to install the dnsmasq package if you continue to have connectivity issues with Anbox, according to
[this](https://github.com/anbox/anbox/issues/118#issuecomment-295270113)user. But this wasn't required on my Ubuntu 18.04 desktop. |
10,282 | 2018 重温 Unix 哲学 | https://opensource.com/article/18/11/revisiting-unix-philosophy-2018 | 2018-11-27T12:32:00 | [
"Unix",
"微服务"
] | https://linux.cn/article-10282-1.html |
>
> 在现代微服务环境中,构建小型、单一的应用程序的旧策略又再一次流行了起来。
>
>
>

1984 年,Rob Pike 和 Brian W. Kernighan 在 AT&T 贝尔实验室技术期刊上发表了名为 “[Unix 环境编程](http://harmful.cat-v.org/cat-v/)” 的文章,其中他们使用 BSD 的 `cat -v` 例子来认证 Unix 哲学。简而言之,Unix 哲学是:构建小型、单一的应用程序 —— 不管用什么语言 —— 只做一件小而美的事情,用 `stdin` / `stdout` 进行通信,并通过管道进行连接。
听起来是不是有点耳熟?
是的,我也这么认为。这就是 James Lewis 和 Martin Fowler 给出的 [微服务的定义](https://martinfowler.com/articles/microservices.html) 。
>
> 简单来说,微服务架构的风格是将单个 应用程序开发为一套小型服务的方法,每个服务都运行在它的进程中,并用轻量级机制进行通信,通常是 HTTP 资源 API 。
>
>
>
虽然一个 \*nix 程序或者是一个微服务本身可能非常局限甚至不是很有用,但是当这些独立工作的单元组合在一起的时候就显示出了它们真正的好处和强大。
### \*nix程序 vs 微服务
下面的表格对比了 \*nix 环境中的程序(例如 `cat` 或 `lsof`)与微服务环境中的程序。
| | \*nix 程序 | 微服务 |
| --- | --- | --- |
| 执行单元 | 程序使用 `stdin`/`stdout` | 使用 HTTP 或 gRPC API |
| 数据流 | 管道 | ? |
| 可配置和参数化 | 命令行参数、环境变量和配置文件 | JSON/YAML 文档 |
| 发现 | 包管理器、man、make | DNS、环境变量、OpenAPI |
让我们详细的看看每一行。
#### 执行单元
\*nix 系统(如 Linux)中的执行单元是一个可执行的文件(二进制或者是脚本),理想情况下,它们从 `stdin` 读取输入并将输出写入 `stdout`。而微服务通过暴露一个或多个通信接口来提供服务,比如 HTTP 和 gRPC API。在这两种情况下,你都会发现无状态示例(本质上是纯函数行为)和有状态示例,除了输入之外,还有一些内部(持久)状态决定发生了什么。
#### 数据流
传统的,\*nix 程序能够通过管道进行通信。换句话说,我们要感谢 [Doug McIlroy](https://en.wikipedia.org/wiki/Douglas_McIlroy),你不需要创建临时文件来传递,而可以在每个进程之间处理无穷无尽的数据流。据我所知,除了我在 [2017 年做的基于 Apache Kafka 小实验](https://speakerdeck.com/mhausenblas/distributed-named-pipes-and-other-inter-services-communication),没有什么能比得上管道化的微服务了。
#### 可配置和参数化
你是如何配置程序或者服务的,无论是永久性的服务还是即时的服务?是的,在 \*nix 系统上,你通常有三种方法:命令行参数、环境变量,或全面的配置文件。在微服务架构中,典型的做法是用 YAML(或者甚至是 JSON)文档,定制好一个服务的布局和配置以及依赖的组件和通信、存储和运行时配置。例如 [Kubernetes 资源定义](http://kubernetesbyexample.com/)、[Nomad 工作规范](https://www.nomadproject.io/docs/job-specification/index.html) 或 [Docker 编排](https://docs.docker.com/compose/overview/) 文档。这些可能参数化也可能不参数化;也就是说,除非你知道一些模板语言,像 Kubernetes 中的 [Helm](https://helm.sh/),否则你会发现你使用了很多 `sed -i` 这样的命令。
#### 发现
你怎么知道有哪些程序和服务可用,以及如何使用它们?在 \*nix 系统中通常都有一个包管理器和一个很好用的 man 页面;使用它们,应该能够回答你所有的问题。在微服务的设置中,在寻找一个服务的时候会相对更自动化一些。除了像 [Airbnb 的 SmartStack](https://github.com/airbnb/smartstack-cookbook) 或 [Netflix 的 Eureka](https://github.com/Netflix/eureka) 等可以定制以外,通常还有基于环境变量或基于 DNS 的[方法](https://kubernetes.io/docs/concepts/services-networking/service/#discovering-services),允许您动态的发现服务。同样重要的是,事实上 [OpenAPI](https://www.openapis.org/) 为 HTTP API 提供了一套标准文档和设计模式,[gRPC](https://grpc.io/) 为一些耦合性强的高性能项目也做了同样的事情。最后非常重要的一点是,考虑到开发者经验(DX),应该从写一份好的 [Makefile](https://suva.sh/posts/well-documented-makefiles/) 开始,并以编写符合 [风格](https://www.linux.com/news/improve-your-writing-gnu-style-checkers) 的文档结束。
### 优点和缺点
\*nix 系统和微服务都提供了许多挑战和机遇。
#### 模块性
要设计一个简洁、有清晰的目的,并且能够很好地和其它模块配合的某个东西是很困难的。甚至是在不同版本中实现并引入相应的异常处理流程都很困难的。在微服务中,这意味着重试逻辑和超时机制,或者将这些功能外包到<ruby> 服务网格 <rt> service mesh </rt></ruby>是不是一个更好的选择呢?这确实比较难,可如果你做好了,那它的可重用性是巨大的。
#### 可观测性
在一个<ruby> 独石 <rt> monolith </rt></ruby>(2018 年)或是一个试图做任何事情的大型程序(1984 年),当情况恶化的时候,应当能够直接的找到问题的根源。但是在一个
```
yes | tr \\n x | head -c 450m | grep n
```
或者在一个微服务设置中请求一个路径,例如,涉及 20 个服务,你怎么弄清楚是哪个服务的问题?幸运的是,我们有很多标准,特别是 [OpenCensus](https://opencensus.io/) 和 [OpenTracing](https://opentracing.io/)。如果您希望转向微服务,可预测性仍然可能是最大的问题。
#### 全局状态
对于 \*nix 程序来说可能不是一个大问题,但在微服务中,全局状态仍然是一个需要讨论的问题。也就是说,如何确保有效的管理本地化(持久性)的状态以及尽可能在少做变更的情况下使全局保持一致。
### 总结一下
最后,问题仍然是:你是否在使用合适的工具来完成特定的工作?也就是说,以同样的方式实现一个特定的 \*nix 程序在某些时候或者阶段会是一个更好的选择,它是可能在你的组织或工作过程中的一个[最好的选择](https://robertnorthard.com/devops-days-well-architected-monoliths-are-okay/)。无论如何,我希望这篇文章可以让你看到 Unix 哲学和微服务之间许多强有力的相似之处。也许我们可以从前者那里学到一些东西使后者受益。
---
via: <https://opensource.com/article/18/11/revisiting-unix-philosophy-2018>
作者:[Michael Hausenblas](https://opensource.com/users/mhausenblas) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Jamskr](https://github.com/Jamskr) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In 1984, Rob Pike and Brian W. Kernighan published an article called "[Program Design in the Unix Environment](http://harmful.cat-v.org/cat-v/)" in the AT&T Bell Laboratories Technical Journal, in which they argued the Unix philosophy, using the example of BSD's **cat -v** implementation. In a nutshell that philosophy is: Build small, focused programs—in whatever language—that do only one thing but do this thing well, communicate via **stdin**/**stdout**, and are connected through pipes.
Sound familiar?
Yeah, I thought so. That's pretty much the [definition of microservices](https://martinfowler.com/articles/microservices.html) offered by James Lewis and Martin Fowler:
In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API.
While one *nix program or one microservice may be very limited or not even very interesting on its own, it's the combination of such independently working units that reveals their true benefit and, therefore, their power.
## *nix vs. microservices
The following table compares programs (such as **cat** or **lsof**) in a *nix environment against programs in a microservices environment.
*nix | Microservices | |
---|---|---|
Unit of execution | program using stdin/stdout |
service with HTTP or gRPC API |
Data flow | Pipes | ? |
Configuration & parameterization | Command-line arguments, environment variables, config files |
JSON/YAML docs |
Discovery | Package manager, man, make |
DNS, environment variables, OpenAPI |
Let's explore each line in slightly greater detail.
### Unit of execution
The unit of execution in *nix (such as Linux) is an executable file (binary or interpreted script) that, ideally, reads input from **stdin** and writes output to **stdout**. A microservices setup deals with a service that exposes one or more communication interfaces, such as HTTP or gRPC APIs. In both cases, you'll find stateless examples (essentially a purely functional behavior) and stateful examples, where, in addition to the input, some internal (persisted) state decides what happens.
### Data flow
Traditionally, *nix programs could communicate via pipes. In other words, thanks to [Doug McIlroy](https://en.wikipedia.org/wiki/Douglas_McIlroy), you don't need to create temporary files to pass around and each can process virtually endless streams of data between processes. To my knowledge, there is nothing comparable to a pipe standardized in microservices, besides my little [Apache Kafka-based experiment from 2017](https://speakerdeck.com/mhausenblas/distributed-named-pipes-and-other-inter-services-communication).
### Configuration and parameterization
How do you configure a program or service—either on a permanent or a by-call basis? Well, with *nix programs you essentially have three options: command-line arguments, environment variables, or full-blown config files. In microservices, you typically deal with YAML (or even worse, JSON) documents, defining the layout and configuration of a single microservice as well as dependencies and communication, storage, and runtime settings. Examples include [Kubernetes resource definitions](http://kubernetesbyexample.com/), [Nomad job specifications](https://www.nomadproject.io/docs/job-specification/index.html), or [Docker Compose](https://docs.docker.com/compose/overview/) files. These may or may not be parameterized; that is, either you have some templating language, such as [Helm](https://helm.sh/) in Kubernetes, or you find yourself doing an awful lot of **sed -i** commands.
### Discovery
How do you know what programs or services are available and how they are supposed to be used? Well, in *nix, you typically have a package manager as well as good old man; between them, they should be able to answer all the questions you might have. In a microservices setup, there's a bit more automation in finding a service. In addition to bespoke approaches like [Airbnb's SmartStack](https://github.com/airbnb/smartstack-cookbook) or [Netflix's Eureka](https://github.com/Netflix/eureka), there usually are environment variable-based or DNS-based [approaches](https://kubernetes.io/docs/concepts/services-networking/service/#discovering-services) that allow you to discover services dynamically. Equally important, [OpenAPI](https://www.openapis.org/) provides a de-facto standard for HTTP API documentation and design, and [gRPC](https://grpc.io/) does the same for more tightly coupled high-performance cases. Last but not least, take developer experience (DX) into account, starting with writing good [Makefiles](https://suva.sh/posts/well-documented-makefiles/) and ending with writing your docs with (or in?) [ style](https://www.linux.com/news/improve-your-writing-gnu-style-checkers).
## Pros and cons
Both *nix and microservices offer a number of challenges and opportunities
### Composability
It's hard to design something that has a clear, sharp focus and can also play well with others. It's even harder to get it right across different versions and to introduce respective error case handling capabilities. In microservices, this could mean retry logic and timeouts—maybe it's a better option to outsource these features into a service mesh? It's hard, but if you get it right, its reusability can be enormous.
### Observability
In a monolith (in 2018) or a big program that tries to do it all (in 1984), it's rather straightforward to find the culprit when things go south. But, in a
`yes | tr \\n x | head -c 450m | grep n`
or a request path in a microservices setup that involves, say, 20 services, how do you even *start* to figure out which one is behaving badly? Luckily we have standards, notably [OpenCensus](https://opencensus.io/) and [OpenTracing](https://opentracing.io/). Observability still might be the biggest single blocker if you are looking to move to microservices.
### Global state
While it may not be such a big issue for *nix programs, in microservices, global state remains something of a discussion. Namely, how to make sure the local (persistent) state is managed effectively and how to make the global state consistent with as little effort as possible.
## Wrapping up
In the end, the question remains: Are you using the right tool for a given task? That is, in the same way a specialized *nix program implementing a range of functions might be the better choice for certain use cases or phases, it might be that a monolith [is the best option](https://robertnorthard.com/devops-days-well-architected-monoliths-are-okay/) for your organization or workload. Regardless, I hope this article helps you see the many, strong parallels between the Unix philosophy and microservices—maybe we can learn something from the former to benefit the latter.
## 5 Comments |
10,283 | 举例说明 alias 和 unalias 命令 | https://www.ostechnix.com/the-alias-and-unalias-commands-explained-with-examples/ | 2018-11-27T22:44:43 | [
"alias",
"别名"
] | https://linux.cn/article-10283-1.html | 
如果不是一个命令行重度用户的话,过了一段时间之后,你就可能已经忘记了这些复杂且冗长的 Linux 命令了。当然,有很多方法可以让你 [回想起遗忘的命令](https://www.ostechnix.com/easily-recall-forgotten-linux-commands/)。你可以简单的 [保存常用的命令](https://www.ostechnix.com/save-commands-terminal-use-demand/) 然后按需使用。也可以在终端里 [标记重要的命令](https://www.ostechnix.com/bookmark-linux-commands-easier-repeated-invocation/),然后在任何时候你想要的时间使用它们。而且,Linux 有一个内建命令 `history` 可以帮助你记忆这些命令。另外一个记住这些如此长的命令的简便方式就是为这些命令创建一个别名。你可以为任何经常重复调用的常用命令创建别名,而不仅仅是长命令。通过这种方法,你不必再过多地记忆这些命令。这篇文章中,我们将会在 Linux 环境下举例说明 `alias` 和 `unalias` 命令。
### alias 命令
`alias` 使用一个用户自定义的字符串来代替一个或者一串命令(包括多个选项、参数)。这个字符串可以是一个简单的名字或者缩写,不管这个命令原来多么复杂。`alias` 命令已经预装在 shell(包括 BASH、Csh、Ksh 和 Zsh 等) 当中。
`alias` 的通用语法是:
```
alias [alias-name[=string]...]
```
接下来看几个例子。
#### 列出别名
可能在你的系统中已经设置了一些别名。有些应用在你安装它们的时候可能已经自动创建了别名。要查看已经存在的别名,运行:
```
$ alias
```
或者,
```
$ alias -p
```
在我的 Arch Linux 系统中已经设置了下面这些别名。
```
alias betty='/home/sk/betty/main.rb'
alias ls='ls --color=auto'
alias pbcopy='xclip -selection clipboard'
alias pbpaste='xclip -selection clipboard -o'
alias update='newsbeuter -r && sudo pacman -Syu'
```
#### 创建一个新的别名
像我之前说的,你不必去记忆这些又臭又长的命令。你甚至不必一遍一遍的运行长命令。只需要为这些命令创建一个简单易懂的别名,然后在任何你想使用的时候运行这些别名就可以了。这种方式会让你爱上命令行。
```
$ du -h --max-depth=1 | sort -hr
```
这个命令将会查找当前工作目录下的各个子目录占用的磁盘大小,并按照从大到小的顺序进行排序。这个命令有点长。我们可以像下面这样轻易地为其创建一个 别名:
```
$ alias du='du -h --max-depth=1 | sort -hr'
```
这里的 `du` 就是这条命令的别名。这个别名可以被设置为任何名字,主要便于记忆和区别。
在创建一个别名的时候,使用单引号或者双引号都是可以的。这两种方法最后的结果没有任何区别。
现在你可以运行这个别名(例如我们这个例子中的 `du` )。它和上面的原命令将会产生相同的结果。
这个别名仅限于当前 shell 会话中。一旦你退出了当前 shell 会话,别名也就失效了。为了让这些别名长久有效,你需要把它们添加到你 shell 的配置文件当中。
BASH,编辑 `~/.bashrc` 文件:
```
$ nano ~/.bashrc
```
一行添加一个别名:

保存并退出这个文件。然后运行以下命令更新修改:
```
$ source ~/.bashrc
```
现在,这些别名在所有会话中都可以永久使用了。
ZSH,你需要添加这些别名到 `~/.zshrc`文件中。Fish,跟上面的类似,添加这些别名到 `~/.config/fish/config.fish` 文件中。
#### 查看某个特定的命令别名
像我上面提到的,你可以使用 `alias` 命令列出你系统中所有的别名。如果你想查看跟给定的别名有关的命令,例如 `du`,只需要运行:
```
$ alias du
alias du='du -h --max-depth=1 | sort -hr'
```
像你看到的那样,上面的命令可以显示与单词 `du` 有关的命令。
关于 `alias` 命令更多的细节,参阅 man 手册页:
```
$ man alias
```
### unalias 命令
跟它的名字说的一样,`unalias` 命令可以很轻松地从你的系统当中移除别名。`unalias` 命令的通用语法是:
```
unalias <alias-name>
```
要移除命令的别名,像我们之前创建的 `du`,只需要运行:
```
$ unalias du
```
`unalias` 命令不仅会从当前会话中移除别名,也会从你的 shell 配置文件中永久地移除别名。
还有一种移除别名的方法,是创建具有相同名称的新别名。
要从当前会话中移除所有的别名,使用 `-a` 选项:
```
$ unalias -a
```
更多细节,参阅 man 手册页。
```
$ man unalias
```
如果你经常一遍又一遍的运行这些繁杂又冗长的命令,给它们创建别名可以节省你的时间。现在是你为常用命令创建别名的时候了。
这就是所有的内容了。希望可以帮到你。还有更多的干货即将到来,敬请期待!
祝近祺!
---
via: <https://www.ostechnix.com/the-alias-and-unalias-commands-explained-with-examples/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,284 | 如何在终端中浏览 Stack Overflow | https://www.ostechnix.com/how-to-browse-stack-overflow-from-terminal/ | 2018-11-27T23:46:00 | [
"StackOverflow"
] | https://linux.cn/article-10284-1.html | 
前段时间,我们写了一篇关于 [SoCLI](https://www.ostechnix.com/search-browse-stack-overflow-website-commandline/) 的文章,它是一个从命令行搜索和浏览 Stack Overflow 网站的 python 脚本。今天,我们将讨论一个名为 “how2” 的类似工具。它是一个命令行程序,可以从终端浏览 Stack Overflow。你可以如你在 [Google 搜索](https://www.ostechnix.com/google-search-navigator-enhance-keyboard-navigation-in-google-search/)中那样直接用英语查询,然后它会使用 Google 和 Stackoverflow API 来搜索给定的查询。它是使用 NodeJS 编写的自由开源程序。
### 使用 how2 从终端浏览 Stack Overflow
由于 `how2` 是一个 NodeJS 包,我们可以使用 Npm 包管理器安装它。如果你尚未安装 Npm 和 NodeJS,请参考以下指南。
在安装 Npm 和 NodeJS 后,运行以下命令安装 how2。
```
$ npm install -g how2
```
现在让我们看下如何使用这个程序浏览 Stack Overflow。使用 `how2` 搜索 Stack Overflow 站点的典型用法是:
```
$ how2 <search-query>
```
例如,我将搜索如何创建 tgz 存档。
```
$ how2 create archive tgz
```
哎呀!我收到以下错误。
```
/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js:59
Transport.prototype.__proto__ = EventEmitter.prototype;
^
TypeError: Cannot read property 'prototype' of undefined
at Object.<anonymous> (/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js:59:46)
at Module._compile (internal/modules/cjs/loader.js:654:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:665:10)
at Module.load (internal/modules/cjs/loader.js:566:32)
at tryModuleLoad (internal/modules/cjs/loader.js:506:12)
at Function.Module._load (internal/modules/cjs/loader.js:498:3)
at Module.require (internal/modules/cjs/loader.js:598:17)
at require (internal/modules/cjs/helpers.js:11:18)
at Object.<anonymous> (/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/stream.js:8:17)
at Module._compile (internal/modules/cjs/loader.js:654:30)
```
我可能遇到了一个 bug。我希望它在未来版本中得到修复。但是,我在[这里](https://github.com/santinic/how2/issues/79)找到了一个临时方法。
要临时修复此错误,你需要使用以下命令编辑 `transport.js`:
```
$ vi /home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js
```
此文件的实际路径将显示在错误输出中。用你自己的文件路径替换上述文件路径。然后找到以下行:
```
var EventEmitter = process.EventEmitter;
```
并用以下行替换它:
```
var EventEmitter = require('events');
```
按 `ESC` 并输入 `:wq` 以保存并退出文件。
现在再次搜索查询。
```
$ how2 create archive tgz
```
这是我的 Ubuntu 系统的示例输出。

如果你要查找的答案未显示在上面的输出中,请按**空格键**键开始交互式搜索,你可以通过它查看 Stack Overflow 站点中的所有建议问题和答案。

使用向上/向下箭头在结果之间移动。得到正确的答案/问题后,点击空格键或回车键在终端中打开它。

要返回并退出,请按 `ESC`。
**搜索特定语言的答案**
如果你没有指定语言,它**默认为 Bash** unix 命令行,并立即为你提供最可能的答案。你还可以将结果缩小到特定语言,例如 perl、python、c、Java 等。
例如,使用 `-l` 标志仅搜索与 “Python” 语言相关的查询,如下所示。
```
$ how2 -l python linked list
```
[](http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-4.png)
要获得快速帮助,请输入:
```
$ how2 -h
```
### 总结
`how2` 是一个基本的命令行程序,它可以快速搜索 Stack Overflow 中的问题和答案,而无需离开终端,并且它可以很好地完成这项工作。但是,它只是 Stack overflow 的 CLI 浏览器。对于一些高级功能,例如搜索投票最多的问题,使用多个标签搜索查询,彩色界面,提交新问题和查看问题统计信息等,**SoCLI** 做得更好。
就是这些了。希望这篇文章有用。我将很快写一篇新的指南。在此之前,请继续关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-browse-stack-overflow-from-terminal/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,285 | GPL 合作承诺的发展历程 | https://opensource.com/article/18/11/gpl-cooperation-commitment | 2018-11-28T10:18:29 | [
"GPL"
] | https://linux.cn/article-10285-1.html |
>
> <ruby> GPL 合作承诺 <rt> GPL Cooperation Commitment </rt></ruby>消除了开发者对许可证失效的顾虑,从而达到促进技术创新的目的。
>
>
>

假如能免于顾虑,技术创新和发展将会让世界发生天翻地覆的改变。<ruby> <a href="https://gplcc.github.io/gplcc/"> GPL 合作承诺 </a> <rt> GPL Cooperation Commitment </rt></ruby>就这样应运而生,只为通过公平、一致、可预测的许可证来让科技创新无后顾之忧。
去年,我曾经写过一篇文章,讨论了许可证对开源软件下游用户的影响。在进行研究的时候,我就发现许可证的约束力并不强,而且很多情况下是不可预测的。因此,我在文章中提出了一个能使开源许可证具有一致性和可预测性的潜在解决方案。但我只考虑到了诸如通过法律系统立法的“传统”方法。
2017 年 11 月,RedHat、IBM、Google 和 Facebook 提出了这种我从未考虑过的非传统的解决方案:GPL 合作承诺。GPL 合作承诺规定了 GPL 公平一致执行的方式。我认为,GPL 合作承诺之所以有这么深刻的意义,有以下两个原因:一是许可证的公平性和一致性对于开源社区的发展来说至关重要,二是法律对不可预测性并不容忍。
### 了解 GPL
要了解 GPL 合作承诺,首先要了解什么是 GPL。GPL 是 <ruby> <a href="https://www.gnu.org/licenses/licenses.en.html"> GNU 通用许可证 </a> <rt> GNU General Public License </rt></ruby>的缩写,它是一个公共版权的开源许可证,这就意味着开源软件的分发者必须向下游用户公开源代码。GPL 还禁止对下游的使用作出限制,要求个人用户不得拒绝他人对开源软件的使用自由、研究自由、共享自由和改进自由。GPL 规定,只要下游用户满足了许可证的要求和条件,就可以使用该许可证。如果被许可人出现了不符合许可证的情况,则视为违规。
按照第二版 GPL(GPLv2)的描述,许可证会在任何违规的情况下自动终止,这就导致了部分开发者对 GPL 有所抗拒。而在第三版 GPL(GPLv3)中则引入了“<ruby> <a href="https://opensource.com/article/18/6/gplv3-anniversary"> 治愈条款 </a> <rt> cure provision </rt></ruby>”,这一条款规定,被许可人可以在 30 天内对违反 GPL 的行为进行改正,如果在这个缓冲期内改正完成,许可证就不会被终止。
这一规定消除了许可证被无故终止的顾虑,从而让软件的开发者和用户专注于开发和创新。
### GPL 合作承诺做了什么
GPL 合作承诺将 GPLv3 的治愈条款应用于使用 GPLv2 的软件上,让使用 GPLv2 许可证的开发者避免许可证无故终止的窘境,并与 GPLv3 许可证保持一致。
很多软件开发者都希望正确合规地做好一件事情,但有时候却不了解具体的实施细节。因此,GPL 合作承诺的重要性就在于能够对软件开发者们做出一些引导,让他们避免因一些简单的错误导致许可证违规终止。
Linux 基金会技术顾问委员会在 2017 年宣布,Linux 内核项目将会[采用 GPLv3 的治愈条款](https://www.kernel.org/doc/html/v4.16/process/kernel-enforcement-statement.html)。在 GPL 合作承诺的推动下,很多大型科技公司和个人开发者都做出了相同的承诺,会将该条款扩展应用于他们采用 GPLv2(或 LGPLv2.1)许可证的所有软件,而不仅仅是对 Linux 内核的贡献。
GPL 合作承诺的广泛采用将会对开源社区产生非常积极的影响。如果更多的公司和个人开始采用 GPL 合作承诺,就能让大量正在使用 GPLv2 或 LGPLv2.1 许可证的软件以更公平和更可预测的形式履行许可证中的条款。
截至 2018 年 11 月,包括 IBM、Google、亚马逊、微软、腾讯、英特尔、RedHat 在内的 40 余家行业巨头公司都已经[签署了 GPL 合作承诺](https://gplcc.github.io/gplcc/Company/Company-List.html),以期为开源社区创立公平的标准以及提供可预测的执行力。GPL 合作承诺是开源社区齐心协力引领开源未来发展方向的一个成功例子。
GPL 合作承诺能够让下游用户了解到开发者对他们的尊重,同时也表示了开发者使用了 GPLv2 许可证的代码是安全的。如果你想查阅更多信息,包括如何将自己的名字添加到 GPL 合作承诺中,可以访问 [GPL 合作承诺的网站](http://gplcc.github.io/gplcc)。
---
via: <https://opensource.com/article/18/11/gpl-cooperation-commitment>
作者:[Brooke Driver](https://opensource.com/users/bdriver) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Imagine what the world would look like if growth, innovation, and development were free from fear. Innovation without fear is fostered by consistent, predictable, and fair license enforcement. That is what the [GPL Cooperation Commitment](https://gplcc.github.io/gplcc/) aims to accomplish.
Last year, I wrote an article about licensing effects on downstream users of open source software. As I was conducting research for that article, it became apparent that license enforcement is infrequent and often unpredictable. In that article, I offered potential solutions to the need to make open source license enforcement consistent and predictable. However, I only considered "traditional" methods (e.g., through the court system or some form of legislative action) that a law student might consider.
In November 2017, Red Hat, IBM, Google, and Facebook proposed the the "non-traditional" solution I had not considered: the GPL Cooperation Commitment, which provides for fair and consistent enforcement of the GPL. I believe the GPL Cooperation Commitment is critical for two reasons: First, consistent and fair license enforcement is crucial for growth in the open source community; second, unpredictability is undesirable in the legal community.
## Understanding the GPL
To understand the GPL Cooperation Commitment, you must first understand the GPL's history. GPL is short for [GNU General Public License](https://www.gnu.org/licenses/licenses.en.html). The GPL is a "copyleft" open source license, meaning that a software's distributor must make the source code available to downstream users. The GPL also prohibits placing restrictions on downstream use. These requirements keep individual users from denying freedoms (to use, study, share, and improve the software) to others. Under the GPL, a license to use the code is granted to all downstream users, provided they meet the requirements and conditions of the license. If a licensee does not meet the license's requirements, they are non-compliant.
Under the second version of the GPL (GPLv2), a license automatically terminates upon any non-compliance, which causes some software developers to shy away from using the GPL. However, the third version of the GPL (GPLv3) [added a "cure provision"](https://opensource.com/article/18/6/gplv3-anniversary) that gives a 30-day period for a licensee to remediate any GPL violation. If the violation is cured within 30 days following notification of non-compliance, the license is not terminated.
This provision eliminates the fear of termination due to an innocent mistake, thus fostering development and innovation by bringing peace of mind to users and distributors of the software.
## What the GPL Cooperation Commitment does
The GPL Cooperation Commitment applies the GPLv3's cure provisions to GPLv2-licensed software, thereby protecting licensees of GPLv2 code from the automatic termination of their license, consistent with the protections afforded by the GPLv3.
The GPL Cooperation Commitment is important because, while software engineers typically want to do the right thing and maintain compliance, they sometimes misunderstand how to do so. This agreement enables developers to avoid termination when they are non-compliant due to confusion or simple mistakes.
The GPL Cooperation Commitment spawned from an announcement in 2017 by the Linux Foundation Technical Advisory Board that the Linux kernel project would [adopt the cure provision from GPLv3](https://www.kernel.org/doc/html/v4.16/process/kernel-enforcement-statement.html). With the GPL Cooperation Commitment, many major technology companies and individual developers made the same commitment and expanded it by applying the cure period to *all* of their software licensed under GPLv2 (and LGPLv2.1), not only to contributions to the Linux kernel.
Broad adoption of the GPL Cooperation Commitment will have a positive impact on the open source community because a significant amount of software is licensed under GPLv2. An increasing number of companies and individuals are expected to adopt the GPL Cooperation Commitment, which will lead to a significant amount of GPLv2 (and LGPLv2.1) code under license terms that promote fair and predictable approaches to license enforcement.
In fact, as of November 2018, more than 40 companies, including industry leaders IBM, Google, Amazon, Microsoft, Tencent, Intel, and Red Hat, have [signed onto the GPL Cooperation Commitment](https://gplcc.github.io/gplcc/Company/Company-List.html) and are working collaboratively to create a standard of fair and predictable enforcement within the open source community. The GPL Cooperation Commitment is just one example of how the community comes together to ensure the future of open source.
The GPL Cooperation Commitment tells downstream licensees that you respect their good intentions and that your GPLv2 code is safe for them to use. More information, including about how you can add your name to the commitment, is available on the [GPL Cooperation Commitment website](http://gplcc.github.io/gplcc).
## Comments are closed. |
10,286 | i3 窗口管理器使 Linux 更美好 | https://opensource.com/article/18/8/i3-tiling-window-manager | 2018-11-28T11:47:44 | [
"i3",
"窗口管理器"
] | https://linux.cn/article-10286-1.html |
>
> 通过键盘操作的 i3 平铺窗口管理器使用 Linux 桌面。
>
>
>

Linux(和一般的开源软件)最美好的一点是自由 —— 可以在不同的替代方案中进行选择以满足我们的需求。
我使用 Linux 已经很长时间了,但我从来没有对可选用的桌面环境完全满意过。直到去年,[Xfce](https://xfce.org/) 还是我认为在功能和性能之间的平和最接近满意的一个桌面环境。然后我发现了 [i3](https://i3wm.org/),这是一个改变了我的生活的惊人的软件。
i3 是一个平铺窗口管理器。窗口管理器的目标是控制窗口系统中窗口的外观和位置。窗口管理器通常用作功能齐全的桌面环境 (如 GONME 或 Xfce ) 的一部分,但也有一些可以用作独立的应用程序。
平铺式窗口管理器会自动排列窗口,以不重叠的方式占据整个屏幕。其他流行的平铺式窗口管理器还有 [wmii](https://code.google.com/archive/p/wmii/) 和 [xmonad](https://xmonad.org/) 。

*带有三个的 i3 屏幕截图*
为了获得更好的 Linux 桌面体验,以下是我使用和推荐 i3 窗口管理器的五个首要原因。
### 1、极简艺术
i3 速度很快。它既不冗杂、也不花哨。它的设计简单而高效。作为开发人员,我重视这些功能,因为我可以使用更多的功能以丰富我最喜欢的开发工具,或者使用容器或虚拟机在本地测试内容。
此外, i3 是一个窗口管理器,与功能齐全的桌面环境不同,它并不规定您应该使用的应用程序。您是否想使用 Xfce 的 Thunar 作为文件管理器?GNOME 的 gedit 去编辑文本? i3 并不在乎。选择对您的工作流最有意义的工具,i3 将以相同的方式管理它们。
### 2、屏幕实际使用面积
作为平铺式窗口管理器,i3 将自动 “平铺”,以不重叠的方式定位窗口,类似于在墙上放置瓷砖。因为您不需要担心窗口定位,i3 一般会更好地利用您的屏幕空间。它还可以让您更快地找到您需要的东西。
对于这种情况有很多有用的例子。例如,系统管理员可以打开多个终端来同时监视或在不同的远程系统上工作;开发人员可以使用他们最喜欢的 IDE 或编辑器和几个终端来测试他们的程序。
此外,i3 具有灵活性。如果您需要为特定窗口提供更多空间,请启用全屏模式或切换到其他布局,如堆叠或选项卡式(标签式)。
### 3、键盘式工作流程
i3 广泛使用键盘快捷键来控制环境的不同方面。其中包括打开终端和其他程序、调整大小和定位窗口、更改布局,甚至退出 i3。当您开始使用 i3 时,您需要记住其中的一些快捷方式才能使用,随着时间的推移,您会使用更多的快捷方式。
主要好处是,您不需要经常在键盘和鼠标之间切换。通过练习,您将提高工作流程的速度和效率。
例如, 要打开新的终端,请按 `<SUPER>+<ENTER>`。由于窗口是自动定位的,您可以立即开始键入命令。结合一个很好的终端文本编辑器(如 Vim)和一个以面向键盘的浏览器,形成一个完全由键盘驱动的工作流程。
在 i3 中,您可以为所有内容定义快捷方式。下面是一些示例:
* 打开终端
* 打开浏览器
* 更改布局
* 调整窗口大小
* 控制音乐播放器
* 切换工作区
现在我已经习惯了这个工作形式,我已无法回到了常规的桌面环境。
### 4、灵活
i3 力求极简,使用很少的系统资源,但这并不意味着它不能变漂亮。i3 是灵活且可通过多种方式进行自定义以改善视觉体验。因为 i3 是一个窗口管理器,所以它没有提供启用自定义的工具,你需要外部工具来实现这一点。一些例子:
* 用 `feh` 定义桌面的背景图片。
* 使用合成器管理器,如 `compton` 以启用窗口淡入淡出和透明度等效果。
* 用 `dmenu` 或 `rofi` 以启用可从键盘快捷方式启动的可自定义菜单。
* 用 `dunst` 用于桌面通知。
i3 是可完全配置的,您可以通过更新默认配置文件来控制它的各个方面。从更改所有键盘快捷键,到重新定义工作区的名称,再到修改状态栏,您都可以使 i3 以任何最适合您需要的方式运行。

*i3 与 `rofi` 菜单和 `dunst` 桌面通知。*
最后,对于更高级的用户,i3 提供了完整的进程间通信([IPC](https://i3wm.org/docs/ipc.html))接口,允许您使用偏好的语言来开发脚本或程序,以实现更多的自定义选项。
### 5、工作空间
在 i3 中,工作区是对窗口进行分组的一种简单方法。您可以根据您的工作流以不同的方式对它们进行分组。例如,您可以将浏览器放在一个工作区上,终端放在另一个工作区上,将电子邮件客户端放在第三个工作区上等等。您甚至可以更改 i3 的配置,以便始终将特定应用程序分配给它们自己的工作区。
切换工作区既快速又简单。像 i3 中的惯例,使用键盘快捷方式执行此操作。按 `<SUPER>+num` 切换到工作区 `num` 。如果您养成了始终将应用程序组的窗口分配到同一个工作区的习惯,则可以在它们之间快速切换,这使得工作区成为非常有用的功能。
此外,还可以使用工作区来控制多监视器环境,其中每个监视器都有个初始工作区。如果切换到该工作区,则切换到该监视器,而无需让手离开键盘。
最后,i3 中还有另一种特殊类型的工作空间:the scratchpad(便笺簿)。它是一个不可见的工作区,通过按快捷方式显示在其他工作区的中间。这是一种访问您经常使用的窗口或程序的方便方式,如电子邮件客户端或音乐播放器。
### 尝试一下吧
如果您重视简洁和效率,并且不惮于使用键盘,i3 就是您的窗口管理器。有人说是为高级用户准备的,但情况不一定如此。你需要学习一些基本的快捷方式来度过开始的阶段,不久就会越来越自然并且不假思索地使用它们。
这篇文章只是浅浅谈及了 i3 能做的事情。欲了解更多详情,请参阅 [i3 的文档](https://i3wm.org/docs/userguide.html)。
---
via: <https://opensource.com/article/18/8/i3-tiling-window-manager>
作者:[Ricardo Gerardi](https://opensource.com/users/rgerardi) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lixinyuxx](https://github.com/lixinyuxx) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the nicest things about Linux (and open source software in general) is the freedom to choose among different alternatives to address our needs.
I've been using Linux for a long time, but I was never entirely happy with the desktop environment options available. Until last year, [Xfce](https://xfce.org/) was the closest to what I consider a good compromise between features and performance. Then I found [i3](https://i3wm.org/), an amazing piece of software that changed my life.
I3 is a tiling window manager. The goal of a window manager is to control the appearance and placement of windows in a windowing system. Window managers are often used as part a full-featured desktop environment (such as GNOME or Xfce), but some can also be used as standalone applications.
A tiling window manager automatically arranges the windows to occupy the whole screen in a non-overlapping way. Other popular tiling window managers include [wmii](https://code.google.com/archive/p/wmii/) and [xmonad](https://xmonad.org/).
Following are the top five reasons I use the i3 window manager and recommend it for a better Linux desktop experience.
## 1. Minimalism
I3 is fast. It is neither bloated nor fancy. It is designed to be simple and efficient. As a developer, I value these features, as I can use the extra capacity to power my favorite development tools or test stuff locally using containers or virtual machines.
In addition, i3 is a window manager and, unlike full-featured desktop environments, it does not dictate the applications you should use. Do you want to use Thunar from Xfce as your file manager? GNOME's gedit to edit text? I3 does not care. Pick the tools that make the most sense for your workflow, and i3 will manage them all in the same way.
## 2. Screen real estate
As a tiling window manager, i3 will automatically "tile" or position the windows in a non-overlapping way, similar to laying tiles on a wall. Since you don't need to worry about window positioning, i3 generally makes better use of your screen real estate. It also allows you to get to what you need faster.
There are many useful cases for this. For example, system administrators can open several terminals to monitor or work on different remote systems simultaneously; and developers can use their favorite IDE or editor and a few terminals to test their programs.
In addition, i3 is flexible. If you need more space for a particular window, enable full-screen mode or switch to a different layout, such as stacked or tabbed.
## 3. Keyboard-driven workflow
I3 makes extensive use of keyboard shortcuts to control different aspects of your environment. These include opening the terminal and other programs, resizing and positioning windows, changing layouts, and even exiting i3. When you start using i3, you need to memorize a few of those shortcuts to get around and, with time, you'll use more of them.
The main benefit is that you don't often need to switch contexts from the keyboard to the mouse. With practice, it means you'll improve the speed and efficiency of your workflow.
For example, to open a new terminal, press `<SUPER>+<ENTER>`
. Since the windows are automatically positioned, you can start typing your commands right away. Combine that with a nice terminal-driven text editor (e.g., Vim) and a keyboard-focused browser for a fully keyboard-driven workflow.
In i3, you can define shortcuts for everything. Here are some examples:
- Open terminal
- Open browser
- Change layouts
- Resize windows
- Control music player
- Switch workspaces
Now that I am used to this workflow, I can't see myself going back to a regular desktop environment.
## 4. Flexibility
I3 strives to be minimal and use few system resources, but that does not mean it can't be pretty. I3 is flexible and can be customized in several ways to improve the visual experience. Because i3 is a window manager, it doesn't provide tools to enable customizations; you need external tools for that. Some examples:
- Use
`feh`
to define a background picture for your desktop. - Use a compositor manager such as
`compton`
to enable effects like window fading and transparency. - Use
`dmenu`
or`rofi`
to enable customizable menus that can be launched from a keyboard shortcut. - Use
`dunst`
for desktop notifications.
I3 is fully configurable, and you can control every aspect of it by updating the default configuration file. From changing all keyboard shortcuts, to redefining the name of the workspaces, to modifying the status bar, you can make i3 behave in any way that makes the most sense for your needs.
i3 with rofi menu and dunst desktop notifications
Finally, for more advanced users, i3 provides a full interprocess communication ([IPC](https://i3wm.org/docs/ipc.html)) interface that allows you to use your favorite language to develop scripts or programs for even more customization options.
## 5. Workspaces
In i3, a workspace is an easy way to group windows. You can group them in different ways according to your workflow. For example, you can put the browser on one workspace, the terminal on another, an email client on a third, etc. You can even change i3's configuration to always assign specific applications to their own workspaces.
Switching workspaces is quick and easy. As usual in i3, do it with a keyboard shortcut. Press `<SUPER>+num`
to switch to workspace `num`
. If you get into the habit of always assigning applications/groups of windows to the same workspace, you can quickly switch between them, which makes workspaces a very useful feature.
In addition, you can use workspaces to control multi-monitor setups, where each monitor gets an initial workspace. If you switch to that workspace, you switch to that monitor—without moving your hand off the keyboard.
Finally, there is another, special type of workspace in i3: the scratchpad. It is an invisible workspace that shows up in the middle of the other workspaces by pressing a shortcut. This is a convenient way to access windows or programs that you frequently use, such as an email client or your music player.
## Give it a try
If you value simplicity and efficiency and are not afraid of working with the keyboard, i3 is the window manager for you. Some say it is for advanced users, but that is not necessarily the case. You need to learn a few basic shortcuts to get around at the beginning, but they'll soon feel natural and you'll start using them without thinking.
This article just scratches the surface of what i3 can do. For more details, consult [i3's documentation](https://i3wm.org/docs/userguide.html).
## 16 Comments |
10,287 | 使用 Pandoc 将你的书转换成网页和电子书 | https://opensource.com/article/18/10/book-to-website-epub-using-pandoc | 2018-11-28T18:25:18 | [
"Pandoc"
] | https://linux.cn/article-10287-1.html |
>
> 通过 Markdown 和 Pandoc,可以做到编写一次,发布两次。
>
>
>

Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为另一种标记语言。在我 [对 Pandoc 的简介](/article-10228-1.html) 一文中,我演示了如何把 Markdown 编写的文本转换为网页、幻灯片和 PDF。
在这篇后续文章中,我将深入探讨 [Pandoc](https://pandoc.org/),展示如何从同一个 Markdown 源文件生成网页和 ePub 格式的电子书。我将使用我即将发布的电子书《[面向对象思想的 GRASP 原则](https://www.programmingfightclub.com/)》为例进行讲解,这本电子书正是通过以下过程创建的。
首先,我将解释这本书使用的文件结构,然后介绍如何使用 Pandoc 生成网页并将其部署在 GitHub 上;最后,我演示了如何生成对应的 ePub 格式电子书。
你可以在我的 GitHub 仓库 [Programming Fight Club](https://github.com/kikofernandez/programmingfightclub) 中找到相应代码。
### 设置图书结构
我用 Markdown 语法完成了所有的写作,你也可以使用 HTML 标记,但是当 Pandoc 将 Markdown 转换为 ePub 文档时,引入的 HTML 标记越多,出现问题的风险就越高。我的书按照每章一个文件的形式进行组织,用 Markdown 的 `H1` 标记(`#`)声明每章的标题。你也可以在每个文件中放置多个章节,但将它们放在单独的文件中可以更轻松地查找内容并在以后进行更新。
元信息遵循类似的模式,每种输出格式都有自己的元信息文件。元信息文件定义有关文档的信息,例如要添加到 HTML 中的文本或 ePub 的许可证。我将所有 Markdown 文档存储在名为 `parts` 的文件夹中(这对于用来生成网页和 ePub 的 Makefile 非常重要)。下面以一个例子进行说明,让我们看一下目录,前言和关于本书(分为 `toc.md`、`preface.md` 和 `about.md` 三个文件)这三部分,为清楚起见,我们将省略其余的章节。
关于本书这部分内容的开头部分类似:
```
# About this book {-}
## Who should read this book {-}
Before creating a complex software system one needs to create a solid foundation.
General Responsibility Assignment Software Principles (GRASP) are guidelines to assign
responsibilities to software classes in object-oriented programming.
```
每一章完成后,下一步就是添加元信息来设置网页和 ePub 的格式。
### 生成网页
#### 创建 HTML 元信息文件
我创建的网页的元信息文件(`web-metadata.yaml`)是一个简单的 YAML 文件,其中包含 `<head>` 标签中的作者、标题、和版权等信息,以及 HTML 文件中开头和结尾的内容。
我建议(至少)包括 `web-metadata.yaml` 文件中的以下字段:
```
---
title: <a href="/grasp-principles/toc/">GRASP principles for the Object-oriented mind</a>
author: Kiko Fernandez-Reyes
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
header-includes:
- |
```{=html}
<link href="https://fonts.googleapis.com/css?family=Inconsolata" rel="stylesheet">
<link href="https://fonts.googleapis.com/css?family=Gentium+Basic|Inconsolata" rel="stylesheet">
```
include-before:
- |
```{=html}
<p>If you like this book, please consider
spreading the word or
<a href="https://www.buymeacoffee.com/programming">
buying me a coffee
</a>
</p>
```
include-after:
- |
```{=html}
<div class="footnotes">
<hr>
<div class="container">
<nav class="pagination" role="pagination">
<ul>
<p>
<span class="page-number">Designed with</span> ❤️ <span class="page-number"> from Uppsala, Sweden</span>
</p>
<p>
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png" /></a>
</p>
</ul>
</nav>
</div>
</div>
```
---
```
下面几个变量需要注意一下:
* `header-includes` 变量包含将要嵌入 `<head>` 标签的 HTML 文本。
* 调用变量后的下一行必须是 `- |`。再往下一行必须以与 `|` 对齐的三个反引号开始,否则 Pandoc 将无法识别。`{= html}` 告诉 Pandoc 其中的内容是原始文本,不应该作为 Markdown 处理。(为此,需要检查 Pandoc 中的 `raw_attribute` 扩展是否已启用。要进行此检查,键入 `pandoc --list-extensions | grep raw` 并确保返回的列表包含名为 `+ raw_html` 的项目,加号表示已启用。)
* 变量 `include-before` 在网页开头添加一些 HTML 文本,此处我请求读者帮忙宣传我的书或给我打赏。
* `include-after` 变量在网页末尾添加原始 HTML 文本,同时显示我的图书许可证。
这些只是其中一部分可用的变量,查看 HTML 中的模板变量(我的文章 [Pandoc简介](/article-10228-1.html) 中介绍了如何查看 LaTeX 的模版变量,查看 HTML 模版变量的过程是相同的)对其余变量进行了解。
#### 将网页分成多章
网页可以作为一个整体生成,这会产生一个包含所有内容的长页面;也可以分成多章,我认为这样会更容易阅读。我将解释如何将网页划分为多章,以便读者不会被长网页吓到。
为了使网页易于在 GitHub Pages 上部署,需要创建一个名为 `docs` 的根文件夹(这是 GitHub Pages 默认用于渲染网页的根文件夹)。然后我们需要为 `docs` 下的每一章创建文件夹,将 HTML 内容放在各自的文件夹中,将文件内容放在名为 `index.html` 的文件中。
例如,`about.md` 文件将转换成名为 `index.html` 的文件,该文件位于名为 `about`(`about/index.html`)的文件夹中。这样,当用户键入 `http://<your-website.com>/about/` 时,文件夹中的 `index.html` 文件将显示在其浏览器中。
下面的 `Makefile` 将执行上述所有操作:
```
# Your book files
DEPENDENCIES= toc preface about
# Placement of your HTML files
DOCS=docs
all: web
web: setup $(DEPENDENCIES)
@cp $(DOCS)/toc/index.html $(DOCS)
# Creation and copy of stylesheet and images into
# the assets folder. This is important to deploy the
# website to Github Pages.
setup:
@mkdir -p $(DOCS)
@cp -r assets $(DOCS)
# Creation of folder and index.html file on a
# per-chapter basis
$(DEPENDENCIES):
@mkdir -p $(DOCS)/$@
@pandoc -s --toc web-metadata.yaml parts/[email protected] \
-c /assets/pandoc.css -o $(DOCS)/$@/index.html
clean:
@rm -rf $(DOCS)
.PHONY: all clean web setup
```
选项 `- c /assets/pandoc.css` 声明要使用的 CSS 样式表,它将从 `/assets/pandoc.cs` 中获取。也就是说,在 `<head>` 标签内,Pandoc 会添加这样一行:
```
<link rel="stylesheet" href="/assets/pandoc.css">
```
使用下面的命令生成网页:
```
make
```
根文件夹现在应该包含如下所示的文件结构:
```
.---parts
| |--- toc.md
| |--- preface.md
| |--- about.md
|
|---docs
|--- assets/
|--- index.html
|--- toc
| |--- index.html
|
|--- preface
| |--- index.html
|
|--- about
|--- index.html
```
#### 部署网页
通过以下步骤将网页部署到 GitHub 上:
1. 创建一个新的 GitHub 仓库
2. 将内容推送到新创建的仓库
3. 找到仓库设置中的 GitHub Pages 部分,选择 `Source` 选项让 GitHub 使用主分支的内容
你可以在 [GitHub Pages](https://pages.github.com/) 的网站上获得更多详细信息。
[我的书的网页](https://www.programmingfightclub.com/grasp-principles/) 便是通过上述过程生成的,可以在网页上查看结果。
### 生成电子书
#### 创建 ePub 格式的元信息文件
ePub 格式的元信息文件 `epub-meta.yaml` 和 HTML 元信息文件是类似的。主要区别在于 ePub 提供了其他模板变量,例如 `publisher` 和 `cover-image` 。ePub 格式图书的样式表可能与网页所用的不同,在这里我使用一个名为 `epub.css` 的样式表。
```
---
title: 'GRASP principles for the Object-oriented Mind'
publisher: 'Programming Language Fight Club'
author: Kiko Fernandez-Reyes
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
cover-image: assets/cover.png
stylesheet: assets/epub.css
...
```
将以下内容添加到之前的 `Makefile` 中:
```
epub:
@pandoc -s --toc epub-meta.yaml \
$(addprefix parts/, $(DEPENDENCIES:=.md)) -o $(DOCS)/assets/book.epub
```
用于产生 ePub 格式图书的命令从 HTML 版本获取所有依赖项(每章的名称),向它们添加 Markdown 扩展,并在它们前面加上每一章的文件夹路径,以便让 Pandoc 知道如何进行处理。例如,如果 `$(DEPENDENCIES` 变量只包含 “前言” 和 “关于本书” 两章,那么 `Makefile` 将会这样调用:
```
@pandoc -s --toc epub-meta.yaml \
parts/preface.md parts/about.md -o $(DOCS)/assets/book.epub
```
Pandoc 将提取这两章的内容,然后进行组合,最后生成 ePub 格式的电子书,并放在 `Assets` 文件夹中。
这是使用此过程创建 ePub 格式电子书的一个 [示例](https://github.com/kikofernandez/programmingfightclub/raw/master/docs/web_assets/demo.epub)。
### 过程总结
从 Markdown 文件创建网页和 ePub 格式电子书的过程并不困难,但有很多细节需要注意。遵循以下大纲可能使你更容易使用 Pandoc。
* HTML 图书:
+ 使用 Markdown 语法创建每章内容
+ 添加元信息
+ 创建一个 `Makefile` 将各个部分组合在一起
+ 设置 GitHub Pages
+ 部署
* ePub 电子书:
+ 使用之前创建的每一章内容
+ 添加新的元信息文件
+ 创建一个 `Makefile` 以将各个部分组合在一起
+ 设置 GitHub Pages
+ 部署
---
via: <https://opensource.com/article/18/10/book-to-website-epub-using-pandoc>
作者:[Kiko Fernandez-Reyes](https://opensource.com/users/kikofernandez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jlztan](https://github.com/jlztan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Pandoc is a command-line tool for converting files from one markup language to another. In my [introduction to Pandoc](https://opensource.com/article/18/9/intro-pandoc), I explained how to convert text written in Markdown into a website, a slideshow, and a PDF.
In this follow-up article, I'll dive deeper into [Pandoc](https://pandoc.org/), showing how to produce a website and an ePub book from the same Markdown source file. I'll use my upcoming e-book, * GRASP Principles for the Object-Oriented Mind*, which I created using this process, as an example.
First I will explain the file structure used for the book, then how to use Pandoc to generate a website and deploy it in GitHub. Finally, I demonstrate how to generate its companion ePub book.
You can find the code in my [Programming Fight Club](https://github.com/kikofernandez/programmingfightclub) GitHub repository.
## Setting up the writing structure
I do all of my writing in Markdown syntax. You can also use HTML, but the more HTML you introduce the highest risk that problems arise when Pandoc converts Markdown to an ePub document. My books follow the one-chapter-per-file pattern. Declare chapters using the Markdown heading H1 (**#**). You can put more than one chapter in each file, but putting them in separate files makes it easier to find content and do updates later.
The meta-information follows a similar pattern: each output format has its own meta-information file. Meta-information files define information about your documents, such as text to add to your HTML or the license of your ePub. I store all of my Markdown documents in a folder named *parts* (this is important for the Makefile that generates the website and ePub). As an example, let's take the table of contents, the preface, and the about chapters (divided into the files toc.md, preface.md, and about.md) and, for clarity, we will leave out the remaining chapters.
My about file might begin like:
```
# About this book {-}
## Who should read this book {-}
Before creating a complex software system one needs to create a solid foundation.
General Responsibility Assignment Software Principles (GRASP) are guidelines to assign
responsibilities to software classes in object-oriented programming.
```
Once the chapters are finished, the next step is to add meta-information to setup the format for the website and the ePub.
## Generating the website
### Create the HTML meta-information file
The meta-information file (web-metadata.yaml) for my website is a simple YAML file that contains information about the author, title, rights, content for the **<head>** tag, and content for the beginning and end of the HTML file.
I recommend (at minimum) including the following fields in the web-metadata.yaml file:
```
---
title: <a href="https://opensource.com/grasp-principles/toc/">GRASP principles for the Object-oriented mind</a>
author: Kiko Fernandez-Reyes
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
header-includes:
- |
```{=html}
<link href="https://fonts.googleapis.com/css?family=Inconsolata" rel="stylesheet">
<link href="https://fonts.googleapis.com/css?family=Gentium+Basic|Inconsolata" rel="stylesheet">
```
include-before:
- |
```{=html}
<p>If you like this book, please consider
spreading the word or
<a href="https://www.buymeacoffee.com/programming">
buying me a coffee
</a>
</p>
```
include-after:
- |
```{=html}
<div class="footnotes">
<hr>
<div class="container">
<nav class="pagination" role="pagination">
<ul>
<p>
<span class="page-number">Designed with</span> ❤️ <span class="page-number"> from Uppsala, Sweden</span>
</p>
<p>
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png" /></a>
</p>
</ul>
</nav>
</div>
</div>
```
---
```
Some variables to note:
- The
**header-includes**variable contains HTML that will be embedded inside the**<head>**tag. - The line after calling a variable must be
**- |**. The next line must begin with triple backquotes that are aligned with the**|**or Pandoc will reject it.**{=html}**tells Pandoc that this is raw text and should not be processed as Markdown. (For this to work, you need to check that the**raw_attribute**extension in Pandoc is enabled. To check, type**pandoc --list-extensions | grep raw**and make sure the returned list contains an item named**+raw_html**; the plus sign indicates it is enabled.) - The variable
**include-before**adds some HTML at the beginning of your website, and I ask readers to consider spreading the word or buying me a coffee. - The
**include-after**variable appends raw HTML at the end of the website and shows my book's license.
These are only some of the fields available; take a look at the template variables in HTML (my article [introduction to Pandoc](https://opensource.com/article/18/9/intro-pandoc) covered this for LaTeX but the process is the same for HTML) to learn about others.
### Split the website into chapters
The website can be generated as a whole, resulting in a long page with all the content, or split into chapters, which I think is easier to read. I'll explain how to divide the website into chapters so the reader doesn't get intimidated by a long website.
To make the website easy to deploy on GitHub Pages, we need to create a root folder called *docs* (which is the root folder that GitHub Pages uses by default to render a website). Then we need to create folders for each chapter under *docs*, place the HTML chapters in their own folders, and the file content in a file named index.html.
For example, the about.md file is converted to a file named index.html that is placed in a folder named *about* (about/index.html). This way, when users type **http://<your-website.com>/about/**, the index.html file from the folder *about* will be displayed in their browser.
The following Makefile does all of this:
```
# Your book files
DEPENDENCIES= toc preface about
# Placement of your HTML files
DOCS=docs
all: web
web: setup $(DEPENDENCIES)
@cp $(DOCS)/toc/index.html $(DOCS)
# Creation and copy of stylesheet and images into
# the assets folder. This is important to deploy the
# website to Github Pages.
setup:
@mkdir -p $(DOCS)
@cp -r assets $(DOCS)
# Creation of folder and index.html file on a
# per-chapter basis
$(DEPENDENCIES):
@mkdir -p $(DOCS)/$@
@pandoc -s --toc web-metadata.yaml parts/[email protected] \
-c /assets/pandoc.css -o $(DOCS)/$@/index.html
clean:
@rm -rf $(DOCS)
.PHONY: all clean web setup
```
The option **-c /assets/pandoc.css** declares which CSS stylesheet to use; it will be fetched from **/assets/pandoc.css**. In other words, inside the **<head>** HTML tag, Pandoc adds the following line:
`<link rel="stylesheet" href="https://opensource.com/assets/pandoc.css">`
To generate the website, type:
`make`
The root folder should contain now the following structure and files:
```
.---parts
| |--- toc.md
| |--- preface.md
| |--- about.md
|
|---docs
|--- assets/
|--- index.html
|--- toc
| |--- index.html
|
|--- preface
| |--- index.html
|
|--- about
|--- index.html
```
### Deploy the website
To deploy the website on GitHub, follow these steps:
- Create a new repository
- Push your content to the repository
- Go to the GitHub Pages section in the repository's Settings and select the option for GitHub to use the content from the Master branch
You can get more details on the [GitHub Pages](https://pages.github.com/) site.
Check out [my book's website](https://www.programmingfightclub.com/grasp-principles/), generated using this process, to see the result.
## Generating the ePub book
### Create the ePub meta-information file
The ePub meta-information file, epub-meta.yaml, is similar to the HTML meta-information file. The main difference is that ePub offers other template variables, such as **publisher** and **cover-image**. Your ePub book's stylesheet will probably differ from your website's; mine uses one named epub.css.
```
---
title: 'GRASP principles for the Object-oriented Mind'
publisher: 'Programming Language Fight Club'
author: Kiko Fernandez-Reyes
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
cover-image: assets/cover.png
stylesheet: assets/epub.css
...
```
### Update the Makefile and deploy the ePub
Add the following content to the previous Makefile:
```
epub:
@pandoc -s --toc epub-meta.yaml \
$(addprefix parts/, $(DEPENDENCIES:=.md)) -o $(DOCS)/assets/book.epub
```
The command for the ePub target takes all the dependencies from the HTML version (your chapter names), appends to them the Markdown extension, and prepends them with the path to the folder chapters' so Pandoc knows how to process them. For example, if **$(DEPENDENCIES)** was only **preface about**, then the Makefile would call:
```
@pandoc -s --toc epub-meta.yaml \
parts/preface.md parts/about.md -o $(DOCS)/assets/book.epub
```
Pandoc would take these two chapters, combine them, generate an ePub, and place the book under the Assets folder.
Here's an [example](https://github.com/kikofernandez/programmingfightclub/raw/master/docs/web_assets/demo.epub) of an ePub created using this process.
## Summarizing the process
The process to create a website and an ePub from a Markdown file isn't difficult, but there are a lot of details. The following outline may make it easier for you to follow.
- HTML book:
- Write chapters in Markdown
- Add metadata
- Create a Makefile to glue pieces together
- Set up GitHub Pages
- Deploy
- ePub book:
- Reuse chapters from previous work
- Add new metadata file
- Create a Makefile to glue pieces together
- Set up GitHub Pages
- Deploy
## Comments are closed. |
10,288 | 什么是 SRE?它和 DevOps 是怎么关联的? | https://opensource.com/article/18/10/sre-startup | 2018-11-28T21:38:09 | [
"SRE",
"DevOps"
] | https://linux.cn/article-10288-1.html |
>
> 大型企业里 SRE 角色比较常见,不过小公司也需要 SRE。
>
>
>

虽然<ruby> 站点可靠性工程师 <rt> site reliability engineer </rt></ruby>(SRE)角色在近几年变得流行起来,但是很多人 —— 甚至是软件行业里的 —— 还不知道 SRE 是什么或者 SRE 都干些什么。为了搞清楚这些问题,这篇文章解释了 SRE 的含义,还有 SRE 怎样关联 DevOps,以及在工程师团队规模不大的组织里 SRE 该如何工作。
### 什么是站点可靠性工程?
谷歌的几个工程师写的《[SRE:谷歌运维解密](http://shop.oreilly.com/product/0636920041528.do)》被认为是站点可靠性工程的权威书籍。谷歌的工程副总裁 Ben Treynor Sloss 在二十一世纪初[创造了这个术语](https://landing.google.com/sre/interview/ben-treynor.html)。他是这样定义的:“当你让软件工程师设计运维功能时,SRE 就产生了。”
虽然系统管理员从很久之前就在写代码,但是过去的很多时候系统管理团队是手动管理机器的。当时他们管理的机器可能有几十台或者上百台,不过当这个数字涨到了几千甚至几十万的时候,就不能简单的靠人去解决问题了。规模如此大的情况下,很明显应该用代码去管理机器(以及机器上运行的软件)。
另外,一直到近几年,运维团队和开发团队都还是完全独立的。两个岗位的技能要求也被认为是完全不同的。SRE 的角色想尝试把这两份工作结合起来。
在深入探讨什么是 SRE 以及 SRE 如何和开发团队协作之前,我们需要先了解一下 SRE 在 DevOps 范例中是怎么工作的。
### SRE 和 DevOps
站点可靠性工程的核心,就是对 DevOps 范例的实践。[DevOps 的定义](https://opensource.com/resources/devops)有很多种方式。开发团队(“dev”)和运维(“ops”)团队相互分离的传统模式下,写代码的团队在将服务交付给用户使用之后就不再对服务状态负责了。开发团队“把代码扔到墙那边”让运维团队去部署和支持。
这种情况会导致大量失衡。开发和运维的目标总是不一致 —— 开发希望用户体验到“最新最棒”的代码,但是运维想要的是变更尽量少的稳定系统。运维是这样假定的,任何变更都可能引发不稳定,而不做任何变更的系统可以一直保持稳定。(减少软件的变更次数并不是避免故障的唯一因素,认识到这一点很重要。例如,虽然你的 web 应用保持不变,但是当用户数量涨到十倍时,服务可能就会以各种方式出问题。)
DevOps 理念认为通过合并这两个岗位就能够消灭争论。如果开发团队时刻都想把新代码部署上线,那么他们也必须对新代码引起的故障负责。就像亚马逊的 [Werner Vogels 说的](https://queue.acm.org/detail.cfm?id=1142065)那样,“谁开发,谁运维”(生产环境)。但是开发人员已经有一大堆问题了。他们不断的被推动着去开发老板要的产品功能。再让他们去了解基础设施,包括如何部署、配置还有监控服务,这对他们的要求有点太多了。所以就需要 SRE 了。
开发一个 web 应用的时候经常是很多人一起参与。有用户界面设计师、图形设计师、前端工程师、后端工程师,还有许多其他工种(视技术选型的具体情况而定)。如何管理写好的代码也是需求之一(例如部署、配置、监控)—— 这是 SRE 的专业领域。但是,就像前端工程师受益于后端领域的知识一样(例如从数据库获取数据的方法),SRE 理解部署系统的工作原理,知道如何满足特定的代码或者项目的具体需求。
所以 SRE 不仅仅是“写代码的运维工程师”。相反,SRE 是开发团队的成员,他们有着不同的技能,特别是在发布部署、配置管理、监控、指标等方面。但是,就像前端工程师必须知道如何从数据库中获取数据一样,SRE 也不是只负责这些领域。为了提供更容易升级、管理和监控的产品,整个团队共同努力。
当一个团队在做 DevOps 实践,但是他们意识到对开发的要求太多了,过去由运维团队做的事情,现在需要一个专家来专门处理。这个时候,对 SRE 的需求很自然地就出现了。
### SRE 在初创公司怎么工作
如果你们公司有好几百位员工,那是非常好的(如果到了 Google 和 Facebook 的规模就更不用说了)。大公司的 SRE 团队分散在各个开发团队里。但是一个初创公司没有这种规模经济,工程师经常身兼数职。那么小公司该让谁做 SRE 呢?其中一种方案是完全践行 DevOps,那些大公司里属于 SRE 的典型任务,在小公司就让开发者去负责。另一种方案,则是聘请专家 —— 也就是 SRE。
让开发人员做 SRE 最显著的优点是,团队规模变大的时候也能很好的扩展。而且,开发人员将会全面地了解应用的特性。但是,许多初创公司的基础设施包含了各种各样的 SaaS 产品,这种多样性在基础设施上体现的最明显,因为连基础设施本身也是多种多样。然后你们在某个基础设施上引入指标系统、站点监控、日志分析、容器等等。这些技术解决了一部分问题,也增加了复杂度。开发人员除了要了解应用程序的核心技术(比如开发语言),还要了解上述所有技术和服务。最终,掌握所有的这些技术让人无法承受。
另一种方案是聘请专家专职做 SRE。他们专注于发布部署、配置管理、监控和指标,可以节省开发人员的时间。这种方案的缺点是,SRE 的时间必须分配给多个不同的应用(就是说 SRE 需要贯穿整个工程部门)。 这可能意味着 SRE 没时间对任何应用深入学习,然而他们可以站在一个能看到服务全貌的高度,知道各个部分是怎么组合在一起的。 这个“三万英尺高的视角”可以帮助 SRE 从系统整体上考虑,哪些薄弱环节需要优先修复。
有一个关键信息我还没提到:其他的工程师。他们可能很渴望了解发布部署的原理,也很想尽全力学会使用指标系统。而且,雇一个 SRE 可不是一件简单的事儿。因为你要找的是一个既懂系统管理又懂软件工程的人。(我之所以明确地说软件工程而不是说“能写代码”,是因为除了写代码之外软件工程还包括很多东西,比如编写良好的测试或文档。)
因此,在某些情况下让开发人员做 SRE 可能更合理一些。如果这样做了,得同时关注代码和基础设施(购买 SaaS 或内部自建)的复杂程度。这两边的复杂性,有时候能促进专业化。
### 总结
在初创公司做 DevOps 实践最有效的方式是组建 SRE 小组。我见过一些不同的方案,但是我相信初创公司(尽早)招聘专职 SRE 可以解放开发人员,让开发人员专注于特定的挑战。SRE 可以把精力放在改善工具(流程)上,以提高开发人员的生产力。不仅如此,SRE 还专注于确保交付给客户的产品是可靠且安全的。
---
via: <https://opensource.com/article/18/10/sre-startup>
作者:[Craig Sebenik](https://opensource.com/users/craig5) 选题:[lujun9972](https://github.com/lujun9972) 译者:[BeliteX](https://github.com/belitex) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Even though the site reliability engineer (SRE) role has become prevalent in recent years, many people—even in the software industry—don't know what it is or does. This article aims to clear that up by explaining what an SRE is, how it relates to DevOps, and how an SRE works when your entire engineering organization can fit in a coffee shop.
## What is site reliability engineering?
* Site Reliability Engineering: How Google Runs Production Systems*, written by a group of Google engineers, is considered the definitive book on site reliability engineering. Google vice president of engineering Ben Treynor Sloss
[coined the term](https://landing.google.com/sre/interview/ben-treynor.html)back in the early 2000s. He defined it as: "It's what happens when you ask a software engineer to design an operations function."
Sysadmins have been writing code for a long time, but for many of those years, a team of sysadmins managed many machines manually. Back then, "many" may have been dozens or hundreds, but when you scale to thousands or hundreds of thousands of hosts, you simply can't continue to throw people at the problem. When the number of machines gets that large, the obvious solution is to use code to manage hosts (and the software that runs on them).
Also, until fairly recently, the operations team was completely separate from the developers. The skillsets for each job were considered completely different. The SRE role tries to bring both jobs together.
Before we dig deeper into what makes an SRE and how SREs work with the development team, we need to understand how site reliability engineering works within the DevOps paradigm.
## Site reliability engineering and DevOps
At its core, site reliability engineering is an implementation of the DevOps paradigm. There seems to be a wide array of ways to [define DevOps](https://opensource.com/resources/devops). The traditional model, where the development ("devs") and operations ("ops") teams were separated, led to the team that writes the code not being responsible for how it works when customers start using it. The development team would "throw the code over the wall" to the operations team to install and support.
This situation can lead to a significant amount of dysfunction. The goals of the dev and ops teams are constantly at odds—a developer wants customers to use the "latest and greatest" piece of code, but the operations team wants a steady system with as little change as possible. Their premise is that any change can introduce instability, while a system with no changes should continue to behave in the same manner. (Noting that minimizing change on the software side is not the only factor in preventing instability is important. For example, if your web application stays exactly the same, but the number of customers grows by 10x, your application may break in many different ways.)
The premise of DevOps is that by merging these two distinct jobs into one, you eliminate contention. If the "dev" wants to deploy new code all the time, they have to deal with any fallout the new code creates. As Amazon's [Werner Vogels said](https://queue.acm.org/detail.cfm?id=1142065), "you build it, you run it" (in production). But developers already have a lot to worry about. They are continually pushed to develop new features for their employer's products. Asking them to understand the infrastructure, including how to deploy, configure, and monitor their service, may be asking a little too much from them. This is where an SRE steps in.
When a web application is developed, there are often many people that contribute. There are user interface designers, graphic designers, frontend engineers, backend engineers, and a whole host of other specialties (depending on the technologies used). Requirements include how the code gets managed (e.g., deployed, configured, monitored)—which are the SRE's areas of specialty. But, just as an engineer developing a nice look and feel for an application benefits from knowledge of the backend-engineer's job (e.g., how data is fetched from a database), the SRE understands how the deployment system works and how to adapt it to the specific needs of that particular codebase or project.
So, an SRE is not just "an ops person who codes." Rather, the SRE is another member of the development team with a different set of skills particularly around deployment, configuration management, monitoring, metrics, etc. But, just as an engineer developing a nice look and feel for an application must know how data is fetched from a data store, an SRE is not singly responsible for these areas. The entire team works together to deliver a product that can be easily updated, managed, and monitored.
The need for an SRE naturally comes about when a team is implementing DevOps but realizes they are asking too much of the developers and need a specialist for what the ops team used to handle.
## How the SRE works at a startup
This is great when there are hundreds of employees (let alone when you are the size of Google or Facebook). Large companies have SRE teams that are split up and embedded into each development team. But a startup doesn't have those economies of scale, and engineers often wear many hats. So, where does the "SRE hat" sit in a small company? One approach is to fully adopt DevOps and have the developers be responsible for the typical tasks an SRE would perform at a larger company. On the other side of the spectrum, you hire specialists — a.k.a., SREs.
The most obvious advantage of trying to put the SRE hat on a developer's head is it scales well as your team grows. Also, the developer will understand all the quirks of the application. But many startups use a wide variety of SaaS products to power their infrastructure. The most obvious is the infrastructure platform itself. Then you add in metrics systems, site monitoring, log analysis, containers, and more. While these technologies solve some problems, they create an additional complexity cost. The developer would need to understand all those technologies and services in addition to the core technologies (e.g., languages) the application uses. In the end, keeping on top of all of that technology can be overwhelming.
The other option is to hire a specialist to handle the SRE job. Their responsibility would be to focus on deployment, configuration, monitoring, and metrics, freeing up the developer's time to write the application. The disadvantage is that the SRE would have to split their time between multiple, different applications (i.e., the SRE needs to support the breadth of applications throughout engineering). This likely means they may not have the time to gain any depth of knowledge of any of the applications; however, they would be in a position to see how all the different pieces fit together. This "30,000-foot view" can help prioritize the weak spots to fix in the system as a whole.
There is one key piece of information I am ignoring: your other engineers. They may have a deep desire to understand how deployment works and how to use the metrics system to the best of their ability. Also, hiring an SRE is not an easy task. You are looking for a mix of sysadmin skills and software engineering skills. (I am specific about software engineers, vs. just "being able to code," because software engineering involves more than just writing code [e.g., writing good tests or documentation].)
Therefore, in some cases, it may make more sense for the "SRE hat" to live on a developer's head. If so, keep an eye on the amount of complexity in both the code and the infrastructure (SaaS or internal). At some point, the complexity on either end will likely push toward more specialization.
## Conclusion
An SRE team is one of the most efficient ways to implement the DevOps paradigm in a startup. I have seen a couple of different approaches, but I believe that hiring a dedicated SRE (pretty early) at your startup will free up time for the developers to focus on their specific challenges. The SRE can focus on improving the tools (and processes) that make the developers more productive. Also, an SRE will focus on making sure your customers have a product that is reliable and secure.
*Craig Sebenik will present SRE (and DevOps) at a Startup at LISA18, October 29-31 in Nashville, Tennessee.*
## 2 Comments |
10,289 | 如何更换 Ubuntu 系统的 GDM 登录界面背景 | https://www.ostechnix.com/how-to-change-gdm-login-screen-background-in-ubuntu/ | 2018-11-28T21:51:00 | [
"背景",
"GDM"
] | https://linux.cn/article-10289-1.html | 
Ubuntu 18.04 LTS 桌面系统在登录、锁屏和解锁状态下,我们会看到一个纯紫色的背景。它是 GDM(<ruby> GNOME 显示管理器 <rt> GNOME Display Manager </rt></ruby>)从 ubuntu 17.04 版本开始使用的默认背景。有一些人可能会不喜欢这个纯色的背景,想换一个酷一点、更吸睛的!如果是这样,你找对地方了。这篇短文将会告诉你如何更换 Ubuntu 18.04 LTS 的 GDM 登录界面的背景。
### 更换 Ubuntu 的登录界面背景
这是 Ubuntu 18.04 LTS 桌面系统默认的登录界面。

不管你喜欢与否,你总是会不经意在登录、解屏/锁屏的时面对它。别担心!你可以随便更换一个你喜欢的图片。
在 Ubuntu 上更换桌面壁纸和用户的资料图像不难。我们可以点击鼠标就搞定了。但更换解屏/锁屏的背景则需要修改文件 `ubuntu.css`,它位于 `/usr/share/gnome-shell/theme`。
修改这个文件之前,最好备份一下它。这样我们可以避免出现问题时可以恢复它。
```
$ sudo cp /usr/share/gnome-shell/theme/ubuntu.css /usr/share/gnome-shell/theme/ubuntu.css.bak
```
修改文件 `ubuntu.css`:
```
$ sudo nano /usr/share/gnome-shell/theme/ubuntu.css
```
在文件中找到关键字 `lockDialogGroup`,如下行:
```
#lockDialogGroup {
background: #2c001e url(resource:///org/gnome/shell/theme/noise-texture.png);
background-repeat: repeat;
}
```

可以看到,GDM 默认登录的背景图片是 `noise-texture.png`。
现在修改为你自己的图片路径。也可以选择 .jpg 或 .png 格式的文件,两种格式的图片文件都是支持的。修改完成后的文件内容如下:
```
#lockDialogGroup {
background: #2c001e url(file:///home/sk/image.png);
background-repeat: no-repeat;
background-size: cover;
background-position: center;
}
```
请注意 `ubuntu.css` 文件里这个关键字的修改,我把修改点加粗了。
你可能注意到,我把原来的 `... url(resource:///org/gnome/shell/theme/noise-texture.png);` 修改为 `... url(file:///home/sk/image.png);`。也就是说,你可以把 `... url(resource ...` 修改为 `.. url(file ...`。
同时,你可以把参数 `background-repeat:` 的值 `repeat` 修改为 `no-repeat`,并增加另外两行。你可以直接复制上面几行的修改到你的 `ubuntu.css` 文件,对应的修改为你的图片路径。
修改完成后,保存和关闭此文件。然后系统重启生效。
下面是 GDM 登录界面的最新背景图片:

是不是很酷,你都看到了,更换 GDM 登录的默认背景很简单。你只需要修改 `ubuntu.css` 文件中图片的路径然后重启系统。是不是很简单也很有意思.
你可以修改 `/usr/share/gnome-shell/theme` 目录下的文件 `gdm3.css` ,具体修改内容和修改结果和上面一样。同时记得修改前备份要修改的文件。
就这些了。如果有好的东东再分享了,请大家关注!
后会有期。
---
via: <https://www.ostechnix.com/how-to-change-gdm-login-screen-background-in-ubuntu/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Guevaraya](https://github.com/guevaraya) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,290 | IssueHunt:一个新的开源软件打赏平台 | https://itsfoss.com/issuehunt/ | 2018-11-28T22:11:09 | [
"FOSS",
"打赏"
] | https://linux.cn/article-10290-1.html | 
许多开源开发者和公司都在努力解决的问题之一就是资金问题。社区中有一种假想,甚至是期望,必须免费提供自由开源软件(FOSS)。但即使是 FOSS 也需要资金来继续开发。如果我们不建立让软件持续开发的系统,我们怎能期待更高质量的软件?
我们已经写了一篇关于[开源资金平台](https://itsfoss.com/open-source-funding-platforms/)的文章来试图解决这个缺点,截至今年 7 月,市场上出现了一个新的竞争者,旨在帮助填补这个空白:[IssueHunt](https://issuehunt.io)。
### IssueHunt: 开源软件打赏平台

IssueHunt 提供了一种服务,对自由开发者的开源代码贡献进行支付。它通过所谓的赏金来实现:给予解决特定问题的任何人财务奖励。这些奖励的资金来自任何愿意捐赠以修复任何特定 bug 或添加功能的人。
如果你想修复的某个开源软件存在问题,你可以根据自己选择的方式提供奖励金额。
想要自己的产品被争抢解决么?在 IssueHunt 上向任何解决问题的人提供奖金就好了。就这么简单。
如果你是程序员,则可以浏览未解决的问题。解决这个问题(如果你可以的话),在 GitHub 存储库上提交拉取请求,如果你的拉取请求被合并,那么你就会得到了钱。
#### IssueHunt 最初是 Boostnote 的内部项目
当笔记应用 [Boostnote](https://itsfoss.com/boostnote-linux-review/) 背后的开发人员联系社区为他们的产品做出贡献时,该产品出现了。
在使用 IssueHunt 的前两年,Boostnote 通过数百名贡献者和压倒性的捐款收到了超过 8,400 个 Github star。
该产品非常成功,团队决定将其开放给社区的其他成员。
如今,[列表中在使用这个服务的项目](https://issuehunt.io/repos)提供了数千美元的赏金。
Boostnote 号称有 [$2,800 的总赏金](https://issuehunt.io/repos/53266139),而 Settings Sync,以前称为 Visual Studio Code Settings Sync,提供了[超过 $1,600 的赏金](https://issuehunt.io/repos/47984369)。
还有其他服务提供类似于 IssueHunt 在此提供的内容。也许最引人注目的是 [Bountysource](https://www.bountysource.com/),它提供与 IssueHunt 类似的赏金服务,同时还提供类似于 [Librepay](https://liberapay.com/) 的订阅支付处理。
#### 你怎么看待 IssueHunt?
在撰写本文时,IssueHunt 还处于起步阶段,但我非常高兴看到这个项目在这些年里的成果。
我不知道你会怎么看,但我非常乐意为 FOSS 付款。如果产品质量高,并为我的生活增添价值,那么我很乐意向开发者支付产品费用。特别是 FOSS 的开发者正在创造尊重我自由的产品。
话虽如此,我一定会关注 IssueHunt 的继续前进,我可以用自己的钱或者在需要贡献的地方传播这个它来支持社区。
但你怎么看?你是否同意我的看法,或者你认为软件应该免费提供,并且应该在志愿者的基础上做出贡献?请在下面的评论中告诉我们你的想法。
---
via: <https://itsfoss.com/issuehunt/>
作者:[Phillip Prado](https://itsfoss.com/author/phillip/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the issues that many open-source developers and companies struggle with is funding. There is an assumption, an expectation even, among the community that Free and Open Source Software must be provided free of cost. But even FOSS needs funding for continued development. How can we keep expecting better quality software if we don’t create systems that enable continued development?
We already wrote an article about [open source funding platforms](https://itsfoss.com/open-source-funding-platforms/) out there that try to tackle this shortcoming, as of this July there is a new contender in the market that aims to help fill this gap: [IssueHunt](https://issuehunt.io).
## IssueHunt: A Bounty Hunting platform for Open Source Software
IssueHunt offers a service that pays freelance developers for contributing to open-source code. It does so through what are called bounties: financial rewards granted to whoever solves a given problem. The funding for these bounties comes from anyone who is willing to donate to have any given bug fixed or feature added.
If there is a problem with a
Do you want your own product snapped? Offer a bounty on IssueHunt to whoever snaps it. It’s as simple as that.
And if you are a programmer, you can browse through open issues. Fix the issue (if you could), submit a pull request on the GitHub repository and if your pull request is merged, you get the money.
[irp posts=27428]
### IssueHunt was originally an internal project for Boostnote

The product came to be when the developers behind the note-taking app [Boostnote](https://itsfoss.com/boostnote-linux-review/) reached out to the community for contributions to their own product.
In the first two years of utilizing IssueHunt, Boostnote received over 8,400 Github stars through hundreds contributors and overwhelming donations.
The product was so successful that the team decided to open it up to the rest of the community.
Today, [a list of projects utilize this service](https://issuehunt.io/repos), offering thousands of dollars in bounties among them.
Boostnote boasts [$2,800 in total bounties](https://issuehunt.io/repos/53266139), while Settings Sync, previously known as Visual Studio Code Settings Sync, offers [more than $1,600 in bounties.](https://issuehunt.io/repos/47984369)
There are other services that provide something similar to what IssueHunt is offering here. Perhaps the most notable is [Bountysource](https://www.bountysource.com/), which offers a similar bounty service to IssueHunt, while also offering subscription payment processing similar to [Librepay](https://liberapay.com/).
[irp posts=29274]
### What do you think of IssueHunt?
At the time of writing this article, IssueHunt is in its infancy, but I am incredibly excited to see where this project ends up in the comings years.
I don’t know about you, but I am more than happy paying for FOSS. If the product is high quality and adds value to my life, then I will happily pay the developer the product. Especially since FOSS developers are creating products that respect my freedom in the process.
That being said, I will definitely keep my eye on IssueHunt moving forward for ways I can support the community either with my own money or by spreading the word where contribution is needed.
But what do you think? Do you agree with me, or do you think software should be Gratis free, and that contributions should be made on a volunteer basis? Let us know what you think in the comments below. |
10,291 | 如何使用多种编程语言而又不失理智 | https://opensource.com/article/18/11/multiple-programming-languages | 2018-11-29T18:50:26 | [
"编程语言"
] | https://linux.cn/article-10291-1.html |
>
> 多语言编程环境是一把双刃剑,既带来好处,也带来可能威胁组织的复杂性。
>
>
>

如今,随着各种不同的编程语言的出现,许多组织已经变成了<ruby> 数字多语种组织 <rt> digital polyglots </rt></ruby>。开源打开了一个语言和技术堆栈的世界,开发人员可以使用这些语言和技术堆栈来完成他们的任务,包括开发、支持过时的和现代的软件应用。
与那些只说母语的人相比,通晓多种语言的人可以与数百万人交谈。在软件环境中,开发人员不会引入新的语言来达到特定的目的,也不会更好地交流。一些语言对于一项任务来说很棒,但是对于另一项任务来说却不行,因此使用多种编程语言可以让开发人员使用合适的工具来完成这项任务。这样,所有的开发都是多语种的;这只是野兽的本性。
多语种环境的创建通常是渐进的和情景化的。例如,当一家企业收购一家公司时,它就承担了该公司的技术堆栈 —— 包括其编程语言。或者,随着技术领导的改变,新的领导者可能会将不同的技术纳入其中。技术也有过时的时候,随着时间的推移,增加了组织必须维护的编程语言和技术的数量。
多语言环境对企业来说是一把双刃剑,既带来好处,也带来复杂性和挑战。最终,如果这种情况得不到控制,多语言将会扼杀你的企业。
### 棘手的技术绕口令
如果有多种不同的技术 —— 编程语言、过时的工具和新兴的技术堆栈 —— 就有复杂性。工程师团队花更多的时间努力改进编程语言,包括许可证、安全性和依赖性。与此同时,管理层缺乏对代码合规性的监督,无法衡量风险。
发生的情况是,企业具有不同程度的编程语言质量和工具支持的高度可变性。当你需要和十几个人一起工作时,很难成为一种语言的专家。一个能流利地说法语和意大利语的人和一个能用八种语言串成几个句子的人在技能水平上有很大差异。开发人员和编程语言也是如此。
随着更多编程语言的加入,困难只会增加,导致数字巴别塔的出现。
答案是不要拿走开发人员工作所需的工具。添加新的编程语言可以建立他们的技能基础,并为他们提供合适的设备来完成他们的工作。所以,你想对你的开发者说“是”,但是随着越来越多的编程语言被添加到企业中,它们会拖累你的软件开发生命周期(SDLC)。在规模上,所有这些语言和工具都可能扼杀企业。
企业应注意三个主要问题:
1. **可见性:** 团队聚在一起执行项目,然后解散。应用程序已经发布,但从未更新 —— 为什么要修复那些没有被破坏的东西?因此,当发现一个关键漏洞时,企业可能无法了解哪些应用程序受到影响,这些应用程序包含哪些库,甚至无法了解它们是用什么语言构建的。这可能导致成本高昂的“勘探项目”,以确保漏洞得到适当解决。
2. **更新或编码:** 一些企业将更新和修复功能集中在一个团队中。其他人要求每个“比萨团队”管理自己的开发工具。无论是哪种情况,工程团队和管理层都要付出机会成本:这些团队没有编码新特性,而是不断更新和修复开源工具中的库,因为它们移动得如此之快。
3. **重新发明轮子:** 由于代码依赖性和库版本不断更新,当发现漏洞时,与应用程序原始版本相关联的工件可能不再可用。因此,许多开发周期都被浪费在试图重新创建一个可以修复漏洞的环境上。
将你组织中的每种编程语言乘以这三个问题,开始时被认为是分子一样小的东西突然看起来像珠穆朗玛峰。就像登山者一样,没有合适的设备和工具,你将无法生存。
### 找到你的罗塞塔石碑
一个全面的解决方案可以满足 SDLC 中企业及其个人利益相关者的需求。企业可以使用以下最佳实践创建解决方案:
1. 监控生产中运行的代码,并根据应用程序中使用的标记组件(例如,常见漏洞和暴露组件)的风险做出响应。
2. 定期接收更新以保持代码的最新和无错误。
3. 使用商业开源支持来获得编程语言版本和平台的帮助,这些版本和平台已经接近尾声,并且不受社区支持。
4. 标准化整个企业中的特定编程语言构建,以实现跨团队的一致环境,并最大限度地减少依赖性。
5. 根据相关性设置何时触发更新、警报或其他类型事件的阈值。
6. 为您的包管理创建一个单一的可信来源;这可能需要知识渊博的技术提供商的帮助。
7. 根据您的特定标准,只使用您需要的软件包获得较小的构建版本。
使用这些最佳实践,开发人员可以最大限度地利用他们的时间为企业创造更多价值,而不是执行基本的工具或构建工程任务。这将在软件开发生命周期(SDLC)的所有环境中创建代码一致性。由于维护编程语言和软件包分发所需的资源更少,这也将提高效率和节约成本。这种新的操作方式将使技术人员和管理人员的生活更加轻松。
---
via: <https://opensource.com/article/18/11/multiple-programming-languages>
作者:[Bart Copeland](https://opensource.com/users/bartcopeland) 选题:[lujun9972](https://github.com/lujun9972) 译者:[heguangzhi](https://github.com/heguangzhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | With all the different programming languages available today, many organizations have become digital polyglots. Open source opens up a world of languages and technology stacks developers can use to accomplish their tasks, including developing and supporting legacy and modern software applications.
Polyglots can talk with millions more people than those who only speak their native language. In software environments, developers don't introduce new languages to achieve specifc ends, not to communicate better. Some languages are great for one task but not another, so working with multiple programming languages enables developers to use the right tool for the job. In this way, all development is polyglot; it's just the nature of the beast.
The creation of a polyglot environment is often gradual and situational. For example, when an enterprise acquires a company, it takes on the company's technology stacks—including its programming languages. Or as tech leadership changes, new leaders may bring different technologies into the fold. Technologies also fall in and out of fashion, expanding the number of programming languages and technologies an organization has to maintain over time.
A polyglot environment is a double-edged sword for enterprises, bringing benefits but also complexities and challenges. Ultimately, if the situation remains unchecked, polyglot will kill your enterprise.
## Tricky technical tongue-twisters
Where there are multiple different technologies—programming languages, legacy tools, and up-and-coming technology stacks—there is complexity. Engineering teams spend more time wrestling to retrofit programming languages with licenses, security, and dependencies. At the same time, management lacks oversight on code compliance and can't gauge risk.
What happens is that enterprises have varying degrees of programming language quality and high variability in tooling support. It's hard to become an expert in one language when you're required to work with a dozen. There's a big difference in skill level between a person who speaks French and Italian fluently and a person who can string a few sentences together in eight languages. The same is true for developers and programming languages.
The difficulties only increase with the addition of more programming languages, leading to a digital Tower of Babel.
The answer is not to take away the tools your developers need for the job. Adding new programming languages builds their skill base and empowers them with the right equipment to fulfill their craft. So, you want to say "yes" to your developers, but as more and more programming languages are added to the enterprise, they impose a drag on your software development lifecycle (SDLC). At scale, all these languages and tools can kill the enterprise.
There are three main issues enterprises should pay attention to:
**Visibility:**Teams come together for a project, then disband. Applications are released and never updated—why fix what's not broken? As a result, when a critical vulnerability is discovered, the enterprise may not have visibility into which applications are affected, which libraries those applications contain, or even what languages they were built with. This can result in costly "exploration projects" to ensure the vulnerability is properly addressed.**Updating or coding:**Some enterprises centralize the updating and fixing function in a single team. Others require that each "pizza team" manage its own development tools. In either case, the engineering team and management pay an opportunity cost: rather than coding new features, these teams are constantly updating and fixing libraries in their open source tools since they move so quickly.**Reinventing the wheel:**Since code dependencies and library versions are constantly being updated, the artifacts associated with the original build of an application may no longer be available when a vulnerability is found. As a result, many development cycles are wasted trying to recreate an environment in which the vulnerability can be fixed.
Multiply each programming language in your organization by these three issues, and what started out as a molehill suddenly looks like Mount Everest. And just like a mountain climber, you won't survive without the proper equipment and tools.
## Finding your Rosetta Stone
A comprehensive solution that serves the needs of the enterprise and its individual stakeholders in the SDLC is in order. Enterprises can create this solution using these best practices:
- Monitor code running in production and respond based on risk of flagged components (e.g., common vulnerabilities and exposures components) used in your applications.
- Receive regular updates to keep code current and bug-free.
- Use commercial open source support to get help with programming language versions and platforms that are near end-of-life and not supported by the community.
- Standardize specific programming language builds across your enterprise to enable consistent environments across teams and minimize dependencies.
- Set thresholds for when to trigger an update, alarm, or another kind of event based on dependencies.
- Create a single source of truth for your package management; this may require the assistance of a knowledgeable technology provider.
- Get smaller build distributions with only the packages you need, based on your specific criteria.
Using these best practices, developers can maximize their time to create more value for the enterprise instead of doing basic tooling or build-engineering tasks. This will create code consistency in all environments in the software development life cycle (SDLC). It will also create greater efficiency and cost savings as fewer resources are needed to maintain programming languages and package distributions. This new way of operating will make the lives of both technical staff and management easier.
## 1 Comment |
10,292 | 构建满足用户需求的云环境的五个步骤 | https://opensource.com/article/18/4/5-steps-building-your-cloud-correctly | 2018-11-29T21:16:30 | [
"云环境"
] | https://linux.cn/article-10292-1.html |
>
> 在投入时间和资金开发你的云环境之前,确认什么是你的用户所需要的。
>
>
>

无论你如何定义,云就是你的用户展现其在组织中的价值的另一个工具。当谈论新的范例或者技术(云是两者兼有)的时候很容易被它的新特性所分心。由一系列无止境的问题引发的对话能够很快的被发展为功能愿景清单,所有下面的这些都是你可能已经考虑到的:
* 是公有云、私有云还是混合云?
* 会使用虚拟机还是容器,或者是两者?
* 会提供自助服务吗?
* 从开发到生产是完全自动的,还是它将需要手动操作?
* 我们能以多块的速度做到?
* 关于某某工具?
这样的清单还可以列举很多。
当开始 IT 现代化,或者数字转型,无论你是如何称呼的,通常方法是开始回答更高管理层的一些高层次问题,这种方法的结果是可以预想到的:失败。经过大范围的调研并且花费了数月的时间(如果不是几年的话)部署了这个最炫的新技术,而这个新的云技术却从未被使用过,而且陷入了荒废,直到它最终被丢弃或者遗忘在数据中心的一角和预算之中。
这是因为无论你交付的是什么工具,都不是用户所想要或者需要的。更加糟糕的是,它可能是一个单一的工具,而用户真正需要的是一系列工具 —— 能够随着时间推移,更换升级为更新的、更漂亮的工具,以更好地满足其需求。
### 专注于重要的事情
问题在于关注,传统上一直是关注于工具。但工具并不是要增加到组织价值中的东西;终端用户利用它做什么才是目的。你需要将你的注意力从创建云(例如技术和工具)转移到你的人员和用户身上。
事实上,除了使用工具的用户(而不是工具本身)是驱动价值的因素之外,聚焦注意力在用户身上也是有其它原因的。工具是给用户使用去解决他们的问题并允许他们创造价值的,所以这就导致了如果那些工具不能满足那些用户的需求,那么那些工具将不会被使用。如果你交付给你的用户的工具并不是他们喜欢的,他们将不会使用,这就是人类的人性行为。
数十年来,IT 产业只为用户提供一种解决方案,因为仅有一个或两个选择,用户是没有权力去改变的。现在情况已经不同了。我们现在生活在一个技术选择的世界中。不给用户一个选择的机会的情况将不会被接受的;他们在个人的科技生活中有选择,同时希望在工作中也有选择。现在的用户都是受过教育的并且知道将会有比你所提供的更好选择。
因此,在物理上的最安全的地点之外,没有能够阻止他们只做他们自己想要的东西的方法,我们称之为“影子 IT”。如果你的组织有如此严格的安全策略和承诺策略而不允许影子 IT,许多员工将会感到灰心丧气并且会离职去其他能提供更好机会的公司。
基于以上所有的原因,你必须牢记要首先和你的最终用户设计你的昂贵又费时的云项目。
### 创建满足用户需求的云五个步骤的过程
既然我们已经知道了为什么,接下来我们来讨论一下怎么做。你如何去为终端用户创建一个云?你怎样重新将你的注意力从技术转移到使用技术的用户身上?
根据以往的经验,我们知道最好的方法中包含两件重要的事情:从你的用户中得到及时的反馈,在创建中和用户进行更多的互动。
你的云环境将继续随着你的组织不断发展。下面的五个步骤将会帮助你创建满足用户需求的云环境。
#### 1、识别谁将是你的用户
在你开始询问用户问题之前,你首先必须识别谁将是你的新的云环境的用户。他们可能包括将在云上创建开发应用的开发者;也可能是运营、维护或者或者创建该云的运维团队;还可能是保护你的组织的安全团队。在第一次迭代时,将你的用户数量缩小至人数较少的小组防止你被大量的反馈所淹没,让你识别的每个小组指派两个代表(一个主要的一个辅助的)。这将使你的第一次交付在规模和时间上都很小。
#### 2、和你的用户面对面的交谈来收获有价值的输入。
获得反馈的最佳途径是和用户直接交谈。群发的邮件会自行挑选出受访者——如果你能收到回复的话。小组讨论会很有帮助的,但是当人们有个私密的、专注的对话者时,他们会比较的坦诚。
和你的第一批用户安排个面对面的个人的会谈,并且向他们询问以下的问题:
* 为了完成你的任务,你需要什么?
* 为了完成你的任务,你想要什么?
* 你现在最头疼的技术痛点是什么?
* 你现在最头疼的政策或者流程痛点是哪个?
* 关于解决你的需求、希望或痛点,你有什么建议?
这些问题只是指导性的,并不一定适合每个组织。你不应该只询问这些问题,他们应该导向更深层次的讨论。确保告诉用户他们任何所说的和被问的都被视作反馈,所有的反馈都是有帮助的,无论是消极的还是积极的。这些对话将会帮助你设置你的开发优先级。
收集这种个性化的反馈是保持初始用户群较小的另一个原因:这将会花费你大量的时间来和每个用户交流,但是我们已经发现这是相当值得付出的投入。
#### 3、设计并交付你的解决方案的第一个版本
一旦你收到初始用户的反馈,就是时候开始去设计并交付一部分的功能了。我们不推荐尝试一次性交付整个解决方案。设计和交付的时期要短;这可以避免你花费一年的时间去构建一个你*认为*正确的解决方案,而只会让你的用户拒绝它,因为对他们来说毫无用处。创建你的云所需要的工具取决于你的组织和它的特殊需求。只需确保你的解决方案是建立在用户的反馈的基础上的,你将功能小块化的交付并且要经常的去征求用户的反馈。
#### 4、询问用户对第一个版本的反馈
太棒了,现在你已经设计并向你的用户交付了你的炫酷的新的云环境的第一个版本!你并不是花费一整年去完成它而是将它处理成小的模块。为什么将其分为小的模块如此重要呢?因为你要回到你的用户组并且向他们收集关于你的设计和交付的功能。他们喜欢什么?不喜欢什么?你正确的处理了他们所关注的吗?是技术功能上很厉害,但系统进程或者策略方面仍然欠缺吗?
再重申一次,你要问的问题取决于你的组织;这里的关键是继续前一个阶段的讨论。毕竟你正在为用户创建云环境,所以确保它对用户来说是有用的并且能够有效利用每个人的时间。
#### 5、回到第一步。
这是一个迭代的过程。你的首次交付应该是快速而小规模的,而且以后的迭代也应该是这样的。不要期待仅仅按照这个流程完成了一次、两次甚至是三次就能完成。一旦你持续的迭代,你将会吸引更多的用户从而能够在这个过程中得到更好的回报。你将会从用户那里得到更多的支持。你能够迭代的更迅速并且更可靠。到最后,你将会通过改变你的流程来满足用户的需求。
用户是这个过程中最重要的一部分,但迭代是第二重要的因为它让你能够回到用户中进行持续沟通从而得到更多有用的信息。在每个阶段,记录哪些是有效的哪些没有起到应有的效果。要自省,要对自己诚实。我们所花费的时间提供了最有价值的了吗?如果不是,在下一个阶段尝试些不同的。在每次循环中不要花费太多时间的最重要的部分是,如果某部分在这次不起作用,你能够很容易的在下一次中调整它,直到你找到能够在你组织中起作用的方法。
### 这仅仅是开始
通过许多客户约见,从他们那里收集反馈,以及在这个领域的同行的经验,我们一次次的发现在创建云的时候最重要事就是和你的用户交谈。这似乎是很明显的,但很让人惊讶的是很多组织却偏离了这个方向去花费数月或者数年的时间去创建,然后最终发现它对终端用户甚至一点用处都没有。
现在你已经知道为什么你需要将你的注意力集中到终端用户身上并且在中心节点和用户一起的互动创建云。剩下的是我们所喜欢的部分,你自己去做的部分。
这篇文章是基于一篇作者在 [Red Hat Summit 2018](https://www.redhat.com/en/summit/2018) 上发表的文章“[为终端用户设计混合云,要么失败]”。
---
via: <https://opensource.com/article/18/4/5-steps-building-your-cloud-correctly>
作者:[Cameron Wyatt](https://opensource.com/users/cameronmwyatt), [Ian Teksbury](https://opensource.com/users/itewk) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FelixYFZ](https://github.com/FelixYFZ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *This article was co-written with Ian Tewksbury.*
However you define it, a cloud is simply another tool for your users to perform their part of your organization's value stream. It can be easy when talking about any new paradigm or technology (the cloud is arguably both) to get distracted by the shiny newness of it. Conversations can quickly devolve into feature wish lists set off by a series of never-ending questions, all of which you probably have already considered:
- Will it be public, private, or hybrid?
- Will it use virtual machines or containers, or both?
- Will it be self-service?
- Will it be fully automated from development to production, or will it have manual gates?
- How fast can we make it?
- What about tool X, Y, or Z?
The list goes on.
The usual approach to beginning IT modernization, or digital transformation, or whatever you call it is to start answering high-level questions in the higher-level echelons of management. The outcome of this approach is predictable: failure. After extensively researching and spending months, if not years, deploying the fanciest new technology, the new cloud is never used and falls into disrepair until it is eventually scrapped or forgotten in the dustier corners of the datacenter and budget.
That's because whatever was delivered was not the tool the users wanted or needed. Worse yet, it likely was a single tool when users really needed a collection of tools that could be swapped out over time as newer, shinier, upgraded tools come along that better meet their needs.
## Focus on what matters
The problem is focus, which has traditionally been on the tools. But the tools are not what add to your organization's value stream; end users making use of tools are what do that. You need to shift your focus from building your cloud—for example, the technology and the tools, to your people, your users.
Beyond the fact that users using tools (not the tools themselves) are what drive value, there are other reasons to focus attention on the users. The tools are for the users to use to solve their problems and allow them to create value, so it follows that if those tools don't meet those users' needs, then those tools won't be used. If you deliver tools that your users don't like, they won't use them. This is natural human behavior.
The IT industry got away with providing a single solution to users for decades because there were only one or two options, and the users had no power to change that. That is no longer the case. We now live in the world of technological choice. It is no longer acceptable to users to not be given a choice; they have choices in their personal technological lives, and they expect it in the workplace, too. Today's users are educated and know there are better options than the ones you've been providing.
As a result, outside the most physically secure locations, there is no way to stop them from just doing what they want, which we call "shadow IT." If your organization has such strict security and compliance polices that shadow IT is impossible, many of your best people will grow frustrated and leave for other organizations that offer them choices.
For all of these reasons, you *must* design your expensive and time-consuming cloud project with your end user foremost in mind.
## Five-step process to build a cloud for users' needs
Now that we know the *why*, let's talk about the *how*. How do you build a cloud for the end user? How do you start refocusing your attention from the technology to the people using that technology?
Through experience, we've learned that the best approach involves two things: getting constant feedback from your users, and building things iteratively.
Your cloud environment will continually evolve with your organization. The following five-step process will help you create a cloud that meets your users' needs.
### 1. Identify who your users will be.
Before you can start asking users questions, you first must identify who the users of your new cloud will be. They will likely include developers who build applications on the cloud; the operations team who will operate, maintain, and likely build the cloud; and the security team who protects your organization. For the first iteration, scope down your users to a smaller group so you're less overwhelmed by feedback. Ask each of your identified user groups to appoint two liaisons (a primary and a secondary) who will represent their team on this journey. This will also keep your first delivery small in both size and time.
### 2. Talk to your users face-to-face to get valuable input.
The best way to get users' feedback is through direct communication. Mass emails asking for input will self-select respondents—if you even get a response. Group discussions can be helpful, but people tend to be more candid when they have a private, attentive audience.
Schedule in-person, individual meetings with your first set of users to ask them questions like the following:
- What do you
*need*in order to accomplish your tasks? - What do you
*want*in order to accomplish your tasks? - What is your current, most annoying technological pain?
- What is your current, most annoying policy or procedural pain?
- What ideas do you have to address any of your needs, wants, or pains?
These questions are guidelines and not ideal for every organization. They should not be the only questions you ask, and they should lead to further discussion. Be sure to tell people that anything said or asked is taken as feedback, and all feedback is helpful, whether positive or negative. The outcome of these conversations will help set your development priorities.
Gathering this level of personalized feedback is another reason to keep your initial group of users small: It takes a lot of time to sit down with each user, but we have found it is absolutely worth the investment.
### 3. Design and deliver your first iteration of the solution.
Once you've collected feedback from your initial users, it is time to design and deliver a piece of functionality. We *do not* recommend trying to deliver the entire solution. The design and delivery phase should be short; this is to avoid making the huge mistake of spending a year building what you *think* is the correct solution, only to have your users reject it because it isn't beneficial to them. The specific tools you choose for building your cloud will depend on your organization and its specific needs. Just make sure that the solution you build is based on your users' feedback and that you deliver it in small chunks to solicit feedback from them as often as possible.
### 4. Ask users for feedback on the first iteration.
Great, now you've designed and delivered the first iteration of your fancy new cloud to your end users! You didn't spend a year doing it but instead tackled it in small pieces. Why is it important to do things in small chunks? It's because you're going back to your user groups and collecting feedback about your design and delivery. What do they like? What don't they like? Did you properly address their concerns? Is the technology great, but the process or policy side of the system still lacking?
Again, the questions you'll ask depend on your organization; the key here is to continue the discussions from the earlier phases. You're building this cloud for users after all, so make sure it's useful for them and a productive use of everyone's time.
### 5. Return to step 1.
This is an iterative process. Your first delivery should have been quick and small, and all future iterations should be, too. Don't expect to be able to follow this process once, twice, or even three times and be done. As you iterate, you will introduce more users and get better at the process. You will get more buy-in from users. You will be able to iterate faster and more reliably. And, finally, you will change your process to meet your users' needs.
Users are the most important part of this process, but the iteration is the second most important part because it allows you to keep going back to the users and getting more information. Throughout each phase, take note of what worked and what didn't. Be introspective and honest with yourself. Are we providing the most value possible for the time we spent? If not, try something different in the next phase. The great part about not spending too much time in each cycle is that, if something doesn't work this time, you can easily tweak it for next time, until you find an approach that works for your organization.
## This is just the beginning
Through many customer engagements, feedback gathered from users, and experiences from peers in the field, we've found time and time again that the most important thing you can do when building a cloud is to talk to your users. It seems obvious, but it is surprising how many organizations will go off and build something for months or years, then find out it isn't even useful to end users.
Now you know why you should keep your focus on the end users *and* have a process for building a cloud with them at the center. The remaining piece is the part that we all enjoy, the part where you go out and do it.
This article is based on "[Design your hybrid cloud for the end user—or fail](https://agenda.summit.redhat.com/SessionDetail.aspx?id=154225)," a talk the authors will be giving at [Red Hat Summit 2018](https://www.redhat.com/en/summit/2018), which will be held May 8-10 in San Francisco.
[Register by May 7](https://www.redhat.com/en/summit/2018) to save US$ 500 off of registration. Use discount code **OPEN18** on the payment page to apply the discount.
## Comments are closed. |
10,293 | Android 9.0 概览 | https://www.linux.com/learn/2018/10/overview-android-pie | 2018-11-29T22:51:00 | [
"Android",
"安卓"
] | https://linux.cn/article-10293-1.html |
>
> 第九代 Android 带来了更令人满意的用户体验。
>
>
>

我们来谈论一下 Android。尽管 Android 只是一款内核经过修改的 Linux,但经过多年的发展,Android 开发者们(或许包括正在阅读这篇文章的你)已经为这个平台的演变做出了很多值得称道的贡献。当然,可能很多人都已经知道,但我们还是要说,Android 并不完全开源,当你使用 Google 服务的时候,就已经接触到闭源的部分了。Google Play 商店就是其中之一,它不是一个开放的服务。不过无论 Android 开源与否,这就是一个美味、营养、高效、省电的馅饼(LCTT 译注:Android 9.0 代号为 Pie)。
我在我的 Essential PH-1 手机上运行了 Android 9.0(我真的很喜欢这款手机,也知道这家公司的境况并不好)。在我自己体验了一段时间之后,我认为它是会被大众接受的。那么 Android 9.0 到底好在哪里呢?下面我们就来深入探讨一下。我们的出发点是用户的角度,而不是开发人员的角度,因此我也不会深入探讨太底层的方面。
### 手势操作
Android 系统在新的手势操作方面投入了很多,但实际体验却不算太好。这个功能确实引起了我的兴趣。在这个功能发布之初,大家都对它了解甚少,纷纷猜测它会不会让用户使用多点触控的手势来浏览 Android 界面?又或者会不会是一个完全颠覆人们认知的东西?
实际上,手势操作比大多数人设想的要更加微妙而简单,因为很多功能都浓缩到了 Home 键上。打开手势操作功能之后,Recent 键的功能就合并到 Home 键上了。因此,如果需要查看最近打开的应用程序,就不能简单地通过 Recent 键来查看,而应该从 Home 键向上轻扫一下。(图 1)

*图 1:Android 9.0 中的”最近的应用程序“界面。*
另一个不同的地方是 App Drawer。类似于查看最近打开的应用,需要在 Home 键向上滑动才能打开 App Drawer。
而后退按钮则没有去掉。在应用程序需要用到后退功能时,它就会出现在主屏幕的左下方。有时候即使应用程序自己带有后退按钮,Android 的后退按钮也会出现。
当然,如果你不喜欢使用手势操作,也可以禁用这个功能。只需要按照下列步骤操作:
1. 打开”设置“
2. 向下滑动并进入“系统 > 手势”
3. 从 Home 键向上滑动
4. 将 On/Off 滑块(图 2)滑动至 Off 位置

*图 2:关闭手势操作。*
### 电池寿命
人工智能已经在 Android 得到了充分的使用。现在,Android 使用人工智能大大提供了电池的续航时间,这样的新技术称为自适应电池。自适应电池可以根据用户的个人使用习惯来决定各种应用和服务的耗电优先级。通过使用人工智能技术,Android 可以分析用户对每一个应用或服务的使用情况,并适当地关闭未使用的应用程序,以免长期驻留在内存中白白消耗电池电量。
对于这个功能的唯一一个警告是,如果人工智能出现问题并导致电池电量过早耗尽,就只能通过恢复出厂设置来解决这个问题了。尽管有这样的缺陷,在电池续航时间方面,Android 9.0 也比 Android 8.0 有所改善。
### 分屏功能的变化
分屏对于 Android 来说不是一个新功能,但在 Android 9.0 上,它的使用方式和以往相比略有不同,而且只对于手势操作有影响,不使用手势操作的用户不受影响。要在 Android 9.0 上使用分屏功能,需要按照下列步骤操作:
1. 从 Home 键向上滑动,打开“最近的应用程序”。
2. 找到需要放置在屏幕顶部的应用程序。
3. 长按应用程序顶部的图标以显示新的弹出菜单。(图 3)
4. 点击分屏,应用程序会在屏幕的上半部分打开。
5. 找到要打开的第二个应用程序,然后点击它添加到屏幕的下半部分。

*图 3:在 Android 9.0 上将应用添加到分屏模式中。*
使用分屏功能关闭应用程序的方法和原来保持一致。
### 应用操作
这个功能在早前已经引入了,但直到 Android 9.0 发布,人们才开始对它产生明显的关注。应用操作功能可以让用户直接从应用启动器来执行应用里的某些操作。
例如,长按 GMail 启动器,就可以执行回复最近的邮件、撰写新邮件等功能。在 Android 8.0 中,这个功能则以弹出动作列表的方式展现。在 Android 9.0 中,这个功能更契合 Google 的<ruby> 材料设计 <rt> Material Design </rt></ruby>风格(图 4)。

*图 4:Android 应用操作。*
### 声音控制
在 Android 中,声音控制的方式经常发生变化。在 Android 8.0 对“请勿打扰”功能进行调整之后,声音控制已经做得相当不错了。而在 Android 9.0 当中,声音控制再次进行了优化。
Android 9.0 这次优化针对的是设备上快速控制声音的按钮。如果用户按下音量增大或减小按钮,就会看到一个新的弹出菜单,可以让用户控制设备的静音和震动情况。点击这个弹出菜单顶部的图标(图 5),可以在完全静音、静音和正常声音几种状态之间切换。

*图 5:Android 9.0 上的声音控制。*
### 屏幕截图
由于我要撰写关于 Android 的文章,所以我会常常需要进行屏幕截图。而 Android 9.0 有一项我最喜欢的更新,就是分享屏幕截图。Android 9.0 可以在截取屏幕截图后,直接共享、编辑,或者删除不喜欢的截图,而不需要像以前一样打开 Google 相册、找到要共享的屏幕截图、打开图像然后共享图像。
如果你想分享屏幕截图,只需要在截图后等待弹出菜单,点击分享(图 6),从标准的 Android 分享菜单中分享即可。

*图 6:共享屏幕截图变得更加容易。*
### 更令人满意的 Android 体验
Android 9.0 带来了更令人满意的用户体验。当然,以上说到的内容只是它的冰山一角。如果需要更多信息,可以查阅 Google 的官方 [Android 9.0 网站](https://www.android.com/versions/pie-9-0/)。如果你的设备还没有收到升级推送,请耐心等待,Android 9.0 值得等待。
---
via: <https://www.linux.com/learn/2018/10/overview-android-pie>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,294 | 如何从 Windows 7、8 和 10 创建可启动的 Linux USB 盘? | https://www.2daygeek.com/create-a-bootable-live-usb-drive-from-windows-using-universal-usb-installer/ | 2018-11-30T09:44:18 | [
"USB",
"启动盘"
] | https://linux.cn/article-10294-1.html | 
如果你想了解 Linux,首先要做的是在你的系统上安装 Linux 系统。
它可以通过两种方式实现,使用 Virtualbox、VMWare 等虚拟化应用,或者在你的系统上安装 Linux。
如果你倾向于从 Windows 系统迁移到 Linux 系统或计划在备用机上安装 Linux 系统,那么你须为此创建可启动的 USB 盘。
我们已经写过许多[在 Linux 上创建可启动 USB 盘](https://www.2daygeek.com/category/bootable-usb/) 的文章,如 [BootISO](https://www.2daygeek.com/bootiso-a-simple-bash-script-to-securely-create-a-bootable-usb-device-in-linux-from-iso-file/)、[Etcher](https://www.2daygeek.com/etcher-easy-way-to-create-a-bootable-usb-drive-sd-card-from-an-iso-image-on-linux/) 和 [dd 命令](https://www.2daygeek.com/create-a-bootable-usb-drive-from-an-iso-image-using-dd-command-on-linux/),但我们从来没有机会写一篇文章关于在 Windows 中创建 Linux 可启动 USB 盘的文章。不管怎样,我们今天有机会做这件事了。
在本文中,我们将向你展示如何从 Windows 10 创建可启动的 Ubuntu USB 盘。
这些步骤也适用于其他 Linux,但你必须从下拉列表中选择相应的操作系统而不是 Ubuntu。
### 步骤 1:下载 Ubuntu ISO
访问 [Ubuntu 发布](http://releases.ubuntu.com/) 页面并下载最新版本。我想建议你下载最新的 LTS 版而不是普通的发布。
通过 MD5 或 SHA256 验证校验和,确保下载了正确的 ISO。输出值应与 Ubuntu 版本页面值匹配。
### 步骤 2:下载 Universal USB Installer
有许多程序可供使用,但我的首选是 [Universal USB Installer](https://www.pendrivelinux.com/universal-usb-installer-easy-as-1-2-3/),它使用起来非常简单。只需访问 Universal USB Installer 页面并下载该程序即可。
### 步骤3:创建可启动的 Ubuntu ISO
这个程序在使用上不复杂。首先连接 USB 盘,然后点击下载的 Universal USB Installer。启动后,你可以看到类似于我们的界面。

* 步骤 1:选择 Ubuntu 系统。
* 步骤 2:选择 Ubuntu ISO 下载位置。
* 步骤 3:它默认选择的是 USB 盘,但是要验证一下,接着勾选格式化选项。

当你点击 “Create” 按钮时,它会弹出一个带有警告的窗口。不用担心,只需点击 “Yes” 继续进行此操作即可。

USB 盘分区正在进行中。

要等待一会儿才能完成。如你您想将它移至后台,你可以点击 “Background” 按钮。

好了,完成了。

现在你可以进行[安装 Ubuntu 系统](https://www.2daygeek.com/how-to-install-ubuntu-16-04/)了。但是,它也提供了一个 live 模式,如果你想在安装之前尝试,那么可以使用它。
---
via: <https://www.2daygeek.com/create-a-bootable-live-usb-drive-from-windows-using-universal-usb-installer/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,295 | Python Web 应用程序 Django 框架简介 | https://opensource.com/article/18/8/django-framework | 2018-11-30T19:00:57 | [
"Django",
"Python"
] | https://linux.cn/article-10295-1.html |
>
> 在这个比较 Python 框架的最后一篇中,让我们看看 Django。
>
>
>

