
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
9,597 | 在 Linux 下 9 个有用的 touch 命令示例 | https://www.linuxtechi.com/9-useful-touch-command-examples-linux/ | 2018-05-02T12:43:20 | [
"touch"
] | https://linux.cn/article-9597-1.html | `touch` 命令用于创建空文件,也可以更改 Unix 和 Linux 系统上现有文件时间戳。这里所说的更改时间戳意味着更新文件和目录的访问以及修改时间。

让我们来看看 `touch` 命令的语法和选项:
**语法**:
```
# touch {选项} {文件}
```
`touch` 命令中使用的选项:

在这篇文章中,我们将介绍 Linux 中 9 个有用的 `touch` 命令示例。
### 示例:1 使用 touch 创建一个空文件
要在 Linux 系统上使用 `touch` 命令创建空文件,键入 `touch`,然后输入文件名。如下所示:
```
[root@linuxtechi ~]# touch devops.txt
[root@linuxtechi ~]# ls -l devops.txt
-rw-r--r--. 1 root root 0 Mar 29 22:39 devops.txt
```
### 示例:2 使用 touch 创建批量空文件
可能会出现一些情况,我们必须为某些测试创建大量空文件,这可以使用 `touch` 命令轻松实现:
```
[root@linuxtechi ~]# touch sysadm-{1..20}.txt
```
在上面的例子中,我们创建了 20 个名为 `sysadm-1.txt` 到 `sysadm-20.txt` 的空文件,你可以根据需要更改名称和数字。
### 示例:3 改变/更新文件和目录的访问时间
假设我们想要改变名为 `devops.txt` 文件的访问时间,在 `touch` 命令中使用 `-a` 选项,然后输入文件名。如下所示:
```
[root@linuxtechi ~]# touch -a devops.txt
```
现在使用 `stat` 命令验证文件的访问时间是否已更新:
```
[root@linuxtechi ~]# stat devops.txt
File: 'devops.txt'
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd00h/64768d Inode: 67324178 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Context: unconfined_u:object_r:admin_home_t:s0
Access: 2018-03-29 23:03:10.902000000 -0400
Modify: 2018-03-29 22:39:29.365000000 -0400
Change: 2018-03-29 23:03:10.902000000 -0400
Birth: -
```
**改变目录的访问时间:**
假设我们在 `/mnt` 目录下有一个 `nfsshare` 文件夹,让我们用下面的命令改变这个文件夹的访问时间:
```
[root@linuxtechi ~]# touch -m /mnt/nfsshare/
[root@linuxtechi ~]# stat /mnt/nfsshare/
File: '/mnt/nfsshare/'
Size: 6 Blocks: 0 IO Block: 4096 directory
Device: fd00h/64768d Inode: 2258 Links: 2
Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Context: unconfined_u:object_r:mnt_t:s0
Access: 2018-03-29 23:34:38.095000000 -0400
Modify: 2018-03-03 10:42:45.194000000 -0500
Change: 2018-03-29 23:34:38.095000000 -0400
Birth: -
```
### 示例:4 更改访问时间而不用创建新文件
在某些情况下,如果文件存在,我们希望更改文件的访问时间,并避免创建文件。在 touch 命令中使用 `-c` 选项即可,如果文件存在,那么我们可以改变文件的访问时间,如果不存在,我们也可不会创建它。
```
[root@linuxtechi ~]# touch -c sysadm-20.txt
[root@linuxtechi ~]# touch -c winadm-20.txt
[root@linuxtechi ~]# ls -l winadm-20.txt
ls: cannot access winadm-20.txt: No such file or directory
```
### 示例:5 更改文件和目录的修改时间
在 `touch` 命令中使用 `-m` 选项,我们可以更改文件和目录的修改时间。
让我们更改名为 `devops.txt` 文件的更改时间:
```
[root@linuxtechi ~]# touch -m devops.txt
```
现在使用 `stat` 命令来验证修改时间是否改变:
```
[root@linuxtechi ~]# stat devops.txt
File: 'devops.txt'
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd00h/64768d Inode: 67324178 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Context: unconfined_u:object_r:admin_home_t:s0
Access: 2018-03-29 23:03:10.902000000 -0400
Modify: 2018-03-29 23:59:49.106000000 -0400
Change: 2018-03-29 23:59:49.106000000 -0400
Birth: -
```
同样的,我们可以改变一个目录的修改时间:
```
[root@linuxtechi ~]# touch -m /mnt/nfsshare/
```
使用 `stat` 交叉验证访问和修改时间:
```
[root@linuxtechi ~]# stat devops.txt
File: 'devops.txt'
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd00h/64768d Inode: 67324178 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Context: unconfined_u:object_r:admin_home_t:s0
Access: 2018-03-30 00:06:20.145000000 -0400
Modify: 2018-03-30 00:06:20.145000000 -0400
Change: 2018-03-30 00:06:20.145000000 -0400
Birth: -
```
### 示例:7 将访问和修改时间设置为特定的日期和时间
每当我们使用 `touch` 命令更改文件和目录的访问和修改时间时,它将当前时间设置为该文件或目录的访问和修改时间。
假设我们想要将特定的日期和时间设置为文件的访问和修改时间,这可以使用 `touch` 命令中的 `-c` 和 `-t` 选项来实现。
日期和时间可以使用以下格式指定:
```
{CCYY}MMDDhhmm.ss
```
其中:
* `CC` – 年份的前两位数字
* `YY` – 年份的后两位数字
* `MM` – 月份 (01-12)
* `DD` – 天 (01-31)
* `hh` – 小时 (00-23)
* `mm` – 分钟 (00-59)
让我们将 `devops.txt` 文件的访问和修改时间设置为未来的一个时间(2025 年 10 月 19 日 18 时 20 分)。
```
[root@linuxtechi ~]# touch -c -t 202510191820 devops.txt
```
使用 `stat` 命令查看更新访问和修改时间:

根据日期字符串设置访问和修改时间,在 `touch` 命令中使用 `-d` 选项,然后指定日期字符串,后面跟文件名。如下所示:
```
[root@linuxtechi ~]# touch -c -d "2010-02-07 20:15:12.000000000 +0530" sysadm-29.txt
```
使用 `stat` 命令验证文件的状态:
```
[root@linuxtechi ~]# stat sysadm-20.txt
File: ‘sysadm-20.txt’
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd00h/64768d Inode: 67324189 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Context: unconfined_u:object_r:admin_home_t:s0
Access: 2010-02-07 20:15:12.000000000 +0530
Modify: 2010-02-07 20:15:12.000000000 +0530
Change: 2018-03-30 10:23:31.584000000 +0530
Birth: -
```
**注意:**在上述命令中,如果我们不指定 `-c`,如果系统中不存在该文件那么 `touch` 命令将创建一个新文件,并将时间戳设置为命令中给出的。
### 示例:8 使用参考文件设置时间戳(-r)
在 `touch` 命令中,我们可以使用参考文件来设置文件或目录的时间戳。假设我想在 `devops.txt` 文件上设置与文件 `sysadm-20.txt` 文件相同的时间戳,`touch` 命令中使用 `-r` 选项可以轻松实现。
**语法:**
```
# touch -r {参考文件} 真正文件
```
```
[root@linuxtechi ~]# touch -r sysadm-20.txt devops.txt
```
### 示例:9 在符号链接文件上更改访问和修改时间
默认情况下,每当我们尝试使用 `touch` 命令更改符号链接文件的时间戳时,它只会更改原始文件的时间戳。如果你想更改符号链接文件的时间戳,则可以使用 `touch` 命令中的 `-h` 选项来实现。
**语法:**
```
# touch -h {符号链接文件}
```
```
[root@linuxtechi opt]# ls -l /root/linuxgeeks.txt
lrwxrwxrwx. 1 root root 15 Mar 30 10:56 /root/linuxgeeks.txt -> linuxadmins.txt
[root@linuxtechi ~]# touch -t 203010191820 -h linuxgeeks.txt
[root@linuxtechi ~]# ls -l linuxgeeks.txt
lrwxrwxrwx. 1 root root 15 Oct 19 2030 linuxgeeks.txt -> linuxadmins.txt
```
这就是本教程的全部了。我希望这些例子能帮助你理解 `touch` 命令。请分享你的宝贵意见和评论。
---
via: <https://www.linuxtechi.com/9-useful-touch-command-examples-linux/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this blog post, we will cover touch command in Linux with 9 useful practical examples.
Touch command is used to change file timestamps and also used to create empty or blank files in Linux.
#### Syntax
# touch {options} {file}
Options:
Let’s delve into some practical examples to showcase its utility.
## 1) Create an empty file
One of the main function of touch command is to create empty or blank file, example is shown below:
[root@linuxtechi ~]# touch devops.txt [root@linuxtechi ~]# ls -l devops.txt -rw-r--r--. 1 root root 0 Mar 29 22:39 devops.txt [root@linuxtechi ~]#
## 2) Create empty files in bulk
There can be some scenarios where we have to create lots of empty files for some testing, this can be easily achieved using touch command with regular expression as shown,
[root@linuxtechi ~]# touch sysadm-{1..20}.txt
In the above example, we have created 20 empty files with name sysadm-1.txt to sysadm-20.txt, you can change the name and numbers based on your requirements.
## 3) Update access time of a file and directory
Let’s assume we want to change access time of a file called “**devops.txt**“, to do this use ‘**-a**‘ option in touch command followed by file name, example is shown below,
[root@linuxtechi ~]# touch -a devops.txt [root@linuxtechi ~]#
Now verify whether access time of a file has been updated or not using ‘stat’ command
```
[root@linuxtechi ~]# stat devops.txt
File: ‘devops.txt’
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd00h/64768d Inode: 67324178 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Context: unconfined_u:object_r:admin_home_t:s0
Access: 2018-03-29 23:03:10.902000000 -0400
Modify: 2018-03-29 22:39:29.365000000 -0400
Change: 2018-03-29 23:03:10.902000000 -0400
Birth: -
[root@linuxtechi ~]#
```
**Change access time of a directory**,
Let’s assume we have a ‘nfsshare’ folder under /mnt, Let’s change the access time of this folder using the below command,
[root@linuxtechi ~]# touch -a /mnt/nfsshare/ [root@linuxtechi ~]#
```
[root@linuxtechi ~]# stat /mnt/nfsshare/
File: ‘/mnt/nfsshare/’
Size: 6 Blocks: 0 IO Block: 4096 directory
Device: fd00h/64768d Inode: 2258 Links: 2
Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Context: unconfined_u:object_r:mnt_t:s0
Access: 2018-03-29 23:34:38.095000000 -0400
Modify: 2018-03-03 10:42:45.194000000 -0500
Change: 2018-03-29 23:34:38.095000000 -0400
Birth: -
[root@linuxtechi ~]#
```
## 4) Change Access time without creating new file
There can be some situations where we want to change access time of a file if it exists and avoid creating the file. Using ‘**-c**‘ option in touch command, we can change access time of a file if it exists and will not a create a file, if it doesn’t exist.
[root@linuxtechi ~]# touch -c sysadm-20.txt [root@linuxtechi ~]# touch -c winadm-20.txt [root@linuxtechi ~]# ls -l winadm-20.txt ls: cannot access winadm-20.txt: No such file or directory [root@linuxtechi ~]#
Note: winadm-20.txt does not exist the file, that’s why we are getting an error while listing file.
## 5) Change Modification time of a file and directory
Using ‘**-m**‘ option in touch command, we can change the modification time of a file and directory,
Let’s change the modification time of a file called “devops.txt”,
[root@linuxtechi ~]# touch -m devops.txt [root@linuxtechi ~]#
Now verify whether modification time has been changed or not using stat command,
```
[root@linuxtechi ~]# stat devops.txt
File: ‘devops.txt’
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd00h/64768d Inode: 67324178 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Context: unconfined_u:object_r:admin_home_t:s0
Access: 2018-03-29 23:03:10.902000000 -0400
Modify: 2018-03-29 23:59:49.106000000 -0400
Change: 2018-03-29 23:59:49.106000000 -0400
Birth: -
[root@linuxtechi ~]#
```
Similarly, we can change modification time of a directory,
[root@linuxtechi ~]# touch -m /mnt/nfsshare/ [root@linuxtechi ~]#
## 6) Changing access and modification time in one go
Use “**-am**” option in touch command to change the access and modification together or in one go, example is shown below,
[root@linuxtechi ~]# touch -am devops.txt [root@linuxtechi ~]#
Cross verify the access and modification time using stat,
[root@linuxtechi ~]# stat devops.txt File: ‘devops.txt’ Size: 0 Blocks: 0 IO Block: 4096 regular empty file Device: fd00h/64768d Inode: 67324178 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Context: unconfined_u:object_r:admin_home_t:s0 Access: 2018-03-30 00:06:20.145000000 -0400 Modify: 2018-03-30 00:06:20.145000000 -0400 Change: 2018-03-30 00:06:20.145000000 -0400 Birth: - [root@linuxtechi ~]#
## 7) Set the Access & modification time to a specific date and time
Whenever we do change access and modification time of a file & directory using touch command, then it set the current time as access & modification time of that file or directory,
Let’s assume we want to set specific date and time as access & modification time of a file, this is can be achieved using ‘-c’ & ‘-t’ option in touch command,
Date and Time can be specified in the format: {CCYY}MMDDhhmm.ss
Where:
- CC – First two digits of a year
- YY – Second two digits of a year
- MM – Month of the Year (01-12)
- DD – Day of the Month (01-31)
- hh – Hour of the day (00-23)
- mm – Minutes of the hour (00-59)
Let’s set the access & modification time of devops.txt file for future date and time( 2025 year, 10th Month, 19th day of month, 18th hours and 20th minute)
[root@linuxtechi ~]# touch -c -t 202510191820 devops.txt
Use stat command to view the update access & modification time,
Set the Access and Modification time based on date string, Use ‘-d’ option in touch command and then specify the date string followed by the file name, example is shown below,
[root@linuxtechi ~]# touch -c -d "2010-02-07 20:15:12.000000000 +0530" sysadm-29.txt [root@linuxtechi ~]#
Verify the status using stat command,
[root@linuxtechi ~]# stat sysadm-20.txt File: ‘sysadm-20.txt’ Size: 0 Blocks: 0 IO Block: 4096 regular empty file Device: fd00h/64768d Inode: 67324189 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Context: unconfined_u:object_r:admin_home_t:s0 Access: 2010-02-07 20:15:12.000000000 +0530 Modify: 2010-02-07 20:15:12.000000000 +0530 Change: 2018-03-30 10:23:31.584000000 +0530 Birth: - [root@linuxtechi ~]#
**Note:** In above commands, if we don’t specify ‘-c’ then touch command will create a new file in case it doesn’t exist on the system and will set the timestamps whatever is mentioned in the command.
## 8) Set timestamps to a file using a reference file
In touch command we can use a reference file for setting the timestamps of file or directory. Let’s assume I want to set the same timestamps of file “sysadm-20.txt” on “devops.txt” file. This can be easily achieved using ‘-r’ option in touch.
Syntax:
# touch -r {reference-file} actual-file
[root@linuxtechi ~]# touch -r sysadm-20.txt devops.txt [root@linuxtechi ~]#
## 9) Change Access & Modification time on symbolic link file
By default, whenever we try to change timestamps of a symbolic link file using touch command then it will change the timestamps of original file only, In case you want to change timestamps of a symbolic link file then this can be achieved using ‘-h’ option in touch command,
Syntax:
# touch -h {symbolic link file}
[root@linuxtechi opt]# ls -l /root/linuxgeeks.txt lrwxrwxrwx. 1 root root 15 Mar 30 10:56 /root/linuxgeeks.txt -> linuxadmins.txt [root@linuxtechi ~]# touch -t 203010191820 -h linuxgeeks.txt [root@linuxtechi ~]# ls -l linuxgeeks.txt lrwxrwxrwx. 1 root root 15 Oct 19 2030 linuxgeeks.txt -> linuxadmins.txt [root@linuxtechi ~]#
That’s all from this blog post, I hope you have found these examples useful and informative. Please do share your queries and feedback in below comments section.
Read Also: [17 useful rsync (remote sync) Command Examples in Linux](https://www.linuxtechi.com/rsync-command-examples-linux/)
Jason PerryYou’ve got a slight typo… your example for “Change access time of a directory” using -m instead of -a… which would change the Modification Time, not the Access Time.
Pradeep KumarHi Jason, Thank You very much for pointing out the typo, i have corrected it now. |
9,599 | 如何使用 rsync 通过 SSH 恢复部分传输的文件 | https://www.ostechnix.com/how-to-resume-partially-downloaded-or-transferred-files-using-rsync/ | 2018-05-02T21:36:09 | [
"scp",
"rsync"
] | https://linux.cn/article-9599-1.html | 
由于诸如电源故障、网络故障或用户干预等各种原因,使用 `scp` 命令通过 SSH 复制的大型文件可能会中断、取消或损坏。有一天,我将 Ubuntu 16.04 ISO 文件复制到我的远程系统。不幸的是断电了,网络连接立即断了。结果么?复制过程终止!这只是一个简单的例子。Ubuntu ISO 并不是那么大,一旦电源恢复,我就可以重新启动复制过程。但在生产环境中,当你在传输大型文件时,你可能并不希望这样做。
而且,你不能继续使用 `scp` 命令恢复被中止的进度。因为,如果你这样做,它只会覆盖现有的文件。这时你会怎么做?别担心!这是 `rsync` 派上用场的地方!`rsync` 可以帮助你恢复中断的复制或下载过程。对于那些好奇的人,`rsync` 是一个快速、多功能的文件复制程序,可用于复制和传输远程和本地系统中的文件或文件夹。
它提供了大量控制其各种行为的选项,并允许非常灵活地指定要复制的一组文件。它以增量传输算法而闻名,它通过仅发送源文件和目标中现有文件之间的差异来减少通过网络发送的数据量。 `rsync` 广泛用于备份和镜像,以及日常使用中改进的复制命令。
就像 `scp` 一样,`rsync` 也会通过 SSH 复制文件。如果你想通过 SSH 下载或传输大文件和文件夹,我建议您使用 `rsync`。请注意,应该在两边(远程和本地系统)都安装 `rsync` 来恢复部分传输的文件。
### 使用 rsync 恢复部分传输的文件
好吧,让我给你看一个例子。我将使用命令将 Ubuntu 16.04 ISO 从本地系统复制到远程系统:
```
$ scp Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso [email protected]:/home/sk/
```
这里,
* `sk`是我的远程系统的用户名
* `192.168.43.2` 是远程机器的 IP 地址。
现在,我按下 `CTRL+C` 结束它。
示例输出:
```
[email protected]'s password:
ubuntu-16.04-desktop-amd64.iso 26% 372MB 26.2MB/s 00:39 ETA^c
```

正如你在上面的输出中看到的,当它达到 26% 时,我终止了复制过程。
如果我重新运行上面的命令,它只会覆盖现有的文件。换句话说,复制过程不会在我断开的地方恢复。
为了恢复复制过程,我们可以使用 `rsync` 命令,如下所示。
```
$ rsync -P -rsh=ssh Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso [email protected]:/home/sk/
```
示例输出:
```
[email protected]'s password:
sending incremental file list
ubuntu-16.04-desktop-amd64.iso
380.56M 26% 41.05MB/s 0:00:25
```

看见了吗?现在,复制过程在我们之前断开的地方恢复了。你也可以像下面那样使用 `-partial` 而不是 `-P` 参数。
```
$ rsync --partial -rsh=ssh Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso [email protected]:/home/sk/
```
这里,参数 `-partial` 或 `-P` 告诉 `rsync` 命令保留部分下载的文件并恢复进度。
或者,我们也可以使用以下命令通过 SSH 恢复部分传输的文件。
```
$ rsync -avP Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso [email protected]:/home/sk/
```
或者,
```
rsync -av --partial Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso [email protected]:/home/sk/
```
就是这样了。你现在知道如何使用 `rsync` 命令恢复取消、中断和部分下载的文件。正如你所看到的,它也不是那么难。如果两个系统都安装了 `rsync`,我们可以轻松地通过上面描述的那样恢复复制的进度。
如果你觉得本教程有帮助,请在你的社交、专业网络上分享,并支持我们。还有更多的好东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-resume-partially-downloaded-or-transferred-files-using-rsync/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,600 | Pet:一个简单的命令行片段管理器 | https://www.ostechnix.com/pet-simple-command-line-snippet-manager/ | 2018-05-02T21:53:06 | [
"命令行"
] | https://linux.cn/article-9600-1.html | 
我们不可能记住所有的命令,对吧?是的。除了经常使用的命令之外,我们几乎不可能记住一些很少使用的长命令。这就是为什么需要一些外部工具来帮助我们在需要时找到命令。在过去,我们已经点评了两个有用的工具,名为 “Bashpast” 和 “Keep”。使用 Bashpast,我们可以轻松地为 Linux 命令添加书签,以便更轻松地重复调用。而 Keep 实用程序可以用来在终端中保留一些重要且冗长的命令,以便你可以随时使用它们。今天,我们将看到该系列中的另一个工具,以帮助你记住命令。现在让我们认识一下 “Pet”,这是一个用 Go 语言编写的简单的命令行代码管理器。
使用 Pet,你可以:
* 注册/添加你重要的、冗长和复杂的命令片段。
* 以交互方式来搜索保存的命令片段。
* 直接运行代码片段而无须一遍又一遍地输入。
* 轻松编辑保存的代码片段。
* 通过 Gist 同步片段。
* 在片段中使用变量
* 还有很多特性即将来临。
### 安装 Pet 命令行接口代码管理器
由于它是用 Go 语言编写的,所以确保你在系统中已经安装了 Go。
安装 Go 后,从 [**Pet 发布页面**](https://github.com/knqyf263/pet/releases) 获取最新的二进制文件。
```
wget https://github.com/knqyf263/pet/releases/download/v0.2.4/pet_0.2.4_linux_amd64.zip
```
对于 32 位计算机:
```
wget https://github.com/knqyf263/pet/releases/download/v0.2.4/pet_0.2.4_linux_386.zip
```
解压下载的文件:
```
unzip pet_0.2.4_linux_amd64.zip
```
对于 32 位:
```
unzip pet_0.2.4_linux_386.zip
```
将 `pet` 二进制文件复制到 PATH(即 `/usr/local/bin` 之类的)。
```
sudo cp pet /usr/local/bin/
```
最后,让它可以执行:
```
sudo chmod +x /usr/local/bin/pet
```
如果你使用的是基于 Arch 的系统,那么你可以使用任何 AUR 帮助工具从 AUR 安装它。
使用 [Pacaur](https://www.ostechnix.com/install-pacaur-arch-linux/):
```
pacaur -S pet-git
```
使用 [Packer](https://www.ostechnix.com/install-packer-arch-linux-2/):
```
packer -S pet-git
```
使用 [Yaourt](https://www.ostechnix.com/install-yaourt-arch-linux/):
```
yaourt -S pet-git
```
使用 [Yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/):
```
yay -S pet-git
```
此外,你需要安装 [fzf](https://github.com/junegunn/fzf) 或 [peco](https://github.com/peco/peco) 工具以启用交互式搜索。请参阅官方 GitHub 链接了解如何安装这些工具。
### 用法
运行没有任何参数的 `pet` 来查看可用命令和常规选项的列表。
```
$ pet
pet - Simple command-line snippet manager.
Usage:
pet [command]
Available Commands:
configure Edit config file
edit Edit snippet file
exec Run the selected commands
help Help about any command
list Show all snippets
new Create a new snippet
search Search snippets
sync Sync snippets
version Print the version number
Flags:
--config string config file (default is $HOME/.config/pet/config.toml)
--debug debug mode
-h, --help help for pet
Use "pet [command] --help" for more information about a command.
```
要查看特定命令的帮助部分,运行:
```
$ pet [command] --help
```
#### 配置 Pet
默认配置其实工作的挺好。但是,你可以更改保存片段的默认目录,选择要使用的选择器(fzf 或 peco),编辑片段的默认文本编辑器,添加 GIST id 详细信息等。
要配置 Pet,运行:
```
$ pet configure
```
该命令将在默认的文本编辑器中打开默认配置(例如我是 vim),根据你的要求更改或编辑特定值。
```
[General]
snippetfile = "/home/sk/.config/pet/snippet.toml"
editor = "vim"
column = 40
selectcmd = "fzf"
[Gist]
file_name = "pet-snippet.toml"
access_token = ""
gist_id = ""
public = false
~
```
#### 创建片段
为了创建一个新的片段,运行:
```
$ pet new
```
添加命令和描述,然后按下回车键保存它。
```
Command> echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9'
Description> Remove numbers from output.
```

这是一个简单的命令,用于从 `echo` 命令输出中删除所有数字。你可以很轻松地记住它。但是,如果你很少使用它,几天后你可能会完全忘记它。当然,我们可以使用 `CTRL+R` 搜索历史记录,但 Pet 会更容易。另外,Pet 可以帮助你添加任意数量的条目。
另一个很酷的功能是我们可以轻松添加以前的命令。为此,在你的 `.bashrc` 或 `.zshrc` 文件中添加以下行。
```
function prev() {
PREV=$(fc -lrn | head -n 1)
sh -c "pet new `printf %q "$PREV"`"
}
```
执行以下命令来使保存的更改生效。
```
source .bashrc
```
或者:
```
source .zshrc
```
现在,运行任何命令,例如:
```
$ cat Documents/ostechnix.txt | tr '|' '\n' | sort | tr '\n' '|' | sed "s/.$/\\n/g"
```
要添加上述命令,你不必使用 `pet new` 命令。只需要:
```
$ prev
```
将说明添加到该命令代码片段中,然后按下回车键保存。

#### 片段列表
要查看保存的片段,运行:
```
$ pet list
```

#### 编辑片段
如果你想编辑代码片段的描述或命令,运行:
```
$ pet edit
```
这将在你的默认文本编辑器中打开所有保存的代码片段,你可以根据需要编辑或更改片段。
```
[[snippets]]
description = "Remove numbers from output."
command = "echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9'"
output = ""
[[snippets]]
description = "Alphabetically sort one line of text"
command = "\t prev"
output = ""
```
#### 在片段中使用标签
要将标签用于判断,使用下面的 `-t` 标志。
```
$ pet new -t
Command> echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9
Description> Remove numbers from output.
Tag> tr command examples
```
#### 执行片段
要执行一个保存的片段,运行:
```
$ pet exec
```
从列表中选择你要运行的代码段,然后按回车键来运行它:

记住你需要安装 fzf 或 peco 才能使用此功能。
#### 寻找片段
如果你有很多要保存的片段,你可以使用字符串或关键词如 below.qjz 轻松搜索它们。
```
$ pet search
```
输入搜索字词或关键字以缩小搜索结果范围。

#### 同步片段
首先,你需要获取访问令牌。转到此链接 <https://github.com/settings/tokens/new> 并创建访问令牌(只需要 “gist” 范围)。
使用以下命令来配置 Pet:
```
$ pet configure
```
将令牌设置到 `[Gist]` 字段中的 `access_token`。
设置完成后,你可以像下面一样将片段上传到 Gist。
```
$ pet sync -u
Gist ID: 2dfeeeg5f17e1170bf0c5612fb31a869
Upload success
```
你也可以在其他 PC 上下载片段。为此,编辑配置文件并在 `[Gist]` 中将 `gist_id` 设置为 GIST id。
之后,使用以下命令下载片段:
```
$ pet sync
Download success
```
获取更多细节,参阅帮助选项:
```
pet -h
```
或者:
```
pet [command] -h
```
这就是全部了。希望这可以帮助到你。正如你所看到的,Pet 使用相当简单易用!如果你很难记住冗长的命令,Pet 实用程序肯定会有用。
干杯!
---
via: <https://www.ostechnix.com/pet-simple-command-line-snippet-manager/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,601 | 每个 Linux 新手都应该知道的 10 个命令 | https://opensource.com/article/18/4/10-commands-new-linux-users | 2018-05-02T22:17:37 | [
"命令行"
] | https://linux.cn/article-9601-1.html |
>
> 通过这 10 个基础命令开始掌握 Linux 命令行。
>
>
>

你可能认为你是 Linux 新手,但实际上并不是。全球互联网用户有 [3.74 亿](https://hostingcanada.org/state-of-the-internet/),他们都以某种方式使用 Linux,因为 Linux 服务器占据了互联网的 90%。大多数现代路由器运行 Linux 或 Unix,[TOP500 超级计算机](https://www.top500.org/statistics/details/osfam/1) 也依赖于 Linux。如果你拥有一台 Android 智能手机,那么你的操作系统就是由 Linux 内核构建的。
换句话说,Linux 无处不在。
但是使用基于 Linux 的技术和使用 Linux 本身是有区别的。如果你对 Linux 感兴趣,但是一直在使用 PC 或者 Mac 桌面,你可能想知道你需要知道什么才能使用 Linux 命令行接口(CLI),那么你来到了正确的地方。
下面是你需要知道的基本的 Linux 命令。每一个都很简单,也很容易记住。换句话说,你不必成为比尔盖茨就能理解它们。
### 1、 ls
你可能会想:“这是(is)什么东西?”不,那不是一个印刷错误 —— 我真的打算输入一个小写的 l。`ls`,或者说 “list”, 是你需要知道的使用 Linux CLI 的第一个命令。这个 list 命令在 Linux 终端中运行,以显示在存放在相应文件系统下的所有主要目录。例如,这个命令:
```
ls /applications
```
显示存储在 `applications` 文件夹下的每个文件夹,你将使用它来查看文件、文件夹和目录。
显示所有隐藏的文件都可以使用命令 `ls -a`。
### 2、 cd
这个命令是你用来跳转(或“更改”)到一个目录的。它指导你如何从一个文件夹导航到另一个文件夹。假设你位于 `Downloads` 文件夹中,但你想到名为 `Gym Playlist` 的文件夹中,简单地输入 `cd Gym Playlist` 将不起作用,因为 shell 不会识别它,并会报告你正在查找的文件夹不存在(LCTT 译注:这是因为目录名中有空格)。要跳转到那个文件夹,你需要包含一个反斜杠。改命令如下所示:
```
cd Gym\ Playlist
```
要从当前文件夹返回到上一个文件夹,你可以在该文件夹输入 `cd ..`。把这两个点想象成一个后退按钮。
### 3、 mv
该命令将文件从一个文件夹转移到另一个文件夹;`mv` 代表“移动”。你可以使用这个简单的命令,就像你把一个文件拖到 PC 上的一个文件夹一样。
例如,如果我想创建一个名为 `testfile` 的文件来演示所有基本的 Linux 命令,并且我想将它移动到我的 `Documents` 文件夹中,我将输入这个命令:
```
mv /home/sam/testfile /home/sam/Documents/
```
命令的第一部分(`mv`)说我想移动一个文件,第二部分(`home/sam/testfile`)表示我想移动的文件,第三部分(`/home/sam/Documents/`)表示我希望传输文件的位置。
### 4、 快捷键
好吧,这不止一个命令,但我忍不住把它们都包括进来。为什么?因为它们能节省时间并避免经历头痛。
* `CTRL+K` 从光标处剪切文本直至本行结束
* `CTRL+Y` 粘贴文本
* `CTRL+E` 将光标移到本行的末尾
* `CTRL+A` 将光标移动到本行的开头
* `ALT+F` 跳转到下一个空格处
* `ALT+B` 回到前一个空格处
* `ALT+Backspace` 删除前一个词
* `CTRL+W` 剪切光标前一个词
* `Shift+Insert` 将文本粘贴到终端中
* `Ctrl+D` 注销
这些命令在许多方面都能派上用场。例如,假设你在命令行文本中拼错了一个单词:
```
sudo apt-get intall programname
```
你可能注意到 `install` 拼写错了,因此该命令无法工作。但是快捷键可以让你很容易回去修复它。如果我的光标在这一行的末尾,我可以按下两次 `ALT+B` 来将光标移动到下面用 `^` 符号标记的地方:
```
sudo apt-get^intall programname
```
现在,我们可以快速地添加字母 `s` 来修复 `install`,十分简单!
### 5、 mkdir
这是你用来在 Linux 环境下创建目录或文件夹的命令。例如,如果你像我一样喜欢 DIY,你可以输入 `mkdir DIY` 为你的 DIY 项目创建一个目录。
### 6、 at
如果你想在特定时间运行 Linux 命令,你可以将 `at` 添加到语句中。语法是 `at` 后面跟着你希望命令运行的日期和时间,然后命令提示符变为 `at>`,这样你就可以输入在上面指定的时间运行的命令。
例如:
```
at 4:08 PM Sat
at> cowsay 'hello'
at> CTRL+D
```
这将会在周六下午 4:08 运行 `cowsay` 程序。
### 7、 rmdir
这个命令允许你通过 Linux CLI 删除一个目录。例如:
```
rmdir testdirectory
```
请记住,这个命令不会删除里面有文件的目录。这只在删除空目录时才起作用。
### 8、 rm
如果你想删除文件,`rm` 命令就是你想要的。它可以删除文件和目录。要删除一个文件,键入 `rm testfile`,或者删除一个目录和里面的文件,键入 `rm -r`。
### 9、 touch
`touch` 命令,也就是所谓的 “make file 的命令”,允许你使用 Linux CLI 创建新的、空的文件。很像 `mkdir` 创建目录,`touch` 会创建文件。例如,`touch testfile` 将会创建一个名为 testfile 的空文件。
### 10、 locate
这个命令是你在 Linux 系统中用来查找文件的命令。就像在 Windows 中搜索一样,如果你忘了存储文件的位置或它的名字,这是非常有用的。
例如,如果你有一个关于区块链用例的文档,但是你忘了标题,你可以输入 `locate -blockchain` 或者通过用星号分隔单词来查找 "blockchain use cases",或者星号(`*`)。例如:
```
locate -i*blockchain*use*cases*
```
还有很多其他有用的 Linux CLI 命令,比如 `pkill` 命令,如果你开始关机但是你意识到你并不想这么做,那么这条命令很棒。但是这里描述的 10 个简单而有用的命令是你开始使用 Linux 命令行所需的基本知识。
---
via: <https://opensource.com/article/18/4/10-commands-new-linux-users>
作者:[Sam Bocetta](https://opensource.com/users/sambocetta) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You may think you're new to Linux, but you're really not. There are [3.74 billion](https://hostingcanada.org/state-of-the-internet/) global internet users, and all of them use Linux in some way since Linux servers power 90% of the internet. Most modern routers run Linux or Unix, and the [TOP500 supercomputers](https://www.top500.org/statistics/details/osfam/1) also rely on Linux. If you own an Android smartphone, your operating system is constructed from the Linux kernel.
In other words, Linux is everywhere.
But there's a difference between using Linux-based technologies and using Linux itself. If you're interested in Linux, but have been using a PC or Mac desktop, you may be wondering what you need to know to use the Linux command line interface (CLI). You've come to the right place.
The following are the fundamental Linux commands you need to know. Each is simple and easy to commit to memory. In other words, you don't have to be Bill Gates to understand them.
## 1. ls
You're probably thinking, "Is what?" No, that wasn't a typographical error – I really intended to type a lower-case L. `ls`
, or "list," is the number one command you need to know to use the Linux CLI. This list command functions within the Linux terminal to reveal all the major directories filed under a respective filesystem. For example, this command:
`ls /applications`
shows every folder stored in the applications folder. You'll use it to view files, folders, and directories.
All hidden files are viewable by using the command `ls -a`
.
## 2. cd
This command is what you use to go (or "change") to a directory. It is how you navigate from one folder to another. Say you're in your Downloads folder, but you want to go to a folder called Gym Playlist. Simply typing `cd Gym Playlist`
won't work, as the shell won't recognize it and will report the folder you're looking for doesn't exist. To bring up that folder, you'll need to include a backslash. The command should look like this:
`cd Gym\ Playlist`
To go back from the current folder to the previous one, you can type in the folder name followed by `cd ..`
. Think of the two dots like a back button.
## 3. mv
This command transfers a file from one folder to another; `mv`
stands for "move." You can use this short command like you would drag a file to a folder on a PC.
For example, if I create a file called `testfile`
to demonstrate all the basic Linux commands, and I want to move it to my Documents folder, I would issue this command:
`mv /home/sam/testfile /home/sam/Documents/`
The first piece of the command (`mv`
) says I want to move a file, the second part (`home/sam/testfile`
) names the file I want to move, and the third part (`/home/sam/Documents/`
) indicates the location where I want the file transferred.
## 4. Keyboard shortcuts
Okay, this is more than one command, but I couldn't resist including them all here. Why? Because they save time and take the headache out of your experience.
`CTRL+K`
Cuts text from the cursor until the end of the line
`CTRL+Y`
Pastes text
`CTRL+E`
Moves the cursor to the end of the line
`CTRL+A`
Moves the cursor to the beginning of the line
`ALT+F `
Jumps forward to the next space
`ALT+B`
Skips back to the previous space
`ALT+Backspace`
Deletes the previous word
`CTRL+W`
Cuts the word behind the cursor
`Shift+Insert`
Pastes text into the terminal
`Ctrl+D`
Logs you out
These commands come in handy in many ways. For example, imagine you misspell a word in your command text:
`sudo apt-get intall programname`
You probably noticed "install" is misspelled, so the command won't work. But keyboard shortcuts make it easy to go back and fix it. If my cursor is at the end of the line, I can click `ALT+B`
twice to move the cursor to the place noted below with the `^`
symbol:
`sudo apt-get^intall programname`
Now, we can quickly add the letter `s`
to fix `install`
. Easy peasy!
## 5. mkdir
This is the command you use to make a directory or a folder in the Linux environment. For example, if you're big into DIY hacks like I am, you could enter `mkdir DIY`
to make a directory for your DIY projects.
## 6. at
If you want to run a Linux command at a certain time, you can add `at`
to the equation. The syntax is `at`
followed by the date and time you want the command to run. Then the command prompt changes to `at>`
so you can enter the command(s) you want to run at the time you specified above
For example:
`at 4:08 PM Sat`
`at> cowsay 'hello'`
`at> CTRL+D`
This will run the program cowsay at 4:08 p.m. on Saturday night.
## 7. rmdir
This command allows you to remove a directory through the Linux CLI. For example:
`rmdir testdirectory`
Bear in mind that this command will *not* remove a directory that has files inside. This only works when removing empty directories.
## 8. rm
If you want to remove files, the `rm`
command is what you want. It can delete files and directories. To delete a single file, type `rm testfile`
, or to delete a directory and the files inside it, type `rm -r`
.
## 9. touch
The `touch`
command, otherwise known as the "make file command," allows you to create new, empty files using the Linux CLI. Much like `mkdir`
creates directories, `touch`
creates files. For example, `touch testfile`
will make an empty file named testfile.
## 10. locate
This command is what you use to find a file in a Linux system. Think of it like search in Windows. It's very useful if you forget where you stored a file or what you named it.
For example, if you have a document about blockchain use cases, but you can't think of the title, you can punch in `locate -blockchain `
or you can look for "blockchain use cases" by separating the words with an asterisk or asterisks (`*`
). For example:
`locate -i*blockchain*use*cases*`
.
There are tons of other helpful Linux CLI commands, like the `pkill`
command, which is great if you start a shutdown and realize you didn't mean to. But the 10 simple and useful commands described here are the essentials you need to get started using the Linux command line.
## 14 Comments |
9,602 | 如何在 Linux 中快速监控多个主机 | https://www.ostechnix.com/how-to-quickly-monitor-multiple-hosts-in-linux/ | 2018-05-03T21:27:00 | [
"who",
"rwho"
] | https://linux.cn/article-9602-1.html | 
有很多监控工具可用来监控本地和远程 Linux 系统,一个很好的例子是 [Cockpit](https://www.ostechnix.com/cockpit-monitor-administer-linux-servers-via-web-browser/)。但是,这些工具的安装和使用比较复杂,至少对于新手管理员来说是这样。新手管理员可能需要花一些时间来弄清楚如何配置这些工具来监视系统。如果你想要以快速且粗略地在局域网中一次监控多台主机,你可能需要了解一下 “rwho” 工具。只要安装了 rwho 实用程序,它将立即快速地监控本地和远程系统。你什么都不用配置!你所要做的就是在要监视的系统上安装 “rwho” 工具。
请不要将 rwho 视为功能丰富且完整的监控工具。这只是一个简单的工具,它只监视远程系统的“正常运行时间”(`uptime`),“负载”(`load`)和**登录的用户**。使用 “rwho” 使用程序,我们可以发现谁在哪台计算机上登录;一个被监视的计算机的列表,列出了正常运行时间(自上次重新启动以来的时间);有多少用户登录了;以及在过去的 1、5、15 分钟的平均负载。不多不少!而且,它只监视同一子网中的系统。因此,它非常适合小型和家庭办公网络。
### 在 Linux 中监控多台主机
让我来解释一下 `rwho` 是如何工作的。每个在网络上使用 `rwho` 的系统都将广播关于它自己的信息,其他计算机可以使用 `rwhod` 守护进程来访问这些信息。因此,网络上的每台计算机都必须安装 `rwho`。此外,为了分发或访问其他主机的信息,必须允许 `rwho` 端口(例如端口 `513/UDP`)通过防火墙/路由器。
好的,让我们来安装它。
我在 Ubuntu 16.04 LTS 服务器上进行了测试,`rwho` 在默认仓库中可用,所以,我们可以使用像下面这样的 APT 软件包管理器来安装它。
```
$ sudo apt-get install rwho
```
在基于 RPM 的系统如 CentOS、 Fedora、 RHEL 上,使用以下命令来安装它:
```
$ sudo yum install rwho
```
如果你在防火墙/路由器之后,确保你已经允许使用 rwhod 513 端口。另外,使用命令验证 `rwhod` 守护进程是否正在运行:
```
$ sudo systemctl status rwhod
```
如果它尚未启动,运行以下命令启用并启动 `rwhod` 服务:
```
$ sudo systemctl enable rwhod
$ sudo systemctl start rwhod
```
现在是时候来监视系统了。运行以下命令以发现谁在哪台计算机上登录:
```
$ rwho
ostechni ostechnix:pts/5 Mar 12 17:41
root server:pts/0 Mar 12 17:42
```
正如你所看到的,目前我的局域网中有两个系统。本地系统用户是 `ostechnix` (Ubuntu 16.04 LTS),远程系统的用户是 `root` (CentOS 7)。可能你已经猜到了,`rwho` 与 `who` 命令相似,但它会监视远程系统。
而且,我们可以使用以下命令找到网络上所有正在运行的系统的正常运行时间:
```
$ ruptime
ostechnix up 2:17, 1 user, load 0.09, 0.03, 0.01
server up 1:54, 1 user, load 0.00, 0.01, 0.05
```
这里,`ruptime`(类似于 `uptime` 命令)显示了我的 Ubuntu(本地) 和 CentOS(远程)系统的总运行时间。明白了吗?棒极了!以下是我的 Ubuntu 16.04 LTS 系统的示例屏幕截图:

你可以在以下位置找到有关局域网中所有其他机器的信息:
```
$ ls /var/spool/rwho/
whod.ostechnix whod.server
```
它很小,但却非常有用,可以发现谁在哪台计算机上登录,以及正常运行时间和系统负载详情。
**建议阅读:**
请注意,这种方法有一个严重的漏洞。由于有关每台计算机的信息都通过网络进行广播,因此该子网中的每个人都可能获得此信息。通常情况下可以,但另一方面,当有关网络的信息分发给非授权用户时,这可能是不必要的副作用。因此,强烈建议在受信任和受保护的局域网中使用它。
更多的信息,查找 man 手册页。
```
$ man rwho
```
好了,这就是全部了。更多好东西要来了,敬请期待!
干杯!
---
via: <https://www.ostechnix.com/how-to-quickly-monitor-multiple-hosts-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,603 | 如何使用 Linux 防火墙隔离本地欺骗地址 | https://opensource.com/article/18/2/block-local-spoofed-addresses-using-linux-firewall | 2018-05-04T07:33:12 | [
"iptables",
"防火墙"
] | https://linux.cn/article-9603-1.html |
>
> 如何使用 iptables 防火墙保护你的网络免遭黑客攻击。
>
>
>

即便是被入侵检测和隔离系统所保护的远程网络,黑客们也在寻找各种精巧的方法入侵。IDS/IPS 不能停止或者减少那些想要接管你的网络控制权的黑客攻击。不恰当的配置允许攻击者绕过所有部署的安全措施。
在这篇文章中,我将会解释安全工程师或者系统管理员该怎样避免这些攻击。
几乎所有的 Linux 发行版都带着一个内建的防火墙来保护运行在 Linux 主机上的进程和应用程序。大多数防火墙都按照 IDS/IPS 解决方案设计,这样的设计的主要目的是检测和避免恶意包获取网络的进入权。
Linux 防火墙通常有两种接口:iptables 和 ipchains 程序(LCTT 译注:在支持 systemd 的系统上,采用的是更新的接口 firewalld)。大多数人将这些接口称作 iptables 防火墙或者 ipchains 防火墙。这两个接口都被设计成包过滤器。iptables 是有状态防火墙,其基于先前的包做出决定。ipchains 不会基于先前的包做出决定,它被设计为无状态防火墙。
在这篇文章中,我们将会专注于内核 2.4 之后出现的 iptables 防火墙。
有了 iptables 防火墙,你可以创建策略或者有序的规则集,规则集可以告诉内核该如何对待特定的数据包。在内核中的是Netfilter 框架。Netfilter 既是框架也是 iptables 防火墙的项目名称。作为一个框架,Netfilter 允许 iptables 勾连被设计来操作数据包的功能。概括地说,iptables 依靠 Netfilter 框架构筑诸如过滤数据包数据的功能。
每个 iptables 规则都被应用到一个表中的链上。一个 iptables 链就是一个比较包中相似特征的规则集合。而表(例如 `nat` 或者 `mangle`)则描述不同的功能目录。例如, `mangle` 表用于修改包数据。因此,特定的修改包数据的规则被应用到这里;而过滤规则被应用到 `filter` 表,因为 `filter` 表过滤包数据。
iptables 规则有一个匹配集,以及一个诸如 `Drop` 或者 `Deny` 的目标,这可以告诉 iptables 对一个包做什么以符合规则。因此,没有目标和匹配集,iptables 就不能有效地处理包。如果一个包匹配了一条规则,目标会指向一个将要采取的特定措施。另一方面,为了让 iptables 处理,每个数据包必须匹配才能被处理。
现在我们已经知道 iptables 防火墙如何工作,让我们着眼于如何使用 iptables 防火墙检测并拒绝或丢弃欺骗地址吧。
### 打开源地址验证
作为一个安全工程师,在处理远程的欺骗地址的时候,我采取的第一步是在内核打开源地址验证。
源地址验证是一种内核层级的特性,这种特性丢弃那些伪装成来自你的网络的包。这种特性使用反向路径过滤器方法来检查收到的包的源地址是否可以通过包到达的接口可以到达。(LCTT 译注:到达的包的源地址应该可以从它到达的网络接口反向到达,只需反转源地址和目的地址就可以达到这样的效果)
利用下面简单的脚本可以打开源地址验证而不用手工操作:
```
#!/bin/sh
#作者: Michael K Aboagye
#程序目标: 打开反向路径过滤
#日期: 7/02/18
#在屏幕上显示 “enabling source address verification”
echo -n "Enabling source address verification…"
#将值0覆盖为1来打开源地址验证
echo 1 > /proc/sys/net/ipv4/conf/default/rp_filter
echo "completed"
```
上面的脚本在执行的时候只显示了 `Enabling source address verification` 这条信息而不会换行。默认的反向路径过滤的值是 `0`,`0` 表示没有源验证。因此,第二行简单地将默认值 `0` 覆盖为 `1`。`1` 表示内核将会通过确认反向路径来验证源地址。
最后,你可以使用下面的命令通过选择 `DROP` 或者 `REJECT` 目标之一来丢弃或者拒绝来自远端主机的欺骗地址。但是,处于安全原因的考虑,我建议使用 `DROP` 目标。
像下面这样,用你自己的 IP 地址代替 `IP-address` 占位符。另外,你必须选择使用 `REJECT` 或者 `DROP` 中的一个,这两个目标不能同时使用。
```
iptables -A INPUT -i internal_interface -s IP_address -j REJECT / DROP
iptables -A INPUT -i internal_interface -s 192.168.0.0/16 -j REJECT / DROP
```
这篇文章只提供了如何使用 iptables 防火墙来避免远端欺骗攻击的基础知识。
---
via: <https://opensource.com/article/18/2/block-local-spoofed-addresses-using-linux-firewall>
作者:[Michael Kwaku Aboagye](https://opensource.com/users/revoks) 译者:[leemeans](https://github.com/leemeans) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Attackers are finding sophisticated ways to penetrate even remote networks that are protected by intrusion detection and prevention systems. No IDS/IPS can halt or minimize attacks by hackers who are determined to take over your network. Improper configuration allows attackers to bypass all implemented network security measures.
In this article, I will explain how security engineers or system administrators can prevent these attacks.
Almost all Linux distributions come with a built-in firewall to secure processes and applications running on the Linux host. Most firewalls are designed as IDS/IPS solutions, whose primary purpose is to detect and prevent malicious packets from gaining access to a network.
A Linux firewall usually comes with two interfaces: iptables and ipchains. Most people refer to these interfaces as the "iptables firewall" or the "ipchains firewall." Both interfaces are designed as packet filters. Iptables acts as a stateful firewall, making decisions based on previous packets. Ipchains does not make decisions based on previous packets; hence, it is designed as a stateless firewall.
In this article, we will focus on the iptables firewall, which comes with kernel version 2.4 and beyond.
With the iptables firewall, you can create policies, or ordered sets of rules, which communicate to the kernel how it should treat specific classes of packets. Inside the kernel is the Netfilter framework. Netfilter is both a framework and the project name for the iptables firewall. As a framework, Netfilter allows iptables to hook functions designed to perform operations on packets. In a nutshell, iptables relies on the Netfilter framework to build firewall functionality such as filtering packet data.
Each iptables rule is applied to a chain within a table. An *iptables chain* is a collection of rules that are compared against packets with similar characteristics, while a table (such as nat or mangle) describes diverse categories of functionality. For instance, a mangle table alters packet data. Thus, specialized rules that alter packet data are applied to it, and filtering rules are applied to the filter table because the filter table filters packet data.
Iptables rules have a set of matches, along with a target, such as `Drop`
or `Deny`
, that instructs iptables what to do with a packet that conforms to the rule. Thus, without a target and a set of matches, iptables can’t effectively process packets. A target simply refers to a specific action to be taken if a packet matches a rule. Matches, on the other hand, must be met by every packet in order for iptables to process them.
Now that we understand how the iptables firewall operates, let's look at how to use iptables firewall to detect and reject or drop spoofed addresses.
## Turning on source address verification
The first step I, as a security engineer, take when I deal with spoofed addresses from remote hosts is to turn on source address verification in the kernel.
Source address verification is a kernel-level feature that drops packets pretending to come from your network. It uses the reverse path filter method to check whether the source of the received packet is reachable through the interface it came in.
To turn source address verification, utilize the simple shell script below instead of doing it manually:
```
``````
#!/bin/sh
#author’s name: Michael K Aboagye
#purpose of program: to enable reverse path filtering
#date: 7/02/18
#displays “enabling source address verification” on the screen
echo -n "Enabling source address verification…"
#Overwrites the value 0 to 1 to enable source address verification
echo 1 > /proc/sys/net/ipv4/conf/default/rp_filter
echo "completed"
```
The preceding script, when executed, displays the message `Enabling source address verification`
without appending a new line. The default value of the reverse path filter is 0.0, which means no source validation. Thus, the second line simply overwrites the default value 0 to 1. 1 means that the kernel will validate the source by confirming the reverse path.
Finally, you can use the following command to drop or reject spoofed addresses from remote hosts by choosing either one of these targets: `DROP`
or `REJECT`
. However, I recommend using `DROP`
for security reasons.
Replace the “IP-address” placeholder with your own IP address, as shown below. Also, you must choose to use either `REJECT`
or `DROP`
; the two targets don’t work together.
```
``````
iptables -A INPUT -i internal_interface -s IP_address -j REJECT / DROP
iptables -A INPUT -i internal_interface -s 192.168.0.0/16 -j REJECT/ DROP
```
This article provides only the basics of how to prevent spoofing attacks from remote hosts using the iptables firewall.
## 7 Comments |
9,605 | 为什么MIT的专利许可不讨人喜欢? | https://opensource.com/article/18/3/patent-grant-mit-license | 2018-05-04T19:53:56 | [
"MIT",
"许可证",
"专利"
] | https://linux.cn/article-9605-1.html |
>
> 提要:传统观点认为,Apache 许可证拥有“真正”的专利许可,那 MIT 许可证呢?
>
>
>

我经常听到说,[MIT 许可证](https://opensource.org/licenses/MIT)中没有专利许可,或者它只有一些“默示”专利许可的可能性。如果 MIT 许可证很敏感的话,那么它可能会因为大家对其较为年轻的同伴 [Apache 许可证](https://www.apache.org/licenses/LICENSE-2.0)的不断称赞而产生自卑感,传统观点认为,Apache 许可证拥有“真正”的专利许可。
这种区分经常重复出现,以至于人们认为,在许可证文本中是否出现“专利”一词具有很大的法律意义。不过,对“专利”一词的强调是错误的。1927 年,[美国最高法院表示](https://scholar.google.com/scholar_case?case=6603693344416712533):
>
> “专利所有人使用的任何语言,或者专利所有人向其他人展示的任何行为,使得其他人可以从中合理地推断出专利所有人同意他依据专利来制造、使用或销售,便构成了许可行为,并可以作为侵权行为的辩护理由。”
>
>
>
MIT 许可证无疑拥有明示许可。该许可证不限于授予任何特定类型的知识产权。但其许可证声明里不使用“专利”或“版权”一词。您上次听到有人表示担心 MIT 许可证仅包含默示版权许可是什么时候了?
既然授予权利的文本中没有“版权”和“专利”,让我们来研究一下 MIT 许可证中的字眼,看看我们能否了解到哪些权利被授予。
| | |
| --- | --- |
| **特此授予以下权限,** | 这是授予权限的直接开始。 |
| *免费,* | 为了获得权限,不需要任何费用。 |
| *任何人获得本软件的副本和相关文档文件(本“软件”),* | 我们定义了一些基本知识:许可的主体和受益人。 |
| **无限制地处理本软件,** | 不错,这很好。现在我们正在深究此事。我们并没有因为细微差别而乱搞,“无限制”非常明确。 |
| *包括但不限于* | 对示例列表的介绍指出,该列表不是一种转弯抹角的限制,它只是一个示例列表。 |
| *使用、复制、修改、合并、发布、分发、再许可和/或销售本软件副本的权利,并允许获得本软件的人员享受同等权利,* | 我们可以对软件采取各种各样的行动。虽然有一些建议涉及[专利所有人的专有权](http://uscode.house.gov/view.xhtml?req=granuleid:USC-prelim-title35-section271&num=0&edition=prelim)和[版权所有者的专有权](https://www.copyright.gov/title17/92chap1.html#106),但这些建议并不真正关注特定知识产权法提供的专有权的具体清单;重点是软件。 |
| *受以下条件限制:* | 权限受条件限制。 |
| *上述版权声明和权限声明应包含在本软件的所有副本或主要部分中。* | 这种情况属于所谓的<ruby> 不设限许可 <rp> ( </rp> <rt> permissive license </rt> <rp> ) </rp></ruby>。 |
| *本软件按“原样”提供,不附有任何形式的明示或暗示保证,包括但不限于对适销性、特定用途适用性和非侵权性的保证。在任何情况下,作者或版权所有者都不承担任何索赔、损害或其他责任。无论它是以合同形式、侵权或是其他方式,如由它引起,在其作用范围内、与该软件有联系、该软件的使用或者由这个软件引起的其他行为。* | 为了完整起见,我们添加免责声明。 |
没有任何信息会导致人们认为,许可人会保留对使用专利所有人创造的软件的行为起诉专利侵权的权利,并允许其他人“无限制地处理本软件”。
为什么说这是默示专利许可呢?没有充足的理由这么做。我们来看一个默示专利许可的案例。[Met-Coil Systems Corp. 诉Korners Unlimited](https://scholar.google.com/scholar_case?case=4152769754469052201) 的专利纠纷涉及专利的默示许可([美国专利 4,466,641](https://patents.google.com/patent/US4466641),很久以前已过期),该专利涉及用于连接供暖和空调系统中使用的金属管道段。处理该专利纠纷上诉的美国法院认定,专利权人(Met-Coil)出售其成型机(一种不属于专利保护主体的机器,但用于弯曲金属管道端部的法兰,使其作为以专利方式连接管道的一部分)授予其客户默示专利许可;因此,所谓的专利侵权者(Korners Unlimited)向这些客户出售某些与专利有关的部件(与 Met-Coil 机器弯曲产生的法兰一起使用的特殊角件)并不促成专利的侵权,因为客户被授予了许可(默示许可)。
通过销售其目的是在使用受专利保护的发明中发挥作用的金属弯曲机,专利权人向机器的购买者授予了专利许可。在 Met-Coil 案例中,可以看到需要谈论“默示”许可,因为根本不存在书面许可;法院也试图寻找由行为默示的许可。

现在,让我们回到 MIT 许可证。这是一个明示许可证。这个明示许可证授予了专利许可吗?事实上,在授予“无限制地处理软件”权限的情况下,MIT 许可证的确如此。没有比通过直接阅读授予许可的文字来得出结论更有效的办法了。
“明示专利许可”一词可以用于两种含义之一:
* 包括授予专利权利的明示许可证,或
* 明确提及专利权利的许可证。
其中第一项是与默示专利许可的对比。如果没有授予专利权利的明示许可,人们可以在分析中继续查看是否默示了专利许可。
人们经常使用第二个含义“明示专利许可”。不幸的是,这导致一些人错误地认为缺乏这样的“明示专利许可”会让人寻找默示许可。但是,第二种含义没有特别的法律意义。没有明确提及专利权利并不意味着没有授予专利权利的明示许可。因此,没有明确提及专利权利并不意味着仅受限于专利权利的默示许可。
说完这一切之后,那它究竟有多重要呢?
并没有多重要。当个人和企业根据 MIT 协议贡献软件时,他们并不希望稍后对那些使用专利所有人为之做出贡献的软件的人们主张专利权利。这是一个强有力的声明,当然,我没有直接看到贡献者的期望。但是根据 20 多年来我对依据 MIT 许可证贡献代码的观察,我没有看到任何迹象表明贡献者认为他们应该保留后续对使用其贡献的代码的行为征收专利许可费用的权利。恰恰相反,我观察到了与许可证中“无限制”这个短语一致的行为。
本讨论基于美国法律。其他司法管辖区的法律专家可以针对在其他国家的结果是否有所不同提出意见。
---
作者简介:Scott Peterson 是红帽公司(Red Hat)法律团队成员。很久以前,一位工程师就一个叫做 GPL 的奇怪文件向 Scott 征询法律建议,这个决定性的问题让 Scott 走上了探索包括技术标准和开源软件在内的协同开发法律问题的纠结之路。
译者简介:薛亮,集慧智佳知识产权咨询公司高级咨询师,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 200 | OK | Too often, I hear it said that the [MIT License](https://opensource.org/licenses/MIT) has no patent license, or that it has merely some possibility of an "implied" patent license. If the MIT License was sensitive, it might develop an inferiority complex in light of the constant praise heaped on its younger sibling, the [Apache License](https://www.apache.org/licenses/LICENSE-2.0), which conventional wisdom says has a "real" patent license.
This distinction is repeated so often that one might be tempted to think there is some great legal significance in whether or not the word "patent" appears in the text of a license. That emphasis on the word "patent" is misguided. In 1927, the [U.S. Supreme Court said](https://scholar.google.com/scholar_case?case=6603693344416712533):
"Any language used by the owner of the patent, or any conduct on his part exhibited to another from which that other may properly infer that the owner consents to his use of the patent in making or using it, or selling it, upon which the other acts, constitutes a license and a defense to an action for a tort."
The MIT License unquestionably has an express license. That license is not limited to the granting of any particular flavor of intellectual property rights. The statement of license does not use the word "patent" or the word "copyright." When was the last time you heard someone expressing concern that the MIT License merely had an implied copyright license?
Since neither "copyright" nor "patent" appear in the text of the grant of rights, let us look to the words in the MIT License to see what we might learn about what rights are being granted.
|
That's a straightforward start to the granting of permissions. |
|
No fee is needed in order to benefit from the permission. |
|
We have some basics defined: subject of the license and who is to benefit. |
|
Well, that's pretty good. Now we are getting to the heart of the matter. We are not messing around with nuance: "without restriction" is pretty clear. |
|
This introduction to a list of examples points out that the list is not a backhanded limitation: It is a list of examples. |
|
We have a mixed assortment of actions one might undertake with respect to software. While there is some suggestion of |
|
The permissions are subject to a condition. |
|
The condition is of the type that has become typical of so-called permissive licenses. |
|
For completeness, let's include the disclaimer. |
There is nothing that would lead one to believe that the licensor wanted to preserve their right to pursue patent infringement claims against the use of software that the patent owner created and permitted others "to deal in the Software without restriction."
Why call this an implied patent license? There is no good reason to do so. Let's look at an example of an implied patent license. The patent dispute in [Met-Coil Systems Corp. v. Korners Unlimited](https://scholar.google.com/scholar_case?case=4152769754469052201) concerns an implied license for a patent ([US Patent 4,466,641](https://patents.google.com/patent/US4466641), long ago expired) on a way of connecting sections of metal ducts of the kind used in heating and air conditioning systems. The U.S. court that handles appeals in patent disputes concluded that the patent owner's (Met-Coil) sale of its roll-forming machine (a machine that is not the subject of the patent, but that is used to bend flanges at the ends of metal ducts as a part of making duct connections in a patented way) granted an implied license under the patent to its customers; thus, sale by the alleged patent infringer (Korners Unlimited) of certain patent-related components (special corner pieces for use with the flanges that resulted from the Met-Coil machine's bending) to those customers was not a contributory patent infringement because the customers were licensed (with an implied license).
By selling the metal-bending machine whose purpose was to play a role in using the patented invention, the patent owner granted a patent license to purchasers of the machine. In the Met-Coil case, one can see a need to talk about an "implied" license because there was no written license at all; the court was finding a license implied by behavior.
Now, let's return to the MIT License. There is an express license. Does that express license grant patent rights? Indeed, with permission granted "to deal in the Software without restriction," it does. And there is no need to arrive at that conclusion via anything more than a direct reading of the words that grant the license.
The phrase "express patent license" could be used with either of two intended meanings:
- an express license that includes a grant of patent rights, or
- a license that expressly refers to patent rights.
The first of those is the contrast to an implied patent license. If there is no express license that grants patent rights, one might move on in the analysis to see if a patent license might be implied.
People have often used the phrase "express patent license" with the second meaning. Unfortunately, that has led some to incorrectly assume that lack of such an "express patent license" leaves one looking for an implied license. However, the second meaning has no particular legal significance. The lack of expressly referring to patent rights does not mean that there is no express license that grants patent rights, and thus the lack of expressly referring to patent rights does not mean that one is limited to an implied grant of patent rights.
Having said all this, how much does it matter?
Not much. When people and companies contribute software under the MIT License, they do so without expecting to be able to later assert patent rights against those who use the software that the patent owner has contributed. That's a strong statement, and of course, I cannot see directly the expectations of contributors. But over the 20+ years that I have observed contribution of code under the MIT License, I see no indication that contributors think that they are reserving the right to later charge patent license fees for use of their contributed code. Quite the contrary: I observe behavior consistent with the "without restriction" phrase in the license.
This discussion is based on the law in the United States. I invite experts on the law in other jurisdictions to offer their views on whether the result would be different in other countries.
## 1 Comment |
9,606 | vrms 助你在 Debian 中查找非自由软件 | https://www.ostechnix.com/the-vrms-program-helps-you-to-find-non-free-software-in-debian/ | 2018-05-04T20:06:26 | [
"自由软件",
"vrms",
"rms"
] | https://linux.cn/article-9606-1.html | 
有一天,我在 Digital ocean 上读到一篇有趣的指南,它解释了[自由和开源软件之间的区别](https://www.digitalocean.com/community/tutorials/Free-vs-Open-Source-Software)。在此之前,我认为两者都差不多。但是,我错了。它们之间有一些显著差异。在阅读那篇文章时,我想知道如何在 Linux 中找到非自由软件,因此有了这篇文章。
### 向 “Virtual Richard M. Stallman” 问好,这是一个在 Debian 中查找非自由软件的 Perl 脚本
**Virtual Richard M. Stallman** ,简称 **vrms**,是一个用 Perl 编写的程序,它在你基于 Debian 的系统上分析已安装软件的列表,并报告所有来自非自由和 contrib 树的已安装软件包。对于那些不太清楚区别的人,自由软件应该符合以下[**四项基本自由**](https://www.gnu.org/philosophy/free-sw.html)。
* **自由 0** – 不管任何目的,随意运行程序的自由。
* **自由 1** – 研究程序如何工作的自由,并根据你的需求进行调整。访问源代码是一个先决条件。
* **自由 2** – 重新分发副本的自由,这样你可以帮助别人。
* **自由 3** – 改进程序,并向公众发布改进的自由,以便整个社区获益。访问源代码是一个先决条件。
任何不满足上述四个条件的软件都不被视为自由软件。简而言之,**自由软件意味着用户有运行、复制、分发、研究、修改和改进软件的自由。**
现在让我们来看看安装的软件是自由的还是非自由的,好么?
vrms 包存在于 Debian 及其衍生版(如 Ubuntu)的默认仓库中。因此,你可以使用 `apt` 包管理器安装它,使用下面的命令。
```
$ sudo apt-get install vrms
```
安装完成后,运行以下命令,在基于 debian 的系统中查找非自由软件。
```
$ vrms
```
在我的 Ubuntu 16.04 LTS 桌面版上输出的示例。
```
Non-free packages installed on ostechnix
unrar Unarchiver for .rar files (non-free version)
1 non-free packages, 0.0% of 2103 installed packages.
```

如你在上面的截图中看到的那样,我的 Ubuntu 中安装了一个非自由软件包。
如果你的系统中没有任何非自由软件包,则应该看到以下输出。
```
No non-free or contrib packages installed on ostechnix! rms would be proud.
```
vrms 不仅可以在 Debian 上找到非自由软件包,还可以在 Ubuntu、Linux Mint 和其他基于 deb 的系统中找到非自由软件包。
**限制**
vrms 虽然有一些限制。就像我已经提到的那样,它列出了安装的非自由和 contrib 部分的软件包。但是,某些发行版并未遵循确保专有软件仅在 vrms 识别为“非自由”的仓库中存在,并且它们不努力维护这种分离。在这种情况下,vrms 将不能识别非自由软件,并且始终会报告你的系统上安装了非自由软件。如果你使用的是像 Debian 和 Ubuntu 这样的发行版,遵循将专有软件保留在非自由仓库的策略,vrms 一定会帮助你找到非自由软件包。
就是这些。希望它是有用的。还有更好的东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/the-vrms-program-helps-you-to-find-non-free-software-in-debian/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,607 | 用 PGP 保护代码完整性(三):生成 PGP 子密钥 | https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys | 2018-05-04T20:29:00 | [
"PGP"
] | https://linux.cn/article-9607-1.html |
>
> 在第三篇文章中,我们将解释如何生成用于日常工作的 PGP 子密钥。
>
>
>

在本系列教程中,我们提供了使用 PGP 的实用指南。在此之前,我们介绍了[基本工具和概念](/article-9524-1.html),并介绍了如何[生成并保护您的主 PGP 密钥](/article-9529-1.html)。在第三篇文章中,我们将解释如何生成用于日常工作的 PGP 子密钥。
#### 清单
1. 生成 2048 位加密子密钥(必要)
2. 生成 2048 位签名子密钥(必要)
3. 生成一个 2048 位验证子密钥(推荐)
4. 将你的公钥上传到 PGP 密钥服务器(必要)
5. 设置一个刷新的定时任务(必要)
#### 注意事项
现在我们已经创建了主密钥,让我们创建用于日常工作的密钥。我们创建 2048 位的密钥是因为很多专用硬件(我们稍后会讨论这个)不能处理更长的密钥,但同样也是出于实用的原因。如果我们发现自己处于一个 2048 位 RSA 密钥也不够好的世界,那将是由于计算或数学有了基本突破,因此更长的 4096 位密钥不会产生太大的差别。
#### 创建子密钥
要创建子密钥,请运行:
```
$ gpg --quick-add-key [fpr] rsa2048 encr
$ gpg --quick-add-key [fpr] rsa2048 sign
```
用你密钥的完整指纹替换 `[fpr]`。
你也可以创建验证密钥,这能让你将你的 PGP 密钥用于 ssh:
```
$ gpg --quick-add-key [fpr] rsa2048 auth
```
你可以使用 `gpg --list-key [fpr]` 来查看你的密钥信息:
```
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
111122223333444455556666AAAABBBBCCCCDDDD
uid [ultimate] Alice Engineer <[email protected]>
uid [ultimate] Alice Engineer <[email protected]>
sub rsa2048 2017-12-06 [E]
sub rsa2048 2017-12-06 [S]
```
#### 上传你的公钥到密钥服务器
你的密钥创建已完成,因此现在需要你将其上传到一个公共密钥服务器,使其他人能更容易找到密钥。 (如果你不打算实际使用你创建的密钥,请跳过这一步,因为这只会在密钥服务器上留下垃圾数据。)
```
$ gpg --send-key [fpr]
```
如果此命令不成功,你可以尝试指定一台密钥服务器以及端口,这很有可能成功:
```
$ gpg --keyserver hkp://pgp.mit.edu:80 --send-key [fpr]
```
大多数密钥服务器彼此进行通信,因此你的密钥信息最终将与所有其他密钥信息同步。
**关于隐私的注意事项:**密钥服务器是完全公开的,因此在设计上会泄露有关你的潜在敏感信息,例如你的全名、昵称以及个人或工作邮箱地址。如果你签名了其他人的钥匙或某人签名了你的钥匙,那么密钥服务器还会成为你的社交网络的泄密者。一旦这些个人信息发送给密钥服务器,就不可能被编辑或删除。即使你撤销签名或身份,它也不会将你的密钥记录删除,它只会将其标记为已撤消 —— 这甚至会显得更显眼。
也就是说,如果你参与公共项目的软件开发,以上所有信息都是公开记录,因此通过密钥服务器另外让这些信息可见,不会导致隐私的净损失。
#### 上传你的公钥到 GitHub
如果你在开发中使用 GitHub(谁不是呢?),则应按照他们提供的说明上传密钥:
* [添加 PGP 密钥到你的 GitHub 账户](https://help.github.com/articles/adding-a-new-gpg-key-to-your-github-account/)
要生成适合粘贴的公钥输出,只需运行:
```
$ gpg --export --armor [fpr]
```
#### 设置一个刷新定时任务
你需要定期刷新你的钥匙环,以获取其他人公钥的最新更改。你可以设置一个定时任务来做到这一点:
```
$ crontab -e
```
在新行中添加以下内容:
```
@daily /usr/bin/gpg2 --refresh >/dev/null 2>&1
```
**注意:**检查你的 `gpg` 或 `gpg2` 命令的完整路径,如果你的 `gpg` 是旧式的 GnuPG v.1,请使用 gpg2。
通过 Linux 基金会和 edX 的免费“[Introduction to Linux](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)” 课程了解关于 Linux 的更多信息。
---
via: <https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys>
作者:[Konstantin Ryabitsev](https://www.linux.com/users/mricon) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,608 | Caffeinated 6.828:练习 shell | https://sipb.mit.edu/iap/6.828/lab/shell/ | 2018-05-06T10:31:57 | [
"MIT"
] | https://linux.cn/article-9608-1.html | 
通过在 shell 中实现多项功能,该作业将使你更加熟悉 Unix 系统调用接口和 shell。你可以在支持 Unix API 的任何操作系统(一台 Linux Athena 机器、装有 Linux 或 Mac OS 的笔记本电脑等)上完成此作业。请在第一次上课前将你的 shell 提交到[网站](https://exokernel.scripts.mit.edu/submit/)。
如果你在练习中遇到困难或不理解某些内容时,你不要羞于给[员工邮件列表](mailto:[email protected])发送邮件,但我们确实希望全班的人能够自行处理这级别的 C 编程。如果你对 C 不是很熟悉,可以认为这个是你对 C 熟悉程度的检查。再说一次,如果你有任何问题,鼓励你向我们寻求帮助。
下载 xv6 shell 的[框架](https://sipb.mit.edu/iap/6.828/files/sh.c),然后查看它。框架 shell 包含两个主要部分:解析 shell 命令并实现它们。解析器只能识别简单的 shell 命令,如下所示:
```
ls > y
cat < y | sort | uniq | wc > y1
cat y1
rm y1
ls | sort | uniq | wc
rm y
```
将这些命令剪切并粘贴到 `t.sh` 中。
你可以按如下方式编译框架 shell 的代码:
```
$ gcc sh.c
```
它会生成一个名为 `a.out` 的文件,你可以运行它:
```
$ ./a.out < t.sh
```
执行会崩溃,因为你还没有实现其中的几个功能。在本作业的其余部分中,你将实现这些功能。
### 执行简单的命令
实现简单的命令,例如:
```
$ ls
```
解析器已经为你构建了一个 `execcmd`,所以你唯一需要编写的代码是 `runcmd` 中的 case ' '。要测试你可以运行 “ls”。你可能会发现查看 `exec` 的手册页是很有用的。输入 `man 3 exec`。
你不必实现引用(即将双引号之间的文本视为单个参数)。
### I/O 重定向
实现 I/O 重定向命令,这样你可以运行:
```
echo "6.828 is cool" > x.txt
cat < x.txt
```
解析器已经识别出 '>' 和 '<',并且为你构建了一个 `redircmd`,所以你的工作就是在 `runcmd` 中为这些符号填写缺少的代码。确保你的实现在上面的测试输入中正确运行。你可能会发现 `open`(`man 2 open`) 和 `close` 的 man 手册页很有用。
请注意,此 shell 不会像 `bash`、`tcsh`、`zsh` 或其他 UNIX shell 那样处理引号,并且你的示例文件 `x.txt` 预计包含引号。
### 实现管道
实现管道,这样你可以运行命令管道,例如:
```
$ ls | sort | uniq | wc
```
解析器已经识别出 “|”,并且为你构建了一个 `pipecmd`,所以你必须编写的唯一代码是 `runcmd` 中的 case '|'。测试你可以运行上面的管道。你可能会发现 `pipe`、`fork`、`close` 和 `dup` 的 man 手册页很有用。
现在你应该可以正确地使用以下命令:
```
$ ./a.out < t.sh
```
无论是否完成挑战任务,不要忘记将你的答案提交给[网站](https://exokernel.scripts.mit.edu/submit/)。
### 挑战练习
如果你想进一步尝试,可以将所选的任何功能添加到你的 shell。你可以尝试以下建议之一:
* 实现由 `;` 分隔的命令列表
* 通过实现 `(` 和 `)` 来实现子 shell
* 通过支持 `&` 和 `wait` 在后台执行命令
* 实现参数引用
所有这些都需要改变解析器和 `runcmd` 函数。
---
via: <https://sipb.mit.edu/iap/6.828/lab/shell/>
作者:[mit](https://sipb.mit.edu) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
9,609 | 递归:梦中梦 | https://manybutfinite.com/post/recursion/ | 2018-05-06T11:15:00 | [
"递归"
] | https://linux.cn/article-9609-1.html |
>
> “方其梦也,不知其梦也。梦之中又占其梦焉,觉而后知其梦也。”
>
>
> —— 《庄子·齐物论》
>
>
>

**递归**是很神奇的,但是在大多数的编程类书藉中对递归讲解的并不好。它们只是给你展示一个递归阶乘的实现,然后警告你递归运行的很慢,并且还有可能因为栈缓冲区溢出而崩溃。“你可以将头伸进微波炉中去烘干你的头发,但是需要警惕颅内高压并让你的头发生爆炸,或者你可以使用毛巾来擦干头发。”难怪人们不愿意使用递归。但这种建议是很糟糕的,因为在算法中,递归是一个非常强大的思想。

我们来看一下这个经典的递归阶乘:
```
#include <stdio.h>
int factorial(int n)
{
int previous = 0xdeadbeef;
if (n == 0 || n == 1) {
return 1;
}
previous = factorial(n-1);
return n * previous;
}
int main(int argc)
{
int answer = factorial(5);
printf("%d\n", answer);
}
```
*递归阶乘 - factorial.c*
函数调用自身的这个观点在一开始是让人很难理解的。为了让这个过程更形象具体,下图展示的是当调用 `factorial(5)` 并且达到 `n == 1`这行代码 时,[栈上](https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-gdb-output.txt) 端点的情况:

每次调用 `factorial` 都生成一个新的 [栈帧](https://manybutfinite.com/post/journey-to-the-stack)。这些栈帧的创建和 [销毁](https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/) 是使得递归版本的阶乘慢于其相应的迭代版本的原因。在调用返回之前,累积的这些栈帧可能会耗尽栈空间,进而使你的程序崩溃。
而这些担心经常是存在于理论上的。例如,对于每个 `factorial` 的栈帧占用 16 字节(这可能取决于栈排列以及其它因素)。如果在你的电脑上运行着现代的 x86 的 Linux 内核,一般情况下你拥有 8 GB 的栈空间,因此,`factorial` 程序中的 `n` 最多可以达到 512,000 左右。这是一个 [巨大无比的结果](https://gist.github.com/gduarte/9944878),它将花费 8,971,833 比特来表示这个结果,因此,栈空间根本就不是什么问题:一个极小的整数 —— 甚至是一个 64 位的整数 —— 在我们的栈空间被耗尽之前就早已经溢出了成千上万次了。
过一会儿我们再去看 CPU 的使用,现在,我们先从比特和字节回退一步,把递归看作一种通用技术。我们的阶乘算法可归结为:将整数 N、N-1、 … 1 推入到一个栈,然后将它们按相反的顺序相乘。实际上我们使用了程序调用栈来实现这一点,这是它的细节:我们在堆上分配一个栈并使用它。虽然调用栈具有特殊的特性,但是它也只是又一种数据结构而已,你可以随意使用。我希望这个示意图可以让你明白这一点。
当你将栈调用视为一种数据结构,有些事情将变得更加清晰明了:将那些整数堆积起来,然后再将它们相乘,这并不是一个好的想法。那是一种有缺陷的实现:就像你拿螺丝刀去钉钉子一样。相对更合理的是使用一个迭代过程去计算阶乘。
但是,螺丝钉太多了,我们只能挑一个。有一个经典的面试题,在迷宫里有一只老鼠,你必须帮助这只老鼠找到一个奶酪。假设老鼠能够在迷宫中向左或者向右转弯。你该怎么去建模来解决这个问题?
就像现实生活中的很多问题一样,你可以将这个老鼠找奶酪的问题简化为一个图,一个二叉树的每个结点代表在迷宫中的一个位置。然后你可以让老鼠在任何可能的地方都左转,而当它进入一个死胡同时,再回溯回去,再右转。这是一个老鼠行走的 [迷宫示例](https://github.com/gduarte/blog/blob/master/code/x86-stack/maze.h):

每到边缘(线)都让老鼠左转或者右转来到达一个新的位置。如果向哪边转都被拦住,说明相关的边缘不存在。现在,我们来讨论一下!这个过程无论你是调用栈还是其它数据结构,它都离不开一个递归的过程。而使用调用栈是非常容易的:
```
#include <stdio.h>
#include "maze.h"
int explore(maze_t *node)
{
int found = 0;
if (node == NULL)
{
return 0;
}
if (node->hasCheese){
return 1;// found cheese
}
found = explore(node->left) || explore(node->right);
return found;
}
int main(int argc)
{
int found = explore(&maze);
}
```
*递归迷宫求解 [下载](https://manybutfinite.com/code/x86-stack/maze.c)*
当我们在 `maze.c:13` 中找到奶酪时,栈的情况如下图所示。你也可以在 [GDB 输出](https://github.com/gduarte/blog/blob/master/code/x86-stack/maze-gdb-output.txt) 中看到更详细的数据,它是使用 [命令](https://github.com/gduarte/blog/blob/master/code/x86-stack/maze-gdb-commands.txt) 采集的数据。

它展示了递归的良好表现,因为这是一个适合使用递归的问题。而且这并不奇怪:当涉及到算法时,*递归是规则,而不是例外*。它出现在如下情景中——进行搜索时、进行遍历树和其它数据结构时、进行解析时、需要排序时——它无处不在。正如众所周知的 pi 或者 e,它们在数学中像“神”一样的存在,因为它们是宇宙万物的基础,而递归也和它们一样:只是它存在于计算结构中。
Steven Skienna 的优秀著作 [算法设计指南](http://www.amazon.com/Algorithm-Design-Manual-Steven-Skiena/dp/1848000693/) 的精彩之处在于,他通过 “战争故事” 作为手段来诠释工作,以此来展示解决现实世界中的问题背后的算法。这是我所知道的拓展你的算法知识的最佳资源。另一个读物是 McCarthy 的 [关于 LISP 实现的的原创论文](https://github.com/papers-we-love/papers-we-love/blob/master/comp_sci_fundamentals_and_history/recursive-functions-of-symbolic-expressions-and-their-computation-by-machine-parti.pdf)。递归在语言中既是它的名字也是它的基本原理。这篇论文既可读又有趣,在工作中能看到大师的作品是件让人兴奋的事情。
回到迷宫问题上。虽然它在这里很难离开递归,但是并不意味着必须通过调用栈的方式来实现。你可以使用像 `RRLL` 这样的字符串去跟踪转向,然后,依据这个字符串去决定老鼠下一步的动作。或者你可以分配一些其它的东西来记录追寻奶酪的整个状态。你仍然是实现了一个递归的过程,只是需要你实现一个自己的数据结构。
那样似乎更复杂一些,因为栈调用更合适。每个栈帧记录的不仅是当前节点,也记录那个节点上的计算状态(在这个案例中,我们是否只让它走左边,或者已经尝试向右)。因此,代码已经变得不重要了。然而,有时候我们因为害怕溢出和期望中的性能而放弃这种优秀的算法。那是很愚蠢的!
正如我们所见,栈空间是非常大的,在耗尽栈空间之前往往会遇到其它的限制。一方面可以通过检查问题大小来确保它能够被安全地处理。而对 CPU 的担心是由两个广为流传的有问题的示例所导致的:<ruby> 哑阶乘 <rt> dumb factorial </rt></ruby>和可怕的无记忆的 O( 2<sup> n</sup> ) [Fibonacci 递归](http://stackoverflow.com/questions/360748/computational-complexity-of-fibonacci-sequence)。它们并不是栈递归算法的正确代表。
事实上栈操作是非常快的。通常,栈对数据的偏移是非常准确的,它在 [缓存](https://manybutfinite.com/post/intel-cpu-caches/) 中是热数据,并且是由专门的指令来操作它的。同时,使用你自己定义的在堆上分配的数据结构的相关开销是很大的。经常能看到人们写的一些比栈调用递归更复杂、性能更差的实现方法。最后,现代的 CPU 的性能都是 [非常好的](https://manybutfinite.com/post/what-your-computer-does-while-you-wait/) ,并且一般 CPU 不会是性能瓶颈所在。在考虑牺牲程序的简单性时要特别注意,就像经常考虑程序的性能及性能的[测量](https://manybutfinite.com/post/performance-is-a-science)那样。
下一篇文章将是探秘栈系列的最后一篇了,我们将了解尾调用、闭包、以及其它相关概念。然后,我们就该深入我们的老朋友—— Linux 内核了。感谢你的阅读!

---
via:<https://manybutfinite.com/post/recursion/>
作者:[Gustavo Duarte](http://duartes.org/gustavo/blog/about/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[FSSlc](https://github.com/FSSlc)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Recursion** is magic, but it suffers from the most awkward introduction in
programming books. They’ll show you a recursive factorial implementation, then
warn you that while it sort of works it’s terribly slow and might crash due to
stack overflows. “You could always dry your hair by sticking your head
into the microwave, but watch out for intracranial pressure and head explosions.
Or you can use a towel.” No wonder people are suspicious of it. Which is too
bad, because **recursion is the single most powerful idea in algorithms**.
Let’s take a look at the classic recursive factorial:
1 |
|
The idea of a function calling itself is mystifying at first. To make it
concrete, here is *exactly* what is [on the stack](https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-gdb-output.txt) when
`factorial(5)`
is called and reaches `n == 1`
:

Each call to `factorial`
generates a new [stack frame](/post/journey-to-the-stack). The creation and
[destruction](/post/epilogues-canaries-buffer-overflows/) of these stack frames is what makes the recursive
factorial slower than its iterative counterpart. The accumulation of these
frames before the calls start returning is what can potentially exhaust stack
space and crash your program.
These concerns are often theoretical. For example, the stack frames for
`factorial`
take 16 bytes each (this can vary depending on stack alignment and
other factors). If you are running a modern x86 Linux kernel on a computer, you
normally have 8 megabytes of stack space, so factorial could handle `n`
up to
~512,000. This is a [monstrously large result](https://gist.github.com/gduarte/9944878) that takes
8,971,833 bits to represent, so stack space is the least of our problems: a puny
integer - even a 64-bit one - will overflow tens of thousands of times over
before we run out of stack space.
We’ll look at CPU usage in a moment, but for now let’s take a step back from the bits and bytes and look at recursion as a general technique. Our factorial algorithm boils down to pushing integers N, N-1, … 1 onto a stack, then multiplying them in reverse order. The fact we’re using the program’s call stack to do this is an implementation detail: we could allocate a stack on the heap and use that instead. While the call stack does have special properties, it’s just another data structure at your disposal. I hope the diagram makes that clear.
Once you see the call stack as a data structure, something else becomes clear:
piling up all those integers to multiply them afterwards is *one dumbass idea*.
*That* is the real lameness of this implementation: it’s using a screwdriver to
hammer a nail. It’s far more sensible to use an iterative process to calculate
factorials.
But there are *plenty* of screws out there, so let’s pick one. There is
a traditional interview question where you’re given a mouse in a maze, and you
must help the mouse search for cheese. Suppose the mouse can turn either left
or right in the maze. How would you model and solve this problem?
Like most problems in life, you can reduce this rodent quest to a graph, in
particular a binary tree where the nodes represent positions in the maze.
You could then have the mouse attempt left turns whenever possible, and
backtrack to turn right when it reaches a dead end. Here’s the mouse walk in an
[example maze](https://github.com/gduarte/blog/blob/master/code/x86-stack/maze.h):

Each edge (line) is a left or right turn taking our mouse to a new position. If
either turn is blocked, the corresponding edge does not exist. Now we’re
talking! This process is *inherently* recursive whether you use the call stack
or another data structure. But using the call stack is just *so easy*:
[view raw](/code/x86-stack/maze.c)
1 |
|
Below is the stack when we find the cheese in maze.c:13. You can also
see the detailed [GDB output](https://github.com/gduarte/blog/blob/master/code/x86-stack/maze-gdb-output.txt) and [commands](https://github.com/gduarte/blog/blob/master/code/x86-stack/maze-gdb-commands.txt)
used to gather data.

This shows recursion in a much better light because it’s a suitable problem. And
that’s no oddity: when it comes to algorithms, *recursion is the rule, not the
exception*. It comes up when we search, when we traverse trees and other data
structures, when we parse, when we sort: it’s *everywhere*. You know how **pi**
or **e** come up in math all the time because they’re in the foundations of the
universe? Recursion is like that: it’s in the fabric of computation.
Steven Skienna’s excellent [Algorithm Design Manual](http://www.amazon.com/Algorithm-Design-Manual-Steven-Skiena/dp/1848000693/) is a great place to
see that in action as he works through his “war stories” and shows the reasoning
behind algorithmic solutions to real-world problems. It’s the best resource
I know of to develop your intuition for algorithms. Another good read is
McCarthy’s [original paper on LISP](https://github.com/papers-we-love/papers-we-love/blob/master/comp_sci_fundamentals_and_history/recursive-functions-of-symbolic-expressions-and-their-computation-by-machine-parti.pdf). Recursion is both in its title
and in the foundations of the language. The paper is readable and fun, it’s
always a pleasure to see a master at work.
Back to the maze. While it’s hard to get away from recursion here, it doesn’t
mean it must be done via the call stack. You could for example use a string like
`RRLL`
to keep track of the turns, and rely on the string to decide on the
mouse’s next move. Or you can allocate something else to record the state of the
cheese hunt. You’d still be implementing a recursive process, but rolling your
own data structure.
That’s likely to be more complex because the call stack fits like a glove. Each stack frame records not only the current node, but also the state of computation in that node (in this case, whether we’ve taken only the left, or are already attempting the right). Hence the code becomes trivial. Yet we sometimes give up this sweetness for fear of overflows and hopes of performance. That can be foolish.
As we’ve seen, the stack is large and frequently other constraints kick
in before stack space does. One can also check the problem size and ensure it
can be handled safely. The CPU worry is instilled chiefly by two widespread
pathological examples: the dumb factorial and the hideous O(2n)
[recursive Fibonacci](http://stackoverflow.com/questions/360748/computational-complexity-of-fibonacci-sequence) without memoization. These are **not** indicative of
sane stack-recursive algorithms.
The reality is that stack operations are *fast*. Often the offsets to data are
known exactly, the stack is hot in the [caches](/post/intel-cpu-caches/), and there are dedicated
instructions to get things done. Meanwhile, there is substantial overhead
involved in using your own heap-allocated data structures. It’s not uncommon to
see people write something that ends up *more complex and less performant* than
call-stack recursion. Finally, modern CPUs are [pretty good](/post/what-your-computer-does-while-you-wait/)
and often not the bottleneck. Be careful about sacrificing simplicity and as
always with performance, [measure](/post/performance-is-a-science).
The next post is the last in this stack series, and we’ll look at Tail Calls, Closures, and Other Fauna. Then it’ll be time to visit our old friend, the Linux kernel. Thanks for reading!

## Comments |
9,610 | 在 Linux 上使用 groff -me 格式化你的学术论文 | https://opensource.com/article/18/2/how-format-academic-papers-linux-groff-me | 2018-05-06T13:49:28 | [
"groff"
] | https://linux.cn/article-9610-1.html |
>
> 学习用简单的宏为你的课程论文添加脚注、引用、子标题及其它格式。
>
>
>

当我在 1993 年发现 Linux 时,我还是一名本科生。我很兴奋在我的宿舍里拥有 Unix 系统的强大功能,但是尽管它有很多功能,但 Linux 却缺乏应用程序。像 LibreOffice 和 OpenOffice 这样的文字处理程序还需要几年的时间才出现。如果你想使用文字处理器,你可能会将你的系统引导到 MS-DOS 中,并使用 WordPerfect、共享软件 GalaxyWrite 或类似的程序。
这就是我的方法,因为我需要为我的课程写论文,但我更喜欢呆在 Linux 中。我从我们的 “大 Unix” 校园计算机实验室得知,Unix 系统提供了一组文本格式化的程序 `nroff` 和 `troff` ,它们是同一系统的不同接口:`nroff` 生成纯文本输出,适用于屏幕或行式打印机,而 `troff` 产生非常优美的输出,通常用于在激光打印机上打印。
在 Linux 上,`nroff` 和 `troff` 被合并为 GNU troff,通常被称为 [groff](https://www.gnu.org/software/groff/)。 我很高兴看到早期的 Linux 发行版中包含了某个版本的 groff,因此我着手学习如何使用它来编写课程论文。 我学到的第一个宏集是 `-me` 宏包,一个简单易学的宏集。
关于 `groff` ,首先要了解的是它根据一组宏来处理和格式化文本。宏通常是个两个字符的命令,它自己设置在一行上,并带有一个引导点。宏可能包含一个或多个选项。当 `groff` 在处理文档时遇到这些宏中的一个时,它会自动对文本进行格式化。
下面,我将分享使用 `groff -me` 编写课程论文等简单文档的基础知识。 我不会深入细节进行讨论,比如如何创建嵌套列表,保存和显示,以及使用表格和数字。
### 段落
让我们从一个简单的例子开始,在几乎所有类型的文档中都可以看到:段落。段落可以格式化为首行缩进或不缩进(即,与左边齐平)。 包括学术论文,杂志,期刊和书籍在内的许多印刷文档都使用了这两种类型的组合,其中文档或章节中的第一个(主要)段落左侧对齐,而所有其他(常规)的段落缩进。 在 `groff -me`中,您可以使用两种段落类型:前导段落(`.lp`)和常规段落(`.pp`)。
```
.lp
This is the first paragraph.
.pp
This is a standard paragraph.
```
### 文本格式
用粗体格式化文本的宏是 `.b`,斜体格式是 `.i` 。 如果您将 `.b` 或 `.i` 放在一行上,则后面的所有文本将以粗体或斜体显示。 但更有可能你只是想用粗体或斜体来表示一个或几个词。 要将一个词加粗或斜体,将该单词放在与 `.b` 或 `.i` 相同的行上作为选项。 要用粗体或斜体格式化多个单词,请将文字用引号引起来。
```
.pp
You can do basic formatting such as
.i italics
or
.b "bold text."
```
在上面的例子中,粗体文本结尾的句点也是粗体。 在大多数情况下,这不是你想要的。 只要文字是粗体字,而不是后面的句点也是粗体字。 要获得您想要的效果,您可以向 `.b` 或 `.i` 添加第二个参数,以指示以粗体或斜体显示的文本后面跟着的任意文本以正常类型显示。 您可以这样做,以确保尾随句点不会以粗体显示。
```
.pp
You can do basic formatting such as
.i italics
or
.b "bold text" .
```
### 列表
使用 `groff -me`,您可以创建两种类型的列表:无序列表(`.bu`)和有序列表(`.np`)。
```
.pp
Bullet lists are easy to make:
.bu
Apple
.bu
Banana
.bu
Pineapple
.pp
Numbered lists are as easy as:
.np
One
.np
Two
.np
Three
.pp
Note that numbered lists will reset at the next pp or lp.
```
### 副标题
如果你正在写一篇长论文,你可能想把你的内容分成几部分。使用 `groff -me`,您可以创建编号的标题(`.sh`) 和未编号的标题 (`.uh`)。在这两种方法中,将节标题作为参数括起来。对于编号的标题,您还需要提供标题级别 `:1` 将给出一个一级标题(例如,`1`)。同样,`2` 和 `3` 将给出第二和第三级标题,如 `2.1` 或 `3.1.1`。
```
.uh Introduction
.pp
Provide one or two paragraphs to describe the work
and why it is important.
.sh 1 "Method and Tools"
.pp
Provide a few paragraphs to describe how you
did the research, including what equipment you used
```
### 智能引号和块引号
在任何学术论文中,引用他人的工作作为证据都是正常的。如果你引用一个简短的引用来突出一个关键信息,你可以在你的文本周围键入引号。但是 groff 不会自动将你的引用转换成现代文字处理系统所使用的“智能”或“卷曲”引用。要在 `groff -me` 中创建它们,插入一个内联宏来创建左引号(`\*(lq`)和右引号(`\*(rq`)。
```
.pp
Christine Peterson coined the phrase \*(lqopen source.\*(rq
```
`groff -me` 中还有一个快捷方式来创建这些引号(`.q`),我发现它更易于使用。
```
.pp
Christine Peterson coined the phrase
.q "open source."
```
如果引用的是跨越几行的较长的引用,则需要使用一个块引用。为此,在引用的开头和结尾插入块引用宏(`.(q`)。
```
.pp
Christine Peterson recently wrote about open source:
.(q
On April 7, 1998, Tim O'Reilly held a meeting of key
leaders in the field. Announced in advance as the first
.q "Freeware Summit,"
by April 14 it was referred to as the first
.q "Open Source Summit."
.)q
```
### 脚注
要插入脚注,请在脚注文本前后添加脚注宏(`.(f`),并使用内联宏(`\**`)添加脚注标记。脚注标记应出现在文本中和脚注中。
```
.pp
Christine Peterson recently wrote about open source:\**
.(f
\**Christine Peterson.
.q "How I coined the term open source."
.i "OpenSource.com."
1 Feb 2018.
.)f
.(q
On April 7, 1998, Tim O'Reilly held a meeting of key
leaders in the field. Announced in advance as the first
.q "Freeware Summit,"
by April 14 it was referred to as the first
.q "Open Source Summit."
.)q
```
### 封面
大多数课程论文都需要一个包含论文标题,姓名和日期的封面。 在 `groff -me` 中创建封面需要一些组件。 我发现最简单的方法是使用居中的文本块并在标题、名字和日期之间添加额外的行。 (我倾向于在每一行之间使用两个空行)。在文章顶部,从标题页(`.tp`)宏开始,插入五个空白行(`.sp 5`),然后添加居中文本(`.(c`) 和额外的空白行(`.sp 2`)。
```
.tp
.sp 5
.(c
.b "Writing Class Papers with groff -me"
.)c
.sp 2
.(c
Jim Hall
.)c
.sp 2
.(c
February XX, 2018
.)c
.bp
```
最后一个宏(`.bp`)告诉 groff 在标题页后添加一个分页符。
### 更多内容
这些是用 `groff-me` 写一份专业的论文非常基础的东西,包括前导和缩进段落,粗体和斜体,有序和无需列表,编号和不编号的章节标题,块引用以及脚注。
我已经包含一个[示例 groff 文件](https://opensource.com/sites/default/files/lorem-ipsum.me_.txt)来演示所有这些格式。 将 `lorem-ipsum.me` 文件保存到您的系统并通过 groff 运行。 `-Tps` 选项将输出类型设置为 `PostScript` ,以便您可以将文档发送到打印机或使用 `ps2pdf` 程序将其转换为 [PDF 文件](https://opensource.com/sites/default/files/lorem-ipsum.me_.pdf)。
```
groff -Tps -me lorem-ipsum.me > lorem-ipsum.me.ps
ps2pdf lorem-ipsum.me.ps lorem-ipsum.me.pdf
```
如果你想使用 `groff -me` 的更多高级功能,请参阅 Eric Allman 所著的 “使用 Groff -me 来写论文”,你可以在你系统的 groff 的 `doc` 目录下找到一个名叫 `meintro.me` 的文件。这份文档非常完美的说明了如何使用 `groff-me` 宏来格式化你的论文。
---
via: <https://opensource.com/article/18/2/how-format-academic-papers-linux-groff-me>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,611 | ImageMagick 的一些高级图片查看技巧 | https://opensource.com/article/17/9/imagemagick-viewing-images | 2018-05-06T18:06:52 | [
"ImageMagick"
] | https://linux.cn/article-9611-1.html |
>
> 用这些 ImageMagick 命令行图像编辑应用的技巧更好的管理你的数码照片集。
>
>
>

在我先前的[ImageMagick 入门:使用命令行来编辑图片](/article-8851-1.html) 文章中,我展示了如何使用 ImageMagick 的菜单栏进行图片的编辑和变换风格。在这篇续文里,我将向你展示使用这个开源的图像编辑器来查看图片的另外方法。
### 别样的风格
在深入 ImageMagick 的高级图片查看技巧之前,我想先分享另一个使用 `convert` 达到的有趣但简单的效果,在[上一篇文章](/article-8851-1.html)中我已经详细地介绍了 `convert` 命令,这个技巧涉及这个命令的 `edge` 和 `negate` 选项:
```
convert DSC_0027.JPG -edge 3 -negate edge3+negate.jpg
```

*使用`edge` 和 `negate` 选项前后的图片对比*
这些使我更喜爱编辑后的图片:海的外观,作为前景和背景的植被,特别是太阳及其在海上的反射,最后是天空。
### 使用 display 来查看一系列图片
假如你跟我一样是个命令行用户,你就知道 shell 为复杂任务提供了更多的灵活性和快捷方法。下面我将展示一个例子来佐证这个观点。ImageMagick 的 `display` 命令可以克服我在 GNOME 桌面上使用 [Shotwell](https://wiki.gnome.org/Apps/Shotwell) 图像管理器导入图片时遇到的问题。
Shotwell 会根据每张导入图片的 [Exif](https://en.wikipedia.org/wiki/Exif) 数据,创建以图片被生成或者拍摄时的日期为名称的目录结构。最终的效果是最上层的目录以年命名,接着的子目录是以月命名 (01、 02、 03 等等),然后是以每月的日期命名的子目录。我喜欢这种结构,因为当我想根据图片被创建或者拍摄时的日期来查找它们时将会非常方便。
但这种结构也并不是非常完美的,当我想查看最近几个月或者最近一年的所有图片时就会很麻烦。使用常规的图片查看器,我将不停地在不同层级的目录间跳转,但 ImageMagick 的 `display` 命令可以使得查看更加简单。例如,假如我想查看最近一年的图片,我便可以在命令行中键入下面的 `display` 命令:
```
display -resize 35% 2017/*/*/*.JPG
```
我可以一个月又一个月,一天又一天地遍历这一年。
现在假如我想查看某张图片,但我不确定我是在 2016 年的上半年还是在 2017 的上半年拍摄的,那么我便可以使用下面的命令来找到它:
```
display -resize 35% 201[6-7]/0[1-6]/*/*.JPG
```
这限制查看的图片拍摄于 2016 和 2017 年的一月到六月
### 使用 montage 来查看图片的缩略图
假如现在我要查找一张我想要编辑的图片,使用 `display` 的一个问题是它只会显示每张图片的文件名,而不显示其在目录结构中的位置,所以想要找到那张图片并不容易。另外,假如我很偶然地在从相机下载图片的过程中将这些图片从相机的内存里面清除了它们,结果使得下次拍摄照片的名称又从 `DSC_0001.jpg` 开始命名,那么当使用 `display` 来展示一整年的图片时,将会在这 12 个月的图片中花费很长的时间来查找它们。
这时 `montage` 命令便可以派上用场了。它可以将一系列的图片缩略图放在一张图片中,这样就会非常有用。例如可以使用下面的命令来完成上面的任务:
```
montage -label %d/%f -title 2017 -tile 5x -resize 10% -geometry +4+4 2017/0[1-4]/*/*.JPG 2017JanApr.jpg
```
从左到右,这个命令以标签开头,标签的形式是包含文件名(`%f`)和以 `/` 分割的目录(`%d`)结构,接着这个命令以目录的名称(2017)来作为标题,然后将图片排成 5 列,每个图片缩放为 10% (这个参数可以很好地匹配我的屏幕)。`geometry` 的设定将在每张图片的四周留白,最后指定那些图片要包括到这张合成图片中,以及一个合适的文件名称(`2017JanApr.jpg`)。现在图片 `2017JanApr.jpg` 便可以成为一个索引,使得我可以不时地使用它来查看这个时期的所有图片。
### 注意内存消耗
你可能会好奇为什么我在上面的合成图中只特别指定了为期 4 个月(从一月到四月)的图片。因为 `montage` 将会消耗大量内存,所以你需要多加注意。我的相机产生的图片每张大约有 2.5MB,我发现我的系统可以很轻松地处理 60 张图片。但一旦图片增加到 80 张,如果此时还有另外的程序(例如 Firefox 、Thunderbird)在后台工作,那么我的电脑将会死机,这似乎和内存使用相关,`montage`可能会占用可用 RAM 的 80% 乃至更多(你可以在此期间运行 `top` 命令来查看内存占用)。假如我关掉其他的程序,我便可以在我的系统死机前处理 80 张图片。
下面的命令可以让你知晓在你运行 `montage` 命令前你需要处理图片张数:
```
ls 2017/0[1-4/*/*.JPG > filelist; wc -l filelist
```
`ls` 命令生成我们搜索的文件的列表,然后通过重定向将这个列表保存在任意以名为 `filelist` 的文件中。接着带有 `-l` 选项的 `wc` 命令输出该列表文件共有多少行,换句话说,展示出了需要处理的文件个数。下面是我运行命令后的输出:
```
163 filelist
```
啊呀!从一月到四月我居然有 163 张图片,使用这些图片来创建一张合成图一定会使得我的系统死机的。我需要将这个列表减少点,可能只处理到 3 月份或者更早的图片。但如果我在 4 月 20 号到 30 号期间拍摄了很多照片,我想这便是问题的所在。下面的命令便可以帮助指出这个问题:
```
ls 2017/0[1-3]/*/*.JPG > filelist; ls 2017/04/0[1-9]/*.JPG >> filelist; ls 2017/04/1[0-9]/*.JPG >> filelist; wc -l filelist
```
上面一行中共有 4 个命令,它们以分号分隔。第一个命令特别指定从一月到三月期间拍摄的照片;第二个命令使用 `>>` 将拍摄于 4 月 1 日至 9 日的照片追加到这个列表文件中;第三个命令将拍摄于 4 月 10 日到 19 日的照片追加到列表中。最终它的显示结果为:
```
81 filelist
```
我知道假如我关掉其他的程序,处理 81 张图片是可行的。
使用 `montage` 来处理它们是很简单的,因为我们只需要将上面所做的处理添加到 `montage` 命令的后面即可:
```
montage -label %d/%f -title 2017 -tile 5x -resize 10% -geometry +4+4 2017/0[1-3]/*/*.JPG 2017/04/0[1-9]/*.JPG 2017/04/1[0-9]/*.JPG 2017Jan01Apr19.jpg
```
从左到右,`montage` 命令后面最后的那个文件名将会作为输出,在它之前的都是输入。这个命令将花费大约 3 分钟来运行,并生成一张大小约为 2.5MB 的图片,但我的系统只是有一点反应迟钝而已。
### 展示合成图片
当你第一次使用 `display` 查看一张巨大的合成图片时,你将看到合成图的宽度很合适,但图片的高度被压缩了,以便和屏幕相适应。不要慌,只需要左击图片,然后选择 `View > Original Size` 便会显示整个图片。再次点击图片便可以使菜单栏隐藏。
我希望这篇文章可以在你使用新方法查看图片时帮助你。在我的下一篇文章中,我将讨论更加复杂的图片操作技巧。
### 作者简介
Greg Pittman - Greg 肯塔基州路易斯维尔的一名退休的神经科医生,对计算机和程序设计有着长期的兴趣,最早可以追溯到 1960 年代的 Fortran IV 。当 Linux 和开源软件相继出现时,他开始学习更多的相关知识,并分享自己的心得。他是 Scribus 团队的成员。
---
via: <https://opensource.com/article/17/9/imagemagick-viewing-images>
作者:[Greg Pittman](https://opensource.com/users/greg-p) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my [introduction to ImageMagick](https://opensource.com/article/17/8/imagemagick), I showed how to use the application's menus to edit and add effects to your images. In this follow-up, I'll show additional ways to use this open source image editor to view your images.
## Another effect
Before diving into advanced image viewing with ImageMagick, I want to share another interesting, yet simple, effect using the **convert** command, which I discussed in detail in my previous article. This involves the
**-edge** option, then **negate**:
```
````convert DSC_0027.JPG -edge 3 -negate edge3+negate.jpg`

opensource.com
There are a number of things I like about the edited image—the appearance of the sea, the background and foreground vegetation, but especially the sun and its reflection, and also the sky.
## Using display to view a series of images
If you're a command-line user like I am, you know that the shell provides a lot of flexibility and shortcuts for complex tasks. Here I'll show one example: the way ImageMagick's **display** command can overcome a problem I've had reviewing images I import with the [Shotwell](https://wiki.gnome.org/Apps/Shotwell) image manager for the GNOME desktop.
Shotwell creates a nice directory structure that uses each image's [Exif](https://en.wikipedia.org/wiki/Exif) data to store imported images based on the date they were taken or created. You end up with a top directory for the year, subdirectories for each month (01, 02, 03, and so on), followed by another level of subdirectories for each day of the month. I like this structure, because finding an image or set of images based on when they were taken is easy.
This structure is not so great, however, when I want to review all my images for the last several months or even the whole year. With a typical image viewer, this involves a lot of jumping up and down the directory structure, but ImageMagick's **display** command makes it simple. For example, imagine that I want to look at all my pictures for this year. If I enter **display** on the command line like this:
```
````display -resize 35% 2017/*/*/*.JPG`
I can march through the year, month by month, day by day.
Now imagine I'm looking for an image, but I can't remember whether I took it in the first half of 2016 or the first half of 2017. This command:
```
````display -resize 35% 201[6-7]/0[1-6]/*/*.JPG`
restricts the images shown to January through June of 2016 and 2017.
## Using montage to view thumbnails of images
Now say I'm looking for an image that I want to edit. One problem is that **display** shows each image's filename, but not its place in the directory structure, so it's not obvious where I can find that image. Also, when I (sporadically) download images from my camera, I clear them from the camera's storage, so the filenames restart at **DSC_0001.jpg** at unpredictable times. Finally, it can take a lot of time to go through 12 months of images when I use **display** to show an entire year.
This is where the **montage** command, which puts thumbnail versions of a series of images into a single image, can be very useful. For example:
```
````montage -label %d/%f -title 2017 -tile 5x -resize 10% -geometry +4+4 2017/0[1-4]/*/*.JPG 2017JanApr.jpg`
From left to right, this command starts by specifying a label for each image that consists of the filename (**%f**) and its directory (**%d**) structure, separated with **/**. Next, the command specifies the main directory as the title, then instructs the montage to tile the images in five columns, with each image resized to 10% (which fits my monitor's screen easily). The geometry setting puts whitespace around each image. Finally, it specifies which images to include in the montage, and an appropriate filename to save the montage (**2017JanApr.jpg**). So now the image **2017JanApr.jpg** becomes a reference I can use over and over when I want to view all my images from this time period.
## Managing memory
You might wonder why I specified just a four-month period (January to April) for this montage. Here is where you need to be a bit careful, because **montage** can consume a lot of memory. My camera creates image files that are about 2.5MB each, and I have found that my system's memory can pretty easily handle 60 images or so. When I get to around 80, my computer freezes when other programs, such as Firefox and Thunderbird, are running the background. This seems to relate to memory usage, which goes up to 80% or more of available RAM for **montage**. (You can check this by running **top** while you do this procedure.) If I shut down all other programs, I can manage 80 images before my system freezes.
Here's how you can get some sense of how many files you're dealing with before running the **montage** command:
```
````ls 2017/0[1-4/*/*.JPG > filelist; wc -l filelist`
The command **ls** generates a list of the files in our search and saves it to the arbitrarily named filelist. Then, the **wc** command with the **-l** option reports how many lines are in the file, in other words, how many files **ls** found. Here's my output:
```
````163 filelist`
Oops! There are 163 images taken from January through April, and creating a montage of all of them would almost certainly freeze up my system. I need to trim down the list a bit, maybe just to March or even earlier. But what if I took a lot of pictures from April 20 to 30, and I think that's a big part of my problem. Here's how the shell can help us figure this out:
```
````ls 2017/0[1-3]/*/*.JPG > filelist; ls 2017/04/0[1-9]/*.JPG >> filelist; ls 2017/04/1[0-9]/*.JPG >> filelist; wc -l filelist`
This is a series of four commands all on one line, separated by semicolons. The first command specifies the number of images taken from January to March; the second adds April 1 through 9 using the **>>** append operator; the third appends April 10 through 19. The fourth command, **wc -l**, reports:
```
````81 filelist`
I know 81 files should be doable if I shut down my other applications.
Managing this with the **montage** command is easy, since we're just transposing what we did above:
```
````montage -label %d/%f -title 2017 -tile 5x -resize 10% -geometry +4+4 2017/0[1-3]/*/*.JPG 2017/04/0[1-9]/*.JPG 2017/04/1[0-9]/*.JPG 2017Jan01Apr19.jpg`
The last filename in the **montage** command will be the output; everything before that is input and is read from left to right. This took just under three minutes to run and resulted in an image about 2.5MB in size, but my system was sluggish for a bit afterward.
## Displaying the montage
When you first view a large montage using the **display** command, you may see that the montage's width is OK, but the image is squished vertically to fit the screen. Don't worry; just left-click the image and select **View > Original Size**. Click again to hide the menu.
I hope this has been helpful in showing you new ways to view your images. In my next article, I'll discuss more complex image manipulation.
## 2 Comments |
9,612 | Gotop:另一个 TUI 图形活动监视器,使用 Go 编写 | https://www.ostechnix.com/gotop-yet-another-tui-graphical-activity-monitor-written-in-go/ | 2018-05-07T09:19:34 | [
"top"
] | https://linux.cn/article-9612-1.html | 
你已经知道 `top` 命令,对么?是的,它提供类 Unix 操作系统中运行中的进程的动态实时信息。一些开发人员为 `top` 命令构建了图形前端,因此用户可以在图形窗口中轻松找到他们系统的活动。其中之一是 **Gotop**。顾名思义,Gotop 是一个 TUI 图形活动监视器,使用 **Go** 语言编写。它是完全免费、开源的,受到了 [gtop](https://github.com/aksakalli/gtop) 和 [vtop](https://github.com/MrRio/vtop) 的启发。
在此简要的指南中,我们将讨论如何安装和使用 Gotop 来监视 Linux 系统的活动。
### 安装 Gotop
Gotop 是用 Go 编写的,所以我们需要先安装它。要在 Linux 中安装 Go 语言,请参阅以下指南。
安装 Go 之后,使用以下命令下载最新的 Gotop 二进制文件。
```
$ sh -c "$(curl https://raw.githubusercontent.com/cjbassi/gotop/master/download.sh)"
```
然后,将下载的二进制文件移动到您的 `$PATH` 中,例如 `/usr/local/bin/`。
```
$ cp gotop /usr/local/bin
```
最后,用下面的命令使其可执行:
```
$ chmod +x /usr/local/bin/gotop
```
如果你使用的是基于 Arch 的系统,Gotop 存在于 **AUR** 中,所以你可以使用任何 AUR 助手程序进行安装。
使用 [**Cower**](https://www.ostechnix.com/cower-simple-aur-helper-arch-linux/):
```
$ cower -S gotop
```
使用 [**Pacaur**](https://www.ostechnix.com/install-pacaur-arch-linux/):
```
$ pacaur -S gotop
```
使用 [**Packer**](https://www.ostechnix.com/install-packer-arch-linux-2/):
```
$ packer -S gotop
```
使用 [**Trizen**](https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/):
```
$ trizen -S gotop
```
使用 [**Yay**](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/):
```
$ yay -S gotop
```
使用 [yaourt](https://www.ostechnix.com/install-yaourt-arch-linux/):
```
$ yaourt -S gotop
```
### 用法
Gotop 的使用非常简单!你所要做的就是从终端运行以下命令。
```
$ gotop
```
这样就行了!你将在简单的 TUI 窗口中看到系统 CPU、磁盘、内存、网络、CPU温度和进程列表的使用情况。

