
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
10,848 | TLP:一个可以延长 Linux 笔记本电池寿命的高级电源管理工具 | https://www.2daygeek.com/tlp-increase-optimize-linux-laptop-battery-life/ | 2019-05-13T09:44:00 | [
"电池",
"笔记本",
"TPL"
] | https://linux.cn/article-10848-1.html | 
笔记本电池是针对 Windows 操作系统进行了高度优化的,当我在笔记本电脑中使用 Windows 操作系统时,我已经意识到这一点,但对于 Linux 来说却不一样。
多年来,Linux 在电池优化方面取得了很大进步,但我们仍然需要做一些必要的事情来改善 Linux 中笔记本电脑的电池寿命。
当我考虑延长电池寿命时,我没有多少选择,但我觉得 TLP 对我来说是一个更好的解决方案,所以我会继续使用它。
在本教程中,我们将详细讨论 TLP 以延长电池寿命。
我们之前在我们的网站上写过三篇关于 Linux [笔记本电池节电工具](https://www.2daygeek.com/check-laptop-battery-status-and-charging-state-in-linux-terminal/) 的文章:[PowerTOP](https://www.2daygeek.com/powertop-monitors-laptop-battery-usage-linux/) 和 [电池充电状态](https://www.2daygeek.com/monitor-laptop-battery-charging-state-linux/)。
### TLP
[TLP](https://linrunner.de/en/tlp/docs/tlp-linux-advanced-power-management.html) 是一款自由开源的高级电源管理工具,可在不进行任何配置更改的情况下延长电池寿命。
由于它的默认配置已针对电池寿命进行了优化,因此你可能只需要安装,然后就忘记它吧。
此外,它可以高度定制化,以满足你的特定要求。TLP 是一个具有自动后台任务的纯命令行工具。它不包含GUI。
TLP 适用于各种品牌的笔记本电脑。设置电池充电阈值仅适用于 IBM/Lenovo ThinkPad。
所有 TLP 设置都存储在 `/etc/default/tlp` 中。其默认配置提供了开箱即用的优化的节能设置。
以下 TLP 设置可用于自定义,如果需要,你可以相应地进行必要的更改。
### TLP 功能
* 内核笔记本电脑模式和脏缓冲区超时
* 处理器频率调整,包括 “turbo boost”/“turbo core”
* 限制最大/最小的 P 状态以控制 CPU 的功耗
* HWP 能源性能提示
* 用于多核/超线程的功率感知进程调度程序
* 处理器性能与节能策略(`x86_energy_perf_policy`)
* 硬盘高级电源管理级别(APM)和降速超时(按磁盘)
* AHCI 链路电源管理(ALPM)与设备黑名单
* PCIe 活动状态电源管理(PCIe ASPM)
* PCI(e) 总线设备的运行时电源管理
* Radeon 图形电源管理(KMS 和 DPM)
* Wifi 省电模式
* 关闭驱动器托架中的光盘驱动器
* 音频省电模式
* I/O 调度程序(按磁盘)
* USB 自动暂停,支持设备黑名单/白名单(输入设备自动排除)
* 在系统启动和关闭时启用或禁用集成的 wifi、蓝牙或 wwan 设备
* 在系统启动时恢复无线电设备状态(从之前的关机时的状态)
* 无线电设备向导:在网络连接/断开和停靠/取消停靠时切换无线电
* 禁用 LAN 唤醒
* 挂起/休眠后恢复集成的 WWAN 和蓝牙状态
* 英特尔处理器的动态电源降低 —— 需要内核和 PHC-Patch 支持
* 电池充电阈值 —— 仅限 ThinkPad
* 重新校准电池 —— 仅限 ThinkPad
### 如何在 Linux 上安装 TLP
TLP 包在大多数发行版官方存储库中都可用,因此,使用发行版的 [包管理器](https://www.2daygeek.com/category/package-management/) 来安装它。
对于 Fedora 系统,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 安装 TLP。
```
$ sudo dnf install tlp tlp-rdw
```
ThinkPad 需要一些附加软件包。
```
$ sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
$ sudo dnf install http://repo.linrunner.de/fedora/tlp/repos/releases/tlp-release.fc$(rpm -E %fedora).noarch.rpm
$ sudo dnf install akmod-tp_smapi akmod-acpi_call kernel-devel
```
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
```
$ sudo dnf install smartmontools
```
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 安装 TLP。
```
$ sudo apt install tlp tlp-rdw
```
ThinkPad 需要一些附加软件包。
```
$ sudo apt-get install tp-smapi-dkms acpi-call-dkms
```
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
```
$ sudo apt-get install smartmontools
```
当基于 Ubuntu 的系统的官方软件包过时时,请使用以下 PPA 存储库,该存储库提供最新版本。运行以下命令以使用 PPA 安装 TLP。
```
$ sudo add-apt-repository ppa:linrunner/tlp
$ sudo apt-get update
$ sudo apt-get install tlp
```
对于基于 Arch Linux 的系统,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 安装 TLP。
```
$ sudo pacman -S tlp tlp-rdw
```
ThinkPad 需要一些附加软件包。
```
$ pacman -S tp_smapi acpi_call
```
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
```
$ sudo pacman -S smartmontools
```
对于基于 Arch Linux 的系统,在启动时启用 TLP 和 TLP-Sleep 服务。
```
$ sudo systemctl enable tlp.service
$ sudo systemctl enable tlp-sleep.service
```
对于基于 Arch Linux 的系统,你还应该屏蔽以下服务以避免冲突,并确保 TLP 的无线电设备切换选项的正确操作。
```
$ sudo systemctl mask systemd-rfkill.service
$ sudo systemctl mask systemd-rfkill.socket
```
对于 RHEL/CentOS 系统,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 安装 TLP。
```
$ sudo yum install tlp tlp-rdw
```
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
```
$ sudo yum install smartmontools
```
对于 openSUSE Leap 系统,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 安装 TLP。
```
$ sudo zypper install TLP
```
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
```
$ sudo zypper install smartmontools
```
成功安装 TLP 后,使用以下命令启动服务。
```
$ systemctl start tlp.service
```
### 使用方法
#### 显示电池信息
```
$ sudo tlp-stat -b
或
$ sudo tlp-stat --battery
```
```
--- TLP 1.1 --------------------------------------------
+++ Battery Status
/sys/class/power_supply/BAT0/manufacturer = SMP
/sys/class/power_supply/BAT0/model_name = L14M4P23
/sys/class/power_supply/BAT0/cycle_count = (not supported)
/sys/class/power_supply/BAT0/energy_full_design = 60000 [mWh]
/sys/class/power_supply/BAT0/energy_full = 48850 [mWh]
/sys/class/power_supply/BAT0/energy_now = 48850 [mWh]
/sys/class/power_supply/BAT0/power_now = 0 [mW]
/sys/class/power_supply/BAT0/status = Full
Charge = 100.0 [%]
Capacity = 81.4 [%]
```
#### 显示磁盘信息
```
$ sudo tlp-stat -d
或
$ sudo tlp-stat --disk
```
```
--- TLP 1.1 --------------------------------------------
+++ Storage Devices
/dev/sda:
Model = WDC WD10SPCX-24HWST1
Firmware = 02.01A02
APM Level = 128
Status = active/idle
Scheduler = mq-deadline
Runtime PM: control = on, autosuspend_delay = (not available)
SMART info:
4 Start_Stop_Count = 18787
5 Reallocated_Sector_Ct = 0
9 Power_On_Hours = 606 [h]
12 Power_Cycle_Count = 1792
193 Load_Cycle_Count = 25775
194 Temperature_Celsius = 31 [°C]
+++ AHCI Link Power Management (ALPM)
/sys/class/scsi_host/host0/link_power_management_policy = med_power_with_dipm
/sys/class/scsi_host/host1/link_power_management_policy = med_power_with_dipm
/sys/class/scsi_host/host2/link_power_management_policy = med_power_with_dipm
/sys/class/scsi_host/host3/link_power_management_policy = med_power_with_dipm
+++ AHCI Host Controller Runtime Power Management
/sys/bus/pci/devices/0000:00:17.0/ata1/power/control = on
/sys/bus/pci/devices/0000:00:17.0/ata2/power/control = on
/sys/bus/pci/devices/0000:00:17.0/ata3/power/control = on
/sys/bus/pci/devices/0000:00:17.0/ata4/power/control = on
```
#### 显示 PCI 设备信息
```
$ sudo tlp-stat -e
或
$ sudo tlp-stat --pcie
```
```
$ sudo tlp-stat -e
or
$ sudo tlp-stat --pcie
--- TLP 1.1 --------------------------------------------
+++ Runtime Power Management
Device blacklist = (not configured)
Driver blacklist = amdgpu nouveau nvidia radeon pcieport
/sys/bus/pci/devices/0000:00:00.0/power/control = auto (0x060000, Host bridge, skl_uncore)
/sys/bus/pci/devices/0000:00:01.0/power/control = auto (0x060400, PCI bridge, pcieport)
/sys/bus/pci/devices/0000:00:02.0/power/control = auto (0x030000, VGA compatible controller, i915)
/sys/bus/pci/devices/0000:00:14.0/power/control = auto (0x0c0330, USB controller, xhci_hcd)
......
```
#### 显示图形卡信息
```
$ sudo tlp-stat -g
或
$ sudo tlp-stat --graphics
```
```
--- TLP 1.1 --------------------------------------------
+++ Intel Graphics
/sys/module/i915/parameters/enable_dc = -1 (use per-chip default)
/sys/module/i915/parameters/enable_fbc = 1 (enabled)
/sys/module/i915/parameters/enable_psr = 0 (disabled)
/sys/module/i915/parameters/modeset = -1 (use per-chip default)
```
#### 显示处理器信息
```
$ sudo tlp-stat -p
或
$ sudo tlp-stat --processor
```
```
--- TLP 1.1 --------------------------------------------
+++ Processor
CPU model = Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
/sys/devices/system/cpu/cpu0/cpufreq/scaling_driver = intel_pstate
/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor = powersave
/sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors = performance powersave
/sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq = 800000 [kHz]
/sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq = 3500000 [kHz]
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_preference = balance_power
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
......
/sys/devices/system/cpu/intel_pstate/min_perf_pct = 22 [%]
/sys/devices/system/cpu/intel_pstate/max_perf_pct = 100 [%]
/sys/devices/system/cpu/intel_pstate/no_turbo = 0
/sys/devices/system/cpu/intel_pstate/turbo_pct = 33 [%]
/sys/devices/system/cpu/intel_pstate/num_pstates = 28
x86_energy_perf_policy: program not installed.
/sys/module/workqueue/parameters/power_efficient = Y
/proc/sys/kernel/nmi_watchdog = 0
+++ Undervolting
PHC kernel not available.
```
#### 显示系统数据信息
```
$ sudo tlp-stat -s
或
$ sudo tlp-stat --system
```
```
--- TLP 1.1 --------------------------------------------
+++ System Info
System = LENOVO Lenovo ideapad Y700-15ISK 80NV
BIOS = CDCN35WW
Release = "Manjaro Linux"
Kernel = 4.19.6-1-MANJARO #1 SMP PREEMPT Sat Dec 1 12:21:26 UTC 2018 x86_64
/proc/cmdline = BOOT_IMAGE=/boot/vmlinuz-4.19-x86_64 root=UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f rw quiet resume=UUID=a2092b92-af29-4760-8e68-7a201922573b
Init system = systemd
Boot mode = BIOS (CSM, Legacy)
+++ TLP Status
State = enabled
Last run = 11:04:00 IST, 596 sec(s) ago
Mode = battery
Power source = battery
```
#### 显示温度和风扇速度信息
```
$ sudo tlp-stat -t
或
$ sudo tlp-stat --temp
```
```
--- TLP 1.1 --------------------------------------------
+++ Temperatures
CPU temp = 36 [°C]
Fan speed = (not available)
```
#### 显示 USB 设备数据信息
```
$ sudo tlp-stat -u
或
$ sudo tlp-stat --usb
```
```
--- TLP 1.1 --------------------------------------------
+++ USB
Autosuspend = disabled
Device whitelist = (not configured)
Device blacklist = (not configured)
Bluetooth blacklist = disabled
Phone blacklist = disabled
WWAN blacklist = enabled
Bus 002 Device 001 ID 1d6b:0003 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 3.0 root hub (hub)
Bus 001 Device 003 ID 174f:14e8 control = auto, autosuspend_delay_ms = 2000 -- Syntek (uvcvideo)
......
```
#### 显示警告信息
```
$ sudo tlp-stat -w
或
$ sudo tlp-stat --warn
```
```
--- TLP 1.1 --------------------------------------------
No warnings detected.
```
#### 状态报告及配置和所有活动的设置
```
$ sudo tlp-stat
```
```
--- TLP 1.1 --------------------------------------------
+++ Configured Settings: /etc/default/tlp
TLP_ENABLE=1
TLP_DEFAULT_MODE=AC
TLP_PERSISTENT_DEFAULT=0
DISK_IDLE_SECS_ON_AC=0
DISK_IDLE_SECS_ON_BAT=2
MAX_LOST_WORK_SECS_ON_AC=15
MAX_LOST_WORK_SECS_ON_BAT=60
......
+++ System Info
System = LENOVO Lenovo ideapad Y700-15ISK 80NV
BIOS = CDCN35WW
Release = "Manjaro Linux"
Kernel = 4.19.6-1-MANJARO #1 SMP PREEMPT Sat Dec 1 12:21:26 UTC 2018 x86_64
/proc/cmdline = BOOT_IMAGE=/boot/vmlinuz-4.19-x86_64 root=UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f rw quiet resume=UUID=a2092b92-af29-4760-8e68-7a201922573b
Init system = systemd
Boot mode = BIOS (CSM, Legacy)
+++ TLP Status
State = enabled
Last run = 11:04:00 IST, 684 sec(s) ago
Mode = battery
Power source = battery
+++ Processor
CPU model = Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
/sys/devices/system/cpu/cpu0/cpufreq/scaling_driver = intel_pstate
/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor = powersave
/sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors = performance powersave
......
/sys/devices/system/cpu/intel_pstate/min_perf_pct = 22 [%]
/sys/devices/system/cpu/intel_pstate/max_perf_pct = 100 [%]
/sys/devices/system/cpu/intel_pstate/no_turbo = 0
/sys/devices/system/cpu/intel_pstate/turbo_pct = 33 [%]
/sys/devices/system/cpu/intel_pstate/num_pstates = 28
x86_energy_perf_policy: program not installed.
/sys/module/workqueue/parameters/power_efficient = Y
/proc/sys/kernel/nmi_watchdog = 0
+++ Undervolting
PHC kernel not available.
+++ Temperatures
CPU temp = 42 [°C]
Fan speed = (not available)
+++ File System
/proc/sys/vm/laptop_mode = 2
/proc/sys/vm/dirty_writeback_centisecs = 6000
/proc/sys/vm/dirty_expire_centisecs = 6000
/proc/sys/vm/dirty_ratio = 20
/proc/sys/vm/dirty_background_ratio = 10
+++ Storage Devices
/dev/sda:
Model = WDC WD10SPCX-24HWST1
Firmware = 02.01A02
APM Level = 128
Status = active/idle
Scheduler = mq-deadline
Runtime PM: control = on, autosuspend_delay = (not available)
SMART info:
4 Start_Stop_Count = 18787
5 Reallocated_Sector_Ct = 0
9 Power_On_Hours = 606 [h]
12 Power_Cycle_Count = 1792
193 Load_Cycle_Count = 25777
194 Temperature_Celsius = 31 [°C]
+++ AHCI Link Power Management (ALPM)
/sys/class/scsi_host/host0/link_power_management_policy = med_power_with_dipm
/sys/class/scsi_host/host1/link_power_management_policy = med_power_with_dipm
/sys/class/scsi_host/host2/link_power_management_policy = med_power_with_dipm
/sys/class/scsi_host/host3/link_power_management_policy = med_power_with_dipm
+++ AHCI Host Controller Runtime Power Management
/sys/bus/pci/devices/0000:00:17.0/ata1/power/control = on
/sys/bus/pci/devices/0000:00:17.0/ata2/power/control = on
/sys/bus/pci/devices/0000:00:17.0/ata3/power/control = on
/sys/bus/pci/devices/0000:00:17.0/ata4/power/control = on
+++ PCIe Active State Power Management
/sys/module/pcie_aspm/parameters/policy = powersave
+++ Intel Graphics
/sys/module/i915/parameters/enable_dc = -1 (use per-chip default)
/sys/module/i915/parameters/enable_fbc = 1 (enabled)
/sys/module/i915/parameters/enable_psr = 0 (disabled)
/sys/module/i915/parameters/modeset = -1 (use per-chip default)
+++ Wireless
bluetooth = on
wifi = on
wwan = none (no device)
hci0(btusb) : bluetooth, not connected
wlp8s0(iwlwifi) : wifi, connected, power management = on
+++ Audio
/sys/module/snd_hda_intel/parameters/power_save = 1
/sys/module/snd_hda_intel/parameters/power_save_controller = Y
+++ Runtime Power Management
Device blacklist = (not configured)
Driver blacklist = amdgpu nouveau nvidia radeon pcieport
/sys/bus/pci/devices/0000:00:00.0/power/control = auto (0x060000, Host bridge, skl_uncore)
/sys/bus/pci/devices/0000:00:01.0/power/control = auto (0x060400, PCI bridge, pcieport)
/sys/bus/pci/devices/0000:00:02.0/power/control = auto (0x030000, VGA compatible controller, i915)
......
+++ USB
Autosuspend = disabled
Device whitelist = (not configured)
Device blacklist = (not configured)
Bluetooth blacklist = disabled
Phone blacklist = disabled
WWAN blacklist = enabled
Bus 002 Device 001 ID 1d6b:0003 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 3.0 root hub (hub)
Bus 001 Device 003 ID 174f:14e8 control = auto, autosuspend_delay_ms = 2000 -- Syntek (uvcvideo)
Bus 001 Device 002 ID 17ef:6053 control = on, autosuspend_delay_ms = 2000 -- Lenovo (usbhid)
Bus 001 Device 004 ID 8087:0a2b control = auto, autosuspend_delay_ms = 2000 -- Intel Corp. (btusb)
Bus 001 Device 001 ID 1d6b:0002 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 2.0 root hub (hub)
+++ Battery Status
/sys/class/power_supply/BAT0/manufacturer = SMP
/sys/class/power_supply/BAT0/model_name = L14M4P23
/sys/class/power_supply/BAT0/cycle_count = (not supported)
/sys/class/power_supply/BAT0/energy_full_design = 60000 [mWh]
/sys/class/power_supply/BAT0/energy_full = 51690 [mWh]
/sys/class/power_supply/BAT0/energy_now = 50140 [mWh]
/sys/class/power_supply/BAT0/power_now = 12185 [mW]
/sys/class/power_supply/BAT0/status = Discharging
Charge = 97.0 [%]
Capacity = 86.2 [%]
```
---
via: <https://www.2daygeek.com/tlp-increase-optimize-linux-laptop-battery-life/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,850 | 使用 Python 和 Pygame 模块构建一个游戏框架 | https://opensource.com/article/17/12/game-framework-python | 2019-05-13T21:51:36 | [
"Python",
"Pygame"
] | https://linux.cn/article-10850-1.html |
>
> 这系列的第一篇通过创建一个简单的骰子游戏来探究 Python。现在是来从零制作你自己的游戏的时间。
>
>
>

在我的[这系列的第一篇文章](/article-9071-1.html) 中, 我已经讲解如何使用 Python 创建一个简单的、基于文本的骰子游戏。这次,我将展示如何使用 Python 模块 Pygame 来创建一个图形化游戏。它将需要几篇文章才能来得到一个确实做成一些东西的游戏,但是到这系列的结尾,你将更好地理解如何查找和学习新的 Python 模块和如何从其基础上构建一个应用程序。
在开始前,你必须安装 [Pygame](http://www.pygame.org/wiki/about)。
### 安装新的 Python 模块
有几种方法来安装 Python 模块,但是最通用的两个是:
* 从你的发行版的软件存储库
* 使用 Python 的软件包管理器 `pip`
两个方法都工作的很好,并且每一个都有它自己的一套优势。如果你是在 Linux 或 BSD 上开发,可以利用你的发行版的软件存储库来自动和及时地更新。
然而,使用 Python 的内置软件包管理器可以给予你控制更新模块时间的能力。而且,它不是特定于操作系统的,这意味着,即使当你不是在你常用的开发机器上时,你也可以使用它。`pip` 的其它的优势是允许本地安装模块,如果你没有正在使用的计算机的管理权限,这是有用的。
### 使用 pip
如果 Python 和 Python3 都安装在你的系统上,你想使用的命令很可能是 `pip3`,它用来区分 Python 2.x 的 `pip` 的命令。如果你不确定,先尝试 `pip3`。
`pip` 命令有些像大多数 Linux 软件包管理器一样工作。你可以使用 `search` 搜索 Python 模块,然后使用 `install` 安装它们。如果你没有你正在使用的计算机的管理权限来安装软件,你可以使用 `--user` 选项来仅仅安装模块到你的家目录。
```
$ pip3 search pygame
[...]
Pygame (1.9.3) - Python Game Development
sge-pygame (1.5) - A 2-D game engine for Python
pygame_camera (0.1.1) - A Camera lib for PyGame
pygame_cffi (0.2.1) - A cffi-based SDL wrapper that copies the pygame API.
[...]
$ pip3 install Pygame --user
```
Pygame 是一个 Python 模块,这意味着它仅仅是一套可以使用在你的 Python 程序中的库。换句话说,它不是一个像 [IDLE](https://en.wikipedia.org/wiki/IDLE) 或 [Ninja-IDE](http://ninja-ide.org/) 一样可以让你启动的程序。
### Pygame 新手入门
一个电子游戏需要一个背景设定:故事发生的地点。在 Python 中,有两种不同的方法来创建你的故事背景:
* 设置一种背景颜色
* 设置一张背景图片
你的背景仅是一张图片或一种颜色。你的电子游戏人物不能与在背景中的东西相互作用,因此,不要在后面放置一些太重要的东西。它仅仅是设置装饰。
### 设置你的 Pygame 脚本
要开始一个新的 Pygame 工程,先在计算机上创建一个文件夹。游戏的全部文件被放在这个目录中。在你的工程文件夹内部保持所需要的所有的文件来运行游戏是极其重要的。

一个 Python 脚本以文件类型、你的姓名,和你想使用的许可证开始。使用一个开放源码许可证,以便你的朋友可以改善你的游戏并与你一起分享他们的更改:
```
#!/usr/bin/env python3
# by Seth Kenlon
## GPLv3
# This program is free software: you can redistribute it and/or
# modify it under the terms of the GNU General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
```
然后,你告诉 Python 你想使用的模块。一些模块是常见的 Python 库,当然,你想包括一个你刚刚安装的 Pygame 模块。
```
import pygame # 加载 pygame 关键字
import sys # 让 python 使用你的文件系统
import os # 帮助 python 识别你的操作系统
```
由于你将用这个脚本文件做很多工作,在文件中分成段落是有帮助的,以便你知道在哪里放代码。你可以使用块注释来做这些,这些注释仅在看你的源文件代码时是可见的。在你的代码中创建三个块。
```
'''
Objects
'''
# 在这里放置 Python 类和函数
'''
Setup
'''
# 在这里放置一次性的运行代码
'''
Main Loop
'''
# 在这里放置游戏的循环代码指令
```
接下来,为你的游戏设置窗口大小。注意,不是每一个人都有大计算机屏幕,所以,最好使用一个适合大多数人的计算机的屏幕大小。
这里有一个方法来切换全屏模式,很多现代电子游戏都会这样做,但是,由于你刚刚开始,简单起见仅设置一个大小即可。
```
'''
Setup
'''
worldx = 960
worldy = 720
```
在脚本中使用 Pygame 引擎前,你需要一些基本的设置。你必须设置帧频,启动它的内部时钟,然后开始 (`init`)Pygame 。
```
fps = 40 # 帧频
ani = 4 # 动画循环
clock = pygame.time.Clock()
pygame.init()
```
现在你可以设置你的背景。
### 设置背景
在你继续前,打开一个图形应用程序,为你的游戏世界创建一个背景。在你的工程目录中的 `images` 文件夹内部保存它为 `stage.png` 。
这里有一些你可以使用的自由图形应用程序。
* [Krita](http://krita.org) 是一个专业级绘图素材模拟器,它可以被用于创建漂亮的图片。如果你对创建电子游戏艺术作品非常感兴趣,你甚至可以购买一系列的[游戏艺术作品教程](https://gumroad.com/l/krita-game-art-tutorial-1)。
* [Pinta](https://pinta-project.com/pintaproject/pinta/releases) 是一个基本的,易于学习的绘图应用程序。
* [Inkscape](http://inkscape.org) 是一个矢量图形应用程序。使用它来绘制形状、线、样条曲线和贝塞尔曲线。
你的图像不必很复杂,你可以以后回去更改它。一旦有了它,在你文件的 Setup 部分添加这些代码:
```
world = pygame.display.set_mode([worldx,worldy])
backdrop = pygame.image.load(os.path.join('images','stage.png').convert())
backdropbox = world.get_rect()
```
如果你仅仅用一种颜色来填充你的游戏的背景,你需要做的就是:
```
world = pygame.display.set_mode([worldx,worldy])
```
你也必须定义颜色以使用。在你的 Setup 部分,使用红、绿、蓝 (RGB) 的值来创建一些颜色的定义。
```
'''
Setup
'''
BLUE = (25,25,200)
BLACK = (23,23,23 )
WHITE = (254,254,254)
```
至此,你理论上可以启动你的游戏了。问题是,它可能仅持续了一毫秒。
为证明这一点,保存你的文件为 `your-name_game.py`(用你真实的名称替换 `your-name`)。然后启动你的游戏。
如果你正在使用 IDLE,通过选择来自 “Run” 菜单的 “Run Module” 来运行你的游戏。
如果你正在使用 Ninja,在左侧按钮条中单击 “Run file” 按钮。

你也可以直接从一个 Unix 终端或一个 Windows 命令提示符中运行一个 Python 脚本。
```
$ python3 ./your-name_game.py
```
如果你正在使用 Windows,使用这命令:
```
py.exe your-name_game.py
```
启动它,不过不要期望很多,因为你的游戏现在仅仅持续几毫秒。你可以在下一部分中修复它。
### 循环
除非另有说明,一个 Python 脚本运行一次并仅一次。近来计算机的运行速度是非常快的,所以你的 Python 脚本运行时间会少于 1 秒钟。
为强制你的游戏来处于足够长的打开和活跃状态来让人看到它(更不要说玩它),使用一个 `while` 循环。为使你的游戏保存打开,你可以设置一个变量为一些值,然后告诉一个 `while` 循环只要变量保持未更改则一直保存循环。
这经常被称为一个“主循环”,你可以使用术语 `main` 作为你的变量。在你的 Setup 部分的任意位置添加代码:
```
main = True
```
在主循环期间,使用 Pygame 关键字来检查键盘上的按键是否已经被按下或释放。添加这些代码到你的主循环部分:
```
'''
Main loop
'''
while main == True:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit(); sys.exit()
main = False
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
pygame.quit()
sys.exit()
main = False
```
也是在你的循环中,刷新你世界的背景。
如果你使用一个图片作为背景:
```
world.blit(backdrop, backdropbox)
```
如果你使用一种颜色作为背景:
```
world.fill(BLUE)
```
最后,告诉 Pygame 来重新刷新屏幕上的所有内容,并推进游戏的内部时钟。
```
pygame.display.flip()
clock.tick(fps)
```
保存你的文件,再次运行它来查看你曾经创建的最无趣的游戏。
退出游戏,在你的键盘上按 `q` 键。
在这系列的 [下一篇文章](https://opensource.com/article/17/12/program-game-python-part-3-spawning-player) 中,我将向你演示,如何加强你当前空空如也的游戏世界,所以,继续学习并创建一些将要使用的图形!
---
via: <https://opensource.com/article/17/12/game-framework-python>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my [first article in this series](https://opensource.com/article/17/10/python-101), I explained how to use Python to create a simple, text-based dice game. You also used the Turtle module to generate some simple graphics. In this article, you start using a module called Pygame to create a game with graphics.
The Turtle module is included with Python by default. Anyone who's got Python installed also has Turtle. The same is not true for an advanced module like Pygame. Because it's a specialized code library, you must install Pygame yourself. Modern Python development uses the concept of virtual *environments*, which provides your Python code its own space to run in, and also helps manage which code libraries your application uses. This ensures that when you pass your Python application to another user to play, you know exactly what they need to install to make it work.
You can manage your Python virtual environment manually, or you can let your IDE help you. For now, you can let PyCharm do all the work. If you're not using PyCharm, [read László Kiss Kollár's article about managing Python packages](https://opensource.com/article/19/4/managing-python-packages).
## Getting started with Pygame
Pygame is a library, or *Python module*. It's a collection of common code that prevents you from having to reinvent the wheel with every new game you write. You've already used the Turtle module, and you can imagine how complex that could have been if you'd had to write the code to create a pen before drawing with it. Pygame offers similar advantages, but for video games.
A video game needs a setting, a world in which it takes place. In Pygame, there are two different ways to create your setting:
- Set a background color
- Set a background image
Either way, your background is only an image or a color. Your video game characters can't interact with things in the background, so don't put anything too important back there. It's just set dressing.
## Setting up your first Pygame script
To start a new Python project, you would normally create a new folder on your computer and place all your game files go into this directory. It's vitally important that you keep all the files needed to run your game inside of your project folder.
PyCharm (or whatever IDE you use) can do this for you.
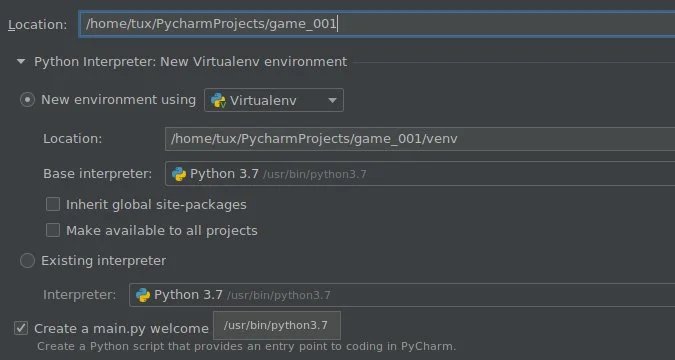
To create a new project in PyCharm, navigate to the **File** menu and select **New Project**. In the window that appears, enter a name for your project (such as **game_001**.) Notice that this project is saved into a special **PycharmProjects** folder in your home directory. This ensures that all the files your game needs stays in one place.
When creating a new project, let PyCharm create a new environment using Virtualenv, and accept all defaults. Enable the option to create a **main.py** file (and to set up some important defaults.)
opensource.com
After you've clicked the **Create** button, a new project appears in your PyCharm window. The project consists of a virtual environment (the **venv** directory listed in the left column) and a demo file called **main.py**.
Delete all the contents of **main.py** so you can enter your own custom code. A Python script starts with the file type, your name, and the license you want to use. Use an open source license so your friends can improve your game and share their changes with you:
```
#!/usr/bin/env python3
# by Seth Kenlon
## GPLv3
# This program is free software: you can redistribute it and/or
# modify it under the terms of the GNU General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
```
Then tell Python what modules you want to use. In this code sample, you don't have to type the # character or anything after it on each line. The # character in Python represents a *comment*, notes in code left for yourself and other coders.
```
import pygame # load pygame keywords
import sys # let python use your file system
import os # help python identify your OS
```
Notice that PyCharm doesn't understand what Pygame is, and underlines it to mark it as an error. This is because Pygame, unlike sys and os, isn't included with Python by default. You need to include Pygame in your project directory before you can use it successfully in code. To include it, hover your mouse over the word **pygame** until you see a notification popup explaining the error.
Click the **Install package pygame** link in the alert box, and wait for PyCharm to install Pygame into your virtual environment.
Once it's installed, the error disappears.
Without an IDE like PyCharm, you can install Pygame into your virtual environment manually using the **pip **command.
## Code sections
Because you'll be working a lot with this script file, it helps to make sections within the file so you know where to put stuff. You do this with block comments, which are comments that are visible only when looking at your source code. Create four blocks in your code. These are all comments that Python ignores, but they're good placeholders for you as you follow along with these lessons. I still use placeholders when I code, because it helps me organize and plan.
```
'''
Variables
'''
# put variables here
'''
Objects
'''
# put Python classes and functions here
'''
Setup
'''
# put run-once code here
'''
Main Loop
'''
# put game loop here
```
Next, set the window size for your game. Keep in mind that not everyone has a big computer screen, so it's best to use a screen size that fits on "most" people's computers.
There is a way to toggle full-screen mode, the way many modern video games do, but since you're just starting out, keep it simple and just set one size.
```
'''
Variables
'''
worldx = 960
worldy = 720
```
The Pygame engine requires some basic setup before you can use it in a script. You must set the frame rate, start its internal clock, and start (using the keyword `init`
, for *initialize*) Pygame.
Add these variables:
```
fps = 40 # frame rate
ani = 4 # animation cycles
```
Add instructions to start Pygame's internal clock in the Setup section:
```
'''
Setup
'''
clock = pygame.time.Clock()
pygame.init()
```
Now you can set your background.
## Setting the background
Before you continue, open a graphics application and create a background for your game world. Save it as `stage.png`
inside a folder called `images`
in your project directory. If you need a starting point, you can download a set of [Creative Commons](https://opensource.com/article/20/1/what-creative-commons) backgrounds from [kenny.nl](https://kenney.nl/assets/background-elements-redux).
There are several free graphic applications you can use to create, resize, or modify graphics for your games.
[Pinta](https://pinta-project.com/pintaproject/pinta/releases)is a basic, easy to learn paint application.[Krita](http://krita.org)is a professional-level paint materials emulator that can be used to create beautiful images. If you're very interested in creating art for video games, you can even purchase a series of online[game art tutorials](https://gumroad.com/l/krita-game-art-tutorial-1).[Inkscape](http://inkscape.org)is a vector graphics application. Use it to draw with shapes, lines, splines, and Bézier curves.
Your graphic doesn't have to be complex, and you can always go back and change it later. Once you have a background, add this code in the setup section of your file:
```
world = pygame.display.set_mode([worldx,worldy])
backdrop = pygame.image.load(os.path.join('images','stage.png'))
backdropbox = world.get_rect()
```
If you're just going to fill the background of your game world with a color, all you need is:
`world = pygame.display.set_mode([worldx, worldy])`
You also must define a color to use. In your setup section, create some color definitions using values for red, green, and blue (RGB).
```
'''
Variables
'''
BLUE = (25, 25, 200)
BLACK = (23, 23, 23)
WHITE = (254, 254, 254)
```
## Look out for errors
PyCharm is strict, and that's pretty typical for programming. Syntax is paramount! As you enter your code into PyCharm, you see warnings and errors. The warnings are yellow and the errors are red.
PyCharm can be over-zealous sometimes, though, so it's usually safe to ignore warnings. You may be violating the "Python style", but these are subtle conventions that you'll learn in time. Your code will still run as expected.
Errors, on the other hand, prevent your code (and sometimes PyCharm) from doing what you expect. For instance, PyCharm is very insistent that there's a newline character at the end of the last line of code, so you **must** press **Enter** or **Return** on your keyboard at the end of your code. If you don't, PyCharm quietly refuses to run your code.
## Running the game
At this point, you could theoretically start your game. The problem is, it would only last for a millisecond.
To prove this, save and then run your game.
If you are using IDLE, run your game by selecting `Run Module`
from the Run menu.
If you are using PyCharm, click the `Run file`
button in the top right toolbar.
opensource.com
You can also run a Python script straight from a Unix terminal or a Windows command prompt, as long as you're in your virtual environment.
However you launch it, don't expect much, because your game only lasts a few milliseconds right now. You can fix that in the next section.
## Looping
Unless told otherwise, a Python script runs once and only once. Computers are very fast these days, so your Python script runs in less than a second.
To force your game to stay open and active long enough for someone to see it (let alone play it), use a `while`
loop. To make your game remain open, you can set a variable to some value, then tell a `while`
loop to keep looping for as long as the variable remains unchanged.
This is often called a "main loop," and you can use the term `main`
as your variable. Add this anywhere in your Variables section:
`main = True`
During the main loop, use Pygame keywords to detect if keys on the keyboard have been pressed or released. Add this to your main loop section:
```
'''
Main loop
'''
while main:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
pygame.quit()
try:
sys.exit()
finally:
main = False
```
Be sure to press **Enter** or **Return** after the final line of your code so there's an empty line at the bottom of your file.
Also in your main loop, refresh your world's background.
If you are using an image for the background:
`world.blit(backdrop, backdropbox)`
If you are using a color for the background:
`world.fill(BLUE)`
Finally, tell Pygame to refresh everything on the screen and advance the game's internal clock.
```
pygame.display.flip()
clock.tick(fps)
```
Save your file, and run it again to see the most boring game ever created.
To quit the game, press `q`
on your keyboard.
## Freeze your Python environment
PyCharm is managing your code libraries, but your users aren't going to run your game from PyCharm. Just as you save your code file, you also need to preserve your virtual environment.
Go to the **Tools** menu and select **Sync Python Requirements**. This saves your library dependencies to a special file called **requirements.txt**. The first time you sync your requirements, PyCharm prompts you to install a plugin and to add dependencies. Click to accept these offers.
opensource.com
A **requirements.txt** is generated for you, and placed into your project directory.
## Code
Here's what your code should look like so far:
```
#!/usr/bin/env python3
# by Seth Kenlon
# GPLv3
# This program is free software: you can redistribute it and/or
# modify it under the terms of the GNU General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import pygame
import sys
import os
'''
Variables
'''
worldx = 960
worldy = 720
fps = 40 # frame rate
ani = 4 # animation cycles
main = True
BLUE = (25, 25, 200)
BLACK = (23, 23, 23)
WHITE = (254, 254, 254)
'''
Objects
'''
# put Python classes and functions here
'''
Setup
'''
clock = pygame.time.Clock()
pygame.init()
world = pygame.display.set_mode([worldx, worldy])
backdrop = pygame.image.load(os.path.join('images', 'stage.png'))
backdropbox = world.get_rect()
'''
Main Loop
'''
while main:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
pygame.quit()
try:
sys.exit()
finally:
main = False
world.blit(backdrop, backdropbox)
pygame.display.flip()
clock.tick(fps)
```
## What to do next
In the [next article](https://opensource.com/article/17/12/program-game-python-part-3-spawning-player) of this series, I'll show you how to add to your currently empty game world, so start creating or finding some graphics to use!
## 6 Comments |
10,851 | 如何在 Linux 中创建 SSH 别名 | https://www.ostechnix.com/how-to-create-ssh-alias-in-linux/ | 2019-05-13T22:29:35 | [
"SSH",
"别名"
] | https://linux.cn/article-10851-1.html | 
如果你经常通过 SSH 访问许多不同的远程系统,这个技巧将为你节省一些时间。你可以通过 SSH 为频繁访问的系统创建 SSH 别名,这样你就不必记住所有不同的用户名、主机名、SSH 端口号和 IP 地址等。此外,它避免了在 SSH 到 Linux 服务器时重复输入相同的用户名、主机名、IP 地址、端口号。
### 在 Linux 中创建 SSH 别名
在我知道这个技巧之前,我通常使用以下任意一种方式通过 SSH 连接到远程系统。
使用 IP 地址:
```
$ ssh 192.168.225.22
```
或使用端口号、用户名和 IP 地址:
```
$ ssh -p 22 [email protected]
```
或使用端口号、用户名和主机名:
```
$ ssh -p 22 [email protected]
```
这里
* `22` 是端口号,
* `sk` 是远程系统的用户名,
* `192.168.225.22` 是我远程系统的 IP,
* `server.example.com` 是远程系统的主机名。
我相信大多数 Linux 新手和(或一些)管理员都会以这种方式通过 SSH 连接到远程系统。但是,如果你通过 SSH 连接到多个不同的系统,记住所有主机名或 IP 地址,还有用户名是困难的,除非你将它们写在纸上或者将其保存在文本文件中。别担心!这可以通过为 SSH 连接创建别名(或快捷方式)轻松解决。
我们可以用两种方法为 SSH 命令创建别名。
#### 方法 1 – 使用 SSH 配置文件
这是我创建别名的首选方法。
我们可以使用 SSH 默认配置文件来创建 SSH 别名。为此,编辑 `~/.ssh/config` 文件(如果此文件不存在,只需创建一个):
```
$ vi ~/.ssh/config
```
添加所有远程主机的详细信息,如下所示:
```
Host webserver
HostName 192.168.225.22
User sk
Host dns
HostName server.example.com
User root
Host dhcp
HostName 192.168.225.25
User ostechnix
Port 2233
```

*使用 SSH 配置文件在 Linux 中创建 SSH 别名*
将 `Host`、`Hostname`、`User` 和 `Port` 配置的值替换为你自己的值。添加所有远程主机的详细信息后,保存并退出该文件。
现在你可以使用以下命令通过 SSH 进入系统:
```
$ ssh webserver
$ ssh dns
$ ssh dhcp
```
就是这么简单!
看看下面的截图。

*使用 SSH 别名访问远程系统*
看到了吗?我只使用别名(例如 `webserver`)来访问 IP 地址为 `192.168.225.22` 的远程系统。
请注意,这只使用于当前用户。如果要为所有用户(系统范围内)提供别名,请在 `/etc/ssh/ssh_config` 文件中添加以上行。
你还可以在 SSH 配置文件中添加许多其他内容。例如,如果你[已配置基于 SSH 密钥的身份验证](https://www.ostechnix.com/configure-ssh-key-based-authentication-linux/),说明 SSH 密钥文件的位置,如下所示:
```
Host ubuntu
HostName 192.168.225.50
User senthil
IdentityFIle ~/.ssh/id_rsa_remotesystem
```
确保已使用你自己的值替换主机名、用户名和 SSH 密钥文件路径。
现在使用以下命令连接到远程服务器:
```
$ ssh ubuntu
```
这样,你可以添加希望通过 SSH 访问的任意多台远程主机,并使用别名快速访问它们。
#### 方法 2 – 使用 Bash 别名
这是创建 SSH 别名的一种应急变通的方法,可以加快通信的速度。你可以使用 [alias 命令](https://www.ostechnix.com/the-alias-and-unalias-commands-explained-with-examples/)使这项任务更容易。
打开 `~/.bashrc` 或者 `~/.bash_profile` 文件:
```
alias webserver='ssh [email protected]'
alias dns='ssh [email protected]'
alias dhcp='ssh [email protected] -p 2233'
alias ubuntu='ssh [email protected] -i ~/.ssh/id_rsa_remotesystem'
```
再次确保你已使用自己的值替换主机、主机名、端口号和 IP 地址。保存文件并退出。
然后,使用命令应用更改:
```
$ source ~/.bashrc
```
或者
```
$ source ~/.bash_profile
```
在此方法中,你甚至不需要使用 `ssh 别名` 命令。相反,只需使用别名,如下所示。
```
$ webserver
$ dns
$ dhcp
$ ubuntu
```

这两种方法非常简单,但对于经常通过 SSH 连接到多个不同系统的人来说非常有用,而且非常方便。使用适合你的上述任何一种方法,通过 SSH 快速访问远程 Linux 系统。
建议阅读:
* [允许或拒绝 SSH 访问 Linux 中的特定用户或组](https://www.ostechnix.com/allow-deny-ssh-access-particular-user-group-linux/)
* [如何在 Linux 上 SSH 到特定目录](https://www.ostechnix.com/how-to-ssh-into-a-particular-directory-on-linux/)
* [如何在 Linux 中断开 SSH 会话](https://www.ostechnix.com/how-to-stop-ssh-session-from-disconnecting-in-linux/)
* [4 种方式在退出 SSH 会话后保持命令运行](https://www.ostechnix.com/4-ways-keep-command-running-log-ssh-session/)
* [SSLH – 共享相同端口的 HTTPS 和 SSH](https://www.ostechnix.com/sslh-share-port-https-ssh/)
目前这就是全部了,希望它对你有帮助。更多好东西要来了,敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-create-ssh-alias-in-linux/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,852 | 使用 Python 进行社交媒体情感分析入门 | https://opensource.com/article/19/4/social-media-sentiment-analysis-python | 2019-05-14T00:30:14 | [
"情感",
"NLP"
] | https://linux.cn/article-10852-1.html |
>
> 学习自然语言处理的基础知识并探索两个有用的 Python 包。
>
>
>

自然语言处理(NLP)是机器学习的一种,它解决了口语或书面语言和计算机辅助分析这些语言之间的相关性。日常生活中我们经历了无数的 NLP 创新,从写作帮助和建议到实时语音翻译,还有口译。
本文研究了 NLP 的一个特定领域:情感分析。重点是确定输入语言的积极、消极或中性性质。本部分将解释 NLP 和情感分析的背景,并探讨两个开源的 Python 包。[第 2 部分](https://opensource.com/article/19/4/social-media-sentiment-analysis-python-part-2)将演示如何开始构建自己的可扩展情感分析服务。
在学习情感分析时,对 NLP 有一个大体了解是有帮助的。本文不会深入研究数学本质。相反,我们的目标是阐明 NLP 中的关键概念,这些概念对于将这些方法实际结合到你的解决方案中至关重要。
### 自然语言和文本数据
合理的起点是从定义开始:“什么是自然语言?”它是我们人类相互交流的方式,沟通的主要方式是口语和文字。我们可以更进一步,只关注文本交流。毕竟,生活在 Siri、Alexa 等无处不在的时代,我们知道语音是一组与文本无关的计算。
### 数据前景和挑战
我们只考虑使用文本数据,我们可以对语言和文本做什么呢?首先是语言,特别是英语,除了规则还有很多例外,含义的多样性和语境差异,这些都可能使人类口译员感到困惑,更不用说计算机翻译了。在小学,我们学习文章和标点符号,通过讲母语,我们获得了寻找直觉上表示唯一意义的词的能力。比如,出现诸如 “a”、“the” 和 “or” 之类的文章,它们在 NLP 中被称为*停止词*,因为传统上 NLP 算法是在一个序列中找到这些词时意味着搜索停止。
由于我们的目标是自动将文本分类为情感类,因此我们需要一种以计算方式处理文本数据的方法。因此,我们必须考虑如何向机器表示文本数据。众所周知,利用和解释语言的规则很复杂,输入文本的大小和结构可能会有很大差异。我们需要将文本数据转换为数字数据,这是机器和数学的首选方式。这种转变属于*特征提取*的范畴。
在提取输入文本数据的数字表示形式后,一个改进可能是:给定一个文本输入体,为上面列出的文章确定一组向量统计数据,并根据这些数据对文档进行分类。例如,过多的副词可能会使撰稿人感到愤怒,或者过度使用停止词可能有助于识别带有内容填充的学期论文。诚然,这可能与我们情感分析的目标没有太大关系。
### 词袋
当你评估一个文本陈述是积极还是消极的时候,你使用哪些上下文来评估它的极性?(例如,文本中是否具有积极的、消极的或中性的情感)一种方式是隐含形容词:被称为 “disgusting”(恶心) 的东西被认为是消极的,但如果同样的东西被称为 “beautiful”(漂亮),你会认为它是积极的。从定义上讲,俗语给人一种熟悉感,通常是积极的,而脏话可能是敌意的表现。文本数据也可以包括表情符号,它带有固定的情感。
理解单个单词的极性影响为文本的<ruby> <a href="https://en.wikipedia.org/wiki/Bag-of-words_model"> 词袋 </a> <rt> bag-of-words </rt></ruby>(BoW)模型提供了基础。它分析一组单词或词汇表,并提取关于这些单词在输入文本中是否存在的度量。词汇表是通过处理已知极性的文本形成称为*标记的训练数据*。从这组标记数据中提取特征,然后分析特征之间的关系,并将标记与数据关联起来。
“词袋”这个名称说明了它的用途:即不考虑空间位置或上下文的的单个词。词汇表通常是由训练集中出现的所有单词构建的,训练后往往会被修剪。如果在训练之前没有清理停止词,那么停止词会因为其高频率和低语境而被移除。很少使用的单词也可以删除,因为缺乏为一般输入实例提供的信息。
但是,重要的是要注意,你可以(并且应该)进一步考虑单词在单个训练数据实例之外的情形,这称为<ruby> <a href="https://en.wikipedia.org/wiki/Tf%E2%80%93idf#Term_frequency"> 词频 </a> <rt> term frequency </rt></ruby>(TF)。你还应该考虑输入数据在所有训练实例中的单词计数,通常,出现在所有文档中的低频词更重要,这被称为<ruby> <a href="https://en.wikipedia.org/wiki/Tf%E2%80%93idf#Inverse_document_frequency"> 逆文本频率指数 </a> <rt> inverse document frequency </rt></ruby>(IDF)。这些指标一定会在本主题系列的其他文章和软件包中提及,因此了解它们会有所帮助。
词袋在许多文档分类应用程序中很有用。然而,在情感分析中,当缺乏情境意识的问题被利用时,事情就可以解决。考虑以下句子:
* 我们不喜欢这场战争。
* 我讨厌下雨天,好事是今天是晴天。
* 这不是生死攸关的问题。
这些短语的情感对于人类口译员来说是有难度的,而且通过严格关注单个词汇的实例,对于机器翻译来说也是困难的。
在 NLP 中也可以使用称为 “n-grams” 的单词分组。一个二元组考虑两个相邻单词组成的组而不是(或除了)单个词袋。这应该可以缓解诸如上述“不喜欢”之类的情况,但由于缺乏语境意思,它仍然是个问题。此外,在上面的第二句中,下半句的情感语境可以被理解为否定前半部分。因此,这种方法中也会丢失上下文线索的空间局部性。从实用角度来看,使问题复杂化的是从给定输入文本中提取的特征的稀疏性。对于一个完整的大型词汇表,每个单词都有一个计数,可以将其视为一个整数向量。大多数文档的向量中都有大量的零计数向量,这给操作增加了不必要的空间和时间复杂度。虽然已经提出了许多用于降低这种复杂性的简便方法,但它仍然是一个问题。
### 词嵌入
<ruby> 词嵌入 <rt> Word embedding </rt></ruby>是一种分布式表示,它允许具有相似含义的单词具有相似的表示。这是基于使用实值向量来与它们周围相关联。重点在于使用单词的方式,而不仅仅是它们的存在与否。此外,词嵌入的一个巨大实用优势是它们关注于密集向量。通过摆脱具有相应数量的零值向量元素的单词计数模型,词嵌入在时间和存储方面提供了一个更有效的计算范例。
以下是两个优秀的词嵌入方法。
#### Word2vec
第一个是 [Word2vec](https://en.wikipedia.org/wiki/Word2vec),它是由 Google 开发的。随着你对 NLP 和情绪分析研究的深入,你可能会看到这种嵌入方法。它要么使用一个<ruby> 连续的词袋 <rt> continuous bag of words </rt></ruby>(CBOW),要么使用一个连续 skip-gram 模型。在 CBOW 中,一个单词的上下文是在训练中根据围绕它的单词来学习的。连续 skip-gram 学习倾向于围绕给定的单词学习单词。虽然这可能超出了你需要解决的问题,但是如果你曾经面对必须生成自己的词嵌入情况,那么 Word2vec 的作者就提倡使用 CBOW 方法来提高速度并评估频繁的单词,而 skip-gram 方法更适合嵌入稀有单词更重要的嵌入。
#### GloVe
第二个是<ruby> <a href="https://en.wikipedia.org/wiki/GloVe_(machine_learning)"> 用于词表示的全局向量 </a> <rt> Global Vectors for Word Representation </rt></ruby>(GloVe),它是斯坦福大学开发的。它是 Word2vec 方法的扩展,试图通过将经典的全局文本统计特征提取获得的信息与 Word2vec 确定的本地上下文信息相结合。实际上,在一些应用程序中,GloVe 性能优于 Word2vec,而在另一些应用程序中则不如 Word2vec。最终,用于词嵌入的目标数据集将决定哪种方法最优。因此,最好了解它们的存在性和高级机制,因为你很可能会遇到它们。
#### 创建和使用词嵌入
最后,知道如何获得词嵌入是有用的。在第 2 部分中,你将看到我们通过利用社区中其他人的实质性工作,站到了巨人的肩膀上。这是获取词嵌入的一种方法:即使用现有的经过训练和验证的模型。实际上,有无数的模型适用于英语和其他语言,一定会有一种模型可以满足你的应用程序,让你开箱即用!
如果没有的话,就开发工作而言,另一个极端是培训你自己的独立模型,而不考虑你的应用程序。实质上,你将获得大量标记的训练数据,并可能使用上述方法之一来训练模型。即使这样,你仍然只是在理解你输入文本数据。然后,你需要为你应用程序开发一个特定的模型(例如,分析软件版本控制消息中的情感价值),这反过来又需要自己的时间和精力。
你还可以对针对你的应用程序的数据训练一个词嵌入,虽然这可以减少时间和精力,但这个词嵌入将是特定于应用程序的,这将会降低它的可重用性。
### 可用的工具选项
考虑到所需的大量时间和计算能力,你可能想知道如何才能找到解决问题的方法。的确,开发可靠模型的复杂性可能令人望而生畏。但是,有一个好消息:已经有许多经过验证的模型、工具和软件库可以为我们提供所需的大部分内容。我们将重点关注 [Python](https://www.python.org/),因为它为这些应用程序提供了大量方便的工具。
#### SpaCy
[SpaCy](https://pypi.org/project/spacy/) 提供了许多用于解析输入文本数据和提取特征的语言模型。它经过了高度优化,并被誉为同类中最快的库。最棒的是,它是开源的!SpaCy 会执行标识化、词性分类和依赖项注释。它包含了用于执行此功能的词嵌入模型,还有用于为超过 46 种语言的其他特征提取操作。在本系列的第二篇文章中,你将看到它如何用于文本分析和特征提取。
#### vaderSentiment
[vaderSentiment](https://pypi.org/project/vaderSentiment/) 包提供了积极、消极和中性情绪的衡量标准。正如 [原论文](http://comp.social.gatech.edu/papers/icwsm14.vader.hutto.pdf) 的标题(《VADER:一个基于规则的社交媒体文本情感分析模型》)所示,这些模型是专门为社交媒体文本数据开发和调整的。VADER 接受了一组完整的人类标记过的数据的训练,包括常见的表情符号、UTF-8 编码的表情符号以及口语术语和缩写(例如 meh、lol、sux)。
对于给定的输入文本数据,vaderSentiment 返回一个极性分数百分比的三元组。它还提供了一个单个的评分标准,称为 *vaderSentiment 复合指标*。这是一个在 `[-1, 1]` 范围内的实值,其中对于分值大于 `0.05` 的情绪被认为是积极的,对于分值小于 `-0.05` 的被认为是消极的,否则为中性。
在[第 2 部分](https://opensource.com/article/19/4/social-media-sentiment-analysis-python-part-2)中,你将学习如何使用这些工具为你的设计添加情感分析功能。
---
via: <https://opensource.com/article/19/4/social-media-sentiment-analysis-python>
作者:[Michael McCune](https://opensource.com/users/elmiko/users/jschlessman) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Natural language processing (NLP) is a type of machine learning that addresses the correlation between spoken/written languages and computer-aided analysis of those languages. We experience numerous innovations from NLP in our daily lives, from writing assistance and suggestions to real-time speech translation and interpretation.
This article examines one specific area of NLP: sentiment analysis, with an emphasis on determining the positive, negative, or neutral nature of the input language. This part will explain the background behind NLP and sentiment analysis and explore two open source Python packages. [Part 2](https://opensource.com/article/19/4/social-media-sentiment-analysis-python-part-2) will demonstrate how to begin building your own scalable sentiment analysis services.
When learning sentiment analysis, it is helpful to have an understanding of NLP in general. This article won't dig into the mathematical guts, rather our goal is to clarify key concepts in NLP that are crucial to incorporating these methods into your solutions in practical ways.
## Natural language and text data
A reasonable place to begin is defining: "What is natural language?" It is the means by which we, as humans, communicate with one another. The primary modalities for communication are verbal and text. We can take this a step further and focus solely on text communication; after all, living in an age of pervasive Siri, Alexa, etc., we know speech is a group of computations away from text.
## Data landscape and challenges
Limiting ourselves to textual data, what can we say about language and text? First, language, particularly English, is fraught with exceptions to rules, plurality of meanings, and contextual differences that can confuse even a human interpreter, let alone a computational one. In elementary school, we learn articles of speech and punctuation, and from speaking our native language, we acquire intuition about which words have less significance when searching for meaning. Examples of the latter would be articles of speech such as "a," "the," and "or," which in NLP are referred to as *stop words*, since traditionally an NLP algorithm's search for meaning stops when reaching one of these words in a sequence.
Since our goal is to automate the classification of text as belonging to a sentiment class, we need a way to work with text data in a computational fashion. Therefore, we must consider how to represent text data to a machine. As we know, the rules for utilizing and interpreting language are complicated, and the size and structure of input text can vary greatly. We'll need to transform the text data into numeric data, the form of choice for machines and math. This transformation falls under the area of *feature extraction*.
Upon extracting numeric representations of input text data, one refinement might be, given an input body of text, to determine a set of quantitative statistics for the articles of speech listed above and perhaps classify documents based on them. For example, a glut of adverbs might make a copywriter bristle, or excessive use of stop words might be helpful in identifying term papers with content padding. Admittedly, this may not have much bearing on our goal of sentiment analysis.
## Bag of words
When you assess a text statement as positive or negative, what are some contextual clues you use to assess its polarity (i.e., whether the text has positive, negative, or neutral sentiment)? One way is connotative adjectives: something called "disgusting" is viewed as negative, but if the same thing were called "beautiful," you would judge it as positive. Colloquialisms, by definition, give a sense of familiarity and often positivity, whereas curse words could be a sign of hostility. Text data can also include emojis, which carry inherent sentiments.
Understanding the polarity influence of individual words provides a basis for the [ bag-of-words](https://en.wikipedia.org/wiki/Bag-of-words_model) (BoW) model of text. It considers a set of words or vocabulary and extracts measures about the presence of those words in the input text. The vocabulary is formed by considering text where the polarity is known, referred to as
*labeled training data*. Features are extracted from this set of labeled data, then the relationships between the features are analyzed and labels are associated with the data.
The name "bag of words" illustrates what it utilizes: namely, individual words without consideration of spatial locality or context. A vocabulary typically is built from all words appearing in the training set, which tends to be pruned afterward. Stop words, if not cleaned prior to training, are removed due to their high frequency and low contextual utility. Rarely used words can also be removed, given the lack of information they provide for general input cases.
It is important to note, however, that you can (and should) go further and consider the appearance of words beyond their use in an individual instance of training data, or what is called [ term frequency](https://en.wikipedia.org/wiki/Tf%E2%80%93idf#Term_frequency) (TF). You should also consider the counts of a word through all instances of input data; typically the infrequency of words among all documents is notable, which is called the
[(IDF). These metrics are bound to be mentioned in other articles and software packages on this subject, so having an awareness of them can only help.](https://en.wikipedia.org/wiki/Tf%E2%80%93idf#Inverse_document_frequency)
*inverse document frequency*BoW is useful in a number of document classification applications; however, in the case of sentiment analysis, things can be gamed when the lack of contextual awareness is leveraged. Consider the following sentences:
- We are not enjoying this war.
- I loathe rainy days, good thing today is sunny.
- This is not a matter of life and death.
The sentiment of these phrases is questionable for human interpreters, and by strictly focusing on instances of individual vocabulary words, it's difficult for a machine interpreter as well.
Groupings of words, called *n-grams*, can also be considered in NLP. A bigram considers groups of two adjacent words instead of (or in addition to) the single BoW. This should alleviate situations such as "not enjoying" above, but it will remain open to gaming due to its loss of contextual awareness. Furthermore, in the second sentence above, the sentiment context of the second half of the sentence could be perceived as negating the first half. Thus, spatial locality of contextual clues also can be lost in this approach. Complicating matters from a pragmatic perspective is the sparsity of features extracted from a given input text. For a thorough and large vocabulary, a count is maintained for each word, which can be considered an integer vector. Most documents will have a large number of zero counts in their vectors, which adds unnecessary space and time complexity to operations. While a number of clever approaches have been proposed for reducing this complexity, it remains an issue.
## Word embeddings
Word embeddings are a distributed representation that allows words with a similar meaning to have a similar representation. This is based on using a real-valued vector to represent words in connection with the company they keep, as it were. The focus is on the manner that words are used, as opposed to simply their existence. In addition, a huge pragmatic benefit of word embeddings is their focus on dense vectors; by moving away from a word-counting model with commensurate amounts of zero-valued vector elements, word embeddings provide a more efficient computational paradigm with respect to both time and storage.
Following are two prominent word embedding approaches.
### Word2vec
The first of these word embeddings, [Word2vec](https://en.wikipedia.org/wiki/Word2vec), was developed at Google. You'll probably see this embedding method mentioned as you go deeper in your study of NLP and sentiment analysis. It utilizes either a *continuous bag of words* (CBOW) or a *continuous skip-gram* model. In CBOW, a word's context is learned during training based on the words surrounding it. Continuous skip-gram learns the words that tend to surround a given word. Although this is more than what you'll probably need to tackle, if you're ever faced with having to generate your own word embeddings, the author of Word2vec advocates the CBOW method for speed and assessment of frequent words, while the skip-gram approach is better suited for embeddings where rare words are more important.
### GloVe
The second word embedding, [ Global Vectors for Word Representation](https://en.wikipedia.org/wiki/GloVe_(machine_learning)) (GloVe), was developed at Stanford. It's an extension to the Word2vec method that attempts to combine the information gained through classical global text statistical feature extraction with the local contextual information determined by Word2vec. In practice, GloVe has outperformed Word2vec for some applications, while falling short of Word2vec's performance in others. Ultimately, the targeted dataset for your word embedding will dictate which method is optimal; as such, it's good to know the existence and high-level mechanics of each, as you'll likely come across them.
### Creating and using word embeddings
Finally, it's useful to know how to obtain word embeddings; in part 2, you'll see that we are standing on the shoulders of giants, as it were, by leveraging the substantial work of others in the community. This is one method of acquiring a word embedding: namely, using an existing trained and proven model. Indeed, myriad models exist for English and other languages, and it's possible that one does what your application needs out of the box!
If not, the opposite end of the spectrum in terms of development effort is training your own standalone model without consideration of your application. In essence, you would acquire substantial amounts of labeled training data and likely use one of the approaches above to train a model. Even then, you are still only at the point of acquiring understanding of your input-text data; you then need to develop a model specific for your application (e.g., analyzing sentiment valence in software version-control messages) which, in turn, requires its own time and effort.
You also could train a word embedding on data specific to your application; while this could reduce time and effort, the word embedding would be application-specific, which would reduce reusability.
## Available tooling options
You may wonder how you'll ever get to a point of having a solution for your problem, given the intensive time and computing power needed. Indeed, the complexities of developing solid models can be daunting; however, there is good news: there are already many proven models, tools, and software libraries available that may provide much of what you need. We will focus on [Python](https://www.python.org/), which conveniently has a plethora of tooling in place for these applications.
### SpaCy
[SpaCy](https://pypi.org/project/spacy/) provides a number of language models for parsing input text data and extracting features. It is highly optimized and touted as the fastest library of its kind. Best of all, it's open source! SpaCy performs tokenization, parts-of-speech classification, and dependency annotation. It contains word embedding models for performing this and other feature extraction operations for over 46 languages. You will see how it can be used for text analysis and feature extraction in the second article in this series.
### vaderSentiment
The [vaderSentiment](https://pypi.org/project/vaderSentiment/) package provides a measure of positive, negative, and neutral sentiment. As the [original paper](http://comp.social.gatech.edu/papers/icwsm14.vader.hutto.pdf)'s title ("VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text") indicates, the models were developed and tuned specifically for social media text data. VADER was trained on a thorough set of human-labeled data, which included common emoticons, UTF-8 encoded emojis, and colloquial terms and abbreviations (e.g., meh, lol, sux).
For given input text data, vaderSentiment returns a 3-tuple of polarity score percentages. It also provides a single scoring measure, referred to as *vaderSentiment's compound metric*. This is a real-valued measurement within the range **[-1, 1]** wherein sentiment is considered positive for values greater than **0.05**, negative for values less than **-0.05**, and neutral otherwise.
In [part 2](https://opensource.com/article/19/4/social-media-sentiment-analysis-python-part-2), you will learn how to use these tools to add sentiment analysis capabilities to your designs.
## Comments are closed. |
10,854 | 将 Fedora 29 升级到 Fedora 30 | https://fedoramagazine.org/upgrading-fedora-29-to-fedora-30/ | 2019-05-14T12:51:00 | [
"Fedora"
] | https://linux.cn/article-10854-1.html | 
Fedora 30 [已经发布了](https://fedoramagazine.org/announcing-fedora-30/)。你可能希望将系统升级到最新版本的 Fedora。Fedora 工作站版本有图形化升级的方法。另外,Fedora 也提供了一个命令行方法,用于将 Fedora 29 升级到 Fedora 30。
### 将 Fedora 29 工作站版本升级到 Fedora 30
在发布不久后,桌面会显示一条通知告诉你可以升级。你可以单击通知启动 “GNOME 软件” 应用。或者你可以从 GNOME Shell 中选择“软件”。
在 “GNOME 软件” 中选择*更新*选项卡,你会看到一个页面通知你可以更新 Fedora 30。
如果你在屏幕上看不到任何内容,请尝试点击左上角的重新加载按钮。发布后,所有系统都可能需要一段时间才能看到可用的升级。
选择“下载”获取升级包。你可以继续做其他的事直到下载完成。然后使用 “GNOME 软件” 重启系统并应用升级。升级需要时间,因此你可以喝杯咖啡,稍后再回来。
### 使用命令行
如果你过去升级过 Fedora 版本,你可能熟悉 `dnf upgrade` 插件。这是从 Fedora 29 升级到 Fedora 30 的推荐和支持的方式。使用这个插件将使你的 Fedora 30 升级简单易行。
#### 1、更新软件并备份系统
在你执行任何操作之前,你需要确保在开始升级之前拥有 Fedora 29 的最新软件。要更新软件,请使用 “GNOME 软件” 或在终端中输入以下命令。
```
sudo dnf upgrade --refresh
```
此外,请确保在继续之前备份系统。关于备份的帮助,请参阅 Fedora Magazine 上的[备份系列](https://fedoramagazine.org/taking-smart-backups-duplicity/)。
#### 2、安装 DNF 插件
接下来,打开终端并输入以下命令来安装插件:
```
sudo dnf install dnf-plugin-system-upgrade
```
#### 3、使用 DNF 开始更新
现在你的系统是最新的,完成了备份,并且已安装 DNF 插件,你可以在终端中使用以下命令开始升级:
```
sudo dnf system-upgrade download --releasever=30
```
此命令将开始在本地下载所有升级文件以准备升级。如果你因为没有更新包、错误的依赖,或过时的包在升级时遇到问题,请在输入上面的命令时添加 `-- allowerasing` 标志。这将允许 DNF 删除可能阻止系统升级的软件包。
#### 4、重启并升级
当前面的命令完成下载所有升级文件后,你的系统就可以重启了。要将系统引导至升级过程,请在终端中输入以下命令:
```
sudo dnf system-upgrade reboot
```
此后你的系统将重启。在许多版本之前,`fedup` 工具将在内核选择/引导页面上创建一个新选项。使用 `dnf-plugin-system-upgrade` 包,你的系统将使用当前 Fedora 29 安装的内核重启。这个是正常的。在内核选择页面后不久,系统开始升级过程。
现在可以休息一下了!完成后你的系统将重启,你就可以登录新升级的 Fedora 30 了。

### 解决升级问题
升级系统时偶尔可能会出现意外问题。如果你遇到任何问题,请访问 [DNF 系统升级的维基页面](https://fedoraproject.org/wiki/DNF_system_upgrade#Resolving_post-upgrade_issues),以获取有关出现问题时的故障排除的更多信息。
如果你在升级时遇到问题并在系统上安装了第三方仓库,那么可能需要在升级时禁用这些仓库。有关 Fedora 对未提供仓库的支持,请与仓库的提供商联系。
---
via: <https://fedoramagazine.org/upgrading-fedora-29-to-fedora-30/>
作者:[Ryan Lerch](https://fedoramagazine.org/author/ryanlerch/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fedora 30 i[s available now](https://fedoramagazine.org/announcing-fedora-30/). You’ll likely want to upgrade your system to the latest version of Fedora. Fedora Workstation has a graphical upgrade method. Alternatively, Fedora offers a command-line method for upgrading Fedora 29 to Fedora 30.
## Upgrading Fedora 29 Workstation to Fedora 30
Soon after release time, a notification appears to tell you an upgrade is available. You can click the notification to launch the **GNOME Software** app. Or you can choose Software from GNOME Shell.
Choose the *Updates* tab in GNOME Software and you should see a screen informing you that Fedora 30 is Now Available.
If you don’t see anything on this screen, try using the reload button at the top left. It may take some time after release for all systems to be able to see an upgrade available.
Choose *Download* to fetch the upgrade packages. You can continue working until you reach a stopping point, and the download is complete. Then use GNOME Software to restart your system and apply the upgrade. Upgrading takes time, so you may want to grab a coffee and come back to the system later.
## Using the command line
If you’ve upgraded from past Fedora releases, you are likely familiar with the *dnf upgrade* plugin. This method is the recommended and supported way to upgrade from Fedora 29 to Fedora 30. Using this plugin will make your upgrade to Fedora 30 simple and easy.
#### 1. Update software and back up your system
Before you do anything, you will want to make sure you have the latest software for Fedora 29 before beginning the upgrade process. To update your software, use *GNOME Software* or enter the following command in a terminal.
sudo dnf upgrade --refresh
Additionally, make sure you back up your system before proceeding. For help with taking a backup, see [the backup series](https://fedoramagazine.org/taking-smart-backups-duplicity/) on the Fedora Magazine.
#### 2. Install the DNF plugin
Next, open a terminal and type the following command to install the plugin:
sudo dnf install dnf-plugin-system-upgrade
#### 3. Start the update with DNF
Now that your system is up-to-date, backed up, and you have the DNF plugin installed, you can begin the upgrade by using the following command in a terminal:
sudo dnf system-upgrade download --releasever=30
This command will begin downloading all of the upgrades for your machine locally to prepare for the upgrade. If you have issues when upgrading because of packages without updates, broken dependencies, or retired packages, add the *‐‐allowerasing* flag when typing the above command. This will allow DNF to remove packages that may be blocking your system upgrade.
#### 4. Reboot and upgrade
Once the previous command finishes downloading all of the upgrades, your system will be ready for rebooting. To boot your system into the upgrade process, type the following command in a terminal:
sudo dnf system-upgrade reboot
Your system will restart after this. Many releases ago, the *fedup* tool would create a new option on the kernel selection / boot screen. With the *dnf-plugin-system-upgrade* package, your system reboots into the current kernel installed for Fedora 29; this is normal. Shortly after the kernel selection screen, your system begins the upgrade process.
Now might be a good time for a coffee break! Once it finishes, your system will restart and you’ll be able to log in to your newly upgraded Fedora 30 system.
## Resolving upgrade problems
On occasion, there may be unexpected issues when you upgrade your system. If you experience any issues, please visit the [DNF system upgrade wiki page](https://fedoraproject.org/wiki/DNF_system_upgrade#Resolving_post-upgrade_issues) for more information on troubleshooting in the event of a problem.
If you are having issues upgrading and have third-party repositories installed on your system, you may need to disable these repositories while you are upgrading. For support with repositories not provided by Fedora, please contact the providers of the repositories.
## Punch- to
Better to backup your data and install Fedora 30, reinstall your apps and data. It takes a very long time to update.
## Stephen Snow
I have used the update method since Fedora 19 with no issue ever. The dnf upgrade plugin is even better than
was, again upgrades of the released Fedora have never left me with a broken system. I think the update is on par with the length of time to backup your data, and do a bare metal install, overwriting everything. However, I haven’t timed both to get a definitive answer. I can imagine the upgrade would need to do more dependency checking, which of course you would want, to ensure your system started up as you had it when beginning the upgrade.
## Gary Traverson
How long is “very” – My upgrade appears to be stuck around step 81 of 5757 (xemacs-filesystem)
## Michael Williamson
It took me about 15 minutes to download the updates, then I rebooted for the upgrade before lunch and had F30 when I got back.
## nathan
Upgrade to me about 10-15 minutes on my Thinkpad X380 Yoga. No problems at all.
## Leslie Satenstein
Hi Robin,.
Do you have an idea why the plugin is not integrated automatically into dnf? The plugin is actually dormant until invoked. It being integrated into dnf in the current version or the new version would make upgrades actions easier for users.
The following is off topic, but I see the upgrade responsibility being assigned to Anaconda. I envision the user launching Anaconda and clicking a checkbox to indicate a new installation or upgrade. It seems to me that it being within Anaconda fits in with Fedora upgrade management.
By the way, Fedora 30 is GREAT!!
## Erick
How do you see it?? its faster??
## simon
Because you need to install the command mediawriter and install the version, use media wrighted to pase a custom image on a flash drive. no need to make it bootable, mediawrighter does that for you.
## Leslie Satenstein
Fedora 3o includes a new user interface Deepin”.
I have been using it since it was made available. It is very good. I like it as much as I like GNOME. It is an up and coming winner interface.
## Robert
Step 1 has a typo that states “Before you do anything, you will want to make sure you have the latest software for Fedora 39 before beginning the upgrade process.” I’m sure the author meant 29.
## Markus
had to recover my grub config as described in the ‘common F30 bugs’ document. It’s a i686 VM running in virtualbox with legacy boot.
First install was F27. So I guess all i686 fedora installations might not boot after ‘dnf system-upgrade reboot’
## Dave Hugh
Thanks for the post. I upgraded both my personal laptop and a DIY wireless router from 29 to 30 without issue.
(PS In “1” did you mean 29 as opposed to 39?)
## Parveen
Yes.
## Alan Olsen
If you have downloaded extensions from extensions.gnome.org, you will want to disable them and then update them after the upgrade. Some of them cause the gnome-shell to crash, which prevents you from logging in.
The extensions are in the users home directory in .local/share/gnome-shell/extensions
## John Smith
That is a useful tip.
Two points about this:
1) It would be nice if the most common Gnome extensions would be integrated better. For example, before upgrading to F30, I used a nice-and-easy audio extension which allowed me to quickly change from headphones to monitor speaker. After upgrading, it disappeared, too bad! Changing speakers/headphones is in my opinion too “clumsy” with the default settings (too many clicks, takes too long).
2) It would be nice if Gnome shell does not hang/crash when an extension misbehaves. Sometimes, switching between Xorg and Wayland (login screen option) fixes such problems. That should be improved: There should be a clear feedback message for the user what the problem is and the crashing extension should be switched off automatically. After all, I assume most Gnome users will use extensions and are so all at risk.
## Brian Vaughan
I wish I’d seen this tip before I spent several hours trying to figure out why gnome-shell kept core-dumping.
## km
If do not disable Gnome extensions and have problems getting the desktop to appear, consider using another desktop such as KDE, Mate Cinammon. Cfter logging in change to the terminal interface using ctl+alt+F2, then
sudo dnf group install “KDE Plasma Workspaces”
then reboot and choose an alternate desktop when logging in.
More information for older Fedora versions is at:
https://computingforgeeks.com/install-kde-plasma-environment-on-fedora-29-fedora-28/
https://fedoramag.wpengine.com/installing-another-desktop/
## Greg
I could not login to Gnome Shell after upgrade to F30 too. I logged in via ssh (you can also via vt) and run:
$ gsettings set org.gnome.shell disable-user-extensions true
Then I was able to login to Gnome.
It would be nice if Gnome/Fedora would ignore and auto-disable crashing and misbehaving extensions.
## Gayland Gump
Greg, I much appreciate your sharing this. I’d used the remove the .config directory with root to solve what I believe was the same problem. Consequently, considerable loss of my prior configuration was effected. Since I had saved my original .config directory, I was able to restore it in place of the newly created .config directory, apply your fix and recovered my prior setup. I concur with your wish to the developers. Thanks again.
## David Nowak
The GNOME interface hangs upon bootup on my Raspberry Pi 3b/3b+. I am not a programmer, but would it not be better to develop a separate video interface module (container, I think they call them) which when added to the upgraded server code create an image could be a repeatable bootable from release to release?
## Boris
Source code pro regular 10? lol why?
## Pawan Kumar
After upgrading to fedora 30, my broadcom wifi stopped working.
I have reinstalled the broadcom driver from rpm fusion, still it is not working.
## Stephen Snow
You should definitely check out if this has been answered here https://ask.fedoraproject.org/
Since that is the place to start for issues with using fedora.
## David
Ever miss the old days when you needed ndiswrapper to get Broadcom wifi to work? Or alternate kernel drivers? You haven’t lived until you’ve done that.
## Peter Braet
Same here, no more wifi BCM43142, and I can’t find it anymore on the old “Ask Fedora” either. Reinstalled everything, doesn’t work. Where is “Howto install BCM 43142” gone?
## Peter Braet
OK, got it back by reinstalling akmods akmod-wl and broadcom-wl, but had to do ‘$ sudo systemctl enable NetworkManager’ and ‘sudo systemctl reboot’ The connection is restored, but the WiFi icon is still missing.
## John Smith
I have same problem, my Broadcom BCM4360 worked fine in previous Fedoras, but stopped in F30. Hope to find tips in the magazine how to fix this.
## Peter Braet
Will Fedora please explain howto build (f30-candidate, wpa_supplicant-2.8-1.fc30.bz1703745rebuild.src.rpm)? That is the solution according to “Ask Fedora”, something from Koji, I don’t even know what that is. Please Fedora, explain howto do this and make broadcom work, because the solutions I tried only worked temporally.
## Jonathon Poppleton
You can download the binary rpm and right click to install it in gnome. You don’t need to build the source rpm.
RPM:
https://kojipkgs.fedoraproject.org//packages/wpa_supplicant/2.8/1.fc30/x86_64/wpa_supplicant-2.8-1.fc30.x86_64.rpm
To install using the terminal:
[jonathon@here ~]$ cd Downloads
[jonathon@here ~]$ wget https://kojipkgs.fedoraproject.org//packages/wpa_supplicant/2.8/1.fc30/x86_64/wpa_supplicant-2.8-1.fc30.x86_64.rpm
–2019-05-09 22:09:49– https://kojipkgs.fedoraproject.org//packages/wpa_supplicant/2.8/1.fc30/x86_64/wpa_supplicant-2.8-1.fc30.x86_64.rpm
Resolving kojipkgs.fedoraproject.org (kojipkgs.fedoraproject.org)… 209.132.181.15, 209.132.181.16
Connecting to kojipkgs.fedoraproject.org (kojipkgs.fedoraproject.org)|209.132.181.15|:443… connected.
HTTP request sent, awaiting response… 200 OK
Length: 1982324 (1.9M) [application/x-rpm]
Saving to: ‘wpa_supplicant-2.8-1.fc30.x86_64.rpm’
wpa_supplicant-2.8- 100%[===================>] 1.89M 1.33MB/s in 1.4s
2019-05-09 22:09:52 (1.33 MB/s) – ‘wpa_supplicant-2.8-1.fc30.x86_64.rpm’ saved [1982324/1982324]
[jonathon@here Downloads]$ su -c “dnf install wpa_supplicant-2.8-1.fc30.x86_64.rpm”
Password:
Last metadata expiration check: 0:20:47 ago on Thu 09 May 2019 21:50:54 AEST.
Dependencies resolved.
Package Architecture Version Repository Size
Upgrading:
wpa_supplicant x86_64 1:2.8-1.fc30 @commandline 1.9 M
Transaction Summary
Upgrade 1 Package
Total size: 1.9 M
Is this ok [y/N]:
If you want to build the source rpm let me know.
## Jonathon Poppleton
This is how i used wpa supplicant in the past (no guarantees it will work since i am using a pc now):
Obtain the name of your wifi interface:
ip link
Take note of wifi interface:
eg wlo1
Stop network manager:
su -c “systemctl stop NetworkManager”
Set SSID and password:
su -c “wpa_passphrase MYROUTER > /etc/wpa_supplicant/wpa_supplicant.conf
mypassphrase”
Enable wpa_supplicant:
su -c “wpa_supplicant -B -iwlo1 -c/etc/wpa_supplicant/wpa_supplicant.conf”
Obtain ip address:
su -c “dhcpcd wlo1”
Check ip address:
ping -c 3 http://www.google.com
## Erich Küster
Broadcom BCM4331 doesn’t work, too. Best solution for me was not UPgrading to wpa_supplicant-2.8 but DOWNgrading to the old wpa_supplicant of Fedora 29. In Terminal remove the actual version
$ sudo rpm -e –nodeps wpa_supplicant-2.7-5.fc30.x86_64
and install the old one
$ sudo dnf install wpa_supplicant-2.7-1.fc29.x86_64
You will have to reboot.
## Plamen Vasileff
Same problem here with Broadcom wireless card on Lenovo laptop.
I fix the problem when use this solution:
https://www.reddit.com/r/Fedora/comments/bj95zy/wifi_stuck_on_connecting_after_upgrade_to_fedora/
We waiting for update for wpa_supplicant package for f30.
## Erich Küster
In the meantime a new kernel 5.0.16-300.fc30.x86_64 is out with wpa_supplicant-2.8, but do NOT install, if you are using broadcom wifi, especially Broadcom BCM4331 (as in MacBook Retina late 2012). Going back to kernel 5.0.13-300.fc30.x86_64 and wpa_supplicant-2.7-5.fc30.x86_64 will work again. Still waiting for a better fix …
## Groovie
Update and install work without any problems.
Thanks for your professional work!
## sam0hack
Had an issue with normal upgrade command (sudo dnf system-upgrade download –releasever=30) but with
sudo dnf system-upgrade download –releasever=30 –allowerasing
Works like a charm.
## Jason Tingle
Same here, had issues with python3-hawkeye and the dnf package.
## Muu
Who was able to convert encrypted disks Luks1 to Luks2 including / , /home and swap?
Could you please assist me to convert my encrypted partitions of Luks1 after upgraded to Fedora 30.
$ ▶ sudo cryptsetup convert /dev/sda3 –type luks2
Operation aborted, device NOT converted.
## Cornel Panceac
Generating “/run/initramfs/rdsosreport.txt”
After upgrade, system is no longer booting, just gets tuck with the above message.
Hopefully it’ just me 🙂
will investigate and provide more details.
## Cornel Panceac
I’ve found that dnf erased fedora-release package. It probably conflicted with fedora-release-matecompiz or similar. Still not clear why two packages that are not providing files with same name/intent conflict one with the other. Also i ad to use rpm –force –nodeps to be able to install it. Worth a ticket, in my opinion. Also, what is ‘system-release’ ? fedora-release conflicted with it too, according to RPM database.
## Nathan D
I found this in an older Fedora forum upgrade when someone hit the same error. I hit this today when going from Fedora 29 to 30
Hope it helps you as it did me:
After you get into emergency mode execute:
mount -o remount,rw /sysroot
rm -f /sysroot/etc/os-release
cp /usr/lib/os-release /sysroot/etc/
exit
## Cornel Panceac
For me it helped to install fedora-release RPM, with –force, since dnf was unnable to solve dependencies, again.
Your solution would not have workd for me since the files just were not there.
## pimou
Just done upgrade on 2 pcs via gnome software manager. All is ok. Good work !
## eckart
It needed a longer time but the dnf update was problemfree.
To give a statement about fedora 30 I must make a few experiences, but it seems fantastic.
## David Levner
I upgraded from Fedora 28 to 30 with shell commands. I have some more testing to do but so far everything works fine.
## Justin
After upgrading to 30 last night, when I turn on my computer, after the TOSHIBA screen, I get this for about 1 second:
error: ../../grub-core/kern/misc.c :465:unrecognized number
How do I fix this error? Thanks
## Pete
I had the same issue and have not been able to get find any definite answer.
From what I pieced together, it’s related to the default entry for the grub2 selection. The error does not appear if I use left-shift during bootup, which unhides the grub2 menu.
I found info from a closed bug report where the submitter believes the default option got corrupted on upgrade: https://bugzilla.redhat.com/show_bug.cgi?id=1674512
I issued the command he used (sudo grub2-set-default 0) and the problem went away for me on the next boot.
## Cory Hilliard
Upgrade went smoothly. It took about 1.5 hours. (I have slowish high-speed).
I had some conflicting packages, so I had to use the “–allowerasing” flag to get it to work. Otherwise, no issues at all.
## Turgut Kalfaoğlu
after the upgrade gnome (none of them) work. After I enter my password I get back to choosing my user screen.. Good thing I had plasma loaded as well ..
## Maksym Sanzharov
Maybe you have the same issue as me.
My journalctl shows the following:
gnome-shell[2285]: JS ERROR: TypeError: b.location.get_timezone(…) is null
So my system is affected by this bug: https://gitlab.gnome.org/GNOME/gnome-shell/issues/1062
## Ilya Olkhovskiy
Hey thanks, uninstalling gnome-clock worked for me.
## Satheesh
It was a smooth upgrade…it just worked!
$ uname -a
Linux sathnaga86 5.0.9-301.fc30.x86_64 #1 SMP Tue Apr 23 23:57:35 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
## Lois
Fantastisch wie immer. Die besten Jungs am Werk
## Bernd
Lots of problems with the Eclipse installation. Nothing works. Endless dependency issues.
## Marcelo
Updated in two workstations, no issues.
## Skeetre
My F29 system couldn’t find any of the repos to update, (failed to sync repo) I had to manually hardcode them all to repo mirrors to finally be able to update.
Even though tons of searches on google gave links to ask fedora answers, any I clicked on said oops, page doesn’t exist. I tried searching on askfedora and couldn’t get any hits either. Seemed pretty odd.
Then after updating 29 I thought I was ready to do the system-upgrade, which downloaded everything, rebooted, said almost instantly that upgrade was complete, but never gave me a login screen or rebooted or anything after waiting about an hour. I ctrl-alt-del rebooted and it hung.
I got tired of dealing with it and tried the windows disc writer to download and burn the iso to usb drive. Then installed from scratch.
That worked and finally able to log in. Then followed https://www.if-not-true-then-false.com/2015/fedora-nvidia-guide/ to install Nvidia drivers
## River14
I’ll wait to upgrade to F30 until Nvidia-Linux-x86_64-430.09 not be beta.
Two birds with one stone !!!
## Johnny B
I have several external repositories, and my spin is KDE. Should I disable the non Fedora repositories before I start the upgrade? Is there something to watch out for or precautions to be taken since my spin 8s KDE? TIA.
## James Brock
Thanks for Fedora 30!
prints the message
Maybe this article should mention that too.
## Kris
After update gnome doesn`t load… How to resolve it? (I tried to disable all extensions as written above, but no effect).
## Michael
After upgrading to fedora 30 using dnf gnome session won’t start. I’m getting only black screen with a mouse pointer. XFCE is working fine. Any recommendations on how to fix GNOME?
## Maksym Sanzharov
For me Gnome on Wayland exits immediately after login, and Gnome on Xorg hangs in the similar way. i3wm works fine.
Maybe you are affected by this bug: https://gitlab.gnome.org/GNOME/gnome-shell/issues/1062
## theodore
i have installed fedora 30 beta (with no issues, works very well) . Upgrade instructions as 29-30?
thank you
## Jon
Upgrade from 29 to 30 went smooth as silk. Zero issues. HP Elitebook Thanks!
## Ernst
ERROR: Failed to load zone file ‘/usr/lib/firewalld/zones/libvirt.xml’: PARSE_ERROR: rule: Unexpected attribute priority
Is that serious?
Also what do you think of :
gkr-pam: unable to locate daemon control file
This looks serious what do you think?
Failed to start System Security Services Daemon.
I have another concern:
chroot.c: open() failed: Permission denied
I’m a novice user so I thought to ask.
## Tulio
I had some packages that I’d not find in F30, so I tried to use ‐‐allowerasing flag, but the download command of dnf don’t recognize this flag. I’ve unisntalled all packages that don’t have a correspondence in F30 before the command begins successfuly.
## Bill Chatfield
Upgrade from Gnome Software failed. It would not boot. I had to reinstall from scratch. First time since Fedora 20 the upgrade failed.
## Earl Ramirez
Thanks for sharing, and thanks for the Fedora devs for another flawless upgrade.
## Massimo
Hi my upgrade failed with the following error :
Running transaction test
The downloaded packages were saved in cache until the next successful transaction.
You can remove cached packages by executing ‘dnf clean packages’.
Error: Transaction check error:
file /usr/bin/pipelight-plugin conflicts between attempted installs of pipelight-0.2.8.2-13.fc30.i686 and pipelight-0.2.8.2-13.fc30.x86_64
Error Summary
## Stephen Snow
Are you running both i686 and x86_64 packages of pipelight? There is very likely conflicts between the two.
## Jonathon Poppleton
Smooth upgrade from Fedora 29 to 30. My nextcloud server started without issue:
systemctl disable httpd
sudo dnf upgrade –refresh
sudo dnf install dnf-plugin-system-upgrade
sudo systemctl set-default multi-user.target
sudo reboot
sudo dnf system-upgrade download –best –allowerasing –refresh –releasever=30
sudo dnf system-upgrade reboot
login
sudo systemctl set-default graphical.target
systemctl enable httpd
reboot
## River14
I’ve just upgraded to Fedora 30 -I couldn’t wait any more-.
Any trouble !! Everything works like a charm !!
I only had to reinstall the Nvidia-Linux-x86_64-418.56 proprietary driver!!
Great great job !!
Congrats !!
## Sergey
For some reason nouveau is broken after the update (spamming in dmesg). Was needed to blacklist the module to run gdm.
## Finn
unrecognized arguments: -releasever = 30???
## River14
–releasever=30 –allowerasing (two dashes)
## Stephen Snow
unrecognized arguments: -releasever = 30???
I think the command option needs two dashes, so
## Earl Ramirez
its –releasever not -releasever, it’s two hyphen
## Luya Tshimbalanga
–releasever=30 . Note the missing extra “-“
## Sam
Upgraded and now I get …
Free magic is broken at 0xad2c9500: ….
If I let it count down on the grub menu selection it fails. If I select the version from the menu it boots fine. This is an issue as this pc is scheduled to startup by itself…
## Sam
Update…
I ran dnf update which found software updates including a new kernel. After updating and rebooting all seems to be good now.
## Peter Braet
Too buggy to release already. Sorry, Fedora30 needs to upgrade urgently. This is much worse than only WiFi not working. It is full of bugs.
## Peter Braet
Will Fedora please explain howto build (f30-candidate, wpa_supplicant-2.8-1.fc30.bz1703745rebuild.src.rpm)? That is the solution according to “Ask Fedora”, something from Koji, I don’t even know what that is. Please Fedora, explain howto do this and make broadcom work.
## Amit Samanta
The fedora upgraded from 29 to 30 has broke my system. After upgrade to fedora 30, the whole graphics has become fuzzy and blurry. It looks like old days TV screen. Do any body has nay idea how can I resolve this issue.
## Charles
Hi, try to create a new account and login using the new account. This solution should work but not very good, because you have to reconfigure your account. Delete .config folder maybe also work. Remember to backup your home folder before do this.
## EIner Petersen
Hi Amit,
Which graphics card/chip?
(This sounds like a kernel command line issue, specifically the nomodeset or nouveau.modeset=0 )
What happens is that if the high resolution graphics driver has a problem, the kernel uses the default BIOS VGA resolution of 640×480 == looks like an old TV ………..
## Flo
I have successfully upgraded from 29 to 30 via dnf commands. The only thing that did not work properly afterwards was my sound (using a Focusrite Scarlett as my main sound interface). There seemed to be some problem in parsing the config for the interface.
To resolve the issue all I had to do is clear the configs for pulseaudio (rm -r ~/.config/pulse) and restart it/let it write new configs. I hope this helps people facing the same issue.
## Sad
PSA: Your bookmarks can completely disappear from Epiphany (Gnome Web) after the upgrade. Make backups!
## Donald O'Dona
updated this morning. Started it, gone shopping, watching the final steps on return. No problems. Thanks RH & Fedora people!!!
## pete forde
after upgrading to fedora 30 I get the login screen with my user i attempt to login it acepts passowrd but goes back to login screen.
## Einer Petersen
Log in as root and remove the .config directory in your regular home directory (the easy fix that worked for me)
## Gayland Gump
After upgrading to FEDORA 30: I am able to login under my normal user name via ssh so I did so and renamed the .config directory to .config-old but I am still unable to get logged into the GUI. I am able to get into the GUI though as root but not as my normal user. The login screen presents with my name, requesting my password, when I click but once the screen has cleared, it returns to the login screen. Any other simple fix suggestions?
## Erich Küster
What about using a Fedora 30 Live Cd and renaming .config.old to .config again? Then a reboot will be necessary, of course.
## Gayland Gump
Oddly and to my mind inexplicably, I logged in via ssh using my normal user and copied the .config-old directory back to .config, logged out and logged into the GUI as root where I opened a terminal and manually rm -Rf /home/username/.config. I rebooted and this time was able to log into the GUI using my normal user login. I am sure that I’d done a complete reboot with all the prior attempts. I did encounter a problem with the mouse freezing up after my first successful login as my normal user which has not recurred during subsequent logins.
## Maksym Sanzharov
I had this issue, but the latest updates fix it for me. Did you try to update packages?
## Charles
Fedora 30 sometimes get frozen about 5 seconds when:
1) move cursor
2) drop a video file to a running SMPlayer instance
I’m using Nvidia by the way. I can see message ‘/usr/lib/gdm-x-session[11388]: nvLock: client timed out, taking the lock. ‘ in ‘journalctl -f’.
Any advice?
## Einer Petersen
I had the same problem and traced it back to the kernel nvidia DRM module ….. (very annoying I might add because it all worked in F29..). I am using the proprietary drivers.
Modify the grub kernel command line to disable the Nvidia DRM
nvidia-drm.modeset=0
My machine also has the Intel 630 (due to i7-8750)
so my kernel command line looks like this and it is working flawlessly:
nouveau.modeset=0 rd.driver.blacklist=nouveau i915.modeset=1 nvidia-drm.modeset=0 resume=/dev/mapper/fedora-swap rd.lvm.lv=fedora/swap rhgb
Yes, it is still using the Nvidia card …. just not using the Nvidia Kernel DRM
Also, I am betting the good folks at the GNOME project just had to screwed things up because in F29 kernel+nvidia DRM worked just fine and I tested the previous kernel/nvidia driver setup after the upgrade to F30 and the only real diff is the upgrade of GNOME to GNOME 3.32 form 3.31. (Linus had to take a “Be Nice Vow” ……… I didn’t :-D)
## Charles
Hi, thanks for your reply.
I’m curious that how did you trace this issue back to the kernel nvidia DRM module?
I’v changed ‘nvidia-drm.modeset’ to 0 from 1 in the file ‘/etc/default/grub’, and then execute the command ‘grub2-mkconfig -o /boot/efi/EFI/fedora/grub.cfg’. Then reboot.
Now the Nvidia DRM is disabled.
Whether or not this workround works, I’ll reply here later.
By the way, does disabling the Nvidia DRM have side effect?
I’v filled a bug report in there: https://bugzilla.redhat.com/show_bug.cgi?id=1706512
## Einer Petersen
Hi Charles 🙂
My first clue was the CPU utilization going to 100% across a 12 threads. My second was seeing that nvLock timeout in /var/log/messages. My third was that it wasn’t happening in KDE. These 3 things usually suggest a bad driver or the driver is being used incorrectly and given that the GNOME project has a very LONG history of screwing things up due to 1) knee-jerk changes and 2) miserable QA …………
Side effects so far:
1) no more kernel race —- probably due to a lock (nvLock) no longer being abused by the application (GNOME Shell?) trying to use it :-/
2) no other issues or degradation on anything I have tried so far since I disabled the Nvidia DRM module 🙂
3) I am happy about it (the work-around) so far 🙂
4) Still love/hate GNOME
## Charles
Whatever, this workaround does works for me. I’m happy to use Fedora 30.
## Murpholinox Peligro
Same problem with the driver bcm 43142 not working. Used to work fine with Fedora 29. c.c
## Peter Braet
Will Fedora please explain howto build (f30-candidate, wpa_supplicant-2.8-1.fc30.bz1703745rebuild.src.rpm)? That is the solution according to “Ask Fedora”, something from Koji, I don’t even know what that is. Please Fedora, explain howto do this and make broadcom work.
## Baruch
Command in section 3 must be
sudo dnf system-upgrade download –refresh –releasever=30
## Maricela
The wifi driver for BCM4312 is not working!!!!
## Peter Braet
Will Fedora please explain howto build (f30-candidate, wpa_supplicant-2.8-1.fc30.bz1703745rebuild.src.rpm)? That is the solution according to “Ask Fedora”, something from Koji, I don’t even know what that is. Please Fedora, explain howto do this and make broadcom work.
## Lionel
Updated my laptop 29 -> 30
KDE (plasma) freeze averytime I try to use an item in the control panel…
## Brian
Do you have nouveau driver installed? I have the same problem.
Log is full of:
nouveau 0000:01:00.0: gr: ILLEGAL_CLASS ch 10 [003f774000 plasmashell[7023]] subc 0 class 0000 mthd 35f0 data 0000005f
## Lionel
Yes, nouveau.
I went back to the 29. It was impossible to work.
## Jont Allen
For those of us with thinkpad X1 Extreme, with dual video cards, one of which is the nouveau, we know how to deal with this problem. There are two options:
1) use the “discrete” video card
2) use the nouveau (aka “Hybrid” video in the BIOS)
These may be chosen during boot time, in the bios.
If you want to have suspend work it is necessary to pick 1, as the nouveau is called
during the resume cycle. Suspend works, but resume fails when it tries to load the nouveau. The solution is to blacklist the nouveau, and chose option 1. Then suspend/resume works fine.
With this option you will not be able to use thunderbold (an external monitor). A relatively small price to pay compared to resume.
One must go with option 2 to boot the system from a USB stick, else it hangs. One may then install Fedora using the nouveau,
but there is no suspend resume. Once the system is booted it is necessary to black list the nouveau. This is about a 10 step
proceedure, which works fine for me, once I got it down. The blacklist proceedure may be found at:
https://www.if-not-true-then-false.com/2015/fedora-nvidia-guide/
Its an ugly set of choices, but it all works for me no, 100% as long as I dont boot the Hybrid/nouveau video and have it blacklisted.
The proceedure is messy to blacklist. I think there is a better solution during boot, but I have not tried that one, but would like to.
Here is all I know about that option:
https://fedoramag.wpengine.com/upgrading-fedora-29-to-fedora-30/
couldnt boot; nvideo problems
After you get into emergency mode execute:
mount -o remount,rw /sysroot
rm -f /sysroot/etc/os-release
cp /usr/lib/os-release /sysroot/etc/
exit
END
## Craig
Are the instructions identical for the KDE Spin?
## Olaf
Somehow Eclipse ain’t working anymore.
The needed “ant” repo has the wrong version. Hope that gets fixed soon.
## jont allen
can one simply boot into 29 rather than 30, after installing 30?
## Anton
DEEPIN is a very beautiful but uncomfortable interface. I dream to return to GNOME
## FMP
Successfully upgraded Fedora 29 to Fedora 30 it took the upgrade for a45 minutes.
I’m not sure what took place but for my case, I have to re do the process before Fedora 30 kicked in. Any input on this is highly appreciated.
## Keli
Upgrade for KDE was easy and no problems arose. Thanks Fedora!!!!
## Craig
Glad to hear it!
Did you do the upgrade described on this article page? Is there anything that needs to be done for the KDE Spin that’s not described here?
Thanks!
## svsv sarma
FWS 30 on the 30th day is fine. The dnf upgrade allowerasing did the trick smoothly. I congratulate the team for the taming. However, ‘error: ../../grub-core/fs/fat.c:447:not a FAT file system’ alert at boot time is intimidating.
## Dirk Gottschalk
IS there any way to upgrade offline?
I moved to another location and it takes a while until my internet is switched. I updates my notebook at work and would like to upgrade my home server for various reasons. Is there any workaroung for such situations?
## Luis
After upgrade from 29 to F30, i can’t log on on my desktop just ask for password and don’t enter, help please.
## Gabriel
Anyone any luck with VMWARE with kernel > 4.18? other than dodgy custom kernel patches?
## Gabriel
on fc29 I had to keep off the 5.0 bandwagon due to VMware…
does anyone have had any exp in running the latest’s of the 4.x mainline with fedora 30. that’s the only thing holding me back to upgrade to 30 right now.
## Brian D
If you have NVidia graphics on your system–maybe that’s my trouble — you might want to stay put at Fedora 28. I had to back up from Fedora 29 after it went berserk last December. Gnome Display manager failed. All kinds of weird dependency problems…. Gnome on Fedora 30 works fine, but KDE-Plasma hangs and freezes immediately when an attempt is made to invoke the Application Menu. I suspect that PKCON may also be part of the problem, as it was in Fedora 29, but I’m not sure yet. I should have stayed put. Fedora 28 worked just fine. My fault for being curious. Fortunately I have Linux Mint Debian and Debian Stretch installed on other partitions. Good Luck. Thanks to Fedora team for all the work, but since last December 16th, Fedora 29 update, something has gone awry. Fedora 29 was initially an excellent desktop.
## Einer Petersen
Hi Brian,
Yup, systems with Nvidia cards can be tricky at times 🙂
Recently, the part that has been causing most of the problems has been the Nvidia DRM Kernel module (see comments/reply for Charles).
I have had Fedora on my systems since it came out and the Nvidia drivers have always been challenging (putting it nicely at least :-)). The worst Nvidia driver I have dealt with is the Nouveau driver so, I have completely abandoned it in favor of the proprietary driver from Nvidia. The proprietary driver is a bit of a dance when the kernel or OS are upgraded, it takes planning 🙂
Steps I use:
1) dnf update
2) download the driver from Nvidia
3) systemctl set-default multi-user.target
4) reboot
5) build/install the new Nvidia driver
6) reboot (because I like double-checking that the kernel is still alive/not hosed :-))
7) startx (double-check that the GUI desktop comes up and things actually work) — and in the case of the kernel command line setting for nouveau.modeset=0 rd.driver.blacklist=nouveau nvidia-drm.modeset=0
(also I am lucky that I also have an i7 with the embedded graphics so I also set i915.modeset=1)
8) IF everything is doing what it is supposed to do, systemctl set-default graphical.target
9) reboot
— IF things go kaboom!, reboot single user and fix it
— IF things go as planned, enjoy the OS and go back to love/hate of GNOME
This has worked for me for many years now 🙂
## Brian D
After the latest update today Saturday, May 11– KDE-Plasma now works beautifully.
Gnome– not my first choice works better than ever, and I could actually learn to like it.
Congratulations to Fedora for the improvements. I am running with an older NVidia card and the nouveau driver. I could probably do better with the proprietary driver, but I am satisfied with the system as it stands. THANKYOU.
## Gio
upgrade from 28 to 30 will be “dangerous” ? or better do 28 -> 29 -> 30 ?
## Kamal Mehta
Hi there
Very happy after upgrading my local development server from fedora 29 to 30.
I just followed the instructions and it’s done without any issue.
Thanks!
Regards
Kamal Mehta
https://www.smiansh.com
## Samuel
After upgrading my UHD display resolution is reduced to 1024 x 768 and I can’t change it in Gnome display settings, or ~/.config/monitors.xml. The Resolution is already applied when being prompted for the LUKS password of my root partition during boot – so I assume it’s not a userspace problem. Does anyone know which other configs could be interfering?
## Vaclav
Hi, I have the same issue. After upgrade I have some unsupported resolution on my second UHD monitor during the boot (from the LUKS prompt). The monitor must be reconnected after the boot to Gnome, then it works.
## Vaclav
Update: my issue is only with more screens. So maybe the resolution is set accordingly to primary screen and then applied to the second screen, that can not display it. The bad thing is that the resolution stays the same in Gnome, so I must unplug the connector or turn off the secondary screen. When I boot only with secondary screen, the resolution is setted properly.
## JC
My upgrade failed with “unable to allocate memory” errors about 30% of the way through. I had to revert to a backup as it FUBAR’ed the DNF/YUM subsystem. Tried twice, the second time after doubling the memory, still failed. My estimate, had it run to completion, would have been about 4 hours to complete. Something’s not right, I’ll wait.
## dextre
hello friends, I have a laptop with wifi broadcom and ith the update in F30 , my wifi not work anymore , is it posible avoid the update for “wpa_supplicant” end leave it in a version of F29?
## Erich Küster
Sorry, my fingers were quicker than my brain: It is important to look every time when dnfdragora offers a list of available updates on them: Will update the old wpa_supplicant, of course. Do not select this request !!
## Erich Küster
Please look at the comments of Jonathon Poppleton and myself from above. You must remove the new wpa_suppplicant, then download an old version (in the moment I am using wpa_supplicant-2.7-1.fc30.x86_64.rpm). At first look that does not work as expected. Strange enough I installed in addition wpa_supplicant-gui-2.7-1.fc30.x86_64.rpm and … all worked fine. |
10,855 | 如何在 Ubuntu 和其他 Linux 发行版上使用 7Zip | https://itsfoss.com/use-7zip-ubuntu-linux/ | 2019-05-14T15:55:00 | [
"7zip",
"7z"
] | https://linux.cn/article-10855-1.html |
>
> 不能在 Linux 中提取 .7z 文件?学习如何在 Ubuntu 和其他 Linux 发行版中安装和使用 7zip。
>
>
>

[7Zip](https://www.7-zip.org/)(更适当的写法是 7-Zip)是一种在 Windows 用户中广泛流行的归档格式。一个 7Zip 归档文件通常以 .7z 扩展结尾。它大部分是开源的,除了包含一些少量解压 rar 文件的代码。
默认大多数 Linux 发行版不支持 7Zip。如果你试图提取它,你会看见这个错误:
>
> 不能打开这种文件类型
>
>
> 没有已安装的适用 7-zip 归档文件的命令。你想搜索一个命令来打开这个文件吗?
>
>
>

不要担心,你可以轻松的在 Ubuntu 和其他 Linux 发行版中安装 7zip。
一个问题是你会注意到如果你试图用 [apt-get install 命令](https://itsfoss.com/apt-get-linux-guide/),你会发现没有以 7zip 开头的候选安装。因为在 Linux 中 7Zip 包的名字是 [p7zip](https://sourceforge.net/projects/p7zip/)。以字母 “p” 开头而不是预期的数字 “7”。
让我们看一下如何在 Ubuntu 和其他 Linux 发行版中安装 7zip。
### 在 Ubuntu Linux 中安装 7Zip
你需要做的第一件事是安装 p7zip 包。你会在 Ubuntu 中发现 3 个包:p7zip、p7zip-full 和 pzip-rar。
pzip 和 p7zip-full 的不同是 pzip 是一个轻量级的版本,仅仅对 .7z 文件提供支持,而 p7zip-full 提供了更多的 7z 压缩算法(例如音频文件)。
p7zip-rar 包在 7z 中提供了对 [RAR 文件](https://itsfoss.com/use-rar-ubuntu-linux/) 的支持
在大多数情况下安装 p7zip-full 就足够了,但是你可能想安装 p7zip-rar 来支持 rar 文件的解压。
p7zip 包在 [Ubuntu 的 universe 仓库](https://itsfoss.com/ubuntu-repositories/) 因此保证你可以使用以下命令:
```
sudo add-apt-repository universe
sudo apt update
```
在 Ubuntu 和基于 Debian 的发行版中使用以下命令。
```
sudo apt install p7zip-full p7zip-rar
```
这很好。现在在你的系统就有了 7zip 归档的支持。
### 在 Linux 中提取 7Zip 归档文件
安装了 7Zip 后,在 Linux 中,你可以在图形用户界面或者 命令行中提取 7zip 文件。
在图形用户界面,你可以像提取其他压缩文件一样提取 .7z 文件。右击文件来提取它。
在终端中,你可以使用下列命令提取 .7z 归档文件:
```
7z e file.7z
```
### 在 Linux 中压缩文件为 7zip 归档格式
你可以在图形界面压缩文件为 7zip 归档格式。简单的在文件或目录上右击,选择“压缩”。你应该看到几种类型的文件格式选项。选择 .7z。

作为替换,你也可以在命令行中使用。这里是你可以用来压缩的命令:
```
7z a 输出的文件名 要压缩的文件
```
默认,归档文件有 .7z 扩展。你可以通过在指定输出文件扩展名为 .zip 以压缩为 zip 格式。
### 总结
就是这样。看,在 Linux 中使用 7zip 多简单?我希望你喜欢这个快速指南。如果你有问题或者建议,请随意在下方评论让我知道。
---
via: <https://itsfoss.com/use-7zip-ubuntu-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[7Zip](https://www.7-zip.org/?ref=itsfoss.com) (properly written as 7-Zip) is an archive format hugely popular among Windows users. A 7Zip archive file usually ends in .7z extension. It’s mostly an open source software, barring a few parts of the code that deals with [unRAR](https://itsfoss.com/use-rar-ubuntu-linux/).
The 7Zip support is not enabled by default in most Linux distributions. If you try to extract it, you may see this error:
**Could not open this file type**
**There is no command installed for 7-zip archive files. Do you want to search for a command to open this file?**
Don’t worry, you can easily install 7zip in Ubuntu or other Linux distributions.
The one problem you’ll notice if you try to use the [apt-get install command](https://itsfoss.com/apt-get-linux-guide/), you’ll see that there are no installation candidates that start with 7zip. It’s because the 7Zip package in Linux is named [p7zip](https://sourceforge.net/projects/p7zip/?ref=itsfoss.com), starting with the letter ‘p’ instead of the expected number ‘7’.
Let’s see how to install 7zip in Ubuntu and (possibly) other Linux distributions.
## Install 7Zip in Ubuntu Linux
The first thing you need is to install the p7zip package. You’ll find three 7zip packages in Ubuntu:
- p7zip
- p7zip-full
- p7zip-rar.
The difference between *p7zip* and *p7zip-full* is that *p7zip* is a lighter version providing support only for .7z while the full version provides support for more 7z compression algorithms (for audio files etc.).
The p7zip-rar package provides support for [RAR files](https://itsfoss.com/use-rar-ubuntu-linux/) along with 7z.
Installing *p7zip-full* should be sufficient in most cases, but you may also install *p7zip-rar* for additional support for the RAR file.
p7zip packages are in the [universe repository in Ubuntu](https://itsfoss.com/ubuntu-repositories/) so make sure that you have enabled it using this command:
```
sudo add-apt-repository universe
sudo apt update
```
Use the following command to install 7zip support in Ubuntu and Debian based distributions.
`sudo apt install p7zip-full p7zip-rar`
That’s good. Now you have 7zip archive support in your system.
## Extract 7Zip archive file in Linux
With 7Zip installed, you can either use the GUI or the command line to extract 7zip files in Linux.
In the terminal, you can extract a .7z archive file using this command:
`7z e file.7z`
In the GUI, you can extract a .7z file as you extract any other compressed file. You right-click on the file and proceed to extract it.
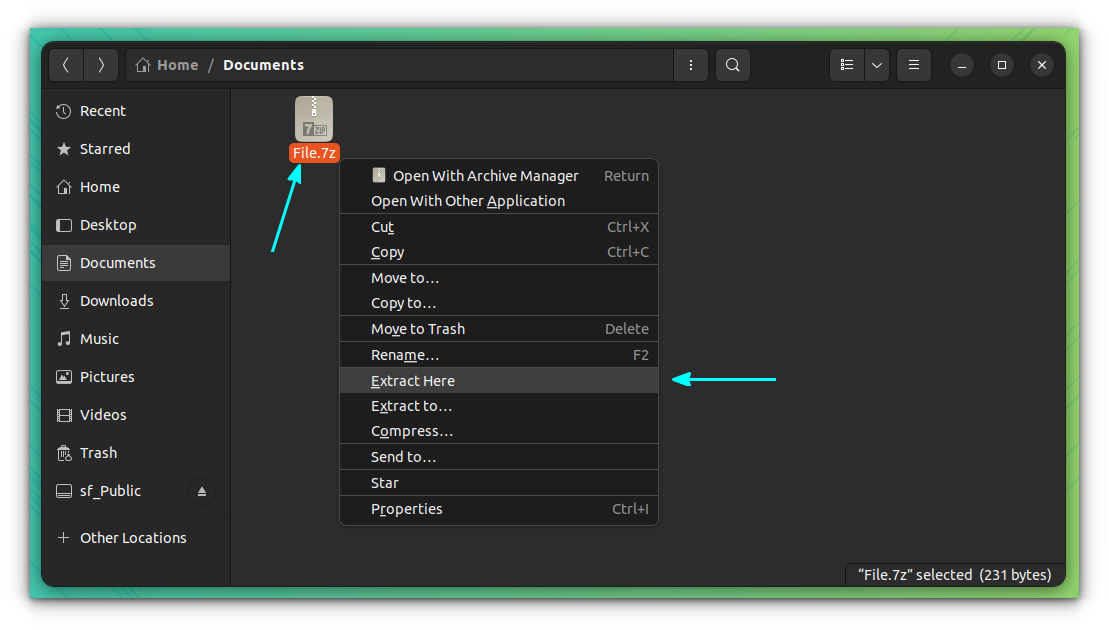
## Compress a file in 7zip archive format in Linux
You can also use the command line, if it suits you, for this purpose:
`7z a OutputFile files_to_compress`
By default, the archived file will have .7z extension. You can [compress the file in zip format](https://itsfoss.com/linux-zip-folder/) by specifying the extension (.zip) of the output file.
You can compress a file in 7zip archive format graphically. Right-click on the file/directory, and select **Compress**. You should see several types of archive format options. Choose .7z for 7zip.
## Conclusion
That’s it. See how easy it is to use 7zip in Linux. I hope you liked this quick tip.
Similarly, you can [use RAR files in Linux](https://itsfoss.com/use-rar-ubuntu-linux/).
[How to Use RAR files in Ubuntu Linux [Quick Tip]Looking for WinRAR in Linux? Here’s how to extract and use RAR files in Linux. RAR is a quite good archive file format. But, it isn’t the best when you’ve got 7-zip in Linux offering great compression ratios and Zip files being easily supported across multiple platforms](https://itsfoss.com/use-rar-ubuntu-linux/)

If you have questions or suggestions, feel free to let me know in the comment sections. |
10,858 | 如何在你的 Python 游戏中添加一个玩家 | https://opensource.com/article/17/12/game-python-add-a-player | 2019-05-15T22:06:00 | [
"Python",
"Pygame"
] | https://linux.cn/article-10858-1.html |
>
> 这是用 Python 从头开始构建游戏的系列文章的第三部分。
>
>
>

在 [这个系列的第一篇文章](/article-9071-1.html) 中,我解释了如何使用 Python 创建一个简单的基于文本的骰子游戏。在第二部分中,我向你们展示了如何从头开始构建游戏,即从 [创建游戏的环境](/article-10850-1.html) 开始。但是每个游戏都需要一名玩家,并且每个玩家都需要一个可操控的角色,这也就是我们接下来要在这个系列的第三部分中需要做的。
在 Pygame 中,玩家操控的图标或者化身被称作<ruby> 妖精 <rt> sprite </rt></ruby>。如果你现在还没有任何可用于玩家妖精的图像,你可以使用 [Krita](http://krita.org) 或 [Inkscape](http://inkscape.org) 来自己创建一些图像。如果你对自己的艺术细胞缺乏自信,你也可以在 [OpenClipArt.org](http://openclipart.org) 或 [OpenGameArt.org](https://opengameart.org/) 搜索一些现成的图像。如果你还未按照上一篇文章所说的单独创建一个 `images` 文件夹,那么你需要在你的 Python 项目目录中创建它。将你想要在游戏中使用的图片都放 `images` 文件夹中。
为了使你的游戏真正的刺激,你应该为你的英雄使用一张动态的妖精图片。这意味着你需要绘制更多的素材,并且它们要大不相同。最常见的动画就是走路循环,通过一系列的图像让你的妖精看起来像是在走路。走路循环最快捷粗糙的版本需要四张图像。

注意:这篇文章中的代码示例同时兼容静止的和动态的玩家妖精。
将你的玩家妖精命名为 `hero.png`。如果你正在创建一个动态的妖精,则需要在名字后面加上一个数字,从 `hero1.png` 开始。
### 创建一个 Python 类
在 Python 中,当你在创建一个你想要显示在屏幕上的对象时,你需要创建一个类。
在你的 Python 脚本靠近顶端的位置,加入如下代码来创建一个玩家。在以下的代码示例中,前三行已经在你正在处理的 Python 脚本中:
```
import pygame
import sys
import os # 以下是新代码
class Player(pygame.sprite.Sprite):
'''
生成一个玩家
'''
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.images = []
img = pygame.image.load(os.path.join('images','hero.png')).convert()
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
```
如果你的可操控角色拥有一个走路循环,在 `images` 文件夹中将对应图片保存为 `hero1.png` 到 `hero4.png` 的独立文件。
使用一个循环来告诉 Python 遍历每个文件。
```
'''
对象
'''
class Player(pygame.sprite.Sprite):
'''
生成一个玩家
'''
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.images = []
for i in range(1,5):
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
```
### 将玩家带入游戏世界
现在已经创建好了一个 Player 类,你需要使用它在你的游戏世界中生成一个玩家妖精。如果你不调用 Player 类,那它永远不会起作用,(游戏世界中)也就不会有玩家。你可以通过立马运行你的游戏来验证一下。游戏会像上一篇文章末尾看到的那样运行,并得到明确的结果:一个空荡荡的游戏世界。
为了将一个玩家妖精带到你的游戏世界,你必须通过调用 Player 类来生成一个妖精,并将它加入到 Pygame 的妖精组中。在如下的代码示例中,前三行是已经存在的代码,你需要在其后添加代码:
```
world = pygame.display.set_mode([worldx,worldy])
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
backdropbox = screen.get_rect()
# 以下是新代码
player = Player() # 生成玩家
player.rect.x = 0 # 移动 x 坐标
player.rect.y = 0 # 移动 y 坐标
player_list = pygame.sprite.Group()
player_list.add(player)
```
尝试启动你的游戏来看看发生了什么。高能预警:它不会像你预期的那样工作,当你启动你的项目,玩家妖精没有出现。事实上它生成了,只不过只出现了一毫秒。你要如何修复一个只出现了一毫秒的东西呢?你可能回想起上一篇文章中,你需要在主循环中添加一些东西。为了使玩家的存在时间超过一毫秒,你需要告诉 Python 在每次循环中都绘制一次。
将你的循环底部的语句更改如下:
```
world.blit(backdrop, backdropbox)
player_list.draw(screen) # 绘制玩家
pygame.display.flip()
clock.tick(fps)
```
现在启动你的游戏,你的玩家出现了!
### 设置 alpha 通道
根据你如何创建你的玩家妖精,在它周围可能会有一个色块。你所看到的是 alpha 通道应该占据的空间。它本来是不可见的“颜色”,但 Python 现在还不知道要使它不可见。那么你所看到的,是围绕在妖精周围的边界区(或现代游戏术语中的“<ruby> 命中区 <rt> hit box </rt></ruby>”)内的空间。

你可以通过设置一个 alpha 通道和 RGB 值来告诉 Python 使哪种颜色不可见。如果你不知道你使用 alpha 通道的图像的 RGB 值,你可以使用 Krita 或 Inkscape 打开它,并使用一种独特的颜色,比如 `#00ff00`(差不多是“绿屏绿”)来填充图像周围的空白区域。记下颜色对应的十六进制值(此处为 `#00ff00`,绿屏绿)并将其作为 alpha 通道用于你的 Python 脚本。
使用 alpha 通道需要在你的妖精生成相关代码中添加如下两行。类似第一行的代码已经存在于你的脚本中,你只需要添加另外两行:
```
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
img.convert_alpha() # 优化 alpha
img.set_colorkey(ALPHA) # 设置 alpha
```
除非你告诉它,否则 Python 不知道将哪种颜色作为 alpha 通道。在你代码的设置相关区域,添加一些颜色定义。将如下的变量定义添加于你的设置相关区域的任意位置:
```
ALPHA = (0, 255, 0)
```
在以上示例代码中,`0,255,0` 被我们使用,它在 RGB 中所代表的值与 `#00ff00` 在十六进制中所代表的值相同。你可以通过一个优秀的图像应用程序,如 [GIMP](http://gimp.org)、Krita 或 Inkscape,来获取所有这些颜色值。或者,你可以使用一个优秀的系统级颜色选择器,如 [KColorChooser](https://github.com/KDE/kcolorchooser),来检测颜色。

如果你的图像应用程序将你的妖精背景渲染成了其他的值,你可以按需调整 `ALPHA` 变量的值。不论你将 alpha 设为多少,最后它都将“不可见”。RGB 颜色值是非常严格的,因此如果你需要将 alpha 设为 000,但你又想将 000 用于你图像中的黑线,你只需要将图像中线的颜色设为 111。这样一来,(图像中的黑线)就足够接近黑色,但除了电脑以外没有人能看出区别。
运行你的游戏查看结果。

在 [这个系列的第四篇文章](https://opensource.com/article/17/12/program-game-python-part-4-moving-your-sprite) 中,我会向你们展示如何使你的妖精动起来。多么的激动人心啊!
---
via: <https://opensource.com/article/17/12/game-python-add-a-player>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[cycoe](https://github.com/cycoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For the [first article of this series](https://opensource.com/article/17/10/python-101), I explained how to use Python to create a simple, text-based dice game. In the second part, I showed you how to build a game from scratch, starting with [creating the game's environment](https://opensource.com/article/17/12/program-game-python-part-2-creating-game-world). But every game needs a player, and every player needs a playable character, so that's what you'll do next in this third part of the series.
In Pygame, the icon or avatar that a player controls is called a *sprite*. If you don't have any graphics to use for a player sprite yet, download the [walk-0.png, walk-2.png, walk-4.png, and walk-5.png files](https://github.com/SuperTux/supertux/tree/master/data/images/creatures/tux/small) from the classic open source game [Supertux](https://www.supertux.org) and rename them hero1.png to hero4.png Alternately, you can create something for yourself using [Krita](http://krita.org) or [Inkscape](http://inkscape.org), or search [OpenGameArt.org](https://opengameart.org/) for other options. Then, if you didn't already do so in the previous article, create a directory called `images`
within your Python project directory. Put the images you want to use in your game into the `images`
folder.
To make your game truly exciting, you ought to use an animated sprite for your hero. If you're drawing your characters yourself, this means you have to draw more assets, but it makes a big difference. The most common animation is a *walk cycle*, a series of drawings that make it look like your sprite is walking. The quick and dirty version of a walk cycle requires four drawings.

CC BY-SA Seth Kenlon
Note: The code samples in this article allow for both a static player sprite and an animated one.
Name your player sprite `hero.png`
. If you're creating an animated sprite for a walk cycle, append a digit after the name, starting with `hero1.png`
. Save you hero image into a directory called `images`
in your Python project directory.
## Create a Python class
In Python, when you create an object that you want to appear on screen, you create a class.
Near the top of your Python script, in the Objects section, add the code to create a player. If you're using a static image with no walk cycle, use this code (note that this code goes in the `Objects`
section of your file):
```
'''
Objects
'''
class Player(pygame.sprite.Sprite):
"""
Spawn a player
"""
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.images = []
img = pygame.image.load(os.path.join('images', 'hero.png')).convert()
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
```
This code block creates a virtual "object" for Python to use when referencing your hero sprite. In object-oriented programming, an "object" is referred to as a *class*. The object template (specifically, `pygame.sprite.Sprite`
) is provided by Pygame. That's what makes it possible for you to define an image to represent the player character. If you had to program that from scratch, you'd have to learn a lot more about Python before you could start creating a game, and that's the advantage of using a framework like Pygame.
If you have a walk cycle for your playable character, save each drawing as an individual file called `hero1.png`
to `hero4.png`
in your project's `images`
folder. Then use a loop to tell Python to cycle through each file. This is one of the features of object-oriented programming: each class can have tasks assigned exclusively to it, which occurs without affecting the "world" around it. In this case, your player character sprite is programmed to cycle through four different images to create the illusion of walking, and this can happen regardless of what else is happening around it.
```
'''
Objects
'''
class Player(pygame.sprite.Sprite):
"""
Spawn a player
"""
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.images = []
for i in range(1, 5):
img = pygame.image.load(os.path.join('images', 'hero' + str(i) + '.png')).convert()
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
```
## Bring the player into the game world
Now that a Player class exists, you must use it to spawn a player sprite in your game world. If you never call on the Player class, it never runs, and there will be no player. You can test this out by running your game now. The game runs just as well as it did at the end of the previous article, with the exact same results: an empty game world.
To bring a player sprite into your world, you must "call" the Player class to generate a sprite and then add it to a Pygame sprite group. Add these lines to your Setup section:
```
player = Player() # spawn player
player.rect.x = 0 # go to x
player.rect.y = 0 # go to y
player_list = pygame.sprite.Group()
player_list.add(player)
```
Try launching your game to see what happens. Warning: it won't do what you expect. When you launch your project, the player sprite doesn't spawn. Actually, it spawns, but only for a millisecond. How do you fix something that only happens for a millisecond? You might recall from the previous article that you need to add something to the *main loop*. To make the player spawn for longer than a millisecond, tell Python to draw it once per loop.
Change the drawing clause of your main loop to look like this:
```
world.blit(backdrop, backdropbox)
player_list.draw(world) # draw player
pygame.display.flip()
clock.tick(fps)
```
Launch your game now. Your player spawns!
## Setting the alpha channel
Depending on how you created your player sprite, it may have a colored block around it. What you are seeing is the space that ought to be occupied by an *alpha channel*. It's meant to be the "color" of invisibility, but Python doesn't know to make it invisible yet. What you are seeing, then, is the space within the bounding box (or "hit box," in modern gaming terms) around the sprite.

You can tell Python what color to make invisible by setting an alpha channel and using RGB values. If you don't know the RGB values your drawing uses as alpha, open your drawing in Pinta or Inkscape and fill the empty space around your drawing with a unique color, like #00ff00 (more or less a "greenscreen green"). Take note of the color's hex value (#00ff00, for greenscreen green) and use that in your Python script as the alpha channel.
Using alpha requires the addition of two lines in your Sprite creation code. Some version of the first line is already in your code. Add the other two lines:
```
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
img.convert_alpha() # optimise alpha
img.set_colorkey(ALPHA) # set alpha
```
Python doesn't know what to use as alpha unless you tell it.
If you believe your image already has an alpha channel, you can try setting a variable `ALPHA`
to 0 or 255, both of which are common places for alpha to be stored. One of those may work, but maybe due to my background in film production, I prefer to explicitly create and set my own alpha channel.
## Setting your own alpha
In the Variable section of your code, add this variable definition:
```
ALPHA = (0, 255, 0)
```
In this example code, **0,255,0** is used, which is the same value in RGB as #00ff00 is in hex. You can get all of these color values from a good graphics application like [GIMP](http://gimp.org), Krita, or Inkscape. Alternately, you can also detect color values with a good system-wide color chooser, like [KColorChooser](https://github.com/KDE/kcolorchooser) or [ColourPicker](https://github.com/stuartlangridge/ColourPicker).
opensource.com
If your graphics application is rendering your sprite's background as some other value, adjust the values of your alpha variable as needed. No matter what you set your alpha value, it will be made "invisible." RGB values are very strict, so if you need to use 000 for alpha, but you need 000 for the black lines of your drawing, just change the lines of your drawing to 111, which is close enough to black that nobody but a computer can tell the difference.
Launch your game to see the results.

Here's the code in its entirety so far:
```
#!/usr/bin/env python3
# by Seth Kenlon
# GPLv3
# This program is free software: you can redistribute it and/or
# modify it under the terms of the GNU General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
from typing import Tuple
import pygame
import sys
import os
'''
Variables
'''
worldx = 960
worldy = 720
fps = 40 # frame rate
ani = 4 # animation cycles
world = pygame.display.set_mode([worldx, worldy])
BLUE = (25, 25, 200)
BLACK = (23, 23, 23)
WHITE = (254, 254, 254)
ALPHA = (0, 255, 0)
'''
Objects
'''
class Player(pygame.sprite.Sprite):
"""
Spawn a player
"""
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.images = []
for i in range(1, 5):
img = pygame.image.load(os.path.join('images', 'hero' + str(i) + '.png')).convert()
img.convert_alpha() # optimise alpha
img.set_colorkey(ALPHA) # set alpha
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
'''
Setup
'''
backdrop = pygame.image.load(os.path.join('images', 'stage.png'))
clock = pygame.time.Clock()
pygame.init()
backdropbox = world.get_rect()
main = True
player = Player() # spawn player
player.rect.x = 0 # go to x
player.rect.y = 0 # go to y
player_list = pygame.sprite.Group()
player_list.add(player)
'''
Main Loop
'''
while main:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
pygame.quit()
try:
sys.exit()
finally:
main = False
world.blit(backdrop, backdropbox)
player_list.draw(world)
pygame.display.flip()
clock.tick(fps)
```
*In the fourth part of this series, I'll show you how to make your sprite move. How exciting!*
## 1 Comment |
10,859 | 使用 Cython 为 Python 编写更快的 C 扩展 | https://opensource.com/article/19/5/python-cython | 2019-05-15T22:55:00 | [
"Python",
"Cython"
] | /article-10859-1.html |
>
> 在我们这个包含了 7 个 PyPI 库的系列文章中学习解决常见的 Python 问题的方法。
>
>
>

Python 是当今使用最多的[流行编程语言](https://opensource.com/article/18/5/numbers-python-community-trends)之一,因为:它是开源的,它有广泛的用途(例如 Web 编程、业务应用、游戏、科学编程等等),它有一个充满活力和专注的社区支持它。这个社区可以让我们在 [Python Package Index](https://pypi.org/)(PyPI)中有如此庞大、多样化的软件包,用以扩展和改进 Python 并解决不可避免的问题。
在本系列中,我们将介绍七个可以帮助你解决常见 Python 问题的 PyPI 库。首先是 [Cython](https://pypi.org/project/Cython/),一个简化 Python 编写 C 扩展的语言。
### Cython
使用 Python 很有趣,但有时,用它编写的程序可能很慢。所有的运行时动态调度会带来很大的代价:有时它比用 C 或 Rust 等系统语言编写的等效代码慢 10 倍。
将代码迁移到一种全新的语言可能会在成本和可靠性方面付出巨大代价:所有的手工重写工作都将不可避免地引入错误。我们可以两者兼得么?
为了练习一下优化,我们需要一些慢代码。有什么比斐波那契数列的意外指数实现更慢?
```
def fib(n):
if n < 2:
return 1
return fib(n-1) + fib(n-2)
```
由于对 `fib` 的调用会导致两次再次调用,因此这种效率极低的算法需要很长时间才能执行。例如,在我的新笔记本电脑上,`fib(36)` 需要大约 4.5 秒。这个 4.5 秒会成为我们探索 Python 的 Cython 扩展能提供的帮助的基准。
使用 Cython 的正确方法是将其集成到 `setup.py` 中。然而,使用 `pyximport` 可以快速地进行尝试。让我们将 `fib` 代码放在 `fib.pyx` 中并使用 Cython 运行它。
```
>>> import pyximport; pyximport.install()
>>> import fib
>>> fib.fib(36)
```
只使用 Cython 而不*修改*代码,这个算法在我笔记本上花费的时间减少到大约 2.5 秒。几乎无需任何努力,这几乎减少了 50% 的运行时间。当然,得到了一个不错的成果。
加把劲,我们可以让它变得更快。
```
cpdef int fib(int n):
if n < 2:
return 1
return fib(n - 1) + fib(n - 2)
```
我们将 `fib` 中的代码变成用 `cpdef` 定义的函数,并添加了两个类型注释:它接受一个整数并返回一个整数。
这个变得快*多*了,大约只用了 0.05 秒。它是如此之快,以至于我可能开始怀疑我的测量方法包含噪声:之前,这种噪声在信号中丢失了。
当下次你的 Python 代码花费太多 CPU 时间时,也许会导致风扇狂转,为何不看看 Cython 是否可以解决问题呢?
在本系列的下一篇文章中,我们将看一下 Black,一个自动纠正代码格式错误的项目。
(题图:[Subgrafik San](https://dribbble.com))
---
via: <https://opensource.com/article/19/5/python-cython>
作者:[Moshe Zadka](https://opensource.com/users/moshez/users/moshez/users/foundjem/users/jugmac00) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,860 | 用于黑客渗透测试的 21 个最佳 Kali Linux 工具 | https://itsfoss.com/best-kali-linux-tools/ | 2019-05-15T23:41:00 | [
"安全",
"黑客",
"Kali"
] | https://linux.cn/article-10860-1.html |
>
> 这里是最好的 Kali Linux 工具列表,它们可以让你评估 Web 服务器的安全性,并帮助你执行黑客渗透测试。
>
>
>
如果你读过 [Kali Linux 点评](https://itsfoss.com/kali-linux-review/),你就知道为什么它被认为是[最好的黑客渗透测试的 Linux 发行版](https://itsfoss.com/linux-hacking-penetration-testing/)之一,而且名副其实。它带有许多工具,使你可以更轻松地测试、破解以及进行与数字取证相关的任何其他工作。
它是<ruby> 道德黑客 <rt> ethical hacker </rt></ruby>最推荐的 Linux 发行版之一。即使你不是黑客而是网站管理员 —— 你仍然可以利用其中某些工具轻松地扫描你的网络服务器或网页。
在任何一种情况下,无论你的目的是什么 —— 让我们来看看你应该使用的一些最好的 Kali Linux 工具。
*注意:这里不是所提及的所有工具都是开源的。*
### 用于黑客渗透测试的 Kali Linux 工具

Kali Linux 预装了几种类型的工具。如果你发现有的工具没有安装,只需下载并进行设置即可。这很简单。
#### 1、Nmap

[Nmap](https://nmap.org/) (即 “<ruby> 网络映射器 <rt> Network Mapper </rt></ruby>”)是 Kali Linux 上最受欢迎的信息收集工具之一。换句话说,它可以获取有关主机的信息:其 IP 地址、操作系统检测以及网络安全的详细信息(如开放的端口数量及其含义)。
它还提供防火墙规避和欺骗功能。
#### 2、Lynis

[Lynis](https://cisofy.com/lynis/) 是安全审计、合规性测试和系统强化的强大工具。当然,你也可以将其用于漏洞检测和渗透测试。
它将根据检测到的组件扫描系统。例如,如果它检测到 Apache —— 它将针对入口信息运行与 Apache 相关的测试。
#### 3、WPScan

WordPress 是[最好的开源 CMS](https://itsfoss.com/open-source-cms/)之一,而这个工具是最好的免费 WordpPress 安全审计工具。它是免费的,但不是开源的。
如果你想知道一个 WordPress 博客是否在某种程度上容易受到攻击,[WPScan](https://wpscan.org/) 就是你的朋友。
此外,它还为你提供了所用的插件的详细信息。当然,一个安全性很好的博客可能不会暴露给你很多细节,但它仍然是 WordPress 安全扫描找到潜在漏洞的最佳工具。
#### 4、Aircrack-ng

[Aircrack-ng](https://www.aircrack-ng.org/) 是评估 WiFi 网络安全性的工具集合。它不仅限于监控和获取信息 —— 还包括破坏网络(WEP、WPA 1 和 WPA 2)的能力。
如果你忘记了自己的 WiFi 网络的密码,可以尝试使用它来重新获得访问权限。它还包括各种无线攻击能力,你可以使用它们来定位和监控 WiFi 网络以增强其安全性。
#### 5、Hydra

如果你正在寻找一个有趣的工具来破解登录密码,[Hydra](https://github.com/vanhauser-thc/thc-hydra) 将是 Kali Linux 预装的最好的工具之一。
它可能不再被积极维护,但它现在放在 [GitHub](https://github.com/vanhauser-thc/THC-Archive) 上,所以你也可以为它做贡献。
#### 6、Wireshark

[Wireshark](https://www.wireshark.org/) 是 Kali Linux 上最受欢迎的网络分析仪。它也可以归类为用于网络嗅探的最佳 Kali Linux 工具之一。
它正在积极维护,所以我肯定会建议你试试它。
#### 7、Metasploit Framework

[Metsploit Framework](https://github.com/rapid7/metasploit-framework)(MSF)是最常用的渗透测试框架。它提供两个版本:一个开源版,另外一个是其专业版。使用此工具,你可以验证漏洞、测试已知漏洞并执行完整的安全评估。
当然,免费版本不具备所有功能,所以如果你在意它们的区别,你应该在[这里](https://www.rapid7.com/products/metasploit/download/editions/)比较一下版本。
#### 8、Skipfish

与 WPScan 类似,但它不仅仅专注于 WordPress。[Skipfish](https://gitlab.com/kalilinux/packages/skipfish/) 是一个 Web 应用扫描程序,可以为你提供几乎所有类型的 Web 应用程序的洞察信息。它快速且易于使用。此外,它的递归爬取方法使它更好用。
Skipfish 生成的报告可以用于专业的 Web 应用程序安全评估。
#### 9、Maltego

[Maltego](https://www.paterva.com/web7/buy/maltego-clients.php) 是一种令人印象深刻的数据挖掘工具,用于在线分析信息并连接信息点(如果有的话)。 根据这些信息,它创建了一个有向图,以帮助分析这些数据之间的链接。
请注意,这不是一个开源工具。
它已预装,但你必须注册才能选择要使用的版本。如果个人使用,社区版就足够了(只需要注册一个帐户),但如果想用于商业用途,则需要订阅 classic 或 XL 版本。
#### 10、Nessus

如果你的计算机连接到了网络,Nessus 可以帮助你找到潜在攻击者可能利用的漏洞。当然,如果你是多台连接到网络的计算机的管理员,则可以使用它并保护这些计算机。
但是,它不再是免费的工具了,你可以从[官方网站](https://www.tenable.com/try)免费试用 7 天。
#### 11、Burp Suite Scanner

[Burp Suite Scanner](https://portswigger.net/burp) 是一款出色的网络安全分析工具。与其它 Web 应用程序安全扫描程序不同,Burp 提供了 GUI 和一些高级工具。
社区版仅将功能限制为一些基本的手动工具。对于专业人士,你必须考虑升级。与前面的工具类似,这也不是开源的。
我使用过免费版本,但是如果你想了解更多细节,你应该查看他们[官方网站](https://portswigger.net/burp)上提供的功能。
#### 12、BeEF

BeEF(<ruby> 浏览器利用框架 <rt> Browser Exploitation Framework </rt></ruby>)是另一个令人印象深刻的工具。它专为渗透测试人员量身定制,用于评估 Web 浏览器的安全性。
这是最好的 Kali Linux 工具之一,因为很多用户在谈论 Web 安全时希望了解并修复客户端的问题。
#### 13、Apktool

[Apktool](https://github.com/iBotPeaches/Apktool) 确实是 Kali Linux 上用于逆向工程 Android 应用程序的流行工具之一。当然,你应该正确利用它 —— 出于教育目的。
使用此工具,你可以自己尝试一下,并让原开发人员了解你的想法。你认为你会用它做什么?
#### 14、sqlmap

如果你正在寻找一个开源渗透测试工具 —— [sqlmap](http://sqlmap.org/) 是最好的之一。它可以自动化利用 SQL 注入漏洞的过程,并帮助你接管数据库服务器。
#### 15、John the Ripper

[John the Ripper](https://github.com/magnumripper/JohnTheRipper) 是 Kali Linux 上流行的密码破解工具。它也是自由开源的。但是,如果你对[社区增强版](https://github.com/magnumripper/JohnTheRipper)不感兴趣,可以用于商业用途的[专业版](https://www.openwall.com/john/pro/)。
#### 16、Snort
想要实时流量分析和数据包记录功能吗?[Snort](https://www.snort.org/) 可以鼎力支持你。即使它是一个开源的入侵防御系统,也有很多东西可以提供。
如果你还没有安装它,[官方网站](https://www.snort.org/#get-started)提及了安装过程。

#### 17、Autopsy Forensic Browser

[Autopsy](https://www.sleuthkit.org/autopsy/) 是一个数字取证工具,用于调查计算机上发生的事情。那么,你也可以使用它从 SD 卡恢复图像。它也被执法官员使用。你可以阅读[文档](https://www.sleuthkit.org/autopsy/docs.php)来探索可以用它做什么。
你还应该查看他们的 [GitHub 页面](https://github.com/sleuthkit/autopsy)。
#### 18、King Phisher

网络钓鱼攻击现在非常普遍。[King Phisher 工具](https://github.com/securestate/king-phisher)可以通过模拟真实的网络钓鱼攻击来帮助测试和提升用户意识。出于显而易见的原因,在模拟一个组织的服务器内容前,你需要获得许可。
#### 19、Nikto

[Nikto](https://gitlab.com/kalilinux/packages/nikto/) 是一款功能强大的 Web 服务器扫描程序 —— 这使其成为最好的 Kali Linux 工具之一。 它会检查存在潜在危险的文件/程序、过时的服务器版本等等。
#### 20、Yersinia

[Yersinia](https://github.com/tomac/yersinia) 是一个有趣的框架,用于在网络上执行第 2 层攻击(第 2 层是指 [OSI 模型](https://en.wikipedia.org/wiki/OSI_model)的数据链路层)。当然,如果你希望你的网络安全,则必须考虑所有七个层。但是,此工具侧重于第 2 层和各种网络协议,包括 STP、CDP,DTP 等。
#### 21、Social Engineering Toolkit (SET)

如果你正在进行相当严格的渗透测试,那么这应该是你应该检查的最佳工具之一。社交工程是一个大问题,使用 [SET](https://www.trustedsec.com/social-engineer-toolkit-set/) 工具,你可以帮助防止此类攻击。
### 总结
实际上 Kali Linux 捆绑了很多工具。请参考 Kali Linux 的[官方工具列表页面](https://tools.kali.org/tools-listing)来查找所有内容。
你会发现其中一些是完全自由开源的,而有些则是专有解决方案(但是免费)。但是,出于商业目的,你应该始终选择高级版本。
我们可能错过了你最喜欢的某个 Kali Linux 工具。请在下面的评论部分告诉我们。
---
via: <https://itsfoss.com/best-kali-linux-tools/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you read the [Kali Linux review](https://itsfoss.com/kali-linux-review/), you know why it is considered one of the [best Linux distributions for hacking and pen-testing](https://itsfoss.com/linux-hacking-penetration-testing/) and rightly so. It comes baked in with a lot of tools to make it easier for you to test, hack, and for anything else related to digital forensics.
It is one of the most recommended Linux distro for ethical hackers. Even if you are not a hacker but a webmaster – you can still utilize some of the tools to easily run a scan of your web server or web page.
In either case, no matter what your purpose is – we shall take a look at some of the best Kali Linux tools that you should be using.
**Non-FOSS Warning!**Some of the applications mentioned here are not open source. They have been included in the context of Linux usage.
There are several types of tools that comes pre-installed. If you do not find a tool installed, simply download it and set it up. It’s easy.
## 1. Nmap
[Nmap](https://nmap.org/?ref=itsfoss.com) or “Network Mapper” is one of the most popular tools on Kali Linux for information gathering. In other words, to get insights about the host, its IP address, OS detection, and similar network security details (like the number of open ports and what they are).
It also offers features for firewall evasion and spoofing.
## 2. Lynis
[Lynis](https://cisofy.com/lynis/?ref=itsfoss.com) is a powerful tool for security auditing, compliance testing, and system hardening. Of course, you can also utilize this for vulnerability detection and penetration testing as well.
It will scan the system according to the components it detects. For example, if it detects Apache – it will run Apache-related tests for pin point information.
## 3. WPScan
WordPress is one of the [best open source CMS](https://itsfoss.com/open-source-cms/) and this would be the best free WordPress security auditing tool. It’s free but not open source.
If you want to know whether a WordPress blog is vulnerable in some way, [WPScan](https://wpscan.org/?ref=itsfoss.com) is your friend.
In addition, it also gives you details of the plugins active. Of course, a well-secured blog may not give you a lot of details, but it is still the best tool for WordPress security scans to find potential vulnerabilities.
## 4. Aircrack-ng
[Aircrack-ng](https://www.aircrack-ng.org/?ref=itsfoss.com) is a collection of tools to assess WiFi network security. It isn’t just limited to monitor and get insights – but it also includes the ability to compromise a network (WEP, WPA 1, and WPA 2).
If you forgot the password of your own WiFi network – you can try using this to regain access. It also includes a variety of wireless attacks with which you can target/monitor a WiFi network to enhance its security.
## 5. Hydra
If you are looking for an interesting tool to crack login/password pairs, [Hydra](https://github.com/vanhauser-thc/thc-hydra?ref=itsfoss.com) will be one of the best Kali Linux tools that comes pre-installed.
It may not be actively maintained anymore – but it is now on [GitHub](https://github.com/vanhauser-thc/THC-Archive?ref=itsfoss.com), so you can contribute working on it as well.
## 6. Wireshark
[Wireshark](https://www.wireshark.org/?ref=itsfoss.com) is the most popular network analyzer that comes baked in with Kali Linux. It can be categorized as one of the best Kali Linux tools for network sniffing as well.
It is being actively maintained, so I would definitely recommend trying this out. And it’s really easy to [install Wireshark on Linux](https://itsfoss.com/install-wireshark-ubuntu/).
## 7. Metasploit Framework
[Metsploit Framework](https://github.com/rapid7/metasploit-framework?ref=itsfoss.com) is the most used penetration testing framework. It offers two editions – one (open source) and the second is the pro version to it. With this tool, you can verify vulnerabilities, test known exploits, and perform a complete security assessment.
Of course, the free version won’t have all the features, so if you are into serious stuff, you should compare the editions [here](https://www.rapid7.com/products/metasploit/download/editions/?ref=itsfoss.com).
## 8. Skipfish
Similar to WPScan, but not just focused for WordPress. [Skipfish](https://gitlab.com/kalilinux/packages/skipfish/?ref=itsfoss.com) is a web application scanner that would give you insights for almost every type of web applications. It’s fast and easy to use. In addition, its recursive crawl method makes it even better.
For professional web application security assessments, the report generated by Skipfish will come in handy.
## 9. Maltego
[Maltego](https://www.paterva.com/web7/buy/maltego-clients.php?ref=itsfoss.com) is an impressive data mining tool to analyze information online and connect the dots (if any). As per the information, it creates a directed graph to help analyze the link between those pieces of data.
Do note, that this isn’t an open source tool.
It comes pre-installed, however, you will have to sign up in order to select which edition you want to use. If you want for personal use, the community edition will suffice (you just need to register for an account) but if you want to utilize for commercial purpose, you need the subscription to the classic or XL version.
## 10. Nessus
If you have a computer connected to a network, Nessus can help find vulnerabilities that a potential attacker may take advantage of. Of course, if you are an administrator for multiple computers connected to a network, you can make use of it and secure those computers.
However, this is not a free tool anymore, you can try it free for 7 days on from its [official website](https://www.tenable.com/try?ref=itsfoss.com).
## 11. Burp Suite Scanner
[Burp Suite Scanner](https://portswigger.net/burp?ref=itsfoss.com) is a fantastic web security analysis tool. Unlike other web application security scanner, Burp offers a GUI and quite a few advanced tools.
However, the community edition restricts the features to only some essential manual tools. For professionals, you will have to consider upgrading. Similar to the previous tool, this isn’t open source either.
I’ve used the free version, but if you want more details on it, you should check out the features available on their [official website](https://portswigger.net/burp?ref=itsfoss.com).
## 12. BeEF
BeEF (Browser Exploitation Framework) is yet another impressive tool. It has been tailored for penetration testers to assess the security of a web browser.
This is one of the best Kali Linux tools because a lot of users do want to know and fix the client-side problems when talking about web security.
## 13. Apktool
[Apktool](https://github.com/iBotPeaches/Apktool?ref=itsfoss.com) is indeed one of the popular tools found on Kali Linux for reverse engineering Android apps. Of course, you should make good use of it – for educational purposes.
With this tool, you can experiment some stuff yourself and let the original developer know about your idea as well. What do you think you’ll be using it for?
## 14. sqlmap
If you were looking for an open source penetration testing tool – [sqlmap](http://sqlmap.org/?ref=itsfoss.com) is one of the best. It automates the process of exploiting SQL injection flaws and helps you take over database servers.
## 15. John the Ripper
[John the Ripper](https://github.com/magnumripper/JohnTheRipper?ref=itsfoss.com) is a popular password cracker tool available on Kali Linux. It’s free and open source as well. But, if you are not interested in the [community-enhanced version](https://github.com/magnumripper/JohnTheRipper?ref=itsfoss.com), you can choose the [pro version](https://www.openwall.com/john/pro/?ref=itsfoss.com) for commercial use.
## 16. Snort
Want real-time traffic analysis and packet logging capability? [Snort](https://www.snort.org/?ref=itsfoss.com) has got your back. Even being an open source intrusion prevention system, it has a lot to offer.
The [official website](https://www.snort.org/?ref=itsfoss.com#get-started) mentions the procedure to get it installed if you don’t have it already.
## 17. Autopsy Forensic Browser
[Autopsy](https://www.sleuthkit.org/autopsy/?ref=itsfoss.com) is a digital forensic tool to investigate what happened on your computer. Well, you can also use it to recover images from SD card. It is also being used by law enforcement officials. You can read the [documentation](https://www.sleuthkit.org/autopsy/docs.php?ref=itsfoss.com) to explore what you can do with it.
You should also check out their [GitHub page](https://github.com/sleuthkit/autopsy?ref=itsfoss.com).
## 18. King Phisher
Phishing attacks are very common nowadays. And, [King Phisher tool](https://github.com/securestate/king-phisher?ref=itsfoss.com) helps test, and promote user awareness by simulating real-world phishing attacks. For obvious reasons, you will need permission to simulate it on a server content of an organization.
## 19. Nikto
[Nikto](https://gitlab.com/kalilinux/packages/nikto/?ref=itsfoss.com) is a powerful web server scanner – that makes it one of the best Kali Linux tools available. It checks in against potentially dangerous files/programs, outdated versions of server, and many more things.
## 20. Yersinia
[Yersinia](https://github.com/tomac/yersinia?ref=itsfoss.com) is an interesting framework to perform Layer 2 attacks (Layer 2 refers to the data link layer of [OSI model](https://en.wikipedia.org/wiki/OSI_model?ref=itsfoss.com)) on a network. Of course, if you want a network to be secure, you will have to consider all the seven layers. However, this tool focuses on Layer 2 and a variety of network protocols that include STP, CDP, DTP, and so on.
## 21. Social Engineering Toolkit (SET)
If you are into pretty serious penetration testing stuff, this should be one of the best tools you should check out. Social engineering is a big deal and with [SET](https://www.trustedsec.com/social-engineer-toolkit-set/?ref=itsfoss.com) tool, you can help protect against such attacks.
## Wrapping Up
There’s actually a lot of tools that comes bundled with Kali Linux. Do refer to Kali Linux’ [official tool listing page](https://tools.kali.org/tools-listing?ref=itsfoss.com) to find them all.
You will find some of them to be completely free and open source while some to be proprietary solutions (yet free). However, for commercial purpose, you should always opt for the premium editions.
We might have missed one of your favorite Kali Linux tools. Did we? Let us know about it in the comments section below. |
10,862 | Maker DAO 通证解释:DAI、WETH、PETH、SIN、MKR 都是什么?(一) | https://medium.com/coinmonks/makerdao-tokens-explained-dai-weth-peth-sin-mkr-part-1-a46a0f687d5e | 2019-05-16T12:26:57 | [
"通证",
"DAI"
] | https://linux.cn/article-10862-1.html | 
>
> Maker DAO 使用了多个用于特定目的 ERC-20 通证,以确保 DAI 稳定币的稳定性。本文描述了基于 Bloxy.info 通证流工具的角色和使用模式。
>
>
>
### Maker DAO 通证
Maker DAO 系统是由多个智能合约(Sai Tap、Sai Tub、Vox、Medianiser 等)和 ERC-20 通证组成. 它们一起来确保 DAI 通证的稳定性。
在这篇文章中,我们主要关注通证是如何周转和使用的。下图显示了主要的通证流动周转和智能合约的使用方式,如何将一个通证转换为另一个通证:

*Maker DAO 通证流动周转和智能合约的使用方式*
上图中通证显示为圆形,而智能合约及其实体显示为圆角矩形。图表上的箭头表示使用这些智能合约的方法,你可以将余额从一个通证转换为另一个通证。
例如,调用 `join()` 将从你那里删除 WETH 通证,并为你提供适当数量的 PETH 通证。
### 不稳定(类“ETH”)通证
图的左侧显示了与以太币相关的令牌:
| | |
| --- | --- |
| | [ETH](https://bloxy.info/tokens/ETH):它本身并没有在 Maker DAO 系统中直接使用。如果你原来有 ETH (和我们大多数人一样),你必须首先将它转换成 WETH(“<ruby> 包装过的 ETH <rt> Wrapped ETH </rt></ruby>”)通证。 |
| | [WETH](https://bloxy.info/address/0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2):是 ETH 的一对一映射,但是作为 ERC-20 的通证存在。在任何时候,你都可以把 ETH 换成 WETH,或反之。缺点是,每一次这样的转变都需要花费燃料。 |
| | [PETH](https://bloxy.info/address/0xf53ad2c6851052a81b42133467480961b2321c09):是 “<ruby> 集合 ETH <rt> Pooled Ether </rt></ruby>”的缩写。当你把 WETH 存入 Maker DAO 时,你会得到这个通证。请注意,它并不完全是一对一的,它的汇率是计算出来的。 |
### 稳定(类“DAI”)通证
| | |
| --- | --- |
| | [DAI](https://bloxy.info/address/0x89d24a6b4ccb1b6faa2625fe562bdd9a23260359):MakerDAO 的稳定币,预计将接近 1 美元。当你用 CDP 生成贷款时,它会为你创造 DAI。 |
| | [SIN](https://bloxy.info/address/0x79f6d0f646706e1261acf0b93dcb864f357d4680):代表已清算的债务。它的价值等于 1DAI,在债务清算过程中使用而不是 DAI。 |
### Maker DAO 功能通证
| | |
| --- | --- |
| | [MKR](https://bloxy.info/address/0x9f8f72aa9304c8b593d555f12ef6589cc3a579a2):用于偿还债务时支付佣金的通证(通过擦除方法)。 |
### 智能合约
| | |
| --- | --- |
| | [Sai Tub 智能合约](https://bloxy.info/address/0x448a5065aebb8e423f0896e6c5d525c040f59af3):抵押债仓(CDP)系统。CDP 是你在 PETH 抵押后生成的 DAI 的债务。Maker DAO 的大多数操作都是使用它完成的。 |
| | [Sai Tap 智能合约](https://bloxy.info/address/0xbda109309f9fafa6dd6a9cb9f1df4085b27ee8ef):可以用于清算债务并从中产生利润。 |
### 智能合约使用方法
Maker DAO 智能合约有很多的使用方法,下表对其中的主要部分进行了分类:

*Maker DAO 智能合约使用方法*
大多数方法都是使用我们上面列出的通证来操作,并且 CDP 作为 Sai Tub 内部的实体。这些方法的更详细描述可以在 [Maker DAO 事务图解](https://medium.com/coinmonks/maker-dao-transactions-illustrated-691ad2715cf7)这篇文章之中看到。
### 通证使用模式
下面的材料是基于 [Bloxy.info](https://bloxy.info/) 通证的周转工具和 Maker DAO 分析的[仪表板](https://stat.bloxy.info/superset/dashboard/makerdao/?standalone=true)。
>
> [Bloxy.info](https://bloxy.info/) 网站为分析师、交易者、公司和加密爱好者提供了一套工具。
>
>
> 这些工具包括 API、仪表板和搜索引擎,所有这些都是现场提供,提供准确的数据,直接从区块链实时节点索引。
>
>
> Bloxy 的使命是使区块链更加透明,让人们和企业都可以访问。
>
>
> 请引用本文时指出数据来源。
>
>
>
我们的目标是将智能合约代码和上面的图表与关于这些通证的实际通证周转和用户操作相匹配。我们将使用我们的工具和分析方法,从不同的角度逐一调查这些通证。
我们要看的第一个通证是…
#### WETH(Wrapped Ether)
WETH 解释在 [weth.io](https://weth.io/) 网站上。WETH 被称为“<ruby> 包装过的 ETH <rt> Wrapped ETH </rt></ruby>”,可以在需要 ERC-20 通证的地方代替 ETH。我们首先想到的是去中心化交换 (DEX)。通常,DEX 协议更希望使用 ERC20 通证作为买/卖方之间的资产,并且不能直接使用 ETH。所以你先把你的 ETH 包装成 WETH,交换后的 WETH 可以换回 ETH。
这个通证与 Maker DAO 协议于 2017 年 12 月同时发起。请注意,其最大的持有者是 Maker DAO 的智能合约:

*WETH最大持有者*
所有者与其他通证的交集还显示了 Maker DAO 通证:

*共同持有者相关的令牌,来源: [bloxy.info](https://bloxy.info/token_holders/0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2)*
Maker DAO Sai Tub 智能合约上出现的这种高 WETH 余额,是因为用户将 WETH 存入 Maker DAO 的 Sai Tub 智能合约,以便之后创建 CDP。我们分析了这个过程中动态的 [MakerDAO 仪表板](https://stat.bloxy.info/superset/dashboard/makerdao/?standalone=true):

*WETH 锁定的金额、存款和取款。来源: bloxy.info [MakerDAO dashboard](https://stat.bloxy.info/superset/dashboard/makerdao/?standalone=true)*
从这张图表中可以看出,在 2019 年 5 月 10 日,锁定的 WETH 金额约为 200 万 ETH (橙色线),而创造的总金额超过了 400 万 ETH。
参与这项活动的人有多少?交易者的数量可以通过唯一地址在 Sai Tub 智能合约上启动的退出/加入交易记录来估计:

*在 Maker DAO 智能合约上唯一的地址数、锁定和释放 WETH。来源:bloxy.info [MakerDAO dashboard](https://stat.bloxy.info/superset/dashboard/makerdao/?standalone=true)*
交易者的行为是由每月锁定和释放的 WETH 数量来呈现的:

*每月锁定和释放 WETH 的金额。来源: bloxy.info [MakerDAO dashboard](https://stat.bloxy.info/superset/dashboard/makerdao/?standalone=true)*
图中右侧的两列展示了,在 2019 年 4 月前,当更多的人开始从 Maker DAO 锁定和释放 WETH 时,锁定和释放的数量的趋势相当对称。那反过来也可导致 Maker DAO 的 WETH 数量减少。
#### Maker DAO 之外的 WETH?
那么问题来了,除了 Maker DAO 之外,它可以在任何地方使用吗?
答案是肯定的。首先,它在 ZeroX 和 Oasis (匹配市场) 交易所交易中非常活跃,下图是 bloxyinfo 中展示的 [WETH 交易页面](http://localhost:3000/token_trades/0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2)。
[通证周转工具](http://localhost:3000/token_graphs/0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2#) 显示 WETH 的主要流量:

*主要的 WETH 周转路线。来源: [bloxy.info](http://localhost:3000/token_graphs/0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2#)*
正如你所看到的,WETH 通证 有几个 “重心”:
1. MakerDAI 的 Sai Tub 合约
2. Oasis、DDEX 等交易所
3. ZeroX(不涉及转账,所以没有在这个图表上明确显示)
我们拿 DEX(去中心化交易所)上一个最活跃的交易者的 WETH 交易作为例子:

*DEX 上 WETH/DAI 交易对的多方交易。来源: [bloxy.info](https://bloxy.info/tx/0xc538725a76c26695c3fae183bea430bfb86449bc9a066288e52716d22b10f009)*
WETH 的交易不仅仅是针对 DAI 的交易,以下是 DEX 交易所的前 10 组交易对:

*DEX 上的前 10 组 WETH 交易对。来源: [bloxy.info DEX API](https://bloxy.info/api_methods)*
#### PETH(Pooled Ether)
PETH 代表了 ETH,你在 Maker DAO 智能合约中投入了 ETH,以在未来创造 DAI 债务。它对 WETH 的费率等于:
```
PETH = WETH * (Total PETH supply) / (WETH balance )
```
现在等于 1.04,因为 PETH 的一部分由于债务清算而被销毁。如图所示,这个数字随着时间的推移而增加:

*与 PETH/WETH 相关的费率和利润。来源:bloxy.info [MakerDAO dashboard](https://stat.bloxy.info/superset/dashboard/makerdao/?standalone=true)*
PETH/WETH 费率的变化为早期进入并用 PETH 换取 WETH 的用户创造了<ruby> 年利率 <rt> Annual Percentage Rate </rt></ruby>(APR)和利润,他们的总利润估计在 80,000 ETH 左右。
PETH 是不能在 DEX 上进行交易的,似乎只作为 Maker DAO 的基础设施在其内部使用。
下面的通证周转显示,主要的 PETH 周转量是 Sai Tub 智能合约之间的互相转移。然后,部分周转量会转到 Sai Tap (在债务清算的情况下),或者转到系统地址(用于销毁):

*PETH 通证周转。来源:[bloxy.info token flow tool](https://bloxy.info/token_graphs/0xf53ad2c6851052a81b42133467480961b2321c09#)*
继续! 在第二部分,我们将讨论 DAI、MKR 和 SIN 通证 !
---
via:<https://medium.com/coinmonks/makerdao-tokens-explained-dai-weth-peth-sin-mkr-part-1-a46a0f687d5e>
作者:Aleksey Studnev 译者:zionfuo
| 200 | OK | # MakerDAO Tokens Explained: DAI, WETH, PETH, SIN, MKR. Part 1
## Maker DAO uses multiple ERC-20 tokens for specific purposes to ensure DAI stable coin stability. This article describe their roles and usage patterns based on Bloxy.info token flow tool.
# Maker DAO Tokens
Maker DAO system consists of several smart contracts ( Sai Tap, Sai Tub, Vox, Medianiser, etc.), and ERC-20 tokens. Together they work to ensure the stability of DAI token.
In this article we mostly focus on how tokens are rotated, and used. The diagram below shows the main token flows and smart contract methods, used to convert one token to another:
Tokens are shown as circles, while smart contracts and their entities are rounded rectangular. The arrows on the diagram means that using these smart contract methods you can change the balance from one token to another.
For example, calling join() will remove WETH tokens from you and give you appropriate amount of PETH tokens instead.
# Unstable ( “Ether”-like) Tokens
The left side of the diagram shows tokens, related to Ether:
*Ether** itself is not directly used in Maker DAO system. If you have Ether originally ( as most of us ), you have to first convert it to WETH ( Wrapped ETH ) token.*
*WETH** is one-to-one reflection of ETH, but as ERC-20 token. In any moment you can change Ether to WETH and back. The downside is that every such transformation requires gas.*
*PETH** is short for “Pooled Ether”. When you deposit WETH to Maker DAO, you get back this token. Note, that It is not exactly one-to-one to Ether, it rate is calculated.*
# Smart Contracts
[ Sai Tub smart contract](https://bloxy.info/address/0x448a5065aebb8e423f0896e6c5d525c040f59af3) stores CDP’s. CDP is your debt in DAI leveraged by PETH. Most operations with Maker DAO done using it.
[ Sai Tap smart contract](https://bloxy.info/address/0xbda109309f9fafa6dd6a9cb9f1df4085b27ee8ef) allows to liquidate the debt and generate the profit from it.
# Smart Contract Methods
Maker DAO smart contracts have a lot of methods, major of them are categorized in the table below:
Most of the method operate with the tokens we listed above and with CDP as internal Sai Tub entity.
More detailed description of these methods you can find in [Maker DAO transactions Illustrated](/coinmonks/maker-dao-transactions-illustrated-691ad2715cf7) article.
# Token Usage Patterns
The material below is created based on the [Bloxy.info](https://bloxy.info) Token Flow tool and Maker DAO analytical [dashboard](https://stat.bloxy.info/superset/dashboard/makerdao/?standalone=true).
*Bloxy.info** web site provides a set of tools for analytics, traders, companies and crypto enthusiasts.*
The tools include APIs, dashboards and search engine, all available on-site, providing accurate data, indexed directly from the blockchain live node.
Bloxy mission is to make blockchain more transparent and accessible to people and businesses.
Please, make a reference to the source of data when referencing this article.
Our goal was to match the smart contract code and the diagram above with actual token flows and user actions regarding these tokens. We will investigate tokens one by one, from different perspectives, using our tools and analytical approach.
And our first token is….
# WETH ( Wrapped Ether)
WETH explanation is on the [weth.io](https://weth.io) web site. It is wrapped Ether, and can be used instead of Ether where ERC-20 tokens are expected. The first coming to mind are decentralized exchanges (DEX). Typically DEX protocols expect ERC20 tokens as buy/sell side assets, and they can not work with Ether directly. So you first change your Ether to WETH, exchange it , amd later WETH can be changed back to Ether.
This token started at December, 2017, the same time as Maker DAO protocol. Note, that the largest holder is Maker DAO smart contract:
The intersection by owners with other tokens also shows Maker DAO tokens:
[bloxy.info](https://bloxy.info/token_holders/0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2)
This high WETH balance on SaiTub MaerDAO smart contract appear, as users deposit WETH to Maker DAO’s SaiTub smart contract to create CDPs later. We analyzed the dynamics of this process on the [MakerDAO dashboard](https://stat.bloxy.info/superset/dashboard/makerdao/?standalone=true):
[MakerDAO dashboard](https://stat.bloxy.info/superset/dashboard/makerdao/?standalone=true)
As seen from this graph, on 10 May, 2019 the locked WETH amount is approx. 2 million ETH ( orange line), while totally minted amount is above 4 million ETH.
How many people involved in this activity? The number of traders can be estimated by unique addresses, initiating exit/join transactions on SaiTub smart contract:
[MakerDAO dashboard](https://stat.bloxy.info/superset/dashboard/makerdao/?standalone=true)
Traders behavior is described by how many WETH the lock and free each month:
[MakerDAO dashboard](https://stat.bloxy.info/superset/dashboard/makerdao/?standalone=true)
Interesting trend that the lock and free amount looks rather symmetrical, before the April 2019, when more people started to withdraw ( free ) WETH from Maker DAO, comparing to deposit ( lock ) it. These are 2 right columns of this diagram. This in turn caused that reduction in WETH balance on Maker DAO.
# WETH outside Maker DAO?
The question is — is it used anywhere except Maker DAO?
Answer is yes. First, it is very actively traded on ZeroX and Oasis ( Matching Market ) exchanges, as shown on Bloxy.info [WETH trading page](http://localhost:3000/token_trades/0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2).
[Token Flow Tool](http://localhost:3000/token_graphs/0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2#) shows major flows of WETH:
[bloxy.info](http://localhost:3000/token_graphs/0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2#)
As you see, there are several “centers of gravity” for WETH token:
- SaiTub from MakerDAI
- Oasis, DDEX exchanges
- ZeroX (not involved in transfers, so not explicitly shown on this graph)
Example of WETH trading by one of the most active traders on DEX is this transaction:
[bloxy.info](https://bloxy.info/tx/0xc538725a76c26695c3fae183bea430bfb86449bc9a066288e52716d22b10f009)
WETH is traded not just agains DAI, here is the list of top 10 pairs on DEX exchanges:
[bloxy.info DEX API](https://bloxy.info/api_methods)
# PETH ( Pooled Ether)
PETH represents ETH, that you put into Maker DAO smart contract to create DAI debt in the future. It has the rate against WETH, equals to
PETH = (WETH balance ) / (Total PETH supply) WETH
It is now equal to 1.04, as part of PETH has been burnt due to debt liquidations. This number increased with time as shown on the diagram:
[MakerDAO dashboard](https://stat.bloxy.info/superset/dashboard/makerdao/?standalone=true)
*The change of PETH/WETH rate generate the APR and profit for the users, who joined the pool and received PETH in exchange to WETH, long time ago. Their summary profit is estimated around 80,000 ETH.*
PETH is not traded on DEX and seems to be used solely inside MakerDAO infrastructure.
Token flow below shows, that the major PETH flow goes from traders to Sai Tub smart contract. Part of the flow then goes to SaiTap ( in case of debt liquidation), or to system address ( for burning ):
[bloxy.info token flow tool](https://bloxy.info/token_graphs/0xf53ad2c6851052a81b42133467480961b2321c09#) |
10,864 | 使用 Black 自由格式化 Python | https://opensource.com/article/19/5/python-black | 2019-05-16T22:04:00 | [
"Python"
] | https://linux.cn/article-10864-1.html |
>
> 在我们覆盖 7 个 PyPI 库的系列文章中了解解决 Python 问题的更多信息。
>
>
>

Python 是当今使用最多的[流行编程语言](https://opensource.com/article/18/5/numbers-python-community-trends)之一,因为:它是开源的,它有广泛的用途(例如 Web 编程、业务应用、游戏、科学编程等等),它有一个充满活力和专注的社区支持它。这个社区可以让我们在 [Python Package Index](https://pypi.org/)(PyPI)中有如此庞大、多样化的软件包,用以扩展和改进 Python 并解决不可避免的问题。
在本系列中,我们将介绍七个可以帮助你解决常见 Python 问题的 PyPI 库。在第一篇文章中,我们了解了 [Cython](https://opensource.com/article/19/4/7-python-problems-solved-cython)。今天,我们将使用 [Black](https://pypi.org/project/black/) 这个代码格式化工具。
### Black
有时创意可能是一件美妙的事情。有时它只是一种痛苦。我喜欢创造性地解决难题,但我希望我的 Python 格式尽可能一致。没有人对使用“有趣”缩进的代码印象深刻。
但是比不一致的格式更糟糕的是除了检查格式之外什么都没有做的代码审查。这对审查者来说很烦人,对于被审查者来说甚至更烦人。当你的 linter 告诉你代码缩进不正确时,但没有提示*正确*的缩进量,这也会令人气愤。
使用 Black,它不会告诉你*要*做什么,它是一个优良、勤奋的机器人:它将为你修复代码。
要了解它如何工作的,请随意写一些非常不一致的内容,例如:
```
def add(a, b): return a+b
def mult(a, b):
return \
a * b
```
Black 抱怨了么?并没有,它为你修复了!
```
$ black math
reformatted math
All done! ✨ ? ✨
1 file reformatted.
$ cat math
def add(a, b):
return a + b
def mult(a, b):
return a * b
```
Black 确实提供了报错而不是修复的选项,甚至还有输出 diff 编辑样式的选项。这些选项在持续集成 (CI)系统中非常有用,可以在本地强制运行 Black。此外,如果 diff 输出被记录到 CI 输出中,你可以直接将其粘贴到 `patch` 中,以便在极少数情况下你需要修复输出,但无法本地安装 Black 使用。
```
$ black --check --diff bad
--- math 2019-04-09 17:24:22.747815 +0000
+++ math 2019-04-09 17:26:04.269451 +0000
@@ -1,7 +1,7 @@
-def add(a, b): return a + b
+def add(a, b):
+ return a + b
def mult(a, b):
- return \
- a * b
+ return a * b
would reformat math
All done! ? ? ?
1 file would be reformatted.
$ echo $?
1
```
在本系列的下一篇文章中,我们将介绍 attrs ,这是一个可以帮助你快速编写简洁、正确的代码的库。
(题图:[Subgrafik San](https://dribbble.com/))
---
via: <https://opensource.com/article/19/5/python-black>
作者:[Moshe Zadka](https://opensource.com/users/moshez/users/moshez/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Python is one of the most [popular programming languages](https://opensource.com/article/18/5/numbers-python-community-trends) in use today—and for good reasons: it's open source, it has a wide range of uses (such as web programming, business applications, games, scientific programming, and much more), and it has a vibrant and dedicated community supporting it. This community is the reason we have such a large, diverse range of software packages available in the [Python Package Index](https://pypi.org/) (PyPI) to extend and improve Python and solve the inevitable glitches that crop up.
In this series, we'll look at seven PyPI libraries that can help you solve common Python problems. In the first article, we learned about [Cython](https://opensource.com/article/19/4/7-python-problems-solved-cython); today, we'll examine the ** Black** code formatter.
## Black
Sometimes creativity can be a wonderful thing. Sometimes it is just a pain. I enjoy solving hard problems creatively, but I want my Python formatted as consistently as possible. Nobody has ever been impressed by code that uses "interesting" indentation.
But even worse than inconsistent formatting is a code review that consists of nothing but formatting nits. It is annoying to the reviewer—and even more annoying to the person whose code is reviewed. It's also infuriating when your linter tells you that your code is indented incorrectly, but gives no hint about the *correct* amount of indentation.
Enter Black. Instead of telling you *what* to do, Black is a good, industrious robot: it will fix your code for you.
To see how it works, feel free to write something beautifully inconsistent like:
```
def add(a, b): return a+b
def mult(a, b):
return \
a * b
```
Does Black complain? Goodness no, it just fixes it for you!
```
$ black math
reformatted math
All done! ✨ ? ✨
1 file reformatted.
$ cat math
def add(a, b):
return a + b
def mult(a, b):
return a * b
```
Black does offer the option of failing instead of fixing and even outputting a **diff**-style edit. These options are great in a continuous integration (CI) system that enforces running Black locally. In addition, if the **diff** output is logged to the CI output, you can directly paste it into **patch** in the rare case that you need to fix your output but cannot install Black locally.
```
$ black --check --diff bad
--- math 2019-04-09 17:24:22.747815 +0000
+++ math 2019-04-09 17:26:04.269451 +0000
@@ -1,7 +1,7 @@
-def add(a, b): return a + b
+def add(a, b):
+ return a + b
def mult(a, b):
- return \
- a * b
+ return a * b
would reformat math
All done! ? ? ?
1 file would be reformatted.
$ echo $?
1
```
In the next article in this series, we'll look at **attrs**, a library that helps you write concise, correct code quickly.
## 3 Comments |
10,865 | 如何使用 rsync 的高级用法进行大型备份 | https://opensource.com/article/19/5/advanced-rsync | 2019-05-16T23:15:33 | [
"rsync",
"备份"
] | https://linux.cn/article-10865-1.html |
>
> 基础的 `rsync` 命令通常足够来管理你的 Linux 备份,但是额外的选项使大型备份集更快、更强大。
>
>
>

很明显,备份一直是 Linux 世界的热门话题。回到 2017,David Both 为 [Opensource.com](http://Opensource.com) 的读者在[使用 rsync 备份 Linux 系统](/article-8237-1.html)方面提了一些建议,在这年的更早时候,他发起了一项问卷调查询问大家,[在 Linux 中你的 /home 目录的主要备份策略是什么](https://opensource.com/poll/19/4/backup-strategy-home-directory-linux),在今年的另一个问卷调查中,Don Watkins 问到,[你使用哪种开源备份解决方案](https://opensource.com/article/19/2/linux-backup-solutions)。
我的回复是 [rsync](https://en.wikipedia.org/wiki/Rsync)。我真的非常喜欢 rsync!市场上有大量大而复杂的工具,对于管理磁带机或者存储库设备,这些可能是必要的,但是可能你需要的只是一个简单的开源命令行工具。
### rsync 基础
我为一个大概拥有 35,000 开发者并有着几十 TB 文件的全球性机构管理二进制仓库。我经常一次移动或者归档上百 GB 的数据。使用的是 `rsync`。这种经历使我对这个简单的工具充满信心。(所以,是的,我在家使用它来备份我的 Linux 系统)
基础的 `rsync` 命令很简单。
```
rsync -av 源目录 目的地目录
```
实际上,在各种指南中教的 `rsync` 命令在大多数通用情况下都运行的很好。然而,假设我们需要备份大量的数据。例如包含 2,000 个子目录的目录,每个包含 50GB 到 700GB 的数据。在这个目录运行 `rsync` 可能需要大量时间,尤其是当你使用校验选项时(我倾向使用)。
当我们试图同步大量数据或者通过慢的网络连接时,可能遇到性能问题。让我给你展示一些我使用的方法来确保好的性能和可靠性。
### rsync 高级用法
`rsync` 运行时出现的第一行是:“正在发送增量文件列表。” 如果你在网上搜索这一行,你将看到很多类似的问题:为什么它一直运行,或者为什么它似乎挂起了。
这里是一个基于这个场景的例子。假设我们有一个 `/storage` 的目录,我们想要备份到一个外部 USB 磁盘,我们可以使用下面的命令:
```
rsync -cav /storage /media/WDPassport
```
`-c` 选项告诉 `rsync` 使用文件校验和而不是时间戳来决定改变的文件,这通常消耗的时间更久。为了分解 `/storage` 目录,我通过子目录同步,使用 `find` 命令。这是一个例子:
```
find /storage -type d -exec rsync -cav {} /media/WDPassport \;
```
这看起来可以,但是如果 `/storage` 目录有任何文件,它们将被跳过。因此,我们如何同步 `/storage` 目录中的文件呢?同样有一个细微的差别是这些选项将造成 `rsync` 会同步 `.` 目录,该目录是源目录自身;这意味着它会同步子目录两次,这并不是我们想要的。
长话短说,我的解决方案是一个 “双-递增”脚本。这允许我分解一个目录,例如,当你的家目录有多个大的目录,例如音乐或者家庭照片时,分解 `/home` 目录为单个的用户家目录。
这是我的脚本的一个例子:
```
HOMES="alan"
DRIVE="/media/WDPassport"
for HOME in $HOMES; do
cd /home/$HOME
rsync -cdlptgov --delete . /$DRIVE/$HOME
find . -maxdepth 1 -type d -not -name "." -exec rsync -crlptgov --delete {} /$DRIVE/$HOME \;
done
```
第一个 `rsync` 命令拷贝它在源目录中发现的文件和目录。然而,它将目录留着不处理,因此我们能够通过 `find` 命令迭代它们。这通过传递 `-d` 参数来完成,它告诉 `rsync` 不要递归目录。
```
-d, --dirs 传输目录而不递归
```
然后 `find` 命令传递每个目录来单独运行 `rsync`。之后 `rsync` 拷贝目录的内容。这通过传递 `-r` 参数来完成,它告诉 `rsync` 要递归目录。
```
-r, --recursive 递归进入目录
```
这使得 `rsync` 使用的增量文件保持在一个合理的大小。
大多数 `rsync` 指南为了简便使用 `-a` (或者 `archive`) 参数。这实际是一个复合参数。
```
-a, --archive 归档模式;等价于 -rlptgoD(没有 -H,-A,-X)
```
我传递的其他参数包含在 `a` 中;这些是 `-l`、`-p`、`-t`、`-g`和 `-o`。
```
-l, --links 复制符号链接作为符号链接
-p, --perms 保留权限
-t, --times 保留修改时间
-g, --group 保留组
-o, --owner 保留拥有者(只适用于超级管理员)
```
`--delete` 选项告诉 `rsync` 删除目的地目录中所有在源目录不存在的任意文件。这种方式,运行的结果仅仅是复制。你同样可以排除 `.Trash` 目录或者 MacOS 创建的 `.DS_Store` 文件。
```
-not -name ".Trash*" -not -name ".DS_Store"
```
### 注意
最后一条建议: `rsync` 可以是破坏性的命令。幸运的是,它的睿智的创造者提供了 “空运行” 的能力。如果我们加入 `n` 选项,rsync 会显示预期的输出但不写任何数据。
```
`rsync -cdlptgovn --delete . /$DRIVE/$HOME`
```
这个脚本适用于非常大的存储规模和高延迟或者慢链接的情况。一如既往,我确信仍有提升的空间。如果你有任何建议,请在下方评论中分享。
---
via: <https://opensource.com/article/19/5/advanced-rsync>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss/users/marcobravo) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It seems clear that backups are always a hot topic in the Linux world. Back in 2017, David Both offered [Opensource.com](http://Opensource.com) readers tips on "[Using rsync to back up your Linux system](https://opensource.com/article/17/1/rsync-backup-linux)," and earlier this year, he published a poll asking us, "[What's your primary backup strategy for the /home directory in Linux?](https://opensource.com/poll/19/4/backup-strategy-home-directory-linux)" In another poll this year, Don Watkins asked, "[Which open source backup solution do you use?](https://opensource.com/article/19/2/linux-backup-solutions)"
My response is [rsync](https://en.wikipedia.org/wiki/Rsync). I really like rsync! There are plenty of large and complex tools on the market that may be necessary for managing tape drives or storage library devices, but a simple open source command line tool may be all you need.
## Basic rsync
I managed the binary repository system for a global organization that had roughly 35,000 developers with multiple terabytes of files. I regularly moved or archived hundreds of gigabytes of data at a time. Rsync was used. This experience gave me confidence in this simple tool. (So, yes, I use it at home to back up my Linux systems.)
The basic rsync command is simple.
`rsync -av SRC DST`
Indeed, the rsync commands taught in any tutorial will work fine for most general situations. However, suppose we need to back up a very large amount of data. Something like a directory with 2,000 sub-directories, each holding anywhere from 50GB to 700GB of data. Running rsync on this directory could take a tremendous amount of time, particularly if you're using the checksum option, which I prefer.
Performance is likely to suffer if we try to sync large amounts of data or sync across slow network connections. Let me show you some methods I use to ensure good performance and reliability.
## Advanced rsync
One of the first lines that appears when rsync runs is: "sending incremental file list." If you do a search for this line, you'll see many questions asking things like: why is it taking forever? or why does it seem to hang up?
Here's an example based on this scenario. Let's say we have a directory called **/storage** that we want to back up to an external USB device mounted at **/media/WDPassport**.
If we want to back up **/storage** to a USB external drive, we could use this command:
`rsync -cav /storage /media/WDPassport`
The **c** option tells rsync to use file checksums instead of timestamps to determine changed files, and this usually takes longer. In order to break down the **/storage** directory, I sync by subdirectory, using the **find** command. Here's an example:
`find /storage -type d -exec rsync -cav {} /media/WDPassport \;`
This looks OK, but if there are any files in the **/storage** directory, they will not be copied. So, how can we sync the files in **/storage**? There is also a small nuance where certain options will cause rsync to sync the **.** directory, which is the root of the source directory; this means it will sync the subdirectories twice, and we don't want that.
Long story short, the solution I settled on is a "double-incremental" script. This allows me to break down a directory, for example, breaking **/home** into the individual users' home directories or in cases when you have multiple large directories, such as music or family photos.
Here is an example of my script:
```
HOMES="alan"
DRIVE="/media/WDPassport"
for HOME in $HOMES; do
cd /home/$HOME
rsync -cdlptgov --delete . /$DRIVE/$HOME
find . -maxdepth 1 -type d -not -name "." -exec rsync -crlptgov --delete {} /$DRIVE/$HOME \;
done
```
The first rsync command copies the files and directories that it finds in the source directory. However, it leaves the directories empty so we can iterate through them using the **find** command. This is done by passing the **d** argument, which tells rsync not to recurse the directory.
`-d, --dirs transfer directories without recursing`
The **find** command then passes each directory to rsync individually. Rsync then copies the directories' contents. This is done by passing the **r** argument, which tells rsync to recurse the directory.
`-r, --recursive recurse into directories`
This keeps the increment file that rsync uses to a manageable size.
Most rsync tutorials use the **a** (or **archive**) argument for convenience. This is actually a compound argument.
`-a, --archive archive mode; equals -rlptgoD (no -H,-A,-X)`
The other arguments that I pass would have been included in the **a**; those are **l**, **p**, **t**, **g**, and **o**.
```
-l, --links copy symlinks as symlinks
-p, --perms preserve permissions
-t, --times preserve modification times
-g, --group preserve group
-o, --owner preserve owner (super-user only)
```
The **--delete** option tells rsync to remove any files on the destination that no longer exist on the source. This way, the result is an exact duplication. You can also add an exclude for the **.Trash** directories or perhaps the **.DS_Store** files created by MacOS.
`-not -name ".Trash*" -not -name ".DS_Store"`
## Be careful
One final recommendation: rsync can be a destructive command. Luckily, its thoughtful creators provided the ability to do "dry runs." If we include the **n** option, rsync will display the expected output without writing any data.
`rsync -cdlptgovn --delete . /$DRIVE/$HOME`
This script is scalable to very large storage sizes and large latency or slow link situations. I'm sure there is still room for improvement, as there always is. If you have suggestions, please share them in the comments.
## 1 Comment |
10,867 | 使用 Python 构建可扩展的社交媒体情感分析服务 | https://opensource.com/article/19/4/social-media-sentiment-analysis-python-scalable | 2019-05-17T23:53:00 | [
"情感"
] | https://linux.cn/article-10867-1.html |
>
> 学习如何使用 spaCy、vaderSentiment、Flask 和 Python 来为你的作品添加情感分析能力。
>
>
>

本系列的[第一部分](/article-10852-1.html)提供了情感分析工作原理的一些背景知识,现在让我们研究如何将这些功能添加到你的设计中。
### 探索 Python 库 spaCy 和 vaderSentiment
#### 前提条件
* 一个终端 shell
* shell 中的 Python 语言二进制文件(3.4+ 版本)
* 用于安装 Python 包的 `pip` 命令
* (可选)一个 [Python 虚拟环境](https://virtualenv.pypa.io/en/stable/)使你的工作与系统隔离开来
#### 配置环境
在开始编写代码之前,你需要安装 [spaCy](https://pypi.org/project/spacy/) 和 [vaderSentiment](https://pypi.org/project/vaderSentiment/) 包来设置 Python 环境,同时下载一个语言模型来帮助你分析。幸运的是,大部分操作都容易在命令行中完成。
在 shell 中,输入以下命令来安装 spaCy 和 vaderSentiment 包:
```
pip install spacy vaderSentiment
```
命令安装完成后,安装 spaCy 可用于文本分析的语言模型。以下命令将使用 spaCy 模块下载并安装英语[模型](https://spacy.io/models):
```
python -m spacy download en_core_web_sm
```
安装了这些库和模型之后,就可以开始编码了。
#### 一个简单的文本分析
使用 [Python 解释器交互模式](https://docs.python.org/3.6/tutorial/interpreter.html) 编写一些代码来分析单个文本片段。首先启动 Python 环境:
```
$ python
Python 3.6.8 (default, Jan 31 2019, 09:38:34)
[GCC 8.2.1 20181215 (Red Hat 8.2.1-6)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
```
*(你的 Python 解释器版本打印可能与此不同。)*
1、导入所需模块:
```
>>> import spacy
>>> from vaderSentiment import vaderSentiment
```
2、从 spaCy 加载英语语言模型:
```
>>> english = spacy.load("en_core_web_sm")
```
3、处理一段文本。本例展示了一个非常简单的句子,我们希望它能给我们带来些许积极的情感:
```
>>> result = english("I like to eat applesauce with sugar and cinnamon.")
```
4、从处理后的结果中收集句子。SpaCy 已识别并处理短语中的实体,这一步为每个句子生成情感(即时在本例中只有一个句子):
```
>>> sentences = [str(s) for s in result.sents]
```
5、使用 vaderSentiments 创建一个分析器:
```
>>> analyzer = vaderSentiment.SentimentIntensityAnalyzer()
```
6、对句子进行情感分析:
```
>>> sentiment = [analyzer.polarity_scores(str(s)) for s in sentences]
```
`sentiment` 变量现在包含例句的极性分数。打印出这个值,看看它是如何分析这个句子的。
```
>>> print(sentiment)
[{'neg': 0.0, 'neu': 0.737, 'pos': 0.263, 'compound': 0.3612}]
```
这个结构是什么意思?
表面上,这是一个只有一个字典对象的数组。如果有多个句子,那么每个句子都会对应一个字典对象。字典中有四个键对应不同类型的情感。`neg` 键表示负面情感,因为在本例中没有报告任何负面情感,`0.0` 值证明了这一点。`neu` 键表示中性情感,它的得分相当高,为 `0.737`(最高为 `1.0`)。`pos` 键代表积极情感,得分适中,为 `0.263`。最后,`cmpound` 键代表文本的总体得分,它可以从负数到正数,`0.3612` 表示积极方面的情感多一点。
要查看这些值可能如何变化,你可以使用已输入的代码做一个小实验。以下代码块显示了如何对类似句子的情感评分的评估。
```
>>> result = english("I love applesauce!")
>>> sentences = [str(s) for s in result.sents]
>>> sentiment = [analyzer.polarity_scores(str(s)) for s in sentences]
>>> print(sentiment)
[{'neg': 0.0, 'neu': 0.182, 'pos': 0.818, 'compound': 0.6696}]
```
你可以看到,通过将例句改为非常积极的句子,`sentiment` 的值发生了巨大变化。
### 建立一个情感分析服务
现在你已经为情感分析组装了基本的代码块,让我们将这些东西转化为一个简单的服务。
在这个演示中,你将使用 Python [Flask 包](http://flask.pocoo.org/) 创建一个 [RESTful](https://en.wikipedia.org/wiki/Representational_state_transfer) HTTP 服务器。此服务将接受英文文本数据并返回情感分析结果。请注意,此示例服务是用于学习所涉及的技术,而不是用于投入生产的东西。
#### 前提条件
* 一个终端 shell
* shell 中的 Python 语言二进制文件(3.4+ 版本)
* 安装 Python 包的 `pip` 命令
* `curl` 命令
* 一个文本编辑器
* (可选) 一个 [Python 虚拟环境](https://virtualenv.pypa.io/en/stable/)使你的工作与系统隔离开来
#### 配置环境
这个环境几乎与上一节中的环境相同,唯一的区别是在 Python 环境中添加了 Flask 包。
1、安装所需依赖项:
```
pip install spacy vaderSentiment flask
```
2、安装 spaCy 的英语语言模型:
```
python -m spacy download en_core_web_sm
```
#### 创建应用程序文件
打开编辑器,创建一个名为 `app.py` 的文件。添加以下内容 *(不用担心,我们将解释每一行)*:
```
import flask
import spacy
import vaderSentiment.vaderSentiment as vader
app = flask.Flask(__name__)
analyzer = vader.SentimentIntensityAnalyzer()
english = spacy.load("en_core_web_sm")
def get_sentiments(text):
result = english(text)
sentences = [str(sent) for sent in result.sents]
sentiments = [analyzer.polarity_scores(str(s)) for s in sentences]
return sentiments
@app.route("/", methods=["POST", "GET"])
def index():
if flask.request.method == "GET":
return "To access this service send a POST request to this URL with" \
" the text you want analyzed in the body."
body = flask.request.data.decode("utf-8")
sentiments = get_sentiments(body)
return flask.json.dumps(sentiments)
```
虽然这个源文件不是很大,但它非常密集。让我们来看看这个应用程序的各个部分,并解释它们在做什么。
```
import flask
import spacy
import vaderSentiment.vaderSentiment as vader
```
前三行引入了执行语言分析和 HTTP 框架所需的包。
```
app = flask.Flask(__name__)
analyzer = vader.SentimentIntensityAnalyzer()
english = spacy.load("en_core_web_sm")
```
接下来的三行代码创建了一些全局变量。第一个变量 `app`,它是 Flask 用于创建 HTTP 路由的主要入口点。第二个变量 `analyzer` 与上一个示例中使用的类型相同,它将用于生成情感分数。最后一个变量 `english` 也与上一个示例中使用的类型相同,它将用于注释和标记初始文本输入。
你可能想知道为什么全局声明这些变量。对于 `app` 变量,这是许多 Flask 应用程序的标准过程。但是,对于 `analyzer` 和 `english` 变量,将它们设置为全局变量的决定是基于与所涉及的类关联的加载时间。虽然加载时间可能看起来很短,但是当它在 HTTP 服务器的上下文中运行时,这些延迟会对性能产生负面影响。
```
def get_sentiments(text):
result = english(text)
sentences = [str(sent) for sent in result.sents]
sentiments = [analyzer.polarity_scores(str(s)) for s in sentences]
return sentiments
```
这部分是服务的核心 —— 一个用于从一串文本生成情感值的函数。你可以看到此函数中的操作对应于你之前在 Python 解释器中运行的命令。这里它们被封装在一个函数定义中,`text` 源作为文本变量传入,最后 `sentiments` 变量返回给调用者。
```
@app.route("/", methods=["POST", "GET"])
def index():
if flask.request.method == "GET":
return "To access this service send a POST request to this URL with" \
" the text you want analyzed in the body."
body = flask.request.data.decode("utf-8")
sentiments = get_sentiments(body)
return flask.json.dumps(sentiments)
```
源文件的最后一个函数包含了指导 Flask 如何为服务配置 HTTP 服务器的逻辑。它从一行开始,该行将 HTTP 路由 `/` 与请求方法 `POST` 和 `GET` 相关联。
在函数定义行之后,`if` 子句将检测请求方法是否为 `GET`。如果用户向服务发送此请求,那么下面的行将返回一条指示如何访问服务器的文本消息。这主要是为了方便最终用户。
下一行使用 `flask.request` 对象来获取请求的主体,该主体应包含要处理的文本字符串。`decode` 函数将字节数组转换为可用的格式化字符串。经过解码的文本消息被传递给 `get_sentiments` 函数以生成情感分数。最后,分数通过 HTTP 框架返回给用户。
你现在应该保存文件,如果尚未保存,那么返回 shell。
#### 运行情感服务
一切就绪后,使用 Flask 的内置调试服务器运行服务非常简单。要启动该服务,请从与源文件相同的目录中输入以下命令:
```
FLASK_APP=app.py flask run
```
现在,你将在 shell 中看到来自服务器的一些输出,并且服务器将处于运行状态。要测试服务器是否正在运行,你需要打开第二个 shell 并使用 `curl` 命令。
首先,输入以下命令检查是否打印了指令信息:
```
curl http://localhost:5000
```
你应该看到说明消息:
```
To access this service send a POST request to this URI with the text you want analyzed in the body.
```
接下来,运行以下命令发送测试消息,查看情感分析:
```
curl http://localhost:5000 --header "Content-Type: application/json" --data "I love applesauce!"
```
你从服务器获得的响应应类似于以下内容:
```
[{"compound": 0.6696, "neg": 0.0, "neu": 0.182, "pos": 0.818}]
```
恭喜!你现在已经实现了一个 RESTful HTTP 情感分析服务。你可以在 [GitHub 上找到此服务的参考实现和本文中的所有代码](https://github.com/elmiko/social-moments-service)。
### 继续探索
现在你已经了解了自然语言处理和情感分析背后的原理和机制,下面是进一步发现探索该主题的一些方法。
#### 在 OpenShift 上创建流式情感分析器
虽然创建本地应用程序来研究情绪分析很方便,但是接下来需要能够部署应用程序以实现更广泛的用途。按照[Radnaalytics.io](https://github.com/radanalyticsio/streaming-lab) 提供的指导和代码进行操作,你将学习如何创建一个情感分析仪,可以容器化并部署到 Kubernetes 平台。你还将了解如何将 Apache Kafka 用作事件驱动消息传递的框架,以及如何将 Apache Spark 用作情绪分析的分布式计算平台。
#### 使用 Twitter API 发现实时数据
虽然 [Radanalytics.io](http://Radanalytics.io) 实验室可以生成合成推文流,但你可以不受限于合成数据。事实上,拥有 Twitter 账户的任何人都可以使用 [Tweepy Python](https://github.com/tweepy/tweepy) 包访问 Twitter 流媒体 API 对推文进行情感分析。
---
via: <https://opensource.com/article/19/4/social-media-sentiment-analysis-python-scalable>
作者:[Michael McCune](https://opensource.com/users/elmiko/users/jschlessman) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [first part](https://opensource.com/article/19/4/social-media-sentiment-analysis-python-part-1) of this series provided some background on how sentiment analysis works. Now let's investigate how to add these capabilities to your designs.
## Exploring spaCy and vaderSentiment in Python
### Prerequisites
- A terminal shell
- Python language binaries (version 3.4+) in your shell
- The
**pip**command for installing Python packages - (optional) A
[Python Virtualenv](https://virtualenv.pypa.io/en/stable/)to keep your work isolated from the system
### Configure your environment
Before you begin writing code, you will need to set up the Python environment by installing the [spaCy](https://pypi.org/project/spacy/) and [vaderSentiment](https://pypi.org/project/vaderSentiment/) packages and downloading a language model to assist your analysis. Thankfully, most of this is relatively easy to do from the command line.
In your shell, type the following command to install the spaCy and vaderSentiment packages:
`pip install spacy vaderSentiment`
After the command completes, install a language model that spaCy can use for text analysis. The following command will use the spaCy module to download and install the English language [model](https://spacy.io/models):
`python -m spacy download en_core_web_sm`
With these libraries and models installed, you are now ready to begin coding.
### Do a simple text analysis
Use the [Python interpreter interactive mode](https://docs.python.org/3.6/tutorial/interpreter.html) to write some code that will analyze a single text fragment. Begin by starting the Python environment:
```
$ python
Python 3.6.8 (default, Jan 31 2019, 09:38:34)
[GCC 8.2.1 20181215 (Red Hat 8.2.1-6)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
```
*(Your Python interpreter version print might look different than this.)*
- Import the necessary modules:
`>>> import spacy >>> from vaderSentiment import vaderSentiment`
- Load the English language model from spaCy:
`>>> english = spacy.load("en_core_web_sm")`
- Process a piece of text. This example shows a very simple sentence that we expect to return a slightly positive sentiment:
`>>> result = english("I like to eat applesauce with sugar and cinnamon.")`
- Gather the sentences from the processed result. SpaCy has identified and processed the entities within the phrase; this step generates sentiment for each sentence (even though there is only one sentence in this example):
`>>> sentences = [str(s) for s in result.sents]`
- Create an analyzer using vaderSentiments:
`>>> analyzer = vaderSentiment.SentimentIntensityAnalyzer()`
- Perform the sentiment analysis on the sentences:
`>>> sentiment = [analyzer.polarity_scores(str(s)) for s in sentences]`
The sentiment variable now contains the polarity scores for the example sentence. Print out the value to see how it analyzed the sentence.
```
>>> print(sentiment)
[{'neg': 0.0, 'neu': 0.737, 'pos': 0.263, 'compound': 0.3612}]
```
What does this structure mean?
On the surface, this is an array with a single dictionary object; had there been multiple sentences, there would be a dictionary for each one. There are four keys in the dictionary that correspond to different types of sentiment. The **neg** key represents negative sentiment, of which none has been reported in this text, as evidenced by the **0.0** value. The **neu** key represents neutral sentiment, which has gotten a fairly high score of **0.737** (with a maximum of **1.0**). The **pos** key represents positive sentiments, which has a moderate score of **0.263**. Last, the **compound** key represents an overall score for the text; this can range from negative to positive scores, with the value **0.3612** representing a sentiment more on the positive side.
To see how these values might change, you can run a small experiment using the code you already entered. The following block demonstrates an evaluation of sentiment scores on a similar sentence.
```
>>> result = english("I love applesauce!")
>>> sentences = [str(s) for s in result.sents]
>>> sentiment = [analyzer.polarity_scores(str(s)) for s in sentences]
>>> print(sentiment)
[{'neg': 0.0, 'neu': 0.182, 'pos': 0.818, 'compound': 0.6696}]
```
You can see that by changing the example sentence to something overwhelmingly positive, the sentiment values have changed dramatically.
## Building a sentiment analysis service
Now that you have assembled the basic building blocks for doing sentiment analysis, let's turn that knowledge into a simple service.
For this demonstration, you will create a [RESTful](https://en.wikipedia.org/wiki/Representational_state_transfer) HTTP server using the Python [Flask package](http://flask.pocoo.org/). This service will accept text data in English and return the sentiment analysis. Please note that this example service is for learning the technologies involved and not something to put into production.
### Prerequisites
- A terminal shell
- The Python language binaries (version 3.4+) in your shell.
- The
**pip**command for installing Python packages - The
**curl**command - A text editor
- (optional) A
[Python Virtualenv](https://virtualenv.pypa.io/en/stable/)to keep your work isolated from the system
### Configure your environment
This environment is nearly identical to the one in the previous section. The only difference is the addition of the Flask package to Python.
- Install the necessary dependencies:
`pip install spacy vaderSentiment flask`
- Install the English language model for spaCy:
`python -m spacy download en_core_web_sm`
### Create the application file
Open your editor and create a file named **app.py**. Add the following contents to it *(don't worry, we will review every line)*:
```
import flask
import spacy
import vaderSentiment.vaderSentiment as vader
app = flask.Flask(__name__)
analyzer = vader.SentimentIntensityAnalyzer()
english = spacy.load("en_core_web_sm")
def get_sentiments(text):
result = english(text)
sentences = [str(sent) for sent in result.sents]
sentiments = [analyzer.polarity_scores(str(s)) for s in sentences]
return sentiments
@app.route("/", methods=["POST", "GET"])
def index():
if flask.request.method == "GET":
return "To access this service send a POST request to this URL with" \
" the text you want analyzed in the body."
body = flask.request.data.decode("utf-8")
sentiments = get_sentiments(body)
return flask.json.dumps(sentiments)
```
Although this is not an overly large source file, it is quite dense. Let's walk through the pieces of this application and describe what they are doing.
```
import flask
import spacy
import vaderSentiment.vaderSentiment as vader
```
The first three lines bring in the packages needed for performing the language analysis and the HTTP framework.
```
app = flask.Flask(__name__)
analyzer = vader.SentimentIntensityAnalyzer()
english = spacy.load("en_core_web_sm")
```
The next three lines create a few global variables. The first variable, **app**, is the main entry point that Flask uses for creating HTTP routes. The second variable, **analyzer**, is the same type used in the previous example, and it will be used to generate the sentiment scores. The last variable, **english**, is also the same type used in the previous example, and it will be used to annotate and tokenize the initial text input.
You might be wondering why these variables have been declared globally. In the case of the **app** variable, this is standard procedure for many Flask applications. But, in the case of the **analyzer** and **english** variables, the decision to make them global is based on the load times associated with the classes involved. Although the load time might appear minor, when it's run in the context of an HTTP server, these delays can negatively impact performance.
```
def get_sentiments(text):
result = english(text)
sentences = [str(sent) for sent in result.sents]
sentiments = [analyzer.polarity_scores(str(s)) for s in sentences]
return sentiments
```
The next piece is the heart of the service—a function for generating sentiment values from a string of text. You can see that the operations in this function correspond to the commands you ran in the Python interpreter earlier. Here they're wrapped in a function definition with the source **text** being passed in as the variable text and finally the **sentiments** variable returned to the caller.
```
@app.route("/", methods=["POST", "GET"])
def index():
if flask.request.method == "GET":
return "To access this service send a POST request to this URL with" \
" the text you want analyzed in the body."
body = flask.request.data.decode("utf-8")
sentiments = get_sentiments(body)
return flask.json.dumps(sentiments)
```
The last function in the source file contains the logic that will instruct Flask how to configure the HTTP server for the service. It starts with a line that will associate an HTTP route **/** with the request methods **POST** and **GET**.
After the function definition line, the **if** clause will detect if the request method is **GET**. If a user sends this request to the service, the following line will return a text message instructing how to access the server. This is largely included as a convenience to end users.
The next line uses the **flask.request** object to acquire the body of the request, which should contain the text string to be processed. The **decode** function will convert the array of bytes into a usable, formatted string. The decoded text message is now passed to the **get_sentiments** function to generate the sentiment scores. Last, the scores are returned to the user through the HTTP framework.
You should now save the file, if you have not done so already, and return to the shell.
### Run the sentiment service
With everything in place, running the service is quite simple with Flask's built-in debugging server. To start the service, enter the following command from the same directory as your source file:
`FLASK_APP=app.py flask run`
You will now see some output from the server in your shell, and the server will be running. To test that the server is running, you will need to open a second shell and use the **curl** command.
First, check to see that the instruction message is printed by entering this command:
`curl http://localhost:5000`
You should see the instruction message:
`To access this service send a POST request to this URI with the text you want analyzed in the body.`
Next, send a test message to see the sentiment analysis by running the following command:
`curl http://localhost:5000 --header "Content-Type: application/json" --data "I love applesauce!"`
The response you get from the server should be similar to the following:
`[{"compound": 0.6696, "neg": 0.0, "neu": 0.182, "pos": 0.818}]`
Congratulations! You have now implemented a RESTful HTTP sentiment analysis service. You can find a link to a [reference implementation of this service and all the code from this article on GitHub](https://github.com/elmiko/social-moments-service).
## Continue exploring
Now that you have an understanding of the principles and mechanics behind natural language processing and sentiment analysis, here are some ways to further your discovery of this topic.
### Create a streaming sentiment analyzer on OpenShift
While creating local applications to explore sentiment analysis is a convenient first step, having the ability to deploy your applications for wider usage is a powerful next step. By following the instructions and code in this [workshop from Radanalytics.io](https://github.com/radanalyticsio/streaming-lab), you will learn how to create a sentiment analyzer that can be containerized and deployed to a Kubernetes platform. You will also see how Apache Kafka is used as a framework for event-driven messaging and how Apache Spark can be used as a distributed computing platform for sentiment analysis.
### Discover live data with the Twitter API
Although the [Radanalytics.io](http://Radanalytics.io) lab generated synthetic tweets to stream, you are not limited to synthetic data. In fact, anyone with a Twitter account can access the Twitter streaming API and perform sentiment analysis on tweets with the [Tweepy Python](https://github.com/tweepy/tweepy) package.
## Comments are closed. |
10,868 | 用 Linux Shell 脚本来监控磁盘使用情况并发送邮件 | https://www.2daygeek.com/linux-shell-script-to-monitor-disk-space-usage-and-send-email/ | 2019-05-18T00:21:30 | [
"磁盘"
] | https://linux.cn/article-10868-1.html | 
市场上有很多用来监控 Linux 系统的监控工具,当系统到达阀值后它将发送一封邮件。它监控所有的东西例如 CPU 利用率、内存利用率、交换空间利用率、磁盘空间利用率等等。然而,它更适合小环境和大环境。
想一想如果你只有少量系统,那么什么是最好的方式来应对这种情况。
是的,我们想要写一个 [shell 脚本](https://www.2daygeek.com/category/shell-script/) 来实现。
在这篇指南中我们打算写一个 shell 脚本来监控系统的磁盘空间使用率。当系统到达给定的阀值,它将给对应的邮件地址发送一封邮件。在这篇文章中我们总共添加了四个 shell 脚本,每个用于不同的目的。之后,我们会想出其他 shell 脚本来监控 CPU,内存和交换空间利用率。
在此之前,我想澄清一件事,根据我观察的磁盘空间使用率 shell 脚本使用情况。
大多数用户在多篇博客中评论说,当他们运行磁盘空间使用率脚本时他们获得了以下错误。
```
# sh /opt/script/disk-usage-alert-old.sh
/dev/mapper/vg_2g-lv_root
test-script.sh: line 7: [: /dev/mapper/vg_2g-lv_root: integer expression expected
/ 9.8G
```
是的,这是对的。甚至,当我第一次运行这个脚本的时候我遇到了相同的问题。之后,我发现了根本原因。
当你在基于 RHEL 5 & RHEL 6 的系统上运行包含用于磁盘空间警告的 `df -h` 或 `df -H` 的 shell 脚本中时,你会发现上述错误信息,因为输出格式不对,查看下列输出。
为了解决这个问题,我们需要用 `df -Ph` (POSIX 输出格式),但是默认的 `df -h` 在基于 RHEL 7 的系统上运行的很好。
```
# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg_2g-lv_root
10G 6.7G 3.4G 67% /
tmpfs 7.8G 0 7.8G 0% /dev/shm
/dev/sda1 976M 95M 830M 11% /boot
/dev/mapper/vg_2g-lv_home
5.0G 4.3G 784M 85% /home
/dev/mapper/vg_2g-lv_tmp
4.8G 14M 4.6G 1% /tmp
```
### 方法一:Linux Shell 脚本来监控磁盘空间使用率和发送邮件
你可以使用下列 shell 脚本在 Linux 系统中来监控磁盘空间使用率。
当系统到达给定的阀值限制时,它将发送一封邮件。在这个例子中,我们设置阀值为 60% 用于测试目的,你可以改变这个限制来符合你的需求。
如果超过一个文件系统到达给定的阀值,它将发送多封邮件,因为这个脚本使用了循环。
同样,替换你的邮件地址来获取这份警告。
```
# vi /opt/script/disk-usage-alert.sh
#!/bin/sh
df -Ph | grep -vE '^Filesystem|tmpfs|cdrom' | awk '{ print $5,$1 }' | while read output;
do
echo $output
used=$(echo $output | awk '{print $1}' | sed s/%//g)
partition=$(echo $output | awk '{print $2}')
if [ $used -ge 60 ]; then
echo "The partition \"$partition\" on $(hostname) has used $used% at $(date)" | mail -s "Disk Space Alert: $used% Used On $(hostname)" [email protected]
fi
done
```
输出:我获得了下列两封邮件警告。
```
The partition "/dev/mapper/vg_2g-lv_home" on 2g.CentOS7 has used 85% at Mon Apr 29 06:16:14 IST 2019
The partition "/dev/mapper/vg_2g-lv_root" on 2g.CentOS7 has used 67% at Mon Apr 29 06:16:14 IST 2019
```
最终添加了一个 [cronjob](https://www.2daygeek.com/crontab-cronjob-to-schedule-jobs-in-linux/) 来自动完成。它会每 10 分钟运行一次。
```
# crontab -e
*/10 * * * * /bin/bash /opt/script/disk-usage-alert.sh
```
### 方法二:Linux Shell 脚本来监控磁盘空间使用率和发送邮件
作为代替,你可以使用下列的 shell 脚本。对比上面的脚本我们做了少量改变。
```
# vi /opt/script/disk-usage-alert-1.sh
#!/bin/sh
df -Ph | grep -vE '^Filesystem|tmpfs|cdrom' | awk '{ print $5,$1 }' | while read output;
do
max=60%
echo $output
used=$(echo $output | awk '{print $1}')
partition=$(echo $output | awk '{print $2}')
if [ ${used%?} -ge ${max%?} ]; then
echo "The partition \"$partition\" on $(hostname) has used $used at $(date)" | mail -s "Disk Space Alert: $used Used On $(hostname)" [email protected]
fi
done
```
输出:我获得了下列两封邮件警告。
```
The partition "/dev/mapper/vg_2g-lv_home" on 2g.CentOS7 has used 85% at Mon Apr 29 06:16:14 IST 2019
The partition "/dev/mapper/vg_2g-lv_root" on 2g.CentOS7 has used 67% at Mon Apr 29 06:16:14 IST 2019
```
最终添加了一个 [cronjob](https://www.2daygeek.com/crontab-cronjob-to-schedule-jobs-in-linux/) 来自动完成。它会每 10 分钟运行一次。
```
# crontab -e
*/10 * * * * /bin/bash /opt/script/disk-usage-alert-1.sh
```
### 方法三:Linux Shell 脚本来监控磁盘空间使用率和发送邮件
我更喜欢这种方法。因为,它工作起来很有魔力,你只会收到一封关于所有事的邮件。
这相当简单和直接。
```
*/10 * * * * df -Ph | sed s/%//g | awk '{ if($5 > 60) print $0;}' | mail -s "Disk Space Alert On $(hostname)" [email protected]
```
输出: 我获得了一封关于所有警告的邮件。
```
Filesystem Size Used Avail Use Mounted on
/dev/mapper/vg_2g-lv_root 10G 6.7G 3.4G 67 /
/dev/mapper/vg_2g-lv_home 5.0G 4.3G 784M 85 /home
```
### 方法四:Linux Shell 脚本来监控某个分区的磁盘空间使用情况和发送邮件
```
# vi /opt/script/disk-usage-alert-2.sh
#!/bin/bash
used=$(df -Ph | grep '/dev/mapper/vg_2g-lv_dbs' | awk {'print $5'})
max=80%
if [ ${used%?} -ge ${max%?} ]; then
echo "The Mount Point "/DB" on $(hostname) has used $used at $(date)" | mail -s "Disk space alert on $(hostname): $used used" [email protected]
fi
```
输出: 我得到了下面的邮件警告。
```
The partition /dev/mapper/vg_2g-lv_dbs on 2g.CentOS6 has used 82% at Mon Apr 29 06:16:14 IST 2019
```
最终添加了一个 [cronjob](https://www.2daygeek.com/crontab-cronjob-to-schedule-jobs-in-linux/) 来自动完成这些工作。它将每 10 分钟运行一次。
```
# crontab -e
*/10 * * * * /bin/bash /opt/script/disk-usage-alert-2.sh
```
注意: 你将在 10 分钟后收到一封邮件警告,因为这个脚本被计划为每 10 分钟运行一次(但也不是精确的 10 分钟,取决于时间)。
例如这个例子。如果你的系统在 8:25 到达了限制,你将在 5 分钟后收到邮件警告。希望现在讲清楚了。
---
via: <https://www.2daygeek.com/linux-shell-script-to-monitor-disk-space-usage-and-send-email/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,870 | 9102 年的 PHP | https://stitcher.io/blog/php-in-2019 | 2019-05-18T18:32:00 | [
"PHP"
] | https://linux.cn/article-10870-1.html | 
你还记得篇流行的博客文章《[PHP:设计糟糕的分形](https://eev.ee/blog/2012/04/09/php-a-fractal-of-bad-design/)》吗?我第一次读到它时,我在一个有很多遗留的 PHP 项目的糟糕地方工作。这篇文章让我觉得我是否应该放弃,并去做与编程完全不同的事情。
还好,我之后很快就换了工作,更重要的是,自从 5.x 版本以来,PHP 成功地进步了很多。今天,我在向那些不再使用 PHP 编程,或者陷入遗留项目的人们致意。
剧透:今天有些事情仍然很糟糕,就像几乎每种编程语言都有它的怪癖一样。许多核心功能仍然有不一致的调用方法,仍然有令人困惑的配置设置,仍然有许多开发人员在那里写蹩脚的代码 —— 因为他们必须如此,或是他们不知道更好的写法。
今天我想看看好的一面:让我们关注已经发生变化的事情,以及编写干净而可维护的 PHP 代码的方法。在此之前,我想请你暂时搁置任何偏见。
然后,你可以像以前一样对 PHP 自由吐槽。虽然,你可能会对 PHP 在过去的几年里的一些改进感到惊讶。(LCTT 译注:说实话,我是真的感到吃惊)
### 提前看结论
* PHP 在积极地开发,每年都有新版本
* 自 PHP 5 时代以来的性能已经翻倍,如果不是三倍的话
* 有一个非常活跃的框架、包和平台的生态系统
* PHP 在过去几年中添加了许多新功能,并且这种语言在不断发展
* 像静态分析这样的工具在过去几年中已经成熟,并且一直保持增长 更新:人们让我展示一些实际的代码。我觉得这没问题!这是我的一个业余项目的[源代码](https://github.com/brendt/aggregate.stitcher.io),用 PHP 和 Laravel 编写的;[这里](https://spatie.be/open-source/packages)列出了我们在办公室维护的几百个自由开源软件包。这两者都是现代 PHP 项目的好例子。
那让我们开始吧。
### 历史总结
出于更好地衡量的目的,让我们快速回顾一下如今的 PHP 发布周期。我们现在的 PHP 为 7.3,预计在 2019 年底为 7.4。PHP 8.0 将是 7.4 之后的下一个版本。
自从 5.x 时代以来,核心团队试图保持每年发布一个版本的周期,并且他们在过去的四年中成功地做到了这一点。
一般来说,每个新版本都会在两年内得到积极支持,并再获得一年以上的“安全修复”。其目标是激励 PHP 开发人员尽可能保持最新:例如,每年进行小规模升级比在 5.4 到 7.0 之间跳转更容易。
可以在 [这里](https://www.php.net/supported-versions.php) 找到 PHP 时间轴的活动概述。

最后,PHP 5.6 是最新的 5.x 版本,而 8.0 是当前的下一个大版本。如果你想知道 PHP 6 发生了什么,你可以听听 [PHP Roundtable 播客](https://www.phproundtable.com/episode/what-happened-to-php-6)。
了解了这个,让我们揭穿一些关于现代 PHP 的常见误解。
### PHP 的性能
早在 5.x 时代,PHP 的表现就是……嗯,平均水平。但是在 7.0 版本中,PHP 从头开始重写了核心部分,导致其性能提升了两到三倍!
但光是嘴说是不够的。让我们来看看基准测试。幸运的是,人们花了很多时间对 PHP 性能进行了基准测试。 我发现 [Kinsta](https://kinsta.com/blog/php-benchmarks/) 有一个很好的更新的测试列表。
自 7.0 升级以来,性能就一直在提升而没有回退。PHP Web 应用程序的性能可与其它语言中的 Web 框架相提并论,甚至在某些情况下更好。你可以看看这个[广泛的基准测试套件](https://github.com/the-benchmarker/web-frameworks)。
当然 PHP 框架不会胜过 C 和 Rust,但它们比 Rails 或 Django 要好得多,并且与 ExpressJS 相当。
### 框架和生态系统
说到框架:PHP 可不仅仅是 WordPress。让我告诉你 —— 某些专业的 PHP 开发人员:WordPress 绝不代表当代的 PHP 生态系统。
一般来说,有两个主要的 Web 应用程序框架,[Symfony](https://symfony.com/) 和 [Laravel](https://laravel.com/),以及一些较小的应用程序框架。当然还有 Zend、Yii、Cake、Code Igniter 等等,但是如果你想知道现代 PHP 开发是怎么样的,这两者之一都是很好的选择。
这两个框架都有一个庞大的包和产品的生态系统。从管理面板和 CRM 到独立软件包,从 CI 到分析器,以及几个 Web 套接字服务器、队列管理器、支付集成等众多服务。老实说,要列出的内容太多了。
这些框架虽然适用于实际开发。如果你只是需要个内容管理系统(CMS),WordPress 和 CraftCMS 等平台就够了。
衡量 PHP 生态系统当前状态的一种方法是查看 Packagist,这是 PHP 主要的软件包存储库。它现在呈指数级增长。每天下载量达到了 2500 万次,可以说 PHP 生态系统已不再是以前的小型弱势群体了。
请查看此图表,它列出一段时间内的软件包和版本数量变化。它也可以在 [Packagist 网站](https://packagist.org/statistics)上找到它。

除了应用程序框架和 CMS 之外,我们还看到过去几年里异步框架的兴起。
这些是用 PHP 或其他语言编写的框架和服务器,允许用户运行真正的异步 PHP,这些例子包括 [Swoole](https://www.swoole.co.uk/)(创始人韩天峰),以及 [Amp](https://amphp.org/) 和 [ReactPHP](https://reactphp.org/)。
我们已经进入了异步的世界,像 Web 套接字和具有大量 I/O 的应用程序之类的东西在 PHP 世界中已经变得非常重要。
在内部邮件列表里(PHP 核心开发人员讨论语言开发的地方)已经谈到了[将 libuv 添加到核心](https://externals.io/message/102415#102415)。如果你还不知道 libuv:Node.js 全有赖它提供异步性。
### 语言本身
虽然尚未提供 `async` 和 `await`,但在过去几年中,PHP 语言本身已经有了很多改进。这是 PHP 中新功能的非详尽列表:
* [短闭包](https://stitcher.io/blog/short-closures-in-php)(箭头函数)
* [Null 合并操作符](https://stitcher.io/blog/shorthand-comparisons-in-php#null-coalescing-operator)(`??`)
* [Trait](https://www.php.net/manual/en/language.oop5.traits.php)(一种代码重用方式)
* [属性类型](https://stitcher.io/blog/new-in-php-74#typed-properties-rfc)
* [展开操作符](https://wiki.php.net/rfc/argument_unpacking)(参数解包 `...`)
* [JIT 编译器](https://wiki.php.net/rfc/jit)(即时编译器)
* [FFI](https://wiki.php.net/rfc/ffi)(外部函数接口)
* [匿名类](https://www.php.net/manual/en/language.oop5.anonymous.php)
* [返回类型声明](https://www.php.net/manual/en/functions.returning-values.php#functions.returning-values.type-declaration)
* [现代化的加密支持](https://wiki.php.net/rfc/libsodium)
* [生成器](https://wiki.php.net/rfc/generators)
* [等等](https://www.php.net/ChangeLog-7.php)
当我们讨论语言功能时,我们还要谈谈当今该语言的发展过程。虽然社区可以提出 RFC,但是得有一个活跃的志愿者核心团队才能推着它前进。
接下来,这些 RFC 将在“内部”邮件列表中进行讨论,这个邮件列表也可以[在线阅读](https://externals.io/)。在添加新的语言特性之前,必须进行投票。只有得到了至少 2/3 多数同意的 RFC 才能进入核心。
可能有大约 100 人能够投票,但不需要每个人对每个 RFC 进行投票。核心团队的成员当然可以投票,他们是维护代码库的人。除了他们之外,还有一群人从 PHP 社区中被单独挑选出来。这些人包括 PHP 文档的维护者,对 PHP 项目整体有贡献的人,以及 PHP 社区中的杰出开发人员。
虽然大多数核心开发都是在自愿的基础上完成的,但其中一位核心 PHP 开发人员 Nikita Popov 最近受雇于 [JetBrains](https://blog.jetbrains.com/phpstorm/2019/01/nikita-popov-joins-phpstorm-team/) 全职从事于 PHP 语言的开发。另一个例子是 Linux 基金会最近决定[投资 Zend 框架](https://getlaminas.org/)。像这样的雇佣和收购确保了 PHP 未来发展的稳定性。
### 工具
除了核心本身,我们看到过去几年中围绕它的工具有所增加。首先浮现于我脑海中的是静态分析器,比如由 Vimeo 创建 [Psalm](https://github.com/vimeo/psalm),以及 [Phan](https://github.com/phan/phan) 和 [PHPStan](https://github.com/phpstan/phpstan)。
这些工具将静态分析你的 PHP 代码并报告任何类型错误和可能的错误等。在某种程度上,它们提供的功能可以与 TypeScript 进行比较,但是现在这种语言不能<ruby> 转译 <rt> transpiling </rt></ruby>,因此不支持使用自定义语法。
尽管这意味着我们需要依赖 docblocks,但是 PHP 之父 Rasmus Lerdorf 确实提到了[添加静态分析引擎](https://externals.io/message/101477#101592)到核心的想法。虽然会有很多潜力,但这是一项艰巨的任务。
说到转译,以及受到 JavaScript 社区的启发;他们已经努力在用户领域中扩展 PHP 语法。一个名为 [Pre](https://preprocess.io/) 的项目正是如此:允许将新的 PHP 语法转译为普通的 PHP 代码。
虽然这个思路已经在 JavaScript 世界中被证明了,但如果提供了适当的 IDE 和静态分析支持,它就能在 PHP 中工作了。这是一个非常有趣的想法,但必须发展起来才能称之为“主流”。
### 结语
尽管如此,你仍然可以将 PHP 视为一种糟糕的语言。虽然这种语言肯定有它的缺点和背负了 20 年的遗产;但我可以放胆地说,我喜欢用它工作。
根据我的经验,我能够创建可靠、可维护和高质量的软件。我工作的客户对最终结果感到满意,“俺也一样”。
尽管仍然可以用 PHP 做很多乱七八糟的事情,但我认为如果明智和正确地使用的话,它是 Web 开发的绝佳选择。
你不同意吗?让我知道为什么!你可以通过 [Twitter](https://twitter.com/brendt_gd) 或 [电子邮件](mailto:[email protected]) 与我联系。
---
via: <https://stitcher.io/blog/php-in-2019>
作者:[Brent](https://stitcher.io/blog/php-in-2019) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # PHP in 2019
Do you remember the popular "[PHP: a fractal of bad design](https://eev.ee/blog/2012/04/09/php-a-fractal-of-bad-design/)" blog post?
The first time I read it, I was working in a crappy place with lots of legacy PHP projects.
This article got me wondering whether I should just quit and go do something entirely different than programming.
Luckily for me I was able to switch jobs shortly thereafter and, more importantly, PHP managed to evolve quite a bit since the 5.* days. Today I'm addressing the people who are either not programming in PHP anymore, or are stuck in legacy projects.
Spoiler: some things still suck today, just like almost every programming language has its quirks. Many core functions still have their inconsistent method signatures, there are still confusing configuration settings, there are still many developers out there writing crappy code — because they have to, or because they don't know better.
Today I want to look at the bright side: let's focus on the things that have changed and ways to write clean and maintainable PHP code. I want to ask you to set aside any prejudice for just a few minutes.
Afterwards you're free to think exactly the same about PHP as you did before. Though chances are you will be surprised by some of the improvements made to PHP in the last few years.
[#](#tl;dr) TL;DR
- PHP is actively developed with a new release each year
- PHP 7.4 is one of the
[most feature-packed](/blog/new-in-php-74)releases ever - Performance since the PHP 5 era has doubled, if not tripled
- There's a extremely active eco system of frameworks, packages and platforms
- PHP has had lots of new features added to it over the past few years, and the language keeps evolving
- Tooling like static analysers has matured over the past years, and only keeps growing
Update: people asked me to show some actual code.
I'm happy to say that's possible! Here's the [source code](https://github.com/brendt/aggregate.stitcher.io)
of one of my hobby projects, written in PHP and Laravel;
and [here](https://spatie.be/open-source/packages) is a list of a few hundred OSS packages we maintain at our office.
Both are good examples of what modern PHP projects look like.
Let's start.
[#](#history-summarized) History summarized
For good measure, let's quickly review PHP's release cycle today. We're at PHP 7.4 now, and PHP 8.0 will be the next version after that.
Ever since the late 5.* era, the core team tries to keep a yearly release cycle, and have succeeded in doing so for the past four years.
In general, every new release is actively supported for two years, and gets one more year of "security fixes only". The goal is to motivate PHP developers to stay up-to-date as much as possible: small upgrades every year are way more easy than making the jump between 5.4 to 7.0, for example.
An active overview of PHP's timeline can be found [here](https://www.php.net/supported-versions.php).
Lastly, PHP 5.6 was the latest 5.* release, with 7.0 being the next one.
If you want to know what happened to PHP 6, you can listen to the [PHP Roundtable podcast](https://www.phproundtable.com/episode/what-happened-to-php-6).
With that out of the way, let's debunk some common misconceptions about modern PHP.
[#](#php's-performance) PHP's performance
Back in the 5.* days, PHP's performance was… average at best. With 7.0 though, large parts of PHP's core were rewritten from the ground up, resulting in two or three times performance increases.
Words don't suffice though. Let's look at benchmarks.
Luckily other people have spent lots of time in benchmarking PHP performance.
I find that [Kinsta](https://kinsta.com/blog/php-benchmarks/) has a good updated list.
Ever since the 7.0 upgrade, performance only increased.
So much that PHP web applications have comparable — in some cases better — performance than web frameworks in other languages.
Take a look at this [extensive benchmark suite](https://github.com/the-benchmarker/web-frameworks).
Sure PHP frameworks won't outperform C and Rust, but they are equally performant as Django, Rails or Express.
[#](#frameworks-and-ecosystem) Frameworks and ecosystem
Speaking of frameworks: PHP isn't just WordPress anymore. Let me tell you something as a professional PHP developer: WordPress isn't in any way representative of the contemporary ecosystem.
In general there are two major web application frameworks, and a few smaller ones: [Symfony](https://symfony.com/) and [Laravel](https://laravel.com/).
Sure there's also Zend, now called Laminas; Yii, Cake, Code Igniter etc.
— but if you want to know what modern PHP development looks like, you're good with one of the first two.
Both frameworks have a large ecosystem of packages and products. Ranging from admin panels and CRMs to standalone packages, CI to profilers, numerous services like web sockets servers, queuing managers, payment integrations; honestly there's too much to list.
These frameworks are meant for actual development though. If you're in need of pure content management, platforms like WordPress and CraftCMS are only improving more and more.
One way to measure the current state of PHP's ecosystem is to look at Packagist, the main package repository for PHP. It has seen exponential growth. With ±25 million downloads a day, it's fair to say that the PHP ecosystem isn't the small underdog it used to be.
Take a look at this graph, listing the amount of packages and versions over time.
It can also be found on [the Packagist website](https://packagist.org/statistics).
Besides application frameworks and CMSs, we've also seen the rise of asynchronous frameworks the past years.
These are frameworks and servers, written in PHP or other languages,
that allow users to run truly asynchronous PHP.
A few examples include [Swoole](https://www.swoole.co.uk/), [Amp](https://amphp.org/) and [ReactPHP](https://reactphp.org/).
Since we've ventured into the async world, stuff like web sockets and applications with lots of IO have become actually relevant in the PHP world.
There has also been talk on the internals mailing list — the place where core developers discuss the development of the language —
to [add libuv to the core](https://externals.io/message/102415#102415).
For those unaware of libuv: it's the same library Node.js uses to allow all its asynchronicity.
[#](#the-language-itself) The language itself
While `async`
and `await`
are not available yet, lots of improvements to the language itself have been made over the past years.
Here's a non-exhaustive list of new features in PHP:
-
[Short closures](/blog/short-closures-in-php) -
[Union types](https://wiki.php.net/rfc/union_types_v2)(PHP 8.0) -
[Null coalescing operator](/blog/shorthand-comparisons-in-php#null-coalescing-operator) -
[Traits](https://www.php.net/manual/en/language.oop5.traits.php) -
[Typed properties](/blog/new-in-php-74#typed-properties-rfc) -
[Spread operator](https://wiki.php.net/rfc/argument_unpacking) -
[JIT compiler](https://wiki.php.net/rfc/jit)(PHP 8.0) -
[FFI](https://wiki.php.net/rfc/ffi) -
[Anonymous classes](https://www.php.net/manual/en/language.oop5.anonymous.php) -
[Return type declarations](https://www.php.net/manual/en/functions.returning-values.php#functions.returning-values.type-declaration) -
[Contemporary cryptography](https://wiki.php.net/rfc/libsodium) -
[Generators](https://wiki.php.net/rfc/generators) -
[Lots more](/blog/new-in-php-74)
While we're on the topic of language features, let's also talk about the process of how the language is developed today. There's an active core team of volunteers who move the language forward, though the community is allowed to propose RFCs.
Next, these RFCs are discussed on the "internals" mailing list, which can also be [read online](https://externals.io/).
Before a new language feature is added, there must be a vote.
Only RFC with at least a 2/3 majority are allowed in the core.
Recently there has been an effort to move RFC discussions to GitHub, where the code actually lives. It seems like the small group of developers who's actively invested in PHP, are on board. You can read about the process [here](https://externals.io/message/107747).
It's still a work in progress because some people don't like GitHub. It's clear though that the most active contributors are on board with the decision, so it's fair to say the RFC discussion process will be moved to GitHub entirely within the next year or so.
Once an RFC is discussed, it goes into the voting phase. There are probably around 100 people allowed to vote, though you're not required to vote on each RFC. Members of the core team are of course allowed to vote, they have to maintain the code base. Besides them, there's a group of people who have been individually picked from the PHP community. These people include maintainers of the PHP docs, contributors to the PHP project as a whole, and prominent developers in the PHP community.
While most of core development is done on a voluntary basis, one of the core PHP developers,
Nikita Popov, has recently been [employed by JetBrains](https://blog.jetbrains.com/phpstorm/2019/01/nikita-popov-joins-phpstorm-team/)
to work on the language full time.
Another example is the Linux foundation who recently decided to [invest into Zend framework](https://getlaminas.org/), now called Laminas.
Employments and acquisitions like these ensure stability for the future development of PHP.
[#](#tooling) Tooling
Besides lots of features and improvements added to PHP's core, we've seen an increase in tools around it the past few years.
What comes to mind are static analysers like [Psalm](https://github.com/vimeo/psalm), created by Vimeo;
[Phan](https://github.com/phan/phan) and [PHPStan](https://github.com/phpstan/phpstan).
These tools will statically analyse your PHP code and report any type errors, possible bugs etc. In some way, the functionality they provide can be compared to TypeScript, though for now the language isn't transpiled, so no custom syntax is allowed.
Even though that means we need to rely on docblocks, Rasmus Lerdorf, the original creator of PHP,
did mention the idea of [adding a static analysis engine](https://externals.io/message/101477#101592) to the core.
While there would be lots of potential, it is a huge undertaking.
Speaking of transpiling, and inspired by the JavaScript community;
there have been efforts to extend PHPs syntax in user land.
A project called [Pre](https://web.archive.org/web/20190828000023/https://preprocess.io/#/) does exactly that:
allow new PHP syntax which is transpiled to normal PHP code.
While the idea has proven itself in the JavaScript world,
it could only work in PHP if proper IDE- and static analysis support was provided.
It's a very interesting idea, but has to grow before being able to call it "mainstream".
[#](#in-closing) In closing
All of that being said, feel free to still think of PHP as a crappy language. While the language definitely has its drawbacks and 20 years of legacy to carry with it; I can say in confidence that I enjoy working with it.
In my experience, I'm able to create reliable, maintainable and quality software. The clients I work for are happy with the end result, as am I. While it's still possible to do lots of messed up things with PHP, I'd say it's a great choice for web development if used wise and correct.
Don't you agree? Let me know why!
You can reach me via [Twitter](https://twitter.com/brendt_gd) or [e-mail](mailto:[email protected]). |
10,871 | 使用 attrs 来告别 Python 中的样板 | https://opensource.com/article/19/5/python-attrs | 2019-05-18T21:14:00 | [
"Python"
] | /article-10871-1.html |
>
> 在我们覆盖 7 个 PyPI 库的系列文章中了解更多解决 Python 问题的信息。
>
>
>

Python是当今使用最多[流行的编程语言](https://opensource.com/article/18/5/numbers-python-community-trends)之一,因为:它是开源的,它具有广泛的用途(例如 Web 编程、业务应用、游戏、科学编程等等),它有一个充满活力和专注的社区支持它。这个社区是我们在 [Python Package Index](https://pypi.org/)(PyPI)中提供如此庞大、多样化的软件包的原因,用以扩展和改进 Python。并解决不可避免的问题。
在本系列中,我们将介绍七个可以帮助你解决常见 Python 问题的 PyPI 库。今天,我们将研究 [attrs](https://pypi.org/project/attrs/),这是一个帮助你快速编写简洁、正确的代码的 Python 包。
### attrs
如果你已经写过一段时间的 Python,那么你可能习惯这样写代码:
```
class Book(object):
def __init__(self, isbn, name, author):
self.isbn = isbn
self.name = name
self.author = author
```
接着写一个 `__repr__` 函数。否则,很难记录 `Book` 的实例:
```
def __repr__(self):
return f"Book({self.isbn}, {self.name}, {self.author})"
```
接下来你会写一个好看的 docstring 来记录期望的类型。但是你注意到你忘了添加 `edition` 和 `published_year` 属性,所以你必须在五个地方修改它们。
如果你不必这么做如何?
```
@attr.s(auto_attribs=True)
class Book(object):
isbn: str
name: str
author: str
published_year: int
edition: int
```
使用新的类型注释语法注释类型属性,`attrs` 会检测注释并创建一个类。
ISBN 有特定格式。如果我们想强行使用该格式怎么办?
```
@attr.s(auto_attribs=True)
class Book(object):
isbn: str = attr.ib()
@isbn.validator
def pattern_match(self, attribute, value):
m = re.match(r"^(\d{3}-)\d{1,3}-\d{2,3}-\d{1,7}-\d$", value)
if not m:
raise ValueError("incorrect format for isbn", value)
name: str
author: str
published_year: int
edition: int
```
`attrs` 库也对[不可变式编程](https://opensource.com/article/18/10/functional-programming-python-immutable-data-structures)支持良好。将第一行改成 `@attr.s(auto_attribs=True, frozen=True)` 意味着 `Book` 现在是不可变的:尝试修改一个属性将会引发一个异常。相反,比如,如果希望将发布日期向后一年,我们可以修改成 `attr.evolve(old_book, published_year=old_book.published_year+1)` 来得到一个*新的*实例。
本系列的下一篇文章我们将来看下 `singledispatch`,一个能让你向 Python 库添加方法的库。
**查看本系列先前的文章:**
* [Cython](/article-10859-1.html)
* [Black](/article-10864-1.html)
---
via: <https://opensource.com/article/19/5/python-attrs>
作者:[Moshe Zadka](https://opensource.com/users/moshez/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,872 | 如何在 Ubuntu 桌面手动添加应用快捷方式 | https://itsfoss.com/ubuntu-desktop-shortcut/ | 2019-05-18T22:25:55 | [
"GNOME",
"桌面"
] | https://linux.cn/article-10872-1.html |
>
> 在这篇快速指南中,你将学到如何在 Ubuntu 桌面和其他使用 GNOME 桌面的发行版中添加应用图标。
>
>
>
一个经典的桌面操作系统在“桌面屏”上总是有图标的。这些桌面图标包括文件管理器、回收站和应用图标。
当在 Windows 中安装应用时,一些程序会询问你是否在桌面创建一个快捷方式。但在 Linux 系统中不是这样。
但是如果你热衷于这个特点,让我给你展示如何在 Ubuntu 桌面和其他使用 GNOME 桌面的发行版中创建应用的快捷方式。

如果你想知道我的桌面外观,我正在使用 Ant 主题和 Tela 图标集。你可以获取一些 [GTK 主题](https://itsfoss.com/best-gtk-themes/) 和 [为 Ubuntu 准备的图标集](https://itsfoss.com/best-icon-themes-ubuntu-16-04/)并换成你喜欢的。
### 在 Ubuntu 中添加桌面快捷方式

个人来讲,我更喜欢为应用图标准备的 Ubuntu 启动器方式。如果我经常使用一个程序,我会添加到启动器。但是我知道不是每个人都有相同的偏好,可能少数人更喜欢桌面的快捷方式。
让我们看在桌面中创建应用快捷方式的最简单方式。
>
> 免责声明
>
>
> 这篇指南已经在 Ubuntu 18.04 LTS 的 GNOME 桌面上测试过了。它可能在其他发行版和桌面环境上也能发挥作用,但你必须自己尝试。一些 GNOME 特定步骤可能会变,所以请在[其他桌面环境](https://itsfoss.com/best-linux-desktop-environments/)尝试时注意。
>
>
>
#### 准备
首先最重要的事是确保你有 GNOME 桌面的图标权限。
如果你跟随 Ubuntu 18.04 自定义提示,你会知道如何安装 GNOME Tweaks 工具。在这个工具中,确保你设置“Show Icons”选项为启用。

一旦你确保已经设置,是时候在桌面添加应用快捷方式了。
#### 第一步:定位应用的 .desktop 文件
到 “Files -> Other Location -> Computer”。

从这里,到目录 “usr -> share -> applications”。你会在这里看到几个你已经安装的 [Ubuntu 应用](https://itsfoss.com/best-ubuntu-apps/)。即使你没有看到图标,你应该看到被命名为“应用名.desktop”形式的文件。

#### 第二步:拷贝 .desktop 文件到桌面
现在你要做的只是查找应用图标(或者它的 desktop 文件)。当你找到后,拖文件到桌面或者拷贝文件(使用 `Ctrl+C` 快捷方式)并在桌面粘贴(使用 `Ctrl+V` 快捷方式)。

#### 第三步:运行 desktop 文件
当你这么做,你应该在桌面上看到一个图标的文本文件而不是应用 logo。别担心,一会就不一样了。
你要做的就是双击桌面的那个文件。它将警告你它是一个“未信任的应用启动器’,点击“信任并启动”。

这个应用像往常一样启动,好事是你会察觉到 .desktop 文件现在已经变成应用图标了。我相信你喜欢应用图标的方式,不是吗?

#### Ubuntu 19.04 或者 GNOME 3.32 用户的疑难杂症
如果你使用 Ubuntu 19.04 或者 GNOME 3.32,你的 .desktop 文件可能根本不会启动。你应该右击 .desktop 文件并选择 “允许启动”。
在这之后,你应该能够启动应用并且桌面上的应用快捷方式能够正常显示了。
### 总结
如果你不喜欢桌面的某个应用启动器,选择删除就是了。它会删除应用快捷方式,但是应用仍安全的保留在你的系统中。
我希望你发现这篇快速指南有帮助并喜欢在 Ubuntu 桌面上的应用快捷方式。
如果你有问题或建议,请在下方评论让我知道。
---
via: <https://itsfoss.com/ubuntu-desktop-shortcut/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

A classic desktop operating system always has icons on the ‘desktop screen’. These desktop icons could include the file manager, the trash bin and the shortcut to various applications.
While installing applications on Windows, some programs ask if you want to create a shortcut on the desktop. That’s not the case on Linux, though.
But if you are a fan of this feature, let me show you how you can add desktop shortcuts to your favorite applications on [Ubuntu](https://www.ubuntu.com/?ref=itsfoss.com) and other Linux distributions.
## Adding Desktop Shortcuts in Ubuntu
Personally, I prefer the Ubuntu launcher for application shortcuts. If I use a program frequently, I add it to the launcher. But I know not everyone has the same preference, and a few people prefer shortcuts on the desktop.
Anyway, let’s see the simplest way of creating an application shortcut on the Ubuntu desktop.
### Step 1: Locate the .desktop files of applications
Go to **Files → Other Locations → Computer**.
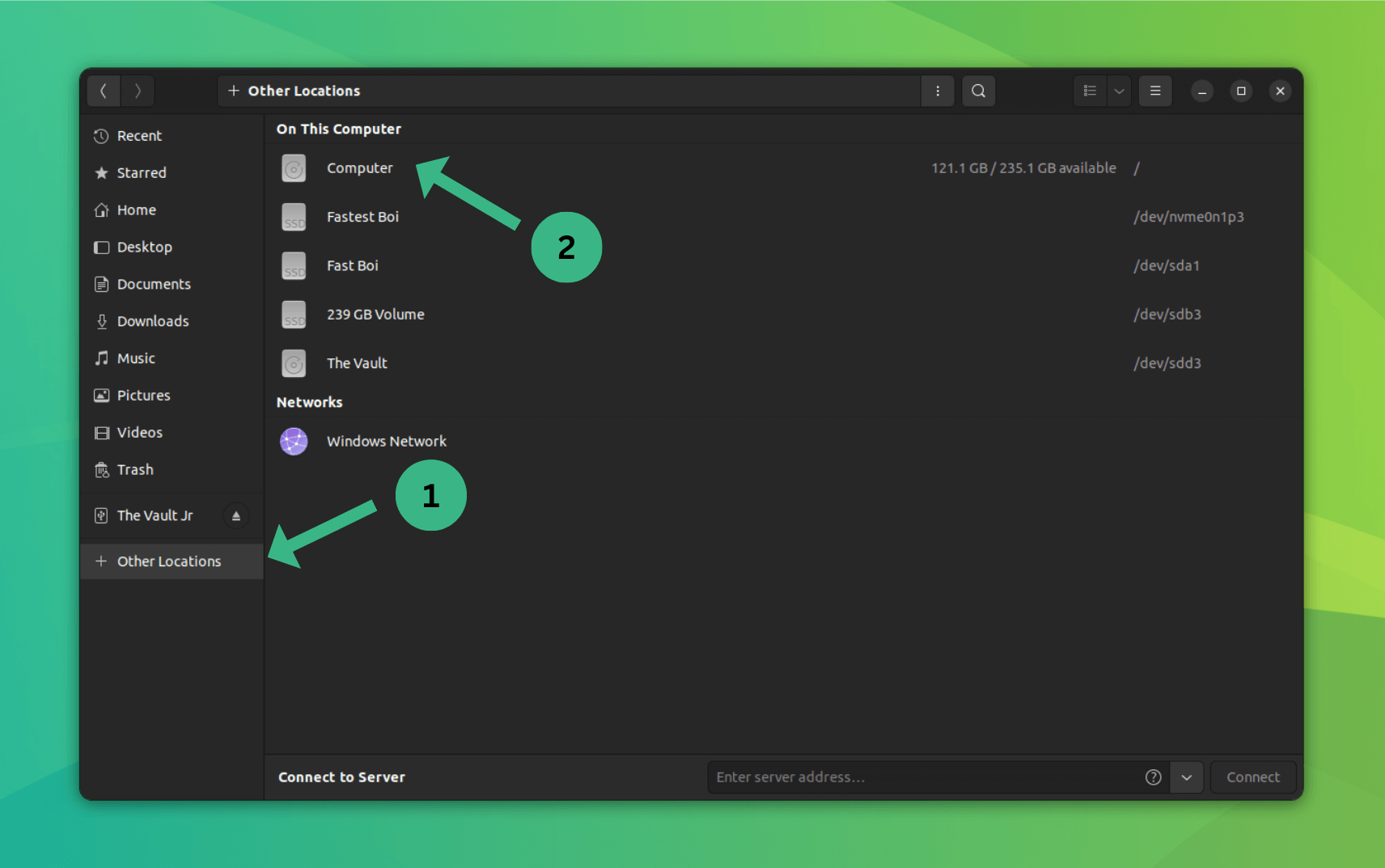
From here, go to the directory **usr → share → applications**.
You’ll see icons of several [Ubuntu applications](https://itsfoss.com/best-ubuntu-apps/) you have installed here. Even if you don’t see the icons, you should see the .desktop files that are named as **application.desktop**.
### Step 2: Copy the .desktop file to the desktop
Now, all you have to do here is to look for the application icon (or its .desktop file). When you find it, either drag-drop the file to the desktop or copy the file (Ctrl+C shortcut) and paste it on the desktop (Ctrl+V).
### Step 3: Run the desktop file
When you do that, you should see an image file style icon on the desktop instead of the logo of the application. Don’t worry, things will be different soon.
You just have to right-click on the .desktop file and click on “**Properties**”. In here, allow the file execution permission.
Now, if you right-click on the file, you will find an “**Allow Launching**” option. Select it, and you will see that the file has turned into an application shortcut.
Next, you can double-click it or right-click on it to hit open to launch the application.
I believe you like the application shortcuts this way, don’t you?
### Troubleshoot for Flatpak apps
For users of Flatpak apps, the method is slightly different. The .desktop files are located elsewhere. You can follow this path instead:
First, Go to **Files → Other Locations → Computer**.
Next, navigate your way to the app directory of Flatpak:**var → lib → flatpak → app**.
Thereafter, go into the folder for the app of your choice.
Finally, head into **current → active → export → share → applications**.
You will find the .desktop file for the app in there. Subsequently, just follow the instructions from '**Step 2**' onwards as shown above.
## Conclusion
Even if you don’t like a certain app shortcut on the desktop, you can just select it and delete it. It will delete the shortcut, but the application will remain safely in your system.
I hope you found this quick tip helpful, and can now enjoy the application shortcuts on Ubuntu's desktop screen.
*💬 If you have questions or suggestions, please let me know in the comments below.* |
10,874 | 用 Pygame 使你的游戏角色移动起来 | https://opensource.com/article/17/12/game-python-moving-player | 2019-05-19T23:11:50 | [
"Pygame"
] | https://linux.cn/article-10874-1.html |
>
> 在本系列的第四部分,学习如何编写移动游戏角色的控制代码。
>
>
>

在这个系列的第一篇文章中,我解释了如何使用 Python 创建一个简单的[基于文本的骰子游戏](/article-9071-1.html)。在第二部分中,我向你们展示了如何从头开始构建游戏,即从 [创建游戏的环境](/article-10850-1.html) 开始。然后在第三部分,我们[创建了一个玩家妖精](/article-10858-1.html),并且使它在你的(而不是空的)游戏世界内生成。你可能已经注意到,如果你不能移动你的角色,那么游戏不是那么有趣。在本篇文章中,我们将使用 Pygame 来添加键盘控制,如此一来你就可以控制你的角色的移动。
在 Pygame 中有许多函数可以用来添加(除键盘外的)其他控制,但如果你正在敲击 Python 代码,那么你一定是有一个键盘的,这将成为我们接下来会使用的控制方式。一旦你理解了键盘控制,你可以自己去探索其他选项。
在本系列的第二篇文章中,你已经为退出游戏创建了一个按键,移动角色的(按键)原则也是相同的。但是,使你的角色移动起来要稍微复杂一点。
让我们从简单的部分入手:设置控制器按键。
### 为控制你的玩家妖精设置按键
在 IDLE、Ninja-IDE 或文本编辑器中打开你的 Python 游戏脚本。
因为游戏需要时刻“监听”键盘事件,所以你写的代码需要连续运行。你知道应该把需要在游戏周期中持续运行的代码放在哪里吗?
如果你回答“放在主循环中”,那么你是正确的!记住除非代码在循环中,否则(大多数情况下)它只会运行仅一次。如果它被写在一个从未被使用的类或函数中,它可能根本不会运行。
要使 Python 监听传入的按键,将如下代码添加到主循环。目前的代码还不能产生任何的效果,所以使用 `print` 语句来表示成功的信号。这是一种常见的调试技术。
```
while main == True:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit(); sys.exit()
main = False
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT or event.key == ord('a'):
print('left')
if event.key == pygame.K_RIGHT or event.key == ord('d'):
print('right')
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
print('left stop')
if event.key == pygame.K_RIGHT or event.key == ord('d'):
print('right stop')
if event.key == ord('q'):
pygame.quit()
sys.exit()
main = False
```
一些人偏好使用键盘字母 `W`、`A`、`S` 和 `D` 来控制玩家角色,而另一些偏好使用方向键。因此确保你包含了两种选项。
注意:当你在编程时,同时考虑所有用户是非常重要的。如果你写代码只是为了自己运行,那么很可能你会成为你写的程序的唯一用户。更重要的是,如果你想找一个通过写代码赚钱的工作,你写的代码就应该让所有人都能运行。给你的用户选择权,比如提供使用方向键或 WASD 的选项,是一个优秀程序员的标志。
使用 Python 启动你的游戏,并在你按下“上下左右”方向键或 `A`、`D` 和 `W` 键的时候查看控制台窗口的输出。
```
$ python ./your-name_game.py
left
left stop
right
right stop
jump
```
这验证了 Pygame 可以正确地检测按键。现在是时候来完成使妖精移动的艰巨任务了。
### 编写玩家移动函数
为了使你的妖精移动起来,你必须为你的妖精创建一个属性代表移动。当你的妖精没有在移动时,这个变量被设为 `0`。
如果你正在为你的妖精设置动画,或者你决定在将来为它设置动画,你还必须跟踪帧来使走路循环保持在轨迹上。
在 `Player` 类中创建如下变量。开头两行作为上下文对照(如果你一直跟着做,你的代码中就已经有这两行),因此只需要添加最后三行:
```
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0 # 沿 X 方向移动
self.movey = 0 # 沿 Y 方向移动
self.frame = 0 # 帧计数
```
设置好了这些变量,是时候去为妖精移动编写代码了。
玩家妖精不需要时刻响应控制,有时它并没有在移动。控制妖精的代码,仅仅只是玩家妖精所有能做的事情中的一小部分。在 Python 中,当你想要使一个对象做某件事并独立于剩余其他代码时,你可以将你的新代码放入一个函数。Python 的函数以关键词 `def` 开头,(该关键词)代表了定义函数。
在你的 `Player` 类中创建如下函数,来为你的妖精在屏幕上的位置增加几个像素。现在先不要担心你增加几个像素,这将在后续的代码中确定。
```
def control(self,x,y):
'''
控制玩家移动
'''
self.movex += x
self.movey += y
```
为了在 Pygame 中移动妖精,你需要告诉 Python 在新的位置重绘妖精,以及这个新位置在哪里。
因为玩家妖精并不总是在移动,所以更新只需要是 Player 类中的一个函数。将此函数添加前面创建的 `control` 函数之后。
要使妖精看起来像是在行走(或者飞行,或是你的妖精应该做的任何事),你需要在按下适当的键时改变它在屏幕上的位置。要让它在屏幕上移动,你需要将它的位置(由 `self.rect.x` 和 `self.rect.y` 属性指定)重新定义为当前位置加上已应用的任意 `movex` 或 `movey`。(移动的像素数量将在后续进行设置。)
```
def update(self):
'''
更新妖精位置
'''
self.rect.x = self.rect.x + self.movex
```
对 Y 方向做同样的处理:
```
self.rect.y = self.rect.y + self.movey
```
对于动画,在妖精移动时推进动画帧,并使用相应的动画帧作为玩家的图像:
```
# 向左移动
if self.movex < 0:
self.frame += 1
if self.frame > 3*ani:
self.frame = 0
self.image = self.images[self.frame//ani]
# 向右移动
if self.movex > 0:
self.frame += 1
if self.frame > 3*ani:
self.frame = 0
self.image = self.images[(self.frame//ani)+4]
```
通过设置一个变量来告诉代码为你的妖精位置增加多少像素,然后在触发你的玩家妖精的函数时使用这个变量。
首先,在你的设置部分创建这个变量。在如下代码中,开头两行是上下文对照,因此只需要在你的脚本中增加第三行代码:
```
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10 # 移动多少个像素
```
现在你已经有了适当的函数和变量,使用你的按键来触发函数并将变量传递给你的妖精。
为此,将主循环中的 `print` 语句替换为玩家妖精的名字(`player`)、函数(`.control`)以及你希望玩家妖精在每个循环中沿 X 轴和 Y 轴移动的步数。
```
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(-steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps,0)
if event.key == ord('q'):
pygame.quit()
sys.exit()
main = False
```
记住,`steps` 变量代表了当一个按键被按下时,你的妖精会移动多少个像素。如果当你按下 `D` 或右方向键时,你的妖精的位置增加了 10 个像素。那么当你停止按下这个键时,你必须(将 `step`)减 10(`-steps`)来使你的妖精的动量回到 0。
现在尝试你的游戏。注意:它不会像你预想的那样运行。
为什么你的妖精仍无法移动?因为主循环还没有调用 `update` 函数。
将如下代码加入到你的主循环中来告诉 Python 更新你的玩家妖精的位置。增加带注释的那行:
```
player.update() # 更新玩家位置
player_list.draw(world)
pygame.display.flip()
clock.tick(fps)
```
再次启动你的游戏来见证你的玩家妖精在你的命令下在屏幕上来回移动。现在还没有垂直方向的移动,因为这部分函数会被重力控制,不过这是另一篇文章中的课程了。
与此同时,如果你拥有一个摇杆,你可以尝试阅读 Pygame 中 [joystick](http://pygame.org/docs/ref/joystick.html) 模块相关的文档,看看你是否能通过这种方式让你的妖精移动起来。或者,看看你是否能通过[鼠标](http://pygame.org/docs/ref/mouse.html#module-pygame.mouse)与你的妖精互动。
最重要的是,玩的开心!
### 本教程中用到的所有代码
为了方便查阅,以下是目前本系列文章用到的所有代码。
```
#!/usr/bin/env python3
# 绘制世界
# 添加玩家和玩家控制
# 添加玩家移动控制
# GNU All-Permissive License
# Copying and distribution of this file, with or without modification,
# are permitted in any medium without royalty provided the copyright
# notice and this notice are preserved. This file is offered as-is,
# without any warranty.
import pygame
import sys
import os
'''
Objects
'''
class Player(pygame.sprite.Sprite):
'''
生成玩家
'''
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.images = []
for i in range(1,5):
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def control(self,x,y):
'''
控制玩家移动
'''
self.movex += x
self.movey += y
def update(self):
'''
更新妖精位置
'''
self.rect.x = self.rect.x + self.movex
self.rect.y = self.rect.y + self.movey
# 向左移动
if self.movex < 0:
self.frame += 1
if self.frame > 3*ani:
self.frame = 0
self.image = self.images[self.frame//ani]
# 向右移动
if self.movex > 0:
self.frame += 1
if self.frame > 3*ani:
self.frame = 0
self.image = self.images[(self.frame//ani)+4]
'''
设置
'''
worldx = 960
worldy = 720
fps = 40 # 帧刷新率
ani = 4 # 动画循环
clock = pygame.time.Clock()
pygame.init()
main = True
BLUE = (25,25,200)
BLACK = (23,23,23 )
WHITE = (254,254,254)
ALPHA = (0,255,0)
world = pygame.display.set_mode([worldx,worldy])
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
backdropbox = world.get_rect()
player = Player() # 生成玩家
player.rect.x = 0
player.rect.y = 0
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10 # 移动速度
'''
主循环
'''
while main == True:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit(); sys.exit()
main = False
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(-steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps,0)
if event.key == ord('q'):
pygame.quit()
sys.exit()
main = False
# world.fill(BLACK)
world.blit(backdrop, backdropbox)
player.update()
player_list.draw(world) # 更新玩家位置
pygame.display.flip()
clock.tick(fps)
```
你已经学了很多,但还仍有许多可以做。在接下来的几篇文章中,你将实现添加敌方妖精、模拟重力等等。与此同时,练习 Python 吧!
---
via: <https://opensource.com/article/17/12/game-python-moving-player>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[cycoe](https://github.com/cycoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the first article in this series, I explained how to use Python to create a simple, [text-based dice game](https://opensource.com/article/17/10/python-101). In the second part, you began building a game from scratch, starting with [creating the game's environment](https://opensource.com/article/17/12/program-game-python-part-2-creating-game-world). And in the third installment, you [created a player sprite](https://opensource.com/article/17/12/program-game-python-part-3-spawning-player) and made it spawn in your (rather empty) game world. As you've probably noticed, a game isn't much fun when you can't move your character around. In this article, you'll use Pygame to add keyboard controls so you can direct your character's movement.
There are functions in Pygame to add other kinds of controls (such as a mouse or game controller), but since you certainly have a keyboard if you're typing out Python code, that's what this article covers. Once you understand keyboard controls, you can explore other options on your own.
You created a key to quit your game in the second article in this series, and the principle is the same for movement. However, getting your character to move is a little more complex.
Start with the easy part: setting up the controller keys.
## Setting up keys for controlling your player sprite
Open your Python game script in IDLE, PyCharm, or a text editor.
Because the game must constantly "listen" for keyboard events, you'll be writing code that needs to run continuously. Can you figure out where to put code that needs to run constantly for the duration of the game?
If you answered "in the main loop," you're correct! Remember that unless code is in a loop, it runs (at most) only once—and it may not run at all if it's hidden away in a class or function that never gets used.
To make Python monitor for incoming key presses, add this code to the main loop. There's no code to make anything happen yet, so use `print`
statements to signal success. This is a common debugging technique.
```
while main:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit(); sys.exit()
main = False
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT or event.key == ord('a'):
print('left')
if event.key == pygame.K_RIGHT or event.key == ord('d'):
print('right')
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
print('left stop')
if event.key == pygame.K_RIGHT or event.key == ord('d'):
print('right stop')
if event.key == ord('q'):
pygame.quit()
sys.exit()
main = False
```
Some people prefer to control player characters with the keyboard characters W, A, S, and D, and others prefer to use arrow keys. Be sure to include *both* options.
**Note:** It's vital that you consider all of your users when programming. If you write code that works only for you, it's very likely that you'll be the only one who uses your application. More importantly, if you seek out a job writing code for money, you are expected to write code that works for everyone. Giving your users choices, such as the option to use either arrow keys or WASD (it's called *accessibility*), is a sign of a good programmer.
Launch your game using Python, and watch the console window for output when you press the right, left, and up arrows, or the A, D, and W keys.
```
$ python ./your-name_game.py
left
left stop
right
right stop
jump
```
This confirms that Pygame detects your key presses correctly. Now it's time to do the hard work of making the sprite move.
## Coding the player movement function
To make your sprite move, you must create a property for your sprite that represents movement. When your sprite is not moving, this variable is set to `0`
.
If you are animating your sprite, or should you decide to animate it in the future, you also must track frames so the walk cycle stays on track.
Create these variables in the Player class. The first two lines are for context (you already have them in your code, if you've been following along), so add only the last three:
```
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0 # move along X
self.movey = 0 # move along Y
self.frame = 0 # count frames
```
With those variables set, it's time to code the sprite's movement.
The player sprite doesn't need to respond to control all the time because sometimes it isn't being told to move. The code that controls the sprite, therefore, is only one small part of all the things the player sprite can do. When you want to make an object in Python do something independent of the rest of its code, you place your new code in a *function*. Python functions start with the keyword `def`
, which stands for *define*.
Make a function in your Player class to add *some number* of pixels to your sprite's position on screen. Don't worry about how many pixels you add yet; that will be decided in later code.
```
def control(self,x,y):
"""
control player movement
"""
self.movex += x
self.movey += y
```
To move a sprite in Pygame, you must tell Python to redraw the sprite in its new location—and where that new location is.
Since the Player sprite isn't always moving, make these updates a dedicated function within the Player class. Add this function after the `control`
function you created earlier.
To make it appear that the sprite is walking (or flying, or whatever it is your sprite is supposed to do), you need to change its position on screen when the appropriate key is pressed. To get it to move across the screen, you redefine its position, designated by the `self.rect.x`
and `self.rect.y`
properties, to its current position plus whatever amount of `movex`
or `movey`
is applied. (The number of pixels the move requires is set later.)
```
def update(self):
"""
Update sprite position
"""
self.rect.x = self.rect.x + self.movex
```
Do the same thing for the Y position:
```
self.rect.y = self.rect.y + self.movey
```
For animation, advance the animation frames whenever your sprite is moving, and use the corresponding animation frame as the player image:
```
# moving left
if self.movex < 0:
self.frame += 1
if self.frame > 3*ani:
self.frame = 0
self.image = self.images[self.frame//ani]
# moving right
if self.movex > 0:
self.frame += 1
if self.frame > 3*ani:
self.frame = 0
self.image = self.images[self.frame//ani]
```
Tell the code how many pixels to add to your sprite's position by setting a variable, then use that variable when triggering the functions of your Player sprite.
First, create the variable in your setup section. In this code, the first two lines are for context, so just add the third line to your script:
```
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10 # how many pixels to move
```
Now that you have the appropriate function and variable, use your key presses to trigger the function and send the variable to your sprite.
Do this by replacing the `print`
statements in your main loop with the Player sprite's name (player), the function (.control), and how many steps along the X axis and Y axis you want the player sprite to move with each loop.
```
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(-steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps,0)
if event.key == ord('q'):
pygame.quit()
sys.exit()
main = False
```
Remember, `steps`
is a variable representing how many pixels your sprite moves when a key is pressed. If you add 10 pixels to the location of your player sprite when you press D or the right arrow, then when you stop pressing that key you must subtract 10 (`-steps`
) to return your sprite's momentum back to 0.
Try your game now. Warning: it won't do what you expect.
## Updating the sprite graphic
Why doesn't your sprite move yet? Because the main loop doesn't call the `update`
function.
Add code to your main loop to tell Python to update the position of your player sprite. Add the line with the comment:
```
player.update() # update player position
player_list.draw(world)
pygame.display.flip()
clock.tick(fps)
```
Launch your game again to witness your player sprite move across the screen at your bidding. There's no vertical movement yet because those functions will be controlled by gravity, but that's another lesson for another article.
Movement works, but there's still one small problem: your hero graphic doesn't turn to face the direction it's walking. In other words, if you designed your hero facing right, then it looks like it's walking backwards when you press the left arrow key. Normally, you'd expect your hero to turn left when walking left, and turn right again to walk to the right.
## Flipping your sprite
You can flip a graphic with Pygame's `transform`
function. This, like all the other functions you've been using for this game, is a lot of complex code and maths distilled into a single, easy to use, Python keyword. This is a great example of why a framework helps you code. Instead of having to learn basic principles of drawing pixels on screen, you can let Pygame do all the work and just make a call to a funciton that already exists.
You only need the transform on the instance when your graphic is walking the opposite way it's facing by default. My graphic faces right, so I apply the transform to the left code block. The `pygame.transform.flip`
function takes three arguments, [according to Pygame documentation](https://www.pygame.org/docs/ref/transform.html#pygame.transform.flip): what to flip, whether to flip horizontally, and whether to flip vertically. In this case, those are the graphic (which you've already defined in the existing code), True for horizontal, and False for a vertical flip.
Update your code:
```
# moving left
if self.movex < 0:
self.frame += 1
if self.frame > 3*ani:
self.frame = 0
self.image = pygame.transform.flip(self.images[self.frame // ani], True, False)
```
Notice that the transform function is inserted into your existing code. The variable `self.image`
is still getting defined as an image from your list of hero images, but it's getting "wrapped" in the transform function.
Try your code now, and watch as your hero does an about-face each time you point it in a different direction.
That's enough of a lesson for now. Until the next article, you might try exploring other ways to control your hero. For intance, should you have access to a joystick, try reading Pygame's documentation for its [joystick](http://pygame.org/docs/ref/joystick.html) module and see if you can make your sprite move that way. Alternately, see if you can get the [mouse](http://pygame.org/docs/ref/mouse.html#module-pygame.mouse) to interact with your sprite.
Most importantly, have fun!
## All the code used in this tutorial
For your reference, here is all the code used in this series of articles so far.
```
#!/usr/bin/env python3
# by Seth Kenlon
# GPLv3
# This program is free software: you can redistribute it and/or
# modify it under the terms of the GNU General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
from typing import Tuple
import pygame
import sys
import os
'''
Variables
'''
worldx = 960
worldy = 720
fps = 40
ani = 4
world = pygame.display.set_mode([worldx, worldy])
BLUE = (25, 25, 200)
BLACK = (23, 23, 23)
WHITE = (254, 254, 254)
ALPHA = (0, 255, 0)
'''
Objects
'''
class Player(pygame.sprite.Sprite):
"""
Spawn a player
"""
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.images = []
for i in range(1, 5):
img = pygame.image.load(os.path.join('images', 'hero' + str(i) + '.png')).convert()
img.convert_alpha() # optimise alpha
img.set_colorkey(ALPHA) # set alpha
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def control(self, x, y):
"""
control player movement
"""
self.movex += x
self.movey += y
def update(self):
"""
Update sprite position
"""
self.rect.x = self.rect.x + self.movex
self.rect.y = self.rect.y + self.movey
# moving left
if self.movex < 0:
self.frame += 1
if self.frame > 3*ani:
self.frame = 0
self.image = pygame.transform.flip(self.images[self.frame // ani], True, False)
# moving right
if self.movex > 0:
self.frame += 1
if self.frame > 3*ani:
self.frame = 0
self.image = self.images[self.frame//ani]
'''
Setup
'''
backdrop = pygame.image.load(os.path.join('images', 'stage.png'))
clock = pygame.time.Clock()
pygame.init()
backdropbox = world.get_rect()
main = True
player = Player() # spawn player
player.rect.x = 0 # go to x
player.rect.y = 0 # go to y
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10
'''
Main Loop
'''
while main:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(-steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(steps, 0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps, 0)
world.blit(backdrop, backdropbox)
player.update()
player_list.draw(world)
pygame.display.flip()
clock.tick(fps)
```
You've come far and learned much, but there's a lot more to do. In the next few articles, you'll [add enemy sprites](https://opensource.com/article/18/5/pygame-enemy), emulated gravity, and lots more. In the mean time, practice with Python!
## 5 Comments |
10,875 | 使用 restic 和 systemd 自动备份 | https://fedoramagazine.org/automate-backups-with-restic-and-systemd/ | 2019-05-19T23:19:56 | [
"备份"
] | https://linux.cn/article-10875-1.html | 
及时备份很重要。即使在 [Fedora Magazine](https://fedoramagazine.org/?s=backup) 中,[备份软件](https://restic.net/) 也是一个常见的讨论话题。本文演示了如何仅使用 systemd 以及 `restic` 来自动备份。
有关 `restic` 的介绍,请查看我们的文章[在 Fedora 上使用 restic 进行加密备份](https://fedoramagazine.org/use-restic-encrypted-backups/)。然后继续阅读以了解更多详情。
为了自动创建快照以及清理数据,需要运行两个 systemd 服务。第一个运行*备份*命令的服务需要以常规频率运行。第二个服务负责数据清理。
如果你根本不熟悉 systemd,那么这是个很好的学习机会。查看 [Magazine 上关于 systemd 的系列文章](https://fedoramagazine.org/series/systemd-series/),从单元文件的这个入门开始:
* [systemd 单元文件基础](https://fedoramagazine.org/systemd-getting-a-grip-on-units/)
如果你还没有安装 `restic`,请注意它在官方的 Fedora 仓库中。要安装它,请[带上 sudo](https://fedoramagazine.org/howto-use-sudo/) 运行此命令:
```
$ sudo dnf install restic
```
### 备份
首先,创建 `~/.config/systemd/user/restic-backup.service`。将下面的文本复制并粘贴到文件中以获得最佳效果。
```
[Unit]
Description=Restic backup service
[Service]
Type=oneshot
ExecStart=restic backup --verbose --one-file-system --tag systemd.timer $BACKUP_EXCLUDES $BACKUP_PATHS
ExecStartPost=restic forget --verbose --tag systemd.timer --group-by "paths,tags" --keep-daily $RETENTION_DAYS --keep-weekly $RETENTION_WEEKS --keep-monthly $RETENTION_MONTHS --keep-yearly $RETENTION_YEARS
EnvironmentFile=%h/.config/restic-backup.conf
```
此服务引用环境文件来加载密钥(例如 `RESTIC_PASSWORD`)。创建 `~/.config/restic-backup.conf`。复制并粘贴以下内容以获得最佳效果。此示例使用 BackBlaze B2 存储。请相应地调整 ID、密钥、仓库和密码值。
```
BACKUP_PATHS="/home/rupert"
BACKUP_EXCLUDES="--exclude-file /home/rupert/.restic_excludes --exclude-if-present .exclude_from_backup"
RETENTION_DAYS=7
RETENTION_WEEKS=4
RETENTION_MONTHS=6
RETENTION_YEARS=3
B2_ACCOUNT_ID=XXXXXXXXXXXXXXXXXXXXXXXXX
B2_ACCOUNT_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
RESTIC_REPOSITORY=b2:XXXXXXXXXXXXXXXXXX:/
RESTIC_PASSWORD=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
```
现在已安装该服务,请重新加载 systemd:`systemctl -user daemon-reload`。尝试手动运行该服务以创建备份:`systemctl -user start restic-backup`。
因为该服务类型是*一次性*,它将运行一次并退出。验证服务运行并根据需要创建快照后,设置计时器以定期运行此服务。例如,要每天运行 `restic-backup.service`,请按如下所示创建 `~/.config/systemd/user/restic-backup.timer`。再次复制并粘贴此文本:
```
[Unit]
Description=Backup with restic daily
[Timer]
OnCalendar=daily
Persistent=true
[Install]
WantedBy=timers.target
```
运行以下命令启用:
```
$ systemctl --user enable --now restic-backup.timer
```
### 清理
虽然主服务运行 `forget` 命令仅保留保留策略中的快照,但实际上并未从 `restic` 仓库中删除数据。 `prune` 命令检查仓库和当前快照,并删除与快照无关的所有数据。由于 `prune` 可能是一个耗时的过程,因此无需在每次运行备份时运行。这是第二个服务和计时器的场景。首先,通过复制和粘贴此文本来创建文件 `~/.config/systemd/user/restic-prune.service`:
```
[Unit]
Description=Restic backup service (data pruning)
[Service]
Type=oneshot
ExecStart=restic prune
EnvironmentFile=%h/.config/restic-backup.conf
```
与主 `restic-backup.service` 服务类似,`restic-prune` 也是一次性服务,并且可以手动运行。设置完服务后,创建 `~/.config/systemd/user/restic-prune.timer` 并启用相应的计时器:
```
[Unit]
Description=Prune data from the restic repository monthly
[Timer]
OnCalendar=monthly
Persistent=true
[Install]
WantedBy=timers.target
```
就是这些了!`restic` 将会每日运行并按月清理数据。
---
图片来自 [Unsplash](https://unsplash.com/search/photos/archive?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 由 [Samuel Zeller](https://unsplash.com/photos/JuFcQxgCXwA?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 拍摄。
---
via: <https://fedoramagazine.org/automate-backups-with-restic-and-systemd/>
作者:[Link Dupont](https://fedoramagazine.org/author/linkdupont/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Timely backups are important. So much so that [backing up software](https://restic.net/) is a common topic of discussion, even [here on the Fedora Magazine](https://fedoramagazine.org/?s=backup). This article demonstrates how to automate backups with **restic** using only systemd unit files.
For an introduction to restic, be sure to check out our article [Use restic on Fedora for encrypted backups](https://fedoramagazine.org/use-restic-encrypted-backups/). Then read on for more details.
Two systemd services are required to run in order to automate taking snapshots and keeping data pruned. The first service runs the *backup* command needs to be run on a regular frequency. The second service takes care of data pruning.
If you’re not familiar with systemd at all, there’s never been a better time to learn. Check out [the series on systemd here at the Magazine](https://fedoramagazine.org/series/systemd-series/), starting with this primer on unit files:
If you haven’t installed restic already, note it’s in the official Fedora repositories. To install use this command [with sudo](https://fedoramagazine.org/howto-use-sudo/):
$ sudo dnf install restic
## Backup
First, create the *~/.config/systemd/user/restic-backup.service* file. Copy and paste the text below into the file for best results.
[Unit]
Description=Restic backup service
[Service]
Type=oneshot
ExecStart=restic backup --verbose --one-file-system --tag systemd.timer $BACKUP_EXCLUDES $BACKUP_PATHS
ExecStartPost=restic forget --verbose --tag systemd.timer --group-by "paths,tags" --keep-daily $RETENTION_DAYS --keep-weekly $RETENTION_WEEKS --keep-monthly $RETENTION_MONTHS --keep-yearly $RETENTION_YEARS
EnvironmentFile=%h/.config/restic-backup.conf
This service references an environment file in order to load secrets (such as *RESTIC_PASSWORD*). Create the *~/.config/restic-backup.conf* file. Copy and paste the content below for best results. This example uses BackBlaze B2 buckets. Adjust the ID, key, repository, and password values accordingly.
BACKUP_PATHS="/home/rupert"
BACKUP_EXCLUDES="--exclude-file /home/rupert/.restic_excludes --exclude-if-present .exclude_from_backup"
RETENTION_DAYS=7
RETENTION_WEEKS=4
RETENTION_MONTHS=6
RETENTION_YEARS=3
B2_ACCOUNT_ID=XXXXXXXXXXXXXXXXXXXXXXXXX
B2_ACCOUNT_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
RESTIC_REPOSITORY=b2:XXXXXXXXXXXXXXXXXX:/
RESTIC_PASSWORD=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Now that the service is installed, reload systemd: *systemctl –user daemon-reload*. Try running the service manually to create a backup: *systemctl –user start restic-backup*.
Because the service is a *oneshot*, it will run once and exit. After verifying that the service runs and creates snapshots as desired, set up a timer to run this service regularly. For example, to run the *restic-backup.service* daily, create *~/.config/systemd/user/restic-backup.timer* as follows. Again, copy and paste this text:
[Unit]
Description=Backup with restic daily
[Timer]
OnCalendar=daily
Persistent=true
[Install]
WantedBy=timers.target
Enable it by running this command:
$ systemctl --user enable --now restic-backup.timer
## Prune
While the main service runs the *forget* command to only keep snapshots within the keep policy, the data is not actually removed from the restic repository. The *prune* command inspects the repository and current snapshots, and deletes any data not associated with a snapshot. Because *prune* can be a time-consuming process, it is not necessary to run every time a backup is run. This is the perfect scenario for a second service and timer. First, create the file *~/.config/systemd/user/restic-prune.service* by copying and pasting this text:
[Unit]
Description=Restic backup service (data pruning)
[Service]
Type=oneshot
ExecStart=restic prune
EnvironmentFile=%h/.config/restic-backup.conf
Similarly to the main *restic-backup.service*, *restic-prune* is a oneshot service and can be run manually. Once the service has been set up, create and enable a corresponding timer at *~/.config/systemd/user/restic-prune.timer*:
[Unit]
Description=Prune data from the restic repository monthly
[Timer]
OnCalendar=monthly
Persistent=true
[Install]
WantedBy=timers.target
That’s it! Restic will now run daily and prune data monthly.
*Photo by **Samuel Zeller** on **Unsplash**.*
## Rajat Kumar Singh
when we run this command systemctl –user daemon-reload got this error
“Failed to connect to bus: Operation not permitted”
## Stephen
You would likely need to use sudo to do that.
## Stephen
Sorry, my bad. You may need two dashes ahead of user so
## Link Dupont
Yes, this appears to be a formatting error with the HTML. WordPress renders it as two dashes, but when viewing the post itself, the two dashes appear to be squashed together into an emdash. Since all the unit files are installed as the running user, you must interact with the user systemd session.
## Rajat Kumar Singh
tried the same systemctl –user daemon-reload with root access.
[Rajat@www ~]$ su
Password:
[root@www Rajat]# sudo systemctl –user daemon-reload
Failed to connect to bus: No such file or directory
or
[Rajat@www ~]$ sudo systemctl –user daemon-reload
[sudo] password for Rajat:
Failed to connect to bus: No such file or directory
## Link Dupont
You do not need to run this as root. The service files should be installed into your user systemd directory: ~/.config/systemd/user. So you should interact with systemd as your normal user (via the –user flag).
[link@localhost ~]$
## Rajat Kumar Singh
Thank you it works , somehow for learning what would be the changes in restic-backup.conf file for local repository .
we want to take backups from local machine and store in the same machine in another directory
BACKUP_PATHS=”/home/rupert”
BACKUP_EXCLUDES=”–exclude-file /home/rupert/.restic_excludes –exclude-if-present .exclude_from_backup”
RETENTION_DAYS=7
RETENTION_WEEKS=4
RETENTION_MONTHS=6
RETENTION_YEARS=3
B2_ACCOUNT_ID=XXXXXXXXXXXXXXXXXXXXXXXXX
B2_ACCOUNT_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
RESTIC_REPOSITORY=b2:XXXXXXXXXXXXXXXXXX:/
RESTIC_PASSWORD=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
## Sebastiaan Franken
The single dash should be two, so
systemctl (dash dash)user daemon-reload
Otherwise use sudo
## duba
as root?
## Zerocool
Install package for dbus user session
## ert
duplicity are better
and normal rsync for other server
## Daniel
Better how? Both duplicity and Restic supports backup encryption and backing up to multiple cloud providers as well as local and networked backup destinations.
Restic lets you deduplicate data from multiple systems in a single backup repository. It can give you really great savings on how much storage is required to backup a single and especially multiple systems. The program has excellent snapshot management and you can mount any snapshot to explore previous versions of your files.
## Lance Haverkamp
Old School (Duplicity)
In the old school model, data is written sequentially to the storage medium. Once a section of data is recorded, new data is written starting where that section of data ends. It’s not possible to go back and change the data that’s already been written.
New School (Restic)
With the arrival of non-sequential storage medium, such as disk drives, and new ideas such as deduplication, comes the new school approach, which is used by Restic. Data can be written and changed anywhere on the storage medium. This efficiency comes largely through the use of deduplication. Deduplication is a process that eliminates redundant copies of data and reduces storage overhead. Data deduplication techniques ensure that only one unique instance of data is retained on storage media, greatly increasing storage efficiency and flexibility.
Sounce: https://www.backblaze.com/blog/backing-linux-backblaze-b2-duplicity-restic/
## Steve
Starting to get feature parity with stuff I wrote 5+ years ago:
https://www.crc.id.au/backups-and-filesystem-deduplication/
## John Mesgrenado
Duplicity is also good but restic is much lighter, you should give it a try
## Hans
For remote servers rdiff-backup also works nicely.
## Daniel
You do
notwant to run “ExecStartPost=restic forget” after each backup run as suggested here. It can be very time consuming for large backups. Replace the second service file with “restic forget –prune” instead to run both of the time consuming maintenance operations at the same time.You also don’t want to run “ExecStartPre=restic unlock” before every backup. You could interrupt another operation like the pruning task and potentially causing it to never finish or outright break. The backup repository is usually locked for a reason. You might want to run unlock when you boot your system to clean out any orphaned locks, however.
This all being said: Restic is a really excellent piece of software and this article doesn’t do it justice. You just have to set aside some time to learn how to use it properly.
## Link Dupont
Thank you for the suggestions; I will make those adjustments to the sample unit files here in the article. I am still learning restic myself, but I find it a very useful backup tool.
## Link Dupont
I have found that restic forget does not take a long time. It inspects the repository and just drops whatever snapshots no longer meet the keep policies. What part of running forget is time consuming?
## Sten
I like this, but I don’t like having “restic unlock” in “ExecStartPre” – wouldn’t that risk removing a lock for a backup that was already running?
Similarly, could systemd prevent running a prune while a backup is running? If you ran into a situation where prune happened during a backup, I expect it would fail, then you won’t prune again until the next month.
## Brian Exelbierd
Very timely and useful article for me – Thank you!
How long have you been running restic? Have you found any love/hate with it?
## Manos Th.
Where is the restore process or what happens if i want only one file from a backup!!!
All of this are in the backup process
## Igor Bajo
My questions:
The B2_ACCOUNT_ID and a B2_ACCOUNT_KEY need to be created?
The RESTIC_REPOSITORY could be a second harddrive on the same computer, or a USB harddrive?
I need to set RESTIC_PASSWORD where?
Thanks
## Link Dupont
These are environment variables that restic references to determine how and where to back up. I include them in the service via the EnvironmentFile= key, but you need to decide what backup destination works best for your set up. See the docs for details on what environment variables make sense for your use case.
## langdon
is there anyway to instruct the systemd timer to only run if the system isn’t busy?
## Brian Exelbierd
I’d like to see how to do this too, however, for restic in my use case it may not be needed. Inspired by this article I have been doing some manual testing. After a day of use, the update backup of most of my home directory runs in less than a minute.
## Brian Exelbierd
@langdon doing a little reading I think “IOSchedulingClass=idle” in systemd might do the trick. See /usr/lib/systemd/user/systemd-tmpfiles-clean.service — I haven’t had time to experiment yet.
## Arshad Mahmood
It is really worthful and all-needed solution for Back up. But it is silent about what to do when this Pruned Backup needs to be restored. Please write a few words about Restoring it.
Thanks
## Link Dupont
If you’re unfamiliar with restic, make sure you understand the basics of taking backups and restoring them. Take a look at our article introducing restic to get started.
## Fredrik Rambris
I have this setup now. Thanks for the article. I have made the following tweaks:
restic-backup.service runs daily. Does only backup (no forget or prune). I changed the type to simple and have Restart=on-failure and RestartSec=30. This is because I run this job on multiple hosts to the same shared repository. The other hosts connect to central repository over sftp.
restic-backup.timer added RandomizedDelaySec=300 so that two restic instances does not start att the exact same time on different hosts. I was paranoid about the locks.
restic-prune.service runs monthly with forget –prune, grouping by host,tag,path. Runs only on the host with the repository.
rclone is used to sync the local repository to backblaze. Restic can interact directly with the repo at backblaze too, if needed. I prefer to have quick access to backups but also stored offsite in case of disaster.
I have everything deployed with ansible. I did not use the copr repository but rather just put the binary in ansible. Different distros had different versions. The binary is quite portable.
## Brian Exelbierd
I like your setup ideas and would like to implement a variation of them for me. Do you have your ansible playbook publicly viewable?
## Fredrik Rambris
https://mega.nz/#!1AdkmKBT!1QdGk95XLiQnV9x6tPtRJO382kwS2E9F2slxmtcwZYQ
## Joffa Mac
I tried to find this without having to ask here but was unsuccessful – my apologies for asking something that maybe isn’t related.
I have followed the steps above and have it working, however I have 70GB of photos that with my ridiculously slow internet will take a week to backup. Without changing my system sleep/suspend settings, I use the Gnome extension ‘Caffeine’ to do so, prevent my computer suspending etc.
I wanted a better way so after some previous reading about systemd-inhibit, thought I could use it but I can’t find anything on how I make it work with another systemctl function. i.e. I can’t run systemd-inhibit systemctl –user start restic-backup.service (well at least for me nothing happened).
So I ask here for any tips on keeping my computer automatically running whilst these backup functions work, then allowing suspend etc. to kick in as usual.
Thanks in advance |
10,876 | 思科针对 Nexus 数据中心交换机发出危急安全预警 | https://www.networkworld.com/article/3392858/cisco-issues-critical-security-warning-for-nexus-data-center-switches.html | 2019-05-19T23:38:44 | [
"思科",
"安全"
] | https://linux.cn/article-10876-1.html |
>
> 思科围绕着 Nexus 的交换机、Firepower 防火墙和其他设备,发布了 40 个安全报告。
>
>
>

日前,思科发布了 40 个左右的安全报告,但只有其中的一个被评定为“[危急](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-nexus9k-sshkey)”:思科 Nexus 9000 系列应用中心基础设施(ACI)模式数据中心交换机中的一个漏洞,可能会让攻击者隐秘地访问到系统资源。
这个新发现的漏洞,被通用漏洞评分系统给到了 9.8 分(满分 10 分),思科表示,它是思科 Nexus 9000 系列的安全 shell (ssh)密钥管理方面的问题,这个漏洞允许远程攻击者以 root 用户的权限来连接到受影响的系统。
思科表示,“**这个漏洞是因为所有的设备都存在一对默认的 ssh 密钥对**,攻击者可以使用提取到的密钥材料,并通过 IPv6 来创建连接到目标设备的 SSH 连接。这个漏洞仅能通过 IPv6 来进行利用,IPv4 不会被攻击”。
型号为 Nexus 9000 系列且 NX-OS 软件版本在 14.1 之前的设备会受此漏洞的影响,该公司表示没有解决这个问题的变通办法。
然而,思科公司已经为解决这个漏洞[发布了免费的软件更新](https://www.cisco.com/c/en/us/about/legal/cloud-and-software/end_user_license_agreement.html)。
该公司同样对 Nexus 9000 系列发布了一个“高危”级别的安全预警报告,报告中表示存在一种攻击,允许攻击者以 root 用户权限在受影响的设备上执行任意操作系统命令。思科表示,如果要用这种方式攻击成功,攻击者需要对应设备的有效的管理员用户凭证。
[思科表示](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-nexus9k-rpe),这个漏洞是由于过于宽泛的系统文件权限造成的。攻击者可以通过向受影响的设备进行认证,构造一个精心设计的命令字符串,并将这个字符串写入到特定位置的文件里。攻击者通过这种方式来利用这个漏洞。
思科发布了解决这个漏洞的软件更新。
另外两个被评为“高危”级别的漏洞的影响范围同样包括 Nexus 9000 系列:
* 思科 Nexus 9000 系列软件后台操作功能中的[漏洞](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-aci-hw-clock-util),能够允许一个已认证的本地攻击者在受影响的设备上提权到 root 权限。这个漏洞是由于在受影响的设备上用户提供的文件验证不充分。思科表示,攻击者可以通过登录到受影响设备的命令行界面,并在文件系统的特定目录中构造一个精心设计过的文件,以此来利用这个漏洞。
* 交换机软件后台操作功能中的[弱点](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-aci-hw-clock-util)能够允许攻击者登录到受影响设备的命令行界面,并在文件系统的特定目录里创建一个精心构造过的文件。思科表示,这个漏洞是由于在受影响的设备上用户提供的文件验证不充分。
思科同样为这些漏洞[发布了软件更新](https://www.cisco.com/c/en/us/about/legal/cloud-and-software/end_user_license_agreement.html)。
此外,这些安全警告中的一部分是针对思科 FirePower 防火墙系列中大量的“高危”漏洞警告。
例如,思科[写道](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-frpwr-smb-snort),思科 Firepower 威胁防御软件的 SMB 协议预处理检测引擎中的多个漏洞能够允许未认证的相邻、远程攻击者造成拒绝服务攻击(DoS)的情况。
思科表示,思科 Firepower 2100 系列中思科 Firepower 软件里的内部数据包处理功能有[另一个漏洞](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-frpwr-dos),能够让未认证的远程攻击者造成受影响的设备停止处理流量,从而导致 DOS 的情况。
[软件补丁](https://www.cisco.com/c/en/us/about/legal/cloud-and-software/end_user_license_agreement.html)可用于这些漏洞。
其他的产品,比如思科[自适应安全虚拟设备](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-asa-ipsec-dos)和 [web 安全设备](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-wsa-privesc)同样也有高优先级的补丁。
---
via: <https://www.networkworld.com/article/3392858/cisco-issues-critical-security-warning-for-nexus-data-center-switches.html>
作者:[Michael Cooney](https://www.networkworld.com/author/Michael-Cooney/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,880 | 使用 Libki 来管理公共用户访问计算机 | https://opensource.com/article/19/5/libki-computer-access | 2019-05-20T23:02:49 | [
"公共",
"计算机"
] | https://linux.cn/article-10880-1.html |
>
> Libki 是一个跨平台的计算机预约和用时管理系统。
>
>
>

提供公共计算机的图书馆、学校、学院和其他组织需要一种管理用户访问权限的好方法 —— 否则,就无法阻止某些人独占机器并确保每个人都有公平的用时。这是 [Libki](https://libki.org/) 要解决的问题。
Libki 是一个面向 Windows 和 Linux PC 的开源、跨平台的计算机预约和用时管理系统。它提供了一个基于 Web 的服务器和一个基于 Web 的管理系统,员工可以使用它来管理计算机访问,包括创建和删除用户、设置帐户用时限制、登出和禁止用户以及设置访问限制。
根据其首席开发人员 [Kyle Hall](https://www.linkedin.com/in/kylemhallinfo/) 所说,Libki 主要用于 PC 用时控制,作为 Envisionware 出品的专有计算机访问控制软件的开源替代品。当用户登录 Libki 管理的计算机时,他们会有一段使用计算机的时间。时间到了之后,他们就会被登出。时间默认设置为 45 分钟,但可以使用基于 Web 的管理系统轻松调整。一些组织在登出用户之前提供 24 小时访问权限,而有的组织则使用它来跟踪使用情况而不设置用时限制。
Kyle 目前是 [ByWater Solutions](https://opensource.com/article/19/4/software-libraries) 的首席开发人员,该公司为图书馆提供开源软件解决方案(包括 Libki)。在职业生涯早期,他在宾夕法尼亚州的[米德维尔公共图书馆](https://meadvillelibrary.org/)担任 IT 技术时开发了 Libki。在其他员工的午休期间,偶尔会要求他关注孩子们的房间。图书馆使用纸质注册表来管理对儿童房间计算机的访问,这意味着不断的监督和检查,以确保来到那里的人能够公平地使用。
Kyle 说,“我发现这很笨拙而不便的,我想找到一个解决方案。这个解决方案需要同时是 FOSS 和跨平台的。最后,没有现有的软件适合我们的特殊需求,那就是为什么我开发了 Libki。“
或者,正如 Libki 的网站所宣称的那样,“Libki 的诞生是为了避免与青少年打交道(的麻烦),现在允许图书馆员避免与世界各地的青少年打交道(的麻烦)!”
### 易于安装和使用
我最近决定在我经常在那里做志愿者的当地的公共图书馆尝试 Libki。我按照[文档](https://manual.libki.org/master/libki-manual.html#_automatic_installation)在 Ubuntu 18.04 Server 中自动进行了安装,它很快就启动起来了。
我计划在我们当地的图书馆支持 Libki,但我想知道在那些没有 IT 相关经验的人或者无法构建和部署服务器的图书馆是怎样的。Kyle 说:“ByWater Solutions 可以云端托管 Libki 服务器,这使得每个人的维护和管理变得更加简单。”
Kyle 表示,ByWater 并不打算将 Libki 与其最受欢迎的产品,开源集成图书馆系统 (ILS)Koha 或其支持的任何其他[项目](https://bywatersolutions.com/projects)捆绑在一起。他说: “Libki 和 Koha 是不同[类型]的软件,满足不同的需求,但它们在图书馆中确实很好地协同工作。事实上,我很早就开发了 Libki 的 SIP2 集成,因此它可以支持使用 Koha 进行单点登录。“
### 如何贡献
Libki 客户端是 GPLv3 许可,Libki 服务器是 AGPLv3 许可。Kyle 说他希望 Libki 拥有一个更加活跃和强大的社区,项目一直在寻找新人加入其[贡献者](https://github.com/Libki/libki-server/graphs/contributors)。如果你想参加,请访问 [Libki 社区页面](https://libki.org/community/)并加入邮件列表。
---
via: <https://opensource.com/article/19/5/libki-computer-access>
作者:[Don Watkins](https://opensource.com/users/don-watkins/users/tony-thomas) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Libraries, schools, colleges, and other organizations that provide public computers need a good way to manage users' access—otherwise, there's no way to prevent some people from monopolizing the machines and ensure everyone has a fair amount of time. This is the problem that [Libki](https://libki.org/) was designed to solve.
Libki is an open source, cross-platform, computer reservation and time management system for Windows and Linux PCs. It provides a web-based server and a web-based administration system that staff can use to manage computer access, including creating and deleting users, setting time limits on accounts, logging out and banning users, and setting access restrictions.
According to lead developer [Kyle Hall](https://www.linkedin.com/in/kylemhallinfo/), Libki is mainly used for PC time control as an open source alternative to Envisionware's proprietary computer access control software. When users log into a Libki-managed computer, they get a block of time to use the computer; once that time is up, they are logged off. The default setting is 45 minutes, but that can easily be adjusted using the web-based administration system. Some organizations offer 24 hours of access before logging users off, and others use it to track usage without setting time limits.
Kyle is currently lead developer at [ByWater Solutions](https://opensource.com/article/19/4/software-libraries), which provides open source software solutions (including Libki) to libraries. He developed Libki early in his career when he was the IT tech at the [Meadville Public Library](https://meadvillelibrary.org/) in Pennsylvania. He was occasionally asked to cover the children's room during lunch breaks for other employees. The library used a paper sign-up sheet to manage access to the computers in the children's room, which meant constant supervision and checking to ensure equitable access for the people who came there.
Kyle said, "I found this system to be cumbersome and awkward, and I wanted to find a solution. That solution needed to be both FOSS and cross-platform. In the end, no existing software package suited our particular needs, and that is why I developed Libki."
Or, as Libki's website proclaims, "Libki was born of the need to avoid interacting with teenagers and now allows librarians to avoid interacting with teenagers around the world!"
## Easy to set up and use
I recently decided to try Libki in our local public library, where I frequently volunteer. I followed the [documentation](https://manual.libki.org/master/libki-manual.html#_automatic_installation) for the automatic installation, using Ubuntu 18.04 Server, and very quickly had it up and running.
I am planning to support Libki in our local library, but I wondered about libraries that don't have someone with IT experience or the ability to build and deploy a server. Kyle says, "ByWater Solutions can cloud-host a Libki server, which makes maintenance and management much simpler for everyone."
Kyle says ByWater is not planning to bundle Libki with its most popular offering, open source integrated library system (ILS) Koha, or any of the other [projects](https://bywatersolutions.com/projects) it supports. "Libki and Koha are different [types of] software serving different needs, but they definitely work well together in a library setting. In fact, it was quite early on that I developed Libki's SIP2 integration so it could support single sign-on using Koha," he says.
## How you can contribute
Libki client is licensed under the GPLv3 and Libki server is licensed under the AGPLv3. Kyle says he would love Libki to have a more active and robust community, and the project is always looking for new people to join its [contributors](https://github.com/Libki/libki-server/graphs/contributors). If you would like to participate, visit [Libki's Community page](https://libki.org/community/) and join the mailing list.
## 1 Comment |
10,881 | 在 Linux 命令行下使用“原力” | https://opensource.com/article/19/5/may-the-force-linux | 2019-05-21T08:39:00 | [
"命令行",
"强制"
] | https://linux.cn/article-10881-1.html |
>
> 和绝地武士的原力一样,`-f` 参数是很强大的,并伴随着潜在的毁灭性,在你能用好的时候又很便利。
>
>
>