在本系列(由四部分组成)的前三篇文章中,我们讨论了 [Pyramid](https://opensource.com/article/18/5/pyramid-framework)、[Flask](https://opensource.com/article/18/4/flask) 和 [Tornado](https://opensource.com/article/18/6/tornado-framework) 这 3 个 Web 框架。我们已经构建了三次相同的应用程序,最终我们遇到了 [Django](https://www.djangoproject.com)。总的来说,Django 是目前 Python 开发人员使用的主要 Web 框架,并且原因显而易见。它擅长隐藏大量的配置逻辑,让你专注于能够快速构建大型应用程序。
也就是说,当涉及到小型项目时,比如我们的待办事项列表应用程序,Django 可能有点像用消防水管来进行水枪大战。让我们来看看它们是如何结合在一起的。
### 关于 Django
Django 将自己定位为“一个鼓励快速开发和整洁、实用的设计的高级 Python Web 框架。它由经验丰富的开发人员构建,解决了 Web 开发的很多麻烦,因此你可以专注于编写应用程序而无需重新发明轮子”。而且它确实做到了!这个庞大的 Web 框架附带了非常多的工具,以至于在开发过程中,如何将所有内容组合在一起协同工作可能是个谜。
除了框架本身很大,Django 社区也是非常庞大的。事实上,它非常庞大和活跃,以至于有[一个网站](https://djangopackages.org/)专门用于为人们收集第三方包,这些第三方包可集成进 Django 来做一大堆事情。包括从身份验证和授权到完全基于 Django 的内容管理系统,电子商务附加组件以及与 Stripe(LCTT 译注:美版“支付宝”)集成的所有内容。至于不要重新发明轮子:如果你想用 Django 完成一些事情,有人可能已经做过了,你只需将它集成进你的项目就行。
为此,我们希望使用 Django 构建 REST API,因此我们将使用流行的 [Django REST 框架](http://www.django-rest-framework.org/)。它的工作是将 Django 框架(Django 使用自己的模板引擎构建 HTML 页面)转换为专门用于有效地处理 REST 交互的系统。让我们开始吧。
### Django 启动和配置
```
$ mkdir django_todo
$ cd django_todo
$ pipenv install --python 3.6
$ pipenv shell
(django-someHash) $ pipenv install django djangorestframework
```
作为参考,我们使用的是 `django-2.0.7` 和 `djangorestframework-3.8.2`。
与 Flask, Tornado 和 Pyramid 不同,我们不需要自己编写 `setup.py` 文件,我们并不是在做一个可安装的 Python 发布版。像很多事情一样,Django 以自己的方式处理这个问题。我们仍然需要一个 `requirements.txt` 文件来跟踪我们在其它地方部署的所有必要安装。但是,就 Django 项目中的目标模块而言,Django 会让我们列出我们想要访问的子目录,然后允许我们从这些目录中导入,就像它们是已安装的包一样。
首先,我们必须创建一个 Django 项目。
当我们安装了 Django 后,我们还安装了命令行脚本 `django-admin`。它的工作是管理所有与 Django 相关的命令,这些命令有助于我们将项目整合在一起,并在我们继续开发的过程中对其进行维护。`django-admin` 并不是让我们从头开始构建整个 Django 生态系统,而是让我们从标准 Django 项目所需的所有必要文件(以及更多)的基础上开始。
调用 `django-admin` 的 `start-project` 命令的语法是 `django-admin startproject <项目名称> <存放目录>`。我们希望文件存于当前的工作目录中,所以:
```
(django-someHash) $ django-admin startproject django_todo .
```
输入 `ls` 将显示一个新文件和一个新目录。
```
(django-someHash) $ ls
manage.py django_todo
```
`manage.py` 是一个可执行命令行 Python 文件,它最终成为 `django-admin` 的封装。因此,它的工作与 `django-admin` 是一样的:帮助我们管理项目。因此得名 `manage.py`。
它在 `django_todo` 目录里创建了一个新目录 `django_todo`,其代表了我们项目的配置根目录。现在让我们深入研究一下。
### 配置 Django
可以将 `django_todo` 目录称为“配置根目录”,我们的意思是这个目录包含了通常配置 Django 项目所需的文件。几乎所有这个目录之外的内容都只关注与项目模型、视图、路由等相关的“业务逻辑”。所有连接项目的点都将在这里出现。
在 `django_todo` 目录中调用 `ls` 会显示以下四个文件:
```
(django-someHash) $ cd django_todo
(django-someHash) $ ls
__init__.py settings.py urls.py wsgi.py
```
* `__init__.py` 文件为空,之所以存在是为了将此目录转换为可导入的 Python 包。
* `settings.py` 是设置大多数配置项的地方。例如项目是否处于 DEBUG 模式,正在使用哪些数据库,Django 应该定位文件的位置等等。它是配置根目录的“主要配置”部分,我们将在一会深入研究。
* `urls.py` 顾名思义就是设置 URL 的地方。虽然我们不必在此文件中显式写入项目的每个 URL,但我们需要让此文件知道在其他任何地方已声明的 URL。如果此文件未指向其它 URL,则那些 URL 就不存在。
* `wsgi.py` 用于在生产环境中提供应用程序。就像 Pyramid、 Tornado 和 Flask 暴露了一些 “app” 对象一样,它们用来提供配置好的应用程序,Django 也必须暴露一个,就是在这里完成的。它可以和 [Gunicorn](http://gunicorn.org/)、[Waitress](https://docs.pylonsproject.org/projects/waitress/en/latest/) 或者 [uWSGI](https://uwsgi-docs.readthedocs.io/en/latest/) 一起配合来提供服务。
#### 设置 settings
看一看 `settings.py`,它里面有大量的配置项,那些只是默认值!这甚至不包括数据库、静态文件、媒体文件、任何集成的钩子,或者可以配置 Django 项目的任何其它几种方式。让我们从上到下看看有什么:
* `BASE_DIR` 设置目录的绝对路径,或者是 `manage.py` 所在的目录。这对于定位文件非常有用。
* `SECRET_KEY` 是用于 Django 项目中加密签名的密钥。在实际中,它用于会话、cookie、CSRF 保护和身份验证令牌等。最好在第一次提交之前,尽快应该更改 `SECRET_KEY` 的值并将其放置到环境变量中。
* `DEBUG` 告诉 Django 是以开发模式还是生产模式运行项目。这是一个非常关键的区别。
+ 在开发模式下,当弹出一个错误时,Django 将显示导致错误的完整堆栈跟踪,以及运行项目所涉及的所有设置和配置。如果在生产环境中将 `DEBUG` 设置为 `True`,这可能成为一个巨大的安全问题。
+ 在生产模式下,当出现问题时,Django 会显示一个简单的错误页面,即除错误代码外不提供任何信息。
+ 保护我们项目的一个简单方法是将 `DEBUG` 设置为环境变量,如 `bool(os.environ.get('DEBUG', ''))`。
* `ALLOWED_HOSTS` 是应用程序提供服务的主机名的列表。在开发模式中,这可能是空的;但是在生产环境中,如果为项目提供服务的主机不在 `ALLOWED_HOSTS` 列表中,Django 项目将无法运行。这是设置为环境变量的另一种情况。
* `INSTALLED_APPS` 是我们的 Django 项目可以访问的 Django “apps” 列表(将它们视为子目录,稍后会详细介绍)。默认情况下,它将提供:
+ 内置的 Django 管理网站
+ Django 的内置认证系统
+ Django 的数据模型通用管理器
+ 会话管理
+ Cookie 和基于会话的消息传递
+ 站点固有的静态文件的用法,比如 `css` 文件、`js` 文件、任何属于我们网站设计的图片等。
* `MIDDLEWARE` 顾名思义:帮助 Django 项目运行的中间件。其中很大一部分用于处理各种类型的安全,尽管我们可以根据需要添加其它中间件。
* `ROOT_URLCONF` 设置基本 URL 配置文件的导入路径。还记得我们之前见过的那个 `urls.py` 吗?默认情况下,Django 指向该文件以此来收集所有的 URL。如果我们想让 Django 在其它地方寻找,我们将在这里设置 URL 位置的导入路径。
* `TEMPLATES` 是 Django 用于我们网站前端的模板引擎列表,假如我们依靠 Django 来构建我们的 HTML。我们在这里不需要,那就无关紧要了。
* `WSGI_APPLICATION` 设置我们的 WSGI 应用程序的导入路径 —— 在生产环境下使用的东西。默认情况下,它指向 `wsgi.py` 中的 `application` 对象。这很少(如果有的话)需要修改。
* `DATABASES` 设置 Django 项目将访问那些数据库。必须设置 `default` 数据库。我们可以通过名称设置别的数据库,只要我们提供 `HOST`、`USER`、`PASSWORD`、`PORT`、数据库名称 `NAME` 和合适的 `ENGINE`。可以想象,这些都是敏感的信息,因此最好将它们隐藏在环境变量中。[查看 Django 文档](https://docs.djangoproject.com/en/2.0/ref/settings/#databases)了解更多详情。
+ 注意:如果不是提供数据库的每个单个部分,而是提供完整的数据库 URL,请查看 [djdatabaseurl](https://pypi.org/project/dj-database-url/)。
* `AUTH_PASSWORD_VALIDATORS` 实际上是运行以检查输入密码的函数列表。默认情况下我们有一些,但是如果我们有其它更复杂的验证需求:不仅仅是检查密码是否与用户的属性匹配,是否超过最小长度,是否是 1000 个最常用的密码之一,或者密码完全是数字,我们可以在这里列出它们。
* `LANGUAGE_CODE` 设置网站的语言。默认情况下它是美国英语,但我们可以将其切换为其它语言。
* `TIME_ZONE` 是我们 Django 项目后中自动生成的时间戳的时区。我强调坚持使用 UTC 并在其它地方执行任何特定于时区的处理,而不是尝试重新配置此设置。正如[这篇文章](http://yellerapp.com/posts/2015-01-12-the-worst-server-setup-you-can-make.html) 所述,UTC 是所有时区的共同点,因为不需要担心偏移。如果偏移很重要,我们可以根据需要使用与 UTC 的适当偏移来计算它们。
* `USE_I18N` 将让 Django 使用自己的翻译服务来为前端翻译字符串。I18N = 国际化(internationalization,“i” 和 “n” 之间共 18 个字符)。
* `USE_L10N` L10N = 本地化(localization,在 l 和 n 之间共 10 个字符) 。如果设置为 `True`,那么将使用数据的公共本地格式。一个很好的例子是日期:在美国它是 MM-DD-YYYY。在欧洲,日期往往写成 DD-MM-YYYY。
* `STATIC_URL` 是用于提供静态文件的主体部分。我们将构建一个 REST API,因此我们不需要考虑静态文件。通常,这会为每个静态文件的域名设置根路径。所以,如果我们有一个 Logo 图像,那就是 `http://<domainname>/<STATIC_URL>/logo.gif`。
默认情况下,这些设置已准备就绪。我们必须改变的一个选项是 `DATABASES` 设置。首先,我们创建将要使用的数据库:
```
(django-someHash) $ createdb django_todo
```
我们想要像使用 Flask、Pyramid 和 Tornado 一样使用 PostgreSQL 数据库,这意味着我们必须更改 `DATABASES` 设置以允许我们的服务器访问 PostgreSQL 数据库。首先是引擎。默认情况下,数据库引擎是 `django.db.backends.sqlite3`,我们把它改成 `django.db.backends.postgresql`。
有关 Django 可用引擎的更多信息,[请查看文档](https://docs.djangoproject.com/en/2.0/ref/settings/#std:setting-DATABASE-ENGINE)。请注意,尽管技术上可以将 NoSQL 解决方案整合到 Django 项目中,但为了开箱即用,Django 强烈偏向于 SQL 解决方案。
接下来,我们必须为连接参数的不同部分指定键值对。
* `NAME` 是我们刚刚创建的数据库的名称。
* `USER` 是 Postgres 数据库用户名。
* `PASSWORD` 是访问数据库所需的密码。
* `HOST` 是数据库的主机。当我们在本地开发时,`localhost` 或 `127.0.0.1` 都将起作用。
* `PORT` 是我们为 Postgres 开放的端口,它通常是 `5432`。
`settings.py` 希望我们为每个键提供字符串值。但是,这是高度敏感的信息。任何负责任的开发人员都不应该这样做。有几种方法可以解决这个问题,一种是我们需要设置环境变量。
```
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': os.environ.get('DB_NAME', ''),
'USER': os.environ.get('DB_USER', ''),
'PASSWORD': os.environ.get('DB_PASS', ''),
'HOST': os.environ.get('DB_HOST', ''),
'PORT': os.environ.get('DB_PORT', ''),
}
}
```
在继续之前,请确保设置环境变量,否则 Django 将无法工作。此外,我们需要在此环境中安装 `psycopg2`,以便我们可以与数据库通信。
### Django 路由和视图
让我们在这个项目中实现一些函数。我们将使用 Django REST 框架来构建 REST API,所以我们必须确保在 `settings.py` 中将 `rest_framework` 添加到 `INSTALLED_APPS` 的末尾。
```
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework'
]
```
虽然 Django REST 框架并不专门需要基于类的视图(如 Tornado)来处理传入的请求,但类是编写视图的首选方法。让我们来定义一个类视图。
让我们在 `django_todo` 创建一个名为 `views.py` 的文件。在 `views.py` 中,我们将创建 “Hello, world!” 视图。
```
# in django_todo/views.py
from rest_framework.response import JsonResponse
from rest_framework.views import APIView
class HelloWorld(APIView):
def get(self, request, format=None):
"""Print 'Hello, world!' as the response body."""
return JsonResponse("Hello, world!")
```
每个 Django REST 框架基于类的视图都直接或间接地继承自 `APIView`。`APIView` 处理大量的东西,但针对我们的用途,它做了以下特定的事情:
```
* 根据 HTTP 方法(例如 GET、POST、PUT、DELETE)来设置引导对应请求所需的方法
* 用我们需要的所有数据和属性来填充 `request` 对象,以便解析和处理传入的请求
* 采用 `Response` 或 `JsonResponse`,每个调度方法(即名为 `get`、`post`、`put`、`delete` 的方法)返回并构造格式正确的 HTTP 响应。
```
终于,我们有一个视图了!它本身没有任何作用,我们需要将它连接到路由。
如果我们跳转到 `django_todo/urls.py`,我们会到达默认的 URL 配置文件。如前所述:如果 Django 项目中的路由不包含在此处,则它不存在。
我们在给定的 `urlpatterns` 列表中添加所需的 URL。默认情况下,我们有一整套 URL 用于 Django 的内置管理后端系统。我们会完全删除它。
我们还得到一些非常有用的文档字符串,它告诉我们如何向 Django 项目添加路由。我们需要调用 `path()`,伴随三个参数:
* 所需的路由,作为字符串(没有前导斜线)
* 处理该路由的视图函数(只能有一个函数!)
* 在 Django 项目中路由的名称
让我们导入 `HelloWorld` 视图并将其附加到主路径 `/` 。我们可以从 `urlpatterns` 中删除 `admin` 的路径,因为我们不会使用它。
```
# django_todo/urls.py, after the big doc string
from django.urls import path
from django_todo.views import HelloWorld
urlpatterns = [
path('', HelloWorld.as_view(), name="hello"),
]
```
好吧,这里有一点不同。我们指定的路由只是一个空白字符串,为什么它会工作?Django 假设我们声明的每个路由都以一个前导斜杠开头,我们只是在初始域名后指定资源路由。如果一条路由没有去往一个特定的资源,而只是一个主页,那么该路由是 `''`,实际上是“没有资源”。
`HelloWorld` 视图是从我们刚刚创建的 `views.py` 文件导入的。为了执行此导入,我们需要更新 `settings.py` 中的 `INSTALLED_APPS` 列表使其包含 `django_todo`。是的,这有点奇怪。以下是一种理解方式。
`INSTALLED_APPS` 指的是 Django 认为可导入的目录或包的列表。它是 Django 处理项目的各个组件的方式,比如安装了一个包,而不需要经过 `setup.py` 的方式。我们希望将 `django_todo` 目录视为可导入的包,因此我们将该目录包含在 `INSTALLED_APPS` 中。现在,在该目录中的任何模块也是可导入的。所以我们得到了我们的视图。
`path` 函数只将视图函数作为第二个参数,而不仅仅是基于类的视图。幸运的是,所有有效的基于 Django 类的视图都包含 `.as_view()` 方法。它的工作是将基于类的视图的所有优点汇总到一个视图函数中并返回该视图函数。所以,我们永远不必担心转换的工作。相反,我们只需要考虑业务逻辑,让 Django 和 Django REST 框架处理剩下的事情。
让我们在浏览器中打开它!
Django 提供了自己的本地开发服务器,可通过 `manage.py` 访问。让我们切换到包含 `manage.py` 的目录并输入:
```
(django-someHash) $ ./manage.py runserver
Performing system checks...
System check identified no issues (0 silenced).
August 01, 2018 - 16:47:24
Django version 2.0.7, using settings 'django_todo.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
```
当 `runserver` 执行时,Django 会检查以确保项目(或多或少)正确连接在一起。这不是万无一失的,但确实会发现一些明显的问题。如果我们的数据库与代码不同步,它会通知我们。毫无疑问,因为我们没有将任何应用程序的东西提交到我们的数据库,但现在这样做还是可以的。让我们访问 `http://127.0.0.1:8000` 来查看 `HelloWorld` 视图的输出。
咦?这不是我们在 Pyramid、Flask 和 Tornado 中看到的明文数据。当使用 Django REST 框架时,HTTP 响应(在浏览器中查看时)是这样呈现的 HTML,以红色显示我们的实际 JSON 响应。
但不要担心!如果我们在命令行中使用 `curl` 快速访问 `http://127.0.0.1:8000`,我们就不会得到任何花哨的 HTML,只有内容。
```
# 注意:在不同的终端口窗口中执行此操作,在虚拟环境之外
$ curl http://127.0.0.1:8000
"Hello, world!"
```
棒极了!
Django REST 框架希望我们在使用浏览器浏览时拥有一个人性化的界面。这是有道理的,如果在浏览器中查看 JSON,通常是因为人们想要检查它是否正确,或者在设计一些消费者 API 时想要了解 JSON 响应。这很像你从 [Postman](https://www.getpostman.com/) 中获得的东西。
无论哪种方式,我们都知道我们的视图工作了!酷!让我们概括一下我们做过的事情:
1. 使用 `django-admin startproject <项目名称>` 开始一个项目
2. 使用环境变量来更新 `django_todo/settings.py` 中的 `DEBUG`、`SECRET_KEY`,还有 `DATABASES` 字典
3. 安装 Django REST 框架,并将它添加到 `INSTALLED_APPS`
4. 创建 `django_todo/views.py` 来包含我们的第一个类视图,它返回响应 “Hello, world!”
5. 更新 `django_todo/urls.py`,其中包含我们的根路由
6. 在 `django_todo/settings.py` 中更新 `INSTALLED_APPS` 以包含 `django_todo` 包
### 创建模型
现在让我们来创建数据模型吧。
Django 项目的整个基础架构都是围绕数据模型构建的,它是这样编写的,每个数据模型够可以拥有自己的小天地,拥有自己的视图,自己与其资源相关的 URL 集合,甚至是自己的测试(如果我们想要的话)。
如果我们想构建一个简单的 Django 项目,我们可以通过在 `django_todo` 目录中编写我们自己的 `models.py` 文件并将其导入我们的视图来避免这种情况。但是,我们想以“正确”的方式编写 Django 项目,因此我们应该尽可能地将模型拆分成符合 Django Way™(Django 风格)的包。
Django Way 涉及创建所谓的 Django “应用程序”,它本身并不是单独的应用程序,它们没有自己的设置和诸如此类的东西(虽然它们也可以)。但是,它们可以拥有一个人们可能认为属于独立应用程序的东西:
* 一组自建的 URL
* 一组自建的 HTML 模板(如果我们想要提供 HTML)
* 一个或多个数据模型
* 一套自建的视图
* 一套自建的测试
它们是独立的,因此可以像独立应用程序一样轻松共享。实际上,Django REST 框架是 Django 应用程序的一个例子。它包含自己的视图和 HTML 模板,用于提供我们的 JSON。我们只是利用这个 Django 应用程序将我们的项目变成一个全面的 RESTful API 而不用那么麻烦。
要为我们的待办事项列表项创建 Django 应用程序,我们将要使用 `manage.py` 的 `startapp` 命令。
```
(django-someHash) $ ./manage.py startapp todo
```
`startapp` 命令成功执行后没有输出。我们可以通过使用 `ls` 来检查它是否完成它应该做的事情。
```
(django-someHash) $ ls
Pipfile Pipfile.lock django_todo manage.py todo
```
看看:我们有一个全新的 `todo` 目录。让我们看看里面!
```
(django-someHash) $ ls todo
__init__.py admin.py apps.py migrations models.py tests.py views.py
```
以下是 `manage.py startapp` 创建的文件:
* `__init__.py` 是空文件。它之所以存在是因为此目录可看作是模型、视图等的有效导入路径。
* `admin.py` 不是空文件。它用于在 Django admin 中规范化这个应用程序的模型,我们在本文中没有涉及到它。
* `apps.py` 这里基本不起作用。它有助于规范化 Django admin 的模型。
* `migrations` 是一个包含我们数据模型快照的目录。它用于更新数据库。这是少数几个内置了数据库管理的框架之一,其中一部分允许我们更新数据库,而不必拆除它并重建它以更改 Schema。
* `models.py` 是数据模型所在。
* `tests.py` 是测试所在的地方,如果我们需要写测试。
* `views.py` 用于我们编写的与此应用程序中的模型相关的视图。它们不是一定得写在这里。例如,我们可以在 `django_todo/views.py` 中写下我们所有的视图。但是,它在这个应用程序中更容易将我们的概念理清。在覆盖了许多概念的扩展应用程序的关系之间会变得更加密切。
它并没有为这个应用程序创建 `urls.py` 文件,但我们可以自己创建。
```
(django-someHash) $ touch todo/urls.py
```
在继续之前,我们应该帮自己一个忙,将这个新 Django 应用程序添加到 `django_todo/settings.py` 中的 `INSTALLED_APPS` 列表中。
```
# settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'django_todo',
'todo' # <--- 添加了这行
]
```
检查 `todo/models.py` 发现 `manage.py` 已经为我们编写了一些代码。不同于在 Flask、Tornado 和 Pyramid 实现中创建模型的方式,Django 不利用第三方来管理数据库会话或构建其对象实例。它全部归入 Django 的 `django.db.models` 子模块。
然而,建立模型的方式或多或少是相同的。要在 Django 中创建模型,我们需要构建一个继承自 `models.Model` 的 `class`,将应用于该模型实例的所有字段都应视为类属性。我们不像过去那样从 SQLAlchemy 导入列和字段类型,而是直接从 `django.db.models` 导入。
```
# todo/models.py
from django.db import models
class Task(models.Model):
"""Tasks for the To Do list."""
name = models.CharField(max_length=256)
note = models.TextField(blank=True, null=True)
creation_date = models.DateTimeField(auto_now_add=True)
due_date = models.DateTimeField(blank=True, null=True)
completed = models.BooleanField(default=False)
```
虽然 Django 的需求和基于 SQLAlchemy 的系统之间存在一些明显的差异,但总体内容和结构或多或少相同。让我们来指出这些差异。
我们不再需要为对象实例声明自动递增 ID 的单独字段。除非我们指定一个不同的字段作为主键,否则 Django 会为我们构建一个。
我们只是直接引用数据类型作为列本身,而不是实例化传递数据类型对象的 `Column` 对象。
`Unicode` 字段变为 `models.CharField` 或 `models.TextField`。`CharField` 用于特定最大长度的小文本字段,而 `TextField` 用于任何数量的文本。
`TextField` 应该是空白的,我们以两种方式指定它。`blank = True` 表示当构建此模型的实例,并且正在验证附加到该字段的数据时,该数据是可以为空的。这与 `null = True` 不同,后者表示当构造此模型类的表时,对应于 `note` 的列将允许空白或为 `NULL`。因此,总而言之,`blank = True` 控制如何将数据添加到模型实例,而 `null = True` 控制如何构建保存该数据的数据库表。
`DateTime` 字段增加了一些属性,并且能够为我们做一些工作,使得我们不必修改类的 `__init__` 方法。对于 `creation_date` 字段,我们指定 `auto_now_add = True`。在实际意义上意味着,当创建一个新模型实例时,Django 将自动记录现在的日期和时间作为该字段的值。这非常方便!
当 `auto_now_add` 及其类似属性 `auto_now` 都没被设置为 `True` 时,`DateTimeField` 会像其它字段一样需要预期的数据。它需要提供一个适当的 `datetime` 对象才能生效。`due_date` 列的 `blank` 和 `null` 属性都设置为 `True`,这样待办事项列表中的项目就可以成为将来某个时间点完成,没有确定的日期或时间。
`BooleanField` 最终可以取两个值:`True` 或 `False`。这里,默认值设置为 `False`。
#### 管理数据库
如前所述,Django 有自己的数据库管理方式。我们可以利用 Django 提供的 `manage.py` 脚本,而不必编写任何关于数据库的代码。它不仅可以管理我们数据库的表的构建,还可以管理我们希望对这些表进行的任何更新,而不必将整个事情搞砸!
因为我们构建了一个新模型,所以我们需要让数据库知道它。首先,我们需要将与此模型对应的模式放入代码中。`manage.py` 的 `makemigrations` 命令对我们构建的模型类及其所有字段进行快照。它将获取该信息并将其打包成一个 Python 脚本,该脚本将存在于特定 Django 应用程序的 `migrations` 目录中。永远没有理由直接运行这个迁移脚本。它的存在只是为了让 Django 可以使用它作为更新数据库表的基础,或者在我们更新模型类时继承信息。
```
(django-someHash) $ ./manage.py makemigrations
Migrations for 'todo':
todo/migrations/0001_initial.py
- Create model Task
```
这将查找 `INSTALLED_APPS` 中列出的每个应用程序,并检查这些应用程序中存在的模型。然后,它将检查相应的 `migrations` 目录中的迁移文件,并将它们与每个 `INSTALLED_APPS` 中的模型进行比较。如果模型已经升级超出最新迁移所应存在的范围,则将创建一个继承自最新迁移文件的新迁移文件,它将自动命名,并且还会显示一条消息,说明自上次迁移以来发生了哪些更改。
如果你上次处理 Django 项目已经有一段时间了,并且不记得模型是否与迁移同步,那么你无需担心。`makemigrations` 是一个幂等操作。无论你运行 `makemigrations` 一次还是 20 次,`migrations` 目录只有一个与当前模型配置的副本。更棒的是,当我们运行 `./manage.py runserver` 时,Django 检测到我们的模型与迁移不同步,它会用彩色文本告诉我们以便我们可以做出适当的选择。
下一个要点是至少让每个人访问一次:创建一个迁移文件不会立即影响我们的数据库。当我们运行 `makemigrations` 时,我们布置我们的 Django 项目定义了给定的表应该如何创建和最终查找。我们仍要将这些更改应用于数据库。这就是 `migrate` 命令的用途。
```
(django-someHash) $ ./manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, sessions, todo
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying sessions.0001_initial... OK
Applying todo.0001_initial... OK
```
当我们应用这些迁移时,Django 首先检查其他 `INSTALLED_APPS` 是否有需要应用的迁移,它大致按照列出的顺序检查它们。我们希望我们的应用程序最后列出,因为我们希望确保,如果我们的模型依赖于任何 Django 的内置模型,我们所做的数据库更新不会受到依赖性问题的影响。
我们还有另一个要构建的模型:`User` 模型。但是,因为我们正在使用 Django,事情有一些变化。许多应用程序需要某种类型的用户模型,Django 的 `django.contrib.auth` 包构建了自己的用户模型供我们使用。如果无需用户所需要的身份验证令牌,我们可以继续使用它而不是重新发明轮子。
但是,我们需要那个令牌。我们可以通过两种方式来处理这个问题。
* 继承 Django 的 `User` 对象,我们自己的对象通过添加 `token` 字段来扩展它
* 创建一个与 Django 的 `User` 对象一对一关系的新对象,其唯一目的是持有一个令牌
我习惯于建立对象关系,所以让我们选择第二种选择。我们称之为 `Owner`,因为它基本上具有与 `User` 类似的内涵,这就是我们想要的。
出于纯粹的懒惰,我们可以在 `todo/models.py` 中包含这个新的 `Owner` 对象,但是不要这样做。`Owner` 没有明确地与任务列表上的项目的创建或维护有关。从概念上讲,`Owner` 只是任务的所有者。甚至有时候我们想要扩展这个 `Owner` 以包含与任务完全无关的其他数据。
为了安全起见,让我们创建一个 `owner` 应用程序,其工作是容纳和处理这个 `Owner` 对象。
```
(django-someHash) $ ./manage.py startapp owner
```
不要忘记在 `settings.py` 文件中的 `INSTALLED_APPS` 中添加它。 `INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'django_todo',
'todo',
'owner'
]`
如果我们查看 Django 项目的根目录,我们现在有两个 Django 应用程序:
```
(django-someHash) $ ls
Pipfile Pipfile.lock django_todo manage.py owner todo
```
在 `owner/models.py` 中,让我们构建这个 `Owner` 模型。如前所述,它与 Django 的内置 `User` 对象有一对一的关系。我们可以用 Django 的 `models.OneToOneField` 强制实现这种关系。
```
# owner/models.py
from django.db import models
from django.contrib.auth.models import User
import secrets
class Owner(models.Model):
"""The object that owns tasks."""
user = models.OneToOneField(User, on_delete=models.CASCADE)
token = models.CharField(max_length=256)
def __init__(self, *args, **kwargs):
"""On construction, set token."""
self.token = secrets.token_urlsafe(64)
super().__init__(*args, **kwargs)
```
这表示 `Owner` 对象对应到 `User` 对象,每个 `user` 实例有一个 `owner` 实例。`on_delete = models.CASCADE` 表示如果相应的 `User` 被删除,它所对应的 `Owner` 实例也将被删除。让我们运行 `makemigrations` 和 `migrate` 来将这个新模型放入到我们的数据库中。
```
(django-someHash) $ ./manage.py makemigrations
Migrations for 'owner':
owner/migrations/0001_initial.py
- Create model Owner
(django-someHash) $ ./manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, owner, sessions, todo
Running migrations:
Applying owner.0001_initial... OK
```
现在我们的 `Owner` 需要拥有一些 `Task` 对象。它与上面看到的 `OneToOneField` 非常相似,只不过我们会在 `Task` 对象上贴一个 `ForeignKey` 字段指向 `Owner`。
```
# todo/models.py
from django.db import models
from owner.models import Owner
class Task(models.Model):
"""Tasks for the To Do list."""
name = models.CharField(max_length=256)
note = models.TextField(blank=True, null=True)
creation_date = models.DateTimeField(auto_now_add=True)
due_date = models.DateTimeField(blank=True, null=True)
completed = models.BooleanField(default=False)
owner = models.ForeignKey(Owner, on_delete=models.CASCADE)
```
每个待办事项列表任务只有一个可以拥有多个任务的所有者。删除该所有者后,他们拥有的任务都会随之删除。
现在让我们运行 `makemigrations` 来获取我们的数据模型设置的新快照,然后运行 `migrate` 将这些更改应用到我们的数据库。
```
(django-someHash) django $ ./manage.py makemigrations
You are trying to add a non-nullable field 'owner' to task without a default; we can't do that (the database needs something to populate existing rows).
Please select a fix:
1) Provide a one-off default now (will be set on all existing rows with a null value for this column)
2) Quit, and let me add a default in models.py
```
不好了!出现了问题!发生了什么?其实,当我们创建 `Owner` 对象并将其作为 `ForeignKey` 添加到 `Task` 时,要求每个 `Task` 都需要一个 `Owner`。但是,我们为 `Task` 对象进行的第一次迁移不包括该要求。因此,即使我们的数据库表中没有数据,Django 也会对我们的迁移进行预先检查,以确保它们兼容,而我们提议的这种新迁移不是。
有几种方法可以解决这类问题:
1. 退出当前迁移并构建一个包含当前模型配置的新迁移
2. 将一个默认值添加到 `Task` 对象的 `owner` 字段
3. 允许任务为 `owner` 字段设置 `NULL` 值
方案 2 在这里没有多大意义。我们建议,默认情况下,任何创建的 `Task` 都会对应到某个默认所有者,尽管默认所有者不一定存在。 方案 1 要求我们销毁和重建我们的迁移,而我们应该把它们留下。
让我们考虑选项 3。在这种情况下,如果我们允许 `Task` 表为所有者提供空值,它不会很糟糕。从这一点开始创建的任何任务都必然拥有一个所有者。如果你的数据库表并非不能接受重新架构,请删除该迁移、删除表并重建迁移。
```
# todo/models.py
from django.db import models
from owner.models import Owner
class Task(models.Model):
"""Tasks for the To Do list."""
name = models.CharField(max_length=256)
note = models.TextField(blank=True, null=True)
creation_date = models.DateTimeField(auto_now_add=True)
due_date = models.DateTimeField(blank=True, null=True)
completed = models.BooleanField(default=False)
owner = models.ForeignKey(Owner, on_delete=models.CASCADE, null=True)
(django-someHash) $ ./manage.py makemigrations
Migrations for 'todo':
todo/migrations/0002_task_owner.py
- Add field owner to task
(django-someHash) $ ./manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, owner, sessions, todo
Running migrations:
Applying todo.0002_task_owner... OK
```
酷!我们有模型了!欢迎使用 Django 声明对象的方式。
出于更好的权衡,让我们确保无论何时制作 `User`,它都会自动与新的 `Owner` 对象对应。我们可以使用 Django 的 `signals` 系统来做到这一点。基本上,我们确切地表达了意图:“当我们得到一个新的 `User` 被构造的信号时,构造一个新的 `Owner` 并将新的 `User` 设置为 `Owner` 的 `user` 字段。”在实践中看起来像这样:
```
# owner/models.py
from django.contrib.auth.models import User
from django.db import models
from django.db.models.signals import post_save
from django.dispatch import receiver
import secrets
class Owner(models.Model):
"""The object that owns tasks."""
user = models.OneToOneField(User, on_delete=models.CASCADE)
token = models.CharField(max_length=256)
def __init__(self, *args, **kwargs):
"""On construction, set token."""
self.token = secrets.token_urlsafe(64)
super().__init__(*args, **kwargs)
@receiver(post_save, sender=User)
def link_user_to_owner(sender, **kwargs):
"""If a new User is saved, create a corresponding Owner."""
if kwargs['created']:
owner = Owner(user=kwargs['instance'])
owner.save()
```
我们设置了一个函数,用于监听从 Django 中内置的 `User` 对象发送的信号。它正在等待 `User` 对象被保存之后的情况。这可以来自新的 `User` 或对现有 `User` 的更新。我们在监听功能中辨别出两种情况。
如果发送信号的东西是新创建的实例,`kwargs ['created']` 将具有值 `True`。如果是 `True` 的话,我们想做点事情。如果它是一个新实例,我们创建一个新的 `Owner`,将其 `user` 字段设置为创建的新 `User` 实例。之后,我们 `save()` 新的 `Owner`。如果一切正常,这将提交更改到数据库。如果数据没通过我们声明的字段的验证,它将失败。
现在让我们谈谈我们将如何访问数据。
### 访问模型数据
在 Flask、Pyramid 和 Tornado 框架中,我们通过对某些数据库会话运行查询来访问模型数据。也许它被附加到 `request` 对象,也许它是一个独立的 `session` 对象。无论如何,我们必须建立与数据库的实时连接并在该连接上进行查询。
这不是 Django 的工作方式。默认情况下,Django 不利用任何第三方对象关系映射(ORM)与数据库进行通信。相反,Django 允许模型类维护自己与数据库的对话。
从 `django.db.models.Model` 继承的每个模型类都会附加一个 `objects` 对象。这将取代我们熟悉的 `session` 或 `dbsession`。让我们打开 Django 给我们的特殊 shell,并研究这个 `objects` 对象是如何工作的。
```
(django-someHash) $ ./manage.py shell
Python 3.7.0 (default, Jun 29 2018, 20:13:13)
[Clang 9.1.0 (clang-902.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>>
```
Django shell 与普通的 Python shell 不同,因为它知道我们正在构建的 Django 项目,可以轻松导入我们的模型、视图、设置等,而不必担心安装包。我们可以通过简单的 `import` 访问我们的模型。
```
>>> from owner.models import Owner
>>> Owner
<class 'owner.models.Owner'>
```
目前,我们没有 `Owner` 实例。我们可以通过 `Owner.objects.all()` 查询它们。
```
>>> Owner.objects.all()
<QuerySet []>
```
无论何时我们在 `<Model> .objects` 对象上运行查询方法,我们都会得到 `QuerySet`。为了我们的目的,它实际上是一个列表,这个列表向我们显示它是空的。让我们通过创建一个 `User` 来创建一个 `Owner`。
```
>>> from django.contrib.auth.models import User
>>> new_user = User(username='kenyattamurphy', email='[email protected]')
>>> new_user.set_password('wakandaforever')
>>> new_user.save()
```
如果我们现在查询所有的 `Owner`,我们应该会找到 Kenyatta。
```
>>> Owner.objects.all()
<QuerySet [<Owner: Owner object (1)>]>
```
棒极了!我们得到了数据!
### 序列化模型
我们将在 “Hello World” 之外来回传递数据。因此,我们希望看到某种类似于 JSON 类型的输出,它可以很好地表示数据。获取该对象的数据并将其转换为 JSON 对象以通过 HTTP 提交是数据序列化的一种方式。在序列化数据时,我们正在获取我们目前拥有的数据并重新格式化以适应一些标准的、更易于理解的形式。
如果我用 Flask、Pyramid 和 Tornado 这样做,我会在每个模型上创建一个新方法,让用户可以直接调用 `to_json()`。`to_json()` 的唯一工作是返回一个 JSON 可序列化的(即数字、字符串、列表、字典)字典,其中包含我想要为所讨论的对象显示的任何字段。
对于 `Task` 对象,它可能看起来像这样:
```
class Task(Base):
...all the fields...
def to_json(self):
"""Convert task attributes to a JSON-serializable dict."""
return {
'id': self.id,
'name': self.name,
'note': self.note,
'creation_date': self.creation_date.strftime('%m/%d/%Y %H:%M:%S'),
'due_date': self.due_date.strftime('%m/%d/%Y %H:%M:%S'),
'completed': self.completed,
'user': self.user_id
}
```
这不花哨,但它确实起到了作用。
然而,Django REST 框架为我们提供了一个对象,它不仅可以为我们这样做,还可以在我们想要创建新对象实例或更新现有实例时验证输入,它被称为 [ModelSerializer](http://www.django-rest-framework.org/api-guide/serializers/#modelserializer)。
Django REST 框架的 `ModelSerializer` 是我们模型的有效文档。如果没有附加模型,它们就没有自己的生命(因为那里有 [Serializer](http://www.django-rest-framework.org/api-guide/serializers/) 类)。它们的主要工作是准确地表示我们的模型,并在我们的模型数据需要序列化并通过线路发送时,将其转换为 JSON。
Django REST 框架的 `ModelSerializer` 最适合简单对象。举个例子,假设我们在 `Task` 对象上没有 `ForeignKey`。我们可以为 `Task` 创建一个序列化器,它将根据需要将其字段值转换为 JSON,声明如下:
```
# todo/serializers.py
from rest_framework import serializers
from todo.models import Task
class TaskSerializer(serializers.ModelSerializer):
"""Serializer for the Task model."""
class Meta:
model = Task
fields = ('id', 'name', 'note', 'creation_date', 'due_date', 'completed')
```
在我们新的 `TaskSerializer` 中,我们创建了一个 `Meta` 类。`Meta` 的工作就是保存关于我们试图序列化的东西的信息(或元数据)。然后,我们会注意到要显示的特定字段。如果我们想要显示所有字段,我们可以简化过程并使用 `__all __`。或者,我们可以使用 `exclude` 关键字而不是 `fields` 来告诉 Django REST 框架我们想要除了少数几个字段以外的每个字段。我们可以拥有尽可能多的序列化器,所以也许我们想要一个用于一小部分字段,而另一个用于所有字段?在这里都可以。
在我们的例子中,每个 `Task` 和它的所有者 `Owner` 之间都有一个关系,必须在这里反映出来。因此,我们需要借用 `serializers.PrimaryKeyRelatedField` 对象来指定每个 `Task` 都有一个 `Owner`,并且该关系是一对一的。它的所有者将从已有的全部所有者的集合中找到。我们通过对这些所有者进行查询并返回我们想要与此序列化程序关联的结果来获得该集合:`Owner.objects.all()`。我们还需要在字段列表中包含 `owner`,因为我们总是需要一个与 `Task` 相关联的 `Owner`。
```
# todo/serializers.py
from rest_framework import serializers
from todo.models import Task
from owner.models import Owner
class TaskSerializer(serializers.ModelSerializer):
"""Serializer for the Task model."""
owner = serializers.PrimaryKeyRelatedField(queryset=Owner.objects.all())
class Meta:
model = Task
fields = ('id', 'name', 'note', 'creation_date', 'due_date', 'completed', 'owner')
```
现在构建了这个序列化器,我们可以将它用于我们想要为我们的对象做的所有 CRUD 操作:
* 如果我们想要 `GET` 一个特定的 `Task` 的 JSON 类型版本,我们可以做 `TaskSerializer((some_task).data`
* 如果我们想接受带有适当数据的 `POST` 来创建一个新的 `Task`,我们可以使用 `TaskSerializer(data = new_data).save()`
* 如果我们想用 `PUT` 更新一些现有数据,我们可以用 `TaskSerializer(existing_task, data = data).save()`
我们没有包括 `delete`,因为我们不需要对 `delete` 操作做任何事情。如果你可以删除一个对象,只需使用 `object_instance.delete()`。
以下是一些序列化数据的示例:
```
>>> from todo.models import Task
>>> from todo.serializers import TaskSerializer
>>> from owner.models import Owner
>>> from django.contrib.auth.models import User
>>> new_user = User(username='kenyatta', email='[email protected]')
>>> new_user.save_password('wakandaforever')
>>> new_user.save() # creating the User that builds the Owner
>>> kenyatta = Owner.objects.first() # 找到 kenyatta 的所有者
>>> new_task = Task(name="Buy roast beef for the Sunday potluck", owner=kenyatta)
>>> new_task.save()
>>> TaskSerializer(new_task).data
{'id': 1, 'name': 'Go to the supermarket', 'note': None, 'creation_date': '2018-07-31T06:00:25.165013Z', 'due_date': None, 'completed': False, 'owner': 1}
```
使用 `ModelSerializer` 对象可以做更多的事情,我建议查看[文档](http://www.django-rest-framework.org/api-guide/serializers/#serializers)以获得更强大的功能。否则,这就是我们所需要的。现在是时候深入视图了。
### 查看视图
我们已经构建了模型和序列化器,现在我们需要为我们的应用程序设置视图和 URL。毕竟,对于没有视图的应用程序,我们无法做任何事情。我们已经看到了上面的 `HelloWorld` 视图的示例。然而,这总是一个人为的、概念验证的例子,并没有真正展示 Django REST 框架的视图可以做些什么。让我们清除 `HelloWorld` 视图和 URL,这样我们就可以从我们的视图重新开始。
我们要构建的第一个视图是 `InfoView`。与之前的框架一样,我们只想打包并发送一个我们用到的路由的字典。视图本身可以存在于 `django_todo.views` 中,因为它与特定模型无关(因此在概念上不属于特定应用程序)。
```
# django_todo/views.py
from rest_framework.response import JsonResponse
from rest_framework.views import APIView
class InfoView(APIView):
"""List of routes for this API."""
def get(self, request):
output = {
'info': 'GET /api/v1',
'register': 'POST /api/v1/accounts',
'single profile detail': 'GET /api/v1/accounts/<username>',
'edit profile': 'PUT /api/v1/accounts/<username>',
'delete profile': 'DELETE /api/v1/accounts/<username>',
'login': 'POST /api/v1/accounts/login',
'logout': 'GET /api/v1/accounts/logout',
"user's tasks": 'GET /api/v1/accounts/<username>/tasks',
"create task": 'POST /api/v1/accounts/<username>/tasks',
"task detail": 'GET /api/v1/accounts/<username>/tasks/<id>',
"task update": 'PUT /api/v1/accounts/<username>/tasks/<id>',
"delete task": 'DELETE /api/v1/accounts/<username>/tasks/<id>'
}
return JsonResponse(output)
```
这与我们在 Tornado 中所拥有的完全相同。让我们将它放置到合适的路由并继续。为了更好的测试,我们还将删除 `admin/` 路由,因为我们不会在这里使用 Django 管理后端。
```
# in django_todo/urls.py
from django_todo.views import InfoView
from django.urls import path
urlpatterns = [
path('api/v1', InfoView.as_view(), name="info"),
]
```
#### 连接模型与视图
让我们弄清楚下一个 URL,它将是创建新的 `Task` 或列出用户现有任务的入口。这应该存在于 `todo` 应用程序的 `urls.py` 中,因为它必须专门处理 `Task`对象而不是整个项目的一部分。
```
# in todo/urls.py
from django.urls import path
from todo.views import TaskListView
urlpatterns = [
path('', TaskListView.as_view(), name="list_tasks")
]
```
这个路由处理的是什么?我们根本没有指定特定用户或路径。由于会有一些路由需要基本路径 `/api/v1/accounts/<username>/tasks`,为什么我们只需写一次就能一次又一次地写它?
Django 允许我们用一整套 URL 并将它们导入 `django_todo/urls.py` 文件。然后,我们可以为这些导入的 URL 中的每一个提供相同的基本路径,只关心可变部分,你知道它们是不同的。
```
# in django_todo/urls.py
from django.urls import include, path
from django_todo.views import InfoView
urlpatterns = [
path('api/v1', InfoView.as_view(), name="info"),
path('api/v1/accounts/<str:username>/tasks', include('todo.urls'))
]
```
现在,来自 `todo/urls.py` 的每个 URL 都将以路径 `api/v1/accounts/<str:username>/tasks` 为前缀。
让我们在 `todo/views.py` 中构建视图。
```
# todo/views.py
from django.shortcuts import get_object_or_404
from rest_framework.response import JsonResponse
from rest_framework.views import APIView
from owner.models import Owner
from todo.models import Task
from todo.serializers import TaskSerializer
class TaskListView(APIView):
def get(self, request, username, format=None):
"""Get all of the tasks for a given user."""
owner = get_object_or_404(Owner, user__username=username)
tasks = Task.objects.filter(owner=owner).all()
serialized = TaskSerializer(tasks, many=True)
return JsonResponse({
'username': username,
'tasks': serialized.data
})
```
这里一点代码里面有许多要说明的,让我们来看看吧。
我们从与我们一直使用的 `APIView` 的继承开始,为我们的视图奠定基础。我们覆盖了之前覆盖的相同 `get` 方法,添加了一个参数,允许我们的视图从传入的请求中接收 `username`。
然后我们的 `get` 方法将使用 `username` 来获取与该用户关联的 `Owner`。这个 `get_object_or_404` 函数允许我们这样做,添加一些特殊的东西以方便使用。
如果无法找到指定的用户,那么查找任务是没有意义的。实际上,我们想要返回 404 错误。`get_object_or_404` 根据我们传入的任何条件获取单个对象,并返回该对象或引发 [Http 404 异常](https://docs.djangoproject.com/en/2.0/topics/http/views/#the-http404-exception)。我们可以根据对象的属性设置该条件。`Owner` 对象都通过 `user` 属性附加到 `User`。但是,我们没有要搜索的 `User` 对象,我们只有一个 `username`。所以,当你寻找一个 `Owner` 时,我们对 `get_object_or_404` 说:通过指定 `user__username`(这是两个下划线)来检查附加到它的 `User` 是否具有我想要的 `username`。通过 `QuerySet` 过滤时,这两个下划线表示 “此嵌套对象的属性”。这些属性可以根据需要进行深度嵌套。
我们现在拥有与给定用户名相对应的 `Owner`。我们使用 `Owner` 来过滤所有任务,只用 `Task.objects.filter` 检索它拥有的任务。我们可以使用与 `get_object_or_404` 相同的嵌套属性模式来钻入连接到 `Tasks` 的 `Owner` 的 `User`(`tasks = Task.objects.filter(owner__user__username = username)).all()`),但是没有必要那么宽松。
`Task.objects.filter(owner = owner).all()` 将为我们提供与我们的查询匹配的所有 `Task` 对象的`QuerySet`。很棒。然后,`TaskSerializer` 将获取 `QuerySet` 及其所有数据以及 `many = True` 标志,以通知其为项目集合而不是仅仅一个项目,并返回一系列序列化结果。实际上是一个词典列表。最后,我们使用 JSON 序列化数据和用于查询的用户名提供传出响应。
#### 处理 POST 请求
`post` 方法看起来与我们之前看到的有些不同。
```
# still in todo/views.py
# ...other imports...
from rest_framework.parsers import JSONParser
from datetime import datetime
class TaskListView(APIView):
def get(self, request, username, format=None):
...
def post(self, request, username, format=None):
"""Create a new Task."""
owner = get_object_or_404(Owner, user__username=username)
data = JSONParser().parse(request)
data['owner'] = owner.id
if data['due_date']:
data['due_date'] = datetime.strptime(data['due_date'], '%d/%m/%Y %H:%M:%S')
new_task = TaskSerializer(data=data)
if new_task.is_valid():
new_task.save()
return JsonResponse({'msg': 'posted'}, status=201)
return JsonResponse(new_task.errors, status=400)
```
当我们从客户端接收数据时,我们使用 `JSONParser().parse(request)` 将其解析为字典。我们将所有者添加到数据中并格式化任务的 `due_date`(如果存在)。
我们的 `TaskSerializer` 完成了繁重的任务。它首先接收传入的数据并将其转换为我们在模型上指定的字段。然后验证该数据以确保它适合指定的字段。如果附加到新 `Task` 的数据有效,它将使用该数据构造一个新的 `Task` 对象并将其提交给数据库。然后我们发回适当的“耶!我们做了一件新东西!”响应。如果没有,我们收集 `TaskSerializer` 生成的错误,并将这些错误发送回客户端,并返回 `400 Bad Request` 状态代码。
如果我们要构建 `put` 视图来更新 `Task`,它看起来会非常相似。主要区别在于,当我们实例化 `TaskSerializer` 时,我们将传递旧对象和该对象的新数据,如 `TaskSerializer(existing_task,data = data)`。我们仍然会进行有效性检查并发回我们想要发回的响应。
### 总结
Django 作为一个框架是高度可定制的,每个人都有自己打造 Django 项目的方式。我在这里写出来的方式不一定是 Django 建立项目的确切方式。它只是 a) 我熟悉的方式,以及 b) 利用 Django 的管理系统。当你将概念切分到不同的小块时,Django 项目的复杂性会增加。这样做是为了让多个人更容易为整个项目做出贡献,而不会麻烦彼此。
然而,作为 Django 项目的大量文件映射并不能使其更高效或自然地偏向于微服务架构。相反,它很容易成为一个令人困惑的独石应用,这可能对你的项目仍然有用,它也可能使你的项目难以管理,尤其是随着项目的增长。
仔细考虑你的需求并使用合适的工具来完成正确的工作。对于像这样的简单项目,Django 可能不是合适的工具。
Django 旨在处理多种模型,这些模型涵盖了不同的项目领域,但它们可能有一些共同点。这个项目是一个小型的双模型项目,有一些路由。即便我们把它构建更复杂,也只有七条路由,而仍然只是相同的两个模型。这还不足以证明一个完整的 Django 项目。
如果我们期望这个项目能够拓展,那么将会是一个很好的选择。这不是那种项目。这就是使用火焰喷射器来点燃蜡烛,绝对是大材小用了。
尽管如此,Web 框架就是一个 Web 框架,无论你使用哪个框架。它都可以接收请求并做出任何响应,因此你可以按照自己的意愿进行操作。只需要注意你选择的框架所带来的开销。
就是这样!我们已经到了这个系列的最后!我希望这是一次启发性的冒险。当你在考虑如何构建你的下一个项目时,它将帮助你做出的不仅仅是最熟悉的选择。请务必阅读每个框架的文档,以扩展本系列中涉及的任何内容(因为它没有那么全面)。每个人都有一个广阔的世界。愉快地写代码吧!
---
via: <https://opensource.com/article/18/8/django-framework>
作者:[Nicholas Hunt-Walker](https://opensource.com/users/nhuntwalker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[Bestony](https://github.com/bestony), [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the first three articles of this four-part series comparing different Python web frameworks, we covered the [Pyramid](https://opensource.com/article/18/5/pyramid-framework), [Flask](https://opensource.com/article/18/4/flask), and [Tornado](https://opensource.com/article/18/6/tornado-framework) web frameworks. We've built the same app three times and have finally made our way to [Django](https://www.djangoproject.com). Django is, by and large, the major web framework for Python developers these days and it's not too hard to see why. It excels in hiding a lot of the configuration logic and letting you focus on being able to build big, quickly.
That said, when it comes to small projects, like our To-Do List app, Django can be a bit like bringing a firehose to a water gun fight. Let's see how it all comes together.
## About Django
Django styles itself as "a high-level Python web framework that encourages rapid development and clean, pragmatic design. Built by experienced developers, it takes care of much of the hassle of web development, so you can focus on writing your app without needing to reinvent the wheel." And they really mean it! This massive web framework comes with so many batteries included that oftentimes during development it can be a mystery as to how everything manages to work together.
In addition to the framework itself being large, the Django community is absolutely massive. In fact, it's so big and active that there's [a whole website](https://djangopackages.org/) devoted to the third-party packages people have designed to plug into Django to do a whole host of things. This includes everything from authentication and authorization, to full-on Django-powered content management systems, to e-commerce add-ons, to integrations with Stripe. Talk about not re-inventing the wheel; chances are if you want something done with Django, someone has already done it and you can just pull it into your project.
For this purpose, we want to build a REST API with Django, so we'll leverage the always popular [Django REST framework](http://www.django-rest-framework.org/). Its job is to turn the Django framework, which was made to serve fully rendered HTML pages built with Django's own templating engine, into a system specifically geared toward effectively handling REST interactions. Let's get going with that.
## Django startup and configuration
```
$ mkdir django_todo
$ cd django_todo
$ pipenv install --python 3.6
$ pipenv shell
(django-someHash) $ pipenv install django djangorestframework
```
For reference, we're working with `django-2.0.7`
and `djangorestframework-3.8.2`
.
Unlike Flask, Tornado, and Pyramid, we don't need to write our own `setup.py`
file. *We're not making an installable Python distribution.* As with many things, Django takes care of that for us in its own Django way. We'll still need a `requirements.txt`
file to track all our necessary installs for deployment elsewhere. However, as far as targeting modules within our Django project goes, Django will let us list the subdirectories we want access to, then allow us to import from those directories as if they're installed packages.
First, we have to create a Django project.
When we installed Django, we also installed the command-line script `django-admin`
. Its job is to manage all the various Django-related commands that help put our project together and maintain it as we continue to develop. Instead of having us build up the entire Django ecosystem from scratch, the `django-admin`
will allow us to get started with all the absolutely necessary files (and more) we need for a standard Django project.
The syntax for invoking `django-admin`
's start-project command is `django-admin startproject <project name> <directory where we want the files>`
. We want the files to exist in our current working directory, so:
`(django-someHash) $ django-admin startproject django_todo .`
Typing `ls`
will show one new file and one new directory.
```
(django-someHash) $ ls
manage.py django_todo
```
`manage.py`
is a command-line-executable Python file that ends up just being a wrapper around `django-admin`
. As such, its job is the same: to help us manage our project. Hence the name `manage.py`
.
The directory it created, the `django_todo`
inside of `django_todo`
, represents *the configuration root for our project*. Let's dig into that now.
## Configuring Django
By calling the `django_todo`
directory the "configuration root," we mean this directory holds the files necessary for generally configuring our Django project. Pretty much everything outside this directory will be focused solely on the "business logic" associated with the project's models, views, routes, etc. All points that connect the project together will lead here.
Calling `ls`
within `django_todo`
reveals four files:
```
(django-someHash) $ cd django_todo
(django-someHash) $ ls
__init__.py settings.py urls.py wsgi.py
```
`__init__.py`
is empty, solely existing to turn this directory into an importable Python package.`settings.py`
is where most configuration items will be set, like whether the project's in DEBUG mode, what databases are in use, where Django should look for files, etc. It is the "main configuration" part of the configuration root, and we'll dig into that momentarily.`urls.py`
is, as the name implies, where the URLs are set. While we don't have to explicitly write*every*URL for the project in this file, weneed to make this file aware of any other places where URLs have been declared.**do***If this file doesn't point to other URLs, those URLs don't exist.***Period.**`wsgi.py`
is for serving the application in production. Just like how Pyramid, Tornado, and Flask exposed some "app" object that was the configured application to be served, Django must also expose one. That's done here. It can then be served with something like[Gunicorn](http://gunicorn.org/),[Waitress](https://docs.pylonsproject.org/projects/waitress/en/latest/), or[uWSGI](https://uwsgi-docs.readthedocs.io/en/latest/).
### Setting the settings
Taking a look inside `settings.py`
will reveal its considerable size—and these are just the defaults! This doesn't even include hooks for the database, static files, media files, any cloud integration, or any of the other dozens of ways that a Django project can be configured. Let's see, top to bottom, what we've been given:
`BASE_DIR`
sets the absolute path to the base directory, or the directory where`manage.py`
is located. This is useful for locating files.`SECRET_KEY`
is a key used for cryptographic signing within the Django project. In practice, it's used for things like sessions, cookies, CSRF protection, and auth tokens. As soon as possible, preferably before the first commit, the value for`SECRET_KEY`
should be changed and moved into an environment variable.`DEBUG`
tells Django whether to run the project in development mode or production mode.*This is an extremely critical distinction.*- In development mode, when an error pops up, Django will show the full stack trace that led to the error, as well as all the settings and configurations involved in running the project. This can be a massive security issue if
`DEBUG`
was set to`True`
in a production environment. - In production, Django shows a plain error page when things go wrong. No information is given beyond an error code.
- A simple way to safeguard our project is to set
`DEBUG`
to an environment variable, like`bool(os.environ.get('DEBUG', ''))`
.
- In development mode, when an error pops up, Django will show the full stack trace that led to the error, as well as all the settings and configurations involved in running the project. This can be a massive security issue if
`ALLOWED_HOSTS`
is the literal list of hostnames from which the application is being served. In development this can be empty, but in production*our Django project will not run if the host that serves the project is not among the list of ALLOWED_HOSTS*. Another thing for the box of environment variables.`INSTALLED_APPS`
is the list of Django "apps" (think of them as subdirectories; more on this later) that our Django project has access to. We're given a few by default to provide…- The built-in Django administrative website
- Django's built-in authentication system
- Django's one-size-fits-all manager for data models
- Session management
- Cookie and session-based messaging
- Usage of static files inherent to the site, like
`css`
files,`js`
files, any images that are a part of our site's design, etc.
`MIDDLEWARE`
is as it sounds: the middleware that helps our Django project run. Much of it is for handling various types of security, although we can add others as we need them.`ROOT_URLCONF`
sets the import path of our base-level URL configuration file. That`urls.py`
that we saw before? By default, Django points to that file to gather all our URLs. If we want Django to look elsewhere, we'll set the import path to that location here.`TEMPLATES`
is the list of template engines that Django would use for our site's frontend if we were relying on Django to build our HTML. Since we're not, it's irrelevant.`WSGI_APPLICATION`
sets the import path of our WSGI application—the thing that gets served when in production. By default, it points to an`application`
object in`wsgi.py`
. This rarely, if ever, needs to be modified.`DATABASES`
sets which databases our Django project will access. The`default`
database*must*be set. We can set others by name, as long as we provide the`HOST`
,`USER`
,`PASSWORD`
,`PORT`
, database`NAME`
, and appropriate`ENGINE`
. As one might imagine, these are all sensitive pieces of information, so it's best to hide them away in environment variables.[Check the Django docs](https://docs.djangoproject.com/en/2.0/ref/settings/#databases)for more details.- Note: If instead of providing individual pieces of a database's location, you'd rather provide the full database URL, check out
[dj_database_url](https://pypi.org/project/dj-database-url/).
- Note: If instead of providing individual pieces of a database's location, you'd rather provide the full database URL, check out
`AUTH_PASSWORD_VALIDATORS`
is effectively a list of functions that run to check input passwords. We get a few by default, but if we had other, more complex validation needs—more than merely checking if the password matches a user's attribute, if it exceeds the minimum length, if it's one of the 1,000 most common passwords, or if the password is entirely numeric—we could list them here.`LANGUAGE_CODE`
will set the language for the site. By default it's US English, but we could switch it up to be other languages.`TIME_ZONE`
is the time zone for any autogenerated timestamps in our Django project.*I cannot stress enough how important it is that we stick to UTC*and perform any time zone-specific processing elsewhere instead of trying to reconfigure this setting. As[this article](http://yellerapp.com/posts/2015-01-12-the-worst-server-setup-you-can-make.html)states, UTC is the common denominator among all time zones because there are no offsets to worry about. If offsets are that important, we could calculate them as needed with an appropriate offset from UTC.`USE_I18N`
will let Django use its own translation services to translate strings for the front end. I18N = internationalization (18 characters between "i" and "n")`USE_L10N`
(L10N = localization [10 characters between "l" and "n"]) will use the common local formatting of data if set to`True`
. A great example is dates: in the US it's MM-DD-YYYY. In Europe, dates tend to be written DD-MM-YYYY`STATIC_URL`
is part of a larger body of settings for serving static files. We'll be building a REST API, so we won't need to worry about static files. In general, this sets the root path after the domain name for every static file. So, if we had a logo image to serve, it'd be`http://<domainname>/<STATIC_URL>/logo.gif`
These settings are pretty much ready to go by default. One thing we'll have to change is the `DATABASES`
setting. First, we create the database that we'll be using with:
`(django-someHash) $ createdb django_todo`
We want to use a PostgreSQL database like we did with Flask, Pyramid, and Tornado. That means we'll have to change the `DATABASES`
setting to allow our server to access a PostgreSQL database. First: the engine. By default, the database engine is `django.db.backends.sqlite3`
. We'll be changing that to `django.db.backends.postgresql`
.
For more information about Django's available engines, [check the docs](https://docs.djangoproject.com/en/2.0/ref/settings/#std:setting-DATABASE-ENGINE). Note that while it is technically possible to incorporate a NoSQL solution into a Django project, out of the box, Django is strongly biased toward SQL solutions.
Next, we have to specify the key-value pairs for the different parts of the connection parameters.
`NAME`
is the name of the database we just created.`USER`
is an individual's Postgres database username`PASSWORD`
is the password needed to access the database`HOST`
is the host for the database.`localhost`
or`127.0.0.1`
will work, as we're developing locally.`PORT`
is whatever PORT we have open for Postgres; it's typically`5432`
.
`settings.py`
expects us to provide string values for each of these keys. However, this is highly sensitive information. That's not going to work for any responsible developer. There are several ways to address this problem, but we'll just set up environment variables.
```
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': os.environ.get('DB_NAME', ''),
'USER': os.environ.get('DB_USER', ''),
'PASSWORD': os.environ.get('DB_PASS', ''),
'HOST': os.environ.get('DB_HOST', ''),
'PORT': os.environ.get('DB_PORT', ''),
}
}
```
Before going forward, make sure to set the environment variables or Django will not work. Also, we need to install `psycopg2`
into this environment so we can talk to our database.
## Django routes and views
Let's make something function inside this project. We'll be using Django REST Framework to construct our REST API, so we have to make sure we can use it by adding `rest_framework`
to the end of `INSTALLED_APPS`
in `settings.py`
.
```
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework'
]
```
While Django REST Framework doesn't exclusively require class-based views (like Tornado) to handle incoming requests, it is the preferred method for writing views. Let's define one.
Let's create a file called `views.py`
in `django_todo`
. Within `views.py`
, we'll create our "Hello, world!" view.
```
# in django_todo/views.py
from rest_framework.response import JsonResponse
from rest_framework.views import APIView
class HelloWorld(APIView):
def get(self, request, format=None):
"""Print 'Hello, world!' as the response body."""
return JsonResponse("Hello, world!")
```
Every Django REST Framework class-based view inherits either directly or indirectly from `APIView`
. `APIView`
handles a ton of stuff, but for our purposes it does these specific things:
- Sets up the methods needed to direct traffic based on the HTTP method (e.g. GET, POST, PUT, DELETE)
- Populates the
`request`
object with all the data and attributes we'll need for parsing and processing any incoming request - Takes the
`Response`
or`JsonResponse`
that every dispatch method (i.e., methods named`get`
,`post`
,`put`
,`delete`
) returns and constructs a properly formatted HTTP response.
Yay, we have a view! On its own it does nothing. We need to connect it to a route.
If we hop into `django_todo/urls.py`
, we reach our default URL configuration file. As mentioned earlier: If a route in our Django project is not included here, *it doesn't exist*.
We add desired URLs by adding them to the given `urlpatterns`
list. By default, we get a whole set of URLs for Django's built-in site administration backend. We'll delete that completely.
We also get some very helpful doc strings that tell us exactly how to add routes to our Django project. We'll need to provide a call to `path()`
with three parameters:
- The desired route, as a string (without the leading slash)
- The view function (only ever a function!) that will handle that route
- The name of the route in our Django project
Let's import our `HelloWorld`
view and attach it to the home route `"/"`
. We can also remove the path to the `admin`
from `urlpatterns`
, as we won't be using it.
```
# django_todo/urls.py, after the big doc string
from django.urls import path
from django_todo.views import HelloWorld
urlpatterns = [
path('', HelloWorld.as_view(), name="hello"),
]
```
Well, this is different. The route we specified is just a blank string. Why does that work? Django assumes that every path we declare begins with a leading slash. We're just specifying routes to resources after the initial domain name. If a route isn't going to a specific resource and is instead just the home page, the route is just `""`
, or effectively "no resource."
The `HelloWorld`
view is imported from that `views.py`
file we just created. In order to do this import, we need to update `settings.py`
to include `django_todo`
in the list of `INSTALLED_APPS`
. Yeah, it's a bit weird. Here's one way to think about it.
`INSTALLED_APPS`
refers to the list of directories or packages that Django sees as importable. It's Django's way of treating individual components of a project like installed packages without going through a `setup.py`
. We want the `django_todo`
directory to be treated like an importable package, so we include that directory in `INSTALLED_APPS`
. Now, any module within that directory is also importable. So we get our view.
The `path`
function will ONLY take a view function as that second argument, not just a class-based view on its own. Luckily, all valid Django class-based views include this `.as_view()`
method. Its job is to roll up all the goodness of the class-based view into a view function and return that view function. So, we never have to worry about making that translation. Instead, we only have to think about the business logic, letting Django and Django REST Framework handle the rest.
Let's crack this open in the browser!
Django comes packaged with its own local development server, accessible through `manage.py`
. Let's navigate to the directory containing `manage.py`
and type:
```
(django-someHash) $ ./manage.py runserver
Performing system checks...
System check identified no issues (0 silenced).
August 01, 2018 - 16:47:24
Django version 2.0.7, using settings 'django_todo.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
```
When `runserver`
is executed, Django does a check to make sure the project is (more or less) wired together correctly. It's not fool-proof, but it does catch some glaring issues. It also notifies us if our database is out of sync with our code. Undoubtedly ours is because we haven't committed any of our application's stuff to our database, but that's fine for now. Let's visit `http://127.0.0.1:8000`
to see the output of the `HelloWorld`
view.
Huh. That's not the plaintext data we saw in Pyramid, Flask, and Tornado. When Django REST Framework is used, the HTTP response (when viewed in the browser) is this sort of rendered HTML, showing our actual JSON response in red.
But don't fret! If we do a quick `curl`
looking at `http://127.0.0.1:8000`
in the command line, we don't get any of that fancy HTML. Just the content.
```
# Note: try this in a different terminal window, outside of the virtual environment above
$ curl http://127.0.0.1:8000
"Hello, world!"
```
Bueno!
Django REST Framework wants us to have a human-friendly interface when using the browser. This makes sense; if JSON is viewed in the browser, it's typically because a human wants to check that it looks right or get a sense of what the JSON response will look like as they design some consumer of an API. It's a lot like what you'd get from a service like [Postman](https://www.getpostman.com/).
Either way, we know our view is working! Woo! Let's recap what we've done:
- Started the project with
`django-admin startproject <project name>`
- Updated the
`django_todo/settings.py`
to use environment variables for`DEBUG`
,`SECRET_KEY`
, and values in the`DATABASES`
dict - Installed
`Django REST Framework`
and added it to the list of`INSTALLED_APPS`
- Created
`django_todo/views.py`
to include our first view class to say Hello to the World - Updated
`django_todo/urls.py`
with a path to our new home route - Updated
`INSTALLED_APPS`
in`django_todo/settings.py`
to include the`django_todo`
package
## Creating models
Let's create our data models now.
*A Django project's entire infrastructure is built around data models.* It's written so each data model can have its own little universe with its own views, its own set of URLs that concern its resources, and even its own tests (if we are so inclined).
If we wanted to build a simple Django project, we could circumvent this by just writing our own `models.py`
file in the `django_todo`
directory and importing it into our views. However, we're trying to write a Django project the "right" way, so we should divide up our models as best we can into their own little packages The Django Way™.
The Django Way involves creating what are called Django "apps." Django "apps" aren't separate applications per se; they don't have their own settings and whatnot (although they can). They can, however, have just about everything else one might think of being in a standalone application:
- Set of self-contained URLs
- Set of self-contained HTML templates (if we want to serve HTML)
- One or more data models
- Set of self-contained views
- Set of self-contained tests
They are made to be independent so they can be easily shared like standalone applications. In fact, Django REST Framework is an example of a Django app. It comes packaged with its own views and HTML templates for serving up our JSON. We just leverage that Django app to turn our project into a full-on RESTful API with less hassle.
To create the Django app for our To-Do List items, we'll want to use the `startapp`
command with `manage.py`
.
`(django-someHash) $ ./manage.py startapp todo`
The `startapp`
command will succeed silently. We can check that it did what it should've done by using `ls`
.
```
(django-someHash) $ ls
Pipfile Pipfile.lock django_todo manage.py todo
```
Look at that: We've got a brand new `todo`
directory. Let's look inside!
```
(django-someHash) $ ls todo
__init__.py admin.py apps.py migrations models.py tests.py views.py
```
Here are the files that `manage.py startapp`
created:
`__init__.py`
is empty; it exists so this directory can be seen as a valid import path for models, views, etc.`admin.py`
is not quite empty; it's used for formatting this app's models in the Django admin, which we're not getting into in this article.`apps.py`
… not much work to do here either; it helps with formatting models for the Django admin.`migrations`
is a directory that'll contain snapshots of our data models; it's used for updating our database. This is one of the few frameworks that comes with database management built-in, and part of that is allowing us to update our database instead of having to tear it down and rebuild it to change the schema.`models.py`
is where the data models live.`tests.py`
is where tests would go—if we wrote any.`views.py`
is for the views we write that pertain to the models in this app. They don't have to be written here. We could, for example, write all our views in`django_todo/views.py`
. It's here, however, so it's easier to separate our concerns. This becomes far more relevant with sprawling applications that cover many conceptual spaces.
What hasn't been created for us is a `urls.py`
file for this app. We can make that ourselves.
`(django-someHash) $ touch todo/urls.py`
Before moving forward we should do ourselves a favor and add this new Django app to our list of `INSTALLED_APPS`
in `django_todo/settings.py`
.
```
# in settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'django_todo',
'todo' # <--- the line was added
]
```
Inspecting `todo/models.py`
shows that `manage.py`
already wrote a bit of code for us to get started. Diverging from how models were created in the Flask, Tornado, and Pyramid implementations, Django doesn't leverage a third party to manage database sessions or the construction of its object instances. It's all rolled into Django's `django.db.models`
submodule.
The way a model is built, however, is more or less the same. To create a model in Django, we'll need to build a `class`
that inherits from `models.Model`
. All the fields that will apply to instances of that model should appear as class attributes. Instead of importing columns and field types from SQLAlchemy like we have in the past, all of our fields will come directly from `django.db.models`
.
```
# todo/models.py
from django.db import models
class Task(models.Model):
"""Tasks for the To Do list."""
name = models.CharField(max_length=256)
note = models.TextField(blank=True, null=True)
creation_date = models.DateTimeField(auto_now_add=True)
due_date = models.DateTimeField(blank=True, null=True)
completed = models.BooleanField(default=False)
```
While there are some definite differences between what Django needs and what SQLAlchemy-based systems need, the overall contents and structure are more or less the same. Let's point out the differences.
We no longer need to declare a separate field for an auto-incremented ID number for our object instances. Django builds one for us unless we specify a different field as the primary key.
Instead of instantiating `Column`
objects that are passed datatype objects, we just directly reference the datatypes as the columns themselves.
The `Unicode`
field became either `models.CharField`
or `models.TextField`
. `CharField`
is for small text fields of a specific maximum length, whereas `TextField`
is for any amount of text.
The `TextField`
should be able to be blank, and we specify this in TWO ways. `blank=True`
says that when an instance of this model is constructed, and the data attached to this field is being validated, it's OK for that data to be empty. This is different from `null=True`
, which says when the table for this model class is constructed, the column corresponding to `note`
will allow for blank or `NULL`
entries. So, to sum that all up, `blank=True`
controls how data gets added to model instances while `null=True`
controls how the database table holding that data is constructed in the first place.
The `DateTime`
field grew some muscle and became able to do some work for us instead of us having to modify the `__init__`
method for the class. For the `creation_date`
field, we specify `auto_now_add=True`
. What this means in a practical sense is that *when a new model instance is created* Django will *automatically* record the date and time of *now* as that field's value. That's handy!
When neither `auto_now_add`
nor its close cousin `auto_now`
are set to `True`
, `DateTimeField`
will expect data like any other field. It'll need to be fed with a proper `datetime`
object to be valid. The `due_date`
column has `blank`
and `null`
both set to `True`
so that an item on the To-Do List can just be an item to be done at some point in the future, with no defined date or time.
`BooleanField`
just ends up being a field that can take one of two values: `True`
or `False`
. Here, the default value is set to be `False`
.
### Managing the database
As mentioned earlier, Django has its own way of doing database management. Instead of having to write… really any code at all regarding our database, we leverage the `manage.py`
script that Django provided on construction. It'll manage not just the construction of the tables for our database, but also any updates we wish to make to those tables *without* necessarily having to blow the whole thing away!
Because we've constructed a *new* model, we need to make our database aware of it. First, we need to put into code the schema that corresponds to this model. The `makemigrations`
command of `manage.py`
will take a snapshot of the model class we built and all its fields. It'll take that information and package it into a Python script that'll live in this particular Django app's `migrations`
directory. *There will never be a reason to run this migration script directly.* It'll exist solely so that Django can use it as a basis to update our database table or to inherit information when we update our model class.
```
(django-someHash) $ ./manage.py makemigrations
Migrations for 'todo':
todo/migrations/0001_initial.py
- Create model Task
```
This will look at every app listed in `INSTALLED_APPS`
and check for models that exist in those apps. It'll then check the corresponding `migrations`
directory for migration files and compare them to the models in each of those `INSTALLED_APPS`
apps. If a model has been upgraded beyond what the latest migration says should exist, a new migration file will be created that inherits from the most recent one. It'll be automatically named and also be given a message that says what changed since the last migration.
If it's been a while since you last worked on your Django project and can't remember if your models were in sync with your migrations, you have no need to fear. `makemigrations`
is an idempotent operation; your `migrations`
directory will have only one copy of the current model configuration whether you run `makemigrations`
once or 20 times. Even better than that, when we run `./manage.py runserver`
, Django will detect that our models are out of sync with our migrations, and it'll just flat out tell us in colored text so we can make the appropriate choice.
This next point is something that trips everybody up at least once: *Creating a migration file does not immediately affect our database*. When we ran `makemigrations`
, we prepared our Django project to define how a given table should be created and end up looking. It's still on us to apply those changes to our database. That's what the `migrate`
command is for.
```
(django-someHash) $ ./manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, sessions, todo
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying sessions.0001_initial... OK
Applying todo.0001_initial... OK
```
When we apply our migrations, Django first checks to see if the other `INSTALLED_APPS`
have migrations to be applied. It checks them in roughly the order they're listed. We want our app to be listed last, because we want to make sure that, in case our model depends on any of Django's built-in models, the database updates we make don't suffer from dependency problems.
We have another model to build: the User model. However, the game has changed a bit since we're using Django. So many applications require some sort of User model that Django's `django.contrib.auth`
package built its own for us to use. If it weren't for the authentication token we require for our users, we could just move on and use it instead of reinventing the wheel.
However, we need that token. There are a couple of ways we can handle this.
- Inherit from Django's
`User`
object, making our own object that extends it by adding a`token`
field - Create a new object that exists in a one-to-one relationship with Django's
`User`
object, whose only purpose is to hold a token
I'm in the habit of building object relationships, so let's go with the second option. Let's call it an `Owner`
as it basically has a similar connotation as a `User`
, which is what we want.
Out of sheer laziness, we could just include this new `Owner`
object in `todo/models.py`
, but let's refrain from that. `Owner`
doesn't explicitly have to do with the creation or maintenance of items on the task list. Conceptually, the `Owner`
is simply the *owner* of the task. There may even come a time where we want to expand this `Owner`
to include other data that has absolutely nothing to do with tasks.
Just to be safe, let's make an `owner`
app whose job is to house and handle this `Owner`
object.
`(django-someHash) $ ./manage.py startapp owner`
Don't forget to add it to the list of `INSTALLED_APPS`
in `settings.py`
.
```
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'django_todo',
'todo',
'owner'
]
```
If we look at the root of our Django project, we now have two Django apps:
```
(django-someHash) $ ls
Pipfile Pipfile.lock django_todo manage.py owner todo
```
In `owner/models.py`
, let's build this `Owner`
model. As mentioned earlier, it'll have a one-to-one relationship with Django's built-in `User`
object. We can enforce this relationship with Django's `models.OneToOneField`
```
# owner/models.py
from django.db import models
from django.contrib.auth.models import User
import secrets
class Owner(models.Model):
"""The object that owns tasks."""
user = models.OneToOneField(User, on_delete=models.CASCADE)
token = models.CharField(max_length=256)
def __init__(self, *args, **kwargs):
"""On construction, set token."""
self.token = secrets.token_urlsafe(64)
super().__init__(*args, **kwargs)
```
This says the `Owner`
object is linked to the `User`
object, with one `owner`
instance per `user`
instance. `on_delete=models.CASCADE`
dictates that if the corresponding `User`
gets deleted, the `Owner`
instance it's linked to will also get deleted. Let's run `makemigrations`
and `migrate`
to bake this new model into our database.
```
(django-someHash) $ ./manage.py makemigrations
Migrations for 'owner':
owner/migrations/0001_initial.py
- Create model Owner
(django-someHash) $ ./manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, owner, sessions, todo
Running migrations:
Applying owner.0001_initial... OK
```
Now our `Owner`
needs to own some `Task`
objects. It'll be very similar to the `OneToOneField`
seen above, except that we'll stick a `ForeignKey`
field on the `Task`
object pointing to an `Owner`
.
```
# todo/models.py
from django.db import models
from owner.models import Owner
class Task(models.Model):
"""Tasks for the To Do list."""
name = models.CharField(max_length=256)
note = models.TextField(blank=True, null=True)
creation_date = models.DateTimeField(auto_now_add=True)
due_date = models.DateTimeField(blank=True, null=True)
completed = models.BooleanField(default=False)
owner = models.ForeignKey(Owner, on_delete=models.CASCADE)
```
Every To-Do List task has exactly one owner who can own multiple tasks. When that owner is deleted, any task they own goes with them.
Let's now run `makemigrations`
to take a new snapshot of our data model setup, then `migrate`
to apply those changes to our database.
```
(django-someHash) django $ ./manage.py makemigrations
You are trying to add a non-nullable field 'owner' to task without a default; we can't do that (the database needs something to populate existing rows).
Please select a fix:
1) Provide a one-off default now (will be set on all existing rows with a null value for this column)
2) Quit, and let me add a default in models.py
```
Oh no! We have a problem! What happened? Well, when we created the `Owner`
object and added it as a `ForeignKey`
to `Task`
, we basically required that every `Task`
requires an `Owner`
. However, the first migration we made for the `Task`
object didn't include that requirement. So, even though there's no data in our database's table, Django is doing a pre-check on our migrations to make sure they're compatible and this new migration we're proposing is not.
There are a few ways to deal with this sort of problem:
- Blow away the current migration and build a new one that includes the current model configuration
- Add a default value to the
`owner`
field on the`Task`
object - Allow tasks to have
`NULL`
values for the`owner`
field.
Option 2 wouldn't make much sense here; we'd be proposing that any `Task`
that was created would, by default, be linked to some default owner despite none necessarily existing.
Option 1 would require us to destroy and rebuild our migrations. We should leave those alone.
Let's go with option 3. In this circumstance, it won't be the end of the world if we allow the `Task`
table to have null values for the owners; any tasks created from this point forward will necessarily have an owner. If you're in a situation where that isn't an acceptable schema for your database table, blow away your migrations, drop the table, and rebuild the migrations.
```
# todo/models.py
from django.db import models
from owner.models import Owner
class Task(models.Model):
"""Tasks for the To Do list."""
name = models.CharField(max_length=256)
note = models.TextField(blank=True, null=True)
creation_date = models.DateTimeField(auto_now_add=True)
due_date = models.DateTimeField(blank=True, null=True)
completed = models.BooleanField(default=False)
owner = models.ForeignKey(Owner, on_delete=models.CASCADE, null=True)
```
```
(django-someHash) $ ./manage.py makemigrations
Migrations for 'todo':
todo/migrations/0002_task_owner.py
- Add field owner to task
(django-someHash) $ ./manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, owner, sessions, todo
Running migrations:
Applying todo.0002_task_owner... OK
```
Woo! We have our models! Welcome to the Django way of declaring objects.
For good measure, let's ensure that whenever a `User`
is made, it's automatically linked with a new `Owner`
object. We can do this using Django's `signals`
system. Basically, we say exactly what we intend: "When we get the signal that a new `User`
has been constructed, construct a new `Owner`
and set that new `User`
as that `Owner`
's `user`
field." In practice that looks like:
```
# owner/models.py
from django.contrib.auth.models import User
from django.db import models
from django.db.models.signals import post_save
from django.dispatch import receiver
import secrets
class Owner(models.Model):
"""The object that owns tasks."""
user = models.OneToOneField(User, on_delete=models.CASCADE)
token = models.CharField(max_length=256)
def __init__(self, *args, **kwargs):
"""On construction, set token."""
self.token = secrets.token_urlsafe(64)
super().__init__(*args, **kwargs)
@receiver(post_save, sender=User)
def link_user_to_owner(sender, **kwargs):
"""If a new User is saved, create a corresponding Owner."""
if kwargs['created']:
owner = Owner(user=kwargs['instance'])
owner.save()
```
We set up a function that listens for signals to be sent from the `User`
object built into Django. It's waiting for just after a `User`
object has been saved. This can come from either a new `User`
or an update to an existing `User`
; we discern between the two scenarios within the listening function.
If the thing sending the signal was a newly created instance, `kwargs['created']`
will have the value of `True`
. We only want to do something if this is `True`
. If it's a new instance, we create a new `Owner`
, setting its `user`
field to be the new `User`
instance that was created. After that, we `save()`
the new `Owner`
. This will commit our change to the database if all is well. It'll fail if the data doesn't validate against the fields we declared.
Now let's talk about how we're going to access the data.
## Accessing model data
In the Flask, Pyramid, and Tornado frameworks, we accessed model data by running queries against some database session. Maybe it was attached to a `request`
object, maybe it was a standalone `session`
object. Regardless, we had to establish a live connection to the database and query on that connection.
This isn't the way Django works. Django, by default, doesn't leverage any third-party object-relational mapping (ORM) to converse with the database. Instead, Django allows the model classes to maintain their own conversations with the database.
Every model class that inherits from `django.db.models.Model`
will have attached to it an `objects`
object. This will take the place of the `session`
or `dbsession`
we've become so familiar with. Let's open the special shell that Django gives us and investigate how this `objects`
object works.
```
(django-someHash) $ ./manage.py shell
Python 3.7.0 (default, Jun 29 2018, 20:13:13)
[Clang 9.1.0 (clang-902.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>>
```
The Django shell is different from a normal Python shell in that it's aware of the Django project we've been building and can do easy imports of our models, views, settings, etc. without having to worry about installing a package. We can access our models with a simple `import`
.
```
>>> from owner.models import Owner
>>> Owner
<class 'owner.models.Owner'>
```
Currently, we have no `Owner`
instances. We can tell by querying for them with `Owner.objects.all()`
.
```
>>> Owner.objects.all()
<QuerySet []>
```
Anytime we run a query method on the `<Model>.objects`
object, we'll get a `QuerySet`
back. For our purposes, it's effectively a `list`
, and this `list`
is showing us that it's empty. Let's make an `Owner`
by making a `User`
.
```
>>> from django.contrib.auth.models import User
>>> new_user = User(username='kenyattamurphy', email='[email protected]')
>>> new_user.set_password('wakandaforever')
>>> new_user.save()
```
If we query for all of our `Owner`
s now, we should find Kenyatta.
```
>>> Owner.objects.all()
<QuerySet [<Owner: Owner object (1)>]>
```
Yay! We've got data!
## Serializing models
We'll be passing data back and forth beyond just "Hello World." As such, we'll want to see some sort of JSON-ified output that represents that data well. Taking that object's data and transforming it into a JSON object for submission across HTTP is a version of *data serialization*. In serializing data, we're taking the data we currently have and reformatting it to fit some standard, more-easily-digestible form.
If I were doing this with Flask, Pyramid, and Tornado, I'd create a new method on each model to give the user direct access to call `to_json()`
. The only job of `to_json()`
would be to return a JSON-serializable (i.e. numbers, strings, lists, dicts) dictionary with whatever fields I want to be displayed for the object in question.
It'd probably look something like this for the `Task`
object:
```
class Task(Base):
...all the fields...
def to_json(self):
"""Convert task attributes to a JSON-serializable dict."""
return {
'id': self.id,
'name': self.name,
'note': self.note,
'creation_date': self.creation_date.strftime('%m/%d/%Y %H:%M:%S'),
'due_date': self.due_date.strftime('%m/%d/%Y %H:%M:%S'),
'completed': self.completed,
'user': self.user_id
}
```
It's not fancy, but it does the job.
Django REST Framework, however, provides us with an object that'll not only do that for us but also validate inputs when we want to create new object instances or update existing ones. It's called the [ModelSerializer](http://www.django-rest-framework.org/api-guide/serializers/#modelserializer).
Django REST Framework's `ModelSerializer`
is effectively documentation for our models. They don't have lives of their own if there are no models attached (for that there's the [Serializer](http://www.django-rest-framework.org/api-guide/serializers/) class). Their main job is to accurately represent our model and make the conversion to JSON thoughtless when our model's data needs to be serialized and sent over a wire.
Django REST Framework's `ModelSerializer`
works best for simple objects. As an example, imagine that we didn't have that `ForeignKey`
on the `Task`
object. We could create a serializer for our `Task`
that would convert its field values to JSON as necessary with the following declaration:
```
# todo/serializers.py
from rest_framework import serializers
from todo.models import Task
class TaskSerializer(serializers.ModelSerializer):
"""Serializer for the Task model."""
class Meta:
model = Task
fields = ('id', 'name', 'note', 'creation_date', 'due_date', 'completed')
```
Inside our new `TaskSerializer`
, we create a `Meta`
class. `Meta`
's job here is just to hold information (or *metadata*) about the thing we're attempting to serialize. Then, we note the specific fields that we want to show. If we wanted to show all the fields, we could just shortcut the process and use `'__all__'`
. We could, alternatively, use the `exclude`
keyword instead of `fields`
to tell Django REST Framework that we want every field except for a select few. We can have as many serializers as we like, so maybe we want one for a small subset of fields and one for all the fields? Go wild here.
In our case, there is a relation between each `Task`
and its owner `Owner`
that must be reflected here. As such, we need to borrow the `serializers.PrimaryKeyRelatedField`
object to specify that each `Task`
will have an `Owner`
and that relationship is one-to-one. Its owner will be found from the set of all owners that exists. We get that set by doing a query for those owners and returning the results we want to be associated with this serializer: `Owner.objects.all()`
. We also need to include `owner`
in the list of fields, as we always need an `Owner`
associated with a `Task`
```
# todo/serializers.py
from rest_framework import serializers
from todo.models import Task
from owner.models import Owner
class TaskSerializer(serializers.ModelSerializer):
"""Serializer for the Task model."""
owner = serializers.PrimaryKeyRelatedField(queryset=Owner.objects.all())
class Meta:
model = Task
fields = ('id', 'name', 'note', 'creation_date', 'due_date', 'completed', 'owner')
```
Now that this serializer is built, we can use it for all the CRUD operations we'd like to do for our objects:
- If we want to
`GET`
a JSONified version of a specific`Task`
, we can do`TaskSerializer(some_task).data`
- If we want to accept a
`POST`
with the appropriate data to create a new`Task`
, we can use`TaskSerializer(data=new_data).save()`
- If we want to update some existing data with a
`PUT`
, we can say`TaskSerializer(existing_task, data=data).save()`
We're not including `delete`
because we don't really need to do anything with information for a `delete`
operation. If you have access to an object you want to delete, just say `object_instance.delete()`
.
Here is an example of what some serialized data might look like:
```
>>> from todo.models import Task
>>> from todo.serializers import TaskSerializer
>>> from owner.models import Owner
>>> from django.contrib.auth.models import User
>>> new_user = User(username='kenyatta', email='[email protected]')
>>> new_user.save_password('wakandaforever')
>>> new_user.save() # creating the User that builds the Owner
>>> kenyatta = Owner.objects.first() # grabbing the Owner that is kenyatta
>>> new_task = Task(name="Buy roast beef for the Sunday potluck", owner=kenyatta)
>>> new_task.save()
>>> TaskSerializer(new_task).data
{'id': 1, 'name': 'Go to the supermarket', 'note': None, 'creation_date': '2018-07-31T06:00:25.165013Z', 'due_date': None, 'completed': False, 'owner': 1}
```
There's a lot more you can do with the `ModelSerializer`
objects, and I suggest checking [the docs](http://www.django-rest-framework.org/api-guide/serializers/#serializers) for those greater capabilities. Otherwise, this is as much as we need. It's time to dig into some views.
## Views for reals
We've built the models and the serializers, and now we need to set up the views and URLs for our application. After all, we can't do anything with an application that has no views. We've already seen an example with the `HelloWorld`
view above. However, that's always a contrived, proof-of-concept example and doesn't really show what can be done with Django REST Framework's views. Let's clear out the `HelloWorld`
view and URL so we can start fresh with our views.
The first view we'll build is the `InfoView`
. As in the previous frameworks, we just want to package and send out a dictionary of our proposed routes. The view itself can live in `django_todo.views`
since it doesn't pertain to a specific model (and thus doesn't conceptually belong in a specific app).
```
# django_todo/views.py
from rest_framework.response import JsonResponse
from rest_framework.views import APIView
class InfoView(APIView):
"""List of routes for this API."""
def get(self, request):
output = {
'info': 'GET /api/v1',
'register': 'POST /api/v1/accounts',
'single profile detail': 'GET /api/v1/accounts/<username>',
'edit profile': 'PUT /api/v1/accounts/<username>',
'delete profile': 'DELETE /api/v1/accounts/<username>',
'login': 'POST /api/v1/accounts/login',
'logout': 'GET /api/v1/accounts/logout',
"user's tasks": 'GET /api/v1/accounts/<username>/tasks',
"create task": 'POST /api/v1/accounts/<username>/tasks',
"task detail": 'GET /api/v1/accounts/<username>/tasks/<id>',
"task update": 'PUT /api/v1/accounts/<username>/tasks/<id>',
"delete task": 'DELETE /api/v1/accounts/<username>/tasks/<id>'
}
return JsonResponse(output)
```
This is pretty much identical to what we had in Tornado. Let's hook it up to an appropriate route and be on our way. For good measure, we'll also remove the `admin/`
route, as we won't be using the Django administrative backend here.
```
# in django_todo/urls.py
from django_todo.views import InfoView
from django.urls import path
urlpatterns = [
path('api/v1', InfoView.as_view(), name="info"),
]
```
### Connecting models to views
Let's figure out the next URL, which will be the endpoint for either creating a new `Task`
or listing a user's existing tasks. This should exist in a `urls.py`
in the `todo`
app since this has to deal specifically with `Task`
objects instead of being a part of the whole project.
```
# in todo/urls.py
from django.urls import path
from todo.views import TaskListView
urlpatterns = [
path('', TaskListView.as_view(), name="list_tasks")
]
```
What's the deal with this route? We didn't specify a particular user or much of a path at all. Since there would be a couple of routes requiring the base path `/api/v1/accounts/<username>/tasks`
, why write it again and again when we can just write it once?
Django allows us to take a whole suite of URLs and import them into the base `django_todo/urls.py`
file. We can then give every one of those imported URLs the same base path, only worrying about the variable parts when, you know, they vary.
```
# in django_todo/urls.py
from django.urls import include, path
from django_todo.views import InfoView
urlpatterns = [
path('api/v1', InfoView.as_view(), name="info"),
path('api/v1/accounts/<str:username>/tasks', include('todo.urls'))
]
```
And now every URL coming from `todo/urls.py`
will be prefixed with the path `api/v1/accounts/<str:username>/tasks`
.
Let's build out the view in `todo/views.py`
```
# todo/views.py
from django.shortcuts import get_object_or_404
from rest_framework.response import JsonResponse
from rest_framework.views import APIView
from owner.models import Owner
from todo.models import Task
from todo.serializers import TaskSerializer
class TaskListView(APIView):
def get(self, request, username, format=None):
"""Get all of the tasks for a given user."""
owner = get_object_or_404(Owner, user__username=username)
tasks = Task.objects.filter(owner=owner).all()
serialized = TaskSerializer(tasks, many=True)
return JsonResponse({
'username': username,
'tasks': serialized.data
})
```
There's a lot going on here in a little bit of code, so let's walk through it.
We start out with the same inheritance of the `APIView`
that we've been using, laying the groundwork for what will be our view. We override the same `get`
method we've overridden before, adding a parameter that allows our view to receive the `username`
from the incoming request.
Our `get`
method will then use that `username`
to grab the `Owner`
associated with that user. This `get_object_or_404`
function allows us to do just that, with a little something special added for ease of use.
It would make sense that there's no point in looking for tasks if the specified user can't be found. In fact, we'd want to return a 404 error. `get_object_or_404`
gets a single object based on whatever criteria we pass in and either returns that object or raises an [Http404 exception](https://docs.djangoproject.com/en/2.0/topics/http/views/#the-http404-exception). We can set that criteria based on attributes of the object. The `Owner`
objects are all attached to a `User`
through their `user`
attribute. We don't have a `User`
object to search with, though. We only have a `username`
. So, we say to `get_object_or_404`
"when you look for an `Owner`
, check to see that the `User`
attached to it has the `username`
that I want" by specifying `user__username`
. That's TWO underscores. When filtering through a QuerySet, the two underscores mean "attribute of this nested object." Those attributes can be as deeply nested as needed.
We now have the `Owner`
corresponding to the given username. We use that `Owner`
to filter through all the tasks, only retrieving the ones it owns with `Task.objects.filter`
. We could've used the same nested-attribute pattern that we did with `get_object_or_404`
to drill into the `User`
connected to the `Owner`
connected to the `Tasks`
(`tasks = Task.objects.filter(owner__user__username=username).all()`
) but there's no need to get that wild with it.
`Task.objects.filter(owner=owner).all()`
will provide us with a `QuerySet`
of all the `Task`
objects that match our query. Great. The `TaskSerializer`
will then take that `QuerySet`
and all its data, along with the flag of `many=True`
to notify it as being a collection of items instead of just one item, and return a serialized set of results. Effectively a list of dictionaries. Finally, we provide the outgoing response with the JSON-serialized data and the username used for the query.
### Handling the POST request
The `post`
method will look somewhat different from what we've seen before.
```
# still in todo/views.py
# ...other imports...
from rest_framework.parsers import JSONParser
from datetime import datetime
class TaskListView(APIView):
def get(self, request, username, format=None):
...
def post(self, request, username, format=None):
"""Create a new Task."""
owner = get_object_or_404(Owner, user__username=username)
data = JSONParser().parse(request)
data['owner'] = owner.id
if data['due_date']:
data['due_date'] = datetime.strptime(data['due_date'], '%d/%m/%Y %H:%M:%S')
new_task = TaskSerializer(data=data)
if new_task.is_valid():
new_task.save()
return JsonResponse({'msg': 'posted'}, status=201)
return JsonResponse(new_task.errors, status=400)
```
When we receive data from the client, we parse it into a dictionary using `JSONParser().parse(request)`
. We add the owner to the data and format the `due_date`
for the task if one exists.
Our `TaskSerializer`
does the heavy lifting. It first takes in the incoming data and translates it into the fields we specified on the model. It then validates that data to make sure it fits the specified fields. If the data being attached to the new `Task`
is valid, it constructs a new `Task`
object with that data and commits it to the database. We then send back an appropriate "Yay! We made a new thing!" response. If not, we collect the errors that `TaskSerializer`
generated and send those back to the client with a `400 Bad Request`
status code.
If we were to build out the `put`
view for updating a `Task`
, it would look very similar to this. The main difference would be that when we instantiate the `TaskSerializer`
, instead of *just* passing in the new data, we'd pass in the old object and the new data for that object like `TaskSerializer(existing_task, data=data)`
. We'd still do the validity check and send back the responses we want to send back.
## Wrapping up
Django as a framework is *highly customizable*, and everyone has their own way of stitching together a Django project. The way I've written it out here isn't necessarily the exact way that a Django project needs to be set up; it's just a) what I'm familiar with, and b) what leverages Django's management system. Django projects grow in complexity as you separate concepts into their own little silos. You do that so it's easier for multiple people to contribute to the overall project without stepping on each other's toes.
The vast map of files that is a Django project, however, doesn't make it more performant or naturally predisposed to a microservice architecture. On the contrary, it can very easily become a confusing monolith. That may still be useful for your project. It may also make it harder for your project to be manageable, especially as it grows.
Consider your options carefully and use the right tool for the right job. *For a simple project like this, Django likely isn't the right tool.*
Django is meant to handle multiple sets of models that cover a variety of different project areas that may share some common ground. This project is a small, two-model project with a handful of routes. If we were to build this out more, we'd only have seven routes and still the same two models. It's hardly enough to justify a full Django project.
It would be a great option if we expected this project to expand. This is not one of those projects. This is choosing a flamethrower to light a candle. It's absolute overkill.
Still, a web framework is a web framework, regardless of which one you use for your project. It can take in requests and respond as well as any other, so you do as you wish. Just be aware of what overhead comes with your choice of framework.
That's it! We've reached the end of this series! I hope it has been an enlightening adventure and will help you make more than just the most-familiar choice when you're thinking about how to build out your next project. Make sure to read the documentation for each framework to expand on anything covered in this series (as it's not even the least bit comprehensive). There's a wide world of stuff to get into for each. Happy coding!
## 7 Comments |
10,296 | Akash Angle:你如何使用 Fedora? | https://fedoramagazine.org/akash-angle-how-do-you-fedora/ | 2018-11-30T22:11:01 | [
"Fedora"
] | https://linux.cn/article-10296-1.html | 
我们最近采访了Akash Angle 来了解他如何使用 Fedora。这是 Fedora Magazine 上 Fedora [系列的一部分](https://fedoramagazine.org/tag/how-do-you-fedora/)。该系列介绍 Fedora 用户以及他们如何使用 Fedora 完成工作。请通过[反馈表单](https://fedoramagazine.org/submit-an-idea-or-tip/)与我们联系表达你对成为受访者的兴趣。
### Akash Angle 是谁?
Akash 是一位不久前抛弃 Windows 的 Linux 用户。作为一名过去 9 年的狂热 Fedora 用户,他已经尝试了几乎所有的 Fedora 定制版和桌面环境来完成他的日常任务。是一位校友给他介绍了 Fedora。
### 使用什么硬件?
Akash 在工作时使用联想 B490。它配备了英特尔酷睿 i3-3310 处理器和 240GB 金士顿 SSD。Akash 说:“这台笔记本电脑非常适合一些日常任务,如上网、写博客,以及一些照片编辑和视频编辑。虽然不是专业的笔记本电脑,而且规格并不是那么高端,但它完美地完成了工作。“
他使用一个入门级的罗技无线鼠标,并希望能有一个机械键盘。他的 PC 是一台定制桌面电脑,拥有最新的第 7 代 Intel i5 7400 处理器和 8GB Corsair Vengeance 内存。

### 使用什么软件?
Akash 是 GNOME 3 桌面环境的粉丝。他喜欢该操作系统为完成基本任务而加入的华丽功能。
出于实际原因,他更喜欢全新安来升级到最新 Fedora 版本。他认为 Fedora 29 可以说是最好的工作站。Akash 说这种说法得到了各种科技传播网站和开源新闻网站评论的支持。
为了播放视频,他的首选是打包为 [Flatpak](https://fedoramagazine.org/getting-started-flatpak/) 的 VLC 视频播放器 ,它提供了最新的稳定版本。当 Akash 想截图时,他的终极工具是 [Shutter,Magazine 曾介绍过](https://fedoramagazine.org/screenshot-everything-shutter-fedora/)。对于图形处理,GIMP 是他不能离开的工具。
Google Chrome 稳定版和开发版是他最常用的网络浏览器。他还使用 Chromium 和 Firefox 的默认版本,有时甚至会使用 Opera。
由于他是一名资深用户,所以 Akash 其余时候都使用终端。GNOME Terminal 是他使用的一个终端。
#### 最喜欢的壁纸
他最喜欢的壁纸之一是下面最初来自 Fedora 16 的壁纸:

这是他目前在 Fedora 29 工作站上使用的壁纸之一:

---
via: <https://fedoramagazine.org/akash-angle-how-do-you-fedora/>
作者:[Adam Šamalík](https://fedoramagazine.org/author/asamalik/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We recently interviewed Akash Angle on how he uses Fedora. This is [part of a series](https://fedoramagazine.org/tag/how-do-you-fedora/) on the Fedora Magazine. The series profiles Fedora users and how they use Fedora to get things done. Contact us on the [feedback form](https://fedoramagazine.org/submit-an-idea-or-tip/) to express your interest in becoming a interviewee.
## Who is Akash Angle?
Akash is a Linux user who ditched Windows some time ago. An avid Fedora user for the past 9 years, he has tried out almost all the Fedora flavors and spins to get his day to day tasks done. He was introduced to Fedora by a school friend.
## What Hardware?
Akash uses a Lenovo B490 at work. It is equipped with an Intel Core i3-3310 Processor, and a 240GB Kingston SSD. “This laptop is great for day to work like surfing the internet, blogging, and a little bit of photo editing and video editing too. Although not a professional laptop and the specs not being that high end, it does the job perfectly,” says Akash.
He uses a Logitech basic wireless mouse and would like to eventually get a mechanical keyboard. His personal computer — which is a custom-built desktop — has the latest 7th-generation Intel i5 7400 processor, and 8GB Corsair Vengeance RAM.
## What Software?
Akash is a fan of the GNOME 3 desktop environment. He loves most of the goodies and bells and whistles the OS can throw in for getting basic tasks done.
For practical reasons he prefers a fresh installation as a way of upgrading to the latest Fedora version. He thinks Fedora 29 is arguably the the best workstation out there. Akash says this has been backed up by reviews of various tech evangelists and open source news sites.
To play videos, his go-to is the VLC video player packaged as a [Flatpak](https://fedoramagazine.org/getting-started-flatpak/), which gives him the latest stable version. When Akash wants to make screenshots, the ultimate tool for him is [Shutter, which the Magazine has covered in the past](https://fedoramagazine.org/screenshot-everything-shutter-fedora/). For graphics, GIMP is something without which he wouldn’t be able to work.
Google Chrome stable, and the dev channel, are his most used web browsers. He also uses Chromium and the default version of Firefox, and sometimes even Opera makes its way into the party as well.
All the rest of the magic Akash does is from the terminal, as he is a power user. The GNOME Terminal app is the one for him.
### Favorite wallpapers
One of his favorite wallpapers originally coming from Fedora 16 is the following one:
And this is the one he currently uses on his Fedora 29 Workstation today:
## Hund
For resources regarding mechanical keyboards I would recommend Geekhack.org and r/MechanicalKeyboard on Reddit.
## Akash Angle
Thanks a ton, the above website is extremely resourceful and has helped me to gain few insights into the mechanical keyboard things, and the reddit threads are simply great and intutuive.
Appreciated, way to go. Cheers !
## Rajeev RK
Hey Akash,
From a long time linux user(+25 years), take my advice, and get a mechanical keyboard ASAP. I’ve been on mechanicals for years, and the precision for command line usage and long scripting sessions is definitely worth it. It especially makes itself visible on high latency SSH sessions, where the character echo back is a little late, as the mechanical gives you the key feedback instantly but on a membrane, i’m always unsure on whether the key was detected, so i end up typing slower.
Also, they are not that expensive either. you can get a TVSE Gold with cherry switches for ~₹2k
Cheers man, and keep rocking.
## Akash Angle
Thanks a ton for your valuable inputs. And yes very soon I’m going to get a mechanical keyboard. The TVSE Gold seems to be adorable as of now.
Much appreciated, yo !
## Bill Chatfield
Good story. I like the Fedora 16 wallpaper too.
## Mohamed Beg
Hi
I’m just a newB to python and as usual, it’s not JUST PYTHON but Django, Fedora etc etc.
Makes one give up!
Anyway, tell me can python 3.6 0r 3.7 run in a virtual environment enabled in win10, and which server would be the best XAMP or any other?
Have more questions but let’s see if you are willing to uplift a newB?
If not all the best to you.
Regards.
MB
## Akash Angle
In case, if you are using Win10 on Fedora? I’m mean Vmware or any other virtual environment software like say boxes or VirtualBox.
Xamp will be alright, and you can run python with virtual environment enabled on win
But I find it easier to use on UNIX or Linux distribution.
For more questions you may directly email me on
[email protected]
## Peter Braet
I’ll dump Fedora for the same reason I’ve dumped Ubuntu: Wayland, if Fedora worked without Wayland I would like it very much. Wayland has intentional bugs. |
10,297 | Emacs 系列(一):抛掉一切,投入 Emacs 和 Org 模式的怀抱 | http://changelog.complete.org/archives/9861-emacs-1-ditching-a-bunch-of-stuff-and-moving-to-emacs-and-org-mode | 2018-11-30T23:19:00 | [
"org-mode",
"Emacs"
] | https://linux.cn/article-10297-1.html | 
我必须承认,在使用了几十年的 vim 后, 我被 [Emacs](https://www.gnu.org/software/emacs/) 吸引了。
长期以来,我一直对如何组织安排事情感到沮丧。我也有用过 [GTD](https://gettingthingsdone.com/) 和 [ZTD](https://zenhabits.net/zen-to-done-the-simple-productivity-e-book/) 之类的方法,但是像邮件或是大型文件这样的事务真的很难来组织安排。
我一直在用 Asana 处理任务,用 Evernote 做笔记,用 Thunderbird 处理邮件,把 ikiwiki 和其他的一些项目组合作为个人知识库,而且还在电脑的归档了各种文件。当我的新工作需要将 Slack 也加入进来时,我终于忍无可忍了。
许多 TODO 管理工具与电子邮件集成的很差。当你想做“提醒我在一周内回复这个邮件”之类的事时,很多时候是不可能的,因为这个工具不能以一种能够轻松回复的方式存储邮件。而这个问题在 Slack 上更为严重。
就在那时,我偶然发现了 [Carsten Dominik 在 Google Talk 上关于 Org 模式的讲话](https://www.youtube.com/watch?v=oJTwQvgfgMM)。Carsten 是 Org 模式的作者,即便是这个讲话已经有 10 年了,但它仍然很具有参考价值。
我之前有用过 [Org 模式](https://orgmode.org/),但是每次我都没有真正的深入研究它, 因为我当时的反应是“一个大纲编辑器?但我需要的是待办事项列表”。我就这么错过了它。但实际上 Org 模式就是我所需要的。
### 什么是 Emacs?什么是 Org 模式?
Emacs 最初是一个文本编辑器,现在依然是一个文本编辑器,而且这种传统无疑贯穿始终。但是说 Emacs 是个编辑器是很不公平的。
Emacs 更像一个平台或是工具包。你不仅可以用它来编辑源代码,而且配置 Emacs 本身也是编程,里面有很多模式。就像编写一个 Firefox 插件一样简单,只要几行代码,然后,模式里的操作就改变了。
Org 模式也一样。确实,它是一个大纲编辑器,但它真正所包含的不止如此。它是一个信息组织平台。它的网站上写着,“你可以用纯文本来记录你的生活:你可以用 Org 模式来记笔记,处理待办事项,规划项目和使用快速有效的纯文本系统编写文档。”
### 捕获
如果你读过基于 GTD 的生产力指南,那么他们强调的一件事就是毫不费力地获取项目。这个想法是,当某件事突然出现在你的脑海里时,把它迅速输入一个受信任的系统,这样你就可以继续做你正在做的事情。Org 模式有一个专门的捕获系统。我可以在 Emacs 的任何地方按下 `C-c c` 键,它就会空出一个位置来记录我的笔记。最关键的是,自动嵌入到笔记中的链接可以链接到我按下 `C-c c` 键时正在编辑的那一行。如果我正在编辑文件,它会链回到那个文件和我所在的行。如果我正在浏览邮件,它就会链回到那封邮件(通过邮件的 Message-Id,这样它就可以在任何一个文件夹中找到邮件)。聊天时也一样,甚至是当你在另一个 Org 模式中也可也这样。
这样我就可以做一个笔记,它会提醒我在一周内回复某封邮件,当我点击这个笔记中的链接时,它会在我的邮件阅读器中弹出这封邮件 —— 即使我随后将它从收件箱中存档。
没错,这正是我要找的!
### 工具套件
一旦你开始使用 Org 模式,很快你就会想将所有的事情都集成到里面。有可以从网络上捕获内容的浏览器插件,也有多个 Emacs 邮件或新闻阅读器与之集成,ERC(IRC 客户端)也不错。所以我将自己从 Thunderbird 和 mairix + mutt (用于邮件归档)换到了 mu4e,从 xchat + slack 换到了 ERC。
你可能不明白,我喜欢这些基于 Emacs 的工具,而不是具有相同功能的单独的工具。
一个小花絮:我又在使用离线 IMAP 了!我甚至在很久以前就用过 GNUS。
### 用一个 Emacs 进程来管理
我以前也经常使用 Emacs,那时,Emacs 是一个“大”的程序(现在显示电源状态的小程序占用的内存要比 Emacs 多)。当时存在在启动时间过长的问题,但是现在已经有连接到一个正在运行的 Emacs 进程的解决方法。
我喜欢用 Mod-p(一个 [xmonad](https://wiki.archlinux.org/index.php/Xmonad_(%E7%AE%80%E4%BD%93%E4%B8%AD%E6%96%87)) 中 [dzen](http://robm.github.io/dzen/) 菜单栏的快捷方式,但是在大多数传统的桌面环境中该功能的快捷键是 `Alt-F2`)来启动程序(LCTT 译注:xmonad 是一种平铺桌面;dzen 是 X11 窗口下管理消息、提醒和菜单的程序)。这个设置在不运行多个<ruby> <a href="https://www.emacswiki.org/emacs/Emacsen"> emacs 们 </a> <rt> emacsen </rt></ruby>时很方便,因为这样就不会在试图捕获另一个打开的文件时出问题。这中方法很简单:创建一个叫 `em` 的脚本并将它放到我自己的环境变量中。就像这样:
```
#!/bin/bash exec emacsclient -c -a "" "$@"
```
如果没有 emacs 进程存在的话,就会创建一个新的 emacs 进程,否则的话就直接使用已存在的进程。这样做还有一个好处:`-nw` 之类的参数工作的很好,它实际上就像在 shell 提示符下输入 `emacs` 一样。它很适合用于设置 `EDITOR` 环境变量。
### 下一篇
接下来我将讨论我的使用情况,并展示以下的配置:
* Org 模式,包括计算机之间的同步、捕获、日程和待办事项、文件、链接、关键字和标记、各种导出(幻灯片)等。
* mu4e,用于电子邮件,包括多个账户,bbdb 集成
* ERC,用于 IRC 和即时通讯
---
via: <http://changelog.complete.org/archives/9861-emacs-1-ditching-a-bunch-of-stuff-and-moving-to-emacs-and-org-mode>
作者:[John Goerzen](http://changelog.complete.org/archives/author/jgoerzen) 译者:[oneforalone](https://github.com/oneforalone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 302 | Found | null |
10,298 | 如何在 SUSE 12 Linux 中进入单用户模式? | https://kerneltalks.com/howto/how-to-enter-single-user-mode-in-suse-12-linux/ | 2018-11-30T23:31:44 | [
"单用户"
] | https://linux.cn/article-10298-1.html |
>
> 一篇了解如何在 SUSE 12 Linux 服务器中进入单用户模式的简短文章。
>
>
>

在这篇简短的文章中,我们将向你介绍在 SUSE 12 Linux 中进入单用户模式的步骤。在排除系统主要问题时,单用户模式始终是首选。单用户模式禁用网络并且没有其他用户登录,你可以排除许多多用户系统的情况,可以帮助你快速排除故障。单用户模式最常见的一种用处是[重置忘记的 root 密码](https://kerneltalks.com/linux/recover-forgotten-root-password-rhel/)。
### 1、暂停启动过程
首先,你需要拥有机器的控制台才能进入单用户模式。如果它是虚拟机那就是虚拟机控制台,如果它是物理机那么你需要连接它的 iLO/串口控制台。重启系统并在 GRUB 启动菜单中按任意键停止内核的自动启动。

### 2、编辑内核的启动选项
进入上面的页面后,在所选内核(通常是你首选的最新内核)上按 `e` 更新其启动选项。你会看到下面的页面。

现在,向下滚动到内核引导行,并在行尾添加 `init=/bin/bash`,如下所示。

### 3、引导编辑后的内核
现在按 `Ctrl-x` 或 `F10` 来启动这个编辑过的内核。内核将以单用户模式启动,你将看到 `#` 号提示符,即有服务器的 root 访问权限。此时,根文件系统以只读模式挂载。因此,你对系统所做的任何更改都不会被保存。
运行以下命令以将根文件系统重新挂载为可重写入的。
```
kerneltalks:/ # mount -o remount,rw /
```
这就完成了!继续在单用户模式中做你必要的事情吧。完成后不要忘了重启服务器引导到普通多用户模式。
---
via: <https://kerneltalks.com/howto/how-to-enter-single-user-mode-in-suse-12-linux/>
作者:[kerneltalks](https://kerneltalks.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A *Short article to learn how to enter a single-user mode in SUSE 12 Linux server.*

In this short article, we will walk you through steps that demonstrate how to enter a single-user mode in SUSE 12 Linux. Single user mode is always preferred when you are troubleshooting major issues with your system. Single user mode disables networking and no other users are logged in, you rule out many situations of the multi-user system and it helps you in troubleshooting fast. One of the most popular uses of single-user mode is to [reset forgotten root password](https://kerneltalks.com/linux/recover-forgotten-root-password-rhel/).
### 1. Halt boot process
First of all, you need to have a console of your machine to get into single-user mode. If its VM then VM console, if its physical machine then you need its iLO/serial console connected. Reboot the system and halt automatic booting of the kernel at the grub boot menu by pressing any key.