要仅显示CPU、内存和进程组件,请使用下面的 `-m` 标志:
```
$ gotop -m
```

你可以使用以下键盘快捷键对进程表进行排序。
* `c` – CPU
* `m` – 内存
* `p` – PID
对于进程浏览,请使用以下键。
* `上/下` 箭头或者 `j/k` 键用于上移下移。
* `Ctrl-d` 和 `Ctrl-u` – 上移和下移半页。
* `Ctrl-f` 和 `Ctrl-b` – 上移和下移整页。
* `gg` 和 `G` – 跳转顶部和底部。
按下 `TAB` 切换进程分组。要杀死选定的进程或进程组,请输入 `dd`。要选择一个进程,只需点击它。要向下/向上滚动,请使用鼠标滚动按钮。要放大和缩小 CPU 和内存的图形,请使用 `h` 和 `l`。要显示帮助菜单,只需按 `?`。
就是这些了。希望这有帮助。还有更多好东西。敬请关注!
### 资源
* [Gotop GitHub Repository](https://github.com/cjbassi/gotop)
---
via: <https://www.ostechnix.com/gotop-yet-another-tui-graphical-activity-monitor-written-in-go/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,613 | moro:一个用于追踪工作时间的命令行生产力工具 | https://www.ostechnix.com/moro-a-command-line-productivity-tool-for-tracking-work-hours/ | 2018-05-07T09:39:05 | [
"moro"
] | https://linux.cn/article-9613-1.html | 
保持对你的工作小时数的追踪将让你知晓在一个特定时间区间内你所完成的工作总量。在网络上有大量的基于 GUI 的生产力工具可以用来追踪工作小时数。但我却不能找到一个基于 CLI 的工具。今天我偶然发现了一个简单而奏效的叫做 Moro 的追踪工作时间数的工具。Moro 是一个芬兰词汇,意为“Hello”。通过使用 Moro,你可以找到你在完成某项特定任务时花费了多少时间。这个工具是自由开源软件,它是通过 NodeJS 编写的。
### Moro - 一个追踪工作时间的命令行生产力工具
由于 Moro 是使用 NodeJS 编写的,保证你的系统上已经安装了 NodeJS。如果你没有安装好 NodeJS,跟随下面的链接在你的 Linux 中安装 NodeJS 和 NPM。
* [如何在 Linux 上安装 NodeJS](https://www.ostechnix.com/install-node-js-linux/)
NodeJS 和NPM一旦装好,运行下面的命令来安装 Moro。
```
$ npm install -g moro
```
### 用法
Moro 的工作概念非常简单。它记录了你的工作开始时间,结束时间和在你的系统上的休息时间。在每天结束时,它将会告知你已经工作了多少时间。
当你到达办公室时,只需键入:
```
$ moro
```
示例输出:
```
Moro \o/
You clocked in at: 9:20
```
Moro 将会把这个时间注册为你的开始时间。
当你离开办公室时,再次键入:
```
$ moro
```
示例输出:
```
Moro \o/
You clocked out at: 19:22
Today looks like this so far:
┌──────────────────┬─────────────────────────┐
│ Today you worked │ 9 Hours and 72 Minutes │
├──────────────────┼─────────────────────────┤
│ Clock in │ 9:20 │
├──────────────────┼─────────────────────────┤
│ Clock out │ 19:22 │
├──────────────────┼─────────────────────────┤
│ Break duration │ 30 minutes │
├──────────────────┼─────────────────────────┤
│ Date │ 2018-03-19 │
└──────────────────┴─────────────────────────┘
Run moro --help to learn how to edit your clock in, clock out or break duration for today
```
Moro 将会把这个时间注册为你的结束时间。
现在,Moro 将会从结束时间减去开始时间,然后从总的时间减去另外的 30 分钟作为休息时间,并给你在那天总的工作时间。抱歉,我的数学计算过程解释实在糟糕。假设你在早上 10:00 来工作并在晚上 17:30 离开。所以,你总共在办公室呆了 7:30 小时(例如 17:30-10)。然后在总的时间减去休息时间(默认是 30 分钟)。因此,你的总工作时间是 7 小时。明白了?很好!
**注意:**不要像我在写这个手册的时候一样把 “moro” 和 “more” 弄混了。
查看你注册的所有小时数,运行:
```
$ moro report --all
```
以防万一,如果你忘记注册开始时间或者结束时间,你一样可以在之后指定这些值。
例如,将上午 10 点注册为开始时间,运行:
```
$ moro hi 10:00
Moro \o/
You clocked in at: 10:00
Working until 18:00 will make it a full (7.5 hours) day
```
注册 17:30 作为结束时间:
```
$ moro bye 17:30
Moro \o/
You clocked out at: 17:30
Today looks like this so far:
┌──────────────────┬───────────────────────┐
│ Today you worked │ 7 Hours and 0 Minutes │
├──────────────────┼───────────────────────┤
│ Clock in │ 10:00 │
├──────────────────┼───────────────────────┤
│ Clock out │ 17:30 │
├──────────────────┼───────────────────────┤
│ Break duration │ 30 minutes │
├──────────────────┼───────────────────────┤
│ Date │ 2018-03-19 │
└──────────────────┴───────────────────────┘
Run moro --help to learn how to edit your clock in, clock out or break duration for today
```
你已经知道 Moro 默认将会减去 30 分钟的休息时间。如果你需要设置一个自定义的休息时间,你可以简单使用以下命令:
```
$ moro break 45
```
现在,休息时间是 45 分钟了。
若要清除所有的数据:
```
$ moro clear --yes
Moro \o/
Database file deleted successfully
```
#### 添加笔记
有时候,你想要在工作时添加笔记。不必去寻找一个独立的作笔记的应用。Moro 将会帮助你添加笔记。要添加笔记,只需运行:
```
$ moro note mynotes
```
要在之后搜索所有已经注册的笔记,只需做:
```
$ moro search mynotes
```
#### 修改默认设置
默认的完整工作时间是 7.5 小时。这是因为开发者来自芬兰,这是官方的工作小时数。但是你也可以修改这个设置为你的国家的工作小时数。
举个例子,要将其设置为 7 小时,运行:
```
$ moro config --day 7
```
同样地,默认的休息时间也可以像下面这样从 30 分钟修改:
```
$ moro config --break 45
```
#### 备份你的数据
正如我已经说了的,Moro 将时间追踪信息存储在你的家目录,文件名是 `.moro-data.db`。
但是,你可以保存备份数据库到不同的位置。要这样做的话,像下面这样将 `.moro-data.db` 文件移到你选择的一个不同的位置并告知 Moro 使用那个数据库文件。
```
$ moro config --database-path /home/sk/personal/moro-data.db
```
在上面的每一个命令,我都已经把默认的数据库文件分配到了 `/home/sk/personal` 目录。
需要帮助的话,运行:
```
$ moro --help
```
正如你所见,Moro 是非常简单而又能用于追踪你完成你的工作使用了多少时间的。对于自由职业者和任何想要在一定时间范围内完成事情的人,它将会是有用的。
并且,这些只是今天的内容。希望这些内容能够有所帮助。更多的好东西将会出现。请保持关注!
干杯!
---
via: <https://www.ostechnix.com/moro-a-command-line-productivity-tool-for-tracking-work-hours/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[leemeans](https://github.com/leemeans) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,614 | 如何使用 npm 管理 NodeJS 包 | https://www.ostechnix.com/manage-nodejs-packages-using-npm/ | 2018-05-07T10:15:54 | [
"npm",
"nodejs"
] | https://linux.cn/article-9614-1.html | 
前一段时间,我们发布了一个[使用 pip 管理 Python 包](https://docs.npmjs.com/getting-started/)的指南。今天,我们将讨论如何使用 npm 管理 NodeJS 包。npm 是最大的软件注册中心,包含 600,000 多个包。每天,世界各地的开发人员通过 npm 共享和下载软件包。在本指南中,我将解释使用 npm 基础知识,例如安装包(本地和全局)、安装特定版本的包、更新、删除和管理 NodeJS 包等等。
### 安装 npm
用于 npm 是用 NodeJS 编写的,我们需要安装 NodeJS 才能使用 npm。要在不同的 Linux 发行版上安装 NodeJS,请参考下面的链接。
* [在 Linux 上安装 NodeJS](https://www.ostechnix.com/install-node-js-linux/)
检查 node 安装的位置:
```
$ which node
/home/sk/.nvm/versions/node/v9.4.0/bin/node
```
检查它的版本:
```
$ node -v
v9.4.0
```
进入 Node 交互式解释器:
```
$ node
> .help
.break Sometimes you get stuck, this gets you out
.clear Alias for .break
.editor Enter editor mode
.exit Exit the repl
.help Print this help message
.load Load JS from a file into the REPL session
.save Save all evaluated commands in this REPL session to a file
> .exit
```
检查 npm 安装的位置:
```
$ which npm
/home/sk/.nvm/versions/node/v9.4.0/bin/npm
```
还有版本:
```
$ npm -v
5.6.0
```
棒极了!Node 和 npm 已安装好!正如你可能已经注意到,我已经在我的 `$HOME` 目录中安装了 NodeJS 和 NPM,这样是为了避免在全局模块时出现权限问题。这是 NodeJS 团队推荐的方法。
那么,让我们继续看看如何使用 npm 管理 NodeJS 模块(或包)。
### 安装 NodeJS 模块
NodeJS 模块可以安装在本地或全局(系统范围)。现在我将演示如何在本地安装包(LCTT 译注:即将包安装到一个 NodeJS 项目当中,所以下面会先创建一个空项目做演示)。
#### 在本地安装包
为了在本地管理包,我们通常使用 `package.json` 文件来管理。
首先,让我们创建我们的项目目录。
```
$ mkdir demo
$ cd demo
```
在项目目录中创建一个 `package.json` 文件。为此,运行:
```
$ npm init
```
输入你的包的详细信息,例如名称、版本、作者、GitHub 页面等等,或者按下回车键接受默认值并键入 `yes` 确认。
```
This utility will walk you through creating a package.json file.
It only covers the most common items, and tries to guess sensible defaults.
See `npm help json` for definitive documentation on these fields
and exactly what they do.
Use `npm install <pkg>` afterwards to install a package and
save it as a dependency in the package.json file.
Press ^C at any time to quit.
package name: (demo)
version: (1.0.0)
description: demo nodejs app
entry point: (index.js)
test command:
git repository:
keywords:
author:
license: (ISC)
About to write to /home/sk/demo/package.json:
{
"name": "demo",
"version": "1.0.0",
"description": "demo nodejs app",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}
Is this ok? (yes) yes
```
上面的命令初始化你的项目并创建了 `package.json` 文件。
你也可以使用命令以非交互式方式执行此操作:
```
npm init --y
```
现在让我们安装名为 [commander](https://www.npmjs.com/package/commander) 的包。
```
$ npm install commander
```
示例输出:
```
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN [email protected] No repository field.
+ [email protected]
added 1 package in 2.519s
```
这将在项目的根目录中创建一个名为 `node_modules` 的目录(如果它不存在的话),并在其中下载包。
让我们检查 `pachage.json` 文件。
```
$ cat package.json
{
"name": "demo",
"version": "1.0.0",
"description": "demo nodejs app",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"commander": "^2.13.0"
}
}
```
你会看到添加了依赖文件,版本号前面的插入符号 ( `^` ) 表示在安装时,npm 将取出它可以找到的最高版本的包。
```
$ ls node_modules/
commander
```
`package.json` 文件的优点是,如果你的项目目录中有 `package.json` 文件,只需键入 `npm install`,那么 `npm` 将查看文件中列出的依赖关系并下载它们。你甚至可以与其他开发人员共享它或将其推送到你的 GitHub 仓库。因此,当他们键入 `npm install` 时,他们将获得你拥有的所有相同的包。
你也可能会注意到另一个名为 `package-lock.json` 的文件,该文件确保在项目安装的所有系统上都保持相同的依赖关系。
要在你的程序中使用已安装的包,使用实际代码在项目目录中创建一个 `index.js`(或者其他任何名称)文件,然后使用以下命令运行它:
```
$ node index.js
```
#### 在全局安装包
如果你想使用一个包作为命令行工具,那么最好在全局安装它。这样,无论你的当前目录是哪个目录,它都能正常工作。
```
$ npm install async -g
+ [email protected]
added 2 packages in 4.695s
```
或者
```
$ npm install async --global
```
要安装特定版本的包,我们可以:
```
$ npm install [email protected] --global
```
### 更新 NodeJS 模块
要更新本地包,转到 `package.json` 所在的项目目录并运行:
```
$ npm update
```
然后,运行以下命令确保所有包都更新了。
```
$ npm outdated
```
如果没有需要更新的,那么它返回空。
要找出哪一个全局包需要更新,运行:
```
$ npm outdated -g --depth=0
```
如果没有输出,意味着所有包都已更新。
更新单个全局包,运行:
```
$ npm update -g <package-name>
```
更新所有的全局包,运行:
```
$ npm update -g
```
### 列出 NodeJS 模块
列出本地包,转到项目目录并运行:
```
$ npm list
[email protected] /home/sk/demo
└── [email protected]
```
如你所见,我在本地安装了 `commander` 这个包。
要列出全局包,从任何位置都可以运行以下命令:
```
$ npm list -g
```
示例输出:
```
/home/sk/.nvm/versions/node/v9.4.0/lib
├─┬ [email protected]
│ └── [email protected]
└─┬ [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
[...]
```
该命令将列出所有模块及其依赖关系。
要仅仅列出顶级模块,使用 `-depth=0` 选项:
```
$ npm list -g --depth=0
/home/sk/.nvm/versions/node/v9.4.0/lib
├── [email protected]
└── [email protected]
```
#### 寻找 NodeJS 模块
要搜索一个模块,使用 `npm search` 命令:
```
npm search <search-string>
```
例如:
```
$ npm search request
```
该命令将显示包含搜索字符串 `request` 的所有模块。
##### 移除 NodeJS 模块
要删除本地包,转到项目目录并运行以下命令,这会从 `node_modules` 目录中删除包:
```
$ npm uninstall <package-name>
```
要从 `package.json` 文件中的依赖关系中删除它,使用如下所示的 `save` 选项:
```
$ npm uninstall --save <package-name>
```
要删除已安装的全局包,运行:
```
$ npm uninstall -g <package>
```
### 清除 npm 缓存
默认情况下,npm 在安装包时,会将其副本保存在 `$HOME` 目录中名为 `.npm` 的缓存文件夹中。所以,你可以在下次安装时不必再次下载。
查看缓存模块:
```
$ ls ~/.npm
```
随着时间的推移,缓存文件夹会充斥着大量旧的包。所以不时清理缓存会好一些。
从 npm@5 开始,npm 缓存可以从 corruption 问题中自行修复,并且保证从缓存中提取的数据有效。如果你想确保一切都一致,运行:
```
$ npm cache verify
```
清除整个缓存,运行:
```
$ npm cache clean --force
```
### 查看 npm 配置
要查看 npm 配置,键入:
```
$ npm config list
```
或者:
```
$ npm config ls
```
示例输出:
```
; cli configs
metrics-registry = "https://registry.npmjs.org/"
scope = ""
user-agent = "npm/5.6.0 node/v9.4.0 linux x64"
; node bin location = /home/sk/.nvm/versions/node/v9.4.0/bin/node
; cwd = /home/sk
; HOME = /home/sk
; "npm config ls -l" to show all defaults.
```
要显示当前的全局位置:
```
$ npm config get prefix
/home/sk/.nvm/versions/node/v9.4.0
```
好吧,这就是全部了。我们刚才介绍的只是基础知识,npm 是一个广泛话题。有关更多详细信息,参阅 [**NPM Getting Started**](https://docs.npmjs.com/getting-started/) 指南。
希望这对你有帮助。更多好东西即将来临,敬请关注!
干杯!
---
via: <https://www.ostechnix.com/manage-nodejs-packages-using-npm/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,615 | Dry:一个命令行交互式 Docker 容器管理器 | https://www.2daygeek.com/dry-an-interactive-cli-manager-for-docker-containers/ | 2018-05-07T22:06:33 | [
"容器",
"Docker"
] | https://linux.cn/article-9615-1.html | 
Docker 是一种所谓容器化的操作系统级的虚拟化软件。
基于 Linux 内核的 cgroup 和 namespace 等资源隔离特性,Docker 可以在单个 Linux 实例中运行多个独立的容器。
通过将应用依赖和相关库打包进容器,Docker 使得应用可以在容器中安全隔离地运行。
### Dry 是什么
[Dry](https://github.com/moncho/dry) 是一个管理并监控 Docker 容器和镜像的命令行工具。
Dry 可以给出容器相关的信息,包括对应镜像、容器名称、网络、容器中运行的命令及容器状态;如果运行在 Docker Swarm 中,工具还会给出 Swarm 集群的各种状态信息。
Dry 可以连接至本地或远程的 Docker 守护进程。如果连接本地 Docker,Docker 主机显示为 `unix:///var/run/docker.sock`。
如果连接远程 Docker,Docker 主机显示为 `tcp://IP Address:Port Number` 或 `tcp://Host Name:Port Number`。
Dry 可以提供类似 `docker ps` 的指标输出,但输出比 `docker ps` 内容详实、富有色彩。
相比 Docker,Dry 还可以手动添加一个额外的名称列,用于降低记忆难度。
**推荐阅读:**
* [Portainer – 用于 Docker 管理的简明 GUI](https://www.2daygeek.com/portainer-a-simple-docker-management-gui/)
* [Rancher – 适用于生产环境的完备容器管理平台](https://www.2daygeek.com/rancher-a-complete-container-management-platform-for-production-environment/)
* [cTop – Linux环境下容器管理与监控的命令行工具](https://www.2daygeek.com/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux/)
### 如何在 Linux 中安装 Dry
在 Linux 中,可以通过一个简单的 shell 脚本安装最新版本的 Dry 工具。Dry 不依赖外部库。对于绝大多数的 Docker 命令,Dry 提供类似样式的命令。
```
$ curl -sSf https://moncho.github.io/dry/dryup.sh | sudo sh
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 10 100 10 0 0 35 0 --:--:-- --:--:-- --:--:-- 35
dryup: downloading dry binary
######################################################################## 100.0%
dryup: Moving dry binary to its destination
dryup: dry binary was copied to /usr/local/bin, now you should 'sudo chmod 755 /usr/local/bin/dry'
```
使用如下命令将文件权限变更为 `755`:
```
$ sudo chmod 755 /usr/local/bin/dry
```
对于使用 Arch Linux 的用户,可以使用 **[Packer](https://www.2daygeek.com/install-packer-aur-helper-on-arch-linux/)** 或 **[Yaourt](https://www.2daygeek.com/install-yaourt-aur-helper-on-arch-linux/)** 包管理器,从 AUR 源安装该工具。
```
$ yaourt -S dry-bin
或者
$ packer -S dry-bin
```
如果希望在 Docker 容器中运行 dry,可以运行如下命令。前提条件是已确认在操作系统中安装了 Docker。
**推荐阅读:**
* [如何在 Linux 中安装 Docker](https://www.2daygeek.com/install-docker-on-centos-rhel-fedora-ubuntu-debian-oracle-archi-scentific-linux-mint-opensuse/)
* [如何在 Linux 中玩转 Docker 镜像](https://www.2daygeek.com/list-search-pull-download-remove-docker-images-on-linux/)
* [如何在 Linux 中玩转 Docker 容器](https://www.2daygeek.com/create-run-list-start-stop-attach-delete-interactive-daemonized-docker-containers-on-linux/)
* [如何在 Docker 容器中安装并运行应用程序](https://www.2daygeek.com/install-run-applications-inside-docker-containers/)
```
$ docker run -it -v /var/run/docker.sock:/var/run/docker.sock moncho/dry
```
### 如何启动并运行 Dry
在控制台运行 `dry` 命令即可启动该工具,其默认输出如下:
```
$ dry
```

### 如何使用 Dry 监控 Docker
你可以在 dry 的界面中按下 `m` 键打开监控模式。

### 如何使用 Dry 管理容器
在选中的容器上单击回车键,即可管理容器。Dry 提供如下操作:查看日志,查看、杀死、删除容器,停止、启动、重启容器,查看容器状态及镜像历史记录等。

### 如何监控容器资源利用率
用户可以使用 `Stats+Top` 选项查看指定容器的资源利用率。
该操作需要在容器管理界面完成(在上一步的基础上,点击 `Stats+Top` 选项)。另外,也可以按下 `s` 打开容器资源利用率界面。

### 如何查看容器、镜像及本地卷的磁盘使用情况
可以使用 `F8` 键查看容器、镜像及本地卷的磁盘使用情况。
该界面明确地给出容器、镜像和卷的总数,哪些处于使用状态,以及整体磁盘使用情况、可回收空间大小的详细信息。

### 如何查看已下载的镜像
按下 `2` 键即可列出全部的已下载镜像。

### 如何查看网络列表
按下 `3` 键即可查看全部网络及网关。

### 如何查看全部 Docker 容器
按下 `F2` 键即可列出列出全部容器,包括运行中和已关闭的容器。

### Dry 快捷键
查看帮助页面或 [dry GitHub](https://github.com/moncho/dry) 即可查看全部快捷键。
---
via: <https://www.2daygeek.com/dry-an-interactive-cli-manager-for-docker-containers/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,616 | 如何使用 virsh 命令创建、还原和删除 KVM 虚拟机快照 | https://www.linuxtechi.com/create-revert-delete-kvm-virtual-machine-snapshot-virsh-command/ | 2018-05-07T22:19:00 | [
"KVM",
"virsh"
] | https://linux.cn/article-9616-1.html | 
在虚拟化平台上进行系统管理工作时,经常需要在开始重大操作比如部署补丁和代码前先设置一个虚拟机<ruby> 快照 <rt> snapshot </rt></ruby>。
虚拟机**快照**是特定时间点的虚拟机磁盘的副本。换句话说,快照保存了给定的时间点虚拟机的状态和数据。
### 我们可以在哪里使用虚拟机快照?
如果你在使用基于 **KVM** 的<ruby> 虚拟机管理程序 <rp> ( </rp> <rt> hypervisor </rt> <rp> ) </rp></ruby>,那么可以使用 `virsh` 命令获取虚拟机或域快照。快照在一种情况下变得非常有用,当你已经在虚拟机上安装或应用了最新的补丁,但是由于某些原因,虚拟机上的程序变得不稳定,开发团队想要还原所有的更改和补丁。如果你在应用补丁之前设置了虚拟机的快照,那么可以使用快照将虚拟机恢复到之前的状态。
**注意:**我们只能对磁盘格式为 **Qcow2** 的虚拟机的进行快照,并且 kvm 的 `virsh` 命令不支持 raw 磁盘格式,请使用以下命令将原始磁盘格式转换为 qcow2。
```
# qemu-img convert -f raw -O qcow2 image-name.img image-name.qcow2
```
### 创建 KVM 虚拟机(域)快照
我假设 KVM 管理程序已经在 CentOS 7 / RHEL 7 机器上配置好了,并且有虚拟机正在运行。我们可以使用下面的 `virsh` 命令列出虚拟机管理程序中的所有虚拟机,
```
[root@kvm-hypervisor ~]# virsh list --all
Id Name State
----------------------------------------------------
94 centos7.0 running
101 overcloud-controller running
102 overcloud-compute2 running
103 overcloud-compute1 running
114 webserver running
115 Test-MTN running
```
假设我们想创建 webserver 虚拟机的快照,运行下面的命令,
**语法:**
```
# virsh snapshot-create-as –domain {vm_name} –name {snapshot_name} –description “enter description here”
```
```
[root@kvm-hypervisor ~]# virsh snapshot-create-as --domain webserver --name webserver_snap --description "snap before patch on 4Feb2018"
Domain snapshot webserver_snap created
```
创建快照后,我们可以使用下面的命令列出与虚拟机相关的快照:
```
[root@kvm-hypervisor ~]# virsh snapshot-list webserver
Name Creation Time State
------------------------------------------------------------
webserver_snap 2018-02-04 15:05:05 +0530 running
[root@kvm-hypervisor ~]#
```
要列出虚拟机快照的详细信息,请运行下面的 `virsh` 命令:
```
[root@kvm-hypervisor ~]# virsh snapshot-info --domain webserver --snapshotname webserver_snap
Name: webserver_snap
Domain: webserver
Current: yes
State: running
Location: internal
Parent: -
Children: 0
Descendants: 0
Metadata: yes
```
我们可以使用下面的 `qemu-img` 命令查看快照的大小:
```
[root@kvm-hypervisor ~]# qemu-img info /var/lib/libvirt/images/snaptestvm.img
```

### 还原 KVM 虚拟机快照
假设我们想要将 webserver 虚拟机还原到我们在上述步骤中创建的快照。使用下面的 `virsh` 命令将 Webserver 虚拟机恢复到其快照 webserver\_snap 时。
**语法:**
```
# virsh snapshot-revert {vm_name} {snapshot_name}
```
```
[root@kvm-hypervisor ~]# virsh snapshot-revert webserver webserver_snap
```
### 删除 KVM 虚拟机快照
要删除 KVM 虚拟机快照,首先使用 `virsh snapshot-list` 命令获取虚拟机的快照详细信息,然后使用 `virsh snapshot-delete` 命令删除快照。如下示例所示:
```
[root@kvm-hypervisor ~]# virsh snapshot-list --domain webserver
Name Creation Time State
------------------------------------------------------------
webserver_snap 2018-02-04 15:05:05 +0530 running
[root@kvm-hypervisor ~]# virsh snapshot-delete --domain webserver --snapshotname webserver_snap
Domain snapshot webserver_snap deleted
```
这就是本文的全部内容,我希望你们能够了解如何使用 `virsh` 命令来管理 KVM 虚拟机快照。请分享你的反馈,并不要犹豫地分享给你的技术朋友
| 200 | OK | In this blog post, we will explain how to create KVM virtual machine (vm) snapshot with virsh command.
While working on the virtualization platform system administrators usually take the snapshot of virtual machine before doing any major activity like deploying the latest patch and code.
Virtual machine snapshot is a copy of virtual machine’s disk at the specific point of time. In other words, snapshots are like frozen moments in time, capturing the state of a virtual machine at a particular point.
#### Why VM Snapshots Matter?
If you are working on KVM based hypervisors we can take virtual machines or domain snapshot using the virsh command. Snapshot becomes very helpful in a situation where you have installed or apply the latest patches on the VM but due to some reasons, application hosted in the VMs becomes unstable and application team wants to revert all the changes or patches. If you had taken the snapshot of the VM before applying patches then we can restore or revert the VM to its previous state using snapshot.
**Note:** We can only take the snapshot of the VMs whose disk format is Qcow2 and raw disk format is not supported by kvm virsh command, Use below command to convert the raw disk format to qcow2
# qemu-img convert -f raw -O qcow2 image-name.img image-name.qcow2
## Create KVM Virtual Machine Snapshot
We are assuming KVM hypervisor is already configured on RHEL 8/9 or Rocky Linux or Ubuntu and VMs are running on it. We can list the all the VMs on hypervisor using below virsh command,
# virsh list --all Id Name State ---------------------------------------------------- 94 centos7.0 running 101 overcloud-controller running 102 overcloud-compute2 running 103 overcloud-compute1 running 114 webserver running 115 Test-MTN running #
Let’s suppose we want to create the snapshot of ‘webserver‘ VM, run the below command,
#### Syntax:
# virsh snapshot-create-as –domain {vm_name} –name {snapshot_name} –description “enter description here”
# virsh snapshot-create-as --domain webserver --name webserver_snap --description "snap before patch on 4Feb2018" Domain snapshot webserver_snap created #
Once the snapshot is created then we can list snapshots related to the VM using beneath command,
# virsh snapshot-list webserver Name Creation Time State ------------------------------------------------------------ webserver_snap 2018-02-04 15:05:05 +0530 running #
To list the detailed info of VM’s snapshot, run the beneath virsh command,
# virsh snapshot-info --domain webserver --snapshotname webserver_snap Name: webserver_snap Domain: webserver Current: yes State: running Location: internal Parent: - Children: 0 Descendants: 0 Metadata: yes #
We can view the size of snapshot using below qemu-img command,
# qemu-img info /var/lib/libvirt/images/snaptestvm.img
## Revert / Restore KVM Virtual Machine to snapshot
Let’s assume we want to revert or restore webserver VM to the snapshot that we have created in above step. Use below virsh command to restore Webserver VM to its snapshot “**webserver_snap**”
**Syntax :**
# virsh snapshot-revert {vm_name} {snapshot_name}
# virsh snapshot-revert webserver webserver_snap
## Delete KVM Virtual Machine Snapshots
To delete KVM virtual machine snapshots, first get the VM’s snapshot details using “virsh snapshot-list” command and then use “virsh snapshot-delete” command to delete the snapshot. Example is shown below:
# virsh snapshot-list --domain webserver Name Creation Time State ------------------------------------------------------------ webserver_snap 2018-02-04 15:05:05 +0530 running #
# virsh snapshot-delete --domain webserver --snapshotname webserver_snap Domain snapshot webserver_snap deleted #
#### Conclusion:
Creating KVM virtual machine snapshots with the Virsh command provides an essential layer of flexibility and security when working with virtualization. Snapshots allow you to experiment, troubleshoot, and maintain system stability effortlessly. By following the steps in this guide, you can harness the power of KVM snapshots to take control of your virtual machines, ensuring your work is safe, efficient, and well-managed.
Also Read : [How to Create and Manage KVM Virtual Machines via Command Line](https://www.linuxtechi.com/create-manage-kvm-virtual-machine-cli/)
sampathThanks dude for the article.
GiriQuestion:
Lets say you have 3 snapshots, A B and C, taken in that order (thats C taken after B taken after A) with C as the current snapshot. If I want to delete the snapshots A and B, will the command still work. If yes, do you see potential problems of doing these?
Samanta Ujjalhi ,
if i destroy the vm Can i recover it from the snapahot
shirishNot able to merge snapshot to existing disk
**KVM and qemu RPM info :-**
[root@shirish_rhel ~]# rpm -qa | grep -i qemu
qemu-kvm-common-1.5.3-167.el7.x86_64
qemu-img-1.5.3-167.el7.x86_64
ipxe-roms-qemu-20180825-2.git133f4c.el7.noarch
libvirt-daemon-driver-qemu-4.5.0-23.el7.x86_64
qemu-kvm-1.5.3-167.el7.x86_64
qemu-kvm-tools-1.5.3-167.el7.x86_64
[root@shirish_rhel ~]# virsh snapshot-list –domain centos7.0
Name Creation Time State
————————————————————
testVM2-firstSNAP35 2019-08-08 13:22:11 -0400 shutoff
testVM2-firstSNAP36 2019-08-08 13:24:48 -0400 shutoff
testVM2-firstSNAP37 2019-08-08 13:27:13 -0400 shutoff
[root@shirish_rhel ~]# virsh snapshot-info –domain centos7.0 –snapshotname testVM2-firstSNAP37
Name: testVM2-firstSNAP37
Domain: centos7.0
Current: yes
State: shutoff
Location: external
Parent: –
Children: 0
Descendants: 0
Metadata: yes
**if VM is shutdown :-**
[root@shirish_rhel ~]# virsh blockcommit centos7.0 vda –active –verbose –pivot
error: Requested operation is not valid: domain is not running
**if VM is Running :-**
[root@shirish_rhel ~]# virsh blockcommit centos7.0 vda –active –verbose –pivot
error: unsupported configuration: online commit not supported with this QEMU binary
Pradeep KumarQEMU libraries are old that’s why online commit is not possible in your current qemu library, You need to install QEMU 2.1 ( and above), libvirt-1.2.9 (and above) |
9,617 | 为什么我喜欢 ARM 和 PowerPC? | https://opensource.com/article/18/4/why-i-love-arm-and-powerpc | 2018-05-07T22:56:19 | [
"ARM",
"PowerPC"
] | https://linux.cn/article-9617-1.html |
>
> 一个学生在搜寻强劲而节能的工作站的历程中怎样对开源系统的热情与日俱增的。
>
>
>

最近我被问起为什么在博客和推特里经常提到 [ARM](https://en.wikipedia.org/wiki/ARM_architecture) 和 [PowerPC](https://en.wikipedia.org/wiki/PowerPC)。我有两个答案:一个是个人原因,另一个是技术上的。
### 个人原因
从前,我是学环境保护的。在我读博的时候,我准备买个新电脑。作为一个环保人士,我需要一台强劲且节能的电脑。这就是我开始对 PowerPC 感兴趣的原因,我找到了 [Pegasos](https://genesi.company/products/opendesktop),这是一台 [Genesi](https://genesi.company/) 公司制造的 PowerPC 工作站。
我还用过 [RS/6000](https://en.wikipedia.org/wiki/RS/6000) (PowerPC)、 [SGI](https://en.wikipedia.org/wiki/Silicon_Graphics#Workstations) (MIPS)、 [HP-UX](https://en.wikipedia.org/wiki/HP-UX) (PA-RISC)和 [VMS](https://en.wikipedia.org/wiki/OpenVMS#Port_to_DEC_Alpha) (Alpha)的服务器和工作站,由于我的 PC 使用 Linux 而非 Windows,所以使用不同的 CPU 架构对我来说并没有什么区别。 [Pegasos](https://en.wikipedia.org/wiki/Pegasos) 是我第一台工作站,它小型而节能而且对家用来说性能足够。
很快我就开始为 Genesi 工作,为 Pegasos 移植 [openSUSE](https://www.opensuse.org/)、 Ubuntu 和其他 Linux 发行版,并提供质量保证和社区支持。继 Pegasos 之后是 [EFIKA](https://genesi.company/products/efika/5200b),这是另一款基于 PowerPC 的开发板。在用过工作站之后,刚开始使用嵌入式系统会感觉有点奇怪。但是作为第一代普及价位的开发板,这是一场革命的开端。
我工作于一个大规模的服务器项目时,我收到 Genesi 的另一块有趣的开发板:基于 ARM 的 [Smarttop](https://genesi.company/products/efika) 和 [Smartbook](https://genesi.company/products/smartbook)。我最喜欢的 Linux 发行版——openSUSE,也收到了一打这种机器。这在当时 ARM 电脑非常稀缺的情况下,极大地促进了 ARM 版 openSUSE 项目的开发。
尽管最近我很忙,我尽量保持对 ARM 和 PowerPC 新闻的关注。这有助于我支持非 x86 平台上的 syslog-ng 用户。只要有半个小时的空,我就会去捣鼓一下 ARM 机器。我在[树莓派2](https://www.raspberrypi.org/products/raspberry-pi-2-model-b/)上做了很多 [syslog-ng](https://syslog-ng.com/open-source-log-management) 的测试,结果令人振奋。我最近在树莓派上做了个音乐播放器,用了一块 USB 声卡和[音乐播放守护进程](https://www.musicpd.org/),我经常使用它。
### 技术方面
美好的多样性:它创造了竞争,而竞争创造了更好的产品。虽然 x86 是一款强劲的通用处理器,但 ARM 和 PowerPC (以及许多其他)这样的芯片在多种特定场景下显得更适合。
如果你有一部运行[安卓](https://www.android.com/)的移动设备或者[苹果](http://www.apple.com/)的 iPhone 或 iPad,极有可能它使用的就是基于ARM 的 SoC (片上系统)。网络存储服务器也一样。原因很简单:省电。你不会希望手机一直在充电,也不想为你的路由器付更多的电费。
ARM 亦在使用 64 位 ARMv8 芯片征战企业级服务器市场。很多任务只需要极少的计算能力,另一方面省电和快速 IO 才是关键,想想存储、静态网页服务器、电子邮件和其他网络/存储相关的功能。一个最好的例子就是 [Ceph](http://ceph.com/),一个分布式的面向对象文件系统。[SoftIron](http://softiron.co.uk/) 就是一个基于 ARMv8 开发版,使用 CentOS 作为基准软件,运行在 Ceph 上的完整存储应用。
众所周知 PowerPC 是旧版苹果 [Mac](https://en.wikipedia.org/wiki/Power_Macintosh) 电脑上的 CPU。虽然它不再作为通用桌面电脑的 CPU ,它依然在路由器和电信设备里发挥作用。而且 [IBM](https://www.ibm.com/us-en/) 仍在为高端服务器制造芯片。几年前,随着 Power8 的引入, IBM 在 [OpenPower 基金会](http://openpowerfoundation.org/) 的支持下开放了架构。 Power8 对于关心内存带宽的设备,比如 HPC 、大数据、数据挖掘来说,是非常理想的平台。目前,Power9 也正呼之欲出。
这些都是服务器应用,但也有计划用于终端用户。猛禽工程团队正在开发一款基于 [Power9 的工作站](https://www.raptorcs.com/TALOSII/),也有一个基于飞思卡尔/恩智浦 QORIQ E6500 芯片[制造笔记本](http://www.powerpc-notebook.org/en/)的倡议。当然,这些电脑并不适合所有人,你不能在它们上面安装 Windows 游戏或者商业应用。但它们对于 PowerPC 开发人员和爱好者,或者任何想要完全开放系统的人来说是理想的选择,因为从硬件到固件到应用程序都是开放的。
### 梦想
我的梦想是完全没有 x86 的环境,不是因为我讨厌 x86 ,而是因为我喜欢多样化而且总是希望使用最适合工作的工具。如果你看看猛禽工程网页上的[图](https://secure.raptorengineering.com/TALOS/power_advantages.php),根据不同的使用情景, ARM 和 POWER 完全可以代替 x86 。现在,我在笔记本的 x86 虚拟机上编译、打包和测试 syslog-ng。如果能用上足够强劲的 ARMv8 或者 PowerPC 电脑,无论工作站还是服务器,我就能避免在 x86 上做这些事。
现在我正在等待下一代[菠萝本](https://www.pine64.org/?page_id=3707)的到来,就像我在二月份 [FOSDEM](https://fosdem.org/2018/) 上说的,下一代有望提供更高的性能。和 Chrome 本不同的是,这个 ARM 笔记本设计用于运行 Linux 而非仅是个客户端(LCTT 译注:Chrome 笔记本只提供基于网页的应用)。作为桌面系统,我在寻找 ARMv8 工作站级别的硬件。有些已经接近完成——就像 Avantek 公司的 [雷神 X 台式机](https://www.avantek.co.uk/store/avantek-32-core-cavium-thunderx-arm-desktop.html)——不过他们还没有装备最新最快最重要也最节能的 ARMv8 CPU。当这些都实现了,我将用我的 Pixel C 笔记本运行安卓。它不像 Linux 那样简单灵活,但它以强大的 ARM SoC 和 Linux 内核为基础。
---
via: <https://opensource.com/article/18/4/why-i-love-arm-and-powerpc>
作者:[Peter Czanik](https://opensource.com/users/czanik) 译者:[kennethXia](https://github.com/kennethXia) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Recently I've been asked why I mention [ARM](https://en.wikipedia.org/wiki/ARM_architecture) and [PowerPC](https://en.wikipedia.org/wiki/PowerPC) so often on my blogs and in my tweets. I have two answers: one is personal, the other technical.
## The personal
Once upon a time, I studied environmental protection. While working on my PhD, I was looking for a new computer. As an environmentally aware person, I wanted a high-performing computer that was also efficient. That is how I first became interested in the PowerPC and discovered [Pegasos](https://genesi.company/products/opendesktop), a PowerPC workstation created by [Genesi](https://genesi.company/).
I had already used [RS/6000](https://en.wikipedia.org/wiki/RS/6000) (PowerPC), [SGI](https://en.wikipedia.org/wiki/Silicon_Graphics#Workstations) (MIPS), [HP-UX](https://en.wikipedia.org/wiki/HP-UX) (PA-RISC), and [VMS](https://en.wikipedia.org/wiki/OpenVMS#Port_to_DEC_Alpha) (Alpha) both as a server and a workstation, and on my PC I used Linux, not Windows, so using a different CPU architecture was not a barrier. [Pegasos](https://en.wikipedia.org/wiki/Pegasos), which was small and efficient enough for home use, was my first workstation.
Soon I was working for Genesi, enabling [openSUSE](https://www.opensuse.org/), Ubuntu, and various other Linux distributions on Pegasos and providing quality assurance and community support. Pegasos was followed by [EFIKA](https://genesi.company/products/efika/5200b), another PowerPC board. It felt strange at first to use an embedded system after using workstations. But as one of the first affordable developer boards, it was the start of a revolution.
I was working on some large-scale server projects when I received another interesting piece of hardware from Genesi: a [Smarttop](https://genesi.company/products/efika) and a [Smartbook](https://genesi.company/products/smartbook) based on ARM. My then-favorite Linux distribution, openSUSE, also received a dozen of these machines. This gave a big boost to ARM-related openSUSE developments at a time when very few ARM machines were available.
Although I have less time available these days, I try to stay up-to-date on ARM and PowerPC news. This helps me support syslog-ng users on non-x86 platforms. And when I have half an hour free, I hack one of my ARM machines. I did some benchmarks on the [Raspberry Pi 2](https://www.raspberrypi.org/products/raspberry-pi-2-model-b/) with [syslog-ng](https://syslog-ng.com/open-source-log-management), and the [results were quite surprising](https://syslog-ng.com/blog/syslog-ng-raspberry-pi-2/). Recently, I built a music player using a Raspberry Pi, a USB sound card, and the [Music Player Daemon](https://www.musicpd.org/), and I use it regularly.
## The technical
Diversity is good: It creates competition, and competition creates better products. While x86 is a solid generic workhorse, chips like ARM and PowerPC (and many others) are better suited in various situations.
If you have an [Android](https://www.android.com/) mobile device or an [Apple](http://www.apple.com/) iPhone or iPad, there's a good chance it is running on an ARM SoC (system on chip). Same with a network-attached storage server. The reason is quite simple: power efficiency. You don't want to constantly recharge batteries or pay more for electricity than you did for your router.
ARM is also conquering the enterprise server world with its 64-bit ARMv8 chips. Many tasks require minimal computing capacity; on the other hand, power efficiency and fast I/O are key— think storage, static web content, email, and other storage- and network-intensive functions. A prime example is [Ceph](http://ceph.com/), a distributed object storage and file system. [SoftIron](http://softiron.co.uk/), which uses CentOS as reference software on its ARMv8 developer hardware, is working on Ceph-based turnkey storage appliances.
Most people know PowerPC as the former CPU of [Apple Mac](https://en.wikipedia.org/wiki/Power_Macintosh) machines. While it is no longer used as a generic desktop CPU, it still functions in routers, telecommunications equipment. And [IBM](https://www.ibm.com/us-en/) continued to produce chips for high-performance servers. A few years ago, with the introduction of POWER8, IBM opened up the architecture under the aegis of the [OpenPOWER Foundation](http://openpowerfoundation.org/). POWER8 is an ideal platform for HPC, big data, and analytics, where memory bandwidth is key. POWER9 is right around the corner.
These are all server applications, but there are plans for end-user devices. Raptor Engineering is working on a [POWER9 workstation](https://www.raptorcs.com/TALOSII/), and there is also an initiative to [create a notebook](http://www.powerpc-notebook.org/en/) based on a Freescale/NXP QorIQ e6500 chip. Of course, these machines are not for everybody—you can't install your favorite Windows game or commercial application on them. But they are great for PowerPC developers and enthusiasts, or anyone wanting a fully open system, from hardware to firmware to applications.
## The dream
My dream is a completely x86-free environment—not because I don't like x86, but because I like diversity and always use the most suitable tool for the job. If you look at the [graph](https://secure.raptorengineering.com/TALOS/power_advantages.php) on Raptor Engineering's page, you will see that, depending on your use case, ARM and POWER can replace most of x86. Right now I compile, package, and test syslog-ng in x86 virtual machines running on my laptop. Using a strong enough ARMv8 or PowerPC machine, either as a workstation or a server, I could avoid x86 for this kind of tasks.
Right now I am waiting for the next generation of [Pinebook](https://www.pine64.org/?page_id=3707) to arrive, as I was told at [FOSDEM](https://fosdem.org/2018/) in February that the next version is expected to offer much higher performance. Unlike Chromebooks, this ARM-powered laptop runs Linux by design, not as a hack. For a desktop, I am looking for ARMv8 workstation-class hardware. Some are already available—like the [ThunderX Desktop](https://www.avantek.co.uk/store/avantek-32-core-cavium-thunderx-arm-desktop.html) from Avantek—but they do not yet feature the latest, fastest, and more importantly, most energy-efficient ARMv8 CPU generations. Until these arrive, I'll use my Pixel C laptop running Android. It's not as easy and flexible as Linux, but it has a powerful ARM SoC and a Linux kernel at its heart.
## 7 Comments |
9,618 | 4 月 COPR 中的 4 个新酷项目 | https://fedoramagazine.org/4-try-copr-april-2018/ | 2018-05-07T23:36:38 | [
"COPR",
"Fedora"
] | https://linux.cn/article-9618-1.html | 
COPR 是一个个人软件仓库[集合](https://copr.fedorainfracloud.org/),它包含 Fedora 所没有提供的软件。这些软件或不符合易于打包的标准,或者它可能不符合其他 Fedora 标准,尽管它是自由且开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件并没有得到 Fedora 基础设施支持,也没有由该项目背书。但是,它可能是尝试新软件或实验软件的一种很好的方式。
这是 COPR 中一些新的和有趣的项目。
### Anki
[Anki](https://apps.ankiweb.net/) 是一个程序,它使用间隔重复帮助你学习和记忆事物。你可以创建卡片并将其组织成卡组,或下载[现有卡组](https://ankiweb.net/shared/decks/)。卡片的一面有问题,另一面有答案。它可能还包括图像、视频或音频。你对每张卡的回答好坏决定了你将来看到特定卡的频率。
虽然 Anki 已经在 Fedora 中,但这个仓库提供了一个更新的版本。

#### 安装说明
仓库目前为 Fedora 27、28 和 Rawhide 提供 Anki。要安装 Anki,请使用以下命令:
```
sudo dnf copr enable thomasfedb/anki
sudo dnf install anki
```
### Fd
[Fd](https://github.com/sharkdp/fd) 是一个命令行工具,它是简单而稍快的替代 [find](https://www.gnu.org/software/findutils/) 的方法。它可以并行地查找项目。fd 也使用彩色输出,并默认忽略隐藏文件和 `.gitignore` 中指定模式的文件。
#### 安装说明
仓库目前为 Fedora 26、27、28 和 Rawhide 提供 `fd`。要安装 fd,请使用以下命令:
```
sudo dnf copr enable keefle/fd
sudo dnf install fd
```
### KeePass
[KeePass](https://keepass.info/) 是一个密码管理器。它将所有密码保存在一个由主密钥或密钥文件锁定的端对端加密数据库中。密码可以组织成组并由程序的内置生成器生成。其他功能包括自动输入,它可以为选定的表单输入用户名和密码。
虽然 KeePass 已经在 Fedora 中,但这个仓库提供了最新版本。

#### 安装说明
仓库目前为 Fedora 26 和 27 提供 KeePass。要安装 KeePass,请使用以下命令:
```
sudo dnf copr enable mavit/keepass
sudo dnf install keepass
```
### jo
[Jo](https://github.com/jpmens/jo) 是一个将输入转换为 JSON 字符串或数组的命令行工具。它有一个简单的[语法](https://github.com/jpmens/jo/blob/master/jo.md)并识别布尔值、字符串和数字。另外,jo 支持嵌套并且可以嵌套自己的输出。
#### 安装说明
目前,仓库为 Fedora 26、27 和 Rawhide 以及 EPEL 6 和 7 提供 jo。要安装 jo,请使用以下命令:
```
sudo dnf copr enable ganto/jo
sudo dnf install jo
```
---
via: <https://fedoramagazine.org/4-try-copr-april-2018/>
作者:[Dominik Turecek](https://fedoramagazine.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | COPR is a [collection](https://copr.fedorainfracloud.org/) of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
Here’s a set of new and interesting projects in COPR.
## Anki
[Anki](https://apps.ankiweb.net/) is a program that helps you learn and remember things using spaced repetition. You can create cards and organize them into decks, or download [existing decks](https://ankiweb.net/shared/decks/). A card has a question on one side and an answer on the other. It may also include images, video or audio. How well you answer each card determines how often you see that particular card in the future.
While *Anki* is already in Fedora, this repo provides a newer version.
### Installation instructions
The repo currently provides *Anki* for Fedora 27, 28, and Rawhide. To install *Anki*, use these commands:
sudo dnf copr enable thomasfedb/anki sudo dnf install anki
## Fd
[Fd](https://github.com/sharkdp/fd) is a command-line utility that’s a simple and slightly faster alternative to [find](https://www.gnu.org/software/findutils/). It can execute commands on found items in parallel. *Fd* also uses colorized terminal output and ignores hidden files and patterns specified in *.gitignore* by default.
### Installation instructions
The repo currently provides *fd* for Fedora 26, 27, 28, and Rawhide. To install *fd*, use these commands:
sudo dnf copr enable keefle/fd sudo dnf install fd
### KeePass
[KeePass](https://keepass.info/) is a password manager. It holds all passwords in one end-to-end encrypted database locked with a master key or key file. The passwords can be organized into groups and generated by the program’s built-in generator. Among its other features is Auto-Type, which can provide a username and password to selected forms.
While *KeePass* is already in Fedora, this repo provides the newest version.
#### Installation instructions
The repo currently provides *KeePass* for Fedora 26 and 27. To install *KeePass*, use these commands:
sudo dnf copr enable mavit/keepass sudo dnf install keepass
### jo
[Jo](https://github.com/jpmens/jo) is a command-line utility that transforms input to JSON strings or arrays. It features a simple [syntax](https://github.com/jpmens/jo/blob/master/jo.md) and recognizes booleans, strings and numbers. In addition, *jo* supports nesting and can nest its own output as well.
#### Installation instructions
The repo currently provides *jo* for Fedora 26, 27, and Rawhide, and for EPEL 6 and 7. To install *jo*, use these commands:
sudo dnf copr enable ganto/jo sudo dnf install jo
## Robert
Cool, thanks for mentioning fd! Going to try now. 🙂
## Dmitry Suserov
wrote an fd like program years ago in pure dash, it’s not that hard.
## David Sirrine
I use Anki! It’s a fantastic tool.
## ganto
Thanks for featuring my COPR repo. 🙂
I just started a rebuild, so that also Fedora 28 (Beta) users can enjoy a native “jo” package.
## hernantz
Another open source alternative to keepass is keepassxc (https://keepassxc.org/)
## Luke
KeePassXC is way better than KeePass!
## Chad
Luke, you forgot to specify what KeePassXC is “way better than KeePass!”
Why?
## Ray M
Jo comes in handy for parsing ansible variables that are nested.
I’m not sure the “dnf” command works for EPEL6 and 7.
I couldn’t get this to work with yum either.
## clime
Hello Ray!
See here about how to enable the repo under EPEL7: https://docs.pagure.org/copr.copr/how_to_enable_repo.html?highlight=yum.
You basically need yum-plugin-copr installed. Then
should work.
For EPEL6, the repo needs to be downloaded manually from a project overview page and put into /etc/yum.repos.d/. |
9,619 | 我们可以在同一个虚拟机中运行 Python 2 和 3 代码而不需要更改代码吗? | http://lukasz.langa.pl/13/could-we-run-python-2-and-python-3-code-same-vm/ | 2018-05-08T19:07:00 | [
"Python"
] | https://linux.cn/article-9619-1.html | 
从理论上来说,可以。Zed Shaw 说过一句著名的话,如果不行,那么 Python 3 一定不是图灵完备的。但在实践中,这是不现实的,我将通过给你们举几个例子来说明原因。
### 对于字典(dict)来说,这意味着什么?
让我们来想象一台拥有 Python 6 的虚拟机,它可以读取 Python 3.6 编写的 `module3.py`。但是在这个模块中,它可以导入 Python 2.7 编写的 `module2.py`,并成功使用它,没有问题。这显然是实验代码,但假设 `module2.py` 包含以下的功能:
```
def update_config_from_dict(config_dict):
items = config_dict.items()
while items:
k, v = items.pop()
memcache.set(k, v)
def config_to_dict():
result = {}
for k, v in memcache.getall():
result[k] = v
return result
def update_in_place(config_dict):
for k, v in config_dict.items():
new_value = memcache.get(k)
if new_value is None:
del config_dict[k]
elif new_value != v:
config_dict[k] = v
```
现在,当我们想从 `module3` 中调用这些函数时,我们遇到了一个问题:Python 3.6 中的字典类型与 Python 2.7 中的字典类型不同。在 Python 2 中,字典是无序的,它们的 `.keys()`, `.values()`, `.items()` 方法返回了正确的序列,这意味着调用 `.items()` 会在字典中创建状态的副本。在 Python 3 中,这些方法返回字典当前状态的动态视图。
这意味着如果 `module3` 调用 `module2.update_config_from_dict(some_dictionary)`,它将无法运行,因为 Python 3 中 `dict.items()` 返回的值不是一个列表,并且没有 `.pop()` 方法。反过来也是如此。如果 `module3` 调用 `module2.config_to_dict()`,它可能会返回一个 Python 2 的字典。现在调用 `.items()` 突然返回一个列表,所以这段代码无法正常工作(这对 Python 3 字典来说工作正常):
```
def main(cmdline_options):
d = module2.config_to_dict()
items = d.items()
for k, v in items:
print(f'Config from memcache: {k}={v}')
for k, v in cmdline_options:
d[k] = v
for k, v in items:
print(f'Config with cmdline overrides: {k}={v}')
```
最后,使用 `module2.update_in_place()` 会失败,因为 Python 3 中 `.items()` 的值现在不允许在迭代过程中改变。
对于字典来说,还有很多问题。Python 2 的字典在 Python 3 上使用 `isinstance(d, dict)` 应该返回 `True` 吗?如果是的话,这将是一个谎言。如果没有,代码将无法继续。
### Python 应该神奇地知道类型并会自动转换!
为什么我们的 Python 6 的虚拟机无法识别 Python 3 的代码,在 Python 2 中调用 `some_dict.keys()` 时,我们还有别的意思吗?好吧,Python 不知道代码的作者在编写代码时,她所认为的 `some_dict` 应该是什么。代码中没有任何内容表明它是否是一个字典。在 Python 2 中没有类型注释,因为它们是可选的,即使在 Python 3 中,大多数代码也不会使用它们。
在运行时,当你调用 `some_dict.keys()` 的时候,Python 只是简单地在对象上查找一个属性,该属性恰好隐藏在 `some_dict` 名下,并试图在该属性上运行 `__call__()`。这里有一些关于方法绑定,描述符,slots 等技术问题,但这是它的核心。我们称这种行为为“鸭子类型”。
由于鸭子类型,Python 6 的虚拟机将无法做出编译时决定,以正确转换调用和属性查找。
### 好的,让我们在运行时做出这个决定
Python 6 的虚拟机可以标记每个属性,通过查找“来自 py2 的调用”或“来自 py3 的调用”的信息来实现这一点,并使对象发送正确的属性。这会让它变得很慢,并且使用更多的内存。这将要求我们在内存中保留两种版本的代码,并通过代理来使用它们。我们需要加倍付出努力,在用户背后同步这些对象的状态。毕竟,新字典的内存表示与 Python 2 不同。
如果你已经被字典问题绕晕了,那么再想想 Python 3 中的 Unicode 字符串和 Python 2 中的字节(byte)字符串的各种问题吧。
### 没有办法了吗?Python 3 根本就不能运行旧代码吗?
不会。每天都会有项目移植到 Python 3。将 Python 2 代码移植到两个版本的 Python 上推荐方法是在你的代码上运行 [Python-Modernize](https://python-modernize.readthedocs.io/)。它会捕获那些在 Python 3 上不起作用的代码,并使用 [six](http://pypi.python.org/pypi/six) 库将其替换,以便它在 Python 2 和 Python 3 上运行。这是 `2to3` 的一个改编版本,用于生成仅针对 Python 3 代码。`Modernize` 是首选,因为它提供了更多的增量迁移路线。所有的这些在 Python 文档中的 [Porting Python 2 Code to Python 3](https://docs.python.org/3/howto/pyporting.html)文档中都有很好的概述。
但是,等一等,你不是说 Python 6 的虚拟机不能自动执行此操作吗?对。`Modernize` 查看你的代码,并试图猜测哪些是安全的。它会做出一些不必要的改变,还会错过其他必要的改变。但是,它不会帮助你处理字符串。如果你的代码没有在“来自外部的二进制数据”和“流程中的文本数据”之间保持界限,那么这种转换就不会那么轻易。
因此,大项目的迁移不能自动完成,并且需要人类进行测试,发现问题并修复它们。它工作吗?是的,我曾帮助[将一百万行代码迁移到 Python 3](https://www.youtube.com/watch?v=66XoCk79kjM),并且这种切换没有造成事故。这一举措让我们重新获得了 1/3 的服务器内存,并使代码运行速度提高了 12%。那是在 Python 3.5 上,但是 Python 3.6 的速度要快得多,根据你的工作量,你甚至可以达到 [4 倍加速](https://twitter.com/llanga/status/963834977745022976)。
### 亲爱的 Zed
hi,伙计,我关注你已经超过 10 年了。我一直在观察,当你感到沮丧的时候,你对 Mongrel 没有任何信任,尽管 Rails 生态系统几乎全部都在上面运行。当你重新设计它并开始 Mongrel 2 项目时,我一直在观察。我一直在关注你使用 Fossil 这一令人惊讶的举动。随着你发布 “Rails 是一个贫民窟”的帖子,我看到你突然离开了 Ruby 社区。当你开始编写《笨方法学 Python》并且开始推荐它时,我感到非常兴奋。2013 年我在 [DjangoCon Europe](https://www.instagram.com/p/ZVC9CwH7G1/) 见过你,我们谈了很多关于绘画,唱歌和倦怠的内容。[你的这张照片](https://www.instagram.com/p/ZXtdtUn7Gk/)是我在 Instagram 上的第一个帖子。
你几乎把另一个“贫民区”的行动与 [“反对 Python 3” 案例](https://learnpythonthehardway.org/book/nopython3.html) 文章拉到一起。我认为你本意是好的,但是这篇文章引起了很多混淆,包括许多人觉得你认为 Python 3 不是图灵完整的。我花了好几个小时让人们相信,你是在开玩笑。但是,鉴于你对《笨方法学 Python》的重大贡献,我认为这是值得的。特别是你为 Python 3 更新了你的书。感谢你做这件事。如果我们社区中真的有人因你的帖子为由要求将你和你的书列入黑名单,而请他们出去。这是一个双输的局面,这是错误的。
说实话,没有一个核心 Python 开发人员认为 Python 2 到 Python 3 的转换过程会顺利而且计划得当,[包括 Guido van Rossum](https://www.youtube.com/watch?v=Oiw23yfqQy8)。真的,可以看那个视频,这有点事后诸葛亮的意思了。从这个意义上说,*我们实际上是积极地相互认同的*。如果我们再做一次,它会看起来不一样。但在这一点上,[在 2020 年 1 月 1 日,Python 2 将会到达终结](https://mail.python.org/pipermail/python-dev/2018-March/152348.html)。大多数第三方库已经支持 Python 3,甚至开始发布只支持 Python 3 的版本(参见 [Django](https://pypi.python.org/pypi/Django/2.0.3) 或 [科学项目关于 Python 3 的声明](http://python3statement.org/))。
我们也积极地就另一件事达成一致。就像你于 Mongrel 一样,Python 核心开发人员是志愿者,他们的工作没有得到报酬。我们大多数人在这个项目上投入了大量的时间和精力,因此[我们自然而然敏感](https://www.youtube.com/watch?v=-Nk-8fSJM6I)于那些对他们的贡献不屑一顾和激烈的评论。特别是如果这个信息既攻击目前的事态,又要求更多的自由贡献。
我希望到 2018 年会让你忘记 2016 发布的帖子,有一堆好的反驳。[我特别喜欢 eevee](https://eev.ee/blog/2016/11/23/a-rebuttal-for-python-3/)(LCTT 译注:eevee 是一个为 Blender 设计的渲染器)。它特别针对“一起运行 Python 2 和 Python 3 ”的场景,这是不现实的,就像在同一个虚拟机中运行 Ruby 1.8 和 Ruby 2.x 一样,或者像 Lua 5.3 和 Lua 5.1 同时运行一样。你甚至不能用 libc.so.6 运行针对 libc.so.5 编译的 C 二进制文件。然而,我发现最令人惊讶的是,你声称 Python 核心开发者是“有目的地”创造诸如 2to3 之类的破坏工具,这些由 Guido 创建,其最大利益就是让每个人尽可能顺利,快速地迁移。我很高兴你在之后的帖子中放弃了这个说法,但是你必须意识到你会激怒那些阅读了原始版本的人。对蓄意伤害的指控最好有强有力的证据支持。
但看起来你仍然会这样做。[就在今天](https://twitter.com/zedshaw/status/977909970795745281)你说 Python 核心开发者“忽略”尝试解决 API 的问题,特别是 `six`。正如我上面写的那样,Python 文档中的官方移植指南涵盖了 `six`。更重要的是,`six` 是由 Python 2.7 的发布管理者 Benjamin Peterson 编写。很多人学会了编程,这要归功于你,而且由于你在网上有大量的粉丝,人们会阅读这样的推文,他们会相信它的价值,这是有害的。
我有一个建议,让我们把 “Python 3 管理不善”的争议搁置起来。Python 2 正在死亡,这个过程会很慢,并且它是丑陋而血腥的,但它是一条单行道。争论那些没有用。相反,让我们专注于我们现在可以做什么来使 Python 3.8 比其他任何 Python 版本更好。也许你更喜欢看外面的角色,但作为这个社区的成员,你会更有影响力。请说“我们”而不是“他们”。
---
via: <http://lukasz.langa.pl/13/could-we-run-python-2-and-python-3-code-same-vm/>
作者:[Łukasz Langa](http://lukasz.langa.pl) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,620 | 如何使用树莓派测定颗粒物(PM 2.5) | https://opensource.com/article/18/3/how-measure-particulate-matter-raspberry-pi | 2018-05-08T23:51:54 | [
"空气",
"树莓派"
] | https://linux.cn/article-9620-1.html |
>
> 使用两个简单的硬件设备和几行代码构建一个空气质量探测器。
>
>
>

我们在东南亚的学校定期测定空气中的颗粒物。这里的测定值非常高,尤其是在二到五月之间,干燥炎热、土地干旱等各种因素都对空气质量产生了不利的影响。我将会在这篇文章中展示如何使用树莓派来测定颗粒物。
### 什么是颗粒物?
颗粒物就是粉尘或者空气中的微小颗粒。其中 PM10 和 PM2.5 之间的差别就是 PM10 指的是粒径小于 10 微米的颗粒,而 PM2.5 指的是粒径小于 2.5 微米的颗粒。在粒径小于 2.5 微米的的情况下,由于它们能被吸入肺泡中并且对呼吸系统造成影响,因此颗粒越小,对人的健康危害越大。
世界卫生组织的建议[颗粒物浓度](https://en.wikipedia.org/wiki/Particulates)是:
* 年均 PM10 不高于 20 µg/m³
* 年均 PM2.5 不高于 10 µg/m³
* 不允许超标时,日均 PM10 不高于 50 µg/m³
* 不允许超标时,日均 PM2.5 不高于 25 µg/m³
以上数值实际上是低于大多数国家的标准的,例如欧盟对于 PM10 所允许的年均值是不高于 40 µg/m³。
### 什么是<ruby> 空气质量指数 <rt> Air Quality Index </rt></ruby>(AQI)?
空气质量指数是按照颗粒物的测定值来评价空气质量的好坏,然而由于各国之间的计算方式有所不同,这个指数并没有统一的标准。维基百科上关于[空气质量指数](https://en.wikipedia.org/wiki/Air_quality_index)的词条对此给出了一个概述。我们学校则以<ruby> <a href="https://en.wikipedia.org/wiki/United_States_Environmental_Protection_Agency"> 美国环境保护协会 </a> <rt> Environment Protection Agency </rt></ruby>(EPA)建立的分类法来作为依据。

*空气质量指数*
### 测定颗粒物需要哪些准备?
测定颗粒物只需要以下两种器材:
* 树莓派(款式不限,最好带有 WiFi)
* SDS011 颗粒物传感器

*颗粒物传感器*
如果是只带有 Micro USB 的树莓派 Zero W,那还需要一根连接到标准 USB 端口的适配线,只需要 20 美元,而传感器则自带适配串行接口的 USB 适配器。
### 安装过程
对于树莓派,只需要下载对应的 Raspbian Lite 镜像并且[写入到 Micro SD 卡](https://www.raspberrypi.org/documentation/installation/installing-images/README.md)上就可以了(网上很多教程都有介绍如何设置 WLAN 连接,我就不细说了)。
如果要使用 SSH,那还需要在启动分区建立一个名为 `ssh` 的空文件。树莓派的 IP 通过路由器或者 DHCP 服务器获取,随后就可以通过 SSH 登录到树莓派了(默认密码是 raspberry):
```
$ ssh [email protected]
```
首先我们需要在树莓派上安装一下这些包:
```
$ sudo apt install git-core python-serial python-enum lighttpd
```
在开始之前,我们可以用 `dmesg` 来获取 USB 适配器连接的串行接口:
```
$ dmesg
[ 5.559802] usbcore: registered new interface driver usbserial
[ 5.559930] usbcore: registered new interface driver usbserial_generic
[ 5.560049] usbserial: USB Serial support registered for generic
[ 5.569938] usbcore: registered new interface driver ch341
[ 5.570079] usbserial: USB Serial support registered for ch341-uart
[ 5.570217] ch341 1–1.4:1.0: ch341-uart converter detected
[ 5.575686] usb 1–1.4: ch341-uart converter now attached to ttyUSB0
```
在最后一行,可以看到接口 `ttyUSB0`。然后我们需要写一个 Python 脚本来读取传感器的数据并以 JSON 格式存储,在通过一个 HTML 页面就可以把数据展示出来了。
### 在树莓派上读取数据
首先创建一个传感器实例,每 5 分钟读取一次传感器的数据,持续 30 秒,这些数值后续都可以调整。在每两次测定的间隔,我们把传感器调到睡眠模式以延长它的使用寿命(厂商认为元件的寿命大约 8000 小时)。
我们可以使用以下命令来下载 Python 脚本:
```
$ wget -O /home/pi/aqi.py https://raw.githubusercontent.com/zefanja/aqi/master/python/aqi.py
```
另外还需要执行以下两条命令来保证脚本正常运行:
```
$ sudo chown pi:pi /var/www/html/
$ echo '[]' > /var/www/html/aqi.json
```
下面就可以执行脚本了:
```
$ chmod +x aqi.p
$ ./aqi.py
PM2.5:55.3, PM10:47.5
PM2.5:55.5, PM10:47.7
PM2.5:55.7, PM10:47.8
PM2.5:53.9, PM10:47.6
PM2.5:53.6, PM10:47.4
PM2.5:54.2, PM10:47.3
…
```
### 自动化执行脚本
只需要使用诸如 crontab 的服务,我们就不需要每次都手动启动脚本了。按照以下命令打开 crontab 文件:
```
$ crontab -e
```
在文件末尾添加这一行:
```
@reboot cd /home/pi/ && ./aqi.py
```
现在我们的脚本就会在树莓派每次重启后自动执行了。
### 展示颗粒物测定值和空气质量指数的 HTML 页面
我们在前面已经安装了一个轻量级的 web 服务器 `lighttpd`,所以我们需要把 HTML、JavaScript、CSS 文件放置在 `/var/www/html` 目录中,这样就能通过电脑和智能手机访问到相关数据了。执行下面的三条命令,可以下载到对应的文件:
```
$ wget -O /var/www/html/index.html https://raw.githubusercontent.com/zefanja/aqi/master/html/index.html
$ wget -O /var/www/html/aqi.js https://raw.githubusercontent.com/zefanja/aqi/master/html/aqi.js
$ wget -O /var/www/html/style.css https://raw.githubusercontent.com/zefanja/aqi/master/html/style.css
```
在 JavaScript 文件中,实现了打开 JSON 文件、提取数据、计算空气质量指数的过程,随后页面的背景颜色将会根据 EPA 的划分标准而变化。
你只需要用浏览器访问树莓派的地址,就可以看到当前颗粒物浓度值等数据了: [http://192.168.1.5:](http://192.168.1.5/)
这个页面比较简单而且可扩展,比如可以添加一个展示过去数小时历史数据的表格等等。
这是[Github上的完整源代码](https://github.com/zefanja/aqi)。
### 总结
在资金相对紧张的情况下,树莓派是一种选择。除此以外,还有很多可以用来测定颗粒物的应用,包括室外固定装置、移动测定设备等等。我们学校则同时采用了这两种:固定装置在室外测定全天颗粒物浓度,而移动测定设备在室内检测空调过滤器的效果。
[Luftdaten.info](http://luftdaten.info/) 提供了一个如何设计类似的传感器的介绍,其中的软件效果出众,而且因为它没有使用树莓派,所以硬件更是小巧。
对于学生来说,设计一个颗粒物传感器确实算得上是一个优秀的课外项目。
你又打算如何使用你的[树莓派](https://openschoolsolutions.org/shutdown-servers-case-power-failure%e2%80%8a-%e2%80%8aups-nut-co/)呢?
---
via: <https://opensource.com/article/18/3/how-measure-particulate-matter-raspberry-pi>
作者:[Stephan Tetzel](https://opensource.com/users/stephan) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We regularly measure particulate matter in the air at our school in Southeast Asia. The values here are very high, particularly between February and May, when weather conditions are very dry and hot, and many fields burn. These factors negatively affect the quality of the air. In this article, I will show you how to measure particulate matter using a Raspberry Pi.
## What is particulate matter?
Particulate matter is fine dust or very small particles in the air. A distinction is made between PM10 and PM2.5: PM10 refers to particles that are smaller than 10µm; PM2.5 refers to particles that are smaller than 2.5µm. The smaller the particles—i.e., anything smaller than 2.5µm—the more dangerous they are to one's health, as they can penetrate into the alveoli and impact the respiratory system.
The World Health Organization recommends [limiting particulate matter](https://en.wikipedia.org/wiki/Particulates) to the following values:
- Annual average PM10 20 µg/m³
- Annual average PM2,5 10 µg/m³ per year
- Daily average PM10 50 µg/m³ without permitted days on which exceeding is possible.
- Daily average PM2,5 25 µg/m³ without permitted days on which exceeding is possible.
These values are below the limits set in most countries. In the European Union, an annual average of 40 µg/m³ for PM10 is allowed.
## What is the Air Quality Index (AQI)?
The Air Quality Index indicates how “good” or “bad” air is based on its particulate measurement. Unfortunately, there is no uniform standard for AQI because not all countries calculate it the same way. The Wikipedia article on the [Air Quality Index](https://en.wikipedia.org/wiki/Air_quality_index) offers a helpful overview. At our school, we are guided by the classification established by the United States' [ Environmental Protection Agency](https://en.wikipedia.org/wiki/United_States_Environmental_Protection_Agency).
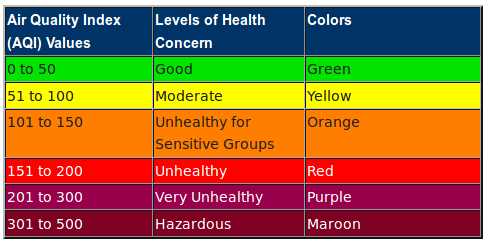
Air quality index
## What do we need to measure particulate matter?
Measuring particulate matter requires only two things:
- A Raspberry Pi (every model works; a model with WiFi is best)
- A particulates sensor SDS011

Particulate sensor
If you are using a Raspberry Pi Zero W, you will also need an adapter cable to a standard USB port because the Zero has only a Micro USB. These are available for about $20. The sensor comes with a USB adapter for the serial interface.
## Installation
For our Raspberry Pi we download the corresponding Raspbian Lite Image and [write it on the Micro SD card](https://www.raspberrypi.org/documentation/installation/installing-images/README.md). (I will not go into the details of setting up the WLAN connection; many tutorials are available online).
If you want to have SSH enabled after booting, you need to create an empty file named `ssh`
in the boot partition. The IP of the Raspberry Pi can best be obtained via your own router/DHCP server. You can then log in via SSH (the default password is *raspberry*):
`$ ssh [email protected]`
First we need to install some packages on the Pi:
`$ sudo apt install git-core python-serial python-enum lighttpd`
Before we can start, we need to know which serial port the USB adapter is connected to. `dmesg`
helps us:
```
$ dmesg
[ 5.559802] usbcore: registered new interface driver usbserial
[ 5.559930] usbcore: registered new interface driver usbserial_generic
[ 5.560049] usbserial: USB Serial support registered for generic
[ 5.569938] usbcore: registered new interface driver ch341
[ 5.570079] usbserial: USB Serial support registered for ch341-uart
[ 5.570217] ch341 1–1.4:1.0: ch341-uart converter detected
[ 5.575686] usb 1–1.4: ch341-uart converter now attached to ttyUSB0
```
In the last line, you can see our interface: `ttyUSB0`
. We now need a small Python script that reads the data and saves it in a JSON file, and then we will create a small HTML page that reads and displays the data.
## Reading data on the Raspberry Pi
We first create an instance of the sensor and then read the sensor every 5 minutes, for 30 seconds. These values can, of course, be adjusted. Between the measuring intervals, we put the sensor into a sleep mode to increase its lifespan (according to the manufacturer, the lifespan totals approximately 8000 hours).
We can download the script with this command:
`$ wget -O /home/pi/aqi.py https://raw.githubusercontent.com/zefanja/aqi/master/python/aqi.py`
For the script to run without errors, two small things are still needed:
```
$ sudo chown pi:pi /var/www/html/
$ echo [] > /var/www/html/aqi.json
```
Now you can start the script:
```
$ chmod +x aqi.py
$ ./aqi.py
PM2.5:55.3, PM10:47.5
PM2.5:55.5, PM10:47.7
PM2.5:55.7, PM10:47.8
PM2.5:53.9, PM10:47.6
PM2.5:53.6, PM10:47.4
PM2.5:54.2, PM10:47.3
…
```
## Run the script automatically
So that we don’t have to start the script manually every time, we can let it start with a cronjob, e.g., with every restart of the Raspberry Pi. To do this, open the crontab file:
`$ crontab -e`
and add the following line at the end:
`@reboot cd /home/pi/ && ./aqi.py`
Now our script starts automatically with every restart.
## HTML page for displaying measured values and AQI
We have already installed a lightweight webserver, `lighttpd`
. So we need to save our HTML, JavaScript, and CSS files in the directory `/var/www/html/`
so that we can access the data from another computer or smartphone. With the next three commands, we simply download the corresponding files:
```
$ wget -O /var/www/html/index.html https://raw.githubusercontent.com/zefanja/aqi/master/html/index.html
$ wget -O /var/www/html/aqi.js https://raw.githubusercontent.com/zefanja/aqi/master/html/aqi.js
$ wget -O /var/www/html/style.css https://raw.githubusercontent.com/zefanja/aqi/master/html/style.css
```
The main work is done in the JavaScript file, which opens our JSON file, takes the last value, and calculates the AQI based on this value. Then the background colors are adjusted according to the scale of the EPA.
Now you simply open the address of the Raspberry Pi in your browser and look at the current particulates values, e.g., [http://192.168.1.5:](http://192.168.1.5/)

The page is very simple and can be extended, for example, with a chart showing the history of the last hours, etc. Pull requests are welcome.
The complete [source code is available on Github](https://github.com/zefanja/aqi).
**[Enter our Raspberry Pi week giveaway for a chance at this arcade gaming kit.]**
## Wrapping up
For relatively little money, we can measure particulate matter with a Raspberry Pi. There are many possible applications, from a permanent outdoor installation to a mobile measuring device. At our school, we use both: There is a sensor that measures outdoor values day and night, and a mobile sensor that checks the effectiveness of the air conditioning filters in our classrooms.
[Luftdaten.info](http://luftdaten.info/) offers guidance to build a similar sensor. The software is delivered ready to use, and the measuring device is even more compact because it does not use a Raspberry Pi. Great project!
Creating a particulates sensor is an excellent project to do with students in computer science classes or a workshop.
What do you use a [Raspberry Pi](https://openschoolsolutions.org/shutdown-servers-case-power-failure%e2%80%8a-%e2%80%8aups-nut-co/) for?
## 6 Comments |
9,621 | DevOps 会让你失业吗? | https://opensource.com/article/17/12/will-devops-steal-my-job | 2018-05-09T00:30:18 | [
"DevOps"
] | https://linux.cn/article-9621-1.html |
>
> 你是否担心工作中自动化将代替人?可能是对的,但是这并不是件坏事。
>
>
>

这是一个很正常的担心:DevOps 最终会让你失业?毕竟,DevOps 意味着开发人员做运营,对吗?DevOps 是自动化的。如果我的工作都自动化了,我去做什么?实行持续分发和容器化意味着运营已经过时了吗?对于 DevOps 来说,所有的东西都是代码:基础设施是代码、测试是代码、这个和那个都是代码。如果我没有这些技能怎么办?
[DevOps](https://opensource.com/resources/devops) 是一个即将到来的变化,它将颠覆这一领域,狂热的拥挤者们正在谈论,如何使用 [三种方法](http://itrevolution.com/the-three-ways-principles-underpinning-devops/) 去改变世界 —— 即 DevOps 的三大基础 —— 去推翻一个旧的世界。它是势不可档的。那么,问题来了 —— DevOps 将会让我失业吗?
### 第一个担心:再也不需要我了
由于开发者来管理应用程序的整个生命周期,接受 DevOps 的理念很容易。容器化可能是影响这一想法的重要因素。当容器化在各种场景下铺开之后,它们被吹嘘成开发者构建、测试和部署他们代码的一站式解决方案。DevOps 对于运营、测试、以及 QA 团队来说,有什么作用呢?
这源于对 DevOps 原则的误解。DevOps 的第一原则,或者第一方法是,<ruby> 系统思考 <rt> Systems Thinking </rt></ruby>,或者强调整体管理方法和了解应用程序或服务的整个生命周期。这并不意味着应用程序的开发者将学习和管理整个过程。相反,是拥有各个专业和技能的人共同合作,以确保成功。让开发者对这一过程完全负责的作法,几乎是将开发者置于使用者的对立面 —— 本质上就是 “将鸡蛋放在了一个篮子里”。
在 DevOps 中有一个为你保留的专门职位。就像将一个受过传统教育的、拥有线性回归和二分查找知识的软件工程师,被用去写一些 Ansible playbooks 和 Docker 文件,这是一种浪费。而对于那些拥有高级技能,知道如何保护一个系统和优化数据库执行的系统管理员,被浪费在写一些 CSS 和设计用户流这样的工作上。写代码、做测试、和维护应用程序的高效团队一般是跨学科、跨职能的、拥有不同专业技术和背景的人组成的混编团队。
### 第二个担心:我的工作将被自动化
或许是,或许不是,DevOps 可能在有时候是自动化的同义词。当自动化构建、测试、部署、监视,以及提醒等事项,已经占据了整个应用程序生命周期管理的时候,还会给我们剩下什么工作呢?这种对自动化的关注可能与第二个方法有关:<ruby> 放大反馈循环 <rt> Amplify Feedback Loops </rt></ruby>。DevOps 的第二个方法是在团队和部署的应用程序之间,采用相反的方向优先处理快速反馈 —— 从监视和维护部署、测试、开发、等等,通过强调,使反馈更加重要并且可操作。虽然这第二种方式与自动化并不是特别相关,许多自动化工具团队在它们的部署流水线中使用,以促进快速提醒和快速行动,或者基于对使用者的支持业务中产生的反馈来改进。传统的做法是靠人来完成的,这就可以理解为什么自动化可能会导致未来一些人失业的焦虑了。
自动化只是一个工具,它并不能代替人。聪明的人使用它来做一些重复的工作,不去开发智力和创造性的财富,而是去按红色的 “George Jetson” 按钮是一种极大的浪费。让每天工作中的苦活自动化,意味着有更多的时间去解决真正的问题和即将到来的创新的解决方案。人类需要解决更多的 “怎么做和为什么” 问题,而计算机只能处理 “复制和粘贴”。
并不会仅限于在可重复的、可预见的事情上进行自动化,自动化让团队有更多的时间和精力去专注于本领域中更高级别的任务上。监视团队不再花费他们的时间去配置报警或者管理传统的配置,它们可能专注于预测可能的报警、相关性统计、以及设计可能的预案。系统管理员从计划补丁或服务器配置中解放出来,可以花费更多的时间专注于整体管理、性能、和可伸缩性。与工厂车间和装配线上完全没有人的景像不同,DevOps 中的自动化任务,意味着人更多关注于创造性的、有更高价值的任务,而不是一些重复的、让人麻木的苦差事。
### 第三个担心:我没有这些技能怎么办
“我怎么去继续做这些事情?我不懂如何自动化。现在所有的工作都是代码 —— 我不是开发人员,我不会做 DevOps 中写代码的工作”,第三个担心是一种不自信的担心。由于文化的改变,是的,团队将也会要求随之改变,一些人可能担心,他们缺乏继续做他们工作的技能。
然而,大多数人或许已经比他们所想的更接近。Dockerfile 是什么,或者像 Puppet 或 Ansible 配置管理是什么,这就是环境即代码,系统管理员已经写了 shell 脚本和 Python 程序去处理他们重复的任务。学习更多的知识并使用已有的工具处理他们的更多问题 —— 编排、部署、维护即代码 —— 尤其是当从繁重的手动任务中解放出来,专注于成长时。
在 DevOps 的使用者中去回答这第三个担心,第三个方法是:<ruby> 一种不断实验和学习的文化 <rt> A Culture of Continual Experimentation and Learning </rt></ruby>。尝试、失败,并从错误中吸取教训而不是责怪它们的能力,是设计出更有创意的解决方案的重要因素。第三个方法是为前两个方法授权 —— 允许快速检测和修复问题,并且开发人员可以自由地尝试和学习,其它的团队也是如此。从未使用过配置管理或者写过自动供给基础设施程序的运营团队也要自由尝试并学习。测试和 QA 团队也要自由实现新测试流水线,并且自动批准和发布新流程。在一个拥抱学习和成长的文化中,每个人都可以自由地获取他们需要的技术,去享受工作带来的成功和喜悦。
### 结束语
在一个行业中,任何可能引起混乱的实践或变化都会产生担心和不确定,DevOps 也不例外。对自己工作的担心是对成百上千的文章和演讲的合理回应,其中列举了无数的实践和技术,而这些实践和技术正致力于授权开发者对行业的各个方面承担职责。
然而,事实上,DevOps 是 “[一个跨学科的沟通实践,致力于研究构建、进化、和运营快速变化的弹性系统](https://theagileadmin.com/what-is-devops/)”。 DevOps 意味着终结 “筒仓”,但并不专业化。它是受委托去做苦差事的自动化系统,解放你,让你去做人类更擅长做的事:思考和想像。并且,如果你愿意去学习和成长,它将不会终结你解决新的、挑战性的问题的机会。
DevOps 会让你失业吗?会的,但它同时给你提供了更好的工作。
---
via: <https://opensource.com/article/17/12/will-devops-steal-my-job>
作者:[Chris Collins](https://opensource.com/users/clcollins) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's a common fear: Will DevOps be the end of my job? After all, DevOps means developers doing operations, right? DevOps is automation. What if I automate myself out of a job? Do continuous delivery and containers mean operations staff are obsolete? DevOps is all about coding: infrastructure-as-code and testing-as-code and this-or-that-as-code. What if I don’t have the skill set to be a part of this?
[DevOps](https://opensource.com/resources/devops) is a looming change, disruptive in the field, with seemingly fanatical followers talking about changing the world with the [Three Ways](http://itrevolution.com/the-three-ways-principles-underpinning-devops/)—the three underpinnings of DevOps—and the tearing down of walls. It can all be overwhelming. So what’s it going to be—is DevOps going to steal my job?
## The first fear: I'm not needed
As developers managing the entire lifecycle of an application, it's all too easy to get caught up in the idea of DevOps. Containers are probably a big contributing factor to this line of thought. When containers exploded onto the scene, they were touted as a way for developers to build, test, and deploy their code all-in-one. What role does DevOps leave for the operations team, or testing, or QA?
This stems from a misunderstanding of the principles of DevOps. The first principle of DevOps, or the First Way, is *Systems Thinking*, or placing emphasis on a holistic approach to managing and understanding the whole lifecycle of an application or service. This does not mean that the developers of the application learn and manage the whole process. Rather, it is the collaboration of talented and skilled individuals to ensure success as a whole. To make developers solely responsible for the process is practically the extreme opposite of this tenant—essentially the enshrining of a single silo with the importance of the entire lifecycle.
There is a place for specialization in DevOps. Just as the classically educated software engineer with knowledge of linear regression and binary search is wasted writing Ansible playbooks and Docker files, the highly skilled sysadmin with the knowledge of how to secure a system and optimize database performance is wasted writing CSS and designing user flows. The most effective group to write, test, and maintain an application is a cross-discipline, functional team of people with diverse skill sets and backgrounds.
## The second fear: My job will be automated
Accurate or not, DevOps can sometimes be seen as a synonym for automation. What work is left for operations staff and testing teams when automated builds, testing, deployment, monitoring, and notifications are a huge part of the application lifecycle? This focus on automation can be partially related to the Second Way: *Amplify Feedback Loops*. This second tenant of DevOps deals with prioritizing quick feedback between teams in the opposite direction an application takes to deployment—from monitoring and maintaining to deployment, testing, development, etc., and the emphasis to make the feedback important and actionable. While the Second Way is not specifically related to automation, many of the automation tools teams use within their deployment pipelines facilitate quick notification and quick action, or course-correction based on feedback in support of this tenant. Traditionally done by humans, it is easy to understand why a focus on automation might lead to anxiety about the future of one's job.
Automation is just a tool, not a replacement for people. Smart people trapped doing the same things over and over, pushing the big red George Jetson button are a wasted, untapped wealth of intelligence and creativity. Automation of the drudgery of daily work means more time to spend solving real problems and coming up with creative solutions. Humans are needed to figure out the "how and why;" computers can handle the "copy and paste."
There will be no end of repetitive, predictable things to automate, and automation frees teams to focus on higher-order tasks in their field. Monitoring teams, no longer spending all their time configuring alerts or managing trending configuration, can start to focus on predicting alarms, correlating statistics, and creating proactive solutions. Systems administrators, freed of scheduled patching or server configuration, can spend time focusing on fleet management, performance, and scaling. Unlike the striking images of factory floors and assembly lines totally devoid of humans, automated tasks in the DevOps world mean humans can focus on creative, rewarding tasks instead of mind-numbing drudgery.
## The third fear: I do not have the skillset for this
"How am I going to keep up with this? I don’t know how to automate. Everything is code now—do I have to be a developer and write code for a living to work in DevOps?" The third fear is ultimately a fear of self-confidence. As the culture changes, yes, teams will be asked to change along with it, and some may fear they lack the skills to perform what their jobs will become.
Most folks, however, are probably already closer than they think. What is the Dockerfile, or configuration management like Puppet or Ansible, but environment as code? System administrators already write shell scripts and Python programs to handle repetitive tasks for them. It's hardly a stretch to learn a little more and begin using some of the tools already at their disposal to solve more problems—orchestration, deployment, maintenance-as-code—especially when freed from the drudgery of manual tasks to focus on growth.
The answer to this fear lies in the third tenant of DevOps, the Third Way: *A Culture of Continual Experimentation and Learning*. The ability to try and fail and learn from mistakes without blame is a major factor in creating ever-more creative solutions. The Third Way is empowered by the first two ways—allowing for for quick detection of and repair of problems, and just as the developer is free to try and learn, other teams are as well. Operations teams that have never used configuration management or written programs to automate infrastructure provisioning are free to try and learn. Testing and QA teams are free to implement new testing pipelines and automate approval and release processes. In a culture that embraces learning and growing, everyone has the freedom to acquire the skills they need to succeed at and enjoy their job.
## Conclusion
Any disruptive practice or change in an industry can create fear or uncertainty, and DevOps is no exception. A concern for one's job is a reasonable response to the hundreds of articles and presentations enumerating the countless practices and technologies seemingly dedicated to empowering developers to take responsibility for every aspect of the industry.
In truth, however, DevOps is "[a cross-disciplinary community of practice dedicated to the study of building, evolving, and operating rapidly changing resilient systems at scale](https://theagileadmin.com/what-is-devops/)." DevOps means the end of silos, but not specialization. It is the delegation of drudgery to automated systems, freeing you to do what people do best: think and imagine. And if you're motivated to learn and grow, there will be no end of opportunities to solve new and challenging problems.
Will DevOps take away your job? Yes, but it will give you a better one.
## 2 Comments |
9,622 | 4 个 Linux 下的命令行笔记程序 | https://opensource.com/article/18/3/command-line-note-taking-applications | 2018-05-09T00:42:42 | [
"笔记"
] | https://linux.cn/article-9622-1.html |
>
> 这些工具可以让你在 Linux 命令行下简单而有效地记录笔记和保存信息。
>
>
>

当你需要保存代码段或 URL、想法或引用时,可能会启动文本编辑器或使用[桌面](https://opensource.com/life/16/9/4-desktop-note-taking-applications)或[基于 Web 的](https://opensource.com/alternatives/evernote)笔记记录工具。但那些不是你唯一的选择。如果你在终端窗口中工作,则可以使用 Linux 命令行下的许多笔记记录工具之一。
我们来看看这四个程序。
### tnote

[tnote](https://github.com/tasdikrahman/tnote) 使在终端窗口中记笔记很简单 —— 几乎太简单了。
tnote 是一个 Python 脚本。首次启动时,它会要求你输入密码和口令来加密存储笔记的 [SQLite 数据库](http://en.wikipedia.org/wiki/SQLite)。完成之后,按 `A` 创建一个笔记。输入你的笔记,然后按 `CTRL-D` 保存。
一旦你有几个(或多个)笔记,你可以查看它们或搜索特定的笔记,单词或短语或标签。tnote 没有很多功能,但它确实实现了任务。
### Terminal Velocity

如果你使用过 Mac OS,你可能会看到一个名为 [Notational Velocity](http://notational.net/) 的流行开源笔记程序,这是一种记录笔记的简单有效方法。[Terminal Velocity](https://vhp.github.io/terminal_velocity/) 在将 Notational Velocity 体验带入命令行方面做得很好。
Terminal Velocity 打开你的默认文本编辑器(由你的 `.profile` 或 `.bashrc` 文件中的 `$EDITOR` 变量设置)。输入你的笔记,然后保存。该笔记出现在 Terminal Velocity 窗口的列表中。
使用键盘上的箭头键滚动查看你的笔记列表。要查看或编辑笔记,请按回车键。如果你有一长串笔记,则可以在 `Find or Create` 字段中输入笔记标题的前几个字符以缩小列表的范围。在那里滚动笔记并按下回车键将其打开。
### pygmynote

在本文中的四个应用中,[pygmynote](https://github.com/dmpop/pygmynote) 可能是最不用户友好的。然而,它是最灵活的。
像 tnote 一样,pygmynote 将你的笔记和附件保存在 SQLite 数据库中。当你启动它时,pygmynote 看起来并不特别有用。在任何时候,输入 `help` 并按下回车键获取命令列表。
你可以添加、编辑、查看和搜索笔记,并在笔记中添加[标签](https://en.wikipedia.org/wiki/Tag_(metadata))。标签使找到笔记更容易,特别是如果你有很多笔记的时候。
pygmynote 的灵活性在于它能够将附件添加到笔记中。这些附件可以是任何东西:图像、文本、word、PDF、电子表格或与笔记相关的任何其他内容。
### jrnl

[jrnl](http://jrnl.sh/) 是这里的一个奇怪应用。正如你可能从它的名字中猜到的那样,jrnl 意在成为一种日记工具。但这并不意味着你不能记笔记。 jrnl 做得很好。
当你第一次启动 jrnl 时,它会询问你想把文件 `journal.txt` (它存储你的笔记)保存的位置以及是否需要密码保护。如果你决定添加密码,那么你在应用内的操作都需要输入密码。
你可以通过两种方式输入笔记:直接从命令行或使用计算机的默认编辑器。你可以将标签(例如,`@opensource.com`)添加到笔记中,并指定日期和时间戳。如果你有很多笔记的话,添加标签和日期可以帮助搜索你的笔记(jrnl 有一个相当不错的搜索功能)。
由于 jrnl 将你的笔记保存为纯文本文件,因此你可以使用 [ownCloud](https://owncloud.com/)、[Nextcloud](https://nextcloud.com/) 或任何你喜欢的文件共享/同步服务在设备间同步它。
你有没有喜欢的工具或自制的命令行笔记工具?请发表评论,随时与社区分享。
---
via: <https://opensource.com/article/18/3/command-line-note-taking-applications>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When you need to save a code snippet or a URL, an idea or a quote, you probably fire up a text editor or turn to a [desktop](https://opensource.com/life/16/9/4-desktop-note-taking-applications) or [web-based](https://opensource.com/alternatives/evernote) note-taking tool. But those aren't your only options. If you spend time working in terminal windows, you can use one of the many note-taking tools available for the Linux command line.
Let's take a look at four of those apps.
## tnote
[tnote](https://github.com/tasdikrahman/tnote) makes taking notes in a terminal window very simple—almost too simple.
tnote is a single Python script. When you start it for the first time, it asks you to enter a password and a passphrase to encrypt the [SQLite database](http://en.wikipedia.org/wiki/SQLite) that stores your notes. Once you've done that, press "A" to create a note. Type your note, then press CTRL-D to save it.
Once you have a few (or more than a few) notes, you can view them or search for specific ones, words or phrases, or tags. tnote doesn't pack a lot of features, but it does get the job done.
## Terminal Velocity
If you've used Mac OS, you might have come across a popular open source note-taking application called [Notational Velocity](http://notational.net/), a simple and effective way to take notes. [Terminal Velocity](https://vhp.github.io/terminal_velocity/) does a good job of bringing the Notational Velocity experience to the command line.
Terminal Velocity opens your default text editor (set by the `$EDITOR`
variable in your `.profile`
or `.bashrc`
file). Type your note, then save it. The note appears in the list in the Terminal Velocity window.
Use the arrow keys on your keyboard to scroll through your list of notes. To view or edit a note, press Enter. If you have a long list of notes, you can enter the first few characters of the note's title in the `Find or Create`
field to narrow down the list. From there, scroll to the note and press Enter to open it.
## pygmynote
Of the four applications in this article, [pygmynote](https://github.com/dmpop/pygmynote) is probably the least user-friendly. It is, however, the most flexible.
Like tnote, pygmynote saves your notes and attachments in an SQLite database. When you fire it up, pygmynote doesn’t look particularly useful. At any time, type `help`
and press Enter to get a list of commands.
You can add and edit notes, view and search for them, and add [tags](https://en.wikipedia.org/wiki/Tag_(metadata)) to your notes. Tags make finding notes easier, especially if you have a lot of them.
What gives pygmynote flexibility is its ability to add attachments to your notes. Those attachments can be anything: an image, a text or word processor file, a PDF, a spreadsheet, or anything else relevant to the note.
## jrnl
[jrnl](http://jrnl.sh/) is the odd application out here. As you've probably guessed from its name, jrnl is intended to be a journaling tool. But that doesn't mean you can't take notes with it. jrnl does that job very well.
When you first start jrnl, it asks you where you want to put the file `journal.txt`
(which stores your notes), and if you want to password-protect the file. If you decide to add a password, you need to enter it whenever you do anything with the application.
You can enter notes in two ways: directly from the command line, or with your computer's default editor. You can add tags—for example,`@opensource.com`
—to your notes, and give them a date and timestamp. Adding tags and dates can help you search for your notes (jrnl has a pretty decent search feature) if you have a lot of them.
Since jrnl saves your notes in a plain text file, you can sync it across your devices using [ownCloud](https://owncloud.com/), [Nextcloud](https://nextcloud.com/), or whatever file sharing/syncing service your prefer.
Do you have a favorite tool or hack for taking notes at the command line? Feel free to share it with the community by leaving a comment.
## 4 Comments |
9,623 | 在 Linux 上寻找你正在寻找的东西 | https://www.networkworld.com/article/3268768/linux/finding-what-you-re-looking-for-on-linux.html | 2018-05-09T08:44:00 | [
"find",
"查找",
"locate"
] | https://linux.cn/article-9623-1.html |
>
> 怎样在 Linux 系统上使用 find、locate、mlocate、which、 whereis、 whatis 和 apropos 命令寻找文件。
>
>
>