近些年来,科幻发烧友开始在每年的 5 月 4 日庆祝[星战节](https://www.starwars.com/star-wars-day),其口号是绝地武士的祝福语”愿<ruby> 原力 <rt> Force </rt></ruby>和你同在“。虽然大多数 Linux 用户可能不是绝地武士,但我们依然可以使用<ruby> 原力 <rt> Force </rt></ruby>。自然,如果尤达大师只是叫天行者卢克输入什么 “man X-Wing 战机“、“man 原力”,或者 RTFM(去读原力手册,肯定是这个意思对不对),那这电影肯定没啥意思。(LCTT 译注:RTFM 是 “Read The Fucking Manual” 的缩写 —— 读读该死的手册吧)。
很多 Linux 命令都有 `-f` 选项,意思你现在肯定也知道了,原力(LCTT 译注:force 选项原意是“强制”)!很多时候你先尝试执行命令然后失败了,或者提示你需要补充输入更多选项。通常这都是为了保护你试着改变的文件,或者告诉用户该设备正忙或文件已经存在之类的。
如果你不想被这些提醒打扰或者压根就不在乎,就使用原力吧!
不过要小心,通常使用原力选项是摧毁性的。所以用户一定要格外注意!并且确保你知道自己在做什么!用原力就要承担后果!
以下是一些常见 Linux 命令的原力选项和它们的效果,以及常见使用场景。
### cp
`cp` 是 “copy” 的缩写,这是个被用来复制文件或者目录的命令。其 [man 页面](http://man7.org/linux/man-pages/man1/cp.1.html) 说:
>
> -f, –force
>
>
> 如果已经存在的目标文件无法被打开,删除它并重试
>
>
>
你可能会用它来处理只读状态的文件:
```
[alan@workstation ~]$ ls -l
total 8
-rw-rw---- 1 alan alan 13 May 1 12:24 Hoth
-r--r----- 1 alan alan 14 May 1 12:23 Naboo
[alan@workstation ~]$ cat Hoth Naboo
Icy Planet
Green Planet
```
如果你想要复制一个叫做 `Hoth` 的文件到 `Naboo`,但因为 `Naboo` 目前是只读状态,`cp` 命令不会执行:
```
[alan@workstation ~]$ cp Hoth Naboo
cp: cannot create regular file 'Naboo': Permission denied
```
但通过使用原力,`cp` 会强制执行。`Hoth` 的内容和文件权限会直接被复制到 `Naboo`:
```
[alan@workstation ~]$ cp -f Hoth Naboo
[alan@workstation ~]$ cat Hoth Naboo
Icy Planet
Icy Planet
[alan@workstation ~]$ ls -l
total 8
-rw-rw---- 1 alan alan 12 May 1 12:32 Hoth
-rw-rw---- 1 alan alan 12 May 1 12:38 Naboo
```
### ln
`ln` 命令是用来在文件之间建立链接的,其 [man 页面](http://man7.org/linux/man-pages/man1/ln.1.html) 描述的原力选项如下:
>
> -f, –force
>
>
> 移除当前存在的文件
>
>
>
假设莱娅公主在维护一个 Java 应用服务器,并且她又一个存放这所有 Java 版本的目录,比如:
```
leia@workstation:/usr/lib/java$ ls -lt
total 28
lrwxrwxrwx 1 leia leia 12 Mar 5 2018 jdk -> jdk1.8.0_162
drwxr-xr-x 8 leia leia 4096 Mar 5 2018 jdk1.8.0_162
drwxr-xr-x 8 leia leia 4096 Aug 28 2017 jdk1.8.0_144
```
正如你所看到的,这里有很多个版本的 JDK,并有一个符号链接指向最新版的 JDK。她接着用一个脚本来安装最新版本的 JDK。但是如果没有原力选项的话以下命令是不会成功的:
```
tar xvzmf jdk1.8.0_181.tar.gz -C jdk1.8.0_181/
ln -vs jdk1.8.0_181 jdk
```
`tar` 命令会解压 .gz 文件到一个特定的目标目录,但 `ln` 命令会失败,因为这个链接已经存在了。这样的结果是该符号链接不会指向最新版本的 JDK:
```
leia@workstation:/usr/lib/java$ ln -vs jdk1.8.0_181 jdk
ln: failed to create symbolic link 'jdk/jdk1.8.0_181': File exists
leia@workstation:/usr/lib/java$ ls -lt
total 28
drwxr-x--- 2 leia leia 4096 May 1 15:44 jdk1.8.0_181
lrwxrwxrwx 1 leia leia 12 Mar 5 2018 jdk -> jdk1.8.0_162
drwxr-xr-x 8 leia leia 4096 Mar 5 2018 jdk1.8.0_162
drwxr-xr-x 8 leia leia 4096 Aug 28 2017 jdk1.8.0_144
```
她可以通过使用原力选项强制 `ln` 更新链接,但这里她还需要使用 `-n`,`-n` 是因为这个情况下链接其实指向一个目录而非文件。这样的话,链接就会正确指向最新版本的JDK了。
```
leia@workstation:/usr/lib/java$ ln -vsnf jdk1.8.0_181 jdk
'jdk' -> 'jdk1.8.0_181'
leia@workstation:/usr/lib/java$ ls -lt
total 28
lrwxrwxrwx 1 leia leia 12 May 1 16:13 jdk -> jdk1.8.0_181
drwxr-x--- 2 leia leia 4096 May 1 15:44 jdk1.8.0_181
drwxr-xr-x 8 leia leia 4096 Mar 5 2018 jdk1.8.0_162
drwxr-xr-x 8 leia leia 4096 Aug 28 2017 jdk1.8.0_144
```
你可以配置 Java 应用使其一直使用在 `/usr/lib/java/jdk` 处的 JDK,而不用每次升级都更新。
### rm
`rm` 命令是 “remove” 的缩写(也叫做删除,因为某些系统 `del` 命令也干这事)。其 [man 页面](http://man7.org/linux/man-pages/man1/rm.1.html) 对原力选项的描述如下:
>
> -f, –force
>
>
> 无视不存在的文件或者参数,不向用户确认
>
>
>
如果你尝试删除一个只读的文件,`rm` 会寻求用户的确认:
```
[alan@workstation ~]$ ls -l
total 4
-r--r----- 1 alan alan 16 May 1 11:38 B-wing
[alan@workstation ~]$ rm B-wing
rm: remove write-protected regular file 'B-wing'?
```
你一定要输入 `y` 或者 `n` 来回答确认才能让 `rm` 命令继续。如果你使用原力选项,`rm` 就不会寻求你的确认而直接删除文件:
```
[alan@workstation ~]$ rm -f B-wing
[alan@workstation ~]$ ls -l
total 0
[alan@workstation ~]$
```
最常见的 `rm` 原力选项用法是用来删除目录。 `-r`(递归)选项会让 `rm` 删除目录,当和原力选项结合起来,它会删除这个文件夹及其内容而无需用户确认。
`rm` 命令和一些选项结合起来是致命的,一直以来互联网上都有关于误用 `rm` 删除整个系统之类的玩笑和鬼故事。比如最出名的一不当心执行 `rm -rf .` 会直接删除目录和文件(没有用户确认)。(LCTT 译注:真的这么干过的校对飘过~~请按下回车前再三确认:我是谁,我在哪里,我在干什么)
### userdel
`userdel` 命令使用来删除用户的。其 [man 页面](http://man7.org/linux/man-pages/man8/userdel.8.html) 是这样描述它的原力选项的:
>
> -f, –force
>
>
> 这个选项会强制移除用户,即便用户当前处于登入状态。它同时还会强制 删除用户的目录和邮件存储,即便这个用户目录被别人共享或者邮件存储并不 属于这个用户。如果 `USERGROUPS_ENAB` 在 `/etc/login.defs` 里是 `yes` 并且有一个组和此用户同名的话,这个组也会被移除,即便这个组还是别 的用户的主要用户组也一样。
>
>
> 注意:这个选项有风险并可能让系统处于不稳定状态。
>
>
>
当欧比旺抵达穆斯塔法星的时候,他知道自己的使命。他需要删掉达斯·维达的用户账户——而达斯还在里面呢。
```
[root@workstation ~]# ps -fu darth
UID PID PPID C STIME TTY TIME CMD
darth 7663 7655 0 13:28 pts/3 00:00:00 -bash
[root@workstation ~]# userdel darth
userdel: user darth is currently used by process 7663
```
因为达斯还登在系统里,欧比旺需要使用原力选项操作 `userdel`。这能强制删除当前登入的用户。
```
[root@workstation ~]# userdel -f darth
userdel: user darth is currently used by process 7663
[root@workstation ~]# finger darth
finger: darth: no such user.
[root@workstation ~]# ps -fu darth
error: user name does not exist
```
正如我们所见到的一样,`finger` 和 `ps` 命令让我们确认了达斯已经被删除了。
### 在 Shell 脚本里使用原力
很多命令都有原力选项,而在 shell 脚本里他们特别有用。因为我们经常使用脚本完成定期或者自动化的任务,避免用户输入至关重要,不然的话自动任务就无法完成了
我希望上面的几个例子能帮你理解一些需要使用原力的情况。你在命令行使用原力或把它们写入脚本之前应当完全理解它们的作用。误用原力会有毁灭性的后果——时常是对整个系统,甚至不仅限于一台设备。
---
via: <https://opensource.com/article/19/5/may-the-force-linux>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Jerry Ling](https://github.com/Moelf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Sometime in recent history, sci-fi nerds began an annual celebration of everything [ Star Wars on May the 4th](https://www.starwars.com/star-wars-day), a pun on the Jedi blessing, "May the Force be with you." Although most Linux users are probably not Jedi, they still have ways to use the force. Of course, the movie might not have been quite as exciting if Yoda simply told Luke to type
**man X-Wing fighter**or
**man force**. Or if he'd said, "RTFM" (Read the Force Manual, of course).
Many Linux commands have an **-f** option, which stands for, you guessed it, force! Sometimes when you execute a command, it fails or prompts you for additional input. This may be an effort to protect the files you are trying to change or inform the user that a device is busy or a file already exists.
If you don't want to be bothered by prompts or don't care about errors, use the force!
Be aware that using a command's force option to override these protections is, generally, destructive. Therefore, the user needs to pay close attention and be sure that they know what they are doing. Using the force can have consequences!
Following are four Linux commands with a force option and a brief description of how and why you might want to use it.
## cp
The **cp** command is short for copy—it's used to copy (or duplicate) a file or directory. The [man page](http://man7.org/linux/man-pages/man1/cp.1.html) describes the force option for **cp** as:
```
-f, --force
if an existing destination file cannot be opened, remove it
and try again
```
This example is for when you are working with read-only files:
```
[alan@workstation ~]$ ls -l
total 8
-rw-rw---- 1 alan alan 13 May 1 12:24 Hoth
-r--r----- 1 alan alan 14 May 1 12:23 Naboo
[alan@workstation ~]$ cat Hoth Naboo
Icy Planet
Green Planet
```
If you want to copy a file called *Hoth* to *Naboo*, the **cp** command will not allow it since *Naboo* is read-only:
```
[alan@workstation ~]$ cp Hoth Naboo
cp: cannot create regular file 'Naboo': Permission denied
```
But by using the force, **cp** will not prompt. The contents and permissions of *Hoth* will immediately be copied to *Naboo*:
```
[alan@workstation ~]$ cp -f Hoth Naboo
[alan@workstation ~]$ cat Hoth Naboo
Icy Planet
Icy Planet
[alan@workstation ~]$ ls -l
total 8
-rw-rw---- 1 alan alan 12 May 1 12:32 Hoth
-rw-rw---- 1 alan alan 12 May 1 12:38 Naboo
```
Oh no! I hope they have winter gear on Naboo.
## ln
The **ln** command is used to make links between files. The [man page](http://man7.org/linux/man-pages/man1/ln.1.html) describes the force option for **ln** as:
```
-f, --force
remove existing destination files
```
Suppose Princess Leia is maintaining a Java application server and she has a directory where all Java versions are stored. Here is an example:
```
leia@workstation:/usr/lib/java$ ls -lt
total 28
lrwxrwxrwx 1 leia leia 12 Mar 5 2018 jdk -> jdk1.8.0_162
drwxr-xr-x 8 leia leia 4096 Mar 5 2018 jdk1.8.0_162
drwxr-xr-x 8 leia leia 4096 Aug 28 2017 jdk1.8.0_144
```
As you can see, there are several versions of the Java Development Kit (JDK) and a symbolic link pointing to the latest one. She uses a script with the following commands to install new JDK versions. However, it won't work without a force option or unless the root user runs it:
```
tar xvzmf jdk1.8.0_181.tar.gz -C jdk1.8.0_181/
ln -vs jdk1.8.0_181 jdk
```
The **tar** command will extract the .gz file to the specified directory, but the **ln** command will fail to upgrade the link because one already exists. The result will be that the link no longer points to the latest JDK:
```
leia@workstation:/usr/lib/java$ ln -vs jdk1.8.0_181 jdk
ln: failed to create symbolic link 'jdk/jdk1.8.0_181': File exists
leia@workstation:/usr/lib/java$ ls -lt
total 28
drwxr-x--- 2 leia leia 4096 May 1 15:44 jdk1.8.0_181
lrwxrwxrwx 1 leia leia 12 Mar 5 2018 jdk -> jdk1.8.0_162
drwxr-xr-x 8 leia leia 4096 Mar 5 2018 jdk1.8.0_162
drwxr-xr-x 8 leia leia 4096 Aug 28 2017 jdk1.8.0_144
```
She can force **ln** to update the link correctly by passing the force option and one other, **-n**. The **-n** is needed because the link points to a directory. Now, the link again points to the latest JDK:
```
leia@workstation:/usr/lib/java$ ln -vsnf jdk1.8.0_181 jdk
'jdk' -> 'jdk1.8.0_181'
leia@workstation:/usr/lib/java$ ls -lt
total 28
lrwxrwxrwx 1 leia leia 12 May 1 16:13 jdk -> jdk1.8.0_181
drwxr-x--- 2 leia leia 4096 May 1 15:44 jdk1.8.0_181
drwxr-xr-x 8 leia leia 4096 Mar 5 2018 jdk1.8.0_162
drwxr-xr-x 8 leia leia 4096 Aug 28 2017 jdk1.8.0_144
```
A Java application can be configured to find the JDK with the path **/usr/lib/java/jdk** instead of having to change it every time Java is updated.
## rm
The **rm** command is short for "remove" (which we often call delete, since some other operating systems have a **del** command for this action). The [man page](http://man7.org/linux/man-pages/man1/rm.1.html) describes the force option for **rm** as:
```
-f, --force
ignore nonexistent files and arguments, never prompt
```
If you try to delete a read-only file, you will be prompted by **rm**:
```
[alan@workstation ~]$ ls -l
total 4
-r--r----- 1 alan alan 16 May 1 11:38 B-wing
[alan@workstation ~]$ rm B-wing
rm: remove write-protected regular file 'B-wing'?
```
You must type either **y** or **n** to answer the prompt and allow the **rm** command to proceed. If you use the force option, **rm** will not prompt you and will immediately delete the file:
```
[alan@workstation ~]$ rm -f B-wing
[alan@workstation ~]$ ls -l
total 0
[alan@workstation ~]$
```
The most common use of force with **rm** is to delete a directory. The **-r** (recursive) option tells **rm** to remove a directory. When combined with the force option, it will remove the directory and all its contents without prompting.
The **rm** command with certain options can be disastrous. Over the years, online forums have filled with jokes and horror stories of users completely wiping their systems. This notorious usage is **rm -rf ***. This will immediately delete all files and directories without any prompt wherever it is used.
## userdel
The **userdel** command is short for user delete, which will delete a user. The [man page](http://man7.org/linux/man-pages/man8/userdel.8.html) describes the force option for **userdel** as:
```
-f, --force
This option forces the removal of the user account, even if the
user is still logged in. It also forces userdel to remove the
user's home directory and mail spool, even if another user uses
the same home directory or if the mail spool is not owned by the
specified user. If USERGROUPS_ENAB is defined to yes in
/etc/login.defs and if a group exists with the same name as the
deleted user, then this group will be removed, even if it is
still the primary group of another user.
Note: This option is dangerous and may leave your system in an
inconsistent state.
```
When Obi-Wan reached the castle on Mustafar, he knew what had to be done. He had to delete Darth's user account—but Darth was still logged in.
```
[root@workstation ~]# ps -fu darth
UID PID PPID C STIME TTY TIME CMD
darth 7663 7655 0 13:28 pts/3 00:00:00 -bash
[root@workstation ~]# userdel darth
userdel: user darth is currently used by process 7663
```
Since Darth is currently logged in, Obi-Wan has to use the force option to **userdel**. This will delete the user account even though it's logged in.
```
[root@workstation ~]# userdel -f darth
userdel: user darth is currently used by process 7663
[root@workstation ~]# finger darth
finger: darth: no such user.
[root@workstation ~]# ps -fu darth
error: user name does not exist
```
As you can see, the **finger** and **ps** commands confirm the user Darth has been deleted.
## Using force in shell scripts
Many other commands have a force option. One place force is very useful is in shell scripts. Since we use scripts in cron jobs and other automated operations, avoiding any prompts is crucial, or else these automated processes will not complete.
I hope the four examples I shared above help you understand how certain circumstances may require the use of force. You should have a strong understanding of the force option when used at the command line or in creating automation scripts. It's misuse can have devastating effects—sometimes across your infrastructure, and not only on a single machine.
## 4 Comments |
10,883 | 如何向你的 Python 游戏中添加一个敌人 | https://opensource.com/article/18/5/pygame-enemy | 2019-05-21T19:16:23 | [
"Pygame"
] | https://linux.cn/article-10883-1.html |
>
> 在本系列的第五部分,学习如何增加一个坏蛋与你的好人战斗。
>
>
>

在本系列的前几篇文章中(参见 [第一部分](/article-9071-1.html)、[第二部分](/article-10850-1.html)、[第三部分](/article-10858-1.html) 以及 [第四部分](/article-10874-1.html)),你已经学习了如何使用 Pygame 和 Python 在一个空白的视频游戏世界中生成一个可玩的角色。但没有恶棍,英雄又将如何?
如果你没有敌人,那将会是一个非常无聊的游戏。所以在此篇文章中,你将为你的游戏添加一个敌人并构建一个用于创建关卡的框架。
在对玩家妖精实现全部功能之前,就来实现一个敌人似乎就很奇怪。但你已经学到了很多东西,创造恶棍与与创造玩家妖精非常相似。所以放轻松,使用你已经掌握的知识,看看能挑起怎样一些麻烦。
针对本次训练,你能够从 [Open Game Art](https://opengameart.org) 下载一些预创建的素材。此处是我使用的一些素材:
* 印加花砖(LCTT 译注:游戏中使用的花砖贴图)
* 一些侵略者
* 妖精、角色、物体以及特效
### 创造敌方妖精
是的,不管你意识到与否,你其实已经知道如何去实现敌人。这个过程与创造一个玩家妖精非常相似:
1. 创建一个类用于敌人生成
2. 创建 `update` 方法使得敌人能够检测碰撞
3. 创建 `move` 方法使得敌人能够四处游荡
从类入手。从概念上看,它与你的 `Player` 类大体相同。你设置一张或者一组图片,然后设置妖精的初始位置。
在继续下一步之前,确保你有一张你的敌人的图像,即使只是一张临时图像。将图像放在你的游戏项目的 `images` 目录(你放置你的玩家图像的相同目录)。
如果所有的活物都拥有动画,那么游戏看起来会好得多。为敌方妖精设置动画与为玩家妖精设置动画具有相同的方式。但现在,为了保持简单,我们使用一个没有动画的妖精。
在你代码 `objects` 节的顶部,使用以下代码创建一个叫做 `Enemy` 的类:
```
class Enemy(pygame.sprite.Sprite):
'''
生成一个敌人
'''
def __init__(self,x,y,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
```
如果你想让你的敌人动起来,使用让你的玩家拥有动画的 [相同方式](/article-10874-1.html)。
### 生成一个敌人
你能够通过告诉类,妖精应使用哪张图像,应出现在世界上的什么地方,来生成不只一个敌人。这意味着,你能够使用相同的敌人类,在游戏世界的任意地方生成任意数量的敌方妖精。你需要做的仅仅是调用这个类,并告诉它应使用哪张图像,以及你期望生成点的 X 和 Y 坐标。
再次,这从原则上与生成一个玩家精灵相似。在你脚本的 `setup` 节添加如下代码:
```
enemy = Enemy(20,200,'yeti.png') # 生成敌人
enemy_list = pygame.sprite.Group() # 创建敌人组
enemy_list.add(enemy) # 将敌人加入敌人组
```
在示例代码中,X 坐标为 20,Y 坐标为 200。你可能需要根据你的敌方妖精的大小,来调整这些数字,但尽量生成在一个范围内,使得你的玩家妖精能够碰到它。`Yeti.png` 是用于敌人的图像。
接下来,将敌人组的所有敌人绘制在屏幕上。现在,你只有一个敌人,如果你想要更多你可以稍后添加。一但你将一个敌人加入敌人组,它就会在主循环中被绘制在屏幕上。中间这一行是你需要添加的新行:
```
player_list.draw(world)
enemy_list.draw(world) # 刷新敌人
pygame.display.flip()
```
启动你的游戏,你的敌人会出现在游戏世界中你选择的 X 和 Y 坐标处。
### 关卡一
你的游戏仍处在襁褓期,但你可能想要为它添加另一个关卡。为你的程序做好未来规划非常重要,因为随着你学会更多的编程技巧,你的程序也会随之成长。即使你现在仍没有一个完整的关卡,你也应该按照假设会有很多关卡来编程。
思考一下“关卡”是什么。你如何知道你是在游戏中的一个特定关卡中呢?
你可以把关卡想成一系列项目的集合。就像你刚刚创建的这个平台中,一个关卡,包含了平台、敌人放置、战利品等的一个特定排列。你可以创建一个类,用来在你的玩家附近创建关卡。最终,当你创建了一个以上的关卡,你就可以在你的玩家达到特定目标时,使用这个类生成下一个关卡。
将你写的用于生成敌人及其群组的代码,移动到一个每次生成新关卡时都会被调用的新函数中。你需要做一些修改,使得每次你创建新关卡时,你都能够创建一些敌人。
```
class Level():
def bad(lvl,eloc):
if lvl == 1:
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # 生成敌人
enemy_list = pygame.sprite.Group() # 生成敌人组
enemy_list.add(enemy) # 将敌人加入敌人组
if lvl == 2:
print("Level " + str(lvl) )
return enemy_list
```
`return` 语句确保了当你调用 `Level.bad` 方法时,你将会得到一个 `enemy_list` 变量包含了所有你定义的敌人。
因为你现在将创造敌人作为每个关卡的一部分,你的 `setup` 部分也需要做些更改。不同于创造一个敌人,取而代之的是你必须去定义敌人在那里生成,以及敌人属于哪个关卡。
```
eloc = []
eloc = [200,20]
enemy_list = Level.bad( 1, eloc )
```
再次运行游戏来确认你的关卡生成正确。与往常一样,你应该会看到你的玩家,并且能看到你在本章节中添加的敌人。
### 痛击敌人
一个敌人如果对玩家没有效果,那么它不太算得上是一个敌人。当玩家与敌人发生碰撞时,他们通常会对玩家造成伤害。
因为你可能想要去跟踪玩家的生命值,因此碰撞检测发生在 `Player` 类,而不是 `Enemy` 类中。当然如果你想,你也可以跟踪敌人的生命值。它们之间的逻辑与代码大体相似,现在,我们只需要跟踪玩家的生命值。
为了跟踪玩家的生命值,你必须为它确定一个变量。代码示例中的第一行是上下文提示,那么将第二行代码添加到你的 Player 类中:
```
self.frame = 0
self.health = 10
```
在你 `Player` 类的 `update` 方法中,添加如下代码块:
```
hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
for enemy in hit_list:
self.health -= 1
print(self.health)
```
这段代码使用 Pygame 的 `sprite.spritecollide` 方法,建立了一个碰撞检测器,称作 `enemy_hit`。每当它的父类妖精(生成检测器的玩家妖精)的碰撞区触碰到 `enemy_list` 中的任一妖精的碰撞区时,碰撞检测器都会发出一个信号。当这个信号被接收,`for` 循环就会被触发,同时扣除一点玩家生命值。
一旦这段代码出现在你 `Player` 类的 `update` 方法,并且 `update` 方法在你的主循环中被调用,Pygame 会在每个时钟滴答中检测一次碰撞。
### 移动敌人
如果你愿意,静止不动的敌人也可以很有用,比如能够对你的玩家造成伤害的尖刺和陷阱。但如果敌人能够四处徘徊,那么游戏将更富有挑战。
与玩家妖精不同,敌方妖精不是由玩家控制,因此它必须自动移动。
最终,你的游戏世界将会滚动。那么,如何在游戏世界自身滚动的情况下,使游戏世界中的敌人前后移动呢?
举个例子,你告诉你的敌方妖精向右移动 10 步,向左移动 10 步。但敌方妖精不会计数,因此你需要创建一个变量来跟踪你的敌人已经移动了多少步,并根据计数变量的值来向左或向右移动你的敌人。
首先,在你的 `Enemy` 类中创建计数变量。添加以下代码示例中的最后一行代码:
```
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0 # 计数变量
```
然后,在你的 `Enemy` 类中创建一个 `move` 方法。使用 if-else 循环来创建一个所谓的死循环:
* 如果计数在 0 到 100 之间,向右移动;
* 如果计数在 100 到 200 之间,向左移动;
* 如果计数大于 200,则将计数重置为 0。
死循环没有终点,因为循环判断条件永远为真,所以它将永远循环下去。在此情况下,计数器总是介于 0 到 100 或 100 到 200 之间,因此敌人会永远地从左向右再从右向左移动。
你用于敌人在每个方向上移动距离的具体值,取决于你的屏幕尺寸,更确切地说,取决于你的敌人移动的平台大小。从较小的值开始,依据习惯逐步提高数值。首先进行如下尝试:
```
def move(self):
'''
敌人移动
'''
distance = 80
speed = 8
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance*2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
```
你可以根据需要调整距离和速度。
当你现在启动游戏,这段代码有效果吗?
当然不,你应该也知道原因。你必须在主循环中调用 `move` 方法。如下示例代码中的第一行是上下文提示,那么添加最后两行代码:
```
enemy_list.draw(world) #refresh enemy
for e in enemy_list:
e.move()
```
启动你的游戏看看当你打击敌人时发生了什么。你可能需要调整妖精的生成地点,使得你的玩家和敌人能够碰撞。当他们发生碰撞时,查看 [IDLE](https://docs.python.org/3/library/idle.html) 或 [Ninja-IDE](http://ninja-ide.org/) 的控制台,你可以看到生命值正在被扣除。

你应该已经注意到,在你的玩家和敌人接触时,生命值在时刻被扣除。这是一个问题,但你将在对 Python 进行更多练习以后解决它。
现在,尝试添加更多敌人。记得将每个敌人加入 `enemy_list`。作为一个练习,看看你能否想到如何改变不同敌方妖精的移动距离。
---
via: <https://opensource.com/article/18/5/pygame-enemy>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[cycoe](https://github.com/cycoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the previous articles in this series (see [part 1](https://opensource.com/article/17/10/python-101), [part 2](https://opensource.com/article/17/12/game-framework-python), [part 3](https://opensource.com/article/17/12/game-python-add-a-player), and [part 4](https://opensource.com/article/17/12/game-python-moving-player)), you learned how to use Pygame and Python to spawn a playable hero character in an as-yet empty video game world. But what's a hero without a villain?
It would make for a pretty boring game if you had no enemies, so in this article, you'll add an enemy to your game and construct a framework for building levels.
It might seem strange to jump ahead to enemies when there's still more to be done to make the player sprite fully functional, but you've learned a lot already, and creating villains is very similar to creating a player sprite. So relax, use the knowledge you already have, and see what it takes to stir up some trouble.
For this exercise, you need an enemy sprite. If you haven't downloaded one already, you can find [Creative Commons](https://opensource.com/article/20/1/what-creative-commons) assets on [OpenGameArt.org](https://opengameart.org/content/opp2017-sprites-characters-objects-effects).
## Creating the enemy sprite
Whether you realize it or not, you already know how to implement enemies. The process is similar to creating a player sprite:
- Make a class so enemies can spawn.
- Create an
`update`
function for the enemy, and update the enemy in your main loop. - Create a
`move`
function so your enemy can roam around.
Start with the class. Conceptually, it's mostly the same as your Player class. You set an image or series of images, and you set the sprite's starting position.
Before continuing, make sure you have placed your enemy graphic in your game project's `images`
directory (the same directory where you placed your player image). In this article's example code, the enemy graphic is named `enemy.png`
.
A game looks a lot better when everything *alive* is animated. Animating an enemy sprite is done the same way as animating a player sprite. For now, though, keep it simple, and use a non-animated sprite.
At the top of the `objects`
section of your code, create a class called Enemy with this code:
```
class Enemy(pygame.sprite.Sprite):
"""
Spawn an enemy
"""
def __init__(self,x,y,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
```
If you want to animate your enemy, do it the [same way](https://opensource.com/article/17/12/game-python-moving-player)[ you animated your player](https://opensource.com/article/17/12/game-python-moving-player).
## Spawning an enemy
You can make the class useful for spawning more than just one enemy by allowing yourself to tell the class which image to use for the sprite and where in the world you want the sprite to appear. This means you can use this same enemy class to generate any number of enemy sprites anywhere in the game world. All you have to do is make a call to the class, and tell it which image to use, along with the X and Y coordinates of your desired spawn point.
Ao you did when spawning a player sprite, add code to designate a spawn point in the `setup`
section of your script:
```
enemy = Enemy(300,0,'enemy.png') # spawn enemy
enemy_list = pygame.sprite.Group() # create enemy group
enemy_list.add(enemy) # add enemy to group
```
In that sample code, you spawn an enemy by creating a new object (called `enemy`
), at 300 pixels on the X axis and 0 on the Y axis. Spawning the enemy at 0 on the Y axis means that its top left corner is located at 0, with the graphic itself descending down from that point. You might need to adjust these numbers, or the numbers for your hero sprite, depending on how big your sprites are, but try to get it to spawn in a place you can reach with your player sprite (accounting for your game's current lack of vertical movement). In the end, I placed my enemy at 0 pixels on the Y axis and my hero at 30 pixels to get them boh to appear on the same plane. Experiment with the spawn points for yourself, keeping in mind that greater Y axis numbers are lower on the screen.
Your hero graphic had an image "hard coded" into its class because there's only one hero, but you may want to use different graphics for each enemy, so the image file is something you can define at sprite creation. The image used for this enemy sprite is `enemy.png`
.
## Drawing a sprite on screen
If you were to launch your game now, it would run but you wouldn't see an enemy. You might recall the same problem when you created your player sprite. Do you remember how to fix it?
To get a sprite to appear on screen, you must add them to your main loop. If something is not in your main loop, then it only happens once, and only for a millisecond. If you want something to persist in your game, it must happen in the main loop.
You must add code to draw all enemies in the enemy group (called `enemy_list`
), which you established in your setup section, on the screen. The middle line in this example code is the new line you need to add:
```
player_list.draw(world)
enemy_list.draw(world) # refresh enemies
pygame.display.flip()
```
Right now, you have only one enemy, but you can add more later if you want. As long as you add an enemy to the enemies group, it will be drawn to the screen during the main loop.
Launch your game. Your enemy appears in the game world at whatever X and Y coordinate you chose.
## Level one
Your game is in its infancy, but you will probably want to add a series of levels, eventually. It's important to plan ahead when you program so your game can grow as you learn more about programming. Even though you don't even have one complete level yet, you should code as if you plan on having many levels.
Think about what a "level" is. How do you know you are at a certain level in a game?
You can think of a level as a collection of items. In a platformer, such as the one you are building here, a level consists of a specific arrangement of platforms, placement of enemies and loot, and so on. You can build a class that builds a level around your player. Eventually, when you create more than one level, you can use this class to generate the next level when your player reaches a specific goal.
Move the code you wrote to create an enemy and its group into a new function that gets called along with each new level. It requires some modification so that each time you create a new level, you can create and place several enemies:
```
class Level():
def bad(lvl,eloc):
if lvl == 1:
enemy = Enemy(eloc[0],eloc[1],'enemy.png') # spawn enemy
enemy_list = pygame.sprite.Group() # create enemy group
enemy_list.add(enemy) # add enemy to group
if lvl == 2:
print("Level " + str(lvl) )
return enemy_list
```
The `return`
statement ensures that when you use the `Level.bad`
function, you're left with an `enemy_list`
containing each enemy you defined.
Since you are creating enemies as part of each level now, your `setup`
section needs to change, too. Instead of creating an enemy, you must define where the enemy will spawn and what level it belongs to.
```
eloc = []
eloc = [300,0]
enemy_list = Level.bad( 1, eloc )
```
Run the game again to confirm your level is generating correctly. You should see your player, as usual, and the enemy you added in this chapter.
## Hitting the enemy
An enemy isn't much of an enemy if it has no effect on the player. It's common for enemies to cause damage when a player collides with them.
Since you probably want to track the player's health, the collision check happens in the Player class rather than in the Enemy class. You can track the enemy's health, too, if you want. The logic and code are pretty much the same, but, for now, just track the player's health.
To track player health, you must first establish a variable for the player's health. The first line in this code sample is for context, so add the second line to your Player class:
```
self.frame = 0
self.health = 10
```
In the `update`
function of your Player class, add this code block:
```
hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
for enemy in hit_list:
self.health -= 1
print(self.health)
```
This code establishes a collision detector using the Pygame function `sprite.spritecollide`
, called `enemy_hit`
. This collision detector sends out a signal any time the hitbox of its parent sprite (the player sprite, where this detector has been created) touches the hitbox of any sprite in `enemy_list`
. The `for`
loop is triggered when such a signal is received and deducts a point from the player's health.
Since this code appears in the `update`
function of your player class and `update`
is called in your main loop, Pygame checks for this collision once every clock tick.
## Moving the enemy
An enemy that stands still is useful if you want, for instance, spikes or traps that can harm your player, but the game is more of a challenge if the enemies move around a little.
Unlike a player sprite, the enemy sprite is not controlled by the user. Its movements must be automated.
Eventually, your game world will scroll, so how do you get an enemy to move back and forth within the game world when the game world itself is moving?
You tell your enemy sprite to take, for example, 10 paces to the right, then 10 paces to the left. An enemy sprite can't count, so you have to create a variable to keep track of how many paces your enemy has moved and program your enemy to move either right or left depending on the value of your counting variable.
First, create the counter variable in your Enemy class. Add the last line in this code sample:
```
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0 # counter variable
```
Next, create a `move`
function in your Enemy class. Use an if-else loop to create what is called an *infinite loop*:
- Move right if the counter is on any number from 0 to 100.
- Move left if the counter is on any number from 100 to 200.
- Reset the counter back to 0 if the counter is greater than 200.
An infinite loop has no end; it loops forever because nothing in the loop is ever untrue. The counter, in this case, is always either between 0 and 100 or 100 and 200, so the enemy sprite walks right to left and right to left forever.
The actual numbers you use for how far the enemy will move in either direction depending on your screen size, and possibly, eventually, the size of the platform your enemy is walking on. Start small and work your way up as you get used to the results. Try this first:
```
def move(self):
'''
enemy movement
'''
distance = 80
speed = 8
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance*2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
```
After you enter this code, PyCharm will offer to simplify the "chained comparison". You can accept its suggestion to optimize your code, and to learn some advanced Python syntax. You can also safely ignore PyCharm. The code works, either way.
You can adjust the distance and speed as needed.
The question is: does this code work if you launch your game now?
Of course not! And you know why: you must call the `move`
function in your main loop.
The first line in this sample code is for context, so add the last two lines:
```
enemy_list.draw(world) #refresh enemy
for e in enemy_list:
e.move()
```
Launch your game and see what happens when you hit your enemy. You might have to adjust where the sprites spawn so that your player and your enemy sprite can collide. When they do collide, look in the console of IDLE or PyCharm to see the health points being deducted.

You may notice that health is deducted for every moment your player and enemy are touching. That's a problem, but it's a problem you'll solve later, after you've had more practice with Python.
For now, try adding some more enemies. Remember to add each enemy to the `enemy_list`
. As an exercise, see if you can think of how you can change how far different enemy sprites move.
## Code so far
For you reference, here's the code so far:
```
#!/usr/bin/env python3
# by Seth Kenlon
# GPLv3
# This program is free software: you can redistribute it and/or
# modify it under the terms of the GNU General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import pygame
import sys
import os
'''
Variables
'''
worldx = 960
worldy = 720
fps = 40
ani = 4
world = pygame.display.set_mode([worldx, worldy])
BLUE = (25, 25, 200)
BLACK = (23, 23, 23)
WHITE = (254, 254, 254)
ALPHA = (0, 255, 0)
'''
Objects
'''
class Player(pygame.sprite.Sprite):
"""
Spawn a player
"""
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.images = []
for i in range(1, 5):
img = pygame.image.load(os.path.join('images', 'hero' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def control(self, x, y):
"""
control player movement
"""
self.movex += x
self.movey += y
def update(self):
"""
Update sprite position
"""
self.rect.x = self.rect.x + self.movex
self.rect.y = self.rect.y + self.movey
# moving left
if self.movex < 0:
self.frame += 1
if self.frame > 3*ani:
self.frame = 0
self.image = pygame.transform.flip(self.images[self.frame // ani], True, False)
# moving right
if self.movex > 0:
self.frame += 1
if self.frame > 3*ani:
self.frame = 0
self.image = self.images[self.frame//ani]
hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
for enemy in hit_list:
self.health -= 1
print(self.health)
class Enemy(pygame.sprite.Sprite):
"""
Spawn an enemy
"""
def __init__(self, x, y, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
"""
enemy movement
"""
distance = 80
speed = 8
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance*2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
class Level():
def bad(lvl, eloc):
if lvl == 1:
enemy = Enemy(eloc[0], eloc[1], 'enemy.png')
enemy_list = pygame.sprite.Group()
enemy_list.add(enemy)
if lvl == 2:
print("Level " + str(lvl) )
return enemy_list
'''
Setup
'''
backdrop = pygame.image.load(os.path.join('images', 'stage.png'))
clock = pygame.time.Clock()
pygame.init()
backdropbox = world.get_rect()
main = True
player = Player() # spawn player
player.rect.x = 0 # go to x
player.rect.y = 30 # go to y
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10
eloc = []
eloc = [300, 0]
enemy_list = Level.bad(1, eloc )
'''
Main Loop
'''
while main:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(-steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(steps, 0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps, 0)
world.blit(backdrop, backdropbox)
player.update()
player_list.draw(world)
enemy_list.draw(world)
for e in enemy_list:
e.move()
pygame.display.flip()
clock.tick(fps)
```
## 4 Comments |
10,884 | 详解 Linux 中的虚拟文件系统 | https://opensource.com/article/19/3/virtual-filesystems-linux | 2019-05-22T00:01:12 | [
"VFS",
"文件系统"
] | https://linux.cn/article-10884-1.html |
>
> 虚拟文件系统是一种神奇的抽象,它使得 “一切皆文件” 哲学在 Linux 中成为了可能。
>
>
>

什么是文件系统?根据早期的 Linux 贡献者和作家 [Robert Love](https://www.pearson.com/us/higher-education/program/Love-Linux-Kernel-Development-3rd-Edition/PGM202532.html) 所说,“文件系统是一个遵循特定结构的数据的分层存储。” 不过,这种描述也同样适用于 VFAT(<ruby> 虚拟文件分配表 <rt> Virtual File Allocation Table </rt></ruby>)、Git 和[Cassandra](http://cassandra.apache.org/)(一种 [NoSQL 数据库](https://en.wikipedia.org/wiki/NoSQL))。那么如何区别文件系统呢?
### 文件系统基础概念
Linux 内核要求文件系统必须是实体,它还必须在持久对象上实现 `open()`、`read()` 和 `write()` 方法,并且这些实体需要有与之关联的名字。从 [面向对象编程](http://lwn.net/Articles/444910/) 的角度来看,内核将通用文件系统视为一个抽象接口,这三大函数是“虚拟”的,没有默认定义。因此,内核的默认文件系统实现被称为虚拟文件系统(VFS)。

*如果我们能够 `open()`、`read()` 和 `write()`,它就是一个文件,如这个主控台会话所示。*
VFS 是著名的类 Unix 系统中 “一切皆文件” 概念的基础。让我们看一下它有多奇怪,上面的小小演示体现了字符设备 `/dev/console` 实际的工作。该图显示了一个在虚拟电传打字控制台(tty)上的交互式 Bash 会话。将一个字符串发送到虚拟控制台设备会使其显示在虚拟屏幕上。而 VFS 甚至还有其它更奇怪的属性。例如,它[可以在其中寻址](https://lwn.net/Articles/22355/)。
我们熟悉的文件系统如 ext4、NFS 和 /proc 都在名为 [file\_operations](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/include/linux/fs.h) 的 C 语言数据结构中提供了三大函数的定义。此外,个别的文件系统会以熟悉的面向对象的方式扩展和覆盖了 VFS 功能。正如 Robert Love 指出的那样,VFS 的抽象使 Linux 用户可以轻松地将文件复制到(或复制自)外部操作系统或抽象实体(如管道),而无需担心其内部数据格式。在用户空间这一侧,通过系统调用,进程可以使用文件系统方法之一 `read()` 从文件复制到内核的数据结构中,然后使用另一种文件系统的方法 `write()` 输出数据。
属于 VFS 基本类型的函数定义本身可以在内核源代码的 [fs/\*.c 文件](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/fs) 中找到,而 `fs/` 的子目录中包含了特定的文件系统。内核还包含了类似文件系统的实体,例如 cgroup、`/dev` 和 tmpfs,在引导过程的早期需要它们,因此定义在内核的 `init/` 子目录中。请注意,cgroup、`/dev` 和 tmpfs 不会调用 `file_operations` 的三大函数,而是直接读取和写入内存。
下图大致说明了用户空间如何访问通常挂载在 Linux 系统上的各种类型文件系统。像管道、dmesg 和 POSIX 时钟这样的结构在此图中未显示,它们也实现了 `struct file_operations`,而且其访问也要通过 VFS 层。

VFS 是个“垫片层”,位于系统调用和特定 `file_operations` 的实现(如 ext4 和 procfs)之间。然后,`file_operations` 函数可以与特定于设备的驱动程序或内存访问器进行通信。tmpfs、devtmpfs 和 cgroup 不使用 `file_operations` 而是直接访问内存。
VFS 的存在促进了代码重用,因为与文件系统相关的基本方法不需要由每种文件系统类型重新实现。代码重用是一种被广泛接受的软件工程最佳实践!唉,但是如果重用的代码[引入了严重的错误](https://lwn.net/Articles/774114/),那么继承常用方法的所有实现都会受到影响。
### /tmp:一个小提示
找出系统中存在的 VFS 的简单方法是键入 `mount | grep -v sd | grep -v :/`,在大多数计算机上,它将列出所有未驻留在磁盘上,同时也不是 NFS 的已挂载文件系统。其中一个列出的 VFS 挂载肯定是 `/tmp`,对吧?

*谁都知道把 /tmp 放在物理存储设备上简直是疯了!图片:<https://tinyurl.com/ybomxyfo>*
为什么把 `/tmp` 留在存储设备上是不可取的?因为 `/tmp` 中的文件是临时的(!),并且存储设备比内存慢,所以创建了 tmpfs 这种文件系统。此外,比起内存,物理设备频繁写入更容易磨损。最后,`/tmp` 中的文件可能包含敏感信息,因此在每次重新启动时让它们消失是一项功能。
不幸的是,默认情况下,某些 Linux 发行版的安装脚本仍会在存储设备上创建 /tmp。如果你的系统出现这种情况,请不要绝望。按照一直优秀的 [Arch Wiki](https://wiki.archlinux.org/index.php/Tmpfs) 上的简单说明来解决问题就行,记住分配给 tmpfs 的内存就不能用于其他目的了。换句话说,包含了大文件的庞大的 tmpfs 可能会让系统耗尽内存并崩溃。
另一个提示:编辑 `/etc/fstab` 文件时,请务必以换行符结束,否则系统将无法启动。(猜猜我怎么知道。)
### /proc 和 /sys
除了 `/tmp` 之外,大多数 Linux 用户最熟悉的 VFS 是 `/proc` 和 `/sys`。(`/dev` 依赖于共享内存,而没有 `file_operations` 结构)。为什么有两种呢?让我们来看看更多细节。
procfs 为用户空间提供了内核及其控制的进程的瞬时状态的快照。在 `/proc` 中,内核发布有关其提供的设施的信息,如中断、虚拟内存和调度程序。此外,`/proc/sys` 是存放可以通过 [sysctl 命令](http://man7.org/linux/man-pages/man8/sysctl.8.html)配置的设置的地方,可供用户空间访问。单个进程的状态和统计信息在 `/proc/<PID>` 目录中报告。

*/proc/meminfo 是一个空文件,但仍包含有价值的信息。*
`/proc` 文件的行为说明了 VFS 可以与磁盘上的文件系统不同。一方面,`/proc/meminfo` 包含了可由命令 `free` 展现出来的信息。另一方面,它还是空的!怎么会这样?这种情况让人联想起康奈尔大学物理学家 N. David Mermin 在 1985 年写的一篇名为《[没有人看见月亮的情况吗?](http://www-f1.ijs.si/%7Eramsak/km1/mermin.moon.pdf)现实和量子理论》。事实是当进程从 `/proc` 请求数据时内核再收集有关内存的统计信息,而且当没有人查看它时,`/proc` 中的文件实际上没有任何内容。正如 [Mermin 所说](https://en.wikiquote.org/wiki/David_Mermin),“这是一个基本的量子学说,一般来说,测量不会揭示被测属性的预先存在的价值。”(关于月球的问题的答案留作练习。)

*当没有进程访问它们时,/proc 中的文件为空。([来源](https://commons.wikimedia.org/wiki/Moon#/media/File:Full_Moon_Luc_Viatour.jpg))*
procfs 的空文件是有道理的,因为那里可用的信息是动态的。sysfs 的情况则不同。让我们比较一下 `/proc` 与 `/sys` 中不为空的文件数量。

procfs 只有一个不为空的文件,即导出的内核配置,这是一个例外,因为每次启动只需要生成一次。另一方面,`/sys` 有许多更大一些的文件,其中大多数由一页内存组成。通常,sysfs 文件只包含一个数字或字符串,与通过读取 `/proc/meminfo` 等文件生成的信息表格形成鲜明对比。
sysfs 的目的是将内核称为 “kobject” 的可读写属性公开给用户空间。kobject 的唯一目的是引用计数:当删除对 kobject 的最后一个引用时,系统将回收与之关联的资源。然而,`/sys` 构成了内核著名的“[到用户空间的稳定 ABI](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/ABI/stable)”,它的大部分内容[在任何情况下都没有人能“破坏”](https://lkml.org/lkml/2012/12/23/75)。但这并不意味着 sysfs 中的文件是静态,这与易失性对象的引用计数相反。
内核的稳定 ABI 限制了 `/sys` 中可能出现的内容,而不是任何给定时刻实际存在的内容。列出 sysfs 中文件的权限可以了解如何设置或读取设备、模块、文件系统等的可配置、可调参数。逻辑上强调 procfs 也是内核稳定 ABI 的一部分的结论,尽管内核的[文档](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/ABI/stable)没有明确说明。

*sysfs 中的文件确切地描述了实体的每个属性,并且可以是可读的、可写的,或两者兼而有之。文件中的“0”表示 SSD 不可移动的存储设备。*
### 用 eBPF 和 bcc 工具一窥 VFS 内部
了解内核如何管理 sysfs 文件的最简单方法是观察它的运行情况,在 ARM64 或 x86\_64 上观看的最简单方法是使用 eBPF。eBPF(<ruby> 扩展的伯克利数据包过滤器 <rt> extended Berkeley Packet Filter </rt></ruby>)由[在内核中运行的虚拟机](https://events.linuxfoundation.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf)组成,特权用户可以从命令行进行查询。内核源代码告诉读者内核可以做什么;而在一个启动的系统上运行 eBPF 工具会显示内核实际上做了什么。
令人高兴的是,通过 [bcc](https://github.com/iovisor/bcc) 工具入门使用 eBPF 非常容易,这些工具在[主要 Linux 发行版的软件包](https://github.com/iovisor/bcc/blob/master/INSTALL.md) 中都有,并且已经由 Brendan Gregg [给出了充分的文档说明](http://brendangregg.com/ebpf.html)。bcc 工具是带有小段嵌入式 C 语言片段的 Python 脚本,这意味着任何对这两种语言熟悉的人都可以轻松修改它们。据当前统计,[bcc/tools 中有 80 个 Python 脚本](https://github.com/iovisor/bcc/tree/master/tools),使得系统管理员或开发人员很有可能能够找到与她/他的需求相关的已有脚本。
要了解 VFS 在正在运行中的系统上的工作情况,请尝试使用简单的 [vfscount](https://github.com/iovisor/bcc/blob/master/tools/vfscount_example.txt) 或 [vfsstat](https://github.com/iovisor/bcc/blob/master/tools/vfsstat.py) 脚本,这可以看到每秒都会发生数十次对 `vfs_open()` 及其相关的调用。

*vfsstat.py 是一个带有嵌入式 C 片段的 Python 脚本,它只是计数 VFS 函数调用。*
作为一个不太重要的例子,让我们看一下在运行的系统上插入 USB 记忆棒时 sysfs 中会发生什么。

*用 eBPF 观察插入 USB 记忆棒时 /sys 中会发生什么,简单的和复杂的例子。*
在上面的第一个简单示例中,只要 `sysfs_create_files()` 命令运行,[trace.py](https://github.com/iovisor/bcc/blob/master/tools/trace_example.txt) bcc 工具脚本就会打印出一条消息。我们看到 `sysfs_create_files()` 由一个 kworker 线程启动,以响应 USB 棒的插入事件,但是它创建了什么文件?第二个例子说明了 eBPF 的强大能力。这里,`trace.py` 正在打印内核回溯(`-K` 选项)以及 `sysfs_create_files()` 创建的文件的名称。单引号内的代码段是一些 C 源代码,包括一个易于识别的格式字符串,所提供的 Python 脚本[引入 LLVM 即时编译器(JIT)](https://events.static.linuxfound.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf) 来在内核虚拟机内编译和执行它。必须在第二个命令中重现完整的 `sysfs_create_files()` 函数签名,以便格式字符串可以引用其中一个参数。在此 C 片段中出错会导致可识别的 C 编译器错误。例如,如果省略 `-I` 参数,则结果为“无法编译 BPF 文本”。熟悉 C 或 Python 的开发人员会发现 bcc 工具易于扩展和修改。
插入 USB 记忆棒后,内核回溯显示 PID 7711 是一个 kworker 线程,它在 sysfs 中创建了一个名为 `events` 的文件。使用 `sysfs_remove_files()` 进行相应的调用表明,删除 USB 记忆棒会导致删除该 `events` 文件,这与引用计数的想法保持一致。在 USB 棒插入期间(未显示)在 eBPF 中观察 `sysfs_create_link()` 表明创建了不少于 48 个符号链接。
无论如何,`events` 文件的目的是什么?使用 [cscope](http://northstar-www.dartmouth.edu/doc/solaris-forte/manuals/c/user_guide/cscope.html) 查找函数 [`__device_add_disk()`](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/block/genhd.c#n665) 显示它调用 `disk_add_events()`,并且可以将 “mediachange” 或 “ejectrequest” 写入到该文件。这里,内核的块层通知用户空间该 “磁盘” 的出现和消失。考虑一下这种检查 USB 棒的插入的工作原理的方法与试图仅从源头中找出该过程的速度有多快。
### 只读根文件系统使得嵌入式设备成为可能
确实,没有人通过拔出电源插头来关闭服务器或桌面系统。为什么?因为物理存储设备上挂载的文件系统可能有挂起的(未完成的)写入,并且记录其状态的数据结构可能与写入存储器的内容不同步。当发生这种情况时,系统所有者将不得不在下次启动时等待 [fsck 文件系统恢复工具](http://www.man7.org/linux/man-pages/man8/fsck.8.html) 运行完成,在最坏的情况下,实际上会丢失数据。
然而,狂热爱好者会听说许多物联网和嵌入式设备,如路由器、恒温器和汽车现在都运行着 Linux。许多这些设备几乎完全没有用户界面,并且没有办法干净地让它们“解除启动”。想一想启动电池耗尽的汽车,其中[运行 Linux 的主机设备](https://wiki.automotivelinux.org/_media/eg-rhsa/agl_referencehardwarespec_v0.1.0_20171018.pdf) 的电源会不断加电断电。当引擎最终开始运行时,系统如何在没有长时间 fsck 的情况下启动呢?答案是嵌入式设备依赖于[只读根文件系统](https://elinux.org/images/1/1f/Read-only_rootfs.pdf)(简称 ro-rootfs)。

*ro-rootfs 是嵌入式系统不经常需要 fsck 的原因。 来源:<https://tinyurl.com/yxoauoub>*
ro-rootfs 提供了许多优点,虽然这些优点不如耐用性那么显然。一个是,如果 Linux 进程不可以写入,那么恶意软件也无法写入 `/usr` 或 `/lib`。另一个是,基本上不可变的文件系统对于远程设备的现场支持至关重要,因为支持人员拥有理论上与现场相同的本地系统。也许最重要(但也是最微妙)的优势是 ro-rootfs 迫使开发人员在项目的设计阶段就决定好哪些系统对象是不可变的。处理 ro-rootfs 可能经常是不方便甚至是痛苦的,[编程语言中的常量变量](https://www.meetup.com/ACCU-Bay-Area/events/drpmvfytlbqb/)经常就是这样,但带来的好处很容易偿还这种额外的开销。
对于嵌入式开发人员,创建只读根文件系统确实需要做一些额外的工作,而这正是 VFS 的用武之地。Linux 需要 `/var` 中的文件可写,此外,嵌入式系统运行的许多流行应用程序会尝试在 `$HOME` 中创建配置的点文件。放在家目录中的配置文件的一种解决方案通常是预生成它们并将它们构建到 rootfs 中。对于 `/var`,一种方法是将其挂载在单独的可写分区上,而 `/` 本身以只读方式挂载。使用绑定或叠加挂载是另一种流行的替代方案。
### 绑定和叠加挂载以及在容器中的使用
运行 [man mount](http://man7.org/linux/man-pages/man8/mount.8.html) 是了解<ruby> 绑定挂载 <rt> bind mount </rt></ruby>和<ruby> 叠加挂载 <rt> overlay mount </rt></ruby>的最好办法,这种方法使得嵌入式开发人员和系统管理员能够在一个路径位置创建文件系统,然后以另外一个路径将其提供给应用程序。对于嵌入式系统,这代表着可以将文件存储在 `/var` 中的不可写闪存设备上,但是在启动时将 tmpfs 中的路径叠加挂载或绑定挂载到 `/var` 路径上,这样应用程序就可以在那里随意写它们的内容了。下次加电时,`/var` 中的变化将会消失。叠加挂载为 tmpfs 和底层文件系统提供了联合,允许对 ro-rootfs 中的现有文件进行直接修改,而绑定挂载可以使新的空 tmpfs 目录在 ro-rootfs 路径中显示为可写。虽然叠加文件系统是一种适当的文件系统类型,而绑定挂载由 [VFS 命名空间工具](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/filesystems/sharedsubtree.txt) 实现的。
根据叠加挂载和绑定挂载的描述,没有人会对 [Linux 容器](https://coreos.com/os/docs/latest/kernel-modules.html) 中大量使用它们感到惊讶。让我们通过运行 bcc 的 `mountsnoop` 工具监视当使用 [systemd-nspawn](https://www.freedesktop.org/software/systemd/man/systemd-nspawn.html) 启动容器时会发生什么:

*在 mountsnoop.py 运行的同时,system-nspawn 调用启动容器。*
让我们看看发生了什么:

*在容器 “启动” 期间运行 `mountsnoop` 可以看到容器运行时很大程度上依赖于绑定挂载。(仅显示冗长输出的开头)*
这里,`systemd-nspawn` 将主机的 procfs 和 sysfs 中的选定文件按其 rootfs 中的路径提供给容器。除了设置绑定挂载时的 `MS_BIND` 标志之外,`mount` 系统调用的一些其它标志用于确定主机命名空间和容器中的更改之间的关系。例如,绑定挂载可以将 `/proc` 和 `/sys` 中的更改传播到容器,也可以隐藏它们,具体取决于调用。
### 总结
理解 Linux 内部结构看似是一项不可能完成的任务,因为除了 Linux 用户空间应用程序和 glibc 这样的 C 库中的系统调用接口,内核本身也包含大量代码。取得进展的一种方法是阅读一个内核子系统的源代码,重点是理解面向用户空间的系统调用和头文件以及主要的内核内部接口,这里以 `file_operations` 表为例。`file_operations` 使得“一切都是文件”得以可以实际工作,因此掌握它们收获特别大。顶级 `fs/` 目录中的内核 C 源文件构成了虚拟文件系统的实现,虚拟文件系统是支持流行的文件系统和存储设备的广泛且相对简单的互操作性的垫片层。通过 Linux 命名空间进行绑定挂载和覆盖挂载是 VFS 魔术,它使容器和只读根文件系统成为可能。结合对源代码的研究,eBPF 内核工具及其 bcc 接口使得探测内核比以往任何时候都更简单。
非常感谢 [Akkana Peck](http://shallowsky.com/) 和 [Michael Eager](http://eagercon.com/) 的评论和指正。
Alison Chaiken 也于 3 月 7 日至 10 日在加利福尼亚州帕萨迪纳举行的第 17 届南加州 Linux 博览会([SCaLE 17x](https://www.socallinuxexpo.org/))上演讲了[本主题](https://www.socallinuxexpo.org/scale/17x/presentations/virtual-filesystems-why-we-need-them-and-how-they-work)。
---
via: <https://opensource.com/article/19/3/virtual-filesystems-linux>
作者:[Alison Chariken](https://opensource.com/users/chaiken) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | What is a filesystem? According to early Linux contributor and author [Robert Love](https://www.pearson.com/us/higher-education/program/Love-Linux-Kernel-Development-3rd-Edition/PGM202532.html), "A filesystem is a hierarchical storage of data adhering to a specific structure." However, this description applies equally well to VFAT (Virtual File Allocation Table), Git, and [Cassandra](http://cassandra.apache.org/) (a [NoSQL database](https://en.wikipedia.org/wiki/NoSQL)). So what distinguishes a filesystem?
## Filesystem basics
The Linux kernel requires that for an entity to be a filesystem, it must also implement the **open()**, **read()**, and **write()** methods on persistent objects that have names associated with them. From the point of view of [object-oriented programming](http://lwn.net/Articles/444910/), the kernel treats the generic filesystem as an abstract interface, and these big-three functions are "virtual," with no default definition. Accordingly, the kernel's default filesystem implementation is called a virtual filesystem (VFS).
*If we can open(), read(), and write(), it is a file as this console session shows.*
VFS underlies the famous observation that in Unix-like systems "everything is a file." Consider how weird it is that the tiny demo above featuring the character device */dev/console* actually works. The image shows an interactive Bash session on a virtual teletype (tty). Sending a string into the virtual console device makes it appear on the virtual screen. VFS has other, even odder properties. For example, it's [possible to seek in them](https://lwn.net/Articles/22355/).
The familiar filesystems like ext4, NFS, and /proc all provide definitions of the big-three functions in a C-language data structure called [file_operations](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/include/linux/fs.h). In addition, particular filesystems extend and override the VFS functions in the familiar object-oriented way. As Robert Love points out, the abstraction of VFS enables Linux users to blithely copy files to and from foreign operating systems or abstract entities like pipes without worrying about their internal data format. On behalf of userspace, via a system call, a process can copy from a file into the kernel's data structures with the read() method of one filesystem, then use the write() method of another kind of filesystem to output the data.
The function definitions that belong to the VFS base type itself are found in the [fs/*.c files](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/fs) in kernel source, while the subdirectories of fs/ contain the specific filesystems. The kernel also contains filesystem-like entities such as cgroups, /dev, and tmpfs, which are needed early in the boot process and are therefore defined in the kernel's init/ subdirectory. Note that cgroups, /dev, and tmpfs do not call the file_operations big-three functions, but directly read from and write to memory instead.
The diagram below roughly illustrates how userspace accesses various types of filesystems commonly mounted on Linux systems. Not shown are constructs like pipes, dmesg, and POSIX clocks that also implement struct file_operations and whose accesses therefore pass through the VFS layer.
*VFS are a "shim layer" between system calls and implementors of specific file_operations like ext4 and*procfs . The file_operations functions can then communicate either with device-specific drivers or with memory accessors. tmpfs , devtmpfs and cgroups don't make use of file_operations but access memory directly.
VFS's existence promotes code reuse, as the basic methods associated with filesystems need not be re-implemented by every filesystem type. Code reuse is a widely accepted software engineering best practice! Alas, if the reused code [introduces serious bugs](https://lwn.net/Articles/774114/), then all the implementations that inherit the common methods suffer from them.
## /tmp: A simple tip
An easy way to find out what VFSes are present on a system is to type **mount | grep -v sd | grep -v :/**, which will list all mounted filesystems that are not resident on a disk and not NFS on most computers. One of the listed VFS mounts will assuredly be /tmp, right?

*Everyone knows that keeping /*
tmp
*on a physical storage device is crazy! credit:*
[https://tinyurl.com/ybomxyfo](https://tinyurl.com/ybomxyfo)Why is keeping /tmp on storage inadvisable? Because the files in /tmp are temporary(!), and storage devices are slower than memory, where tmpfs are created. Further, physical devices are more subject to wear from frequent writing than memory is. Last, files in /tmp may contain sensitive information, so having them disappear at every reboot is a feature.
Unfortunately, installation scripts for some Linux distros still create /tmp on a storage device by default. Do not despair should this be the case with your system. Follow simple instructions on the always excellent [Arch Wiki](https://wiki.archlinux.org/index.php/Tmpfs) to fix the problem, keeping in mind that memory allocated to tmpfs is not available for other purposes. In other words, a system with a gigantic tmpfs with large files in it can run out of memory and crash. Another tip: when editing the /etc/fstab file, be sure to end it with a newline, as your system will not boot otherwise. (Guess how I know.)
## /proc and /sys
Besides /tmp, the VFSes with which most Linux users are most familiar are /proc and /sys. (/dev relies on shared memory and has no file_operations). Why two flavors? Let's have a look in more detail.
The procfs offers a snapshot into the instantaneous state of the kernel and the processes that it controls for userspace. In /proc, the kernel publishes information about the facilities it provides, like interrupts, virtual memory, and the scheduler. In addition, /proc/sys is where the settings that are configurable via the [sysctl command](http://man7.org/linux/man-pages/man8/sysctl.8.html) are accessible to userspace. Status and statistics on individual processes are reported in /proc/<PID> directories.
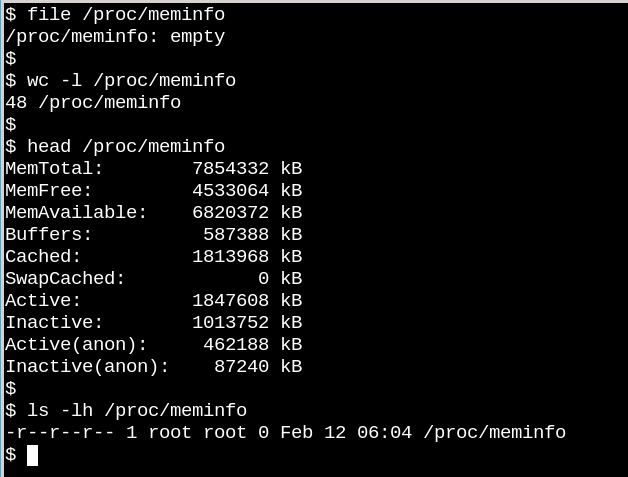
*/proc/*
meminfo
*is an empty file that nonetheless contains valuable information.*
The behavior of /proc files illustrates how unlike on-disk filesystems VFS can be. On the one hand, /proc/meminfo contains the information presented by the command **free**. On the other hand, it's also empty! How can this be? The situation is reminiscent of a famous article written by Cornell University physicist N. David Mermin in 1985 called "[Is the moon there when nobody looks?](http://www-f1.ijs.si/~ramsak/km1/mermin.moon.pdf) Reality and the quantum theory." The truth is that the kernel gathers statistics about memory when a process requests them from /proc, and there actually *is* nothing in the files in /proc when no one is looking. As [Mermin said](https://en.wikiquote.org/wiki/David_Mermin), "It is a fundamental quantum doctrine that a measurement does not, in general, reveal a preexisting value of the measured property." (The answer to the question about the moon is left as an exercise.)

*The files in /proc are empty when no process accesses them. (*
[Source](https://commons.wikimedia.org/wiki/Moon#/media/File:Full_Moon_Luc_Viatour.jpg))The apparent emptiness of procfs makes sense, as the information available there is dynamic. The situation with sysfs is different. Let's compare how many files of at least one byte in size there are in /proc versus /sys.

Procfs has precisely one, namely the exported kernel configuration, which is an exception since it needs to be generated only once per boot. On the other hand, /sys has lots of larger files, most of which comprise one page of memory. Typically, sysfs files contain exactly one number or string, in contrast to the tables of information produced by reading files like /proc/meminfo.
The purpose of sysfs is to expose the readable and writable properties of what the kernel calls "kobjects" to userspace. The only purpose of kobjects is reference-counting: when the last reference to a kobject is deleted, the system will reclaim the resources associated with it. Yet, /sys constitutes most of the kernel's famous "[stable ABI to userspace](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/ABI/stable)" which [no one may ever, under any circumstances, "break."](https://lkml.org/lkml/2012/12/23/75) That doesn't mean the files in sysfs are static, which would be contrary to reference-counting of volatile objects.
The kernel's stable ABI instead constrains what *can* appear in /sys, not what is actually present at any given instant. Listing the permissions on files in sysfs gives an idea of how the configurable, tunable parameters of devices, modules, filesystems, etc. can be set or read. Logic compels the conclusion that procfs is also part of the kernel's stable ABI, although the kernel's [documentation](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/ABI/stable) doesn't state so explicitly.
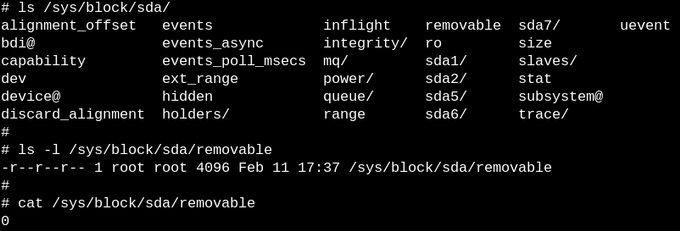
*Files in*
sysfs
*describe exactly one property each for an entity and may be readable, writable or both. The "0" in the file reveals that the SSD is not removable.*
## Snooping on VFS with eBPF and bcc tools
The easiest way to learn how the kernel manages sysfs files is to watch it in action, and the simplest way to watch on ARM64 or x86_64 is to use eBPF. eBPF (extended Berkeley Packet Filter) consists of a [virtual machine running inside the kernel](https://events.linuxfoundation.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf) that privileged users can query from the command line. Kernel source tells the reader what the kernel *can* do; running eBPF tools on a booted system shows instead what the kernel actually *does*.
Happily, getting started with eBPF is pretty easy via the [bcc](https://github.com/iovisor/bcc) tools, which are available as [packages from major Linux distros](https://github.com/iovisor/bcc/blob/master/INSTALL.md) and have been [amply documented](http://brendangregg.com/ebpf.html) by Brendan Gregg. The bcc tools are Python scripts with small embedded snippets of C, meaning anyone who is comfortable with either language can readily modify them. At this count, [there are 80 Python scripts in bcc/tools](https://github.com/iovisor/bcc/tree/master/tools), making it highly likely that a system administrator or developer will find an existing one relevant to her/his needs.
To get a very crude idea about what work VFSes are performing on a running system, try the simple [vfscount](https://github.com/iovisor/bcc/blob/master/tools/vfscount_example.txt) or [vfsstat](https://github.com/iovisor/bcc/blob/master/tools/vfsstat.py), which show that dozens of calls to vfs_open() and its friends occur every second.
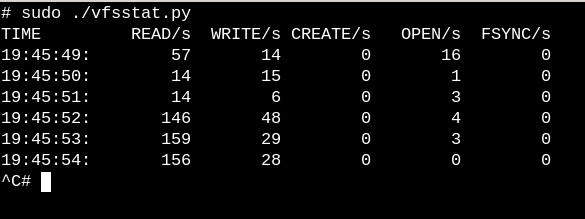
*vfsstat.py is a Python script with an embedded C snippet that simply counts VFS function calls.*
For a less trivial example, let's watch what happens in sysfs when a USB stick is inserted on a running system.
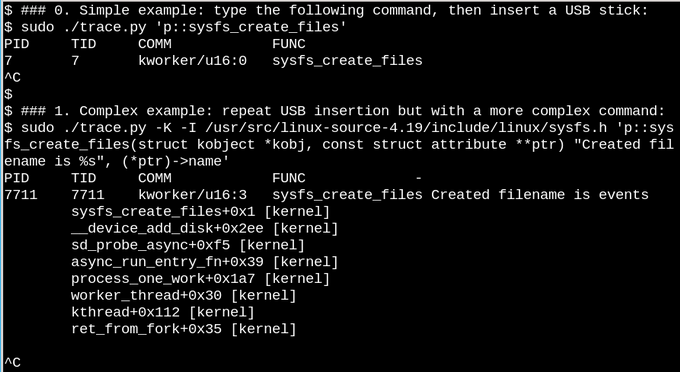
*Watch with eBPF what happens in /sys when a USB stick is inserted, with simple and complex examples.*
In the first simple example above, the [trace.py](https://github.com/iovisor/bcc/blob/master/tools/trace_example.txt) bcc tools script prints out a message whenever the sysfs_create_files() command runs. We see that sysfs_create_files() was started by a kworker thread in response to the USB stick insertion, but what file was created? The second example illustrates the full power of eBPF. Here, trace.py is printing the kernel backtrace (-K option) plus the name of the file created by sysfs_create_files(). The snippet inside the single quotes is some C source code, including an easily recognizable format string, that the provided Python script [induces a LLVM just-in-time compiler](https://events.static.linuxfound.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf) to compile and execute inside an in-kernel virtual machine. The full sysfs_create_files() function signature must be reproduced in the second command so that the format string can refer to one of the parameters. Making mistakes in this C snippet results in recognizable C-compiler errors. For example, if the **-I** parameter is omitted, the result is "Failed to compile BPF text." Developers who are conversant with either C or Python will find the bcc tools easy to extend and modify.
When the USB stick is inserted, the kernel backtrace appears showing that PID 7711 is a kworker thread that created a file called "events" in sysfs. A corresponding invocation with sysfs_remove_files() shows that removal of the USB stick results in removal of the events file, in keeping with the idea of reference counting. Watching sysfs_create_link() with eBPF during USB stick insertion (not shown) reveals that no fewer than 48 symbolic links are created.
What is the purpose of the events file anyway? Using [cscope](http://northstar-www.dartmouth.edu/doc/solaris-forte/manuals/c/user_guide/cscope.html) to find the function [__device_add_disk()](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/block/genhd.c#n665) reveals that it calls disk_add_events(), and either "media_change" or "eject_request" may be written to the events file. Here, the kernel's block layer is informing userspace about the appearance and disappearance of the "disk." Consider how quickly informative this method of investigating how USB stick insertion works is compared to trying to figure out the process solely from the source.
## Read-only root filesystems make embedded devices possible
Assuredly, no one shuts down a server or desktop system by pulling out the power plug. Why? Because mounted filesystems on the physical storage devices may have pending writes, and the data structures that record their state may become out of sync with what is written on the storage. When that happens, system owners will have to wait at next boot for the [fsck filesystem-recovery tool](http://www.man7.org/linux/man-pages/man8/fsck.8.html) to run and, in the worst case, will actually lose data.
Yet, aficionados will have heard that many IoT and embedded devices like routers, thermostats, and automobiles now run Linux. Many of these devices almost entirely lack a user interface, and there's no way to "unboot" them cleanly. Consider jump-starting a car with a dead battery where the power to the [Linux-running head unit](https://wiki.automotivelinux.org/_media/eg-rhsa/agl_referencehardwarespec_v0.1.0_20171018.pdf) goes up and down repeatedly. How is it that the system boots without a long fsck when the engine finally starts running? The answer is that embedded devices rely on [a read-only root fileystem](https://elinux.org/images/1/1f/Read-only_rootfs.pdf) (ro-rootfs for short).
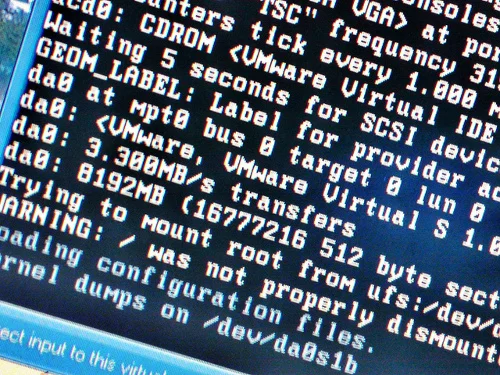
*ro-*
*rootfs*
*are why embedded systems don't frequently need to fsck. Credit (with permission):*
[https://tinyurl.com/yxoauoub](https://tinyurl.com/yxoauoub)A ro-rootfs offers many advantages that are less obvious than incorruptibility. One is that malware cannot write to /usr or /lib if no Linux process can write there. Another is that a largely immutable filesystem is critical for field support of remote devices, as support personnel possess local systems that are nominally identical to those in the field. Perhaps the most important (but also most subtle) advantage is that ro-rootfs forces developers to decide during a project's design phase which system objects will be immutable. Dealing with ro-rootfs may often be inconvenient or even painful, as [const variables in programming languages](https://www.meetup.com/ACCU-Bay-Area/events/drpmvfytlbqb/) often are, but the benefits easily repay the extra overhead.
Creating a read-only rootfs does require some additional amount of effort for embedded developers, and that's where VFS comes in. Linux needs files in /var to be writable, and in addition, many popular applications that embedded systems run will try to create configuration dot-files in $HOME. One solution for configuration files in the home directory is typically to pregenerate them and build them into the rootfs. For /var, one approach is to mount it on a separate writable partition while / itself is mounted as read-only. Using bind or overlay mounts is another popular alternative.
## Bind and overlay mounts and their use by containers
Running ** man mount** is the best place to learn about bind and overlay mounts, which give embedded developers and system administrators the power to create a filesystem in one path location and then provide it to applications at a second one. For embedded systems, the implication is that it's possible to store the files in /var on an unwritable flash device but overlay- or bind-mount a path in a tmpfs onto the /var path at boot so that applications can scrawl there to their heart's delight. At next power-on, the changes in /var will be gone. Overlay mounts provide a union between the tmpfs and the underlying filesystem and allow apparent modification to an existing file in a ro-rootfs, while bind mounts can make new empty tmpfs directories show up as writable at ro-rootfs paths. While overlayfs is a proper filesystem type, bind mounts are implemented by the
[VFS namespace facility](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/filesystems/sharedsubtree.txt).
Based on the description of overlay and bind mounts, no one will be surprised that [Linux containers](https://coreos.com/os/docs/latest/kernel-modules.html) make heavy use of them. Let's spy on what happens when we employ [systemd-nspawn](https://www.freedesktop.org/software/systemd/man/systemd-nspawn.html) to start up a container by running bcc's mountsnoop tool:

*The system-*
nspawn
*invocation fires up the container while mountsnoop.py runs.*
And let's see what happened:
*Running*
mountsnoop
*during the container "boot" reveals that the container runtime relies heavily on bind mounts. (Only the beginning of the lengthy output is displayed)*
Here, systemd-nspawn is providing selected files in the host's procfs and sysfs to the container at paths in its rootfs. Besides the MS_BIND flag that sets bind-mounting, some of the other flags that the "mount" system call invokes determine the relationship between changes in the host namespace and in the container. For example, the bind-mount can either propagate changes in /proc and /sys to the container, or hide them, depending on the invocation.
## Summary
Understanding Linux internals can seem an impossible task, as the kernel itself contains a gigantic amount of code, leaving aside Linux userspace applications and the system-call interface in C libraries like glibc. One way to make progress is to read the source code of one kernel subsystem with an emphasis on understanding the userspace-facing system calls and headers plus major kernel internal interfaces, exemplified here by the file_operations table. The file operations are what makes "everything is a file" actually work, so getting a handle on them is particularly satisfying. The kernel C source files in the top-level fs/ directory constitute its implementation of virtual filesystems, which are the shim layer that enables broad and relatively straightforward interoperability of popular filesystems and storage devices. Bind and overlay mounts via Linux namespaces are the VFS magic that makes containers and read-only root filesystems possible. In combination with a study of source code, the eBPF kernel facility and its bcc interface makes probing the kernel simpler than ever before.
*Much thanks to Akkana Peck and Michael Eager for comments and corrections. *
*Alison Chaiken will present Virtual filesystems: why we need them and how they work at the 17th annual Southern California Linux Expo (SCaLE 17x) March 7-10 in Pasadena, Calif.*
## 6 Comments |
10,885 | 构建更小的容器镜像的技巧 | https://fedoramagazine.org/building-smaller-container-images/ | 2019-05-22T11:13:38 | [
"容器",
"Dockerfile"
] | https://linux.cn/article-10885-1.html | 
Linux 容器已经成为一个热门话题,保证容器镜像较小被认为是一个好习惯。本文提供了有关如何构建较小 Fedora 容器镜像的一些技巧。
### microdnf
Fedora 的 DNF 是用 Python 编写的,因为它有各种各样的插件,因此它的设计是可扩展的。但是 有一个 Fedora 基本容器镜像替代品,它使用一个较小的名为 [microdnf](https://github.com/rpm-software-management/microdnf) 的包管理器,使用 C 编写。要在 Dockerfile 中使用这个最小的镜像,`FROM` 行应该如下所示:
```
FROM registry.fedoraproject.org/fedora-minimal:30
```
如果你的镜像不需要像 Python 这样的典型 DNF 依赖项,例如,如果你在制作 NodeJS 镜像时,那么这是一个重要的节省项。
### 在一个层中安装和清理
为了节省空间,使用 `dnf clean all` 或其 microdnf 等效的 `microdnf clean all` 删除仓库元数据非常重要。但是你不应该分两步执行此操作,因为这实际上会将这些文件保存在容器镜像中,然后在另一层中将其标记为删除。要正确地执行此操作,你应该像这样一步完成安装和清理:
```
FROM registry.fedoraproject.org/fedora-minimal:30
RUN microdnf install nodejs && microdnf clean all
```
### 使用 microdnf 进行模块化
模块化是一种给你选择不同堆栈版本的方法。例如,你可能需要在项目中用非 LTS 的 NodeJS v11,旧的 LTS NodeJS v8 用于另一个,最新的 LTS NodeJS v10 用于另一个。你可以使用冒号指定流。
```
# dnf module list
# dnf module install nodejs:8
```
`dnf module install` 命令意味着两个命令,一个启用流,另一个是从它安装 nodejs。
```
# dnf module enable nodejs:8
# dnf install nodejs
```
尽管 `microdnf` 不提供与模块化相关的任何命令,但是可以启用带有配置文件的模块,并且 libdnf(被 microdnf 使用)[似乎](https://bugzilla.redhat.com/show_bug.cgi?id=1575626)支持模块化流。该文件看起来像这样:
```
/etc/dnf/modules.d/nodejs.module
[nodejs]
name=nodejs
stream=8
profiles=
state=enabled
```
使用模块化的 `microdnf` 的完整 Dockerfile 如下所示:
```
FROM registry.fedoraproject.org/fedora-minimal:30
RUN \
echo -e "[nodejs]\nname=nodejs\nstream=8\nprofiles=\nstate=enabled\n" > /etc/dnf/modules.d/nodejs.module && \
microdnf install nodejs zopfli findutils busybox && \
microdnf clean all
```
### 多阶段构建
在许多情况下,你可能需要大量的无需用于运行软件的构建时依赖项,例如构建一个静态链接依赖项的 Go 二进制文件。多阶段构建是分离应用构建和应用运行时的有效方法。
例如,下面的 Dockerfile 构建了一个 Go 应用 [confd](https://github.com/kelseyhightower/confd)。
```
# building container
FROM registry.fedoraproject.org/fedora-minimal AS build
RUN mkdir /go && microdnf install golang && microdnf clean all
WORKDIR /go
RUN export GOPATH=/go; CGO_ENABLED=0 go get github.com/kelseyhightower/confd
FROM registry.fedoraproject.org/fedora-minimal
WORKDIR /
COPY --from=build /go/bin/confd /usr/local/bin
CMD ["confd"]
```
通过在 `FROM` 指令之后添加 `AS` 并从基本容器镜像中添加另一个 `FROM` 然后使用 `COPY --from=` 指令将内容从*构建*的容器复制到第二个容器来完成多阶段构建。
可以使用 `podman` 构建并运行此 Dockerfile:
```
$ podman build -t myconfd .
$ podman run -it myconfd
```
---
via: <https://fedoramagazine.org/building-smaller-container-images/>
作者:[Muayyad Alsadi](https://fedoramagazine.org/author/alsadi/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux Containers have become a popular topic, making sure that a container image is not bigger than it should be is considered as a good practice. This article give some tips on how to create smaller Fedora container images.
### microdnf
Fedora’s DNF is written in Python and and it’s designed to be extensible as it has wide range of plugins. But Fedora has an alternative base container image which uses an smaller package manager called [microdnf](https://github.com/rpm-software-management/microdnf) written in C. To use this minimal image in a Dockerfile the FROM line should look like this:
FROM registry.fedoraproject.org/fedora-minimal:30
This is an important saving if your image does not need typical DNF dependencies like Python. For example, if you are making a NodeJS image.
### Install and Clean up in one layer
To save space it’s important to remove repos meta data using *dnf clean all* or its microdnf equivalent *microdnf clean all*. But you should not do this in two steps because that would actually store those files in a container image layer then mark them for deletion in another layer. To do it properly you should do the installation and cleanup in one step like this
FROM registry.fedoraproject.org/fedora-minimal:30
RUN microdnf install nodejs && microdnf clean all
### Modularity with microdnf
Modularity is a way to offer you different versions of a stack to choose from. For example you might want non-LTS NodeJS version 11 for a project and old LTS NodeJS version 8 for another and latest LTS NodeJS version 10 for another. You can specify which stream using colon
# dnf module list
# dnf module install nodejs:8
The *dnf module install* command implies two commands one that enables the stream and one that install nodejs from it.
# dnf module enable nodejs:8
# dnf install nodejs
Although microdnf does not offer any command related to modularity, it is possible to enable a module with a configuation file, and libdnf (which microdnf uses) [seems](https://bugzilla.redhat.com/show_bug.cgi?id=1575626) to support modularity streams. The file looks like this
/etc/dnf/modules.d/nodejs.module
[nodejs]
name=nodejs
stream=8
profiles=
state=enabled
A full Dockerfile using modularity with microdnf looks like this:
FROM registry.fedoraproject.org/fedora-minimal:30
RUN \
echo -e "[nodejs]\nname=nodejs\nstream=8\nprofiles=\nstate=enabled\n" > /etc/dnf/modules.d/nodejs.module && \
microdnf install nodejs zopfli findutils busybox && \
microdnf clean all
### Multi-staged builds
In many cases you might have tons of build-time dependencies that are not needed to run the software for example building a Go binary, which statically link dependencies. Multi-stage build are an efficient way to separate the application build and the application runtime.
For example the Dockerfile below builds [confd](https://github.com/kelseyhightower/confd) a Go application.
# building container
FROM registry.fedoraproject.org/fedora-minimal AS build
RUN mkdir /go && microdnf install golang && microdnf clean all
WORKDIR /go
RUN export GOPATH=/go; CGO_ENABLED=0 go get github.com/kelseyhightower/confd
FROM registry.fedoraproject.org/fedora-minimal
WORKDIR /
COPY --from=build /go/bin/confd /usr/local/bin
CMD ["confd"]
The multi-stage build is done by adding *AS* after the *FROM* instruction and by having another *FROM* from a base container image then using C*OPY –from=* instruction to copy content from the *build* container to the second container.
This Dockerfile can then be built and run using podman
$ podman build -t myconfd .
$ podman run -it myconfd
## Bashar Subeh
Thank you. You’re so helpful
## Ard Righ
It would be nice to see this with Buildah and Podman commands as an alternative to relying on a Dockerfile.
## Ard Righ
Something like this will work using Buildah commands
export newcontainer=$(buildah from registry.fedoraproject.org/fedora-minimal:30)
echo $newcontainer
echo -e “[nodejs]\nname=nodejs\nstream=8\nprofiles=\nstate=enabled\n” > nodejs.module
buildah copy $newcontainer nodejs.module /etc/dnf/modules.d/
buildah run $newcontainer — microdnf install nodejs zopfli findutils busybox
buildah run $newcontainer — microdnf clean all
buildah commit $newcontainer nodejs
buildah inspect nodejs
## aairey
Wouldn’t the extra buildah run create an extra layer? In the dockerfile we did
.
## Muayyad Alsadi
If I’m not mistaken, buildah do not do auto-commits, it only adds a layer when you commit. and since he did it once, it would add a single layer.
## Ard Righ
Buildah doesn’t write the layers until you commit. So all the operations before the commit are a single layer. You can check this by using
on the build image.
## Raphael Groner
Why not just use pypy to optimize normal dnf?
## Muayyad Alsadi
microdnf does not depend on python, if you are creating a nodejs images that would be a big saving. but pypy would still pull python-related packages. There is a 170MB difference (47% smaller nodejs image).
## Luiz
I don’t understand so much about theses topics, But I think it’s awesome.
## Sébastien Wilmet
Nice article, I’ve learned new things.
Another thing that I would like to do with containers, when developing them or when I need to debug one, is to plug in an extra layer with all the development tools that I need, plus my bashrc (especially for aliases) and my configuration for other tools. Is there an easy way to do that?
Because with a minimal image, the test/debug experience is quite horrible IMHO, for example if bash-completion is not installed, etc. |
10,887 | 使用 singledispatch 在 Python 中追溯地添加方法 | https://opensource.com/article/19/5/python-singledispatch | 2019-05-23T09:37:20 | [
"Python"
] | https://linux.cn/article-10887-1.html |
>
> 在我们覆盖 7 个 PyPI 库的系列文章中了解更多解决 Python 问题的信息。
>
>
>

Python 是当今使用最多[流行的编程语言](https://opensource.com/article/18/5/numbers-python-community-trends)之一,因为:它是开源的,它具有广泛的用途(例如 Web 编程、业务应用、游戏、科学编程等等),它有一个充满活力和专注的社区支持它。这个社区是我们在 [Python Package Index](https://pypi.org/)(PyPI)中提供如此庞大、多样化的软件包的原因,用以扩展和改进 Python。并解决不可避免的问题。
在本系列中,我们将介绍七个可以帮助你解决常见 Python 问题的 PyPI 库。今天,我们将研究 [singledispatch](https://pypi.org/project/singledispatch/),这是一个能让你追溯地向 Python 库添加方法的库。
### singledispatch
想象一下,你有一个有 Circle、Square 等类的“形状”库。
Circle 类有半径、Square 有边、Rectangle 有高和宽。我们的库已经存在,我们不想改变它。
然而,我们想给库添加一个面积计算。如果我们不会和其他人共享这个库,我们只需添加 `area` 方法,这样我们就能调用 `shape.area()` 而无需关心是什么形状。
虽然可以进入类并添加一个方法,但这是一个坏主意:没有人希望他们的类会被添加新的方法,程序会因奇怪的方式出错。
相反,functools 中的 `singledispatch` 函数可以帮助我们。
```
@singledispatch
def get_area(shape):
raise NotImplementedError("cannot calculate area for unknown shape",
shape)
```
`get_area` 函数的“基类”实现会报错。这保证了如果我们出现一个新的形状时,我们会明确地报错而不是返回一个无意义的结果。
```
@get_area.register(Square)
def _get_area_square(shape):
return shape.side ** 2
@get_area.register(Circle)
def _get_area_circle(shape):
return math.pi * (shape.radius ** 2)
```
这种方式的好处是如果某人写了一个匹配我们代码的*新*形状,它们可以自己实现 `get_area`。
```
from area_calculator import get_area
@attr.s(auto_attribs=True, frozen=True)
class Ellipse:
horizontal_axis: float
vertical_axis: float
@get_area.register(Ellipse)
def _get_area_ellipse(shape):
return math.pi * shape.horizontal_axis * shape.vertical_axis
```
*调用* `get_area` 很直接。
```
print(get_area(shape))
```
这意味着我们可以将大量的 `if isintance()`/`elif isinstance()` 的代码以这种方式修改,而无需修改接口。下一次你要修改 if isinstance,你试试 `singledispatch!
在本系列的下一篇文章中,我们将介绍 tox,一个用于自动化 Python 代码测试的工具。
#### 回顾本系列的前几篇文章:
* [Cython](/article-10859-1.html)
* [Black](/article-10864-1.html)
* [attrs](/article-10871-1.html)
---
via: <https://opensource.com/article/19/5/python-singledispatch>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Python is one of the most [popular programming languages](https://opensource.com/article/18/5/numbers-python-community-trends) in use today—and for good reasons: it's open source, it has a wide range of uses (such as web programming, business applications, games, scientific programming, and much more), and it has a vibrant and dedicated community supporting it. This community is the reason we have such a large, diverse range of software packages available in the [Python Package Index](https://pypi.org/) (PyPI) to extend and improve Python and solve the inevitable glitches that crop up.
In this series, we'll look at seven PyPI libraries that can help you solve common Python problems. Today, we'll examine [ singledispatch](https://pypi.org/project/singledispatch/), a library that allows you to add methods to Python libraries retroactively.
## singledispatch
Imagine you have a "shapes" library with a **Circle** class, a **Square** class, etc.
A **Circle** has a **radius**, a **Square** has a **side**, and a **Rectangle** has **height** and **width**. Our library already exists; we do not want to change it.
However, we do want to add an **area** calculation to our library. If we didn't share this library with anyone else, we could just add an **area** method so we could call **shape.area()** and not worry about what the shape is.
While it is possible to reach into a class and add a method, this is a bad idea: nobody expects their class to grow new methods, and things might break in weird ways.
Instead, the **singledispatch** function in **functools** can come to our rescue.
```
@singledispatch
def get_area(shape):
raise NotImplementedError("cannot calculate area for unknown shape",
shape)
```
The "base" implementation for the **get_area** function fails. This makes sure that if we get a new shape, we will fail cleanly instead of returning a nonsense result.
```
@get_area.register(Square)
def _get_area_square(shape):
return shape.side ** 2
@get_area.register(Circle)
def _get_area_circle(shape):
return math.pi * (shape.radius ** 2)
```
One nice thing about doing things this way is that if someone writes a *new* shape that is intended to play well with our code, they can implement **get_area** themselves.
```
from area_calculator import get_area
@attr.s(auto_attribs=True, frozen=True)
class Ellipse:
horizontal_axis: float
vertical_axis: float
@get_area.register(Ellipse)
def _get_area_ellipse(shape):
return math.pi * shape.horizontal_axis * shape.vertical_axis
```
*Calling* **get_area** is straightforward.
`print(get_area(shape))`
This means we can change a function that has a long **if isintance()/elif isinstance()** chain to work this way, without changing the interface. The next time you are tempted to check **if isinstance**, try using **singledispatch**!
In the next article in this series, we'll look at **tox**, a tool for automating tests on Python code.
## 3 Comments |
10,888 | 新手教程:如何 SSH 进入树莓派 | https://itsfoss.com/ssh-into-raspberry/ | 2019-05-23T10:06:51 | [
"SSH",
"树莓派"
] | https://linux.cn/article-10888-1.html |
>
> 在这篇树莓派文章中,你将学到如何在树莓派中启用 SSH 以及之后如何通过 SSH 进入树莓派。
>
>
>
在你可以用[树莓派](https://www.raspberrypi.org/)做的所有事情中,将其作为一个家庭网络的服务器是十分流行的做法。小体积与低功耗使它成为运行轻量级服务器的完美设备。
在这种情况下你做得到的事情之一是能够每次在树莓派上无须接上显示器、键盘、鼠标以及走到放置你的树莓派的地方就可以运行指令。
你可以从其它任意电脑、笔记本、台式机甚至你的手机通过 SSH([Secure Shell](https://en.wikipedia.org/wiki/Secure_Shell))登入你的树莓派来做到这一点。让我展示给你看:
### 如何 SSH 进入树莓派

我假设你已经[在你的树莓派上运行 Raspbian](https://itsfoss.com/tutorial-how-to-install-raspberry-pi-os-raspbian-wheezy/) 并已经成功通过有线或者无线网连进网络了。你的树莓派接入网络这点是很重要的,否则你无法通过 SSH 连接树莓派(抱歉说出这种显而易见的事实)。
#### 步骤一:在树莓派上启用 SSH
SSH 在树莓派上是默认关闭的,因此在你安装好全新的 Raspbian 后打开树莓派时,你需要启用它。
首先通过菜单进入树莓派的配置界面。

现在进入<ruby> 接口 <rt> interfaces </rt></ruby>标签,启动 SSH 并重启你的树莓派。

你也可以通过终端直接启动 SSH。仅需输入命令 `sudo raspi-config` 然后进入高级设置以启用 SSH。
#### 步骤二: 找到树莓派的 IP 地址
在大多数情况下,你的树莓派会被分配一个看起来长得像 `192.168.x.x` 或者 `10.x.x.x` 的本地 IP 地址。你可以[使用多种 Linux 命令来找到 IP 地址](https://linuxhandbook.com/find-ip-address/)。
我在这使用古老而好用的 `ifconfig` 命令,但是你也可以使用 `ip address`。
```
ifconfig
```

这行命令展现了所有活跃中的网络适配器以及其配置的列表。第一个条目(`eth0`)展示了例如`192.168.2.105` 的有效 IP 地址。我用有线网将我的树莓派连入网络,因此这里显示的是 `eth0`。如果你用无线网的话在叫做 `wlan0` 的条目下查看。
你也可以用其他方法例如查看你的路由器或者调制解调器的网络设备表以找到 IP 地址。
#### 步骤三:SSH 进你的树莓派
既然你已经启用了 SSH 功能并且找到了 IP 地址,你可以从任何电脑 SSH 进入你的树莓派。你同样需要树莓派的用户名和密码。
默认用户名和密码是:
* 用户名:`pi`
* 密码:`raspberry`
如果你已改变了默认的密码,那就使用新的而不是以上的密码。理想状态下你必须改变默认的密码。在过去,有一款[恶意软件感染数千使用默认用户名和密码的树莓派设备](https://itsfoss.com/raspberry-pi-malware-threat/)。
(在 Mac 或 Linux 上)从你想要 SSH 进树莓派的电脑上打开终端输入以下命令,在 Windows 上,你可以用类似 [Putty](https://itsfoss.com/putty-linux/) 的 SSH 客户端。
这里,使用你在之前步骤中找到的 IP 地址。
```
ssh [受保护的邮件]
```
>
> 注意: 确保你的树莓派和你用来 SSH 进入树莓派的电脑接入了同一个网络。
>
>
>

第一次你会看到一个警告,输入 `yes` 并按下回车。

现在,输入密码按下回车。

成功登入你将会看到树莓派的终端。现在你可以通过这个终端无需物理上访问你的树莓派就可以远程(在当前网络内)在它上面运行指令。
在此之上你也可以设置 SSH 密钥这样每次通过 SSH 登入时就可以无需输入密码,但那完全是另一个话题了。
我希望你通过跟着这个教程已能够 SSH 进入你的树莓派。在下方评论中让我知道你打算用你的树莓派做些什么!
---
via: <https://itsfoss.com/ssh-into-raspberry/>
作者:[Chinmay](https://itsfoss.com/author/chinmay/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Out of all the things you can do with [Raspberry Pi](https://www.raspberrypi.org/?ref=itsfoss.com), using it as a server in a home network is very popular. The tiny footprint and low power consumption makes it a perfect device to run light weight servers.
One of the things you should be able to do in such a case is run commands on your Raspberry Pi without needing to plug in a display, keyboard, mouse and having to move yourself to the location of your Raspberry Pi each time.
You achieve this by logging into your Raspberry Pi via SSH ([Secure Shell](https://en.wikipedia.org/wiki/Secure_Shell?ref=itsfoss.com)) from any other computer, your laptop, desktop or even your phone. Let me show you how
## How to SSH into Raspberry Pi
I assume that you are [running Raspbian on your Pi](https://itsfoss.com/tutorial-how-to-install-raspberry-pi-os-raspbian-wheezy/) and have successfully connected to a network via Ethernet or WiFi. It’s important that your Raspberry Pi is connected to a network otherwise you won’t be able to connect to it via SSH (sorry for stating the obvious).
### Step 1: Enable SSH on Raspberry Pi
SSH is disabled by default in Raspberry Pi, hence you’ll have to enable it when you turn on the Pi after a fresh installation of Raspbian.
First go to the Raspberry Pi configuration window by navigating through the menu.
Now, go to the interfaces tab, enable SSH and restart your Pi.
You can also enable SSH without via the terminal. Just enter the command ** sudo raspi-config** and then go to Advanced Options to enable SSH.

#### Pironman 5 Case With Tower Cooler and Fan
This dope Raspberry Pi 5 case has a tower cooler and dual RGB fans to keep the device cool. It also extends your Pi 5 with M.2 SSD slot and 2 standard HDMI ports.
[Explore Pironman 5](https://www.sunfounder.com/products/pironman-5-nvme-m-2-ssd-pcie-mini-pc-case-for-raspberry-pi-5?ref=itsfoss)
### Step 2. Find the IP Address of Raspberry Pi
In most cases your Raspberry Pi will be assigned a local IP address which looks like **192.168.x.x** or **10.x.x.x**. You can [use various Linux commands to find the IP address](https://linuxhandbook.com/find-ip-address/?ref=itsfoss.com).
I am using the good old ifconfig command here but you can also use ** ip address**.
`ifconfig`
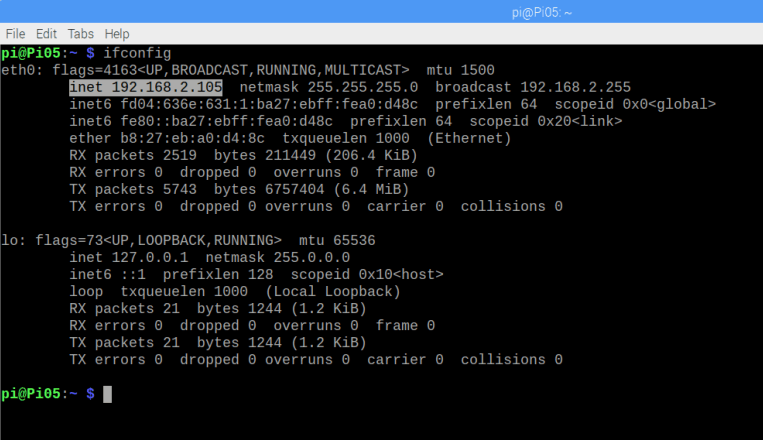
This command shows all the list of active network adapters and their configuration. The first entry(**eth0**) shows IP address as **192.168.2.105** which is valid.I have used Ethernet to connect my Raspberry Pi to the network, hence it is under **eth0**. If you use WiFi check under the entry named ‘**wlan0**‘ .
You can also find out the IP address by other means like checking the network devices list on your router/modem.
### Step 3. SSH into your Raspberry Pi
Now that you have enabled SSH and found out your IP address you can go ahead and SSH into your Raspberry Pi from any other computer. You’ll also need the username and the password for the Raspberry Pi.
The default username and password is:
- username: pi
- password: raspberry
If you have changed the default password then use the new password instead of the above. Ideally you must change the default password. In the past, a [malware infected thousands of Raspberry Pi devices that were using the default username and password](https://itsfoss.com/raspberry-pi-malware-threat/).
Open a terminal (on Mac and Linux) on the computer from which you want to SSH into your Pi and type the command below. On Windows, you can use a SSH client like [Putty](https://itsfoss.com/putty-linux/).
Here, use the IP address you found out in the previous step.
`ssh `[[email protected]](/cdn-cgi/l/email-protection)
You’ll see a warning the first time, type **yes** and press enter.
**‘)**
**raspberry**Now, type in the password and press enter.
On a successful login you’ll be presented with the terminal of your Raspberry Pi. Now you can any commands on your Raspberry Pi through this terminal remotely(within the current network) without having to access your Raspberry Pi physically.
Furthermore, you can also set up SSH-Keys so that you don’t have to type in the password every time you log in via SSH, but that’s a different topic altogether.
I hope you were able to SSH into your Raspberry Pi after following this tutorial. Let me know how you plan to use your Raspberry Pi in the comments below! |
10,889 | xsos:一个在 Linux 上阅读 SOSReport 的工具 | https://www.2daygeek.com/xsos-a-tool-to-read-sosreport-in-linux/ | 2019-05-23T13:33:00 | [
"SOSReport"
] | https://linux.cn/article-10889-1.html | 
我们都已经知道 [SOSReport](https://www.2daygeek.com/how-to-create-collect-sosreport-in-linux/)。它用来收集可用于诊断的系统信息。Redhat 的支持服务建议我们在提交案例时提供 SOSReport 来分析当前的系统状态。
它会收集全部类型的报告,以帮助用户找出问题的根本原因。我们可以轻松地提取和阅读 SOSReport,但它很难阅读。因为它的每个部分都是一个单独的文件。
那么,在 Linux 中使用语法高亮显示阅读所有这些内容的最佳方法是什么。是的,这可以通过 `xsos` 工具做到。
### sosreport
`sosreport` 命令是一个从运行中的系统(尤其是 RHEL 和 OEL 系统)收集大量配置细节、系统信息和诊断信息的工具。它可以帮助技术支持工程师在很多方面分析系统。
此报告包含有关系统的大量信息,例如引导信息、文件系统、内存、主机名、已安装的 RPM、系统 IP、网络详细信息、操作系统版本、已安装的内核、已加载的内核模块、打开的文件列表、PCI 设备列表、挂载点及其细节、运行中的进程信息、进程树输出、系统路由、位于 `/etc` 文件夹中的所有配置文件,以及位于 `/var` 文件夹中的所有日志文件。
这将需要一段时间来生成报告,这取决于你的系统安装和配置。
完成后,`sosreport` 将在 `/tmp` 目录下生成一个压缩的归档文件。
### xsos
[xsos](https://github.com/ryran/xsos) 是一个帮助用户轻松读取 Linux 系统上的 `sosreport` 的工具。另一方面,我们可以说它是 `sosreport` 考官。
它可以立即从 `sosreport` 或正在运行的系统中汇总系统信息。
`xsos` 将尝试简化、解析、计算并格式化来自数十个文件(和命令)的数据,以便为你提供有关系统的详细概述。
你可以通过运行以下命令立即汇总系统信息。
```
# curl -Lo ./xsos bit.ly/xsos-direct; chmod +x ./xsos; ./xsos -ya
```

### 如何在 Linux 上安装 xsos
我们可以使用以下两种方法轻松安装 `xsos`。
如果你正在寻找最新的前沿版本。使用以下步骤:
```
# curl -Lo /usr/local/bin/xsos bit.ly/xsos-direct
# chmod +x /usr/local/bin/xsos
```
下面是安装 `xsos` 的推荐方法。它将从 rpm 文件安装 `xsos`。
```
# yum install http://people.redhat.com/rsawhill/rpms/latest-rsawaroha-release.rpm
# yum install xsos
```
### 如何在 Linux 上使用 xsos
一旦通过上述方法之一安装了 xsos。只需运行 `xsos` 命令,不带任何选项,它们会显示有关系统的基本信息。
```
# xsos
OS
Hostname: CentOS7.2daygeek.com
Distro: [redhat-release] CentOS Linux release 7.6.1810 (Core)
[centos-release] CentOS Linux release 7.6.1810 (Core)
[os-release] CentOS Linux 7 (Core) 7 (Core)
RHN: (missing)
RHSM: (missing)
YUM: 2 enabled plugins: fastestmirror, langpacks
Runlevel: N 5 (default graphical)
SELinux: enforcing (default enforcing)
Arch: mach=x86_64 cpu=x86_64 platform=x86_64
Kernel:
Booted kernel: 3.10.0-957.el7.x86_64
GRUB default: 3.10.0-957.el7.x86_64
Build version:
Linux version 3.10.0-957.el7.x86_64 ([email protected]) (gcc version 4.8.5 20150623 (Red
Hat 4.8.5-36) (GCC) ) #1 SMP Thu Nov 8 23:39:32 UTC 2018
Booted kernel cmdline:
root=/dev/mapper/centos-root ro crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet
LANG=en_US.UTF-8
GRUB default kernel cmdline:
root=/dev/mapper/centos-root ro crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet
LANG=en_US.UTF-8
Taint-check: 0 (kernel untainted)
- - - - - - - - - - - - - - - - - - -
Sys time: Sun May 12 10:05:21 CDT 2019
Boot time: Sun May 12 09:50:20 CDT 2019 (epoch: 1557672620)
Time Zone: America/Chicago
Uptime: 15 min, 1 user
LoadAvg: [1 CPU] 0.00 (0%), 0.04 (4%), 0.09 (9%)
/proc/stat:
procs_running: 2 procs_blocked: 0 processes [Since boot]: 6423
cpu [Utilization since boot]:
us 1%, ni 0%, sys 1%, idle 99%, iowait 0%, irq 0%, sftirq 0%, steal 0%
```
### 如何使用 xsos 命令在 Linux 中查看生成的 SOSReport 输出?
我们需要份 SOSReport 以使用 `xsos` 命令进一步阅读。
是的,我已经生成了一个 SOSReport,文件如下。
```
# ls -lls -lh /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa.tar.xz
9.8M -rw-------. 1 root root 9.8M May 12 10:13 /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa.tar.xz
```
运行如下命令解开它。
```
# tar xf sosreport-CentOS7-01-1005-2019-05-12-pomeqsa.tar.xz
```
要查看全部信息,带上 `-a` 或 `--all` 开关运行 `xsos`:
```
# xsos --all /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
```
要查看 BIOS 信息,带上 `-b` 或 `--bios` 开关运行 `xsos`。
```
# xsos --bios /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
DMIDECODE
BIOS:
Vend: innotek GmbH
Vers: VirtualBox
Date: 12/01/2006
BIOS Rev:
FW Rev:
System:
Mfr: innotek GmbH
Prod: VirtualBox
Vers: 1.2
Ser: 0
UUID: 002f47b8-2af2-48f5-be1d-67b67e03514c
CPU:
0 of 0 CPU sockets populated, 0 cores/0 threads per CPU
0 total cores, 0 total threads
Mfr:
Fam:
Freq:
Vers:
Memory:
Total: 0 MiB (0 GiB)
DIMMs: 0 of 0 populated
MaxCapacity: 0 MiB (0 GiB / 0.00 TiB)
```
要查看系统基本信息,如主机名、发行版、SELinux、内核信息、正常运行时间等,请使用 `-o` 或 `--os` 开关运行 `xsos`。
```
# xsos --os /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
OS
Hostname: CentOS7.2daygeek.com
Distro: [redhat-release] CentOS Linux release 7.6.1810 (Core)
[centos-release] CentOS Linux release 7.6.1810 (Core)
[os-release] CentOS Linux 7 (Core) 7 (Core)
RHN: (missing)
RHSM: (missing)
YUM: 2 enabled plugins: fastestmirror, langpacks
SELinux: enforcing (default enforcing)
Arch: mach=x86_64 cpu=x86_64 platform=x86_64
Kernel:
Booted kernel: 3.10.0-957.el7.x86_64
GRUB default: 3.10.0-957.el7.x86_64
Build version:
Linux version 3.10.0-957.el7.x86_64 ([email protected]) (gcc version 4.8.5 20150623 (Red
Hat 4.8.5-36) (GCC) ) #1 SMP Thu Nov 8 23:39:32 UTC 2018
Booted kernel cmdline:
root=/dev/mapper/centos-root ro crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet
LANG=en_US.UTF-8
GRUB default kernel cmdline:
root=/dev/mapper/centos-root ro crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet
LANG=en_US.UTF-8
Taint-check: 536870912 (see https://access.redhat.com/solutions/40594)
29 TECH_PREVIEW: Technology Preview code is loaded
- - - - - - - - - - - - - - - - - - -
Sys time: Sun May 12 10:12:22 CDT 2019
Boot time: Sun May 12 09:50:20 CDT 2019 (epoch: 1557672620)
Time Zone: America/Chicago
Uptime: 22 min, 1 user
LoadAvg: [1 CPU] 1.19 (119%), 0.27 (27%), 0.14 (14%)
/proc/stat:
procs_running: 8 procs_blocked: 2 processes [Since boot]: 9005
cpu [Utilization since boot]:
us 1%, ni 0%, sys 1%, idle 99%, iowait 0%, irq 0%, sftirq 0%, steal 0%
```
要查看 kdump 配置,请使用 `-k` 或 `--kdump` 开关运行 `xsos`。
```
# xsos --kdump /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
KDUMP CONFIG
kexec-tools rpm version:
kexec-tools-2.0.15-21.el7.x86_64
Service enablement:
UNIT STATE
kdump.service enabled
kdump initrd/initramfs:
13585734 Feb 19 05:51 initramfs-3.10.0-957.el7.x86_64kdump.img
Memory reservation config:
/proc/cmdline { crashkernel=auto }
GRUB default { crashkernel=auto }
Actual memory reservation per /proc/iomem:
2a000000-340fffff : Crash kernel
kdump.conf:
path /var/crash
core_collector makedumpfile -l --message-level 1 -d 31
kdump.conf "path" available space:
System MemTotal (uncompressed core size) { 1.80 GiB }
Available free space on target path's fs { 22.68 GiB } (fs=/)
Panic sysctls:
kernel.sysrq [bitmask] = "16" (see proc man page)
kernel.panic [secs] = 0 (no autoreboot on panic)
kernel.hung_task_panic = 0
kernel.panic_on_oops = 1
kernel.panic_on_io_nmi = 0
kernel.panic_on_unrecovered_nmi = 0
kernel.panic_on_stackoverflow = 0
kernel.softlockup_panic = 0
kernel.unknown_nmi_panic = 0
kernel.nmi_watchdog = 1
vm.panic_on_oom [0-2] = 0 (no panic)
```
要查看有关 CPU 的信息,请使用 `-c` 或 `--cpu` 开关运行 `xsos`。
```
# xsos --cpu /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
CPU
1 logical processors
1 Intel Core i7-6700HQ CPU @ 2.60GHz (flags: aes,constant_tsc,ht,lm,nx,pae,rdrand)
```
要查看内存利用情况,请使用 `-m` 或 `--mem` 开关运行 `xsos`。
```
# xsos --mem /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
MEMORY
Stats graphed as percent of MemTotal:
MemUsed ▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊..................... 58.8%
Buffers .................................................. 0.6%
Cached ▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊................................... 29.9%
HugePages .................................................. 0.0%
Dirty .................................................. 0.7%
RAM:
1.8 GiB total ram
1.1 GiB (59%) used
0.5 GiB (28%) used excluding Buffers/Cached
0.01 GiB (1%) dirty
HugePages:
No ram pre-allocated to HugePages
LowMem/Slab/PageTables/Shmem:
0.09 GiB (5%) of total ram used for Slab
0.02 GiB (1%) of total ram used for PageTables
0.01 GiB (1%) of total ram used for Shmem
Swap:
0 GiB (0%) used of 2 GiB total
```
要查看添加的磁盘信息,请使用 `-d` 和 `-disks` 开关运行 `xsos`。
```
# xsos --disks /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
STORAGE
Whole Disks from /proc/partitions:
2 disks, totaling 40 GiB (0.04 TiB)
- - - - - - - - - - - - - - - - - - - - -
Disk Size in GiB
---- -----------
sda 30
sdb 10
```
要查看网络接口配置,请使用 `-e` 或 `--ethtool` 开关运行 `xsos`。
```
# xsos --ethtool /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
ETHTOOL
Interface Status:
enp0s10 0000:00:0a.0 link=up 1000Mb/s full (autoneg=Y) rx ring 256/4096 drv e1000 v7.3.21-k8-NAPI / fw UNKNOWN
enp0s9 0000:00:09.0 link=up 1000Mb/s full (autoneg=Y) rx ring 256/4096 drv e1000 v7.3.21-k8-NAPI / fw UNKNOWN
virbr0 N/A link=DOWN rx ring UNKNOWN drv bridge v2.3 / fw N/A
virbr0-nic tap link=DOWN rx ring UNKNOWN drv tun v1.6 / fw UNKNOWN
```
要查看有关 IP 地址的信息,请使用 `-i` 或 `--ip` 开关运行 `xsos`。
```
# xsos --ip /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
IP4
Interface Master IF MAC Address MTU State IPv4 Address
========= ========= ================= ====== ===== ==================
lo - - 65536 up 127.0.0.1/8
enp0s9 - 08:00:27:0b:bc:e9 1500 up 192.168.1.8/24
enp0s10 - 08:00:27:b2:08:91 1500 up 192.168.1.9/24
virbr0 - 52:54:00:ae:01:94 1500 up 192.168.122.1/24
virbr0-nic virbr0 52:54:00:ae:01:94 1500 DOWN -
IP6
Interface Master IF MAC Address MTU State IPv6 Address Scope
========= ========= ================= ====== ===== =========================================== =====
lo - - 65536 up ::1/128 host
enp0s9 - 08:00:27:0b:bc:e9 1500 up fe80::945b:8333:f4bc:9723/64 link
enp0s10 - 08:00:27:b2:08:91 1500 up fe80::7ed4:1fab:23c3:3790/64 link
virbr0 - 52:54:00:ae:01:94 1500 up - -
virbr0-nic virbr0 52:54:00:ae:01:94 1500 DOWN - -
```
要通过 `ps` 查看正在运行的进程,请使用 `-p` 或 `--ps` 开关运行 `xsos`。
```
# xsos --ps /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
PS CHECK
Total number of threads/processes:
501 / 171
Top users of CPU & MEM:
USER %CPU %MEM RSS
root 20.6% 14.1% 0.30 GiB
gdm 0.3% 16.8% 0.33 GiB
postfix 0.0% 0.6% 0.01 GiB
polkitd 0.0% 0.6% 0.01 GiB
daygeek 0.0% 0.2% 0.00 GiB
colord 0.0% 0.4% 0.01 GiB
Uninteruptible sleep threads/processes (0/0):
[None]
Defunct zombie threads/processes (0/0):
[None]
Top CPU-using processes:
USER PID %CPU %MEM VSZ-MiB RSS-MiB TTY STAT START TIME COMMAND
root 6542 15.6 4.2 875 78 pts/0 Sl+ 10:11 0:07 /usr/bin/python /sbin/sosreport
root 7582 3.0 0.1 10 2 pts/0 S 10:12 0:00 /bin/bash /usr/sbin/dracut --print-cmdline
root 7969 0.7 0.1 95 4 ? Ss 10:12 0:00 /usr/sbin/certmonger -S -p
root 7889 0.4 0.2 24 4 ? Ss 10:12 0:00 /usr/lib/systemd/systemd-hostnamed
gdm 3866 0.3 7.1 2856 131 ? Sl 09:50 0:04 /usr/bin/gnome-shell
root 8553 0.2 0.1 47 3 ? S 10:12 0:00 /usr/lib/systemd/systemd-udevd
root 6971 0.2 0.4 342 9 ? Sl 10:12 0:00 /usr/sbin/abrt-dbus -t133
root 3200 0.2 0.9 982 18 ? Ssl 09:50 0:02 /usr/sbin/libvirtd
root 2855 0.1 0.1 88 3 ? Ss 09:50 0:01 /sbin/rngd -f
rtkit 2826 0.0 0.0 194 2 ? SNsl 09:50 0:00 /usr/libexec/rtkit-daemon
Top MEM-using processes:
USER PID %CPU %MEM VSZ-MiB RSS-MiB TTY STAT START TIME COMMAND
gdm 3866 0.3 7.1 2856 131 ? Sl 09:50 0:04 /usr/bin/gnome-shell
root 6542 15.6 4.2 875 78 pts/0 Sl+ 10:11 0:07 /usr/bin/python /sbin/sosreport
root 3264 0.0 1.2 271 23 tty1 Ssl+ 09:50 0:00 /usr/bin/X :0 -background
root 3200 0.2 0.9 982 18 ? Ssl 09:50 0:02 /usr/sbin/libvirtd
root 3189 0.0 0.9 560 17 ? Ssl 09:50 0:00 /usr/bin/python2 -Es /usr/sbin/tuned
gdm 4072 0.0 0.9 988 17 ? Sl 09:50 0:00 /usr/libexec/gsd-media-keys
gdm 4076 0.0 0.8 625 16 ? Sl 09:50 0:00 /usr/libexec/gsd-power
gdm 4056 0.0 0.8 697 16 ? Sl 09:50 0:00 /usr/libexec/gsd-color
root 2853 0.0 0.7 622 14 ? Ssl 09:50 0:00 /usr/sbin/NetworkManager --no-daemon
gdm 4110 0.0 0.7 544 14 ? Sl 09:50 0:00 /usr/libexec/gsd-wacom
Top thread-spawning processes:
# USER PID %CPU %MEM VSZ-MiB RSS-MiB TTY STAT START TIME COMMAND
17 root 3200 0.2 0.9 982 18 ? - 09:50 0:02 /usr/sbin/libvirtd
12 root 6542 16.1 4.5 876 83 pts/0 - 10:11 0:07 /usr/bin/python /sbin/sosreport
10 gdm 3866 0.3 7.1 2856 131 ? - 09:50 0:04 /usr/bin/gnome-shell
7 polkitd 2864 0.0 0.6 602 13 ? - 09:50 0:01 /usr/lib/polkit-1/polkitd --no-debug
6 root 2865 0.0 0.0 203 1 ? - 09:50 0:00 /usr/sbin/gssproxy -D
5 root 3189 0.0 0.9 560 17 ? - 09:50 0:00 /usr/bin/python2 -Es /usr/sbin/tuned
5 root 2823 0.0 0.3 443 6 ? - 09:50 0:00 /usr/libexec/udisks2/udisksd
5 gdm 4102 0.0 0.2 461 5 ? - 09:50 0:00 /usr/libexec/gsd-smartcard
4 root 3215 0.0 0.2 470 4 ? - 09:50 0:00 /usr/sbin/gdm
4 gdm 4106 0.0 0.2 444 5 ? - 09:50 0:00 /usr/libexec/gsd-sound
```
---
via: <https://www.2daygeek.com/xsos-a-tool-to-read-sosreport-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,891 | 使用深度学习检测疟疾 | https://opensource.com/article/19/4/detecting-malaria-deep-learning | 2019-05-24T02:00:28 | [
"AI",
"深度学习",
"疟疾"
] | https://linux.cn/article-10891-1.html |
>
> 人工智能结合开源硬件工具能够提升严重传染病疟疾的诊断。
>
>
>

人工智能(AI)和开源工具、技术和框架是促进社会进步的强有力的结合。“健康就是财富”可能有点陈词滥调,但它却是非常准确的!在本篇文章,我们将测试 AI 是如何与低成本、有效、精确的开源深度学习方法结合起来一起用来检测致死的传染病疟疾。
我既不是一个医生,也不是一个医疗保健研究者,我也绝不像他们那样合格,我只是对将 AI 应用到医疗保健研究感兴趣。在这片文章中我的想法是展示 AI 和开源解决方案如何帮助疟疾检测和减少人工劳动的方法。

*Python 和 TensorFlow: 一个构建开源深度学习方法的很棒的结合*
感谢 Python 的强大和像 TensorFlow 这样的深度学习框架,我们能够构建健壮的、大规模的、有效的深度学习方法。因为这些工具是自由和开源的,我们能够构建非常经济且易于被任何人采纳和使用的解决方案。让我们开始吧!
### 项目动机
疟疾是由*疟原虫*造成的致死的、有传染性的、蚊子传播的疾病,主要通过受感染的雌性按蚊叮咬传播。共有五种寄生虫能够引起疟疾,但是大多数病例是这两种类型造成的:恶性疟原虫和间日疟原虫。

这个地图显示了疟疾在全球传播分布形势,尤其在热带地区,但疾病的性质和致命性是该项目的主要动机。
如果一只受感染雌性蚊子叮咬了你,蚊子携带的寄生虫进入你的血液,并且开始破坏携带氧气的红细胞(RBC)。通常,疟疾的最初症状类似于流感病毒,在蚊子叮咬后,他们通常在几天或几周内发作。然而,这些致死的寄生虫可以在你的身体里生存长达一年并且不会造成任何症状,延迟治疗可能造成并发症甚至死亡。因此,早期的检查能够挽救生命。
世界健康组织(WHO)的[疟疾实情](https://www.who.int/features/factfiles/malaria/en/)表明,世界近乎一半的人口面临疟疾的风险,有超过 2 亿的疟疾病例,每年由于疟疾造成的死亡将近 40 万。这是使疟疾检测和诊断快速、简单和有效的一个动机。
### 检测疟疾的方法
有几种方法能够用来检测和诊断疟疾。该文中的项目就是基于 Rajaraman, et al. 的论文:“[预先训练的卷积神经网络作为特征提取器,用于改善薄血涂片图像中的疟疾寄生虫检测](https://peerj.com/articles/4568/)”介绍的一些方法,包含聚合酶链反应(PCR)和快速诊断测试(RDT)。这两种测试通常用于无法提供高质量显微镜服务的地方。
标准的疟疾诊断通常是基于血液涂片工作流程的,根据 Carlos Ariza 的文章“[Malaria Hero:一个更快诊断疟原虫的网络应用](https://blog.insightdatascience.com/https-blog-insightdatascience-com-malaria-hero-a47d3d5fc4bb)”,我从中了解到 Adrian Rosebrock 的“[使用 Keras 的深度学习和医学图像分析](https://www.pyimagesearch.com/2018/12/03/deep-learning-and-medical-image-analysis-with-keras/)”。我感激这些优秀的资源的作者,让我在疟原虫预防、诊断和治疗方面有了更多的想法。

*一个疟原虫检测的血涂片工作流程*
根据 WHO 方案,诊断通常包括对放大 100 倍的血涂片的集中检测。受过训练的人们手工计算在 5000 个细胞中有多少红细胞中包含疟原虫。正如上述解释中引用的 Rajaraman, et al. 的论文:
>
> 厚血涂片有助于检测寄生虫的存在,而薄血涂片有助于识别引起感染的寄生虫种类(疾病控制和预防中心, 2012)。诊断准确性在很大程度上取决于诊断人的专业知识,并且可能受到观察者间差异和疾病流行/资源受限区域大规模诊断所造成的不利影响(Mitiku, Mengistu 和 Gelaw, 2003)。可替代的技术是使用聚合酶链反应(PCR)和快速诊断测试(RDT);然而,PCR 分析受限于它的性能(Hommelsheim, et al., 2014),RDT 在疾病流行的地区成本效益低(Hawkes, Katsuva 和 Masumbuko, 2009)。
>
>
>
因此,疟疾检测可能受益于使用机器学习的自动化。
### 疟疾检测的深度学习
人工诊断血涂片是一个繁重的手工过程,需要专业知识来分类和计数被寄生虫感染的和未感染的细胞。这个过程可能不能很好的规模化,尤其在那些专业人士不足的地区。在利用最先进的图像处理和分析技术提取人工选取特征和构建基于机器学习的分类模型方面取得了一些进展。然而,这些模型不能大规模推广,因为没有更多的数据用来训练,并且人工选取特征需要花费很长时间。
深度学习模型,或者更具体地讲,卷积神经网络(CNN),已经被证明在各种计算机视觉任务中非常有效。(如果你想更多的了解关于 CNN 的背景知识,我推荐你阅读[视觉识别的 CS2331n 卷积神经网络](http://cs231n.github.io/convolutional-networks/)。)简单地讲,CNN 模型的关键层包含卷积和池化层,正如下图所示。

*一个典型的 CNN 架构*
卷积层从数据中学习空间层级模式,它是平移不变的,因此它们能够学习图像的不同方面。例如,第一个卷积层将学习小的和局部图案,例如边缘和角落,第二个卷积层将基于第一层的特征学习更大的图案,等等。这允许 CNN 自动化提取特征并且学习对于新数据点通用的有效的特征。池化层有助于下采样和减少尺寸。
因此,CNN 有助于自动化和规模化的特征工程。同样,在模型末尾加上密集层允许我们执行像图像分类这样的任务。使用像 CNN 这样的深度学习模型自动的疟疾检测可能非常有效、便宜和具有规模性,尤其是迁移学习和预训练模型效果非常好,甚至在少量数据的约束下。
Rajaraman, et al. 的论文在一个数据集上利用六个预训练模型在检测疟疾对比无感染样本获取到令人吃惊的 95.9% 的准确率。我们的重点是从头开始尝试一些简单的 CNN 模型和用一个预训练的训练模型使用迁移学习来查看我们能够从相同的数据集中得到什么。我们将使用开源工具和框架,包括 Python 和 TensorFlow,来构建我们的模型。
### 数据集
我们分析的数据来自 Lister Hill 国家生物医学交流中心(LHNCBC)的研究人员,该中心是国家医学图书馆(NLM)的一部分,他们细心收集和标记了公开可用的健康和受感染的血涂片图像的[数据集](https://ceb.nlm.nih.gov/repositories/malaria-datasets/)。这些研究者已经开发了一个运行在 Android 智能手机的[疟疾检测手机应用](https://www.ncbi.nlm.nih.gov/pubmed/29360430),连接到一个传统的光学显微镜。它们使用吉姆萨染液将 150 个受恶性疟原虫感染的和 50 个健康病人的薄血涂片染色,这些薄血涂片是在孟加拉的吉大港医学院附属医院收集和照相的。使用智能手机的内置相机获取每个显微镜视窗内的图像。这些图片由在泰国曼谷的马希多-牛津热带医学研究所的一个专家使用幻灯片阅读器标记的。
让我们简要地查看一下数据集的结构。首先,我将安装一些基础的依赖(基于使用的操作系统)。

我使用的是云上的带有一个 GPU 的基于 Debian 的操作系统,这样我能更快的运行我的模型。为了查看目录结构,我们必须使用 `sudo apt install tree` 安装 `tree` 及其依赖(如果我们没有安装的话)。

我们有两个文件夹包含血细胞的图像,包括受感染的和健康的。我们通过输入可以获取关于图像总数更多的细节:
```
import os
import glob
base_dir = os.path.join('./cell_images')
infected_dir = os.path.join(base_dir,'Parasitized')
healthy_dir = os.path.join(base_dir,'Uninfected')
infected_files = glob.glob(infected_dir+'/*.png')
healthy_files = glob.glob(healthy_dir+'/*.png')
len(infected_files), len(healthy_files)
# Output
(13779, 13779)
```
看起来我们有一个平衡的数据集,包含 13,779 张疟疾的和 13,779 张非疟疾的(健康的)血细胞图像。让我们根据这些构建数据帧,我们将用这些数据帧来构建我们的数据集。
```
import numpy as np
import pandas as pd
np.random.seed(42)
files_df = pd.DataFrame({
'filename': infected_files + healthy_files,
'label': ['malaria'] * len(infected_files) + ['healthy'] * len(healthy_files)
}).sample(frac=1, random_state=42).reset_index(drop=True)
files_df.head()
```

### 构建和了解图像数据集
为了构建深度学习模型,我们需要训练数据,但是我们还需要使用不可见的数据测试模型的性能。相应的,我们将使用 60:10:30 的比例来划分用于训练、验证和测试的数据集。我们将在训练期间应用训练和验证数据集,并用测试数据集来检查模型的性能。
```
from sklearn.model_selection import train_test_split
from collections import Counter
train_files, test_files, train_labels, test_labels = train_test_split(files_df['filename'].values,
files_df['label'].values,
test_size=0.3, random_state=42)
train_files, val_files, train_labels, val_labels = train_test_split(train_files,
train_labels,
test_size=0.1, random_state=42)
print(train_files.shape, val_files.shape, test_files.shape)
print('Train:', Counter(train_labels), '\nVal:', Counter(val_labels), '\nTest:', Counter(test_labels))
# Output
(17361,) (1929,) (8268,)
Train: Counter({'healthy': 8734, 'malaria': 8627})
Val: Counter({'healthy': 970, 'malaria': 959})
Test: Counter({'malaria': 4193, 'healthy': 4075})
```
这些图片尺寸并不相同,因为血涂片和细胞图像是基于人、测试方法、图片方向不同而不同的。让我们总结我们的训练数据集的统计信息来决定最佳的图像尺寸(牢记,我们根本不会碰测试数据集)。
```
import cv2
from concurrent import futures
import threading
def get_img_shape_parallel(idx, img, total_imgs):
if idx % 5000 == 0 or idx == (total_imgs - 1):
print('{}: working on img num: {}'.format(threading.current_thread().name,
idx))
return cv2.imread(img).shape
ex = futures.ThreadPoolExecutor(max_workers=None)
data_inp = [(idx, img, len(train_files)) for idx, img in enumerate(train_files)]
print('Starting Img shape computation:')
train_img_dims_map = ex.map(get_img_shape_parallel,
[record[0] for record in data_inp],
[record[1] for record in data_inp],
[record[2] for record in data_inp])
train_img_dims = list(train_img_dims_map)
print('Min Dimensions:', np.min(train_img_dims, axis=0))
print('Avg Dimensions:', np.mean(train_img_dims, axis=0))
print('Median Dimensions:', np.median(train_img_dims, axis=0))
print('Max Dimensions:', np.max(train_img_dims, axis=0))
# Output
Starting Img shape computation:
ThreadPoolExecutor-0_0: working on img num: 0
ThreadPoolExecutor-0_17: working on img num: 5000
ThreadPoolExecutor-0_15: working on img num: 10000
ThreadPoolExecutor-0_1: working on img num: 15000
ThreadPoolExecutor-0_7: working on img num: 17360
Min Dimensions: [46 46 3]
Avg Dimensions: [132.77311215 132.45757733 3.]
Median Dimensions: [130. 130. 3.]
Max Dimensions: [385 394 3]
```
我们应用并行处理来加速图像读取,并且基于汇总统计结果,我们将每幅图片的尺寸重新调整到 125x125 像素。让我们载入我们所有的图像并重新调整它们为这些固定尺寸。
```
IMG_DIMS = (125, 125)
def get_img_data_parallel(idx, img, total_imgs):
if idx % 5000 == 0 or idx == (total_imgs - 1):
print('{}: working on img num: {}'.format(threading.current_thread().name,
idx))
img = cv2.imread(img)
img = cv2.resize(img, dsize=IMG_DIMS,
interpolation=cv2.INTER_CUBIC)
img = np.array(img, dtype=np.float32)
return img
ex = futures.ThreadPoolExecutor(max_workers=None)
train_data_inp = [(idx, img, len(train_files)) for idx, img in enumerate(train_files)]
val_data_inp = [(idx, img, len(val_files)) for idx, img in enumerate(val_files)]
test_data_inp = [(idx, img, len(test_files)) for idx, img in enumerate(test_files)]
print('Loading Train Images:')
train_data_map = ex.map(get_img_data_parallel,
[record[0] for record in train_data_inp],
[record[1] for record in train_data_inp],
[record[2] for record in train_data_inp])
train_data = np.array(list(train_data_map))
print('\nLoading Validation Images:')
val_data_map = ex.map(get_img_data_parallel,
[record[0] for record in val_data_inp],
[record[1] for record in val_data_inp],
[record[2] for record in val_data_inp])
val_data = np.array(list(val_data_map))
print('\nLoading Test Images:')
test_data_map = ex.map(get_img_data_parallel,
[record[0] for record in test_data_inp],
[record[1] for record in test_data_inp],
[record[2] for record in test_data_inp])
test_data = np.array(list(test_data_map))
train_data.shape, val_data.shape, test_data.shape
# Output
Loading Train Images:
ThreadPoolExecutor-1_0: working on img num: 0
ThreadPoolExecutor-1_12: working on img num: 5000
ThreadPoolExecutor-1_6: working on img num: 10000
ThreadPoolExecutor-1_10: working on img num: 15000
ThreadPoolExecutor-1_3: working on img num: 17360
Loading Validation Images:
ThreadPoolExecutor-1_13: working on img num: 0
ThreadPoolExecutor-1_18: working on img num: 1928
Loading Test Images:
ThreadPoolExecutor-1_5: working on img num: 0
ThreadPoolExecutor-1_19: working on img num: 5000
ThreadPoolExecutor-1_8: working on img num: 8267
((17361, 125, 125, 3), (1929, 125, 125, 3), (8268, 125, 125, 3))
```
我们再次应用并行处理来加速有关图像载入和重新调整大小的计算。最终,我们获得了所需尺寸的图片张量,正如前面的输出所示。我们现在查看一些血细胞图像样本,以对我们的数据有个印象。
```
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(1 , figsize = (8 , 8))
n = 0
for i in range(16):
n += 1
r = np.random.randint(0 , train_data.shape[0] , 1)
plt.subplot(4 , 4 , n)
plt.subplots_adjust(hspace = 0.5 , wspace = 0.5)
plt.imshow(train_data[r[0]]/255.)
plt.title('{}'.format(train_labels[r[0]]))
plt.xticks([]) , plt.yticks([])
```

基于这些样本图像,我们看到一些疟疾和健康细胞图像的细微不同。我们将使我们的深度学习模型试图在模型训练中学习这些模式。
开始我们的模型训练前,我们必须建立一些基础的配置设置。
```
BATCH_SIZE = 64
NUM_CLASSES = 2
EPOCHS = 25
INPUT_SHAPE = (125, 125, 3)
train_imgs_scaled = train_data / 255.
val_imgs_scaled = val_data / 255.
# encode text category labels
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(train_labels)
train_labels_enc = le.transform(train_labels)
val_labels_enc = le.transform(val_labels)
print(train_labels[:6], train_labels_enc[:6])
# Output
['malaria' 'malaria' 'malaria' 'healthy' 'healthy' 'malaria'] [1 1 1 0 0 1]
```
我们修复我们的图像尺寸、批量大小,和纪元,并编码我们的分类的类标签。TensorFlow 2.0 于 2019 年三月发布,这个练习是尝试它的完美理由。
```
import tensorflow as tf
# Load the TensorBoard notebook extension (optional)
%load_ext tensorboard.notebook
tf.random.set_seed(42)
tf.__version__
# Output
'2.0.0-alpha0'
```
### 深度学习训练
在模型训练阶段,我们将构建三个深度训练模型,使用我们的训练集训练,使用验证数据比较它们的性能。然后,我们保存这些模型并在之后的模型评估阶段使用它们。
#### 模型 1:从头开始的 CNN
我们的第一个疟疾检测模型将从头开始构建和训练一个基础的 CNN。首先,让我们定义我们的模型架构,
```
inp = tf.keras.layers.Input(shape=INPUT_SHAPE)
conv1 = tf.keras.layers.Conv2D(32, kernel_size=(3, 3),
activation='relu', padding='same')(inp)
pool1 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = tf.keras.layers.Conv2D(64, kernel_size=(3, 3),
activation='relu', padding='same')(pool1)
pool2 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = tf.keras.layers.Conv2D(128, kernel_size=(3, 3),
activation='relu', padding='same')(pool2)
pool3 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv3)
flat = tf.keras.layers.Flatten()(pool3)
hidden1 = tf.keras.layers.Dense(512, activation='relu')(flat)
drop1 = tf.keras.layers.Dropout(rate=0.3)(hidden1)
hidden2 = tf.keras.layers.Dense(512, activation='relu')(drop1)
drop2 = tf.keras.layers.Dropout(rate=0.3)(hidden2)
out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
model = tf.keras.Model(inputs=inp, outputs=out)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
# Output
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 125, 125, 3)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 125, 125, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 62, 62, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 62, 62, 64) 18496
_________________________________________________________________
...
...
_________________________________________________________________
dense_1 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 15,102,529
Trainable params: 15,102,529
Non-trainable params: 0
_________________________________________________________________
```
基于这些代码的架构,我们的 CNN 模型有三个卷积和一个池化层,其后是两个致密层,以及用于正则化的失活。让我们训练我们的模型。
```
import datetime
logdir = os.path.join('/home/dipanzan_sarkar/projects/tensorboard_logs',
datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5,
patience=2, min_lr=0.000001)
callbacks = [reduce_lr, tensorboard_callback]
history = model.fit(x=train_imgs_scaled, y=train_labels_enc,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
validation_data=(val_imgs_scaled, val_labels_enc),
callbacks=callbacks,
verbose=1)
# Output
Train on 17361 samples, validate on 1929 samples
Epoch 1/25
17361/17361 [====] - 32s 2ms/sample - loss: 0.4373 - accuracy: 0.7814 - val_loss: 0.1834 - val_accuracy: 0.9393
Epoch 2/25
17361/17361 [====] - 30s 2ms/sample - loss: 0.1725 - accuracy: 0.9434 - val_loss: 0.1567 - val_accuracy: 0.9513
...
...
Epoch 24/25
17361/17361 [====] - 30s 2ms/sample - loss: 0.0036 - accuracy: 0.9993 - val_loss: 0.3693 - val_accuracy: 0.9565
Epoch 25/25
17361/17361 [====] - 30s 2ms/sample - loss: 0.0034 - accuracy: 0.9994 - val_loss: 0.3699 - val_accuracy: 0.9559
```
我们获得了 95.6% 的验证精确率,这很好,尽管我们的模型看起来有些过拟合(通过查看我们的训练精确度,是 99.9%)。通过绘制训练和验证的精度和损失曲线,我们可以清楚地看到这一点。
```
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('Basic CNN Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
max_epoch = len(history.history['accuracy'])+1
epoch_list = list(range(1,max_epoch))
ax1.plot(epoch_list, history.history['accuracy'], label='Train Accuracy')
ax1.plot(epoch_list, history.history['val_accuracy'], label='Validation Accuracy')
ax1.set_xticks(np.arange(1, max_epoch, 5))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(1, max_epoch, 5))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")
```

*基础 CNN 学习曲线*
我们可以看在在第五个纪元,情况并没有改善很多。让我们保存这个模型用于将来的评估。
```
model.save('basic_cnn.h5')
```
#### 深度迁移学习
就像人类有与生俱来在不同任务间传输知识的能力一样,迁移学习允许我们利用从以前任务学到的知识用到新的相关的任务,即使在机器学习或深度学习的情况下也是如此。如果想深入探究迁移学习,你应该看我的文章“[一个易于理解与现实应用一起学习深度学习中的迁移学习的指导实践](https://towardsdatascience.com/a-comprehensive-hands-on-guide-to-transfer-learning-with-real-world-applications-in-deep-learning-212bf3b2f27a)”和我的书《[Python 迁移学习实践](https://github.com/dipanjanS/hands-on-transfer-learning-with-python)》。

在这篇实践中我们想要探索的想法是:
>
> 在我们的问题背景下,我们能够利用一个预训练深度学习模型(在大数据集上训练的,像 ImageNet)通过应用和迁移知识来解决疟疾检测的问题吗?
>
>
>
我们将应用两个最流行的深度迁移学习策略。
* 预训练模型作为特征提取器
* 微调的预训练模型
我们将使用预训练的 VGG-19 深度训练模型(由剑桥大学的视觉几何组(VGG)开发)进行我们的实验。像 VGG-19 这样的预训练模型是在一个大的数据集([Imagenet](http://image-net.org/index))上使用了很多不同的图像分类训练的。因此,这个模型应该已经学习到了健壮的特征层级结构,相对于你的 CNN 模型学到的特征,是空间不变的、转动不变的、平移不变的。因此,这个模型,已经从百万幅图片中学习到了一个好的特征显示,对于像疟疾检测这样的计算机视觉问题,可以作为一个好的合适新图像的特征提取器。在我们的问题中发挥迁移学习的能力之前,让我们先讨论 VGG-19 模型。
##### 理解 VGG-19 模型
VGG-19 模型是一个构建在 ImageNet 数据库之上的 19 层(卷积和全连接的)的深度学习网络,ImageNet 数据库为了图像识别和分类的目的而开发。该模型是由 Karen Simonyan 和 Andrew Zisserman 构建的,在他们的论文“[大规模图像识别的非常深的卷积网络](https://arxiv.org/pdf/1409.1556.pdf)”中进行了描述。VGG-19 的架构模型是:

你可以看到我们总共有 16 个使用 3x3 卷积过滤器的卷积层,与最大的池化层来下采样,和由 4096 个单元组成的两个全连接的隐藏层,每个隐藏层之后跟随一个由 1000 个单元组成的致密层,每个单元代表 ImageNet 数据库中的一个分类。我们不需要最后三层,因为我们将使用我们自己的全连接致密层来预测疟疾。我们更关心前五个块,因此我们可以利用 VGG 模型作为一个有效的特征提取器。
我们将使用模型之一作为一个简单的特征提取器,通过冻结五个卷积块的方式来确保它们的位权在每个纪元后不会更新。对于最后一个模型,我们会对 VGG 模型进行微调,我们会解冻最后两个块(第 4 和第 5)因此当我们训练我们的模型时,它们的位权在每个时期(每批数据)被更新。
#### 模型 2:预训练的模型作为一个特征提取器
为了构建这个模型,我们将利用 TensorFlow 载入 VGG-19 模型并冻结卷积块,因此我们能够将它们用作特征提取器。我们在末尾插入我们自己的致密层来执行分类任务。
```
vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet',
input_shape=INPUT_SHAPE)
vgg.trainable = False
# Freeze the layers
for layer in vgg.layers:
layer.trainable = False
base_vgg = vgg
base_out = base_vgg.output
pool_out = tf.keras.layers.Flatten()(base_out)
hidden1 = tf.keras.layers.Dense(512, activation='relu')(pool_out)
drop1 = tf.keras.layers.Dropout(rate=0.3)(hidden1)
hidden2 = tf.keras.layers.Dense(512, activation='relu')(drop1)
drop2 = tf.keras.layers.Dropout(rate=0.3)(hidden2)
out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
model = tf.keras.Model(inputs=base_vgg.input, outputs=out)
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
# Output
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 125, 125, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 125, 125, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 125, 125, 64) 36928
_________________________________________________________________
...
...
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 3, 3, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 4608) 0
_________________________________________________________________
dense_3 (Dense) (None, 512) 2359808
_________________________________________________________________
dropout_2 (Dropout) (None, 512) 0
_________________________________________________________________
dense_4 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_3 (Dropout) (None, 512) 0
_________________________________________________________________
dense_5 (Dense) (None, 1) 513
=================================================================
Total params: 22,647,361
Trainable params: 2,622,977
Non-trainable params: 20,024,384
_________________________________________________________________
```
从整个输出可以明显看出,在我们的模型中我们有了很多层,我们将只利用 VGG-19 模型的冻结层作为特征提取器。你可以使用下列代码来验证我们的模型有多少层是实际可训练的,以及我们的网络中总共存在多少层。
```
print("Total Layers:", len(model.layers))
print("Total trainable layers:",
sum([1 for l in model.layers if l.trainable]))
# Output
Total Layers: 28
Total trainable layers: 6
```
我们将使用和我们之前的模型相似的配置和回调来训练我们的模型。参考[我的 GitHub 仓库](https://nbviewer.jupyter.org/github/dipanjanS/data_science_for_all/tree/master/os_malaria_detection/)以获取训练模型的完整代码。我们观察下列图表,以显示模型精确度和损失曲线。

*冻结的预训练的 CNN 的学习曲线*
这表明我们的模型没有像我们的基础 CNN 模型那样过拟合,但是性能有点不如我们的基础的 CNN 模型。让我们保存这个模型,以备将来的评估。
```
model.save('vgg_frozen.h5')
```
#### 模型 3:使用图像增强来微调预训练的模型
在我们的最后一个模型中,我们将在预定义好的 VGG-19 模型的最后两个块中微调层的位权。我们同样引入了图像增强的概念。图像增强背后的想法和其名字一样。我们从训练数据集中载入现有图像,并且应用转换操作,例如旋转、裁剪、转换、放大缩小等等,来产生新的、改变过的版本。由于这些随机转换,我们每次获取到的图像不一样。我们将应用 tf.keras 中的一个名为 ImageDataGenerator 的优秀工具来帮助构建图像增强器。
```
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255,
zoom_range=0.05,
rotation_range=25,
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=0.05, horizontal_flip=True,
fill_mode='nearest')
val_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
# build image augmentation generators
train_generator = train_datagen.flow(train_data, train_labels_enc, batch_size=BATCH_SIZE, shuffle=True)
val_generator = val_datagen.flow(val_data, val_labels_enc, batch_size=BATCH_SIZE, shuffle=False)
```
我们不会对我们的验证数据集应用任何转换(除非是调整大小,因为这是必须的),因为我们将使用它评估每个纪元的模型性能。对于在传输学习环境中的图像增强的详细解释,请随时查看我上面引用的[文章](https://towardsdatascience.com/a-comprehensive-hands-on-guide-to-transfer-learning-with-real-world-applications-in-deep-learning-212bf3b2f27a)。让我们从一批图像增强转换中查看一些样本结果。
```
img_id = 0
sample_generator = train_datagen.flow(train_data[img_id:img_id+1], train_labels[img_id:img_id+1],
batch_size=1)
sample = [next(sample_generator) for i in range(0,5)]
fig, ax = plt.subplots(1,5, figsize=(16, 6))
print('Labels:', [item[1][0] for item in sample])
l = [ax[i].imshow(sample[i][0][0]) for i in range(0,5)]
```

你可以清晰的看到与之前的输出的我们图像的轻微变化。我们现在构建我们的学习模型,确保 VGG-19 模型的最后两块是可以训练的。
```
vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet',
input_shape=INPUT_SHAPE)
# Freeze the layers
vgg.trainable = True
set_trainable = False
for layer in vgg.layers:
if layer.name in ['block5_conv1', 'block4_conv1']:
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
base_vgg = vgg
base_out = base_vgg.output
pool_out = tf.keras.layers.Flatten()(base_out)
hidden1 = tf.keras.layers.Dense(512, activation='relu')(pool_out)
drop1 = tf.keras.layers.Dropout(rate=0.3)(hidden1)
hidden2 = tf.keras.layers.Dense(512, activation='relu')(drop1)
drop2 = tf.keras.layers.Dropout(rate=0.3)(hidden2)
out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
model = tf.keras.Model(inputs=base_vgg.input, outputs=out)
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=1e-5),
loss='binary_crossentropy',
metrics=['accuracy'])
print("Total Layers:", len(model.layers))
print("Total trainable layers:", sum([1 for l in model.layers if l.trainable]))
# Output
Total Layers: 28
Total trainable layers: 16
```
在我们的模型中我们降低了学习率,因为我们不想在微调的时候对预训练的层做大的位权更新。模型的训练过程可能有轻微的不同,因为我们使用了数据生成器,因此我们将应用 `fit_generator(...)` 函数。
```
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5,
patience=2, min_lr=0.000001)
callbacks = [reduce_lr, tensorboard_callback]
train_steps_per_epoch = train_generator.n // train_generator.batch_size
val_steps_per_epoch = val_generator.n // val_generator.batch_size
history = model.fit_generator(train_generator, steps_per_epoch=train_steps_per_epoch, epochs=EPOCHS,
validation_data=val_generator, validation_steps=val_steps_per_epoch,
verbose=1)
# Output
Epoch 1/25
271/271 [====] - 133s 489ms/step - loss: 0.2267 - accuracy: 0.9117 - val_loss: 0.1414 - val_accuracy: 0.9531
Epoch 2/25
271/271 [====] - 129s 475ms/step - loss: 0.1399 - accuracy: 0.9552 - val_loss: 0.1292 - val_accuracy: 0.9589
...
...
Epoch 24/25
271/271 [====] - 128s 473ms/step - loss: 0.0815 - accuracy: 0.9727 - val_loss: 0.1466 - val_accuracy: 0.9682
Epoch 25/25
271/271 [====] - 128s 473ms/step - loss: 0.0792 - accuracy: 0.9729 - val_loss: 0.1127 - val_accuracy: 0.9641
```
这看起来是我们的最好的模型。它给了我们近乎 96.5% 的验证精确率,基于训练精度,它看起来不像我们的第一个模型那样过拟合。这可以通过下列的学习曲线验证。

*微调过的预训练 CNN 的学习曲线*
让我们保存这个模型,因此我们能够在测试集上使用。
```
model.save('vgg_finetuned.h5')
```
这就完成了我们的模型训练阶段。现在我们准备好了在测试集上测试我们模型的性能。
### 深度学习模型性能评估
我们将通过在我们的测试集上做预测来评估我们在训练阶段构建的三个模型,因为仅仅验证是不够的!我们同样构建了一个检测工具模块叫做 `model_evaluation_utils`,我们可以使用相关分类指标用来评估使用我们深度学习模型的性能。第一步是扩展我们的数据集。
```
test_imgs_scaled = test_data / 255.
test_imgs_scaled.shape, test_labels.shape
# Output
((8268, 125, 125, 3), (8268,))
```
下一步包括载入我们保存的深度学习模型,在测试集上预测。
```
# Load Saved Deep Learning Models
basic_cnn = tf.keras.models.load_model('./basic_cnn.h5')
vgg_frz = tf.keras.models.load_model('./vgg_frozen.h5')
vgg_ft = tf.keras.models.load_model('./vgg_finetuned.h5')
# Make Predictions on Test Data
basic_cnn_preds = basic_cnn.predict(test_imgs_scaled, batch_size=512)
vgg_frz_preds = vgg_frz.predict(test_imgs_scaled, batch_size=512)
vgg_ft_preds = vgg_ft.predict(test_imgs_scaled, batch_size=512)
basic_cnn_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
for pred in basic_cnn_preds.ravel()])
vgg_frz_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
for pred in vgg_frz_preds.ravel()])
vgg_ft_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
for pred in vgg_ft_preds.ravel()])
```
下一步是应用我们的 `model_evaluation_utils` 模块根据相应分类指标来检查每个模块的性能。
```
import model_evaluation_utils as meu
import pandas as pd
basic_cnn_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=basic_cnn_pred_labels)
vgg_frz_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=vgg_frz_pred_labels)
vgg_ft_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=vgg_ft_pred_labels)
pd.DataFrame([basic_cnn_metrics, vgg_frz_metrics, vgg_ft_metrics],
index=['Basic CNN', 'VGG-19 Frozen', 'VGG-19 Fine-tuned'])
```

看起来我们的第三个模型在我们的测试集上执行的最好,给出了一个模型精确性为 96% 的 F1 得分,这非常好,与我们之前提到的研究论文和文章中的更复杂的模型相当。
### 总结
疟疾检测不是一个简单的过程,全球的合格人员的不足在病例诊断和治疗当中是一个严重的问题。我们研究了一个关于疟疾的有趣的真实世界的医学影像案例。利用 AI 的、易于构建的、开源的技术在检测疟疾方面可以为我们提供最先进的精确性,因此使 AI 具有社会效益。
我鼓励你查看这篇文章中提到的文章和研究论文,没有它们,我就不能形成概念并写出来。如果你对运行和采纳这些技术感兴趣,本篇文章所有的代码都可以在[我的 GitHub 仓库](https://nbviewer.jupyter.org/github/dipanjanS/data_science_for_all/tree/master/os_malaria_detection/)获得。记得从[官方网站](https://ceb.nlm.nih.gov/repositories/malaria-datasets/)下载数据。
让我们希望在健康医疗方面更多的采纳开源的 AI 能力,使它在世界范围内变得更便宜、更易用。
---
via: <https://opensource.com/article/19/4/detecting-malaria-deep-learning>
作者:[Dipanjan (DJ) Sarkar](https://opensource.com/users/djsarkar) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Artificial intelligence (AI) and open source tools, technologies, and frameworks are a powerful combination for improving society. *"Health is wealth"* is perhaps a cliche, yet it's very accurate! In this article, we will examine how AI can be leveraged for detecting the deadly disease malaria with a low-cost, effective, and accurate open source deep learning solution.
While I am neither a doctor nor a healthcare researcher and I'm nowhere near as qualified as they are, I am interested in applying AI to healthcare research. My intent in this article is to showcase how AI and open source solutions can help malaria detection and reduce manual labor.