### 2. Edit boot option of kernel
Once you are on the above screen, press
on selected kernel (which is normally your preferred latest kernel) to update its boot options. You will see be below screen.**e**
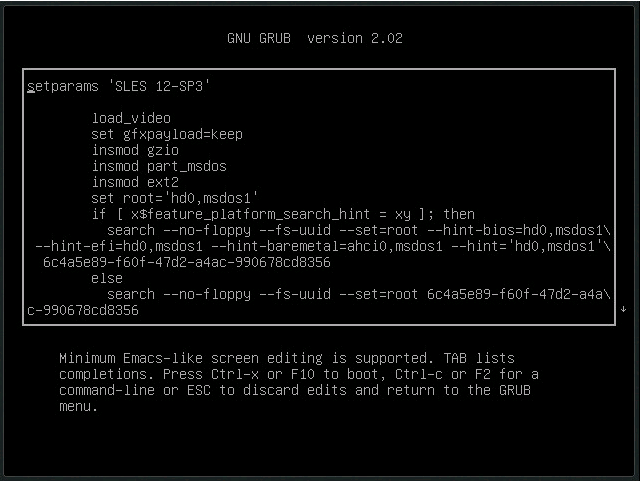
Now, scroll down to your booting kernel line and add `init=/bin/bash`
at the end of the line as shown below.
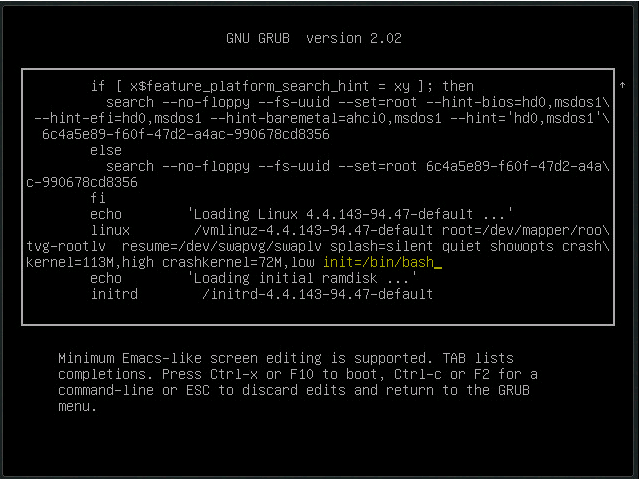
### 3. Boot kernel with edited entry
Now press `Ctrl-x`
or `F10`
to boot this edited kernel. The kernel will be booted in single-user mode and you will be presented with hash prompt i.e. root access to the server. At this point in time, your root file system is mounted in read-only mode. So any changes you are doing to the system won’t be saved.
Run below command to remount root filesystem as re-writable.
```
kerneltalks:/ # mount -o remount,rw /
```
And you are good to go! Go ahead and do your necessary actions in single-user mode. Don’t forget to reboot the server or type `exit`
to boot into normal multiuser mode once you are done.
## Share Your Comments & Feedback: Cancel reply |
10,299 | 流量引导:网络世界的负载均衡解密 | https://opensource.com/article/18/10/internet-scale-load-balancing | 2018-12-01T21:17:05 | [
"负载均衡"
] | https://linux.cn/article-10299-1.html |
>
> 均衡网络流量的常用技术,它们的优势和利弊权衡。
>
>
>

大型的多站点互联网系统,包括内容分发网络(CDN)和云服务提供商,用一些方法来均衡来访的流量。这篇文章我们讲一下常见的流量均衡设计,包括它们的技术手段和利弊权衡。
早期的云计算服务提供商,可以提供单一一台客户 Web 服务器,分配一个 IP 地址,然后用一个便于人读的域名配置一个 DNS 记录指向这个 IP 地址,再将 IP 地址通过边界网关协议(BGP)宣告出去,BGP 是在不同网络之间交换路由信息的标准方式。
这本身并不是负载均衡,但是能在冗余的多条网络路径中进行流量分发,而且可以利用网络技术让流量绕过不可用的网络,从而提高了可用性(也引起了[非对称路由](https://www.noction.com/blog/bgp-and-asymmetric-routing)的现象)。
### 简单的 DNS 负载均衡
随着来自客户的流量变大,老板希望服务是高可用的。你上线第二台 web 服务器,它有自己独立的公网 IP 地址,然后你更新了 DNS 记录,把用户流量引到两台服务器上(内心希望它们均衡地提供服务)。在其中一台服务器出故障之前,这样做一直是没有问题的。假设你能很快地监测到故障,可以更新一下 DNS 配置(手动更新或者通过软件)删除解析到故障机器的记录。
不幸的是,因为 DNS 记录会被缓存,在客户端缓存和它们依赖的 DNS 服务器上的缓存失效之前,大约一半的请求会失败。DNS 记录都有一个几分钟或更长的生命周期(TTL),所以这种方式会对系统可用性造成严重的影响。
更糟糕的是,部分客户端会完全忽略 TTL,所以有一些请求会持续被引导到你的故障机器上。设置很短的 TTL 也不是个好办法,因为这意味着更高的 DNS 服务负载,还有更长的访问时延,因为客户端要做更多的 DNS 查询。如果 DNS 服务由于某种原因不可用了,那设置更短的 TTL 会让服务的访问量更快地下降,因为没那么多客户端有你网站 IP 地址的缓存了。
### 增加网络负载均衡
要解决上述问题,可以增加一对相互冗余的[四层](https://en.wikipedia.org/wiki/Transport_layer)(L4)网络负载均衡器,配置一样的虚拟 IP 地址(VIP)。均衡器可以是硬件的,也可以是像 [HAProxy](https://www.haproxy.com/blog/failover-and-worst-case-management-with-haproxy/) 这样的软件。域名的 DNS 记录指向 VIP,不再承担负载均衡的功能。

*四层负载均衡器能够均衡用户和两台 web 服务器的连接*
四层均衡器将网络流量均衡地引导至后端服务器。通常这是基于对 IP 数据包的五元组做散列(数学函数)来完成的,五元组包括:源地址、源端口、目的地址、目的端口、协议(比如 TCP 或 UDP)。这种方法是快速和高效的(还维持了 TCP 的基本属性),而且不需要均衡器维持每个连接的状态。(更多信息请阅读[谷歌发表的 Maglev 论文](https://ai.google/research/pubs/pub44824),这篇论文详细讨论了四层软件负载均衡器的实现细节。)
四层均衡器可以对后端服务做健康检查,只把流量分发到健康的机器上。和使用 DNS 做负载均衡不同的是,在某个后端 web 服务故障的时候,它可以很快地把流量重新分发到其他机器上,虽然故障机器的已有连接会被重置。
当后端服务器的能力不同时,四层均衡器可以根据权重做流量分发。它为运维人员提供了强大的能力和灵活性,而且硬件成本相对较小。
### 扩展到多站点
系统规模在持续增长。你的客户希望能一直使用服务,即使是数据中心发生故障的时候。所以你建设了一个新的数据中心,另外独立部署了一套服务和四层负载均衡器集群,仍然使用同样的 VIP。DNS 的设置不变。
两个站点的边缘路由器都把自己的地址空间宣告出去,包括 VIP 地址。发往该 VIP 的请求可能到达任何一个站点,取决于用户和系统之间的网络是如何连接的,以及各个网络的路由策略是如何配置的。这就是泛播。大部分时候这种机制可以很好的工作。如果一个站点出问题了,你可以停止通过 BGP 宣告 VIP 地址,客户的请求就会迅速地转移到另外一个站点去。

*多个站点使用泛播提供服务*
这种设置有一些问题。最大的问题是,不能控制请求流向哪个站点,或者限制某个站点的流量。也没有一个明确的方式把用户的请求转到距离他最近的站点(为了降低网络延迟),不过,网络协议和路由选路配置在大部分情况下应该能把用户请求路由到最近的站点。
### 控制多站点系统中的入站请求
为了维持稳定性,需要能够控制每个站点的流量大小。要实现这种控制,可以给每个站点分配不同的 VIP 地址,然后用简单的或者有权重的 DNS [轮询](https://en.wikipedia.org/wiki/Round-robin_scheduling)来做负载均衡。

*多站点提供服务,每个站点使用一个主 VIP,另外一个站点作为备份。基于能感知地理位置的 DNS。*
现在有两个问题。
第一、使用 DNS 均衡意味着会有被缓存的记录,如果你要快速重定向流量的话就麻烦了。
第二、用户每次做新的 DNS 查询,都可能连上任意一个站点,可能不是距离最近的。如果你的服务运行在分布广泛的很多站点上,用户会感受到响应时间有明显的变化,取决于用户和提供服务的站点之间有多大的网络延迟。
让每个站点都配置上其他所有站点的 VIP 地址,并宣告出去(因此也会包含故障的站点),这样可以解决第一个问题。有一些网络上的小技巧,比如备份站点宣告路由时,不像主站点使用那么具体的目的地址,这样可以保证每个 VIP 的主站点只要可用就会优先提供服务。这是通过 BGP 来实现的,所以我们应该可以看到,流量在 BGP 更新后的一两分钟内就开始转移了。
即使离用户最近的站点是健康而且有服务能力的,但是用户真正访问到的却不一定是这个站点,这个问题还没有很好的解决方案。很多大型的互联网服务利用 DNS 给不同地域的用户返回不同的解析结果,也能有一定的效果。不过,因为网络地址的结构和地理位置无关,一个地址段也可能会改变所在位置(例如,当一个公司重新规划网络时),而且很多用户可能使用了同一个 DNS 缓存服务器。所以这种方案有一定的复杂度,而且容易出错。
### 增加七层负载均衡
又过了一段时间,你的客户开始要更多的高级功能。
虽然四层负载均衡可以高效地在多个 web 服务器之间分发流量,但是它们只针对源地址、目标地址、协议和端口来操作,请求的内容是什么就不得而知了,所以很多高级功能在四层负载均衡上实现不了。而七层(L7)负载均衡知道请求的内容和结构,所以能做更多的事情。
七层负载均衡可以实现缓存、限速、错误注入,做负载均衡时可以感知到请求的代价(有些请求需要服务器花更多的时间去处理)。
七层负载均衡还可以基于请求的属性(比如 HTTP cookies)来分发流量,可以终结 SSL 连接,还可以帮助防御应用层的拒绝服务(DoS)攻击。规模大的 L7 负载均衡的缺点是成本 —— 处理请求需要更多的计算,而且每个活跃的请求都占用一些系统资源。在一个或者多个 L7 均衡器前面运行 L4 均衡器集群,对扩展规模有帮助。
### 结论
负载均衡是一个复杂的难题。除了上面说过的策略,还有不同的[负载均衡算法](https://medium.com/netflix-techblog/netflix-edge-load-balancing-695308b5548c),用来实现负载均衡器的高可用技术、客户端负载均衡技术,以及最近兴起的服务网络等等。
核心的负载均衡模式随着云计算的发展而不断发展,而且,随着大型 web 服务商致力于让负载均衡技术更可控和更灵活,这项技术会持续发展下去。
---
via: <https://opensource.com/article/18/10/internet-scale-load-balancing>
作者:[Laura Nolan](https://opensource.com/users/lauranolan) 选题:[lujun9972](https://github.com/lujun9972) 译者:[BeliteX](https://github.com/belitex) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Large, multi-site, internet-facing systems, including content-delivery networks (CDNs) and cloud providers, have several options for balancing traffic coming onto their networks. In this article, we'll describe common traffic-balancing designs, including techniques and trade-offs.
If you were an early cloud computing provider, you could take a single customer web server, assign it an IP address, configure a domain name system (DNS) record to associate it with a human-readable name, and advertise the IP address via the border gateway protocol (BGP), the standard way of exchanging routing information between networks.
It wasn't load balancing per se, but there probably was load distribution across redundant network paths and networking technologies to increase availability by routing around unavailable infrastructure (giving rise to phenomena like [asymmetric routing](https://www.noction.com/blog/bgp-and-asymmetric-routing)).
## Doing simple DNS load balancing
As traffic to your customer's service grows, the business' owners want higher availability. You add a second web server with its own publicly accessible IP address and update the DNS record to direct users to both web servers (hopefully somewhat evenly). This is OK for a while until one web server unexpectedly goes offline. Assuming you detect the failure quickly, you can update the DNS configuration (either manually or with software) to stop referencing the broken server.
Unfortunately, because DNS records are cached, around 50% of requests to the service will likely fail until the record expires from the client caches and those of other nameservers in the DNS hierarchy. DNS records generally have a time to live (TTL) of several minutes or more, so this can create a significant impact on your system's availability.
Worse, some proportion of clients ignore TTL entirely, so some requests will be directed to your offline web server for some time. Setting very short DNS TTLs is not a great idea either; it means higher load on DNS services plus increased latency because clients will have to perform DNS lookups more often. If your DNS service is unavailable for any reason, access to your service will degrade more quickly with a shorter TTL because fewer clients will have your service's IP address cached.
## Adding network load balancing
To work around this problem, you can add a redundant pair of [Layer 4](https://en.wikipedia.org/wiki/Transport_layer) (L4) network load balancers that serve the same virtual IP (VIP) address. They could be hardware appliances or software balancers like [HAProxy](https://www.haproxy.com/blog/failover-and-worst-case-management-with-haproxy/). This means the DNS record points only at the VIP and no longer does load balancing.
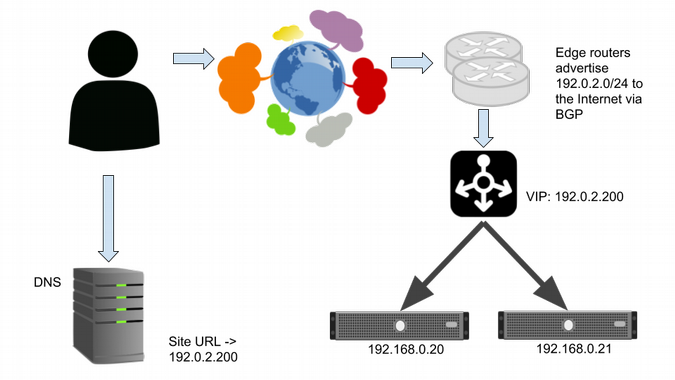
Layer 4 load balancers balance connections from users across two webservers.
The L4 balancers load-balance traffic from the internet to the backend servers. This is generally done based on a hash (a mathematical function) of each IP packet's 5-tuple: the source and destination IP address and port plus the protocol (such as TCP or UDP). This is fast and efficient (and still maintains essential properties of TCP) and doesn't require the balancers to maintain state per connection. (For more information, [Google's paper on Maglev](https://ai.google/research/pubs/pub44824) discusses implementation of a software L4 balancer in significant detail.)
The L4 balancers can do health-checking and send traffic only to web servers that pass checks. Unlike in DNS balancing, there is minimal delay in redirecting traffic to another web server if one crashes, although existing connections will be reset.
L4 balancers can do weighted balancing, dealing with backends with varying capacity. L4 balancing gives significant power and flexibility to operators while being relatively inexpensive in terms of computing power.
## Going multi-site
The system continues to grow. Your customers want to stay up even if your data center goes down. You build a new data center with its own set of service backends and another cluster of L4 balancers, which serve the same VIP as before. The DNS setup doesn't change.
The edge routers in both sites advertise address space, including the service VIP. Requests sent to that VIP can reach either site, depending on how each network between the end user and the system is connected and how their routing policies are configured. This is known as anycast. Most of the time, this works fine. If one site isn't operating, you can stop advertising the VIP for the service via BGP, and traffic will quickly move to the alternative site.
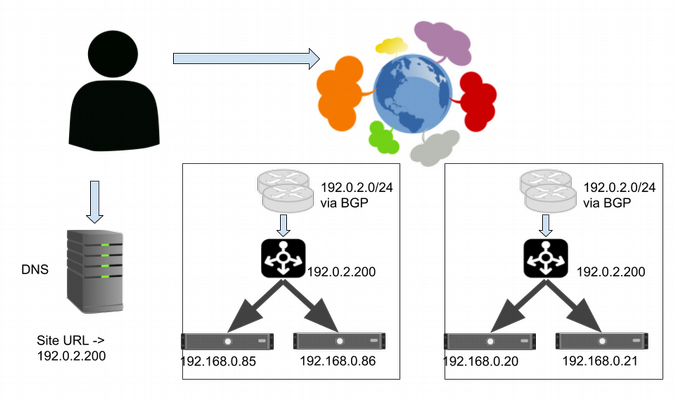
Serving from multiple sites using anycast.
This setup has several problems. Its worst failing is that you can't control where traffic flows or limit how much traffic is sent to a given site. You also don't have an explicit way to route users to the nearest site (in terms of network latency), but the network protocols and configurations that determine the routes should, in most cases, route requests to the nearest site.
## Controlling inbound requests in a multi-site system
To maintain stability, you need to be able to control how much traffic is served to each site. You can get that control by assigning a different VIP to each site and use DNS to balance them using simple or weighted [round-robin](https://en.wikipedia.org/wiki/Round-robin_scheduling).
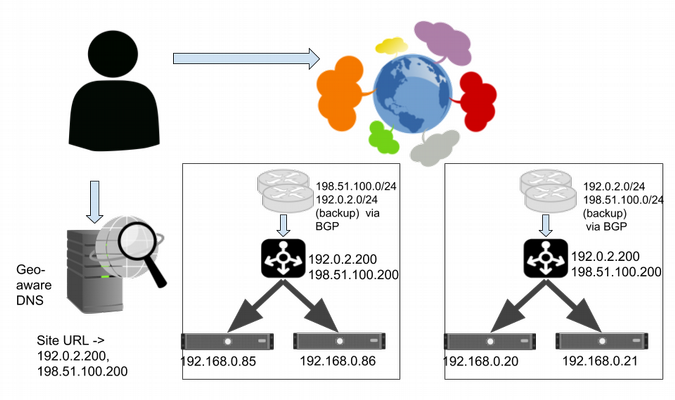
Serving from multiple sites using a primary VIP per site, backed up by secondary sites, with geo-aware DNS.
You now have two new problems.
First, using DNS balancing means you have cached records, which is not good if you need to redirect traffic quickly.
Second, whenever users do a fresh DNS lookup, a VIP connects them to the service at an arbitrary site, which may not be the closest site to them. If your service runs on widely separated sites, individual users will experience wide variations in your system's responsiveness, depending upon the network latency between them and the instance of your service they are using.
You can solve the first problem by having each site constantly advertise and serve the VIPs for all the other sites (and consequently the VIP for any faulty site). Networking tricks (such as advertising less-specific routes from the backups) can ensure that VIP's primary site is preferred, as long as it is available. This is done via BGP, so we should see traffic move within a minute or two of updating BGP.
There isn't an elegant solution to the problem of serving users from sites other than the nearest healthy site with capacity. Many large internet-facing services use DNS services that attempt to return different results to users in different locations, with some degree of success. This approach is always somewhat [complex and error-prone](https://landing.google.com/sre/book/chapters/load-balancing-frontend.html), given that internet-addressing schemes are not organized geographically, blocks of addresses can change locations (e.g., when a company reorganizes its network), and many end users can be served from a single caching nameserver.
## Adding Layer 7 load balancing
Over time, your customers begin to ask for more advanced features.
While L4 load balancers can efficiently distribute load among multiple web servers, they operate only on source and destination IP addresses, protocol, and ports. They don't know anything about the content of a request, so you can't implement many advanced features in an L4 balancer. Layer 7 (L7) load balancers are aware of the structure and contents of requests and can do far more.
Some things that can be implemented in L7 load balancers are caching, rate limiting, fault injection, and cost-aware load balancing (some requests require much more server time to process).
They can also balance based on a request's attributes (e.g., HTTP cookies), terminate SSL connections, and help defend against application layer denial-of-service (DoS) attacks. The downside of L7 balancers at scale is cost—they do more computation to process requests, and each active request consumes some system resources. Running L4 balancers in front of one or more pools of L7 balancers can help with scaling.
## Conclusion
Load balancing is a difficult and complex problem. In addition to the strategies described in this article, there are different [load-balancing algorithms](https://medium.com/netflix-techblog/netflix-edge-load-balancing-695308b5548c), high-availability techniques used to implement load balancers, client load-balancing techniques, and the recent rise of service meshes.
Core load-balancing patterns have evolved alongside the growth of cloud computing, and they will continue to improve as large web services work to improve the control and flexibility that load-balancing techniques offer./p>
*Laura Nolan and Murali Suriar will present Keeping the Balance: Load Balancing Demystified at LISA18, October 29-31 in Nashville, Tennessee, USA.*
## Comments are closed. |
10,300 | 使用 MDwiki 将 Markdown 发布成 HTML | https://opensource.com/article/18/8/markdown-html-publishing | 2018-12-01T22:08:59 | [
"Markdown",
"MDwiki"
] | https://linux.cn/article-10300-1.html |
>
> 用这个有用工具从 Markdown 文件创建一个基础的网站。
>
>
>

有很多理由喜欢 Markdown,这是一门简单的语言,有易于学习的语法,它可以与任何文本编辑器一起使用。使用像 [Pandoc](https://pandoc.org/) 这样的工具,你可以将 Markdown 文本转换为[各种流行格式](https://opensource.com/downloads/pandoc-cheat-sheet),包括 HTML。你还可以在 Web 服务器中自动执行转换过程。由 TimoDörr 创建的名为 [MDwiki](http://dynalon.github.io/mdwiki/#!index.md) 的 HTML5 和 JavaScript 应用可以将一堆 Markdown 文件在浏览器请求它们时转换为网站。MDwiki 网站包含一个操作指南和其他信息可帮助你入门:

*Mdwiki 网站的样子。*
在 Web 服务器内部,基本的 MDwiki 站点如下所示:

*该站点的 web 服务器文件夹的样子*
我将此项目的 MDwiki HTML 文件重命名为 `START.HTML`。还有一个处理导航的 Markdown 文件和一个 JSON 文件来保存一些配置设置。其他的都是网站内容。
虽然整个网站设计被 MDwiki 固定了,但内容、样式和页面数量却没有。你可以在 [MDwiki 站点](http://dynalon.github.io/mdwiki/#!examples.md)查看由 MDwiki 生成的一系列不同站点。公平地说,MDwiki 网站缺乏网页设计师可以实现的视觉吸引力 —— 但它们是功能性的,用户应该平衡其简单的外观与创建和编辑它们的速度和简易性。
Markdown 有不同的风格,可以针对不同的特定目的扩展稳定的核心功能。MDwiki 使用 GitHub 风格 [Markdown](https://guides.github.com/features/mastering-markdown/),它为流行的编程语言添加了格式化代码块和语法高亮等功能,使其非常适合生成程序文档和教程。
MDwiki 还支持 “gimmick”,它增加了如嵌入 YouTube 视频和显示数学公式等额外功能。如果在某些项目中需要它们,这些值得探索。我发现 MDwiki 是创建技术文档和教育资源的理想工具。我还发现了一些可能不会立即显现出来的技巧和 hack。
当部署在 Web 服务器中时,MDwiki 可与任何现代 Web 浏览器一起使用。但是,如果你使用 Mozilla Firefox 访问 MDwiki,那么就不需要 Web 服务器。大多数 MDwiki 用户会选择在 Web 服务器上部署完整的项目,以避免排除潜在用户,但只需使用文本编辑器和 Firefox 即可完成开发和测试。任何现代浏览器都可以读取加载到 Moodle 虚拟学习环境(VLE)中的完整的 MDwiki 项目,这在教育环境中非常有用。 (对于其他 VLE 软件,这可能也是如此,但你应该测试它。)
MDwiki 的默认配色方案并非适用于所有项目,但你可以将其替换为从 [Bootswatch.com](https://bootswatch.com/) 下载的其他主题。为此,只需在编辑器中打开 MDwiki HTML 文件,找到 `extlib/css/bootstrap-3.0.0.min.css`,然后插入下载的 Bootswatch 主题。还有一个 MDwiki gimmick,让用户在浏览器中载入 MDwiki 后,选择 Bootswatch 主题来替换默认值。我经常与有视力障碍的用户一起工作,他们倾向于喜欢高对比度的主题,在深色背景上使用白色文字。

*MDwiki 页面使用 Bootswatch Superhero 主题*
MDwiki、Markdown 文件和静态图像可以用于许多目的。但是,你有时可能希望包含 JavaScript 幻灯片或反馈表单。Markdown 文件可以包含 HTML 代码,但将 Markdown 与 HTML 混合会让人感到困惑。一种解决方案是在单独的 HTML 文件中创建所需的功能,并将其显示在带有 iframe 标记的 Markdown 文件中。我从 [Twine Cookbook](https://github.com/iftechfoundation/twine-cookbook) 知道了这个想法,它是 Twine 交互式小说引擎的支持站点。Twine Cookbook 实际上并没有使用 MDwiki,但结合 Markdown 和 iframe 标签开辟了广泛的创作可能性。
这是一个例子:
此 HTML 将显示由 Markdown 文件中的 Twine 交互式小说引擎创建的 HTML 页面。
```
<iframe height="400" src="sugarcube_dungeonmoving_example.html" width="90%"></iframe>
```
MDwiki 生成的站点结果如下所示:

简而言之,MDwiki 是一个出色的小应用,可以很好地实现其目的。
---
via: <https://opensource.com/article/18/8/markdown-html-publishing>
作者:[Peter Cheer](https://opensource.com/users/petercheer) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are plenty of reasons to like Markdown, a simple language with an easy-to-learn syntax that can be used with any text editor. Using tools like [Pandoc](https://pandoc.org/), you can convert Markdown text to [a variety of popular formats](https://opensource.com/downloads/pandoc-cheat-sheet), including HTML. You can also automate that conversion process in a web server. An HTML5 and JavaScript application called [MDwiki](http://dynalon.github.io/mdwiki/#!index.md), created by Timo Dörr, can take a stack of Markdown files and turn them into a website when requested from a browser. The MDwiki site includes a how-to guide and other information to help you get started:
Inside the web server, a basic MDwiki site looks like this:
I renamed the MDwiki HTML file `START.HTML`
for this project. There is also one Markdown file that deals with navigation and a JSON file to hold a few configuration settings. Everything else is site content.
While the overall website design is pretty much fixed by MDwiki, the content, styling, and number of pages are not. You can view a selection of different sites generated by MDwiki at [the MDwiki site](http://dynalon.github.io/mdwiki/#!examples.md). It is fair to say that MDwiki sites lack the visual appeal that a web designer could achieve—but they are functional, and users should balance their simple appearance against the speed and ease of creating and editing them.
Markdown comes in various flavors that extend a stable core functionality for different specific purposes. MDwiki uses GitHub flavor [Markdown](https://guides.github.com/features/mastering-markdown/), which adds features such as formatted code blocks and syntax highlighting for popular programming languages, making it well-suited for producing program documentation and tutorials.
MDwiki also supports what it calls "gimmicks," which add extra functionality such as embedding YouTube video content and displaying mathematical formulas. These are worth exploring if you need them for specific projects. I find MDwiki an ideal tool for creating technical documentation and educational resources. I have also discovered some tricks and hacks that might not be immediately apparent.
MDwiki works with any modern web browser when deployed in a web server; however, you do not need a web server if you access MDwiki with Mozilla Firefox. Most MDwiki users will opt to deploy completed projects on a web server to avoid excluding potential users, but development and testing can be done with just a text editor and Firefox. Completed MDwiki projects that are loaded into a Moodle Virtual Learning Environment (VLE) can be read by any modern browser, which could be useful in educational contexts. (This is probably also true for other VLE software, but you should test that.)
MDwiki's default color scheme is not ideal for all projects, but you can replace it with another theme downloaded from [Bootswatch.com](https://bootswatch.com/). To do this, simply open the MDwiki HTML file in an editor, take out the `extlib/css/bootstrap-3.0.0.min.css`
code, and insert the downloaded Bootswatch theme. There is also an MDwiki gimmick that lets users choose a Bootswatch theme to replace the default after MDwiki loads in their browser. I often work with users who have visual impairments, and they tend to prefer high-contrast themes, with white text on a dark background.
MDwiki screen using the Bootswatch Superhero theme
MDwiki, Markdown files, and static images are fine for many purposes. However, you might sometimes want to include, say, a JavaScript slideshow or a feedback form. Markdown files can include HTML code, but mixing Markdown with HTML can get confusing. One solution is to create the feature you want in a separate HTML file and display it inside a Markdown file with an iframe tag. I took this idea from the [Twine Cookbook](https://github.com/iftechfoundation/twine-cookbook), a support site for the Twine interactive fiction engine. The Twine Cookbook doesn’t actually use MDwiki, but combining Markdown and iframe tags opens up a wide range of creative possibilities.
Here is an example:
This HTML will display an HTML page created by the Twine interactive fiction engine inside a Markdown file.
`<iframe height="400" src="https://opensource.com/sugarcube_dungeonmoving_example.html" width="90%"></iframe>`
The result in an MDwiki-generated site looks like this:
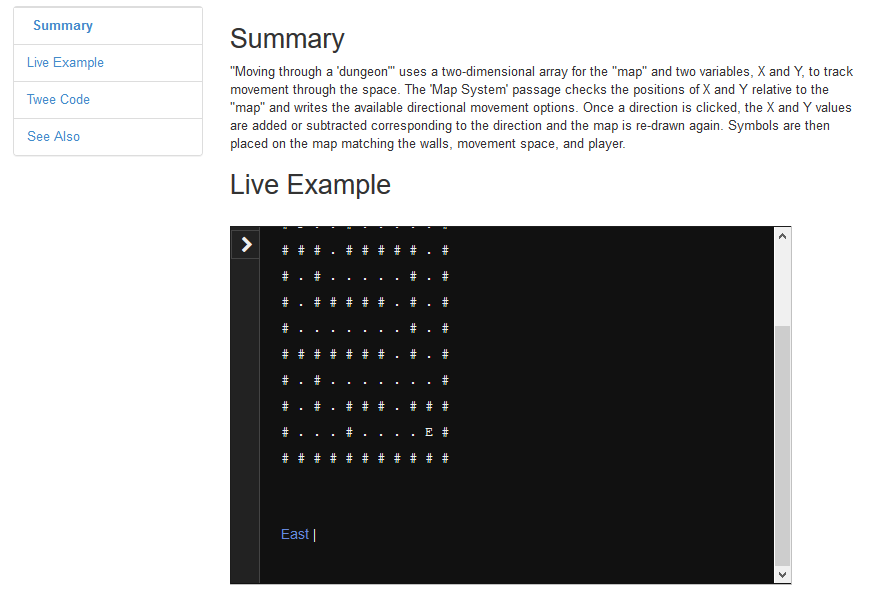
In short, MDwiki is an excellent small application that achieves its purpose extremely well.
## 1 Comment |
10,301 | Systemd 定时器:三种使用场景 | https://www.linux.com/blog/intro-to-linux/2018/8/systemd-timers-two-use-cases-0 | 2018-12-02T09:34:36 | [
"定时器",
"systemd"
] | https://linux.cn/article-10301-1.html |
>
> 继续 systemd 教程,这些特殊的例子可以展示给你如何更好的利用 systemd 定时器单元。
>
>
>

在这个 systemd 系列教程中,我们[已经在某种程度上讨论了 systemd 定时器单元](/article-10182-1.html)。不过,在我们开始讨论 sockets 之前,我们先来看三个例子,这些例子展示了如何最佳化利用这些单元。
### 简单的类 cron 行为
我每周都要去收集 [Debian popcon 数据](https://popcon.debian.org/),如果每次都能在同一时间收集更好,这样我就能看到某些应用程序的下载趋势。这是一个可以使用 cron 任务来完成的典型事例,但 systemd 定时器同样能做到:
```
# 类 cron 的 popcon.timer
[Unit]
Description= 这里描述了下载并处理 popcon 数据的时刻
[Timer]
OnCalendar= Thu *-*-* 05:32:07
Unit= popcon.service
[Install]
WantedBy= basic.target
```
实际的 `popcon.service` 会执行一个常规的 `wget` 任务,并没有什么特别之处。这里的新内容是 `OnCalendar=` 指令。这个指令可以让你在一个特定日期的特定时刻来运行某个服务。在这个例子中,`Thu` 表示 “在周四运行”,`*-*-*` 表示“具体年份、月份和日期无关紧要”,这些可以翻译成 “不管年月日,只在每周四运行”。
这样,你就设置了这个服务的运行时间。我选择在欧洲中部夏令时区的上午 5:30 左右运行,那个时候服务器不是很忙。
如果你的服务器关闭了,而且刚好错过了每周的截止时间,你还可以在同一个计时器中使用像 anacron 一样的功能。
```
# 具备类似 anacron 功能的 popcon.timer
[Unit]
Description= 这里描述了下载并处理 popcon 数据的时刻
[Timer]
Unit=popcon.service
OnCalendar=Thu *-*-* 05:32:07
Persistent=true
[Install]
WantedBy=basic.target
```
当你将 `Persistent=` 指令设为真值时,它会告诉 systemd,如果服务器在本该它运行的时候关闭了,那么在启动后就要立刻运行服务。这意味着,如果机器在周四凌晨停机了(比如说维护),一旦它再次启动后,`popcon.service` 将会立刻执行。在这之后,它的运行时间将会回到例行性的每周四早上 5:32.
到目前为止,就是这么简单直白。
### 延迟执行
但是,我们提升一个档次,来“改进”这个[基于 systemd 的监控系统](https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change)。你应该记得,当你接入摄像头的时候,系统就会开始拍照。假设你并不希望它在你安装摄像头的时候拍下你的脸。你希望将拍照服务的启动时间向后推迟一两分钟,这样你就有时间接入摄像头,然后走到画框外面。
为了完成这件事,首先你要更改 Udev 规则,将它指向一个定时器:
```
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0",
ATTRS{idProduct}=="e207", TAG+="systemd", ENV{SYSTEMD_WANTS}="picchanged.timer",
SYMLINK+="mywebcam", MODE="0666"
```
这个定时器看起来像这样:
```
# picchanged.timer
[Unit]
Description= 在摄像头接入的一分钟后,开始运行 picchanged
[Timer]
OnActiveSec= 1 m
Unit= picchanged.path
[Install]
WantedBy= basic.target
```
在你接入摄像头后,Udev 规则被触发,它会调用定时器。这个定时器启动后会等上一分钟(`OnActiveSec= 1 m`),然后运行 `picchanged.path`,它会[监视主图片的变化](https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories)。`picchanged.path` 还会负责接触 `webcan.service`,这个实际用来拍照的服务。
### 在每天的特定时刻启停 Minetest 服务器
在最后一个例子中,我们认为你决定用 systemd 作为唯一的依赖。讲真,不管怎么样,systemd 差不多要接管你的生活了。为什么不拥抱这个必然性呢?
你有个为你的孩子设置的 Minetest 服务。不过,你还想要假装关心一下他们的教育和成长,要让他们做作业和家务活。所以你要确保 Minetest 只在每天晚上的一段时间内可用,比如五点到七点。
这个跟之前的“在特定时间启动服务”不太一样。写个定时器在下午五点启动服务很简单…:
```
# minetest.timer
[Unit]
Description= 在每天下午五点运行 minetest.service
[Timer]
OnCalendar= *-*-* 17:00:00
Unit= minetest.service
[Install]
WantedBy= basic.target
```
…可是编写一个对应的定时器,让它在特定时刻关闭服务,则需要更大剂量的横向思维。
我们从最明显的东西开始 —— 设置定时器:
```
# stopminetest.timer
[Unit]
Description= 每天晚上七点停止 minetest.service
[Timer]
OnCalendar= *-*-* 19:05:00
Unit= stopminetest.service
[Install]
WantedBy= basic.target
```
这里棘手的部分是如何去告诉 `stopminetest.service` 去 —— 你知道的 —— 停止 Minetest. 我们无法从 `minetest.service` 中传递 Minetest 服务器的 PID. 而且 systemd 的单元词汇表中也没有明显的命令来停止或禁用正在运行的服务。
我们的诀窍是使用 systemd 的 `Conflicts=` 指令。它和 systemd 的 `Wants=` 指令类似,不过它所做的事情正相反。如果你有一个 `b.service` 单元,其中包含一个 `Wants=a.service` 指令,在这个单元启动时,如果 `a.service` 没有运行,则 `b.service` 会运行它。同样,如果你的 `b.service` 单元中有一行写着 `Conflicts= a.service`,那么在 `b.service` 启动时,systemd 会停止 `a.service`.
这种机制用于两个服务在尝试同时控制同一资源时会发生冲突的场景,例如当两个服务要同时访问打印机的时候。通过在首选服务中设置 `Conflicts=`,你就可以确保它会覆盖掉最不重要的服务。
不过,你会在一个稍微不同的场景中来使用 `Conflicts=`. 你将使用 `Conflicts=` 来干净地关闭 `minetest.service`:
```
# stopminetest.service
[Unit]
Description= 关闭 Minetest 服务
Conflicts= minetest.service
[Service]
Type= oneshot
ExecStart= /bin/echo "Closing down minetest.service"
```
`stopminetest.service` 并不会做特别的东西。事实上,它什么都不会做。不过因为它包含那行 `Conflicts=`,所以在它启动时,systemd 会关掉 `minetest.service`.
在你完美的 Minetest 设置中,还有最后一点涟漪:你下班晚了,错过了服务器的开机时间,可当你开机的时候游戏时间还没结束,这该怎么办?`Persistent=` 指令(如上所述)在错过开始时间后仍然可以运行服务,但这个方案还是不行。如果你在早上十一点把服务器打开,它就会启动 Minetest,而这不是你想要的。你真正需要的是一个确保 systemd 只在晚上五到七点启动 Minetest 的方法:
```
# minetest.timer
[Unit]
Description= 在下午五到七点内的每分钟都运行 minetest.service
[Timer]
OnCalendar= *-*-* 17..19:*:00
Unit= minetest.service
[Install]
WantedBy= basic.target
```
`OnCalendar= *-*-* 17..19:*:00` 这一行有两个有趣的地方:(1) `17..19` 并不是一个时间点,而是一个时间段,在这个场景中是 17 到 19 点;以及,(2) 分钟字段中的 `*` 表示服务每分钟都要运行。因此,你会把它读做 “在下午五到七点间的每分钟,运行 minetest.service”
不过还有一个问题:一旦 `minetest.service` 启动并运行,你会希望 `minetest.timer` 不要再次尝试运行它。你可以在 `minetest.service` 中包含一条 `Conflicts=` 指令:
```
# minetest.service
[Unit]
Description= 运行 Minetest 服务器
Conflicts= minetest.timer
[Service]
Type= simple
User= <your user name>
ExecStart= /usr/bin/minetest --server
ExecStop= /bin/kill -2 $MAINPID
[Install]
WantedBy= multi-user.targe
```
上面的 `Conflicts=` 指令会保证在 `minstest.service` 成功运行后,`minetest.timer` 就会立即停止。
现在,启用并启动 `minetest.timer`:
```
systemctl enable minetest.timer
systemctl start minetest.timer
```
而且,如果你在六点钟启动了服务器,`minetest.timer` 会启用;到了五到七点,`minetest.timer` 每分钟都会尝试启动 `minetest.service`。不过,一旦 `minetest.service` 开始运行,systemd 会停止 `minetest.timer`,因为它会与 `minetest.service` “冲突”,从而避免计时器在服务已经运行的情况下还会不断尝试启动服务。
在首先启动某个服务时杀死启动它的计时器,这么做有点反直觉,但它是有效的。
### 总结
你可能会认为,有更好的方式来做上面这些事。我在很多文章中看到过“过度设计”这个术语,尤其是在用 systemd 定时器来代替 cron 的时候。
但是,这个系列文章的目的不是为任何具体问题提供最佳解决方案。它的目的是为了尽可能多地使用 systemd 来解决问题,甚至会到荒唐的程度。它的目的是展示大量的例子,来说明如何利用不同类型的单位及其包含的指令。我们的读者,也就是你,可以从这篇文章中找到所有这些的可实践范例。
尽管如此,我们还有一件事要做:下回中,我们会关注 sockets 和 targets,然后我们将完成对 systemd 单元的介绍。
你可以在 Linux 基金会和 edX 中,通过免费的 [Linux 介绍](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)课程中,学到更多关于 Linux 的知识。
---
via: <https://www.linux.com/blog/intro-to-linux/2018/8/systemd-timers-two-use-cases-0>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[StdioA](https://github.com/StdioA) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,302 | 如何在 Linux 上对驱动器进行分区和格式化 | https://opensource.com/article/18/11/partition-format-drive-linux | 2018-12-02T10:12:46 | [
"分区",
"文件系统",
"硬盘"
] | https://linux.cn/article-10302-1.html |
>
> 这里有所有你想知道的关于设置存储器而又不敢问的一切。
>
>
>

在大多数的计算机系统上,Linux 或者是其它,当你插入一个 USB 设备时,你会注意到一个提示驱动器存在的警告。如果该驱动器已经按你想要的进行分区和格式化,你只需要你的计算机在文件管理器或桌面上的某个地方列出驱动器。这是一个简单的要求,而且通常计算机都能满足。
然而,有时候,驱动器并没有按你想要的方式进行格式化。对于这些,你必须知道如何查找准备连接到您计算机上的存储设备。
### 什么是块设备?
硬盘驱动器通常被称为“块设备”,因为硬盘驱动器以固定大小的块进行读写。这就可以区分硬盘驱动器和其它可能插入到您计算机的一些设备,如打印机、游戏手柄、麦克风,或相机。一个简单的方法用来列出连接到你 Linux 系统上的块设备就是使用 `lsblk` (list block devices)命令:
```
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 238.5G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 237.5G 0 part
└─luks-e2bb...e9f8 253:0 0 237.5G 0 crypt
├─fedora-root 253:1 0 50G 0 lvm /
├─fedora-swap 253:2 0 5.8G 0 lvm [SWAP]
└─fedora-home 253:3 0 181.7G 0 lvm /home
sdb 8:16 1 14.6G 0 disk
└─sdb1 8:17 1 14.6G 0 part
```
最左列是设备标识符,每个都是以 `sd` 开头,并以一个字母结尾,字母从 `a` 开始。每个块设备上的分区分配一个数字,从 `1` 开始。例如,第一个设备上的第二个分区用 `sda2` 表示。如果你不确定到底是哪个分区,那也不要紧,只需接着往下读。
`lsblk` 命令是无损的,仅仅用于检测,所以你可以放心的使用而不用担心破坏你驱动器上的数据。
### 使用 dmesg 进行测试
如果你有疑问,你可以通过在 `dmesg` 命令的最后几行查看驱动器的卷标,这个命令显示了操作系统最近的日志(比如说插入或移除一个驱动器)。一句话,如果你想确认你插入的设备是不是 `/dev/sdc` ,那么,把设备插到你的计算机上,然后运行这个 `dmesg` 命令:
```
$ sudo dmesg | tail
```
显示中列出的最新的驱动器就是你刚刚插入的那个。如果你拔掉它,并再运行这个命令一次,你可以看到,这个设备已经被移除。如果你再插上它再运行命令,这个设备又会出现在那里。换句话说,你可以监控内核对驱动器的识别。
### 理解文件系统
如果你只需要设备卷标,那么你的工作就完成了。但是如果你的目的是想创建一个可用的驱动器,那你还必须给这个驱动器做一个文件系统。
如果你还不知道什么是文件系统,那么通过了解当没有文件系统时会发生什么可能会更容易理解这个概念。如果你有多余的设备驱动器,并且上面没有什么重要的数据资料,你可以跟着做一下下面的这个实验。否则,请不要尝试,因为根据其设计目的,这个肯定会删除您的资料。
当一个驱动器没有文件系统时也是可以使用的。一旦你已经肯定,正确识别了一个驱动器,并且已经确定上面没有任何重要的资料,那就可以把它插到你的计算机上 —— 但是不要挂载它,如果它被自动挂载上了,那就请手动卸载掉它。
```
$ su -
# umount /dev/sdx{,1}
```
为了防止灾难性的复制 —— 粘贴错误,下面的例子将使用不太可能出现的 `sdx` 来作为驱动器的卷标。
现在,这个驱动器已经被卸载了,尝试使用下面的命令:
```
# echo 'hello world' > /dev/sdx
```
你已经可以将数据写入到块设备中,而无需将其挂载到你的操作系统上,也不需要一个文件系统。
再把刚写入的数据取出来,你可以看到驱动器上的原始数据:
```
# head -n 1 /dev/sdx
hello world
```
这看起来工作得很好,但是想象一下如果 “hello world” 这个短语是一个文件,如果你想要用这种方法写入一个新的文件,则必须:
1. 知道第 1 行已经存在一个文件了
2. 知道已经存在的文件只占用了 1 行
3. 创建一种新的方法来在后面添加数据,或者在写第 2 行的时候重写第 1 行
例如:
```
# echo 'hello world
> this is a second file' >> /dev/sdx
```
获取第 1 个文件,没有任何改变。
```
# head -n 1 /dev/sdx
hello world
```
但是,获取第 2 个文件的时候就显得有点复杂了。
```
# head -n 2 /dev/sdx | tail -n 1
this is a second file
```
显然,通过这种方式读写数据并不实用,因此,开发人员创建了一个系统来跟踪文件的组成,并标识一个文件的开始和结束,等等。
大多数的文件系统都需要一个分区。
### 创建分区
分区是硬盘驱动器的一种边界,用来告诉文件系统它可以占用哪些空间。举例来说,你有一个 4GB 的 USB 驱动器,你可以只分一个分区占用一个驱动器 (4GB),或两个分区,每个 2GB (又或者是一个 1GB,一个 3GB,只要你愿意),或者三个不同的尺寸大小,等等。这种组合将是无穷无尽的。
假设你的驱动器是 4GB,你可以使用 GNU `parted` 命令来创建一个大的分区。
```
# parted /dev/sdx --align opt mklabel msdos 0 4G
```
按 `parted` 命令的要求,首先指定了驱动器的路径。
`--align` 选项让 `parted` 命令自动选择一个最佳的开始点和结束点。
`mklabel` 命令在驱动器上创建了一个分区表 (称为磁盘卷标)。这个例子使用了 msdos 磁盘卷标,因为它是一个非常兼容和流行的卷标,虽然 gpt 正变得越来越普遍。
最后定义了分区所需的起点和终点。因为使用了 `--align opt` 标志,所以 `parted` 将根据需要调整大小以优化驱动器的性能,但这些数字仍然可以做为参考。
接下来,创建实际的分区。如果你开始点和结束点的选择并不是最优的, `parted` 会向您发出警告并让您做出调整。
```
# parted /dev/sdx -a opt mkpart primary 0 4G
Warning: The resulting partition is not properly aligned for best performance: 1s % 2048s != 0s
Ignore/Cancel? C
# parted /dev/sdx -a opt mkpart primary 2048s 4G
```
如果你再次运行 `lsblk` 命令,(你可能必须要拔掉驱动器,并把它再插回去),你就可以看到你的驱动器上现在已经有一个分区了。
### 手动创建一个文件系统
我们有很多文件系统可以使用。有些是开源和免费的,另外的一些并不是。一些公司拒绝支持开源文件系统,所以他们的用户无法使用开源的文件系统读取,而开源的用户也无法在不对其进行逆向工程的情况下从封闭的文件系统中读取。
尽管有这种特殊的情况存在,还是仍然有很多文件系统可以使用,选择哪个取决于驱动器的用途。如果你希望你的驱动器兼容多个系统,那么你唯一的选择是 exFAT 文件系统。然而微软尚未向任何开源内核提交 exFAT 的代码,因此你可能必须在软件包管理器中安装 exFAT 支持,但是 Windows 和 MacOS 都支持 exFAT 文件系统。
一旦你安装了 exFAT 支持,你可以在驱动器上你创建好的分区中创建一个 exFAT 文件系统。
```
# mkfs.exfat -n myExFatDrive /dev/sdx1
```
现在你的驱动器可由封闭系统和其它开源的系统(尚未经过微软批准)内核模块进行读写了。
Linux 中常见的文件系统是 [ext4](https://opensource.com/article/17/5/introduction-ext4-filesystem)。但对于便携式的设备来说,这可能是一个麻烦的文件系统,因为它保留了用户的权限,这些权限通常因为计算机而异,但是它通常是一个可靠而灵活的文件系统。只要你熟悉管理权限,那 ext4 对于便携式的设备来说就是一个很棒的文件系统。
```
# mkfs.ext4 -L myExt4Drive /dev/sdx1
```
拔掉你的驱动器,再把它插回去。对于 ext4 文件系统的便携设备来说,使用 `sudo` 创建一个目录,并将该目录的权限授予用户和系统中通用的组。如果你不确定使用哪个用户和组,也可以使用 `sudo` 或 `root` 来修改出现问题的设备的读写权限。
### 使用桌面工具
很高兴知道了在只有一个 Linux shell 的时候如何操作和处理你的块设备,但是,有时候你仅仅是想让一个驱动器可用,而不需要进行那么多的检测。 GNOME 的 KDE 的开发者们提供了这样的一些优秀的工具让这个过程变得简单。
[GNOME 磁盘](https://wiki.gnome.org/Apps/Disks) 和 [KDE 分区管理器](https://www.kde.org/applications/system/kdepartitionmanager/) 是一个图形化的工具,为本文到目前为止提到的一切提供了一个一体化的解决方案。启动其中的任何一个,来查看所有连接的设备(在左侧列表中),创建和调整分区大小,和创建文件系统。

*KDE 分区管理器*
可以预见的是,GNOME 版本会比 KDE 版本更加简单,因此,我将使用复杂的版本进行演示——如果你愿意动手的话,很容易弄清楚 GNOME 磁盘工具的使用。
启动 KDE 分区管理工具,然后输入你的 root 密码。
在最左边的一列,选择你想要格式化的驱动器。如果你的驱动器并没有列出来,确认下是否已经插好,然后选择 “Tools > Refresh devices” (或使用键盘上的 F5 键)。
除非你想销毁驱动器已经存在的分区表,否则请勿继续。选择好驱动器后,单击顶部工具栏中的 “New Partition Table” 。系统会提示你为该分区选择一种卷标:gpt 或 msdos 。前者更加灵活可以处理更大的驱动器,而后者像很多微软的技术一样,是占据大量市场份额的事实上的标准。
现在您有了一个新的分区表,在右侧的面板中右键单击你的设备,然后选择 “New” 来创建新的分区,按照提示设置分区的类型和大小。此操作包括了分区步骤和创建文件系统。

*创建一个新分区*
要将更改应用于你的驱动器,单击窗口左上角的 “Apply” 按钮。
### 硬盘驱动器,轻松驱动
在 Linux 上处理硬盘驱动器很容易,甚至如果你理解硬盘驱动器的语言就更容易了。自从切换到 Linux 系统以来,我已经能够以任何我想要的方式来处理我的硬盘驱动器了。由于 Linux 在处理存储提供的透明性,因此恢复数据也变得更加容易了。
如果你想实验并了解有关硬盘驱动器的更多的信息,请参考下面的几个提示:
1. 备份您的数据,而不仅仅是你在实验的驱动器上。仅仅需要一个小小的错误操作来破坏一个重要驱动器的分区。(这是一个用来学习重建丢失分区的很好的方法,但并不是很有趣)。
2. 反复确认你所定位的驱动器是正确的驱动器。我经常使用 `lsblk` 来确定我并没有移动驱动器。(因为从两个独立的 USB 端口移除两个驱动器很容易,然后以不同的顺序重新连接它们,就会很容易导致它们获得了新的驱动器标签。)
3. 花点时间“销毁”你测试的驱动器,看看你是否可以把数据恢复。在删除文件系统后,重新创建分区表或尝试恢复数据是一个很好的学习体验。
还有一些更好玩的东西,如果你身边有一个封闭的操作系统,在上面尝试使用一个开源的文件系统。有一些项目致力于解决这种兼容性,并且尝试让它们以一种可靠稳定的方式工作是一个很好的业余项目。
---
via: <https://opensource.com/article/18/11/partition-format-drive-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Jamskr](https://github.com/Jamskr) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | On most computer systems, Linux or otherwise, when you plug a USB thumb drive in, you're alerted that the drive exists. If the drive is already partitioned and formatted to your liking, you just need your computer to list the drive somewhere in your file manager window or on your desktop. It's a simple requirement and one that the computer generally fulfills.
Sometimes, however, a drive isn't set up the way you want. For those times, you need to know how to find and prepare a storage device connected to your machine.
## What are block devices?
A hard drive is generically referred to as a "block device" because hard drives read and write data in fixed-size blocks. This differentiates a hard drive from anything else you might plug into your computer, like a printer, gamepad, microphone, or camera. The easy way to list the block devices attached to your Linux system is to use the **lsblk** (list block devices) command:
```
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 238.5G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 237.5G 0 part
└─luks-e2bb...e9f8 253:0 0 237.5G 0 crypt
├─fedora-root 253:1 0 50G 0 lvm /
├─fedora-swap 253:2 0 5.8G 0 lvm [SWAP]
└─fedora-home 253:3 0 181.7G 0 lvm /home
sdb 8:16 1 14.6G 0 disk
└─sdb1 8:17 1 14.6G 0 part
```
The device identifiers are listed in the left column, each beginning with **sd**, and ending with a letter, starting with **a**. Each partition of each drive is assigned a number, starting with **1**. For example, the second partition of the first drive is **sda2**. If you're not sure what a partition is, that's OK—just keep reading.
The **lsblk** command is nondestructive and used only for probing, so you can run it without any fear of ruining data on a drive.
## Testing with dmesg
If in doubt, you can test device label assignments by looking at the tail end of the **dmesg** command, which displays recent system log entries including kernel events (such as attaching and detaching a drive). For instance, if you want to make sure a thumb drive is *really* **/dev/sdc**, plug the drive into your computer and run this **dmesg** command:
`$ sudo dmesg | tail`
The most recent drive listed is the one you just plugged in. If you unplug it and run that command again, you'll see the device has been removed. If you plug it in again and run the command, the device will be there. In other words, you can monitor the kernel's awareness of your drive.
Understanding filesystems
If all you need is the device label, your work is done. But if your goal is to create a usable drive, you must give the drive a filesystem.
If you're not sure what a filesystem is, it's probably easier to understand the concept by learning what happens when you have no filesystem at all. If you have a spare drive that has *no important data on it whatsoever*, you can follow along with this example. Otherwise, *do not* attempt this exercise, because it will DEFINITELY ERASE DATA, by design.
It is possible to utilize a drive without a filesystem. Once you have definitely, correctly identified a drive, and you have *absolutely* verified there is nothing important on it, plug it into your computer—but do not mount it. If it auto-mounts, then unmount it manually.
```
$ su -
# umount /dev/sdx{,1}
```
To safeguard against disastrous copy-paste errors, these examples use the unlikely **sdx** label for the drive.
Now that the drive is unmounted, try this:
`# echo 'hello world' > /dev/sdx`
You have just written data to the block device without it being mounted on your system or having a filesystem.
To retrieve the data you just wrote, you can view the raw data on the drive:
```
# head -n 1 /dev/sdx
hello world
```
That seemed to work pretty well, but imagine that the phrase "hello world" is one file. If you want to write a new "file" using this method, you must:
- Know there's already an existing "file" on line 1
- Know that the existing "file" takes up only 1 line
- Derive a way to append new data, or else rewrite line 1 while writing line 2
For example:
```
# echo 'hello world
> this is a second file' >> /dev/sdx
```
To get the first file, nothing changes.
```
# head -n 1 /dev/sdx
hello world
```
But it's more complex to get the second file.
```
# head -n 2 /dev/sdx | tail -n 1
this is a second file
```
Obviously, this method of writing and reading data is not practical, so developers have created systems to keep track of what constitutes a file, where one file begins and ends, and so on.
Most filesystems require a partition.
## Creating partitions
A partition on a hard drive is a sort of boundary on the device telling each filesystem what space it can occupy. For instance, if you have a 4GB thumb drive, you can have a partition on that device taking up the entire drive (4GB), two partitions that each take 2GB (or 1 and 3, if you prefer), three of some variation of sizes, and so on. The combinations are nearly endless.
Assuming your drive is 4GB, you can create one big partition from a terminal with the GNU **parted** command:
`# parted /dev/sdx --align opt mklabel msdos 0 4G`
This command specifies the device path first, as required by **parted**.
The **--align** option lets **parted** find the partition's optimal starting and stopping point.
The **mklabel** command creates a partition table (called a *disk label*) on the device. This example uses the **msdos** label because it's a very compatible and popular label, although **gpt** is becoming more common.
The desired start and end points of the partition are defined last. Since the **--align opt** flag is used, **parted** will adjust the size as needed to optimize drive performance, but these numbers serve as a guideline.
Next, create the actual partition. If your start and end choices are not optimal, **parted** warns you and asks if you want to make adjustments.
```
# parted /dev/sdx -a opt mkpart primary 0 4G
Warning: The resulting partition is not properly aligned for best performance: 1s % 2048s != 0s
Ignore/Cancel? C
# parted /dev/sdx -a opt mkpart primary 2048s 4G
```
If you run **lsblk** again (you may have to unplug the drive and plug it back in), you'll see that your drive now has one partition on it.
## Manually creating a filesystem
There are many filesystems available. Some are free and open source, while others are not. Some companies decline to support open source filesystems, so their users can't read from open filesystems, while open source users can't read from closed ones without reverse-engineering them.
This disconnect notwithstanding, there are lots of filesystems you can use, and the one you choose depends on the drive's purpose. If you want a drive to be compatible across many systems, then your only choice right now is the exFAT filesystem. Microsoft has not submitted exFAT code to any open source kernel, so you may have to install exFAT support with your package manager, but support for exFAT is included in both Windows and MacOS.
Once you have exFAT support installed, you can create an exFAT filesystem on your drive in the partition you created.
`# mkfs.exfat -n myExFatDrive /dev/sdx1`
Now your drive is readable and writable by closed systems and by open source systems utilizing additional (and as-yet unsanctioned by Microsoft) kernel modules.
A common filesystem native to Linux is [ext4](https://opensource.com/article/17/5/introduction-ext4-filesystem). It's arguably a troublesome filesystem for portable drives since it retains user permissions, which are often different from one computer to another, but it's generally a reliable and flexible filesystem. As long as you're comfortable managing permissions, ext4 is a great, journaled filesystem for portable drives.
`# mkfs.ext4 -L myExt4Drive /dev/sdx1`
Unplug your drive and plug it back in. For ext4 portable drives, use **sudo** to create a directory and grant permission to that directory to a user and a group common across your systems. If you're not sure what user and group to use, you can either modify read/write permissions with **sudo** or root on the system that's having trouble with the drive.
## Using desktop tools
It's great to know how to deal with drives with nothing but a Linux shell standing between you and the block device, but sometimes you just want to get a drive ready to use without so much insightful probing. Excellent tools from both the GNOME and KDE developers can make your drive prep easy.
[GNOME Disks](https://wiki.gnome.org/Apps/Disks) and [KDE Partition Manager](https://www.kde.org/applications/system/kdepartitionmanager/) are graphical interfaces providing an all-in-one solution for everything this article has explained so far. Launch either of these applications to see a list of attached devices (in the left column), create or resize partitions, and create a filesystem.
KDE Partition Manager
The GNOME version is, predictably, simpler than the KDE version, so I'll demo the more complex one—it's easy to figure out GNOME Disks if that's what you have handy.
Launch KDE Partition Manager and enter your root password.
From the left column, select the disk you want to format. If your drive isn't listed, make sure it's plugged in, then select **Tools** > **Refresh devices** (or **F5** on your keyboard).
*Don't continue unless you're ready to destroy the drive's existing partition table.* With the drive selected, click **New Partition Table** in the top toolbar. You'll be prompted to select the label you want to give the partition table: either **gpt** or **msdos**. The former is more flexible and can handle larger drives, while the latter is, like many Microsoft technologies, the de-facto standard by force of market share.
Now that you have a fresh partition table, right-click on your device in the right panel and select **New** to create a new partition. Follow the prompts to set the type and size of your partition. This action combines the partitioning step with creating a filesystem.
Creating a new partition
To apply your changes to the drive, click the **Apply** button in the top-left corner of the window.
## Hard drives, easy drives
Dealing with hard drives is easy on Linux, and it's even easier if you understand the language of hard drives. Since switching to Linux, I've been better equipped to prepare drives in whatever way I want them to work for me. It's also been easier for me to recover lost data because of the transparency Linux provides when dealing with storage.
Here are a final few tips, if you want to experiment and learn more about hard drives:
- Back up your data, and not just the data on the drive you're experimenting with. All it takes is one wrong move to destroy the partition of an important drive (which is a great way to learn about recreating lost partitions, but not much fun).
- Verify and then re-verify that the drive you are targeting is the correct drive. I frequently use
**lsblk**to make sure I haven't moved drives around on myself. (It's easy to remove two drives from two separate USB ports, then mindlessly reattach them in a different order, causing them to get new drive labels.) - Take the time to "destroy" a test drive and see if you can recover the data. It's a good learning experience to recreate a partition table or try to get data back after a filesystem has been removed.
For extra fun, if you have a closed operating system lying around, try getting an open source filesystem working on it. There are a few projects working toward this kind of compatibility, and trying to get them working in a stable and reliable way is a good weekend project.
## Comments are closed. |
10,303 | 使用 Selenium 自动化 Web 浏览器 | https://fedoramagazine.org/automate-web-browser-selenium/ | 2018-12-02T22:11:41 | [
"浏览器",
"测试"
] | https://linux.cn/article-10303-1.html | 
[Selenium](https://www.seleniumhq.org/) 是浏览器自动化的绝佳工具。使用 Selenium IDE,你可以录制命令序列(如单击、拖动和输入),验证结果并最终存储此自动化测试供日后使用。这非常适合在浏览器中进行活跃开发。但是当你想要将这些测试与 CI/CD 流集成时,是时候使用 Selenium WebDriver 了。
WebDriver 公开了一个绑定了许多编程语言的 API,它允许你将浏览器测试与其他测试集成。这篇文章向你展示了如何在容器中运行 WebDriver 并将其与 Python 程序一起使用。
### 使用 Podman 运行 Selenium
Podman 是下面例子的容器运行时。有关如何开始使用 Podman 的信息,请参见[此前文章](/article-10156-1.html)。
此例使用了 Selenium 的独立容器,其中包含 WebDriver 服务器和浏览器本身。要在后台启动服务器容器,请运行以下命令:
```
$ podman run -d --network host --privileged --name server docker.io/selenium/standalone-firefox
```
当你使用特权标志和主机网络运行容器时,你可以稍后从在 Python 中连接到此容器。你不需要使用 `sudo`。
### 在 Python 中使用 Selenium
现在你可以提供一个使用此服务器的简单程序。这个程序很小,但应该会让你知道可以做什么:
```
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
server ="http://127.0.0.1:4444/wd/hub"
driver = webdriver.Remote(command_executor=server,
desired_capabilities=DesiredCapabilities.FIREFOX)
print("Loading page...")
driver.get("https://fedoramagazine.org/")
print("Loaded")
assert "Fedora" in driver.title
driver.quit()
print("Done.")
```
首先,程序连接到你已经启动的容器。然后它加载 Fedora Magazine 网页并判断 “Fedora” 是页面标题的一部分。最后,它退出会话。
需要 Python 绑定才能运行此程序。既然你已经在使用容器了,为什么不在容器中这样做呢?将以下内容保存到 Dockerfile 中:
```
FROM fedora:29
RUN dnf -y install python3
RUN pip3 install selenium
```
然后使用 Podman 在与 Dockerfile 相同的文件夹中构建容器镜像:
```
$ podman build -t selenium-python .
```
要在容器中运行程序,在运行容器时将包含 Python 代码的文件作为卷挂载:
```
$ podman run -t --rm --network host \
-v $(pwd)/browser-test.py:/browser-test.py:z \
selenium-python python3 browser-test.py
```
输出看上去像这样:
```
Loading page...
Loaded
Done.
```
### 接下来做什么
上面的示例程序是最小的,也许没那么有用。但这仅仅是最表面的东西!查看 [Selenium](https://www.seleniumhq.org/docs/) 和 [Python 绑定](https://selenium-python.readthedocs.io) 的文档。在那里,你将找到有关如何在页面中查找元素、处理弹出窗口或填写表单的示例。拖放也是可能的,当然还有等待事件。
在实现一些不错的测试后,你可能希望将它们包含在 CI/CD 流程中。幸运的是,这是相当直接的,因为一切都是容器化的。
你可能也有兴趣设置 [grid](https://www.seleniumhq.org/docs/07_selenium_grid.jsp) 来并行运行测试。这不仅有助于加快速度,还允许你同时测试多个不同的浏览器。
### 清理
当你容器使用完后,可以使用以下命令停止并删除独立容器:
```
$ podman stop server
$ podman rm server
```
如果你还想释放磁盘空间,请运行以下命令删除镜像:
```
$ podman rmi docker.io/selenium/standalone-firefox
$ podman rmi selenium-python fedora:29
```
### 总结
在本篇中,你已经看到使用容器技术开始使用 Selenium 是多么容易。它允许你自动化与网站的交互,以及测试交互。Podman 允许你在没有超级用户权限或 Docker 守护程序的情况下运行所需的容器。最后,Python 绑定允许你使用普通的 Python 代码与浏览器进行交互。
---
via: <https://fedoramagazine.org/automate-web-browser-selenium/>
作者:[Lennart Jern](https://fedoramagazine.org/author/lennartj/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Selenium](https://www.seleniumhq.org/) is a great tool for browser automation. With Selenium IDE you can *record* sequences of commands (like click, drag and type), validate the result and finally store this automated test for later. This is great for active development in the browser. But when you want to integrate these tests with your CI/CD flow it’s time to move on to Selenium WebDriver.
WebDriver exposes an API with bindings for many programming languages, which lets you integrate browser tests with your other tests. This post shows you how to run WebDriver in a container and use it together with a Python program.
## Running Selenium with Podman
Podman is the container runtime in the following examples. See [this previous post](https://fedoramagazine.org/running-containers-with-podman/) for how to get started with Podman.
This example uses a standalone container for Selenium that contains both the WebDriver server and the browser itself. To launch the server container in the background run the following comand:
$ podman run -d --network host --privileged --name server \ docker.io/selenium/standalone-firefox
When you run the container with the privileged flag and host networking, you can connect to this container later from a Python program. You do not need to use *sudo*.
## Using Selenium from Python
Now you can provide a simple program that uses this server. This program is minimal, but should give you an idea about what you can do:
from selenium import webdriver from selenium.webdriver.common.desired_capabilities import DesiredCapabilities server ="http://127.0.0.1:4444/wd/hub" driver = webdriver.Remote(command_executor=server, desired_capabilities=DesiredCapabilities.FIREFOX) print("Loading page...") driver.get("[https://fedoramagazine.org/]") print("Loaded") assert "Fedora" in driver.title driver.quit() print("Done.")
First the program connects to the container you already started. Then it loads the Fedora Magazine web page and asserts that “Fedora” is part of the page title. Finally, it quits the session.
Python bindings are required in order to run the program. And since you’re already using containers, why not do this in a container as well? Save the following to a file name *Dockerfile:*
FROM fedora:29 RUN dnf -y install python3 RUN pip3 install selenium
Then build your container image using Podman, in the same folder as *Dockerfile:*
$ podman build -t selenium-python .
To run your program in the container, mount the file containing your Python code as a volume when you run the container:
$ podman run -t --rm --network host \ -v $(pwd)/browser-test.py:/browser-test.py:z \ selenium-python python3 browser-test.py
The output should look like this:
Loading page... Loaded Done.
## What to do next
The example program above is minimal, and perhaps not that useful. But it barely scratched the surface of what’s possible! Check out the documentation for [Selenium](https://www.seleniumhq.org/docs/) and for the [Python bindings](https://selenium-python.readthedocs.io). There you’ll find examples for how to locate elements in a page, handle popups, or fill in forms. Drag and drop is also possible, and of course waiting for various events.
With a few nice tests implemented, you may want to include the whole thing in your CI/CD pipeline. Luckily enough, this is fairly straightforward since everything was containerized to begin with.
You may also be interested in setting up a [grid](https://www.seleniumhq.org/docs/07_selenium_grid.jsp) to run the tests in parallel. Not only does this help speed things up, but it also allows you to test several different browsers at the same time.
## Cleaning up
When you’re done playing with your containers, you can stop and remove the standalone container with the following commands:
$ podman stop server $ podman rm server
If you also want to free up disk space, run these commands to remove the images as well:
$ podman rmi docker.io/selenium/standalone-firefox $ podman rmi selenium-python fedora:29
## Conclusion
In this post, you’ve seen how easy it is to get started with Selenium using container technology. It allowed you to automate interaction with a website, as well as test the interaction. Podman allowed you to run the containers necessary without super user privileges or the Docker daemon. Finally, the Python bindings let you use normal Python code to interact with the browser.
Photo by [Rodion Kutsaev](https://unsplash.com/photos/kT919LwyxTg?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/search/photos/automation?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText).
## Yazan Al Monshed
Great Tool.
## Hector
Awesome. Enjoyed the article.
## Steve
Loved it! A practical application of Silverblue being used to do real work.
## rfth
how checking error in geted web page?
how simulating moving mouse?
## Lennart Jern
I’m not sure what you mean by error in the page? You can assert all kinds of things, like visibility of an element for example.
As for moving the mouse, check this: https://stackoverflow.com/questions/47261078/how-to-mouse-hover-using-java-through-selenium-webdriver-and-java
It is a bit hard to find documentation about this unfortunately but I was able to find this: https://seleniumhq.github.io/selenium/docs/api/py/webdriver/selenium.webdriver.common.action_chains.html#module-selenium.webdriver.common.action_chains
I hope it helps!
## dee
normal: 404,503, time out, trouble with selenium.
I have very slow internet and sometimes not read big web page.
how load ‘get’ web page if download image save to disk and still wait what load other element etc. |
10,304 | 对网站进行归档 | https://anarc.at/blog/2018-10-04-archiving-web-sites/ | 2018-12-03T10:07:00 | [
"归档",
"Web"
] | https://linux.cn/article-10304-1.html | 
我最近深入研究了网站归档,因为有些朋友担心遇到糟糕的系统管理或恶意删除时失去对放在网上的内容的控制权。这使得网站归档成为系统管理员工具箱中的重要工具。事实证明,有些网站比其他网站更难归档。本文介绍了对传统网站进行归档的过程,并阐述在面对最新流行单页面应用程序(SPA)的现代网站时,它有哪些不足。
### 转换为简单网站
手动编码 HTML 网站的日子早已不复存在。现在的网站是动态的,并使用最新的 JavaScript、PHP 或 Python 框架即时构建。结果,这些网站更加脆弱:数据库崩溃、升级出错或者未修复的漏洞都可能使数据丢失。在我以前是一名 Web 开发人员时,我不得不接受客户这样的想法:希望网站基本上可以永久工作。这种期望与 web 开发“快速行动和破除陈规”的理念不相符。在这方面,使用 [Drupal](https://drupal.org) 内容管理系统(CMS)尤其具有挑战性,因为重大更新会破坏与第三方模块的兼容性,这意味着客户很少承担的起高昂的升级成本。解决方案是将这些网站归档:以实时动态的网站为基础,将其转换为任何 web 服务器可以永久服务的纯 HTML 文件。此过程对你自己的动态网站非常有用,也适用于你想保护但无法控制的第三方网站。
对于简单的静态网站,古老的 [Wget](https://www.gnu.org/software/wget/) 程序就可以胜任。然而镜像保存一个完整网站的命令却是错综复杂的:
```
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
--backup-converted --page-requisites --adjust-extension \
--base=./ --directory-prefix=./ --span-hosts \
--domains=www.example.com,example.com http://www.example.com/
```
以上命令下载了网页的内容,也抓取了指定域名中的所有内容。在对你喜欢的网站执行此操作之前,请考虑此类抓取可能对网站产生的影响。上面的命令故意忽略了 `robots.txt` 规则,就像现在[归档者的习惯做法](https://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/),并以尽可能快的速度归档网站。大多数抓取工具都可以选择在两次抓取间暂停并限制带宽使用,以避免使网站瘫痪。
上面的命令还将获取 “页面所需(LCTT 译注:单页面所需的所有元素)”,如样式表(CSS)、图像和脚本等。下载的页面内容将会被修改,以便链接也指向本地副本。任何 web 服务器均可托管生成的文件集,从而生成原始网站的静态副本。
以上所述是事情一切顺利的时候。任何使用过计算机的人都知道事情的进展很少如计划那样;各种各样的事情可以使程序以有趣的方式脱离正轨。比如,在网站上有一段时间很流行日历块。内容管理系统会动态生成这些内容,这会使爬虫程序陷入死循环以尝试检索所有页面。灵巧的归档者可以使用正则表达式(例如 Wget 有一个 `--reject-regex` 选项)来忽略有问题的资源。如果可以访问网站的管理界面,另一个方法是禁用日历、登录表单、评论表单和其他动态区域。一旦网站变成静态的,(那些动态区域)也肯定会停止工作,因此从原始网站中移除这些杂乱的东西也不是全无意义。
### JavaScript 噩梦
很不幸,有些网站不仅仅是纯 HTML 文件构建的。比如,在单页面网站中,web 浏览器通过执行一个小的 JavaScript 程序来构建内容。像 Wget 这样的简单用户代理将难以重建这些网站的有意义的静态副本,因为它根本不支持 JavaScript。理论上,网站应该使用[渐进增强](https://en.wikipedia.org/wiki/Progressive_enhancement)技术,在不使用 JavaScript 的情况下提供内容和实现功能,但这些指引很少被人遵循 —— 使用过 [NoScript](https://noscript.net/) 或 [uMatrix](https://github.com/gorhill/uMatrix) 等插件的人都知道。
传统的归档方法有时会以最愚蠢的方式失败。在尝试为一个本地报纸网站([pamplemousse.ca](https://pamplemousse.ca/))创建备份时,我发现 WordPress 在包含 的 JavaScript 末尾添加了查询字符串(例如:`?ver=1.12.4`)。这会使提供归档服务的 web 服务器不能正确进行内容类型检测,因为其靠文件扩展名来发送正确的 `Content-Type` 头部信息。在 web 浏览器加载此类归档时,这些脚本会加载失败,导致动态网站受损。
随着 web 向使用浏览器作为执行任意代码的虚拟机转化,依赖于纯 HTML 文件解析的归档方法也需要随之适应。这个问题的解决方案是在抓取时记录(以及重现)服务器提供的 HTTP 头部信息,实际上专业的归档者就使用这种方法。
### 创建和显示 WARC 文件
在 <ruby> <a href="https://archive.org"> 互联网档案馆 </a> <rt> Internet Archive </rt></ruby> 网站,Brewster Kahle 和 Mike Burner 在 1996 年设计了 [ARC](http://www.archive.org/web/researcher/ArcFileFormat.php) (即 “ARChive”)文件格式,以提供一种聚合其归档工作所产生的百万个小文件的方法。该格式最终标准化为 WARC(“Web ARChive”)[规范](https://iipc.github.io/warc-specifications/),并在 2009 年作为 ISO 标准发布,2017 年修订。标准化工作由<ruby> <a href="https://en.wikipedia.org/wiki/International_Internet_Preservation_Consortium"> 国际互联网保护联盟 </a> <rt> International Internet Preservation Consortium </rt></ruby>(IIPC)领导,据维基百科称,这是一个“*为了协调为未来而保护互联网内容的努力而成立的国际图书馆组织和其他组织*”;它的成员包括<ruby> 美国国会图书馆 <rt> US Library of Congress </rt></ruby>和互联网档案馆等。后者在其基于 Java 的 [Heritrix crawler](https://github.com/internetarchive/heritrix3/wiki)(LCTT 译注:一种爬虫程序)内部使用了 WARC 格式。
WARC 在单个压缩文件中聚合了多种资源,像 HTTP 头部信息、文件内容,以及其他元数据。方便的是,Wget 实际上提供了 `--warc` 参数来支持 WARC 格式。不幸的是,web 浏览器不能直接显示 WARC 文件,所以为了访问归档文件,一个查看器或某些格式转换是很有必要的。我所发现的最简单的查看器是 [pywb](https://github.com/webrecorder/pywb),它以 Python 包的形式运行一个简单的 web 服务器提供一个像“<ruby> 时光倒流机网站 <rt> Wayback Machine </rt></ruby>”的界面,来浏览 WARC 文件的内容。执行以下命令将会在 `http://localhost:8080/` 地址显示 WARC 文件的内容:
```
$ pip install pywb
$ wb-manager init example
$ wb-manager add example crawl.warc.gz
$ wayback
```
顺便说一句,这个工具是由 [Webrecorder](https://webrecorder.io/) 服务提供者建立的,Webrecoder 服务可以使用 web 浏览器保存动态页面的内容。
很不幸,pywb 无法加载 Wget 生成的 WARC 文件,因为它[遵循](https://github.com/webrecorder/pywb/issues/294)的 [1.0 规范不一致](https://github.com/iipc/warc-specifications/issues/23),[1.1 规范修复了此问题](https://github.com/iipc/warc-specifications/issues/23)。就算 Wget 或 pywb 修复了这些问题,Wget 生成的 WARC 文件对我的使用来说不够可靠,所以我找了其他的替代品。引起我注意的爬虫程序简称 [crawl](https://git.autistici.org/ale/crawl/)。以下是它的调用方式:
```
$ crawl https://example.com/
```
(它的 README 文件说“非常简单”。)该程序支持一些命令行参数选项,但大多数默认值都是最佳的:它会从其他域获取页面所需(除非使用 `-exclude-related` 参数),但肯定不会递归出域。默认情况下,它会与远程站点建立十个并发连接,这个值可以使用 `-c` 参数更改。但是,最重要的是,生成的 WARC 文件可以使用 pywb 完美加载。
### 未来的工作和替代方案
这里还有更多有关使用 WARC 文件的[资源](https://archiveteam.org/index.php?title=The_WARC_Ecosystem)。特别要提的是,这里有一个专门用来归档网站的 Wget 的直接替代品,叫做 [Wpull](https://github.com/chfoo/wpull)。它实验性地支持了 [PhantomJS](http://phantomjs.org/) 和 [youtube-dl](http://rg3.github.io/youtube-dl/) 的集成,即允许分别下载更复杂的 JavaScript 页面以及流媒体。该程序是一个叫做 [ArchiveBot](https://www.archiveteam.org/index.php?title=ArchiveBot) 的复杂归档工具的基础,ArchiveBot 被那些在 [ArchiveTeam](https://archiveteam.org/) 的“*零散离群的归档者、程序员、作家以及演说家*”使用,他们致力于“*在历史永远丢失之前保存它们*”。集成 PhantomJS 好像并没有如团队期望的那样良好工作,所以 ArchiveTeam 也用其它零散的工具来镜像保存更复杂的网站。例如,[snscrape](https://github.com/JustAnotherArchivist/snscrape) 将抓取一个社交媒体配置文件以生成要发送到 ArchiveBot 的页面列表。该团队使用的另一个工具是 [crocoite](https://github.com/PromyLOPh/crocoite),它使用无头模式的 Chrome 浏览器来归档 JavaScript 较多的网站。
如果没有提到称做“网站复制者”的 [HTTrack](http://www.httrack.com/) 项目,那么这篇文章算不上完整。它工作方式和 Wget 相似,HTTrack 可以对远程站点创建一个本地的副本,但是不幸的是它不支持输出 WRAC 文件。对于不熟悉命令行的小白用户来说,它在人机交互方面显得更有价值。
同样,在我的研究中,我发现了叫做 [Wget2](https://gitlab.com/gnuwget/wget2) 的 Wget 的完全重制版本,它支持多线程操作,这可能使它比前身更快。和 Wget 相比,它[舍弃了一些功能](https://gitlab.com/gnuwget/wget2/wikis/home),但是最值得注意的是拒绝模式、WARC 输出以及 FTP 支持,并增加了 RSS、DNS 缓存以及改进的 TLS 支持。
最后,我个人对这些工具的愿景是将它们与我现有的书签系统集成起来。目前我在 [Wallabag](https://wallabag.org/) 中保留了一些有趣的链接,这是一种自托管式的“稍后阅读”服务,意在成为 [Pocket](https://getpocket.com/)(现在由 Mozilla 拥有)的免费替代品。但是 Wallabag 在设计上只保留了文章的“可读”副本,而不是一个完整的拷贝。在某些情况下,“可读版本”实际上[不可读](https://github.com/wallabag/wallabag/issues/2825),并且 Wallabag 有时[无法解析文章](https://github.com/wallabag/wallabag/issues/2914)。恰恰相反,像 [bookmark-archiver](https://pirate.github.io/bookmark-archiver/) 或 [reminiscence](https://github.com/kanishka-linux/reminiscence) 这样其他的工具会保存页面的屏幕截图以及完整的 HTML 文件,但遗憾的是,它没有 WRAC 文件所以没有办法更可信的重现网页内容。
我所经历的有关镜像保存和归档的悲剧就是死数据。幸运的是,业余的归档者可以利用工具将有趣的内容保存到网上。对于那些不想麻烦的人来说,“互联网档案馆”看起来仍然在那里,并且 ArchiveTeam 显然[正在为互联网档案馆本身做备份](http://iabak.archiveteam.org)。
---
via: <https://anarc.at/blog/2018-10-04-archiving-web-sites/>
作者:[Anarcat](https://anarc.at) 选题:[lujun9972](https://github.com/lujun9972) 译者:[fuowang](https://github.com/fuowang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Archiving web sites
I recently took a deep dive into web site archival for friends who were worried about losing control over the hosting of their work online in the face of poor system administration or hostile removal. This makes web site archival an essential instrument in the toolbox of any system administrator. As it turns out, some sites are much harder to archive than others. This article goes through the process of archiving traditional web sites and shows how it falls short when confronted with the latest fashions in the single-page applications that are bloating the modern web.
Converting simple sites
The days of handcrafted HTML web sites are long gone. Now web sites are
dynamic and built on the fly using the latest JavaScript, PHP, or Python
framework. As a result, the sites are more fragile: a database crash,
spurious upgrade, or unpatched vulnerability might lose data. In my
previous life as web developer, I had to come to terms with the idea
that customers expect web sites to basically work forever. This
expectation matches poorly with "move fast and break things" attitude
of web development. Working with the [Drupal](https://drupal.org) content-management
system (CMS) was particularly challenging in that regard as major
upgrades deliberately break compatibility with third-party modules,
which implies a costly upgrade process that clients could seldom afford.
The solution was to archive those sites: take a living, dynamic web site
and turn it into plain HTML files that any web server can serve forever.
This process is useful for your own dynamic sites but also for
third-party sites that are outside of your control and you might want to
safeguard.
For simple or static sites, the venerable [Wget](https://www.gnu.org/software/wget/) program works well.
The incantation to mirror a full web site, however, is byzantine:
```
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
--backup-converted --page-requisites --adjust-extension \
--base=./ --directory-prefix=./ --span-hosts \
--domains=www.example.com,example.com http://www.example.com/
```
The above downloads the content of the web page, but also crawls
everything within the specified domains. Before you run this against
your favorite site, consider the impact such a crawl might have on the
site. The above command line deliberately ignores [ robots.txt](https://en.wikipedia.org/wiki/Robots_exclusion_standard)
rules, as is now
[common practice for archivists](https://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/), and hammer the website as fast as it can. Most crawlers have options to pause between hits and limit bandwidth usage to avoid overwhelming the target site.
The above command will also fetch "page requisites" like style sheets (CSS), images, and scripts. The downloaded page contents are modified so that links point to the local copy as well. Any web server can host the resulting file set, which results in a static copy of the original web site.
That is, when things go well. Anyone who has ever worked with a computer
knows that things seldom go according to plan; all sorts of things can
make the procedure derail in interesting ways. For example, it was
trendy for a while to have calendar blocks in web sites. A CMS would
generate those on the fly and make crawlers go into an infinite loop
trying to retrieve all of the pages. Crafty archivers can resort to
regular expressions (e.g. Wget has a `--reject-regex`
option) to ignore
problematic resources. Another option, if the administration interface
for the web site is accessible, is to disable calendars, login forms,
comment forms, and other dynamic areas. Once the site becomes static,
those will stop working anyway, so it makes sense to remove such clutter
from the original site as well.
JavaScript doom
Unfortunately, some web sites are built with much more than pure HTML.
In single-page sites, for example, the web browser builds the content
itself by executing a small JavaScript program. A simple user agent like
Wget will struggle to reconstruct a meaningful static copy of those
sites as it does not support JavaScript at all. In theory, web sites
should be using [progressive enhancement](https://en.wikipedia.org/wiki/Progressive_enhancement) to have content and
functionality available without JavaScript but those directives are
rarely followed, as anyone using plugins like [NoScript](https://noscript.net/) or
[uMatrix](https://github.com/gorhill/uMatrix) will confirm.
Traditional archival methods sometimes fail in the dumbest way. When
trying to build an offsite backup of a local newspaper
([pamplemousse.ca](https://pamplemousse.ca/)), I found that WordPress adds query strings (e.g.
`?ver=1.12.4`
) at the end of JavaScript includes. This confuses
content-type detection in the web servers that serve the archive, which
rely on the file extension to send the right `Content-Type`
header. When
such an archive is loaded in a web browser, it fails to load scripts,
which breaks dynamic websites.
As the web moves toward using the browser as a virtual machine to run arbitrary code, archival methods relying on pure HTML parsing need to adapt. The solution for such problems is to record (and replay) the HTTP headers delivered by the server during the crawl and indeed professional archivists use just such an approach.
Creating and displaying WARC files
At the [Internet Archive](https://archive.org), Brewster Kahle and Mike Burner designed the
[ARC](http://www.archive.org/web/researcher/ArcFileFormat.php) (for "ARChive") file format in 1996 to provide a way to
aggregate the millions of small files produced by their archival
efforts. The format was eventually standardized as the WARC ("Web
ARChive") [specification](https://iipc.github.io/warc-specifications/) that was released as an ISO standard in
2009 and revised in 2017. The standardization effort was led by the
[International Internet Preservation Consortium](https://en.wikipedia.org/wiki/International_Internet_Preservation_Consortium) (IIPC), which is an
"*international organization of libraries and other organizations
established to coordinate efforts to preserve internet content for the
future*", according to Wikipedia; it includes members such as the US
Library of Congress and the Internet Archive. The latter uses the WARC
format internally in its Java-based [Heritrix crawler](https://github.com/internetarchive/heritrix3/wiki).
A WARC file aggregates multiple resources like HTTP headers, file
contents, and other metadata in a single compressed archive.
Conveniently, Wget actually supports the file format with the `--warc`
parameter. Unfortunately, web browsers cannot render WARC files
directly, so a viewer or some conversion is necessary to access the
archive. The simplest such viewer I have found is [pywb](https://github.com/webrecorder/pywb), a Python
package that runs a simple webserver to offer a Wayback-Machine-like
interface to browse the contents of WARC files. The following set of
commands will render a WARC file on `http://localhost:8080/`
:
```
$ pip install pywb
$ wb-manager init example
$ wb-manager add example crawl.warc.gz
$ wayback
```
This tool was, incidentally, built by the folks behind the
[Webrecorder](https://webrecorder.io/) service, which can use a web browser to save dynamic
page contents.
Unfortunately, pywb has trouble loading WARC files generated by Wget
because it [followed](https://github.com/webrecorder/pywb/issues/294) an [inconsistency in the 1.0 specification](https://github.com/iipc/warc-specifications/issues/23),
which was [fixed in the 1.1 specification](https://github.com/iipc/warc-specifications/pull/24). Until Wget or pywb fix
those problems, WARC files produced by Wget are not reliable enough for
my uses, so I have looked at other alternatives. A crawler that got my
attention is simply called [crawl](https://git.autistici.org/ale/crawl/). Here is how it is invoked:
```
$ crawl https://example.com/
```
(It *does* say "very simple" in the README.) The program does support
some command-line options, but most of its defaults are sane: it will
fetch page requirements from other domains (unless the
`-exclude-related`
flag is used), but does not recurse out of the
domain. By default, it fires up ten parallel connections to the remote
site, a setting that can be changed with the `-c`
flag. But, best of
all, the resulting WARC files load perfectly in pywb.
Future work and alternatives
There are plenty more [resources](https://archiveteam.org/index.php?title=The_WARC_Ecosystem) for using WARC files. In particular,
there's a Wget drop-in replacement called [Wpull](https://github.com/chfoo/wpull) that is
specifically designed for archiving web sites. It has experimental
support for [PhantomJS](http://phantomjs.org/) and [youtube-dl](http://rg3.github.io/youtube-dl/) integration that should
allow downloading more complex JavaScript sites and streaming
multimedia, respectively. The software is the basis for an elaborate
archival tool called [ArchiveBot](https://www.archiveteam.org/index.php?title=ArchiveBot), which is used by the "*loose
collective of rogue archivists, programmers, writers and loudmouths*"
at [ArchiveTeam](https://archiveteam.org/) in its struggle to "*save the history before it's
lost forever*". It seems that PhantomJS integration does not work as
well as the team wants, so ArchiveTeam also uses a rag-tag bunch of
other tools to mirror more complex sites. For example, [snscrape](https://github.com/JustAnotherArchivist/snscrape) will
crawl a social media profile to generate a list of pages to send into
ArchiveBot. Another tool the team employs is [crocoite](https://github.com/PromyLOPh/crocoite), which uses
the Chrome browser in headless mode to archive JavaScript-heavy sites.
This article would also not be complete without a nod to the [HTTrack](http://www.httrack.com/)
project, the "website copier". Working similarly to Wget, HTTrack
creates local copies of remote web sites but unfortunately does not
support WARC output. Its interactive aspects might be of more interest
to novice users unfamiliar with the command line.
In the same vein, during my research I found a full rewrite of Wget
called [Wget2](https://gitlab.com/gnuwget/wget2) that has support for multi-threaded operation, which
might make it faster than its predecessor. It is [missing some
features](https://gitlab.com/gnuwget/wget2/wikis/home) from Wget, however, most notably reject patterns, WARC
output, and FTP support but adds RSS, DNS caching, and improved TLS
support.
Finally, my personal dream for these kinds of tools would be to have
them integrated with my existing bookmark system. I currently keep
interesting links in [Wallabag](https://wallabag.org/), a self-hosted "read it later"
service designed as a free-software alternative to [Pocket](https://getpocket.com/) (now owned
by Mozilla). But Wallabag, by design, creates only a "readable"
version of the article instead of a full copy. In some cases, the
"readable version" is actually [unreadable](https://github.com/wallabag/wallabag/issues/2825) and Wallabag sometimes
[fails to parse the article](https://github.com/wallabag/wallabag/issues/2914). Instead, other tools like
[bookmark-archiver](https://pirate.github.io/bookmark-archiver/) or [reminiscence](https://github.com/kanishka-linux/reminiscence) save a screenshot of the page
along with full HTML but, unfortunately, no WARC file that would allow
an even more faithful replay.
The sad truth of my experiences with mirrors and archival is that data
dies. Fortunately, amateur archivists have tools at their disposal to
keep interesting content alive online. For those who do not want to go
through that trouble, the Internet Archive seems to be here to stay and
Archive Team is obviously [working on a backup of the Internet Archive
itself](http://iabak.archiveteam.org).
This article[first appeared]in the[Linux Weekly News].As usual, here's the list of issues and patches generated while researching this article:
[fix broken link to WARC specification][sample Apache configuration]for pywb[make job status less chatty]in ArchiveBot[Debian packaging]of the`ia`
commandline tool[document the --large flag]in ArchiveBot[mention collections]in the`ia`
documentation[fix warnings in docs builds]of`ia`
I also want to personally thank the folks in the #archivebot channel for their assistance and letting me play with their toys.
The Pamplemousse crawl is now
[available on the Internet Archive], it might end up in the wayback machine at some point if the Archive curators think it is worth it.Another example of a crawl is
[this archive of two Bloomberg articles]which the "save page now" feature of the Internet archive wasn't able to save correctly. But[webrecorder.io]could! Those pages can be seen in the[web recorder player]to get a better feel of how faithful a WARC file really is.Finally, this article was originally written as a set of notes and documentation in the
[archive]page which may also be of interest to my readers. This blog post will not be updated in the future while the latter wiki page might.
[Edited .](https://gitlab.com/anarcat/anarc.at/-/commits/main/blog/2018-10-04-archiving-web-sites.mdwn) |
10,305 | 提高 Linux 的网络浏览器安全性的 5 个建议 | https://www.linux.com/learn/intro-to-linux/2018/11/5-easy-tips-linux-web-browser-security | 2018-12-03T10:16:59 | [
"浏览器",
"安全"
] | https://linux.cn/article-10305-1.html |
>
> 这些简单的步骤可以大大提高您的在线安全性。
>
>
>

如果你使用 Linux 桌面但从来不使用网络浏览器,那你算得上是百里挑一。网络浏览器是绝大多数人最常用的工具之一,无论是工作、娱乐、看新闻、社交、理财,对网络浏览器的依赖都比本地应用要多得多。因此,我们需要知道如何使用网络浏览器才是安全的。一直以来都有不法的犯罪分子以及他们建立的网页试图窃取私密的信息。正是由于我们需要通过网络浏览器收发大量的敏感信息,安全性就更是至关重要。
对于用户来说,需要采取什么措施呢?在下文中,我会提出一些基本的建议,让你的重要数据不会被他人轻易窃取。尽管我用于演示的是 Firefox 网络浏览器,但其中大部分建议在任何一种网络浏览器当中都可以适用。
### 正确选择浏览器
尽管我提出的建议具有普适性,但是正确选择网络浏览器也是很必要的。网络浏览器的更新频率是它安全性的一个重要体现。网络浏览器会不断暴露出新的问题,因此版本越新的网络浏览器修复的问题就越多,也越安全。在主流的网络浏览器当中,2017 年版本更新的发布量排行榜如下:
1. Chrome 发布了 8 个更新(Chromium 全年跟进发布了大量安全补丁)。
2. Firefox 发布了 7 个更新。
3. Edge 发布了 2 个更新。
4. Safari 发布了 1 个更新(苹果也会每年发布 5 到 6 个安全补丁)。
网络浏览器会经常发布更新,同时用户也要及时升级到最新的版本,否则毫无意义了。尽管大部分流行的 Linux 发行版都会自动更新网络浏览器到最新版本,但还是有一些 Linux 发行版不会自动进行更新,所以最好还是手动保持浏览器更新到最新版本。这就意味着你所使用的 Linux 发行版对应的标准软件库中存放的很可能就不是最新版本的网络浏览器,在这种情况下,你可以随时从网络浏览器开发者提供的最新版本下载页中进行下载安装。
如果你是一个勇于探索的人,你还可以尝试使用测试版或者<ruby> 每日构建 <rt> daily build </rt></ruby>版的网络浏览器,不过,这些版本将伴随着不能稳定运行的可能性。在基于 Ubuntu 的发行版中,你可以使用到每日构建版的 Firefox,只需要执行以下命令添加所需的存储库:
```
sudo apt-add-repository ppa:ubuntu-mozilla-daily/ppa
```
按照以下命令更新 `apt` 并安装每日构建版 Firefox:
```
sudo apt-get update
sudo apt-get install firefox
```
最重要的事情就是永远不要让你的网络浏览器版本过时,必须使用最新版本的网络浏览器。就是这样。如果你没有跟上版本更新的脚步,你使用的将会是一个暴露着各种问题的浏览器。
### 使用隐私窗口
将网络浏览器更新到最新版本之后,又该如何使用呢?答案是使用隐私窗口,如果你确实很重视安全的话。隐私窗口不会保存你的数据:密码?cookie?缓存?历史?什么都不会保存。因此隐私窗口的一个显著缺点就是每次访问常用的网站或者服务时,都得重新输入密码才能登录使用。当然,如果你认为网络浏览器的安全性很重要,就永远都不要保存任何密码。
说到这里,我觉得每一个人都需要让自己的密码变得更强。事实上,大家都应该使用强密码,然后通过管理器来存储。而我的选择是[<ruby> 通用密码管理器 <rt> Universal Password Manager </rt></ruby>](http://upm.sourceforge.net/)。
### 保护好密码
有的人可能会认为,每次都需要重复输入密码,这样的操作太麻烦了。在 Firefox 中,如果你既想保护好自己的密码,又不想经常输入密码,就可以通过<ruby> 主密码 <rt> Master Password </rt></ruby>这一款内置的工具来实现你的需求。起用了这个工具之后,需要输入正确的主密码,才能后续使用保存在浏览器中的其它密码。你可以按照以下步骤进行操作:
1. 打开 Firefox。
2. 点击菜单按钮。
3. 点击“偏好设置”。
4. 在偏好设置页面,点击“隐私与安全”。
5. 在页面中勾选“使用主密码”选项(图 1)。
6. 确认以后,输入新的主密码(图 2)。
7. 重启 Firefox。

*图 1: Firefox 偏好设置页中的主密码设置。*

*图 2:在 Firefox 中设置主密码。*
### 了解你使用的扩展和插件
大多数网络浏览器在保护隐私方面都有很多扩展,你可以根据自己的需求选择不同的扩展。而我自己则选择了一下这些扩展:
* [Firefox Multi-Account Containers](https://addons.mozilla.org/en-US/firefox/addon/multi-account-containers/?src=search) —— 允许将某些站点配置为在容器化选项卡中打开。
* [Facebook Container](https://addons.mozilla.org/en-US/firefox/addon/facebook-container/?src=search) —— 始终在容器化选项卡中打开 Facebook(这个扩展需要 Firefox Multi-Account Containers)。
* [Avast Online Security](https://addons.mozilla.org/en-US/firefox/addon/avast-online-security/?src=search) —— 识别并拦截已知的钓鱼网站,并显示网站的安全评级(由超过 4 亿用户的 Avast 社区支持)。
* [Mining Blocker](https://addons.mozilla.org/en-US/firefox/addon/miningblocker/?src=search) —— 拦截所有使用 CPU 的挖矿工具。
* [PassFF](https://addons.mozilla.org/en-US/firefox/addon/passff/?src=search) —— 通过集成 `pass` (一个 UNIX 密码管理器)以安全存储密码。
* [Privacy Badger](https://addons.mozilla.org/en-US/firefox/addon/privacy-badger17/) —— 自动拦截网站跟踪。
* [uBlock Origin](https://addons.mozilla.org/en-US/firefox/addon/ublock-origin/?src=search) —— 拦截已知的网站跟踪。
除此以外,以下这些浏览器还有很多安全方面的扩展:
* [Firefox](https://addons.mozilla.org/en-US/firefox/search/?q=security)
* [Chrome、Chromium,、Vivaldi](https://chrome.google.com/webstore/search/security)
* [Opera](https://addons.opera.com/en/search/?query=security)
但并非每一个网络浏览器都会向用户提供扩展或插件。例如 Midoria 就只有少量可以开启或关闭的内置插件(图 3),同时这些轻量级浏览器的第三方插件也相当缺乏。

*图 3:Midori 浏览器的插件窗口。*
### 虚拟化
如果担心数据在本地存储会被窃取,也可以在虚拟机上运行网络浏览器。只需要安装诸如 [VirtualBox](https://www.virtualbox.org/) 的软件并安装 Linux 系统,然后就可以在虚拟机中运行任何一款浏览器了。再结合以上几条建议,基本可以保证一定的安全性。
### 事情的真相
实际上,如果你的机器连接到互联网,就永远不能保证 100% 的安全。当然,只要你正确地使用网络浏览器,你的安全系数会更高,数据也不会轻易被窃取。Linux 的一个好处是被安装恶意软件的几率比其它操作系统要低得多。另外,请记住要使用最新版本的网络浏览器、保持更新操作系统,并且谨慎访问一切网站。
你还可以通过 Linux 基金会和 edX 开办的 “[Linux 介绍](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)” 公开课学习到更多这方面的内容。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/11/5-easy-tips-linux-web-browser-security>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,306 | 如何在 Linux 中为每个屏幕设置不同的壁纸 | https://itsfoss.com/wallpaper-multi-monitor/ | 2018-12-03T10:25:46 | [
"壁纸",
"桌面"
] | https://linux.cn/article-10306-1.html |
>
> 如果你想在 Ubuntu 18.04 或任何其他 Linux 发行版上使用 GNOME、MATE 或 Budgie 桌面环境在多个显示器上显示不同的壁纸,这个小工具将帮助你实现这一点。
>
>
>
多显示器设置通常会在 Linux 上出现多个问题,但我不打算在本文中讨论这些问题。我有另外一篇关于 Linux 上多显示器支持的文章。
如果你使用多台显示器,也许你想为每台显示器设置不同的壁纸。我不确定其他 Linux 发行版和桌面环境,但是 [GNOME 桌面](https://www.gnome.org/) 的 Ubuntu 本身并不提供此功能。
不要烦恼!在本教程中,我将向你展示如何使用 GNOME 桌面环境为 Linux 发行版上的每个显示器设置不同的壁纸。
### 在 Ubuntu 18.04 和其他 Linux 发行版上为每个显示器设置不同的壁纸

我将使用一个名为 [HydraPaper](https://github.com/GabMus/HydraPaper) 的小工具在不同的显示器上设置不同的背景。HydraPaper 是一个基于 [GTK](https://www.gtk.org/) 的应用,用于为 [GNOME 桌面环境](https://itsfoss.com/gnome-tricks-ubuntu/)中的每个显示器设置不同的背景。
它还支持 [MATE](https://mate-desktop.org/) 和 [Budgie](https://budgie-desktop.org/home/) 桌面环境。这意味着 Ubuntu MATE 和 [Ubuntu Budgie](https://itsfoss.com/ubuntu-budgie-18-review/) 用户也可以从这个应用中受益。
#### 使用 FlatPak 在 Linux 上安装 HydraPaper
使用 [FlatPak](https://flatpak.org) 可以轻松安装 HydraPaper。Ubuntu 18.04 已 经提供对 FlatPaks 的支持,所以你需要做的就是下载应用文件并双击在 GNOME 软件中心中打开它。
你可以参考这篇文章来了解如何在你的发行版[启用 FlatPak 支持](https://flatpak.org/setup/)。启用 FlatPak 支持后,只需从 [FlatHub](https://flathub.org) 下载并安装即可。
* [下载 HydraPaper](https://flathub.org/apps/details/org.gabmus.hydrapaper)
#### 使用 HydraPaper 在不同的显示器上设置不同的背景
安装完成后,只需在应用菜单中查找 HydraPaper 并启动应用。你将在此处看到“图片”文件夹中的图像,因为默认情况下,应用会从用户的“图片”文件夹中获取图像。
你可以添加自己的文件夹来保存壁纸。请注意,它不会递归地查找图像。如果你有嵌套文件夹,它将只显示顶部文件夹中的图像。

使用 HydraPaper 很简单。只需为每个显示器选择壁纸,然后单击顶部的应用按钮。你可以轻松地用 HDMI 标识来识别外部显示器。

你还可以将选定的壁纸添加到“收藏夹”以便快速访问。这样做会将“最喜欢的壁纸”从“壁纸”选项卡移动到“收藏夹”选项卡。

你不需要在每次启动时启动 HydraPaper。为不同的显示器设置不同的壁纸后,设置将被保存,即使重新启动后你也会看到所选择的壁纸。这当然是预期的行为,但我想特别提一下。
HydraPaper 的一大缺点在于它的设计工作方式。你可以看到,HydraPaper 将你选择的壁纸拼接成一张图像并将其拉伸到屏幕上,给人的印象是每个显示器上都有不同的背景。当你移除外部显示器时,这将成为一个问题。
例如,当我尝试使用没有外接显示器的笔记本电脑时,它向我展示了这样的背景图像。

很明显,这不是我所期望的。
#### 你喜欢它吗?
HydraPaper 使得在不同的显示器上设置不同的背景变得很方便。它支持超过两个显示器和不同的显示器方向。只有所需功能的简单界面使其成为那些总是使用双显示器的人的理想应用。
如何在 Linux 上为不同的显示器设置不同的壁纸?你认为 HydraPaper 是值得安装的应用吗?
请分享您的观点,另外如果你看到这篇文章,请在各种社交媒体渠道上分享,如 Twitter 和 [Reddit](https://www.reddit.com/r/LinuxUsersGroup/)。
---
via: <https://itsfoss.com/wallpaper-multi-monitor/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Multi-monitor setup often leads to multiple issues on Linux but I am not going to discuss those issues in this article. I have rather a positive article on multiple monitor support on Linux.
If you are using multiple monitors, perhaps you would like to set up a different wallpaper for each monitor. I am not sure about other Linux distributions and desktop environments, but Ubuntu with [GNOME desktop](https://www.gnome.org/?ref=itsfoss.com) doesn’t provide this functionality on its own.
Fret not! In this quick tutorial, I’ll show you how to set a different wallpaper for each monitor on Linux distributions.
## Setting up a different wallpaper for each monitor on Ubuntu

I am going to use a nifty tool called [HydraPaper](https://gitlab.com/gabmus/HydraPaper?ref=itsfoss.com) for setting different backgrounds on different monitors. HydraPaper is a [GTK](https://www.gtk.org/?ref=itsfoss.com) based application to span different backgrounds for each monitor in [GNOME desktop environment](https://itsfoss.com/gnome-tricks-ubuntu/).
[MATE](https://mate-desktop.org/?ref=itsfoss.com)and
[Budgie](https://budgie-desktop.org/home/?ref=itsfoss.com)desktop environments. Which means Ubuntu MATE and
[Ubuntu Budgie](https://itsfoss.com/ubuntu-budgie-18-review/)users can also benefit from this application.
### Features of HydraPaper
HydraPaper lets you add your custom wallpaper collection, organize/select the folders you want, and pick wallpapers conveniently.
Some of the essential features include:
- Manager folder collection (toggle them in a single click as required).
- Pick a favorite wallpaper and add them to your favorite collection.
- Position the wallpaper as you prefer (zoom, fit with a black background/blur, center, and more)
- Ability to set a random wallpaper quickly from your collection, if that’s how you decide.
- Customize the wallpaper manager experience with dark mode, choose to save wallpaper separately, clear cache, etc.
- CLI support
- Single spanned wallpaper mode to apply across multi-monitors
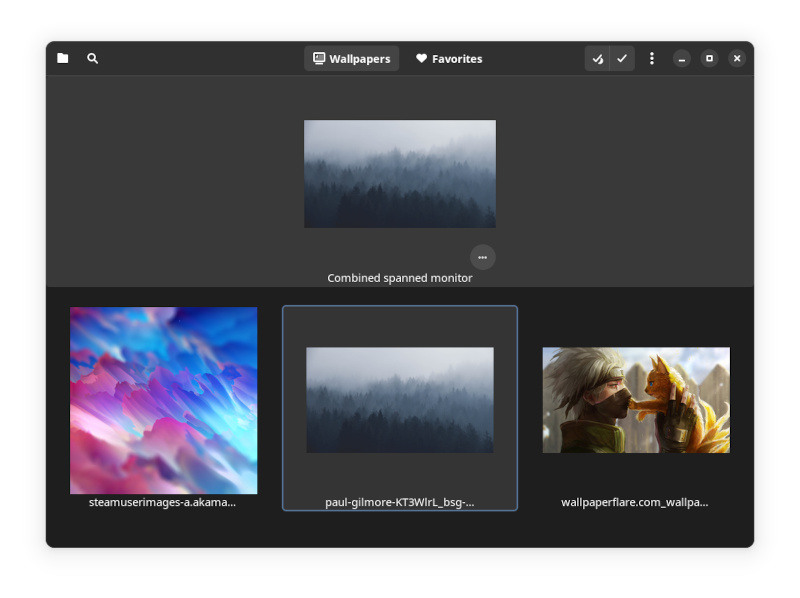
It is pretty simple to use; you can pick and select wallpapers for different monitors or use the single spanned wallpaper mode from the options to apply one across multi-monitors.
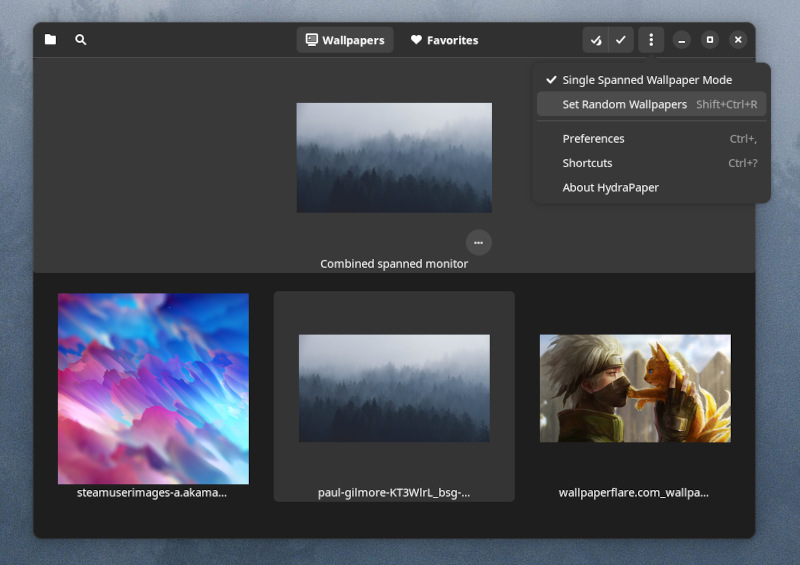
You get to choose/add/delete folders, adjust the position, add favorites, and apply the wallpaper for dark mode.
### Install HydraPaper on Linux using Flatpak
HydraPaper can be installed easily using [Flatpak](https://flatpak.org/?ref=itsfoss.com).
You can refer to this article to learn [how to enable FlatPak support](https://flatpak.org/setup/?ref=itsfoss.com) on your distribution. Once you have the FlatPak support enabled, just use this command to install it.
`flatpak install flathub org.gabmus.hydrapaper`
### Using HydraPaper for setting different background on different monitors
Once installed, just look for [HydraPaper](https://flathub.org/apps/org.gabmus.hydrapaper?ref=itsfoss.com) in the application menu and start the application. You’ll see images from your Pictures folder here because by default the application takes images from the Pictures folder of the user.
You can add your own folder(s) where you keep your wallpapers. Do note that it doesn’t find images recursively. If you have nested folders, it will only show images from the top folder.
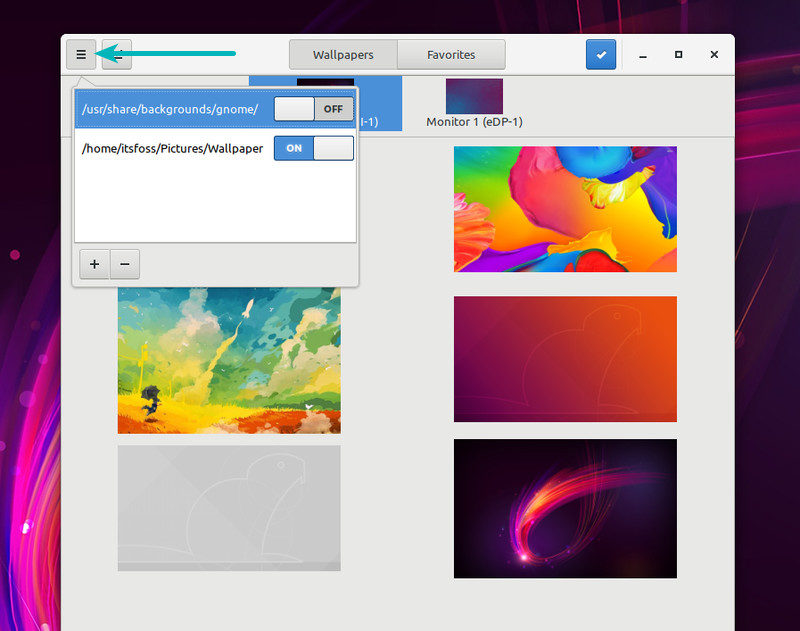
Using HydraPaper is absolutely simple. Just select the wallpapers for each monitor and click on the apply button at the top. You can easily identify external monitor(s) termed with HDMI.
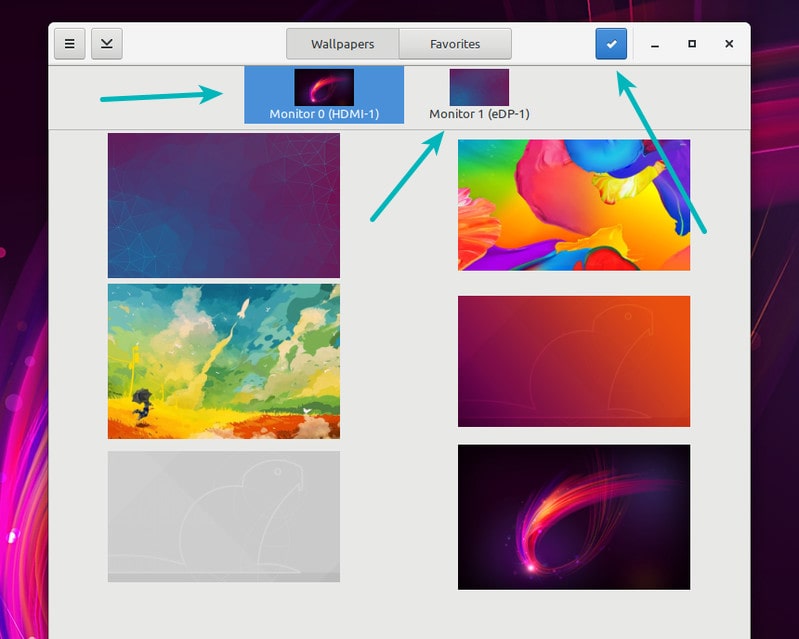
You can also add selected wallpapers to ‘Favorites’ for quick access. Doing this will move the ‘favorite wallpapers’ from Wallpapers tab to Favorites tab.
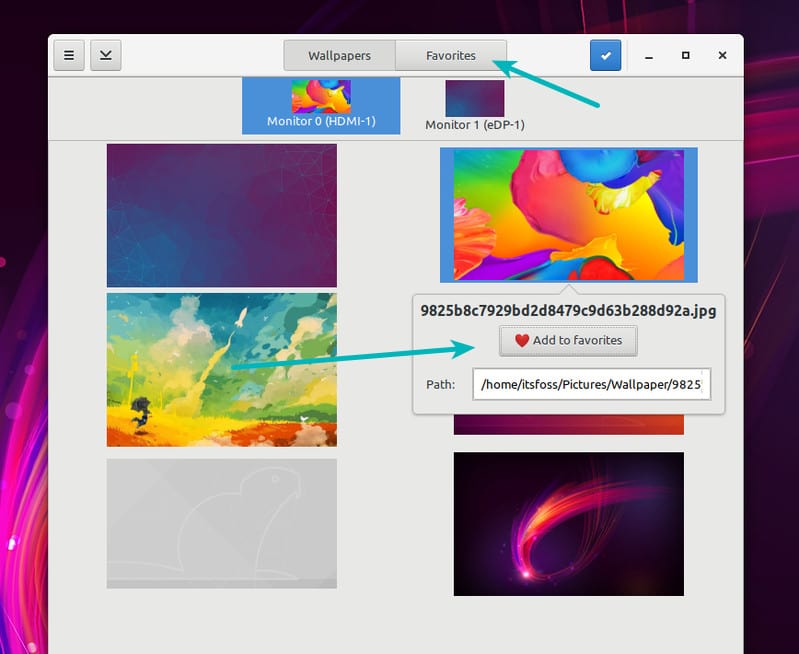
You may also set random wallpapers. You can also span the same wallpaper across all the monitors.