在 Linux 系统上找到你要找的文件或命令并不难, 有很多种方法可以寻找。
### find
最显然的无疑是 `find` 命令,并且 `find` 变得比过去几年更容易使用了。它过去需要一个搜索的起始位置,但是现在,如果你想将搜索限制在当下目录中,你还可以使用仅包含文件名或正则表达式的 `find` 命令。
```
$ find e*
empty
examples.desktop
```
这样,它就像 `ls` 命令一样工作,并没有做太多的搜索。
对于更专业的搜索,`find` 命令需要一个起点和一些搜索条件(除非你只是希望它提供该起点目录的递归列表)。命令 `find -type f` 从当前目录开始将递归列出所有常规文件,而 `find ~nemo -type f -empty` 将在 nemo 的主目录中找到空文件。
```
$ find ~nemo -type f -empty
/home/nemo/empty
```
参见:[11 个好玩的 Linux 终端技巧](http://www.networkworld.com/article/2926630/linux/11-pointless-but-awesome-linux-terminal-tricks.html#tk.nww-fsb)。
### locate
`locate` 命令的名称表明它与 `find` 命令基本相同,但它的工作原理完全不同。`find` 命令可以根据各种条件 —— 名称、大小、所有者、权限、状态(如空文件)等等选择文件并作为搜索选择深度,`locate` 命令通过名为 `/var/lib/mlocate/mlocate.db` 的文件查找你要查找的内容。该数据文件会定期更新,因此你刚创建的文件的位置它可能无法找到。如果这让你感到困扰,你可以运行 `updatedb` 命令立即获得更新。
```
$ sudo updatedb
```
### mlocate
`mlocate` 命令的工作类似于 `locate` 命令,它使用与 `locate` 相同的 `mlocate.db` 文件。
### which
`which` 命令的工作方式与 `find` 命令和 `locate` 命令有很大的区别。它使用你的搜索路径(`$PATH`)并检查其上的每个目录中具有你要查找的文件名的可执行文件。一旦找到一个,它会停止搜索并显示该可执行文件的完整路径。
`which` 命令的主要优点是它回答了“如果我输入此命令,将运行什么可执行文件?”的问题。它会忽略不可执行文件,并且不会列出系统上带有该名称的所有可执行文件 —— 列出的就是它找到的第一个。如果你想查找具有某个名称的所有可执行文件,则可以像这样运行 `find` 命令,但是要比非常高效 `which` 命令用更长的时间。
```
$ find / -name locate -perm -a=x 2>/dev/null
/usr/bin/locate
/etc/alternatives/locate
```
在这个 `find` 命令中,我们在寻找名为 “locate” 的所有可执行文件(任何人都可以运行的文件)。我们也选择了不要查看所有“拒绝访问”的消息,否则这些消息会混乱我们的屏幕。
### whereis
`whereis` 命令与 `which` 命令非常类似,但它提供了更多信息。它不仅仅是寻找可执行文件,它还寻找手册页(man page)和源文件。像 `which` 命令一样,它使用搜索路径(`$PATH`) 来驱动搜索。
```
$ whereis locate
locate: /usr/bin/locate /usr/share/man/man1/locate.1.gz
```
### whatis
`whatis` 命令有其独特的使命。它不是实际查找文件,而是在手册页中查找有关所询问命令的信息,并从手册页的顶部提供该命令的简要说明。
```
$ whatis locate
locate (1) - find files by name
```
如果你询问你刚刚设置的脚本,它不会知道你指的是什么,并会告诉你。
```
$ whatis cleanup
cleanup: nothing appropriate.
```
### apropos
当你知道你想要做什么,但不知道应该使用什么命令来执行此操作时,`apropos` 命令很有用。例如,如果你想知道如何查找文件,那么 `apropos find` 和 `apropos locate` 会提供很多建议。
```
$ apropos find
File::IconTheme (3pm) - find icon directories
File::MimeInfo::Applications (3pm) - Find programs to open a file by mimetype
File::UserDirs (3pm) - find extra media and documents directories
find (1) - search for files in a directory hierarchy
findfs (8) - find a filesystem by label or UUID
findmnt (8) - find a filesystem
gst-typefind-1.0 (1) - print Media type of file
ippfind (1) - find internet printing protocol printers
locate (1) - find files by name
mlocate (1) - find files by name
pidof (8) - find the process ID of a running program.
sane-find-scanner (1) - find SCSI and USB scanners and their device files
systemd-delta (1) - Find overridden configuration files
xdg-user-dir (1) - Find an XDG user dir
$
$ apropos locate
blkid (8) - locate/print block device attributes
deallocvt (1) - deallocate unused virtual consoles
fallocate (1) - preallocate or deallocate space to a file
IO::Tty (3pm) - Low-level allocate a pseudo-Tty, import constants.
locate (1) - find files by name
mlocate (1) - find files by name
mlocate.db (5) - a mlocate database
mshowfat (1) - shows FAT clusters allocated to file
ntfsfallocate (8) - preallocate space to a file on an NTFS volume
systemd-sysusers (8) - Allocate system users and groups
systemd-sysusers.service (8) - Allocate system users and groups
updatedb (8) - update a database for mlocate
updatedb.mlocate (8) - update a database for mlocate
whereis (1) - locate the binary, source, and manual page files for a...
which (1) - locate a command
```
### 总结
Linux 上可用于查找和识别文件的命令有很多种,但它们都非常有用。
---
via: <https://www.networkworld.com/article/3268768/linux/finding-what-you-re-looking-for-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,624 | 如何在 Linux 上查看用户的创建日期 | https://www.2daygeek.com/how-to-check-user-created-date-on-linux/ | 2018-05-10T11:15:55 | [
"用户"
] | https://linux.cn/article-9624-1.html | 
你知道吗,如何在 Linux 系统上查看帐户的创建日期?如果知道,那么有些什么办法。
你成功了么?如果是的话,该怎么做?
基本上 Linux 系统不会跟踪这些信息,因此,获取这些信息的替代方法是什么?
你可能会问为什么我要查看这个?
是的,在某些情况下,你可能需要查看这些信息,那时就会对你会有帮助。
可以使用以下 7 种方法进行验证。
* 使用 `/var/log/secure`
* 使用 `aureport` 工具
* 使用 `.bash_logout`
* 使用 `chage` 命令
* 使用 `useradd` 命令
* 使用 `passwd` 命令
* 使用 `last` 命令
### 方式 1:使用 /var/log/secure
它存储所有安全相关的消息,包括身份验证失败和授权特权。它还会通过系统安全守护进程跟踪 `sudo` 登录、SSH 登录和其他错误记录。
```
# grep prakash /var/log/secure
Apr 12 04:07:18 centos.2daygeek.com useradd[21263]: new group: name=prakash, GID=501
Apr 12 04:07:18 centos.2daygeek.com useradd[21263]: new user: name=prakash, UID=501, GID=501, home=/home/prakash, shell=/bin/bash
Apr 12 04:07:34 centos.2daygeek.com passwd: pam_unix(passwd:chauthtok): password changed for prakash
Apr 12 04:08:32 centos.2daygeek.com sshd[21269]: Accepted password for prakash from 103.5.134.167 port 60554 ssh2
Apr 12 04:08:32 centos.2daygeek.com sshd[21269]: pam_unix(sshd:session): session opened for user prakash by (uid=0)
```
### 方式 2:使用 aureport 工具
`aureport` 工具可以根据记录在审计日志中的事件记录生成汇总和柱状报告。默认情况下,它会查询 `/var/log/audit/` 目录中的所有 `audit.log` 文件来创建报告。
```
# aureport --auth | grep prakash
46. 04/12/2018 04:08:32 prakash 103.5.134.167 ssh /usr/sbin/sshd yes 288
47. 04/12/2018 04:08:32 prakash 103.5.134.167 ssh /usr/sbin/sshd yes 291
```
### 方式 3:使用 .bash\_logout
家目录中的 `.bash_logout` 对 bash 有特殊的含义,它提供了一种在用户退出系统时执行命令的方式。
我们可以查看用户家目录中 `.bash_logout` 的更改日期。该文件是在用户第一次注销时创建的。
```
# stat /home/prakash/.bash_logout
File: `/home/prakash/.bash_logout'
Size: 18 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 256153 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 501/ prakash) Gid: ( 501/ prakash)
Access: 2017-03-22 20:15:00.000000000 -0400
Modify: 2017-03-22 20:15:00.000000000 -0400
Change: 2018-04-12 04:07:18.283000323 -0400
```
### 方式 4:使用 chage 命令
`chage` 意即 “change age”。该命令让用户管理密码过期信息。`chage` 命令可以修改上次密码更改日期后需要更改密码的天数。
系统使用此信息来确定用户何时必须更改其密码。如果用户自帐户创建日期以来没有更改密码,这个就有用。
```
# chage --list prakash
Last password change : Apr 12, 2018
Password expires : never
Password inactive : never
Account expires : never
Minimum number of days between password change : 0
Maximum number of days between password change : 99999
Number of days of warning before password expires : 7
```
### 方式 5:使用 useradd 命令
`useradd` 命令用于在 Linux 中创建新帐户。默认情况下,它不会添加用户创建日期,我们必须使用 “备注” 选项添加日期。
```
# useradd -m prakash -c `date +%Y/%m/%d`
# grep prakash /etc/passwd
prakash:x:501:501:2018/04/12:/home/prakash:/bin/bash
```
### 方式 6:使用 passwd 命令
`passwd` 命令用于将密码分配给本地帐户或用户。如果用户在帐户创建后没有修改密码,那么可以使用 `passwd` 命令查看最后一次密码修改的日期。
```
# passwd -S prakash
prakash PS 2018-04-11 0 99999 7 -1 (Password set, MD5 crypt.)
```
### 方式 7:使用 last 命令
`last` 命令读取 `/var/log/wtmp`,并显示自该文件创建以来所有登录(和退出)用户的列表。
```
# last | grep "prakash"
prakash pts/2 103.5.134.167 Thu Apr 12 04:08 still logged in
```
---
via: <https://www.2daygeek.com/how-to-check-user-created-date-on-linux/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,625 | 在 GitLab CI 中使用 Docker 构建 Go 项目 | https://seandrumm.co.uk/blog/building-go-projects-with-docker-on-gitlab-ci/ | 2018-05-10T11:51:00 | [
"Go",
"CI",
"Docker"
] | https://linux.cn/article-9625-1.html | 
### 介绍
这篇文章是我在 CI 环境(特别是在 Gitlab 中)的 Docker 容器中构建 Go 项目的研究总结。我发现很难解决私有依赖问题(来自 Node/.NET 背景),因此这是我写这篇文章的主要原因。如果 Docker 镜像上存在任何问题或提交请求,请随时与我们联系。
### dep
由于 dep 是现在管理 Go 依赖关系的最佳选择,因此在构建前之前运行 `dep ensure`。
注意:我个人不会将我的 `vendor/` 文件夹提交到源码控制,如果你这样做,我不确定这个步骤是否可以跳过。
使用 Docker 构建的最好方法是使用 `dep ensure -vendor-only`。 [见这里](https://github.com/golang/dep/blob/master/docs/FAQ.md#how-do-i-use-dep-with-docker)。
### Docker 构建镜像
我第一次尝试使用 `golang:1.10`,但这个镜像没有:
* curl
* git
* make
* dep
* golint
我已经创建好了用于构建的镜像([github](https://github.com/sjdweb/go-docker-build/blob/master/Dockerfile) / [dockerhub](https://hub.docker.com/r/sjdweb/go-docker-build/)),我会保持更新,但我不提供任何担保,因此你应该创建并管理自己的 Dockerhub。
### 内部依赖关系
我们完全有能力创建一个有公共依赖关系的项目。但是如果你的项目依赖于另一个私人 Gitlab 仓库呢?
在本地运行 `dep ensure` 应该可以和你的 git 设置一起工作,但是一旦在 CI 上不适用,构建就会失败。
#### Gitlab 权限模型
这是在 [Gitlab 8.12 中添加的](https://docs.gitlab.com/ce/user/project/new_ci_build_permissions_model.html),这个我们最关心的有用的功能是在构建期提供的 `CI_JOB_TOKEN` 环境变量。
这基本上意味着我们可以像这样克隆[依赖仓库](https://docs.gitlab.com/ce/user/project/new_ci_build_permissions_model.html#dependent-repositories):
```
git clone https://gitlab-ci-token:${CI_JOB_TOKEN}@gitlab.com/myuser/mydependentrepo
```
然而,我们希望使这更友好一点,因为 `dep` 在试图拉取代码时不会奇迹般地添加凭据。
我们将把这一行添加到 `.gitlab-ci.yml` 的 `before_script` 部分。
```
before_script:
- echo -e "machine gitlab.com\nlogin gitlab-ci-token\npassword ${CI_JOB_TOKEN}" > ~/.netrc
```
使用 `.netrc` 文件可以指定哪个凭证用于哪个服务器。这种方法可以避免每次从 Git 中拉取(或推送)时输入用户名和密码。密码以明文形式存储,因此你不应在自己的计算机上执行此操作。这实际用于 Git 在背后使用 `cURL`。 [在这里阅读更多](https://github.com/bagder/everything-curl/blob/master/usingcurl-netrc.md)。
### 项目文件
#### Makefile
虽然这是可选的,但我发现它使事情变得更容易。
配置这些步骤意味着在 CI 脚本(和本地)中,我们可以运行 `make lint`、`make build` 等,而无需每次重复步骤。
```
GOFILES = $(shell find . -name '*.go' -not -path './vendor/*')
GOPACKAGES = $(shell go list ./... | grep -v /vendor/)
default: build
workdir:
mkdir -p workdir
build: workdir/scraper
workdir/scraper: $(GOFILES)
GOOS=linux GOARCH=amd64 CGO_ENABLED=0 go build -o workdir/scraper .
test: test-all
test-all:
@go test -v $(GOPACKAGES)
lint: lint-all
lint-all:
@golint -set_exit_status $(GOPACKAGES)
```
#### .gitlab-ci.yml
这是 Gitlab CI 魔术发生的地方。你可能想使用自己的镜像。
```
image: sjdweb/go-docker-build:1.10
stages:
- test
- build
before_script:
- cd $GOPATH/src
- mkdir -p gitlab.com/$CI_PROJECT_NAMESPACE
- cd gitlab.com/$CI_PROJECT_NAMESPACE
- ln -s $CI_PROJECT_DIR
- cd $CI_PROJECT_NAME
- echo -e "machine gitlab.com\nlogin gitlab-ci-token\npassword ${CI_JOB_TOKEN}" > ~/.netrc
- dep ensure -vendor-only
lint_code:
stage: test
script:
- make lint
unit_tests:
stage: test
script:
- make test
build:
stage: build
script:
- make
```
### 缺少了什么
我通常会用我的二进制文件构建 Docker 镜像,并将其推送到 Gitlab 容器注册库中。
你可以看到我正在构建二进制文件并退出,你至少需要将该二进制文件(例如生成文件)存储在某处。
---
via: <https://seandrumm.co.uk/blog/building-go-projects-with-docker-on-gitlab-ci/>
作者:[SEAN DRUMM](https://seandrumm.co.uk/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,626 | Red Hat 的去 Docker 化容器实践 | https://anarc.at/blog/2017-12-20-docker-without-docker/ | 2018-05-10T12:24:36 | [
"容器"
] | https://linux.cn/article-9626-1.html | 
最近几年,开源项目 Docker (已更名为[Moby](https://mobyproject.org/)) 在容器普及化方面建树颇多。然而,它的功能特性不断集中到一个单一、庞大的系统,该系统由具有 root 权限运行的守护进程 `dockerd` 管控,这引发了人们的焦虑。对这些焦虑的阐述,具有代表性的是 Red Hat 公司的容器团队负责人 Dan Walsh 在 [KubeCon + CloudNativecon](http://events.linuxfoundation.org/events/kubecon-and-cloudnativecon-north-america) 会议中的[演讲](https://kccncna17.sched.com/event/CU8j/cri-o-hosted-by-daniel-walsh-red-hat)。Walsh 讲述了他的容器团队目前的工作方向,即使用一系列更小、可协同工作的组件替代 Docker。他的战斗口号是“拒绝臃肿的守护进程”,理由是与公认的 Unix 哲学相违背。
### Docker 模块化实践
就像我们在[早期文献](https://lwn.net/Articles/741897/)中看到的那样,容器的基础操作不复杂:你首先拉取一个容器镜像,利用该镜像创建一个容器,最后启动这个容器。除此之外,你要懂得如何构建镜像并推送至镜像仓库。大多数人在上述这些步骤中使用 Docker,但其实 Docker 并不是唯一的选择,目前的可替换选择是 `rkt`。rkt 引发了一系列标准的创建,包括运行时标准 CRI,镜像标准 OCI 及网络标准 CNI 等。遵守这些标准的后端,如 [CRI-O](http://cri-o.io/) 和 Docker,可以与 [Kubernetes](https://kubernetes.io/) 为代表的管理软件协同工作。
这些标准促使 Red Hat 公司开发了一系列实现了部分标准的“核心应用”供 Kubernetes 使用,例如 CRI-O 运行时。但 Kubernetes 提供的功能不足以满足 Red Hat 公司的 [OpenShift](https://www.openshift.com/) 项目所需。开发者可能需要构建容器并推送至镜像仓库,实现这些操作需要额外的一整套方案。
事实上,目前市面上已有多种构建容器的工具。来自 Sysdig 公司的 Michael Ducy 在[分会场](https://kccncna17.sched.com/event/CU6B/building-better-containers-a-survey-of-container-build-tools-i-michael-ducy-chef)中回顾了 Docker 本身之外的 8 种镜像构建工具,而这也很可能不是全部。Ducy 将理想的构建工具定义如下:可以用可重现的方式创建最小化镜像。最小化镜像并不包含操作系统,只包含应用本身及其依赖。Ducy 认为 [Distroless](https://github.com/GoogleCloudPlatform/distroless), [Smith](https://github.com/oracle/smith) 及 [Source-to-Image](https://github.com/openshift/source-to-image) 都是很好的工具,可用于构建最小化镜像。Ducy 将最小化镜像称为“微容器”。
<ruby> 可重现镜像 <rt> reproducible container </rt></ruby>是指构建多次结果保持不变的镜像。为达到这个目标,Ducy 表示应该使用“宣告式”而不是“命令式”的方式。考虑到 Ducy 来自 Chef 配置管理工具领域,你应该能理解他的意思。Ducy 给出了符合标准的几个不错的实现,包括 [Ansible 容器](https://www.ansible.com/ansible-container)、 [Habitat](https://www.habitat.sh/)、 [nixos-容器](https://nixos.org/nixos/manual/#ch-containers)和 [Simth](https://github.com/oracle/smith) 等,但你需要了解这些项目对应的编程语言。Ducy 额外指出 Habitat 构建的容器自带管理功能,如果你已经使用了 systemd、 Docker 或 Kubernetes 等外部管理工具,Habitat 的管理功能可能是冗余的。除此之外,我们还要提到从 Docker 和 [Buildah](https://github.com/projectatomic/buildah) 项目诞生的新项目 [BuildKit](https://github.com/moby/buildkit), 它是 Red Hat 公司 [Atomic 工程](https://www.projectatomic.io/)的一个组件。
### 使用 Buildah 构建容器
![\[Buildah logo\]](/data/attachment/album/201805/10/122437qhminlii9nhbwbbw.png "Buildah logo")
Buildah 名称显然来自于 Walsh 风趣的 [波士顿口音](https://en.wikipedia.org/wiki/Boston_accent); 该工具的品牌宣传中充满了波士顿风格,例如 logo 使用了波士顿梗犬(如图所示)。该项目的实现思路与 Ducy 不同:为了构建容器,与其被迫使用宣告式配置管理的方案,不如构建一些简单工具,结合你最喜欢的配置管理工具使用。这样你可以如愿的使用命令行,例如使用 `cp` 命令代替 Docker 的自定义指令 `COPY` 。除此之外,你可以使用如下工具为容器提供内容:1) 配置管理工具,例如Ansible 或 Puppet;2) 操作系统相关或编程语言相关的安装工具,例如 APT 和 pip; 3) 其它系统。下面展示了基于通用 shell 命令的容器构建场景,其中只需要使用 `make` 命令即可为容器安装可执行文件。
```
# 拉取基础镜像, 类似 Dockerfile 中的 FROM 命令
buildah from redhat
# 挂载基础镜像, 在其基础上工作
crt=$(buildah mount)
ap foo $crt
make install DESTDIR=$crt
# 下一步,生成快照
buildah commit
```
有趣的是,基于这个思路,你可以复用主机环境中的构建工具,无需在镜像中安装这些依赖,故可以构建非常微小的镜像。通常情况下,构建容器镜像时需要在容器中安装目标应用的构建依赖。例如,从源码构建需要容器中有编译器工具链,这是因为构建并不在主机环境进行。大量的容器也包含了 `ps` 和 `bash` 这样的 Unix 命令,对微容器而言其实是多余的。开发者经常忘记或无法从构建好的容器中移除一些依赖,增加了不必要的开销和攻击面。
Buildah 的模块化方案能够以非 root 方式进行部分构建;但`mount` 命令仍然需要 `CAP_SYS_ADMIN`,有一个 [工单](https://github.com/projectatomic/buildah/issues/171) 试图解决该问题。但 Buildah 与 Docker [都有](https://github.com/projectatomic/buildah/issues/158)同样的[限制](https://github.com/moby/moby/issues/27886#issuecomment-281278525),即无法在容器内构建容器。对于 Docker,你需要使用“特权”模式运行容器,一些特殊的环境很难满足这个条件,例如 [GitLab 持续集成](https://about.gitlab.com/features/gitlab-ci-cd/);即使满足该条件,配置也特别[繁琐](https://jpetazzo.github.io/2015/09/03/do-not-use-docker-in-docker-for-ci/)。
手动提交的步骤可以对创建容器快照的时间节点进行细粒度控制。Dockerfile 每一行都会创建一个新的快照;相比而言,Buildah 的提交检查点都是事先选择好的,这可以减少不必要的快照并节省磁盘空间。这也有利于隔离私钥或密码等敏感信息,避免其出现在公共镜像中。
Docker 构建的镜像是非标准的、仅供其自身使用;相比而言,Buildah 提供[多种输出格式](https://github.com/projectatomic/buildah/blob/master/docs/buildah-push.md),其中包括符合 OCI 标准的镜像。为向后兼容,Buildah 提供了一个“使用 Dockerfile 构建”的命令,即 [`buildah bud`](https://github.com/projectatomic/buildah/blob/master/docs/buildah-bud.md), 它可以解析标准的 Dockerfile。Buildah 提供 `enter` 命令直接查看镜像内部信息,`run` 命令启动一个容器。实现这些功能仅使用了 `runc` 在内的标准工具,无需在后台运行一个“臃肿的守护进程”。
Ducy 对 Buildah 表示质疑,认为采用非宣告性不利于可重现性。如果允许使用 shell 命令,可能产生很多预想不到的情况;例如,一个 shell 脚本下载了任意的可执行程序,但后续无法追溯文件的来源。shell 命令的执行受环境变量影响,执行结果可能大相径庭。与基于 shell 的工具相比,Puppet 或 Chef 这样的配置管理系统在理论上更加可靠,因为它们的设计初衷就是收敛于最终配置;事实上,可以通过配置管理系统调用 shell 命令。但 Walsh 对此提出反驳,认为已有的配置管理工具可以在 Buildah 的基础上工作,用户可以选择是否使用配置管理;这样更加符合“机制与策略分离”的经典 Unix 哲学。
目前 Buildah 处于测试阶段,Red Hat 公司正努力将其集成到 OpenShift。我写这篇文章时已经测试过 Buildah,它缺少一些文档,但基本可以稳定运行。尽管在错误处理方面仍有待提高,但它确实是一款值得你关注的容器工具。
### 替换其它 Docker 命令行
Walsh 在其演讲中还简单介绍了 Red hat 公司 正在开发的另一个暂时叫做 [libpod](https://jpetazzo.github.io/2015/09/03/do-not-use-docker-in-docker-for-ci/) 的项目。项目名称来源于 Kubernetes 中的 “pod”, 在 Kubernetes 中 “pod” 用于分组主机内的容器,分享名字空间等。
Libpod 提供 `kpod` 命令,用于直接检查和操作容器存储。Walsh 分析了该命令发挥作用的场景,例如 `dockerd` 停止响应或 Kubernetes 集群崩溃。基本上,`kpod` 独立地再次实现了 `docker` 命令行工具。`kpod ps` 返回运行中的容器列表,`kpod images` 返回镜像列表。事实上,[命令转换速查手册](https://github.com/projectatomic/libpod/blob/master/transfer.md#development-transfer) 中给出了每一条 Docker 命令对应的 `kpod` 命令。
这种模块化实现的一个好处是,当你使用 `kpod run` 运行容器时,容器直接作为当前 shell 而不是 `dockerd` 的子进程启动。理论上,可以直接使用 systemd 启动容器,这样可以消除 `dockerd` 引入的冗余。这让[由套接字激活的容器](http://0pointer.de/blog/projects/socket-activated-containers.html)成为可能,但暂时基于 Docker 实现该特性[并不容易](https://legacy-developer.atlassian.com/blog/2015/03/docker-systemd-socket-activation/),[即使借助 Kubernetes](https://github.com/kubernetes/kubernetes/issues/484) 也是如此。但我在测试过程中发现,使用 `kpod` 启动的容器有一些基础功能性缺失,具体而言是网络功能(!),相关实现在[活跃开发](https://github.com/projectatomic/libpod/issues/129)过程中。
我们最后提到的命令是 `push`。虽然上述命令已经足以满足本地使用容器的需求,但没有提到远程仓库,借助远程仓库开发者可以活跃地进行应用打包协作。仓库也是持续部署框架的核心组件。[skopeo](https://github.com/projectatomic/skopeo) 项目用于填补这个空白,它是另一个 Atomic 成员项目,按其 `README` 文件描述,“包含容器镜像及镜像库的多种操作”。该项目的设计初衷是,在不用类似 `docker pull` 那样实际去下载可能体积庞大的镜像的前提下,检查容器镜像的内容。Docker [拒绝加入](https://github.com/moby/moby/pull/14258) 检查功能,建议通过一个额外的工具实现该功能,这促成了 Skopeo 项目。除了 `pull`、`push`,Skopeo 现在还可以完成很多其它操作,例如在,不产生本地副本的情况下将镜像在不同的仓库中复制和转换。由于部分功能比较基础,可供其它项目使用,目前很大一部分 Skopeo 代码位于一个叫做 [containers/image](https://github.com/containers/image) 的基础库。[Pivotal](https://pivotal.io/)、 Google 的 [container-diff](https://github.com/GoogleCloudPlatform/container-diff) 、`kpod push` 及 `buildah push` 都使用了该库。
`kpod` 与 Kubernetes 并没有紧密的联系,故未来可能会更换名称(事实上,在本文刊发过程中,已经更名为 [`podman`](https://github.com/projectatomic/libpod/blob/master/docs/podman.1.md)),毕竟 Red Hat 法务部门还没有明确其名称。该团队希望实现更多 pod 级别的命令,这样可以对多个容器进行操作,有点类似于 [`docker compose`](https://docs.docker.com/compose/overview/#compose-documentation) 实现的功能。但在这方面,[Kompose](http://kompose.io/) 是更好的工具,可以通过 [复合 YAML 文件](https://docs.docker.com/compose/compose-file/) 在 Kubernetes 集群中运行容器。按计划,我们不会实现类似于 [`swarm`] 的 Docker 命令,这部分功能最好由 Kubernetes 本身完成。
目前看来,已经持续数年的 Docker 模块化努力终将硕果累累。但目前 `kpod` 处于快速迭代过程中,不太适合用于生产环境,不过那些工具的与众不同的设计理念让人很感兴趣,而且其中大部分的工具已经可以用于开发环境。目前只能通过编译源码的方式安装 libpod,但最终会提供各个发行版的二进制包。
>
> 本文[最初发表](https://lwn.net/Articles/741841/)于 [Linux Weekly News](http://lwn.net/)。
>
>
>
---
via: <https://anarc.at/blog/2017-12-20-docker-without-docker/>
作者:[Anarcat](https://anarc.at) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Containers without Docker at Red Hat
This is one part of my coverage of KubeCon Austin 2017. Other articles include:
[An overview of KubeCon + CloudNativeCon]- Docker without Docker at Red Hat (this article)
[Demystifying Container Runtimes][Monitoring with Prometheus 2.0][Changes in Prometheus 2.0][The cost of hosting in the cloud]
The Docker (now [Moby](https://mobyproject.org/)) project has done a lot
to popularize containers in recent years. Along the way, though, it has
generated concerns about its concentration of functionality into a
single, monolithic system under the control of a single daemon running
with root privileges: `dockerd`
. Those concerns were reflected in a
[talk](https://kccncna17.sched.com/event/CU8j/cri-o-hosted-by-daniel-walsh-red-hat)
by Dan Walsh, head of the container team at Red Hat, at [KubeCon +
CloudNativeCon](http://events.linuxfoundation.org/events/kubecon-and-cloudnativecon-north-america).
Walsh spoke about the work the container team is doing to replace Docker
with a set of smaller, interoperable components. His rallying cry is "no
big fat daemons" as he finds them to be contrary to the venerated Unix
philosophy.
# The quest to modularize Docker
As we saw in an [earlier article](../2017-12-20-demystifying-container-runtimes/), the
basic set of container operations is not that complicated: you need to
pull a container image, create a container from the image, and start it.
On top of that, you need to be able to build images and push them to a
registry. Most people still use Docker for all of those steps but, as it
turns out, Docker isn't the only name in town anymore: an early
alternative was `rkt`
, which led to the creation of various standards
like CRI (runtime), OCI (image), and CNI (networking) that allow
backends like [CRI-O](http://cri-o.io/) or Docker to interoperate with,
for example, [Kubernetes](https://kubernetes.io/).
These standards led Red Hat to create a set of "core utils" like the
CRI-O runtime that implements the parts of the standards that Kubernetes
needs. But Red Hat's [OpenShift](https://www.openshift.com/) project
needs more than what Kubernetes provides. Developers will want to be
able to build containers and push them to the registry. Those operations
need a whole different bag of tricks.
It turns out that there are multiple tools to build containers right
now. Apart from Docker itself, a
[session](https://kccncna17.sched.com/event/CU6B/building-better-containers-a-survey-of-container-build-tools-i-michael-ducy-chef)
from Michael Ducy of Sysdig reviewed eight image builders, and that's
probably not all of them. Ducy identified the ideal build tool as one
that would create a minimal image in a reproducible way. A minimal image
is one where there is no operating system, only the application and its
essential dependencies. Ducy identified
[Distroless](https://github.com/GoogleCloudPlatform/distroless),
[Smith](https://github.com/oracle/smith), and
[Source-to-Image](https://github.com/openshift/source-to-image) as good
tools to build minimal images, which he called "micro-containers".
A reproducible container is one that you can build multiple times and
always get the same result. For that, Ducy said you have to use a
"declarative" approach (as opposed to "imperative"), which is
understandable given that he comes from the Chef
configuration-management world. He gave the examples of [Ansible
Container](https://www.ansible.com/ansible-container),
[Habitat](https://www.habitat.sh/),
[nixos-container](https://nixos.org/nixos/manual/#ch-containers), and
Smith (yes, again) as being good approaches, provided you were familiar
with their domain-specific languages. He added that Habitat ships its
own supervisor in its containers, which may be superfluous if you
already have an external one, like systemd, Docker, or Kubernetes. To
complete the list, we should mention the new
[BuildKit](https://github.com/moby/buildkit) from Docker and
[Buildah](https://github.com/projectatomic/buildah), which is part of
Red Hat's [Project Atomic](https://www.projectatomic.io/).
# Building containers with Buildah
Buildah's name apparently comes from Walsh's colorful
[Boston
accent](https://en.wikipedia.org/wiki/Boston_accent); the Boston theme
permeates the branding of the tool: the logo, for example, is a Boston
terrier dog (seen at right). This project takes a different approach
from Ducy's decree: instead of enforcing a declarative
configuration-management approach to containers, why not build simple
tools that can be used by your favorite configuration-management tool?
If you want to use regular command-line commands like `cp`
(instead of
Docker's custom `COPY`
directive, for example), you can. But you can
also use Ansible or Puppet, OS-specific or language-specific installers
like APT or pip, or whatever other system to provision the content of
your containers. This is what building a container looks like with
regular shell commands and simply using `make`
to install a binary
inside the container:
```
# pull a base image, equivalent to a Dockerfile's FROM command
buildah from redhat
# mount the base image to work on it
crt=$(buildah mount)
cp foo $crt
make install DESTDIR=$crt
# then make a snapshot
buildah commit
```
An interesting thing with this approach is that, since you reuse normal
build tools from the host environment, you can build really minimal
images because you don't need to install all the dependencies in the
image. Usually, when building a container image, the target application
build dependencies need to be installed within the container. For
example, building from source usually requires a compiler toolchain in
the container, because it is not meant to access the host environment. A
lot of containers will also ship basic Unix tools like `ps`
or `bash`
which are not actually necessary in a micro-container. Developers often
forget to (or simply can't) remove some dependencies from the built
containers; that common practice creates unnecessary overhead and attack
surface.
The modular approach of Buildah means you can run at least parts of the
build as non-root: the `mount`
command still needs the `CAP_SYS_ADMIN`
capability, but there is an
[issue](https://github.com/projectatomic/buildah/issues/171) open to
resolve this. However, Buildah
[shares](https://github.com/projectatomic/buildah/issues/158) the same
[limitation](https://github.com/moby/moby/issues/27886#issuecomment-281278525)
as Docker in that it can't build containers inside containers. For
Docker, you need to run the container in "privileged" mode, which is not
possible in certain environments (like [GitLab Continuous
Integration](https://about.gitlab.com/features/gitlab-ci-cd/), for
example) and, even when it is possible, the configuration is
[messy](https://jpetazzo.github.io/2015/09/03/do-not-use-docker-in-docker-for-ci/)
at best.
The manual commit step allows fine-grained control over when to create container snapshots. While in a Dockerfile every line creates a new snapshot, with Buildah commit checkpoints are explicitly chosen, which reduces unnecessary snapshots and saves disk space. This is useful to isolate sensitive material like private keys or passwords which sometimes mistakenly end up in public images as well.
While Docker builds non-standard, Docker-specific images, Buildah
produces standard OCI images among [other output
formats](https://github.com/projectatomic/buildah/blob/master/docs/buildah-push.md).
For backward compatibility, it has a command called
`build-using-dockerfile`
or
[ buildah bud](https://github.com/projectatomic/buildah/blob/master/docs/buildah-bud.md)
that parses normal Dockerfiles. Buildah has a
`enter`
command to inspect
images from the inside directly and a `run`
command to start containers
on the fly. It does all the work without any "fat daemon" running in the
background and uses standard tools like `runc`
.Ducy's criticism of Buildah was that it was not declarative, which made
it less reproducible. When allowing shell commands anything can happen:
for example, a shell script might download arbitrary binaries, without
any way of subsequently retracing where those come from. Shell command
effects may vary according to the environment. In contrast to
shell-based tools, configuration-management systems like Puppet or Chef
are designed to "converge" over a final configuration that is more
reliable, at least in theory: in practice you can call shell commands
from configuration-management systems. Walsh, however, argued that
existing configuration management *can* be used on top of Buildah, but
it doesn't *force* users down that path. This fits well with the classic
"separation" principle of the Unix philosophy ("mechanism not policy").
At this point, Buildah is in beta and Red Hat is working on integrating it into OpenShift. I have tested Buildah while writing this article and, short of some documentation issues, it generally works reliably. It could use some polishing in error handling, but it is definitely a great asset to add to your container toolbox.
# Replacing the rest of the Docker command-line
Walsh continued his presentation by giving an overview of another
project that Red Hat is working on, tentatively called
[libpod](https://github.com/projectatomic/libpod). The name derives from
a "pod" in Kubernetes, which is a way to group containers inside a host,
to share namespaces, for example.
Libpod includes the `kpod`
command to inspect and manipulate container
storage directly. Walsh explained this can be useful if, for example,
`dockerd`
hangs or if a Kubernetes cluster crashes. `kpod`
is basically
an independent re-implementation of the `docker`
command-line tool.
There is a command to list running containers (`kpod ps`
) or images
(`kpod images`
). In fact, there is a [translation cheat
sheet](https://github.com/projectatomic/libpod/blob/master/transfer.md#development-transfer)
documenting all Docker commands with a `kpod`
equivalent.
One of the nice things with the modular approach is that when you run a
container with `kpod run`
, the container is directly started as a
subprocess of the current shell, instead of a subprocess of `dockerd`
.
In theory, this allows running containers directly from systemd,
removing the duplicate work `dockerd`
is doing. It enables things like
[socket-activated
containers](http://0pointer.de/blog/projects/socket-activated-containers.html),
which is something that is [not
straightforward](https://legacy-developer.atlassian.com/blog/2015/03/docker-systemd-socket-activation/)
to do with Docker, or [even with
Kubernetes](https://github.com/kubernetes/kubernetes/issues/484) right
now. In my experiments, however, I have found that containers started
with `kpod`
lack some fundamental functionality, namely networking (!),
although there is an [issue in
progress](https://github.com/projectatomic/libpod/issues/129) to
complete that implementation.
A final command we haven't covered is `push`
. While the above commands
provide a good process for working with local containers, they don't
cover remote registries, which allow developers to actively collaborate
on application packaging. Registries are also an essential part of a
continuous-deployment framework. This is where the
[skopeo](https://github.com/projectatomic/skopeo) project comes in.
Skopeo is another Atomic project that "performs various operations on
container images and image repositories", according to the `README`
file. It was originally designed to inspect the contents of container
registries without actually downloading the sometimes voluminous images
as `docker pull`
does. Docker [refused
patches](https://github.com/moby/moby/pull/14258) to support inspection,
suggesting the creation of a separate tool, which led to Skopeo. After
`pull`
, `push`
was the logical next step and Skopeo can now do a bunch
of other things like copying and converting images between registries
without having to store a copy locally. Because this functionality was
useful to other projects as well, a lot of the Skopeo code now lives in
a reusable library called
[containers/image](https://github.com/containers/image). That library is
in turn used by [Pivotal](https://pivotal.io/), Google's
[container-diff](https://github.com/GoogleCloudPlatform/container-diff),
`kpod push`
, and `buildah push`
.
`kpod`
is not directly tied to Kubernetes, so the name might change in
the future — especially since Red Hat legal has not cleared the name
yet. (In fact, just as this article was going to "press", the name was
changed to
[ podman](https://github.com/projectatomic/libpod/blob/master/docs/podman.1.md).)
The team wants to implement more "pod-level" commands which would allow
operations on multiple containers, a bit like what
[might do. But at that level, a better tool might be](https://docs.docker.com/compose/overview/#compose-documentation)
`docker compose`
[Kompose](http://kompose.io/)which can execute
[Compose YAML files](https://docs.docker.com/compose/compose-file/)into a Kubernetes cluster. Some Docker commands (like
[) will never be implemented, on purpose, as they are best left for Kubernetes itself to handle.](https://docs.docker.com/engine/swarm/)
`swarm`
It seems that the effort to modularize Docker that started a few years
ago is finally bearing fruit. While, at this point, `kpod`
is under
heavy development and probably should not be used in production, the
design of those different tools is certainly interesting; a lot of it is
ready for development environments. Right now, the only way to install
libpod is to compile it from source, but we should expect packages
coming out for your favorite distribution eventually.
This article[first appeared]in the[Linux Weekly News].
[Edited .](https://gitlab.com/anarcat/anarc.at/-/commits/main/blog/2017-12-20-docker-without-docker.mdwn) |
9,627 | 在 Ubuntu 和 Linux Mint 中轻松安装 Android Studio | https://itsfoss.com/install-android-studio-ubuntu-linux/ | 2018-05-10T22:48:27 | [
"Android",
"Eclipse"
] | https://linux.cn/article-9627-1.html | [Android Studio](http://developer.android.com/sdk/installing/studio.html) 是谷歌自己的 Android 开发 IDE,是带 ADT 插件的 Eclipse 的不错替代品。Android Studio 可以通过源代码安装,但在这篇文章中,我们将看到**如何在 Ubuntu 18.04、16.04 和相应的 Linux Mint 变体**中安装 Android Studio。
在继续安装 Android Studio 之前,请确保你已经[在 Ubuntu 中安装了 Java](https://itsfoss.com/install-java-ubuntu-1404/)。

### 使用 Snap 在 Ubuntu 和其他发行版中安装 Android Studio
自从 Ubuntu 开始专注于 Snap 软件包以来,越来越多的软件开始提供易于安装的 Snap 软件包。Android Studio 就是其中之一。Ubuntu 用户可以直接在软件中心找到 Android Studio 程序并从那里安装。

如果你在软件中心安装 Android Studio 时看到错误,则可以使用 [Snap 命令](https://itsfoss.com/install-snap-linux/) 安装 Android Studio。
```
sudo snap install android-studio --classic
```
非常简单!
### 另一种方式 1:在 Ubuntu 中使用 umake 安装 Android Studio
你也可以使用 Ubuntu Developer Tools Center,现在称为 [Ubuntu Make](https://wiki.ubuntu.com/ubuntu-make),轻松安装 Android Studio。Ubuntu Make 提供了一个命令行工具来安装各种开发工具和 IDE 等。Ubuntu Make 在 Ubuntu 仓库中就有。
要安装 Ubuntu Make,请在终端中使用以下命令:
```
sudo apt-get install ubuntu-make
```
安装 Ubuntu Make 后,请使用以下命令在 Ubuntu 中安装 Android Studio:
```
umake android
```
在安装过程中它会给你的几个选项。我认为你可以处理。如果你决定卸载 Android Studio,则可以按照以下方式使用相同的 umake 工具:
```
umake android --remove
```
### 另一种方式 2:通过非官方的 PPA 在 Ubuntu 和 Linux Mint 中安装 Android Studio
感谢 [Paolo Ratolo](https://plus.google.com/+PaoloRotolo),我们有一个 PPA,可用于 Ubuntu 16.04、14.04、Linux Mint 和其他基于 Ubuntu 的发行版中轻松安装 Android Studio。请注意,它将下载大约 650MB 的数据。请注意你的互联网连接以及数据费用(如果有的话)。
打开一个终端并使用以下命令:
```
sudo apt-add-repository ppa:paolorotolo/android-studio
sudo apt-get update
sudo apt-get install android-studio
```
这不容易吗?虽然从源代码安装程序很有趣,但拥有这样的 PPA 总是不错的。我们看到了如何安装 Android Studio,现在来看看如何卸载它。
### 卸载 Android Studio:
如果你还没有安装 PPA Purge:
```
sudo apt-get install ppa-purge
```
现在使用 PPA Purge 来清除已安装的 PPA:
```
sudo apt-get remove android-studio
sudo ppa-purge ppa:paolorotolo/android-studio
```
就是这些了。我希望这能够帮助你**在 Ubuntu 和 Linux Mint 上安装 Android Studio**。在运行 Android Studio 之前,请确保[在 Ubuntu 中安装了Java](https://itsfoss.com/install-java-ubuntu-1404/ "How To Install Java On Ubuntu 14.04")。在类似的文章中,我建议你阅读[如何安装和配置 Ubuntu SDK](https://itsfoss.com/install-configure-ubuntu-sdk/) 和[如何在 Ubuntu 中轻松安装 Microsoft Visual Studio](https://itsfoss.com/install-visual-studio-code-ubuntu/)。
欢迎提出任何问题或建议。再见 :)
---
via: <https://itsfoss.com/install-android-studio-ubuntu-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Android Studio](https://developer.android.com/studio?ref=itsfoss.com), Google’s own IDE for Android development, is a nice alternative to Eclipse with ADT plugin.
The additional advantage of Android Studio is that even if you are not developing apps, create an Android device emulator, which can run popular apps for you.
So, even if it is a workaround, you can [run Android apps on Linux](https://itsfoss.com/android-emulators-linux/) using Android Studio.
In Linux, there is no native package for Android studio that you can install using the package managers like APT.
**To install, you either need to rely on the snap package or install it as mentioned in the official documentation. Both the method will be discussed here. Ubuntu users have a PPA to help them out.**
You have to be careful about the minimum system requirements.
- Any 64-bit Linux distribution that supports GNOME, KDE, or Unity DE; GNU C Library (glibc) 2.31 or later.
- At least 8 GB RAM (16 GB is better) and 8 GB disk space (16 GB or more is better)
- x86_64 CPU architecture; 2nd generation Intel Core or newer, or AMD processor with support for AMD Virtualization (AMD-V) and SSSE3.
[Enable KVM in Ubuntu](https://itsfoss.com/qemu-ubuntu/), for better performance.- A screen resolution of 1920 x 1080 or more
[Java installed in Ubuntu](https://itsfoss.com/install-java-ubuntu/).
## Method 1: Install Android Studio in Ubuntu as a Snap (Easiest)
Ever since Ubuntu started focusing on Snap packages, more software have started providing easy to install Snap packages. Android Studio is one of them. Ubuntu users can find the Android Studio application in the Software Center and install it from there.
If you see an error while installing Android Studio from Software Center, you can use the [Snap commands](https://itsfoss.com/install-snap-linux/) to install Android studio.
```
sudo snap install android-studio --classic
```
### Remove Android Studio Snap
To remove Android Studio, installed as a snap, either use the “Remove” button on Software center or use the command below:
```
sudo snap remove android-studio
```
Easy-peasy!
## Method 2: Install Android Studio in Ubuntu and Linux Mint via unofficial PPA
Thanks to [Paolo Ratolo](https://plus.google.com/+PaoloRotolo?ref=itsfoss.com), and [maarten-fonville](https://github.com/mfonville/android-studio?ref=itsfoss.com) we have a PPA which can be used to easily install Android Studio in Ubuntu, Linux Mint and other Ubuntu-based distributions. Just note that it will download around several hundred MBs of data. So, mind your internet connection as well as data charges (if any).
Open a terminal and use the following commands to install dependencies and libraries and Java.
```
sudo apt-get install libc6:i386 libncurses5:i386 libstdc++6:i386 lib32z1 libbz2-1.0:i386
sudo apt install openjdk-11-jdk
```
In the above step, we have installed Java required for the app to run. Now, [add the PPA](https://itsfoss.com/ppa-guide/) and install Android Studio.
```
sudo add-apt-repository ppa:maarten-fonville/android-studio
sudo apt update
sudo apt install android-studio
```
This will install Android Studio and you can open it from the system menu. Once opened, the remaining setup is described in the method 3.
Was it not easy? While installing a program from source code is fun in a way, it is always nice to have such PPAs. Once we have seen how to install Android Studio, let's see how to uninstall it.
### Remove Android Studio
First remove the Android Studio installed using:
```
sudo apt purge android-studio
```
If you don’t have already, install PPA Purge:
```
sudo apt install ppa-purge
```
Now use the PPA Purge to purge the installed PPA:
## Method 3: Install Android Studio in any Linux Distributions using the official method (Complicated)
Android Studio has a package that will help you easily install it on a Linux system. You should make sure that, the minimum requirements mentioned in the previous section are met.
### Set up the required dependencies and prerequisites
To install from the official files, you need to install some prerequisite libraries and dependencies.
For Debian/Ubuntu-based systems, use the command below:
`sudo apt-get install libc6:i386 libncurses5:i386 libstdc++6:i386 lib32z1 libbz2-1.0:i386`
If you are using Fedora, use the command as given below:
`sudo yum install zlib.i686 ncurses-libs.i686 bzip2-libs.i686`
### Download the Installer File
Android studio provides official files to install the software on Linux distributions. You need to go to the official downloads page and download the installer files.
This will ask you to accept their Terms and Conditions. Scroll down the page and check the Accept button. Now, click on the Download button to start your download.
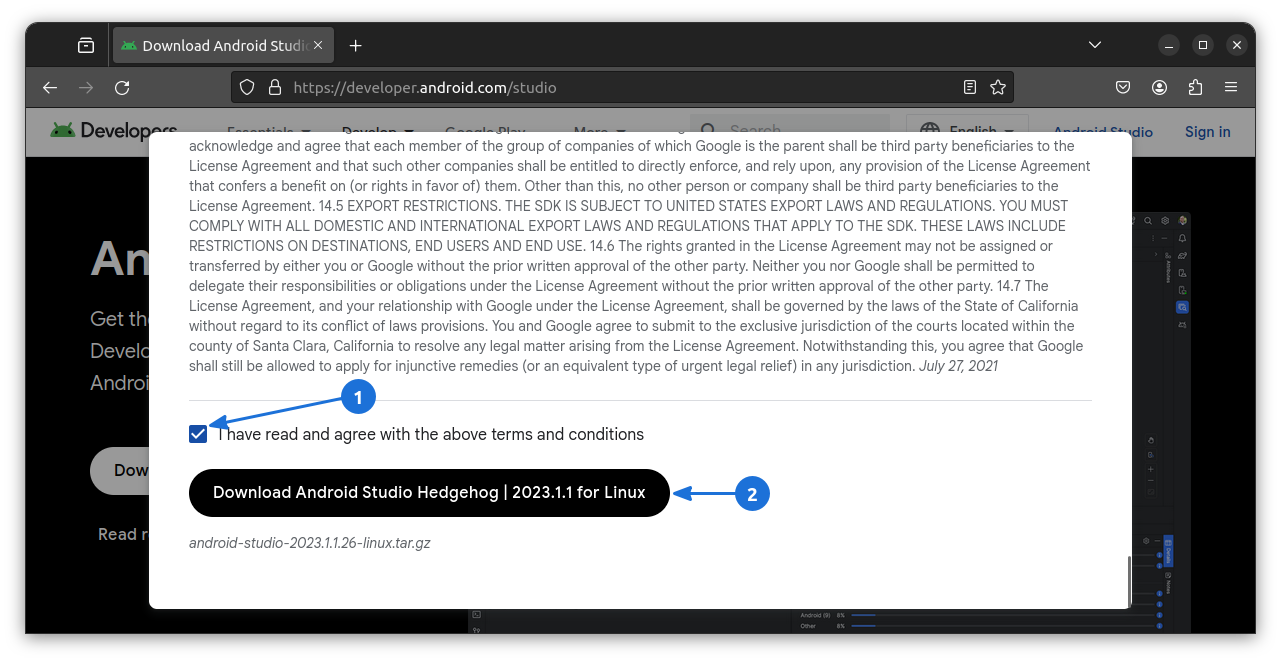
Ensure you have a fast internet connection because the files are around 1.1 GB in size.
### Start the Installer
Once you have downloaded the file, [extract the tar file](https://linuxhandbook.com/basic-tar-commands/?ref=itsfoss.com). You can do this from the file manager, by right-click and selecting Extract.
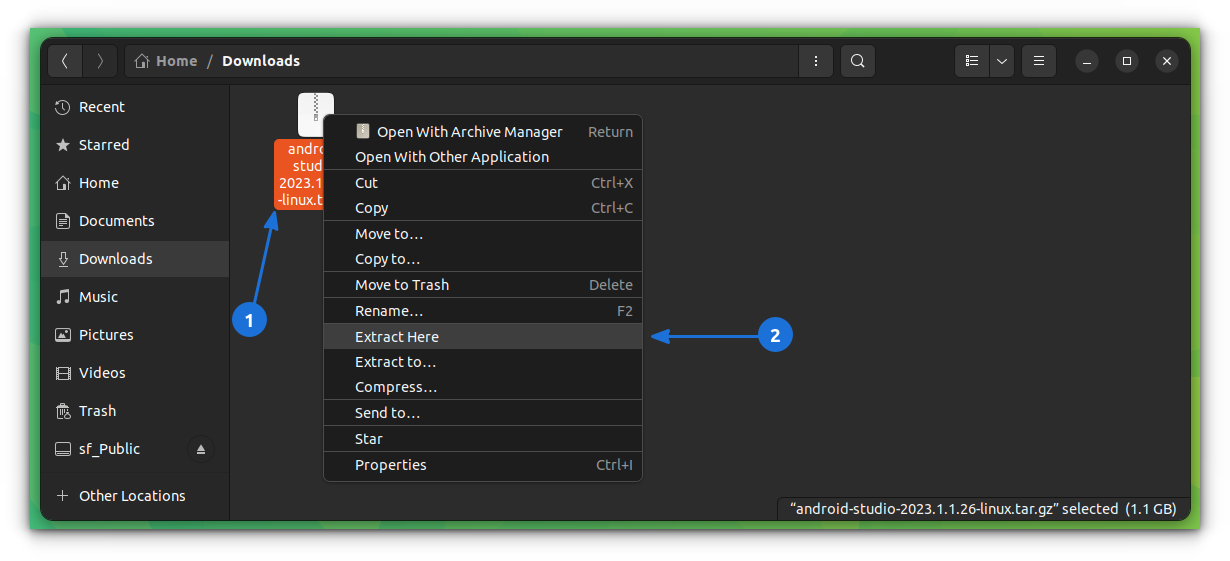
Once extracted, move inside the extracted folder. Now, right-click on an empty place and select “Open in Terminal” to open a terminal there.
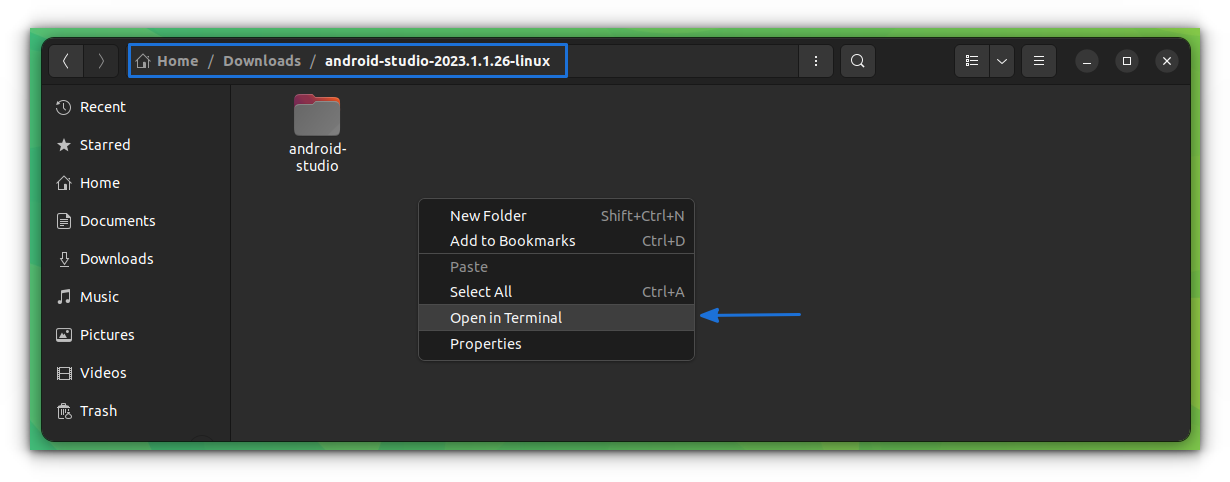
Now, move the `android-studio`
directory to:
`/opt/`
for shared users.`/usr/local/`
for your user.
Use the command like:
```
sudo mv android-studio /opt/
```
Start Android Studio by going inside the `/android-studio/bin`
. Considering you have copied it to `/opt/`
, run:
```
/opt/android-studio/bin/studio.sh
```
Or if you moved it to `/usr/local/`
, then use the command:
```
/usr/local/android-studio/bin/studio.sh
```
This will open the setup. When first opened, select “Do not import Settings” and then press OK.
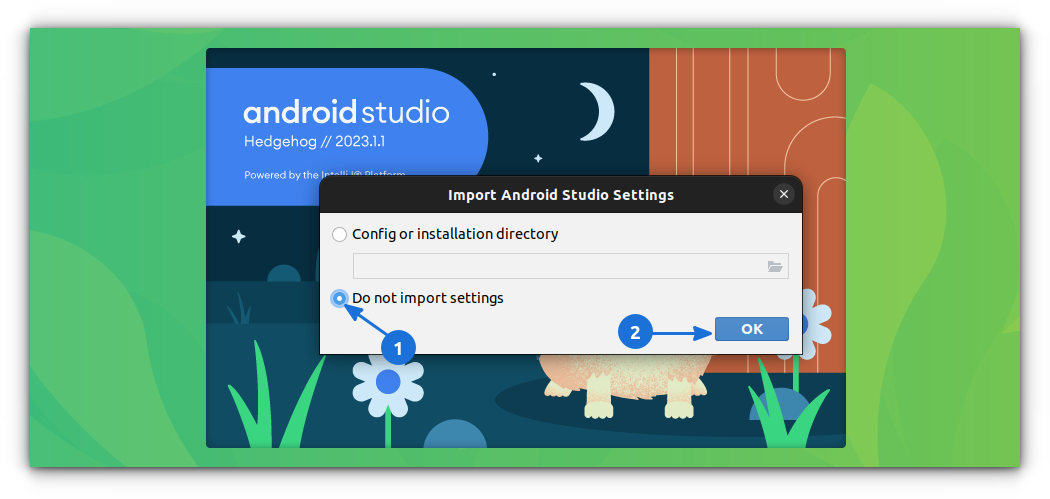
It will then ask for consent to share Usage statistics data with Google. Select accordingly.
Now, on the welcome screen, click on Next.
Set the installation type as Standard and click Next.
The setup wizard will now give you an overview of settings and the files to be downloaded, if you are ok with those, click on Next.
On the next screen, first you need to accept the Android SDK License.
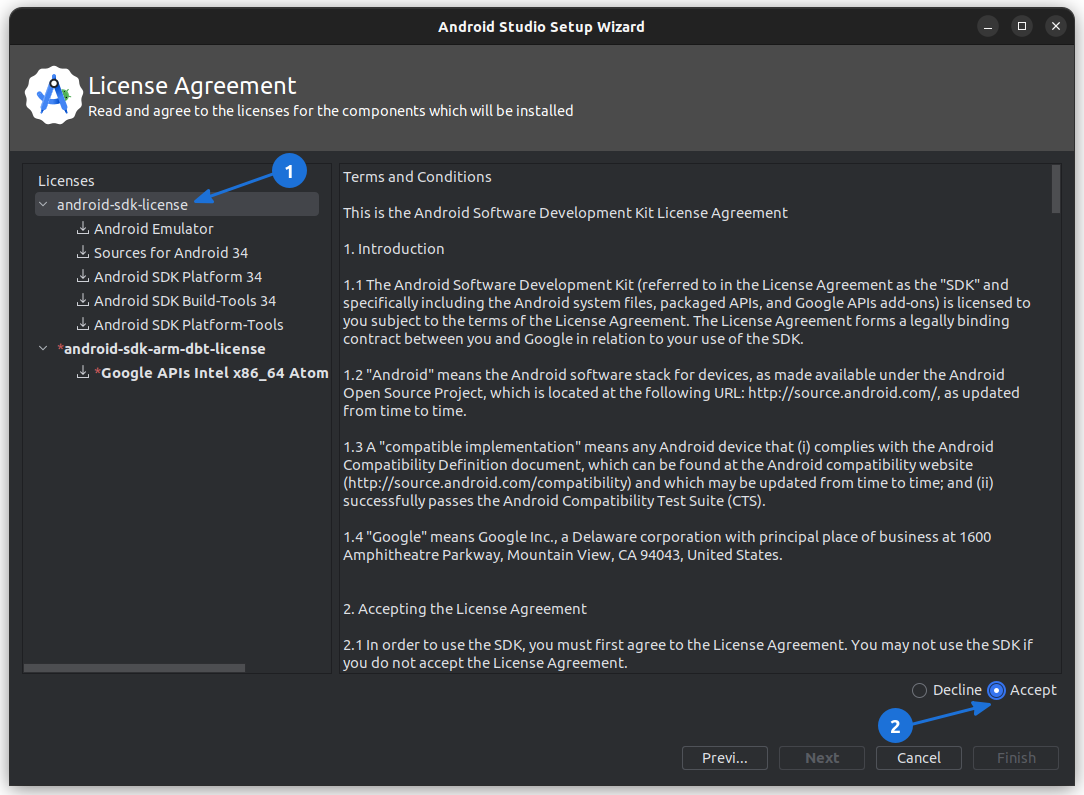
Next, you need to select android-sdk-arm-dbt-license and accept it.
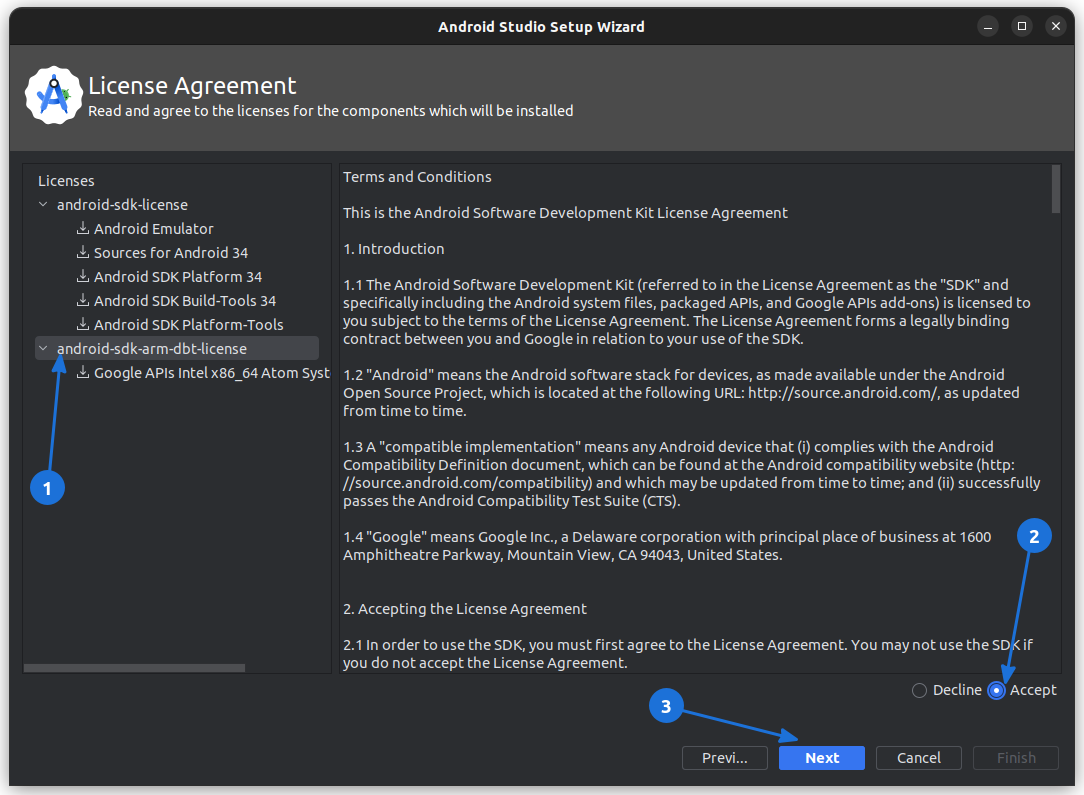
On the next screen, click on the Finish button.
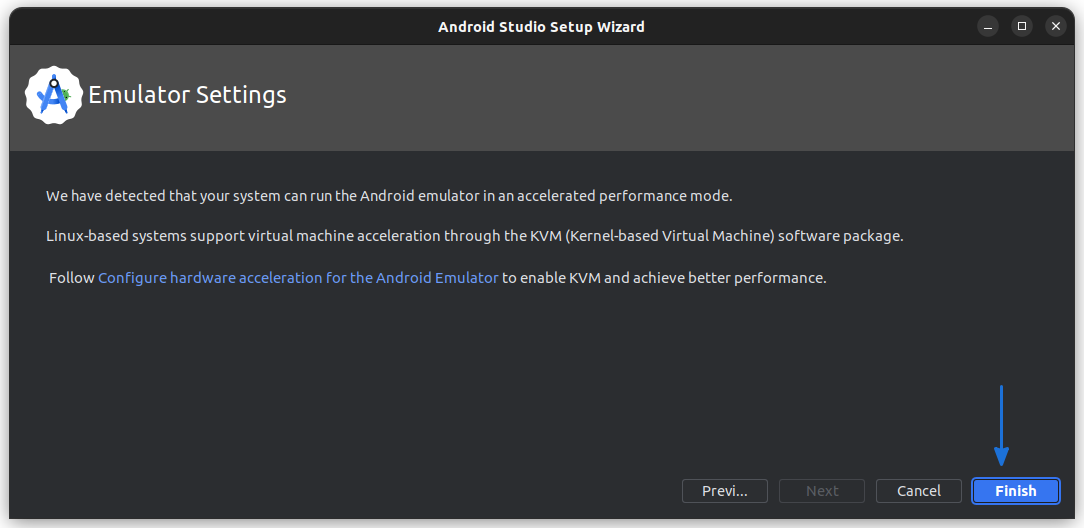
[enable KVM to achieve better performance](https://itsfoss.com/qemu-ubuntu/).
This will start downloading and extracting the required files. You should need a better internet connection and wait for some time for the operation to finish.
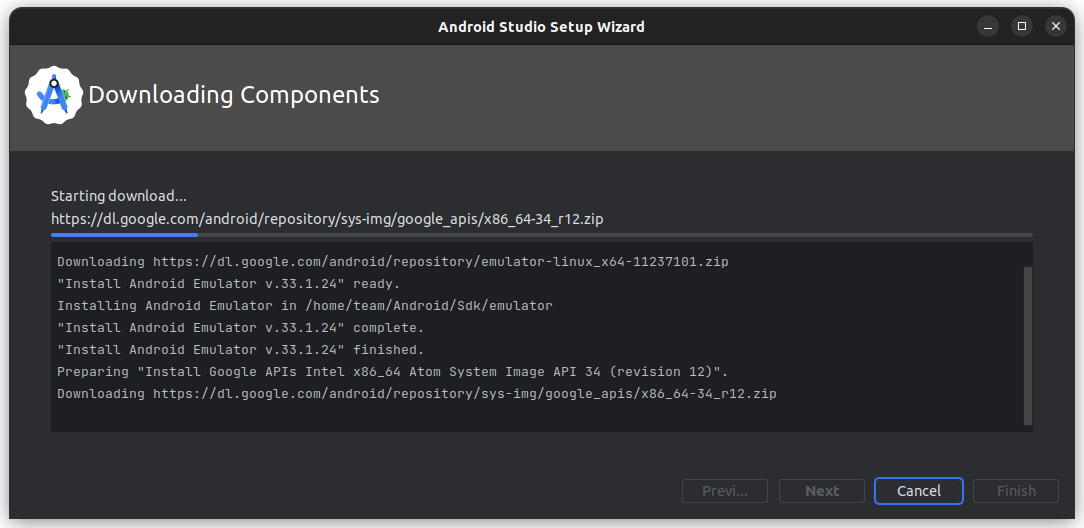
Click on the Finish button, when the processes are completed.
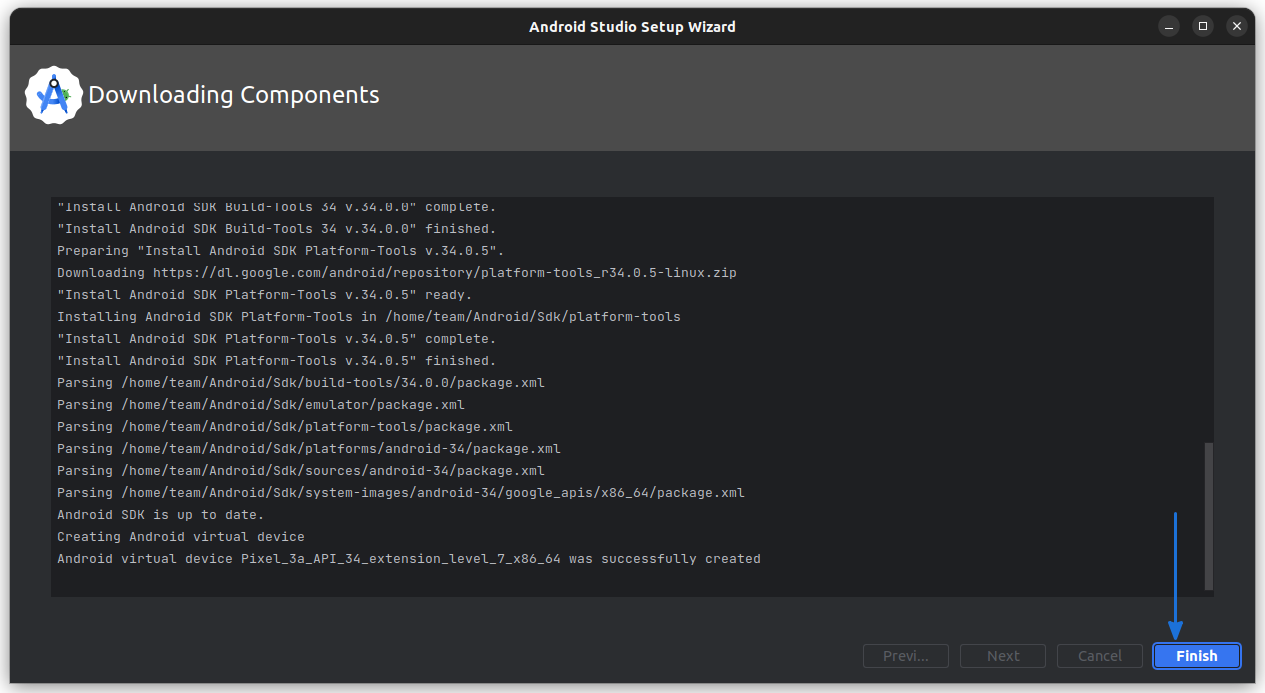
You will reach the welcome screen of Android studio.
### Create a Desktop Entry
For easy access to Android Studio from everywhere, you should create a desktop entry for it. For this, first, click on the gear icon on the Android Studio welcome screen. From the dropdown menu, select “Create a Desktop Entry” item.
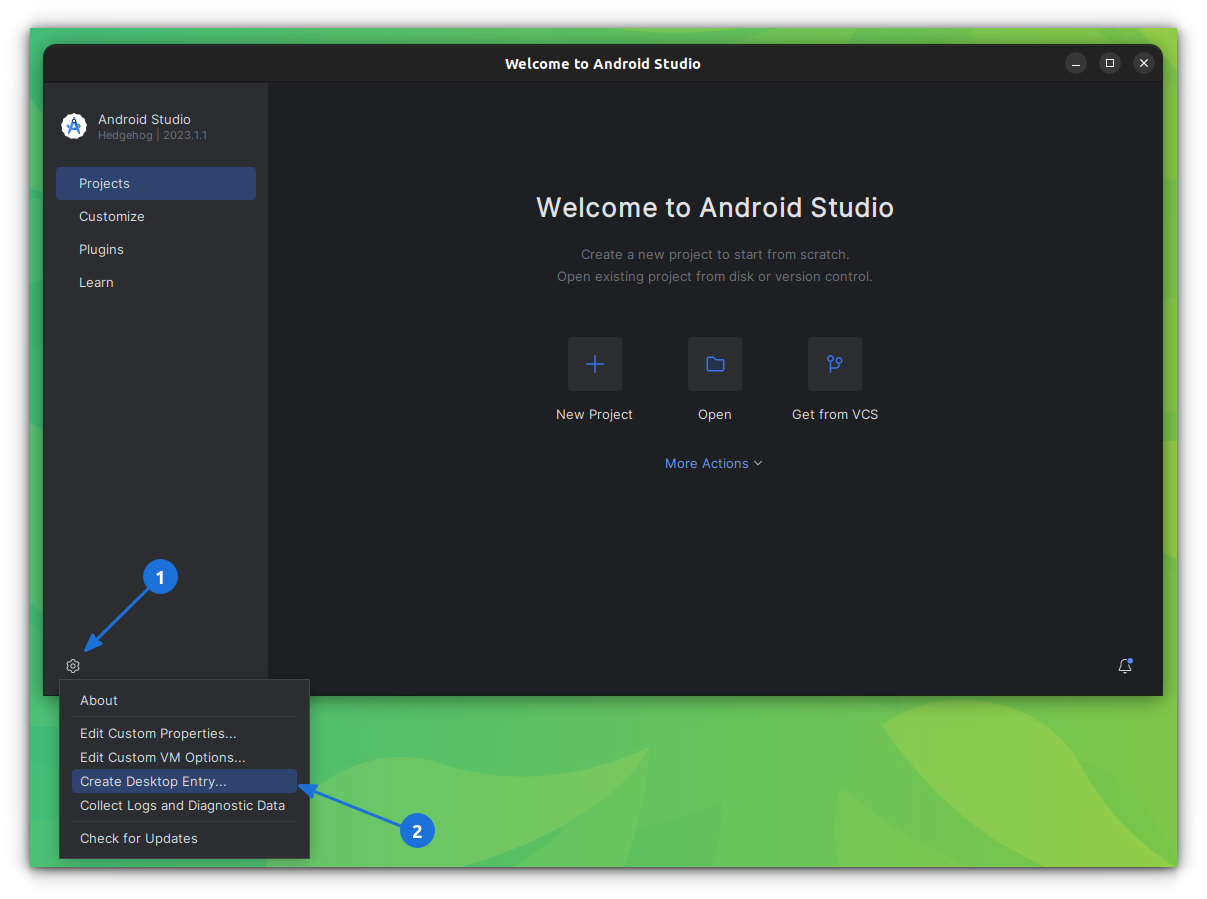
On the next page, you will be asked for whom, this desktop entry be created. If you want to create it for all users (Android Studio Files in /opt/ directory), you need to enter the password as well. Click OK.
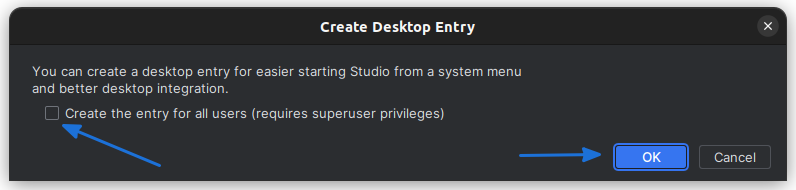
You can now open Android studio from Ubuntu activities overview, or your system menu.

### Updating Android Studio
If you have an update, it will notify you about the same. Or, to check for any update manually, click on Gear Icon **→ Check for Updates.**
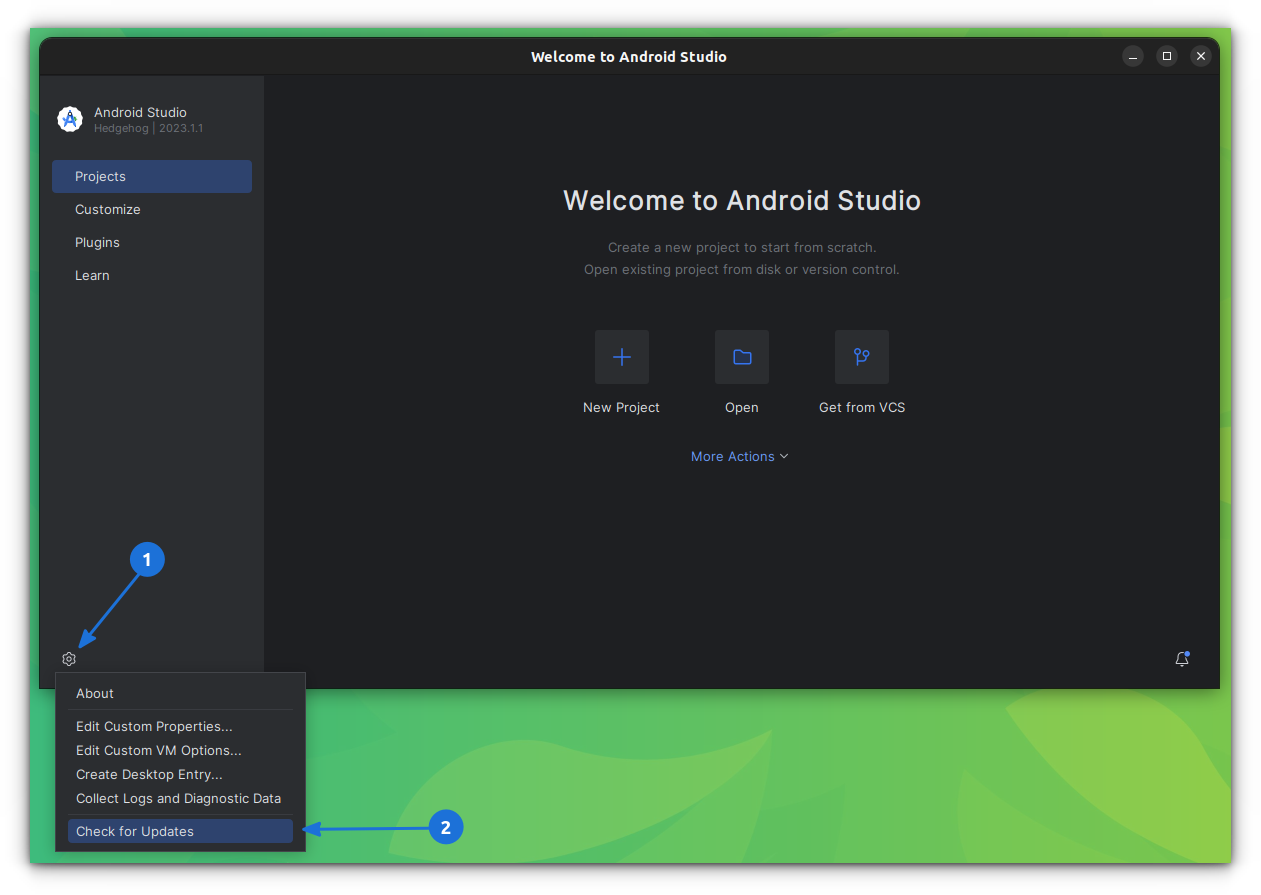
If there is no update, it will be notified, once you do this.

### Removing Android Studio
To remove Android studio, first, you need to remove the desktop file.
```
sudo rm /usr/share/applications/jetbrains-studio.desktop
```
After this, remove the `android-studio`
directory from /opt/.
```
sudo rm -rf /opt/android-studio/
```
Now, you can remove the residual directory from your Home.
`rm -rf ~/Android`
## Wrapping Up
I hope this quick helps you to **install Android Studio in Ubuntu and Linux Mint**, and other Linux distributions. Before you run Android Studio, make sure to [install Java in Ubuntu](https://itsfoss.com/install-java-ubuntu/) first. In similar posts, I advise you to read [how to install and configure the Ubuntu SDK](https://itsfoss.com/install-configure-ubuntu-sdk/) and [how to install Microsoft Visual Studio easily in Ubuntu](https://itsfoss.com/install-visual-studio-code-ubuntu/).
Any questions or suggestions are always welcomed. Ciao 😄
Here is a list of open-source Android apps that you can use.
[40+ Best Open Source Android AppsThe best open source Android apps. Replace the proprietary options to enjoy a potentially better experience!](https://itsfoss.com/open-source-android-apps/)

Looking for some Android emulators? We have got you covered.
[6 Best Android Emulators to Run & Test Android Apps on LinuxWant to run Android on Linux? These Android emulators and solutions should help!](https://itsfoss.com/android-emulators-linux/)
 |
9,628 | 系统调用,让世界转起来! | https://manybutfinite.com/post/system-calls/ | 2018-05-11T00:23:00 | [
"系统调用"
] | https://linux.cn/article-9628-1.html | 
我其实不想将它分解开给你看,用户应用程序其实就是一个可怜的<ruby> 瓮中大脑 <rt> brain in a vat </rt></ruby>:

它与外部世界的*每个*交流都要在内核的帮助下通过**系统调用**才能完成。一个应用程序要想保存一个文件、写到终端、或者打开一个 TCP 连接,内核都要参与。应用程序是被内核高度怀疑的:认为它到处充斥着 bug,甚至是个充满邪恶想法的脑子。
这些系统调用是从一个应用程序到内核的函数调用。出于安全考虑,它们使用了特定的机制,实际上你只是调用了内核的 API。“<ruby> 系统调用 <rt> system call </rt></ruby>”这个术语指的是调用由内核提供的特定功能(比如,系统调用 `open()`)或者是调用途径。你也可以简称为:**syscall**。
这篇文章讲解系统调用,系统调用与调用一个库有何区别,以及在操作系统/应用程序接口上的刺探工具。如果彻底了解了应用程序借助操作系统发生的哪些事情,那么就可以将一个不可能解决的问题转变成一个快速而有趣的难题。
那么,下图是一个运行着的应用程序,一个用户进程:

它有一个私有的 [虚拟地址空间](https://manybutfinite.com/post/anatomy-of-a-program-in-memory)—— 它自己的内存沙箱。整个系统都在它的地址空间中(即上面比喻的那个“瓮”),程序的二进制文件加上它所使用的库全部都 [被映射到内存中](https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/)。内核自身也映射为地址空间的一部分。
下面是我们程序 `pid` 的代码,它通过 [getpid(2)](http://linux.die.net/man/2/getpid) 直接获取了其进程 id:
```
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
int main()
{
pid_t p = getpid();
printf("%d\n", p);
}
```
*pid.c [download](https://manybutfinite.com/code/x86-os/pid.c)*
在 Linux 中,一个进程并不是一出生就知道它的 PID。要想知道它的 PID,它必须去询问内核,因此,这个询问请求也是一个系统调用:

它的第一步是开始于调用 C 库的 [getpid()](https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/getpid.c;h=937b1d4e113b1cff4a5c698f83d662e130d596af;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l49),它是系统调用的一个*封装*。当你调用一些函数时,比如,`open(2)`、`read(2)` 之类,你是在调用这些封装。其实,对于大多数编程语言在这一块的原生方法,最终都是在 libc 中完成的。
封装为这些基本的操作系统 API 提供了方便,这样可以保持内核的简洁。*所有的内核代码*运行在特权模式下,有 bug 的内核代码行将会产生致命的后果。能在用户模式下做的任何事情都应该在用户模式中完成。由库来提供友好的方法和想要的参数处理,像 `printf(3)` 这样。
我们拿一个 web API 进行比较,内核的封装方式可以类比为构建一个尽可能简单的 HTTP 接口去提供服务,然后提供特定语言的库及辅助方法。或者也可能有一些缓存,这就是 libc 的 `getpid()` 所做的:首次调用时,它真实地去执行了一个系统调用,然后,它缓存了 PID,这样就可以避免后续调用时的系统调用开销。
一旦封装完成,它做的第一件事就是进入了内核<ruby> <del> 超空间 </del> <rt> hyperspace </rt></ruby>。这种转换机制因处理器架构设计不同而不同。在 Intel 处理器中,参数和 [系统调用号](https://github.com/torvalds/linux/blob/v3.17/arch/x86/syscalls/syscall_64.tbl#L48) 是 [加载到寄存器中的](https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/x86_64/sysdep.h;h=4a619dafebd180426bf32ab6b6cb0e5e560b718a;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l139),然后,运行一个 [指令](https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/x86_64/sysdep.h;h=4a619dafebd180426bf32ab6b6cb0e5e560b718a;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l179) 将 CPU 置于 [特权模式](https://manybutfinite.com/post/cpu-rings-privilege-and-protection) 中,并立即将控制权转移到内核中的全局系统调用 [入口](https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/entry_64.S#L354-L386)。如果你对这些细节感兴趣,David Drysdale 在 LWN 上有两篇非常好的文章([其一](http://lwn.net/Articles/604287/),[其二](http://lwn.net/Articles/604515/))。
内核然后使用这个系统调用号作为进入 [`sys_call_table`](https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/syscall_64.c#L25) 的一个 [索引](https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/entry_64.S#L422),它是一个函数指针到每个系统调用实现的数组。在这里,调用了 [`sys_getpid`](https://github.com/torvalds/linux/blob/v3.17/kernel/sys.c#L800-L809):

在 Linux 中,系统调用大多数都实现为架构无关的 C 函数,有时候这样做 [很琐碎](https://github.com/torvalds/linux/blob/v3.17/kernel/sys.c#L800-L859),但是通过内核优秀的设计,系统调用机制被严格隔离。它们是工作在一般数据结构中的普通代码。嗯,除了*完全偏执*的参数校验以外。
一旦它们的工作完成,它们就会正常*返回*,然后,架构特定的代码会接手转回到用户模式,封装将在那里继续做一些后续处理工作。在我们的例子中,[getpid(2)](http://linux.die.net/man/2/getpid) 现在缓存了由内核返回的 PID。如果内核返回了一个错误,另外的封装可以去设置全局 `errno` 变量。这些细节可以让你知道 GNU 是怎么处理的。
如果你想要原生的调用,glibc 提供了 [syscall(2)](http://linux.die.net/man/2/syscall) 函数,它可以不通过封装来产生一个系统调用。你也可以通过它来做一个你自己的封装。这对一个 C 库来说,既不神奇,也不特殊。
这种系统调用的设计影响是很深远的。我们从一个非常有用的 [strace(1)](http://linux.die.net/man/1/strace) 开始,这个工具可以用来监视 Linux 进程的系统调用(在 Mac 上,参见 [dtruss(1m)](https://developer.apple.com/library/mac/documentation/Darwin/Reference/ManPages/man1/dtruss.1m.html) 和神奇的 [dtrace](http://dtrace.org/blogs/brendan/2011/10/10/top-10-dtrace-scripts-for-mac-os-x/);在 Windows 中,参见 [sysinternals](http://technet.microsoft.com/en-us/sysinternals/bb842062.aspx))。这是对 `pid` 程序的跟踪:
```
~/code/x86-os$ strace ./pid
execve("./pid", ["./pid"], [/* 20 vars */]) = 0
brk(0) = 0x9aa0000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7767000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat64(3, {st_mode=S_IFREG|0644, st_size=18056, ...}) = 0
mmap2(NULL, 18056, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7762000
close(3) = 0
[...snip...]
getpid() = 14678
fstat64(1, {st_mode=S_IFCHR|0600, st_rdev=makedev(136, 1), ...}) = 0
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7766000
write(1, "14678\n", 614678
) = 6
exit_group(6) = ?
```
输出的每一行都显示了一个系统调用、它的参数,以及返回值。如果你在一个循环中将 `getpid(2)` 运行 1000 次,你就会发现始终只有一个 `getpid()` 系统调用,因为,它的 PID 已经被缓存了。我们也可以看到在格式化输出字符串之后,`printf(3)` 调用了 `write(2)`。
`strace` 可以开始一个新进程,也可以附加到一个已经运行的进程上。你可以通过不同程序的系统调用学到很多的东西。例如,`sshd` 守护进程一天都在干什么?
```
~/code/x86-os$ ps ax | grep sshd
12218 ? Ss 0:00 /usr/sbin/sshd -D
~/code/x86-os$ sudo strace -p 12218
Process 12218 attached - interrupt to quit
select(7, [3 4], NULL, NULL, NULL
[
... nothing happens ...
No fun, it's just waiting for a connection using select(2)
If we wait long enough, we might see new keys being generated and so on, but
let's attach again, tell strace to follow forks (-f), and connect via SSH
]
~/code/x86-os$ sudo strace -p 12218 -f
[lots of calls happen during an SSH login, only a few shown]
[pid 14692] read(3, "-----BEGIN RSA PRIVATE KEY-----\n"..., 1024) = 1024
[pid 14692] open("/usr/share/ssh/blacklist.RSA-2048", O_RDONLY|O_LARGEFILE) = -1 ENOENT (No such file or directory)
[pid 14692] open("/etc/ssh/blacklist.RSA-2048", O_RDONLY|O_LARGEFILE) = -1 ENOENT (No such file or directory)
[pid 14692] open("/etc/ssh/ssh_host_dsa_key", O_RDONLY|O_LARGEFILE) = 3
[pid 14692] open("/etc/protocols", O_RDONLY|O_CLOEXEC) = 4
[pid 14692] read(4, "# Internet (IP) protocols\n#\n# Up"..., 4096) = 2933
[pid 14692] open("/etc/hosts.allow", O_RDONLY) = 4
[pid 14692] open("/lib/i386-linux-gnu/libnss_dns.so.2", O_RDONLY|O_CLOEXEC) = 4
[pid 14692] stat64("/etc/pam.d", {st_mode=S_IFDIR|0755, st_size=4096, ...}) = 0
[pid 14692] open("/etc/pam.d/common-password", O_RDONLY|O_LARGEFILE) = 8
[pid 14692] open("/etc/pam.d/other", O_RDONLY|O_LARGEFILE) = 4
```
看懂 SSH 的调用是块难啃的骨头,但是,如果搞懂它你就学会了跟踪。能够看到应用程序打开的是哪个文件是有用的(“这个配置是从哪里来的?”)。如果你有一个出现错误的进程,你可以 `strace` 它,然后去看它通过系统调用做了什么?当一些应用程序意外退出而没有提供适当的错误信息时,你可以去检查它是否有系统调用失败。你也可以使用过滤器,查看每个调用的次数,等等:
```
~/code/x86-os$ strace -T -e trace=recv curl -silent www.google.com. > /dev/null
recv(3, "HTTP/1.1 200 OK\r\nDate: Wed, 05 N"..., 16384, 0) = 4164 <0.000007>
recv(3, "fl a{color:#36c}a:visited{color:"..., 16384, 0) = 2776 <0.000005>
recv(3, "adient(top,#4d90fe,#4787ed);filt"..., 16384, 0) = 4164 <0.000007>
recv(3, "gbar.up.spd(b,d,1,!0);break;case"..., 16384, 0) = 2776 <0.000006>
recv(3, "$),a.i.G(!0)),window.gbar.up.sl("..., 16384, 0) = 1388 <0.000004>
recv(3, "margin:0;padding:5px 8px 0 6px;v"..., 16384, 0) = 1388 <0.000007>
recv(3, "){window.setTimeout(function(){v"..., 16384, 0) = 1484 <0.000006>
```
我鼓励你在你的操作系统中的试验这些工具。把它们用好会让你觉得自己有超能力。
但是,足够有用的东西,往往要让我们深入到它的设计中。我们可以看到那些用户空间中的应用程序是被严格限制在它自己的虚拟地址空间里,运行在 Ring 3(非特权模式)中。一般来说,只涉及到计算和内存访问的任务是不需要请求系统调用的。例如,像 [strlen(3)](http://linux.die.net/man/3/strlen) 和 [memcpy(3)](http://linux.die.net/man/3/memcpy) 这样的 C 库函数并不需要内核去做什么。这些都是在应用程序内部发生的事。
C 库函数的 man 页面所在的节(即圆括号里的 `2` 和 `3`)也提供了线索。节 2 是用于系统调用封装,而节 3 包含了其它 C 库函数。但是,正如我们在 `printf(3)` 中所看到的,库函数最终可以产生一个或者多个系统调用。
如果你对此感到好奇,这里是 [Linux](https://github.com/torvalds/linux/blob/v3.17/arch/x86/syscalls/syscall_64.tbl) (也有 [Filippo 的列表](https://filippo.io/linux-syscall-table/))和 [Windows](http://j00ru.vexillium.org/ntapi/) 的全部系统调用列表。它们各自有大约 310 和 460 个系统调用。看这些系统调用是非常有趣的,因为,它们代表了*软件*在现代的计算机上能够做什么。另外,你还可能在这里找到与进程间通讯和性能相关的“宝藏”。这是一个“不懂 Unix 的人注定最终还要重新发明一个蹩脚的 Unix ” 的地方。(LCTT 译注:原文 “Those who do not understand Unix are condemned to reinvent it,poorly。” 这句话是 [Henry Spencer](https://en.wikipedia.org/wiki/Henry_Spencer) 的名言,反映了 Unix 的设计哲学,它的一些理念和文化是一种技术发展的必须结果,看似糟糕却无法超越。)
与 CPU 周期相比,许多系统调用花[很长的时间](https://manybutfinite.com/post/what-your-computer-does-while-you-wait/)去执行任务,例如,从一个硬盘驱动器中读取内容。在这种情况下,调用进程在底层的工作完成之前一直*处于休眠状态*。因为,CPU 运行的非常快,一般的程序都因为 **I/O 的限制**在它的生命周期的大部分时间处于休眠状态,等待系统调用返回。相反,如果你跟踪一个计算密集型任务,你经常会看到没有任何的系统调用参与其中。在这种情况下,[top(1)](http://linux.die.net/man/1/top) 将显示大量的 CPU 使用。
在一个系统调用中的开销可能会是一个问题。例如,固态硬盘比普通硬盘要快很多,但是,操作系统的开销可能比 I/O 操作本身的开销 [更加昂贵](http://danluu.com/clwb-pcommit/)。执行大量读写操作的程序可能就是操作系统开销的瓶颈所在。[向量化 I/O](http://en.wikipedia.org/wiki/Vectored_I/O) 对此有一些帮助。因此要做 [文件的内存映射](https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/),它允许一个程序仅访问内存就可以读或写磁盘文件。类似的映射也存在于像视频卡这样的地方。最终,云计算的经济性可能导致内核消除或最小化用户模式/内核模式的切换。
最终,系统调用还有益于系统安全。一是,无论如何来历不明的一个二进制程序,你都可以通过观察它的系统调用来检查它的行为。这种方式可能用于去检测恶意程序。例如,我们可以记录一个未知程序的系统调用的策略,并对它的异常行为进行报警,或者对程序调用指定一个白名单,这样就可以让漏洞利用变得更加困难。在这个领域,我们有大量的研究,和许多工具,但是没有“杀手级”的解决方案。
这就是系统调用。很抱歉这篇文章有点长,我希望它对你有用。接下来的时间,我将写更多(短的)文章,也可以在 [RSS](http://feeds.feedburner.com/GustavoDuarte) 和 [Twitter](http://twitter.com/food4hackers) 关注我。这篇文章献给 glorious Clube Atlético Mineiro。
---
via:<https://manybutfinite.com/post/system-calls/>
作者:[Gustavo Duarte](http://duartes.org/gustavo/blog/about/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I hate to break it to you, but a user application is a helpless brain in a vat:

*Every* interaction with the outside world is mediated by the kernel through
**system calls**. If an app saves a file, writes to the terminal, or opens a TCP
connection, the kernel is involved. Apps are regarded as highly suspicious: at
best a bug-ridden mess, at worst the malicious brain of an evil genius.
These system calls are function calls from an app into the kernel. They use
a specific mechanism for safety reasons, but really you’re just calling the
kernel’s API. The term “system call” can refer to a specific function offered by
the kernel (*e.g.*, the `open()`
system call) or to the calling mechanism. You
can also say **syscall** for short.
This post looks at system calls, how they differ from calls to a library, and
tools to poke at this OS/app interface. A solid understanding of what happens
*within an app* versus what happens through the OS can turn an impossible-to-fix
problem into a quick, fun puzzle.
So here’s a running program, a *user process*:

It has a private [virtual address space](/post/anatomy-of-a-program-in-memory), its very own memory sandbox.
The vat, if you will. In its address space, the program’s binary file plus the
libraries it uses are all [memory mapped](/post/page-cache-the-affair-between-memory-and-files/). Part of the address
space maps the kernel itself.
Below is the code for our program, `pid`
, which simply retrieves its process id
via [getpid(2)](http://linux.die.net/man/2/getpid):
[view raw](/code/x86-os/pid.c)
1 |
|
In Linux, a process isn’t born knowing its PID. It must ask the kernel, so this requires a system call:

It all starts with a call to the C library’s [getpid()](https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/getpid.c;h=937b1d4e113b1cff4a5c698f83d662e130d596af;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l49), which is
a *wrapper* for the system call. When you call functions like `open(2)`
,
`read(2)`
, and friends, you’re calling these wrappers. This is true for many
languages where the native methods ultimately end up in libc.
Wrappers offer convenience atop the bare-bones OS API, helping keep the kernel
lean. Lines of code is where bugs live, and *all kernel code* runs in privileged
mode, where mistakes can be disastrous. Anything that can be done in user mode
should be done in user mode. Let the libraries offer friendly methods and fancy
argument processing a la `printf(3)`
.
Compared to web APIs, this is analogous to building the simplest possible HTTP
interface to a service and then offering language-specific libraries with
helper methods. Or maybe some caching, which is what libc’s
`getpid()`
does: when first called it actually performs a system
call, but the PID is then cached to avoid the syscall overhead in subsequent
invocations.
Once the wrapper has done its initial work it’s time to jump into
~~hyperspace~~ the kernel. The mechanics of this transition vary by
processor architecture. In Intel processors, arguments and the
[syscall number](https://github.com/torvalds/linux/blob/v3.17/arch/x86/syscalls/syscall_64.tbl#L48) are [loaded into registers](https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/x86_64/sysdep.h;h=4a619dafebd180426bf32ab6b6cb0e5e560b718a;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l139),
then an [instruction](https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/x86_64/sysdep.h;h=4a619dafebd180426bf32ab6b6cb0e5e560b718a;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l179) is executed to put the CPU
in [privileged mode](/post/cpu-rings-privilege-and-protection) and immediately transfer control to a global syscall
[entry point](https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/entry_64.S#L354-L386) within the kernel. If you’re interested in
details, David Drysdale has two great articles in LWN ([first](http://lwn.net/Articles/604287/),
[second](http://lwn.net/Articles/604515/)).
The kernel then uses the syscall number as an [index](https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/entry_64.S#L422) into
[sys_call_table](https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/syscall_64.c#L25), an array of function pointers to each syscall implementation.
Here, [sys_getpid](https://github.com/torvalds/linux/blob/v3.17/kernel/sys.c#L800-L809) is called:

In Linux, syscall implementations are mostly arch-independent C functions,
sometimes [trivial](https://github.com/torvalds/linux/blob/v3.17/kernel/sys.c#L800-L859), insulated from the syscall mechanism by
the kernel’s excellent design. They are regular code working on general data
structures. Well, apart from being *completely paranoid* about argument
validation.
Once their work is done they `return`
normally, and the arch-specific code takes
care of transitioning back into user mode where the wrapper does some post
processing. In our example, [getpid(2)](http://linux.die.net/man/2/getpid) now caches the PID returned by the
kernel. Other wrappers might set the global `errno`
variable if the kernel
returns an error. Small things to let you know GNU cares.
If you want to be raw, glibc offers the [syscall(2)](http://linux.die.net/man/2/syscall) function, which makes
a system call without a wrapper. You can also do so yourself in assembly.
There’s nothing magical or privileged about a C library.
This syscall design has far-reaching consequences. Let’s start with the
incredibly useful [strace(1)](http://linux.die.net/man/1/strace), a tool you can use to spy on system calls made by
Linux processes (in Macs, see [dtruss(1m)](https://developer.apple.com/library/mac/documentation/Darwin/Reference/ManPages/man1/dtruss.1m.html) and the amazing [dtrace](http://dtrace.org/blogs/brendan/2011/10/10/top-10-dtrace-scripts-for-mac-os-x/); in Windows,
see [sysinternals](http://technet.microsoft.com/en-us/sysinternals/bb842062.aspx)). Here’s strace on `pid`
:
1 | ~/code/x86-os$ strace ./pid |
Each line of output shows a system call, its arguments, and a return value.
If you put `getpid(2)`
in a loop running 1000 times, you would still have only
one `getpid()`
syscall because of the PID caching. We can also see that
`printf(3)`
calls `write(2)`
after formatting the output string.
`strace`
can start a new process and also attach to an already running one. You
can learn a lot by looking at the syscalls made by different programs. For
example, what does the `sshd`
daemon do all day?
1 | ~/code/x86-os$ ps ax | grep sshd |
SSH is a large chunk to bite off, but it gives a feel for strace usage. Being able to see which files an app opens can be useful (“where the hell is this config coming from?”). If you have a process that appears stuck, you can strace it and see what it might be doing via system calls. When some app is quitting unexpectedly without a proper error message, check if a syscall failure explains it. You can also use filters, time each call, and so so:
1 | ~/code/x86-os$ strace -T -e trace=recv curl -silent www.google.com. > /dev/null |
I encourage you to explore these tools in your OS. Using them well is like having a super power.
But enough useful stuff, let’s go back to design. We’ve seen that a userland app
is trapped in its virtual address space running in ring 3 (unprivileged). In
general, tasks that involve only computation and memory accesses do *not*
require syscalls. For example, C library functions like [strlen(3)](http://linux.die.net/man/3/strlen) and
[memcpy(3)](http://linux.die.net/man/3/memcpy) have nothing to do with the kernel. Those happen within the app.
The man page sections for a C library function (the 2 and 3 in parenthesis) also
offer clues. Section 2 is used for system call wrappers, while section
3 contains other C library functions. However, as we saw with `printf(3)`
,
a library function might ultimately make one or more syscalls.
If you’re curious, here are full syscall listings for [Linux](https://github.com/torvalds/linux/blob/v3.17/arch/x86/syscalls/syscall_64.tbl)
(also [Filippo’s list](https://filippo.io/linux-syscall-table/)) and
[Windows](http://j00ru.vexillium.org/ntapi/). They have ~310 and ~460 system
calls, respectively. It’s fun to look at those because, in a way, they represent
*all that software can do* on a modern computer. Plus, you might find gems to
help with things like interprocess communication and performance. This is an
area where “Those who do not understand Unix are condemned to reinvent it,
poorly.”
Many syscalls perform tasks that take [eons](/post/what-your-computer-does-while-you-wait/) compared to CPU cycles, for
example reading from a hard drive. In those situations the calling process is
often *put to sleep* until the underlying work is completed. Because CPUs are so
fast, your average program is **I/O bound** and spends most of its life
sleeping, waiting on syscalls. By contrast, if you strace a program busy with
a computational task, you often see no syscalls being invoked. In such a case,
[top(1)](http://linux.die.net/man/1/top) would show intense CPU usage.
The overhead involved in a system call can be a problem. For example, SSDs are
so fast that general OS overhead can be [more expensive](http://danluu.com/clwb-pcommit/) than the I/O
operation itself. Programs doing large numbers of reads and writes can also have
OS overhead as their bottleneck. [Vectored I/O](http://en.wikipedia.org/wiki/Vectored_I/O) can help some. So can
[memory mapped files](/post/page-cache-the-affair-between-memory-and-files/), which allow a program to read and write from
disk using only memory access. Analogous mappings exist for things like video
card memory. Eventually, the economics of cloud computing might lead us to
kernels that eliminate or minimize user/kernel mode switches.
Finally, syscalls have interesting security implications. One is that no matter how obfuscated a binary, you can still examine its behavior by looking at the system calls it makes. This can be used to detect malware, for example. We can also record profiles of a known program’s syscall usage and alert on deviations, or perhaps whitelist specific syscalls for programs so that exploiting vulnerabilities becomes harder. We have a ton of research in this area, a number of tools, but not a killer solution yet.
And that’s it for system calls. I’m sorry for the length of this post, I hope it
was helpful. More (and shorter) next week, [RSS](https://manybutfinite.com/feed.xml) and [Twitter](http://twitter.com/manybutfinite). Also, last night
I made a promise to the universe. This post is dedicated to the glorious Clube
Atlético Mineiro.
## Comments |
9,629 | 如何使用 Vim 编辑器编辑多个文件 | https://www.ostechnix.com/how-to-edit-multiple-files-using-vim-editor/ | 2018-05-11T09:22:40 | [
"Vim",
"Vi"
] | https://linux.cn/article-9629-1.html | 
有时候,您可能需要修改多个文件,或要将一个文件的内容复制到另一个文件中。在图形用户界面中,您可以在任何图形文本编辑器(如 gedit)中打开文件,并使用 `CTRL + C` 和 `CTRL + V` 复制和粘贴内容。在命令行模式下,您不能使用这种编辑器。不过别担心,只要有 `vim` 编辑器就有办法。在本教程中,我们将学习使用 `vim` 编辑器同时编辑多个文件。相信我,很有意思哒。
### 安装 Vim
Vim 编辑器可在大多数 Linux 发行版的官方软件仓库中找到,所以您可以用默认的软件包管理器来安装它。例如,在 Arch Linux 及其变体上,您可以使用如下命令:
```
$ sudo pacman -S vim
```
在 Debian 和 Ubuntu 上:
```
$ sudo apt-get install vim
```
在 RHEL 和 CentOS 上:
```
$ sudo yum install vim
```
在 Fedora 上:
```
$ sudo dnf install vim
```
在 openSUSE 上:
```
$ sudo zypper install vim
```
### 使用 Linux 的 Vim 编辑器同时编辑多个文件
现在让我们谈谈正事,我们可以用两种方法做到这一点。
#### 方法一
有两个文件,即 `file1.txt` 和 `file2.txt`,带有一堆随机单词:
```
$ cat file1.txt
ostechnix
open source
technology
linux
unix
$ cat file2.txt
line1
line2
line3
line4
line5
```
现在,让我们同时编辑这两个文件。请运行:
```
$ vim file1.txt file2.txt
```
Vim 将按顺序显示文件的内容。首先显示第一个文件的内容,然后显示第二个文件,依此类推。

##### 在文件中切换
要移至下一个文件,请键入:
```
:n
```

要返回到前一个文件,请键入:
```
:N
```
如果有任何未保存的更改,Vim 将不允许您移动到下一个文件。要保存当前文件中的更改,请键入:
```
ZZ
```
请注意,是两个大写字母 `ZZ`(`SHIFT + zz`)。
要放弃更改并移至上一个文件,请键入:
```
:N!
```
要查看当前正在编辑的文件,请键入:
```
:buffers
```

您将在底部看到加载文件的列表。

要切换到下一个文件,请输入 `:buffer`,后跟缓冲区编号。例如,要切换到第一个文件,请键入:
```
:buffer 1
```

##### 打开其他文件进行编辑
目前我们正在编辑两个文件,即 `file1.txt` 和 `file2.txt`。我想打开另一个名为 `file3.txt` 的文件进行编辑。
您会怎么做?这很容易。只需键入 `:e`,然后输入如下所示的文件名即可:
```
:e file3.txt
```

现在你可以编辑 `file3.txt` 了。
要查看当前正在编辑的文件数量,请键入:
```
:buffers
```

请注意,对于使用 `:e` 打开的文件,您无法使用 `:n` 或 `:N` 进行切换。要切换到另一个文件,请输入 `:buffer`,然后输入文件缓冲区编号。
##### 将一个文件的内容复制到另一个文件中
您已经知道了如何同时打开和编辑多个文件。有时,您可能想要将一个文件的内容复制到另一个文件中。这也是可以做到的。切换到您选择的文件,例如,假设您想将 `file1.txt` 的内容复制到 `file2.txt` 中:
首先,请切换到 `file1.txt`:
```
:buffer 1
```
将光标移动至在想要复制的行的前面,并键入`yy` 以抽出(复制)该行。然后,移至 `file2.txt`:
```
:buffer 2
```
将光标移至要从 `file1.txt` 粘贴复制行的位置,然后键入 `p`。例如,您想要将复制的行粘贴到 `line2` 和 `line3` 之间,请将鼠标光标置于行前并键入 `p`。
输出示例:
```
line1
line2
ostechnix
line3
line4
line5
```

要保存当前文件中所做的更改,请键入:
```
ZZ
```
再次提醒,是两个大写字母 ZZ(`SHIFT + z`)。
保存所有文件的更改并退出 vim 编辑器,键入:
```
:wq
```
同样,您可以将任何文件的任何行复制到其他文件中。
##### 将整个文件内容复制到另一个文件中
我们知道如何复制一行,那么整个文件的内容呢?也是可以的。比如说,您要将 `file1.txt` 的全部内容复制到 `file2.txt` 中。
先打开 `file2.txt`:
```
$ vim file2.txt
```
如果文件已经加载,您可以通过输入以下命令切换到 `file2.txt`:
```
:buffer 2
```
将光标移动到您想要粘贴 `file1.txt` 的内容的位置。我想在 `file2.txt` 的第 5 行之后粘贴 `file1.txt` 的内容,所以我将光标移动到第 5 行。然后,键入以下命令并按回车键:
```
:r file1.txt
```

这里,`r` 代表 “read”。
现在您会看到 `file1.txt` 的内容被粘贴在 `file2.txt` 的第 5 行之后。
```
line1
line2
line3
line4
line5
ostechnix
open source
technology
linux
unix
```

要保存当前文件中的更改,请键入:
```
ZZ
```
要保存所有文件的所有更改并退出 vim 编辑器,请输入:
```
:wq
```
#### 方法二
另一种同时打开多个文件的方法是使用 `-o` 或 `-O` 标志。
要在水平窗口中打开多个文件,请运行:
```
$ vim -o file1.txt file2.txt
```

要在窗口之间切换,请按 `CTRL-w w`(即按 `CTRL + w` 并再次按 `w`)。或者,您可以使用以下快捷方式在窗口之间移动:
* `CTRL-w k` – 上面的窗口
* `CTRL-w j` – 下面的窗口
要在垂直窗口中打开多个文件,请运行:
```
$ vim -O file1.txt file2.txt file3.txt
```

要在窗口之间切换,请按 `CTRL-w w`(即按 `CTRL + w` 并再次按 `w`)。或者,使用以下快捷方式在窗口之间移动:
* `CTRL-w l` – 左面的窗口
* `CTRL-w h` – 右面的窗口
其他的一切都与方法一的描述相同。
例如,要列出当前加载的文件,请运行:
```
:buffers
```
在文件之间切换:
```
:buffer 1
```
打开其他文件,请键入:
```
:e file3.txt
```
将文件的全部内容复制到另一个文件中:
```
:r file1.txt
```
方法二的唯一区别是,只要您使用 `ZZ` 保存对当前文件的更改,文件将自动关闭。然后,您需要依次键入 `:wq` 来关闭文件。但是,如果您按照方法一进行操作,输入 `:wq` 时,所有更改将保存在所有文件中,并且所有文件将立即关闭。
有关更多详细信息,请参阅手册页。
```
$ man vim
```
### 建议阅读
您现在掌握了如何在 Linux 中使用 vim 编辑器编辑多个文件。正如您所见,编辑多个文件并不难。Vim 编辑器还有更强大的功能。我们接下来会提供更多关于 Vim 编辑器的内容。
再见!
---
via: <https://www.ostechnix.com/how-to-edit-multiple-files-using-vim-editor/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[jessie-pang](https://github.com/jessie-pang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,630 | 关于 BPF 和 eBPF 的笔记 | https://jvns.ca/blog/2017/06/28/notes-on-bpf---ebpf/ | 2018-05-12T08:36:09 | [
"eBPF",
"过滤"
] | https://linux.cn/article-9630-1.html | 
今天,我喜欢的 meetup 网站上有一篇我超爱的文章([@tuxology](https://twitter.com/tuxology) 在 twitter/github)的一篇非常棒的关于传统 BPF 和在 Linux 中最新加入的 eBPF 的讨论文章,正是它促使我想去写一个 eBPF 的程序!
这篇文章就是 —— [BSD 包过滤器:一个新的用户级包捕获架构](http://www.vodun.org/papers/net-papers/van_jacobson_the_bpf_packet_filter.pdf)
我想在讨论的基础上去写一些笔记,因为,我觉得它超级棒!
开始前,这里有个 [幻灯片](https://speakerdeck.com/tuxology/the-bsd-packet-filter) 和一个 [pdf](http://step.polymtl.ca/%7Esuchakra/PWL-Jun28-MTL.pdf)。这个 pdf 非常好,结束的位置有一些链接,在 PDF 中你可以直接点击这个链接。
### 什么是 BPF?
在 BPF 出现之前,如果你想去做包过滤,你必须拷贝所有的包到用户空间,然后才能去过滤它们(使用 “tap”)。
这样做存在两个问题:
1. 如果你在用户空间中过滤,意味着你将拷贝所有的包到用户空间,拷贝数据的代价是很昂贵的。
2. 使用的过滤算法很低效。
问题 #1 的解决方法似乎很明显,就是将过滤逻辑移到内核中。(虽然具体实现的细节并没有明确,我们将在稍后讨论)
但是,为什么过滤算法会很低效?
如果你运行 `tcpdump host foo`,它实际上运行了一个相当复杂的查询,用下图的这个树来描述它:

评估这个树有点复杂。因此,可以用一种更简单的方式来表示这个树,像这样:

然后,如果你设置 `ether.type = IP` 和 `ip.src = foo`,你必然明白匹配的包是 `host foo`,你也不用去检查任何其它的东西了。因此,这个数据结构(它们称为“控制流图” ,或者 “CFG”)是表示你真实希望去执行匹配检查的程序的最佳方法,而不是用前面的树。
### 为什么 BPF 要工作在内核中
这里的关键点是,包仅仅是个字节的数组。BPF 程序是运行在这些字节的数组之上。它们不允许有循环(loop),但是,它们 *可以* 有聪明的办法知道 IP 包头(IPv6 和 IPv4 长度是不同的)以及基于它们的长度来找到 TCP 端口:
```
x = ip_header_length
port = *(packet_start + x + port_offset)
```
(看起来不一样,其实它们基本上都相同)。在这个论文/幻灯片上有一个非常详细的虚拟机的描述,因此,我不打算解释它。
当你运行 `tcpdump host foo` 后,这时发生了什么?就我的理解,应该是如下的过程。
1. 转换 `host foo` 为一个高效的 DAG 规则
2. 转换那个 DAG 规则为 BPF 虚拟机的一个 BPF 程序(BPF 字节码)
3. 发送 BPF 字节码到 Linux 内核,由 Linux 内核验证它
4. 编译这个 BPF 字节码程序为一个<ruby> 原生 <rt> native </rt></ruby>代码。例如,这是个[ARM 上的 JIT 代码](https://github.com/torvalds/linux/blob/v4.10/arch/arm/net/bpf_jit_32.c#L512) 以及 [x86](https://github.com/torvalds/linux/blob/v3.18/arch/x86/net/bpf_jit_comp.c#L189) 的机器码
5. 当包进入时,Linux 运行原生代码去决定是否过滤这个包。对于每个需要去处理的包,它通常仅需运行 100 - 200 个 CPU 指令就可以完成,这个速度是非常快的!
### 现状:eBPF
毕竟 BPF 出现已经有很长的时间了!现在,我们可以拥有一个更加令人激动的东西,它就是 eBPF。我以前听说过 eBPF,但是,我觉得像这样把这些片断拼在一起更好(我在 4 月份的 netdev 上我写了这篇 [XDP & eBPF 的文章](https://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/)回复)
关于 eBPF 的一些事实是:
* eBPF 程序有它们自己的字节码语言,并且从那个字节码语言编译成内核原生代码,就像 BPF 程序一样
* eBPF 运行在内核中
* eBPF 程序不能随心所欲的访问内核内存。而是通过内核提供的函数去取得一些受严格限制的所需要的内容的子集
* 它们 *可以* 与用户空间的程序通过 BPF 映射进行通讯
* 这是 Linux 3.18 的 `bpf` 系统调用
### kprobes 和 eBPF
你可以在 Linux 内核中挑选一个函数(任意函数),然后运行一个你写的每次该函数被调用时都运行的程序。这样看起来是不是很神奇。
例如:这里有一个 [名为 disksnoop 的 BPF 程序](https://github.com/iovisor/bcc/blob/0c8c179fc1283600887efa46fe428022efc4151b/examples/tracing/disksnoop.py),它的功能是当你开始/完成写入一个块到磁盘时,触发它执行跟踪。下图是它的代码片断:
```
BPF_HASH(start, struct request *);
void trace_start(struct pt_regs *ctx, struct request *req) {
// stash start timestamp by request ptr
u64 ts = bpf_ktime_get_ns();
start.update(&req, &ts);
}
...
b.attach_kprobe(event="blk_start_request", fn_name="trace_start")
b.attach_kprobe(event="blk_mq_start_request", fn_name="trace_start")
```
本质上它声明一个 BPF 哈希(它的作用是当请求开始/完成时,这个程序去触发跟踪),一个名为 `trace_start` 的函数将被编译进 BPF 字节码,然后附加 `trace_start` 到内核函数 `blk_start_request` 上。
这里使用的是 `bcc` 框架,它可以让你写 Python 式的程序去生成 BPF 代码。你可以在 <https://github.com/iovisor/bcc> 找到它(那里有非常多的示例程序)。
### uprobes 和 eBPF
因为我知道可以附加 eBPF 程序到内核函数上,但是,我不知道能否将 eBPF 程序附加到用户空间函数上!那会有更多令人激动的事情。这是 [在 Python 中使用一个 eBPF 程序去计数 malloc 调用的示例](https://github.com/iovisor/bcc/blob/00f662dbea87a071714913e5c7382687fef6a508/tests/lua/test_uprobes.lua)。
### 附加 eBPF 程序时应该考虑的事情
* 带 XDP 的网卡(我之前写过关于这方面的文章)
* tc egress/ingress (在网络栈上)
* kprobes(任意内核函数)
* uprobes(很明显,任意用户空间函数??像带调试符号的任意 C 程序)
* probes 是为 dtrace 构建的名为 “USDT probes” 的探针(像 [这些 mysql 探针](https://dev.mysql.com/doc/refman/5.7/en/dba-dtrace-ref-query.html))。这是一个 [使用 dtrace 探针的示例程序](https://github.com/iovisor/bcc/blob/master/examples/tracing/mysqld_query.py)
* [JVM](http://blogs.microsoft.co.il/sasha/2016/03/31/probing-the-jvm-with-bpfbcc/)
* 跟踪点
* seccomp / landlock 安全相关的事情
* 等等
### 这个讨论超级棒
在幻灯片里有很多非常好的链接,并且在 iovisor 仓库里有个 [LINKS.md](https://github.com/iovisor/bcc/blob/master/LINKS.md)。虽然现在已经很晚了,但是我马上要去写我的第一个 eBPF 程序了!
---
via: <https://jvns.ca/blog/2017/06/28/notes-on-bpf---ebpf/>
作者:[Julia Evans](https://jvns.ca/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Today it was Papers We Love, my favorite meetup! Today [Suchakra Sharma](http://suchakra.in/) ([@tuxology](https://twitter.com/tuxology) on twitter/github)
gave a GREAT talk about the original BPF paper and recent work in Linux on
eBPF. It really made me want to go write eBPF programs!
The paper is [The BSD Packet Filter: A New Architecture for User-level Packet Capture](http://www.vodun.org/papers/net-papers/van_jacobson_the_bpf_packet_filter.pdf)
I wanted to write some notes on the talk here because I thought it was super super good.
To start, here are the
[slides](https://speakerdeck.com/tuxology/the-bsd-packet-filter) and a
[pdf](http://step.polymtl.ca/~suchakra/PWL-Jun28-MTL.pdf). The pdf is good
because there are links at the end and in the PDF you can click the links.
### what’s BPF?
Before BPF, if you wanted to do packet filtering you had to copy all the packets into userspace and then filter them there (with “tap”).
this had 2 problems:
- if you filter in userspace, it means you have to copy all the packets into userspace, copying data is expensive
- the filtering algorithms people were using were inefficient
The solution to problem #1 seems sort of obvious, move the filtering logic into the kernel somehow. Okay. (though the details of how that’s done isn’t obvious, we’ll talk about that in a second)
But why were the filtering algorithms inefficient! Well!!
If you run `tcpdump host foo`
it actually runs a relatively complicated query,
which you could represent with this tree:
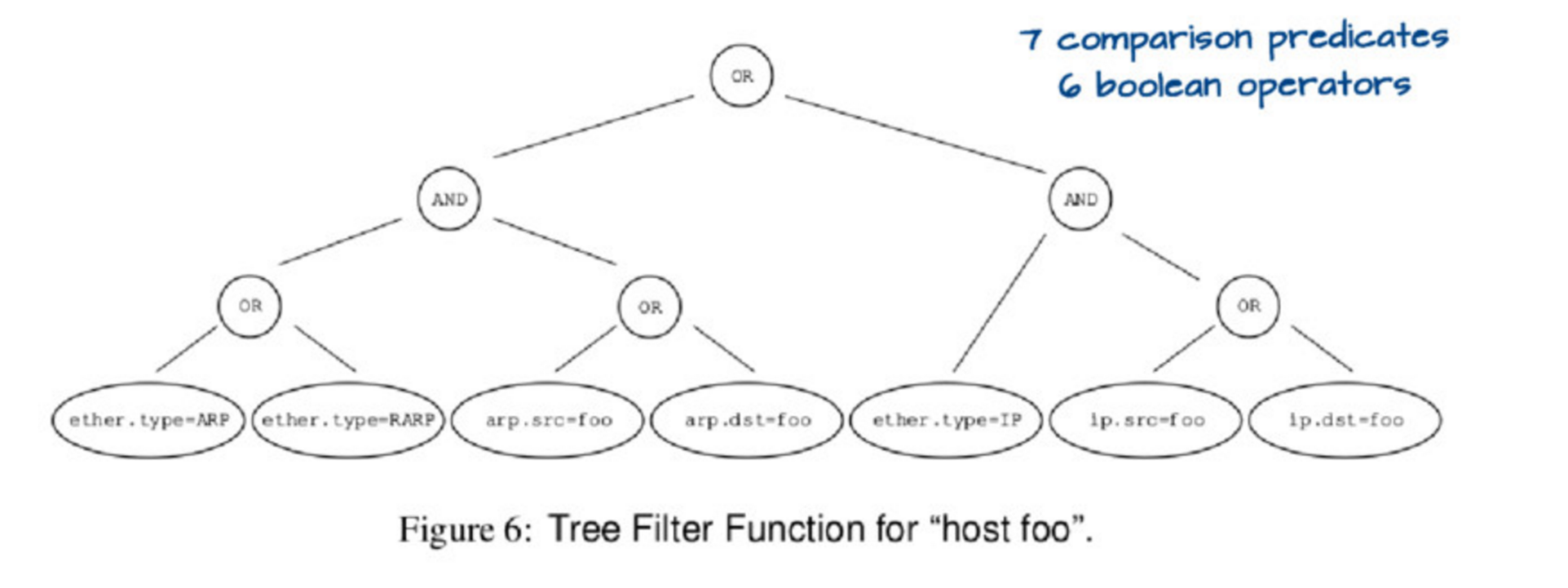
Evaluating this tree is kind of expensive. so the first insight is that you can actually represent this tree in a simpler way, like this:
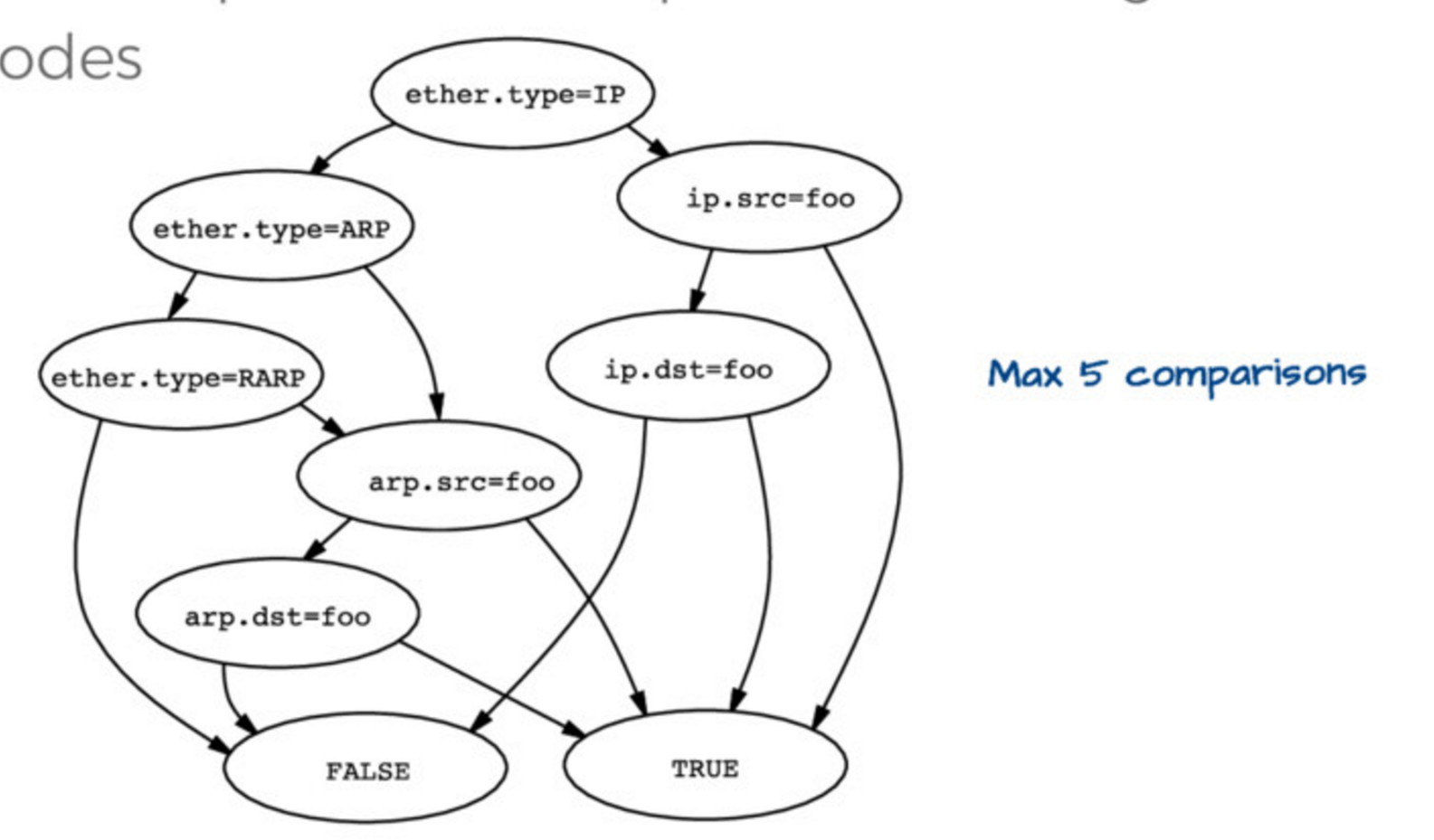
Then if you have `ether.type = IP`
and `ip.src = foo`
you automatically know
that the packet matches `host foo`
, you don’t need to check anything else. So
this data structure (they call it a “control flow graph” or “CFG”) is a way
better representation of the program you actually want to execute to check
matches than the tree we started with.
### How BPF works in the kernel
The main important here is that packets are just arrays of bytes. BPF programs
run on these arrays of bytes. They’re not allowed to have loops but they *can*
have smart stuff to figure out the length of the IP header (IPv6 & IPv4 are
different lengths!) and then find the TCP port based on that length
```
x = ip_header_length
port = *(packet_start + x + port_offset)
```
(it looks different from that but it’s basically the same). There’s a nice description of the virtual machine in the paper/slides so I won’t explain it.
When you run `tcpdump host foo`
this is what happens, as far as I understand
- convert
`host foo`
into an efficient DAG of the rules - convert that DAG into a BPF program (in BPF bytecode) for the BPF virtual machine
- Send the BPF bytecode to the Linux kernel, which verifies it
- compile the BPF bytecode program into native code. For example
[here’s the JIT code for ARM](https://github.com/torvalds/linux/blob/v4.10/arch/arm/net/bpf_jit_32.c#L512)and for[x86](https://github.com/torvalds/linux/blob/v3.18/arch/x86/net/bpf_jit_comp.c#L189) - when packets come in, Linux runs the native code to decide if that packet should be filtered or not. It’l often run only 100-200 CPU instructions for each packet that needs to be processed, which is super fast!
### the present: eBPF
But BPF has been around for a long time! Now we live in the EXCITING FUTURE
which is eBPF. I’d heard about eBPF a bunch before but I felt like this helped
me put the pieces together a little better. (i wrote this [XDP & eBPF post](https://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/) back in April when I was at netdev)
some facts about eBPF:
- eBPF programs have their own bytecode language, and are compiled from that bytecode language into native code in the kernel, just like BPF programs
- eBPF programs run in the kernel
- eBPF programs can’t access arbitrary kernel memory. Instead the kernel provides functions to get at some restricted subset of things.
- they
*can*communicate with userspace programs through BPF maps - there’s a
`bpf`
syscall as of Linux 3.18
### kprobes & eBPF
You can pick a function (any function!) in the Linux kernel and execute a program that you write every time that function happens. This seems really amazing and magical.
For example! There’s this [BPF program called disksnoop](https://github.com/iovisor/bcc/blob/0c8c179fc1283600887efa46fe428022efc4151b/examples/tracing/disksnoop.py) which tracks when you start/finish writing a block to disk.
Here’s a snippet from the code:
```
BPF_HASH(start, struct request *);
void trace_start(struct pt_regs *ctx, struct request *req) {
// stash start timestamp by request ptr
u64 ts = bpf_ktime_get_ns();
start.update(&req, &ts);
}
...
b.attach_kprobe(event="blk_start_request", fn_name="trace_start")
b.attach_kprobe(event="blk_mq_start_request", fn_name="trace_start")
```
This basically declares a BPF hash (which the program uses to keep track of
when the request starts / finishes), a
function called `trace_start`
which is going to be compiled into BPF bytecode,
and attaches `trace_start`
to the `blk_start_request`
kernel function.
This is all using the `bcc`
framework which lets you write Python-ish programs
that generate BPF code. You can find it (it has tons of example programs) at
[https://github.com/iovisor/bcc](https://github.com/iovisor/bcc)
### uprobes & eBPF
So I sort of knew you could attach eBPF programs to kernel functions, but I
didn’t realize you could attach eBPF programs to userspace functions! That’s
really exciting. Here’s
[an example of counting malloc calls in Python using an eBPF program](https://github.com/iovisor/bcc/blob/00f662dbea87a071714913e5c7382687fef6a508/tests/lua/test_uprobes.lua).
### things you can attach eBPF programs to
- network cards, with XDP (which I wrote about a while back)
- tc egress/ingress (in the network stack)
- kprobes (any kernel function)
- uprobes (any userspace function apparently ?? like in any C program with symbols.)
- probes that were built for dtrace called “USDT probes” (like
[these mysql probes](https://dev.mysql.com/doc/refman/5.7/en/dba-dtrace-ref-query.html)). Here’s an[example program using dtrace probes](https://github.com/iovisor/bcc/blob/master/examples/tracing/mysqld_query.py) [the JVM](http://blogs.microsoft.co.il/sasha/2016/03/31/probing-the-jvm-with-bpfbcc/)- tracepoints (not sure what that is yet)
- seccomp / landlock security things
- a bunch more things
### this talk was super cool
There are a bunch of great links in the slides and in
[LINKS.md](https://github.com/iovisor/bcc/blob/master/LINKS.md) in the iovisor
repository. It is late now but soon I want to actually write my first eBPF
program! |
9,631 | 强制关闭你的系统的内核模块 | https://www.ostechnix.com/kgotobed-a-kernel-module-that-forcibly-shutdown-your-system/ | 2018-05-12T08:48:49 | [
"关机",
"内核模块"
] | https://linux.cn/article-9631-1.html | 
我知道熬夜对健康不利。但谁在乎?多年来我一直是一只夜猫子。我通常在 12 点以后睡觉,有时在凌晨 1 点以后睡觉。第二天早上,我至少推迟三次闹钟,醒来后又累又有脾气。每天,我向自己保证早点睡觉,但最终会像平常一样晚睡。而且,这个循环还在继续!如果你和我一样,这有一个好消息。一个同学通宵开发了一个名为 **“Kgotobed”** 的内核模块,它迫使你在特定的时间上床睡觉。也就是说它会强制关闭你的系统。
你可能会问!我为什么要用这个?我有很多其他的选择。我可以设置一个 cron 作业来安排在特定时间关闭系统。我可以设置提醒或闹钟。我可以使用浏览器插件或软件。但是,它们都可以轻易忽略或绕过。Kgotobed 是你不能忽视的东西。**即使您是 root 用户也无法禁用**。是的,它会在指定的时间强制关闭你的系统。没有推迟选项。你不能推迟关机过程,也不能取消它。无论如何,系统都会在指定的时间停止运行。你被警告了!!
### 安装 Kgotobed
确保你已经安装了 `dkms`。它在大多数 Linux 发行版的默认仓库中都有。
例如在 Fedora 上,你可以使用以下命令安装它:
```
$ sudo dnf install kernel-devel-$(uname -r) dkms
```
在 Debian、Ubuntu、linux Mint 上:
```
$ sudo apt install dkms
```
安装完成后,`git clone` Kgotobed 项目。
```
$ git clone https://github.com/nikital/kgotobed.git
```
该命令会在当前工作目录中将所有 Kgotobed 仓库的内容克隆到名为 `kgotobed` 的文件夹中。进入到该目录:
```
$ cd kgotobed/
```
接着,使用命令安装 Kgotobed 驱动:
```
$ sudo make install
```
上面的命令将 `kgotobed.ko` 模块注册到 **DKMS**(这样它会为每个你运行的内核重建)并在 `/usr/local/bin/` 目录下安装 `gotobed`,然后注册、启用并启动 kgotobed 服务。
### 如何运行
默认情况下,Kgotobed 将睡前时间设置为 **1:00 AM**。也就是说,无论你在做什么,你的电脑都会在凌晨 1 点关机。
要查看当前的睡前时间,请运行:
```
$ gotobed
Current bedtime is 2018-04-10 01:00:00
```
要提前睡眠时间,例如 22:00(晚上 10 点),请运行:
```
$ sudo gotobed 22:00
[sudo] password for sk:
Current bedtime is 2018-04-10 00:58:00
Setting bedtime to 2018-04-09 22:00:00
Bedtime will be in 2 hours 16 minutes
```
当你想早点睡觉时,这会很有帮助!
但是,你不能设置更晚的时间也就是凌晨 1 点以后。你无法卸载模块,并且调整系统时钟也无济于事。唯一的出路是重启!
要设置不同的默认时间,您需要自定义 `kgotobed.service`(通过编辑或使用 systemd 工具)。
### 卸载 Kgotobed
对 Kgotobed 不满意?别担心!进入我们先前克隆的 `kgotobed` 文件夹,然后运行以下命令将其卸载。
```
$ sudo make uninstall
```
再一次,我警告你,即使你是 root 用户,也没有办法推迟或取消关机过程。你的系统将在指定的时间强制关闭。这并不适合每个人!当你在做一项重要任务时,它可能会让你疯狂。在这种情况下,请确保你已经不时地保存工作,或使用下面链接中的一些高级工具来帮助你在特定时间自动关闭、重启、暂停和休眠系统。
* [在特定时间自动关闭、重启、暂停和休眠系统](https://www.ostechnix.com/auto-shutdown-reboot-suspend-hibernate-linux-system-specific-time/)
就是这些了。希望你觉得这个指南有帮助。还有更好的东西。敬请关注!
干杯!
### 资源
* [Kgotobed GitHub 仓库](https://github.com/nikital/kgotobed)
---
via: <https://www.ostechnix.com/kgotobed-a-kernel-module-that-forcibly-shutdown-your-system/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,632 | 初识 Python:全局、局部和非局部变量(带示例) | https://www.programiz.com/python-programming/global-local-nonlocal-variables | 2018-05-12T10:47:00 | [
"Python",
"变量"
] | https://linux.cn/article-9632-1.html | 
### 全局变量
在 Python 中,在函数之外或在全局范围内声明的变量被称为全局变量。 这意味着,全局变量可以在函数内部或外部访问。
我们来看一个关于如何在 Python 中创建一个全局变量的示例。
#### 示例 1:创建全局变量
```
x = "global"
def foo():
print("x inside :", x)
foo()
print("x outside:", x)
```
当我们运行代码时,将会输出:
```
x inside : global
x outside: global
```
在上面的代码中,我们创建了 `x` 作为全局变量,并定义了一个 `foo()` 来打印全局变量 `x`。 最后,我们调用 `foo()` 来打印x的值。
倘若你想改变一个函数内的 `x` 的值该怎么办?
```
x = "global"
def foo():
x = x * 2
print(x)
foo()
```
当我们运行代码时,将会输出:
```
UnboundLocalError: local variable 'x' referenced before assignment
```
输出显示一个错误,因为 Python 将 `x` 视为局部变量,而 `x` 没有在 `foo()` 内部定义。
为了运行正常,我们使用 `global` 关键字,查看 [PythonGlobal 关键字](https://www.programiz.com/python-programming/global-keyword)以便了解更多。
### 局部变量
在函数体内或局部作用域内声明的变量称为局部变量。
#### 示例 2:访问作用域外的局部变量
```
def foo():
y = "local"
foo()
print(y)
```
当我们运行代码时,将会输出:
```
NameError: name 'y' is not defined
```
输出显示了一个错误,因为我们试图在全局范围内访问局部变量 `y`,而局部变量只能在 `foo()` 函数内部或局部作用域内有效。
我们来看一个关于如何在 Python 中创建一个局部变量的例子。
#### 示例 3:创建一个局部变量
通常,我们在函数内声明一个变量来创建一个局部变量。
```
def foo():
y = "local"
print(y)
foo()
```
当我们运行代码时,将会输出:
```
local
```
让我们来看看前面的问题,其中x是一个全局变量,我们想修改 `foo()` 内部的 `x`。
### 全局变量和局部变量
在这里,我们将展示如何在同一份代码中使用全局变量和局部变量。
#### 示例 4:在同一份代码中使用全局变量和局部变量
```
x = "global"
def foo():
global x
y = "local"
x = x * 2
print(x)
print(y)
foo()
```
当我们运行代码时,将会输出(LCTT 译注:原文中输出结果的两个 `global` 有空格,正确的是没有空格):
```
globalglobal
local
```
在上面的代码中,我们将 `x` 声明为全局变量,将 `y` 声明为 `foo()` 中的局部变量。 然后,我们使用乘法运算符 `*` 来修改全局变量 `x`,并打印 `x` 和 `y`。
在调用 `foo()` 之后,`x` 的值变成 `globalglobal`了(LCTT 译注:原文同样有空格,正确的是没有空格),因为我们使用 `x * 2` 打印两次 `global`。 之后,我们打印局部变量y的值,即 `local` 。
#### 示例 5:具有相同名称的全局变量和局部变量
```
x = 5
def foo():
x = 10
print("local x:", x)
foo()
print("global x:", x)
```
当我们运行代码时,将会输出:
```
local x: 10
global x: 5
```
在上面的代码中,我们对全局变量和局部变量使用了相同的名称 `x`。 当我们打印相同的变量时却得到了不同的结果,因为这两个作用域内都声明了变量,即 `foo()` 内部的局部作用域和 `foo()` 外面的全局作用域。
当我们在 `foo()` 内部打印变量时,它输出 `local x: 10`,这被称为变量的局部作用域。
同样,当我们在 `foo()` 外部打印变量时,它输出 `global x: 5`,这被称为变量的全局作用域。
### 非局部变量
非局部变量用于局部作用域未定义的嵌套函数。 这意味着,变量既不能在局部也不能在全局范围内。
我们来看一个关于如何在 Python 中创建一个非局部变量的例子。(LCTT 译者注:原文为创建全局变量,疑为笔误)
我们使用 `nonlocal` 关键字来创建非局部变量。
#### 示例 6:创建一个非局部变量
```
def outer():
x = "local"
def inner():
nonlocal x
x = "nonlocal"
print("inner:", x)
inner()
print("outer:", x)
outer()
```
当我们运行代码时,将会输出:
```
inner: nonlocal
outer: nonlocal
```
在上面的代码中有一个嵌套函数 `inner()`。 我们使用 `nonlocal` 关键字来创建非局部变量。`inner()` 函数是在另一个函数 `outer()` 的作用域中定义的。
注意:如果我们改变非局部变量的值,那么变化就会出现在局部变量中。
---
via: <https://www.programiz.com/python-programming/global-local-nonlocal-variables>
作者:[programiz](https://www.programiz.com/) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In Python, we can declare variables in three different scopes: local scope, global, and nonlocal scope.
A variable scope specifies the region where we can access a [variable](https://www.programiz.com/python-programming/variables-constants-literals). For example,
```
``````
def add_numbers():
sum = 5 + 4
```
Here, the `sum` variable is created inside the [function](https://www.programiz.com/python-programming/function), so it can only be accessed within it (local scope). This type of variable is called a local variable.
Based on the scope, we can classify Python variables into three types:
- Local Variables
- Global Variables
- Nonlocal Variables
## Python Local Variables
When we declare variables inside a function, these variables will have a local scope (within the function). We cannot access them outside the function.
These types of variables are called local variables. For example,
```
``````
def greet():
# local variable
message = 'Hello'
print('Local', message)
greet()
# try to access message variable
# outside greet() function
print(message)
```
**Output**
Local Hello NameError: name 'message' is not defined
Here, the `message` variable is local to the `greet()`
function, so it can only be accessed within the function.
That's why we get an error when we try to access it outside the `greet()`
function.
To fix this issue, we can make the variable named `message` global.
## Python Global Variables
In Python, a variable declared outside of the function or in global scope is known as a global variable. This means that a global variable can be accessed inside or outside of the function.
Let's see an example of how a global variable is created in Python.
```
``````
# declare global variable
message = 'Hello'
def greet():
# declare local variable
print('Local', message)
greet()
print('Global', message)
```
**Output**
Local Hello Global Hello
This time we can access the `message` variable from outside of the `greet()`
function. This is because we have created the `message` variable as the global variable.
```
``````
# declare global variable
message = 'Hello'
```
Now, `message` will be accessible from any scope (region) of the program.
## Python Nonlocal Variables
In Python, the `nonlocal`
[keyword](https://www.programiz.com/python-programming/keywords-identifier) is used within nested functions to indicate that a variable is not local to the inner function, but rather belongs to an enclosing function’s scope.
This allows you to modify a variable from the outer function within the nested function, while still keeping it distinct from global variables.
```
``````
# outside function
def outer():
message = 'local'
# nested function
def inner():
# declare nonlocal variable
nonlocal message
message = 'nonlocal'
print("inner:", message)
inner()
print("outer:", message)
outer()
```
**Output**
inner: nonlocal outer: nonlocal
In the above example, there is a nested `inner()`
function. The `inner()`
function is defined in the scope of another function `outer()`
.
We have used the `nonlocal`
keyword to modify the `message`
variable from the outer function within the nested function.
**Note** : If we change the value of a nonlocal variable, the changes appear in the local variable.
**Also Read:** |
9,633 | 放慢速度如何使我变成更好的领导者 | https://opensource.com/open-organization/18/2/open-leadership-patience-listening | 2018-05-12T11:49:15 | [
"领导力"
] | https://linux.cn/article-9633-1.html |
>
> 开放式领导和耐心、倾听一样重要,它们都是关于执行的。
>
>
>

在我职业生涯的早期,我认为我能做的最重要的事情就是行动。如果我的老板说跳,我的回答是“跳多高?”
但是当我成长为一个领导者和管理者时,我意识到了我能提供的最重要的品质是 [耐心](https://opensource.com/open-organization/16/3/my-most-difficult-leadership-lesson) 和倾听。耐心和倾听意味着我关注于真正重要的东西。我很果断,所以我会毫不犹豫地行动。然而我了解到,当我考虑来自多个来源的意见,并就我们应该做什么提供建议,而不仅仅是对眼前的请求做出反应时,我的行动更具影响力。
实行开放式领导需要培养耐心和倾听技能,我需要在[最佳行动计划上进行合作,而不仅仅是最快的计划](https://opensource.com/open-organization/16/3/fastest-result-isnt-always-best-result)。它还为我提供了一些工具,以解释 [为什么我会对某人说“不”](https://opensource.com/open-organization/17/5/saying-no-open-organization) (或者,也许是“不是现在”),这样我就能以透明和自信的方式领导。
如果你正在进行软件开发和实践 scrum 中,那么下面的观点可能会引起你的共鸣:在 sprint 计划和 sprint 演示中,耐心和倾听经理的表现和它的技能一样重要。(LCTT 译注: scrum 是迭代式增量软件开发过程,通常用于敏捷软件开发。 sprint 计划和 sprint 演示是其中的两个术语。)忘掉它们,你会减少你能够产生的影响。
### 专注于耐心
专注和耐心并不总是容易的。通常,我发现自己正坐在会议上,用行动项目填满我的笔记本时,我一般会思考:“我们只要做了某事,另外一件事就会得到改善”。然后我记得事物不是那么线性发展的。
我需要考虑可能影响情况的其他因素。暂停下来从多个人和资源中获取数据可以帮我充实策略,以确保组织长期成功。它还帮助我确定那些短期的里程碑,这些里程碑应该可以让我负责生产的业务完成交付。
这里有一个很好的例子,以前耐心不是我认为应该拥有、以及影响我的表现的东西。当我在北卡罗来纳州工作时,我与一个在亚利桑那州的人共事。我们没有使用视频会议技术,所以当我们交谈时我没有看到她的肢体语言。然而当我负责为我领导的项目交付结果时,她是确保我获得足够支持的两个人之一。
无论出于何种原因,当我与她交谈时,当她要求我做某件事时,我做了。她会为我的绩效评估提供意见,所以我想确保她高兴。那时,我还不够成熟不懂得其实没必要非要讨她开心;我的重点应该放在其他绩效指标上。我本应该花更多的时间倾听并与她合作,而不是在她还在说话的时候拿起第一个“行动项目”并开始工作。
在工作六个月后,她给了我一些负面的反馈。 我很生气,很伤心。 我没有做她所要求的一切吗? 我工作了很长时间,每周工作近七天,为期六个月。 她怎么敢批评我的表现?
然后,在我经历了愤怒和悲伤之后,我想到了她说的话,她的反馈很重要。
在 sprint 计划和 sprint 演示中,耐心和倾听经理的表现和它的技能一样重要。
她对这个项目感到担忧,她继续让我负责是因为我是项目的负责人。我们解决了问题,并且我学到了关于如何领导的重要课程:领导力并不意味着“现在就完成”。 领导力意味着制定战略,然后制定沟通和实施支持战略的计划。这也意味着犯错和从这些问题中学习。
### 经验教训
事后看来,我意识到我可以提出更多的问题来更好地理解她的反馈意图。如果她的指导不符合我收到的其他意见,我也可能会推迟。通过耐心倾听给我的关于项目的各种信息来源,综合我所学到的知识,并创建一个连贯的行动计划,我会成为一个更好的领导者。我也会有更多的目的来推动我正在做的工作。 我不会对单个数据点做出反应,而是会实施一项战略计划。 这样我也会有一个更好的绩效评估。
我最终对她有一些反馈。 下次我们一起工作时,我不想在六个月后听到反馈意见。 我想早些时候和更频繁地听到反馈意见,以便我能够尽早从错误中学习。 关于这项工作的持续讨论是任何团队都应该发生的事情。
当我成为一名管理者和领导者时,我坚持要求我的团队达到相同的标准:计划,执行计划并反思。 重复。 不要让外力造成的麻烦让你偏离你需要实施的计划。 将工作分成小的增量,以便反思和调整计划。 正如 Daniel Goleman 写道:“把注意力放在需要的地方是领导力的一个主要任务。” 不要害怕面对这个挑战。
---
via: <https://opensource.com/open-organization/18/2/open-leadership-patience-listening>
作者:[Angela Robertson](https://opensource.com/users/arobertson98) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Early in my career, I thought the most important thing I could do was act. If my boss said jump, my reply was "how high?"
But as I've grown as a leader and manager, I've realized that the most important traits I can offer are [patience](https://opensource.com/open-organization/16/3/my-most-difficult-leadership-lesson) and listening. This patience and listening means I'm focusing on what's really important. I'm decisive, so I do not hesitate to act. Yet I've learned that my actions are more impactful when I consider input from multiple sources and offer advice on what we should be doing—not simply reacting to an immediate request.
Practicing open leadership involves cultivating the patience and listening skills I need to collaborate on the [ best plan of action, not just the quickest one](https://opensource.com/open-organization/16/3/fastest-result-isnt-always-best-result). It also gives me the tools I need to explain
[(or, perhaps, "not now") to someone, so I can lead with transparency and confidence.](https://opensource.com/open-organization/17/5/saying-no-open-organization)
*why*I'm saying "no"
If you're in software development and practice scrum, then the following argument might resonate with you: The patience and listening a manager displays are *as important* as her skills in sprint planning and running the sprint demo. Forget about them, and you'll lessen the impact you're able to have.
## A focus on patience
Focus and patience do not always come easily. Often, I find myself sitting in meetings and filling my notebook with action items. My default action can be to think: "We can simply do *x* and *y* will improve!" Then I remember that things are not so linear.
I need to think about the *other* factors that can influence a situation. Pausing to take in data from multiple people and resources helps me flesh out a strategy that our organization needs for long-term success. It also helps me identify those shorter-term milestones that should lead us to deliver the business results I'm responsible for producing.
Here's a great example from a time when patience *wasn't* something I valued as I should have—and how that hurt my performance. When I was based on North Carolina, I worked with someone based in Arizona. We didn't use video conferencing technologies, so I didn't get to observe her body language when we talked. While I was responsible for delivering the results for the project I led, she was one of the two people tasked with making sure I had adequate support.
For whatever reason, when I talked with this person, when she asked me to do something, I did it. She would be providing input on my performance evaluation, so I wanted to make sure she was happy. At the time, I didn't possess the maturity to know I didn't need to make her happy; my focus should have been on other performance indicators. I should have spent more time listening and collaborating with her instead of picking up the first "action item" and working on it while she was still talking.
After six months on the job, this person gave me some tough feedback. I was angry and sad. Didn't I do everything she'd asked? I had worked long hours, nearly seven days a week for six months. How dare she criticize my performance?
Then, after I had my moment of anger followed by sadness, I thought about what she said. Her feedback was on point.
She had concerns about the project, and she held me accountable because I was responsible. We worked through the issues, and I learned that vital lesson about how to lead: Leadership does not mean "get it done right now." Leadership means putting together a strategy, then communicating and implementing plans in support of the strategy. It also means making mistakes and learning from these hiccups.
## Lesson learned
In hindsight, I realize I could have asked more questions to better understand the intent of her feedback. I also could have pushed back if the guidance from her did not align with other input I was receiving. By having the patience to listen to the various sources giving me input about the project, synthesizing what I learned, and creating a coherent plan for action, I would have been a better leader. I also would have had more purpose driving the work I was doing. Instead of reacting to a single data point, I would have been implementing a strategic plan. I also would have had a better performance evaluation.
I eventually had some feedback for her. Next time we worked together, I didn't want to hear the feedback after six months. I wanted to hear the feedback *earlier and more often* so I could learn from the mistakes sooner. An ongoing discussion about the work is what should happen on any team.
As I mature as a manager and leader, I hold myself to the same standards I ask my team to meet: Plan, work the plan, and reflect. Repeat. Don't let a fire drill created by an external force distract you from the plan you need to implement. Breaking work into small increments builds in space for reflections and adjustments to the plan. As Daniel Goleman writes, "Directing attention toward where it needs to go is a primal task of leadership." Don't be afraid of meeting this challenge.
## 4 Comments |
9,634 | 5 个最佳实践开始你的 DevOps 之旅 | https://opensource.com/article/17/11/5-keys-get-started-devops | 2018-05-13T07:37:56 | [
"DevOps"
] | /article-9634-1.html |
>
> 想要实现 DevOps 但是不知道如何开始吗?试试这 5 个最佳实践吧。
>
>
>

想要采用 DevOps 的人通常会过早的被它的歧义性给吓跑,更不要说更加深入的使用了。当一些人开始使用 DevOps 的时候都会问:“如何开始使用呢?”,”怎么才算使用了呢?“。这 5 个最佳实践是指导你的 DevOps 之旅的很好的路线图。
### 1、 衡量所有的事情
除非你能够量化输出结果,否则你并不能确认你的努力能否使事情变得更好。新功能能否快速的输出给客户?带给他们的缺陷更少吗?出错了能快速应对和恢复吗?
在你开始做任何修改之前,思考一下你切换到 DevOps 之后想要一些什么样的输出。随着你的 DevOps 之旅,将享受到服务的所有内容的丰富的实时报告,从这两个指标考虑一下:
* **上架时间** 衡量端到端,通常是面向客户的业务经验。这通常从一个功能被正式提出而开始,客户在产品中开始使用这个功能而结束。上架时间不是工程团队的主要指标;更加重要的是,当开发出一个有价值的新功能时,它表明了你完成业务的效率,为系统改进提供了一个机会。
* **时间周期** 衡量工程团队的进度。从开始开发一个新功能开始,到在产品环境中运行需要多久?这个指标对于你了解团队的效率是非常有用的,为团队层面的提升提供了一个机会。
### 2、 放飞你的流程
DevOps 的成功需要团队布置一个定期(但愿有效)流程并且持续提升它。这不总是有效的,但是必须是一个定期的流程。通常它有一些敏捷开发的味道,就像 Scrum 或者 Scrumban 一样;一些时候它也像精益开发。不论你用的什么方法,挑选一个正式的流程,开始使用它,并且做好这些基础。
定期检查和调整流程是 DevOps 成功的关键,抓住相关演示、团队回顾、每日会议的机会来提升你的流程。
DevOps 的成功取决于大家一起有效的工作。团队的成员需要在一个有权改进的公共流程中工作。他们也需要定期找机会分享从这个流程中上游或下游的其他人那里学到的东西。
随着你构建成功,好的流程规范能帮助你的团队以很快的速度体会到 DevOps 其他的好处
尽管更多面向开发的团队采用 Scrum 是常见的,但是以运营为中心的团队(或者其他中断驱动的团队)可能选用一个更短期的流程,例如 Kanban。
### 3、 可视化工作流程
这是很强大的,能够看到哪个人在给定的时间做哪一部分工作,可视化你的工作流程能帮助大家知道接下来应该做什么,流程中有多少工作以及流程中的瓶颈在哪里。
在你看到和衡量之前你并不能有效的限制流程中的工作。同样的,你也不能有效的排除瓶颈直到你清楚的看到它。
全部工作可视化能帮助团队中的成员了解他们在整个工作中的贡献。这样可以促进跨组织边界的关系建设,帮助您的团队更有效地协作,实现共同的成就感。
### 4、 持续化所有的事情
DevOps 应该是强制自动化的。然而罗马不是一日建成的。你应该注意的第一个事情应该是努力的[持续集成(CI)](https://martinfowler.com/articles/continuousIntegration.html),但是不要停留到这里;紧接着的是[持续交付(CD)](https://martinfowler.com/bliki/ContinuousDelivery.html)以及最终的持续部署。
持续部署的过程中是个注入自动测试的好时机。这个时候新代码刚被提交,你的持续部署应该运行测试代码来测试你的代码和构建成功的加工品。这个加工品经受流程的考验被产出,直到最终被客户看到。
另一个“持续”是不太引人注意的持续改进。一个简单的场景是每天询问你旁边的同事:“今天做些什么能使工作变得更好?”,随着时间的推移,这些日常的小改进融合到一起会带来很大的结果,你将很惊喜!但是这也会让人一直思考着如何改进。
### 5、 Gherkinize
促进组织间更有效的沟通对于成功的 DevOps 的系统思想至关重要。在程序员和业务员之间直接使用共享语言来描述新功能的需求文档对于沟通是个好办法。一个好的产品经理能在一天内学会 [Gherkin](https://cucumber.io/docs/reference) 然后使用它以平实的英语构造出明确的描述需求文档,工程师会使用 Gherkin 描述的需求文档来写功能测试,之后开发功能代码直到代码通过测试。这是一个简化的 [验收测试驱动开发](https://en.wikipedia.org/wiki/Acceptance_test%E2%80%93driven_development)(ATDD),能够帮助你开始你的 DevOps 文化和开发实践。
### 开始你旅程
不要自馁哦。希望这五个想法给你坚实的入门方法。
### 关于作者
Magnus Hedemark - Magnus 在 IT 行业已有 20 多年,并且一直热衷于技术。他目前是 nitedHealth Group 的 DevOps 工程师。在业余时间,Magnus 喜欢摄影和划独木舟。
---
via: <https://opensource.com/article/17/11/5-keys-get-started-devops>
作者:[Magnus Hedemark](https://opensource.com/users/magnus919) 译者:[aiwhj](https://github.com/aiwhj) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,635 | 给初学者看的 shuf 命令教程 | https://www.ostechnix.com/the-shuf-command-tutorial-with-examples-for-beginners/ | 2018-05-13T07:48:38 | [
"shuf",
"随机"
] | https://linux.cn/article-9635-1.html | 
`shuf` 命令用于在类 Unix 操作系统中生成随机排列。使用 `shuf` 命令,我们可以随机打乱给定输入文件的行。`shuf` 命令是 GNU Coreutils 的一部分,因此你不必担心安装问题。在这个简短的教程中,让我向你展示一些 `shuf` 命令的例子。
### 带例子的 shuf 命令教程
我有一个名为 `ostechnix.txt` 的文件,内容如下:
```
$ cat ostechnix.txt
line1
line2
line3
line4
line5
line6
line7
line8
line9
line10
```
现在让我们以随机顺序显示上面的行。为此,请运行:
```
$ shuf ostechnix.txt
line2
line8
line5
line10
line7
line1
line4
line6
line9
line3
```
看到了吗?上面的命令将名为 `ostechnix.txt` 中的行随机排列并输出了结果。
你可能想将输出写入另一个文件。例如,我想将输出保存到 `output.txt` 中。为此,请先创建 `output.txt`:
```
$ touch output.txt
```
然后,像下面使用 `-o` 标志将输出写入该文件:
```
$ shuf ostechnix.txt -o output.txt
```
上面的命令将随机随机打乱 `ostechnix.txt` 的内容并将输出写入 `output.txt`。你可以使用命令查看 `output.txt` 的内容:
```
$ cat output.txt
line2
line8
line9
line10
line1
line3
line7
line6
line4
line5
```
我只想显示文件中的任意一行。我该怎么做?很简单!
```
$ shuf -n 1 ostechnix.txt
line6
```
同样,我们可以选择前 “n” 个随机条目。以下命令将只显示前五个随机条目:
```
$ shuf -n 5 ostechnix.txt
line10
line4
line5
line9
line3
```
如下所示,我们可以直接使用 `-e` 标志传入输入,而不是从文件中读取行:
```
$ shuf -e line1 line2 line3 line4 line5
line1
line3
line5
line4
line2
```
你也可以传入数字:
```
$ shuf -e 1 2 3 4 5
3
5
1
4
2
```
要快速在给定范围选择一个,请改用此命令:
```
$ shuf -n 1 -e 1 2 3 4 5
```
或者,选择下面的任意三个随机数字:
```
$ shuf -n 3 -e 1 2 3 4 5
3
5
1
```
我们也可以在特定范围内生成随机数。例如,要显示 1 到 10 之间的随机数,只需使用:
```
$ shuf -i 1-10
1
9
8
2
4
7
6
3
10
5
```
有关更多详细信息,请参阅手册页。
```
$ man shuf
```
今天就是这些。还有更多更好的东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/the-shuf-command-tutorial-with-examples-for-beginners/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,636 | 如何在 Fedora 上开始 Java 开发 | https://fedoramagazine.org/start-developing-java-fedora/ | 2018-05-13T07:56:41 | [
"Java"
] | https://linux.cn/article-9636-1.html | 
Java 是世界上最流行的编程语言之一。它广泛用于开发物联网设备、Android 程序、Web 和企业应用。本文将提供使用 [OpenJDK](http://openjdk.java.net/) 安装和配置工作站的指南。
### 安装编译器和工具
在 Fedora 中安装编译器或 Java Development Kit(JDK)很容易。在写这篇文章时,可以用 v8 和 v9 版本。只需打开一个终端并输入:
```
sudo dnf install java-1.8.0-openjdk-devel
```
这安装 JDK v8。对于 v9,请输入:
```
sudo dnf install java-9-openjdk-devel
```
对于需要其他工具和库(如 Ant 和 Maven)的开发人员,可以使用 **Java Development** 组。要安装套件,请输入:
```
sudo dnf group install "Java Development"
```
要验证编译器是否已安装,请运行:
```
javac -version
```
输出显示编译器版本,如下所示:
```
javac 1.8.0_162
```
### 编译程序
你可以使用任何基本的文本编辑器(如 nano、vim 或 gedit)编写程序。这个例子提供了一个简单的 “Hello Fedora” 程序。
打开你最喜欢的文本编辑器并输入以下内容:
```
public class HelloFedora {
public static void main (String[] args) {
System.out.println("Hello Fedora!");
}
}
```
将文件保存为 `HelloFedora.java`。在终端切换到包含该文件的目录并执行以下操作:
```
javac HelloFedora.java
```
如果编译器遇到任何语法错误,它会发出错误。否则,它只会在下面显示 shell 提示符。
你现在应该有一个名为 `HelloFedora` 的文件,它是编译好的程序。使用以下命令运行它:
```
java HelloFedora
```
输出将显示:
```
Hello Fedora!
```
### 安装集成开发环境(IDE)
有些程序可能更复杂,IDE 可以帮助顺利进行。Java 程序员有很多可用的 IDE,其中包括:
* Geany,一个快速加载的基本 IDE,并提供内置模板
* Anjuta
* GNOME Builder,已经在 [Builder - 这是一个专门面向 GNOME 程序开发人员的新 IDE](https://fedoramagazine.org/builder-a-new-ide-specifically-for-gnome-app-developers-2/) 的文章中介绍过
然而,主要用 Java 编写的最流行的开源 IDE 之一是 [Eclipse](https://www.eclipse.org/)。 Eclipse 在官方仓库中有。要安装它,请运行以下命令:
```
sudo dnf install eclipse-jdt
```
安装完成后,Eclipse 的快捷方式会出现在桌面菜单中。
有关如何使用 Eclipse 的更多信息,请参阅其网站上的[用户指南](http://help.eclipse.org/oxygen/nav/0)。
### 浏览器插件
如果你正在开发 Web 小程序并需要一个用于浏览器的插件,则可以使用 [IcedTea-Web](https://icedtea.classpath.org/wiki/IcedTea-Web)。像 OpenJDK 一样,它是开源的并易于在 Fedora 中安装。运行这个命令:
```
sudo dnf install icedtea-web
```
从 Firefox 52 开始,Web 插件不再有效。有关详细信息,请访问 Mozilla 支持网站 <https://support.mozilla.org/en-US/kb/npapi-plugins?as=u&utm_source=inproduct>。
恭喜,你的 Java 开发环境已准备完毕。
---
via: <https://fedoramagazine.org/start-developing-java-fedora/>
作者:[Shaun Assam](https://fedoramagazine.org/author/sassam/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Java is one of the most popular programming languages in the world. It is widely-used to develop IOT appliances, Android apps, web, and enterprise applications. This article will provide a quick guide to install and configure your workstation using [OpenJDK](http://openjdk.java.net/).
## Installing the compiler and tools
Installing the compiler, or Java Development Kit (JDK), is easy to do in Fedora. At the time of this article, versions 8 and 9 are available. Simply open a terminal and enter:
sudo dnf install java-1.8.0-openjdk-devel
This will install the JDK for version 8. For version 9, enter:
sudo dnf install java-9-openjdk-devel
For the developer who requires additional tools and libraries such as Ant and Maven, the **Java Development** group is available. To install the suite, enter:
sudo dnf group install "Java Development"
To verify the compiler is installed, run:
javac -version
The output shows the compiler version and looks like this:
javac 1.8.0_162
## Compiling applications
You can use any basic text editor such as *nano*, *vim*, or *gedit* to write applications. This example provides a simple “Hello Fedora” program.
Open your favorite text editor and enter the following:
public class HelloFedora { public static void main (String[] args) { System.out.println("Hello Fedora!"); } }
Save the file as *HelloFedora.java*. In the terminal change to the directory containing the file and do:
javac HelloFedora.java
The compiler will complain if it runs into any syntax errors. Otherwise it will simply display the shell prompt beneath.
You should now have a file called *HelloFedora,* which is the compiled program. Run it with the following command:
java HelloFedora
And the output will display:
Hello Fedora!
## Installing an Integrated Development Environment (IDE)
Some programs may be more complex and an IDE can make things flow smoothly. There are quite a few IDEs available for Java programmers including:
[Geany](https://www.geany.org/), a basic IDE that loads quickly, and provides built-in templates[Anjuta](http://anjuta.org/)[GNOME Builder](https://wiki.gnome.org/Apps/Builder), which has been covered in the article[Builder – a new IDE specifically for GNOME app developers](https://fedoramagazine.org/builder-a-new-ide-specifically-for-gnome-app-developers-2/)
However, one of the most popular open-source IDE’s, mainly written in Java, is [Eclipse](https://www.eclipse.org/). Eclipse is available in the official repositories. To install it, run this command:
sudo dnf install eclipse-jdt
When the installation is complete, a shortcut for Eclipse appears in the desktop menu.
For more information on how to use Eclipse, consult the [User Guide](http://help.eclipse.org/oxygen/nav/0) available on their website.
## Browser plugin
If you’re developing web applets and need a plugin for your browser, [IcedTea-Web](https://icedtea.classpath.org/wiki/IcedTea-Web) is available. Like OpenJDK, it is open source and easy to install in Fedora. Run this command:
sudo dnf install icedtea-web
As of Firefox 52, the web plugin no longer works. For details visit the Mozilla support site at [https://support.mozilla.org/en-US/kb/npapi-plugins?as=u&utm_source=inproduct](https://support.mozilla.org/en-US/kb/npapi-plugins?as=u&utm_source=inproduct).
Congratulations, your Java development environment is ready to use.
## Mattias Bengtsson
If you’re developing web applets in 2018 you should probably sit down and reconsider your choices. :/
## Steve
I develop in Java on my Linux box daily. I use IntelliJ’s IDEA IDE. I find it much more intuitive than Elcipse and less bulky than netbeans. It has a fantastic selection of tools, and very useful code completion helpers. It is available as a community edition, but is not packaged with Fedora. It is the same IDE as that which Android uses for development.
## Mostafa Kamel
I expected a very powerful tools for java . Intellij has an open source version “community” . I consider it the best IDE for java . wow applet , applet is a dead man .
Geany and Eclipse isn’t powerful than IntelliJ or Netbeans . Now java8 is considered the legacy for java . the most of java developer still code by java8 .
## satai
As the previous commenters
– don’t develop applets. They are dead.
– don’t start with any other IDE than IntelliJ. (Write your first Java program using an editor of choice to see how everything works behidn the scenes and then install IntelliJ. It’s possible that ypu will be forced to downgrade to Eclipse some time in the future for some reasons such as an plugin used by your employer, but don’t torture yourself from the start).
My points
– use javac for the first “hello world” project but use a project lifecycle tool for the next one (maven and gradle are probably the most popular choices right now).
– have a look at testing tools as soon as possible. It will make your life easier from the begining (JUnit is the common choice, Spock is my recomendation if you need a bit more power.)
## Rene Reichenbach
“don’t start with any other IDE than IntelliJ” <– totally disagree
Choose the tooling that fits YOUR needs including any habits.
Eclipse can do it.
Apache Netbeans can do it.
Well configured VIM/Emacs can do it.
even VSCode with RedHat Java Extension can do it.
anything that edits text can do it …
If you like IntelliJ use it. Its not bad at all. But to declare it the universal truth is just wrong.
If you really “need” IntelliJ. Your Project is usually already to large and you should rethink the architecture.
And as mentioned tools like maven and gradle should be used as soon as you feel save with the language basics.
## Steve
I agree that you should always go with what you feel fits your work flow the best. For instance, my choice of the IntelliJ IDE IDEA over Eclipse and Netbeans was driven from past years experiences with all of them. However I am not “married” to any one of them, and if was asked outright, would likely have a rant list for all three of things I don’t like about them. Definitely familiarization with the build system is a worthwhile effort, and one which seems to be often overlooked by many. As far as size relative to use, I will confess that it is often convenience that drives me in the end, and the desire to ‘get this done’.
## judovana
Applets are dead, but ITW is also javaws (java web start ) provider. And javaws will be with us for some more time…
For fun – ITW can run also browser applets without browser – javaws –html httpx://some/page.html -as major browsers shut down npapi.
Idea have imho worst auto completion. Although in other tooling it is best. Fun is that, NetBeans autocompletion was based on Idea’s one, and then intelijidea left it, and come with the new, – current terrible one. eclipse are someewhere in the middle with autocompeltion.
## weezerwill
I’m new to Java programming. Out of curiosity, what makes the auto completion bad in the IntelliJ IDE? I struggled with getting Netbeans setup and working, but IntelliJ was pretty straight forward. I’m wondering if I need to go back to Netbeans. Thanks in advance.
## Rene Reichenbach
That sounds like some configuration issue. The autocompletion works quite good in Eclipse, Netbeans and IntelliJ. Make sure to use Apache Netbeans and not the “legacy 8.2” from Oracle.
## Aaron
It’s also worth looking at something like SDKMAN for managing different concurrent Java Versions, if for whatever reason you need oracle too etc.
## toquart
Thanks
## Petr "Stone" Hracek
Here is my IntelliJ-IDEA community repo. https://github.com/phracek/IntelliJ-IDEA-community
But I did not update it a couple month ago. |
9,637 | 如何在任何地方使用 Vim 编辑器输入文本 | https://www.ostechnix.com/how-to-use-vim-editor-to-input-text-anywhere/ | 2018-05-14T11:16:58 | [
"Vim"
] | https://linux.cn/article-9637-1.html | 
各位 Vim 使用者大家好!今天,我这里有个好消息告诉大家。我会向大家介绍 **Vim-anywhere**,这是一个简单的脚本,它允许你使用 Vim 编辑器在 Linux 中的任何地方输入文本。这意味着你能简单地调用自己最爱的 Vim 编辑器,输入任何你所想的,并将这些文本粘贴到任意的应用和网站中。这些文本将在剪贴板可用,直到你重启了系统。这个工具对那些喜欢在非 Vim 环境中使用 Vim 键位绑定的人来说十分有用。
### 在 Linux 中安装 Vim-anywhere
Vim-anywhere 工具可以运行在任何基于 GNOME(或其他衍生品)的 Linux 发行版上。另外,确保你已经安装了下面的依赖。
* Curl
* Git
* gVim
* xclip
比如,你可以用下面的命令在 Ubuntu 中安装这些工具:
```
$ sudo apt install curl git vim-gnome xclip
```
然后运行如下的命令来安装 Vim-anywhere:
```
$ curl -fsSL https://raw.github.com/cknadler/vim-anywhere/master/install | bash
```
Vim-anywhere 到此已经安装完成。现在我们来看看如何使用它。
### 在任何地方使用 Vim 编辑器输入文本
假如你需要创建一个 word 文档。但是你更愿意使用 Vim 编辑器,而不是 LibreOffice。没问题,这里 Vim-anywhere 就派上用场了。Vim-anywhere 自动化了整个流程。它仅仅简单地调用 Vim 编辑器,所以你能写任何你所想的,然后将之粘贴到 .doc 文件中。
让我给你展示一个用例。打开 LibreOffice 或者你选的任何图形文本编辑器。然后打开 Vim-anywhere。你只需要按下 `CTRL+ALT+V` 即可。它将会打开 gVim 编辑器。按下 `i` 切换到交互模式然后输入文本。完成之后,键入 `:wq` 关闭并保存文件。

这些文本会在剪贴板中可用,直到你重启了系统。在你关闭编辑器之后,你之前的应用会重新占据主界面。你只需按下 `CTRL+P` 将文本粘贴进去。

这仅仅只是一个例子。你甚至可以使用 Vim-anywhere 在烦人的 web 表单或者其他应用上进行输入。一旦 Vim-anywhere 被调用,它将会打开一个缓冲区。关闭 Vim-anywhere 之后,缓冲器内的内容会自动复制到你的剪贴板中,之前的应用会重新占据主界面。
Vim-anywhere 在被调用的时候会在 `/tmp/vim-anywhere` 中创建一个临时文件。这些临时文件会一致保存着,直到你重启了系统,并为你提供临时的历史记录。
```
$ ls /tmp/vim-anywhere
```
你可以用下面的命令重新打开最近的文件:
```
$ vim $( ls /tmp/vim-anywhere | sort -r | head -n 1 )
```
#### 更新 Vim-anywhere
运行下面的命令来更新 Vim-anywhere:
```
$ ~/.vim-anywhere/update
```
#### 更改快捷键
默认调用 Vim-anywhere 的键位是 `CTRL+ALT+V`。你可以用 `gconf` 工具将其更改为任何自定义的键位绑定。
```
$ gconftool -t str --set /desktop/gnome/keybindings/vim-anywhere/binding <custom binding>
```
#### 卸载 Vim-anywhere
可能有些人觉得每次打开 Vim 编辑器,输入一些文本,然后将文本复制到其他应用中是没有意义也毫无必要的。
如果你不觉得这个工具有用,只需使用下面的命令来卸载它:
```
$ ~/.vim-anywhere/uninstall
```
---
via: <https://www.ostechnix.com/how-to-use-vim-editor-to-input-text-anywhere/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[paperzhang](https://github.com/paperzhang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,638 | 如何在终端中使用 Instagram | https://www.ostechnix.com/how-to-use-instagram-in-terminal/ | 2018-05-14T12:06:57 | [
"Instagram",
"终端"
] | https://linux.cn/article-9638-1.html | 
Instagram 不需要介绍。它是像 Facebook 和 Twitter 之类的流行社交网络平台之一,它可以公开或私下分享照片和视频给确认过的粉丝。它是由两位企业家 **Kevin Systrom** 和 **Mike Krieger**于 2010 年发起的。2012 年,社交网络巨头 Facebook 收购了 Instagram。Android 和 iOS 设备上可以免费下载 Instagram。我们也可以通过网络浏览器在桌面系统中使用它。而且,最酷的是现在你可以在任何类 Unix 操作系统上的终端中使用 Instagram。你兴奋了吗?那么,请阅读以下内容了解如何在终端上查看你的 Instagram feed。
### 终端中的 Instagram
首先,按照以下链接中的说明安装 `pip3`。
然后,git clone 它的脚本仓库。
```
$ git clone https://github.com/billcccheng/instagram-terminal-news-feed.git
```
以上命令会将 instagram 脚本的内容克隆到当前工作目录中名为 `instagram-terminal-news-feed` 的目录中。cd 到该目录:
```
$ cd instagram-terminal-news-feed/
```
然后,运行以下命令安装它:
```
$ pip3 install -r requirements.txt
```
现在,运行以下命令在 Linux 终端中启动 instagram。
```
$ python3 start.py
```
输入你的 Instagram 用户名和密码,并直接从终端中浏览你的 Instagram feed。你的 instragram 用户名和密码将仅本地存储在名为 `credential.json` 的文件中。所以,你不必担心它。你也可以选择不保存默认保存的凭证。
下面是[我的 Instagram 页面](https://www.instagram.com/ostechnix/)的一些截图。



请注意,你只能查看你的 feed。你不能关注任何人,喜欢或评论帖子。这只是一个 instagram feed 阅读器。
该项目可在 GitHub 上免费获得,因此你可以查看源代码,改进它,添加更多功能,修复任何 bug。
玩得开心!干杯!!
---
via: <https://www.ostechnix.com/how-to-use-instagram-in-terminal/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,639 | “Exit Trap” 让你的 Bash 脚本更稳固可靠 | http://redsymbol.net/articles/bash-exit-traps/ | 2018-05-14T15:01:00 | [
"bash",
"脚本"
] | https://linux.cn/article-9639-1.html | 
有个简单实用的技巧可以让你的 bash 脚本更稳健 -- 确保总是执行必要的收尾工作,哪怕是在发生异常的时候。要做到这一点,秘诀就是 bash 提供的一个叫做 EXIT 的伪信号,你可以 [trap](http://www.gnu.org/software/bash/manual/bashref.html#index-trap) 它,当脚本因为任何原因退出时,相应的命令或函数就会执行。我们来看看它是如何工作的。
基本的代码结构看起来像这样:
```
#!/bin/bash
function finish {
# 你的收尾代码
}
trap finish EXIT
```
你可以把任何你觉得务必要运行的代码放在这个 `finish` 函数里。一个很好的例子是:创建一个临时目录,事后再删除它。
```
#!/bin/bash
scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
function finish {
rm -rf "$scratch"
}
trap finish EXIT
```
这样,在你的核心代码中,你就可以在这个 `$scratch` 目录里下载、生成、操作中间或临时数据了。<sup> <a href="http://redsymbol.net/articles/bash-exit-traps/#footnote-1"> 注1 </a></sup>
```
# 下载所有版本的 linux 内核…… 为了科学研究!
for major in {1..4}; do
for minor in {0..99}; do
for patchlevel in {0..99}; do
tarball="linux-${major}-${minor}-${patchlevel}.tar.bz2"
curl -q "http://kernel.org/path/to/$tarball" -o "$scratch/$tarball" || true
if [ -f "$scratch/$tarball" ]; then
tar jxf "$scratch/$tarball"
fi
done
done
done
# 整合成单个文件
# 复制到目标位置
cp "$scratch/frankenstein-linux.tar.bz2" "$1"
# 脚本结束, scratch 目录自动被删除
```
比较一下如果不用 `trap` ,你是怎么删除 `scratch` 目录的:
```
#!/bin/bash
# 别这样做!
scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
# 在这里插入你的几十上百行代码
# 都搞定了,退出之前把目录删除
rm -rf "$scratch"
```
这有什么问题么?很多:
* 如果运行出错导致脚本提前退出, `scratch` 目录及里面的内容不会被删除。这会导致资料泄漏,可能引发安全问题。
* 如果这个脚本的设计初衷就是在脚本末尾以前退出,那么你必须手动复制粘贴 `rm` 命令到每一个出口。
* 这也给维护带来了麻烦。如果今后在脚本某处添加了一个 `exit` ,你很可能就忘了加上删除操作 -- 从而制造潜在的安全漏洞。
### 无论如何,服务要在线
另外一个场景: 想象一下你正在运行一些自动化系统运维任务,要临时关闭一项服务,最后这项服务需要重启,而且要万无一失,即使脚本运行出错。那么你可以这样做:
```
function finish {
# 重启服务
sudo /etc/init.d/something start
}
trap finish EXIT
sudo /etc/init.d/something stop
# 主要任务代码
# 脚本结束,执行 finish 函数重启服务
```
一个具体的实例:比如 Ubuntu 服务器上运行着 MongoDB ,你要为 crond 写一个脚本来临时关闭服务并做一些日常维护工作。你应该这样写:
```
function finish {
# 重启服务
sudo service mongdb start
}
trap finish EXIT
# 关闭 mongod 服务
sudo service mongdb stop
# (如果 mongod 配置了 fork ,比如 replica set ,你可能需要执行 “sudo killall --wait /usr/bin/mongod”)
```
### 控制开销
有一种情况特别能体现 EXIT `trap` 的价值:如果你的脚本运行过程中需要初始化一下成本高昂的资源,结束时要确保把它们释放掉。比如你在 AWS (Amazon Web Services) 上工作,要在脚本中创建一个镜像。
(名词解释: 在亚马逊云上的运行的服务器叫“[实例](http://aws.amazon.com/ec2/)”。实例从<ruby> 亚马逊机器镜像 <rt> Amazon Machine Image </rt></ruby>创建而来,通常被称为 “AMI” 或 “镜像” 。AMI 相当于某个特殊时间点的服务器快照。)
我们可以这样创建一个自定义的 AMI :
1. 基于一个基准 AMI 运行一个实例(例如,启动一个服务器)。
2. 在实例中手动或运行脚本来做一些修改。
3. 用修改后的实例创建一个镜像。
4. 如果不再需要这个实例,可以将其删除。
最后一步**相当重要**。如果你的脚本没有把实例删除掉,它会一直运行并计费。(到月底你的账单让你大跌眼镜时,恐怕哭都来不及了!)
如果把 AMI 的创建封装在脚本里,我们就可以利用 `trap` EXIT 来删除实例了。我们还可以用上 EC2 的命令行工具:
```
#!/bin/bash
# 定义基准 AMI 的 ID
ami=$1
# 保存临时实例的 ID
instance=''
# 作为 IT 人,让我们看看 scratch 目录的另类用法
scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
function finish {
if [ -n "$instance" ]; then
ec2-terminate-instances "$instance"
fi
rm -rf "$scratch"
}
trap finish EXIT
# 创建实例,将输出(包含实例 ID )保存到 scratch 目录下的文件里
ec2-run-instances "$ami" > "$scratch/run-instance"
# 提取实例 ID
instance=$(grep '^INSTANCE' "$scratch/run-instance" | cut -f 2)
```
脚本执行到这里,实例(EC2 服务器)已经开始运行 <sup> <a href="http://redsymbol.net/articles/bash-exit-traps/#footnote-2"> 注2 </a> 。接下来你可以做任何事情:在实例中安装软件,修改配置文件等,然后为最终版本创建一个镜像。实例会在脚本结束时被删除</sup> -- 即使脚本因错误而提前退出。(请确保实例创建成功后再运行业务代码。)
### 更多应用
这篇文章只讲了些皮毛。我已经使用这个 bash 技巧很多年了,现在还能不时发现一些有趣的用法。你也可以把这个方法应用到你自己的场景中,从而提升你的 bash 脚本的可靠性。
### 尾注
* 注1. `mktemp` 的选项 `-t` 在 Linux 上是可选的,在 OS X 上是必需的。带上此选项可以让你的脚本有更好的可移植性。
* 注2. 如果只是为了获取实例 ID ,我们不用创建文件,直接写成 `instance=$(ec2-run-instances "$ami" | grep '^INSTANCE' | cut -f 2)` 就可以。但把输出写入文件可以记录更多有用信息,便于调试 ,代码可读性也更强。
作者简介:美国加利福尼亚旧金山的作家,软件工程师,企业家。[Powerful Python](https://www.amazon.com/d/0692878971) 的作者,他的 [blog](https://powerfulpython.com/blog/)。
---
via: <http://redsymbol.net/articles/bash-exit-traps/>
作者:[aaron maxwell](http://redsymbol.net/) 译者:[Dotcra](https://github.com/Dotcra) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # How "Exit Traps" Can Make Your Bash Scripts Way More Robust And Reliable
There is a simple, useful idiom to make your bash scripts more
robust - ensuring they always perform necessary cleanup
operations, even when something unexpected goes wrong. The secret
sauce is a pseudo-signal provided by bash, called EXIT, that you
can [trap](http://www.gnu.org/software/bash/manual/bashref.html#index-trap);
commands or functions trapped on it will execute when the script
exits for any reason. Let's see how this works.
The basic code structure is like this:
- #!/bin/bash
- function finish {
- # Your cleanup code here
- }
- trap finish EXIT
You place any code that you want to be certain to run in this "finish" function. A good common example: creating a temporary scratch directory, then deleting it after.
- #!/bin/bash
- scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
- function finish {
- rm -rf "$scratch"
- }
- trap finish EXIT
You can then download, generate, slice and dice intermediate or
temporary files to the `$scratch`
directory to your heart's
content. [[1]](#footnote-1)
- # Download every linux kernel ever.... FOR SCIENCE!
- for major in {1..4}; do
- for minor in {0..99}; do
- for patchlevel in {0..99}; do
- tarball="linux-${major}-${minor}-${patchlevel}.tar.bz2"
- curl -q "http://kernel.org/path/to/$tarball" -o "$scratch/$tarball" || true
- if [ -f "$scratch/$tarball" ]; then
- tar jxf "$scratch/$tarball"
- fi
- done
- done
- done
- # magically merge them into some frankenstein kernel ...
- # That done, copy it to a destination
- cp "$scratch/frankenstein-linux.tar.bz2" "$1"
- # Here at script end, the scratch directory is erased automatically
Compare this to how you'd remove the scratch directory without the trap:
- #!/bin/bash
- # DON'T DO THIS!
- scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
-
- # Insert dozens or hundreds of lines of code here...
-
- # All done, now remove the directory before we exit
- rm -rf "$scratch"
What's wrong with this? Plenty:
- If some error causes the script to exit prematurely, the scratch directory and its contents don't get deleted. This is a resource leak, and may have security implications too.
- If the script is designed to exit before the end, you must manually copy 'n paste the rm command at each exit point.
- There are maintainability problems as well. If you later add a new in-script exit, it's easy to forget to include the removal - potentially creating mysterious heisenleaks.
## Keeping Services Up, No Matter What
Another scenario: Imagine you are automating some system administration task, requiring you to temporarily stop a server... and you want to be dead certain it starts again at the end, even if there is some runtime error. Then the pattern is:
- function finish {
- # re-start service
- sudo /etc/init.d/something start
- }
- trap finish EXIT
- sudo /etc/init.d/something stop
- # Do the work...
-
- # Allow the script to end and the trapped finish function to start the
- # daemon back up.
A concrete example: suppose you have MongoDB running on an Ubuntu server, and want a cronned script to temporarily stop the process for some regular maintenance task. The way to handle it is:
- function finish {
- # re-start service
- sudo service mongdb start
- }
- trap finish EXIT
- # Stop the mongod instance
- sudo service mongdb stop
- # (If mongod is configured to fork, e.g. as part of a replica set, you
- # may instead need to do "sudo killall --wait /usr/bin/mongod".)
## Capping Expensive Resources
There is another situation where the exit trap is very useful: if your script initiates an expensive resource, needed only while the script is executing, and you want to make certain it releases that resource once it's done. For example, suppose you are working with Amazon Web Services (AWS), and want a script that creates a new image.
(If you're not familar with this: Servers running on the Amazon
cloud are called "[instances](http://aws.amazon.com/ec2/)". Instances are
launched from Amazon Machine Images, a.k.a. "AMIs" or "images". AMIs
are kind of like a snapshot of a server at a specific moment
in time.)
A common pattern for creating custom AMIs looks like:
- Run an instance (i.e. start a server) from some base AMI.
- Make some modifications to it, perhaps by copying a script over and then executing it.
- Create a new image from this now-modified instance.
- Terminate the running instance, which you no longer need.
That last step is **really important**. If your script fails to
terminate the instance, it will keep running and accruing charges to
your account. (In the worst case, you won't notice until the end of
the month, when your bill is way higher than you expect. Believe
me, that's no fun!)
If our AMI-creation is encapsulated in a script, we can set an exit trap to destroy the instance. Let's rely on the EC2 command line tools:
- #!/bin/bash
- # define the base AMI ID somehow
- ami=$1
- # Store the temporary instance ID here
- instance=''
- # While we are at it, let me show you another use for a scratch directory.
- scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
- function finish {
- if [ -n "$instance" ]; then
- ec2-terminate-instances "$instance"
- fi
- rm -rf "$scratch"
- }
- trap finish EXIT
- # This line runs the instance, and stores the program output (which
- # shows the instance ID) in a file in the scratch directory.
- ec2-run-instances "$ami" > "$scratch/run-instance"
- # Now extract the instance ID.
- instance=$(grep '^INSTANCE' "$scratch/run-instance" | cut -f 2)
At this point in the script, the instance (EC2 server) is running
[[2]](#footnote-2). You can do
whatever you like: install software on the instance, modify its
configuration programatically, et cetera, finally creating an image
from the final version. The instance will be terminated for you when
the script exits - even if some uncaught error causes it to exit
early. (Just make sure to block until the image creation process finishes.)
## Plenty Of Uses
I believe what I've covered in this article only scratches the surface; having used this bash pattern for years, I still find new interesting and fun ways to apply it. You will probably discover your own situations where it will help make your bash scripts more reliable.
## Footnotes
- The -t option to mktemp is optional on Linux, but needed on OS X. Make your scripts using this idiom more portable by including this option.
-
When getting the instance ID, instead of using the scratch file, we could just say:
`instance=$(ec2-run-instances "$ami" | grep '^INSTANCE' | cut -f 2)`
. But using the scratch file makes the code a bit more readable, leaves us with better logging for debugging, and makes it easy to capture other info from ec2-run-instances's output if we wish. |
9,642 | Linux 命令行下的数学运算 | https://www.networkworld.com/article/3268964/linux/how-to-do-math-on-the-linux-command-line.html | 2018-05-14T19:04:00 | [
"数学",
"bc",
"计算",
"expr"
] | https://linux.cn/article-9642-1.html |
>
> 有几个有趣的命令可以在 Linux 系统下做数学运算: `expr`、`factor`、`jot` 和 `bc` 命令。
>
>
>

可以在 Linux 命令行下做数学运算吗?当然可以!事实上,有不少命令可以轻松完成这些操作,其中一些甚至让你大吃一惊。让我们来学习这些有用的数学运算命令或命令语法吧。
### expr
首先,对于在命令行使用命令进行数学运算,可能最容易想到、最常用的命令就是 `expr` (<ruby> 表达式 <rt> expression </rt></ruby>。它可以完成四则运算,也可以用于比较大小。下面是几个例子:
#### 变量递增
```
$ count=0
$ count=`expr $count + 1`
$ echo $count
1
```
#### 完成简单运算
```
$ expr 11 + 123
134
$ expr 134 / 11
12
$ expr 134 - 11
123
$ expr 11 * 123
expr: syntax error <== oops!
$ expr 11 \* 123
1353
$ expr 20 % 3
2
```
注意,你需要在 `*` 运算符之前增加 `\` 符号,避免语法错误(注:`*` 是 bash 的通配符,因此需要用 `\` 转义,下面的 `>` 也是由于是 bash 的管道符而需要转义)。`%` 运算符用于取余运算。
下面是一个稍微复杂的例子:
```
participants=11
total=156
share=`expr $total / $participants`
remaining=`expr $total - $participants \* $share`
echo $share
14
echo $remaining
2
```
假设某个活动中有 11 位参与者,需要颁发的奖项总数为 156,那么平均每个参与者获得 14 项奖项,额外剩余 2 个奖项。
#### 比较
下面让我们看一下比较的操作。从第一印象来看,语句看似有些怪异;这里并不是**设置**数值,而是进行数字比较。在本例中 `expr` 判断表达式是否为真:如果结果是 1,那么表达式为真;反之,表达式为假。
```
$ expr 11 = 11
1
$ expr 11 = 12
0
```
请读作“11 是否等于 11?”及“11 是否等于 12?”,你很快就会习惯这种写法。当然,我们不会在命令行上执行上述比较,可能的比较是 `$age` 是否等于 `11`。
```
$ age=11
$ expr $age = 11
1
```
在本例中,我们判断 10 是否大于 5,以及是否大于 99。
```
$ expr 10 \> 5
1
$ expr 10 \> 99
0
```
的确,返回 1 和 0 分别代表比较的结果为真和假,我们一般预期在 Linux 上得到这个结果。在下面的例子中,按照上述逻辑使用 `expr` 并不正确,因为 `if` 的工作原理刚好相反,即 0 代表真。
```
#!/bin/bash
echo -n "Cost to us> "
read cost
echo -n "Price we're asking> "
read price
if [ `expr $price \> $cost` ]; then
echo "We make money"
else
echo "Don't sell it"
fi
```
下面,我们运行这个脚本:
```
$ ./checkPrice
Cost to us> 11.50
Price we're asking> 6
We make money
```
这显然与我们预期不符!我们稍微修改一下,以便使其按我们预期工作:
```
#!/bin/bash
echo -n "Cost to us> "
read cost
echo -n "Price we're asking> "
read price
if [ `expr $price \> $cost` == 1 ]; then
echo "We make money"
else
echo "Don't sell it"
fi
```
### factor
`factor` 命令的功能基本与你预期相符。你给出一个数字,该命令会给出对应数字的因子。
```
$ factor 111
111: 3 37
$ factor 134
134: 2 67
$ factor 17894
17894: 2 23 389
$ factor 1987
1987: 1987
```
注:`factor` 命令对于最后一个数字没有返回更多因子,这是因为 1987 是一个**质数**。
### jot
`jot` 命令可以创建一系列数字。给定数字总数及起始数字即可。
```
$ jot 8 10
10
11
12
13
14
15
16
17
```
你也可以用如下方式使用 `jot`,这里我们要求递减至数字 2。
```
$ jot 8 10 2
10
9
8
7
5
4
3
2
```
`jot` 可以帮你构造一系列数字组成的列表,该列表可以用于其它任务。
```
$ for i in `jot 7 17`; do echo April $i; done
April 17
April 18
April 19
April 20
April 21
April 22
April 23
```
### bc
`bc` 基本上是命令行数学运算最佳工具之一。输入你想执行的运算,使用管道发送至该命令即可:
```
$ echo "123.4+5/6-(7.89*1.234)" | bc
113.664
```
可见 `bc` 并没有忽略精度,而且输入的字符串也相当直截了当。它还可以进行大小比较、处理布尔值、计算平方根、正弦、余弦和正切等。
```
$ echo "sqrt(256)" | bc
16
$ echo "s(90)" | bc -l
.89399666360055789051
```
事实上,`bc` 甚至可以计算 pi。你需要指定需要的精度。
```
$ echo "scale=5; 4*a(1)" | bc -l
3.14156
$ echo "scale=10; 4*a(1)" | bc -l
3.1415926532
$ echo "scale=20; 4*a(1)" | bc -l
3.14159265358979323844
$ echo "scale=40; 4*a(1)" | bc -l
3.1415926535897932384626433832795028841968
```
除了通过管道接收数据并返回结果,`bc`还可以交互式运行,输入你想执行的运算即可。本例中提到的 `scale` 设置可以指定有效数字的个数。
```
$ bc
bc 1.06.95
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
scale=2
3/4
.75
2/3
.66
quit
```
你还可以使用 `bc` 完成数字进制转换。`obase` 用于设置输出的数字进制。
```
$ bc
bc 1.06.95
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
obase=16
16 <=== entered
10 <=== response
256 <=== entered
100 <=== response
quit
```
按如下方式使用 `bc` 也是完成十六进制与十进制转换的最简单方式之一:
```
$ echo "ibase=16; F2" | bc
242
$ echo "obase=16; 242" | bc
F2
```
在上面第一个例子中,我们将输入进制(`ibase`)设置为十六进制(`hex`),完成十六进制到为十进制的转换。在第二个例子中,我们执行相反的操作,即将输出进制(`obase`)设置为十六进制。
### 简单的 bash 数学运算
通过使用双括号,我们可以在 bash 中完成简单的数学运算。在下面的例子中,我们创建一个变量,为变量赋值,然后依次执行加法、自减和平方。
```
$ (( e = 11 ))
$ (( e = e + 7 ))
$ echo $e
18
$ (( e-- ))
$ echo $e
17
$ (( e = e ** 2 ))
$ echo $e
289
```
允许使用的运算符包括:
```
+ - 加法及减法
++ -- 自增与自减
* / % 乘法、除法及求余数
** 指数运算(bash 中)
^ 指数运算(bc 中)
```
你还可以使用逻辑运算符和布尔运算符:
```
$ ((x=11)); ((y=7))
$ if (( x > y )); then
> echo "x > y"
> fi
x > y
$ ((x=11)); ((y=7)); ((z=3))
$ if (( x > y )) >> (( y > z )); then
> echo "letters roll downhill"
> fi
letters roll downhill
```
或者如下方式:
```
$ if [ x > y ] << [ y > z ]; then echo "letters roll downhill"; fi
letters roll downhill
```
下面计算 2 的 3 次幂:
```
$ echo "2 ^ 3"
2 ^ 3
$ echo "2 ^ 3" | bc
8
```
### 总结
在 Linux 系统中,有很多不同的命令行工具可以完成数字运算。希望你在读完本文之后,能掌握一两个新工具。
感谢 @[no1xsyzy](https://github.com/no1xsyzy) [提出的修改意见](https://github.com/LCTT/TranslateProject/issues/8841)。
---
via: <https://www.networkworld.com/article/3268964/linux/how-to-do-math-on-the-linux-command-line.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,643 | 两款 Linux 桌面端可用的科学计算器 | https://opensource.com/article/18/1/scientific-calculators-linux | 2018-05-15T10:27:00 | [
"计算器"
] | https://linux.cn/article-9643-1.html |
>
> 如果你想找个高级的桌面计算器的话,你可以看看开源软件,以及一些其它有趣的工具。
>
>
>

每个 Linux 桌面环境都至少带有一个功能简单的桌面计算器,但大多数计算器只能进行一些简单的计算。
幸运的是,还是有例外的:不仅可以做得比开平方根和一些三角函数还多,而且还很简单。这里将介绍两款强大的计算器,外加一大堆额外的功能。
### SpeedCrunch
[SpeedCrunch](http://speedcrunch.org/index.html) 是一款高精度科学计算器,有着简明的 Qt5 图像界面,并且强烈依赖键盘。

*SpeedCrunch 运行中*
它支持单位,并且可用在所有函数中。
例如,
```
2 * 10^6 newton / (meter^2)
```
你可以得到:
```
= 2000000 pascal
```
SpeedCrunch 会默认地将结果转化为国际标准单位,但还是可以用 `in` 命令转换:
例如:
```
3*10^8 meter / second in kilo meter / hour
```
结果是:
```
= 1080000000 kilo meter / hour
```
`F5` 键可以将所有结果转为科学计数法(`1.08e9 kilo meter / hour`),`F2` 键可以只将那些很大的数或很小的数转为科学计数法。更多选项可以在配置页面找到。
可用的函数的列表看上去非常壮观。它可以用在 Linux 、 Windows、macOS。许可证是 GPLv2,你可以在 [Bitbucket](https://bitbucket.org/heldercorreia/speedcrunch) 上得到它的源码。
### Qalculate!
[Qalculate!](https://qalculate.github.io/)(有感叹号)有一段长而复杂的历史。
这个项目给了我们一个强大的库,而这个库可以被其它程序使用(在 Plasma 桌面中,krunner 可以用它来计算),以及一个用 GTK3 搭建的图形界面。它允许你转换单位,处理物理常量,创建图像,使用复数,矩阵以及向量,选择任意精度,等等。

*在 Qalculate! 中查看物理常量*
在单位的使用方面,Qalculate! 会比 SppedCrunch 更加直观,而且可以识别一些常用前缀。你有听说过 exapascal 压力吗?反正我没有(太阳的中心大概在 `~26 PPa`),但 Qalculate! ,可以准确 `1 EPa` 的意思。同时,Qalculate! 可以更加灵活地处理语法错误,所以你不需要担心打括号:如果没有歧义,Qalculate! 会直接给出正确答案。
一段时间之后这个项目看上去被遗弃了。但在 2016 年,它又变得强大了,在一年里更新了 10 个版本。它的许可证是 GPLv2 (源码在 [GitHub](https://github.com/Qalculate) 上),提供Linux 、Windows 、macOS的版本。
### 更多计算器
#### ConvertAll
好吧,这不是“计算器”,但这个程序非常好用。
大部分单位转换器只是一个大的基本单位列表以及一大堆基本组合,但 [ConvertAll](http://convertall.bellz.org/) 与它们不一样。有试过把“天文单位每年”转换为“英尺每秒”吗?不管它们说不说得通,只要你想转换任何种类的单位,ConvertAll 就是你要的工具。
只需要在相应的输入框内输入转换前和转换后的单位:如果单位相容,你会直接得到答案。
主程序是在 PyQt5 上搭建的,但也有 [JavaScript 的在线版本](http://convertall.bellz.org/js/)。
#### 带有单位包的 (wx)Maxima
有时候(好吧,很多时候)一款桌面计算器时候不够你用的,然后你需要更多的原力。
[Maxima](http://maxima.sourceforge.net/) 是一款计算机代数系统(LCTT 译注:进行符号运算的软件。这种系统的要件是数学表示式的符号运算),你可以用它计算导数、积分、方程、特征值和特征向量、泰勒级数、拉普拉斯变换与傅立叶变换,以及任意精度的数字计算、二维或三维图像··· ···列出这些都够我们写几页纸的了。
[wxMaxima](https://andrejv.github.io/wxmaxima/) 是一个设计精湛的 Maxima 的图形前端,它简化了许多 Maxima 的选项,但并不会影响其它。在 Maxima 的基础上,wxMaxima 还允许你创建 “笔记本”,你可以在上面写一些笔记,保存你的图像等。其中一项 (wx)Maxima 最惊艳的功能是它可以处理尺寸单位。
在提示符只需要输入:
```
load("unit")
```
按 `Shift+Enter`,等几秒钟的时间,然后你就可以开始了。
默认地,单位包可以用基本的 MKS 单位,但如果你喜欢,例如,你可以用 `N` 为单位而不是 `kg*m/s2`,你只需要输入:`setunits(N)`。
Maxima 的帮助(也可以在 wxMaxima 的帮助菜单中找到)会给你更多信息。
你使用这些程序吗?你知道还有其它好的科学、工程用途的桌面计算器或者其它相关的计算器吗?在评论区里告诉我们吧!
---
via: <https://opensource.com/article/18/1/scientific-calculators-linux>
作者:[Ricardo Berlasso](https://opensource.com/users/rgb-es) 译者:[zyk2290](https://github.com/zyk2290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Every Linux desktop environment comes with at least a simple desktop calculator, but most of those simple calculators are just that: a simple tool for simple calculations.
Fortunately, there are exceptions; programs that go far beyond square roots and a couple of trigonometric functions, yet are still easy to use. Here are two powerful calculator tools for Linux, plus a couple of bonus options.
## SpeedCrunch
[SpeedCrunch](http://speedcrunch.org/index.html) is a high-precision scientific calculator with a simple Qt5 graphical interface and strong focus on the keyboard.
opensource.com
It supports working with units and comes loaded with all kinds of functions.
For example, by writing:
`2 * 10^6 newton / (meter^2)`
you get:
`= 2000000 pascal`
By default, SpeedCrunch delivers its results in the international unit system, but units can be transformed with the "in" instruction.
For example:
`3*10^8 meter / second in kilo meter / hour`
produces:
`= 1080000000 kilo meter / hour`
With the `F5`
key, all results will turn into scientific notation (`1.08e9 kilo meter / hour`
), while with `F2`
only numbers that are small enough or big enough will change. More options are available on the Configuration menu.
The list of available functions is really impressive. It works on Linux, Windows, and MacOS, and it's licensed under GPLv2; you can access its source code on [Bitbucket](https://bitbucket.org/heldercorreia/speedcrunch).
## Qalculate!
[Qalculate!](https://qalculate.github.io/) (with the exclamation point) has a long and complex history.
The project offers a powerful library that can be used by other programs (the Plasma desktop can use it to perform calculations from krunner) and a graphical interface built on GTK3. It allows you to work with units, handle physical constants, create graphics, use complex numbers, matrices, and vectors, choose arbitrary precision, and more.
opensource.com
Its use of units is far more intuitive than SpeedCrunch's and it understands common prefixes without problem. Have you heard of an exapascal pressure? I hadn't (the Sun's core stops at `~26 PPa`
), but Qalculate! has no problem understanding the meaning of `1 EPa`
. Also, Qalculate! is more flexible with syntax errors, so you don't need to worry about closing all those parentheses: if there is no ambiguity, Qalculate! will give you the right answer.
After a long period on which the project seemed orphaned, it came back to life in 2016 and has been going strong since, with more than 10 versions in just one year. It's licensed under GPLv2 (with source code on [GitHub](https://github.com/Qalculate)) and offers versions for Linux and Windows, as well as a MacOS port.
## Bonus calculators
### ConvertAll
OK, it's not a "calculator," yet this simple application is incredibly useful.
Most unit converters stop at a long list of basic units and a bunch of common combinations, but not [ConvertAll](http://convertall.bellz.org/). Trying to convert from astronomical units per year into inches per second? It doesn't matter if it makes sense or not, if you need to transform a unit of any kind, ConvertAll is the tool for you.
Just write the starting unit and the final unit in the corresponding boxes; if the units are compatible, you'll get the transformation without protest.
The main application is written in PyQt5, but there is also an [online version written in JavaScript](http://convertall.bellz.org/js/).
### (wx)Maxima with the units package
Sometimes (OK, many times) a desktop calculator is not enough and you need more raw power.
[Maxima](http://maxima.sourceforge.net/) is a computer algebra system (CAS) with which you can do derivatives, integrals, series, equations, eigenvectors and eigenvalues, Taylor series, Laplace and Fourier transformations, as well as numerical calculations with arbitrary precision, graph on two and three dimensions… we could fill several pages just listing its capabilities.
[wxMaxima](https://andrejv.github.io/wxmaxima/) is a well-designed graphical frontend for Maxima that simplifies the use of many Maxima options without compromising others. On top of the full power of Maxima, wxMaxima allows you to create "notebooks" on which you write comments, keep your graphics with your math, etc. One of the (wx)Maxima combo's most impressive features is that it works with dimension units.
On the prompt, just type:
`load("unit")`
press Shift+Enter, wait a few seconds, and you'll be ready to work.
By default, the unit package works with the basic MKS units, but if you prefer, for instance, to get `N`
instead of `kg*m/s2`
, you just need to type:
`setunits(N)`
Maxima's help (which is also available from wxMaxima's help menu) will give you more information.
Do you use these programs? Do you know another great desktop calculator for scientists and engineers or another related tool? Tell us about them in the comments!
## 6 Comments |
9,644 | 基于命令行的任务管理器 Taskwarrior | https://fedoramagazine.org/getting-started-taskwarrior/ | 2018-05-15T10:46:03 | [
"todo",
"Taskwarrior"
] | https://linux.cn/article-9644-1.html | 
Taskwarrior 是一个灵活的[命令行任务管理程序](https://taskwarrior.org/),用他们[自己的话说](https://taskwarrior.org/docs/start.html):
>
> Taskwarrior 在命令行里管理你的 TODO 列表。它灵活,快速,高效,不显眼,它默默做自己的事情让你避免自己管理。
>
>
>
Taskwarrior 是高度可定制的,但也可以“立即使用”。在本文中,我们将向你展示添加和完成任务的基本命令,然后我们将介绍几个更高级的命令。最后,我们将向你展示一些基本的配置设置,以开始自定义你的设置。
### 安装 Taskwarrior
Taskwarrior 在 Fedora 仓库中是可用的,所有安装它很容易:
```
sudo dnf install task
```
一旦完成安装,运行 `task` 命令。第一次运行将会创建一个 `~/.taskrc` 文件。
```
$ task
A configuration file could not be found in ~
Would you like a sample /home/link/.taskrc created, so Taskwarrior can proceed? (yes/no) yes
[task next]
No matches.
```
### 添加任务
添加任务快速而不显眼。
```
$ task add Plant the wheat
Created task 1.
```
运行 `task` 或者 `task list` 来显示即将来临的任务。
```
$ task list
ID Age Description Urg
1 8s Plant the wheat 0
1 task
```
让我们添加一些任务来完成这个示例。
```
$ task add Tend the wheat
Created task 2.
$ task add Cut the wheat
Created task 3.
$ task add Take the wheat to the mill to be ground into flour
Created task 4.
$ task add Bake a cake
Created task 5.
```
再次运行 `task` 来查看列表。
```
[task next]
ID Age Description Urg
1 3min Plant the wheat 0
2 22s Tend the wheat 0
3 16s Cut the wheat 0
4 8s Take the wheat to the mill to be ground into flour 0
5 2s Bake a cake 0
5 tasks
```
### 完成任务
将一个任务标记为完成, 查找其 ID 并运行:
```
$ task 1 done
Completed task 1 'Plant the wheat'.
Completed 1 task.
```
你也可以用它的描述来标记一个任务已完成。
```
$ task 'Tend the wheat' done
Completed task 1 'Tend the wheat'.
Completed 1 task.
```
通过使用 `add`、`list` 和 `done`,你可以说已经入门了。
### 设定截止日期
很多任务不需要一个截止日期:
```
task add Finish the article on Taskwarrior
```
但是有时候,设定一个截止日期正是你需要提高效率的动力。在添加任务时使用 `due` 修饰符来设置特定的截止日期。
```
task add Finish the article on Taskwarrior due:tomorrow
```
`due` 非常灵活。它接受特定日期 (`2017-02-02`) 或 ISO-8601 (`2017-02-02T20:53:00Z`),甚至相对时间 (`8hrs`)。可以查看所有示例的 [Date & Time](https://taskwarrior.org/docs/dates.html) 文档。
日期也不只有截止日期,Taskwarrior 有 `scheduled`, `wait` 和 `until` 选项。
```
task add Proof the article on Taskwarrior scheduled:thurs
```
一旦日期(本例中的星期四)通过,该任务就会被标记为 `READY` 虚拟标记。它会显示在 `ready` 报告中。
```
$ task ready
ID Age S Description Urg
1 2s 1d Proof the article on Taskwarrior 5
```
要移除一个日期,使用空白值来 `modify` 任务:
```
$ task 1 modify scheduled:
```
### 查找任务
如果没有使用正则表达式搜索的能力,任务列表是不完整的,对吧?
```
$ task '/.* the wheat/' list
ID Age Project Description Urg
2 42min Take the wheat to the mill to be ground into flour 0
1 42min Home Cut the wheat 1
2 tasks
```
### 自定义 Taskwarrior
记得我们在开头创建的文件 (`~/.taskrc`)吗?让我们来看看默认设置:
```
# [Created by task 2.5.1 2/9/2017 16:39:14]
# Taskwarrior program configuration file.
# For more documentation, see http://taskwarrior.org or try 'man task', 'man task-color',
# 'man task-sync' or 'man taskrc'
# Here is an example of entries that use the default, override and blank values
# variable=foo -- By specifying a value, this overrides the default
# variable= -- By specifying no value, this means no default
# #variable=foo -- By commenting out the line, or deleting it, this uses the default
# Use the command 'task show' to see all defaults and overrides
# Files
data.location=~/.task
# Color theme (uncomment one to use)
#include /usr//usr/share/task/light-16.theme
#include /usr//usr/share/task/light-256.theme
#include /usr//usr/share/task/dark-16.theme
#include /usr//usr/share/task/dark-256.theme
#include /usr//usr/share/task/dark-red-256.theme
#include /usr//usr/share/task/dark-green-256.theme
#include /usr//usr/share/task/dark-blue-256.theme
#include /usr//usr/share/task/dark-violets-256.theme
#include /usr//usr/share/task/dark-yellow-green.theme
#include /usr//usr/share/task/dark-gray-256.theme
#include /usr//usr/share/task/dark-gray-blue-256.theme
#include /usr//usr/share/task/solarized-dark-256.theme
#include /usr//usr/share/task/solarized-light-256.theme
#include /usr//usr/share/task/no-color.theme
```
现在唯一生效的选项是 `data.location=~/.task`。要查看活动配置设置(包括内置的默认设置),运行 `show`。
```
task show
```
要改变设置,使用 `config`。
```
$ task config displayweeknumber no
Are you sure you want to add 'displayweeknumber' with a value of 'no'? (yes/no) yes
Config file /home/link/.taskrc modified.
```
### 示例
这些只是你可以用 Taskwarrior 做的一部分事情。
将你的任务分配到一个项目:
```
task 'Fix leak in the roof' modify project:Home
```
使用 `start` 来标记你正在做的事情,这可以帮助你回忆起你周末后在做什么:
```
task 'Fix bug #141291' start
```
使用相关的标签:
```
task add 'Clean gutters' +weekend +house
```
务必阅读[完整文档](https://taskwarrior.org/docs/)以了解你可以编目和组织任务的所有方式。
---
via: <https://fedoramagazine.org/getting-started-taskwarrior/>
作者:[Link Dupont](https://fedoramagazine.org/author/linkdupont/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Taskwarrior is a flexible [command-line task management program](https://taskwarrior.org/). In their [own words](https://taskwarrior.org/docs/start.html):
*Taskwarrior manages your TODO list from your command line. It is flexible, fast, efficient, unobtrusive, does its job then gets out of your way.*
Taskwarrior is highly customizable, but can also be used “right out of the box.” In this article, we’ll show you the basic commands to add and complete tasks. Then we’ll cover a couple more advanced commands. And finally, we’ll show you some basic configuration settings to begin customizing your setup.
## Installing Taskwarrior
Taskwarrior is available in the Fedora repositories, so installing it is simple:
sudo dnf install task
Once installed, run `task`. This first run will create a `~/.taskrc` file for you.
$taskA configuration file could not be found in ~ Would you like a sample /home/link/.taskrc created, so Taskwarrior can proceed? (yes/no) yes [task next] No matches.
## Adding Tasks
Adding tasks is fast and unobtrusive.
$task add Plant the wheatCreated task 1.
Run `task` or `task list` to show upcoming tasks.
$task listID Age Description Urg 1 8s Plant the wheat 0 1 task
Let’s add a few more tasks to round out the example.
$task add Tend the wheatCreated task 2. $task add Cut the wheatCreated task 3. $task add Take the wheat to the mill to be ground into flourCreated task 4. $task add Bake a cakeCreated task 5.
Run `task` again to view the list.
[task next] ID Age Description Urg 1 3min Plant the wheat 0 2 22s Tend the wheat 0 3 16s Cut the wheat 0 4 8s Take the wheat to the mill to be ground into flour 0 5 2s Bake a cake 0 5 tasks
## Completing Tasks
To mark a task as complete, look up its ID and run:
$task 1 doneCompleted task 1 'Plant the wheat'. Completed 1 task.
You can also mark a task done with its description.
$task 'Tend the wheat' doneCompleted task 1 'Tend the wheat'. Completed 1 task.
With `add`, `list` and `done`, you’re all ready to get started with Taskwarrior.
## Setting Due Dates
Many tasks do not require a due date:
task add Finish the article on Taskwarrior
But sometimes, setting a due date is just the kind of motivation you need to get productive. Use the `due` modifier when adding a task to set a specific due date.
task add Finish the article on Taskwarrior due:tomorrow
`due` is highly flexible. It accepts specific dates (“2017-02-02”), or ISO-8601 (“2017-02-02T20:53:00Z”), or even relative time (“8hrs”). See the [Date & Time](https://taskwarrior.org/docs/dates.html) documentation for all the examples.
Dates go beyond due dates too. Taskwarrior has `scheduled`, `wait`, and `until`.
task add Proof the article on Taskwarrior scheduled:thurs
Once the date (Thursday in this example) passes, the task is tagged with the `READY` virtual tag. It will then show up in the `ready` report.
$task readyID Age S Description Urg 1 2s 1d Proof the article on Taskwarrior 5
To remove a date, `modify` the task with a blank value:
$ task 1 modify scheduled:
## Searching Tasks
No task list is complete without the ability to search with regular expressions, right?
$task '/.* the wheat/' listID Age Project Description Urg 2 42min Take the wheat to the mill to be ground into flour 0 1 42min Home Cut the wheat 1 2 tasks
## Customizing Taskwarrior
Remember that file we created back in the beginning (`~/.taskrc`). Let’s take at the defaults:
# [Created by task 2.5.1 2/9/2017 16:39:14] # Taskwarrior program configuration file. # For more documentation, see http://taskwarrior.org or try 'man task', 'man task-color', # 'man task-sync' or 'man taskrc' # Here is an example of entries that use the default, override and blank values # variable=foo -- By specifying a value, this overrides the default # variable= -- By specifying no value, this means no default # #variable=foo -- By commenting out the line, or deleting it, this uses the default # Use the command 'task show' to see all defaults and overrides # Files data.location=~/.task # Color theme (uncomment one to use) #include /usr//usr/share/task/light-16.theme #include /usr//usr/share/task/light-256.theme #include /usr//usr/share/task/dark-16.theme #include /usr//usr/share/task/dark-256.theme #include /usr//usr/share/task/dark-red-256.theme #include /usr//usr/share/task/dark-green-256.theme #include /usr//usr/share/task/dark-blue-256.theme #include /usr//usr/share/task/dark-violets-256.theme #include /usr//usr/share/task/dark-yellow-green.theme #include /usr//usr/share/task/dark-gray-256.theme #include /usr//usr/share/task/dark-gray-blue-256.theme #include /usr//usr/share/task/solarized-dark-256.theme #include /usr//usr/share/task/solarized-light-256.theme #include /usr//usr/share/task/no-color.theme
The only active option right now is `data.location=~/.task`. To view active configuration settings (including the built-in defaults), run `show`.
task show
To change a setting, use `config`.
$task config displayweeknumber noAre you sure you want to add 'displayweeknumber' with a value of 'no'? (yes/no) yes Config file /home/link/.taskrc modified.
## Examples
These are just some of the things you can do with Taskwarrior.
Assign a project to your tasks:
task 'Fix leak in the roof' modify project:Home
Use `start` to mark what you were working on. This can help you remember what you were working on after the weekend:
task 'Fix bug #141291' start
Use relevant tags:
task add 'Clean gutters' +weekend +house
Be sure to read the [complete documentation](https://taskwarrior.org/docs/) to learn all the ways you can catalog and organize your tasks.
## Akinsola
This is a good task app much like Tdo txt
## baoboa
to make it even more useful if your are not comfortable with a terminal.
gnome extension
https://github.com/cinatic/taskwhisperer
web front-end
http://theunraveler.com/taskwarrior-web
## Dirk Deimeke
I would like to add that it is much easier to use the ID for modifying tasks. There is no need to enter the complete description everytime.
## gide0n
Yes, I need this app! Thanks for your sharing 😉
## Sylvia Sanchez
It doesn’t have a graphic interface 🙁
Nice article anyway.
## Nandu
There is one gui under development. pretty usable now. https://bitbucket.org/kvorobyev/taskwarriorc2
## mruwek
Topydo (http://topydo.org) is also very simple and unobtrusive plus it uses TODO.TXT format.
## pjaleeuwen
The simplicity is magnificent
## Ralph Bean
There is an
awesomeAGPL web frontend for this at https://inthe.am/## Justin W. Flory
I’m definitely a big fan of this too – this is what I use as my Taskserver instance to integrate across multiple machines!
## hier
If you want to use taskwarrior/timewarrior with a GUI working with the pomodoro technique:
https://github.com/liloman/pomodoroTasks2
Cheers
## ahmad naser
thanks
## 0x00af
Cute,
You can also modify to
data.location=~/[Your CLOUD STORAGE HERE]/.task
to sync with your devices |
9,645 | 探秘“栈”之旅 | https://manybutfinite.com/post/journey-to-the-stack/ | 2018-05-15T18:31:28 | [
"堆栈",
"栈帧",
"函数"
] | https://linux.cn/article-9645-1.html | 
早些时候,我们探索了 [“内存中的程序之秘”](/article-9255-1.html),我们欣赏了在一台电脑中是如何运行我们的程序的。今天,我们去探索*栈的调用*,它在大多数编程语言和虚拟机中都默默地存在。在此过程中,我们将接触到一些平时很难见到的东西,像<ruby> 闭包 <rt> closure </rt></ruby>、递归、以及缓冲溢出等等。但是,我们首先要作的事情是,描绘出栈是如何运作的。
栈非常重要,因为它追踪着一个程序中运行的*函数*,而函数又是一个软件的重要组成部分。事实上,程序的内部操作都是非常简单的。它大部分是由函数向栈中推入数据或者从栈中弹出数据的相互调用组成的,而在堆上为数据分配内存才能在跨函数的调用中保持数据。不论是低级的 C 软件还是像 JavaScript 和 C# 这样的基于虚拟机的语言,它们都是这样的。而对这些行为的深刻理解,对排错、性能调优以及大概了解究竟发生了什么是非常重要的。
当一个函数被调用时,将会创建一个<ruby> 栈帧 <rt> stack frame </rt></ruby>去支持函数的运行。这个栈帧包含函数的*局部变量*和调用者传递给它的*参数*。这个栈帧也包含了允许被调用的函数(*callee*)安全返回给其调用者的内部事务信息。栈帧的精确内容和结构因处理器架构和函数调用规则而不同。在本文中我们以 Intel x86 架构和使用 C 风格的函数调用(`cdecl`)的栈为例。下图是一个处于栈顶部的一个单个栈帧:

在图上的场景中,有三个 CPU 寄存器进入栈。<ruby> 栈指针 <rt> stack pointer </rt></ruby> `esp`(LCTT 译注:扩展栈指针寄存器) 指向到栈的顶部。栈的顶部总是被最*后一个推入到栈且还没有弹出*的东西所占据,就像现实世界中堆在一起的一叠盘子或者 100 美元大钞一样。
保存在 `esp` 中的地址始终在变化着,因为栈中的东西不停被推入和弹出,而它总是指向栈中的最后一个推入的东西。许多 CPU 指令的一个副作用就是自动更新 `esp`,离开寄存器而使用栈是行不通的。
在 Intel 的架构中,绝大多数情况下,栈的增长是向着*低位内存地址*的方向。因此,这个“顶部” 在包含数据的栈中是处于低位的内存地址(在这种情况下,包含的数据是 `local_buffer`)。注意,关于从 `esp` 到 `local_buffer` 的箭头不是随意连接的。这个箭头代表着事务:它*专门*指向到由 `local_buffer` 所拥有的*第一个字节*,因为,那是一个保存在 `esp` 中的精确地址。
第二个寄存器跟踪的栈是 `ebp`(LCTT 译注:扩展基址指针寄存器),它包含一个<ruby> 基指针 <rt> base pointer </rt></ruby>或者称为<ruby> 帧指针 <rt> frame pointer </rt></ruby>。它指向到一个*当前运行*的函数的栈帧内的固定位置,并且它为参数和局部变量的访问提供一个稳定的参考点(基址)。仅当开始或者结束调用一个函数时,`ebp` 的内容才会发生变化。因此,我们可以很容易地处理在栈中的从 `ebp` 开始偏移后的每个东西。如图所示。
不像 `esp`, `ebp` 大多数情况下是在程序代码中通过花费很少的 CPU 来进行维护的。有时候,完成抛弃 `ebp` 有一些性能优势,可以通过 [编译标志](http://stackoverflow.com/questions/14666665/trying-to-understand-gcc-option-fomit-frame-pointer) 来做到这一点。Linux 内核就是一个这样做的示例。
最后,`eax`(LCTT 译注:扩展的 32 位通用数据寄存器)寄存器惯例被用来转换大多数 C 数据类型返回值给调用者。
现在,我们来看一下在我们的栈帧中的数据。下图清晰地按字节展示了字节的内容,就像你在一个调试器中所看到的内容一样,内存是从左到右、从顶部至底部增长的,如下图所示:

局部变量 `local_buffer` 是一个字节数组,包含一个由 null 终止的 ASCII 字符串,这是 C 程序中的一个基本元素。这个字符串可以读取自任意地方,例如,从键盘输入或者来自一个文件,它只有 7 个字节的长度。因为,`local_buffer` 只能保存 8 字节,所以还剩下 1 个未使用的字节。*这个字节的内容是未知的*,因为栈不断地推入和弹出,*除了你写入的之外*,你根本不会知道内存中保存了什么。这是因为 C 编译器并不为栈帧初始化内存,所以它的内容是未知的并且是随机的 —— 除非是你自己写入。这使得一些人对此很困惑。
再往上走,`local1` 是一个 4 字节的整数,并且你可以看到每个字节的内容。它似乎是一个很大的数字,在8 后面跟着的都是零,在这里可能会误导你。
Intel 处理器是<ruby> 小端 <rt> little endian </rt></ruby>机器,这表示在内存中的数字也是首先从小的一端开始的。因此,在一个多字节数字中,较小的部分在内存中处于最低端的地址。因为一般情况下是从左边开始显示的,这背离了我们通常的数字表示方式。我们讨论的这种从小到大的机制,使我想起《格里佛游记》:就像小人国的人们吃鸡蛋是从小头开始的一样,Intel 处理器处理它们的数字也是从字节的小端开始的。
因此,`local1` 事实上只保存了一个数字 8,和章鱼的腿数量一样。然而,`param1` 在第二个字节的位置有一个值 2,因此,它的数学上的值是 `2 * 256 = 512`(我们与 256 相乘是因为,每个位置值的范围都是从 0 到 255)。同时,`param2` 承载的数量是 `1 * 256 * 256 = 65536`。
这个栈帧的内部数据是由两个重要的部分组成:*前一个*栈帧的地址(保存的 `ebp` 值)和函数退出才会运行的指令的地址(返回地址)。它们一起确保了函数能够正常返回,从而使程序可以继续正常运行。
现在,我们来看一下栈帧是如何产生的,以及去建立一个它们如何共同工作的内部蓝图。首先,栈的增长是非常令人困惑的,因为它与你你预期的方式相反。例如,在栈上分配一个 8 字节,就要从 `esp` 减去 8,去,而减法是与增长不同的奇怪方式。
我们来看一个简单的 C 程序:
```
Simple Add Program - add.c
int add(int a, int b)
{
int result = a + b;
return result;
}
int main(int argc)
{
int answer;
answer = add(40, 2);
}
```
*简单的加法程序 - add.c*
假设我们在 Linux 中不使用命令行参数去运行它。当你运行一个 C 程序时,实际运行的第一行代码是在 C 运行时库里,由它来调用我们的 `main` 函数。下图展示了程序运行时每一步都发生了什么。每个图链接的 GDB 输出展示了内存和寄存器的状态。你也可以看到所使用的 [GDB 命令](https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-commands.txt),以及整个 [GDB 输出](https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-output.txt)。如下:

第 2 步和第 3 步,以及下面的第 4 步,都只是函数的<ruby> 序言 <rt> prologue </rt></ruby>,几乎所有的函数都是这样的:`ebp` 的当前值被保存到了栈的顶部,然后,将 `esp` 的内容拷贝到 `ebp`,以建立一个新的栈帧。`main` 的序言和其它函数一样,但是,不同之处在于,当程序启动时 `ebp` 被清零。
如果你去检查栈下方(右边)的整形变量(`argc`),你将找到更多的数据,包括指向到程序名和命令行参数(传统的 C 的 `argv`)、以及指向 Unix 环境变量以及它们真实的内容的指针。但是,在这里这些并不是重点,因此,继续向前调用 `add()`:

在 `main` 从 `esp` 减去 12 之后得到它所需的栈空间,它为 `a` 和 `b` 设置值。在内存中的值展示为十六进制,并且是小端格式,与你从调试器中看到的一样。一旦设置了参数值,`main` 将调用 `add`,并且开始运行:

现在,有一点小激动!我们进入了另一个函数序言,但这次你可以明确看到栈帧是如何从 `ebp` 到栈建立一个链表。这就是调试器和高级语言中的 `Exception` 对象如何对它们的栈进行跟踪的。当一个新帧产生时,你也可以看到更多这种典型的从 `ebp` 到 `esp` 的捕获。我们再次从 `esp` 中做减法得到更多的栈空间。
当 `ebp` 寄存器的值拷贝到内存时,这里也有一个稍微有些怪异的字节逆转。在这里发生的奇怪事情是,寄存器其实并没有字节顺序:因为对于内存,没有像寄存器那样的“增长的地址”。因此,惯例上调试器以对人类来说最自然的格式展示了寄存器的值:数位从最重要的到最不重要。因此,这个在小端机器中的副本的结果,与内存中常用的从左到右的标记法正好相反。我想用图去展示你将会看到的东西,因此有了下面的图。
在比较难懂的部分,我们增加了注释:

这是一个临时寄存器,用于帮你做加法,因此没有什么警报或者惊喜。对于加法这样的作业,栈的动作正好相反,我们留到下次再讲。
对于任何读到这里的人都应该有一个小礼物,因此,我做了一个大的图表展示了 [组合到一起的所有步骤](https://manybutfinite.com/img/stack/callSequence.png)。
一旦把它们全部布置好了,看上起似乎很乏味。这些小方框给我们提供了很多帮助。事实上,在计算机科学中,这些小方框是主要的展示工具。我希望这些图片和寄存器的移动能够提供一种更直观的构想图,将栈的增长和内存的内容整合到一起。从软件的底层运作来看,我们的软件与一个简单的图灵机器差不多。
这就是我们栈探秘的第一部分,再讲一些内容之后,我们将看到构建在这个基础上的高级编程的概念。下周见!
---
via:<https://manybutfinite.com/post/journey-to-the-stack/>
作者:[Gustavo Duarte](http://duartes.org/gustavo/blog/about/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Earlier we’ve explored the [anatomy of a program in memory](/post/anatomy-of-a-program-in-memory), the
landscape of how our programs run in a computer. Now we turn to the *call
stack*, the work horse in most programming languages and virtual machines.
Along the way we’ll meet fantastic creatures like closures, recursion, and
buffer overflows. But the first step is a precise picture of how the stack
operates.
The stack is so important because it keeps track of the *functions* running in
a program, and functions are in turn the building blocks of software. In fact,
the internal operation of programs is normally very simple. It consists mostly
of functions pushing data onto and popping data off the stack as they call each
other, while allocating memory on the heap for data that must survive across
function calls. This is true for both low-level C software and VM-based
languages like JavaScript and C#. A solid grasp of this reality is invaluable
for debugging, performance tuning and generally knowing what the hell is going
on.
When a function is called, a **stack frame** is created to support the
function’s execution. The stack frame contains the function’s *local variables*
and the *arguments* passed to the function by its caller. The frame also
contains housekeeping information that allows the called function (the *callee*)
to return to the caller safely. The exact contents and layout of the stack vary
by processor architecture and function call convention. In this post we look at
Intel x86 stacks using C-style function calls (`cdecl`
). Here’s a single stack
frame sitting live on top of the stack:

Right away, three CPU registers burst into the scene. The *stack pointer*,
`esp`
, points to the top of the stack. The top is always occupied by the *last
item that was pushed* onto the stack *but has not yet been popped off*, just as
in a real-world stack of plates or $100 bills.
The address stored in `esp`
constantly changes as stack items are pushed and
popped, such that it always points to the last item. Many CPU instructions
automatically update `esp`
as a side effect, and it’s impractical to use the
stack without this register.
In the Intel architecture, as in most, the stack grows towards *lower memory
addresses*. So the “top” is the lowest memory address in the stack containing
live data: `local_buffer`
in this case. Notice there’s nothing vague about the
arrow from `esp`
to `local_buffer`
. This arrow means business: it points
*specifically* to the *first byte* occupied by `local_buffer`
because that is
the exact address stored in `esp`
.
The second register tracking the stack is `ebp`
, the *base pointer* or *frame
pointer*. It points to a fixed location within the stack frame of the function
*currently running* and provides a stable reference point (base) for access to
arguments and local variables. `ebp`
changes only when a function call begins or
ends. Thus we can easily address each item in the stack as an offset from `ebp`
,
as shown in the diagram.
Unlike `esp`
, `ebp`
is mostly maintained by program code with little CPU
interference. Sometimes there are performance benefits in ditching `ebp`
altogether, which can be done via [compiler flags](http://stackoverflow.com/questions/14666665/trying-to-understand-gcc-option-fomit-frame-pointer).
The Linux kernel is one example where this is done.
Finally, the `eax`
register is used by convention to transfer return values back
to the caller for most C data types.
Now let’s inspect the data in our stack frame. These diagram shows precise byte-for-byte contents as you’d see in a debugger, with memory growing left-to-right, top-to-bottom. Here it is:

The local variable `local_buffer`
is a byte array containing a null-terminated
ascii string, a staple of C programs. The string was likely read from somewhere,
for example keyboard input or a file, and it is 7 bytes long. Since
`local_buffer`
can hold 8 bytes, there’s 1 free byte left. The *content of this
byte is unknown* because in the stack’s infinite dance of pushes and pops, you
never know what memory holds *unless you write to it*. Since the C compiler
does not initialize the memory for a stack frame, contents are undetermined
- and somewhat random - until written to. This has driven some into madness.
Moving on, `local1`
is a 4-byte integer and you can see the contents of each
byte. It looks like a big number, with all those zeros following the 8, but
here your intuition leads you astray.
Intel processors are *little endian* machines, meaning that numbers in memory
start with the *little end* first. So the least significant byte of a multi-byte
number is in the lowest memory address. Since that is normally shown leftmost,
this departs from our usual representation of numbers. It helps to know that
this endian talk is borrowed from Gulliver’s Travels: just as folks in Lilliput
eat their eggs starting from the little end, Intel processors eat their numbers
starting from the little byte.
So `local1`
in fact holds the number 8, as in the legs of an octopus. `param1`
,
however, has a value of 2 in the second byte position, so its mathematical value
is 2 * 256 = 512 (we multiply by 256 because each place value ranges from 0 to
255). Meanwhile, `param2`
is carrying weight at 1 * 256 * 256 = 65536.
The housekeeping data in this stack frame consists of two crucial pieces: the
address of the *previous* stack frame (saved ebp) and the address of the
instruction to be executed upon the function’s exit (the return address).
Together, they make it possible for the function to return sanely and for the
program to keep running along.
Now let’s see the birth of a stack frame to build a clear mental picture of how
this all works together. Stack growth is puzzling at first because it happens
*in the opposite direction* you’d expect. For example, to allocate 8 bytes on
the stack one *subtracts* 8 from `esp`
, and subtraction is an odd way to grow
something.
Let’s take a simple C program:
1 | int add(int a, int b) |
Suppose we run this in Linux without command-line parameters. When you run
a C program, the first code to actually execute is in the C runtime library,
which then calls our `main`
function. The diagrams below show step-by-step what
happens as the program runs. Each diagram links to GDB output showing the state
of memory and registers. You may also see the [GDB commands](https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-commands.txt) used and the whole
[GDB output](https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-output.txt). Here we go:
Steps 2 and 3, along with 4 below, are the **function prologue**, which is
common to nearly all functions: the current value of ebp is saved to the top of
the stack, and then `esp`
is copied to `ebp`
, establishing a new frame. main’s
prologue is like any other, but with the peculiarity that `ebp`
is zeroed out
when the program starts.
If you were to inspect the stack below `argc`
(to the right) you’d find more
data, including pointers to the program name and command-line parameters (the
traditional C `argv`
), plus pointers to Unix environment variables and their
actual contents. But that’s not important here, so the ball keeps rolling
towards the `add()`
call:
After `main`
subtracts 12 from `esp`
to get the stack space it needs, it sets
the values for `a`
and `b`
. Values in memory are shown in hex and little-endian
format, as you’d see in a debugger. Once parameter values are set, `main`
calls
`add`
and it starts running:
Now there’s some excitement! We get another prologue, but this time you can see
clearly how the stack frames form a linked list, starting at `ebp`
and going
down the stack. This is how debuggers and `Exception`
objects in higher-level
languages get their stack traces. You can also see the much more typical
catching up of `ebp`
to `esp`
when a new frame is born. And again, we subtract
from `esp`
to get more stack space.
There’s also the slightly weird reversal of bytes when the `ebp`
register value
is copied to memory. What’s happening here is that registers don’t really have
endianness: there are no “growing addresses” inside a register as there are for
memory. Thus by convention debuggers show register values in the most natural
format to humans: most significant to least significant digits. So the results
of the copy in a little-endian machine appear reversed in the usual
left-to-right notation for memory. I want the diagrams to provide an accurate
picture of what you find in the trenches, so there you have it.
With the hard part behind us, we add:
There are guest register appearances to help out with the addition, but
otherwise no alarms and no surprises. `add`
did its job, and at this point the
stack action would go in reverse, but we’ll save that for next time.
Anybody who’s read this far deserves a souvenir, so I’ve made a large diagram
showing [all the steps combined](/img/stack/callSequence.png) in a fit of
nerd pride.
It looks tame once it’s all laid out. Those little boxes help *a lot*. In fact,
little boxes are the chief tool of computer science. I hope the pictures and
register movements provide an intuitive mental picture that integrates stack
growth and memory contents. Up close, our software doesn’t look too far from
a simple Turing machine.
This concludes the first part of our stack tour. There’s some more byte spelunking ahead, and then it’s on to see higher level programming concepts built on this foundation. See you next week.
## Comments |
9,646 | 从专有到开源的十个简单步骤 | https://opensource.com/article/17/11/commonwealth-open-source | 2018-05-16T08:12:18 | [
"开源",
"开源软件"
] | https://linux.cn/article-9646-1.html |
>
> 这个共同福利并不适用于专有软件:保持隐藏的东西是不能照亮或丰富这个世界的。
>
>
>

“开源软件肯定不太安全,因为每个人都能看到它的源代码,而且他们能重新编译它,用他们自己写的不好的东西进行替换。”举手示意:谁之前听说过这个说法?<sup> 注1</sup>
当我和客户讨论的时候(是的,他们有时候会让我和客户交谈),对于这个领域<sup> 注2</sup> 的人来说种问题是很常见的。在前一篇文章中,“[许多只眼睛的审查并不一定能防止错误代码]”,我谈论的是开源软件(尤其是安全软件)并不能神奇地比专有软件更安全,但是和专有软件比起来,我每次还是比较青睐开源软件。但我听到“关于开源软件不是很安全”这种问题表明了有时候只是说“开源需要参与”是不够的,我们也需要积极的参与辩护<sup> 注3</sup> 。
我并不期望能够达到牛顿或者维特根斯坦的逻辑水平,但是我会尽我所能,而且我会在结尾做个总结,如果你感兴趣的话可以去快速的浏览一下。
### 关键因素
首先,我们必须明白没有任何软件是完美的<sup> 注6</sup> 。无论是专有软件还是开源软件。第二,我们应该承认确实还是存在一些很不错的专有软件的,以及第三,也存在一些糟糕的开源软件。第四,有很多非常聪明的,很有天赋的,专业的架构师、设计师和软件工程师设计开发了专有软件。
但也有些问题:第五,从事专有软件的人员是有限的,而且你不可能总是能够雇佣到最好的员工。即使在政府部门或者公共组织 —— 他们拥有丰富的人才资源池,但在安全应用这块,他们的人才也是有限的。第六,可以查看、测试、改进、拆解、再次改进和发布开源软件的人总是无限的,而且还包含最好的人才。第七(也是我最喜欢的一条),这群人也包含很多编写专有软件的人才。第八,许多政府或者公共组织开发的软件也都逐渐开源了。
第九,如果你在担心你在运行的软件的不被支持或者来源不明,好消息是:有一批组织<sup> 注7</sup> 会来检查软件代码的来源,提供支持、维护和补丁更新。他们会按照专利软件模式那样去运行开源软件,你也可以确保你从他们那里得到的软件是正确的软件:他们的技术标准就是对软件包进行签名,以便你可以验证你正在运行的开源软件不是来源不明或者是恶意的软件。
第十(也是这篇文章的重点),当你运行开源软件,测试它,对问题进行反馈,发现问题并且报告的时候,你就是在为<ruby> 共同福利 <rt> commonwealth </rt></ruby>贡献知识、专业技能以及经验,这就是开源,其因为你的所做的这些而变得更好。如果你是通过个人或者提供支持开源软件的商业组织之一<sup> 注8</sup> 参与的,你已经成为了这个共同福利的一部分了。开源让软件变得越来越好,你可以看到它们的变化。没有什么是隐藏封闭的,它是完全开放的。事情会变坏吗?是的,但是我们能够及时发现问题并且修复。
这个共同福利并不适用于专有软件:保持隐藏的东西是不能照亮或丰富这个世界的。
我知道作为一个英国人在使用<ruby> 共同福利 <rt> commonwealth </rt></ruby>这个词的时候要小心谨慎的;它和帝国连接着的,但我所表达的不是这个意思。它不是克伦威尔<sup> 注9</sup> 在对这个词所表述的意思,无论如何,他是一个有争议的历史人物。我所表达的意思是这个词有“共同”和“福利”连接,福利不是指钱而是全人类都能拥有的福利。
我真的很相信这点的。如果i想从这篇文章中得到一些虔诚信息的话,那应该是第十条<sup> 注10</sup> :共同福利是我们的遗产,我们的经验,我们的知识,我们的责任。共同福利是全人类都能拥有的。我们共同拥有它而且它是一笔无法估量的财富。
### 便利贴
1. (几乎)没有一款软件是完美无缺的。
2. 有很好的专有软件。
3. 有不好的专有软件。
4. 有聪明,有才能,专注的人开发专有软件。
5. 从事开发完善专有软件的人是有限的,即使在政府或者公共组织也是如此。
6. 相对来说从事开源软件的人是无限的。
7. …而且包括很多从事专有软件的人才。
8. 政府和公共组织的人经常开源它们的软件。
9. 有商业组织会为你的开源软件提供支持。
10. 贡献--即使是使用--为开源软件贡献。
### 脚注
* 注1: 好的--你现在可以放下手了
* 注2:这应该大写吗?有特定的领域吗?或者它是如何工作的?我不确定。
* 注3:我有一个英国文学和神学的学位--这可能不会惊讶到我的文章的普通读者<sup> 注4</sup> 。
* 注4: 我希望不是,因为我说的太多神学了<sup> 注5</sup> 。但是它经常充满了冗余的,无关紧要的人文科学引用。
* 注5: Emacs,每一次。
* 注6: 甚至是 Emacs。而且我知道有技术能够去证明一些软件的正确性。(我怀疑 Emacs 不能全部通过它们...)
* 注7: 注意这里:我被他们其中之一 [Red Hat](https://www.redhat.com/) 所雇佣,去查看一下--它是一个有趣的工作地方,而且[我们经常在招聘](https://www.redhat.com/en/jobs)。
* 注8: 假设他们完全遵守他们正在使用的开源软件许可证。
* 注9: 昔日的“英格兰、苏格兰、爱尔兰的上帝守护者”--比克伦威尔。
* 注10: 很明显,我选择 Emacs 而不是 Vi 变体。
这篇文章原载于 [Alice, Eve, and Bob - a security blog] 而且已经被授权重新发布。
---
via: <https://opensource.com/article/17/11/commonwealth-open-source>
作者:[Mike Bursell](https://opensource.com/users/mikecamel) 译者:[FelixYFZ](https://github.com/FelixYFZ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | "But surely open source software is less secure, because everybody can see it, and they can just recompile it and replace it with bad stuff they've written." Hands up: who's heard this?[1](#1)
When I talk to customers—yes, they let me talk to customers sometimes—and to folks in the field 2 this comes up quite frequently. In a previous article, "
[Review by many eyes does not always prevent buggy code](https://opensource.com/article/17/10/many-eyes)", I talked about how open source software—particularly security software—isn't magically more secure than proprietary software, but I'd still go with open source over proprietary every time. But the way I've heard the particular question—about open source software being
*less*secure—suggests that sometimes it's not enough to just explain that open source needs work, but we must also actively engage in
[apologetics](https://en.wikipedia.org/wiki/Apologetics)
.
[3](#3)So here goes. I don't expect it to be up to Newton's or Wittgenstein's levels of logic, but I'll do what I can, and I'll summarise at the bottom so you have a quick list of the points if you want it.
## The arguments
First, we should accept that no software is perfect 6. Not proprietary software, not open source software. Second, we should accept that good proprietary software exists, and third, there is also some bad open source software out there. Fourth, there are extremely intelligent, gifted, and dedicated architects, designers, and software engineers who create proprietary software.
But here's the rub: fifth, there is a limited pool of people who will work on or otherwise look at proprietary software. And you can never hire all the best people. Even in government and public sector organisations—who often have a larger talent pool available to them, particularly for *cough* security-related *cough* applications—the pool is limited.
Sixth, the pool of people available to look at, test, improve, break, re-improve, and roll out open source software is almost unlimited and *does *include the best people. Seventh (and I love this one), the pool also includes many of the people writing the proprietary software. Eighth, many of the applications being written by public sector and government organisations are open sourced anyway.
Ninth, if you're worried about running open source software that is unsupported or comes from dodgy, un-provenanced sources, then good news: There are a bunch of organisations 7 who will check the provenance of that code, support, maintain, and patch it. They'll do it along the same type of business lines that you'd expect from a proprietary software provider. You can also ensure that the software you get from them is the right software: Their standard technique is to sign bundles of software so you can verify that what you're installing isn't from some random bad person who's taken that code and done Bad Things™ with it.
Tenth (and here's the point of this article), when you run open source software, when you test it, when you provide feedback on issues, when you discover errors and report them, you are tapping into—and adding to—the commonwealth of knowledge and expertise and experience that is open source, which is made only greater by your doing so. If you do this yourself, or through one of the businesses that support open source software 8, you are part of this commonwealth. Things get better with open source software, and you can see them getting better. Nothing is hidden—it's, well,
*open*. Can things get worse? Yes, they can, but we can see when that happens and fix it.
This commonwealth does not apply to proprietary software: what stays hidden does not enlighten or enrich the world.
I know that I need to be careful about the use of the "commonwealth" as a Briton; it has connotations of (faded…) empires, which I don't intend in this case. It's probably not what Cromwell 9 had in mind when
*he*talked about the "Commonwealth," either, and anyway, he's a somewhat controversial historical figure. What I'm talking about is a concept in which I think the words deserve concatenation—"common" and "wealth"—to show that we're talking about something more than just money, but shared wealth available to all of humanity.
I really believe in this. If you want to take away a religious message from this article, it should be this 10: the commonwealth is our heritage, our experience, our knowledge, our responsibility. The commonwealth is available to all of humanity. We have it in common, and it is an almost inestimable wealth.
## A handy crib sheet
- (Almost) no software is perfect.
- There is good proprietary software.
- There is bad open source software.
- There are clever, talented, and devoted people who create proprietary software.
- The pool of people available to write and improve proprietary software is limited, even within the public sector and government realm.
- The corresponding pool of people for open source is virtually unlimited…
- …and includes a goodly number of the talent pool of people writing proprietary software.
- Public sector and government organisations often open source their software anyway.
- There are businesses that will support open source software for you.
- Contribution—even usage—adds to the commonwealth.
[1]OK—you can put your hands down now.
[2]Should this be capitalized? Is there a particular field, or how does it work? I'm not sure.
[3]I have a degree in English literature and theology—this probably won't surprise regular readers of my articles.[4](#4)
[4]Not, I hope, because I spout too much theology, 5 but because it's often full of long-winded, irrelevant humanities (U.S. English: "liberal arts") references.
[5]Emacs. Every time.
[6]Not even Emacs. And yes, I know that there are techniques to prove the correctness of some software. (I suspect that Emacs doesn't pass many of them…)
[7]Hand up here: I'm employed by one of them, [Red Hat](https://www.redhat.com/). Go have a look—it's a fun place to work, and [we're usually hiring](https://www.redhat.com/en/jobs).
[8]Assuming that they fully abide by the rules of the open source licence(s) they're using, that is.
[9]Erstwhile "Lord Protector of England, Scotland, and Ireland"—that Cromwell.
[10]Oh, and choose Emacs over Vi variants, obviously.
*This article originally appeared on Alice, Eve, and Bob – a security blog and is republished with permission.*
## Comments are closed. |
9,647 | 如何在 Linux 终端下检查笔记本电池状态 | https://www.ostechnix.com/how-to-check-laptop-battery-status-in-terminal-in-linux/ | 2018-05-16T08:23:56 | [
"电池"
] | https://linux.cn/article-9647-1.html | 
在图形界面下查看你的笔记本电池状态是很容易的,只需将鼠标指向任务栏中的电池图标上,你便可以很容易地知道电池的电量。但如果我们想要从命令行中获得这些信息呢?并不是所有人都知道如何做到这点。前几天我的一个朋友询问我如何从他的 Ubuntu 系统里,在终端中查看他的笔记本电池的电量。这便是我写这篇文章的起因。在本文中我概括了三种简单的方法来让你在任何 Linux 发行版本中从终端查看笔记本电池的状态。
### 在终端下检查笔记本电池状态
我们可以使用下面的三种方法来从命令行中查找到笔记本电池状态。
#### 方法一 – 使用 upower 命令
`upower` 命令预装在大多数的 Linux 发行版本中。为了使用 `upower` 命令来展示电池的状态,打开终端并运行如下命令:
```
$ upower -i /org/freedesktop/UPower/devices/battery_BAT0
```
示例输出:
```
native-path: BAT0
vendor: Samsung SDI
model: DELL 7XFJJA2
serial: 4448
power supply: yes
updated: Sat 12 May 2018 06:48:48 PM IST (41 seconds ago)
has history: yes
has statistics: yes
battery
present: yes
rechargeable: yes
state: charging
warning-level: none
energy: 43.3011 Wh
energy-empty: 0 Wh
energy-full: 44.5443 Wh
energy-full-design: 48.84 Wh
energy-rate: 9.8679 W
voltage: 12.548 V
time to full: 7.6 minutes
percentage: 97%
capacity: 91.2045%
technology: lithium-ion
icon-name: 'battery-full-charging-symbolic'
History (charge):
1526131128 97.000 charging
History (rate):
1526131128 9.868 charging
```
正如你所看到的那样,我的电池正处于充电状态,并且它的电量百分比是 97%。
假如上面的命令因为某些未知原因不起作用,可以尝试使用下面的命令:
```
$ upower -i `upower -e | grep 'BAT'`
```
示例输出:
```
native-path: BAT0
vendor: Samsung SDI
model: DELL 7XFJJA2
serial: 4448
power supply: yes
updated: Sat 12 May 2018 06:50:49 PM IST (22 seconds ago)
has history: yes
has statistics: yes
battery
present: yes
rechargeable: yes
state: charging
warning-level: none
energy: 43.6119 Wh
energy-empty: 0 Wh
energy-full: 44.5443 Wh
energy-full-design: 48.84 Wh
energy-rate: 8.88 W
voltage: 12.552 V
time to full: 6.3 minutes
percentage: 97%
capacity: 91.2045%
technology: lithium-ion
icon-name: 'battery-full-charging-symbolic'
History (rate):
1526131249 8.880 charging
```
`upower` 不仅可以显示出电池的状态,它还可以显示出已安装电池的其他完整信息,例如电池型号,供应商名称,电池的序列号,电池的状态,电池的电压等信息。
当然,如果你只想显示电池的状态,你可以可以结合使用 `upower` 命令和[grep](https://www.ostechnix.com/the-grep-command-tutorial-with-examples-for-beginners/) 命令,具体命令如下:
```
$ upower -i $(upower -e | grep BAT) | grep --color=never -E "state|to\ full|to\ empty|percentage"
```
示例输出:
```
state: fully-charged
percentage: 100%
```

从上面的输出中可以看到我的笔记本电池已经完全充满了。
想知晓更多的细节,可以参看 man 页:
```
$ man upower
```
#### 方法二 – 使用 acpi 命令
`acpi` 命令可以用来显示你的 Linux 发行版本中电池的状态以及其他 ACPI 信息。
在某些 Linux 发行版本中,你可能需要安装 `acpi` 命令。
要在 Debian、 Ubuntu 及其衍生版本中安装它,可以使用如下命令:
```
$ sudo apt-get install acpi
```
在 RHEL、 CentOS、 Fedora 等系统中使用:
```
$ sudo yum install acpi
```
或者使用如下命令:
```
$ sudo dnf install acpi
```
在 Arch Linux 及其衍生版本中使用:
```
$ sudo pacman -S acpi
```
一旦 `acpi` 安装好后,运行下面的命令:
```
$ acpi -V
```
注意: 在上面的命令中, `V` 是大写字母。
示例输出:
```
Battery 0: Charging, 99%, 00:02:09 until charged
Battery 0: design capacity 4400 mAh, last full capacity 4013 mAh = 91%
Battery 1: Discharging, 0%, rate information unavailable
Adapter 0: on-line
Thermal 0: ok, 77.5 degrees C
Thermal 0: trip point 0 switches to mode critical at temperature 84.0 degrees C
Cooling 0: Processor 0 of 3
Cooling 1: Processor 0 of 3
Cooling 2: LCD 0 of 15
Cooling 3: Processor 0 of 3
Cooling 4: Processor 0 of 3
Cooling 5: intel_powerclamp no state information available
Cooling 6: x86_pkg_temp no state information available
```
首先让我们来检查电池的电量,可以运行:
```
$ acpi
```
示例输出:
```
Battery 0: Charging, 99%, 00:01:41 until charged
Battery 1: Discharging, 0%, rate information unavailable
```
下面,让我们来查看电池的温度:
```
$ acpi -t
```
示例输出:
```
Thermal 0: ok, 63.5 degrees C
```
如果需要将温度以华氏温标显示,可以使用:
```
$ acpi -t -f
```
示例输出:
```
Thermal 0: ok, 144.5 degrees F
```
如果想看看交流电适配器是否连接上了没有,可以运行:
```
$ acpi -a
```
示例输出:
```
Adapter 0: on-line
```
假如交流电适配器没有连接上,则你将看到如下的输出:
```
Adapter 0: off-line
```
想获取更多的信息,可以查看 man 页:
```
$ man acpi
```
#### 方法三 - 使用 batstat 程序
`batstat` 是一个基于 ncurses 的命令行小工具,使用它可以在类 Unix 系统中展示笔记本电池状态。它可以展示如下具体信息:
* 当前电池电量
* 当前电池所存能量
* 充满时所存能量
* 从程序启动开始经历的时间,它不会追踪记录机器休眠的时间
* 电池电量消耗历史数据
安装 `batstat` 轻而易举。使用下面的命令来克隆该程序的最新版本:
```
$ git clone https://github.com/Juve45/batstat.git
```
上面的命令将拉取 `batstat` 的最新版本并将它的内容保存在一个名为 `batstat` 的文件夹中。
首先将目录切换到 `batstat/bin/` 中:
```
$ cd batstat/bin/
```
接着将 `batstat` 二进制文件复制到 `PATH` 环境变量中的某个目录中,例如 `/usr/local/bin/` 目录:
```
$ sudo cp batstat /usr/local/bin/
```
使用下面的命令来让它可被执行:
```
$ sudo chmod +x /usr/local/bin/batstat
```
最后,使用下面的命令来查看你的电池状态。
```
$ batstat
```
示例输出:

从上面的截图中可以看到我的笔记本电池正处于充电状态。
这个小工具还有某些小的限制。在书写本文之时,`batstat` 仅支持显示一个电池的相关信息。而且它只从 `/sys/class/power_supply/` 目录搜集相关的信息。假如你的电池信息被存放在另外的目录中,则这个小工具就不会起作用了。
想知晓更多信息,可以查看 `batstat` 的 [GitHub 主页](https://github.com/Juve45/batstat)。
上面就是今天我要分享的所有内容。当然,可能还有很多其他的命令或者程序来从 Linux 终端检查笔记本的电池状态。据我所知,上面给出的命令都运行良好。假如你知道其他命令来查看电池的状态,请在下面的评论框中让我们知晓。假如你所给出的方法能够起作用,我将对我的这篇文章进行更新。
最后,上面便是今天的全部内容了。更多的优质内容敬请期待,敬请关注!
欢呼吧!
---
via: <https://www.ostechnix.com/how-to-check-laptop-battery-status-in-terminal-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,648 | 如何在 Linux 中使用 find | https://opensource.com/article/18/4/how-use-find-linux | 2018-05-16T08:37:09 | [
"find"
] | https://linux.cn/article-9648-1.html |
>
> 使用正确的参数,`find` 命令是在你的系统上找到数据的强大而灵活的方式。
>
>
>

在[最近的一篇文章](/article-9585-1.html)中,Lewis Cowles 介绍了 `find` 命令。
`find` 是日常工具箱中功能更强大、更灵活的命令行工具之一,因此值得花费更多的时间。
最简单的,`find` 跟上路径寻找一些东西。例如:
```
find /
```
它将找到(并打印出)系统中的每个文件。而且由于一切都是文件,你会得到很多需要整理的输出。这可能不能帮助你找到你要找的东西。你可以改变路径参数来缩小范围,但它不会比使用 `ls` 命令更有帮助。所以你需要考虑你想要找的东西。
也许你想在主目录中找到所有的 JPEG 文件。 `-name` 参数允许你将结果限制为与给定模式匹配的文件。
```
find ~ -name '*jpg'
```
可是等等!如果它们中的一些是大写的扩展名会怎么样?`-iname` 就像 `-name`,但是不区分大小写。
```
find ~ -iname '*jpg'
```
很好!但是 8.3 名称方案是如此的老。一些图片可能是 .jpeg 扩展名。幸运的是,我们可以将模式用“或”(表示为 `-o`)来组合。
```
find ~ ( -iname 'jpeg' -o -iname 'jpg' )
```
我们正在接近目标。但是如果你有一些以 jpg 结尾的目录呢? (为什么你要命名一个 `bucketofjpg` 而不是 `pictures` 的目录就超出了本文的范围。)我们使用 `-type` 参数修改我们的命令来查找文件。
```
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type f
```
或者,也许你想找到那些命名奇怪的目录,以便稍后重命名它们:
```
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type d
```
你最近拍了很多照片,所以让我们把它缩小到上周更改的文件。
```
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type f -mtime -7
```
你可以根据文件状态更改时间 (`ctime`)、修改时间 (`mtime`) 或访问时间 (`atime`) 来执行时间过滤。 这些是在几天内,所以如果你想要更细粒度的控制,你可以表示为在几分钟内(分别是 `cmin`、`mmin` 和 `amin`)。 除非你确切地知道你想要的时间,否则你可能会在 `+` (大于)或 `-` (小于)的后面加上数字。
但也许你不关心你的照片。也许你的磁盘空间不够用,所以你想在 `log` 目录下找到所有巨大的(让我们定义为“大于 1GB”)文件:
```
find /var/log -size +1G
```
或者,也许你想在 `/data` 中找到 bcotton 拥有的所有文件:
```
find /data -owner bcotton
```
你还可以根据权限查找文件。也许你想在你的主目录中找到对所有人可读的文件,以确保你不会过度分享。
```
find ~ -perm -o=r
```
这篇文章只说了 `find` 能做什么的表面。将测试条件与布尔逻辑相结合可以为你提供难以置信的灵活性,以便准确找到要查找的文件。并且像 `-exec` 或 `-delete` 这样的参数,你可以让 `find` 对它发现的内容采取行动。你有任何最喜欢的 `find` 表达式么?在评论中分享它们!
---
via: <https://opensource.com/article/18/4/how-use-find-linux>
作者:[Ben Cotton](https://opensource.com/users/bcotton) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In [a recent Opensource.com article](https://opensource.com/article/18/4/how-find-files-linux), Lewis Cowles introduced the `find`
command.
`find`
is one of the more powerful and flexible command-line programs in the daily toolbox, so it's worth spending a little more time on it.
At a minimum, `find`
takes a path to find things. For example:
```
``````
find /
```
will find (and print) every file on the system. And since everything is a file, you will get a lot of output to sort through. This probably doesn't help you find what you're looking for. You can change the path argument to narrow things down a bit, but it's still not really any more helpful than using the `ls`
command. So you need to think about what you're trying to locate.
Perhaps you want to find all the JPEG files in your home directory. The `-name`
argument allows you to restrict your results to files that match the given pattern.
```
``````
find ~ -name '*jpg'
```
But wait! What if some of them have an uppercase extension? `-iname`
is like `-name`
, but it is case-insensitive.
```
``````
find ~ -iname '*jpg'
```
Great! But the 8.3 name scheme is so 1985. Some of the pictures might have a .jpeg extension. Fortunately, we can combine patterns with an "or," represented by `-o`
.
```
````find ~ ( -iname 'jpeg' -o -iname 'jpg' )`
We're getting closer. But what if you have some directories that end in jpg? (Why you named a directory `bucketofjpg`
instead of `pictures`
is beyond me.) We can modify our command with the `-type`
argument to look only for files.
```
``````
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type f
```
Or maybe you'd like to find those oddly named directories so you can rename them later:
```
``````
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type d
```
It turns out you've been taking a lot of pictures lately, so let's narrow this down to files that have changed in the last week.
```
``````
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type f -mtime -7
```
You can do time filters based on file status change time (`ctime`
), modification time (`mtime`
), or access time (`atime`
). These are in days, so if you want finer-grained control, you can express it in minutes instead (`cmin`
, `mmin`
, and `amin`
, respectively). Unless you know exactly the time you want, you'll probably prefix the number with `+`
(more than) or `–`
(less than).
But maybe you don't care about your pictures. Maybe you're running out of disk space, so you want to find all the gigantic (let's define that as "greater than 1 gigabyte") files in the `log`
directory:
```
``````
find /var/log -size +1G
```
Or maybe you want to find all the files owned by bcotton in `/data`
:
```
``````
find /data -owner bcotton
```
You can also look for files based on permissions. Perhaps you want to find all the world-readable files in your home directory to make sure you're not oversharing.
```
``````
find ~ -perm -o=r
```
This post only scratches the surface of what `find`
can do. Combining tests with Boolean logic can give you incredible flexibility to find exactly the files you're looking for. And with arguments like `-exec`
or `-delete`
, you can have `find`
take action on what it... finds. Have any favorite `find`
expressions? Share them in the comments!
## 12 Comments |
9,649 | 在 5 分钟内重置丢失的 root 密码 | https://opensource.com/article/18/4/reset-lost-root-password | 2018-05-17T09:02:00 | [
"密码"
] | https://linux.cn/article-9649-1.html |
>
> 如何快速简单地在 Fedora 、 CentOS 及类似的 Linux 发行版上重置 root 密码。
>
>
>