Python and TensorFlow—A great combo to build open source deep learning solutions
Thanks to the power of Python and deep learning frameworks like TensorFlow, we can build robust, scalable, and effective deep learning solutions. Because these tools are free and open source, we can build solutions that are very cost-effective and easily adopted and used by anyone. Let's get started!
## Motivation for the project
Malaria is a deadly, infectious, mosquito-borne disease caused by *Plasmodium* parasites that are transmitted by the bites of infected female *Anopheles* mosquitoes. There are five parasites that cause malaria, but two types—*P. falciparum* and *P. vivax*—cause the majority of the cases.
Image from [Treated.com](https://www.treated.com/)
This map shows that malaria is prevalent around the globe, especially in tropical regions, but the nature and fatality of the disease is the primary motivation for this project.
If an infected mosquito bites you, parasites carried by the mosquito enter your blood and start destroying oxygen-carrying red blood cells (RBC). Typically, the first symptoms of malaria are similar to a virus like the flu and they usually begin within a few days or weeks after the mosquito bite. However, these deadly parasites can live in your body for over a year without causing symptoms, and a delay in treatment can lead to complications and even death. Therefore, early detection can save lives.
The World Health Organization's (WHO) [malaria facts](https://www.who.int/features/factfiles/malaria/en/) indicate that nearly half the world's population is at risk from malaria, and there are over 200 million malaria cases and approximately 400,000 deaths due to malaria every year. This is a motivatation to make malaria detection and diagnosis fast, easy, and effective.
## Methods of malaria detection
There are several methods that can be used for malaria detection and diagnosis. The paper on which our project is based, "[Pre-trained convolutional neural networks as feature extractors toward improved Malaria parasite detection in thin blood smear images](https://peerj.com/articles/4568/)," by Rajaraman, et al., introduces some of the methods, including polymerase chain reaction (PCR) and rapid diagnostic tests (RDT). These two tests are typically used where high-quality microscopy services are not readily available.
The standard malaria diagnosis is typically based on a blood-smear workflow, according to Carlos Ariza's article "[Malaria Hero: A web app for faster malaria diagnosis](https://blog.insightdatascience.com/https-blog-insightdatascience-com-malaria-hero-a47d3d5fc4bb)," which I learned about in Adrian Rosebrock's "[Deep learning and medical image analysis with Keras](https://www.pyimagesearch.com/2018/12/03/deep-learning-and-medical-image-analysis-with-keras/)." I appreciate the authors of these excellent resources for giving me more perspective on malaria prevalence, diagnosis, and treatment.
A blood smear workflow for Malaria detection.
According to WHO protocol, diagnosis typically involves intensive examination of the blood smear at 100X magnification. Trained people manually count how many red blood cells contain parasites out of 5,000 cells. As the Rajaraman, et al., paper cited above explains:
Thick blood smears assist in detecting the presence of parasites while thin blood smears assist in identifying the species of the parasite causing the infection (Centers for Disease Control and Prevention, 2012). The diagnostic accuracy heavily depends on human expertise and can be adversely impacted by the inter-observer variability and the liability imposed by large-scale diagnoses in disease-endemic/resource-constrained regions (Mitiku, Mengistu, and Gelaw, 2003). Alternative techniques such as polymerase chain reaction (PCR) and rapid diagnostic tests (RDT) are used; however, PCR analysis is limited in its performance (Hommelsheim, et al., 2014) and RDTs are less cost-effective in disease-endemic regions (Hawkes, Katsuva, and Masumbuko, 2009).
Thus, malaria detection could benefit from automation using deep learning.
## Deep learning for malaria detection
Manual diagnosis of blood smears is an intensive manual process that requires expertise in classifying and counting parasitized and uninfected cells. This process may not scale well, especially in regions where the right expertise is hard to find. Some advancements have been made in leveraging state-of-the-art image processing and analysis techniques to extract hand-engineered features and build machine learning-based classification models. However, these models are not scalable with more data being available for training and given the fact that hand-engineered features take a lot of time.
Deep learning models, or more specifically convolutional neural networks (CNNs), have proven very effective in a wide variety of computer vision tasks. (If you would like additional background knowledge on CNNs, I recommend reading [CS231n Convolutional Neural Networks for Visual Recognition](http://cs231n.github.io/convolutional-networks/).) Briefly, the key layers in a CNN model include convolution and pooling layers, as shown in the following figure.
A typical CNN architecture.
Convolution layers learn spatial hierarchical patterns from data, which are also translation-invariant, so they are able to learn different aspects of images. For example, the first convolution layer will learn small and local patterns, such as edges and corners, a second convolution layer will learn larger patterns based on the features from the first layers, and so on. This allows CNNs to automate feature engineering and learn effective features that generalize well on new data points. Pooling layers helps with downsampling and dimension reduction.
Thus, CNNs help with automated and scalable feature engineering. Also, plugging in dense layers at the end of the model enables us to perform tasks like image classification. Automated malaria detection using deep learning models like CNNs could be very effective, cheap, and scalable, especially with the advent of transfer learning and pre-trained models that work quite well, even with constraints like less data.
The Rajaraman, et al., paper leverages six pre-trained models on a dataset to obtain an impressive accuracy of 95.9% in detecting malaria vs. non-infected samples. Our focus is to try some simple CNN models from scratch and a couple of pre-trained models using transfer learning to see the results we can get on the same dataset. We will use open source tools and frameworks, including Python and TensorFlow, to build our models.
## The dataset
The data for our analysis comes from researchers at the Lister Hill National Center for Biomedical Communications (LHNCBC), part of the National Library of Medicine (NLM), who have carefully collected and annotated the [publicly available dataset](https://ceb.nlm.nih.gov/repositories/malaria-datasets/) of healthy and infected blood smear images. These researchers have developed a mobile [application for malaria detection](https://www.ncbi.nlm.nih.gov/pubmed/29360430) that runs on a standard Android smartphone attached to a conventional light microscope. They used Giemsa-stained thin blood smear slides from 150 *P. falciparum*-infected and 50 healthy patients, collected and photographed at Chittagong Medical College Hospital, Bangladesh. The smartphone's built-in camera acquired images of slides for each microscopic field of view. The images were manually annotated by an expert slide reader at the Mahidol-Oxford Tropical Medicine Research Unit in Bangkok, Thailand.
Let's briefly check out the dataset's structure. First, I will install some basic dependencies (based on the operating system being used).
I am using a Debian-based system on the cloud with a GPU so I can run my models faster. To view the directory structure, we must install the tree dependency (if we don't have it) using **sudo apt install tree**.
We have two folders that contain images of cells, infected and healthy. We can get further details about the total number of images by entering:
```
import os
import glob
base_dir = os.path.join('./cell_images')
infected_dir = os.path.join(base_dir,'Parasitized')
healthy_dir = os.path.join(base_dir,'Uninfected')
infected_files = glob.glob(infected_dir+'/*.png')
healthy_files = glob.glob(healthy_dir+'/*.png')
len(infected_files), len(healthy_files)
# Output
(13779, 13779)
```
It looks like we have a balanced dataset with 13,779 malaria and 13,779 non-malaria (uninfected) cell images. Let's build a data frame from this, which we will use when we start building our datasets.
```
import numpy as np
import pandas as pd
np.random.seed(42)
files_df = pd.DataFrame({
'filename': infected_files + healthy_files,
'label': ['malaria'] * len(infected_files) + ['healthy'] * len(healthy_files)
}).sample(frac=1, random_state=42).reset_index(drop=True)
files_df.head()
```

## Build and explore image datasets
To build deep learning models, we need training data, but we also need to test the model's performance on unseen data. We will use a 60:10:30 split for train, validation, and test datasets, respectively. We will leverage the train and validation datasets during training and check the performance of the model on the test dataset.
```
from sklearn.model_selection import train_test_split
from collections import Counter
train_files, test_files, train_labels, test_labels = train_test_split(files_df['filename'].values,
files_df['label'].values,
test_size=0.3, random_state=42)
train_files, val_files, train_labels, val_labels = train_test_split(train_files,
train_labels,
test_size=0.1, random_state=42)
print(train_files.shape, val_files.shape, test_files.shape)
print('Train:', Counter(train_labels), '\nVal:', Counter(val_labels), '\nTest:', Counter(test_labels))
# Output
(17361,) (1929,) (8268,)
Train: Counter({'healthy': 8734, 'malaria': 8627})
Val: Counter({'healthy': 970, 'malaria': 959})
Test: Counter({'malaria': 4193, 'healthy': 4075})
```
The images will not be of equal dimensions because blood smears and cell images vary based on the human, the test method, and the orientation of the photo. Let's get some summary statistics of our training dataset to determine the optimal image dimensions (remember, we don't touch the test dataset at all!).
```
import cv2
from concurrent import futures
import threading
def get_img_shape_parallel(idx, img, total_imgs):
if idx % 5000 == 0 or idx == (total_imgs - 1):
print('{}: working on img num: {}'.format(threading.current_thread().name,
idx))
return cv2.imread(img).shape
ex = futures.ThreadPoolExecutor(max_workers=None)
data_inp = [(idx, img, len(train_files)) for idx, img in enumerate(train_files)]
print('Starting Img shape computation:')
train_img_dims_map = ex.map(get_img_shape_parallel,
[record[0] for record in data_inp],
[record[1] for record in data_inp],
[record[2] for record in data_inp])
train_img_dims = list(train_img_dims_map)
print('Min Dimensions:', np.min(train_img_dims, axis=0))
print('Avg Dimensions:', np.mean(train_img_dims, axis=0))
print('Median Dimensions:', np.median(train_img_dims, axis=0))
print('Max Dimensions:', np.max(train_img_dims, axis=0))
# Output
Starting Img shape computation:
ThreadPoolExecutor-0_0: working on img num: 0
ThreadPoolExecutor-0_17: working on img num: 5000
ThreadPoolExecutor-0_15: working on img num: 10000
ThreadPoolExecutor-0_1: working on img num: 15000
ThreadPoolExecutor-0_7: working on img num: 17360
Min Dimensions: [46 46 3]
Avg Dimensions: [132.77311215 132.45757733 3.]
Median Dimensions: [130. 130. 3.]
Max Dimensions: [385 394 3]
```
We apply parallel processing to speed up the image-read operations and, based on the summary statistics, we will resize each image to 125x125 pixels. Let's load up all of our images and resize them to these fixed dimensions.
```
IMG_DIMS = (125, 125)
def get_img_data_parallel(idx, img, total_imgs):
if idx % 5000 == 0 or idx == (total_imgs - 1):
print('{}: working on img num: {}'.format(threading.current_thread().name,
idx))
img = cv2.imread(img)
img = cv2.resize(img, dsize=IMG_DIMS,
interpolation=cv2.INTER_CUBIC)
img = np.array(img, dtype=np.float32)
return img
ex = futures.ThreadPoolExecutor(max_workers=None)
train_data_inp = [(idx, img, len(train_files)) for idx, img in enumerate(train_files)]
val_data_inp = [(idx, img, len(val_files)) for idx, img in enumerate(val_files)]
test_data_inp = [(idx, img, len(test_files)) for idx, img in enumerate(test_files)]
print('Loading Train Images:')
train_data_map = ex.map(get_img_data_parallel,
[record[0] for record in train_data_inp],
[record[1] for record in train_data_inp],
[record[2] for record in train_data_inp])
train_data = np.array(list(train_data_map))
print('\nLoading Validation Images:')
val_data_map = ex.map(get_img_data_parallel,
[record[0] for record in val_data_inp],
[record[1] for record in val_data_inp],
[record[2] for record in val_data_inp])
val_data = np.array(list(val_data_map))
print('\nLoading Test Images:')
test_data_map = ex.map(get_img_data_parallel,
[record[0] for record in test_data_inp],
[record[1] for record in test_data_inp],
[record[2] for record in test_data_inp])
test_data = np.array(list(test_data_map))
train_data.shape, val_data.shape, test_data.shape
# Output
Loading Train Images:
ThreadPoolExecutor-1_0: working on img num: 0
ThreadPoolExecutor-1_12: working on img num: 5000
ThreadPoolExecutor-1_6: working on img num: 10000
ThreadPoolExecutor-1_10: working on img num: 15000
ThreadPoolExecutor-1_3: working on img num: 17360
Loading Validation Images:
ThreadPoolExecutor-1_13: working on img num: 0
ThreadPoolExecutor-1_18: working on img num: 1928
Loading Test Images:
ThreadPoolExecutor-1_5: working on img num: 0
ThreadPoolExecutor-1_19: working on img num: 5000
ThreadPoolExecutor-1_8: working on img num: 8267
((17361, 125, 125, 3), (1929, 125, 125, 3), (8268, 125, 125, 3))
```
We leverage parallel processing again to speed up computations pertaining to image load and resizing. Finally, we get our image tensors of the desired dimensions, as depicted in the preceding output. We can now view some sample cell images to get an idea of how our data looks.
```
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(1 , figsize = (8 , 8))
n = 0
for i in range(16):
n += 1
r = np.random.randint(0 , train_data.shape[0] , 1)
plt.subplot(4 , 4 , n)
plt.subplots_adjust(hspace = 0.5 , wspace = 0.5)
plt.imshow(train_data[r[0]]/255.)
plt.title('{}'.format(train_labels[r[0]]))
plt.xticks([]) , plt.yticks([])
```
Based on these sample images, we can see some subtle differences between malaria and healthy cell images. We will make our deep learning models try to learn these patterns during model training.
Before can we start training our models, we must set up some basic configuration settings.
```
BATCH_SIZE = 64
NUM_CLASSES = 2
EPOCHS = 25
INPUT_SHAPE = (125, 125, 3)
train_imgs_scaled = train_data / 255.
val_imgs_scaled = val_data / 255.
# encode text category labels
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(train_labels)
train_labels_enc = le.transform(train_labels)
val_labels_enc = le.transform(val_labels)
print(train_labels[:6], train_labels_enc[:6])
# Output
['malaria' 'malaria' 'malaria' 'healthy' 'healthy' 'malaria'] [1 1 1 0 0 1]
```
We fix our image dimensions, batch size, and epochs and encode our categorical class labels. The alpha version of TensorFlow 2.0 was released in March 2019, and this exercise is the perfect excuse to try it out.
```
import tensorflow as tf
# Load the TensorBoard notebook extension (optional)
%load_ext tensorboard.notebook
tf.random.set_seed(42)
tf.__version__
# Output
'2.0.0-alpha0'
```
## Deep learning model training
In the model training phase, we will build three deep learning models, train them with our training data, and compare their performance using the validation data. We will then save these models and use them later in the model evaluation phase.
### Model 1: CNN from scratch
Our first malaria detection model will build and train a basic CNN from scratch. First, let's define our model architecture.
```
inp = tf.keras.layers.Input(shape=INPUT_SHAPE)
conv1 = tf.keras.layers.Conv2D(32, kernel_size=(3, 3),
activation='relu', padding='same')(inp)
pool1 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = tf.keras.layers.Conv2D(64, kernel_size=(3, 3),
activation='relu', padding='same')(pool1)
pool2 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = tf.keras.layers.Conv2D(128, kernel_size=(3, 3),
activation='relu', padding='same')(pool2)
pool3 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv3)
flat = tf.keras.layers.Flatten()(pool3)
hidden1 = tf.keras.layers.Dense(512, activation='relu')(flat)
drop1 = tf.keras.layers.Dropout(rate=0.3)(hidden1)
hidden2 = tf.keras.layers.Dense(512, activation='relu')(drop1)
drop2 = tf.keras.layers.Dropout(rate=0.3)(hidden2)
out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
model = tf.keras.Model(inputs=inp, outputs=out)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
# Output
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 125, 125, 3)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 125, 125, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 62, 62, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 62, 62, 64) 18496
_________________________________________________________________
...
...
_________________________________________________________________
dense_1 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 15,102,529
Trainable params: 15,102,529
Non-trainable params: 0
_________________________________________________________________
```
Based on the architecture in this code, our CNN model has three convolution and pooling layers, followed by two dense layers, and dropouts for regularization. Let's train our model.
```
import datetime
logdir = os.path.join('/home/dipanzan_sarkar/projects/tensorboard_logs',
datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5,
patience=2, min_lr=0.000001)
callbacks = [reduce_lr, tensorboard_callback]
history = model.fit(x=train_imgs_scaled, y=train_labels_enc,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
validation_data=(val_imgs_scaled, val_labels_enc),
callbacks=callbacks,
verbose=1)
# Output
Train on 17361 samples, validate on 1929 samples
Epoch 1/25
17361/17361 [====] - 32s 2ms/sample - loss: 0.4373 - accuracy: 0.7814 - val_loss: 0.1834 - val_accuracy: 0.9393
Epoch 2/25
17361/17361 [====] - 30s 2ms/sample - loss: 0.1725 - accuracy: 0.9434 - val_loss: 0.1567 - val_accuracy: 0.9513
...
...
Epoch 24/25
17361/17361 [====] - 30s 2ms/sample - loss: 0.0036 - accuracy: 0.9993 - val_loss: 0.3693 - val_accuracy: 0.9565
Epoch 25/25
17361/17361 [====] - 30s 2ms/sample - loss: 0.0034 - accuracy: 0.9994 - val_loss: 0.3699 - val_accuracy: 0.9559
```
We get a validation accuracy of 95.6%, which is pretty good, although our model looks to be overfitting slightly (based on looking at our training accuracy, which is 99.9%). We can get a clear perspective on this by plotting the training and validation accuracy and loss curves.
```
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('Basic CNN Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
max_epoch = len(history.history['accuracy'])+1
epoch_list = list(range(1,max_epoch))
ax1.plot(epoch_list, history.history['accuracy'], label='Train Accuracy')
ax1.plot(epoch_list, history.history['val_accuracy'], label='Validation Accuracy')
ax1.set_xticks(np.arange(1, max_epoch, 5))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(1, max_epoch, 5))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")
```
We can see after the fifth epoch that things don't seem to improve a whole lot overall. Let's save this model for future evaluation.
`model.save('basic_cnn.h5')`
### Deep transfer learning
Just like humans have an inherent capability to transfer knowledge across tasks, transfer learning enables us to utilize knowledge from previously learned tasks and apply it to newer, related ones, even in the context of machine learning or deep learning. If you are interested in doing a deep-dive on transfer learning, you can read my article "[A comprehensive hands-on guide to transfer learning with real-world applications in deep learning](https://towardsdatascience.com/a-comprehensive-hands-on-guide-to-transfer-learning-with-real-world-applications-in-deep-learning-212bf3b2f27a)" and my book [ Hands-On Transfer Learning with Python](https://github.com/dipanjanS/hands-on-transfer-learning-with-python).
The idea we want to explore in this exercise is:
Can we leverage a pre-trained deep learning model (which was trained on a large dataset, like ImageNet) to solve the problem of malaria detection by applying and transferring its knowledge in the context of our problem?
We will apply the two most popular strategies for deep transfer learning.
- Pre-trained model as a feature extractor
- Pre-trained model with fine-tuning
We will be using the pre-trained VGG-19 deep learning model, developed by the Visual Geometry Group (VGG) at the University of Oxford, for our experiments. A pre-trained model like VGG-19 is trained on a huge dataset ([ImageNet](http://image-net.org/index)) with a lot of diverse image categories. Therefore, the model should have learned a robust hierarchy of features, which are spatial-, rotational-, and translation-invariant with regard to features learned by CNN models. Hence, the model, having learned a good representation of features for over a million images, can act as a good feature extractor for new images suitable for computer vision problems like malaria detection. Let's discuss the VGG-19 model architecture before unleashing the power of transfer learning on our problem.
#### Understanding the VGG-19 model
The VGG-19 model is a 19-layer (convolution and fully connected) deep learning network built on the ImageNet database, which was developed for the purpose of image recognition and classification. This model was built by Karen Simonyan and Andrew Zisserman and is described in their paper "[Very deep convolutional networks for large-scale image recognition](https://arxiv.org/pdf/1409.1556.pdf)." The architecture of the VGG-19 model is:
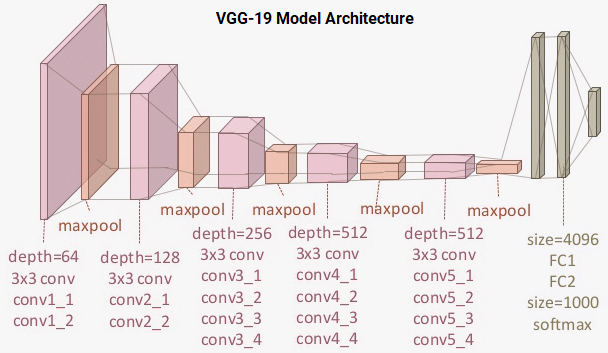
You can see that we have a total of 16 convolution layers using 3x3 convolution filters along with max pooling layers for downsampling and two fully connected hidden layers of 4,096 units in each layer followed by a dense layer of 1,000 units, where each unit represents one of the image categories in the ImageNet database. We do not need the last three layers since we will be using our own fully connected dense layers to predict malaria. We are more concerned with the first five blocks so we can leverage the VGG model as an effective feature extractor.
We will use one of the models as a simple feature extractor by freezing the five convolution blocks to make sure their weights aren't updated after each epoch. For the last model, we will apply fine-tuning to the VGG model, where we will unfreeze the last two blocks (Block 4 and Block 5) so that their weights will be updated in each epoch (per batch of data) as we train our own model.
### Model 2: Pre-trained model as a feature extractor
For building this model, we will leverage TensorFlow to load up the VGG-19 model and freeze the convolution blocks so we can use them as an image feature extractor. We will plug in our own dense layers at the end to perform the classification task.
```
vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet',
input_shape=INPUT_SHAPE)
vgg.trainable = False
# Freeze the layers
for layer in vgg.layers:
layer.trainable = False
base_vgg = vgg
base_out = base_vgg.output
pool_out = tf.keras.layers.Flatten()(base_out)
hidden1 = tf.keras.layers.Dense(512, activation='relu')(pool_out)
drop1 = tf.keras.layers.Dropout(rate=0.3)(hidden1)
hidden2 = tf.keras.layers.Dense(512, activation='relu')(drop1)
drop2 = tf.keras.layers.Dropout(rate=0.3)(hidden2)
out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
model = tf.keras.Model(inputs=base_vgg.input, outputs=out)
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
# Output
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 125, 125, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 125, 125, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 125, 125, 64) 36928
_________________________________________________________________
...
...
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 3, 3, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 4608) 0
_________________________________________________________________
dense_3 (Dense) (None, 512) 2359808
_________________________________________________________________
dropout_2 (Dropout) (None, 512) 0
_________________________________________________________________
dense_4 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_3 (Dropout) (None, 512) 0
_________________________________________________________________
dense_5 (Dense) (None, 1) 513
=================================================================
Total params: 22,647,361
Trainable params: 2,622,977
Non-trainable params: 20,024,384
_________________________________________________________________
```
It is evident from this output that we have a lot of layers in our model and we will be using the frozen layers of the VGG-19 model as feature extractors only. You can use the following code to verify how many layers in our model are indeed trainable and how many total layers are present in our network.
```
print("Total Layers:", len(model.layers))
print("Total trainable layers:",
sum([1 for l in model.layers if l.trainable]))
# Output
Total Layers: 28
Total trainable layers: 6
```
We will now train our model using similar configurations and callbacks to the ones we used in our previous model. Refer to [my GitHub repository](https://nbviewer.jupyter.org/github/dipanjanS/data_science_for_all/tree/master/os_malaria_detection/) for the complete code to train the model. We observe the following plots showing the model's accuracy and loss.
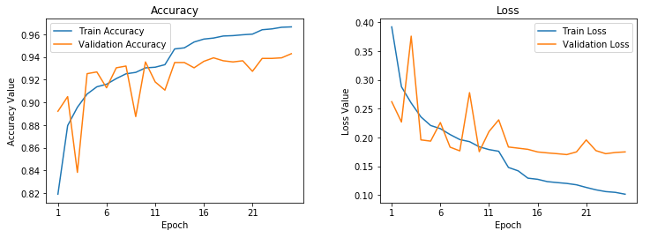
Learning curves for frozen pre-trained CNN.
This shows that our model is not overfitting as much as our basic CNN model, but the performance is slightly less than our basic CNN model. Let's save this model for future evaluation.
`model.save('vgg_frozen.h5')`
### Model 3: Fine-tuned pre-trained model with image augmentation
In our final model, we will fine-tune the weights of the layers in the last two blocks of our pre-trained VGG-19 model. We will also introduce the concept of image augmentation. The idea behind image augmentation is exactly as the name sounds. We load in existing images from our training dataset and apply some image transformation operations to them, such as rotation, shearing, translation, zooming, and so on, to produce new, altered versions of existing images. Due to these random transformations, we don't get the same images each time. We will leverage an excellent utility called **ImageDataGenerator** in **tf.keras** that can help build image augmentors.
```
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255,
zoom_range=0.05,
rotation_range=25,
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=0.05, horizontal_flip=True,
fill_mode='nearest')
val_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
# build image augmentation generators
train_generator = train_datagen.flow(train_data, train_labels_enc, batch_size=BATCH_SIZE, shuffle=True)
val_generator = val_datagen.flow(val_data, val_labels_enc, batch_size=BATCH_SIZE, shuffle=False)
```
We will not apply any transformations on our validation dataset (except for scaling the images, which is mandatory) since we will be using it to evaluate our model performance per epoch. For a detailed explanation of image augmentation in the context of transfer learning, feel free to check out my [article](https://towardsdatascience.com/a-comprehensive-hands-on-guide-to-transfer-learning-with-real-world-applications-in-deep-learning-212bf3b2f27a) cited above. Let's look at some sample results from a batch of image augmentation transforms.
```
img_id = 0
sample_generator = train_datagen.flow(train_data[img_id:img_id+1], train_labels[img_id:img_id+1],
batch_size=1)
sample = [next(sample_generator) for i in range(0,5)]
fig, ax = plt.subplots(1,5, figsize=(16, 6))
print('Labels:', [item[1][0] for item in sample])
l = [ax[i].imshow(sample[i][0][0]) for i in range(0,5)]
```
You can clearly see the slight variations of our images in the preceding output. We will now build our deep learning model, making sure the last two blocks of the VGG-19 model are trainable.
```
vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet',
input_shape=INPUT_SHAPE)
# Freeze the layers
vgg.trainable = True
set_trainable = False
for layer in vgg.layers:
if layer.name in ['block5_conv1', 'block4_conv1']:
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
base_vgg = vgg
base_out = base_vgg.output
pool_out = tf.keras.layers.Flatten()(base_out)
hidden1 = tf.keras.layers.Dense(512, activation='relu')(pool_out)
drop1 = tf.keras.layers.Dropout(rate=0.3)(hidden1)
hidden2 = tf.keras.layers.Dense(512, activation='relu')(drop1)
drop2 = tf.keras.layers.Dropout(rate=0.3)(hidden2)
out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
model = tf.keras.Model(inputs=base_vgg.input, outputs=out)
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=1e-5),
loss='binary_crossentropy',
metrics=['accuracy'])
print("Total Layers:", len(model.layers))
print("Total trainable layers:", sum([1 for l in model.layers if l.trainable]))
# Output
Total Layers: 28
Total trainable layers: 16
```
We reduce the learning rate in our model since we don't want to make to large weight updates to the pre-trained layers when fine-tuning. The model's training process will be slightly different since we are using data generators, so we will be leveraging the **fit_generator(…)** function.
```
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5,
patience=2, min_lr=0.000001)
callbacks = [reduce_lr, tensorboard_callback]
train_steps_per_epoch = train_generator.n // train_generator.batch_size
val_steps_per_epoch = val_generator.n // val_generator.batch_size
history = model.fit_generator(train_generator, steps_per_epoch=train_steps_per_epoch, epochs=EPOCHS,
validation_data=val_generator, validation_steps=val_steps_per_epoch,
verbose=1)
# Output
Epoch 1/25
271/271 [====] - 133s 489ms/step - loss: 0.2267 - accuracy: 0.9117 - val_loss: 0.1414 - val_accuracy: 0.9531
Epoch 2/25
271/271 [====] - 129s 475ms/step - loss: 0.1399 - accuracy: 0.9552 - val_loss: 0.1292 - val_accuracy: 0.9589
...
...
Epoch 24/25
271/271 [====] - 128s 473ms/step - loss: 0.0815 - accuracy: 0.9727 - val_loss: 0.1466 - val_accuracy: 0.9682
Epoch 25/25
271/271 [====] - 128s 473ms/step - loss: 0.0792 - accuracy: 0.9729 - val_loss: 0.1127 - val_accuracy: 0.9641
```
This looks to be our best model yet. It gives us a validation accuracy of almost 96.5% and, based on the training accuracy, it doesn't look like our model is overfitting as much as our first model. This can be verified with the following learning curves.
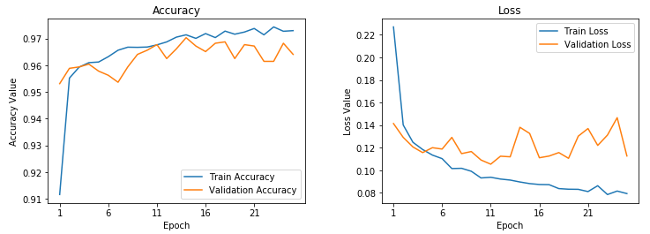
Learning curves for fine-tuned pre-trained CNN.
Let's save this model so we can use it for model evaluation on our test dataset.
`model.save('vgg_finetuned.h5')`
This completes our model training phase. We are now ready to test the performance of our models on the actual test dataset!
## Deep learning model performance evaluation
We will evaluate the three models we built in the training phase by making predictions with them on the data from our test dataset—because just validation is not enough! We have also built a nifty utility module called **model_evaluation_utils**, which we can use to evaluate the performance of our deep learning models with relevant classification metrics. The first step is to scale our test data.
```
test_imgs_scaled = test_data / 255.
test_imgs_scaled.shape, test_labels.shape
# Output
((8268, 125, 125, 3), (8268,))
```
The next step involves loading our saved deep learning models and making predictions on the test data.
```
# Load Saved Deep Learning Models
basic_cnn = tf.keras.models.load_model('./basic_cnn.h5')
vgg_frz = tf.keras.models.load_model('./vgg_frozen.h5')
vgg_ft = tf.keras.models.load_model('./vgg_finetuned.h5')
# Make Predictions on Test Data
basic_cnn_preds = basic_cnn.predict(test_imgs_scaled, batch_size=512)
vgg_frz_preds = vgg_frz.predict(test_imgs_scaled, batch_size=512)
vgg_ft_preds = vgg_ft.predict(test_imgs_scaled, batch_size=512)
basic_cnn_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
for pred in basic_cnn_preds.ravel()])
vgg_frz_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
for pred in vgg_frz_preds.ravel()])
vgg_ft_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
for pred in vgg_ft_preds.ravel()])
```
The final step is to leverage our **model_evaluation_utils** module and check the performance of each model with relevant classification metrics.
```
import model_evaluation_utils as meu
import pandas as pd
basic_cnn_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=basic_cnn_pred_labels)
vgg_frz_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=vgg_frz_pred_labels)
vgg_ft_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=vgg_ft_pred_labels)
pd.DataFrame([basic_cnn_metrics, vgg_frz_metrics, vgg_ft_metrics],
index=['Basic CNN', 'VGG-19 Frozen', 'VGG-19 Fine-tuned'])
```
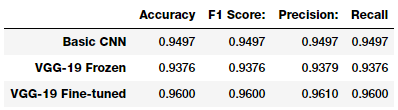
It looks like our third model performs best on the test dataset, giving a model accuracy and an F1-score of 96%, which is pretty good and quite comparable to the more complex models mentioned in the research paper and articles we mentioned earlier.
## Conclusion
Malaria detection is not an easy procedure, and the availability of qualified personnel around the globe is a serious concern in the diagnosis and treatment of cases. We looked at an interesting real-world medical imaging case study of malaria detection. Easy-to-build, open source techniques leveraging AI can give us state-of-the-art accuracy in detecting malaria, thus enabling AI for social good.
I encourage you to check out the articles and research papers mentioned in this article, without which it would have been impossible for me to conceptualize and write it. If you are interested in running or adopting these techniques, all the code used in this article is available on [my GitHub repository](https://nbviewer.jupyter.org/github/dipanjanS/data_science_for_all/tree/master/os_malaria_detection/). Remember to download the data from the [official website](https://ceb.nlm.nih.gov/repositories/malaria-datasets/).
Let's hope for more adoption of open source AI capabilities in healthcare to make it less expensive and more accessible for everyone around the world!
## Comments are closed. |
10,892 | Duc:一个能够可视化洞察硬盘使用情况的工具包 | https://www.ostechnix.com/duc-a-collection-of-tools-to-inspect-and-visualize-disk-usage/ | 2019-05-24T12:27:44 | [
"磁盘",
"duc"
] | https://linux.cn/article-10892-1.html | 
Duc 是一个在类 Unix 操作系统上可以用来索引、洞察及可视化硬盘使用情况的工具包。别把它当成一个仅能用漂亮图表展现硬盘使用情况的 CLI 工具。它对巨大的文件系统也支持的很好。Duc 已在由超过五亿个文件和几 PB 的存储组成的系统上测试过,没有任何问题。
Duc 是一个快速而且灵活的工具。它将你的硬盘使用情况存在一个优化过的数据库里,这样你就可以在索引完成后迅速找到你的数据。此外,它自带不同的用户交互界面与后端以访问数据库并绘制图表。
以下列出的是目前支持的用户界面(UI):
1. 命令行界面(`duc ls`)
2. Ncurses 控制台界面(`duc ui`)
3. X11 GUI(`duc gui`)
4. OpenGL GUI(`duc gui`)
支持的后端数据库:
* Tokyocabinet
* Leveldb
* Sqlite3
Duc 默认使用 Tokyocabinet 作为后端数据库。
### 安装 Duc
Duc 可以从 Debian 以及其衍生品例如 Ubuntu 的默认仓库中获取。因此在基于 DEB 的系统上安装 Duc 是小菜一碟。
```
$ sudo apt-get install duc
```
在其它 Linux 发行版上你需要像以下所展示的那样手动从源代码编译安装 Duc。
可以从 Github 上的[发行](https://github.com/zevv/duc/releases)页面下载最新的 Duc 源代码的 .tgz 文件。在写这篇教程的时候,最新的版本是1.4.4。
```
$ wget https://github.com/zevv/duc/releases/download/1.4.4/duc-1.4.4.tar.gz
```
然后一个接一个地运行以下命令来安装 DUC。
```
$ tar -xzf duc-1.4.4.tar.gz
$ cd duc-1.4.4
$ ./configure
$ make
$ sudo make install
```
### 使用 Duc
`duc` 的典型用法是:
```
$ duc <subcommand> <options>
```
你可以通过运行以下命令来浏览总的选项列表以及子命令:
```
$ duc help
```
你也可以像下面这样了解一个特定子命令的用法。
```
$ duc help <subcommand>
```
要查看所有命令与其选项的列表,仅需运行:
```
$ duc help --all
```
让我们看看一些 `duc` 工具的特定用法。
### 创建索引(数据库)
首先,你需要创建一个你文件系统的索引文件(数据库)。使用 `duc index` 命令以创建索引文件。
比如说,要创建你的 `/home` 目录的索引,仅需运行:
```
$ duc index /home
```
上述命令将会创建你的 `/home` 目录的索引,并将其保存在 `$HOME/.duc.db` 文件中。如果你以后需要往 `/home` 目录添加新的文件或目录,只要在之后重新运行一下上面的命令来重建索引。
### 查询索引
Duc 有不同的子命令来查询并探索索引。
要查看可访问的索引列表,运行:
```
$ duc info
```
示例输出:
```
Date Time Files Dirs Size Path
2019-04-09 15:45:55 3.5K 305 654.6M /home
```
如你在上述输出所见,我已经索引好了 `/home` 目录。
要列出当前工作目录中所有的文件和目录,你可以这样做:
```
$ duc ls
```
要列出指定的目录,例如 `/home/sk/Downloads` 中的文件/目录,仅需像下面这样将路径作为参数传过去。
```
$ duc ls /home/sk/Downloads
```
类似的,运行 `duc ui` 命令来打开基于 ncurses 的控制台用户界面以探索文件系统使用情况,运行`duc gui` 以打开图形界面(X11)来探索文件系统。
要了解更多子命令的用法,仅需参考帮助部分。
```
$ duc help ls
```
上述命令将会展现 `ls` 子命令的帮助部分。
### 可视化硬盘使用状况
在之前的部分我们以及看到如何用 duc 子命令列出文件和目录。在此之外,你甚至可以用一张漂亮的图表展示文件大小。
要展示所提供目录的图表,像以下这样使用 `ls` 子命令。
```
$ duc ls -Fg /home/sk
```
示例输出:

如你在上述输出所见,`ls` 子命令查询 duc 数据库并列出了所提供目录包含的文件与目录的大小,在这里就是 `/home/sk/`。
这里 `-F` 选项是往条目中用来添加文件类型指示符(`/`),`-g` 选项是用来绘制每个条目相对大小的图表。
请注意如果未提供任何路径,就会使用当前工作目录。
你可以使用 `-R` 选项来用[树状结构](https://www.ostechnix.com/view-directory-tree-structure-linux/)浏览硬盘使用情况。
```
$ duc ls -R /home/sk
```

要查询 duc 数据库并打开基于 ncurses 的控制台以探索所提供的目录,像以下这样使用 `ui` 子命令。
```
$ duc ui /home/sk
```

类似的,我们使用 `gui *` 子命令来查询 duc 数据库以及打开一个图形界面(X11)来了解指定路径的硬盘使用情况。
```
$ duc gui /home/sk
```

像我之前所提到的,我们可以像下面这样了解更多关于特定子命令的用法。
```
$ duc help <子命令名字>
```
我仅仅覆盖了基本用法的部分,参考 man 页面了解关于 `duc` 工具的更多细节。
```
$ man duc
```
相关阅读:
* [Filelight – 在你的 Linux 系统上可视化硬盘使用情况](https://www.ostechnix.com/filelight-visualize-disk-usage-on-your-linux-system/)
* [一些好的 du 命令的替代品](https://www.ostechnix.com/some-good-alternatives-to-du-command/)
* [如何在 Linux 中用 Ncdu 检查硬盘使用情况](https://www.ostechnix.com/check-disk-space-usage-linux-using-ncdu/)
* [Agedu——发现 Linux 中被浪费的硬盘空间](https://www.ostechnix.com/agedu-find-out-wasted-disk-space-in-linux/)
* [如何在 Linux 中找到目录大小](https://www.ostechnix.com/find-size-directory-linux/)
* [为初学者打造的带有示例的 df 命令教程](https://www.ostechnix.com/the-df-command-tutorial-with-examples-for-beginners/)
### 总结
Duc 是一款简单却有用的硬盘用量查看器。如果你想要快速简便地知道哪个文件/目录占用你的硬盘空间,Duc 可能是一个好的选择。你还等什么呢?获取这个工具,扫描你的文件系统,摆脱无用的文件/目录。
现在就到此为止了。希望这篇文章有用处。更多好东西马上就到。保持关注!
欢呼吧!
资源:
* [Duc 网站](https://duc.zevv.nl/)
---
via: <https://www.ostechnix.com/duc-a-collection-of-tools-to-inspect-and-visualize-disk-usage/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,894 | PiShrink:使树莓派镜像更小 | https://www.ostechnix.com/pishrink-make-raspberry-pi-images-smaller/ | 2019-05-24T12:44:14 | [
"树莓派",
"镜像"
] | https://linux.cn/article-10894-1.html | 
树莓派不需要过多介绍。它是一款小巧、价格实惠,只有信用卡大小的电脑,它可以连接到显示器或电视。我们可以连接一个标准的键盘和鼠标,并将其用作一台成熟的台式计算机来完成日常任务,如互联网浏览、播放视频/玩游戏、文字处理和电子表格制作等。它主要是为学校的计算机科学教学而开发的。如今,树莓派被广泛用于大学、中小型组织和研究所来教授编码。
如果你有一台树莓派,你可能需要了解一个名为 PiShrink 的 bash 脚本,该脚本可使树莓派镜像更小。PiShrink 将自动缩小镜像,然后在启动时将其调整为 SD 卡的最大大小。这能更快地将镜像复制到 SD 卡中,同时缩小的镜像将更好地压缩。这对于将大容量镜像放入 SD 卡非常有用。在这个简短的指南中,我们将学习如何在类 Unix 系统中将树莓派镜像缩小到更小。
### 安装 PiShrink
要在 Linux 机器上安装 PiShrink,请先使用以下命令下载最新版本:
```
$ wget https://raw.githubusercontent.com/Drewsif/PiShrink/master/pishrink.sh
```
接下来,将下载的 PiShrink 变成二进制可执行文件:
```
$ chmod +x pishrink.sh
```
最后,移动到目录:
```
$ sudo mv pishrink.sh /usr/local/bin/
```
### 使树莓派镜像更小
你可能已经知道,Raspbian 是所有树莓派型号的官方操作系统。树莓派基金会为 PC 和 Mac 开发了树莓派桌面版本。你可以创建一个 live CD,并在虚拟机中运行它,甚至也可以将其安装在桌面上。树莓派也有少量非官方操作系统镜像。为了测试,我从[官方下载页面](https://www.raspberrypi.org/downloads/)下载了官方的 Raspbian 系统。
解压下载的系统镜像:
```
$ unzip 2019-04-08-raspbian-stretch-lite.zip
```
上面的命令将提取当前目录中 `2019-04-08-raspbian-stretch-lite.zip` 文件的内容。
让我们看下提取文件的实际大小:
```
$ du -h 2019-04-08-raspbian-stretch-lite.img
1.7G 2019-04-08-raspbian-stretch-lite.img
```
如你所见,提取的树莓派系统镜像大小为 1.7G。
现在,使用 PiShrink 缩小此文件的大小,如下所示:
```
$ sudo pishrink.sh 2019-04-08-raspbian-stretch-lite.img
```
示例输出:
```
Creating new /etc/rc.local
rootfs: 39795/107072 files (0.1% non-contiguous), 239386/428032 blocks
resize2fs 1.45.0 (6-Mar-2019)
resize2fs 1.45.0 (6-Mar-2019)
Resizing the filesystem on /dev/loop1 to 280763 (4k) blocks.
Begin pass 3 (max = 14)
Scanning inode table XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Begin pass 4 (max = 3728)
Updating inode references XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
The filesystem on /dev/loop1 is now 280763 (4k) blocks long.
Shrunk 2019-04-08-raspbian-stretch-lite.img from 1.7G to 1.2G
```
正如你在上面的输出中看到的,树莓派镜像的大小已减少到 1.2G。
你还可以使用 `-s` 标志跳过该过程的自动扩展部分。
```
$ sudo pishrink.sh -s 2019-04-08-raspbian-stretch-lite.img newpi.img
```
这将创建一个源镜像文件(即 `2019-04-08-raspbian-stretch-lite.img`)的副本到一个新镜像文件(`newpi.img`)并进行处理。有关更多详细信息,请查看最后给出的官方 GitHub 页面。
就是这些了。希望本文有用。还有更多好东西,敬请期待!
资源:
* [PiShrink 的 GitHub 仓库](https://github.com/Drewsif/PiShrink)
* [树莓派网站](https://www.raspberrypi.org/)
---
via: <https://www.ostechnix.com/pishrink-make-raspberry-pi-images-smaller/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,895 | 使用 Ispell 在命令行中检查拼写 | https://opensource.com/article/19/5/spelling-command-line-ispell | 2019-05-24T19:27:04 | [
"拼写"
] | https://linux.cn/article-10895-1.html |
>
> Ispell 可以帮助你在纯文本中消除超过 50 种语言的拼写错误。
>
>
>

好的拼写是一种技巧。它是一项需要时间学习和掌握的技能。也就是说,有些人从来没有完全掌握这种技能,我知道有两三个出色的作家就无法完全掌握拼写。
即使你拼写得很好,偶尔也会输入错字。特别是在最后期限前如果你快速敲击键盘,那就更是如此。无论你的拼写的是什么,通过拼写检查器检查你所写的内容总是一个好主意。
我用[纯文本](https://plaintextproject.online)完成了我的大部分写作,并经常使用名为 [Aspell](https://opensource.com/article/18/2/how-check-spelling-linux-command-line-aspell) 的命令行拼写检查器来完成这项工作。Aspell 不是唯一的工具。你可能还想要看下不错的 [Ispell](https://www.cs.hmc.edu/%7Egeoff/ispell.html)。
### 入门
自 1971 年以来,Ispell 就以各种形式出现过。不要被它的年龄欺骗。Ispell 仍然是一个可以在 21 世纪高效使用的应用。
在开始之前,请打开终端窗口并输入 `which ispell` 来检查计算机上是否安装了 Ispell。如果未安装,请打开发行版的软件包管理器并从那里安装 Ispell。
不要忘记为你使用的语言安装词典。我唯一使用的语言是英语,所以我只需下载美国和英国英语字典。你可以不局限于我的(也是唯一的)母语。Ispell 有[超过 50 种语言的词典](https://www.cs.hmc.edu/%7Egeoff/ispell-dictionaries.html)。

### 使用 Ispell
如果你还没有猜到,Ispell 只能用在文本文件。这包括用 HTML、LaTeX 和 [nroff 或 troff](https://opensource.com/article/18/2/how-format-academic-papers-linux-groff-me) 标记的文档。之后会有更多相关内容。
要开始使用,请打开终端窗口并进入包含要运行拼写检查的文件的目录。输入 `ispell` 后跟文件名,然后按回车键。

Ispell 高亮了它无法识别的第一个词。如果单词拼写错误,Ispell 通常会提供一个或多个备选方案。按下 `R`,然后按下正确选择旁边的数字。在上面的截图中,我按了 `R` 和 `0` 来修复错误。
另一方面,如果单词拼写正确,请按下 `A` 然后移动到下一个拼写错误的单词。
继续这样做直到到达文件的末尾。Ispell 会保存你的更改,创建你刚检查的文件的备份(扩展名为 `.bak`),然后关闭。
### 其他几个选项
此示例说明了 Ispell 的基本用法。这个程序有[很多选项](https://www.cs.hmc.edu/%7Egeoff/ispell-man.html),有些你*可能*会用到,而另一些你*可能永远*不会使用。让我们快速看下我经常使用的一些。
之前我提到过 Ispell 可以用于某些标记语言。你需要告诉它文件的格式。启动 Ispell 时,为 TeX 或 LaTeX 文件添加 `-t`,为 HTML 文件添加 `-H`,对于 groff 或 troff 文件添加 `-n`。例如,如果输入 `ispell -t myReport.tex`,Ispell 将忽略所有标记。
如果你不想在检查文件后创建备份文件,请将 `-x` 添加到命令行。例如,`ispell -x myFile.txt`。
如果 Ispell 遇到拼写正确但不在其字典中的单词,比如名字,会发生什么?你可以按 `I` 将该单词添加到个人单词列表中。这会将单词保存到 `/home` 目录下的 `.ispell_default` 的文件中。
这些是我在使用 Ispell 时最有用的选项,但请查看 [Ispell 的手册页](https://www.cs.hmc.edu/%7Egeoff/ispell-man.html)以了解其所有选项。
Ispell 比 Aspell 或其他命令行拼写检查器更好或者更快么?我会说它不比其他的差或者慢。Ispell 不是适合所有人。它也许也不适合你。但有更多选择也不错,不是么?
---
via: <https://opensource.com/article/19/5/spelling-command-line-ispell>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Good spelling is a skill. A skill that takes time to learn and to master. That said, there are people who never quite pick that skill up—I know a couple or three outstanding writers who can't spell to save their lives.
Even if you spell well, the occasional typo creeps in. That's especially true if you're quickly banging on your keyboard to meet a deadline. Regardless of your spelling chops, it's always a good idea to run what you've written through a spelling checker.
I do most of my writing in [plain text](https://plaintextproject.online) and often use a command line spelling checker called [Aspell](https://opensource.com/article/18/2/how-check-spelling-linux-command-line-aspell) to do the deed. Aspell isn't the only game in town. You might also want to check out the venerable [Ispell](https://www.cs.hmc.edu/~geoff/ispell.html).
## Getting started
Ispell's been around, in various forms, since 1971. Don't let its age fool you. Ispell is still a peppy application that you can use effectively in the 21st century.
Before doing anything else, check whether or not Ispell is installed on your computer by cracking open a terminal window and typing **which ispell**. If it isn't installed, fire up your distribution's package manager and install Ispell from there.
Don't forget to install dictionaries for the languages you work in, too. My only language is English, so I just need to worry about grabbing the US and British English dictionaries. You're not limited to my mother (and only) tongue. Ispell has [dictionaries for over 50 languages](https://www.cs.hmc.edu/~geoff/ispell-dictionaries.html).
## Using Ispell
If you haven't guessed already, Ispell only works with text files. That includes ones marked up with HTML, LaTeX, and [nroff or troff](https://opensource.com/article/18/2/how-format-academic-papers-linux-groff-me). More on this in a few moments.
To get to work, open a terminal window and navigate to the directory containing the file where you want to run a spelling check. Type **ispell** followed by the file's name and then press Enter.
Ispell highlights the first word it doesn't recognize. If the word is misspelled, Ispell usually offers one or more alternatives. Press **R** and then the number beside the correct choice. In the screen capture above, I'd press **R** and **0** to fix the error.
If, on the other hand, the word is correctly spelled, press **A** to move to the next misspelled word.
Keep doing that until you reach the end of the file. Ispell saves your changes, creates a backup of the file you just checked (with the extension *.bak*), and shuts down.
## A few other options
This example illustrates basic Ispell usage. The program has a [number of options](https://www.cs.hmc.edu/~geoff/ispell-man.html), some of which you *might* use and others you *might never* use. Let's take a quick peek at some of the ones I regularly use.
A few paragraphs ago, I mentioned that Ispell works with certain markup languages. You need to tell it a file's format. When starting Ispell, add **-t** for a TeX or LaTeX file, **-H** for an HTML file, or **-n** for a groff or troff file. For example, if you enter **ispell -t myReport.tex**, Ispell ignores all markup.
If you don't want the backup file that Ispell creates after checking a file, add **-x** to the command line—for example, **ispell -x myFile.txt**.
What happens if Ispell runs into a word that's spelled correctly but isn't in its dictionary, like a proper name? You can add that word to a personal word list by pressing **I**. This saves the word to a file called *.ispell_default* in the root of your */home* directory.
Those are the options I find most useful when working with Ispell, but check out [Ispell's man page](https://www.cs.hmc.edu/~geoff/ispell-man.html) for descriptions of all its options.
Is Ispell any better or faster than Aspell or any other command line spelling checker? I have to say it's no worse than any of them, nor is it any slower. Ispell's not for everyone. It might not be for you. But it is good to have options, isn't it?
## Comments are closed. |
10,897 | 在 Ubuntu 中使用 Slimbook Battery Optimizer 切换电源模式 | https://itsfoss.com/slimbook-battry-optimizer-ubuntu/ | 2019-05-25T10:13:46 | [
"电源",
"电池"
] | https://linux.cn/article-10897-1.html |
>
> Slimbook Battery Optimizer 是一个美观实用的指示器小程序,它可以让你在安装了 Linux 的笔记本上快速切换电源模式来延长续航时间。
>
>
>
[Slimbook](https://slimbook.es/en/) 是一个销售 [预装 Linux 的笔记本电脑](https://itsfoss.com/get-linux-laptops/) 的西班牙电脑制造商,他们发布了一款好用的小程序,用来在基于 Ubuntu 的 Linux 发行版下调整电池性能。
因为 Slimbook 销售他们自己的 Linux 系统,所以他们制作了一些在 Linux 上用于调整他们自己硬件性能的小工具。Battery Optimizer 就是这样一个工具。
要使用这个实用小程序,你不必购买 Slimbook 的产品,因为 Slimbook 已经将它在 [他们的官方 PPA 源](https://launchpad.net/%7Eslimbook/+archive/ubuntu/slimbook) 发行了。
### Slimbook Battery Optimizer 简介
这个程序叫 Slimbook Battery。它是一个常驻顶栏的指示器小程序,使得你可以快速切换电源模式。

你可能在 Windows 中见过类似的程序。Slimbook Battery 和它们一样,提供了类似的电源计划:
* 节能:最大程度延长电池续航时间
* 平衡:性能与节能间的最佳平衡
* 高性能:最大程度提高性能
你可以在高级模式中配置这些模式:

如果你觉得你把设置调乱了,你可以用“恢复默认设置”的按钮还原它。
你也可以修改像程序自启或默认电源模式这样的通用设置。

Slimbook 有专门为多种电源管理参数提供的页面。如果你希望自己配置,请参照 [此页](https://slimbook.es/en/tutoriales/aplicaciones-slimbook/398-slimbook-battery-3-application-for-optimize-battery-of-your-laptop)。
不过,我认为 Slimbook 的界面需要一些改进。例如,某些页面上的“问题标记”的图标应该改为可点击的,以此提供更多信息。然而,在我写这篇文章时,那个标记仍然无法点击。
总的来说,Slimbook Battery 是一个小巧精美的软件,你可以用它来快速切换电源模式。如果你决定在 Ubuntu 及其衍生发行版上(比如 Linux Mint 或 elementary OS 等),你可以使用官方 [PPA 源](https://itsfoss.com/ppa-guide/)。
#### 在基于 Ubuntu 的发行版上安装 Slimbook Battery
打开终端,一步一步地使用以下命令:
```
sudo add-apt-repository ppa:slimbook/slimbook
sudo apt update
sudo apt install slimbookbattery
```
安装好之后,在菜单中搜索 Slimbook Battery:

在你点击它之后,你会发现它出现在了顶栏。你可以在这里选择你希望使用的电源模式。

#### 卸载 Slimbook Battery
如果你不再使用它,你可以通过以下命令来卸载它:
```
sudo apt remove slimbookbattery
sudo add-apt-repository -r ppa:slimbook/slimbook
```
在我看来,这样的应用程序为某些特定的目的服务,这是值得鼓励的。这个工具给了你一条调整电源模式的捷径,和调整性能的更多选项。
你用过 Slimbook Battery 吗?你觉得它如何?
---
via: <https://itsfoss.com/slimbook-battry-optimizer-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zhs852](https://github.com/zhs852) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Slimbook Battery is a nifty applet indicator that allows you to quickly change the power mode on your Linux laptop and thus save battery life.*
[Slimbook](https://slimbook.es/en/), the Spanish computer vendor that sells [laptops preloaded with Linux](https://itsfoss.com/get-linux-laptops/), has released a handy little application to optimize battery performance in Ubuntu-based Linux distributions.
Since Slimbook sells its own Linux systems, they have created a few applications to tweak the performance of Linux on their hardware. This battery optimizer is one such tool.
You don’t need to buy a Slimbook product to use this nifty application because Slimbook has made it available via [their official PPA](https://launchpad.net/~slimbook/+archive/ubuntu/slimbook).
## Slimbook battery optimizer application
The application is called Slimbook Battery. It is basically an applet indicator that sits on the top panel and gives you quick access to various power/battery modes.
You might have seen it in Windows where you can put your laptop in one of the power modes. Slimbook Battery also offers similar battery saving modes here:
- Energy Saving: For maximum battery saving
- Balanced: A compromise between performance and power saving
- Maximum Performance: For maximum performance obviously
You can configure all these modes from the advanced mode:
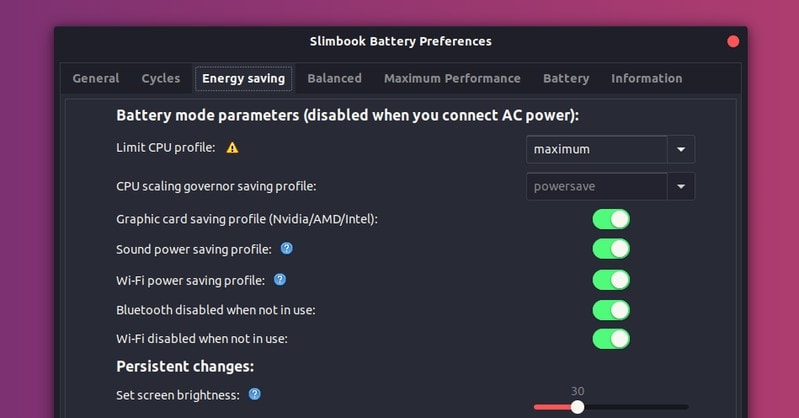
If you feel like you have messed up the configuration, you can set things back to normal with ‘restore default values’ option.
You can also change the general configuration of the application like auto-start, default power mode etc.
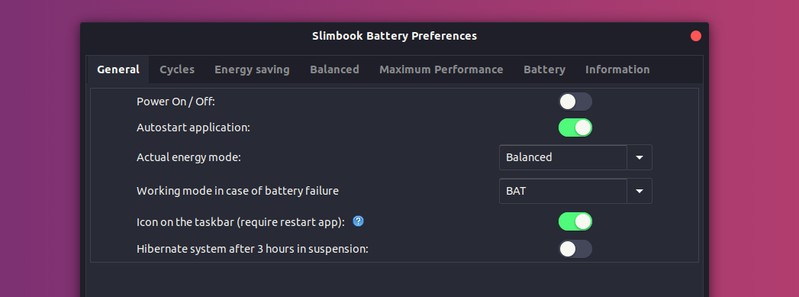
Skimbook has a dedicated page that provides more information on various power saving parameters. If you want to configure things on your own, you should refer to [this page](https://slimbook.es/en/tutoriales/aplicaciones-slimbook/398-slimbook-battery-3-application-for-optimize-battery-of-your-laptop).
I have noticed that the interface of Slimbook Battery needs some improvements. For example, the ‘question mark’ icon on some parameters should be clickable to provide more information. But clicking the question mark icon doesn’t do anything at the time of writing this article.
Altogether, Slimbook Battery is a handy app you can use for quickly switching the power mode. If you decide to install it on Ubuntu and other Ubuntu-based distributions such as Linux Mint, elementary OS etc, you can use its official [PPA](https://itsfoss.com/ppa-guide/).
### Install Slimbook Batter in Ubuntu-based distributions
Open a terminal and use the following commands one by one:
sudo add-apt-repository ppa:slimbook/slimbook
sudo apt update
sudo apt install slimbookbattery
Once installed, search for Slimbook Battery in the menu:

When you click on it to start it, you’ll find it in the top panel. From here, you can select your desired power mode.

### Remove Slimbook Battery
If you don’t want to use this application, you can remove it using the following commands:
sudo apt remove slimbookbattery
sudo add-apt-repository -r ppa:slimbook/slimbook
In my opinion, such applications serves a certain purpose and should be encouraged. This tool gives you an easy way to change the power mode and at the same time, it gives you more tweaking options for various performance settings.
Did you use Slimbook Battery? What’s your experience with it? |
10,899 | PHP PDO 简单教程 | http://www.theitstuff.com/easiest-pdo-tutorial-basics | 2019-05-26T10:46:00 | [
"PHP",
"PDO"
] | https://linux.cn/article-10899-1.html | 
大约 80% 的 Web 应用程序由 PHP 提供支持。类似地,SQL 也是如此。PHP 5.5 版本之前,我们有用于访问 MySQL 数据库的 mysql\_ 命令,但由于安全性不足,它们最终被弃用。
弃用这件事是发生在 2013 年的 PHP 5.5 上,我写这篇文章的时间是 2018 年,PHP 版本为 7.2。mysql\_ 的弃用带来了访问数据库的两种主要方法:mysqli 和 PDO 库。
虽然 mysqli 库是官方指定的,但由于 mysqli 只能支持 mysql 数据库,而 PDO 可以支持 12 种不同类型的数据库驱动程序,因此 PDO 获得了更多的赞誉。此外,PDO 还有其它一些特性,使其成为大多数开发人员的更好选择。你可以在下表中看到一些特性比较:
| | PDO | MySQLi |
| --- | --- | --- |
| 数据库支持 | 12 种驱动 | 只有 MySQL |
| 范例 | OOP | 过程 + OOP |
| 预处理语句(客户端侧) | Yes | No |
| 1命名参数 | Yes | No |
现在我想对于大多数开发人员来说,PDO 是首选的原因已经很清楚了。所以让我们深入研究它,并希望在本文中尽量涵盖关于 PDO 你需要的了解的。
### 连接
第一步是连接到数据库,由于 PDO 是完全面向对象的,所以我们将使用 PDO 类的实例。
我们要做的第一件事是定义主机、数据库名称、用户名、密码和数据库字符集。
```
$host = 'localhost';
$db = 'theitstuff';
$user = 'root';
$pass = 'root';
$charset = 'utf8mb4';
$dsn = "mysql:host=$host;dbname=$db;charset=$charset";
$conn = new PDO($dsn, $user, $pass);
```
之后,正如你在上面的代码中看到的,我们创建了 DSN 变量,DSN 变量只是一个保存数据库信息的变量。对于一些在外部服务器上运行 MySQL 的人,你还可以通过提供一个 `port=$port_number` 来调整端口号。
最后,你可以创建一个 PDO 类的实例,我使用了 `$conn` 变量,并提供了 `$dsn`、`$user`、`$pass` 参数。如果你遵循这些步骤,你现在应该有一个名为 `$conn` 的对象,它是 PDO 连接类的一个实例。现在是时候进入数据库并运行一些查询。
### 一个简单的 SQL 查询
现在让我们运行一个简单的 SQL 查询。
```
$tis = $conn->query('SELECT name, age FROM students');
while ($row = $tis->fetch())
{
echo $row['name']."\t";
echo $row['age'];
echo "<br>";
}
```
这是使用 PDO 运行查询的最简单形式。我们首先创建了一个名为 `tis`(TheITStuff 的缩写 )的变量,然后你可以看到我们使用了创建的 `$conn` 对象中的查询函数。
然后我们运行一个 `while` 循环并创建了一个 `$row` 变量来从 `$tis` 对象中获取内容,最后通过调用列名来显示每一行。
很简单,不是吗?现在让我们来看看预处理语句。
### 预处理语句
预处理语句是人们开始使用 PDO 的主要原因之一,因为它提供了可以阻止 SQL 注入的语句。
有两种基本方法可供使用,你可以使用位置参数或命名参数。
#### 位置参数
让我们看一个使用位置参数的查询示例。
```
$tis = $conn->prepare("INSERT INTO STUDENTS(name, age) values(?, ?)");
$tis->bindValue(1,'mike');
$tis->bindValue(2,22);
$tis->execute();
```
在上面的例子中,我们放置了两个问号,然后使用 `bindValue()` 函数将值映射到查询中。这些值绑定到语句问号中的位置。
我还可以使用变量而不是直接提供值,通过使用 `bindParam()` 函数相同例子如下:
```
$name='Rishabh'; $age=20;
$tis = $conn->prepare("INSERT INTO STUDENTS(name, age) values(?, ?)");
$tis->bindParam(1,$name);
$tis->bindParam(2,$age);
$tis->execute();
```
### 命名参数
命名参数也是预处理语句,它将值/变量映射到查询中的命名位置。由于没有位置绑定,因此在多次使用相同变量的查询中非常有效。
```
$name='Rishabh'; $age=20;
$tis = $conn->prepare("INSERT INTO STUDENTS(name, age) values(:name, :age)");
$tis->bindParam(':name', $name);
$tis->bindParam(':age', $age);
$tis->execute();
```
你可以注意到,唯一的变化是我使用 `:name` 和 `:age` 作为占位符,然后将变量映射到它们。冒号在参数之前使用,让 PDO 知道该位置是一个变量,这非常重要。
你也可以类似地使用 `bindValue()` 来使用命名参数直接映射值。
### 获取数据
PDO 在获取数据时非常丰富,它实际上提供了许多格式来从数据库中获取数据。
你可以使用 `PDO::FETCH_ASSOC` 来获取关联数组,`PDO::FETCH_NUM` 来获取数字数组,使用 `PDO::FETCH_OBJ` 来获取对象数组。
```
$tis = $conn->prepare("SELECT * FROM STUDENTS");
$tis->execute();
$result = $tis->fetchAll(PDO::FETCH_ASSOC);
```
你可以看到我使用了 `fetchAll`,因为我想要所有匹配的记录。如果只需要一行,你可以简单地使用 `fetch`。
现在我们已经获取了数据,现在是时候循环它了,这非常简单。
```
foreach ($result as $lnu){
echo $lnu['name'];
echo $lnu['age']."<br>";
}
```
你可以看到,因为我请求了关联数组,所以我正在按名称访问各个成员。
虽然在定义希望如何传输递数据方面没有要求,但在定义 `$conn` 变量本身时,实际上可以将其设置为默认值。
你需要做的就是创建一个 `$options` 数组,你可以在其中放入所有默认配置,只需在 `$conn` 变量中传递数组即可。
```
$options = [
PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_ASSOC,
];
$conn = new PDO($dsn, $user, $pass, $options);
```
这是一个非常简短和快速的 PDO 介绍,我们很快就会制作一个高级教程。如果你在理解本教程的任何部分时遇到任何困难,请在评论部分告诉我,我会在那你为你解答。
---
via: <http://www.theitstuff.com/easiest-pdo-tutorial-basics>
作者:[Rishabh Kandari](http://www.theitstuff.com/author/reevkandari) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 520 | null |
|
10,900 | API 演进的正确方式 | https://opensource.com/article/19/5/api-evolution-right-way | 2019-05-26T13:42:16 | [
"Python",
"类库"
] | /article-10900-1.html |
>
> 负责任的库作者与其用户的十个约定。
>
>
>

想象一下你是一个造物主,为一个生物设计一个身体。出于仁慈,你希望它能随着时间进化:首先,因为它必须对环境的变化作出反应;其次,因为你的智慧在增长,你对这个小东西想到了更好的设计,它不应该永远保持一个样子。

然而,这个生物可能有赖于其目前解剖学的特征。你不能无所顾忌地添加翅膀或改变它的身材比例。它需要一个有序的过程来适应新的身体。作为一个负责任的设计者,你如何才能温柔地引导这种生物走向更大的进步呢?
对于负责任的库维护者也是如此。我们向依赖我们代码的人保证我们的承诺:我们会发布 bug 修复和有用的新特性。如果对库的未来有利,我们有时会删除某些特性。我们会不断创新,但我们不会破坏使用我们库的人的代码。我们怎样才能一次实现所有这些目标呢?
### 添加有用的特性
你的库不应该永远保持不变:你应该添加一些特性,使你的库更适合用户。例如,如果你有一个爬行动物类,并且如果有个可以飞行的翅膀是有用的,那就去添加吧。
```
class Reptile:
@property
def teeth(self):
return 'sharp fangs'
# 如果 wings 是有用的,那就添加它!
@property
def wings(self):
return 'majestic wings'
```
但要注意,特性是有风险的。考虑 Python 标准库中以下功能,看看它出了什么问题。
```
bool(datetime.time(9, 30)) == True
bool(datetime.time(0, 0)) == False
```
这很奇怪:将任何时间对象转换为布尔值都会得到 True,但午夜时间除外。(更糟糕的是,时区感知时间的规则更加奇怪。)
我已经写了十多年的 Python 了,但直到上周才发现这条规则。这种奇怪的行为会在用户代码中引起什么样的 bug?
比如说一个日历应用程序,它带有一个创建事件的函数。如果一个事件有一个结束时间,那么函数也应该要求它有一个开始时间。
```
def create_event(day,
start_time=None,
end_time=None):
if end_time and not start_time:
raise ValueError("Can't pass end_time without start_time")
# 女巫集会从午夜一直开到凌晨 4 点
create_event(datetime.date.today(),
datetime.time(0, 0),
datetime.time(4, 0))
```
不幸的是,对于女巫来说,从午夜开始的事件无法通过校验。当然,一个了解午夜怪癖的细心程序员可以正确地编写这个函数。
```
def create_event(day,
start_time=None,
end_time=None):
if end_time is not None and start_time is None:
raise ValueError("Can't pass end_time without start_time")
```
但这种微妙之处令人担忧。如果一个库作者想要创建一个伤害用户的 API,那么像午夜的布尔转换这样的“特性”很有效。

但是,负责任的创建者的目标是使你的库易于正确使用。
这个功能是由 Tim Peters 在 2002 年首次编写 datetime 模块时造成的。即时是像 Tim 这样的奠基 Python 的高手也会犯错误。[这个怪异之处后来被消除了](https://bugs.python.org/issue13936),现在所有时间的布尔值都是 True。
```
# Python 3.5 以后
bool(datetime.time(9, 30)) == True
bool(datetime.time(0, 0)) == True
```
不知道午夜怪癖的古怪之处的程序员现在可以从这种晦涩的 bug 中解脱出来,但是一想到任何依赖于古怪的旧行为的代码现在没有注意变化,我就会感到紧张。如果从来没有实现这个糟糕的特性,情况会更好。这就引出了库维护者的第一个承诺:
#### 第一个约定:避免糟糕的特性
最痛苦的变化是你必须删除一个特性。一般来说,避免糟糕特性的一种方法是少添加特性!没有充分的理由,不要使用公共方法、类、功能或属性。因此:
#### 第二个约定:最小化特性
特性就像孩子:在充满激情的瞬间孕育,但是它们必须要支持多年(LCTT 译注:我怀疑作者在开车,可是我没有证据)。不要因为你能做傻事就去做傻事。不要画蛇添足!

但是,当然,在很多情况下,用户需要你的库中尚未提供的东西,你如何选择合适的功能给他们?以下另一个警示故事。
### 一个来自 asyncio 的警示故事
你可能知道,当你调用一个协程函数,它会返回一个协程对象:
```
async def my_coroutine():
pass
print(my_coroutine())
```
```
<coroutine object my_coroutine at 0x10bfcbac8>
```
你的代码必须 “<ruby> 等待 <rt> await </rt></ruby>” 这个对象以此来运行协程。人们很容易忘记这一点,所以 asyncio 的开发人员想要一个“调试模式”来捕捉这个错误。当协程在没有等待的情况下被销毁时,调试模式将打印一个警告,并在其创建的行上进行回溯。
当 Yury Selivanov 实现调试模式时,他添加了一个“协程装饰器”的基础特性。装饰器是一个函数,它接收一个协程并返回任何内容。Yury 使用它在每个协程上接入警告逻辑,但是其他人可以使用它将协程转换为字符串 “hi!”。
```
import sys
def my_wrapper(coro):
return 'hi!'
sys.set_coroutine_wrapper(my_wrapper)
async def my_coroutine():
pass
print(my_coroutine())
```
```
hi!
```
这是一个地狱般的定制。它改变了 “<ruby> 异步 <rt> async </rt></ruby>“ 的含义。调用一次 `set_coroutine_wrapper` 将在全局永久改变所有的协程函数。正如 [Nathaniel Smith 所说](https://bugs.python.org/issue32591):“一个有问题的 API” 很容易被误用,必须被删除。如果 asyncio 开发人员能够更好地按照其目标来设计该特性,他们就可以避免删除该特性的痛苦。负责任的创建者必须牢记这一点:
#### 第三个约定:保持特性单一
幸运的是,Yury 有良好的判断力,他将该特性标记为临时,所以 asyncio 用户知道不能依赖它。Nathaniel 可以用更单一的功能替换 `set_coroutine_wrapper`,该特性只定制回溯深度。
```
import sys
sys.set_coroutine_origin_tracking_depth(2)
async def my_coroutine():
pass
print(my_coroutine())
```
```
<coroutine object my_coroutine at 0x10bfcbac8>
RuntimeWarning:'my_coroutine' was never awaited
Coroutine created at (most recent call last)
File "script.py", line 8, in <module>
print(my_coroutine())
```
这样好多了。没有可以更改协程的类型的其他全局设置,因此 asyncio 用户无需编写防御代码。造物主应该像 Yury 一样有远见。
#### 第四个约定:标记实验特征“临时”
如果你只是预感你的生物需要犄角和四叉舌,那就引入这些特性,但将它们标记为“临时”。

你可能会发现犄角是无关紧要的,但是四叉舌是有用的。在库的下一个版本中,你可以删除前者并标记后者为正式的。
### 删除特性
无论我们如何明智地指导我们的生物进化,总会有一天想要删除一个正式特征。例如,你可能已经创建了一只蜥蜴,现在你选择删除它的腿。也许你想把这个笨拙的家伙变成一条时尚而现代的蟒蛇。

删除特性主要有两个原因。首先,通过用户反馈或者你自己不断增长的智慧,你可能会发现某个特性是个坏主意。午夜怪癖的古怪行为就是这种情况。或者,最初该特性可能已经很好地适应了你的库环境,但现在生态环境发生了变化,也许另一个神发明了哺乳动物,你的生物想要挤进哺乳动物的小洞穴里,吃掉里面美味的哺乳动物,所以它不得不失去双腿。

同样,Python 标准库会根据语言本身的变化删除特性。考虑 asyncio 的 Lock 功能,在把 `await` 作为一个关键字添加进来之前,它一直在等待:
```
lock = asyncio.Lock()
async def critical_section():
await lock
try:
print('holding lock')
finally:
lock.release()
```
但是现在,我们可以做“异步锁”:
```
lock = asyncio.Lock()
async def critical_section():
async with lock:
print('holding lock')
```
新方法好多了!很短,并且在一个大函数中使用其他 try-except 块时不容易出错。因为“尽量找一种,最好是唯一一种明显的解决方案”,[旧语法在 Python 3.7 中被弃用](https://bugs.python.org/issue32253),并且很快就会被禁止。
不可避免的是,生态变化会对你的代码产生影响,因此要学会温柔地删除特性。在此之前,请考虑删除它的成本或好处。负责任的维护者不会愿意让用户更改大量代码或逻辑。(还记得 Python 3 在重新添加会 `u` 字符串前缀之前删除它是多么痛苦吗?)如果代码删除是机械性的动作,就像一个简单的搜索和替换,或者如果该特性是危险的,那么它可能值得删除。
#### 是否删除特性

| 反对 | 支持 |
| --- | --- |
| 代码必须改变 | 改变是机械性的 |
| 逻辑必须改变 | 特性是危险的 |
就我们饥饿的蜥蜴而言,我们决定删除它的腿,这样它就可以滑进老鼠洞里吃掉它。我们该怎么做呢?我们可以删除 `walk` 方法,像下面一样修改代码:
```
class Reptile:
def walk(self):
print('step step step')
```
变成这样:
```
class Reptile:
def slither(self):
print('slide slide slide')
```
这不是一个好主意,这个生物习惯于走路!或者,就库而言,你的用户拥有依赖于现有方法的代码。当他们升级到最新库版本时,他们的代码将会崩溃。
```
# 用户的代码,哦,不!
Reptile.walk()
```
因此,负责任的创建者承诺:
#### 第五条预定:温柔地删除
温柔地删除一个特性需要几个步骤。从用腿走路的蜥蜴开始,首先添加新方法 `slither`。接下来,弃用旧方法。
```
import warnings
class Reptile:
def walk(self):
warnings.warn(
"walk is deprecated, use slither",
DeprecationWarning, stacklevel=2)
print('step step step')
def slither(self):
print('slide slide slide')
```
Python 的 warnings 模块非常强大。默认情况下,它会将警告输出到 stderr,每个代码位置只显示一次,但你可以禁用警告或将其转换为异常,以及其它选项。
一旦将这个警告添加到库中,PyCharm 和其他 IDE 就会使用删除线呈现这个被弃用的方法。用户马上就知道该删除这个方法。
>
> Reptile().~~walk()~~
>
>
>
当他们使用升级后的库运行代码时会发生什么?
```
$ python3 script.py
DeprecationWarning: walk is deprecated, use slither
script.py:14: Reptile().walk()
step step step
```
默认情况下,他们会在 stderr 上看到警告,但脚本会成功并打印 “step step step”。警告的回溯显示必须修复用户代码的哪一行。(这就是 `stacklevel` 参数的作用:它显示了用户需要更改的调用,而不是库中生成警告的行。)请注意,错误消息有指导意义,它描述了库用户迁移到新版本必须做的事情。
你的用户可能会希望测试他们的代码,并证明他们没有调用弃用的库方法。仅警告不会使单元测试失败,但异常会失败。Python 有一个命令行选项,可以将弃用警告转换为异常。
```
> python3 -Werror::DeprecationWarning script.py
Traceback (most recent call last):
File "script.py", line 14, in <module>
Reptile().walk()
File "script.py", line 8, in walk
DeprecationWarning, stacklevel=2)
DeprecationWarning: walk is deprecated, use slither
```
现在,“step step step” 没有输出出来,因为脚本以一个错误终止。
因此,一旦你发布了库的一个版本,该版本会警告已启用的 `walk` 方法,你就可以在下一个版本中安全地删除它。对吧?
考虑一下你的库用户在他们项目的 `requirements` 中可能有什么。
```
# 用户的 requirements.txt 显示 reptile 包的依赖关系
reptile
```
下次他们部署代码时,他们将安装最新版本的库。如果他们尚未处理所有的弃用,那么他们的代码将会崩溃,因为代码仍然依赖 `walk`。你需要温柔一点,你必须向用户做出三个承诺:维护更改日志,选择版本化方案和编写升级指南。
#### 第六个约定:维护变更日志
你的库必须有更改日志,其主要目的是宣布用户所依赖的功能何时被弃用或删除。
>
> **版本 1.1 中的更改**
>
>
> **新特性**
>
>
> * 新功能 Reptile.slither()
>
>
> **弃用**
>
>
> * Reptile.walk() 已弃用,将在 2.0 版本中删除,请使用 slither()
>
>
>
负责任的创建者会使用版本号来表示库发生了怎样的变化,以便用户能够对升级做出明智的决定。“版本化方案”是一种用于交流变化速度的语言。
#### 第七个约定:选择一个版本化方案
有两种广泛使用的方案,[语义版本控制](https://semver.org)和基于时间的版本控制。我推荐任何库都进行语义版本控制。Python 的风格在 [PEP 440](https://www.python.org/dev/peps/pep-0440/) 中定义,像 `pip` 这样的工具可以理解语义版本号。
如果你为库选择语义版本控制,你可以使用版本号温柔地删除腿,例如:
>
> 1.0: 第一个“稳定”版,带有 `walk()` 1.1: 添加 `slither()`,废弃 `walk()` 2.0: 删除 `walk()`
>
>
>
你的用户依赖于你的库的版本应该有一个范围,例如:
```
# 用户的 requirements.txt
reptile>=1,<2
```
这允许他们在主要版本中自动升级,接收错误修正并可能引发一些弃用警告,但不会升级到**下**个主要版本并冒着更改破坏其代码的风险。
如果你遵循基于时间的版本控制,则你的版本可能会编号:
>
> 2017.06.0: 2017 年 6 月的版本 2018.11.0: 添加 `slither()`,废弃 `walk()` 2019.04.0: 删除 `walk()`
>
>
>
用户可以这样依赖于你的库:
```
# 用户的 requirements.txt,基于时间控制的版本
reptile==2018.11.*
```
这非常棒,但你的用户如何知道你的版本方案,以及如何测试代码来进行弃用呢?你必须告诉他们如何升级。
#### 第八个约定:写一个升级指南
下面是一个负责任的库创建者如何指导用户:
>
> **升级到 2.0**
>
>
> **从弃用的 API 迁移**
>
>
> 请参阅更改日志以了解已弃用的特性。
>
>
> **启用弃用警告**
>
>
> 升级到 1.1 并使用以下代码测试代码:
>
>
> `python -Werror::DeprecationWarning`
>
>
> 现在可以安全地升级了。
>
>
>
你必须通过向用户显示命令行选项来教会用户如何处理弃用警告。并非所有 Python 程序员都知道这一点 —— 我自己就每次都得查找这个语法。注意,你必须*发布*一个版本,它输出来自每个弃用的 API 的警告,以便用户可以在再次升级之前使用该版本进行测试。在本例中,1.1 版本是小版本。它允许你的用户逐步重写代码,分别修复每个弃用警告,直到他们完全迁移到最新的 API。他们可以彼此独立地测试代码和库的更改,并隔离 bug 的原因。
如果你选择语义版本控制,则此过渡期将持续到下一个主要版本,从 1.x 到 2.0,或从 2.x 到 3.0 以此类推。删除生物腿部的温柔方法是至少给它一个版本来调整其生活方式。不要一次性把腿删掉!

版本号、弃用警告、更改日志和升级指南可以协同工作,在不违背与用户约定的情况下温柔地改进你的库。[Twisted 项目的兼容性政策](https://twistedmatrix.com/documents/current/core/development/policy/compatibility-policy.html) 解释的很漂亮:
>
> “先行者总是自由的”
>
>
> 运行的应用程序在没有任何警告的情况下都可以升级为 Twisted 的一个次要版本。
>
>
> 换句话说,任何运行其测试而不触发 Twisted 警告的应用程序应该能够将其 Twisted 版本升级至少一次,除了可能产生新警告之外没有任何不良影响。
>
>
>
现在,我们的造物主已经获得了智慧和力量,可以通过添加方法来添加特性,并温柔地删除它们。我们还可以通过添加参数来添加特性,但这带来了新的难度。你准备好了吗?
### 添加参数
想象一下,你只是给了你的蛇形生物一对翅膀。现在你必须允许它选择是滑行还是飞行。目前它的 `move` 功能只接受一个参数。
```
# 你的库代码
def move(direction):
print(f'slither {direction}')
# 用户的应用
move('north')
```
你想要添加一个 `mode` 参数,但如果用户升级库,这会破坏他们的代码,因为他们只传递了一个参数。
```
# 你的库代码
def move(direction, mode):
assert mode in ('slither', 'fly')
print(f'{mode} {direction}')
# 一个用户的代码,出现错误!
move('north')
```
一个真正聪明的创建者者会承诺不会以这种方式破坏用户的代码。
#### 第九条约定:兼容地添加参数
要保持这个约定,请使用保留原始行为的默认值添加每个新参数。
```
# 你的库代码
def move(direction, mode='slither'):
assert mode in ('slither', 'fly')
print(f'{mode} {direction}')
# 用户的应用
move('north')
```
随着时间推移,参数是函数演化的自然历史。它们首先列出最老的参数,每个都有默认值。库用户可以传递关键字参数以选择特定的新行为,并接受所有其他行为的默认值。
```
# 你的库代码
def move(direction,
mode='slither',
turbo=False,
extra_sinuous=False,
hail_lyft=False):
# ...
# 用户应用
move('north', extra_sinuous=True)
```
但是有一个危险,用户可能会编写如下代码:
```
# 用户应用,简写
move('north', 'slither', False, True)
```
如果在你在库的下一个主要版本中去掉其中一个参数,例如 `turbo`,会发生什么?
```
# 你的库代码,下一个主要版本中 "turbo" 被删除
def move(direction,
mode='slither',
extra_sinuous=False,
hail_lyft=False):
# ...
# 用户应用,简写
move('north', 'slither', False, True)
```
用户的代码仍然能编译,这是一件坏事。代码停止了曲折的移动并开始招呼 Lyft,这不是它的本意。我相信你可以预测我接下来要说的内容:删除参数需要几个步骤。当然,首先弃用 `trubo` 参数。我喜欢这种技术,它可以检测任何用户的代码是否依赖于这个参数。
```
# 你的库代码
_turbo_default = object()
def move(direction,
mode='slither',
turbo=_turbo_default,
extra_sinuous=False,
hail_lyft=False):
if turbo is not _turbo_default:
warnings.warn(
"'turbo' is deprecated",
DeprecationWarning,
stacklevel=2)
else:
# The old default.
turbo = False
```
但是你的用户可能不会注意到警告。警告声音不是很大:它们可以在日志文件中被抑制或丢失。用户可能会漫不经心地升级到库的下一个主要版本——那个删除 `turbo` 的版本。他们的代码运行时将没有错误、默默做错误的事情!正如 Python 之禅所说:“错误绝不应该被默默 pass”。实际上,爬行动物的听力很差,所有当它们犯错误时,你必须非常大声地纠正它们。

保护用户的最佳方法是使用 Python 3 的星型语法,它要求调用者传递关键字参数。
```
# 你的库代码
# 所有 “*” 后的参数必须以关键字方式传输。
def move(direction,
*,
mode='slither',
turbo=False,
extra_sinuous=False,
hail_lyft=False):
# ...
# 用户代码,简写
# 错误!不能使用位置参数,关键字参数是必须的
move('north', 'slither', False, True)
```
有了这个星,以下是唯一允许的语法:
```
# 用户代码
move('north', extra_sinuous=True)
```
现在,当你删除 `turbo` 时,你可以确定任何依赖于它的用户代码都会明显地提示失败。如果你的库也支持 Python2,这没有什么大不了。你可以模拟星型语法([归功于 Brett Slatkin](http://www.informit.com/articles/article.aspx?p=2314818)):
```
# 你的库代码,兼容 Python 2
def move(direction, **kwargs):
mode = kwargs.pop('mode', 'slither')
turbo = kwargs.pop('turbo', False)
sinuous = kwargs.pop('extra_sinuous', False)
lyft = kwargs.pop('hail_lyft', False)
if kwargs:
raise TypeError('Unexpected kwargs: %r'
% kwargs)
# ...
```
要求关键字参数是一个明智的选择,但它需要远见。如果允许按位置传递参数,则不能仅在以后的版本中将其转换为仅关键字。所以,现在加上星号。你可以在 asyncio API 中观察到,它在构造函数、方法和函数中普遍使用星号。尽管到目前为止,`Lock` 只接受一个可选参数,但 asyncio 开发人员立即添加了星号。这是幸运的。
```
# In asyncio.
class Lock:
def __init__(self, *, loop=None):
# ...
```
现在,我们已经获得了改变方法和参数的智慧,同时保持与用户的约定。现在是时候尝试最具挑战性的进化了:在不改变方法或参数的情况下改变行为。
### 改变行为
假设你创造的生物是一条响尾蛇,你想教它一种新行为。

横向移动!这个生物的身体看起来是一样的,但它的行为会发生变化。我们如何为这一进化步骤做好准备?

*Image by HCA [[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0)], [via Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Neonate_sidewinder_sidewinding_with_tracks_unlabeled.jpg), 由 Opensource.com 修改*
当行为在没有新函数或新参数的情况下发生更改时,负责任的创建者可以从 Python 标准库中学习。很久以前,os 模块引入了 `stat` 函数来获取文件统计信息,比如创建时间。起初,这个时间总是整数。
```
>>> os.stat('file.txt').st_ctime
1540817862
```
有一天,核心开发人员决定在 `os.stat` 中使用浮点数来提供亚秒级精度。但他们担心现有的用户代码还没有做好准备更改。于是他们在 Python 2.3 中创建了一个设置 `stat_float_times`,默认情况下是 `False` 。用户可以将其设置为 True 来选择浮点时间戳。
```
>>> # Python 2.3.
>>> os.stat_float_times(True)
>>> os.stat('file.txt').st_ctime
1540817862.598021
```
从 Python 2.5 开始,浮点时间成为默认值,因此 2.5 及之后版本编写的任何新代码都可以忽略该设置并期望得到浮点数。当然,你可以将其设置为 `False` 以保持旧行为,或将其设置为 `True` 以确保所有 Python 版本都得到浮点数,并为删除 `stat_float_times` 的那一天准备代码。
多年过去了,在 Python 3.1 中,该设置已被弃用,以便为人们为遥远的未来做好准备,最后,经过数十年的旅程,[这个设置被删除](https://bugs.python.org/issue31827)。浮点时间现在是唯一的选择。这是一个漫长的过程,但负责任的神灵是有耐心的,因为我们知道这个渐进的过程很有可能于意外的行为变化拯救用户。
#### 第十个约定:逐渐改变行为
以下是步骤:
* 添加一个标志来选择新行为,默认为 `False`,如果为 `False` 则发出警告
* 将默认值更改为 `True`,表示完全弃用标记
* 删除该标志
如果你遵循语义版本控制,版本可能如下:
| 库版本 | 库 API | 用户代码 |
| --- | --- | --- |
| 1.0 | 没有标志 | 预期的旧行为 |
| 1.1 | 添加标志,默认为 `False`,如果是 `False`,则警告 | 设置标志为 `True`,处理新行为 |
| 2.0 | 改变默认为 `True`,完全弃用标志 | 处理新行为 |
| 3.0 | 移除标志 | 处理新行为 |
你需要**两**个主要版本来完成该操作。如果你直接从“添加标志,默认为 `False`,如果是 `False` 则发出警告”变到“删除标志”,而没有中间版本,那么用户的代码将无法升级。为 1.1 正确编写的用户代码必须能够升级到下一个版本,除了新警告之外,没有任何不良影响,但如果在下一个版本中删除了该标志,那么该代码将崩溃。一个负责任的神明从不违反扭曲的政策:“先行者总是自由的”。
### 负责任的创建者

我们的 10 个约定大致可以分为三类:
**谨慎发展**
1. 避免不良功能
2. 最小化特性
3. 保持功能单一
4. 标记实验特征“临时”
5. 温柔删除功能
**严格记录历史**
1. 维护更改日志
2. 选择版本方案
3. 编写升级指南
**缓慢而明显地改变**
1. 兼容添加参数
2. 逐渐改变行为
如果你对你所创造的物种保持这些约定,你将成为一个负责任的造物主。你的生物的身体可以随着时间的推移而进化,一直在改善和适应环境的变化,而不是在生物没有准备好就突然改变。如果你维护一个库,请向用户保留这些承诺,这样你就可以在不破坏依赖该库的代码的情况下对库进行更新。
---
这篇文章最初是在 [A. Jesse Jiryu Davis 的博客上'](https://emptysqua.re/blog/api-evolution-the-right-way/)出现的,经允许转载。
插图参考:
* [《世界进步》, Delphian Society, 1913](https://www.gutenberg.org/files/42224/42224-h/42224-h.htm)
* [《走进蛇的历史》, Charles Owen, 1742](https://publicdomainreview.org/product-att/artist/charles-owen/)
* [关于哥斯达黎加的 batrachia 和爬行动物,关于尼加拉瓜和秘鲁的爬行动物和鱼类学的记录, Edward Drinker Cope, 1875](https://archive.org/details/onbatrachiarepti00cope/page/n3)
* [《自然史》, Richard Lydekker et. al., 1897](https://www.flickr.com/photos/internetarchivebookimages/20556001490)
* [Mes Prisons, Silvio Pellico, 1843](https://www.oldbookillustrations.com/illustrations/stationery/)
* [Tierfotoagentur / m.blue-shadow](https://www.alamy.com/mediacomp/ImageDetails.aspx?ref=D7Y61W)
* [洛杉矶公共图书馆, 1930](https://www.vintag.es/2013/06/riding-alligator-c-1930s.html)
---
via: <https://opensource.com/article/19/5/api-evolution-right-way>
作者:[A. Jesse](https://opensource.com/users/emptysquare) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,902 | 在 Pygame 游戏中放置平台 | https://opensource.com/article/18/7/put-platforms-python-game | 2019-05-26T20:36:59 | [
"Pygame"
] | https://linux.cn/article-10902-1.html |
>
> 在这个从零构建一个 Python 游戏系列的第六部分中,为你的角色创建一些平台来旅行。
>
>
>

这是仍在进行中的关于使用 Pygame 模块来在 Python 3 中创建电脑游戏的系列文章的第六部分。先前的文章是:
* [通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程](/article-9071-1.html)
* [使用 Python 和 Pygame 模块构建一个游戏框架](/article-10850-1.html)
* [如何在你的 Python 游戏中添加一个玩家](/article-10858-1.html)
* [用 Pygame 使你的游戏角色移动起来](/article-10874-1.html)
* [如何向你的 Python 游戏中添加一个敌人](/article-10883-1.html)
一个平台类游戏需要平台。
在 [Pygame](https://www.pygame.org/news) 中,平台本身也是个妖精,正像你那个可玩的妖精。这一点是重要的,因为有个是对象的平台,可以使你的玩家妖精更容易与之互动。
创建平台有两个主要步骤。首先,你必须给该对象编写代码,然后,你必须映射出你希望该对象出现的位置。
### 编码平台对象
要构建一个平台对象,你要创建一个名为 `Platform` 的类。它是一个妖精,正像你的 `Player` [妖精](https://opensource.com/article/17/12/game-python-add-a-player) 一样,带有很多相同的属性。
你的 `Platform` 类需要知道很多平台类型的信息,它应该出现在游戏世界的哪里、它应该包含的什么图片等等。这其中很多信息可能还尚不存在,这要看你为你的游戏计划了多少,但是没有关系。正如直到[移动你的游戏角色](https://opensource.com/article/17/12/game-python-moving-player)那篇文章结束时,你都没有告诉你的玩家妖精移动速度有多快,你不必事先告诉 `Platform` 每一件事。
在这系列中你所写的脚本的开头附近,创建一个新的类。在这个代码示例中前三行是用于说明上下文,因此在注释的下面添加代码:
```
import pygame
import sys
import os
## 新代码如下:
class Platform(pygame.sprite.Sprite):
# x location, y location, img width, img height, img file
def __init__(self,xloc,yloc,imgw,imgh,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img)).convert()
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
```
当被调用时,这个类在某个 X 和 Y 位置上创建一个屏上对象,具有某种宽度和高度,并使用某种图像作为纹理。这与如何在屏上绘制出玩家或敌人非常类似。
### 平台的类型
下一步是绘制出你的平台需要出现的地方。
#### 瓷砖方式
实现平台类游戏世界有几种不同的方法。在最初的横向滚轴游戏中,例如,马里奥超级兄弟和刺猬索尼克,这个技巧是使用“瓷砖”方式,也就是说有几个代表地面和各种平台的块,并且这些块被重复使用来制作一个关卡。你只能有 8 或 12 种不同的块,你可以将它们排列在屏幕上来创建地面、浮动的平台,以及你游戏中需要的一切其它的事物。有人发现这是制作游戏最容易的方法了,因为你只需要制作(或下载)一小组关卡素材就能创建很多不同的关卡。然而,这里的代码需要一点数学知识。

*[SuperTux](https://www.supertux.org/) ,一个基于瓷砖的电脑游戏。*
#### 手工绘制方式
另一种方法是将每个素材作为一个整体图像。如果你喜欢为游戏世界创建素材,那你会在用图形应用程序构建游戏世界的每个部分上花费很多时间。这种方法不需要太多的数学知识,因为所有的平台都是整体的、完整的对象,你只需要告诉 [Python](https://www.python.org/) 将它们放在屏幕上的什么位置。
每种方法都有优势和劣势,并且根据于你选择使用的方式,代码稍有不同。我将覆盖这两方面,所以你可以在你的工程中使用一种或另一种,甚至两者的混合。
### 关卡绘制
总的来说,绘制你的游戏世界是关卡设计和游戏编程中的一个重要的部分。这需要数学知识,但是没有什么太难的,而且 Python 擅长数学,它会有所帮助。
你也许发现先在纸张上设计是有用的。拿一张表格纸,并绘制一个方框来代表你的游戏窗体。在方框中绘制平台,并标记其每一个平台的 X 和 Y 坐标,以及它的宽度和高度。在方框中的实际位置没有必要是精确的,你只要保持数字合理即可。譬如,假设你的屏幕是 720 像素宽,那么你不能在一个屏幕上放 8 块 100 像素的平台。
当然,不是你游戏中的所有平台都必须容纳在一个屏幕大小的方框里,因为你的游戏将随着你的玩家行走而滚动。所以,可以继续绘制你的游戏世界到第一屏幕的右侧,直到关卡结束。
如果你更喜欢精确一点,你可以使用方格纸。当设计一个瓷砖类的游戏时,这是特别有用的,因为每个方格可以代表一个瓷砖。

*一个关卡地图示例。*
#### 坐标系
你可能已经在学校中学习过[笛卡尔坐标系](https://en.wikipedia.org/wiki/Cartesian_coordinate_system)。你学习的东西也适用于 Pygame,除了在 Pygame 中你的游戏世界的坐标系的原点 `0,0` 是放置在你的屏幕的左上角而不是在中间,是你在地理课上用过的坐标是在中间的。

*在 Pygame 中的坐标示例。*
X 轴起始于最左边的 0,向右无限增加。Y 轴起始于屏幕顶部的 0,向下延伸。
#### 图片大小
如果你不知道你的玩家、敌人、平台是多大的,绘制出一个游戏世界是毫无意义的。你可以在图形程序中找到你的平台或瓷砖的尺寸。例如在 [Krita](https://krita.org/en/) 中,单击“图像”菜单,并选择“属性”。你可以在“属性”窗口的最顶部处找到它的尺寸。
另外,你也可以创建一个简单的 Python 脚本来告诉你的一个图像的尺寸。打开一个新的文本文件,并输入这些代码到其中:
```
#!/usr/bin/env python3
from PIL import Image
import os.path
import sys
if len(sys.argv) > 1:
print(sys.argv[1])
else:
sys.exit('Syntax: identify.py [filename]')
pic = sys.argv[1]
dim = Image.open(pic)
X = dim.size[0]
Y = dim.size[1]
print(X,Y)
```
保存该文本文件为 `identify.py`。
要使用这个脚本,你必须安装一些额外的 Python 模块,它们包含了这个脚本中新使用的关键字:
```
$ pip3 install Pillow --user
```
一旦安装好,在你游戏工程目录中运行这个脚本:
```
$ python3 ./identify.py images/ground.png
(1080, 97)
```
在这个示例中,地面平台的图形的大小是 1080 像素宽和 97 像素高。
### 平台块
如果你选择单独地绘制每个素材,你必须创建想要插入到你的游戏世界中的几个平台和其它元素,每个素材都放在它自己的文件中。换句话说,你应该让每个素材都有一个文件,像这样:

*每个对象一个图形文件。*
你可以按照你希望的次数重复使用每个平台,只要确保每个文件仅包含一个平台。你不能使用一个文件包含全部素材,像这样:

*你的关卡不能是一个图形文件。*
当你完成时,你可能希望你的游戏看起来像这样,但是如果你在一个大文件中创建你的关卡,你就没有方法从背景中区分出一个平台,因此,要么把对象绘制在它们自己的文件中,要么从一个更大的文件中裁剪出它们,并保存为单独的副本。
**注意:** 如同你的其它素材,你可以使用 [GIMP](https://www.gimp.org/)、Krita、[MyPaint](http://mypaint.org/about/),或 [Inkscape](https://inkscape.org/en/) 来创建你的游戏素材。
平台出现在每个关卡开始的屏幕上,因此你必须在你的 `Level` 类中添加一个 `platform` 函数。在这里特例是地面平台,它重要到应该拥有它自己的一个组。通过把地面看作一组特殊类型的平台,你可以选择它是否滚动,或它上面是否可以站立,而其它平台可以漂浮在它上面。这取决于你。
添加这两个函数到你的 `Level` 类:
```
def ground(lvl,x,y,w,h):
ground_list = pygame.sprite.Group()
if lvl == 1:
ground = Platform(x,y,w,h,'block-ground.png')
ground_list.add(ground)
if lvl == 2:
print("Level " + str(lvl) )
return ground_list
def platform( lvl ):
plat_list = pygame.sprite.Group()
if lvl == 1:
plat = Platform(200, worldy-97-128, 285,67,'block-big.png')
plat_list.add(plat)
plat = Platform(500, worldy-97-320, 197,54,'block-small.png')
plat_list.add(plat)
if lvl == 2:
print("Level " + str(lvl) )
return plat_list
```
`ground` 函数需要一个 X 和 Y 位置,以便 Pygame 知道在哪里放置地面平台。它也需要知道平台的宽度和高度,这样 Pygame 知道地面延伸到每个方向有多远。该函数使用你的 `Platform` 类来生成一个屏上对象,然后将这个对象添加到 `ground_list` 组。
`platform` 函数本质上是相同的,除了其有更多的平台。在这个示例中,仅有两个平台,但是你可以想有多少就有多少。在进入一个平台后,在列出另一个前你必须添加它到 `plat_list` 中。如果你不添加平台到组中,那么它将不出现在你的游戏中。
>
> **提示:** 很难想象你的游戏世界的 0 是在顶部,因为在真实世界中发生的情况是相反的;当估计你有多高时,你不会从上往下测量你自己,而是从脚到头顶来测量。
>
>
> 如果对你来说从“地面”上来构建你的游戏世界更容易,将 Y 轴值表示为负数可能有帮助。例如,你知道你的游戏世界的底部是 `worldy` 的值。因此 `worldy` 减去地面的高度(在这个示例中是 97)是你的玩家正常站立的位置。如果你的角色是 64 像素高,那么地面减去 128 正好是你的玩家的两倍高。事实上,一个放置在 128 像素处平台大约是相对于你的玩家的两层楼高度。一个平台在 -320 处比三层楼更高。等等。
>
>
>
正像你现在可能所知的,如果你不使用它们,你的类和函数是没有价值的。添加这些代码到你的设置部分(第一行只是上下文,所以添加最后两行):
```
enemy_list = Level.bad( 1, eloc )
ground_list = Level.ground( 1,0,worldy-97,1080,97 )
plat_list = Level.platform( 1 )
```
并把这些行加到你的主循环(再一次,第一行仅用于上下文):
```
enemy_list.draw(world) # 刷新敌人
ground_list.draw(world) # 刷新地面
plat_list.draw(world) # 刷新平台
```
### 瓷砖平台
瓷砖类游戏世界更容易制作,因为你只需要在前面绘制一些块,就能在游戏中一再使用它们创建每个平台。在像 [OpenGameArt.org](https://opengameart.org/content/simplified-platformer-pack) 这样的网站上甚至有一套瓷砖供你来使用。
`Platform` 类与在前面部分中的类是相同的。
`ground` 和 `platform` 在 `Level` 类中,然而,必须使用循环来计算使用多少块来创建每个平台。
如果你打算在你的游戏世界中有一个坚固的地面,这种地面是很简单的。你只需要从整个窗口的一边到另一边“克隆”你的地面瓷砖。例如,你可以创建一个 X 和 Y 值的列表来规定每个瓷砖应该放置的位置,然后使用一个循环来获取每个值并绘制每一个瓷砖。这仅是一个示例,所以不要添加这到你的代码:
```
# Do not add this to your code
gloc = [0,656,64,656,128,656,192,656,256,656,320,656,384,656]
```
不过,如果你仔细看,你可以看到所有的 Y 值是相同的,X 值以 64 的增量不断地增加 —— 这就是瓷砖的大小。这种重复是精确地,是计算机擅长的,因此你可以使用一点数学逻辑来让计算机为你做所有的计算:
添加这些到你的脚本的设置部分:
```
gloc = []
tx = 64
ty = 64
i=0
while i <= (worldx/tx)+tx:
gloc.append(i*tx)
i=i+1
ground_list = Level.ground( 1,gloc,tx,ty )
```
现在,不管你的窗口的大小,Python 会通过瓷砖的宽度分割游戏世界的宽度,并创建一个数组列表列出每个 X 值。这里不计算 Y 值,因为在平的地面上这个从不会变化。
为了在一个函数中使用数组,使用一个 `while` 循环,查看每个条目并在适当的位置添加一个地面瓷砖:
```
def ground(lvl,gloc,tx,ty):
ground_list = pygame.sprite.Group()
i=0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i],worldy-ty,tx,ty,'tile-ground.png')
ground_list.add(ground)
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return ground_list
```
除了 `while` 循环,这几乎与在上面一部分中提供的瓷砖类平台的 `ground` 函数的代码相同。
对于移动的平台,原理是相似的,但是这里有一些技巧可以使它简单。
你可以通过它的起始像素(它的 X 值)、距地面的高度(它的 Y 值)、绘制多少瓷砖来定义一个平台,而不是通过像素绘制每个平台。这样,你不必操心每个平台的宽度和高度。
这个技巧的逻辑有一点复杂,因此请仔细复制这些代码。有一个 `while` 循环嵌套在另一个 `while` 循环的内部,因为这个函数必须考虑每个数组项的三个值来成功地建造一个完整的平台。在这个示例中,这里仅有三个平台以 `ploc.append` 语句定义,但是你的游戏可能需要更多,因此你需要多少就定义多少。当然,有一些不会出现,因为它们远在屏幕外,但是一旦当你进行滚动时,它们将呈现在眼前。
```
def platform(lvl,tx,ty):
plat_list = pygame.sprite.Group()
ploc = []
i=0
if lvl == 1:
ploc.append((200,worldy-ty-128,3))
ploc.append((300,worldy-ty-256,3))
ploc.append((500,worldy-ty-128,4))
while i < len(ploc):
j=0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0]+(j*tx)),ploc[i][1],tx,ty,'tile.png')
plat_list.add(plat)
j=j+1
print('run' + str(i) + str(ploc[i]))
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return plat_list
```
要让这些平台出现在你的游戏世界,它们必须出现在你的主循环中。如果你还没有这样做,添加这些行到你的主循环(再一次,第一行仅被用于上下文)中:
```
enemy_list.draw(world) # 刷新敌人
ground_list.draw(world) # 刷新地面
plat_list.draw(world) # 刷新平台
```
启动你的游戏,根据需要调整你的平台的放置位置。如果你看不见屏幕外产生的平台,不要担心;你不久后就可以修复它。
到目前为止,这是游戏的图片和代码:

*到目前为止,我们的 Pygame 平台。*
```
#!/usr/bin/env python3
# draw a world
# add a player and player control
# add player movement
# add enemy and basic collision
# add platform
# GNU All-Permissive License
# Copying and distribution of this file, with or without modification,
# are permitted in any medium without royalty provided the copyright
# notice and this notice are preserved. This file is offered as-is,
# without any warranty.
import pygame
import sys
import os
'''
Objects
'''
class Platform(pygame.sprite.Sprite):
# x location, y location, img width, img height, img file
def __init__(self,xloc,yloc,imgw,imgh,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img)).convert()
self.image.convert_alpha()
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
class Player(pygame.sprite.Sprite):
'''
Spawn a player
'''
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.score = 1
self.images = []
for i in range(1,9):
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def control(self,x,y):
'''
control player movement
'''
self.movex += x
self.movey += y
def update(self):
'''
Update sprite position
'''
self.rect.x = self.rect.x + self.movex
self.rect.y = self.rect.y + self.movey
# moving left
if self.movex < 0:
self.frame += 1
if self.frame > ani*3:
self.frame = 0
self.image = self.images[self.frame//ani]
# moving right
if self.movex > 0:
self.frame += 1
if self.frame > ani*3:
self.frame = 0
self.image = self.images[(self.frame//ani)+4]
# collisions
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
for enemy in enemy_hit_list:
self.health -= 1
print(self.health)
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.health -= 1
print(self.health)
class Enemy(pygame.sprite.Sprite):
'''
Spawn an enemy
'''
def __init__(self,x,y,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img))
#self.image.convert_alpha()
#self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
'''
enemy movement
'''
distance = 80
speed = 8
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance*2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
class Level():
def bad(lvl,eloc):
if lvl == 1:
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # spawn enemy
enemy_list = pygame.sprite.Group() # create enemy group
enemy_list.add(enemy) # add enemy to group
if lvl == 2:
print("Level " + str(lvl) )
return enemy_list
def loot(lvl,lloc):
print(lvl)
def ground(lvl,gloc,tx,ty):
ground_list = pygame.sprite.Group()
i=0
if lvl == 1:
while i < len(gloc):
print("blockgen:" + str(i))
ground = Platform(gloc[i],worldy-ty,tx,ty,'ground.png')
ground_list.add(ground)
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return ground_list
'''
Setup
'''
worldx = 960
worldy = 720
fps = 40 # frame rate
ani = 4 # animation cycles
clock = pygame.time.Clock()
pygame.init()
main = True
BLUE = (25,25,200)
BLACK = (23,23,23 )
WHITE = (254,254,254)
ALPHA = (0,255,0)
world = pygame.display.set_mode([worldx,worldy])
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
backdropbox = world.get_rect()
player = Player() # spawn player
player.rect.x = 0
player.rect.y = 0
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10 # how fast to move
eloc = []
eloc = [200,20]
gloc = []
#gloc = [0,630,64,630,128,630,192,630,256,630,320,630,384,630]
tx = 64 #tile size
ty = 64 #tile size
i=0
while i <= (worldx/tx)+tx:
gloc.append(i*tx)
i=i+1
print("block: " + str(i))
enemy_list = Level.bad( 1, eloc )
ground_list = Level.ground( 1,gloc,tx,ty )
'''
Main loop
'''
while main == True:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit(); sys.exit()
main = False
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(-steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps,0)
if event.key == ord('q'):
pygame.quit()
sys.exit()
main = False
# world.fill(BLACK)
world.blit(backdrop, backdropbox)
player.update()
player_list.draw(world) #refresh player position
enemy_list.draw(world) # refresh enemies
ground_list.draw(world) # refresh enemies
for e in enemy_list:
e.move()
pygame.display.flip()
clock.tick(fps)
```
(LCTT 译注:到本文翻译完为止,该系列已经近一年没有继续更新了~)
---
via: <https://opensource.com/article/18/7/put-platforms-python-game>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *This is part 6 in an ongoing series about creating video games in Python 3 using the Pygame module. Previous articles are:*
[Learn how to program in Python by building a simple dice game](https://opensource.com/article/17/10/python-101)[Build a game framework with Python using the Pygame module](https://opensource.com/article/17/12/game-framework-python)[How to add a player to your Python game](https://opensource.com/article/17/12/game-python-add-a-player)[Using Pygame to move your game character around](https://opensource.com/article/17/12/game-python-moving-player)[What's a hero without a villain? How to add one to your Python game](https://opensource.com/article/18/5/pygame-enemy)
A platformer game needs platforms.
In [Pygame](https://www.pygame.org/news), the platforms themselves are sprites, just like your playable sprite. That's important because having platforms that are objects makes it a lot easier for your player sprite to interact with them.
There are two major steps in creating platforms. First, you must code the objects, and then you must map out where you want the objects to appear.
## Coding platform objects
To build a platform object, you create a class called `Platform`
. It's a sprite, just like your `Player`
[ sprite](https://opensource.com/article/17/12/game-python-add-a-player), with many of the same properties.
Your `Platform`
class needs to know a lot of information about what kind of platform you want, where it should appear in the game world, and what image it should contain. A lot of that information might not even exist yet, depending on how much you have planned out your game, but that's all right. Just as you didn't tell your Player sprite how fast to move until the end of the [Movement article](https://opensource.com/article/17/12/game-python-moving-player), you don't have to tell `Platform`
everything upfront.
In the objects section of your script, create a new class:
```
# x location, y location, img width, img height, img file
class Platform(pygame.sprite.Sprite):
def __init__(self, xloc, yloc, imgw, imgh, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img)).convert()
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
```
When called, this class creates an object onscreen in *some* X and Y location, with *some* width and height, using *some* image file for texture. It's very similar to how players or enemies are drawn onscreen. You probably recognize this same code structure from the Player and Enemy classes.
## Types of platforms
The next step is to map out where all your platforms need to appear.
### The tile method
There are a few different ways to implement a platform game world. In the original side-scroller games, such as Mario Super Bros. and Sonic the Hedgehog, the technique was to use "tiles," meaning that there were a few blocks to represent the ground and various platforms, and these blocks were used and reused to make a level. You have only eight or 12 different kinds of blocks, and you line them up onscreen to create the ground, floating platforms, and whatever else your game needs. Some people find this the easier way to make a game since you just have to make (or download) a small set of level assets to create many different levels. The code, however, requires a little more math.

[SuperTux](https://www.supertux.org/), a tile-based video game.
### The hand-painted method
Another method is to make each and every asset as one whole image. If you enjoy creating assets for your game world, this is a great excuse to spend time in a graphics application, building each and every part of your game world. This method requires less math, because all the platforms are whole, complete objects, and you tell Python where to place them onscreen.
Each method has advantages and disadvantages, and the code you must use is slightly different depending on the method you choose. I'll cover both so you can use one or the other, or even a mix of both, in your project.
## Level mapping
Mapping out your game world is a vital part of level design and game programming in general. It does involve math, but nothing too difficult, and Python is good at math so it can help some.
You might find it helpful to design on paper first. Get a sheet of paper and draw a box to represent your game window. Draw platforms in the box, labeling each with its X and Y coordinates, as well as its intended width and height. The actual positions in the box don't have to be exact, as long as you keep the numbers realistic. For instance, if your screen is 720 pixels wide, then you can't fit eight platforms at 100 pixels each all on one screen.
Of course, not all platforms in your game have to fit in one screen-sized box, because your game will scroll as your player walks through it. So keep drawing your game world to the right of the first screen until the end of the level.
If you prefer a little more precision, you can use graph paper. This is especially helpful when designing a game with tiles because each grid square can represent one tile.
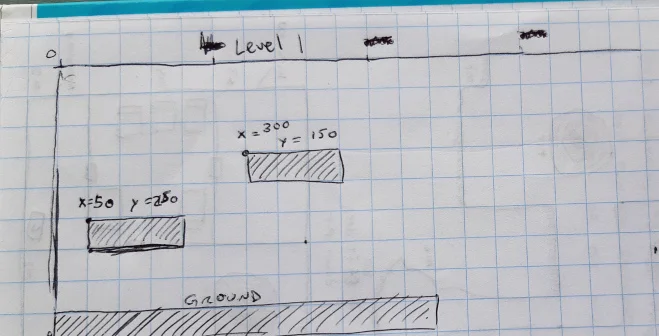
### Coordinates
You may have learned in school about the [Cartesian coordinate system](https://en.wikipedia.org/wiki/Cartesian_coordinate_system). What you learned applies to Pygame, except that in Pygame, your game world's coordinates place `0,0`
in the top-left corner of your screen instead of in the middle, which is probably what you're used to from Geometry class.
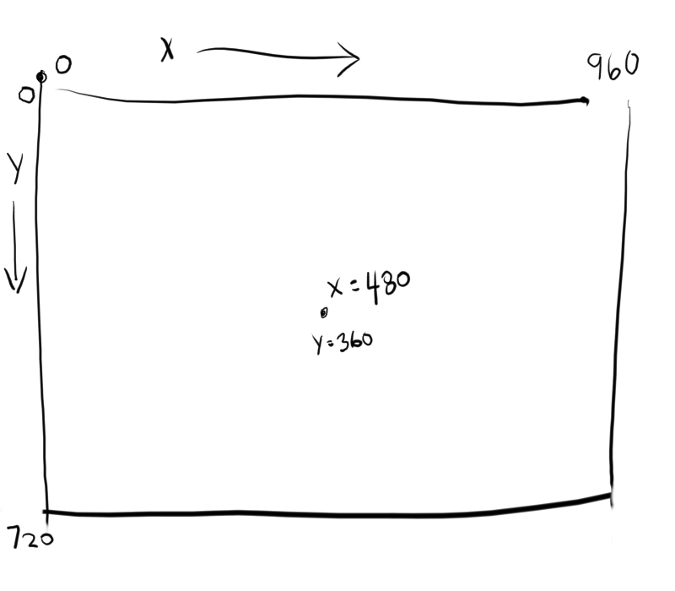
Example of coordinates in Pygame.
The X axis starts at 0 on the far left and increases infinitely to the right. The Y axis starts at 0 at the top of the screen and extends down.
### Image sizes
Mapping out a game world is meaningless if you don't know how big your players, enemies, and platforms are. You can find the dimensions of your platforms or tiles in a graphics program. In [Krita](https://krita.org/en/), for example, click on the **Image** menu and select **Properties**. You can find the dimensions at the very top of the **Properties** window.
Alternately, you can create a simple Python script to tell you the dimensions of an image. To do that, you must install a Python module called Pillow, which provides the Python Image Library (PIL). Add Pillow to your project's `requirements.txt`
file:
```
pygame~=1.9.6
Pillow
```
Create a new Python file in PyCharm and name it `identify`
. Type this code into it:
```
#!/usr/bin/env python3
# GNU All-Permissive License
# Copying and distribution of this file, with or without modification,
# are permitted in any medium without royalty provided the copyright
# notice and this notice are preserved. This file is offered as-is,
# without any warranty.
from PIL import Image
import os.path
import sys
if len(sys.argv) > 1:
print(sys.argv[1])
else:
sys.exit('Syntax: identify.py [filename]')
pic = sys.argv[1]
img = Image.open(pic)
X = img.size[0]
Y = img.size[1]
print(X, Y)
```
Click on the **Terminal** tab at the bottom of the PyCharm window to open a terminal within your virtual environment. Now you can install the Pillow module into your environment:
```
(venv) pip install -r requirements.txt
Requirement already satisfied: pygame~=1.9.6 [...]
Installed Pillow [...]
```
Once that is installed, run your script from within your game project directory:
```
(venv) python ./identify.py images/ground.png
(1080, 97)
```
The image size of the ground platform in this example is 1080 pixels wide and 97 high.
## Platform blocks
If you choose to draw each asset individually, you must create several platforms and any other elements you want to insert into your game world, each within its own file. In other words, you should have one file per asset, like this:

One image file per object.
You can reuse each platform as many times as you want, just make sure that each file only contains one platform. You cannot use a file that contains everything, like this:

Your level cannot be one image file.
You might want your game to look like that when you've finished, but if you create your level in one big file, there is no way to distinguish a platform from the background, so either paint your objects in their own file or crop them from a large file and save individual copies.
**Note:** As with your other assets, you can use [GIMP](https://www.gimp.org/), [Krita](http://krita.org), [MyPaint](http://mypaint.org/about/), or [Inkscape](https://inkscape.org/en/) to create your game assets.
Platforms appear on the screen at the start of each level, so you must add a `platform`
function in your `Level`
class. The special case here is the ground platform, which is important enough to be treated as its own platform group. By treating the ground as its own special kind of platform, you can choose whether it scrolls or whether it stands still while other platforms float over the top of it. It's up to you.
Add these two functions to your `Level`
class:
```
def ground(lvl,x,y,w,h):
ground_list = pygame.sprite.Group()
if lvl == 1:
ground = Platform(x,y,w,h,'block-ground.png')
ground_list.add(ground)
if lvl == 2:
print("Level " + str(lvl) )
return ground_list
def platform( lvl ):
plat_list = pygame.sprite.Group()
if lvl == 1:
plat = Platform(200, worldy-97-128, 285,67,'block-big.png')
plat_list.add(plat)
plat = Platform(500, worldy-97-320, 197,54,'block-small.png')
plat_list.add(plat)
if lvl == 2:
print("Level " + str(lvl) )
return plat_list
```
The `ground`
function requires an X and Y location so Pygame knows where to place the ground platform. It also requires the width and height of the platform so Pygame knows how far the ground extends in each direction. The function uses your `Platform`
class to generate an object onscreen, and then adds that object to the `ground_list`
group.
The `platform`
function is essentially the same, except that there are more platforms to list. In this example, there are only two, but you can have as many as you like. After entering one platform, you must add it to the `plat_list`
before listing another. If you don't add a platform to the group, then it won't appear in your game.
Tip:It can be difficult to think of your game world with 0 at the top, since the opposite is what happens in the real world; when figuring out how tall you are, you don't measure yourself from the sky down, you measure yourself from your feet to the top of your head.If it's easier for you to build your game world from the "ground" up, it might help to express Y-axis values as negatives. For instance, you know that the bottom of your game world is the value of
`worldy`
. So`worldy`
minus the height of the ground (97, in this example) is where your player is normally standing. If your character is 64 pixels tall, then the ground minus 128 is exactly twice as tall as your player. Effectively, a platform placed at 128 pixels is about two stories tall, relative to your player. A platform at -320 is three more stories. And so on.
As you probably know by now, none of your classes and functions are worth much if you don't *use* them. Add this code to your setup section:
```
ground_list = Level.ground(1, 0, worldy-97, 1080, 97)
plat_list = Level.platform(1)
```
And add these lines to your main loop (again, the first line is just for context):
```
enemy_list.draw(world) # refresh enemies
ground_list.draw(world) # refresh ground
plat_list.draw(world) # refresh platforms
```
## Tiled platforms
Tiled game worlds are considered easier to make because you just have to draw a few blocks upfront and can use them over and over to create every platform in the game. There are sets of tiles with a [Creative Commons license](https://opensource.com/article/20/1/what-creative-commons) for you to use on sites like [kenney.nl](https://kenney.nl/assets/simplified-platformer-pack) and [OpenGameArt.org](https://opengameart.org/content/simplified-platformer-pack). The simplified-platformer-pack from kenney.nl are 64 pixels square, so that's the dimension for tiles this article uses. Should you download or create tiles with a different size, adjust the code as needed.
The `Platform`
class is the same as the one provided in the previous sections.
The `ground`
and `platform`
in the `Level`
class, however, must use loops to calculate how many blocks to use to create each platform.
If you intend to have one solid ground in your game world, the ground is simple. You just "clone" your ground tile across the whole window. For instance, you could create a list of X and Y values to dictate where each tile should be placed, and then use a loop to take each value and draw one tile. This is just an example, so don't add this to your code:
```
# Do not add this to your code
gloc = [0,656,64,656,128,656,192,656,256,656,320,656,384,656]
```
If you look carefully, though, you can see all the Y values are always the same (656, to be specific), and the X values increase steadily in increments of 64, which is the size of the tile. That kind of repetition is exactly what computers are good at, so you can use a little bit of math logic to have the computer do all the calculations for you:
Add this to the setup part of your script:
```
gloc = []
tx = 64
ty = 64
i=0
while i <= (worldx/tx)+tx:
gloc.append(i*tx)
i=i+1
ground_list = Level.ground( 1,gloc,tx,ty )
```
With this code, regardless of the size of your window, Python divides the width of the game world by the width of the tile and creates an array listing each X value. This doesn't calculate the Y value, but that never changes on flat ground anyway.
To use the array in a function, use a `while`
loop that looks at each entry and adds a ground tile at the appropriate location. Add this function to your `Level`
class:
```
def ground(lvl,gloc,tx,ty):
ground_list = pygame.sprite.Group()
i=0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i],worldy-ty,tx,ty,'tile-ground.png')
ground_list.add(ground)
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return ground_list
```
This is nearly the same code as the `ground`
function for the block-style platformer, provided in the previous section, aside from the `while`
loop.
For moving platforms, the principle is similar, but there are some tricks you can use to make your life easier.
Rather than mapping every platform by pixels, you can define a platform by its starting pixel (its X value), the height from the ground (its Y value), and how many tiles to draw. That way, you don't have to worry about the width and height of every platform.
The logic for this trick is a little more complex, so copy this code carefully. There is a `while`
loop inside of another `while`
loop because this function must look at all three values within each array entry to successfully construct a full platform. In this example, there are only three platforms defined as `ploc.append`
statements, but your game probably needs more, so define as many as you need. Of course, some won't appear yet because they're far offscreen, but they'll come into view once you implement scrolling.
```
def platform(lvl,tx,ty):
plat_list = pygame.sprite.Group()
ploc = []
i=0
if lvl == 1:
ploc.append((200,worldy-ty-128,3))
ploc.append((300,worldy-ty-256,3))
ploc.append((500,worldy-ty-128,4))
while i < len(ploc):
j=0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0]+(j*tx)),ploc[i][1],tx,ty,'tile.png')
plat_list.add(plat)
j=j+1
print('run' + str(i) + str(ploc[i]))
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return plat_list
```
Of course, this has only created a function to calculate platforms for each level. You code doesn't invoke the function yet.
In the setup section of your program, add this line:
`plat_list = Level.platform(1, tx, ty)`
To get the platforms to appear in your game world, they must be in your main loop. If you haven't already done so, add these lines to your main loop (again, the first line is just for context):
```
enemy_list.draw(world) # refresh enemies
ground_list.draw(world) # refresh ground
plat_list.draw(world) # refresh platforms
```
Launch your game, and adjust the placement of your platforms as needed. Don't worry that you can't see the platforms that are spawned offscreen; you'll fix that soon.

## Applying what you know
I haven't demonstrated how to place your enemy in your game world, but apply what you've learnt so far to position the enemy sprite either on a platform or down on the ground.
Don't position your hero sprite yet. That must be managed by the forces of gravity (or at least an emulation of it), which you'll learn in the next two articles.
For now, here's the code so far:
```
#!/usr/bin/env python3
# by Seth Kenlon
# GPLv3
# This program is free software: you can redistribute it and/or
# modify it under the terms of the GNU General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import pygame
import sys
import os
'''
Variables
'''
worldx = 960
worldy = 720
fps = 40
ani = 4
world = pygame.display.set_mode([worldx, worldy])
BLUE = (25, 25, 200)
BLACK = (23, 23, 23)
WHITE = (254, 254, 254)
ALPHA = (0, 255, 0)
'''
Objects
'''
# x location, y location, img width, img height, img file
class Platform(pygame.sprite.Sprite):
def __init__(self, xloc, yloc, imgw, imgh, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img)).convert()
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
class Player(pygame.sprite.Sprite):
"""
Spawn a player
"""
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.images = []
for i in range(1, 5):
img = pygame.image.load(os.path.join('images', 'hero' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def control(self, x, y):
"""
control player movement
"""
self.movex += x
self.movey += y
def update(self):
"""
Update sprite position
"""
self.rect.x = self.rect.x + self.movex
self.rect.y = self.rect.y + self.movey
# moving left
if self.movex < 0:
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = pygame.transform.flip(self.images[self.frame // ani], True, False)
# moving right
if self.movex > 0:
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = self.images[self.frame // ani]
hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
for enemy in hit_list:
self.health -= 1
print(self.health)
class Enemy(pygame.sprite.Sprite):
"""
Spawn an enemy
"""
def __init__(self, x, y, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
"""
enemy movement
"""
distance = 80
speed = 8
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance * 2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
class Level:
def ground(lvl, gloc, tx, ty):
ground_list = pygame.sprite.Group()
i = 0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i], worldy - ty, tx, ty, 'tile-ground.png')
ground_list.add(ground)
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return ground_list
def bad(lvl, eloc):
if lvl == 1:
enemy = Enemy(eloc[0], eloc[1], 'enemy.png')
enemy_list = pygame.sprite.Group()
enemy_list.add(enemy)
if lvl == 2:
print("Level " + str(lvl))
return enemy_list
# x location, y location, img width, img height, img file
def platform(lvl, tx, ty):
plat_list = pygame.sprite.Group()
ploc = []
i = 0
if lvl == 1:
ploc.append((200, worldy - ty - 128, 3))
ploc.append((300, worldy - ty - 256, 3))
ploc.append((500, worldy - ty - 128, 4))
while i < len(ploc):
j = 0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0] + (j * tx)), ploc[i][1], tx, ty, 'tile.png')
plat_list.add(plat)
j = j + 1
print('run' + str(i) + str(ploc[i]))
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return plat_list
'''
Setup
'''
backdrop = pygame.image.load(os.path.join('images', 'stage.png'))
clock = pygame.time.Clock()
pygame.init()
backdropbox = world.get_rect()
main = True
player = Player() # spawn player
player.rect.x = 0 # go to x
player.rect.y = 30 # go to y
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10
eloc = []
eloc = [300, 0]
enemy_list = Level.bad(1, eloc)
gloc = []
tx = 64
ty = 64
i = 0
while i <= (worldx / tx) + tx:
gloc.append(i * tx)
i = i + 1
ground_list = Level.ground(1, gloc, tx, ty)
plat_list = Level.platform(1, tx, ty)
'''
Main Loop
'''
while main:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(-steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(steps, 0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps, 0)
world.blit(backdrop, backdropbox)
player.update()
player_list.draw(world)
enemy_list.draw(world)
ground_list.draw(world)
plat_list.draw(world)
for e in enemy_list:
e.move()
pygame.display.flip()
clock.tick(fps)
```
## 6 Comments |
10,903 | 3 款在 Fedora 中管理个人财务的应用 | https://fedoramagazine.org/3-apps-to-manage-personal-finances-in-fedora/ | 2019-05-26T23:36:28 | [
"财务"
] | https://linux.cn/article-10903-1.html | 
网上有很多可以用来管理你个人财务的服务。虽然它们可能很方便,但这通常也意味着将你最宝贵的个人数据放在你无法监控的公司。也有些人对这些不太在意。
无论你是否在意,你可能会对你自己系统上的应用感兴趣。这意味着如果你不想,你的数据永远不会离开自己的计算机。这三款之一可能就是你想找的。
### HomeBank
HomeBank 是一款可以管理多个账户的全功能软件。它很容易设置并保持更新。它有多种方式画出你的分类和负债,以便你可以看到资金流向何处。它可以通过官方 Fedora 仓库下载。

要安装 HomeBank,请打开“软件中心”,搜索 “HomeBank”,然后选择该应用。单击“安装”将其添加到你的系统中。HomeBank 也可以通过 Flatpak 安装。
### KMyMoney
KMyMoney 是一个成熟的应用,它已经存在了很长一段时间。它有一系列稳定的功能,可帮助你管理多个帐户,包括资产、负债、税收等。KMyMoney 包含一整套用于管理投资和进行预测的工具。它还提供大量报告,以了解你的资金运作方式。

要安装它,请使用软件中心,或使用命令行:
```
$ sudo dnf install kmymoney
```
### GnuCash
用于个人财务的最受欢迎的免费 GUI 应用之一是 GnuCash。GnuCash 不仅可以用于个人财务。它还有管理企业收入、资产和负债的功能。这并不意味着你不能用它来管理自己的账户。从查看[在线教程和指南](https://www.gnucash.org/viewdoc.phtml?rev=3&lang=C&doc=guide)开始了解。

打开“软件中心”,搜索 “GnuCash”,然后选择应用。单击“安装”将其添加到你的系统中。或者如上所述使用 `dnf install` 来安装 “gnucash” 包。
它现在可以通过 Flathub 安装,这使得安装变得简单。如果你没有安装 Flathub,请查看 [Fedora Magazine 上的这篇文章](https://fedoramagazine.org/install-flathub-apps-fedora/)了解如何使用它。这样你也可以在终端使用 `flatpak install gnucash` 命令。
---
照片由 [Fabian Blank](https://unsplash.com/photos/pElSkGRA2NU?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 拍摄,发布在 [Unsplash](https://unsplash.com/search/photos/money?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 上。
---
via: <https://fedoramagazine.org/3-apps-to-manage-personal-finances-in-fedora/>
作者:[Paul W. Frields](https://fedoramagazine.org/author/pfrields/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are numerous services available on the web for managing your personal finances. Although they may be convenient, they also often mean leaving your most valuable personal data with a company you can’t monitor. Some people are comfortable with this level of trust.
Whether you are or not, you might be interested in an app you can maintain on your own system. This means your data never has to leave your own computer if you don’t want. One of these three apps might be what you’re looking for.
## HomeBank
HomeBank is a fully featured way to manage multiple accounts. It’s easy to set up and keep updated. It has multiple ways to categorize and graph income and liabilities so you can see where your money goes. It’s available through the official Fedora repositories.
To install HomeBank, open the *Software* app, search for *HomeBank*, and select the app. Then click *Install* to add it to your system. HomeBank is also available via a Flatpak.
## KMyMoney
The KMyMoney app is a mature app that has been around for a long while. It has a robust set of features to help you manage multiple accounts, including assets, liabilities, taxes, and more. KMyMoney includes a full set of tools for managing investments and making forecasts. It also sports a huge set of reports for seeing how your money is doing.
To install, use a software center app, or use the command line:
$ sudo dnf install kmymoney
## GnuCash
One of the most venerable free GUI apps for personal finance is GnuCash. GnuCash is not just for personal finances. It also has functions for managing income, assets, and liabilities for a business. That doesn’t mean you can’t use it for managing just your own accounts. Check out [the online tutorial and guide](https://www.gnucash.org/viewdoc.phtml?rev=3&lang=C&doc=guide) to get started.
Open the *Software* app, search for *GnuCash*, and select the app. Then click *Install* to add it to your system. Or use *dnf install* as above to install the *gnucash* package.
It’s now available via Flathub which makes installation easy. If you don’t have Flathub support, check out [this article on the Fedora Magazine](https://fedoramagazine.org/install-flathub-apps-fedora/) for how to use it. Then you can also use the *flatpak install GnuCash* command with a terminal.
*Photo by **Fabian Blank** on *[ Unsplash](https://unsplash.com/search/photos/money?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText).
## Yazan Al Monshed
Nice Blog. Thank you
## Ph0zzy
There is a better way to install homebank:
https://flathub.org/apps/details/fr.free.Homebank
Use flatpak, Luke!
## Paul W. Frields
@Ph0zzy: Fixed! Thanks for the tip. For some reason it wasn’t showing up in Software for me, but appears fine now.
## Michael Carpino
Been using KMyMoney for a few years now after converting from Quicken. I first tried GnuCash but found it to be a little more cumbersome to use as compared to KMyMoney. KMyMoney is feature rich and runs faster than Quicken when the database becomes larger. I will never go back to Quicken after using KMyMoney.
## Connie Kaiser-Pereira DC
Thank you
## Jens Petersen
We also have hledger in Fedora if you like command-line interface.
## Cyril
What’s about Grisbi ?
http://en.grisbi.org/
## RolandC
I have only tried GNU Cash out of those three, but I can recommend it and only it, by far. GNU Cash is the closest piece of software to Quicken you could ever find.
I have managed my personal finances on it for almost three years now, without any real trouble. Beware though, unless you work as an accountant, read at least about basic principles as described at the beginning of the documentation so you avoid frustration later on. Enjoy!
## Drakkai
Hombank the best 🙂
## bill
Probably worth noting that you have also listed them in order of complexity/learning curve.
## Kiuj
Thank you. Hombank the best
## jesse
I am having a hard time choosing between KmyMoney and Gnucash.
I have used both and I think both have strenghts and weaknesses.
KMyMoney lets you input transactions with a Payee, Category, and you can tag transactions. KMM, keeps a list of the tags you have created, a list of the Payees you have, and a list of Categories. You can report on Transactions by Payee, by Category, by Account(for Assets/Liabilities). It features tons of reports. Although nice, these are not GAAP type reports. For example Cash Flow in KMyMoney is not the same as a Statement of CashFlows, AKA CashFlow Statement. Although KMyMoney is a double-entry system, the reports do not show the Debits and Credits as being you would expect from a double-entry system. Debits in one column, Credits in another. It seems to use Double-Entry as the balancing equation but does not fully implement it down to the reporting methods GAAP would ask. I wish it would as it would then fit all scenarios. I don’t want to see negative values in my reports such as liabilities having negative values vs Assets having positive values. They should all be absolute values in reporting(meaning unsigned).
Gnucash, althought harder to grasp than KMyMoney, and really only because you have to consider Expense/Income Categories are actually Accounts in GnuCash. Where in KMyMoney they are simply Categories without an Account. GnuCash keeps to the Business GAAP requirements of having Accounts, not Categories. GnuCash features tons of reports that can help your business, and you, grow. If you have an accountant, they will love the output of GnuCash since it already breaks information down to the type of reports they expect to produce in GAAP fashion. Gnucash does not keep a list of Payees, allow for Tags. It allows for ‘Categories’ but it implements them as Accounts.
Reporting wise, both have the benefits. KMM has very flexible reports, GnuCash has fewer options to configure and you cannot do a side by side comparison by month or year easily. In KMM, this is an easy thing to do. In GnuCash, you have to generate thereports by year or month, and then export it to excel to see a side by side comparison of the numbers. GnuCash does offer a graph that shows you the growth trend, but you cannot see the numbers side by side. If it had that, it would be perfectly ideal.
## Michael Andrews
I’ve been using KMyMoney for over eight years now and can highly recommend it. I was a Quicken refugee and found it the easier to understand than GnuCash.
## Connie KAISER-PEREIRA DC
Thank you for SHARING $$$$
## CJung
No Skrooge mention?
I use it for 10 years and it rocks! |
10,906 | 用 GHTorrent 和 Libraries.io 查询 10 年的 GitHub 数据 | https://opensource.com/article/19/5/chaossearch-github-ghtorrent | 2019-05-27T22:02:14 | [
"GitHub"
] | https://linux.cn/article-10906-1.html |
>
> 有一种方法可以在没有任何本地基础设施的情况下使用开源数据集探索 GitHub 数据。
>
>
>

我一直在寻找新的数据集,以用它们来展示我们团队工作的力量。[CHAOSSEARCH](https://chaossearch.io/) 可以将你的 [Amazon S3](https://aws.amazon.com/s3/) 对象存储数据转换为完全可搜索的 [Elasticsearch](https://www.elastic.co/) 式集群。使用 Elasticsearch API 或 [Kibana](https://www.elastic.co/products/kibana) 等工具,你可以查询你所要找的任何数据。
当我找到 [GHTorrent](http://ghtorrent.org) 项目进行探索时,我很兴奋。GHTorrent 旨在通过 GitHub API 构建所有可用数据的离线版本。如果你喜欢数据集,这是一个值得一看的项目,甚至你可以考虑[捐赠一个 GitHub API 密钥](http://ghtorrent.org/services.html)。
### 访问 GHTorrent 数据
有许多方法可以访问和使用 [GHTorrent 的数据](http://ghtorrent.org/downloads.html),它以 [NDJSON](http://ndjson.org) 格式提供。这个项目可以以多种形式提供数据,包括用于恢复到 [MySQL](https://en.wikipedia.org/wiki/MySQL) 数据库的 [CSV](https://en.wikipedia.org/wiki/Comma-separated_values),可以转储所有对象的 [MongoDB](https://www.mongodb.com/),以及用于将数据直接导出到 Google 对象存储中的 Google Big Query(免费)。 有一点需要注意:这个数据集有从 2008 年到 2017 年几乎完整的数据集,但从 2017 年到现在的数据还不完整。这将影响我们确定性查询的能力,但它仍然是一个令人兴奋的信息量。
我选择 Google Big Query 来避免自己运行任何数据库,那么我就可以很快下载包括用户和项目在内的完整数据库。CHAOSSEARCH 可以原生分析 NDJSON 格式,因此在将数据上传到 Amazon S3 之后,我能够在几分钟内对其进行索引。CHAOSSEARCH 平台不要求用户设置索引模式或定义其数据的映射,它可以发现所有字段本身(字符串、整数等)。
随着我的数据完全索引并准备好进行搜索和聚合,我想深入了解看看我们可以发现什么,比如哪些软件语言是 GitHub 项目最受欢迎的。
(关于格式化的说明:下面这是一个有效的 JSON 查询,我们不会在这里正确格式化以避免滚动疲劳。要正确格式化它,你可以在本地复制它并发送到命令行实用程序,如 [jq](https://stedolan.github.io/jq/)。)
```
{"aggs":{"2":{"date_histogram":{"field":"root.created_at","interval":"1M","time_zone":"America/New_York","min_doc_count":1}}},"size":0,"_source":{"excludes":[]},"stored_fields":["*"],"script_fields":{},"docvalue_fields":["root.created_at","root.updated_at"],"query":{"bool":{"must":[],"filter":[{"match_all":{}}],"should":[],"must_not":[{"match_phrase":{"root.language":{"query":""}}}]}}}
```
对于那些近年来跟踪开源语言状态的人来说,这个结果并不令人惊讶。

[JavaScript](https://en.wikipedia.org/wiki/JavaScript) 仍然是卫冕冠军,虽然有些人认为 JavaScript 正在逐渐消失,但它仍然是 800 磅重的大猩猩,很可能会保持这种状态一段时间。[Java](/resources/java) 面临类似的谣言,但这些数据表明它是开源生态系统的重要组成部分。
考虑到像 [Docker](/resources/what-docker) 和 [Kubernetes](/resources/what-is-kubernetes) 这样的项目的流行,你可能会想,“Go([Golang](https://golang.org/))怎么样?”这是一个提醒的好时机,这里讨论的 GitHub 数据集包含一些空缺,最明显的是在 2017 年之后我看到 Golang 项目随处可见,而这里并没有显示。我希望用完整的 GitHub 数据集重复此搜索,看看它是否会改变排名。
现在让我们来探讨项目创建的速度。 (提醒:这是为了便于阅读而合并的有效 JSON。)
```
{"aggs":{"2":{"date_histogram":{"field":"root.created_at","interval":"1M","time_zone":"America/New_York","min_doc_count":1}}},"size":0,"_source":{"excludes":[]},"stored_fields":["*"],"script_fields":{},"docvalue_fields":["root.created_at","root.updated_at"],"query":{"bool":{"must":[],"filter":[{"match_all":{}}],"should":[],"must_not":[{"match_phrase":{"root.language":{"query":""}}}]}}}
```
我们可以看到创建新项目的速度,也会给人留下深刻的印象,从 2012 年左右开始大幅增长:

既然我知道了创建项目的速度以及用于创建这些项目的最流行的语言,我还想知道这些项目选择的开源许可证。遗憾的是,这个 GitHub 项目数据集中并不存在这些数据,但是 [Tidelift](https://tidelift.com) 的精彩团队在 [Libraries.io](http://libraries.io/) [数据](https://libraries.io/data) 里发布了一个 GitHub 项目的详细列表,包括使用的许可证以及其中有关开源软件状态的其他详细信息。将此数据集导入 CHAOSSEARCH 只花了几分钟,让我看看哪些开源软件许可证在 GitHub 上最受欢迎:
(提醒:这是为了便于阅读而合并的有效 JSON。)
```
{"aggs":{"2":{"terms":{"field":"Repository License","size":10,"order":{"_count":"desc"}}}},"size":0,"_source":{"excludes":[]},"stored_fields":["*"],"script_fields":{},"docvalue_fields":["Created Timestamp","Last synced Timestamp","Latest Release Publish Timestamp","Updated Timestamp"],"query":{"bool":{"must":[],"filter":[{"match_all":{}}],"should":[],"must_not":[{"match_phrase":{"Repository License":{"query":""}}}]}}}
```
结果显示了一些重要的异常值:

如你所见,[MIT 许可证](https://opensource.org/licenses/MIT) 和 [Apache 2.0 许可证](https://opensource.org/licenses/Apache-2.0) 的开源项目远远超过了其他大多数开源许可证,而 [各种 BSD 和 GPL 许可证](https://opensource.org/licenses) 则差得很远。鉴于 GitHub 的开放模式,我不能说我对这些结果感到惊讶。我猜想是用户(而不是公司)创建了大多数项目,并且他们使用 MIT 许可证可以使其他人轻松地使用、共享和贡献。而鉴于有不少公司希望确保其商标得到尊重并为其业务提供开源组件,那么 Apache 2.0 许可证数量高企的背后也是有道理的。
现在我确定了最受欢迎的许可证,我很想看看最少使用的许可证。通过调整我的上一个查询,我将前 10 名逆转为最后 10 名,并且只找到了两个使用 [伊利诺伊大学 - NCSA 开源许可证](https://tldrlegal.com/license/university-of-illinois---ncsa-open-source-license-(ncsa)) 的项目。我之前从未听说过这个许可证,但它与 Apache 2.0 非常接近。看到所有 GitHub 项目中使用了多少个不同的软件许可证,这很有意思。

之后,我针对特定语言(JavaScript)来查看最常用的许可证。(提醒:这是为了便于阅读而合并的有效JSON。)
```
{"aggs":{"2":{"terms":{"field":"Repository License","size":10,"order":{"_count":"desc"}}}},"size":0,"_source":{"excludes":[]},"stored_fields":["*"],"script_fields":{},"docvalue_fields":["Created Timestamp","Last synced Timestamp","Latest Release Publish Timestamp","Updated Timestamp"],"query":{"bool":{"must":[{"match_phrase":{"Repository Language":{"query":"JavaScript"}}}],"filter":[{"match_all":{}}],"should":[],"must_not":[{"match_phrase":{"Repository License":{"query":""}}}]}}}
```
这个输出有一些意外。

尽管使用 `npm init` 创建的 [NPM](https://www.npmjs.com/) 模块的默认许可证是来自 [Internet Systems Consortium(ISC)](https://en.wikipedia.org/wiki/ISC_license) 的许可证,但你可以看到相当多的这些项目使用 MIT 以及 Apache 2.0 的开源许可证。
由于 Libraries.io 数据集中包含丰富的开源项目内容,并且由于 GHTorrent 数据缺少最近几年的数据(因此缺少有关 Golang 项目的任何细节),因此我决定运行类似的查询来查看 Golang 项目是如何许可他们的代码的。
(提醒:这是为了便于阅读而合并的有效 JSON。)
```
{"aggs":{"2":{"terms":{"field":"Repository License","size":10,"order":{"_count":"desc"}}}},"size":0,"_source":{"excludes":[]},"stored_fields":["*"],"script_fields":{},"docvalue_fields":["Created Timestamp","Last synced Timestamp","Latest Release Publish Timestamp","Updated Timestamp"],"query":{"bool":{"must":[{"match_phrase":{"Repository Language":{"query":"Go"}}}],"filter":[{"match_all":{}}],"should":[],"must_not":[{"match_phrase":{"Repository License":{"query":""}}}]}}}
```
结果与 Javascript 完全不同。

Golang 项目与 JavaScript 项目惊人逆转 —— 使用 Apache 2.0 的 Golang 项目几乎是 MIT 许可证的三倍。虽然很难准确地解释为什么会出现这种情况,但在过去的几年中,Golang 已经出现了大规模的增长,特别是在开源和商业化的项目和软件产品公司中。
正如我们上面所了解的,这些公司中的许多公司都希望强制执行其商标策略,因此转向 Apache 2.0 许可证是有道理的。
#### 总结
最后,我通过深入了解 GitHub 用户和项目的数据找到了一些有趣的结果。其中一些我肯定会猜到,但是一些结果对我来说也是惊喜,特别是像很少使用的 NCSA 许可证这样的异常值。
总而言之,你可以看到 CHAOSSEARCH 平台能够快速轻松地找到有趣问题的复杂答案。我无需自己运行任何数据库就可以深入研究这个数据集,甚至可以在 Amazon S3 上以低成本的方式存储数据,因此无需维护。 现在,我可以随时查询有关这些数据的任何其他问题。
你对数据提出了哪些其他问题,以及你使用了哪些数据集?请在评论或推特上告诉我 [@petecheslock](https://twitter.com/petecheslock)。
本文的一个版本最初发布在 [CHAOSSEARCH](https://chaossearch.io/blog/where-are-the-github-users-part-1/),有更多结果可供发现。
---
via: <https://opensource.com/article/19/5/chaossearch-github-ghtorrent>
作者:[Pete Cheslock](https://opensource.com/users/petecheslock/users/ghaff/users/payalsingh/users/davidmstokes) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I’m always on the lookout for new datasets that we can use to show off the power of my team's work. [ CHAOSSEARCH](https://chaossearch.io/) turns your
[Amazon S3](https://aws.amazon.com/s3/)object storage data into a fully searchable
[Elasticsearch](https://www.elastic.co/)-like cluster. With the Elasticsearch API or tools like
[Kibana](https://www.elastic.co/products/kibana), you can then query whatever data you find.
I was excited when I found the [GHTorrent](http://ghtorrent.org) project to explore. GHTorrent aims to build an offline version of all data available through the GitHub APIs. If datasets are your thing, this is a project worth checking out or even consider [donating one of your GitHub API keys](http://ghtorrent.org/services.html).
# Accessing GHTorrent data
There are many ways to gain access to and use [GHTorrent’s data](http://ghtorrent.org/downloads.html), which is available in [NDJSON](http://ndjson.org)** **format. This project does a great job making the data available in multiple forms, including [CSV](https://en.wikipedia.org/wiki/Comma-separated_values) for restoring into a [MySQL](https://en.wikipedia.org/wiki/MySQL) database, [MongoDB](https://www.mongodb.com/) dumps of all objects, and Google Big Query** **(free) for exporting data directly into Google’s object storage. There is one caveat: this dataset has a nearly complete dataset from 2008 to 2017 but is not as complete from 2017 to today. That will impact our ability to query with certainty, but it is still an exciting amount of information.
I chose Google Big Query to avoid running any database myself, so I was quickly able to download a full corpus of data including users and projects. **CHAOS**SEARCH can natively analyze the NDJSON format, so after uploading the data to Amazon S3 I was able to index it in just a few minutes. The **CHAOS**SEARCH platform doesn’t require users to set up index schemas or define mappings for their data, so it discovered all of the fields—strings, integers, etc.—itself.
With my data fully indexed and ready for search and aggregation, I wanted to dive in and see what insights we can learn, like which software languages are the most popular for GitHub projects.
(A note on formatting: this is a valid JSON query that we won't format correctly here to avoid scroll fatigue. To properly format it, you can copy it locally and send to a command-line utility like [jq](https://stedolan.github.io/jq/).)
```
````{"aggs":{"2":{"date_histogram":{"field":"root.created_at","interval":"1M","time_zone":"America/New_York","min_doc_count":1}}},"size":0,"_source":{"excludes":[]},"stored_fields":["*"],"script_fields":{},"docvalue_fields":["root.created_at","root.updated_at"],"query":{"bool":{"must":[],"filter":[{"match_all":{}}],"should":[],"must_not":[{"match_phrase":{"root.language":{"query":""}}}]}}}`
This result is of little surprise to anyone who’s followed the state of open source languages over recent years.
[JavaScript](https://en.wikipedia.org/wiki/JavaScript) is still the reigning champion, and while some believe JavaScript is on its way out, it remains the 800-pound gorilla and is likely to remain that way for some time. [Java](https://opensource.com/resources/java) faces similar rumors and this data shows that it's a major part of the open source ecosystem.
Given the popularity of projects like [Docker](https://opensource.com/resources/what-docker) and [Kubernetes](https://opensource.com/resources/what-is-kubernetes), you might be wondering, “What about Go ([Golang](https://golang.org/))?” This is a good time for a reminder that the GitHub dataset discussed here contains some gaps, most significantly after 2017, which is about when I saw Golang projects popping up everywhere. I hope to repeat this search with a complete GitHub dataset and see if it changes the rankings at all.
Now let's explore the rate of project creation. (Reminder: this is valid JSON consolidated for readability.)
```
``````
{"aggs":{"2":{"date_histogram":{"field":"root.created_at","interval":"1M","time_zone":"America/New_York","min_doc_count":1}}},"size":0,"_source":{"excludes":[]},"stored_fields":["*"],"script_fields":{},"docvalue_fields":["root.created_at","root.updated_at"],"query":{"bool":{"must":[],"filter":[{"match_all":{}}],"should":[],"must_not":[{"match_phrase":{"root.language":{"query":""}}}]}}}
```
Seeing the rate at which new projects are created would be fun impressive as well, with tremendous growth starting around 2012:
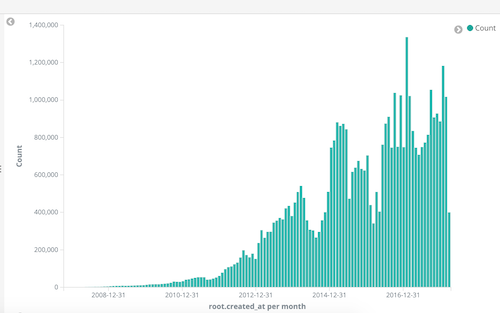
Now that I knew the rate of projects created as well as the most popular languages used to create these projects, I wanted to find out what open source licenses these projects chose. Unfortunately, this data doesn’t exist in the GitHub projects dataset, but the fantastic team over at [Tidelift](https://tidelift.com) publishes a detailed list of GitHub projects, licenses used, and other details regarding the state of open source software in their [Libraries.io](http://libraries.io/)[ data](https://libraries.io/data). Ingesting this dataset into **CHAOS**SEARCH took just minutes, letting me see which open source software licenses are the most popular on GitHub:
(Reminder: this is valid JSON consolidated for readability.)
```
````{"aggs":{"2":{"terms":{"field":"Repository License","size":10,"order":{"_count":"desc"}}}},"size":0,"_source":{"excludes":[]},"stored_fields":["*"],"script_fields":{},"docvalue_fields":["Created Timestamp","Last synced Timestamp","Latest Release Publish Timestamp","Updated Timestamp"],"query":{"bool":{"must":[],"filter":[{"match_all":{}}],"should":[],"must_not":[{"match_phrase":{"Repository License":{"query":""}}}]}}}`
The results show some significant outliers:
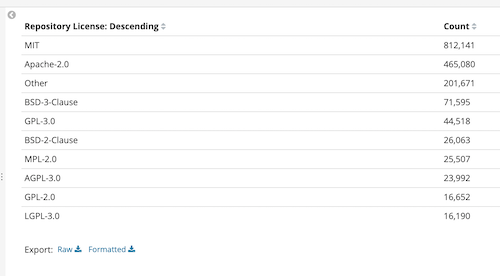
As you can see, the [MIT license](https://opensource.org/licenses/MIT) and the [Apache 2.0 license](https://opensource.org/licenses/Apache-2.0) by far outweighs most of the other open source licenses used for these projects, while [various BSD and GPL licenses](https://opensource.org/licenses) follow far behind. I can’t say that I’m surprised by these results given GitHub’s open model. I would guess that users, not companies, create most projects and that they use the MIT license to make it simple for other people to use, share, and contribute. That Apache 2.0** **licensing is right behind also makes sense, given just how many companies want to ensure their trademarks are respected and have an open source component to their businesses.
Now that I identified the most popular licenses, I was curious to see the least used ones. By adjusting my last query, I reversed the top 10 into the bottom 10 and was able to find just two projects using the [University of Illinois—NCSA Open Source License](https://tldrlegal.com/license/university-of-illinois---ncsa-open-source-license-(ncsa)). I had never heard of this license before, but it’s pretty close to Apache 2.0. It’s interesting to see just how many different software licenses are in use across all GitHub projects.
The University of Illinois/NCSA open source license.
After that, I dove into a specific language (JavaScript) to see the most popular license used there. (Reminder: this is valid JSON consolidated for readability.)
```
``````
{"aggs":{"2":{"terms":{"field":"Repository License","size":10,"order":{"_count":"desc"}}}},"size":0,"_source":{"excludes":[]},"stored_fields":["*"],"script_fields":{},"docvalue_fields":["Created Timestamp","Last synced Timestamp","Latest Release Publish Timestamp","Updated Timestamp"],"query":{"bool":{"must":[{"match_phrase":{"Repository Language":{"query":"JavaScript"}}}],"filter":[{"match_all":{}}],"should":[],"must_not":[{"match_phrase":{"Repository License":{"query":""}}}]}}}
```
There were some surprises in this output.
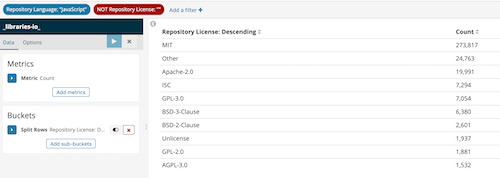
Even though the default license for [NPM](https://www.npmjs.com/) modules when created with **npm init **is the one from [Internet Systems Consortium (ISC)](https://en.wikipedia.org/wiki/ISC_license), you can see that a considerable number of these projects use MIT as well as Apache 2.0 for their open source license.
Since the Libraries.io dataset is rich in open source project content, and since the GHTorrent data is missing the last few years’ data (and thus missing any details about Golang projects), I decided to run a similar query to see how Golang projects license their code.
(Reminder: this is valid JSON consolidated for readability.)
```
````{"aggs":{"2":{"terms":{"field":"Repository License","size":10,"order":{"_count":"desc"}}}},"size":0,"_source":{"excludes":[]},"stored_fields":["*"],"script_fields":{},"docvalue_fields":["Created Timestamp","Last synced Timestamp","Latest Release Publish Timestamp","Updated Timestamp"],"query":{"bool":{"must":[{"match_phrase":{"Repository Language":{"query":"Go"}}}],"filter":[{"match_all":{}}],"should":[],"must_not":[{"match_phrase":{"Repository License":{"query":""}}}]}}}`
The results were quite different than Javascript.
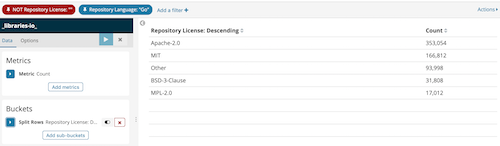
Golang offers a stunning reversal from JavaScript—nearly three times as many Golang projects are licensed with Apache 2.0 over MIT. While it’s hard precisely explain why this is the case, over the last few years there’s been massive growth in Golang, especially among companies building projects and software offerings, both open source and commercially.
As we learned above, many of these companies want to enforce their trademarks, thus the move to the Apache 2.0 license makes sense.
## Conclusion
In the end, I found some interesting results by diving into the GitHub users and projects data dump. Some of these I definitely would have guessed, but a few results were surprises to me as well, especially the outliers like the rarely-used NCSA license.
All in all, you can see how quickly and easily the **CHAOS**SEARCH platform lets us find complicated answers to interesting questions. I dove into this dataset and received deep analytics without having to run any databases myself, and even stored the data inexpensively on Amazon S3—so there’s little maintenance involved. Now I can ask any other questions regarding the data anytime I want.
What other questions are you asking your data, and what data sets do you use? Let me know in the comments or on Twitter [@petecheslock](https://twitter.com/petecheslock).
*A version of this article was originally posted on *
**CHAOS**SEARCH.
## Comments are closed. |
10,907 | systemd 代码已超 120 万行!五年间翻了一番 | https://www.phoronix.com/scan.php?page=news_item&px=Systemd-1.2-Million | 2019-05-27T22:40:00 | [
"systemd"
] | /article-10907-1.html | 
五年前, Phoronix 发现 [systemd 源码树已经接近 55 万行](https://www.phoronix.com/scan.php?page=news_item&px=MTY5NjM),所以好奇之下,让我们来看看今天的 systemd Git 存储库有多大:现在已超过 120 万行了!