**You don’t need to start HydraPaper at each boot**. Once you set a different wallpaper for different monitor, the settings are saved and you’ll see your chosen wallpapers even after restart. This would be expected behaviour of course but I thought I would mention the obvious.
**One big downside of HydraPaper** is in the way it is designed to work. You see, HydraPaper combines your selected wallpapers into one single image and stretches it across the screens giving an impression of having different background on each display. And this becomes an issue when you remove the external display.
For example, when I tried using my laptop without the external display, it showed me an background image like this.
Quite obviously, this is not what I would expect.
### Did you like it?
HydraPaper makes setting up different backgrounds on different monitors a painless task. It supports more than two monitors and monitors with different orientation. Simple interface with only the required features makes it an ideal application for those who always use dual monitors.
How do you set different wallpaper for different monitor on Linux? Do you think HydraPaper is an application worth installing?
Do share your views and if you find this article, please share it on various social media channels such as Twitter and [Reddit](https://www.reddit.com/r/LinuxUsersGroup/?ref=itsfoss.com). |
10,307 | Caffeinated 6.828:实验 3:用户环境 | https://pdos.csail.mit.edu/6.828/2018/labs/lab3/ | 2018-12-03T22:53:00 | [
"6.828"
] | https://linux.cn/article-10307-1.html | 
### 简介
在本实验中,你将要实现一个基本的内核功能,要求它能够保护运行的用户模式环境(即:进程)。你将去增强这个 JOS 内核,去配置数据结构以便于保持对用户环境的跟踪、创建一个单一用户环境、将程序镜像加载到用户环境中、并将它启动运行。你也要写出一些 JOS 内核的函数,用来处理任何用户环境生成的系统调用,以及处理由用户环境引进的各种异常。
**注意:** 在本实验中,术语**“环境”** 和**“进程”** 是可互换的 —— 它们都表示同一个抽象概念,那就是允许你去运行的程序。我在介绍中使用术语**“环境”**而不是使用传统术语**“进程”**的目的是为了强调一点,那就是 JOS 的环境和 UNIX 的进程提供了不同的接口,并且它们的语义也不相同。
#### 预备知识
使用 Git 去提交你自实验 2 以后的更改(如果有的话),获取课程仓库的最新版本,以及创建一个命名为 `lab3` 的本地分支,指向到我们的 lab3 分支上 `origin/lab3` :
```
athena% cd ~/6.828/lab
athena% add git
athena% git commit -am 'changes to lab2 after handin'
Created commit 734fab7: changes to lab2 after handin
4 files changed, 42 insertions(+), 9 deletions(-)
athena% git pull
Already up-to-date.
athena% git checkout -b lab3 origin/lab3
Branch lab3 set up to track remote branch refs/remotes/origin/lab3.
Switched to a new branch "lab3"
athena% git merge lab2
Merge made by recursive.
kern/pmap.c | 42 +++++++++++++++++++
1 files changed, 42 insertions(+), 0 deletions(-)
athena%
```
实验 3 包含一些你将探索的新源文件:
```
inc/ env.h Public definitions for user-mode environments
trap.h Public definitions for trap handling
syscall.h Public definitions for system calls from user environments to the kernel
lib.h Public definitions for the user-mode support library
kern/ env.h Kernel-private definitions for user-mode environments
env.c Kernel code implementing user-mode environments
trap.h Kernel-private trap handling definitions
trap.c Trap handling code
trapentry.S Assembly-language trap handler entry-points
syscall.h Kernel-private definitions for system call handling
syscall.c System call implementation code
lib/ Makefrag Makefile fragment to build user-mode library, obj/lib/libjos.a
entry.S Assembly-language entry-point for user environments
libmain.c User-mode library setup code called from entry.S
syscall.c User-mode system call stub functions
console.c User-mode implementations of putchar and getchar, providing console I/O
exit.c User-mode implementation of exit
panic.c User-mode implementation of panic
user/ * Various test programs to check kernel lab 3 code
```
另外,一些在实验 2 中的源文件在实验 3 中将被修改。如果想去查看有什么更改,可以运行:
```
$ git diff lab2
```
你也可以另外去看一下 [实验工具指南](/article-10273-1.html),它包含了与本实验有关的调试用户代码方面的信息。
#### 实验要求
本实验分为两部分:Part A 和 Part B。Part A 在本实验完成后一周内提交;你将要提交你的更改和完成的动手实验,在提交之前要确保你的代码通过了 Part A 的所有检查(如果你的代码未通过 Part B 的检查也可以提交)。只需要在第二周提交 Part B 的期限之前代码检查通过即可。
由于在实验 2 中,你需要做实验中描述的所有正则表达式练习,并且至少通过一个挑战(是指整个实验,不是每个部分)。写出详细的问题答案并张贴在实验中,以及一到两个段落的关于你如何解决你选择的挑战问题的详细描述,并将它放在一个名为 `answers-lab3.txt` 的文件中,并将这个文件放在你的 `lab` 目标的根目录下。(如果你做了多个问题挑战,你仅需要提交其中一个即可)不要忘记使用 `git add answers-lab3.txt` 提交这个文件。
#### 行内汇编语言
在本实验中你可能发现使用了 GCC 的行内汇编语言特性,虽然不使用它也可以完成实验。但至少你需要去理解这些行内汇编语言片段,这些汇编语言(`asm` 语句)片段已经存在于提供给你的源代码中。你可以在课程 [参考资料](https://pdos.csail.mit.edu/6.828/2018/labs/reference.html) 的页面上找到 GCC 行内汇编语言有关的信息。
### Part A:用户环境和异常处理
新文件 `inc/env.h` 中包含了在 JOS 中关于用户环境的基本定义。现在就去阅读它。内核使用数据结构 `Env` 去保持对每个用户环境的跟踪。在本实验的开始,你将只创建一个环境,但你需要去设计 JOS 内核支持多环境;实验 4 将带来这个高级特性,允许用户环境去 `fork` 其它环境。
正如你在 `kern/env.c` 中所看到的,内核维护了与环境相关的三个全局变量:
```
struct Env *envs = NULL; // All environments
struct Env *curenv = NULL; // The current env
static struct Env *env_free_list; // Free environment list
```
一旦 JOS 启动并运行,`envs` 指针指向到一个数组,即数据结构 `Env`,它保存了系统中全部的环境。在我们的设计中,JOS 内核将同时支持最大值为 `NENV` 个的活动的环境,虽然在一般情况下,任何给定时刻运行的环境很少。(`NENV` 是在 `inc/env.h` 中用 `#define` 定义的一个常量)一旦它被分配,对于每个 `NENV` 可能的环境,`envs` 数组将包含一个数据结构 `Env` 的单个实例。
JOS 内核在 `env_free_list` 上用数据结构 `Env` 保存了所有不活动的环境。这样的设计使得环境的分配和回收很容易,因为这只不过是添加或删除空闲列表的问题而已。
内核使用符号 `curenv` 来保持对任意给定时刻的 当前正在运行的环境 进行跟踪。在系统引导期间,在第一个环境运行之前,`curenv` 被初始化为 `NULL`。
#### 环境状态
数据结构 `Env` 被定义在文件 `inc/env.h` 中,内容如下:(在后面的实验中将添加更多的字段):
```
struct Env {
struct Trapframe env_tf; // Saved registers
struct Env *env_link; // Next free Env
envid_t env_id; // Unique environment identifier
envid_t env_parent_id; // env_id of this env's parent
enum EnvType env_type; // Indicates special system environments
unsigned env_status; // Status of the environment
uint32_t env_runs; // Number of times environment has run
// Address space
pde_t *env_pgdir; // Kernel virtual address of page dir
};
```
以下是数据结构 `Env` 中的字段简介:
* `env_tf`: 这个结构定义在 `inc/trap.h` 中,它用于在那个环境不运行时保持它保存在寄存器中的值,即:当内核或一个不同的环境在运行时。当从用户模式切换到内核模式时,内核将保存这些东西,以便于那个环境能够在稍后重新运行时回到中断运行的地方。
* `env_link`: 这是一个链接,它链接到在 `env_free_list` 上的下一个 `Env` 上。`env_free_list` 指向到列表上第一个空闲的环境。
* `env_id`: 内核在数据结构 `Env` 中保存了一个唯一标识当前环境的值(即:使用数组 `envs` 中的特定槽位)。在一个用户环境终止之后,内核可能给另外的环境重新分配相同的数据结构 `Env` —— 但是新的环境将有一个与已终止的旧的环境不同的 `env_id`,即便是新的环境在数组 `envs` 中复用了同一个槽位。
* `env_parent_id`: 内核使用它来保存创建这个环境的父级环境的 `env_id`。通过这种方式,环境就可以形成一个“家族树”,这对于做出“哪个环境可以对谁做什么”这样的安全决策非常有用。
* `env_type`: 它用于去区分特定的环境。对于大多数环境,它将是 `ENV_TYPE_USER` 的。在稍后的实验中,针对特定的系统服务环境,我们将引入更多的几种类型。
* `env_status`: 这个变量持有以下几个值之一:
+ `ENV_FREE`: 表示那个 `Env` 结构是非活动的,并且因此它还在 `env_free_list` 上。
+ `ENV_RUNNABLE`: 表示那个 `Env` 结构所代表的环境正等待被调度到处理器上去运行。
+ `ENV_RUNNING`: 表示那个 `Env` 结构所代表的环境当前正在运行中。
+ `ENV_NOT_RUNNABLE`: 表示那个 `Env` 结构所代表的是一个当前活动的环境,但不是当前准备去运行的:例如,因为它正在因为一个来自其它环境的进程间通讯(IPC)而处于等待状态。
+ `ENV_DYING`: 表示那个 `Env` 结构所表示的是一个僵尸环境。一个僵尸环境将在下一次被内核捕获后被释放。我们在实验 4 之前不会去使用这个标志。
* `env_pgdir`: 这个变量持有这个环境的内核虚拟地址的页目录。
就像一个 Unix 进程一样,一个 JOS 环境耦合了“线程”和“地址空间”的概念。线程主要由保存的寄存器来定义(`env_tf` 字段),而地址空间由页目录和 `env_pgdir` 所指向的页表所定义。为运行一个环境,内核必须使用保存的寄存器值和相关的地址空间去设置 CPU。
我们的 `struct Env` 与 xv6 中的 `struct proc` 类似。它们都在一个 `Trapframe` 结构中持有环境(即进程)的用户模式寄存器状态。在 JOS 中,单个的环境并不能像 xv6 中的进程那样拥有它们自己的内核栈。在这里,内核中任意时间只能有一个 JOS 环境处于活动中,因此,JOS 仅需要一个单个的内核栈。
#### 为环境分配数组
在实验 2 的 `mem_init()` 中,你为数组 `pages[]` 分配了内存,它是内核用于对页面分配与否的状态进行跟踪的一个表。你现在将需要去修改 `mem_init()`,以便于后面使用它分配一个与结构 `Env` 类似的数组,这个数组被称为 `envs`。
>
> **练习 1**、修改在 `kern/pmap.c` 中的 `mem_init()`,以用于去分配和映射 `envs` 数组。这个数组完全由 `Env` 结构分配的实例 `NENV` 组成,就像你分配的 `pages` 数组一样。与 `pages` 数组一样,由内存支持的数组 `envs` 也将在 `UENVS`(它的定义在 `inc/memlayout.h` 文件中)中映射用户只读的内存,以便于用户进程能够从这个数组中读取。
>
>
>
你应该去运行你的代码,并确保 `check_kern_pgdir()` 是没有问题的。
#### 创建和运行环境
现在,你将在 `kern/env.c` 中写一些必需的代码去运行一个用户环境。因为我们并没有做一个文件系统,因此,我们将设置内核去加载一个嵌入到内核中的静态的二进制镜像。JOS 内核以一个 ELF 可运行镜像的方式将这个二进制镜像嵌入到内核中。
在实验 3 中,`GNUmakefile` 将在 `obj/user/` 目录中生成一些二进制镜像。如果你看到 `kern/Makefrag`,你将注意到一些奇怪的的东西,它们“链接”这些二进制直接进入到内核中运行,就像 `.o` 文件一样。在链接器命令行上的 `-b binary` 选项,将因此把它们链接为“原生的”不解析的二进制文件,而不是由编译器产生的普通的 `.o` 文件。(就链接器而言,这些文件压根就不是 ELF 镜像文件 —— 它们可以是任何东西,比如,一个文本文件或图片!)如果你在内核构建之后查看 `obj/kern/kernel.sym` ,你将会注意到链接器很奇怪的生成了一些有趣的、命名很费解的符号,比如像 `_binary_obj_user_hello_start`、`_binary_obj_user_hello_end`、以及 `_binary_obj_user_hello_size`。链接器通过改编二进制文件的命令来生成这些符号;这种符号为普通内核代码使用一种引入嵌入式二进制文件的方法。
在 `kern/init.c` 的 `i386_init()` 中,你将写一些代码在环境中运行这些二进制镜像中的一种。但是,设置用户环境的关键函数还没有实现;将需要你去完成它们。
>
> **练习 2**、在文件 `env.c` 中,写完以下函数的代码:
>
>
> * `env_init()`
>
>
> 初始化 `envs` 数组中所有的 `Env` 结构,然后把它们添加到 `env_free_list` 中。也称为 `env_init_percpu`,它通过配置硬件,在硬件上为 level 0(内核)权限和 level 3(用户)权限使用单独的段。
> * `env_setup_vm()`
>
>
> 为一个新环境分配一个页目录,并初始化新环境的地址空间的内核部分。
> * `region_alloc()`
>
>
> 为一个新环境分配和映射物理内存
> * `load_icode()`
>
>
> 你将需要去解析一个 ELF 二进制镜像,就像引导加载器那样,然后加载它的内容到一个新环境的用户地址空间中。
> * `env_create()`
>
>
> 使用 `env_alloc` 去分配一个环境,并调用 `load_icode` 去加载一个 ELF 二进制
> * `env_run()`
>
>
> 在用户模式中开始运行一个给定的环境
>
>
> 在你写这些函数时,你可能会发现新的 cprintf 动词 `%e` 非常有用 – 它可以输出一个错误代码的相关描述。比如:
>
>
>
> ```
> r = -E_NO_MEM;
> panic("env_alloc: %e", r);
> ```
>
> 中 panic 将输出消息 env\_alloc: out of memory。
>
>
>
下面是用户代码相关的调用图。确保你理解了每一步的用途。
* `start` (`kern/entry.S`)
* `i386_init` (`kern/init.c`)
+ `cons_init`
+ `mem_init`
+ `env_init`
+ `trap_init`(到目前为止还未完成)
+ `env_create`
+ `env_run`
- `env_pop_tf`
在完成以上函数后,你应该去编译内核并在 QEMU 下运行它。如果一切正常,你的系统将进入到用户空间并运行二进制的 `hello` ,直到使用 `int` 指令生成一个系统调用为止。在那个时刻将存在一个问题,因为 JOS 尚未设置硬件去允许从用户空间到内核空间的各种转换。当 CPU 发现没有系统调用中断的服务程序时,它将生成一个一般保护异常,找到那个异常并去处理它,还将生成一个双重故障异常,同样也找到它并处理它,并且最后会出现所谓的“三重故障异常”。通常情况下,你将随后看到 CPU 复位以及系统重引导。虽然对于传统的应用程序(在 [这篇博客文章](http://blogs.msdn.com/larryosterman/archive/2005/02/08/369243.aspx) 中解释了原因)这是重大的问题,但是对于内核开发来说,这是一个痛苦的过程,因此,在打了 6.828 补丁的 QEMU 上,你将可以看到转储的寄存器内容和一个“三重故障”的信息。
我们马上就会去处理这些问题,但是现在,我们可以使用调试器去检查我们是否进入了用户模式。使用 `make qemu-gdb` 并在 `env_pop_tf` 处设置一个 GDB 断点,它是你进入用户模式之前到达的最后一个函数。使用 `si` 单步进入这个函数;处理器将在 `iret` 指令之后进入用户模式。然后你将会看到在用户环境运行的第一个指令,它将是在 `lib/entry.S` 中的标签 `start` 的第一个指令 `cmpl`。现在,在 `hello` 中的 `sys_cputs()` 的 `int $0x30` 处使用 `b *0x...`(关于用户空间的地址,请查看 `obj/user/hello.asm` )设置断点。这个指令 `int` 是系统调用去显示一个字符到控制台。如果到 `int` 还没有运行,那么可能在你的地址空间设置或程序加载代码时发生了错误;返回去找到问题并解决后重新运行。
#### 处理中断和异常
到目前为止,在用户空间中的第一个系统调用指令 `int $0x30` 已正式寿终正寝了:一旦处理器进入用户模式,将无法返回。因此,现在,你需要去实现基本的异常和系统调用服务程序,因为那样才有可能让内核从用户模式代码中恢复对处理器的控制。你所做的第一件事情就是彻底地掌握 x86 的中断和异常机制的使用。
>
> **练习 3**、如果你对中断和异常机制不熟悉的话,阅读 80386 程序员手册的第 9 章(或 IA-32 开发者手册的第 5 章)。
>
>
>
在这个实验中,对于中断、异常、以其它类似的东西,我们将遵循 Intel 的术语习惯。由于如<ruby> 异常 <rt> exception </rt></ruby>、<ruby> 陷阱 <rt> trap </rt></ruby>、<ruby> 中断 <rt> interrupt </rt></ruby>、<ruby> 故障 <rt> fault </rt></ruby>和<ruby> 中止 <rt> abort </rt></ruby>这些术语在不同的架构和操作系统上并没有一个统一的标准,我们经常在特定的架构下(如 x86)并不去考虑它们之间的细微差别。当你在本实验以外的地方看到这些术语时,它们的含义可能有细微的差别。
#### 受保护的控制转移基础
异常和中断都是“受保护的控制转移”,它将导致处理器从用户模式切换到内核模式(`CPL=0`)而不会让用户模式的代码干扰到内核的其它函数或其它的环境。在 Intel 的术语中,一个中断就是一个“受保护的控制转移”,它是由于处理器以外的外部异步事件所引发的,比如外部设备 I/O 活动通知。而异常正好与之相反,它是由当前正在运行的代码所引发的同步的、受保护的控制转移,比如由于发生了一个除零错误或对无效内存的访问。
为了确保这些受保护的控制转移是真正地受到保护,处理器的中断/异常机制设计是:当中断/异常发生时,当前运行的代码不能随意选择进入内核的位置和方式。而是,处理器在确保内核能够严格控制的条件下才能进入内核。在 x86 上,有两种机制协同来提供这种保护:
1. **中断描述符表** 处理器确保中断和异常仅能够导致内核进入几个特定的、由内核本身定义好的、明确的入口点,而不是去运行中断或异常发生时的代码。
x86 允许最多有 256 个不同的中断或异常入口点去进入内核,每个入口点都使用一个不同的中断向量。一个向量是一个介于 0 和 255 之间的数字。一个中断向量是由中断源确定的:不同的设备、错误条件、以及应用程序去请求内核使用不同的向量生成中断。CPU 使用向量作为进入处理器的中断描述符表(IDT)的索引,它是内核设置的内核私有内存,GDT 也是。从这个表中的适当的条目中,处理器将加载:
* 将值加载到指令指针寄存器(EIP),指向内核代码设计好的,用于处理这种异常的服务程序。
* 将值加载到代码段寄存器(CS),它包含运行权限为 0—1 级别的、要运行的异常服务程序。(在 JOS 中,所有的异常处理程序都运行在内核模式中,运行级别为 0。)
2. **任务状态描述符表** 处理器在中断或异常发生时,需要一个地方去保存旧的处理器状态,比如,处理器在调用异常服务程序之前的 `EIP` 和 `CS` 的原始值,这样那个异常服务程序就能够稍后通过还原旧的状态来回到中断发生时的代码位置。但是对于已保存的处理器的旧状态必须被保护起来,不能被无权限的用户模式代码访问;否则代码中的 bug 或恶意用户代码将危及内核。
基于这个原因,当一个 x86 处理器产生一个中断或陷阱时,将导致权限级别的变更,从用户模式转换到内核模式,它也将导致在内核的内存中发生栈切换。有一个被称为 TSS 的任务状态描述符表规定段描述符和这个栈所处的地址。处理器在这个新栈上推送 `SS`、`ESP`、`EFLAGS`、`CS`、`EIP`、以及一个可选的错误代码。然后它从中断描述符上加载 `CS` 和 `EIP` 的值,然后设置 `ESP` 和 `SS` 去指向新的栈。
虽然 TSS 很大并且默默地为各种用途服务,但是 JOS 仅用它去定义当从用户模式到内核模式的转移发生时,处理器即将切换过去的内核栈。因为在 JOS 中的“内核模式”仅运行在 x86 的运行级别 0 权限上,当进入内核模式时,处理器使用 TSS 上的 `ESP0` 和 `SS0` 字段去定义内核栈。JOS 并不去使用 TSS 的任何其它字段。
#### 异常和中断的类型
所有的 x86 处理器上的同步异常都能够产生一个内部使用的、介于 0 到 31 之间的中断向量,因此它映射到 IDT 就是条目 0-31。例如,一个页故障总是通过向量 14 引发一个异常。大于 31 的中断向量仅用于软件中断,它由 `int` 指令生成,或异步硬件中断,当需要时,它们由外部设备产生。
在这一节中,我们将扩展 JOS 去处理向量为 0-31 之间的、内部产生的 x86 异常。在下一节中,我们将完成 JOS 的 48(0x30)号软件中断向量,JOS 将(随意选择的)使用它作为系统调用中断向量。在实验 4 中,我们将扩展 JOS 去处理外部生成的硬件中断,比如时钟中断。
#### 一个示例
我们把这些片断综合到一起,通过一个示例来巩固一下。我们假设处理器在用户环境下运行代码,遇到一个除零问题。
1. 处理器去切换到由 TSS 中的 `SS0` 和 `ESP0` 定义的栈,在 JOS 中,它们各自保存着值 `GD_KD` 和 `KSTACKTOP`。
2. 处理器在内核栈上推入异常参数,起始地址为 `KSTACKTOP`:
```
+--------------------+ KSTACKTOP
| 0x00000 | old SS | " - 4
| old ESP | " - 8
| old EFLAGS | " - 12
| 0x00000 | old CS | " - 16
| old EIP | " - 20 <---- ESP
+--------------------+
```
3. 由于我们要处理一个除零错误,它将在 x86 上产生一个中断向量 0,处理器读取 IDT 的条目 0,然后设置 `CS:EIP` 去指向由条目描述的处理函数。
4. 处理服务程序函数将接管控制权并处理异常,例如中止用户环境。
对于某些类型的 x86 异常,除了以上的五个“标准的”寄存器外,处理器还推入另一个包含错误代码的寄存器值到栈中。页故障异常,向量号为 14,就是一个重要的示例。查看 80386 手册去确定哪些异常推入一个错误代码,以及错误代码在那个案例中的意义。当处理器推入一个错误代码后,当从用户模式中进入内核模式,异常处理服务程序开始时的栈看起来应该如下所示:
```
+--------------------+ KSTACKTOP
| 0x00000 | old SS | " - 4
| old ESP | " - 8
| old EFLAGS | " - 12
| 0x00000 | old CS | " - 16
| old EIP | " - 20
| error code | " - 24 <---- ESP
+--------------------+
```
#### 嵌套的异常和中断
处理器能够处理来自用户和内核模式中的异常和中断。当收到来自用户模式的异常和中断时才会进入内核模式中,而且,在推送它的旧寄存器状态到栈中和通过 IDT 调用相关的异常服务程序之前,x86 处理器会自动切换栈。如果当异常或中断发生时,处理器已经处于内核模式中(`CS` 寄存器低位两个比特为 0),那么 CPU 只是推入一些值到相同的内核栈中。在这种方式中,内核可以优雅地处理嵌套的异常,嵌套的异常一般由内核本身的代码所引发。在实现保护时,这种功能是非常重要的工具,我们将在稍后的系统调用中看到它。
如果处理器已经处于内核模式中,并且发生了一个嵌套的异常,由于它并不需要切换栈,它也就不需要去保存旧的 `SS` 或 `ESP` 寄存器。对于不推入错误代码的异常类型,在进入到异常服务程序时,它的内核栈看起来应该如下图:
```
+--------------------+ <---- old ESP
| old EFLAGS | " - 4
| 0x00000 | old CS | " - 8
| old EIP | " - 12
+--------------------+
```
对于需要推入一个错误代码的异常类型,处理器将在旧的 `EIP` 之后,立即推入一个错误代码,就和前面一样。
关于处理器的异常嵌套的功能,这里有一个重要的警告。如果处理器正处于内核模式时发生了一个异常,并且不论是什么原因,比如栈空间泄漏,都不会去推送它的旧的状态,那么这时处理器将不能做任何的恢复,它只是简单地重置。毫无疑问,内核应该被设计为禁止发生这种情况。
#### 设置 IDT
到目前为止,你应该有了在 JOS 中为了设置 IDT 和处理异常所需的基本信息。现在,我们去设置 IDT 以处理中断向量 0-31(处理器异常)。我们将在本实验的稍后部分处理系统调用,然后在后面的实验中增加中断 32-47(设备 IRQ)。
在头文件 `inc/trap.h` 和 `kern/trap.h` 中包含了中断和异常相关的重要定义,你需要去熟悉使用它们。在文件`kern/trap.h` 中包含了到内核的、严格的、秘密的定义,可是在 `inc/trap.h` 中包含的定义也可以被用到用户级程序和库上。
注意:在范围 0-31 中的一些异常是被 Intel 定义为保留。因为在它们的处理器上从未产生过,你如何处理它们都不会有大问题。你想如何做它都是可以的。
你将要实现的完整的控制流如下图所描述:
```
IDT trapentry.S trap.c
+----------------+
| &handler1 |----> handler1: trap (struct Trapframe *tf)
| | // do stuff {
| | call trap // handle the exception/interrupt
| | // ... }
+----------------+
| &handler2 |----> handler2:
| | // do stuff
| | call trap
| | // ...
+----------------+
.
.
.
+----------------+
| &handlerX |----> handlerX:
| | // do stuff
| | call trap
| | // ...
+----------------+
```
每个异常或中断都应该在 `trapentry.S` 中有它自己的处理程序,并且 `trap_init()` 应该使用这些处理程序的地址去初始化 IDT。每个处理程序都应该在栈上构建一个 `struct Trapframe`(查看 `inc/trap.h`),然后使用一个指针调用 `trap()`(在 `trap.c` 中)到 `Trapframe`。`trap()` 接着处理异常/中断或派发给一个特定的处理函数。
>
> 练习 4、编辑 `trapentry.S` 和 `trap.c`,然后实现上面所描述的功能。在 `trapentry.S` 中的宏 `TRAPHANDLER` 和 `TRAPHANDLER_NOEC` 将会帮你,还有在 `inc/trap.h` 中的 T\_\* defines。你需要在 `trapentry.S` 中为每个定义在 `inc/trap.h` 中的陷阱添加一个入口点(使用这些宏),并且你将有 t、o 提供的 `_alltraps`,这是由宏 `TRAPHANDLER`指向到它。你也需要去修改 `trap_init()` 来初始化 `idt`,以使它指向到每个在 `trapentry.S` 中定义的入口点;宏 `SETGATE` 将有助你实现它。
>
>
> 你的 `_alltraps` 应该:
>
>
> 1. 推送值以使栈看上去像一个结构 Trapframe
> 2. 加载 `GD_KD` 到 `%ds` 和 `%es`
> 3. `pushl %esp` 去传递一个指针到 Trapframe 以作为一个 trap() 的参数
> 4. `call trap` (`trap` 能够返回吗?)
>
>
> 考虑使用 `pushal` 指令;它非常适合 `struct Trapframe` 的布局。
>
>
> 使用一些在 `user` 目录中的测试程序来测试你的陷阱处理代码,这些测试程序在生成任何系统调用之前能引发异常,比如 `user/divzero`。在这时,你应该能够成功完成 `divzero`、`softint`、以有 `badsegment` 测试。
>
>
>
.
>
> **小挑战!**目前,在 `trapentry.S` 中列出的 `TRAPHANDLER` 和他们安装在 `trap.c` 中可能有许多代码非常相似。清除它们。修改 `trapentry.S` 中的宏去自动为 `trap.c` 生成一个表。注意,你可以直接使用 `.text` 和 `.data` 在汇编器中切换放置其中的代码和数据。
>
>
>
.
>
> **问题**
>
>
> 在你的 `answers-lab3.txt` 中回答下列问题:
>
>
> 1. 为每个异常/中断设置一个独立的服务程序函数的目的是什么?(即:如果所有的异常/中断都传递给同一个服务程序,在我们的当前实现中能否提供这样的特性?)
> 2. 你需要做什么事情才能让 `user/softint` 程序正常运行?评级脚本预计将会产生一个一般保护故障(trap 13),但是 `softint` 的代码显示为 `int $14`。为什么它产生的中断向量是 13?如果内核允许 `softint` 的 `int $14` 指令去调用内核页故障的服务程序(它的中断向量是 14)会发生什么事情? “`
>
>
>
本实验的 Part A 部分结束了。不要忘了去添加 `answers-lab3.txt` 文件,提交你的变更,然后在 Part A 作业的提交截止日期之前运行 `make handin`。
### Part B:页故障、断点异常、和系统调用
现在,你的内核已经有了最基本的异常处理能力,你将要去继续改进它,来提供依赖异常服务程序的操作系统原语。
#### 处理页故障
页故障异常,中断向量为 14(`T_PGFLT`),它是一个非常重要的东西,我们将通过本实验和接下来的实验来大量练习它。当处理器产生一个页故障时,处理器将在它的一个特定的控制寄存器(`CR2`)中保存导致这个故障的线性地址(即:虚拟地址)。在 `trap.c` 中我们提供了一个专门处理它的函数的一个雏形,它就是 `page_fault_handler()`,我们将用它来处理页故障异常。
>
> **练习 5**、修改 `trap_dispatch()` 将页故障异常派发到 `page_fault_handler()` 上。你现在应该能够成功测试 `faultread`、`faultreadkernel`、`faultwrite` 和 `faultwritekernel` 了。如果它们中的任何一个不能正常工作,找出问题并修复它。记住,你可以使用 `make run-x` 或 `make run-x-nox` 去重引导 JOS 进入到一个特定的用户程序。比如,你可以运行 `make run-hello-nox` 去运行 `hello` 用户程序。
>
>
>
下面,你将进一步细化内核的页故障服务程序,因为你要实现系统调用了。
#### 断点异常
断点异常,中断向量为 3(`T_BRKPT`),它一般用在调试上,它在一个程序代码中插入断点,从而使用特定的 1 字节的 `int3` 软件中断指令来临时替换相应的程序指令。在 JOS 中,我们将稍微“滥用”一下这个异常,通过将它打造成一个伪系统调用原语,使得任何用户环境都可以用它来调用 JOS 内核监视器。如果我们将 JOS 内核监视认为是原始调试器,那么这种用法是合适的。例如,在 `lib/panic.c` 中实现的用户模式下的 `panic()` ,它在显示它的 `panic` 消息后运行一个 `int3` 中断。
>
> **练习 6**、修改 `trap_dispatch()`,让它在调用内核监视器时产生一个断点异常。你现在应该可以在 `breakpoint` 上成功完成测试。
>
>
>
.
>
> **小挑战!**修改 JOS 内核监视器,以便于你能够从当前位置(即:在 `int3` 之后,断点异常调用了内核监视器) ‘继续’ 异常,并且因此你就可以一次运行一个单步指令。为了实现单步运行,你需要去理解 `EFLAGS` 寄存器中的某些比特的意义。
>
>
> 可选:如果你富有冒险精神,找一些 x86 反汇编的代码 —— 即通过从 QEMU 中、或从 GNU 二进制工具中分离、或你自己编写 —— 然后扩展 JOS 内核监视器,以使它能够反汇编,显示你的每步的指令。结合实验 1 中的符号表,这将是你写的一个真正的内核调试器。
>
>
>
.
>
> **问题**
>
>
> 1. 在断点测试案例中,根据你在 IDT 中如何初始化断点条目的不同情况(即:你的从 `trap_init` 到 `SETGATE` 的调用),既有可能产生一个断点异常,也有可能产生一个一般保护故障。为什么?为了能够像上面的案例那样工作,你需要如何去设置它,什么样的不正确设置才会触发一个一般保护故障?
> 2. 你认为这些机制的意义是什么?尤其是要考虑 `user/softint` 测试程序的工作原理。
>
>
>
#### 系统调用
用户进程请求内核为它做事情就是通过系统调用来实现的。当用户进程请求一个系统调用时,处理器首先进入内核模式,处理器和内核配合去保存用户进程的状态,内核为了完成系统调用会运行有关的代码,然后重新回到用户进程。用户进程如何获得内核的关注以及它如何指定它需要的系统调用的具体细节,这在不同的系统上是不同的。
在 JOS 内核中,我们使用 `int` 指令,它将导致产生一个处理器中断。尤其是,我们使用 `int $0x30` 作为系统调用中断。我们定义常量 `T_SYSCALL` 为 48(0x30)。你将需要去设置中断描述符表,以允许用户进程去触发那个中断。注意,那个中断 0x30 并不是由硬件生成的,因此允许用户代码去产生它并不会引起歧义。
应用程序将在寄存器中传递系统调用号和系统调用参数。通过这种方式,内核就不需要去遍历用户环境的栈或指令流。系统调用号将放在 `%eax` 中,而参数(最多五个)将分别放在 `%edx`、`%ecx`、`%ebx`、`%edi`、和 `%esi` 中。内核将在 `%eax` 中传递返回值。在 `lib/syscall.c` 中的 `syscall()` 中已为你编写了使用一个系统调用的汇编代码。你可以通过阅读它来确保你已经理解了它们都做了什么。
>
> **练习 7**、在内核中为中断向量 `T_SYSCALL` 添加一个服务程序。你将需要去编辑 `kern/trapentry.S` 和 `kern/trap.c` 的 `trap_init()`。还需要去修改 `trap_dispatch()`,以便于通过使用适当的参数来调用 `syscall()` (定义在 `kern/syscall.c`)以处理系统调用中断,然后将系统调用的返回值安排在 `%eax` 中传递给用户进程。最后,你需要去实现 `kern/syscall.c` 中的 `syscall()`。如果系统调用号是无效值,确保 `syscall()` 返回值一定是 `-E_INVAL`。为确保你理解了系统调用的接口,你应该去阅读和掌握 `lib/syscall.c` 文件(尤其是行内汇编的动作),对于在 `inc/syscall.h` 中列出的每个系统调用都需要通过调用相关的内核函数来处理A。
>
>
> 在你的内核中运行 `user/hello` 程序(make run-hello)。它应该在控制台上输出 `hello, world`,然后在用户模式中产生一个页故障。如果没有产生页故障,可能意味着你的系统调用服务程序不太正确。现在,你应该有能力成功通过 `testbss` 测试。
>
>
>
.
>
> 小挑战!使用 `sysenter` 和 `sysexit` 指令而不是使用 `int 0x30` 和 `iret` 来实现系统调用。
>
>
> `sysenter/sysexit` 指令是由 Intel 设计的,它的运行速度要比 `int/iret` 指令快。它使用寄存器而不是栈来做到这一点,并且通过假定了分段寄存器是如何使用的。关于这些指令的详细内容可以在 Intel 参考手册 2B 卷中找到。
>
>
> 在 JOS 中添加对这些指令支持的最容易的方法是,在 `kern/trapentry.S` 中添加一个 `sysenter_handler`,在它里面保存足够多的关于用户环境返回、设置内核环境、推送参数到 `syscall()`、以及直接调用 `syscall()` 的信息。一旦 `syscall()` 返回,它将设置好运行 `sysexit` 指令所需的一切东西。你也将需要在 `kern/init.c` 中添加一些代码,以设置特殊模块寄存器(MSRs)。在 AMD 架构程序员手册第 2 卷的 6.1.2 节中和 Intel 参考手册的 2B 卷的 SYSENTER 上都有关于 MSRs 的很详细的描述。对于如何去写 MSRs,在[这里](http://ftp.kh.edu.tw/Linux/SuSE/people/garloff/linux/k6mod.c)你可以找到一个添加到 `inc/x86.h` 中的 `wrmsr` 的实现。
>
>
> 最后,`lib/syscall.c` 必须要修改,以便于支持用 `sysenter` 来生成一个系统调用。下面是 `sysenter` 指令的一种可能的寄存器布局:
>
>
>
> ```
> eax - syscall number
> edx, ecx, ebx, edi - arg1, arg2, arg3, arg4
> esi - return pc
> ebp - return esp
> esp - trashed by sysenter
> ```
>
> GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的值。不要忘了同时去保存(`push`)和恢复(`pop`)你使用的其它寄存器,或告诉内联汇编器你正在使用它们。内联汇编器不支持保存 `%ebp`,因此你需要自己去增加一些代码来保存和恢复它们,返回地址可以使用一个像 `leal after_sysenter_label, %%esi` 的指令置入到 `%esi` 中。
>
>
> 注意,它仅支持 4 个参数,因此你需要保留支持 5 个参数的系统调用的旧方法。而且,因为这个快速路径并不更新当前环境的 trap 帧,因此,在我们添加到后续实验中的一些系统调用上,它并不适合。
>
>
> 在接下来的实验中我们启用了异步中断,你需要再次去评估一下你的代码。尤其是,当返回到用户进程时,你需要去启用中断,而 `sysexit` 指令并不会为你去做这一动作。
>
>
>
#### 启动用户模式
一个用户程序是从 `lib/entry.S` 的顶部开始运行的。在一些配置之后,代码调用 `lib/libmain.c` 中的 `libmain()`。你应该去修改 `libmain()` 以初始化全局指针 `thisenv`,使它指向到这个环境在数组 `envs[]` 中的 `struct Env`。(注意那个 `lib/entry.S` 中已经定义 `envs` 去指向到在 Part A 中映射的你的设置。)提示:查看 `inc/env.h` 和使用 `sys_getenvid`。
`libmain()` 接下来调用 `umain`,在 hello 程序的案例中,`umain` 是在 `user/hello.c` 中。注意,它在输出 ”`hello, world`” 之后,它尝试去访问 `thisenv->env_id`。这就是为什么前面会发生故障的原因了。现在,你已经正确地初始化了 `thisenv`,它应该不会再发生故障了。如果仍然会发生故障,或许是因为你没有映射 `UENVS` 区域为用户可读取(回到前面 Part A 中 查看 `pmap.c`);这是我们第一次真实地使用 `UENVS` 区域)。
>
> **练习 8**、添加要求的代码到用户库,然后引导你的内核。你应该能够看到 `user/hello` 程序会输出 `hello, world` 然后输出 `i am environment 00001000`。`user/hello` 接下来会通过调用 `sys_env_destroy()`(查看`lib/libmain.c` 和 `lib/exit.c`)尝试去“退出”。由于内核目前仅支持一个用户环境,它应该会报告它毁坏了唯一的环境,然后进入到内核监视器中。现在你应该能够成功通过 `hello` 的测试。
>
>
>
#### 页故障和内存保护
内存保护是一个操作系统中最重要的特性,通过它来保证一个程序中的 bug 不会破坏其它程序或操作系统本身。
操作系统一般是依靠硬件的支持来实现内存保护。操作系统会告诉硬件哪些虚拟地址是有效的,而哪些是无效的。当一个程序尝试去访问一个无效地址或它没有访问权限的地址时,处理器会在导致故障发生的位置停止程序运行,然后捕获内核中关于尝试操作的相关信息。如果故障是可修复的,内核可能修复它并让程序继续运行。如果故障不可修复,那么程序就不能继续,因为它绝对不会跳过那个导致故障的指令。
作为一个可修复故障的示例,假设一个自动扩展的栈。在许多系统上,内核初始化分配一个单栈页,然后如果程序发生的故障是去访问这个栈页下面的页,那么内核会自动分配这些页,并让程序继续运行。通过这种方式,内核只分配程序所需要的内存栈,但是程序可以运行在一个任意大小的栈的假像中。
对于内存保护,系统调用中有一个非常有趣的问题。许多系统调用接口让用户程序传递指针到内核中。这些指针指向用户要读取或写入的缓冲区。然后内核在执行系统调用时废弃这些指针。这样就有两个问题:
1. 内核中的页故障可能比用户程序中的页故障多的多。如果内核在维护它自己的数据结构时发生页故障,那就是一个内核 bug,而故障服务程序将使整个内核(和整个系统)崩溃。但是当内核废弃了由用户程序传递给它的指针后,它就需要一种方式去记住那些废弃指针所导致的页故障其实是代表用户程序的。
2. 一般情况下内核拥有比用户程序更多的权限。用户程序可以传递一个指针到系统调用,而指针指向的区域有可能是内核可以读取或写入而用户程序不可访问的区域。内核必须要非常小心,不能被废弃的这种指针欺骗,因为这可能导致泄露私有信息或破坏内核的完整性。
由于以上的原因,内核在处理由用户程序提供的指针时必须格外小心。
现在,你可以通过使用一个简单的机制来仔细检查所有从用户空间传递给内核的指针来解决这个问题。当一个程序给内核传递指针时,内核将检查它的地址是否在地址空间的用户部分,然后页表才允许对内存的操作。
这样,内核在废弃一个用户提供的指针时就绝不会发生页故障。如果内核出现这种页故障,它应该崩溃并终止。
>
> **练习 9**、如果在内核模式中发生一个页故障,修改 `kern/trap.c` 去崩溃。
>
>
> 提示:判断一个页故障是发生在用户模式还是内核模式,去检查 `tf_cs` 的低位比特即可。
>
>
> 阅读 `kern/pmap.c` 中的 `user_mem_assert` 并在那个文件中实现 `user_mem_check`。
>
>
> 修改 `kern/syscall.c` 去常态化检查传递给系统调用的参数。
>
>
> 引导你的内核,运行 `user/buggyhello`。环境将被毁坏,而内核将不会崩溃。你将会看到:
>
>
>
> ```
> [00001000] user_mem_check assertion failure for va 00000001
> [00001000] free env 00001000
> Destroyed the only environment - nothing more to do!
> ```
>
> 最后,修改在 `kern/kdebug.c` 中的 `debuginfo_eip`,在 `usd`、`stabs`、和 `stabstr` 上调用 `user_mem_check`。如果你现在运行 `user/breakpoint`,你应该能够从内核监视器中运行回溯,然后在内核因页故障崩溃前看到回溯进入到 `lib/libmain.c`。是什么导致了这个页故障?你不需要去修复它,但是你应该明白它是如何发生的。
>
>
>
注意,刚才实现的这些机制也同样适用于恶意用户程序(比如 `user/evilhello`)。
>
> **练习 10**、引导你的内核,运行 `user/evilhello`。环境应该被毁坏,并且内核不会崩溃。你应该能看到:
>
>
>
> ```
> [00000000] new env 00001000
> ...
> [00001000] user_mem_check assertion failure for va f010000c
> [00001000] free env 00001000
> ```
>
>
**本实验到此结束。**确保你通过了所有的等级测试,并且不要忘记去写下问题的答案,在 `answers-lab3.txt` 中详细描述你的挑战练习的解决方案。提交你的变更并在 `lab` 目录下输入 `make handin` 去提交你的工作。
在动手实验之前,使用 `git status` 和 `git diff` 去检查你的变更,并不要忘记去 `git add answers-lab3.txt`。当你完成后,使用 `git commit -am 'my solutions to lab 3’` 去提交你的变更,然后 `make handin` 并关注这个指南。
---
via: <https://pdos.csail.mit.edu/6.828/2018/labs/lab3/>
作者:[csail.mit](https://pdos.csail.mit.edu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **
Part A due Thursday, October 4, 2018
Part B due Thursday, October 11, 2018
**
In this lab you will implement the basic kernel facilities required to get a protected user-mode environment (i.e., "process") running. You will enhance the JOS kernel to set up the data structures to keep track of user environments, create a single user environment, load a program image into it, and start it running. You will also make the JOS kernel capable of handling any system calls the user environment makes and handling any other exceptions it causes.
**Note:**
In this lab, the terms *environment* and *process* are
interchangeable - both refer to an abstraction that allows you to run a program. We introduce the
term "environment" instead of the traditional term "process"
in order to stress the point that JOS environments and UNIX processes
provide different interfaces, and do not provide
the same semantics.
Use Git to commit your changes after your Lab 2 submission (if any),
fetch the latest version of the course repository,
and then
create a local branch called `lab3` based on our lab3
branch, `origin/lab3`:
athena%cd ~/6.828/labathena%add gitathena%git commit -am 'changes to lab2 after handin'Created commit 734fab7: changes to lab2 after handin 4 files changed, 42 insertions(+), 9 deletions(-) athena%git pullAlready up-to-date. athena%git checkout -b lab3 origin/lab3Branch lab3 set up to track remote branch refs/remotes/origin/lab3. Switched to a new branch "lab3" athena%git merge lab2Merge made by recursive. kern/pmap.c | 42 +++++++++++++++++++ 1 files changed, 42 insertions(+), 0 deletions(-) athena%
Lab 3 contains a number of new source files, which you should browse:
inc/ |
env.h |
Public definitions for user-mode environments |
trap.h |
Public definitions for trap handling | |
syscall.h |
Public definitions for system calls from user environments to the kernel | |
lib.h |
Public definitions for the user-mode support library | |
kern/ |
env.h |
Kernel-private definitions for user-mode environments |
env.c |
Kernel code implementing user-mode environments | |
trap.h |
Kernel-private trap handling definitions | |
trap.c |
Trap handling code | |
trapentry.S |
Assembly-language trap handler entry-points | |
syscall.h |
Kernel-private definitions for system call handling | |
syscall.c |
System call implementation code | |
lib/ |
Makefrag |
Makefile fragment to build user-mode library,
obj/lib/libjos.a |
entry.S |
Assembly-language entry-point for user environments | |
libmain.c |
User-mode library setup code called from entry.S | |
syscall.c |
User-mode system call stub functions | |
console.c |
User-mode implementations of
putchar and getchar,
providing console I/O | |
exit.c |
User-mode implementation of exit | |
panic.c |
User-mode implementation of panic | |
user/ |
* |
Various test programs to check kernel lab 3 code |
In addition, a number of the source files we handed out for lab2 are modified in lab3. To see the differences, you can type:
$git diff lab2
You may also want to take another look at the [lab tools guide](../../labguide.html), as it includes
information on debugging user code that becomes relevant in this lab.
This lab is divided into two parts, A and B.
Part A is due a week after this lab was assigned;
you should commit your changes and `make handin`
your lab before the Part A deadline,
making sure your code passes all of the Part A tests (it is okay
if your code does not pass the Part B tests yet).
You only need to have the Part B tests passing
by the Part B deadline at the end of the second week.
As in lab 2,
you will need to do all of the regular exercises described in the lab
and *at least one* challenge problem (for the entire lab, not for
each part).
Write up brief answers
to the questions posed in the lab
and a one or two paragraph description of what you did
to solve your chosen challenge problem
in a file called `answers-lab3.txt`
in the top level of your `lab` directory.
(If you implement more than one challenge problem,
you only need to describe one of them in the write-up.)
Do not forget to include the answer file in your submission with
`git add answers-lab3.txt`.
In this lab you may find GCC's inline assembly language feature useful,
although it is also possible to complete the lab without using it.
At the very least, you will need to be able to understand
the fragments of inline assembly language ("`asm`" statements)
that already exist in the source code we gave you.
You can find several sources of information
on GCC inline assembly language
on the class [reference materials](../../reference.html) page.
The new include file `inc/env.h`
contains basic definitions for user environments in JOS.
Read it now.
The kernel uses the `Env`
data structure
to keep track of each user environment.
In this lab you will initially create just one environment,
but you will need to design the JOS kernel
to support multiple environments;
lab 4 will take advantage of this feature
by allowing a user environment to `fork`
other environments.
As you can see in `kern/env.c`,
the kernel maintains three main global variables
pertaining to environments:
struct Env *envs = NULL; // All environments struct Env *curenv = NULL; // The current env static struct Env *env_free_list; // Free environment list
Once JOS gets up and running,
the `envs`
pointer points to an array of `Env`
structures
representing all the environments in the system.
In our design,
the JOS kernel will support a maximum of `NENV`
simultaneously active environments,
although there will typically be far fewer running environments
at any given time.
(`NENV`
is a constant `#define`
'd in `inc/env.h`.)
Once it is allocated,
the `envs`
array will contain
a single instance of the `Env`
data structure
for each of the `NENV`
possible environments.
The JOS kernel keeps all of the inactive `Env`
structures
on the `env_free_list`
.
This design allows easy allocation and
deallocation of environments,
as they merely have to be added to or removed from the free list.
The kernel uses the `curenv`
symbol
to keep track of the *currently executing* environment at any given time.
During boot up, before the first environment is run,
`curenv`
is initially set to `NULL`
.
The `Env`
structure
is defined in `inc/env.h` as follows
(although more fields will be added in future labs):
struct Env { struct Trapframe env_tf; // Saved registers struct Env *env_link; // Next free Env envid_t env_id; // Unique environment identifier envid_t env_parent_id; // env_id of this env's parent enum EnvType env_type; // Indicates special system environments unsigned env_status; // Status of the environment uint32_t env_runs; // Number of times environment has run // Address space pde_t *env_pgdir; // Kernel virtual address of page dir };
Here's what the `Env`
fields are for:
`Env`
on the
`env_free_list`
. `env_free_list`
points
to the first free environment on the list.`Env`
structure
(i.e., using this particular slot in the `envs`
array).
After a user environment terminates,
the kernel may re-allocate
the same `Env`
structure to a different environment -
but the new environment
will have a different `env_id`
from the old one
even though the new environment
is re-using the same slot in the `envs`
array.`env_id`
of the environment that created this environment.
In this way the environments can form a “family tree,”
which will be useful for making security decisions
about which environments are allowed to do what to whom.`ENV_TYPE_USER`
. We'll introduce
a few more types for special system service environments in later labs.
`ENV_FREE`
:`Env`
structure is inactive,
and therefore on the `env_free_list`
.`ENV_RUNNABLE`
:`Env`
structure
represents an environment that is waiting to run on the
processor.`ENV_RUNNING`
:`Env`
structure
represents the currently running environment.`ENV_NOT_RUNNABLE`
:`Env`
structure
represents a currently active environment,
but it is not currently ready to run:
for example, because it is waiting
for an interprocess communication (IPC)
from another environment.`ENV_DYING`
:`Env`
structure
represents a zombie environment. A zombie environment will be
freed the next time it traps to the kernel. We will not use
this flag until Lab 4.
Like a Unix process, a JOS environment couples the concepts of
"thread" and "address space". The thread is defined primarily by the
saved registers (the `env_tf`
field), and the address space
is defined by the page directory and page tables pointed to by
`env_pgdir`
. To run an
environment, the kernel must set up the CPU with *both* the saved
registers and the appropriate address space.
Our `struct Env`
is analogous to `struct proc`
in xv6. Both structures hold the environment's (i.e., process's)
user-mode register state in a `Trapframe`
structure. In JOS,
individual environments do not have their own kernel stacks as
processes do in xv6. There can be only one JOS environment active in
the kernel at a time, so JOS needs only a
*single* kernel stack.
In lab 2,
you allocated memory in `mem_init()`
for the `pages[]`
array,
which is a table the kernel uses to keep track of
which pages are free and which are not.
You will now need to modify `mem_init()`
further
to allocate a similar array of `Env`
structures,
called `envs`
.
Exercise 1.
Modify `mem_init()`
in `kern/pmap.c`
to allocate and map the `envs`
array.
This array consists of
exactly `NENV`
instances of the `Env`
structure allocated much like how you allocated the
`pages`
array.
Also like the `pages`
array, the memory backing
`envs`
should also be mapped user read-only at
`UENVS`
(defined in `inc/memlayout.h`) so
user processes can read from this array.
You should run your code and make sure
`check_kern_pgdir()`
succeeds.
You will now write the code in `kern/env.c` necessary to run a
user environment. Because we do not yet have a filesystem, we will
set up the kernel to load a static binary image that is *embedded
within the kernel itself*. JOS embeds
this binary in the kernel as a ELF executable image.
The Lab 3 `GNUmakefile` generates a number of binary images in
the `obj/user/` directory. If you look at
`kern/Makefrag`, you will notice some magic that "links" these
binaries directly into the kernel executable as if they were
`.o` files. The `-b binary` option on the linker
command line causes these files to be linked in as "raw" uninterpreted
binary files rather than as regular `.o` files produced by the
compiler. (As far as the linker is concerned, these files do not have
to be ELF images at all - they could be anything, such as text files
or pictures!) If you look at `obj/kern/kernel.sym` after
building the kernel, you will notice that the linker has "magically"
produced a number of funny symbols with obscure names like
`_binary_obj_user_hello_start`,
`_binary_obj_user_hello_end`, and
`_binary_obj_user_hello_size`. The linker generates these
symbol names by mangling the file names of the binary files; the
symbols provide the regular kernel code with a way to reference the
embedded binary files.
In `i386_init()`
in `kern/init.c` you'll see code to run
one of these binary images in an environment. However, the critical
functions to set up user environments are not complete; you will need
to fill them in.
Exercise 2.
In the file `env.c`,
finish coding the following functions:
`env_init()`
`Env`
structures
in the `envs`
array and
add them to the `env_free_list`
.
Also calls `env_init_percpu`
, which
configures the segmentation hardware with
separate segments for privilege level 0 (kernel) and
privilege level 3 (user).`env_setup_vm()`
`region_alloc()`
`load_icode()`
`env_create()`
`env_alloc`
and call `load_icode`
to load an ELF binary into it.`env_run()`
As you write these functions,
you might find the new cprintf verb `%e`
useful -- it prints a description corresponding to an error code.
For example,
r = -E_NO_MEM; panic("env_alloc: %e", r);
will panic with the message "env_alloc: out of memory".
Below is a call graph of the code up to the point where the user code is invoked. Make sure you understand the purpose of each step.
`start`
(`kern/entry.S`
)`i386_init`
(`kern/init.c`
)
`cons_init`
`mem_init`
`env_init`
`trap_init`
(still incomplete at this point)`env_create`
`env_run`
`env_pop_tf`
Once you are done you should compile your kernel and run it under QEMU.
If all goes well, your system should enter user space and execute the
`hello` binary until it makes a system call with the
`int`
instruction. At that point there will be trouble, since
JOS has not set up the hardware to allow any kind of transition
from user space into the kernel.
When the CPU discovers that it is not set up to handle this system
call interrupt, it will generate a general protection exception, find
that it can't handle that, generate a double fault exception, find
that it can't handle that either, and finally give up with what's
known as a "triple fault". Usually, you would then see the CPU reset
and the system reboot. While this is important for legacy
applications (see [
this blog post](http://blogs.msdn.com/larryosterman/archive/2005/02/08/369243.aspx) for an explanation of why), it's a pain for kernel
development, so with the 6.828 patched QEMU you'll instead see a
register dump and a "Triple fault." message.
We'll address this problem shortly, but for now we can use the
debugger to check that we're entering user mode. Use `make
qemu-gdb` and set a GDB breakpoint at `env_pop_tf`
,
which should be the last function you hit before actually entering user mode.
Single step through this function using `si`;
the processor should enter user mode after the `iret`
instruction.
You should then see the first instruction
in the user environment's executable,
which is the `cmpl`
instruction at the label `start`
in `lib/entry.S`.
Now use `b *0x...` to set a breakpoint at the
`int $0x30`
in `sys_cputs()`
in `hello`
(see `obj/user/hello.asm` for the user-space address).
This `int`
is the system call to display a character to
the console.
If you cannot execute as far as the `int`
,
then something is wrong with your address space setup
or program loading code;
go back and fix it before continuing.
At this point,
the first `int $0x30`
system call instruction in user space
is a dead end:
once the processor gets into user mode,
there is no way to get back out.
You will now need to implement
basic exception and system call handling,
so that it is possible for the kernel to recover control of the processor
from user-mode code.
The first thing you should do
is thoroughly familiarize yourself with
the x86 interrupt and exception mechanism.
Exercise 3.
Read
[
Chapter 9, Exceptions and Interrupts](../../readings/i386/c09.htm)
in the
[80386 Programmer's Manual](../../readings/i386/toc.htm)
(or Chapter 5 of the [
IA-32 Developer's Manual](../../readings/ia32/IA32-3A.pdf)),
if you haven't already.
In this lab we generally follow Intel's terminology for interrupts, exceptions, and the like. However, terms such as exception, trap, interrupt, fault and abort have no standard meaning across architectures or operating systems, and are often used without regard to the subtle distinctions between them on a particular architecture such as the x86. When you see these terms outside of this lab, the meanings might be slightly different.
Exceptions and interrupts are both
"protected control transfers,"
which cause the processor to switch from user to kernel mode
(CPL=0) without giving the user-mode code any opportunity
to interfere with the functioning of the kernel or other environments.
In Intel's terminology,
an *interrupt* is a protected control transfer
that is caused by an asynchronous event usually external to the processor,
such as notification of external device I/O activity.
An *exception*, in contrast,
is a protected control transfer
caused synchronously by the currently running code,
for example due to a divide by zero or an invalid memory access.
In order to ensure that these protected control transfers
are actually *protected*,
the processor's interrupt/exception mechanism is designed so that
the code currently running when the interrupt or exception occurs
*does not get to choose arbitrarily where the kernel is entered or how*.
Instead,
the processor ensures that the kernel can be entered
only under carefully controlled conditions.
On the x86, two mechanisms work together to provide this protection:
**The Interrupt Descriptor Table.**
The processor ensures that interrupts and exceptions
can only cause the kernel to be entered
at a few specific, well-defined entry-points
*determined by the kernel itself*,
and not by the code running
when the interrupt or exception is taken.
The x86 allows up to 256 different
interrupt or exception entry points into the kernel,
each with a different *interrupt vector*.
A vector is a number between 0 and 255.
An interrupt's vector is determined by the
source of the interrupt: different devices, error
conditions, and application requests to the kernel
generate interrupts with different vectors.
The CPU uses the vector as an index
into the processor's *interrupt descriptor table* (IDT),
which the kernel sets up in kernel-private memory,
much like the GDT.
From the appropriate entry in this table
the processor loads:
**The Task State Segment.**
The processor needs a place
to save the *old* processor state
before the interrupt or exception occurred,
such as the original values of `EIP` and `CS`
before the processor invoked the exception handler,
so that the exception handler can later restore that old state
and resume the interrupted code from where it left off.
But this save area for the old processor state
must in turn be protected from unprivileged user-mode code;
otherwise buggy or malicious user code
could compromise the kernel.
For this reason,
when an x86 processor takes an interrupt or trap
that causes a privilege level change from user to kernel mode,
it also switches to a stack in the kernel's memory.
A structure called the *task state segment* (TSS) specifies
the segment selector and address where this stack lives.
The processor pushes (on this new stack)
`SS`, `ESP`, `EFLAGS`, `CS`, `EIP`, and an optional error code.
Then it loads the `CS` and `EIP` from the interrupt descriptor,
and sets the `ESP` and `SS` to refer to the new stack.
Although the TSS is large
and can potentially serve a variety of purposes,
JOS only uses it to define
the kernel stack that the processor should switch to
when it transfers from user to kernel mode.
Since "kernel mode" in JOS
is privilege level 0 on the x86,
the processor uses the `ESP0` and `SS0` fields of the TSS
to define the kernel stack when entering kernel mode.
JOS doesn't use any other TSS fields.
All of the synchronous exceptions
that the x86 processor can generate internally
use interrupt vectors between 0 and 31,
and therefore map to IDT entries 0-31.
For example,
a page fault always causes an exception through vector 14.
Interrupt vectors greater than 31 are only used by
*software interrupts*,
which can be generated by the `int`
instruction, or
asynchronous *hardware interrupts*,
caused by external devices when they need attention.
In this section we will extend JOS to handle the internally generated x86 exceptions in vectors 0-31. In the next section we will make JOS handle software interrupt vector 48 (0x30), which JOS (fairly arbitrarily) uses as its system call interrupt vector. In Lab 4 we will extend JOS to handle externally generated hardware interrupts such as the clock interrupt.
Let's put these pieces together and trace through an example. Let's say the processor is executing code in a user environment and encounters a divide instruction that attempts to divide by zero.
`GD_KD`
and `KSTACKTOP`
, respectively.`KSTACKTOP`
:
+--------------------+ KSTACKTOP | 0x00000 | old SS | " - 4 | old ESP | " - 8 | old EFLAGS | " - 12 | 0x00000 | old CS | " - 16 | old EIP | " - 20 <---- ESP +--------------------+
For certain types of x86 exceptions,
in addition to the "standard" five words above,
the processor pushes onto the stack another word
containing an *error code*.
The page fault exception, number 14,
is an important example.
See the 80386 manual to determine for which exception numbers
the processor pushes an error code,
and what the error code means in that case.
When the processor pushes an error code,
the stack would look as follows at the beginning of the exception handler
when coming in from user mode:
+--------------------+ KSTACKTOP | 0x00000 | old SS | " - 4 | old ESP | " - 8 | old EFLAGS | " - 12 | 0x00000 | old CS | " - 16 | old EIP | " - 20 | error code | " - 24 <---- ESP +--------------------+
The processor can take exceptions and interrupts
both from kernel and user mode.
It is only when entering the kernel from user mode, however,
that the x86 processor automatically switches stacks
before pushing its old register state onto the stack
and invoking the appropriate exception handler through the IDT.
If the processor is *already* in kernel mode
when the interrupt or exception occurs
(the low 2 bits of the `CS` register are already zero),
then the CPU just pushes more values on the same kernel stack.
In this way, the kernel can gracefully handle *nested exceptions*
caused by code within the kernel itself.
This capability is an important tool in implementing protection,
as we will see later in the section on system calls.
If the processor is already in kernel mode
and takes a nested exception,
since it does not need to switch stacks,
it does not save the old `SS` or `ESP` registers.
For exception types that do not push an error code,
the kernel stack therefore looks like the following
on entry to the exception handler:
+--------------------+ <---- old ESP | old EFLAGS | " - 4 | 0x00000 | old CS | " - 8 | old EIP | " - 12 +--------------------+
For exception types that push an error code,
the processor pushes the error code immediately after the old `EIP`,
as before.
There is one important caveat to the processor's nested exception capability.
If the processor takes an exception while already in kernel mode,
and *cannot push its old state onto the kernel stack* for any reason
such as lack of stack space,
then there is nothing the processor can do to recover,
so it simply resets itself.
Needless to say, the kernel should be designed so that this can't happen.
You should now have the basic information you need in order to set up the IDT and handle exceptions in JOS. For now, you will set up the IDT to handle interrupt vectors 0-31 (the processor exceptions). We'll handle system call interrupts later in this lab and add interrupts 32-47 (the device IRQs) in a later lab.
The header files `inc/trap.h` and `kern/trap.h`
contain important definitions related to interrupts and exceptions
that you will need to become familiar with.
The file `kern/trap.h` contains definitions
that are strictly private to the kernel,
while `inc/trap.h`
contains definitions that may also be useful
to user-level programs and libraries.
Note: Some of the exceptions in the range 0-31 are defined by Intel to be reserved. Since they will never be generated by the processor, it doesn't really matter how you handle them. Do whatever you think is cleanest.
The overall flow of control that you should achieve is depicted below:
IDT trapentry.S trap.c +----------------+ | &handler1 |---------> handler1: trap (struct Trapframe *tf) | | // do stuff { | | call trap // handle the exception/interrupt | | // ... } +----------------+ | &handler2 |--------> handler2: | | // do stuff | | call trap | | // ... +----------------+ . . . +----------------+ | &handlerX |--------> handlerX: | | // do stuff | | call trap | | // ... +----------------+
Each exception or interrupt should have
its own handler in `trapentry.S`
and `trap_init()`
should initialize the IDT with the addresses
of these handlers.
Each of the handlers should build a `struct Trapframe`
(see `inc/trap.h`) on the stack and call
`trap()`
(in `trap.c`)
with a pointer to the Trapframe.
`trap()`
then handles the
exception/interrupt or dispatches to a specific
handler function.
Exercise 4.
Edit `trapentry.S` and `trap.c` and
implement the features described above. The macros
`TRAPHANDLER`
and `TRAPHANDLER_NOEC`
in
`trapentry.S` should help you, as well as the T_*
defines in `inc/trap.h`. You will need to add an
entry point in `trapentry.S` (using those macros)
for each trap defined in `inc/trap.h`, and
you'll have to provide `_alltraps`
which the
`TRAPHANDLER`
macros refer to. You will
also need to modify `trap_init()`
to initialize the
`idt`
to point to each of these entry points
defined in `trapentry.S`; the `SETGATE`
macro will be helpful here.
Your `_alltraps`
should:
`GD_KD`
into `pushl %esp`
to pass a pointer to the Trapframe as an argument to trap()`call trap`
(can `trap`
ever return?)
Consider using the `pushal`
instruction; it fits nicely with the layout of the ```
struct
Trapframe
```
.
Test your trap handling code
using some of the test programs in the `user` directory
that cause exceptions before making any system calls,
such as `user/divzero`.
You should be able to get `make grade`
to succeed on the `divzero`, `softint`,
and `badsegment` tests at this point.
Challenge!
You probably have a lot of very similar code
right now, between the lists of `TRAPHANDLER`
in
`trapentry.S` and their installations in
`trap.c`. Clean this up. Change the macros in
`trapentry.S` to automatically generate a table for
`trap.c` to use. Note that you can switch between
laying down code and data in the assembler by using the
directives `.text`
and `.data`
.
Questions
Answer the following questions in your `answers-lab3.txt`:
`int $14`
.
`int $14`
instruction to invoke the kernel's page fault handler
(which is interrupt vector 14)?This concludes part A of the lab. Don't forget to add
`answers-lab3.txt`, commit your changes, and run `make
handin` before the part A deadline.
Now that your kernel has basic exception handling capabilities, you will refine it to provide important operating system primitives that depend on exception handling.
The page fault exception, interrupt vector 14 (`T_PGFLT`
),
is a particularly important one that we will exercise heavily
throughout this lab and the next.
When the processor takes a page fault,
it stores the linear (i.e., virtual) address that caused the fault
in a special processor control register, `CR2`.
In `trap.c`
we have provided the beginnings of a special function,
`page_fault_handler()`
,
to handle page fault exceptions.
Exercise 5.
Modify `trap_dispatch()`
to dispatch page fault exceptions
to `page_fault_handler()`
.
You should now be able to get `make grade`
to succeed on the `faultread`, `faultreadkernel`,
`faultwrite`, and `faultwritekernel` tests.
If any of them don't work, figure out why and fix them.
Remember that you can boot JOS into a particular user program
using `make run- x` or
You will further refine the kernel's page fault handling below, as you implement system calls.
The breakpoint exception, interrupt vector 3 (`T_BRKPT`
),
is normally used to allow debuggers
to insert breakpoints in a program's code
by temporarily replacing the relevant program instruction
with the special 1-byte `int3`
software interrupt instruction.
In JOS we will abuse this exception slightly
by turning it into a primitive pseudo-system call
that any user environment can use to invoke the JOS kernel monitor.
This usage is actually somewhat appropriate
if we think of the JOS kernel monitor as a primitive debugger.
The user-mode implementation of `panic()`
in `lib/panic.c`,
for example,
performs an `int3`
after displaying its panic message.
Exercise 6.
Modify `trap_dispatch()`
to make breakpoint exceptions invoke the kernel monitor.
You should now be able to get `make grade`
to succeed on the `breakpoint` test.
Challenge!
Modify the JOS kernel monitor so that
you can 'continue' execution from the current location
(e.g., after the `int3`
,
if the kernel monitor was invoked via the breakpoint exception),
and so that you can single-step one instruction at a time.
You will need to understand certain bits
of the `EFLAGS` register
in order to implement single-stepping.
Optional: If you're feeling really adventurous, find some x86 disassembler source code - e.g., by ripping it out of QEMU, or out of GNU binutils, or just write it yourself - and extend the JOS kernel monitor to be able to disassemble and display instructions as you are stepping through them. Combined with the symbol table loading from lab 1, this is the stuff of which real kernel debuggers are made.
Questions
`SETGATE`
from `trap_init`
). Why?
How do you need to set it up in order to get the breakpoint exception
to work as specified above and what incorrect setup would
cause it to trigger a general protection fault?User processes ask the kernel to do things for them by invoking system calls. When the user process invokes a system call, the processor enters kernel mode, the processor and the kernel cooperate to save the user process's state, the kernel executes appropriate code in order to carry out the system call, and then resumes the user process. The exact details of how the user process gets the kernel's attention and how it specifies which call it wants to execute vary from system to system.
In the JOS kernel, we will use the `int`
instruction, which causes a processor interrupt.
In particular, we will use `int $0x30`
as the system call interrupt.
We have defined the constant
`T_SYSCALL`
to 48 (0x30) for you. You will have to
set up the interrupt descriptor to allow user processes to
cause that interrupt. Note that interrupt 0x30 cannot be
generated by hardware, so there is no ambiguity caused by
allowing user code to generate it.
The application will pass the system call number and
the system call arguments in registers. This way, the kernel won't
need to grub around in the user environment's stack
or instruction stream. The
system call number will go in `%eax`
, and the
arguments (up to five of them) will go in `%edx`
,
`%ecx`
, `%ebx`
, `%edi`
,
and `%esi`
, respectively. The kernel passes the
return value back in `%eax`
. The assembly code to
invoke a system call has been written for you, in
`syscall()`
in `lib/syscall.c`. You
should read through it and make sure you understand what
is going on.
Exercise 7.
Add a handler in the kernel
for interrupt vector `T_SYSCALL`
.
You will have to edit `kern/trapentry.S` and
`kern/trap.c`'s `trap_init()`
. You
also need to change `trap_dispatch()`
to handle the
system call interrupt by calling `syscall()`
(defined in `kern/syscall.c`)
with the appropriate arguments,
and then arranging for
the return value to be passed back to the user process
in `%eax`
.
Finally, you need to implement `syscall()`
in
`kern/syscall.c`.
Make sure `syscall()`
returns `-E_INVAL`
if the system call number is invalid.
You should read and understand `lib/syscall.c`
(especially the inline assembly routine) in order to confirm
your understanding of the system call interface.
Handle all the system calls listed in `inc/syscall.h` by
invoking the corresponding kernel function for each call.
Run the `user/hello` program under your kernel
(`make run-hello`).
It should print "`hello, world`" on the console
and then cause a page fault in user mode.
If this does not happen, it probably means
your system call handler isn't quite right.
You should also now be able to get `make grade`
to succeed on the `testbss` test.
Challenge!
Implement system calls using the `sysenter`
and
`sysexit`
instructions instead of using
`int 0x30`
and `iret`
.
The `sysenter/sysexit`
instructions were designed
by Intel to be faster than `int/iret`
. They do
this by using registers instead of the stack and by making
assumptions about how the segmentation registers are used.
The exact details of these instructions can be found in Volume
2B of the Intel reference manuals.
The easiest way to add support for these instructions in JOS
is to add a `sysenter_handler`
in
`kern/trapentry.S` that saves enough information about
the user environment to return to it, sets up the kernel
environment, pushes the arguments to
`syscall()`
and calls `syscall()`
directly. Once `syscall()`
returns, set everything
up for and execute the `sysexit`
instruction.
You will also need to add code to `kern/init.c` to
set up the necessary model specific registers (MSRs). Section
6.1.2 in Volume 2 of the AMD Architecture Programmer's Manual
and the reference on SYSENTER in Volume 2B of the Intel
reference manuals give good descriptions of the relevant MSRs.
You can find an implementation of `wrmsr`
to add to
`inc/x86.h` for writing to these MSRs [here](http://ftp.kh.edu.tw/Linux/SuSE/people/garloff/linux/k6mod.c).
Finally, `lib/syscall.c` must be changed to support
making a system call with `sysenter`
. Here is a
possible register layout for the `sysenter`
instruction:
eax - syscall number edx, ecx, ebx, edi - arg1, arg2, arg3, arg4 esi - return pc ebp - return esp esp - trashed by sysenter
GCC's inline assembler will automatically save registers that
you tell it to load values directly into. Don't forget to
either save (push) and restore (pop) other registers that you
clobber, or tell the inline assembler that you're clobbering
them. The inline assembler doesn't support saving
`%ebp`
, so you will need to add code to save and
restore it yourself. The return
address can be put into `%esi`
by using an
instruction like ```
leal after_sysenter_label,
%%esi
```
.
Note that this only supports 4 arguments, so you will need to leave the old method of doing system calls around to support 5 argument system calls. Furthermore, because this fast path doesn't update the current environment's trap frame, it won't be suitable for some of the system calls we add in later labs.
You may have to revisit your code once we enable asynchronous
interrupts in the next lab. Specifically, you'll need to
enable interrupts when returning to the user process, which
`sysexit`
doesn't do for you.
A user program starts running at the top of
`lib/entry.S`. After some setup, this code
calls `libmain()`
, in `lib/libmain.c`.
You should modify `libmain()` to initialize the global pointer
`thisenv`
to point at this environment's
`struct Env`
in the `envs[]`
array.
(Note that `lib/entry.S` has already defined `envs`
to point at the `UENVS`
mapping you set up in Part A.)
Hint: look in `inc/env.h` and use
`sys_getenvid`
.
`libmain()`
then calls `umain`
, which,
in the case of the hello program, is in
`user/hello.c`. Note that after printing
"`hello, world`", it tries to access
`thisenv->env_id`
. This is why it faulted earlier.
Now that you've initialized `thisenv`
properly,
it should not fault.
If it still faults, you probably haven't mapped the
`UENVS`
area user-readable (back in Part A in
`pmap.c`; this is the first time we've actually
used the `UENVS`
area).
Exercise 8.
Add the required code to the user library, then
boot your kernel. You should see `user/hello`
print "`hello, world`" and then print "`i
am environment 00001000`".
`user/hello` then attempts to "exit"
by calling `sys_env_destroy()`
(see `lib/libmain.c` and `lib/exit.c`).
Since the kernel currently only supports one user environment,
it should report that it has destroyed the only environment
and then drop into the kernel monitor.
You should be able to get `make grade`
to succeed on the `hello` test.
Memory protection is a crucial feature of an operating system, ensuring that bugs in one program cannot corrupt other programs or corrupt the operating system itself.
Operating systems usually rely on hardware support to implement memory protection. The OS keeps the hardware informed about which virtual addresses are valid and which are not. When a program tries to access an invalid address or one for which it has no permissions, the processor stops the program at the instruction causing the fault and then traps into the kernel with information about the attempted operation. If the fault is fixable, the kernel can fix it and let the program continue running. If the fault is not fixable, then the program cannot continue, since it will never get past the instruction causing the fault.
As an example of a fixable fault, consider an automatically extended stack. In many systems the kernel initially allocates a single stack page, and then if a program faults accessing pages further down the stack, the kernel will allocate those pages automatically and let the program continue. By doing this, the kernel only allocates as much stack memory as the program needs, but the program can work under the illusion that it has an arbitrarily large stack.
System calls present an interesting problem for memory protection. Most system call interfaces let user programs pass pointers to the kernel. These pointers point at user buffers to be read or written. The kernel then dereferences these pointers while carrying out the system call. There are two problems with this:
For both of these reasons the kernel must be extremely careful when handling pointers presented by user programs.
You will now solve these two problems with a single mechanism that scrutinizes all pointers passed from userspace into the kernel. When a program passes the kernel a pointer, the kernel will check that the address is in the user part of the address space, and that the page table would allow the memory operation.
Thus, the kernel will never suffer a page fault due to dereferencing a user-supplied pointer. If the kernel does page fault, it should panic and terminate.
Exercise 9.
Change `kern/trap.c`
to panic if a page
fault happens in kernel mode.
Hint: to determine whether a fault happened in user mode or
in kernel mode, check the low bits of the `tf_cs`
.
Read `user_mem_assert`
in `kern/pmap.c`
and implement `user_mem_check`
in that same file.
Change `kern/syscall.c` to sanity check arguments
to system calls.
Boot your kernel, running `user/buggyhello`.
The environment should be destroyed,
and the kernel should *not* panic.
You should see:
[00001000] user_mem_check assertion failure for va 00000001 [00001000] free env 00001000 Destroyed the only environment - nothing more to do!
Finally, change `debuginfo_eip`
in
`kern/kdebug.c` to call `user_mem_check`
on
`usd`
, `stabs`
, and
`stabstr`
. If you now run
`user/breakpoint`, you should be able to run
`backtrace` from the kernel monitor and see the
backtrace traverse into `lib/libmain.c` before the
kernel panics with a page fault. What causes this page fault?
You don't need to fix it, but you should understand why it
happens.
Note that the same mechanism you just implemented also works for
malicious user applications (such as `user/evilhello`).
Exercise 10.
Boot your kernel, running `user/evilhello`.
The environment should be destroyed,
and the kernel should not panic.
You should see:
[00000000] new env 00001000 ... [00001000] user_mem_check assertion failure for va f010000c [00001000] free env 00001000
**This completes the lab.**
Make sure you pass all of the `make grade` tests and
don't forget to write up your answers to the questions and a
description of your challenge exercise solution in
`answers-lab3.txt`. Commit your changes
and type `make handin` in the `lab` directory to
submit your work.
Before handing in, use `git status` and `git diff`
to examine your changes and don't forget to `git add
answers-lab3.txt`. When you're ready, commit your changes with
`git commit -am 'my solutions to lab 3'`, then `make
handin` and follow the directions. |
10,308 | 编写你的第一行 HTML 代码,来帮助蝙蝠侠写一封情书 | https://medium.freecodecamp.org/for-your-first-html-code-lets-help-batman-write-a-love-letter-64c203b9360b | 2018-12-04T09:59:00 | [
"HTML"
] | https://linux.cn/article-10308-1.html | 
在一个美好的夜晚,你的肚子拒绝消化你在晚餐吃的大块披萨,所以你不得不在睡梦中冲进洗手间。
在浴室里,当你在思考为什么会发生这种情况时,你听到一个来自通风口的低沉声音:“嘿,我是蝙蝠侠。”
这时,你会怎么做呢?
在你恐慌并处于关键时刻之前,蝙蝠侠说:“我需要你的帮助。我是一个超级极客,但我不懂 HTML。我需要用 HTML 写一封情书,你愿意帮助我吗?”
谁会拒绝蝙蝠侠的请求呢,对吧?所以让我们用 HTML 来写一封蝙蝠侠的情书。
### 你的第一个 HTML 文件
HTML 网页与你电脑上的其它文件一样。就同一个 .doc 文件以 MS Word 打开,.jpg 文件在图像查看器中打开一样,一个 .html 文件在浏览器中打开。
那么,让我们来创建一个 .html 文件。你可以在 Notepad 或其它任何编辑器中完成此任务,但我建议使用 VS Code。[在这里下载并安装 VS Code](https://code.visualstudio.com/)。它是免费的,也是我唯一喜欢的微软产品。
在系统中创建一个目录,将其命名为 “HTML Practice”(不带引号)。在这个目录中,再创建一个名为 “Batman’s Love Letter”(不带引号)的目录,这将是我们的项目根目录。这意味着我们所有与这个项目相关的文件都会在这里。
打开 VS Code,按下 `ctrl+n` 创建一个新文件,按下 `ctrl+s` 保存文件。切换到 “Batman’s Love Letter” 文件夹并将其命名为 “loveletter.html”,然后单击保存。
现在,如果你在文件资源管理器中双击它,它将在你的默认浏览器中打开。我建议使用 Firefox 来进行 web 开发,但 Chrome 也可以。
让我们将这个过程与我们已经熟悉的东西联系起来。还记得你第一次拿到电脑吗?我做的第一件事是打开 MS Paint 并绘制一些东西。你在 Paint 中绘制一些东西并将其另存为图像,然后你可以在图像查看器中查看该图像。之后,如果要再次编辑该图像,你在 Paint 中重新打开它,编辑并保存它。
我们目前的流程非常相似。正如我们使用 Paint 创建和编辑图像一样,我们使用 VS Code 来创建和编辑 HTML 文件。就像我们使用图像查看器查看图像一样,我们使用浏览器来查看我们的 HTML 页面。
### HTML 中的段落
我们有一个空的 HTML 文件,以下是蝙蝠侠想在他的情书中写的第一段。
“After all the battles we fought together, after all the difficult times we saw together, and after all the good and bad moments we’ve been through, I think it’s time I let you know how I feel about you.”
复制这些到 VS Code 中的 loveletter.html。单击 “View -> Toggle Word Wrap (alt+z)” 自动换行。
保存并在浏览器中打开它。如果它已经打开,单击浏览器中的刷新按钮。
瞧!那是你的第一个网页!
我们的第一段已准备就绪,但这不是在 HTML 中编写段落的推荐方法。我们有一种特定的方法让浏览器知道一个文本是一个段落。
如果你用 `<p>` 和 `</p>` 来包裹文本,那么浏览器将识别 `<p>` 和 `</p>` 中的文本是一个段落。我们这样做:
```
<p>After all the battles we fought together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.</p>
```
通过在 `<p>` 和 `</p>`中编写段落,你创建了一个 HTML 元素。一个网页就是 HTML 元素的集合。
让我们首先来认识一些术语:`<p>` 是开始标签,`</p>` 是结束标签,“p” 是标签名称。元素开始和结束标签之间的文本是元素的内容。
### “style” 属性
在上面,你将看到文本覆盖屏幕的整个宽度。
我们不希望这样。没有人想要阅读这么长的行。让我们设定段落宽度为 550px。
我们可以通过使用元素的 `style` 属性来实现。你可以在其 `style` 属性中定义元素的样式(例如,在我们的示例中为宽度)。以下行将在 `p` 元素上创建一个空样式属性:
```
<p style="">...</p>
```
你看到那个空的 `""` 了吗?这就是我们定义元素外观的地方。现在我们要将宽度设置为 550px。我们这样做:
```
<p style="width:550px;">
After all the battles we fought together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
```
我们将 `width` 属性设置为 `550px`,用冒号 `:` 分隔,以分号 `;` 结束。
另外,注意我们如何将 `<p>` 和 `</p>` 放在单独的行中,文本内容用一个制表符缩进。像这样设置代码使其更具可读性。
### HTML 中的列表
接下来,蝙蝠侠希望列出他所钦佩的人的一些优点,例如:
```
You complete my darkness with your light. I love:
- the way you see good in the worst things
- the way you handle emotionally difficult situations
- the way you look at Justice
I have learned a lot from you. You have occupied a special place in my heart over time.
```
这看起来很简单。
让我们继续,在 `</p>` 下面复制所需的文本:
```
<p style="width:550px;">
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<p style="width:550px;">
You complete my darkness with your light. I love:
- the way you see good in the worse
- the way you handle emotionally difficult situations
- the way you look at Justice
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
```
保存并刷新浏览器。

哇!这里发生了什么,我们的列表在哪里?
如果你仔细观察,你会发现没有显示换行符。在代码中我们在新的一行中编写列表项,但这些项在浏览器中显示在一行中。
如果你想在 HTML(新行)中插入换行符,你必须使用 `<br>`。让我们来使用 `<br>`,看看它长什么样:
```
<p style="width:550px;">
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<p style="width:550px;">
You complete my darkness with your light. I love: <br>
- the way you see good in the worse <br>
- the way you handle emotionally difficult situations <br>
- the way you look at Justice <br>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
```
保存并刷新:

好的,现在它看起来就像我们想要的那样!
另外,注意我们没有写一个 `</br>`。有些标签不需要结束标签(它们被称为自闭合标签)。
还有一件事:我们没有在两个段落之间使用 `<br>`,但第二个段落仍然是从一个新行开始,这是因为 `<p>` 元素会自动插入换行符。
我们使用纯文本编写列表,但是有两个标签可以供我们使用来达到相同的目的:`<ul>` and `<li>`。
让我们解释一下名字的意思:ul 代表<ruby> 无序列表 <rt> Unordered List </rt></ruby>,li 代表<ruby> 列表项目 <rt> List Item </rt></ruby>。让我们使用它们来展示我们的列表:
```
<p style="width:550px;">
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
```
```
<p style="width:550px;">
You complete my darkness with your light. I love:
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
```
在复制代码之前,注意差异部分:
* 我们删除了所有的 `<br>`,因为每个 `<li>` 会自动显示在新行中
* 我们将每个列表项包含在 `<li>` 和 `</li>` 之间
* 我们将所有列表项的集合包裹在 `<ul>` 和 `</ul>` 之间
* 我们没有像 `<p>` 元素那样定义 `<ul>` 元素的宽度。这是因为 `<ul>` 是 `<p>` 的子节点,`<p>` 已经被约束到 550px,所以 `<ul>` 不会超出这个范围。
让我们保存文件并刷新浏览器以查看结果:

你会立即注意到在每个列表项之前显示了重点标志。我们现在不需要在每个列表项之前写 “-”。
经过仔细检查,你会注意到最后一行超出 550px 宽度。这是为什么?因为 HTML 不允许 `<ul>` 元素出现在 `<p>` 元素中。让我们将第一行和最后一行放在单独的 `<p>` 元素中:
```
<p style="width:550px;">
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
```
```
<p style="width:550px;">
You complete my darkness with your light. I love:
</p>
```
```
<ul style="width:550px;">
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
```
```
<p style="width:550px;">
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
```
保存并刷新。
注意,这次我们还定义了 `<ul>` 元素的宽度。那是因为我们现在已经将 `<ul>` 元素放在了 `<p>` 元素之外。
定义情书中所有元素的宽度会变得很麻烦。我们有一个特定的元素用于此目的:`<div>` 元素。一个 `<div>` 元素就是一个通用容器,用于对内容进行分组,以便轻松设置样式。
让我们用 `<div>` 元素包装整个情书,并为其赋予宽度:550px 。
```
<div style="width:550px;">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
</div>
```
棒极了,我们的代码现在看起来简洁多了。
### HTML 中的标题
到目前为止,蝙蝠侠对结果很高兴,他希望在情书上标题。他想写一个标题: “Bat Letter”。当然,你已经看到这个名字了,不是吗?:D
你可以使用 `<h1>`、`<h2>`、`<h3>`、`<h4>`、`<h5>` 和 `<h6>` 标签来添加标题,`<h1>` 是最大的标题和最主要的标题,`<h6>` 是最小的标题。

让我们在第二段之前使用 `<h1>` 做主标题和一个副标题:
```
<div style="width:550px;">
<h1>Bat Letter</h1>
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
```
```
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
</div>
```
保存,刷新。

### HTML 中的图像
我们的情书尚未完成,但在继续之前,缺少一件大事:蝙蝠侠标志。你见过是蝙蝠侠的东西但没有蝙蝠侠的标志吗?
并没有。
所以,让我们在情书中添加一个蝙蝠侠标志。
在 HTML 中包含图像就像在一个 Word 文件中包含图像一样。在 MS Word 中,你到 “菜单 -> 插入 -> 图像 -> 然后导航到图像位置为止 -> 选择图像 -> 单击插入”。
在 HTML 中,我们使用 `<img>` 标签让浏览器知道我们需要加载的图像,而不是单击菜单。我们在 `src` 属性中写入文件的位置和名称。如果图像在项目根目录中,我们可以简单地在 `src` 属性中写入图像文件的名称。
在我们深入编码之前,从[这里](https://www.pexels.com/photo/batman-black-and-white-logo-93596/)下载蝙蝠侠标志。你可能希望裁剪图像中的额外空白区域。复制项目根目录中的图像并将其重命名为 “bat-logo.jpeg”。
```
<div style="width:550px;">
<h1>Bat Letter</h1>
<img src="bat-logo.jpeg">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
```
```
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
</div>
```
我们在第 3 行包含了 `<img>` 标签。这个标签也是一个自闭合的标签,所以我们不需要写 `</img>`。在 `src` 属性中,我们给出了图像文件的名称。这个名称应与图像名称完全相同,包括扩展名(.jpeg)及其大小写。
保存并刷新,查看结果。

该死的!刚刚发生了什么?
当使用 `<img>` 标签包含图像时,默认情况下,图像将以其原始分辨率显示。在我们的例子中,图像比 550px 宽得多。让我们使用 `style` 属性定义它的宽度:
```
<div style="width:550px;">
<h1>Bat Letter</h1>
<img src="bat-logo.jpeg" style="width:100%">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
```
```
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
</div>
```
你会注意到,这次我们定义宽度使用了 “%” 而不是 “px”。当我们在 “%” 中定义宽度时,它将占据父元素宽度的百分比。因此,100% 的 550px 将为我们提供 550px。
保存并刷新,查看结果。

太棒了!这让蝙蝠侠的脸露出了羞涩的微笑 :)。
### HTML 中的粗体和斜体
现在蝙蝠侠想在最后几段中承认他的爱。他有以下文本供你用 HTML 编写:
“I have a confession to make
It feels like my chest does have a heart. You make my heart beat. Your smile brings a smile to my face, your pain brings pain to my heart.
I don’t show my emotions, but I think this man behind the mask is falling for you.”
当阅读到这里时,你会问蝙蝠侠:“等等,这是给谁的?”蝙蝠侠说:
“这是给超人的。”

你说:哦!我还以为是给神奇女侠的呢。
蝙蝠侠说:不,这是给超人的,请在最后写上 “I love you Superman.”。
好的,我们来写:
```
<div style="width:550px;">
<h1>Bat Letter</h1>
<img src="bat-logo.jpeg" style="width:100%">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
```
```
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest does have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p>I love you Superman.</p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
```
这封信差不多完成了,蝙蝠侠另外想再做两次改变。蝙蝠侠希望在最后段落的第一句中的 “does” 一词是斜体,而 “I love you Superman” 这句话是粗体的。
我们使用 `<em>` 和 `<strong>` 以斜体和粗体显示文本。让我们来更新这些更改:
```
<div style="width:550px;">
<h1>Bat Letter</h1>
<img src="bat-logo.jpeg" style="width:100%">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
```
```
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p><strong>I love you Superman.</strong></p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
```

### HTML 中的样式
你可以通过三种方式设置样式或定义 HTML 元素的外观:
* 内联样式:我们使用元素的 `style` 属性来编写样式。这是我们迄今为止使用的,但这不是一个好的实践。
* 嵌入式样式:我们在由 `<style>` 和 `</style>` 包裹的 “style” 元素中编写所有样式。
* 链接样式表:我们在具有 .css 扩展名的单独文件中编写所有元素的样式。此文件称为样式表。
让我们来看看如何定义 `<div>` 的内联样式:
```
<div style="width:550px;">
```
我们可以在 `<style>` 和 `</style>` 里面写同样的样式:
```
div{
width:550px;
}
```
在嵌入式样式中,我们编写的样式是与元素分开的。所以我们需要一种方法来关联元素及其样式。第一个单词 “div” 就做了这样的活。它让浏览器知道花括号 `{...}` 里面的所有样式都属于 “div” 元素。由于这种语法确定要应用样式的元素,因此它称为一个选择器。
我们编写样式的方式保持不变:属性(`width`)和值(`550px`)用冒号(`:`)分隔,以分号(`;`)结束。
让我们从 `<div>` 和 `<img>` 元素中删除内联样式,将其写入 `<style>` 元素:
```
<style>
div{
width:550px;
}
img{
width:100%;
}
</style>
```
```
<div>
<h1>Bat Letter</h1>
<img src="bat-logo.jpeg">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
```
```
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p><strong>I love you Superman.</strong></p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
```
保存并刷新,结果应保持不变。
但是有一个大问题,如果我们的 HTML 文件中有多个 `<div>` 和 `<img>` 元素该怎么办?这样我们在 `<style>` 元素中为 div 和 img 定义的样式就会应用于页面上的每个 div 和 img。
如果你在以后的代码中添加另一个 div,那么该 div 也将变为 550px 宽。我们并不希望这样。
我们想要将我们的样式应用于现在正在使用的特定 div 和 img。为此,我们需要为 div 和 img 元素提供唯一的 id。以下是使用 `id` 属性为元素赋予 id 的方法:
```
<div id="letter-container">
```
以下是如何在嵌入式样式中将此 id 用作选择器:
```
#letter-container{
...
}
```
注意 `#` 符号。它表示它是一个 id,`{...}` 中的样式应该只应用于具有该特定 id 的元素。
让我们来应用它:
```
<style>
#letter-container{
width:550px;
}
#header-bat-logo{
width:100%;
}
</style>
```
```
<div id="letter-container">
<h1>Bat Letter</h1>
<img id="header-bat-logo" src="bat-logo.jpeg">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
```
```
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p><strong>I love you Superman.</strong></p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
```
HTML 已经准备好了嵌入式样式。
但是,你可以看到,随着我们包含越来越多的样式,`<style></style>` 将变得很大。这可能很快会混乱我们的主 HTML 文件。
因此,让我们更进一步,通过将 `<style>` 标签内的内容复制到一个新文件来使用链接样式。
在项目根目录中创建一个新文件,将其另存为 “style.css”:
```
#letter-container{
width:550px;
}
#header-bat-logo{
width:100%;
}
```
我们不需要在 CSS 文件中写 `<style>` 和 `</style>`。
我们需要使用 HTML 文件中的 `<link>` 标签来将新创建的 CSS 文件链接到 HTML 文件。以下是我们如何做到这一点:
```
<link rel="stylesheet" type="text/css" href="style.css">
```
我们使用 `<link>` 元素在 HTML 文档中包含外部资源,它主要用于链接样式表。我们使用的三个属性是:
* `rel`:关系。链接文件与文档的关系。具有 .css 扩展名的文件称为样式表,因此我们保留 rel=“stylesheet”。
* `type`:链接文件的类型;对于一个 CSS 文件来说它是 “text/css”。
* `href`:超文本参考。链接文件的位置。
link 元素的结尾没有 `</link>`。因此,`<link>` 也是一个自闭合的标签。
```
<link rel="gf" type="cute" href="girl.next.door">
```
如果只是得到一个女朋友,那么很容易:D
可惜没有那么简单,让我们继续前进。
这是我们 “loveletter.html” 的内容:
```
<link rel="stylesheet" type="text/css" href="style.css">
<div id="letter-container">
<h1>Bat Letter</h1>
<img id="header-bat-logo" src="bat-logo.jpeg">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p><strong>I love you Superman.</strong></p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
```
“style.css” 内容:
```
#letter-container{
width:550px;
}
#header-bat-logo{
width:100%;
}
```
保存文件并刷新,浏览器中的输出应保持不变。
### 一些手续
我们的情书已经准备好给蝙蝠侠,但还有一些正式的片段。
与其他任何编程语言一样,HTML 自出生以来(1990 年)经历过许多版本,当前版本是 HTML5。
那么,浏览器如何知道你使用哪个版本的 HTML 来编写页面呢?要告诉浏览器你正在使用 HTML5,你需要在页面顶部包含 `<!DOCTYPE html>`。对于旧版本的 HTML,这行不同,但你不需要了解它们,因为我们不再使用它们了。
此外,在之前的 HTML 版本中,我们曾经将整个文档封装在 `<html></html>` 标签内。整个文件分为两个主要部分:头部在 `<head></head>` 里面,主体在 `<body></body>` 里面。这在 HTML5 中不是必须的,但由于兼容性原因,我们仍然这样做。让我们用 `<Doctype>`, `<html>`、 `<head>` 和 `<body>` 更新我们的代码:
```
<!DOCTYPE html>
<html>
<head>
<link rel="stylesheet" type="text/css" href="style.css">
</head>
<body>
<div id="letter-container">
<h1>Bat Letter</h1>
<img id="header-bat-logo" src="bat-logo.jpeg">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p><strong>I love you Superman.</strong></p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
</body>
</html>
```
主要内容在 `<body>` 里面,元信息在 `<head>` 里面。所以我们把 `<div>` 保存在 `<body>` 里面并加载 `<head>` 里面的样式表。
保存并刷新,你的 HTML 页面应显示与之前相同的内容。
### HTML 的标题
我发誓,这是最后一次改变。
你可能已经注意到选项卡的标题正在显示 HTML 文件的路径:

我们可以使用 `<title>` 标签来定义 HTML 文件的标题。标题标签也像链接标签一样在 `<head>` 内部。让我们我们在标题中加上 “Bat Letter”:
```
<!DOCTYPE html>
<html>
<head>
<title>Bat Letter</title>
<link rel="stylesheet" type="text/css" href="style.css">
</head>
<body>
<div id="letter-container">
<h1>Bat Letter</h1>
<img id="header-bat-logo" src="bat-logo.jpeg">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p><strong>I love you Superman.</strong></p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
</body>
</html>
```
保存并刷新,你将看到在选项卡上显示的是 “Bat Letter” 而不是文件路径。
蝙蝠侠的情书现在已经完成。
恭喜!你用 HTML 制作了蝙蝠侠的情书。

### 我们学到了什么
我们学习了以下新概念:
* 一个 HTML 文档的结构
* 在 HTML 中如何写元素(`<p></p>`)
* 如何使用 style 属性在元素内编写样式(这称为内联样式,尽可能避免这种情况)
* 如何在 `<style>...</style>` 中编写元素的样式(这称为嵌入式样式)
* 在 HTML 中如何使用 `<link>` 在单独的文件中编写样式并链接它(这称为链接样式表)
* 什么是标签名称,属性,开始标签和结束标签
* 如何使用 id 属性为一个元素赋予 id
* CSS 中的标签选择器和 id 选择器
我们学习了以下 HTML 标签:
* `<p>`:用于段落
* `<br>`:用于换行
* `<ul>`、`<li>`:显示列表
* `<div>`:用于分组我们信件的元素
* `<h1>`、`<h2>`:用于标题和子标题
* `<img>`:用于插入图像
* `<strong>`、`<em>`:用于粗体和斜体文字样式
* `<style>`:用于嵌入式样式
* `<link>`:用于包含外部样式表
* `<html>`:用于包裹整个 HTML 文档
* `<!DOCTYPE html>`:让浏览器知道我们正在使用 HTML5
* `<head>`:包裹元信息,如 `<link>` 和 `<title>`
* `<body>`:用于实际显示的 HTML 页面的主体
* `<title>`:用于 HTML 页面的标题
我们学习了以下 CSS 属性:
* width:用于定义元素的宽度
* CSS 单位:“px” 和 “%”
朋友们,这就是今天的全部了,下一个教程中见。
---
作者简介:开发者 + 作者 | supersarkar.com | twitter.com/supersarkar
---
via: <https://medium.freecodecamp.org/for-your-first-html-code-lets-help-batman-write-a-love-letter-64c203b9360b>
作者:[Kunal Sarkar](https://medium.freecodecamp.org/@supersarkar) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,309 | GPaste:Gnome Shell 中优秀的剪贴板管理器 | https://www.linuxuprising.com/2018/08/gpaste-is-great-clipboard-manager-for.html | 2018-12-04T10:30:00 | [
"剪贴板",
"GPaste"
] | https://linux.cn/article-10309-1.html | 
[GPaste](https://github.com/Keruspe/GPaste) 是一个剪贴板管理系统,它包含了库、守护程序以及命令行和 Gnome 界面(使用原生 Gnome Shell 扩展)。
剪贴板管理器能够跟踪你正在复制和粘贴的内容,从而能够访问以前复制的项目。GPaste 带有原生的 Gnome Shell 扩展,是那些寻找 Gnome 剪贴板管理器的人的完美补充。

*GPaste Gnome Shell扩展*
在 Gnome 中使用 GPaste,你只需单击顶部面板即可得到可配置的、可搜索的剪贴板历史记录。GPaste 不仅会记住你复制的文本,还能记住文件路径和图像(后者需要在设置中启用,因为默认情况下它被禁用)。
不仅如此,GPaste 还可以检测到增长的行,这意味着当检测到新文本是另一个文本的增长时,它会替换它,这对于保持剪贴板整洁非常有用。
在扩展菜单中,你可以暂停 GPaste 跟踪剪贴板,并从剪贴板历史记录或整个历史记录中删除项目。你还会发现一个启动 GPaste 用户界面窗口的按钮。
如果你更喜欢使用键盘,你可以使用快捷键从顶栏开启 GPaste 历史记录(`Ctrl + Alt + H`)或打开全部的 GPaste GUI(`Ctrl + Alt + G`)。
该工具还包含这些键盘快捷键(可以更改):
* 从历史记录中删除活动项目: `Ctrl + Alt + V`
* 将活动项目显示为密码(在 GPaste 中混淆剪贴板条目): `Ctrl + Alt + S`
* 将剪贴板同步到主选择: `Ctrl + Alt + O`
* 将主选择同步到剪贴板:`Ctrl + Alt + P`
* 将活动项目上传到 pastebin 服务:`Ctrl + Alt + U`

*GPaste GUI*
GPaste 窗口界面提供可供搜索的剪贴板历史记录(包括清除、编辑或上传项目的选项)、暂停 GPaste 跟踪剪贴板的选项、重启 GPaste 守护程序,备份当前剪贴板历史记录,还有它的设置。

*GPaste GUI*
在 GPaste 界面中,你可以更改以下设置:
* 启用或禁用 Gnome Shell 扩展
* 将守护程序状态与扩展程序的状态同步
* 主选区生效历史
* 使剪贴板与主选区同步
* 图像支持
* 修整条目
* 检测增长行
* 保存历史
* 历史记录设置,如最大历史记录大小、内存使用情况、最大文本长度等
* 键盘快捷键
### 下载 GPaste
* [下载 GPaste](https://github.com/Keruspe/GPaste)
Gpaste 项目页面没有链接到任何 GPaste 二进制文件,它只有源码安装说明。非 Debian 或 Ubuntu 的 Linux 发行版的用户(你可以在下面找到 GPaste 安装说明)可以在各自的发行版仓库中搜索 GPaste。
不要将 GPaste 与 Gnome Shell 扩展网站上发布的 GPaste Integration 扩展混淆。这是一个使用 GPaste 守护程序的 Gnome Shell 扩展,它不再维护。内置于 GPaste 中的原生 Gnome Shell 扩展仍然维护。
#### 在 Ubuntu(18.04、16.04)或 Debian(Jessie 和更新版本)中安装 GPaste
对于 Debian,GPaste 可用于 Jessie 和更新版本,而对于 Ubuntu,GPaste 在 16.04 及更新版本的仓库中(因此可在 Ubuntu 18.04 Bionic Beaver 中使用)。
你可以使用以下命令在 Debian 或 Ubuntu 中安装 GPaste(守护程序和 Gnome Shell 扩展):
```
sudo apt install gnome-shell-extensions-gpaste gpaste
```
安装完成后,按下 `Alt + F2` 并输入 `r` 重新启动 Gnome Shell,然后按回车键。现在应该启用了 GPaste Gnome Shell 扩展,其图标应显示在顶部 Gnome Shell 面板上。如果没有,请使用 Gnome Tweaks(Gnome Tweak Tool)启用扩展。
[Debian](https://packages.debian.org/buster/gpaste) 和 [Ubuntu](https://launchpad.net/ubuntu/+source/gpaste) 的 GPaste 3.28.0 中有一个错误,如果启用了图像支持选项会导致它崩溃,所以现在不要启用此功能。这在 GPaste 3.28.2 中被标记为[已修复](https://www.imagination-land.org/posts/2018-04-13-gpaste-3.28.2-released.html),但 Debian 和 Ubuntu 仓库中尚未提供此包。
---
via: <https://www.linuxuprising.com/2018/08/gpaste-is-great-clipboard-manager-for.html>
作者:[Logix](https://plus.google.com/118280394805678839070) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # GPaste Is A Great Clipboard Manager For Gnome Shell
[GPaste](https://github.com/Keruspe/GPaste)is a clipboard management system that consists of a library, daemon, and interfaces for the command line and Gnome (using a native Gnome Shell extension).A clipboard manager allows keeping track of what you're copying and pasting, providing access to previously copied items. GPaste, with its native Gnome Shell extension, makes the perfect addition for those looking for a Gnome clipboard manager.
![]() |
**Using GPaste in Gnome, you get a configurable, searchable clipboard history, available with a click on the top panel. GPaste remembers not only the text you copy, but also file paths and images**(the latter needs to be enabled from its settings as it's disabled by default).
What's more, GPaste can detect growing lines, meaning it can detect when a new text copy is an extension of another and replaces it if it's true, useful for keeping your clipboard clean.
From the extension menu you can pause GPaste from tracking the clipboard, and remove items from the clipboard history or the whole history. You'll also find a button that launches the GPaste user interface window.
**If you prefer to use the keyboard, you can use a key shortcut to open the GPaste history from the top bar**(
`Ctrl + Alt + H`
), **or open the full GPaste GUI**(
`Ctrl + Alt + G`
).The tool also incorporates keyboard shortcuts to (can be changed):
- delete the active item from history:
`Ctrl + Alt + V`
**mark the active item as being a password (which obfuscates the clipboard entry in GPaste):**`Ctrl + Alt + S`
- sync the clipboard to the primary selection:
`Ctrl + Alt + O`
- sync the primary selection to the clipboard:
`Ctrl + Alt + P`
- upload the active item to a pastebin service:
`Ctrl + Alt + U`
![]() |
The GPaste interface window provides access to the clipboard history (with options to clear, edit or upload items), which can be searched, an option to pause GPaste from tracking the clipboard, restart the GPaste daemon, backup current clipboard history, as well as to its settings.
![]() |
From the GPaste UI you can change settings like:
- Enable or disable the Gnome Shell extension
- Sync the daemon state with the extension's one
- Primary selection affects history
- Synchronize clipboard with primary selection
- Image support
- Trim items
- Detect growing lines
- Save history
- History settings like max history size, memory usage, max text item length, and more
- Keyboard shortcuts
## Download GPaste
The Gpaste project page does not link to any GPaste binaries, and only source installation instructions. Users running Linux distributions other than Debian or Ubuntu (for which you'll find GPaste installation instructions below) can search their distro repositories for GPaste.
Do not confuse GPaste with the GPaste Integration extension posted on the Gnome Shell extension website. That is a Gnome Shell extension that uses GPaste daemon, which is no longer maintained. The native Gnome Shell extension built into GPaste is still maintained.
### Install GPaste in Ubuntu (18.04, 16.04) or Debian (Jessie and newer)
**For Debian, GPaste is available for Jessie and newer, while for Ubuntu, GPaste is in the repositories for 16.04 and newer (so it's available in the Ubuntu 18.04 Bionic Beaver).**
**You can install GPaste (the daemon and the Gnome Shell extension) in Debian or Ubuntu using this command:**
`sudo apt install gnome-shell-extensions-gpaste gpaste`
After the installation completes, restart Gnome Shell by pressing
`Alt + F2`
and typing `r`
, then pressing the `Enter`
key. The GPaste Gnome Shell extension should now be enabled and its icon should show up on the top Gnome Shell panel. If it's not, use Gnome Tweaks (Gnome Tweak Tool) to enable the extension.**The GPaste 3.28.0 package from**This was marked as
[Debian](https://packages.debian.org/buster/gpaste)and[Ubuntu](https://launchpad.net/ubuntu/+source/gpaste)has a bug that makes it crash if the image support option is enabled, so do not enable this feature for now.[fixed](https://www.imagination-land.org/posts/2018-04-13-gpaste-3.28.2-released.html)in GPaste 3.28.2, but this package is not yet available in the Debian and Ubuntu repositories. |
10,310 | 有所为,有所不为:在 Linux 中使用超级用户权限 | https://www.networkworld.com/article/3322504/linux/selectively-deploying-your-superpowers-on-linux.html | 2018-12-04T15:02:38 | [
"sudo",
"root"
] | https://linux.cn/article-10310-1.html |
>
> sudo 命令允许特权用户以 root 用户身份运行全部或部分命令,但是理解其能做什么和不能做什么很有帮助。
>
>
>

在你想要使用超级权限临时运行一条命令时,`sudo` 命令非常方便,但是当它不能如你期望的工作时,你也会遇到一些麻烦。比如说你想在某些日志文件结尾添加一些重要的信息,你可能会尝试这样做:
```
$ echo "Important note" >> /var/log/somelog
-bash: /var/log/somelog: Permission denied
```
好吧,看起来你似乎需要一些额外的特权。一般来说,你不能使用你的用户账号向系统日志中写入东西。我们使用 `sudo` 再尝试一次吧。
```
$ sudo !!
sudo echo "Important note" >> /var/log/somelog
-bash: /var/log/somelog: Permission denied
```
嗯,它还是没有啥反应。我们来试点不同的吧。
```
$ sudo 'echo "Important note" >> /var/log/somelog'
sudo: echo "Important note" >> /var/log/somelog: command not found
```
也可以查看:[在 Linux 下排查故障的宝贵提示和技巧](https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html)。
### 接下来该干什么?
上面在执行完第一条命令后的回应显示,我们缺少向日志文件写入时必须的特权。第二次,我们使用 root 权限运行了第一次的命令,但是返回了一个“没有权限”的错误。第三次,我们把整个命令放在一个引号里面再运行了一遍,返回了一个“没有发现命令”的错误。所以,到底错在哪里了呢?
* 第一条命令:没有 root 特权,你无法向这个日志中写入东西。
* 第二条命令:你的超级权限没有延伸到重定向。
* 第三条命令:`sudo` 不理解你用引号括起来的整个 “命令”。
而且如果你的用户还未添加到 sudo 用户组的时候,如果尝试使用 `sudo`,你可能已经看到过像下面的这么一条错误了:
```
nemo is not in the sudoers file. This incident will be reported.
```
### 你可以做什么?
一个相当简单的选择就是使用 `sudo` 命令暂时成为 root。鉴于你已经有了 sudo 特权,你可以使用下面的命令执行此操作:
```
$ sudo su
[sudo] password for nemo:
#
```
注意这个改变的提示符表明了你的新身份。然后你就可以以 root 运行之前的命令了:
```
# echo "Important note" >> /var/log/somelog
```
接着你可以输入 `^d` 返回你之前的身份。当然了,一些 sudo 的配置可能会阻止你使用 `sudo` 命令成为 root。
另一个切换用户为 root 的方法是仅用 `su` 命令,但是这需要你知道 root 密码。许多人被赋予了访问 sudo 的权限,而并不知道 root 密码,所以这并不是总是可行。
(采用 su 直接)切换到 root 之后,你就可以以 root 的身份运行任何你想执行的命令了。这种方式的问题是:1) 每个想要使用 root 特权的人都需要事先知道 root 的密码(这样不很安全);2) 如果在运行需要 root 权限的特定命令后未能退出特权状态,你的系统可能会受到一些重大错误的波及。`sudo` 命令旨在允许您仅在真正需要时使用 root 权限,并控制每个 sudo 用户应具有的 root 权限。它也可以使你在使用完 root 特权之后轻松地回到普通用户的状态。
另外请注意,整个讨论的前提是你可以正常地访问 sudo,并且你的访问权限没有受限。详细的内容后面会介绍到。
还有一个选择就是使用一个不同的命令。如果通过编辑文件从而在其后添加内容是一种选择的话,你也许可以使用 `sudo vi /var/log/somelog`,虽然编辑一个活跃的日志文件通常不是一个好主意,因为系统可能会频繁的向这个文件中进行写入操作。
最后一个但是有点复杂的选择是,使用下列命令之一可以解决我们之前看到的问题,但是它们涉及到了很多复杂的语法。第一个命令允许你在得到 “没有权限” 的拒绝之后可以使用 `!!` 重复你的命令:
```
$ sudo echo "Important note" >> /var/log/somelog
-bash: /var/log/somelog: Permission denied
$ !!:gs/>/|sudo tee -a / <=====
$ tail -1 /var/log/somelog
Important note
```
第二种是通过 `sudo` 命令,把你想要添加的信息传递给 `tee`。注意,`-a` 指定了你要**附加**文本到目标文件:
```
$ echo "Important note" | sudo tee -a /var/log/somelog
$ tail -1 /var/log/somelog
Important note
```
### sudo 有多可控?
回答这个问题最快速的回答就是,它取决于管理它的人。大多数 Linux 的默认设置都非常简单。如果一个用户被安排到了一个特别的组中,例如 `wheel` 或者 `admin` 组,那这个用户无需知道 root 的密码就可以拥有运行任何命令的能力。这就是大多数 Linux 系统中的默认设置。一旦在 `/etc/group` 中添加了一个用户到了特权组中,这个用户就可以以 root 的权力运行任何命令。另一方面,可以配置 sudo,以便一些用户只能够以 root 身份运行单一指令或者一组命令中的任何一个。
如果把像下面展示的这些行添加到了 `/etc/sudoers` 文件中,例如 “nemo” 这个用户可以以 root 身份运行 `whoami` 命令。在现实中,这可能不会造成任何影响,它非常适合作为一个例子。
```
# User alias specification
nemo ALL=(root) NOPASSWD: WHOAMI
# Cmnd alias specification
Cmnd_Alias WHOAMI = /usr/bin/whoami
```
注意,我们添加了一个命令别名(`Cmnd_Alias`),它指定了一个可以运行的命令的全路径,以及一个用户别名,允许这个用户无需密码就可以使用 `sudo` 执行的单个命令。
当 nemo 运行 `sudo whoami` 命令的时候,他将会看到这个:
```
$ sudo whoami
root
```
注意这个,因为 nemo 使用 `sudo` 执行了这条命令,`whoami` 会显示该命令运行时的用户是 `root`。
至于其他的命令,nemo 将会看到像这样的一些内容:
```
$ sudo date
[sudo] password for nemo:
Sorry, user nemo is not allowed to execute '/bin/date' as root on butterfly.
```
### sudo 的默认设置
在默认路径中,我们会利用像下面展示的 `/etc/sudoers` 文件中的几行:
```
$ sudo egrep "admin|sudo" /etc/sudoers
# Members of the admin group may gain root privileges
%admin ALL=(ALL) ALL <=====
# Allow members of group sudo to execute any command
%sudo ALL=(ALL:ALL) ALL <=====
```
在这几行中,`%admin` 和 `%sudo` 都说明了任何添加到这些组中的人都可以使用 `sudo` 命令以 root 的身份运行任何命令。
下面列出的是 `/etc/group` 中的一行,它意味着每一个在该组中列出的成员,都拥有了 sudo 特权,而无需在 `/etc/sudoers` 中进行任何修改。
```
sudo:x:27:shs,nemo
```
### 总结
`sudo` 命令意味着你可以根据需要轻松地部署超级用户的访问权限,而且只有在需要的时候才能赋予用户非常有限的特权访问权限。你可能会遇到一些与简单的 `sudo command` 不同的问题,不过在 `sudo` 的回应中应该会显示你遇到了什么问题。
---
via: <https://www.networkworld.com/article/3322504/linux/selectively-deploying-your-superpowers-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dianbanjiu](https://github.com/dianbanjiu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,311 | 学习 Linux/*BSD/Unix 的 30 个最佳在线文档 | https://www.cyberciti.biz/tips/linux-unix-bsd-documentations.html | 2018-12-04T18:39:00 | [
"文档"
] | https://linux.cn/article-10311-1.html | 
手册页(man)是由系统管理员和 IT 技术开发人员写的,更多的是为了作为参考而不是教你如何使用。手册页对于已经熟悉使用 Linux、Unix 和 BSD 操作系统的人来说是非常有用的。如果你仅仅需要知道某个命令或者某个配置文件的格式那么你可以使用手册页,但是手册页对于 Linux 新手来说并没有太大的帮助。想要通过使用手册页来学习一些新东西不是一个好的选择。这里有将提供 30 个学习 Linux 和 Unix 操作系统的最佳在线网页文档。

值得一提的是,相对于 Linux,BSD 的手册页更好。
### #1:Red Hat Enterprise Linux(RHEL)

RHEL 是由红帽公司开发的面向商业市场的 Linux 发行版。红帽的文档是最好的文档之一,涵盖从 RHEL 的基础到一些高级主题比如安全、SELinux、虚拟化、目录服务器、服务器集群、JBOSS 应用程序服务器、高性能计算(HPC)等。红帽的文档已经被翻译成 22 种语言,发布成多页面 HTML、单页面 HTML、PDF、EPUB 等文件格式。好消息同样的文档你可以用于 Centos 和 Scientific Linux(社区企业发行版)。这些文档随操作系统一起下载提供,也就是说当你没有网络的时候,你也可以使用它们。RHEL 的文档**涵盖从安装到配置器群的所有内容**。唯一的缺点是你需要成为付费用户。当然这对于企业公司来说是一件完美的事。
1. RHEL 文档:[HTML/PDF格式](https://access.redhat.com/documentation/en-us/)(LCTT 译注:**此链接**需要付费用户才可以访问)
2. 是否支持论坛:只能通过红帽公司的用户网站提交支持案例。
#### 关于 CentOS Wiki 和论坛的说明

CentOS(<ruby> 社区企业操作系统 <rt> Community ENTerprise Operating System </rt></ruby>)是由 RHEL 提供的自由源码包免费重建的。它为个人电脑或其它用途提供了可靠的、免费的企业级 Linux。你可以不用付出任何支持和认证费用就可以获得 RHEL 的稳定性。CentOS的 wiki 分为 Howto、技巧等等部分,链接如下:
1. 文档:[wiki 格式](https://wiki.centos.org/)
2. 是否支持论坛:[是](https://www.centos.org/forums/)
### #2:Arch 的 Wiki 和论坛

Arch linux 是一个独立开发的 Linux 操作系统,它有基于 wiki 网站形式的非常不错的文档。它是由 Arch 社区的一些用户共同协作开发出来的,并且允许任何用户添加或修改内容。这些文档教程被分为几类比如说优化、软件包管理、系统管理、X window 系统还有获取安装 Arch Linux 等。它的[官方论坛](https://bbs.archlinux.org/)在解决许多问题的时候也非常有用。它有总共 4 万多个注册用户、超过 1 百万个帖子。 该 wiki 包含一些 **其它 Linux 发行版也适用的通用信息**。
1. Arch 社区文档:[Wiki 格式](https://wiki.archlinux.org/)
2. 是否支持论坛:[是](https://bbs.archlinux.org/)
### #3:Gentoo Linux Wiki 和论坛

Gentoo Linux 基于 Portage 包管理系统。Gentoo Linux 用户根据它们选择的配置在本地编译源代码。多数 Gentoo Linux 用户都会定制自己独有的程序集。 Gentoo Linux 的文档会给你一些有关 Gentoo Linux 操作系统的说明和一些有关安装、软件包、网络和其它等主要出现的问题的解决方法。Gentoo 有对你来说 **非常有用的论坛**,论坛中有超过 13 万 4 千的用户,总共发了有 5442416 个文章。
1. Gentoo 社区文档:[手册](http://www.gentoo.org/doc/en/handbook/) 和 [Wiki 格式](https://wiki.gentoo.org)
2. 是否支持论坛:[是](https://forums.gentoo.org/)
### #4:Ubuntu Wiki 和文档

Ubuntu 是领先的台式机和笔记本电脑发行版之一。其官方文档由 Ubuntu 文档工程开发维护。你可以在从官方文档中查看大量的信息,比如如何开始使用 Ubuntu 的教程。最好的是,此处包含的这些信息也可用于基于 Debian 的其它系统。你可能会找到由 Ubuntu 的用户们创建的社区文档,这是一份有关 Ubuntu 的使用教程和技巧等。Ubuntu Linux 有着网络上最大的 Linux 社区的操作系统,它对新用户和有经验的用户均有助益。
1. Ubuntu 社区文档:[wiki 格式](https://help.ubuntu.com/community)
2. Ubuntu 官方文档:[wiki 格式](https://help.ubuntu.com/)
3. 是否支持论坛:[是](https://ubuntuforums.org/)
### #5:IBM Developer Works

IBM Developer Works 为 Linux 程序员和系统管理员提供技术资源,其中包含数以百计的文章、教程和技巧来协助 Linux 程序员的编程工作和应用开发还有系统管理员的日常工作。
1. IBM 开发者项目文档:[HTML 格式](https://www.ibm.com/developerworks/learn/linux/index.html)
2. 是否支持论坛:[是](https://www.ibm.com/developerworks/community/forums/html/public?lang=en)
### #6:FreeBSD 文档和手册

FreeBSD 的手册是由 <ruby> FreeBSD 文档项目 <rt> FreeBSD Documentation Project </rt></ruby>所创建的,它介绍了 FreeBSD 操作系统的安装、管理和一些日常使用技巧等内容。FreeBSD 的手册页通常比 GNU Linux 的手册页要好一点。FreeBSD **附带有全部最新手册页的文档**。 FreeBSD 手册涵盖任何你想要的内容。手册包含一些通用的 Unix 资料,这些资料同样适用于其它的 Linux 发行版。FreeBSD 官方论坛会在你遇到棘手问题时给予帮助。
1. FreeBSD 文档:[HTML/PDF 格式](https://www.freebsd.org/docs.html)
2. 是否支持论坛:[是](https://forums.freebsd.org/)
### #7:Bash Hackers Wiki

这是一个对于 bash 使用者来说非常好的资源。Bash 使用者的 wiki 是为了归纳所有类型的 GNU Bash 文档。这个项目的动力是为了提供可阅读的文档和资料来避免用户被迫一点一点阅读 Bash 的手册,有时候这是非常麻烦的。Bash Hackers Wiki 分为各个类,比如说脚本和通用资料、如何使用、代码风格、bash 命令格式和其它。
1. Bash 用户教程:[wiki 格式](http://wiki.bash-hackers.org/doku.php)
### #8:Bash 常见问题

这是一个为 bash 新手设计的一个 wiki。它收集了 IRC 网络的 #bash 频道里常见问题的解决方法,这些解决方法是由该频道的普通成员提供。当你遇到问题的时候不要忘了在 [BashPitfalls](http://mywiki.wooledge.org/BashPitfalls) 部分检索查找答案。这些常见问题的解决方法可能会倾向于 Bash,或者偏向于最基本的 Bourne Shell,这决定于是谁给出的答案。大多数情况会尽力提供可移植的(Bourne)和高效的(Bash,在适当情况下)的两类答案。
1. Bash 常见问题:[wiki 格式](https://mywiki.wooledge.org/BashFAQ)
### #9: Howtoforge - Linux 教程

博客作者 Falko 在 Howtoforge 上有一些非常不错的东西。这个网站提供了 Linux 关于各种各样主题的教程,比如说其著名的“最佳服务器系列”,网站将主题分为几类,比如说 web 服务器、linux 发行版、DNS 服务器、虚拟化、高可用性、电子邮件和反垃圾邮件、FTP 服务器、编程主题还有一些其它的内容。这个网站也支持德语。
1. Howtoforge: [html 格式](https://howtoforge.com/)
2. 是否支持论坛:是
### #10:OpenBSD 常见问题和文档

OpenBSD 是另一个基于 BSD 的类 Unix 计算机操作系统。OpenBSD 是由 NetBSD 项目分支而来。OpenBSD 因高质量的代码和文档、对软件许可协议的坚定立场和强烈关注安全问题而闻名。OpenBSD 的文档分为多个主题类别,比如说安装、包管理、防火墙设置、用户管理、网络、磁盘和磁盘阵列管理等。
1. OpenBSD:[html 格式](https://www.openbsd.org/faq/index.html)
2. 是否支持论坛:否,但是可以通过 [邮件列表](https://www.openbsd.org/mail.html) 来咨询
### #11: Calomel - 开源研究和参考文档

这个极好的网站是专门作为开源软件和那些特别专注于 OpenBSD 的软件的文档来使用的。这是最简洁的引导网站之一,专注于高质量的内容。网站内容分为多个类,比如说 DNS、OpenBSD、安全、web 服务器、Samba 文件服务器、各种工具等。
1. Calomel 官网:[html 格式](https://calomel.org)
2. 是否支持论坛:否
### #12:Slackware 书籍项目

Slackware Linux 是我的第一个 Linux 发行版。Slackware 是基于 Linux 内核的最早的发行版之一,也是当前正在维护的最古老的 Linux 发行版。 这个发行版面向专注于稳定性的高级用户。 Slackware 也是很少有的的“类 Unix” 的 Linux 发行版之一。官方的 Slackware 手册是为了让用户快速开始了解 Slackware 操作系统的使用方法而设计的。 这不是说它将包含发行版的每一个方面,而是为了说明它的实用性和给使用者一些有关系统的基础工作使用方法。手册分为多个主题,比如说安装、网络和系统配置、系统管理、包管理等。
1. Slackware Linux 手册:[html 格式](http://www.slackbook.org/)、pdf 和其它格式
2. 是否支持论坛:是
### #13:Linux 文档项目(TLDP)

<ruby> Linux 文档项目 <rt> Linux Documentation Project </rt></ruby>旨在给 Linux 操作系统提供自由、高质量文档。网站是由志愿者创建和维护的。网站分为具体主题的帮助、由浅入深的指南等。在此我想推荐一个非常好的[文档](http://tldp.org/LDP/abs/html/index.html),这个文档既是一个教程也是一个 shell 脚本编程的参考文档,对于新用户来说这个 HOWTO 的[列表](http://tldp.org/HOWTO/HOWTO-INDEX/howtos.html)也是一个不错的开始。
1. Linux [文档工程](http://tldp.org/) 支持多种查阅格式
2. 是否支持论坛:否
### #14:Linux Home Networking

Linux Home Networking 是学习 linux 的另一个比较好的资源,这个网站包含了 Linux 软件认证考试的内容比如 RHCE,还有一些计算机培训课程。网站包含了许多主题,比如说网络、Samba 文件服务器、无线网络、web 服务器等。
1. Linux [home networking](http://www.linuxhomenetworking.com/) 可通过 html 格式和 PDF(少量费用)格式查阅
2. 是否支持论坛:是
### #15:Linux Action Show

Linux Action Show(LAS) 是一个关于 Linux 的播客。这个网站是由 Bryan Lunduke、Allan Jude 和 Chris Fisher 共同管理的。它包含了 FOSS 的最新消息。网站内容主要是评论一些应用程序和 Linux 发行版。有时候也会发布一些和开源项目著名人物的采访视频。
1. Linux [action show](http://www.jupiterbroadcasting.com/show/linuxactionshow/) 支持音频和视频格式
2. 是否支持论坛:是
### #16:Commandlinefu

Commandlinefu 列出了各种有用或有趣的 shell 命令。这里所有命令都可以评论、讨论和投票(支持或反对)。对于所有 Unix 命令行用户来说是一个极好的资源。不要忘了查看[评选出来的最佳命令](https://www.commandlinefu.com/commands/browse/sort-by-votes)。
1. [Commandlinefu](https://commandlinefu.com/) 支持 html 格式
2. 是否支持论坛:否
### #17:Debian 管理技巧和资源

这个网站包含一些只和 Debian GNU/Linux 相关的主题、技巧和教程,特别是包含了关于系统管理的有趣和有用的信息。你可以在上面贡献文章、建议和问题。提交了之后不要忘记查看[最佳文章列表](https://www.debian-administration.org/hof)里有没有你的文章。
1. Debian [系统管理](https://www.debian-administration.org/) 支持 html 格式
2. 是否支持论坛:否
### #18: Catonmat - Sed、Awk、Perl 教程

这个网站是由博客作者 Peteris Krumins 维护的。主要关注命令行和 Unix 编程主题,比如说 sed 流编辑器、perl 语言、AWK 文本处理工具等。不要忘了查看 [sed 介绍](http://www.catonmat.net/blog/worlds-best-introduction-to-sed/)、sed 含义解释,还有命令行历史的[权威介绍](https://www.catonmat.net/blog/the-definitive-guide-to-bash-command-line-history/)。
1. [catonmat](https://catonmat.net/) 支持 html 格式
2. 是否支持论坛:否
### #19:Debian GNU/Linux 文档和 Wiki

Debian 是另外一个 Linux 操作系统,其主要使用的软件以 GNU 许可证发布。Debian 因严格坚持 Unix 和自由软件的理念而闻名,它也是很受欢迎并且有一定影响力的 Linux 发行版本之一。 Ubuntu 等发行版本都是基于 Debian 的。Debian 项目以一种易于访问的形式提供给用户合适的文档。这个网站分为 Wiki、安装指导、常见问题、支持论坛几个模块。
1. Debian GNU/Linux [文档](https://www.debian.org/doc/) 支持 html 和其它格式访问
2. Debian GNU/Linux [wiki](https://wiki.debian.org/)
3. 是否支持论坛:[是](https://www.debian.org/support)
### #20:Linux Sea
Linux Sea 这本书提供了比较通俗易懂但充满技术(从最终用户角度来看)的 Linux 操作系统的介绍,使用 Gentoo Linux 作为例子。它既没有谈论 Linux 内核或 Linux 发行版的历史,也没有谈到 Linux 用户不那么感兴趣的细节。
1. Linux [sea](http://swift.siphos.be/linux_sea/) 支持 html 格式访问
2. 是否支持论坛: 否
### #21:O'reilly Commons

O'reilly 出版社发布了不少 wiki 格式的文章。这个网站主要是为了给那些喜欢创作、参考、使用、修改、更新和修订来自 O'Reilly 或者其它来源的素材的社区提供资料。这个网站包含关于 Ubuntu、PHP、Spamassassin、Linux 等的免费书籍。
1. Oreilly [commons](http://commons.oreilly.com/wiki/index.php/O%27Reilly_Commons) 支持 Wiki 格式
2. 是否支持论坛:否
### #22:Ubuntu 袖珍指南

这本书的作者是 Keir Thomas。这本指南(或者说是书籍)对于所有 ubuntu 用户来说都值得一读。这本书旨在向用户介绍 Ubuntu 操作系统和其所依赖的理念。你可以从官网下载这本书的 PDF 版本,也可以在亚马逊买印刷版。
1. Ubuntu [pocket guide](http://ubuntupocketguide.com/) 支持 PDF 和印刷版本.
2. 是否支持论坛:否
### #23: Linux: Rute User’s Tutorial and Exposition

这本书涵盖了 GNU/LINUX 系统管理,主要是对主流的发布版本比如红帽和 Debian 的说明,可以作为新用户的教程和高级管理员的参考。这本书旨在给出 Unix 系统的每个面的简明彻底的解释和实践性的例子。想要全面了解 Linux 的人都不需要再看了 —— 这里没有涉及的内容。
1. Linux: [Rute User’s Tutorial and Exposition](https://web.archive.org/web/20160204213406/http://rute.2038bug.com/rute.html.gz) 支持印刷版和 html 格式
2. 是否支持论坛:否
### #24:高级 Linux 编程

这本书是写给那些已经熟悉了 C 语言编程的程序员的。这本书采取一种教程式的方式来讲述大多数在 GNU/Linux 系统应用编程中重要的概念和功能特性。如果你是一个已经对 GNU/Linux 系统编程有一定经验的开发者,或者是对其它类 Unix 系统编程有一定经验的开发者,或者对 GNU/Linux 软件开发有兴趣,或者想要从非 Unix 系统环境转换到 Unix 平台并且已经熟悉了优秀软件的开发原则,那你很适合读这本书。另外,你会发现这本书同样适合于 C 和 C++ 编程。
1. [高级 Linux 编程](https://github.com/MentorEmbedded/advancedlinuxprogramming) 支持印刷版和 PDF 格式
2. 是否支持论坛:否
### #25: LPI 101 Course Notes

LPIC 1、2、3 级是用于 Linux 系统管理员认证的。这个网站提供了 LPI 101 和 LPI 102 的测试训练。这些是根据 <ruby> GNU 自由文档协议 <rt> GNU Free Documentation Licence </rt></ruby>(FDL)发布的。这些课程材料基于 Linux 国际专业协会的 LPI 101 和 102 考试的目标。这个课程是为了提供给你一些必备的 Linux 系统的操作和管理的技能。
1. LPI [训练手册](http://academy.delmar.edu/Courses/ITSC1358/eBooks/LPI-101.LinuxTrainingCourseNotes.pdf) 支持 PDF 格式
2. 是否支持论坛:否
### #26: FLOSS 手册

FLOSS 手册是一系列关于自由和开源软件以及用于创建它们的工具和使用这些工具的社区的手册。社区的成员包含作者、编辑、设计师、软件开发者、积极分子等。这些手册中说明了怎样安装使用一些自由和开源软件,如何操作(比如设计和维持在线安全)开源软件,这其中也包含如何使用或支持自由软件和格式的自由文化服务手册。你也会发现关于一些像 VLC、 [Linux 视频编辑](//www.cyberciti.biz/faq/top5-linux-video-editing-system-software/)、 Linux、 OLPC / SUGAR、 GRAPHICS 等软件的手册。
1. 你可以浏览 [FOSS 手册](https://flossmanuals.net/) 支持 Wiki 格式
2. 是否支持论坛:否
### #27:Linux 入门包

刚接触 Linux 这个美好世界?想找一个简单的入门方式?你可以下载一个 130 页的指南来入门。这个指南会向你展示如何在你的个人电脑上安装 Linux,如何浏览桌面,掌握最主流行的 Linux 程序和修复可能出现的问题的方法。
1. [Linux 入门包](http://www.tuxradar.com/linuxstarterpack)支持 PDF 格式
2. 是否支持论坛:否
### #28:Linux.com - Linux 信息来源
Linux.com 是 Linux 基金会的一个产品。这个网站上提供一些新闻、指南、教程和一些关于 Linux 的其它信息。利用全球 Linux 用户的力量来通知、写作、连接 Linux 的事务。
1. 在线访问 [Linux.com](https://linux.com)
2. 是否支持论坛:是
### #29: LWN
LWN 是一个注重自由软件及用于 Linux 和其它类 Unix 操作系统的软件的网站。这个网站有周刊、基本上每天发布的单独文章和文章的讨论对话。该网站提供有关 Linux 和 FOSS 相关的开发、法律、商业和安全问题的全面报道。
1. 在线访问 [lwn.net](https://lwn.net/)
2. 是否支持论坛:否
### #30:Mac OS X 相关网站
与 Mac OS X 相关网站的快速链接:
* [Mac OS X 提示](http://hints.macworld.com/) —— 这个网站专用于苹果的 Mac OS X Unix 操作系统。网站有很多有关 Bash 和 Mac OS X 的使用建议、技巧和教程
* [Mac OS 开发库](https://developer.apple.com/library/mac/navigation/) —— 苹果拥有大量和 OS X 开发相关的优秀系列内容。不要忘了看一看 [bash shell 脚本入门](https://developer.apple.com/library/mac/#documentation/OpenSource/Conceptual/ShellScripting/Introduction/Introduction.html)
* [Apple 知识库](https://support.apple.com/kb/index?page=search&locale=en_US&q=) - 这个有点像 RHN 的知识库。这个网站提供了所有苹果产品包括 OS X 相关的指南和故障报修建议。
### #30: NetBSD
(LCTT 译注:没错,又一个 30)
NetBSD 是另一个基于 BSD Unix 操作系统的自由开源操作系统。NetBSD 项目专注于系统的高质量设计、稳定性和性能。由于 NetBSD 的可移植性和伯克利式的许可证,NetBSD 常用于嵌入式系统。这个网站提供了一些 NetBSD 官方文档和各种第三方文档的链接。
1. 在线访问 [netbsd](https://www.netbsd.org/docs/) 文档,支持 html、PDF 格式
2. 是否支持论坛:否
### 你要做的事
这是我的个人列表,这可能并不完全是权威的,因此如果你有你自己喜欢的独特 Unix/Linux 网站,可以在下方参与评论分享。
// 图片来源: [Flickr photo](https://www.flickr.com/photos/9479603@N02/3311745151/in/set-72157614479572582/) PanelSwitchman。一些连接是用户在我们的 Facebook 粉丝页面上建议添加的。
### 关于作者
作者是 nixCraft 的创建者和经验丰富的系统管理员以及 Linux 操作系统 / Unix shell 脚本的培训师。它曾与全球客户及各行各业合作,包括 IT、教育,国防和空间研究以及一些非营利部门。可以关注作者的 [Twitter](https://twitter.com/nixcraft)、[Facebook](https://facebook.com/nixcraft)、[Google+](https://plus.google.com/+CybercitiBiz)。
---
via: <https://www.cyberciti.biz/tips/linux-unix-bsd-documentations.html>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[ScarboroughCoral](https://github.com/ScarboroughCoral) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,312 | Emacs 系列(二):Org 模式介绍 | https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode | 2018-12-04T22:30:00 | [
"Emacs"
] | https://linux.cn/article-10312-1.html | 
在我 Emacs 系列中的[第一篇文章](/article-10297-1.html)里,我介绍了我在用了几十年的 vim 后转向了 Emacs,Org 模式就是我为什么这样做的原因。
Org 模式的精简和高效真的震惊了我,它真的是个“杀手”应用。
### 所以,Org 模式到底是什么呢?
这是我昨天写的:
>
> 它是一个组织信息的平台,它的主页上这样写着:“一切都是纯文本:Org 模式用于记笔记、维护待办事项列表、计划项目和使用快速有效的纯文本系统编写文档。”
>
>
>
这是事实,但并不是很准确。Org 模式是一个你用来组织事务的小工具。它有一些非常合理的默认设置,但也允许你自己定制。
主要突出在这几件事上:
* **维护待办事项列表**:项目可以分散在 Org 文件中,包含附件,有标签、截止日期、时间表。有一个方便的“日程”视图,显示需要做什么。项目也可以重复。
* **编写文档**:Org 模式有个特殊的功能来生成 HTML、LaTeX、幻灯片(用 LaTeX beamer)和其他所有的格式。它也支持直接在缓冲区中运行和以 Emacs 所支持的的语言进行<ruby> 文学编程 <rt> literate programming </rt></ruby>。如果你想要深入了解这项功能的话,参阅[这篇文学式 DevOps 的文章](http://www.howardism.org/Technical/Emacs/literate-devops.html)。而 [整个 Worg 网站](https://orgmode.org/worg/) 是用 Org 模式开发的。
* **记笔记**:对,它也能做笔记。通过全文搜索,文件的交叉引用(类似 wiki),UUID,甚至可以与其他的系统进行交互(通过 Message-ID 与 mu4e 交互,通过 ERC 的日志等等……)。
### 入门
我强烈建议去阅读 [Carsten Dominik 关于 Org 模式的一篇很棒的 Google 讲话](https://www.youtube.com/watch?v=oJTwQvgfgMM)。那篇文章真的很赞。
在 Emacs 中带有 Org 模式,但如果你想要个比较新的版本的话,Debian 用户可以使用命令 `apt-get install org-mode` 来更新,或者使用 Emacs 的包管理系统命令 `M-x package-install RET org-mode RET`。
现在,你可能需要阅读一下 Org 模式的精简版教程中的[导读部分](https://orgmode.org/guide/Introduction.html#Introduction),特别注意,你要设置下[启动部分](https://orgmode.org/guide/Activation.html#Activation)中提到的那些键的绑定。
### 一份好的教程
我会给出一些好的教程和介绍的链接,但这篇文章不会是一篇教程。特别是在本文末尾,有两个很不错的视频链接。
### 我的一些配置
我将在这里记录下一些我的配置并介绍它的作用。你没有必要每行每句将它拷贝到你的配置中 —— 这只是一个参考,告诉你哪些可以配置,要怎么在手册中查找,或许只是一个“我现在该怎么做”的参考。
首先,我将 Emacs 的编码默认设置为 UTF-8。
```
(prefer-coding-system 'utf-8)
(set-language-environment "UTF-8")
```
Org 模式中可以打开 URL。默认的,它会在 Firefox 中打开,但我喜欢用 Chromium。
```
(setq browse-url-browser-function 'browse-url-chromium)
```
我把基本的键的绑定和设为教程里的一样,再加上 `M-RET` 的操作的配置。
```
(global-set-key "\C-cl" 'org-store-link)
(global-set-key "\C-ca" 'org-agenda)
(global-set-key "\C-cc" 'org-capture)
(global-set-key "\C-cb" 'org-iswitchb)
(setq org-M-RET-may-split-line nil)
```
### 捕获配置
我可以在 Emacs 的任何模式中按 `C-c c`,按下后它就会[帮我捕获某些事](https://orgmode.org/guide/Capture.html#Capture),其中包括一个指向我正在处理事务的链接。
你可以通过定义[捕获模板](https://orgmode.org/guide/Capture-templates.html#Capture-templates)来配置它。我将保存两个日志文件,作为会议、电话等的通用记录。一个是私人用的,一个是办公用的。如果我按下 `C-c c j`,它就会帮我捕获为私人项. 下面包含 `%a` 的配置是表示我当前的位置(或是我使用 `C-c l` 保存的链接)的链接。
```
(setq org-default-notes-file "~/org/tasks.org")
(setq org-capture-templates
'(
("t" "Todo" entry (file+headline "inbox.org" "Tasks")
"* TODO %?\n %i\n %u\n %a")
("n" "Note/Data" entry (file+headline "inbox.org" "Notes/Data")
"* %? \n %i\n %u\n %a")
("j" "Journal" entry (file+datetree "~/org/journal.org")
"* %?\nEntered on %U\n %i\n %a")
("J" "Work-Journal" entry (file+datetree "~/org/wjournal.org")
"* %?\nEntered on %U\n %i\n %a")
))
(setq org-irc-link-to-logs t)
```
我喜欢通过 UUID 来建立链接,这让我在文件之间移动而不会破坏位置。当我要 Org 存储一个链接目标以便将来插入时,以下配置有助于生成 UUID。
```
(require 'org-id)
(setq org-id-link-to-org-use-id 'create-if-interactive)
```
### 议程配置
我喜欢将星期天作为一周的开始,当我将某件事标记为完成时,我也喜欢记下时间。
```
(setq org-log-done 'time)
(setq org-agenda-start-on-weekday 0)
```
### 文件归档配置
在这我将配置它,让它知道在议程中该使用哪些文件,而且在纯文本的搜索中添加一点点小功能。我喜欢保留一个通用的文件夹(我可以从其中移动或“重新归档”内容),然后将个人和工作项的任务、日志和知识库分开。
```
(setq org-agenda-files (list "~/org/inbox.org"
"~/org/email.org"
"~/org/tasks.org"
"~/org/wtasks.org"
"~/org/journal.org"
"~/org/wjournal.org"
"~/org/kb.org"
"~/org/wkb.org"
))
(setq org-agenda-text-search-extra-files
(list "~/org/someday.org"
"~/org/config.org"
))
(setq org-refile-targets '((nil :maxlevel . 2)
(org-agenda-files :maxlevel . 2)
("~/org/someday.org" :maxlevel . 2)
("~/org/templates.org" :maxlevel . 2)
)
)
(setq org-outline-path-complete-in-steps nil) ; Refile in a single go
(setq org-refile-use-outline-path 'file)
```
### 外观配置
我喜欢一个较漂亮的的屏幕。在你开始习惯 Org 模式之后,你可以试试这个。
```
(add-hook 'org-mode-hook
(lambda ()
(org-bullets-mode t)))
(setq org-ellipsis "⤵")
```
### 下一篇
希望这篇文章展示了 Org 模式的一些功能。接下来,我将介绍如何定制 `TODO` 关键字和标记、归档旧任务、将电子邮件转发到 Org 模式,以及如何使用 `git` 在不同电脑之间进行同步。
你也可以查看[本系列的所有文章列表](https://changelog.complete.org/archives/tag/emacs2018)。
---
via: <https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode>
作者:[John Goerzen](http://changelog.complete.org/archives/author/jgoerzen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[oneforalone](https://github.com/oneforalone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In [my first post in my series on Emacs](https://changelog.complete.org/archives/9861-emacs-1-ditching-a-bunch-of-stuff-and-moving-to-emacs-and-org-mode), I described returning to Emacs after over a decade of vim, and org-mode being the reason why.
I really am astounded at the usefulness, and simplicity, of org-mode. It is really a killer app.
**So what exactly is org-mode?**
I wrote yesterday:
It’s an information organization platform. Its website says “Your life in plain text: Org mode is for keeping notes, maintaining TODO lists, planning projects, and authoring documents with a fast and effective plain-text system.”
That’s true, but doesn’t quite capture it. org-mode is a toolkit for you to organize things. It has reasonable out-of-the-box defaults, but it’s designed throughout for you to customize.
To highlight a few things:
**Maintaining TODO lists**: items can be scattered across org-mode files, contain attachments, have tags, deadlines, schedules. There is a convenient “agenda” view to show you what needs to be done. Items can repeat.**Authoring documents**: org-mode has special features for generating HTML, LaTeX, slides (with LaTeX beamer), and all sorts of other formats. It also supports direct evaluation of code in-buffer and literate programming in virtually any Emacs-supported language. If you want to bend your mind on this stuff, read[this article on literate devops](http://www.howardism.org/Technical/Emacs/literate-devops.html). The[entire Worg website](https://orgmode.org/worg/)
is made with org-mode.**Keeping notes**: yep, it can do that too. With full-text search, cross-referencing by file (as a wiki), by UUID, and even into other systems (into mu4e by Message-ID, into ERC logs, etc, etc.)
**Getting started**
I highly recommend watching [Carsten Dominik’s excellent Google Talk on org-mode](https://www.youtube.com/watch?v=oJTwQvgfgMM). It is an excellent introduction.
org-mode is included with Emacs, but you’ll often want a more recent version. Debian users can `apt-get install org-mode`, or it comes with the Emacs packaging system; `M-x package-install RET org-mode RET` may do it for you.
Now, you’ll probably want to start with the org-mode compact guide’s [introduction section](https://orgmode.org/guide/Introduction.html#Introduction), noting in particular to set the keybindings mentioned in the [activation section](https://orgmode.org/guide/Activation.html#Activation).
**A good tutorial…**
I’ve linked to a number of excellent tutorials and introductory items; this post is not going to serve as a tutorial. There are two good videos linked at the end of this post, in particular.
**Some of my configuration**
I’ll document some of my configuration here, and go into a bit of what it does. This isn’t necessarily because you’ll want to copy all of this verbatim — but just to give you a bit of an idea of some of what can be configured, an idea of what to look up in the manual, and maybe a reference for “now how do I do that?”
First, I set up Emacs to work in UTF-8 by default.
(prefer-coding-system 'utf-8)
(set-language-environment "UTF-8")
org-mode can follow URLs. By default, it opens in Firefox, but I use Chromium.
(setq browse-url-browser-function 'browse-url-chromium)
I set the basic key bindings as documented in the Guide, plus configure the M-RET behavior.
`(global-set-key "\C-cl" 'org-store-link)`
(global-set-key "\C-ca" 'org-agenda)
(global-set-key "\C-cc" 'org-capture)
(global-set-key "\C-cb" 'org-iswitchb)
(setq org-M-RET-may-split-line nil)
**Configuration: Capturing**
I can press `C-c c` from anywhere in Emacs. It will [capture something for me](https://orgmode.org/guide/Capture.html#Capture), and include a link back to whatever I was working on.
You can define [capture templates](https://orgmode.org/guide/Capture-templates.html#Capture-templates) to set how this will work. I am going to keep two journal files for general notes about meetings, phone calls, etc. One for personal, one for work items. If I press `C-c c j`, then it will capture a personal item. The %a in all of these includes the link to where I was (or a link I had stored with `C-c l`).
(setq org-default-notes-file "~/org/tasks.org") (setq org-capture-templates '( ("t" "Todo" entry (file+headline "inbox.org" "Tasks") "* TODO %?\n %i\n %u\n %a") ("n" "Note/Data" entry (file+headline "inbox.org" "Notes/Data") "* %? \n %i\n %u\n %a") ("j" "Journal" entry (file+datetree "~/org/journal.org") "* %?\nEntered on %U\n %i\n %a") ("J" "Work-Journal" entry (file+datetree "~/org/wjournal.org") "* %?\nEntered on %U\n %i\n %a") )) (setq org-irc-link-to-logs t)
I like to link by UUIDs, which lets me move things between files without breaking locations. This helps generate UUIDs when I ask Org to store a link target for future insertion.
(require 'org-id)
(setq org-id-link-to-org-use-id 'create-if-interactive)
**Configuration: agenda views**
I like my week to start on a Sunday, and for org to note the time when I mark something as done.
(setq org-log-done 'time)
(setq org-agenda-start-on-weekday 0)
**Configuration: files and refiling**
Here I tell it what files to use in the agenda, and to add a few more to the plain text search. I like to keep a general inbox (from which I can move, or “refile”, content), and then separate tasks, journal, and knowledge base for personal and work items.
(setq org-agenda-files (list "~/org/inbox.org" "~/org/email.org" "~/org/tasks.org" "~/org/wtasks.org" "~/org/journal.org" "~/org/wjournal.org" "~/org/kb.org" "~/org/wkb.org" )) (setq org-agenda-text-search-extra-files (list "~/org/someday.org" "~/org/config.org" )) (setq org-refile-targets '((nil :maxlevel . 2) (org-agenda-files :maxlevel . 2) ("~/org/someday.org" :maxlevel . 2) ("~/org/templates.org" :maxlevel . 2) ) ) (setq org-outline-path-complete-in-steps nil) ; Refile in a single go (setq org-refile-use-outline-path 'file)
**Configuration: Appearance**
I like a pretty screen. After you’ve gotten used to org a bit, you might try this.
(require 'org-bullets) (add-hook 'org-mode-hook (lambda () (org-bullets-mode t))) (setq org-ellipsis "⤵")
**Coming up next…**
This hopefully showed a few things that org-mode can do. Coming up next, I’ll cover how to customize TODO keywords and tags, archiving old tasks, forwarding emails to org-mode, and using git to synchronize between machines.
You can also see a [list of all articles in this series](https://changelog.complete.org/archives/tag/emacs2018).
**Resources to accompany this article**
[org-mode compact guide](https://orgmode.org/guide/)[Full org manual](https://orgmode.org/org.html)[List of tutorials](https://orgmode.org/worg/org-tutorials/)[Carsten Dominik’s excellent Google Talk on org-mode](https://www.youtube.com/watch?v=oJTwQvgfgMM)- A great intro:
[“My workflow with org-agenda”](http://cachestocaches.com/2016/9/my-workflow-org-agenda/) [A more detailed intro](http://doc.norang.ca/org-mode.html)[David O’Toole’s org-mode tutorial](https://orgmode.org/worg/org-tutorials/orgtutorial_dto.html)[Getting Started with org-mode video by Harry Schwartz](https://www.youtube.com/watch?v=SzA2YODtgK4)(another excellent watch). He also has his[example config files](https://github.com/hrs/dotfiles/blob/master/emacs/.emacs.d/configuration.org)available.
I *love* org. I have used it as my main tool for basically anything for around five years. I don’t use much of its organization tools (perhaps I should)… But I love it for the ease to author complex texts. I have so far written one text book, two theses, two book chapters, and tens of smaller pieces. Having all the power of LaTeX with none of its pain is great :-]
Wow, that’s impressive. I figured I’d have to go back to raw LaTeX for more “serious” things at some point. But, I guess, I would have never used Beamer manually and yet here it just works so easily. I can see the structure of the whole presentation and muck about with it quite nicely.
Excellent org-mode series! I’m in the process of learning emacs and org-mode as a total newbie. This seems like a really dumb question, but it’s the one thing I can’t seem to find a clear answer to (or I’m just missing it)… Anyway, where do all these custom configuration settings go? Where is the emacs config file? Is there one by default or do I create one? And if I create it, where does it go?
No problem! You can create it, and this page https://www.gnu.org/software/emacs/manual/html_node/emacs/Init-File.html describes the various locations you can put it.
Thank you John! That seems way simpler than I was making it. LOL! The learning curve for emacs is quite steep due to the VAST amount of info and custom configs out there. Everyone has their own “opinion” as to how it should be configured. :)
One of my goals (eventually) is to get away from using Evernote for notes & document management. I’d love to read more about how you managed that if you’re ever feeling so inclined to write another post. Currently, I don’t see how one could possibly manage PDF files and/or other scanned documents using emacs. Evernote contains my life — business receipts, tax documents, medical info, TONS of tech KB stuff, and so on. Evernote is awesome, but I’m no longer comfortable having all my info in a proprietary system that could disappear one day with zero warning.
Emacs is a bit like an operating system or a phone in the sense that it’s more a base to start from rather than something completed. There is no one “right” way to configure it.
In my own setup, I use gscan2pdf (which integrates Tesseract OCR) to scan receipts, records, etc. I keep these in a directory tree outside org-mode. Mostly they are written much more than they are read, and this works fine. I can always link to one if I need to from within org-mode.
org does have a notion of attachments.
I’ve been using ikiwiki for KB stuff, though I am possibly going to migrate that to org as well.
I tried the commands in your appearance section, and got this error:
Warning (initialization): An error occurred while loading ‘c:/org/.emacs.d/init.el’:
File error: Cannot open load file, No such file or directory, org-bullets
Ahh, you’ll need to install the org-bullets package. Sorry about that oversight. See https://www.emacswiki.org/emacs/InstallingPackages for details on how to install packages.
Thanks John – I really appreciate the help!
I tried M-x list-packages but I don’t see org-bullets (or any variation) listed. I’ll keep poking around to see if there is another way to install it.
Well, I stand corrected a SECOND time. org-bullets comes with org-mode, at least on Debian.
I had to add this:
(add-to-list ‘load-path “/usr/share/org-mode/lisp”) ; for bullets
It’s at https://github.com/jwiegley/org-mode/tree/master/contrib/lisp and can be added to the load path if need be.
Cool – thanks again! I guess we’re all learning a few things! LOL :)
I’m just taking baby steps at this point. Trying to learn all the key-bindings in emacs and switching over to org-mode for my todo’s. I’ll add more as I get comfortable with each thing.
Emacs didn’t do any good for me because of the stupid key bindings that are too painful for my wrists |
10,313 | 持续基础设施:另一个 CI | https://opensource.com/article/17/11/continuous-infrastructure-other-ci | 2018-12-04T23:46:57 | [
"CI",
"DevOps"
] | /article-10313-1.html |
>
> 想要提升你的 DevOps 效率吗?将基础设施当成你的 CI 流程中的重要的一环。
>
>
>