系统管理员可以轻松地为忘记密码的用户重置密码。但是如果系统管理员忘记 root 密码或他从公司离职了,会发生什么情况?本指南将向你介绍如何在不到 5 分钟的时间内在 Red Hat 兼容系统(包括 Fedora 和 CentOS)上重置丢失或忘记的 root 密码。
请注意,如果整个系统硬盘已用 LUKS 加密,则需要在出现提示时提供 LUKS 密码。此外,此过程适用于运行 systemd 的系统,该系统自 Fedora 15、CentOS 7.14.04 和 Red Hat Enterprise Linux 7.0 以来一直是缺省的初始系统。
首先你需要中断启动的过程,因此你需要启动或者如果已经启动就重启它。第一步可能有点棘手因为 GRUB 菜单会在屏幕上快速地闪烁过去。你可能需要尝试几次,直到你能够做到这一点。
当你看到这个屏幕时,按下键盘上的 `e` 键:

如果你正确地做了这点,你应该看到一个类似于这个的屏幕:

使用箭头键移动到 `Linux16` 这行:

使用你的 `del` 键或你的 `backspace` 键,删除 `rhgb quiet` 并替换为以下内容:
```
rd.break enforcing=0
```

设置 `enforcing=0` 可以避免执行完整的系统 SELinux 重标记。一旦系统重新启动,你只需要为 `/etc/shadow` 恢复正确的 SELinux 上下文。我会告诉你如何做到这一点。
按下 `Ctrl-x` 启动。
**系统现在将处于紧急模式。**
以读写权限重新挂载硬盘驱动器:
```
# mount –o remount,rw /sysroot
```
运行 `chroot` 来访问系统:
```
# chroot /sysroot
```
你现在可以更改 root 密码:
```
# passwd
```
出现提示时,输入新的 root 密码两次。如果成功,你应该看到一条消息显示 “all authentication tokens updated successfully”。
输入 `exit` 两次以重新启动系统。
以 root 身份登录并恢复 `/etc/shadow` 的 SELinux 标签。
```
# restorecon -v /etc/shadow
```
将 SELinux 回到 enforce 模式:
```
# setenforce 1
```
---
via: <https://opensource.com/article/18/4/reset-lost-root-password>
作者:[Curt Warfield](https://opensource.com/users/rcurtiswarfield) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A system administrator can easily reset passwords for users who have forgotten theirs. But what happens if the system administrator forgets the root password, or leaves the company? This guide will show you how to reset a lost or forgotten root password on a Red Hat-compatible system, including Fedora and CentOS, in less than 5 minutes.
Please note, if the entire system hard disk has been encrypted with LUKS, you would need to provide the LUKS password when prompted. Also, this procedure is applicable to systems running systemd which has been the default init system since Fedora 15, CentOS 7.14.04, and Red Hat Enterprise Linux 7.0.
First, you need to interrupt the boot process, so you'll need to turn the system on or restart it if it’s already powered on. The first step is tricky because the GRUB menu tends to flash very quickly on the screen. You may need to try this a few times until you are able to do it.
Press ** e** on your keyboard when you see this screen:
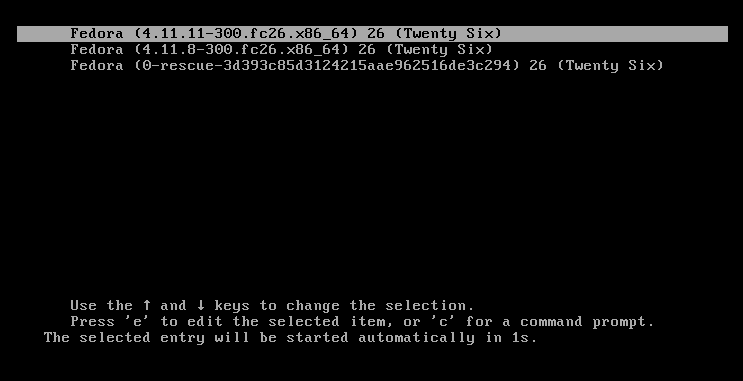
If you've done this correctly, you should see a screen similar to this one:

Use your arrow keys to move to the Linux16 line:
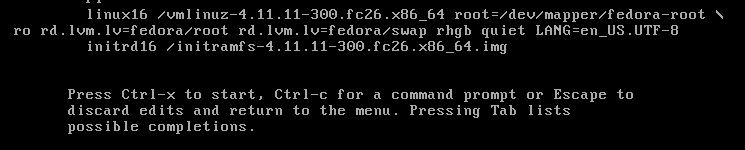
Using your ** del** key or your
**key, remove**
*backspace*`rhgb quiet`
and replace with the following:`rd.break enforcing=0`
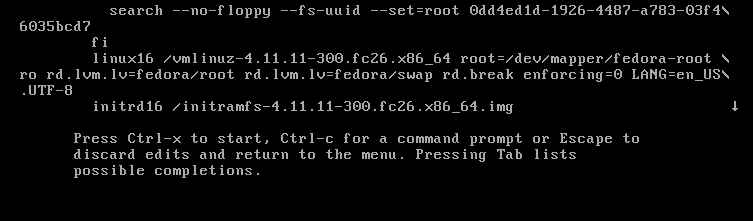
Setting `enforcing=0`
will allow you to avoid performing a complete system SELinux relabeling. Once the system is rebooted, you'll only have to restore the correct SELinux context for the `/etc/shadow`
file. I'll show you how to do this too.
Press ** Ctrl-x **to start.
*The system will now be in emergency mode.*
Remount the hard drive with read-write access:
```
````# mount –o remount,rw /sysroot`
Run `chroot`
to access the system:
```
````# chroot /sysroot`
You can now change the root password:
```
````# passwd`
Type the new root password twice when prompted. If you are successful, you should see a message that reads "** all authentication tokens updated successfully**."
Type ** exit** twice to reboot the system.
Log in as root and restore the SELinux label to the `/etc/shadow`
file.
```
````# restorecon -v /etc/shadow`
Turn SELinux back to enforcing mode:
```
````# setenforce 1`
## 4 Comments |
9,650 | 使用 syslog-ng 可靠地记录物联网事件 | https://opensource.com/article/18/3/logging-iot-events-syslog-ng | 2018-05-17T09:48:59 | [
"日志",
"物联网",
"syslog"
] | https://linux.cn/article-9650-1.html |
>
> 用增强的日志守护进程 syslog-ng 来监控你的物联网设备。
>
>
>

现在,物联网设备和嵌入式系统越来越多。对于许多连接到因特网或者一个网络的设备来说,记录事件很有必要,因为你需要知道这些设备都做了些什么事情,这样你才能够解决可能出现的问题。
可以考虑去使用的一个监视工具是开源的 [syslog-ng](https://syslog-ng.com/open-source-log-management) 应用程序,它是一个强化的、致力于可移植的、中心化的日志收集守护程序。它可以从许多不同种类的来源、进程来收集日志,并且可以对这些日志进行处理和过滤,也可以存储或者路由它们,以便于做进一步的分析。syslog-ng 的大多数代码是用高效率的、高可移植的 C 代码写成的。它能够适用于各种场景,无论你是将它运行在一个处理能力很弱的设备上做一些简单的事情,还是运行在数据中心从成千上万的机器中收集日志的强大应用,它都能够胜任。
你可能注意到在这个段落中,我使用了大量的溢美词汇。为了让你更清晰地了解它,我们来复习一下,但这将花费更多的时间,也了解的更深入一些。
### 日志
首先解释一下日志。<ruby> 日志 <rt> logging </rt></ruby>是记录一台计算机上事件的东西。在一个典型的 Linux 机器上,你可以在 `/var/log` 目录中找到这些信息。例如,如果你通过 SSH 登录到机器中,你将可以在其中一个日志文件中找到类似于如下内容的信息:
```
Jan 14 11:38:48 linux-0jbu sshd[7716]: Accepted publickey for root from 127.0.0.1 port 48806 ssh2
```
日志的内容可能是关于你的 CPU 过热、通过 HTTP 下载了一个文档,或者你的应用程序认为重要的任何东西。
### syslog-ng
正如我在上面所写的那样,syslog-ng 应用程序是一个强化的、致力于可移植性、和中心化的日志收集守护程序。守护程序的意思是,syslog-ng 是一个持续运行在后台的应用程序,在这里,它用于收集日志信息。
虽然现在大多数应用程序的 Linux 测试是限制在 x86\_64 的机器上,但是,syslog-ng 也可以运行在大多数 BSD 和商业 UNIX 变种版本上的。从嵌入式/物联网的角度来看,这种能够运行在不同的 CPU 架构(包括 32 位和 64 位的 ARM、PowerPC、MIPS 等等)的能力甚至更为重要。(有时候,我通过阅读关于 syslog-ng 是如何使用它们的来学习新架构)
为什么中心化的日志收集如此重要?其中一个很重要的原因是易于使用,因为它放在一个地方,不用到成百上千的机器上挨个去检查它们的日志。另一个原因是可用性 —— 即使一个设备不论是什么原因导致了它不可用,你都可以检查这个设备的日志信息。第三个原因是安全性;当你的设备被黑,检查设备日志可以发现攻击的踪迹。
### syslog-ng 的四种用法
syslog-ng 有四种主要的用法:收集、处理、过滤、和保存日志信息。
**收集信息:** syslog-ng 能够从各种各样的 [特定平台源](https://syslog-ng.com/documents/html/syslog-ng-ose-latest-guides/en/syslog-ng-ose-guide-admin/html/sources.html) 上收集信息,比如 `/dev/log`,`journal`,或者 `sun-streams`。作为一个中心化的日志收集器,传统的(`rfc3164`)和最新的(`rfc5424`)系统日志协议、以及它们基于 UDP、TCP 和加密连接的各种变种,它都是支持的。你也可以从管道、套接字、文件、甚至应用程序输出来收集日志信息(或者各种文本数据)。
**处理日志信息:** 它的处理能力几乎是无限的。你可以用它内置的解析器来分类、规范,以及结构化日志信息。如果它没有为你提供在你的应用场景中所需要的解析器,你甚至可以用 Python 来自己写一个解析器。你也可以使用地理数据来丰富信息,或者基于信息内容来附加一些字段。日志信息可以按处理它的应用程序所要求的格式进行重新格式化。你也可以重写日志信息 —— 当然了,不是篡改日志内容 —— 比如在某些情况下,需要满足匿名要求的信息。
**过滤日志:** 过滤日志的用法主要有两种:丢弃不需要保存的日志信息 —— 像调试级别的信息;和路由日志信息—— 确保正确的日志到达正确的目的地。后一种用法的一个例子是,转发所有的认证相关的信息到一个安全信息与事件管理系统(SIEM)。
**保存信息:** 传统的做法是,将文件保存在本地或者发送到中心化日志服务器;不论是哪种方式,它们都被发送到一个[普通文件](https://en.wikipedia.org/wiki/Flat_file_database)。经过这些年的改进,syslog-ng 已经开始支持 SQL 数据库,并且在过去的几年里,包括 HDFS、Kafka、MongoDB、和 Elasticsearch 在内的大数据存储,都被加入到 syslog-ng 的支持中。
### 消息格式
当在你的 `/var/log` 目录中查看消息时,你将看到(如上面的 SSH 信息)大量的消息都是如下格式的内容:
```
日期 + 主机名 + 应用名 + 一句几乎完整的英文信息
```
在这里的每个应用程序事件都是用不同的语法描述的,基于这些数据去创建一个报告是个痛苦的任务。
解决这种混乱信息的一个方案是使用结构化日志。在这种情况下,事件被表示为键-值对,而不是随意的日志信息。比如,一个 SSH 日志能够按应用程序名字、源 IP 地址、用户名、认证方法等等来描述。
你可以从一开始就对你的日志信息按合适的格式进行结构化处理。当处理传统的日志信息时,你可以在 syslog-ng 中使用不同的解析器,转换非结构化(和部分结构化)的信息为键-值对格式。一旦你的日志信息表示为键-值对,那么,报告、报警、以及简单查找信息将变得很容易。
### 物联网日志
我们从一个棘手的问题开始:哪个版本的 syslog-ng 最流行?在你回答之前,想想如下这些事实:这个项目启动于 20 年以前,Red Hat 企业版 Linux EPEL 已经有了 3.5 版,而当前版本是 3.14。当我在我的演讲中问到这个问题时,观众通常回答是他们用的 Linux 发行版中自带的那个。你们绝对想不到的是,正确答案竟然是 1.6 版最流行,这个版本已经有 15 年的历史的。这什么这个版本是最为流行的,因为它是包含在亚马逊 Kindle 阅读器中的版本,它是电子书阅读器,因为它运行在全球范围内超过 1 亿台的设备上。另外一个在消费类设备上运行 syslog-ng 的例子是 BMW i3 电动汽车。
Kindle 使用 syslog-ng 去收集关于用户在这台设备上都做了些什么事情等所有可能的信息。在 BMW 电动汽车上,syslog-ng 所做的事情更复杂,基于内容过滤日志信息,并且在大多数情况下,只记录最重要的日志。
使用 syslog-ng 的其它类别设备还有网络和存储。一些比较知名的例子有,Turris Omnia 开源 Linux 路由器和群晖 NAS 设备。在大多数案例中,syslog-ng 是在设备上作为一个日志客户端来运行,但是在有些案例中,它运行为一个有丰富 Web 界面的中心日志服务器。
你还可以在一些行业服务中找到 syslog-ng 的身影。它运行在来自美国国家仪器有限公司(NI)的实时 Linux 设备上,执行测量和自动化任务。它也被用于从定制开发的应用程序中收集日志。从命令行就可以做配置,但是一个漂亮的 GUI 可用于浏览日志。
最后,还有大量的项目,比如,汽车和飞机,syslog-ng 在它们上面既可以运行为客户端,也可以运行为服务端。在这种使用案例中,syslog-ng 一般用来收集所有的日志和测量数据,然后发送它们到处理这些日志的中心化服务器集群上,然后保存它们到支持大数据的目的地,以备进一步分析。
### 对物联网的整体益处
在物联网环境中使用 syslog-ng 有几个好处。第一,它的分发性能很高,并且是一个可靠的日志收集器。第二,它的架构也很简单,因此,系统、应用程序日志、以及测量数据可以被一起收集。第三,它使数据易于使用,因为,数据可以被解析和表示为易于使用的格式。最后,通过 syslog-ng 的高效路由和过滤功能,可以显著降低处理程序的负载水平。
---
via: <https://opensource.com/article/18/3/logging-iot-events-syslog-ng>
作者:[Peter Czanik](https://opensource.com/users/czanik) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For any device connected to the internet or a network, it's essential that you log events so you know what the device is doing and can address any potential problems. Increasingly those devices include Internet of Things (IoT) devices and embedded systems.
One monitoring tool to consider is the open source [syslog-ng](https://syslog-ng.com/open-source-log-management) application, an enhanced logging daemon with a focus on portability and central log collection. It collects logs from many different sources, processes and filters them, and stores or routes them for further analysis. Most of syslog-ng is written in efficient and highly portable C code. It's suitable for a wide range of scenarios, whether you need something simple enough to run with a really small footprint on underpowered devices or a solution powerful enough to reside in your data center and collect logs from tens of thousands of devices.
You probably noticed the abundance of buzzwords I wrote in that single paragraph. To clarify what this all means, let's go over them, but this time slower and in more depth.
## Logging
First things first. Logging is the recording of events on a computer. On a typical Linux machine, you can find these log messages in the `/var/log`
directory. For example, if you log into your machine through SSH, you will find a message similar to this in one of the files:
`Jan 14 11:38:48 `
`linux`
`-0jbu sshd[7716]: Accepted `
`publickey`
` for root from 127.0.0.1 port 48806 ssh2`
It could be about your CPU running too hot, a document downloaded through HTTP, or just about anything one of your applications considers important.
## syslog-ng
As I wrote above, the syslog-ng application is an enhanced logging daemon with a focus on *portability* and *central log collection*. Daemon means syslog-ng is an application running continuously in the background; in this case, it's collecting log messages.
While Linux testing for many of today's applications is limited to x86_64 machines, syslog-ng also works on many BSD and commercial UNIX variants. What is even more important from the embedded/IoT standpoint is that it runs on many different CPU architectures, including 32- and 64-bit ARM, PowerPC, MIPS, and more. (Sometimes I learn about new architectures just by reading about how syslog-ng is used.)
Why is central collection of logs such a big deal? One reason is ease of use, as it creates a single place to check instead of tens or thousands of devices. Another reason is availability—you can check a device's log messages even if the device is unavailable for any reason. A third reason is security; when your device is hacked, checking the logs can uncover traces of the hack.
## Four roles of syslog-ng
Syslog-ng has four major roles: collecting, processing, filtering, and storing log messages.
**Collecting messages:** syslog-ng can collect from a wide variety of [platform-specific sources](https://syslog-ng.com/documents/html/syslog-ng-ose-latest-guides/en/syslog-ng-ose-guide-admin/html/sources.html), like `/dev/log`
, `journal`
, or `sun-streams`
. As a central log collector, it speaks both the legacy (`rfc3164`
) and the new (`rfc5424`
) syslog protocols and all their variants over User Datagram Protocol (UDP), TCP, and encrypted connections. You can also collect log messages (or any kind of text data) from pipes, sockets, files, and even application output.
**Processing log messages:** The possibilities here are almost endless. You can classify, normalize, and structure log messages with built-in parsers. You can even write your own parser in Python if none of the available parsers suits your needs. You can also enrich messages with geolocation data or additional fields based on the message content. Log messages can be reformatted to suit the requirements of the application processing the logs. You can also rewrite log messages—not to falsify messages, of course—for things such as anonymizing log messages as required by many compliance regulations.
**Filtering logs:** There are two main uses for filtering logs: To discard surplus log messages—like debug-level messages—to save on storage, and for log routing—making sure the right logs reach the right destinations. An example of the latter is forwarding all authentication-related messages to a security information and event management (SIEM) system.
**Storing messages:** Traditionally, files were saved locally or sent to a central syslog server; either way, they'd be sent to [flat files](https://en.wikipedia.org/wiki/Flat_file_database). Over the years, syslog-ng began supporting SQL databases, and in the past few years Big Data destinations, including HDFS, Kafka, MongoDB, and Elasticsearch, were added to syslog-ng.
## Message formats
When you look at your log messages under the `/var/log`
directory, you will see (like in the SSH message above) most are in the form:
`date + host name + application name + an almost complete English sentence`
Where each application event is described by a different sentence, creating a report based on this data is quite a painful job.
The solution to this mess is to use structured logging. In this case, events are represented as name-value pairs instead of freeform log messages. For example, an SSH login can be described by the application name, source IP address, username, authentication method, and so on.
You can take a structured approach for your log messages right from the beginning. When working with legacy log messages, you can use the different parsers in syslog-ng to turn unstructured (and some of the structured) message formats into name-value pairs. Once you have your logs available as name-value pairs, reporting, alerting, and simply finding the information you are looking for becomes a lot easier.
## Logging IoT
Let's start with a tricky question: Which version of syslog-ng is the most popular? Before you answer, consider these facts: The project started 20 years ago, Red Hat Enterprise Linux EPEL has version 3.5, and the current version is 3.14. When I ask this question during my presentations, the audience members usually suggest the one in their favorite Linux distribution. Surprisingly, the correct answer is version 1.6, almost 15 years old. That's because it is the version included in the Amazon Kindle e-book readers, so it's running on over 100 million devices worldwide. Another example of a consumer device running syslog-ng is the BMW i3 all-electric car.
The Kindle uses syslog-ng to collect all possible information about what the user is doing on the device. On the BMW, syslog-ng does very complex, content-based filtering of log messages, and most it likely records only the most important logs.
Networking and storage are other categories of devices that often use syslog-ng. Networking and storage are other categories of devices that often use syslog-ng. Some better known examples are the Turris Omnia open source Linux router and Synology NAS devices. In most cases, syslog-ng started out as a logging client on these devices, but in some cases it's evolved into a central logging server with a rich web interface.
You can find syslog-ng in industrial devices, as well. It runs on all real-time Linux devices from National Instruments doing measurements and automation. It is also used to collect logs from customer-developed applications. Configuration is done from the command line, but a nice GUI is available to browse the logs.
Finally, there are some large-scale projects, such as cars and airplanes, where syslog-ng runs on both the client and server side. The common theme here is that syslog-ng collects all log and metrics data, sends it to a central cluster of servers where logs are processed, and saves it to one of the supported Big Data destinations where it waits for further analysis.
## Overall benefits for IoT
There are several benefits of using syslog-ng in an IoT environment. First, it delivers high performance and reliable log collection. It also simplifies the architecture, as system and application logs and metrics data can be collected together. Third, it makes it easier to use data, as data is parsed and presented in a ready-to-use format. Finally, efficient routing and filtering by syslog-ng can significantly decrease processing load.
## Comments are closed. |
9,652 | 在 KVM 中测试 IPv6 网络:第 2 部分 | https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-2 | 2018-05-17T21:52:57 | [
"IPv6",
"KVM"
] | https://linux.cn/article-9652-1.html | 
我们又见面了,在上一篇 [在 KVM 中测试 IPv6 网络:第 1 部分](/article-9594-1.html) 中,我们学习了有关 IPv6 私有地址的内容。今天,我们将使用 KVM 创建一个网络,去测试上一星期学习的 IPv6 的内容。
如果你想重新温习如何使用 KVM,可以查看 [在 KVM 中创建虚拟机:第 1 部分](https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-1) 和 [在 KVM 中创建虚拟机:第 2 部分— 网络](https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-2-networking)。
### 在 KVM 中创建网络
在 KVM 中你至少需要两个虚拟机。当然了,如果你愿意,也可以创建更多的虚拟机。在我的系统中有 Fedora、Ubuntu、以及 openSUSE。去创建一个新的 IPv6 网络,在主虚拟机管理窗口中打开 “Edit > Connection Details > Virtual Networks”。点击左下角的绿色十字按钮去创建一个新的网络(图 1)。

*图 1:创建一个网络*
给新网络输入一个名字,然后,点击 “Forward” 按钮。如果你愿意,也可以不创建 IPv4 网络。当你创建一个新的 IPv4 网络时,虚拟机管理器将不让你创建重复网络,或者是使用了一个无效地址。在我的宿主机 Ubuntu 系统上,有效的地址是以绿色高亮显示的,而无效地址是使用高亮的玫瑰红色调。在我的 openSUSE 机器上没有高亮颜色。启用或不启用 DHCP,以及创建或不创建一个静态路由,然后进入下一个窗口。
选中 “Enable IPv6 network address space definition”,然后输入你的私有地址范围。你可以使用任何你希望的 IPv6 地址类,但是要注意,不能将你的实验网络泄漏到公网上去。我们将使用非常好用的 IPv6 唯一本地地址(ULA),并且使用在 [Simple DNS Plus](http://simpledns.com/private-ipv6.aspx) 上的在线地址生成器,去创建我们的网络地址。拷贝 “Combined/CID” 地址到网络框中(图 2)。

*图 2:拷贝 "Combined/CID" 地址到网络框中*
虚拟机认为我的地址是无效的,因为,它显示了高亮的玫瑰红色。它做的对吗?我们使用 `ipv6calc` 去验证一下:
```
$ ipv6calc -qi fd7d:844d:3e17:f3ae::/64
Address type: unicast, unique-local-unicast, iid, iid-local
Registry for address: reserved(RFC4193#3.1)
Address type has SLA: f3ae
Interface identifier: 0000:0000:0000:0000
Interface identifier is probably manual set
```
`ipv6calc` 认为没有问题。如果感兴趣,你可以改变其中一个数字为无效的东西,比如字母 `g`,然后再试一次。(问 “如果…?”,试验和错误是最好的学习方法)。
我们继续进行,启用 DHCPv6(图 3)。你可以接受缺省值,或者输入一个你自己的设置值。

*图 3: 启用 DHCPv6*
我们将跳过缺省路由定义这一步,继续进入下一屏,在那里我们将启用 “Isolated Virtual Network” 和 “Enable IPv6 internal routing/networking”。
### 虚拟机网络选择
现在,你可以配置你的虚拟机去使用新的网络。打开你的虚拟机,然后点击顶部左侧的 “i” 按钮去打开 “Show virtual hardware details” 屏幕。在 “Add Hardware” 列点击 “NIC” 按钮去打开网络选择器,然后选择你喜欢的新的 IPv6 网络。点击 “Apply”,然后重新启动。(或者使用你喜欢的方法去重新启动网络,或者更新你的 DHCP 租期。)
### 测试
`ifconfig` 告诉我们它做了什么?
```
$ ifconfig
ens3: flags=4163 UP,BROADCAST,RUNNING,MULTICAST mtu 1500
inet 192.168.30.207 netmask 255.255.255.0
broadcast 192.168.30.255
inet6 fd7d:844d:3e17:f3ae::6314
prefixlen 128 scopeid 0x0
inet6 fe80::4821:5ecb:e4b4:d5fc
prefixlen 64 scopeid 0x20
```
这是我们新的 ULA,`fd7d:844d:3e17:f3ae::6314`,它是自动生成的本地链路地址。如果你有兴趣,可以 ping 一下,ping 网络上的其它虚拟机:
```
vm1 ~$ ping6 -c2 fd7d:844d:3e17:f3ae::2c9f
PING fd7d:844d:3e17:f3ae::2c9f(fd7d:844d:3e17:f3ae::2c9f) 56 data bytes
64 bytes from fd7d:844d:3e17:f3ae::2c9f: icmp_seq=1 ttl=64 time=0.635 ms
64 bytes from fd7d:844d:3e17:f3ae::2c9f: icmp_seq=2 ttl=64 time=0.365 ms
vm2 ~$ ping6 -c2 fd7d:844d:3e17:f3ae:a:b:c:6314
PING fd7d:844d:3e17:f3ae:a:b:c:6314(fd7d:844d:3e17:f3ae:a:b:c:6314) 56 data bytes
64 bytes from fd7d:844d:3e17:f3ae:a:b:c:6314: icmp_seq=1 ttl=64 time=0.744 ms
64 bytes from fd7d:844d:3e17:f3ae:a:b:c:6314: icmp_seq=2 ttl=64 time=0.364 ms
```
当你努力去理解子网时,这是一个可以让你尝试不同地址是否可以正常工作的快速易用的方法。你可以给单个接口分配多个 IP 地址,然后 ping 它们去看一下会发生什么。在一个 ULA 中,接口,或者主机是 IP 地址的最后四部分,因此,你可以在那里做任何事情,只要它们在同一个子网中即可,在那个例子中是 `f3ae`。在我的其中一个虚拟机上,我只改变了这个示例的接口 ID,以展示使用这四个部分,你可以做任何你想做的事情:
```
vm1 ~$ sudo /sbin/ip -6 addr add fd7d:844d:3e17:f3ae:a:b:c:6314 dev ens3
vm2 ~$ ping6 -c2 fd7d:844d:3e17:f3ae:a:b:c:6314
PING fd7d:844d:3e17:f3ae:a:b:c:6314(fd7d:844d:3e17:f3ae:a:b:c:6314) 56 data bytes
64 bytes from fd7d:844d:3e17:f3ae:a:b:c:6314: icmp_seq=1 ttl=64 time=0.744 ms
64 bytes from fd7d:844d:3e17:f3ae:a:b:c:6314: icmp_seq=2 ttl=64 time=0.364 ms
```
现在,尝试使用不同的子网,在下面的示例中使用了 `f4ae` 代替 `f3ae`:
```
$ ping6 -c2 fd7d:844d:3e17:f4ae:a:b:c:6314
PING fd7d:844d:3e17:f4ae:a:b:c:6314(fd7d:844d:3e17:f4ae:a:b:c:6314) 56 data bytes
From fd7d:844d:3e17:f3ae::1 icmp_seq=1 Destination unreachable: No route
From fd7d:844d:3e17:f3ae::1 icmp_seq=2 Destination unreachable: No route
```
这也是练习路由的好机会,以后,我们将专门做一期,如何在不使用 DHCP 情况下实现自动寻址。
---
via: <https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-2>
作者:[CARLA SCHRODER](https://www.linux.com/users/cschroder) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,653 | 成为你所在社区的美好力量 | https://opensource.com/open-organization/17/1/force-for-good-community | 2018-05-17T22:41:00 | [
"开放组织"
] | https://linux.cn/article-9653-1.html |
>
> 明白如何传递美好,了解积极意愿的力量,以及更多。
>
>
>

激烈的争论是开源社区和开放组织的标志特征之一。在好的时候,这些争论充满活力和建设性。他们面红耳赤的背后其实是幽默和善意。各方实事求是,共同解决问题,推动持续改进。对我们中的许多人来说,他们只是单纯的喜欢而已。
然而在那些不好的日子里,这些争论演变成了对旧话题的反复争吵。或者我们用各种方式来传递伤害和相互攻击,或是使用卑劣的手段,而这些侵蚀着我们社区的激情、信任和生产力。
我们茫然四顾,束手无策,因为社区的对话开始变得有毒。然而,正如 [DeLisa Alexander 最近的分享](https://opensource.com/business/15/5/5-ways-promote-inclusive-environment),我们每个人都有很多方法可以成为我们社区的一种力量。
在这个“开源文化”系列的第一篇文章中,我将分享一些策略,教你如何在这个关键时刻进行干预,引导每个人走向更积极、更有效率的方向。
### 不要将人推开,而是将人推向前方
最近,我和我的朋友和同事 [Mark Rumbles](https://twitter.com/leadership_365) 一起吃午饭。多年来,我们在许多支持开源文化和引领 Red Hat 的项目中合作。在这一天,Mark 问我,他看到我最近介入了一个邮件列表的对话,当其中的辩论越来越过分时我是怎么坚持的。
幸运的是,这事早已尘埃落定,事实上我几乎忘记了谈话的内容。然而,它让我们开始讨论如何在一个拥有数千名成员的社区里,公开和坦率的辩论。
Mark 说了一些让我印象深刻的话。他说:“你知道,作为一个社区,我们真的很擅长将人推开。但我想看到的是,我们更多的是互相扶持 *向前* 。”
Mark 是绝对正确的。在我们的社区里,我们成为一种美好力量的最好的方法之一就是:以一种迫使每个人提升他们的行为的方式回应冲突,而不是使冲突升级的方式。
### 积极意愿假想
我们可以从一个简单的假想开始,当我们在一个激烈的对话中观察到不良行为时:完全有可能该不良行为其实有着积极意愿。
诚然,这不是一件容易的事情。当我看到一场辩论正在变得肮脏的迹象时,我停下来问自己,史蒂芬·科维(Steven Covey)所说的人性化问题是什么:
>
> “为什么一个理性、正直的人会做这样的事情?”
>
>
>
现在,如果他是你的一个“普通的观察对象”—— 一个有消极行为倾向的社区成员——也许你的第一个想法是,“嗯,也许这个人是个不靠谱,不理智的人”
回过头来说。我并不是说你让你自欺欺人。这其实就是人性化的问题,不仅是因为它让你理解别人的立场,它还让你变得人性化。
而这反过来又能帮助你做出反应,或者从最有效率的地方进行干预。
### 寻求了解社区异议的原因
当我再一次问自己为什么一个理性的、正直的人可能会做这样的事情时,归结为几个原因:
* 他认为没人聆听他
* 他认为没人尊重他
* 他认为没人理解他
一个简单的积极意愿假想,我们可以适用于几乎所有的不良行为,其实就是那个人想要被聆听,被尊重,或被理解。我想这是相当合理的。
通过站在这个更客观、更有同情心的角度,我们可以看到他们的行为几乎肯定 ***不会*** 帮助他们得到他们想要的东西,而社区也会因此而受到影响。如果没有我们的帮助的话。
对我来说,这激发了一个愿望:帮助每个人从我们所处的这个丑陋的地方“摆脱困境”。
在我介入之前,我问自己一个后续的问题:是否有其他积极的意图可能会驱使这种行为
容易想到的例子包括:
* 他们担心我们错过了一些重要的东西,或者我们犯了一个错误,没有人能看到它。
* 他们想感受到自己的贡献的价值。
* 他们精疲力竭,因为在社区里工作过度或者在他们的个人生活中发生了一些事情。
* 他们讨厌一些东西被破坏,并感到沮丧,因为没有人能看到造成的伤害或不便。
* ……诸如此类。
有了这些,我就有了丰富的积极的意图假想,我可以为他们的行为找到原因。我准备伸出援助之手,向他们提供一些帮助。
### 传递美好,挣脱泥潭
什么是 an out?(LCTT 译注:类似与佛家“解脱法门”的意思)把它想象成一个逃跑的门。这是一种退出对话的方式,或者放弃不良的行为,恢复表现得像一个体面的人,而不是丢面子。是叫某人振作向上,而不是叫他走开。
你可能经历过这样的事情,在你的生活中,当 *你* 在一次谈话中表现不佳时,咆哮着,大喊大叫,对某事大惊小怪,而有人慷慨地给 *你* 提供了一个台阶下。也许他们选择不去和你“抬杠”,相反,他们说了一些表明他们相信你是一个理性、正直的人,他们采用积极意愿假想,比如:
>
> 所以,嗯,我听到的是你真的很担心,你很沮丧,因为似乎没有人在听。或者你担心我们忽略了它的重要性。是这样对吧?
>
>
>
于是乎:即使这不是完全正确的(也许你的意图不那么高尚),在那一刻,你可能抓住了他们提供给你的台阶,并欣然接受了重新定义你的不良行为的机会。你几乎可以肯定地转向一个更富有成效的角度,甚至你自己可能都没有意识到。
也许你这样说,“哦,虽然不完全是这样,但我只是担心,我们这样会走向歧途,我明白你说的,作为社区,我们不能同时解决所有问题,但如果我们不尽快解决这个问题,会有更多不好的事情要发生……”
最后,谈话几乎可以肯定地开始转移到一个更有效率的方向。
我们都有机会让一个沮丧的人挣脱泥潭,而这就是方法。
### 坏行为还是坏人?
如果这个人特别激动,他们可能不会听到或者接受你给出的第一个台阶。没关系。最可能的是,他们迟钝的大脑已经被史前曾经对人类生存至关重要的杏仁体接管了,他们需要更多的时间来认识到你并不是一个威胁。只是需要你保持温和的态度,坚定地对待他们,就好像他们 *曾经是* 一个理性、正直的人,看看会发生什么。
根据我的经验,这些社区干预以三种方式结束:
大多数情况下,这个人实际上 *是* 一个理性的人,很快,他们就感激地接受了这个事实。在这个过程中,每个人都跳出了“黑与白”,“赢或输”的心态。人们开始思考创造性的选择和“双赢”的结果,每个人都将受益。
>
> 为什么一个理性、正直的人会做这样的事呢?
>
>
>
有时候,这个人天生不是特别理性或正直的,但当他被你以如此一致的、不知疲倦的、耐心的慷慨和善良的对待的时候,他们就会羞愧地从谈话中撤退。这听起来像是,“嗯,我想我已经说了所有要说的了。谢谢你听我的意见”。或者,对于不那么开明的人来说,“嗯,我厌倦了这种谈话。让我们结束吧。”(好的,谢谢)。
更少的情况是,这个人是一个“*坏人*”,或者在社区管理圈子里,是一个“搅屎棍”。这些人确实存在,而且他们在演戏方面很有发展。你猜怎么着?通过持续地以一种友善、慷慨、以社区为中心的方式,完全无视所有试图使局势升级的尝试,你有效地将谈话变成了一个对他们没有兴趣的领域。他们别无选择,只能放弃它。你成为赢家。
这就是积极意愿假想的力量。通过对愤怒和充满敌意的言辞做出回应,优雅而有尊严地回应,你就能化解一场战争,理清混乱,解决棘手的问题,而且在这个过程中很有可能会交到一个新朋友。
我每次应用这个原则都成功吗?见鬼,不会。但我从不后悔选择了积极意愿。但是我能生动的回想起,当我采用消极意愿假想时,将问题变得更糟糕的场景。
现在轮到你了。我很乐意听到你提出的一些策略和原则,当你的社区里的对话变得激烈的时候,要成为一股好力量。在下面的评论中分享你的想法。
下次,我们将探索更多的方法,在你的社区里成为一个美好力量,我将分享一些处理“坏脾气先生”的技巧。
---
作者简介:
<ruby> 丽贝卡·费尔南德斯 <rp> ( </rp> <rt> Rebecca Fernandez </rt> <rp> ) </rp></ruby>是红帽公司的首席就业品牌 + 通讯专家,是《开放组织》书籍的贡献者,也是开源决策框架的维护者。她的兴趣是开源和业务管理模型的开源方式。Twitter:@ruhbehka
---
via: <https://opensource.com/open-organization/17/1/force-for-good-community>
作者:[Rebecca Fernandez](https://opensource.com/users/rebecca) 译者:[chao-zhi](https://github.com/chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Passionate debate is among the hallmark traits of open source communities and open organizations. On our best days, these debates are energetic and constructive. They are heated, yet moderated with humor and goodwill. All parties remain focused on facts, on the shared purpose of collaborative problem-solving, and driving continuous improvement. And for many of us, they're just plain fun.
On our worst days, these debates devolve into rehashing the same old arguments on the same old topics. Or we turn on one another, delivering insults—passive-aggressive or outright nasty, depending on our style—and eroding the passion, trust, and productivity of our communities.
We've all been there, watching and feeling helpless, as a community conversation begins to turn toxic. Yet, as [DeLisa Alexander recently shared](https://opensource.com/business/15/5/5-ways-promote-inclusive-environment), there are so many ways that each and every one of us can be a force for good in our communities.
In the first article of this "open culture" series, I will share a few strategies for how you can intervene, in that crucial moment, and steer everyone to a more positive and productive place.
## Don't call people out. Call them up.
Recently, I had lunch with my friend and colleague, [Mark Rumbles](https://twitter.com/leadership_365). Over the years, we've collaborated on a number of projects that support open culture and leadership at Red Hat. On this day, Mark asked me how I was holding up, as he saw I'd recently intervened in a mailing list conversation when I saw the debate was getting ugly.
Fortunately, the dust had long since settled, and in fact I'd almost forgotten about the conversation. Nevertheless, it led us to talk about the challenges of open and frank debate in a community that has thousands of members.
Mark said something that struck me as rather insightful. He said, "You know, as a community, we are really good at calling each other out. But what I'd like to see us do more of is calling each other *up*."
Mark is absolutely right. One of the biggest ways we can be a force for good in our communities is to respond to conflict in a way that compels everyone to elevate their behavior, rather than escalate it.
## Assume positive intent
We can start by making a simple assumption when we observe poor behavior in a heated conversation: It's entirely possible that there are positive intentions somewhere in the mix.
This is admittedly not an easy thing to do. When I see signs that a debate is turning nasty, I pause and ask myself what Steven Covey calls The Humanizing Question:
"Why would a reasonable, rational, and decent person do something like this?"
Now, if this is one of your "usual suspects"—a community member with a propensity toward negative behavior--perhaps your first thought is, "Um, what if this person *isn't* reasonable, rational, or decent?"
Stay with me, now. I'm not suggesting that you engage in some touchy-feely form of self-delusion. It's called The Humanizing Question not only because asking it humanizes the other person, but also because it humanizes *you*.
And that, in turn, helps you respond or intervene from the most productive possible place.
## Seek to understand the reasons for community dissent
When I ask myself why a reasonable, rational, and decent person might do something like this, time and again, it comes down to the same few reasons:
- They don't feel heard.
- They don't feel respected.
- They don't feel understood.
One easy positive intention we can apply to almost any poor behavior, then, is that the person wants to be heard, respected, or understood. That's pretty reasonable, I suppose.
By standing in this more objective and compassionate place, we can see that their behavior is *almost certainly **not** going to help them get what they want, *and that the community will suffer as a result . . . without our help.
For me, that inspires a desire to help everyone get "unstuck" from this ugly place we're in.
Before I intervene, though, I ask myself a follow-up question: *What other positive intentions might be driving this behavior?*
Examples that readily jump to mind include:
- They are worried that we're missing something important, or we're making a mistake, and no one else seems to see it.
- They want to feel valued for their contributions.
- They are burned out, because of overworking in the community or things happening in their personal life.
- They are tired of something being broken and frustrated that no one else seems to see the damage or inconvenience that creates.
- ...and so on and so forth.
With that, I have a rich supply of positive intent that I can ascribe to their behavior. I'm ready to reach out and offer them some help, in the form of an out.
## Give the gift of an out
What is an out? Think of it as an escape hatch. It's a way to exit the conversation, or abandon the poor behavior and resume behaving like a decent person, without losing face. It's calling someone up, rather than calling them out.
You've probably experienced this, as some point in your life, when *you* were behaving poorly in a conversation, ranting and hollering and generally raising a fuss about something or another, and someone graciously offered *you* a way out. Perhaps they chose not to "take the bait" by responding to your unkind choice of words, and instead, said something that demonstrated they believed you were a reasonable, rational, and decent human being with positive intentions, such as:
So, uh, what I'm hearing is that you're really worried about this, and you're frustrated because it seems like no one is listening. Or maybe you're concerned that we're missing the significance of it. Is that about right?
And here's the thing: Even if that wasn't entirely true (perhaps you had less-than-noble intentions), in that moment, you probably grabbed ahold of that life preserver they handed you, and gladly accepted the opportunity to reframe your poor behavior. You almost certainly pivoted and moved to a more productive place, likely without even recognizing it.
Perhaps you said something like, "Well, it's not that exactly, but I just worry that we're headed down the wrong path here, and I get what you're saying that as community, we can't solve every problem at the same time, but if we don't solve this one soon, bad things are going to happen…"
In the end, the conversation almost certainly began to move to a more productive place, or you all agreed to disagree.
We all have the opportunity to offer an upset person a safe way out of that destructive place they're operating from. Here's how.
## Bad behavior or bad actor?
If the person is particularly agitated, they may not hear or accept the first out you hand them. That's okay. Most likely, their lizard brain--that prehistoric amygdala that was once critical for human survival—has taken over, and they need a few more moments to recognize you're not a threat. Just keep gently but firmly treating them as if they *were* a rational, reasonable, decent human being, and watch what happens.
In my experience, these community interventions end in one of three ways:
Most often, the person actually *is* a reasonable person, and soon enough, they gratefully and graciously accept the out. In the process, everyone breaks out of the black vs. white, "win or lose" mindset. People begin to think up creative alternatives and "win-win" outcomes that benefit everyone.
Occasionally, the person is not particularly reasonable, rational, or decent by nature, but when treated with such consistent, tireless, patient generosity and kindness (by you), they are shamed into retreating from the conversation. This sounds like, "Well, I think I've said all I have to say. Thanks for hearing me out." Or, for less enlightened types, "Well, I'm tired of this conversation. Let's drop it." (Yes, please. Thank you.)
Less often, the person is what's known as a *bad actor*, or in community management circles, a pot-stirrer. These folks do exist, and they thrive on drama. Guess what? By consistently engaging in a kind, generous, community-calming way, and entirely ignoring all attempts to escalate the situation, you effectively shift the conversation into an area that holds little interest for them. They have no choice but to abandon it. Winners all around.
That's the power of assuming positive intent. By responding to angry and hostile words with grace and dignity, you can diffuse a flamewar, untangle and solve tricky problems, and quite possibly make a new friend or two in the process.
Am I successful every time I apply this principle? Heck, no. But I never regret the choice to assume positive intent. And I can vividly recall a few unfortunate occasions when I assumed negative intent and responded in a way that further contributed to the problem.
Now it's your turn. I'd love to hear about some strategies and principles you apply, to be a force for good when conversations get heated in your community. Share your thoughts in the comments below.
Next time, we'll explore more ways to be a force for good in your community, and I'll share some tips for handling "Mr. Grumpy."
## 3 Comments |
9,654 | 使用树莓派和 projectx/os 托管你自己的电子邮件 | https://opensource.com/article/18/3/host-your-own-email | 2018-05-18T12:06:25 | [
"邮件",
"树莓派"
] | https://linux.cn/article-9654-1.html |
>
> 这个开源项目可以通过低成本的服务器设施帮助你保护你的数据隐私和所有权。
>
>
>

现在有大量的理由,不能再将存储你的数据的任务委以他人之手,也不能在第三方公司运行你的服务;隐私、所有权,以及防范任何人拿你的数据去“赚钱”。但是对于大多数人来说,自己去运行一个服务器,是件即费时间又需要太多的专业知识的事情。不得已,我们只能妥协。抛开这些顾虑,使用某些公司的云服务,随之而来的就是广告、数据挖掘和售卖、以及其它可能的任何东西。
[projectx/os](https://git.sigbus.net/projectx/os) 项目就是要去除这种顾虑,它可以在家里毫不费力地做服务托管,并且可以很容易地创建一个类似于 Gmail 的帐户。实现上述目标,你只需一个 $35 的树莓派 3 和一个基于 Debian 的操作系统镜像 —— 并且不需要很多的专业知识。仅需要四步就可以实现:
1. 解压缩一个 ZIP 文件到 SD 存储卡中。
2. 编辑 SD 卡上的一个文本文件以便于它连接你的 WiFi(如果你不使用有线网络的话)。
3. 将这个 SD 卡插到树莓派 3 中。
4. 使用你的智能手机在树莓派 3 上安装 “email 服务器” 应用并选择一个二级域。
服务器应用程序(比如电子邮件服务器)被分解到多个容器中,它们中的每个都只能够使用指定的方式与外界通讯,它们使用了管理粒度非常细的隔离措施以提高安全性。例如,入站 SMTP、[SpamAssassin](http://spamassassin.apache.org/)(反垃圾邮件平台)、[Dovecot](https://www.dovecot.org/) (安全的 IMAP 服务器),以及 webmail 都使用了独立的容器,它们之间相互不能看到对方的数据,因此,单个守护进程出现问题不会波及其它的进程。
另外,它们都是无状态容器,比如 SpamAssassin 和入站 SMTP,每次收到电子邮件之后,它们的容器都会被销毁并重建,因此,即便是有人找到了 bug 并利用了它,他们也不能访问以前的电子邮件或者接下来的电子邮件;他们只能访问他们自己挖掘出漏洞的那封电子邮件。幸运的是,大多数对外发布的、最容易受到攻击的服务都是隔离的和无状态的。
所有存储的数据都使用 [dm-crypt](https://gitlab.com/cryptsetup/cryptsetup/wikis/DMCrypt) 进行加密。非公开的服务,比如 Dovecot(IMAP)或者 webmail,都是在内部监听,并使用 [ZeroTier One](https://www.zerotier.com/download.shtml) 所提供的私有的加密层叠网络,因此只有你的设备(智能手机、笔记本电脑、平板等等)才能访问它们。
虽然电子邮件并不是端到端加密的(除非你使用了 [PGP](https://en.wikipedia.org/wiki/Pretty_Good_Privacy)),但是非加密的电子邮件绝不会跨越网络,并且也不会存储在磁盘上。现在明文的电子邮件只存在于双方的私有邮件服务器上,它们都在他们的家中受到很好的安全保护并且只能通过他们的客户端访问(智能手机、笔记本电脑、平板等等)。
另一个好处就是,个人设备都使用一个密码保护(不是指纹或者其它生物识别技术),而且在你家中的设备都受到美国的 [第四宪法修正案](https://simple.wikipedia.org/wiki/Fourth_Amendment_to_the_United_States_Constitution) 的保护,比起由公司所有的第三方数据中心,它们受到更强的法律保护。当然,如果你的电子邮件使用的是 Gmail,Google 还保存着你的电子邮件的拷贝。
### 展望
电子邮件是我使用 project/os 项目打包的第一个应用程序。想像一下,一个应用程序商店有全部的服务器软件,打包起来易于安装和使用。想要一个博客?添加一个 WordPress 应用程序!想替换安全的 Dropbox ?添加一个 [Seafile](https://www.seafile.com/en/home/) 应用程序或者一个 [Syncthing](https://syncthing.net/) 后端应用程序。 [IPFS](https://ipfs.io/) 节点? [Mastodon](https://github.com/tootsuite/mastodon) 实例?GitLab 服务器?各种家庭自动化/物联网后端服务?这里有大量的非常好的开源服务器软件 ,它们都非常易于安装,并且可以使用它们来替换那些有专利的云服务。
---
via: <https://opensource.com/article/18/3/host-your-own-email>
作者:[Nolan Leake](https://opensource.com/users/nolan) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are plenty of reasons not to want to hand off the tasks of storing your data and running your services to third-party companies; privacy, ownership, and avoiding abusive "monetization" are some of the top ones. But for most people, the task of running a server is just too time-consuming and requires too much-specialized knowledge. Instead, we compromise. We put aside our worries and just use cloud-hosted corporate services, with all the advertising, data mining and selling, and everything else that comes with them.
This project aims to eliminate that compromise: [projectx/os](https://git.sigbus.net/projectx/os) makes hosting services at home cheap and nearly as easy as creating a Gmail account. All you need is a $35 Raspberry Pi 3 and a Debian-derived OS image—and very little technical knowledge. There are only four steps:
- Unzip a ZIP file onto a Secure Digital memory card.
- Edit a text file on the SD card with your WiFi password (if you're not using wired Ethernet).
- Place the SD card into the slot on the Raspberry Pi 3.
- Use your smartphone to choose a subdomain and install the "email server" app on the Raspberry Pi 3.
Server applications (such as email servers) are broken into multiple containers, which can only communicate with the outside world and each other in declaratively specified ways, using fine-grained isolation to improve security. For example, incoming SMTP, [SpamAssassin](http://spamassassin.apache.org/) (anti-spam platform), [Dovecot](https://www.dovecot.org/) (secure IMAP server), and webmail are all separate containers that can't see each other's data, so compromising an individual daemon does not compromise the others.
In addition, stateless containers, such as SpamAssassin and incoming SMTP, can be torn down and recreated after each incoming email, so even if someone finds a bug and exploits it, they can't access previous emails or subsequent emails; they can only access their own exploit email. Fortunately, the services that are most exposed to attack are the easiest to run isolated and stateless.
All storage is encrypted using [dm-crypt](https://gitlab.com/cryptsetup/cryptsetup/wikis/DMCrypt). Non-public services, such as Dovecot (IMAP) or webmail, listen on a private, encrypted overlay network provided by [ZeroTier One](https://www.zerotier.com/download.shtml), so only your devices (phones, laptops, tablets, etc.) can access them.
While emails aren't encrypted end-to-end (unless you use [PGP](https://en.wikipedia.org/wiki/Pretty_Good_Privacy)), the unencrypted email never crosses a network and is never stored on disk. It is present in plaintext only on the two parties' private mail servers, which are secured in their homes and on their clients (phones, laptops, etc.).
One other advantage is that personal devices secured with a passcode (not a fingerprint or other biometrics) and devices in your home receive far stronger [Fourth Amendment](https://simple.wikipedia.org/wiki/Fourth_Amendment_to_the_United_States_Constitution) legal protections in the United States than data on a server in a third-party data center owned by a company that wants to avoid downtime or be seen as uncooperative. Of course, if you email with a Gmail user, for example, Google still gets a copy.
## Going forward
Email is the first application I've packaged with projectx/os. Imagine an app store full of server software, packaged up for ease of installation and use. Want a blog? Add a WordPress app! Secure Dropbox replacement? Add a [Seafile](https://www.seafile.com/en/home/) app or a [Syncthing](https://syncthing.net/) backend app. [IPFS](https://ipfs.io/) node? [Mastodon](https://github.com/tootsuite/mastodon) instance? GitLab server? Various home automation/IoT backend services? There are tons of great open source server software that is as easy to install and use as the proprietary cloud services they replace.
*Nolan Leake will be presenting A cloud in every home: Host servers at home with 0 sysadmin skills at the Southern California Linux Expo in Pasadena, March 8-11. To attend and get 50% of your ticket, register using promo code *
**OSDC**.
## 8 Comments |
9,655 | 使用 AppImageLauncher 轻松运行和集成 AppImage 文件 | https://www.linuxuprising.com/2018/04/easily-run-and-integrate-appimage-files.html | 2018-05-18T12:28:00 | [
"AppImage"
] | https://linux.cn/article-9655-1.html | 你有没有下载过 AppImage 文件,而你不知道如何使用它?或许你可能知道如何使用它,但是你每次要运行它时必须要进入到下载了该 .AppImage 的文件夹中来运行它,或者手动为其创建启动程序。
使用 AppImageLauncher,这些就都是过去的问题。该程序可让你轻松运行 AppImage 文件,而无需使其可执行。但它最有趣的特点是可以轻松地将 AppImage 与你的系统进行整合:AppImageLauncher 可以自动将 AppImage 程序快捷方式添加到桌面环境的程序启动器/菜单(包括程序图标和合适的说明)中。
这 里有个例子,我想在 Ubuntu 上使用 [Kdenlive](https://kdenlive.org/download/),但我不想从仓库中安装它,因为它有大量的 KDE 依赖,我不想把它们弄到我的 Gnome 系统中。因为没有它的 Flatpak 或 Snap 镜像,我只能去下载了 Kdenlive 的 AppImage。
在没有把下载的 [Kdenline](https://kdenlive.org/download/) AppImage 变成可执行的情况下,我第一次双击它时(安装好了 AppImageLauncher),AppImageLauncher 提供了两个选项:
“Run once”或者“Integrate and run”。

点击 “Integrate and run”,这个 AppImage 就被复制到 `~/.bin/` (家目录中的隐藏文件夹)并添加到菜单中,然后启动该程序。
要删除它也很简单,只要您使用的桌面环境支持桌面动作就行。例如,在 Gnome Shell 中,只需右键单击“活动概览”中的应用程序图标,然后选择“Remove from system”:

更新:该应用只初步为 Ubuntu 和 Mint 做了开发,但它最近会提供 Debian、 Netrunner 和 openSUSE 支持。本文首次发布后添加的另一个功能是支持 AppImage 的更新;你在启动器中可以找到 “Update AppImage”。
### 下载 AppImageLauncher
AppImageLauncher 支持 Ubuntu、 Debian、Netrunner 和 openSUSE。如果你使用 Ubuntu 18.04,请确保你下载的 deb 包的名字中有“bionic”,而其它的 deb 是用于旧一些的 Ubuntu 版本的。
* [下载 AppImageLauncher](https://github.com/TheAssassin/AppImageLauncher/releases)
---
via: <https://www.linuxuprising.com/2018/04/easily-run-and-integrate-appimage-files.html>
作者:[Logix](https://plus.google.com/118280394805678839070) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy) 选题:[lujun9972](https://github.com/lujun9972)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Easily Run And Integrate AppImage Files With AppImageLauncher
Did you ever download an AppImage file and you didn't know how to use it? Or maybe you know how to use it but you have to navigate to the folder where you downloaded the .AppImage file every time you want to run it, or manually create a launcher for it.
With
Here's an example. I want to use
Without making the downloaded Kdenline AppImage executable manually, the first time I double click it (having AppImageLauncher installed), AppImageLauncher presents two options: Run once or Integrate and run.
Clicking on Integrate and run, the AppImage is copied to the ~/Applications folder (in your home directory) and is added to the menu, then the app is launched.
AppImageLauncher supports Ubuntu, Debian, Netrunner and openSUSE. If you use Ubuntu 18.04, make sure to download the deb that includes "bionic" in its name, as the other deb is for older Ubuntu versions.
With
[AppImageLauncher](https://github.com/TheAssassin/AppImageLauncher), these are problems of the past. The application lets you**easily run AppImage files, without having to make them executable**. But its most interesting feature is easily integrating AppImages with your system:**AppImageLauncher can automatically add an AppImage application shortcut to your desktop environment's application launcher / menu (including the app icon and proper description).**Here's an example. I want to use
[Kdenlive](https://kdenlive.org/download/)in Ubuntu but I don't want to install it from the repositories, because it has a large number of KDE dependencies, and I don't want them on my Gnome system. Since there are no Flatpak or Snap images for it, I'll go ahead and download the Kdenlive AppImage.Without making the downloaded Kdenline AppImage executable manually, the first time I double click it (having AppImageLauncher installed), AppImageLauncher presents two options: Run once or Integrate and run.
Clicking on Integrate and run, the AppImage is copied to the ~/Applications folder (in your home directory) and is added to the menu, then the app is launched.
**Updating or removing AppImage files is just as simple**, as long as the desktop environment you're using has support for desktop actions. For example, in Gnome Shell, simply**right click the application icon in the Activities Overview and select "Update AppImage" or "Remove from system**:"**Update:**The application was initially developed for Ubuntu and Linux Mint only, but it was recently updated with Debian, Netrunner and openSUSE support. Another feature added since this article was initially published is support for updating the AppImages; you should find an Update AppImage entry in the launcher now.## Download AppImageLauncher
AppImageLauncher supports Ubuntu, Debian, Netrunner and openSUSE. If you use Ubuntu 18.04, make sure to download the deb that includes "bionic" in its name, as the other deb is for older Ubuntu versions. |
9,656 | 如何创建适合移动设备的文档 | https://opensource.com/article/17/12/think-mobile | 2018-05-18T17:06:00 | [
"移动",
"文档"
] | https://linux.cn/article-9656-1.html |
>
> 帮助用户在智能手机或平板上快速轻松地找到他们所需的信息。
>
>
>

我并不是完全相信[移动为先](https://www.uxmatters.com/mt/archives/2012/03/mobile-first-what-does-it-mean.php)的理念,但是我确实发现更多的人使用智能手机和平板电脑等移动设备来获取信息。这包括在线的软件和硬件文档,但它们大部分都是冗长的,不适合小屏幕。通常情况下,它的伸缩性不太好,而且很难导航。
当用户使用移动设备访问文档时,他们通常需要迅速获取信息以了解如何执行任务或解决问题,他们不想通过看似无尽的页面来寻找他们需要的特定信息。幸运的是,解决这个问题并不难。以下是一些技巧,可以帮助你构建文档以满足移动阅读器的需求。
### 简短一点
这意味着简短的句子,简短的段落和简短的流程。你不是在写一部长篇小说或一段长新闻。使你的文档简洁。尽可能使用少量的语言来获得想法和信息。
以广播新闻报道为示范:关注关键要素,用简单直接的语言对其进行解释。不要让你的读者在屏幕上看到冗长的文字。
另外,直接切入重点。关注读者需要的信息。在线发布的文档不应该像以前厚厚的手册一样。不要把所有东西都放在一个页面上,把你的信息分成更小的块。接下来是怎样做到这一点:
### 主题
在技术写作的世界里,主题是独立的,独立的信息块。每个主题都由你网站上的单个页面组成。读者应该能从特定的主题中获取他们需要的信息 -- 并且只是那些信息。要做到这一点,选择哪些主题要包含在文档中并决定如何组织它们:
### DITA
<ruby> <a href="https://en.wikipedia.org/wiki/Darwin_Information_Typing_Architecture"> 达尔文信息类型化体系结构 </a> <rt> Darwin Information Typing Architecture </rt></ruby> (DITA) 是用于编写和发布的一个 XML 模型。它[广泛采用](http://dita.xml.org/book/list-of-organizations-using-dita)在技术写作中,特别是作为较长的文档集中。
我并不是建议你将文档转换为 XML(除非你真的想)。相反,考虑将 DITA 的不同类型主题的概念应用到你的文档中:
* 一般:概述信息
* 任务:分步骤的流程
* 概念:背景或概念信息
* 参考:API 参考或数据字典等专用信息
* 术语表:定义术语
* 故障排除:有关用户可能遇到的问题以及如何解决问题的信息
你会得到很多单独的页面。要连接这些页面:
### 链接
许多内容管理系统、维基和发布框架都包含某种形式的导航 —— 通常是目录或[面包屑导航](https://en.wikipedia.org/wiki/Breadcrumb_(navigation)),这是一种在移动设备上逐渐消失的导航。
为了加强导航,在主题之间添加明确的链接。将这些链接放在每个主题末尾的“另请参阅”或“相关主题”的标题处。每个部分应包含两到五个链接,指向与当前主题相关的概述、概念和参考主题。
如果你需要指向文档集之外的信息,请确保链接在浏览器新的选项卡中打开。这将把读者送到另一个网站,同时也将读者继续留你的网站上。
这解决了文本问题,那么图片呢?
### 不使用图片
除少数情况之外,不应该加太多图片到文档中。仔细查看文档中的每个图片,然后问自己:
* 它有用吗?
* 它是否增强了文档?
* 如果删除它,读者会错过这张图片吗?
如果回答否,那么移除图片。
另一方面,如果你绝对不能没有图片,就让它变成[响应式的](https://en.wikipedia.org/wiki/Responsive_web_design)。这样,图片就会自动调整以适应更小的屏幕。
如果你仍然不确定图片是否应该出现,Opensource.com 社区版主 Ben Cotton 提供了一个关于在文档中使用屏幕截图的[极好的解释](https://opensource.com/business/15/9/when-does-your-documentation-need-screenshots)。
### 最后的想法
通过少量努力,你就可以构建适合移动设备用户的文档。此外,这些更改也改进了桌面计算机和笔记本电脑用户的文档体验。
---
via: <https://opensource.com/article/17/12/think-mobile>
作者:[Scott Nesbitt](https://opensource.com/users/chrisshort) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I'm not sold on the whole idea of * mobile first*, but I do know that more people than ever are using mobile devices like smartphones and tablets to get information on the go. That includes online software and hardware documentation, much of which is lengthy and poorly suited for small screens. Often, it doesn't scale properly, and it can be difficult to navigate.
When people access documentation using a mobile device, they usually want a quick hit of information to learn how to perform a task or solve a problem. They don't want to wade through seemingly endless pages to find the specific piece of information they need. Fortunately, it's not hard to address this problem. Here are a few tips to help you structure your documentation to meet the needs of mobile readers.
## Think short
That means short sentences, short paragraphs, and short procedures. You're not writing a novel or a piece of long-form journalism. Make your documentation concise. Use as few words as possible to get ideas and information across.
Use a radio news report as a guide: Focus on the key elements and explain them in simple, direct language. Don't make your reader wade through screen after screen of turgid text.
Also, get straight to the point. Focus on the information readers need when they need it. Documentation published online shouldn't resemble the thick manuals of yore. Don't lump everything together on a single page. Break your information into smaller chunks. Here's how to do that:## Think topics
In the technical writing world, topics are individual, stand-alone chunks of information. Each topic comprises a single page on your site. Readers should be able to get the information they need—and only that information—from a specific topic. To make that happen, choose which topics to include in your documentation and decide how to organize them:
## Think DITA
[Darwin Information Typing Architecture](https://en.wikipedia.org/wiki/Darwin_Information_Typing_Architecture), or DITA, is an XML model for writing and publishing. It's been [widely adopted](http://dita.xml.org/book/list-of-organizations-using-dita) in the technical writing world, especially for longer documentation sets.
I'm not suggesting that you convert your documentation to XML (unless you really want to). Instead, consider applying DITA's concept of separate types of topics to your documentation:
- General: overview information
- Task: step-by-step procedures
- Concept: background or conceptual information
- Reference: specialized information like API references or data dictionaries
- Glossary: to define terms
- Troubleshooting: information on problems users may encounter and how to fix them
You'll wind up with a lot of individual pages. To connect those pages:
## Think linking
Many content management systems, wikis, and publishing frameworks include some form of navigation—usually a table of contents or [breadcrumbs](https://en.wikipedia.org/wiki/Breadcrumb_(navigation)). It's the kind of navigation that fades into the background on a mobile device.
For stronger navigation, add explicit links between topics. Place those links at the end of each topic with the heading **See Also** or **Related Topics**. Each section should contain two to five links that point to overview, concept, and reference topics related to the current topic.
If you need to point to information outside of your documentation set, make sure the link opens in a new browser tab. That sends the reader to another site while also keeping them on your site.
That takes care of the text. What about graphics?## Think unadorned
With a few exceptions, images don't add much to documentation. Take a critical look at each image in your documentation. Then ask:
- Does it serve a purpose?
- Does it enhance the documentation?
- Will readers miss this image if I remove it?
*no*, remove the image.
On the other hand, if you absolutely can't do without an image, make it [responsive](https://en.wikipedia.org/wiki/Responsive_web_design). That way, the image will automatically resize to fit in a smaller screen.
If you're still not sure about an image, Opensource.com community moderator Ben Cotton offers an [excellent explanation](https://opensource.com/business/15/9/when-does-your-documentation-need-screenshots) of when to use screen captures in documentation.
## A final thought
With a little effort, you can structure your documentation to work well for mobile device users. Another plus: These changes improve documentation for desktop computer and laptop users, too.
## 2 Comments |
9,657 | Linux 局域网路由新手指南:第 1 部分 | https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginners-part-1 | 2018-05-19T10:44:37 | [
"路由",
"IPv4",
"ipcalc"
] | https://linux.cn/article-9657-1.html | 
前面我们学习了 [IPv6 路由](https://www.linux.com/learn/intro-to-linux/2017/7/practical-networking-linux-admins-ipv6-routing)。现在我们继续深入学习 Linux 中的 IPv4 路由的基础知识。我们从硬件概述、操作系统和 IPv4 地址的基础知识开始,下周我们将继续学习它们如何配置,以及测试路由。
### 局域网路由器硬件
Linux 实际上是一个网络操作系统,一直都是,从一开始它就有内置的网络功能。要将你的局域网连入因特网,构建一个局域网路由器比起构建网关路由器要简单的多。你不要太过于执念安全或者防火墙规则,对于处理网络地址转换(NAT)它还是比较复杂的,NAT是 IPv4 的一个痛点。我们为什么不放弃 IPv4 去转到 IPv6 呢?这样将使网络管理员的工作更加简单。
有点跑题了。从理论上讲,你的 Linux 路由器是一个至少有两个网络接口的小型机器。Linux Gizmos 有一个很大的单板机名单:[98 个开放规格、适于黑客的 SBC 的目录](http://linuxgizmos.com/catalog-of-98-open-spec-hacker-friendly-sbcs/#catalog)。你能够使用一个很老的笔记本电脑或者台式计算机。你也可以使用一个紧凑型计算机,像 ZaReason Zini 或者 System76 Meerkat 一样,虽然这些有点贵,差不多要 $600。但是它们又结实又可靠,并且你不用在 Windows 许可证上浪费钱。
如果对路由器的要求不高,使用树莓派 3 Model B 作为路由器是一个非常好的选择。它有一个 10/100 以太网端口,板载 2.4GHz 的 802.11n 无线网卡,并且它还有四个 USB 端口,因此你可以插入多个 USB 网卡。USB 2.0 和低速板载网卡可能会让树莓派变成你的网络上的瓶颈,但是,你不能对它期望太高(毕竟它只有 $35,既没有存储也没有电源)。它支持很多种风格的 Linux,因此你可以选择使用你喜欢的版本。基于 Debian 的树莓派是我的最爱。
### 操作系统
你可以在你选择的硬件上安装将你喜欢的 Linux 的简化版,因为定制的路由器操作系统,比如 OpenWRT、 Tomato、DD-WRT、Smoothwall、Pfsense 等等,都有它们自己的非标准界面。我的观点是,没有必要这么麻烦,它们对你并没有什么帮助。尽量使用标准的 Linux 工具,因为你只需要学习它们一次就够了。
Debian 的网络安装镜像大约有 300MB 大小,并且支持多种架构,包括 ARM、i386、amd64 和 armhf。Ubuntu 的服务器网络安装镜像也小于 50MB,这样你就可以控制你要安装哪些包。Fedora、Mageia、和 openSUSE 都提供精简的网络安装镜像。如果你需要创意,你可以浏览 [Distrowatch](http://distrowatch.org/)。
### 路由器能做什么
我们需要网络路由器做什么?一个路由器连接不同的网络。如果没有路由,那么每个网络都是相互隔离的,所有的悲伤和孤独都没有人与你分享,所有节点只能孤独终老。假设你有一个 192.168.1.0/24 和一个 192.168.2.0/24 网络。如果没有路由器,你的两个网络之间不能相互沟通。这些都是 C 类的私有地址,它们每个都有 254 个可用网络地址。使用 `ipcalc` 可以非常容易地得到它们的这些信息:
```
$ ipcalc 192.168.1.0/24
Address: 192.168.1.0 11000000.10101000.00000001. 00000000
Netmask: 255.255.255.0 = 24 11111111.11111111.11111111. 00000000
Wildcard: 0.0.0.255 00000000.00000000.00000000. 11111111
=>
Network: 192.168.1.0/24 11000000.10101000.00000001. 00000000
HostMin: 192.168.1.1 11000000.10101000.00000001. 00000001
HostMax: 192.168.1.254 11000000.10101000.00000001. 11111110
Broadcast: 192.168.1.255 11000000.10101000.00000001. 11111111
Hosts/Net: 254 Class C, Private Internet
```
我喜欢 `ipcalc` 的二进制输出信息,它更加可视地表示了掩码是如何工作的。前三个八位组表示了网络地址,第四个八位组是主机地址,因此,当你分配主机地址时,你将 “掩盖” 掉网络地址部分,只使用剩余的主机部分。你的两个网络有不同的网络地址,而这就是如果两个网络之间没有路由器它们就不能互相通讯的原因。
每个八位组一共有 256 字节,但是它们并不能提供 256 个主机地址,因为第一个和最后一个值 ,也就是 0 和 255,是被保留的。0 是网络标识,而 255 是广播地址,因此,只有 254 个主机地址。`ipcalc` 可以帮助你很容易地计算出这些。
当然,这并不意味着你不能有一个结尾是 0 或者 255 的主机地址。假设你有一个 16 位的前缀:
```
$ ipcalc 192.168.0.0/16
Address: 192.168.0.0 11000000.10101000. 00000000.00000000
Netmask: 255.255.0.0 = 16 11111111.11111111. 00000000.00000000
Wildcard: 0.0.255.255 00000000.00000000. 11111111.11111111
=>
Network: 192.168.0.0/16 11000000.10101000. 00000000.00000000
HostMin: 192.168.0.1 11000000.10101000. 00000000.00000001
HostMax: 192.168.255.254 11000000.10101000. 11111111.11111110
Broadcast: 192.168.255.255 11000000.10101000. 11111111.11111111
Hosts/Net: 65534 Class C, Private Internet
```
`ipcalc` 列出了你的第一个和最后一个主机地址,它们是 192.168.0.1 和 192.168.255.254。你是可以有以 0 或者 255 结尾的主机地址的,例如,192.168.1.0 和 192.168.0.255,因为它们都在最小主机地址和最大主机地址之间。
不论你的地址块是私有的还是公共的,这个原则同样都是适用的。不要羞于使用 `ipcalc` 来帮你计算地址。
### CIDR
CIDR(无类域间路由)就是通过可变长度的子网掩码来扩展 IPv4 的。CIDR 允许对网络空间进行更精细地分割。我们使用 `ipcalc` 来演示一下:
```
$ ipcalc 192.168.1.0/22
Address: 192.168.1.0 11000000.10101000.000000 01.00000000
Netmask: 255.255.252.0 = 22 11111111.11111111.111111 00.00000000
Wildcard: 0.0.3.255 00000000.00000000.000000 11.11111111
=>
Network: 192.168.0.0/22 11000000.10101000.000000 00.00000000
HostMin: 192.168.0.1 11000000.10101000.000000 00.00000001
HostMax: 192.168.3.254 11000000.10101000.000000 11.11111110
Broadcast: 192.168.3.255 11000000.10101000.000000 11.11111111
Hosts/Net: 1022 Class C, Private Internet
```
网络掩码并不局限于整个八位组,它可以跨越第三和第四个八位组,并且子网部分的范围可以是从 0 到 3,而不是非得从 0 到 255。可用主机地址的数量并不一定是 8 的倍数,因为它是由整个八位组定义的。
给你留一个家庭作业,复习 CIDR 和 IPv4 地址空间是如何在公共、私有和保留块之间分配的,这个作业有助你更好地理解路由。一旦你掌握了地址的相关知识,配置路由器将不再是件复杂的事情了。
从 [理解 IP 地址和 CIDR 图表](https://www.ripe.net/about-us/press-centre/understanding-ip-addressing)、[IPv4 私有地址空间和过滤](https://www.arin.net/knowledge/address_filters.html)、以及 [IANA IPv4 地址空间注册](https://www.iana.org/assignments/ipv4-address-space/ipv4-address-space.xhtml) 开始。接下来的我们将学习如何创建和管理路由器。
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)学习更多 Linux 知识。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginners-part-1>
作者:[Carla Schroder](https://www.linux.com/users/cschroder) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,658 | 使用交互式 shell 来增强你的 Python | https://fedoramagazine.org/enhance-python-interactive-shell/ | 2018-05-19T20:52:40 | [
"Python",
"shell"
] | https://linux.cn/article-9658-1.html | 
Python 编程语言已经成为 IT 中使用的最流行的语言之一。成功的一个原因是它可以用来解决各种问题。从网站开发到数据科学、机器学习到任务自动化,Python 生态系统有丰富的框架和库。本文将介绍 Fedora 软件包集合中提供的一些有用的 Python shell 来简化开发。
### Python Shell
Python Shell 让你以交互模式使用解释器。这在测试代码或尝试新库时非常有用。在 Fedora 中,你可以通过在终端会话中输入 `python3` 来调用默认的 shell。虽然 Fedora 提供了一些更高级和增强的 shell。
### IPython
IPython 为 Python shell 提供了许多有用的增强功能。例如包括 tab 补全,对象内省,系统 shell 访问和命令历史检索。许多功能也被 [Jupyter Notebook](https://ipython.org/notebook.html) 使用,因为它底层使用 IPython。
#### 安装和运行 IPython
```
dnf install ipython3
ipython3
```
使用 tab 补全会提示你可能的选择。当你使用不熟悉的库时,此功能会派上用场。

如果你需要更多信息,输入 `?` 命令来查看文档。对此的更多详细信息,你可以使用 `??` 命令。

另一个很酷的功能是使用 `!` 字符执行系统 shell 命令的能力。然后可以在 IPython shell 中引用该命令的结果。

IPython 完整的功能列表可在[官方文档](https://ipython.readthedocs.io/en/stable/overview.html#main-features-of-the-interactive-shell)中找到。
### bpython
bpython 并不能像 IPython 做那么多,但它却在一个简单的轻量级包中提供了一系列有用功能。除其他功能之外,bpython 提供:
* 内嵌语法高亮显示
* 在你输入时提供自动补全建议
* 可预期的参数列表
* 能够将代码发送或保存到 pastebin 服务或文件中
#### 安装和运行 bpython
```
dnf install bpython3
bpython3
```
在你输入的时候,`bpython` 为你提供了选择来自动补全你的代码。

当你调用函数或方法时,会自动显示需要的参数和文档字符串。

另一个很好的功能是可以使用功能键 `F7` 在外部编辑器(默认为 Vim)中打开当前的 `bpython` 会话。这在测试更复杂的程序时非常有用。
有关配置和功能的更多细节,请参考 bpython [文档](https://docs.bpython-interpreter.org/)。
### 总结
使用增强的 Python shell 是提高生产力的好方法。它为你提供增强的功能来编写快速原型或尝试新库。你在使用增强的 Python shell 吗?请随意在评论区留言。
图片由 [David Clode](https://unsplash.com/photos/d0CasEMHDQs?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 在 [Unsplash](https://unsplash.com/search/photos/python?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 上发布
---
via: <https://fedoramagazine.org/enhance-python-interactive-shell/>
作者:[Clément Verna](https://fedoramagazine.org/author/cverna/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Python programming language has become one of the most popular languages used in IT. One reason for this success is it can be used to solve a variety of problems. From web development to data science, machine learning to task automation, the Python ecosystem is rich in popular frameworks and libraries. This article presents some useful Python shells available in the Fedora packages collection to make development easier.
## Python Shell
The Python Shell lets you use the interpreter in an interactive mode. It’s very useful to test code or try a new library. In Fedora you can invoke the default shell by typing *python3* in a terminal session. Some more advanced and enhanced shells are available to Fedora, though.
## IPython
IPython provides many useful enhancements to the Python shell. Examples include tab completion, object introspection, system shell access and command history retrieval. Many of these features are also used by the [Jupyter Notebook](https://ipython.org/notebook.html) , since it uses IPython underneath.
### Install and run IPython
dnf install ipython3 ipython3
Using tab completion prompts you with possible choices. This features comes in handy when you use an unfamiliar library.
If you need more information, use the documentation by typing the *?* command. For more details, you can use the *??* command.
Another cool feature is the ability to execute a system shell command using the *!* character. The result of the command can then be referenced in the IPython shell.
A comprehensive list of IPython features is available in the [official documentation](https://ipython.readthedocs.io/en/stable/overview.html#main-features-of-the-interactive-shell).
## bpython
bpython doesn’t do as much as IPython, but nonetheless it provides a useful set of features in a simple and lightweight package. Among other features, bpython provides:
- In-line syntax highlighting
- Autocomplete with suggestions as you type
- Expected parameter list
- Ability to send or save code to a pastebin service or file
### Install and run bpython
dnf install bpython3 bpython3
As you type, bpython offers you choices to autocomplete your code.
When you call a function or method, the expected parameters and the docstring are automatically displayed.
Another neat feature is the ability to open the current bpython session in an external editor (*Vim* by default) using the function key *F7*. This is very useful when testing more complex programs.
For more details about configuration and features, consult the bpython [documentation](https://docs.bpython-interpreter.org/).
## Conclusion
Using an enhanced Python shell is a good way to increase productivity. It gives you enhanced features to write a quick prototype or try out a new library. Are you using an enhanced Python shell? Feel free to mention it in the comment section below.
*Photo by David Clode on Unsplash*
## sabino
great suggestions !!!
I learned something new.
Thank you
## Dan
Have you seen xonsh (http://xonsh.org/) ? It’s a shell with the power of Python, very cool.
(I’m trying to use it as default shell, but I’m stuck when using it in x2go).
## Clément Verna
I did, I try it a while ago and thought it was still a little bit too fresh. Maybe I should give a go again 🙂
## Apostolos
ptipython (uses ipython) also offers handy features.
## Jon Hannah
Another great Python 3+ light weight IPython-style REPL is hiss. See https://github.com/sixninetynine/hiss but in pip too!
## Cyril
Just…the image is that of an arboreal pit viper (Tropidolaemus Waglerii?), not a python 😉
## crossingtheair.wordpress.com
Yes, you’re right, that’s not a python. |
9,659 | 如何使用 Ansible 打补丁以及安装应用 | https://opensource.com/article/18/3/ansible-patch-systems | 2018-05-20T03:59:00 | [
"Ansible"
] | https://linux.cn/article-9659-1.html |
>
> 使用 Ansible IT 自动化引擎节省更新的时间。
>
>
>