*systemd 代码行数*
在 2017 年超过 [systemd 的代码超过了 100 万行](https://www.phoronix.com/scan.php?page=news_item&px=systemd-2017-Git-Activity)之后,如今在 systemd 的 Git 存储库上运行 GitStats 时,发现它已经有 1,207,302 行了。这 120 万行分布在 3,260 个文件中,来自近 1,400 个不同作者的 40,057 个提交。

*systemd 提交数*
去年,systemd 出现了创纪录的提交数量,但到目前为止,2019 年恐怕很难再次看到突破该记录。到目前为止,今年已有 2,145 个提交,而去年有 6,245 个提交,而 2016 年和 2017 年每年的提交总数不到 4 千个。
Lennart Poettering 依旧是 systemd 最多产的贡献者,今年迄今为止他贡献了超过 32% 的提交。今年其他多产贡献者包括 Yu Watanabe、ZbigniewJędrzejewski-Szmek、Frantisek Sumsal、Susant Sahani 和 Evgeny Vereshchagin 等人。到目前为止,已有大约 142 人为 systemd 的源代码树做出了贡献。
对于那些对其他系统统计数据感兴趣的人,请参阅[最新的 GitStats 输出](https://phoronix.com/misc/systemd-201905/index.html)。
| null | HTTPSConnectionPool(host='www.phoronix.com', port=443): Read timed out. (read timeout=10) | null |
10,908 | 使用 k3s 在 Fedora IoT 上运行 K8S | https://fedoramagazine.org/kubernetes-on-fedora-iot-with-k3s/ | 2019-05-28T09:41:48 | [
"K8S",
"k3s"
] | https://linux.cn/article-10908-1.html | 
Fedora IoT 是一个即将发布的、面向物联网的 Fedora 版本。去年 Fedora Magazine 的《[如何使用 Fedora IoT 点亮 LED 灯](/article-10380-1.html)》一文第一次介绍了它。从那以后,它与 Fedora Silverblue 一起不断改进,以提供针对面向容器的工作流的不可变基础操作系统。
Kubernetes 是一个颇受欢迎的容器编排系统。它可能最常用在那些能够处理巨大负载的强劲硬件上。不过,它也能在像树莓派 3 这样轻量级的设备上运行。让我们继续阅读,来了解如何运行它。
### 为什么用 Kubernetes?
虽然 Kubernetes 在云计算领域风靡一时,但让它在小型单板机上运行可能并不是常见的。不过,我们有非常明确的理由来做这件事。首先,这是一个不需要昂贵硬件就可以学习并熟悉 Kubernetes 的好方法;其次,由于它的流行性,市面上有[大量应用](https://hub.helm.sh/)进行了预先打包,以用于在 Kubernetes 集群中运行。更不用说,当你遇到问题时,会有大规模的社区用户为你提供帮助。
最后但同样重要的是,即使是在家庭实验室这样的小规模环境中,容器编排也确实能够使事情变得更加简单。虽然在学习曲线方面,这一点并不明显,但这些技能在你将来与任何集群打交道的时候都会有帮助。不管你面对的是一个单节点树莓派集群,还是一个大规模的机器学习场,它们的操作方式都是类似的。
#### K3s - 轻量级的 Kubernetes
一个“正常”安装的 Kubernetes(如果有这么一说的话)对于物联网来说有点沉重。K8s 的推荐内存配置,是每台机器 2GB!不过,我们也有一些替代品,其中一个新人是 [k3s](https://k3s.io) —— 一个轻量级的 Kubernetes 发行版。
K3s 非常特殊,因为它将 etcd 替换成了 SQLite 以满足键值存储需求。还有一点,在于整个 k3s 将使用一个二进制文件分发,而不是每个组件一个。这减少了内存占用并简化了安装过程。基于上述原因,我们只需要 512MB 内存即可运行 k3s,极度适合小型单板电脑!
### 你需要的东西
1. Fedora IoT 运行在虚拟机或实体设备中运行的。在[这里](https://docs.fedoraproject.org/en-US/iot/getting-started/)可以看到优秀的入门指南。一台机器就足够了,不过两台可以用来测试向集群添加更多节点。
2. [配置防火墙](https://github.com/rancher/k3s#open-ports--network-security),允许 6443 和 8372 端口的通信。或者,你也可以简单地运行 `systemctl stop firewalld` 来为这次实验关闭防火墙。
### 安装 k3s
安装 k3s 非常简单。直接运行安装脚本:
```
curl -sfL https://get.k3s.io | sh -
```
它会下载、安装并启动 k3s。安装完成后,运行以下命令来从服务器获取节点列表:
```
kubectl get nodes
```
需要注意的是,有几个选项可以通过环境变量传递给安装脚本。这些选项可以在[文档](https://github.com/rancher/k3s#systemd)中找到。当然,你也完全可以直接下载二进制文件来手动安装 k3s。
对于实验和学习来说,这样已经很棒了,不过单节点的集群也不能算一个集群。幸运的是,添加另一个节点并不比设置第一个节点要难。只需要向安装脚本传递两个环境变量,它就可以找到第一个节点,而不用运行 k3s 的服务器部分。
```
curl -sfL https://get.k3s.io | K3S_URL=https://example-url:6443 \
K3S_TOKEN=XXX sh -
```
上面的 `example-url` 应被替换为第一个节点的 IP 地址,或一个完全限定域名。在该节点中,(用 XXX 表示的)令牌可以在 `/var/lib/rancher/k3s/server/node-token` 文件中找到。
### 部署一些容器
现在我们有了一个 Kubernetes 集群,我们可以真正做些什么呢?让我们从部署一个简单的 Web 服务器开始吧。
```
kubectl create deployment my-server --image nginx
```
这会从名为 `nginx` 的容器镜像中创建出一个名叫 `my-server` 的 [部署](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/)(默认使用 docker hub 注册中心,以及 `latest` 标签)。
```
kubectl get pods
```
为了访问到 pod 中运行的 nginx 服务器,首先通过一个 [服务](https://kubernetes.io/docs/concepts/services-networking/service/) 来暴露该部署。以下命令将创建一个与该部署同名的服务。
```
kubectl expose deployment my-server --port 80
```
服务将作为一种负载均衡器和 Pod 的 DNS 记录来工作。比如,当运行第二个 Pod 时,我们只需指定 `my-server`(服务名称)就可以通过 `curl` 访问 nginx 服务器。有关如何操作,可以看下面的实例。
```
# 启动一个 pod,在里面以交互方式运行 bash
kubectl run debug --generator=run-pod/v1 --image=fedora -it -- bash
# 等待 bash 提示符出现
curl my-server
# 你可以看到“Welcome to nginx!”的输出页面
```
### Ingress 控制器及外部 IP
默认状态下,一个服务只能获得一个 ClusterIP(只能从集群内部访问),但你也可以通过把它的类型设置为 [LoadBalancer](https://kubernetes.io/docs/concepts/services-networking/service/#loadbalancer) 为该服务申请一个外部 IP。不过,并非所有应用都需要自己的 IP 地址。相反,通常可以通过基于 Host 请求头部或请求路径进行路由,从而使多个服务共享一个 IP 地址。你可以在 Kubernetes 使用 [Ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/) 完成此操作,而这也是我们要做的。Ingress 也提供了额外的功能,比如无需配置应用即可对流量进行 TLS 加密。
Kubernetes 需要 Ingress 控制器来使 Ingress 资源工作,k3s 包含 [Traefik](https://traefik.io/) 正是出于此目的。它还包含了一个简单的服务负载均衡器,可以为集群中的服务提供外部 IP。这篇[文档](https://github.com/rancher/k3s/blob/master/README.md#service-load-balancer)描述了这种服务:
>
> k3s 包含一个使用可用主机端口的基础服务负载均衡器。比如,如果你尝试创建一个监听 80 端口的负载均衡器,它会尝试在集群中寻找一个 80 端口空闲的节点。如果没有可用端口,那么负载均衡器将保持在 Pending 状态。
>
>
> k3s README
>
>
>
Ingress 控制器已经通过这个负载均衡器暴露在外。你可以使用以下命令找到它正在使用的 IP 地址。
```
$ kubectl get svc --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.43.0.1 443/TCP 33d
default my-server ClusterIP 10.43.174.38 80/TCP 30m
kube-system kube-dns ClusterIP 10.43.0.10 53/UDP,53/TCP,9153/TCP 33d
kube-system traefik LoadBalancer 10.43.145.104 10.0.0.8 80:31596/TCP,443:31539/TCP 33d
```
找到名为 `traefik` 的服务。在上面的例子中,我们感兴趣的 IP 是 10.0.0.8。
### 路由传入的请求
让我们创建一个 Ingress,使它通过基于 Host 头部的路由规则将请求路由至我们的服务器。这个例子中我们使用 [xip.io](http://xip.io/) 来避免必要的 DNS 记录配置工作。它的工作原理是将 IP 地址作为子域包含,以使用 `10.0.0.8.xip.io` 的任何子域来达到 IP `10.0.0.8`。换句话说,`my-server.10.0.0.8.xip.io` 被用于访问集群中的 Ingress 控制器。你现在就可以尝试(使用你自己的 IP,而不是 10.0.0.8)。如果没有 Ingress,你应该会访问到“默认后端”,只是一个写着“404 page not found”的页面。
我们可以使用以下 Ingress 让 Ingress 控制器将请求路由到我们的 Web 服务器的服务。
```
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: my-server
spec:
rules:
- host: my-server.10.0.0.8.xip.io
http:
paths:
- path: /
backend:
serviceName: my-server
servicePort: 80
```
将以上片段保存到 `my-ingress.yaml` 文件中,然后运行以下命令将其加入集群:
```
kubectl apply -f my-ingress.yaml
```
你现在应该能够在你选择的完全限定域名中访问到 nginx 的默认欢迎页面了。在我的例子中,它是 `my-server.10.0.0.8.xip.io`。Ingress 控制器会通过 Ingress 中包含的信息来路由请求。对 `my-server.10.0.0.8.xip.io` 的请求将被路由到 Ingress 中定义为 `backend` 的服务和端口(在本例中为 `my-server` 和 `80`)。
### 那么,物联网呢?
想象如下场景:你的家或农场周围有很多的设备。它是一个具有各种硬件功能、传感器和执行器的物联网设备的异构集合。也许某些设备拥有摄像头、天气或光线传感器。其它设备可能会被连接起来,用来控制通风、灯光、百叶窗或闪烁的 LED。
这种情况下,你想从所有传感器中收集数据,在最终使用它来制定决策和控制执行器之前,也可能会对其进行处理和分析。除此之外,你可能还想配置一个仪表盘来可视化那些正在发生的事情。那么 Kubernetes 如何帮助我们来管理这样的事情呢?我们怎么保证 Pod 在合适的设备上运行?
简单的答案就是“标签”。你可以根据功能来标记节点,如下所示:
```
kubectl label nodes <node-name> <label-key>=<label-value>
# 举例
kubectl label nodes node2 camera=available
```
一旦它们被打上标签,我们就可以轻松地使用 [nodeSelector](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/) 为你的工作负载选择合适的节点。拼图的最后一块:如果你想在*所有*合适的节点上运行 Pod,那应该使用 [DaemonSet](https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/) 而不是部署。换句话说,应为每个使用唯一传感器的数据收集应用程序创建一个 DaemonSet,并使用 nodeSelector 确保它们仅在具有适当硬件的节点上运行。
服务发现功能允许 Pod 通过服务名称来寻找彼此,这项功能使得这类分布式系统的管理工作变得易如反掌。你不需要为应用配置 IP 地址或自定义端口,也不需要知道它们。相反,它们可以通过集群中的命名服务轻松找到彼此。
#### 充分利用空闲资源
随着集群的启动并运行,收集数据并控制灯光和气候,可能使你觉得你已经把它完成了。不过,集群中还有大量的计算资源可以用于其它项目。这才是 Kubernetes 真正出彩的地方。
你不必担心这些资源的确切位置,或者去计算是否有足够的内存来容纳额外的应用程序。这正是编排系统所解决的问题!你可以轻松地在集群中部署更多的应用,让 Kubernetes 来找出适合运行它们的位置(或是否适合运行它们)。
为什么不运行一个你自己的 [NextCloud](https://nextcloud.com/) 实例呢?或者运行 [gitea](https://gitea.io/en-us/)?你还可以为你所有的物联网容器设置一套 CI/CD 流水线。毕竟,如果你可以在集群中进行本地构建,为什么还要在主计算机上构建并交叉编译它们呢?
这里的要点是,Kubernetes 可以更容易地利用那些你可能浪费掉的“隐藏”资源。Kubernetes 根据可用资源和容错处理规则来调度 Pod,因此你也无需手动完成这些工作。但是,为了帮助 Kubernetes 做出合理的决定,你绝对应该为你的工作负载添加[资源请求](https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/)配置。
### 总结
尽管 Kuberenetes 或一般的容器编排平台通常不会与物联网相关联,但在管理分布式系统时,使用一个编排系统肯定是有意义的。你不仅可以使用统一的方式来处理多样化和异构的设备,还可以简化它们的通信方式。此外,Kubernetes 还可以更好地对闲置资源加以利用。
容器技术使构建“随处运行”应用的想法成为可能。现在,Kubernetes 可以更轻松地来负责“随处”的部分。作为构建一切的不可变基础,我们使用 Fedora IoT。
---
via: <https://fedoramagazine.org/kubernetes-on-fedora-iot-with-k3s/>
作者:[Lennart Jern](https://fedoramagazine.org/author/lennartj/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[StdioA](https://github.com/StdioA) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fedora IoT is an upcoming Fedora edition targeted at the Internet of Things. It was introduced last year on Fedora Magazine in the article [How to turn on an LED with Fedora IoT](https://fedoramagazine.org/turnon-led-fedora-iot/). Since then, it has continued to improve together with Fedora Silverblue to provide an immutable base operating system aimed at container-focused workflows.
Kubernetes is an immensely popular container orchestration system. It is perhaps most commonly used on powerful hardware handling huge workloads. However, it can also be used on lightweight devices such as the Raspberry Pi 3. Read on to find out how.
## Why Kubernetes?
While Kubernetes is all the rage in the cloud, it may not be immediately obvious to run it on a small single board computer. But there are certainly reasons for doing it. First of all it is a great way to learn and get familiar with Kubernetes without the need for expensive hardware. Second, because of its popularity, there are [tons of applications](https://hub.helm.sh/) that comes pre-packaged for running in Kubernetes clusters. Not to mention the large community to provide help if you ever get stuck.
Last but not least, container orchestration may actually make things easier, even at the small scale in a home lab. This may not be apparent when tackling the the learning curve, but these skills will help when dealing with any cluster in the future. It doesn’t matter if it’s a single node Raspberry Pi cluster or a large scale machine learning farm.
### K3s – a lightweight Kubernetes
A “normal” installation of Kubernetes (if such a thing can be said to exist) is a bit on the heavy side for IoT. The recommendation is a minimum of 2 GB RAM per machine! However, there are plenty of alternatives, and one of the newcomers is [k3s](https://k3s.io) – a lightweight Kubernetes distribution.
K3s is quite special in that it has replaced etcd with SQLite for its key-value storage needs. Another thing to note is that k3s ships as a single binary instead of one per component. This diminishes the memory footprint and simplifies the installation. Thanks to the above, k3s should be able to run k3s with just 512 MB of RAM, perfect for a small single board computer!
## What you will need
- Fedora IoT in a virtual machine or on a physical device. See the excellent getting started guide
[here](https://docs.fedoraproject.org/en-US/iot/getting-started/). One machine is enough but two will allow you to test adding more nodes to the cluster. [Configure the firewall](https://github.com/rancher/k3s#open-ports--network-security)to allow traffic on ports 6443 and 8472. Or simply disable it for this experiment by running “systemctl stop firewalld”.
## Install k3s
Installing k3s is very easy. Simply run the installation script:
curl -sfL https://get.k3s.io | sh -
This will download, install and start up k3s. After installation, get a list of nodes from the server by running the following command:
kubectl get nodes
Note that there are several options that can be passed to the installation script through environment variables. These can be found in the [documentation](https://github.com/rancher/k3s#systemd). And of course, there is nothing stopping you from installing k3s manually by downloading the binary directly.
While great for experimenting and learning, a single node cluster is not much of a cluster. Luckily, adding another node is no harder than setting up the first one. Just pass two environment variables to the installation script to make it find the first node and avoid running the server part of k3s
curl -sfL https://get.k3s.io | K3S_URL=https://example-url:6443 \
K3S_TOKEN=XXX sh -
The example-url above should be replaced by the IP address or fully qualified domain name of the first node. On that node the token (represented by XXX) is found in the file /var/lib/rancher/k3s/server/node-token.
## Deploy some containers
Now that we have a Kubernetes cluster, what can we actually do with it? Let’s start by deploying a simple web server.
kubectl create deployment my-server --image nginx
This will create a [Deployment](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/) named “my-server” from the container image “nginx” (defaulting to docker hub as registry and the latest tag). You can see the Pod created by running the following command.
kubectl get pods
In order to access the nginx server running in the pod, first expose the Deployment through a [Service](https://kubernetes.io/docs/concepts/services-networking/service/). The following command will create a Service with the same name as the deployment.
kubectl expose deployment my-server --port 80
The Service works as a kind of load balancer and DNS record for the Pods. For instance, when running a second Pod, we will be able to *curl* the nginx server just by specifying *my-server* (the name of the Service). See the example below for how to do this.
# Start a pod and run bash interactively in it
kubectl run debug --generator=run-pod/v1 --image=fedora -it -- bash
# Wait for the bash prompt to appear
curl my-server
# You should get the "Welcome to nginx!" page as output
## Ingress controller and external IP
By default, a Service only get a ClusterIP (only accessible inside the cluster), but you can also request an external IP for the service by setting its type to [LoadBalancer](https://kubernetes.io/docs/concepts/services-networking/service/#loadbalancer). However, not all applications require their own IP address. Instead, it is often possible to share one IP address among many services by routing requests based on the host header or path. You can accomplish this in Kubernetes with an [Ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/), and this is what we will do. Ingresses also provide additional features such as TLS encryption of the traffic without having to modify your application.
Kubernetes needs an ingress controller to make the Ingress resources work and k3s includes [Traefik](https://traefik.io/) for this purpose. It also includes a simple service load balancer that makes it possible to get an external IP for a Service in the cluster. The [documentation](https://github.com/rancher/k3s/blob/master/README.md#service-load-balancer) describes the service like this:
k3s includes a basic service load balancer that uses available host ports. If you try to create a load balancer that listens on port 80, for example, it will try to find a free host in the cluster for port 80. If no port is available the load balancer will stay in Pending.
k3s README
The ingress controller is already exposed with this load balancer service. You can find the IP address that it is using with the following command.
$ kubectl get svc --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.43.0.1 443/TCP 33d
default my-server ClusterIP 10.43.174.38 80/TCP 30m
kube-system kube-dns ClusterIP 10.43.0.10 53/UDP,53/TCP,9153/TCP 33d
kube-system traefik LoadBalancer 10.43.145.104 10.0.0.8 80:31596/TCP,443:31539/TCP 33d
Look for the Service named traefik. In the above example the IP we are interested in is 10.0.0.8.
## Route incoming requests
Let’s create an Ingress that routes requests to our web server based on the host header. This example uses [xip.io](http://xip.io/) to avoid having to set up DNS records. It works by including the IP adress as a subdomain, to use any subdomain of 10.0.0.8.xip.io to reach the IP 10.0.0.8. In other words, my-server.10.0.0.8.xip.io is used to reach the ingress controller in the cluster. You can try this right now (with your own IP instead of 10.0.0.8). Without an ingress in place you should reach the “default backend” which is just a page showing “404 page not found”.
We can tell the ingress controller to route requests to our web server Service with the following Ingress.
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: my-server
spec:
rules:
- host: my-server.10.0.0.8.xip.io
http:
paths:
- path: /
backend:
serviceName: my-server
servicePort: 80
Save the above snippet in a file named *my-ingress.yaml* and add it to the cluster by running this command:
kubectl apply -f my-ingress.yaml
You should now be able to reach the default nginx welcoming page on the fully qualified domain name you chose. In my example this would be my-server.10.0.0.8.xip.io. The ingress controller is routing the requests based on the information in the Ingress. A request to my-server.10.0.0.8.xip.io will be routed to the Service and port defined as backend in the Ingress (my-server and 80 in this case).
## What about IoT then?
Imagine the following scenario. You have dozens of devices spread out around your home or farm. It is a heterogeneous collection of IoT devices with various hardware capabilities, sensors and actuators. Maybe some of them have cameras, weather or light sensors. Others may be hooked up to control the ventilation, lights, blinds or blink LEDs.
In this scenario, you want to gather data from all the sensors, maybe process and analyze it before you finally use it to make decisions and control the actuators. In addition to this, you may want to visualize what’s going on by setting up a dashboard. So how can Kubernetes help us manage something like this? How can we make sure that Pods run on suitable devices?
The simple answer is labels. You can label the nodes according to capabilities, like this:
kubectl label nodes <node-name> <label-key>=<label-value>
# Example
kubectl label nodes node2 camera=available
Once they are labeled, it is easy to select suitable nodes for your workload with [nodeSelectors](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/). The final piece to the puzzle, if you want to run your Pods on *all* suitable nodes is to use [DaemonSets](https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/) instead of Deployments. In other words, create one DaemonSet for each data collecting application that uses some unique sensor and use nodeSelectors to make sure they only run on nodes with the proper hardware.
The service discovery feature that allows Pods to find each other simply by Service name makes it quite easy to handle these kinds of distributed systems. You don’t need to know or configure IP addresses or custom ports for the applications. Instead, they can easily find each other through named Services in the cluster.
### Utilize spare resources
With the cluster up and running, collecting data and controlling your lights and climate control you may feel that you are finished. However, there are still plenty of compute resources in the cluster that could be used for other projects. This is where Kubernetes really shines.
You shouldn’t have to worry about where exactly those resources are or calculate if there is enough memory to fit an extra application here or there. This is exactly what orchestration solves! You can easily deploy more applications in the cluster and let Kubernetes figure out where (or if) they will fit.
Why not run your own [NextCloud](https://nextcloud.com/) instance? Or maybe [gitea](https://gitea.io/en-us/)? You could also set up a CI/CD pipeline for all those IoT containers. After all, why would you build and cross compile them on your main computer if you can do it natively in the cluster?
The point here is that Kubernetes makes it easier to make use of the “hidden” resources that you often end up with otherwise. Kubernetes handles scheduling of Pods in the cluster based on available resources and fault tolerance so that you don’t have to. However, in order to help Kubernetes make reasonable decisions you should definitely add [resource requests](https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/) to your workloads.
## Summary
While Kubernetes, or container orchestration in general, may not usually be associated with IoT, it certainly makes a lot of sense to have an orchestrator when you are dealing with distributed systems. Not only does is allow you to handle a diverse and heterogeneous fleet of devices in a unified way, but it also simplifies communication between them. In addition, Kubernetes makes it easier to utilize spare resources.
Container technology made it possible to build applications that could “run anywhere”. Now Kubernetes makes it easier to manage the “anywhere” part. And as an immutable base to build it all on, we have Fedora IoT.
## Jakob
Nice, interesting article? (but what is “kebernetes?”)
## Paul W. Frields
Heh, just a goof when we were making the article image. Should be fixed shortly.
## Sheogorath
Great article in general, but there is one big no-no in there: curl | sh
Please don’t recommend anyone to do this, it’s more than just an anti-pattern, it’s really dangerous!
The script will for sure ask for a sudo password and cause problems.
Please, when you want people to install things using a random shell script from the internet, let them download it first, inspect it and then install. Everything else only causes harm in a longterm perspective.
## Lennart Jern
Fair enough. I will keep this in mind for future articles. It is however this way of installing that is used in all k3s documentation. But I agree with you that just piping things directly to your shell from the internet is never a good idea.
## Christian M. Grube
I said the same on Reddit after posting this.
And the answer it is in the documentation and I’ll make it like it’s said there… so wrong in every way.
Go on and fix it.
And send an email that they should their fix documentation.
## Stephen Snow
I like the idea of using K3s in an Iot capacity, the only question I have in general when it comes to Iot as I have noted it being used is, what about determinism? In my experience, it is not feasible to for instance try to run interpolated motion without deterministic timing of the control system. This comment was really meant for the author but is a general question I have had of Iot for some time. |
10,912 | Adobe Lightroom 的三个开源替代品 | https://opensource.com/alternatives/adobe-lightroom | 2019-05-29T07:10:46 | [
"RAW",
"图像",
"照片"
] | https://linux.cn/article-10912-1.html |
>
> 摄影师们:在没有 Lightroom 套件的情况下,可以看看这些 RAW 图像处理器。
>
>
>

如今智能手机的摄像功能已经完备到多数人认为可以代替传统摄影了。虽然这在傻瓜相机的市场中是个事实,但是对于许多摄影爱好者和专业摄影师看来,一个高端单反相机所能带来的照片景深、清晰度以及真实质感是口袋中的智能手机无法与之相比的。
所有的这些功能在便利性上要付出一些很小的代价;就像传统的胶片相机中的反色负片,单反照相得到的 RAW 格式文件必须预先处理才能印刷或编辑;因此对于单反相机,照片的后期处理是无可替代的,并且 首选应用就是 Adobe Lightroom。但是由于 Adobe Lightroom 的昂贵价格、基于订阅的定价模式以及专有许可证都使更多人开始关注其开源替代品。
Lightroom 有两大主要功能:处理 RAW 格式的图片文件,以及数字资产管理系统(DAM) —— 通过标签、评星以及其他元数据信息来简单清晰地整理照片。
在这篇文章中,我们将介绍三个开源的图片处理软件:Darktable、LightZone 以及 RawTherapee。所有的软件都有 DAM 系统,但没有任何一个具有 Lightroom 基于机器学习的图像分类和标签功能。如果你想要知道更多关于开源的 DAM 系统的软件,可以看 Terry Hacock 的文章:“[开源项目的 DAM 管理](https://opensource.com/article/18/3/movie-open-source-software)”,他分享了他在自己的 [Lunatics!](http://lunatics.tv/) 电影项目研究过的开源多媒体软件。
### Darktable

类似其他两个软件,Darktable 可以处理 RAW 格式的图像并将它们转换成可用的文件格式 —— JPEG、PNG、TIFF、PPM、PFM 和 EXR,它同时支持 Google 和 Facebook 的在线相册,上传至 Flikr,通过邮件附件发送以及创建在线相册。
它有 61 个图像处理模块,可以调整图像的对比度、色调、明暗、色彩、噪点;添加水印;切割以及旋转;等等。如同另外两个软件一样,不论你做出多少次修改,这些修改都是“无损的” —— 你的初始 RAW 图像文件始终会被保存。
Darktable 可以从 400 多种相机型号中直接导入照片,以及有 JPEG、CR2、DNG、OpenEXR 和 PFM 等格式的支持。图像在一个数据库中显示,因此你可以轻易地过滤并查询这些元数据,包括了文字标签、评星以及颜色标签。软件同时支持 21 种语言,支持 Linux、MacOS、BSD、Solaris 11/GNOME 以及 Windows(Windows 版本是最新发布的,Darktable 声明它比起其他版本可能还有一些不完备之处,有一些未实现的功能)。
Darktable 在开源许可证 [GPLv3](https://github.com/darktable-org/darktable/blob/master/LICENSE) 下发布,你可以了解更多它的 [特性](https://www.darktable.org/about/features/),查阅它的 [用户手册](https://www.darktable.org/resources/),或者直接去 Github 上看[源代码](https://github.com/darktable-org/darktable) 。
### LightZone

[LightZone](http://www.lightzoneproject.org/) 和其他两个软件类似同样是无损的 RAW 格式图像处理工具:它是跨平台的,有 Windows、MacOS 和 Linux 版本,除 RAW 格式之外,它还支持 JPG 和 TIFF 格式的图像处理。接下来说说 LightZone 其他独特特性。
这个软件最初在 2005 年时,是以专有许可证发布的图像处理软件,后来在 BSD 证书下开源。此外,在你下载这个软件之前,你必须注册一个免费账号,以便 LightZone的 开发团队可以跟踪软件的下载数量以及建立相关社区。(许可很快,而且是自动的,因此这不是一个很大的使用障碍。)
除此之外的一个特性是这个软件的图像处理通常是通过很多可组合的工具实现的,而不是叠加滤镜(就像大多数图像处理软件),这些工具组可以被重新编排以及移除,以及被保存并且复制用到另一些图像上。如果想要编辑图片的部分区域,你还可以通过矢量工具或者根据色彩和亮度来选择像素。
想要了解更多,见 LightZone 的[论坛](http://www.lightzoneproject.org/Forum) 或者查看 Github上的 [源代码](https://github.com/ktgw0316/LightZone)。
### RawTherapee

[RawTherapee](http://rawtherapee.com/) 是另一个值得关注的开源([GPL](https://github.com/Beep6581/RawTherapee/blob/dev/LICENSE.txt))的 RAW 图像处理器。就像 Darktable 和 LightZone,它是跨平台的(支持 Windows、MacOS 和 Linux),一切修改都在无损条件下进行,因此不论你叠加多少滤镜做出多少改变,你都可以回到你最初的 RAW 文件。
RawTherapee 采用的是一个面板式的界面,包括一个历史记录面板来跟踪你做出的修改,以方便随时回到先前的图像;一个快照面板可以让你同时处理一张照片的不同版本;一个可滚动的工具面板可以方便准确地选择工具。这些工具包括了一系列的调整曝光、色彩、细节、图像变换以及去马赛克功能。
这个软件可以从多数相机直接导入 RAW 文件,并且支持超过 25 种语言,得到了广泛使用。批量处理以及 [SSE](https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions) 优化这类功能也进一步提高了图像处理的速度以及对 CPU 性能的利用。
RawTherapee 还提供了很多其他 [功能](http://rawpedia.rawtherapee.com/Features);可以查看它的 [官方文档](http://rawpedia.rawtherapee.com/Main_Page) 以及 [源代码](https://github.com/Beep6581/RawTherapee) 了解更多细节。
你是否在摄影中使用另外的开源 RAW 图像处理工具?有任何建议和推荐都可以在评论中分享。
---
via: <https://opensource.com/alternatives/adobe-lightroom>
作者:[Opensource.com](https://opensource.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[scoutydren](https://github.com/scoutydren) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You wouldn't be wrong to wonder whether the smartphone, that modern jack-of-all-trades, is taking over photography. While that might be valid in the point-and-shoot camera market, there are a sizeable number of photography professionals and hobbyists who recognize that a camera that fits in your pocket can never replace a high-end DSLR camera and the depth, clarity, and realism of its photos.
All of that power comes with a small price in terms of convenience; like negatives from traditional film cameras, the [raw image](https://en.wikipedia.org/wiki/Raw_image_format) files produced by DSLRs must be processed before they can be edited or printed. For this, a digital image processing application is indispensable, and the go-to application has been Adobe Lightroom. But for many reasons—including its expensive, subscription-based pricing model and its proprietary license—there's a lot of interest in open source and other alternatives.
Lightroom has two main functions: processing raw image files and digital asset management (DAM)—organizing images with tags, ratings, and other metadata to make it easier to keep track of them.
In this article, we'll look at three open source image processing applications: Darktable, LightZone, and RawTherapee. All of them have DAM capabilities, but none has Lightroom's machine learning-based image categorization and tagging features. If you're looking for more information about open source DAM software, check out Terry Hancock's article "[Digital asset management for an open movie project](https://opensource.com/article/18/3/movie-open-source-software)," where he shares his research on software to organize multimedia files for his [ Lunatics!](http://lunatics.tv/) open movie project.
## Darktable
Like the other applications on our list, [darktable](http://www.darktable.org/) processes raw images into usable file formats—it exports into JPEG, PNG, TIFF, PPM, PFM, and EXR, and it also supports Google and Facebook web albums, Flickr uploads, email attachments, and web gallery creation.
Its 61 image operation modules allow you to adjust contrast, tone, exposure, color, noise, etc.; add watermarks; crop and rotate; and much more. As with the other applications described in this article, those edits are "non-destructive"—that is, your original raw image is preserved no matter how many tweaks and modifications you make.
Darktable imports raw images from more than 400 cameras plus JPEG, CR2, DNG, OpenEXR, and PFM; images are managed in a database so you can filter and search using metadata including tags, ratings, and color. It's also available in 21 languages and is supported on Linux, MacOS, BSD, Solaris 11/GNOME, and Windows. (The [Windows port](https://www.darktable.org/about/faq/#faq-windows) is new, and darktable warns it may have "rough edges or missing functionality" compared to other versions.)
Darktable is licensed under [GPLv3](https://github.com/darktable-org/darktable/blob/master/LICENSE); you can learn more by perusing its [features](https://www.darktable.org/about/features/), viewing the [user manual](https://www.darktable.org/resources/), or accessing its [source code](https://github.com/darktable-org/darktable) on GitHub.
## LightZone
As a non-destructive raw image processing tool, [LightZone](http://www.lightzoneproject.org/) is similar to the other two applications on this list: it's cross-platform, operating on Windows, MacOS, and Linux, and it supports JPG and TIFF images in addition to raw. But it's also unique in several ways.
For one thing, it started out in 2005 as a proprietary image processing tool and later became an open source project under a BSD license. Also, before you can download the application, you must register for a free account; this is so the LightZone development community can track downloads and build the community. (Approval is quick and automated, so it's not a large barrier.)
Another difference is that image modifications are done using stackable tools, rather than filters (like most image-editing applications); tool stacks can be rearranged or removed, as well as saved and copied to a batch of images. You can also edit certain parts of an image using a vector-based tool or by selecting pixels based on color or brightness.
You can get more information on LightZone by searching its [forums](http://www.lightzoneproject.org/Forum) or accessing its [source code](https://github.com/ktgw0316/LightZone) on GitHub.
## RawTherapee
[RawTherapee](http://rawtherapee.com/) is another popular open source ([GPL](https://github.com/Beep6581/RawTherapee/blob/dev/LICENSE.txt)) raw image processor worth your attention. Like darktable and LightZone, it is cross-platform (Windows, MacOS, and Linux) and implements edits in a non-destructive fashion, so you maintain access to your original raw image file no matter what filters or changes you make.
RawTherapee uses a panel-based interface, including a history panel to keep track of your changes and revert to a previous point; a snapshot panel that allows you to work with multiple versions of a photo; and scrollable tool panels to easily select a tool without worrying about accidentally using the wrong one. Its tools offer a wide variety of exposure, color, detail, transformation, and demosaicing features.
The application imports raw files from most cameras and is localized to more than 25 languages, making it widely usable. Features like batch processing and [SSE](https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions) optimizations improve speed and CPU performance.
RawTherapee offers many other [features](http://rawpedia.rawtherapee.com/Features); check out its [documentation](http://rawpedia.rawtherapee.com/Main_Page) and [source code](https://github.com/Beep6581/RawTherapee) for details.
Do you use another open source raw image processing tool in your photography? Do you have any related tips or suggestions for other photographers? If so, please share your recommendations in the comments.
## 1 Comment |
10,914 | 区块链 2.0:房地产区块链(四) | https://www.ostechnix.com/blockchain-2-0-blockchain-in-real-estate/ | 2019-05-29T21:56:09 | [
"区块链",
"房地产"
] | https://linux.cn/article-10914-1.html | 
### 区块链 2.0:“更”智能的房地产
在本系列的[上一篇文章](/article-10689-1.html)中我们探讨了区块链的特征,这些区块链将使机构能够将**传统银行**和**融资系统**转换和交织在一起。这部分将探讨**房地产区块链**。房地产业正在走向革命。它是人类已知的交易最活跃、最重要的资产类别之一。然而,由于充满了监管障碍和欺诈、欺骗的无数可能性,它也是最难参与交易的之一。利用适当的共识算法的区块链的分布式分类账本功能被吹捧为这个行业的前进方向,而这个行业传统上被认为其面对变革是保守的。
就其无数的业务而言,房地产一直是一个非常保守的行业。这似乎也是理所当然的。2008 年金融危机或 20 世纪上半叶的大萧条等重大经济危机成功摧毁了该行业及其参与者。然而,与大多数具有经济价值的产品一样,房地产行业具有弹性,而这种弹性则源于其保守性。
全球房地产市场由价值 228 万亿 <sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup> 美元的资产类别组成,出入不大。其他投资资产,如股票、债券和股票合计价值仅为 170 万亿美元。显然,在这样一个行业中实施的交易在很大程度上都是精心策划和执行的。很多时候,房地产也因许多欺诈事件而臭名昭著,并且随之而来的是毁灭性的损失。由于其运营非常保守,该行业也难以驾驭。它受到了法律的严格监管,创造了一个交织在一起的细微差别网络,这对于普通人来说太难以完全理解,使得大多数人无法进入和参与。如果你曾参与过这样的交易,那么你就会知道纸质文件的重要性和长期性。
从一个微不足道的开始,虽然是一个重要的例子,以显示当前的记录管理实践在房地产行业有多糟糕,考虑一下[产权保险业务](https://www.forbes.com/sites/jordanlulich/2018/06/21/what-is-title-insurance-and-why-its-important/#1472022b12bb) <sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup>。产权保险用于对冲土地所有权和所有权记录不可接受且从而无法执行的可能性。诸如此类的保险产品也称为赔偿保险。在许多情况下,法律要求财产拥有产权保险,特别是在处理多年来多次易手的财产时。抵押贷款公司在支持房地产交易时也可能坚持同样的要求。事实上,这种产品自 19 世纪 50 年代就已存在,并且仅在美国每年至少有 1.5 万亿美元的商业价值这一事实证明了一开始的说法。在这种情况下,这些记录的维护方式必须进行改革,区块链提供了一个可持续解决方案。根据[美国土地产权协会](https://www.cbinsights.com/research/blockchain-real-estate-disruption/#financing),平均每个案例的欺诈平均约为 10 万美元,并且涉及交易的所有产权中有 25% 的文件存在问题。区块链允许设置一个不可变的永久数据库,该数据库将跟踪资产本身,记录已经进入的每个交易或投资。这样的分类帐本系统将使包括一次性购房者在内的房地产行业的每个人的生活更加轻松,并使诸如产权保险等金融产品基本上无关紧要。将诸如房地产之类的实物资产转换为这样的数字资产是非常规的,并且目前仅在理论上存在。然而,这种变化迫在眉睫,而不是迟到 <sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup>。
区块链在房地产中影响最大的领域如上所述,在维护透明和安全的产权管理系统方面。基于区块链的财产记录可以包含有关财产、其所在地、所有权历史以及相关的公共记录的[信息](https://www2.deloitte.com/us/en/pages/financial-services/articles/blockchain-in-commercial-real-estate.html)。这将允许房地产交易快速完成,并且无需第三方监控和监督。房地产评估和税收计算等任务成为有形的、客观的参数问题,而不是主观测量和猜测,因为可靠的历史数据是可公开验证的。[UBITQUITY](https://www.ubitquity.io/) 就是这样一个平台,为企业客户提供定制的基于区块链的解决方案。该平台允许客户跟踪所有房产细节、付款记录、抵押记录,甚至允许运行智能合约,自动处理税收和租赁。
这为我们带来了房地产区块链的第二大机遇和用例。由于该行业受到众多第三方的高度监管,除了参与交易的交易对手外,尽职调查和财务评估可能非常耗时。这些流程主要通过离线渠道进行,文书工作需要在最终评估报告出来之前进行数天。对于公司房地产交易尤其如此,这构成了顾问所收取的总计费时间的大部分。如果交易由抵押背书,则这些过程的重复是不可避免的。一旦与所涉及的人员和机构的数字身份相结合,就可以完全避免当前的低效率,并且可以在几秒钟内完成交易。租户、投资者、相关机构、顾问等可以单独验证数据并达成一致的共识,从而验证永久性的财产记录 <sup id="fnref4"> <a href="#fn4" rel="footnote"> 4 </a></sup>。这提高了验证流程的准确性。房地产巨头 RE/MAX 最近宣布与服务提供商 XYO Network Partners 合作,[建立墨西哥房上市地产国家数据库](https://www.businesswire.com/news/home/20181012005068/en/XYO-Network-Partners-REMAX-M%C3%A9xico-Bring-Blockchain)。他们希望有朝一日能够创建世界上最大的(截至目前)去中心化房地产登记中心之一。
然而,区块链可以带来的另一个重要且可以说是非常民主的变化是投资房地产。与其他投资资产类别不同,即使是小型家庭投资者也可能参与其中,房地产通常需要大量的手工付款才能参与。诸如 ATLANT 和 BitOfProperty 之类的公司将房产的账面价值代币化,并将其转换为加密货币的等价物。这些代币随后在交易所出售,类似于股票和股票的交易方式。[房地产后续产生的任何现金流都会根据其在财产中的“份额”记入贷方或借记给代币所有者](https://www.cbinsights.com/research/blockchain-real-estate-disruption/#financing)。
然而,尽管如此,区块链技术仍处于房地产领域的早期采用阶段,目前的法规还没有明确定义它。诸如分布式应用程序、分布式匿名组织(DAO)、智能合约等概念在许多国家的法律领域是闻所未闻的。一旦所有利益相关者充分接受了区块链复杂性的良好教育,就会彻底改革现有的法规和指导方针,这是最务实的前进方式。 同样,这将是一个缓慢而渐进的变化,但是它是一个急需的变化。本系列的下一篇文章将介绍 “智能合约”,例如由 UBITQUITY 和 XYO 等公司实施的那些是如何在区块链中创建和执行的。
---
1. HSBC, “Global Real Estate,” no. April, 2008 [↩](#fnref1)
2. D. B. Burke, Law of title insurance. Aspen Law & Business, 2000. [↩](#fnref2)
3. M. Swan, O’Reilly – Blockchain. Blueprint for a New Economy – 2015. [↩](#fnref3)
4. Deloite, “Blockchain in commercial real estate The future is here ! Table of contents.” [↩](#fnref4)
---
via: <https://www.ostechnix.com/blockchain-2-0-blockchain-in-real-estate/>
作者:[ostechnix](https://www.ostechnix.com/author/editor/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,915 | ddgr:一个从终端搜索 DuckDuckGo 的命令行工具 | https://www.2daygeek.com/ddgr-duckduckgo-search-from-the-command-line-in-linux/ | 2019-05-29T22:43:00 | [
"DuckDuckGo",
"ddgr"
] | https://linux.cn/article-10915-1.html | 
在 Linux 中,Bash 技巧非常棒,它使 Linux 中的一切成为可能。
对于开发人员或系统管理员来说,它真的很管用,因为他们大部分时间都在使用终端。你知道他们为什么喜欢这种技巧吗?
因为这些技巧可以提高他们的工作效率,也能使他们工作更快。
### 什么是 ddgr
[ddgr](https://github.com/jarun/ddgr) 是一个命令行实用程序,用于从终端搜索 DuckDuckGo。如果设置了 `BROWSER` 环境变量,ddgr 可以在几个基于文本的浏览器中开箱即用。
确保你的系统安装了任何一个基于文本的浏览器。你可能知道 [googler](https://www.2daygeek.com/googler-google-search-from-the-command-line-on-linux/),它允许用户从 Linux 命令行进行 Google 搜索。
它在命令行用户中非常受欢迎,他们期望对隐私敏感的 DuckDuckGo 也有类似的实用程序,这就是 `ddgr` 出现的原因。
与 Web 界面不同,你可以指定每页要查看的搜索结果数。
**建议阅读:**
* [Googler – 从 Linux 命令行搜索 Google](https://www.2daygeek.com/googler-google-search-from-the-command-line-on-linux/)
* [Buku – Linux 中一个强大的命令行书签管理器](https://www.2daygeek.com/buku-command-line-bookmark-manager-linux/)
* [SoCLI – 从终端搜索和浏览 StackOverflow 的简单方法](https://www.2daygeek.com/socli-search-and-browse-stack-overflow-from-linux-terminal/)
* [RTV(Reddit 终端查看器)- 一个简单的 Reddit 终端查看器](https://www.2daygeek.com/rtv-reddit-terminal-viewer-a-simple-terminal-viewer-for-reddit/)
### 什么是 DuckDuckGo
DDG 即 DuckDuckGo。DuckDuckGo(DDG)是一个真正保护用户搜索和隐私的互联网搜索引擎。它没有过滤用户的个性化搜索结果,对于给定的搜索词,它会向所有用户显示相同的搜索结果。
大多数用户更喜欢谷歌搜索引擎,但是如果你真的担心隐私,那么你可以放心地使用 DuckDuckGo。
### ddgr 特性
* 快速且干净(没有广告、多余的 URL 或杂物参数),自定义颜色
* 旨在以最小的空间提供最高的可读性
* 指定每页显示的搜索结果数
* 可以在 omniprompt 中导航结果,在浏览器中打开 URL
* 用于 Bash、Zsh 和 Fish 的搜索和选项补完脚本
* 支持 DuckDuckGo Bang(带有自动补完)
* 直接在浏览器中打开第一个结果(如同 “I’m Feeling Ducky”)
* 不间断搜索:无需退出即可在 omniprompt 中触发新搜索
* 关键字支持(例如:filetype:mime、site:somesite.com)
* 按时间、指定区域搜索,禁用安全搜索
* 支持 HTTPS 代理,支持 Do Not Track,可选择禁用用户代理字符串
* 支持自定义 URL 处理程序脚本或命令行实用程序
* 全面的文档,man 页面有方便的使用示例
* 最小的依赖关系
### 需要条件
`ddgr` 需要 Python 3.4 或更高版本。因此,确保你的系统应具有 Python 3.4 或更高版本。
```
$ python3 --version
Python 3.6.3
```
### 如何在 Linux 中安装 ddgr
我们可以根据发行版使用以下命令轻松安装 `ddgr`。
对于 Fedora ,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/)来安装 `ddgr`。
```
# dnf install ddgr
```
或者我们可以使用 [SNAP 命令](https://www.2daygeek.com/snap-command-examples/)来安装 `ddgr`。
```
# snap install ddgr
```
对于 LinuxMint/Ubuntu,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/)来安装 `ddgr`。
```
$ sudo add-apt-repository ppa:twodopeshaggy/jarun
$ sudo apt-get update
$ sudo apt-get install ddgr
```
对于基于 Arch Linux 的系统,使用 [Yaourt 命令](https://www.2daygeek.com/install-yaourt-aur-helper-on-arch-linux/)或 [Packer 命令](https://www.2daygeek.com/install-packer-aur-helper-on-arch-linux/)从 AUR 仓库安装 `ddgr`。
```
$ yaourt -S ddgr
或
$ packer -S ddgr
```
对于 Debian,使用 [DPKG 命令](https://www.2daygeek.com/dpkg-command-to-manage-packages-on-debian-ubuntu-linux-mint-systems/) 安装 `ddgr`。
```
# wget https://github.com/jarun/ddgr/releases/download/v1.2/ddgr_1.2-1_debian9.amd64.deb
# dpkg -i ddgr_1.2-1_debian9.amd64.deb
```
对于 CentOS 7,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/)来安装 `ddgr`。
```
# yum install https://github.com/jarun/ddgr/releases/download/v1.2/ddgr-1.2-1.el7.3.centos.x86_64.rpm
```
对于 opensuse,使用 [zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/)来安装 `ddgr`。
```
# zypper install https://github.com/jarun/ddgr/releases/download/v1.2/ddgr-1.2-1.opensuse42.3.x86_64.rpm
```
### 如何启动 ddgr
在终端上输入 `ddgr` 命令,不带任何选项来进行 DuckDuckGo 搜索。你将获得类似于下面的输出。
```
$ ddgr
```

### 如何使用 ddgr 进行搜索
我们可以通过两种方式启动搜索。从 omniprompt 或者直接从终端开始。你可以搜索任何你想要的短语。
直接从终端:
```
$ ddgr 2daygeek
```

从 omniprompt:

### Omniprompt 快捷方式
输入 `?` 以获得 omniprompt,它将显示关键字列表和进一步使用 `ddgr` 的快捷方式。

### 如何移动下一页、上一页和第一页
它允许用户移动下一页、上一页或第一页。
* `n`: 移动到下一组搜索结果
* `p`: 移动到上一组搜索结果
* `f`: 跳转到第一页

### 如何启动新搜索
`d` 选项允许用户从 omniprompt 发起新的搜索。例如,我搜索了 “2daygeek website”,现在我将搜索 “Magesh Maruthamuthu” 这个新短语。
从 omniprompt:
```
ddgr (? for help) d magesh maruthmuthu
```

### 在搜索结果中显示完整的 URL
默认情况下,它仅显示文章标题,在搜索中添加 `x` 选项以在搜索结果中显示完整的文章网址。
```
$ ddgr -n 5 -x 2daygeek
```

### 限制搜索结果
默认情况下,搜索结果每页显示 10 个结果。如果你想为方便起见限制页面结果,可以使用 `ddgr` 带有 `--num` 或 `-n` 参数。
```
$ ddgr -n 5 2daygeek
```

### 网站特定搜索
要搜索特定网站的特定页面,使用以下格式。这将从网站获取给定关键字的结果。例如,我们在 2daygeek 网站下搜索 “Package Manager”,查看结果。
```
$ ddgr -n 5 --site 2daygeek "package manager"
```

---
via: <https://www.2daygeek.com/ddgr-duckduckgo-search-from-the-command-line-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy) 选题:[lujun9972](https://github.com/lujun9972)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,916 | 如何管理你的 Linux 环境变量 | https://www.networkworld.com/article/3385516/how-to-manage-your-linux-environment.html | 2019-05-29T23:41:34 | [
"环境变量"
] | https://linux.cn/article-10916-1.html |
>
> Linux 用户环境变量可以帮助你找到你需要的命令,无须了解系统如何配置的细节而完成大量工作。而这些设置来自哪里和如何被修改它们是另一个话题。
>
>
>

在 Linux 系统上的用户账户配置以多种方法简化了系统的使用。你可以运行命令,而不需要知道它们的位置。你可以重新使用先前运行的命令,而不用发愁系统是如何追踪到它们的。你可以查看你的电子邮件,查看手册页,并容易地回到你的家目录,而不用管你在文件系统中身在何方。并且,当需要的时候,你可以调整你的账户设置,以便其更符合你喜欢的方式。
Linux 环境设置来自一系列的文件:一些是系统范围(意味着它们影响所有用户账户),一些是处于你的家目录中的配置文件里。系统范围的设置在你登录时生效,而本地设置在其后生效,所以,你在你账户中作出的更改将覆盖系统范围设置。对于 bash 用户,这些文件包含这些系统文件:
```
/etc/environment
/etc/bash.bashrc
/etc/profile
```
以及一些本地文件:
```
~/.bashrc
~/.profile # 如果有 ~/.bash_profile 或 ~/.bash_login 就不会读此文件
~/.bash_profile
~/.bash_login
```
你可以修改本地存在的四个文件的任何一个,因为它们处于你的家目录,并且它们是属于你的。
### 查看你的 Linux 环境设置
为查看你的环境设置,使用 `env` 命令。你的输出将可能与这相似:
```
$ env
LS_COLORS=rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;
01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:
*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:
*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:
*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;
31:*.zst=01;31:*.tzst=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:
*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:
*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:
*.wim=01;31:*.swm=01;31:*.dwm=01;31:*.esd=01;31:*.jpg=01;35:*.jpeg=01;35:*.mjpg=01;35:
*.mjpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:
*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:
*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:
*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:
*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:
*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:
*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:
*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:
*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.spf=00;36:
SSH_CONNECTION=192.168.0.21 34975 192.168.0.11 22
LESSCLOSE=/usr/bin/lesspipe %s %s
LANG=en_US.UTF-8
OLDPWD=/home/shs
XDG_SESSION_ID=2253
USER=shs
PWD=/home/shs
HOME=/home/shs
SSH_CLIENT=192.168.0.21 34975 22
XDG_DATA_DIRS=/usr/local/share:/usr/share:/var/lib/snapd/desktop
SSH_TTY=/dev/pts/0
MAIL=/var/mail/shs
TERM=xterm
SHELL=/bin/bash
SHLVL=1
LOGNAME=shs
DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/1000/bus
XDG_RUNTIME_DIR=/run/user/1000
PATH=/home/shs/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
LESSOPEN=| /usr/bin/lesspipe %s
_=/usr/bin/env
```
虽然你可能会看到大量的输出,上面显示的第一大部分用于在命令行上使用颜色标识各种文件类型。当你看到类似 `*.tar=01;31:` 这样的东西,这告诉你 `tar` 文件将以红色显示在文件列表中,然而 `*.jpg=01;35:` 告诉你 jpg 文件将以紫色显现出来。这些颜色旨在使它易于从一个文件列表中分辨出某些文件。你可以在《[在 Linux 命令行中自定义你的颜色](https://www.networkworld.com/article/3269587/customizing-your-text-colors-on-the-linux-command-line.html)》处学习更多关于这些颜色的定义,和如何自定义它们。
当你更喜欢一种不加装饰的显示时,一种关闭颜色显示的简单方法是使用如下命令:
```
$ ls -l --color=never
```
这个命令可以简单地转换到一个别名:
```
$ alias ll2='ls -l --color=never'
```
你也可以使用 `echo` 命令来单独地显现某个设置。在这个命令中,我们显示在历史缓存区中将被记忆命令的数量:
```
$ echo $HISTSIZE
1000
```
如果你已经移动到某个位置,你在文件系统中的最后位置会被记在这里:
```
PWD=/home/shs
OLDPWD=/tmp
```
### 作出更改
你可以使用一个像这样的命令更改环境设置,但是,如果你希望保持这个设置,在你的 `~/.bashrc` 文件中添加一行代码,例如 `HISTSIZE=1234`。
```
$ export HISTSIZE=1234
```
### “export” 一个变量的本意是什么
导出一个环境变量可使设置用于你的 shell 和可能的子 shell。默认情况下,用户定义的变量是本地的,并不被导出到新的进程,例如,子 shell 和脚本。`export` 命令使得环境变量可用在子进程中发挥功用。
### 添加和移除变量
你可以很容易地在命令行和子 shell 上创建新的变量,并使它们可用。然而,当你登出并再次回来时这些变量将消失,除非你也将它们添加到 `~/.bashrc` 或一个类似的文件中。
```
$ export MSG="Hello, World!"
```
如果你需要,你可以使用 `unset` 命令来消除一个变量:
```
$ unset MSG
```
如果变量是局部定义的,你可以通过加载你的启动文件来简单地将其设置回来。例如:
```
$ echo $MSG
Hello, World!
$ unset $MSG
$ echo $MSG
$ . ~/.bashrc
$ echo $MSG
Hello, World!
```
### 小结
用户账户是用一组恰当的启动文件设立的,创建了一个有用的用户环境,而个人用户和系统管理员都可以通过编辑他们的个人设置文件(对于用户)或很多来自设置起源的文件(对于系统管理员)来更改默认设置。
---
via: <https://www.networkworld.com/article/3385516/how-to-manage-your-linux-environment.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,918 | 命令别名:保护和服务 | https://www.linux.com/blog/learn/2019/1/aliases-protect-and-serve | 2019-05-30T21:45:34 | [
"别名"
] | https://linux.cn/article-10918-1.html |
>
> Linux shell 允许你将命令彼此链接在一起,一次触发执行复杂的操作,并且可以对此创建别名作为快捷方式。
>
>
>

让我们将继续我们的别名系列。到目前为止,你可能已经阅读了我们的[关于别名的第一篇文章](/article-10377-1.html),并且应该非常清楚它们是如何为你省去很多麻烦的最简单方法。例如,你已经看到它们帮助我们减少了输入,让我们看看别名派上用场的其他几个案例。
### 别名即快捷方式
Linux shell 最美妙的事情之一是可以使用数以万计的选项和把命令连接在一起执行真正复杂的操作。好吧,也许这种美丽是在旁观者的眼中的,但是我们觉得这个功能很实用。
不利的一面是,你经常需要记得难以记忆或难以打字出来的命令组合。比如说硬盘上的空间非常宝贵,而你想要做一些清洁工作。你的第一步可能是寻找隐藏在你的家目录里的东西。你可以用来判断的一个标准是查找不再使用的内容。`ls` 可以帮助你:
```
ls -lct
```
上面的命令显示了每个文件和目录的详细信息(`-l`),并显示了每一项上次访问的时间(`-c`),然后它按从最近访问到最少访问的顺序排序这个列表(`-t`)。
这难以记住吗?你可能不会每天都使用 `-c` 和 `-t` 选项,所以也许是吧。无论如何,定义一个别名,如:
```
alias lt='ls -lct'
```
会更容易一些。
然后,你也可能希望列表首先显示最旧的文件:
```
alias lo='lt -F | tac'
```

*图 1:使用 lt 和 lo 别名。*
这里有一些有趣的事情。首先,我们使用别名(`lt`)来创建另一个别名 —— 这是完全可以的。其次,我们将一个新参数传递给 `lt`(后者又通过 `lt` 别名的定义传递给了 `ls`)。
`-F` 选项会将特殊符号附加到项目的名称后,以便更好地区分常规文件(没有符号)和可执行文件(附加了 `*`)、目录文件(以 `/` 结尾),以及所有链接文件、符号链接文件(以 `@` 符号结尾)等等。`-F` 选项是当你回归到单色终端的日子里,没有其他方法可以轻松看到列表项之间的差异时用的。在这里使用它是因为当你将输出从 `lt` 传递到 `tac` 时,你会丢失 `ls` 的颜色。
第三件我们需要注意的事情是我们使用了管道。管道用于你将一个命令的输出传递给另外一个命令时。第二个命令可以使用这些输出作为它的输入。在包括 Bash 在内的许多 shell 里,你可以使用管道符(`|`) 来做传递。
在这里,你将来自 `lt -F` 的输出导给 `tac`。`tac` 这个命令有点玩笑的意思,你或许听说过 `cat` 命令,它名义上用于将文件彼此连接(con`cat`),而在实践中,它被用于将一个文件的内容打印到终端。`tac` 做的事情一样,但是它是以逆序将接收到的内容输出出来。明白了吗?`cat` 和 `tac`,技术人有时候也挺有趣的。
`cat` 和 `tac` 都能输出通过管道传递过来的内容,在这里,也就是一个按时间顺序排序的文件列表。
那么,在有些离题之后,最终我们得到的就是这个列表将当前目录中的文件和目录以新鲜度的逆序列出(即老的在前)。
最后你需要注意的是,当在当前目录或任何目录运行 `lt` 时:
```
# 这可以工作:
lt
# 这也可以:
lt /some/other/directory
```
……而 `lo` 只能在当前目录奏效:
```
# 这可工作:
lo
# 而这不行:
lo /some/other/directory
```
这是因为 Bash 会展开别名的组分。当你键入:
```
lt /some/other/directory
```
Bash 实际上运行的是:
```
ls -lct /some/other/directory
```
这是一个有效的 Bash 命令。
而当你键入:
```
lo /some/other/directory
```
Bash 试图运行:
```
ls -lct -F | tac /some/other/directory
```
这不是一个有效的命令,主要是因为 `/some/other/directory` 是个目录,而 `cat` 和 `tac` 不能用于目录。
### 更多的别名快捷方式
* `alias lll='ls -R'` 会打印出目录的内容,并深入到子目录里面打印子目录的内容,以及子目录的子目录,等等。这是一个查看一个目录下所有内容的方式。
* `mkdir='mkdir -pv'` 可以让你一次性创建目录下的目录。按照 `mkdir` 的基本形式,要创建一个包含子目录的目录,你必须这样:
```
mkdir newdir
mkdir newdir/subdir
```
或这样:
```
mkdir -p newdir/subdir
```
而用这个别名你将只需要这样就行:
```
mkdir newdir/subdir
```
你的新 `mkdir` 也会告诉你创建子目录时都做了什么。
### 别名也是一种保护
别名的另一个好处是它可以作为防止你意外地删除或覆写已有的文件的保护措施。你可能听说过这个 Linux 新用户的传言,当他们以 root 身份运行:
```
rm -rf /
```
整个系统就爆了。而决定输入如下命令的用户:
```
rm -rf /some/directory/ *
```
就很好地干掉了他们的家目录的全部内容。这里不小心键入的目录和 `*` 之间的那个空格有时候很容易就会被忽视掉。
这两种情况我们都可以通过 `alias rm='rm -i'` 别名来避免。`-i` 选项会使 `rm` 询问用户是否真的要做这个操作,在你对你的文件系统做出不可弥补的损失之前给你第二次机会。
对于 `cp` 也是一样,它能够覆盖一个文件而不会给你任何提示。创建一个类似 `alias cp='cp -i'` 来保持安全吧。
### 下一次
我们越来越深入到了脚本领域,下一次,我们将沿着这个方向,看看如何在命令行组合命令以给你真正的乐趣,并可靠地解决系统管理员每天面临的问题。
---
via: <https://www.linux.com/blog/learn/2019/1/aliases-protect-and-serve>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,919 | 在 Ubuntu 上安装 Budgie 桌面 | https://itsfoss.com/install-budgie-ubuntu/ | 2019-05-31T08:48:30 | [
"Budgie"
] | https://linux.cn/article-10919-1.html |
>
> 在这个逐步的教程中学习如何在 Ubuntu 上安装 Budgie 桌面。
>
>
>

在所有[各种 Ubuntu 版本](https://itsfoss.com/which-ubuntu-install/)中,[Ubuntu Budgie](https://ubuntubudgie.org/) 是最被低估的版本。它外观优雅,而且需要的资源也不多。
阅读这篇 《[Ubuntu Budgie 点评](https://itsfoss.com/ubuntu-budgie-18-review/)》或观看下面的视频,了解 Ubuntu Budgie 18.04 的外观如何。
如果你喜欢 [Budgie 桌面](https://github.com/solus-project/budgie-desktop)但你正在使用其他版本的 Ubuntu,例如默认 Ubuntu 带有 GNOME 桌面,我有个好消息。你可以在当前的 Ubuntu 系统上安装 Budgie 并切换桌面环境。
在这篇文章中,我将告诉你到底该怎么做。但首先,对那些不了解 Budgie 的人进行一点介绍。
Budgie 桌面环境主要由 [Solus Linux 团队开发](https://getsol.us/home/)。它的设计注重优雅和现代使用。Budgie 适用于所有主流 Linux 发行版,可以让用户在其上尝试体验这种新的桌面环境。Budgie 现在非常成熟,并提供了出色的桌面体验。
>
> 警告
>
>
> 在同一系统上安装多个桌面可能会导致冲突,你可能会遇到一些问题,如面板中缺少图标或同一程序的多个图标。
>
>
> 你也许不会遇到任何问题。是否要尝试不同桌面由你决定。
>
>
>
### 在 Ubuntu 上安装 Budgie
此方法未在 Linux Mint 上进行测试,因此我建议你 Mint 上不要按照此指南进行操作。
对于正在使用 Ubuntu 的人,Budgie 现在默认是 Ubuntu 仓库的一部分。因此,我们不需要添加任何 PPA 来下载 Budgie。
要安装 Budgie,只需在终端中运行此命令即可。我们首先要确保系统已完全更新。
```
sudo apt update && sudo apt upgrade
sudo apt install ubuntu-budgie-desktop
```
下载完成后,你将看到选择显示管理器的提示。选择 “lightdm” 以获得完整的 Budgie 体验。

安装完成后,重启计算机。然后,你会看到 Budgie 的登录页面。输入你的密码进入主屏幕。

### 切换到其他桌面环境

你可以单击登录名旁边的 Budgie 图标获取登录选项。在那里,你可以在已安装的桌面环境(DE)之间进行选择。就我而言,我看到了 Budgie 和默认的 Ubuntu(GNOME)桌面。

因此,无论何时你想登录 GNOME,都可以使用此菜单执行此操作。
### 如何删除 Budgie
如果你不喜欢 Budgie 或只是想回到常规的以前的 Ubuntu,你可以如上节所述切换回常规桌面。
但是,如果你真的想要删除 Budgie 及其组件,你可以按照以下命令回到之前的状态。
**在使用这些命令之前先切换到其他桌面环境:**
```
sudo apt remove ubuntu-budgie-desktop ubuntu-budgie* lightdm
sudo apt autoremove
sudo apt install --reinstall gdm3
```
成功运行所有命令后,重启计算机。
现在,你将回到 GNOME 或其他你有的桌面。
### 你对 Budgie 有什么看法?
Budgie 是[最佳 Linux 桌面环境](https://itsfoss.com/best-linux-desktop-environments/)之一。希望这个简短的指南帮助你在 Ubuntu 上安装了很棒的 Budgie 桌面。
如果你安装了 Budgie,你最喜欢它的什么?请在下面的评论中告诉我们。像往常一样,欢迎任何问题或建议。
---
via: <https://itsfoss.com/install-budgie-ubuntu/>
作者:[Atharva Lele](https://itsfoss.com/author/atharva/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Among all the [various Ubuntu versions](https://itsfoss.com/which-ubuntu-install/), [Ubuntu Budgie](https://ubuntubudgie.org/?ref=itsfoss.com) is the most underrated one. It looks elegant and it’s not heavy on resources.
Read this [Ubuntu Budgie review](https://itsfoss.com/ubuntu-budgie-18-review/) or simply watch this video to see what Ubuntu Budgie 18.04 looks like.
If you like [Budgie desktop](https://github.com/solus-project/budgie-desktop?ref=itsfoss.com) but you are using some other version of Ubuntu such as the default Ubuntu with GNOME desktop, I have good news for you. You can install Budgie on your current Ubuntu system and switch the [desktop environments](https://itsfoss.com/best-linux-desktop-environments/).
In this post, I will tell you exactly how to do that. But first, a little introduction to Budgie for those who are unaware of it.
Budgie desktop environment is developed mainly by [Solus Linux team.](https://getsol.us/home/?ref=itsfoss.com) It is designed with focus on elegance and modern usage. Budgie is available for all major Linux distributions for users to try and experience this new [desktop environment](https://itsfoss.com/what-is-desktop-environment/). Budgie is pretty mature by now and provides a great desktop experience.
You may not see any issue at all as well. It’s your call if you want to try different desktop.
## Install Budgie on Ubuntu
This method is not tested on Linux Mint, so I recommend that you not follow this guide for Mint.
For those on Ubuntu, Budgie is now a part of the Ubuntu repositories by default. Hence, we don’t need to add any PPAs in order to get Budgie.
To install Budgie, simply run this command in terminal. We’ll first make sure that the system is fully updated.
`sudo apt update && sudo apt upgrade`
`sudo apt install ubuntu-budgie-desktop`
When everything is done downloading, you will get a prompt to choose your [display manager](https://itsfoss.com/display-manager/). Select ‘lightdm’ to get the full Budgie experience.
After the installation is complete, reboot your computer. You will be then greeted by the Budgie login screen. Enter your password to go into the homescreen.
## Switching to other desktop environments

You can click the Budgie icon next to your name to get options for login. From there you can select between the installed Desktop Environments (DEs). In my case, I see Budgie and the default Ubuntu (GNOME) DEs.

Hence whenever you feel like logging into GNOME, you can do so using this menu.
## How to Remove Budgie
If you don’t like Budgie or just want to go back to your regular old Ubuntu, you can switch back to your regular desktop as described in the above section.
However, if you really want to remove Budgie and its components, you can follow the following commands to get back to a clean slate.
```
sudo apt remove ubuntu-budgie-desktop ubuntu-budgie* lightdm
sudo apt autoremove
sudo apt install --reinstall gdm3
```
After running all the commands successfully, reboot your computer.
Now, you will be back to GNOME or whichever [desktop environment](https://itsfoss.com/what-is-desktop-environment/) you had.
## More desktop choices are available
The classic KDE desktop can also be easily installed on Ubuntu.
[How to Install KDE on Ubuntu [Beginner’s Guide]This screenshot tutorial demonstrates the steps to install KDE Plasma desktop environment on Ubuntu Linux.](https://itsfoss.com/install-kde-on-ubuntu/)

Speaking of classic, how about getting the classic GNOME looks back in the form of Cinnamon desktop?
[How to Install Cinnamon Desktop on UbuntuTutorial with screenshots to show you how to install Cinnamon desktop environment on Ubuntu.](https://itsfoss.com/install-cinnamon-on-ubuntu/)

Budgie is one of the [best desktop environments for Linux](https://itsfoss.com/best-linux-desktop-environments/). Hope this short guide helped you install the awesome Budgie desktop on your Ubuntu system.
If you did install Budgie, what do you like about it the most? Let us know in the comments below. And as usual, any questions or suggestions are always welcome. |
10,921 | 自己成为一个证书颁发机构(CA) | https://opensource.com/article/19/4/certificate-authority | 2019-05-31T09:10:51 | [
"CA",
"证书"
] | /article-10921-1.html |
>
> 为你的微服务架构或者集成测试创建一个简单的内部 CA。
>
>
>

传输层安全([TLS](https://en.wikipedia.org/wiki/Transport_Layer_Security))模型(有时也称它的旧名称 SSL)基于<ruby> <a href="https://en.wikipedia.org/wiki/Certificate_authority"> 证书颁发机构 </a> <rt> certificate authoritie </rt></ruby>(CA)的概念。这些机构受到浏览器和操作系统的信任,从而*签名*服务器的的证书以用于验证其所有权。
但是,对于内部网络,微服务架构或集成测试,有时候*本地 CA*更有用:一个只在内部受信任的 CA,然后签名本地服务器的证书。
这对集成测试特别有意义。获取证书可能会带来负担,因为这会占用服务器几分钟。但是在代码中使用“忽略证书”可能会被引入到生产环境,从而导致安全灾难。
CA 证书与常规服务器证书没有太大区别。重要的是它被本地代码信任。例如,在 Python `requests` 库中,可以通过将 `REQUESTS_CA_BUNDLE` 变量设置为包含此证书的目录来完成。
在为集成测试创建证书的例子中,不需要*长期的*证书:如果你的集成测试需要超过一天,那么你应该已经测试失败了。
因此,计算**昨天**和**明天**作为有效期间隔:
```
>>> import datetime
>>> one_day = datetime.timedelta(days=1)
>>> today = datetime.date.today()
>>> yesterday = today - one_day
>>> tomorrow = today - one_day
```
现在你已准备好创建一个简单的 CA 证书。你需要生成私钥,创建公钥,设置 CA 的“参数”,然后自签名证书:CA 证书*总是*自签名的。最后,导出证书文件以及私钥文件。
```
from cryptography.hazmat.primitives.asymmetric import rsa
from cryptography.hazmat.primitives import hashes, serialization
from cryptography import x509
from cryptography.x509.oid import NameOID
private_key = rsa.generate_private_key(
public_exponent=65537,
key_size=2048,
backend=default_backend()
)
public_key = private_key.public_key()
builder = x509.CertificateBuilder()
builder = builder.subject_name(x509.Name([
x509.NameAttribute(NameOID.COMMON_NAME, 'Simple Test CA'),
]))
builder = builder.issuer_name(x509.Name([
x509.NameAttribute(NameOID.COMMON_NAME, 'Simple Test CA'),
]))
builder = builder.not_valid_before(yesterday)
builder = builder.not_valid_after(tomorrow)
builder = builder.serial_number(x509.random_serial_number())
builder = builder.public_key(public_key)
builder = builder.add_extension(
x509.BasicConstraints(ca=True, path_length=None),
critical=True)
certificate = builder.sign(
private_key=private_key, algorithm=hashes.SHA256(),
backend=default_backend()
)
private_bytes = private_key.private_bytes(
encoding=serialization.Encoding.PEM,
format=serialization.PrivateFormat.TraditionalOpenSSL,
encryption_algorithm=serialization.NoEncrption())
public_bytes = certificate.public_bytes(
encoding=serialization.Encoding.PEM)
with open("ca.pem", "wb") as fout:
fout.write(private_bytes + public_bytes)
with open("ca.crt", "wb") as fout:
fout.write(public_bytes)
```
通常,真正的 CA 会需要[证书签名请求](https://en.wikipedia.org/wiki/Certificate_signing_request)(CSR)来签名证书。但是,当你是自己的 CA 时,你可以制定自己的规则!可以径直签名你想要的内容。
继续集成测试的例子,你可以创建私钥并立即签名相应的公钥。注意 `COMMON_NAME` 需要是 `https` URL 中的“服务器名称”。如果你已配置名称查询,你需要服务器能响应对 `service.test.local` 的请求。
```
service_private_key = rsa.generate_private_key(
public_exponent=65537,
key_size=2048,
backend=default_backend()
)
service_public_key = service_private_key.public_key()
builder = x509.CertificateBuilder()
builder = builder.subject_name(x509.Name([
x509.NameAttribute(NameOID.COMMON_NAME, 'service.test.local')
]))
builder = builder.not_valid_before(yesterday)
builder = builder.not_valid_after(tomorrow)
builder = builder.public_key(public_key)
certificate = builder.sign(
private_key=private_key, algorithm=hashes.SHA256(),
backend=default_backend()
)
private_bytes = service_private_key.private_bytes(
encoding=serialization.Encoding.PEM,
format=serialization.PrivateFormat.TraditionalOpenSSL,
encryption_algorithm=serialization.NoEncrption())
public_bytes = certificate.public_bytes(
encoding=serialization.Encoding.PEM)
with open("service.pem", "wb") as fout:
fout.write(private_bytes + public_bytes)
```
现在 `service.pem` 文件有一个私钥和一个“有效”的证书:它已由本地的 CA 签名。该文件的格式可以给 Nginx、HAProxy 或大多数其他 HTTPS 服务器使用。
通过将此逻辑用在测试脚本中,只要客户端配置信任该 CA,那么就可以轻松创建看起来真实的 HTTPS 服务器。
---
via: <https://opensource.com/article/19/4/certificate-authority>
作者:[Moshe Zadka](https://opensource.com/users/moshez/users/elenajon123) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,922 | Zettlr:适合写作者和研究人员的 Markdown 编辑器 | https://itsfoss.com/zettlr-markdown-editor/ | 2019-06-01T12:34:00 | [
"Markdown",
"作家",
"写作者"
] | https://linux.cn/article-10922-1.html | 有很多[适用于 Linux 的 Markdown 编辑器](https://itsfoss.com/best-markdown-editors-linux/),并且还在继续增加。问题是,像 [Boostnote](https://itsfoss.com/boostnote-linux-review/) 一样,大多数是为编码人员设计的,可能不会受到非技术人员的欢迎。让我们看一个想要替代 Word 和昂贵的文字处理器,适用于非技术人员的 Markdown 编辑器。我们来看看 Zettlr 吧。
### Zettlr Markdown 编辑器

我可能在网站上提到过一两次,我更喜欢用 [Markdown](https://daringfireball.net/projects/markdown/) 写下我的所有文档。它易于学习,不会让你受困于专有文档格式。我还在我的[适合作者的开源工具列表](https://itsfoss.com/open-source-tools-writers/)中提到了 Markdown 编辑器。
我用过许多 Markdown 编辑器,但是我一直有兴趣尝试新的。最近,我遇到了 Zettlr,一个开源 Markdown 编辑器。
[Zettlr](https://www.zettlr.com/) 是一位名叫 [Hendrik Erz](https://github.com/nathanlesage) 的德国社会学家/政治理论家创建的。Hendrik 创建了 Zettlr,因为他对目前的文字处理器感到不满意。他想要可以让他“专注于写作和阅读”的编辑器。
在发现 Markdown 之后,他在不同的操作系统上尝试了几个 Markdown 编辑器。但它们都没有他想要的东西。[根据 Hendrik 的说法](https://www.zettlr.com/about),“但我不得不意识到没有为高效组织大量文本而写的编辑器。大多数编辑都是由编码人员编写的,因此可以满足工程师和数学家的需求。没有为我这样的社会科学、历史或政治学的学生的编辑器。“
所以他决定创造自己的。2017 年 11 月,他开始编写 Zettlr。

#### Zettlr 功能
Zettlr 有许多简洁的功能,包括:
* 从 [Zotero 数据库](https://www.zotero.org/)导入源并在文档中引用它们 \* 使用可选的行屏蔽,让你无打扰地专注于写作 \* 支持代码高亮 \* 使用标签对信息进行排序 \* 能够为该任务设定写作目标 \* 查看一段时间的写作统计 \* 番茄钟计时器 \* 浅色/深色主题 \* 使用 [reveal.js](https://revealjs.com/#/) 创建演示文稿 \* 快速预览文档 \* 可以在一个项目文件夹中搜索 Markdown 文档,并用热图展示文字搜索密度。 \* 将文件导出为 HTML、PDF、ODT、DOC、reStructuredText、LaTex、TXT、Emacs ORG、[TextBundle](http://textbundle.org/) 和 Textpack \* 将自定义 CSS 添加到你的文档
当我写这篇文章时,一个对话框弹出来告诉我最近发布了 [1.3.0 beta](https://github.com/Zettlr/Zettlr/releases/tag/v1.3.0-beta)。此测试版将包括几个新的主题,以及一大堆修复,新功能和改进。

#### 安装 Zettlr
目前,唯一可安装 Zettlr 的 Linux 存储库是 [AUR](https://aur.archlinux.org/packages/zettlr-bin/)。如果你的 Linux 发行版不是基于 Arch 的,你可以从网站上下载 macOS、Windows、Debian 和 Fedora 的[安装程序](https://www.zettlr.com/download)。
#### 对 Zettlr 的最后一点想法
注意:为了测试 Zettlr,我用它来写这篇文章。
Zettlr 有许多我希望我之前选择的编辑器 (ghostwriter) 有的简洁的功能,例如为文档设置字数目标。我也喜欢在不打开文档的情况下预览文档的功能。

我也遇到了几个问题,但这些更多的是因为 Zettlr 与 ghostwriter 的工作方式略有不同。例如,当我尝试从网站复制引用或名称时,它会将内嵌样式粘贴到 Zettlr 中。幸运的是,它有一个“不带样式粘贴”的选项。有几次我在打字时有轻微的延迟。但那可能是因为它是一个 Electron 程序。
总的来说,我认为 Zettlr 是第一次使用 Markdown 用户的好选择。它有许多 Markdown 编辑器已有的功能,并为那些只使用过文字处理器的用户增加了一些功能。
正如 Hendrik 在 [Zettlr 网站](https://www.zettlr.com/about)中所说的那样,“让自己摆脱文字处理器的束缚,看看你的写作过程如何通过身边的技术得到改善!”
如果你觉得 Zettlr 有用,请考虑支持 [Hendrik](https://www.zettlr.com/supporters)。正如他在网站上所说,“它是免费的,因为我不相信激烈竞争、早逝的创业文化。我只是想帮忙。”
你有没有用过 Zettlr?你最喜欢的 Markdown 编辑器是什么?请在下面的评论中告诉我们。
如果你觉得这篇文章有趣,请在社交媒体,Hacker News 或 [Reddit](http://reddit.com/r/linuxusersgroup) 上分享它。
---
via: <https://itsfoss.com/zettlr-markdown-editor/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are quite a few [Markdown editors available for Linux](https://itsfoss.com/best-markdown-editors-linux/), with more popping up all of the time. The problem is that like [Boostnote](https://itsfoss.com/boostnote-linux-review/), most are designed for coders and may not be as welcoming to non-techie people. Let’s take a look at a Markdown editor that wants to replace Word and expensive word processors for the non-techies. Let’s take a look at Zettlr.
## Zettlr Markdown Editor
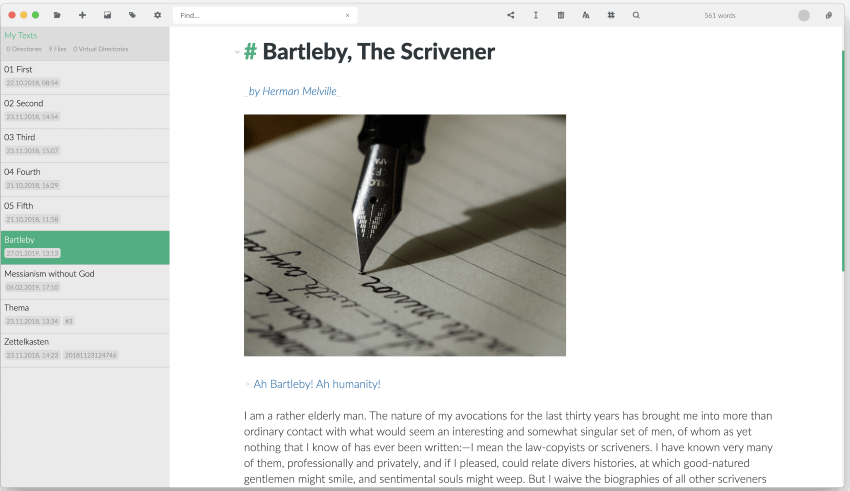
I may have mentioned it a time or two on this site, but I prefer to write all of my documents in [Markdown](https://daringfireball.net/projects/markdown/). It is simple to learn and does not leave you tied to a proprietary document format. I have also mentioned Markdown editor among my [list of open source tools for writers](https://itsfoss.com/open-source-tools-writers/).
I have used a number of Markdown editors and am always interested to try out someone’s new take on the idea. Recently, I came across Zettlr, an open source markdown editor.
[Zettlr](https://www.zettlr.com/) is the creation of a German sociologist/political theorist named [Hendrik Erz](https://github.com/nathanlesage). Hendrik created Zettlr because he was frustrated by the current line up of word processors. He wanted something that would allow him to “focus on writing and reading only”.
After discovering Markdown, he tried several Markdown editors on different operating systems. But none of them had what he was looking for. [According to Hendrik](https://www.zettlr.com/about), “But I had to realize that there are simply none written for the needs of organizing a huge amount of text efficiently. Most editors have been written by coders, therefore tailored to the needs of engineers and mathematicians. No luck for a student of social sciences, history or political science like me.”
So he decided to create his own. In November of 2017, he started to work on Zettlr.

### Zettlr Features
Zettlr has a number of neat features, including:
- Import sources from your
[Zotero database](https://www.zotero.org/)and cite them in your document - Focus on your writing with the distraction free mode with optional line muting
- Support for code highlighting
- Use tags to sort information
- Ability to set writing goals for the session
- View writing stats over time
- Pomodoro Timer
- Light/Dark theme
- Create presentation using
[reveal.js](https://revealjs.com/#/) - Quick preview of a document
- Search all Markdown documents in a project folder with heatmap showing the density of word searched
- Export files to HTML, PDF, ODT, DOC, reStructuredText, LaTex, TXT, Emacs ORG,
[TextBundle](http://textbundle.org/), and Textpack - Add custom CSS to your document
As I am writing this article, a dialog box popped up telling me about the recently released [1.3.0 beta](https://github.com/Zettlr/Zettlr/releases/tag/v1.3.0-beta). This beta will include several new themes, as well as, a boatload of fixes, new features and under the hood improvements.
### Installing Zettlr
Currently, the only Linux repository that has Zettlr for you to install is the [AUR](https://aur.archlinux.org/packages/zettlr-bin/). If your Linux distro is not Arch-based, you can [download an installer](https://www.zettlr.com/download) from the website for macOS, Windows, Debian, and Fedora.
### Final Thoughts on Zettlr
Note: In order to test Zettlr, I used it to write this article.
Zettlr has a number of neat features that I wish my Markdown editor of choice (ghostwriter) had, such as the ability to set a word count goal for the document. I also like the option to preview a document without having to open it.
I did run into a couple issues, but they had more to do with the fact that Zettlr works a little bit different than ghostwriter. For example, when I tried to copy a quote or name from a web site, it pasted the in-line styling into Zettlr. Fortunately, there is an option to “Paste without Style”. A couple times I ran into a slight delay when I was trying to type. But that could because it is an Electron app.
Overall, I think that Zettlr is a good option for a first time Markdown user. It has features that many Markdown editors already have and adds a few more for those who only ever used word processors
As Hendrik says on the [Zettlr site](https://www.zettlr.com/about), “Free yourselves from the fetters of word processors and see how your writing process can be improved by using technology that’s right at hand!”
If you do find Zettlr useful, please consider supporting [Hendrik](https://www.zettlr.com/supporters). As he says on the site, “And this free of any charge, because I do not believe in the fast-living, early-dying startup culture. I simply want to help.”
Have you ever used Zettlr? What is your favorite Markdown editor? Please let us know in the comments below.
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit](http://reddit.com/r/linuxusersgroup). |
10,923 | 如何在 Linux 上安装/卸载一个文件中列出的软件包? | https://www.2daygeek.com/how-to-install-uninstall-listed-packages-from-a-file-in-linux/ | 2019-06-01T12:56:12 | [
"软件包"
] | https://linux.cn/article-10923-1.html | 
在某些情况下,你可能想要将一个服务器上的软件包列表安装到另一个服务器上。例如,你已经在服务器 A 上安装了 15 个软件包并且这些软件包也需要被安装到服务器 B、服务器 C 上等等。
我们可以手动去安装这些软件但是这将花费大量的时间。你可以手动安装一俩个服务器,但是试想如果你有大概十个服务器呢。在这种情况下你无法手动完成工作,那么怎样才能解决问题呢?
不要担心我们可以帮你摆脱这样的情况和场景。我们在这篇文章中增加了四种方法来克服困难。
我希望这可以帮你解决问题。我已经在 Centos7 和 Ubuntu 18.04 上测试了这些命令。
我也希望这可以在其他发行版上工作。这仅仅需要使用该发行版的官方包管理器命令替代本文中的包管理器命令就行了。
如果想要 [检查 Linux 系统上已安装的软件包列表](/article-10116-1.html),请点击链接。
例如,如果你想要在基于 RHEL 系统上创建软件包列表请使用以下步骤。其他发行版也一样。
```
# rpm -qa --last | head -15 | awk '{print $1}' > /tmp/pack1.txt
# cat /tmp/pack1.txt
mariadb-server-5.5.60-1.el7_5.x86_64
perl-DBI-1.627-4.el7.x86_64
perl-DBD-MySQL-4.023-6.el7.x86_64
perl-PlRPC-0.2020-14.el7.noarch
perl-Net-Daemon-0.48-5.el7.noarch
perl-IO-Compress-2.061-2.el7.noarch
perl-Compress-Raw-Zlib-2.061-4.el7.x86_64
mariadb-5.5.60-1.el7_5.x86_64
perl-Data-Dumper-2.145-3.el7.x86_64
perl-Compress-Raw-Bzip2-2.061-3.el7.x86_64
httpd-2.4.6-88.el7.centos.x86_64
mailcap-2.1.41-2.el7.noarch
httpd-tools-2.4.6-88.el7.centos.x86_64
apr-util-1.5.2-6.el7.x86_64
apr-1.4.8-3.el7_4.1.x86_64
```
### 方法一:如何在 Linux 上使用 cat 命令安装文件中列出的包?
为实现这个目标,我将使用简单明了的第一种方法。为此,创建一个文件并添加上你想要安装的包列表。
出于测试的目的,我们将只添加以下的三个软件包名到文件中。
```
# cat /tmp/pack1.txt
apache2
mariadb-server
nano
```
只要简单的运行 [apt 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 就能在 Ubuntu/Debian 系统上一次性安装所有的软件包。
```
# apt -y install $(cat /tmp/pack1.txt)
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages were automatically installed and are no longer required:
libopts25 sntp
Use 'sudo apt autoremove' to remove them.
Suggested packages:
apache2-doc apache2-suexec-pristine | apache2-suexec-custom spell
The following NEW packages will be installed:
apache2 mariadb-server nano
0 upgraded, 3 newly installed, 0 to remove and 24 not upgraded.
Need to get 339 kB of archives.
After this operation, 1,377 kB of additional disk space will be used.
Get:1 http://in.archive.ubuntu.com/ubuntu bionic-updates/main amd64 apache2 amd64 2.4.29-1ubuntu4.6 [95.1 kB]
Get:2 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 nano amd64 2.9.3-2 [231 kB]
Get:3 http://in.archive.ubuntu.com/ubuntu bionic-updates/universe amd64 mariadb-server all 1:10.1.38-0ubuntu0.18.04.1 [12.9 kB]
Fetched 339 kB in 19s (18.0 kB/s)
Selecting previously unselected package apache2.
(Reading database ... 290926 files and directories currently installed.)
Preparing to unpack .../apache2_2.4.29-1ubuntu4.6_amd64.deb ...
Unpacking apache2 (2.4.29-1ubuntu4.6) ...
Selecting previously unselected package nano.
Preparing to unpack .../nano_2.9.3-2_amd64.deb ...
Unpacking nano (2.9.3-2) ...
Selecting previously unselected package mariadb-server.
Preparing to unpack .../mariadb-server_1%3a10.1.38-0ubuntu0.18.04.1_all.deb ...
Unpacking mariadb-server (1:10.1.38-0ubuntu0.18.04.1) ...
Processing triggers for ufw (0.36-0ubuntu0.18.04.1) ...
Setting up apache2 (2.4.29-1ubuntu4.6) ...
Processing triggers for ureadahead (0.100.0-20) ...
Processing triggers for install-info (6.5.0.dfsg.1-2) ...
Setting up nano (2.9.3-2) ...
update-alternatives: using /bin/nano to provide /usr/bin/editor (editor) in auto mode
update-alternatives: using /bin/nano to provide /usr/bin/pico (pico) in auto mode
Processing triggers for systemd (237-3ubuntu10.20) ...
Processing triggers for man-db (2.8.3-2ubuntu0.1) ...
Setting up mariadb-server (1:10.1.38-0ubuntu0.18.04.1) ...
```
至于删除,需要使用相同的命令格式和适当的选项。
```
# apt -y remove $(cat /tmp/pack1.txt)
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages were automatically installed and are no longer required:
apache2-bin apache2-data apache2-utils galera-3 libaio1 libapr1 libaprutil1 libaprutil1-dbd-sqlite3 libaprutil1-ldap libconfig-inifiles-perl libdbd-mysql-perl libdbi-perl libjemalloc1 liblua5.2-0
libmysqlclient20 libopts25 libterm-readkey-perl mariadb-client-10.1 mariadb-client-core-10.1 mariadb-common mariadb-server-10.1 mariadb-server-core-10.1 mysql-common sntp socat
Use 'apt autoremove' to remove them.
The following packages will be REMOVED:
apache2 mariadb-server nano
0 upgraded, 0 newly installed, 3 to remove and 24 not upgraded.
After this operation, 1,377 kB disk space will be freed.
(Reading database ... 291046 files and directories currently installed.)
Removing apache2 (2.4.29-1ubuntu4.6) ...
Removing mariadb-server (1:10.1.38-0ubuntu0.18.04.1) ...
Removing nano (2.9.3-2) ...
update-alternatives: using /usr/bin/vim.tiny to provide /usr/bin/editor (editor) in auto mode
Processing triggers for ufw (0.36-0ubuntu0.18.04.1) ...
Processing triggers for install-info (6.5.0.dfsg.1-2) ...
Processing triggers for man-db (2.8.3-2ubuntu0.1) ...
```
使用 [yum 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 在基于 RHEL (如 Centos、RHEL (Redhat) 和 OEL (Oracle Enterprise Linux)) 的系统上安装文件中列出的软件包。
```
# yum -y install $(cat /tmp/pack1.txt)
```
使用以命令在基于 RHEL (如 Centos、RHEL (Redhat) 和 OEL (Oracle Enterprise Linux)) 的系统上卸载文件中列出的软件包。
```
# yum -y remove $(cat /tmp/pack1.txt)
```
使用以下 [dnf 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 在 Fedora 系统上安装文件中列出的软件包。
```
# dnf -y install $(cat /tmp/pack1.txt)
```
使用以下命令在 Fedora 系统上卸载文件中列出的软件包。
```
# dnf -y remove $(cat /tmp/pack1.txt)
```
使用以下 [zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 在 openSUSE 系统上安装文件中列出的软件包。
```
# zypper -y install $(cat /tmp/pack1.txt)
```
使用以下命令从 openSUSE 系统上卸载文件中列出的软件包。
```
# zypper -y remove $(cat /tmp/pack1.txt)
```
使用以下 [pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 在基于 Arch Linux (如 Manjaro 和 Antergos) 的系统上安装文件中列出的软件包。
```
# pacman -S $(cat /tmp/pack1.txt)
```
使用以下命令从基于 Arch Linux (如 Manjaro 和 Antergos) 的系统中卸载文件中列出的软件包。
```
# pacman -Rs $(cat /tmp/pack1.txt)
```
### 方法二:如何使用 cat 和 xargs 命令在 Linux 中安装文件中列出的软件包。
甚至,我更喜欢使用这种方法,因为这是一种非常简单直接的方法。
使用以下 `apt` 命令在基于 Debian 的系统 (如 Debian、Ubuntu 和 Linux Mint) 上安装文件中列出的软件包。
```
# cat /tmp/pack1.txt | xargs apt -y install
```
使用以下 `apt` 命令 从基于 Debian 的系统 (如 Debian、Ubuntu 和 Linux Mint) 上卸载文件中列出的软件包。
```
# cat /tmp/pack1.txt | xargs apt -y remove
```
使用以下 `yum` 命令在基于 RHEL (如 Centos,RHEL (Redhat) 和 OEL (Oracle Enterprise Linux)) 的系统上安装文件中列出的软件包。
```
# cat /tmp/pack1.txt | xargs yum -y install
```
使用以命令从基于 RHEL (如 Centos、RHEL (Redhat) 和 OEL (Oracle Enterprise Linux)) 的系统上卸载文件中列出的软件包。
```
# cat /tmp/pack1.txt | xargs yum -y remove
```
使用以下 `dnf` 命令在 Fedora 系统上安装文件中列出的软件包。
```
# cat /tmp/pack1.txt | xargs dnf -y install
```
使用以下命令从 Fedora 系统上卸载文件中列出的软件包。
```
# cat /tmp/pack1.txt | xargs dnf -y remove
```
使用以下 `zypper` 命令在 openSUSE 系统上安装文件中列出的软件包。
```
# cat /tmp/pack1.txt | xargs zypper -y install
```
使用以下命令从 openSUSE 系统上卸载文件中列出的软件包。
```
# cat /tmp/pack1.txt | xargs zypper -y remove
```
使用以下 `pacman` 命令在基于 Arch Linux (如 Manjaro 和 Antergos) 的系统上安装文件中列出的软件包。
```
# cat /tmp/pack1.txt | xargs pacman -S
```
使用下以命令从基于 Arch Linux (如 Manjaro 和 Antergos) 的系统上卸载文件中列出的软件包。
```
# cat /tmp/pack1.txt | xargs pacman -Rs
```
### 方法三 : 如何使用 For 循环在 Linux 上安装文件中列出的软件包
我们也可以使用 `for` 循环命令来实现此目的。
安装批量包可以使用以下一条 `for` 循环的命令。
```
# for pack in `cat /tmp/pack1.txt` ; do apt -y install $i; done
```
要使用 shell 脚本安装批量包,请使用以下 `for` 循环。
```
# vi /opt/scripts/bulk-package-install.sh
#!/bin/bash
for pack in `cat /tmp/pack1.txt`
do apt -y remove $pack
done
```
为 `bulk-package-install.sh` 设置可执行权限。
```
# chmod + bulk-package-install.sh
```
最后运行这个脚本。
```
# sh bulk-package-install.sh
```
### 方法四:如何使用 While 循环在 Linux 上安装文件中列出的软件包
我们也可以使用 `while` 循环命令来实现目的。
安装批量包可以使用以下一条 `while` 循环的命令。
```
# file="/tmp/pack1.txt"; while read -r pack; do apt -y install $pack; done < "$file"
```
要使用 shell 脚本安装批量包,请使用以下 `while` 循环。
```
# vi /opt/scripts/bulk-package-install.sh
#!/bin/bash
file="/tmp/pack1.txt"
while read -r pack
do apt -y remove $pack
done < "$file"
```
为 `bulk-package-install.sh` 设置可执行权限。
```
# chmod + bulk-package-install.sh
```
最后运行这个脚本。
```
# sh bulk-package-install.sh
```
---
via: <https://www.2daygeek.com/how-to-install-uninstall-listed-packages-from-a-file-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[way-ww](https://github.com/way-ww) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,925 | Dockly:从终端管理 Docker 容器 | https://www.ostechnix.com/dockly-manage-docker-containers-from-terminal/ | 2019-06-01T14:41:00 | [
"容器",
"Docker"
] | https://linux.cn/article-10925-1.html | 
几天前,我们发布了一篇指南,其中涵盖了[开始使用 Docker](https://www.ostechnix.com/getting-started-with-docker/) 时需要了解的几乎所有细节。在该指南中,我们向你展示了如何详细创建和管理 Docker 容器。还有一些可用于管理 Docker 容器的非官方工具。如果你看过我们以前的文章,你可能会看到两个基于 Web 的工具,[Portainer](https://www.ostechnix.com/portainer-an-easiest-way-to-manage-docker/) 和 [PiCluster](https://www.ostechnix.com/picluster-simple-web-based-docker-management-application/)。它们都使得 Docker 管理任务在 Web 浏览器中变得更加容易和简单。今天,我遇到了另一个名为 Dockly 的 Docker 管理工具。
与上面的工具不同,Dockly 是一个 TUI(文本界面)程序,用于在类 Unix 系统中从终端管理 Docker 容器和服务。它是使用 NodeJS 编写的自由开源工具。在本简要指南中,我们将了解如何安装 Dockly 以及如何从命令行管理 Docker 容器。
### 安装 Dockly
确保已在 Linux 上安装了 NodeJS。如果尚未安装,请参阅以下指南。
* [如何在 Linux 上安装 NodeJS](https://www.ostechnix.com/install-node-js-linux/)
安装 NodeJS 后,运行以下命令安装 Dockly:
```
# npm install -g dockly
```
### 使用 Dockly 在终端管理 Docker 容器
使用 Dockly 管理 Docker 容器非常简单!你所要做的就是打开终端并运行以下命令:
```
# dockly
```
Dockly 将通过 unix 套接字自动连接到你的本机 docker 守护进程,并在终端中显示正在运行的容器列表,如下所示。

*使用 Dockly 管理 Docker 容器*
正如你在上面的截图中看到的,Dockly 在顶部显示了运行容器的以下信息:
* 容器 ID,
* 容器名称,
* Docker 镜像,
* 命令,
* 运行中容器的状态,
* 状态。
在右上角,你将看到容器的 CPU 和内存利用率。使用向上/向下箭头键在容器之间移动。
在底部,有少量的键盘快捷键来执行各种 Docker 管理任务。以下是目前可用的键盘快捷键列表:
* `=` - 刷新 Dockly 界面,
* `/` - 搜索容器列表视图,
* `i` - 显示有关当前所选容器或服务的信息,
* `回车` - 显示当前容器或服务的日志,
* `v` - 在容器和服务视图之间切换,
* `l` - 在选定的容器上启动 `/bin/bash` 会话,
* `r` - 重启选定的容器,
* `s` - 停止选定的容器,
* `h` - 显示帮助窗口,
* `q` - 退出 Dockly。
#### 查看容器的信息
使用向上/向下箭头选择一个容器,然后按 `i` 以显示所选容器的信息。

*查看容器的信息*
#### 重启容器
如果你想随时重启容器,只需选择它并按 `r` 即可重新启动。

*重启 Docker 容器*
#### 停止/删除容器和镜像
如果不再需要容器,我们可以立即停止和/或删除一个或所有容器。为此,请按 `m` 打开菜单。

*停止,删除 Docker 容器和镜像*
在这里,你可以执行以下操作。
* 停止所有 Docker 容器,
* 删除选定的容器,
* 删除所有容器,
* 删除所有 Docker 镜像等。
#### 显示 Dockly 帮助部分
如果你有任何疑问,只需按 `h` 即可打开帮助部分。

*Dockly 帮助*
有关更多详细信息,请参考最后给出的官方 GitHub 页面。
就是这些了。希望这篇文章有用。如果你一直在使用 Docker 容器,请试试 Dockly,看它是否有帮助。
建议阅读:
* [如何自动更新正在运行的 Docker 容器](https://www.ostechnix.com/automatically-update-running-docker-containers/)
* [ctop:一个 Linux 容器的命令行监控工具](https://www.ostechnix.com/ctop-commandline-monitoring-tool-linux-containers/)
资源:
* [Dockly 的 GitHub 仓库](https://github.com/lirantal/dockly)
---
via: <https://www.ostechnix.com/dockly-manage-docker-containers-from-terminal/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,926 | 4 款“吃草”的开源应用 | https://opensource.com/article/19/4/apps-plant-based-diets | 2019-06-01T19:33:26 | [
"素食"
] | /article-10926-1.html |
>
> 这些应用使素食者、纯素食主义者和那些想吃得更健康的杂食者找到可以吃的食物。
>
>
>

减少对肉类、乳制品和加工食品的消费对地球来说更好,也对你的健康更有益。改变你的饮食习惯可能很困难,但是一些开源的 Android 应用可以让你吃的更清淡。无论你是参加[无肉星期一](https://www.meatlessmonday.com/)、践行 Mark Bittman 的 [6:00 前的素食](https://www.amazon.com/dp/0385344740/)指南,还是完全切换到<ruby> <a href="https://nutritionstudies.org/whole-food-plant-based-diet-guide/"> 植物全食饮食 </a> <rt> whole-food, plant-based diet </rt></ruby>(WFPB),这些应用能帮助你找出要吃什么、发现素食和素食友好的餐馆,并轻松地将你的饮食偏好传达给他人,来助你更好地走这条路。所有这些应用都是开源的,可从 [F-Droid 仓库](https://f-droid.org/)下载。
### Daily Dozen

[Daily Dozen](https://f-droid.org/en/packages/org.nutritionfacts.dailydozen/) 提供了医学博士、美国法医学会院士(FACLM) Michael Greger 推荐的项目清单作为健康饮食和生活方式的一部分。Greger 博士建议食用由多种食物组成的基于植物的全食饮食,并坚持日常锻炼。该应用可以让你跟踪你吃的每种食物的份数,你喝了多少份水(或其他获准的饮料,如茶),以及你是否每天锻炼。每类食物都提供食物分量和属于该类别的食物清单。例如,十字花科蔬菜类包括白菜、花椰菜、抱子甘蓝等许多其他建议。
### Food Restrictions

[Food Restrictions](https://f-droid.org/en/packages/br.com.frs.foodrestrictions/) 是一个简单的应用,它可以帮助你将你的饮食限制传达给他人,即使这些人不会说你的语言。用户可以输入七种不同类别的食物限制:鸡肉、牛肉、猪肉、鱼、奶酪、牛奶和辣椒。每种类别都有“我不吃”和“我过敏”选项。“不吃”选项会显示带有红色 X 的图标。“过敏” 选项显示 “X” 和小骷髅图标。可以使用文本而不是图标显示相同的信息,但文本仅提供英语和葡萄牙语。还有一个选项可以显示一条文字信息,说明用户是素食主义者或纯素食主义者,它比选择选项更简洁、更准确地总结了这些饮食限制。纯素食主义者的文本清楚地提到不吃鸡蛋和蜂蜜,这在选择选项中是没有的。但是,就像选择选项方式的文字版本一样,这些句子仅提供英语和葡萄牙语。
### OpenFoodFacts

购买杂货时避免买入不必要的成分可能令人沮丧,但 [OpenFoodFacts](https://f-droid.org/en/packages/openfoodfacts.github.scrachx.openfood/) 可以帮助简化流程。该应用可让你扫描产品上的条形码,以获得有关产品成分和是否健康的报告。即使产品符合纯素产品的标准,产品仍然可能非常不健康。拥有成分列表和营养成分可让你在购物时做出明智的选择。此应用的唯一缺点是数据是用户贡献的,因此并非每个产品都可有数据,但如果你想回馈项目,你可以贡献新数据。
### OpenVegeMap

使用 [OpenVegeMap](https://f-droid.org/en/packages/pro.rudloff.openvegemap/) 查找你附近的纯素食或素食主义餐厅。此应用可以通过手机的当前位置或者输入地址来搜索。餐厅分类为仅限纯素食者、适合纯素食者,仅限素食主义者,适合素食者,非素食和未知。该应用使用来自 [OpenStreetMap](https://www.openstreetmap.org/) 的数据和用户提供的有关餐馆的信息,因此请务必仔细检查以确保所提供的信息是最新且准确的。
---
via: <https://opensource.com/article/19/4/apps-plant-based-diets>
作者:[Joshua Allen Holm](https://opensource.com/users/holmja) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,929 | 在 Linux 上监控 CPU 和 GPU 温度 | https://itsfoss.com/monitor-cpu-gpu-temp-linux/ | 2019-06-02T10:39:19 | [
"温度"
] | https://linux.cn/article-10929-1.html |
>
> 本篇文章讨论了在 Linux 命令行中监控 CPU 和 GPU 温度的两种简单方式。
>
>
>
由于 [Steam](https://itsfoss.com/install-steam-ubuntu-linux/)(包括 [Steam Play](https://itsfoss.com/steam-play-proton/),即 Proton)和一些其他的发展,GNU/Linux 正在成为越来越多计算机用户的日常游戏平台的选择。也有相当一部分用户在遇到像[视频编辑](https://itsfoss.com/best-video-editing-software-linux/)或图形设计等(Kdenlive 和 [Blender](https://www.blender.org/) 是这类应用程序中很好的例子)资源消耗型计算任务时,也会使用 GNU/Linux。
不管你是否是这些用户中的一员或其他用户,你也一定想知道你的电脑 CPU 和 GPU 能有多热(如果你想要超频的话更会如此)。如果是这样,那么继续读下去。我们会介绍两个非常简单的命令来监控 CPU 和 GPU 温度。
我的装置包括一台 [Slimbook Kymera](https://slimbook.es/) 和两台显示器(一台 TV 和一台 PC 监视器),使得我可以用一台来玩游戏,另一台来留意监控温度。另外,因为我使用 [Zorin OS](https://zorinos.com/),我会将关注点放在 Ubuntu 和 Ubuntu 的衍生发行版上。
为了监控 CPU 和 GPU 的行为,我们将利用实用的 `watch` 命令在每几秒钟之后动态地得到读数。