持续交付(CD)和持续集成(CI)是 DevOps 的两个众所周知的方面。但在 CI 大肆流行的今天却忽略了另一个关键性的 I:<ruby> 基础设施 <rt> infrastructure </rt></ruby>。
曾经有一段时间 “基础设施”就意味着<ruby> 无头 <rt> headless </rt></ruby>的黑盒子、庞大的服务器,和高耸的机架 —— 更不用说漫长的采购流程和对盈余负载的错误估计。后来到了虚拟机时代,把基础设施处理得很好,虚拟化 —— 以前的世界从未有过这样。我们不再需要管理实体的服务器。仅仅是简单的点击,我们就可以创建和销毁、开始和停止、升级和降级我们的服务器。
有一个关于银行的流行故事:它们实现了数字化,并且引入了在线表格,用户需要手动填写表格、打印,然后邮寄回银行(LCTT 译注:我真的遇到过有人问我这样的需求怎么办)。这就是我们今天基础设施遇到的情况:使用新技术来做和以前一样的事情。
在这篇文章中,我们会看到在基础设施管理方面的进步,将基础设施视为一个版本化的组件并试着探索<ruby> 不可变服务器 <rt> immutable server </rt></ruby>的概念。在后面的文章中,我们将了解如何使用开源工具来实现持续的基础设施。

*实践中的持续集成流程*
这是我们熟悉的 CI,尽早发布、经常发布的循环流程。这个流程缺少一个关键的组件:基础设施。
突击小测试:
* 你怎样创建和升级你的基础设施?
* 你怎样控制和追溯基础设施的改变?
* 你的基础设施是如何与你的业务进行匹配的?
* 你是如何确保在正确的基础设施配置上进行测试的?
要回答这些问题,就要了解<ruby> 持续基础设施 <rt> continuous infrastructure </rt></ruby>。把 CI 构建流程分为<ruby> 代码持续集成 <rt> continuous integration code </rt></ruby>(CIc)和<ruby> 基础设施持续集成 <rt> continuous integration infrastructure </rt></ruby>(CIi)来并行开发和构建代码和基础设施,再将两者融合到一起进行测试。把基础设施构建视为 CI 流程中的重要的一环。

*包含持续基础设施的 CI 流程*
关于 CIi 定义的几个方面:
1. 代码
通过代码来创建基础设施架构,而不是通过安装。<ruby> 基础设施如代码 <rt> Infrastructure as code </rt></ruby>(IaC)是使用配置脚本创建基础设施的现代最流行的方法。这些脚本遵循典型的编码和单元测试周期(请参阅下面关于 Terraform 脚本的示例)。
2. 版本
IaC 组件在源码仓库中进行版本管理。这让基础设施的拥有了版本控制的所有好处:一致性,可追溯性,分支和标记。
3. 管理
通过编码和版本化的基础设施管理,你可以使用你所熟悉的测试和发布流程来管理基础设施的开发。
CIi 提供了下面的这些优势:
1. <ruby> 一致性 <rt> Consistency </rt></ruby>
版本化和标记化的基础设施意味着你可以清楚的知道你的系统使用了哪些组件和配置。这建立了一个非常好的 DevOps 实践,用来鉴别和管理基础设施的一致性。
2. <ruby> 可重现性 <rt> Reproducibility </rt></ruby>
通过基础设施的标记和基线,重建基础设施变得非常容易。想想你是否经常听到这个:“但是它在我的机器上可以运行!”现在,你可以在本地的测试平台中快速重现类似生产环境,从而将环境像变量一样在你的调试过程中删除。
3. <ruby> 可追溯性 <rt> Traceability </rt></ruby>
你是否还记得曾经有过多少次寻找到底是谁更改了文件夹权限的经历,或者是谁升级了 `ssh` 包?代码化的、版本化的,发布的基础设施消除了临时性变更,为基础设施的管理带来了可追踪性和可预测性。
4. <ruby> 自动化 <rt> Automation </rt></ruby>
借助脚本化的基础架构,自动化是下一个合乎逻辑的步骤。自动化允许你按需创建基础设施,并在使用完成后销毁它,所以你可以将更多宝贵的时间和精力用在更重要的任务上。
5. <ruby> 不变性 <rt> Immutability </rt></ruby>
CIi 带来了不可变基础设施等创新。你可以创建一个新的基础设施组件而不是通过升级(请参阅下面有关不可变设施的说明)。
持续基础设施是从运行基础环境到运行基础组件的进化。像处理代码一样,通过证实的 DevOps 流程来完成。对传统的 CI 的重新定义包含了缺少的那个 “i”,从而形成了连贯的 CD 。
**(CIc + CIi) = CI -> CD**
### 基础设施如代码 (IaC)
CIi 流程的一个关键推动因素是<ruby> 基础设施如代码 <rt> infrastructure as code </rt></ruby>(IaC)。IaC 是一种使用配置文件进行基础设施创建和升级的机制。这些配置文件像其他的代码一样进行开发,并且使用版本管理系统进行管理。这些文件遵循一般的代码开发流程:单元测试、提交、构建和发布。IaC 流程拥有版本控制带给基础设施开发的所有好处,如标记、版本一致性,和修改可追溯。
这有一个简单的 Terraform 脚本用来在 AWS 上创建一个双层基础设施的简单示例,包括虚拟私有云(VPC)、弹性负载(ELB),安全组和一个 NGINX 服务器。[Terraform](https://github.com/hashicorp/terraform) 是一个通过脚本创建和更改基础设施架构和开源工具。

*Terraform 脚本创建双层架构设施的简单示例*
完整的脚本请参见 [GitHub](https://github.com/terraform-providers/terraform-provider-aws/tree/master/examples/two-tier)。
### 不可变基础设施
你有几个正在运行的虚拟机,需要更新安全补丁。一个常见的做法是推送一个远程脚本单独更新每个系统。
要是不更新旧系统,如何才能直接丢弃它们并部署安装了新安全补丁的新系统呢?这就是<ruby> 不可变基础设施 <rt> immutable infrastructure </rt></ruby>。因为之前的基础设施是版本化的、标签化的,所以安装补丁就只是更新该脚本并将其推送到发布流程而已。
现在你知道为什么要说基础设施在 CI 流程中特别重要了吗?
---
via: <https://opensource.com/article/17/11/continuous-infrastructure-other-ci>
作者:[Girish Managoli](https://opensource.com/users/gammay) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Jamskr](https://github.com/Jamskr) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,314 | 如何实现 Linux + Windows 双系统启动 | https://opensource.com/article/18/5/dual-boot-linux | 2018-12-05T22:19:16 | [
"双引导",
"Windows"
] | https://linux.cn/article-10314-1.html |
>
> 设置你的计算机根据需要启动 Windows 10 或 Ubuntu 18.04。
>
>
>

尽管 Linux 是一个有着广泛的硬件和软件支持的操作系统,但事实上有时你仍需要使用 Windows,也许是因为有些不能在 Linux 下运行的重要软件。但幸运地是,双启动 Windows 和 Linux 是很简单的 —— 在这篇文章中我将会向你展示如何实现 Windows 10 + Ubuntu 18.04 双系统启动。
在你开始之前,确保你已经备份了你的电脑文件。虽然设置双启动过程不是非常复杂,但意外有可能仍会发生。所以花一点时间来备份你的重要文件以防混沌理论发挥作用。除了备份你的文件之外,考虑制作一份备份镜像也是个不错的选择,虽然这不是必需的且会变成一个更高级的过程。
### 要求
为了开始,你将需要以下 5 项东西:
#### 1、两个 USB 闪存盘(或者 DVD-R)
我推荐用 USB 闪存盘来安装 Windows 和 Ubuntu,因为他们比 DVD 更快。这通常是毋庸置疑的, 但是创建一个可启动的介质会抹除闪存盘上的一切东西。因此,确保闪存盘是空的或者其包含的文件是你不再需要的。
如果你的电脑不支持从 USB 启动,你可以创建 DVD 介质来代替。不幸的是,因为电脑上的 DVD 烧录软件似乎各有不同,所以我无法使用这一过程。然而,如果你的 DVD 烧录软件有从一个 ISO 镜像中烧录的选项,这个选项是你需要的。
#### 2、一份 Windows 10 许可证
如果你的电脑已经安装 Windows 10,那么许可证将会被安装到你的电脑中,所以你不需要担心在安装过程中输入它。如果你购买的是零售版,你应该拥有一个需要在安装过程中输入的产品密钥。
#### 3、Windows 10 介质创建工具
下载并运行 Windows 10 [介质创建工具](https://www.microsoft.com/en-us/software-download/windows10)。一旦你运行这个工具,它将会引导你完成在一个 USB 或者 DVD-R 上创建 Windows 安装介质的所需步骤。注意:即使你已经安装了 Windows 10,创建一个可引导的介质也是一个不错的主意,万一刚好系统出错了且需要你重新安装。
#### 4、Ubuntu 18.04 安装介质
下载 [Ubuntu 18.04](https://www.ubuntu.com/download/desktop) ISO 镜像。
#### 5、Etcher 软件(用于制作一个可引导 Ubuntu 的 USB 驱动器)
用于为任何 Linux 发行版创建可启动的介质的工具,我推荐 [Etcher](http://www.etcher.io)。Etcher 可以在三大主流操作系统(Linux、MacOS 和 Windows)上运行且不会让你覆盖当前操作系统的分区。
一旦你下载完成并运行 Etcher,点击选择镜像并指向你在步骤 4 中下载的 Ubuntu ISO 镜像, 接下来,点击驱动器以选择你的闪存驱动器,然后点击 “Flash!” 开始将闪存驱动器转化为一个 Ubuntu 安装器的过程。 (如果你正使用一个 DVD-R,使用你电脑中的 DVD 烧录软件来完成此过程。)
### 安装 Windows 和 Ubuntu
你应该准备好了,此时,你应该完成以下操作:
* 备份你重要的文件
* 创建 Windows 安装介质
* 创建 Ubuntu 安装介质
有两种方法可以进行安装。首先,如果你已经安装了 Windows 10 ,你可以让 Ubuntu 安装程序调整分区大小,然后在空白区域上进行安装。或者,如果你尚未安装 Windows 10,你可以在安装过程中将它(Windows)安装在一个较小的分区上(下面我将描述如何去做)。第二种方法是首选的且出错率较低。很有可能你不会遇到任何问题,但是手动安装 Windows 并给它一个较小的分区,然后再安装 Ubuntu 是最简单的方法。
如果你的电脑上已经安装了 Windows 10,那么请跳过以下的 Windows 安装说明并继续安装 Ubuntu。
#### 安装 Windows
将创建的 Windows 安装介质插入你的电脑中并引导其启动。这如何做取决于你的电脑。但大多数有一个可以按下以显示启动菜单的快捷键。例如,在戴尔的电脑上就是 F12 键。如果闪存盘并未作为一个选项显示,那么你可能需要重新启动你的电脑。有时候,只有在启动电脑前插入介质才能使其显示出来。如果看到类似“请按任意键以从安装介质中启动”的信息,请按下任意一个键。然后你应该会看到如下的界面。选择你的语言和键盘样式,然后单击 “Next”。

点击“现在安装”启动 Windows 安装程序。

在下一个屏幕上,它会询问你的产品密钥。如果因你的电脑在出厂时已经安装了 Windows 10 而没有密钥的话,请选择“我没有一个产品密钥”。在安装完成后更新该密码后会自动激活。如果你有一个产品密钥,输入密钥并单击“下一步”。

选择你想要安装的 Windows 版本。如果你有一个零售版,封面标签(LCTT 译注:类似于 CPU 型号的 logo 贴标)会告诉你你有什么版本。否则,它通常在你的计算机的附带文档中可以找到。在大多数情况下,它要么是 Windows 10 家庭版或者 Windows 10 专业版。大多数带有 家庭版的电脑都有一个简单的标签,上面写着“Windows 10”,而专业版则会明确标明。

勾选复选框以接受许可协议,然后单击“下一步”。

在接受协议后,你有两种可用的安装选项。选择第二个选项“自定义:只安装 Windows (高级)”。

接下来应该会显示你当前的硬盘配置。

你的结果可能看起来和我的不一样。我以前从来没有用过这个硬盘,所以它是完全未分配的。你可能会看到你当前操作系统的一个或多个分区。选中每个分区并移除它。(LCTT 译注:确保这些分区中没有你需要的数据!!)
此时,你的电脑屏幕将显示未分配的整个磁盘。创建一个新的分区以继续安装。

你可以看到我通过创建一个 81920MB 大小的分区(接近 160GB 的一半)将驱动器分成了一半(或者说接近一半)。给 Windows 至少 40GB,最好 64GB 或者更多。把剩下的硬盘留着不要分配,作为以后安装 Ubuntu 的分区。
你的结果应该看起来像这样:

确认分区看起来合理,然后单击“下一步”。现在将开始安装 Windows。

如果你的电脑成功地引导进入了 Windows 桌面环境,你就可以进入下一步了。

#### 安装 Ubuntu
无论你是已经安装了 Windows,还是完成了上面的步骤,现在你已经安装了 Windows。现在用你之前创建的 Ubuntu 安装介质来引导进入 Ubuntu。继续插入安装介质并从中引导你的电脑,同样,启动引导菜单的快捷键因计算机型号而异,因此如果你不确定,请查阅你的文档。如果一切顺利的话,当安装介质加载完成之后,你将会看到以下界面:

在这里,你可以选择 “尝试 Ubuntu” 或者 “安装 Ubuntu”。现在不要安装,相反,点击 “尝试 Ubuntu”。当完成加载之后,你应该可以看到 Ubuntu 桌面。

通过单击“尝试 Ubuntu”,你已经选择在安装之前试用 Ubuntu。 在 Live 模式下,你可以试用 Ubuntu,确保在你安装之前一切正常。Ubuntu 能兼容大多数 PC 硬件,但最好提前测试一下。确保你可以访问互联网并可以正常播放音频和视频。登录 YouTube 播放视频是一次性完成所有这些工作的好方法(LCTT 译注:国情所限,这个方法在这里并不奏效)。如果你需要连接到无线网络,请单击屏幕右上角的网络图标。在那里,你可以找到一个无线网络列表并连接到你的无线网络。
准备好之后,双击桌面上的 “安装 Ubuntu 18.04 LTS” 图标启动安装程序。
选择要用于安装过程的语言,然后单击 “继续”。

接下来,选择键盘布局。完成后选择后,单击“继续”。

在下面的屏幕上有一些选项。你可以选择一个正常安装或最小化安装。对大多数人来说,普通安装是理想的。高级用户可能想要默认安装应用程序比较少的最小化安装。此外,你还可以选择下载更新以及是否包含第三方软件和驱动程序。我建议同时检查这两个方框。完成后,单击“继续”。

下一个屏幕将询问你是要擦除磁盘还是设置双启动。由于你是双启动,因此请选择“安装 Ubuntu,与 Windows 10共存”,单击“现在安装”。

可能会出现以下屏幕。如果你从头开始安装 Windows 并在磁盘上保留了未分区的空间,Ubuntu 将会自动在空白区域中自行设置分区,因此你将看不到此屏幕。如果你已经安装了 Windows 10 并且它占用了整个驱动器,则会出现此屏幕,并在顶部为你提供一个选择磁盘的选项。如果你只有一个磁盘,则可以选择从 Windows 窃取多少空间给 Ubuntu。你可以使用鼠标左右拖动中间的垂直线以从其中一个分区中拿走一些空间并给另一个分区,按照你自己想要的方式调整它,然后单击“现在安装”。

你应该会看到一个显示 Ubuntu 计划将要做什么的确认屏幕,如果一切正常,请单击“继续”。

Ubuntu 正在后台安装。不过,你仍需要进行一些配置。当 Ubuntu 试图找到你的位置时,你可以点击地图来缩小范围以确保你的时区和其他设置是正确的。

接下来,填写用户账户信息:你的姓名、计算机名、用户名和密码。完成后单击“继续”。

现在你就拥有它了,安装完成了。继续并重启你的电脑。

如果一切按计划进行,你应该会在计算机重新启动时看到类似的屏幕,选择 Ubuntu 或 Windows 10,其他选项是用于故障排除,所以我们一般不会选择进入其中。

尝试启动并进入 Ubuntu 或 Windows 以测试是否安装成功并确保一切按预期地正常工作。如果没有问题,你已经在你的电脑上安装了 Windows 和 Ubuntu 。
---
via: <https://opensource.com/article/18/5/dual-boot-linux>
作者:[Jay LaCroix](https://opensource.com/users/jlacroix) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Auk7F7](https://github.com/Auk7F7) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux is a great operating system with widespread hardware and software support, but the reality is that sometimes you have to use Windows, perhaps due to key apps that won't run on Linux. Thankfully, dual-booting Windows and Linux is very straightforward—and I'll show you how to set it up, with Windows 10 and Ubuntu, in this article.
Before you get started, make sure you've backed up your computer. Although the dual-boot setup process is not very involved, accidents can still happen. So take the time to back up your important files in case chaos theory comes into play. In addition to backing up your files, consider taking an image backup of the disk as well, though that's not required and can be a more advanced process.
## Prerequisites
To get started, you will need the following five items:
### 1. Two USB flash drives (or DVD-Rs)
I recommend installing Windows and Ubuntu via flash drives since they're faster than DVDs. It probably goes without saying, but creating bootable media erases everything on the flash drive. Therefore, make sure the flash drives are empty or contain data you don't care about losing.
If your machine doesn't support booting from USB, you can create DVD media instead. Unfortunately, because no two computers seem to have the same DVD-burning software, I can't walk you through that process. However, if your DVD-burning application has an option to burn from an ISO image, that's the option you need.
### 2. A Windows 10 license
If Windows 10 came with your PC, the license will be built into the computer, so you don't need to worry about entering it during installation. If you bought the retail edition, you should have a product key, which you will need to enter during the installation process.
### 3. Windows 10 Media Creation Tool
Download and launch the Windows 10 [Media Creation Tool](https://www.microsoft.com/en-us/software-download/windows10). Once you launch the tool, it will walk you through the steps required to create the Windows media on a USB or DVD-R. Note: Even if you already have Windows 10 installed, it's a good idea to create bootable media anyway, just in case something goes wrong and you need to reinstall it.
### 4. Ubuntu installation media
Download the [Ubuntu ISO image](https://www.ubuntu.com/download/desktop).
### 5. Etcher software (for making a bootable Ubuntu USB drive)
For creating bootable media for any Linux distribution, I recommend [Etcher](http://www.etcher.io). Etcher works on all three major operating systems (Linux, MacOS, and Windows) and is careful not to let you overwrite your current operating system partition.
Les Pounder, CC-BY-SA 4.0
Once you have downloaded and launched Etcher, click *Select image*, and point it to the Ubuntu ISO you downloaded in step 4. Next, click *Select drive* to choose your flash drive, and click *Flash!* to start the process of turning a flash drive into an Ubuntu installer. (If you're using a DVD-R, use your computer's DVD-burning software instead.)
## Install Windows and Ubuntu
You should be ready to begin. At this point, you should have accomplished the following:
- Backed up your important files
- Created Windows installation media
- Created Ubuntu installation media
There are two ways of going about the installation. First, if you already have Windows 10 installed, you can have the Ubuntu installer resize the partition, and the installation will proceed in the empty space. Or, if you haven't installed Windows 10, install it on a smaller partition you can set up during the installation process. (I'll describe how to do that below.) The second way is preferred and less error-prone. There's a good chance you won't have any issues either way, but installing Windows manually and giving it a smaller partition, then installing Ubuntu, is the easiest way to go.
If you already have Windows 10 on your computer, skip the following Windows installation instructions and proceed to [Installing Ubuntu](#Ubuntu).
### Installing Windows
Insert the Windows installation media you created into your computer and boot from it. How you do this depends on your computer, but most have a key you can press to initiate the boot menu. On a Dell PC for example, that key is F12. If the flash drive doesn't show up as an option, you may need to restart the computer. Sometimes it will show up only if you've inserted the media before turning on the computer. If you see a message like, "press any key to boot from the installation media," press a key. You should see the following screen. Select your language and keyboard style and click *Next*.
Click on *Install now* to start the Windows installer.
On the next screen, it asks for your product key. If you don't have one because Windows 10 came with your PC, select "I don't have a product key." It should automatically activate after the installation once it catches up with updates. If you do have a product key, type that in and click Next.
Select which version of Windows you want to install. If you have a retail copy, the label will tell you what version you have. Otherwise, it is typically located with the documentation that came with your computer. In most cases, it's going to be either Windows 10 Home or Windows 10 Pro. Most PCs that come with the Home edition have a label that simply reads "Windows 10," while Pro is clearly marked.
Accept the license agreement by checking the box, then click *Next*.
After accepting the agreement, you have two installation options available. Choose the second option, *Custom: Install Windows only (advanced)*.
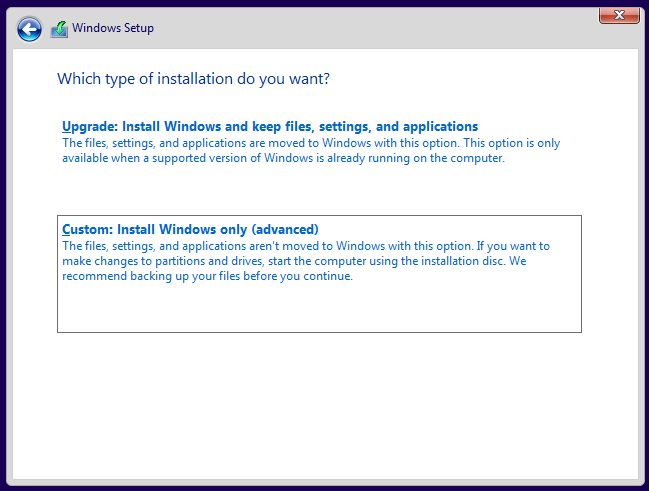
The next screen should show your current hard disk configuration.
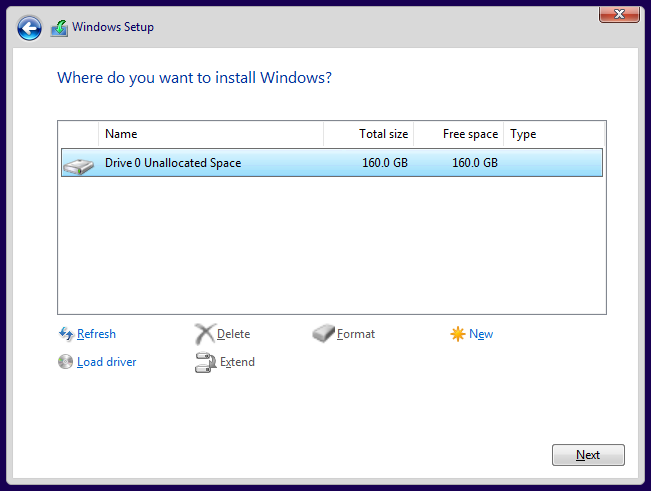
Your results will probably look different than mine. I have never used this hard disk before, so it's completely unallocated. You will probably see one or more partitions for your current operating system. Highlight each partition and remove it.
At this point, your screen will show your entire disk as unallocated. To continue, create a new partition.
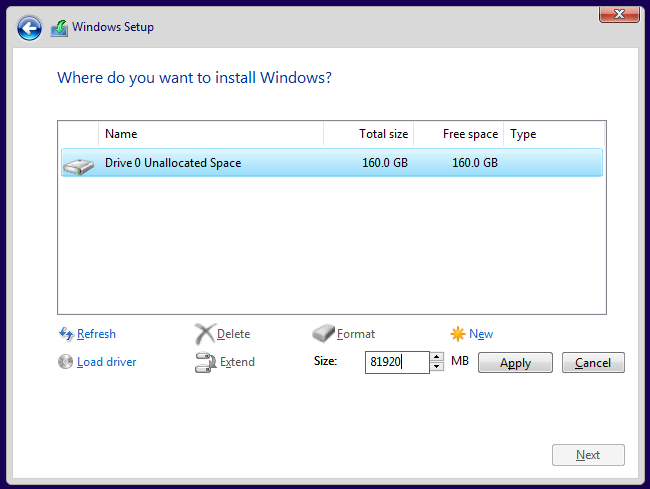
Here you can see that I divided the drive in half (or close enough) by creating a partition of 81,920MB (which is close to half of 160GB). Give Windows at least 40GB, preferably 64GB or more. Leave the rest of the drive unallocated, as that's where you'll install Ubuntu later.
Your results will look similar to this:
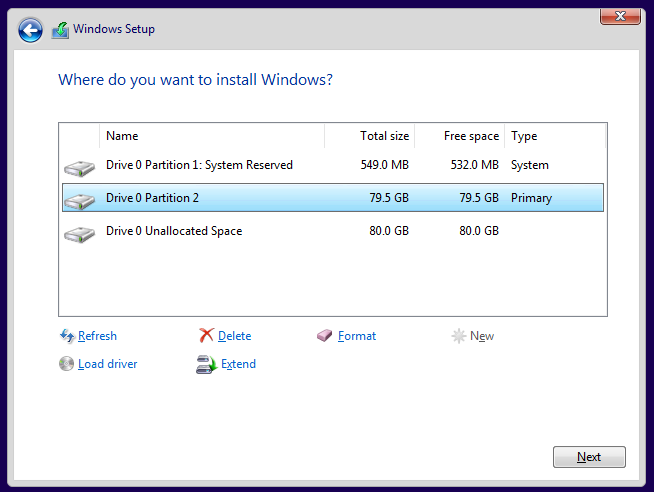
Confirm the partitioning looks good to you and click *Next*. Windows will begin installing.
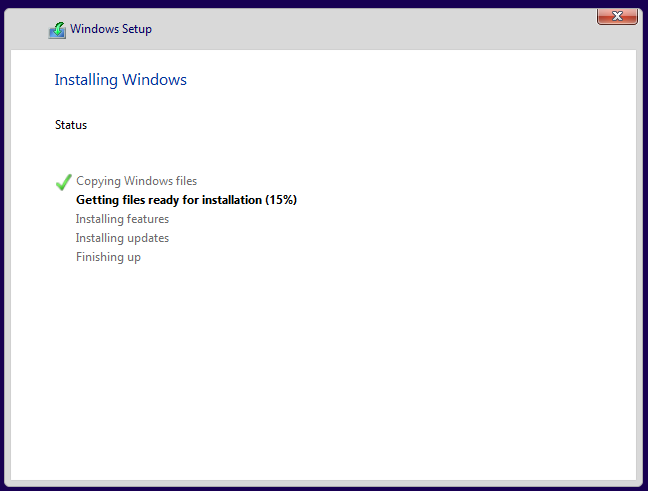
If your computer successfully boots into Windows, you're all set to move on to the next step.
Install Ubuntu
Whether it was already there or you worked through the steps above, at this point you have Windows installed. Now use the Ubuntu installation media you created earlier to boot into Ubuntu. Insert the media and boot your computer from it. Again, the exact sequence of keys to access the boot menu varies from one computer to another, so check your documentation if you're not sure. If all goes well, you see the following screen once the media finishes loading:
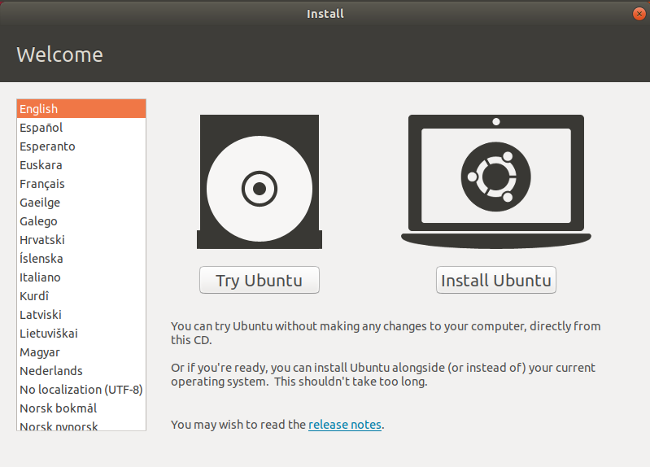
Here, you can select between *Try Ubuntu* or *Install Ubuntu*. Don't install just yet; instead, click *Try Ubuntu*. After it finishes loading, you should see the Ubuntu desktop.
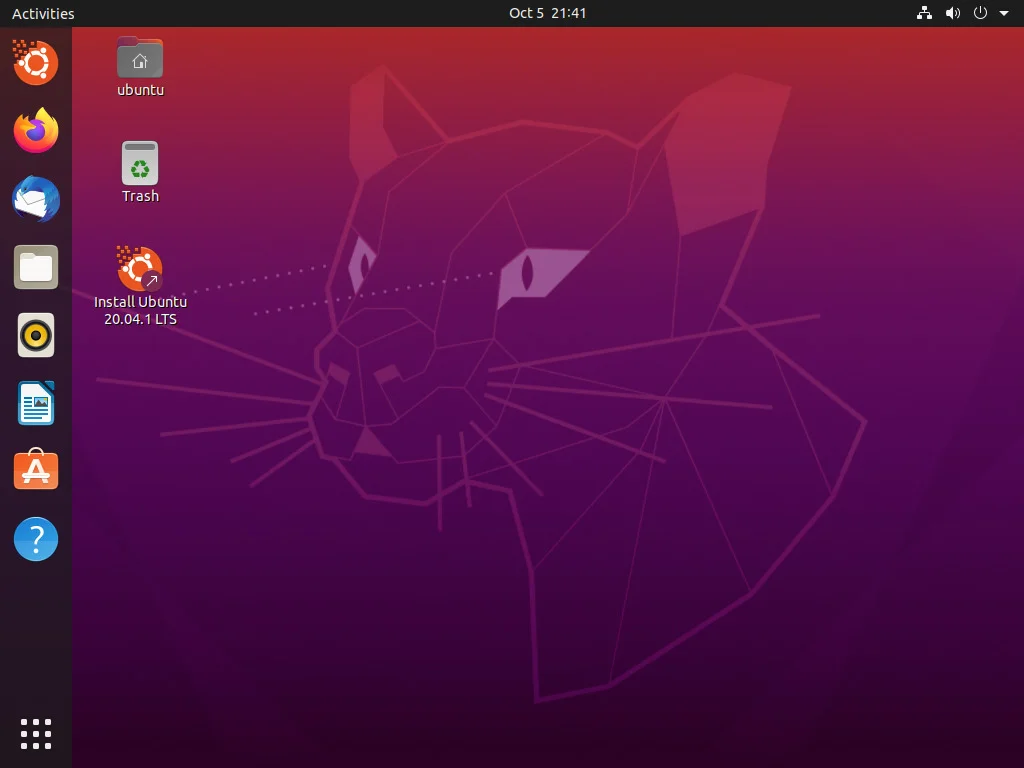
opensource.com
By clicking *Try Ubuntu*, you opt to try out Ubuntu before you install it. Here, in Live mode, you can play around with Ubuntu and make sure everything works before you commit to the installation. Ubuntu works with most PC hardware, but it's always better to test it out beforehand. Make sure you can access the internet and get audio and video playback. Going to YouTube and playing a video is a good way of doing all of that at once. If you need to connect to a wireless network, click on the networking icon at the top-right of the screen. There, you can find a list of wireless networks and connect to yours.
Once you're ready to go, double-click on the *Install Ubuntu 20.04 LTS* icon on the desktop to launch the installer.
Choose the language you want to use for the installation process, then click *Continue*.
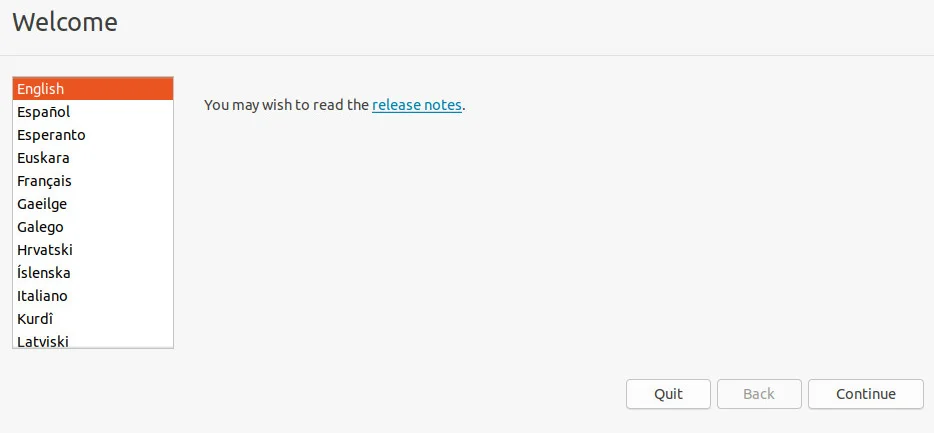
Next, choose the keyboard layout. Once you've made your selection, click *Continue*.
You have a few options on the next screen. You can choose a Normal or a Minimal installation. For most people, Normal installation is ideal. Advanced users may want to do a Minimal install instead, which has fewer software applications installed by default. In addition, you can choose to download updates and whether or not to include third-party software and drivers. I recommend checking both of those boxes. When done, click *Continue*.
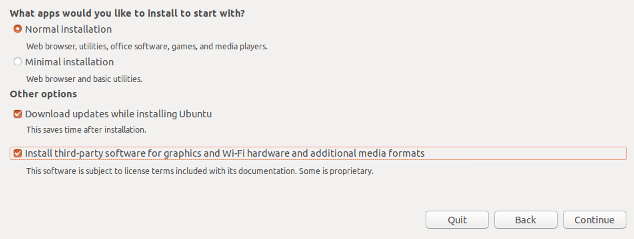
The next screen asks whether you want to erase the disk or set up a dual-boot. Since you're dual-booting, choose *Install Ubuntu alongside Windows 10*. Click *Install Now*.
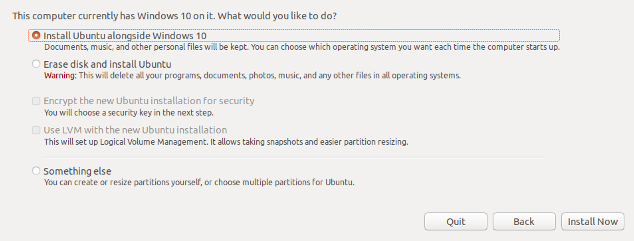
The following screen may appear. If you installed Windows from scratch and left unallocated space on the disk, Ubuntu will automatically set itself up in the empty space, so you won't see this screen. If you already had Windows 10 installed and it's taking up the entire drive, this screen will appear and give you an option to select a disk at the top. If you have just one disk, you can choose how much space to steal from Windows and apply to Ubuntu. You can drag the vertical line in the middle left and right with your mouse to take space away from one and gives it to the other. Adjust this exactly the way you want it, then click *Install Now*.
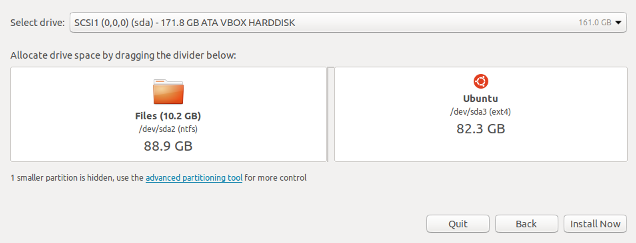
You should see a confirmation screen indicating what Ubuntu plans on doing. If everything looks right, click *Continue*.
Ubuntu installs in the background, but you still have some configuration to do. While Ubuntu tries its best to figure out your location, you can click on the map to narrow it down to ensure your time zone and other things are set correctly.
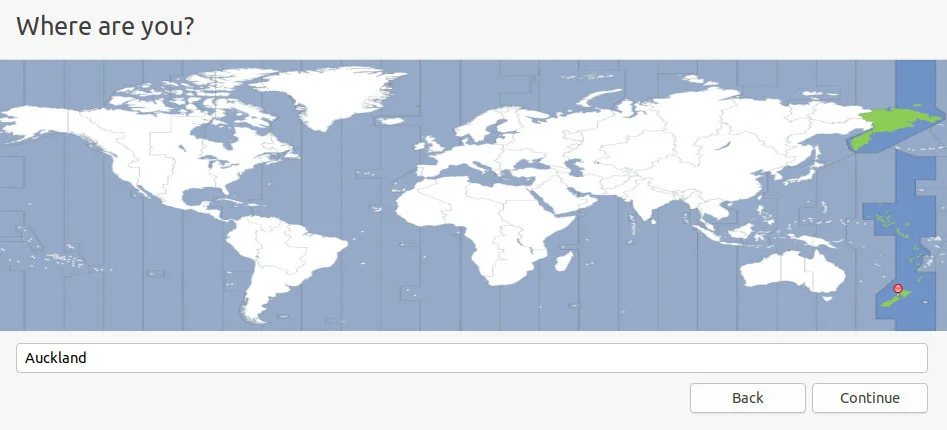
Next, fill in the user account information: your name, computer name, username, and password. Click *Continue* when you're done.
Once the installation finishes, reboot your PC.
If all went according to plan, you should see a screen similar to this when your computer restarts. Choose Ubuntu or Windows 10; the other options are for troubleshooting, so I won't go into them.
Try booting into both Ubuntu and Windows to test them out and make sure everything works as expected. If it does, you now have both Windows and Ubuntu installed on your computer.
This article was originally published in 2018 and has been updated by [Seth Kenlon](http://opensource.com/users/seth).
## 11 Comments |
10,315 | 如何用 Python 编写你喜爱的 R 函数 | https://opensource.com/article/18/10/write-favorite-r-functions-python | 2018-12-05T23:42:00 | [
"Python",
"统计"
] | https://linux.cn/article-10315-1.html |
>
> R 还是 Python ? Python 脚本模仿易使用的 R 风格函数,使得数据统计变得简单易行。
>
>
>

“Python vs. R” 是数据科学和机器学习的现代战争之一。毫无疑问,近年来这两者发展迅猛,成为数据科学、预测分析和机器学习领域的顶级编程语言。事实上,根据 IEEE 最近的一篇文章,Python 已在 [最受欢迎编程语言排行榜](https://spectrum.ieee.org/at-work/innovation/the-2018-top-programming-languages) 中超越 C++ 成为排名第一的语言,并且 R 语言也稳居前 10 位。
但是,这两者之间存在一些根本区别。[R](https://www.coursera.org/lecture/r-programming/overview-and-history-of-r-pAbaE) 语言设计的初衷主要是作为统计分析和数据分析问题的快速原型设计的工具,另一方面,Python 是作为一种通用的、现代的面向对象语言而开发的,类似 C++ 或 Java,但具有更简单的学习曲线和更灵活的语言风格。因此,R 仍在统计学家、定量生物学家、物理学家和经济学家中备受青睐,而 Python 已逐渐成为日常脚本、自动化、后端 Web 开发、分析和通用机器学习框架的顶级语言,拥有广泛的支持基础和开源开发社区。
### 在 Python 环境中模仿函数式编程
[R 作为函数式编程语言的本质](http://adv-r.had.co.nz/Functional-programming.html)为用户提供了一个极其简洁的用于快速计算概率的接口,还为数据分析问题提供了必不可少的描述统计和推论统计方法(LCTT 译注:统计学从功能上分为描述统计学和推论统计学)。例如,只用一个简洁的函数调用来解决以下问题难道不是很好吗?
* 如何计算数据向量的平均数 / 中位数 / 众数。
* 如何计算某些服从正态分布的事件的累积概率。如果服<ruby> 从泊松分布 <rt> Poisson distribution </rt></ruby>又该怎样计算呢?
* 如何计算一系列数据点的四分位距。
* 如何生成服从学生 t 分布的一些随机数(LCTT 译注: 在概率论和统计学中,学生 t-分布(Student’s t-distribution)可简称为 t 分布,用于根据小样本来估计呈正态分布且方差未知的总体的均值)。
R 编程环境可以完成所有这些工作。
另一方面,Python 的脚本编写能力使分析师能够在各种分析流程中使用这些统计数据,具有无限的复杂性和创造力。
要结合二者的优势,你只需要一个简单的 Python 封装的库,其中包含与 R 风格定义的概率分布和描述性统计相关的最常用函数。 这使你可以非常快速地调用这些函数,而无需转到正确的 Python 统计库并理解整个方法和参数列表。
### 便于调用 R 函数的 Python 包装脚本
[我编写了一个 Python 脚本](https://github.com/tirthajyoti/StatsUsingPython/blob/master/R_Functions.py) ,用 Python 简单统计分析定义了最简洁和最常用的 R 函数。导入此脚本后,你将能够原生地使用这些 R 函数,就像在 R 编程环境中一样。
此脚本的目标是提供简单的 Python 函数,模仿 R 风格的统计函数,以快速计算密度估计和点估计、累积分布和分位数,并生成重要概率分布的随机变量。
为了延续 R 风格,脚本不使用类结构,并且只在文件中定义原始函数。因此,用户可以导入这个 Python 脚本,并在需要单个名称调用时使用所有功能。
请注意,我使用 mimic 这个词。 在任何情况下,我都声称要模仿 R 的真正的函数式编程范式,该范式包括深层环境设置以及这些环境和对象之间的复杂关系。 这个脚本允许我(我希望无数其他的 Python 用户)快速启动 Python 程序或 Jupyter 笔记本程序、导入脚本,并立即开始进行简单的描述性统计。这就是目标,仅此而已。
如果你已经写过 R 代码(可能在研究生院)并且刚刚开始学习并使用 Python 进行数据分析,那么你将很高兴看到并在 Jupyter 笔记本中以类似在 R 环境中一样使用一些相同的知名函数。
无论出于何种原因,使用这个脚本很有趣。
### 简单的例子
首先,只需导入脚本并开始处理数字列表,就好像它们是 R 中的数据向量一样。
```
from R_functions import *
lst=[20,12,16,32,27,65,44,45,22,18]
<more code, more statistics...>
```
假设你想从数据向量计算 [Tuckey 五数](https://en.wikipedia.org/wiki/Five-number_summary)摘要。 你只需要调用一个简单的函数 `fivenum`,然后将向量传进去。 它将返回五数摘要,存在 NumPy 数组中。
```
lst=[20,12,16,32,27,65,44,45,22,18]
fivenum(lst)
> array([12. , 18.5, 24.5, 41. , 65. ])
```
或许你想要知道下面问题的答案:
>
> 假设一台机器平均每小时输出 10 件成品,标准偏差为 2。输出模式遵循接近正态的分布。 机器在下一个小时内输出至少 7 个但不超过 12 个单位的概率是多少?
>
>
>
答案基本上是这样的:

使用 `pnorm` ,你可以只用一行代码就能获得答案:
```
pnorm(12,10,2)-pnorm(7,10,2)
> 0.7745375447996848
```
或者你可能需要回答以下问题:
>
> 假设你有一个不公平硬币,每次投它时有 60% 可能正面朝上。 你正在玩 10 次投掷游戏。 你如何绘制并给出这枚硬币所有可能的胜利数(从 0 到 10)的概率?
>
>
>
只需使用一个函数 `dbinom` 就可以获得一个只有几行代码的美观条形图:
```
probs=[]
import matplotlib.pyplot as plt
for i in range(11):
probs.append(dbinom(i,10,0.6))
plt.bar(range(11),height=probs)
plt.grid(True)
plt.show()
```

### 简单的概率计算接口
R 提供了一个非常简单直观的接口,可以从基本概率分布中快速计算。 接口如下:
* **d** 分布:给出点 **x** 处的密度函数值
* **p** 分布:给出 **x** 点的累积值
* **q** 分布:以概率 **p** 给出分位数函数值
* **r** 分布:生成一个或多个随机变量
在我们的实现中,我们坚持使用此接口及其关联的参数列表,以便你可以像在 R 环境中一样执行这些函数。
### 目前已实现的函数
脚本中实现了以下 R 风格函数,以便快速调用。
* 平均数、中位数、方差、标准差
* Tuckey 五数摘要、<ruby> 四分位距 <rt> interquartile range </rt></ruby>(IQR)
* 矩阵的协方差或两个向量之间的协方差
* 以下分布的密度、累积概率、分位数函数和随机变量生成:正态、均匀、二项式、<ruby> 泊松 <rt> Poisson </rt></ruby>、F、<ruby> 学生 t <rt> Student’s t </rt></ruby>、<ruby> 卡方 <rt> Chi-square </rt></ruby>、<ruby> 贝塔 <rt> beta </rt></ruby>和<ruby> 伽玛 <rt> gamma </rt></ruby>
### 进行中的工作
显然,这是一项正在进行的工作,我计划在此脚本中添加一些其他方便的R函数。 例如,在 R 中,单行命令 `lm` 可以为数字数据集提供一个简单的最小二乘拟合模型,其中包含所有必要的推理统计(P 值,标准误差等)。 这非常简洁! 另一方面,Python 中的标准线性回归问题经常使用 [Scikit-learn](http://scikit-learn.org/stable/) 库来处理,此用途需要更多的脚本,所以我打算使用 Python 的 [statsmodels](https://www.statsmodels.org/stable/index.html) 库合并这个单函数线性模型来拟合功能。
如果你喜欢这个脚本,并且愿意在工作中使用,请 [GitHub 仓库](https://github.com/tirthajyoti/StatsUsingPython)点个 star 或者 fork 帮助其他人找到它。 另外,你可以查看我其他的 [GitHub 仓库](https://github.com/tirthajyoti?tab=repositories),了解 Python、R 或 MATLAB 中的有趣代码片段以及一些机器学习资源。
如果你有任何问题或想法要分享,请通过 [tirthajyoti [AT] gmail.com](mailto:[email protected]) 与我联系。 如果你像我一样热衷于机器学习和数据科学,请 [在 LinkedIn 上加我为好友](https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/)或者[在 Twitter 上关注我](https://twitter.com/tirthajyotiS)。
本篇文章最初发表于[走向数据科学](https://towardsdatascience.com/how-to-write-your-favorite-r-functions-in-python-11e1e9c29089)。 请在 [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/) 协议下转载。
---
via: <https://opensource.com/article/18/10/write-favorite-r-functions-python>
作者:[Tirthajyoti Sarkar](https://opensource.com/users/tirthajyoti) 选题:[lujun9972](https://github.com/lujun9972) 译者:[yongshouzhang](https://github.com/yongshouzhang) 校对:[Flowsnow](https://github.com/Flowsnow)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the great modern battles of data science and machine learning is "Python vs. R." There is no doubt that both have gained enormous ground in recent years to become top programming languages for data science, predictive analytics, and machine learning. In fact, according to a recent IEEE article, Python overtook C++ as the [top programming language](https://spectrum.ieee.org/at-work/innovation/the-2018-top-programming-languages) and R firmly secured its spot in the top 10.
However, there are some fundamental differences between these two. [R was developed primarily](https://www.coursera.org/lecture/r-programming/overview-and-history-of-r-pAbaE) as a tool for statistical analysis and quick prototyping of a data analysis problem. Python, on the other hand, was developed as a general purpose, modern object-oriented language in the same vein as C++ or Java but with a simpler learning curve and more flexible demeanor. Consequently, R continues to be extremely popular among statisticians, quantitative biologists, physicists, and economists, whereas Python has slowly emerged as the top language for day-to-day scripting, automation, backend web development, analytics, and general machine learning frameworks and has an extensive support base and open source development community work.
## Mimicking functional programming in a Python environment
[R's nature as a functional programming language](http://adv-r.had.co.nz/Functional-programming.html) provides users with an extremely simple and compact interface for quick calculations of probabilities and essential descriptive/inferential statistics for a data analysis problem. For example, wouldn't it be great to be able to solve the following problems with just a single, compact function call?
- How to calculate the mean/median/mode of a data vector.
- How to calculate the cumulative probability of some event following a normal distribution. What if the distribution is Poisson?
- How to calculate the inter-quartile range of a series of data points.
- How to generate a few random numbers following a Student's t-distribution.
The R programming environment can do all of these.
On the other hand, Python's scripting ability allows analysts to use those statistics in a wide variety of analytics pipelines with limitless sophistication and creativity.
To combine the advantages of both worlds, you just need a simple Python-based wrapper library that contains the most commonly used functions pertaining to probability distributions and descriptive statistics defined in R-style. This enables you to call those functions really fast without having to go to the proper Python statistical libraries and figure out the whole list of methods and arguments.
## Python wrapper script for most convenient R-functions
[I wrote a Python script](https://github.com/tirthajyoti/StatsUsingPython/blob/master/R_Functions.py) to define the most convenient and widely used R-functions in simple, statistical analysis—in Python. After importing this script, you will be able to use those R-functions naturally, just like in an R programming environment.
The goal of this script is to *provide simple Python subroutines mimicking R-style statistical functions for quickly calculating density/point estimates, cumulative distributions, and quantiles and generating random variates for important probability distributions.*
To maintain the spirit of R styling, the script uses no class hierarchy and only raw functions are defined in the file. Therefore, a user can import this one Python script and use all the functions whenever they're needed with a single name call.
Note that I use the word *mimic*. Under no circumstance am I claiming to emulate R's true functional programming paradigm, which consists of a deep environmental setup and complex relationships between those environments and objects. This script allows me (and I hope countless other Python users) to quickly fire up a Python program or Jupyter notebook, import the script, and start doing simple descriptive statistics in no time. That's the goal, nothing more, nothing less.
If you've coded in R (maybe in grad school) and are just starting to learn and use Python for data analysis, you will be happy to see and use some of the same well-known functions in your Jupyter notebook in a manner similar to how you use them in your R environment.
Whatever your reason, using this script is fun.
## Simple examples
To start, just import the script and start working with lists of numbers as if they were data vectors in R.
```
from R_functions import *
lst=[20,12,16,32,27,65,44,45,22,18]
<more code, more statistics...>
```
Say you want to calculate the [Tuckey five-number](https://en.wikipedia.org/wiki/Five-number_summary) summary from a vector of data points. You just call one simple function, **fivenum**, and pass on the vector. It will return the five-number summary in a NumPy array.
```
lst=[20,12,16,32,27,65,44,45,22,18]
fivenum(lst)
> array([12. , 18.5, 24.5, 41. , 65. ])
```
Maybe you want to know the answer to the following question:
*Suppose a machine outputs 10 finished goods per hour on average with a standard deviation of 2. The output pattern follows a near normal distribution. What is the probability that the machine will output at least 7 but no more than 12 units in the next hour?*
The answer is essentially this:
You can obtain the answer with just one line of code using **pnorm**:
```
pnorm(12,10,2)-pnorm(7,10,2)
> 0.7745375447996848
```
Or maybe you need to answer the following:
*Suppose you have a loaded coin with the probability of turning heads up 60% every time you toss it. You are playing a game of 10 tosses. How do you plot and map out the chances of all the possible number of wins (from 0 to 10) with this coin?*
You can obtain a nice bar chart with just a few lines of code using just one function, **dbinom**:
```
probs=[]
import matplotlib.pyplot as plt
for i in range(11):
probs.append(dbinom(i,10,0.6))
plt.bar(range(11),height=probs)
plt.grid(True)
plt.show()
```
## Simple interface for probability calculations
R offers an extremely simple and intuitive interface for quick calculations from essential probability distributions. The interface goes like this:
{distribution} gives the density function value at a point*d**x*{distribution} gives the cumulative value at a point*p**x*{distribution} gives the quantile function value at a probability*q**p*{distribution} generates one or multiple random variates*r*
In our implementation, we stick to this interface and its associated argument list so you can execute these functions exactly like you would in an R environment.
## Currently implemented functions
The following R-style functions are implemented in the script for fast calling.
- Mean, median, variance, standard deviation
- Tuckey five-number summary, IQR
- Covariance of a matrix or between two vectors
- Density, cumulative probability, quantile function, and random variate generation for the following distributions: normal, uniform, binomial, Poisson, F, Student's t, Chi-square, beta, and gamma.
## Work in progress
Obviously, this is a work in progress, and I plan to add some other convenient R-functions to this script. For example, in R, a single line of command **lm** can get you an ordinary least-square fitted model to a numerical dataset with all the necessary inferential statistics (P-values, standard error, etc.). This is powerfully brief and compact! On the other hand, standard linear regression problems in Python are often tackled using [Scikit-learn](http://scikit-learn.org/stable/), which needs a bit more scripting for this use, so I plan to incorporate this single function linear model fitting feature using Python's [statsmodels](https://www.statsmodels.org/stable/index.html) backend.
If you like and use this script in your work, please help others find it by starring or forking its [GitHub repository](https://github.com/tirthajyoti/StatsUsingPython). Also, you can check my other [GitHub repos](https://github.com/tirthajyoti?tab=repositories) for fun code snippets in Python, R, or MATLAB and some machine learning resources.
If you have any questions or ideas to share, please contact me at [tirthajyoti[AT]gmail.com](mailto:[email protected]). If you are, like me, passionate about machine learning and data science, please [add me on LinkedIn](https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/) or [follow me on Twitter. ](https://twitter.com/tirthajyotiS)
*Originally published on Towards Data Science. Reposted under CC BY-SA 4.0.*
## 2 Comments |
10,316 | 5 个保护你隐私的 Firefox 扩展 | https://opensource.com/article/18/7/firefox-extensions-protect-privacy | 2018-12-06T11:23:20 | [
"浏览器",
"隐私"
] | https://linux.cn/article-10316-1.html |
>
> 用这些关注隐私的工具使你的浏览器免于泄露数据。
>
>
>

在<ruby> 剑桥分析公司 <rt> Cambridge Analytica </rt></ruby>这件事后,我仔细研究了我让 Facebook 渗透到我的网络生活的程度。由于我一般担心单点故障,我不是一个使用社交登录的人。我使用密码管理器为每个站点创建唯一的登录(你也应该这样做)。
我最担心的 Facebook 对我的数字生活的普遍侵扰。在深入了解剑桥分析公司这件事后,我几乎立即卸载了 Facebook 的移动程序。我还从 Facebook [断开了对所有应用、游戏和网站的连接](https://www.facebook.com/help/211829542181913)。是的,这将改变你在 Facebook 上的体验,但它也将保护您的隐私。作为一名有遍布全球朋友的人,保持 Facebook 的社交连接对我来说非常重要。
我还仔细审查了其他服务。我检查了 Google、Twitter、GitHub 以及任何未使用的连接应用。但我知道这还不够。我需要我的浏览器主动防止侵犯我隐私的行为。我开始研究如何做到最好。当然,我可以锁定浏览器,但是我需要使我用的网站和工具正常使用,同时试图防止它们泄露数据。
以下是五种可在使用浏览器时保护你隐私的工具。前三个扩展可用于 Firefox 和 Chrome,而后两个仅适用于 Firefox。
### Privacy Badger
我已经使用 [Privacy Badger](https://www.eff.org/privacybadger) 有一段时间了。其他内容或广告拦截器做得更好吗?也许。很多内容拦截器的问题在于它们的“付费显示”。这意味着他们有收费的“合作伙伴”白名单。这就站在了为什么存在内容拦截器这件事的对立面。Privacy Badger 是由电子前沿基金会 (EFF) 制作的,这是一家以捐赠为基础的商业模式的非营利实体。Privacy Badger 承诺从你的浏览习惯中学习,并且很少需要调整。例如,我只需将一些网站列入白名单。Privacy Badger 允许精确控制在哪些站点上启用哪些跟踪器。这是我无论在哪个浏览器必须安装的头号扩展。
### DuckDuckGo Privacy Essentials
搜索引擎 DuckDuckGo 通常有隐私意识。[DuckDuckGo Privacy Essentials](https://duckduckgo.com/app) 适用于主流的移动设备和浏览器。它的独特之处在于它根据你提供的设置对网站进行评分。例如,即使启用了隐私保护,Facebook 也会获得 D。同时,[chrisshort.net](https://chrisshort.net) 在启用隐私保护时获得 B 和禁用时获得 C。如果你因任何原因不喜欢 EFF 或 Privacy Badger,我会推荐 DuckDuckGo Privacy Essentials(选择一个,而不是两个,因为它们基本上做同样的事情)。
### HTTPS Everywhere
[HTTPS Everywhere](https://www.eff.org/https-everywhere) 是 EFF 的另一个扩展。根据 HTTPS Everywhere 的说法,“网络上的许多网站都通过 HTTPS 提供一些有限的加密支持,但使它难以使用。例如,它们可能默认为未加密的 HTTP 或在加密的页面里面使用返回到未加密站点的链接。HTTPS Everywhere 扩展通过使用聪明的技术将对这些站点的请求重写为 HTTPS 来解决这些问题。“虽然许多网站和浏览器在实施 HTTPS 方面越来越好,但仍有很多网站仍需要帮助。HTTPS Everywhere 将尽力确保你的流量已加密。
### NoScript Security Suite
[NoScript Security Suite](https://noscript.net/) 不适合胆小的人。虽然这个 Firefox 独有扩展“允许 JavaScript、Java、Flash 和其他插件只能由你选择的受信任网站执行”,但它并不能很好地确定你的选择。但是,毫无疑问,防止泄漏数据的可靠方法是不执行可能会泄露数据的代码。NoScript 通过其“基于白名单的抢占式脚本阻止”实现了这一点。这意味着你需要为尚未加入白名单的网站构建白名单。请注意,NoScript 仅适用于 Firefox。
### Facebook Container
[Facebook Container](https://addons.mozilla.org/en-US/firefox/addon/facebook-container/) 使 Firefox 成为我在使用 Facebook 时的唯一浏览器。 “Facebook Container 的工作原理是将你的 Facebook 身份隔离到一个单独的容器中,这使得 Facebook 更难以使用第三方 Cookie 跟踪你访问其他网站。” 这意味着 Facebook 无法窥探浏览器中其他地方发生的活动。 突然间,这些令人毛骨悚然的广告将停止频繁出现(假设你在移动设备上卸载了 Facebook 应用)。 在隔离的空间中使用 Facebook 将阻止任何额外的数据收集。 请记住,你已经提供了 Facebook 数据,而 Facebook Container 无法阻止这些数据被共享。
这些是我浏览器隐私的首选扩展。 你的是什么? 请在评论中分享。
---
via: <https://opensource.com/article/18/7/firefox-extensions-protect-privacy>
作者:[Chris Short](https://opensource.com/users/chrisshort) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the wake of the Cambridge Analytica story, I took a hard look at how far I had let Facebook penetrate my online presence. As I'm generally concerned about single points of failure (or compromise), I am not one to use social logins. I use a password manager and create unique logins for every site (and you should, too).
What I was most perturbed about was the pervasive intrusion Facebook was having on my digital life. I uninstalled the Facebook mobile app almost immediately after diving into the Cambridge Analytica story. I also [disconnected all apps, games, and websites](https://www.facebook.com/help/211829542181913) from Facebook. Yes, this will change your experience on Facebook, but it will also protect your privacy. As a veteran with friends spread out across the globe, maintaining the social connectivity of Facebook is important to me.
I went about the task of scrutinizing other services as well. I checked Google, Twitter, GitHub, and more for any unused connected applications. But I know that's not enough. I need my browser to be proactive in preventing behavior that violates my privacy. I began the task of figuring out how best to do that. Sure, I can lock down a browser, but I need to make the sites and tools I use work while trying to keep them from leaking data.
Following are five tools that will protect your privacy while using your browser. The first three extensions are available for Firefox and Chrome, while the latter two are only available for Firefox.
## Privacy Badger
[Privacy Badger](https://www.eff.org/privacybadger) has been my go-to extension for quite some time. Do other content or ad blockers do a better job? Maybe. The problem with a lot of content blockers is that they are "pay for play." Meaning they have "partners" that get whitelisted for a fee. That is the antithesis of why content blockers exist. Privacy Badger is made by the Electronic Frontier Foundation (EFF), a nonprofit entity with a donation-based business model. Privacy Badger promises to learn from your browsing habits and requires minimal tuning. For example, I have only had to whitelist a handful of sites. Privacy Badger also allows granular controls of exactly which trackers are enabled on what sites. It's my #1, must-install extension, no matter the browser.
## DuckDuckGo Privacy Essentials
The search engine DuckDuckGo has typically been privacy-conscious. [DuckDuckGo Privacy Essentials](https://duckduckgo.com/app) works across major mobile devices and browsers. It's unique in the sense that it grades sites based on the settings you give them. For example, Facebook gets a D, even with Privacy Protection enabled. Meanwhile, [chrisshort.net](https://chrisshort.net) gets a B with Privacy Protection enabled and a C with it disabled. If you're not keen on EFF or Privacy Badger for whatever reason, I would recommend DuckDuckGo Privacy Essentials (choose one, not both, as they essentially do the same thing).
## HTTPS Everywhere
[HTTPS Everywhere](https://www.eff.org/https-everywhere) is another extension from the EFF. According to HTTPS Everywhere, "Many sites on the web offer some limited support for encryption over HTTPS, but make it difficult to use. For instance, they may default to unencrypted HTTP or fill encrypted pages with links that go back to the unencrypted site. The HTTPS Everywhere extension fixes these problems by using clever technology to rewrite requests to these sites to HTTPS." While a lot of sites and browsers are getting better about implementing HTTPS, there are a lot of sites that still need help. HTTPS Everywhere will try its best to make sure your traffic is encrypted.
## NoScript Security Suite
[NoScript Security Suite](https://noscript.net/) is not for the faint of heart. While the Firefox-only extension "allows JavaScript, Java, Flash, and other plugins to be executed only by trusted websites of your choice," it doesn't do a great job at figuring out what your choices are. But, make no mistake, a surefire way to prevent leaking data is not executing code that could leak it. NoScript enables that via its "whitelist-based preemptive script blocking." This means you will need to build the whitelist as you go for sites not already on it. Note that NoScript is only available for Firefox.
## Facebook Container
[Facebook Container](https://addons.mozilla.org/en-US/firefox/addon/facebook-container/) makes Firefox the only browser where I will use Facebook. "Facebook Container works by isolating your Facebook identity into a separate container that makes it harder for Facebook to track your visits to other websites with third-party cookies." This means Facebook cannot snoop on activity happening elsewhere in your browser. Suddenly those creepy ads will stop appearing so frequently (assuming you uninstalled the Facebook app from your mobile devices). Using Facebook in an isolated space will prevent any additional collection of data. Remember, you've given Facebook data already, and Facebook Container can't prevent that data from being shared.
These are my go-to extensions for browser privacy. What are yours? Please share them in the comments.
## 6 Comments |
10,317 | 使用 GNOME Web “安装”独立 Web 应用 | https://fedoramagazine.org/standalone-web-applications-gnome-web/ | 2018-12-06T14:43:09 | [
"SPA",
"浏览器"
] | https://linux.cn/article-10317-1.html | 
你是否经常使用单页 Web 应用(SPA),但失去了一些完整桌面应用的好处? GNOME Web 浏览器,简称为 Web(又名 Epiphany)有一个非常棒的功能,它允许你“安装” 一个 Web 应用。安装完成后,Web 应用将显示在应用菜单、GNOME shell 搜索中,并且它在切换窗口时是一个单独的项目。这个简短的教程将引导你完成使用 GNOME Web “安装” Web 应用的步骤。
### 安装 GNOME Web
GNOME Web 未包含在默认的 Fedora 安装中。要安装它,请在软件中心搜索 “web”,然后安装。

或者,在终端中使用以下命令:
```
sudo dnf install epiphany
```
### 安装为 Web 应用
接下来,启动 GNOME Web,然后去浏览要安装的 Web 应用。使用浏览器连接到应用,然后从菜单中选择“将站点安装为 Web 应用”:

GNOME Web 接下来会出现一个用于编辑应用名称的对话框。将其保留为默认值 (URL) 或更改为更具描述性的内容:

最后,按下“创建”以 “安装” 你的新 Web 应用。创建 Web 应用后,关闭 GNOME Web。
### 使用新的 Web 应用
像使用任何典型的桌面应用一样启动 Web 应用。在 GNOME Shell Overview 中搜索它:

此外,Web 应用将在 `alt-tab` 应用切换器中显示为单独的应用:

另一个额外的功能是来自“已安装”的 Web 应用的所有 Web 通知都显示为常规 GNOME 通知。
---
via: <https://fedoramagazine.org/standalone-web-applications-gnome-web/>
作者:[Ryan Lerch](https://fedoramagazine.org/introducing-flatpak/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Do you regularly use a single-page web application, but miss some of the benefits of a full-fledged desktop application? The GNOME Web browser, simply named Web (aka Epiphany) has an awesome feature that allows you to ‘install’ a web application. By doing this, the web application is then presented in the applications menus, GNOME shell search, and is a separate item when switching windows. This short tutorial walks you through the steps of ‘installing’ a web application with GNOME Web.
### Install GNOME Web
GNOME Web is not included in the default Fedora install. To install, search in the Software application for ‘web’, and install.
Alternatively, use the following command in the terminal:
sudo dnf install epiphany
### Install as Web Application
Next, launch GNOME Web, and browse to the web application you wish to install. Connect to the application using the browser, and choose ‘Install site as Web Application’ from the menu:
GNOME Web next presents a dialog to edit the name of the application. Either leave it as the default (the URL) or change to something more descriptive:
Finally, press **Create **to ‘install’ your new web application. After creating the web application, close GNOME Web.
### Using the new web application
Launch the web application as you would with any typical desktop application. Search for it in the GNOME Shell Overview:
Additionally, the web application will appear as a separate application in the alt-tab application switcher:
One additional feature this adds is that all web notifications from the ‘installed’ web application are presented as regular GNOME notifications.
## Dragos
The standalone web applications run in isolated containers or share the cookies and stored site data with the browser?
## Michael Catanzaro
Well it’s not a Linux container, but cookies and website data are completely isolated, yes.
## Daniel
You get a copy of the origin’s cookies and data when you create the app, but from that point forward they’re separate.
## Drew
When I was logged into something in Web before making a Web Application, the login information did not carry over. Unfortunately the Login button leads to another page which doesn’t transfer back to the Web Application.
So for sites that require a log-in, Web can’t do it. Unless I am missing something here (see my other comment for details).
## Michael Catanzaro
There’s a preferences dialog to add extra hosts. It’s undiscoverable and there is a bug complaining that it doesn’t work, but it exists and you can try it. Just whitelist the hostname of the login page there.
## Michael Catanzaro
This used to be right until a couple years ago. We discovered that copying cookies into the web app was impossible to do safely, so stopped doing so. Problem was that we copied cookies from some Google domain (I think it was plus.google.com), which caused the website to break because it was expecting cookies from some different domain to be set as well: having just the cookies from the web app domain without the cookies from the other domain caused the website to break. There’s no way to make it safe, so nowadays no more copying.
## Steven
That’s good ti know, thanks
## Marcus
This is one of my favorite things about epiphany. I have also extended this to allow links to open up specific epiphany web apps. I wrote up a blog about it here:
https://blog.line72.net/2018/05/07/supporting-deep-links-in-linux-with-gnome-and-epiphany-web-apps/
## Daniel
Okay, that’s cool. Too bad you can’t manage something like this from within Epiphany itself. The about:applications manager could possibly be expanded to map URLs like this.
## Michael Catanzaro
There is an issue to add this feature upstream: https://gitlab.gnome.org/GNOME/epiphany/issues/277
Would be cool and shouldn’t be difficult, but it’d have to be done in C rather than bash. 😉
## Ondrej
I Cant see the option in gnome-apps-nightly Epiphany flatpak. Is it removed/reworked?
## Michael Catanzaro
It’s not supported under flatpak. And it’s not clear how this could ever work, since we don’t have access to the home directory to install desktop files there.
## urandom
AFAIK you can put desktop files to /var/lib/flatpak/exports/share or ~/.local/share/flatpak/exports/share, which are probably added to $XDG_DATA_DIRS by flatpak.
## Drew
That helps “fill in the blanks” with some applications you really need but there’s no Linux version of it and there is a web version.
Chrome kept trying to put saved shortcuts all over the place, but Web is a lot lighter so it comes up quicker. A better choice for stand-alone applications.
## Nick A
So Progressive Web Apps then? I know chrome has been pushing this new format, and I adore PWAs so much so I can’t not make all my web experiments that way, but I wonder how much modern web standards gnome web supports, I’ll have to look into it
## Michael Catanzaro
Nope, not at all, sorry. There’s zero support for app manifest. And service workers are supported only in development builds of WebKit, not releases. For PWA to happen would require a volunteer to push things forward.
## Drew
I just installed Web and was making a Web App for Google Hangouts. So I opened Web, navigated to the site and logged into my Google account. Then I made it into a Web Application.
When I opened the Web Application, I was not logged in. I guess this means information between Web and Web Applications are not shared.
I tried to log in, but the button opens up a new window for me to log in. When I made Web my default and clicked Log In button in the Web Application, it opened me up to Google Hangouts in Web … already logged in.
So the good news is that Web Applications are isolated from the Web’s stored data.
The bad news is, I don’t know how to set up Web to open Hangouts with me logged in.
Otherwise I like Web; it’s fast to load and if I can get the Web Applications working, will make life easier.
## hyakosm
To remove an installed webapp, it’s in “about:applications”. There is no link to this page in Gnome Web, why ?
## Michael Catanzaro
Nobody ever added a way to get there. See https://gitlab.gnome.org/GNOME/epiphany/issues/439
## Michael Tunnell
@Michael Catanzaro – they have known about this issue for at least 3 years now as that was when I submitted it to their bugzilla.
## Damon
I am interested will it work offline? For example if i create web application for google keep and edit notes offline will it synchronize next time when i connect to internet?
## Daniel
That is entirely up to the web app to handle (using WebWorkers and local storage). There is no difference between using Epiphany regularly and in webapp mode when it comes to these things.
## Channah Trimble
The epiphany browser has been getting a lot of improvements. Its performance seems comparable to safari and is amazingly lightweight. Extensions are still an issue but I cannot wait to see where epiphany goes
## Dr. Chuck
Thanks for the article. Is there anyway to have the web application run in the background, while still providing notifications? This would be particularly useful for a messaging website.
## Ranjandas
Looks like Epiphany (Web) does not support Proxy PACs. I am not able to browse anything when PAC is configured in GNOME NetworkManager settings.
## Andrew
Firefox’s Test Pilot program has a add-on “Side View” that opens web sites in a panel on the left side of the browser window. It’s another way of opening pages like chat sessions or notepads that don’t need a whole browser tab.
## henryf16
I usually like ICE for this (Peppermint OS guys, their Site Specific Browser solution). Very simple to use but not sure how it compares – speedwise – vs Web/Epiphany. Time to do a little testing…
Related: avoid electron apps because of all the fat so ICE was a great find for me.
## Torsten
Been trying to use it for https://outlook.office.com – but the login opens in a new browser window, and it seems that the app never registers that the login was successful.
Is there an option to make it work with the SSO from Microsoft?
## Michael Tunnell
I like Epiphany’s webapp system overall but there are still glaring problems they need to address.
You can’t remove CSDs so they are wasting a ton of space for no reason in a webapp.
I reported this bug to GNOME/Epiphany devs over 3 years ago . . . nothing.
It is way too hard to find the webapp manager for removal, you have to know the url address rather than built into the GUI.
I also reported this bug over 3 years ago . . .
## Alex
Some websites are added with a small icon, or no icon at all, sometimes.
I can’t find how to remove these apps. It’s a promising feature, but still lacks improvements in UX. I will check more of it out in my spare time and see if I can contribute somehow!
## Michael Tunnell
@Alex to manage the webapps in Epiphany, type in “about:applications” (without quotes) into your URL bar and that will take you to the webapp manager. Yes, this is bad that you have to know this to edit them.
I wrote an article on this topic, Webapps in Epiphany, for MakeUseOf a couple years ago and it is still fairly accurate so if you want to check that out. https://www.makeuseof.com/tag/epiphany-web-apps-integrate-web-desktop/
## Mik
There is a Gnome extension that puts a handy, drop down, menu – for all the installed webapps, – on the Gnome’s Top Bar but it’s awfully outdated.
I’ve tinkered, a bit, with its source code and managed to make it work from Fedora 27 all the way to the Fedora 29 release. Unfortunately, it stopped working the moment I’ve upgraded to Fedora 30 Beta Release.
## Leslie
Chrome does this kind of functionality for SPA’s already though
## Michael Tunnell
@Leslie Chrome doesn’t actually do this function. They make it seem like they do but it is different. In Chrome all of the webapp windows share the same session with the main Chrome instance so you can’t have multiple webapps of the same site. Epiphany has separate sessions per webapp making it much more useful in that sense because you can make as many as you want without session overlap.
## vancha
I tried using this with a chat application, but it keeps trying to sign in on another page, which then directs me to a new window, where i am already logged in. 🙁 |
10,318 | 混合软件开发角色效果更佳 | https://opensource.com/article/18/8/mixing-roles-engineering | 2018-12-06T15:26:35 | [
"开发"
] | https://linux.cn/article-10318-1.html |
>
> 为什么在工程中混合角色对用户更好的三个原因。
>
>
>

大多数开源社区没有很多正式的角色。当然,也有一些固定人员帮助处理系统管理员任务、测试、编写文档以及翻译或开发代码。但开源社区的人员通常在不同的角色之间流动,往往同时履行几个角色的职责。
相反,大多数传统公司的团队成员都定义了角色,例如,负责文档、技术支持、质量检验和其他领域。
为什么开源社区采取共享角色的方法,更重要的是,这种协作方式如何影响产品和客户?
[Nextcloud](https://nextcloud.com/) 采用了这种社区式的混合角色的做法,我们看到了我们的客户和用户受益颇多。
### 1、更好的产品测试
每个测试人员都会说测试是一项困难的工作。你需要了解工程师开发的产品,并且需要设计测试案例、执行测试案例并将结果返回给开发人员。完成该过程后,开发人员将进行更改,然后重复该过程,根据需要来回进行多次,直到任务完成。
在社区中,贡献者通常会对他们开发的项目负责,因此他们会对这些项目进行广泛的测试和记录,然后再将其交给用户。贴近项目的用户通常会与开发人员协作,帮助测试、翻译和编写文档。这将创建一个更紧密、更快的反馈循环,从而加快开发速度并提高质量。
当开发人员不断面对他们的工作结果时,会鼓励他们以最大限度地减少测试和调试的方式去书写。自动化测试是开发中的一个重要元素,反馈循环可以确保正确地完成操作:开发人员主观能动的来实现自动化 —— 而不过于简化也不过于复杂。当然,他们可能希望别人做更多的测试或自动化的测试,但当测试是正确的选择时,他们就会这样做。此外,他们还审查对方的代码,因为他们知道问题往往会在以后让他们付出代价。
因此,虽然我不认为放弃专用测试人员更好,但在没有社区志愿者进行测试的项目中,测试人员应该是开发人员,并密切嵌入到开发团队中。结果如何?客户得到的产品是由 100% 有动机的人测试和开发的,以确保它是稳定和可靠的。
### 2、开发和客户需求之间的密切协作
要使产品开发与客户需求保持一致是非常困难的。每个客户都有自己独特的需求,有长期和短期的因素需要考虑 —— 当然,作为一家公司,你对你的发展方向有想法。你如何整合所有这些想法和愿景?
公司通常会创建与工程和产品开发分开的角色,如产品管理、支持、质量检测等。这背后的想法是,人们在专攻的时候做得最好,工程师不应该为测试或支持等 “简单” 的任务而烦恼。
实际上,这种角色分离是一项削减成本的措施。它使管理层能够进行微观管理,并更能掌握全局,因为他们可以简单地进行产品管理,例如,确定路线图项目的优先次序。(它还创建了更多的会议!)
另一方面,在社区,“决定权在工作者手上”。开发人员通常也是用户(或由用户支付报酬),因此他们自然地与用户的需求保持一致。当用户帮助进行测试时(如上所述),开发人员会不断地与他们合作,因此双方都完全了解什么是可行的,什么是需要的。
这种开放的合作方式使用户和项目紧密协作。在没有管理层干涉和指手画脚的情况下,用户最迫切的需求可以迅速得到满足,因为工程师已经非常了解这些需求。
在 nextcloud 中,客户永远不需要解释两次,也不需要依靠初级支持团队成员将问题准确地传达给工程师。我们的工程师根据客户的实际需求不断调整他们的优先级。同时,基于对客户的深入了解,合作制定长期目标。
### 3、最佳支持
与专有的或 <ruby> <a href="https://en.wikipedia.org/wiki/Open_core"> 开放源核心 </a> <rt> open core </rt></ruby>的供应商不同,开源供应商有强大的动力提供尽可能最好的支持:这是与其他公司在其生态系统中的关键区别。
为什么项目背后的推动者(比如 [Collabora](https://www.collaboraoffice.com/) 在 [LibreOffice](https://www.libreoffice.org/) 背后,[The Qt Company](https://www.qt.io/) 在 [Qt](https://www.qt.io/developers/) 背后,或者 [Red Hat](https://www.redhat.com/en) 在 [RHEL](https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux) 背后)是客户支持的最佳来源呢?
当然是直接接触工程师。这些公司并不阻断来自工程团队的支持,而是为客户提供了获得工程师专业知识的机会。这有助于确保客户始终尽快获得最佳答案。虽然一些工程师可能比其他人在支持上花费更多的时间,但整个工程团队在客户成功方面发挥着作用。专有供应商可能会为客户提供一个专门的现场工程师,费用相当高,但一个开源公司,如 [OpenNMS](https://www.opennms.org/en) 可以在您的支持合同中提供相同级别的服务,即使您不是财富 500 强客户也是如此。
还有一个好处,那就是与测试和客户协作有关:共享角色可确保工程师每天处理客户问题和愿望,从而促使他们快速解决最常见的问题。他们还倾向于构建额外的工具和功能,以满足客户预期。
简单地说,将质量检测、支持、产品管理和其他工程角色合并为一个团队,可确保优秀开发人员的三大优点 —— <ruby> <a href="http://threevirtues.com/"> 从简、精益求精、高度自我要求 </a> <rt> laziness,impatience,and hubris </rt></ruby> —— 与客户紧密保持一致。
---
via: <https://opensource.com/article/18/8/mixing-roles-engineering>
作者:[Jos Poortvliet](https://opensource.com/users/jospoortvliet) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lixinyuxx](https://github.com/lixinyuxx) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Most open source communities don’t have a lot of formal roles. There are certainly people who help with sysadmin tasks, testing, writing documentation, and translating or developing code. But people in open source communities typically move among different roles, often fulfilling several at once.
In contrast, team members at most traditional companies have defined roles, working on documentation, support, QA, and in other areas.
Why do open source communities take a shared-role approach, and more importantly, how does this way of collaborating affect products and customers?
[Nextcloud](https://nextcloud.com/) has adopted this community-style practice of mixing roles, and we see large benefits for our customers and our users.
## 1. Better product testing
Testing is a difficult job, as any tester can tell you. You need to understand the products engineers develop, and you need to devise test plans, execute them, and return the results to the developers. When that process is done, the developer makes changes, and you repeat the process, going back-and-forth as many times as necessary until the job is done.
In a community, contributors typically feel responsible for the projects they develop, so they test and document them extensively before handing them to users. Users close to the project often help test, translate, and write documentation in collaboration with developers. This creates a much tighter, faster feedback loop, speeding up development and improving quality.
When developers continuously confront the results of their work, it encourages them to write in a way that minimizes testing and debugging. Automated testing is an important element in development, and the feedback loop ensures that it is done right: Developers are organically motivated to automate what should be automated—no more and no less. Sure, they might *want* others to do more testing or test automation, but when testing is the right thing to do, they do it. Moreover, they review each others' code because they know that issues tend to come back bite them later.
So, while I won't argue that it's better to forgo dedicated testers, certainly in a project without community volunteers who test, testers should be developers and closely embedded in the development team. The result? Customers get a product that was tested and developed by people who are 100% motivated to ensure that it is stable and reliable.
## 2. Close alignment between development and customer needs
It is extraordinarily difficult to align product development with customer needs. Every customer has their own unique needs, there are long- and short-term factors to consider—and of course, as a company, you have ideas on where you want to go. How do you integrate all these ideas and visions?
Companies typically create roles like product management, support, QA, and others, which are separate from engineering and product development. The idea behind this is that people do best when they specialize, and engineers shouldn't be bothered with "simple" tasks like testing or support.
In effect, this role separation is a cost-cutting measure. It enables management to micromanage and feel more in control as they can simply order product management, for example, to prioritize items on the roadmap. (It also creates more meetings!)
In communities, on the other hand, "those who do the work decide." Developers are often also users (or are paid by users), so they align with users’ needs naturally. When users help with testing (as described above), developers work with them constantly, so both sides fully understand what is possible and what is needed.
This open way of working closely aligns users and projects. Without management interference and overhead, users' most pressing needs can be quickly met because engineers already intimately understand them.
At Nextcloud, customers never need to explain things twice or rely on a junior support team member to accurately communicate issues to an engineer. Our engineers continuously calibrate their priorities based on real customer needs. Meanwhile, long-term goals are set collaboratively, based on a deep knowledge of our customers.
## 3. The best support
Unlike proprietary or [open core](https://en.wikipedia.org/wiki/Open_core) vendors, open source vendors have a powerful incentive to offer the best possible support: It is a key differentiator from other companies in their ecosystem.
Why is the driving force behind a project—think [Collabora](https://www.collaboraoffice.com/) behind [LibreOffice](https://www.libreoffice.org/), [The Qt Company](https://www.qt.io/) behind [Qt](https://www.qt.io/developers/), or [Red Hat](https://www.redhat.com/en) behind [RHEL](https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux)—the best source of customer support?
Direct access to engineers, of course. Rather than walling off support from engineering, many of these companies offer customers access to engineers' expertise. This helps ensure that customers always get the best answers as quickly as possible. While some engineers may spend more time than others on support, the entire engineering team plays a role in customer success. Proprietary vendors might provide customers a dedicated on-site engineer for a considerable cost, for example, but an open source company like [OpenNMS](https://www.opennms.org/en) offers that same level of service in your support contract—even if you’re not a Fortune 500 customer.
There's another benefit, which relates back to testing and customer alignment: Sharing roles ensures that engineers deal with customer issues and wishes daily, which motivates them to fix the most common problems quickly. They also tend to build extra tools and features to save customers from asking.
Put simply, folding QA, support, product management, and other engineering roles into one team ensures that the three famous virtues of great developers—[laziness, impatience, and hubris](http://threevirtues.com/)—closely align with customers.
## Comments are closed. |
10,319 | Git 前时代:使用 CVS 进行版本控制 | https://twobithistory.org/2018/07/07/cvs.html | 2018-12-06T18:50:00 | [
"Git",
"CVS"
] | https://linux.cn/article-10319-1.html | 
GitHub 网站发布于 2008 年。如果你的软件工程师职业生涯跟我一样,也是晚于此时间的话,Git 可能是你用过的唯一版本控制软件。虽然其陡峭的学习曲线和不直观地用户界面时常会遭人抱怨,但不可否认的是,Git 已经成为学习版本控制的每个人的选择。Stack Overflow 2015 年进行的开发者调查显示,69.3% 的被调查者在使用 Git,几乎是排名第二的 Subversion 版本控制系统使用者数量的两倍。<sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup> 2015 年之后,也许是因为 Git 太受欢迎了,大家对此话题不再感兴趣,所以 Stack Overflow 停止了关于开发人员使用的版本控制系统的问卷调查。
GitHub 的发布时间距离 Git 自身发布时间很近。2005 年,Linus Torvalds 发布了 Git 的首个版本。现在的年经一代开发者可能很难想象“版本控制软件”一词所代表的世界并不仅仅只有 Git,虽然这样的世界诞生的时间并不长。除了 Git 外,还有很多可供选择。那时,开源开发者较喜欢 Subversion,企业和视频游戏公司使用 Perforce (到如今有些仍在用),而 Linux 内核项目依赖于名为 BitKeeper 的版本控制系统。
其中一些系统,特别是 BitKeeper,会让年经一代的 Git 用户感觉很熟悉,上手也很快,但大多数相差很大。除了 BitKeeper,Git 之前的版本控制系统都是以不同的架构模型为基础运行的。《[Version Control By Example](https://ericsink.com/vcbe/index.html)》一书的作者 Eric Sink 在他的书中对版本控制进行了分类,按其说法,Git 属于第三代版本控制系统,而大多数 Git 的前身,即流行于二十世纪九零年代和二十一世纪早期的系统,都属于第二代版本控制系统。<sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup> 第三代版本控制系统是分布式的,第二代是集中式。你们以前大概都听过 Git 被描述为一款“分布式”版本控制系统。我一直都不明白分布式/集中式之间的区别,随后自己亲自安装了一款第二代的集中式版本控件系统,并做了相关实验,至少明白了一些。
我安装的版本系统是 CVS。CVS,即 “<ruby> 并发版本系统 <rt> Concurrent Versions System </rt></ruby>” 的缩写,是最初的第二代版本控制系统。大约十年间,它是最为流行的版本控制系统,直到 2000 年被 Subversion 所取代。即便如此,Subversion 被认为是 “更好的 CVS”,这更进一步突出了 CVS 在二十世纪九零年代的主导地位。
CVS 最早是由一位名叫 Dick Grune 的荷兰科学家在 1986 年开发的,当时有一个编译器项目,他正在寻找一种能与其学生合作的方法。<sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup> CVS 最初仅仅只是一个包装了 RCS(<ruby> 修订控制系统 <rt> Revision Control System </rt></ruby>) 的 Shell 脚本集合,Grune 想改进这个第一代的版本控制系统。 RCS 是按悲观锁模式工作的,这意味着两个程序员不可以同时处理同一个文件。需要编辑一个文件话,首先得向 RCS 系统请求一个排它锁,锁定此文件直到完成编辑,如果你想编辑的文件有人正在编辑,你就必须等待。CVS 在 RCS 基础上改进,并把悲观锁模型替换成乐观锁模型,迎来了第二代版本控制系统的时代。现在,程序员可以同时编辑同一个文件、合并编辑部分,随后解决合并冲突问题。(后来接管 CVS 项目的工程师 Brian Berliner 于 1990 年撰写了一篇非常易读的关于 CVS 创新的 [论文](https://docs.freebsd.org/44doc/psd/28.cvs/paper.pdf)。)
从这个意义上来讲,CVS 与 Git 并无差异,因为 Git 也是运行于乐观锁模式的,但也仅仅只有此点相似。实际上,Linus Torvalds 开发 Git 时,他的一个指导原则是 WWCVSND,即 “<ruby> CVS 不能做的 <rt> What Would CVS Not Do </rt></ruby>”。每当他做决策时,他都会力争选择那些在 CVS 设计里没有使用的功能选项。<sup id="fnref4"> <a href="#fn4" rel="footnote"> 4 </a></sup> 所以即使 CVS 要早于 Git 十多年,但它对 Git 的影响是反面的。
我非常喜欢折腾 CVS。我认为要弄明白为什么 Git 的分布式特性是对以前的版本控制系统的极大改善的话,除了折腾 CVS 外,没有更好的办法。因此,我邀请你跟我一起来一段激动人心的旅程,并在接下来的十分钟内了解下这个近十年来无人使用的软件。(可以看看文末“修正”部分)
### CVS 入门
CVS 的安装教程可以在其 [项目主页](https://www.nongnu.org/cvs/) 上找到。MacOS 系统的话,可以使用 Homebrew 安装。
由于 CVS 是集中式的,所以它有客户端和服务端之区分,这种模式 Git 是没有的。两端分别有不同的可执行文件,其区别不太明显。但要开始使用 CVS 的话,即使只在你的本地机器上使用,也必须设置 CVS 的服务后端。
CVS 的后端,即所有代码的中央存储区,被叫做<ruby> 存储库 <rt> repository </rt></ruby>。在 Git 中每一个项目都有一个存储库,而 CVS 中一个存储库就包含所有的项目。尽管有办法保证一次只能访问一个项目,但一个中央存储库包含所有东西是改变不了的。
要在本地创建存储库的话,请运行 `init` 命令。你可以像如下所示在家目录创建,也可以在你本地的任何地方创建。
```
$ cvs -d ~/sandbox init
```
CVS 允许你将选项传递给 `cvs` 命令本身或 `init` 子命令。出现在 `cvs` 命令之后的选项默认是全局的,而出现在子命令之后的是子命令特有选项。上面所示例子中,`-d` 标志是全局选项。在这儿是告诉 CVS 我们想要创建存储库路径在哪里,但一般 `-d` 标志指的是我们想要使用的且已经存在的存储库位置。一直使用 `-d` 标志很单调乏味,所以可以设置 `CVSROOT` 环境变量来代替。
因为我们只是在本地操作,所以仅仅使用 `-d` 参考来传递路径就可以,但也可以包含个主机名。
此命令在你的家目录创建了一个名叫 `sandbox` 的目录。 如果你列出 `sandbox` 内容,会发现下面包含有名为 `CVSROOT` 的目录。请不要把此目录与我们的环境变量混淆,它保存存储库的管理文件。
恭喜! 你刚刚创建了第一个 CVS 存储库。
### 检入代码
假设你决定留存下自己喜欢的颜色清单。因为你是一个有艺术倾向但很健忘的人,所以你键入颜色列表清单,并保存到一个叫 `favorites.txt` 的文件中:
```
blue
orange
green
definitely not yellow
```
我们也假设你把文件保存到一个叫 `colors` 的目录中。现在你想要把喜欢的颜色列表清单置于版本控制之下,因为从现在起的五十年间你会回顾下,随着时间的推移自己的品味怎么变化,这件事很有意思。
为此,你必须将你的目录导入为新的 CVS 项目。可以使用 `import` 命令:
```
$ cvs -d ~/sandbox import -m "" colors colors initial
N colors/favorites.txt
No conflicts created by this import
```
这里我们再次使用 `-d` 标志来指定存储库的位置,其余的参数是传输给 `import` 子命令的。必须要提供一条消息,但这儿没必要,所以留空。下一个参数 `colors`,指定了存储库中新目录的名字,这儿给的名字跟检入的目录名称一致。最后的两个参数分别指定了 “vendor” 标签和 “release” 标签。我们稍后就会谈论标签。
我们刚将 `colors` 项目拉入 CVS 存储库。将代码引入 CVS 有很多种不同的方法,但这是 《[Pragmatic Version Control Using CVS](http://shop.oreilly.com/product/9780974514000.do)》 一书所推荐方法,这是一本关于 CVS 的程序员实用指导书籍。使用这种方法有点尴尬的就是你得重新<ruby> 检出 <rt> check out </rt></ruby>工作项目,即使已经存在有 `colors` 此项目了。不要使用该目录,首先删除它,然后从 CVS 中检出刚才的版本,如下示:
```
$ cvs -d ~/sandbox co colors
cvs checkout: Updating colors
U colors/favorites.txt
```
这个过程会创建一个新的目录,也叫做 `colors`。此目录里会发现你的源文件 `favorites.txt`,还有一个叫 `CVS` 的目录。这个 `CVS` 目录基本上与每个 Git 存储库的 `.git` 目录等价。
### 做出改动
准备旅行。
和 Git 一样,CVS 也有 `status` 命令:
```
$ cvs status
cvs status: Examining .
===================================================================
File: favorites.txt Status: Up-to-date
Working revision: 1.1.1.1 2018-07-06 19:27:54 -0400
Repository revision: 1.1.1.1 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
Commit Identifier: fD7GYxt035GNg8JA
Sticky Tag: (none)
Sticky Date: (none)
Sticky Options: (none)
```
到这儿事情开始陌生起来了。CVS 没有提交对象这一概念。如上示,有一个叫 “<ruby> 提交标识符 <rt> Commit Identifier </rt></ruby>” 的东西,但这可能是一个较新版本的标识,在 2003 年出版的《Pragmatic Version Control Using CVS》一书中并没有提到 “提交标识符” 这个概念。 (CVS 的最新版本于 2008 年发布的。<sup id="fnref5"> <a href="#fn5" rel="footnote"> 5 </a></sup> )
在 Git 中,我们所谈论某文件版本其实是在谈论如 `commit 45de392` 相关的东西,而 CVS 中文件是独立版本化的。文件的第一个版本为 1.1 版本,下一个是 1.2 版本,依此类推。涉及分支时,会在后面添加扩展数字。因此你会看到如上所示的 `1.1.1.1` 的内容,这就是示例的版本号,即使我们没有创建分支,似乎默认的会给加上。
一个项目中会有很多的文件和很多次的提交,如果你运行 `cvs log` 命令(等同于 `git log`),会看到每个文件提交历史信息。同一个项目中,有可能一个文件处于 1.2 版本,一个文件处于 1.14 版本。
继续,我们对 1.1 版本的 `favorites.txt` 文件做些修改(LCTT 译注:原文此处示例有误):
```
blue
orange
green
cyan
definitely not yellow
```
修改完成,就可以运行 `cvs diff` 来看看 CVS 发生了什么:
```
$ cvs diff
cvs diff: Diffing .
Index: favorites.txt
===================================================================
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
retrieving revision 1.1.1.1
diff -r1.1.1.1 favorites.txt
3a4
> cyan
```
CVS 识别出我们我在文件中添加了一个包含颜色 “cyan” 的新行。(实际上,它说我们已经对 “RCS” 文件进行了更改;你可以看到,CVS 底层使用的还是 RCS。) 此差异指的是当前工作目录中的 `favorites.txt` 副本与存储库中 1.1.1.1 版本的文件之间的差异。
为了更新存储库中的版本,我们必须提交更改。Git 中,这个操作要好几个步骤。首先,暂存此修改,使其在索引中出现,然后提交此修改,最后,为了使此修改让其他人可见,我们必须把此提交推送到源存储库中。
而 CVS 中,只需要运行 `cvs commit` 命令就搞定一切。CVS 会汇集它所找到的变化,然后把它们放到存储库中:
```
$ cvs commit -m "Add cyan to favorites."
cvs commit: Examining .
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
new revision: 1.2; previous revision: 1.1
```
我已经习惯了 Git,所以这种操作会让我感到十分恐惧。因为没有变更暂存区的机制,工作目录下任何你动过的东西都会一股脑给提交到公共存储库中。你有过因为不爽,私下里重写了某个同事不佳的函数实现,但仅仅只是自我宣泄一下并不想让他知道的时候吗?如果不小心提交上去了,就太糟糕了,他会认为你是个混蛋。在推送它们之前,你也不能对提交进行编辑,因为提交就是推送。还是你愿意花费 40 分钟的时间来反复运行 `git rebase -i` 命令,以使得本地提交历史记录跟数学证明一样清晰严谨?很遗憾,CVS 里不支持,结果就是,大家都会看到你没有先写测试用例。
不过,到现在我终于理解了为什么那么多人都觉得 Git 没必要搞那么复杂。对那些早已经习惯直接 `cvs commit` 的人来说,进行暂存变更和推送变更操作确实是毫无意义的差事。
人们常谈论 Git 是一个 “分布式” 系统,其中分布式与非分布式的主要区别为:在 CVS 中,无法进行本地提交。提交操作就是向中央存储库提交代码,所以没有网络连接,就无法执行操作,你本地的那些只是你的工作目录而已;在 Git 中,会有一个完完全全的本地存储库,所以即使断网了也可以无间断执行提交操作。你还可以编辑那些提交、回退、分支,并选择你所要的东西,没有任何人会知道他们必须知道的之外的东西。
因为提交是个大事,所以 CVS 用户很少做提交。提交会包含很多的内容修改,就像如今我们能在一个含有十次提交的拉取请求中看到的一样多。特别是在提交触发了 CI 构建和自动测试程序时如此。
现在我们运行 `cvs status`,会看到产生了文件的新版本:
```
$ cvs status
cvs status: Examining .
===================================================================
File: favorites.txt Status: Up-to-date
Working revision: 1.2 2018-07-06 21:18:59 -0400
Repository revision: 1.2 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
Commit Identifier: pQx5ooyNk90wW8JA
Sticky Tag: (none)
Sticky Date: (none)
Sticky Options: (none)
```
### 合并
如上所述,在 CVS 中,你可以同时编辑其他人正在编辑的文件。这是 CVS 对 RCS 的重大改进。当需要将更改的部分重新组合在一起时会发生什么?
假设你邀请了一些朋友来将他们喜欢的颜色添加到你的列表中。在他们添加的时候,你确定了不再喜欢绿色,然后把它从列表中删除。
当你提交更新的时候,会发现 CVS 报出了个问题:
```
$ cvs commit -m "Remove green"
cvs commit: Examining .
cvs commit: Up-to-date check failed for `favorites.txt'
cvs [commit aborted]: correct above errors first!
```
这看起来像是朋友们首先提交了他们的变化。所以你的 `favorites.txt` 文件版本没有更新到存储库中的最新版本。此时运行 `cvs status` 就可以看到,本地的 `favorites.txt` 文件副本有一些本地变更且是 1.2 版本的,而存储库上的版本号是 1.3,如下示:
```
$ cvs status
cvs status: Examining .
===================================================================
File: favorites.txt Status: Needs Merge
Working revision: 1.2 2018-07-07 10:42:43 -0400
Repository revision: 1.3 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
Commit Identifier: 2oZ6n0G13bDaldJA
Sticky Tag: (none)
Sticky Date: (none)
Sticky Options: (none)
```
你可以运行 `cvs diff` 来了解 1.2 版本与 1.3 版本的确切差异:
```
$ cvs diff -r HEAD favorites.txt
Index: favorites.txt
===================================================================
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
retrieving revision 1.3
diff -r1.3 favorites.txt
3d2
< green
7,10d5
<
< pink
< hot pink
< bubblegum pink
```
看来我们的朋友是真的喜欢粉红色,但好在他们编辑的是此文件的不同部分,所以很容易地合并此修改。跟 `git pull` 类似,只要运行 `cvs update` 命令,CVS 就可以为我们做合并操作,如下示:
```
$ cvs update
cvs update: Updating .
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
retrieving revision 1.2
retrieving revision 1.3
Merging differences between 1.2 and 1.3 into favorites.txt
M favorites.txt
```
此时查看 `favorites.txt` 文件内容的话,你会发现你的朋友对文件所做的更改已经包含进去了,你的修改也在里面。现在你可以自由的提交文件了,如下示:
```
$ cvs commit
cvs commit: Examining .
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
new revision: 1.4; previous revision: 1.3
```
最终的结果就跟在 Git 中运行 `git pull --rebase` 一样。你的修改是添加在你朋友的修改之后的,所以没有 “合并提交” 这操作。
某些时候,对同一文件的修改可能导致冲突。例如,如果你的朋友把 “green” 修改成 “olive”,同时你完全删除 “green”,就会出现冲突。CVS 早期的时候,正是这种情况导致人们担心 CVS 不安全,而 RCS 的悲观锁机制可以确保此情况永不会发生。但 CVS 提供了一个安全保障机制,可以确保不会自动的覆盖任何人的修改。因此,当运行 `cvs update` 的时候,你必须告诉 CVS 想要保留哪些修改才能继续下一步操作。CVS 会标记文件的所有变更,这跟 Git 检测到合并冲突时所做的方式一样,然后,你必须手工编辑文件,选择需要保留的变更进行合并。
这儿需要注意的有趣事情就是在进行提交之前必须修复并合并冲突。这是 CVS 集中式特性的另一个结果。而在 Git 里,在推送本地的提交内容之前,你都不用担心合并冲突问题。
### 标记与分支
由于 CVS 没有易于寻址的提交对象,因此对变更集合进行分组的唯一方法就是对于特定的工作目录状态打个标记。
创建一个标记是很容易的:
```
$ cvs tag VERSION_1_0
cvs tag: Tagging .
T favorites.txt
```
稍后,运行 `cvs update` 命令并把标签传输给 `-r` 标志就可以把文件恢复到此状态,如下示:
```
$ cvs update -r VERSION_1_0
cvs update: Updating .
U favorites.txt
```
因为你需要一个标记来回退到早期的工作目录状态,所以 CVS 鼓励创建大量的抢先标记。例如,在重大的重构之前,你可以创建一个 `BEFORE_REFACTOR_01` 标记,如果重构出错,就可以使用此标记回退。你如果想生成整个项目的差异文件的话,也可以使用标记。基本上,如今我们惯常使用提交的哈希值完成的事情都必须在 CVS 中提前计划,因为你必须首先有个标签才行。
可以在 CVS 中创建分支。分支只是一种特殊的标记,如下示:
```
$ cvs rtag -b TRY_EXPERIMENTAL_THING colors
cvs rtag: Tagging colors
```
这命令仅仅只是创建了分支(每个人都这样觉得吧),所以还需要使用 `cvs update` 命令来切换分支,如下示:
```
$ cvs update -r TRY_EXPERIMENTAL_THING
```
上面的命令就会把你的当前工作目录切换到新的分支,但《Pragmatic Version Control Using CVS》一书实际上是建议创建一个新的目录来房子你的新分支。估计,其作者发现在 CVS 里切换目录要比切换分支来得更简单吧。
此书也建议不要从现有分支创建分支,而只在主线分支(Git 中被叫做 `master`)上创建分支。一般来说,分支在 CVS 中主认为是 “高级” 技能。而在 Git 中,你几乎可以任性创建新分支,但 CVS 中要在真正需要的时候才能创建,比如发布项目。
稍后可以使用 `cvs update` 和 `-j` 标志将分支合并回主线:
```
$ cvs update -j TRY_EXPERIMENTAL_THING
```
### 感谢历史上的贡献者
2007 年,Linus Torvalds 在 Google 进行了一场关于 Git 的 [演讲](https://www.youtube.com/watch?v=4XpnKHJAok8)。当时 Git 是很新的东西,整场演讲基本上都是在说服满屋子都持有怀疑态度的程序员们:尽管 Git 是如此的与众不同,也应该使用 Git。如果没有看过这个视频的话,我强烈建议你去看看。Linus 是个有趣的演讲者,即使他有些傲慢。他非常出色地解释了为什么分布式的版本控制系统要比集中式的优秀。他的很多评论是直接针对 CVS 的。
Git 是一个 [相当复杂的工具](https://xkcd.com/1597/)。学习起来是一个令人沮丧的经历,但也不断的给我惊喜:Git 还能做这样的事情。相比之下,CVS 简单明了,但是,许多我们认为理所当然的操作都做不了。想要对 Git 的强大功能和灵活性有全新的认识的话,就回过头来用用 CVS 吧,这是种很好的学习方式。这很好的诠释了为什么理解软件的开发历史可以让人受益匪浅。重拾过期淘汰的工具可以让我们理解今天所使用的工具后面所隐藏的哲理。
如果你喜欢此博文的话,每两周会有一次更新!请在 Twitter 上关注 [@TwoBitHistory](https://twitter.com/TwoBitHistory) 或都通过 [RSS feed](https://twobithistory.org/feed.xml) 订阅,新博文出来会有通知。
### 修正
有人告诉我,有很多组织企业,特别是像做医疗设备软件等这种规避风险类的企业,仍在使用 CVS。这些企业中的程序员通过使用一些小技巧来解决 CVS 的限制,例如为几乎每个更改创建一个新分支以避免直接提交给 `HEAD`。 (感谢 Michael Kohne 指出这一点。)
(题图:[plasticscm](https://www.plasticscm.com/images/art/wallpapers/plastic-wallpaper-version-control-history-1024x768.png))
---
via: <https://twobithistory.org/2018/07/07/cvs.html>
作者:[Two-Bit History](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[runningwater](https://github.com/runningwater) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
---
1. “2015 Developer Survey,” Stack Overflow, accessed July 7, 2018, <https://insights.stackoverflow.com/survey/2015#tech-sourcecontrol>. [↩](#fnref1)
2. Eric Sink, “A History of Version Control,” Version Control By Example, 2011, accessed July 7, 2018, <https://ericsink.com/vcbe/html/history_of_version_control.html>. [↩](#fnref2)
3. Dick Grune, “Concurrent Versions System CVS,” dickgrune.com, accessed July 7, 2018, <https://dickgrune.com/Programs/CVS.orig/#History>. [↩](#fnref3)
4. “Tech Talk: Linus Torvalds on Git,” YouTube, May 14, 2007, accessed July 7, 2018, <https://www.youtube.com/watch?v=4XpnKHJAok8>. [↩](#fnref4)
5. “Concurrent Versions System - News,” Savannah, accessed July 7, 2018, <http://savannah.nongnu.org/news/?group=cvs>. [↩](#fnref5)
| 200 | OK | Github was launched in 2008. If your software engineering career, like mine, is
no older than Github, then Git may be the only version control software you
have ever used. While people sometimes grouse about its steep learning curve or
unintuitive interface, Git has become everyone’s go-to for version control. In
Stack Overflow’s 2015 developer survey, 69.3% of respondents used Git, almost
twice as many as used the second-most-popular version control system,
Subversion. 1 After 2015, Stack Overflow stopped asking developers about the
version control systems they use, perhaps because Git had become so popular
that the question was uninteresting.
Git itself is not much older than Github. Linus Torvalds released the first version of Git in 2005. Though today younger developers might have a hard time conceiving of a world where the term “version control software” didn’t more or less just mean Git, such a world existed not so long ago. There were lots of alternatives to choose from. Open source developers preferred Subversion, enterprises and video game companies used Perforce (some still do), while the Linux kernel project famously relied on a version control system called BitKeeper.
Some of these systems, particularly BitKeeper, might feel familiar to a young
Git user transported back in time. Most would not. BitKeeper aside, the version
control systems that came before Git worked according to a fundamentally
different paradigm. In a taxonomy offered by Eric Sink, author of *Version
Control by Example*, Git is a third-generation version control system, while
most of Git’s predecessors, the systems popular in the 1990s and early 2000s,
are second-generation version control systems. 2 Where third-generation
version control systems are distributed, second-generation version control
systems are centralized. You have almost certainly heard Git described as a
“distributed” version control system before. I never quite understood the
distributed/centralized distinction, at least not until I installed and
experimented with a centralized second-generation version control system
myself.
The system I installed was CVS. CVS, short for Concurrent Versions System, was the very first second-generation version control system. It was also the most popular version control system for about a decade until it was replaced in 2000 by Subversion. Even then, Subversion was supposed to be “CVS but better,” which only underscores how dominant CVS had become throughout the 1990s.
CVS was first developed in 1986 by a Dutch computer scientist named Dick Grune,
who was looking for a way to collaborate with his students on a compiler
project. 3 CVS was initially little more than a collection of shell scripts
wrapping RCS (Revision Control System), a first-generation version control
system that Grune wanted to improve. RCS works according to a pessimistic
locking model, meaning that no two programmers can work on a single file at
once. In order to edit a file, you have to first ask RCS for an exclusive lock
on the file, which you keep until you are finished editing. If someone else is
already editing a file you need to edit, you have to wait. CVS improved on RCS
and ushered in the second generation of version control systems by trading the
pessimistic locking model for an optimistic one. Programmers could now edit the
same file at the same time, merging their edits and resolving any conflicts
later. (Brian Berliner, an engineer who later took over the CVS project, wrote
a very readable
[paper](https://docs.freebsd.org/44doc/psd/28.cvs/paper.pdf)about CVS’ innovations in 1990.)
In that sense, CVS wasn’t all that different from Git, which also works
according to an optimistic model. But that’s where the similarities end. In
fact, when Linus Torvalds was developing Git, one of his guiding principles was
WWCVSND, or “What Would CVS Not Do.” Whenever he was in doubt about a decision,
he strove to choose the option that had not been chosen in the design of
CVS. 4 So even though CVS predates Git by over a decade, it influenced Git as
a kind of negative template.
I’ve really enjoyed playing around with CVS. I think there’s no better way to
understand why Git’s distributed nature is such an improvement on what came
before. So I invite you to come along with me on an exciting journey and
spend the next ten minutes of your life learning about a piece of software
nobody has used in the last decade. (*See correction.*)
## Getting Started with CVS
Instructions for installing CVS can be found on the [project’s
homepage](https://www.nongnu.org/cvs/). On MacOS, you can install CVS using
Homebrew.
Since CVS is centralized, it distinguishes between the client-side universe and the server-side universe in a way that something like Git does not. The distinction is not so pronounced that there are different executables. But in order to start using CVS, even on your own machine, you’ll have to set up the CVS backend.
The CVS backend, the central store for all your code, is called the repository. Whereas in Git you would typically have a repository for every project, in CVS the repository holds all of your projects. There is one central repository for everything, though there are ways to work with only a project at a time.
To create a local repository, you run the `init`
command. You would do this
somewhere global like your home directory.
```
$ cvs -d ~/sandbox init
```
CVS allows you to pass options to either the `cvs`
command itself or to the
`init`
subcommand. Options that appear after the `cvs`
command are global in
nature, while options that appear after the subcommand are specific to the
subcommand. In this case, the `-d`
flag is global. Here it happens to tell CVS
where we want to create our repository, but in general the `-d`
flag points to
the location of the repository we want to use for any given action. It can be
tedious to supply the `-d`
flag all the time, so the `CVSROOT`
environment
variable can be set instead.
Since we’re working locally, we’ve just passed a path for our `-d`
argument,
but we could also have included a hostname.
The command creates a directory called `sandbox`
in your home directory. If you
list the contents of `sandbox`
, you’ll find that it contains another directory
called `CVSROOT`
. This directory, not to be confused with the environment
variable, holds administrative files for the repository.
Congratulations! You’ve just created your first CVS repository.
## Checking In Code
Let’s say that you’ve decided to keep a list of your favorite colors. You are
an artistically inclined but extremely forgetful person. You type up your list
of colors and save it as a file called `favorites.txt`
:
```
blue
orange
green
definitely not yellow
```
Let’s also assume that you’ve saved your file in a new directory called
`colors`
. Now you’d like to put your favorite color list under version control,
because fifty years from now it will be interesting to look back and see how
your tastes changed through time.
In order to do that, you will have to import your directory as a new CVS
project. You can do that using the `import`
command:
```
$ cvs -d ~/sandbox import -m "" colors colors initial
N colors/favorites.txt
No conflicts created by this import
```
Here we are specifying the location of our repository with the `-d`
flag
again. The remaining arguments are passed to the `import`
subcommand. We have
to provide a message, but here we don’t really need one, so we’ve left it
blank. The next argument, `colors`
, specifies the name of our new directory in
the repository; here we’ve just used the same name as the directory we are in.
The last two arguments specify the vendor tag and the release tag respectively.
We’ll talk more about tags in a minute.
You’ve just pulled your “colors” project into the CVS repository. There are a
couple different ways to go about bringing code into CVS, but this is the
method recommended by [ Pragmatic Version Control Using
CVS](http://shop.oreilly.com/product/9780974514000.do), the Pragmatic
Programmer book about CVS. What makes this method a little awkward is that you
then have to check out your work fresh, even though you’ve already got an
existing
`colors`
directory. Instead of using that directory, you’re going to
delete it and then check out the version that CVS already knows about:```
$ cvs -d ~/sandbox co colors
cvs checkout: Updating colors
U colors/favorites.txt
```
This will create a new directory, also called `colors`
. In this directory you
will find your original `favorites.txt`
file along with a directory called
`CVS`
. The `CVS`
directory is basically CVS’ equivalent of the `.git`
directory
in every Git repository.
## Making Changes
Get ready for a trip.
Just like Git, CVS has a `status`
subcommand:
```
$ cvs status
cvs status: Examining .
===================================================================
File: favorites.txt Status: Up-to-date
Working revision: 1.1.1.1 2018-07-06 19:27:54 -0400
Repository revision: 1.1.1.1 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
Commit Identifier: fD7GYxt035GNg8JA
Sticky Tag: (none)
Sticky Date: (none)
Sticky Options: (none)
```
This is where things start to look alien. CVS doesn’t have commit objects. In
the above, there is something called a “Commit Identifier,” but this might be
only a relatively recent edition—no mention of a “Commit Identifier” appears in
*Pragmatic Version Control Using CVS*, which was published in 2003. (The last
update to CVS was released in 2008. 5)
Whereas with Git you’d talk about the version of a file associated with commit
`45de392`
, in CVS files are versioned separately. The first version of your
file is version 1.1, the next version is 1.2, and so on. When branches are
involved, extra numbers are appended, so you might end up with something like
the `1.1.1.1`
above, which appears to be the default in our case even though we
haven’t created any branches.
If you were to run `cvs log`
(equivalent to `git log`
) in a project with lots
of files and commits, you’d see an individual history for each file. You might
have a file at version 1.2 and a file at version 1.14 in the same project.
Let’s go ahead and make a change to version 1.1 of our `favorites.txt`
file:
```
blue
orange
green
+cyan
definitely not yellow
```
Once we’ve made the change, we can run `cvs diff`
to see what CVS thinks we’ve
done:
```
$ cvs diff
cvs diff: Diffing .
Index: favorites.txt
===================================================================
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
retrieving revision 1.1.1.1
diff -r1.1.1.1 favorites.txt
3a4
> cyan
```
CVS recognizes that we added a new line containing the color “cyan” to the
file. (Actually, it says we’ve made changes to the “RCS” file; you can see that
CVS never fully escaped its original association with RCS.) The diff we are
being shown is the diff between the copy of `favorites.txt`
in our working
directory and the 1.1.1.1 version stored in the repository.
In order to update the version stored in the repository, we have to commit the change. In Git, this would be a multi-step process. We’d have to stage the change so that it appears in our index. Then we’d commit the change. Finally, to make the change visible to anyone else, we’d have to push the commit up to the origin repository.
In CVS, *all* of these things happen when you run `cvs commit`
. CVS just
bundles up all the changes it can find and puts them in the repository:
```
$ cvs commit -m "Add cyan to favorites."
cvs commit: Examining .
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
new revision: 1.2; previous revision: 1.1
```
I’m so used to Git that this strikes me as terrifying. Without an opportunity
to stage changes, any old thing that you’ve touched in your working directory
might end up as part of the public repository. Did you passive-aggressively
rewrite a coworker’s poorly implemented function out of cathartic necessity,
never intending for him to know? Too bad, he now thinks you’re a dick. You also
can’t edit your commits before pushing them, since a commit *is* a push. Do you
enjoy spending 40 minutes repeatedly running `git rebase -i`
until your local
commit history flows like the derivation of a mathematical proof? Sorry, you
can’t do that here, and everyone is going to find out that you don’t actually
write your tests first.
But I also now understand why so many people find Git needlessly complicated.
If `cvs commit`
is what you were used to, then I’m sure staging and pushing
changes would strike you as a pointless chore.
When people talk about Git being a “distributed” system, this is primarily the difference they mean. In CVS, you can’t make commits locally. A commit is a submission of code to the central repository, so it’s not something you can do without a connection. All you’ve got locally is your working directory. In Git, you have a full-fledged local repository, so you can make commits all day long even while disconnected. And you can edit those commits, revert, branch, and cherry pick as much as you want, without anybody else having to know.
Since commits were a bigger deal, CVS users often made them infrequently. Commits would contain as many changes as today we might expect to see in a ten-commit pull request. This was especially true if commits triggered a CI build and an automated test suite.
If we now run `cvs status`
, we can see that we have a new version of our file:
```
$ cvs status
cvs status: Examining .
===================================================================
File: favorites.txt Status: Up-to-date
Working revision: 1.2 2018-07-06 21:18:59 -0400
Repository revision: 1.2 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
Commit Identifier: pQx5ooyNk90wW8JA
Sticky Tag: (none)
Sticky Date: (none)
Sticky Options: (none)
```
## Merging
As mentioned above, in CVS you can edit a file that someone else is already editing. That was CVS’ big improvement on RCS. What happens when you need to bring your changes back together?
Let’s say that you have invited some friends to add their favorite colors to your list. While they are adding their colors, you decide that you no longer like the color green and remove it from the list.
When you go to commit your changes, you might discover that CVS notices a problem:
```
$ cvs commit -m "Remove green"
cvs commit: Examining .
cvs commit: Up-to-date check failed for `favorites.txt'
cvs [commit aborted]: correct above errors first!
```
It looks like your friends committed their changes first. So your version of
`favorites.txt`
is not up-to-date with the version in the repository. If you
run `cvs status`
, you’ll see that your local copy of `favorites.txt`
is version
1.2 with some local changes, but the repository version is 1.3:
```
$ cvs status
cvs status: Examining .
===================================================================
File: favorites.txt Status: Needs Merge
Working revision: 1.2 2018-07-07 10:42:43 -0400
Repository revision: 1.3 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
Commit Identifier: 2oZ6n0G13bDaldJA
Sticky Tag: (none)
Sticky Date: (none)
Sticky Options: (none)
```
You can run `cvs diff`
to see exactly what the differences between 1.2 and
1.3 are:
```
$ cvs diff -r HEAD favorites.txt
Index: favorites.txt
===================================================================
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
retrieving revision 1.3
diff -r1.3 favorites.txt
3d2
< green
7,10d5
<
< pink
< hot pink
< bubblegum pink
```
It seems that our friends really like pink. In any case, they’ve edited a
different part of the file than we have, so the changes are easy to merge. CVS
can do that for us when we run `cvs update`
, which is similar to `git pull`
:
```
$ cvs update
cvs update: Updating .
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
retrieving revision 1.2
retrieving revision 1.3
Merging differences between 1.2 and 1.3 into favorites.txt
M favorites.txt
```
If you now take a look at `favorites.txt`
, you’ll find that it has been
modified to include the changes that your friends made to the file. Your
changes are still there too. Now you are free to commit the file:
```
$ cvs commit
cvs commit: Examining .
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
new revision: 1.4; previous revision: 1.3
```
The end result is what you’d get in Git by running `git pull --rebase`
. Your
changes have been added on top of your friends’ changes. There is no “merge
commit.”
Sometimes, changes to the same file might be incompatible. If your friends had
changed “green” to “olive,” for example, that would have conflicted with your
change removing “green” altogether. In the early days of CVS, this was exactly
the kind of case that caused people to worry that CVS wasn’t safe; RCS’
pessimistic locking ensured that such a case could never arise. But CVS
guarantees safety by making sure that nobody’s changes get overwritten
automatically. You have to tell CVS which change you want to keep going
forward, so when you run `cvs update`
, CVS marks up the file with both changes
in the same way that Git does when Git detects a merge conflict. You then have
to manually edit the file and pick the change you want to keep.
The interesting thing to note here is that merge conflicts have to be fixed before you can commit. This is another consequence of CVS’ centralized nature. In Git, you don’t have to worry about resolving merges until you push the commits you’ve got locally.
## Tags and Branches
Since CVS doesn’t have easily addressable commit objects, the only way to group a collection of changes is to mark a particular working directory state with a tag.
Creating a tag is easy:
```
$ cvs tag VERSION_1_0
cvs tag: Tagging .
T favorites.txt
```
You’ll later be able to return files to this state by running `cvs update`
and
passing the tag to the `-r`
flag:
```
$ cvs update -r VERSION_1_0
cvs update: Updating .
U favorites.txt
```
Because you need a tag to rewind to an earlier working directory state, CVS
encourages a lot of preemptive tagging. Before major refactors, for example,
you might create a `BEFORE_REFACTOR_01`
tag that you could later use if the
refactor went wrong. People also used tags if they wanted to generate
project-wide diffs. Basically, all the things we routinely do today with commit
hashes have to be anticipated and planned for with CVS, since you needed to
have the tags available already.
Branches can be created in CVS, sort of. Branches are just a special kind of tag:
```
$ cvs rtag -b TRY_EXPERIMENTAL_THING colors
cvs rtag: Tagging colors
```
That only creates the branch (in full view of everyone, by the way), so you
still need to switch to it using `cvs update`
:
```
$ cvs update -r TRY_EXPERIMENTAL_THING
```
The above commands switch onto the new branch in your current working
directory, but *Pragmatic Version Control Using CVS* actually advises that you
create a new directory to hold your new branch. Presumably its authors found
switching directories easier than switching branches in CVS.
*Pragmatic Version Control Using CVS* also advises against creating branches
off of an existing branch. They recommend only creating branches off of the
mainline branch, which in Git is known as `master`
. In general, branching was
considered an “advanced” CVS skill. In Git, you might start a new branch for
almost any trivial reason, but in CVS branching was typically used only when
really necessary, such as for releases.
A branch could later be merged back into the mainline using `cvs update`
and
the `-j`
flag:
```
$ cvs update -j TRY_EXPERIMENTAL_THING
```
## Thanks for the Commit Histories
In 2007, Linus Torvalds gave [a
talk](https://www.youtube.com/watch?v=4XpnKHJAok8) about Git at Google. Git was
very new then, so the talk was basically an attempt to persuade a roomful of
skeptical programmers that they should use Git, even though Git was so
different from anything then available. If you haven’t already seen the talk, I
highly encourage you to watch it. Linus is an entertaining speaker, even if he
never fails to be his brash self. He does an excellent job of explaining why
the distributed model of version control is better than the centralized one. A
lot of his criticism is reserved for CVS in particular.
Git is a [complex tool](https://xkcd.com/1597/). Learning it can be a
frustrating experience. But I’m also continually amazed at the things that Git
can do. In comparison, CVS is simple and straightforward, though often unable
to do many of the operations we now take for granted. Going back and using CVS
for a while is an excellent way to find yourself with a new appreciation for
Git’s power and flexibility. It illustrates well why understanding the history
of software development can be so beneficial—picking up and re-examining
obsolete tools will teach you volumes about the *why* behind the tools we use
today.
*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
*
### Correction
I’ve been told that there are many organizations, particularly risk-adverse
organizations that do things like make medical device software, that still use
CVS. Programmers in these organizations have developed little tricks for
working around CVS’ limitations, such as making a new branch for almost every
change to avoid committing directly to `HEAD`
. (Thanks to Michael Kohne for
pointing this out.)
-
“2015 Developer Survey,” Stack Overflow, accessed July 7, 2018,
[https://insights.stackoverflow.com/survey/2015#tech-sourcecontrol](https://insights.stackoverflow.com/survey/2015#tech-sourcecontrol).[↩](#fnref:1) -
Eric Sink, “A History of Version Control,” Version Control By Example, 2011, accessed July 7, 2018,
[https://ericsink.com/vcbe/html/history_of_version_control.html](https://ericsink.com/vcbe/html/history_of_version_control.html).[↩](#fnref:2) -
Dick Grune, “Concurrent Versions System CVS,” dickgrune.com, accessed July 7, 2018,
[https://dickgrune.com/Programs/CVS.orig/#History](https://dickgrune.com/Programs/CVS.orig/#History).[↩](#fnref:3) -
“Tech Talk: Linus Torvalds on Git,” YouTube, May 14, 2007, accessed July 7, 2018,
[https://www.youtube.com/watch?v=4XpnKHJAok8](https://www.youtube.com/watch?v=4XpnKHJAok8).[↩](#fnref:4) -
“Concurrent Versions System - News,” Savannah, accessed July 7, 2018,
[http://savannah.nongnu.org/news/?group=cvs](http://savannah.nongnu.org/news/?group=cvs).[↩](#fnref:5) |
10,320 | 4 个 Markdown 开源编辑器 | https://opensource.com/article/18/11/markdown-editors | 2018-12-07T23:16:22 | [
"Markdown"
] | https://linux.cn/article-10320-1.html |
>
> 如果你正在寻找一种简便的方法去格式化 Markdown 文本,那么这些编辑器可能会满足你的需求。
>
>
>

我的文章、散文、博客等等基本上都是在文本编辑器上使用 [Markdown](https://en.wikipedia.org/wiki/Markdown) 写作的。当然,我不是唯一使用 Markdown 写作的人。不仅仅无数的人在使用 Markdown,而且也产生了许多服务于 Markdown 的工具。
谁能想到由 John Gruber 和之后的 Aaron Schwartz 创造的一种格式化网页文档的简便的方法如此的受欢迎呢?
我的大多数协作都是在文本编辑器上进行,我能理解为什么 Markdown 编辑器会如此受欢迎 —— 可以快速格式化,可以轻便的将文档转换为其他的格式,可以实时预览。
如果你想用 Markdown 和寻找一个专用的 Markdown 编辑器,那么这里有四个开源编辑器可能会让你写作更加轻松。
### Ghostwriter
在我使用过的或试过的 Markdown 编辑器中 [Ghostwriter](https://wereturtle.github.io/ghostwriter/) 能排进前三。我已经使用或试了不少。

作为一个编辑器,Ghostwriter 就像一个画布,你可以手动进行编辑和添加格式。如果你不想这么做或者只想学习 Markdown 或者不知道如何添加,你可以从 Ghostwriter 的格式化菜单中选择你想要的格式。
一般的,它只有一个基本的格式:列表、字符格式化和缩进。所以你必须手动的添加标题、代码。而且它有一个有趣的任务列表选项,很多人都在用 Markdown 去创造任务列表,这个功能可以让你更加容易去创造和维护任务列表。
Ghostwriter 区别于其他的 Markdown 编辑器的是它有更多的导出选项。你可以选择你想使用的 Markdown 编译器,包括 [Sundown](https://github.com/vmg/sundown)、[Pandoc](https://pandoc.org) 或 [Discount](https://www.pell.portland.or.us/%7Eorc/Code/discount/)。只需要点击两次,你可以轻松的将你写的内容转换为 HTML5、ODT、EPUB、LaTeX、PDF 或 Word 文档。
### Abricotine
如果喜欢简洁的 Markdown 编辑器,你会爱上 [Abricotine](http://abricotine.brrd.fr/)。但是不要让它的简单性欺骗了你;Abricotine 包含了很多强大的功能。

与其他的编辑器一样,你可以手动格式化文档或使用它的格式化菜单或插入菜单。Abricotine 有一个插入 [GitHub 式 Markdown](https://guides.github.com/features/mastering-markdown/) 表格的菜单。它预装了 16 个表样式,你可以在你需要的地方添加行或列。如果这个表看起来有点复杂,你可以使用 `Ctrl+Shift+B` 去使它看起来更整洁优美。
Abricotine 可以自动显示图片、连接和数学公式。当然你也可以关闭这些选项。可惜的是,这个编辑器只能导出为 HTML 格式。
### Mark Text
像 Abricotine 一样,[Mark Text](https://marktext.github.io/website/) 也是一个简洁的 Markdown 编辑器。它有一些你可能没有预料到但能够很好的处理 Markdown 文档的功能。

Mark Text 有点奇怪,它没有菜单或工具条。你需要点击编辑器左上角的弹出式菜单得到命令和功能。它就是让你专注于你的内容。
虽然当你添加内容后,可以在预览区实时看到你所写的内容,但它仍然是一个半所见即所得的编辑器。Mark Text 支持 GitHub 式 Markdown 格式,所以你可以添加表和语法高亮的代码块。在缺省的预览中,编辑器会显示你文档的所有图片。
与 Ghostwriter 相比,你只能将你的文档保存为 HTML 或 PDF 格式。这个输出看起来也不是很糟糕。
### Remarkable
[Remarkable](https://remarkableapp.github.io/) 复杂性介乎于 Ghostwriter 和 Abricotine 或 Mark Text 之间。它有一个带点现代风格的双栏界面。它有一些有用的特点。

你注意到的第一件事是它受到 [Material Design](https://en.wikipedia.org/wiki/Material_Design) 启发的界面外观。它不是每一个人都能习惯的,老实说:我花费了很多时间去适应它。一旦你适应了,它使用起来很简单。
你可以在工具条和菜单上快速访问格式化功能。你可以使用内置的 11 种 CSS 样式或你自己创造的去定制预览框的样式。
Remarkable 的导出选项是有限的 —— 你只能导出为 HTML 或 PDF 格式文件。然而你可以复制整个文档或挑选一部分作为 HTML,粘贴到另一个文档或编辑器中。
你有最喜爱的 Markdown 编辑器吗?为什么不在评论区分享它呢?
---
via: <https://opensource.com/article/18/11/markdown-editors>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxfminions](https://github.com/lxfminions) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I do most of my writing in a text editor and format it with [Markdown](https://en.wikipedia.org/wiki/Markdown)—articles, essays, blog posts, and much more. I'm not the only one, either. Not only do countless people write with Markdown, but there are also more than a few publishing tools built around it.
Who'd have thought that a simple way to format web documents created by John Gruber and the late Aaron Schwartz would become so popular?
While most of my writing takes place in a text editor, I can understand the appeal of a dedicated Markdown editor. You get quick access to formatting, you can easily convert your documents to other formats, and you can get an instant preview.
If you're thinking about going Markdown and are looking for a dedicated editor, here are four open source options for your writing pleasure.
## Ghostwriter
[Ghostwriter](https://wereturtle.github.io/ghostwriter/) ranks in the top three of the dedicated Markdown editors I've used or tried. And I've used or tried a few!
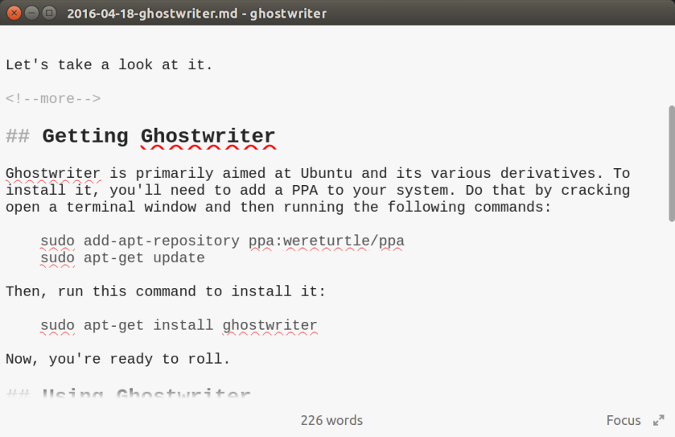
As an editor, Ghostwriter is pretty much a blank canvas. Start typing and adding formatting by hand. If you don't want to do that, or are just learning Markdown and don't know what to add, you can select certain formatting from Ghostwriter's Format menu.
Admittedly, it's just basic formatting—lists, character formatting, and indenting. You'll have to add headings, code, and the like by hand. But the Task List option is interesting. I know a few people who create their to-do lists in Markdown, and this option makes creating and maintaining one much easier.
What sets Ghostwriter apart from other Markdown editors is its range of export options. You can choose the Markdown processor you want to use, including [Sundown](https://github.com/vmg/sundown), [Pandoc](https://pandoc.org), or [Discount](https://www.pell.portland.or.us/~orc/Code/discount/). With a couple of clicks, you can convert what you're writing to HTML5, ODT, EPUB, LaTeX, PDF, or a Word document.
## Abricotine
If you like your Markdown editors simple, you'll like [Abricotine](http://abricotine.brrd.fr/). But don't let its simplicity fool you; Abricotine packs quite a punch.
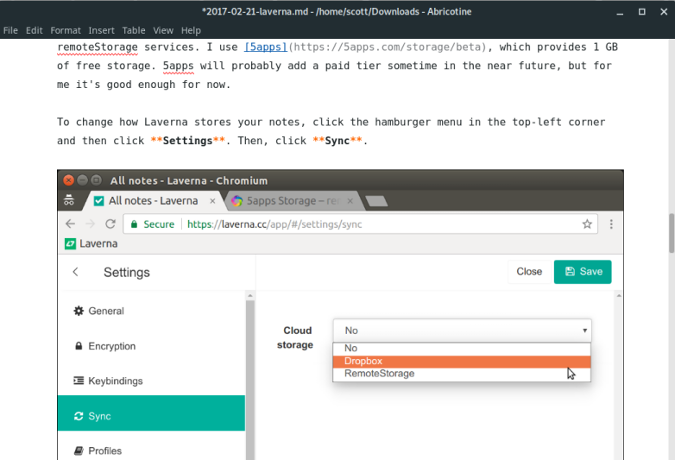
Like any other editor, you can enter formatting by hand or use the Format or Insert menus. Abricotine also has a menu for inserting a [GitHub Flavored Markdown](https://guides.github.com/features/mastering-markdown/) table. There are 16 pre-packaged table formats, and you can add rows or columns as you need them. If the tables are looking a bit messy, you can pretty them up by pressing Ctrl+Shift+B.
Abricotine can automatically display images, links, and math. You can turn all that off if you want to. The editor is, however, limited to exporting documents as HTML.
## Mark Text
Like Abricotine, [Mark Text](https://marktext.github.io/website/) is a simple Markdown editor that might surprise you. It has a few features you might not expect and does quite a good job of handling documents formatted with Markdown.
Mark Text stays out of your way. There are no menus or toolbars. You get to the commands and functions by clicking the stacked menu in the top-left corner of the editor window. It's just you and your words.
The editor's default mode is a semi-WYSIWYG view, although you can change that to see the formatting code you've added to your writing. As for that formatting, Mark Text supports GitHub Flavored Markdown, so you can add tables and formatted blocks of code with syntax highlighting. In its default view, the editor displays any images in your document.
While Mark Text lacks Ghostwriter's range of export options, you can save your files as HTML or PDF. The output doesn't look too bad, either.
## Remarkable
[Remarkable](https://remarkableapp.github.io/) lies somewhere between Ghostwriter and Abricotine or Mark Text. It has that two-paned interface, but with a slightly more modern look. And it has a few useful features.
The first thing you notice about Remarkable is its [Material Design](https://en.wikipedia.org/wiki/Material_Design)-inspired look and feel. It's not for everyone, and I'll be honest: It took me a little while to get used to it. Once you do, it's easy to use.
You get quick access to formatting from the toolbar and the menus. You can also change the preview pane's style using one of 11 built-in Cascading Style Sheets or by creating one of your own.
Remarkable's export options are limited—you can export your work only as HTML or PDF files. You can, however, copy an entire document or a selected portion as HTML, which you can paste into another document or editor.
Do you have a favorite dedicated Markdown editor? Why not share it by leaving a comment?
## 12 Comments |
10,321 | 如何在 Linux 中从一个 PDF 文件中移除密码 | https://www.ostechnix.com/how-to-remove-password-from-a-pdf-file-in-linux/ | 2018-12-07T23:44:00 | [
"PDF"
] | https://linux.cn/article-10321-1.html | 
今天,我碰巧分享一个受密码保护的 PDF 文件给我的一个朋友。我知道这个 PDF 文件的密码,但是我不想透露密码。作为代替,我只想移除密码并发送文件给他。我开始在因特网上查找一些简单的方法来从 PDF 文件中移除密码保护。在快速 google 搜索后,在 Linux 中,我带来四种方法来从一个 PDF 文件中移除密码。有趣的事是,在几年以前我已经做过这事情但是我忘记了。如果你想知道,如何在 Linux 中从一个 PDF 文件移除密码,继续读!它是不难的。
### 在Linux中从一个PDF文件中移除密码
#### 方法 1 – 使用 Qpdf
**Qpdf** 是一个 PDF 转换软件,它被用于加密和解密 PDF 文件,转换 PDF 文件到其他等效的 PDF 文件。 Qpdf 在大多数 Linux 发行版中的默认存储库中是可用的,所以你可以使用默认的软件包安装它。
例如,Qpdf 可以被安装在 Arch Linux 和它的衍生版,使用 [pacman](https://www.ostechnix.com/getting-started-pacman/) ,像下面显示。
```
$ sudo pacman -S qpdf
```
在 Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt-get install qpdf
```
现在,让我们使用 qpdf 从一个 pdf 文件移除密码。
我有一个受密码保护的 PDF 文件,名为 `secure.pdf`。每当我打开这个文件时,它提示我输入密码来显示它的内容。