你有没有想过,如何打补丁、重启系统,然后继续工作?
如果你的回答是肯定的,那就需要了解一下 [Ansible](https://www.ansible.com/overview/how-ansible-works) 了。它是一个配置管理工具,对于一些复杂的有时候需要几个小时才能完成的系统管理任务,又或者对安全性有比较高要求的时候,使用 Ansible 能够大大简化工作流程。
以我作为系统管理员的经验,打补丁是一项最有难度的工作。每次遇到<ruby> 公共漏洞批露 <rt> Common Vulnearbilities and Exposure </rt></ruby>(CVE)通知或者<ruby> 信息保障漏洞预警 <rt> Information Assurance Vulnerability Alert </rt></ruby>(IAVA)时都必须要高度关注安全漏洞,否则安全部门将会严肃追究自己的责任。
使用 Ansible 可以通过运行[封装模块](https://docs.ansible.com/ansible/latest/list_of_packaging_modules.html)以缩短打补丁的时间,下面以 [yum 模块](https://docs.ansible.com/ansible/latest/yum_module.html)更新系统为例,使用 Ansible 可以执行安装、更新、删除、从其它地方安装(例如持续集成/持续开发中的 `rpmbuild`)。以下是系统更新的任务:
```
- name: update the system
yum:
name: "*"
state: latest
```
在第一行,我们给这个任务命名,这样可以清楚 Ansible 的工作内容。第二行表示使用 `yum` 模块在CentOS虚拟机中执行更新操作。第三行 `name: "*"` 表示更新所有程序。最后一行 `state: latest` 表示更新到最新的 RPM。
系统更新结束之后,需要重新启动并重新连接:
```
- name: restart system to reboot to newest kernel
shell: "sleep 5 && reboot"
async: 1
poll: 0
- name: wait for 10 seconds
pause:
seconds: 10
- name: wait for the system to reboot
wait_for_connection:
connect_timeout: 20
sleep: 5
delay: 5
timeout: 60
- name: install epel-release
yum:
name: epel-release
state: latest
```
`shell` 模块中的命令让系统在 5 秒休眠之后重新启动,我们使用 `sleep` 来保持连接不断开,使用 `async` 设定最大等待时长以避免发生超时,`poll` 设置为 0 表示直接执行不需要等待执行结果。暂停 10 秒钟以等待虚拟机恢复,使用 `wait_for_connection` 在虚拟机恢复连接后尽快连接。随后由 `install epel-release` 任务检查 RPM 的安装情况。你可以对这个剧本执行多次来验证它的幂等性,唯一会显示造成影响的是重启操作,因为我们使用了 `shell` 模块。如果不想造成实际的影响,可以在使用 `shell` 模块的时候 `changed_when: False`。
现在我们已经知道如何对系统进行更新、重启虚拟机、重新连接、安装 RPM 包。下面我们通过 [Ansible Lightbulb](https://github.com/ansible/lightbulb/tree/master/examples/nginx-role) 来安装 NGINX:
```
- name: Ensure nginx packages are present
yum:
name: nginx, python-pip, python-devel, devel
state: present
notify: restart-nginx-service
- name: Ensure uwsgi package is present
pip:
name: uwsgi
state: present
notify: restart-nginx-service
- name: Ensure latest default.conf is present
template:
src: templates/nginx.conf.j2
dest: /etc/nginx/nginx.conf
backup: yes
notify: restart-nginx-service
- name: Ensure latest index.html is present
template:
src: templates/index.html.j2
dest: /usr/share/nginx/html/index.html
- name: Ensure nginx service is started and enabled
service:
name: nginx
state: started
enabled: yes
- name: Ensure proper response from localhost can be received
uri:
url: "http://localhost:80/"
return_content: yes
register: response
until: 'nginx_test_message in response.content'
retries: 10
delay: 1
```
以及用来重启 nginx 服务的操作文件:
```
# 安装 nginx 的操作文件
- name: restart-nginx-service
service:
name: nginx
state: restarted
```
在这个角色里,我们使用 RPM 安装了 `nginx`、`python-pip`、`python-devel`、`devel`,用 PIP 安装了 `uwsgi`,接下来使用 `template` 模块复制 `nginx.conf` 和 `index.html` 以显示页面,并确保服务在系统启动时启动。然后就可以使用 `uri` 模块检查到页面的连接了。
这个是一个系统更新、系统重启、安装 RPM 包的剧本示例,后续可以继续安装 nginx,当然这里可以替换成任何你想要的角色和应用程序。
```
- hosts: all
roles:
- centos-update
- nginx-simple
```
这只是关于如何更新系统、重启以及后续工作的示例。简单起见,我只添加了不带[变量](https://docs.ansible.com/ansible/latest/playbooks_variables.html)的包,当你在操作大量主机的时候,你就需要修改其中的一些设置了:
* [async & poll](https://docs.ansible.com/ansible/latest/playbooks_async.html)
* [serial](https://docs.ansible.com/ansible/latest/playbooks_delegation.html#rolling-update-batch-size)
* [forks](https://docs.ansible.com/ansible/latest/intro_configuration.html#forks)
这是由于在生产环境中如果你想逐一更新每一台主机的系统,你需要花相当一段时间去等待主机重启才能够继续下去。
---
via: <https://opensource.com/article/18/3/ansible-patch-systems>
作者:[Jonathan Lozada De La Matta](https://opensource.com/users/jlozadad) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Have you ever wondered how to patch your systems, reboot, and continue working?
If so, you'll be interested in [Ansible](https://www.ansible.com/overview/how-ansible-works), a simple configuration management tool that can make some of the hardest work easy. For example, system administration tasks that can be complicated, take hours to complete, or have complex requirements for security.
**[ Advance your automation expertise. Get the Ansible checklist: 5 reasons to migrate to Red Hat Ansible Automation Platform 2 ]**
In my experience, one of the hardest parts of being a sysadmin is patching systems. Every time you get a Common Vulnerabilities and Exposure (CVE) notification or Information Assurance Vulnerability Alert (IAVA) mandated by security, you have to kick into high gear to close the security gaps. (And, believe me, your security officer will hunt you down unless the vulnerabilities are patched.)
Ansible can reduce the time it takes to patch systems by running [packaging modules](https://docs.ansible.com/ansible/latest/list_of_packaging_modules.html). To demonstrate, let's use the [yum module](https://docs.ansible.com/ansible/latest/yum_module.html) to update the system. Ansible can install, update, remove, or install from another location (e.g., `rpmbuild`
from continuous integration/continuous development). Here is the task for updating the system:
```
``````
- name: update the system
yum:
name: "*"
state: latest
```
In the first line, we give the task a meaningful `name`
so we know what Ansible is doing. In the next line, the `yum module`
updates the CentOS virtual machine (VM), then `name: "*"`
tells yum to update everything, and, finally, `state: latest`
updates to the latest RPM.
After updating the system, we need to restart and reconnect:
```
``````
- name: restart system to reboot to newest kernel
shell: "sleep 5 && reboot"
async: 1
poll: 0
- name: wait for 10 seconds
pause:
seconds: 10
- name: wait for the system to reboot
wait_for_connection:
connect_timeout: 20
sleep: 5
delay: 5
timeout: 60
- name: install epel-release
yum:
name: epel-release
state: latest
```
The `shell module`
puts the system to sleep for 5 seconds then reboots. We use `sleep`
to prevent the connection from breaking, `async`
to avoid timeout, and `poll`
to fire & forget. We pause for 10 seconds to wait for the VM to come back and use `wait_for_connection`
to connect back to the VM as soon as it can make a connection. Then we `install epel-release`
to test the RPM installation. You can run this playbook multiple times to show the `idempotent`
, and the only task that will show as changed is the reboot since we are using the `shell`
module. You can use `changed_when: False`
to ignore the change when using the `shell`
module if you expect no actual changes.
So far we've learned how to update a system, restart the VM, reconnect, and install a RPM. Next we will install NGINX using the role in [Ansible Lightbulb](https://github.com/ansible/lightbulb/tree/master/examples/nginx-role).
```
``````
- name: Ensure nginx packages are present
yum:
name: nginx, python-pip, python-devel, devel
state: present
notify: restart-nginx-service
- name: Ensure uwsgi package is present
pip:
name: uwsgi
state: present
notify: restart-nginx-service
- name: Ensure latest default.conf is present
template:
src: templates/nginx.conf.j2
dest: /etc/nginx/nginx.conf
backup: yes
notify: restart-nginx-service
- name: Ensure latest index.html is present
template:
src: templates/index.html.j2
dest: /usr/share/nginx/html/index.html
- name: Ensure nginx service is started and enabled
service:
name: nginx
state: started
enabled: yes
- name: Ensure proper response from localhost can be received
uri:
url: "http://localhost:80/"
return_content: yes
register: response
until: 'nginx_test_message in response.content'
retries: 10
delay: 1
```
And the handler that restarts the nginx service:
```
``````
# handlers file for nginx-example
- name: restart-nginx-service
service:
name: nginx
state: restarted
```
In this role, we install the RPMs `nginx`
, `python-pip`
, `python-devel`
, and `devel`
and install `uwsgi`
with PIP. Next, we use the `template`
module to copy over the `nginx.conf`
and `index.html`
for the page to display. After that, we make sure the service is enabled on boot and started. Then we use the `uri`
module to check the connection to the page.
Here is a playbook showing an example of updating, restarting, and installing an RPM. Then continue installing nginx. This can be done with any other roles/applications you want.
```
``````
- hosts: all
roles:
- centos-update
- nginx-simple
```
Watch this demo video for more insight on the process.
This was just a simple example of how to update, reboot, and continue. For simplicity, I added the packages without [variables](https://docs.ansible.com/ansible/latest/playbooks_variables.html). Once you start working with a large number of hosts, you will need to change a few settings:
This is because on your production environment you might want to update one system at a time (not fire & forget) and actually wait a longer time for your system to reboot and continue.
For more ways to automate your work with this tool, take a look at the other [Ansible articles on Opensource.com](https://opensource.com/tags/ansible).
## 1 Comment |
9,660 | 如何改善应用程序在 Linux 中的启动时间 | https://www.ostechnix.com/how-to-improve-application-startup-time-in-linux/ | 2018-05-20T11:22:19 | [
"Preload"
] | https://linux.cn/article-9660-1.html | 
大多数 Linux 发行版在默认配置下已经足够快了。但是,我们仍然可以借助一些额外的应用程序和方法让它们启动更快一点。其中一个可用的这种应用程序就是 Preload。它监视用户使用频率比较高的应用程序,并将它们添加到内存中,这样就比一般的方式加载更快一点。因为,正如你所知道的,内存的读取速度远远快于硬盘。Preload 以守护进程的方式在后台中运行,并记录用户使用较为频繁的程序的文件使用相关的统计数据。然后,它将这些二进制文件及它们的依赖项加载进内存,以改善应用程序的加载时间。简而言之,一旦安装了 Preload,你使用较为频繁的应用程序将可能加载的更快。
在这篇详细的教程中,我们将去了解如何安装和使用 Preload,以改善应用程序在 Linux 中的启动时间。
### 在 Linux 中使用 Preload 改善应用程序启动时间
Preload 可以在 [AUR](https://aur.archlinux.org/packages/preload/) 上找到。因此,你可以使用 AUR 助理程序在任何基于 Arch 的系统上去安装它,比如,Antergos、Manjaro Linux。
使用 [Pacaur](https://www.ostechnix.com/install-pacaur-arch-linux/):
```
$ pacaur -S preload
```
使用 [Packer](https://www.ostechnix.com/install-packer-arch-linux-2/):
```
$ packer -S preload
```
使用 [Trizen](https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/):
```
$ trizen -S preload
```
使用 [Yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/):
```
$ yay -S preload
```
使用 [Yaourt](https://www.ostechnix.com/install-yaourt-arch-linux/):
```
$ yaourt -S preload
```
在 Debian、Ubuntu、Linux Mint 上,Preload 可以在默认仓库中找到。因此,你可以像下面一样,使用 APT 包管理器去安装它。
```
$ sudo apt-get install preload
```
Preload 安装完成后,重新启动你的系统。从现在开始,Preload 将监视频繁使用的应用程序,并将它们的二进制文件和库添加到内存中,以使它的启动速度更快。比如,如果你经常使用 Firefox、Chrome 以及 LibreOffice,Preload 将添加这些二进制文件和库到内存中,因此,这些应用程序将启动的更快。而且更好的是,它不需要做任何配置。它是开箱即用的。但是,如果你想去对它进行微调,你可以通过编辑缺省的配置文件 `/etc/preload.conf` 来实现。
### Preload 并不一定适合每个人!
以下是 Preload 的一些缺点,它并不是对每个人都有帮助,在这个 [跟贴](https://askubuntu.com/questions/110335/drawbacks-of-using-preload-why-isnt-it-included-by-default) 中有讨论到。
1. 我使用的是一个有 8GB 内存的现代系统。因此,我的系统总体上来说很快。我每天只打开狂吃内存的应用程序(比如,Firefox、Chrome、VirtualBox、Gimp 等等)一到两次,并且它们始终处于打开状态,因此,它们的二进制文件和库被预读到内存中,并始终整天在内存中。我一般很少去关闭和打开这些应用程序,因此,内存使用纯属浪费。
2. 如果你使用的是带有 SSD 的现代系统,Preload 是绝对没用的。因为 SSD 的访问时间比起一般的硬盘来要快的多,因此,使用 Preload 是没有意义的。
3. Preload 显著影响启动时间。因为更多的应用程序要被预读到内存中,这将让你的系统启动运行时间更长。
你只有在每天都在大量的重新加载应用程序时,才能看到真正的差别。因此,Preload 最适合开发人员和测试人员,他们每天都打开和关闭应用程序好多次。
关于 Preload 更多的信息和它是如何工作的,请阅读它的作者写的完整版的 [Preload 论文](https://cs.uwaterloo.ca/%7Ebrecht/courses/702/Possible-Readings/prefetching-to-memory/preload-thesis.pdf)。
教程到此为止,希望能帮到你。后面还有更精彩的内容,请继续关注!
再见!
---
via: <https://www.ostechnix.com/how-to-improve-application-startup-time-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,661 | 如何使用 Buildah 构建容器镜像 | https://fedoramagazine.org/daemon-less-container-management-buildah/ | 2018-05-21T07:19:18 | [
"Buildah",
"容器"
] | https://linux.cn/article-9661-1.html | 
Project Atomic 通过他们在 Open Container Initiative(OCI)上的努力创造了一个名为 [Buildah](https://github.com/projectatomic/buildah) 的伟大工具。Buildah 能帮助创建、构建和更新,它支持 Docker 容器镜像以及 OCI 兼容镜像。
Buildah 处理构建容器镜像时无需安装完整的容器运行时或守护进程。这对建立容器的持续集成和持续交付管道尤其有用。
Buildah 使容器的文件系统可以直接供构建主机使用。这意味着构建工具在主机上可用就行,而不需要在容器镜像中可用,从而使构建更快速,镜像更小,更安全。Buildah 有 CentOS、Fedora 和 Debian 的软件包。
### 安装 Buildah
从 Fedora 26 开始 Buildah 可以使用 `dnf` 进行安装。
```
$ sudo dnf install buildah -y
```
`buildah` 的当前版本为 0.16,可以通过以下命令显示。
```
$ buildah --version
```
### 基本命令
构建容器镜像的第一步是获取基础镜像,这是通过 Dockerfile 中的 `FROM` 语句完成的。Buildah 以类似的方式处理这个。
```
$ sudo buildah from fedora
```
该命令将拉取 Fedora 的基础镜像并存储在主机上。通过执行以下操作可以检查主机上可用的镜像。
```
$ sudo buildah images
IMAGE ID IMAGE NAME CREATED AT SIZE
9110ae7f579f docker.io/library/fedora:latest Mar 7, 2018 20:51 234.7 MB
```
在拉取基础镜像后,有一个该镜像的运行容器实例,这是一个“工作容器”。
以下命令显示正在运行的容器。
```
$ sudo buildah containers
CONTAINER ID BUILDER IMAGE ID IMAGE NAME
CONTAINER NAME
6112db586ab9 * 9110ae7f579f docker.io/library/fedora:latest fedora-working-container
```
Buildah 还提供了一个非常有用的命令来停止和删除当前正在运行的所有容器。
```
$ sudo buildah rm --all
```
完整的命令列表可以使用 `--help` 选项。
```
$ buildah --help
```
### 构建一个 Apache Web 服务器容器镜像
让我们看看如何使用 Buildah 在 Fedora 基础镜像上安装 Apache Web 服务器,然后复制一个可供服务的自定义 `index.html`。
首先让我们创建自定义的 `index.html`。
```
$ echo "Hello Fedora Magazine !!!" > index.html
```
然后在正在运行的容器中安装 httpd 包。
```
$ sudo buildah from fedora
$ sudo buildah run fedora-working-container dnf install httpd -y
```
让我们将 `index.html` 复制到 `/var/www/html/`。
```
$ sudo buildah copy fedora-working-container index.html /var/www/html/index.html
```
然后配置容器入口点以启动 httpd。
```
$ sudo buildah config --entrypoint "/usr/sbin/httpd -DFOREGROUND" fedora-working-container
```
现在为了使“工作容器”可用,`commit` 命令将容器保存到镜像。
```
$ sudo buildah commit fedora-working-container hello-fedora-magazine
```
hello-fedora-magazine 镜像现在可用,并且可以推送到仓库以供使用。
```
$ sudo buildah images
IMAGE ID IMAGE NAME CREATED
AT SIZE
9110ae7f579f docker.io/library/fedora:latest
Mar 7, 2018 22:51 234.7 MB
49bd5ec5be71 docker.io/library/hello-fedora-magazine:latest
Apr 27, 2018 11:01 427.7 MB
```
通过运行以下步骤,还可以使用 Buildah 来测试此镜像。
```
$ sudo buildah from --name=hello-magazine docker.io/library/hello-fedora-magazine
$ sudo buildah run hello-magazine
```
访问 <http://localhost> 将显示 “Hello Fedora Magazine !!!”
---
via: <https://fedoramagazine.org/daemon-less-container-management-buildah/>
作者:[Ashutosh Sudhakar Bhakare](https://fedoramagazine.org/author/ashutoshbhakare/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Project Atomic, through their efforts on the Open Container Initiative (OCI), have created a great tool called [Buildah](https://github.com/projectatomic/buildah). Buildah helps with creating, building and updating container images supporting Docker formatted images as well as OCI compliant images.
Buildah handles building container images without the need to have a full container runtime or daemon installed. This particularly shines for setting up a continuous integration and continuous delivery pipeline for building containers.
Buildah makes the container’s filesystem directly available to the build host. Meaning that the build tooling is available on the host and not needed in the container image, keeping the build faster and the image smaller and safer. There are Buildah packages for CentOS, Fedora, and Debian.
**Installing Buildah**
Since Fedora 26 Buildah can be installed using dnf.
$ sudo dnf install buildah -y
The current version of buildah is 0.16, which can be displayed by the following command.
$ buildah --version
## Basic commands
The first step needed to build a container image is to get a base image, this is done by the FROM statement in a Dockerfile. Buildah does handle this in a similar way.
$ sudo buildah from fedora
This command pulls the Fedora based image and stores it on the host. It is possible to inspect the images available on the host, by running the following.
$ sudo buildah images IMAGE ID IMAGE NAME CREATED AT SIZE 9110ae7f579f docker.io/library/fedora:latest Mar 7, 2018 20:51 234.7 MB
After pulling the base image, a running container instance of this image is available, this is a “working-container”.
The following command displays the running containers.
$ sudo buildah containers CONTAINER ID BUILDER IMAGE ID IMAGE NAME CONTAINER NAME 6112db586ab9 * 9110ae7f579f docker.io/library/fedora:latest fedora-working-container
Buildah also provides a very useful command to stop and remove all the containers that are currently running.
$ sudo buildah rm --all
The full list of command is available using the *–help* option.
$ buildah --help
**Building an Apache web server container image**
Let’s see how to use Buildah to install an Apache web server on a Fedora base image, then copy a custom index.html to be served by the server.
First let’s create the custom index.html.
$ echo "Hello Fedora Magazine !!!" > index.html
Then install the httpd package inside the running container.
$ sudo buildah from fedora $ sudo buildah run fedora-working-container dnf install httpd -y
Let’s copy index.html to /var/www/html/.
$ sudo buildah copy fedora-working-container index.html /var/www/html/index.html
Then configure the container entrypoint to start httpd.
$ sudo buildah config --entrypoint "/usr/sbin/httpd -DFOREGROUND" fedora-working-container
Now to make the “working-container” available, the *commit* command saves the container to an image.
$ sudo buildah commit fedora-working-container hello-fedora-magazine
The *hello-fedora-magazine *image is now available, and can be pushed to a registry to be used.
$ sudo buildah images IMAGE ID IMAGE NAME CREATED AT SIZE 9110ae7f579f docker.io/library/fedora:latest Mar 7, 2018 22:51 234.7 MB 49bd5ec5be71 docker.io/library/hello-fedora-magazine:latest Apr 27, 2018 11:01 427.7 MB
It is also possible to use Buildah to test this image by running the following steps.
$ sudo buildah from --name=hello-magazine docker.io/library/hello-fedora-magazine $ sudo buildah run hello-magazine
Accessing [http://localhost](http://localhost) will display “*Hello Fedora Magazine !!!*“
## pixdrift
You may have issues with Buildah executing entrypoint as this is not the expected behaviour from Buildah. Your final command to ‘buildah run hello-magazine’ should use ‘podman run’ if you want it to use the configured container entrypoint.
## Ashutosh
Had tested and works fine
## pixdrift
The version used for this test may have worked correctly, but future versions may experience issues as it isn’t expected behaviour:
https://github.com/projectatomic/buildah/issues/607
## pixdrift
Apologies, this is related to parameters on entrypoint.
## Hushen Beg
It is very nice Ashutosh sir. I am also working on Aws,Docker,Swarm ,Ec2 etc .Now a days buildah is very useful for updating and building the container images.
## prafful chavan
nice sir….????
Is that same way to install in redhat as well or not ?
## Erik
Being in New England, gotta love the name! (It is how Builder would be pronounced with a local accent).
## Paul W. Frields
@Erik: That’s exactly how it got its name — a tribute to the very pronounced accent of Dan Walsh, who works on container technologies.
## FeRDNYC
I’m a little disappointed, though, because at no point does anyone ever point out that Buildah is “a wicked good tool for maintaining yah containahs”. #MissedOpportunity
## Madhusudan Upadhyay
“Buildah makes the container’s filesystem directly available to the build host”
That is good news. Perhaps, utilities from container host can be leveraged as a part of the build now and that would in turn enhance the overall performance of the build process.
Impressive and quite self-explanatory article Ashutosh Sir. Good work.
## umesh
It is very nice Ashutosh sir. I am also working on docker .Now a days buildah is very useful for updating and building the container images.
It is easy to use.
## Akshay Wani
Very helpful article to start with Buildah . People currently working on Docker should definately try out Buildah.
## Keecheril Jobin Varghese
Perfectly explained. Thank you for making it easier to understand!
## clime
Personally, I don’t understand the ‘sudos’ in every single command. Do they really need to be there? I would like to see a tool that is able to create a container image from host without having to use a privileged user.
## Athavan Kanapuli
Does buildah allows more than one process to run inside a single container? Taking back the httpd example in the article, I need redis server to run in the same container along with httpd. Does builah has an init system to manage multiple services? |
9,662 | 有用的资源,献给那些想更多了解 Linux 的人 | https://linuxaria.com/article/useful-resources-for-those-who-want-to-know-more-about-linux | 2018-05-21T07:34:00 | [
"Linux"
] | https://linux.cn/article-9662-1.html | 
Linux 是最流行和多功能的操作系统之一,它可以用在智能手机,电脑甚至汽车上。自 20 世纪 90 年代以来,Linux 存在至今,并且仍然是最普遍的操作系统之一。
Linux 实际上用于运行大多数网络服务,因为与其他操作系统相比,它被认为是相当稳定的。这是[人们选择 Linux 多于 Windows 的原因](https://www.lifewire.com/windows-vs-linux-mint-2200609)之一。此外,Linux 为用户提供了隐私,根本不收集用户信息,而 Windows 10 及其 Cortana 语音控制系统总是需要更新你的个人信息。
Linux 有很多优点。然而,人们并没有听到太多关于它的消息,因为它已被 Windows 和 Mac 挤出(桌面)场。许多人开始使用 Linux 时会感到困惑,因为它与流行的操作系统有点不同。
为了帮助你,我们为那些想要了解更多关于 Linux 的人收集了 5 个有用的资源。
### 1、[Linux 纯新手](https://www.eduonix.com/courses/system-programming/linux-for-absolute-beginners)
如果你想尽可能多地学习 Linux,你应该考虑 Eduonix 为[初学者提供的 Linux 完整教程](https://www.eduonix.com/courses/system-programming/linux-for-absolute-beginners)。这个课程将向你介绍 Linux 的所有功能,并为你提供所有必要的资料,以帮助你了解更多关于 Linux 工作原理的特性。
如果你是以下情况,你应该选择本课程:
* 你想了解有关 Linux 操作系统的详细信息;
* 你想知道如何安装它;
* 你想了解 Linux 如何与硬件配合使用;
* 你想学习如何操作 Linux 命令行。
### 2、[PC World: Linux 初学者指南](https://www.pcworld.com/article/2918397/operating-systems/how-to-get-started-with-linux-a-beginners-guide.html)
为想要在一个地方学习所有有关 Linux 的人提供[免费资源](https://www.pcworld.com/article/2918397/operating-systems/how-to-get-started-with-linux-a-beginners-guide.html)。PC World 专注于计算机操作系统的各个方面,并为订阅用户提供最准确和最新的信息。在这里,你还可以了解更多关于 [Linux 的好处](https://www.popsci.com/switch-to-linux-operating-system#page-4) 和关于其操作系统的最新消息。
该资源为你提供以下信息:
* 如何安装 Linux;
* 如何使用命令行;
* 如何安装软件;
* 如何操作 Linux 桌面环境。
### 3、[Linux.com:Linux 培训](https://www.linux.com/learn/training)
很多使用计算机的人都需要学习如何操作 Linux,以防 Windows 操作系统突然崩溃。还有什么比使用官方资源来启动你的 [Linux 培训](https://www.linux.com/learn/training)更好呢?
该资源可用让你在线注册 Linux 训练,你可以从官方来源获取最新信息。“一年前,我们的 IT 部门在官方网站上为我们提供了 Linux 培训” [Assignmenthelper.com.au](https://www.assignmenthelper.com.au/) 的开发人员 Martin Gibson 说道。“我们选择了这门课,因为我们需要学习如何将我们的所有文件备份到另一个系统,为我们的客户提供最大的安全性,而且这个资源真的教会了我们所有的东西。”
所以你肯定应该使用这个资源,如果:
* 你想获得有关操作系统的第一手信息;
* 想要了解如何在你的计算机上运行 Linux 的特性;
* 想要与其他 Linux 用户联系并与他们分享你的经验。
### 4、 [Linux 基金会:视频培训](https://training.linuxfoundation.org/free-linux-training/linux-training-videos)
如果你在阅读大量资源时容易感到无聊,那么该网站绝对适合你。Linux 基金会提供了由 IT 专家、软件开发技术人员和技术顾问举办的[视频培训](https://training.linuxfoundation.org/free-linux-training/linux-training-videos),讲座和在线研讨会。
所有培训视频分为以下类别:
* 开发人员: 使用 Linux 内核来处理 Linux 设备驱动程序、Linux 虚拟化等;
* 系统管理员:在 Linux 上开发虚拟主机,构建防火墙,分析 Linux 性能等;
* 用户:Linux 入门,介绍嵌入式 Linux 等。
### 5、 [LinuxInsider](https://www.linuxinsider.com/)
你知道吗?微软对 Linux 的效率感到惊讶,它[允许用户在微软云计算设备上运行 Linux](https://www.wired.com/2016/08/linux-took-web-now-taking-world/)。如果你想了解更多关于 Linux 操作系统的知识,[Linux Insider](https://www.linuxinsider.com/) 会向用户提供关于 Linux 操作系统的最新消息,以及最新更新和 Linux 特性的信息。
在此资源上,你将有机会:
* 参与 Linux 社区;
* 了解如何在各种设备上运行 Linux;
* 看看评论;
* 参与博客讨论并阅读科技博客。
### 总结一下
Linux 提供了很多好处,包括完全的隐私,稳定的操作甚至恶意软件保护。它绝对值得尝试,学习如何使用会帮助你更好地了解你的计算机如何工作以及它需要如何平稳运行。
### 关于作者
Lucy Benton 是一位数字营销专家,商业顾问,帮助人们将他们的梦想变为有利润的业务。现在她正在为营销和商业资源撰写。Lucy 还有自己的博客 [*Prowritingpartner.com*](https://prowritingpartner.com/),在那里你可以查看她最近发表的文章。
---
via: <https://linuxaria.com/article/useful-resources-for-those-who-want-to-know-more-about-linux>
作者:[Lucy Benton](https://www.lifewire.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Guest post by Lucy Benton
Linux is one of the most popular and versatile operating systems available. It can be used on a smartphone, computer and even a car. Linux has been around since the 1990s and is still one of the most widespread operating systems.
Linux is actually used to run most of the Internet as it is considered to be rather stable compared to other operating systems. This is one of the [reasons why people choose Linux over Windows](https://www.lifewire.com/windows-vs-linux-mint-2200609). Besides, Linux provides its users with privacy and doesn’t collect their data at all, while Windows 10 and its Cortana voice control system always require updating your personal information.
Linux has many advantages. However, people do not hear much about it, as it has been squeezed out from the market by Windows and Mac. And many people get confused when they start using Linux, as it’s a bit different from popular operating systems.
So to help you out we’ve collected 5 useful resources for those who want to know more about Linux.
**1. ****Linux for Absolute Beginners**
If you want to learn as much about Linux as you can, you should consider taking a full course for beginners, provided by Eduonix. This course will introduce you to all features of Linux and provide you with all necessary materials to help you find out more about the peculiarities of how Linux works.
You should definitely choose this course if:
- you want to learn the details about the Linux operating system;
- you want to find out how to install it;
- you want to understand how Linux cooperates with your hardware;
- you want to learn how to operate Linux command line.
**2. ****PC World: A Linux Beginner’s Guide**
A free resource for those who want to learn everything about Linux in one place. PC World specializes in various aspects of working with computer operating systems, and it provides its subscribers with the most accurate and up-to-date information. Here you can also learn more about the [benefits of Linux](https://www.popsci.com/switch-to-linux-operating-system#page-4) and latest news about his operating system.
This resource provides you with information on:
- how to install Linux;
- how to use command line;
- how to install additional software;
- how to operate Linux desktop environment.
A lot of people who work with computers are required to learn how to operate Linux in case Windows operating system suddenly crashes. And what can be better than using an official resource to start your Linux training?
This resource provides online enrollment on the Linux training, where you can get the most updated information from the authentic source. “A year ago our IT department offered us a Linux training on the official website”, says Martin Gibson, a developer at [Assignmenthelper.com.au](https://www.assignmenthelper.com.au/). “We took this course because we needed to learn how to back up all our files to another system to provide our customers with maximum security, and this resource really taught us everything.”
So you should definitely use this resource if:
- you want to receive firsthand information about the operating system;
- want to learn the peculiarities of how to run Linux on your computer;
- want to connect with other Linux users and share your experience with them.
**4. ****The Linux Foundation: Training Videos**
If you easily get bored from reading a lot of resources, this website is definitely for you. The Linux Foundation provides training videos, lectures and webinars, held by IT specialists, software developers and technical consultants.
All the training videos are subdivided into categories for:
- Developers: working with Linux Kernel, handling Linux Device Drivers, Linux virtualization etc.;
- System Administrators: developing virtual hosts on Linux, building a Firewall, analyzing Linux performance etc.;
- Users: getting started using Linux, introduction to embedded Linux and so on.
**5. ****LinuxInsider**
Did you know that Microsoft was so amazed by the efficiency of Linux that it [allowed users to run Linux on Microsoft cloud computing device](https://www.wired.com/2016/08/linux-took-web-now-taking-world/)? If you want to learn more about this operating system, Linux Insider provides its subscribers with the latest news on Linux operating systems, gives information about the latest updates and Linux features.
On this resource, you will have the opportunity to:
- participate in Linux community;
- learn about how to run Linux on various devices;
- check out reviews;
- participate in blog discussions and read the tech blog.
**Wrapping up…**
Linux offers a lot of benefits, including complete privacy, stable operation and even malware protection. It’s definitely worth trying, learning how to use will help you better understand how your computer works and what it needs to operate smoothly.
*Lucy Benton is a digital marketing specialist, business consultant and helps people to turn their dreams into the profitable business**.** Now she is writing for marketing and business resources. Also Lucy has her own blog **Prowritingpartner.com** ,where you can check her last publications. *
### Popular Posts:
- None Found |
9,663 | 一个可以更好地调试的 Perl 模块 | https://opensource.com/article/18/4/perl-module-debugging-code | 2018-05-21T07:55:10 | [
"Perl",
"调试"
] | /article-9663-1.html |
>
> 这个简单优雅的模块可以让你包含调试或仅用于开发环境的代码,而在产品环境中隐藏它们。
>
>
>

仅用于调试或开发调整时的 Perl 代码块有时会很有用。这很好,但是这样的代码块可能会对性能产生很大的影响, 尤其是在运行时才决定是否执行它。
[Curtis "Ovid" Poe](https://metacpan.org/author/OVID) 最近编写了一个可以帮助解决这个问题的模块:[Keyword::DEVELOPMENT](https://metacpan.org/pod/release/OVID/Keyword-DEVELOPMENT-0.04/lib/Keyword/DEVELOPMENT.pm)。该模块利用 `Keyword::Simple` 和 Perl 5.012 中引入的可插入关键字架构来创建了新的关键字:`DEVELOPMENT`。它使用 `PERL_KEYWORD_DEVELOPMENT` 环境变量的值来确定是否要执行一段代码。
使用它不能更容易了:
```
use Keyword::DEVELOPMENT;
sub doing_my_big_loop {
my $self = shift;
DEVELOPMENT {
# insert expensive debugging code here!
}
}
```
在编译时,`DEVELOPMENT` 块内的代码已经被优化掉了,根本就不存在。
你看到好处了么?在沙盒中将 `PERL_KEYWORD_DEVELOPMENT` 环境变量设置为 `true`,在生产环境设为 `false`,并且可以将有价值的调试工具提交到你的代码库中,在你需要的时候随时可用。
在缺乏高级配置管理的系统中,你也可以使用此模块来处理生产和开发或测试环境之间的设置差异:
```
sub connect_to_my_database {
my $dsn = "dbi:mysql:productiondb";
my $user = "db_user";
my $pass = "db_pass";
DEVELOPMENT {
# Override some of that config information
$dsn = "dbi:mysql:developmentdb";
}
my $db_handle = DBI->connect($dsn, $user, $pass);
}
```
稍后对此代码片段的增强使你能在其他地方,比如 YAML 或 INI 中读取配置信息,但我希望您能在此看到该工具。
我查看了关键字 `Keyword::DEVELOPMENT` 的源码,花了大约半小时研究,“天哪,我为什么没有想到这个?”安装 `Keyword::Simple` 后,Curtis 给我们的模块就非常简单了。这是我长期以来在自己的编码实践中所需要的一个优雅解决方案。
---
via: <https://opensource.com/article/18/4/perl-module-debugging-code>
作者:[Ruth Holloway](https://opensource.com/users/druthb) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,664 | Jupyter Notebooks 入门 | https://opensource.com/article/18/3/getting-started-jupyter-notebooks | 2018-05-21T08:24:16 | [
"Jupyter",
"IPython",
"笔记"
] | https://linux.cn/article-9664-1.html |
>
> 通过 Jupyter 使用实时代码、方程式和可视化及文本创建交互式的共享笔记本。
>
>
>

自从有了纸莎草纸以来,出版人们一直在努力以吸引读者的方式来格式化数据。尤其是在数学、科学、和编程领域,设计良好的图表、插图和方程式可以成为帮助人们理解技术信息的关键。
[Jupyter Notebook](http://jupyter.org/) 通过重新构想我们如何制作教学文本来解决这个问题。Jupyter (我在 2017 年 10 月在 [All Things Open](https://allthingsopen.org/) 上首次了解到)是一款开源应用程序,它使用户能够创建包含实时代码、方程式、可视化和文本的交互式共享笔记本。
Jupyter 从 [IPython 项目](http://ipython.org/)发展而来,它是个具有交互式 shell 和基于浏览器的笔记本,支持代码、文本和数学表达式。Jupyter 支持超过 40 种编程语言,包括 Python、R 和 Julia,其代码可以导出为 HTML、LaTeX、PDF、图像和视频,或者作为 [IPyhton](https://en.wikipedia.org/wiki/IPython) 笔记本与其他用户共享。
>
> 一个有趣的事实是:“Jupyter” 是 “Julia、Python 和 R” 的缩写。
>
>
>
根据 Jupyter 项目网站介绍,它的一些用途包括“数据清理和转换,数值模拟,统计建模,数据可视化,机器学习等等”。科学机构正在使用 Jupyter Notebooks 来解释研究结果。代码可以来自实际数据,可以调整和重新调整以可视化成不同的结果和情景。通过这种方式,Jupyter Notebooks 变成了生动的文本和报告。
### 安装并开始 Jupyter
Jupyter 软件是开源的,其授权于[修改过的 BSD 许可证](https://opensource.org/licenses/BSD-3-Clause),它可以[安装在 Linux、MacOS 或 Windows 上](http://jupyter.org/install.html)。有很多种方法可以安装 Jupyter;我在 Linux 和 MacOS 上试过 PIP 和 [Anaconda](https://www.anaconda.com/download/#linux) 安装方式。PIP 安装要求你的计算机上已经安装了 Python;Jupyter 推荐 Python 3。
由于 Python 3 已经安装在我的电脑上,我通过在终端(在 Linux 或 Mac 上)运行以下命令来安装 Jupyter:
```
$ python3 -m pip install --upgrade pip
$ python3 -m pip install jupyter
```
在终端提示符输入以下命令立即启动应用程序:
```
$ jupyter notebook
```
很快,我的浏览器打开并显示了我在 `http://localhost:8888` 的 Jupyter Notebook 服务器。(支持的浏览器有 Google Chrome、Firefox 和 Safari)

在右上角有一个标有 “New” 的下拉菜单,它使我能够根据自己的指示和代码快速创建新的笔记本。请注意,我的新笔记本默认为 Python 3,这是我目前的环境。

一个带有一些默认值的新笔记本,它可以被改变(包括笔记本的名字),已打开。

笔记本有两种不同的模式:“命令模式”和“编辑模式”。命令模式允许你添加或删除单元格。你可以通过按下 `Escape` 键进入命令模式,按 `Enter` 键或单击单元格进入编辑模式。
单元格周围的绿色高亮显示你处于编辑模式,蓝色高亮显示你处于命令模式。以下笔记本处于命令模式并准备好执行单元中的 Python 代码。注意,我已将笔记本的名称更改为 “First Notebook”。

### 使用 Jupyter
Jupyter Notebooks 的强大之处在于除了能够输入代码之外,你还可以用 Markdown 添加叙述性和解释性文本。我想添加一个标题,所以我在代码上面添加了一个单元格,并以 Markdown 输入了一个标题。当我按下 `Ctrl+Enter` 时,我的标题转换为 HTML。(LCTT 译注:或者可以按下 Run 按钮。)

我可以通过在命令前追加 `!` 来添加 Bash 命令或脚本的输出。

我也可以利用 IPython 的 [line magic 和 cell magic](http://ipython.readthedocs.io/en/stable/interactive/magics.html) 命令。你可以通过在代码单元内附加 `%` 或 `%%` 符号来列出魔术命令。例如,`%lsmagic` 将输出所有可用于 Jupyter notebooks 的魔法命令。

这些魔术命令的例子包括 `%pwd`——它输出当前工作目录(例如 `/Users/YourName`)和 `%ls`——它列出当前工作目录中的所有文件和子目录。另一个神奇命令显示从笔记本中的 `matplotlib` 生成的图表。`%%html` 将该单元格中的任何内容呈现为 HTML,这对嵌入视频和链接很有用,还有 JavaScript 和 Bash 的单元魔术命令。
如果你需要更多关于使用 Jupyter Notebooks 和它的特性的信息,它的帮助部分是非常完整的。
人们用许多有趣的方式使用 Jupyter Notebooks;你可以在这个[展示栏目](https://github.com/jupyter/jupyter/wiki/a-gallery-of-interesting-jupyter-notebooks#mathematics)里找到一些很好的例子。你如何使用 Jupyter 笔记本?请在下面的评论中分享你的想法。
---
via: <https://opensource.com/article/18/3/getting-started-jupyter-notebooks>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Since the days of papyrus, publishers have struggled with formatting data in ways that engage readers. This is a particular issue in the areas of mathematics, science, and programming, where well-designed charts, illustrations, and equations can be key to helping people understand technical information.
[The Jupyter Notebook](http://jupyter.org/) is addressing this problem by reimagining how we produce instructional texts. Jupyter (which I first learned about at [All Things Open](https://allthingsopen.org/) in October 2017) is an open source application that enables users to create interactive, shareable notebooks that contain live code, equations, visualizations, and text.
Jupyter evolved from the [IPython Project](http://ipython.org/), which features an interactive shell and a browser-based notebook with support for code, text, and mathematical expressions. Jupyter offers support for over 40 programming languages, including Python, R, and Julia, and its code can be exported to HTML, LaTeX, PDF, images, and videos or as [IPython](https://en.wikipedia.org/wiki/IPython) notebooks to be shared with other users.
*Fun fact: "Jupyter" is an acronym for "Julia, Python, **and** R."*
Some of its uses, according to Project Jupyter's website, include "data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more." Scientific institutions are using Jupyter Notebooks to explain research results. The code, which can come from actual data, can be tweaked and re-tweaked to visualize different results and scenarios. In this way, Jupyter Notebooks have become living texts and reports.
## Installing and starting Jupyter
The Jupyter software is open source, licensed under the [modified BSD license](https://opensource.org/licenses/BSD-3-Clause), and it can be [installed on Linux, MacOS, or Windows](http://jupyter.org/install.html). There are a number of ways to install Jupyter; I tried the PIP and the [Anaconda](https://www.anaconda.com/download/#linux) installs on Linux and MacOS. A PIP install requires that Python is already installed on your computer; Jupyter recommends Python 3.
Since Python 3 was already installed on my computers, I installed Jupyter by running the following commands in the terminal (on Linux or Mac):
```
``````
$ python3 -m pip install --upgrade pip
$ python3 -m pip install jupyter
```
Entering the following command at the terminal prompt started the application right away:
```
````$ jupyter notebook`
Soon my browser opened and displayed my Jupyter Notebook server at `http://localhost:8888`
. (Supported browsers are Google Chrome, Firefox, and Safari.)
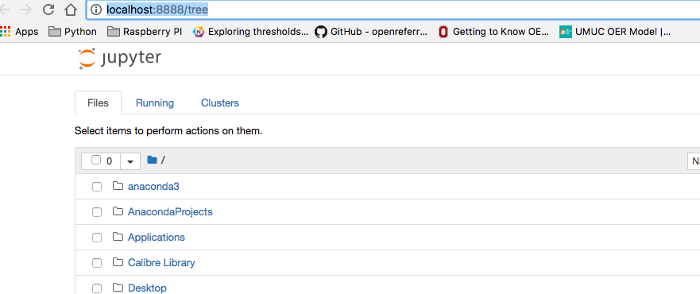
opensource.com
There's a drop-down menu labeled "New" in the upper-right corner. It enabled me to quickly create a new notebook for my own instructions and code. Note that my new notebook defaults to Python 3, which is my current environment.
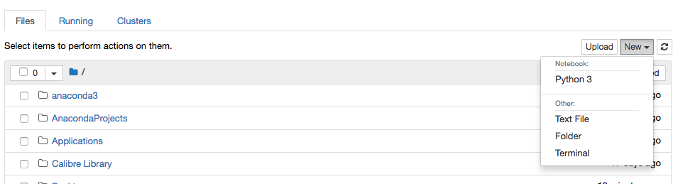
opensource.com
A new notebook with some default values, which can be changed (including the name of the notebook), opened.
opensource.com
Notebooks have two different modes: Command and Edit. Command mode allows you to add or delete cells. You can enter Command mode by pressing the Escape key, and you can get into Edit mode by pressing the Enter key or by clicking in a cell.
A green highlight around a cell indicates you are in Edit mode, and a blue highlight means you're in Command mode. The following notebook is in Command mode and ready for me to execute the Python code in the cell. Note that I've changed the name of the notebook to First Notebook.
opensource.com
## Using Jupyter
A strength of Jupyter Notebooks is that besides being able to enter code, you can also add Markdown with narrative and explanatory text. I wanted to add a heading, so I added a cell above my code and typed a heading in Markdown. When I pressed `Ctrl+Enter`
, my heading converted to HTML.
opensource.com
I can add output from a Bash command or script by appending an `!`
to a command.
opensource.com
I can also take advantage of IPython's [line magic and cell magic](http://ipython.readthedocs.io/en/stable/interactive/magics.html) commands. You can list the magic commands by appending a `%`
or `%%`
sign to commands inside a code cell. For example, `%lsmagic`
produces all the magic commands that can be used in Jupyter notebooks.
opensource.com
Examples of these magic commands include `%pwd`
, which outputs the present working directory (e.g., `/Users/YourName`
) and `%ls`
, which lists all the files and subdirectories in the current working directory. Another magic command displays charts generated from `matplotlib`
in the notebook. `%%html`
renders anything in that cell as HTML, which is useful for embedding video and links. There are cell magic commands for JavaScript and Bash, also.
If you need more information about using Jupyter Notebooks and its features, the Help section is incredibly complete.
People are using Jupyter Notebooks in many interesting ways; you can find some great examples in this [gallery](https://github.com/jupyter/jupyter/wiki/a-gallery-of-interesting-jupyter-notebooks#mathematics). How are you using Jupyter notebooks? Please share your ideas in the comments below.
## 1 Comment |
9,665 | 如何编译 Linux 内核 | https://www.linux.com/learn/intro-to-linux/2018/4/how-compile-linux-kernel-0 | 2018-05-22T12:56:00 | [
"内核",
"编译"
] | https://linux.cn/article-9665-1.html |
>
> Jack 将带你在 Ubuntu 16.04 服务器上走过内核编译之旅。
>
>
>

曾经有一段时间,升级 Linux 内核让很多用户打心里有所畏惧。在那个时候,升级内核包含了很多步骤,也需要很多时间。现在,内核的安装可以轻易地通过像 `apt` 这样的包管理器来处理。通过添加特定的仓库,你能很轻易地安装实验版本的或者指定版本的内核(比如针对音频产品的实时内核)。
考虑一下,既然升级内核如此容易,为什么你不愿意自行编译一个呢?这里列举一些可能的原因:
* 你想要简单了解编译内核的过程
* 你需要启用或者禁用内核中特定的选项,因为它们没有出现在标准选项里
* 你想要启用标准内核中可能没有添加的硬件支持
* 你使用的发行版需要你编译内核
* 你是一个学生,而编译内核是你的任务
不管出于什么原因,懂得如何编译内核是非常有用的,而且可以被视作一个通行权。当我第一次编译一个新的 Linux 内核(那是很久以前了),然后尝试从它启动,我从中(系统马上就崩溃了,然后不断地尝试和失败)感受到一种特定的兴奋。
既然这样,让我们来实验一下编译内核的过程。我将使用 Ubuntu 16.04 Server 来进行演示。在运行了一次常规的 `sudo apt upgrade` 之后,当前安装的内核版本是 `4.4.0-121`。我想要升级内核版本到 `4.17`, 让我们小心地开始吧。
有一个警告:强烈建议你在虚拟机里实验这个过程。基于虚拟机,你总能创建一个快照,然后轻松地从任何问题中回退出来。不要在产品机器上使用这种方式升级内核,除非你知道你在做什么。
### 下载内核
我们要做的第一件事是下载内核源码。在 [Kernel.org](https://www.kernel.org/) 找到你要下载的所需内核的 URL。找到 URL 之后,使用如下命令(我以 `4.17 RC2` 内核为例) 来下载源码文件:
```
wget https://git.kernel.org/torvalds/t/linux-4.17-rc2.tar.gz
```
在下载期间,有一些事需要去考虑。
### 安装需要的环境
为了编译内核,我们首先得安装一些需要的环境。这可以通过一个命令来完成:
```
sudo apt-get install git fakeroot build-essential ncurses-dev xz-utils libssl-dev bc flex libelf-dev bison
```
务必注意:你将需要至少 12 GB 的本地可用磁盘空间来完成内核的编译过程。因此你必须确保有足够的空间。
### 解压源码
在新下载的内核所在的文件夹下,使用该命令来解压内核:
```
tar xvzf linux-4.17-rc2.tar.gz
```
使用命令 `cd linux-4.17-rc2` 进入新生成的文件夹。
### 配置内核
在正式编译内核之前,我们首先必须配置需要包含哪些模块。实际上,有一些非常简单的方式来配置。使用一个命令,你能拷贝当前内核的配置文件,然后使用可靠的 `menuconfig` 命令来做任何必要的更改。使用如下命令来完成:
```
cp /boot/config-$(uname -r) .config
```
现在你有一个配置文件了,输入命令 `make menuconfig`。该命令将打开一个配置工具(图 1),它可以让你遍历每个可用模块,然后启用或者禁用你需要或者不需要的模块。

*图 1: 运行中的 `make menuconfig`*
很有可能你会禁用掉内核中的一个重要部分,所以在 `menuconfig` 期间小心地一步步进行。如果你对某个选项不确定,不要去管它。或者更好的方法是使用我们拷贝的当前运行的内核的配置文件(因为我们知道它可以工作)。一旦你已经遍历了整个配置列表(它非常长),你就准备好开始编译了。
### 编译和安装
现在是时候去实际地编译内核了。第一步是使用 `make` 命令去编译。调用 `make` 命令然后回答必要的问题(图 2)。这些问题取决于你将升级的现有内核以及升级后的内核。相信我,将会有非常多的问题要回答,因此你得预留大量的时间。

*图 2: 回答 `make` 命令的问题*
回答了长篇累牍的问题之后,你就可以用如下的命令安装那些之前启用的模块:
```
make modules_install
```
又来了,这个命令将耗费一些时间,所以要么坐下来看着编译输出,或者去做些其他事(因为编译期间不需要你的输入)。可能的情况是,你想要去进行别的任务(除非你真的喜欢看着终端界面上飞舞而过的输出)。
现在我们使用这个命令来安装内核:
```
sudo make install
```
又一次,另一个将要耗费大量可观时间的命令。事实上,`make install` 命令将比 `make modules_install` 命令花费更多的时间。去享用午餐,配置一个路由器,将 Linux 安装在一些服务器上,或者小睡一会吧。
### 启用内核作为引导
一旦 `make install` 命令完成了,就是时候将内核启用来作为引导。使用这个命令来实现:
```
sudo update-initramfs -c -k 4.17-rc2
```
当然,你需要将上述内核版本号替换成你编译完的。当命令执行完毕后,使用如下命令来更新 grub:
```
sudo update-grub
```
现在你可以重启系统并且选择新安装的内核了。
### 恭喜!
你已经编译了一个 Linux 内核!它是一项耗费时间的活动;但是,最终你的 Linux 发行版将拥有一个定制的内核,同时你也将拥有一项被许多 Linux 管理员所倾向忽视的重要技能。
从 Linux 基金会和 edX 提供的免费 [“Introduction to Linux”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 课程来学习更多的 Linux 知识。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/4/how-compile-linux-kernel-0>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[icecoobe](https://github.com/icecoobe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,666 | 6 个 Python 的日期时间库 | https://opensource.com/article/18/4/python-datetime-libraries | 2018-05-22T16:13:09 | [
"时间",
"日期",
"Python"
] | https://linux.cn/article-9666-1.html |
>
> 在 Python 中有许多库可以很容易地测试、转换和读取日期和时间信息。
>
>
>

*这篇文章是与 [Jeff Triplett](https://opensource.com/users/jefftriplett) 一起合写的。*
曾几何时,我们中的一个人(Lacey)盯了一个多小时的 [Python 文档](https://docs.python.org/3/library/datetime.html#strftime-strptime-behavior)中描述日期和时间格式化字符串的表格。当我试图编写从 API 中将日期时间字符串转换为 [Python datetime](https://opensource.com/article/17/5/understanding-datetime-python-primer) 对象时,我很难理解其中的特定部分,因此我决定请求帮助。
有人问道:“为什么你不使用 `dateutil` 呢?”
读者,如果你没有从这个月的 Python 专栏中获得任何东西,只是学习到有比 datetime 的 `strptime` 更容易地将 datetime 字符串转换为 datetime 对象的方法,那么我们觉得就已经成功了。
但是,除了将字符串转换为更有用的 Python 对象之外,还有许多库都有一些有用的方法和工具,可以让您更轻松地进行时间测试、将时间转换为不同的时区、以人类可读的格式传递时间信息,等等。如果这是你在 Python 中第一次接触日期和时间,请暂停并阅读 *[如何使用 Python的日期和时间](https://opensource.com/article/17/5/understanding-datetime-python-primer)* 。要理解为什么在编程中处理日期和时间是困难的,请阅读 [愚蠢的程序员相信时间](http://infiniteundo.com/post/25326999628/falsehoods-programmers-believe-about-time)。
这篇文章将会向你介绍以下库:
* [Dateutil](https://opensource.com/#Dateutil)
* [Arrow](https://opensource.com/#Arrow)
* [Moment](https://opensource.com/#Moment)
* [Maya](https://opensource.com/#Maya)
* [Delorean](https://opensource.com/#Delorean)
* [Freezegun](https://opensource.com/#Freezegun)
随意跳过那些你已经熟悉的库,专注于那些对你而言是新的库。
### 内建的 datetime 模块
在跳转到其他库之前,让我们回顾一下如何使用 `datetime` 模块将日期字符串转换为 Python datetime 对象。
假设我们从 API 接受到一个日期字符串,并且需要它作为 Python datetime 对象存在:
```
2018-04-29T17:45:25Z
```
这个字符串包括:
* 日期是 `YYYY-MM-DD` 格式的
* 字母 `T` 表示时间即将到来
* 时间是 `HH:II:SS` 格式的
* 表示此时间的时区指示符 `Z` 采用 UTC (详细了解[日期时间字符格式](https://www.w3.org/TR/NOTE-datetime))
要使用 `datetime` 模块将此字符串转换为 Python datetime 对象,你应该从 `strptime` 开始。 `datetime.strptime` 接受日期字符串和格式化字符并返回一个 Python datetime 对象。
我们必须手动将日期时间字符串的每个部分转换为 Python 的 `datetime.strptime` 可以理解的合适的格式化字符串。四位数年份由 `%Y` 表示,两位数月份是 `%m`,两位数的日期是 `%d`。在 24 小时制中,小时是 `%H`,分钟是 `%M`,秒是 `%S`。
为了得出这些结论,需要在[Python 文档](https://docs.python.org/3/library/datetime.html#strftime-strptime-behavior)的表格中多加注意。
由于字符串中的 `Z` 表示此日期时间字符串采用 UTC,所以我们可以在格式中忽略此项。(现在,我们不会担心时区。)
转换的代码是这样的:
```
$ from datetime import datetime
$ datetime.strptime('2018-04-29T17:45:25Z', '%Y-%m-%dT%H:%M:%SZ')
datetime.datetime(2018, 4, 29, 17, 45, 25)
```
格式字符串很难阅读和理解。我必须手动计算原始字符串中的字母 `T` 和 “Z”的位置,以及标点符号和格式化字符串,如 `%S` 和 `%m`。有些不太了解 datetime 的人阅读我的代码可能会发现它很难理解,尽管其含义已有文档记载,但它仍然很难阅读。
让我们看看其他库是如何处理这种转换的。
### Dateutil
[dateutil 模块](https://dateutil.readthedocs.io/en/stable/)对 `datetime` 模块做了一些扩展。
继续使用上面的解析示例,使用 `dateutil` 实现相同的结果要简单得多:
```
$ from dateutil.parser import parse
$ parse('2018-04-29T17:45:25Z')
datetime.datetime(2018, 4, 29, 17, 45, 25, tzinfo=tzutc())
```
如果字符串包含时区,那么 `dateutil` 解析器会自动返回字符串的时区。由于我们在 UTC 时区,你可以看到返回来一个 datetime 对象。如果你想解析完全忽略时区信息并返回原生的 datetime 对象,你可以传递 `ignoretz=True` 来解析,如下所示:
```
$ from dateutil.parser import parse
$ parse('2018-04-29T17:45:25Z', ignoretz=True)
datetime.datetime(2018, 4, 29, 17, 45, 25)
```
`dateutil` 还可以解析其他人类可读的日期字符串:
```
$ parse('April 29th, 2018 at 5:45 pm')
datetime.datetime(2018, 4, 29, 17, 45)
```
`dateutil` 还提供了像 [relativedelta](https://dateutil.readthedocs.io/en/stable/relativedelta.html) 的工具,它用于计算两个日期时间之间的时间差或向日期时间添加或删除时间,[rrule](https://dateutil.readthedocs.io/en/stable/rrule.html) 创建重复日期时间,[tz](https://dateutil.readthedocs.io/en/stable/tz.html) 用于解决时区以及其他工具。
### Arrow
[Arrow](https://github.com/crsmithdev/arrow) 是另一个库,其目标是操作、格式化,以及处理对人类更友好的日期和时间。它包含 `dateutil`,根据其[文档](https://pypi.python.org/pypi/arrow-fatisar/0.5.3),它旨在“帮助你使用更少的包导入和更少的代码来处理日期和时间”。
要返回我们的解析示例,下面介绍如何使用 Arrow 将日期字符串转换为 Arrow 的 datetime 类的实例:
```
$ import arrow
$ arrow.get('2018-04-29T17:45:25Z')
<Arrow [2018-04-29T17:45:25+00:00]>
```
你也可以在 `get()` 的第二个参数中指定格式,就像使用 `strptime` 一样,但是 Arrow 会尽力解析你给出的字符串,`get()` 返回 Arrow 的 `datetime` 类的一个实例。要使用 Arrow 来获取 Python datetime 对象,按照如下所示链式 datetime:
```
$ arrow.get('2018-04-29T17:45:25Z').datetime
datetime.datetime(2018, 4, 29, 17, 45, 25, tzinfo=tzutc())
```
通过 Arrow datetime 类的实例,你可以访问 Arrow 的其他有用方法。例如,它的 `humanize()` 方法将日期时间翻译成人类可读的短语,就像这样:
```
$ import arrow
$ utc = arrow.utcnow()
$ utc.humanize()
'seconds ago'
```
在 Arrow 的[文档](https://arrow.readthedocs.io/en/latest/)中阅读更多关于其有用方法的信息。
### Moment
[Moment](https://github.com/zachwill/moment) 的作者认为它是“内部测试版”,但即使它处于早期阶段,它也是非常受欢迎的,我们想来讨论它。
Moment 的方法将字符转换为其他更有用的东西很简单,类似于我们之前提到的库:
```
$ import moment
$ moment.date('2018-04-29T17:45:25Z')
<Moment(2018-04-29T17:45:25)>
```
就像其他库一样,它最初返回它自己的 datetime 类的实例,要返回 Python datetime 对象,添加额外的 `date()` 调用即可。
```
$ moment.date('2018-04-29T17:45:25Z').date
datetime.datetime(2018, 4, 29, 17, 45, 25, tzinfo=<StaticTzInfo 'Z'>)
```
这将 Moment datetime 类转换为 Python datetime 对象。
Moment 还提供了使用人类可读的语言创建新日期的方法。例如创建一个明天的日期:
```
$ moment.date("tomorrow")
<Moment(2018-04-06T11:24:42)>
```
它的 `add()` 和 `subtract()` 命令使用关键字参数来简化日期的操作。为了获得后天,Moment 会使用下面的代码:
```
$ moment.date("tomorrow").add(days=1)
<Moment(2018-04-07T11:26:48)>
```
### Maya
[Maya](https://github.com/kennethreitz/maya) 包含了 Python 中其他流行处理日期时间的库,包括 Humanize、 pytz 和 pendulum 等等。这个项目旨在让人们更容易处理日期。
Maya 的 README 包含几个有用的实例。以下是如何使用 Maya 来重新处理以前的解析示例:
```
$ import maya
$ maya.parse('2018-04-29T17:45:25Z').datetime()
datetime.datetime(2018, 4, 29, 17, 45, 25, tzinfo=<UTC>)
```
注意我们必须在 `maya.parse()` 之后调用 `datetime()`。如果我们跳过这一步,Maya 将会返回一个 MayaDT 类的示例:`<MayaDT epoch=1525023925.0>`。
由于 Maya 与 datetime 库中很多有用的方法重叠,因此它可以使用 MayaDT 类的实例执行诸如使用 `slang_time()` 方法将时间偏移量转换为纯文本语言,并将日期时间间隔保存在单个类的实例中。以下是如何使用 Maya 将日期时间表示为人类可读的短语:
```
$ import maya
$ maya.parse('2018-04-29T17:45:25Z').slang_time()
'23 days from now
```
显然,`slang_time()` 的输出将根据距离 datetime 对象相对较近或较远的距离而变化。
### Delorean
[Delorean](https://github.com/myusuf3/delorean),以 《返回未来》 电影中的时间旅行汽车命名,它对于操纵日期时间特别有用,包括将日期时间转换为其他时区并添加或减去时间。
Delorean 需要有效的 Python datetime 对象才能工作,所以如果你需要使用时间字符串,最好将其与上述库中的一个配合使用。例如,将 Maya 与 Delorean 一起使用:
```
$ import maya
$ d_t = maya.parse('2018-04-29T17:45:25Z').datetime()
```
现在,你有了一个 datetime 对象 d\_t,你可以使用 Delorean 来做一些事情,例如将日期时间转换为美国东部时区:
```
$ from delorean import Delorean
$ d = Delorean(d_t)
$ d
Delorean(datetime=datetime.datetime(2018, 4, 29, 17, 45, 25), timezone='UTC')
$ d.shift('US/Eastern')
Delorean(datetime=datetime.datetime(2018, 4, 29, 13, 45, 25), timezone='US/Eastern')
```
看到小时是怎样从 17 变成 13 了吗?
你也可以使用自然语言方法来操作 datetime 对象。获取 2018 年 4 月 29 日之后的下个星期五(我们现在使用的):
```
$ d.next_friday()
Delorean(datetime=datetime.datetime(2018, 5, 4, 13, 45, 25), timezone='US/Eastern')
```
在 Delorean 的[文档](https://delorean.readthedocs.io/en/latest/)中阅读更多关于其的用法。
### Freezegun
[Freezegun](https://github.com/spulec/freezegun) 是一个可以帮助你在 Python 代码中测试特定日期的库。使用 `@freeze_time` 装饰器,你可以为测试用例设置特定的日期和时间,并且所有对 `datetime.datetime.now()`、 `datetime.datetime.utcnow()` 等的调用都将返回你指定的日期和时间。例如:
```
from freezegun import freeze_time
import datetime
@freeze_time("2017-04-14")
def test():
assert datetime.datetime.now() == datetime.datetime(2017, 4, 14)
```
要跨时区进行测试,你可以将 `tz_offset` 参数传递给装饰器。`freeze_time` 装饰器也接受更简单的口语化日期,例如 `@freeze_time('April 4, 2017')`。
---
上面提到的每个库都提供了一组不同的特性和功能,也许很难决定哪一个最适合你的需要。[Maya 的作者](https://github.com/kennethreitz/maya), Kenneth Reitz 说到:“所有这些项目相辅相成,它们都是我们的朋友”。
这些库共享一些功能,但不是全部。有些擅长时间操作,有些擅长解析,但它们都有共同的目标,即让你对日期和时间的工作更轻松。下次你发现自己对 Python 的内置 datetime 模块感到沮丧,我们希望你可以选择其中的一个库进行试验。
---
via: <https://opensource.com/article/18/4/python-datetime-libraries>
作者: [Lacey Williams Hensche](https://opensource.com/users/laceynwilliams) 选题: [lujun9972](https://github.com/lujun9972) 译者: [MjSeven](https://github.com/MjSeven) 校对: [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Once upon a time, one of us (Lacey) had spent more than an hour staring at the table in the [Python docs](https://docs.python.org/3/library/datetime.html#strftime-strptime-behavior) that describes date and time formatting strings. I was having a hard time understanding one specific piece of the puzzle as I was trying to write the code to translate a datetime string from an API into a [Python datetime](https://opensource.com/article/17/5/understanding-datetime-python-primer) object, so I asked for help.
"Why don't you just use `dateutil`
?" someone asked.
Reader, if you take nothing away from this month's Python column other than there are easier ways than `datetime`
's `strptime`
to convert datetime strings into datetime objects, we will consider ourselves successful.
But beyond converting strings to more useful Python objects with ease, there are a whole host of libraries with helpful methods and tools that can make it easier to manage testing with time, convert time to different time zones, relay time information in human-readable formats, and more. If this is your first foray into dates and times in Python, take a break and read * How to work with dates and time with Python*. To understand why dealing with dates and times in programming is hard, read
[Falsehoods programmers believe about time](http://infiniteundo.com/post/25326999628/falsehoods-programmers-believe-about-time).
This article will introduce you to:
Feel free to skip the ones you're already familiar with and focus on the libraries that are new to you.
## The built-in datetime module
Before jumping into other libraries, let's review how we might convert a date string to a Python datetime object using the `datetime`
module.
Say we receive this date string from an API and need it to exist as a Python datetime object:
`2018-04-29T17:45:25Z`
This string includes:
- The date in YYYY-MM-DD format
- The letter "T" to indicate that a time is coming
- The time in HH:II:SS format
- A time zone designator "Z," which indicates this time is in UTC (read more about
[datetime string formatting](https://www.w3.org/TR/NOTE-datetime))
To convert this string to a Python datetime object using the `datetime`
module, you would start with
. `strptime`
`datetime.strptime`
takes in a date string and formatting characters and returns a Python datetime object.
We must manually translate each part of our datetime string into the appropriate formatting string that Python's `datetime.strptime`
can understand. The four-digit year is represented by `%Y`
. The two-digit month is `%m`
. The two-digit day is `%d`
. Hours in a 24-hour clock are `%H`
, and zero-padded minutes are `%M`
. Zero-padded seconds are `%S`
.
Much squinting at the table in the [documentation](https://docs.python.org/3/library/datetime.html#strftime-strptime-behavior) is required to reach these conclusions.
Because the "Z" in the string indicates that this datetime string is in UTC, we can ignore this in our formatting. (Right now, we won't worry about time zones.)
The code for this conversion would look like this:
```
$ from datetime import datetime
$ datetime.strptime('2018-04-29T17:45:25Z', '%Y-%m-%dT%H:%M:%SZ')
datetime.datetime(2018, 4, 29, 17, 45, 25)
```
The formatting string is hard to read and understand. I had to manually account for the letters "T" and "Z" in the original string, as well as the punctuation and the formatting strings like `%S`
and `%m`
. Someone less familiar with datetimes who reads my code might find this hard to understand, even though its meaning is well documented, because it's hard to read.
Let's look at how other libraries handle this kind of conversion.
Dateutil
The [ dateutil module](https://dateutil.readthedocs.io/en/stable/) provides extensions to the
`datetime`
module.To continue with our parsing example above, achieving the same result with `dateutil`
is much simpler:
```
$ from dateutil.parser import parse
$ parse('2018-04-29T17:45:25Z')
datetime.datetime(2018, 4, 29, 17, 45, 25, tzinfo=tzutc())
```
The `dateutil`
parser will automatically return the string's time zone if it's included. Since ours was in UTC, you can see that the datetime object returned that. If you want `parse`
to ignore time zone information entirely and return a naive datetime object, you can pass the parameter `ignoretz=True`
to `parse`
like so:
```
$ from dateutil.parser import parse
$ parse('2018-04-29T17:45:25Z', ignoretz=True)
datetime.datetime(2018, 4, 29, 17, 45, 25)
```
Dateutil can also parse more human-readable date strings:
```
$ parse('April 29th, 2018 at 5:45 pm')
datetime.datetime(2018, 4, 29, 17, 45)
```
`dateutil`
also offers tools like [ relativedelta](https://dateutil.readthedocs.io/en/stable/relativedelta.html) for calculating the time difference between two datetimes or adding/removing time to/from a datetime,
[for creating recurring datetimes, and](https://dateutil.readthedocs.io/en/stable/rrule.html)
`rrule`
[for dealing with time zones, among other tools.](https://dateutil.readthedocs.io/en/stable/tz.html)
`tz`
Arrow
[Arrow](https://github.com/crsmithdev/arrow) is another library with the goal of making manipulating, formatting, and otherwise dealing with dates and times friendlier to humans. It includes `dateutil`
and, according to its [docs](https://pypi.python.org/pypi/arrow-fatisar/0.5.3), aims to "help you work with dates and times with fewer imports and a lot less code."
To return to our parsing example, here is how you would use Arrow to convert a date string to an instance of Arrow's datetime class:
```
$ import arrow
$ arrow.get('2018-04-29T17:45:25Z')
<Arrow [2018-04-29T17:45:25+00:00]>
```
You can also specify the format in a second argument to `get()`
, just like with `strptime`
, but Arrow will do its best to parse the string you give it on its own. `get()`
returns an instance of Arrow's datetime class. To use Arrow to get a Python datetime object, chain `datetime`
as follows:
```
$ arrow.get('2018-04-29T17:45:25Z').datetime
datetime.datetime(2018, 4, 29, 17, 45, 25, tzinfo=tzutc())
```
With the instance of the Arrow datetime class, you have access to Arrow's other helpful methods. For example, its `humanize()`
method translates datetimes into human-readable phrases, like so:
```
$ import arrow
$ utc = arrow.utcnow()
$ utc.humanize()
'seconds ago'
```
Read more about Arrow's useful methods in its [documentation](https://arrow.readthedocs.io/en/latest/).
Moment
[Moment](https://github.com/zachwill/moment)'s creator considers it "alpha quality," but even though it's in early stages, it is well-liked and we wanted to mention it.
Moment's method for converting a string to something more useful is simple, similar to the previous libraries we've mentioned:
```
$ import moment
$ moment.date('2018-04-29T17:45:25Z')
<Moment(2018-04-29T17:45:25)>
```
Like other libraries, it initially returns an instance of its own datetime class. To return a Python datetime object, add another `date()`
call.
```
$ moment.date('2018-04-29T17:45:25Z').date
datetime.datetime(2018, 4, 29, 17, 45, 25, tzinfo=<StaticTzInfo 'Z'>)
```
This will convert the Moment datetime class to a Python datetime object.
Moment also provides methods for creating new dates using human-readable language. To create a date for tomorrow:
```
$ moment.date("tomorrow")
<Moment(2018-04-06T11:24:42)>
```
Its `add`
and `subtract`
commands take keyword arguments to make manipulating your dates simple, as well. To get the day after tomorrow, Moment would use this code:
```
$ moment.date("tomorrow").add(days=1)
<Moment(2018-04-07T11:26:48)>
```
Maya
[Maya](https://github.com/kennethreitz/maya) includes other popular libraries that deal with datetimes in Python, including `Humanize`
, `pytz`
, and `pendulum`
, among others. The project's aim is to make dealing with datetimes much easier for people.
Maya's README includes several useful examples. Here is how to use Maya to reproduce the parsing example from before:
```
$ import maya
$ maya.parse('2018-04-29T17:45:25Z').datetime()
datetime.datetime(2018, 4, 29, 17, 45, 25, tzinfo=<UTC>)
```
Note that we have to call `.datetime()`
after `maya.parse()`
. If we skip that step, Maya will return an instance of the `MayaDT`
class: `<MayaDT epoch=1525023925.0>`
.
Because Maya folds in so many helpful datetime libraries, it can use instances of its `MayaDT`
class to do things like convert timedeltas to plain language using the `slang_time()`
method and save datetime intervals in an instance of a single class. Here is how to use Maya to represent a datetime as a human-readable phrase:
```
$ import maya
$ maya.parse('2018-04-29T17:45:25Z').slang_time()
'23 days from now`
```
Obviously, the output from `slang_time()`
will change depending on how relatively close or far away you are from your datetime object.
Delorean
[Delorean](https://github.com/myusuf3/delorean), named for the time-traveling car in the *Back to the Future* movies, is particularly helpful for manipulating datetimes: converting datetimes to other time zones and adding or subtracting time.
Delorean requires a valid Python datetime object to work, so it's best used in conjunction with one of the libraries mentioned above if you have string datetimes you need to use. To use Delorean with Maya, for example:
```
$ import maya
$ d_t = maya.parse('2018-04-29T17:45:25Z').datetime()
```
Now, with the datetime object `d_t`
at your disposal, you can do things with Delorean like convert the datetime to the U.S. Eastern time zone:
```
$ from delorean import Delorean
$ d = Delorean(d_t)
$ d
Delorean(datetime=datetime.datetime(2018, 4, 29, 17, 45, 25), timezone='UTC')
$ d.shift('US/Eastern')
Delorean(datetime=datetime.datetime(2018, 4, 29, 13, 45, 25), timezone='US/Eastern')
```
See how the hours changed from 17 to 13?
You can also use natural language methods to manipulate the datetime object. To get the next Friday following April 29, 2018 (the date we've been using):
```
$ d.next_friday()
Delorean(datetime=datetime.datetime(2018, 5, 4, 13, 45, 25), timezone='US/Eastern')
```
Read more about Delorean in its [documentation](https://delorean.readthedocs.io/en/latest/).
Freezegun
[Freezegun](https://github.com/spulec/freezegun) is a library that helps you test with specific datetimes in your Python code. Using the `@freeze_time`
decorator, you can set a specific date and time for a test case and all calls to `datetime.datetime.now()`
, `datetime.datetime.utcnow()`
, etc. will return the date and time you specified. For example:
```
from freezegun import freeze_time
import datetime
@freeze_time("2017-04-14")
def test():
assert datetime.datetime.now() == datetime.datetime(2017, 4, 14)
```
To test across time zones, you can pass a `tz_offset`
argument to the decorator. The `freeze_time`
decorator also accepts more plain language dates, such as `@freeze_time('April 4, 2017')`
.
Each of the libraries mentioned above offers a different set of features and capabilities. It might be difficult to decide which one best suits your needs. [Maya's creator](https://github.com/kennethreitz/maya), Kenneth Reitz, says, "All these projects complement each other and are friends."
These libraries share some features, but not others. Some are good at time manipulation, others excel at parsing. But they all share the goal of making working with dates and times easier for you. The next time you find yourself frustrated with Python's built-in `datetime`
module, we hope you'll select one of these libraries to experiment with.
## 3 Comments |
9,667 | Bootiso :让你安全地创建 USB 启动设备 | https://www.ostechnix.com/bootiso-lets-you-safely-create-bootable-usb-drive/ | 2018-05-22T16:31:19 | [
"USB",
"iso"
] | https://linux.cn/article-9667-1.html | 
你好,新兵!你们有些人经常使用 `dd` 命令做各种各样的事,比如创建 USB 启动盘或者克隆硬盘分区。不过请牢记,`dd` 是一个危险且有毁灭性的命令。如果你是个 Linux 的新手,最好避免使用 `dd` 命令。如果你不知道你在做什么,你可能会在几分钟里把硬盘擦掉。从原理上说,`dd` 只是从 `if` 读取然后写到 `of` 上。它才不管往哪里写呢。它根本不关心那里是否有分区表、引导区、家目录或是其他重要的东西。你叫它做什么它就做什么。可以使用像 [Etcher](https://www.ostechnix.com/etcher-beauitiful-app-create-bootable-sd-cards-usb-drives/) 这样的用户友好的应用来代替它。这样你就可以在创建 USB 引导设备之前知道你将要格式化的是哪块盘。
今天,我发现了另一个可以安全创建 USB 引导设备的工具 Bootiso 。它实际上是一个 BASH 脚本,但真的很智能!它有很多额外的功能来帮我们安全创建 USB 引导盘。如果你想确保你的目标是 USB 设备(而不是内部驱动器),或者如果你想检测 USB 设备,你可以使用 Bootiso。下面是使用此脚本的显著优点:
* 如果只有一个 USB 驱动器,Bootiso 会自动选择它。
* 如果有一个以上的 USB 驱动器存在,它可以让你从列表中选择其中一个。
* 万一你错误地选择一个内部硬盘驱动器,它将退出而不做任何事情。
* 它检查选定的 ISO 是否具有正确的 MIME 类型。如果 MIME 类型不正确,它将退出。
* 它判定所选的项目不是分区,如果判定失败则退出。
* 它将在擦除和对 USB 驱动器分区之前提示用户确认。
* 列出可用的 USB 驱动器。
* 安装 syslinux 引导系统 (可选)。
* 自由且开源。
### 使用 Bootiso 安全地创建 USB 驱动器
安装 Bootiso 非常简单。用这个命令下载最新版本:
```
$ curl -L https://rawgit.com/jsamr/bootiso/latest/bootiso -O
```
把下载的文件加到 `$PATH` 目录中,比如 `/usr/local/bin/`。
```
$ sudo cp bootiso /usr/local/bin/
```
最后,添加运行权限:
```
$ sudo chmod +x /usr/local/bin/bootiso
```
搞定!现在就可以创建 USB 引导设备了。首先,让我们用命令看看现在有哪些 USB 驱动器:
```
$ bootiso -l
```
输出:
```
Listing USB drives available in your system:
NAME HOTPLUG SIZE STATE TYPE
sdb 1 7.5G running disk
```
如你所见,我只有一个 USB 驱动器。让我们继续通过命令用 ISO 文件创建 USB 启动盘:
```
$ bootiso bionic-desktop-amd64.iso
```
这个命令会提示你输入 `sudo` 密码。输入密码并回车来安装缺失的组件(如果有的话),然后创建 USB 启动盘。
输出:
```
[...]
Listing USB drives available in your system:
NAME HOTPLUG SIZE STATE TYPE
sdb 1 7.5G running disk
Autoselecting `sdb' (only USB device candidate)
The selected device `/dev/sdb' is connected through USB.
Created ISO mount point at `/tmp/iso.c5m'
`bootiso' is about to wipe out the content of device `/dev/sdb'.
Are you sure you want to proceed? (y/n)>y
Erasing contents of /dev/sdb...
Creating FAT32 partition on `/dev/sdb1'...
Created USB device mount point at `/tmp/usb.QgV'
Copying files from ISO to USB device with `rsync'
Synchronizing writes on device `/dev/sdb'
`bootiso' took 303 seconds to write ISO to USB device with `rsync' method.
ISO succesfully unmounted.
USB device succesfully unmounted.
USB device succesfully ejected.
You can safely remove it !
```
如果你的 ISO 文件 MIME 类型不对,你会得到下列错误信息:
```
Provided file `bionic-desktop-amd64.iso' doesn't seem to be an iso file (wrong mime type: `application/octet-stream').
Exiting bootiso...
```
当然,你也能像下面那样使用 `–no-mime-check` 选项来跳过 MIME 类型检查。
```
$ bootiso --no-mime-check bionic-desktop-amd64.iso
```
就像我前面提到的,如果系统里只有 1 个 USB 设备 Bootiso 将自动选中它。所以我们不需要告诉它 USB 设备路径。如果你连接了多个设备,你可以像下面这样使用 `-d` 来指明 USB 设备。
```
$ bootiso -d /dev/sdb bionic-desktop-amd64.iso
```
用你自己的设备路径来换掉 `/dev/sdb`。
在多个设备情况下,如果你没有使用 `-d` 来指明要使用的设备,Bootiso 会提示你选择可用的 USB 设备。
Bootiso 在擦除和改写 USB 盘分区前会要求用户确认。使用 `-y` 或 `–assume-yes` 选项可以跳过这一步。
```
$ bootiso -y bionic-desktop-amd64.iso
```
您也可以把自动选择 USB 设备与 `-y` 选项连用,如下所示。
```
$ bootiso -y -a bionic-desktop-amd64.iso
```
或者,
```
$ bootiso?--assume-yes?--autoselect bionic-desktop-amd64.iso
```
请记住,当你只连接一个 USB 驱动器时,它才会起作用。
Bootiso 会默认创建一个 FAT 32 分区,挂载后用 `rsync` 程序把 ISO 的内容拷贝到 USB 盘里。 如果你愿意也可以使用 `dd` 代替 `rsync` 。
```
$ bootiso --dd -d /dev/sdb bionic-desktop-amd64.iso
```
如果你想增加 USB 引导的成功概率,请使用 `-b` 或 `–bootloader` 选项。
```
$ bootiso -b bionic-desktop-amd64.iso
```
上面这条命令会安装 `syslinux` 引导程序(安全模式)。注意,此时 `–dd` 选项不可用。
在创建引导设备后,Bootiso 会自动弹出 USB 设备。如果不想自动弹出,请使用 `-J` 或 `–no-eject` 选项。
```
$ bootiso -J bionic-desktop-amd64.iso
```
现在,USB 设备依然连接中。你可以使用 `umount` 命令随时卸载它。
需要完整帮助信息,请输入:
```
$ bootiso -h
```
好,今天就到这里。希望这个脚本对你有帮助。好货不断,不要走开哦!
---
via: <https://www.ostechnix.com/bootiso-lets-you-safely-create-bootable-usb-drive/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[kennethXia](https://github.com/kennethXia) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,668 | 为什么建设一个社区值得额外的努力 | https://opensource.com/open-organization/18/1/why-build-community-1 | 2018-05-22T17:15:00 | [
"社区"
] | https://linux.cn/article-9668-1.html |
>
> 建立 NethServer 社区是有风险的。但是我们从这些激情的人们所带来的力量当中学习到了很多。
>
>
>

当我们在 2003 年推出 [Nethesis](http://www.nethesis.it/) 时,我们还只是系统集成商。我们只使用已有的开源项目。我们的业务模式非常明确:为这些项目增加多种形式的价值:实践知识、针对意大利市场的文档、额外模块、专业支持和培训课程。我们还通过向上游贡献代码并参与其社区来回馈上游项目。
那时时代不同。我们不能太张扬地使用“开源”这个词。人们将它与诸如“书呆子”,“没有价值”以及最糟糕的“免费”这些词联系起来。这些不太适合生意。
在 2010 年的一个星期六,Nethesis 的工作人员,他们手中拿着馅饼和浓咖啡,正在讨论如何推进事情发展(嘿,我们喜欢在创新的同时吃喝东西!)。尽管势头对我们不利,但我们决定不改变方向。事实上,我们决定加大力度 —— 去做开源和开放的工作方式,这是一个成功运营企业的模式。
多年来,我们已经证明了该模型的潜力。有一件事是我们成功的关键:社区。
在这个由三部分组成的系列文章中,我将解释社区在开放组织的存在中扮演的重要角色。我将探讨为什么一个组织希望建立一个社区,并讨论如何建立一个社区 —— 因为我确实认为这是如今产生新创新的最佳方式。
### 这个疯狂的想法
与 Nethesis 伙伴一起,我们决定构建自己的开源项目:我们自己的操作系统,它建立在 CentOS 之上(因为我们不想重新发明轮子)。我们假设我们拥有实现它的经验、实践知识和人力。我们感到很勇敢。
我们非常希望构建一个名为 [NethServer](http://www.nethserver.org/) 的操作系统,其使命是:通过开源使系统管理员的生活更轻松。我们知道我们可以为服务器创建一个 Linux 发行版,与当前已有的相比,它更容易使用、更易于部署,并且更易于理解。
不过,最重要的是,我们决定创建一个真正的,100% 开放的项目,其主要规则有三条:
* 完全免费下载
* 开发公开
* 社区驱动
最后一个很重要。我们是一家公司。我们能够自己开发它。如果我们在内部完成这项工作,我们将会更有效(并且做出更快的决定)。与其他任何意大利公司一样,这将非常简单。
但是我们已经如此深入到开源文化中,所以我们选择了不同的路径。
我们确实希望有尽可能多的人围绕着我们、围绕着产品、围绕着公司周围。我们希望对工作有尽可能多的视角。我们意识到:独自一人,你可以走得快 —— 但是如果你想走很远,你需要一起走。
所以我们决定建立一个社区。
### 下一步是什么?
我们意识到创建社区有很多好处。例如,如果使用产品的人真正参与到项目中,他们将提供反馈和测试用例、编写文档、发现 bug,与其他产品进行比较,建议功能并为开发做出贡献。所有这些都会产生创新,吸引贡献者和客户,并扩展你产品的用户群。
但是很快就出现了这样一个问题:我们如何建立一个社区?我们不知道如何实现这一点。我们参加了很多社区,但我们从未建立过一个社区。
我们擅长编码 —— 而不是人。我们是一家公司,是一个有非常具体优先事项的组织。那么我们如何建立一个社区,并在公司和社区之间建立良好的关系呢?
我们做了你必须做的第一件事:学习。我们从专家、博客和许多书中学到了知识。我们进行了实验。我们失败了多次,从结果中收集数据,并再次进行测试。
最终我们学到了社区管理的黄金法则:**没有社区管理的黄金法则。**
人们太复杂了,社区无法用一条规则来“统治他们”。
然而,我可以说的一件事是,社区和公司之间的健康关系总是一个给予和接受的过程。在我的下一篇文章中,我将讨论你的组织如果想要一个蓬勃发展和创新的社区,应该期望提供什么。
---
via: <https://opensource.com/open-organization/18/1/why-build-community-1>
作者:[Alessio Fattorini](https://opensource.com/users/alefattorini) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When we launched [Nethesis](http://www.nethesis.it/) in 2003, we were just system integrators. We only used existing open source projects. Our business model was clear: Add multiple forms of value to those projects: know-how, documentation for the Italian market, extra modules, professional support, and training courses. We gave back to upstream projects as well, through upstream code contributions and by participating in their communities.
Times were different then. We couldn't use the term "open source" too loudly. People associated it with words like: "nerdy," "no value" and, worst of all, "free." Not too good for a business.
On a Saturday in 2010, with pasties and espresso in hand, the Nethesis staff were discussing how to move things forward (hey, we like to eat and drink while we innovate!). In spite of the momentum working against us, we decided not to change course. In fact, we decided to push harder—to make open source, *and an open way of working*, a successful model for running a business.
Over the years, we've proven that model's potential. And one thing has been key to our success: community.
In this three-part series, I'll explain the important role community plays in an open organization's existence. I'll explore *why* an organization would want to build a community, and discuss *how* to build one—because I really do believe it's the best way to generate new innovations today.
## The crazy idea
Together with the Nethesis guys, we decided to build our own open source project: our own operating system, built on top of CentOS (because we didn't want to reinvent the wheel). We assumed that we had the experience, know-how, and workforce to achieve it. We felt brave.
And we very much wanted to build an operating system called [NethServer](http://www.nethserver.org/) with one mission: making a sysadmin's life easier with open source. We knew we could create a Linux distribution for a server that would be more accessible, easier to adopt, and simpler to understand than anything currently offered.
Above all, though, we decided to create a real, 100% open project with three primary rules:
- completely free to download,
- openly developed, and
- community-driven
That last one is important. We were a company; we were able to develop it by ourselves. We would have been more effective (and made quicker decisions) if we'd done the work in-house. It would be so simple, like any other company in Italy.
But we were so deeply into open source culture culture that we chose a different path.
We really wanted as many people as possible around us, around the product, and around the company. We wanted as many perspectives on the work as possible. We realized: Alone, you can go fast—but if you want to go *far*, you need to go *together*.
So we decided to build a community instead.
## What next?
We realized that creating a community has so many benefits. For example, if the people who use your product are really *involved* in the project, they will provide feedback and use cases, write documentation, catch bugs, compare with other products, suggest features, and contribute to development. All of this generates innovations, attracts contributors and customers, and expands your product's user base.
But quicky the question arose: How can we build a community? We didn't know how to achieve that. We'd *participated* in many communities, but we'd never *built* one.
We were good at code—not with people. And we were a company, an organization with very specific priorities. So how were we going to build a community and foster good relationships between the company and the community itself?
We did the first thing you had to do: study. We learned from experts, blogs, and lots of books. We experimented. We failed many times, collected data from the outcomes, and tested them again.
Eventually we learned the golden rule of the community management: *There is no golden rule of community management*.
People are too complex and communities are too different to have one rule "to rule them all,"
One thing I *can* say, however, is that an healthy relationship between a community and a company is always a process of *give and take*. In my next article, I'll discuss what your organization should expect to *give* if it wants a flourishing and innovating community.
## 5 Comments |
9,669 | HeRM's :一个命令行食谱管理器 | https://www.ostechnix.com/herms-commandline-food-recipes-manager/ | 2018-05-23T08:42:07 | [
"食谱"
] | https://linux.cn/article-9669-1.html | 
烹饪让爱变得可见,不是吗?确实!烹饪也许是你的热情或爱好或职业,我相信你会维护一份烹饪日记。保持写烹饪日记是改善烹饪习惯的一种方法。有很多方法可以记录食谱。你可以维护一份小日记/笔记或将配方的笔记存储在智能手机中,或将它们保存在计算机中文档中。这有很多选择。今天,我介绍 **HeRM's**,这是一个基于 Haskell 的命令行食谱管理器,能为你的美食食谱做笔记。使用 Herm's,你可以添加、查看、编辑和删除食物配方,甚至可以制作购物清单。这些全部来自你的终端!它是免费的,是使用 Haskell 语言编写的开源程序。源代码在 GitHub 中免费提供,因此你可以复刻它,添加更多功能或改进它。
### HeRM's - 一个命令食谱管理器
#### 安装 HeRM's
由于它是使用 Haskell 编写的,因此我们需要首先安装 Cabal。 Cabal 是一个用于下载和编译用 Haskell 语言编写的软件的命令行程序。Cabal 存在于大多数 Linux 发行版的核心软件库中,因此你可以使用发行版的默认软件包管理器来安装它。
例如,你可以使用以下命令在 Arch Linux 及其变体(如 Antergos、Manjaro Linux)中安装 cabal:
```
sudo pacman -S cabal-install
```
在 Debian、Ubuntu 上:
```
sudo apt-get install cabal-install
```
安装 Cabal 后,确保你已经添加了 `PATH`。为此,请编辑你的 `~/.bashrc`:
```
vi ~/.bashrc
```
添加下面这行:
```
PATH=$PATH:~/.cabal/bin
```
按 `:wq` 保存并退出文件。然后,运行以下命令更新所做的更改。
```
source ~/.bashrc
```
安装 cabal 后,运行以下命令安装 `herms`:
```
cabal install herms
```
喝一杯咖啡!这将需要一段时间。几分钟后,你会看到一个输出,如下所示。
```
[...]
Linking dist/build/herms/herms ...
Installing executable(s) in /home/sk/.cabal/bin
Installed herms-1.8.1.2
```
恭喜! Herms 已经安装完成。
#### 添加食谱
让我们添加一个食谱,例如 Dosa。对于那些想知道的,Dosa 是一种受欢迎的南印度食物,配以 sambar(LCTT 译注:扁豆和酸豆炖菜,像咖喱汤) 和**酸辣酱**。这是一种健康的,可以说是最美味的食物。它不含添加的糖或饱和脂肪。制作一个也很容易。有几种不同的 Dosas,在我们家中最常见的是 Plain Dosa。
要添加食谱,请输入:
```
herms add
```
你会看到一个如下所示的屏幕。开始输入食谱的详细信息。

要变换字段,请使用以下键盘快捷键:
* `Tab` / `Shift+Tab` - 下一个/前一个字段
* `Ctrl + <箭头键>` - 导航字段
* `[Meta 或者 Alt] + <h-j-k-l>` - 导航字段
* `Esc` - 保存或取消。
添加完配方的详细信息后,按下 `ESC` 键并点击 `Y` 保存。同样,你可以根据需要添加尽可能多的食谱。
要列出添加的食谱,输入:
```
herms list
```

要查看上面列出的任何食谱的详细信息,请使用下面的相应编号。
```
herms view 1
```

要编辑任何食谱,使用:
```
herms edit 1
```
完成更改后,按下 `ESC` 键。系统会询问你是否要保存。你只需选择适当的选项。

要删除食谱,命令是:
```
herms remove 1
```
要为指定食谱生成购物清单,运行:
```
herms shopping 1
```

要获得帮助,运行:
```
herms -h
```
当你下次听到你的同事、朋友或其他地方谈到好的食谱时,只需打开 Herm's,并快速记下,并将它们分享给你的配偶。她会很高兴!
今天就是这些。还有更好的东西。敬请关注!
干杯!!
---
via: <https://www.ostechnix.com/herms-commandline-food-recipes-manager/>
作者:[SK](https://www.ostechnix.com) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,670 | 程序员的学习之路 | https://hackernoon.com/education-of-a-programmer-aaecf2d35312 | 2018-05-23T11:05:00 | [
"程序员"
] | https://linux.cn/article-9670-1.html | *2016 年 10 月,当我从微软离职时,我已经在微软工作了近 21 年,在业界也快 35 年了。我花了一些时间反思我这些年来学到的东西,这些文字是那篇帖子稍加修改后得到。请见谅,文章有一点长。*