### 在 Linux 中监控 CPU 温度
对于 CPU 温度,我们将结合使用 `watch` 与 `sensors` 命令。一篇关于[此工具的图形用户界面版本](https://itsfoss.com/check-laptop-cpu-temperature-ubuntu/)的有趣文章已经在 It’s FOSS 中介绍过了。然而,我们将在此处使用命令行版本:
```
watch -n 2 sensors
```
`watch` 保证了读数会在每 2 秒钟更新一次(当然,这个周期值能够根据你的需要去更改):
```
Every 2,0s: sensors
iwlwifi-virtual-0
Adapter: Virtual device
temp1: +39.0°C
acpitz-virtual-0
Adapter: Virtual device
temp1: +27.8°C (crit = +119.0°C)
temp2: +29.8°C (crit = +119.0°C)
coretemp-isa-0000
Adapter: ISA adapter
Package id 0: +37.0°C (high = +82.0°C, crit = +100.0°C)
Core 0: +35.0°C (high = +82.0°C, crit = +100.0°C)
Core 1: +35.0°C (high = +82.0°C, crit = +100.0°C)
Core 2: +33.0°C (high = +82.0°C, crit = +100.0°C)
Core 3: +36.0°C (high = +82.0°C, crit = +100.0°C)
Core 4: +37.0°C (high = +82.0°C, crit = +100.0°C)
Core 5: +35.0°C (high = +82.0°C, crit = +100.0°C)
```
除此之外,我们还能得到如下信息:
* 我们有 5 个核心正在被使用(并且当前的最高温度为 37.0℃)。
* 温度超过 82.0℃ 会被认为是过热。
* 超过 100.0℃ 的温度会被认为是超过临界值。
根据以上的温度值我们可以得出结论,我的电脑目前的工作负载非常小。
### 在 Linux 中监控 GPU 温度
现在让我们来看看显卡。我从来没使用过 AMD 的显卡,因此我会将重点放在 Nvidia 的显卡上。我们需要做的第一件事是从 [Ubuntu 的附加驱动](https://itsfoss.com/install-additional-drivers-ubuntu/) 中下载合适的最新驱动。
在 Ubuntu(Zorin 或 Linux Mint 也是相同的)中,进入“软件和更新 > 附加驱动”选项,选择最新的可用驱动。另外,你可以添加或启用显示卡的官方 ppa(通过命令行或通过“软件和更新 > 其他软件”来实现)。安装驱动程序后,你将可以使用 “Nvidia X Server” 的 GUI 程序以及命令行工具 `nvidia-smi`(Nvidia 系统管理界面)。因此我们将使用 `watch` 和 `nvidia-smi`:
```
watch -n 2 nvidia-smi
```
与 CPU 的情况一样,我们会在每两秒得到一次更新的读数:
```
Every 2,0s: nvidia-smi
Fri Apr 19 20:45:30 2019
+-----------------------------------------------------------------------------+
| Nvidia-SMI 418.56 Driver Version: 418.56 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 106... Off | 00000000:01:00.0 On | N/A |
| 0% 54C P8 10W / 120W | 433MiB / 6077MiB | 4% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1557 G /usr/lib/xorg/Xorg 190MiB |
| 0 1820 G /usr/bin/gnome-shell 174MiB |
| 0 7820 G ...equest-channel-token=303407235874180773 65MiB |
+-----------------------------------------------------------------------------+
```
从这个表格中我们得到了关于显示卡的如下信息:
* 它正在使用版本号为 418.56 的开源驱动。
* 显示卡的当前温度为 54.0℃,并且风扇的使用量为 0%。
* 电量的消耗非常低:仅仅 10W。
* 总量为 6GB 的 vram(视频随机存取存储器),只使用了 433MB。
* vram 正在被 3 个进程使用,他们的 ID 分别为 1557、1820 和 7820。
大部分这些事实或数值都清晰地表明,我们没有在玩任何消耗系统资源的游戏或处理大负载的任务。当我们开始玩游戏、处理视频或其他类似任务时,这些值就会开始上升。
#### 结论
即便我们有 GUI 工具,但我还是发现这两个命令对于实时监控硬件非常的顺手。
你将如何去使用它们呢?你可以通过阅读他们的 man 手册来学习更多关于这些工具的使用技巧。
你有其他偏爱的工具吗?在评论里分享给我们吧 ;)。
玩得开心!
---
via: <https://itsfoss.com/monitor-cpu-gpu-temp-linux/>
作者:[Alejandro Egea-Abellán](https://itsfoss.com/author/itsfoss/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[cycoe](https://github.com/cycoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Because of [ Steam](https://itsfoss.com/install-steam-ubuntu-linux/) (including
[, aka](https://itsfoss.com/steam-play-proton/)
*Steam Play**) and other developments,*
*Proton***GNU/Linux**is becoming the gaming platform of choice for more and more computer users every day.
A good number of users are also going for **GNU/Linux** when it comes to other resource-consuming computing tasks such as [video editing](https://itsfoss.com/best-video-editing-software-linux/) or graphic design (* Kdenlive* and
*are good examples of programs for these).*
[Blender](https://www.blender.org/?ref=itsfoss.com)Whether you are one of those users or otherwise, you are bound to have wondered how hot your computer’s CPU and GPU can get (even more so if you do overclocking). If that is the case, keep reading. We will be looking at a couple of very simple commands to monitor CPU and GPU temps.
Since we are talking about commands, you may want to [learn how to get GPU details in Linux command line](https://itsfoss.com/check-graphics-card-linux/).
My setup includes a [Slimbook Kymera](https://slimbook.es/?ref=itsfoss.com) and two displays (a TV set and a PC monitor) which allows me to use one for playing games and the other to keep an eye on the temperatures. Also, since I use [Zorin OS](https://zorinos.com/?ref=itsfoss.com) I will be focusing on **Ubuntu** and **Ubuntu** derivatives.
To monitor the behaviour of both CPU and GPU we will be making use of the [watch command](https://linuxhandbook.com/watch-command/?ref=itsfoss.com) to have dynamic readings every certain number of seconds.
## Monitoring CPU Temperature in Linux
For CPU temps, we will combine sensors with the [watch command](https://linuxhandbook.com/watch-command/?ref=itsfoss.com). The sensors command is already installed on Ubuntu and many other Linux distributions. If not, you can install it using your distribution’s package manager. It is available as sensors or lm-sensors package.
An interesting article about a [gui version of this tool to check CPU temperature has already been covered on It’s FOSS](https://itsfoss.com/check-laptop-cpu-temperature-ubuntu/). However, we will use the terminal version here:
```
watch -n 2 sensors
```
The watch command guarantees that the readings will be updated every 2 seconds (and this value can — of course — be changed to what best fit your needs):
```
Every 2,0s: sensors
iwlwifi-virtual-0
Adapter: Virtual device
temp1: +39.0°C
acpitz-virtual-0
Adapter: Virtual device
temp1: +27.8°C (crit = +119.0°C)
temp2: +29.8°C (crit = +119.0°C)
coretemp-isa-0000
Adapter: ISA adapter
Package id 0: +37.0°C (high = +82.0°C, crit = +100.0°C)
Core 0: +35.0°C (high = +82.0°C, crit = +100.0°C)
Core 1: +35.0°C (high = +82.0°C, crit = +100.0°C)
Core 2: +33.0°C (high = +82.0°C, crit = +100.0°C)
Core 3: +36.0°C (high = +82.0°C, crit = +100.0°C)
Core 4: +37.0°C (high = +82.0°C, crit = +100.0°C)
Core 5: +35.0°C (high = +82.0°C, crit = +100.0°C)
```
Amongst other things, we get the following information:
- We have 6 cores in use at the moment (with the current highest temperature being 37.0ºC).
- Values higher than 82.0ºC are considered high.
- A value over 100.0ºC is deemed critical.
The values above lead us to conclude that the computer’s workload is very light.
If you are interested, there is an [advanced tool called CoreFreq that you can use to get detailed CPU information](https://itsfoss.com/know-cpu-linux-corefreq/).
## Monitoring GPU Temperature in Linux
Let us turn to the graphics card now. I have never used an **AMD** dedicated graphics card, so I will be focusing on **Nvidia** ones. The first thing to do is download the appropriate, current driver through [additional drivers in Ubuntu](https://itsfoss.com/install-additional-drivers-ubuntu/).
On **Ubuntu** (and its derivatives such as **Zorin** or **Linux Mint**), going to * Software & Updates* >
*and selecting the most recent one normally suffices.*
*Additional Drivers*Additionally, you can add or enable the [official graphics PPA](https://itsfoss.com/ubuntu-official-ppa-graphics/) (either through the command line or via * Software & Updates* >
*).*
*Other Software*After installing the driver you will have at your disposal the * Nvidia X Server* gui application along with the command line utility
*(Nvidia System Management Interface). So we will use*
`nvidia-smi`
`watch`
and `nvidia-smi`
:```
watch -n 2 nvidia-smi
```
And — the same as for the CPU — we will get updated readings every two seconds:
```
Every 2,0s: nvidia-smi
Fri Apr 19 20:45:30 2019
+-----------------------------------------------------------------------------+
| Nvidia-SMI 418.56 Driver Version: 418.56 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 106... Off | 00000000:01:00.0 On | N/A |
| 0% 54C P8 10W / 120W | 433MiB / 6077MiB | 4% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1557 G /usr/lib/xorg/Xorg 190MiB |
| 0 1820 G /usr/bin/gnome-shell 174MiB |
| 0 7820 G ...equest-channel-token=303407235874180773 65MiB |
+-----------------------------------------------------------------------------+
```
The chart gives the following information about the graphics card:
- it is using the open source driver version 418.56.
- the current temperature of the card is 54.0ºC — with the fan at 0% of its capacity.
- the power consumption is very low: only 10W.
- out of 6 GB of vram (video random access memory), it only uses 433 MB.
- the used vram is being taken by three processes whose IDs are — respectively — 1557, 1820 and 7820.
Most of these facts/values show that — clearly — I am not playing any resource-consuming games or dealing with heavy workloads. Should I start playing a game, processing a video — or the like — the values would increase.
## Conclusion
Although there are GUI tools, these two commands are very handy for checking [your hardware](https://itsfoss.com/hardinfo/) in real-time.
What do you make of them? You can learn more about the utilities involved by reading their man pages.
Do you have other preferences? Share them with us in the comments, ;).
Halof!!! (Have a lot of fun!!!). |
10,930 | Linux 下的进程间通信:套接字和信号 | https://opensource.com/article/19/4/interprocess-communication-linux-networking | 2019-06-02T23:44:52 | [
"IPC",
"进程间通信"
] | /article-10930-1.html |
>
> 学习在 Linux 中进程是如何与其他进程进行同步的。
>
>
>

本篇是 Linux 下[进程间通信](https://en.wikipedia.org/wiki/Inter-process_communication)(IPC)系列的第三篇同时也是最后一篇文章。[第一篇文章](/article-10826-1.html)聚焦在通过共享存储(文件和共享内存段)来进行 IPC,[第二篇文章](/article-10845-1.html)则通过管道(无名的或者命名的)及消息队列来达到相同的目的。这篇文章将目光从高处(套接字)然后到低处(信号)来关注 IPC。代码示例将用力地充实下面的解释细节。
### 套接字
正如管道有两种类型(命名和无名)一样,套接字也有两种类型。IPC 套接字(即 Unix 套接字)给予进程在相同设备(主机)上基于通道的通信能力;而网络套接字给予进程运行在不同主机的能力,因此也带来了网络通信的能力。网络套接字需要底层协议的支持,例如 TCP(传输控制协议)或 UDP(用户数据报协议)。
与之相反,IPC 套接字依赖于本地系统内核的支持来进行通信;特别的,IPC 通信使用一个本地的文件作为套接字地址。尽管这两种套接字的实现有所不同,但在本质上,IPC 套接字和网络套接字的 API 是一致的。接下来的例子将包含网络套接字的内容,但示例服务器和客户端程序可以在相同的机器上运行,因为服务器使用了 `localhost`(127.0.0.1)这个网络地址,该地址表示的是本地机器上的本地机器地址。
套接字以流的形式(下面将会讨论到)被配置为双向的,并且其控制遵循 C/S(客户端/服务器端)模式:客户端通过尝试连接一个服务器来初始化对话,而服务器端将尝试接受该连接。假如万事顺利,来自客户端的请求和来自服务器端的响应将通过管道进行传输,直到其中任意一方关闭该通道,从而断开这个连接。
一个迭代服务器(只适用于开发)将一直和连接它的客户端打交道:从最开始服务第一个客户端,然后到这个连接关闭,然后服务第二个客户端,循环往复。这种方式的一个缺点是处理一个特定的客户端可能会挂起,使得其他的客户端一直在后面等待。生产级别的服务器将是并发的,通常使用了多进程或者多线程的混合。例如,我台式机上的 Nginx 网络服务器有一个 4 个<ruby> 工人 <rt> worker </rt></ruby>的进程池,它们可以并发地处理客户端的请求。在下面的代码示例中,我们将使用迭代服务器,使得我们将要处理的问题保持在一个很小的规模,只关注基本的 API,而不去关心并发的问题。
最后,随着各种 POSIX 改进的出现,套接字 API 随着时间的推移而发生了显著的变化。当前针对服务器端和客户端的示例代码特意写的比较简单,但是它着重强调了基于流的套接字中连接的双方。下面是关于流控制的一个总结,其中服务器端在一个终端中开启,而客户端在另一个不同的终端中开启:
* 服务器端等待客户端的连接,对于给定的一个成功连接,它就读取来自客户端的数据。
* 为了强调是双方的会话,服务器端会对接收自客户端的数据做回应。这些数据都是 ASCII 字符代码,它们组成了一些书的标题。
* 客户端将书的标题写给服务器端的进程,并从服务器端的回应中读取到相同的标题。然后客户端和服务器端都在屏幕上打印出标题。下面是服务器端的输出,客户端的输出也和它完全一样:
```
Listening on port 9876 for clients...
War and Peace
Pride and Prejudice
The Sound and the Fury
```
#### 示例 1. 使用套接字的客户端程序
```
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/tcp.h>
#include <arpa/inet.h>
#include "sock.h"
void report(const char* msg, int terminate) {
perror(msg);
if (terminate) exit(-1); /* failure */
}
int main() {
int fd = socket(AF_INET, /* network versus AF_LOCAL */
SOCK_STREAM, /* reliable, bidirectional: TCP */
0); /* system picks underlying protocol */
if (fd < 0) report("socket", 1); /* terminate */
/* bind the server's local address in memory */
struct sockaddr_in saddr;
memset(&saddr, 0, sizeof(saddr)); /* clear the bytes */
saddr.sin_family = AF_INET; /* versus AF_LOCAL */
saddr.sin_addr.s_addr = htonl(INADDR_ANY); /* host-to-network endian */
saddr.sin_port = htons(PortNumber); /* for listening */
if (bind(fd, (struct sockaddr *) &saddr, sizeof(saddr)) < 0)
report("bind", 1); /* terminate */
/* listen to the socket */
if (listen(fd, MaxConnects) < 0) /* listen for clients, up to MaxConnects */
report("listen", 1); /* terminate */
fprintf(stderr, "Listening on port %i for clients...\n", PortNumber);
/* a server traditionally listens indefinitely */
while (1) {
struct sockaddr_in caddr; /* client address */
int len = sizeof(caddr); /* address length could change */
int client_fd = accept(fd, (struct sockaddr*) &caddr, &len); /* accept blocks */
if (client_fd < 0) {
report("accept", 0); /* don't terminated, though there's a problem */
continue;
}
/* read from client */
int i;
for (i = 0; i < ConversationLen; i++) {
char buffer[BuffSize + 1];
memset(buffer, '\0', sizeof(buffer));
int count = read(client_fd, buffer, sizeof(buffer));
if (count > 0) {
puts(buffer);
write(client_fd, buffer, sizeof(buffer)); /* echo as confirmation */
}
}
close(client_fd); /* break connection */
} /* while(1) */
return 0;
}
```
上面的服务器端程序执行典型的 4 个步骤来准备回应客户端的请求,然后接受其他的独立请求。这里每一个步骤都以服务器端程序调用的系统函数来命名。
1. `socket(…)`:为套接字连接获取一个文件描述符
2. `bind(…)`:将套接字和服务器主机上的一个地址进行绑定
3. `listen(…)`:监听客户端请求
4. `accept(…)`:接受一个特定的客户端请求
上面的 `socket` 调用的完整形式为:
```
int sockfd = socket(AF_INET, /* versus AF_LOCAL */
SOCK_STREAM, /* reliable, bidirectional */
0); /* system picks protocol (TCP) */
```
第一个参数特别指定了使用的是一个网络套接字,而不是 IPC 套接字。对于第二个参数有多种选项,但 `SOCK_STREAM` 和 `SOCK_DGRAM`(数据报)是最为常用的。基于流的套接字支持可信通道,在这种通道中如果发生了信息的丢失或者更改,都将会被报告。这种通道是双向的,并且从一端到另外一端的有效载荷在大小上可以是任意的。相反的,基于数据报的套接字大多是不可信的,没有方向性,并且需要固定大小的载荷。`socket` 的第三个参数特别指定了协议。对于这里展示的基于流的套接字,只有一种协议选择:TCP,在这里表示的 `0`。因为对 `socket` 的一次成功调用将返回相似的文件描述符,套接字可以被读写,对应的语法和读写一个本地文件是类似的。
对 `bind` 的调用是最为复杂的,因为它反映出了在套接字 API 方面上的各种改进。我们感兴趣的点是这个调用将一个套接字和服务器端所在机器中的一个内存地址进行绑定。但对 `listen` 的调用就非常直接了:
```
if (listen(fd, MaxConnects) < 0)
```
第一个参数是套接字的文件描述符,第二个参数则指定了在服务器端处理一个拒绝连接错误之前,有多少个客户端连接被允许连接。(在头文件 `sock.h` 中 `MaxConnects` 的值被设置为 `8`。)
`accept` 调用默认将是一个阻塞等待:服务器端将不做任何事情直到一个客户端尝试连接它,然后进行处理。`accept` 函数返回的值如果是 `-1` 则暗示有错误发生。假如这个调用是成功的,则它将返回另一个文件描述符,这个文件描述符被用来指代另一个可读可写的套接字,它与 `accept` 调用中的第一个参数对应的接收套接字有所不同。服务器端使用这个可读可写的套接字来从客户端读取请求然后写回它的回应。接收套接字只被用于接受客户端的连接。
在设计上,服务器端可以一直运行下去。当然服务器端可以通过在命令行中使用 `Ctrl+C` 来终止它。
#### 示例 2. 使用套接字的客户端
```
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <netinet/tcp.h>
#include <netdb.h>
#include "sock.h"
const char* books[] = {"War and Peace",
"Pride and Prejudice",
"The Sound and the Fury"};
void report(const char* msg, int terminate) {
perror(msg);
if (terminate) exit(-1); /* failure */
}
int main() {
/* fd for the socket */
int sockfd = socket(AF_INET, /* versus AF_LOCAL */
SOCK_STREAM, /* reliable, bidirectional */
0); /* system picks protocol (TCP) */
if (sockfd < 0) report("socket", 1); /* terminate */
/* get the address of the host */
struct hostent* hptr = gethostbyname(Host); /* localhost: 127.0.0.1 */
if (!hptr) report("gethostbyname", 1); /* is hptr NULL? */
if (hptr->h_addrtype != AF_INET) /* versus AF_LOCAL */
report("bad address family", 1);
/* connect to the server: configure server's address 1st */
struct sockaddr_in saddr;
memset(&saddr, 0, sizeof(saddr));
saddr.sin_family = AF_INET;
saddr.sin_addr.s_addr =
((struct in_addr*) hptr->h_addr_list[0])->s_addr;
saddr.sin_port = htons(PortNumber); /* port number in big-endian */
if (connect(sockfd, (struct sockaddr*) &saddr, sizeof(saddr)) < 0)
report("connect", 1);
/* Write some stuff and read the echoes. */
puts("Connect to server, about to write some stuff...");
int i;
for (i = 0; i < ConversationLen; i++) {
if (write(sockfd, books[i], strlen(books[i])) > 0) {
/* get confirmation echoed from server and print */
char buffer[BuffSize + 1];
memset(buffer, '\0', sizeof(buffer));
if (read(sockfd, buffer, sizeof(buffer)) > 0)
puts(buffer);
}
}
puts("Client done, about to exit...");
close(sockfd); /* close the connection */
return 0;
}
```
客户端程序的设置代码和服务器端类似。两者主要的区别既不是在于监听也不在于接收,而是连接:
```
if (connect(sockfd, (struct sockaddr*) &saddr, sizeof(saddr)) < 0)
```
对 `connect` 的调用可能因为多种原因而导致失败,例如客户端拥有错误的服务器端地址或者已经有太多的客户端连接上了服务器端。假如 `connect` 操作成功,客户端将在一个 `for` 循环中,写入它的请求然后读取返回的响应。在会话后,服务器端和客户端都将调用 `close` 去关闭这个可读可写套接字,尽管任何一边的关闭操作就足以关闭它们之间的连接。此后客户端可以退出了,但正如前面提到的那样,服务器端可以一直保持开放以处理其他事务。
从上面的套接字示例中,我们看到了请求信息被回显给客户端,这使得客户端和服务器端之间拥有进行丰富对话的可能性。也许这就是套接字的主要魅力。在现代系统中,客户端应用(例如一个数据库客户端)和服务器端通过套接字进行通信非常常见。正如先前提及的那样,本地 IPC 套接字和网络套接字只在某些实现细节上面有所不同,一般来说,IPC 套接字有着更低的消耗和更好的性能。它们的通信 API 基本是一样的。
### 信号
信号会中断一个正在执行的程序,在这种意义下,就是用信号与这个程序进行通信。大多数的信号要么可以被忽略(阻塞)或者被处理(通过特别设计的代码)。`SIGSTOP` (暂停)和 `SIGKILL`(立即停止)是最应该提及的两种信号。这种符号常量有整数类型的值,例如 `SIGKILL` 对应的值为 `9`。
信号可以在与用户交互的情况下发生。例如,一个用户从命令行中敲了 `Ctrl+C` 来终止一个从命令行中启动的程序;`Ctrl+C` 将产生一个 `SIGTERM` 信号。`SIGTERM` 意即终止,它可以被阻塞或者被处理,而不像 `SIGKILL` 信号那样。一个进程也可以通过信号和另一个进程通信,这样使得信号也可以作为一种 IPC 机制。
考虑一下一个多进程应用,例如 Nginx 网络服务器是如何被另一个进程优雅地关闭的。`kill` 函数:
```
int kill(pid_t pid, int signum); /* declaration */
```
可以被一个进程用来终止另一个进程或者一组进程。假如 `kill` 函数的第一个参数是大于 `0` 的,那么这个参数将会被认为是目标进程的 `pid`(进程 ID),假如这个参数是 `0`,则这个参数将会被视作信号发送者所属的那组进程。
`kill` 的第二个参数要么是一个标准的信号数字(例如 `SIGTERM` 或 `SIGKILL`),要么是 `0` ,这将会对信号做一次询问,确认第一个参数中的 `pid` 是否是有效的。这样优雅地关闭一个多进程应用就可以通过向组成该应用的一组进程发送一个终止信号来完成,具体来说就是调用一个 `kill` 函数,使得这个调用的第二个参数是 `SIGTERM` 。(Nginx 主进程可以通过调用 `kill` 函数来终止其他工人进程,然后再停止自己。)就像许多库函数一样,`kill` 函数通过一个简单的可变语法拥有更多的能力和灵活性。
#### 示例 3. 一个多进程系统的优雅停止
```
#include <stdio.h>
#include <signal.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
void graceful(int signum) {
printf("\tChild confirming received signal: %i\n", signum);
puts("\tChild about to terminate gracefully...");
sleep(1);
puts("\tChild terminating now...");
_exit(0); /* fast-track notification of parent */
}
void set_handler() {
struct sigaction current;
sigemptyset(¤t.sa_mask); /* clear the signal set */
current.sa_flags = 0; /* enables setting sa_handler, not sa_action */
current.sa_handler = graceful; /* specify a handler */
sigaction(SIGTERM, ¤t, NULL); /* register the handler */
}
void child_code() {
set_handler();
while (1) { /` loop until interrupted `/
sleep(1);
puts("\tChild just woke up, but going back to sleep.");
}
}
void parent_code(pid_t cpid) {
puts("Parent sleeping for a time...");
sleep(5);
/* Try to terminate child. */
if (-1 == kill(cpid, SIGTERM)) {
perror("kill");
exit(-1);
}
wait(NULL); /` wait for child to terminate `/
puts("My child terminated, about to exit myself...");
}
int main() {
pid_t pid = fork();
if (pid < 0) {
perror("fork");
return -1; /* error */
}
if (0 == pid)
child_code();
else
parent_code(pid);
return 0; /* normal */
}
```
上面的停止程序模拟了一个多进程系统的优雅退出,在这个例子中,这个系统由一个父进程和一个子进程组成。这次模拟的工作流程如下:
* 父进程尝试去 `fork` 一个子进程。假如这个 `fork` 操作成功了,每个进程就执行它自己的代码:子进程就执行函数 `child_code`,而父进程就执行函数 `parent_code`。
* 子进程将会进入一个潜在的无限循环,在这个循环中子进程将睡眠一秒,然后打印一个信息,接着再次进入睡眠状态,以此循环往复。来自父进程的一个 `SIGTERM` 信号将引起子进程去执行一个信号处理回调函数 `graceful`。这样这个信号就使得子进程可以跳出循环,然后进行子进程和父进程之间的优雅终止。在终止之前,进程将打印一个信息。
* 在 `fork` 一个子进程后,父进程将睡眠 5 秒,使得子进程可以执行一会儿;当然在这个模拟中,子进程大多数时间都在睡眠。然后父进程调用 `SIGTERM` 作为第二个参数的 `kill` 函数,等待子进程的终止,然后自己再终止。
下面是一次运行的输出:
```
% ./shutdown
Parent sleeping for a time...
Child just woke up, but going back to sleep.
Child just woke up, but going back to sleep.
Child just woke up, but going back to sleep.
Child just woke up, but going back to sleep.
Child confirming received signal: 15 ## SIGTERM is 15
Child about to terminate gracefully...
Child terminating now...
My child terminated, about to exit myself...
```
对于信号的处理,上面的示例使用了 `sigaction` 库函数(POSIX 推荐的用法)而不是传统的 `signal` 函数,`signal` 函数有移植性问题。下面是我们主要关心的代码片段:
* 假如对 `fork` 的调用成功了,父进程将执行 `parent_code` 函数,而子进程将执行 `child_code` 函数。在给子进程发送信号之前,父进程将会等待 5 秒:
```
puts("Parent sleeping for a time...");
sleep(5);
if (-1 == kill(cpid, SIGTERM)) {
...sleepkillcpidSIGTERM...
```
假如 `kill` 调用成功了,父进程将在子进程终止时做等待,使得子进程不会变成一个僵尸进程。在等待完成后,父进程再退出。
* `child_code` 函数首先调用 `set_handler` 然后进入它的可能永久睡眠的循环。下面是我们将要查看的 `set_handler` 函数:
```
void set_handler() {
struct sigaction current; /* current setup */
sigemptyset(¤t.sa_mask); /* clear the signal set */
current.sa_flags = 0; /* for setting sa_handler, not sa_action */
current.sa_handler = graceful; /* specify a handler */
sigaction(SIGTERM, ¤t, NULL); /* register the handler */
}
```
上面代码的前三行在做相关的准备。第四个语句将为 `graceful` 设定为句柄,它将在调用 `_exit` 来停止之前打印一些信息。第 5 行和最后一行的语句将通过调用 `sigaction` 来向系统注册上面的句柄。`sigaction` 的第一个参数是 `SIGTERM` ,用作终止;第二个参数是当前的 `sigaction` 设定,而最后的参数(在这个例子中是 `NULL` )可被用来保存前面的 `sigaction` 设定,以备后面的可能使用。
使用信号来作为 IPC 的确是一个很轻量的方法,但确实值得尝试。通过信号来做 IPC 显然可以被归入 IPC 工具箱中。
### 这个系列的总结
在这个系列中,我们通过三篇有关 IPC 的文章,用示例代码介绍了如下机制:
* 共享文件
* 共享内存(通过信号量)
* 管道(命名和无名)
* 消息队列
* 套接字
* 信号
甚至在今天,在以线程为中心的语言,例如 Java、C# 和 Go 等变得越来越流行的情况下,IPC 仍然很受欢迎,因为相比于使用多线程,通过多进程来实现并发有着一个明显的优势:默认情况下,每个进程都有它自己的地址空间,除非使用了基于共享内存的 IPC 机制(为了达到安全的并发,竞争条件在多线程和多进程的时候必须被加上锁),在多进程中可以排除掉基于内存的竞争条件。对于任何一个写过即使是基本的通过共享变量来通信的多线程程序的人来说,他都会知道想要写一个清晰、高效、线程安全的代码是多么具有挑战性。使用单线程的多进程的确是很有吸引力的,这是一个切实可行的方式,使用它可以利用好今天多处理器的机器,而不需要面临基于内存的竞争条件的风险。
当然,没有一个简单的答案能够回答上述 IPC 机制中的哪一个更好。在编程中每一种 IPC 机制都会涉及到一个取舍问题:是追求简洁,还是追求功能强大。以信号来举例,它是一个相对简单的 IPC 机制,但并不支持多个进程之间的丰富对话。假如确实需要这样的对话,另外的选择可能会更合适一些。带有锁的共享文件则相对直接,但是当要处理大量共享的数据流时,共享文件并不能很高效地工作。管道,甚至是套接字,有着更复杂的 API,可能是更好的选择。让具体的问题去指导我们的选择吧。
尽管所有的示例代码(可以在[我的网站](http://condor.depaul.edu/mkalin)上获取到)都是使用 C 写的,其他的编程语言也经常提供这些 IPC 机制的轻量包装。这些代码示例都足够短小简单,希望这样能够鼓励你去进行实验。
---
via: <https://opensource.com/article/19/4/interprocess-communication-linux-networking>
作者:[Marty Kalin](https://opensource.com/users/mkalindepauledu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,931 | 5 个可以满足你的生产力、沟通和娱乐需求的开源手机应用 | https://opensource.com/article/19/4/mobile-apps | 2019-06-03T00:20:00 | [
"手机"
] | https://linux.cn/article-10931-1.html |
>
> 你可以依靠这些应用来满足你的生产力、沟通和娱乐需求。
>
>
>

像世界上大多数人一样,我的手似乎就没有离开过手机。多亏了我从 Google Play 和 F-Droid 安装的开源移动应用程序,让我的 Android 设备好像提供了无限的沟通、生产力和娱乐服务一样。
在我的手机上的许多开源应用程序中,当想听音乐、与朋友/家人和同事联系、或者在旅途中完成工作时,以下五个是我一直使用的。
### MPDroid
一个音乐播放器进程 (MPD)的 Android 控制器。

MPD 是将音乐从小型音乐服务器电脑传输到大型的黑色立体声音箱的好方法。它直连 ALSA,因此可以通过 ALSA 硬件接口与数模转换器(DAC)对话,它可以通过我的网络进行控制——但是用什么东西控制呢?好吧,事实证明 MPDroid 是一个很棒的 MPD 控制器。它可以管理我的音乐数据库,显示专辑封面,处理播放列表,并支持互联网广播。而且它是开源的,所以如果某些东西不好用的话……
MPDroid 可在 [Google Play](https://play.google.com/store/apps/details?id=com.namelessdev.mpdroid&hl=en_US) 和 [F-Droid](https://f-droid.org/en/packages/com.namelessdev.mpdroid/) 上找到。
### RadioDroid
一台能单独使用及与 Chromecast 搭配使用的 Android 网络收音机。

RadioDroid 是一个网络收音机,而 MPDroid 则管理我音乐的数据库;从本质上讲,RadioDroid 是 [Internet-Radio.com](https://www.internet-radio.com/) 的一个前端。此外,通过将耳机插入 Android 设备,通过耳机插孔或 USB 将 Android 设备直接连接到立体声系统,或通过兼容设备使用其 Chromecast 功能,可以享受 RadioDroid。这是一个查看芬兰天气情况,听取排名前 40 的西班牙语音乐,或收到到最新新闻消息的好方法。
RadioDroid 可在 [Google Play](https://play.google.com/store/apps/details?id=net.programmierecke.radiodroid2) 和 [F-Droid](https://f-droid.org/en/packages/net.programmierecke.radiodroid2/) 上找到。
### Signal
一个支持 Android、iOS,还有桌面系统的安全即时消息客户端。

如果你喜欢 WhatsApp,但是因为它与 Facebook [日益密切](https://opensource.com/article/19/3/open-messenger-client)的关系而感到困扰,那么 Signal 应该是你的下一个产品。Signal 的唯一问题是说服你的朋友们最好用 Signal 取代 WhatsApp。但除此之外,它有一个与 WhatsApp 类似的界面;很棒的语音和视频通话;很好的加密;恰到好处的匿名;并且它受到了一个不打算通过使用软件来获利的基金会的支持。为什么不喜欢它呢?
Signal 可用于 [Android](https://play.google.com/store/apps/details?id=org.thoughtcrime.securesms)、[iOS](https://itunes.apple.com/us/app/signal-private-messenger/id874139669?mt=8) 和 [桌面](https://signal.org/download/)。
### ConnectBot
Android SSH 客户端。

有时我离电脑很远,但我需要登录服务器才能办事。[ConnectBot](https://connectbot.org/) 是将 SSH 会话搬到手机上的绝佳解决方案。
ConnectBot 可在 [Google Play](https://play.google.com/store/apps/details?id=org.connectbot) 上找到。
### Termux
有多种熟悉的功能的安卓终端模拟器。

你是否需要在手机上运行 `awk` 脚本?[Termux](https://termux.com/) 是个解决方案。如果你需要做终端类的工作,而且你不想一直保持与远程计算机的 SSH 连接,请使用 ConnectBot 将文件放到手机上,然后退出会话,在 Termux 中执行你的操作,用 ConnectBot 发回结果。
Termux 可在 [Google Play](https://play.google.com/store/apps/details?id=com.termux) 和 [F-Droid](https://f-droid.org/packages/com.termux/) 上找到。
---
你最喜欢用于工作或娱乐的开源移动应用是什么呢?请在评论中分享它们。
---
via: <https://opensource.com/article/19/4/mobile-apps>
作者:[Chris Hermansen](https://opensource.com/users/clhermansen/users/bcotton/users/clhermansen/users/bcotton/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[fuzheng1998](https://github.com/fuzheng1998) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Like most people in the world, I'm rarely further than an arm's reach from my smartphone. My Android device provides a seemingly limitless number of communication, productivity, and entertainment services thanks to the open source mobile apps I've installed from Google Play and F-Droid.
Of the many open source apps on my phone, the following five are the ones I consistently turn to whether I want to listen to music; connect with friends, family, and colleagues; or get work done on the go.
## MPDroid
*An Android controller for the Music Player Daemon (MPD)*
MPD is a great way to get music from little music server computers out to the big black stereo boxes. It talks straight to ALSA and therefore to the Digital-to-Analog Converter ([DAC](https://opensource.com/article/17/4/fun-new-gadget)) via the ALSA hardware interface, and it can be controlled over my network—but by what? Well, it turns out that MPDroid is a great MPD controller. It manages my music database, displays album art, handles playlists, and supports internet radio. And it's open source, so if something doesn't work…
MPDroid is available on [Google Play](https://play.google.com/store/apps/details?id=com.namelessdev.mpdroid&hl=en_US) and [F-Droid](https://f-droid.org/en/packages/com.namelessdev.mpdroid/).
## RadioDroid
*An Android internet radio tuner that I use standalone and with Chromecast*
RadioDroid is to internet radio as MPDroid is to managing my music database; essentially, RadioDroid is a frontend to [Internet-Radio.com](https://www.internet-radio.com/). Moreover, RadioDroid can be enjoyed by plugging headphones into the Android device, by connecting the Android device directly to the stereo via the headphone jack or USB, or by using its Chromecast capability with a compatible device. It's a fine way to check the weather in Finland, listen to the Spanish top 40, or hear the latest news from down under.
RadioDroid is available on [Google Play](https://play.google.com/store/apps/details?id=net.programmierecke.radiodroid2) and [F-Droid](https://f-droid.org/en/packages/net.programmierecke.radiodroid2/).
## Signal
*A secure messaging client for Android, iOS, and desktop*
If you like WhatsApp but are bothered by its [getting-closer-every-day](https://opensource.com/article/19/3/open-messenger-client) relationship to Facebook, Signal should be your next thing. The only problem with Signal is convincing your contacts they're better off replacing WhatsApp with Signal. But other than that, it has a similar interface; great voice and video calling; great encryption; decent anonymity; and it's supported by a foundation that doesn't plan to monetize your use of the software. What's not to like?
Signal is available for [Android](https://play.google.com/store/apps/details?id=org.thoughtcrime.securesms), [iOS](https://itunes.apple.com/us/app/signal-private-messenger/id874139669?mt=8), and [desktop](https://signal.org/download/).
## ConnectBot
*Android SSH client*
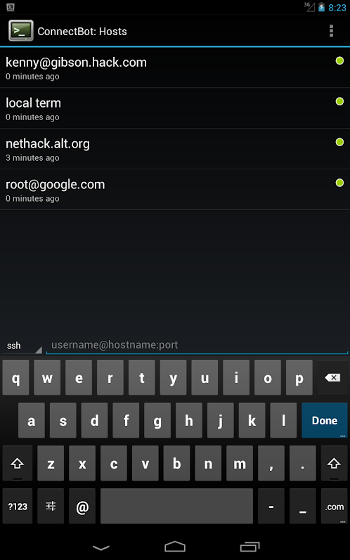
Sometimes I'm far away from my computer, but I need to log into the server to do something. [ConnectBot](https://connectbot.org/) is a great solution for moving SSH sessions onto my phone.
ConnectBot is available on [Google Play](https://play.google.com/store/apps/details?id=org.connectbot).
## Termux
*Android terminal emulator with many familiar utilities*
Have you ever needed to run an **awk** script on your phone? [Termux](https://termux.com/) is your solution. If you need to do terminal-type stuff, and you don't want to maintain an SSH connection to a remote computer the whole time, bring the files over to your phone with ConnectBot, quit the session, do your stuff in Termux, and send the results back with ConnectBot.
Termux is available on [Google Play](https://play.google.com/store/apps/details?id=com.termux) and [F-Droid](https://f-droid.org/packages/com.termux/).
What are your favorite open source mobile apps for work or fun? Please share them in the comments.
## 4 Comments |
10,932 | 给新手的 20 多个 FFmpeg 命令示例 | https://www.ostechnix.com/20-ffmpeg-commands-beginners/ | 2019-06-03T01:20:00 | [
"FFmpeg"
] | https://linux.cn/article-10932-1.html | 
在这个指南中,我将用示例来阐明如何使用 FFmpeg 媒体框架来做各种各样的音频、视频转码和转换的操作。我已经为初学者汇集了最常用的 20 多个 FFmpeg 命令,我将不时地添加更多的示例来保持更新这个指南。请给这个指南加书签,以后回来检查更新。让我们开始吧,如果你还没有在你的 Linux 系统中安装 FFmpeg,参考下面的指南。
* [在 Linux 中安装 FFmpeg](https://www.ostechnix.com/install-ffmpeg-linux/)
### 针对初学者的 20 多个 FFmpeg 命令
FFmpeg 命令的典型语法是:
```
ffmpeg [全局选项] {[输入文件选项] -i 输入_url_地址} ...
{[输出文件选项] 输出_url_地址} ...
```
现在我们将查看一些重要的和有用的 FFmpeg 命令。
#### 1、获取音频/视频文件信息
为显示你的媒体文件细节,运行:
```
$ ffmpeg -i video.mp4
```
样本输出:
```
ffmpeg version n4.1.3 Copyright (c) 2000-2019 the FFmpeg developers
built with gcc 8.2.1 (GCC) 20181127
configuration: --prefix=/usr --disable-debug --disable-static --disable-stripping --enable-fontconfig --enable-gmp --enable-gnutls --enable-gpl --enable-ladspa --enable-libaom --enable-libass --enable-libbluray --enable-libdrm --enable-libfreetype --enable-libfribidi --enable-libgsm --enable-libiec61883 --enable-libjack --enable-libmodplug --enable-libmp3lame --enable-libopencore_amrnb --enable-libopencore_amrwb --enable-libopenjpeg --enable-libopus --enable-libpulse --enable-libsoxr --enable-libspeex --enable-libssh --enable-libtheora --enable-libv4l2 --enable-libvidstab --enable-libvorbis --enable-libvpx --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxcb --enable-libxml2 --enable-libxvid --enable-nvdec --enable-nvenc --enable-omx --enable-shared --enable-version3
libavutil 56. 22.100 / 56. 22.100
libavcodec 58. 35.100 / 58. 35.100
libavformat 58. 20.100 / 58. 20.100
libavdevice 58. 5.100 / 58. 5.100
libavfilter 7. 40.101 / 7. 40.101
libswscale 5. 3.100 / 5. 3.100
libswresample 3. 3.100 / 3. 3.100
libpostproc 55. 3.100 / 55. 3.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'video.mp4':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1mp41
encoder : Lavf58.20.100
Duration: 00:00:28.79, start: 0.000000, bitrate: 454 kb/s
Stream #0:0(und): Video: h264 (High) (avc1 / 0x31637661), yuv420p(tv, smpte170m/bt470bg/smpte170m), 1920x1080 [SAR 1:1 DAR 16:9], 318 kb/s, 30 fps, 30 tbr, 15360 tbn, 60 tbc (default)
Metadata:
handler_name : ISO Media file produced by Google Inc. Created on: 04/08/2019.
Stream #0:1(eng): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 128 kb/s (default)
Metadata:
handler_name : ISO Media file produced by Google Inc. Created on: 04/08/2019.
At least one output file must be specified
```
如你在上面的输出中看到的,FFmpeg 显示该媒体文件信息,以及 FFmpeg 细节,例如版本、配置细节、版权标记、构建参数和库选项等等。
如果你不想看 FFmpeg 标语和其它细节,而仅仅想看媒体文件信息,使用 `-hide_banner` 标志,像下面。
```
$ ffmpeg -i video.mp4 -hide_banner
```
样本输出:

*使用 FFMpeg 查看音频、视频文件信息。*
看见了吗?现在,它仅显示媒体文件细节。
#### 2、转换视频文件到不同的格式
FFmpeg 是强有力的音频和视频转换器,因此,它能在不同格式之间转换媒体文件。举个例子,要转换 mp4 文件到 avi 文件,运行:
```
$ ffmpeg -i video.mp4 video.avi
```
类似地,你可以转换媒体文件到你选择的任何格式。
例如,为转换 YouTube flv 格式视频为 mpeg 格式,运行:
```
$ ffmpeg -i video.flv video.mpeg
```
如果你想维持你的源视频文件的质量,使用 `-qscale 0` 参数:
```
$ ffmpeg -i input.webm -qscale 0 output.mp4
```
为检查 FFmpeg 的支持格式的列表,运行:
```
$ ffmpeg -formats
```
#### 3、转换视频文件到音频文件
我转换一个视频文件到音频文件,只需具体指明输出格式,像 .mp3,或 .ogg,或其它任意音频格式。
上面的命令将转换 input.mp4 视频文件到 output.mp3 音频文件。
```
$ ffmpeg -i input.mp4 -vn output.mp3
```
此外,你也可以对输出文件使用各种各样的音频转换编码选项,像下面演示。
```
$ ffmpeg -i input.mp4 -vn -ar 44100 -ac 2 -ab 320 -f mp3 output.mp3
```
在这里,
* `-vn` – 表明我们已经在输出文件中禁用视频录制。
* `-ar` – 设置输出文件的音频频率。通常使用的值是22050 Hz、44100 Hz、48000 Hz。
* `-ac` – 设置音频通道的数目。
* `-ab` – 表明音频比特率。
* `-f` – 输出文件格式。在我们的实例中,它是 mp3 格式。
#### 4、更改视频文件的分辨率
如果你想设置一个视频文件为指定的分辨率,你可以使用下面的命令:
```
$ ffmpeg -i input.mp4 -filter:v scale=1280:720 -c:a copy output.mp4
```
或,
```
$ ffmpeg -i input.mp4 -s 1280x720 -c:a copy output.mp4
```
上面的命令将设置所给定视频文件的分辨率到 1280×720。
类似地,为转换上面的文件到 640×480 大小,运行:
```
$ ffmpeg -i input.mp4 -filter:v scale=640:480 -c:a copy output.mp4
```
或者,
```
$ ffmpeg -i input.mp4 -s 640x480 -c:a copy output.mp4
```
这个技巧将帮助你缩放你的视频文件到较小的显示设备上,例如平板电脑和手机。
#### 5、压缩视频文件
减小媒体文件的大小到较小来节省硬件的空间总是一个好主意.
下面的命令将压缩并减少输出文件的大小。
```
$ ffmpeg -i input.mp4 -vf scale=1280:-1 -c:v libx264 -preset veryslow -crf 24 output.mp4
```
请注意,如果你尝试减小视频文件的大小,你将损失视频质量。如果 24 太有侵略性,你可以降低 `-crf` 值到或更低值。
你也可以通过下面的选项来转换编码音频降低比特率,使其有立体声感,从而减小大小。
```
-ac 2 -c:a aac -strict -2 -b:a 128k
```
#### 6、压缩音频文件
正像压缩视频文件一样,为节省一些磁盘空间,你也可以使用 `-ab` 标志压缩音频文件。
例如,你有一个 320 kbps 比特率的音频文件。你想通过更改比特率到任意较低的值来压缩它,像下面。
```
$ ffmpeg -i input.mp3 -ab 128 output.mp3
```
各种各样可用的音频比特率列表是:
1. 96kbps
2. 112kbps
3. 128kbps
4. 160kbps
5. 192kbps
6. 256kbps
7. 320kbps
#### 7、从一个视频文件移除音频流
如果你不想要一个视频文件中的音频,使用 `-an` 标志。
```
$ ffmpeg -i input.mp4 -an output.mp4
```
在这里,`-an` 表示没有音频录制。
上面的命令会撤销所有音频相关的标志,因为我们不要来自 input.mp4 的音频。
#### 8、从一个媒体文件移除视频流
类似地,如果你不想要视频流,你可以使用 `-vn` 标志从媒体文件中简单地移除它。`-vn` 代表没有视频录制。换句话说,这个命令转换所给定媒体文件为音频文件。
下面的命令将从所给定媒体文件中移除视频。
```
$ ffmpeg -i input.mp4 -vn output.mp3
```
你也可以使用 `-ab` 标志来指出输出文件的比特率,如下面的示例所示。
```
$ ffmpeg -i input.mp4 -vn -ab 320 output.mp3
```
#### 9、从视频中提取图像
FFmpeg 的另一个有用的特色是我们可以从一个视频文件中轻松地提取图像。如果你想从一个视频文件中创建一个相册,这可能是非常有用的。
为从一个视频文件中提取图像,使用下面的命令:
```
$ ffmpeg -i input.mp4 -r 1 -f image2 image-%2d.png
```
在这里,
* `-r` – 设置帧速度。即,每秒提取帧到图像的数字。默认值是 25。
* `-f` – 表示输出格式,即,在我们的实例中是图像。
* `image-%2d.png` – 表明我们如何想命名提取的图像。在这个实例中,命名应该像这样image-01.png、image-02.png、image-03.png 等等开始。如果你使用 `%3d`,那么图像的命名像 image-001.png、image-002.png 等等开始。
#### 10、裁剪视频
FFMpeg 允许以我们选择的任何范围裁剪一个给定的媒体文件。
裁剪一个视频文件的语法如下给定:
```
ffmpeg -i input.mp4 -filter:v "crop=w:h:x:y" output.mp4
```
在这里,
* `input.mp4` – 源视频文件。
* `-filter:v` – 表示视频过滤器。
* `crop` – 表示裁剪过滤器。
* `w` – 我们想自源视频中裁剪的矩形的宽度。
* `h` – 矩形的高度。
* `x` – 我们想自源视频中裁剪的矩形的 x 坐标 。
* `y` – 矩形的 y 坐标。
比如说你想要一个来自视频的位置 (200,150),且具有 640 像素宽度和 480 像素高度的视频,命令应该是:
```
$ ffmpeg -i input.mp4 -filter:v "crop=640:480:200:150" output.mp4
```
请注意,剪切视频将影响质量。除非必要,请勿剪切。
#### 11、转换一个视频的具体的部分
有时,你可能想仅转换视频文件的一个具体的部分到不同的格式。以示例说明,下面的命令将转换所给定视频input.mp4 文件的开始 10 秒到视频 .avi 格式。
```
$ ffmpeg -i input.mp4 -t 10 output.avi
```
在这里,我们以秒具体说明时间。此外,以 `hh.mm.ss` 格式具体说明时间也是可以的。
#### 12、设置视频的屏幕高宽比
你可以使用 `-aspect` 标志设置一个视频文件的屏幕高宽比,像下面。
```
$ ffmpeg -i input.mp4 -aspect 16:9 output.mp4
```
通常使用的高宽比是:
* 16:9
* 4:3
* 16:10
* 5:4
* 2:21:1
* 2:35:1
* 2:39:1
#### 13、添加海报图像到音频文件
你可以添加海报图像到你的文件,以便图像将在播放音频文件时显示。这对托管在视频托管主机或共享网站中的音频文件是有用的。
```
$ ffmpeg -loop 1 -i inputimage.jpg -i inputaudio.mp3 -c:v libx264 -c:a aac -strict experimental -b:a 192k -shortest output.mp4
```
#### 14、使用开始和停止时间剪下一段媒体文件
可以使用开始和停止时间来剪下一段视频为小段剪辑,我们可以使用下面的命令。
```
$ ffmpeg -i input.mp4 -ss 00:00:50 -codec copy -t 50 output.mp4
```
在这里,
* `–ss` – 表示视频剪辑的开始时间。在我们的示例中,开始时间是第 50 秒。
* `-t` – 表示总的持续时间。
当你想使用开始和结束时间从一个音频或视频文件剪切一部分时,它是非常有用的。
类似地,我们可以像下面剪下音频。
```
$ ffmpeg -i audio.mp3 -ss 00:01:54 -to 00:06:53 -c copy output.mp3
```
#### 15、切分视频文件为多个部分
一些网站将仅允许你上传具体指定大小的视频。在这样的情况下,你可以切分大的视频文件到多个较小的部分,像下面。
```
$ ffmpeg -i input.mp4 -t 00:00:30 -c copy part1.mp4 -ss 00:00:30 -codec copy part2.mp4
```
在这里,
* `-t 00:00:30` 表示从视频的开始到视频的第 30 秒创建一部分视频。
* `-ss 00:00:30` 为视频的下一部分显示开始时间戳。它意味着第 2 部分将从第 30 秒开始,并将持续到原始视频文件的结尾。
#### 16、接合或合并多个视频部分到一个
FFmpeg 也可以接合多个视频部分,并创建一个单个视频文件。
创建包含你想接合文件的准确的路径的 `join.txt`。所有的文件都应该是相同的格式(相同的编码格式)。所有文件的路径应该逐个列出,像下面。
```
file /home/sk/myvideos/part1.mp4
file /home/sk/myvideos/part2.mp4
file /home/sk/myvideos/part3.mp4
file /home/sk/myvideos/part4.mp4
```
现在,接合所有文件,使用命令:
```
$ ffmpeg -f concat -i join.txt -c copy output.mp4
```
如果你得到一些像下面的错误;
```
[concat @ 0x555fed174cc0] Unsafe file name '/path/to/mp4'
join.txt: Operation not permitted
```
添加 `-safe 0` :
```
$ ffmpeg -f concat -safe 0 -i join.txt -c copy output.mp4
```
上面的命令将接合 part1.mp4、part2.mp4、part3.mp4 和 part4.mp4 文件到一个称为 output.mp4 的单个文件中。
#### 17、添加字幕到一个视频文件
我们可以使用 FFmpeg 来添加字幕到视频文件。为你的视频下载正确的字幕,并如下所示添加它到你的视频。
```
$ fmpeg -i input.mp4 -i subtitle.srt -map 0 -map 1 -c copy -c:v libx264 -crf 23 -preset veryfast output.mp4
```
#### 18、预览或测试视频或音频文件
你可能希望通过预览来验证或测试输出的文件是否已经被恰当地转码编码。为完成预览,你可以从你的终端播放它,用命令:
```
$ ffplay video.mp4
```
类似地,你可以测试音频文件,像下面所示。
```
$ ffplay audio.mp3
```
#### 19、增加/减少视频播放速度
FFmpeg 允许你调整视频播放速度。
为增加视频播放速度,运行:
```
$ ffmpeg -i input.mp4 -vf "setpts=0.5*PTS" output.mp4
```
该命令将双倍视频的速度。
为降低你的视频速度,你需要使用一个大于 1 的倍数。为减少播放速度,运行:
```
$ ffmpeg -i input.mp4 -vf "setpts=4.0*PTS" output.mp4
```
#### 20、创建动画的 GIF
出于各种目的,我们在几乎所有的社交和专业网络上使用 GIF 图像。使用 FFmpeg,我们可以简单地和快速地创建动画的视频文件。下面的指南阐释了如何在类 Unix 系统中使用 FFmpeg 和 ImageMagick 创建一个动画的 GIF 文件。
* [在 Linux 中如何创建动画的 GIF](https://www.ostechnix.com/create-animated-gif-ubuntu-16-04/)
#### 21、从 PDF 文件中创建视频
我长年累月的收集了很多 PDF 文件,大多数是 Linux 教程,保存在我的平板电脑中。有时我懒得从平板电脑中阅读它们。因此,我决定从 PDF 文件中创建一个视频,在一个大屏幕设备(像一台电视机或一台电脑)中观看它们。如果你想知道如何从一批 PDF 文件中制作一个电影,下面的指南将帮助你。
* [在 Linux 中如何从 PDF 文件中创建一个视频](https://www.ostechnix.com/create-video-pdf-files-linux/)
#### 22、获取帮助
在这个指南中,我已经覆盖大多数常常使用的 FFmpeg 命令。它有很多不同的选项来做各种各样的高级功能。要学习更多用法,请参考手册页。
```
$ man ffmpeg
```
这就是全部了。我希望这个指南将帮助你入门 FFmpeg。如果你发现这个指南有用,请在你的社交和专业网络上分享它。更多好东西将要来。敬请期待!
谢谢!
---
via: <https://www.ostechnix.com/20-ffmpeg-commands-beginners/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,934 | 法国 IT 巨头 Atos 进军边缘计算 | https://www.networkworld.com/article/3397139/atos-is-the-latest-to-enter-the-edge-computing-business.html | 2019-06-03T17:37:39 | [
"边缘计算"
] | https://linux.cn/article-10934-1.html |
>
> Atos 另辟蹊径,通过一种只有行李箱大小的设备 BullSequana Edge 进军边缘计算。
>
>
>

法国 IT 巨头 Atos 是最近才开展边缘计算业务的,他们的产品是一个叫做 BullSequana Edge 的小型设备。和竞争对手们的集装箱大小的设备不同(比如说 Vapor IO 和 Schneider Electronics 的产品),Atos 的边缘设备完全可以被放进衣柜里。
Atos 表示,他们的这个设备使用人工智能应用提供快速响应,适合需要快速响应的领域比如生产 4.0、自动驾驶汽车、健康管理,以及零售业和机场的安保系统。在这些领域,数据需要在边缘进行实时处理和分析。
[延伸阅读:[什么是边缘计算?](https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html) 以及 [边缘网络和物联网如何重新定义数据中心](https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html)]
BullSequana Edge 可以作为独立的基础设施单独采购,也可以和 Atos 的边缘软件捆绑采购,并且这个软件还是非常出色的。Atos 表示 BullSequana Edge 主要支持三种使用场景:
* AI(人工智能):Atos 的边缘计算机视觉软件为监控摄像头提供先进的特征抽取和分析技术,包括人像、人脸、行为等特征。这些分析可以支持系统做出自动化响应。
* 大数据:Atos 边缘数据分析系统通过预测性和规范性的解决方案,帮助机构优化商业模型。它使用数据湖的功能,确保数据的可信度和可用性。
* 容器:Atos 边缘数据容器(EDC)是一种一体化容器解决方案。它可以作为一个去中心化的 IT 系统在边缘运行,并且可以在没有数据中心的环境下自动运行,而不需要现场操作。
由于体积小,BullSequana Edge 并不具备很强的处理能力。它装载一个 16 核的 Intel Xeon 中央处理器,可以装备最多两枚英伟达 Tesla T4 图形处理器或者是 FPGA(现场可编程门阵列)。Atos 表示,这就足够让复杂的 AI 模型在边缘进行低延迟的运行了。
考虑到数据的敏感性,BullSequana Edge 同时装备了一个入侵感应器,用来在遭遇物理入侵的时候禁用机器。
虽然大多数边缘设备都被安放在信号塔附近,但是考虑到边缘系统可能被安放在任何地方,BullSequana Edge 还支持通过无线电、全球移动通信系统(GSM),或者 Wi-Fi 来进行通信。
Atos 在美国也许不是一个家喻户晓的名字,但是在欧洲它可以和 IBM 相提并论,并且在过去的十年里已经收购了诸如 Bull SA、施乐 IT 外包以及西门子 IT 等 IT 巨头们。
关于边缘网络的延伸阅读:
* [边缘网络和物联网如何重新定义数据中心](https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html)
* [边缘计算的最佳实践](https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html)
* [边缘计算如何提升物联网安全](https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html)
---
via: <https://www.networkworld.com/article/3397139/atos-is-the-latest-to-enter-the-edge-computing-business.html>
作者:[Andy Patrizio](https://www.networkworld.com/author/Andy-Patrizio/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chen-ni](https://github.com/chen-ni) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,935 | 在 Windows 中运行 Linux 命令的 4 种方法 | https://itsfoss.com/run-linux-commands-in-windows/ | 2019-06-04T09:38:20 | [
"Windows",
"WSL"
] | https://linux.cn/article-10935-1.html |
>
> 想要使用 Linux 命令,但又不想离开 Windows ?以下是在 Windows 中运行 Linux bash 命令的几种方法。
>
>
>
如果你正在课程中正在学习 shell 脚本,那么需要使用 Linux 命令来练习命令和脚本。
你的学校实验室可能安装了 Linux,但是你自己没有安装了 [Linux 的笔记本电脑](https://itsfoss.com/get-linux-laptops/),而是像其他人一样的 Windows 计算机。你的作业需要运行 Linux 命令,你或许想知道如何在 Windows 上运行 Bash 命令和脚本。
你可以[在双启动模式下同时安装 Windows 和 Linux](https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/)。此方法能让你在启动计算机时选择 Linux 或 Windows。但是,为了运行 Linux 命令而使用单独分区的麻烦可能不适合所有人。
你也可以[使用在线 Linux 终端](https://itsfoss.com/online-linux-terminals/),但你的作业无法保存。
好消息是,有几种方法可以在 Windows 中运行 Linux 命令,就像其他常规应用一样。不是很酷吗?
### 在 Windows 中使用 Linux 命令

作为一个热心的 Linux 用户和推广者,我希望看到越来越多的人使用“真正的” Linux,但我知道有时候,这不是优先考虑的问题。如果你只是想练习 Linux 来通过考试,可以使用这些方法之一在 Windows 上运行 Bash 命令。
#### 1、在 Windows 10 上使用 Linux Bash Shell
你是否知道可以在 Windows 10 中运行 Linux 发行版? [Windows 的 Linux 子系统 (WSL)](https://itsfoss.com/bash-on-windows/) 能让你在 Windows 中运行 Linux。即将推出的 WSL 版本将在 Windows 内部使用真正 Linux 内核。
此 WSL 也称为 Bash on Windows,它作为一个常规的 Windows 应用运行,并提供了一个命令行模式的 Linux 发行版。不要害怕命令行模式,因为你的目的是运行 Linux 命令。这就是你所需要的。

你可以在 Windows 应用商店中找到一些流行的 Linux 发行版,如 Ubuntu、Kali Linux、openSUSE 等。你只需像任何其他 Windows 应用一样下载和安装它。安装后,你可以运行所需的所有 Linux 命令。

请参考教程:[在 Windows 上安装 Linux bash shell](https://itsfoss.com/install-bash-on-windows/)。
#### 2、使用 Git Bash 在 Windows 上运行 Bash 命令
你可能知道 [Git](https://itsfoss.com/basic-git-commands-cheat-sheet/) 是什么。它是由 [Linux 创建者 Linus Torvalds](https://itsfoss.com/linus-torvalds-facts/) 开发的版本控制系统。
[Git for Windows](https://gitforwindows.org/) 是一组工具,能让你在命令行和图形界面中使用 Git。Git for Windows 中包含的工具之一是 Git Bash。
Git Bash 为 Git 命令行提供了仿真层。除了 Git 命令,Git Bash 还支持许多 Bash 程序,如 `ssh`、`scp`、`cat`、`find` 等。

换句话说,你可以使用 Git Bash 运行许多常见的 Linux/Bash 命令。
你可以从其网站免费下载和安装 Git for Windows 工具来在 Windows 中安装 Git Bash。
* [下载 Git for Windows](https://gitforwindows.org/)
#### 3、使用 Cygwin 在 Windows 中使用 Linux 命令
如果要在 Windows 中运行 Linux 命令,那么 Cygwin 是一个推荐的工具。Cygwin 创建于 1995 年,旨在提供一个原生运行于 Windows 中的 POSIX 兼容环境。Cygwin 是由 Red Hat 员工和许多其他志愿者维护的自由开源软件。
二十年来,Windows 用户使用 Cygwin 来运行和练习 Linux/Bash 命令。十多年前,我甚至用 Cygwin 来学习 Linux 命令。

你可以从下面的官方网站下载 Cygwin。我还建议你参考这个 [Cygwin 备忘录](http://www.voxforge.org/home/docs/cygwin-cheat-sheet)来开始使用。
* [下载 Cygwin](https://www.cygwin.com/)
#### 4、在虚拟机中使用 Linux
另一种方法是使用虚拟化软件并在其中安装 Linux。这样,你可以在 Windows 中安装 Linux 发行版(带有图形界面)并像常规 Windows 应用一样运行它。
这种方法要求你的系统有大的内存,至少 4GB ,但如果你有超过 8GB 的内存那么更好。这里的好处是你可以真实地使用桌面 Linux。如果你喜欢这个界面,那么你可能会在以后决定[切换到 Linux](https://itsfoss.com/reasons-switch-linux-windows-xp/)。

有两种流行的工具可在 Windows 上创建虚拟机,它们是 Oracle VirtualBox 和 VMware Workstation Player。你可以使用两者中的任何一个。就个人而言,我更喜欢 VirtualBox。
你可以按照[本教程学习如何在 VirtualBox 中安装 Linux](https://itsfoss.com/install-linux-in-virtualbox/)。
### 总结
运行 Linux 命令的最佳方法是使用 Linux。当选择不安装 Linux 时,这些工具能让你在 Windows 上运行 Linux 命令。都试试看,看哪种适合你。
---
via: <https://itsfoss.com/run-linux-commands-in-windows/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you are learning Shell scripting probably as a part of your course curriculum, you need to use Linux commands to practice the commands and scripting.
Your school lab might have Linux installed but you don’t have a [Linux laptop](https://itsfoss.com/get-linux-laptops/) but a regular Windows computer like everyone else. Your homework needs to run Linux commands and you wonder how to run Bash commands and scripts on Windows.
You can [install Linux alongside Windows in dual boot mode](https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/). This method allows you to choose either Linux or Windows when you start your computer. But taking all the trouble to mess with partitions for the sole purpose of running Linux commands may not be for everyone.
You can also [use Linux terminals online](https://itsfoss.com/online-linux-terminals/) but your work won’t be saved here.
The good news is that there are several ways you can run Linux commands inside Windows, like any regular application. Isn’t it cool?
## Using Linux commands inside Windows

As an ardent Linux user and promoter, I would like to see more and more people using ‘real’ Linux but I understand that at times, that’s not the priority. If you are just looking to practice Linux to pass your exams, you can use one method to run Bash commands on Windows.
### 1. Use Linux Bash Shell on Windows 10 with WSL
Did you know that you can run a Linux distribution inside Windows 10? The [Windows Subsystem for Linux (WSL)](https://itsfoss.com/bash-on-windows/) allows you to run Linux inside Windows. The upcoming version of WSL will be using the real Linux kernel inside Windows.
This WSL, also called Bash on Windows, gives you a Linux distribution in command-line mode running as a regular Windows application. Don’t be scared with the command line mode because your purpose is to run Linux commands. That’s all you need.
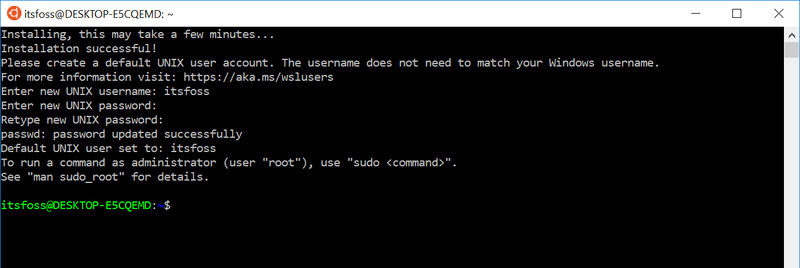
You can find some popular Linux distributions like Ubuntu, Kali Linux, openSUSE etc in Windows Store. You just have to download and install it like any other Windows application. Once installed, you can run all the Linux commands you want.
Please refer to this tutorial about [installing Linux bash shell on Windows](https://itsfoss.com/install-bash-on-windows/).
[How to Install Linux Bash Shell on Windows [Step-by-Step Guide]Step-by-step screenshot guide to show you how to install bash on Windows 11 and 10.](https://itsfoss.com/install-bash-on-windows/)

### 2. Use Git Bash to run Bash commands on Windows
You probably know what [Git](https://itsfoss.com/basic-git-commands-cheat-sheet/) is. It’s a version control system developed by [Linux creator Linus Torvalds](https://itsfoss.com/linus-torvalds-facts/).
[Git for Windows](https://gitforwindows.org/) is a set of tools that allows you to use Git in both command line and graphical interfaces. One of the tools included in Git for Windows is Git Bash.
Git Bash application provides and emulation layer for Git command line. Apart from Git commands, Git Bash also supports many Bash utilities such as ssh, scp, cat, find etc.
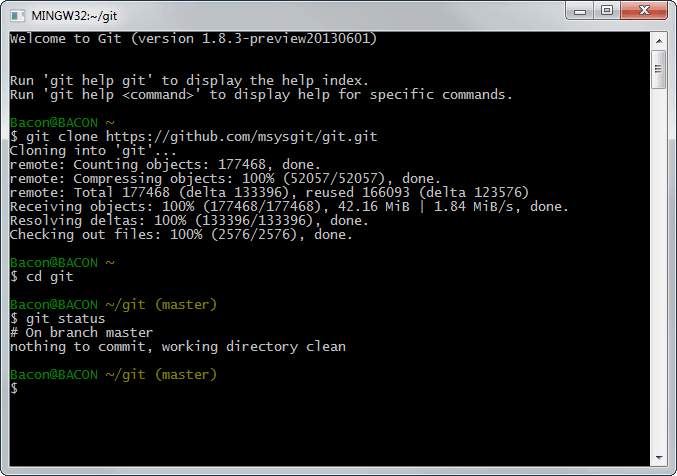
In other words, you can run many common Linux/Bash commands using the Git Bash application.
You can install Git Bash in Windows by downloading and installing the Git for Windows tool for free from its website.
### 3. Using Linux commands in Windows with Cygwin
If you want to run Linux commands in Windows, Cygwin is a recommended tool. Cygwin was created in 1995 to provide a POSIX-compatible environment that runs natively on Windows. Cygwin is a free and open source software maintained by Red Hat employees and many other volunteers.
For two decades, Windows users use Cygwin for running and practicing Linux/Bash commands. Even I used Cygwin to learn Linux commands more than a decade ago.
[Image Credit](http://www.es.ele.tue.nl/education/5JJ55-65/mmips-lab/cygwin.php)
You can download Cygwin from its official website below. I also advise you to refer to this [Cygwin cheat sheet](http://www.voxforge.org/home/docs/cygwin-cheat-sheet) to get started with it.
### 4. Use Linux in a virtual machine
Another way is to use virtualization software and install Linux in it. This way, you install a Linux distribution (with a graphical interface) inside Windows and run it like a regular Windows application.
This method requires that your system has a good amount of RAM, at least 4 GB but better if you have over 8 GB of RAM. The good thing here is that you get the real feel of using a desktop Linux. If you like the interface, you may later decide to [switch to Linux](https://itsfoss.com/reasons-switch-linux-windows-xp/) completely.
There are two popular tools for creating virtual machines on Windows, Oracle VirtualBox and VMware Workstation Player. You can use either of the two. Personally, I prefer VirtualBox.
You can follow [this tutorial to learn how to install Linux in VirtualBox](https://itsfoss.com/install-linux-in-virtualbox/).
[Install Linux Inside Windows Using VirtualBox [Step by Step Guide]Brief: Using Linux in a virtual machine gives you the option to try Linux within Windows. This step-by-step guide shows you how to install Linux inside Windows using VirtualBox. There are several ways to install Linux. You can clean everything from your system and install Linux. You can dual bo…](https://itsfoss.com/install-linux-in-virtualbox/)

## Conclusion
The best way to run Linux commands is to use Linux. When installing Linux is not an option, these tools allow you to run Linux commands on Windows. Give them a try and see which method is best suited for you. |
10,936 | 5 个可在家中使用的树莓派项目 | https://opensource.com/article/17/4/5-projects-raspberry-pi-home | 2019-06-04T11:09:45 | [
"树莓派",
"家庭"
] | https://linux.cn/article-10936-1.html | 
[树莓派](https://www.raspberrypi.org/) 电脑可被用来进行多种设置用于不同的目的。显然它在教育市场帮助学生在教室和创客空间中学习编程与创客技巧方面占有一席之地,它在工作场所和工厂中有大量行业应用。我打算介绍五个你可能想要在你的家中构建的项目。
### 媒体中心
在家中人们常用树莓派作为媒体中心来服务多媒体文件。它很容易搭建,树莓派提供了大量的 GPU(图形处理单元)运算能力来在大屏电视上渲染你的高清电视节目和电影。将 [Kodi](https://kodi.tv/)(从前的 XBMC)运行在树莓派上是一个很棒的方式,它可以播放你的硬盘或网络存储上的任何媒体。你同样可以安装一个插件来播放 YouTube 视频。
还有几个略微不同的选择,最常见的是 [OSMC](https://osmc.tv/)(开源媒体中心)和 [LibreELEC](https://libreelec.tv/),都是基于 Kodi 的。它们在放映媒体内容方面表现的都非常好,但是 OSMC 有一个更酷炫的用户界面,而 LibreElec 更轻量级。你要做的只是选择一个发行版,下载镜像并安装到一个 SD 卡中(或者仅仅使用 [NOOBS](https://www.raspberrypi.org/downloads/noobs/)),启动,然后就准备好了。

*LibreElec;树莓派基金会, CC BY-SA*

*OSMC.tv, 版权所有, 授权使用*
在往下走之前,你需要决定[使用哪种树莓派](https://opensource.com/life/16/10/which-raspberry-pi-should-you-choose-your-project)。这些发行版在任何树莓派(1、2、3 或 Zero)上都能运行,视频播放在这些树莓派中的任何一个上都能胜任。除了 Pi 3(和 Zero W)有内置 Wi-Fi,唯一可察觉的不同是用户界面的反应速度,在 Pi 3 上更快。Pi 2 也不会慢太多,所以如果你不需要 Wi-Fi 它也是可以的,但是当切换菜单时,你会注意到 Pi 3 比 Pi 1 和 Zero 表现的更好。
### SSH 网关
如果你想从外部网络访问你的家庭局域网的电脑和设备,你必须打开这些设备的端口来允许外部访问。在互联网中开放这些端口有安全风险,意味着你总是你总是处于被攻击、滥用或者其他各种未授权访问的风险中。然而,如果你在你的网络中安装一个树莓派,并且设置端口映射来仅允许通过 SSH 访问树莓派,你可以这么用来作为一个安全的网关来跳到网络中的其他树莓派和 PC。
大多数路由允许你配置端口映射规则。你需要给你的树莓派一个固定的内网 IP 地址来设置你的路由器端口 22 映射到你的树莓派端口 22。如果你的网络服务提供商给你提供了一个静态 IP 地址,你能够通过 SSH 和主机的 IP 地址访问(例如,`ssh [email protected]`)。如果你有一个域名,你可以配置一个子域名指向这个 IP 地址,所以你没必要记住它(例如,`ssh [email protected]`)。

然而,如果你不想将树莓派暴露在互联网上,你应该非常小心,不要让你的网络处于危险之中。如果你遵循一些简单的步骤来使它更安全:
1. 大多数人建议你更换你的登录密码(有道理,默认密码 “raspberry” 是众所周知的),但是这不能阻挡暴力攻击。你可以改变你的密码并添加一个双重验证(所以你需要你的密码*和*一个手机生成的与时间相关的密码),这么做更安全。但是,我相信最好的方法阻止入侵者访问你的树莓派是在你的 SSH 配置中[禁止密码认证](http://stackoverflow.com/questions/20898384/ssh-disable-password-authentication),这样只能通过 SSH 密匙进入。这意味着任何试图猜测你的密码尝试登录的人都不会成功。只有你的私有密匙可以访问。简单来说,很多人建议将 SSH 端口从默认的 22 换成其他的,但是通过简单的 [Nmap](https://nmap.org/) 扫描你的 IP 地址,你信任的 SSH 端口就会暴露。
2. 最好,不要在这个树莓派上运行其他的软件,这样你不会意外暴露其他东西。如果你想要运行其他软件,你最好在网络中的其他树莓派上运行,它们没有暴露在互联网上。确保你经常升级来保证你的包是最新的,尤其是 `openssh-server` 包,这样你的安全缺陷就被打补丁了。
3. 安装 [sshblack](http://www.pettingers.org/code/sshblack.html) 或 [fail2ban](https://www.fail2ban.org/wiki/index.php/Main_Page) 来将任何表露出恶意的用户加入黑名单,例如试图暴力破解你的 SSH 密码。
使树莓派安全后,让它在线,你将可以在世界的任何地方登录你的网络。一旦你登录到你的树莓派,你可以用 SSH 访问本地网络上的局域网地址(例如,192.168.1.31)访问其他设备。如果你在这些设备上有密码,用密码就好了。如果它们同样只允许 SSH 密匙,你需要确保你的密匙通过 SSH 转发,使用 `-A` 参数:`ssh -A [email protected]`。
### CCTV / 宠物相机
另一个很棒的家庭项目是安装一个相机模块来拍照和录视频,录制并保存文件,在内网或者外网中进行流式传输。你想这么做有很多原因,但两个常见的情况是一个家庭安防相机或监控你的宠物。
[树莓派相机模块](https://www.raspberrypi.org/products/camera-module-v2/) 是一个优秀的配件。它提供全高清的相片和视频,包括很多高级配置,很[容易编程](https://opensource.com/life/15/6/raspberry-pi-camera-projects)。[红外线相机](https://www.raspberrypi.org/products/pi-noir-camera-v2/)用于这种目的是非常理想的,通过一个红外线 LED(树莓派可以控制的),你就能够在黑暗中看见东西。
如果你想通过一定频率拍摄静态图片来留意某件事,你可以仅仅写一个简短的 [Python](http://picamera.readthedocs.io/) 脚本或者使用命令行工具 [raspistill](https://www.raspberrypi.org/documentation/usage/camera/raspicam/raspistill.md), 在 [Cron](https://www.raspberrypi.org/documentation/linux/usage/cron.md) 中规划它多次运行。你可能想将它们保存到 [Dropbox](https://github.com/RZRZR/plant-cam) 或另一个网络服务,上传到一个网络服务器,你甚至可以创建一个[web 应用](https://github.com/bennuttall/bett-bot)来显示他们。
如果你想要在内网或外网中流式传输视频,那也相当简单。在 [picamera 文档](http://picamera.readthedocs.io/en/release-1.13/recipes2.html#web-streaming)中(在 “web streaming” 章节)有一个简单的 MJPEG(Motion JPEG)例子。简单下载或者拷贝代码到文件中,运行并访问树莓派的 IP 地址的 8000 端口,你会看见你的相机的直播输出。
有一个更高级的流式传输项目 [pistreaming](https://github.com/waveform80/pistreaming) 也可以,它通过在网络服务器中用 [JSMpeg](http://jsmpeg.com/) (一个 JavaScript 视频播放器)和一个用于相机流的单独运行的 websocket。这种方法性能更好,并且和之前的例子一样简单,但是如果要在互联网中流式传输,则需要包含更多代码,并且需要你开放两个端口。
一旦你的网络流建立起来,你可以将你的相机放在你想要的地方。我用一个来观察我的宠物龟:

*Ben Nuttall, CC BY-SA*
如果你想控制相机位置,你可以用一个舵机。一个优雅的方案是用 Pimoroni 的 [Pan-Tilt HAT](https://shop.pimoroni.com/products/pan-tilt-hat),它可以让你简单的在二维方向上移动相机。为了与 pistreaming 集成,可以看看该项目的 [pantilthat 分支](https://github.com/waveform80/pistreaming/tree/pantilthat).

*Pimoroni.com, Copyright, 授权使用*
如果你想将你的树莓派放到户外,你将需要一个防水的外围附件,并且需要一种给树莓派供电的方式。POE(通过以太网提供电力)电缆是一个不错的实现方式。
### 家庭自动化或物联网
现在是 2017 年(LCTT 译注:此文发表时间),到处都有很多物联网设备,尤其是家中。我们的电灯有 Wi-Fi,我们的面包烤箱比过去更智能,我们的茶壶处于俄国攻击的风险中,除非你确保你的设备安全,不然别将没有必要的设备连接到互联网,之后你可以在家中充分的利用物联网设备来完成自动化任务。
市场上有大量你可以购买或订阅的服务,像 Nest Thermostat 或 Philips Hue 电灯泡,允许你通过你的手机控制你的温度或者你的亮度,无论你是否在家。你可以用一个树莓派来催动这些设备的电源,通过一系列规则包括时间甚至是传感器来完成自动交互。用 Philips Hue,你做不到的当你进房间时打开灯光,但是有一个树莓派和一个运动传感器,你可以用 Python API 来打开灯光。类似地,当你在家的时候你可以通过配置你的 Nest 打开加热系统,但是如果你想在房间里至少有两个人时才打开呢?写一些 Python 代码来检查网络中有哪些手机,如果至少有两个,告诉 Nest 来打开加热器。
不用选择集成已存在的物联网设备,你可以用简单的组件来做的更多。一个自制的窃贼警报器,一个自动化的鸡笼门开关,一个夜灯,一个音乐盒,一个定时的加热灯,一个自动化的备份服务器,一个打印服务器,或者任何你能想到的。
### Tor 协议和屏蔽广告
Adafruit 的 [Onion Pi](https://learn.adafruit.com/onion-pi/overview) 是一个 [Tor](https://www.torproject.org/) 协议来使你的网络通讯匿名,允许你使用互联网而不用担心窥探者和各种形式的监视。跟随 Adafruit 的指南来设置 Onion Pi,你会找到一个舒服的匿名的浏览体验。

*Onion-pi from Adafruit, Copyright, 授权使用*

可以在你的网络中安装一个树莓派来拦截所有的网络交通并过滤所有广告。简单下载 [Pi-hole](https://pi-hole.net/) 软件到 Pi 中,你的网络中的所有设备都将没有广告(甚至屏蔽你的移动设备应用内的广告)。
树莓派在家中有很多用法。你在家里用树莓派来干什么?你想用它干什么?
在下方评论让我们知道。
---
via: <https://opensource.com/article/17/4/5-projects-raspberry-pi-home>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [Raspberry Pi](https://www.raspberrypi.org/) computer can be used in all kinds of settings and for a variety of purposes. It obviously has a place in education for helping students with learning programming and maker skills in the classroom and the hackspace, and it has plenty of industrial applications in the workplace and in factories. I'm going to introduce five projects you might want to build in your own home.
## Media center
One of the most common uses for Raspberry Pi in people's homes is behind the TV running media center software serving multimedia files. It's easy to set this up, and the Raspberry Pi provides plenty of GPU (Graphics Processing Unit) power to render HD TV shows and movies to your big screen TV. [Kodi](https://kodi.tv/) (formerly XBMC) on a Raspberry Pi is a great way to playback any media you have on a hard drive or network-attached storage. You can also install a plugin to play YouTube videos.
There are a few different options available, most prominently [OSMC](https://osmc.tv/) (Open Source Media Center) and [LibreELEC](https://libreelec.tv/), both based on Kodi. They both perform well at playing media content, but OSMC has a more visually appearing user interface, while LibreElec is much more lightweight. All you have to do is choose a distribution, download the image and install on an SD card (or just use [NOOBS](https://www.raspberrypi.org/downloads/noobs/)), boot it up, and you're ready to go.
LibreElec; Raspberry Pi Foundation, CC BY-SA
OSMC.tv, Copyright, Used with permission
Before proceeding you'll need to decide [w](https://opensource.com/life/16/10/which-raspberry-pi-should-you-choose-your-project)[hich Raspberry Pi model to use](https://opensource.com/life/16/10/which-raspberry-pi-should-you-choose-your-project). These distributions will work on any Pi (1, 2, 3, or Zero), and video playback will essentially be matched on each of these. Apart from the Pi 3 (and Zero W) having built-in Wi-Fi, the only noticeable difference is the reaction speed of the user interface, which will be much faster on a Pi 3. A Pi 2 will not be much slower, so that's fine if you don't need Wi-Fi, but the Pi 3 will noticeably outperform the Pi 1 and Zero when it comes to flicking through the menus.
## SSH gateway
If you want to be able to access computers and devices on your home network from outside over the internet, you have to open up ports on those devices to allow outside traffic. Opening ports to the internet is a security risk, meaning you're always at risk of attack, misuse, or any kind of unauthorized access. However, if you install a Raspberry Pi on your network and set up port forwarding to allow only SSH access to that Pi, you can use that as a secure gateway to hop onto other Pis and PCs on the network.
Most routers allow you to configure port-forwarding rules. You'll need to give your Pi a fixed internal IP address and set up port 22 on your router to map to port 22 on your Raspberry Pi. If your ISP provides you with a static IP address, you'll be able to SSH into it with this as the host address (for example, **ssh [email protected]**). If you have a domain name, you can configure a subdomain to point to this IP address, so you don't have to remember it (for example, **ssh [email protected]**).
However, if you're going to expose a Raspberry Pi to the internet, you should be very careful not to put your network at risk. There are a few simple procedures you can follow to make it sufficiently secure:
1. Most people suggest you change your login password (which makes sense, seeing as the default password “raspberry” is well known), but this does not protect against brute-force attacks. You could change your password and add a two-factor authentication (so you need your password *and* a time-dependent passcode generated by your phone), which is more secure. However, I believe the best way to secure your Raspberry Pi from intruders is to [disable ](http://stackoverflow.com/questions/20898384/ssh-disable-password-authentication)[“password authentication”](http://stackoverflow.com/questions/20898384/ssh-disable-password-authentication) in your SSH configuration, so you allow only SSH key access. This means that anyone trying to SSH in by guessing your password will never succeed. Only with your private SSH key can anyone gain access. Similarly, most people suggest changing the SSH port from the default 22 to something unexpected, but a simple [Nmap](https://nmap.org/) of your IP address will reveal your true SSH port.
2. Ideally, you would not run much in the way of other software on this Pi, so you don't end up accidentally exposing anything else. If you want to run other software, you might be better running it on another Pi on the network that is not exposed to the internet. Ensure that you keep your packages up to date by upgrading regularly, particularly the **openssh-server** package, so that any security vulnerabilities are patched.
3. Install [sshblack](http://www.pettingers.org/code/sshblack.html) or [fail2ban](https://www.fail2ban.org/wiki/index.php/Main_Page) to blacklist any users who seem to be acting maliciously, such as attempting to brute force your SSH password.
Once you've secured your Raspberry Pi and put it online, you'll be able to log in to your network from anywhere in the world. Once you're on your Raspberry Pi, you can SSH into other devices on the network using their local IP address (for example, 192.168.1.31). If you have passwords on these devices, just use the password. If they're also SSH-key-only, you'll need to ensure your key is forwarded over SSH by using the **-A** flag: **ssh -A [email protected]**.
## CCTV / pet camera
Another great home project is to set up a camera module to take photos or stream video, capture and save files, or streamed internally or to the internet. There are many reasons you might want to do this, but two common use cases are for a homemade security camera or to monitor a pet.
The [Raspberry Pi camera module](https://www.raspberrypi.org/products/camera-module-v2/) is a brilliant accessory. It provides full HD photo and video, lots of advanced configuration, and is [easy to ](https://opensource.com/life/15/6/raspberry-pi-camera-projects)[program](https://opensource.com/life/15/6/raspberry-pi-camera-projects). The [infrared camera](https://www.raspberrypi.org/products/pi-noir-camera-v2/) is ideal for this kind of use, and with an infrared LED (which the Pi can control) you can see in the dark!
If you want to take still images on a regular basis to keep an eye on things, you can just write a short [Python](http://picamera.readthedocs.io/) script or use the command line tool [raspistill](https://www.raspberrypi.org/documentation/usage/camera/raspicam/raspistill.md), and schedule it to recur in [Cron](https://www.raspberrypi.org/documentation/linux/usage/cron.md). You might want to have it save them to [Dropbox](https://github.com/RZRZR/plant-cam) or another web service, upload them to a web server, or you can even create a [web app](https://github.com/bennuttall/bett-bot) to display them.
If you want to stream video, internally or externally, that's really easy, too. A simple MJPEG (Motion JPEG) example is provided in the [picamera documentation](http://picamera.readthedocs.io/en/release-1.13/recipes2.html#web-streaming) (under “web streaming”). Just download or copy that code into a file, run it and visit the Pi's IP address at port 8000, and you'll see your camera's output live.
A more advanced streaming project, [pistreaming](https://github.com/waveform80/pistreaming), is available, which uses [JSMpeg](http://jsmpeg.com/) (a JavaScript video player) with the web server and a websocket for the camera stream running separately. This method is more performant and is just as easy to get running as the previous example, but there is more code involved and if set up to stream on the internet, requires you to open two ports.
Once you have web streaming set up, you can position the camera where you want it. I have one set up to keep an eye on my pet tortoise:
Ben Nuttall, CC BY-SA
If you want to be able to control where the camera actually points, you can do so using servos. A neat solution is to use Pimoroni's [Pan-Tilt HAT](https://shop.pimoroni.com/products/pan-tilt-hat), which allows you to move the camera easily in two dimensions. To integrate this with pistreaming, see the project's [pantilthat branch](https://github.com/waveform80/pistreaming/tree/pantilthat).
Pimoroni.com, Copyright, Used with permission
If you want to position your Pi outside, you'll need a waterproof enclosure and some way of getting power to the Pi. PoE (Power-over-Ethernet) cables can be a good way of achieving this.
## Home automation and IoT
It's 2017 and there are internet-connected devices everywhere, especially in the home. Our lightbulbs have Wi-Fi, our toasters are smarter than they used to be, and our tea kettles are at risk of attack from Russia. As long as you keep your devices secure, or don't connect them to the internet if they don't need to be, then you can make great use of IoT devices to automate tasks around the home.
There are plenty of services you can buy or subscribe to, like Nest Thermostat or Philips Hue lightbulbs, which allow you to control your heating or your lighting from your phone, respectively—whether you're inside or away from home. You can use a Raspberry Pi to boost the power of these kinds of devices by automating interactions with them according to a set of rules involving timing or even sensors. One thing you can't do with Philips Hue is have the lights come on when you enter the room, but with a Raspberry Pi and a motion sensor, you can use a Python API to turn on the lights. Similarly, you can configure your Nest to turn on the heating when you're at home, but what if you only want it to turn on if there's at least two people home? Write some Python code to check which phones are on the network and if there are at least two, tell the Nest to turn on the heat.
You can do a great deal more without integrating with existing IoT devices and with only using simple components. A homemade burglar alarm, an automated chicken coop door opener, a night light, a music box, a timed heat lamp, an automated backup server, a print server, or whatever you can imagine.
## Tor proxy and blocking ads
Adafruit's [Onion Pi](https://learn.adafruit.com/onion-pi/overview) is a [Tor](https://www.torproject.org/) proxy that makes your web traffic anonymous, allowing you to use the internet free of snoopers and any kind of surveillance. Follow Adafruit's tutorial on setting up Onion Pi and you're on your way to a peaceful anonymous browsing experience.
Onion-pi from Adafruit, Copyright, Used with permission
You can install a Raspberry Pi on your network that intercepts all web traffic and filters out any advertising. Simply download the
[Pi-hole](https://pi-hole.net/) software onto the Pi, and all devices on your network will be ad-free (it even blocks in-app ads on your mobile devices).
There are plenty more uses for the Raspberry Pi at home. What do you use Raspberry Pi for at home? What do you want to use it for?
Let us know in the comments.
## 7 Comments |
10,938 | 如何在 CentOS 或 RHEL 系统上检查可用的安全更新? | https://www.2daygeek.com/check-list-view-find-available-security-updates-on-redhat-rhel-centos-system/ | 2019-06-05T00:39:34 | [
"补丁",
"安全"
] | https://linux.cn/article-10938-1.html | 
当你更新系统时,根据你所在公司的安全策略,有时候可能只需要打上与安全相关的补丁。大多数情况下,这应该是出于程序兼容性方面的考量。那该怎样实践呢?有没有办法让 `yum` 只安装安全补丁呢?
答案是肯定的,可以用 `yum` 包管理器轻松实现。
在这篇文章中,我们不但会提供所需的信息。而且,我们会介绍一些额外的命令,可以帮你获取指定安全更新的详实信息。
希望这样可以启发你去了解并修复你列表上的那些漏洞。一旦有安全漏洞被公布,就必须更新受影响的软件,这样可以降低系统中的安全风险。
对于 RHEL 或 CentOS 6 系统,运行下面的 [Yum 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 来安装 yum 安全插件。
```
# yum -y install yum-plugin-security
```
在 RHEL 7&8 或是 CentOS 7&8 上面,这个插件已经是 `yum` 的一部分了,不用单独安装。
要列出全部可用的补丁(包括安全、Bug 修复以及产品改进),但不安装它们:
```
# yum updateinfo list available
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos,
: subscription-manager, verify, versionlock
RHSA-2014:1031 Important/Sec. 389-ds-base-1.3.1.6-26.el7_0.x86_64
RHSA-2015:0416 Important/Sec. 389-ds-base-1.3.3.1-13.el7.x86_64
RHBA-2015:0626 bugfix 389-ds-base-1.3.3.1-15.el7_1.x86_64
RHSA-2015:0895 Important/Sec. 389-ds-base-1.3.3.1-16.el7_1.x86_64
RHBA-2015:1554 bugfix 389-ds-base-1.3.3.1-20.el7_1.x86_64
RHBA-2015:1960 bugfix 389-ds-base-1.3.3.1-23.el7_1.x86_64
RHBA-2015:2351 bugfix 389-ds-base-1.3.4.0-19.el7.x86_64
RHBA-2015:2572 bugfix 389-ds-base-1.3.4.0-21.el7_2.x86_64
RHSA-2016:0204 Important/Sec. 389-ds-base-1.3.4.0-26.el7_2.x86_64
RHBA-2016:0550 bugfix 389-ds-base-1.3.4.0-29.el7_2.x86_64
RHBA-2016:1048 bugfix 389-ds-base-1.3.4.0-30.el7_2.x86_64
RHBA-2016:1298 bugfix 389-ds-base-1.3.4.0-32.el7_2.x86_64
```
要统计补丁的大约数量,运行下面的命令:
```
# yum updateinfo list available | wc -l
11269
```
想列出全部可用的安全补丁但不安装,以下命令用来展示你系统里已安装和待安装的推荐补丁:
```
# yum updateinfo list security all
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos,
: subscription-manager, verify, versionlock
RHSA-2014:1031 Important/Sec. 389-ds-base-1.3.1.6-26.el7_0.x86_64
RHSA-2015:0416 Important/Sec. 389-ds-base-1.3.3.1-13.el7.x86_64
RHSA-2015:0895 Important/Sec. 389-ds-base-1.3.3.1-16.el7_1.x86_64
RHSA-2016:0204 Important/Sec. 389-ds-base-1.3.4.0-26.el7_2.x86_64
RHSA-2016:2594 Moderate/Sec. 389-ds-base-1.3.5.10-11.el7.x86_64
RHSA-2017:0920 Important/Sec. 389-ds-base-1.3.5.10-20.el7_3.x86_64
RHSA-2017:2569 Moderate/Sec. 389-ds-base-1.3.6.1-19.el7_4.x86_64
RHSA-2018:0163 Important/Sec. 389-ds-base-1.3.6.1-26.el7_4.x86_64
RHSA-2018:0414 Important/Sec. 389-ds-base-1.3.6.1-28.el7_4.x86_64
RHSA-2018:1380 Important/Sec. 389-ds-base-1.3.7.5-21.el7_5.x86_64
RHSA-2018:2757 Moderate/Sec. 389-ds-base-1.3.7.5-28.el7_5.x86_64
RHSA-2018:3127 Moderate/Sec. 389-ds-base-1.3.8.4-15.el7.x86_64
RHSA-2014:1031 Important/Sec. 389-ds-base-libs-1.3.1.6-26.el7_0.x86_64
```
要显示所有待安装的安全补丁:
```
# yum updateinfo list security all | grep -v "i"
RHSA-2014:1031 Important/Sec. 389-ds-base-1.3.1.6-26.el7_0.x86_64
RHSA-2015:0416 Important/Sec. 389-ds-base-1.3.3.1-13.el7.x86_64
RHSA-2015:0895 Important/Sec. 389-ds-base-1.3.3.1-16.el7_1.x86_64
RHSA-2016:0204 Important/Sec. 389-ds-base-1.3.4.0-26.el7_2.x86_64
RHSA-2016:2594 Moderate/Sec. 389-ds-base-1.3.5.10-11.el7.x86_64
RHSA-2017:0920 Important/Sec. 389-ds-base-1.3.5.10-20.el7_3.x86_64
RHSA-2017:2569 Moderate/Sec. 389-ds-base-1.3.6.1-19.el7_4.x86_64
RHSA-2018:0163 Important/Sec. 389-ds-base-1.3.6.1-26.el7_4.x86_64
RHSA-2018:0414 Important/Sec. 389-ds-base-1.3.6.1-28.el7_4.x86_64
RHSA-2018:1380 Important/Sec. 389-ds-base-1.3.7.5-21.el7_5.x86_64
RHSA-2018:2757 Moderate/Sec. 389-ds-base-1.3.7.5-28.el7_5.x86_64
```
要统计全部安全补丁的大致数量,运行下面的命令:
```
# yum updateinfo list security all | wc -l
3522
```
下面根据已装软件列出可更新的安全补丁。这包括 bugzilla(bug 修复)、CVE(知名漏洞数据库)、安全更新等:
```
# yum updateinfo list security
或者
# yum updateinfo list sec
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos,
: subscription-manager, verify, versionlock
RHSA-2018:3665 Important/Sec. NetworkManager-1:1.12.0-8.el7_6.x86_64
RHSA-2018:3665 Important/Sec. NetworkManager-adsl-1:1.12.0-8.el7_6.x86_64
RHSA-2018:3665 Important/Sec. NetworkManager-bluetooth-1:1.12.0-8.el7_6.x86_64
RHSA-2018:3665 Important/Sec. NetworkManager-config-server-1:1.12.0-8.el7_6.noarch
RHSA-2018:3665 Important/Sec. NetworkManager-glib-1:1.12.0-8.el7_6.x86_64
RHSA-2018:3665 Important/Sec. NetworkManager-libnm-1:1.12.0-8.el7_6.x86_64
RHSA-2018:3665 Important/Sec. NetworkManager-ppp-1:1.12.0-8.el7_6.x86_64
RHSA-2018:3665 Important/Sec. NetworkManager-team-1:1.12.0-8.el7_6.x86_64
RHSA-2018:3665 Important/Sec. NetworkManager-tui-1:1.12.0-8.el7_6.x86_64
RHSA-2018:3665 Important/Sec. NetworkManager-wifi-1:1.12.0-8.el7_6.x86_64
RHSA-2018:3665 Important/Sec. NetworkManager-wwan-1:1.12.0-8.el7_6.x86_64
```
显示所有与安全相关的更新,并且返回一个结果来告诉你是否有可用的补丁:
```
# yum --security check-update
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
rhel-7-server-rpms | 2.0 kB 00:00:00
--> policycoreutils-devel-2.2.5-20.el7.x86_64 from rhel-7-server-rpms excluded (updateinfo)
--> smc-raghumalayalam-fonts-6.0-7.el7.noarch from rhel-7-server-rpms excluded (updateinfo)
--> amanda-server-3.3.3-17.el7.x86_64 from rhel-7-server-rpms excluded (updateinfo)
--> 389-ds-base-libs-1.3.4.0-26.el7_2.x86_64 from rhel-7-server-rpms excluded (updateinfo)
--> 1:cups-devel-1.6.3-26.el7.i686 from rhel-7-server-rpms excluded (updateinfo)
--> openwsman-client-2.6.3-3.git4391e5c.el7.i686 from rhel-7-server-rpms excluded (updateinfo)
--> 1:emacs-24.3-18.el7.x86_64 from rhel-7-server-rpms excluded (updateinfo)
--> augeas-libs-1.4.0-2.el7_4.2.i686 from rhel-7-server-rpms excluded (updateinfo)
--> samba-winbind-modules-4.2.3-10.el7.i686 from rhel-7-server-rpms excluded (updateinfo)
--> tftp-5.2-11.el7.x86_64 from rhel-7-server-rpms excluded (updateinfo)
.
.
35 package(s) needed for security, out of 115 available
NetworkManager.x86_64 1:1.12.0-10.el7_6 rhel-7-server-rpms
NetworkManager-adsl.x86_64 1:1.12.0-10.el7_6 rhel-7-server-rpms
NetworkManager-bluetooth.x86_64 1:1.12.0-10.el7_6 rhel-7-server-rpms
NetworkManager-config-server.noarch 1:1.12.0-10.el7_6 rhel-7-server-rpms
NetworkManager-glib.x86_64 1:1.12.0-10.el7_6 rhel-7-server-rpms
NetworkManager-libnm.x86_64 1:1.12.0-10.el7_6 rhel-7-server-rpms
NetworkManager-ppp.x86_64 1:1.12.0-10.el7_6 rhel-7-server-rpms
```
列出所有可用的安全补丁,并且显示其详细信息:
```
# yum info-sec
.
.
===============================================================================
tzdata bug fix and enhancement update
===============================================================================
Update ID : RHBA-2019:0689
Release : 0
Type : bugfix
Status : final
Issued : 2019-03-28 19:27:44 UTC
Description : The tzdata packages contain data files with rules for various
: time zones.
:
: The tzdata packages have been updated to version
: 2019a, which addresses recent time zone changes.
: Notably:
:
: * The Asia/Hebron and Asia/Gaza zones will start
: DST on 2019-03-30, rather than 2019-03-23 as
: previously predicted.
: * Metlakatla rejoined Alaska time on 2019-01-20,
: ending its observances of Pacific standard time.
:
: (BZ#1692616, BZ#1692615, BZ#1692816)
:
: Users of tzdata are advised to upgrade to these
: updated packages.
Severity : None
```
如果你想要知道某个更新的具体内容,可以运行下面这个命令:
```
# yum updateinfo RHSA-2019:0163
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
rhel-7-server-rpms | 2.0 kB 00:00:00
===============================================================================
Important: kernel security, bug fix, and enhancement update
===============================================================================
Update ID : RHSA-2019:0163
Release : 0
Type : security
Status : final
Issued : 2019-01-29 15:21:23 UTC
Updated : 2019-01-29 15:23:47 UTC Bugs : 1641548 - CVE-2018-18397 kernel: userfaultfd bypasses tmpfs file permissions
: 1641878 - CVE-2018-18559 kernel: Use-after-free due to race condition in AF_PACKET implementation
CVEs : CVE-2018-18397
: CVE-2018-18559
Description : The kernel packages contain the Linux kernel, the core of any
: Linux operating system.
:
: Security Fix(es):
:
: * kernel: Use-after-free due to race condition in
: AF_PACKET implementation (CVE-2018-18559)
:
: * kernel: userfaultfd bypasses tmpfs file
: permissions (CVE-2018-18397)
:
: For more details about the security issue(s),
: including the impact, a CVSS score, and other
: related information, refer to the CVE page(s)
: listed in the References section.
:
: Bug Fix(es):
:
: These updated kernel packages include also
: numerous bug fixes and enhancements. Space
: precludes documenting all of the bug fixes in this
: advisory. See the descriptions in the related
: Knowledge Article:
: https://access.redhat.com/articles/3827321
Severity : Important
updateinfo info done
```
跟之前类似,你可以只查询那些通过 CVE 释出的系统漏洞:
```
# yum updateinfo list cves
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos,
: subscription-manager, verify, versionlock
CVE-2018-15688 Important/Sec. NetworkManager-1:1.12.0-8.el7_6.x86_64
CVE-2018-15688 Important/Sec. NetworkManager-adsl-1:1.12.0-8.el7_6.x86_64
CVE-2018-15688 Important/Sec. NetworkManager-bluetooth-1:1.12.0-8.el7_6.x86_64
CVE-2018-15688 Important/Sec. NetworkManager-config-server-1:1.12.0-8.el7_6.noarch
CVE-2018-15688 Important/Sec. NetworkManager-glib-1:1.12.0-8.el7_6.x86_64
CVE-2018-15688 Important/Sec. NetworkManager-libnm-1:1.12.0-8.el7_6.x86_64
CVE-2018-15688 Important/Sec. NetworkManager-ppp-1:1.12.0-8.el7_6.x86_64
CVE-2018-15688 Important/Sec. NetworkManager-team-1:1.12.0-8.el7_6.x86_64
```
你也可以查看那些跟 bug 修复相关的更新,运行下面的命令:
```
# yum updateinfo list bugfix | less
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos,
: subscription-manager, verify, versionlock
RHBA-2018:3349 bugfix NetworkManager-1:1.12.0-7.el7_6.x86_64
RHBA-2019:0519 bugfix NetworkManager-1:1.12.0-10.el7_6.x86_64
RHBA-2018:3349 bugfix NetworkManager-adsl-1:1.12.0-7.el7_6.x86_64
RHBA-2019:0519 bugfix NetworkManager-adsl-1:1.12.0-10.el7_6.x86_64
RHBA-2018:3349 bugfix NetworkManager-bluetooth-1:1.12.0-7.el7_6.x86_64
RHBA-2019:0519 bugfix NetworkManager-bluetooth-1:1.12.0-10.el7_6.x86_64
RHBA-2018:3349 bugfix NetworkManager-config-server-1:1.12.0-7.el7_6.noarch
RHBA-2019:0519 bugfix NetworkManager-config-server-1:1.12.0-10.el7_6.noarch
```
要想得到待安装更新的摘要信息,运行这个:
```
# yum updateinfo summary
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
rhel-7-server-rpms | 2.0 kB 00:00:00
Updates Information Summary: updates
13 Security notice(s)
9 Important Security notice(s)
3 Moderate Security notice(s)
1 Low Security notice(s)
35 Bugfix notice(s)
1 Enhancement notice(s)
updateinfo summary done
```
如果只想打印出低级别的安全更新,运行下面这个命令。类似的,你也可以只查询重要级别和中等级别的安全更新。
```
# yum updateinfo list sec | grep -i "Low"
RHSA-2019:0201 Low/Sec. libgudev1-219-62.el7_6.3.x86_64
RHSA-2019:0201 Low/Sec. systemd-219-62.el7_6.3.x86_64
RHSA-2019:0201 Low/Sec. systemd-libs-219-62.el7_6.3.x86_64
RHSA-2019:0201 Low/Sec. systemd-sysv-219-62.el7_6.3.x86_64
```
---
via: <https://www.2daygeek.com/check-list-view-find-available-security-updates-on-redhat-rhel-centos-system/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jdh8383](https://github.com/jdh8383) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,939 | 如何用树莓派搭建一个颗粒物传感器 | https://opensource.com/article/19/3/mobile-particulate-matter-sensor | 2019-06-05T00:51:40 | [
"颗粒物",
"PM2.5",
"树莓派"
] | https://linux.cn/article-10939-1.html |
>
> 用树莓派、一个廉价的传感器和一个便宜的屏幕监测空气质量。
>
>
>

大约一年前,我写了一篇关于如何使用树莓派和廉价传感器测量[空气质量](/article-9620-1.html)的文章。我们这几年已在学校里和私下使用了这个项目。然而它有一个缺点:由于它基于无线/有线网,因此它不是便携的。如果你的树莓派、你的智能手机和电脑不在同一个网络的话,你甚至都不能访问传感器测量的数据。
为了弥补这一缺陷,我们给树莓派添加了一块小屏幕,这样我们就可以直接从该设备上读取数据。以下是我们如何为我们的移动细颗粒物传感器搭建并配置好屏幕。
### 为树莓派搭建好屏幕
在[亚马逊](https://www.amazon.com/gp/search/ref=as_li_qf_sp_sr_tl?ie=UTF8&tag=openschoolsol-20&keywords=lcd%20raspberry&index=aps&camp=1789&creative=9325&linkCode=ur2&linkId=51d6d7676e10d6c7db203c4a8b3b529a)、阿里巴巴以及其它来源有许多可以买到的树莓派屏幕,从 ePaper 屏幕到可触控 LCD。我们选择了一个便宜的带触控功能且分辨率为 320\*480 像素的[3.5英寸 LCD](https://www.amazon.com/gp/search/ref=as_li_qf_sp_sr_tl?ie=UTF8&tag=openschoolsol-20&keywords=lcd%20raspberry&index=aps&camp=1789&creative=9325&linkCode=ur2&linkId=51d6d7676e10d6c7db203c4a8b3b529a),可以直接插进树莓派的 GPIO 引脚。3.5 英寸屏幕和树莓派几乎一样大,这一点不错。
当你第一次启动屏幕打开树莓派的时候,会因为缺少驱动屏幕会保持白屏。你得首先为屏幕安装[合适的驱动](https://github.com/goodtft/LCD-show)。通过 SSH 登入并执行以下命令:
```
$ rm -rf LCD-show
$ git clone <https://github.com/goodtft/LCD-show.git>
$ chmod -R 755 LCD-show
$ cd LCD-show/
```
为你的屏幕执行合适的命令以安装驱动。例如这是给我们 MPI3501 型屏幕的命令:
```
$ sudo ./LCD35-show
```
这行命令会安装合适的驱动并重启树莓派。
### 安装 PIXEL 桌面并设置自动启动
以下是我们想要我们项目能够做到的事情:如果树莓派启动,我们想要展现一个有我们空气质量测量数据的网站。
首先,安装树莓派的[PIXEL 桌面环境](/article-8459-1.html):
```
$ sudo apt install raspberrypi-ui-mods
```
然后安装 Chromium 浏览器以显示网站:
```
$ sudo apt install chromium-browser
```
需要自动登录以使测量数据在启动后直接显示;否则你将只会看到登录界面。然而树莓派用户并没有默认设置好自动登录。你可以用 `raspi-config` 工具设置自动登录:
```
$ sudo raspi-config
```
在菜单中,选择:“3 Boot Options → B1 Desktop / CLI → B4 Desktop Autologin”。
在启动后用 Chromium 打开我们的网站这块少了一步。创建文件夹 `/home/pi/.config/lxsession/LXDE-pi/`:
```
$ mkdir -p /home/pi/config/lxsession/LXDE-pi/
```
然后在该文件夹里创建 `autostart` 文件:
```
$ nano /home/pi/.config/lxsession/LXDE-pi/autostart
```
并粘贴以下代码:
```
#@unclutter
@xset s off
@xset -dpms
@xset s noblank
# Open Chromium in Full Screen Mode
@chromium-browser --incognito --kiosk <http://localhost>
```
如果你想要隐藏鼠标指针,你得安装 `unclutter` 包并移除 `autostart` 文件开头的注释。
```
$ sudo apt install unclutter
```

我对去年的代码做了些小修改。因此如果你之前搭建过空气质量项目,确保用[原文章](/article-9620-1.html)中的指导为 AQI 网站重新下载脚本和文件。
通过添加触摸屏,你现在拥有了一个便携的颗粒物传感器!我们在学校用它来检查教室里的空气质量或者进行比较测量。使用这种配置,你无需再依赖网络连接或 WLAN。你可以在任何地方使用这个小型测量站——你甚至可以使用移动电源以摆脱电网。
---
这篇文章原来在<ruby> <a href="https://openschoolsolutions.org/mobile-particulate-matter-sensor/"> 开源学校解决方案 </a> <rt> Open Scool Solutions </rt></ruby>上发表,获得许可重新发布。
---
via: <https://opensource.com/article/19/3/mobile-particulate-matter-sensor>
作者:[Stephan Tetzel](https://opensource.com/users/stephan) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | About a year ago, I wrote about [measuring air quality](https://opensource.com/article/18/3/how-measure-particulate-matter-raspberry-pi) using a Raspberry Pi and a cheap sensor. We've been using this project in our school and privately for a few years now. However, it has one disadvantage: It is not portable because it depends on a WLAN network or a wired network connection to work. You can't even access the sensor's measurements if the Raspberry Pi and the smartphone or computer are not on the same network.
To overcome this limitation, we added a small screen to the Raspberry Pi so we can read the values directly from the device. Here's how we set up and configured a screen for our mobile fine particulate matter sensor.
## Setting up the screen for the Raspberry Pi
There is a wide range of Raspberry Pi displays available from [Amazon](https://www.amazon.com/gp/search/ref=as_li_qf_sp_sr_tl?ie=UTF8&tag=openschoolsol-20&keywords=lcd%20raspberry&index=aps&camp=1789&creative=9325&linkCode=ur2&linkId=51d6d7676e10d6c7db203c4a8b3b529a), AliExpress, and other sources. They range from ePaper screens to LCDs with touch function. We chose an inexpensive [3.5″ LCD](https://amzn.to/2CcvgpC) with touch and a resolution of 320×480 pixels that can be plugged directly into the Raspberry Pi's GPIO pins. It's also nice that a 3.5″ display is about the same size as a Raspberry Pi.
The first time you turn on the screen and start the Raspberry Pi, the screen will remain white because the driver is missing. You have to install [the appropriate drivers](https://github.com/goodtft/LCD-show) for the display first. Log in with SSH and execute the following commands:
```
$ rm -rf LCD-show
$ git clone https://github.com/goodtft/LCD-show.git
$ chmod -R 755 LCD-show
$ cd LCD-show/
```
Execute the appropriate command for your screen to install the drivers. For example, this is the command for our model MPI3501 screen:
`$ sudo ./LCD35-show`
This command installs the appropriate drivers and restarts the Raspberry Pi.
## Installing PIXEL desktop and setting up autostart
Here is what we want our project to do: If the Raspberry Pi boots up, we want to display a small website with our air quality measurements.
First, install the Raspberry Pi's [PIXEL desktop environment](https://opensource.com/article/17/1/try-raspberry-pis-pixel-os-your-pc):
`$ sudo apt install raspberrypi-ui-mods`
Then install the Chromium browser to display the website:
`$ sudo apt install chromium-browser`
Autologin is required for the measured values to be displayed directly after startup; otherwise, you will just see the login screen. However, autologin is not configured for the "pi" user by default. You can configure autologin with the **raspi-config** tool:
`$ sudo raspi-config`
In the menu, select: **3 Boot Options → B1 Desktop / CLI → B4 Desktop Autologin**.
There is a step missing to start Chromium with our website right after boot. Create the folder **/home/pi/.config/lxsession/LXDE-pi/**:
`$ mkdir -p /home/pi/config/lxsession/LXDE-pi/`
Then create the **autostart** file in this folder:
`$ nano /home/pi/.config/lxsession/LXDE-pi/autostart`
and paste the following code:
```
#@unclutter
@xset s off
@xset -dpms
@xset s noblank
# Open Chromium in Full Screen Mode
@chromium-browser --incognito --kiosk http://localhost
```
If you want to hide the mouse pointer, you have to install the package **unclutter** and remove the comment character at the beginning of the **autostart** file:
`$ sudo apt install unclutter`

I've made a few small changes to the code in the last year. So, if you set up the air quality project before, make sure to re-download the script and files for the AQI website using the instructions in the [original article](https://opensource.com/article/18/3/how-measure-particulate-matter-raspberry-pi).
By adding the touch screen, you now have a mobile particulate matter sensor! We use it at our school to check the quality of the air in the classrooms or to do comparative measurements. With this setup, you are no longer dependent on a network connection or WLAN. You can use the small measuring station everywhere—you can even use it with a power bank to be independent of the power grid.
*This article originally appeared on Open School Solutions and is republished with permission.*
## 2 Comments |
10,940 | Docker 入门指南 | https://www.ostechnix.com/getting-started-with-docker/ | 2019-06-05T01:37:00 | [
"容器",
"Docker"
] | https://linux.cn/article-10940-1.html | 
在我们的上一个教程中,我们已经了解[如何在 Ubuntu 上安装 Docker](https://www.ostechnix.com/wp-content/uploads/2016/04/docker-basics-720x340.png),和如何在 [CentOS 上安装 Docker](http://www.ostechnix.com/install-docker-ubuntu/)。今天,我们将会了解 Docker 的一些基础用法。该教程包含了如何创建一个新的 Docker 容器,如何运行该容器,如何从现有的 Docker 容器中创建自己的 Docker 镜像等 Docker 的一些基础知识、操作。所有步骤均在 Ubuntu 18.04 LTS server 版本下测试通过。
### 入门指南
在开始指南之前,不要混淆 Docker 镜像和 Docker 容器这两个概念。在之前的教程中,我就解释过,Docker 镜像是决定 Docker 容器行为的一个文件,Docker 容器则是 Docker 镜像的运行态或停止态。(LCTT 译注:在 macOS 下使用 Docker 终端时,不需要加 `sudo`)
#### 1、搜索 Docker 镜像
我们可以从 Docker 仓库中获取镜像,例如 [Docker hub](https://www.ostechnix.com/install-docker-centos/),或者自己创建镜像。这里解释一下,Docker hub 是一个云服务器,用来提供给 Docker 的用户们创建、测试,和保存他们的镜像。
Docker hub 拥有成千上万个 Docker 镜像文件。你可以通过 `docker search`命令在这里搜索任何你想要的镜像。
例如,搜索一个基于 Ubuntu 的镜像文件,只需要运行:
```
$ sudo docker search ubuntu
```
示例输出:

搜索基于 CentOS 的镜像,运行:
```
$ sudo docker search centos
```
搜索 AWS 的镜像,运行:
```
$ sudo docker search aws
```
搜索 WordPress 的镜像:
```
$ sudo docker search wordpress
```
Docker hub 拥有几乎所有种类的镜像,包含操作系统、程序和其他任意的类型,这些你都能在 Docker hub 上找到已经构建完的镜像。如果你在搜索时,无法找到你想要的镜像文件,你也可以自己构建一个,将其发布出去,或者仅供你自己使用。
#### 2、下载 Docker 镜像
下载 Ubuntu 的镜像,你需要在终端运行以下命令:
```
$ sudo docker pull ubuntu
```
这条命令将会从 Docker hub 下载最近一个版本的 Ubuntu 镜像文件。
示例输出:
```
Using default tag: latest
latest: Pulling from library/ubuntu
6abc03819f3e: Pull complete
05731e63f211: Pull complete
0bd67c50d6be: Pull complete
Digest: sha256:f08638ec7ddc90065187e7eabdfac3c96e5ff0f6b2f1762cf31a4f49b53000a5
Status: Downloaded newer image for ubuntu:latest
```

你也可以下载指定版本的 Ubuntu 镜像。运行以下命令:
```
$ docker pull ubuntu:18.04
```
Docker 允许在任意的宿主机操作系统下,下载任意的镜像文件,并运行。
例如,下载 CentOS 镜像:
```
$ sudo docker pull centos
```
所有下载的镜像文件,都被保存在 `/var/lib/docker` 文件夹下。(LCTT 译注:不同操作系统存放的文件夹并不是一致的,具体存放位置请在官方查询)
查看已经下载的镜像列表,可以使用以下命令:
```
$ sudo docker images
```
示例输出:
```
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu latest 7698f282e524 14 hours ago 69.9MB
centos latest 9f38484d220f 2 months ago 202MB
hello-world latest fce289e99eb9 4 months ago 1.84kB
```
正如你看到的那样,我已经下载了三个镜像文件:`ubuntu`、`centos` 和 `hello-world`。
现在,让我们继续,来看一下如何运行我们刚刚下载的镜像。
#### 3、运行 Docker 镜像
运行一个容器有两种方法。我们可以使用标签或者是镜像 ID。标签指的是特定的镜像快照。镜像 ID 是指镜像的唯一标识。
正如上面结果中显示,`latest` 是所有镜像的一个标签。`7698f282e524` 是 Ubuntu Docker 镜像的镜像 ID,`9f38484d220f`是 CentOS 镜像的镜像 ID,`fce289e99eb9` 是 hello\_world 镜像的 镜像 ID。
下载完 Docker 镜像之后,你可以通过下面的命令来使用其标签来启动:
```
$ sudo docker run -t -i ubuntu:latest /bin/bash
```
在这条语句中:
* `-t`:在该容器中启动一个新的终端
* `-i`:通过容器中的标准输入流建立交互式连接
* `ubuntu:latest`:带有标签 `latest` 的 Ubuntu 容器
* `/bin/bash`:在新的容器中启动 BASH Shell
或者,你可以通过镜像 ID 来启动新的容器:
```
$ sudo docker run -t -i 7698f282e524 /bin/bash
```
在这条语句里:
* `7698f282e524` — 镜像 ID
在启动容器之后,将会自动进入容器的 shell 中(注意看命令行的提示符)。

*Docker 容器的 Shell*
如果想要退回到宿主机的终端(在这个例子中,对我来说,就是退回到 18.04 LTS),并且不中断该容器的执行,你可以按下 `CTRL+P`,再按下 `CTRL+Q`。现在,你就安全的返回到了你的宿主机系统中。需要注意的是,Docker 容器仍然在后台运行,我们并没有中断它。
可以通过下面的命令来查看正在运行的容器:
```
$ sudo docker ps
```
示例输出:
```
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
32fc32ad0d54 ubuntu:latest "/bin/bash" 7 minutes ago Up 7 minutes modest_jones
```

*列出正在运行的容器*
可以看到:
* `32fc32ad0d54` – 容器 ID
* `ubuntu:latest` – Docker 镜像
需要注意的是,容器 ID 和 Docker 的镜像 ID是不同的。
可以通过以下命令查看所有正在运行和停止运行的容器:
```
$ sudo docker ps -a
```
在宿主机中断容器的执行:
```
$ sudo docker stop <container-id>
```
例如:
```
$ sudo docker stop 32fc32ad0d54
```
如果想要进入正在运行的容器中,你只需要运行:
```
$ sudo docker attach 32fc32ad0d54
```
正如你看到的,`32fc32ad0d54` 是一个容器的 ID。当你在容器中想要退出时,只需要在容器内的终端中输入命令:
```
# exit
```
你可以使用这个命令查看后台正在运行的容器:
```
$ sudo docker ps
```
#### 4、构建自己的 Docker 镜像
Docker 不仅仅可以下载运行在线的容器,你也可以创建你的自己的容器。
想要创建自己的 Docker 镜像,你需要先运行一个你已经下载完的容器:
```
$ sudo docker run -t -i ubuntu:latest /bin/bash
```
现在,你运行了一个容器,并且进入了该容器。然后,在该容器安装任意一个软件或做任何你想做的事情。
例如,我们在容器中安装一个 Apache web 服务器。
当你完成所有的操作,安装完所有的软件之后,你可以执行以下的命令来构建你自己的 Docker 镜像:
```
# apt update
# apt install apache2
```
同样的,在容器中安装和测试你想要安装的所有软件。
当你安装完毕之后,返回的宿主机的终端。记住,不要关闭容器。想要返回到宿主机而不中断容器。请按下`CTRL+P`,再按下 `CTRL+Q`。
从你的宿主机的终端中,运行以下命令如寻找容器的 ID:
```
$ sudo docker ps
```
最后,从一个正在运行的容器中创建 Docker 镜像:
```
$ sudo docker commit 3d24b3de0bfc ostechnix/ubuntu_apache
```
示例输出:
```
sha256:ce5aa74a48f1e01ea312165887d30691a59caa0d99a2a4aa5116ae124f02f962
```
在这里:
* `3d24b3de0bfc` — 指 Ubuntu 容器的 ID。
* `ostechnix` — 我们创建的容器的用户名称
* `ubuntu_apache` — 我们创建的镜像
让我们检查一下我们新创建的 Docker 镜像:
```
$ sudo docker images
```
示例输出:
```
REPOSITORY TAG IMAGE ID CREATED SIZE
ostechnix/ubuntu_apache latest ce5aa74a48f1 About a minute ago 191MB
ubuntu latest 7698f282e524 15 hours ago 69.9MB
centos latest 9f38484d220f 2 months ago 202MB
hello-world latest fce289e99eb9 4 months ago 1.84kB
```

*列出所有的 Docker 镜像*
正如你看到的,这个新的镜像就是我们刚刚在本地系统上从运行的容器上创建的。
现在,你可以从这个镜像创建一个新的容器。
```
$ sudo docker run -t -i ostechnix/ubuntu_apache /bin/bash
```
#### 5、删除容器
如果你在 Docker 上的工作已经全部完成,你就可以删除那些你不需要的容器。
想要删除一个容器,首先,你需要停止该容器。
我们先来看一下正在运行的容器有哪些
```
$ sudo docker ps
```
示例输出:
```
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3d24b3de0bfc ubuntu:latest "/bin/bash" 28 minutes ago Up 28 minutes goofy_easley
```
使用容器 ID 来停止该容器:
```
$ sudo docker stop 3d24b3de0bfc
```
现在,就可以删除该容器了。
```
$ sudo docker rm 3d24b3de0bfc
```
你就可以按照这样的方法来删除那些你不需要的容器了。
当需要删除的容器数量很多时,一个一个删除也是很麻烦的,我们可以直接删除所有的已经停止的容器。只需要运行:
```
$ sudo docker container prune
```
按下 `Y`,来确认你的操作:
```
WARNING! This will remove all stopped containers.
Are you sure you want to continue? [y/N] y
Deleted Containers:
32fc32ad0d5445f2dfd0d46121251c7b5a2aea06bb22588fb2594ddbe46e6564
5ec614e0302061469ece212f0dba303c8fe99889389749e6220fe891997f38d0
Total reclaimed space: 5B
```
这个命令仅支持最新的 Docker。(LCTT 译注:仅支持 1.25 及以上版本的 Docker)
#### 6、删除 Docker 镜像
当你删除了不要的 Docker 容器后,你也可以删除你不需要的 Docker 镜像。
列出已经下载的镜像:
```
$ sudo docker images
```
示例输出:
```
REPOSITORY TAG IMAGE ID CREATED SIZE
ostechnix/ubuntu_apache latest ce5aa74a48f1 5 minutes ago 191MB
ubuntu latest 7698f282e524 15 hours ago 69.9MB
centos latest 9f38484d220f 2 months ago 202MB
hello-world latest fce289e99eb9 4 months ago 1.84kB
```
由上面的命令可以知道,在本地的系统中存在三个镜像。
使用镜像 ID 来删除镜像。
```
$ sudo docekr rmi ce5aa74a48f1
```
示例输出:
```
Untagged: ostechnix/ubuntu_apache:latest
Deleted: sha256:ce5aa74a48f1e01ea312165887d30691a59caa0d99a2a4aa5116ae124f02f962
Deleted: sha256:d21c926f11a64b811dc75391bbe0191b50b8fe142419f7616b3cee70229f14cd
```
#### 解决问题
Docker 禁止我们删除一个还在被容器使用的镜像。
例如,当我试图删除 Docker 镜像 `b72889fa879c` 时,我只能获得一个错误提示:
```
Error response from daemon: conflict: unable to delete b72889fa879c (must be forced) - image is being used by stopped container dde4dd285377
```
这是因为这个 Docker 镜像正在被一个容器使用。
所以,我们来检查一个正在运行的容器:
```
$ sudo docker ps
```
示例输出:

注意,现在并没有正在运行的容器!!!
查看一下所有的容器(包含所有的正在运行和已经停止的容器):
```
$ sudo docker pa -a
```
示例输出:

可以看到,仍然有一些已经停止的容器在使用这些镜像。
让我们把这些容器删除:
```
$ sudo docker rm 12e892156219
```
我们仍然使用容器 ID 来删除这些容器。
当我们删除了所有使用该镜像的容器之后,我们就可以删除 Docker 的镜像了。
例如:
```
$ sudo docekr rmi b72889fa879c
```
我们再来检查一下本机存在的镜像:
```
$ sudo docker images
```
想要知道更多的细节,请参阅本指南末尾给出的官方资源的链接或者在评论区进行留言。
这就是全部的教程了,希望你可以了解 Docker 的一些基础用法。
更多的教程马上就会到来,敬请关注。
---
via: <https://www.ostechnix.com/getting-started-with-docker/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zhang5788](https://github.com/zhang5788) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,943 | 使用 Testinfra 和 Ansible 验证服务器状态 | https://opensource.com/article/19/5/using-testinfra-ansible-verify-server-state | 2019-06-06T08:29:32 | [
"Ansible"
] | /article-10943-1.html |
>
> Testinfra 是一个功能强大的库,可用于编写测试来验证基础设施的状态。另外它与 Ansible 和 Nagios 相结合,提供了一个用于架构即代码 (IaC) 的简单解决方案。
>
>
>

根据设计,[Ansible](https://www.ansible.com/) 传递机器的期望状态,以确保 Ansible 剧本或角色的内容部署到目标机器上。但是,如果你需要确保所有基础架构更改都在 Ansible 中,该怎么办?或者想随时验证服务器的状态?
[Testinfra](https://testinfra.readthedocs.io/en/latest/) 是一个基础架构测试框架,它可以轻松编写单元测试来验证服务器的状态。它是一个 Python 库,使用强大的 [pytest](https://pytest.org/) 测试引擎。
### 开始使用 Testinfra
可以使用 Python 包管理器(`pip`)和 Python 虚拟环境轻松安装 Testinfra。
```
$ python3 -m venv venv
$ source venv/bin/activate
(venv) $ pip install testinfra
```
Testinfra 也可以通过 Fedora 和 CentOS 的 EPEL 仓库中使用。例如,在 CentOS 7 上,你可以使用以下命令安装它:
```
$ yum install -y epel-release
$ yum install -y python-testinfra
```
#### 一个简单的测试脚本
在 Testinfra 中编写测试很容易。使用你选择的代码编辑器,将以下内容添加到名为 `test_simple.py` 的文件中:
```
import testinfra
def test_os_release(host):
assert host.file("/etc/os-release").contains("Fedora")
def test_sshd_inactive(host):
assert host.service("sshd").is_running is False
```
默认情况下,Testinfra 为测试用例提供了一个 `host` 对象,该对象能访问不同的辅助模块。例如,第一个测试使用 `file` 模块来验证主机上文件的内容,第二个测试用例使用 `service` 模块来检查 systemd 服务的状态。
要在本机运行这些测试,请执行以下命令:
```
(venv)$ pytest test_simple.py
================================ test session starts ================================
platform linux -- Python 3.7.3, pytest-4.4.1, py-1.8.0, pluggy-0.9.0
rootdir: /home/cverna/Documents/Python/testinfra
plugins: testinfra-3.0.0
collected 2 items
test_simple.py ..
================================ 2 passed in 0.05 seconds ================================
```
有关 Testinfra API 的完整列表,你可以参考[文档](https://testinfra.readthedocs.io/en/latest/modules.html#modules)。
### Testinfra 和 Ansible
Testinfra 支持的后端之一是 Ansible,这意味着 Testinfra 可以直接使用 Ansible 的清单文件和清单中定义的一组机器来对它们进行测试。
我们使用以下清单文件作为示例:
```
[web]
app-frontend01
app-frontend02
[database]
db-backend01
```
我们希望确保我们的 Apache Web 服务器在 `app-frontend01` 和 `app-frontend02` 上运行。让我们在名为 `test_web.py` 的文件中编写测试:
```
def check_httpd_service(host):
"""Check that the httpd service is running on the host"""
assert host.service("httpd").is_running
```
要使用 Testinfra 和 Ansible 运行此测试,请使用以下命令:
```
(venv) $ pip install ansible
(venv) $ py.test --hosts=web --ansible-inventory=inventory --connection=ansible test_web.py
```
在调用测试时,我们使用 Ansible 清单文件的 `[web]` 组作为目标计算机,并指定我们要使用 Ansible 作为连接后端。
#### 使用 Ansible 模块
Testinfra 还为 Ansible 提供了一个很好的可用于测试的 API。该 Ansible 模块能够在测试中运行 Ansible 动作,并且能够轻松检查动作的状态。
```
def check_ansible_play(host):
"""
Verify that a package is installed using Ansible
package module
"""
assert not host.ansible("package", "name=httpd state=present")["changed"]
```
默认情况下,Ansible 的[检查模式](https://docs.ansible.com/ansible/playbooks_checkmode.html)已启用,这意味着 Ansible 将报告在远程主机上执行动作时会发生的变化。
### Testinfra 和 Nagios
现在我们可以轻松地运行测试来验证机器的状态,我们可以使用这些测试来触发监控系统上的警报。这是捕获意外的更改的好方法。
Testinfra 提供了与 [Nagios](https://www.nagios.org/) 的集成,它是一种流行的监控解决方案。默认情况下,Nagios 使用 [NRPE](https://en.wikipedia.org/wiki/Nagios#NRPE) 插件对远程主机进行检查,但使用 Testinfra 可以直接从 Nagios 主控节点上运行测试。
要使 Testinfra 输出与 Nagios 兼容,我们必须在触发测试时使用 `--nagios` 标志。我们还使用 `-qq` 这个 pytest 标志来启用 pytest 的静默模式,这样就不会显示所有测试细节。
```
(venv) $ py.test --hosts=web --ansible-inventory=inventory --connection=ansible --nagios -qq line test.py
TESTINFRA OK - 1 passed, 0 failed, 0 skipped in 2.55 seconds
```
Testinfra 是一个功能强大的库,可用于编写测试以验证基础架构的状态。 另外与 Ansible 和 Nagios 相结合,提供了一个用于架构即代码 (IaC) 的简单解决方案。 它也是使用 [Molecule](https://github.com/ansible/molecule) 开发 Ansible 角色过程中添加测试的关键组件。
---
via: <https://opensource.com/article/19/5/using-testinfra-ansible-verify-server-state>
作者:[Clement Verna](https://opensource.com/users/cverna/users/paulbischoff/users/dcritch/users/cobiacomm/users/wgarry155/users/kadinroob/users/koreyhilpert) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,945 | 使用 stunnel 保护 telnet 连接 | https://fedoramagazine.org/securing-telnet-connections-with-stunnel/ | 2019-06-06T13:46:36 | [
"telnet",
"stunnel"
] | https://linux.cn/article-10945-1.html | 
Telnet 是一种客户端-服务端协议,通过 TCP 的 23 端口连接到远程服务器。Telnet 并不加密数据,因此它被认为是不安全的,因为数据是以明文形式发送的,所以密码很容易被嗅探。但是,仍有老旧系统需要使用它。这就是用到 **stunnel** 的地方。
stunnel 旨在为使用不安全连接协议的程序增加 SSL 加密。本文将以 telnet 为例介绍如何使用它。
### 服务端安装
[使用 sudo](https://fedoramagazine.org/howto-use-sudo/) 安装 stunnel 以及 telnet 的服务端和客户端:
```
sudo dnf -y install stunnel telnet-server telnet
```
添加防火墙规则,在提示时输入你的密码:
```
firewall-cmd --add-service=telnet --perm
firewall-cmd --reload
```
接下来,生成 RSA 私钥和 SSL 证书:
```
openssl genrsa 2048 > stunnel.key
openssl req -new -key stunnel.key -x509 -days 90 -out stunnel.crt
```
系统将一次提示你输入以下信息。当询问 `Common Name` 时,你必须输入正确的主机名或 IP 地址,但是你可以按回车键跳过其他所有内容。
```
You are about to be asked to enter information that will be
incorporated into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [XX]:
State or Province Name (full name) []:
Locality Name (eg, city) [Default City]:
Organization Name (eg, company) [Default Company Ltd]:
Organizational Unit Name (eg, section) []:
Common Name (eg, your name or your server's hostname) []:
Email Address []
```
将 RSA 密钥和 SSL 证书合并到单个 `.pem` 文件中,并将其复制到 SSL 证书目录:
```
cat stunnel.crt stunnel.key > stunnel.pem
sudo cp stunnel.pem /etc/pki/tls/certs/
```
现在可以定义服务和用于加密连接的端口了。选择尚未使用的端口。此例使用 450 端口进行隧道传输 telnet。编辑或创建 `/etc/stunnel/telnet.conf`:
```
cert = /etc/pki/tls/certs/stunnel.pem
sslVersion = TLSv1
chroot = /var/run/stunnel
setuid = nobody
setgid = nobody
pid = /stunnel.pid
socket = l:TCP_NODELAY=1
socket = r:TCP_NODELAY=1
[telnet]
accept = 450
connect = 23
```
`accept` 选项是服务器将监听传入 telnet 请求的接口。`connect` 选项是 telnet 服务器的内部监听接口。
接下来,创建一个 systemd 单元文件的副本来覆盖原来的版本:
```
sudo cp /usr/lib/systemd/system/stunnel.service /etc/systemd/system
```
编辑 `/etc/systemd/system/stunnel.service` 来添加两行。这些行在启动时为服务创建 chroot 监狱。
```
[Unit]
Description=TLS tunnel for network daemons
After=syslog.target network.target
[Service]
ExecStart=/usr/bin/stunnel
Type=forking
PrivateTmp=true
ExecStartPre=-/usr/bin/mkdir /var/run/stunnel
ExecStartPre=/usr/bin/chown -R nobody:nobody /var/run/stunnel
[Install]
WantedBy=multi-user.target
```
接下来,配置 SELinux 以在你刚刚指定的新端口上监听 telnet:
```
sudo semanage port -a -t telnetd_port_t -p tcp 450
```
最后,添加新的防火墙规则:
```
firewall-cmd --add-port=450/tcp --perm
firewall-cmd --reload
```
现在你可以启用并启动 telnet 和 stunnel。
```
systemctl enable telnet.socket [email protected] --now
```
要注意 `systemctl` 命令是有顺序的。systemd 和 stunnel 包默认提供额外的[模板单元文件](https://fedoramagazine.org/systemd-template-unit-files/)。该模板允许你将 stunnel 的多个配置文件放到 `/etc/stunnel` 中,并使用文件名启动该服务。例如,如果你有一个 `foobar.conf` 文件,那么可以使用 `systemctl start [email protected]` 启动该 stunnel 实例,而无需自己编写任何单元文件。
如果需要,可以将此 stunnel 模板服务设置为在启动时启动:
```
systemctl enable [email protected]
```
### 客户端安装
本文的这部分假设你在客户端系统上以普通用户([拥有 sudo 权限](https://fedoramagazine.org/howto-use-sudo/))身份登录。安装 stunnel 和 telnet 客户端:
```
dnf -y install stunnel telnet
```
将 `stunnel.pem` 从远程服务器复制到客户端的 `/etc/pki/tls/certs` 目录。在此例中,远程 telnet 服务器的 IP 地址为 `192.168.1.143`。
```
sudo scp [email protected]:/etc/pki/tls/certs/stunnel.pem
/etc/pki/tls/certs/
```
创建 `/etc/stunnel/telnet.conf`:
```
cert = /etc/pki/tls/certs/stunnel.pem
client=yes
[telnet]
accept=450
connect=192.168.1.143:450
```
`accept` 选项是用于 telnet 会话的端口。`connect` 选项是你远程服务器的 IP 地址以及监听的端口。
接下来,启用并启动 stunnel:
```
systemctl enable [email protected] --now
```
测试你的连接。由于有一条已建立的连接,你会 `telnet` 到 `localhost` 而不是远程 telnet 服务器的主机名或者 IP 地址。
```
[user@client ~]$ telnet localhost 450
Trying ::1...
telnet: connect to address ::1: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Kernel 5.0.9-301.fc30.x86_64 on an x86_64 (0)
server login: myuser
Password: XXXXXXX
Last login: Sun May 5 14:28:22 from localhost
[myuser@server ~]$
```
---
via: <https://fedoramagazine.org/securing-telnet-connections-with-stunnel/>
作者:[Curt Warfield](https://fedoramagazine.org/author/rcurtiswarfield/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Telnet is a client-server protocol that connects to a remote server through TCP over port 23. Telnet does not encrypt data and is considered insecure and passwords can be easily sniffed because data is sent in the clear. However there are still legacy systems that need to use it. This is where **stunnel** comes to the rescue.
Stunnel is designed to add SSL encryption to programs that have insecure connection protocols. This article shows you how to use it, with telnet as an example.
## Server Installation
Install stunnel along with the telnet server and client [using sudo](https://fedoramagazine.org/howto-use-sudo/):
sudo dnf -y install stunnel telnet-server telnet
Add a firewall rule, entering your password when prompted:
firewall-cmd --add-service=telnet --perm
firewall-cmd --reload
Next, generate an RSA private key and an SSL certificate:
openssl genrsa 2048 > stunnel.key
openssl req -new -key stunnel.key -x509 -days 90 -out stunnel.crt
You will be prompted for the following information one line at a time. When asked for *Common Name* you must enter the correct host name or IP address, but everything else you can skip through by hitting the **Enter** key.
You are about to be asked to enter information that will be
incorporated into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [XX]:
State or Province Name (full name) []:
Locality Name (eg, city) [Default City]:
Organization Name (eg, company) [Default Company Ltd]:
Organizational Unit Name (eg, section) []:
Common Name (eg, your name or your server's hostname) []:
Email Address []
Merge the RSA key and SSL certificate into a single *.pem* file, and copy that to the SSL certificate directory:
cat stunnel.crt stunnel.key > stunnel.pem
sudo cp stunnel.pem /etc/pki/tls/certs/
Now it’s time to define the service and the ports to use for encrypting your connection. Choose a port that is not already in use. This example uses port 450 for tunneling telnet. Edit or create the */etc/stunnel/telnet.conf* file:
cert = /etc/pki/tls/certs/stunnel.pem
sslVersion = TLSv1
chroot = /var/run/stunnel
setuid = nobody
setgid = nobody
pid = /stunnel.pid
socket = l:TCP_NODELAY=1
socket = r:TCP_NODELAY=1
[telnet]
accept = 450
connect = 23
The **accept **option is the port the server will listen to for incoming telnet requests. The **connect** option is the internal port the telnet server listens to.
Next, make a copy of the systemd unit file that allows you to override the packaged version:
sudo cp /usr/lib/systemd/system/stunnel.service /etc/systemd/system
Edit the */etc/systemd/system/stunnel.service* file to add two lines. These lines create a chroot jail for the service when it starts.
[Unit]
Description=TLS tunnel for network daemons
After=syslog.target network.target
[Service]
ExecStart=/usr/bin/stunnel
Type=forking
PrivateTmp=trueExecStartPre=-/usr/bin/mkdir /var/run/stunnel
ExecStartPre=/usr/bin/chown -R nobody:nobody /var/run/stunnel
[Install]
WantedBy=multi-user.target
Next, configure SELinux to listen to telnet on the new port you just specified:
sudo semanage port -a -t telnetd_port_t -p tcp 450
Finally, add a new firewall rule:
firewall-cmd --add-port=450/tcp --perm
firewall-cmd --reload
Now you can enable and start telnet and stunnel.
systemctl enable telnet.socket [email protected] --now
A note on the *systemctl* command is in order. Systemd and the stunnel package provide an additional [template unit file](https://fedoramagazine.org/systemd-template-unit-files/) by default. The template lets you drop multiple configuration files for stunnel into */etc/stunnel*, and use the filename to start the service. For instance, if you had a *foobar.conf* file, you could start that instance of stunnel with *systemctl start [email protected]*, without having to write any unit files yourself.
If you want, you can set this stunnel template service to start on boot:
systemctl enable [email protected]
## Client Installation
This part of the article assumes you are logged in as a normal user ([with sudo privileges](https://fedoramagazine.org/howto-use-sudo/)) on the client system. Install stunnel and the telnet client:
dnf -y install stunnel telnet
Copy the *stunnel.pem* file from the remote server to your client */etc/pki/tls/certs* directory. In this example, the IP address of the remote telnet server is 192.168.1.143.
sudo scp [email protected]:/etc/pki/tls/certs/stunnel.pem
/etc/pki/tls/certs/
Create the */etc/stunnel/telnet.conf* file:
cert = /etc/pki/tls/certs/stunnel.pem
client=yes
[telnet]
accept=450
connect=192.168.1.143:450
The **accept **option is the port that will be used for telnet sessions. The **connect** option is the IP address of your remote server and the port it’s listening on.
Next, enable and start stunnel:
systemctl enable [email protected] --now
Test your connection. Since you have a connection established, you will telnet to *localhost* instead of the hostname or IP address of the remote telnet server:
[user@client ~]$telnet localhost 450
Trying ::1...
telnet: connect to address ::1: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Kernel 5.0.9-301.fc30.x86_64 on an x86_64 (0)
server login:myuser
Password:XXXXXXX
Last login: Sun May 5 14:28:22 from localhost
[myuser@server ~]$
## Paul Gresham
Thank you Curt. This and other articles in the Fedora Magazine are outstanding.
## Curt Warfield
You’re welcome. Thanks so much for your feedback.
## Einer
I guess I don’t see the point of this because:
1) I would not use the telnet server
2) If I am going to put something in an encrypted tunnel, I would just use SSH
## Curt Warfield
Hi Einer,
There are a lot of legacy systems that still need to use telnet.
The point of the article is to show you how to make your telnet sessions more secure if you are in a situation where you need to use it.
## Einer
Hi Curt 🙂
I am not so sure I agree with you. Here’s why:
1) let’s say its a Cisco router
2) can only use telnet to get a console session on the router via the network
1) you can’t install stunnel on that Cisco router
== no way to encapsulate the telnet session in SSL/stunnel== wasted effort 🙂
same applies to an old Unix system that has no support for stunnel
Bottom line is that BOTH ends of the conversation/session must be able to support stunnel ……. if you can’t install on one end or the other (most likely due to age of one of the endpoints) …………
see where I’m going? 🙂
## Supersonic Tumbleweed
You can very much use telnet with ssh, ssh with telnet, and any combination of those you can think of… so it’s an additional layer of configs.
But also an additional layer of abstraction for programs that have telnet invocation hardcoded into them, that allows to work with those programs securely too, so that’s nice.
## Supersonic Tumbleweed
Actually, scratch that, it just opens a tunnel.
Yeah, that can be done pretty easily without an additional tool. Nice for managing keys.
## Stuart D Gathman
The title is misleading. The point is to illustrate how to use stunnel with something simple like telnet. The point is that you can add security to any TCP service with stunnel. Telnet is just a simple example. Did you build a simple tcp service in python? Don’t want to deal with adding SSL support for use over the public internet? Use stunnel!
## Radosław
I see several issues with this article, assuming that it is aimed towards beginners.
There’s little point in generating insecure, self-signed certificates, when Let’s Encrypt is available and well integrated in Fedora. I strongly believe that recommending self-signed certificates is harmful. The article should be updated to reference certbot or at least explain why is it a terrible idea to use self-signed certs.
Also, when you’re using stunnel for a single, local service that you want to provide as encrypted, I’d say it is much better idea to use systemd socket activation. This way it won’t be necessary to restart stunnel service every time you update the certificate (because it will be started on-demand by systemd every time when the incoming connection arrives).
The encrypted-telnet.socket file could look like:
[Socket]
ListenStream=450
Accept=yes
[Install]
WantedBy=sockets.target
And the appropriate [email protected]:
[Service]
ExecStart=/usr/bin/stunnel /etc/stunnel/telnet.conf
StandardInput=socket
[Install]
WantedBy=multi-user.target
The stunnel server telnet.conf file would also be much simpler:
cert = /etc/letsencrypt/live/example.com/fullchain.pem
key = /etc/letsencrypt/live/example.com/privkey.pem
connect = localhost:450
Much easier, yes?
## Radosław
And of course I made a mistake in the example above, as connect should be done to local port 23, so:
connect = localhost:23
## Bob
Using self-signed certificates are no more or less secure than certificates signed by a CA like Let’s Encrypt. The purpose of the CA is to help us trust other certificates more easily. By trusting a CA you trust all certificates issued by it. If you’re building an STunnel connection and are in control of both sides of the connection and the certificates in use their is no reason not to trust the self-signed certificates you generate.
## Curt Warfield
Thanks for your feedback. I appreciate it!
## varesa
Self-signed certificates can be quite useful in self contained internal systems. Unless you can/want to use certificate pinning, it can even be more secure as then nobody but you (unlike for example a third party CA) can issue certificates to impersonate your secure connection.
Useful for web services? Not really. Useful for internal secure tunneling (VPNs, etc.)? Yes
## ss
I wouldn’t personally use Stunnel+telnet as the other commenter wrote but it is still useful for securing of any TCP service – maybe POP3 server or some embedded REST clients. I usually use SSH or ncat –ssl for quick security but If I ever need a certificates issued by a trusted CA, stunnel would probably do the job
## Ed H.
That’s a lot of configuration tweaks. Why not just use secure shell (ssh)?
## wsanders
Best way to handle telnet:
yum erase telnet
I haven’t installed it in years. If you need to test a TCP connection use nc.
## wsanders
However, to edit that remark, stunnel is useful. |
10,946 | Linux 上的 NVMe | https://www.networkworld.com/article/3397006/nvme-on-linux.html | 2019-06-06T20:34:03 | [
"NVMe",
"SSD"
] | https://linux.cn/article-10946-1.html |
>
> 如果你还没注意到,一些极速的固态磁盘技术已经可以用在 Linux 和其他操作系统上了。
>
>
>

NVMe 意即<ruby> 非易失性内存主机控制器接口规范 <rt> non-volatile memory express </rt></ruby>,它是一个主机控制器接口和存储协议,用于加速企业和客户端系统以及固态驱动器(SSD)之间的数据传输。它通过电脑的高速 PCIe 总线工作。每当我看到这些名词时,我的感受是“羡慕”。而羡慕的原因很重要。
使用 NVMe,数据传输的速度比旋转磁盘快很多。事实上,NVMe 驱动能够比 SATA SSD 快 7 倍。这比我们今天很多人用的固态硬盘快了 7 倍多。这意味着,如果你用一个 NVMe 驱动盘作为启动盘,你的系统能够启动的非常快。事实上,如今任何人买一个新的系统可能都不会考虑那些没有自带 NVMe 的,不管是服务器或者个人电脑。
### NVMe 在 Linux 下能工作吗?
是的!NVMe 自 Linux 内核 3.3 版本就支持了。然而,要升级系统,通常同时需要一个 NVMe 控制器和一个 NVMe 磁盘。一些外置磁盘也行,但是要连接到系统上,需要的可不仅仅是通用的 USB 接口。
先使用下列命令检查内核版本:
```
$ uname -r
5.0.0-15-generic
```
如果你的系统已经用了 NVMe,你将看到一个设备(例如,`/dev/nvme0`),但是只有在你安装了 NVMe 控制器的情况下才显示。如果你没有 NVMe 控制器,你可以用下列命令获取使用 NVMe 的相关信息。
```
$ modinfo nvme | head -6
filename: /lib/modules/5.0.0-15-generic/kernel/drivers/nvme/host/nvme.ko
version: 1.0
license: GPL
author: Matthew Wilcox <[email protected]>
srcversion: AA383008D5D5895C2E60523
alias: pci:v0000106Bd00002003sv*sd*bc*sc*i*
```
### 了解更多
如果你想了解极速的 NVMe 存储的更多细节,可在 [PCWorld](https://www.pcworld.com/article/2899351/everything-you-need-to-know-about-nvme.html) 获取。
规范、白皮书和其他资源可在 [NVMexpress.org](https://nvmexpress.org/) 获取。
---
via: <https://www.networkworld.com/article/3397006/nvme-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[warmfrog](https://github.com/warmfrog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,947 | 更深入地了解 Linux 权限 | https://www.networkworld.com/article/3397790/a-deeper-dive-into-linux-permissions.html | 2019-06-07T15:07:33 | [
"权限"
] | https://linux.cn/article-10947-1.html |
>
> 在 Linux 上查看文件权限时,有时你会看到的不仅仅是普通的 r、w、x 和 -。如何更清晰地了解这些字符试图告诉你什么以及这些权限如何工作?
>
>
>

在 Linux 上查看文件权限时,有时你会看到的不仅仅是普通的 `r`、`w`、`x` 和 `-`。除了在所有者、组和其他中看到 `rwx` 之外,你可能会看到 `s` 或者 `t`,如下例所示:
```
drwxrwsrwt
```
要进一步明确的方法之一是使用 `stat` 命令查看权限。`stat` 的第四行输出以八进制和字符串格式显示文件权限:
```
$ stat /var/mail
File: /var/mail
Size: 4096 Blocks: 8 IO Block: 4096 directory
Device: 801h/2049d Inode: 1048833 Links: 2
Access: (3777/drwxrwsrwt) Uid: ( 0/ root) Gid: ( 8/ mail)
Access: 2019-05-21 19:23:15.769746004 -0400
Modify: 2019-05-21 19:03:48.226656344 -0400
Change: 2019-05-21 19:03:48.226656344 -0400
Birth: -
```
这个输出提示我们,分配给文件权限的位数超过 9 位。事实上,有 12 位。这些额外的三位提供了一种分配超出通常的读、写和执行权限的方法 - 例如,`3777`(二进制 `011111111111`)表示使用了两个额外的设置。
该值的第一个 `1` (第二位)表示 SGID(设置 GID),为运行文件而赋予临时权限,或以该关联组的权限来使用目录。
```
011111111111
^
```
SGID 将正在使用该文件的用户作为该组成员之一而分配临时权限。
第二个 `1`(第三位)是“粘连”位。它确保*只有*文件的所有者能够删除或重命名该文件或目录。
```
011111111111
^
```
如果权限是 `7777` 而不是 `3777`,我们知道 SUID(设置 UID)字段也已设置。
```
111111111111
^
```
SUID 将正在使用该文件的用户作为文件拥有者分配临时权限。
至于我们上面看到的 `/var/mail` 目录,所有用户都需要访问,因此需要一些特殊值来提供它。
但现在让我们更进一步。
特殊权限位的一个常见用法是使用 `passwd` 之类的命令。如果查看 `/usr/bin/passwd` 文件,你会注意到 SUID 位已设置,它允许你更改密码(以及 `/etc/shadow` 文件的内容),即使你是以普通(非特权)用户身份运行,并且对此文件没有读取或写入权限。当然,`passwd` 命令很聪明,不允许你更改其他人的密码,除非你是以 root 身份运行或使用 `sudo`。
```
$ ls -l /usr/bin/passwd
-rwsr-xr-x 1 root root 63736 Mar 22 14:32 /usr/bin/passwd
$ ls -l /etc/shadow
-rw-r----- 1 root shadow 2195 Apr 22 10:46 /etc/shadow
```
现在,让我们看一下使用这些特殊权限可以做些什么。
### 如何分配特殊文件权限
与 Linux 命令行中的许多东西一样,你可以有不同的方法设置。 `chmod` 命令允许你以数字方式或使用字符表达式更改权限。
要以数字方式更改文件权限,你可以使用这样的命令来设置 SUID 和 SGID 位:
```
$ chmod 6775 tryme
```
或者你可以使用这样的命令:
```
$ chmod ug+s tryme <== 用于 SUID 和 SGID 权限
```
如果你要添加特殊权限的文件是脚本,你可能会对它不符合你的期望感到惊讶。这是一个非常简单的例子:
```
$ cat tryme
#!/bin/bash
echo I am $USER
```
即使设置了 SUID 和 SGID 位,并且 root 是文件所有者,运行脚本也不会产生你可能期望的 “I am root”。为什么?因为 Linux 会忽略脚本的 SUID 和 SGID 位。
```
$ ls -l tryme
-rwsrwsrwt 1 root root 29 May 26 12:22 tryme
$ ./tryme
I am jdoe
```
另一方面,如果你对一个编译的程序之类进行类似的尝试,就像下面这个简单的 C 程序一样,你会看到不同的效果。在此示例程序中,我们提示用户输入文件名并创建它,并给文件写入权限。
```
#include <stdlib.h>
int main()
{
FILE *fp; /* file pointer*/
char fName[20];
printf("Enter the name of file to be created: ");
scanf("%s",fName);
/* create the file with write permission */
fp=fopen(fName,"w");
/* check if file was created */
if(fp==NULL)
{
printf("File not created");
exit(0);
}
printf("File created successfully\n");
return 0;
}
```
编译程序并运行该命令以使 root 用户成为所有者并设置所需权限后,你将看到它以预期的 root 权限运行 - 留下新创建的 root 为所有者的文件。当然,你必须具有 `sudo` 权限才能运行一些需要的命令。
```
$ cc -o mkfile mkfile.c <== 编译程序
$ sudo chown root:root mkfile <== 更改所有者和组为 “root”
$ sudo chmod ug+s mkfile <== 添加 SUID and SGID 权限
$ ./mkfile <== 运行程序
Enter name of file to be create: empty
File created successfully
$ ls -l empty
-rw-rw-r-- 1 root root 0 May 26 13:15 empty
```
请注意,文件所有者是 root - 如果程序未以 root 权限运行,则不会发生这种情况。
权限字符串中不常见设置的位置(例如,rw**s**rw**s**rw**t**)可以帮助提醒我们每个位的含义。至少第一个 “s”(SUID) 位于所有者权限区域中,第二个 (SGID) 位于组权限区域中。为什么粘连位是 “t” 而不是 “s” 超出了我的理解。也许创造者想把它称为 “tacky bit”,但由于这个词的不太令人喜欢的第二个定义而改变了他们的想法。无论如何,额外的权限设置为 Linux 和其他 Unix 系统提供了许多额外的功能。
---
via: <https://www.networkworld.com/article/3397790/a-deeper-dive-into-linux-permissions.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,949 | 如何写好 C main 函数 | https://opensource.com/article/19/5/how-write-good-c-main-function | 2019-06-08T21:15:00 | [
"C语言"
] | https://linux.cn/article-10949-1.html |
>
> 学习如何构造一个 C 文件并编写一个 C main 函数来成功地处理命令行参数。
>
>
>

我知道,现在孩子们用 Python 和 JavaScript 编写他们的疯狂“应用程序”。但是不要这么快就否定 C 语言 —— 它能够提供很多东西,并且简洁。如果你需要速度,用 C 语言编写可能就是你的答案。如果你正在寻找稳定的职业或者想学习如何捕获[空指针解引用](https://www.owasp.org/index.php/Null_Dereference),C 语言也可能是你的答案!在本文中,我将解释如何构造一个 C 文件并编写一个 C main 函数来成功地处理命令行参数。
我:一个顽固的 Unix 系统程序员。
你:一个有编辑器、C 编译器,并有时间打发的人。
让我们开工吧。
### 一个无聊但正确的 C 程序

C 程序以 `main()` 函数开头,通常保存在名为 `main.c` 的文件中。
```
/* main.c */
int main(int argc, char *argv[]) {
}
```
这个程序可以*编译*但不*干*任何事。
```
$ gcc main.c
$ ./a.out -o foo -vv
$
```
正确但无聊。
### main 函数是唯一的。
`main()` 函数是开始执行时所执行的程序的第一个函数,但不是第一个执行的函数。*第一个*函数是 `_start()`,它通常由 C 运行库提供,在编译程序时自动链入。此细节高度依赖于操作系统和编译器工具链,所以我假装没有提到它。
`main()` 函数有两个参数,通常称为 `argc` 和 `argv`,并返回一个有符号整数。大多数 Unix 环境都希望程序在成功时返回 `0`(零),失败时返回 `-1`(负一)。
| 参数 | 名称 | 描述 |
| --- | --- | --- |
| `argc` | 参数个数 | 参数向量的个数 |
| `argv` | 参数向量 | 字符指针数组 |
参数向量 `argv` 是调用你的程序的命令行的标记化表示形式。在上面的例子中,`argv` 将是以下字符串的列表:
```
argv = [ "/path/to/a.out", "-o", "foo", "-vv" ];
```
参数向量在其第一个索引 `argv[0]` 中确保至少会有一个字符串,这是执行程序的完整路径。
### main.c 文件的剖析
当我从头开始编写 `main.c` 时,它的结构通常如下:
```
/* main.c */
/* 0 版权/许可证 */
/* 1 包含 */
/* 2 定义 */
/* 3 外部声明 */
/* 4 类型定义 */
/* 5 全局变量声明 */
/* 6 函数原型 */
int main(int argc, char *argv[]) {
/* 7 命令行解析 */
}
/* 8 函数声明 */
```
下面我将讨论这些编号的各个部分,除了编号为 0 的那部分。如果你必须把版权或许可文本放在源代码中,那就放在那里。
另一件我不想讨论的事情是注释。
```
“评论谎言。”
- 一个愤世嫉俗但聪明又好看的程序员。
```
与其使用注释,不如使用有意义的函数名和变量名。
鉴于程序员固有的惰性,一旦添加了注释,维护负担就会增加一倍。如果更改或重构代码,则需要更新或扩充注释。随着时间的推移,代码会变得面目全非,与注释所描述的内容完全不同。
如果你必须写注释,不要写关于代码正在做*什么*,相反,写下代码*为什么*要这样写。写一些你将要在五年后读到的注释,那时你已经将这段代码忘得一干二净。世界的命运取决于你。*不要有压力。*
#### 1、包含
我添加到 `main.c` 文件的第一个东西是包含文件,它们为程序提供大量标准 C 标准库函数和变量。C 标准库做了很多事情。浏览 `/usr/include` 中的头文件,你可以了解到它们可以做些什么。
`#include` 字符串是 [C 预处理程序](https://en.wikipedia.org/wiki/C_preprocessor)(cpp)指令,它会将引用的文件完整地包含在当前文件中。C 中的头文件通常以 `.h` 扩展名命名,且不应包含任何可执行代码。它只有宏、定义、类型定义、外部变量和函数原型。字符串 `<header.h>` 告诉 cpp 在系统定义的头文件路径中查找名为 `header.h` 的文件,它通常在 `/usr/include` 目录中。
```
/* main.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <libgen.h>
#include <errno.h>
#include <string.h>
#include <getopt.h>
#include <sys/types.h>
```
这是我默认会全局包含的最小包含集合,它将引入:
| #include 文件 | 提供的东西 |
| --- | --- |
| stdio | 提供 `FILE`、`stdin`、`stdout`、`stderr` 和 `fprint()` 函数系列 |
| stdlib | 提供 `malloc()`、`calloc()` 和 `realloc()` |
| unistd | 提供 `EXIT_FAILURE`、`EXIT_SUCCESS` |
| libgen | 提供 `basename()` 函数 |
| errno | 定义外部 `errno` 变量及其可以接受的所有值 |
| string | 提供 `memcpy()`、`memset()` 和 `strlen()` 函数系列 |
| getopt | 提供外部 `optarg`、`opterr`、`optind` 和 `getopt()` 函数 |
| sys/types | 类型定义快捷方式,如 `uint32_t` 和 `uint64_t` |
#### 2、定义
```
/* main.c */
<...>
#define OPTSTR "vi:o:f:h"
#define USAGE_FMT "%s [-v] [-f hexflag] [-i inputfile] [-o outputfile] [-h]"
#define ERR_FOPEN_INPUT "fopen(input, r)"
#define ERR_FOPEN_OUTPUT "fopen(output, w)"
#define ERR_DO_THE_NEEDFUL "do_the_needful blew up"
#define DEFAULT_PROGNAME "george"
```
这在现在没有多大意义,但 `OPTSTR` 定义我这里会说明一下,它是程序推荐的命令行开关。参考 [getopt(3)](https://linux.die.net/man/3/getopt) man 页面,了解 `OPTSTR` 将如何影响 `getopt()` 的行为。
`USAGE_FMT` 定义了一个 `printf()` 风格的格式字符串,它用在 `usage()` 函数中。
我还喜欢将字符串常量放在文件的 `#define` 这一部分。如果需要,把它们收集在一起可以更容易地修正拼写、重用消息和国际化消息。
最后,在命名 `#define` 时全部使用大写字母,以区别变量和函数名。如果需要,可以将单词放连在一起或使用下划线分隔,只要确保它们都是大写的就行。
#### 3、外部声明
```
/* main.c */
<...>
extern int errno;
extern char *optarg;
extern int opterr, optind;
```
`extern` 声明将该名称带入当前编译单元的命名空间(即 “文件”),并允许程序访问该变量。这里我们引入了三个整数变量和一个字符指针的定义。`opt` 前缀的几个变量是由 `getopt()` 函数使用的,C 标准库使用 `errno` 作为带外通信通道来传达函数可能的失败原因。
#### 4、类型定义
```
/* main.c */
<...>
typedef struct {
int verbose;
uint32_t flags;
FILE *input;
FILE *output;
} options_t;
```
在外部声明之后,我喜欢为结构、联合和枚举声明 `typedef`。命名一个 `typedef` 是一种传统习惯。我非常喜欢使用 `_t` 后缀来表示该名称是一种类型。在这个例子中,我将 `options_t` 声明为一个包含 4 个成员的 `struct`。C 是一种空格无关的编程语言,因此我使用空格将字段名排列在同一列中。我只是喜欢它看起来的样子。对于指针声明,我在名称前面加上星号,以明确它是一个指针。
#### 5、全局变量声明
```
/* main.c */
<...>
int dumb_global_variable = -11;
```
全局变量是一个坏主意,你永远不应该使用它们。但如果你必须使用全局变量,请在这里声明,并确保给它们一个默认值。说真的,*不要使用全局变量*。
#### 6、函数原型
```
/* main.c */
<...>
void usage(char *progname, int opt);
int do_the_needful(options_t *options);
```
在编写函数时,将它们添加到 `main()` 函数之后而不是之前,在这里放函数原型。早期的 C 编译器使用单遍策略,这意味着你在程序中使用的每个符号(变量或函数名称)必须在使用之前声明。现代编译器几乎都是多遍编译器,它们在生成代码之前构建一个完整的符号表,因此并不严格要求使用函数原型。但是,有时你无法选择代码要使用的编译器,所以请编写函数原型并继续这样做下去。
当然,我总是包含一个 `usage()` 函数,当 `main()` 函数不理解你从命令行传入的内容时,它会调用这个函数。
#### 7、命令行解析
```
/* main.c */
<...>
int main(int argc, char *argv[]) {
int opt;
options_t options = { 0, 0x0, stdin, stdout };
opterr = 0;
while ((opt = getopt(argc, argv, OPTSTR)) != EOF)
switch(opt) {
case 'i':
if (!(options.input = fopen(optarg, "r")) ){
perror(ERR_FOPEN_INPUT);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
break;
case 'o':
if (!(options.output = fopen(optarg, "w")) ){
perror(ERR_FOPEN_OUTPUT);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
break;
case 'f':
options.flags = (uint32_t )strtoul(optarg, NULL, 16);
break;
case 'v':
options.verbose += 1;
break;
case 'h':
default:
usage(basename(argv[0]), opt);
/* NOTREACHED */
break;
}
if (do_the_needful(&options) != EXIT_SUCCESS) {
perror(ERR_DO_THE_NEEDFUL);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
return EXIT_SUCCESS;
}
```
好吧,代码有点多。这个 `main()` 函数的目的是收集用户提供的参数,执行最基本的输入验证,然后将收集到的参数传递给使用它们的函数。这个示例声明一个使用默认值初始化的 `options` 变量,并解析命令行,根据需要更新 `options`。
`main()` 函数的核心是一个 `while` 循环,它使用 `getopt()` 来遍历 `argv`,寻找命令行选项及其参数(如果有的话)。文件前面定义的 `OPTSTR` 是驱动 `getopt()` 行为的模板。`opt` 变量接受 `getopt()` 找到的任何命令行选项的字符值,程序对检测命令行选项的响应发生在 `switch` 语句中。
如果你注意到了可能会问,为什么 `opt` 被声明为 32 位 `int`,但是预期是 8 位 `char`?事实上 `getopt()` 返回一个 `int`,当它到达 `argv` 末尾时取负值,我会使用 `EOF`(*文件末尾*标记)匹配。`char` 是有符号的,但我喜欢将变量匹配到它们的函数返回值。
当检测到一个已知的命令行选项时,会发生特定的行为。在 `OPTSTR` 中指定一个以冒号结尾的参数,这些选项可以有一个参数。当一个选项有一个参数时,`argv` 中的下一个字符串可以通过外部定义的变量 `optarg` 提供给程序。我使用 `optarg` 来打开文件进行读写,或者将命令行参数从字符串转换为整数值。
这里有几个关于代码风格的要点:
* 将 `opterr` 初始化为 `0`,禁止 `getopt` 触发 `?`。
* 在 `main()` 的中间使用 `exit(EXIT_FAILURE);` 或 `exit(EXIT_SUCCESS);`。
* `/* NOTREACHED */` 是我喜欢的一个 lint 指令。
* 在返回 int 类型的函数末尾使用 `return EXIT_SUCCESS;`。
* 显示强制转换隐式类型。
这个程序的命令行格式,经过编译如下所示:
```
$ ./a.out -h
a.out [-v] [-f hexflag] [-i inputfile] [-o outputfile] [-h]
```
事实上,在编译后 `usage()` 就会向 `stderr` 发出这样的内容。
#### 8、函数声明
```
/* main.c */
<...>
void usage(char *progname, int opt) {
fprintf(stderr, USAGE_FMT, progname?progname:DEFAULT_PROGNAME);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
int do_the_needful(options_t *options) {
if (!options) {
errno = EINVAL;
return EXIT_FAILURE;
}
if (!options->input || !options->output) {
errno = ENOENT;
return EXIT_FAILURE;
}
/* XXX do needful stuff */
return EXIT_SUCCESS;
}
```
我最后编写的函数不是个样板函数。在本例中,函数 `do_the_needful()` 接受一个指向 `options_t` 结构的指针。我验证 `options` 指针不为 `NULL`,然后继续验证 `input` 和 `output` 结构成员。如果其中一个测试失败,返回 `EXIT_FAILURE`,并且通过将外部全局变量 `errno` 设置为常规错误代码,我可以告知调用者常规的错误原因。调用者可以使用便捷函数 `perror()` 来根据 `errno` 的值发出便于阅读的错误消息。
函数几乎总是以某种方式验证它们的输入。如果完全验证代价很大,那么尝试执行一次并将验证后的数据视为不可变。`usage()` 函数使用 `fprintf()` 调用中的条件赋值验证 `progname` 参数。接下来 `usage()` 函数就退出了,所以我不会费心设置 `errno`,也不用操心是否使用正确的程序名。
在这里,我要避免的最大错误是解引用 `NULL` 指针。这将导致操作系统向我的进程发送一个名为 `SYSSEGV` 的特殊信号,导致不可避免的死亡。用户最不希望看到的是由 `SYSSEGV` 而导致的崩溃。最好是捕获 `NULL` 指针以发出更合适的错误消息并优雅地关闭程序。
有些人抱怨在函数体中有多个 `return` 语句,他们喋喋不休地说些“控制流的连续性”之类的东西。老实说,如果函数中间出现错误,那就应该返回这个错误条件。写一大堆嵌套的 `if` 语句只有一个 `return` 绝不是一个“好主意”™。
最后,如果你编写的函数接受四个以上的参数,请考虑将它们绑定到一个结构中,并传递一个指向该结构的指针。这使得函数签名更简单,更容易记住,并且在以后调用时不会出错。它还可以使调用函数速度稍微快一些,因为需要复制到函数堆栈中的东西更少。在实践中,只有在函数被调用数百万或数十亿次时,才会考虑这个问题。如果认为这没有意义,那也无所谓。
### 等等,你不是说没有注释吗!?!!
在 `do_the_needful()` 函数中,我写了一种特殊类型的注释,它被是作为占位符设计的,而不是为了说明代码:
```
/* XXX do needful stuff */
```
当你写到这里时,有时你不想停下来编写一些特别复杂的代码,你会之后再写,而不是现在。那就是我留给自己再次回来的地方。我插入一个带有 `XXX` 前缀的注释和一个描述需要做什么的简短注释。之后,当我有更多时间的时候,我会在源代码中寻找 `XXX`。使用什么前缀并不重要,只要确保它不太可能在另一个上下文环境(如函数名或变量)中出现在你代码库里。
### 把它们组合在一起
好吧,当你编译这个程序后,它*仍然*几乎没有任何作用。但是现在你有了一个坚实的骨架来构建你自己的命令行解析 C 程序。
```
/* main.c - the complete listing */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <libgen.h>
#include <errno.h>
#include <string.h>
#include <getopt.h>
#define OPTSTR "vi:o:f:h"
#define USAGE_FMT "%s [-v] [-f hexflag] [-i inputfile] [-o outputfile] [-h]"
#define ERR_FOPEN_INPUT "fopen(input, r)"
#define ERR_FOPEN_OUTPUT "fopen(output, w)"
#define ERR_DO_THE_NEEDFUL "do_the_needful blew up"
#define DEFAULT_PROGNAME "george"
extern int errno;
extern char *optarg;
extern int opterr, optind;
typedef struct {
int verbose;
uint32_t flags;
FILE *input;
FILE *output;
} options_t;
int dumb_global_variable = -11;
void usage(char *progname, int opt);
int do_the_needful(options_t *options);
int main(int argc, char *argv[]) {
int opt;
options_t options = { 0, 0x0, stdin, stdout };
opterr = 0;
while ((opt = getopt(argc, argv, OPTSTR)) != EOF)
switch(opt) {
case 'i':
if (!(options.input = fopen(optarg, "r")) ){
perror(ERR_FOPEN_INPUT);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
break;
case 'o':
if (!(options.output = fopen(optarg, "w")) ){
perror(ERR_FOPEN_OUTPUT);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
break;
case 'f':
options.flags = (uint32_t )strtoul(optarg, NULL, 16);
break;
case 'v':
options.verbose += 1;
break;
case 'h':
default:
usage(basename(argv[0]), opt);
/* NOTREACHED */
break;
}
if (do_the_needful(&options) != EXIT_SUCCESS) {
perror(ERR_DO_THE_NEEDFUL);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
return EXIT_SUCCESS;
}
void usage(char *progname, int opt) {
fprintf(stderr, USAGE_FMT, progname?progname:DEFAULT_PROGNAME);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
int do_the_needful(options_t *options) {
if (!options) {
errno = EINVAL;
return EXIT_FAILURE;
}
if (!options->input || !options->output) {
errno = ENOENT;
return EXIT_FAILURE;
}
/* XXX do needful stuff */
return EXIT_SUCCESS;
}
```
现在,你已经准备好编写更易于维护的 C 语言。如果你有任何问题或反馈,请在评论中分享。
---
via: <https://opensource.com/article/19/5/how-write-good-c-main-function>
作者:[Erik O'Shaughnessy](https://opensource.com/users/jnyjny) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I know, Python and JavaScript are what the kids are writing all their crazy "apps" with these days. But don't be so quick to dismiss C—it's a capable and concise language that has a lot to offer. If you need speed, writing in C could be your answer. If you are looking for job security and the opportunity to learn how to hunt down [null pointer dereferences](https://www.owasp.org/index.php/Null_Dereference), C could also be your answer! In this article, I'll explain how to structure a C file and write a C main function that handles command line arguments like a champ.
**Me**: a crusty Unix system programmer.
**You**: someone with an editor, a C compiler, and some time to kill.
*Let's do this.*
## A boring but correct C program

A C program starts with a **main()** function, usually kept in a file named **main.c**.
```
/* main.c */
int main(int argc, char *argv[]) {
}
```
This program *compiles* but doesn't *do* anything.
```
$ gcc main.c
$ ./a.out -o foo -vv
$
```
Correct and boring.
## Main functions are unique
The **main()** function is the first function in your program that is executed when it begins executing, but it's not the first function executed. The *first* function is **_start()**, which is typically provided by the C runtime library, linked in automatically when your program is compiled. The details are highly dependent on the operating system and compiler toolchain, so I'm going to pretend I didn't mention it.
The **main()** function has two arguments that traditionally are called **argc** and **argv** and return a signed integer. Most Unix environments expect programs to return **0** (zero) on success and **-1** (negative one) on failure.
Argument | Name | Description |
---|---|---|
argc | Argument count | Length of the argument vector |
argv | Argument vector | Array of character pointers |
The argument vector, **argv**, is a tokenized representation of the command line that invoked your program. In the example above, **argv** would be a list of the following strings:
`argv = [ "/path/to/a.out", "-o", "foo", "-vv" ];`
The argument vector is guaranteed to always have at least one string in the first index, **argv[0]**, which is the full path to the program executed.
## Anatomy of a main.c file
When I write a **main.c** from scratch, it's usually structured like this:
```
/* main.c */
/* 0 copyright/licensing */
/* 1 includes */
/* 2 defines */
/* 3 external declarations */
/* 4 typedefs */
/* 5 global variable declarations */
/* 6 function prototypes */
int main(int argc, char *argv[]) {
/* 7 command-line parsing */
}
/* 8 function declarations */
```
I'll talk about each of these numbered sections, except for zero, below. If you have to put copyright or licensing text in your source, put it there.
Another thing I won't talk about adding to your program is comments.
```
"Comments lie."
- A cynical but smart and good looking programmer.
```
Instead of comments, use meaningful function and variable names.
Appealing to the inherent laziness of programmers, once you add comments, you've doubled your maintenance load. If you change or refactor the code, you need to update or expand the comments. Over time, the code mutates away from anything resembling what the comments describe.
If you have to write comments, do not write about *what* the code is doing. Instead, write about *why* the code is doing what it's doing. Write comments that you would want to read five years from now when you've forgotten everything about this code. And the fate of the world is depending on you. *No pressure*.
### 1. Includes
The first things I add to a **main.c** file are includes to make a multitude of standard C library functions and variables available to my program. The standard C library does lots of things; explore header files in **/usr/include** to find out what it can do for you.
The **#include** string is a [C preprocessor](https://en.wikipedia.org/wiki/C_preprocessor) (cpp) directive that causes the inclusion of the referenced file, in its entirety, in the current file. Header files in C are usually named with a **.h** extension and should not contain any executable code; only macros, defines, typedefs, and external variable and function prototypes. The string **<header.h>** tells cpp to look for a file called **header.h** in the system-defined header path, usually **/usr/include**.
```
/* main.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <libgen.h>
#include <errno.h>
#include <string.h>
#include <getopt.h>
#include <sys/types.h>
```
This is the minimum set of global includes that I'll include by default for the following stuff:
#include File | Stuff It Provides |
---|---|
stdio | Supplies FILE, stdin, stdout, stderr, and the fprint() family of functions |
stdlib | Supplies malloc(), calloc(), and realloc() |
unistd | Supplies EXIT_FAILURE, EXIT_SUCCESS |
libgen | Supplies the basename() function |
errno | Defines the external errno variable and all the values it can take on |
string | Supplies memcpy(), memset(), and the strlen() family of functions |
getopt | Supplies external optarg, opterr, optind, and getopt() function |
sys/types | Typedef shortcuts like uint32_t and uint64_t |
### 2. Defines
```
/* main.c */
<...>
#define OPTSTR "vi:o:f:h"
#define USAGE_FMT "%s [-v] [-f hexflag] [-i inputfile] [-o outputfile] [-h]"
#define ERR_FOPEN_INPUT "fopen(input, r)"
#define ERR_FOPEN_OUTPUT "fopen(output, w)"
#define ERR_DO_THE_NEEDFUL "do_the_needful blew up"
#define DEFAULT_PROGNAME "george"
```
This doesn't make a lot of sense right now, but the **OPTSTR** define is where I will state what command line switches the program will recommend. Consult the [ getopt(3)](https://linux.die.net/man/3/getopt) man page to learn how
**OPTSTR**will affect
**getopt()**'s behavior.
The **USAGE_FMT** define is a **printf()**-style format string that is referenced in the **usage()** function.
I also like to gather string constants as **#defines** in this part of the file. Collecting them makes it easier to fix spelling, reuse messages, and internationalize messages, if required.
Finally, use all capital letters when naming a **#define** to distinguish it from variable and function names. You can run the words together if you want or separate words with an underscore; just make sure they're all upper case.
### 3. External declarations
```
/* main.c */
<...>
extern int errno;
extern char *optarg;
extern int opterr, optind;
```
An **extern** declaration brings that name into the namespace of the current compilation unit (aka "file") and allows the program to access that variable. Here we've brought in the definitions for three integer variables and a character pointer. The **opt** prefaced variables are used by the **getopt()** function, and **errno** is used as an out-of-band communication channel by the standard C library to communicate why a function might have failed.
### 4. Typedefs
```
/* main.c */
<...>
typedef struct {
int verbose;
uint32_t flags;
FILE *input;
FILE *output;
} options_t;
```
After external declarations, I like to declare **typedefs** for structures, unions, and enumerations. Naming a **typedef** is a religion all to itself; I strongly prefer a **_t** suffix to indicate that the name is a type. In this example, I've declared **options_t** as a **struct** with four members. C is a whitespace-neutral programming language, so I use whitespace to line up field names in the same column. I just like the way it looks. For the pointer declarations, I prepend the asterisk to the name to make it clear that it's a pointer.
### 5. Global variable declarations
```
/* main.c */
<...>
int dumb_global_variable = -11;
```
Global variables are a bad idea and you should never use them. But if you have to use a global variable, declare them here and be sure to give them a default value. Seriously, *don't use global variables*.
### 6. Function prototypes
```
/* main.c */
<...>
void usage(char *progname, int opt);
int do_the_needful(options_t *options);
```
As you write functions, adding them after the **main()** function and not before, include the function prototypes here. Early C compilers used a single-pass strategy, which meant that every symbol (variable or function name) you used in your program had to be declared before you used it. Modern compilers are nearly all multi-pass compilers that build a complete symbol table before generating code, so using function prototypes is not strictly required. However, you sometimes don't get to choose what compiler is used on your code, so write the function prototypes and drive on.
As a matter of course, I always include a **usage()** function that **main()** calls when it doesn't understand something you passed in from the command line.
### 7. Command line parsing
```
/* main.c */
<...>
int main(int argc, char *argv[]) {
int opt;
options_t options = { 0, 0x0, stdin, stdout };
opterr = 0;
while ((opt = getopt(argc, argv, OPTSTR)) != EOF)
switch(opt) {
case 'i':
if (!(options.input = fopen(optarg, "r")) ){
perror(ERR_FOPEN_INPUT);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
break;
case 'o':
if (!(options.output = fopen(optarg, "w")) ){
perror(ERR_FOPEN_OUTPUT);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
break;
case 'f':
options.flags = (uint32_t )strtoul(optarg, NULL, 16);
break;
case 'v':
options.verbose += 1;
break;
case 'h':
default:
usage(basename(argv[0]), opt);
/* NOTREACHED */
break;
}
if (do_the_needful(&options) != EXIT_SUCCESS) {
perror(ERR_DO_THE_NEEDFUL);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
return EXIT_SUCCESS;
}
```
OK, that's a lot. The purpose of the **main()** function is to collect the arguments that the user provides, perform minimal input validation, and then pass the collected arguments to functions that will use them. This example declares an **options** variable initialized with default values and parse the command line, updating **options** as necessary.
The guts of this **main()** function is a **while** loop that uses **getopt()** to step through **argv** looking for command line options and their arguments (if any). The **OPTSTR** **#define** earlier in the file is the template that drives **getopt()**'s behavior. The **opt** variable takes on the character value of any command line options found by **getopt()**, and the program's response to the detection of the command line option happens in the **switch** statement.
Those of you paying attention will now be questioning why **opt** is declared as a 32-bit **int** but is expected to take on an 8-bit **char**? It turns out that **getopt()** returns an **int** that takes on a negative value when it gets to the end of **argv**, which I check against **EOF** (the *End of File* marker). A **char** is a signed quantity, but I like matching variables to their function return values.
When a known command line option is detected, option-specific behavior happens. Some options have an argument, specified in **OPTSTR** with a trailing colon. When an option has an argument, the next string in **argv** is available to the program via the externally defined variable **optarg**. I use **optarg** to open files for reading and writing or converting a command line argument from a string to an integer value.
There are a couple of points for style here:
- Initialize
**opterr**to 0, which disables**getopt**from emiting a**?**. - Use
**exit(EXIT_FAILURE);**or**exit(EXIT_SUCCESS);**in the middle of**main()**. **/* NOTREACHED */**is a lint directive that I like.- Use
**return EXIT_SUCCESS;**at the end of functions that return**int**. - Explicitly cast implicit type conversions.
The command line signature for this program, if it were compiled, would look something like this:
```
$ ./a.out -h
a.out [-v] [-f hexflag] [-i inputfile] [-o outputfile] [-h]
```
In fact, that's what **usage()** will emit to **stderr** once compiled.
### 8. Function declarations
```
/* main.c */
<...>
void usage(char *progname, int opt) {
fprintf(stderr, USAGE_FMT, progname?progname:DEFAULT_PROGNAME);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
int do_the_needful(options_t *options) {
if (!options) {
errno = EINVAL;
return EXIT_FAILURE;
}
if (!options->input || !options->output) {
errno = ENOENT;
return EXIT_FAILURE;
}
/* XXX do needful stuff */
return EXIT_SUCCESS;
}
```
Finally, I write functions that aren't boilerplate. In this example, function **do_the_needful()** accepts a pointer to an **options_t** structure. I validate that the **options** pointer is not **NULL** and then go on to validate the **input** and **output** structure members. **EXIT_FAILURE** returns if either test fails and, by setting the external global variable **errno** to a conventional error code, I signal to the caller a general reason. The convenience function **perror()** can be used by the caller to emit human-readable-ish error messages based on the value of **errno**.
Functions should almost always validate their input in some way. If full validation is expensive, try to do it once and treat the validated data as immutable. The **usage()** function validates the **progname** argument using a conditional assignment in the **fprintf()** call. The **usage()** function is going to exit anyway, so I don't bother setting **errno** or making a big stink about using a correct program name.
The big class of errors I am trying to avoid here is de-referencing a **NULL** pointer. This will cause the operating system to send a special signal to my process called **SYSSEGV**, which results in unavoidable death. The last thing users want to see is a crash due to **SYSSEGV**. It's much better to catch a **NULL** pointer in order to emit better error messages and shut down the program gracefully.
Some people complain about having multiple **return** statements in a function body. They make arguments about "continuity of control flow" and other stuff. Honestly, if something goes wrong in the middle of a function, it's a good time to return an error condition. Writing a ton of nested **if** statements to just have one return is never a "good idea."™
Finally, if you write a function that takes four or more arguments, consider bundling them in a structure and passing a pointer to the structure. This makes the function signatures simpler, making them easier to remember and not screw up when they're called later. It also makes calling the function slightly faster, since fewer things need to be copied into the function's stack frame. In practice, this will only become a consideration if the function is called millions or billions of times. Don't worry about it if that doesn't make sense.
## Wait, you said no comments!?!!
In the **do_the_needful()** function, I wrote a specific type of comment that is designed to be a placeholder rather than documenting the code:
`/* XXX do needful stuff */`
When you are in the zone, sometimes you don't want to stop and write some particularly gnarly bit of code. You'll come back and do it later, just not now. That's where I'll leave myself a little breadcrumb. I insert a comment with a **XXX** prefix and a short remark describing what needs to be done. Later on, when I have more time, I'll grep through source looking for **XXX**. It doesn't matter what you use, just make sure it's not likely to show up in your codebase in another context, as a function name or variable, for instance.
## Putting it all together
OK, this program *still* does almost nothing when you compile and run it. But now you have a solid skeleton to build your own command line parsing C programs.
```
/* main.c - the complete listing */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <libgen.h>
#include <errno.h>
#include <string.h>
#include <getopt.h>
#define OPTSTR "vi:o:f:h"
#define USAGE_FMT "%s [-v] [-f hexflag] [-i inputfile] [-o outputfile] [-h]"
#define ERR_FOPEN_INPUT "fopen(input, r)"
#define ERR_FOPEN_OUTPUT "fopen(output, w)"
#define ERR_DO_THE_NEEDFUL "do_the_needful blew up"
#define DEFAULT_PROGNAME "george"
extern int errno;
extern char *optarg;
extern int opterr, optind;
typedef struct {
int verbose;
uint32_t flags;
FILE *input;
FILE *output;
} options_t;
int dumb_global_variable = -11;
void usage(char *progname, int opt);
int do_the_needful(options_t *options);
int main(int argc, char *argv[]) {
int opt;
options_t options = { 0, 0x0, stdin, stdout };
opterr = 0;
while ((opt = getopt(argc, argv, OPTSTR)) != EOF)
switch(opt) {
case 'i':
if (!(options.input = fopen(optarg, "r")) ){
perror(ERR_FOPEN_INPUT);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
break;
case 'o':
if (!(options.output = fopen(optarg, "w")) ){
perror(ERR_FOPEN_OUTPUT);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
break;
case 'f':
options.flags = (uint32_t )strtoul(optarg, NULL, 16);
break;
case 'v':
options.verbose += 1;
break;
case 'h':
default:
usage(basename(argv[0]), opt);
/* NOTREACHED */
break;
}
if (do_the_needful(&options) != EXIT_SUCCESS) {
perror(ERR_DO_THE_NEEDFUL);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
return EXIT_SUCCESS;
}
void usage(char *progname, int opt) {
fprintf(stderr, USAGE_FMT, progname?progname:DEFAULT_PROGNAME);
exit(EXIT_FAILURE);
/* NOTREACHED */
}
int do_the_needful(options_t *options) {
if (!options) {
errno = EINVAL;
return EXIT_FAILURE;
}
if (!options->input || !options->output) {
errno = ENOENT;
return EXIT_FAILURE;
}
/* XXX do needful stuff */
return EXIT_SUCCESS;
}
```
Now you're ready to write C that will be easier to maintain. If you have any questions or feedback, please share them in the comments.
## 38 Comments |
10,951 | 如何在 Linux 下确认 NTP 是否同步? | https://www.2daygeek.com/check-verify-ntp-sync-is-working-or-not-in-linux-using-ntpq-ntpstat-timedatectl/ | 2019-06-08T21:57:00 | [
"NTP"
] | https://linux.cn/article-10951-1.html | 
NTP 意即<ruby> 网络时间协议 <rt> Network Time Protocol </rt></ruby>,它通过网络同步计算机系统之间的时钟。NTP 服务器可以使组织中的所有服务器保持同步,以准确时间执行基于时间的作业。NTP 客户端会将其时钟与 NTP 服务器同步。
我们已经写了一篇关于 NTP 服务器和客户端安装和配置的文章。如果你想查看这些文章,请导航至以下链接。
* [如何在 Linux 上安装、配置 NTP 服务器和客户端?](/article-10811-1.html)
* [如何安装和配置 Chrony 作为 NTP 客户端?](/article-10820-1.html)
我假设你已经使用上述链接设置了 NTP 服务器和 NTP 客户端。现在,如何验证 NTP 设置是否正常工作?
Linux 中有三个命令可用于验证 NTP 同步情况。详情如下。在本文中,我们将告诉您如何使用所有这些命令验证 NTP 同步。
* `ntpq`:ntpq 是一个标准的 NTP 查询程序。
* `ntpstat`:显示网络世界同步状态。
* `timedatectl`:它控制 systemd 系统中的系统时间和日期。
### 方法 1:如何使用 ntpq 命令检查 NTP 状态?
`ntpq` 实用程序用于监视 NTP 守护程序 `ntpd` 的操作并确定性能。
该程序可以以交互模式运行,也可以使用命令行参数进行控制。它通过向服务器发送多个查询来打印出连接的对等项列表。如果 NTP 正常工作,你将获得类似于下面的输出。
```
# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*CentOS7.2daygee 133.243.238.163 2 u 14 64 37 0.686 0.151 16.432
```
细节:
* `-p`:打印服务器已知的对等项列表以及其状态摘要。
### 方法 2:如何使用 ntpstat 命令检查 NTP 状态?
`ntpstat` 将报告在本地计算机上运行的 NTP 守护程序(`ntpd`)的同步状态。如果发现本地系统与参考时间源保持同步,则 `ntpstat` 将报告大致的时间精度。
`ntpstat` 命令根据 NTP 同步状态返回三种状态码。详情如下。
* `0`:如果时钟同步则返回 0。
* `1`:如果时钟不同步则返回 1。
* `2`:如果时钟状态不确定,则返回 2,例如 ntpd 不可联系时。
```
# ntpstat
synchronised to NTP server (192.168.1.8) at stratum 3
time correct to within 508 ms
polling server every 64 s
```
### 方法 3:如何使用 timedatectl 命令检查 NTP 状态?
[timedatectl 命令](https://www.2daygeek.com/change-set-time-date-and-timezone-on-linux/)用于查询和更改系统时钟及其在 systmed 系统中的设置。
```
# timedatectl
或
# timedatectl status
Local time: Thu 2019-05-30 05:01:05 CDT
Universal time: Thu 2019-05-30 10:01:05 UTC
RTC time: Thu 2019-05-30 10:01:05
Time zone: America/Chicago (CDT, -0500)
NTP enabled: yes
NTP synchronized: yes
RTC in local TZ: no
DST active: yes
Last DST change: DST began at
Sun 2019-03-10 01:59:59 CST
Sun 2019-03-10 03:00:00 CDT
Next DST change: DST ends (the clock jumps one hour backwards) at
Sun 2019-11-03 01:59:59 CDT
Sun 2019-11-03 01:00:00 CST
```
### 更多技巧
Chrony 是一个 NTP 客户端的替代品。它可以更快地同步系统时钟,时间精度更高,对于一直不在线的系统尤其有用。
chronyd 较小,它使用较少的内存,只在必要时才唤醒 CPU,这样可以更好地节省电能。即使网络拥塞较长时间,它也能很好地运行。
你可以使用以下任何命令来检查 Chrony 状态。
检查 Chrony 跟踪状态。
```
# chronyc tracking
Reference ID : C0A80105 (CentOS7.2daygeek.com)
Stratum : 3
Ref time (UTC) : Thu Mar 28 05:57:27 2019
System time : 0.000002545 seconds slow of NTP time
Last offset : +0.001194361 seconds
RMS offset : 0.001194361 seconds
Frequency : 1.650 ppm fast
Residual freq : +184.101 ppm
Skew : 2.962 ppm
Root delay : 0.107966967 seconds
Root dispersion : 1.060455322 seconds
Update interval : 2.0 seconds
Leap status : Normal
```
运行 `sources` 命令以显示有关当前时间源的信息。
```
# chronyc sources
210 Number of sources = 1
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* CentOS7.2daygeek.com 2 6 17 62 +36us[+1230us] +/- 1111ms
```
---
via: <https://www.2daygeek.com/check-verify-ntp-sync-is-working-or-not-in-linux-using-ntpq-ntpstat-timedatectl/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,952 | 5 个 Linux 新手会犯的失误 | https://opensource.com/article/19/4/linux-rookie-mistakes | 2019-06-09T10:37:23 | [
"新手"
] | https://linux.cn/article-10952-1.html |
>
> Linux 爱好者们分享了他们犯下的一些最大错误。
>
>
>

终身学习是明智的 —— 它可以让你的思维敏捷,让你在就业市场上更具竞争力。但是有些技能比其他技能更难学,尤其是那些小菜鸟错误,当你尝试修复它们时可能会花费你很多时间,给你带来很大困扰。
以学习 [Linux](https://opensource.com/resources/linux) 为例。如果你习惯于在 Windows 或 MacOS 图形界面中工作,那么转移到 Linux,要将不熟悉的命令输入到终端中,可能会有很大的学习曲线。但是,其回报是值得的,因为已经有数以百万计的人们已经证明了这一点。
也就是说,这趟学习之旅并不是一帆风顺的。我们让一些 Linux 爱好者回想了一下他们刚开始使用 Linux 的时候,并告诉我们他们犯下的最大错误。
“不要进入[任何类型的命令行界面(CLI)工作]时就期望命令会以合理或一致的方式工作,因为这可能会导致你感到挫折。这不是因为设计选择不当 —— 虽然当你在键盘上敲击时就像在敲在你的脑袋上一样 —— 而是反映了这些系统是历经了几代的软件和操作系统的发展而陆续添加完成的事实。顺其自然,写下或记住你需要的命令,并且(尽量不要)在[事情不是你所期望的](https://lintqueen.com/2017/07/02/learning-while-frustrated/)时感到沮丧。” —— [Gina Likins](https://opensource.com/users/lintqueen)
“尽可能简单地复制和粘贴命令以使事情顺利进行,首先阅读命令,至少对将要执行的操作有一个大致的了解,特别是如果有管道命令时,如果有多个管道更要特别注意。有很多破坏性的命令看起来无害 —— 直到你意识到它们能做什么(例如 `rm`、`dd`),而你不会想要意外破坏什么东西(别问我怎么知道)。” —— [Katie McLaughlin](https://opensource.com/users/glasnt)
“在我的 Linux 之旅的早期,我并不知道我所处在文件系统中的位置的重要性。我正在删除一些我认为是我的主目录的文件,我输入了 `sudo rm -rf *`,然后就删除了我系统上的所有启动文件。现在,我经常使用 `pwd` 来确保我在发出这样的命令之前确认我在哪里。幸运的是,我能够使用 USB 驱动器启动被搞坏的笔记本电脑并恢复我的文件。” —— [Don Watkins](https://opensource.com/users/don-watkins)
“不要因为你认为‘权限很难理解’而你希望应用程序可以访问某些内容时就将整个文件系统的权限重置为 [777](https://www.maketecheasier.com/file-permissions-what-does-chmod-777-means/)。”—— [Matthew Helmke](https://twitter.com/matthewhelmke)
“我从我的系统中删除一个软件包,而我没有检查它依赖的其他软件包。我只是让它删除它想删除要的东西,最终导致我的一些重要程序崩溃并变得不可用。” —— [Kedar Vijay Kulkarni](https://opensource.com/users/kkulkarn)
你在学习使用 Linux 时犯过什么错误?请在评论中分享。
---
via: <https://opensource.com/article/19/4/linux-rookie-mistakes>
作者:[Jen Wike Huger](https://opensource.com/users/jen-wike/users/bcotton/users/petercheer/users/greg-p/users/greg-p) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's smart to learn new skills throughout your life—it keeps your mind nimble and makes you more competitive in the job market. But some skills are harder to learn than others, especially those where small rookie mistakes can cost you a lot of time and trouble when you're trying to fix them.
Take learning [Linux](https://opensource.com/resources/linux), for example. If you're used to working in a Windows or MacOS graphical interface, moving to Linux, with its unfamiliar commands typed into a terminal, can have a big learning curve. But the rewards are worth it, as the millions and millions of people who have gone before you have proven.
That said, the journey won't be without pitfalls. We asked some of Linux enthusiasts to think back to when they first started using Linux and tell us about the biggest mistakes they made.
"Don't go into [any sort of command line interface (CLI) work] with an expectation that commands work in rational or consistent ways, as that is likely to lead to frustration. This is not due to poor design choices—though it can feel like it when you're banging your head against the proverbial desk—but instead reflects the fact that these systems have evolved and been added onto through generations of software and OS evolution. Go with the flow, write down or memorize the commands you need, and (try not to) get frustrated when [things aren't what you'd expect](https://lintqueen.com/2017/07/02/learning-while-frustrated/)." *— Gina Likins*
"As easy as it might be to just copy and paste commands to make the thing go, read the command first and at least have a general understanding of the actions that are about to be performed. Especially if there is a pipe command. Double especially if there is more than one. There are a lot of destructive commands that look innocuous until you realize what they can do (e.g., **rm**, **dd**), and you don't want to accidentally destroy things. (Ask me how I know.)" *— Katie McLaughlin*
"Early on in my Linux journey, I wasn't as aware of the importance of knowing where you are in the filesystem. I was deleting some file in what I thought was my home directory, and I entered **sudo rm -rf *** and deleted all of the boot files on my system. Now, I frequently use **pwd** to ensure that I am where I think I am before issuing such commands. Fortunately for me, I was able to boot my wounded laptop with a USB drive and recover my files." *— Don Watkins*
"Do not reset permissions on the entire file system to [777](https://www.maketecheasier.com/file-permissions-what-does-chmod-777-means/) because you think 'permissions are hard to understand' and you want an application to have access to something."* — Matthew Helmke*
"I was removing a package from my system, and I did not check what other packages it was dependent upon. I just let it remove whatever it wanted and ended up causing some of my important programs to crash and become unavailable." *— Kedar Vijay Kulkarni*
What mistakes have you made while learning to use Linux? Share them in the comments.
## 14 Comments |
10,953 | 什么是翻译平台最重要的地方? | https://opensource.com/article/19/5/translation-platforms | 2019-06-09T11:22:49 | [
"翻译"
] | https://linux.cn/article-10953-1.html |
>
> 技术上的考虑并不是判断一个好的翻译平台的最佳方式。
>
>
>

语言翻译可以使开源软件能够被世界各地的人们使用,这是非开发人员参与他们喜欢的(开源)项目的好方法。有许多[翻译工具](https://opensource.com/article/17/6/open-source-localization-tools),你可以根据他们处理翻译中涉及的主要功能区域的能力来评估:技术交互能力、团队支持能力和翻译支持能力。
技术交互方面包括:
* 支持的文件格式
* 与开源存储库的同步
* 自动化支持工具
* 接口可能性
对团队合作(也可称为“社区活力”)的支持包括该平台如何:
* 监控变更(按译者、项目等)
* 跟进由项目推动的更新
* 显示进度状态
* 是否启用审核和验证步骤
* 协助(来自同一团队和跨语言的)翻译人员和项目维护人员之间的讨论
* 平台支持的全球通讯(新闻等)
翻译协助包括:
* 清晰、符合人体工程学的界面
* 简单几步就可以找到项目并开始工作
* 可以简单地了解到翻译和分发之间流程
* 可以使用翻译记忆机
* 词汇表丰富
前两个功能区域与源代码管理平台的差别不大,只有一些小的差别。我觉得最后一个区域也主要与源代码有关。但是,它们处理的数据非常不同,翻译平台的用户通常也不如开发人员了解技术,而数量也更多。
### 我的推荐
在我看来,GNOME 平台提供了最好的翻译平台,原因如下:
* 其网站包含了团队组织和翻译平台。很容易看出谁在负责以及他们在团队中的角色。一切都集中在几个屏幕之内。
* 很容易找到要处理的内容,并且你会很快意识到你必须将文件下载到本地计算机并在修改后将其发回。这个流程不是很先进,但逻辑很容易理解。
* 一旦你发回文件,平台就可以向邮件列表发送通告,以便团队知道后续步骤,并且可以全局轻松讨论翻译(而不是评论特定句子)。
* 它支持多达 297 种语言。
* 它显示了基本句子、高级菜单和文档的明确的进度百分比。 再加上可预测的 GNOME 发布计划,社区可以使用一切可以促进社区工作的工具。
如果我们看看 Debian 翻译团队,他们多年来一直在为 Debian (LCTT 译注:此处原文是“Fedora”,疑为笔误)翻译了难以想象的大量内容(尤其是新闻),我们看到他们有一个高度以来于规则的翻译流程,完全基于电子邮件,手动推送到存储库。该团队还将所有内容都放在流程中,而不是工具中,尽管这似乎需要相当大的技术能力,但它已成为领先的语言群体之一,已经运作多年。
我认为,成功的翻译平台的主要问题不是基于单一的(技术、翻译)工作的能力,而是基于如何构建和支持翻译团队的流程。这就是可持续性的原因。
生产过程是构建团队最重要的方式;通过正确地将它们组合在一起,新手很容易理解该过程是如何工作的,采用它们,并将它们解释给下一组新人。
要建立一个可持续发展的社区,首先要考虑的是支持协同工作的工具,然后是可用性。
这解释了我为什么对 [Zanata](http://zanata.org/) 工具沮丧,从技术和界面的角度来看,这是有效的,但在帮助构建社区方面却很差。我认为翻译是一个社区驱动的过程(可能是开源软件开发中最受社区驱动的过程之一),这对我来说是一个关键问题。
---
本文改编自“[什么是一个好的翻译平台?](https://jibecfed.fedorapeople.org/blog-hugo/en/2016/09/whats-a-good-translation-platform/)”,最初发表在 Jibec 期刊上,并经许可重复使用。
---
via: <https://opensource.com/article/19/5/translation-platforms>
作者:[Jean-Baptiste Holcroft](https://opensource.com/users/jibec/users/annegentle/users/bcotton) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Language translation enables open source software to be used by people all over the world, and it's a great way for non-developers to get involved in their favorite projects. There are many [translation tools](https://opensource.com/article/17/6/open-source-localization-tools) available that you can evaluate according to how well they handle the main functional areas involved in translations: technical interaction capabilities, teamwork support capabilities, and translation support capabilities.
Technical interaction considerations include:
- Supported file formats
- Synchronization with the source repository
- Automation support tools
- Interface possibilities
Support for teamwork (which could also be called "community animation") includes how a platform:
- Monitors changes (by a translator, on a project, etc.)
- Follows up on updates pushed by projects
- Displays the state of the situation
- Enables or not review and validation steps
- Assists in discussions between translators (from the same team and inter-languages) and with project maintainers
- Supports global communication on the platform (news, etc.)
Translator assistance includes:
- A clear and ergonomic interface
- A limited number of steps to find a project and start working
- A simple way to read the flow between translation and distribution
- Access to a translation memory machine
- Glossary enrichment
There are no major differences, though there are some minor ones, between source code management platforms relating to the first two functional areas.** **I suspect that the last area pertains mainly to source code. However, the data handled is quite different and users are usually much less technically sophisticated than developers, as well as more numerous.
## My recommendation
In my opinion, the GNOME platform offers the best translation platform for the following reasons:
- Its site contains both the team organization and the translation platform. It's easy to see who is responsible and their roles on the team. Everything is concentrated on a few screens.
- It's easy to find what to work on, and you quickly realize you'll have to download files to your computer and send them back once you modify them. It's not very sexy, but the logic is easy to understand.
- Once you send a file back, the platform can send an alert to the mailing list so the team knows the next steps and the translation can be easily discussed at the global level (rather than commenting on specific sentences).
- It has 297 languages.
- It shows clear percentages on progress, both on basic sentences and advanced menus and documentation.
Coupled with a predictable GNOME release schedule, everything is available for the community to work well because the tool promotes community work.
If we look at the Debian translation team, which has been doing a good job for years translating an unimaginable amount of content for Fedora (especially news), we see there is a highly codified translation process based exclusively on emails with a manual push in the repositories. This team also puts everything into the process, rather than the tools, and—despite the considerable energy this seems to require—it has worked for many years while being among the leading group of languages.
My perception is that the primary issue for a successful translation platform is not based on the ability to make the unitary (technical, translation) work, but on how it structures and supports the translation team's processes. This is what gives sustainability.
The production processes are the most important way to structure a team; by putting them together correctly, it's easy for newcomers to understand how processes work, adopt them, and explain them to the next group of newcomers.
To build a sustainable community, the first consideration must be on a tool that supports collaborative work, then on its usability.
This explains my frustration with the [Zanata](http://zanata.org/) tool, which is efficient from a technical and interface standpoint, but poor when it comes to helping to structure a community. GIven that translation is a community-driven process (possibly one of the most community-driven processes in open source software development), this is a critical problem for me.
*This article is adapted from " What's a good translation platform?" originally published on the Jibec Journal and is reused with permission.*
## 1 Comment |
10,955 | 如何在 Linux 上识别同样内容的文件 | https://www.networkworld.com/article/3390204/how-to-identify-same-content-files-on-linux.html | 2019-06-09T23:44:23 | [
"重复"
] | https://linux.cn/article-10955-1.html |
>
> 有时文件副本相当于对硬盘空间的巨大浪费,并会在你想要更新文件时造成困扰。以下是用来识别这些文件的六个命令。
>
>
>

在最近的帖子中,我们看了[如何识别并定位硬链接的文件](https://www.networkworld.com/article/3387961/how-to-identify-duplicate-files-on-linux.html)(即,指向同一硬盘内容并共享 inode)。在本文中,我们将查看能找到具有相同*内容*,却不相链接的文件的命令。
硬链接很有用是因为它们能够使文件存放在文件系统内的多个地方却不会占用额外的硬盘空间。另一方面,有时文件副本相当于对硬盘空间的巨大浪费,在你想要更新文件时也会有造成困扰之虞。在本文中,我们将看一下多种识别这些文件的方式。
### 用 diff 命令比较文件
可能比较两个文件最简单的方法是使用 `diff` 命令。输出会显示你文件的不同之处。`<` 和 `>` 符号代表在当参数传过来的第一个(`<`)或第二个(`>`)文件中是否有额外的文字行。在这个例子中,在 `backup.html` 中有额外的文字行。
```
$ diff index.html backup.html
2438a2439,2441
> <pre>
> That's all there is to report.
> </pre>
```
如果 `diff` 没有输出那代表两个文件相同。
```
$ diff home.html index.html
$
```
`diff` 的唯一缺点是它一次只能比较两个文件并且你必须指定用来比较的文件,这篇帖子中的一些命令可以为你找到多个重复文件。
### 使用校验和
`cksum`(checksum) 命令计算文件的校验和。校验和是一种将文字内容转化成一个长数字(例如2819078353 228029)的数学简化。虽然校验和并不是完全独有的,但是文件内容不同校验和却相同的概率微乎其微。
```
$ cksum *.html
2819078353 228029 backup.html
4073570409 227985 home.html
4073570409 227985 index.html
```
在上述示例中,你可以看到产生同样校验和的第二个和第三个文件是如何可以被默认为相同的。
### 使用 find 命令
虽然 `find` 命令并没有寻找重复文件的选项,它依然可以被用来通过名字或类型寻找文件并运行 `cksum` 命令。例如:
```
$ find . -name "*.html" -exec cksum {} \;
4073570409 227985 ./home.html
2819078353 228029 ./backup.html
4073570409 227985 ./index.html
```
### 使用 fslint 命令
`fslint` 命令可以被特地用来寻找重复文件。注意我们给了它一个起始位置。如果它需要遍历相当多的文件,这就需要花点时间来完成。注意它是如何列出重复文件并寻找其它问题的,比如空目录和坏 ID。
```
$ fslint .
-----------------------------------file name lint
-------------------------------Invalid utf8 names
-----------------------------------file case lint
----------------------------------DUPlicate files <==
home.html
index.html
-----------------------------------Dangling links
--------------------redundant characters in links
------------------------------------suspect links
--------------------------------Empty Directories
./.gnupg
----------------------------------Temporary Files
----------------------duplicate/conflicting Names
------------------------------------------Bad ids
-------------------------Non Stripped executables
```
你可能需要在你的系统上安装 `fslint`。你可能也需要将它加入你的命令搜索路径:
```
$ export PATH=$PATH:/usr/share/fslint/fslint
```
### 使用 rdfind 命令
`rdfind` 命令也会寻找重复(相同内容的)文件。它的名字意即“重复数据搜寻”,并且它能够基于文件日期判断哪个文件是原件——这在你选择删除副本时很有用因为它会移除较新的文件。
```
$ rdfind ~
Now scanning "/home/shark", found 12 files.
Now have 12 files in total.
Removed 1 files due to nonunique device and inode.
Total size is 699498 bytes or 683 KiB
Removed 9 files due to unique sizes from list.2 files left.
Now eliminating candidates based on first bytes:removed 0 files from list.2 files left.
Now eliminating candidates based on last bytes:removed 0 files from list.2 files left.
Now eliminating candidates based on sha1 checksum:removed 0 files from list.2 files left.
It seems like you have 2 files that are not unique
Totally, 223 KiB can be reduced.
Now making results file results.txt
```
你可以在 `dryrun` 模式中运行这个命令 (换句话说,仅仅汇报可能会另外被做出的改动)。
```
$ rdfind -dryrun true ~
(DRYRUN MODE) Now scanning "/home/shark", found 12 files.
(DRYRUN MODE) Now have 12 files in total.
(DRYRUN MODE) Removed 1 files due to nonunique device and inode.
(DRYRUN MODE) Total size is 699352 bytes or 683 KiB
Removed 9 files due to unique sizes from list.2 files left.
(DRYRUN MODE) Now eliminating candidates based on first bytes:removed 0 files from list.2 files left.
(DRYRUN MODE) Now eliminating candidates based on last bytes:removed 0 files from list.2 files left.
(DRYRUN MODE) Now eliminating candidates based on sha1 checksum:removed 0 files from list.2 files left.
(DRYRUN MODE) It seems like you have 2 files that are not unique
(DRYRUN MODE) Totally, 223 KiB can be reduced.
(DRYRUN MODE) Now making results file results.txt
```
`rdfind` 命令同样提供了类似忽略空文档(`-ignoreempty`)和跟踪符号链接(`-followsymlinks`)的功能。查看 man 页面获取解释。
```
-ignoreempty ignore empty files
-minsize ignore files smaller than speficied size
-followsymlinks follow symbolic links
-removeidentinode remove files referring to identical inode
-checksum identify checksum type to be used
-deterministic determiness how to sort files
-makesymlinks turn duplicate files into symbolic links
-makehardlinks replace duplicate files with hard links
-makeresultsfile create a results file in the current directory
-outputname provide name for results file
-deleteduplicates delete/unlink duplicate files
-sleep set sleep time between reading files (milliseconds)
-n, -dryrun display what would have been done, but don't do it
```
注意 `rdfind` 命令提供了 `-deleteduplicates true` 的设置选项以删除副本。希望这个命令语法上的小问题不会惹恼你。;-)
```
$ rdfind -deleteduplicates true .
...
Deleted 1 files. <==
```
你将可能需要在你的系统上安装 `rdfind` 命令。试验它以熟悉如何使用它可能是一个好主意。
### 使用 fdupes 命令
`fdupes` 命令同样使得识别重复文件变得简单。它同时提供了大量有用的选项——例如用来迭代的 `-r`。在这个例子中,它像这样将重复文件分组到一起:
```
$ fdupes ~
/home/shs/UPGRADE
/home/shs/mytwin
/home/shs/lp.txt
/home/shs/lp.man
/home/shs/penguin.png
/home/shs/penguin0.png
/home/shs/hideme.png
```
这是使用迭代的一个例子,注意许多重复文件是重要的(用户的 `.bashrc` 和 `.profile` 文件)并且不应被删除。
```
# fdupes -r /home
/home/shark/home.html
/home/shark/index.html
/home/dory/.bashrc
/home/eel/.bashrc
/home/nemo/.profile
/home/dory/.profile
/home/shark/.profile
/home/nemo/tryme
/home/shs/tryme
/home/shs/arrow.png
/home/shs/PNGs/arrow.png
/home/shs/11/files_11.zip
/home/shs/ERIC/file_11.zip
/home/shs/penguin0.jpg
/home/shs/PNGs/penguin.jpg
/home/shs/PNGs/penguin0.jpg
/home/shs/Sandra_rotated.png
/home/shs/PNGs/Sandra_rotated.png
```
`fdupe` 命令的许多选项列如下。使用 `fdupes -h` 命令或者阅读 man 页面获取详情。
```
-r --recurse recurse
-R --recurse: recurse through specified directories
-s --symlinks follow symlinked directories
-H --hardlinks treat hard links as duplicates
-n --noempty ignore empty files
-f --omitfirst omit the first file in each set of matches
-A --nohidden ignore hidden files
-1 --sameline list matches on a single line
-S --size show size of duplicate files
-m --summarize summarize duplicate files information
-q --quiet hide progress indicator
-d --delete prompt user for files to preserve
-N --noprompt when used with --delete, preserve the first file in set
-I --immediate delete duplicates as they are encountered
-p --permissions don't soncider files with different owner/group or
permission bits as duplicates
-o --order=WORD order files according to specification
-i --reverse reverse order while sorting
-v --version display fdupes version
-h --help displays help
```
`fdupes` 命令是另一个你可能需要安装并使用一段时间才能熟悉其众多选项的命令。
### 总结
Linux 系统提供能够定位并(潜在地)能移除重复文件的一系列的好工具,以及能让你指定搜索区域及当对你所发现的重复文件时的处理方式的选项。
---
via: <https://www.networkworld.com/article/3390204/how-to-identify-same-content-files-on-linux.html#tk.rss_all>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,956 | 区块链 2.0:智能合约及其类型(五) | https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/ | 2019-06-10T00:55:00 | [
"区块链",
"智能合约"
] | https://linux.cn/article-10956-1.html | 
这是 区块链 2.0 系列的第 5 篇文章。本系列的前一篇文章探讨了我们如何[在房地产行业实现区块链](/article-10914-1.html)。本文简要探讨了区块链及相关技术领域内的<ruby> 智能合约 <rt> Smart Contract </rt></ruby>主题。智能合约是在区块链上验证和创建新“数据块”的基本协议,它被吹捧为该系统未来发展和应用的焦点。 然而,像所有“万灵药”一样,它不是一切的答案。我们将从基础知识中探索这个概念,以了解“智能合约”是什么以及它们不是什么。
### 不断发展的合同
这个世界建立在合同(合约)之上。在当前社会,没有合约的使用和再利用,地球上任何个人或公司都无法运作。订立、维护和执行合同的任务变得如此复杂,以至于整个司法和法律系统都必须以“合同法”的名义建立起来以支持它。事实上,大多数合同都是由一个“可信的”第三方监督,以确保最终的利益攸关者按照达成的条件得到妥善处理。有些合同甚至涉及到了第三方受益人。此类合同旨在对不是合同的活跃(或参与)方的第三方产生影响。解决和争论合同义务占据了民事诉讼所涉及的大部分法律纠纷。当然,更好的处理合同的方式来对于个人和企业来说都是天赐之物。更不用说它将以核查和证明的名义节省政府的巨大的[文书工作](http://www.legal-glossary.org/) <sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup>。
本系列中的大多数文章都研究了如何利用现有的区块链技术。相比之下,这篇文章将更多地讲述对未来几年的预期。关于“智能合约”的讨论源于前一篇文章中提出的财产讨论。当前这篇文章旨在概述区块链自动执行“智能”可执行程序的能力。务实地处理这个问题意味着我们首先必须定义和探索这些“智能合约”是什么,以及它们如何适应现有的合同系统。我们将在下一篇题为“区块链 2.0:正在进行的项目”的文章中查看当前该领域正在进行的主要应用和项目。
### 定义智能合约
[本系列的第一篇文章](/article-10650-1.html)从基本的角度来看待区块链,将其看作由数据块组成的“分布式分类账本”,这些数据块是:
* 防篡改
* 不可否认(意味着每个数据块都是由某人显式创建的,并且该人不能否认相同的责任)
* 安全,且能抵御传统的网络攻击方法
* 几乎是永久性的(当然这取决于区块链协议层)
* 高度冗余,通过存在于多个网络节点或参与者系统上,其中一个节点的故障不会以任何方式影响系统的功能,并且,
* 根据应用的不同可以提供更快的处理速度。
由于每个数据实例都是安全存储和通过适当的凭证访问的,因此区块链网络可以为精确验证事实和信息提供简便的基础,而无需第三方监督。区块链 2.0 开发也允许“分布式应用程序(DApp)”(我们将在接下来的文章中详细介绍这个术语)。这些分布式应用程序要求存在网络上并在其上运行。当用户需要它们时就会调用它们,并通过使用已经过审核并存储在区块链上的信息来执行它们。
上面的最后一段为智能合约的定义提供了基础。<ruby> 数字商会 <rt> The Chamber for Digital Commerce </rt></ruby>提供了一个许多专家都同意的智能合约定义。
>
> “(智能合约是一种)计算机代码,在发生指定条件时,能够根据预先指定的功能自动运行。该代码可以在分布式分类帐本上存储和处理,并将产生的任何更改写入分布式分类帐本” <sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup>。
>
>
>
智能合约如上所述是一种简单的计算机程序,就像 “if-then” 或 “if-else if” 语句一样工作。关于其“智能”的方面来自这样一个事实,即该程序的预定义输入来自区块链分类账本,如上所述,它是一个记录信息的安全可靠的来源。如有必要,程序可以调用外部服务或来源以获取信息,以验证操作条款,并且仅在满足所有预定义条件后才执行。
必须记住,与其名称所暗示的不同,智能合约通常不是自治实体,严格来说,也不是合同。1996 年,Nick Szabo 很早就提到了智能合约,他将其与接受付款并交付用户选择的产品的自动售货机进行了比较。可以在[这里](http://www.fon.hum.uva.nl/rob/Courses/InformationInSpeech/CDROM/Literature/LOTwinterschool2006/szabo.best.vwh.net/smart_contracts_2.html)查看全文。此外,人们正在制定允许智能合约进入主流合同使用的法律框架,因此目前该技术的使用仅限于法律监督不那么明确和严格的领域 <sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup>。
### 智能合约的主要类型
假设读者对合同和计算机编程有基本的了解,并且基于我们对智能合约的定义,我们可以将智能合约和协议粗略地分类为以下主要类别。
#### 1、智能法律合约
这大概是最明显的一种。大多数(如果不是全部)合同都具有法律效力。在不涉及太多技术问题的情况下,智能法律合约是涉及到严格的法律追索权的合同,以防参与合同的当事人不履行其交易的目的。如前所述,不同国家和地区的现行法律框架对区块链上的智能和自动化合约缺乏足够的支持,其法律地位也不明确。但是,一旦制定了法律,就可以订立智能合约,以简化目前涉及严格监管的流程,如金融和房地产市场交易、政府补贴、国际贸易等。
#### 2、DAO
<ruby> 去中心化自治组织 <rt> Decentralized Autonomous Organization </rt></ruby>,即DAO,可以粗略地定义为区块链上存在的社区。该社区可以通过一组规则来定义,这些规则通过智能合约来体现并放入代码中。然后,每个参与者的每一个行动都将受到这些规则的约束,其任务是在程序中断的情况下执行并获得追索权。许多智能合约构成了这些规则,它们协同监管和监督参与者。
名为“创世纪 DAO” 的 DAO 是由以太坊参与者于 2016 年 5 月创建。该社区旨在成为众筹和风险投资平台。在极短的时间内,他们设法筹集了惊人的 1.5 亿美元。然而,由于黑客在系统中发现了漏洞,并设法从众筹投资者手中窃取价值约 5000 万美元的以太币。这次黑客破坏的后果导致以太坊区块链[分裂为两个](https://futurism.com/the-dao-heist-undone-97-of-eth-holders-vote-for-the-hard-fork/),以太坊和以太坊经典。
#### 3、应用逻辑合约(ALC)
如果你已经听说过与区块链相结合的物联网,那么很可能它涉及到了<ruby> 应用逻辑合约 <rt> Application logic contract </rt></ruby>,即 ALC。此类智能合约包含特定于应用的代码,这些代码可以与区块链上的其他智能合约和程序一起工作。它们有助于与设备进行通信并验证设备之间的通信(在物联网领域)。ALC 是每个多功能智能合约的关键部分,并且大多数都是在一个管理程序下工作。在这里引用的大多数例子中,它们到处都能找到[应用](https://www.everestgrp.com/2016-10-types-smart-contracts-based-applications-market-insights-36573.html/) <sup id="fnref4"> <a href="#fn4" rel="footnote"> 4 </a></sup>。
*由于该领域还在开发中,因此目前所说的任何定义或标准最多只能说是变化而模糊的。*
### 智能合约是如何工作的?
为简化起见,让我们用个例子来说明。
约翰和彼得是两个争论足球比赛得分的人。他们对比赛结果持有相互矛盾的看法,他们都支持不同的球队(这是背景情况)。由于他们两个都需要去其他地方并且无法看完比赛,所以约翰认为如果 A 队在比赛中击败 B 队,他就*支付*给彼得 100 美元。彼得*考虑*之后*接受*了该赌注,同时明确表示他们必须接受这些条款。但是,他们没有兑现该赌注的相互信任,也没有时间和钱来指定第三方监督赌注。
假设约翰和彼得都使用像 [Etherparty](https://etherparty.com/) 这样的智能合约平台,它可以在合约谈判时自动结算赌注,他们都会将基于区块链的身份链接到该合约,并设置条款,明确表示一旦比赛结束,该程序将找出获胜方是谁,并自动将该金额从输家中归入获胜者银行账户。一旦比赛结束并且媒体报道同样的结果,该程序将在互联网上搜索规定的来源,确定哪支球队获胜,将其与合约条款联系起来,在这种情况下,如果 A 队赢了彼得将从约翰哪里得到钱,也就是说将约翰的 100 美元转移到彼得的账户。执行完毕后,除非另有说明,否则智能合约将终止并在未来所有的时间内处于非活动状态。
抛开例子的简单不说,这种情况涉及到一个经典的合同,而参与者选择使用智能合约实现了相同目的。所有的智能合约基本上都遵循类似的原则,对程序进行编码,以便在预定义的参数上执行,并且只抛出预期的输出。智能合同咨询的外部来源可以是有时被称为 IT 世界中的<ruby> 神谕 <rt> Oracle </rt></ruby>。神谕是当今全球许多智能合约系统的常见部分。
在这种情况下使用智能合约使参与者可以获得以下好处:
* 它比在一起并手动结算更快。
* 从其中删除了信任问题。
* 消除了受信任的第三方代表有关各方处理和解的必要性。
* 执行时无需任何费用。
* 在如何处理参数和敏感数据方面是安全的。
* 相关数据将永久保留在他们运行的区块链平台中,未来可以通过调用相同的函数并为其提供更多输入来设置投注。
* 随着时间的推移,假设约翰和彼得变得赌博成瘾,该程序可以帮助他们开发可靠的统计数据来衡量他们的连胜纪录。 现在我们知道**什么是智能合约**和**它们如何工作**,我们还没有解决**为什么我们需要它们**。
### 智能合约的需要
正如之前的例子我们重点提到过的,出于各种原因,我们需要智能合约。
#### 透明度
交易对手非常清楚所涉及的条款和条件。此外,由于程序或智能合约的执行涉及某些明确的输入,因此用户可以非常直接地核实会影响他们和合约受益人的因素。
#### 时间效率
如上所述,智能合约一旦被控制变量或用户调用所触发,就立即开始工作。由于数据是通过区块链和网络中的其它来源即时提供给系统,因此执行不需要任何时间来验证和处理信息并解决交易。例如,转移土地所有权契约,这是一个涉及手工核实大量文书工作并且需要数周时间的过程,可以在几分钟甚至几秒钟内通过智能合约程序来处理文件和相关各方。
#### 精度
由于平台基本上只是计算机代码和预定义的内容,因此不存在主观错误,所有结果都是精确的,完全没有人为错误。
#### 安全
区块链的一个固有特征是每个数据块都是安全加密的。这意味着为了实现冗余,即使数据存储在网络上的多个节点上,**也只有数据所有者才能访问以查看和使用数据**。类似地,利用区块链在过程中存储重要变量和结果,所有过程都将是完全安全和防篡改的。同样也通过按时间顺序为审计人员提供原始的、未经更改的和不可否认的数据版本,简化了审计和法规事务。
#### 信任
这个文章系列开篇说到区块链为互联网及其上运行的服务增加了急需的信任层。智能合约在任何情况下都不会在执行协议时表现出偏见或主观性,这意味着所涉及的各方对结果完全有约束力,并且可以不附带任何条件地信任该系统。这也意味着,在具有重要价值的传统合同中所需的“可信第三方”,在此处不需要。当事人之间的犯规和监督将成为过去的问题。
#### 成本效益
如示例中所强调的,使用智能合约需要最低的成本。企业通常有专门从事使其交易合法并遵守法规的行政人员。如果交易涉及多方,则重复工作是不可避免的。智能合约基本上使前者无关紧要,并且消除了重复,因为双方可以同时完成尽职调查。
### 智能合约的应用
基本上,如果两个或多个参与方使用共同的区块链平台,并就一组原则或业务逻辑达成一致,他们可以一起在区块链上创建一个智能合约,并且在没有人为干预的情况下执行。没有人可以篡改所设置的条件,如果原始代码允许,任何更改都会加上时间戳并带有编辑者的指纹,从而增加了问责制。想象一下,在更大的企业级规模上出现类似的情况,你就会明白智能合约的能力是什么,实际上从 2016 年开始的 **Capgemini 研究** 发现智能合约实际上可能是**“未来几年的”** <sup id="fnref5"> <a href="#fn5" rel="footnote"> 5 </a></sup> 商业主流。商业的应用涉及保险、金融市场、物联网、贷款、身份管理系统、托管账户、雇佣合同以及专利和版税合同等用途。像以太坊这样的区块链平台,是一个设计时就考虑了智能合约的系统,它允许个人私人用户免费使用智能合约。
通过对处理智能合约的公司的探讨,本系列的下一篇文章中将更全面地概述智能合约在当前技术问题上的应用。
### 那么,它有什么缺点呢?
这并不是说对智能合约的使用没有任何顾虑。这种担忧实际上也减缓了这方面的发展。所有区块链的防篡改性质实质上使得,如果所涉及的各方需要在没有重大改革或法律追索的情况下,几乎不可能修改或添加现有条款的新条款。
其次,即使公有链上的活动是开放的,所有人都可以看到和观察。交易中涉及的各方的个人身份并不总是已知的。这种匿名性造成在任何一方违约的情况下法律有罪不罚的问题,特别是因为现行法律和立法者并不完全适应现代技术。
第三,区块链和智能合约在很多方面仍然存在安全缺陷,因为对其所以涉及的技术仍处于发展的初期阶段。 对代码和平台的这种缺乏经验最终导致了 2016 年的 DAO 事件。
所有这些都可能导致企业或公司在需要调整区块链以供其使用时需要大量的初始投资。然而,这些是最初的一次性投资,并且随之而来的是潜在的节约,这才是人们感兴趣的。
### 结论
目前的法律框架并没有真正支持一个全面的智能合约的社会,并且由于显然的原因,在不久的将来也不会支持。一个解决方案是选择**“混合”合约**,它将传统的法律文本和文件与在为此目的设计的区块链上运行的智能合约代码相结合。然而,即使是混合合约仍然很大程度上尚未得到探索,因为需要创新的立法机构才能实现这些合约。这里简要提到的应用以及更多内容将在[本系列的下一篇文章](https://www.ostechnix.com/blockchain-2-0-ongoing-projects-the-state-of-smart-contracts-now/)中详细探讨。
---
1. S. C. A. Chamber of Digital Commerce, “Smart contracts – Is the law ready,” no. September, 2018. [↩](#fnref1)
2. S. C. A. Chamber of Digital Commerce, “Smart contracts – Is the law ready,” no. September, 2018. [↩](#fnref2)
3. Cardozo Blockchain Project, “‘Smart Contracts’ & Legal Enforceability,” vol. 2, p. 28, 2018. [↩](#fnref3)
4. F. Idelberger, G. Governatori, R. Riveret, and G. Sartor, “Evaluation of Logic-Based Smart Contracts for Blockchain Systems,” 2016, pp. 167–183. [↩](#fnref4)
5. B. Cant et al., “Smart Contracts in Financial Services : Getting from Hype to Reality,” Capgemini Consult., pp. 1–24, 2016. [↩](#fnref5)
---
via: <https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/>
作者:[ostechnix](https://www.ostechnix.com/author/editor/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,957 | 我们是如何使用 Electron 构建 Linux 桌面应用程序的 | https://opensource.com/article/19/4/linux-desktop-electron | 2019-06-10T12:31:53 | [
"Electron"
] | https://linux.cn/article-10957-1.html |
>
> 这是借助 Electron 框架,构建一个在 Linux 桌面上原生运行的开源电子邮件服务的故事。
>
>
>

[Tutanota](https://tutanota.com/) 是一种安全的开源电子邮件服务,它可通过浏览器使用,也有 iOS 和 Android 应用。其客户端代码在 GPLv3 下发布,Android 应用程序可在 [F-Droid](https://f-droid.org/en/packages/de.tutao.tutanota/) 上找到,以便每个人都可以使用完全与 Google 无关的版本。
由于 Tutanota 关注开源和 Linux 客户端开发,因此我们希望为 Linux 和其他平台发布一个桌面应用程序。作为一个小团队,我们很快就排除了为 Linux、Windows 和 MacOS 构建原生应用程序的可能性,并决定使用 [Electron](https://electronjs.org/) 来构建我们的应用程序。
对于任何想要快速交付视觉一致的跨平台应用程序的人来说,Electron 是最适合的选择,尤其是如果你已经有一个 Web 应用程序,想要从浏览器 API 的束缚中摆脱出来时。Tutanota 就是这样一个案例。
Tutanota 基于 [SystemJS](https://github.com/systemjs/systemjs) 和 [Mithril](https://mithril.js.org/),旨在为每个人提供简单、安全的电子邮件通信。 因此,它必须提供很多用户期望从电子邮件客户端获得的标准功能。
由于采用了现代 API 和标准,其中一些功能(如基本的推送通知、搜索文本和联系人以及支持双因素身份验证)很容易在浏览器中提供。其它功能(例如自动备份或无需我们的服务器中转的 IMAP 支持)需要对系统资源的限制性访问,而这正是 Electron 框架提供的功能。
虽然有人批评 Electron “只是一个基本的包装”,但它有明显的好处:
* Electron 可以使你能够快速地为 Linux、Windows 和 MacOS 桌面构造 Web 应用。事实上,大多数 Linux 桌面应用都是使用 Electron 构建的。
* Electron 可以轻松地将桌面客户端与 Web 应用程序达到同样的功能水准。
* 发布桌面应用程序后,你可以自由使用开发功能添加桌面端特定的功能,从而增强可用性和安全性。
* 最后但同样重要的是,这是让应用程序具备原生的感觉、融入用户系统,而同时保持其识别度的好方法。 ### 满足用户的需求
Tutanota 不依靠于大笔的投资资金,而是依靠社区驱动的项目。基于越来越多的用户升级到我们的免费服务的付费计划,我们有机地发展我们的团队。倾听用户的需求不仅对我们很重要,而且对我们的成功至关重要。
提供桌面客户端是 Tutanota 用户[最想要的功能](https://tutanota.uservoice.com/forums/237921-general/filters/top?status_id=1177482),我们感到自豪的是,我们现在可以为所有用户提供免费的桌面客户端测试版。(我们还实现了另一个高度要求的功能 —— [搜索加密数据](https://tutanota.com/blog/posts/first-search-encrypted-data/) —— 但这是另一个主题了。)
我们喜欢为用户提供签名版本的 Tutanota 并支持浏览器中无法实现的功能,例如通过后台进程推送通知。 现在,我们计划添加更多特定于桌面的功能,例如 IMAP 支持(而不依赖于我们的服务器充当代理),自动备份和离线可用性。
我们选择 Electron 是因为它的 Chromium 和 Node.js 的组合最适合我们的小型开发团队,因为它只需要对我们的 Web 应用程序进行最小的更改。在我们开始使用时,可以将浏览器 API 用于所有功能特别有用,随着我们的进展,慢慢地用更多原生版本替换这些组件。这种方法对附件下载和通知特别方便。
### 调整安全性
我们知道有些人关注 Electron 的安全问题,但我们发现 Electron 在 Web 应用程序中微调访问的选项非常令人满意。你可以使用 Electron 的[安全文档](https://electronjs.org/docs/tutorial/security)和 Luca Carettoni 的[Electron 安全清单](https://www.blackhat.com/docs/us-17/thursday/us-17-Carettoni-Electronegativity-A-Study-Of-Electron-Security-wp.pdf)等资源,来帮助防止 Web 应用程序中不受信任的内容发生灾难性事故。
### 实现特定功能
Tutanota Web 客户端从一开始就构建了一个用于进程间通信的可靠协议。我们利用 Web 线程在加密和请求数据时保持用户界面(UI)响应性。当我们开始实现我们的移动应用时,这就派上用场,这些应用程序使用相同的协议在原生部分和 Web 视图之间进行通信。
这就是为什么当我们开始构建桌面客户端时,很多用于本机推送通知、打开邮箱和使用文件系统的部分等已经存在,因此只需要实现原生端(Node.js)。
另一个便利是我们的构建过程使用 [Babel 转译器](https://babeljs.io/),它允许我们以现代 ES6 JavaScript 编写整个代码库,并在不同环境之间混合和匹配功能模块。这使我们能够快速调整基于 Electron 的桌面应用程序的代码。但是,我们也遇到了一些挑战。
### 克服挑战
虽然 Electron 允许我们很容易地与不同平台的桌面环境集成,但你不能低估投入的时间!最后,正是这些小事情占用了比我们预期更多的时间,但对完成桌面客户端项目也至关重要。
特定于平台的代码导致了大部分阻碍:
* 例如,窗口管理和托盘仍然在三个平台上以略有不同的方式处理。
* 注册 Tutanota 作为默认邮件程序并设置自动启动需要深入 Windows 注册表,同时确保以 [UAC](https://en.wikipedia.org/wiki/User_Account_Control) 兼容的方式提示用户进行管理员访问。
* 我们需要使用 Electron 的 API 作为快捷方式和菜单,以提供复制、粘贴、撤消和重做等标准功能。
由于用户对不同平台上的应用程序的某些(有时不直接兼容)行为的期望,此过程有点复杂。使三个版本感觉像原生的需要一些迭代,甚至需要对 Web 应用程序进行一些适度的补充,以提供类似于浏览器中的文本搜索的功能。
### 总结
我们在 Electron 方面的经验基本上是积极的,我们在不到四个月的时间内完成了该项目。尽管有一些相当耗时的功能,但我们感到惊讶的是,我们可以轻松地为 Linux 提供一个测试版的 [Tutanota 桌面客户端](https://tutanota.com/blog/posts/desktop-clients/)。如果你有兴趣,可以深入了解 [GitHub](https://www.github.com/tutao/tutanota) 上的源代码。
---
via: <https://opensource.com/article/19/4/linux-desktop-electron>
作者:[Nils Ganther](https://opensource.com/users/nils-ganther) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Tutanota](https://tutanota.com/) is a secure, open source email service that's been available as an app for the browser, iOS, and Android. The client code is published under GPLv3 and the Android app is available on [F-Droid](https://f-droid.org/en/packages/de.tutao.tutanota/) to enable everyone to use a completely Google-free version.
Because Tutanota focuses on open source and develops on Linux clients, we wanted to release a desktop app for Linux and other platforms. Being a small team, we quickly ruled out building native apps for Linux, Windows, and MacOS and decided to adapt our app using [Electron](https://electronjs.org/).
Electron is the go-to choice for anyone who wants to ship visually consistent, cross-platform applications, fast—especially if there's already a web app that needs to be freed from the shackles of the browser API. Tutanota is exactly such a case.
Tutanota is based on [SystemJS](https://github.com/systemjs/systemjs) and [Mithril](https://mithril.js.org/) and aims to offer simple, secure email communications for everybody. As such, it has to provide a lot of the standard features users expect from any email client.
Some of these features, like basic push notifications, search for text and contacts, and support for two-factor authentication are easy to offer in the browser thanks to modern APIs and standards. Other features (such as automatic backups or IMAP support without involving our servers) need less-restricted access to system resources, which is exactly what the Electron framework provides.
While some criticize Electron as "just a basic wrapper," it has obvious benefits:
- Electron enables you to adapt a web app quickly for Linux, Windows, and MacOS desktops. In fact, most Linux desktop apps are built with Electron.
- Electron enables you to easily bring the desktop client to feature parity with the web app.
- Once you've published the desktop app, you can use free development capacity to add desktop-specific features that enhance usability and security.
- And last but certainly not least, it's a great way to make the app feel native and integrated into the user's system while maintaining its identity.
## Meeting users' needs
At Tutanota, we do not rely on big investor money, rather we are a community-driven project. We grow our team organically based on the increasing number of users upgrading to our freemium service's paid plans. Listening to what users want is not only important to us, it is essential to our success.
Offering a desktop client was users' [most-wanted feature](https://tutanota.uservoice.com/forums/237921-general/filters/top?status_id=1177482) in Tutanota, and we are proud that we can now offer free beta desktop clients to all of our users. (We also implemented another highly requested feature—[search on encrypted data](https://tutanota.com/blog/posts/first-search-encrypted-data/)—but that's a topic for another time.)
We liked the idea of providing users with signed versions of Tutanota and enabling functions that are impossible in the browser, such as push notifications via a background process. Now we plan to add more desktop-specific features, such as IMAP support without depending on our servers to act as a proxy, automatic backups, and offline availability.
We chose Electron because its combination of Chromium and Node.js promised to be the best fit for our small development team, as it required only minimal changes to our web app. It was particularly helpful to use the browser APIs for everything as we got started, slowly replacing those components with more native versions as we progressed. This approach was especially handy with attachment downloads and notifications.
## Tuning security
We were aware that some people cite security problems with Electron, but we found Electron's options for fine-tuning access in the web app quite satisfactory. You can use resources like the Electron's [security documentation](https://electronjs.org/docs/tutorial/security) and Luca Carettoni's [Electron Security Checklist](https://www.blackhat.com/docs/us-17/thursday/us-17-Carettoni-Electronegativity-A-Study-Of-Electron-Security-wp.pdf) to help prevent catastrophic mishaps with untrusted content in your web app.
## Achieving feature parity
The Tutanota web client was built from the start with a solid protocol for interprocess communication. We utilize web workers to keep user interface (UI) rendering responsive while encrypting and requesting data. This came in handy when we started implementing our mobile apps, which use the same protocol to communicate between the native part and the web view.
That's why when we started building the desktop clients, a lot of bindings for things like native push notifications, opening mailboxes, and working with the filesystem were already there, so only the native (node) side had to be implemented.
Another convenience was our build process using the [Babel transpiler](https://babeljs.io/), which allows us to write the entire codebase in modern ES6 JavaScript and mix-and-match utility modules between the different environments. This enabled us to speedily adapt the code for the Electron-based desktop apps. However, we encountered some challenges.
## Overcoming challenges
While Electron allows us to integrate with the different platforms' desktop environments pretty easily, you can't underestimate the time investment to get things just right! In the end, it was these little things that took up much more time than we expected but were also crucial to finish the desktop client project.
The places where platform-specific code was necessary caused most of the friction:
- Window management and the tray, for example, are still handled in subtly different ways on the three platforms.
- Registering Tutanota as the default mail program and setting up autostart required diving into the Windows Registry while making sure to prompt the user for admin access in a
[UAC](https://en.wikipedia.org/wiki/User_Account_Control)-compatible way. - We needed to use Electron's API for shortcuts and menus to offer even standard features like copy, paste, undo, and redo.
This process was complicated a bit by users' expectations of certain, sometimes not directly compatible behavior of the apps on different platforms. Making the three versions feel native required some iteration and even some modest additions to the web app to offer a text search similar to the one in the browser.
## Wrapping up
Our experience with Electron was largely positive, and we completed the project in less than four months. Despite some rather time-consuming features, we were surprised about the ease with which we could ship a beta version of the [Tutanota desktop client for Linux](https://tutanota.com/blog/posts/desktop-clients/). If you're interested, you can dive into the source code on [GitHub](https://www.github.com/tutao/tutanota).
## 4 Comments |
10,960 | 在 RHEL 和 CentOS 上检查或列出已安装的安全更新的两种方法 | https://www.2daygeek.com/check-installed-security-updates-on-redhat-rhel-and-centos-system/ | 2019-06-11T10:08:00 | [
"安全更新"
] | https://linux.cn/article-10960-1.html | 
我们过去曾写过两篇关于这个主题的文章,每篇文章都是根据不同的要求发表的。如果你想在开始之前浏览这些文章。请通过以下链接:
* [如何检查 RHEL 和 CentOS 上的可用安全更新?](/article-10938-1.html)
* [在 RHEL 和 CentOS 上安装安全更新的四种方法?](https://www.2daygeek.com/install-security-updates-on-redhat-rhel-centos-system/)
这些文章与其他文章相互关联,因此,在深入研究之前,最好先阅读这些文章。
在本文中,我们将向你展示如何检查已安装的安全更新。我会介绍两种方法,你可以选择最适合你的。
此外,我还添加了一个小的 shell 脚本,它为你提供已安装的安全包计数。
运行以下命令获取系统上已安装的安全更新的列表。
```
# yum updateinfo list security installed
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos,
: subscription-manager, verify, versionlock
RHSA-2015:2315 Moderate/Sec. ModemManager-glib-1.1.0-8.git20130913.el7.x86_64
RHSA-2015:2315 Moderate/Sec. NetworkManager-1:1.0.6-27.el7.x86_64
RHSA-2016:2581 Low/Sec. NetworkManager-1:1.4.0-12.el7.x86_64
RHSA-2017:2299 Moderate/Sec. NetworkManager-1:1.8.0-9.el7.x86_64
RHSA-2015:2315 Moderate/Sec. NetworkManager-adsl-1:1.0.6-27.el7.x86_64
RHSA-2016:2581 Low/Sec. NetworkManager-adsl-1:1.4.0-12.el7.x86_64
RHSA-2017:2299 Moderate/Sec. NetworkManager-adsl-1:1.8.0-9.el7.x86_64
RHSA-2015:2315 Moderate/Sec. NetworkManager-bluetooth-1:1.0.6-27.el7.x86_64
```
要计算已安装的安全包的数量,请运行以下命令:
```
# yum updateinfo list security installed | wc -l
1046
```
仅打印安装包列表:
```
# yum updateinfo list security all | grep -w "i"
i RHSA-2015:2315 Moderate/Sec. ModemManager-glib-1.1.0-8.git20130913.el7.x86_64
i RHSA-2015:2315 Moderate/Sec. NetworkManager-1:1.0.6-27.el7.x86_64
i RHSA-2016:2581 Low/Sec. NetworkManager-1:1.4.0-12.el7.x86_64
i RHSA-2017:2299 Moderate/Sec. NetworkManager-1:1.8.0-9.el7.x86_64
i RHSA-2015:2315 Moderate/Sec. NetworkManager-adsl-1:1.0.6-27.el7.x86_64
i RHSA-2016:2581 Low/Sec. NetworkManager-adsl-1:1.4.0-12.el7.x86_64
i RHSA-2017:2299 Moderate/Sec. NetworkManager-adsl-1:1.8.0-9.el7.x86_64
i RHSA-2015:2315 Moderate/Sec. NetworkManager-bluetooth-1:1.0.6-27.el7.x86_64
i RHSA-2016:2581 Low/Sec. NetworkManager-bluetooth-1:1.4.0-12.el7.x86_64
i RHSA-2017:2299 Moderate/Sec. NetworkManager-bluetooth-1:1.8.0-9.el7.x86_64
i RHSA-2015:2315 Moderate/Sec. NetworkManager-config-server-1:1.0.6-27.el7.x86_64
i RHSA-2016:2581 Low/Sec. NetworkManager-config-server-1:1.4.0-12.el7.x86_64
i RHSA-2017:2299 Moderate/Sec. NetworkManager-config-server-1:1.8.0-9.el7.noarch
```
要计算已安装的安全包的数量,请运行以下命令:
```
# yum updateinfo list security all | grep -w "i" | wc -l
1043
```
或者,你可以检查指定包修复的漏洞列表。
在此例中,我们将检查 “openssh” 包中已修复的漏洞列表:
```
# rpm -q --changelog openssh | grep -i CVE
- Fix for CVE-2017-15906 (#1517226)
- CVE-2015-8325: privilege escalation via user's PAM environment and UseLogin=yes (#1329191)
- CVE-2016-1908: possible fallback from untrusted to trusted X11 forwarding (#1298741)
- CVE-2016-3115: missing sanitisation of input for X11 forwarding (#1317819)
- prevents CVE-2016-0777 and CVE-2016-0778
- Security fixes released with openssh-6.9 (CVE-2015-5352) (#1247864)
- only query each keyboard-interactive device once (CVE-2015-5600) (#1245971)
- add new option GSSAPIEnablek5users and disable using ~/.k5users by default CVE-2014-9278
- prevent a server from skipping SSHFP lookup - CVE-2014-2653 (#1081338)
- change default value of MaxStartups - CVE-2010-5107 (#908707)
- CVE-2010-4755
- merged cve-2007_3102 to audit patch
- fixed audit log injection problem (CVE-2007-3102)
- CVE-2006-5794 - properly detect failed key verify in monitor (#214641)
- CVE-2006-4924 - prevent DoS on deattack detector (#207957)
- CVE-2006-5051 - don't call cleanups from signal handler (#208459)
- use fork+exec instead of system in scp - CVE-2006-0225 (#168167)
```
同样,你可以通过运行以下命令来检查相应的包中是否修复了指定的漏洞:
```
# rpm -q --changelog openssh | grep -i CVE-2016-3115
- CVE-2016-3115: missing sanitisation of input for X11 forwarding (#1317819)
```
### 如何使用 Shell 脚本计算安装的安全包?
我添加了一个小的 shell 脚本,它可以帮助你计算已安装的安全包列表。
```
# vi /opt/scripts/security-check.sh
#!/bin/bash
echo "+-------------------------+"
echo "|Security Advisories Count|"
echo "+-------------------------+"
for i in Important Moderate Low
do
sec=$(yum updateinfo list security installed | grep $i | wc -l)
echo "$i: $sec"
done | column -t
echo "+-------------------------+"
```
给 `security-check.sh` 文件执行权限。
```
$ chmod +x security-check.sh
```
最后执行脚本统计。
```
# sh /opt/scripts/security-check.sh
+-------------------------+
|Security Advisories Count|
+-------------------------+
Important: 480
Moderate: 410
Low: 111
+-------------------------+
```
---
via: <https://www.2daygeek.com/check-installed-security-updates-on-redhat-rhel-and-centos-system/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,961 | 当物联网系统出现故障:使用低质量物联网数据的风险 | https://www.networkworld.com/article/3396230/when-iot-systems-fail-the-risk-of-having-bad-iot-data.html | 2019-06-11T11:51:24 | [
"IoT",
"汽车",
"保险"
] | https://linux.cn/article-10961-1.html |
>
> 伴随着物联网设备使用量的增长,这些设备产生的数据可以让消费者节约巨大的开支,也给商家带来新的机遇。但是当故障不可避免地出现的时候,会发生什么呢?
>
>
>

不管你看的是什么统计数字,很明显物联网正在走进个人和私人生活的方方面面。这种增长虽然有不少好处,但是也带来了新的风险。一个很重要的问题是,出现问题的时候谁来负责呢?
也许最大的问题出在基于物联网数据进行的个性化营销以及定价策略上。[保险公司长期以来致力于寻找利用物联网数据的最佳方式](https://www.networkworld.com/article/3264655/most-insurance-carriers-not-ready-to-use-iot-data.html),我去年写过家庭财产保险公司是如何开始利用物联网传感器减少水灾带来的损失的。一些公司正在研究保险公司竞购消费者的可能性:这种业务基于智能家居数据所揭示的风险的高低。
但是最大的进步出现在汽车保险领域。许多汽车保险公司已经可以让客户在车辆上安装追踪设备,如果数据证明他们的驾驶习惯良好就可以获取保险折扣。
* 延伸阅读:[保险公司终于有了一个利用智能家居物联网的好办法](https://www.networkworld.com/article/3296706/finally-a-smart-way-for-insurers-to-leverage-iot-in-smart-homes.html)
### UBI 车险的崛起
UBI(<ruby> 基于使用的保险 <rt> usage-based insurance </rt></ruby>)车险是一种“按需付费”的业务,可以通过追踪速度、位置,以及其他因素来评估风险并计算车险保费。到 2020 年,预计有 [5000 万美国司机](https://www.businessinsider.com/iot-is-changing-the-auto-insurance-industry-2015-8)会加入到 UBI 车险的项目中。
不出所料,保险公司对 UBI 车险青睐有加,因为 UBI 车险可以帮助他们更加精确地计算风险。事实上,[AIG 爱尔兰已经在尝试让国家向 25 岁以下的司机强制推行 UBI 车险](https://www.iotforall.com/iot-data-is-disrupting-the-insurance-industry/)。并且,被认定为驾驶习惯良好的司机自然也很乐意节省一笔费用。当然也有反对的声音了,大多数是来自于隐私权倡导者,以及会因此支付更多费用的群体。
### 出了故障会发生什么?
但是还有一个更加令人担忧的潜在问题:当物联网设备提供的数据有错误,或者在传输过程中出了问题会发生什么?因为尽管有自动化程序、错误检查等等,还是不可避免地会偶尔发生一些故障。
不幸的是,这并不是一个理论上某天会给细心的司机不小心多扣几块钱保费的问题。这已经是一个会带来严重后果的现实问题。就像[保险行业仍然没有想清楚谁应该“拥有”面向客户的物联网设备产生的数据](https://www.sas.com/en_us/insights/articles/big-data/5-challenges-for-iot-in-insurance-industry.html)一样,我们也不清楚谁将对这些数据所带来的问题负责。
计算机“故障”据说曾导致赫兹的出租车辆被误报为被盗(虽然在这个例子中这并不是一个严格意义上的物联网问题),并且导致无辜的租车人被逮捕并扣留。结果呢?刑事指控,多年的诉讼官司,以及舆论的指责。非常强烈的舆论指责。
我们非常容易想象一些类似的情况,比如说一个物联网传感器出了故障,然后报告说某辆车超速了,然而事实上并没有超速。想想为这件事打官司的麻烦吧,或者想想和你的保险公司如何争执不下。
(当然,这个问题还有另外一面:消费者可能会想办法篡改他们的物联网设备上的数据,以获得更低的费率或者转移事故责任。我们同样也没有可行的办法来应对*这个问题*。)
### 政府监管是否有必要
考虑到这些问题的潜在影响,以及所涉及公司对处理这些问题的无动于衷,我们似乎有理由猜想政府干预的必要性。
这可能是美国众议员 Bob Latta(俄亥俄州,共和党)[重新引入 SMART IOT(物联网现代应用、研究及趋势的现状)法案](https://www.multichannel.com/news/latta-re-ups-smart-iot-act)背后的一个动机。这项由 Latta 和美国众议员 Peter Welch(佛蒙特州,民主党)领导的两党合作物联网工作组提出的[法案](https://latta.house.gov/uploadedfiles/smart_iot_116th.pdf),于去年秋天通过美国众议院,但被美国参议院驳回了。美国商务部需要研究物联网行业的状况,并在两年后向美国众议院能源与商业部和美国参议院商务委员会报告。
Latta 在一份声明中表示,“由于预计会有数万亿美元的经济影响,我们需要考虑物联网所带来的的政策,机遇和挑战。SMART IoT 法案会让人们更容易理解美国政府在物联网政策上的做法、可以改进的地方,以及美国联邦政策如何影响尖端技术的研究和发明。”
这项研究受到了欢迎,但该法案甚至可能不会被通过。即便通过了,物联网在两年的等待时间里也可能会翻天覆地,让美国政府还是无法跟上。
---
via: <https://www.networkworld.com/article/3396230/when-iot-systems-fail-the-risk-of-having-bad-iot-data.html>
作者:[Fredric Paul](https://www.networkworld.com/author/Fredric-Paul/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chen-ni](https://github.com/chen-ni) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,962 | screen 命令示例:管理多个终端会话 | https://www.ostechnix.com/screen-command-examples-to-manage-multiple-terminal-sessions/ | 2019-06-11T12:48:00 | [
"Tmux",
"Screen",
"复用"
] | https://linux.cn/article-10962-1.html | 
GNU Screen 是一个终端多路复用器(窗口管理器)。顾名思义,Screen 可以在多个交互式 shell 之间复用物理终端,因此我们可以在每个终端会话中执行不同的任务。所有的 Screen 会话都完全独立地运行程序。因此,即使会话意外关闭或断开连接,在 Screen 会话内运行的程序或进程也将继续运行。例如,当通过 SSH [升级 Ubuntu](https://www.ostechnix.com/how-to-upgrade-to-ubuntu-18-04-lts-desktop-and-server/) 服务器时,`screen` 命令将继续运行升级过程,以防万一 SSH 会话因任何原因而终止。
GNU Screen 允许我们轻松创建多个 Screen 会话,在不同会话之间切换,在会话之间复制文本,随时连上或脱离会话等等。它是每个 Linux 管理员应该在必要时学习和使用的重要命令行工具之一。在本简要指南中,我们将看到 `screen` 命令的基本用法以及在 Linux 中的示例。
### 安装 GNU Screen
GNU Screen 在大多数 Linux 操作系统的默认存储库中都可用。
要在 Arch Linux 上安装 GNU Screen,请运行:
```
$ sudo pacman -S screen
```
在 Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt-get install screen
```
在 Fedora 上:
```
$ sudo dnf install screen
```
在 RHEL、CentOS 上:
```
$ sudo yum install screen
```
在 SUSE/openSUSE 上:
```
$ sudo zypper install screen
```
让我们继续看一些 `screen` 命令示例。
### 管理多个终端会话的 Screen 命令示例
在 Screen 中所有命令的默认前缀快捷方式是 `Ctrl + a`。使用 Screen 时,你需要经常使用此快捷方式。所以,要记住这个键盘快捷键。
#### 创建新的 Screen 会话
让我们创建一个新的 Screen 会话并连上它。为此,请在终端中键入以下命令:
```
screen
```
现在,在此会话中运行任何程序或进程,即使你与此会话断开连接,正在运行的进程或程序也将继续运行。
#### 从 Screen 会话脱离
要从屏幕会话中脱离,请按 `Ctrl + a` 和 `d`。你无需同时按下两个组合键。首先按 `Ctrl + a` 然后按 `d`。从会话中脱离后,你将看到类似下面的输出。
```
[detached from 29149.pts-0.sk]
```
这里,`29149` 是 Screen ID,`pts-0.sk` 是屏幕会话的名称。你可以使用 Screen ID 或相应的会话名称来连上、脱离和终止屏幕会话。
#### 创建命名会话
你还可以用你选择的任何自定义名称创建一个 Screen 会话,而不是默认用户名,如下所示。
```
screen -S ostechnix
```
上面的命令将创建一个名为 `xxxxx.ostechnix` 的新 Screen 会话,并立即连上它。要从当前会话中脱离,请按 `Ctrl + a`,然后按 `d`。
当你想要查找哪些进程在哪些会话上运行时,命名会话会很有用。例如,当在会话中设置 LAMP 系统时,你可以简单地将其命名为如下所示。
```
screen -S lampstack
```
#### 创建脱离的会话
有时,你可能想要创建一个会话,但不希望自动连上该会话。在这种情况下,运行以下命令来创建名为`senthil` 的已脱离会话:
```
screen -S senthil -d -m
```
也可以缩短为:
```
screen -dmS senthil
```
上面的命令将创建一个名为 `senthil` 的会话,但不会连上它。
#### 列出屏幕会话
要列出所有正在运行的会话(连上的或脱离的),请运行:
```
screen -ls
```
示例输出:
```
There are screens on:
29700.senthil (Detached)
29415.ostechnix (Detached)
29149.pts-0.sk (Detached)
3 Sockets in /run/screens/S-sk.
```
如你所见,我有三个正在运行的会话,并且所有会话都已脱离。
#### 连上 Screen 会话
如果你想连上会话,例如 `29415.ostechnix`,只需运行:
```
screen -r 29415.ostechnix
```
或:
```
screen -r ostechnix
```
或使用 Screen ID:
```
screen -r 29415
```
要验证我们是否连上到上述会话,只需列出打开的会话并检查。
```
screen -ls
```
示例输出:
```
There are screens on:
29700.senthil (Detached)
29415.ostechnix (Attached)
29149.pts-0.sk (Detached)
3 Sockets in /run/screens/S-sk.
```
如你所见,在上面的输出中,我们目前已连上到 `29415.ostechnix` 会话。要退出当前会话,请按 `ctrl + a d`。
#### 创建嵌套会话
当我们运行 `screen` 命令时,它将为我们创建一个会话。但是,我们可以创建嵌套会话(会话内的会话)。
首先,创建一个新会话或连上已打开的会话。然后我将创建一个名为 `nested` 的新会话。
```
screen -S nested
```
现在,在会话中按 `Ctrl + a` 和 `c` 创建另一个会话。只需重复此操作即可创建任意数量的嵌套 Screen 会话。每个会话都将分配一个号码。号码将从 `0` 开始。
你可以按 `Ctrl + n` 移动到下一个会话,然后按 `Ctrl + p` 移动到上一个会话。
以下是管理嵌套会话的重要键盘快捷键列表。
* `Ctrl + a "` - 列出所有会话
* `Ctrl + a 0` - 切换到会话号 0
* `Ctrl + a n` - 切换到下一个会话
* `Ctrl + a p` - 切换到上一个会话
* `Ctrl + a S` - 将当前区域水平分割为两个区域
* `Ctrl + a l` - 将当前区域垂直分割为两个区域
* `Ctrl + a Q` - 关闭除当前会话之外的所有会话
* `Ctrl + a X` - 关闭当前会话
* `Ctrl + a \` - 终止所有会话并终止 Screen
* `Ctrl + a ?` - 显示键绑定。要退出,请按回车 #### 锁定会话
Screen 有一个锁定会话的选项。为此,请按 `Ctrl + a` 和 `x`。 输入你的 Linux 密码以锁定。
```
Screen used by sk <sk> on ubuntuserver.
Password:
```
#### 记录会话
你可能希望记录 Screen 会话中的所有内容。为此,只需按 `Ctrl + a` 和 `H` 即可。
或者,你也可以使用 `-L` 参数启动新会话来启用日志记录。
```
screen -L
```
从现在开始,你在会话中做的所有活动都将记录并存储在 `$HOME` 目录中名为 `screenlog.x` 的文件中。这里,`x` 是一个数字。
你可以使用 `cat` 命令或任何文本查看器查看日志文件的内容。