我知道上面 PDF 文件的密码。然而,我不想与任何人共享密码。所以,我将要做的事是简单地移除 PDF 文件的密码,使用 Qpdf 功能带有下面的命令。
```
$ qpdf --password='123456' --decrypt secure.pdf output.pdf
```
相当简单,不是吗?是的,它是!这里,`123456` 是 `secure.pdf` 文件的密码。用你自己的密码替换。
#### 方法 2 – 使用 Pdftk
**Pdftk** 是另一个用于操作 PDF 文件的好软件。 Pdftk 可以做几乎所有的 PDF 操作,例如:
* 加密和解密 PDF 文件。
* 合并 PDF 文档。
* 整理 PDF 页扫描。
* 拆分 PDF 页。
* 旋转 PDF 文件或页。
* 用 X/FDF 数据 填充 PDF 表单,和/或摧毁表单。
* 从 PDF 表单中生成 PDF数据模板。
* 应用一个背景水印,或一个前景印记。
* 报告 PDF 度量标准、书签和元数据。
* 添加/更新 PDF 书签或元数据。
* 附加文件到 PDF 页,或 PDF 文档。
* 解包 PDF 附件。
* 拆解一个 PDF 文件到单页中。
* 压缩和解压缩页流。
* 修复破损的 PDF 文件。
Pddftk 在 AUR 中是可用的,所以你可以在 Arch Linux 和它的衍生版上使用任意 AUR 帮助程序安装它。
使用 [Pacaur](https://www.ostechnix.com/install-pacaur-arch-linux/):
```
$ pacaur -S pdftk
```
使用 [Packer](https://www.ostechnix.com/install-packer-arch-linux-2/):
```
$ packer -S pdftk
```
使用 [Trizen](https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/):
```
$ trizen -S pdftk
```
使用 [Yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/):
```
$ yay -S pdftk
```
使用 [Yaourt](https://www.ostechnix.com/install-yaourt-arch-linux/):
```
$ yaourt -S pdftk
```
在 Debian、Ubuntu、Linux Mint 上,运行:
```
$ sudo apt-get instal pdftk
```
在 CentOS、Fedora、Red Hat 上:
首先,安装 EPEL 仓库:
```
$ sudo yum install epel-release
```
或
```
$ sudo dnf install epel-release
```
然后,安装 PDFtk 应用程序,使用命令:
```
$ sudo yum install pdftk
```
或者
```
$ sudo dnf install pdftk
```
一旦 pdftk 安装,你可以从一个 PDF 文档移除密码,使用命令:
```
$ pdftk secure.pdf input_pw 123456 output output.pdf
```
用你正确的密码替换 `123456`。这个命令解密 `secure.pdf` 文件,并创建一个相同的名为 `output.pdf` 的无密码保护的文件。
**参阅:**
* [How To Merge PDF Files In Command Line On Linux](https://www.ostechnix.com/how-to-merge-pdf-files-in-command-line-on-linux/)
* [How To Split or Extract Particular Pages From A PDF File](https://www.ostechnix.com/extract-particular-pages-pdf-file/)
#### 方法 3 – 使用 Poppler
**Poppler** 是一个基于 xpdf-3.0 代码库的 PDF 渲染库。它包含下列用于操作 PDF 文档的命令行功能集。
* `pdfdetach` – 列出或提取嵌入的文件。
* `pdffonts` – 字体分析器。
* `pdfimages` – 图片提取器。
* `pdfinfo` – 文档信息。
* `pdfseparate` – 页提取工具。
* `pdfsig` – 核查数字签名。
* `pdftocairo` – PDF 到 PNG/JPEG/PDF/PS/EPS/SVG 转换器,使用 Cairo 。
* `pdftohtml` – PDF 到 HTML 转换器。
* `pdftoppm` – PDF 到 PPM/PNG/JPEG 图片转换器。
* `pdftops` – PDF 到 PostScript (PS) 转换器。
* `pdftotext` – 文本提取。
* `pdfunite` – 文档合并工具。
因这个指南的目的,我们仅使用 `pdftops` 功能。
在基于 Arch Linux 的发行版上,安装 Poppler,运行:
```
$ sudo pacman -S poppler
```
在 Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt-get install poppler-utils
```
在 RHEL、CentOS、Fedora 上:
```
$ sudo yum install poppler-utils
```
一旦 Poppler 安装,运行下列命令来解密密码保护的 PDF 文件,并创建一个新的相同的名为 `output.pdf` 的文件。
```
$ pdftops -upw 123456 secure.pdf output.pdf
```
再一次,用你的 pdf 密码替换 `123456` 。
正如你在上面方法中可能注意到,我们仅转换密码保护的名为 `secure.pdf` 的 PDF 文件到另一个相同的名为 `output.pdf` 的 PDF 文件。技术上讲,我们并没有真的从源文件中移除密码,作为代替,我们解密它,并保存它为另一个相同的没有密码保护的 PDF 文件。
#### 方法 4 – 打印到一个文件
这是在所有上面方法中的最简单的方法。你可以使用你存在的 PDF 查看器,例如 Atril 文档查看器、Evince 等等,并打印密码保护的 PDF 文件到另一个文件。
在你的 PDF 查看器应用程序中打开密码保护的文件。转到 “File - > Print” 。并在你选择的某个位置保存 PDF 文件。

于是,这是全部。希望这是有用的。你知道/使用一些其它方法来从从 PDF 文件中移除密码保护吗?在下面的评价区让我们知道。
更多好东西来了。敬请期待!
谢谢!
---
via: <https://www.ostechnix.com/how-to-remove-password-from-a-pdf-file-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,322 | 为什么未来的学校是开放式的 | https://opensource.com/open-organization/18/9/modern-education-open-education | 2018-12-08T13:20:40 | [
"教育"
] | https://linux.cn/article-10322-1.html |
>
> 一个学生对现代教育并不那么悲观的观点。
>
>
>

最近有些人和我说现代教育会是什么样子,我回答说:就像过去一百年一样。我们为什么会对我们的教育体系保持悲观态度呢?
这不是一个悲观的观点,而是一个务实的观点。任何花时间在学校的人都会有同样的感觉,我们对教导年轻人的方式固执地抵制变革。随着美国学校开始新的一年,大多数学生回到了桌子排成一排排的教室。教学环境主要以教师为中心,学生的进步由卡内基单位和 A-F 评分来衡量,而合作通常被认为是作弊。
我们从哪能够找到证据指出这种工业化模式正在产生所预想的结果?每个孩子都得到个人关注,以培养对学习的热爱,并发展出当今创新经济中茁壮成长所需的技能,我们很可能对现状非常满意。 但是,任何真实客观地看待当前的指标都表明要从基本开始改变。
但我的观点并非悲观。 事实上,非常乐观。
尽管我们可以很容易的阐述现代教育的问题所在,但我也知道一个例子,教育利益相关者愿意走出那些舒适的环境,并挑战这个对变革无动于衷的体系。教师要与同龄人进行更多的合作,并采取更多方式公开透明的对原型创意进行展示,从而为学生带来真正的创新 —— 而不是通过技术重新包装传统方法。管理员通过以社区为中心,基于项目的学习,实现更深入、更紧密的学习实际的应用程序 —— 不仅仅是在孤立的教室中“做项目”。 父母们想把学习的快乐回归到学校的文化,这些文化因强调考试而受到损害。
所有文化变革向来都不容易,特别是在面对任何考试成绩下降(无论统计意义如何重要)都面临政治反弹的环境中,因此人们不愿意承担风险。 那么为什么我乐观地认为我们正在接近一个临界点,我们所需要的变化确实可以克服长期挫败它们的惯性呢?
因为在我们的现代时代,社会中还有其他东西在以前没有出现过:开放的精神,由数字技术催化。
想一想:如果你需要为即将到来的法国旅行学习基本的法语,你该怎么办? 您可以在当地社区学院注册一门课程或者从图书馆借书,但很有可能,您会用免费在线视频并了解旅行所需的基本知识。人类历史上从未有过免费的按需学习。事实上,人们可以参加麻省理工学院关于“[应用数学的专题:线性代数和变异微积分](https://ocw.mit.edu/courses/mechanical-engineering/2-035-special-topics-in-mathematics-with-applications-linear-algebra-and-the-calculus-of-variations-spring-2007/)的免费在线课程。报名参加吧!
为什么麻省理工学院、斯坦福大学和哈佛大学等学校提供免费课程? 为什么人们和公司愿意公开分享曾经严格控制的知识产权?为什么全球各地的人们都愿意花时间,无偿地帮助公民科学项目呢?
David Price 在他那本很棒的书《[开放:我们将如何在未来工作和学习](https://www.goodreads.com/book/show/18730272-open)》中,清楚地描述了非正式的社交学习如何成为新的学习规范,尤其是习惯于能够及时获取他们需要的知识学习的年轻人。通过一系列案例研究,Price 清楚地描绘了当传统制度不适应这种新现实并因此变得越来越不相关时会发生什么。这是缺失的元素,它能让众包产生积极的颠覆性的影响。
Price 指出(以及人们现在对基层的要求)正是一场开放的运动,人们认识到开放式合作和自由交换思想已经破坏了从音乐到软件再到出版的生态系统。 而且,除了任何自上而下推动的“改革”之外,这种对开放性的期望有可能从根本上改变长期以来一直抵制变革的教育体系。事实上,开放精神的标志之一是,它期望知识的透明和公平民主化,造福所有人。那么,对于这样一种精神而言,还有什么生态系统能比试图让年轻人做好准备,继承这个世界、让这个世界变得更好呢?
当然,也有另一种悲观的声音说,我早期关于教育未来的预测可能确实是短期未来的教育状况。但我也非常乐观地认为,这种说法将被证明是错误的。 我知道我和许多其他志趣相投的教育工作者每天都在努力证明这是错误的。 当我们开始帮助我们的学校[转变为开放式组织](https://opensource.com/open-organization/resources/open-org-definition) —— 从过时的传统模式过渡到更开放、灵活,响应每个学生和他们服务的社区需要的时候,你会加入我吗?
这是适合现代时代的真正教育模式。
---
via: <https://opensource.com/open-organization/18/9/modern-education-open-education>
作者:[Ben Owens](https://opensource.com/users/engineerteacher) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hkurj](https://github.com/hkurj) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Someone recently asked me what education will look like in the modern era. My response: Much like it has for the last 100 years. How's that for a pessimistic view of our education system?
It's not a pessimistic view as much as it is a *pragmatic* one. Anyone who spends time in schools could walk away feeling similarly, given that the ways we teach young people are stubbornly resistant to change. As schools in the United States begin a new year, most students are returning to classrooms where desks are lined-up in rows, the instructional environment is primarily teacher-centred, progress is measured by Carnegie units and A-F grading, and collaboration is often considered cheating.
Were we able to point to evidence that this industrialized model was producing the kind of results that are required, where every child is given the personal attention needed to grow a love of learning and develop the skills needed to thrive in today's innovation economy, then we could very well be satisfied with the status quo. But any honest and objective look at current metrics speaks to the need for fundamental change.
But my view isn't a pessimistic one. In fact, it's quite *optimistic*.
For as easy as it is to dwell on what's wrong with our current education model, I also know of example after example of where education stakeholders are willing to step out of what's comfortable and challenge this system that is so immune to change. Teachers are demanding more collaboration with peers and more ways to be open and transparent about prototyping ideas that lead to true innovation for students—not just repackaging of traditional methods with technology. Administrators are enabling deeper, more connected learning to real-world applications through community-focused, project-based learning—not just jumping through hoops of "doing projects" in isolated classrooms. And parents are demanding that the joy and wonder of learning return to the culture of their schools that have been corrupted by an emphasis on test prep.
These and other types of cultural changes are never easy, especially in an environment so reluctant to take risks in the face of political backlash from any dip in test scores (regardless of statistical significance). So why am I optimistic that we are approaching a tipping point where the type of changes we desperately need can indeed overcome the inertia that has thwarted them for too long?
Because there is something else in water at this point in our modern era that was not present before: *an ethos of openness*, catalyzed by digital technology.
Think for a moment: If you need to learn how to speak basic French for an upcoming trip to France, where do you turn? You could sign up for a course at a local community college or check out a book from the library, but in all likelihood, you'll access a free online video and learn the basics you will need for your trip. Never before in human history has free, on-demand learning been so accessible. In fact, one can sign up right now for a free, online course from MIT on "[Special Topics in Mathematics with Applications: Linear Algebra and the Calculus of Variations](https://ocw.mit.edu/courses/mechanical-engineering/2-035-special-topics-in-mathematics-with-applications-linear-algebra-and-the-calculus-of-variations-spring-2007/)." Sign me up!
Why do schools such as MIT, Stanford, and Harvard offer free access to their courses? Why are people and corporations willing to openly share what was once tightly controlled intellectual property? Why are people all over the planet willing to invest their time—for no pay—to help with citizen science projects?
In his wonderful book [ Open: How We'll Work Live and Learn in the Future](https://www.goodreads.com/book/show/18730272-open), author David Price clearly describes how informal, social learning is becoming the new
*norm*of learning, especially among young people accustomed to being able to get the "just in time" knowledge they need. Through a series of case studies, Price paints a clear picture of what happens when traditional institutions don't adapt to this new reality and thus become less and less relevant. That's the missing ingredient that has the crowdsourced power of creating positive disruption.
What Price points out (and what people are now demanding at a grassroots level) is nothing short of an open movement, one recognizing that open collaboration and free exchange of ideas have already disrupted ecosystems from music to software to publishing. And more than any top-down driven "reform," this expectation for openness has the potential to fundamentally alter an educational system that has resisted change for too long. In fact, one of the hallmarks of the open ethos is that it expects the transparent and fair democratization of knowledge for the benefit of all. So what better ecosystem for such an ethos to thrive than within the one that seeks to prepare young people to inherit the world and make it better?
Sure, the pessimist in me says that my earlier prediction about the future of education may indeed be the state of education in the short term future. But I am also very optimistic that this prediction will be proven to be dead wrong. I know that I and many other kindred-spirit educators are working every day to ensure that it's wrong. Won't you join me as we start a movement to help our schools [transform into open organizations](https://opensource.com/open-organization/resources/open-org-definition)—to transition from from an outdated, legacy model to one that is more open, nimble, and responsive to the needs of every student and the communities in which they serve?
That's a true education model appropriate for the modern era.
## 2 Comments |
10,323 | 关于 top 工具的 6 个替代方案 | https://www.ostechnix.com/some-alternatives-to-top-command-line-utility-you-might-want-to-know/ | 2018-12-08T13:45:49 | [
"top"
] | https://linux.cn/article-10323-1.html | 
在 GitHub 和 GitLab 上,不断有来自世界各地的开源应用程序和工具涌现。其中有全新的应用程序,也有针对现有各种被广泛使用的 Linux 程序的替代方案。在本文档中,我会介绍一些针对 [top](https://www.ostechnix.com/the-top-command-tutorial-with-examples-for-beginners/) 工具(也就是命令行任务管理器程序)的替代方案。
### top 工具的替代方案
在本文中,将会介绍以下 6 种 `top` 工具的替代方案:
1. Htop
2. Vtop
3. Gtop
4. Gotop
5. Ptop
6. Hegemon
如果后续有更多类似的工具,原作者会在原文进行更新。如果你对此有兴趣,可以持续关注。
#### Htop
`htop` 是一个流行的开源跨平台交互式进程管理器,也是我最喜欢的系统活动监控工具。`htop` 是对原版 `top` 工具的扩展。它最初只是用于 Linux 系统,后来开发者们不断为其添加对其它类 Unix 操作系统的支持,包括 FreeBSD 和 Mac OS。`htop` 还是一个自由开源软件,它基于 ncurses 并按照 GPLv2 发布。
和原版的 `top` 工具相比,`htop` 工具有这些优势:
* `htop` 比 `top` 启动更快
* `htop` 支持横向滚动和纵向滚动浏览进程列表,以便看到所有的进程和完整的命令行
* 在 `top` 工具中进行杀死进程、更改进程优先级这些操作时,需要输入进程 ID,而在 `htop` 工具中则不需要输入
* 在 `htop` 中可以同时杀死多个进程
* 在 `top` 中每次输入一个未预设的键都要等待一段时间,尤其是在多个键组成转义字符串的时候就更麻烦了
在很多 Linux 发行版的默认软件仓库中,都带有了 `htop`。
在基于 Arch 的操作系统中则可以执行以下命令来安装 `htop`:
```
$ sudo pacman -S htop
```
在基于 Debian 的操作系统使用以下命令:
```
$ sudo apt install htop
```
在使用 RPM 软件管理的操作系统使用以下命令:
```
$ sudo dnf install htop
```
或者
```
$ sudo yum install htop
```
在 openSUSE 系统中:
```
$ sudo zypper in htop
```
**用法**
不带任何参数执行 `htop` 时,会显示如下画面:
```
$ htop
```

从图上可以看出,`htop` 会在界面顶部显示内存、交换空间、任务总数、系统平均负载、系统正常运行时间这些常用指标,在下方则和 `top` 一样显示进程列表,并且将进程的 ID、用户、进程优先级、进程 nice 值、虚拟内存使用情况、CPU 使用情况、内存使用情况等信息以多列显示出来。如果你想详细了解这些数据的含义,可以在[这里](https://www.ostechnix.com/the-top-command-tutorial-with-examples-for-beginners/)阅读参考。
和 `top` 不同的是,`htop` 支持对不同的操作使用专有的按键。以下列出一些用于与 `htop` 交互的快捷键:
* `F1`、`h`、`?`:进入帮助界面。
* `F2`、`Shift+s`:进入设置界面。在设置界面中可以配置仪表板界面顶部显示哪些数据,以及设置颜色方案、显示列、显示顺序等等多种参数。
* `F3`、`/`:在进程列表中进行搜索。
* `F4`、`\`:进入筛选模式。输入一个字符串,筛选出包含这个字符串的进程。进入筛选模式后再按一次 `F4` 或者 `ESC` 可以退出筛选模式。
* `F5`、`t`:切换默认显示模式和树型显示模式,在树型显示模式下按 `+` 可以查看子树。
* `F6`、`<`、`>`:依次按照进程 ID、用户、进程优先级、进程 nice 值、CPU 使用率、内存使用率排序显示。
* `F7`、`]`:提高所选进程的优先级。
* `F8`、`[`:降低所选进程的优先级。
* `F9`、`k`:杀死所选进程。可以用 `↑` / `↓` 键选择不同的进程并按 `F9` 杀死进程。
* `F10`、`q`: 退出 `htop`
以上这些快捷键都在 `htop` 界面底部显示。
需要注意的是,这其中有一些快捷键可能会与已有的快捷键发生冲突。例如按 `F2` 之后可能没有进入 `htop` 的设置界面,而是开始了对终端窗口的重命名。在这种情况下,你可能要更改一下快捷键的设置。
除了以上列出的快捷键以外,还有一些带有其它功能的快捷键,例如:
* `u` 可以选择显示某个用户的进程。
* `Shift+m` 可以按照内存使用量对进程列表排序。
* `Shift+p` 可以按照 CPU 使用量对进程列表排序。
* `Shit+t` 可以按照进程启动时间对进程列表排序。
* `CTRL+l` 刷新界面。
`htop` 的所有功能都可以在启动后通过快捷键来调用,而不需要在启动的时候带上某个参数。当然,`htop` 也支持带参数启动。
例如按照以下方式启动 `htop` 就可以只显示某个用户的进程:
```
$ htop -u <username>
```
更改界面自动刷新的时间间隔:
```
$ htop -d 10
```
看,`htop` 确实比 `top` 好用多了。
想了解 `htop` 的更多细节,可以查阅它的手册页面:
```
$ man htop
```
也可以查看它的[项目主页](http://hisham.hm/htop/) 和 [GitHub 仓库](https://github.com/hishamhm/htop)。
#### Vtop
`vtop` 是 `top` 工具的另一个替代方案。它是一个使用 NodeJS 编写的、自由开源的命令行界面系统活动监视器,并使用 MIT 许可证发布。`vtop` 通过使用 unicode 中的盲文字符来绘制 CPU 和内存使用情况的可视化图表。
在安装 `vtop` 之前,需要先安装 NodeJS。如果还没有安装 NodeJS,可以按照[这个教程](https://www.ostechnix.com/install-node-js-linux/)进行安装。
NodeJS 安装完毕之后,执行以下命令安装 `vtop`:
```
$ npm install -g vtop
```
安装好 `vtop` 就可以执行以下命令开始监控了。
```
$ vtop
```
显示界面如下:

如上图所示,`vtop` 界面和 `top`、`htop` 都有所不同,它将不同的内容分别以多个框的布局显示。另外在界面底部也展示了用于与 `vtop` 交互的所有快捷键。
`vtop` 有这些快捷键:
* `dd` :杀死一个进程。
* `↑`、`k`:向上移动。
* `↓`、`j`:向下移动。
* `←`、`h` :放大图表。
* `→`、`l`:缩小图表。
* `g` :跳转到进程列表顶部。
* `Shift+g` :跳转到进程列表底部。
* `c` :以 CPU 使用量对进程排序。
* `m` :以内存使用量对进程排序。
想要了解更多关于 `vtop` 的细节,可以查阅它的[项目主页](http://parall.ax/vtop)或者 [GitHub 仓库](https://github.com/MrRio/vtop)。
#### Gtop
`gtop` 和 `vtop` 一样,都是一个使用 NodeJS 编写、在 MIT 许可下发布的系统活动监视器。
执行以下命令安装 `gtop`:
```
$ npm install gtop -g
```
然后执行以下命令启动:
```
$ gtop
```
显示界面如下:

`gtop` 有一个优点,就是它会以不同的颜色来显示不同的模块,这种表现形式非常清晰明了。
主要的快捷键包括:
* `p`:按照进程 ID 对进程排序。
* `c`:按照 CPU 使用量对进程排序。
* `m`:按照内存使用量对进程排序。
* `q`、`Ctrl+c`:退出。
想要了解更多关于 `gtop` 的细节,可以查阅它的 [GitHub 仓库](https://github.com/aksakalli/gtop)。
#### Gotop
`gotop` 也是一个完全自由和开源的图表式系统活动监视器。顾名思义,它是在受到 `gtop` 和 `vtop` 的启发之后用 Go 语言编写的,因此也不再对其展开过多的赘述了。如果你有兴趣了解这个项目,可以阅读《[gotop:又一个图表式系统活动监视器](https://www.ostechnix.com/manage-python-packages-using-pip/)》这篇文章。
#### Ptop
有些人对 NodeJS 和 Go 语言的项目可能不太感冒。如果你也是其中之一,你可以试一下使用 Python 编写的 `ptop`。它同样是一个自由开源的、在 MIT 许可下发布的系统活动监视器。
`ptop` 同时兼容 Python2.x 和 Python3.x,因此可以使用 Python 的软件包管理器 `pip` 轻松安装。如果你没有安装 `pip`,也可以参考[这个教程](https://www.ostechnix.com/manage-python-packages-using-pip/)进行安装。
安装 `pip` 之后,执行以下命令就可以安装 `ptop`:
```
$ pip install ptop
```
又或者按照以下方式通过源代码安装:
```
$ git clone https://github.com/darxtrix/ptop
$ cd ptop/
$ pip install -r requirements.txt # install requirements
$ sudo python setup.py install
```
如果需要对 `ptop` 进行更新,可以这样操作:
```
$ pip install --upgrade ptop
```
即使你不执行更新,`ptop` 也会在第一次启动的时候提示你是否需要更新到最新的版本。
现在可以看一下启动 `ptop` 后的界面。
```
$ ptop
```
就像下面这样:

`ptop` 的快捷键包括以下这些:
* `Ctrl+k`:杀死一个进程。
* `Ctrl+n`:按照内存使用量对进程排序。
* `Ctrl+t`:按照进程启动时间对进程排序。
* `Ctrl+r`:重置所有数据。
* `Ctrl+f`:对进程进行筛选,输入进程的名称就能够筛选出符合条件的进程。
* `Ctrl+l`:查看所选进程的详细信息。
* `g`:跳转到进程列表顶部。
* `Ctrl+q`:退出。
`ptop` 还支持更改显示主题。如果你想让 `ptop` 更好看,可以选择你喜欢的主题。可用的主题包括以下这些:
* colorful
* elegant
* simple
* dark
* light
如果需要更换主题(例如更换到 colorful 主题),可以执行以下命令:
```
$ ptop -t colorful
```
使用 `-h` 参数可以查看帮助页面:
```
$ ptop -h
```
想要了解更多关于 `ptop` 的细节,可以查阅它的 [GitHub 仓库](https://github.com/darxtrix/ptop)。
#### Hegemon
`hegemon` 是一个使用 Rust 编写的系统活动监视器,如果你对 Rust 感兴趣,也可以了解一下。我们最近有一篇关于 `hegemon` 的[文章](https://www.ostechnix.com/hegemon-a-modular-system-monitor-application-written-in-rust/),想要详细了解的读者不妨阅读。
### 总结
以上就是关于 `top` 工具的 6 个替代方案。我并不会说它们比 `top` 更好或者可以完全替代 `top`,但多了解一些类似的工具总是好的。你有使用过这些工具吗?哪个是你最喜欢的?欢迎在评论区留言。
---
via: <https://www.ostechnix.com/some-alternatives-to-top-command-line-utility-you-might-want-to-know/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,324 | 如何在 Ubuntu 18.04 LTS 中配置 IP 地址 | https://www.ostechnix.com/how-to-configure-ip-address-in-ubuntu-18-04-lts/ | 2018-12-09T10:09:28 | [
"netplan"
] | https://linux.cn/article-10324-1.html | 
在 Ubuntu 18.04 LTS 中配置 IP 地址的方法和以往使用的配置方法有很大的不同。和旧版本的不同之处在于,Ubuntu 18.04 使用 **Netplan** 来配置 IP 地址,**Netplan** 是一个新的命令行网络配置工具。其实在 Ubuntu 17.10 的时候 Ubuntu 开发者就已经介绍过 Netplan 了。接下来要介绍的新的 IP 配置方法不会再用到 `/etc/network/interfaces` 这个文件,取而代之的是一个 YAML 文件。默认的 Netplan 配置文件一般在 `/etc/netplan` 目录下。 在这篇教程中,我们会去学习在 **Ubuntu 18.04 LTS** 的最小化服务器中配置静态 IP 和动态 IP 。
### 在 Ubuntu 18.04 LTS 中配置静态 IP 地址
首先先找到 Netplan 默认的网络配置文件所在之处:
```
$ ls /etc/netplan/
50-cloud-init.yaml
```
我们可以看到,默认的网络配置文件是 `50-cloud-init.yaml` ,这是一个 YAML 文件。
然后我们再看一下这个文件的内容是什么:
```
$ cat /etc/netplan/50-cloud-init.yaml
```
我在之前安装 Ubuntu 18.04 的时候为了从 DHCP 服务器获取 IP 地址已经已经做过了网卡的相关配置,所以详细配置直接看下图:

可以看到这边有两个网卡,分别是 `enp0s3` 和 `enp0s8` ,并且这两个网卡都配置为从 DHCP 服务器中获取 IP。
现在我们给这两个网卡都配置为静态 IP 地址,先用任意一种编辑器来编辑配置文件。
```
$ sudo nano /etc/netplan/50-cloud-init.yaml
```
接下来我们分别添加 IP 地址、子网掩码、网关、DNS 服务器等配置。分别用 `192.168.225.50` 作为网卡 `enp0s3` 的 IP 地址, `192.168.225.51` 作为网卡 `enp0s8` 的 IP 地址, `192.168.225.1` 作为网关地址, `255.255.255.0` 作为子网掩码。然后用 `8.8.8.8` 、 `8.8.4.4` 这两个 DNS 服务器 IP。

要注意的一点是,在 Ubuntu 18.04 里,这个配置文件的每一行都必须靠空格来缩进,不能用 `TAB` 来代替,否则配置会不起作用。如上图所示的配置文件中每行的缩进都是靠空格键实现的。
同时,在 Ubuntu 18.04 中,我们定义子网掩码的时候不是像旧版本的那样把 IP 和子网掩码分成两项配置。在旧版本的 Ubuntu 里,我们一般配置的 IP 和子网掩码是这样的:
```
address = 192.168.225.50
netmask = 255.255.255.0
```
而在 netplan 中,我们把这两项合并成一项,就像这样:
```
addresses : [192.168.225.50/24]
```
配置完成之后保存并关闭配置文件。然后用下面这行命令来应用刚才的配置:
```
$ sudo netplan apply
```
如果在应用配置的时候有出现问题的话,可以通过如下的命令来查看刚才配置的内容出了什么问题。
```
$ sudo netplan --debug apply
```
这行命令会输出这些 debug 信息:
```
** (generate:1556): DEBUG: 09:14:47.220: Processing input file //etc/netplan/50-cloud-init.yaml..
** (generate:1556): DEBUG: 09:14:47.221: starting new processing pass
** (generate:1556): DEBUG: 09:14:47.221: enp0s8: setting default backend to 1
** (generate:1556): DEBUG: 09:14:47.222: enp0s3: setting default backend to 1
** (generate:1556): DEBUG: 09:14:47.222: Generating output files..
** (generate:1556): DEBUG: 09:14:47.223: NetworkManager: definition enp0s8 is not for us (backend 1)
** (generate:1556): DEBUG: 09:14:47.223: NetworkManager: definition enp0s3 is not for us (backend 1)
DEBUG:netplan generated networkd configuration exists, restarting networkd
DEBUG:no netplan generated NM configuration exists
DEBUG:device enp0s3 operstate is up, not replugging
DEBUG:netplan triggering .link rules for enp0s3
DEBUG:device lo operstate is unknown, not replugging
DEBUG:netplan triggering .link rules for lo
DEBUG:device enp0s8 operstate is up, not replugging
DEBUG:netplan triggering .link rules for enp0s8
```
如果配置正常且生效的话,我们可以用下面这个命令来查看一下 ip:
```
$ ip addr
```
在我的 Ubuntu 18.04 中配置完之后执行命令输出的信息如下:

到此为止,我们已经成功地在 Ubuntu 18.04 LTS 中用 Netplan 完成了静态 IP 的配置。
更多关于 Netplan 的信息,可以在用 man 命令在手册中查看:
```
$ man netplan
```
### 在 Ubuntu 18.04 LTS 中配置动态 IP 地址
其实配置文件中的初始配置就是动态 IP 的配置,所以你想要使用动态 IP 的话不需要再去做任何的配置操作。如果你已经配置了静态 IP 地址,想要恢复之前动态 IP 的配置,就把在上面静态 IP 配置中所添加的相关配置项删除,把整个配置文件恢复成上面的图 1 所示的样子就行了。
现在你已经学会在 Ubuntu 18.04 中配置静态和动态 IP 地址了。个人而言,我其实不太喜欢这种方式,旧的配置方式反而来得简单。你们觉得呢 ?
---
via: <https://www.ostechnix.com/how-to-configure-ip-address-in-ubuntu-18-04-lts/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chenxinlong](https://github.com/chenxinlong) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,325 | 如何在 Linux 上管理字体 | https://www.linux.com/learn/intro-to-linux/2018/5/how-manage-fonts-linux | 2018-12-09T11:11:00 | [
"字体"
] | https://linux.cn/article-10325-1.html | 
我不仅写技术文档,还写小说。并且因为我对 GIMP 等工具感到满意,所以我也(LCTT 译注:此处应指使用 GIMP)为自己的书籍创作了封面(并为少数客户做了图形设计)。艺术创作取决于很多东西,包括字体。
虽然字体渲染已经在过去的几年里取得了长足进步,但它在 Linux 平台上仍是个问题。如果你在 Linux 和 macOS 平台上比较相同字体的外观,差别是显而易见的,尤其是你要盯着屏幕一整天的时候。虽然在 Linux 平台上尚未找到完美的字体渲染方案,但开源平台做的很好一件事的就是允许用户轻松地管理他们的字体。通过选择、添加、缩放和调整,你可以在 Linux 平台上相当轻松地使用字体。
此处,我将分享一些这些年来我的一些技巧,可以帮我在 Linux 上扩展“字体能力”。这些技巧将对那些在开源平台上进行艺术创作的人有特别的帮助。因为 Linux 平台上有非常多可用的桌面界面(每种界面以不同的方式处理字体),因此当桌面环境成为字体管理的中心时,我将主要聚焦在 GNOME 和 KDE 上。
话虽如此,让我们开始吧。
### 添加新字体
在相当长的一段时间里,我都是一个字体收藏家,甚至有些人会说我有些痴迷。从我使用 Linux 的早期开始,我就总是用相同的方法向我的桌面添加字体。有两种方法可以做到这一点:
* 使字体按用户可用;
* 使字体在系统范围内可用。
因为我的桌面从没有其他用户(除了我自己),我只使用了按用户可用的字体设置。然而,我会向你演示如何完成这两种设置。首先,让我们来看一下如何向用户添加新字体。你首先要做的是找到字体文件,True Type 字体(TTF)和 Open Type 字体(OTF)都可以添加。我选择手动添加字体,也就是说,我在 `~/` 目录下新建了一个名为 `~/.fonts` 的隐藏目录。该操作可由以下命令完成:
```
mkdir ~/.fonts
```
当此文件夹新建完成,我将所有 TTF 和 OTF 字体文件移动到此文件夹中。也就是说,你在此文件夹中添加的所有字体都可以在已安装的应用中使用了。但是要记住,这些字体只会对这一个用户可用。
如果你想要使这个字体集合对所有用户可用,你可以如下操作:
1. 打开一个终端窗口;
2. 切换路径到包含你所有字体的目录中;
3. 使用 `sudo cp *.ttf *.TTF /usr/share/fonts/truetype/` 和 `sudo cp *.otf *.OTF /usr/share/fonts/opentype` 命令拷贝所有字体。
当下次用户登录时,他们就将可以使用所有这些漂亮的字体。
### 图形界面字体管理
在 Linux 上你有许多方式来管理你的字体,如何完成取决于你的桌面环境。让我们以 KDE 为例。使用以 KDE 作为桌面环境的 Kubuntu 18.04,你能够找到一个预装的字体管理工具。打开此工具,你就能轻松地添加、移除、启用或禁用字体(当然也包括获得所有已安装字体的详细信息)。这个工具也能让你轻松地针对每个用户或在系统范围内添加和删除字体。假如你想要为用户添加一个特定的字体,你需要下载该字体并打开“字体管理”工具。在此工具中(图 1),点击“个人字体”并点击“+”号添加按钮。

*图 1: 在 KDE 中添加个人字体。*
导航至你的字体路径,选择它们,然后点击打开。你的字体就会被添加进了个人区域,并且立即可用(图 2)。

*图 2: 使用 KDE 字体管理添加字体*
在 GNOME 中做同样的事需要安装一个应用。打开 GNOME 软件中心或者 Ubuntu 软件中心(取决于你使用的发行版)并搜索字体管理器。选择“字体管理器”并点击安装按钮。一但安装完成,你就可以从桌面菜单中启动它,然后让我们安装个人字体。下面是如何安装:
1. 从左侧窗格选择“用户”(图 3);
2. 点击窗口顶部的 “+” 按钮;
3. 浏览并选择已下载的字体;
4. 点击“打开”。

*图 3: 在 GNOME 中添加字体*
### 调整字体
首先你需要理解 3 个概念:
* **字体提示:** 使用数学指令调整字体轮廓显示,使其与光栅化网格对齐。
* **抗锯齿:** 一种通过使曲线和斜线锯齿状边缘光滑化,提高数字图像真实性的技术。
* **缩放因子:** 一个允许你倍增字体大小的缩放单元。也就是说如果你的字体是 12pt 并且缩放因子为 1,那么字体大小将会是 12pt。如果你的缩放因子为 2,那么字体将会是 24pt。
假设你已经安装好了你的字体,但它们看起来并不像你想的那么好。你将如何调整字体的外观?在 KDE 和 GNOME 中,你都可以做一些调整。在调整字体时需要考虑的一件事是,关于字体的口味是非常主观的。你也许会发现你只得不停地调整,直到你得到了看起来确实满意的字体(由你的需求和特殊口味决定)。让我们先看一下 KDE 下的情况吧。
打开“系统设置”工具并点击“字体”。在此节中,你不仅能切换不同字体,你也能够启用或配置抗锯齿或启用字体缩放因子(图 4)。

*图 4: 在 KDE 中配置字体*
要配置抗锯齿,在下拉菜单中选择“启用”并点击“配置”。在结果窗口中(图 5),你可以配置“排除范围”、“子像素渲染类型”和“提示类型”。
一但你做了更改,点击“应用”。重启所有正在运行的程序,然后新的设置就会生效。
要在 GNOME 中这么做,你需要安装“字体管理器”或 GNOME Tweaks。在此处,GNOME Tweaks 是更好的工具。如果你打开 GNOME Dash 菜单但没有找到 Tweaks,打开 GNOME “软件”(或 Ubuntu “软件”)并安装 GNOME Tweaks。安装完毕,打开并点击“字体”,此处你可以配置提示、抗锯齿和缩放因子(图 6)。

*图 6: 在 GNOME 中调整字体*
### 美化你的字体
以上便是使你的 Linux 字体尽可能漂亮的要旨。你可能得不到像 macOS 那样渲染的字体,但你一定可以提升字体外观。最后,你选择的字体会很大程度地影响视觉效果,因此请确保你安装的字体是干净并且完整适配的,否则你将输掉这次对抗。
通过 The Linux Foundation 和 edX 平台的免费课程 [初识 Linux](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 了解更多关于 Linux 的信息。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/5/how-manage-fonts-linux>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[cycoe](https://github.com/cycoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,326 | 9 个鲜为人知的 Python 数据科学库 | https://opensource.com/article/18/11/python-libraries-data-science | 2018-12-09T11:54:58 | [
"数据科学"
] | https://linux.cn/article-10326-1.html |
>
> 除了 pandas、scikit-learn 和 matplotlib,还要学习一些用 Python 进行数据科学的新技巧。
>
>
>

Python 是一种令人惊叹的语言。事实上,它是世界上增长最快的编程语言之一。它一次又一次地证明了它在各个行业的开发者和数据科学者中的作用。Python 及其库的整个生态系统使其成为全世界用户的恰当选择,无论是初学者还是高级用户。它成功和受欢迎的原因之一是它的一组强大的库,使它如此动态和快速。
在本文中,我们将看到 Python 库中的一些数据科学工具,而不是那些常用的工具,如 pandas、scikit-learn 和 matplotlib。虽然像 pandas、scikit-learn 这样的库是机器学习中最常想到的,但是了解这个领域的其他 Python 库也是非常有帮助的。
### Wget
提取数据,尤其是从网络中提取数据,是数据科学家的重要任务之一。[Wget](https://pypi.org/project/wget/) 是一个免费的工具,用于从网络上非交互式下载文件。它支持 HTTP、HTTPS 和 FTP 协议,以及通过 HTTP 代理进行访问。因为它是非交互式的,所以即使用户没有登录,它也可以在后台工作。所以下次你想下载一个网站或者网页上的所有图片,wget 会提供帮助。
安装:
```
$ pip install wget
```
例子:
```
import wget
url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3'
filename = wget.download(url)
100% [................................................] 3841532 / 3841532
filename
'razorback.mp3'
```
### 钟摆
对于在 Python 中处理日期时间感到沮丧的人来说, [Pendulum](https://github.com/sdispater/pendulum) 库是很有帮助的。这是一个 Python 包,可以简化日期时间操作。它是 Python 原生类的一个替代品。有关详细信息,请参阅其[文档](https://pendulum.eustace.io/docs/#installation)。
安装:
```
$ pip install pendulum
```
例子:
```
import pendulum
dt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto')
dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver')
print(dt_vancouver.diff(dt_toronto).in_hours())
3
```
### 不平衡学习
当每个类别中的样本数几乎相同(即平衡)时,大多数分类算法会工作得最好。但是现实生活中的案例中充满了不平衡的数据集,这可能会影响到机器学习算法的学习和后续预测。幸运的是,[imbalanced-learn](https://github.com/scikit-learn-contrib/imbalanced-learn) 库就是为了解决这个问题而创建的。它与 [scikit-learn](http://scikit-learn.org/stable/) 兼容,并且是 [scikit-learn-contrib](https://github.com/scikit-learn-contrib) 项目的一部分。下次遇到不平衡的数据集时,可以尝试一下。
安装:
```
pip install -U imbalanced-learn
# or
conda install -c conda-forge imbalanced-learn
```
例子:
有关用法和示例,请参阅其[文档](http://imbalanced-learn.org/en/stable/api.html) 。
### FlashText
在自然语言处理(NLP)任务中清理文本数据通常需要替换句子中的关键词或从句子中提取关键词。通常,这种操作可以用正则表达式来完成,但是如果要搜索的术语数达到数千个,它们可能会变得很麻烦。
Python 的 [FlashText](https://github.com/vi3k6i5/flashtext) 模块,基于 [FlashText 算法](https://arxiv.org/abs/1711.00046),为这种情况提供了一个合适的替代方案。FlashText 的最佳部分是运行时间与搜索项的数量无关。你可以在其 [文档](https://flashtext.readthedocs.io/en/latest/) 中读到更多关于它的信息。
安装:
```
$ pip install flashtext
```
例子:
提取关键词:
```
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
# keyword_processor.add_keyword(<unclean name>, <standardised name>)
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
keywords_found
['New York', 'Bay Area']
```
替代关键词:
```
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
'I love New York and NCR region.'
```
有关更多示例,请参阅文档中的 [用法](https://flashtext.readthedocs.io/en/latest/#usage) 一节。
### 模糊处理
这个名字听起来很奇怪,但是 [FuzzyWuzzy](https://github.com/seatgeek/fuzzywuzzy) 在字符串匹配方面是一个非常有用的库。它可以很容易地实现字符串匹配率、令牌匹配率等操作。对于匹配保存在不同数据库中的记录也很方便。
安装:
```
$ pip install fuzzywuzzy
```
例子:
```
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# 简单的匹配率
fuzz.ratio("this is a test", "this is a test!")
97
# 部分的匹配率
fuzz.partial_ratio("this is a test", "this is a test!")
100
```
更多的例子可以在 FuzzyWuzy 的 [GitHub 仓库](https://github.com/seatgeek/fuzzywuzzy)得到。
### PyFlux
时间序列分析是机器学习中最常遇到的问题之一。[PyFlux](https://github.com/RJT1990/pyflux) 是 Python 中的开源库,专门为处理时间序列问题而构建的。该库拥有一系列优秀的现代时间序列模型,包括但不限于 ARIMA、GARCH 以及 VAR 模型。简而言之,PyFlux 为时间序列建模提供了一种概率方法。这值得一试。
安装:
```
pip install pyflux
```
例子:
有关用法和示例,请参阅其 [文档](https://pyflux.readthedocs.io/en/latest/index.html)。
### IPyvolume
交流结果是数据科学的一个重要方面,可视化结果提供了显著优势。 [IPyvolume](https://github.com/maartenbreddels/ipyvolume) 是一个 Python 库,用于在 Jupyter 笔记本中可视化 3D 体积和形状(例如 3D 散点图),配置和工作量极小。然而,它目前处于 1.0 之前的阶段。一个很好的类比是这样的: IPyVolumee volshow 是 3D 阵列,Matplotlib 的 imshow 是 2D 阵列。你可以在其 [文档](https://ipyvolume.readthedocs.io/en/latest/?badge=latest) 中读到更多关于它的信息。
安装:
```
Using pip
$ pip install ipyvolume
Conda/Anaconda
$ conda install -c conda-forge ipyvolume
```
例子:
动画:

体绘制:

### Dash
[Dash](https://github.com/plotly/dash) 是一个用于构建 Web 应用程序的高效 Python 框架。它构建于 Flask、Plotty.js 和 Response.js 之上,将下拉菜单、滑块和图形等流行 UI 元素与你的 Python 分析代码联系起来,而不需要JavaScript。Dash 非常适合构建可在 Web 浏览器中呈现的数据可视化应用程序。有关详细信息,请参阅其 [用户指南](https://dash.plot.ly/) 。
安装:
```
pip install dash==0.29.0 # The core dash backend
pip install dash-html-components==0.13.2 # HTML components
pip install dash-core-components==0.36.0 # Supercharged components
pip install dash-table==3.1.3 # Interactive DataTable component (new!)
```
例子:
下面的示例显示了一个具有下拉功能的高度交互的图表。当用户在下拉列表中选择一个值时,应用程序代码将数据从 Google Finance 动态导出到 Pandas 数据框架中。

### Gym
从 [OpenAI](https://openai.com/) 而来的 [Gym](https://github.com/openai/gym) 是开发和比较强化学习算法的工具包。它与任何数值计算库兼容,如 TensorFlow 或 Theano。Gym 是一个测试问题的集合,也称为“环境”,你可以用它来制定你的强化学习算法。这些环境有一个共享的接口,允许您编写通用算法。
安装:
```
pip install gym
```
例子:
以下示例将在 [CartPole-v0](https://gym.openai.com/envs/CartPole-v0) 环境中,运行 1000 次,在每一步渲染环境。

你可以在 Gym 网站上读到 [其它的环境](https://gym.openai.com/) 。
### 结论
这些是我挑选的有用但鲜为人知的数据科学 Python 库。如果你知道另一个要添加到这个列表中,请在下面的评论中提及。
本文最初发表在 [Analytics Vidhya](https://medium.com/analytics-vidhya/python-libraries-for-data-science-other-than-pandas-and-numpy-95da30568fad) 的媒体频道上,并经许可转载。
---
via: <https://opensource.com/article/18/11/python-libraries-data-science>
作者:[Parul Pandey](https://opensource.com/users/parul-pandey) 选题:[lujun9972](https://github.com/lujun9972) 译者:[heguangzhi](https://github.com/heguangzhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Python is an amazing language. In fact, it's one of the fastest growing programming languages in the world. It has time and again proved its usefulness both in developer job roles and data science positions across industries. The entire ecosystem of Python and its libraries makes it an apt choice for users (beginners and advanced) all over the world. One of the reasons for its success and popularity is its set of robust libraries that make it so dynamic and fast.
In this article, we will look at some of the Python libraries for data science tasks other than the commonly used ones like **pandas, scikit-learn**, and **matplotlib**. Although libraries like **pandas and scikit-learn** are the ones that come to mind for machine learning tasks, it's always good to learn about other Python offerings in this field.
## Wget
Extracting data, especially from the web, is one of a data scientist's vital tasks. [Wget](https://pypi.org/project/wget/) is a free utility for non-interactive downloading files from the web. It supports HTTP, HTTPS, and FTP protocols, as well as retrieval through HTTP proxies. Since it is non-interactive, it can work in the background even if the user isn't logged in. So the next time you want to download a website or all the images from a page, **wget** will be there to assist.
### Installation
`$ pip install wget`
### Example
```
import wget
url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3'
filename = wget.download(url)
100% [................................................] 3841532 / 3841532
filename
'razorback.mp3'
```
## Pendulum
For people who get frustrated when working with date-times in Python, ** Pendulum** is here. It is a Python package to ease
**datetime**manipulations. It is a drop-in replacement for Python's native class. Refer to the
[documentation](https://pendulum.eustace.io/docs/#installation)for in-depth information.
### Installation
`$ pip install pendulum`
### Example
```
import pendulum
dt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto')
dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver')
print(dt_vancouver.diff(dt_toronto).in_hours())
3
```
## Imbalanced-learn
Most classification algorithms work best when the number of samples in each class is almost the same (i.e., balanced). But real-life cases are full of imbalanced datasets, which can have a bearing upon the learning phase and the subsequent prediction of machine learning algorithms. Fortunately, the ** imbalanced-learn** library was created to address this issue. It is compatible with
[and is part of](http://scikit-learn.org/stable/)
**scikit-learn****projects. Try it the next time you encounter imbalanced datasets.**
[scikit-learn-contrib](https://github.com/scikit-learn-contrib)### Installation
```
pip install -U imbalanced-learn
# or
conda install -c conda-forge imbalanced-learn
```
### Example
For usage and examples refer to the [documentation](http://imbalanced-learn.org/en/stable/api.html).
## FlashText
Cleaning text data during natural language processing (NLP) tasks often requires replacing keywords in or extracting keywords from sentences. Usually, such operations can be accomplished with regular expressions, but they can become cumbersome if the number of terms to be searched runs into the thousands.
Python's ** FlashText** module, which is based upon the
[FlashText algorithm](https://arxiv.org/abs/1711.00046), provides an apt alternative for such situations. The best part of FlashText is the runtime is the same irrespective of the number of search terms. You can read more about it in the
[documentation](https://flashtext.readthedocs.io/en/latest/).
### Installation
`$ pip install flashtext`
### Examples
**Extract keywords:**
```
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
# keyword_processor.add_keyword(<unclean name>, <standardised name>)
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
keywords_found
['New York', 'Bay Area']
```
**Replace keywords:**
```
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
'I love New York and NCR region.'
```
For more examples, refer to the [usage](https://flashtext.readthedocs.io/en/latest/#usage) section in the documentation.
## FuzzyWuzzy
The name sounds weird, but ** FuzzyWuzzy** is a very helpful library when it comes to string matching. It can easily implement operations like string comparison ratios, token ratios, etc. It is also handy for matching records kept in different databases.
### Installation
`$ pip install fuzzywuzzy`
### Example
```
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# Simple Ratio
fuzz.ratio("this is a test", "this is a test!")
97
# Partial Ratio
fuzz.partial_ratio("this is a test", "this is a test!")
100
```
More examples can be found in FuzzyWuzzy's [GitHub repo.](https://github.com/seatgeek/fuzzywuzzy)
## PyFlux
Time-series analysis is one of the most frequently encountered problems in machine learning. ** PyFlux** is an open source library in Python that was explicitly built for working with time-series problems. The library has an excellent array of modern time-series models, including but not limited to
**ARIMA**,
**GARCH**, and
**VAR**models. In short, PyFlux offers a probabilistic approach to time-series modeling. It's worth trying out.
### Installation
`pip install pyflux`
### Example
Please refer to the [documentation](https://pyflux.readthedocs.io/en/latest/index.html) for usage and examples.
## IPyvolume
Communicating results is an essential aspect of data science, and visualizing results offers a significant advantage. is a Python library to visualize 3D volumes and glyphs (e.g., 3D scatter plots) in the Jupyter notebook with minimal configuration and effort. However, it is currently in the pre-1.0 stage. A good analogy would be something like this: IPyvolume's
**IPyvolume**
**volshow**is to 3D arrays what matplotlib's
**imshow**is to 2D arrays. You can read more about it in the
[documentation](https://ipyvolume.readthedocs.io/en/latest/?badge=latest).
### Installation
```
Using pip
$ pip install ipyvolume
Conda/Anaconda
$ conda install -c conda-forge ipyvolume
```
### Examples
**Animation:**
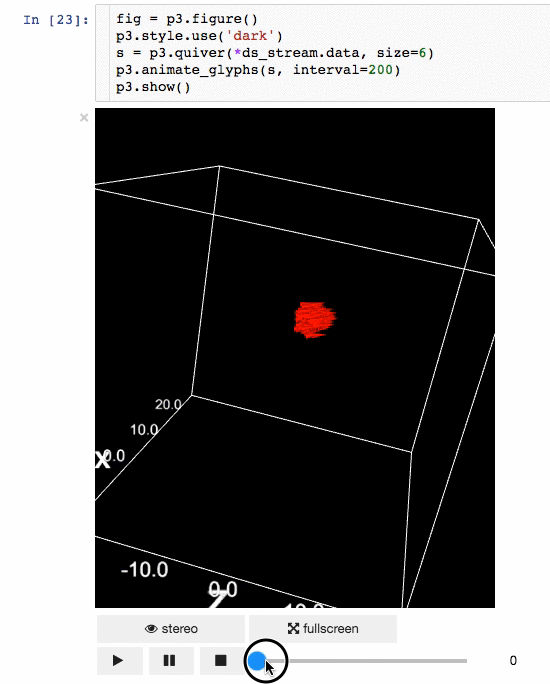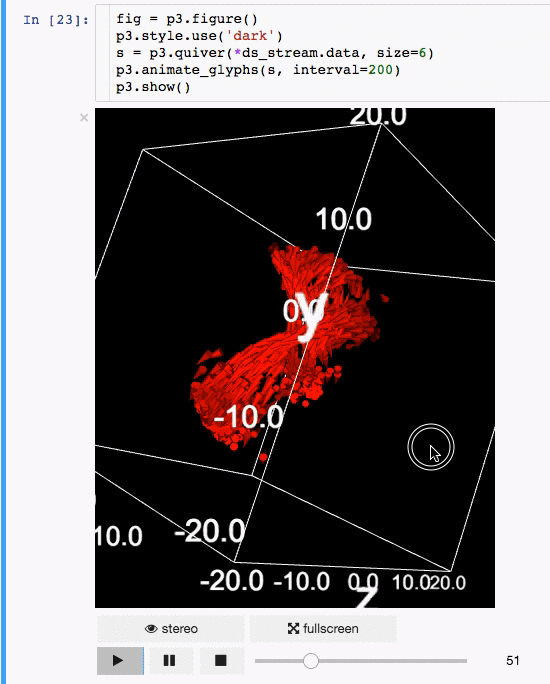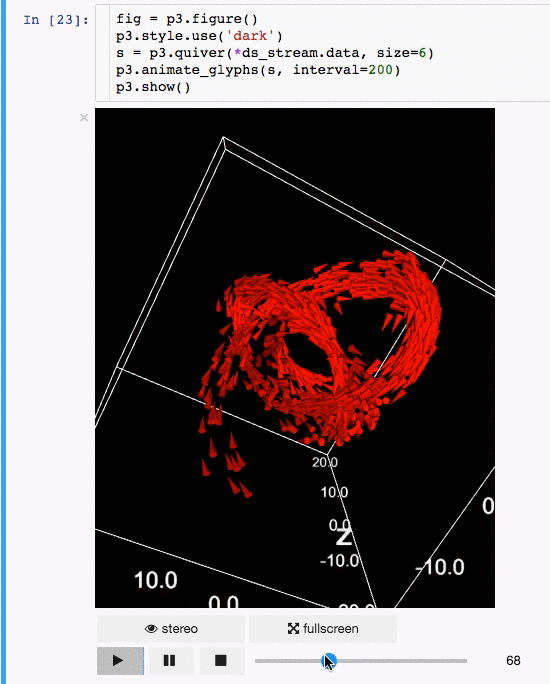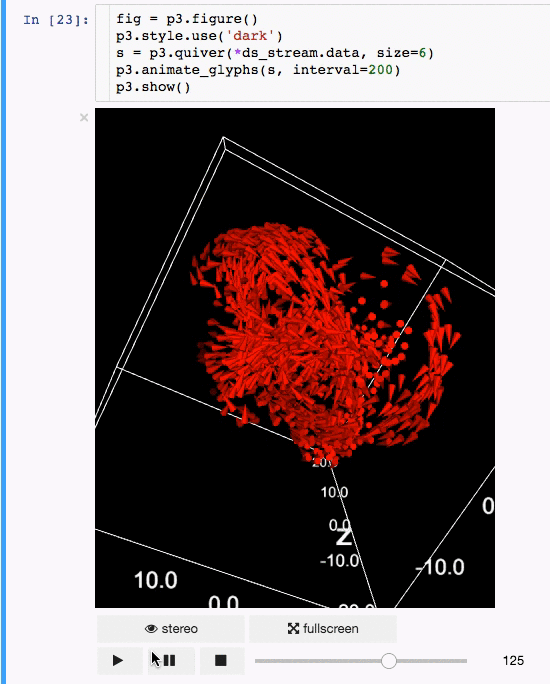
**Volume rendering:**
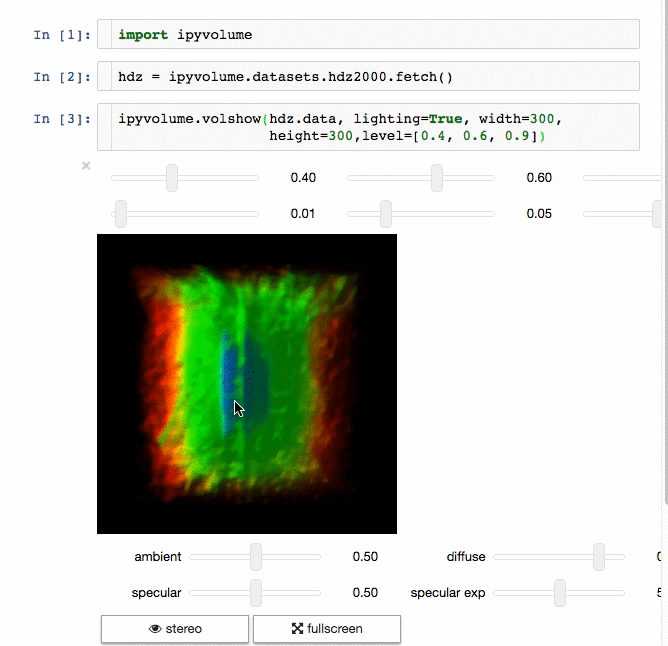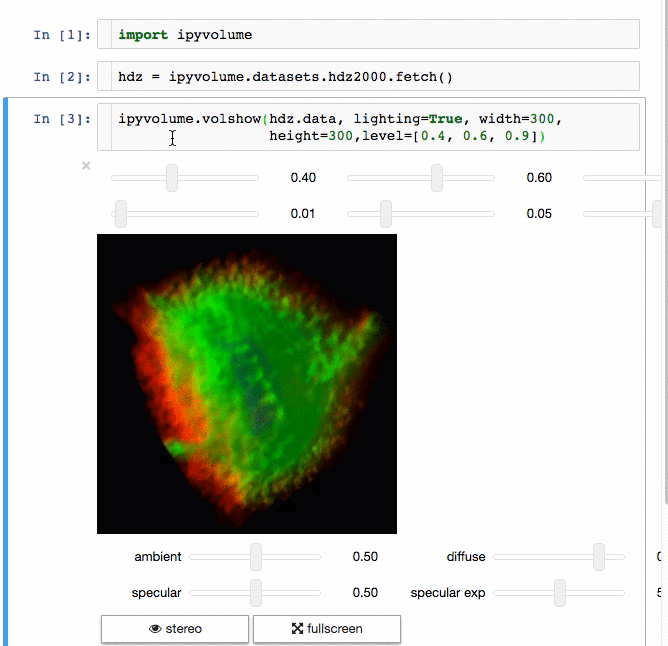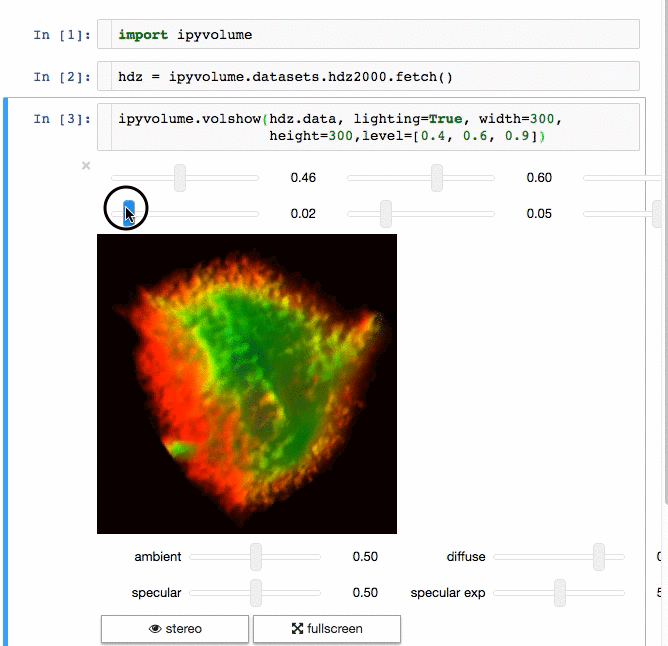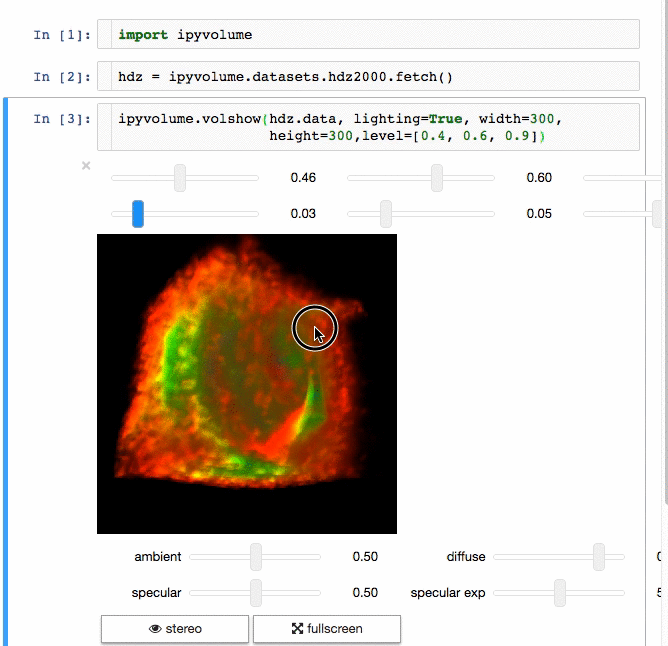
## Dash
** Dash** is a productive Python framework for building web applications. It is written on top of Flask, Plotly.js, and React.js and ties modern UI elements like drop-downs, sliders, and graphs to your analytical Python code without the need for JavaScript. Dash is highly suitable for building data visualization apps that can be rendered in the web browser. Consult the
[user guide](https://dash.plot.ly/)for more details.
### Installation
```
pip install dash==0.29.0 # The core dash backend
pip install dash-html-components==0.13.2 # HTML components
pip install dash-core-components==0.36.0 # Supercharged components
pip install dash-table==3.1.3 # Interactive DataTable component (new!)
```
### Example
The following example shows a highly interactive graph with drop-down capabilities. As the user selects a value in the drop-down, the application code dynamically exports data from Google Finance into a Pandas DataFrame.
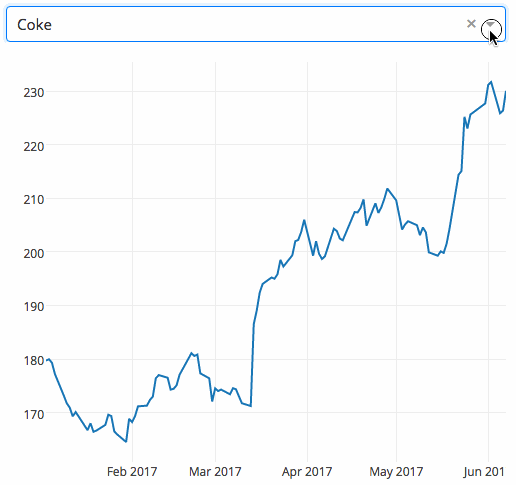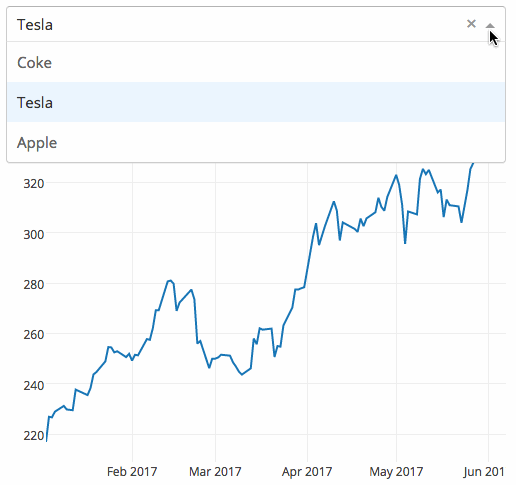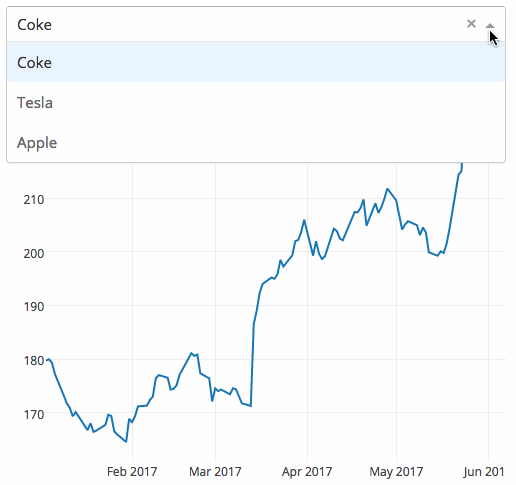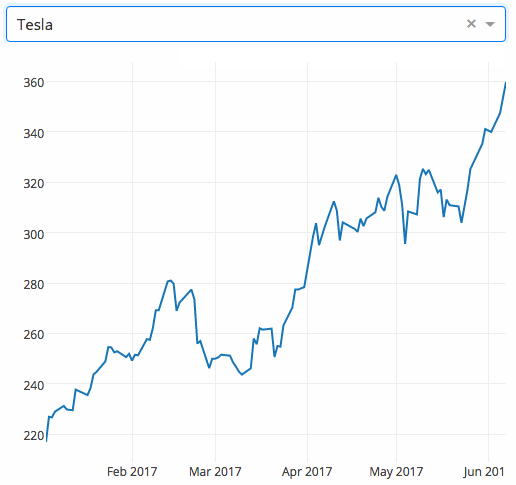
Dash app that ties a drop-down to a D3.js Plotly graph. ( Source)
## Gym
** Gym** from
[OpenAI](https://openai.com/)is a toolkit for developing and comparing reinforcement learning algorithms. It is compatible with any numerical computation library, such as TensorFlow or Theano. The Gym library is a collection of test problems, also called environments, that you can use to work out your reinforcement-learning algorithms. These environments have a shared interface, which allows you to write general algorithms.
### Installation
`pip install gym`
### Example
The following example will run an instance of the environment ** CartPole-v0** for 1,000 timesteps, rendering the environment at each step.
You can read about [other environments](https://gym.openai.com/) on the Gym website.
## Conclusion
These are my picks for useful, but little-known Python libraries for data science. If you know another one to add to this list, please mention it in the comments below.
*This was originally published on the Analytics Vidhya Medium channel and is reprinted with permission.*
## 6 Comments |
10,327 | Emacs 系列(三): Org 模式的补充 | https://changelog.complete.org/archives/9877-emacs-3-more-on-org-mode | 2018-12-09T19:50:15 | [
"Org模式"
] | https://linux.cn/article-10327-1.html | 
这是 [Emacs 和 Org 模式系列](https://changelog.complete.org/archives/tag/emacs2018)的第三篇。
### Todo 的跟进及关键字
当你使用 Org 模式来跟进你的 TODO 时,它有多种状态。你可以用 `C-c C-t` 来快速切换状态。我将它设为这样:
```
(setq org-todo-keywords '(
(sequence "TODO(t!)" "NEXT(n!)" "STARTED(a!)" "WAIT(w@/!)" "OTHERS(o!)" "|" "DONE(d)" "CANCELLED(c)")
))
```
在这里,我设置了一个任务未完成的五种状态:`TODO`、`NEXT`、`STARTED`、`WAIT` 及 `OTHERS`。每一个状态都有单个字的快捷键(`t`、`n`、`a` 等)。管道符(`|`)之后的状态被认为是“完成”的状态。我有两个“完成”状态:`DONE`(已经完成)及 `CANCELLED`(还没完成,但由于其它的原因无法完成)。
`!` 的含义是记录某项更改为状态的时间。我不把这个添加到完成的状态,是因为它们已经被记录了。`@` 符号表示带理由的提示,所以当切换到 `WAIT` 时,Org 模式会问我为什么,并将这个添加到笔记中。
以下是项目状态发生变化的例子:
```
** DONE This is a test
CLOSED: [2018-03-02 Fri 03:05]
- State "DONE" from "WAIT" [2018-03-02 Fri 03:05]
- State "WAIT" from "TODO" [2018-03-02 Fri 03:05] \\
waiting for pigs to fly
- State "TODO" from "NEXT" [2018-03-02 Fri 03:05]
- State "NEXT" from "TODO" [2018-03-02 Fri 03:05]
```
在这里,最新的项目在最上面。
### 议程模式,日程及期限
当你处在一个待办事项时,`C-c C-s` 或 `C-c C-d` 可以为其设置相应的日程或期限。这些都是在议程模式中的功能。它们的区别在于其意图和表现。日程是你希望在某个时候完成的事情,而期限是在某个特定的时间应该完成的事情。默认情况下,议程视图将在项目的截止日期前提醒你。
在此过程中,[议程视图](https://orgmode.org/guide/Agenda-Views.html#Agenda-Views)将显示即将出现的项目,提供了一种基于纯文本或标记搜索项目的方法,甚至可以进行跨多个文件处理项目的批量操作。我在本系列的[第 2 部分](/article-10312-1.html)中介绍了为议程模式配置。
### 标签
Org 模式当然也支持标签了。你可以通过 `C-c C-q` 快速的建立标签。
你可能会想为一些常用的标签设置快捷键。就像这样:
```
(setq org-tag-persistent-alist
'(("@phone" . ?p)
("@computer" . ?c)
("@websurfing" . ?w)
("@errands" . ?e)
("@outdoors" . ?o)
("MIT" . ?m)
("BIGROCK" . ?b)
("CONTACTS" . ?C)
("INBOX" . ?i)
))
```
你还可以按文件向该列表添加标记,也可以按文件为某些内容设置标记。我就在我的 `inbox.org` 和 `email.org` 文件中设置了一个 `INBOX` 的标签。然后我可以每天从日程视图中查看所有标记为 `INBOX` 的项目,像将它们重新归档到其他文件中的这样的简单操作将让它们去掉 `INBOX` 标记。
### 重新归档
“重新归档”就是在文件中或其他地方移动。它是使用标题来完成的。`C-c C-w` 就是做这个的。我设置成这样:
```
(setq org-outline-path-complete-in-steps nil) ; Refile in a single go
(setq org-refile-use-outline-path 'file)
```
### 归档分类
一段时间后,你的文件就会被已经完成的事情弄得乱七八糟。Org 模式有一个[归档](https://orgmode.org/guide/Archiving.html#Archiving)特性,可以将主 `.org` 文件移到其他文件中,以备将来参考。如果你在 `git` 或其他软件中 有 Org 文件,你可能希望删除这些其他文件,因为无论如何都会在历史中拥有这些文件,但是我发现它们对于析取和搜索非常方便。
我会定期检查并归档文件中的所有内容。基于 [stackoverflow 的讨论](https://stackoverflow.com/questions/6997387/how-to-archive-all-the-done-tasks-using-a-single-command),我有以下代码:
```
(defun org-archive-done-tasks ()
(interactive)
(org-map-entries
(lambda ()
(org-archive-subtree)
(setq org-map-continue-from (outline-previous-heading)))
"/DONE" 'file)
(org-map-entries
(lambda ()
(org-archive-subtree)
(setq org-map-continue-from (outline-previous-heading)))
"/CANCELLED" 'file)
)
```
这基于[一个特定的答案](https://stackoverflow.com/a/27043756) —— 你可以从评论那获得一些额外的提示。现在你可以运行 `M-x org-archive-done-tasks`,当前文件中所有标记为 `DONE` 或 `CANCELED` 的内容都将放到另一个文件中。
### 下一篇
我将通过讨论在 Org 模式中自动接受邮件以及在不同的机器上同步来对 Org 模式进行总结。
---
via: <https://changelog.complete.org/archives/9877-emacs-3-more-on-org-mode>
作者:[John Goerzen](http://changelog.complete.org/archives/author/jgoerzen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[oneforalone](https://github.com/oneforalone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is third in [a series on Emacs and org-mode](https://changelog.complete.org/archives/tag/emacs2018).
**Todo tracking and keywords**
When using org-mode to [track your TODOs](https://orgmode.org/guide/TODO-Items.html#TODO-Items), it can have multiple states. You can press `C-c C-t` for a quick shift between states. I have set this:
(setq org-todo-keywords '( (sequence "TODO(t!)" "NEXT(n!)" "STARTED(a!)" "WAIT(w@/!)" "OTHERS(o!)" "|" "DONE(d)" "CANCELLED(c)") ))
Here, I set up 5 states that are for a task that is not yet done: TODO, NEXT, STARTED, WAIT, and OTHERS. Each has a single-character shortcut (t, n, a, etc). The states after the pipe symbol are ones that are considered “done”. I have two: DONE (for things that I have done) and CANCELED (for things that I haven’t done, but for whatever reason, won’t).
The exclamation mark means to log the time when an item was changed to a state. I don’t add this to the done states because those are already logged anyhow. The @ sign means to prompt for a reason; so when switching to WAIT, org-mode will ask me why and add this to the note.
Here’s an example of an entry that has had some state changes:
** DONE This is a test CLOSED: [2018-03-02 Fri 03:05] - State "DONE" from "WAIT" [2018-03-02 Fri 03:05] - State "WAIT" from "TODO" [2018-03-02 Fri 03:05] \\ waiting for pigs to fly - State "TODO" from "NEXT" [2018-03-02 Fri 03:05] - State "NEXT" from "TODO" [2018-03-02 Fri 03:05]
Here, the most recent items are on top.
**Agenda mode, schedules, and deadlines**
When you’re in a todo item, C-c C-s or C-c C-d can set a schedule or a deadline for it, respectively. These show up in agenda mode. The difference is in intent and presentation. A schedule is something that you expect to work on at around a time, while a deadline is something that is due at a specific time. By default, the agenda view will start warning you about deadline items in advance.
And while we’re at it, the [agenda view](https://orgmode.org/guide/Agenda-Views.html#Agenda-Views) will show you the items that you have coming up, offers a nice way to search for items based on plain text or tags, and handles bulk manipulation of items even across multiple files. I covered setting the files for agenda mode in [part 2](https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode) of this series.
**Tags**
Of course org-mode has [tags](https://orgmode.org/guide/Tags.html#Tags). You can quickly set them with C-c C-q.
You can set shortcuts for tags you might like to use often. Perhaps something like this:
(setq org-tag-persistent-alist '(("@phone" . ?p) ("@computer" . ?c) ("@websurfing" . ?w) ("@errands" . ?e) ("@outdoors" . ?o) ("MIT" . ?m) ("BIGROCK" . ?b) ("CONTACTS" . ?C) ("INBOX" . ?i) ))
You can also add tags to this list on a per-file basis, and also set tags for something on a per-file basis. I use that for my inbox.org and email.org files to set an INBOX tag. I can then review all items tagged INBOX from the agenda view each day, and the simple act of refiling them into other files will cause them to lost the INBOX tag.
**Refiling**
“Refiling” is moving things around, either within a file or elsewhere. It has completion using your headlines. `C-c C-w` does this. I like these settings:
(setq org-outline-path-complete-in-steps nil) ; Refile in a single go (setq org-refile-use-outline-path 'file)
**Archiving**
After awhile, you’ll get your files all cluttered with things that are done. org-mode has an [archive](https://orgmode.org/guide/Archiving.html#Archiving) feature to move things out of your main .org files and into some other files for future reference. If you have your org files in git or something, you may wish to delete these other files since you’d have things in history anyhow, but I find them handy for grepping and searching.
I periodically want to go through and archive everything in my files. Based on a [stackoverflow discussion](https://stackoverflow.com/questions/6997387/how-to-archive-all-the-done-tasks-using-a-single-command), I have this code:
(defun org-archive-done-tasks () (interactive) (org-map-entries (lambda () (org-archive-subtree) (setq org-map-continue-from (outline-previous-heading))) "/DONE" 'file) (org-map-entries (lambda () (org-archive-subtree) (setq org-map-continue-from (outline-previous-heading))) "/CANCELLED" 'file) )
This is based on [a particular answer](https://stackoverflow.com/a/27043756) — see the comments there for some additional hints. Now you can run `M-x org-archive-done-tasks` and everything in the current file marked DONE or CANCELED will be pulled out into a different file.
**Up next**
I’ll wrap up org-mode with a discussion of automatically receiving emails into org, and syncing org between machines.
**Resources to accompany this article**
What is the semantics of NEXT keyword? I’ve seen it in several setups but don’t get it.
It’s nothing special to the software, only to me. The rough meanings I have assigned for myself are:
TODO – working on it now
NEXT – I’ll work on it very soon (next actions)
STARTED – I omit this in some of my setups, but it’s an item I’ve begun work on
WAIT – I can’t do it right now because of something (waiting for a reply from someone, for someone else to do something, etc)
OTHERS – Someone else is doing it, but I’m keeping track of it
DONE / CANCELED – I did it, or I decided I won’t do it |
10,328 | 30 个 Openstack 经典面试问题和解答 | https://www.linuxtechi.com/openstack-interview-questions-answers/ | 2018-12-09T21:20:30 | [
"OpenStack",
"面试"
] | https://linux.cn/article-10328-1.html | 现在,大多数公司都试图将它们的 IT 基础设施和电信设施迁移到私有云, 如 OpenStack。如果你打算面试 OpenStack 管理员这个岗位,那么下面列出的这些面试问题可能会帮助你通过面试。

### Q:1 说一下 OpenStack 及其主要组件?
答: OpenStack 是一系列开源软件,这些软件组成了一个云供给软件,也就是 OpenStack,意即开源软件或项目栈。
下面是 OpenStack 的主要关键组件:
* **Nova** – 用于在计算级别管理虚拟机,并在计算或管理程序级别执行其他计算任务。
* **Neutron** – 为虚拟机、计算和控制节点提供网络功能。
* **Keystone** – 为所有云用户和 OpenStack 云服务提供身份认证服务。换句话说,我们可以说 Keystone 是一个提供给云用户和云服务访问权限的方法。
* **Horizon** – 用于提供图形用户界面。使用图形化管理界面可以很轻松地完成各种日常操作任务。
* **Cinder** – 用于提供块存储功能。通常来说 OpenStack 的 Cinder 中集成了 Chef 和 ScaleIO 来共同为计算和控制节点提供块存储服务。
* **Swift** – 用于提供对象存储功能。通常来说,Glance 管理的镜像是存储在对象存储空间的。像 ScaleIO 这样的外部存储也可以提供对象存储,可以很容易的集成 Glance 服务。
* **Glance** – 用于提供镜像服务。使用 Glance 的管理平台来上传和下载云镜像。
* **Heat** – 用于提供编排服务或功能。使用 Heat 管理平台可以轻松地将虚拟机作为堆栈,并且根据需要可以将虚拟机扩展或收缩。
* **Ceilometer** – 用于提供计量与监控功能。
### Q:2 什么服务通常在控制节点上运行?
答: 以下服务通常在控制节点上运行:
* 认证服务(KeyStone)
* 镜像服务(Glance)
* Nova 服务比如 Nova API、Nova Scheduler 和 Nova DB
* 块存储和对象存储服务
* Ceilometer 服务
* MariaDB / MySQL 和 RabbitMQ 服务
* 网络(Neutron)和网络代理的管理服务
* 编排服务(Heat)
### Q:3 什么服务通常在计算节点上运行?
答: 以下服务通常在计算节点运行:
* Nova 计算
* 网络服务,比如 OVS
### Q:4 计算节点上虚拟机的默认地址是什么?
答: 虚拟机存储在计算节点的 `/var/lib/nova/instances`。
### Q:5 Glance 镜像的默认地址是什么?
答: 因为 Glance 服务运行在控制节点上,所以 Glance 镜像都被存储在控制节点的 `/var/lib/glance/images` 文件夹下。
想了解更多请访问:[在 OpenStack 中如何使用命令行创建和删除虚拟机](https://www.linuxtechi.com/create-delete-virtual-machine-command-line-openstack/)
### Q:6 说一下如何使用命令行启动一个虚拟机?
答: 我们可以使用如下 OpenStack 命令来启动一个新的虚拟机:
```
# openstack server create --flavor {flavor-name} --image {Image-Name-Or-Image-ID} --nic net-id={Network-ID} --security-group {Security_Group_ID} –key-name {Keypair-Name} <VM_Name>
```
### Q:7 如何在 OpenStack 中显示用户的网络命名空间列表?
答: 可以使用 `ip net ns` 命令来列出用户的网络命名空间。
```
~# ip netns list
qdhcp-a51635b1-d023-419a-93b5-39de47755d2d
haproxy
vrouter
```
### Q:8 如何在 OpenStack 中执行网络命名空间内的命令?
答: 假设我们想在 `qdhcp-a51635b1-d023-419a-93b5-39de47755d2d` 网络命名空间中执行 `ifconfig` 命令,我们可以执行如下命令。
命令格式 : `ip netns exec {network-space} <command>`:
```
~# ip netns exec qdhcp-a51635b1-d023-419a-93b5-39de47755d2d "ifconfig"
```
### Q:9 在 Glance 服务中如何使用命令行上传和下载镜像?
答: Glance 服务中云镜像上传可以使用如下 OpenStack 命令:
```
~# openstack image create --disk-format qcow2 --container-format bare --public --file {Name-Cloud-Image}.qcow2 <Cloud-Image-Name>
```
下载云镜像则使用如下命令:
```
~# glance image-download --file <Cloud-Image-Name> --progress <Image-ID>
```
### Q:10 OpenStack 如何将虚拟机从错误状态转换为活动状态?
答: 在某些情况下虚拟机可能会进入错误状态,可以使用如下命令将错误状态转换为活动状态:
```
~# nova reset-state --active {Instance_id}
```
### Q:11 如何使用命令行来获取可使用的浮动 IP 列表?
答: 可使用如下命令来显示可用浮动 IP 列表:
```
~]# openstack ip floating list | grep None | head -10
```
### Q:12 如何在特定可用区域中或在计算主机上配置虚拟机?
答: 假设我们想在 compute-02 中的可用区 NonProduction 上配置虚拟机,可以使用如下命令:
```
~]# openstack server create --flavor m1.tiny --image cirros --nic net-id=e0be93b8-728b-4d4d-a272-7d672b2560a6 --security-group NonProd_SG --key-name linuxtec --availability-zone NonProduction:compute-02 nonprod_testvm
```
### Q:13 如何在特定计算节点上获取配置的虚拟机列表?
答: 假设我们想要获取在 compute-0-19 中配置的虚拟机列表,可以使用如下命令:
命令格式: `openstack server list –all-projects –long -c Name -c Host | grep -i {Compute-Node-Name}`:
```
~# openstack server list --all-projects --long -c Name -c Host | grep -i compute-0-19
```
### Q:14 如何使用命令行查看 OpenStack 实例的控制台日志?
答: 使用如下命令可查看实例的控制台日志。
首先获取实例的 ID,然后使用如下命令:
```
~# openstack console log show {Instance-id}
```
### Q:15 如何获取 OpenStack 实例的控制台的 URL 地址?
答: 可以使用以下 OpenStack 命令从命令行检索实例的控制台 URL 地址:
```
~# openstack console url show {Instance-id}
```
### Q:16 如何使用命令行创建可启动的 cinder / block 存储卷?
答: 假设创建一个 8GB 可启动存储卷,可参考如下步骤:
* 使用如下命令获取镜像列表
```
~# openstack image list | grep -i cirros
| 89254d46-a54b-4bc8-8e4d-658287c7ee92 | cirros | active |
```
* 使用 cirros 镜像创建 8GB 的可启动存储卷
```
~# cinder create --image-id 89254d46-a54b-4bc8-8e4d-658287c7ee92 --display-name cirros-bootable-vol 8
```
### Q:17 如何列出所有在你的 OpenStack 中创建的项目或用户?
答: 可以使用如下命令来检索所有项目和用户:
```
~# openstack project list --long
```
### Q:18 如何显示 OpenStack 服务端点列表?
答: OpenStack 服务端点被分为 3 类:
* 公共端点
* 内部端点
* 管理端点
使用如下 OpenStack 命令来查看各种 OpenStack 服务端点:
```
~# openstack catalog list
```
可通过以下命令来显示特定服务端点(比如说 keystone)列表:
```
~# openstack catalog show keystone
```
想了解更多请访问:[OpenStack 中的实例创建流程](https://www.linuxtechi.com/step-by-step-instance-creation-flow-in-openstack/)。
### Q:19 在控制节点上你应该按照什么步骤来重启 nova 服务?
答: 应该按照如下步骤来重启 OpenStack 控制节点的 nova 服务:
* `service nova-api restart`
* `service nova-cert restart`
* `service nova-conductor restart`
* `service nova-consoleauth restart`
* `service nova-scheduler restart`
### Q:20 假如计算节点上为数据流量配置了一些 DPDK 端口,你如何检查 DPDK 端口的状态呢?
答: 因为我们使用 openvSwitch (OVS) 来配置 DPDK 端口,因此可以使用如下命令来检查端口的状态:
```
root@compute-0-15:~# ovs-appctl bond/show | grep dpdk
active slave mac: 90:38:09:ac:7a:99(dpdk0)
slave dpdk0: enabled
slave dpdk1: enabled
root@compute-0-15:~#
root@compute-0-15:~# dpdk-devbind.py --status
```
### Q:21 如何使用命令行在 OpenStack 中向存在的安全组 SG(安全组)中添加新规则?
答: 可以使用 `neutron` 命令向 OpenStack 已存在的安全组中添加新规则:
```
~# neutron security-group-rule-create --protocol <tcp or udp> --port-range-min <port-number> --port-range-max <port-number> --direction <ingress or egress> --remote-ip-prefix <IP-address-or-range> Security-Group-Name
```
### Q:22 如何查看控制节点和计算节点的 OVS 桥配置?
答: 控制节点和计算节点的 OVS 桥配置可使用以下命令来查看:
```
~]# ovs-vsctl show
```
### Q:23 计算节点上的集成桥(br-int)的作用是什么?
答: 集成桥(br-int)对来自和运行在计算节点上的实例的流量执行 VLAN 标记和取消标记。
数据包从实例的 n/w 接口发出使用虚拟接口 qvo 通过 Linux 桥(qbr)。qvb 接口是用来连接 Linux 桥的,qvo 接口是用来连接集成桥的。集成桥上的 qvo 端口有一个内部 VLAN 标签,这个标签是用于当数据包到达集成桥的时候贴到数据包头部的。
### Q:24 隧道桥(br-tun)在计算节点上的作用是什么?
答: 隧道桥(br-tun)根据 OpenFlow 规则将 VLAN 标记的流量从集成网桥转换为隧道 ID。
隧道桥允许不同网络的实例彼此进行通信。隧道有利于封装在非安全网络上传输的流量,它支持两层网络,即 GRE 和 VXLAN。
### Q:25 外部 OVS 桥(br-ex)的作用是什么?
答: 顾名思义,此网桥转发来往网络的流量,以允许外部访问实例。br-ex 连接物理接口比如 eth2,这样用户网络的浮动 IP 数据从物理网络接收并路由到用户网络端口。
### Q:26 OpenStack 网络中 OpenFlow 规则的作用是什么?
答: OpenFlow 规则是一种机制,这种机制定义了一个数据包如何从源到达目的地。OpenFlow 规则存储在 flow 表中。flow 表是 OpenFlow 交换机的一部分。
当一个数据包到达交换机就会被第一个 flow 表检查,如果不匹配 flow 表中的任何入口,那这个数据包就会被丢弃或者转发到其他 flow 表中。
### Q:27 怎样查看 OpenFlow 交换机的信息(比如端口、表编号、缓存编号等)?
答: 假如我们要显示 OpenFlow 交换机的信息(br-int),需要执行如下命令:
```
root@compute-0-15# ovs-ofctl show br-int
OFPT_FEATURES_REPLY (xid=0x2): dpid:0000fe981785c443
n_tables:254, n_buffers:256
capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP
actions: output enqueue set_vlan_vid set_vlan_pcp strip_vlan mod_dl_src mod_dl_dst mod_nw_src mod_nw_dst mod_nw_tos mod_tp_src mod_tp_dst
1(patch-tun): addr:3a:c6:4f:bd:3e:3b
config: 0
state: 0
speed: 0 Mbps now, 0 Mbps max
2(qvob35d2d65-f3): addr:b2:83:c4:0b:42:3a
config: 0
state: 0
current: 10GB-FD COPPER
speed: 10000 Mbps now, 0 Mbps max
………………………………………
```
### Q:28 如何显示交换机中的所有 flow 的入口?
答: 可以使用命令 `ovs-ofctl dump-flows` 来查看交换机的 flow 入口。
假设我们想显示 OVS 集成桥(br-int)的所有 flow 入口,可以使用如下命令:
```
[root@compute01 ~]# ovs-ofctl dump-flows br-int
```
### Q:29 什么是 Neutron 代理?如何显示所有 Neutron 代理?
答: OpenStack Neutron 服务器充当中心控制器,实际网络配置是在计算节点或者网络节点上执行的。Neutron 代理是计算节点或者网络节点上进行配置更新的软件实体。Neutron 代理通过 Neuron 服务和消息队列来和中心 Neutron 服务通信。
可通过如下命令查看 Neutron 代理列表:
```
~# openstack network agent list -c ‘Agent type’ -c Host -c Alive -c State
```
### Q:30 CPU Pinning 是什么?
答: CPU Pinning 是指为某个虚拟机保留物理核心。它也称为 CPU 隔离或处理器关联。有两个目的:
* 它确保虚拟机只能在专用核心上运行
* 它还确保公共主机进程不在这些核心上运行
我们也可以认为 Pinning 是物理核心到一个用户虚拟 CPU(vCPU)的一对一映射。
---
via: <https://www.linuxtechi.com/openstack-interview-questions-answers/>
作者:[Pradeep Kumar](http://www.linuxtechi.com/author/pradeep/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ScarboroughCoral](https://github.com/ScarboroughCoral) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Now a days most of the firms are trying to migrate their IT infrastructure and Telco Infra into private cloud i.e OpenStack. If you planning to give interviews on Openstack admin profile, then below list of interview questions might help you to crack the interview.
##### Q:1 Define OpenStack and its key components?
Ans: It is a bundle of opensource software, which all in combine forms a provide cloud software known as OpenStack.OpenStack is known as Stack of Open source Software or Projects.
Following are the key components of OpenStack
**Nova**– It handles the Virtual machines at compute level and performs other computing task at compute or hypervisor level.**Neutron**– It provides the networking functionality to VMs, Compute and Controller Nodes.**Keystone**– It provides the identity service for all cloud users and openstack services. In other words, we can say Keystone a method to provide access to cloud users and services.**Horizon**– It provides a GUI (Graphical User Interface), using the GUI Admin can all day to day operations task at ease.**Cinder**– It provides the block storage functionality, generally in OpenStack Cinder is integrated with Chef and ScaleIO to service block storage to Compute & Controller nodes.**Swift**– It provides the object storage functionality. Generally, Glance images are on object storage. External storage like ScaleIO can work as Object storage too and can easily be integrated with Glance Service.**Glance**– It provides Cloud image services, using glance admin used to upload and download cloud images.**Heat**– It provides an orchestration service or functionality. Using Heat admin can easily VMs as stack and based on requirements VMs in the stack can be scale-in and Scale-out**Ceilometer**– It provides the telemetry and billing services.
##### Q:2 What are services generally run on a controller node?
Ans: Following services run on a controller node:
- Identity Service ( KeyStone)
- Image Service ( Glance)
- Nova Services like Nova API, Nova Scheduler & Nova DB
- Block & Object Service
- Ceilometer Service
- MariaDB / MySQL and RabbitMQ Service
- Management services of Networking (Neutron) and Networking agents
- Orchestration Service (Heat)
##### Q:3 What are the services generally run on a Compute Node?
Ans: Following services run on a compute node,
- Nova-Compute
- Networking Services like OVS
##### Q:4 What is the default location of VMs on the Compute Nodes?
Ans: VMs in the Compute node are stored at “**/var/lib/nova/instances**”
##### Q:5 What is default location of glance images?
Ans: As the Glance service runs on a controller node, all the glance images are store under the folder “**/var/lib/glance/images**” on a controller node.
Read More : **How to Create and Delete Virtual Machine(VM) from Command line in OpenStack**
##### Q:6 Tell me the command how to spin a VM from Command Line?
Ans: We can easily spin a new VM using the following openstack command,
# openstack server create --flavor {flavor-name} --image {Image-Name-Or-Image-ID} --nic net-id={Network-ID} --security-group {Security_Group_ID} –key-name {Keypair-Name} <VM_Name>
##### Q:7 How to list the network namespace of a tenant in OpenStack?
Ans: Network namespace of a tenant can be listed using “ip net ns” command
~# ip netns list qdhcp-a51635b1-d023-419a-93b5-39de47755d2d haproxy vrouter
##### Q:8 How to execute command inside network namespace in openstack?
Ans: Let’s assume we want to execute “ifconfig” command inside the network namespace “qdhcp-a51635b1-d023-419a-93b5-39de47755d2d”, then run the beneath command,
Syntax : ip netns exec {network-space} <command>
~# ip netns exec qdhcp-a51635b1-d023-419a-93b5-39de47755d2d "ifconfig"
##### Q:9 How to upload and download a cloud image in Glance from command line?
Ans: A Cloud image can be uploaded in glance from command using beneath openstack command,
~# openstack image create --disk-format qcow2 --container-format bare --public --file {Name-Cloud-Image}.qcow2 <Cloud-Image-Name>
Use below openstack command to download a cloud image from command line,
~# glance image-download --file <Cloud-Image-Name> --progress <Image-ID>
##### Q:10 How to reset error state of a VM into active in OpenStack env?
Ans: There are some scenarios where some VMs went to error state and this error state can be changed into active state using below commands,
~# nova reset-state --active {Instance_id}
##### Q:11 How to get list of available Floating IPs from command line?
Ans: Available floating ips can be listed using the below command,
~]# openstack ip floating list | grep None | head -10
##### Q:12 How to provision a virtual machine in specific availability zone and compute Host?
Ans: Let’s assume we want to provision a VM on the availability zone NonProduction in compute-02, use the beneath command to accomplish this,
~]# openstack server create --flavor m1.tiny --image cirros --nic net-id=e0be93b8-728b-4d4d-a272-7d672b2560a6 --security-group NonProd_SG --key-name linuxtec --availability-zone NonProduction:compute-02 nonprod_testvm
##### Q:13 How to get list of VMs which are provisioned on a specific Compute node?
Ans: Let’s assume we want to list the vms which are provisioned on compute-0-19, use below
Syntax: openstack server list –all-projects –long -c Name -c Host | grep -i {Compute-Node-Name}
~# openstack server list --all-projects --long -c Name -c Host | grep -i compute-0-19
##### Q:14 How to view the console log of an openstack instance from command line?
Ans: Console logs of an instance can be viewed from the command line using the following commands,
First get the ID of an instance and then use the below command,
~# openstack console log show {Instance-id}
##### Q:15 How to get console URL of an openstack instance?
Ans: Console URL of an instance can be retrieved from command line using the below openstack command,
~# openstack console url show {Instance-id}
##### Q:16 How to create a bootable cinder / block storage volume from command line?
Ans: To Create a bootable cinder or block storage volume (assume 8 GB) , refer the below steps:
- Get Image list using below
~# openstack image list | grep -i cirros | 89254d46-a54b-4bc8-8e4d-658287c7ee92 | cirros | active |
- Create bootable volume of size 8 GB using cirros image
~# cinder create --image-id 89254d46-a54b-4bc8-8e4d-658287c7ee92 --display-name cirros-bootable-vol 8
##### Q:17 How to list all projects or tenants that has been created in your opentstack?
Ans: Projects or tenants list can be retrieved from the command using the below openstack command,
~# openstack project list --long
##### Q:18 How to list the endpoints of openstack services?
Ans: Openstack service endpoints are classified into three categories,
- Public Endpoint
- Internal Endpoint
- Admin Endpoint
Use below openstack command to view endpoints of each openstack service,
~# openstack catalog list
To list the endpoint of a specific service like keystone use below,
~# openstack catalog show keystone
Read More : **Step by Step Instance Creation Flow in OpenStack**
##### Q:19 In which order we should restart nova services on a controller node?
Ans: Following order should be followed to restart the nova services on openstack controller node,
- service nova-api restart
- service nova-cert restart
- service nova-conductor restart
- service nova-consoleauth restart
- service nova-scheduler restart
##### Q:20 Let’s assume DPDK ports are configured on compute node for data traffic, now how you will check the status of dpdk ports?
Ans: As DPDK ports are configured via openvSwitch (OVS), use below commands to check the status,
root@compute-0-15:~# ovs-appctl bond/show | grep dpdk active slave mac: 90:38:09:ac:7a:99(dpdk0) slave dpdk0: enabled slave dpdk1: enabled root@compute-0-15:~# root@compute-0-15:~# dpdk-devbind.py --status
##### Q:21 How to add new rules to the existing SG(Security Group) from command line in openstack?
Ans: New rules to the existing SG in openstack can be added using the neutron command,
~# neutron security-group-rule-create --protocol <tcp or udp> --port-range-min <port-number> --port-range-max <port-number> --direction <ingress or egress> --remote-ip-prefix <IP-address-or-range> Security-Group-Name
##### Q:22 How to view the OVS bridges configured on Controller and Compute Nodes?
Ans: OVS bridges on Controller and Compute nodes can be viewed using below command,
~]# ovs-vsctl show
##### Q:23 What is the role of Integration Bridge(br-int) on the Compute Node ?
Ans: The integration bridge (br-int) performs VLAN tagging and untagging for the traffic coming from and to the instance running on the compute node.
Packets leaving the n/w interface of an instance goes through the linux bridge (qbr) using the virtual interface qvo. The interface qvb is connected to the Linux Bridge & interface qvo is connected to integration bridge (br-int). The qvo port on integration bridge has an internal VLAN tag that gets appended to packet header when a packet reaches to the integration bridge.
##### Q:24 What is the role of Tunnel Bridge (br-tun) on the compute node?
Ans: The tunnel bridge (br-tun) translates the VLAN tagged traffic from integration bridge to the tunnel ids using OpenFlow rules.
br-tun (tunnel bridge) allows the communication between the instances on different networks. Tunneling helps to encapsulate the traffic travelling over insecure networks, br-tun supports two overlay networks i.e GRE and VXLAN
##### Q:25 What is the role of external OVS bridge (br-ex)?
Ans: As the name suggests, this bridge forwards the traffic coming to and from the network to allow external access to instances. br-ex connects to the physical interface like eth2, so that floating IP traffic for tenants networks is received from the physical network and routed to the tenant network ports.
##### Q:26 What is function of OpenFlow rules in OpenStack Networking?
Ans: OpenFlow rules is a mechanism that define how a packet will reach to destination starting from its source. OpenFlow rules resides in flow tables. The flow tables are part of OpenFlow switch.
When a packet arrives to a switch, it is processed by the first flow table, if it doesn’t match any flow entries in the table then packet is dropped or forwarded to another table.
##### Q:27 How to display the information about a OpenFlow switch (like ports, no. of tables, no of buffer)?
Ans: Let’s assume we want to display the information about OpenFlow switch (br-int), run the following command,
[root@compute01 ~]# ovs-ofctl show br-int OFPT_FEATURES_REPLY (xid=0x2): dpid:0000fe981785c443 n_tables:254, n_buffers:256 capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP actions: output enqueue set_vlan_vid set_vlan_pcp strip_vlan mod_dl_src mod_dl_dst mod_nw_src mod_nw_dst mod_nw_tos mod_tp_src mod_tp_dst 1(patch-tun): addr:3a:c6:4f:bd:3e:3b config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max 2(qvob35d2d65-f3): addr:b2:83:c4:0b:42:3a config: 0 state: 0 current: 10GB-FD COPPER speed: 10000 Mbps now, 0 Mbps max ………………………………………
##### Q:28 How to display the entries for all the flows in a switch?
Ans: Flows entries of a switch can be displayed using the command ‘**ovs-ofctl dump-flows**‘
Let’s assume we want to display flow entries of OVS integration bridge (br-int),
[root@compute01 ~]# ovs-ofctl dump-flows br-int
##### Q:29 What are Neutron Agents and how to list all neutron agents?
Ans: OpenStack neutron server acts as the centralized controller, the actual network configurations are executed either on compute and network nodes. Neutron agents are software entities that carry out configuration changes on compute or network nodes. Neutron agents communicate with the main neutron service via Neuron API and message queue.
Neutron agents can be listed using the following command,
~# openstack network agent list -c ‘Agent type’ -c Host -c Alive -c State
##### Q:30 What is CPU pinning?
Ans: CPU pinning refers to reserving the physical cores for specific virtual machine. It is also known as CPU isolation or processor affinity. The configuration is in two parts:
- it ensures that virtual machine can only run on dedicated cores
- it also ensures that common host processes don’t run on those cores
In other words we can say pinning is one to one mapping of a physical core to a guest vCPU.
**Read Also** :** How to Install OpenStack on CentOS 8 with Packstack** |
10,329 | udev 入门:管理设备事件的 Linux 子系统 | https://opensource.com/article/18/11/udev | 2018-12-09T22:12:08 | [
"udev",
"设备"
] | https://linux.cn/article-10329-1.html |
>
> 创建这样一个脚本,当指定的设备插入时触发你的计算机去做一个指定动作。
>
>
>

udev 是一个为你的计算机提供设备事件的 Linux 子系统。通俗来讲就是,当你的计算机上插入了像网卡、外置硬盘(包括 U 盘)、鼠标、键盘、游戏操纵杆和手柄、DVD-ROM 驱动器等等设备时,代码能够检测到它们。这样就能写出很多可能非常有用的实用程序,而它已经很好了,普通用户就可以写出脚本去做一些事情,比如当某个硬盘驱动器插入时,执行某个任务。
这篇文章教你去如何写一个由一些 udev 事件触发的 [udev](https://linux.die.net/man/8/udev) 脚本,比如插入了一个 U 盘。当你理解了 udev 的工作原理,你就可以用它去做各种事情,比如当一个游戏手柄连接后加载一个指定的驱动程序,或者当你用于备份的驱动器连接后,自动执行备份工作。
### 一个初级的脚本
使用 udev 的最佳方式是从一个小的代码块开始。不要指望从一开始就写出完整的脚本,而是从最简单的确认 udev 触发了某些指定的事件开始。
对于你的脚本,依据你的目标,并不是在任何情况下都能保证你亲眼看到你的脚本运行结果的,因此需要在你的脚本日志中确认它成功触发了。而日志文件通常放在 `/var` 目录下,但那个目录通常是 root 用户的领地。对于测试目的,可以使用 `/tmp`,它可以被普通用户访问并且在重启动后就被清除了。
打开你喜欢的文本编辑器,然后输入下面的简单脚本:
```
#!/usr/bin/bash
echo $date > /tmp/udev.log
```
把这个脚本放在 `/usr/local/bin` 或缺省可运行路径的位置中。将它命名为 `trigger.sh`,并运行 `chmod +x` 授予可运行权限:
```
$ sudo mv trigger.sh /usr/local/bin
$ sudo chmod +x /usr/local/bin/trigger.sh
```
这个脚本没有任何和 udev 有关的事情。当它运行时,这个脚本将在文件 `/tmp/udev.log` 中放入当前的时间戳。你可以自己测试一下这个脚本:
```
$ /usr/local/bin/trigger.sh
$ cat /tmp/udev.log
Tue Oct 31 01:05:28 NZDT 2035
```
接下来让 udev 去触发这个脚本。
### 唯一设备识别
为了让你的脚本能够被一个设备事件触发,udev 必须要知道在什么情况下调用该脚本。在现实中,你可以通过它的颜色、制造商、以及插入到你的计算机这一事实来识别一个 U 盘。而你的计算机,它需要一系列不同的标准。
udev 通过序列号、制造商、以及提供商 ID 和产品 ID 号来识别设备。由于现在你的 udev 脚本还处于它的生命周期的早期阶段,因此要尽可能地宽泛、非特定和包容。换句话说就是,你希望首先去捕获尽可能多的有效 udev 事件来触发你的脚本。
使用 `udevadm monitor` 命令你可以实时利用 udev,并且可以看到当你插入不同设备时发生了什么。用 root 权限试一试。
```
$ su
# udevadm monitor
```
该监视函数输出接收到的事件:
* UDEV:在规则处理之后发出 udev 事件
* KERNEL:内核发送 uevent 事件
在 `udevadm monitor` 命令运行时,插入一个 U 盘,你将看到各种信息在你的屏幕上滚动而出。注意那一个 `ADD` 事件的事件类型。这是你所需要的识别事件类型的一个好方法。
`udevadm monitor` 命令提供了许多很好的信息,但是你可以使用 `udevadm info` 命令以更好看的格式来看到它,假如你知道你的 U 盘当前已经位于你的 `/dev` 树。如果不在这个树下,拔下它并重新插入,然后立即运行这个命令:
```
$ su -c 'dmesg | tail | fgrep -i sd*'
```
举例来说,如果那个命令返回 `sdb: sdb1`,说明内核已经给你的 U 盘分配了 `sdb` 卷标。
或者,你可以使用 `lsblk` 命令去查看所有连接到你的系统上的驱动器,包括它的大小和分区。
现在,你的驱动器已经处于你的文件系统中了,你可以使用下面的命令去查看那个设备的相关 udev 信息:
```
# udevadm info -a -n /dev/sdb | less
```
这个命令将返回许多信息。现在我们只关心信息中的第一个块。
你的任务是从 udev 的报告中找出能唯一标识那个设备的部分,然后当计算机检测到这些唯一属性时,告诉 udev 去触发你的脚本。
`udevadm info` 命令处理一个(由设备路径指定的)设备上的报告,接着“遍历”父级设备链。对于找到的大多数设备,它以一个“键值对”格式输出所有可能的属性。你可以写一个规则,从一个单个的父级设备属性上去匹配插入设备的属性。
```
looking at device '/devices/000:000/blah/blah//block/sdb':
KERNEL=="sdb"
SUBSYSTEM=="block"
DRIVER==""
ATTR{ro}=="0"
ATTR{size}=="125722368"
ATTR{stat}==" 2765 1537 5393"
ATTR{range}=="16"
ATTR{discard\_alignment}=="0"
ATTR{removable}=="1"
ATTR{blah}=="blah"
```
一个 udev 规则必须包含来自单个父级设备的一个属性。
父级属性是描述一个设备的最基本的东西,比如它是插入到一个物理端口的东西、或是一个容量多大的东西、或这是一个可移除的设备。
由于 `KERNEL` 卷标 `sdb` 可能会由于分配给在它之前插入的其它驱动器而发生变化,因此卷标并不是一个 udev 规则的父级属性的好选择。但是,在做概念论证时你可以使用它。一个事件的最佳候选者是 `SUBSYSTEM` 属性,它表示那个设备是一个 “block” 系统设备(也就是为什么我们要使用 `lsblk` 命令来列出设备的原因)。
在 `/etc/udev/rules.d` 目录中打开一个名为 `80-local.rules` 的文件,然后输入如下代码:
```
SUBSYSTEM=="block", ACTION=="add", RUN+="/usr/local/bin/trigger.sh"
```
保存文件,拔下你的测试 U 盘,然后重启动系统。
等等,重启动 Linux 机器?
理论上说,你只需要运行 `udevadm control —reload` 即可,它将重新加载所有规则,但是在我们实验的现阶段,最好要排除可能影响实验结果的所有因素。udev 是非常复杂的,为了不让你躺在床上整晚都在思考为什么这个规则不能正常工作,是因为语法错误吗?还是应该重启动一下。所以,不管 POSIX 自负地告诉你过什么,你都应该去重启动一下。
当你的系统重启动完毕之后,(使用 `Ctl+Alt+F3` 或类似快捷键)切换到一个文本控制台,并插入你的 U 盘。如果你运行了一个最新的内核,当你插入 U 盘后你或许可以看到一大堆输出。如果看到一个错误信息,比如 “Could not execute /usr/local/bin/trigger.sh”,或许是因为你忘了授予这个脚本可运行的权限。否则你将看到的是,一个设备插入,它得到内核设备分配的一些东西,等等。
现在,见证奇迹的时刻到了。
```
$ cat /tmp/udev.log
Tue Oct 31 01:35:28 NZDT 2035
```
如果你在 `/tmp/udev.log` 中看到了最新的日期和时间,那么说明 udev 已经成功触发了你的脚本。
### 改进规则做一些有用的事情
现在的问题是使用的规则太通用了。插入一个鼠标、一个 U 盘、或某个人的 U 盘都将盲目地触发这个脚本。现在,我们开始专注于希望触发你的脚本的是确定的某个 U 盘。
实现上述目标的一种方式是使用提供商 ID 和产品 ID。你可以使用 `lsusb` 命令去得到这些数字。
```
$ lsusb
Bus 001 Device 002: ID 8087:0024 Slacker Corp. Hub
Bus 002 Device 002: ID 8087:0024 Slacker Corp. Hub
Bus 003 Device 005: ID 03f0:3307 TyCoon Corp.
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 hub
Bus 001 Device 003: ID 13d3:5165 SBo Networks
```
在这个例子中,`TyCoon Corp` 前面的 `03f0:3307` 就表示了提供商 ID 和产品 ID 的属性。你也可以通过 `udevadm info -a -n /dev/sdb | grep vendor` 的输出来查看这些数字,但是从 `lsusb` 的输出中可以很容易地一眼找到这些数字。
现在,可以在你的脚本中包含这些属性了。
```
SUBSYSTEM=="block", ATTRS{idVendor}=="03f0", ACTION=="add", RUN+="/usr/local/bin/thumb.sh"
```
测试它(是的,为了确保不会有来自 udev 的影响因素,我们仍然建议先重新启动一下),它应该会像前面一样工作,现在,如果你插入一个不同公司制造的 U 盘(因为它们的提供商 ID 不一样)、或插入一个鼠标、或插入一个打印机,这个脚本将不会被触发。
继续添加新属性来进一步专注于你希望去触发你的脚本的那个唯一的 U 盘。使用 `udevadm info -a -n /dev/sdb` 命令,你可以找出像提供商名字、序列号、或产品名这样的东西。
为了保证思路清晰,确保每次只添加一个新属性。我们(和在网上看到的其他人)在 udev 规则中所遇到的大多数错误都是因为一次添加了太多的属性,而奇怪为什么不能正常工作了。逐个测试属性是最安全的作法,这样可以确保 udev 能够成功识别到你的设备。
### 安全
编写 udev 规则当插入一个驱动器后自动去做一些事情,将带来安全方面的担忧。在我的机器上,我甚至都没有打开自动挂载功能,而基于本文的目的,当设备插入时,脚本和规则可以运行一些命令来做一些事情。
在这里需要记住两个事情。
1. 聚焦于你的 udev 规则,当你真实地使用它们时,一旦让规则发挥作用将触发脚本。执行一个脚本去盲目地复制数据到你的计算上,或从你的计算机上复制出数据,是一个很糟糕的主意,因为有可能会遇到一个人拿着和你相同品牌的 U 盘插入到你的机器上的情况。
2. 不要在写了 udev 规则和脚本后忘记了它们的存在。我知道哪个计算上有我的 udev 规则,这些机器一般是我的个人计算机,而不是那些我带着去开会或办公室工作的计算机。一台计算机的 “社交” 程度越高,它就越不能有 udev 规则存在于它上面,因为它将潜在地导致我的数据最终可能会出现在某个人的设备、或某个人的数据中、或在我的设备上出现恶意程序。
换句话说就是,随着一个 GNU 系统提供了一个这么强大的功能,你的任务是小心地如何使用它们的强大功能。如果你滥用它或不小心谨慎地使用它,最终将让你出问题,它非常可能会导致可怕的问题。
### 现实中的 Udev
现在,你可以确认你的脚本是由 udev 触发的,那么,可以将你的关注点转到脚本功能上了。到目前为止,这个脚本是没有用的,它除了记录脚本已经运行过了这一事实外,再没有做更多的事情。
我使用 udev 去触发我的 U 盘的 [自动备份](https://gitlab.com/slackermedia/attachup) 。这个创意是,将我正在处理的文档的主副本保存在我的 U 盘上(因为我随身带着它,这样就可以随时处理它),并且在我每次将 U 盘插入到那台机器上时,这些主文档将备份回我的计算机上。换句话说就是,我的计算机是备份驱动器,而产生的数据是移动的。源代码是可用的,你可以随意查看 `attachup` 的代码,以进一步限制你的 udev 的测试示例。
虽然我使用 udev 最多的情况就是这个例子,但是 udev 能抓取很多的事件,像游戏手柄(当连接游戏手柄时,让系统去加载 xboxdrv 模块)、摄像头、麦克风(当指定的麦克风连接时用于去设置输入),所以应该意识到,它能做的事情远比这个示例要多。
我的备份系统的一个简化版本是由两个命令组成的一个过程:
```
SUBSYSTEM=="block", ATTRS{idVendor}=="03f0", ACTION=="add", SYMLINK+="safety%n"
SUBSYSTEM=="block", ATTRS{idVendor}=="03f0", ACTION=="add", RUN+="/usr/local/bin/trigger.sh"
```
第一行使用属性去检测我的 U 盘,这在前面已经讨论过了,接着在设备树中为我的 U 盘分配一个符号链接,给它分配的符号连接是 `safety%n`。这个 `%n` 是一个 udev 宏,它是内核分配给这个设备的任意数字,比如 sdb1、sdb2、sdb3、等等。因此 `%n` 应该是 1 或 2 或 3。
这将在 dev 树中创建一个符号链接,因此它不会干涉插入一个设备的正常过程。这意味着,如果你在自动挂载设备的桌面环境中使用它,将不会出现问题。
第二行运行这个脚本。
我的备份脚本如下:
```
#!/usr/bin/bash
mount /dev/safety1 /mnt/hd
sleep 2
rsync -az /mnt/hd/ /home/seth/backups/ && umount /dev/safety1
```
这个脚本使用符号链接,这将避免出现 udev 命名导致的意外情况(例如,假设一个命名为 DISK 的 U 盘已经插入到我的计算机上,而我插入的其它 U 盘恰好名字也是 DISK,那么第二个 U 盘的卷标将被命名为 `DISK_`,这将导致我的脚本不会正常运行),它在我喜欢的挂载点 `/mnt/hd` 上挂载了 `safety1`(驱动器的第一个分区)。
一旦 `safely` 挂载之后,它将使用 [rsync](https://opensource.com/article/17/1/rsync-backup-linux) 将驱动器备份到我的备份文件夹(我真实使用的脚本用的是 `rdiff-backup`,而你可以使用任何一个你喜欢的自动备份解决方案)。
### udev 让你的设备你做主
udev 是一个非常灵活的系统,它可以让你用其它系统很少敢提供给用户的方式去定义规则和功能。学习它,使用它,去享受 POSIX 的强大吧。
本文内容来自 [Slackermedia Handbook](http://slackermedia.info/handbook/doku.php?id=backup),它以 [GNU Free Documentation License 1.3](http://www.gnu.org/licenses/fdl-1.3.html) 许可证授权使用。
---
via: <https://opensource.com/article/18/11/udev>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Udev is the Linux subsystem that supplies your computer with device events. In plain English, that means it's the code that detects when you have things plugged into your computer, like a network card, external hard drives (including USB thumb drives), mouses, keyboards, joysticks and gamepads, DVD-ROM drives, and so on. That makes it a potentially useful utility, and it's well-enough exposed that a standard user can manually script it to do things like performing certain tasks when a certain hard drive is plugged in.
This article teaches you how to create a [udev](https://linux.die.net/man/8/udev) script triggered by some udev event, such as plugging in a specific thumb drive. Once you understand the process for working with udev, you can use it to do all manner of things, like loading a specific driver when a gamepad is attached, or performing an automatic backup when you attach your backup drive.
## A basic script
The best way to work with udev is in small chunks. Don't write the entire script upfront, but instead start with something that simply confirms that udev triggers some custom event.
Depending on your goal for your script, you can't guarantee you will ever see the results of a script with your own eyes, so make sure your script logs that it was successfully triggered. The usual place for log files is in the **/var** directory, but that's mostly the root user's domain. For testing, use **/tmp**, which is accessible by normal users and usually gets cleaned out with a reboot.
Open your favorite text editor and enter this simple script:
```
#!/usr/bin/bash
/usr/bin/date >> /tmp/udev.log
```
Place this in **/usr/local/bin** or some such place in the default executable path. Call it **trigger.sh** and, of course, make it executable with **chmod +x**.
```
$ sudo mv trigger.sh /usr/local/bin
$ sudo chmod +x /usr/local/bin/trigger.sh
```
This script has nothing to do with udev. When it executes, the script places a timestamp in the file **/tmp/udev.log**. Test the script yourself:
```
$ /usr/local/bin/trigger.sh
$ cat /tmp/udev.log
Tue Oct 31 01:05:28 NZDT 2035
```
The next step is to make udev trigger the script.
## Unique device identification
In order for your script to be triggered by a device event, udev must know under what conditions it should call the script. In real life, you can identify a thumb drive by its color, the manufacturer, and the fact that you just plugged it into your computer. Your computer, however, needs a different set of criteria.
Udev identifies devices by serial numbers, manufacturers, and even vendor ID and product ID numbers. Since this is early in your udev script's lifespan, be as broad, non-specific, and all-inclusive as possible. In other words, you want first to catch nearly any valid udev event to trigger your script.
With the **udevadm monitor** command, you can tap into udev in real time and see what it sees when you plug in different devices. Become root and try it.
```
$ su
# udevadm monitor
```
The monitor function prints received events for:
- UDEV: the event udev sends out after rule processing
- KERNEL: the kernel uevent
With **udevadm monitor** running, plug in a thumb drive and watch as all kinds of information is spewed out onto your screen. Notice that the type of event is an **ADD** event. That's a good way to identify what type of event you want.
The **udevadm monitor** command provides a lot of good info, but you can see it with prettier formatting with the command **udevadm info**, assuming you know where your thumb drive is currently located in your **/dev** tree. If not, unplug and plug your thumb drive back in, then immediately issue this command:
`$ su -c 'dmesg | tail | fgrep -i sd*'`
If that command returned **sdb: sdb1**, for instance, you know the kernel has assigned your thumb drive the **sdb** label.
Alternately, you can use the **lsblk** command to see all drives attached to your system, including their sizes and partitions.
Now that you have established where your drive is located in your filesystem, you can view udev information about that device with this command:
`# udevadm info -a -n /dev/sdb | less`
This returns a lot of information. Focus on the first block of info for now.
Your job is to pick out parts of udev's report about a device that are most unique to that device, then tell udev to trigger your script when those unique attributes are detected.
The **udevadm info** process reports on a device (specified by the device path), then "walks" up the chain of parent devices. For every device found, it prints all possible attributes using a key-value format. You can compose a rule to match according to the attributes of a device plus attributes from one single parent device.
```
looking at device '/devices/000:000/blah/blah//block/sdb':
KERNEL=="sdb"
SUBSYSTEM=="block"
DRIVER==""
ATTR{ro}=="0"
ATTR{size}=="125722368"
ATTR{stat}==" 2765 1537 5393"
ATTR{range}=="16"
ATTR{discard\_alignment}=="0"
ATTR{removable}=="1"
ATTR{blah}=="blah"
```
A udev rule must contain one attribute from one single parent device.
Parent attributes are things that describe a device from the most basic level, such as *it's something that has been plugged into a physical port* or *it is something with a size* or *this is a removable device*.
Since the KERNEL label of **sdb** can change depending upon how many other drives were plugged in before you plugged that thumb drive in, that's not the optimal parent attribute for a udev rule. However, it works for a proof of concept, so you could use it. An even better candidate is the SUBSYSTEM attribute, which identifies that this is a "block" system device (which is why the **lsblk** command lists the device).
Open a file called **80-local.rules** in **/etc/udev/rules.d** and enter this code:
`SUBSYSTEM=="block", ACTION=="add", RUN+="/usr/local/bin/trigger.sh"`
Save the file, unplug your test thumb drive, and reboot.
Wait, *reboot* on a Linux machine?
Theoretically, you can just issue **udevadm control --reload**, which should load all rules, but at this stage in the game, it's best to eliminate all variables. Udev is complex enough, and you don't want to be lying in bed all night wondering if that rule didn't work because of a syntax error or if you just should have rebooted. So reboot regardless of what your POSIX pride tells you.
When your system is back online, switch to a text console (with Ctl+Alt+F3 or similar) and plug in your thumb drive. If you are running a recent kernel, you will probably see a bunch of output in your console when you plug in the drive. If you see an error message such as *Could not execute /**usr**/local/bin/trigger.sh*, you probably forgot to make the script executable. Otherwise, hopefully all you see is a device was plugged in, it got some kind of kernel device assignment, and so on.
Now, the moment of truth:
```
$ cat /tmp/udev.log
Tue Oct 31 01:35:28 NZDT 2035
```
If you see a very recent date and time returned from **/tmp/udev.log**, udev has successfully triggered your script.
## Refining the rule into something useful
The problem with this rule is that it's very generic. Plugging in a mouse, a thumb drive, or someone else's thumb drive will indiscriminately trigger your script. Now is the time to start focusing on the exact thumb drive you want to trigger your script.
One way to do this is with the vendor ID and product ID. To get these numbers, you can use the **lsusb** command.
```
$ lsusb
Bus 001 Device 002: ID 8087:0024 Slacker Corp. Hub
Bus 002 Device 002: ID 8087:0024 Slacker Corp. Hub
Bus 003 Device 005: ID 03f0:3307 TyCoon Corp.
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 hub
Bus 001 Device 003: ID 13d3:5165 SBo Networks
```
In this example, the **03f0:3307** before **TyCoon Corp.** denotes the idVendor and idProduct attributes. You can also see these numbers in the output of **udevadm info -a -n /dev/sdb | grep vendor**, but I find the output of **lsusb** a little easier on the eyes.
You can now include these attributes in your rule.
`SUBSYSTEM=="block", ATTRS{idVendor}=="03f0", ACTION=="add", RUN+="/usr/local/bin/thumb.sh"`
Test this (yes, you should still reboot, just to make sure you're getting fresh reactions from udev), and it should work the same as before, only now if you plug in, say, a thumb drive manufactured by a different company (therefore with a different idVendor) or a mouse or a printer, the script won't be triggered.
Keep adding new attributes to further focus in on that *one* unique thumb drive you want to trigger your script. Using **udevadm info -a -n /dev/sdb**, you can find out things like the vendor name, sometimes a serial number, or the product name, and so on.
For your own sanity, be sure to add only one new attribute at a time. Most mistakes I have made (and have seen other people online make) is to throw a bunch of attributes into their udev rule and wonder why the thing no longer works. Testing attributes one by one is the safest way to ensure udev can identify your device successfully.
## Security
This brings up the security concerns of writing udev rules to automatically do something when a drive is plugged in. On my machines, I don't even have auto-mount turned on, and yet this article proposes scripts and rules that execute commands just by having something plugged in.
Two things to bear in mind here.
- Focus your udev rules once you have them working so they trigger scripts
*only*when you really want them to. Executing a script that blindly copies data to or from your computer is a bad idea in case anyone who happens to be carrying the same brand of thumb drive plugs it into your box. - Do not write your udev rule and scripts and forget about them. I know which computers have my udev rules on them, and those boxes are most often my personal computers, not the ones I take around to conferences or have in my office at work. The more "social" a computer is, the less likely it is to get a udev rule on it that could potentially result in my data ending up on someone else's device or someone else's data or malware on
*my*device.
In other words, as with so much of the power provided by a GNU system, it is your job to be mindful of how you are wielding that power. If you abuse it or fail to treat it with respect, it very well could go horribly wrong.
## Udev in the real world
Now that you can confirm that your script is triggered by udev, you can turn your attention to the function of the script. Right now, it is useless, doing nothing more than logging the fact that it has been executed.
I use udev to trigger [automated backups](https://gitlab.com/slackermedia/attachup) of my thumb drives. The idea is that the master copies of my active documents are on my thumb drive (since it goes everywhere I go and could be worked on at any moment), and those master documents get backed up to my computer each time I plug the drive into that machine. In other words, my computer is the backup drive and my production data is mobile. The source code is available, so feel free to look at the code of attachup for further examples of constraining your udev tests.
Since that's what I use udev for the most, it's the example I'll use here, but udev can grab lots of other things, like gamepads (this is useful on systems that aren't set to load the xboxdrv module when a gamepad is attached) and cameras and microphones (useful to set inputs when a specific mic is attached), so realize that it's good for a lot more than this one example.
A simple version of my backup system is a two-command process:
```
SUBSYSTEM=="block", ATTRS{idVendor}=="03f0", ACTION=="add", SYMLINK+="safety%n"
SUBSYSTEM=="block", ATTRS{idVendor}=="03f0", ACTION=="add", RUN+="/usr/local/bin/trigger.sh"
```
The first line detects my thumb drive with the attributes already discussed, then assigns the thumb drive a symlink within the device tree. The symlink it assigns is **safety%n**. The **%n** is a udev macro that resolves to *whatever number the kernel gives to the device*, such as sdb1, sdb2, sdb3, and so on. So **%n** would be the 1 or the 2 or the 3.
This creates a symlink in the dev tree, so it does not interfere with the normal process of plugging in a device. This means that if you use a desktop environment that likes to auto-mount devices, you won't be causing problems for it.
The second line runs the script.
My backup script looks like this:
```
#!/usr/bin/bash
mount /dev/safety1 /mnt/hd
sleep 2
rsync -az /mnt/hd/ /home/seth/backups/ && umount /dev/safety1
```
The script uses the symlink, which avoids the possibility of udev naming the drive something unexpected (for instance, if I have a thumb drive called DISK plugged into my computer already, and I plug in my other thumb drive also called DISK, the second one will be labeled DISK_, which would foil my script). It mounts **safety1** (the first partition of the drive) at my preferred mount point of **/mnt/hd**.
Once safely mounted, it uses [rsync](https://opensource.com/article/17/1/rsync-backup-linux) to back up the drive to my backup folder (my actual script uses rdiff-backup, and yours can use whatever automated backup solution you prefer).
## Udev is your dev
Udev is a very flexible system and enables you to define rules and functions in ways that few other systems dare provide users. Learn it and use it, and enjoy the power of POSIX.
*This article builds on content from the Slackermedia Handbook, which is licensed under the GNU Free Documentation License 1.3.*
## 6 Comments |
10,330 | NASA 在开放科学方面做了些什么 | https://itsfoss.com/nasa-open-science/ | 2018-12-10T18:55:27 | [
"NASA",
"开源"
] | https://linux.cn/article-10330-1.html | 
最近我们刚为开设了一个新的“[科学类](https://itsfoss.com/category/science/)”的文章分类。其中发表的最新一篇文章名为:[开源是怎样影响科学的](https://itsfoss.com/open-source-impact-on-science/)。在这篇文章中我们主要讨论了 [NASA](https://www.nasa.gov/) 的积极努力,这些努力包括他们通过开源实践来促进科学研究的积极作用。
### NASA 是怎样使用开源手段促进科学研究的
NASA 将他们的整个研究库对整个公共领域开放,这是一项[壮举](https://futurism.com/free-science-nasa-just-opened-its-entire-research-library-to-the-public/)。
没错!每个人都能访问他们的整个研究库,并能从他们的研究中获益。
他们现已开放的资料可以大致分为以下三类:
* 开源 NASA
* 开放 API
* 开放数据
### 1、开源 NASA
这里有一份 [GitHub](https://github.com/) 的联合创始人之一和执行总裁 [Chris Wanstrath](http://chriswanstrath.com/) 的采访,他向我们介绍道,一切都是从很多年前开始的。
该项目名为 “[code.nasa.gov](http://code.nasa.gov)”,截至本文发表为止,NASA 已经[通过 GitHub 开源](https://github.com/open-source)了 365 个科学软件(LCTT 译注:本文原文发表于 2018/3/28,截止至本译文发布,已经有 454 个项目了)。对于一位热爱程序的开发者来说,即使一天研究一个软件,想把 NASA 的这些软件全部研究过来也要整整一年的时间。
即使你不是一位开发者,你也可以在这个门户网站浏览这个壮观的软件合集。
其中就有[阿波罗 11 号](https://www.nasa.gov/mission_pages/apollo/missions/apollo11.html)的制导计算机的源代码。阿波罗 11 号空间飞行器[首次将两名人类带上月球](https://www.space.com/16758-apollo-11-first-moon-landing.html),分别是 [Neil Armstrong](https://www.jsc.nasa.gov/Bios/htmlbios/armstrong-na.html) 和 [Edwin Aldrin](https://www.jsc.nasa.gov/Bios/htmlbios/aldrin-b.html) 。如果你对 Edwin Aldrin 感兴趣,可以点击[这里](https://buzzaldrin.com/the-man/)了解更多。
#### NASA 开源代码促进会使用的开源代码许可
它们采用了几种[开源许可证](https://itsfoss.com/open-source-licenses-explained/),其分类如下:
* [Apache 许可证 2.0](https://www.apache.org/licenses/LICENSE-2.0)
* [Nasa 开源许可证 3.0](https://opensource.org/licenses/NASA-1.3)
* [GPL v3](https://www.gnu.org/licenses/gpl.html)
* [MIT 许可证](https://en.wikipedia.org/wiki/MIT_License)
### 2、开放 API
开放 [API](https://en.wikipedia.org/wiki/Application_programming_interface) 在推行开放科学中起到了很大作用。与[开源促进会](https://opensource.org/)类似,对于 API,也有一个 [开放 API 促进会](https://www.openapis.org/)。下面这张示意图可以告诉你 API 是怎样将应用程序和它的开发者连接起来的。

记得点击这个[链接](https://sproutsocial.com/insights/what-is-an-api/)看看。链接内的文章使用了简单易懂的方法解读了 API ,文末总结了五大要点。

这会让你感受到专有 API 和开放 API 会有多么大的不同。

[NASA 的 Open API](https://api.nasa.gov/) 主要针对应用程序开发者,旨在显著改善数据的可访问性,也包括图片内容在内。该网站有一个实时编辑器,可供你调用[每日天文一图(APOD)](https://apod.nasa.gov/apod/astropix.html) 的 API。
#### 3、开放数据

在[我们发布的第一篇开放科学的文章](https://itsfoss.com/open-source-impact-on-science/)中,我们在“开放科学”段落下提到的三个国家 —— 法国、印度和美国的多种开放数据形式。NASA 有着类似的想法和行为。这种重要的意识形态已经被[多个国家](https://www.xbrl.org/the-standard/why/ten-countries-with-open-data/)所接受。
[NASA 的开放数据门户](https://data.nasa.gov/)致力于开放,拥有不断增长的可供大众自由使用的开放数据。将数据集纳入到这个数据集对于任何研究活动来说都是必要且重要的。NASA 还在他们的门户网站上征集各方的数据需求,以一同收录在他们的数据库中。这一举措不仅是领先的、创新的,还顺应了[数据科学](https://en.wikipedia.org/wiki/Data_science)、[AI 和深度学习](https://www.kdnuggets.com/2017/07/ai-deep-learning-explained-simply.html)的趋势。
下面的视频讲的是学者和学生们是怎样通过大量研究得出对数据科学的定义的。这个过程十分的激动人心。瑞尔森大学罗杰斯商学院的 [Murtaza Haider 教授](https://www.ryerson.ca/tedrogersschool/bm/programs/real-estate-management/murtaza-haider/)在视频结尾中提到了开源的出现对数据科学的改变,尤其让是旧有的闭源方式逐渐变得开放。而这也确实成为了现实。

现在任何人都能在 NASA 上征集数据。正如前面的视频中所说,NASA 的举措很大程度上与征集和分析优化数据有关。

你只需要免费注册即可。考虑到论坛上的公开讨论以及数据集在可能存在的每一类分析领域中的重要性,这一举措在未来会有非常积极的影响,对数据的统计分析当然也会大幅进展。在之后的文章中我们还会具体讨论这些细节,还有它们和开源模式之间的相关性。
以上就是对 NASA 开放科学模式的一些探索成就,希望您能继续关注我们接下来的相关文章!
---
via: <https://itsfoss.com/nasa-open-science/>
作者:[Avimanyu Bandyopadhyay](https://itsfoss.com/author/avimanyu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Valoniakim](https://github.com/Valoniakim) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

## How NASA is using Open Source approach to improve science
It was a great [initiative](https://futurism.com/free-science-nasa-just-opened-its-entire-research-library-to-the-public/?ref=itsfoss.com) by NASA that they made their entire research library freely available on the public domain.
Yes! Entire research library for everyone to access and get benefit from it in their research.
Their open science resources can now be mainly classified into these three categories as follows:
- Open Source NASA
- Open API
- Open Data
### 1. Open Source NASA
Here’s an interesting interview of [Chris Wanstrath](http://chriswanstrath.com/?ref=itsfoss.com), co-founder and CEO of [GitHub](https://github.com/?ref=itsfoss.com), about how it all began to form many years ago:
Uniquely named “[code.nasa.gov](http://code.nasa.gov/?ref=itsfoss.com)“, NASA now has precisely 365 scientific software available as [open source via GitHub](https://github.com/open-source?ref=itsfoss.com) as of the time of this post. So if you are a developer who loves coding, you can study each one of them every day for a year’s time!
Even if you are not a developer, you can still browse through the fantastic collection of open source packages enlisted on the portal!
One of the interesting open source packages listed here is the source code of [Apollo 11](https://www.nasa.gov/mission_pages/apollo/missions/apollo11.html?ref=itsfoss.com)‘s guidance computer. The Apollo 11 spaceflight took [the first two humans to the Moon](https://www.space.com/16758-apollo-11-first-moon-landing.html?ref=itsfoss.com), namely, [Neil Armstrong](https://www.jsc.nasa.gov/Bios/htmlbios/armstrong-na.html?ref=itsfoss.com) and [Edwin Aldrin](https://www.jsc.nasa.gov/Bios/htmlbios/aldrin-b.html?ref=itsfoss.com) ! If you want to know more about Edwin Aldrin, you might want to pay a visit [here](https://buzzaldrin.com/the-man/?ref=itsfoss.com).
#### Licenses being used by NASA’s Open Source Initiative:
Here are the different [open source licenses](https://itsfoss.com/open-source-licenses-explained/) categorized as under:
### 2. Open API
An Open [Application Programming Interface](https://en.wikipedia.org/wiki/Application_programming_interface?ref=itsfoss.com) or API plays a significant role in practicing Open Science. Just like [The Open Source Initiative](https://opensource.org/?ref=itsfoss.com), there is also one for API, called [The Open API Initiative](https://www.openapis.org/?ref=itsfoss.com). Here is a simple illustration of how an API bridges an application with its developer:
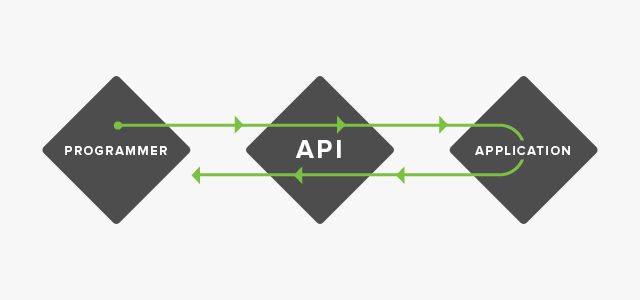
Do check out the link in the caption in the image above. The API has been explained in a straightforward manner. It concludes with five exciting takeaways in the end.
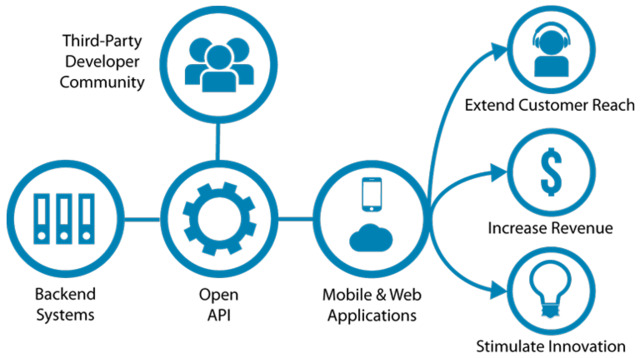
Makes one wonder how different [an open vs a proprietary API](http://www.apiacademy.co/resources/api-strategy-lesson-201-private-apis-vs-open-apis/?ref=itsfoss.com) would be.
Targeted towards application developers, [NASA’s open API](https://api.nasa.gov/?ref=itsfoss.com) is an initiative to significantly improve the accessibility of data that could also contain image content. The site has a live editor, allowing you check out the [API](https://en.wikipedia.org/wiki/Application_programming_interface?ref=itsfoss.com) behind [Astronomy Picture of the Day (APOD)](https://apod.nasa.gov/apod/astropix.html?ref=itsfoss.com).