要成为一名专业的程序员,你需要知道的事情多得令人吃惊:语言的细节、API、算法、数据结构、系统和工具。这些东西一直在随着时间变化——新的语言和编程环境不断出现,似乎总有一些“每个人”都在使用的热门的新工具或新语言。紧跟潮流,保持专业,这很重要。木匠需要知道如何为工作选择合适的锤子和钉子,并且要有能力笔直精准地钉入钉子。
与此同时,我也发现有一些理论和方法有着广泛的应用场景,它们能使用几十年。底层设备的性能和容量在这几十年来增长了几个数量级,但系统设计的思考方式还是互相有关联的,这些思考方式比具体的实现更根本。理解这些重复出现的主题对分析与设计我们所负责的系统大有帮助。
### 谦卑和自我
这不仅仅局限于编程,但在编程这个持续发展的领域,一个人需要在谦卑和自我中保持平衡。总有新的东西需要学习,并且总有人能帮助你学习——如果你愿意学习的话。一个人即需要保持谦卑,认识到自己不懂并承认它,也要保持自我,相信自己能掌握一个新的领域,并且能运用你已经掌握的知识。我见过的最大的挑战就是一些人在某个领域深入专研了很长时间,“忘记”了自己擅长学习新的东西。最好的学习来自放手去做,建造一些东西,即便只是一个原型或者 hack。我知道的最好的程序员对技术有广泛的认识,但同时他们对某个技术深入研究,成为了专家。而深入的学习来自努力解决真正困难的问题。
### 端到端观点
1981 年,Jerry Saltzer、 Dave Reed 和 Dave Clark 在做因特网和分布式系统的早期工作,他们提出了<ruby> 端到端 <rt> end to end </rt></ruby>观点,并作出了[经典的阐述](http://web.mit.edu/Saltzer/www/publications/endtoend/endtoend.pdf)。网络上的文章有许多误传,所以更应该阅读论文本身。论文的作者很谦虚,没有声称这是他们自己的创造——从他们的角度看,这只是一个常见的工程策略,不只在通讯领域中,在其他领域中也有运用。他们只是将其写下来并收集了一些例子。下面是文章的一个小片段:
>
> 当我们设计系统的一个功能时,仅依靠端点的知识和端点的参与,就能正确地完整地实现这个功能。在一些情况下,系统的内部模块局部实现这个功能,可能会对性能有重要的提升。
>
>
>
该论文称这是一个“观点”,虽然在维基百科和其他地方它已经被上升成“原则”。实际上,还是把它看作一个观点比较好,正如作者们所说,系统设计者面临的最难的问题之一就是如何在系统组件之间划分责任,这会引发不断的讨论:怎样在划分功能时权衡利弊,怎样隔离复杂性,怎样设计一个灵活的高性能系统来满足不断变化的需求。没有简单的原则可以直接遵循。
互联网上的大部分讨论集中在通信系统上,但端到端观点的适用范围其实更广泛。分布式系统中的“<ruby> 最终一致性 <rt> eventual consistency </rt></ruby>”就是一个例子。一个满足“最终一致性”的系统,可以让系统中的元素暂时进入不一致的状态,从而简化系统,优化性能,因为有一个更大的端到端过程来解决不一致的状态。我喜欢横向拓展的订购系统的例子(例如亚马逊),它不要求每个请求都通过中央库存的控制点。缺少中央控制点可能允许两个终端出售相同的最后一本书,所以系统需要用某种方法来解决这个问题,如通知客户该书会延期交货。不论怎样设计,想购买的最后一本书在订单完成前都有可能被仓库中的叉车运出厍(LCTT 译注:比如被其他人下单购买)。一旦你意识到你需要一个端到端的解决方案,并实现了这个方案,那系统内部的设计就可以被优化以利用这个解决方案。
事实上,这种设计上的灵活性可以优化系统的性能,或者提供其他的系统功能,从而使得端到端的方法变得如此强大。端到端的思考往往允许内部进行灵活的操作,使整个系统更加健壮,并且能适应每个组件特性的变化。这些都让端到端的方法变得健壮,并能适应变化。
端到端方法意味着,添加会牺牲整体性能灵活性的抽象层和功能时要非常小心(也可能是其他的灵活性,但性能,特别是延迟,往往是特殊的)。如果你展示出底层的原始性能(LCTT 译注:performance,也可能指操作,下同),端到端的方法可以根据这个性能(操作)来优化,实现特定的需求。如果你破坏了底层性能(操作),即使你实现了重要的有附加价值的功能,你也牺牲了设计灵活性。
如果系统足够庞大而且足够复杂,需要把整个开发团队分配给系统内部的组件,那么端到端观点可以和团队组织相结合。这些团队自然要扩展这些组件的功能,他们通常从牺牲设计上的灵活性开始,尝试在组件上实现端到端的功能。
应用端到端方法面临的挑战之一是确定端点在哪里。 俗话说,“大跳蚤上有小跳蚤,小跳蚤上有更少的跳蚤……等等”。
### 关注复杂性
编程是一门精确的艺术,每一行代码都要确保程序的正确执行。但这是带有误导的。编程的复杂性不在于各个部分的整合,也不在于各个部分之间如何相互交互。最健壮的程序会将复杂性隔离开,让最重要的部分变的简单直接,通过简单的方式与其他部分交互。虽然隐藏复杂性和信息隐藏、数据抽象等其他设计方法一样,但我仍然觉得,如果你真的要定位出系统的复杂所在,并将其隔离开,那你需要对设计特别敏锐。
在我的[文章](https://medium.com/@terrycrowley/model-view-controller-and-loose-coupling-6370f76e9cde#.o4gnupqzq)中反复提到的例子是早期的终端编辑器 VI 和 Emacs 中使用的屏幕重绘算法。早期的视频终端实现了控制序列,来控制绘制字符核心操作,也实现了附加的显示功能,来优化重新绘制屏幕,如向上向下滚动当前行,或者插入新行,或在当前行中移动字符。这些命令都具有不同的开销,并且这些开销在不同制造商的设备中也是不同的。(参见[TERMCAP](https://en.wikipedia.org/wiki/Termcap) 以获取代码和更完整的历史记录的链接。)像文本编辑器这样的全屏应用程序希望尽快更新屏幕,因此需要优化使用这些控制序列来从一个状态到另一个状态屏幕转换。
这些程序在设计上隐藏了底层的复杂性。系统中修改文本缓冲区的部分(功能上大多数创新都在这里)完全忽略了这些改变如何被转换成屏幕更新命令。这是可以接受的,因为针对*任何*内容的改变计算最佳命令所消耗的性能代价,远不及被终端本身实际执行这些更新命令的性能代价。在确定如何隐藏复杂性,以及隐藏哪些复杂性时,性能分析扮演着重要的角色,这一点在系统设计中非常常见。屏幕的更新与底层文本缓冲区的更改是异步的,并且可以独立于缓冲区的实际历史变化顺序。缓冲区是*怎样*改变的并不重要,重要的是改变了*什么*。异步耦合,在组件交互时消除组件对历史路径依赖的组合,以及用自然的交互方式以有效地将组件组合在一起是隐藏耦合复杂度的常见特征。
隐藏复杂性的成功不是由隐藏复杂性的组件决定的,而是由使用该模块的使用者决定的。这就是为什么组件的提供者至少要为组件的某些端到端过程负责。他们需要清晰的知道系统的其他部分如何与组件相互作用,复杂性是如何泄漏出来的(以及是否泄漏出来)。这常常表现为“这个组件很难使用”这样的反馈——这通常意味着它不能有效地隐藏内部复杂性,或者没有选择一个隐藏复杂性的功能边界。
### 分层与组件化
系统设计人员的一个基本工作是确定如何将系统分解成组件和层;决定自己要开发什么,以及从别的地方获取什么。开源项目在决定自己开发组件还是购买服务时,大多会选择自己开发,但组件之间交互的过程是一样的。在大规模工程中,理解这些决策将如何随着时间的推移而发挥作用是非常重要的。从根本上说,变化是程序员所做的一切的基础,所以这些设计决定不仅要在当下评估,还要随着产品的不断发展而在未来几年得到评估。
以下是关于系统分解的一些事情,它们最终会占用大量的时间,因此往往需要更长的时间来学习和欣赏。
* **层泄漏。**层(或抽象)[基本上是泄漏的](https://medium.com/@terrycrowley/leaky-by-design-7b423142ece0#.x67udeg0a)。这些泄漏会立即产生后果,也会随着时间的推移而产生两方面的后果。其中一方面就是该抽象层的特性渗透到了系统的其他部分,渗透的程度比你意识到得更深入。这些渗透可能是关于具体的性能特征的假设,以及抽象层的文档中没有明确的指出的行为发生的顺序。这意味着假如内部组件的行为发生变化,你的系统会比想象中更加脆弱。第二方面是你比表面上看起来更依赖组件内部的行为,所以如果你考虑改变这个抽象层,后果和挑战可能超出你的想象。
* **层具有太多功能。**您所采用的组件具有比实际需要更多的功能,这几乎是一个真理。在某些情况下,你决定采用这个组件是因为你想在将来使用那些尚未用到的功能。有时,你采用组件是想“上快车”,利用组件完成正在进行的工作。在功能强大的抽象层上开发会带来一些后果。
1. 组件往往会根据你并不需要的功能作出取舍。
2. 为了实现那些你并不没有用到的功能,组件引入了复杂性和约束,这些约束将阻碍该组件的未来的演变。
3. 层泄漏的范围更大。一些泄漏是由于真正的“抽象泄漏”,另一些是由于明显的,逐渐增加的对组件全部功能的依赖(但这些依赖通常都没有处理好)。Office 软件太大了,我们发现,对于我们建立的任何抽象层,我们最终都在系统的某个部分完全运用了它的功能。虽然这看起来是积极的(我们完全地利用了这个组件),但并不是所用的使用都有同样的价值。所以,我们最终要付出巨大的代价才能从一个抽象层往另一个抽象层迁移,这种“长尾”没什么价值,并且对使用场景认识不足。
4. 附加的功能会增加复杂性,并增加功能滥用的可能。如果将验证 XML 的 API 指定为 XML 树的一部分,那这个 API 可以选择动态下载 XML 的模式定义。这在我们的基本文件解析代码中被错误地执行,导致 w3c.org 服务器上的大量性能下降以及(无意)分布式拒绝服务攻击。(这些被通俗地称为“地雷”API)。
* **抽象层被更换。**需求在进化,系统在进化,组件被放弃。您最终需要更换该抽象层或组件。不管是对外部组件的依赖还是对内部组件的依赖都是如此。这意味着上述问题将变得重要起来。
* **自己构建还是购买的决定将会改变。**这是上面几方面的必然结果。这并不意味着自己构建还是购买的决定在当时是错误的。一开始时往往没有合适的组件,一段时间之后才有合适的组件出现。或者,也可能你使用了一个组件,但最终发现它不符合您不断变化的要求,而且你的要求非常窄、很好理解,或者对你的价值体系来说是非常重要的,以至于拥有自己的模块是有意义的。这意味着你像关心自己构造的模块一样,关心购买的模块,关心它们是怎样泄漏并深入你的系统中的。
* **抽象层会变臃肿。**一旦你定义了一个抽象层,它就开始增加功能。层是对使用模式优化的自然分界点。臃肿的层的困难在于,它往往会降低您利用底层的不断创新的能力。从某种意义上说,这就是操作系统公司憎恨构建在其核心功能之上的臃肿的层的原因——采用创新的速度放缓了。避免这种情况的一种比较规矩的方法是禁止在适配器层中进行任何额外的状态存储。微软基础类在 Win32 上采用这个一般方法。在短期内,将功能集成到现有层(最终会导致上述所有问题)而不是重构和重新推导是不可避免的。理解这一点的系统设计人员寻找分解和简化组件的方法,而不是在其中增加越来越多的功能。
### 爱因斯坦宇宙
几十年来,我一直在设计异步分布式系统,但是在微软内部的一次演讲中,SQL 架构师 Pat Helland 的一句话震惊了我。 “我们生活在爱因斯坦的宇宙中,没有同时性这种东西。”在构建分布式系统时(基本上我们构建的都是分布式系统),你无法隐藏系统的分布式特性。这是物理的。我一直感到远程过程调用在根本上错误的,这是一个原因,尤其是那些“透明的”远程过程调用,它们就是想隐藏分布式的交互本质。你需要拥抱系统的分布式特性,因为这些意义几乎总是需要通过系统设计和用户体验来完成。
拥抱分布式系统的本质则要遵循以下几个方面:
* 一开始就要思考设计对用户体验的影响,而不是试图在处理错误,取消请求和报告状态上打补丁。
* 使用异步技术来耦合组件。同步耦合是*不可能*的。如果某些行为看起来是同步的,是因为某些内部层尝试隐藏异步,这样做会遮蔽(但绝对不隐藏)系统运行时的基本行为特征。
* 认识到并且明确设计了交互状态机,这些状态表示长期的可靠的内部系统状态(而不是由深度调用堆栈中的变量值编码的临时,短暂和不可发现的状态)。
* 认识到失败是在所难免的。要保证能检测出分布式系统中的失败,唯一的办法就是直接看你的等待时间是否“太长”。这自然意味着[取消的等级最高](https://medium.com/@terrycrowley/how-to-think-about-cancellation-3516fc342ae#.3pfjc5b54)。系统的某一层(可能直接通向用户)需要决定等待时间是否过长,并取消操作。取消只是为了重建局部状态,回收局部的资源——没有办法在系统内广泛使用取消机制。有时用一种低成本,不可靠的方法广泛使用取消机制对优化性能可能有用。
* 认识到取消不是回滚,因为它只是回收本地资源和状态。如果回滚是必要的,它必须实现成一个端到端的功能。
* 承认永远不会真正知道分布式组件的状态。只要你发现一个状态,它可能就已经改变了。当你发送一个操作时,请求可能在传输过程中丢失,也可能被处理了但是返回的响应丢失了,或者请求需要一定的时间来处理,这样远程状态最终会在未来的某个任意的时间转换。这需要像幂等操作这样的方法,并且要能够稳健有效地重新发现远程状态,而不是期望可靠地跟踪分布式组件的状态。“[最终一致性](http://queue.acm.org/detail.cfm?id=2462076)”的概念简洁地捕捉了这其中大多数想法。
我喜欢说你应该“陶醉在异步”。与其试图隐藏异步,不如接受异步,为异步而设计。当你看到像幂等性或不变性这样的技术时,你就认识到它们是拥抱宇宙本质的方法,而不仅仅是工具箱中的一个设计工具。
### 性能
我确信 Don Knuth 会对人们怎样误解他的名言“过早的优化是一切罪恶的根源”而感到震惊。事实上,性能,及性能的持续超过 60 年的指数增长(或超过 10 年,取决于您是否愿意将晶体管,真空管和机电继电器的发展算入其中),为所有行业内的惊人创新和影响经济的“软件吃掉全世界”的变化打下了基础。
要认识到这种指数变化的一个关键是,虽然系统的所有组件正在经历指数级变化,但这些指数是不同的。硬盘容量的增长速度与内存容量的增长速度不同,与 CPU 的增长速度不同,与内存 CPU 之间的延迟的性能改善速度也不用。即使性能发展的趋势是由相同的基础技术驱动的,增长的指数也会有分歧。[延迟的改进跟不上带宽改善](http://www.ll.mit.edu/HPEC/agendas/proc04/invited/patterson_keynote.pdf)。指数变化在近距离或者短期内看起来是线性的,但随着时间的推移可能是压倒性的。系统不同组件的性能的增长不同,会出现压倒性的变化,并迫使对设计决策定期进行重新评估。
这样做的结果是,几年后,一度有意义的设计决策就不再有意义了。或者在某些情况下,二十年前有意义的方法又开始变成一个好的决策。现代内存映射的特点看起来更像是早期分时的进程切换,而不像分页那样。 (这样做有时会让我这样的老人说“这就是我们在 1975 年时用的方法”——忽略了这种方法在 40 年都没有意义,但现在又重新成为好的方法,因为两个组件之间的关系——可能是闪存和 NAND 而不是磁盘和核心内存——已经变得像以前一样了)。
当这些指数超越人自身的限制时,重要的转变就发生了。你能从 2 的 16 次方个字符(一个人可以在几个小时打这么多字)过渡到 2 的 32 次方个字符(远超出了一个人打字的范围)。你可以捕捉比人眼能感知的分辨率更高的数字图像。或者你可以将整个音乐专辑存在小巧的磁盘上,放在口袋里。或者你可以将数字化视频录制存储在硬盘上。再通过实时流式传输的能力,可以在一个地方集中存储一次,不需要在数千个本地硬盘上重复记录。
但有的东西仍然是根本的限制条件,那就是空间的三维和光速。我们又回到了爱因斯坦的宇宙。内存的分级结构将始终存在——它是物理定律的基础。稳定的存储和 IO、内存、计算和通信也都将一直存在。这些模块的相对容量,延迟和带宽将会改变,但是系统始终要考虑这些元素如何组合在一起,以及它们之间的平衡和折衷。Jim Gary 是这方面的大师。
空间和光速的根本限制造成的另一个后果是,性能分析主要是关于三件事:<ruby> 局部化 <rt> locality </rt></ruby>、<ruby> 局部化 <rt> locality </rt></ruby>、<ruby> 局部化 <rt> locality </rt></ruby>。无论是将数据打包在磁盘上,管理处理器缓存的层次结构,还是将数据合并到通信数据包中,数据如何打包在一起,如何在一段时间内从局部获取数据,数据如何在组件之间传输数据是性能的基础。把重点放在减少管理数据的代码上,增加空间和时间上的局部性,是消除噪声的好办法。
Jon Devaan 曾经说过:“设计数据,而不是设计代码”。这也通常意味着当查看系统结构时,我不太关心代码如何交互——我想看看数据如何交互和流动。如果有人试图通过描述代码结构来解释一个系统,而不理解数据流的速率和数量,他们就不了解这个系统。
内存的层级结构也意味着缓存将会一直存在——即使某些系统层正在试图隐藏它。缓存是根本的,但也是危险的。缓存试图利用代码的运行时行为,来改变系统中不同组件之间的交互模式。它们需要对运行时行为进行建模,即使模型填充缓存并使缓存失效,并测试缓存命中。如果模型由于行为改变而变差或变得不佳,缓存将无法按预期运行。一个简单的指导方针是,缓存必须被检测——由于应用程序行为的改变,事物不断变化的性质和组件之间性能的平衡,缓存的行为将随着时间的推移而退化。每一个老程序员都有缓存变糟的经历。
我很幸运,我的早期职业生涯是在互联网的发源地之一 BBN 度过的。 我们很自然地将将异步组件之间的通信视为系统连接的自然方式。流量控制和队列理论是通信系统的基础,更是任何异步系统运行的方式。流量控制本质上是资源管理(管理通道的容量),但资源管理是更根本的关注点。流量控制本质上也应该由端到端的应用负责,所以用端到端的方式思考异步系统是自然的。[缓冲区膨胀](https://en.wikipedia.org/wiki/Bufferbloat)的故事在这种情况下值得研究,因为它展示了当对端到端行为的动态性以及技术“改进”(路由器中更大的缓冲区)缺乏理解时,在整个网络基础设施中导致的长久的问题。
我发现“<ruby> 光速 <rt> light speed </rt></ruby>”的概念在分析任何系统时都非常有用。光速分析并不是从当前的性能开始分析,而是问“这个设计理论上能达到的最佳性能是多少?”真正传递的信息是什么,以什么样的速度变化?组件之间的底层延迟和带宽是多少?光速分析迫使设计师深入思考他们的方法能否达到性能目标,或者否需要重新考虑设计的基本方法。它也迫使人们更深入地了解性能在哪里损耗,以及损耗是由固有的,还是由于一些不当行为产生的。从构建的角度来看,它迫使系统设计人员了解其构建的模块的真实性能特征,而不是关注其他功能特性。
我的职业生涯大多花费在构建图形应用程序上。用户坐在系统的一端,定义关键的常量和约束。人类的视觉和神经系统没有经历过指数性的变化。它们固有地受到限制,这意味着系统设计者可以利用(必须利用)这些限制,例如,通过虚拟化(限制底层数据模型需要映射到视图数据结构中的数量),或者通过将屏幕更新的速率限制到人类视觉系统的感知限制。
### 复杂性的本质
我的整个职业生涯都在与复杂性做斗争。为什么系统和应用变得复杂呢?为什么在一个应用领域内进行开发并没有随着时间变得简单,而基础设施却没有变得更复杂,反而变得更强大了?事实上,管理复杂性的一个关键方法就是“走开”然后重新开始。通常新的工具或语言迫使我们从头开始,这意味着开发人员将工具的优点与从新开始的优点结合起来。从新开始是重要的。这并不是说新工具,新平台,或新语言可能不好,但我保证它们不能解决复杂性增长的问题。控制复杂性的最简单的方法就是用更少的程序员,建立一个更小的系统。
当然,很多情况下“走开”并不是一个选择——Office 软件建立在有巨大的价值的复杂的资源上。通过 OneNote, Office 从 Word 的复杂性上“走开”,从而在另一个维度上进行创新。Sway 是另一个例子, Office 决定从限制中跳出来,利用关键的环境变化,抓住机会从底层上采取全新的设计方案。我们有 Word、Excel、PowerPoint 这些应用,它们的数据结构非常有价值,我们并不能完全放弃这些数据结构,它们成为了开发中持续的显著的限制条件。
我受到 Fred Brook 讨论软件开发中的意外和本质的文章[《没有银弹》](http://worrydream.com/refs/Brooks-NoSilverBullet.pdf)的影响,他希望用两个趋势来尽可能地推动程序员的生产力:一是在选择自己开发还是购买时,更多地关注购买——这预示了开源社区和云架构的改变;二是从单纯的构建方法转型到更“有机”或者“生态”的增量开发方法。现代的读者可以认为是向敏捷开发和持续开发的转型。但那篇文章可是写于 1986 年!
我很欣赏 Stuart Kauffman 的在复杂性的基本性上的研究工作。Kauffman 从一个简单的布尔网络模型(“[NK 模型](https://en.wikipedia.org/wiki/NK_model)”)开始建立起来,然后探索这个基本的数学结构在相互作用的分子,基因网络,生态系统,经济系统,计算机系统(以有限的方式)等系统中的应用,来理解紧急有序行为的数学基础及其与混沌行为的关系。在一个高度连接的系统中,你固有地有一个相互冲突的约束系统,使得它(在数学上)很难向前发展(这被看作是在崎岖景观上的优化问题)。控制这种复杂性的基本方法是将系统分成独立元素并限制元素之间的相互连接(实质上减少 NK 模型中的“N”和“K”)。当然对那些使用复杂隐藏,信息隐藏和数据抽象,并且使用松散异步耦合来限制组件之间的交互的技术的系统设计者来说,这是很自然的。
我们一直面临的一个挑战是,我们想到的许多拓展系统的方法,都跨越了所有的方面。实时共同编辑是 Office 应用程序最近的一个非常具体的(也是最复杂的)例子。
我们的数据模型的复杂性往往等同于“能力”。设计用户体验的固有挑战是我们需要将有限的一组手势,映射到底层数据模型状态空间的转换。增加状态空间的维度不可避免地在用户手势中产生模糊性。这是“[纯数学](https://medium.com/@terrycrowley/the-math-of-easy-to-use-14645f819201#.untmk9eq7)”,这意味着确保系统保持“易于使用”的最基本的方式常常是约束底层的数据模型。
### 管理
我从高中开始担任一些领导角色(学生会主席!),对承担更多的责任感到理所当然。同时,我一直为自己在每个管理阶段都坚持担任全职程序员而感到自豪。但 Office 软件的开发副总裁最终还是让我从事管理,离开了日常的编程工作。当我在去年离开那份工作时,我很享受重返编程——这是一个出奇地充满创造力的充实的活动(当修完“最后”的 bug 时,也许也会有一点令人沮丧)。
尽管在我加入微软前已经做了十多年的“主管”,但是到了 1996 年我加入微软才真正了解到管理。微软强调“工程领导是技术领导”。这与我的观点一致,帮助我接受并承担更大的管理责任。
主管的工作是设计项目并透明地推进项目。透明并不简单,它不是自动的,也不仅仅是有好的意愿就行。透明需要被设计进系统中去。透明工作的最好方式是能够记录每个工程师每天活动的产出,以此来追踪项目进度(完成任务,发现 bug 并修复,完成一个情景)。留意主观上的红/绿/黄,点赞或踩的仪表板。
我过去说我的工作是设计反馈回路。独立工程师,经理,行政人员,每一个项目的参与者都能通过分析记录的项目数据,推进项目,产出结果,了解自己在整个项目中扮演的角色。最终,透明化最终成为增强能力的一个很好的工具——管理者可以将更多的局部控制权给予那些最接近问题的人,因为他们对所取得的进展有信心。这样的话,合作自然就会出现。
关键需要确定目标框架(包括关键资源的约束,如发布的时间表)。如果决策需要在管理链上下不断流动,那说明管理层对目标和约束的框架不好。
当我在 Beyond Software 工作时,我真正理解了一个项目拥有一个唯一领导的重要性。原来的项目经理离职了(后来从 FrontPage 团队雇佣了我)。我们四个主管在是否接任这个岗位上都有所犹豫,这不仅仅由于我们都不知道要在这家公司坚持多久。我们都技术高超,并且相处融洽,所以我们决定以同级的身份一起来领导这个项目。然而这槽糕透了。有一个显而易见的问题,我们没有相应的战略用来在原有的组织之间分配资源——这应当是管理者的首要职责之一!当你知道你是唯一的负责人时,你会有很深的责任感,但在这个例子中,这种责任感缺失了。我们没有真正的领导来负责统一目标和界定约束。
我有清晰地记得,我第一次充分认识到*倾听*对一个领导者的重要性。那时我刚刚担任了 Word、OneNote、Publisher 和 Text Services 团队的开发经理。关于我们如何组织文本服务团队,我们有一个很大的争议,我走到了每个关键参与者身边,听他们想说的话,然后整合起来,写下了我所听到的一切。当我向其中一位主要参与者展示我写下的东西时,他的反应是“哇,你真的听了我想说的话”!作为一名管理人员,我所经历的所有最大的问题(例如,跨平台和转型持续工程)涉及到仔细倾听所有的参与者。倾听是一个积极的过程,它包括:尝试以别人的角度去理解,然后写出我学到的东西,并对其进行测试,以验证我的理解。当一个关键的艰难决定需要发生的时候,在最终决定前,每个人都知道他们的想法都已经被听到并理解(不论他们是否同意最后的决定)。
在 FrontPage 团队担任开发经理的工作,让我理解了在只有部分信息的情况下做决定的“操作困境”。你等待的时间越长,你就会有更多的信息做出决定。但是等待的时间越长,实际执行的灵活性就越低。在某个时候,你仅需要做出决定。
设计一个组织涉及类似的两难情形。您希望增加资源领域,以便可以在更大的一组资源上应用一致的优先级划分框架。但资源领域越大,越难获得作出决定所需要的所有信息。组织设计就是要平衡这两个因素。软件复杂化,因为软件的特点可以在任意维度切入设计。Office 软件部门已经使用[共享团队](https://medium.com/@terrycrowley/breaking-conways-law-a0fdf8500413#.gqaqf1c5k)来解决这两个问题(优先次序和资源),让跨领域的团队能与需要产品的团队分享工作(增加资源)。
随着管理阶梯的提升,你会懂一个小秘密:你和你的新同事不会因为你现在承担更多的责任,就突然变得更聪明。这强调了整个组织比顶层领导者更聪明。赋予每个级别在一致框架下拥有自己的决定是实现这一目标的关键方法。听取并使自己对组织负责,阐明和解释决策背后的原因是另一个关键策略。令人惊讶的是,害怕做出一个愚蠢的决定可能是一个有用的激励因素,以确保你清楚地阐明你的推理,并确保你听取所有的信息。
### 结语
我离开大学寻找第一份工作时,面试官在最后一轮面试时问我对做“系统”和做“应用”哪一个更感兴趣。我当时并没有真正理解这个问题。在软件技术栈的每一个层面都会有趣的难题,我很高兴深入研究这些问题。保持学习。
---
via: <https://hackernoon.com/education-of-a-programmer-aaecf2d35312>
作者:[Terry Crowley](https://hackernoon.com/@terrycrowley) 译者:[explosic4](https://github.com/explosic4) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
*When I left Microsoft in October 2016 after almost 21 years there and almost 35 years in the industry, I took some time to reflect on what I had learned over all those years. This is a lightly edited version of that post. Pardon the length!*
There are an amazing number of things you need to know to be a proficient programmer — details of languages, APIs, algorithms, data structures, systems and tools. These things change all the time — new languages and programming environments spring up and there always seems to be some hot new tool or language that “everyone” is using. It is important to stay current and proficient. A carpenter needs to know how to pick the right hammer and nail for the job and needs to be competent at driving the nail straight and true.
At the same time, I’ve found that there are some concepts and strategies that are applicable over a wide range of scenarios and across decades. We have seen multiple orders of magnitude change in the performance and capability of our underlying devices and yet certain ways of thinking about the design of systems still say relevant. These are more fundamental than any specific implementation. Understanding these recurring themes is hugely helpful in both the analysis and design of the complex systems we build.
**Humility and Ego**
This is not limited to programming, but in an area like computing which exhibits so much constant change, one needs a healthy balance of humility and ego. There is always more to learn and there is always someone who can help you learn it — if you are willing and open to that learning. One needs both the humility to recognize and acknowledge what you don’t know and the ego that gives you confidence to master a new area and apply what you already know. The biggest challenges I have seen are when someone works in a single deep area for a long time and “forgets” how good they are at learning new things. The best learning comes from actually getting hands dirty and building something, even if it is just a prototype or hack. The best programmers I know have had both a broad understanding of technology while at the same time have taken the time to go deep into some technology and become the expert. The deepest learning happens when you struggle with truly hard problems.
**End to End Argument**
Back in 1981, Jerry Saltzer, Dave Reed and Dave Clark were doing early work on the Internet and distributed systems and wrote up their [classic description](http://web.mit.edu/Saltzer/www/publications/endtoend/endtoend.pdf?ref=hackernoon.com) of the end to end argument. There is much misinformation out there on the Internet so it can be useful to go back and read the original paper. They were humble in not claiming invention — from their perspective this was a common engineering strategy that applies in many areas, not just in communications. They were simply writing it down and gathering examples. A minor paraphrasing is:
When implementing some function in a system, it can be implemented correctly and completely only with the knowledge and participation of the endpoints of the system. In some cases, a partial implementation in some internal component of the system may be important for performance reasons.
The SRC paper calls this an “argument”, although it has been elevated to a “principle” on Wikipedia and in other places. In fact, it is better to think of it as an argument — as they detail, one of the hardest problem for a system designer is to determine how to divide responsibilities between components of a system. This ends up being a discussion that involves weighing the pros and cons as you divide up functionality, isolate complexity and try to design a reliable, performant system that will be flexible to evolving requirements. There is no simple set of rules to follow.
Much of the discussion on the Internet focuses on communications systems, but the end-to-end argument applies in a much wider set of circumstances. One example in distributed systems is the idea of “eventual consistency”. An eventually consistent system can optimize and simplify by letting elements of the system get into a temporarily inconsistent state, knowing that there is a larger end-to-end process that can resolve these inconsistencies. I like the example of a scaled-out ordering system (e.g. as used by Amazon) that doesn’t require every request go through a central inventory control choke point. This lack of a central control point might allow two endpoints to sell the same last book copy, but the overall system needs some type of resolution system in any case, e.g. by notifying the customer that the book has been backordered. That last book might end up getting run over by a forklift in the warehouse before the order is fulfilled anyway. Once you realize an end-to-end resolution system is required and is in place, the internal design of the system can be optimized to take advantage of it.
In fact, it is this design flexibility in the service of either ongoing performance optimization or delivering other system features that makes this end-to-end approach so powerful. End-to-end thinking often allows internal performance flexibility which makes the overall system more robust and adaptable to changes in the characteristics of each of the components. This makes an end-to-end approach “anti-fragile” and resilient to change over time.
An implication of the end-to-end approach is that you want to be extremely careful about adding layers and functionality that eliminates overall performance flexibility. (Or other flexibility, but performance, especially latency, tends to be special.) If you expose the raw performance of the layers you are built on, end-to-end approaches can take advantage of that performance to optimize for their specific requirements. If you chew up that performance, even in the service of providing significant value-add functionality, you eliminate design flexibility.
The end-to-end argument intersects with organizational design when you have a system that is large and complex enough to assign whole teams to internal components. The natural tendency of those teams is to extend the functionality of those components, often in ways that start to eliminate design flexibility for applications trying to deliver end-to-end functionality built on top of them.
One of the challenges in applying the end-to-end approach is determining where the end is. “Little fleas have lesser fleas… and so on ad infinitum.”
**Concentrating Complexity**
Coding is an incredibly precise art, with each line of execution required for correct operation of the program. But this is misleading. Programs are not uniform in the overall complexity of their components or the complexity of how those components interact. The most robust programs isolate complexity in a way that lets significant parts of the system appear simple and straightforward and interact in simple ways with other components in the system. Complexity hiding can be isomorphic with other design approaches like information hiding and data abstraction but I find there is a different design sensibility if you really focus on identifying where the complexity lies and how you are isolating it.
The example I’ve returned to over and over again in my [writing](https://medium.com/@terrycrowley/model-view-controller-and-loose-coupling-6370f76e9cde?ref=hackernoon.com#.o4gnupqzq) is the screen repaint algorithm that was used by early character video terminal editors like VI and EMACS. The early video terminals implemented control sequences for the core action of painting characters as well as additional display functions to optimize redisplay like scrolling the current lines up or down or inserting new lines or moving characters within a line. Each of those commands had different costs and those costs varied across different manufacturer’s devices. (See [TERMCAP](https://en.wikipedia.org/wiki/Termcap?ref=hackernoon.com) for links to code and a fuller history.) A full-screen application like a text editor wanted to update the screen as quickly as possible and therefore needed to optimize its use of these control sequences to transition the screen from one state to another.
These applications were designed so this underlying complexity was hidden. The parts of the system that modify the text buffer (where most innovation in functionality happens) completely ignore how these changes are converted into screen update commands. This is possible because the performance cost of computing the optimal set of updates for *any* change in the content is swamped by the performance cost of actually executing the update commands on the terminal itself. It is a common pattern in systems design that performance analysis plays a key part in determining how and where to hide complexity. The screen update process can be asynchronous to the changes in the underlying text buffer and can be independent of the actual historical sequence of changes to the buffer. It is not important *how* the buffer changed, but only *what* changed. This combination of asynchronous coupling, elimination of the combinatorics of historical path dependence in the interaction between components and having a natural way for interactions to efficiently batch together are common characteristics used to hide coupling complexity.
Success in hiding complexity is determined not by the component doing the hiding but by the consumers of that component. This is one reason why it is often so critical for a component provider to actually be responsible for at least some piece of the end-to-end use of that component. They need to have clear optics into how the rest of the system interacts with their component and how (and whether) complexity leaks out. This often shows up as feedback like “this component is hard to use” — which typically means that it is not effectively hiding the internal complexity or did not pick a functional boundary that was amenable to hiding that complexity.
**Layering and Componentization**
It is the fundamental role of a system designer to determine how to break down a system into components and layers; to make decisions about what to build and what to pick up from elsewhere. Open Source may keep money from changing hands in this “build vs. buy” decision but the dynamics are the same. An important element in large scale engineering is understanding how these decisions will play out over time. Change fundamentally underlies everything we do as programmers, so these design choices are not only evaluated in the moment, but are evaluated in the years to come as the product continues to evolve.
Here are a few things about system decomposition that end up having a large element of time in them and therefore tend to take longer to learn and appreciate.
**Einsteinian Universe**
I had been designing asynchronous distributed systems for decades but was struck by this quote from Pat Helland, a SQL architect, at an internal Microsoft talk. “We live in an Einsteinian universe — there is no such thing as simultaneity. “ When building distributed systems — and virtually everything we build is a distributed system — you cannot hide the distributed nature of the system. It’s just physics. This is one of the reasons I’ve always felt Remote Procedure Call, and especially “transparent” RPC that explicitly tries to hide the distributed nature of the interaction, is fundamentally wrong-headed. You need to embrace the distributed nature of the system since the implications almost always need to be plumbed completely through the system design and into the user experience.
Embracing the distributed nature of the system leads to a number of things:
I like to say you should “revel in the asynchrony”. Rather than trying to hide it, you accept it and design for it. When you see a technique like idempotency or immutability, you recognize them as ways of embracing the fundamental nature of the universe, not just one more design tool in your toolbox.
**Performance**
I am sure Don Knuth is horrified by how misunderstood his partial quote “Premature optimization is the root of all evil” has been. In fact, performance, and the incredible exponential improvements in performance that have continued for over 6 decades (or more than 10 decades depending on how willing you are to project these trends through discrete transistors, vacuum tubes and electromechanical relays), underlie all of the amazing innovation we have seen in our industry and all the change rippling through the economy as “software eats the world”.
A key thing to recognize about this exponential change is that while all components of the system are experiencing exponential change, these exponentials are divergent. So the rate of increase in capacity of a hard disk changes at a different rate from the capacity of memory or the speed of the CPU or the latency between memory and CPU. Even when trends are driven by the same underlying technology, exponentials diverge. [Latency improvements fundamentally trail bandwidth improvements](http://www.ll.mit.edu/HPEC/agendas/proc04/invited/patterson_keynote.pdf?ref=hackernoon.com). Exponential change tends to look linear when you are close to it or over short periods but the effects over time can be overwhelming. This overwhelming change in the relationship between the performance of components of the system forces reevaluation of design decisions on a regular basis.
A consequence of this is that design decisions that made sense at one point no longer make sense after a few years. Or in some cases an approach that made sense two decades ago starts to look like a good trade-off again. Modern memory mapping has characteristics that look more like process swapping of the early time-sharing days than it does like demand paging. (This does sometimes result in old codgers like myself claiming that “that’s just the same approach we used back in ‘75” — ignoring the fact that it didn’t make sense for 40 years and now does again because some balance between two components — maybe flash and NAND rather than disk and core memory — has come to resemble a previous relationship).
Important transitions happen when these exponentials cross human constraints. So you move from a limit of two to the sixteenth characters (which a single user can type in a few hours) to two to the thirty-second (which is beyond what a single person can type). So you can capture a digital image with higher resolution than the human eye can perceive. Or you can store an entire music collection on a hard disk small enough to fit in your pocket. Or you can store a digitized video recording on a hard disk. And then later the ability to stream that recording in real time makes it possible to “record” it by storing it once centrally rather than repeatedly on thousands of local hard disks.
The things that stay as a fundamental constraint are three dimensions and the speed of light. We’re back to that Einsteinian universe. We will always have memory hierarchies — they are fundamental to the laws of physics. You will always have stable storage and IO, memory, computation and communications. The relative capacity, latency and bandwidth of these elements will change, but the system is always about how these elements fit together and the balance and tradeoffs between them. Jim Gray was the master of this analysis.
Another consequence of the fundamentals of 3D and the speed of light is that much of performance analysis is about three things: locality, locality, locality. Whether it is packing data on disk, managing processor cache hierarchies, or coalescing data into a communications packet, how data is packed together, the patterns for how you touch that data with locality over time and the patterns of how you transfer that data between components is fundamental to performance. Focusing on less code operating on less data with more locality over space and time is a good way to cut through the noise.
Jon Devaan used to say “design the data, not the code”. This also generally means when looking at the structure of a system, I’m less interested in seeing how the code interacts — I want to see how the data interacts and flows. If someone tries to explain a system by describing the code structure and does not understand the rate and volume of data flow, they do not understand the system.
A memory hierarchy also implies we will always have caches — even if some system layer is trying to hide it. Caches are fundamental but also dangerous. Caches are trying to leverage the runtime behavior of the code to change the pattern of interaction between different components in the system. They inherently need to model that behavior, even if that model is implicit in how they fill and invalidate the cache and test for a cache hit. If the model is poor *or becomes* poor as the behavior changes, the cache will not operate as expected. A simple guideline is that caches *must* be instrumented — their behavior will degrade over time because of changing behavior of the application and the changing nature and balance of the performance characteristics of the components you are modeling. Every long-time programmer has cache horror stories.
I was lucky that my early career was spent at BBN, one of the birthplaces of the Internet. It was very natural to think about communications between asynchronous components as the natural way systems connect. Flow control and queueing theory are fundamental to communications systems and more generally the way that any asynchronous system operates. Flow control is inherently resource management (managing the capacity of a channel) but resource management is the more fundamental concern. Flow control also is inherently an end-to-end responsibility, so thinking about asynchronous systems in an end-to-end way comes very naturally. The story of [buffer bloat](https://en.wikipedia.org/wiki/Bufferbloat?ref=hackernoon.com) is well worth understanding in this context because it demonstrates how lack of understanding the dynamics of end-to-end behavior coupled with technology “improvements” (larger buffers in routers) resulted in very long-running problems in the overall network infrastructure.
The concept of “light speed” is one that I’ve found useful in analyzing any system. A light speed analysis doesn’t start with the current performance, it asks “what is the best theoretical performance I could achieve with this design?” What is the real information content being transferred and at what rate of change? What is the underlying latency and bandwidth between components? A light speed analysis forces a designer to have a deeper appreciation for whether their approach could ever achieve the performance goals or whether they need to rethink their basic approach. It also forces a deeper understanding of where performance is being consumed and whether this is inherent or potentially due to some misbehavior. From a constructive point of view, it forces a system designer to understand what are the true performance characteristics of their building blocks rather than focusing on the other functional characteristics.
I spent much of my career building graphical applications. A user sitting at one end of the system defines a key constant and constraint in any such system. The human visual and nervous system is not experiencing exponential change. The system is inherently constrained, which means a system designer can leverage (*must* leverage) those constraints, e.g. by virtualization (limiting how much of the underlying data model needs to be mapped into view data structures) or by limiting the rate of screen update to the perception limits of the human visual system.
**The Nature of Complexity**
I have struggled with complexity my entire career. Why do systems and apps get complex? Why doesn’t development within an application domain get easier over time as the infrastructure gets more powerful rather than getting harder and more constrained? In fact, one of our key approaches for managing complexity is to “walk away” and start fresh. Often new tools or languages force us to start from scratch which means that developers end up conflating the benefits of the tool with the benefits of the clean start. The clean start is what is fundamental. This is not to say that some new tool, platform or language might not be a great thing, but I can guarantee it will not solve the problem of complexity growth. The simplest way of controlling complexity growth is to build a smaller system with fewer developers.
Of course, in many cases “walking away” is not an alternative — the Office business is built on hugely valuable and complex assets. With OneNote, Office “walked away” from the complexity of Word in order to innovate along a different dimension. Sway is another example where Office decided that we needed to free ourselves from constraints in order to really leverage key environmental changes and the opportunity to take fundamentally different design approaches. With the Word, Excel and PowerPoint web apps, we decided that the linkage with our immensely valuable data formats was too fundamental to walk away from and that has served as a significant and ongoing constraint on development.
I was influenced by Fred Brook’s “[No Silver Bullet](http://worrydream.com/refs/Brooks-NoSilverBullet.pdf?ref=hackernoon.com)” essay about accident and essence in software development. There is much irreducible complexity embedded in the essence of what the software is trying to model. I just recently re-read that essay and found it surprising on re-reading that two of the trends he imbued with the most power to impact future developer productivity were increasing emphasis on “buy” in the “build vs. buy” decision — foreshadowing the change that open-source and cloud infrastructure has had. The other trend was the move to more “organic” or “biological” incremental approaches over more purely constructivist approaches. A modern reader sees that as the shift to agile and continuous development processes. This in 1986!
I have been much taken with the work of Stuart Kauffman on the fundamental nature of complexity. Kauffman builds up from a simple model of Boolean networks (“[NK models](https://en.wikipedia.org/wiki/NK_model?ref=hackernoon.com)”) and then explores the application of this fundamentally mathematical construct to things like systems of interacting molecules, genetic networks, ecosystems, economic systems and (in a limited way) computer systems to understand the mathematical underpinning to emergent ordered behavior and its relationship to chaotic behavior. In a highly connected system, you inherently have a system of conflicting constraints that makes it (mathematically) hard to evolve that system forward (viewed as an optimization problem over a rugged landscape). A fundamental way of controlling this complexity is to batch the system into independent elements and limit the interconnections between elements (essentially reducing both “N” and “K” in the NK model). Of course this feels natural to a system designer applying techniques of complexity hiding, information hiding and data abstraction and using loose asynchronous coupling to limit interactions between components.
A challenge we always face is that many of the ways we want to evolve our systems cut across all dimensions. Real-time co-authoring has been a very concrete (and complex) recent example for the Office apps.
Complexity in our data models often equates with “power”. An inherent challenge in designing user experiences is that we need to map a limited set of gestures into a transition in the underlying data model state space. Increasing the dimensions of the state space inevitably creates ambiguity in the user gesture. This is “[just math](https://medium.com/@terrycrowley/the-math-of-easy-to-use-14645f819201?ref=hackernoon.com#.untmk9eq7)” which means that often times the most fundamental way to ensure that a system stays “easy to use” is to constrain the underlying data model.
**Management**
I started taking leadership roles in high school (student council president!) and always found it natural to take on larger responsibilities. At the same time, I was always proud that I continued to be a full-time programmer through every management stage. VP of development for Office finally pushed me over the edge and away from day-to-day programming. I’ve enjoyed returning to programming as I stepped away from that job over the last year — it is an incredibly creative and fulfilling activity (and maybe a little frustrating at times as you chase down that “last” bug).
Despite having been a “manager” for over a decade by the time I arrived at Microsoft, I really learned about management after my arrival in 1996. Microsoft reinforced that “engineering leadership is technical leadership”. This aligned with my perspective and helped me both accept and grow into larger management responsibilities.
The thing that most resonated with me on my arrival was the fundamental culture of transparency in Office. The manager’s job was to design and use transparent processes to drive the project. Transparency is not simple, automatic, or a matter of good intentions — it needs to be designed into the system. The best transparency comes by being able to track progress as the granular output of individual engineers in their day-to-day activity (work items completed, bugs opened and fixed, scenarios complete). Beware subjective red/green/yellow, thumbs-up/thumbs-down dashboards!
I used to say my job was to design feedback loops. Transparent processes provide a way for every participant in the process — from individual engineer to manager to exec to use the data being tracked to drive the process and result and understand the role they are playing in the overall project goals. Ultimately transparency ends up being a great tool for empowerment — the manager can invest more and more local control in those closest to the problem because of confidence they have visibility to the progress being made. Coordination emerges naturally.
Key to this is that the goal has actually been properly framed (including key resource constraints like ship schedule). Decision-making that needs to constantly flow up and down the management chain usually reflects poor framing of goals and constraints by management.
I was at Beyond Software when I really internalized the importance of having a singular leader over a project. The engineering manager departed (later to hire me away for FrontPage) and all four of the leads were hesitant to step into the role — not least because we did not know how long we were going to stick around. We were all very technically sharp and got along well so we decided to work as peers to lead the project. It was a mess. The one obvious problem is that we had no strategy for allocating resources between the pre-existing groups — one of the top responsibilities of management! The deep accountability one feels when you know you are personally in charge was missing. We had no leader really accountable for unifying goals and defining constraints.
I have a visceral memory of the first time I fully appreciated the importance of *listening* for a leader. I had just taken on the role of Group Development Manager for Word, OneNote, Publisher and Text Services. There was a significant controversy about how we were organizing the text services team and I went around to each of the key participants, heard what they had to say and then integrated and wrote up all I had heard. When I showed the write-up to one of the key participants, his reaction was “wow, you really heard what I had to say”! All of the largest issues I drove as a manager (e.g. cross-platform and the shift to continuous engineering) involved carefully listening to all the players. Listening is an active process that involves trying to understand the perspectives and then writing up what I learned and testing it to validate my understanding. When a key hard decision needed to happen, by the time the call was made everyone knew they had been heard and understood (whether they agreed with the decision or not).
It was the previous job, as FrontPage development manager, where I internalized the “operational dilemma” inherent in decision making with partial information. The longer you wait, the more information you will have to make a decision. But the longer you wait, the less flexibility you will have to actually implement it. At some point you just need to make a call.
Designing an organization involves a similar tension. You want to increase the resource domain so that a consistent prioritization framework can be applied across a larger set of resources. But the larger the resource domain, the harder it is to actually have all the information you need to make good decisions. An organizational design is about balancing these two factors. Software complicates this because characteristics of the software can cut across the design in an arbitrary dimensionality. Office has used [shared teams](https://medium.com/@terrycrowley/breaking-conways-law-a0fdf8500413?ref=hackernoon.com#.gqaqf1c5k) to address both these issues (prioritization and resources) by having cross-cutting teams that can share work (add resources) with the teams they are building for.
One dirty little secret you learn as you move up the management ladder is that you and your new peers aren’t suddenly smarter because you now have more responsibility. This reinforces that the organization as a whole better be smarter than the leader at the top. Empowering every level to own their decisions within a consistent framing is the key approach to making this true. Listening and making yourself accountable to the organization for articulating and explaining the reasoning behind your decisions is another key strategy. Surprisingly, fear of making a dumb decision can be a useful motivator for ensuring you articulate your reasoning clearly and make sure you listen to all inputs.
**Conclusion**
At the end of my interview round for my first job out of college, the recruiter asked if I was more interested in working on “systems” or “apps”. I didn’t really understand the question. Hard, interesting problems arise at every level of the software stack and I’ve had fun plumbing all of them. Keep learning.
[Hacker Noon]is how hackers start their afternoons. We’re a part of the[@AMI]family. We are now[accepting submissions]and happy to[discuss advertising & sponsorship]opportunities.
To learn more,
[read our about page],[like/message us on Facebook], or simply,[tweet/DM @HackerNoon.]
If you enjoyed this story, we recommend reading our
[latest tech stories]and[trending tech stories]. Until next time, don’t take the realities of the world for granted! |
9,671 | 开始 Vagrant 之旅 | https://opensource.com/article/18/4/getting-started-vagrant | 2018-05-23T11:43:34 | [
"Vagrant"
] | https://linux.cn/article-9671-1.html |
>
> 用管理虚拟机和容器的工具 Vagrant 清理你的开发环境和依赖。
>
>
>

如果你和我一样,你可能在某一个地方有一个“沙盒”,你可以在那里进行你正在做的任何项目。随着时间的推移,沙盒会变得杂乱无章,充斥着各种想法、工具链元素、你不使用的代码模块,以及其他你不需要的东西。当你完成某件事情时,这会使你的部署变得复杂,因为你可能不确定项目的实际依赖关系 —— 随着时间推移你在沙盒中已经有了一些工具,但是你忘了必须安装它。你需要一个干净的环境,将所有的依赖关系放在一个地方,以便以后更方便。
或者你可能工作在 DevOps 中,你所服务的开发人员用模糊的依赖关系来编写代码,这使得测试变得更加困难。你需要一种方法来获得一个干净的盒子,将代码放入其中,并通过它运行代码,而且你希望这些环境是一次性的和可重复的。
那么选择 [Vagrant](https://vagrantup.com) 吧。由 HashiCorp 在 [MIT 许可证](https://opensource.org/licenses/MIT)下创建,Vagrant 可充当 VirtualBox、Microsoft Hyper-V 或 Docker 容器的包装器和前端,并且可以通过[许多其他供应商](https://github.com/hashicorp/vagrant/wiki/Available-Vagrant-Plugins#providers)的插件进行扩展。你可以配置 Vagrant 以提供可重复的、干净的环境,并且已安装需要的基础架构。配置脚本是可移植的,因此,如果你的仓库和 Vagrant 配置脚本位于基于云存储上,那么你只需要很少的限制就可以启动并在多台机器机器上工作。让我们来看一看。
### 安装
对于本次安装,我的环境是 Linux Mint 桌面,版本是 18.3 Cinnamon 64 位,在其他大多数 Debian 派生系统上安装非常类似。在大多数发行版中,对于基于 RPM 的系统也有类似的安装程序。Vagrant 的[安装页面](https://www.vagrantup.com/downloads.html)为 Debian、 Windows、 CentOS、 MacOS 和 Arch Linux 都提供下载,但是我在我的软件包管理器中找到了它,所以我在那进行了安装。
最简单的安装使用了 VirtualBox 作为虚拟化提供者,所以我需要安装它:
```
sudo apt-get install virtualbox vagrant
```
安装程序将会获取依赖项 —— 主要是 Ruby 的一些东西,安装它们。
### 建立一个项目
在设置你的项目之前,你需要了解一些你想要运行它的环境。你可以在 [Vagrant Boxes 仓库](https://app.vagrantup.com/boxes/search)中找到为许多虚拟化供应商提供的大量预配置的<ruby> 系统 <rt> box </rt></ruby>。许多会预先配置一些你可能需要的核心基础设置,比如 PHP、 MySQL 和 Apache,但是对于本次测试,我将安装一个 Debian 8 64 位 “Jessie” 裸机沙盒并手动安装一些东西,这样你就可以看到具体过程了。
```
mkdir ~/myproject
cd ~/myproject
vagrant init debian/contrib-jessie64
vagrant up
```
最后一条命令将根据需要从仓库中获取或更新 VirtualBox 镜像,然后运行启动器,你的系统上会出现一个运行的系统!下次启动这个项目时,除非镜像已经在仓库中更新,否则不会花费太长时间。
要访问该沙盒,只需要输入 `vagrant ssh`,你将进入虚拟机的全功能 SSH 会话中,你将会是 `vagrant` 用户,但也是 `sudo` 组的成员,所以你可以切换到 root,并在这里做你想做的任何事情。
你会在沙盒中看到一个名为 `/vagrant` 目录,对这个目录小心点,因为它与你主机上的 `~/myproject` 文件夹保持同步。在虚拟机 `/vagrant` 下建立一个文件它会立即复制到主机上,反之亦然。注意,有些沙盒并没有安装 VirtualBox 的附加功能,所以拷贝只能在启动时才起作用。有一些用于手动同步的命令行工具,这可能是测试环境中非常有用的特性。我倾向于坚持使用那些有附加功能的沙盒,所以这个目录可以正常工作,不必考虑它。
这个方案的好处很快显现出来了: 如果你在主机上有一个代码编辑工具链,并处于某种原因不希望它出现在虚拟机上,那么这不是问题 —— 在主机上进行编辑,虚拟机会立刻更改。快速更改虚拟机,它也将其同步到主机上的“官方”副本 。
让我们关闭这个系统,这样我们就可以在这个系统里提供一些我们需要的东西:
```
vagrant halt
```
### 在虚拟机上安装额外的软件
对于这个例子,我将使用 [Apache](https://httpd.apache.org/)、 [PostgreSQL](https://postgresql.org) 和 Perl 的 [Dancer](https://perldancer.org) web 框架进行项目开发。我将修改Vagrant 配置脚本,以便我需要的东西已经安装。 为了使之稍后更容易保持更新,我将在项目根目录下创建一个脚本`~/myproject/Vagrantfile`:
```
$provision_script = <<SCRIPT
export DEBIAN_FRONTEND=noninteractive
apt-get update
apt-get -y install \
apache2 \
postgresql-client-9.4 \
postgresql-9.4 \
libdbd-pg-perl \
libapache2-mod-fastcgi \
libdata-validate-email-perl \
libexception-class-perl \
libexception-class-trycatch-perl \
libtemplate-perl \
libtemplate-plugin-json-escape-perl \
libdbix-class-perl \
libyaml-tiny-perl \
libcrypt-saltedhash-perl \
libdancer2-perl \
libtemplate-plugin-gravatar-perl \
libtext-csv-perl \
libstring-tokenizer-perl \
cpanminus
cpanm -f -n \
Dancer2::Session::Cookie \
Dancer2::Plugin::DBIC \
Dancer2::Plugin::Auth::Extensible::Provider::DBIC \
Dancer2::Plugin::Locale \
Dancer2::Plugin::Growler
sudo a2enmod rewrite fastcgi
sudo apache2ctl restart
SCRIPT
```
在 Vagrantfile 结尾附近,你会发现一行 `config.vm.provision` 变量,正如你在示例中看到的那样,你可以在此处以内联方式进行操作,只需通过取消注释以下行:
```
# config.vm.provision "shell", inline: <<-SHELL
# sudo apt-get update
# sudo apt-get install -y apache2
# SHELL
```
相反,将那四行替换为使用你在文件顶部定义为变量的配置脚本:
```
config.vm.provision "shell", inline: $provision_script
```
你可能还希望将转发的端口设置为从主机访问虚拟机上的 Apache。寻找包含 `forwarded_port` 的行并取消注释它。如果你愿意,也可以将端口从 8080 更改为其他内容。我通常使用端口 5000,并在我的浏览器浏览 http://localhost:5000 就可以访问我虚拟机上的 Apache 服务器。
这里有一个设置提示:如果你的仓库位于云存储上,为了在多台机器上使用 Vagrant,你可能希望将不同机器上的 `VAGRANT_HOME` 环境变量设置为不同的东西。以 VirtualBox 的工作方式,你需要分别为这些系统存储状态信息,确保你的版本控制系统忽略了用于此的目录 —— 我将 `.vagrant.d*` 添加到仓库的 `.gitignore` 文件中。不过,我确实让 Vagrantfile 成为仓库的一部分!
### 好了!
我输入 `vagrant up`,我准备开始写代码了。一旦你做了一两次,你可能会想到你可以循环利用很多的 Vagrantfile 模板文件(就像我刚刚那样),这就是 Vagrant 的优势之一。你可以更快地完成实际的编码工作,并将很少的时间花在基础设施上!
你可以使用 Vagrant 做更多事情。配置工具存在于许多工具链中,因此,无论你需要复制什么环境,它都是快速而简单的。
---
via: <https://opensource.com/article/18/4/getting-started-vagrant>
作者:[Ruth Holloway](https://opensource.com/users/druthb) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you're like me, you probably have a "sandbox" somewhere, a place where you hack on whatever projects you're working on. Over time, the sandbox will get crufty and cluttered with bits and pieces of ideas, toolchain elements, code modules you aren't using, and other stuff you don't need. When you finish something, this can complicate your deployment, because you may be unsure of the actual dependencies of your project—you've had some tool in your sandbox for so long that you forget it must be installed. You need a clean environment, with all your dependencies in one place, to make things easier later.
Or maybe you're in DevOps, and the developers you serve hand you code with muddy dependencies, and it makes testing that much harder. You need a way to have a clean box to pull in the code and run it through its paces. You want these environments to be disposable and repeatable.
Enter [Vagrant](https://vagrantup.com). Created by HashiCorp under the [MIT License](https://opensource.org/licenses/MIT), Vagrant acts as a wrapper and frontend for VirtualBox, Microsoft Hyper-V, or Docker containers, and it is extensible with plugins for [a great many other providers](https://github.com/hashicorp/vagrant/wiki/Available-Vagrant-Plugins#providers). You can configure Vagrant to provide repeatably clean environments with needed infrastructure already installed. The configuration script is portable, so if your repository and Vagrant configuration script are on cloud-based storage, you can spin up and work on multiple machines with just a few limitations. Let's take a look.
## Installation
For this installation, I'm working on my Linux Mint desktop, version 18.3 Cinnamon 64-bit. Installation is very similar on most other Debian-derived systems, and there are similar installers for RPM-based systems on most distributions. Vagrant's [installation page](https://www.vagrantup.com/downloads.html) provides downloads for Debian, Windows, CentOS, MacOS, and Arch Linux, but I found it in my package manager, so I'll install that.
The easiest install uses VirtualBox for the virtualization provider, so I'll need to install that, as well.
```
``````
sudo apt-get install virtualbox vagrant
```
The installer will pick up the dependencies—mostly Ruby stuff—and install them.
## Setting up a project
Before setting up your project, you'll need to know a bit about the environment where you want to run it. You can find a whole bunch of preconfigured boxes for many virtualization providers at the [Vagrant Boxes repository](https://app.vagrantup.com/boxes/search). Many will be pre-configured with some core infrastructure you might need, like PHP, MySQL, and Apache, but for this test, I'm going to install a bare Debian 8 64-bit "Jessie" box and manually install a few things, just so you can see how.
```
``````
mkdir ~/myproject
cd ~/myproject
vagrant init debian/contrib-jessie64
vagrant up
```
The last command will fetch or update the VirtualBox image from the library, as needed, then pull the starter, and you'll have a running box on your system! The next time you start the box, it won't take as long, unless the image has been updated in the repository.
To access the box, just enter `vagrant ssh`
. You'll be dropped into a fully functional SSH session on the virtual machine. You'll be user `vagrant`
, but you're a member of the `sudo`
group, so you can change to root and do whatever you want from here.
You'll see a directory named `/vagrant`
on the box. Be careful with this directory, as it'll be synced with the `~/myproject`
folder on the host machine. Touch a file in `/vagrant`
on the virtual machine, and it's immediately copied out to the host, and vice versa. Be aware that some boxes do not have the VirtualBox guest additions installed, so the copy works only one-way and only at boot time! There are some command-line tools for manual syncing, which might be a really useful feature in a testing environment. I tend to stick to boxes that have the additions in place, so this directory syncing just works without me having to think about it.
The benefits of this scheme become quickly apparent: If you have a code-editing toolchain on the host and don't want it on the virtual machine for any reason, that's not a problem—edit on the host, and the VM sees the change at once. Make a quick change on the VM, and it's synced to the "official" copy on the host, as well.
Let's shut the box down so we can provision some things we'll need on this box: `vagrant halt`
.
## Installing additional software on the VM, consistently
For this example, I'm going to work on a project using [Apache](https://httpd.apache.org/), [PostgreSQL](https://postgresql.org), and the [Dancer](https://perldancer.org) web framework for Perl. I'll modify the Vagrant configuration script so that the things I need are already installed. Just to make things easy to keep it updated later, I'll create a script at the top of `~/myproject/Vagrantfile`
:
```
``````
$provision_script = <<SCRIPT
export DEBIAN_FRONTEND=noninteractive
apt-get update
apt-get -y install \
apache2 \
postgresql-client-9.4 \
postgresql-9.4 \
libdbd-pg-perl \
libapache2-mod-fastcgi \
libdata-validate-email-perl \
libexception-class-perl \
libexception-class-trycatch-perl \
libtemplate-perl \
libtemplate-plugin-json-escape-perl \
libdbix-class-perl \
libyaml-tiny-perl \
libcrypt-saltedhash-perl \
libdancer2-perl \
libtemplate-plugin-gravatar-perl \
libtext-csv-perl \
libstring-tokenizer-perl \
cpanminus
cpanm -f -n \
Dancer2::Session::Cookie \
Dancer2::Plugin::DBIC \
Dancer2::Plugin::Auth::Extensible::Provider::DBIC \
Dancer2::Plugin::Locale \
Dancer2::Plugin::Growler
sudo a2enmod rewrite fastcgi
sudo apache2ctl restart
SCRIPT
```
Down near the end of the Vagrantfile, you'll find a line for the `config.vm.provision`
variable. You could do that inline here, as you see in the example, merely by uncommenting these lines:
```
``````
# config.vm.provision "shell", inline: <<-SHELL
# sudo apt-get update
# sudo apt-get install -y apache2
# SHELL
```
But instead, replace those four lines to use the provisioning script you defined as a variable at the top of the file:
```
````config.vm.provision "shell", inline: $provision_script`
You'll probably also want to set the forwarded port to access Apache on the VM from your host machine. Look for the line containing `forwarded_port`
and uncomment it. You can change the port from 8080 to something else, if you want, as well. I normally use port 5000, and accessing `http://localhost:5000`
in my browser gets me to the Apache server on the virtual machine.
Here's a setup tip: if your repository is on cloud storage, in order to use Vagrant on multiple machines, you'll probably want to set the `VAGRANT_HOME`
environment variable on different machines to different things. With the way VirtualBox works, you'll want to store state information separately for these systems. Make sure the directories being used for this are ignored by your version control—I add `.vagrant.d*`
to my `.gitignore`
file for the repository. I *do* let the Vagrantfile be part of the repository, though!
## All done!
I enter `vagrant up`
, and I'm ready to start writing code. Once you've done this once or twice, you'll probably come up with some Vagrantfile boilerplates you'll recycle a lot (like the one I just used), and that's one of the strengths of Vagrant. You get to the actual coding work quicker and spend less time on infrastructure!
There's a lot more you can do with Vagrant. Provisioning tools exist for many toolchains, so no matter what environment you need to replicate, it's quick and easy.
## Comments are closed. |
9,674 | LikeCoin,一种给开放式许可的内容创作者的加密货币 | https://opensource.com/article/18/5/likecoin | 2018-05-24T08:46:07 | [
"以太坊",
"CC",
"内容"
] | https://linux.cn/article-9674-1.html |
>
> 在共创协议下授权作品和挣钱这二者不再是一种争议。
>
>
>

传统观点认为,作家、摄影师、艺术家和其他创作者在<ruby> 共创协议 <rt> Creative Commons </rt></ruby>和其他开放许可下免费共享内容的不会得到报酬。这意味着大多数独立创作者无法通过在互联网上发布他们的作品来赚钱。而现在有了 [LikeCoin](https://like.co/):一个新的开源项目,旨在使这个让艺术家们经常为了贡献而不得不妥协或牺牲的常识成为过去。
LikeCoin 协议旨在通过创意内容获利,以便创作者可以专注于创造出色的内容而不是出售它。
该协议同样基于去中心化技术,它可以跟踪何时使用内容,并使用 LikeCoin 这种 [以太坊 ERC-20](https://en.wikipedia.org/wiki/ERC20) 加密货币通证来奖励其创作者。它通过“<ruby> 创造性共识 <rt> Proof of Creativity </rt></ruby>”算法进行操作,该算法一部分根据作品收到多少个“喜欢”,一部分根据有多少作品衍生自它而分配 LikeCoin。由于开放式授权的内容有更多机会被重复使用并获得 LikeCoin 令牌,因此系统鼓励内容创作者在<ruby> 共创协议 <rt> Creative Commons </rt></ruby>许可下发布。
### 如何运作的
当通过 LikeCoin 协议上传创意片段时,内容创作者也将包括作品的元数据,包括作者信息及其 InterPlanetary 关联数据([IPLD](https://ipld.io/))。这些数据构成了衍生作品的家族图谱;我们称作品与其衍生品之间的关系为“内容足迹”。这种结构使得内容的继承树可以很容易地追溯到原始作品。
LikeCoin 通证会使用作品的衍生历史记录的信息来将其分发给创作者。由于所有创意作品都包含作者钱包的元数据,因此相应的 LikeCoin 份额可以通过算法计算并分发。
LikeCoin 可以通过两种方式获得奖励:要么由想要通过支付给内容创建者来表示赞赏的个人直接给予,或通过 Creators Pool 收集观众的“赞”的并根据内容的 LikeRank 分配 LikeCoin。基于在 LikeCoin 协议中的内容追踪,LikeRank 衡量作品重要性(或者我们在这个场景下定义的创造性)。一般来说,一副作品有越多的衍生作品,创意内容的创新就越多,内容就会有更高的 LikeRank。 LikeRank 是内容创新性的量化者。
### 如何参与?
LikeCoin 仍然非常新,我们期望在 2018 年晚些时候推出我们的第一个去中心化程序来奖励<ruby> 共创协议 <rt> Creative Commons </rt></ruby>的内容,并与更大的社区无缝连接。
LikeCoin 的大部分代码都可以在 [LikeCoin GitHub](https://github.com/likecoin) 仓库中通过 [GPL 3.0 许可证](https://www.gnu.org/licenses/gpl-3.0.en.html)访问。由于它仍处于积极开发阶段,一些实验代码尚未公开,但我们会尽快完成。
我们欢迎功能请求、拉取请求、复刻和星标。请参与我们在 Github 上的开发,并加入我们在 [Telegram](https://t.me/likecoin) 的讨论组。我们同样在 [Medium](http://medium.com/likecoin)、[Facebook](http://fb.com/likecoin.foundation)、[Twitter](https://twitter.com/likecoin_fdn) 和我们的网站 [like.co](https://like.co/) 发布关于我们进展的最新消息。
---
via: <https://opensource.com/article/18/5/likecoin>
作者:[Kin Ko](https://opensource.com/users/ckxpress) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Conventional wisdom indicates that writers, photographers, artists, and other creators who share their content for free, under Creative Commons and other open licenses, won't get paid. That means most independent creators don't make any money by publishing their work on the internet. Enter [LikeCoin](https://like.co/): a new, open source project that intends to make this convention, where artists often have to compromise or sacrifice in order to contribute, a thing of the past.
The LikeCoin protocol is designed to monetize creative content so creators can focus on creating great material rather than selling it.
The protocol is also based on decentralized technologies that track when content is used and reward its creators with LikeCoin, an [Ethereum ERC-20](https://en.wikipedia.org/wiki/ERC20) cryptocurrency token. It operates through a "Proof of Creativity" algorithm which assigns LikeCoins based partially on how many "likes" a piece of content receives *and* how many derivative works are produced from it. Because openly licensed content has more opportunity to be reused and earn LikeCoin tokens, the system encourages content creators to publish under Creative Commons licenses.
## How it works
When a creative piece is uploaded via the LikeCoin protocol, the content creator includes the work's metadata, including author information and its InterPlanetary Linked Data ([IPLD](https://ipld.io/)). This data forms a family graph of derivative works; we call the relationships between a work and its derivatives the "content footprint." This structure allows a content's inheritance tree to be easily traced all the way back to the original work.
LikeCoin tokens will be distributed to creators using information about a work's derivation history. Since all creative works contain the metadata of the author's wallet, the corresponding LikeCoin shares can be calculated through the algorithm and distributed accordingly.
LikeCoins are awarded in two ways: either directly by individuals who want to show their appreciation by paying a content creator, or through the Creators Pool, which collects viewers' "Likes" and distributes LikeCoin according to a content's LikeRank. Based on content-footprint tracing in the LikeCoin protocol, the LikeRank measures the importance (or creativity as we define it in this context) of a creative content. In general, the more derivative works a creative content generates, the more creative the creative content is, and thus the higher LikeRank of the content. LikeRank is the quantifier of the creativity of contents.
## Want to get involved?
LikeCoin is still very new, and we expect to launch our first decentralized application later in 2018 to reward Creative Commons content and connect seamlessly with a much larger and established community.
Most of LikeCoin's code can be accessed in the [LikeCoin GitHub](https://github.com/likecoin) repository under a [GPL 3.0 license](https://www.gnu.org/licenses/gpl-3.0.en.html). Since it's still under active development, some of the experimental code is not yet open to the public, but we will make it so as soon as possible.
We welcome feature requests, pull requests, forks, and stars. Please join our development on GitHub and our general discussions on [Telegram](https://t.me/likecoin). We also release updates about our progress on [Medium](http://medium.com/likecoin), [Facebook](http://fb.com/likecoin.foundation), [Twitter](https://twitter.com/likecoin_fdn), and our website, [like.co](https://like.co/).
## Comments are closed. |
9,675 | Linux 局域网路由新手指南:第 2 部分 | https://www.linux.com/learn/intro-to-linux/2018/3/linux-lan-routing-beginners-part-2 | 2018-05-24T09:09:00 | [
"IPv4",
"路由"
] | https://linux.cn/article-9675-1.html | 
上周 [我们学习了 IPv4 地址](/article-9657-1.html) 和如何使用管理员不可或缺的工具 —— `ipcalc`,今天我们继续学习更精彩的内容:局域网路由器。
VirtualBox 和 KVM 是测试路由的好工具,在本文中的所有示例都是在 KVM 中执行的。如果你喜欢使用物理硬件去做测试,那么你需要三台计算机:一台用作路由器,另外两台用于表示两个不同的网络。你也需要两台以太网交换机和相应的线缆。
我们假设这个示例是一个有线以太局域网,为了更符合真实使用场景,我们将假设有一些桥接的无线接入点,当然我并不会使用这些无线接入点做任何事情。(我也不会去尝试所有的无线路由器,以及使用一个移动宽带设备连接到以太网的局域网口进行混合组网,因为它们需要进一步的安装和设置)
### 网段
最简单的网段是两台计算机连接在同一个交换机上的相同地址空间中。这样两台计算机不需要路由器就可以相互通讯。这就是我们常说的术语 —— “广播域”,它表示所有在相同的网络中的一组主机。它们可能连接到一台单个的以太网交换机上,也可能是连接到多台交换机上。一个广播域可以包括通过以太网桥连接的两个不同的网络,通过网桥可以让两个网络像一个单个网络一样运转。无线访问点一般是桥接到有线以太网上。
一个广播域仅当在它们通过一台网络路由器连接的情况下,才可以与不同的广播域进行通讯。
### 简单的网络
以下示例的命令并不是永久生效的,重启之后你所做的改变将会消失。
一个广播域需要一台路由器才可以与其它广播域通讯。我们使用两台计算机和 `ip` 命令来解释这些。我们的两台计算机是 192.168.110.125 和 192.168.110.126,它们都插入到同一台以太网交换机上。在 VirtualBox 或 KVM 中,当你配置一个新网络的时候会自动创建一个虚拟交换机,因此,当你分配一个网络到虚拟虚拟机上时,就像是插入一个交换机一样。使用 `ip addr show` 去查看你的地址和网络接口名字。现在,这两台主机可以互 ping 成功。
现在,给其中一台主机添加一个不同网络的地址:
```
# ip addr add 192.168.120.125/24 dev ens3
```
你可以指定一个网络接口名字,在示例中它的名字是 `ens3`。这不需要去添加一个网络前缀,在本案例中,它是 `/24`,但是显式地添加它并没有什么坏处。你可以使用 `ip` 命令去检查你的配置。下面的示例输出为了清晰其见进行了删减:
```
$ ip addr show
ens3:
inet 192.168.110.125/24 brd 192.168.110.255 scope global dynamic ens3
valid_lft 875sec preferred_lft 875sec
inet 192.168.120.125/24 scope global ens3
valid_lft forever preferred_lft forever
```
主机在 192.168.120.125 上可以 ping 它自己(`ping 192.168.120.125`),这是对你的配置是否正确的一个基本校验,这个时候第二台计算机就已经不能 ping 通那个地址了。
现在我们需要做一些网络变更。添加第三台主机作为路由器。它需要两个虚拟网络接口并添加第二个虚拟网络。在现实中,你的路由器必须使用一个静态 IP 地址,但是现在,我们可以让 KVM 的 DHCP 服务器去为它分配地址,所以,你仅需要两个虚拟网络:
* 第一个网络:192.168.110.0/24
* 第二个网络:192.168.120.0/24
接下来你的路由器必须配置去转发数据包。数据包转发默认是禁用的,你可以使用 `sysctl` 命令去检查它的配置:
```
$ sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 0
```
`0` 意味着禁用,使用如下的命令去启用它:
```
# echo 1 > /proc/sys/net/ipv4/ip_forward
```
接下来配置你的另一台主机做为第二个网络的一部分,你可以通过将原来在 192.168.110.0/24 的网络中的一台主机分配到 192.168.120.0/24 虚拟网络中,然后重新启动两个 “连网的” 主机,注意不是路由器。(或者重启动主机上的网络服务;我年龄大了还有点懒,我记不住那些重启服务的奇怪命令,还不如重启主机来得干脆。)重启后各台机器的地址应该如下所示:
* 主机 1: 192.168.110.125
* 主机 2: 192.168.120.135
* 路由器: 192.168.110.126 和 192.168.120.136
现在可以去随意 ping 它们,可以从任何一台计算机上 ping 到任何一台其它计算机上。使用虚拟机和各种 Linux 发行版做这些事时,可能会产生一些意想不到的问题,因此,有时候 ping 的通,有时候 ping 不通。不成功也是一件好事,这意味着你需要动手去创建一条静态路由。首先,查看已经存在的路由表。主机 1 和主机 2 的路由表如下所示:
```
$ ip route show
default via 192.168.110.1 dev ens3 proto static metric 100
192.168.110.0/24 dev ens3 proto kernel scope link src 192.168.110.164 metric 100
$ ip route show
default via 192.168.110.1 dev ens3 proto static metric 100
default via 192.168.120.1 dev ens3 proto static metric 101
169.254.0.0/16 dev ens3 scope link metric 1000
192.168.110.0/24 dev ens3 proto kernel scope link
src 192.168.110.126 metric 100
192.168.120.0/24 dev ens9 proto kernel scope link
src 192.168.120.136 metric 100
```
这显示了我们使用的由 KVM 分配的缺省路由。169.\* 地址是自动链接的本地地址,我们不去管它。接下来我们看两条路由,这两条路由指向到我们的路由器。你可以有多条路由,在这个示例中我们将展示如何在主机 1 上添加一个非默认路由:
```
# ip route add 192.168.120.0/24 via 192.168.110.126 dev ens3
```
这意味着主机 1 可以通过路由器接口 192.168.110.126 去访问 192.168.110.0/24 网络。看一下它们是如何工作的?主机 1 和路由器需要连接到相同的地址空间,然后路由器转发到其它的网络。
以下的命令去删除一条路由:
```
# ip route del 192.168.120.0/24
```
在真实的案例中,你不需要像这样手动配置一台路由器,而是使用一个路由器守护程序,并通过 DHCP 做路由器通告,但是理解基本原理很重要。接下来我们将学习如何去配置一个易于使用的路由器守护程序来为你做这些事情。
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 来学习更多 Linux 的知识。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/3/linux-lan-routing-beginners-part-2>
作者:[CARLA SCHRODER](https://www.linux.com/users/cschroder) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,676 | 在 Linux 中轻松搜索和安装 Google Web 字体 | https://www.ostechnix.com/font-finder-easily-search-and-install-google-web-fonts-in-linux/ | 2018-05-24T12:37:47 | [
"字体"
] | https://linux.cn/article-9676-1.html | 
Font Finder 是旧的 [Typecatcher](https://www.ostechnix.com/install-google-web-fonts-ubuntu/) 的 Rust 实现,用于从 [Google 的字体存档](https://fonts.google.com/)中轻松搜索和安装 Google Web 字体。它可以帮助你在 Linux 桌面上安装数百种免费和开源字体。如果你正在为你的 Web 项目和应用以及其他任何地方寻找好看的字体,Font Finder 可以轻松地为你提供。它是用 Rust 编程语言编写的自由、开源的 GTK3 应用程序。与使用 Python 编写的 Typecatcher 不同,Font Finder 可以按类别过滤字体,没有 Python 运行时依赖关系,并且有更好的性能和更低的资源消耗。
在这个简短的教程中,我们将看到如何在 Linux 中安装和使用 Font Finder。
### 安装 Font Finder
由于 Fond Finder 是使用 Rust 语言编写的,因此你需要向下面描述的那样在系统中安装 Rust。
安装 Rust 后,运行以下命令安装 Font Finder:
```
$ cargo install fontfinder
```
Font Finder 也可以从 [flatpak app](https://flathub.org/apps/details/io.github.mmstick.FontFinder) 安装。首先在你的系统中安装 Flatpak,如下面的链接所述。
然后,使用命令安装 Font Finder:
```
$ flatpak install flathub io.github.mmstick.FontFinder
```
### 在 Linux 中使用 Font Finder 搜索和安装 Google Web 字体
你可以从程序启动器启动 Font Finder,也可以运行以下命令启动它。
```
$ flatpak run io.github.mmstick.FontFinder
```
这是 Font Finder 默认界面的样子。

正如你所看到的,Font Finder 的用户界面非常简单。所有 Google Web 字体都列在左侧窗格中,相应字体的预览显示在右侧窗格中。你可以在预览框中输入任何单词以查看单词在所选字体中的外观。在左上方还有一个搜索框,可以让你快速搜索你选择的字体。
默认情况下,Font Finder 显示所有类型的字体。但是,你可以通过搜索框上方的类别下拉框中的分类显示字体。

要安装字体,只需选择它并点击顶部的 “Install” 按钮即可。

你可以在任何文本处理程序中测试新安装的字体。

同样,要删除字体,只需从 Font Finder 面板中选择它并单击 “Uninstall” 按钮。就这么简单!
左上角的设置按钮(齿轮按钮)提供了切换到暗色预览的选项。

如你所见,Font Finder 非常简单,完全可以像在主页上宣传的那样完成工作。如果你正在寻找安装 Google Web 字体的程序,Font Finder 就是这样的一个程序。
今天就是这些。希望这有帮助。还有更好的东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/font-finder-easily-search-and-install-google-web-fonts-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,677 | 使用树莓派构建一个婴儿监视器 | https://opensource.com/article/18/3/build-baby-monitor-raspberry-pi | 2018-05-24T17:47:55 | [
"树莓派"
] | https://linux.cn/article-9677-1.html |
>
> 比一般的视频监控还要好,这种 DIY 型号还有婴儿房间的自动室温控制功能。
>
>
>

香港很湿热,即便是晚上,许多人为了更舒适,在家里也使用空调。当我的大儿子还是一个小婴儿的时候,他卧室的空调还是需要手动控制的,没有温度自动调节的功能。它的控制器只有开或者关,让空调整个晚上持续运行会导致房间过冷,并且也浪费能源和钱。
我决定使用一个基于 [树莓派](https://opensource.com/tags/raspberry-pi) 的 [物联网](https://opensource.com/tags/internet-things) 解决方案去修复这个问题。后来我进一步为它添加了一个[婴儿监视器](https://opensource.com/article/17/9/gonimo)插件。在这篇文章中,我将解释我是如何做的,它的代码在 [我的 GitHub](https://github.com/jervine/rpi-temp-humid-monitor) 页面上。
### 设计空调控制器
解决我的问题的第一个部分是使用了一个 Orvibo S20 [可通过 WiFi 连接的智能插头](https://www.amazon.co.uk/marsboy-S20-Automation-Control-Smartphone/dp/B01LXKPUDK/ref=sr_1_1/258-6082934-2585109?ie=UTF8&qid=1520578769&sr=8-1&keywords=orvibo+s20)和智能手机应用程序。虽然这样可以让我通过远程来控制空调,但是它还是手动处理的,而我希望尝试让它自动化。我在 [Instructables](http://www.instructables.com/id/Raspberry-Pi-Temperature-Humidity-Network-Monitor/) 上找到了一个满足我的需求的项目:他使用树莓派从一个 [AM2302 传感器](https://www.adafruit.com/product/393) 上测量附近的温度和湿度,并将它们记录到一个 MySQL 数据库中。
使用压接头将温度/湿度传感器连接到树莓派的相应 GPIO 针脚上。幸运的是,AM2302 传感器有一个用于读取的 [开源软件](https://github.com/adafruit/Adafruit_Python_DHT),并且同时提供了 [Python](https://opensource.com/tags/python) 示例。
与我的项目放在一起的用于 [AM2302 传感器](https://github.com/adafruit/Adafruit-Raspberry-Pi-Python-Code/tree/legacy/Adafruit_DHT_Driver_Python) 接口的软件已经更新了,并且我使用的原始代码现在应该已经过时了,停止维护了。这个代码是由一个小的二进制组成,用于连接到传感器以及解释读取并返回正确值的 Python 脚本。

*树莓派、传感器、以及用于构建温度/湿度监视器的 Python 代码。*
将传感器连接到树莓派,这些 Python 代码能够正确地返回温度和湿度读数。将 Python 连接到 MySQL 数据库很简单,并且也有大量的使用 python-mysql 绑定的代码示例。因为我需要持续地监视温度和湿度,所以我写软件来实现这些。
事实上,最终我用了两个解决方案,一是作为一个持续运行的进程,周期性(一般是间隔一分钟)地获取传感器数据,另一种是让 Python 脚本运行一次然后退出。我决定使用第二种方法,并使用 cron 去每分钟调用一次这个脚本。之所以选择这种方法的主要原因是,(通过循环实现的)持续的脚本偶尔会不返回读数,这将导致尝试读取传感器的进程出现堆积,最终可能会导致系统挂起而缺乏可用资源。
我也找到了可以用程序来控制我的智能插头的一个 [Perl 脚本](https://github.com/franc-carter/bauhn-wifi)。它是解决这种问题所需的一部分,因此当某些温度/湿度达到触发条件,将触发这个 Perl 脚本。在做了一些测试之后,我决定去设计一个独立的 `checking` 脚本,从 MySQL 去拉取最新的数据,然后根据返回的值去设置智能开关为开或关。将插头控制逻辑与传感器读取脚本分开,意味着它们是各自独立运行的,就算是传感器读取脚本写的有问题也没事。
配置一个打开/关闭空调的温度值是很有意义的,因此,我将这些值转移到控制脚本读取的配置文件中。我也发现,虽然传感器的值一般都很准确,但是,偶尔也会出现返回不正确读数的情况。这个传感器脚本被修改为不向 MySQL 数据库中写入与前值差异非常大的值。同样也在配置文件中写入了连续读取的温度/湿度之间允许的最大差异值,如果读取的值处于这些限制值以外,这些值写不会提交到数据库中。
虽然,做这个自动调节器似乎花费了很多努力,但是,这意味着,记录到 MySQL 数据库的数据是有效的、可用于进一步去分析识别用户使用模式的有用数据。可以用多种图形方式去展示来自 MySQL 数据库中的数据,而我决定使用 [Google Chart](https://developers.google.com/chart/) 在一个 Web 页面上显示数据。

*过去六小时内测量到的温度和湿度*
### 添加一个婴儿监视摄像头
树莓派开放的性能意味着我可以不断地为它增加功能 —— 并且我有大量的未使用的可用 GPIO 针脚。我的下一个创意是去添加一个摄像头模块,将它放在孩子的卧室中,配置它去监视婴儿。
我需要一个能够在黑暗环境中工作的摄像头,而 [Pi Noir](https://www.raspberrypi.org/products/pi-noir-camera-v2/) 摄像头模块是非常适合这种条件的。Pi Noir 除了没有红外过滤之外,同样也是树莓派常用的摄像头模块。这意味着它在白天时的图像可能有点偏紫色,但是它可以在黑暗中借助红外灯来显示图像。
现在我需要一个红外光源。由于树莓派非常流行,并且进入门槛很低,因此它有大量的外围配件和插件。也有适合它的各种红外光源,我注意到的其中一个是 [Bright Pi](https://www.pi-supply.com/product/bright-pi-bright-white-ir-camera-light-raspberry-pi/)。它可以从树莓派上供电,并且它很适合为树莓派的摄像头模块提供红外光和普通光。它唯一的缺点是太考验我的焊接技能了。
我的焊接技能还是不错的,但是可能花费的时间比其他人更长。我成功地连接了外壳上所有的红外 LEDs,并将它们连接到树莓派的 GPIO 针脚上。这意味着树莓派能够编程控制红外 LED 是否点亮,以及它的亮度。
通过一个 Web 流去公开捕获的视频也很有意义,因为这样我就可以从 Web 页面上查看温度和湿度的读数图表。进一步研究之后,我选择了一个使用 M-JPEG 捕获器的 [流软件](https://elinux.org/RPi-Cam-Web-Interface)。通过 Web 页面公开 JPG 源,我可以在我的智能手机上去连接摄像头查看程序,去查看摄像头的输出。
### 做最后的修饰
没有哪个树莓派项目都已经完成了还没有为它选择一个合适的外壳,并且它有各种零件。在大量搜索和比较之后,有了一个显然的 [赢家](https://smarticase.com/collections/all/products/smartipi-kit-3):SmartPi 的乐高积木式外壳。乐高的兼容性可以让我去安装温度/湿度传感器和摄像头。下面是最终的成果图:

在这以后,我对我的这个作品作了一些改变和更新:
* 我将它从树莓派 2 Model B 升级到了 [树莓派 3](https://opensource.com/article/18/3/raspberry-pi-3b-model-news),这意味着我可以使用 USB WiFi 模块。
* 我用一个 [TP-Link HS110](https://www.tp-link.com/uk/products/details/cat-5258_HS110.html) 智能插头替换了 Orvibo S20。
* 我也将树莓派插到了一个智能插头上,这样我就可以远程重启/重置它了。
* 我从树莓派上将 MySQL 数据库移走了,它现在运行在一个 NAS 设备上的容器中。
* 我增加了一个非常 [灵活的三角夹](https://www.amazon.com/Flexpod-Flexible-Tripod-Discontinued-Manufacturer/dp/B000JC8WYA),这样我就可以调整到最佳角度。
* 我重新编译了 USB WiFi 模块,禁用了板载 LED 指示灯,这就是升级到树莓派 3 的其中一个好处。
* 我因此为我的第二个孩子设计了另外一个监视器。
* 因为没有时间去折腾,我为我的第三个孩子购买了夜用摄像头。
想学习更多的东西吗?所有的代码都在 [我的 GitHub](https://github.com/jervine/rpi-temp-humid-monitor) 页面上。
想分享你的树莓派项目吗?[将你的故事和创意发送给我们](http://opensource.com/story)。
---
via: <https://opensource.com/article/18/3/build-baby-monitor-raspberry-pi>
作者:[Jonathan Ervine](https://opensource.com/users/jervine) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hong Kong can be hot and humid, even at night, and many people use air conditioning to make their homes more bearable. When my oldest son was a baby, the air conditioning unit in his bedroom had manual controls and no thermostat functionality. It was either on or off, and allowing it to run continuously overnight caused the room to get cold and wasted energy and money.
I decided to fix this problem with an [Internet of Things](https://opensource.com/tags/internet-things) solution based on a [Raspberry Pi](https://opensource.com/tags/raspberry-pi). Later I took it a step further with a [baby monitor](https://opensource.com/article/17/9/gonimo) add-on. In this article, I'll explain how I did it, and the code is [available on my GitHub](https://github.com/jervine/rpi-temp-humid-monitor) page.
## Setting up the air conditioner controller
I solved the first part of my problem with an Orvibo S20 [WiFi-connected smart plug](https://www.amazon.co.uk/marsboy-S20-Automation-Control-Smartphone/dp/B01LXKPUDK/ref=sr_1_1/258-6082934-2585109?ie=UTF8&qid=1520578769&sr=8-1&keywords=orvibo+s20) and smartphone application. Although this allowed me to control the air conditioning unit remotely, it was still a manual process, and I wanted to try and automate it. I found a project on [Instructables](http://www.instructables.com/id/Raspberry-Pi-Temperature-Humidity-Network-Monitor/) that seemed to match my requirements: It used a Raspberry Pi to measure local temperature and humidity readings from an [AM2302 sensor](https://www.adafruit.com/product/393) and record them to a MySQL database.
Using crimp terminal contacts with crimp housings made it a pinch to connect the temperature/humidity sensor to the correct GPIO pins on the Raspberry Pi. Fortunately, the AM2302 sensor has [open source software](https://github.com/adafruit/Adafruit_Python_DHT) for taking readings, with helpful [Python](https://opensource.com/tags/python) examples.
The software for [interfacing with the AM2302 sensor](https://github.com/adafruit/Adafruit-Raspberry-Pi-Python-Code/tree/legacy/Adafruit_DHT_Driver_Python) has been updated since I put my project together, and the original code I used is now considered legacy and unmaintained. The code is made up of a small binary object to connect to the sensor and some Python scripts to interpret the readings and return the correct values.
opensource.com
With the sensor connected to the Raspberry Pi, the Python code can correctly return temperature and humidity readings. Connecting Python to a MySQL database is straightforward, and there are plenty of code examples that use the `python-`
`mysql`
bindings. Because I needed to monitor the temperature and humidity continuously, I wrote software to do this.
In fact, I ended up with two solutions, one that would run continuously as a process and periodically poll the sensor (typically at one-minute intervals), and another Python script that ran once and exited. I decided to use the run-once-and-exit approach coupled with cron to call this script every minute. The main reason was that the continuous (looped) script occasionally would not return a reading, which could lead to a buildup of processes trying to read the sensor, and that would eventually cause a system to hang due to lack of available resources.
I also found a convenient [Perl script](https://github.com/franc-carter/bauhn-wifi) to programmatically control my smart plug. This was an essential piece of the jigsaw, as it meant I could trigger the Perl script if certain temperature and/or humidity conditions were met. After some testing, I decided to create a separate `checking`
script that would pull the latest values from the MySQL database and set the smart plug on or off depending upon the values returned. Separating the logic to run the plug control script from the sensor-reading script also meant that it operated independently and would continue to run, even if the sensor-reading script developed problems.
It made sense to make the temperature at which the air conditioner would switch on/off configurable, so I moved these values to a configuration file that the control script read. I also found that, although the sensor was generally accurate, occasionally it would return incorrect readings. The sensor script was modified to not write temperature or humidity values to the MySQL database that were significantly different from the previous values. Likewise the allowed variance of temperature or humidity between consecutive readings was set in a general configuration file, and if the reading was outside these limits the values would not be committed to the database.
Although this seemed like quite a lot of effort to make a thermostat, recording the data to a MySQL database meant it was available for further analysis to identify usage patterns. There are many graphing options available to present data from a MySQL database, and I decided to use [Google Chart ](https://developers.google.com/chart/)to display the data on a web page.
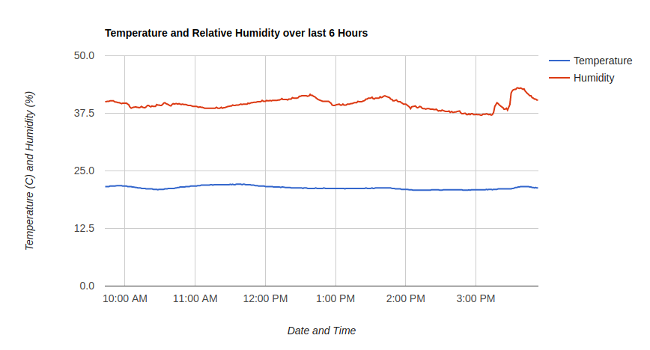
opensource.com
## Adding a baby monitor camera
The open nature of the Raspberry Pi meant I could continue to add functionality—and I had plenty of open GPIO pins available. My next idea was to add a camera module to set it up as a baby monitor, given that the device was already in the baby's bedroom.
I needed a camera that works in the dark, and the [Pi Noir](https://www.raspberrypi.org/products/pi-noir-camera-v2/) camera module is perfect for this. The Pi Noir is the same as the Raspberry Pi's regular camera module, except it doesn't have an infrared (IR) filter. This means daytime images may have a slightly purple tint, but it will display images lit with IR light in the dark.
Now I needed a source of IR light. Due to the Pi's popularity and low barrier of entry, there are a huge number of peripherals and add-ons for it. Of the many IR sources available, the one that caught my attention was the [Bright Pi](https://www.pi-supply.com/product/bright-pi-bright-white-ir-camera-light-raspberry-pi/). It draws power from the Raspberry Pi and fits around the camera Pi module to provide a source of IR and normal light. The only drawback was I needed to dust off my rusty soldering skills.
It might have taken me longer than most, but my soldering skills were up to it, and I was able to successfully attach all the IR LEDs to the housing and connect the IR light source to the Pi's GPIO pins. This also meant that the Pi could programmatically control when the IR LEDs were lit, as well as their light intensity.
It also made sense to have the video capture exposed via a web stream so I could watch it from the web page with the temperature and humidity readings chart. After further research, I chose to use a [streaming software](https://elinux.org/RPi-Cam-Web-Interface) that used M-JPEG captures. Exposing the JPG source via the web page also allowed me to connect camera viewer applications on my smartphone to view the camera output there, as well.
## Putting on the finishing touches
No Raspberry Pi project is complete without selecting an appropriate case for the Pi and its various components. After a lot of searching and comparing, there was one clear [winner](https://smarticase.com/collections/all/products/smartipi-kit-3): SmartPi's Lego-style case. The Lego compatibility allowed me to build mounts for the temperature/humidity sensor and camera. Here's the final outcome:

opensource.com
Since then, I've made other changes and updates to my setup:
- I upgraded from a Raspberry Pi 2 Model B to a
[Raspberry Pi 3](https://opensource.com/article/18/3/raspberry-pi-3b-model-news), which meant I could do away with the USB WiFi module. - I replaced the Orvibo S20 with a
[TP-Link HS110](https://www.tp-link.com/uk/products/details/cat-5258_HS110.html)smart plug. - I also plugged the Pi into a smart plug so I can do remote reboots/resets.
- I migrated the MySQL database off the Raspberry Pi, and it now runs in a container on a NAS device.
- I added a
[flexible tripod](https://www.amazon.com/Flexpod-Flexible-Tripod-Discontinued-Manufacturer/dp/B000JC8WYA)to allow for the best camera angle. - I recompiled the USB WiFi module to disable the onboard flashing LED, which was one of the main advantages to upgrading to a Raspberry Pi 3.
- I've since built another monitor for my second child.
- I bought a bespoke night camera for my third child … due to lack of time.
Want to learn more? All the code is [available on my GitHub](https://github.com/jervine/rpi-temp-humid-monitor) page.
*Do you have a Raspberry Pi project to share? Send us your story idea.*
## Comments are closed. |
9,678 | You-Get:支持 80 多个网站的命令行多媒体下载器 | https://www.ostechnix.com/you-get-a-cli-downloader-to-download-media-from-80-websites/ | 2018-05-25T09:15:28 | [
"下载",
"Youtube-dl",
"You-Get"
] | https://linux.cn/article-9678-1.html | 
你们大多数人可能用过或听说过 **Youtube-dl**,这个命令行程序可以从包括 Youtube 在内的 100+ 网站下载视频。我偶然发现了一个类似的工具,名字叫做 **You-Get**。这是一个 Python 编写的命令行下载器,可以让你从 Youtube、Facebook、Twitter 等很多热门网站下载图片,音频和视频(LCTT 译注:首先,它们得是存在的网站)。目前该下载器支持 80+ 站点,点击[这里](https://you-get.org/#supported-sites)查看所有支持的网站。
You-Get 不仅仅是一个下载器,它还可以将在线视频导流至你的视频播放器。更进一步,它还允许你在 Google 上搜索视频,只要给出搜索项,You-Get 使用 Google 搜索并下载相关度最高的视频。另外值得一提的特性是,它允许你暂停和恢复下载过程。它是一个完全自由、开源及跨平台的应用,适用于 Linux、MacOS 及 Windows。
### 安装 You-Get
确保你已经安装如下依赖项:
* Python 3
* FFmpeg (强烈推荐) 或 Libav
* (可选) RTMPDump
有多种方式安装 You-Get,其中官方推荐采用 pip 包管理器安装。如果你还没有安装 pip,可以参考如下链接:
* [如何使用 pip 管理 Python 软件包](https://www.ostechnix.com/manage-python-packages-using-pip/)
需要注意的是,你需要安装 Python 3 版本的 `pip`。
接下来,运行如下命令安装 You-Get:
```
$ pip3 install you-get
```
可以使用命令升级 You-Get 至最新版本:
```
$ pip3 install --upgrade you-get
```
### 开始使用 You-Get
使用方式与 Youtube-dl 工具基本一致。
#### 下载视频
下载视频,只需运行:
```
$ you-get https://www.youtube.com/watch?v=HXaglTFJLMc
```
输出示例:
```
site: YouTube
title: The Last of The Mohicans by Alexandro Querevalú
stream:
- itag: 22
container: mp4
quality: hd720
size: 56.9 MiB (59654303 bytes)
# download-with: you-get --itag=22 [URL]
Downloading The Last of The Mohicans by Alexandro Querevalú.mp4 ...
100% ( 56.9/ 56.9MB) ├███████████████████████████████████████████████████████┤[1/1] 752 kB/s
```
下载视频前,你可能希望查看视频的细节信息。You-Get 提供了 `–info` 或 `-i` 参数,使用该参数可以获得给定视频所有可用的分辨率和格式。
```
$ you-get -i https://www.youtube.com/watch?v=HXaglTFJLMc
```
或者
```
$ you-get --info https://www.youtube.com/watch?v=HXaglTFJLMc
```
输出示例如下:
```
site: YouTube
title: The Last of The Mohicans by Alexandro Querevalú
streams: # Available quality and codecs
[ DASH ] ____________________________________
- itag: 137
container: mp4
quality: 1920x1080
size: 101.9 MiB (106816582 bytes)
# download-with: you-get --itag=137 [URL]
- itag: 248
container: webm
quality: 1920x1080
size: 90.3 MiB (94640185 bytes)
# download-with: you-get --itag=248 [URL]
- itag: 136
container: mp4
quality: 1280x720
size: 56.9 MiB (59672392 bytes)
# download-with: you-get --itag=136 [URL]
- itag: 247
container: webm
quality: 1280x720
size: 52.6 MiB (55170859 bytes)
# download-with: you-get --itag=247 [URL]
- itag: 135
container: mp4
quality: 854x480
size: 32.2 MiB (33757856 bytes)
# download-with: you-get --itag=135 [URL]
- itag: 244
container: webm
quality: 854x480
size: 28.0 MiB (29369484 bytes)
# download-with: you-get --itag=244 [URL]
[ DEFAULT ] _________________________________
- itag: 22
container: mp4
quality: hd720
size: 56.9 MiB (59654303 bytes)
# download-with: you-get --itag=22 [URL]
```
默认情况下,You-Get 会下载标记为 “DEFAULT” 的格式。如果你对格式或分辨率不满意,可以选择你喜欢的格式,使用格式对应的 itag 值即可。
```
$ you-get --itag=244 https://www.youtube.com/watch?v=HXaglTFJLMc
```
#### 下载音频
执行下面的命令,可以从 soundcloud 网站下载音频:
```
$ you-get 'https://soundcloud.com/uiceheidd/all-girls-are-same-999-prod-nick-mira'
Site: SoundCloud.com
Title: ALL GIRLS ARE THE SAME (PROD. NICK MIRA)
Type: MP3 (audio/mpeg)
Size: 2.58 MiB (2710046 Bytes)
Downloading ALL GIRLS ARE THE SAME (PROD. NICK MIRA).mp3 ...
100% ( 2.6/ 2.6MB) ├███████████████████████████████████████████████████████┤[1/1] 983 kB/s
```
查看音频文件细节,使用 `-i` 参数:
```
$ you-get -i 'https://soundcloud.com/uiceheidd/all-girls-are-same-999-prod-nick-mira'
```
#### 下载图片
运行如下命令下载图片:
```
$ you-get https://pixabay.com/en/mountain-crumpled-cyanus-montanus-3393209/
```
You-Get 也可以下载网页中的全部图片:
```
$ you-get https://www.ostechnix.com/pacvim-a-cli-game-to-learn-vim-commands/
```
#### 搜索视频
你只需向 You-Get 传递一个任意的搜索项,而无需给出有效的 URL;You-Get 会使用 Google 搜索并下载与你给出搜索项最相关的视频。(LCTT 译注:Google 的机器人检测机制可能导致 503 报错导致该功能无法使用)。
```
$ you-get 'Micheal Jackson'
Google Videos search:
Best matched result:
site: YouTube
title: Michael Jackson - Beat It (Official Video)
stream:
- itag: 43
container: webm
quality: medium
size: 29.4 MiB (30792050 bytes)
# download-with: you-get --itag=43 [URL]
Downloading Michael Jackson - Beat It (Official Video).webm ...
100% ( 29.4/ 29.4MB) ├███████████████████████████████████████████████████████┤[1/1] 2 MB/s
```
#### 观看视频
You-Get 可以将在线视频导流至你的视频播放器或浏览器,跳过广告和评论部分。(LCTT 译注:使用 `-p` 参数需要对应的 vlc/chrominum 命令可以调用,一般适用于具有图形化界面的操作系统)。
以 VLC 视频播放器为例,使用如下命令在其中观看视频:
```
$ you-get -p vlc https://www.youtube.com/watch?v=HXaglTFJLMc
```
或者
```
$ you-get --player vlc https://www.youtube.com/watch?v=HXaglTFJLMc
```
类似地,将视频导流至以 chromium 为例的浏览器中,使用如下命令:
```
$ you-get -p chromium https://www.youtube.com/watch?v=HXaglTFJLMc
```

在上述屏幕截图中,可以看到并没有广告和评论部分,只是一个包含视频的简单页面。
#### 设置下载视频的路径及文件名
默认情况下,使用视频标题作为默认文件名,下载至当前工作目录。当然,你可以按照你的喜好进行更改,使用 `–output-dir` 或 `-o` 参数可以指定路径,使用 `–output-filename` 或 `-O` 参数可以指定下载文件的文件名。
```
$ you-get -o ~/Videos -O output.mp4 https://www.youtube.com/watch?v=HXaglTFJLMc
```
#### 暂停和恢复下载
按 `CTRL+C` 可以取消下载。一个以 `.download` 为扩展名的临时文件会保存至输出路径。下次你使用相同的参数下载时,下载过程将延续上一次的过程。
当文件下载完成后,以 `.download` 为扩展名的临时文件会自动消失。如果这时你使用同样参数下载,You-Get 会跳过下载;如果你想强制重新下载,可以使用 `–force` 或 `-f` 参数。
查看命令的帮助部分可以获取更多细节,命令如下:
```
$ you-get --help
```
这次的分享到此结束,后续还会介绍更多的优秀工具,敬请期待!
感谢各位阅读!
---
via: <https://www.ostechnix.com/you-get-a-cli-downloader-to-download-media-from-80-websites/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,679 | 如何在 Ubuntu 上安装和优化 Apache | https://thishosting.rocks/how-to-install-optimize-apache-ubuntu/ | 2018-05-25T10:30:22 | [
"Apache"
] | https://linux.cn/article-9679-1.html | 
这是我们的 LAMP 系列教程的开始:如何在 Ubuntu 上安装 Apache web 服务器。
这些说明适用于任何基于 Ubuntu 的发行版,包括 Ubuntu 14.04、 Ubuntu 16.04、 [Ubuntu 18.04](https://thishosting.rocks/ubuntu-18-04-new-features-release-date/),甚至非 LTS 的 Ubuntu 发行版,例如 Ubuntu 17.10。这些说明经过测试并为 Ubuntu 16.04 编写。
Apache (又名 httpd) 是最受欢迎和使用最广泛的 web 服务器,所以这应该对每个人都有用。
### 开始安装 Apache 之前
在我们开始之前,这里有一些要求和说明:
* Apache 可能已经在你的服务器上安装了,所以开始之前首先检查一下。你可以使用 `apachectl -V` 命令来显示你正在使用的 Apache 的版本和一些其他信息。
* 你需要一个 Ubuntu 服务器。你可以从 [Vultr](https://thishosting.rocks/go/vultr/) 购买一个,它们是[最便宜的云托管服务商](https://thishosting.rocks/cheap-cloud-hosting-providers-comparison/)之一。它们的服务器价格每月 2.5 美元起。(LCTT 译注:广告 ≤\_≤ )
* 你需要有 root 用户或具有 sudo 访问权限的用户。下面的所有命令都由 root 用户执行,所以我们不必为每个命令都添加 `sudo`。
* 如果你使用 Ubuntu,则需要[启用 SSH](https://thishosting.rocks/how-to-enable-ssh-on-ubuntu/),如果你使用 Windows,则应该使用类似 [MobaXterm](https://mobaxterm.mobatek.net/) 的 SSH 客户端。
这就是全部要求和注释了,让我们进入安装过程。
### 在 Ubuntu 上安装 Apache
你需要做的第一件事就是更新 Ubuntu,这是在你做任何事情之前都应该做的。你可以运行:
```
apt-get update && apt-get upgrade
```
接下来,安装 Apache,运行以下命令:
```
apt-get install apache2
```
如果你愿意,你也可以安装 Apache 文档和一些 Apache 实用程序。对于我们稍后将要安装的一些模块,你将需要一些 Apache 实用程序。
```
apt-get install apache2-doc apache2-utils
```
\**就是这样。你已经成功安装了 Apache \**
你仍然需要配置它。
### 在 Ubuntu 上配置和优化 Apache
你可以在 Apache 上做各种各样的配置,但是主要的和最常见的配置将在下面做出解释。
#### 检查 Apache 是否正在运行
默认情况下,Apache 设置为在机器启动时自动启动,因此你不必手动启用它。你可以使用以下命令检查它是否正在运行以及其他相关信息:
```
systemctl status apache2
```
[](https://thishosting.rocks/wp-content/uploads/2018/01/apache-running.jpg)
并且你可以检查你正在使用的版本:
```
apachectl -V
```
一种更简单的检查方法时访问服务器的 IP 地址,如果你得到默认的 Apache 页面,那么一切都正常。
#### 更新你的防火墙
如果你使用防火墙(你应该使用它),则可能需要更新防火墙规则并允许访问默认端口。Ubuntu 上最常用的防火墙是 UFW,因此以下说明使用于 UFW。
要允许通过 80(http)和 443(https)端口的流量,运行以下命令:
```
ufw allow 'Apache Full'
```
#### 安装常见的 Apache 模块
一些模块经常被建议使用,所以你应该安装它们。我们将包含最常见模块的说明:
##### 使用 PageSpeed 加速你的网站
PageSpeed 模块将自动优化并加速你的 Apache 服务器。
首先,进入 [PageSpeed 下载页](https://www.modpagespeed.com/doc/download)并选择你需要的的文件。我们使用的是 64 位 Ubuntu 服务器,所以我们安装最新的稳定版本。使用 `wget` 下载它:
```
wget https://dl-ssl.google.com/dl/linux/direct/mod-pagespeed-stable_current_amd64.deb
```
然后,使用以下命令安装它:
```
dpkg -i mod-pagespeed-stable_current_amd64.deb
apt-get -f install
```
重启 Apache 以使更改生效:
```
systemctl restart apache2
```
##### 使用 mod\_rewrite 模块启动重写/重定向
顾名思义,该模块用于重写(重定向)。如果你使用 WordPress 或任何其他 CMS 来处理此问题,你就需要它。要安装它,只需运行:
```
a2enmod rewrite
```
然后再次重新启动 Apache。你可能需要一些额外的配置,具体取决于你使用的 CMS,如果有的话。为你的设置 Google 一下得到它的具体说明。
##### 使用 ModSecurity 模块保护你的 Apache
顾名思义,ModSecurity 是一个用于安全性的模块,它基本上起着防火墙的作用,它可以监控你的流量。要安装它,运行以下命令:
```
apt-get install libapache2-modsecurity
```
再次重启 Apache:
```
systemctl restart apache2
```
ModSecurity 自带了一个默认的设置,但如果你想扩展它,你可以使用 [OWASP 规则集](https://www.owasp.org/index.php/Category:OWASP_ModSecurity_Core_Rule_Set_Project)。
##### 使用 mod\_evasive 模块抵御 DDoS 攻击
尽管 mod\_evasive 在防止攻击方面有多大用处值得商榷,但是你可以使用它来阻止和防止服务器上的 DDoS 攻击。要安装它,使用以下命令:
```
apt-get install libapache2-mod-evasive
```
默认情况下,mod\_evasive 是禁用的,要启用它,编辑以下文件:
```
nano /etc/apache2/mods-enabled/evasive.conf
```
取消注释所有行(即删除 `#`),根据你的要求进行配置。如果你不知道要编辑什么,你可以保持原样。
[](https://thishosting.rocks/wp-content/uploads/2018/01/mod_evasive.jpg)
创建一个日志文件:
```
mkdir /var/log/mod_evasive
chown -R www-data:www-data /var/log/mod_evasive
```
就是这样。现在重启 Apache 以使更改生效。
```
systemctl restart apache2
```
你可以安装和配置[附加模块](https://httpd.apache.org/docs/2.4/mod/),但完全取决于你和你使用的软件。它们通常不是必需的。甚至我们上面包含的 4 个模块也不是必需的。如果特定应用需要模块,那么它们可能会注意到这一点。
#### 用 Apache2Buddy 脚本优化 Apache
Apache2Buddy 是一个可以自动调整 Apache 配置的脚本。你唯一需要做的就是运行下面的命令,脚本会自动完成剩下的工作:
```
curl -sL https://raw.githubusercontent.com/richardforth/apache2buddy/master/apache2buddy.pl | perl
```
如果你没有安装 `curl`,那么你可能需要安装它。使用以下命令来安装 `curl`:
```
apt-get install curl
```
#### 额外配置
用 Apache 还可以做一些额外的东西,但我们会留下它们作为另一个教程。像启用 http/2 支持,关闭(或打开) KeepAlive,调整你的 Apache 甚至更多。这些东西你现在不需要做,但是如果你在网上找到了教程,并且如果你等不及我们的教程,那就去做吧。
### 使用 Apache 创建你的第一个网站
现在我们已经完成了所有的调优工作,让我们开始创建一个实际的网站。按照我们的指示创建一个简单的 HTML 页面和一个在 Apache 上运行的虚拟主机。
你需要做的第一件事是为你的网站创建一个新的目录。运行以下命令来执行此操作:
```
mkdir -p /var/www/example.com/public_html
```
当然,将 `example.com` 替换为你所需的域名。你可以从 [Namecheap](https://thishosting.rocks/neamcheap-review-cheap-domains-cool-names) 获得一个便宜的域名。
不要忘记在下面的所有命令中替换 `example.com`。
接下来,创建一个简单的静态网页。创建 HTML 文件:
```
nano /var/www/example.com/public_html/index.html
```
粘贴这些:
```
<html>
<head>
<title>Simple Page</title>
</head>
<body>
<p>If you're seeing this in your browser then everything works.</p>
</body>
</html>
```
保存并关闭文件。
配置目录的权限:
```
chown -R www-data:www-data /var/www/example.com
chmod -R og-r /var/www/example.com
```
为你的网站创建一个新的虚拟主机:
```
nano /etc/apache2/sites-available/example.com.conf
```
粘贴以下内容:
```
<VirtualHost *:80>
ServerAdmin [email protected]
ServerName example.com
ServerAlias www.example.com
DocumentRoot /var/www/example.com/public_html
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
</VirtualHost>
```
这是一个基础的虚拟主机。根据你的设置,你可能需要更高级的 `.conf` 文件。
在更新所有内容后保存并关闭文件。
现在,使用以下命令启用虚拟主机:
```
a2ensite example.com.conf
```
最后,重启 Apache 以使更改生效:
```
systemctl restart apache2
```
这就是全部了,你做完了。现在你可以访问 example.com 并查看你的页面。
---
via: <https://thishosting.rocks/how-to-install-optimize-apache-ubuntu/>
作者:[ThisHosting](https://thishosting.rocks) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the beginning of our LAMP tutorial series: how to install the Apache web server on Ubuntu.
These instructions should work on any Ubuntu-based distro, including Ubuntu 16.04, [Ubuntu 18.04](https://thishosting.rocks/ubuntu-18-04-new-features-release-date/), Ubuntu 20.04 and even non-LTS Ubuntu releases like Ubuntu 20.10. They were tested and written for Ubuntu 18.04.
Apache (aka httpd) is the most popular and most widely used web server, so this should be useful for everyone.
## Before we begin installing Apache
Some requirements and notes before we begin:
- Apache may already be installed on your server, so check if it is first. You can do so with the “apachectl -V” command that outputs the Apache version you’re using and some other information.
- You’ll need an Ubuntu server. You can buy one from
[Vultr](https://thishosting.rocks/go/vultr/), they’re one of the[best and cheapest cloud hosting providers](https://thishosting.rocks/cheap-cloud-hosting-providers-comparison/). Their servers start from $2.5 per month. - You’ll need the root user or a user with sudo access. All commands below are executed by the root user so we didn’t have to append ‘sudo’ to each command.
- You’ll need
[SSH enabled](https://thishosting.rocks/how-to-enable-ssh-on-ubuntu/)if you use Ubuntu or an SSH client like[MobaXterm](https://mobaxterm.mobatek.net/)if you use Windows.
That’s most of it. Let’s move onto the installation.
## Install Apache on Ubuntu
The first thing you always need to do is update Ubuntu before you do anything else. You can do so by running:
apt-get update && apt-get upgrade
Next, to install Apache, run the following command:
apt-get install apache2
If you want to, you can also install the Apache documentation and some Apache utilities. You’ll need the Apache utilities for some of the modules we’ll install later.
apt-get install apache2-doc apache2-utils
**And that’s it. You’ve successfully installed Apache.**
You’ll still need to configure it.
## Configure and Optimize Apache on Ubuntu
There are various configs you can do on Apache, but the main and most common ones are explained below.
### Check if Apache is running
By default, Apache is configured to start automatically on boot, so you don’t have to enable it. You can check if it’s running and other relevant information with the following command:
systemctl status apache2
And you can check what version you’re using with
apachectl -V
A simpler way of checking this is by visiting your server’s IP address. If you get the default Apache page, then everything’s working fine.
### Update your firewall
If you use a firewall (which you should), you’ll probably need to update your firewall rules and allow access to the default ports. The most common firewall used on Ubuntu is UFW, so the instructions below are for UFW.
To allow traffic through both the 80 (http) and 443 (https) ports, run the following command:
ufw allow 'Apache Full'
### Install common Apache modules
Some modules are frequently recommended and you should install them. We’ll include instructions for the most common ones:
#### Speed up your website with the PageSpeed module
The PageSpeed module will optimize and speed up your Apache server automatically.
First, go to the [PageSpeed download page](https://www.modpagespeed.com/doc/download) and choose the file you need. We’re using a 64-bit Ubuntu server and we’ll install the latest stable version. Download it using wget:
wget https://dl-ssl.google.com/dl/linux/direct/mod-pagespeed-stable_current_amd64.deb
Then, install it with the following commands:
dpkg -i mod-pagespeed-stable_current_amd64.deb apt-get -f install
Restart Apache for the changes to take effect:
systemctl restart apache2
#### Enable rewrites/redirects using the mod_rewrite module
This module is used for rewrites (redirects), as the name suggests. You’ll need it if you use WordPress or any other CMS for that matter. To install it, just run:
a2enmod rewrite
And restart Apache again. You may need some extra configurations depending on what CMS you’re using, if any. Google it for specific instructions for your setup.
#### Secure your Apache with the ModSecurity module
ModSecurity is a module used for security, again, as the name suggests. It basically acts as a firewall, and it monitors your traffic. To install it, run the following command:
apt-get install libapache2-modsecurity
And restart Apache again:
systemctl restart apache2
ModSecurity comes with a default setup that’s enough by itself, but if you want to extend it, you can use the [OWASP rule set](https://www.owasp.org/index.php/Category:OWASP_ModSecurity_Core_Rule_Set_Project).
#### Block DDoS attacks using the mod_evasive module
You can use the mod_evasive module to block and prevent DDoS attacks on your server, though it’s debatable how useful it is in preventing attacks. To install it, use the following command:
apt-get install libapache2-mod-evasive
By default, mod_evasive is disabled, to enable it, edit the following file:
nano /etc/apache2/mods-enabled/evasive.conf
And uncomment all the lines (remove #) and configure it per your requirements. You can leave everything as-is if you don’t know what to edit.
And create a log file:
mkdir /var/log/mod_evasive chown -R www-data:www-data /var/log/mod_evasive
That’s it. Now restart Apache for the changes to take effect:
systemctl restart apache2
There are [additional modules](https://httpd.apache.org/docs/2.4/mod/) you can install and configure, but it’s all up to you and the software you’re using. They’re usually not required. Even the 4 modules we included are not required. If a module is required for a specific application, then they’ll probably note that.
### Optimize Apache with the Apache2Buddy script
Apache2Buddy is a script that will automatically fine-tune your Apache configuration. The only thing you need to do is run the following command and the script does the rest automatically:
curl -sL https://raw.githubusercontent.com/richardforth/apache2buddy/master/apache2buddy.pl | perl
You may need to install curl if you don’t have it already installed. Use the following command to install curl:
apt-get install curl
### Additional configurations
There’s some extra stuff you can do with Apache, but we’ll leave them for another tutorial. Stuff like enabling http/2 support, turning off (or on) KeepAlive, tuning your Apache even more. You don’t have to do any of this, but you can find tutorials online and do it if you can’t wait for our tutorials.
## Create your first website with Apache
Now that we’re done with all the tuning, let’s move onto creating an actual website. Follow our instructions to create a simple HTML page and a virtual host that’s going to run on Apache.
The first thing you need to do is create a new directory for your website. Run the following command to do so:
mkdir -p /var/www/example.com/public_html
Of course, replace example.com with your desired domain. You can get a cheap domain name from [Namecheap](https://thishosting.rocks/neamcheap-review-cheap-domains-cool-names).
*Don’t forget to replace example.com in all of the commands below.*
Next, create a simple, static web page. Create the HTML file:
nano /var/www/example.com/public_html/index.html
And paste this:
<html> <head> <title>Simple Page</title> </head> <body> <p>If you're seeing this in your browser then everything works.</p> </body> </html>
Save and close the file.
Configure the permissions of the directory:
chown -R www-data:www-data /var/www/example.com chmod -R og-r /var/www/example.com
Create a new virtual host for your site:
nano /etc/apache2/sites-available/example.com.conf
And paste the following:
<VirtualHost *:80> ServerAdmin [email protected] ServerName example.com ServerAlias www.example.com DocumentRoot /var/www/example.com/public_html ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined </VirtualHost>
This is a basic virtual host. You may need a more advanced .conf file depending on your setup.
Save and close the file after updating everything accordingly.
Now, enable the virtual host with the following command:
a2ensite example.com.conf
And finally, restart Apache for the changes to take effect:
systemctl restart apache2
That’s it. You’re done. Now you can visit example.com and view your page. |
9,680 | 在 CentOS 6 系统上安装最新版 Python3 软件包的 3 种方法 | https://www.2daygeek.com/3-methods-to-install-latest-python3-package-on-centos-6-system/ | 2018-05-26T07:10:31 | [
"Python"
] | https://linux.cn/article-9680-1.html | 
CentOS 克隆自 RHEL,无需付费即可使用。CentOS 是一个企业级标准的、前沿的操作系统,被超过 90% 的网络主机托管商采用,因为它提供了技术领先的服务器控制面板 cPanel/WHM。
该控制面板使得用户无需进入命令行即可通过其管理一切。
众所周知,RHEL 提供长期支持,出于稳定性考虑,不提供最新版本的软件包。
如果你想安装的最新版本软件包不在默认源中,你需要手动编译源码安装。但手动编译安装的方式有不小的风险,即如果出现新版本,无法升级手动安装的软件包;你不得不重新手动安装。
那么在这种情况下,安装最新版软件包的推荐方法和方案是什么呢?是的,可以通过为系统添加所需的第三方源来达到目的。
可供企业级 Linux 使用的第三方源有很多,但只有几个是 CentOS 社区推荐使用的,它们在很大程度上不修改基础软件包。
这几个推荐的源维护的很好,为 CentOS 提供大量补充软件包。
在本教程中,我们将向你展示,如何在 CentOS 6 操作系统上安装最新版本的 Python 3 软件包。
### 方法 1:使用 Software Collections 源 (SCL)
SCL 源目前由 CentOS SIG 维护,除了重新编译构建 Red Hat 的 Software Collections 外,还额外提供一些它们自己的软件包。
该源中包含不少程序的更高版本,可以在不改变原有旧版本程序包的情况下安装,使用时需要通过 `scl` 命令调用。
运行如下命令可以在 CentOS 上安装 SCL 源:
```
# yum install centos-release-scl
```
检查可用的 Python 3 版本:
```
# yum info rh-python35
Loaded plugins: fastestmirror, security
Loading mirror speeds from cached hostfile
* epel: ewr.edge.kernel.org
* remi-safe: mirror.team-cymru.com
Available Packages
Name : rh-python35
Arch : x86_64
Version : 2.0
Release : 2.el6
Size : 0.0
Repo : installed
From repo : centos-sclo-rh
Summary : Package that installs rh-python35
License : GPLv2+
Description : This is the main package for rh-python35 Software Collection.
```
运行如下命令从 `scl` 源安装可用的最新版 python 3:
```
# yum install rh-python35
```
运行如下特殊的 `scl` 命令,在当前 shell 中启用安装的软件包:
```
# scl enable rh-python35 bash
```
运行如下命令检查安装的 python3 版本:
```
# python --version
Python 3.5.1
```
运行如下命令获取系统已安装的 SCL 软件包列表:
```
# scl -l
rh-python35
```
### 方法 2:使用 EPEL 源 (Extra Packages for Enterprise Linux)
EPEL 是 Extra Packages for Enterprise Linux 的缩写,该源由 Fedora SIG (Special Interest Group)维护。
该 SIG 为企业级 Linux 创建、维护并管理了一系列高品质补充软件包,受益的企业级 Linux 发行版包括但不限于红帽企业级 Linux (RHEL)、 CentOS、 Scientific Linux (SL) 和 Oracle Linux (OL)等。
EPEL 通常基于 Fedora 对应代码提供软件包,不会与企业级 Linux 发行版中的基础软件包冲突或替换其中的软件包。
**推荐阅读:** [在 RHEL, CentOS, Oracle Linux 或 Scientific Linux 上安装启用 EPEL 源](https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/)
EPEL 软件包位于 CentOS 的 Extra 源中,已经默认启用,故我们只需运行如下命令即可:
```
# yum install epel-release
```
检查可用的 python 3 版本:
```
# yum --disablerepo="*" --enablerepo="epel" info python34
Loaded plugins: fastestmirror, security
Loading mirror speeds from cached hostfile
* epel: ewr.edge.kernel.org
Available Packages
Name : python34
Arch : x86_64
Version : 3.4.5
Release : 4.el6
Size : 50 k
Repo : epel
Summary : Version 3 of the Python programming language aka Python 3000
URL : http://www.python.org/
License : Python
Description : Python 3 is a new version of the language that is incompatible with the 2.x
: line of releases. The language is mostly the same, but many details, especially
: how built-in objects like dictionaries and strings work, have changed
: considerably, and a lot of deprecated features have finally been removed.
```
运行如下命令从 EPEL 源安装可用的最新版 python 3 软件包:
```
# yum --disablerepo="*" --enablerepo="epel" install python34
```
默认情况下并不会安装 `pip` 和 `setuptools`,我们需要运行如下命令手动安装:
```
# curl -O https://bootstrap.pypa.io/get-pip.py
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1603k 100 1603k 0 0 2633k 0 --:--:-- --:--:-- --:--:-- 4816k
# /usr/bin/python3.4 get-pip.py
Collecting pip
Using cached https://files.pythonhosted.org/packages/0f/74/ecd13431bcc456ed390b44c8a6e917c1820365cbebcb6a8974d1cd045ab4/pip-10.0.1-py2.py3-none-any.whl
Collecting setuptools
Downloading https://files.pythonhosted.org/packages/8c/10/79282747f9169f21c053c562a0baa21815a8c7879be97abd930dbcf862e8/setuptools-39.1.0-py2.py3-none-any.whl (566kB)
100% |████████████████████████████████| 573kB 4.0MB/s
Collecting wheel
Downloading https://files.pythonhosted.org/packages/1b/d2/22cde5ea9af055f81814f9f2545f5ed8a053eb749c08d186b369959189a8/wheel-0.31.0-py2.py3-none-any.whl (41kB)
100% |████████████████████████████████| 51kB 8.0MB/s
Installing collected packages: pip, setuptools, wheel
Successfully installed pip-10.0.1 setuptools-39.1.0 wheel-0.31.0
```
运行如下命令检查已安装的 python3 版本:
```
# python3 --version
Python 3.4.5
```
### 方法 3:使用 IUS 社区源
IUS 社区是 CentOS 社区批准的第三方 RPM 源,为企业级 Linux (RHEL 和 CentOS) 5、 6 和 7 版本提供最新上游版本的 PHP、 Python、 MySQL 等软件包。
IUS 社区源依赖于 EPEL 源,故我们需要先安装 EPEL 源,然后再安装 IUS 社区源。按照下面的步骤安装启用 EPEL 源和 IUS 社区源,利用该 RPM 系统安装软件包。
**推荐阅读:** [在 RHEL 或 CentOS 上安装启用 IUS 社区源](https://www.2daygeek.com/install-enable-ius-community-repository-on-rhel-centos/)
EPEL 软件包位于 CentOS 的 Extra 源中,已经默认启用,故我们只需运行如下命令即可:
```
# yum install epel-release
```
下载 IUS 社区源安装脚本:
```
# curl 'https://setup.ius.io/' -o setup-ius.sh
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1914 100 1914 0 0 6563 0 --:--:-- --:--:-- --:--:-- 133k
```
安装启用 IUS 社区源:
```
# sh setup-ius.sh
```
检查可用的 python 3 版本:
```
# yum --enablerepo=ius info python36u
Loaded plugins: fastestmirror, security
Loading mirror speeds from cached hostfile
* epel: ewr.edge.kernel.org
* ius: mirror.team-cymru.com
* remi-safe: mirror.team-cymru.com
Available Packages
Name : python36u
Arch : x86_64
Version : 3.6.5
Release : 1.ius.centos6
Size : 55 k
Repo : ius
Summary : Interpreter of the Python programming language
URL : https://www.python.org/
License : Python
Description : Python is an accessible, high-level, dynamically typed, interpreted programming
: language, designed with an emphasis on code readability.
: It includes an extensive standard library, and has a vast ecosystem of
: third-party libraries.
:
: The python36u package provides the "python3.6" executable: the reference
: interpreter for the Python language, version 3.
: The majority of its standard library is provided in the python36u-libs package,
: which should be installed automatically along with python36u.
: The remaining parts of the Python standard library are broken out into the
: python36u-tkinter and python36u-test packages, which may need to be installed
: separately.
:
: Documentation for Python is provided in the python36u-docs package.
:
: Packages containing additional libraries for Python are generally named with
: the "python36u-" prefix.
```
运行如下命令从 IUS 源安装最新可用版本的 python 3 软件包:
```
# yum --enablerepo=ius install python36u
```
运行如下命令检查已安装的 python3 版本:
```
# python3.6 --version
Python 3.6.5
```
---
via: <https://www.2daygeek.com/3-methods-to-install-latest-python3-package-on-centos-6-system/>
作者:[PRAKASH SUBRAMANIAN](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,681 | 更深入的理解 Python 中的迭代 | https://opensource.com/article/18/3/loop-better-deeper-look-iteration-python | 2018-05-26T08:04:00 | [
"Python",
"循环",
"迭代"
] | https://linux.cn/article-9681-1.html |
>
> 深入探讨 Python 的 `for` 循环来看看它们在底层如何工作,以及为什么它们会按照它们的方式工作。
>
>
>