*记录 Screen 会话*
#### 终止 Screen 会话
如果不再需要会话,只需杀死它。要杀死名为 `senthil` 的脱离会话:
```
screen -r senthil -X quit
```
或:
```
screen -X -S senthil quit
```
或:
```
screen -X -S 29415 quit
```
如果没有打开的会话,你将看到以下输出:
```
$ screen -ls
No Sockets found in /run/screens/S-sk.
```
更多细节请参照 man 手册页:
```
$ man screen
```
还有一个名为 Tmux 的类似的命令行实用程序,它与 GNU Screen 执行相同的工作。要了解更多信息,请参阅以下指南。
* [Tmux 命令示例:管理多个终端会话](https://www.ostechnix.com/tmux-command-examples-to-manage-multiple-terminal-sessions/)
### 资源
* [GNU Screen 主页](https://www.gnu.org/software/screen/)
---
via: <https://www.ostechnix.com/screen-command-examples-to-manage-multiple-terminal-sessions/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,964 | 从零写一个时间序列数据库 | https://fabxc.org/blog/2017-04-10-writing-a-tsdb/ | 2019-06-11T18:08:00 | [
"监控",
"时间",
"Prometheus"
] | https://linux.cn/article-10964-1.html | 编者按:Prometheus 是 CNCF 旗下的开源监控告警解决方案,它已经成为 Kubernetes 生态圈中的核心监控系统。本文作者 Fabian Reinartz 是 Prometheus 的核心开发者,这篇文章是其于 2017 年写的一篇关于 Prometheus 中的时间序列数据库的设计思考,虽然写作时间有点久了,但是其中的考虑和思路非常值得参考。长文预警,请坐下来慢慢品味。
---

我从事监控工作。特别是在 [Prometheus](https://prometheus.io/) 上,监控系统包含一个自定义的时间序列数据库,并且集成在 [Kubernetes](https://kubernetes.io/) 上。
在许多方面上 Kubernetes 展现出了 Prometheus 所有的设计用途。它使得<ruby> 持续部署 <rt> continuous deployments </rt></ruby>,<ruby> 弹性伸缩 <rt> auto scaling </rt></ruby>和其他<ruby> 高动态环境 <rt> highly dynamic environments </rt></ruby>下的功能可以轻易地访问。查询语句和操作模型以及其它概念决策使得 Prometheus 特别适合这种环境。但是,如果监控的工作负载动态程度显著地增加,这就会给监控系统本身带来新的压力。考虑到这一点,我们就可以特别致力于在高动态或<ruby> 瞬态服务 <rt> transient services </rt></ruby>环境下提升它的表现,而不是回过头来解决 Prometheus 已经解决的很好的问题。
Prometheus 的存储层在历史以来都展现出卓越的性能,单一服务器就能够以每秒数百万个时间序列的速度摄入多达一百万个样本,同时只占用了很少的磁盘空间。尽管当前的存储做的很好,但我依旧提出一个新设计的存储子系统,它可以修正现存解决方案的缺点,并具备处理更大规模数据的能力。
>
> 备注:我没有数据库方面的背景。我说的东西可能是错的并让你误入歧途。你可以在 Freenode 的 #prometheus 频道上对我(fabxc)提出你的批评。
>
>
>
问题,难题,问题域
---------
首先,快速地概览一下我们要完成的东西和它的关键难题。我们可以先看一下 Prometheus 当前的做法 ,它为什么做的这么好,以及我们打算用新设计解决哪些问题。
### 时间序列数据
我们有一个收集一段时间数据的系统。
```
identifier -> (t0, v0), (t1, v1), (t2, v2), (t3, v3), ....
```
每个数据点是一个时间戳和值的元组。在监控中,时间戳是一个整数,值可以是任意数字。64 位浮点数对于计数器和测量值来说是一个好的表示方法,因此我们将会使用它。一系列严格单调递增的时间戳数据点是一个序列,它由标识符所引用。我们的标识符是一个带有<ruby> 标签维度 <rt> label dimensions </rt></ruby>字典的度量名称。标签维度划分了单一指标的测量空间。每一个指标名称加上一个唯一标签集就成了它自己的时间序列,它有一个与之关联的<ruby> 数据流 <rt> value stream </rt></ruby>。
这是一个典型的<ruby> 序列标识符 <rt> series identifier </rt></ruby>集,它是统计请求指标的一部分:
```
requests_total{path="/status", method="GET", instance=”10.0.0.1:80”}
requests_total{path="/status", method="POST", instance=”10.0.0.3:80”}
requests_total{path="/", method="GET", instance=”10.0.0.2:80”}
```
让我们简化一下表示方法:度量名称可以当作另一个维度标签,在我们的例子中是 `__name__`。对于查询语句,可以对它进行特殊处理,但与我们存储的方式无关,我们后面也会见到。
```
{__name__="requests_total", path="/status", method="GET", instance=”10.0.0.1:80”}
{__name__="requests_total", path="/status", method="POST", instance=”10.0.0.3:80”}
{__name__="requests_total", path="/", method="GET", instance=”10.0.0.2:80”}
```
我们想通过标签来查询时间序列数据。在最简单的情况下,使用 `{__name__="requests_total"}` 选择所有属于 `requests_total` 指标的数据。对于所有选择的序列,我们在给定的时间窗口内获取数据点。
在更复杂的语句中,我们或许想一次性选择满足多个标签的序列,并且表示比相等条件更复杂的情况。例如,非语句(`method!="GET"`)或正则表达式匹配(`method=~"PUT|POST"`)。
这些在很大程度上定义了存储的数据和它的获取方式。
### 纵与横
在简化的视图中,所有的数据点可以分布在二维平面上。水平维度代表着时间,序列标识符域经纵轴展开。
```
series
^
| . . . . . . . . . . . . . . . . . . . . . . {__name__="request_total", method="GET"}
| . . . . . . . . . . . . . . . . . . . . . . {__name__="request_total", method="POST"}
| . . . . . . .
| . . . . . . . . . . . . . . . . . . . ...
| . . . . . . . . . . . . . . . . . . . . .
| . . . . . . . . . . . . . . . . . . . . . {__name__="errors_total", method="POST"}
| . . . . . . . . . . . . . . . . . {__name__="errors_total", method="GET"}
| . . . . . . . . . . . . . .
| . . . . . . . . . . . . . . . . . . . ...
| . . . . . . . . . . . . . . . . . . . .
v
<-------------------- time --------------------->
```
Prometheus 通过定期地抓取一组时间序列的当前值来获取数据点。我们从中获取到的实体称为目标。因此,写入模式完全地垂直且高度并发,因为来自每个目标的样本是独立摄入的。
这里提供一些测量的规模:单一 Prometheus 实例从数万个目标中收集数据点,每个数据点都暴露在数百到数千个不同的时间序列中。
在每秒采集数百万数据点这种规模下,批量写入是一个不能妥协的性能要求。在磁盘上分散地写入单个数据点会相当地缓慢。因此,我们想要按顺序写入更大的数据块。
对于旋转式磁盘,它的磁头始终得在物理上向不同的扇区上移动,这是一个不足为奇的事实。而虽然我们都知道 SSD 具有快速随机写入的特点,但事实上它不能修改单个字节,只能写入一页或更多页的 4KiB 数据量。这就意味着写入 16 字节的样本相当于写入满满一个 4Kib 的页。这一行为就是所谓的[写入放大](https://en.wikipedia.org/wiki/Write_amplification),这种特性会损耗你的 SSD。因此它不仅影响速度,而且还毫不夸张地在几天或几个周内破坏掉你的硬件。
关于此问题更深层次的资料,[“Coding for SSDs”系列](http://codecapsule.com/2014/02/12/coding-for-ssds-part-1-introduction-and-table-of-contents/)博客是极好的资源。让我们想想主要的用处:顺序写入和批量写入分别对于旋转式磁盘和 SSD 来说都是理想的写入模式。大道至简。
查询模式比起写入模式明显更不同。我们可以查询单一序列的一个数据点,也可以对 10000 个序列查询一个数据点,还可以查询一个序列几个周的数据点,甚至是 10000 个序列几个周的数据点。因此在我们的二维平面上,查询范围不是完全水平或垂直的,而是二者形成矩形似的组合。
[记录规则](https://prometheus.io/docs/practices/rules/)可以减轻已知查询的问题,但对于<ruby> 点对点 <rt> ad-hoc </rt></ruby>查询来说并不是一个通用的解决方法。
我们知道我们想要批量地写入,但我们得到的仅仅是一系列垂直数据点的集合。当查询一段时间窗口内的数据点时,我们不仅很难弄清楚在哪才能找到这些单独的点,而且不得不从磁盘上大量随机的地方读取。也许一条查询语句会有数百万的样本,即使在最快的 SSD 上也会很慢。读入也会从磁盘上获取更多的数据而不仅仅是 16 字节的样本。SSD 会加载一整页,HDD 至少会读取整个扇区。不论哪一种,我们都在浪费宝贵的读取吞吐量。
因此在理想情况下,同一序列的样本将按顺序存储,这样我们就能通过尽可能少的读取来扫描它们。最重要的是,我们仅需要知道序列的起始位置就能访问所有的数据点。
显然,将收集到的数据写入磁盘的理想模式与能够显著提高查询效率的布局之间存在着明显的抵触。这是我们 TSDB 需要解决的一个基本问题。
#### 当前的解决方法
是时候看一下当前 Prometheus 是如何存储数据来解决这一问题的,让我们称它为“V2”。
我们创建一个时间序列的文件,它包含所有样本并按顺序存储。因为每几秒附加一个样本数据到所有文件中非常昂贵,我们在内存中打包 1Kib 样本序列的数据块,一旦打包完成就附加这些数据块到单独的文件中。这一方法解决了大部分问题。写入目前是批量的,样本也是按顺序存储的。基于给定的同一序列的样本相对之前的数据仅发生非常小的改变这一特性,它还支持非常高效的压缩格式。Facebook 在他们 Gorilla TSDB 上的论文中描述了一个相似的基于数据块的方法,并且[引入了一种压缩格式](http://www.vldb.org/pvldb/vol8/p1816-teller.pdf),它能够减少 16 字节的样本到平均 1.37 字节。V2 存储使用了包含 Gorilla 变体等在内的各种压缩格式。
```
+----------+---------+---------+---------+---------+ series A
+----------+---------+---------+---------+---------+
+----------+---------+---------+---------+---------+ series B
+----------+---------+---------+---------+---------+
. . .
+----------+---------+---------+---------+---------+---------+ series XYZ
+----------+---------+---------+---------+---------+---------+
chunk 1 chunk 2 chunk 3 ...
```
尽管基于块存储的方法非常棒,但为每个序列保存一个独立的文件会给 V2 存储带来麻烦,因为:
* 实际上,我们需要的文件比当前收集数据的时间序列数量要多得多。多出的部分在<ruby> 序列分流 <rt> Series Churn </rt></ruby>上。有几百万个文件,迟早会使用光文件系统中的 [inode](https://en.wikipedia.org/wiki/Inode)。这种情况我们只能通过重新格式化来恢复磁盘,这种方式是最具有破坏性的。我们通常不想为了适应一个应用程序而格式化磁盘。
* 即使是分块写入,每秒也会产生数千块的数据块并且准备持久化。这依然需要每秒数千次的磁盘写入。尽管通过为每个序列打包好多个块来缓解,但这反过来还是增加了等待持久化数据的总内存占用。
* 要保持所有文件打开来进行读写是不可行的。特别是因为 99% 的数据在 24 小时之后不再会被查询到。如果查询它,我们就得打开数千个文件,找到并读取相关的数据点到内存中,然后再关掉。这样做就会引起很高的查询延迟,数据块缓存加剧会导致新的问题,这一点在“资源消耗”一节另作讲述。
* 最终,旧的数据需要被删除,并且数据需要从数百万文件的头部删除。这就意味着删除实际上是写密集型操作。此外,循环遍历数百万文件并且进行分析通常会导致这一过程花费数小时。当它完成时,可能又得重新来过。喔天,继续删除旧文件又会进一步导致 SSD 产生写入放大。
* 目前所积累的数据块仅维持在内存中。如果应用崩溃,数据就会丢失。为了避免这种情况,内存状态会定期的保存在磁盘上,这比我们能接受数据丢失窗口要长的多。恢复检查点也会花费数分钟,导致很长的重启周期。
我们能够从现有的设计中学到的关键部分是数据块的概念,我们当然希望保留这个概念。最新的数据块会保持在内存中一般也是好的主意。毕竟,最新的数据会大量的查询到。
一个时间序列对应一个文件,这个概念是我们想要替换掉的。
### 序列分流
在 Prometheus 的<ruby> 上下文 <rt> context </rt></ruby>中,我们使用术语<ruby> 序列分流 <rt> series churn </rt></ruby>来描述一个时间序列集合变得不活跃,即不再接收数据点,取而代之的是出现一组新的活跃序列。
例如,由给定微服务实例产生的所有序列都有一个相应的“instance”标签来标识其来源。如果我们为微服务执行了<ruby> 滚动更新 <rt> rolling update </rt></ruby>,并且为每个实例替换一个新的版本,序列分流便会发生。在更加动态的环境中,这些事情基本上每小时都会发生。像 Kubernetes 这样的<ruby> 集群编排 <rt> Cluster orchestration </rt></ruby>系统允许应用连续性的自动伸缩和频繁的滚动更新,这样也许会创建成千上万个新的应用程序实例,并且伴随着全新的时间序列集合,每天都是如此。
```
series
^
| . . . . . .
| . . . . . .
| . . . . . .
| . . . . . . .
| . . . . . . .
| . . . . . . .
| . . . . . .
| . . . . . .
| . . . . .
| . . . . .
| . . . . .
v
<-------------------- time --------------------->
```
所以即便整个基础设施的规模基本保持不变,过一段时间后数据库内的时间序列还是会成线性增长。尽管 Prometheus 很愿意采集 1000 万个时间序列数据,但要想在 10 亿个序列中找到数据,查询效果还是会受到严重的影响。
#### 当前解决方案
当前 Prometheus 的 V2 存储系统对所有当前保存的序列拥有基于 LevelDB 的索引。它允许查询语句含有给定的<ruby> 标签对 <rt> label pair </rt></ruby>,但是缺乏可伸缩的方法来从不同的标签选集中组合查询结果。
例如,从所有的序列中选择标签 `__name__="requests_total"` 非常高效,但是选择 `instance="A" AND __name__="requests_total"` 就有了可伸缩性的问题。我们稍后会重新考虑导致这一点的原因和能够提升查找延迟的调整方法。
事实上正是这个问题才催生出了对更好的存储系统的最初探索。Prometheus 需要为查找亿万个时间序列改进索引方法。
### 资源消耗
当试图扩展 Prometheus(或其他任何事情,真的)时,资源消耗是永恒不变的话题之一。但真正困扰用户的并不是对资源的绝对渴求。事实上,由于给定的需求,Prometheus 管理着令人难以置信的吞吐量。问题更在于面对变化时的相对未知性与不稳定性。通过其架构设计,V2 存储系统缓慢地构建了样本数据块,这一点导致内存占用随时间递增。当数据块完成之后,它们可以写到磁盘上并从内存中清除。最终,Prometheus 的内存使用到达稳定状态。直到监测环境发生了改变——每次我们扩展应用或者进行滚动更新,序列分流都会增加内存、CPU、磁盘 I/O 的使用。
如果变更正在进行,那么它最终还是会到达一个稳定的状态,但比起更加静态的环境,它的资源消耗会显著地提高。过渡时间通常为数个小时,而且难以确定最大资源使用量。
为每个时间序列保存一个文件这种方法也使得一个单个查询就很容易崩溃 Prometheus 进程。当查询的数据没有缓存在内存中,查询的序列文件就会被打开,然后将含有相关数据点的数据块读入内存。如果数据量超出内存可用量,Prometheus 就会因 OOM 被杀死而退出。
在查询语句完成之后,加载的数据便可以被再次释放掉,但通常会缓存更长的时间,以便更快地查询相同的数据。后者看起来是件不错的事情。
最后,我们看看之前提到的 SSD 的写入放大,以及 Prometheus 是如何通过批量写入来解决这个问题的。尽管如此,在许多地方还是存在因为批量太小以及数据未精确对齐页边界而导致的写入放大。对于更大规模的 Prometheus 服务器,现实当中会发现缩减硬件寿命的问题。这一点对于高写入吞吐量的数据库应用来说仍然相当普遍,但我们应该放眼看看是否可以解决它。
### 重新开始
到目前为止我们对于问题域、V2 存储系统是如何解决它的,以及设计上存在的问题有了一个清晰的认识。我们也看到了许多很棒的想法,这些或多或少都可以拿来直接使用。V2 存储系统相当数量的问题都可以通过改进和部分的重新设计来解决,但为了好玩(当然,在我仔细的验证想法之后),我决定试着写一个完整的时间序列数据库——从头开始,即向文件系统写入字节。
性能与资源使用这种最关键的部分直接影响了存储格式的选取。我们需要为数据找到正确的算法和磁盘布局来实现一个高性能的存储层。
这就是我解决问题的捷径——跳过令人头疼、失败的想法,数不尽的草图,泪水与绝望。
### V3—宏观设计
我们存储系统的宏观布局是什么?简而言之,是当我们在数据文件夹里运行 `tree` 命令时显示的一切。看看它能给我们带来怎样一副惊喜的画面。
```
$ tree ./data
./data
+-- b-000001
| +-- chunks
| | +-- 000001
| | +-- 000002
| | +-- 000003
| +-- index
| +-- meta.json
+-- b-000004
| +-- chunks
| | +-- 000001
| +-- index
| +-- meta.json
+-- b-000005
| +-- chunks
| | +-- 000001
| +-- index
| +-- meta.json
+-- b-000006
+-- meta.json
+-- wal
+-- 000001
+-- 000002
+-- 000003
```
在最顶层,我们有一系列以 `b-` 为前缀编号的<ruby> 块 <rt> block </rt></ruby>。每个块中显然保存了索引文件和含有更多编号文件的 `chunk` 文件夹。`chunks` 目录只包含不同序列<ruby> 数据点的原始块 <rt> raw chunks of data points </rt> <ruby> 。与 V2 存储系统一样,这使得通过时间窗口读取序列数据非常高效并且允许我们使用相同的有效压缩算法。这一点被证实行之有效,我们也打算沿用。显然,这里并不存在含有单个序列的文件,而是一堆保存着许多序列的数据块。 </ruby></ruby>
`index` 文件的存在应该不足为奇。让我们假设它拥有黑魔法,可以让我们找到标签、可能的值、整个时间序列和存放数据点的数据块。
但为什么这里有好几个文件夹都是索引和块文件的布局?并且为什么存在最后一个包含 `wal` 文件夹?理解这两个疑问便能解决九成的问题。
#### 许多小型数据库
我们分割横轴,即将时间域分割为不重叠的块。每一块扮演着完全独立的数据库,它包含该时间窗口所有的时间序列数据。因此,它拥有自己的索引和一系列块文件。
```
t0 t1 t2 t3 now
+-----------+ +-----------+ +-----------+ +-----------+
| | | | | | | | +------------+
| | | | | | | mutable | <--- write ---- ┤ Prometheus |
| | | | | | | | +------------+
+-----------+ +-----------+ +-----------+ +-----------+ ^
+--------------+-------+------+--------------+ |
| query
| |
merge -------------------------------------------------+
```
每一块的数据都是<ruby> 不可变的 <rt> immutable </rt></ruby>。当然,当我们采集新数据时,我们必须能向最近的块中添加新的序列和样本。对于该数据块,所有新的数据都将写入内存中的数据库中,它与我们的持久化的数据块一样提供了查找属性。内存中的数据结构可以高效地更新。为了防止数据丢失,所有传入的数据同样被写入临时的<ruby> 预写日志 <rt> write ahead log </rt></ruby>中,这就是 `wal` 文件夹中的一些列文件,我们可以在重新启动时通过它们重新填充内存数据库。
所有这些文件都带有序列化格式,有我们所期望的所有东西:许多标志、偏移量、变体和 CRC32 校验和。纸上得来终觉浅,绝知此事要躬行。
这种布局允许我们扩展查询范围到所有相关的块上。每个块上的部分结果最终合并成完整的结果。
这种横向分割增加了一些很棒的功能:
* 当查询一个时间范围,我们可以简单地忽略所有范围之外的数据块。通过减少需要检查的数据集,它可以初步解决序列分流的问题。
* 当完成一个块,我们可以通过顺序的写入大文件从内存数据库中保存数据。这样可以避免任何的写入放大,并且 SSD 与 HDD 均适用。
* 我们延续了 V2 存储系统的一个好的特性,最近使用而被多次查询的数据块,总是保留在内存中。
* 很好,我们也不再受限于 1KiB 的数据块尺寸,以使数据在磁盘上更好地对齐。我们可以挑选对单个数据点和压缩格式最合理的尺寸。
* 删除旧数据变得极为简单快捷。我们仅仅只需删除一个文件夹。记住,在旧的存储系统中我们不得不花数个小时分析并重写数亿个文件。
每个块还包含了 `meta.json` 文件。它简单地保存了关于块的存储状态和包含的数据,以便轻松了解存储状态及其包含的数据。
##### mmap
将数百万个小文件合并为少数几个大文件使得我们用很小的开销就能保持所有的文件都打开。这就解除了对 [mmap(2)](https://en.wikipedia.org/wiki/Mmap) 的使用的阻碍,这是一个允许我们通过文件透明地回传虚拟内存的系统调用。简单起见,你可以将其视为<ruby> 交换空间 <rt> swap space </rt></ruby>,只是我们所有的数据已经保存在了磁盘上,并且当数据换出内存后不再会发生写入。
这意味着我们可以当作所有数据库的内容都视为在内存中却不占用任何物理内存。仅当我们访问数据库文件某些字节范围时,操作系统才会从磁盘上<ruby> 惰性加载 <rt> lazy load </rt></ruby>页数据。这使得我们将所有数据持久化相关的内存管理都交给了操作系统。通常,操作系统更有资格作出这样的决定,因为它可以全面了解整个机器和进程。查询的数据可以相当积极的缓存进内存,但内存压力会使得页被换出。如果机器拥有未使用的内存,Prometheus 目前将会高兴地缓存整个数据库,但是一旦其他进程需要,它就会立刻返回那些内存。
因此,查询不再轻易地使我们的进程 OOM,因为查询的是更多的持久化的数据而不是装入内存中的数据。内存缓存大小变得完全自适应,并且仅当查询真正需要时数据才会被加载。
就个人理解,这就是当今大多数数据库的工作方式,如果磁盘格式允许,这是一种理想的方式,——除非有人自信能在这个过程中超越操作系统。我们做了很少的工作但确实从外面获得了很多功能。
#### 压缩
存储系统需要定期“切”出新块并将之前完成的块写入到磁盘中。仅在块成功的持久化之后,才会被删除之前用来恢复内存块的日志文件(wal)。
我们希望将每个块的保存时间设置的相对短一些(通常配置为 2 小时),以避免内存中积累太多的数据。当查询多个块,我们必须将它们的结果合并为一个整体的结果。合并过程显然会消耗资源,一个星期的查询不应该由超过 80 个的部分结果所组成。
为了实现两者,我们引入<ruby> 压缩 <rt> compaction </rt></ruby>。压缩描述了一个过程:取一个或更多个数据块并将其写入一个可能更大的块中。它也可以在此过程中修改现有的数据。例如,清除已经删除的数据,或重建样本块以提升查询性能。
```
t0 t1 t2 t3 t4 now
+------------+ +----------+ +-----------+ +-----------+ +-----------+
| 1 | | 2 | | 3 | | 4 | | 5 mutable | before
+------------+ +----------+ +-----------+ +-----------+ +-----------+
+-----------------------------------------+ +-----------+ +-----------+
| 1 compacted | | 4 | | 5 mutable | after (option A)
+-----------------------------------------+ +-----------+ +-----------+
+--------------------------+ +--------------------------+ +-----------+
| 1 compacted | | 3 compacted | | 5 mutable | after (option B)
+--------------------------+ +--------------------------+ +-----------+
```
在这个例子中我们有顺序块 `[1,2,3,4]`。块 1、2、3 可以压缩在一起,新的布局将会是 `[1,4]`。或者,将它们成对压缩为 `[1,3]`。所有的时间序列数据仍然存在,但现在整体上保存在更少的块中。这极大程度地缩减了查询时间的消耗,因为需要合并的部分查询结果变得更少了。
#### 保留
我们看到了删除旧的数据在 V2 存储系统中是一个缓慢的过程,并且消耗 CPU、内存和磁盘。如何才能在我们基于块的设计上清除旧的数据?相当简单,只要删除我们配置的保留时间窗口里没有数据的块文件夹即可。在下面的例子中,块 1 可以被安全地删除,而块 2 则必须一直保留,直到它落在保留窗口边界之外。
```
|
+------------+ +----+-----+ +-----------+ +-----------+ +-----------+
| 1 | | 2 | | | 3 | | 4 | | 5 | . . .
+------------+ +----+-----+ +-----------+ +-----------+ +-----------+
|
|
retention boundary
```
随着我们不断压缩先前压缩的块,旧数据越大,块可能变得越大。因此必须为其设置一个上限,以防数据块扩展到整个数据库而损失我们设计的最初优势。
方便的是,这一点也限制了部分存在于保留窗口内部分存在于保留窗口外的块的磁盘消耗总量。例如上面例子中的块 2。当设置了最大块尺寸为总保留窗口的 10% 后,我们保留块 2 的总开销也有了 10% 的上限。
总结一下,保留与删除从非常昂贵到了几乎没有成本。
>
> 如果你读到这里并有一些数据库的背景知识,现在你也许会问:这些都是最新的技术吗?——并不是;而且可能还会做的更好。
>
>
> 在内存中批量处理数据,在预写日志中跟踪,并定期写入到磁盘的模式在现在相当普遍。
>
>
> 我们看到的好处无论在什么领域的数据里都是适用的。遵循这一方法最著名的开源案例是 LevelDB、Cassandra、InfluxDB 和 HBase。关键是避免重复发明劣质的轮子,采用经过验证的方法,并正确地运用它们。
>
>
> 脱离场景添加你自己的黑魔法是一种不太可能的情况。
>
>
>
### 索引
研究存储改进的最初想法是解决序列分流的问题。基于块的布局减少了查询所要考虑的序列总数。因此假设我们索引查找的复杂度是 `O(n^2)`,我们就要设法减少 n 个相当数量的复杂度,之后就相当于改进 `O(n^2)` 复杂度。——恩,等等……糟糕。
快速回顾一下“算法 101”课上提醒我们的,在理论上它并未带来任何好处。如果之前就很糟糕,那么现在也一样。理论是如此的残酷。
实际上,我们大多数的查询已经可以相当快响应。但是,跨越整个时间范围的查询仍然很慢,尽管只需要找到少部分数据。追溯到所有这些工作之前,最初我用来解决这个问题的想法是:我们需要一个更大容量的[倒排索引](https://en.wikipedia.org/wiki/Inverted_index)。
倒排索引基于数据项内容的子集提供了一种快速的查找方式。简单地说,我可以通过标签 `app="nginx"` 查找所有的序列而无需遍历每个文件来看它是否包含该标签。
为此,每个序列被赋上一个唯一的 ID ,通过该 ID 可以恒定时间内检索它(`O(1)`)。在这个例子中 ID 就是我们的正向索引。
>
> 示例:如果 ID 为 10、29、9 的序列包含标签 `app="nginx"`,那么 “nginx”的倒排索引就是简单的列表 `[10, 29, 9]`,它就能用来快速地获取所有包含标签的序列。即使有 200 多亿个数据序列也不会影响查找速度。
>
>
>
简而言之,如果 `n` 是我们序列总数,`m` 是给定查询结果的大小,使用索引的查询复杂度现在就是 `O(m)`。查询语句依据它获取数据的数量 `m` 而不是被搜索的数据体 `n` 进行缩放是一个很好的特性,因为 `m` 一般相当小。
为了简单起见,我们假设可以在恒定时间内查找到倒排索引对应的列表。
实际上,这几乎就是 V2 存储系统具有的倒排索引,也是提供在数百万序列中查询性能的最低需求。敏锐的人会注意到,在最坏情况下,所有的序列都含有标签,因此 `m` 又成了 `O(n)`。这一点在预料之中,也相当合理。如果你查询所有的数据,它自然就会花费更多时间。一旦我们牵扯上了更复杂的查询语句就会有问题出现。
#### 标签组合
与数百万个序列相关的标签很常见。假设横向扩展着数百个实例的“foo”微服务,并且每个实例拥有数千个序列。每个序列都会带有标签 `app="foo"`。当然,用户通常不会查询所有的序列而是会通过进一步的标签来限制查询。例如,我想知道服务实例接收到了多少请求,那么查询语句便是 `__name__="requests_total" AND app="foo"`。
为了找到满足两个标签选择子的所有序列,我们得到每一个标签的倒排索引列表并取其交集。结果集通常会比任何一个输入列表小一个数量级。因为每个输入列表最坏情况下的大小为 `O(n)`,所以在嵌套地为每个列表进行<ruby> 暴力求解 <rt> brute force solution </rt> <ruby> 下,运行时间为 <code> O(n^2) </code> 。相同的成本也适用于其他的集合操作,例如取并集( <code> app="foo" OR app="bar" </code> )。当在查询语句上添加更多标签选择子,耗费就会指数增长到 <code> O(n^3) </code> 、 <code> O(n^4) </code> 、 <code> O(n^5) </code> …… <code> O(n^k) </code> 。通过改变执行顺序,可以使用很多技巧以优化运行效率。越复杂,越是需要关于数据特征和标签之间相关性的知识。这引入了大量的复杂度,但是并没有减少算法的最坏运行时间。 </ruby></ruby>
这便是 V2 存储系统使用的基本方法,幸运的是,看似微小的改动就能获得显著的提升。如果我们假设倒排索引中的 ID 都是排序好的会怎么样?
假设这个例子的列表用于我们最初的查询:
```
__name__="requests_total" -> [ 9999, 1000, 1001, 2000000, 2000001, 2000002, 2000003 ]
app="foo" -> [ 1, 3, 10, 11, 12, 100, 311, 320, 1000, 1001, 10002 ]
intersection => [ 1000, 1001 ]
```
它的交集相当小。我们可以为每个列表的起始位置设置游标,每次从最小的游标处移动来找到交集。当二者的数字相等,我们就添加它到结果中并移动二者的游标。总体上,我们以锯齿形扫描两个列表,因此总耗费是 `O(2n)=O(n)`,因为我们总是在一个列表上移动。
两个以上列表的不同集合操作也类似。因此 `k` 个集合操作仅仅改变了因子 `O(k*n)` 而不是最坏情况下查找运行时间的指数 `O(n^k)`。
我在这里所描述的是几乎所有[全文搜索引擎](https://en.wikipedia.org/wiki/Search_engine_indexing#Inverted_indices)使用的标准搜索索引的简化版本。每个序列描述符都视作一个简短的“文档”,每个标签(名称 + 固定值)作为其中的“单词”。我们可以忽略搜索引擎索引中通常遇到的很多附加数据,例如单词位置和和频率。
关于改进实际运行时间的方法似乎存在无穷无尽的研究,它们通常都是对输入数据做一些假设。不出意料的是,还有大量技术来压缩倒排索引,其中各有利弊。因为我们的“文档”比较小,而且“单词”在所有的序列里大量重复,压缩变得几乎无关紧要。例如,一个真实的数据集约有 440 万个序列与大约 12 个标签,每个标签拥有少于 5000 个单独的标签。对于最初的存储版本,我们坚持使用基本的方法而不压缩,仅做微小的调整来跳过大范围非交叉的 ID。
尽管维持排序好的 ID 听起来很简单,但实践过程中不是总能完成的。例如,V2 存储系统为新的序列赋上一个哈希值来当作 ID,我们就不能轻易地排序倒排索引。
另一个艰巨的任务是当磁盘上的数据被更新或删除掉后修改其索引。通常,最简单的方法是重新计算并写入,但是要保证数据库在此期间可查询且具有一致性。V3 存储系统通过每块上具有的独立不可变索引来解决这一问题,该索引仅通过压缩时的重写来进行修改。只有可变块上的索引需要被更新,它完全保存在内存中。
基准测试
----
我从存储的基准测试开始了初步的开发,它基于现实世界数据集中提取的大约 440 万个序列描述符,并生成合成数据点以输入到这些序列中。这个阶段的开发仅仅测试了单独的存储系统,对于快速找到性能瓶颈和高并发负载场景下的触发死锁至关重要。
在完成概念性的开发实施之后,该基准测试能够在我的 Macbook Pro 上维持每秒 2000 万的吞吐量 —— 并且这都是在打开着十几个 Chrome 的页面和 Slack 的时候。因此,尽管这听起来都很棒,它这也表明推动这项测试没有的进一步价值(或者是没有在高随机环境下运行)。毕竟,它是合成的数据,因此在除了良好的第一印象外没有多大价值。比起最初的设计目标高出 20 倍,是时候将它部署到真正的 Prometheus 服务器上了,为它添加更多现实环境中的开销和场景。
我们实际上没有可重现的 Prometheus 基准测试配置,特别是没有对于不同版本的 A/B 测试。亡羊补牢为时不晚,[不过现在就有一个了](https://github.com/prometheus/prombench)!
我们的工具可以让我们声明性地定义基准测试场景,然后部署到 AWS 的 Kubernetes 集群上。尽管对于全面的基准测试来说不是最好环境,但它肯定比 64 核 128GB 内存的专用<ruby> 裸机服务器 <rt> bare metal servers </rt></ruby>更能反映出我们的用户群体。
我们部署了两个 Prometheus 1.5.2 服务器(V2 存储系统)和两个来自 2.0 开发分支的 Prometheus (V3 存储系统)。每个 Prometheus 运行在配备 SSD 的专用服务器上。我们将横向扩展的应用部署在了工作节点上,并且让其暴露典型的微服务度量。此外,Kubernetes 集群本身和节点也被监控着。整套系统由另一个 Meta-Prometheus 所监督,它监控每个 Prometheus 的健康状况和性能。
为了模拟序列分流,微服务定期的扩展和收缩来移除旧的 pod 并衍生新的 pod,生成新的序列。通过选择“典型”的查询来模拟查询负载,对每个 Prometheus 版本都执行一次。
总体上,伸缩与查询的负载以及采样频率极大的超出了 Prometheus 的生产部署。例如,我们每隔 15 分钟换出 60% 的微服务实例去产生序列分流。在现代的基础设施上,一天仅大约会发生 1-5 次。这就保证了我们的 V3 设计足以处理未来几年的工作负载。就结果而言,Prometheus 1.5.2 和 2.0 之间的性能差异在极端的环境下会变得更大。
总而言之,我们每秒从 850 个目标里收集大约 11 万份样本,每次暴露 50 万个序列。
在此系统运行一段时间之后,我们可以看一下数字。我们评估了两个版本在 12 个小时之后到达稳定时的几个指标。
>
> 请注意从 Prometheus 图形界面的截图中轻微截断的 Y 轴
>
>
>

*堆内存使用(GB)*
内存资源的使用对用户来说是最为困扰的问题,因为它相对的不可预测且可能导致进程崩溃。
显然,查询的服务器正在消耗内存,这很大程度上归咎于查询引擎的开销,这一点可以当作以后优化的主题。总的来说,Prometheus 2.0 的内存消耗减少了 3-4 倍。大约 6 小时之后,在 Prometheus 1.5 上有一个明显的峰值,与我们设置的 6 小时的保留边界相对应。因为删除操作成本非常高,所以资源消耗急剧提升。这一点在下面几张图中均有体现。

*CPU 使用(核心/秒)*
类似的模式也体现在 CPU 使用上,但是查询的服务器与非查询的服务器之间的差异尤为明显。每秒获取大约 11 万个数据需要 0.5 核心/秒的 CPU 资源,比起评估查询所花费的 CPU 时间,我们的新存储系统 CPU 消耗可忽略不计。总的来说,新存储需要的 CPU 资源减少了 3 到 10 倍。

*磁盘写入(MB/秒)*
迄今为止最引人注目和意想不到的改进表现在我们的磁盘写入利用率上。这就清楚的说明了为什么 Prometheus 1.5 很容易造成 SSD 损耗。我们看到最初的上升发生在第一个块被持久化到序列文件中的时期,然后一旦删除操作引发了重写就会带来第二个上升。令人惊讶的是,查询的服务器与非查询的服务器显示出了非常不同的利用率。
在另一方面,Prometheus 2.0 每秒仅向其预写日志写入大约一兆字节。当块被压缩到磁盘时,写入定期地出现峰值。这在总体上节省了:惊人的 97-99%。

*磁盘大小(GB)*
与磁盘写入密切相关的是总磁盘空间占用量。由于我们对样本(这是我们的大部分数据)几乎使用了相同的压缩算法,因此磁盘占用量应当相同。在更为稳定的系统中,这样做很大程度上是正确地,但是因为我们需要处理高的序列分流,所以还要考虑每个序列的开销。
如我们所见,Prometheus 1.5 在这两个版本达到稳定状态之前,使用的存储空间因其保留操作而急速上升。Prometheus 2.0 似乎在每个序列上的开销显著降低。我们可以清楚的看到预写日志线性地充满整个存储空间,然后当压缩完成后瞬间下降。事实上对于两个 Prometheus 2.0 服务器,它们的曲线并不是完全匹配的,这一点需要进一步的调查。
前景大好。剩下最重要的部分是查询延迟。新的索引应当优化了查找的复杂度。没有实质上发生改变的是处理数据的过程,例如 `rate()` 函数或聚合。这些就是查询引擎要做的东西了。

*第 99 个百分位查询延迟(秒)*
数据完全符合预期。在 Prometheus 1.5 上,查询延迟随着存储的序列而增加。只有在保留操作开始且旧的序列被删除后才会趋于稳定。作为对比,Prometheus 2.0 从一开始就保持在合适的位置。
我们需要花一些心思在数据是如何被采集上,对服务器发出的查询请求通过对以下方面的估计来选择:范围查询和即时查询的组合,进行更轻或更重的计算,访问更多或更少的文件。它并不需要代表真实世界里查询的分布。也不能代表冷数据的查询性能,我们可以假设所有的样本数据都是保存在内存中的热数据。
尽管如此,我们可以相当自信地说,整体查询效果对序列分流变得非常有弹性,并且在高压基准测试场景下提升了 4 倍的性能。在更为静态的环境下,我们可以假设查询时间大多数花费在了查询引擎上,改善程度明显较低。

*摄入的样本/秒*
最后,快速地看一下不同 Prometheus 服务器的摄入率。我们可以看到搭载 V3 存储系统的两个服务器具有相同的摄入速率。在几个小时之后变得不稳定,这是因为不同的基准测试集群节点由于高负载变得无响应,与 Prometheus 实例无关。(两个 2.0 的曲线完全匹配这一事实希望足够具有说服力)
尽管还有更多 CPU 和内存资源,两个 Prometheus 1.5.2 服务器的摄入率大大降低。序列分流的高压导致了无法采集更多的数据。
那么现在每秒可以摄入的<ruby> 绝对最大 <rt> absolute maximum </rt></ruby>样本数是多少?
但是现在你可以摄取的每秒绝对最大样本数是多少?
我不知道 —— 虽然这是一个相当容易的优化指标,但除了稳固的基线性能之外,它并不是特别有意义。
有很多因素都会影响 Prometheus 数据流量,而且没有一个单独的数字能够描述捕获质量。最大摄入率在历史上是一个导致基准出现偏差的度量,并且忽视了更多重要的层面,例如查询性能和对序列分流的弹性。关于资源使用线性增长的大致猜想通过一些基本的测试被证实。很容易推断出其中的原因。
我们的基准测试模拟了高动态环境下 Prometheus 的压力,它比起真实世界中的更大。结果表明,虽然运行在没有优化的云服务器上,但是已经超出了预期的效果。最终,成功将取决于用户反馈而不是基准数字。
>
> 注意:在撰写本文的同时,Prometheus 1.6 正在开发当中,它允许更可靠地配置最大内存使用量,并且可能会显著地减少整体的消耗,有利于稍微提高 CPU 使用率。我没有重复对此进行测试,因为整体结果变化不大,尤其是面对高序列分流的情况。
>
>
>
总结
--
Prometheus 开始应对高基数序列与单独样本的吞吐量。这仍然是一项富有挑战性的任务,但是新的存储系统似乎向我们展示了未来的一些好东西。
第一个配备 V3 存储系统的 [alpha 版本 Prometheus 2.0](https://prometheus.io/blog/2017/04/10/promehteus-20-sneak-peak/) 已经可以用来测试了。在早期阶段预计还会出现崩溃,死锁和其他 bug。
存储系统的代码可以在[这个单独的项目中找到](https://github.com/prometheus/tsdb)。Prometheus 对于寻找高效本地存储时间序列数据库的应用来说可能非常有用,这一点令人非常惊讶。
>
> 这里需要感谢很多人作出的贡献,以下排名不分先后:
>
>
> Bjoern Rabenstein 和 Julius Volz 在 V2 存储引擎上的打磨工作以及 V3 存储系统的反馈,这为新一代的设计奠定了基础。
>
>
> Wilhelm Bierbaum 对新设计不断的建议与见解作出了很大的贡献。Brian Brazil 不断的反馈确保了我们最终得到的是语义上合理的方法。与 Peter Bourgon 深刻的讨论验证了设计并形成了这篇文章。
>
>
> 别忘了我们整个 CoreOS 团队与公司对于这项工作的赞助与支持。感谢所有那些听我一遍遍唠叨 SSD、浮点数、序列化格式的同学。
>
>
>
---
via: <https://fabxc.org/blog/2017-04-10-writing-a-tsdb/>
作者:[Fabian Reinartz](https://twitter.com/fabxc) 译者:[LuuMing](https://github.com/LuuMing) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,965 | 开源新闻:开源仿生腿、Python 数据管道、数据泄露检测 | https://opensource.com/article/19/6/news-june-8 | 2019-06-11T22:16:03 | [
"仿生"
] | https://linux.cn/article-10965-1.html |
>
> 了解过去两周来最大的开源头条新闻。
>
>
>

在本期开源新闻综述中,我们将介绍一个开源仿生腿、一个新的开源医学影像组织,麦肯锡发布的首个开源软件,以及更多!
### 使用开源推进仿生学
我们这一代人从电视剧《六百万美元人》和《仿生女人》中学到了仿生学一词。让科幻小说(尽管基于事实)正在成为现实的,要归功于[由密歇根大学和 Shirley Ryan AbilityLab 设计](https://news.umich.edu/open-source-bionic-leg-first-of-its-kind-platform-aims-to-rapidly-advance-prosthetics/)的假肢。
该腿采用简单、低成本的模块化设计,“旨在通过为仿生学领域的零碎研究工作提供统一的平台,提高患者的生活质量并加速科学进步”。根据首席设计师 Elliot Rouse 的说法,它将“使研究人员能够有效地解决与一系列的实验室和社区活动中控制仿生腿相关的挑战。”
你可以从[开源腿](https://opensourceleg.com/)网站了解有该腿的更多信息并下载该设计。
### 麦肯锡发布了一个用于构建产品级数据管道的 Python 库
咨询巨头麦肯锡公司最近发布了其[第一个开源工具](https://www.information-age.com/kedro-mckinseys-open-source-software-tool-123482991/),名为 Kedro,它是一个用于创建机器学习和数据管道的 Python 库。
Kedro 使得“管理大型工作流程更加容易,并确保整个项目的代码质量始终如一”,产品经理 Yetunde Dada 说。虽然它最初是作为一种专有的工具,但麦肯锡开源了 Kedro,因此“客户可以在我们离开项目后使用它 —— 这是我们回馈的方式,”工程师 Nikolaos Tsaousis 说。
如果你有兴趣了解一下,可以从 GitHub 上获取 [Kedro 的源代码](https://github.com/quantumblacklabs/kedro)。
### 新联盟推进开源医学成像
一组专家和患者倡导者聚集在一起组成了[开源成像联盟](https://pulmonaryfibrosisnews.com/2019/05/31/international-open-source-imaging-consortium-osic-launched-to-advance-ipf-diagnosis/)。该联盟旨在“通过数字成像和机器学习帮助推进特发性肺纤维化和其他间质性肺病的诊断。”
根据联盟执行董事 Elizabeth Estes 的说法,该项目旨在“协作加速诊断,帮助预后处置,最终让医生更有效地治疗患者”。为此,他们正在组织和分享“来自患者的 15,000 个匿名图像扫描和临床数据,这将作为机器学习程序的输入数据来开发算法。”
### Mozilla 发布了一种简单易用的方法,以确定你是否遭受过数据泄露
向不那么精通软件的人解释安全性始终是一项挑战,无论你的技能水平如何,都很难监控你的风险。Mozilla 发布了 [Firefox Monitor](https://monitor.firefox.com/),其数据由 [Have I Been Pwned](https://haveibeenpwned.com/) 提供,它是一种查看你的任何电子邮件是否出现在重大数据泄露事件中的简单方式。你可以输入电子邮件逐个搜索,或注册他们的服务以便将来通知你。
该网站还提供了大量有用的教程,用于了解黑客如何做的,数据泄露后如何处理以及如何创建强密码。请务必将网站加入书签,以防家人要求你在假日期间提供建议。
### 其它新闻
* [想要一款去谷歌化的 Android?把你的手机发送给这个人](https://fossbytes.com/want-a-google-free-android-send-your-phone-to-this-guy/)
* [CockroachDB 发行版使用了非 OSI 批准的许可证,但仍然保持开源](https://www.cockroachlabs.com/blog/oss-relicensing-cockroachdb/)
* [基础设施自动化公司 Chef 承诺开源](https://www.infoq.com/news/2019/05/chef-open-source/)
* [俄罗斯的 Windows 替代品将获得安全升级](https://www.nextgov.com/cybersecurity/2019/05/russias-would-be-windows-replacement-gets-security-upgrade/157330/)
* [使用此代码在几分钟内从 Medium 切换到你自己的博客](https://github.com/mathieudutour/medium-to-own-blog)
* [开源推进联盟宣布与台湾自由软件协会建立新合作伙伴关系](https://opensource.org/node/994)
---
via: <https://opensource.com/article/19/6/news-june-8>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this edition of our open source news roundup, we take a look at an open source bionic leg, a new open source medical imaging organization, McKinsey's first open source release, and more!
## Using open source to advance bionics
A generation of people learned the term *bionics* from the TV series **The Six Million Dollar Man** and **The Bionic Woman**. What was science fiction (although based on fact) is closer to becoming a reality thanks to prosthetic leg [designed by the University of Michigan and the Shirley Ryan AbilityLab](https://news.umich.edu/open-source-bionic-leg-first-of-its-kind-platform-aims-to-rapidly-advance-prosthetics/).
The leg, which incorporates a simple, low-cost modular design, is "intended to improve the quality of life of patients and accelerate scientific advances by offering a unified platform to fragmented research efforts across the field of bionics." It will, according to lead designer Elliot Rouse, "enable investigators to efficiently solve challenges associated with controlling bionic legs across a range of activities in the lab and out in the community."
You can learn more about the leg, and download designs, from the [Open Source Leg](https://opensourceleg.com/) website.
## McKinsey releases a Python library for building production-ready data pipelines
Consulting giant McKinsey and Co. recently released its [first open source tool](https://www.information-age.com/kedro-mckinseys-open-source-software-tool-123482991/). Called Kedro, it's a Python library for creating machine learning and data pipelines.
Kedro makes "it easier to manage large workflows and ensuring a consistent quality of code throughout a project," said product manager Yetunde Dada. While it started as a proprietary tool, McKinsey open sourced Kedro so "clients can use it after we leave a project — it is our way of giving back," said engineer Nikolaos Tsaousis.
If you're interested in taking a peek, you can grab [Kedro's source code](https://github.com/quantumblacklabs/kedro) off GitHub.
## New consortium to advance open source medical imaging
A group of experts and patient advocates have come together to form the [Open Source Imaging Consortium](https://pulmonaryfibrosisnews.com/2019/05/31/international-open-source-imaging-consortium-osic-launched-to-advance-ipf-diagnosis/). The consortium aims to "advance the diagnosis of idiopathic pulmonary fibrosis and other interstitial lung diseases with the help of digital imaging and machine learning."
According to the consortium's executive director, Elizabeth Estes, the project aims to "collectively speed diagnosis, aid prognosis, and ultimately allow doctors to treat patients more efficiently and effectively." To do that, they're assembling and sharing "15,000 anonymous image scans and clinical data from patients, which will serve as input data for machine learning programs to develop algorithms."
## Mozilla releases a simple-to-use way to see if you've been part of a data breach
Explaining security to the less software-savvy has always been a challenge, and monitoring your exposure to risk is difficult regardless of your skill level. Mozilla released [Firefox Monitor](https://monitor.firefox.com/), with data provided by [Have I Been Pwned](https://haveibeenpwned.com/), as a straightforward way to see if any of your emails have been part of a major data breach. You can enter emails to search one by one, or sign up for their service to notify you in the future.
The site is also full of helpful tutorials on understanding how hackers work, what to do after a data breach, and how to create strong passwords. Be sure to bookmark this one for around the holidays when family members are asking for advice.
### In other news
[Want a Google-free Android? Send your phone to this guy](https://fossbytes.com/want-a-google-free-android-send-your-phone-to-this-guy/)[CockroachDB releases with a non-OSI approved license, remains source available](https://www.cockroachlabs.com/blog/oss-relicensing-cockroachdb/)[Infrastructure automation company Chef commits to Open Source](https://www.infoq.com/news/2019/05/chef-open-source/)[Russia’s would-be Windows replacement gets a security upgrade](https://www.nextgov.com/cybersecurity/2019/05/russias-would-be-windows-replacement-gets-security-upgrade/157330/)[Switch from Medium to your own blog in a few minutes with this code](https://github.com/mathieudutour/medium-to-own-blog)[Open Source Initiative Announces New Partnership with Software Liberty Association Taiwan](https://opensource.org/node/994)
*Thanks, as always, to Opensource.com staff members and moderators for their help this week.*
## Comments are closed. |
10,966 | 为 man 手册页编写解析器的备忘录 | https://monades.roperzh.com/memories-writing-parser-man-pages/ | 2019-06-11T23:57:00 | [
"groff",
"手册页",
"man"
] | /article-10966-1.html | 
我一般都很喜欢无所事事,但有时候太无聊了也不行 —— 2015 年的一个星期天下午就是这样,我决定开始写一个开源项目来让我不那么无聊。
在我寻求创意时,我偶然发现了一个请求,要求构建一个由 [Mathias Bynens](https://mathiasbynens.be/) 提出的“[按 Web 标准构建的 Man 手册页查看器](https://github.com/h5bp/lazyweb-requests/issues/114)”。没有考虑太多,我开始使用 JavaScript 编写一个手册页解析器,经过大量的反复思考,最终做出了一个 [Jroff](jroff)。
那时候,我非常熟悉手册页这个概念,而且使用过很多次,但我知道的仅止于此,我不知道它们是如何生成的,或者是否有一个标准。在经过两年后,我有了一些关于此事的想法。
### man 手册页是如何写的
当时令我感到惊讶的第一件事是,手册页的核心只是存储在系统某处的纯文本文件(你可以使用 `manpath` 命令检查这些目录)。
此文件中不仅包含文档,还包含使用了 20 世纪 70 年代名为 `troff` 的排版系统的格式化信息。
>
> troff 及其 GNU 实现 groff 是处理文档的文本描述以生成适合打印的排版版本的程序。**它更像是“你所描述的即你得到的”,而不是你所见即所得的。**
>
>
> * 摘自 [troff.org](https://www.troff.org/)
>
>
>
如果你对排版格式毫不熟悉,可以将它们视为 steroids 期刊用的 Markdown,但其灵活性带来的就是更复杂的语法:

`groff` 文件可以手工编写,也可以使用许多不同的工具从其他格式生成,如 Markdown、Latex、HTML 等。
为什么 `groff` 和 man 手册页绑在一起是有历史原因的,其格式[随时间有变化](https://manpages.bsd.lv/history.html),它的血统由一系列类似命名的程序组成:RUNOFF > roff > nroff > troff > groff。
但这并不一定意味着 `groff` 与手册页有多紧密的关系,它是一种通用格式,已被用于[书籍](https://rkrishnan.org/posts/2016-03-07-how-is-gopl-typeset.html),甚至用于[照相排版](https://en.wikipedia.org/wiki/Phototypesetting)。
此外,值得注意的是 `groff` 也可以调用后处理器将其中间输出结果转换为最终格式,这对于终端显示来说不一定是 ascii !一些支持的格式是:TeX DVI、HTML、Canon、HP LaserJet4 兼容格式、PostScript、utf8 等等。
### 宏
该格式的其他很酷的功能是它的可扩展性,你可以编写宏来增强其基本功能。
鉴于 \*nix 系统的悠久历史,有几个可以根据你想要生成的输出而将特定功能组合在一起的宏包,例如 `man`、`mdoc`、`mom`、`ms`、`mm` 等等。
手册页通常使用 `man` 和 `mdoc` 宏包编写。
区分原生的 `groff` 命令和宏的方式是通过标准 `groff` 包大写其宏名称。对于 `man` 宏包,每个宏的名称都是大写的,如 `.PP`、`.TH`、`.SH` 等。对于 `mdoc` 宏包,只有第一个字母是大写的: `.Pp`、`.Dt`、`.Sh`。

### 挑战
无论你是考虑编写自己的 `groff` 解析器,还是只是好奇,这些都是我发现的一些更具挑战性的问题。
#### 上下文敏感的语法
表面上,`groff` 的语法是上下文无关的,遗憾的是,因为宏描述的是主体不透明的令牌,所以包中的宏集合本身可能不会实现上下文无关的语法。
这导致我在那时做不出来一个解析器生成器(不管好坏)。
#### 嵌套的宏
`mdoc` 宏包中的大多数宏都是可调用的,这差不多意味着宏可以用作其他宏的参数,例如,你看看这个:
* 宏 `Fl`(Flag)会在其参数中添加破折号,因此 `Fl s` 会生成 `-s`
* 宏 `Ar`(Argument)提供了定义参数的工具
* 宏 `Op`(Optional)会将其参数括在括号中,因为这是将某些东西定义为可选的标准习惯用法
* 以下组合 `.Op Fl s Ar file` 将生成 `[-s file]`,因为 `Op` 宏可以嵌套。
#### 缺乏适合初学者的资源
让我感到困惑的是缺乏一个规范的、定义明确的、清晰的来源,网上有很多信息,这些信息对读者来说很重要,需要时间来掌握。
### 有趣的宏
总结一下,我会向你提供一个非常简短的宏列表,我在开发 jroff 时发现它很有趣:
`man` 宏包:
* `.TH`:用 `man` 宏包编写手册页时,你的第一个不是注释的行必须是这个宏,它接受五个参数:`title`、`section`、`date`、`source`、`manual`。
* `.BI`:粗体加斜体(特别适用于函数格式)
* `.BR`:粗体加正体(特别适用于参考其他手册页)
`mdoc` 宏包:
* `.Dd`、`.Dt`、`.Os`:类似于 `man` 宏包需要 `.TH`,`mdoc` 宏也需要这三个宏,需要按特定顺序使用。它们的缩写分别代表:文档日期、文档标题和操作系统。
* `.Bl`、`.It`、`.El`:这三个宏用于创建列表,它们的名称不言自明:开始列表、项目和结束列表。
---
via: <https://monades.roperzh.com/memories-writing-parser-man-pages/>
作者:[Roberto Dip](https://monades.roperzh.com) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy) 选题:[lujun9972](https://github.com/lujun9972)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='monades.roperzh.com', port=443): Max retries exceeded with url: /memories-writing-parser-man-pages/ (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x7b83409d2b60>: Failed to resolve 'monades.roperzh.com' ([Errno -2] Name or service not known)")) | null |
10,968 | 有了 Lutris,Linux 现在也可以启动 Epic 游戏商城 | https://itsfoss.com/epic-games-lutris-linux/ | 2019-06-12T14:48:00 | [
"游戏"
] | https://linux.cn/article-10968-1.html |
>
> 开源游戏平台 Lutris 现在使你能够在 Linux 上使用 Epic 游戏商城。我们使用 Ubuntu 19.04 版本进行了测试,以下是我们的使用体验。
>
>
>
[在 Linux 上玩游戏](/article-7316-1.html) 正变得越来越容易。Steam [正在开发中的](/article-10054-1.html) 特性可以帮助你实现 [在 Linux 上玩 Windows 游戏](/article-10061-1.html)。
如果说 Steam 在 Linux 运行 Windows 游戏领域还是新玩家,而 Lutris 却已从事多年。
[Lutris](https://lutris.net/) 是一款为 Linux 开发的开源游戏平台,提供诸如 Origin、Steam、战网等平台的游戏安装器。它使用 Wine 来运行 Linux 不能支持的程序。
Lutris 近期宣布你可以通过它来运行 Epic 游戏商店。
### Lutris 为 Linux 带来了 Epic 游戏

[Epic 游戏商城](https://www.epicgames.com/store/en-US/) 是一个类似 Steam 的电子游戏分销平台。它目前只支持 Windows 和 macOS。
Lutris 团队付出了大量努力使 Linux 用户可以通过 Lutris 使用 Epic 游戏商城。虽然我不用 Epic 商城,但可以通过 Lutris 在 Linux 上运行 Epic 商城终归是个好消息。
>
> 好消息! 你现在可以通过 Lutris 安装获得 [@EpicGames](https://twitter.com/EpicGames?ref_src=twsrc%5Etfw) 商城在 Linux 下的全功能支持!没有发现任何问题。 <https://t.co/cYmd7PcYdG>[@TimSweeneyEpic](https://twitter.com/TimSweeneyEpic?ref_src=twsrc%5Etfw) 可能会很喜欢 ?
>
>
> 
>
>
> — Lutris Gaming (@LutrisGaming) [April 17, 2019](https://twitter.com/LutrisGaming/status/1118552969816018948?ref_src=twsrc%5Etfw)
>
>
>
作为一名狂热的游戏玩家和 Linux 用户,我立即得到了这个消息,并安装了 Lutris 来运行 Epic 游戏。
**备注:** 我使用 [Ubuntu 19.04](https://itsfoss.com/ubuntu-19-04-release-features/) 来测试 Linux 环境下的游戏运行情况。
### 通过 Lutris 在 Linux 下使用 Epic 游戏商城
为了在你的 Linux 系统中安装 Epic 游戏商城,请确保你已经安装了 Wine 和 Python 3。接下来,[在 Ubuntu 中安装 Wine](https://itsfoss.com/install-latest-wine/) ,或任何你正在使用的 Linux 发行版本也都可以。然后, [从官方网站下载 Lutris](https://lutris.net/downloads/).
#### 安装 Epic 游戏商城
Lutris 安装成功后,直接启动它。
当我尝试时,我遇到了一个问题(当我用 GUI 启动时却没有遇到)。当我尝试在命令行输入 `lutris` 来启动时,我发现了下图所示的错误:

感谢 Abhishek,我了解到了这是一个常见问题 (你可以在 [GitHub](https://github.com/lutris/lutris/issues/660) 上查看这个问题)。
总之,为了解决这个问题,我需要在命令行中输入以下命令:
```
export LC_ALL=C
```
当你遇到同样的问题时,只要你输入这个命令,就能正常启动 Lutris 了。
**注意**:每次启动 Lutris 时都必须输入这个命令。因此,最好将其添加到 `.bashrc` 文件或环境变量列表中。
上述操作完成后,只要启动并搜索 “Epic Games Store” 会显示以下图片中的内容:

在这里,我已经安装过了,所以你将会看到“安装”选项,它会自动询问你是否需要安装需要的包。只需要继续操作就可以成功安装。就是这样,不需要任何黑科技。
#### 玩一款 Epic 游戏商城中的游戏

现在我们已经通过 Lutris 在 Linux 上安装了 Epic 游戏商城,启动它并登录你的账号就可以开始了。
但这真会奏效吗?
*是的,Epic 游戏商城可以运行。* **但是所有游戏都不能玩。**(LCTT 译注:莫生气,请看文末的进一步解释!)
好吧,我并没有尝试过所有内容,但是我拿了一个免费的游戏(Transistor —— 一款回合制 ARPG 游戏)来检查它是否工作。

很不幸,游戏没有启动。当我运行时界面显示了 “Running” 不过什么都没有发生。
到目前为止,我还不知道有什么解决方案 —— 所以如果我找到解决方案,我会尽力让你们知道最新情况。
### 总结
通过 Lutris 这样的工具使 Linux 的游戏场景得到了改善,这终归是个好消息 。不过,仍有许多工作要做。
对于在 Linux 上运行的游戏来说,无障碍运行仍然是一个挑战。其中可能就会有我遇到的这种问题,或者其它类似的。但它正朝着正确的方向发展 —— 即使还存在着一些问题。
你有什么看法吗?你是否也尝试用 Lutris 在 Linux 上启动 Epic 游戏商城?在下方评论让我们看看你的意见。
### 补充
Transistor 实际上有一个原生的 Linux 移植版。到目前为止,我从 Epic 获得的所有游戏都是如此。它们都是免费的,所以我会试着压下我的郁闷,而因为 Epic 只让你玩你通过他们的商店/启动器购买的游戏,所以在 Linux 机器上用 Lutris 玩这个原生的 Linux 游戏是不可能的。这简直愚蠢极了。Steam 有一个原生的 Linux 启动器,虽然不是很理想,但它可以工作。GOG 允许你从网站下载购买的内容,可以在你喜欢的任何平台上玩这些游戏。他们的启动器完全是可选的。
我对此非常恼火,因为我在我的 Epic 库中的游戏都是可以在我的笔记本电脑上运行得很好的游戏,当我坐在桌面前时,玩起来很有趣。但是因为那台桌面机是我唯一拥有的 Windows 机器……
我选择使用 Linux 时已经知道会存在兼容性问题,并且我有一个专门用于游戏的 Windows 机器,而我通过 Epic 获得的游戏都是免费的,所以我在这里只是表示一下不满。但是,他们两个作为最著名的竞争对手,Epic 应该有在我的 Linux 机器上玩原生 Linux 移植版的机制。
---
via: <https://itsfoss.com/epic-games-lutris-linux/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Modrisco](https://github.com/Modrisco) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Open Source gaming platform Lutris now enables you to use Epic Games Store on Linux. We tried it on Ubuntu and here’s our experience with it.*
[Gaming on Linux](https://itsfoss.com/linux-gaming-guide/) just keeps getting better. Want to [play Windows games on Linux](https://itsfoss.com/steam-play/), Steam’s new [in-progress feature](https://itsfoss.com/steam-play-proton/) enables you to do that.
Steam might be new in the field of Windows games on Linux but Lutris has been doing it for years.
[Lutris](https://lutris.net/) is an open source gaming platform for Linux where it provides installers for game clients like Origin, Steam, Blizzard.net app and so on. It utilizes Wine to run stuff that isn’t natively supported on Linux.
Lutris has recently announced that you can now use Epic Games Store using Lutris.
## Lutris brings Epic Games to Linux

[Epic Games Store](https://www.epicgames.com/store/en-US/) is a digital video game distribution platform like Steam. It only supports Windows and macOS for the moment.
The Lutris team worked hard to bring Epic Games Store to Linux via Lutris. Even though I’m not a big fan of Epic Games Store, it was good to know about the support for Linux via Lutris.
As an avid gamer and Linux user, I immediately jumped upon this news and installed Lutris to run Epic Games on it.
**Note:** *I used Ubuntu 19.04 to test Epic Games store for Linux.*
## Using Epic Games Store for Linux using Lutris
To install Epic Games Store on your Linux system, make sure that you have [Lutris](https://lutris.net/) installed with its pre-requisites Wine and Python 3. So, first [install Wine on Ubuntu](https://itsfoss.com/install-latest-wine/) or whichever Linux you are using and then [download Lutris from its website](https://lutris.net/downloads/).
### Installing Epic Games Store
Once the installation of Lutris is successful, simply launch it.
While I tried this, I encountered an error (nothing happened when I tried to launch it using the GUI). However, when I typed in “**lutris**” on the terminal to launch it otherwise, I noticed an error that looked like this:
Thanks to Abhishek, I learned that this is a common issue (you can check that on [GitHub](https://github.com/lutris/lutris/issues/660)).
So, to fix it, all I had to do was – type in a command in the terminal:
export LC_ALL=C
Just copy it and enter it in your terminal if you face the same issue. And, then, you will be able to open Lutris.
**Note:** *You’ll have to enter this command every time you launch Lutris. So better to add it to your .bashrc or list of environment variable.*
Once that is done, simply launch it and search for “**Epic Games Store**” as shown in the image below:
Here, I have it installed already, so you will get the option to “Install” it and then it will automatically ask you to install the required packages that it needs. You just have to proceed in order to successfully install it. That’s it – no rocket science involved.
### Playing a Game on Epic Games Store
Now that we have Epic Games store via Lutris on Linux, simply launch it and log in to your account to get started.
But, does it really work?
*Yes, the Epic Games Store does work.* **But, all the games don’t.**
Well, I haven’t tried everything, but I grabbed a free game (Transistor – a turn-based ARPG game) to check if that works.
Unfortunately, it didn’t. It says that it is “Running” when I launch it but then again, nothing happens.
As of now, I’m not aware of any solutions to that – so I’ll try to keep you guys updated if I find a fix.
**Wrapping Up**
It’s good to see the gaming scene improve on Linux thanks to the solutions like Lutris for users. However, there’s still a lot of work to be done.
For a game to run hassle-free on Linux is still a challenge. There can be issues like this which I encountered or similar. But, it’s going in the right direction – even if it has issues.
What do you think of Epic Games Store on Linux via Lutris? Have you tried it yet? Let us know your thoughts in the comments below. |
10,969 | GoAccess:一个实时的 Web 日志分析器及交互式查看器 | https://www.2daygeek.com/goaccess-a-real-time-web-server-log-analyzer-and-interactive-viewer/ | 2019-06-12T22:29:00 | [
"日志"
] | https://linux.cn/article-10969-1.html | 
分析日志文件对于 Linux 管理员来说是一件非常令人头疼的事情,因为它记录了很多东西。大多数新手和初级管理员都不知道如何分析。如果你在分析日志方面拥有很多知识,那么你就成了 \*NIX 系统高手。
Linux 中有许多工具可以轻松分析日志。GoAccess 是允许用户轻松分析 Web 服务器日志的工具之一。我们将在本文中详细讨论 GoAccess 工具。
### GoAccess
GoAccess 是一个实时 Web 日志分析器和交互式查看器,可以在 \*nix 系统中的终端运行或通过浏览器访问。
GoAccess 需要的依赖极少,它是用 C 语言编写的,只需要 ncurses。
它支持 Apache、Nginx 和 Lighttpd 日志。它为需要动态可视化服务器报告的系统管理员即时提供了快速且有价值的 HTTP 统计信息。
GoAccess 可以解析指定的 Web 日志文件并将数据输出到 X 终端和浏览器。
GoAccess 被设计成一个基于终端的快速日志分析器。其核心思想是实时快速分析和查看 Web 服务器统计信息,而无需使用浏览器。
默认输出是在终端输出,它也能够生成完整的、自包含的实时 HTML 报告,以及 JSON 和 CSV 报告。
GoAccess 支持任何自定义日志格式,并包含以下预定义日志格式选项:Apache/Nginx 中的组合日志格式 XLF/ELF,Apache 中的通用日志格式 CLF,但不限于此。
### GoAccess 功能
* 完全实时:所有指标在终端上每 200 毫秒更新一次,在 HTML 输出上每秒更新一次。
* 跟踪应用程序响应时间:跟踪服务请求所需的时间。如果你想跟踪减慢了网站速度的网页,则非常有用。
* 访问者:按小时或日期确定最慢运行的请求的点击量、访问者数、带宽数和指标。
* 按虚拟主机的度量标准:如果有多个虚拟主机(`Server`),它提供了一个面板,可显示哪些虚拟主机正在消耗大部分 Web 服务器资源。
### 如何安装 GoAccess?
我建议用户在包管理器的帮助下从发行版官方的存储库安装 GoAccess。它在大多数发行版官方存储库中都可用。
我们知道,我们在标准发行方式的发行版中得到的是过时的软件包,而滚动发行方式的发行版总是包含最新的软件包。
如果你使用标准发行方式的发行版运行操作系统,我建议你检查替代选项,如 PPA 或 GoAccess 官方维护者存储库等,以获取最新的软件包。
对于 Debian / Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/)或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/)在你的系统上安装 GoAccess。
```
# apt install goaccess
```
要获取最新的 GoAccess 包,请使用以下 GoAccess 官方存储库。
```
$ echo "deb https://deb.goaccess.io/ $(lsb_release -cs) main" | sudo tee -a /etc/apt/sources.list.d/goaccess.list
$ wget -O - https://deb.goaccess.io/gnugpg.key | sudo apt-key add -
$ sudo apt-get update
$ sudo apt-get install goaccess
```
对于 RHEL / CentOS 系统,使用 [YUM 包管理器](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/)在你的系统上安装 GoAccess。
```
# yum install goaccess
```
对于 Fedora 系统,使用 [DNF 包管理器](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/)在你的系统上安装 GoAccess。
```
# dnf install goaccess
```
对于基于 ArchLinux / Manjaro 的系统,使用 [Pacman 包管理器](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/)在你的系统上安装 GoAccess。
```
# pacman -S goaccess
```
对于 openSUSE Leap 系统,使用[Zypper 包管理器](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/)在你的系统上安装 GoAccess。
```
# zypper install goaccess
# zypper ar -f obs://server:http
# zypper ref && zypper in goaccess
```
### 如何使用 GoAccess?
成功安装 GoAccess 后。只需输入 `goaccess` 命令,然后输入 Web 服务器日志位置即可查看。
```
# goaccess [options] /path/to/Web Server/access.log
# goaccess /var/log/apache/2daygeek_access.log
```
执行上述命令时,它会要求您选择日志格式配置。

我用 Apache 访问日志对此进行了测试。Apache 日志被分为十五个部分。详情如下。主要部分显示了这十五个部分的摘要。
以下屏幕截图包括四个部分,例如唯一身份访问者、请求的文件、静态请求、未找到的网址。

以下屏幕截图包括四个部分,例如访客主机名和 IP、操作系统、浏览器、时间分布。

以下屏幕截图包括四个部分,例如来源网址、来源网站,Google 的搜索引擎结果、HTTP状态代码。

如果要生成 html 报告,请使用以下命令。最初我在尝试生成 html 报告时遇到错误。
```
# goaccess 2daygeek_access.log -a > report.html
GoAccess - version 1.3 - Nov 23 2018 11:28:19
Config file: No config file used
Fatal error has occurred
Error occurred at: src/parser.c - parse_log - 2764
No time format was found on your conf file.Parsing... [0] [0/s]
```
它说“你的 conf 文件没有找到时间格式”。要解决此问题,请为其添加 “COMBINED” 日志格式选项。
```
# goaccess -f 2daygeek_access.log --log-format=COMBINED -o 2daygeek.html
Parsing...[0,165] [50,165/s]
```

GoAccess 也允许你访问和分析实时日志并进行过滤和解析。
```
# tail -f /var/log/apache/2daygeek_access.log | goaccess -
```
更多细节请参考其 man 手册页或帮助。
```
# man goaccess
或
# goaccess --help
```
---
via: <https://www.2daygeek.com/goaccess-a-real-time-web-server-log-analyzer-and-interactive-viewer/>
作者:[Vinoth Kumar](https://www.2daygeek.com/author/vinoth/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,972 | 在 Windows 中运行 Linux:WSL 2 使用入门 | https://devblogs.microsoft.com/commandline/wsl-2-is-now-available-in-windows-insiders/ | 2019-06-14T10:49:00 | [
"WSL"
] | https://linux.cn/article-10972-1.html | 
继微软发布了 WSL 2 (Windows Subsystem for Linux 2)之后,前两天正式提供了 WSL2 更新,处于 Insider Fast 通道中的用户可以通过安装 Windows build 18917 更新来体验最新版本的 WSL2。
在这篇文章中,我们将介绍如何入门、新的 `wsl.exe` 命令以及一些重要提示。有关 WSL 2 的完整文档可在[微软的文档页面](https://docs.microsoft.com/en-us/windows/wsl/wsl2-index)上找到。
### 安装 WSL 2
要安装并开始使用 WSL 2,请完成以下步骤:
* 启用“<ruby> 虚拟机平台 <rp> ( </rp> <rt> Virtual Machine Platform </rt> <rp> ) </rp></ruby>”可选组件
* 使用命令行设置要由 WSL 2 支持的发行版
* 验证你的发行版使用的 WSL 版本
请注意,你需要运行 Windows 10 build 18917 或更高版本才能使用 WSL 2,并且你需要安装 WSL(可以在[此处](https://docs.microsoft.com/en-us/windows/wsl/install-win10)找到相关说明)。
#### 启用“虚拟机平台”可选组件
以管理员身份打开 PowerShell 并运行:
```
Enable-WindowsOptionalFeature -Online -FeatureName VirtualMachinePlatform
```
启用这些更改后,你需要重新启动计算机。
#### 使用命令行设置要由 WSL 2 支持的发行版
在 PowerShell 中运行:
```
wsl --set-version <Distro> 2
```
并确保将 `<Distro>` 替换为发行版的实际名称。 (你可以使用以下命令找到它们:`wsl -l`)。 你也可以通过运行与上面相同的命令随时更改回 WSL 1,但将“`2`”替换为“`1`”。
此外,如果你想使 WSL 2 成为默认架构,可以使用以下命令执行此操作:
```
wsl --set-default-version 2
```
这将使你安装的任何新发行版初始化为 WSL 2 发行版。
#### 完成验证发行版使用的 WSL 版本
要验证每个发行版使用的 WSL 版本,请使用以下命令:
```
wsl --list --verbose
或
wsl -l -v
```
你在上面选择的发行版现在应该在“version”列下显示“2”。 现在完成了,你随时可以开始使用你的 WSL 2 发行版了!
### WSL 2 的体验变化
首次开始使用 WSL 时,你会注意到一些用户体验变化。以下是此预览中两个最重要的变化。
#### 将 Linux 文件放在 Linux 根文件系统中
确保将 Linux 应用程序中经常访问的文件放在 Linux 根文件系统中,以享受文件性能优势。过去微软一直强调在使用 WSL 1 时将文件放入 C 盘,但 WSL 2 中的情况并非如此。要享受 WSL 2 中更快的文件系统访问权限,这些文件必须放在 Linux 根文件系统里面。而且现在 Windows 应用程序可以访问 Linux 根文件系统(如文件资源管理器!尝试在 Linux 发行版的主目录中运行:`explorer.exe .` 看看会发生什么),这将使这种转换变得更加容易。
#### 在初始构建中使用动态 IP 地址访问 Linux 网络应用程序
WSL 2 做了架构的巨大变更,使用了虚拟化技术,并仍在努力改进网络支持。由于 WSL 2 现在运行在虚拟机中,因此你从 Windows 访问 Linux 网络应用程序需要使用该 VM 的 IP 地址,反之亦然,你需要 Windows 主机的 IP 地址才能从 Linux 中访问 Windows 网络应用程序。 WSL 2 的目标是尽可能使用 `localhost` 访问网络应用程序!可以在[文档中](https://docs.microsoft.com/en-us/windows/wsl/wsl2-ux-changes#accessing-network-applications)找到有关如何执行此操作的完整详细信息和步骤。
要了解有关用户体验更改的更多信息,请参阅文档:[WSL 1 和 WSL 2 之间的用户体验变化](https://docs.microsoft.com/en-us/windows/wsl/wsl2-ux-changes)。
### 新的 WSL 命令
WSL 添加了一些新命令选项来帮助控制和查看 WSL 版本和发行版。
除了上面提到的 `--set-version` 和 `--set-default-version` 之外,还有:
* `wsl --shutdown`
立即终止所有正在运行的发行版和 WSL 2 轻量级实用程序虚拟机。
一般来说,支持 WSL 2 发行版的虚拟机是由 WSL 来管理的,因此会在需要时将其打开并在不需要时将其关闭。但也可能存在你希望手动关闭它的情况,此命令允许你通过终止所有发行版并关闭 WSL 2 虚拟机来执行此操作。
* `wsl --list --quiet`
仅列出发行版名称。此命令对于脚本编写很有用,因为它只会输出你已安装的发行版的名称,而不显示其他信息,如默认发行版、版本等。
* `wsl --list --verbose`
显示有关所有发行版的详细信息。此命令列出每个发行版的名称,发行版所处的状态以及正在运行的版本。默认发行版标以星号。
### 反馈意见
如果你遇到任何问题, 请在 Github 上提交问题: <https://github.com/microsoft/wsl/issues> ,如果你对 WSL 有一般性问题,你可以在这个[推特列表](https://twitter.com/craigaloewen/lists/wsl-team-members/members)上找到该团队所有成员的 Twitter。
| 200 | OK | We’re excited to announce starting today you can try the [Windows Subsystem for Linux 2](https://devblogs.microsoft.com/commandline/announcing-wsl-2/) by installing Windows build 18917 in the Insider Fast ring! In this blog post we’ll cover how to get started, the new wsl.exe commands, and some important tips. Full documentation about WSL 2 is available on [our docs page](https://docs.microsoft.com/en-us/windows/wsl/wsl2-index).
# Getting Started with WSL 2
We can’t wait to see how you start using WSL 2. Our goal is to make WSL 2 feel the same as WSL 1, and we look forward to hearing your feedback on how we can improve. The [Installing WSL 2](https://docs.microsoft.com/en-us/windows/wsl/wsl2-install) docs explains how to get up and running with WSL 2.
There are some user experience changes that you’ll notice when you first start using WSL 2. Here are the two most important changes in this initial preview.
## Place your Linux files in your Linux root file system
Make sure to put the files that you will be accessing frequently with Linux applications inside of your Linux root file system to enjoy the file performance benefits. We understand that we have spent the past three years telling you to put your files into your C drive when using WSL 1, but this is not the case in WSL 2. To enjoy the faster file system access in WSL 2 these files must be inside of the Linux root file system. We have also made it possible for Windows apps to access the Linux root file system (like File Explorer! Try running: `explorer.exe .`
in the home directory of your Linux distro and see what happens) which will make this transition significantly easier.
## Access your Linux network applications with a dynamic IP address in initial builds
WSL 2 includes a huge architecture change using virtualization technology, and we are still working on improving the networking support. Since WSL 2 now runs in a virtual machine, you will need to use that VM’s IP address to access Linux networking applications from Windows, and vice versa you will need the Windows host’s IP address to access Windows networking applications from Linux. We aim to include the ability for WSL 2 to access network applications with `localhost`
as soon as we can! You can find full details and steps on how to do this in our documentation [here](https://docs.microsoft.com/en-us/windows/wsl/wsl2-ux-changes#accessing-network-applications).
To read more about the user experience changes please see our documentation: [User Experience Changes Between WSL 1 and WSL 2](https://docs.microsoft.com/en-us/windows/wsl/wsl2-ux-changes).
# New WSL Commands
We’ve also added some new commands to help you control and view your WSL versions and distros.
-
`wsl --set-version <Distro> <Version>`
Use this command to convert a distro to use the WSL 2 architecture or use the WSL 1 architecture.: the specific Linux distro (e.g. “Ubuntu”) : 1 or 2 (for WSL 1 or 2) -
`wsl --set-default-version <Version>`
Changes the default install version (WSL 1 or 2) for new distributions. -
`wsl --shutdown`
Immediately terminates all running distributions and the WSL 2 lightweight utility virtual machine.The VM that powers WSL 2 distros is something that we aim to manage entirely for you, and so we spin it up when you need it and shut it down when you don’t. There could be cases where you would want to shut it down manually, and this command lets you do that by terminating all distributions and shutting down the WSL 2 VM.
-
`wsl --list --quiet`
Only list the distribution names.This command is useful for scripting since it will only output the names of distributions you have installed without showing other information like the default distro, versions, etc.
-
`wsl --list --verbose`
Shows detailed information about all the distributions.This command lists the name of each distro, what state the distro is in, and what version it is running. It also shows which distributions is default with an asterisk.
# Looking ahead and hearing your feedback
You can expect to get more features, bugfixes, and general updates to WSL 2 inside of the Windows Insiders program. Stay tuned to their experience blog and this blog right here to learn more WSL 2 news.
If you run into any issues, or have feedback for our team please file an issue on our Github at: https://github.com/microsoft/wsl/issues , and if you have general questions about WSL you can find all of our team members that are on Twitter on [this twitter list](https://twitter.com/craigaloewen/lists/wsl-team-members/members).
Updates:
- Changed the instruction to access your Linux files from Windows to
`explorer.exe .`
- Changed first sentence of post to spell out the WSL acronym.
## 69 comments |
10,973 | 使用 Kubernetes 的 5 个理由 | https://opensource.com/article/19/6/reasons-kubernetes | 2019-06-14T11:07:22 | [
"Kubernetes",
"k8s"
] | https://linux.cn/article-10973-1.html |
>
> Kubernetes 解决了一些开发和运维团队每天关注的的常见问题。
>
>
>

[Kubernetes](https://opensource.com/resources/what-is-kubernetes)(K8S)是面向企业的开源容器编排工具的事实标准。它提供了应用部署、扩展、容器管理和其他功能,使企业能够通过容错能力快速优化硬件资源利用率并延长生产环境运行时间。该项目最初由谷歌开发,并将该项目捐赠给[云原生计算基金会](https://www.cncf.io/projects/)(CNCF)。2018 年,它成为第一个从 CNCF [毕业](https://www.cncf.io/blog/2018/03/06/kubernetes-first-cncf-project-graduate/)的项目。
这一切都很好,但它并不能解释为什么开发者和运维人员应该在 Kubernetes 上投入宝贵的时间和精力。Kubernetes 之所以如此有用,是因为它有助于开发者和运维人员迅速解决他们每天都在努力解决的问题。
以下是 Kubernetes 帮助开发者和运维人员解决他们最常见问题的五种能力。
### 1、厂商无关
许多公有云提供商不仅提供托管 Kubernetes 服务,还提供许多基于这些服务构建的云产品,来用于本地应用容器编排。由于与供应商无关,使运营商能够轻松、安全地设计、构建和管理多云和混合云平台,而不会有供应商锁定的风险。Kubernetes 还消除了运维团队对复杂的多云/混合云战略的担忧。
### 2、服务发现
为了开发微服务应用,Java 开发人员必须控制服务可用性(就应用是否可以提供服务而言),并确保服务持续存在,以响应客户端的请求,而没有任何例外。Kubernetes 的[服务发现功能](https://kubernetes.io/docs/concepts/services-networking/service/)意味着开发人员不再需要自己管理这些东西。
### 3、触发
你的 DevOps 会如何在上千台虚拟机上部署多语言、云原生应用?理想情况下,开发和运维会在 bug 修复、功能增强、新功能、安全更新时触发部署。Kubernetes 的[部署功能](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/)会自动化这个日常工作。更重要的时,它支持高级部署策略,例如[蓝绿部署和金丝雀部署](https://opensource.com/article/17/5/colorful-deployments)。
### 4、可伸缩性
自动扩展是处理云环境中大量工作负载所需的关键功能。通过构建容器平台,你可以为终端用户提高系统可靠性。[Kubernetes Horizontal Pod Autoscaler](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/)(HPA)允许一个集群增加或减少应用程序(或 Pod)的数量,以应对峰值流量或性能峰值,从而减少对意外系统中断的担忧。
### 5、容错性
在现代应用体系结构中,应考虑故障处理代码来控制意外错误并快速从中恢复。但是开发人员需要花费大量的时间和精力来模拟偶然的错误。Kubernetes 的 [ReplicaSet](https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/) 通过确保指定数量的 Pod 持续保持活动来帮助开发人员解决此问题。
### 结论
Kubernetes 使企业能够轻松、快速、安全地解决常见的开发和运维问题。它还提供其他好处,例如构建无缝的多云/混合云战略,节省基础架构成本以及加快产品上市时间。
---
via: <https://opensource.com/article/19/6/reasons-kubernetes>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Kubernetes](https://opensource.com/resources/what-is-kubernetes) is the de facto open source container orchestration tool for enterprises. It provides application deployment, scaling, container management, and other capabilities, and it enables enterprises to optimize hardware resource utilization and increase production uptime through fault-tolerant functionality at speed. The project was initially developed by Google, which donated the project to the [Cloud-Native Computing Foundation](https://www.cncf.io/projects/). In 2018, it became the first CNCF project to [graduate](https://www.cncf.io/blog/2018/03/06/kubernetes-first-cncf-project-graduate/).
This is all well and good, but it doesn't explain why development and operations should invest their valuable time and effort in Kubernetes. The reason Kubernetes is so useful is that it helps dev and ops quickly solve the problems they struggle with every day.
Following are five ways Kubernetes' capabilities help dev and ops professionals address their most common problems.
## 1. Vendor-agnostic
Many public cloud providers not only serve managed Kubernetes services but also lots of cloud products built on top of those services for on-premises application container orchestration. Being vendor-agnostic enables operators to design, build, and manage multi-cloud and hybrid cloud platforms easily and safely without risk of vendor lock-in. Kubernetes also eliminates the ops team's worries about a complex multi/hybrid cloud strategy.
## 2. Service discovery
To develop microservices applications, Java developers must control service availability (in terms of whether the application is ready to serve a function) and ensure the service continues living, without any exceptions, in response to the client's requests. Kubernetes' [service discovery feature](https://kubernetes.io/docs/concepts/services-networking/service/) means developers don't have to manage these things on their own anymore.
## 3. Invocation
How would your DevOps initiative deploy polyglot, cloud-native apps over thousands of virtual machines? Ideally, dev and ops could trigger deployments for bug fixes, function enhancements, new features, and security patches. Kubernetes' [deployment feature](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/) automates this daily work. More importantly, it enables advanced deployment strategies, such as [blue-green and canary](https://opensource.com/article/17/5/colorful-deployments) deployments.
## 4. Elasticity
Autoscaling is the key capability needed to handle massive workloads in cloud environments. By building a container platform, you can increase system reliability for end users. [Kubernetes Horizontal Pod Autoscaler](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/) (HPA) allows a cluster to increase or decrease the number of applications (or Pods) to deal with peak traffic or performance spikes, reducing concerns about unexpected system outages.
## 5. Resilience
In a modern application architecture, failure-handling codes should be considered to control unexpected errors and recover from them quickly. But it takes a lot of time and effort for developers to simulate all the occasional errors. Kubernetes' [ReplicaSet](https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/) helps developers solve this problem by ensuring a specified number of Pods are kept alive continuously.
## Conclusion
Kubernetes enables enterprises to solve common dev and ops problems easily, quickly, and safely. It also provides other benefits, such as building a seamless multi/hybrid cloud strategy, saving infrastructure costs, and speeding time to market.
## Comments are closed. |
10,974 | Unity 编辑器现已正式面向 Linux 推出 | https://itsfoss.com/unity-editor-linux/ | 2019-06-14T11:21:00 | [
"Unity"
] | https://linux.cn/article-10974-1.html | 如果你是设计师、开发者或艺术家,你可能一直在使用 Linux 上的实验性 [Unity 编辑器](https://unity3d.com/unity/editor)。然而,不能一直用实验性版本 —— 开发者需要一个完整稳定的工作经验。
因此,他们最近宣布你可以在 Linux 上使用完整功能的 Unity 编辑器了。
虽然这是一个令人兴奋的消息,但它正式支持哪些 Linux 发行版?我们来谈谈更多细节……
>
> 非 FOSS 警告
>
>
> Linux (或任何其他平台)上的 Unity 编辑器不是开源软件。我们在这里介绍它是因为:
>
>
>
### 官方支持 Ubuntu 和 CentOS 7

无论你拥有个人许可还是专业许可,如果你安装了 Unity 2019.1 或更高版本,都可以使用该编辑器。
此外,他们优先支持 Ubuntu 16.04、Ubuntu 18.04 和 CentOS 7。
在[公告](https://blogs.unity3d.com/2019/05/30/announcing-the-unity-editor-for-linux/)中,他们还提到了支持的配置:
* x86-64 架构
* 运行在 X11 窗口系统之上的 Gnome 桌面环境
* Nvidia 官方专有显卡驱动和 AMD Mesa 显卡驱动
* 桌面计算机,在没有仿真或兼容层的设备/硬件上运行
你可以尝试其他的 —— 但最好坚持官方要求以获得最佳体验。
>
> 关于第三方工具的说明
>
>
> 如果你碰巧在某个项目中使用了任何第三方工具,那么必须单独检查它们是否支持。
>
>
>
### 如何在 Linux 上安装 Unity 编辑器
现在你已经了解了,那么该如何安装?
要安装 Unity,你需要下载并安装 [Unity Hub](https://forum.unity.com/threads/unity-hub-v-1-6-0-is-now-available.640792/)。

你需要完成以下步骤:
* 从[官方论坛页面](https://forum.unity.com/threads/unity-hub-v-1-6-0-is-now-available.640792/)下载适用于 Linux 的 Unity Hub。
* 它将下载一个 AppImage 文件。简单地说,让它可执行并运行它。如果你不了解,你应该查看关于[如何在 Linux 上使用 AppImage](https://itsfoss.com/use-appimage-linux/) 的指南。
* 启动 Unity Hub 后,它会要求你使用 Unity ID 登录(或注册)以激活许可证。有关许可证生效的更多信息,请参阅他们的 [FAQ 页面](https://support.unity3d.com/hc/en-us/categories/201268913-Licenses)。
* 使用 Unity ID 登录后,进入 “Installs” 选项(如上图所示)并添加所需的版本/组件。
就是这些了。这就是获取并快速安装的最佳方法。
### 总结
即使这是一个令人兴奋的消息,但官方配置支持似乎并不广泛。如果你在 Linux 上使用它,请在[他们的 Linux 论坛帖子](https://forum.unity.com/forums/linux-editor.93/)上分享你的反馈和意见。
你觉得怎么样?此外,你是使用 Unity Hub 安装它,还是有更好的方法来安装?
请在下面的评论中告诉我们你的想法。
---
via: <https://itsfoss.com/unity-editor-linux/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you are a designer, developer, or artist, you probably should have known about Unity Editor and its wide range of features. It’s encouraging news that Unity offers several installation methods in Linux distributions.
While this is exciting news, what Linux distributions does it officially support? Let us talk about a few more details.
**Non-FOSS Alert**: Unity Editor on Linux (or any other platform) is not open-source software. It is covered here because it supports to install in Linux distribution.
## Official Support for Ubuntu and CentOS 7