### 3. Open Data
[NASA’s Open Data Portal](https://data.nasa.gov/?ref=itsfoss.com)
In [our first science article](https://itsfoss.com/open-source-impact-on-science/), we shared with you the various open data models of three countries mentioned under the “Open Science” section, namely, France, India and the U.S. NASA also has a similar approach towards the same idea. This is a very important ideology that is being adopted by [many countries](https://www.xbrl.org/the-standard/why/ten-countries-with-open-data/?ref=itsfoss.com).
[NASA’s Open Data Portal](https://data.nasa.gov/?ref=itsfoss.com) focuses on openness by having an ever-growing catalog of data, available for anyone to access freely. The inclusion of datasets within this collection is an essential and radical step towards the development of research of any kind. NASA have even taken a fantastic initiative to ask for dataset suggestions for submission on their portal and that’s really very innovative, considering the growing trends of [data science](https://www.odinschool.com/blog/statistics-for-data-science-importance-skills-demand-and-salary), [AI and deep learning](https://www.kdnuggets.com/2017/07/ai-deep-learning-explained-simply.html?ref=itsfoss.com).
The following video shows students and scientists coming up with their own definitions of Data Science based on their personal experience and research. That is really encouraging! [Dr. Murtaza Haider](https://www.ryerson.ca/tedrogersschool/bm/programs/real-estate-management/murtaza-haider/?ref=itsfoss.com), Ted Rogers School of Management, Ryerson University, mentions the difference Open Source is making in the field of Data Science before the video ends. He explains in very simple terms, how development models transitioned from a closed source approach to an open one. The vision has proved to be sufficiently true enough in today’s time.

Now anyone can suggest a dataset of any kind on NASA. Coming back to the video above, NASA’s initiative can be related so much with submitting datasets and working on analyzing them for better Data Science!
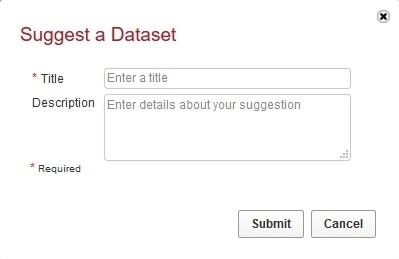
You just need to signup for free. This initiative will have a very positive effect in the future, considering open discussions on the public forum and the significance of datasets in every type of analytical field that could exist. Statistical studies will also significantly improve for sure. We will talk about these concepts in detail in a future article and also about their relativeness to an open source model.
So thus concludes an exploration into NASA’s open science model. See you soon in another open science article! |
10,331 | 一个免费、安全、跨平台的密码管理器 | https://www.ostechnix.com/buttercup-a-free-secure-and-cross-platform-password-manager/ | 2018-12-10T22:24:00 | [
"密码管理器"
] | https://linux.cn/article-10331-1.html | 
在这个现代化的互联网时代,你一定在许多网站上有多个账户,它可能是个人或官方邮箱账户、社交或专业网络账户、GitHub 账户和电子商务账户等。因此,对于不同的账户,你应该设置多个不同的密码。我相信你应该已经意识到为多个账户设置相同的密码是件疯狂又危险的事情。如果攻击者设法破解了你的一个账户,那么他/她很可能尝试使用相同的密码访问你的其他账户。所以,**强烈建议为不同的账户设置不同的密码**。
不过,记住好几个密码是很困难的。你可以把它们写在纸上,但那也不是一个有效的方法,你可能会在一段时间后失去它们。这时密码管理器就派上用场了。密码管理器就像一个存储库,你可以在其中存储不同账户的所有密码,并用一个主密码将其锁定。这样,你需要记住的就只剩下主密码了。之前我们介绍过一个叫 [KeeWeb](/article-10211-1.html) 的开源密码管理器,今天,我们将介绍另外一款密码管理器 ——— Buttercup。
### 关于 Buttercup
Buttercup 是一个自由、开源、安全、跨平台的密码管理器,使用 **NodeJS** 编写。它可以帮助你将不同账户的所有登录凭证存储到加密存档中,该存档可以保存在本地系统或任何远程服务(如 DropBox、OwnCloud、NextCloud 和基于 WebDAV 的服务)中。它使用强大的 **256 位 AES 加密算法**,用主密码保存你的敏感数据。所以,除了拥有主密码的人以外,没有人可以访问你的登录信息。Buttercup 目前支持 Linux、Mac OS 和 Windows,还提供了一个浏览器扩展和移动应用程序。因此,你也可以在 Android 和 iOS 设备中的桌面应用程序和浏览器扩展程序中使用相同的存档。
### 安装 Buttercup 密码管理器
Buttercup 目前在 Linux 平台上有 .deb、.rpm 软件包、可移植的 AppImage 和 tar 归档文件等安装包。转到其 [发布页](https://github.com/buttercup/buttercup-desktop/releases/latest) 下载安装你想要的版本。
Buttercup 桌面应用程序在 [AUR](https://aur.archlinux.org/packages/buttercup-desktop/) 中也可用,你可以使用 AUR 帮助程序(如 [Yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/))在基于 Arch 的系统上安装,如下所示:
```
$ yay -S buttercup-desktop
```
如果你已经下载了方便的 AppImage 文件,使用如下命令让它执行:
```
$ chmod +x buttercup-desktop-1.11.0-x86_64.AppImage
```
然后,使用命令启动它:
```
$ ./buttercup-desktop-1.11.0-x86_64.AppImage
```
运行此命令后,会提示是否要将 Buttercup AppImage 集成到你的系统中。如果选择 “Yes”,则会将其添加到应用程序菜单并安装图标。如果不这样做,你仍然可以通过双击 AppImage 或在终端中使用上述命令启动应用程序。
### 添加存档
第一次启动时,会看到下面的欢迎界面:

我们还没有添加任何存档,所以让我们添加一个吧。单击 “New Archive File” 按钮,输入存档文件的名称,并选择它的保存位置。

你可以随意命名。我把它命名为 “mypass”,存档将以 .bcup 为扩展名保存在你选择的位置。
如果你已经创建了一个,只需单击 “Open Archive File” 来选择它。
接下来,Buttercup 将提示你为新创建的存档输入主密码,建议提供一个强级别的密码,以保护存档不会被未经授权访问。

现在我们已经创建了一个存档并使用主密码对其进行了保护。类似地,你可以创建任意数量的存档,并使用密码保护它们。
让我们继续在存档中添加账户的详细信息。
### 在存档中添加条目(登录凭证)
创建或打开存档后,你将看到下面的界面。

它就像一个保险库,我们将保存不同账户的登录凭证。如你所见,我们并没有添加任何条目。让我们添加一些。
点击右下角的 “ADD ENTRY” 按钮来添加新的条目,输入你想要保存的账户的信息。

在每个条目下面都有一个 “ADD NEW FIELD” 选项,可以用来添加其他的细节。只需点击它,然后添加要包含在条目中的字段。
添加完所有条目后,你将在 Buttercup 界面的右侧窗格中看到它们。

### 添加新的分组
你还可以将登录的详细信息分组到不同的名称下,以便于识别。例如,你可以将所有邮箱账户分组到一个名为 “my\_mails” 的名称下。默认情况下,你的登录详细信息将保存在 “General” 群组下。要创建新的群组,请点击 “NEW GROUP” 按钮并输入名称。在新的群组中创建新条目时,与上述的步骤相同,只需单击组名并开始添加条目。
### 管理和访问登录的详细信息
存储在存档中的数据可以随时编辑、移动到其他组或彻底删除。例如,如果要将用户名或密码复制到剪切板,请右击该条目,然后选择 “Copy to Clipboard”。

要进一步编辑/修改数据,只需点击所选条目下的 “Edit” 按钮。
### 在远程保存存档
默认情况下,Buttercup 会将数据保存在本地系统上。但是,你可以将它们保存在不同的远程服务(例如 Dropbox、OwnCloud、NextCloud 和基于 WebDAV 的服务)上。
要连接这些服务,请点击 “File -> Connect Cloud Sources”。

接下来,选择要连接的服务并对其授权以保存数据。

你还可以在添加存档时在 Buttercup 的欢迎界面连接这些服务。
### 导入/导出
Buttercup 允许你向其他密码管理器(例如 1Password、Lastpass 和 KeePass)导入导出数据。你也可以导出数据,在另一个系统或设备(例如 Android)中访问它们。你还可以将 Buttercup 保险库导出为 CSV 格式文件。

Buttercup 是一个简单但成熟、功能齐全的密码管理器。多年来它一直在积极开发。如果你需要密码管理器,Buttercup 可能是个不错的选择。有关更多的详细信息,请参阅项目网站和 GitHub 页面。
那就介绍到这里,希望它对你有用。更多的精彩内容即将到来,敬请关注!
谢谢!
### 资源
* [Buttercup 网站](https://buttercup.pw/)
* [Buttercup GitHub 仓库](https://github.com/buttercup/buttercup-desktop)
---
via: <https://www.ostechnix.com/buttercup-a-free-secure-and-cross-platform-password-manager/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[seriouszyx](https://github.com/seriouszyx) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,332 | 极客漫画:编程语言之战 | http://turnoff.us/geek/programming-languages-battle/ | 2018-12-10T22:34:04 | [
"编程语言"
] | https://linux.cn/article-10332-1.html | 
这篇漫画生动的描绘了不同时期不同编程语言的“战争”。
COBOL 是一种面向数据处理的、面向文件的、面向过程(POL)的高级编程语言,功能强大,但缺点是语法繁杂,代码冗长(看它肥的)。而 Java 当时还是个弱小的新生事物。
后来,Java 慢慢发展壮大了,内存吃的越来越多了(都和 COBOL 一样又高又肥了),当 Java 准备再去打一架的时候,COBOL 提醒他注意身后想打他们两个的三个小娃娃(Scala、Kotlin、Go)。
长江后浪推前浪。编程语言的发展很快,不停的会有功能更强的新“轮子”出现在我们眼前。而我们则需了解各个语言的优缺点,与时俱进地看待它们。
---
via: <http://turnoff.us/geek/programming-languages-battle/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者:[ItsLucas](https://github.com/ItsLucas) 点评:[ItsLucas](https://github.com/ItsLucas) 校对:[Bestony](https://github.com/bestony) 合成:[Bestony](https://github.com/bestony)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,333 | 感谢开源和自由软件维护者的 10 种方法 | https://opensource.com/article/18/11/ways-give-thanks-open-source | 2018-12-11T12:48:23 | [
"感谢"
] | https://linux.cn/article-10333-1.html |
>
> 如何表达你的感激之情。
>
>
>

每天,我使用的那些高质量的软件 —— 开发和维护这些软件的人不需要我为之付款,他们尊重我的自由,并且慷慨地付出时间和精力。
在这个感恩的季节,我鼓励那些也使用和欣赏开源和自由软件维护者工作的人表达你的感激之情。以下是十种方法:
### 容易做到的
1、发送电子邮件感谢开发人员。具体点说,告诉他们你使用他们的什么软件以及它是如何帮助了你。
2、使用你最喜爱的社交媒体平台宣传它。
3、写一篇关于你最喜欢的软件的博客文章。
### 捐款
4、如果你最喜欢的开源项目接受捐款,请汇款。
5、如果你受雇于使用开源软件的公司,看你是否可以说服管理层赞助某些项目。
6、尽你所能地捐款。社交动机能做的不可思议!
### 花费时间
7、帮助审查补丁。
8、帮助分类 bug。
9、回答 IRC、邮件列表或 [Stack Overflow](https://meta.stackoverflow.com/) 中的问题。
**10、额外的:**如果你像我一样,你在某个时候对开源社区的其他人说了一些严厉的话。承诺做得更好:用善良和开放沟通。感谢的最好方式是让开源社区成为人们能舒适沟通的地方。
---
via: <https://opensource.com/article/18/11/ways-give-thanks-open-source>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Every day, I use high-quality software that is developed and maintained by people who do not ask for payment, who respect my freedoms, and who are generous with their time and energy.
In this season of giving thanks, I encourage those of you who also use and appreciate the work of open source and free software maintainers to express your gratitude. Here are ten ways to do that:
## Easy to do
- Send an e-mail thanking the developers. Be specific—tell them what you are using their software for and how it has benefited you.
- Use your favorite social media platform to spread the word.
- Write a blog post about your favorite software.
## Give money
- If your favorite open source projects accept donations, send money.
- If you are employed by a company that uses open source software, see if you can convince management to sponsor some of the projects.
- Offer to match donations up to a set amount. It is amazing what social motivation can do!
## Give time
- Help review patches.
- Help triage bugs.
- Answer questions on IRC, mailing lists, or
[Stack Overflow](https://meta.stackoverflow.com/).
**10. Bonus:** If you are like me, you have at some point said harsh words to other people in the open source community. Commit to do better: Communicate with kindness and openness. The best way to give thanks is to make the open source community a place where people feel comfortable communicating.
## 4 Comments |
10,334 | Emacs 系列(四):使用 Org 模式自动管理邮件及同步文档 | http://changelog.complete.org/archives/9898-emacs-4-automated-emails-to-org-mode-and-org-mode-syncing | 2018-12-11T13:05:44 | [
"Emacs",
"Org模式"
] | https://linux.cn/article-10334-1.html | 
这是 [Emacs 和 Org 模式系列](https://www.emacswiki.org/emacs/mu4e)的第四篇。
至今为止,你已经见识到了 Org 模式的强大和高效,如果你像我一样,你可能会想:
>
> “我真的很想让它在我所有的设备上同步。”
>
>
>
或者是说:
>
> “我能在 Org 模式中转发邮件吗?”
>
>
>
答案当然是肯定的,因为这就是 Emacs。
### 同步
由于 Org 模式只使用文本文件,所以使用任意工具都可以很容易地实现同步。我使用的是 git 的 `git-remote-gcrypt`。由于 `git-remote-gcrypt` 的一些限制,每台机器都倾向于推到自己的分支,并使用命令来控制。每台机器都会先合并其它所有的分支,然后再将合并后的结果推送到主干上。cron 作业可以实现将机器上的分支推送上去,而 elisp 会协调这一切 —— 确保在同步之前保存缓冲区,在同步之后从磁盘刷新缓冲区,等等。
这篇文章的代码有点多,所以我将把它链接到 github 上,而不是写在这里。
我有一个用来存放我所有的 Org 模式的文件的目录 `$HOME/org`,在 `~/org` 目录下有个 [Makefile](https://github.com/jgoerzen/public-snippets/blob/master/emacs/org-tools/Makefile) 文件来处理同步。该文件定义了以下目标:
* `push`: 添加、提交和推送到以主机命名的分支上
* `fetch`: 一个简单的 `git fetch` 操作
* `sync`: 添加、提交和拉取远程的修改,合并,并(假设合并成功)将其推送到以主机命名的分支和主干上
现在,在我的用户 crontab 中有这个:
```
*/15 * * * * make -C $HOME/org push fetch 2>&1 | logger --tag 'orgsync'
```
[与之相关的 elisp 代码](https://github.com/jgoerzen/public-snippets/blob/master/emacs/org-tools/emacs-config.org) 定义了一个快捷键(`C-c s`)来调用同步。多亏了 cronjob,只要文件被保存 —— 即使我没有在另一个机器上同步 —— 它们也会被拉取进来。
我发现这个设置非常好用。
### 用 Org 模式发邮件
在继续下去之前,首先要问自己一下:你真的需要它吗? 我用的是带有 [mu4e](https://www.emacswiki.org/emacs/mu4e) 的 Org 模式,而且它集成的也很好;任何 Org 模式的任务都可以通过 `Message-id` 链接到电子邮件,这很理想 —— 它可以让一个人做一些事情,比如提醒他在一周内回复一条消息。
然而,Org 模式不仅仅只有提醒。它还是一个知识库、创作系统等,但是并不是我所有的邮件客户端都使用 mu4e。(注意:移动设备中有像 MobileOrg 这样的应用)。我并没有像我想的那样经常使用它,但是它有它的用途,所以我认为我也应该在这里记录它。
现在我不仅想处理纯文本电子邮件。我希望能够处理附件、HTML 邮件等。这听起来很快就有问题了 —— 但是通过使用 ripmime 和 pandoc 这样的工具,情况还不错。
第一步就是要用某些方法将获取到的邮件放入指定的文件夹下。扩展名、特殊用户等。然后我用一个 [fetchmail 配置](https://github.com/jgoerzen/public-snippets/blob/master/emacs/org-tools/fetchmailrc.orgmail) 来将它拉取下来并运行我自己的 [insorgmail](https://github.com/jgoerzen/public-snippets/blob/master/emacs/org-tools/insorgmail) 脚本。
这个脚本就是处理所有有趣的部分了。它开始用 ripmime 处理消息,用 pandoc 将 HTML 的部分转换为 Org 模式的格式。 Org 模式的层次结构是用来尽可能最好地表示 email 的结构。使用 HTML 和其他工具时,email 可能会变得相当复杂,但我发现这对于我来说是可以接受的。
### 下一篇
我最后一篇关于 Org 模式的文章将讨论如何使用它来编写文档和准备幻灯片 —— 我发现自己对 Org 模式的使用非常满意,但这需要一些调整。
---
via: <http://changelog.complete.org/archives/9898-emacs-4-automated-emails-to-org-mode-and-org-mode-syncing>
作者:[John Goerzen](http://changelog.complete.org/) 译者:[oneforalone](https://github.com/oneforalone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 302 | Found | null |
10,335 | 在 Linux 命令行下进行时间管理 | https://opensource.com/article/18/2/getting-to-done-agile-linux-command-line | 2018-12-11T21:36:00 | [
"TODO",
"GTD"
] | /article-10335-1.html |
>
> 学习如何在命令行下用这些方法自己组织待办事项。
>
>
>

关于如何在命令行下进行<ruby> 时间管理 <rt> getting things done </rt></ruby>(GTD)有很多讨论。不知有多少文章在讲使用 ls 晦涩的选项、配合 Sed 和 Awk 的一些神奇的正则表达式,以及用 Perl 解析一大堆的文本。但这些都不是问题的重点。
本文章是关于“[如何完成](https://www.scruminc.com/getting-done/)”,在我们不需要图形桌面、网络浏览器或网络连接情况下,用命令行操作能实际完成事务的跟踪。为了达到这一点,我们将介绍四种跟踪待办事项的方式:纯文件文件、Todo.txt、TaskWarrior 和 Org 模式。
### 简单纯文本

*我喜欢用 Vim,其实你也可以用 Nano。*
最直接管理你的待办事项的方式就是用纯文本文件来编辑。只需要打开一个空文件,每一行添加一个任务。当任务完成后,删除这一行。简单有效,无论你用它做什么都没关系。不过这个方法也有两个缺点,一但你删除一行并保存了文件,它就是永远消失了。如果你想知道本周或者上周都做了哪些事情,就成了问题。使用简单文本文件很方便却也容易导致混乱。
### Todo.txt: 纯文件的升级版

*整洁,有条理,易用*
这就是我们要说的 [Todo.txt](http://todotxt.org/) 文件格式和应用程序。安装很简单,可从 GitHub [下载](https://github.com/todotxt/todo.txt-cli/releases)最新的版本解压后并执行命令 `sudo make install` 。

*也可以从 Git 克隆一个。*
Todo.txt 可以很容易的增加新任务,并能显示任务列表和已完成任务的标记:
| 命令 | 说明 |
| --- | --- |
| `todo.sh add "某任务"` | 增加 “某任务” 到你的待办列表 |
| `todo.sh ls` | 显示所有的任务 |
| `todo.sh ls due:2018-02-15` | 显示2018-02-15之前的所有任务 |
| `todo.sh do 3` | 标记任务3 为已完成任务 |
这个清单实际上仍然是纯文本,你可以用你喜欢的编辑器遵循[正确的格式](https://github.com/todotxt/todo.txt)编辑它。
该应用程序同时也内置了一个强大的帮助系统。

*你可以使用语法高亮的功能*
此外,还有许多附加组件可供选择,以及编写自己的附件组件规范。甚至有浏览器组件、移动设备应用程序和桌面应用程序支持 Todo.txt 的格式。

*GNOME的扩展组件*
Todo.txt 最大的缺点是缺少自动或内置的同步机制。大多数(不是全部)的浏览器扩展程序和移动应用程序需要用 Dropbox 实现桌面系统和应用程序直接的数据同步。如果你想内置同步机制,我们有……
### Taskwarrior: 现在我们用 Python 做事了

*花哨吗?*
[Taskwarrior](https://taskwarrior.org/) 是一个与 Todo.txt 有许多相同功能的 Python 工具。但不同的是它的数据保存在数据库里并具有内置的数据同步功能。它还可以跟踪即将要做的任务,可以提醒某个任务持续了多久,可以提醒你一些重要的事情应该马上去做。

*看起来不错*
[安装](https://taskwarrior.org/download/) Taskwarrior 可以通过通过发行版自带的包管理器,或通过 Python 命令 `pip` 安装,或者用源码编译。用法也和 Todo.txt 的命令完全一样:
| 命令 | 说明 |
| --- | --- |
| `task add "某任务"` | 增加 “某任务” 到任务清单 |
| `task list` | 列出所有任务 |
| `task list due``:today` | 列出截止今天的任务 |
| `task do 3` | 标记编号是3的任务为完成状态 |
Taskwarrior 还有漂亮的文本用户界面。

*我喜欢 Vit, 它的设计灵感来自 Vim*
不同于 Todo.txt,Taskwarrior 可以和本地或远程服务器同步信息。如果你希望运行自己的同步服务器可以使用名为 `taskd` 的非常基本的服务器,如果不使用自己的服务器也有好几个可用服务器。
Taskwarriot 还拥有一个蓬勃发展的插件和扩展生态系统,以及移动和桌面系统的应用。

*在 GNOME 下的 Taskwarrior 看起来还是很漂亮的。*
Taskwarrior 有一个唯一的缺点,你是不能直接修改待办任务的,这和其他的工具不一样。你只能把任务清单按照格式导出,然后修改导出文件后,重新再导入,这样相对于编辑器直接编辑任务还是挺麻烦的。
谁能给我们带来最大的希望呢……
### Emacs Org 模式:牛X的任务收割机

*Emacs 啥都有*
Emacs [Org 模式](https://orgmode.org/) 是目前为止最强大、最灵活的开源待办事项管理器。它支持多文件、使用纯文本、高度可定制、自动识别日期、截止日期和任务计划。相对于我们这里介绍的其他工具,它的配置也更复杂一些。但是一旦配置好,它可以比其他工具完成更多功能。如果你是熟悉或者是 [Bullet Journals](http://bulletjournal.com/) 的粉丝,Org 模式可能是在桌面程序里最像[Bullet Journals](http://bulletjournal.com/) 的了。
Emacs 能运行,Org 模式就能运行,一些移动应用程序可以和它很好交互。但是不幸的是,目前没有桌面程序或浏览器插件支持 Org 模式。尽管如此,Org 模式仍然是跟踪待办事项最好的应用程序之一,因为它确实很强大。
### 选择适合自己的工具
最后,这些程序目的是帮助你跟踪待办事项,并确保不会忘记做某个事情。这些程序的基础功能都大同小异,那一款适合你取决于多种因素。有的人需要自带同步功能,有的人需要一个移动客户端,有的人要必须支持插件。不管你选择什么,请记住程序本身不会让你更有调理,但是可以帮助你。
---
via: <https://opensource.com/article/18/2/getting-to-done-agile-linux-command-line>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 译者:[guevaraya](https://github.com/guevaraya) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,336 | 无服务器架构的三个意义 | https://opensource.com/article/18/12/serverless-podcast-command-line-heros | 2018-12-11T23:11:10 | [
"无服务器",
"Serverless"
] | https://linux.cn/article-10336-1.html |
>
> 以及,对于<ruby> 无服务器 <rt> Serverless </rt></ruby>架构,什么时候该用,什么时候不该用呢?
>
>
>

如果将如今互联网体验中最方便实用的那一部分去掉,那么留下来的基本就是<ruby> 客户端-服务端 <rt> client-server </rt></ruby>模式了。这一个模式在互联网建立初期就已经在使用了,直到目前都没有太大的变化,也就是说,这个模式仍然在为我们服务。
那么,当人们谈论<ruby> 无服务器 <rt> Serverless </rt></ruby>架构的时候,到底是指什么呢?其实,无服务器架构并不是说不使用服务器了。恰恰相反,客户端-服务端模式仍然在其中发挥着重要的作用。
无服务器架构实际上指的是能够让开发者在不需要关心服务器上架、为操作系统打补丁、创建容器镜像这些工作的情况下,就能够完成编码、部署和创建应用这一整套流程的架构。
### 无服务器架构的三个重要意义
1. 一些缺乏开发经验的人员现在要参与到开发工作中来了。无服务器架构能够让他们尽量只学习必要的工作内容,把更多的时间放在更具创造性的开发工作中。
2. 开发者不再需要重复造轮子。运行和维护服务器、为操作系统打补丁、创建容器等这一系列工作,都可以由更专业的无服务器架构提供商来完成。
3. 最现实的一点是,如果不使用无服务器架构,那么在服务器管理方面,总需要有一个作最终决策的人。当服务器发生崩溃时,或是需要在服务器上执行某些操作时,总是需要这样一个统领全局的人来作出决策。因此最佳的方案是使用无服务器架构。
### 什么时候该用或者不该用无服务器架构?
听起来无服务器架构是个好东西。但事实上,无服务器架构并不是万能的,在使用之前还需要考虑以下这些因素:
1. 成本
2. 使用范围
3. 时间
4. 控制方式
其中值得注意的是控制方式。现在已经有一些项目为开发者提供了操作和控制无服务器架构计算环境的工具了,[Apache OpenWhisk](https://opensource.com/article/18/11/developing-functions-service-apache-openwhisk) 就是其中之一。
### 为什么要将无服务器架构开源?
关于这方面的更多内容,可以观看无服务器架构方面的专家 Saron Yitbarek 在 [Command Line Heroes](https://www.redhat.com/en/command-line-heroes) 节目中的访谈。
---
via: <https://opensource.com/article/18/12/serverless-podcast-command-line-heros>
作者:[Jen Wike Huger](https://opensource.com/users/remyd) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you strip away all of the modern conveniences and features that make up your internet experience today, what you're left with is the client-server model. This distributed network was what the internet was built on in the beginning, and that part hasn't changed. You could say, it is still *serving* us well.
So, when people talk about serverless, what does it mean? Well, it doesn't mean servers are GONE. Of course not: That "client-server model" is still the backbone of how things are getting done.
Serverless refers to a developer's ability to code, deploy, and create applications without having to know how to do the rest of it, like rack the servers, patch the operating system, and create container images.
## Top 3 implications of serverless
- People who might not have been before are becoming developers now. Why? They have to learn less of that kind of stuff and get to do more of the creative stuff.
- Developers don't have the recreate the wheel. Why? They let serverless providers do what they do best: run and maintain the servers, patch the operating systems, and build containers.
- Reality check: Someone on your team still has to think about the big picture, about operations. Why? Because when your server crashes or any decision at all needs to be made about the server-side of your project or product, your phone will ring and
*someone*has to pick up. Preferably someone who knows the gameplan, your strategy for going serverless.
## When to serverless and when to not?
So, serverless is great, right? But, the truth is it isn't *always* the right call. What are the factors that should be considered?
- Cost
- Scale
- Time
- Control
The last one, *control*, is where things get interesting. Projects like [Apache OpenWhisk](https://opensource.com/article/18/11/developing-functions-service-apache-openwhisk) have developed processes and tools to make it possible for you, as a developer, to operate and control your serverless computing environments.
## Why *open source* serverless?
For more on this, check out conversations with leading serverless thinkers and host Saron Yitbarek in [Episode 7 of Command Line Heroes podcast](https://www.redhat.com/en/command-line-heroes).
## 1 Comment |
10,337 | OpenSnitch:一个 Linux 上的应用程序防火墙 | https://itsfoss.com/opensnitch-firewall-linux/ | 2018-12-12T13:03:32 | [
"防火墙"
] | https://linux.cn/article-10337-1.html | 不能因为 Linux 比 Windows 更安全,就可以在 Linux 上放松警惕。Linux 上可以使用的防火墙很多,它们可以让你的 Linux 系统更安全。今天,我们将带你了解一个这样的防火墙工具,它就是 OpenSnitch。
### OpenSnitch 是什么?

[OpenSnitch](https://www.opensnitch.io/) 是从 Little Snitch 上移植过来的。而 Little Snitch 是专门为 Mac OS 设计的一款应用程序防火墙。OpenSnitch 是由 [Simone Margaritelli](https://github.com/evilsocket) 设计,也称为 [evilsocket](https://twitter.com/evilsocket)。
OpenSnitch 所做的主要事情就是跟踪你机器上安装的应用程序所发起的互联网请求。OpenSnitch 允许你去创建规则以同意或阻止那个应用程序发起的互联网访问。当一个应用程序尝试去访问互联网而没有相应的访问规则存在时,就会出现一个对话框,这个对话框让你去选择允许还是阻止那个连接。
你也可以决定这个新规则是应用到进程上、具体的 URL 上、域名上、单个实例上,以及本次会话还是永久有效。

*OpenSnatch 规则请求*
你创建的所有规则都保存为 [JSON 文件](https://www.json.org/),如果以后需要修改它,就可以去修改这个文件。比如说,你错误地阻止了一个应用程序。
OpenSnitch 也有一个漂亮的、一目了然的图形用户界面:
* 是什么应用程序访问 web
* 它们使用哪个 IP 地址
* 属主用户是谁
* 使用哪个端口
如果你愿意,也可以将这些信息导出到一个 CSV 文件中。
OpenSnitch 遵循 GPL v3 许可证使用。

*OpenSnitch 进程标签页*
### 在 Linux 中安装 OpenSnitch
[OpenSnitch GitHub 页面](https://github.com/evilsocket/opensnitch) 上的安装介绍是针对 Ubuntu 用户的。如果你使用的是其它发行版,你需要调整一下相关的命令。据我所知,这个应用程序仅在 [Arch User Repository](https://aur.archlinux.org/packages/opensnitch-git) 中打包了。
在你开始之前,你必须正确安装了 Go,并且已经定义好了 `$GOPATH` 环境变量。
首先,安装必需的依赖。
```
sudo apt-get install protobuf-compiler libpcap-dev libnetfilter-queue-dev python3-pip
go get github.com/golang/protobuf/protoc-gen-go
go get -u github.com/golang/dep/cmd/dep
python3 -m pip install --user grpcio-tools
```
接下来,克隆 OpenSnitch 仓库。这里可能会出现一个没有 Go 文件的信息,不用理它。如果出现 git 没有找到的信息,那么你需要首先去安装 Git。
```
go get github.com/evilsocket/opensnitch
cd $GOPATH/src/github.com/evilsocket/opensnitch
```
如果没有正确设置 `$GOPATH` 环境变量,运行上面的命令时将会出现一个 “no such folder found” 的错误信息。只需要进入到你刚才克隆仓库位置的 `evilsocket/opensnitch` 文件夹中即可。
现在,我们构建并安装它。
```
make
sudo make install
```
如果出现 “dep command could not be found” 的错误信息,在 `$PATH` 中添加 `$GOPATH/bin` 即可。
安装完成后,我们将要启动它的守护程序和图形用户界面。
```
sudo systemctl enable opensnitchd
sudo service opensnitchd start
opensnitch-ui
```

*运行在 Manjaro 上的 OpenSnitch*
### 使用体验
实话实说:我使用 OpenSnitch 的体验并不好。我开始在 Fedora 上尝试安装它。遇到了许多依赖问题。我又转到 Manjaro 上,在 Arch User Repository 上我很容易地找到了这些依赖。
不幸的是,我安装之后,不能启动图形用户界面。因此,我手动去运行最后三个步骤。一切似乎很顺利。如果我想让 Firefox 去访问 Manjaro 的网站,对话框就会弹出来询问我。
有趣的是,当我运行一个 [AUR 工具](https://itsfoss.com/best-aur-helpers/) `yay` 去更新我的系统时,弹出对话框要求了 `yay`、`pacman`、`pamac`、和 `git` 的访问规则。后来,我关闭并重启动 GUI,因为它当前是激活的。当我重启动它时,它不再要求我去创建规则了。我安装了 Falkon,而 OpenSnitch 并没有询问我去授予它任何权限。它甚至在 OpenSnitch 的 GUI 中没有列出 Falkon。我重新安装了 OpenSnitch 后,这个问题依旧存在。
然后,我转到 Ubuntu Mate 上安装 OpenSnitch,因为安装介绍就是针对 Ubuntu 所写的,进展很顺利。但是,我遇到了几个问题。我调整了一下上面介绍的安装过程以解决我遇到的问题。
安装的问题并不是我遇到的唯一问题。每次一个新的应用程序创建一个连接时弹出的对话框仅存在 10 秒钟。这么短的时间根本不够去浏览所有的可用选项。大多数情况下,这点时间只够我去永久允许一个(我信任的)应用程序访问 web。
GUI 也有一点需要去改进。由于某些原因,每次窗口都被放在顶部。而且不能通过设置来修改这个问题。如果能够从 GUI 中改变规则将是一个不错的选择。

*OpenSnitch 的 hosts 标签*
### 对 OpenSnitch 的最后意见
我很喜欢 OpenSnitch 的目标:用任何简单的方式控制离开你的计算机的信息。但是,它还很粗糙,我不能将它推荐给普通或业余用户。如果你是一个高级用户,很乐意去摆弄或挖掘这些问题,那么它可能很适合你。
这有点令人失望。我希望即将到来的 1.0 版本能够做的更好。
你以前用过 OpenSnitch 吗?如果没有,你最喜欢的防火墙应用是什么?你是如何保护你的 Linux 系统的?在下面的评论区告诉我们吧。
如果你对本文感兴趣,请花一点时间将它分享到社交媒体上吧,Hacker News 或 [Reddit](http://reddit.com/r/linuxusersgroup) 都行。
---
via: <https://itsfoss.com/opensnitch-firewall-linux/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Just because Linux is a lot more secure than Windows, there is no reason you should not be cautious. There are a number of firewalls available for Linux that you can use to make your Linux system more secure. Today we will be taking a look at one of such firewall tool called OpenSnitch.
## What is OpenSnitch?

[OpenSnitch](https://github.com/evilsocket/opensnitch) is a port of Little Snitch. Little Snitch, in turn, is an application firewall designed solely for Mac OS. OpenSnitch is created by [Simone Margaritelli](https://github.com/evilsocket?ref=itsfoss.com), also known as [evilsocket](https://twitter.com/evilsocket?ref=itsfoss.com).
The main thing that OpenSnitch does is track internet requests made by applications you have installed. OpenSnitch allows you to create rules for which apps to allow to access the internet and which to block. Each time an application that does not have a rule in place tries to access the internet, a dialog box appears. This dialog box gives you the option to allow or block the connection.
You can also decide whether this new rule applies to the process, the exact URL it is attempting to reach, the domain that it is attempting to reach, to this single instance, to this session or forever.
All of the rules that you create are stored as [JSON files](https://www.json.org/?ref=itsfoss.com) so you can change them later if you need to. For example, if you incorrectly blocked an application.
OpenSnitch also has a nice graphical user interface that lets you see at a glance:
- What applications are accessing the web
- What IP address they are using
- What User owns it
- What port is being used
You can also export the information to a CSV file if you wish.
OpenSnitch is available under the GPL v3 license.
## Installing OpenSnitch in Linux
The installation instructions on the [OpenSnitch GitHub page](https://github.com/evilsocket/opensnitch?ref=itsfoss.com) are aimed at Ubuntu users. If you are using another distro, you will have to adjust the commands. As far as I know, this application is only packaged in the [Arch User Repository](https://aur.archlinux.org/packages/opensnitch-git?ref=itsfoss.com).
Before you start, you need to have Go properly installed and the `$GOPATH`
environment variable is defined.
First, install the necessary dependencies.
`sudo apt-get install protobuf-compiler libpcap-dev libnetfilter-queue-dev python3-pip`
`go get github.com/golang/protobuf/protoc-gen-go`
`go get -u github.com/golang/dep/cmd/dep`
`python3 -m pip install --user grpcio-tools`
Next, you will need to clone the OpenSnitch repo. There will probably be a message that no Go files where found. Ignore it. If you get a message that git is missing, just install it.
`go get github.com/evilsocket/opensnitch`
`cd $GOPATH/src/github.com/evilsocket/opensnitch`
If the `$GOPATH`
environment variable is not setup correctly, you will get a “no such folder found” error on the previous command. just `cd`
into the location of the “evilsocket/opensnitch” folder that was listed when you cloned it to your system.
Now, we build and install it.
`make`
`sudo make install`
If you get an error that the `dep`
command could not be found, add `GOPATH/bin`
is in the `PATH`
.
Once that is finished, we will initiate the daemon and start the graphical user environment.
`sudo systemctl enable opensnitchd`
`sudo service opensnitchd start`
`opensnitch-ui`
## Experience
I’ll be honest: my experience with OpenSnitch was not great. I started by trying to install it on Fedora. I had trouble finding some of the dependencies. I switched over to Manjaro and was happy to find it in the Arch User Repository.
Unfortunately, after I ran the installation, I could not launch the graphical user interface. So I ran the last three steps by hand. Everything seemed to be working fine. The dialog box popped up asking me if I wanted to let Firefox visit the Manjaro website.
Interestingly, when I ran an [AUR tool](https://itsfoss.com/best-aur-helpers/) `yay`
to update my system, the dialog box requested rules for `yay`
, `pacman`
, `pamac`
, and `git`
. Later, I had to close and restart the GUI because it was acting up. When I restart it, it stopped asking me to create rules. I installed Falkon and OpenSnitch did not ask me to give it any permissions. It did not even list Falkon in the OpenSnithch GUI. I reinstalled OpenSnitch. Same issue.
Then I moved to Ubuntu Mate. Since the installation instructions were written for Ubuntu, things went easier. However, I ran into a couple issues. I tweaked the installation instructions above to fix the problems I encountered.
Installation was not the only issue that I ran into. The dialog box that appeared every time a new app created a connection only lasted for 10 seconds. That was barely enough time to explore the available options. Most of the time, I only had time to allow an application (only the ones I trust) to access the web forever.
The GUI also left a bit to be desired. For some reason, the window was set to be on top all of the time. On top of that, there are no setting to change it. It would also have been nice to have the option to change rules from the GUI.
## Final Thoughts on OpenSnitch
I like what OpenSnitch is aiming for: any easy way to control what information leaves your computer. However, it has too many rough edges for me to recommend it to a regular or hobby user. If you are a power user, who likes to tinker and dig for answers then maybe this is for you.
It’s kinda disappointing. I would have hoped that an application that recently hit 1.0 would be in a little better shape.
Have you ever used OpenSnitch? If not, what is your favorite firewall app? How do you make your Linux system more secure? Let us know in the comments below.
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit](http://reddit.com/r/linuxusersgroup?ref=itsfoss.com). |
10,338 | 12 条实用的 zypper 命令范例 | https://kerneltalks.com/commands/12-useful-zypper-command-examples/ | 2018-12-12T13:29:35 | [
"zypper",
"包管理器"
] | https://linux.cn/article-10338-1.html | `zypper` 是 Suse Linux 系统的包和补丁管理器,你可以根据下面的 12 条附带输出示例的实用范例来学习 `zypper` 命令的使用。

Suse Linux 使用 `zypper` 进行包管理,其是一个由 [ZYpp 包管理引擎](https://en.wikipedia.org/wiki/ZYpp)提供的包管理系统。在此篇文章中我们将分享 12 条附带输出示例的实用 `zypper` 命令,能帮助你处理日常的系统管理任务。
不带参数的 `zypper` 命令将列出所有可用的选项,这比参考详细的 man 手册要容易上手得多。
```
root@kerneltalks # zypper
用法:
zypper [--global-options] <command> [--command-options] [arguments]
zypper <subcommand> [--command-options] [arguments]
全局选项:
--help, -h 帮助
--version, -V 输出版本号
--promptids 输出 zypper 用户提示符列表
--config, -c <file> 使用指定的配置文件来替代默认的
--userdata <string> 在历史和插件中使用的用户自定义事务 id
--quiet, -q 忽略正常输出,只打印错误信息
--verbose, -v 增加冗长程度
--color
--no-color 是否启用彩色模式,如果 tty 支持的话
--no-abbrev, -A 表格中的文字不使用缩写
--table-style, -s 表格样式(整型)
--non-interactive, -n 不询问任何选项,自动使用默认答案
--non-interactive-include-reboot-patches
针对带有重启标志的补丁,不使用交互模式
--xmlout, -x 切换至 XML 输出
--ignore-unknown, -i 忽略未知的包
--reposd-dir, -D <dir> 使用自定义仓库文件目录
--cache-dir, -C <dir> 为所有缓存启用可选路径
--raw-cache-dir <dir> 启用可选 raw 元数据缓存路径
--solv-cache-dir <dir> 启用可选 solv 文件缓存路径
--pkg-cache-dir <dir> 启用可选包缓存路径
仓库选项:
--no-gpg-checks 忽略 GPG 检查失败并跳过
--gpg-auto-import-keys 自动信任并导入新仓库的签名密钥
--plus-repo, -p <URI> 使用附加仓库
--plus-content <tag> 另外使用禁用的仓库来提供特定的关键词
尝试使用 '--plus-content debug' 选项来启用仓库
--disable-repositories 不从仓库中读取元数据
--no-refresh 不刷新仓库
--no-cd 忽略 CD/DVD 中的仓库
--no-remote 忽略远程仓库
--releasever 设置所有 .repo 文件中的 $releasever 变量(默认值:发行版版本)
Target Options:
--root, -R <dir> 在另一个根路径下进行操作
--disable-system-resolvables
不读取已安装包
命令:
help, ? 打印帮助
shell, sh 允许多命令
仓库管理:
repos, lr 列出所有自定义仓库
addrepo, ar 添加一个新仓库
removerepo, rr 移除指定仓库
renamerepo, nr 重命名指定仓库
modifyrepo, mr 修改指定仓库
refresh, ref 刷新所有仓库
clean 清除本地缓存
服务管理:
services, ls 列出所有自定义服务
addservice, as 添加一个新服务
modifyservice, ms 修改指定服务
removeservice, rs 移除指定服务
refresh-services, refs 刷新所有服务
软件管理:
install, in 安装包
remove, rm 移除包
verify, ve 确认包依赖的完整性
source-install, si 安装源码包及其构建依赖
install-new-recommends, inr
安装由已安装包建议一并安装的新包
更新管理:
update, up 更新已安装包至更新版本
list-updates, lu 列出可用更新
patch 安装必要的补丁
list-patches, lp 列出必要的补丁
dist-upgrade, dup 进行发行版更新
patch-check, pchk 检查补丁
查询:
search, se 查找符合匹配模式的包
info, if 展示特定包的完全信息
patch-info 展示特定补丁的完全信息
pattern-info 展示特定模式的完全信息
product-info 展示特定产品的完全信息
patches, pch 列出所有可用的补丁
packages, pa 列出所有可用的包
patterns, pt 列出所有可用的模式
products, pd 列出所有可用的产品
what-provides, wp 列出提供特定功能的包
包锁定:
addlock, al 添加一个包锁定
removelock, rl 移除一个包锁定
locks, ll 列出当前的包锁定
cleanlocks, cl 移除无用的锁定
其他命令:
versioncmp, vcmp 比较两个版本字符串
targetos, tos 打印目标操作系统 ID 字符串
licenses 打印已安装包的证书和 EULAs 报告
download 使用命令行下载指定 rpm 包到本地目录
source-download 下载所有已安装包的源码 rpm 包到本地目录
子命令:
subcommand 列出可用子命令
输入 'zypper help <command>' 来获得特定命令的帮助。
```
### 如何使用 zypper 安装包
`zypper` 通过 `in` 或 `install` 子命令来在你的系统上安装包。它的用法与 [yum 软件包安装](https://kerneltalks.com/tools/package-installation-linux-yum-apt/) 相同。你只需要提供包名作为参数,包管理器(此处是 `zypper`)就会处理所有的依赖并与你指定的包一并安装。
```
# zypper install telnet
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
Resolving package dependencies...
The following NEW package is going to be installed:
telnet
1 new package to install.
Overall download size: 51.8 KiB. Already cached: 0 B. After the operation, additional 113.3 KiB will be used.
Continue? [y/n/...? shows all options] (y): y
Retrieving package telnet-1.2-165.63.x86_64 (1/1), 51.8 KiB (113.3 KiB unpacked)
Retrieving: telnet-1.2-165.63.x86_64.rpm .........................................................................................................................[done]
Checking for file conflicts: .....................................................................................................................................[done]
(1/1) Installing: telnet-1.2-165.63.x86_64 .......................................................................................................................[done]
```
以上是我们安装 `telnet` 包时的输出,供你参考。
推荐阅读:[在 YUM 和 APT 系统中安装包](https://kerneltalks.com/tools/package-installation-linux-yum-apt/)
### 如何使用 zypper 移除包
要在 Suse Linux 中擦除或移除包,使用 `zypper` 附带 `remove` 或 `rm` 子命令。
```
root@kerneltalks # zypper rm telnet
Loading repository data...
Reading installed packages...
Resolving package dependencies...
The following package is going to be REMOVED:
telnet
1 package to remove.
After the operation, 113.3 KiB will be freed.
Continue? [y/n/...? shows all options] (y): y
(1/1) Removing telnet-1.2-165.63.x86_64 ..........................................................................................................................[done]
```
我们在此处移除了先前安装的 telnet 包。
### 使用 zypper 检查依赖或者认证已安装包的完整性
有时可以通过强制忽略依赖关系来安装软件包。`zypper` 使你能够扫描所有已安装的软件包并检查其依赖性。如果缺少任何依赖项,它将提供你安装或重新安装它的机会,从而保持已安装软件包的完整性。
使用附带 `verify` 或 `ve` 子命令的 `zypper` 命令来检查已安装包的完整性。
```
root@kerneltalks # zypper ve
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
Dependencies of all installed packages are satisfied.
```
在上面的输出中,你能够看到最后一行说明已安装包的所有依赖都已安装完全,并且无需更多操作。
### 如何在 Suse Linux 中使用 zypper 下载包
`zypper` 提供了一种方法使得你能够将包下载到本地目录而不去安装它。你可以在其他具有同样配置的系统上使用这个已下载的软件包。包会被下载至 `/var/cache/zypp/packages/<repo>/<arch>/` 目录。
```
root@kerneltalks # zypper download telnet
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
Retrieving package telnet-1.2-165.63.x86_64 (1/1), 51.8 KiB (113.3 KiB unpacked)
(1/1) /var/cache/zypp/packages/SMT-http_smt-ec2_susecloud_net:SLES12-SP3-Pool/x86_64/telnet-1.2-165.63.x86_64.rpm ................................................[done]
download: Done.
# ls -lrt /var/cache/zypp/packages/SMT-http_smt-ec2_susecloud_net:SLES12-SP3-Pool/x86_64/
total 52
-rw-r--r-- 1 root root 53025 Feb 21 03:17 telnet-1.2-165.63.x86_64.rpm
```
你能看到我们使用 `zypper` 将 telnet 包下载到了本地。
推荐阅读:[在 YUM 和 APT 系统中只下载包而不安装](https://kerneltalks.com/howto/download-package-using-yum-apt/)
### 如何使用 zypper 列出可用包更新
`zypper` 允许你浏览已安装包的所有可用更新,以便你可以提前计划更新活动。使用 `list-updates` 或 `lu` 子命令来显示已安装包的所有可用更新。
```
root@kerneltalks # zypper lu
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
S | Repository | Name | Current Version | Available Version | Arch
--|-----------------------------------|----------------------------|-------------------------------|------------------------------------|-------
v | SLES12-SP3-Updates | at-spi2-core | 2.20.2-12.3 | 2.20.2-14.3.1 | x86_64
v | SLES12-SP3-Updates | bash | 4.3-82.1 | 4.3-83.5.2 | x86_64
v | SLES12-SP3-Updates | ca-certificates-mozilla | 2.7-11.1 | 2.22-12.3.1 | noarch
v | SLE-Module-Containers12-Updates | containerd | 0.2.5+gitr639_422e31c-20.2 | 0.2.9+gitr706_06b9cb351610-16.8.1 | x86_64
v | SLES12-SP3-Updates | crash | 7.1.8-4.3.1 | 7.1.8-4.6.2 | x86_64
v | SLES12-SP3-Updates | rsync | 3.1.0-12.1 | 3.1.0-13.10.1 | x86_64
```
输出特意被格式化以便于阅读。每一列分别代表包所属仓库名称、包名、已安装版本、可用的更新版本和架构。
### 在 Suse Linux 中列出和安装补丁
使用 `list-patches` 或 `lp` 子命令来显示你的 Suse Linux 系统需要被应用的所有可用补丁。
```
root@kerneltalks # zypper lp
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
Repository | Name | Category | Severity | Interactive | Status | Summary
----------------------------------|------------------------------------------|-------------|-----------|-------------|--------|------------------------------------------------------------------------------------
SLE-Module-Containers12-Updates | SUSE-SLE-Module-Containers-12-2018-273 | security | important | --- | needed | Version update for docker, docker-runc, containerd, golang-github-docker-libnetwork
SLE-Module-Containers12-Updates | SUSE-SLE-Module-Containers-12-2018-62 | recommended | low | --- | needed | Recommended update for sle2docker
SLE-Module-Public-Cloud12-Updates | SUSE-SLE-Module-Public-Cloud-12-2018-268 | recommended | low | --- | needed | Recommended update for python-ecdsa
SLES12-SP3-Updates | SUSE-SLE-SERVER-12-SP3-2018-116 | security | moderate | --- | needed | Security update for rsync
---- output clipped ----
SLES12-SP3-Updates | SUSE-SLE-SERVER-12-SP3-2018-89 | security | moderate | --- | needed | Security update for perl-XML-LibXML
SLES12-SP3-Updates | SUSE-SLE-SERVER-12-SP3-2018-90 | recommended | low | --- | needed | Recommended update for lvm2
Found 37 applicable patches:
37 patches needed (18 security patches)
```
使用相应的表头可以很好地组织输出。你可以轻松地找出并根据情况计划你的补丁更新。我们能看到在我们的系统中,37 个可用补丁中有 18 个是安全补丁,需要被高优先级应用!
你可以通过发出 `zypper patch` 命令安装所有需要的补丁。
##### 如何使用 zypper 更新包
要使用 `zypper` 更新包,使用 `update` 或 `up` 子命令后接包名。在上述列出的更新命令中,我们知道在我们的服务器上 `rsync` 包更新可用。让我们现在来更新它吧!
```
root@kerneltalks # zypper update rsync
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
Resolving package dependencies...
The following package is going to be upgraded:
rsync
1 package to upgrade.
Overall download size: 325.2 KiB. Already cached: 0 B. After the operation, additional 64.0 B will be used.
Continue? [y/n/...? shows all options] (y): y
Retrieving package rsync-3.1.0-13.10.1.x86_64 (1/1), 325.2 KiB (625.5 KiB unpacked)
Retrieving: rsync-3.1.0-13.10.1.x86_64.rpm .......................................................................................................................[done]
Checking for file conflicts: .....................................................................................................................................[done]
(1/1) Installing: rsync-3.1.0-13.10.1.x86_64 .....................................................................................................................[done]
```
### 在 Suse Linux 上使用 zypper 查找包
如果你不确定包的全名也不要担心。你可以使用 `zypper` 附带的 `se` 或 `search` 子命令并提供查找字符串来查找包。
```
root@kerneltalks # zypper se lvm
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
S | Name | Summary | Type
---|---------------|------------------------------|-----------
| libLLVM | Libraries for LLVM | package
| libLLVM-32bit | Libraries for LLVM | package
| llvm | Low Level Virtual Machine | package
| llvm-devel | Header Files for LLVM | package
| lvm2 | Logical Volume Manager Tools | srcpackage
i+ | lvm2 | Logical Volume Manager Tools | package
| lvm2-devel | Development files for LVM2 | package
```
在上述示例中我们查找了 `lvm` 字符串并得到了如上输出列表。你能在 `zypper install/remove/update` 命令中使用 `Name` 字段的名字。
### 使用 zypper 检查已安装包信息
你能够使用 `zypper` 检查已安装包的详细信息。`info` 或 `if` 子命令将列出已安装包的信息。它也可以显示未安装包的详细信息,在该情况下,`Installed` 参数将返回 `No` 值。
```
root@kerneltalks # zypper info rsync
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
Information for package rsync:
------------------------------
Repository : SLES12-SP3-Updates
Name : rsync
Version : 3.1.0-13.10.1
Arch : x86_64
Vendor : SUSE LLC <https://www.suse.com/>
Support Level : Level 3
Installed Size : 625.5 KiB
Installed : Yes
Status : up-to-date
Source package : rsync-3.1.0-13.10.1.src
Summary : Versatile tool for fast incremental file transfer
Description :
Rsync is a fast and extraordinarily versatile file copying tool. It can copy
locally, to/from another host over any remote shell, or to/from a remote rsync
daemon. It offers a large number of options that control every aspect of its
behavior and permit very flexible specification of the set of files to be
copied. It is famous for its delta-transfer algorithm, which reduces the amount
of data sent over the network by sending only the differences between the
source files and the existing files in the destination. Rsync is widely used
for backups and mirroring and as an improved copy command for everyday use.
```
### 使用 zypper 列出仓库
使用 `zypper` 命令附带 `lr` 或 `repos` 子命令列出仓库。
```
root@kerneltalks # zypper lr
Refreshing service 'cloud_update'.
Repository priorities are without effect. All enabled repositories share the same priority.
# | Alias | Name | Enabled | GPG Check | Refresh
---|--------------------------------------------------------------------------------------|-------------------------------------------------------|---------|-----------|--------
1 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Debuginfo-Pool | SLE-Module-Adv-Systems-Management12-Debuginfo-Pool | No | ---- | ----
2 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Debuginfo-Updates | SLE-Module-Adv-Systems-Management12-Debuginfo-Updates | No | ---- | ----
3 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Pool | SLE-Module-Adv-Systems-Management12-Pool | Yes | (r ) Yes | No
4 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Updates | SLE-Module-Adv-Systems-Management12-Updates | Yes | (r ) Yes | Yes
5 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Containers12-Debuginfo-Pool | SLE-Module-Containers12-Debuginfo-Pool | No | ---- | ----
6 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Containers12-Debuginfo-Updates | SLE-Module-Containers12-Debuginfo-Updates | No | ---- | ----
```
此处你需要检查 `enabled` 列来确定哪些仓库是已被启用的而哪些没有。
### 在 Suse Linux 中使用 zypper 添加或移除仓库
要添加仓库你需要仓库或 .repo 文件的 URI,否则你会遇到如下错误。
```
root@kerneltalks # zypper addrepo -c SLES12-SP3-Updates
If only one argument is used, it must be a URI pointing to a .repo file.
```
使用 URI,你可以像如下方式添加仓库:
```
root@kerneltalks # zypper addrepo -c http://smt-ec2.susecloud.net/repo/SUSE/Products/SLE-SDK/12-SP3/x86_64/product?credentials=SMT-http_smt-ec2_susecloud_net SLE-SDK12-SP3-Pool
Adding repository 'SLE-SDK12-SP3-Pool' ...........................................................................................................................[done]
Repository 'SLE-SDK12-SP3-Pool' successfully added
URI : http://smt-ec2.susecloud.net/repo/SUSE/Products/SLE-SDK/12-SP3/x86_64/product?credentials=SMT-http_smt-ec2_susecloud_net
Enabled : Yes
GPG Check : Yes
Autorefresh : No
Priority : 99 (default priority)
Repository priorities are without effect. All enabled repositories share the same priority.
```
在 Suse 中使用附带 `addrepo` 或 `ar` 子命令的 `zypper` 命令添加仓库,后接 URI 以及你需要提供一个别名。
要在 Suse 中移除一个仓库,使用附带 `removerepo` 或 `rr` 子命令的 `zypper` 命令。
```
root@kerneltalks # zypper removerepo nVidia-Driver-SLE12-SP3
Removing repository 'nVidia-Driver-SLE12-SP3' ....................................................................................................................[done]
Repository 'nVidia-Driver-SLE12-SP3' has been removed.
```
### 清除 zypper 本地缓存
使用 `zypper clean` 命令清除 zypper 本地缓存。
```
root@kerneltalks # zypper clean
All repositories have been cleaned up.
```
---
via: <https://kerneltalks.com/commands/12-useful-zypper-command-examples/>
作者:[KernelTalks](https://kerneltalks.com) 译者:[cycoe](https://github.com/cycoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Learn the zypper command with 12 useful examples along with sample outputs. zypper is used for package and patch management in Suse Linux systems.*

zypper is a package management system powered by [ZYpp package manager engine](https://en.wikipedia.org/wiki/ZYpp). Suse Linux uses zypper for package management. In this article, we will be sharing 12 useful zypper commands along with examples that are helpful for your day to day sysadmin tasks.
Without any argument `zypper`
command will list you all available switches which can be used. It’s quite handy than referring to the man page which is pretty much in detail.
```
root@kerneltalks # zypper
Usage:
zypper [--global-options] <command> [--command-options] [arguments]
zypper <subcommand> [--command-options] [arguments]
Global Options:
--help, -h Help.
--version, -V Output the version number.
--promptids Output a list of zypper's user prompts.
--config, -c <file> Use specified config file instead of the default .
--userdata <string> User defined transaction id used in history and plugins.
--quiet, -q Suppress normal output, print only error
messages.
--verbose, -v Increase verbosity.
--color
--no-color Whether to use colors in output if tty supports it.
--no-abbrev, -A Do not abbreviate text in tables.
--table-style, -s Table style (integer).
--non-interactive, -n Do not ask anything, use default answers
automatically.
--non-interactive-include-reboot-patches
Do not treat patches as interactive, which have
the rebootSuggested-flag set.
--xmlout, -x Switch to XML output.
--ignore-unknown, -i Ignore unknown packages.
--reposd-dir, -D <dir> Use alternative repository definition file
directory.
--cache-dir, -C <dir> Use alternative directory for all caches.
--raw-cache-dir <dir> Use alternative raw meta-data cache directory.
--solv-cache-dir <dir> Use alternative solv file cache directory.
--pkg-cache-dir <dir> Use alternative package cache directory.
Repository Options:
--no-gpg-checks Ignore GPG check failures and continue.
--gpg-auto-import-keys Automatically trust and import new repository
signing keys.
--plus-repo, -p <URI> Use an additional repository.
--plus-content <tag> Additionally use disabled repositories providing a specific keyword.
Try '--plus-content debug' to enable repos indic ating to provide debug packages.
--disable-repositories Do not read meta-data from repositories.
--no-refresh Do not refresh the repositories.
--no-cd Ignore CD/DVD repositories.
--no-remote Ignore remote repositories.
--releasever Set the value of $releasever in all .repo files (default: distribution version)
Target Options:
--root, -R <dir> Operate on a different root directory.
--disable-system-resolvables
Do not read installed packages.
Commands:
help, ? Print help.
shell, sh Accept multiple commands at once.
Repository Management:
repos, lr List all defined repositories.
addrepo, ar Add a new repository.
removerepo, rr Remove specified repository.
renamerepo, nr Rename specified repository.
modifyrepo, mr Modify specified repository.
refresh, ref Refresh all repositories.
clean Clean local caches.
Service Management:
services, ls List all defined services.
addservice, as Add a new service.
modifyservice, ms Modify specified service.
removeservice, rs Remove specified service.
refresh-services, refs Refresh all services.
Software Management:
install, in Install packages.
remove, rm Remove packages.
verify, ve Verify integrity of package dependencies.
source-install, si Install source packages and their build
dependencies.
install-new-recommends, inr
Install newly added packages recommended
by installed packages.
Update Management:
update, up Update installed packages with newer versions.
list-updates, lu List available updates.
patch Install needed patches.
list-patches, lp List needed patches.
dist-upgrade, dup Perform a distribution upgrade.
patch-check, pchk Check for patches.
Querying:
search, se Search for packages matching a pattern.
info, if Show full information for specified packages.
patch-info Show full information for specified patches.
pattern-info Show full information for specified patterns.
product-info Show full information for specified products.
patches, pch List all available patches.
packages, pa List all available packages.
patterns, pt List all available patterns.
products, pd List all available products.
what-provides, wp List packages providing specified capability.
Package Locks:
addlock, al Add a package lock.
removelock, rl Remove a package lock.
locks, ll List current package locks.
cleanlocks, cl Remove unused locks.
Other Commands:
versioncmp, vcmp Compare two version strings.
targetos, tos Print the target operating system ID string.
licenses Print report about licenses and EULAs of
installed packages.
download Download rpms specified on the commandline to a local directory.
source-download Download source rpms for all installed packages
to a local directory.
Subcommands:
subcommand Lists available subcommands.
Type 'zypper help <command>' to get command-specific help.
```
### How to install the package using zypper
`zypper`
takes `in`
or `install`
switch to install the package on your system. It’s the same as [yum package installation](https://kerneltalks.com/tools/package-installation-linux-yum-apt/), supplying package name as an argument, and package manager (zypper here) will resolve all dependencies and install them along with your required package.
```
# zypper install telnet
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
Resolving package dependencies...
The following NEW package is going to be installed:
telnet
1 new package to install.
Overall download size: 51.8 KiB. Already cached: 0 B. After the operation, additional 113.3 KiB will be used.
Continue? [y/n/...? shows all options] (y): y
Retrieving package telnet-1.2-165.63.x86_64 (1/1), 51.8 KiB (113.3 KiB unpacked)
Retrieving: telnet-1.2-165.63.x86_64.rpm .........................................................................................................................[done]
Checking for file conflicts: .....................................................................................................................................[done]
(1/1) Installing: telnet-1.2-165.63.x86_64 .......................................................................................................................[done]
```
Above output for your reference in which we installed `telnet`
package.
Suggested read: [Install packages in YUM and APT systems](https://kerneltalks.com/tools/package-installation-linux-yum-apt/)
### How to remove package using zypper
For erasing or removing packages in Suse Linux, use `zypper`
with `remove`
or `rm`
switch.
```
root@kerneltalks # zypper rm telnet
Loading repository data...
Reading installed packages...
Resolving package dependencies...
The following package is going to be REMOVED:
telnet
1 package to remove.
After the operation, 113.3 KiB will be freed.
Continue? [y/n/...? shows all options] (y): y
(1/1) Removing telnet-1.2-165.63.x86_64 ..........................................................................................................................[done]
```
We removed previously installed telnet package here.
### Check dependencies and verify the integrity of installed packages using zypper
There are times when one can install the package by force ignoring dependencies. `zypper`
gives you the power to scan all installed packages and checks for their dependencies too. If any dependency is missing, it offers you to install/remove it and hence maintain the integrity of your installed packages.
Use `verify`
or `ve`
switch with `zypper`
to check the integrity of installed packages.
```
root@kerneltalks # zypper ve
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
Dependencies of all installed packages are satisfied.
```
In the above output, you can see the last line confirms that all dependencies of installed packages are completed and no action required.
### How to download package using zypper in Suse Linux
`zypper`
offers a way to download the package in the local directory without installation. You can use this downloaded package on another system with the same configuration. Packages will be downloaded to `/var/cache/zypp/packages/<repo>/<arch>/`
directory.
```
root@kerneltalks # zypper download telnet
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
Retrieving package telnet-1.2-165.63.x86_64 (1/1), 51.8 KiB (113.3 KiB unpacked)
(1/1) /var/cache/zypp/packages/SMT-http_smt-ec2_susecloud_net:SLES12-SP3-Pool/x86_64/telnet-1.2-165.63.x86_64.rpm ................................................[done]
download: Done.
# ls -lrt /var/cache/zypp/packages/SMT-http_smt-ec2_susecloud_net:SLES12-SP3-Pool/x86_64/
total 52
-rw-r--r-- 1 root root 53025 Feb 21 03:17 telnet-1.2-165.63.x86_64.rpm
```
You can see we have downloaded telnet package locally using `zypper`
Suggested read: [Download packages in YUM and APT systems without installing](https://kerneltalks.com/howto/download-package-using-yum-apt/)
### How to list available package update in zypper
`zypper`
allows you to view all available updates for your installed packages so that you can plan update activity in advance. Use list-updates or lu switch to show you a list of all available updates for installed packages.
```
root@kerneltalks # zypper lu
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
S | Repository | Name | Current Version | Available Version | Arch
--+-----------------------------------+----------------------------+-------------------------------+------------------------------------+-------
v | SLES12-SP3-Updates | at-spi2-core | 2.20.2-12.3 | 2.20.2-14.3.1 | x86_64
v | SLES12-SP3-Updates | bash | 4.3-82.1 | 4.3-83.5.2 | x86_64
v | SLES12-SP3-Updates | ca-certificates-mozilla | 2.7-11.1 | 2.22-12.3.1 | noarch
v | SLE-Module-Containers12-Updates | containerd | 0.2.5+gitr639_422e31c-20.2 | 0.2.9+gitr706_06b9cb351610-16.8.1 | x86_64
v | SLES12-SP3-Updates | crash | 7.1.8-4.3.1 | 7.1.8-4.6.2 | x86_64
v | SLES12-SP3-Updates | rsync | 3.1.0-12.1 | 3.1.0-13.10.1 | x86_64
```
The output is properly formatted for easy reading. Column wise it shows the name of repo where package belongs, package name, installed version, new updated available version & architecture.
### List and install patches in Suse linux
Use `list-patches`
or `lp`
switch to display all available patches for your Suse Linux system which needs to be applied.
```
root@kerneltalks # zypper lp
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
Repository | Name | Category | Severity | Interactive | Status | Summary
----------------------------------+------------------------------------------+-------------+-----------+-------------+--------+------------------------------------------------------------------------------------
SLE-Module-Containers12-Updates | SUSE-SLE-Module-Containers-12-2018-273 | security | important | --- | needed | Version update for docker, docker-runc, containerd, golang-github-docker-libnetwork
SLE-Module-Containers12-Updates | SUSE-SLE-Module-Containers-12-2018-62 | recommended | low | --- | needed | Recommended update for sle2docker
SLE-Module-Public-Cloud12-Updates | SUSE-SLE-Module-Public-Cloud-12-2018-268 | recommended | low | --- | needed | Recommended update for python-ecdsa
SLES12-SP3-Updates | SUSE-SLE-SERVER-12-SP3-2018-116 | security | moderate | --- | needed | Security update for rsync
---- output clipped ----
SLES12-SP3-Updates | SUSE-SLE-SERVER-12-SP3-2018-89 | security | moderate | --- | needed | Security update for perl-XML-LibXML
SLES12-SP3-Updates | SUSE-SLE-SERVER-12-SP3-2018-90 | recommended | low | --- | needed | Recommended update for lvm2
Found 37 applicable patches:
37 patches needed (18 security patches)
```
The output is pretty much nicely organized with respective headers. You can easily figure out and plan your patch update accordingly. We can see out of 37 patches available on our system 18 are security ones and needs to be applied on high priority!
You can install all needed patches by issuing `zypper patch`
command.
### How to update package using zypper
To update package using zypper, use `update`
or `up`
switch followed by package name. In the above list updates command, we learned that `rsync`
package update is available on our server. Let update it now –
```
root@kerneltalks # zypper update rsync
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
Resolving package dependencies...
The following package is going to be upgraded:
rsync
1 package to upgrade.
Overall download size: 325.2 KiB. Already cached: 0 B. After the operation, additional 64.0 B will be used.
Continue? [y/n/...? shows all options] (y): y
Retrieving package rsync-3.1.0-13.10.1.x86_64 (1/1), 325.2 KiB (625.5 KiB unpacked)
Retrieving: rsync-3.1.0-13.10.1.x86_64.rpm .......................................................................................................................[done]
Checking for file conflicts: .....................................................................................................................................[done]
(1/1) Installing: rsync-3.1.0-13.10.1.x86_64 .....................................................................................................................[done]
```
### Search package using zypper in Suse Linux
If you are not sure about the full package name, no worries. You can search packages in zypper by supplying search string with `se`
or `search`
switch
```
root@kerneltalks # zypper se lvm
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
S | Name | Summary | Type
---+---------------+------------------------------+-----------
| libLLVM | Libraries for LLVM | package
| libLLVM-32bit | Libraries for LLVM | package
| llvm | Low Level Virtual Machine | package
| llvm-devel | Header Files for LLVM | package
| lvm2 | Logical Volume Manager Tools | srcpackage
i+ | lvm2 | Logical Volume Manager Tools | package
| lvm2-devel | Development files for LVM2 | package
```
In the above example, we searched `lvm`
string and came up with the list shown above. You can use `Name`
in zypper install/remove/update commands.
### Check installed package information using zypper
You can check installed packages details using zypper. `info`
or `if`
switch will list out information of the installed package. It can also display package details which are not installed. In that case, `Installed`
parameter will reflect `No`
value.
```
root@kerneltalks # zypper info rsync
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
Refreshing service 'cloud_update'.
Loading repository data...
Reading installed packages...
Information for package rsync:
------------------------------
Repository : SLES12-SP3-Updates
Name : rsync
Version : 3.1.0-13.10.1
Arch : x86_64
Vendor : SUSE LLC <https://www.suse.com/>
Support Level : Level 3
Installed Size : 625.5 KiB
Installed : Yes
Status : up-to-date
Source package : rsync-3.1.0-13.10.1.src
Summary : Versatile tool for fast incremental file transfer
Description :
Rsync is a fast and extraordinarily versatile file copying tool. It can copy
locally, to/from another host over any remote shell, or to/from a remote rsync
daemon. It offers a large number of options that control every aspect of its
behavior and permit very flexible specification of the set of files to be
copied. It is famous for its delta-transfer algorithm, which reduces the amount
of data sent over the network by sending only the differences between the
source files and the existing files in the destination. Rsync is widely used
for backups and mirroring and as an improved copy command for everyday use.
```
### List repositories using zypper
To list repo use `lr`
or `repos`
switch with zypper command. It will list all available repos which include enabled and not-enabled both repos.
```
root@kerneltalks # zypper lr
Refreshing service 'cloud_update'.
Repository priorities are without effect. All enabled repositories share the same priority.
# | Alias | Name | Enabled | GPG Check | Refresh
---+--------------------------------------------------------------------------------------+-------------------------------------------------------+---------+-----------+--------
1 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Debuginfo-Pool | SLE-Module-Adv-Systems-Management12-Debuginfo-Pool | No | ---- | ----
2 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Debuginfo-Updates | SLE-Module-Adv-Systems-Management12-Debuginfo-Updates | No | ---- | ----
3 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Pool | SLE-Module-Adv-Systems-Management12-Pool | Yes | (r ) Yes | No
4 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Updates | SLE-Module-Adv-Systems-Management12-Updates | Yes | (r ) Yes | Yes
5 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Containers12-Debuginfo-Pool | SLE-Module-Containers12-Debuginfo-Pool | No | ---- | ----
6 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Containers12-Debuginfo-Updates | SLE-Module-Containers12-Debuginfo-Updates | No | ---- | ----
```
here you need to check enabled column to check which repos are enabled and which are not.
Recommended read :
[How to list repositories in RHEL]&[List of online package repositories]
### Add and remove repo in Suse Linux using zypper
To add repo you will need URI of repo/.repo file or else you end up in below error.
```
root@kerneltalks # zypper addrepo -c SLES12-SP3-Updates
If only one argument is used, it must be a URI pointing to a .repo file.
```
With URI, you can add repo like below :
```
root@kerneltalks # zypper addrepo -c http://smt-ec2.susecloud.net/repo/SUSE/Products/SLE-SDK/12-SP3/x86_64/product?credentials=SMT-http_smt-ec2_susecloud_net SLE-SDK12-SP3-Pool
Adding repository 'SLE-SDK12-SP3-Pool' ...........................................................................................................................[done]
Repository 'SLE-SDK12-SP3-Pool' successfully added
URI : http://smt-ec2.susecloud.net/repo/SUSE/Products/SLE-SDK/12-SP3/x86_64/product?credentials=SMT-http_smt-ec2_susecloud_net
Enabled : Yes
GPG Check : Yes
Autorefresh : No
Priority : 99 (default priority)
Repository priorities are without effect. All enabled repositories share the same priority.
```
Use `addrepo`
or `ar`
switch with `zypper`
to add a repo in Suse. Followed by URI and lastly, you need to provide alias as well.
To remove repo in Suse, use `removerepo`
or `rr`
switch with `zypper`
.
```
root@kerneltalks # zypper removerepo nVidia-Driver-SLE12-SP3
Removing repository 'nVidia-Driver-SLE12-SP3' ....................................................................................................................[done]
Repository 'nVidia-Driver-SLE12-SP3' has been removed.
```
### Clean local zypper cache
Cleaning up local zypper caches with `zypper clean`
command –
```
root@kerneltalks # zypper clean
All repositories have been cleaned up.
```
I want to update offline. When I’ve downloaded thousands of packages, I don’t want to update them all at that time. I want to update when I’m not on the web. |
10,339 | Cat 命令的源码历史 | https://twobithistory.org/2018/11/12/cat.html | 2018-12-12T16:40:50 | [
"历史",
"cat"
] | https://linux.cn/article-10339-1.html | 
以前我和我的一些亲戚争论过计算机科学的学位值不值得读。当时我正在上大学,并要决定是不是该主修计算机。我姨和我表姐觉得我不应该主修计算机。她们承认知道如何编程肯定是很有用且对自己有利的一件事,但是她们认为计算机科学现在发展的如此迅速以至于我学的东西几乎马上就过时了。建议我更好是把编程作为辅业,选择一个基础原理可以受用终身的领域主修,比如经济学或物理学。
我知道我姨和我表姐说的不对,并决定主修计算机科学。(对不住啊!)平常人可能会觉得像计算机科学领域和软件工程专业每隔几年就完全和之前不一样了。其原因很容易理解。我们有了个人电脑,然后有了互联网,有了手机,之后还有了机器学习…… 科技总是在更新,支撑科技发展的原理和技能当然也在改变。当然,最惊人的是其实原理的改变竟然如此之小。我敢肯定,大多数人在知道了他们电脑里一些重要的软件的历史是多么久远时他们一定会深感震惊。当然我不是说那些刷版本号的浮夸软件 —— 我电脑上的 Firefox 浏览器副本,可能是我用的最多的软件,可能两周前就更新过。如果你看了比如 `grep` 的手册页,你就会发现它在 2010 年后就没有过更新了(至少在 MacOS 上如此)。初版 `grep` 是在 1974 年写就的,那时可以算是计算机世界的侏罗纪了。直到现在,人们(还有程序)仍然依赖 `grep` 来完成日常工作。
我姨和我表姐认为计算机技术就像一系列日渐精致的沙堡,在潮水抹净沙滩后新的沙堡完全取代旧的。但事实上,在很多领域上,我们都是不断积累能够解决问题的程序。我们可能不得不偶尔修改这些程序以避免软件无法使用,但大多数情况下我们都可以不修改。`grep` 是一个简单的程序,可以解决一个仍然存在的需求,所以它能够存活下来。 大多数应用程序编程都是在非常高的级别上完成的,它们建立在解决了旧问题的旧程序的金字塔上。 30 年或 40 年前的思路和概念,远非过时,在很多情况下它们依然在您的笔记本电脑上软件中存在着。
我想追溯这样的老程序自第一次写就以来改变了多少回很有趣。 `cat` 可能是所有 Unix 实用程序中最简单的,因此我们以它为例。Ken Thompson 于 1969 年编写了 `cat` 的原始实现。如果我告诉别人我的电脑上安装了个来自 1969 年的程序,这准确吗?我们电脑上的程序多大了?
感谢这种[这种](https://github.com/dspinellis/unix-history-repo)仓库,我们可以完整的看到 `cat` 自 1969 年后是如何发展的。我会先聚焦于可以算得上是我的 MacBook 上的 `cat` 的祖先的 `cat` 实现。随着我们从 Unix 上的第一版 `cat` 追踪到现在 MacOS 上的 `cat`,你会发现,这个程序被重写的次数比你想的还要多 —— 但是直到现在它运行的方式和五十年前多少是完全一致的。
### 研究 Unix
Ken Thompson 和 Dennis Ritchie 在 PDP 7 上开始写 Unix。那还是 1969 年,C 还没被发明出来,因此所有早期的 Unix 软件都是用 PDP 7 汇编实现的。他们使用的汇编种类是 Unix 特有的,Ken Thompson 在 DEC(PDP 7 的厂商)提供的汇编器之上加了些特性,实现了自己的汇编器。Thompson 的更改在[最初的 Unix 程序员手册](https://www.bell-labs.com/usr/dmr/www/man11.pdf)的 `as`(也就是汇编器)条目下均有所记录。
因此,[最初的](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-1-cat-pdp7-s) `cat` 也是使用 PDP 7 汇编实现的。 我添加了一些注释,试图解释每条指令的作用,但除非你理解 Thompson 在编写汇编器时加的特性,否则程序仍然很难理解。在那些特性中有两个很重要:其一是 `;` 这个字符可以在一行中用来分隔多条语句,它多出现于在使用 `sys` 指令时将系统调用的多个参数放在同一行上。其二是, Thompson 的汇编器支持使用 0 到 9 作为“临时标签”,这是在程序内可以重用的标签。因此。就如 Unix 程序员手册中所说:“对程序员的想象力和汇编程序的符号空间的要求都降低了”。在任何给定的指令内,你都可以使用 `nf` 和 `nb` 来引用下一个或最近的临时标签 `n`。 例如,如果存在标记为 `1:` 的代码块,你就可以使用指令 `jmp 1b` 从下游代码跳回该块。 (但是你不使用 `jmp 1f` 的话就没法从上面的代码跳到这里。)
初版 `cat` 最有趣的就是它包含着我们应该认识的符号。有一块指令块标记为 `getc`,还有一个标记为 `putc`,可以看到这两个符号比 C 标准还古老。第一版的 `cat` 函数实际上已经包含了这两个函数的实现。该实现做了输入缓存,这样它就不需要一次只读写一个字母。
`cat` 的第一个版本并没有持续多久。 Ken Thompson 和 Dennis Ritchie 说服贝尔实验室购买了 PDP 11,这样他们就能够继续扩展和改进 Unix。 PDP 11 的指令集和之前不一样,因此必须重写 `cat`。 我也注释了[这个第二版](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-2-cat-pdp11-s) `cat`。 它为新的指令集使用新的汇编程序助记符,并利用了 PDP 11 的各种[寻址模式](https://en.wikipedia.org/wiki/PDP-11_architecture#Addressing_modes)。(如果你对源代码中的括号和美元符号感到困惑,那是因为这些符号用于指示不同的寻址模式。)但它也使用 `;` 字符和临时标签,和 `cat` 的第一个版本一样,这意味着当把 `as` 移植到 PDP 11 上时,必须要保留这些功能。
`cat` 的第二个版本比第一个版本简单得多。 它也更有 Unix 味儿,它不只是依靠参数列表,一旦没给参数列表,它将从 `stdin` 读取数据,这也就是今天 `cat` 仍在做的事情。 你也可以在此版本的 `cat` 中以 `-` 为参数,以表示它应该从`stdin`读取。
在 1973 年,为了准备发布第四版 Unix,大部分代码都用 C 语言重写了。但是 `cat` 似乎在之后一段时间内并没有使用 C 重写。 [cat 的第一个 C 语言实现](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-3-cat-v7-c)出现在第七版 Unix 中。 这个实现非常有趣,因为它很简单。 在所有以后的实现中,这个实现和在 K&R 的 C 语言教科书中用作教学示范的理想化 `cat` 最相似。这个程序的核心就是经典的两行:
```
while ((c = getc(fi)) != EOF)
putchar(c);
```
当然实际代码要比这多一些,额外的代码主要是为了确保你没有在读/写同一个文件。另一个有趣的事情是,`cat` 的这一版实现只识别一个标志位 `-u`。 `-u` 标志可用于避免缓冲输入和输出,否则 `cat` 将以 512 字节为块进行输入输出。
### BSD
在第七版 Unix 之后,Unix 出现了各种衍生品和分支。 MacOS 建立于 Darwin 之上,而 Darwin 又源自<ruby> 伯克利软件分发版 <rt> Berkeley Software Distribution </rt></ruby>(BSD),因此 BSD 是我们最感兴趣的 Unix 分支。 BSD 最初只是 Unix 中的实用程序和附加组件的集合,但它最终成为了一个完整的操作系统。直到第四版 BSD,人称 4BSD,为一大堆新标志添加了支持之前,BSD 似乎还是依赖于最初的 `cat` 实现的。`cat` 的 [4BSD 实现](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-4-cat-bsd4-c) 显然是从原始实现中衍生出来的,尽管它添加了一个新函数来实现由新标志触发的行为。已经在文件中使用的 `fflg` 变量(用于标记输入是从 `stdin` 还是文件读取的)的命名约定,被新添加的 `nflg`、`bflg`、`vflg`、`sflg`、`eflg` 和 `tflg` 沿袭了下来,这些变量记录了在调用程序时是否使用了这些新标志。这些是最后一批添加到 `cat` 的命令行标志。如今 `cat` 的手册页列出了这些标志,没有其他的标志了,至少在 Mac OS 上是如此。 4BSD 于 1980 年发布,因此这套标志已有 38 年历史。
`cat` 最后一次被完全重写是在 BSD NET/2 上,其目的是通过替换 AT&T 发布的全部 Unix 源代码来规避许可证问题。BSD Net/2 在 1991 年发布。这一版本的 `cat` 是由 Kevin Fall 重写的。 Kevin Fall 于 1988 年毕业于加州大学伯克利分校并在下一年成为<ruby> 计算机系统研究组 <rt> Computer Systems Research Group </rt></ruby>(CSRG)的组员,Fall 和我说当时使用 AT&T 代码的 Unix 工具被列在了 CSRG 的墙上,组员需要从中选出他们想要重写的工具; Fall 选了 `cat` 以及 `mknod`。 MacOS 系统内自带的 `cat` 实现源码的最上面还有着他的名字。他的这一版 `cat`,尽管平淡无奇,在今天还是被无数人使用着。
[Fall 的原始 cat 实现](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-5-cat-net2-c) 比我们迄今为止看到的版本都要长。 除了支持 `-?` 帮助标志外,它没有增加任何新功能。 从概念上讲,它与 4BSD 的实现非常相似。 它长是因为 Fall 将实现分为 “原始” 模式和 “加工” 模式。 “原始” 模式是 `cat` 的经典实现;它一个字符一个字符的打印文件。 “加工” 模式是带有所有 4BSD 命令行选项的 `cat`。 如此区别不无道理,但这么办也扩充了实现规模,因此乍一看其源码似乎比实际上更复杂。文件末尾还有一个奇特的错误处理函数,进一步地增加了实现的长度。
### MacOS
在 2001 年,苹果发布了 MacOS X。这一发布对苹果意义重大。因为苹果用了多年的时间尝试以取代其现有的老旧操作系统(经典的 Mac OS),但是都失败了。 在 Mac OS X 之前苹果两次尝试在内部创建一个新的操作系统,但两者都无疾而终。 最后,苹果收购了史蒂夫·乔布斯的 NeXT 公司,后者开发了一个名为 NeXTSTEP 的操作系统和面向对象编程框架。 苹果将 NeXTSTEP 作为 Mac OS X 的基础。因为 NeXTSTEP 部分基于 BSD,使以 NeXTSTEP 为基础的 Mac OS X 的自然就把 BSD 系的代码直接带入苹果宇宙的中心。
因此,Mac OS X 的非常早期的第一个版本包含了从 NetBSD 项目中提取的 `cat` 的[实现](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-6-cat-macosx-c)。如今仍保持开发的 NetBSD 最初是 386BSD 的分支,而后者又直接基于 BSD Net/2。所以 Mac OS X 里面的第一个 `cat` 的实现就是 Kevin Fall 的 `cat`。唯一改变的是,Fall 的错误处理函数 `err()` 被 `err.h` 提供的 `err()` 函数取代了。 `err.h` 是 C 标准库的 BSD 扩展。
之后不久,这里的 `cat` 的 NetBSD 实现被换成了 FreeBSD 中的 `cat` 实现。 [根据维基百科](https://en.wikipedia.org/wiki/Darwin_(operating_system)),苹果在 Mac OS X 10.3(Panther)中开始使用 FreeBSD 的实现而不是 NetBSD 的实现。但根据苹果自己开源的版本,`cat` 的 Mac OS X 实现在 2007 年发布的 Mac OS X 10.5(Leopard)之前没有被替换。苹果为 Leopard 替换的的 [FreeBSD 实现](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-7-cat-macos-10-13-c)与今天苹果计算机上的实现相同。截至 2018 年,2007 年以来的这个实现仍未被更新或修改。
所以 Mac OS 上的 `cat` 已经很老了。实际上,这一实现在 2007 年在 MacOS X 上露面两年前就被发布了。 [这个 2005 年的修改](https://github.com/freebsd/freebsd/commit/a76898b84970888a6fd015e15721f65815ea119a#diff-6e405d5ab5b47ca2a131ac7955e5a16b) 在 FreeBSD 的 Github 镜像中可见,是在苹果将其合并入 Mac OS X 前对 FreeBSD 的 `cat` 实现进行的最后一次更改。所以 Mac OS X 中的实现没有与 FreeBSD 的 `cat` 实现保持同步,它如今已经 13 岁了。对于软件修改了多少代码才能仍是算是同一软件这一话题有着旷日持久的争论。不过,在这种情况下,源文件自 2005 年以来根本没有变化。
现在 Mac OS 使用的 `cat` 实现与 Fall 1991 年为 BSD Net/2 版本编写的实现没有什么不同。最大的区别是添加了一个全新的功能来提供 Unix 域套接字支持。FreeBSD 开发人员似乎将 Fall 的 `raw_args()` 函数和 `cook_args()` 函数组合成一个名为`scanfiles()` 的函数。否则,程序的核心就仍是 Fall 的代码。
我问过 Fall 对编写了如今被数以百万计的苹果用户(直接或者间接通过依赖 `cat` 的某些程序)使用的 `cat` 实现有何感想。Fall,如今是一位顾问,也是最新版《TCP/IP 详解》的合著者,他说,当人们从了解他对 `cat` 所做的工作中收获颇丰时,他感到很惊讶。 Fall 在计算机领域有着悠久的职业生涯,曾参与许多备受瞩目的项目,但似乎很多人仍对他在 1989 年重写 `cat` 的那六个月的工作感到最为兴奋。
### 百年老程序
在宏伟的发明史中,计算机并不是一项古老的发明。我们已经习惯了百年的照片甚至是百年的视频短片。但是计算机程序不一样 —— 它们代表着高科技和新技术。至少,他们是现代的技术造出来的。随着计算行业的成熟,我们有朝一日会发现自己正在使用有着接近百年历史的程序吗?
计算机硬件可能会发生较大的变化,使得我们也许无法让现在编译的可执行文件在一个世纪后的硬件上运行。也许编程语言设计的进步让未来没有人能理解 C 语言,`cat` 将来也可能也被别的语言重写很久了。 (尽管 C 已经存在了五十年了,而且它似乎不会很快就被替换掉。)但除此之外,为什么不永远使用我们现在的 `cat`?
我认为 `cat` 的历史表明,计算机科学中的一些想法确实非常持久。事实上,对于 `cat`,这个想法和程序本身都很古老。不准确地说,我的电脑上的 `cat` 来自 1969 年。但我也可以说我的计算机上的 `cat` 来自1989 年,当时 Fall 写了他的 `cat` 实现。许多其他软件也同样古老。因此,也许我们不应该把计算机科学和软件开发视为不断破坏现状和发明新事物的领域。我们的计算机系统是由诸多历史文物构建的。有时,我们可能会花费更多时间在理解和维护这些历史文物上,而不是花在编写新代码上。
如果你喜欢本文,你可能更喜欢两周来一篇更新!在推特上关注 [@TwoBitHistory](https://twitter.com/TwoBitHistory) 或者订阅这个 [RSS 源](https://twobithistory.org/feed.xml) 以保证接受到新的文章。
---
via: <https://twobithistory.org/2018/11/12/cat.html>
作者:[Two-Bit History](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[name1e5s](https://github.com/name1e5s) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I once had a debate with members of my extended family about whether a computer science degree is a degree worth pursuing. I was in college at the time and trying to decide whether I should major in computer science. My aunt and a cousin of mine believed that I shouldn’t. They conceded that knowing how to program is of course a useful and lucrative thing, but they argued that the field of computer science advances so quickly that everything I learned would almost immediately be outdated. Better to pick up programming on the side and instead major in a field like economics or physics where the basic principles would be applicable throughout my lifetime.
I knew that my aunt and cousin were wrong and decided to major in computer
science. (Sorry, aunt and cousin!) It is easy to see why the average person
might believe that a field like computer science, or a profession like software
engineering, completely reinvents itself every few years. We had personal
computers, then the web, then phones, then machine learning… technology is
always changing, so surely all the underlying principles and techniques change
too. Of course, the amazing thing is how little actually changes. Most people,
I’m sure, would be stunned to know just how old some of the important software
on their computer really is. I’m not talking about flashy application software,
admittedly—my copy of Firefox, the program I probably use the most on my
computer, is not even two weeks old. But, if you pull up the manual page for
something like `grep`
, you will see that it has not been updated since 2010 (at
least on MacOS). And the original version of `grep`
was written in 1974, which
in the computing world was back when dinosaurs roamed Silicon Valley. People
(and programs) still depend on `grep`
every day.
My aunt and cousin thought of computer technology as a series of increasingly
elaborate sand castles supplanting one another after each high tide clears the
beach. The reality, at least in many areas, is that we steadily accumulate
programs that have solved problems. We might have to occasionally modify these
programs to avoid software rot, but otherwise they can be left alone. `grep`
is
a simple program that solves a still-relevant problem, so it survives. Most
application programming is done at a very high level, atop a pyramid of much
older code solving much older problems. The ideas and concepts of 30 or 40
years ago, far from being obsolete today, have in many cases been embodied in
software that you can still find installed on your laptop.
I thought it would be interesting to take a look at one such old program and
see how much it had changed since it was first written. `cat`
is maybe the
simplest of all the Unix utilities, so I’m going to use it as my example.
Ken Thompson wrote the original implementation of `cat`
in 1969. If I were to
tell somebody that I have a program on my computer from 1969, would that be
accurate? How much has `cat`
really evolved over the decades? How old is the
software on our computers?
Thanks to repositories like [this
one](https://github.com/dspinellis/unix-history-repo), we can see exactly how
`cat`
has evolved since 1969. I’m going to focus on implementations of `cat`
that are ancestors of the implementation I have on my Macbook. You will see, as
we trace `cat`
from the first versions of Unix down to the `cat`
in MacOS
today, that the program has been rewritten more times than you might expect—but
it ultimately works more or less the same way it did fifty years ago.
## Research Unix
Ken Thompson and Dennis Ritchie began writing Unix on a
PDP 7. This was in 1969, before C, so all of the early Unix software was
written in PDP 7 assembly. The exact flavor of assembly they used was unique to
Unix, since Ken Thompson wrote his own assembler that added some features on
top of the assembler provided by DEC, the PDP 7’s manufacturer. Thompson’s
changes are all documented in [the original Unix Programmer’s
Manual](https://www.bell-labs.com/usr/dmr/www/man11.pdf) under the entry for
`as`
, the assembler.
[The first
implementation](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-1-cat-pdp7-s)
of `cat`
is thus in PDP 7 assembly. I’ve added comments that try to
explain what each instruction is doing, but the program is still difficult to
follow unless you understand some of the extensions Thompson made while writing
his assembler. There are two important ones. First, the `;`
character can be
used to separate multiple statements on the same line. It appears that this was
used most often to put system call arguments on the same line as the `sys`
instruction. Second, Thompson added support for “temporary labels” using the
digits 0 through 9. These are labels that can be reused throughout a program,
thus being, according to the Unix Programmer’s Manual, “less taxing both on the
imagination of the programmer and on the symbol space of the assembler.”
From any given instruction, you can refer to the next or most recent temporary
label `n`
using `nf`
and `nb`
respectively. For example, if you have some code
in a block labeled `1:`
, you can jump back to that block from further down by
using the instruction `jmp 1b`
. (But you cannot jump *forward* to that block
from above without using `jmp 1f`
instead.)
The most interesting thing about this first version of `cat`
is that it
contains two names we should recognize. There is a block of instructions
labeled `getc`
and a block of instructions labeled `putc`
, demonstrating that
these names are older than the C standard library. The first version
of `cat`
actually contained implementations of both functions. The
implementations buffered input so that reads and writes were not done a
character at a time.
The first version of `cat`
did not last long. Ken Thompson and Dennis Ritchie
were able to persuade Bell Labs to buy them a PDP 11 so that they could
continue to expand and improve Unix. The PDP 11 had a different instruction
set, so `cat`
had to be rewritten. I’ve marked up [this second
version](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-2-cat-pdp11-s)
of `cat`
with comments as well. It uses new assembler mnemonics for the new
instruction set and takes advantage of the PDP 11’s various [addressing
modes](https://en.wikipedia.org/wiki/PDP-11_architecture#Addressing_modes). (If
you are confused by the parentheses and dollar signs in the source code, those
are used to indicate different addressing modes.) But it also leverages the `;`
character and temporary labels just like the first version of `cat`
, meaning
that these features must have been retained when `as`
was adapted for the
PDP 11.
The second version of `cat`
is significantly simpler than the first. It is also
more “Unix-y” in that it doesn’t just expect a list of filename arguments—it
will, when given no arguments, read from `stdin`
, which is what `cat`
still
does today. You can also give this version of `cat`
an argument of `-`
to
indicate that it should read from `stdin`
.
In 1973, in preparation for the release of the Fourth Edition of Unix, much of
Unix was rewritten in C. But `cat`
does not seem to have been rewritten in C
until a while after that. [The first C
implementation](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-3-cat-v7-c)
of `cat`
only shows up in the Seventh Edition of Unix. This implementation is
really fun to look through because it is so simple. Of all the implementations
to follow, this one most resembles the idealized `cat`
used as a pedagogic
demonstration in K&R C. The heart of the program is the classic two-liner:
```
while ((c = getc(fi)) != EOF)
putchar(c);
```
There is of course quite a bit more code than that, but the extra code is
mostly there to ensure that you aren’t reading and writing to the same file.
The other interesting thing to note is that this implementation of `cat`
only
recognized one flag, `-u`
. The `-u`
flag could be used to avoid buffering input
and output, which `cat`
would otherwise do in blocks of 512 bytes.
## BSD
After the Seventh Edition, Unix spawned all sorts of derivatives and offshoots.
MacOS is built on top of Darwin, which in turn is derived from the Berkeley
Software Distribution (BSD), so BSD is the Unix offshoot we are most interested
in. BSD was originally just a collection of useful programs and add-ons for
Unix, but it eventually became a complete operating system. BSD seems to have
relied on the original `cat`
implementation up until the fourth BSD release,
known as 4BSD, when support was added for a whole slew of new flags. [The 4BSD
implementation](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-4-cat-bsd4-c)
of `cat`
is clearly derived from the original implementation, though it
adds a new function to implement the behavior triggered by the new flags. The
naming conventions already used in the file were adhered to—the `fflg`
variable, used to mark whether input was being read from `stdin`
or a file, was
joined by `nflg`
, `bflg`
, `vflg`
, `sflg`
, `eflg`
, and `tflg`
, all there to
record whether or not each new flag was supplied in the invocation of the
program. These were the last command-line flags added to `cat`
; the man page
for `cat`
today lists these flags and no others, at least on Mac OS. 4BSD was
released in 1980, so this set of flags is 38 years old.
`cat`
would be entirely rewritten a final time for BSD Net/2, which was, among
other things, an attempt to avoid licensing issues by replacing all AT&T
Unix-derived code with new code. BSD Net/2 was released in 1991. This final
rewrite of `cat`
was done by Kevin Fall, who graduated from Berkeley in 1988
and spent the next year working as a staff member at the Computer Systems
Research Group (CSRG). Fall told me that a list of Unix utilities still
implemented using AT&T code was put up on a wall at CSRG and staff were told to
pick the utilities they wanted to reimplement. Fall picked `cat`
and `mknod`
.
The `cat`
implementation bundled with MacOS today is built from a source file
that still bears his name at the very top. His version of `cat`
, even though it
is a relatively trivial program, is today used by millions.
[Fall’s original
implementation](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-5-cat-net2-c)
of `cat`
is much longer than anything we have seen so far. Other than
support for a `-?`
help flag, it adds nothing in the way of new functionality.
Conceptually, it is very similar to the 4BSD implementation. It is only
longer because Fall separates the implementation into a “raw” mode and a
“cooked” mode. The “raw” mode is `cat`
classic; it prints a file character for
character. The “cooked” mode is `cat`
with all the 4BSD command-line options.
The distinction makes sense but it also pads out the implementation so that it
seems more complex at first glance than it actually is. There is also a fancy
error handling function at the end of the file that further adds to its length.
## MacOS
In 2001, Apple launched Mac OS X. The launch was an important one for Apple, because Apple had spent many years trying and failing to replace its existing operating system (classic Mac OS), which had long been showing its age. There were two previous attempts to create a new operating system internally, but both went nowhere; in the end, Apple bought NeXT, Steve Jobs’ company, which had developed an operating system and object-oriented programming framework called NeXTSTEP. Apple took NeXTSTEP and used it as a basis for Mac OS X. NeXTSTEP was in part built on BSD, so using NeXTSTEP as a starting point for Mac OS X brought BSD-derived code right into the center of the Apple universe.
The very first release of Mac OS X thus includes [an
implementation](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-6-cat-macosx-c)
of `cat`
pulled from the NetBSD project. NetBSD, which remains in development
today, began as a fork of 386BSD, which in turn was based directly on BSD
Net/2. So the first Mac OS X implementation of `cat`
*is* Kevin Fall’s `cat`
.
The only thing that had changed over the intervening decade was that Fall’s
error-handling function `err()`
was removed and the `err()`
function made
available by `err.h`
was used in its place. `err.h`
is a BSD extension to the C
standard library.
The NetBSD implementation of `cat`
was later swapped out for FreeBSD’s
implementation of `cat`
. [According to
Wikipedia](https://en.wikipedia.org/wiki/Darwin_(operating_system)), Apple
began using FreeBSD instead of NetBSD in Mac OS X 10.3 (Panther). But the Mac
OS X implementation of `cat`
, according to Apple’s own open source releases,
was not replaced until Mac OS X 10.5 (Leopard) was released in 2007. The
[FreeBSD
implementation](https://gist.github.com/sinclairtarget/47143ba52b9d9e360d8db3762ee0cbf5#file-7-cat-macos-10-13-c)
that Apple swapped in for the Leopard release is the same implementation on
Apple computers today. As of 2018, the implementation has not been
updated or changed at all since 2007.
So the Mac OS `cat`
is old. As it happens, it is actually two
years older than its 2007 appearance in MacOS X would suggest. [This 2005
change](https://github.com/freebsd/freebsd/commit/a76898b84970888a6fd015e15721f65815ea119a#diff-6e405d5ab5b47ca2a131ac7955e5a16b),
which is visible in FreeBSD’s Github mirror, was the last change made to
FreeBSD’s `cat`
before Apple pulled it into Mac OS X. So the Mac OS X `cat`
implementation, which has not been kept in sync with FreeBSD’s `cat`
implementation, is officially 13 years old. There’s a larger debate to be had
about how much software can change before it really counts as the same
software; in this case, the source file *has not changed at all* since 2005.
The `cat`
implementation used by Mac OS today is not that different from the
implementation that Fall wrote for the 1991 BSD Net/2 release. The biggest
difference is that a whole new function was added to provide Unix domain socket
support. At some point, a FreeBSD developer also seems to have decided that
Fall’s `raw_args()`
function and `cook_args()`
should be combined into a single
function called `scanfiles()`
. Otherwise, the heart of the program is still
Fall’s code.
I asked Fall how he felt about having written the `cat`
implementation now used
by millions of Apple users, either directly or indirectly through some program
that relies on `cat`
being present. Fall, who is now a consultant and a
co-author of the most recent editions of *TCP/IP Illustrated*, says that he is
surprised when people get such a thrill out of learning about his work on
`cat`
. Fall has had a long career in computing and has worked on many
high-profile projects, but it seems that many people still get most excited
about the six months of work he put into rewriting `cat`
in 1989.
## The Hundred-Year-Old Program
In the grand scheme of things, computers are not an old invention. We’re used to hundred-year-old photographs or even hundred-year-old camera footage. But computer programs are in a different category—they’re high-tech and new. At least, they are now. As the computing industry matures, will we someday find ourselves using programs that approach the hundred-year-old mark?
Computer hardware will presumably change enough that we won’t be able to
take an executable compiled today and run it on hardware a century from now.
Perhaps advances in programming language design will also mean that nobody will
understand C in the future and `cat`
will have long since been rewritten in
another language. (Though C has already been around for fifty years, and it
doesn’t look like it is about to be replaced any time soon.) But barring all
that, why not just keep using the `cat`
we have forever?
I think the history of `cat`
shows that some ideas in computer science are in
fact very durable. Indeed, with `cat`
, both the idea and the program itself are
old. It may not be accurate to say that the `cat`
on my computer is from 1969.
But I could make a case for saying that the `cat`
on my computer is from 1989,
when Fall wrote his implementation of `cat`
. Lots of other software is just as
ancient. So maybe we shouldn’t think of computer science and software
development primarily as fields that disrupt the status quo and invent new
things. Our computer systems are built out of historical artifacts. At some
point, we may all spend more time trying to understand and maintain those
historical artifacts than we spend writing new code.
*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
*
*Previously on TwoBitHistory…*
My post on Lisp. It's basically a long explanation of that xkcd comic where Lisp is the key to understanding the structure of the universe. When and why did people start talking about Lisp that way?
— TwoBitHistory (@TwoBitHistory)
Would love to know if your theories differ from mine![https://t.co/yHF3CxG7oN][October 15, 2018] |
10,340 | Emacs 系列(五):Org 模式之文档与演示稿 | http://changelog.complete.org/archives/9900-emacs-5-documents-and-presentations-with-org-mode | 2018-12-12T22:59:00 | [
"Org模式",
"Emacs"
] | https://linux.cn/article-10340-1.html | 
这是 [Emacs 和 Org 模式系列](https://changelog.complete.org/archives/tag/emacs2018)的第五篇。
这篇博文是由 Org 模式的源文件生成的,其有几种格式:[博客页面](https://github.com/jgoerzen/public-snippets/blob/master/emacs/emacs-org-beamer/emacs-org-beamer.org)、[演示稿](http://changelog.complete.org/archives/9900-emacs-5-documents-and-presentations-with-org-mode) 和 [PDF 文档](https://github.com/jgoerzen/public-snippets/raw/master/emacs/emacs-org-beamer/emacs-org-beamer.pdf)。
### 1 Org 模式的输出
#### 1.1 背景
Org 模式不仅仅只是一个议程生成程序,它也能输出许多不同的格式: LaTeX、PDF、Beamer、iCalendar(议程)、HTML、Markdown、ODT、普通文本、手册页和其它更多的复杂的格式,比如说网页文件。
这也不只是一些事后的想法,这是 Org 模式的设计核心部分并且集成的很好。
这一个文件可以同时是源代码、自动生成的输出、任务列表、文档和展示。
有些人将 Org 模式作为他们首选的标记格式,甚至对于 LaTeX 文档也是如此。Org 模式手册中的 [输出一节](https://orgmode.org/manual/Exporting.html#Exporting) 有更详细的介绍。
#### 1.2 开始
对于任意的 Org 模式的文档,只要按下 `C-c C-e` 键,就会弹出一个让你选择多种输出格式和选项的菜单。这些选项通常是次键选择,所以很容易设置和执行。例如:要输出一个 PDF 文档,按 `C-c C-e l p`,要输出 HMTL 格式的, 按 `C-c C-e h h`。
对于所有的输出选项,都有许多可用的设置;详情参见手册。事实上,使用 LaTeX 格式相当于同时使用 LaTeX 和 HTML 模式,在不同的模式中插入任意的前言和设置等。
#### 1.3 第三方插件
[ELPA](https://www.emacswiki.org/emacs/ELPA) 中也包含了许多额外的输出格式,详情参见 [ELPA](https://www.emacswiki.org/emacs/ELPA)。
### 2 Org 模式的 Beamer 演示
#### 2.1 关于 Beamer
[Beamer](https://en.wikipedia.org/wiki/Beamer_(LaTeX)) 是一个生成演示稿的 LaTeX 环境. 它包括了以下特性:
* 在演示稿中自动生成结构化的元素(例如 [Marburg 主题](https://hartwork.org/beamer-theme-matrix/all/beamer-albatross-Marburg-1.png))。 在演示稿中,这个特性可以为观众提供了视觉参考。
* 对组织演示稿有很大的帮助。
* 主题
* 完全支持 LaTeX
#### 2.2 Org 模式中 Beamer 的优点
在 Org 模式中用 Beamer 有很多好处,总的来说:
* Org 模式很简单而且对可视化支持的很好,同时改变结构可以快速的重组你的材料。
* 与 org-babel 绑定在一起,实时语法高亮源码和内嵌结果。
* 语法通常更容易使用。
我已经完全用 Org 模式和 beamer 替换掉使用 LibreOffice/Powerpoint/GoogleDocs。事实上,当我必须使用其中一种工具时,这是相当令人沮丧的,因为它们在可视化表示演讲稿结构方面远远比不上 Org 模式。
#### 2.3 标题层次
Org 模式的 Beamer 会将你文档中的部分(文中定义了标题的)转换成幻灯片。当然,问题是:哪些部分?这是由 H [输出设置](https://orgmode.org/manual/Export-settings.html#Export-settings)(`org-export-headline-levels`)决定的。
针对不同的人,有许多不同的方法。我比较喜欢我的演示稿这样:
```
#+OPTIONS: H:2
#+BEAMER_HEADER: \AtBeginSection{\frame{\sectionpage}}
```
这将为每个主题提供了独立部分,以突出主题的改变然后使用级别 2(两个星号)的标题来设置幻灯片。许多 Beamer 主题也有第三个间接层次,所以你可以将 H 设为 3。
#### 2.4 主题和配置
你可以在 Org 模式的文件顶部来插入几行来配置 Beamer 和 LaTeX。在本文中,例如,你可以这样定义:
```
#+TITLE: Documents and presentations with org-mode
#+AUTHOR: John Goerzen
#+BEAMER_HEADER: \institute{The Changelog}
#+PROPERTY: comments yes
#+PROPERTY: header-args :exports both :eval never-export
#+OPTIONS: H:2
#+BEAMER_THEME: CambridgeUS
#+BEAMER_COLOR_THEME: default
```
#### 2.5 高级设置
我比教喜欢修改颜色、项目符号样式等。我的配置如下:
```
# We can't just +BEAMER_INNER_THEME: default because that picks the theme default.
# Override per https://tex.stackexchange.com/questions/11168/change-bullet-style-formatting-in-beamer
#+BEAMER_INNER_THEME: default
#+LaTeX_CLASS_OPTIONS: [aspectratio=169]
#+BEAMER_HEADER: \definecolor{links}{HTML}{0000A0}
#+BEAMER_HEADER: \hypersetup{colorlinks=,linkcolor=,urlcolor=links}
#+BEAMER_HEADER: \setbeamertemplate{itemize items}[default]
#+BEAMER_HEADER: \setbeamertemplate{enumerate items}[default]
#+BEAMER_HEADER: \setbeamertemplate{items}[default]
#+BEAMER_HEADER: \setbeamercolor*{local structure}{fg=darkred}
#+BEAMER_HEADER: \setbeamercolor{section in toc}{fg=darkred}
#+BEAMER_HEADER: \setlength{\parskip}{\smallskipamount}
```
在这里,`aspectratio=169` 将纵横比设为 16:9, 其它部分都是标准的 LaTeX/Beamer 配置。
#### 2.6 缩小 (适应屏幕)
有时你会遇到一些非常大的代码示例,你可能更倾向与将幻灯片缩小以适应它们。
只要按下 `C-c C-c p` 将 `BEAMER_opt` 属性设为 `shrink=15`\。(或者设为更大的 shrink 值)。上一张幻灯片就用到了这个。
#### 2.7 效果
这就是最终的效果:
[](https://www.flickr.com/photos/jgoerzen/26366340577/in/dateposted/)
### 3 幻灯片之间的交互
#### 3.1 交互式的 Emacs 幻灯片
使用 [org-tree-slide](https://orgmode.org/worg/org-tutorials/non-beamer-presentations.html#org-tree-slide) 这个插件的话,就可以在 Emacs 的右侧显示幻灯片了。 只要按下 `M-x`,然后输入 `org-tree-slide-mode`,回车,然后你就可以用 `C->` 和 `C-<` 在幻灯片之间切换了。
你可能会发现 `C-c C-x C-v` (即 `org-toggle-inline-images`)有助于使系统显示内嵌的图像。
#### 3.2 HTML 幻灯片
有许多方式可以将 Org 模式的演讲稿导出为 HTML,并有不同级别的 JavaScript 集成。有关详细信息,请参见 Org 模式的 wiki 中的 [非 beamer 演讲稿一节](https://orgmode.org/worg/org-tutorials/non-beamer-presentations.html)。
### 4 更多
#### 4.1 本文中的附加资源
* [orgmode.org beamer tutorial](https://orgmode.org/worg/exporters/beamer/tutorial.html)
* [LaTeX wiki](https://en.wikibooks.org/wiki/LaTeX/Presentations)
* [Generating section title slides](https://tex.stackexchange.com/questions/117658/automatically-generate-section-title-slides-in-beamer/117661)
* [Shrinking content to fit on slide](https://tex.stackexchange.com/questions/78514/content-doesnt-fit-in-one-slide)
* 很棒的资源: refcard-org-beamer
+ 详情参见其 [Github repo](https://github.com/fniessen/refcard-org-beamer) 中的 PDF 和 .org 文件。
* 很漂亮的主题: [Theme matrix](https://hartwork.org/beamer-theme-matrix/)
#### 4.2 下一个 Emacs 系列
mu4e 邮件!
---
via: <http://changelog.complete.org/archives/9900-emacs-5-documents-and-presentations-with-org-mode>
作者:[John Goerzen](http://changelog.complete.org/archives/author/jgoerzen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[oneforalone](https://github.com/oneforalone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 302 | Found | null |
10,341 | 降低项目失败率的三个原则 | https://opensource.com/open-organization/18/2/constructing-project-requirements | 2018-12-13T16:33:46 | [
"项目"
] | https://linux.cn/article-10341-1.html |
>
> 透明和包容性的项目要求可以降低您的失败率。 以下是如何协作收集它们。
>
>
>

众所周知,明确、简洁和可衡量的需求会带来更多成功的项目。一项[麦肯锡与牛津大学](http://calleam.com/WTPF/?page_id=1445)的关于大型项目的研究表明:“平均而言,大型 IT 项目超出预算 45%,时间每推移 7%,价值就比预期低 56% 。”该研究还表明,造成这种失败的一些原因是“模糊的业务目标,不同步的利益相关者以及过度的返工。”
业务分析师经常发现自己通过持续对话来构建这些需求。为此,他们必须吸引多个利益相关方,并确保参与者提供明确的业务目标。这样可以减少返工,提高更多项目的成功率。
他们可以用开放和包容的方式做到这一点。
### 成功的框架
提高项目成功率的一个工具是[开放决策框架](https://opensource.com/open-organization/resources/open-decision-framework)。开放决策框架是一种资源,可以帮助用户在拥抱[开放原则](https://opensource.com/open-organization/resources/open-org-definition)的组织中做出更有效的决策。该框架强调三个主要原则:透明、包容、以客户为中心。
**透明**。很多时候,开发人员和产品设计人员都认为他们知道利益相关者如何使用特定工具或软件。但这些假设往往是不正确的,并导致对利益相关者实际需求的误解。开发人员和企业主讨论时实行透明势在必行。开发团队不仅需要了解一些好的情景,还需要了解利益相关方面对某些工具或流程所面临的挑战。提出诸如以下问题:“必须手动完成哪些步骤?”以及“这个工具是否按预期运行?”这提供了对问题的共同理解和讨论的基准。
**包容**。对于业务分析师来说,在收集需求时观察肢体语言和视觉暗示非常重要。如果有人双臂交叉或睁着眼睛坐着,那么这清楚地表明他们感觉没被聆听。业务分析师必须鼓励那些不被聆听的人公开交流,并给他们机会被聆听。在开始会议之前,制定基本规则,使所有人都能发表意见并分享他们的想法。聆听提供的反馈,并在收到反馈时礼貌地回复。多样化的意见和协作解决问题将为会议带来令人兴奋的想法。
**以顾客为中心**。以客户为中心的第一步是识别客户。谁从这种变化、更新或开发中受益?在项目早期,进行利益相关者映射,以帮助确定关键利益相关者,他们在项目中的角色以及他们适应大局的方式。让合适的客户参与并确保满足他们的需求将会确定更成功的要求,进行更现实(现实)的测试,并最终成功交付。
当你的需求会议透明、包容和以客户为中心时,你将收集更好的需求。当你使用[开放决策框架](https://opensource.com/open-organization/16/6/introducing-open-decision-framework)来进行会议时,参与者会感觉有更多参与与授权,他们会提供更准确和完整的需求。换一种说法:
**透明+包容+以客户为中心=更好的需求=成功的项目**
---
via: <https://opensource.com/open-organization/18/2/constructing-project-requirements>
作者:[Tracy Buckner](https://opensource.com/users/tracyb) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's no secret that clear, concise, and measurable requirements lead to more successful projects. A study about large scale projects by [McKinsey & Company in conjunction with the University of Oxford](http://calleam.com/WTPF/?page_id=1445) revealed that "on average, large IT projects run 45 percent over budget and 7 percent over time, while delivering 56 percent less value than predicted." The research also showed that some of the causes for this failure were "fuzzy business objectives, out-of-sync stakeholders, and excessive rework."
Business analysts often find themselves constructing these requirements through ongoing conversations. To do this, they must engage multiple stakeholders and ensure that engaged participants provide clear business objectives. This leads to less rework and more projects with a higher rate of success.
And they can do it in an open and inclusive way.
## A framework for success
One tool for increasing project success rate is the [Open Decision Framework](https://opensource.com/open-organization/resources/open-decision-framework). The Open Decision Framework is an resource that can help users make more effective decisions in organizations that embrace [open principles](https://opensource.com/open-organization/resources/open-org-definition). The framework stresses three primary principles: being transparent, being inclusive, and being customer-centric.
**Transparent**. Many times, developers and product designers assume they know how stakeholders use a particular tool or piece of software. But these assumptions are often incorrect and lead to misconceptions about what stakeholders actually need. Practicing transparency when having discussions with developers and business owners is imperative. Development teams need to see not only the "sunny day" scenario but also the challenges that stakeholders face with certain tools or processes. Ask questions such as: "What steps must be done manually?" and "Is this tool performing as you expect?" This provides a shared understanding of the problem and a common baseline for discussion.
**Inclusive**. It is vitally important for business analysts to look at body language and visual cues when gathering requirements. If someone is sitting with arms crossed or rolling their eyes, then it's a clear indication that they do not feel heard. A BA must encourage open communication by reaching out to those that don't feel heard and giving them the opportunity to be heard. Prior to starting the session, lay down ground rules that make the place safe for all to speak their opinions and to share their thoughts. Listen to the feedback provided and respond politely when feedback is offered. Diverse opinions and collaborative problem solving will bring exciting ideas to the session.
**Customer-centric**. The first step to being customer-centric is to recognize the customer. Who is benefiting from this change, update, or development? Early in the project, conduct a stakeholder mapping to help determine the key stakeholders, their roles in the project, and the ways they fit into the big picture. Involving the right customers and assuring that their needs are met will lead to more successful requirements being identified, more realistic (real-life) tests being conducted, and, ultimately, a successful delivery.
When your requirement sessions are transparent, inclusive, and customer-centric, you'll gather better requirements. And when you use the [Open Decision Framework](https://opensource.com/open-organization/16/6/introducing-open-decision-framework) for running those sessions, participants feel more involved and empowered, and they deliver more accurate and complete requirements. In other words:
**Transparent + Inclusive + Customer-Centric = Better Requirements = Successful Projects**
## Comments are closed. |
10,342 | 数据科学家的命令行技巧 | http://kadekillary.work/post/cli-4-ds/ | 2018-12-13T22:11:41 | [
"命令行",
"数据科学"
] | https://linux.cn/article-10342-1.html | 
对于许多数据科学家来说,数据操作从始至终就是 Pandas 或 Tidyverse。从理论上讲,这样做没有任何问题。毕竟,这就是这些工具存在的原因。然而,对于像分隔符转换这样的简单任务,这些工具是大材小用了。
立志掌握命令行应该在每个开发人员的学习清单上,特别是数据科学家。学习 shell 的来龙去脉将无可否认地提高你的生产力。除此之外,命令行还是计算领域的一个重要历史课程。例如,awk —— 一种数据驱动的脚本语言。1977 年,在 [Brain Kernighan](https://en.wikipedia.org/wiki/Brian_Kernighan)(即传奇的 [K&R 书](https://en.wikipedia.org/wiki/The_C_Programming_Language)中 K)的帮助下,awk 首次出现。今天,大约五十年过去了,awk 仍然活跃在每年[新出版的书](https://www.amazon.com/Learning-AWK-Programming-cutting-edge-text-processing-ebook/dp/B07BT98HDS)里面。因此,可以安全地假设对命令行魔法的付出不会很快贬值。
### 我们将涵盖什么
* ICONV
* HEAD
* TR
* WC
* SPLIT
* SORT & UNIQ
* CUT
* PASTE
* JOIN
* GREP
* SED
* AWK
### ICONV
文件编码可能会很棘手。现在大部分文件都是 UTF-8 编码的。要了解 UTF-8 背后的一些魔力,请查看这个出色的[视频](https://www.youtube.com/watch?v=MijmeoH9LT4)。尽管如此,有时我们收到的文件不是这种编码。这可能引起对改变编码模式的一些胡乱尝试。这里,`iconv` 是一个拯救者。`iconv` 是一个简单的程序,它将获取采用一种编码的文本并输出采用另一种编码的文本。
```
# Converting -f (from) latin1 (ISO-8859-1)
# -t (to) standard UTF_8
iconv -f ISO-8859-1 -t UTF-8 < input.txt > output.txt
```
实用选项:
* `iconv -l` 列出所有已知编码
* `iconv -c` 默默丢弃无法转换的字符
### HEAD
如果你是一个 Pandas 重度用户,那么会很熟悉 `head`。通常在处理新数据时,我们想做的第一件事就是了解其内容。这就得启动 Pandas,读取数据然后调用 `df.head()` —— 要说这有点费劲。没有任何选项的 `head` 将打印出文件的前 10 行。`head` 的真正力量在于干净利落的测试操作。例如,如果我们想将文件的分隔符从逗号更改为管道。一个快速测试将是:`head mydata.csv | sed 's/,/|/g'`。
```
# Prints out first 10 lines
head filename.csv
# Print first 3 lines
head -n 3 filename.csv
```
实用选项:
* `head -n` 打印特定行数
* `head -c` 打印特定字节数
### TR
`tr` 类似于翻译。这个功能强大的实用程序是文件基础清理的主力。理想的用例是替换文件中的分隔符。
```
# Converting a tab delimited file into commas
cat tab_delimited.txt | tr "\t" "," comma_delimited.csv
```
`tr` 另一个功能是你可以用内建 `[:class:]` 变量(POSIX 字符类)发挥威力。这些包括了:
* `[:alnum:]` 所有字母和数字
* `[:alpha:]` 所有字母
* `[:blank:]` 所有水平空白
* `[:cntrl:]` 所有控制字符
* `[:digit:]` 所有数字
* `[:graph:]` 所有可打印字符,但不包括空格
* `[:lower:]` 所有小写字母
* `[:print:]` 所有可打印字符,包括空格
* `[:punct:]` 所有标点符号
* `[:space:]` 所有水平或垂直空白
* `[:upper:]` 所有大写字母
* `[:xdigit:]` 所有 16 进制数字
你可以将这些连接在一起以组成强大的程序。以下是一个基本的字数统计程序,可用于检查 README 是否被滥用。
```
cat README.md | tr "[:punct:][:space:]" "\n" | tr "[:upper:]" "[:lower:]" | grep . | sort | uniq -c | sort -nr
```
另一个使用基本正则表达式的例子:
```
# Converting all upper case letters to lower case
cat filename.csv | tr '[A-Z]' '[a-z]'
```
实用选项:
* `tr -d` 删除字符
* `tr -s` 压缩字符
* `\b` 退格
* `\f` 换页
* `\v` 垂直制表符
* `\NNN` 八进制字符
### WC
单词计数。它的价值主要来自其 `-l` 选项,它会给你提供行数。
```
# Will return number of lines in CSV
wc -l gigantic_comma.csv
```
这个工具可以方便地确认各种命令的输出。所以,如果我们在转换文件中的分隔符之后运行 `wc -l`,我们会期待总行数是一样的,如果不一致,我们就知道有地方出错了。
实用选项:
* `wc -c` 打印字节数
* `wc -m` 打印字符数
* `wc -L` 打印最长行的长度
* `wc -w` 打印单词数量
### SPLIT
文件大小的范围可以很广。对于有的任务,拆分文件或许是有好处的,所以使用 `split` 吧。`split` 的基本语法是:
```
# We will split our CSV into new_filename every 500 lines
split -l 500 filename.csv new_filename_
# filename.csv
# ls output
# new_filename_aaa
# new_filename_aab
# new_filename_aa
```
它有两个奇怪的地方是命名约定和缺少文件扩展名。后缀约定可以通过 `-d` 标志变为数字。要添加文件扩展名,你需要运行以下 `find` 命令。它将通过附加 `.csv` 扩展名来更改当前目录中所有文件的名称,所以小心了。
```
find . -type f -exec mv '{}' '{}'.csv \;
# ls output
# filename.csv.csv
# new_filename_aaa.csv
# new_filename_aab.csv
# new_filename_aac.csv
```
实用选项:
* `split -b N` 按特定字节大小分割
* `split -a N` 生成长度为 N 的后缀
* `split -x` 使用十六进制后缀
### SORT & UNIQ
上面两个命令很明显:它们的作用就是字面意思。这两者结合起来可以提供最强大的冲击 (例如,唯一单词的数量)。这是由于 `uniq` 只作用于重复的相邻行。这也是在输出前进行 `sort` 的原因。一个有趣的事情是 `sort -u` 会达到和典型的 `sort file.txt | uniq` 模式一样的结果。
`sort` 对数据科学家来说确实具有潜在的有用能力:能够根据特定列对整个 CSV 进行排序。
```
# Sorting a CSV file by the second column alphabetically
sort -t"," -k2,2 filename.csv
# Numerically
sort -t"," -k2n,2 filename.csv
# Reverse order
sort -t"," -k2nr,2 filename.csv
```
这里的 `-t` 选项将逗号指定为分隔符,通常假设分隔符是空格或制表符。此外,`-k` 选项是为了确定我们的键。这里的语法是 `-km,n`,`m` 作为开始列,`n` 作为结束列。
实用选项:
* `sort -f` 忽略大小写
* `sort -r` 反向排序
* `sort -R` 乱序
* `uniq -c` 统计出现次数
* `uniq -d` 只打印重复行
### CUT
`cut` 用于删除列。作为演示,如果我们只想删除第一和第三列。
```
cut -d, -f 1,3 filename.csv
```
要选择除了第一行外的所有行。
```
cut -d, -f 2- filename.csv
```
结合其他命令,将 `cut` 用作过滤器。
```
# Print first 10 lines of column 1 and 3, where "some_string_value" is present
head filename.csv | grep "some_string_value" | cut -d, -f 1,3
```
查出第二列中唯一值的数量。
```
cat filename.csv | cut -d, -f 2 | sort | uniq | wc -l
# Count occurences of unique values, limiting to first 10 results
cat filename.csv | cut -d, -f 2 | sort | uniq -c | head
```
### PASTE
`paste` 是一个带有趣味性功能的特定命令。如果你有两个需要合并的文件,并且它们已经排序好了,`paste` 帮你解决了接下来的步骤。
```
# names.txt
adam
john
zach
# jobs.txt
lawyer
youtuber
developer
# Join the two into a CSV
paste -d ',' names.txt jobs.txt > person_data.txt
# Output
adam,lawyer
john,youtuber
zach,developer
```
更多 SQL 式变种,见下文。
### JOIN
`join` 是一个简单的、<ruby> 准切向的 <rt> quasi-tangential </rt></ruby> SQL。最大的区别是 `join` 将返回所有列以及只能在一个字段上匹配。默认情况下,`join` 将尝试使用第一列作为匹配键。为了获得不同结果,必须使用以下语法:
```
# Join the first file (-1) by the second column
# and the second file (-2) by the first
join -t "," -1 2 -2 1 first_file.txt second_file.txt
```
标准的 `join` 是内连接。然而,外连接通过 `-a` 选项也是可行的。另一个值得一提的技巧是 `-q` 标志,如果发现有缺失的字段,可用于替换值。
```
# Outer join, replace blanks with NULL in columns 1 and 2
# -o which fields to substitute - 0 is key, 1.1 is first column, etc...
join -t"," -1 2 -a 1 -a2 -e ' NULL' -o '0,1.1,2.2' first_file.txt second_file.txt
```
它不是最用户友好的命令,而是绝望时刻的绝望措施。
实用选项:
* `join -a` 打印不可配对的行
* `join -e` 替换丢失的输入字段
* `join -j` 相当于 `-1 FIELD -2 FIELD`
### GREP
`grep` 即 <ruby> 用正则表达式全局搜索并且打印 <rt> Global search for a Regular Expression and Print </rt></ruby>,可能是最有名的命令,并且名副其实。`grep` 很强大,特别适合在大型代码库中查找。在数据科学的王国里,它充当其他命令的提炼机制。虽然它的标准用途也很有价值。
```
# Recursively search and list all files in directory containing 'word'
grep -lr 'word' .
# List number of files containing word
grep -lr 'word' . | wc -l
```
计算包含单词或模式的总行数。
```
grep -c 'some_value' filename.csv
# Same thing, but in all files in current directory by file name
grep -c 'some_value' *
```
对多个值使用“或”运算符: `\|`。
```
grep "first_value\|second_value" filename.csv
```
实用选项:
* `alias grep="grep --color=auto"` 使 grep 色彩丰富
* `grep -E` 使用扩展正则表达式
* `grep -w` 只匹配整个单词
* `grep -l` 打印匹配的文件名
* `grep -v` 非匹配
### 大人物们
`sed` 和 `awk` 是本文中最强大的两个命令。为简洁起见,我不打算详细讨论这两个命令。相反,我将介绍各种能证明其令人印象深刻的力量的命令。如果你想了解更多,[这儿就有一本书](https://www.amazon.com/sed-awk-Dale-Dougherty/dp/1565922255/ref=sr_1_1?ie=UTF8&qid=1524381457&sr=8-1&keywords=sed+and+awk)是关于它们的。
### SED
`sed` 本质上是一个流编辑器。它擅长替换,但也可以用于所有输出重构。
最基本的 `sed` 命令由 `s/old/new/g` 组成。它的意思是搜索 `old`,全局替换为 `new`。 如果没有 `/g`,我们的命令将在 `old` 第一次出现后终止。
为了快速了解它的功能,我们可以深入了解一个例子。 在以下情景中,你已有以下文件:
```
balance,name
$1,000,john
$2,000,jack
```
我们可能想要做的第一件事是删除美元符号。`-i` 标志表示原位。`''` 表示零长度文件扩展名,从而覆盖我们的初始文件。理想情况下,你可以单独测试,然后输出到新文件。
```
sed -i '' 's/\$//g' data.txt
# balance,name
# 1,000,john
# 2,000,jack
```
接下来,去除 `blance` 列的逗号。
```
sed -i '' 's/\([0-9]\),\([0-9]\)/\1\2/g' data.txt
# balance,name
# 1000,john
# 2000,jack
```
最后 jack 有一天决定辞职。所以,再见了,我的朋友。
```
sed -i '' '/jack/d' data.txt
# balance,name
# 1000,john
```
正如你所看到的,`sed` 有很多强大的功能,但乐趣并不止于此。
### AWK
最好的留在最后。`awk` 不仅仅是一个简单的命令:它是一个成熟的语言。在本文中涉及的所有内容中,`awk` 是目前为止最酷的。如果你感兴趣,这里有很多很棒的资源 —— 看 [这里](https://www.amazon.com/AWK-Programming-Language-Alfred-Aho/dp/020107981X/ref=sr_1_1?ie=UTF8&qid=1524388936&sr=8-1&keywords=awk)、[这里](http://www.grymoire.com/Unix/Awk.html) 和 [这里](https://www.tutorialspoint.com/awk/index.htm)。
`awk` 的常见用例包括:
* 文字处理
* 格式化文本报告
* 执行算术运算
* 执行字符串操作
`awk` 可以以最原生的形式并行 `grep`。
```
awk '/word/' filename.csv
```
或者更加神奇:将 `grep` 和 `cut` 组合起来。在这里,对于所有带我们指定单词 `word` 的行,`awk` 打印第三和第四列,用 `tab` 分隔。`-F,` 用于指定切分时的列分隔符为逗号。
```
awk -F, '/word/ { print $3 "\t" $4 }' filename.csv
```
`awk` 内置了许多精巧的变量。比如,`NF` —— 字段数,和 `NR` —— 记录数。要获取文件中的第 53 条记录:
```
awk -F, 'NR == 53' filename.csv
```
更多的花招是其基于一个或多个值进行过滤的能力。下面的第一个示例将打印第一列等于给定字符串的行的行号和列。
```
awk -F, ' $1 == "string" { print NR, $0 } ' filename.csv
# Filter based off of numerical value in second column
awk -F, ' $2 == 1000 { print NR, $0 } ' filename.csv
```
多个数值表达式:
```
# Print line number and columns where column three greater
# than 2005 and column five less than one thousand
awk -F, ' $3 >= 2005 && $5 <= 1000 { print NR, $0 } ' filename.csv
```
求出第三列的总和:
```
awk -F, '{ x+=$3 } END { print x }' filename.csv
```
在第一列等于 `something` 的那些行,求出第三列值的总和。
```
awk -F, '$1 == "something" { x+=$3 } END { print x }' filename.csv
```
获取文件的行列数:
```
awk -F, 'END { print NF, NR }' filename.csv
# Prettier version
awk -F, 'BEGIN { print "COLUMNS", "ROWS" }; END { print NF, NR }' filename.csv
```
打印出现了两次的行:
```
awk -F, '++seen[$0] == 2' filename.csv
```
删除重复的行:
```
# Consecutive lines
awk 'a !~ $0; {a=$0}']
# Nonconsecutive lines
awk '! a[$0]++' filename.csv
# More efficient
awk '!($0 in a) {a[$0];print}
```
使用内置函数 `gsub()` 替换多个值。
```
awk '{gsub(/scarlet|ruby|puce/, "red"); print}'
```
这个 `awk` 命令将组合多个 CSV 文件,忽略标题,然后在最后附加它。
```
awk 'FNR==1 && NR!=1{next;}{print}' *.csv > final_file.csv
```
需要缩小一个庞大的文件? `awk` 可以在 `sed` 的帮助下处理它。具体来说,该命令根据行数将一个大文件分成多个较小的文件。这个一行脚本将增加一个扩展名。
```
sed '1d;$d' filename.csv | awk 'NR%NUMBER_OF_LINES==1{x="filename-"++i".csv";}{print > x}'
# Example: splitting big_data.csv into data_(n).csv every 100,000 lines
sed '1d;$d' big_data.csv | awk 'NR%100000==1{x="data_"++i".csv";}{print > x}'
```
### 结语
命令行拥有无穷无尽的力量。本文中介绍的命令足以将你从一无所知提升到英雄人物。除了涵盖的内容之外,还有许多实用程序可以考虑用于日常数据操作。[Csvkit](http://csvkit.readthedocs.io/en/1.0.3/)、[xsv](https://github.com/BurntSushi/xsv) 还有 [q](https://github.com/harelba/q) 是需要记住的三个。如果你希望更深入地了解命令行数据科学,查看[这本书](https://www.amazon.com/Data-Science-Command-Line-Time-Tested/dp/1491947853/ref=sr_1_1?ie=UTF8&qid=1524390894&sr=8-1&keywords=data+science+at+the+command+line)。它也可以[免费](https://www.datascienceatthecommandline.com/)在线获得!
---
via: <http://kadekillary.work/post/cli-4-ds/>
作者:[Kade Killary](http://kadekillary.work/authors/kadekillary) 选题:[lujun9972](https://github.com/lujun9972) 译者:[GraveAccent](https://github.com/graveaccent) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,343 | 给写作者们的 7 个命令行工具 | https://opensource.com/article/18/11/command-line-tools-writers | 2018-12-13T22:43:40 | [
"写作"
] | https://linux.cn/article-10343-1.html |
>
> 扔掉你的文字编辑器,然后使用这些开源工具在命令行上写作吧。
>
>
>

对于大多数人(尤其是非技术人员),写作意味着在 LibreOffice Writer 或者其他带图形界面的文字处理应用上编辑文本。但是还有许多可行的方法可以让任何人通过文本传递他们的信息,尤其是越来越多的作者选择[拥抱纯文本](https://plaintextproject.online)。
在使用图形界面写作的世界同样有命令行工具的一席之地。这些命令行工具可以帮助他们进行写作,检查他们的拼写等等 —— 无论是在写一篇文章、博客或者故事;写一个 README 文件;或者准备一份技术文档的时候。
下面是一些在任何写作情况下都有用的命令行工具。
### 编辑器
没错,你可以在命令行进行真正的写作。我知道一些写作者会使用 [Nano](https://www.nano-editor.org/)、[Vim](https://www.vim.org)、[Emacs](https://www.gnu.org/software/emacs/)、以及 [Jove](https://opensource.com/article/17/1/jove-lightweight-alternative-vim) 等编辑器在终端窗口中进行工作。而这些编辑器[并非屈指可数](https://en.wikipedia.org/wiki/List_of_text_editors#Text_user_interface)。文本编辑器的优势在于它们简单易用以及更专注于文本。非常适合用于编辑任何文本的初稿甚至完成一个漫长而复杂的写作项目。
如果你想在命令行中获得更像文字编辑器的体验,不妨了解一下 [WordGrinder](https://cowlark.com/wordgrinder/)。它是一款简单但拥有足够的编写和发布功能的文字编辑器。它支持基本的格式和样式,并且你可以将你的文字以 Markdown、ODT、LaTeX 或者 HTML 等格式导出。
### 拼写检查
每个写作者在完成他们的工作前至少要(或者说应该要)进行一次拼写检查。为什么呢?在写作的世界里有个永恒的定律,无论你检查了多少次手稿,拼写错误和错字依然会存在。
我曾经详细[介绍](https://opensource.com/article/18/2/how-check-spelling-linux-command-line-aspell)过我最喜欢的命令行拼写检查工具 [GNU Aspell](http://aspell.net/)。交互式检测文本文档的 Aspell 不仅能够高亮显示拼写错误还能在拼写错误的上方提供正确的拼写建议。Aspell 在进行拼写检查时同样能够忽略许多语法标记。
另一个够老但仍然有用的代替品是 [Ispell](https://www.cs.hmc.edu/%7Egeoff/ispell.html)。虽然它比 Aspell 稍慢一点,但它们都以相同的方式工作。当你在你的文本文件上工作时,Ispell 将提供正确的建议。Ispell 同样也对英语以外的语言提供了良好的支持。
### 文章 linter
软件开发人员使用 [linter](https://en.wikipedia.org/wiki/Lint_(software)) 来检查他们的代码是否存在错误或者 bug。同样也有用于检查文本样式或语法错误的 linter;而该命令行工具会认为这些错误是样式元素。任何写作者都可以(也应该)使用它,一个文章 linter 对于要求文档风格和样式一致的文档团队项目而言尤其有用。
[Proselint](http://proselint.com/) 是一款全能的实时检查工具。它会找出行话、大话、不正确日期和时间格式、滥用的术语[等等](http://proselint.com/checks/)。它也很容易运行并忽略文本中的标记。
[Alex](https://github.com/get-alex/alex) 是一个简单但有用的文章 linter。 对明文文本或者格式为 Markdown 或 HTML 的文档使用它。Alex 会对“性别偏好、极端主义、种族相关、宗教,或者文章中其他不平等的措辞”产生警告。如果你想要试试看 Alex,这里有一个在线 [demo](https://alexjs.com/#demo)。
### 其他工具
有时候你找不到一个单词的恰当的同义词。但你不需要去呆板的词库中抓取或者去专门的网站完善你的单词完整。仅仅需要对你想要替换的单词运行 [Aiksaurus](http://aiksaurus.sourceforge.net/),然后它就会为你完成这个工作。但是,这个程序最大的缺点是它只支持英语。
即使是只会很少(甚至只有一项)技术技能的写作者都能接受 [Markdown](https://en.wikipedia.org/wiki/Markdown) 来快速而简单地格式化他们的作品。但是,有时候你也需要将使用 Markdown 格式的文件转换成其他格式。这就是 [Pandoc](https://pandoc.org) 的用武之地。你可以用它来将你的文档转换成 HTML、Word、LibreOffice Writer、LaTeX、EPUB 以及其他格式。你甚至可以用 Pandoc 来生成书籍和[研究论文](https://opensource.com/article/18/9/pandoc-research-paper)。
你有最喜欢的命令行写作工具吗?在社区发表评论分享它吧。
---
via: <https://opensource.com/article/18/11/command-line-tools-writers>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LazyWolfLin](https://github.com/LazyWolfLin) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For most people (especially non-techies), the act of writing means tapping out words using LibreOffice Writer or another GUI word processing application. But there are many other options available to help anyone communicate their message in writing, especially for the growing number of writers [embracing plaintext](https://plaintextproject.online).
There's also room in a GUI writer's world for command line tools that can help them write, check their writing, and more—regardless of whether they're banging out an article, blog post, or story; writing a README; or prepping technical documentation.
Here's a look at some command-line tools that any writer will find useful.
## Editors
Yes, you *can* do actual writing at the command line. I know writers who do their work using editors like [Nano](https://www.nano-editor.org/), [Vim](https://www.vim.org), [Emacs](https://www.gnu.org/software/emacs/), and [Jove](https://opensource.com/article/17/1/jove-lightweight-alternative-vim) in a terminal window. And those editors [aren't the only games in town](https://en.wikipedia.org/wiki/List_of_text_editors#Text_user_interface). Text editors are great because they (at a basic level, anyway) are easy to use and distraction free. They're perfect for tapping out a first draft of anything or even completing a long and complicated writing project.
If you want a more word processor-like experience at the command line, take a look at [WordGrinder](https://cowlark.com/wordgrinder/). WordGrinder is a bare-bones word processor, but it has more than enough features for writing and publishing your work. It supports basic formatting and styles, and you can export your writing to formats like Markdown, ODT, LaTeX, and HTML.
## Spell checkers
Every writer does (or at least should do) a spelling check on their work at least once. Why? An immutable law of the writing universe states that, no matter how many times you look over your manuscript, a spelling mistake or typo will creep in.
My favorite command-line spelling checker is [GNU Aspell](http://aspell.net/), which I previously [looked at](https://opensource.com/article/18/2/how-check-spelling-linux-command-line-aspell) in detail. Aspell checks plaintext documents interactively and not only highlights errors but often puts the best correction at the top of its list of suggestions. Aspell also ignores many markup languages while doing its thing.
A much older but still useful alternative is [Ispell](https://www.cs.hmc.edu/~geoff/ispell.html). It's a bit slower than Aspell, but both utilities work the same way. As you interact with your text file, Ispell suggests corrections. Ispell also has good support for foreign languages.
## Prose linters
Software developers use [linters](https://en.wikipedia.org/wiki/Lint_(software)) to check their code for errors or bugs. There are also linters for prose that check for style and syntax errors; think of them as the *Elements of Style* for the command line. While any writer can (and probably should) use one, a prose linter is especially useful for team documentation projects that require a consistent voice and style.
[Proselint](http://proselint.com/) is a comprehensive tool for checking what you're writing. It looks for jargon, hyperbole, incorrect date and time format, misused terms, and [much more](http://proselint.com/checks/). It's also easy to run and ignores markup in a plaintext file.
[Alex](https://github.com/get-alex/alex) is a simple yet powerful prose linter. Run it against a plaintext document or one formatted with Markdown or HTML. Alex pumps out warnings of "gender favouring, polarising, race related, religion inconsiderate, or other unequal phrasing in text." If you want to give Alex a test drive, there's an [online demo](https://alexjs.com/#demo).
## Other tools
Sometimes you just can't find the right synonym for a word. But you don't need to grab a "dead tree" thesaurus or go to a dedicated website to perfect your word choice. Just run [Aiksaurus](http://aiksaurus.sourceforge.net/) against the word you want to replace, and it does the work for you. This utility's main drawback, though, is that it supports English only.
Even writers with few (if any) technical skills are embracing [Markdown](https://en.wikipedia.org/wiki/Markdown) to quickly and easily format their work. Sometimes, though, you need to convert files formatted with Markdown to something else. That's where [Pandoc](https://pandoc.org) comes in. You can use it to convert your documents to HTML, Word, LibreOffice Writer, LaTeX, EPUB, and other formats. You can even use Pandoc to produce books and [research papers](https://opensource.com/article/18/9/pandoc-research-paper).
Do you have a favorite command-line tool for writing? Share it with the Opensource.com community by leaving a comment.
## 5 Comments |
10,344 | Bash 中使用控制运算符连接命令 | https://opensource.com/article/18/11/control-operators-bash-shell | 2018-12-13T23:48:25 | [
"脚本",
"流程"
] | https://linux.cn/article-10344-1.html |
>
> 在命令行中,使用控制运算符为复合命令添加逻辑。
>
>
>

经常会使用一些简单的复合指令,比如说在一个命令行中连接几个命令。这些命令使用分号分隔,表示一个命令结束。为了在一个命令行中创建一系列简单的 shell 命令,只需要使用分号把每一条命令分隔开,就像下面这样:
```
command1 ; command2 ; command3 ; command4 ;
```
最后一个分号你可以不用添加,因为当你按下回车键时就表示一个命令的结束,但是为了和其它的保持一致,还是建议加上比较好。
所有的命令执行都没有什么问题 —— 只要没有什么意外发生。但是当出问题时到底发生了什么呢?我们可以预测,并且通过 Bash 中内置的 `&&` 和 `||` 运算符跟踪这些错误。这两个控制运算符提供了一些流控制,可以让我们改变代码执行队列的顺序。分号和换行符也被认为是 Bash 的控制运算符。
`&&` 运算符意义简单来说就是“如果 `command1` 执行成功,就接着执行 `command2`。”如果 `command1` 因为任何原因执行失败,那么 `command2` 将不执行。这个语法看下来像这样:
```
command1 && command2
```
这样写是允许的,因为每一个命令都会返回一个值(RC)给 shell 来表示这个命令在执行的过程中是否执行成功或者失败。通常,返回值是 `0` 表示成功,而一个正数值表示不同种类的错误。有一些系统管理工具仅仅返回一个 `1` 来表示所有的错误,但是也有很多工具使用其它的正数的返回值来表示各种类型错误。
我们可以很容易的使用脚本来检查 shell 变量 `$?`,可以通过命令列表中的下一个命令,或者可以直接使用系统管理工具检查。我们一起来看这些返回值。运行一个简单的命令然后立即检查它的返回值,这个返回值始终是属于最后一个运行的命令。
```
[student@studentvm1 ~]$ ll ; echo "RC = $?"
total 284
-rw-rw-r-- 1 student student 130 Sep 15 16:21 ascii-program.sh
drwxrwxr-x 2 student student 4096 Nov 10 11:09 bin
<snip>
drwxr-xr-x. 2 student student 4096 Aug 18 10:21 Videos
RC = 0
[student@studentvm1 ~]$
```
这个返回值是 `0`,表示这个命令执行成功了。现在尝试使用同样的命令在一些我们没有权限的目录上。
```
[student@studentvm1 ~]$ ll /root ; echo "RC = $?"
ls: cannot open directory '/root': Permission denied
RC = 2
[student@studentvm1 ~]$
```
这个返回值的含义可以在 [ls 命令的 man 页面](http://man7.org/linux/man-pages/man1/ls.1.html) 中找到。
现在我们来试试 `&&` 这个控制运算符,因为它也可能会被用在一个命令行程序中。我们将从一个简单的示例开始:创建一个新目录,如果创建成功就在这个目录中创建一个文件。
我们需要一个目录可以创建其它的目录。首先,在你的家目录中创建一个临时的目录用来做测试。
```
[student@studentvm1 ~]$ cd ; mkdir testdir
```
在 `~/testdir` 中新建一个目录,这也应该是一个空目录,因为是你刚刚创建的,然后创建一个新的空文件在这个新目录中。下面的命令可以做这些事情。
```
[student@studentvm1 ~]$ mkdir ~/testdir/testdir2 && touch ~/testdir/testdir2/testfile1
[student@studentvm1 ~]$ ll ~/testdir/testdir2/
total 0
-rw-rw-r-- 1 student student 0 Nov 12 14:13 testfile1
[student@studentvm1 ~]$
```
我们看到一切都运行得很好,因为 `testdir` 目录是访问且可写的。然后我们改变 `testdir` 目录的权限,让用户 `student` 不再具有访问的权限。操作如下:
```
[student@studentvm1 ~]$ chmod 076 testdir ; ll | grep testdir
d---rwxrw-. 3 student student 4096 Nov 12 14:13 testdir
[student@studentvm1 ~]$
```
在长列表(`ll`)命令后面使用 `grep` 命令来列出 `testdir` 目录。你可以看到用户 `student` 不再有 `testdir` 目录的访问权限。现在我们像之前一样运行同样的命令,但是在 `testdir` 目录中创建的是一个不同的目录。
```
[student@studentvm1 ~]$ mkdir ~/testdir/testdir3 && touch ~/testdir/testdir3/testfile1
mkdir: cannot create directory ‘/home/student/testdir/testdir3’: Permission denied
[student@studentvm1 ~]$
```
尽管我们也同样得到了一个错误的消息,但 `&&` 控制运算符阻止了 `touch` 命令的运行,因为在创建 `testdir3` 目录的时候发生了错误。通过这种复合的流控制可以阻止一些错误的发生使事情变乱。但是这样看起来变得稍微复杂了一些。
`||` 控制运算符允许添加另一个命令,这个命令在初始程序语句返回值大于 0 时执行。
```
[student@studentvm1 ~]$ mkdir ~/testdir/testdir3 && touch ~/testdir/testdir3/testfile1 || echo "An error occurred while creating the directory."
mkdir: cannot create directory ‘/home/student/testdir/testdir3’: Permission denied
An error occurred while creating the directory.
[student@studentvm1 ~]$
```
当我们使用 `&&` 和 `||` 控制运算符时,使用流控制的复合命令的语法格式通常是下面这样的形式。
```
preceding commands ; command1 && command2 || command3 ; following commands
```
使用控制运算符的复合命令可以在其它命令之前或者之后,这些和控制运算符流控制有关系,但是不受控制运算符流控制的影响。如果不考虑复合命令的流控制中发生的任何事情那么所有的命令都将执行。
当程序出问题时,这些流控制运算符使得在命令中处理出错和通知我们变得更有效率。我直接在命令行中使用它们,也在脚本中使用。
你可以以 root 用户的身份来删除这个目录和它里面的内容。
```
[root@studentvm1 ~]# rm -rf /home/student/testdir
```
你是怎样使用 Bash 控制运算符的呢?在评论区中告诉我们。
---
via: <https://opensource.com/article/18/11/control-operators-bash-shell>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Jamskr](https://github.com/Jamskr) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Simple compound commands—such as stringing several commands together in a sequence on the command line—are used often. Such commands are separated by semicolons, which define the end of a command. To create a simple series of shell commands on a single line, simply separate each command using a semicolon, like this:
`command1 ; command2 ; command3 ; command4 ; `
You don't need to add a final semicolon because pressing the Enter key implies the end of the final command, but it's fine to add it for consistency.
All the commands will run without a problem—as long as no error occurs. But what happens if an error happens? We can anticipate and allow for errors using the **&&** and **||** control operators built into Bash. These two control operators provide some flow control and enable us to alter the code-execution sequence. The semicolon and the **newline** character are also considered to be Bash control operators.
The **&&** operator simply says "if command1 is successful, then run command2." If command1 fails for any reason, command2 won't run. That syntax looks like:
`command1 && command2`
This works because every command returns a code to the shell that indicates whether it completed successfully or failed during execution. By convention, a return code (RC) of 0 (zero) indicates success and any positive number indicates some type of failure. Some sysadmin tools just return a 1 to indicate any failure, but many use other positive numerical codes to indicate the type of failure.
The Bash shell's **$?** variable can be checked very easily by a script, by the next command in a list of commands, or even directly by a sysadmin. Let's look at RCs. We can run a simple command and immediately check the RC, which will always pertain to the last command that ran.
```
[student@studentvm1 ~]$ ll ; echo "RC = $?"
total 284
-rw-rw-r-- 1 student student 130 Sep 15 16:21 ascii-program.sh
drwxrwxr-x 2 student student 4096 Nov 10 11:09 bin
<snip>
drwxr-xr-x. 2 student student 4096 Aug 18 10:21 Videos
RC = 0
[student@studentvm1 ~]$
```
This RC is 0, which means the command completed successfully. Now try the same command on a directory where we don't have permissions.
```
[student@studentvm1 ~]$ ll /root ; echo "RC = $?"
ls: cannot open directory '/root': Permission denied
RC = 2
[student@studentvm1 ~]$
```
This RC's meaning can be found in the [ ls command's man page](http://man7.org/linux/man-pages/man1/ls.1.html).
Let's try the **&&** control operator as it might be used in a command-line program. We'll start with something simple: Create a new directory and, if that is successful, create a new file in it.
We need a directory where we can create other directories. First, create a temporary directory in your home directory where you can do some testing.
`[student@studentvm1 ~]$ cd ; mkdir testdir`
Create a new directory in **~/testdir**, which should be empty because you just created it, and then create a new, empty file in that new directory. The following command will do those tasks.
```
[student@studentvm1 ~]$ mkdir ~/testdir/testdir2 && touch ~/testdir/testdir2/testfile1
[student@studentvm1 ~]$ ll ~/testdir/testdir2/
total 0
-rw-rw-r-- 1 student student 0 Nov 12 14:13 testfile1
[student@studentvm1 ~]$
```
We know everything worked as it should because the **testdir** directory is accessible and writable. Change the permissions on **testdir** so it is no longer accessible to the user **student** as follows:
```
[student@studentvm1 ~]$ chmod 076 testdir ; ll | grep testdir
d---rwxrw-. 3 student student 4096 Nov 12 14:13 testdir
[student@studentvm1 ~]$
```
Using the **grep** command after the long list (**ll**) shows the listing for **testdir**. You can see that the user **student** no longer has access to the **testdir** directory. Now let's run almost the same command as before but change it to create a different directory name inside **testdir**.
```
[student@studentvm1 ~]$ mkdir ~/testdir/testdir3 && touch ~/testdir/testdir3/testfile1
mkdir: cannot create directory ‘/home/student/testdir/testdir3’: Permission denied
[student@studentvm1 ~]$
```
Although we received an error message, using the **&&** control operator prevents the **touch** command from running because there was an error in creating **testdir3**. This type of command-line logical flow control can prevent errors from compounding and making a real mess of things. But let's make it a little more complicated.
The **||** control operator allows us to add another command that executes when the initial program statement returns a code larger than zero.
```
[student@studentvm1 ~]$ mkdir ~/testdir/testdir3 && touch ~/testdir/testdir3/testfile1 || echo "An error occurred while creating the directory."
mkdir: cannot create directory ‘/home/student/testdir/testdir3’: Permission denied
An error occurred while creating the directory.
[student@studentvm1 ~]$
```
Our compound command syntax using flow control takes this general form when we use the **&&** and **||** control operators:
`preceding commands ; command1 && command2 || command3 ; following commands`
The compound command using the control operators may be preceded and followed by other commands that can be related to the ones in the flow-control section but which are unaffected by the flow control. All of those commands will execute without regard to anything that takes place inside the flow-control compound command.
These flow-control operators can make working at the command line more efficient by handling decisions and letting us know when a problem has occurred. I use them directly on the command line as well as in scripts.
You can clean up as the root user to delete the directory and its contents.
`[root@studentvm1 ~]# rm -rf /home/student/testdir`
How do you use Bash control operators? Let us know in the comment section.
## 5 Comments |
10,345 | 一种新的安全检测的方法 | https://opensource.com/article/18/4/new-approach-security-instrumentation | 2018-12-14T12:37:41 | [
"安全"
] | https://linux.cn/article-10345-1.html |
>
> 不要只测试已有系统,强安全要求更积极主动的策略。
>
>
>

我们当中有多少人曾说出过下面这句话:“我希望这能起到作用!”?
毫无疑问,我们中的大多数人可能都不止一次地说过这句话。这句话不是用来激发信心的,相反它揭示了我们对自身能力和当前正在测试的功能的怀疑。不幸的是,这句话非常好地描述了我们传统的安全模型。我们的运营基于这样的假设,并希望我们实施的控制措施 —— 从 web 应用的漏扫到终端上的杀毒软件 —— 防止恶意的病毒和软件进入我们的系统,损坏或偷取我们的信息。
渗透测试通过积极地尝试侵入网络、向 web 应用注入恶意代码或者通过发送钓鱼邮件来传播病毒等等这些步骤来避免我们对假设的依赖。由于我们在不同的安全层面上来发现和渗透漏洞,手动测试无法解决漏洞被主动打开的情况。在安全实验中,我们故意在受控的情形下创造混乱,模拟事故的情形,来客观地检测我们检测、阻止这类问题的能力。
>
> “安全实验为分布式系统的安全性实验提供了一种方法,以建立对抗恶意攻击的能力的信心。”
>
>
>
在分布式系统的安全性和复杂性方面,需要反复地重申混沌工程界的一句名言,“希望不是一种有效的策略”。我们多久会主动测试一次我们设计或构建的系统,来确定我们是否已失去对它的控制?大多数组织都不会发现他们的安全控制措施失效了,直到安全事件的发生。我们相信“安全事件不是侦察措施”,而且“希望不要出事也不是一个有效的策略”应该是 IT 专业人士执行有效安全实践的口号。
行业在传统上强调预防性的安全措施和纵深防御,但我们的任务是通过侦探实验来驱动对安全工具链的新知识和见解。因为过于专注于预防机制,我们很少尝试一次以上地或者年度性地手动测试要求的安全措施,来验证这些控件是否按设计的那样执行。
随着现代分布式系统中的无状态变量的不断改变,人们很难充分理解他们的系统的行为,因为会随时变化。解决这个问题的一种途径是通过强大的系统性的设备进行检测,对于安全性检测,你可以将这个问题分成两个主要方面:**测试**,和我们称之为**实验**的部分。测试是对我们已知部分的验证和评估,简单来说,就是我们在开始找之前,要先弄清楚我们在找什么。另一方面,实验是去寻找获得我们之前并不清楚的见解和知识。虽然测试对于一个成熟的安全团队来说是一项重要实践,但以下示例会有助于进一步地阐述两者之间的差异,并对实验的附加价值提供一个更为贴切的描述。
### 示例场景:精酿啤酒
思考一个用于接收精酿啤酒订单的 web 服务或者 web 应用。
这是这家精酿啤酒运输公司的一项重要服务,这些订单来自客户的移动设备、网页,和通过为这家公司精酿啤酒提供服务的餐厅的 API。这项重要服务运行在 AWS EC2 环境上,并且公司认为它是安全的。这家公司去年成功地通过了 PCI 规则,并且每年都会请第三方进行渗透测试,所以公司认为这个系统是安全的。
这家公司有时一天两次部署来进行 DevOps 和持续交付工作,公司为其感到自豪。
在了解了混沌工程和安全实验方面的东西后,该公司的开发团队希望能确定,在一个连续不断的基础上,他们的安全系统对真实世界事件的有效性和快速恢复性怎么样。与此同时,确保他们不会把安全控件不能检测到的新问题引入到系统中。
该团队希望能小规模地通过评估端口安全和防火墙设置来让他们能够检测、阻止和警告他们 EC2 安全组上端口设置的错误配置更改。
* 该团队首先对他们正常状态下的假设进行总结。
* 在 EC2 实例里为端口安全进行一个假设。
* 为未认证的端口改变实验选择和配置 YAML 文件。
* 该配置会从已选择的目标中随机指定对象,同时端口的范围和数量也会被改变。
* 团队还会设置进行实验的时间并缩小爆破攻击的范围,来确保对业务的影响最小。
* 对于第一次测试,团队选择在他们的测试环境中运行实验并运行一个单独的测试。
* 在真实的<ruby> 游戏日 <rt> Game Day </rt></ruby>风格里,团队在预先计划好的两个小时的窗口期内,选择<ruby> 灾难大师 <rt> Master of Disaster </rt></ruby>来运行实验。在那段窗口期内,灾难大师会在 EC2 实例安全组中的一个实例上执行这次实验。
* 一旦游戏日结束,团队就会开始进行一个彻底的、免于指责的事后练习。它的重点在于针对稳定状态和原始假设的实验结果。问题会类似于下面这些:
### 事后验证问题
* 防火墙是否检测到未经授权的端口更改?
* 如果更改被检测到,更改是否会被阻止?
* 防火墙是否会将有用的日志信息记录到日志聚合工具中?
* SIEM 是否会对未经授权的更改发出警告?
* 如果防火墙没有检测到未经授权的更改,那么配置的管理工具是否发现了这次更改?
* 配置管理工具是否向日志聚合工具报告了完善的信息?
* SIEM 最后是否进行了关联报警?
* 如果 SIEM 发出了警报,安全运营中心是否能收到这个警报?
* 获得警报的 SOC 分析师是否能对警报采取措施,还是缺少必要的信息?
* 如果 SOC 确定警报是真实的,那么安全事件响应是否能简单地从数据中进行分类活动?
我们系统中对失败的承认和预期已经开始揭示我们对系统工作的假设。我们的使命是利用我们所学到的,并更加广泛地应用它。以此来真正主动地解决安全问题,来超越当前传统主流的被动处理问题的安全模型。
随着我们继续在这个新领域内进行探索,我们一定会发布我们的研究成果。如果您有兴趣想了解更多有关研究的信息或是想参与进来,请随时联系 Aaron Rinehart 或者 Grayson Brewer。
特别感谢 Samuel Roden 对本文提供的见解和想法。
* [看我们相关的文章:是否需要 DevSecOps 这个词?](https://opensource.com/article/18/4/devsecops)
---
via: <https://opensource.com/article/18/4/new-approach-security-instrumentation>
作者:[Aaron Rinehart](https://opensource.com/users/aaronrinehart) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | How many of us have ever uttered the following phrase: *“I hope this works!”*?
Without a doubt, most of us have, likely more than once. It’s not a phrase that inspires confidence, as it reveals doubts about our abilities or the functionality of whatever we are testing. Unfortunately, this very phrase defines our traditional security model all too well. We operate based on the assumption and the hope that the controls we put in place—from vulnerability scanning on web applications to anti-virus on endpoints—prevent malicious actors and software from entering our systems and damaging or stealing our information.
Penetration testing took a step to combat relying on assumptions by actively trying to break into the network, inject malicious code into a web application, or spread “malware” by sending out phishing emails. Composed of finding and poking holes in our different security layers, pen testing fails to account for situations in which holes are actively opened. In security experimentation, we intentionally create chaos in the form of controlled, simulated incident behavior to objectively instrument our ability to detect and deter these types of activities.
“Security experimentation provides a methodology for the experimentation of the security of distributed systems to build confidence in the ability to withstand malicious conditions.”
When it comes to security and complex distributed systems, a common adage in the chaos engineering community reiterates that “hope is not an effective strategy.” How often do we proactively instrument what we have designed or built to determine if the controls are failing? Most organizations do not discover that their security controls are failing until a security incident results from that failure. We believe that “Security incidents are not detective measures” and “Hope is not an effective strategy” should be the mantras of IT professionals operating effective security practices.
The industry has traditionally emphasized preventative security measures and defense-in-depth, whereas our mission is to drive new knowledge and insights into the security toolchain through detective experimentation. With so much focus on the preventative mechanisms, we rarely attempt beyond one-time or annual pen testing requirements to validate whether or not those controls are performing as designed.
With all of these constantly changing, stateless variables in modern distributed systems, it becomes next to impossible for humans to adequately understand how their systems behave, as this can change from moment to moment. One way to approach this problem is through robust systematic instrumentation and monitoring. For instrumentation in security, you can break down the domain into two primary buckets: **testing**, and what we call **experimentation**. Testing is the validation or assessment of a previously known outcome. In plain terms, we know what we are looking for before we go looking for it. On the other hand, experimentation seeks to derive new insights and information that was previously unknown. While testing is an important practice for mature security teams, the following example should help further illuminate the differences between the two, as well as provide a more tangible depiction of the added value of experimentation.
## Example scenario: Craft beer delivery
Consider a simple web service or web application that takes orders for craft beer deliveries.
This is a critical service for this craft beer delivery company, whose orders come in from its customers' mobile devices, the web, and via its API from restaurants that serve its craft beer. This critical service runs in the company's AWS EC2 environment and is considered by the company to be secure. The company passed its PCI compliance with flying colors last year and annually performs third-party penetration tests, so it assumes that its systems are secure.
This company also prides itself on its DevOps and continuous delivery practices by deploying sometimes twice in the same day.
After learning about chaos engineering and security experimentation, the company's development teams want to determine, on a continuous basis, how resilient and effective its security systems are to real-world events, and furthermore, to ensure that they are not introducing new problems into the system that the security controls are not able to detect.
The team wants to start small by evaluating port security and firewall configurations for their ability to detect, block, and alert on misconfigured changes to the port configurations on their EC2 security groups.
- The team begins by performing a summary of their assumptions about the normal state.
- Develops a hypothesis for port security in their EC2 instances
- Selects and configures the YAML file for the Unauthorized Port Change experiment.
- This configuration would designate the objects to randomly select from for targeting, as well as the port ranges and number of ports that should be changed.
- The team also configures when to run the experiment and shrinks the scope of its blast radius to ensure minimal business impact.
- For this first test, the team has chosen to run the experiment in their stage environments and run a single run of the test.
- In true Game Day style, the team has elected a Master of Disaster to run the experiment during a predefined two-hour window. During that window of time, the Master of Disaster will execute the experiment on one of the EC2 Instance Security Groups.
- Once the Game Day has finished, the team begins to conduct a thorough, blameless post-mortem exercise where the focus is on the results of the experiment against the steady state and the original hypothesis. The questions would be something similar to the following:
## Post-mortem questions
- Did the firewall detect the unauthorized port change?
- If the change was detected, was it blocked?
- Did the firewall report log useful information to the log aggregation tool?
- Did the SIEM throw an alert on the unauthorized change?
- If the firewall did not detect the change, did the configuration management tool discover the change?
- Did the configuration management tool report good information to the log aggregation tool?
- Did the SIEM finally correlate an alert?
- If the SIEM threw an alert, did the Security Operations Center get the alert?
- Was the SOC analyst who got the alert able to take action on the alert, or was necessary information missing?
- If the SOC alert determined the alert to be credible, was Security Incident Response able to conduct triage activities easily from the data?
The acknowledgment and anticipation of failure in our systems have already begun unraveling our assumptions about how our systems work. Our mission is to take what we have learned and apply it more broadly to begin to truly address security weaknesses proactively, going beyond the reactive processes that currently dominate traditional security models.
As we continue to explore this new domain, we will be sure to post our findings. For those interested in learning more about the research or getting involved, please feel free to contact [Aaron Rinehart](https://twitter.com/aaronrinehart) or [Grayson Brewer](https://twitter.com/BrewerSecurity).
*Special thanks to Samuel Roden for the insights and thoughts provided in this article.*
**[See our related story, Is the term DevSecOps necessary?]**
## Comments are closed. |
10,346 | 在 Linux 命令行上拥有一头奶牛 | https://opensource.com/article/18/12/linux-toy-cowsay | 2018-12-14T13:27:00 | [
"cowsay"
] | https://linux.cn/article-10346-1.html |
>
> 使用 cowsay 实用程序将牛的话语带到你的终端输出。
>
>
>

欢迎来到 Linux 命令行玩具第四天。如果这是你第一次访问这个系列,你可能会问自己,什么是命令行玩具。我们也在考虑这一点,但是一般来说,这可能是一个游戏,或者任何简单的娱乐,可以帮助你在终端玩得开心。
你们中的一些人会见过我们之前的选中的各种玩具,但是我们希望至少有一个对每个人来说都是新的。因为几乎所有我告诉他这个系列的人都已经问过它了,所以今天的选中的玩具是必须提及的。
你也不会认为我们会在不提及 `cowsay` 的情况下完成这个系列,对吧?
`cowsay` 是一个神奇的实用程序,它将文本作为 ASCII 艺术牛的讲话文本输出。
你可能会发现 `cowsay` 打包在你的默认存储库中,甚至可能已经安装了。对我来说,在 Fedora,像这样安装:
```
$ sudo dnf install -y cowsay
```
然后,用 `cowsay` 调用它,然后是你的消息。也许你想到昨天我们谈到的 [fortune 应用](https://opensource.com/article/18/12/linux-toy-fortune) 连接起来。
```
$ fortune | cowsay
_________________________________________
/ If at first you do succeed, try to hide \
\ your astonishment. /
-----------------------------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
```
就这样!`cowsay` 还有点小变体,称为 cow 文件,通常可以在 `/usr/share/cowsay` 找到 ,要查看系统上可用的 cow 文件,请在 `cowsay` 之后使用 `-l` 。然后,用 `-f` 试试其中之一。
```
$ cowsay -f dragon "Run for cover, I feel a sneeze coming on."
_______________________________________
/ Run for cover, I feel a sneeze coming \
\ on. /
---------------------------------------
\ / \ //\
\ |\___/| / \// \\
/0 0 \__ / // | \ \
/ / \/_/ // | \ \
@_^_@'/ \/_ // | \ \
//_^_/ \/_ // | \ \
( //) | \/// | \ \
( / /) _|_ / ) // | \ _\
( // /) '/,_ _ _/ ( ; -. | _ _\.-~ .-~~~^-.
(( / / )) ,-{ _ `-.|.-~-. .~ `.
(( // / )) '/\ / ~-. _ .-~ .-~^-. \
(( /// )) `. { } / \ \
(( / )) .----~-.\ \-' .~ \ `. \^-.
///.----..> \ _ -~ `. ^-` ^-_
///-._ _ _ _ _ _ _}^ - - - - ~ ~-- ,.-~
/.-~
```
我对 `cowsay` 的真正不满是,我今天没有足够的时间来为牛的挤奶 —— 一语双关。牛排价格太高了,我只是开个玩笑。
更严重的是,我已经完全忘记了 `cowsay` 直到我在学习 Ansible 的剧本时再次遇到它。如果你碰巧安装了 `cowsay`,当你运行Ansible 的剧本时,你会从一队奶牛那里获得输出。例如,运行这个剧本:
```
- hosts:
- localhost
tasks:
- action: ping
```
可能会给你以下信息:
```
$ ansible-playbook playbook.yml
__________________
< PLAY [localhost] >
------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
________________________
< TASK [Gathering Facts] >
------------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
ok: [localhost]
_____________
< TASK [ping] >
-------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
ok: [localhost]
____________
< PLAY RECAP >
------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
localhost : ok=2 changed=0 unreachable=0 failed=0
```
`cowsay` 在 GPLv3 许可证下可用,您可以在 GitHub 上找到 它的 Perl [源代码](https://github.com/tnalpgge/rank-amateur-cowsay)。我也见过其他语言的版本,所以可以看看其他变体;例如,这是 [R 语言版](https://github.com/sckott/cowsay)。用你选择的语言实现你自己的版本可能是一项有趣的编程学习任务。
既然讲完了 `cowsay`,我们可以去更绿色的牧场了。
你有希望我来介绍的喜欢的命令行玩具吗?这个系列的排期大部分都填好了,但我还有一些空位方。在下面的评论中让我知道,我会来看看。如果有空间,我会尝试把它包括进去。如果没有,但是我收到了一些好的意见,我在结尾提及。
看看昨天的玩具,[如何给你的 Linux 终端带来好运](https://opensource.com/article/18/12/linux-toy-fortune),明天再来看看另一个!
---
via: <https://opensource.com/article/18/12/linux-toy-cowsay>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[heguangzhi](https://github.com/heguangzhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Welcome to the fourth day of the Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself, what’s a command-line toy. We’re figuring that out as we go, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
Some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone. Because just about everyone who I’ve mentioned this series to has asked me about it already, today’s selection is an obligatory one.
You didn’t think we’d make it through this series without mentioning cowsay, did you?
Cowsay is an udderly fantastic utility that takes text and outputs it as the spoken text of an ASCII-art bovine.
You’ll likely find cowsay packaged in your default repositories, and perhaps even already installed. For me, in Fedora, all it took to install was:
`$ sudo dnf install cowsay`
Then, invoke it with cowsay followed by your message. Perhaps you’d like to pipe in the [fortune ](https://opensource.com/article/18/12/linux-toy-fortune)[utility](https://opensource.com/article/18/12/linux-toy-fortune) we talked about yesterday.
```
$ fortune | cowsay
_________________________________________
/ If at first you do succeed, try to hide \
\ your astonishment. /
-----------------------------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
```
That’s it! **Cowsay** ships with few variations, called cow files, that can usually be found in **/usr/share/cowsay.** To see the cow file options available on your system, use **-l** flag after cowsay. Then, use the **-f **flag to try one out.
```
$ cowsay -f dragon "Run for cover, I feel a sneeze coming on."
_______________________________________
/ Run for cover, I feel a sneeze coming \
\ on. /
---------------------------------------
\ / \ //\
\ |\___/| / \// \\
/0 0 \__ / // | \ \
/ / \/_/ // | \ \
@_^_@'/ \/_ // | \ \
//_^_/ \/_ // | \ \
( //) | \/// | \ \
( / /) _|_ / ) // | \ _\
( // /) '/,_ _ _/ ( ; -. | _ _\.-~ .-~~~^-.
(( / / )) ,-{ _ `-.|.-~-. .~ `.
(( // / )) '/\ / ~-. _ .-~ .-~^-. \
(( /// )) `. { } / \ \
(( / )) .----~-.\ \-' .~ \ `. \^-.
///.----..> \ _ -~ `. ^-` ^-_
///-._ _ _ _ _ _ _}^ - - - - ~ ~-- ,.-~
/.-~
```
My real beef with** cowsay** is that I don’t have enough time today to really milk the cow puns for all they are worth. The steaks are just too high, and I might butcher the joke.
On a more serious note, I had completely forgotten about **cowsay** until I re-encountered it when learning Ansible playbooks. If you happen to have **cowsay **installed, when you run a playbook, you’ll get your output from a series of cows. For example, running this playbook:
```
- hosts:
- localhost
tasks:
- action: ping
```
Might give you the following:
```
$ ansible-playbook playbook.yml
__________________
< PLAY [localhost] >
------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
________________________
< TASK [Gathering Facts] >
------------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
ok: [localhost]
_____________
< TASK [ping] >
-------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
ok: [localhost]
____________
< PLAY RECAP >
------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
localhost : ok=2 changed=0 unreachable=0 failed=0
```
**Cowsay** is available under a GPLv3 license, and you can find the Perl [source code](https://github.com/tnalpgge/rank-amateur-cowsay) on GitHub. I’ve also seen versions floating around in other languages, so take a look around for other variants; here’s [one in R](https://github.com/sckott/cowsay), for example. Implementing your own version in your language of choice might even be a fun programming learning task.
Now that **cowsay** is out of the way, we can move on to greener pastures.
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
Check out yesterday's toy, [How to bring good fortune to your Linux terminal](https://opensource.com/article/18/12/linux-toy-fortune), and check back tomorrow for another!
## 4 Comments |
10,347 | 你所不知道的知识共享(CC) | https://opensource.com/article/18/1/creative-commons-real-world | 2018-12-14T18:28:51 | [
"CC",
"知识共享"
] | https://linux.cn/article-10347-1.html |
>
> 知识共享为艺术家提供访问权限和原始素材。大公司也从中受益。
>
>
>

我毕业于电影学院,毕业后在一所电影学校教书,之后进入一家主流电影工作室,我一直在从事电影相关的工作。创意产业的方方面面面临着同一个问题:创作者需要原材料。有趣的是,自由文化运动提出了解决方案,具体来说是在自由文化运动中出现的<ruby> 知识共享 <rt> Creative Commons </rt></ruby>组织。
### 知识共享能够为我们提供展示片段和小样
和其他事情一样,创造力也需要反复练习。幸运的是,在我刚开始接触电脑时,就在一本关于渲染工场的专业杂志中接触到了开源这个存在。当时我并不理解所谓的“开源”是什么,但我知道只有开源工具能帮助我在领域内稳定发展。对我来说,知识共享也是如此。知识共享可以为艺术家们提供充满丰富艺术资源的工作室。
我在电影学院任教时,经常需要给学生们准备练习编辑、录音、拟音、分级、评分的示例录像。在 Jim Munroe 的独立作品 [Infest Wisely](http://infestwisely.com) 中和 [Vimeo](https://vimeo.com/creativecommons) 上的知识共享内容里我总能找到我想要的。这些逼真的镜头覆盖内容十分广泛,从独立制作到昂贵的高品质的升降镜头(一般都会用无人机代替)都有。

对实验主义艺术来说,确有无尽可能。知识共享提供了丰富的素材,这些材料可以用来整合、混剪等等,可以满足一位视觉先锋能够想到的任何用途。
在接触知识共享之前,如果我想要使用写实镜头,如果在大学,只能用之前的学生和老师拍摄的或者直接使用版权库里的镜头,或者使用有受限的版权保护的镜头。
### 坚守版权的底线很重要
知识共享同样能够创造经济效益。在某大型计算机公司的渲染工场工作时,我负责在某些硬件设施上测试渲染的运行情况,而这个测试时刻面临着被搁置的风险。做这些测试时,我用的都是[大雄兔](https://peach.blender.org/)的资源,因为这个电影和它的组件都是可以免费使用和分享的。如果没有这个小短片,在接触写实资源之前我都没法完成我的实验,因为对于一个计算机公司来说,雇佣一只 3D 艺术家来按需布景是不太现实的。
令我震惊的是,与开源类似,知识共享已经用我们难以想象的方式支撑起了大公司。知识共享的使用可能会也可能不会影响公司的日常流程,但它填补了不足,让工作流程顺利进行。我没见到谁在他们的书中将流畅工作归功于知识共享的应用,但它确实无处不在。

我也见过一些开放版权的电影,比如[辛特尔](https://durian.blender.org/),在最近的电视节目中播放了它的短片,电视的分辨率已经超过了标准媒体。
### 知识共享可以提供大量原材料
艺术家需要原材料。画家需要颜料、画笔和画布。雕塑家需要陶土和工具。数字内容编辑师需要数字内容,无论它是剪贴画还是音效或者是电子游戏里的现成的精灵。
数字媒介赋予了人们超能力,让一个人就能完成需要一组人员才能完成的工作。事实上,我们大部分都好高骛远。我们想做高大上的项目,想让我们的成果不论是视觉上还是听觉上都无与伦比。我们想塑造的是宏大的世界,紧张的情节,能引起共鸣的作品,但我们所拥有的时间精力和技能与之都不匹配,达不到想要的效果。
是知识共享再一次拯救了我们,在 [Freesound.org](http://freesound.org)、 [Openclipart.org](http://openclipart.org)、 [OpenGameArt.org](http://opengameart.org) 等等网站上都有大量的开放版权艺术材料。通过知识共享,艺术家可以使用各种他们自己没办法创造的原材料,来完成他们原本完不成的工作。
最神奇的是,不用自己投资,你放在网上给大家使用的原材料就能变成精美的作品,而这是你从没想过的。我在知识共享上面分享了很多音乐素材,它们现在用于无数的专辑和电子游戏里。有些人用了我的材料会通知我,有些是我自己发现的,所以这些材料的应用可能比我知道的还有多得多。有时我会偶然看到我亲手画的标志出现在我从没听说过的软件里。我见到过我为 [Opensource.com](https://opensource.com/) 写的文章在别处发表,有的是论文的参考文献,白皮书或者参考资料中。
### 知识共享所代表的自由文化也是一种文化
“自由文化”这个说法过于累赘,文化,从概念上来说,是一个有机的整体。在这种文化中社会逐渐成长发展,从一个人到另一个。它是人与人之间的互动和思想交流。自由文化是自由缺失的现代世界里的特殊产物。
如果你也想对这样的局限进行反抗,想把你的思想、作品、你自己的文化分享给全世界的人,那么就来和我们一起,使用知识共享吧!
---
via: <https://opensource.com/article/18/1/creative-commons-real-world>
作者:[Seth Kenlon](https://opensource.com/users/seth) 译者:[Valoniakim](https://github.com/Valoniakim) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I attended film school, and later I taught at a film school, and even later I worked at a major film studio. There was a common thread through all these different angles of the creative industry: creators need content. Interestingly, one movement kept providing the solution, and that was free culture, or, as it has been formalized, [Creative Commons](https://opensource.com/article/20/1/what-creative-commons).
## Showpieces and demos
Like anything else in life, creativity requires practice. I luckily stumbled into open source early in my experience with computers, through an article in a trade magazine about render farms. I didn't yet understand what "open source" meant, but I knew that the tools labeled open source were the only tools that provided me reliable access to the technology I wanted to explore. The same has been true for the Creative Commons content that I use. Creative Commons provides artists an entire studio full of artistic resources.
When I was teaching in film and needed sample footage for students to edit, overdub, foley, grade, or score, I always had what I needed from films like Jim Munroe's independent masterpiece [ Infest Wisely](http://infestwisely.com) or from the Creative Commons content on
[Vimeo](https://vimeo.com/creativecommons). These provide realistic footage, spanning the whole spectrum from indie productions to expensive, high-quality crane (actually drone, usually) shots.

opensource.com
For experimentalist art, the possibilities are truly endless. Creative Commons provides a wealth of stock footage to integrate into video art, video DJ mixes, and whatever else a visual pioneer dreams up.
Before Creative Commons, the only ways to get experience with real-world footage were either to use footage that former students or professors generated, assuming you were at a university, or to use copyrighted footage despite the restrictions.
## It's all about the bottom line
There's a more business-centric use for all of this, as well. When working deep in the render farms of a large computer company, I was tasked with performing render tests on some hardware that was under the threat of being discontinued. For this job, I used the assets of [Big Buck Bunny](https://peach.blender.org/) because not just the movie itself, but also its components, are free to use and share. If it hadn't been for this short film, I could not have done my tests until I'd acquired realistic assets, which would likely never have happened because computer companies are busy places that don't typically employ a team of 3D artists to compose a scene on call.
It struck me that, much like open source itself, Creative Commons is already propping up big companies in ways no one really thinks about. The use of Creative Commons in a company may or may not make or break the daily process, but it's filling gaps and making people's jobs and workflows move smoothly. I don't think anyone's accounting for this benefit in their books, but Creative Commons content is everywhere.

opensource.com
I've even seen Blender open movies, like [Sintel](https://durian.blender.org/), as the demo films playing on the latest television screens when a TV resolution exceeds what is currently available on standard media.
## Raw materials
Artists need raw materials. A painter needs paint, brushes, and a canvas. Sculptors need clay and modeling tools. And digital content creators need digital content, whether it's clipart or sound effects or ready-made sprites for a video game.
The digital medium has bestowed upon one individual creator the power to *apparently* make works of art that should take a group of people to complete. The reality is, though, that most of us like to think big. We want to make projects that look and sound good. We want big worlds, intense stories, evocative works, but we don't have the time or the variety of skills to make it all happen.
It's here that Creative Commons saves the day, yet again, with the little bits and pieces of free art that abound on sites like [Freesound.org](http://freesound.org), [FreeSVG.org](http://freesvg.org), [OpenGameArt.org](http://opengameart.org), and many, many more. Artists are able, through the Commons, to use raw material that they could not have produced themselves to produce works they couldn't otherwise make alone.
Possibly even more significantly, though, is the fact that *your* raw material that you put up on the internet for reuse can bring you, without any further investment, into amazing works of art that you'd never dream of producing yourself. I have contributed to countless musical albums and video games with sound clips I've added to the Commons. Sometimes the artist notifies me, others I find on my own, and probably even more exist than I know about. I've seen icons that I've drawn pop up in software projects that I never knew existed. I've seen articles I've written for [Opensource.com](https://opensource.com/) published elsewhere, and things I've written in the bibliographies of thesis projects, white papers, and reference materials.
## Free culture is culture
"Free culture" is a redundant term that shouldn't be part of our vocabulary. Culture, conceptually, is an organic process. It's the way a society develops and grows, from one person to another. It's about the interactions and the ideas that people *share*. It's a unique product of the modern world that culture is *not* free by default.
If you want to combat that, and prefer to share your culture with your fellow human beings across the globe, support Creative Commons by contributing to it, using it, and supporting those who do.
## 2 Comments |
10,348 | 使用 gorilla/mux 进行 HTTP 请求路由和验证 | https://opensource.com/article/18/8/http-request-routing-validation-gorillamux | 2018-12-15T09:10:42 | [
"HTTP"
] | https://linux.cn/article-10348-1.html |
>
> gorilla/mux 包以直观的 API 提供了 HTTP 请求路由、验证和其它服务。
>
>
>

Go 网络库包括 `http.ServeMux` 结构类型,它支持 HTTP 请求多路复用(路由):Web 服务器将托管资源的 HTTP 请求与诸如 `/sales4today` 之类的 URI 路由到代码处理程序;处理程序在发送 HTTP 响应(通常是 HTML 页面)之前执行适当的逻辑。 这是该体系的草图:
```
+-----------+ +--------+ +---------+
HTTP 请求---->| web 服务器 |---->| 路由 |---->| 处理程序 |
+-----------+ +--------+ +---------+
```
调用 `ListenAndServe` 方法后启动 HTTP 服务器:
```
http.ListenAndServe(":8888", nil) // args: port & router
```
第二个参数 `nil` 意味着 `DefaultServeMux` 用于请求路由。
`gorilla/mux` 库包含 `mux.Router` 类型,可替代 `DefaultServeMux` 或自定义请求多路复用器。 在 `ListenAndServe` 调用中,`mux.Router` 实例将代替 `nil` 作为第二个参数。 下面的示例代码很好的说明了为什么 `mux.Router`如此吸引人:
### 1、一个简单的 CRUD web 应用程序
crud web 应用程序(见下文)支持四种 CRUD(创建/读取/更新/删除)操作,它们分别对应四种 HTTP 请求方法:POST、GET、PUT 和 DELETE。 在这个 CRUD 应用程序中,所管理的资源是套话与反套话的列表,每个都是套话及其反面的的套话,例如这对:
```
Out of sight, out of mind. Absence makes the heart grow fonder.
```
可以添加新的套话对,可以编辑或删除现有的套话对。
CRUD web 应用程序:
```
package main
import (
"gorilla/mux"
"net/http"
"fmt"
"strconv"
)
const GETALL string = "GETALL"
const GETONE string = "GETONE"
const POST string = "POST"
const PUT string = "PUT"
const DELETE string = "DELETE"
type clichePair struct {
Id int
Cliche string
Counter string
}
// Message sent to goroutine that accesses the requested resource.
type crudRequest struct {
verb string
cp *clichePair
id int
cliche string
counter string
confirm chan string
}
var clichesList = []*clichePair{}
var masterId = 1
var crudRequests chan *crudRequest
// GET /
// GET /cliches
func ClichesAll(res http.ResponseWriter, req *http.Request) {
cr := &crudRequest{verb: GETALL, confirm: make(chan string)}
completeRequest(cr, res, "read all")
}
// GET /cliches/id
func ClichesOne(res http.ResponseWriter, req *http.Request) {
id := getIdFromRequest(req)
cr := &crudRequest{verb: GETONE, id: id, confirm: make(chan string)}
completeRequest(cr, res, "read one")
}
// POST /cliches
func ClichesCreate(res http.ResponseWriter, req *http.Request) {
cliche, counter := getDataFromRequest(req)
cp := new(clichePair)
cp.Cliche = cliche
cp.Counter = counter
cr := &crudRequest{verb: POST, cp: cp, confirm: make(chan string)}
completeRequest(cr, res, "create")
}
// PUT /cliches/id
func ClichesEdit(res http.ResponseWriter, req *http.Request) {
id := getIdFromRequest(req)
cliche, counter := getDataFromRequest(req)
cr := &crudRequest{verb: PUT, id: id, cliche: cliche, counter: counter, confirm: make(chan string)}
completeRequest(cr, res, "edit")
}
// DELETE /cliches/id
func ClichesDelete(res http.ResponseWriter, req *http.Request) {
id := getIdFromRequest(req)
cr := &crudRequest{verb: DELETE, id: id, confirm: make(chan string)}
completeRequest(cr, res, "delete")
}
func completeRequest(cr *crudRequest, res http.ResponseWriter, logMsg string) {
crudRequests<-cr
msg := <-cr.confirm
res.Write([]byte(msg))
logIt(logMsg)
}
func main() {
populateClichesList()
// From now on, this gorountine alone accesses the clichesList.
crudRequests = make(chan *crudRequest, 8)
go func() { // resource manager
for {
select {
case req := <-crudRequests:
if req.verb == GETALL {
req.confirm<-readAll()
} else if req.verb == GETONE {
req.confirm<-readOne(req.id)
} else if req.verb == POST {
req.confirm<-addPair(req.cp)
} else if req.verb == PUT {
req.confirm<-editPair(req.id, req.cliche, req.counter)
} else if req.verb == DELETE {
req.confirm<-deletePair(req.id)
}
}
}()
startServer()
}
func startServer() {
router := mux.NewRouter()
// Dispatch map for CRUD operations.
router.HandleFunc("/", ClichesAll).Methods("GET")
router.HandleFunc("/cliches", ClichesAll).Methods("GET")
router.HandleFunc("/cliches/{id:[0-9]+}", ClichesOne).Methods("GET")
router.HandleFunc("/cliches", ClichesCreate).Methods("POST")
router.HandleFunc("/cliches/{id:[0-9]+}", ClichesEdit).Methods("PUT")
router.HandleFunc("/cliches/{id:[0-9]+}", ClichesDelete).Methods("DELETE")
http.Handle("/", router) // enable the router
// Start the server.
port := ":8888"
fmt.Println("\nListening on port " + port)
http.ListenAndServe(port, router); // mux.Router now in play
}
// Return entire list to requester.
func readAll() string {
msg := "\n"
for _, cliche := range clichesList {
next := strconv.Itoa(cliche.Id) + ": " + cliche.Cliche + " " + cliche.Counter + "\n"
msg += next
}
return msg
}
// Return specified clichePair to requester.
func readOne(id int) string {
msg := "\n" + "Bad Id: " + strconv.Itoa(id) + "\n"
index := findCliche(id)
if index >= 0 {
cliche := clichesList[index]
msg = "\n" + strconv.Itoa(id) + ": " + cliche.Cliche + " " + cliche.Counter + "\n"
}
return msg
}
// Create a new clichePair and add to list
func addPair(cp *clichePair) string {
cp.Id = masterId
masterId++
clichesList = append(clichesList, cp)
return "\nCreated: " + cp.Cliche + " " + cp.Counter + "\n"
}
// Edit an existing clichePair
func editPair(id int, cliche string, counter string) string {
msg := "\n" + "Bad Id: " + strconv.Itoa(id) + "\n"
index := findCliche(id)
if index >= 0 {
clichesList[index].Cliche = cliche
clichesList[index].Counter = counter
msg = "\nCliche edited: " + cliche + " " + counter + "\n"
}
return msg
}
// Delete a clichePair
func deletePair(id int) string {
idStr := strconv.Itoa(id)
msg := "\n" + "Bad Id: " + idStr + "\n"
index := findCliche(id)
if index >= 0 {
clichesList = append(clichesList[:index], clichesList[index + 1:]...)
msg = "\nCliche " + idStr + " deleted\n"
}
return msg
}
//*** utility functions
func findCliche(id int) int {
for i := 0; i < len(clichesList); i++ {
if id == clichesList[i].Id {
return i;
}
}
return -1 // not found
}
func getIdFromRequest(req *http.Request) int {
vars := mux.Vars(req)
id, _ := strconv.Atoi(vars["id"])
return id
}
func getDataFromRequest(req *http.Request) (string, string) {
// Extract the user-provided data for the new clichePair
req.ParseForm()
form := req.Form
cliche := form["cliche"][0] // 1st and only member of a list
counter := form["counter"][0] // ditto
return cliche, counter
}
func logIt(msg string) {
fmt.Println(msg)
}
func populateClichesList() {
var cliches = []string {
"Out of sight, out of mind.",
"A penny saved is a penny earned.",
"He who hesitates is lost.",
}
var counterCliches = []string {
"Absence makes the heart grow fonder.",
"Penny-wise and dollar-foolish.",
"Look before you leap.",
}
for i := 0; i < len(cliches); i++ {
cp := new(clichePair)
cp.Id = masterId
masterId++
cp.Cliche = cliches[i]
cp.Counter = counterCliches[i]
clichesList = append(clichesList, cp)
}
}
```
为了专注于请求路由和验证,CRUD 应用程序不使用 HTML 页面作为请求响应。 相反,请求会产生明文响应消息:套话对的列表是对 GET 请求的响应,确认新的套话对已添加到列表中是对 POST 请求的响应,依此类推。 这种简化使得使用命令行实用程序(如 [curl](https://curl.haxx.se/))可以轻松地测试应用程序,尤其是 `gorilla/mux` 组件。
`gorilla/mux` 包可以从 [GitHub](https://github.com/gorilla/mux) 安装。 CRUD app 无限期运行;因此,应使用 `Control-C` 或同等命令终止。 CRUD 应用程序的代码,以及自述文件和简单的 curl 测试,可以在[我的网站](http://condor.depaul.edu/mkalin)上找到。
### 2、请求路由
`mux.Router` 扩展了 REST 风格的路由,它赋给 HTTP 方法(例如,GET)和 URL 末尾的 URI 或路径(例如 `/cliches`)相同的权重。 URI 用作 HTTP 动词(方法)的名词。 例如,在HTTP请求中有一个起始行,例如:
```
GET /cliches
```
意味着得到所有的套话对,而一个起始线,如:
```
POST /cliches
```
意味着从 HTTP 正文中的数据创建一个套话对。
在 CRUD web 应用程序中,有五个函数充当 HTTP 请求的五种变体的请求处理程序:
```
ClichesAll(...) # GET: 获取所有的套话对
ClichesOne(...) # GET: 获取指定的套话对
ClichesCreate(...) # POST: 创建新的套话对
ClichesEdit(...) # PUT: 编辑现有的套话对
ClichesDelete(...) # DELETE: 删除指定的套话对
```
每个函数都有两个参数:一个 `http.ResponseWriter` 用于向请求者发送一个响应,一个指向 `http.Request` 的指针,该指针封装了底层 HTTP 请求的信息。 使用 `gorilla/mux` 包可以轻松地将这些请求处理程序注册到Web服务器,并执行基于正则表达式的验证。
CRUD 应用程序中的 `startServer` 函数注册请求处理程序。 考虑这对注册,`router` 作为 `mux.Router` 实例:
```
router.HandleFunc("/", ClichesAll).Methods("GET")
router.HandleFunc("/cliches", ClichesAll).Methods("GET")
```
这些语句意味着对单斜线 `/` 或 `/cliches` 的 GET 请求应该路由到 `ClichesAll` 函数,然后处理请求。 例如,curl 请求(使用 `%` 作为命令行提示符):
```
% curl --request GET localhost:8888/
```
会产生如下结果:
```
1: Out of sight, out of mind. Absence makes the heart grow fonder.
2: A penny saved is a penny earned. Penny-wise and dollar-foolish.
3: He who hesitates is lost. Look before you leap.
```
这三个套话对是 CRUD 应用程序中的初始数据。
在这句注册语句中:
```
router.HandleFunc("/cliches", ClichesAll).Methods("GET")
router.HandleFunc("/cliches", ClichesCreate).Methods("POST")
```
URI 是相同的(`/cliches`),但动词不同:第一种情况下为 GET 请求,第二种情况下为 POST 请求。 此注册举例说明了 REST 样式的路由,因为仅动词的不同就足以将请求分派给两个不同的处理程序。
注册中允许多个 HTTP 方法,尽管这会影响 REST 风格路由的精髓:
```
router.HandleFunc("/cliches", DoItAll).Methods("POST", "GET")
```
除了动词和 URI 之外,还可以在功能上路由 HTTP 请求。 例如,注册
```
router.HandleFunc("/cliches", ClichesCreate).Schemes("https").Methods("POST")
```
要求对 POST 请求进行 HTTPS 访问以创建新的套话对。以类似的方式,注册可能需要具有指定的 HTTP 头元素(例如,认证凭证)的请求。
### 3、 Request validation
`gorilla/mux` 包采用简单,直观的方法通过正则表达式进行请求验证。 考虑此请求处理程序以获取一个操作:
```
router.HandleFunc("/cliches/{id:[0-9]+}", ClichesOne).Methods("GET")
```
此注册排除了 HTTP 请求,例如:
```
% curl --request GET localhost:8888/cliches/foo
```
因为 foo 不是十进制数字。该请求导致熟悉的 404(未找到)状态码。 在此处理程序注册中包含正则表达式模式可确保仅在请求 URI 以十进制整数值结束时才调用 `ClichesOne` 函数来处理请求:
```
% curl --request GET localhost:8888/cliches/3 # ok
```
另一个例子,请求如下:
```
% curl --request PUT --data "..." localhost:8888/cliches
```
此请求导致状态代码为 405(错误方法),因为 /cliches URI 在 CRUD 应用程序中仅在 GET 和 POST 请求中注册。 像 GET 请求一样,PUT 请求必须在 URI 的末尾包含一个数字 id:
```
router.HandleFunc("/cliches/{id:[0-9]+}", ClichesEdit).Methods("PUT")
```
### 4、并发问题
`gorilla/mux` 路由器作为单独的 Go 协程执行对已注册的请求处理程序的每次调用,这意味着并发性被内置于包中。 例如,如果有十个同时发出的请求,例如
```
% curl --request POST --data "..." localhost:8888/cliches
```
然后 `mux.Router` 启动十个 Go 协程来执行 `ClichesCreate` 处理程序。
GET all、GET one、POST、PUT 和 DELETE 中的五个请求操作中,最后三个改变了所请求的资源,即包含套话对的共享 `clichesList`。 因此,CRUD app 需要通过协调对 `clichesList` 的访问来保证安全的并发性。 在不同但等效的术语中,CRUD app 必须防止 `clichesList` 上的竞争条件。 在生产环境中,可以使用数据库系统来存储诸如 `clichesList` 之类的资源,然后可以通过数据库事务来管理安全并发。
CRUD 应用程序采用推荐的Go方法来实现安全并发:
* 只有一个 Go 协程,资源管理器在 CRUD app `startServer` 函数中启动,一旦 Web 服务器开始侦听请求,就可以访问 `clichesList`。
* 诸如 `ClichesCreate` 和 `ClichesAll` 之类的请求处理程序向 Go 通道发送(指向)`crudRequest` 实例(默认情况下是线程安全的),并且资源管理器单独从该通道读取。 然后,资源管理器对 `clichesList` 执行请求的操作。
安全并发体系结构绘制如下:
```
crudRequest 读/写
请求处理程序 -------------> 资源托管者 ------------> 套话列表
```
在这种架构中,不需要显式锁定 `clichesList`,因为一旦 CRUD 请求开始进入,只有一个 Go 协程(资源管理器)访问 `clichesList`。
为了使 CRUD 应用程序尽可能保持并发,在一方请求处理程序与另一方的单一资源管理器之间进行有效的分工至关重要。 在这里,为了审查,是 `ClichesCreate` 请求处理程序:
```
func ClichesCreate(res http.ResponseWriter, req *http.Request) {
cliche, counter := getDataFromRequest(req)
cp := new(clichePair)
cp.Cliche = cliche
cp.Counter = counter
cr := &crudRequest{verb: POST, cp: cp, confirm: make(chan string)}
completeRequest(cr, res, "create")
}
```
`ClichesCreate` 调用实用函数 `getDataFromRequest`,它从 POST 请求中提取新的套话和反套话。 然后 `ClichesCreate` 函数创建一个新的 `ClichePair`,设置两个字段,并创建一个 `crudRequest` 发送给单个资源管理器。 此请求包括一个确认通道,资源管理器使用该通道将信息返回给请求处理程序。 所有设置工作都可以在不涉及资源管理器的情况下完成,因为尚未访问 `clichesList`。
请求处理程序调用实用程序函数,该函数从 POST 请求中提取新的套话和反套话。 然后,该函数创建一个新的,设置两个字段,并创建一个 crudRequest 发送到单个资源管理器。 此请求包括一个确认通道,资源管理器使用该通道将信息返回给请求处理程序。 所有设置工作都可以在不涉及资源管理器的情况下完成,因为尚未访问它。
`completeRequest` 实用程序函数在 `ClichesCreate` 函数和其他请求处理程序的末尾调用:
```
completeRequest(cr, res, "create") // shown above
```
通过将 `crudRequest` 放入 `crudRequests` 频道,使资源管理器发挥作用:
```
func completeRequest(cr *crudRequest, res http.ResponseWriter, logMsg string) {
crudRequests<-cr // 向资源托管者发送请求
msg := <-cr.confirm // 等待确认
res.Write([]byte(msg)) // 向请求方发送确认
logIt(logMsg) // 打印到标准输出
}
```
对于 POST 请求,资源管理器调用实用程序函数 `addPair`,它会更改 `clichesList` 资源:
```
func addPair(cp *clichePair) string {
cp.Id = masterId // 分配一个唯一的 ID
masterId++ // 更新 ID 计数器
clichesList = append(clichesList, cp) // 更新列表
return "\nCreated: " + cp.Cliche + " " + cp.Counter + "\n"
}
```
资源管理器为其他 CRUD 操作调用类似的实用程序函数。 值得重复的是,一旦 Web 服务器开始接受请求,资源管理器就是唯一可以读取或写入 `clichesList` 的 goroutine。
对于任何类型的 Web 应用程序,`gorilla/mux` 包在简单直观的 API 中提供请求路由、请求验证和相关服务。 CRUD web 应用程序突出了软件包的主要功能。
---
via: <https://opensource.com/article/18/8/http-request-routing-validation-gorillamux>
作者:[Marty Kalin](https://opensource.com/users/mkalindepauledu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[yongshouzhang](https://github.com/yongshouzhang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Go networking library includes the `http.ServeMux`
structure type, which supports HTTP request multiplexing (routing): A web server routes an HTTP request for a hosted resource, with a URI such as */sales4today*, to a code handler; the handler performs the appropriate logic before sending an HTTP response, typically an HTML page. Here’s a sketch of the architecture:
```
+------------+ +--------+ +---------+
HTTP request---->| web server |---->| router |---->| handler |
+------------+ +--------+ +---------+
```
In a call to the `ListenAndServe`
method to start an HTTP server
`http.ListenAndServe(":8888", nil) // args: port & router`
a second argument of `nil`
means that the `DefaultServeMux`
is used for request routing.
The `gorilla/mux`
package has a `mux.Router`
type as an alternative to either the `DefaultServeMux`
or a customized request multiplexer. In the `ListenAndServe`
call, a `mux.Router`
instance would replace `nil`
as the second argument. What makes the `mux.Router`
so appealing is best shown through a code example:
## 1. A sample crud web app
The *crud* web application (see below) supports the four CRUD (Create Read Update Delete) operations, which match four HTTP request methods: POST, GET, PUT, and DELETE, respectively. In the *crud* app, the hosted resource is a list of cliche pairs, each a cliche and a conflicting cliche such as this pair:
`Out of sight, out of mind. Absence makes the heart grow fonder.`
New cliche pairs can be added, and existing ones can be edited or deleted.
**The crud web app**
```
package main
import (
"gorilla/mux"
"net/http"
"fmt"
"strconv"
)
const GETALL string = "GETALL"
const GETONE string = "GETONE"
const POST string = "POST"
const PUT string = "PUT"
const DELETE string = "DELETE"
type clichePair struct {
Id int
Cliche string
Counter string
}
// Message sent to goroutine that accesses the requested resource.
type crudRequest struct {
verb string
cp *clichePair
id int
cliche string
counter string
confirm chan string
}
var clichesList = []*clichePair{}
var masterId = 1
var crudRequests chan *crudRequest
// GET /
// GET /cliches
func ClichesAll(res http.ResponseWriter, req *http.Request) {
cr := &crudRequest{verb: GETALL, confirm: make(chan string)}
completeRequest(cr, res, "read all")
}
// GET /cliches/id
func ClichesOne(res http.ResponseWriter, req *http.Request) {
id := getIdFromRequest(req)
cr := &crudRequest{verb: GETONE, id: id, confirm: make(chan string)}
completeRequest(cr, res, "read one")
}
// POST /cliches
func ClichesCreate(res http.ResponseWriter, req *http.Request) {
cliche, counter := getDataFromRequest(req)
cp := new(clichePair)
cp.Cliche = cliche
cp.Counter = counter
cr := &crudRequest{verb: POST, cp: cp, confirm: make(chan string)}
completeRequest(cr, res, "create")
}
// PUT /cliches/id
func ClichesEdit(res http.ResponseWriter, req *http.Request) {
id := getIdFromRequest(req)
cliche, counter := getDataFromRequest(req)
cr := &crudRequest{verb: PUT, id: id, cliche: cliche, counter: counter, confirm: make(chan string)}
completeRequest(cr, res, "edit")
}
// DELETE /cliches/id
func ClichesDelete(res http.ResponseWriter, req *http.Request) {
id := getIdFromRequest(req)
cr := &crudRequest{verb: DELETE, id: id, confirm: make(chan string)}
completeRequest(cr, res, "delete")
}
func completeRequest(cr *crudRequest, res http.ResponseWriter, logMsg string) {
crudRequests<-cr
msg := <-cr.confirm
res.Write([]byte(msg))
logIt(logMsg)
}
func main() {
populateClichesList()
// From now on, this gorountine alone accesses the clichesList.
crudRequests = make(chan *crudRequest, 8)
go func() { // resource manager
for {
select {
case req := <-crudRequests:
if req.verb == GETALL {
req.confirm<-readAll()
} else if req.verb == GETONE {
req.confirm<-readOne(req.id)
} else if req.verb == POST {
req.confirm<-addPair(req.cp)
} else if req.verb == PUT {
req.confirm<-editPair(req.id, req.cliche, req.counter)
} else if req.verb == DELETE {
req.confirm<-deletePair(req.id)
}
}
}()
startServer()
}
func startServer() {
router := mux.NewRouter()
// Dispatch map for CRUD operations.
router.HandleFunc("/", ClichesAll).Methods("GET")
router.HandleFunc("/cliches", ClichesAll).Methods("GET")
router.HandleFunc("/cliches/{id:[0-9]+}", ClichesOne).Methods("GET")
router.HandleFunc("/cliches", ClichesCreate).Methods("POST")
router.HandleFunc("/cliches/{id:[0-9]+}", ClichesEdit).Methods("PUT")
router.HandleFunc("/cliches/{id:[0-9]+}", ClichesDelete).Methods("DELETE")
http.Handle("/", router) // enable the router
// Start the server.
port := ":8888"
fmt.Println("\nListening on port " + port)
http.ListenAndServe(port, router); // mux.Router now in play
}
// Return entire list to requester.
func readAll() string {
msg := "\n"
for _, cliche := range clichesList {
next := strconv.Itoa(cliche.Id) + ": " + cliche.Cliche + " " + cliche.Counter + "\n"
msg += next
}
return msg
}
// Return specified clichePair to requester.
func readOne(id int) string {
msg := "\n" + "Bad Id: " + strconv.Itoa(id) + "\n"
index := findCliche(id)
if index >= 0 {
cliche := clichesList[index]
msg = "\n" + strconv.Itoa(id) + ": " + cliche.Cliche + " " + cliche.Counter + "\n"
}
return msg
}
// Create a new clichePair and add to list
func addPair(cp *clichePair) string {
cp.Id = masterId
masterId++
clichesList = append(clichesList, cp)
return "\nCreated: " + cp.Cliche + " " + cp.Counter + "\n"
}
// Edit an existing clichePair
func editPair(id int, cliche string, counter string) string {
msg := "\n" + "Bad Id: " + strconv.Itoa(id) + "\n"
index := findCliche(id)
if index >= 0 {
clichesList[index].Cliche = cliche
clichesList[index].Counter = counter
msg = "\nCliche edited: " + cliche + " " + counter + "\n"
}
return msg
}
// Delete a clichePair
func deletePair(id int) string {
idStr := strconv.Itoa(id)
msg := "\n" + "Bad Id: " + idStr + "\n"
index := findCliche(id)
if index >= 0 {
clichesList = append(clichesList[:index], clichesList[index + 1:]...)
msg = "\nCliche " + idStr + " deleted\n"
}
return msg
}
//*** utility functions
func findCliche(id int) int {
for i := 0; i < len(clichesList); i++ {
if id == clichesList[i].Id {
return i;
}
}
return -1 // not found
}
func getIdFromRequest(req *http.Request) int {
vars := mux.Vars(req)
id, _ := strconv.Atoi(vars["id"])
return id
}
func getDataFromRequest(req *http.Request) (string, string) {
// Extract the user-provided data for the new clichePair
req.ParseForm()
form := req.Form
cliche := form["cliche"][0] // 1st and only member of a list
counter := form["counter"][0] // ditto
return cliche, counter
}
func logIt(msg string) {
fmt.Println(msg)
}
func populateClichesList() {
var cliches = []string {
"Out of sight, out of mind.",
"A penny saved is a penny earned.",
"He who hesitates is lost.",
}
var counterCliches = []string {
"Absence makes the heart grow fonder.",
"Penny-wise and dollar-foolish.",
"Look before you leap.",
}
for i := 0; i < len(cliches); i++ {
cp := new(clichePair)
cp.Id = masterId
masterId++
cp.Cliche = cliches[i]
cp.Counter = counterCliches[i]
clichesList = append(clichesList, cp)
}
}
```
To focus on request routing and validation, the *crud* app does not use HTML pages as responses to requests. Instead, requests result in plaintext response messages: A list of the cliche pairs is the response to a GET request, confirmation that a new cliche pair has been added to the list is a response to a POST request, and so on. This simplification makes it easy to test the app, in particular, the `gorilla/mux`
components, with a command-line utility such as * curl*.
The `gorilla/mux`
package can be installed from [GitHub](https://github.com/gorilla/mux). The *crud* app runs indefinitely; hence, it should be terminated with a Control-C or equivalent. The code for the *crud* app, together with a README and sample *curl* tests, is available on [my website](http://condor.depaul.edu/mkalin).
## 2. Request routing
The `mux.Router`
extends REST-style routing, which gives equal weight to the HTTP method (e.g., GET) and the URI or path at the end of a URL (e.g., */cliches*). The URI serves as the noun for the HTTP verb (method). For example, in an HTTP request a startline such as
`GET /cliches`
means *get all of the cliche pairs*, whereas a startline such as
`POST /cliches`
means *create a cliche pair from data in the HTTP body*.
In the *crud* web app, there are five functions that act as request handlers for five variations of an HTTP request:
```
ClichesAll(...) # GET: get all of the cliche pairs
ClichesOne(...) # GET: get a specified cliche pair
ClichesCreate(...) # POST: create a new cliche pair
ClichesEdit(...) # PUT: edit an existing cliche pair
ClichesDelete(...) # DELETE: delete a specified cliche pair
```
Each function takes two arguments: an `http.ResponseWriter`
for sending a response back to the requester, and a pointer to an `http.Request`
, which encapsulates information from the underlying HTTP request. The `gorilla/mux`
package makes it easy to register these request handlers with the web server, and to perform regex-based validation.
The `startServer`
function in the *crud* app registers the request handlers. Consider this pair of registrations, with `router`
as a `mux.Router`
instance:
```
router.HandleFunc("/", ClichesAll).Methods("GET")
router.HandleFunc("/cliches", ClichesAll).Methods("GET")
```
These statements mean that a GET request for either the single slash */* or */cliches* should be routed to the `ClichesAll`
function, which then handles the request. For example, the *curl* request (with % as the command-line prompt)
`% curl --request GET localhost:8888/`
produces this response:
```
1: Out of sight, out of mind. Absence makes the heart grow fonder.
2: A penny saved is a penny earned. Penny-wise and dollar-foolish.
3: He who hesitates is lost. Look before you leap.
```
The three cliche pairs are the initial data in the *crud* app.
In this pair of registration statements
```
router.HandleFunc("/cliches", ClichesAll).Methods("GET")
router.HandleFunc("/cliches", ClichesCreate).Methods("POST")
```
the URI is the same (*/cliches*) but the verbs differ: GET in the first case, and POST in the second. This registration exemplifies REST-style routing because the difference in the verbs alone suffices to dispatch the requests to two different handlers.
More than one HTTP method is allowed in a registration, although this strains the spirit of REST-style routing:
`router.HandleFunc("/cliches", DoItAll).Methods("POST", "GET")`
HTTP requests can be routed on features besides the verb and the URI. For example, the registration
`router.HandleFunc("/cliches", ClichesCreate).Schemes("https").Methods("POST")`
requires HTTPS access for a POST request to create a new cliche pair. In similar fashion, a registration might require a request to have a specified HTTP header element (e.g., an authentication credential).
## 3. Request validation
The `gorilla/mux`
package takes an easy, intuitive approach to request validation through regular expressions. Consider this request handler for a *get one* operation:
`router.HandleFunc("/cliches/{id:[0-9]+}", ClichesOne).Methods("GET")`
This registration rules out HTTP requests such as
`% curl --request GET localhost:8888/cliches/foo`
because *foo* is not a decimal numeral. The request results in the familiar 404 (Not Found) status code. Including the regex pattern in this handler registration ensures that the `ClichesOne`
function is called to handle a request only if the request URI ends with a decimal integer value:
`% curl --request GET localhost:8888/cliches/3 # ok`
As a second example, consider the request
`% curl --request PUT --data "..." localhost:8888/cliches`
This request results in a status code of 405 (Bad Method) because the */cliches* URI is registered, in the *crud* app, only for GET and POST requests. A PUT request, like a GET one request, must include a numeric id at the end of the URI:
`router.HandleFunc("/cliches/{id:[0-9]+}", ClichesEdit).Methods("PUT")`
## 4. Concurrency issues
The `gorilla/mux`
router executes each call to a registered request handler as a separate goroutine, which means that concurrency is baked into the package. For example, if there are ten simultaneous requests such as
`% curl --request POST --data "..." localhost:8888/cliches`
then the `mux.Router`
launches ten goroutines to execute the `ClichesCreate`
handler.
Of the five request operations GET all, GET one, POST, PUT, and DELETE, the last three alter the requested resource, the shared `clichesList`
that houses the cliche pairs. Accordingly, the *crud*app needs to guarantee safe concurrency by coordinating access to the `clichesList`
. In different but equivalent terms, the *crud *app must prevent a race condition on the `clichesList`
. In a production environment, a database system might be used to store a resource such as the `clichesList`
, and safe concurrency then could be managed through database transactions.
The *crud* app takes the recommended Go approach to safe concurrency:
- Only a single goroutine, the
*resource manager*started in the*crud*app`startServer`
function, has access to the`clichesList`
once the web server starts listening for requests. - The request handlers such as
`ClichesCreate`
and`ClichesAll`
send a (pointer to) a`crudRequest`
instance to a Go channel (thread-safe by default), and the resource manager alone reads from this channel. The resource manager then performs the requested operation on the`clichesList`
.
The safe-concurrency architecture can be sketched as follows:
```
crudRequest read/write
request handlers------------->resource manager------------>clichesList
```
With this architecture, no explicit locking of the `clichesList`
is needed because only one goroutine, the resource manager, accesses the `clichesList`
once CRUD requests start coming in.
To keep the *crud* app as concurrent as possible, it’s essential to have an efficient division of labor between the request handlers, on the one side, and the single resource manager, on the other side. Here, for review, is the `ClichesCreate`
request handler:
```
func ClichesCreate(res http.ResponseWriter, req *http.Request) {
cliche, counter := getDataFromRequest(req)
cp := new(clichePair)
cp.Cliche = cliche
cp.Counter = counter
cr := &crudRequest{verb: POST, cp: cp, confirm: make(chan string)}
completeRequest(cr, res, "create")
}
```
The request handler `ClichesCreate`
calls the utility function `getDataFromRequest`
, which extracts the new cliche and counter-cliche from the POST request. The `ClichesCreate`
function then creates a new `ClichePair`
, sets two fields, and creates a `crudRequest`
to be sent to the single resource manager. This request includes a confirmation channel, which the resource manager uses to return information back to the request handler. All of the setup work can be done without involving the resource manager because the `clichesList`
is not being accessed yet.
The `completeRequest`
utility function called at the end of the `ClichesCreate`
function and the other request handlers
`completeRequest(cr, res, "create") // shown above`
brings the resource manager into play by putting a `crudRequest`
into the `crudRequests`
channel:
```
func completeRequest(cr *crudRequest, res http.ResponseWriter, logMsg string) {
crudRequests<-cr // send request to resource manager
msg := <-cr.confirm // await confirmation string
res.Write([]byte(msg)) // send confirmation back to requester
logIt(logMsg) // print to the standard output
}
```
For a POST request, the resource manager calls the utility function `addPair`
, which changes the `clichesList`
resource:
```
func addPair(cp *clichePair) string {
cp.Id = masterId // assign a unique ID
masterId++ // update the ID counter
clichesList = append(clichesList, cp) // update the list
return "\nCreated: " + cp.Cliche + " " + cp.Counter + "\n"
}
```
The resource manager calls similar utility functions for the other CRUD operations. It’s worth repeating that the resource manager is the only goroutine to read or write the `clichesList`
once the web server starts accepting requests.
For web applications of any type, the `gorilla/mux`
package provides request routing, request validation, and related services in a straightforward, intuitive API. The *crud* web app highlights the package’s main features. Give the package a test drive, and you’ll likely be a buyer.
## Comments are closed. |
10,349 | 创建一个容器化的机器学习模型 | https://fedoramagazine.org/create-containerized-machine-learning-model/ | 2018-12-15T09:18:26 | [
"机器学习",
"容器"
] | https://linux.cn/article-10349-1.html | 
数据科学家在创建机器学习模型后,必须将其部署到生产中。要在不同的基础架构上运行它,使用容器并通过 REST API 公开模型是部署机器学习模型的常用方法。本文演示了如何在 [Podman](https://fedoramagazine.org/running-containers-with-podman/) 容器中使用 [Connexion](https://connexion.readthedocs.io/en/latest/) 推出使用 REST API 的 [TensorFlow](https://www.tensorflow.org) 机器学习模型。
### 准备
首先,使用以下命令安装 Podman:
```
sudo dnf -y install podman
```
接下来,为容器创建一个新文件夹并切换到该目录。
```
mkdir deployment_container && cd deployment_container
```
### TensorFlow 模型的 REST API
下一步是为机器学习模型创建 REST API。这个 [github 仓库](https://github.com/svenboesiger/titanic_tf_ml_model)包含一个预训练模型,以及能让 REST API 工作的设置。
使用以下命令在 `deployment_container` 目录中克隆它:
```
git clone https://github.com/svenboesiger/titanic_tf_ml_model.git
```
#### prediction.py 和 ml\_model/
[prediction.py](https://github.com/svenboesiger/titanic_tf_ml_model/blob/master/prediction.py) 能进行 Tensorflow 预测,而 20x20x20 神经网络的权重位于文件夹 [ml\_model/](https://github.com/svenboesiger/titanic_tf_ml_model/tree/master/ml_model/titanic) 中。
#### swagger.yaml
[swagger.yaml](https://github.com/svenboesiger/titanic_tf_ml_model/blob/master/swagger.yaml) 使用 [Swagger规范](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/2.0.md) 定义 Connexion 库的 API。此文件包含让你的服务器提供输入参数验证、输出响应数据验证、URL 端点定义所需的所有信息。
额外地,Connexion 还将给你提供一个简单但有用的单页 Web 应用,它演示了如何使用 Javascript 调用 API 和更新 DOM。
```
swagger: "2.0"
info:
description: This is the swagger file that goes with our server code
version: "1.0.0"
title: Tensorflow Podman Article
consumes:
- "application/json"
produces:
- "application/json"
basePath: "/"
paths:
/survival_probability:
post:
operationId: "prediction.post"
tags:
- "Prediction"
summary: "The prediction data structure provided by the server application"
description: "Retrieve the chance of surviving the titanic disaster"
parameters:
- in: body
name: passenger
required: true
schema:
$ref: '#/definitions/PredictionPost'
responses:
'201':
description: 'Survival probability of an individual Titanic passenger'
definitions:
PredictionPost:
type: object
```
#### server.py 和 requirements.txt
[server.py](https://github.com/svenboesiger/titanic_tf_ml_model/blob/master/server.py) 定义了启动 Connexion 服务器的入口点。
```
import connexion
app = connexion.App(__name__, specification_dir='./')
app.add_api('swagger.yaml')
if __name__ == '__main__':
app.run(debug=True)
```
[requirements.txt](https://github.com/svenboesiger/titanic_tf_ml_model/blob/master/requirements.txt) 定义了运行程序所需的 python 包。
```
connexion
tensorflow
pandas
```
### 容器化!
为了让 Podman 构建映像,请在上面的准备步骤中创建的 `deployment_container` 目录中创建一个名为 `Dockerfile` 的新文件:
```
FROM fedora:28
# File Author / Maintainer
MAINTAINER Sven Boesiger <[email protected]>
# Update the sources
RUN dnf -y update --refresh
# Install additional dependencies
RUN dnf -y install libstdc++
RUN dnf -y autoremove
# Copy the application folder inside the container
ADD /titanic_tf_ml_model /titanic_tf_ml_model
# Get pip to download and install requirements:
RUN pip3 install -r /titanic_tf_ml_model/requirements.txt
# Expose ports
EXPOSE 5000
# Set the default directory where CMD will execute
WORKDIR /titanic_tf_ml_model
# Set the default command to execute
# when creating a new container
CMD python3 server.py
```
接下来,使用以下命令构建容器镜像:
```
podman build -t ml_deployment .
```
### 运行容器
随着容器镜像的构建和准备就绪,你可以使用以下命令在本地运行它:
```
podman run -p 5000:5000 ml_deployment
```
在 Web 浏览器中输入 [http://0.0.0.0:5000/ui](http://0.0.0.0:5000/) 访问 Swagger/Connexion UI 并测试模型:

当然,你现在也可以在应用中通过 REST API 访问模型。
---
via: <https://fedoramagazine.org/create-containerized-machine-learning-model/>
作者:[Sven Bösiger](https://fedoramagazine.org/author/r00nz/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | After data scientists have created a machine learning model, it has to be deployed into production. To run it on different infrastructures, using containers and exposing the model via a REST API is a common way to deploy a machine learning model. This article demonstrates how to roll out a [TensorFlow](https://www.tensorflow.org) machine learning model, with a REST API delivered by [Connexion](https://connexion.readthedocs.io/en/latest/) in a container with [Podman](https://fedoramagazine.org/running-containers-with-podman/).
## Preparation
First, install Podman with the following command:
sudo dnf -y install podman
Next, create a new folder for the container and switch to that directory.
mkdir deployment_container && cd deployment_container
## REST API for the TensorFlow model
The next step is to create the REST-API for the machine learning model. This [github repository](https://github.com/svenboesiger/titanic_tf_ml_model) contains a pretrained model, and well as the setup already configured for getting the REST API working.
Clone this in the deployment_container directory with the command:
git clone https://github.com/svenboesiger/titanic_tf_ml_model.git
#### prediction.py & ml_model/
The [prediction.py](https://github.com/svenboesiger/titanic_tf_ml_model/blob/master/prediction.py) file allows for a Tensorflow prediction, while the weights for the 20x20x20 neural network are located in folder [ ml_model/](https://github.com/svenboesiger/titanic_tf_ml_model/tree/master/ml_model/titanic).
#### swagger.yaml
The file swagger.yaml defines the API for the Connexion library using the [Swagger specification](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/2.0.md). This file contains all of the information necessary to configure your server to provide input parameter validation, output response data validation, URL endpoint definition.
As a bonus Connexion will provide you also with a simple but useful single page web application that demonstrates using the API with JavaScript and updating the DOM with it.
swagger: "2.0" info: description: This is the swagger file that goes with our server code version: "1.0.0" title: Tensorflow Podman Article consumes: - "application/json" produces: - "application/json" basePath: "/" paths: /survival_probability: post: operationId: "prediction.post" tags: - "Prediction" summary: "The prediction data structure provided by the server application" description: "Retrieve the chance of surviving the titanic disaster" parameters: - in: body name: passenger required: true schema: $ref: '#/definitions/PredictionPost' responses: '201': description: 'Survival probability of an individual Titanic passenger' definitions: PredictionPost: type: object
#### server.py & requirements.txt
[ server.py](https://github.com/svenboesiger/titanic_tf_ml_model/blob/master/server.py) defines an entry point to start the Connexion server.
import connexion app = connexion.App(__name__, specification_dir='./') app.add_api('swagger.yaml') if __name__ == '__main__': app.run(debug=True)
[ requirements.txt](https://github.com/svenboesiger/titanic_tf_ml_model/blob/master/requirements.txt) defines the python requirements we need to run the program.
connexion tensorflow pandas
## Containerize!
For Podman to be able to build an image, create a new file called “Dockerfile” in the **deployment_container** directory created in the preparation step above:
FROM fedora:28 # File Author / Maintainer MAINTAINER Sven Boesiger <[email protected]> # Update the sources RUN dnf -y update --refresh # Install additional dependencies RUN dnf -y install libstdc++ RUN dnf -y autoremove # Copy the application folder inside the container ADD /titanic_tf_ml_model /titanic_tf_ml_model # Get pip to download and install requirements: RUN pip3 install -r /titanic_tf_ml_model/requirements.txt # Expose ports EXPOSE 5000 # Set the default directory where CMD will execute WORKDIR /titanic_tf_ml_model # Set the default command to execute # when creating a new container CMD python3 server.py
Next, build the container image with the command:
podman build -t ml_deployment .
## Run the container
With the Container image built and ready to go, you can run it locally with the command:
podman run -p 5000:5000 ml_deployment |
Navigate to [http://0.0.0.0:5000/ui](http://0.0.0.0:5000/) in your web browser to access the Swagger/Connexion UI and to test-drive the model:
Of course you can now also access the model with your application via the REST-API.
## Robert
Hi Sven, really enjoyed about your article. Things like ml, neural, ai, … are very exciting !
If you build “podman build -t ml_deployment . ” , I get this message , “port bindings are not yet supported by rootless containers”
How it works (Fedora 29) for me is build as sudo:
sudo podman build -t ml_deployment .
and run as sudo:
sudo podman run -p 5000:5000 ml_deployment
Thanks to write this awesome article, looking forward to seeing more of these stuff in the future.
## Costas A.
I guess this is not something for the average Joe…
Except if it helps predict lottery winning numbers 😛
## Yazan Al Monshed
Nice Blog , but I need More learn About Podman in the future
## Ejner
Thanks for the article, it is a great demo! – even if I can’t make heads or tails of the results 🙂
To get the page to load correctly, I struggled a bit with the json input for ‘person’, trying to read from the low-res image. So I’ll paste it here:
{
“attributes”: {
“pclass”: 1,
“age”: 66,
“sibsp”: 1,
“parch”: 4,
“sex_male”:1,
“sex_female”:0,
“embarked_C”:1,
“embarked_Q”:0,
“embarked_S”: 0
}
}
Podman is a very nice project, as well as Buildah. Thanks to everybody involved.
## Roberto F.
Hi Sven, nice article!
If you want to get it working in a rooless environment you have to run with the switch –net=host, like below
podman run -p 5000:5000 –net=host ml_deployment
Cheers!
Roberto
## Marcos Insfran
I don’t have enough space in my /home, when run ‘podman build -t ml_deployment .’ show error of space. Is it possible to download podman images in another directory/path (like another disk)?
Tks. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.