No matter whether you have a personal or a professional license, you can access the editor if you have Unity 2019.1 installed or later.
In addition, they are prioritizing the support for Ubuntu 20.04, and CentOS 7.
In their Linux Installation Instructions, they also mentioned the configurations supported for their 2021 LTS release:
- CPU: X64 architecture with SSE2 instruction set support
- Graphics API: OpenGL 3.2+ or Vulkan-capable, Nvidia, and AMD GPUs.
- Additional: Gnome desktop environment running on top of X11 windowing system, Nvidia official proprietary graphics driver or AMD Mesa graphics driver
You can always try on anything else – but it’s better to stick with the official requirements for the best experience.
A Note on 3rd Party Tools: If you happen to utilize any 3rd party tool on any of your projects, you will have to separately check whether they support it or not.
## Step 1: Installing Unity Hub on Linux
You are required to install a tool called Unity Hub first. It’s a management tool that can manage multiple installations of Unity. Once installed, the Unity Hub tool downloads and installs the Unity editor.
### Method 1: Install Unity Hub via terminal (for Ubuntu and Debian)
This is the recommended way of installing Unity Hub on the supported devices, that is Ubuntu and CentOS.
This method will work only in Ubuntu 20.04, 19.04, and CentOS 7. If you are running any of these, let’s jump right in.
Open a terminal and enter the commands one after another:
```
sudo sh -c 'echo "deb https://hub.unity3d.com/linux/repos/deb stable main" > /etc/apt/sources.list.d/unityhub.list'
wget -qO - https://hub.unity3d.com/linux/keys/public | sudo apt-key add -
sudo apt update
sudo apt-get install unityhub
```
This will install Unity Hub to your system. You will be greeted by a screen as shown below:
You now need to sign in with your Unity account. Clicking the sign-in button will open a browser tab and you need to allow the link to open in Unity Hub app:
Now, you will need to choose license Personal, if you do not have a paid plan, from the next screen:
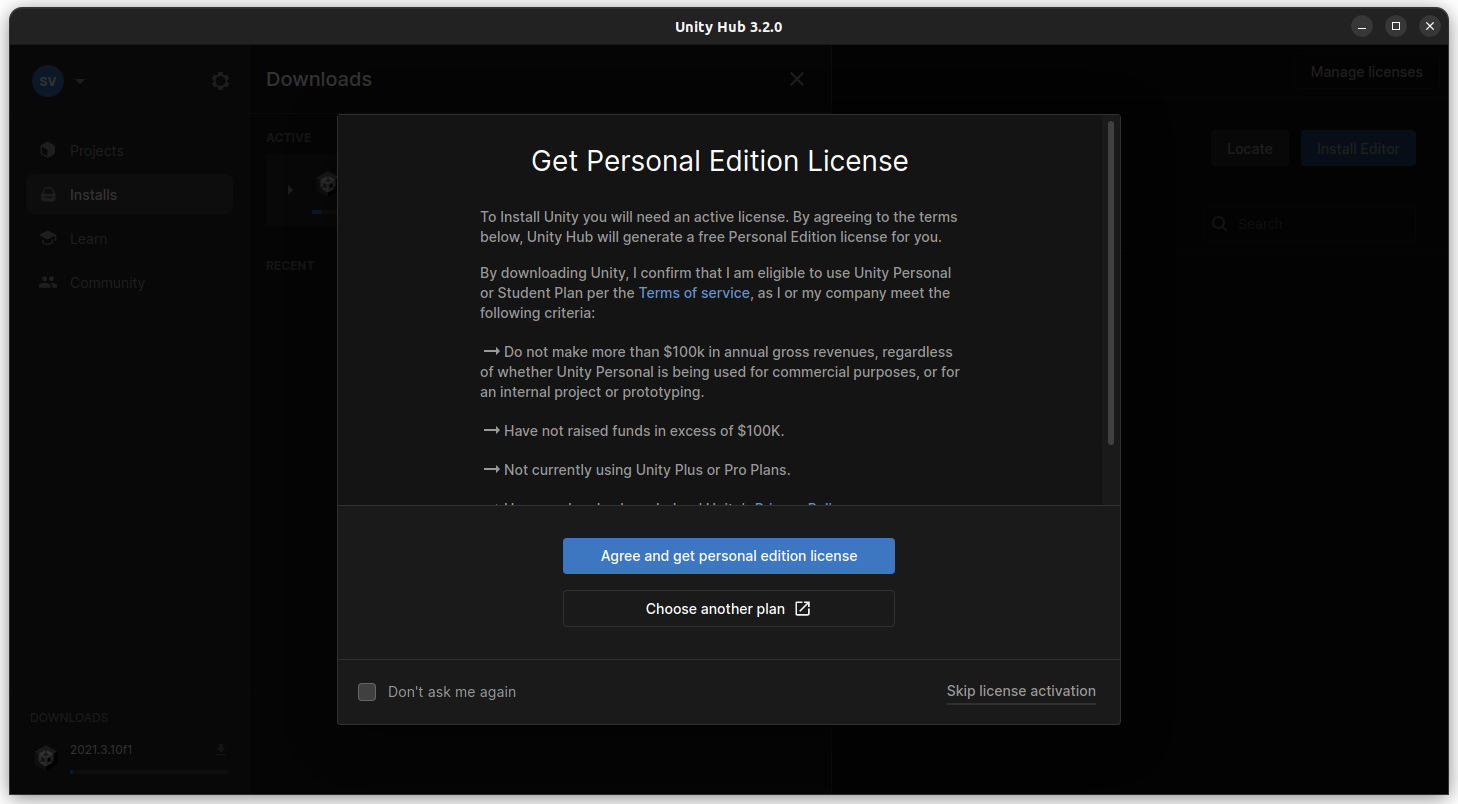
On the next screen, you will be asked to download an editor to work with projects. It normally takes several GBs of download. So sit back and relax while the download completes.
You can now start working on your projects, once everything is finished.
### Method 2: Install Unity Hub through Flatpak
Luckily, Unity Hub is available as a flatpak version, so you can install it in any Linux distribution. You can read [how to work with flatpak apps](https://itsfoss.com/flatpak-guide/), if you are confused.
If you have flatpak installed and flathub repo added, open a terminal and execute the following command:
`flatpak install flathub com.unity.UnityHub`
The rest of the setup is the same as above.
### Method 3: Install Unity Hub using AppImage
To install Unity, you will have to download and run the [Unity Hub AppImage](https://unity3d.com/get-unity/download?ref=itsfoss.com).
Simply, make it executable and run it. In case you are not aware of it, you should check out our guide on [how to use AppImage on Linux](https://itsfoss.com/use-appimage-linux/).
## Step 2: Installing Unity using the Unity Hub tool
Once you launch the Unity Hub, it will ask you to sign in (or sign up) using your Unity ID to activate the licenses. For more info on how the licenses work, do refer to their [FAQ page](https://support.unity3d.com/hc/en-us/categories/201268913-Licenses?ref=itsfoss.com).
After you sign in using your Unity ID, go to the “Installs” option (as shown in the image below) and add the version/components you want.
This will Install an older version of Unity Hub, which will not get any automatic updates.
### Unity Enterprises
Unity editor needs a license to work. If you are a new user of Unity, you can work with their personal or student license, which is free. Also, unity offers several tiers of licenses like Teams, Enterprise, etc.
While you can purchase the licenses for [Teams from their website](https://store.unity.com/?ref=itsfoss.com#plans-business), You cannot purchase the enterprise license. In order to get the enterprise license, you need to [talk to their representative](https://store.unity.com/?ref=itsfoss.com#plans-enterprise).
You can add your Pro or other licenses with the corresponding serial number through Unity Hub interface.
That’s it! This is the best way to get all the latest builds and get it installed in a jiffy.
## Wrapping Up
It’s good to see Unity providing support for the Linux platform. The centralized way of installing everything through Unity Hub keeps things organized. What do you think? |
10,976 | 在免费 RPG 日试玩一下新游戏 | https://opensource.com/article/19/5/free-rpg-day | 2019-06-15T10:39:50 | [
"RPG",
"桌面游戏"
] | /article-10976-1.html |
>
> 6 月 15 日,你可以在当地的游戏商家庆祝桌面角色扮演游戏并获得免费的 RPG 资料。
>
>
>

(LCTT 译注:“<ruby> 免费 RPG 日 <rt> Free RPG Day </rt></ruby>”是受“<ruby> 免费漫画书日 <rt> Free Comic Book Day </rt></ruby>”启发而发起的庆祝活动,从 2007 年开始已经举办多次。这里的 RPG 游戏并非我们通常所指的电脑 RPG 游戏,而是指使用纸和笔的桌面游戏,是一种西方传统游戏形式。)
你有没有想过尝试一下《<ruby> 龙与地下城 <rt> Dungeons & Dragons </rt></ruby>》,但不知道如何开始?你是否在年轻时玩过《<ruby> 开拓者 <rt> Pathfinder </rt></ruby>》并一直在考虑重返快乐时光?你是否对角色扮演游戏(RPG)感到好奇,但不确定你是否想玩一个?你是否对桌面游戏的概念完全陌生,直到现在才听说过这种 RPG 游戏?无论是哪一个并不重要,因为[免费 RPG 日](https://www.freerpgday.com/)适合所有人!
第一个免费 RPG 日活动发生在 2007 年,是由世界各地的桌面游戏商家举办的。这个想法是以 0 美元的价格为新手和有经验的游戏玩家带来新的、独家的 RPG 快速入门规则和冒险体验。在这样的一天里,你可以走进当地的桌面游戏商家,得到一本小册子,其中包含桌面 RPG 的简单的初学者规则,你可以在商家里与那里的人或者回家与朋友一起玩。这本小册子是给你的,应该一直留着的。
这一活动如此的受欢迎,此后该传统一直延续至今。今年,免费 RPG 日定于 6 月 15 日星期六举行。
### 有什么收获?
显然,免费 RPG 日背后的想法是让你沉迷于桌面 RPG 游戏。但在你本能的犬儒主义开始之前,考虑到它会慢慢上瘾,爱上一个鼓励你阅读规则和知识的游戏并不太糟,这样你和你的家人、朋友就有了共度时光的借口了。桌面 RPG 是一个功能强大、富有想象力和有趣的媒介,而免费 RPG 日则是对这种游戏很好的介绍。

### 开源游戏
像许多其他行业一样,开源现象影响了桌面游戏。回到世纪之交,《Magic:The Gathering and Dungeons&Dragons》 的提供者<ruby> <a href="https://company.wizards.com/"> 威世智公司 </a> <rt> Wizards of the Coast </rt></ruby>决定通过开发<ruby> <a href="http://www.opengamingfoundation.org/licenses.html"> 开源游戏许可证 </a> <rt> Open Game License </rt></ruby>(OGL)来采用开源方法。他们将此许可证用于世界上第一个 RPG(《<ruby> 龙与地下城 <rt> Dungeons & Dragons </rt></ruby>》,D&D)的版本 3 和 3.5。几年后,当他们在第四版上(对开源)产生了动摇时,《<ruby> 龙 <rt> Dragon </rt></ruby>》杂志的出版商复刻了 D&D 3.5 的“代码”,将其混制版本发布为《<ruby> 开拓者 <rt> Pathfinder </rt></ruby>》 RPG,从而保持了创新和整个第三方游戏开发者产业的健康发展。最近,威世智公司在 D&D 5e 版本中才又重回了 OGL。
OGL 允许开发人员至少可以在他们自己产品中使用该游戏的机制。不管你可以不可以使用自定义怪物、武器、王国或流行角色的名称,但你可以随时使用 OGL 游戏的规则和数学计算。事实上,OGL 游戏的规则通常作为[系统参考文档](https://www.d20pfsrd.com/)(SRD)免费发布的,因此,无论你是否购买了规则书的副本,你都可以了解游戏的玩法。
如果你之前从未玩过桌面 RPG,那么使用笔和纸玩的游戏也可以拥有游戏引擎似乎很奇怪,但计算就是计算,不管是数字的还是模拟的。作为一个简单的例子:假设游戏引擎规定玩家角色有一个代表其力量的数字。当那个玩家角色与一个有其两倍力量的巨人战斗时,在玩家掷骰子以增加她的角色的力量攻击时,真的会感到紧张。如果没有掷出一个很好的点数的话,她的力量将无法与巨人相匹敌。知道了这一点,第三方或独立开发者就可以为这个游戏引擎设计一个怪物,同时了解骰子滚动可能对玩家的能力得分产生的影响。这意味着他们可以根据游戏引擎的优先级进行数学计算。他们可以设计一系列用来杀死的怪物,在游戏引擎的环境中它们具有有意义的能力和技能,并且他们可以宣称与该引擎的兼容性。
此外,OGL 允许出版商为其材料定义产品标识。产品标识可以是出版物的商业外观(图形元素和布局)、徽标、术语、传说、专有名称等。未经出版商同意,任何定义为产品标识的内容都可能**无法**重复使用。例如,假设一个出版商发行了一本武器手册,其中包括一个名为 Sigint 的魔法砍刀,它对所有针对僵尸的攻击都给予 +2 魔法附加攻击值。这个特性来自一个故事,该砍刀是一个具有潜伏的僵尸基因的科学家锻造的。但是,该出版物在 OGL 第 1e 节中列出的所有武器的正确名称都被保留为产品标识。这意味着你可以在自己的出版物中使用该数字(武器的持久性、它所造成的伤害,+2 魔法奖励等等)以及与该武器相关的传说(它由一个潜伏的僵尸锻造),但是你不能使用该武器的名称(Sigint)。
OGL 是一个非常灵活的许可证,因此开发人员必须仔细阅读其第 1e 节。 一些出版商只保留出版物本身的布局,而其他出版商保留除数字和最通用术语之外的所有内容。
当卓越的 RPG 特许经营权拥抱开源时,至今仍能感受到的它给整个行业掀起的波澜。第三方开发人员可以为 5e 和《开拓者》系统创建内容。由威世智公司创建的整个 [DungeonMastersGuild.com](https://www.dmsguild.com/) 网站为 D&D 5e 制作了独立内容,旨在促进独立出版。[Starfinder](https://paizo.com/starfinder)、[OpenD6](https://ogc.rpglibrary.org/index.php?title=OpenD6)、[战士,盗贼和法师](http://www.stargazergames.eu/games/warrior-rogue-mage/)、[剑与巫师](https://froggodgames.com/frogs/product/swords-wizardry-complete-rulebook/) 等及很多其它游戏都采用了 OGL。其他系统,如 Brent Newhall 的 《[Dungeon Delvers](http://brentnewhall.com/games/doku.php?id=games:dungeon_delvers)》、《[Fate](http://www.faterpg.com/licensing/licensing-fate-cc-by/)》、《[Dungeon World](http://dungeon-world.com/)》 等等,都是根据[知识共享许可](https://creativecommons.org/)授权的的。
### 获取你的 RPG
在免费 RPG 日,你可以前往当地游戏商铺,玩 RPG 以及获取与朋友将来一起玩的 RPG 游戏材料。就像<ruby> <a href="https://www.tldp.org/HOWTO/Installfest-HOWTO/introduction.html"> Linux 安装节 </a> <rt> Linux installfest </rt></ruby> 或 <ruby> <a href="https://www.softwarefreedomday.org/"> 软件自由日 </a> <rt> Software Freedom Day </rt></ruby>一样,该活动的定义很松散。每个商家举办的自由 RPG 日都有所不同,每个商家都可以玩他们选择的任何游戏。但是,游戏发行商捐赠的免费内容每年都是相同的。显然,免费的东西视情况而定,但是当你参加免费 RPG 日活动时,请注意有多少游戏采用了开源许可证(如果是 OGL 游戏,OGL 会打印在书背面)。《开拓者》、《Starfinder》 和 D&D 的任何内容肯定都会带有 OGL 的一些优势。许多其他系统的内容使用知识共享许可。有些则像 90 年代复活的 [Dead Earth](https://mixedsignals.ml/games/blog/blog_dead-earth) RPG 一样,使用 [GNU 自由文档许可证](https://www.gnu.org/licenses/fdl-1.3.en.html)。
有大量的游戏资源是通过开源许可证开发的。你可能需要也可能不需要关心游戏的许可证;毕竟,许可证与你是否可以与朋友一起玩无关。但是如果你喜欢支持[自由文化](https://opensource.com/article/18/1/creative-commons-real-world)而不仅仅是你运行的软件,那么试试一些 OGL 或知识共享游戏吧。如果你不熟悉游戏,请在免费 RPG 日在当地游戏商家试玩桌面 RPG 游戏!
---
via: <https://opensource.com/article/19/5/free-rpg-day>
作者:[Seth Kenlon](https://opensource.com/users/seth/users/erez/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,977 | 让 Emacs shell 命令发送桌面通知 | https://blog.hoetzel.info/post/eshell-notifications/ | 2019-06-15T14:18:00 | [
"Emacs"
] | https://linux.cn/article-10977-1.html | 
我总是使用 [Eshell](https://www.gnu.org/software/emacs/manual/html_mono/eshell.html "Eshell") 来与操作系统进行交互,因为它与 Emacs 无缝整合、支持处理 (远程) [TRAMP](https://www.gnu.org/software/tramp/ "TRAMP") 文件,而且在 Windows 上也能工作得很好。
启动 shell 命令后 (比如耗时严重的构建任务) 我经常会由于切换缓冲区而忘了追踪任务的运行状态。
多亏了 Emacs 的 [钩子](https://www.gnu.org/software/emacs/manual/html_node/emacs/Hooks.html "hooks") 机制,你可以配置 Emacs 在某个外部命令完成后调用一个 elisp 函数。
我使用 [John Wiegleys](https://github.com/jwiegley "John Wiegleys") 所编写的超棒的 [alert](https://github.com/jwiegley/alert "alert") 包来发送桌面通知:
```
(require 'alert)
(defun eshell-command-alert (process status)
"Send `alert' with severity based on STATUS when PROCESS finished."
(let* ((cmd (process-command process))
(buffer (process-buffer process))
(msg (format "%s: %s" (mapconcat 'identity cmd " ") status)))
(if (string-prefix-p "finished" status)
(alert msg :buffer buffer :severity 'normal)
(alert msg :buffer buffer :severity 'urgent))))
(add-hook 'eshell-kill-hook #'eshell-command-alert)
```
[alert](https://github.com/jwiegley/alert "alert") 的规则可以用程序来设置。就我这个情况来看,我只需要当对应的缓冲区不可见时得到通知:
```
(alert-add-rule :status '(buried) ;only send alert when buffer not visible
:mode 'eshell-mode
:style 'notifications)
```
这甚至对于 [TRAMP](https://www.gnu.org/software/tramp/ "TRAMP") 也一样生效。下面这个截屏展示了失败的 `make` 命令产生的 Gnome 桌面通知。

---
via: <https://blog.hoetzel.info/post/eshell-notifications/>
作者:[Jürgen Hötzel](https://blog.hoetzel.info) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Get desktop notifications from Emacs shell commands
When interacting with the operating systems I always use [Eshell](https://www.gnu.org/software/emacs/manual/html_mono/eshell.html)
because it integrates seamlessly with Emacs, supports (remote) [TRAMP](https://www.gnu.org/software/tramp/)
file names and also works nice on Windows.
After starting shell commands (like long running build jobs) I often lose track the task when switching buffers.
Thanks to Emacs [hooks](https://www.gnu.org/software/emacs/manual/html_node/emacs/Hooks.html) mechanism you can customize Emacs to call a
elisp function when an external command finishes.
I use [John Wiegleys](https://github.com/jwiegley) excellent [alert](https://github.com/jwiegley/alert) package to send
desktop notifications:
```
(require 'alert)
(defun eshell-command-alert (process status)
"Send `alert' with severity based on STATUS when PROCESS finished."
(let* ((cmd (process-command process))
(buffer (process-buffer process))
(msg (format "%s: %s" (mapconcat 'identity cmd " ") status)))
(if (string-prefix-p "finished" status)
(alert msg :buffer buffer :severity 'normal)
(alert msg :buffer buffer :severity 'urgent))))
(add-hook 'eshell-kill-hook #'eshell-command-alert)
```
[alert](https://github.com/jwiegley/alert) rules can be setup programmatically. In my case I only want to get
notified if the corresponding buffer is not visible:
```
(alert-add-rule :status '(buried) ;only send alert when buffer not visible
:mode 'eshell-mode
:style 'notifications)
```
This even works on [TRAMP](https://www.gnu.org/software/tramp/)
buffers. Below is a screenshot showing a Gnome desktop notification
of a failed `make`
command.
 |
10,978 | 如何使用 GParted 实用工具缩放根分区 | https://www.2daygeek.com/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility/ | 2019-06-15T14:50:00 | [
"分区",
"GParted"
] | https://linux.cn/article-10978-1.html | 
今天,我们将讨论磁盘分区。这是 Linux 中的一个好话题。这允许用户来重新调整在 Linux 中的活动 root 分区。
在这篇文章中,我们将教你如何使用 GParted 缩放在 Linux 上的活动根分区。
比如说,当我们安装 Ubuntu 操作系统时,并没有恰当地配置,我们的系统仅有 30 GB 磁盘。我们需要安装另一个操作系统,因此我们想在其中制作第二个分区。
虽然不建议重新调整活动分区。然而,我们要执行这个操作,因为没有其它方法来释放系统分区。
>
> 注意:在执行这个动作前,确保你备份了重要的数据,因为如果一些东西出错(例如,电源故障或你的系统重启),你可以得以保留你的数据。
>
>
>
### Gparted 是什么
[GParted](https://gparted.org/) 是一个自由的分区管理器,它使你能够缩放、复制和移动分区,而不丢失数据。通过使用 GParted 的 Live 可启动镜像,我们可以使用 GParted 应用程序的所有功能。GParted Live 可以使你能够在 GNU/Linux 以及其它的操作系统上使用 GParted,例如,Windows 或 Mac OS X 。
#### 1) 使用 df 命令检查磁盘空间利用率
我只是想使用 `df` 命令向你显示我的分区。`df` 命令输出清楚地表明我仅有一个分区。
```
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 30G 3.4G 26.2G 16% /
none 4.0K 0 4.0K 0% /sys/fs/cgroup
udev 487M 4.0K 487M 1% /dev
tmpfs 100M 844K 99M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 152K 497M 1% /run/shm
none 100M 52K 100M 1% /run/user
```
#### 2) 使用 fdisk 命令检查磁盘分区
我将使用 `fdisk` 命令验证这一点。
```
$ sudo fdisk -l
[sudo] password for daygeek:
Disk /dev/sda: 33.1 GB, 33129218048 bytes
255 heads, 63 sectors/track, 4027 cylinders, total 64705504 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x000473a3
Device Boot Start End Blocks Id System
/dev/sda1 * 2048 62609407 31303680 83 Linux
/dev/sda2 62611454 64704511 1046529 5 Extended
/dev/sda5 62611456 64704511 1046528 82 Linux swap / Solaris
```
#### 3) 下载 GParted live ISO 镜像
使用下面的命令来执行下载 GParted live ISO。
```
$ wget https://downloads.sourceforge.net/gparted/gparted-live-0.31.0-1-amd64.iso
```
#### 4) 使用 GParted Live 安装介质启动你的系统
使用 GParted Live 安装介质(如烧录的 CD/DVD 或 USB 或 ISO 镜像)启动你的系统。你将获得类似于下面屏幕的输出。在这里选择 “GParted Live (Default settings)” ,并敲击回车按键。

#### 5) 键盘选择
默认情况下,它选择第二个选项,按下回车即可。

#### 6) 语言选择
默认情况下,它选择 “33” 美国英语,按下回车即可。

#### 7) 模式选择(图形用户界面或命令行)
默认情况下,它选择 “0” 图形用户界面模式,按下回车即可。

#### 8) 加载 GParted Live 屏幕
现在,GParted Live 屏幕已经加载,它显示我以前创建的分区列表。

#### 9) 如何重新调整根分区大小
选择你想重新调整大小的根分区,在这里仅有一个分区,所以我将编辑这个分区以便于安装另一个操作系统。

为做到这一点,按下 “Resize/Move” 按钮来重新调整分区大小。

现在,在第一个框中输入你想从这个分区中取出的大小。我将索要 “10GB”,所以,我添加 “10240MB”,并让该对话框的其余部分为默认值,然后点击 “Resize/Move” 按钮。

它将再次要求你确认重新调整分区的大小,因为你正在编辑活动的系统分区,然后点击 “Ok”。

分区从 30GB 缩小到 20GB 已经成功。也显示 10GB 未分配的磁盘空间。

最后点击 “Apply” 按钮来执行下面剩余的操作。

`e2fsck` 是一个文件系统检查实用程序,自动修复文件系统中与 HDD 相关的坏扇道、I/O 错误。

`resize2fs` 程序将重新调整 ext2、ext3 或 ext4 文件系统的大小。它可以被用于扩大或缩小一个位于设备上的未挂载的文件系统。

`e2image` 程序将保存位于设备上的关键的 ext2、ext3 或 ext4 文件系统的元数据到一个指定文件中。

所有的操作完成,关闭对话框。

现在,我们可以看到未分配的 “10GB” 磁盘分区。

重启系统来检查这一结果。

#### 10) 检查剩余空间
重新登录系统,并使用 `fdisk` 命令来查看在分区中可用的空间。是的,我可以看到这个分区上未分配的 “10GB” 磁盘空间。
```
$ sudo parted /dev/sda print free
[sudo] password for daygeek:
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sda: 32.2GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
32.3kB 10.7GB 10.7GB Free Space
1 10.7GB 32.2GB 21.5GB primary ext4 boot
```
---
via: <https://www.2daygeek.com/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy) 选题:[lujun9972](https://github.com/lujun9972)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,980 | BootISO:从 ISO 文件中创建一个可启动的 USB 设备 | https://www.2daygeek.com/bootiso-a-simple-bash-script-to-securely-create-a-bootable-usb-device-in-linux-from-iso-file/ | 2019-06-16T11:01:48 | [
"ISO",
"USB",
"启动"
] | https://linux.cn/article-10980-1.html | 
为了安装操作系统,我们中的大多数人(包括我)经常从 ISO 文件中创建一个可启动的 USB 设备。为达到这个目的,在 Linux 中有很多自由可用的应用程序。甚至在过去我们写了几篇介绍这种实用程序的文章。
每个人使用不同的应用程序,每个应用程序有它们自己的特色和功能。在这些应用程序中,一些应用程序属于 CLI 程序,一些应用程序则是 GUI 的。
今天,我们将讨论名为 BootISO 的实用程序类似工具。它是一个简单的 bash 脚本,允许用户来从 ISO 文件中创建一个可启动的 USB 设备。
很多 Linux 管理员使用 `dd` 命令开创建可启动的 ISO ,它是一个著名的原生方法,但是与此同时,它也是一个非常危险的命令。因此,小心,当你用 `dd` 命令执行一些动作时。
建议阅读:
* [Etcher:从一个 ISO 镜像中创建一个可启动的 USB 驱动器 & SD 卡的简单方法](https://www.2daygeek.com/etcher-easy-way-to-create-a-bootable-usb-drive-sd-card-from-an-iso-image-on-linux/)
* [在 Linux 上使用 dd 命令来从一个 ISO 镜像中创建一个可启动的 USB 驱动器](https://www.2daygeek.com/create-a-bootable-usb-drive-from-an-iso-image-using-dd-command-on-linux/)
### BootISO 是什么
[BootISO](https://github.com/jsamr/bootiso) 是一个简单的 bash 脚本,允许用户来安全的从一个 ISO 文件中创建一个可启动的 USB 设备,它是用 bash 编写的。
它不提供任何图形用户界面而是提供了大量的选项,可以让初学者顺利地在 Linux 上来创建一个可启动的 USB 设备。因为它是一个智能工具,能自动地选择连接到系统上的 USB 设备。
当系统有多个 USB 设备连接,它将打印出列表。当你手动选择了另一个硬盘而不是 USB 时,在这种情况下,它将安全地退出,而不会在硬盘上写入任何东西。
这个脚本也将检查依赖关系,并提示用户安装,它可以与所有的软件包管理器一起工作,例如 apt-get、yum、dnf、pacman 和 zypper。
### BootISO 的功能
* 它检查选择的 ISO 是否是正确的 mime 类型。如果不是,那么退出。
* 如果你选择除 USB 设备以外的任何其它的磁盘(本地硬盘),BootISO 将自动地退出。
* 当你有多个驱动器时,BootISO 允许用户选择想要使用的 USB 驱动器。
* 在擦除和分区 USB 设备前,BootISO 会提示用户确认。
* BootISO 将正确地处理来自一个命令的任何错误,并退出。
* BootISO 在遇到问题退出时将调用一个清理例行程序。
### 如何在 Linux 中安装 BootISO
在 Linux 中安装 BootISO 有几个可用的方法,但是,我建议用户使用下面的方法安装。
```
$ curl -L https://git.io/bootiso -O
$ chmod +x bootiso
$ sudo mv bootiso /usr/local/bin/
```
一旦 BootISO 已经安装,运行下面的命令来列出可用的 USB 设备。
```
$ bootiso -l
Listing USB drives available in your system:
NAME HOTPLUG SIZE STATE TYPE
sdd 1 32G running disk
```
如果你仅有一个 USB 设备,那么简单地运行下面的命令来从一个 ISO 文件中创建一个可启动的 USB 设备。
```
$ bootiso /path/to/iso file
```
```
$ bootiso /opt/iso_images/archlinux-2018.05.01-x86_64.iso
Granting root privileges for bootiso.
Listing USB drives available in your system:
NAME HOTPLUG SIZE STATE TYPE
sdd 1 32G running disk
Autoselecting `sdd' (only USB device candidate)
The selected device `/dev/sdd' is connected through USB.
Created ISO mount point at `/tmp/iso.vXo'
`bootiso' is about to wipe out the content of device `/dev/sdd'.
Are you sure you want to proceed? (y/n)>y
Erasing contents of /dev/sdd...
Creating FAT32 partition on `/dev/sdd1'...
Created USB device mount point at `/tmp/usb.0j5'
Copying files from ISO to USB device with `rsync'
Synchronizing writes on device `/dev/sdd'
`bootiso' took 250 seconds to write ISO to USB device with `rsync' method.
ISO succesfully unmounted.
USB device succesfully unmounted.
USB device succesfully ejected.
You can safely remove it !
```
当你有多个 USB 设备时,可以使用 `--device` 选项指明你的设备名称。
```
$ bootiso -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
```
默认情况下,BootISO 使用 `rsync` 命令来执行所有的动作,如果你想使用 `dd` 命令代替它,使用下面的格式。
```
$ bootiso --dd -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
```
如果你想跳过 mime 类型检查,BootISO 实用程序带有下面的选项。
```
$ bootiso --no-mime-check -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
```
为 BootISO 添加下面的选项来跳过在擦除和分区 USB 设备前的用户确认。
```
$ bootiso -y -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
```
连同 `-y` 选项一起,启用自动选择 USB 设备。
```
$ bootiso -y -a /opt/iso_images/archlinux-2018.05.01-x86_64.iso
```
为知道更多的 BootISO 选项,运行下面的命令。
```
$ bootiso -h
Create a bootable USB from any ISO securely.
Usage: bootiso [...]
Options
-h, --help, help Display this help message and exit.
-v, --version Display version and exit.
-d, --device Select block file as USB device.
If is not connected through USB, `bootiso' will fail and exit.
Device block files are usually situated in /dev/sXX or /dev/hXX.
You will be prompted to select a device if you don't use this option.
-b, --bootloader Install a bootloader with syslinux (safe mode) for non-hybrid ISOs. Does not work with `--dd' option.
-y, --assume-yes `bootiso' won't prompt the user for confirmation before erasing and partitioning USB device.
Use at your own risks.
-a, --autoselect Enable autoselecting USB devices in conjunction with -y option.
Autoselect will automatically select a USB drive device if there is exactly one connected to the system.
Enabled by default when neither -d nor --no-usb-check options are given.
-J, --no-eject Do not eject device after unmounting.
-l, --list-usb-drives List available USB drives.
-M, --no-mime-check `bootiso' won't assert that selected ISO file has the right mime-type.
-s, --strict-mime-check Disallow loose application/octet-stream mime type in ISO file.
-- POSIX end of options.
--dd Use `dd' utility instead of mounting + `rsync'.
Does not allow bootloader installation with syslinux.
--no-usb-check `bootiso' won't assert that selected device is a USB (connected through USB bus).
Use at your own risks.
Readme
Bootiso v2.5.2.
Author: Jules Samuel Randolph
Bugs and new features: https://github.com/jsamr/bootiso/issues
If you like bootiso, please help the community by making it visible:
* star the project at https://github.com/jsamr/bootiso
* upvote those SE post: https://goo.gl/BNRmvm https://goo.gl/YDBvFe
```
---
via: <https://www.2daygeek.com/bootiso-a-simple-bash-script-to-securely-create-a-bootable-usb-device-in-linux-from-iso-file/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,982 | 可以买到 Linux 电脑的 10 个地方 | https://itsfoss.com/get-linux-laptops/ | 2019-06-16T11:47:00 | [
"笔记本",
"电脑"
] | https://linux.cn/article-10982-1.html |
>
> 你在找 Linux 笔记本吗? 这里列出一些出售 Linux 电脑或者是专注于 Linux 系统的电商。
>
>
>
如今市面上几乎所有的电脑(苹果除外)都预装了 Windows 系统。Linux 使用者的惯常做法就是买一台这样的电脑,然后要么删除 Windows 系统并安装 Linux,要么[安装 Linux 和 Windows 的双系统](https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/)。
但 Windows 系统并非无法避免。你其实也可以买到 Linux 电脑。
不过,既然可以轻松地在任何一台电脑上安装 Linux,为什么还要买一台预装了 Linux 的电脑呢?下面列举几个原因:
* 预装 Windows 系统意味着你额外支付了 Windows 许可证的费用。你可以节省这笔开销。
* 预装 Linux 的电脑都经过了硬件适配测试。你不需要担心系统无法正常运行 WiFi 或者蓝牙,也不再需要亲自去搞定这些事情了。
* 购买 Linux 电脑相当于间接地支持了 Linux。更多的销售额可以反应出对 Linux 产品的需求,也就可能会有更多商家提供 Linux 作为一种可以选择的操作系统。
如果你正想买一台 Linux 的笔记本,不妨考虑一下我的建议。下面这些制造商或者商家都提供开箱即用的 Linux 系统。

### 可以买到 Linux 笔记本或者台式机的 10 个地方
在揭晓这个提供预装 Linux 电脑的商家的清单之前,需要先声明一下。
请根据你的独立决策购买。我在这里只是简单地列出一些售卖 Linux 电脑的商家,并不保证他们的产品质量、售后服务等等这些事情。
这也并不是一个排行榜。清单并不是按照某个特定次序排列的,每一项前面的数字只是为了方便计数,而并不代表名次。
让我们看看你可以在哪儿买到预装 Linux 的台式机或者笔记本吧。
#### 1、戴尔

戴尔提供 Ubuntu 笔记本已经有好几年了。他们的旗舰产品 XPS 系列的亮点之一就是预装了 Ubuntu 的开发者版本系列产品。
如果你读过我的 [戴尔 XPS Ubuntu 版本评测](https://itsfoss.com/dell-xps-13-ubuntu-review/)就知道我是很喜欢这款笔记本的。两年多过去了,这个笔记本依然状况良好,没有性能恶化的迹象。
戴尔 XPS 是售价超过 1000 美元的昂贵设备。如果你的预算没有这么多,可以考虑戴尔更加亲民的 Inspiron 系列笔记本。
值得一提的是,戴尔并没有在它的官网上展示 Ubuntu 或者 Linux 笔记本产品。除非你知道戴尔提供 Linux 笔记本,你是不会找到它们的。
所以,去戴尔的官网上搜索关键字 “Ubuntu” 来获取预装 Ubuntu 的产品的信息吧。
**支持范围**:世界上大部分地区。
* [戴尔](https://www.dell.com)
#### 2、System76
[System76](https://system76.com/) 是 Linux 计算机世界里的一个响亮的名字。这家总部设在美国的企业专注于运行 Linux 的高端技术设备。他们的目标用户群体是软件开发者。
最初,System76 在自己的机器上提供的是 Ubuntu 系统。2017 年,他们发布了属于自己的 Linux 发行版,基于 Ubuntu 的 [Pop!\_OS](https://itsfoss.com/pop-os-linux-review/)。从此以后,Pop!\_OS 就是他们机器上的默认操作系统了,但是仍然保留了 Ubuntu 这个选择。
除了性能之外,System76 还格外重视设计。他们的 [Thelio 系列台式机](https://system76.com/desktops) 采用纯手工木制设计。

你可以在 [这里](https://system76.com/laptops) 查看他们提供的 Linux 笔记本。他们同时也提供 [基于 Linux 的迷你电脑](https://itsfoss.com/4-linux-based-mini-pc-buy-2015/) 和 [服务器](https://system76.com/servers)。
值得一提的是,System76 在美国制造他们的电脑,而没有使用中国大陆或者台湾这种常规的选择。也许是出于这个原因,他们产品的售价较为高昂。
**支持范围**:美国以及其它 60 个国家。在美国境外可能会有额外的关税。更多信息见[这里](https://system76.com/shipping).
* [System76](https://system76.com/)
#### 3、Purism
Purism 是一个总部设在美国的企业,以提供确保数据安全和隐私的产品和服务为荣。这就是为什么 Purism 称自己为 “效力社会的公司”。
Purism 是从一个众筹项目开始的,该项目旨在创造一个几乎没有任何专有软件的高端开源笔记本。2015年,从这个 [成功的 25 万美元的众筹项目](https://www.crowdsupply.com/purism/librem-15) 中诞生了 [Librem 15](https://puri.sm/products/librem-15/) 笔记本。

后来 Purism 发布了一个 13 英寸的版本 [Librem 13](https://puri.sm/products/librem-13/)。Purism 还开发了一个自己的 Linux 发行版 [Pure OS](https://www.pureos.net/),该发行版非常注重隐私和安全问题。
[Pure OS 在台式设备和移动设备上都可以运行](https://itsfoss.com/pureos-convergence/),并且是 Librem 笔记本和[Librem 5 Linux 手机](https://itsfoss.com/librem-linux-phone/) 的默认操纵系统。
Purism 的零部件来自中国大陆、台湾、日本以及美国,并在美国完成组装。他们的所有设备都有可以直接关闭的硬件开关,用来关闭麦克风、摄像头、无线连接或者是蓝牙。
**支持范围**:全世界范围国际免邮。可能需要支付额外的关税。
* [Purism](https://puri.sm/)
#### 4、Slimbook
Slimbook 是一个总部设在西班牙的 Linux 电脑销售商。Slimbook 在发行了 [第一款 KDE 品牌笔记本](https://itsfoss.com/slimbook-kde/)之后成为了人们关注的焦点。
他们的产品不仅限于 KDE Neon。他们还提供 Ubuntu、Kubuntu、Ubuntu MATE、Linux Mint 以及包括 [Lliurex](https://distrowatch.com/table.php?distribution=lliurex) 和 [Max](https://en.wikipedia.org/wiki/MAX_(operating_system)) 这样的西班牙发行版。你也可以选择 Windows(需要额外付费)或者不预装任何操作系统。
Slimbook 有众多 Linux 笔记本、台式机和迷你电脑可供选择。他们另外一个非常不错的产品是一个类似于 iMac 的 24 英寸 [拥有内置 CPU 的曲面显示屏](https://slimbook.es/en/aio-curve-all-in-one-for-gnu-linux)。

想要一台水冷 Linux 电脑吗?Slimbook 的 [Kymera Aqua](https://slimbook.es/en/kymera-aqua-the-gnu-linux-computer-with-custom-water-cooling) 是合适之选。
**支持范围**:全世界范围,不过在邮费和关税上都可能产生额外费用。
* [Slimbook](https://slimbook.es/en/)
#### 5、TUXEDO
作为这个 Linux 电脑销售商清单里的另一个欧洲成员,[TUXEDO](https://www.tuxedocomputers.com/) 总部设在德国,主要服务德国用户,其次是欧洲用户。
TUXEDO 只使用 Linux 系统,产品都是“德国制造”,并且提供 5 年保修和终生售后支持。
TUXEDO 在 Linux 系统的硬件适配上下了很大功夫。并且如果你遇到了麻烦或者是想从头开始,可以通过系统恢复选项,自动恢复出厂设置。

TUXEDO 有许多 Linux 笔记本、台式机和迷你电脑产品可供选择。他们还同时支持 Intel 和 AMD 的处理器。除了电脑,TUXEDO 还提供一系列 Linux 支持的附件,比如扩展坞、DVD 和蓝光刻录机、移动电源以及其它外围设备。
**支持范围**:150 欧元以上的订单在德国和欧洲范围内免邮。欧洲外国家会有额外的运费和关税。更多信息见 [这里](https://www.tuxedocomputers.com/en/Shipping-Returns.tuxedo).
* [TUXEDO](https://www.tuxedocomputers.com/en#)
#### 6、Vikings
[Vikings](https://store.vikings.net/index.php?route=common/home) 的总部设在德国(而不是斯堪的纳维亚半岛,哈哈)。Vikings 拥有[自由软件基金会](https://www.fsf.org)的认证,专注于自由友好的硬件。

Vikings 的 Linux 笔记本和台式机使用的是 [coreboot](https://www.coreboot.org/) 或者 [Libreboot](https://libreboot.org/),而不是像 BIOS 和 UEFI 这样的专有启动系统。你还可以购买不运行任何专有软件的 [硬件服务器](https://store.vikings.net/libre-friendly-hardware/the-server-1u)。
Vikings 还有包括路由器、扩展坞等在内的其它配件。他们的产品都是在德国组装完成的。
**支持范围**:全世界(除了朝鲜)。非欧洲国家可能会有额外关税费用。更多信息见[这里](https://store.vikings.net/index.php?route=information/information&information_id=8)。
* [Vikings](https://store.vikings.net/libre-friendly-hardware)
#### 7、Ubuntushop.be
不不!尽管名字里有 Ubuntu,但这不是官方的 Ubuntu 商店。Ubuntushop 总部位于比利时,最初是销售安装了 Ubuntu 的电脑。
如今,你可以买到预装了包括 Mint、Manjaro、elementrayOS 在内的 Linux 发行版的笔记本电脑。你还可以要求所购买的设备上安装你所选择的发行版。

Ubuntushop 的一个独特之处在于,它的所有电脑都带有默认的 Tails OS live 选项。即使你安装了某个其它的 Linux 发行版作为日常使用的系统,也随时可以选择启动到 Tails OS(不需要使用 live USB)。[Tails OS](https://tails.boum.org/) 是一个基于 Debian 的发行版,它在用户注销后会删除所有使用痕迹,并且在默认情况下使用 Tor 网络。
和此列表中的许多其他重要玩家不同,我觉得 Ubuntushop 所提供的更像是一种“家庭工艺”。商家手动组装一个电脑,安装 Linux 然后卖给你。不过他们也在一些可选项上下了功夫,比如说轻松的重装系统,拥有自己的云服务器等等。
你可以找一台旧电脑快递给他们,就可以变成一台新安装 Linux 的电脑,他们就会在你的旧电脑上安装 [轻量级 Linux](https://itsfoss.com/lightweight-linux-beginners/) 系统然后快递回来,这样你这台旧电脑就可以重新投入使用了。
**支持范围**:比利时以及欧洲的其它地区。
* [Ubuntushop.be](https://www.ubuntushop.be/index.php/en/)
#### 8、Minifree
[Minifree](https://minifree.org/),是<ruby> 自由部门 <rt> Ministry of Freedom </rt></ruby>的缩写,他们是一家注册在英格兰的公司。
你可以猜到 Minifree 非常注重自由。他们提供安全以及注重隐私的电脑,预装 [Libreboot](https://libreboot.org/) 而不是 BIOS 或者 UEFI。
Minifree 的设备经过了 [自由软件基金会](https://www.fsf.org/) 的认证,所以你可以放心买到的电脑都遵循了自由开源软件的指导规则。

和这个清单中许多其它 Linux 笔记本销售商不同,Minifree 的电脑并不是特别贵。花 200 欧元就可以买到一台预装了 Libreboot 和 [Trisquel GNU/Linux](https://trisquel.info/) 的 Linux 电脑。
除了笔记本以外,Minifree 还有一系列的配件,比如 Libre 路由器、平板电脑、扩展坞、电池、键盘、鼠标等等。
如果你和 [Richard Stallman](https://en.wikipedia.org/wiki/Richard_Stallman) 一样,希望只运行 100% 自由的软件的话,Minifree 就再适合不过了。
**支持范围**:全世界。运费信息见 [这里](https://minifree.org/shipping-costs/)。
* [Minifree](https://minifree.org/)
#### 9、Entroware
[Entroware](https://www.entroware.com/) 是另一个总部设在英国的销售商,专注基于 Linux 系统的笔记本、台式机和服务器。
和这个清单里的很多其它商家一样,Entroware 也选择 Ubuntu 作为 Linux 发行版。[Ubuntu MATE 也是 Entroware Linux 笔记本的一种可选系统](https://itsfoss.com/ubuntu-mate-entroware/).

除了笔记本、台式机和服务器之外,Entroware 还拥有自己的 [迷你电脑 Aura](https://itsfoss.com/ubuntu-entroware-aura-mini-pc/),以及一个 iMac 风格的[内置 CPU 的显示器 Ares](https://www.entroware.com/store/ares).
支持范围: 英国、爱尔兰、法国、德国、意大利、西班牙。
* [Entroware](https://www.entroware.com/store/index.php?route=common/home)
#### 10、Juno
这是我们清单上的一个新的 Linux 笔记本销售商。Juno 的总部同样设在英国,提供预装 Linux 的电脑。可选择的 Linux 发行版包括 elementary OS、Ubuntu 和 Solus OS。
Juno 提供一系列的笔记本,以及一款叫做 Olympia 迷你电脑。和列表里其它商家提供的大多数迷你电脑一样,Olympia 也基本上相当于一个 [Intel NUC](https://www.amazon.com/Intel-NUC-Mainstream-Kit-NUC8i3BEH/dp/B07GX4X4PW?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B07GX4X4PW "Intel NUC")。
Juno 的主要特色是 Juve,一款售价 299 美元的 Chromebook 的低成本替代品。它运行一个双系统,包括 Solus 或者 elementray,以及一个基于安卓的电脑操作系统 [Prime OS](https://primeos.in/)。

支持范围:英国、美国、加拿大、墨西哥、南美和欧洲的大部分地区、新西兰、亚洲和非洲的某些地区。更多信息见 [这里](https://junocomputers.com/shipping)。
* [Juno Computers](https://junocomputers.com/)
#### 荣誉奖
我列举了 10 个可以买到 Linux 电脑的地方,但其实还有一些其它类似的商店。清单里放不下这么多,并且它们其中的几个似乎大多数商品都缺货。不过我还是要在这里稍微提一下它们,方便你自己查找相关信息:
* [ZaReason](https://zareason.com/)
* [Libiquity](https://libiquity.com/)
* [StationX](https://stationx.rocks/)
* [Linux Certified](https://www.linuxcertified.com/linux_laptops.html)
* [Think Penguin](https://www.thinkpenguin.com/)
包括宏碁和联想在内的其它主流电脑生产商可能也有基于 Linux 系统的产品,所以你不妨也查看一下他们的产品目录吧。
你有没有买过 Linux 电脑?在哪儿买的?使用体验怎么样?Linux 笔记本值不值得买?分享一下你的想法吧。
---
via: <https://itsfoss.com/get-linux-laptops/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chen-ni](https://github.com/chen-ni) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Almost all the non-Apple computers sold today come with Windows preinstalled. The standard procedure for Linux users is to buy such a computer and then either remove Windows and install Linux or [dual boot Linux with Windows](https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/).
But you don’t always have to go through Windows. You can buy Linux computers as well.
So why buy a computer preinstalled with Linux when you can easily install Linux on any computer? Here are some reasons:
- A computer with Windows always has a higher price for the Windows license. You can avoid that.
- Computers preinstalled with Linux are well-tested for hardware compatibility. You can be sure that your system will have WiFi and Bluetooth working instead of figuring these things out on your own.
- Buying Linux laptops and desktops indirectly supports Linux. More sales indicate a demand for Linux products, and thus, more vendors may be inclined to provide Linux as a choice of the operating system.
If you want a new Linux laptop, let me suggest a few manufacturers and vendors that provide ready-to-use Linux systems.
**Note**: *This is not a ranked list.*
## 1. Dell

Dell has been offering Ubuntu laptops for several years now. Their flagship product XPS features a **Developer Edition** series with Ubuntu preinstalled. With this edition, the laptop has been certified to work perfectly fine with Ubuntu.
Even if it is not the developer edition, the XPS series generally tends to work well with Linux.
I use Dell XPS laptops as my daily driver for years now. It just works great, and the performance stays consistent for a long time.
[affiliate policy](https://itsfoss.com/affiliate-policy/)for concerns.
For this reason, I strongly recommend it. You can order one from Amazon as they regularly provide attractive deals on it like this:
Dell XPS is an expensive device, with a price tag of **around $1000**. If that’s out of your budget, Dell also has an inexpensive offering in its **Inspiron laptop line**. In case you cannot find Dell's Linux offerings, go to their official website and enter “Ubuntu” in its search box to see the products that ship with Ubuntu Linux preinstalled.
**Availability**: Most parts of the world.
## 2. System76
[System76](https://system76.com/?ref=itsfoss.com) is a prominent name in the world of Linux computers. This US-based company specializes in high-end computing devices that run Linux. Their targeted user base is power users and creators.
They offer [Pop!_OS](https://itsfoss.com/pop-os-20-04-review/), based on Ubuntu as their take on a Linux distribution. The distribution features a desktop environment based on GNOME, which is soon to be replaced by their own desktop environment that looks similar.
In addition to performance, System76 has put a great emphasis on the design of its computers. Their [Thelio desktop series](https://system76.com/desktops?ref=itsfoss.com) is popular for its handcrafted wooden design.

You may check their Linux laptops offerings [here](https://system76.com/laptops?ref=itsfoss.com). They also offer [Linux-based mini PCs](https://itsfoss.com/linux-based-mini-pc/) and [servers](https://system76.com/servers?ref=itsfoss.com).
Did I mention that System76 manufactures its computers in America instead of the obvious choices of China and Taiwan? Their products are on the expensive side, perhaps for this reason.
**Availability**: USA and 60 other countries. Extra custom duty may be applicable outside the US. More info [here](https://system76.com/shipping?ref=itsfoss.com).
## 3. Lenovo
Lenovo ThinkPads are quite popular among Linux users, even with mixed feelings about them for its compatibility with Linux in the past. And, now that [most of the Lenovo laptops will be Linux certified](https://itsfoss.com/lenovo-linux-certified/), it could be one of the best choices to go with to get a Laptop. And, you can order one for yourself through their official site or Amazon.
The flagship models are definitely expensive, but you will find a wide range of variants available starting from $500 range. Of course, the pricing will vary depending on your country but Lenovo laptops or ThinkPads in general is considered as a durable machine.

Lenovo’s laptops aren’t really known for any crazy design but the build quality. So, you have to keep that in mind and compare the prices accordingly.
It is also worth noting that you get the choice of having Fedora or Ubuntu pre-installed depending on what Laptop you’re going for (mostly in the U.S and Canada). However, that choice may not be available for other countries.
**Availability**: Most parts of the world.
## 4. Purism
Purism is a US-based company that takes pride in creating products and services that help you secure your data and privacy. That’s the reason why Purism calls itself a “Social Purpose Corporation.”
Purism started with a crowdfunding campaign for creating a high-end open source laptop with (almost) no proprietary software. The [successful $250,000 crowdfunding campaign](https://www.crowdsupply.com/purism/librem-15?ref=itsfoss.com) resulted in the [Librem 15](https://puri.sm/products/librem-15/?ref=itsfoss.com) laptop in 2015.

Purism features a [Librem 14](https://itsfoss.com/purism-librem-14/) laptop for Linux users, including its own distribution, [Pure OS](https://www.pureos.net/?ref=itsfoss.com), designed for keeping privacy and security in mind.
[Pure OS can run on both desktop and mobile devices](https://itsfoss.com/pureos-convergence/), and it is the default choice of operating system on Librem laptops and [Librem 5 Linux phone](https://itsfoss.com/librem-linux-phone/).
Purism gets its components from China, Taiwan, Japan, and the United States, and assembles them in the US. All their devices have hardware kill switches to turn off the microphone/camera and wireless/bluetooth.
**Availability**: Worldwide with free international shipping. Custom duty may cost extra.
## 5. Slimbook
Slimbook is a Linux computer vendor based in Spain. Slimbook enetered the limelight after launching the [first KDE branded laptop](https://itsfoss.com/slimbook-kde/).

Their offerings are not limited to just KDE. They offer Ubuntu, Kubuntu, Ubuntu MATE, Linux Mint, and Spanish distributions like [Lliurex](https://distrowatch.com/table.php?distribution=lliurex&ref=itsfoss.com) and [Max](https://en.wikipedia.org/wiki/MAX_(operating_system)?ref=itsfoss.com). You can also choose Windows, at an additional cost, or opt for no operating system at all.
Slimbook has a wide variety of Linux laptops, desktops, and mini PCs available.
Want a liquid cooled Linux computer? Slimbook’s [Kymera Aqua](https://slimbook.es/en/kymera-aqua-the-gnu-linux-computer-with-custom-water-cooling?ref=itsfoss.com) is for you.
**Availability**: Worldwide but may cost extra in shipping and custom duty
## 6. TUXEDO Computers

Another European candidate on this list of Linux computer vendors, [TUXEDO Computers](https://www.tuxedocomputers.com/?ref=itsfoss.com) is based out of Germany.
TUXEDO Computers only uses Linux, and the computers are “manufactured in Germany” and come with a 5 year guarantee and lifetime support. They also feature their own [TUXEDO OS](https://www.tuxedocomputers.com/en/TUXEDO-OS_1.tuxedo) (based on Ubuntu) with out of the box tools required to fine tune your hardware. You can opt to have it pre-installed or choose other distros.
**Availability**: Free shipping in Germany and Europe Extra shipping charges and custom duty for non-EU countries. More info [here](https://www.tuxedocomputers.com/en/Shipping-Returns.tuxedo?ref=itsfoss.com).
## 7. Vikings
[Vikings](https://store.vikings.net/index.php?route=common%2Fhome&ref=itsfoss.com) is based in Germany (instead of Scandinavia 😛). Certified by the [Free Software Foundation](https://www.fsf.org/?ref=itsfoss.com), Vikings focuses exclusively on Libre-friendly hardware.

The Linux laptops and desktops by Vikings come with [coreboot](https://www.coreboot.org/?ref=itsfoss.com) or [Libreboot](https://libreboot.org/?ref=itsfoss.com) instead of proprietary boot systems like BIOS and UEFI. You can also buy [server hardware](https://store.vikings.net/libre-friendly-hardware/the-server-1u?ref=itsfoss.com) running no proprietary software.
Vikings also has other accessories, like routers, docking stations, etc. The products are assembled in Germany.
Note that they do not manufacture the laptops, the products are mostly refurbished and customized.
**Availability**: Worldwide (except North Korea). Non-EU countries may charge custom duty. More information [here](https://store.vikings.net/index.php?route=information%2Finformation&%3Binformation_id=8&ref=itsfoss.com).
## 8. Ubuntushop.be
No, it’s not the official Ubuntu Shop, even though it has Ubuntu in its name.
Ubuntushop is based in Belgium and originally started selling computers installed with Ubuntu.
Today, you can get laptops preloaded with Linux distributions like Mint, Manjaro, and Debian. You can also request a distribution of your choice to be installed on the system you buy.

One unique thing about Ubuntushop is that all of its computers come with a default [Tails OS](https://tails.boum.org/?ref=itsfoss.com) live option for privacy-minded users. So even if it has another Linux distribution installed for regular use, you can always choose to boot into the Tails OS (without a live USB).
Unlike many other big players on this list, I feel that Ubuntushop is more of a “domestic operation,” where someone manually assembles your computer and installs Linux on it. But they have done quite a good job providing options like easy re-install, their own cloud server, etc.
**Availability**: Belgium and rest of Europe.
## 9. RetroFreedom
[Minifree](https://minifree.org/?ref=itsfoss.com), short for Ministry of Freedom, was a company registered in England. However, amidst the pandemic, it temporarily shutdown its operations in June 2020 and has resumed operations with a re-brand to [RetroFreedom](https://retrofreedom.com/?ref=itsfoss.com).
It provides secure and privacy-respecting computers that come with [Libreboot](https://libreboot.org/?ref=itsfoss.com) instead of BIOS or UEFI.
These laptops come pre-installed with [Trisquel](https://trisquel.info/?ref=itsfoss.com), endorsed by [Free Software Foundation](https://www.fsf.org/?ref=itsfoss.com), which means that you can be sure that their computers adhere to the guidelines and principles of Free and Open Source Software.
Unlike many other Linux laptop vendors on this list, computers from RetroFreedom are not super-expensive. You can get a Libreboot Linux laptop running [Trisquel GNU/Linux](https://trisquel.info/?ref=itsfoss.com) starting from 200 euro.
You get a 2-Year warranty for all the products. If you care to run only 100% free software like [Richard Stallman](https://en.wikipedia.org/wiki/Richard_Stallman?ref=itsfoss.com), RetroFreedom is for you.
**Availability**: Worldwide. Shipping information is available [here](https://retrofreedom.com/shipping-costs/?ref=itsfoss.com).
## 10. Entroware
[Entroware](https://www.entroware.com/?ref=itsfoss.com) is another UK-based vendor that specializes in Linux-based laptops, desktop, and servers.

Like many others on the list, Entroware also has Ubuntu as its choice of Linux distribution.
Apart from laptops, and desktops, Entroware also has their [mini-PC Aura](https://www.entroware.com/store/aura).
Availability: UK, Ireland France, Germany, Italy, Spain
## 11. StarLabs

StarLabs is a manufacturer that features laptops that you can customize to your heart's desire.
They focuse on providing you a good out-of-the-box privacy and security (thanks to [coreboot](https://github.com/StarLabsLtd/coreboot-configurator)) along with great compatibility. You can opt for premium laptops with maxed out specs and latest processors or go for an affordable one.
StarLabs laptops offer both Intel and AMD powered options.
**Availability: **Worldwide. More info [here](https://support.starlabs.systems/kb/faqs/where-do-you-ship-to).
## 12. Juno Computers
Juno Computers is also based in the UK and offers computers preinstalled with Linux.

Juno offers a range of laptops and a mini-PC called Olympia.
In addition to the usual offering, you can also find a Tablet with Manjaro Plasma as an option for the OS.
Availability: UK, Europe, USA, and Canada. More information [here](https://junocomputers.com/shipping?ref=itsfoss.com).
## 13. Pine64

Pine64 is known for its single board computers. It also offers a budget laptop series called Pinebook.
[Pinebook](https://itsfoss.com/pinebook-linux-notebook/) is basically a [single board computer like Raspberry Pi](https://itsfoss.com/raspberry-pi-alternatives/), inside a plastic body. This laptop costs less than $100.
Since Pinebook is too low-end to be a usable desktop computer, Pine64 has an upgraded model called [Pinebook Pro](https://www.pine64.org/pinebook-pro/?ref=itsfoss.com). This one has decent specifications for an entry level laptop.
Additionally, you will find several devices like smartwatches, IP cameras, and more.
## 14. Laptop with Linux

Yes, you heard that right. That's the name of the company/website. It is a Netherlands-based company that helps you with and [mini-PCs](https://itsfoss.com/linux-based-mini-pc/) as well.
It lets you configure the specifications of your desired laptop offering a minimum 2 years warranty. You can choose from a range of Linux distros that includes Linux Mint and Ubuntu, among others.
The laptops offered are usually premium-looking with backlit keyboards in most of the cases. You can explore their website to know more about them.
## 15. MALIBAL
MALIBAL is an interesting company that focuses on making high-performance Linux laptops.

At the time of updating this article, MALIBAL offered the fairly new [Vanilla OS](https://news.itsfoss.com/vanilla-os-release/) along with the usual popular distros as choices, which was refreshing to see.
**Availability**: Worldwide, with local VAT and extra customs for countries outside US. Check out its [FAQ](https://www.malibal.com/) to learn more.
### Honorable mentions
I have listed 13 places to get Linux computers, but there are several other such shops available. I cannot include all of them on the main list, and a couple of them seem to be out of stock for most products. However, I am going to mention them here so that you may check them on your own:
Other mainstream computer manufacturers like Acer, Lenovo, etc. may also have some Linux systems in their catalog, so you may check their products as well.
If you are looking for [Linux-based tablets](https://itsfoss.com/linux-tablets/) instead, there are a few options available as well.
[Looking for Linux Tablets? Here are Your OptionsThere are Linux laptops, Linux mini PCs and Linux Phones. What about Linux-based tablets? What if you want to use a real Linux on a tab? Here are your options.](https://itsfoss.com/linux-tablets/)

In either case, if you have an old laptop around, try some of the lightweight Linux distributions to revive them:
[16 Best Lightweight Linux Distributions for Older ComputersDon’t throw your old computer just yet. Use a lightweight Linux distro and revive that decades-old system.](https://itsfoss.com/lightweight-linux-beginners/)

*Have you ever bought a Linux computer? Where did you buy it? How’s your experience with it? Is it worth buying a Linux laptop? Do share your thoughts.* |
10,983 | expand 与 unexpand 命令实例教程 | https://www.ostechnix.com/expand-and-unexpand-commands-tutorial-with-examples/ | 2019-06-16T23:25:10 | [
"空格",
"TAB",
"expand"
] | https://linux.cn/article-10983-1.html | 
本指南通过实际的例子解释两个 Linux 命令,即 `expand` 和 `unexpand`。对于好奇的人,`expand` 和 `unexpand` 命令用于将文件中的 `TAB` 字符替换为空格,反之亦然。在 MS-DOS 中也有一个名为 `expand` 的命令,它用于解压压缩文件。但 Linux 的 `expand` 命令只是将 `TAB` 转换为空格。这两个命令是 GNU coreutils 包的一部分,由 David MacKenzie 编写。
为了演示,我将在本文使用名为 `ostechnix.txt` 的文本文件。下面给出的所有命令都在 Arch Linux 中进行测试。
### expand 命令示例
与我之前提到的一样,`expand` 命令使用空格替换文件中的 `TAB` 字符。
现在,让我们将 `ostechnix.txt` 中的 `TAB` 转换为空格,并将结果写入标准输出:
```
$ expand ostechnix.txt
```
如果你不想在标准输出中显示结果,只需将其写入另一个文件,如下所示。
```
$ expand ostechnix.txt>output.txt
```
我们还可以将标准输入中的 `TAB` 转换为空格。为此,只需运行 `expand` 命令而不带文件名:
```
$ expand
```
只需输入文本并按回车键就能将 `TAB` 转换为空格。按 `CTRL+C` 退出。
如果你不想转换非空白字符后的 `TAB`,请使用 `-i` 标记,如下所示。
```
$ expand -i ostechnix.txt
```
我们还可以设置每个 `TAB` 为指定数字的宽度,而不是 `8`(默认值)。
```
$ expand -t=5 ostechnix.txt
```
我们甚至可以使用逗号分隔指定多个 `TAB` 位置,如下所示。
```
$ expand -t 5,10,15 ostechnix.txt
```
或者,
```
$ expand -t "5 10 15" ostechnix.txt
```
有关更多详细信息,请参阅手册页。
```
$ man expand
```
### unexpand 命令示例
正如你可能已经猜到的那样,`unexpand` 命令将执行与 `expand` 命令相反的操作。即它会将空格转换为 `TAB`。让我向你展示一些例子,以了解如何使用 `unexpand` 命令。
要将文件中的空白(当然是空格)转换为 `TAB` 并将输出写入标准输出,请执行以下操作:
```
$ unexpand ostechnix.txt
```
如果要将输出写入文件而不是仅将其显示到标准输出,请使用以下命令:
```
$ unexpand ostechnix.txt>output.txt
```
从标准输出读取内容,将空格转换为制表符:
```
$ unexpand
```
默认情况下,`unexpand` 命令仅转换初始的空格。如果你想转换所有空格而不是只是一行开头的空格,请使用 `-a` 标志:
```
$ unexpand -a ostechnix.txt
```
仅转换一行开头的空格(请注意它会覆盖 `-a`):
```
$ unexpand --first-only ostechnix.txt
```
使多少个空格替换成一个 `TAB`,而不是 `8`(会启用 `-a`):
```
$ unexpand -t 5 ostechnix.txt
```
相似地,我们可以使用逗号分隔指定多个 `TAB` 的位置。
```
$ unexpand -t 5,10,15 ostechnix.txt
```
或者,
```
$ unexpand -t "5 10 15" ostechnix.txt
```
有关更多详细信息,请参阅手册页。
```
$ man unexpand
```
在处理大量文件时,`expand` 和 `unexpand` 命令对于用空格替换不需要的 `TAB` 时非常有用,反之亦然。
---
via: <https://www.ostechnix.com/expand-and-unexpand-commands-tutorial-with-examples/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,984 | 反向运行 LED 能够冷却计算机 | https://www.networkworld.com/article/3386876/running-leds-in-reverse-could-cool-computers.html | 2019-06-17T00:44:26 | [
"LED",
"冷却"
] | https://linux.cn/article-10984-1.html |
>
> 电子产品的小型化正在触及其极限,部分原因在于热量管理。许多人现在都在积极地尝试解决这个问题。其中一种正在探索的途径是反向运行的 LED。
>
>
>

寻找更有效的冷却计算机的方法,几乎与渴望发现更好的电池化学成分一样,在科学家的研究日程中也处于重要位置。
更多的冷却手段对于降低成本至关重要。冷却技术也使得在较小的空间中可以进行更强大的处理,其有限的处理能力应该是进行计算而不是浪费热量。冷却技术可以阻止热量引起的故障,从而延长部件的使用寿命,并且可以促进环保的数据中心 —— 更少的热量意味着对环境的影响更小。
如何从微处理器中消除热量是科学家们一直在探索的一个方向,他们认为他们已经提出了一个简单而不寻常、且反直觉的解决方案。他们说可以运行一个发光二极管(LED)的变体,其电极反转可以迫使该元件表现得像处于异常低温下工作一样。如果将其置于较热的电子设备旁边,然后引入纳米级间隙,可以使 LED 吸收热量。
“一旦 LED 反向偏置,它就会像一个非常低温的物体一样,吸收光子,”密歇根大学机械工程教授埃德加·梅霍夫在宣布了这一突破的[新闻稿](https://news.umich.edu/running-an-led-in-reverse-could-cool-future-computers/)中说。 “与此同时,该间隙可防止热量返回,从而产生冷却效果。”
研究人员表示,LED 和相邻的电子设备(在这种情况下是热量计,通常用于测量热能)必须非常接近。他们说他们已经能够证明达到了每平方米 6 瓦的冷却功率。他们解释说,这是差不多是地球表面所接受到的阳光的能量。
物联网(IoT)设备和智能手机可能是最终将受益于这种 LED 改造的电子产品。这两种设备都需要在更小的空间中容纳更多的计算功率。
“从微处理器中可以移除的热量开始限制在给定空间内容纳的功率,”密歇根大学的公告说。
### 材料科学和冷却计算机
[我之前写过关于新形式的计算机冷却的文章](https://www.networkworld.com/article/3326831/computers-could-soon-run-cold-no-heat-generated.html)。源自材料科学的外来材料是正在探索的想法之一。美国能源部劳伦斯伯克利国家实验室表示,钠铋(Na3Bi)可用于晶体管设计。这种新物质带电荷,重要的是具有可调节性;但是,它不需要像超导体那样进行冷却。
事实上,这是超导体的一个问题。不幸的是,它们比大多数电子设备需要更多的冷却 —— 通过极端冷却消除电阻。
另外,[康斯坦茨大学的德国研究人员](https://www.uni-konstanz.de/en/university/news-and-media/current-announcements/news/news-in-detail/Supercomputer-ohne-Abwaerme/)表示他们很快将拥有超导体驱动的计算机,没有废热。他们计划使用电子自旋 —— 一种新的电子物理维度,可以提高效率。该大学去年在一份新闻稿中表示,这种方法“显著降低了计算中心的能耗”。
另一种减少热量的方法可能是用嵌入在微处理器上的[螺旋和回路来取代传统的散热器](https://www.networkworld.com/article/3322956/chip-cooling-breakthrough-will-reduce-data-center-power-costs.html)。宾汉姆顿大学的科学家们表示,印在芯片上的微小通道可以为冷却剂提供单独的通道。
康斯坦茨大学说:“半导体技术的小型化正在接近其物理极限。”热管理现在被科学家提上了议事日程。这是“小型化的一大挑战”。
---
via: <https://www.networkworld.com/article/3386876/running-leds-in-reverse-could-cool-computers.html#tk.rss_all>
作者:[Patrick Nelson](https://www.networkworld.com/author/Patrick-Nelson/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,986 | 如何用 Linux 帮助你拼写 | https://www.networkworld.com/article/3400942/how-linux-can-help-with-your-spelling.html | 2019-06-17T21:47:30 | [
"拼写",
"aspell"
] | https://linux.cn/article-10986-1.html |
>
> 无论你是纠结一个难以理解的单词,还是在将报告发给老板之前再检查一遍,Linux 都可以帮助你解决拼写问题。
>
>
>

Linux 为数据分析和自动化提供了各种工具,它也帮助我们解决了一个一直都在纠结的问题 —— 拼写!无论在写每周报告时努力拼出一个单词,还是在提交商业计划书之前想要借助计算机的“眼睛”来找出你的拼写错误。现在我们来看一下它是如何帮助你的。
### look
`look` 是其中一款工具。如果你知道一个单词的开头,你就可以用这个命令来获取以这些字母开头的单词列表。除非提供了替代词源,否则 `look` 将使用 `/usr/share/dict/words` 中的内容来为你标识单词。这个文件有数十万个单词,可以满足我们日常使用的大多数英语单词的需要,但是它可能不包含我们计算机领域中的一些人倾向于使用的更加生僻的单词,如 zettabyte。
`look` 命令的语法非常简单。输入 `look word` ,它将遍历单词文件中的所有单词并找到匹配项。
```
$ look amelio
ameliorable
ameliorableness
ameliorant
ameliorate
ameliorated
ameliorates
ameliorating
amelioration
ameliorations
ameliorativ
ameliorative
amelioratively
ameliorator
amelioratory
```
如果你遇到系统中单词列表中未包含的单词,将无法获得任何输出。
```
$ look zetta
$
```
如果你没有看到你所希望出现的单词,也不要绝望。你可以在你的单词文件中添加单词,甚至引用一个完全不同的单词列表,在网上找一个或者干脆自己创建一个。你甚至不必将添加的单词放在按字母顺序排列的正确位置;只需将其添加到文件的末尾即可。但是,你必须以 root 用户身份执行此操作。例如(要注意 `>>`!):
```
# echo “zettabyte” >> /usr/share/dict/words
```
当使用不同的单词列表时,例如这个例子中的 “jargon” ,你只需要添加文件的名称。如果不采用默认文件时,请使用完整路径。
```
$ look nybble /usr/share/dict/jargon
nybble
nybbles
```
`look` 命令大小写不敏感,因此你不必关心要查找的单词是否应该大写。
```
$ look zet
ZETA
Zeta
zeta
zetacism
Zetana
zetas
Zetes
zetetic
Zethar
Zethus
Zetland
Zetta
```
当然,不是所有的单词列表都是一样的。一些 Linux 发行版在单词文件中提供了*多得多*的内容。你的文件中可能有十万或者更多倍的单词。
在我的一个 Linux 系统中:
```
$ wc -l /usr/share/dict/words
102402 /usr/share/dict/words
```
在另一个系统中:
```
$ wc -l /usr/share/dict/words
479828 /usr/share/dict/words
```
请记住,`look` 命令只适用于通过单词开头查找,但如果你不想从单词的开头查找,还可以使用其他选项。
### grep
我们深爱的 `grep` 命令像其他工具一样可以从一个单词文件中选出单词。如果你正在找以某些字母开头或结尾的单词,使用 `grep` 命令是自然而然的事情。它可以通过单词的开头、结尾或中间部分来匹配单词。系统中的单词文件可以像使用 `look` 命令时在 `grep` 命令中轻松使用。不过唯一的缺点是你需要指定文件,这一点与 `look` 不尽相同。
在单词的开头前加上 `^`:
```
$ grep ^terra /usr/share/dict/words
terrace
terrace's
terraced
terraces
terracing
terrain
terrain's
terrains
terrapin
terrapin's
terrapins
terraria
terrarium
terrarium's
terrariums
```
在单词的结尾后加上 `$`:
```
$ grep bytes$ /usr/share/dict/words
bytes
gigabytes
kilobytes
megabytes
terabytes
```
使用 `grep` 时,你需要考虑大小写,不过 `grep` 命令也提供了一些选项。
```
$ grep ^[Zz]et /usr/share/dict/words
Zeta
zeta
zetacism
Zetana
zetas
Zetes
zetetic
Zethar
Zethus
Zetland
Zetta
zettabyte
```
为单词文件添加软连接能使这种搜索方式更加便捷:
```
$ ln -s /usr/share/dict/words words
$ grep ^[Zz]et words
Zeta
zeta
zetacism
Zetana
zetas
Zetes
zetetic
Zethar
Zethus
Zetland
Zetta
zettabytye
```
### aspell
`aspell` 命令提供了一种不同的方式。它提供了一种方法来检查你提供给它的任何文件或文本的拼写。你可以通过管道将文本传递给它,然后它会告诉你哪些单词看起来有拼写错误。如果所有单词都拼写正确,则不会有任何输出。
```
$ echo Did I mispell that? | aspell list
mispell
$ echo I can hardly wait to try out aspell | aspell list
aspell
$ echo Did I misspell anything? | aspell list
$
```
`list` 参数告诉 `aspell` 为标准输入单词提供拼写错误的单词列表。
你还可以使用 `aspell` 来定位和更正文本文件中的单词。如果它发现一个拼写错误的单词,它将为你提供一个相似(但拼写正确的)单词列表来替换这个单词,你也可以将该单词加入个人词库(`~/.aspell.en.pws`)并忽略拼写错误,或者完全中止进程(使文件保持处理前的状态)。
```
$ aspell -c mytext
```
一旦 `aspell` 发现一个单词出现了拼写错误,它将会为不正确的 “mispell” 提供一个选项列表:
```
1) mi spell 6) misplay
2) mi-spell 7) spell
3) misspell 8) misapply
4) Ispell 9) Aspell
5) misspells 0) dispel
i) Ignore I) Ignore all
r) Replace R) Replace all
a) Add l) Add Lower
b) Abort x) Exit
```
请注意,备选单词和拼写是数字编号的,而其他选项是由字母选项表示的。你可以选择备选拼写中的一项或者自己输入替换项。“Abort” 选项将使文件保持不变,即使你已经为某些单词选择了替换。你选择添加的单词将被插入到本地单词文件中(例如 `~/.aspell.en.pws`)。
#### 其他单词列表
厌倦了英语? `aspell` 命令可以在其他语言中使用,只要你添加了相关语言的单词列表。例如,在 Debian 系统中添加法语的词库,你可以这样做:
```
$ sudo apt install aspell-fr
```
这个新的词库文件会被安装为 `/usr/share/dict/French`。为了使用它,你只需要简单地告诉 `aspell` 你想要使用替换的单词列表:
```
$ aspell --lang=fr -c mytext
```
这种情况下,当 `aspell` 读到单词 “one” 时,你可能会看到下面的情况:
```
1) once 6) orné
2) onde 7) ne
3) ondé 8) né
4) onze 9) on
5) orne 0) cône
i) Ignore I) Ignore all
r) Replace R) Replace all
a) Add l) Add Lower
b) Abort x) Exit
```
你也可以从 [GNU 官网](ftp://ftp.gnu.org/gnu/aspell/dict/0index.html)获取其他语言的词库。
### 总结
即使你是全国拼字比赛的冠军,你可能偶尔也会需要一点拼写方面的帮助,哪怕只是为了找出你手滑打错的单词。`aspell` 工具,加上 `look` 和 `grep` 命令已经准备来助你一臂之力了。
---
via: <https://www.networkworld.com/article/3400942/how-linux-can-help-with-your-spelling.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Modrisco](https://github.com/Modrisco) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,987 | 迎接区块链 3.0 | https://www.ostechnix.com/welcoming-blockchain-3-0/ | 2019-06-17T23:04:20 | [
"区块链",
"DLT"
] | https://linux.cn/article-10987-1.html | 
“[区块链 2.0](/article-10650-1.html)” 系列文章讨论了自 2008 年比特币等加密货币问世以来区块链技术的发展。本文将探讨区块链的未来发展。**区块链 3.0** 这一新的 DLT(<ruby> 分布式分类帐本技术 <rt> Distributed Ledger Technology </rt></ruby>)演进浪潮将回答当前区块链所面临的问题(每一个问题都会在这里总结)。下一版本的技术标准也将带来全新的应用和使用案例。在本文的最后,我们也会看一些当前使用这些原则的案例。
以下是现有区块链平台的几个缺点,并针对这些缺点给出了建议的解决方案。
### 问题 1:可扩展性
这个问题 <sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup>被视为普遍采用该技术的第一个主要障碍。正如之前所讨论的,很多因素限制了区块链同时处理大量交易的能力。诸如 [以太坊](https://www.ostechnix.com/blockchain-2-0-what-is-ethereum/) 之类的现有网络每秒能够进行 10-15 次交易(TPS),而像 Visa 所使用的主流网络每秒能够进行超过 2000 次交易。**可扩展性**是困扰所有现代数据库系统的问题。正如我们在这里看到的那样,改进的共识算法和更好的区块链架构设计正在改进它。
#### 解决可扩展性
已经提出了更精简、更有效的一致性算法来解决可扩展性问题,并且不会影响区块链的主要结构。虽然大多数加密货币和区块链平台使用资源密集型的 PoW 算法(例如,比特币和以太坊)来生成区块,但是存在更新的 DPoS 和 PoET 算法来解决这个问题。DPoS 和 PoET 算法(还有一些正在开发中)需要更少的资源来维持区块链,并且已显示具有高达 1000 TPS 的吞吐量,可与流行的非区块链系统相媲美。
可扩展性问题的第二个解决方案是完全改变区块链结构和功能。我们不会详细介绍这一点,但已经提出了诸如<ruby> 有向无环图 <rt> Directed Acyclic Graph </rt></ruby>(DAG)之类的替代架构来处理这个问题。从本质上讲,这项工作假设并非所有网络节点都需要整个区块链的副本才能使区块链正常工作,或者并非所有的参与者需要从 DLT 系统获得好处。系统不要求所有参与者验证交易,只需要交易发生在共同的参考框架中并相互链接。
在比特币系统中使用<ruby> <a href="https://cryptoslate.com/beyond-blockchain-directed-acylic-graphs-dag/"> 闪电网络 </a> <rt> Lightning network </rt></ruby>来实现 DAG,而以太坊使用他们的<ruby> <a href="https://github.com/ethereum/wiki/wiki/Sharding-FAQ#introduction"> 切片 </a> <rt> Sharding </rt></ruby> 协议来实现 DAG。本质上,从技术上来看 DAG 实现并不是区块链。它更像是一个错综复杂的迷宫,只是仍然保留了区块链的点对点和分布式数据库属性。稍后我们将在另一篇文章中探讨 DAG 和 Tangle 网络。
### 问题 2:互通性
**互通性**<sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup> <sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup> 被称为跨链访问,基本上就是指不同区块链之间彼此相互通信以交换指标和信息。由于目前有数不清的众多平台,不同公司为各种应用提供了各种专有系统,平台之间的互操作性就至关重要。例如,目前在一个平台上拥有数字身份的人无法利用其他平台提供的功能,因为各个区块链彼此之间互不了解、不能沟通。这是由于缺乏可靠的验证、令牌交换等有关的问题仍然存在。如果平台之间不能够相互通信,面向全球推出[智能合约](https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/)也是不可行的。
#### 解决互通性
有一些协议和平台专为实现互操作性而设计。这些平台实现了原子交换协议,并向不同的区块链系统提供开放场景,以便在它们之间进行通信和交换信息。**“0x (ZRX)”** 就是其中的一个例子,稍后将对进行描述。
### 问题 3:治理
公有链中的治理 <sup id="fnref4"> <a href="#fn4" rel="footnote"> 4 </a></sup> 本身不是限制,而是需要像社区道德指南针一样,在区块链的运作中考虑每个人的意见。结合起来并规模性地看,能预见这样一个问题,即要么协议更改太频繁,要么协议被拥有最多令牌的“中央”权威一时冲动下修改。不过这不是大多数公共区块链目前正在努力避免的问题,因为其运营规模和运营性质不需要更严格的监管。
#### 解决治理问题
上面提到的复杂的框架或 DAG 几乎可以消除对全球(平台范围)治理法规的需要和使用。相反,程序可以自动监督事务和用户类型,并决定需要执行的法律。
### 问题 4:可持续性
可持续性再次建立在可扩展性问题的基础上。当前的区块链和加密货币因不可长期持续而倍遭批评,这是由于仍然需要大量的监督,并且需要大量资源保持系统运行。如果你读过最近“挖掘加密货币”已经没有这么大利润的相关报道,你就知道“挖矿”图利就是它的本来面目。保持现有平台运行所需的资源量在全球范围和主流使用方面根本不实用。
#### 解决不可持续性问题
从资源或经济角度来看,可持续性的答案与可扩展性的答案类似。但是,要在全球范围内实施这一制度,法律和法规必须予以认可。然而,这取决于世界各国政府。来自美国和欧洲政府的有利举措重新燃起了对这方面的希望。
### 问题 5:用户采用
目前,阻止消费者广泛采用 <sup id="fnref5"> <a href="#fn5" rel="footnote"> 5 </a></sup> 基于区块链的应用程序的一个障碍是消费者对平台及其底层的技术不熟悉。事实上,大多数应用程序都需要某种技术和计算背景来弄清楚它们是如何工作的,这在这方面也没有帮助。区块链开发的第三次浪潮旨在缩小消费者知识与平台可用性之间的差距。
#### 解决用户采用问题
互联网花了很长的时间才发展成现在的样子。多年来,人们在开发标准化互联网技术栈方面做了大量的工作,使 Web 能够像现在这样运作。开发人员正在开发面向用户的前端分布式应用程序,这些应用程序应作为现有 Web 3.0 技术之上的一层,同时由下面的区块链和开放协议的支持。这样的[分布式应用](https://www.ostechnix.com/blockchain-2-0-explaining-distributed-computing-and-distributed-applications/)将使用户更熟悉底层技术,从而增加主流采用。
### 在当前场景中的应用
我们已经从理论上讨论了上述问题的解决方法,现在我们将继续展示这些方法在当前场景中的应用。
* [0x](https://0x.org/) – 是一种去中心化的令牌交换,不同平台的用户可以在不需要中央权威机构审查的情况下交换令牌。他们的突破在于,他们如何设计系统使得仅在交易结算后才记录和审查数据块,而不是通常的在交易之间进行(为了验证上下文,通常也会验证交易之前的数据块)。这使在线数字资产交换更快速。
* [Cardano](https://www.cardano.org/en/home/) – 由以太坊的联合创始人之一创建,Cardano 自诩为一个真正“科学”的平台,和采用了严格的协议,对开发的代码和算法进行了多次审查。Cardano 的所有内容都在数学上尽可能的进行了优化。他们的共识算法叫做 **Ouroboros**,是一种改进的<ruby> 权益证明 <rt> Proof of Stake </rt></ruby>(PoS)算法。Cardano 是用 [**haskell**](https://www.ostechnix.com/getting-started-haskell-programming-language/) 开发的,智能合约引擎使用 haskell 的衍生工具 **plutus** 进行操作。这两者都是函数式编程语言,可以保证安全交易而不会影响效率。
* EOS – 我们已经在 [这篇文章](https://www.ostechnix.com/blockchain-2-0-eos-io-is-building-infrastructure-for-developing-dapps/) 中描述了 EOS。
* [COTI](https://coti.io/) – 一个鲜为人知的架构,COTI 不需要挖矿,而且在运行过程中趋近于零功耗。它还将资产存储在本地用户设备上的离线钱包中,而不是存储在纯粹的对等网络上。它们也遵循基于 DAG 的架构,并声称处理吞吐量高达 10000 TPS。他们的平台允许企业在不利用区块链的情况下建立自己的加密货币和数字化货币钱包。
---
1. A. P. Paper, K. Croman, C. Decker, I. Eyal, A. E. Gencer, and A. Juels, “On Scaling Decentralized Blockchains | SpringerLink,” 2018. [↩](#fnref1)
2. [Why is blockchain interoperability important](https://www.capgemini.com/2019/02/can-the-interoperability-of-blockchains-change-the-world/) [↩](#fnref2)
3. [The Importance of Blockchain Interoperability](https://medium.com/wanchain-foundation/the-importance-of-blockchain-interoperability-b6a0bbd06d11) [↩](#fnref3)
4. R. Beck, C. Müller-Bloch, and J. L. King, “Governance in the Blockchain Economy: A Framework and Research Agenda,” J. Assoc. Inf. Syst., pp. 1020–1034, 2018. [↩](#fnref4)
5. J. M. Woodside, F. K. A. Jr, W. Giberson, F. K. J. Augustine, and W. Giberson, “Blockchain Technology Adoption Status and Strategies,” J. Int. Technol. Inf. Manag., vol. 26, no. 2, pp. 65–93, 2017. [↩](#fnref5)
---
via: <https://www.ostechnix.com/welcoming-blockchain-3-0/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[murphyzhao](https://github.com/murphyzhao) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,988 | Graviton:极简的开源代码编辑器 | https://itsfoss.com/graviton-code-editor/ | 2019-06-17T23:39:03 | [
"编辑器"
] | https://linux.cn/article-10988-1.html | [Graviton](https://graviton.ml/)是一款开发中的自由开源的跨平台代码编辑器。他的开发者 16 岁的 Marc Espin 强调说,它是一个“极简”的代码编辑器。我不确定这点,但它确实有一个清爽的用户界面,就像其他的[现代代码编辑器,如 Atom](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/)。

开发者还将其称为轻量级代码编辑器,尽管 Graviton 基于 [Electron](https://electronjs.org/)。
Graviton 拥有你在任何标准代码编辑器中所期望的功能,如语法高亮、自动补全等。由于 Graviton 仍处于测试阶段,因此未来版本中将添加更多功能。

### Graviton 代码编辑器的特性
Graviton 一些值得一说的特性有:
* 使用 [CodeMirrorJS](https://codemirror.net/) 为多种编程语言提供语法高亮 \* 自动补全 \* 支持插件和主题。 \* 提供英语、西班牙语和一些其他欧洲语言。 \* 适用于 Linux、Windows 和 macOS。
我快速看来一下 Graviton,它可能不像 [VS Code](https://itsfoss.com/install-visual-studio-code-ubuntu/) 或 [Brackets](https://itsfoss.com/install-brackets-ubuntu/) 那样功能丰富,但对于一些简单的代码编辑来说,它还算不错的工具。
### 下载并安装 Graviton

如上所述,Graviton 是一个可用于 Linux、Windows 和 macOS 的跨平台代码编辑器。它仍处于测试阶段,这意味着将来会添加更多功能,并且你可能会遇到一些 bug。
你可以在其发布页面上找到最新版本的 Graviton。Debian 和 [Ubuntu 用户可以使用 .deb 安装](https://itsfoss.com/install-deb-files-ubuntu/)。它已提供 [AppImage](https://itsfoss.com/use-appimage-linux/),以便可以在其他发行版中使用它。DMG 和 EXE 文件也分别可用于 macOS 和 Windows。
* [下载 Graviton](https://github.com/Graviton-Code-Editor/Graviton-App/releases)
如果你有兴趣,你可以在 GitHub 仓库中找到 Graviton 的源代码:
* [GitHub 中 Graviton 的源码](https://github.com/Graviton-Code-Editor/Graviton-App)
如果你决定使用 Graviton 并发现了一些问题,请在[此处](https://github.com/Graviton-Code-Editor/Graviton-App/issues)写一份错误报告。如果你使用 GitHub,你可能想为 Graviton 项目加星。这可以提高开发者的士气,因为他知道有更多的用户欣赏他的努力。
如果你看到现在,我相信你了解[如何从源码安装软件](https://itsfoss.com/install-software-from-source-code/)
### 写在最后
有时,简单本身就成了一个特性,而 Graviton 专注于极简可以帮助它在已经拥挤的代码编辑器世界中获取一席之地。
---
via: <https://itsfoss.com/graviton-code-editor/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Graviton](https://graviton.ml/) is a free and open source, cross-platform code editor in development. The sixteen years old developer, Marc Espin, emphasizes that it is a ‘minimalist’ code editor. I am not sure about that but it does have a clean user interface like other [modern code editors like Atom](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/).
The developer also calls it a lightweight code editor despite the fact that Graviton is based on [Electron](https://electronjs.org/).
Graviton comes with features you expect in any standard code editors like syntax highlighting, auto-completion etc. Since Graviton is still in the beta phase of development, more features will be added to it in the future releases.
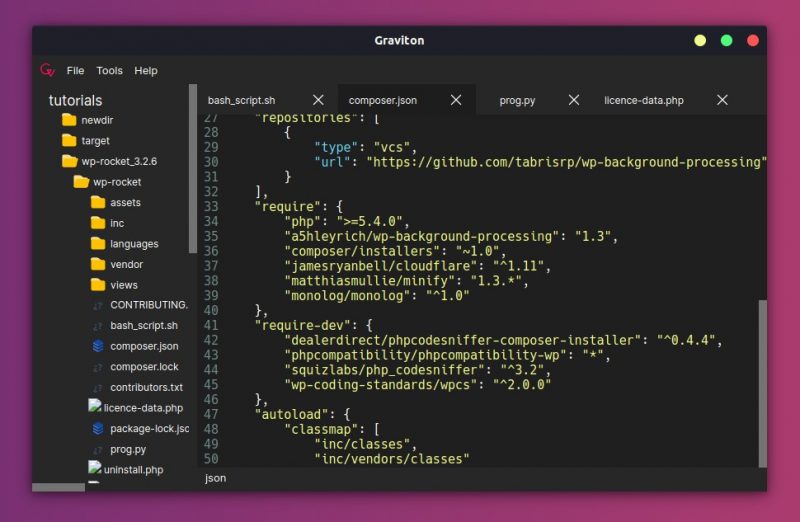
## Feature of Graviton code editor
Some of the main highlights of Graviton features are:
- Syntax highlighting for a number of programming languages using
[CodeMirrorJS](https://codemirror.net/) - Autocomplete
- Support for plugins and themes.
- Available in English, Spanish and a few other European languages.
- Available for Linux, Windows and macOS.
I had a quick look at Graviton and it might not be as feature-rich as [VS Code](https://itsfoss.com/install-visual-studio-code-ubuntu/) or [Brackets](https://itsfoss.com/install-brackets-ubuntu/), but for some simple code editing, it’s not a bad tool.
## Download and install Graviton
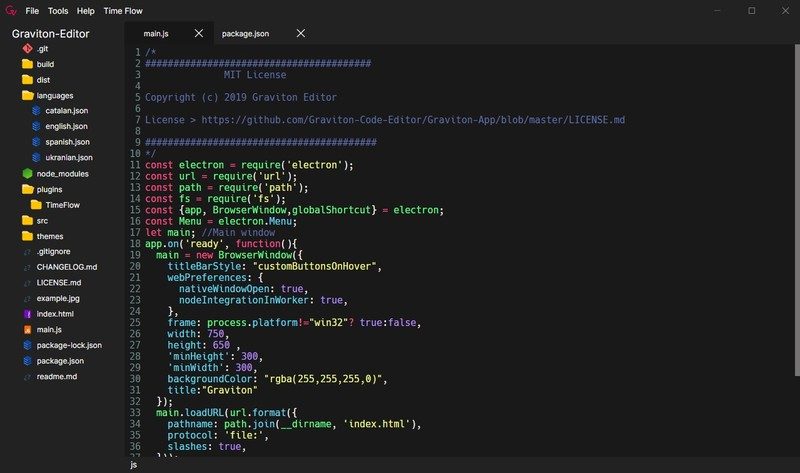
As mentioned earlier, Graviton is a cross-platform code editor available for Linux, Windows and macOS. It is still in beta stages which means that more features will be added in future and you may encounter some bugs.
You can find the latest version of Graviton on its release page. Debian and [Ubuntu users can install it from .deb file](https://itsfoss.com/install-deb-files-ubuntu/). [AppImage](https://itsfoss.com/use-appimage-linux/) has been provided so that it could be used in other distributions. DMG and EXE files are also available for macOS and Windows respectively.
If you are interested, you can find the source code of Graviton on its GitHub repository:
If you decided to use Graviton and find some issues, please open a bug report [here](https://github.com/Graviton-Code-Editor/Graviton-App/issues). If you use GitHub, you may want to star the Graviton project. This boosts the morale of the developer as he would know that more users are appreciating his efforts.
I believe you know [how to install a software from source code](https://itsfoss.com/install-software-from-source-code/) if you are taking that path.
**In the end…**
Sometimes, simplicity itself becomes a feature and the Graviton’s focus on being minimalist could help it form a niche for itself in the already crowded segment of code editors.
At It’s FOSS, we try to highlight open source software. If you know some interesting open source software that you would like more people to know about, [do send us a note](https://itsfoss.com/contact-us/). |
10,990 | 一条日志消息的现代生活 | https://opensource.com/article/18/9/life-log-message | 2019-06-18T19:30:56 | [
"日志",
"Kubernetes",
"OKD"
] | /article-10990-1.html |
>
> 从一条日志消息的角度来巡览现代分布式系统。
>
>
>

混沌系统往往是不可预测的。在构建像分布式系统这样复杂的东西时,这一点尤其明显。如果不加以控制,这种不可预测性会无止境的浪费时间。因此,分布式系统的每个组件,无论多小,都必须设计成以简化的方式组合在一起。
[Kubernetes](https://kubernetes.io/) 为抽象计算资源提供了一个很有前景的模型 —— 但即使是它也必须与其他分布式平台(如 [Apache Kafka](https://kafka.apache.org/))协调一致,以确保可靠的数据传输。如果有人要整合这两个平台,它会如何运作?此外,如果你通过这样的系统跟踪像日志消息这么简单的东西,它会是什么样子?本文将重点介绍来自在 [OKD](https://www.okd.io/) 内运行的应用程序的日志消息如何通过 Kafka 进入数据仓库(OKD 是为 Red Hat OpenShift 提供支持的 Kubernetes 的原初社区发行版)。
### OKD 定义的环境
这样的旅程始于 OKD,因为该容器平台完全覆盖了它抽象的硬件。这意味着日志消息等待由驻留在容器中的应用程序写入 stdout 或 stderr 流。从那里,日志消息被容器引擎(例如 [CRI-O](http://cri-o.io/))重定向到节点的文件系统。

在 OpenShift 中,一个或多个容器封装在称为 pod(豆荚)的虚拟计算节点中。实际上,在 OKD 中运行的所有应用程序都被抽象为 pod。这允许应用程序以统一的方式操纵。这也大大简化了分布式组件之间的通信,因为 pod 可以通过 IP 地址和[负载均衡服务](https://kubernetes.io/docs/concepts/services-networking/service/)进行系统寻址。因此,当日志消息由日志收集器应用程序从节点的文件系统获取时,它可以很容易地传递到在 OpenShift 中运行的另一个 pod 中。
### 在豆荚里的两个豌豆
为了确保可以在整个分布式系统中四处传播日志消息,日志收集器需要将日志消息传递到在 OpenShift 中运行的 Kafka 集群数据中心。通过 Kafka,日志消息可以以可靠且容错的方式低延迟传递给消费应用程序。但是,为了在 OKD 定义的环境中获得 Kafka 的好处,Kafka 需要完全集成到 OKD 中。
运行 [Strimzi 操作子](http://strimzi.io/)将所有 Kafka 组件实例化为 pod,并将它们集成在 OKD 环境中运行。 这包括用于排队日志消息的 Kafka 代理,用于从 Kafka 代理读取和写入的 Kafka 连接器,以及用于管理 Kafka 集群状态的 Zookeeper 节点。Strimzi 还可以将日志收集器实例化兼做 Kafka 连接器,允许日志收集器将日志消息直接提供给在 OKD 中运行的 Kafka 代理 pod。
### 在 OKD 内的 Kafka
当日志收集器 pod 将日志消息传递给 Kafka 代理时,收集器会写到单个代理分区,并将日志消息附加到该分区的末尾。使用 Kafka 的一个优点是它将日志收集器与日志的最终目标分离。由于解耦,日志收集器不关心日志最后是放在 [Elasticsearch](https://www.elastic.co/)、Hadoop、Amazon S3 中的某个还是全都。Kafka 与所有基础设施连接良好,因此 Kafka 连接器可以在任何需要的地方获取日志消息。
一旦写入 Kafka 代理的分区,该日志消息就会在 Kafka 集群内的跨代理分区复制。这是它的一个非常强大的概念;结合平台的自愈功能,它创建了一个非常有弹性的分布式系统。例如,当节点变得不可用时,(故障)节点上运行的应用程序几乎立即在健康节点上生成。因此,即使带有 Kafka 代理的节点丢失或损坏,日志消息也能保证存活在尽可能多的节点上,并且新的 Kafka 代理将快速原位取代。
### 存储起来
在日志消息被提交到 Kafka 主题后,它将等待 Kafka 连接器使用它,该连接器将日志消息中继到分析引擎或日志记录仓库。在传递到其最终目的地时,可以分析日志消息以进行异常检测,也可以查询日志以立即进行根本原因分析,或用于其他目的。无论哪种方式,日志消息都由 Kafka 以安全可靠的方式传送到目的地。
OKD 和 Kafka 是正在迅速发展的功能强大的分布式平台。创建能够在不影响性能的情况下抽象出分布式计算的复杂特性的系统至关重要。毕竟,如果我们不能简化单一日志消息的旅程,我们怎么能夸耀全系统的效率呢?
---
via: <https://opensource.com/article/18/9/life-log-message>
作者:[Josef Karásek](https://opensource.com/users/jkarasek) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,991 | Neofetch:在终端中显示 Linux 系统信息 | https://www.ostechnix.com/neofetch-display-linux-systems-information/ | 2019-06-19T10:33:29 | [
"Neofetch"
] | https://linux.cn/article-10991-1.html | 
Neofetch 是一个简单但有用的命令行系统信息工具,它用 Bash 编写。它会收集有关系统软硬件的信息,并在终端中显示结果。默认情况下,系统信息将与操作系统的 logo 一起显示。但是,你可以进一步地自定义使用 ascii 图像或其他任何图片。你还可以配置 Neofetch 显示的信息、信息的显示位置和时间。Neofetch 主要用于系统信息的截图。它支持 Linux、BSD、Mac OS X、iOS 和 Windows 操作系统。在这个简短的教程中,让我们看看如何使用 Neofetch 显示 Linux 系统信息。
### 安装 Neofetch
Neofetch 可在大多数 Linux 发行版的默认仓库中找到。
在 Arch Linux 及其衍生版上,使用这个命令安装它:
```
$ sudo pacman -S netofetch
```
在 Debian(Stretch / Sid)上:
```
$ sudo apt-get install neofetch
```
在 Fedora 27 上:
```
$ sudo dnf install neofetch
```
在 RHEL、CentOS 上:
启用 EPEL 仓库:
```
# yum install epel-relase
```
获取 neofetch 仓库:
```
# curl -o /etc/yum.repos.d/konimex-neofetch-epel-7.repo
https://copr.fedorainfracloud.org/coprs/konimex/neofetch/repo/epel-7/konimex-neofetch-epel-7.repo
```
然后,安装 Neofetch:
```
# yum install neofetch
```
在 Ubuntu 17.10 和更新版本上:
```
$ sudo apt-get install neofetch
```
在 Ubuntu 16.10 和更低版本上:
```
$ sudo add-apt-repository ppa:dawidd0811/neofetch
$ sudo apt update
$ sudo apt install neofetch
```
在 NixOS 上:
```
$ nix-env -i neofetch
```
### 使用 Neofetch 显示 Linux 系统信息
Neofetch 非常简单直接。让我们看一些例子。
打开终端,然后运行以下命令:
```
$ neofetch
```
示例输出:

*使用 Neofetch 显示 Linux 系统信息*
正如你在上面的输出中所看到的,Neofetch 显示了我的 Arch Linux 系统的以下详细信息:
* 已安装操作系统的名称,
* 笔记本型号,
* 内核详细信息,
* 系统运行时间,
* 默认和其他软件包管理器安装的软件数量
* 默认 shell,
* 屏幕分辨率,
* 桌面环境,
* 窗口管理器,
* 窗口管理器的主题,
* 系统主题,
* 系统图标,
* 默认终端,
* CPU 类型,
* GPU 类型,
* 已安装的内存。
Neofetch 还有很多其他选项。我们会看到其中一些。
### 如何在 Neofetch 输出中使用自定义图像?
默认情况下,Neofetch 将显示你的操作系统 logo 以及系统信息。当然,你可以根据需要更改图像。
要显示图像,Linux 系统应该安装以下依赖项:
1. w3m-img(用于显示图像。w3m-img 有时与 w3m 包捆绑在一起),
2. Imagemagick(用于创建缩略图),
3. 支持 `\033[14t` 或者 xdotool 或者 xwininfo + xprop 或者 xwininfo + xdpyinfo 的终端。
大多数 Linux 发行版的默认仓库中都提供了 W3m-img 和 ImageMagick 包。因此,你可以使用你的发行版的默认包管理器来安装它们。
例如,运行以下命令在 Debian、Ubuntu、Linux Mint 上安装 w3m-img 和 ImageMagick:
```
$ sudo apt install w3m-img imagemagick
```
以下是带 w3m-img 支持的终端列表:
1. Gnome-terminal,
2. Konsole,
3. st,
4. Terminator,
5. Termite,
6. URxvt,
7. Xfce4-Terminal,
8. Xterm
如果你的系统上已经有了 kitty、Terminology 和 iTerm,那么就无需安装 w3m-img。
现在,运行以下命令以使用自定义图像显示系统信息:
```
$ neofetch --w3m /home/sk/Pictures/image.png
```
或者,
```
$ neofetch --w3m --source /home/sk/Pictures/image.png
```
示例输出:

*使用自定义 logo 的 Neofetch 输出*
使用你自己的图片替换上面图片的路径。
或者,你可以指向包含以下图像的目录。
```
$ neofetch --w3m <path-to-directory>
```
### 配置 Neofetch
当我们第一次运行 Neofetch 时,它默认会为每个用户在 `$HOME/.config/neofetch/config.conf` 中创建一个配置文件。它还会在 `$HOME/.config/neofetch/config` 中创建一个全局的 neofetch 配置文件。你可以调整此文件来告诉 neofetch 该显示、删除和/或修改哪些详细信息。
还可以在不同版本中保留此配置文件。这意味着你只需根据自己的喜好自定义一次,并在升级到更新版本后使用相同的设置。你甚至可以将此文件共享给你的朋友和同事,使他拥有与你相同的设置。
要查看 Neofetch 帮助部分,请运行:
```
$ neofetch --help
```
就我测试的 Neofetch 而言,它在我的 Arch Linux 系统中完美地工作。它是一个非常方便的工具,可以在终端中轻松快速地打印系统的详细信息。
相关阅读:
* [如何使用 inxi 查看 Linux 系统详细信息](https://www.ostechnix.com/how-to-find-your-system-details-using-inxi/)
资源:
* [Neofetch 的 GitHub 页面](https://github.com/dylanaraps/neofetch)
---
via: <https://www.ostechnix.com/neofetch-display-linux-systems-information/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,992 | DevOps 思维模式的 5 个基本价值观 | https://opensource.com/article/19/5/values-devops-mindset | 2019-06-19T11:15:26 | [
"DevOps"
] | https://linux.cn/article-10992-1.html |
>
> 人和流程比在解决的业务问题的任何技术“银弹”更重要,且需要花更多的时间。
>
>
>

今天的许多 IT 专业人士都在努力适应变化和扰动。这么说吧,你是否正在努力适应变化?你觉得不堪重负吗?这并不罕见。今天,IT 的现状还不够好,所以需要不断尝试重新自我演进。
凭借 30 多年的IT综合经验,我们见证了人员与关系对于 IT 企业提高效率和帮助企业蓬勃发展的重要性。但是,在大多数情况下,我们关于 IT 解决方案的对话始于技术,而不是从人员和流程开始。寻找“银弹”来解决业务和 IT 挑战的倾向过于普遍。但你不能想着可以买到创新、DevOps 或有效的团队和工作方式;他们需要得到培养,支持和引导。
由于扰动如此普遍,并且对变革速度存在如此迫切的需求,我们需要纪律和围栏。下面描述的 DevOps 思维模式的五个基本价值观将支持将我们的实践。这些价值观不是新观念;正如我们从经验中学到的那样,它们被重构了。一些价值观可以互换的,它们是灵活的,并且它们如支柱一样导向了支持这五个价值观的整体原则。

### 1、利益相关方的反馈至关重要
我们如何知道我们是否为我们创造了比利益相关方更多的价值?我们需要持久的质量数据来分析、通知并推动更好的决策。来自可靠来源的相关信息对于任何业务的蓬勃发展至关重要。我们需要倾听并理解我们的利益相关方所说的,而不是说我们需要以一种方式实施变革,使我们能够调整我们的思维、流程和技术,并根据需要对其进行调整以使我们的利益相关者满意。由于信息(数据)不正确,我们常常看到的变化过少,或者由于错误的原因而发生了很多变化。因此,将变更与利益相关方的反馈结合起来是一项基本价值观,并有助我们专注于使公司成功最重要的事情。
>
> 关注我们的利益相关方及其反馈,而不仅仅是为了改变而改变。
>
>
>
### 2、超越当今流程的极限进行改进
我们希望我们的产品和服务能够不断让客户满意,他们是我们最重要的利益相关方。因此,我们需要不断改进。这不仅仅是关系到质量;它还可能意味着成本、可用性、相关性以及许多其他目标和因素。创建可重复的流程或使用通用框架是非常棒的,它们可以改善治理和许多其他问题。但是,这不应该是我们的最终目标。在寻找改进方法时,我们必须调整我们的流程,并辅以正确的技术和工具。可能有理由抛出一个“所谓的”框架,因为不这样做可能会增加浪费,更糟糕的是只是“货物结果”(做一些没有价值或目的的东西)。
>
> 力争始终创新并改进可重复的流程和框架。
>
>
>
### 3、不要用新的孤岛来打破旧的孤岛
孤岛和 DevOps 是不兼容的。我们经常能看到:IT 主管带来了所谓的“专家”来实施敏捷和 DevOps,他们做了什么?这些“专家”在现有问题的基础上创建了一个新问题,这是 IT 部门和业务中又增加了一个孤岛。创造“DevOps”职位违背了敏捷和 DevOps 基于打破孤岛的原则。在敏捷和 DevOps 中,团队合作是必不可少的,如果你不在自组织团队中工作,那么你就不会做任何事情。
>
> 相互激励和共享,而不是成为英雄或创建一个孤岛。
>
>
>
### 4、了解你的客户意味着跨组织协作
企业的任何一个部分都不是一个独立的实体,因为它们都有利益相关方,主要利益相关方始终是客户。“客户永远是对的”(或国王,我喜欢这样说)。关键是,没有客户就真的没有业务,而且为了保持业务,如今我们需要与竞争对手“区别对待”。我们还需要了解客户对我们的看法以及他们对我们的期望。了解客户的需求势在必行,需要及时反馈,以确保业务能够快速、负责地满足这些主要利益相关者的需求和关注。

无论是想法、概念、假设还是直接利益相关方的反馈,我们都需要通过使用探索、构建、测试和交付生命周期来识别和衡量我们的产品提供的功能或服务。从根本上说,这意味着我们需要在整个组织中“插入”我们的组织。在持续创新、学习和 DevOps 方面没有任何边界。因此,当我们在整个企业中进行衡量时,我们可以理解整体并采取可行的、有意义的步骤来改进。
>
> 衡量整个组织的绩效,而不仅仅是在业务范围内。
>
>
>
### 5、通过热情鼓励采纳
不是每个人都要被驱使去学习、适应和改变;然而,就像微笑可能具有传染性一样,学习和意愿成为变革文化的一部分也是如此。在学习文化中适应和演化为一群人提供了学习和传递信息(即文化传播)的自然机制。学习风格、态度、方法和过程不断演化,因此我们可以改进它们。下一步是应用所学和改进的内容并与同事分享信息。学习不会自动发生;它需要努力、评估、纪律、意识,特别是沟通;遗憾的是,这些都是工具和自动化无法提供的。检查你的流程、自动化、工具策略和实施工作,使其透明化,并与你的同事协作重复使用和改进。
>
> 通过精益交付促进学习文化,而不仅仅是工具和自动化。
>
>
>
### 总结

随着我们的公司采用 DevOps,我们继续在各种书籍、网站或自动化软件上倡导这五个价值观。采用这种思维方式需要时间,这与我们以前作为系统管理员所做的完全不同。这是一种全新的工作方式,需要很多年才能成熟。这些原则是否与你自己的原则一致?在评论或我们的网站 [Agents of chaos](http://agents-of-chaos.org) 上分享。
---
via: <https://opensource.com/article/19/5/values-devops-mindset>
作者:[Brent Aaron Reed](https://opensource.com/users/brentaaronreed/users/wpschaub/users/wpschaub/users/wpschaub/users/cobiacomm/users/marcobravo/users/brentaaronreed) 选题:[lujun9972](https://github.com/lujun9972) 译者:[arrowfeng](https://github.com/arrowfeng) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Many IT professionals today struggle with adapting to change and disruption. Are you struggling with just trying to keep the lights on, so to speak? Do you feel overwhelmed? This is not uncommon. Today, the status quo is not enough, so IT constantly tries to re-invent itself.
With over 30 years of combined IT experience, we have witnessed how important people and relationships are to IT's ability to be effective and help the business thrive. However, most of the time, our conversations about IT solutions start with technology rather than people and process. The propensity to look for a "silver bullet" to address business and IT challenges is far too common. But you can't just buy innovation, DevOps, or effective teams and ways of working; they need to be nurtured, supported, and guided.
With disruption so prevalent and there being such a critical demand for speed of change, we need both discipline and guardrails. The five essential values for the DevOps mindset, described below, will support the practices that will get us there. These values are not new ideas; they are refactored as we've learned from our experience. Some of the values may be interchangeable, they are flexible, and they guide overall principles that support (like a pillar) these five values.
## 1. Feedback from stakeholders is essential
How do we know if we are creating more value for us than for our stakeholders? We need persistent quality data to analyze, inform, and drive better decisions. Relevant information from trusted sources is vital for any business to thrive. We need to listen to and understand what our stakeholders are saying—and not saying—and we need to implement changes in a way that enables us to adjust our thinking—and our processes and technologies—and adapt them as needed to delight our stakeholders. Too often, we see little change, or lots of change for the wrong reasons, because of incorrect information (data). Therefore, aligning change to our stakeholders' feedback is an essential value and helps us focus on what is most important to making our company successful.
Focus on our stakeholders and their feedback rather than simply changing for the sake of change.
## 2. Improve beyond the limits of today's processes
We want our products and services to continuously delight our customers—our most important stakeholders—therefore, we need to improve continually. This is not only about quality; it could also mean costs, availability, relevance, and many other goals and factors. Creating repeatable processes or utilizing a common framework is great—they can improve governance and a host of other issues—however, that should not be our end goal. As we look for ways to improve, we must adjust our processes, complemented by the right tech and tools. There may be reasons to throw out a "so-called" framework because not doing so could add waste—or worse, simply "cargo culting" (doing something with of no value or purpose).
Strive to always innovate and improve beyond repeatable processes and frameworks.
## 3. No new silos to break down silos
Silos and DevOps are incompatible. We see this all the time: an IT director brings in so-called "experts" to implement agile and DevOps, and what do they do? These "experts" create a new problem on top of the existing problem, which is another silo added to an IT department and a business riddled with silos. Creating "DevOps" titles goes against the very principles of agile and DevOps, which are based on the concept of breaking down silos. In both agile and DevOps, teamwork is essential, and if you don't work in a self-organizing team, you're doing neither of them.
Inspire and share collaboratively instead of becoming a hero or creating a silo.
## 4. Knowing your customer means cross-organization collaboration
No part of the business is an independent entity because they all have stakeholders, and the primary stakeholder is always the customer. "The customer is always right" (or the king, as I like to say). The point is, without the customer, there really is no business, and to stay in business today, we need to "differentiate" from our competitors. We also need to know how our customers feel about us and what they want from us. Knowing what the customer wants is imperative and requires timely feedback to ensure the business addresses these primary stakeholders' needs and concerns quickly and responsibly.
Whether it comes from an idea, a concept, an assumption, or direct stakeholder feedback, we need to identify and measure the feature or service our product delivers by using the explore, build, test, deliver lifecycle. Fundamentally, this means that we need to be "plugged into" our organization across the organization. There are no borders in continuous innovation, learning, and DevOps. Thus when we measure across the enterprise, we can understand the whole and take actionable, meaningful steps to improve.
Measure performance across the organization, not just in a line of business.
## 5. Inspire adoption through enthusiasm
Not everyone is driven to learn, adapt, and change; however, just like smiles can be infectious, so can learning and wanting to be part of a culture of change. Adapting and evolving within a culture of learning provides a natural mechanism for a group of people to learn and pass on information (i.e., cultural transmission). Learning styles, attitudes, methods, and processes continually evolve so we can improve upon them. The next step is to apply what was learned and improved and share the information with colleagues. Learning does not happen automatically; it takes effort, evaluation, discipline, awareness, and especially communication; unfortunately these are things that tools and automation alone will not provide. Review your processes, automation, tool strategies, and implementation work, make it transparent, and collaborate with your colleagues on reuse and improvement.
Promote a culture of learning through lean quality deliverables, not just tools and automation.
## Summary
As our companies adopt DevOps, we continue to champion these five values over any book, website, or automation software. It takes time to adopt this mindset, and this is very different than what we used to do as sysadmins. It's a wholly new way of working that will take many years to mature. Do these principles align with your own? Share them in the comments or on our website, [Agents of chaos](http://agents-of-chaos.org).
## 6 Comments |
10,994 | 在 AppImage、Flathub 和 Snapcraft 平台上搜索 Linux 应用 | https://www.ostechnix.com/search-linux-applications-on-appimage-flathub-and-snapcraft-platforms/ | 2019-06-19T14:39:19 | [
"应用",
"安装"
] | https://linux.cn/article-10994-1.html | 
Linux 一直在发展。过去,开发人员必须分别为不同的 Linux 发行版构建应用。由于存在多种 Linux 变体,因此为所有发行版构建应用变得很繁琐,而且非常耗时。后来一些开发人员发明了包转换器和构建器,如 [Checkinstall](https://www.ostechnix.com/build-packages-source-using-checkinstall/)、[Debtap](https://www.ostechnix.com/convert-deb-packages-arch-linux-packages/) 和 [Fpm](https://www.ostechnix.com/build-linux-packages-multiple-platforms-easily/)。但他们也没有完全解决问题。所有这些工具都只是将一种包格式转换为另一种包格式。我们仍然需要找到应用并安装运行所需的依赖项。
好吧,时代已经变了。我们现在有了通用的 Linux 应用。这意味着我们可以在大多数 Linux 发行版上安装这些应用。无论是 Arch Linux、Debian、CentOS、Redhat、Ubuntu 还是任何流行的 Linux 发行版,通用应用都可以正常使用。这些应用与所有必需的库和依赖项打包在一个包中。我们所要做的就是在我们使用的任何 Linux 发行版上下载并运行它们。流行的通用应用格式有 AppImage、[Flatpak](https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/) 和 [Snap](https://www.ostechnix.com/introduction-ubuntus-snap-packages/)。
AppImage 由 Simon peter 创建和维护。许多流行的应用,如 Gimp、Firefox、Krita 等等,都有这些格式,并可直接在下载页面下载。只需下载它们,使其可执行并立即运行它。你甚至无需 root 权限来运行 AppImage。
Flatpak 的开发人员是 Alexander Larsson(RedHat 员工)。Flatpak 应用托管在名为 “Flathub” 的中央仓库(商店)中。如果你是开发人员,建议你使用 Flatpak 格式构建应用,并通过 Flathub 将其分发给用户。
Snap 由 Canonical 而建,主要用于 Ubuntu。但是,其他 Linux 发行版的开发人员开始为 Snap 打包格式做出贡献。因此,Snap 也开始适用于其他 Linux 发行版。Snap 可以直接从应用的下载页面下载,也可以从 Snapcraft 商店下载。
许多受欢迎的公司和开发人员已经发布了 AppImage、Flatpak 和 Snap 格式的应用。如果你在寻找一款应用,只需进入相应的商店并获取你选择的应用并运行它,而不用管你使用何种 Linux 发行版。
还有一个名为 “Chob” 的命令行通用应用搜索工具可在 AppImage、Flathub 和 Snapcraft 平台上轻松搜索 Linux 应用。此工具仅搜索给定的应用并在默认浏览器中显示官方链接。它不会安装它们。本指南将解释如何安装 Chob 并使用它来搜索 Linux 上的 AppImage、Flatpak 和 Snap。
### 使用 Chob 在 AppImage、Flathub 和 Snapcraft 平台上搜索 Linux 应用
从[发布页面](https://github.com/MuhammedKpln/chob/releases)下载最新的 Chob 二进制文件。在编写本指南时,最新版本为 0.3.5。
```
$ wget https://github.com/MuhammedKpln/chob/releases/download/0.3.5/chob-linux
```
使其可执行:
```
$ chmod +x chob-linux
```
最后,搜索你想要的应用。例如,我将搜索与 Vim 相关的应用。
```
$ ./chob-linux vim
```
Chob 将在 AppImage、Flathub 和 Snapcraft 平台上搜索给定的应用(和相关应用)并显示结果。

*使用 Chob 搜索 Linux 应用*
只需要输入你想要应用前面的数字就可在默认浏览器中打开它的官方链接,并可在其中阅读应用的详细信息。

*在浏览器中查看 Linux 应用的详细信息*
有关更多详细信息,请查看下面的 Chob 官方 GitHub 页面。
资源:
* [Chob 的 GitHub 仓库](https://github.com/MuhammedKpln/chob)
---
via: <https://www.ostechnix.com/search-linux-applications-on-appimage-flathub-and-snapcraft-platforms/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,995 | 优麒麟:Ubuntu 的官方中文版本 | https://itsfoss.com/ubuntu-kylin/ | 2019-06-19T21:48:00 | [
"Ubuntu",
"优麒麟"
] | https://linux.cn/article-10995-1.html |
>
> 让我们来看看国外是如何看优麒麟的。
>
>
>
[Ubuntu 有几个官方特色版本](https://itsfoss.com/which-ubuntu-install/),优麒麟(Ubuntu Kylin)是它们中的一个。在这篇文章中,你将了解到优麒麟,它是什么,它为什么被创建,它的特色是什么。
麒麟操作系统最初由中华人民共和国的[国防科技大学](https://english.nudt.edu.cn)的院士在 2001 年开发。名字来源于[麒麟](https://www.thoughtco.com/what-is-a-qilin-195005),这是一种来自中国神话的神兽。
麒麟操作系统的第一个版本基于 [FreeBSD](https://itsfoss.com/freebsd-12-release/),计划用于中国军方和其它政府组织。麒麟 3.0 完全基于 Linux 内核,并且在 2010 年 12 月发布一个称为 [NeoKylin](https://thehackernews.com/2015/09/neokylin-china-linux-os.html) 的版本。
在 2013 年,[Canonical](https://www.canonical.com/) (Ubuntu 的母公司) 与中华人民共和国的[工业和信息化部](http://english.gov.cn/state_council/2014/08/23/content_281474983035940.htm) 达成共识,共同创建和发布一个针对中国市场特色的基于 Ubuntu 的操作系统。

### 优麒麟是什么?
根据上述 2013 年的共识,优麒麟现在是 Ubuntu 的官方中国版本。它不仅仅是语言本地化。事实上,它决心服务中国市场,就像 Ubuntu 服务全球市场一样。
[优麒麟](http://www.ubuntukylin.com/)的第一个版本与 Ubuntu 13.04 一起到来。像 Ubuntu 一样,优麒麟也有 LTS (长期支持)和非 LTS 版本。
当前,优麒麟 19.04 LTS 采用了 [UKUI](http://ukui.org) 桌面环境,修改了启动动画、登录/锁屏程序和操作系统主题。为给用户提供更友好的体验,它修复了一些错误,带有文件预览、定时注销等功能,最新的 [WPS 办公组件](https://www.wps.com/)和 [搜狗](https://en.wikipedia.org/wiki/Sogou_Pinyin) 输入法集成于其中。
银河麒麟 4.0.2 是一个基于优麒麟 16.04 LTS 的社区版本。它包含一些带有长期稳定支持的第三方应用程序。它非常适合服务器和日常桌面办公使用,欢迎开发者[下载](http://www.ubuntukylin.com/downloads/show.php?lang=en&id=122)。麒麟论坛积极地获取来自提供的反馈以及解决问题来找到解决方案。
#### UKUI:优麒麟的桌面环境

[UKUI](http://www.ukui.org/) 由优麒麟开发小组设计和开发,有一些非常好的特色和预装软件:
* 类似 Windows 的交互功能,带来更友好的用户体验。安装导向易于使用,用户可以快速使用优麒麟。
* 控制中心对主题和窗口采用了新的设置。如开始菜单、任务栏、文件管理器、窗口管理器和其它的组件进行了更新。
* 在 Ubuntu 和 Debian 存储库上都可用,为 Debian/Ubuntu 发行版和其全球衍生版的的用户提供一个新单独桌面环境。
* 新的登录和锁定程序,它更稳定和具有很多功能。
* 包括一个反馈问题的实用的反馈程序。
#### 麒麟软件中心

麒麟有一个软件中心,类似于 Ubuntu 软件中心,并被称为优麒麟软件中心。它是优麒麟软件商店的一部分,该商店也包含优麒麟开发者平台和优麒麟存储库,具有一个简单的用户界面,并功能强大。它同时支持 Ubuntu 和优麒麟存储库,并特别适用于由优麒麟小组开发的中文特有的软件的快速安装!
#### 优客:一系列的工具
优麒麟也有一系列被命名为优客的工具。在麒麟开始菜单中输入 “Youker” 将带来麒麟助手。如果你在键盘上按 “Windows” 按键,像你在 Windows 上一样,它将打开麒麟开始菜单。

其它麒麟品牌的应用程序包括麒麟影音(播放器)、麒麟刻录,优客天气、优客 Fcitx 输入法,它们更好地支持办公工作和个人娱乐。

#### 特别专注于中文
通过与金山软件合作,优麒麟开发者也致力于 Linux 版本的搜狗拼音输入法、快盘和优麒麟版本的金山 WPS,并解决了智能拼音、云存储和办公应用程序方面的问题。[拼音](https://en.wikipedia.org/wiki/Pinyin) 是中文字符的拉丁化系统。使用这个系统,用户用英文键盘输入,但在屏幕上将显示中文字符。
#### 有趣的事实:优麒麟运行在中国超级计算机上

众所周知[世界上最快的超级计算机 500 强都在运行 Linux](https://itsfoss.com/linux-runs-top-supercomputers/)。中国超级计算机[天河-1](https://en.wikipedia.org/wiki/Tianhe-1)和[天河-2](https://en.wikipedia.org/wiki/Tianhe-2)都使用优麒麟的 64 位版本,致力于高性能的[并行计算](https://en.wikipedia.org/wiki/Parallel_computing)优化、电源管理和高性能的[虚拟化计算](https://computer.howstuffworks.com/how-virtual-computing-works.htm)。
### 总结
我希望你喜欢这篇优麒麟世界的介绍。你可以从它的[官方网站](http://www.ubuntukylin.com)获得优麒麟 19.04 或基于 Ubuntu 16.04 的社区版本(银河麒麟)。
---
via: <https://itsfoss.com/ubuntu-kylin/>
作者:[Avimanyu Bandyopadhyay](https://itsfoss.com/author/avimanyu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Kylin was originally developed in 2001 by academicians at the [National University of Defense Technology](https://english.nudt.edu.cn/?ref=itsfoss.com) in the People’s Republic of China. The name is derived from [Qilin](https://www.thoughtco.com/what-is-a-qilin-195005?ref=itsfoss.com), a beast from Chinese mythology.
The first versions of Kylin were based on [FreeBSD](https://itsfoss.com/freebsd-12-release/) and were intended for use by the Chinese military and other government organizations. Kylin 3.0 was purely based on the Linux kernel, and a version called [NeoKylin](https://thehackernews.com/2015/09/neokylin-china-linux-os.html?ref=itsfoss.com) which was announced in December 2010.
In 2013, [Canonical](https://www.canonical.com/?ref=itsfoss.com) (parent company of Ubuntu) reached an agreement with the [Ministry of Industry and Information Technology](http://english.gov.cn/state_council/2014/08/23/content_281474983035940.htm?ref=itsfoss.com) of the People’s Republic of China to co-create and release an Ubuntu-based OS with features targeted at the Chinese market.

## What is Ubuntu Kylin?
Following the 2013 agreement mentioned above, Ubuntu Kylin is now the official Chinese version of Ubuntu. It is much more than just language localization. In fact, it is determined to serve the Chinese market the same way as Ubuntu serves the global market.
The first version of [Ubuntu Kylin](http://www.ubuntukylin.com/?ref=itsfoss.com) came with Ubuntu 13.04. Like Ubuntu, Kylin too has LTS (long-term support) and non-LTS versions.
Currently, Ubuntu Kylin 19.04 LTS implements the [UKUI](http://ukui.org/?ref=itsfoss.com) desktop environment with a revised boot-up animation, log-in/screen-lock program and OS theme. To offer a more friendly experience for users, it has fixed bugs, has a file preview function, timer log out, the latest [WPS office suite](https://www.wps.com/?ref=itsfoss.com) and [Sogou](https://en.wikipedia.org/wiki/Sogou_Pinyin?ref=itsfoss.com) put-in methods integrated within.
Kylin 4.0.2 is a community edition based on Ubuntu Kylin 16.04 LTS. It includes several third-party applications with long-term and stable support. It’s perfect for both server and desktop usage for daily office work and welcomed by the developers to [download](http://www.ubuntukylin.com/downloads/show.php?lang=en&id=122&ref=itsfoss.com). The Kylin forums are actively available to provide feedback and also troubleshoot to find solutions.
### UKUI: The desktop environment by Ubuntu Kylin

[UKUI](http://www.ukui.org/?ref=itsfoss.com) is designed and developed by the Ubuntu Kylin team and has some great features and provisions:
- Windows-like interactive functions to bring more friendly user experiences. The Setup Wizard is user-friendly so that users can get started with Ubuntu Kylin quickly.
- Control Center has new settings for theme and window. Updated components such as Start Menu, taskbar, notification bar, file manager, window manager and others.
- Available separately on both Ubuntu and Debian repositories to provide a new desktop environment for users of Debian/Ubuntu distributions and derivatives worldwide.
- New login and lock programs, which is more stable and with many functions.
- Includes a feedback program convenient for feedback and questions.
### Kylin Software Center

Kylin has a software center similar to the Ubuntu software center and is called Ubuntu Kylin Software Center. It’s part of the Ubuntu Kylin Software Store that also includes the Ubuntu Kylin Developer Platform and Ubuntu Kylin Repository with a simple interface and powerful function. It supports both Ubuntu and Ubuntu Kylin Repositories and is especially convenient for quick installation of Chinese characteristic software developed by the Ubuntu Kylin team!
### Youker: A series of tools
Ubuntu Kylin has also a series of tools named as Youker. Typing in “Youker” in the Kylin start menu will bring up the Kylin assistant. If you press the “Windows” key on the keyboard, you will get a response exactly like you would on Windows. It will fire up the Kylin start menu.
Other Kylin branded applications include Kylin Video (player), Kylin Burner, Youker Weather and Youker Fcitx which supports better office work and personal entertainment.
### Special focus on Chinese characters
In cooperation with Kingsoft, Ubuntu Kylin developers also work on Sogou Pinyin for Linux, Kuaipan for Linux and Kingsoft WPS for Ubuntu Kylin, and also address issues with smart pinyin, cloud storage service and office applications. [Pinyin](https://en.wikipedia.org/wiki/Pinyin?ref=itsfoss.com) is romanization system for Chinese characters. With this, user inputs with English keyboard but Chinese characters are displayed on the screen.
### Fun Fact: Ubuntu Kylin runs on Chinese supercomputers

It’s already in public knowledge that the [world’s top 500 fastest supercomputers run Linux](https://itsfoss.com/linux-runs-top-supercomputers/). Chinese supercomputers [Tianhe-1](https://en.wikipedia.org/wiki/Tianhe-1?ref=itsfoss.com) and [Tianhe-2](https://en.wikipedia.org/wiki/Tianhe-2?ref=itsfoss.com) both use the 64-bit version of Kylin Linux, dedicated to high-performance [parallel computing](https://en.wikipedia.org/wiki/Parallel_computing?ref=itsfoss.com) optimization, power management and high-performance [virtual computing](https://computer.howstuffworks.com/how-virtual-computing-works.htm?ref=itsfoss.com).
### Summary
I hope you liked this introduction in the world of Ubuntu Kylin. You can get either of Ubuntu Kylin 19.04 or the community edition based on Ubuntu 16.04 from its [official website](http://www.ubuntukylin.com/?ref=itsfoss.com). |
10,997 | 5 个提高效率的 GNOME 快捷键 | https://fedoramagazine.org/5-gnome-keyboard-shortcuts-to-be-more-productive/ | 2019-06-19T22:54:00 | [
"GNOME"
] | https://linux.cn/article-10997-1.html | 
对于某些人来说,使用 GNOME Shell 作为传统的桌面管理器可能会感觉沮丧,因为它通常需要更多的鼠标操作。事实上,GNOME Shell 也是一个专为键盘操作而设计的[桌面管理器](https://fedoramagazine.org/gnome-3-32-released-coming-to-fedora-30/)。通过这五种使用键盘而不是鼠标的方法,了解如何使用 GNOME Shell 提高效率。
### GNOME 活动概述
可以使用键盘上的 `Super` 键轻松打开活动概述。(`Super` 键通常有一个标识——比如 Windows 徽标……)这在启动应用程序时非常有用。例如,使用以下键序列 `Super + f i r + Enter` 可以轻松启动 Firefox Web 浏览器

### 消息托盘
在 GNOME 中,消息托盘中提供了通知。这也是日历和世界时钟出现的地方。要使用键盘打开信息托盘,请使用 `Super + m` 快捷键。要关闭消息托盘,只需再次使用相同的快捷方式。

### 在 GNOME 中管理工作空间
GNOME Shell 使用动态工作空间,这意味着它可以根据需要创建更多工作空间。使用 GNOME 提高工作效率的一个好方法是为每个应用程序或每个专用活动使用一个工作区,然后使用键盘在这些工作区之间导航。
让我们看一个实际的例子。要在当前工作区中打开终端,请按以下键:`Super + t e r + Enter`。然后,要打开新工作区,请按 `Super + PgDn`。 打开 Firefox( `Super + f i r + Enter`)。 要返回终端(所在的工作空间),请使用 `Super + PgUp`。

### 管理应用窗口
使用键盘也可以轻松管理应用程序窗口的大小。最小化、最大化和将应用程序移动到屏幕的左侧或右侧只需几个击键即可完成。使用 `Super + ↑` 最大化、`Super + ↓` 最小化、`Super + ←` 和 `Super + →` 左右移动窗口。

### 同一个应用的多个窗口
使用活动概述启动应用程序非常有效。但是,尝试从已经运行的应用程序打开一个新窗口只能将焦点转移到已经打开的窗口。要创建一个新窗口,就不是简单地按 `Enter` 启动应用程序,请使用 `Ctrl + Enter`。
因此,例如,使用应用程序概述启动终端的第二个实例,`Super + t e r + (Ctrl + Enter)`。

然后你可以使用 `Super + `` 在同一个应用程序的窗口之间切换。

如图所示,当用键盘控制时,GNOME Shell 是一个非常强大的桌面环境。学习使用这些快捷方式并训练你的肌肉记忆以不使用鼠标将为你提供更好的用户体验,并在使用 GNOME 时提高你的工作效率。有关其他有用的快捷方式,请查看 [GNOME wiki 上的此页面](https://wiki.gnome.org/Design/OS/KeyboardShortcuts)。
*图片来自 [1AmFcS](https://unsplash.com/photos/MuTWth_RnEs?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText),[Unsplash](https://unsplash.com/search/photos/keyboard?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)*
---
via: <https://fedoramagazine.org/5-gnome-keyboard-shortcuts-to-be-more-productive/>
作者:[Clément Verna](https://fedoramagazine.org/author/cverna/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For some people, using GNOME Shell as a traditional desktop manager may be frustrating since it often requires more action of the mouse. In fact, GNOME Shell is also a [desktop manager](https://fedoramagazine.org/gnome-3-32-released-coming-to-fedora-30/) designed for and meant to be driven by the keyboard. Learn how to be more efficient with GNOME Shell with these 5 ways to use the keyboard instead of the mouse.
### GNOME activities overview
The activities overview can be easily opened using the **Super** key from the keyboard. (The **Super** key usually has a logo on it.) This is really useful when it comes to start an application. For example, it’s easy to start the Firefox web browser with the following key sequence **Super + fir + Enter.**

### Message tray
In GNOME, notifications are available in the message tray. This is also the place where the calendar and world clocks are available. To open the message tray using the keyboard use the **Super+m** shortcut. To close the message tray simply use the same shortcut again.
### Managing workspaces in GNOME
Gnome Shell uses dynamic workspaces, meaning it creates additional workspaces as they are needed. A great way to be more productive using Gnome is to use one workspace per application or per dedicated activity, and then use the keyboard to navigate between these workspaces.
Let’s look at a practical example. To open a Terminal in the current workspace press the following keys: **Super + ter + Enter.** Then, to open a new workspace press **Super + PgDn**. Open Firefox (**Super + fir + Enter)**. To come back to the terminal, use **Super + PgUp**.
### Managing an application window
Using the keyboard it is also easy to manage the size of an application window. Minimizing, maximizing and moving the application to the left or the right of the screen can be done with only a few key strokes. Use **Super+up** to maximize, **Super+down** to minimize, **Super+left** and **Super+right** to move the window left and right.
### Multiple windows from the same application
Using the activities overview to start an application is very efficient. But trying to open a new window from an application already running only results in focusing on the open window. To create a new window, instead of simply hitting **Enter** to start the application, use **Ctrl+Enter**.
So for example, to start a second instance of the terminal using the application overview, **Super + ter + (Ctrl+Enter)**.
Then you can use **Super+`** to switch between windows of the same application.
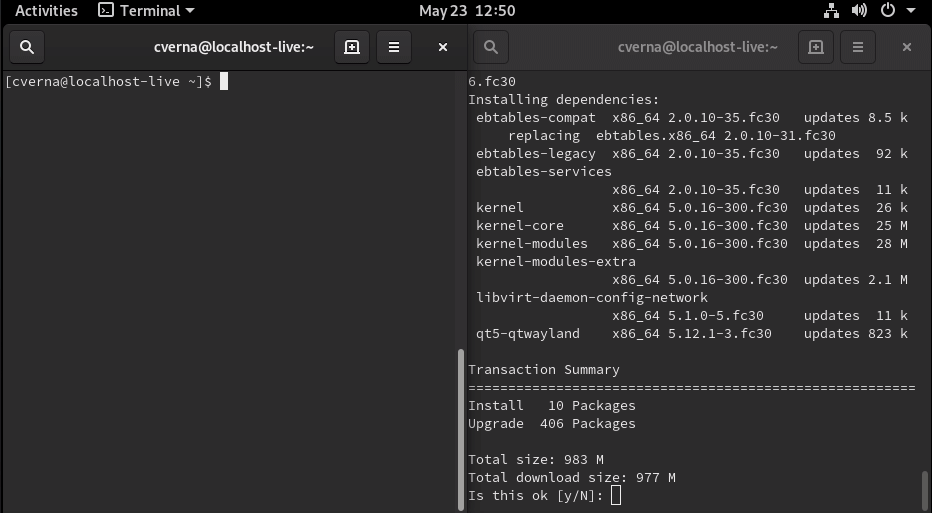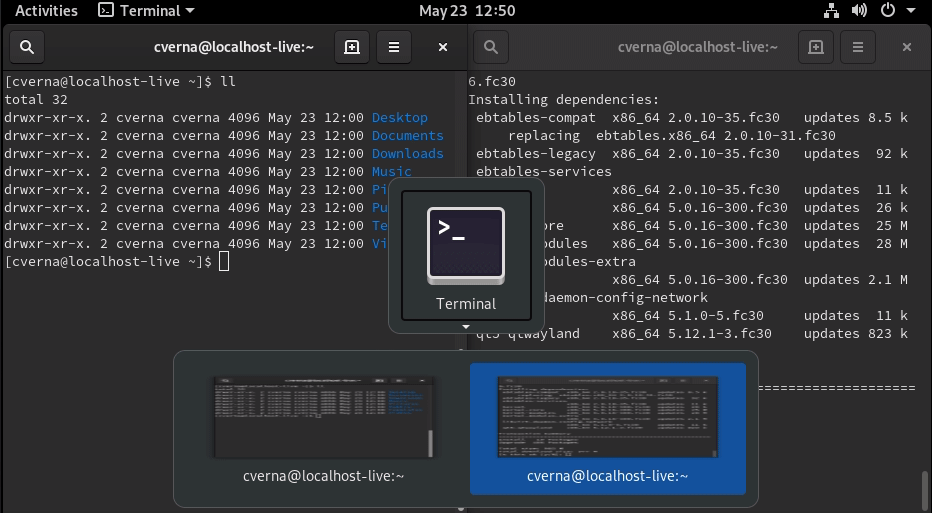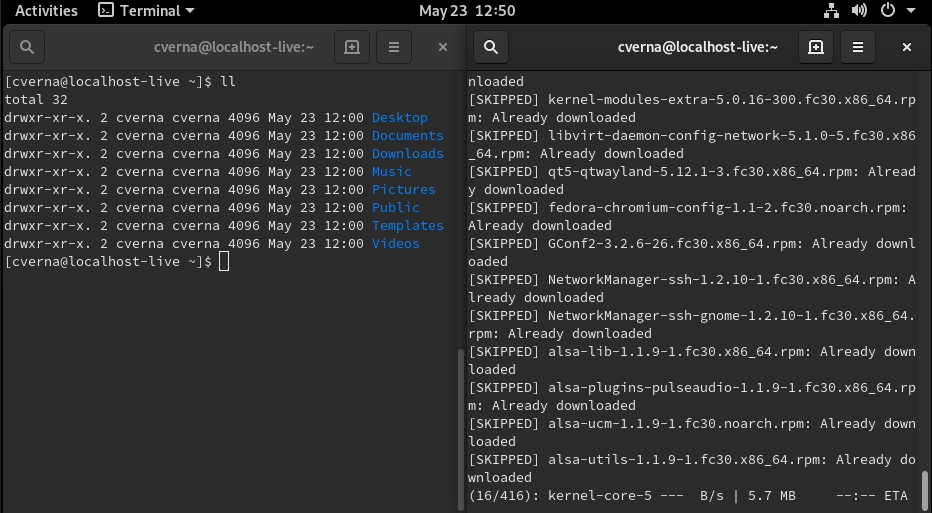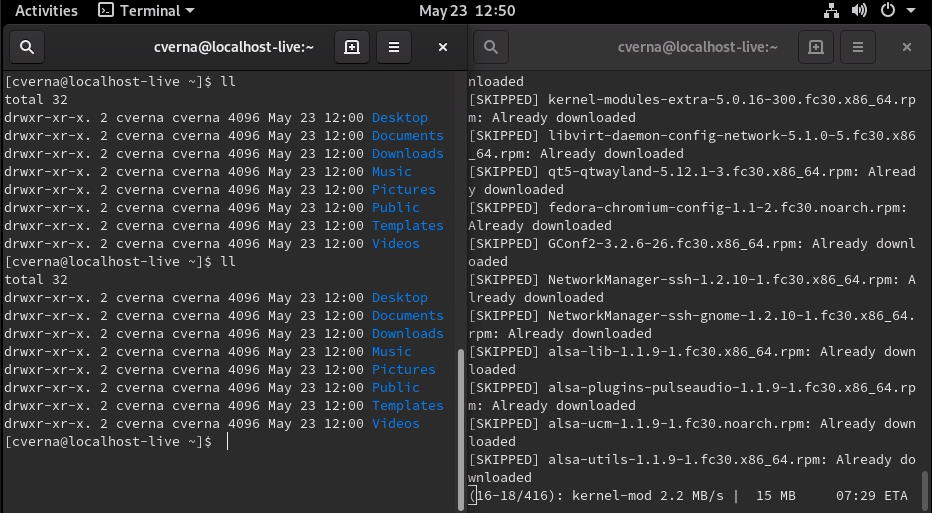
As shown, GNOME Shell is a really powerful desktop environment when controlled from the keyboard. Learning to use these shortcuts and train your muscle memory to not use the mouse will give you a better user experience, and make you more productive when using GNOME. For other useful shortcuts, check out [this page on the GNOME wiki](https://wiki.gnome.org/Design/OS/KeyboardShortcuts).
## Gianluca Cherubini
Thank you! I was struggling figuring out the shortcut key combo to switch between different windows for the same application, which in my Italian Keyboard is Super+| (the same as Super+accent)
## Joao Rodrigues
You could also:
Hold Alt and press Tab to select the desired application and while keeping Alt held down, press the Down key and then use Left and Right keys to select the window.
Or, you can change the default behaviour of Alt+Tab to switch windows instead of applications.
Go to:
Settings > Devices > Keyboard
And in the Navigation section (or use the magnifying glass button and search for “switch windows”), click on “Switch windows” and input Alt+Tab. Then click on the “Replace” button.
## Someone
Thank you!!
## Matthew Bunt
Great post to explain the basics. One change I add to the keybindings for GNOME is setting switch to workspace 1-4 to alt+1-4. That is workspace one is alt+1, workspace two is alt+2, etc. These and other keybindings can be set or changed under Devices > Keyboard in GNOME Settings.
This provides two benefits. First, you can specify exactly which workspace you want to switch to. Secondly, you can switch workspaces with one hand which I find more ergonomic than using PgUp and PgDn, especially if using graphical applications with a mouse.
NOTE: This setup will conflict with the default tab switching key bindings in the Terminal. Desktop keybindings will take precedence over the application bindings. Either change the bindings in GNOME Terminal or use something like screen or tmux.
## Stan Genchev
You forgot to mention that you can launch your favorite applications (the ones locked on the dock/taskbar) using Super+. The apps are numerated from top to bottom.
For example on a fresh Fedora install, Super+1 will launch Firefox.
## toni
that comment saved my day, thank you!
## ricardotiellet
Bem explicado com bons exemplos e ótimas ilustrações. Muito obrigado! 🙂
## Jorge
The use of the addition ‘+’ symbol is a bit confusing, because it’s difficult to differentiate a sequence (key one then key two) with a combination (key one and two simultaneously). The use of commas or semicolons might make it more clear (just a tip for future articles).
## Danniello
Unfortunately open new window via Ctrl+Enter is not always working. For example LibreOffice Writer is not supporting it (at least not in Fedora 29).
Win -> “wri” -> Ctrl+Enter will always switch to already opened Writer…
So the real universal solution is this:
Win -> “wri” -> Menu key -> choose with arrows option “New document”
But it is a lot less practical:(
## Matthew Bunt
This is interesting. The ctrl+enter shortcut seems to work with gedit and other GNOME applications, but not libreoffice.
If you prefer the launcher to always open a new window, you can install the GNOME shell extension ‘launch new instance’. It’s not a perfect solution, but this allows the launcher to always create new windows, even in libreoffice.
## Eduardo Osorio
Managing an application window section does not display the options properly (macosx firefox developer edition)
… Use Super+???? to maximize, Super+???? to minimize, Super+???? and Super+???? to move the window left and right.
## A
You shoulld rewrite some of these hacks to use the greatest keyboard shortcut of them all : ctrl-alt-t to open a terminal.
## Erwin Baeyens
Gnome shell is a great and powerful desktop environment. Sadly it is crippled by the fact that the default settings do their best to hide all the powerful things and a lot of the shortcuts are disabled by default. Also the tendency to hide and limit what can be changed in the preferences of the applications is really limiting . I understand the need for a simple and straightforward desktop environment, and hiding some of the complexity is part of that,. But there is a difference between the hiding of that complexity and taking a way the options. The last one is limiting the usability of the environment. |
10,998 | 音乐家和音乐爱好者的开放硬件 | https://opensource.com/article/19/6/hardware-music | 2019-06-21T01:27:00 | [
"开源硬件",
"乐器"
] | https://linux.cn/article-10998-1.html |
>
> 从 3D 打印乐器到无线播放声音的设备,有很多通过开放硬件项目来奏乐的方法。
>
>
>

这个世界到处都是很棒的[开源音乐播放器](https://opensource.com/article/19/2/audio-players-linux),但为什么只是将开源用在播放音乐上呢?你还可以使用开源硬件奏乐。本文中描述的所有工具都是经过了[开源硬件协会](https://certification.oshwa.org/)(OSHWA)认证的。这意味着你可以自由地构建它们,重新组合它们,或者用它们做任何其他事情。
### 开源乐器
当你想奏乐时使用乐器总是最好的方式之一。如果你喜欢传统的的乐器,那么 [F-F-Fiddle](https://certification.oshwa.org/us000010.html) 可能适合你。

F-F-Fiddle 是一款全尺寸电子小提琴,你可以使用标准的桌面 3D 打印机制作(采用[熔丝制造](https://en.wikipedia.org/wiki/Fused_filament_fabrication))。如果你想眼见为真,那么这里有一个 F-F-Fiddle 的视频:
如果你精通小提琴,但还对一些更具异国情调的东西感兴趣?<ruby> <a href="https://certification.oshwa.org/ch000001.html"> 开源的特雷门琴 </a> <rt> Open Theremin </rt></ruby>怎么样?

与所有特雷门琴一样,开源特雷门琴可让你在不触碰乐器的情况下播放音乐。当然,它特别擅长为你的下一个科幻视频或空间主题派对制作[令人毛骨悚然的空间声音](https://youtu.be/p05ZSHRYXVA?t=771)。
[Waft](https://certification.oshwa.org/uk000005.html) 的操作类似,也可以远程控制声音。它使用[激光雷达](https://en.wikipedia.org/wiki/Lidar)来测量手与传感器的距离。看看这个:
Waft 是特雷门琴吗?我不确定算不算,特雷门琴高手可以在下面的评论里发表一下看法。
如果特雷门琴对你来说太熟悉了,[SIGNUM](https://certification.oshwa.org/es000003.html) 可能就是你想要的。用其开发人员的话说,SIGNUM 通过将不可见的无线通信转换为可听信号来“揭示加密的信息代码和人/机通信的语言”。

这是演示:
### 输入
无论你使用什么乐器,都需要将其接到某些东西上。如果你想要连接到树莓派,请尝试 [AudioSense-Pi](https://certification.oshwa.org/in000007.html),它允许你一次将多个输入和输出连接到你的树莓派。

### 合成器
合成器怎么样?SparkFun 的 [SparkPunk Sound Kit](https://certification.oshwa.org/us000016.html) 是一个简单的合成器,为你提供了很多音色。

### 耳机
制作所有这些音乐很棒,但你还需要考虑如何听它。幸运的是,[EQ-1耳机](https://certification.oshwa.org/us000038.html)是开源,支持 3D 打印。

你用开源硬件制作音乐吗?让我们在评论中知道!
---
via: <https://opensource.com/article/19/6/hardware-music>
作者:[Michael Weinberg](https://opensource.com/users/mweinberg) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The world is full of great [open source music players](https://opensource.com/article/19/2/audio-players-linux), but why stop at using open source just to *play* music? You can also use open source hardware to make music. All of the instruments described in this article are [certified by the Open Source Hardware Association](https://certification.oshwa.org/) (OSHWA). That means you are free to build upon them, remix them, or do anything else with them.
## Open source instruments
Instruments are always a good place to start when you want to make music. If your instrument choices lean towards the more traditional, the [F-F-Fiddle](https://certification.oshwa.org/us000010.html) may be the one for you.

The F-F-Fiddle is a full-sized electric violin that you can make with a standard desktop 3D printer ([fused filament fabrication](https://en.wikipedia.org/wiki/Fused_filament_fabrication)—get it?). If you need to see it to believe it, here is a video of the F-F-Fiddle in action:
Mastered the fiddle and interested in something a bit more exotic? How about the [Open Theremin](https://certification.oshwa.org/ch000001.html)?

Like all theremins, Open Theremin lets you play music without touching the instrument. It is, of course, especially good at making [creepy space sounds](https://youtu.be/p05ZSHRYXVA?t=771) for your next sci-fi video or space-themed party.
The [Waft](https://certification.oshwa.org/uk000005.html) operates similarly by allowing you to control sounds remotely. It uses [Lidar](https://en.wikipedia.org/wiki/Lidar) to measure the distance of your hand from the sensor. Check it out:
Is the Waft a theremin? I'm not sure—theremin pedants should weigh in below in the comments.
If theremins are too well-known for you, [SIGNUM](https://certification.oshwa.org/es000003.html) may be just what you are looking for. In the words of its developers, SIGNUM "uncovers the encrypted codes of information and the language of man/machine communication" by turning invisible wireless communications into audible signals.

Here is in action:
## Inputs
Regardless of what instrument you use, you will need to plug it into something. If you want that something to be a Raspberry Pi, try the [AudioSense-Pi](https://certification.oshwa.org/in000007.html), which allows you to connect multiple inputs and outputs to your Pi at once.

## Synths
What about synthesizers? SparkFun's [SparkPunk Sound Kit](https://certification.oshwa.org/us000016.html) is a simple synth that gives you lots of room to play.

## Headphones
Making all this music is great, but you also need to think about how you will listen to it. Fortunately, [EQ-1 headphones](https://certification.oshwa.org/us000038.html) are open source and 3D-printable.

Are you making music with open source hardware? Let us know in the comments!
## Comments are closed. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.