Python 的 `for` 循环不会像其他语言中的 `for` 循环那样工作。在这篇文章中,我们将深入探讨 Python 的 `for` 循环来看看它们在底层如何工作,以及为什么它们会按照它们的方式工作。
### 循环的问题
我们将通过看一些“陷阱”开始我们的旅程,在我们了解循环如何在 Python 中工作之后,我们将再次看看这些问题并解释发生了什么。
#### 问题 1:循环两次
假设我们有一个数字列表和一个生成器,生成器会返回这些数字的平方:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> squares = (n**2 for n in numbers)
```
我们可以将生成器对象传递给 `tuple` 构造器,从而使其变为一个元组:
```
>>> tuple(squares)
(1, 4, 9, 25, 49)
```
如果我们使用相同的生成器对象并将其传给 `sum` 函数,我们可能会期望得到这些数的和,即 `88`。
```
>>> sum(squares)
0
```
但是我们得到了 `0`。
#### 问题 2:包含的检查
让我们使用相同的数字列表和相同的生成器对象:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> squares = (n**2 for n in numbers)
```
如果我们询问 `9` 是否在 `squares` 生成器中,Python 将会告诉我们 9 在 `squares` 中。但是如果我们再次询问相同的问题,Python 会告诉我们 9 不在 `squares` 中。
```
>>> 9 in squares
True
>>> 9 in squares
False
```
我们询问相同的问题两次,Python 给了两个不同的答案。
#### 问题 3 :拆包
这个字典有两个键值对:
```
>>> counts = {'apples': 2, 'oranges': 1}
```
让我们使用多个变量来对这个字典进行拆包:
```
>>> x, y = counts
```
你可能会期望当我们对这个字典进行拆包时,我们会得到键值对或者得到一个错误。
但是解包字典不会引发错误,也不会返回键值对。当你解包一个字典时,你会得到键:
```
>>> x
'apples'
```
### 回顾:Python 的 for 循环
在我们了解一些关于这些 Python 片段的逻辑之后,我们将回到这些问题。
Python 没有传统的 `for` 循环。为了解释我的意思,让我们看一看另一种编程语言的 `for` 循环。
这是一种传统 C 风格的 `for` 循环,用 JavaScript 编写:
```
let numbers = [1, 2, 3, 5, 7];
for (let i = 0; i < numbers.length; i += 1) {
print(numbers[i])
}
```
JavaScript、 C、 C++、 Java、 PHP 和一大堆其他编程语言都有这种风格的 `for` 循环,但是 Python **确实没有**。
Python **确实没有** 传统 C 风格的 `for` 循环。在 Python 中确实有一些我们称之为 `for` 循环的东西,但是它的工作方式类似于 [foreach 循环](https://en.wikipedia.org/wiki/Foreach_loop)。
这是 Python 的 `for` 循环的风格:
```
numbers = [1, 2, 3, 5, 7]
for n in numbers:
print(n)
```
与传统 C 风格的 `for` 循环不同,Python 的 `for` 循环没有索引变量,没有索引变量初始化,边界检查,或者索引递增。Python 的 `for` 循环完成了对我们的 `numbers` 列表进行遍历的所有工作。
因此,当我们在 Python 中确实有 `for` 循环时,我们没有传统 C 风格的 `for` 循环。我们称之为 for 循环的东西的工作机制与之相比有很大的不同。
### 定义:可迭代和序列
既然我们已经解决了 Python 世界中无索引的 `for` 循环,那么让我们在此之外来看一些定义。
**可迭代**是任何你可以用 Python 中的 `for` 循环遍历的东西。可迭代意味着可以遍历,任何可以遍历的东西都是可迭代的。
```
for item in some_iterable:
print(item)
```
序列是一种非常常见的可迭代类型,列表,元组和字符串都是序列。
```
>>> numbers = [1, 2, 3, 5, 7]
>>> coordinates = (4, 5, 7)
>>> words = "hello there"
```
序列是可迭代的,它有一些特定的特征集。它们可以从 `0` 开始索引,以小于序列的长度结束,它们有一个长度并且它们可以被切分。列表,元组,字符串和其他所有序列都是这样工作的。
```
>>> numbers[0]
1
>>> coordinates[2]
7
>>> words[4]
'o'
```
Python 中很多东西都是可迭代的,但不是所有可迭代的东西都是序列。集合、字典、文件和生成器都是可迭代的,但是它们都不是序列。
```
>>> my_set = {1, 2, 3}
>>> my_dict = {'k1': 'v1', 'k2': 'v2'}
>>> my_file = open('some_file.txt')
>>> squares = (n**2 for n in my_set)
```
因此,任何可以用 `for` 循环遍历的东西都是可迭代的,序列只是一种可迭代的类型,但是 Python 也有许多其他种类的迭代器。
### Python 的 for 循环不使用索引
你可能认为,Python 的 `for` 循环在底层使用了索引进行循环。在这里我们使用 `while` 循环和索引手动遍历:
```
numbers = [1, 2, 3, 5, 7]
i = 0
while i < len(numbers):
print(numbers[i])
i += 1
```
这适用于列表,但它不会对所有东西都起作用。这种循环方式**只适用于序列**。
如果我们尝试用索引去手动遍历一个集合,我们会得到一个错误:
```
>>> fruits = {'lemon', 'apple', 'orange', 'watermelon'}
>>> i = 0
>>> while i < len(fruits):
... print(fruits[i])
... i += 1
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
TypeError: 'set' object does not support indexing
```
集合不是序列,所以它们不支持索引。
我们不能使用索引手动对 Python 中的每一个迭代对象进行遍历。对于那些不是序列的迭代器来说,这是行不通的。
### 迭代器驱动 for 循环
因此,我们已经看到,Python 的 `for` 循环在底层不使用索引。相反,Python 的 `for` 循环使用**迭代器**。
迭代器就是可以驱动可迭代对象的东西。你可以从任何可迭代对象中获得迭代器,你也可以使用迭代器来手动对它的迭代进行遍历。
让我们来看看它是如何工作的。
这里有三个可迭代对象:一个集合,一个元组和一个字符串。
```
>>> numbers = {1, 2, 3, 5, 7}
>>> coordinates = (4, 5, 7)
>>> words = "hello there"
```
我们可以使用 Python 的内置 `iter` 函数来访问这些迭代器,将一个迭代器传递给 `iter` 函数总会给我们返回一个迭代器,无论我们正在使用哪种类型的迭代器。
```
>>> iter(numbers)
<set_iterator object at 0x7f2b9271c860>
>>> iter(coordinates)
<tuple_iterator object at 0x7f2b9271ce80>
>>> iter(words)
<str_iterator object at 0x7f2b9271c860>
```
一旦我们有了迭代器,我们可以做的事情就是通过将它传递给内置的 `next` 函数来获取它的下一项。
```
>>> numbers = [1, 2, 3]
>>> my_iterator = iter(numbers)
>>> next(my_iterator)
1
>>> next(my_iterator)
2
```
迭代器是有状态的,这意味着一旦你从它们中消耗了一项,它就消失了。
如果你从迭代器中请求 `next` 项,但是其中没有更多的项了,你将得到一个 `StopIteration` 异常:
```
>>> next(my_iterator)
3
>>> next(my_iterator)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
```
所以你可以从每个迭代中获得一个迭代器,迭代器唯一能做的事情就是用 `next` 函数请求它们的下一项。如果你将它们传递给 `next`,但它们没有下一项了,那么就会引发 `StopIteration` 异常。
你可以将迭代器想象成 Pez 分配器(LCTT 译注:Pez 是一个结合玩具的独特复合式糖果),不能重新分配。你可以把 Pez 拿出去,但是一旦 Pez 被移走,它就不能被放回去,一旦分配器空了,它就没用了。
### 没有 for 的循环
既然我们已经了解了迭代器和 `iter` 以及 `next` 函数,我们将尝试在不使用 `for` 循环的情况下手动遍历迭代器。
我们将通过尝试将这个 `for` 循环变为 `while` 循环:
```
def funky_for_loop(iterable, action_to_do):
for item in iterable:
action_to_do(item)
```
为了做到这点,我们需要:
1. 从给定的可迭代对象中获得迭代器
2. 反复从迭代器中获得下一项
3. 如果我们成功获得下一项,就执行 `for` 循环的主体
4. 如果我们在获得下一项时得到了一个 `StopIteration` 异常,那么就停止循环
```
def funky_for_loop(iterable, action_to_do):
iterator = iter(iterable)
done_looping = False
while not done_looping:
try:
item = next(iterator)
except StopIteration:
done_looping = True
else:
action_to_do(item)
```
我们只是通过使用 `while` 循环和迭代器重新定义了 `for` 循环。
上面的代码基本上定义了 Python 在底层循环的工作方式。如果你理解内置的 `iter` 和 `next` 函数的遍历循环的工作方式,那么你就会理解 Python 的 `for` 循环是如何工作的。
事实上,你不仅仅会理解 `for` 循环在 Python 中是如何工作的,所有形式的遍历一个可迭代对象都是这样工作的。
<ruby> 迭代器协议 <rt> iterator protocol </rt></ruby> 是一种很好表示 “在 Python 中遍历迭代器是如何工作的”的方式。它本质上是对 `iter` 和 `next` 函数在 Python 中是如何工作的定义。Python 中所有形式的迭代都是由迭代器协议驱动的。
迭代器协议被 `for` 循环使用(正如我们已经看到的那样):
```
for n in numbers:
print(n)
```
多重赋值也使用迭代器协议:
```
x, y, z = coordinates
```
星型表达式也是用迭代器协议:
```
a, b, *rest = numbers
print(*numbers)
```
许多内置函数依赖于迭代器协议:
```
unique_numbers = set(numbers)
```
在 Python 中任何与迭代器一起工作的东西都可能以某种方式使用迭代器协议。每当你在 Python 中遍历一个可迭代对象时,你将依赖于迭代器协议。
### 生成器是迭代器
所以你可能会想:迭代器看起来很酷,但它们看起来像一个实现细节,我们作为 Python 的使用者,可能不需要关心它们。
我有消息告诉你:在 Python 中直接使用迭代器是很常见的。
这里的 `squares` 对象是一个生成器:
```
>>> numbers = [1, 2, 3]
>>> squares = (n**2 for n in numbers)
```
生成器是迭代器,这意味着你可以在生成器上调用 `next` 来获得它的下一项:
```
>>> next(squares)
1
>>> next(squares)
4
```
但是如果你以前用过生成器,你可能也知道可以循环遍历生成器:
```
>>> squares = (n**2 for n in numbers)
>>> for n in squares:
... print(n)
...
1
4
9
```
如果你可以在 Python 中循环遍历某些东西,那么它就是**可迭代的**。
所以**生成器是迭代器**,但是生成器也是可迭代的,这又是怎么回事呢?
### 我欺骗了你
所以在我之前解释迭代器如何工作时,我跳过了它们的某些重要的细节。
#### 生成器是可迭代的
我再说一遍:Python 中的每一个迭代器都是可迭代的,意味着你可以循环遍历迭代器。
因为迭代器也是可迭代的,所以你可以使用内置 `next` 函数从可迭代对象中获得迭代器:
```
>>> numbers = [1, 2, 3]
>>> iterator1 = iter(numbers)
>>> iterator2 = iter(iterator1)
```
请记住,当我们在可迭代对象上调用 `iter` 时,它会给我们返回一个迭代器。
当我们在迭代器上调用 `iter` 时,它会给我们返回它自己:
```
>>> iterator1 is iterator2
True
```
迭代器是可迭代的,所有的迭代器都是它们自己的迭代器。
```
def is_iterator(iterable):
return iter(iterable) is iterable
```
迷惑了吗?
让我们回顾一些这些措辞。
* 一个**可迭代对象**是你可以迭代的东西
* 一个**迭代对象器**是一种实际上遍历可迭代对象的代理
此外,在 Python 中迭代器也是可迭代的,它们充当它们自己的迭代器。
所以迭代器是可迭代的,但是它们没有一些可迭代对象拥有的各种特性。
迭代器没有长度,它们不能被索引:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> iterator = iter(numbers)
>>> len(iterator)
TypeError: object of type 'list_iterator' has no len()
>>> iterator[0]
TypeError: 'list_iterator' object is not subscriptable
```
从我们作为 Python 程序员的角度来看,你可以使用迭代器来做的唯一有用的事情是将其传递给内置的 `next` 函数,或者对其进行循环遍历:
```
>>> next(iterator)
1
>>> list(iterator)
[2, 3, 5, 7]
```
如果我们第二次循环遍历迭代器,我们将一无所获:
```
>>> list(iterator)
[]
```
你可以把迭代器看作是**惰性迭代器**,它们是**一次性使用**,这意味着它们只能循环遍历一次。
正如你在下面的真值表中所看到的,可迭代对象并不总是迭代器,但是迭代器总是可迭代的:
| 对象 | 可迭代? | 迭代器? |
| --- | --- | --- |
| 可迭代对象 | V | ? |
| 迭代器 | V | V |
| 生成器 | V | V |
| 列表 | V | X |
### 全部的迭代器协议
让我们从 Python 的角度来定义迭代器是如何工作的。
可迭代对象可以被传递给 `iter` 函数,以便为它们获得迭代器。
迭代器:
* 可以传递给 `next` 函数,它将给出下一项,如果没有下一项,那么它将会引发 `StopIteration` 异常
* 可以传递给 `iter` 函数,它会返回一个自身的迭代器
这些语句反过来也是正确的:
* 任何可以在不引发 `TypeError` 异常的情况下传递给 `iter` 的东西都是可迭代的
* 任何可以在不引发 `TypeError` 异常的情况下传递给 `next` 的东西都是一个迭代器
* 当传递给 `iter` 时,任何返回自身的东西都是一个迭代器
这就是 Python 中的迭代器协议。
#### 迭代器的惰性
迭代器允许我们一起工作,创建**惰性可迭代对象**,即在我们要求它们提供下一项之前,它们不做任何事情。因为可以创建惰性迭代器,所以我们可以创建无限长的迭代器。我们可以创建对系统资源比较保守的迭代器,可以节省我们的内存,节省 CPU 时间。
### 迭代器无处不在
你已经在 Python 中看到过许多迭代器,我也提到过生成器是迭代器。Python 的许多内置类型也是迭代器。例如,Python 的 `enumerate` 和 `reversed` 对象就是迭代器。
```
>>> letters = ['a', 'b', 'c']
>>> e = enumerate(letters)
>>> e
<enumerate object at 0x7f112b0e6510>
>>> next(e)
(0, 'a')
```
在 Python 3 中,`zip`, `map` 和 `filter` 也是迭代器。
```
>>> numbers = [1, 2, 3, 5, 7]
>>> letters = ['a', 'b', 'c']
>>> z = zip(numbers, letters)
>>> z
<zip object at 0x7f112cc6ce48>
>>> next(z)
(1, 'a')
```
Python 中的文件对象也是迭代器。
```
>>> next(open('hello.txt'))
'hello world\n'
```
在 Python 标准库和第三方库中内置了大量的迭代器。这些迭代器首先惰性迭代器一样,延迟工作直到你请求它们下一项。
### 创建你自己的迭代器
知道你已经在使用迭代器是很有用的,但是我希望你也知道,你可以创建自己的迭代器和你自己的惰性迭代器。
下面这个类构造了一个迭代器接受一个可迭代的数字,并在循环结束时提供每个数字的平方。
```
class square_all:
def __init__(self, numbers):
self.numbers = iter(numbers)
def __next__(self):
return next(self.numbers) * 2
def __iter__(self):
return self
```
但是在我们开始对该类的实例进行循环遍历之前,没有任何工作要做。
这里,我们有一个无限长的可迭代对象 `count`,你可以看到 `square_all` 接受 `count` 而不用完全循环遍历这个无限长的迭代:
```
>>> from itertools import count
>>> numbers = count(5)
>>> squares = square_all(numbers)
>>> next(squares)
25
>>> next(squares)
36
```
这个迭代器类是有效的,但我们通常不会这样做。通常,当我们想要做一个定制的迭代器时,我们会生成一个生成器函数:
```
def square_all(numbers):
for n in numbers:
yield n**2
```
这个生成器函数等价于我们上面所做的类,它的工作原理是一样的。
这种 `yield` 语句似乎很神奇,但它非常强大:`yield` 允许我们在调用 `next` 函数之间暂停生成器函数。`yield` 语句是将生成器函数与常规函数分离的东西。
另一种实现相同迭代器的方法是使用生成器表达式。
```
def square_all(numbers):
return (n**2 for n in numbers)
```
这和我们的生成器函数确实是一样的,但是它使用的语法看起来[像是一个列表推导一样](http://treyhunner.com/2015/12/python-list-comprehensions-now-in-color/)。如果你需要在代码中使用惰性迭代,请考虑迭代器,并考虑使用生成器函数或生成器表达式。
### 迭代器如何改进你的代码
一旦你已经接受了在代码中使用惰性迭代器的想法,你就会发现有很多可能来发现或创建辅助函数,以此来帮助你循环遍历和处理数据。
#### 惰性求和
这是一个 `for` 循环,它对 Django queryset 中的所有工作时间求和:
```
hours_worked = 0
for event in events:
if event.is_billable():
hours_worked += event.duration
```
下面是使用生成器表达式进行惰性评估的代码:
```
billable_times = (
event.duration
for event in events
if event.is_billable()
)
hours_worked = sum(billable_times)
```
请注意,我们代码的形状发生了巨大变化。
将我们的计算工作时间变成一个惰性迭代器允许我们能够命名以前未命名(`billable_times`)的东西。这也允许我们使用 `sum` 函数,我们以前不能使用 `sum` 函数是因为我们甚至没有一个可迭代对象传递给它。迭代器允许你从根本上改变你组织代码的方式。
#### 惰性和打破循环
这段代码打印出日志文件的前 10 行:
```
for i, line in enumerate(log_file):
if i >= 10:
break
print(line)
```
这段代码做了同样的事情,但是我们使用的是 `itertools.islice` 函数来惰性地抓取文件中的前 10 行:
```
from itertools import islice
first_ten_lines = islice(log_file, 10)
for line in first_ten_lines:
print(line)
```
我们定义的 `first_ten_lines` 变量是迭代器,同样,使用迭代器允许我们给以前未命名的东西命名(`first_ten_lines`)。命名事物可以使我们的代码更具描述性,更具可读性。
作为奖励,我们还消除了在循环中使用 `break` 语句的需要,因为 `islice` 实用函数为我们处理了中断。
你可以在标准库中的 [itertools](https://docs.python.org/3/library/itertools.html) 中找到更多的迭代辅助函数,以及诸如 [boltons](https://boltons.readthedocs.io) 和 [more-itertools](https://more-itertools.readthedocs.io) 之类的第三方库。
#### 创建自己的迭代辅助函数
你可以在标准库和第三方库中找到用于循环的辅助函数,但你也可以自己创建!
这段代码列出了序列中连续值之间的差值列表。
```
current = readings[0]
for next_item in readings[1:]:
differences.append(next_item - current)
current = next_item
```
请注意,这段代码中有一个额外的变量,我们每次循环时都要指定它。还要注意,这段代码只适用于我们可以切片的东西,比如序列。如果 `readings` 是一个生成器,一个 zip 对象或其他任何类型的迭代器,那么这段代码就会失败。
让我们编写一个辅助函数来修复代码。
这是一个生成器函数,它为给定的迭代中的每个项目提供了当前项和下一项:
```
def with_next(iterable):
"""Yield (current, next_item) tuples for each item in iterable."""
iterator = iter(iterable)
current = next(iterator)
for next_item in iterator:
yield current, next_item
current = next_item
```
我们从可迭代对象中手动获取一个迭代器,在它上面调用 `next` 来获取第一项,然后循环遍历迭代器获取后续所有的项目,跟踪后一个项目。这个函数不仅适用于序列,而且适用于任何类型迭代。
这段代码和以前代码是一样的,但是我们使用的是辅助函数而不是手动跟踪 `next_item`:
```
differences = []
for current, next_item in with_next(readings):
differences.append(next_item - current)
```
请注意,这段代码不会挂在我们循环周围的 `next_item` 上,`with_next` 生成器函数处理跟踪 `next_item` 的工作。
还要注意,这段代码已足够紧凑,如果我们愿意,我们甚至可以[将方法复制到列表推导中来](http://treyhunner.com/2015/12/python-list-comprehensions-now-in-color/)。
```
differences = [
(next_item - current)
for current, next_item in with_next(readings)
]
```
### 再次回顾循环问题
现在我们准备回到之前看到的那些奇怪的例子并试着找出到底发生了什么。
#### 问题 1:耗尽的迭代器
这里我们有一个生成器对象 `squares`:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> squares = (n**2 for n in numbers)
```
如果我们把这个生成器传递给 `tuple` 构造函数,我们将会得到它的一个元组:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> squares = (n**2 for n in numbers)
>>> tuple(squares)
(1, 4, 9, 25, 49)
```
如果我们试着计算这个生成器中数字的和,使用 `sum`,我们就会得到 `0`:
```
>>> sum(squares)
0
```
这个生成器现在是空的:我们已经把它耗尽了。如果我们试着再次创建一个元组,我们会得到一个空元组:
```
>>> tuple(squares)
()
```
生成器是迭代器,迭代器是一次性的。它们就像 Hello Kitty Pez 分配器那样不能重新加载。
#### 问题 2:部分消耗一个迭代器
再次使用那个生成器对象 `squares`:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> squares = (n**2 for n in numbers)
```
如果我们询问 `9` 是否在 `squares` 生成器中,我们会得到 `True`:
```
>>> 9 in squares
True
```
但是我们再次询问相同的问题,我们会得到 `False`:
```
>>> 9 in squares
False
```
当我们询问 `9` 是否在迭代器中时,Python 必须对这个生成器进行循环遍历来找到 `9`。如果我们在检查了 `9` 之后继续循环遍历,我们只会得到最后两个数字,因为我们已经在找到 9 之前消耗了这些数字:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> squares = (n**2 for n in numbers)
>>> 9 in squares
True
>>> list(squares)
[25, 49]
```
询问迭代器中是否包含某些东西将会部分地消耗迭代器。如果没有循环遍历迭代器,那么是没有办法知道某个东西是否在迭代器中。
#### 问题 3:拆包是迭代
当你在字典上循环时,你会得到键:
```
>>> counts = {'apples': 2, 'oranges': 1}
>>> for key in counts:
... print(key)
...
apples
oranges
```
当你对一个字典进行拆包时,你也会得到键:
```
>>> x, y = counts
>>> x, y
('apples', 'oranges')
```
循环依赖于迭代器协议,可迭代对象拆包也依赖于有迭代器协议。拆包一个字典与在字典上循环遍历是一样的,两者都使用迭代器协议,所以在这两种情况下都得到相同的结果。
### 回顾
序列是迭代器,但是不是所有的迭代器都是序列。当有人说“迭代器”这个词时,你只能假设他们的意思是“你可以迭代的东西”。不要假设迭代器可以被循环遍历两次、询问它们的长度或者索引。
迭代器是 Python 中最基本的可迭代形式。如果你想在代码中做一个惰性迭代,请考虑迭代器,并考虑使用生成器函数或生成器表达式。
最后,请记住,Python 中的每一种迭代都依赖于迭代器协议,因此理解迭代器协议是理解 Python 中的循环的关键。
这里有一些我推荐的相关文章和视频:
* [Loop Like a Native](https://nedbatchelder.com/text/iter.html), Ned Batchelder 在 PyCon 2013 的讲演
* [Loop Better](https://www.youtube.com/watch?v=V2PkkMS2Ack) ,这篇文章是基于这个讲演的
* [The Iterator Protocol: How For Loops Work](http://treyhunner.com/2016/12/python-iterator-protocol-how-for-loops-work/),我写的关于迭代器协议的短文
* [Comprehensible Comprehensions](https://www.youtube.com/watch?v=5_cJIcgM7rw),关于推导和迭代器表达器的讲演
* [Python: Range is Not an Iterator](http://treyhunner.com/2018/02/python-range-is-not-an-iterator/),我关于范围和迭代器的文章
* [Looping Like a Pro in Python](https://www.youtube.com/watch?v=u8g9scXeAcI),DB 的 PyCon 2017 讲演
本文是基于作者去年在 [DjangoCon AU](https://www.youtube.com/watch?v=JYuE8ZiDPl4)、 [PyGotham](https://www.youtube.com/watch?v=Wd7vcuiMhxU) 和 [North Bay Python](https://www.youtube.com/watch?v=V2PkkMS2Ack) 中发表的 Loop Better 演讲。有关更多内容,请参加将于 2018 年 5 月 9 日至 17 日在 Columbus, Ohio 举办的 [PYCON](https://us.pycon.org/2018/)。
---
via: <https://opensource.com/article/18/3/loop-better-deeper-look-iteration-python>
作者:[Trey Hunner](https://opensource.com/users/treyhunner) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Python's `for`
loops don't work the way `for`
loops do in other languages. In this article we'll dive into Python's `for`
loops to take a look at how they work under the hood and why they work the way they do.
## Looping gotchas
We're going to start off our journey by taking a look at some "gotchas." After we've learned how looping works in Python, we'll take another look at these gotchas and explain what's going on.
### Gotcha 1: Looping twice
Let's say we have a list of numbers and a generator that will give us the squares of those numbers:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> squares = (n**2 for n in numbers)
```
We can pass our generator object to the `tuple`
constructor to make a tuple out of it:
```
>>> tuple(squares)
(1, 4, 9, 25, 49)
```
If we then take the same generator object and pass it to the `sum`
function, we might expect that we'd get the sum of these numbers, which would be 88.
```
>>> sum(squares)
0
```
Instead we get `0`
.
### Gotcha 2: Containment checking
Let's take the same list of numbers and the same generator object:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> squares = (n**2 for n in numbers)
```
If we ask whether `9`
is in our `squares`
generator, Python will tell us that 9 *is* in `squares`
. But if we ask the *same question again*, Python will tell us that 9 *is not* in `squares`
.
```
>>> 9 in squares
True
>>> 9 in squares
False
```
We asked the same question twice and Python gave us two different answers.
### Gotcha 3: Unpacking
This dictionary has two key-value pairs:
```
>>> counts = {'apples': 2, 'oranges': 1}
```
Let's unpack this dictionary using multiple assignment:
```
>>> x, y = counts
```
You might expect that when unpacking this dictionary, we'll get key-value pairs or maybe we'll get an error.
But unpacking dictionaries doesn't raise errors and it doesn't return key-value pairs. When you unpack dictionaries you get keys:
```
>>> x
'apples'
```
We'll come back to these gotchas after we've learned a bit about the logic that powers these Python snippets.
## Review: Python's *for* loop
Python doesn't have traditional `for`
loops. To explain what I mean, let's take a look at a `for`
loop in another programming language.
This is a traditional C-style `for`
loop written in JavaScript:
```
let numbers = [1, 2, 3, 5, 7];
for (let i = 0; i < numbers.length; i += 1) {
print(numbers[i])
}
```
JavaScript, C, C++, Java, PHP, and a whole bunch of other programming languages all have this kind of `for`
loop. But Python **does not**.
Python **does not** have traditional C-style `for`
loops. We do have something that we *call* a `for`
loop in Python, but it works like a [foreach loop](https://en.wikipedia.org/wiki/Foreach_loop).
This is Python's flavor of `for`
loop:
```
numbers = [1, 2, 3, 5, 7]
for n in numbers:
print(n)
```
Unlike traditional C-style `for`
loops, Python's `for`
loops don't have index variables. There's no index initializing, bounds checking, or index incrementing. Python's `for`
loops do *all the work* of looping over our `numbers`
list for us.
So while we do have `for`
loops in Python, we do not have have traditional C-style `for`
loops. The thing that *we* call a for loop works very differently.
## Definitions: Iterables and sequences
Now that we've addressed the index-free `for`
loop in our Python room, let's get some definitions out of the way.
An **iterable** is anything you can loop over with a `for`
loop in Python. Iterables can be looped over, and anything that can be looped over is an iterable.
```
for item in some_iterable:
print(item)
```
Sequences are a very common type of iterable. Lists, tuples, and strings are all sequences.
```
>>> numbers = [1, 2, 3, 5, 7]
>>> coordinates = (4, 5, 7)
>>> words = "hello there"
```
Sequences are iterables that have a specific set of features. They can be indexed starting from `0`
and ending at one less than the length of the sequence, they have a length, and they can be sliced. Lists, tuples, strings, and *all other* sequences work this way.
```
>>> numbers[0]
1
>>> coordinates[2]
7
>>> words[4]
'o'
```
Lots of things in Python are iterables, but not all iterables are sequences. Sets, dictionaries, files, and generators are all iterables but none of these things are sequences.
```
>>> my_set = {1, 2, 3}
>>> my_dict = {'k1': 'v1', 'k2': 'v2'}
>>> my_file = open('some_file.txt')
>>> squares = (n**2 for n in my_set)
```
So anything that can be looped over with a `for`
loop is an iterable, and sequences are one type of iterable, but Python has many other kinds of iterables as well.
## Python's *for* loops don't use indexes
You might think that under the hood Python's `for`
loops use indexes to loop. Here we're manually looping over an iterable using a `while`
loop and indexes:
```
numbers = [1, 2, 3, 5, 7]
i = 0
while i < len(numbers):
print(numbers[i])
i += 1
```
This works for lists, but it won't work everything. This way of looping **only works for sequences**.
If we try to manually loop over a set using indexes, we'll get an error:
```
>>> fruits = {'lemon', 'apple', 'orange', 'watermelon'}
>>> i = 0
>>> while i < len(fruits):
... print(fruits[i])
... i += 1
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
TypeError: 'set' object does not support indexing
```
Sets are not sequences, so they don't support indexing.
We *cannot* manually loop over every iterable in Python by using indexes. This simply won't work for iterables that aren't sequences.
## Iterators power *for* loops
So we've seen that Python's `for`
loops must not be using indexes under the hood. Instead, Python's `for`
loops use **iterators**.
Iterators are the things that power iterables. You can get an iterator from *any* iterable. And you can use an iterator to manually loop over the iterable it came from.
Let's take a look at how that works.
Here are three iterables: a set, a tuple, and a string.
```
>>> numbers = {1, 2, 3, 5, 7}
>>> coordinates = (4, 5, 7)
>>> words = "hello there"
```
We can ask each of these iterables for an *iterator* using Python's built-in `iter`
function. Passing an iterable to the `iter`
function will always give us back an iterator, no matter what type of iterable we're working with.
```
>>> iter(numbers)
<set_iterator object at 0x7f2b9271c860>
>>> iter(coordinates)
<tuple_iterator object at 0x7f2b9271ce80>
>>> iter(words)
<str_iterator object at 0x7f2b9271c860>
```
Once we have an iterator, the one thing we can do with it is get its next item by passing it to the built-in `next`
function.
```
>>> numbers = [1, 2, 3]
>>> my_iterator = iter(numbers)
>>> next(my_iterator)
1
>>> next(my_iterator)
2
```
Iterators are stateful, meaning once you've consumed an item from them, it's gone.
If you ask for the `next`
item from an iterator and there are no more items, you'll get a `StopIteration`
exception:
```
>>> next(my_iterator)
3
>>> next(my_iterator)
Traceback (most recent call last):
File "
```", line 1, in
StopIteration
So you can get an iterator from every iterable. The only thing you can do with iterators is ask them for their next item using the `next`
function. And if you pass them to `next`
but they don't have a next item, a `StopIteration`
exception will be raised.
You can think of iterators as Pez dispensers that cannot be reloaded. You can take Pez out, but once a Pez is removed it can't be put back, and once the dispenser is empty, it's useless.
## Looping without a *for* loop
Now that we've learned about iterators and the `iter`
and `next`
functions, we'll try to manually loop over an iterable without using a `for`
loop.
We'll do so by attempting to turn this `for`
loop into a `while`
loop:
```
def funky_for_loop(iterable, action_to_do):
for item in iterable:
action_to_do(item)
```
To do this we'll:
- Get an iterator from the given iterable
- Repeatedly get the next item from the iterator
- Execute the body of the
`for`
loop if we successfully got the next item - Stop our loop if we got a
`StopIteration`
exception while getting the next item
```
def funky_for_loop(iterable, action_to_do):
iterator = iter(iterable)
done_looping = False
while not done_looping:
try:
item = next(iterator)
except StopIteration:
done_looping = True
else:
action_to_do(item)
```
We've just reinvented a `for`
loop by using a `while`
loop and iterators.
The above code pretty much defines the way looping works under the hood in Python. If you understand the way the built-in `iter`
and `next`
functions work for looping over things, you understand how Python's `for`
loops work.
In fact you'll understand a little bit more than just how `for`
loops work in Python. All forms of looping over iterables work this way.
The** iterator protocol** is a fancy way of saying "how looping over iterables works in Python." It's essentially the definition of the way the `iter`
and `next`
functions work in Python. All forms of iteration in Python are powered by the iterator protocol.
The iterator protocol is used by `for`
loops (as we've already seen):
```
for n in numbers:
print(n)
```
Multiple assignment also uses the iterator protocol:
```
x, y, z = coordinates
```
Star expressions use the iterator protocol:
```
a, b, *rest = numbers
print(*numbers)
```
And many built-in functions rely on the iterator protocol:
```
unique_numbers = set(numbers)
```
Anything in Python that works with an *iterable* probably uses the iterator protocol in some way. Anytime you're looping over an iterable in Python, you're relying on the iterator protocol.
## Generators are iterators
So you might be thinking: Iterators seem cool, but they also just seem like an implementation detail and we, as users of Python, might not need to *care* about them.
I have news for you: It's very common to work directly with iterators in Python.
The `squares`
object here is a generator:
```
>>> numbers = [1, 2, 3]
>>> squares = (n**2 for n in numbers)
```
And generators are iterators, meaning you can call `next`
on a generator to get its next item:
```
>>> next(squares)
1
>>> next(squares)
4
```
But if you've ever used a generator before, you probably know that you can also loop over generators:
```
>>> squares = (n**2 for n in numbers)
>>> for n in squares:
... print(n)
...
1
4
9
```
If you can loop over something in Python, it's an **iterable**.
So **generators are iterators**, but generators are also iterables. What's going on here?
## I lied to you
So when I explained how iterators worked earlier, I skipped over an important detail about them.
**Iterators are iterables.**
I'll say that again: Every iterator in Python is also an iterable, which means you can loop over iterators.
Because iterators are also iterables, you can get an iterator from an iterator using the built-in `iter`
function:
```
>>> numbers = [1, 2, 3]
>>> iterator1 = iter(numbers)
>>> iterator2 = iter(iterator1)
```
Remember that iterables give us iterators when we call `iter`
on them.
When we call `iter`
on an iterator it will always give us itself back:
```
>>> iterator1 is iterator2
True
```
Iterators are iterables and all iterators are their own iterators.
```
def is_iterator(iterable):
return iter(iterable) is iterable
```
Confused yet?
Let's recap these terms.
- An iter
**able**is something you're able to iterate over - An iter
**ator**is the agent that actually does the iterating over an iterable
Additionally, in Python iterators are also iterables and they act as *their own* iterators.
So iterators are iterables, but they don't have the variety of features that some iterables have.
Iterators have no length and they can't be indexed:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> iterator = iter(numbers)
>>> len(iterator)
TypeError: object of type 'list_iterator' has no len()
>>> iterator[0]
TypeError: 'list_iterator' object is not subscriptable
```
From our perspective as Python programmers, the only useful things you can do with an iterator are to pass it to the built-in `next`
function or to loop over it:
```
>>> next(iterator)
1
>>> list(iterator)
[2, 3, 5, 7]
```
And if we loop over an iterator a second time, we'll get nothing back:
```
>>> list(iterator)
[]
```
You can think of iterators as **lazy iterables** that are **single-use**, meaning they can be looped over one time only.
As you can see in the truth table below, iterables are not always iterators but iterators are always iterables:
Object | Iterable? | Iterator? |
---|---|---|
Iterable | ✔️ | ❓ |
Iterator | ✔️ | ✔️ |
Generator | ✔️ | ✔️ |
List | ✔️ | ❌ |
## The iterator protocol in full
Let's define how iterators work from Python's perspective.
Iterables can be passed to the `iter`
function to get an iterator for them.
Iterators:
- Can be passed to the
`next`
function, which will give their next item or raise a`StopIteration`
exception if there are no more items - Can be passed to the
`iter`
function and will return themselves back
The inverse of these statements also holds true:
- Anything that can be passed to
`iter`
without a`TypeError`
is an iterable - Anything that can be passed to
`next`
without a`TypeError`
is an iterator - Anything that returns itself when passed to
`iter`
is an iterator
That's the iterator protocol in Python.
## Iterators enable laziness
Iterators allow us to both work with and create **lazy iterables** that don't do any work until we ask them for their next item. Because we can create lazy iterables, we can make infinitely long iterables. And we can create iterables that are conservative with system resources, can save us memory, and can save us CPU time.
## Iterators are everywhere
You've already seen lots of iterators in Python. I've already mentioned that generators are iterators. Many of Python's built-in classes are iterators also. For example Python's `enumerate`
and `reversed`
objects are iterators.
```
>>> letters = ['a', 'b', 'c']
>>> e = enumerate(letters)
>>> e
<enumerate object at 0x7f112b0e6510>
>>> next(e)
(0, 'a')
```
In Python 3, `zip`
, `map`
, and `filter`
objects are iterators too.
```
>>> numbers = [1, 2, 3, 5, 7]
>>> letters = ['a', 'b', 'c']
>>> z = zip(numbers, letters)
>>> z
<zip object at 0x7f112cc6ce48>
>>> next(z)
(1, 'a')
```
And file objects in Python are iterators also.
```
>>> next(open('hello.txt'))
'hello world\n'
```
There are lots of iterators built into Python, in the standard library, and in third-party Python libraries. These iterators all act like lazy iterables by delaying work until the moment you ask them for their next item.
## Creating your own iterator
It's useful to know that you're already using iterators, but I'd like you to also know that you can create your own iterators and your own lazy iterables.
This class makes an iterator that accepts an iterable of numbers and provides squares of each of the numbers as it's looped over.
```
class square_all:
def __init__(self, numbers):
self.numbers = iter(numbers)
def __next__(self):
return next(self.numbers) ** 2
def __iter__(self):
return self
```
But no work will be done until we start looping over an instance of this class.
Here we have an infinitely long iterable `count`
and you can see that `square_all`
accepts `count`
without fully looping over this infinitely long iterable:
```
>>> from itertools import count
>>> numbers = count(5)
>>> squares = square_all(numbers)
>>> next(squares)
25
>>> next(squares)
36
```
This iterator class works, but we don't usually make iterators this way. Usually when we want to make a custom iterator, we make a generator function:
```
def square_all(numbers):
for n in numbers:
yield n**2
```
This generator function is equivalent to the class we made above, and it works essentially the same way.
That `yield`
statement probably seems magical, but it is very powerful: `yield`
allows us to put our generator function on pause between calls from the `next`
function. The `yield`
statement is the thing that separates generator functions from regular functions.
Another way we could implement this same iterator is with a generator expression.
```
def square_all(numbers):
return (n**2 for n in numbers)
```
This does the same thing as our generator function, but it uses a syntax that looks [like a list comprehension](http://treyhunner.com/2015/12/python-list-comprehensions-now-in-color/). If you need to make a lazy iterable in your code, think of iterators and consider making a generator function or a generator expression.
## How iterators can improve your code
Once you've embraced the idea of using lazy iterables in your code, you'll find that there are lots of possibilities for discovering or creating helper functions that assist you in looping over iterables and processing data.
### Laziness and summing
This is a `for`
loop that sums up all billable hours in a Django queryset:
```
hours_worked = 0
for event in events:
if event.is_billable():
hours_worked += event.duration
```
Here is code that does the same thing by using a generator expression for lazy evaluation:
```
billable_times = (
event.duration
for event in events
if event.is_billable()
)
hours_worked = sum(billable_times)
```
Notice that the shape of our code has changed dramatically.
Turning our billable times into a lazy iterable has allowed us to name something (`billable_times`
) that was previously unnamed. This has also allowed us to use the `sum`
function. We couldn't have used `sum`
before because we didn't even have an iterable to pass to it. Iterators allow you to fundamentally change the way you structure your code.
### Laziness and breaking out of loops
This code prints out the first 10 lines of a log file:
```
for i, line in enumerate(log_file):
if i >= 10:
break
print(line)
```
This code does the same thing, but we're using the `itertools.islice`
function to lazily grab the first 10 lines of our file as we loop:
```
from itertools import islice
first_ten_lines = islice(log_file, 10)
for line in first_ten_lines:
print(line)
```
The `first_ten_lines`
variable we've made is an iterator. Again, using an iterator allowed us to give a name to something (`first_ten_lines`
) that was previously unnamed. Naming things can make our code more descriptive and more readable.
As a bonus, we also removed the need for a `break`
statement in our loop because the `islice`
utility handles the breaking for us.
You can find many more iteration helper functions in [itertools](https://docs.python.org/3/library/itertools.html) in the standard library as well as in third-party libraries such as [boltons](https://boltons.readthedocs.io) and [more-itertools](https://more-itertools.readthedocs.io).
### Creating your own iteration helpers
You can find helper functions for looping in the standard library and in third-party libraries, but you can also make your own!
This code makes a list of the differences between consecutive values in a sequence.
```
current = readings[0]
for next_item in readings[1:]:
differences.append(next_item - current)
current = next_item
```
Notice that this code has an extra variable that we need to assign each time we loop. Also note that this code works only with things we can slice, like sequences. If `readings`
were a generator, a zip object, or any other type of iterator, this code would fail.
Let's write a helper function to fix our code.
This is a generator function that gives us the current item and the item following it for every item in a given iterable:
```
def with_next(iterable):
"""Yield (current, next_item) tuples for each item in iterable."""
iterator = iter(iterable)
current = next(iterator)
for next_item in iterator:
yield current, next_item
current = next_item
```
We're manually getting an iterator from our iterable, calling `next`
on it to grab the first item, then looping over our iterator to get all subsequent items, keeping track of our last item along the way. This function works not just with sequences, but with any type of iterable.
This is the same code as before, but we're using our helper function instead of manually keeping track of `next_item`
:
```
differences = []
for current, next_item in with_next(readings):
differences.append(next_item - current)
```
Notice that this code doesn't have awkward assignments to `next_item`
hanging around our loop. The `with_next`
generator function handles the work of keeping track of `next_item`
for us.
Also note that this code has been compacted enough that we could even [copy-paste our way into a list comprehension](http://treyhunner.com/2015/12/python-list-comprehensions-now-in-color/) if we wanted to.
```
differences = [
(next_item - current)
for current, next_item in with_next(readings)
]
```
## Looping gotchas revisited
Now we're ready to jump back to those odd examples we saw earlier and try to figure out what was going on.
### Gotcha 1: Exhausting an iterator
Here we have a generator object, `squares`
:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> squares = (n**2 for n in numbers)
```
If we pass this generator to the `tuple`
constructor, we'll get a tuple of its items back:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> squares = (n**2 for n in numbers)
>>> tuple(squares)
(1, 4, 9, 25, 49)
```
If we then try to compute the `sum`
of the numbers in this generator, we'll get `0`
:
```
>>> sum(squares)
0
```
This generator is now empty: we've exhausted it. If we try to make a tuple out of it again, we'll get an empty tuple:
```
>>> tuple(squares)
()
```
Generators are iterators. And iterators are single-use iterables. They're like Hello Kitty Pez dispensers that cannot be reloaded.
### Gotcha 2: Partially consuming an iterator
Again we have a generator object, `squares`
:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> squares = (n**2 for n in numbers)
```
If we ask whether `9`
is in this `squares`
generator, we'll get `True`
:
```
>>> 9 in squares
True
```
But if we ask the same question again, we'll get `False`
:
```
>>> 9 in squares
False
```
When we ask whether `9`
is in this generator, Python has to loop over this generator to find `9`
. If we kept looping over it after checking for `9`
, we'll only get the last two numbers because we've already consumed the numbers before this point:
```
>>> numbers = [1, 2, 3, 5, 7]
>>> squares = (n**2 for n in numbers)
>>> 9 in squares
True
>>> list(squares)
[25, 49]
```
Asking whether something is *contained* in an iterator will partially consume the iterator. There is no way to know whether something is in an iterator without starting to loop over it.
### Gotcha 3: Unpacking is iteration
When you *loop* over dictionaries you get keys:
```
>>> counts = {'apples': 2, 'oranges': 1}
>>> for key in counts:
... print(key)
...
apples
oranges
```
You also get keys when you unpack a dictionary:
```
>>> x, y = counts
>>> x, y
('apples', 'oranges')
```
Looping relies on the iterator protocol. Iterable unpacking also relies on the iterator protocol. Unpacking a dictionary is really the same as looping over the dictionary. Both use the iterator protocol, so you get the same result in both cases.
## Recap and related resources
Sequences are iterables, but not all iterables are sequences. When someone says the word "iterable," you can only assume they mean "something that you can iterate over." Don't assume iterables can be looped over twice, asked for their length, or indexed.
Iterators are the most rudimentary form of iterables in Python. If you'd like to make a lazy iterable in your code, think of iterators and consider making a generator function or a generator expression.
And finally, remember that every type of iteration in Python relies on the iterator protocol, so understanding the iterator protocol is the key to understanding quite a bit about looping in Python in general.
Here are related articles and videos I recommend:
[Loop Like a Native](https://nedbatchelder.com/text/iter.html), Ned Batchelder's PyCon 2013 talk[Loop Better](https://www.youtube.com/watch?v=V2PkkMS2Ack), the talk this article is based on[The Iterator Protocol: How](http://treyhunner.com/2016/12/python-iterator-protocol-how-for-loops-work/), a short article I wrote on the iterator protocol`For`
Loops Work[Comprehensible Comprehensions](https://www.youtube.com/watch?v=5_cJIcgM7rw), my talk on comprehensions and generator expressions[Python: Range is Not an Iterator](http://treyhunner.com/2018/02/python-range-is-not-an-iterator/), my article on range and iterators[Looping Like a Pro in Python](https://www.youtube.com/watch?v=u8g9scXeAcI), DB's PyCon 2017 talk
*This article is based on the Loop Better talk the author gave last year at DjangoCon AU, PyGotham, and North Bay Python. For more content like this, attend PYCON, which will be held May 9-17, 2018, in Columbus, Ohio.*
## 4 Comments |
9,682 | DevOps 如何消除了 Ranger 社区的瓶颈 | https://opensource.com/article/17/11/devops-rangers-transformation | 2018-05-26T23:45:00 | [
"DevOps"
] | /article-9682-1.html |
>
> 拥抱 DevOps 让 Ranger 成员们变得更灵活、快捷和成为开发者社区更有价值的成员。
>
>
>

Visual Studio 的<ruby> 应用周期管理 <rt> Application Lifecycle Management </rt></ruby>(ALM)项目 —— [Ranger](https://aka.ms/vsaraboutus) 是一个志愿者社区,它提供专业的指导、实践经验、以及开发者社区的漏洞修补解决方案。它创建于 2006 年,作为微软内部社区去 “将产品组与大家相连接,并去除推广阻力”。 在 2009 时,社区已经有超过 200 位成员,这导致了协作和计划面临很大的挑战,在依赖和手工流程上产生了瓶颈,并导致了开发者社区不断增加的延迟和各种报怨。在 2010 时,计划进一步去扩充包括微软最有价值专家(MVP)在内的分布在全球的社区。
这个社区被分割成十几个活跃的团队。每个团队都致力于通过它的生命周期去设计、构建和支持一个指导或处理项目。在以前,团队的瓶颈在团队管理级别上,原因是严格的、瀑布式的流程和高度依赖一个或多个项目经理。在制作、发布和“为什么、做什么、和怎么做”驱动的决定上,项目经理都要介入其中。另外,缺乏一个实时的指标阻止了团队对他们的解决方案效率的监控,以及对来自社区的关于 bug 和常见问题的关注。
是时候去寻找一些做好这些事情的方法了,更好地实现开发者社区的价值。
### DevOps 去“灭火”
>
> “DevOps 是人员、流程和产品的结合,使我们的最终用户能够持续传递价值。” --[Donovan Brown](http://donovanbrown.com/post/what-is-devops)
>
>
>
为解决这些挑战,社区停止了所有对新项目的冲刺,去探索敏捷实践和新产品。致力于使社区重新活跃起来,为找到促进自治、掌控、和目标的方法,正如在 Daniel H. Pink 的书《[Drive](http://www.danpink.com/books/drive/)》中所说的那样,对僵化的流程和产品进行彻底的改革。
>
> “成熟的自组织、自管理和跨职能团队,在自治、掌控和目标上茁壮成长。" --Drive, Daniel H. Pink.
>
>
>
从文化开始 —— 人 —— 第一步是去拥抱 DevOps。社区实现了 [Scrum](http://www.scrumguides.org/scrum-guide.html) 框架,使用 [kanban](https://leankit.com/learn/kanban/what-is-kanban/) 去提升工程化流程,并且通过可视化去提升透明度、意识和最重要的东西 —— 信任。使用自组织团队后,传统的等级制度和指挥系统消失了。自管理促使团队去积极监视和设计它们自己的流程。
在 2010 年 4 月份,社区再次实施了另外的关键一步,切换并提交它们的文化、流程、以及产品到云上。虽然开放的“为社区而社区”的核心 [解决方案](https://aka.ms/vsarsolutions) 仍然是指导和补充,但是在开源解决方案(OSS)上大量增加投资去研究和共享 DevOps 转换的成就。
持续集成(CI)和持续交付(CD)使用自动化流水线代替了死板的人工流程。这使得团队在不受来自项目经理的干预的情况下为早期问题和早期应用者部署解决方案。增加遥测技术可以使团队关注他们的解决方案,以及在用户注意到它们之前,检测和处理未知的问题。
DevOps 转变是一个持续进化的过程,通过实验去探索和验证人、流程和产品的改革。最新的试验引入了流水线革新,它可以持续提升价值流。自动扫描组件、持续地以及静默地检查安全、协议和开源组件的品质。部署环和特性标志允许团队对所有或者特定用户进行更细粒度的控制。
在 2017 年 10 月,社区将大部分的私有版本控制仓库转移到 [GitHub](https://github.com/ALM-Rangers) 上。将所有仓库转移所有者和管理职责到 ALM DevOps Rangers 社区,给团队提供自治和机会,去激励更多的社区对开源解决方案作贡献。团队被授权向他们的最终用户交付质量和价值。
### 好处和成就
拥抱 DevOps 使 Ranger 社区变得更加敏捷,实现了对市场的快速反应和快速学习和反应的流程,减少了宝贵的时间投入,并宣布自治。
下面是从这个转变中观察到的一个列表,排列没有特定的顺序:
* 自治、掌控和目标是核心。
* 从可触摸的和可迭代的东西开始 —— 避免摊子铺的过大。
* 可触摸的和可操作的指标很重要 —— 确保不要掺杂其它东西。
* 人(文化)的转变是最具挑战的部分。
* 没有蓝图;任何一个组织和任何一个团队都是独一无二的。
* 转变是一个持续的过程。
* 透明和可视非常关键。
* 使用工程化流程去强化预期行为。
转换变化表:
| | 过去 | 当前 | 想象 |
| --- | --- | --- | --- |
| 分支 | 服务于发布隔离 | 特性 | 主分支 |
| 构建 | 手动且易错 | 自动而一致 | |
| 问题检测 | 来自用户 | 主动感知 | |
| 问题解决 | 几天到几周 | 几分钟到几天 | 几分钟 |
| 计划 | 详细的设计 | 原型与故事板 | |
| 流程管理 | 2 个流程经理(PM) | 0.25 个 PM | 0.125 个 PM |
| 发布终止 | 6 到 12 个月 | 3 到 5 周期 | 每个周期 |
| 发布 | 手动且易错 | 自动而一致 | |
| 周期 | 1 个月 | 3 周 | |
| 团队规模 | 10 到 15 | 2 到 5 | |
| 构建时间 | 几小时 | 几秒钟 | |
| 发布时间 | 几天 | 几分钟 | |
但是,我们还没有做完,相反,我们就是一个令人兴奋的、持续不断的、几乎从不结束的转变的一部分。
如果你想去学习更多的关于我们的转变、有益的经验、以及想知道我们所经历的挑战,请查看 [转变到 DevOps 文化的记录](https://github.com/ALM-Rangers/Guidance/blob/master/src/Stories/our-journey-of-transforming-to-a-devops-culture.md)。"
---
via: <https://opensource.com/article/17/11/devops-rangers-transformation>
作者:[Willy Schaub](https://opensource.com/users/wpschaub) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,683 | 如何在 Linux 中找到你的 IP 地址 | https://opensource.com/article/18/5/how-find-ip-address-linux | 2018-05-27T07:02:00 | [
"IP"
] | https://linux.cn/article-9683-1.html |
>
> 每个网站都有一个独有的公开 IP 地址,可供任何人从任何地方访问。
>
>
>

<ruby> 互联网协议 <rt> Internet Protocol </rt></ruby>(IP)不需要介绍 —— 我们每天都在使用它。即使你不直接使用它,当你在浏览器上输入 website-name.com 时,它会查找该 URL 的 IP 地址,然后加载该网站。
我们将 IP 地址分为两类:私有和公共。私有 IP 地址是你的无线路由(和公司内网)提供的私有 IP 地址。它们的范围是 10.xxx、172.16.xx-172.31.xx 和 192.168.xx,其中 x=0 到 255。公有 IP 地址,顾名思义,是“公共”的,你可以在世界上任何地方访问它。每个网站都有一个唯一的 IP 地址,任何人可在任何地点访问,这可被视为公共 IP 地址。
此外,还有两种类型的 IP 地址:IPv4 和 IPv6。
IPv4 地址格式为 x.x.x.x,其中 x=0 到 255。有 2<sup> 32(大约</sup> 40 亿个)可能的 IPv4 地址。
IPv6 地址使用更复杂的十六进制。总的比特数是 128,这意味着有 2<sup> 128</sup> (340 后面有 36 个零!)个可能的 IPv6 地址。IPv6 已经被引入解决了可预见的 IPv4 地址耗尽问题。
作为网络工程师,我建议不要与任何人共享你机器的公有 IP 地址。你的 WiFi 路由器有公共 IP,即 WAN(广域网)IP 地址,并且连接到该 WiFi 的任何设备都是相同的。连接到相同 WiFi 的所有设备都有上面所说的私有 IP 地址。例如,我的笔记本电脑的 IP 地址 192.168.0.5,而我的电话是 192.168.0.8。这些是私有 IP 地址,但两者都有相同的公有 IP 地址。
以下命令将列出IP地址列表,以查找你计算机的公有 IP 地址:
1. `ifconfig.me`
2. `curl -4/-6 icanhazip.com`
3. `curl ipinfo.io/ip`
4. `curl api.ipify.org`
5. `curl checkip.dyndns.org`
6. `dig +short myip.opendns.com @resolver1.opendns.com`
7. `host myip.opendns.com resolver1.opendns.com`
8. `curl ident.me`
9. `curl bot.whatismyipaddress.com`
10. `curl ipecho.net/plain`
以下命令将为你提供接口的私有 IP 地址:
1. `ifconfig -a`
2. `ip addr (ip a)`
3. `hostname -I | awk ‘{print $1}’`
4. `ip route get 1.2.3.4 | awk '{print $7}'`
5. `(Fedora) Wifi-Settings→ click the setting icon next to the Wifi name that you are connected to → Ipv4 and Ipv6 both can be seen`
6. `nmcli -p device show`
*注意:一些工具需要根据你正在使用的 Linux 发行版安装在你的系统上。另外,一些提到的命令使用第三方网站来获取 IP*
---
via: <https://opensource.com/article/18/5/how-find-ip-address-linux>
作者:[Archit Modi](https://opensource.com/users/architmodi) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We all use the Internet Protocol (IP) daily, whether we're aware of it or not. For instance, any time you type a website name or a search term into your web browser, it looks up the IP address of that URL (or of a search engine) and then loads the website.
Let's divide IP addresses into two categories: private and public. Private IP addresses are the ones your WiFi box (and company intranet) provide. They are in the range of *10.x.x.x*, *172.16.x.x-172.31.x.x*, and *192.168.x.x*, where *x*=0 to 255. Public IP addresses, as the name suggests, are "public" and you can reach them from anywhere in the world. Every website has a unique IP address that can be reached by anyone and from anywhere; that is considered a public IP address.
Furthermore, there are two types of IP addresses: IPv4 and IPv6.
IPv4 addresses have the format *x.x.x.x*, where *x*=0 to 255. There are 2^32 (approximately 4 billion) possible IPv4 addresses.
IPv6 addresses have a more complex format using hex numbers. The total number of bits is 128, which means there are 2^128—340 undecillion!—possible IPv6 addresses. IPv6 was introduced to tackle the foreseeable exhaustion of IPv4 addresses in the near future.
As a network engineer, I recommend not sharing your machine’s public IP address with anyone. Your WiFi router has a public IP, which is the WAN (wide-area network) IP address, and it will be the same for any device connected to that WiFi. All the devices connected to the same WiFi have private IP addresses locally identified by the range provided above. For example, my laptop is connected with the IP address 192.168.0.5, and my phone is connected with 192.168.0.8. These are private IP addresses, but both would have the same public IP address.
The following commands will get you the IP address list to find public IP addresses for your machine:
`curl ifconfig.me`
`curl -4/-6 icanhazip.com`
`curl ipinfo.io/ip`
`curl api.ipify.org`
`curl checkip.dyndns.org`
`dig +short myip.opendns.com @resolver1.opendns.com`
`host myip.opendns.com resolver1.opendns.com`
`curl ident.me`
`curl bot.whatismyipaddress.com`
`curl ipecho.net/plain`
The following commands will get you the private IP address of your interfaces:
`ifconfig -a`
`ip addr (ip a)`
`hostname -I | awk '{print $1}'`
`ip route get 1.2.3.4 | awk '{print $7}'`
`(Fedora) Wifi-Settings→ click the setting icon next to the Wifi name that you are connected to → Ipv4 and Ipv6 both can be seen`
`nmcli -p device show`
*Note: Some utilities need to be installed on your system based on the Linux distro you are using. Also, some of the noted commands use a third-party website to get the IP*
## Finding your IP address in the GNOME desktop
If you're using Linux, you can find your IP address using some basic desktop utilities. First, go to your Activities screen and type Network (for a wired connection) or Wi-Fi (for wireless).
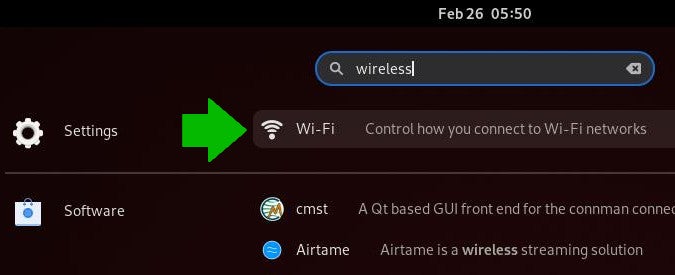
In the Networks settings window, click the Gear icon next to the network you're on.
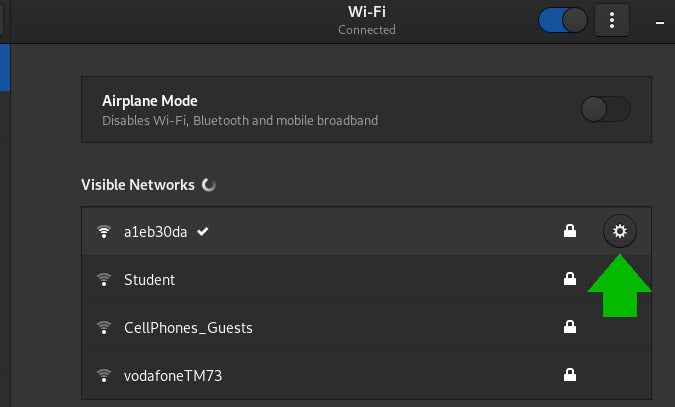
Your IP address is listed in the Network profile.
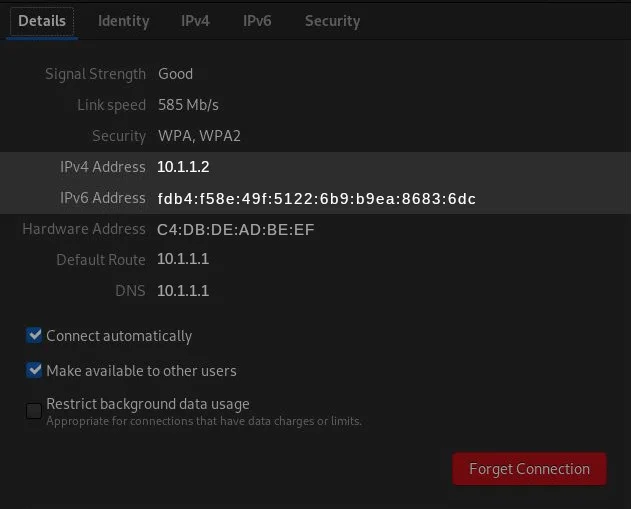
In this example screenshot, my IPv4 address is 10.1.1.2 and the gateway is 10.1.1.1.
## Public and private IP addresses
To understand the significance of public and private IP addresses, let's have a look at a concept called NAT (Network Address Translation) and PAT (Port Address Translation).
Private addresses are used in Local Area Networks (LAN). They are bound to a specific network.
Public addresses are necessary for establishing external connectivity to other networks, most notably the "Worldwide Web" (www) of the Internet.
NAT is a translation of a private IP to a public one, and consists of three major types: static, dynamic, and PAT. In static NAT, one private IP is mapped to one public IP. A common example ru ydco is a firewall. In dynamic NAT, a private IP address is mapped to a public IP but from a pool of public IP addresses.
With a total of 2^32 IPv4 addresses, out of which approximately just 3.7 billion are public addresses, there are literally more people and devices than there are IP addresses. And yet we haven't run out of addresses. That's because of a concept called PAT, which allows for a single public IP address to be translated from multiple (generally all) private IP addresses using port numbers. Here, instead of assigning a public address to each device, a single public address is allocated to the external side, and private addresses are assigned to each device within the internal network. PAT is most widely used in residential wireless routers, which we use to connect to the Internet.
### Private Ipv4 addresses
-
Local addresses are only used within an internal network.
-
The range is 10.x.x.x, 172.16.x.x-172.31.x.x, and 192.168.x.x, (x is a number from 0 to 255).
-
Used in Local Area Networks (LAN).
-
Not globally reachable, and cannot be searched globally.
-
Not unique: the same private IP can be used in two different networks.
-
Each router comes with a private IP address, which multiple devices can connect to. Users don’t need to pay extra to obtain a private address.
-
Some example private IP addresses: 10.0.0.4, 172.16.4.5, 192.168.9.8
### Public Ipv4 addresses
-
Public addresses are used to connect to external networks.
-
Ranges from 0.0.0.0 to 255.255.255.255, except for private IP addresses and few unusable or reserved IPs.
-
Used in connecting to the Internet.
-
Globally reachable and can be searched. These are often used to determine geolocation.
-
Unique across all of the Internet.
-
A private address costs money because they are unique, limited, and accessible from the Internet. Each website has a domain name mapped to a public IP. For example, the public IP address for opensource.com is 54.204.39.132
## Finding your way with IP
An IP address is the most direct route to a computer over a network. There are other systems, such as DNS and Avahi, to help route one computer to another, but when those are unavailable or undesired for any reason, the IP protocol is what you use. Now you understand why, and more importantly, how to find your own.
*Editor's note: This article was originally published in May 2018 and has been updated.*
## 9 Comments |
9,684 | zzupdate:单条命令升级 Ubuntu 18.04 LTS | https://www.2daygeek.com/zzupdate-single-command-to-upgrade-ubuntu-18-04/ | 2018-05-27T07:18:06 | [
"zzupdate"
] | https://linux.cn/article-9684-1.html | Ubuntu 18.04 版本已经发布,并得到各个社区的一致好评,因为 Ubuntu 18.04 可能是 Ubuntu 多年来最令人兴奋的版本。
通常情况下,Ubuntu 及其衍生版可以使用命令从一个版本升级到最新版本或者其它版本,这也是官方推荐的升级方式。
### Ubuntu 18.04 特性/亮点
这次更新包含大量改进和新功能,这里只列举的几个主要的。如果您想要更详细的更新信息,请访问 [Ubuntu 18.04 官方](https://wiki.ubuntu.com/BionicBeaver/ReleaseNotes) 页面。
* 使用 Linux 4.15 内核,提供了从上游继承的新功能
* 它具有最新版本的 GNOME 3.28
* 它提供了与 RHEL 相似的最简安装选项,该选项可安装只包含一个 web 浏览器和核心系统程序的基本桌面环境
* 对于新安装,交换文件将取代默认的交换分区
* 您可以启用 Livepatch 安装内核更新而无需重新启动
* 笔记本电脑在使用电池供电时会在无操作 20 分钟后自动待机
* 不再提供 32 位的 Ubuntu 桌面安装程序映像
注意:
1. 不要忘记备份重要数据。如果升级出现问题,我们将重新安装并恢复数据。
2. 安装所需时间取决于您的网络状况和安装的程序。

### zzupdate 是什么?
我们可以只通过一条命令使用 [zzupdate](https://github.com/TurboLabIt/zzupdate) 工具中将 Ubuntu PC/Server 从一个版本升级到另一个版本。它是一个自由开源工具,使用它不需要任何脚本知识,因为它只需要配置文件即可运行。
工具中提供两个默认 shell 文件。`setup.sh` 自动安装、更新代码,将脚本转换为一个简单的 zzupdate shell 命令。`zzupdate.sh` 将执行版本间的升级。
### 如何安装 zzupdate?
要安装 `zzupdate`,只需执行以下命令:
```
$ curl -s https://raw.githubusercontent.com/TurboLabIt/zzupdate/master/setup.sh | sudo sh
.
.
Installing...
-------------
Cloning into 'zzupdate'...
remote: Counting objects: 57, done.
remote: Total 57 (delta 0), reused 0 (delta 0), pack-reused 57
Unpacking objects: 100% (57/57), done.
Checking connectivity... done.
Already up-to-date.
Setup completed!
----------------
See https://github.com/TurboLabIt/zzupdate for the quickstart guide.
```
将 Ubuntu 系统从一个版本升级到另一个版本,您不需要输入很多命令,也不需要重新启动,只需要运行下面的 `zzupdate` 命令并坐下喝杯咖啡就可以了。
请注意,当您远程升级系统时,建议您使用以下的工具来帮助您在任何断开连接时重新连接会话。
建议阅读: [如何让一个进程/命令在 SSH 连接断开后继续运行](https://www.2daygeek.com/how-to-keep-a-process-command-running-after-disconnecting-ssh-session/)
### 如何配置 zzupdate(可选)
默认情况下,`zzupdate` 可以开箱即用,不需要配置任何东西。当然,如果您想要自己配置一些内容也是可以的。复制提供的示例配置文件 `zzupdate.default.conf` 到 `zzupdate.conf`,并在 `zzupdate.conf` 中配置您的首选项。
```
$ sudo cp /usr/local/turbolab.it/zzupdate/zzupdate.default.conf /etc/turbolab.it/zzupdate.conf
```
打开文件,默认配置如下。
```
$ sudo nano /etc/turbolab.it/zzupdate.conf
REBOOT=1
REBOOT_TIMEOUT=15
VERSION_UPGRADE=1
VERSION_UPGRADE_SILENT=0
COMPOSER_UPGRADE=1
SWITCH_PROMPT_TO_NORMAL=0
```
* `REBOOT=1`:系统在更新完成后自动重启
* `REBOOT_TIMEOUT=15`:重启的默认超时值
* `VERSION_UPGRADE=1`:执行从一个版本到另一个版本的版本升级
* `VERSION_UPGRADE_SILENT=0`:禁用自动升级
* `COMPOSER_UPGRADE=1`:自动升级
* `SWITCH_PROMPT_TO_NORMAL=0`:如果值为 `0`,将寻找相同种类的版本升级。例如您正在运行 LTS 的版本,那么将寻找 LTS 的版本升级,而不是用于正常版本升级。如果值为 `1`,那么无论您是运行 LTS 还是正常版本,都会查找最新版本
我现在正在使用 Ubuntu 17.10 ,查看一下详细信息。
```
$ cat /etc/*-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=17.10
DISTRIB_CODENAME=artful
DISTRIB_DESCRIPTION="Ubuntu 17.10"
NAME="Ubuntu"
VERSION="17.10 (Artful Aardvark)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 17.10"
VERSION_ID="17.10"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=artful
UBUNTU_CODENAME=artful
```
要升级 Ubuntu 到最新版本,只需要执行以下命令:
```
$ sudo zzupdate
O===========================================================O
zzupdate - Wed May 2 17:31:16 IST 2018
O===========================================================O
Self-update and update of other zzScript
----------------------------------------
.
.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
Updating...
----------
Already up-to-date.
Setup completed!
----------------
See https://github.com/TurboLabIt/zzupdate for the quickstart guide.
Channel switching is disabled: using pre-existing setting
---------------------------------------------------------
Cleanup local cache
-------------------
Update available packages informations
--------------------------------------
Hit:1 https://download.docker.com/linux/ubuntu artful InRelease
Ign:2 http://dl.google.com/linux/chrome/deb stable InRelease
Hit:3 http://security.ubuntu.com/ubuntu artful-security InRelease
Hit:4 http://in.archive.ubuntu.com/ubuntu artful InRelease
Hit:5 http://dl.google.com/linux/chrome/deb stable Release
Hit:6 http://in.archive.ubuntu.com/ubuntu artful-updates InRelease
Hit:7 http://in.archive.ubuntu.com/ubuntu artful-backports InRelease
Hit:9 http://ppa.launchpad.net/notepadqq-team/notepadqq/ubuntu artful InRelease
Hit:10 http://ppa.launchpad.net/papirus/papirus/ubuntu artful InRelease
Hit:11 http://ppa.launchpad.net/twodopeshaggy/jarun/ubuntu artful InRelease
.
.
UPGRADE PACKAGES
----------------
Reading package lists...
Building dependency tree...
Reading state information...
Calculating upgrade...
The following packages were automatically installed and are no longer required:
.
.
Interactively upgrade to a new release, if any
----------------------------------------------
Reading cache
Checking package manager
Reading package lists... Done
Building dependency tree
Reading state information... Done
Ign http://dl.google.com/linux/chrome/deb stable InRelease
Hit https://download.docker.com/linux/ubuntu artful InRelease
Hit http://security.ubuntu.com/ubuntu artful-security InRelease
Hit http://dl.google.com/linux/chrome/deb stable Release
Hit http://in.archive.ubuntu.com/ubuntu artful InRelease
Hit http://in.archive.ubuntu.com/ubuntu artful-updates InRelease
Hit http://in.archive.ubuntu.com/ubuntu artful-backports InRelease
Hit http://ppa.launchpad.net/notepadqq-team/notepadqq/ubuntu artful InRelease
Hit http://ppa.launchpad.net/papirus/papirus/ubuntu artful InRelease
Hit http://ppa.launchpad.net/twodopeshaggy/jarun/ubuntu artful InRelease
Fetched 0 B in 6s (0 B/s)
Reading package lists... Done
Building dependency tree
Reading state information... Done
```
我们需要按下回车键禁用第三方仓库以继续升级。
```
Updating repository information
Third party sources disabled
Some third party entries in your sources.list were disabled. You can
re-enable them after the upgrade with the 'software-properties' tool
or your package manager.
To continue please press [ENTER]
.
.
Get:35 http://in.archive.ubuntu.com/ubuntu bionic-updates/universe i386 Packages [2,180 B]
Get:36 http://in.archive.ubuntu.com/ubuntu bionic-updates/universe Translation-en [1,644 B]
Fetched 38.2 MB in 6s (1,276 kB/s)
Checking package manager
Reading package lists... Done
Building dependency tree
Reading state information... Done
Calculating the changes
Calculating the changes
```
开始下载 `Ubuntu 18.04 LTS` 软件包,所需时间取决于您的网络状况,一般情况下这将需要几分钟。
```
Do you want to start the upgrade?
63 installed packages are no longer supported by Canonical. You can
still get support from the community.
4 packages are going to be removed. 175 new packages are going to be
installed. 1307 packages are going to be upgraded.
You have to download a total of 999 M. This download will take about
12 minutes with your connection.
Installing the upgrade can take several hours. Once the download has
finished, the process cannot be canceled.
Continue [yN] Details [d]y
Fetching
Get:1 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 base-files amd64 10.1ubuntu2 [58.2 kB]
Get:2 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 debianutils amd64 4.8.4 [85.7 kB]
Get:3 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 bash amd64 4.4.18-2ubuntu1 [614 kB]
Get:4 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 locales all 2.27-3ubuntu1 [3,612 kB]
.
.
Get:1477 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 liblouisutdml-bin amd64 2.7.0-1 [9,588 B]
Get:1478 http://in.archive.ubuntu.com/ubuntu bionic/universe amd64 libtbb2 amd64 2017~U7-8 [110 kB]
Get:1479 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 libyajl2 amd64 2.1.0-2build1 [20.0 kB]
Get:1480 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 usb-modeswitch amd64 2.5.2+repack0-2ubuntu1 [53.6 kB]
Get:1481 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 usb-modeswitch-data all 20170806-2 [30.7 kB]
Get:1482 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 xbrlapi amd64 5.5-4ubuntu2 [61.8 kB]
Fetched 999 MB in 6s (721 kB/s)
```
安装新软件包时,很少有服务需要重新启动。 点击 `Yes` 按钮,它会自动重启所需的服务。
```
Upgrading
Inhibiting until Ctrl+C is pressed...
Preconfiguring packages ...
Preconfiguring packages ...
Preconfiguring packages ...
Preconfiguring packages ...
(Reading database ... 441375 files and directories currently installed.)
Preparing to unpack .../base-files_10.1ubuntu2_amd64.deb ...
Warning: Stopping motd-news.service, but it can still be activated by:
motd-news.timer
Unpacking base-files (10.1ubuntu2) over (9.6ubuntu102) ...
Setting up base-files (10.1ubuntu2) ...
Installing new version of config file /etc/debian_version ...
Installing new version of config file /etc/issue ...
Installing new version of config file /etc/issue.net ...
Installing new version of config file /etc/lsb-release ...
motd-news.service is a disabled or a static unit, not starting it.
(Reading database ... 441376 files and directories currently installed.)
.
.
Progress: [ 80%]
Progress: [ 85%]
Progress: [ 90%]
Progress: [ 95%]
```
现在删除旧版的、系统不再需要的包。点击 `y` 以删除。
```
Searching for obsolete software
ing package lists... 97%
ding package lists... 98%
Reading package lists... Done
Building dependency tree
Reading state information... Done
Reading state information... 23%
Reading state information... 47%
Reading state information... 71%
Reading state information... 94%
Reading state information... Done
Remove obsolete packages?
88 packages are going to be removed.
Continue [yN] Details [d]y
.
.
.
done
Removing perlmagick (8:6.9.7.4+dfsg-16ubuntu6) ...
Removing snapd-login-service (1.23-0ubuntu1) ...
Processing triggers for libc-bin (2.27-3ubuntu1) ...
Processing triggers for man-db (2.8.3-2) ...
Processing triggers for dbus (1.12.2-1ubuntu1) ...
Fetched 0 B in 0s (0 B/s)
```
升级成功,需要重启系统。点击 `y` 以重启系统。
```
System upgrade is complete.
Restart required
To finish the upgrade, a restart is required.
If you select 'y' the system will be restarted.
Continue [yN]y
```
注意: 少数情况下,会要求您确认配置文件替换以继续安装。
查看升级后的系统详情:
```
$ cat /etc/*-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=18.04
DISTRIB_CODENAME=bionic
DISTRIB_DESCRIPTION="Ubuntu 18.04 LTS"
NAME="Ubuntu"
VERSION="18.04 LTS (Bionic Beaver)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 18.04 LTS"
VERSION_ID="18.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=bionic
UBUNTU_CODENAME=bionic
```
---
via: <https://www.2daygeek.com/zzupdate-single-command-to-upgrade-ubuntu-18-04/>
作者:[PRAKASH SUBRAMANIAN](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[XiatianSummer](https://github.com/XiatianSummer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,685 | 为什么 Oil States 案对于开源界是个好消息 | https://opensource.com/article/18/4/why-oil-states-good-open-source | 2018-05-27T16:23:00 | [
"专利"
] | https://linux.cn/article-9685-1.html |
>
> 提要:对于面临滥用专利制度的实体发起诉讼威胁的技术公司和创新者来说,此案是一个重大胜利。
>
>
>

对于面临滥用专利制度的实体发起诉讼威胁的技术公司和创新者来说,日前美国最高法院对 [Oil States 诉 Greene’s Energy 案](https://www.supremecourt.gov/opinions/17pdf/16-712_87ad.pdf)做出的[裁决是一个重大胜利](http://www.scotusblog.com/wp-content/uploads/2017/11/16-712-bsac-Dell.pdf)。此类滥用专利制度的实体试图从创新者和创造就业机会的企业身上攫取价值。
在 Oil States 案中,美国最高法院对美国专利商标局(USPTO)一项旨在质疑此前授权但存在问题的专利是否有效的行政程序是否违宪做出了裁决。<ruby> 专利流氓 <rp> ( </rp> <rt> patent trolls </rt> <rp> ) </rp></ruby>最喜欢利用此类专利发起诉讼。这一称为<ruby> “双方复审” <rp> ( </rp> <rt> inter partes review </rt> <rp> ) </rp></ruby>的程序已经成为一种应对基于可能无效专利而轻率发起的侵权主张的重要工具,其成本远低于在联邦法院检验此类专利有效性的成本。
美国国会根据<ruby> 《2011年美国发明法案》 <rp> ( </rp> <rt> America Invents Act of 2011 </rt> <rp> ) </rp></ruby>创建了这种双方复审程序,以清理美国国会所认为的大量被不当授权的专利。此类专利被专利流氓用于向创新者谋取费用。自 2012 年实施该程序以来,已经有 7000 多份申请被提交,主要是为了审查计算机和高科技领域的可疑专利,并且有超过 1300 项权利主张被裁定无效。
在 7 比 2 的多数意见中,托马斯法官表示:“授予专利的决定是涉及公共权利的事项。双方复审只是对该授权过程的再审,美国国会已经授权美国专利商标局实施此种再审。”法官认为双方复审程序并没有侵犯专利权人所拥有的案件需由联邦法院裁决(在联邦法院无效专利的成本更高,诉讼费用明显更为昂贵)的宪法权利。
与开发、销售或实施复杂技术的任何实体一样,开发或实施开源软件的成功企业是专利流氓诉讼威胁的颇有吸引力的目标。因此,确认双方复审程序的合宪性不仅提高了专利系统的质量,而且也保留了一种工具来保护开源技术免受那些滥用专利系统的实体的攻击。
美国专利商标局打算评估双方复审程序的实施情况,这可能会影响其作为防御工具的有效性。但科技行业人士应继续让政策制定者保留《2011 年美国发明法案》所带来的有益变革,以保护创新并阻止滥用专利的行为。
---
作者简介:Matt Krupnick 是<ruby> 红帽公司 <rp> ( </rp> <rt> Red Hat </rt> <rp> ) </rp></ruby>公共政策总监,于 2017 年加入红帽公司,负责政策制定以及为一系列对红帽公司及开源技术有潜在影响的各种政策问题提供建议。
译者简介:薛亮,集慧智佳知识产权咨询公司高级咨询师,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 200 | OK | This week’s Supreme Court ruling in [ Oil States v. Greene’s Energy](https://www.supremecourt.gov/opinions/17pdf/16-712_87ad.pdf) was an important
[victory for technology companies and innovators](http://www.scotusblog.com/wp-content/uploads/2017/11/16-712-bsac-Dell.pdf)who face threats of patent litigation from entities that abuse the patent system by seeking to extract value from innovators and companies that create jobs.
In *Oil States*, the Court ruled against a constitutional challenge to the administrative process at the U.S. Patent and Trademark Office (PTO) for disputing the validity of previously-granted, but questionable, patents—the type that are most used by so-called *patent trolls*. This process called *inter partes* review (IPR), has become an important tool for combating frivolous infringement assertions based on likely invalid patents in a way that is much less expensive than testing those patents in federal court.
Congress created the IPR process with the America Invents Act of 2011 (AIA) in order to clean up what Congress saw as an abundance of improperly granted patents, which are used by patent trolls to extract money from innovators. Since the process was implemented in 2012, more than 7,000 petitions have been filed, primarily to review dubious patents in the computer and high-tech field, and more than 1,300 claims have been ruled invalid.
In the 7-2 majority opinion, Justice Thomas stated that “[t]he decision to grant a patent is a matter involving public rights. *Inter partes* review is simply a reconsideration of that grant, and Congress has permissibly reserved the USPTO’s authority to conduct that reconsideration,” holding that the IPR process does not violate a patent owner’s constitutional right to have a case adjudicated by a federal court (where the standard for cancelling a patent is higher and litigation costs are significantly more expensive).
As with any entity developing, selling, or implementing a complex technology, successful companies developing or implementing open source are an attractive target for litigation threats by patent trolls, so confirming the constitutionality of this process not only improves the quality of the patent system, but also retains a tool to protect open source technology against attacks from those that seek to game the system.
The PTO plans to review the implementation of the IPR process, which could affect its effectiveness as a defense tool. But those of us in the technology industry will continue to educate policymakers on the need to preserve the benefits of the reforms contained in the AIA in order to protect innovation and discourage patent abuses.
## Comments are closed. |
9,686 | 在 Ubuntu Snap 应用商店上发现的加密货币 ‘恶意软件’ 是怎么回事? | https://itsfoss.com/snapstore-cryptocurrency-saga/ | 2018-05-27T17:24:16 | [
"Snap",
"挖矿"
] | https://linux.cn/article-9686-1.html | 最近,有发现称一些 Ubuntu Snap 应用商店上的应用包含加密货币挖矿程序。Canonical 公司迅速下架了这些违规的应用,但是留下了几个有待回答的问题。
### 在 Snap 应用商店上发现了加密矿工

5 月 11 号,一位名叫 [tarwirdur](https://github.com/tarwirdur) 的用户在 [snapcraft.io repository](https://github.com/canonical-websites/snapcraft.io/issues/651) 开了一个新的工单 ,他提到一个由 Nicolas Tomb 开发,叫做 2048buntu 的 snap 应用包含加密货币矿工。tarwirdur 询问,他怎样才能出于安全的原因而“投诉该应用” 。tarwirdur 后来发表说其它由 Nicolas Tomb 开发的 snap 应用也都包含加密货币矿工。
看起来该 snap 应用使用了 systemd 在系统启动时自动地运行代码,并在用户不知情的情况下在后台运行。
>
> 对那些不熟悉相关术语的人来说,<ruby> 加密货币 <rt> cryptocurrency </rt></ruby><ruby> 矿工 <rt> miner </rt></ruby>是一段使用计算机的主处理器或者图形处理器来“挖掘”数字货币的程序。“挖矿”通常涉及到解决一个数学等式。在这种情况下,如果你在运行 2048buntu 游戏,这个游戏将会额外使用处理器的计算能力去进行加密货币的挖掘。
>
>
>
Snapcraft 团队迅速地下架了所有由该违规者开发的应用来做出回应。他们同时也开展了调查。
### 隐匿者发声
5 月 13 号,一位同名为 Nicolas Tomb 的 Disqus 用户在 OMGUbuntu 的新闻报道上发表了[评论](https://disqus.com/home/discussion/omgubuntu/malware_found_on_the_ubuntu_snap_store/#comment-3899153046),他在评论中称自己向 snap 应用中添加了加密货币矿工,从而获取收益。他为他的行为道歉,同时承诺将所有挖矿所得的收益送给 Ubuntu 基金会。
我们不能确认这个评论就是由 Nicolas Tomb 发表的,因为这个 Disqus 账户最近才被创建,也只有一条评论与之相关联。现在,我们假设他是。
### Canonical 公司发表了声明
5 月 15 号,Canonical 公司在这种情况下发表了一份声明。标题为 [“在 Snap 应用商店中的信任与安全”](https://blog.ubuntu.com/2018/05/15/trust-and-security-in-the-snap-store),声明开头重申了当下的情况。他们也补充道[重新发布的 snap 应用中已经被删除了加密货币挖矿程序](https://forum.snapcraft.io/t/action-against-snap-store-malware/5417/8)。
Canonical 公司随后尝试调查 Nicolas Tomb 的动机。他们指出,他告诉他们说自己这样做是为了通过应用赚钱(如上所诉),而当面对质疑时就停止了。他们也指出“挖掘加密货币本身并非不合法和不道德的”。然而,他们仍对他没有在 snap 应用描述中披露加密矿工这件事表示了不满意。
随后 Canonical 公司将话题转移到审核软件上。根据这份申明,Snap 应用商店将会采用一种类似 iOS、Android、Windows 的质量控制系统,这个系统将有“自动化的检查点,安装包必须在被接受前通过检查,同时在特殊问题被标记时会进行人工审核”。
然后,Canonical 公司声称“对大规模的软件仓库来说,只接受每个单独文件都被仔细审核过的软件是不可能的”。因此,他们需要信任软件源而不是内容。毕竟,软件源是现在 Ubuntu 软件仓库系统的基础。
Canonical 公司紧接着谈到了 Snap 应用的未来。他们承认现在的系统是不完美的。他们也在不断地进行改善。他们“在开发非常有趣的安全功能,这些功能将会在改善系统安全性同时提升人们在服务器或桌面上进行软件开发的体验”。
其中一个他们正在开发的功能是查看一个软件发布者是否已通过验证。其他的改进包括:“将所有 AppArmor 内核补丁递交到上游”和其它底层修复。
### 一些关于“Snap 应用商店中的恶意软件”的想法
基于我所了解的所有内容,我产生了一些想法和问题。
#### 这种挖矿软件运行多久了?
首先,这些挖矿软件存在于 Snap 应用商店多久了?因为它们已经被下架了,我们没有这样的数据。我可以通过 Google 快照抓取一些 2048buntu 页面的图片,但这没有提供任何可用的信息。根据该软件运行时间,多少系统安装过,挖掘出了什么加密货币,我们能否知道违规者获取的是一点钱还是一笔钱。一个更长远的问题是:Canonical 公司将来有能力捕捉到这样的违规情况吗?
#### 这真的是一个恶意软件吗?
许多新闻网站将之报道为恶意软件感染。我想我甚至可以看到这个事件被称为 Linux 的第一个恶意软件。我不确定这个术语是否精确。Dictionary.com 这样定义 [恶意软件](http://www.dictionary.com/browse/malware?s=t):“意图损害计算机、移动设备、计算机系统或者计算机网络,或者对其运作进行部分控制的软件”。
这个有问题的 snap 应用并没有损害或者控制涉及到的计算机。它同样没有感染其他计算机。它也不能这样做,因为所有的 snap 应用位于沙盒之中。它们最多利用了处理器的计算能力,就是这样。所以,我不会称之为恶意软件。
#### 无孔不入
Nicolas Tomb 使用的一个辩解是在他上传应用的时候 Snap 应用商店没有任何反对加密货币挖矿的规则。(我敢向你打赌他们正在纠正这个错误。)他们之所以没有这样的规则,原因很简单,之前没有人做过这种事。如果 Tomb 想正确地做事,他应该提前询问是否允许这种行为。而事实是他似乎没有指出他知道 Canonical 公司可能会拒绝的事实。至少,Canonical 公司会告诉他将这些写在软件的描述中。
#### 一看就不对劲

如我之前说的,我从 Google 快照获取了一个 2048buntu 的页面截图。仅仅看它就会感觉到一些危险的信号。首先,截图中几乎没有真实的描述。它是这样描述的“类似 2048 的游戏。这个游戏用 ubuntu 主题克隆了流行的游戏 2048。”哇,这将会引来容易上当受骗的人。当我读到类似空洞的描述时,我会多考虑下。
我注意到的另一件事是软件的大小。2048buntu 的 1.0 版本大小将近 140 MB。一个简单的游戏怎么需要这么多的空间?有用 Javascript 写的浏览器版本大概只用了不到它的四分之一。其他 snap 应用商店的 2048 游戏的大小没有一个达到了这个软件的一半。
然后,它有个许可证。这是一个使用了 Ubuntu 主题的流行游戏的克隆。它怎么能被认为是专有软件?我确信,其他合法的开发者会因为该内容而使用了 FOSS (自由开源软件)许可证来上传它。
单是这些因素就使得这个 snap 应用很特殊,应该进行审核。
#### 谁是 Nicolas Tomb?
当第一次了解到这些之后,我决定看看我能否找出造成这些混乱的人。当我搜索 Nicolas Tomb 的时候,我什么都没找到。所有我找到的只是一大堆关于加密货币挖矿 snap 应用的新闻和文章,以及去 tomb of St. Nicolas 旅游的信息。在 Twiter 和 Github 上都没有 Nicolas Tomb 的标志。看起来似乎是为了上传这些 snap 应用才创建的名称。
这同样引出了 Canonical 公司发表的申明中的一点,关于验证发布者。上一次我查看的时候,相当多的 snap 应用不是由应用的维护者发布的。这让我感到担忧。我更乐意相信由 Mozilla 基金会发布的 firefox 的 snap 应用,而不是 Leonard Borsch。如果对应用维护者来说关注应用的 snap 版本太耗费精力,应该有办法让维护者在他们软件的 snap 版本上贴上批准的标签。就像是 Firefox 的 snap 版本由 Fredrick 发布,经 Mozilla 基金会批准。这样才能让用户对下载的内容更放心。
#### 无疑 Snap 应用商店还有改善的空间
在我看来,Snap 应用商店团队应该实现的第一个特性是报告可疑应用的方式。tarwirdur 必须找到该网站的 Github 页面才行。而大多数用户不会想到这一点。如果 Snap 应用商店不能审核每一行代码,那么使用户能够报告问题是退而求其次的办法。即使评分系统也是一个不差的补充。我确信一定有部分人因为 2048buntu 使用了太多系统资源而给它很低的评分。
### 结论
从我所知道的情况来说,我认为这是某个人创建了一些简单的应用,在每个应用中嵌入了加密货币矿工,之后将这些应用上传到 Snap 应用商店,想着捞一笔钱。一旦他们被抓了,他们就声称这仅仅为了通过应用程序获利。如果真的是这样,他们应该在 snap 应用的描述中提到才对。隐藏加密矿工并不是什么[新鲜事](https://krebsonsecurity.com/2018/03/who-and-what-is-coinhive/)。他们通常是一种盗取计算能力的方法。
我希望 Canonical 公司已经具备了解决这个问题的功能,盼望这些功能能很快出来。
你对 Snap 应用商店的“恶意软件风波”有什么看法?你将如何改善这种情况?请在下面的评论中告诉我们。
如果你觉得这篇文章有趣,请花费一点时间将它分享到社交媒体上。
---
via: <https://itsfoss.com/snapstore-cryptocurrency-saga/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[paperzhang](https://github.com/paperzhang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,687 | Cron 任务入门指南 | https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/ | 2018-05-28T06:43:00 | [
"cron",
"定时"
] | https://linux.cn/article-9687-1.html | 
**Cron** 是您可以在任何类 Unix 操作系统中找到的最有用的实用程序之一。它用于安排命令在特定时间执行。这些预定的命令或任务被称为 “Cron 任务”。Cron 通常用于运行计划备份、监视磁盘空间、定期删除不再需要的文件(例如日志文件)、运行系统维护任务等等。在本简要指南中,我们将看到 Linux 中 Cron 任务的基本用法。
### Cron 任务入门指南
cron 任务的典型格式是:
```
分钟(0-59) 小时(0-24) 日(1-31) 月(1-12) 星期(0-6) 要执行的命令
```
只需记住 cron 任务的格式或打印下面的插图并将其放在你桌面上即可。

在上图中,星号表示特定的时间块。
要显示当前登录用户的 crontab 文件的内容:
```
$ crontab -l
```
要编辑当前用户的 cron 任务,请执行以下操作:
```
$ crontab -e
```
如果这是第一次编辑此文件,会询问你使用哪个编辑器来编辑此文件。
```
no crontab for sk - using an empty one
Select an editor. To change later, run 'select-editor'.
1. /bin/nano <---- easiest
2. /usr/bin/vim.basic
3. /usr/bin/vim.tiny
4. /bin/ed
Choose 1-4 [1]:
```
选择适合你的编辑器。这里是一个示例 crontab 文件的样子。

在这个文件中,你需要添加你的 cron 任务。
要编辑其他用户的 crontab,例如 ostechnix,请执行:
```
$ crontab -u ostechnix -e
```
让我们看看一些例子。
要 **每分钟** 执行一次 cron 任务,需使用如下格式。
```
* * * * * <command-to-execute>
```
要每 5 分钟运行一次 cron 任务,请在 crontab 文件中添加以下内容。
```
*/5 * * * * <command-to-execute>
```
要在每 1/4 个小时(每 15 分钟)运行一次 cron 任务,请添加以下内容:
```
*/15 * * * * <command-to-execute>
```
要每小时的第 30 分钟运行一次 cron 任务,请运行:
```
30 * * * * <command-to-execute>
```
您还可以使用逗号定义多个时间间隔。例如,以下 cron 任务每小时运行三次,分别在第 0、 5 和 10 分钟运行:
```
0,5,10 * * * * <command-to-execute>
```
每半小时运行一次 cron 任务:
```
*/30 * * * * <command-to-execute>
```
每小时运行一次:
```
0 * * * * <command-to-execute>
```
每 2 小时运行一次:
```
0 */2 * * * <command-to-execute>
```
每天运行一项(在 00:00 运行):
```
0 0 * * * <command-to-execute>
```
每天凌晨 3 点运行:
```
0 3 * * * <command-to-execute>
```
每周日运行:
```
0 0 * * SUN <command-to-execute>
```
或使用,
```
0 0 * * 0 <command-to-execute>
```
它将在每周日的午夜 00:00 运行。
星期一至星期五每天运行一次,亦即每个工作日运行一次:
```
0 0 * * 1-5 <command-to-execute>
```
这项工作将于 00:00 开始。
每个月运行一次:
```
0 0 1 * * <command-to-execute>
```
于每月第 1 天的 16:15 运行:
```
15 16 1 * * <command-to-execute>
```
每季度运行一次,亦即每隔 3 个月的第 1 天运行:
```
0 0 1 */3 * <command-to-execute>
```
在特定月份的特定时间运行:
```
5 0 * 4 * <command-to-execute>
```
每个四月的 00:05 运行。
每 6 个月运行:
```
0 0 1 */6 * <command-to-execute>
```
这个定时任务将在每六个月的第一天的 00:00 运行。
每年运行:
```
0 0 1 1 * <command-to-execute>
```
这项 cron 任务将于 1 月份的第一天的 00:00 运行。
我们也可以使用以下字符串来定义任务。
`@reboot` 在每次启动时运行一次。 `@yearly` 每年运行一次。 `@annually`(和 `@yearly` 一样)。 `@monthly` 每月运行一次。 `@weekly` 每周运行一次。 `@daily` 每天运行一次。 `@midnight` (和 `@daily` 一样)。 `@hourly` 每小时运行一次。
例如,要在每次重新启动服务器时运行任务,请将此行添加到您的 crontab 文件中。
```
@reboot <command-to-execute>
```
要删除当前用户的所有 cron 任务:
```
$ crontab -r
```
还有一个名为 [crontab.guru](https://crontab.guru/) 的专业网站,用于学习 cron 任务示例。这个网站提供了很多 cron 任务的例子。
有关更多详细信息,请查看手册页。
```
$ man crontab
```
那么,就是这样。到此为止,您应该对 cron 任务以及如何实时使用它们有了一个基本的了解。后续还会介绍更多的优秀工具。敬请关注!!
干杯!
---
via: <https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[KevinSJ](https://github.com/KevinSJ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,688 | 如何在 X 中启动用户软件 | http://www.enricozini.org/blog/2018/debian/starting-user-software/ | 2018-05-28T21:54:53 | [] | https://linux.cn/article-9688-1.html | 
目前有很多方法可以在开启用户会话时启动软件。
这是一篇试图将所有方法聚集在一起的文章。某些部分可能不精确或不正确,但这是一个开始,如果我收到更正,我很乐意保持更新。
### x11-common
```
man xsession
```
* 由显示管理器启动,如 `/usr/share/lightdm/lightdm.conf.d/01_debian.conf` 或 `/etc/gdm3/Xsession`。
* Debian 特定。
* 在 `/etc/X11/Xsession.d/` 中运行脚本。
* `/etc/X11/Xsession.d/40x11-common_xsessionrc` 引用 `~/.xsessionrc` ,它能比设置环境变量能做的多一点,因为它在 X 会话启动时运行。
* 最后,它启动会话管理器(`gnome-session`、`xfce4-session` 等等)。
### systemd --user
* <https://wiki.archlinux.org/index.php/Systemd/User>
* 由 `pam_systemd` 启动,所以在环境变量中可能没有设置 `DISPLAY` 变量。
* 管理单元:
+ `/usr/lib/systemd/user/` 由已安装的软件包提供的单元。
+ `~/.local/share/systemd/user/` 由安装在家目录的软件包提供的单元。
+ `/etc/systemd/user/` 由系统管理员提供的系统范围的用户的单元。
+ `~/.config/systemd/user/` ,用户自己放置的单元。
* 当设置 X 会话和 `DISPLAY` 变量时,启动 systemd 用户单元的技巧是从 `.desktop` 自启动文件调用 `systemctl start`。
### dbus 激活
* <https://dbus.freedesktop.org/doc/system-activation.txt>
* 进行 dbus 请求的用户进程可以触发启动服务器程序。
* 对于系统调试,有没有一种方法可以监控哪些服务正在启动 dbus ?
### X 会话管理器
* <https://en.wikipedia.org/wiki/X_session_manager>
* 由 `x11-common` 的 `Xsession.d` 运行。
* 运行 freedesktop 自动启动的 `.desktop` 文件。
* 运行桌面环境特定的软件。
### xdg 自动启动
* <https://specifications.freedesktop.org/autostart-spec/autostart-spec-latest.html>
* 由会话管理器运行。
* 如果存在 `/etc/xdg/autostart/foo.desktop` 和 `~/.config/autostart/foo.desktop` ,那么只会使用 `~/.config/autostart/foo.desktop`,因为 `~/.config/autostart/` 比 `/etc/xdg/autostart/` 更重要。
* 是顺序的还是并行?
### 其他启动注意事项
#### ~/.Xauthority
要连接到 X 服务器,客户端需要从 `~/.Xauthority` 发送一个令牌,这证明他们可以读取用户的隐私数据。
`~/.Xauthority` 包含显示管理器生成的一个令牌,并在启动时传递给 X。
要查看它的内容,请使用 `xauth -i -f ~/.Xauthority list`。
---
via: <http://www.enricozini.org/blog/2018/debian/starting-user-software/>
作者:[Enrico Zini](http://www.enricozini.org/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 302 | Found | null |
9,690 | 如何在终端中显示图片 | https://www.ostechnix.com/how-to-display-images-in-the-terminal/ | 2018-05-29T07:06:58 | [
"图片",
"终端"
] | https://linux.cn/article-9690-1.html | 
Linux 上有许多 GUI 图片浏览器。但我尚未听说或使用过任何在终端中显示图片的应用程序。幸运的是,我刚刚发现了一个可用于在终端中显示图像的名叫 **FIM** 的图像查看器。FIM 引起了我的注意,是因为与大多数 GUI 图片浏览器相比,它非常轻巧。毫不迟疑,让我们来看看它能做什么。
### 使用 FIM 在终端中显示图像
**FIM** 意即 **F**bi **IM**proved。对于那些不知道的人,**Fbi** 是指 Linux 中的 **f**rame **b**uffer **i**mageviewer。它使用系统的帧缓冲器直接从命令行显示图像。默认情况下,它能用终端显示 bmp、gif、jpeg、PhotoCD、png、ppm、tiff 和 xwd。对于其他格式,它会尝试使用 ImageMagick 的转换。
FIM 基于 Fbi,它是一款高度可高度定制及脚本化的图像浏览器,非常适合使用 Vim 文本编辑器或 Mutt 等软件的用户。它会以全屏显示图像,并可通过键盘快捷键控制(如调整大小、翻转、缩放)。与 Fbi 不同的是,FIM 是通用的:它可以打开许多文件格式,并且可以在以下视频模式下显示图片:
* 使用 Linux framebuffer 设备,以图形方式呈现
* 在 X / Xorg 下,使用 SDL 库,以图形方式呈现
* 在 X / Xorg 下,使用 Imlib2 库,以图形方式呈现。
* 在任何文本控制台中使用 AAlib 库呈现为 ASCII 字符画
FIM 是完全免费且开源的。
### 安装 FIM
基于 DEB 的系统,如 Ubuntu、Linux Mint, 可从默认的仓库中获取 FIM 图像查看器。因此,你可以使用如下命令安装fbi:
```
$ sudo apt-get install fim
```
如果它在你使用的 Linux 发行版的仓库中不包含 FIM,则可以下载源代码进行编译和安装,如下所示。
```
wget http://download.savannah.nongnu.org/releases/fbi-improved/fim-0.6-trunk.tar.gz
wget http://download.savannah.nongnu.org/releases/fbi-improved/fim-0.6-trunk.tar.gz.sig
gpg --search 'dezperado autistici org'
#按照屏幕上的说明,从密钥服务器导入密钥
gpg --verify fim-0.6-trunk.tar.gz.sig
```
```
tar xzf fim-0.6-trunk.tar.gz
cd fim-0.6-trunk
./configure --help=short
#阅读./configure --help=short 的输出:你可以在 ./configure 中添加选项
./configure
make
su -c“make install”
```
### FIM用法
安装完成后,您可以使用以下命令以“自动缩放”显示的图像:
```
$ fim -a dog.jpg
```
这里是我的 Ubuntu 主机的示例输出。

正如你在上面的屏幕截图中看到的,FIM 没有使用任何外部 GUI 图片浏览器。相反,它使用我们系统的帧缓冲器来显示图像。
如果当前目录中有多个 .jpg 文件,可以使用通配符打开所有文件,如下所示。
```
$ fim -a * .jpg
```
要打开目录中的所有图像,例如 `Pictures`,请运行:
```
$ fim Pictures/
```
我们也可以在文件夹及其子文件夹中递归地打开图像,然后像下面那样对列表进行排序。
```
$ fim -R Pictures/ --sort
```
要以 ASCII 格式渲染图像,可以使用 `-t` 标志。
```
$ fim -t dog.jpg
```
要退出 Fim,请按 `ESC` 或 `q`。
#### 键盘快捷键
您可以使用各种键盘快捷键来管理图像。例如,要加载下一张图像和之前的图像,请按下 `PgUp` / `PgDown` 键。成倍放大或缩小,请使用 `+` / `-` 键。以下是用于在FIM中控制图像的常用按键。
* `PageUp` / `Down`:上一张/下一张图片
* `+` / `-` :放大/缩小
* `a`:自动缩放
* `w`:自适应宽度
* `h`:自适应高度
* `j` / `k`:平移/向上
* `f` / `m`:翻转/镜像
* `r` / `R`:旋转(顺时针/逆时针)
* `ESC` / `q`:退出
有关完整详细信息,请参阅手册页。
```
$ man fim
```
那么,就是这样。希望这对你有所帮助。后续还会介绍更多的优秀工具。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-display-images-in-the-terminal/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[KevinSJ](https://github.com/KevinSJ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,691 | DevOps 接下来会发生什么:要关注的 5 个趋势 | https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch | 2018-05-29T07:30:12 | [
"DevOps"
] | https://linux.cn/article-9691-1.html |
>
> 专家们权衡了 DevOps 团队最近会有何期望。
>
>
>

“DevOps” 一词通常认为是来源于 [这篇 2008 年关于敏捷基础设施和运营的讲演中](http://www.jedi.be/presentations/agile-infrastructure-agile-2008.pdf)。现在的 IT 词汇中,它无处不在,这个“混搭”的词汇出现还不到 10 年:我们还在研究它在 IT 中更现代化的工作方法。
诚然,多年来一直在 “从事 DevOps” 的人积累了丰富的知识。但是大多数的 DevOps 环境 —— 人与 [文化](https://enterprisersproject.com/article/2017/9/5-ways-nurture-devops-culture) 、流程与方法、工具与技术的融合 —— 还远远没有成熟。
更多的变化即将到来。Robert Reeves 说 “DevOps 是一个过程,一种算法”,他是 [Datical](https://www.datical.com/) 的 CTO, “它的绝对目标就是随着时间进行改变和演进”,这就是重点。
那我们预计接下来会发生什么呢?这里有一些专家们观察到的重要趋势。
### 1、 预计 DevOps、容器、以及微服务之间的相互依赖会增强
驱动 DevOps 发展的文化本身可能会演进。当然,DevOps 仍然将在根本上摧毁传统的 IT 孤岛和瓶颈,但这样做的理由可能会变得更加急迫。证据 A & B: [对容器和微服务的兴趣](https://enterprisersproject.com/article/2017/9/microservices-and-containers-6-things-know-start-time) 与日俱增。这个技术组合很强大、可连续扩展、与规划和 [持续进行的管理](https://enterprisersproject.com/article/2017/10/microservices-and-containers-6-management-tips-long-haul)配合最佳。
Arvind Soni 说 “影响 DevOps 的其中一个主要因素是向微服务转变”,他是 [Netsil](https://netsil.com/) 的产品副总裁,补充道,容器和业务流程,使开发者打包和交付的速度越来越快。DevOps 团队的任务可能是帮助去加速打包并管理越来越复杂的微服务弹性架构。
### 2、 预计 ”安全网“ 更少
DevOps 使团队可以更快更敏捷地去构建软件,部署速度也更快更频繁、同时还能提升软件质量和稳定性。但是好的 IT 领导通常都不会忽视管理风险,因此,早期大量的 DevOps 迭代都是使用了安全防护 —— 从后备的不重要业务开始的。为了实现更快的速度和敏捷性,越来越多的团队将抛弃他们的 ”辅助轮“(LCTT 译注:意思说减少了安全防护措施)。
Nic Grange 说 “随着团队的成熟,他们决定不再需要一些早期增加的安全 ‘防护栏’ 了”,他是 [Retriever Communications](http://retrievercommunications.com/) 的 CTO。Grange 给出了一个阶段展示的服务器的示例:随着 DevOps 团队的成熟,他们决定不再需要阶段展示的服务器了,尤其是他们很少在试生产环境中发现问题。(Grange 指出,这一举措对于缺乏 DevOps 经验的团队来说,不可轻易效仿)
Grange 说 “这个团队可能在监视和发现并解决生产系统中出现的问题的能力上有足够的信心”,“部署过程和测试阶段,如果没有任何证据证明它的价值,那么它可能会把整个进度拖慢”。
### 3、 预计 DevOps 将在其它领域大面积展开
DevOps 将两个传统的 IT 部门(开发和运营)结合的更紧密。越来越多的公司看到了这种结合的好处,这种文化可能会传播开来。这种情况在一些组织中已经出现,在 “DevSecOps” 一词越来越多出现的情况下,它反映出了在软件开发周期中有意地、越来越早地包含了安全性。
Derek Weeks 说 “DevSecOps 不仅是一个工具,它是将安全思维更早地集成到开发实践中”,它是 [Sonatype](https://www.sonatype.com/) 的副总裁和 DevOps 拥挤者。
[Red Hat](https://www.redhat.com/en/) 的安全策略师 Kirsten Newcomer 说,这种做法并不是一个技术挑战,而是一个文化挑战。
Newcomer 说 “从历史来看,安全团队都是从开发团队中分离出来的 —— 每个团队在它们不同的 IT 领域中形成了各自的专长” ,“它并不需要这种方法。每个关心安全性的企业也关心他们通过软件快速交付业务价值的能力,这些企业正在寻找方法,将安全放进应用程序的开发周期中。它们采用 DevSecOps 通过 CI/CD 流水线去集成安全实践、工具和自动化。为了做的更好,他们整合他们的团队 —— 将安全专家整合到应用程序开发团队中,参与到从设计到产品部署的全过程中。这种做法使双方都看到了价值 —— 每个团队都扩充了它们的技能和知识,使他们成为更有价值的技术专家。DevOps 做对了 —— 或者说是 DevSecOps —— 提升了 IT 安全性。”
除了安全以外,还可以让 DevOps 扩展到其它领域,比如数据库团队、QA,甚至是 IT 以外的潜在领域。
Datical 的 Reeves 说 “这是一件非常 DevOps 化的事情:发现相互掣肘的地方并解决它们”,“对于以前采用 DevOps 的企业来说,安全和数据库是他们面临的最大瓶颈。”
### 4、 预计 ROI 将会增加
Eric Schabell 说,“由于公司深入推进他们的 DevOps 工作,IT 团队在方法、流程、容器和微服务方面的投资将得到更多的回报。” 他是 Red Hat 的全球技术传播总监,Schabell 说 “‘圣杯’将移动的更快、完成的更多、并且变得更灵活。由于这些组件找到了更宽阔的天地,组织在应用程序中更有归属感时,结果就会出现。”
“每当新兴技术获得我们的关注时,任何事都有一个令人兴奋的学习曲线,但当认识到它应用很困难的时候,同时也会经历一个从兴奋到幻灭的低谷。最终,我们将开始看到从低谷中爬出来,并收获到应用 DevOps、容器、和微服务的好处。”
### 5、 预计成功的指标将持续演进
Mike Kail 说 “我相信 DevOps 文化的两个核心原则 —— 自动化和可衡量是从来不会变的”,它是 [CYBRIC](https://www.cybric.io/) 的 CTO,也是 Yahoo 前 CIO。“总是有办法去自动化一个任务,或者提升一个已经自动化的解决方案,而随着时间的推移,重要的事情是测量可能的变化和扩展。这个成熟的过程是一个永不停步的旅行,而不是一个目的地或者已完成的任务。”
在 DevOps 的精神中,成熟和学习也与协作者和分享精神有关。Kail 认为,对于敏捷方法和 DevOps 文化来说,它仍然为时尚早,这意味着它们还有足够的增长空间。
Kail 说 “随着越来越多的成熟组织持续去测量可控指标,我相信(希望) —— 这些经验应该被广泛的分享,以便我们去学习并改善它们。”
作为 Red Hat 技术传播专家,[Gordon Haff](https://enterprisersproject.com/user/gordon-haff) 最近注意到,组织使用业务成果相关的因素去改善他们的 DevOps 指标的工作越来越困难。 [Haff 写道](https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters) “你或许并不真正关心你的开发者写了多少行代码、服务器是否在一夜之间出现了硬件故障、或者你的测试覆盖面是否全面”。事实上,你可能并不直接关心你的网站的响应速度和更新快慢。但是你要注意的是,这些指标可能与消费者放弃购物车或者转到你的竞争对手那里有关。”
与业务成果相关的一些 DevOps 指标的例子包括,消费者交易金额(作为消费者花销统计的指标)和净推荐值(消费者推荐公司产品和服务的意愿)。关于这个主题更多的内容,请查看这篇完整的文章—— [DevOps 指标:你是否测量了重要的东西](https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters)。
### 唯一不变的就是改变
顺利说一句,如果你希望这件事一蹴而就,那你就要倒霉了。
Reeves 说 “如果你认为今天发布非常快,那你就什么也没有看到”,“这就是为什么要让相关者包括数据库团队进入到 DevOps 中的重要原因。因为今天这两组人员的冲突会随着发布速度的提升而呈指数级增长。”
---
via: <https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch>
作者:[Kevin Casey](https://enterprisersproject.com/user/kevin-casey) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The term “DevOps” is typically credited [to this 2008 presentation](http://www.jedi.be/presentations/agile-infrastructure-agile-2008.pdf) on agile infrastructure and operations. Now ubiquitous in IT vocabulary, the mashup word is less than 10 years old: We’re still figuring out this modern way of working in IT.
Sure, people who have been “doing DevOps” for years have accrued plenty of wisdom along the way. But most DevOps environments – and the mix of people and [culture](https://enterprisersproject.com/article/2017/9/5-ways-nurture-devops-culture), process and methodology, and tools and technology – are far from mature.
More change is coming. That’s kind of the whole point. “DevOps is a process, an algorithm,” says Robert Reeves, CTO at [Datical](https://www.datical.com/). “Its entire purpose is to change and evolve over time.”
What should we expect next? Here are some key trends to watch, according to DevOps experts.
## 1. Expect increasing interdependence between DevOps, containers, and microservices
The forces driving the proliferation of DevOps culture themselves may evolve. Sure, DevOps will still fundamentally knock down traditional IT silos and bottlenecks, but the reasons for doing so may become more urgent. Exhibits A & B: Growing interest in and [adoption of containers and microservices](https://enterprisersproject.com/article/2017/9/microservices-and-containers-6-things-know-start-time). The technologies pack a powerful, scalable one-two punch, best paired with planned, [ongoing management](https://enterprisersproject.com/article/2017/10/microservices-and-containers-6-management-tips-long-haul).
“One of the major factors impacting DevOps is the shift towards microservices,” says Arvind Soni, VP of product at [Netsil](https://netsil.com/), adding that containers and orchestration are enabling developers to package and deliver services at an ever-increasing pace. DevOps teams will likely be tasked with helping to fuel that pace and to manage the ongoing complexity of a scalable microservices architecture.
## 2. Expect fewer safety nets
DevOps enables teams to build software with greater speed and agility, deploying faster and more frequently, while improving quality and stability. But good IT leaders don’t typically ignore risk management, so plenty of early DevOps iterations began with safeguards and fallback positions in place. To get to the next level of speed and agility, more teams will take off their training wheels.
“As teams mature, they may decide that some of the guard rails that were added early on may not be required anymore,” says Nic Grange, CTO of [Retriever Communications](http://retrievercommunications.com/). Grange gives the example of a staging server: As DevOps teams mature, they may decide it’s no longer necessary, especially if they’re rarely catching issues in that pre-production environment. (Grange points out that this move isn’t advisable for inexperienced teams.)
“The team may be at a point where it is confident enough with its monitoring and ability to identify and resolve issues in production,” Grange says. “The process of deploying and testing in staging may just be slowing them down without any demonstrable value.”
## 3. Expect DevOps to spread elsewhere
DevOps brings two traditional IT groups, development and operations, into much closer alignment. As more companies see the benefits in the trenches, the culture is likely to spread. It’s already happening in some organizations, evident in the increasing appearance of the term “DevSecOps,” which reflects the intentional and much earlier inclusion of security in the software development lifecycle.
“DevSecOps is not only tools, it is integrating a security mindset into development practices early on,” says Derek Weeks, VP and DevOps advocate at [Sonatype](https://www.sonatype.com/).
Doing that isn’t a technology challenge, it’s a cultural challenge, says [Red Hat](https://www.redhat.com/en/) security strategist Kirsten Newcomer.
“Security teams have historically been isolated from development teams – and each team has developed deep expertise in different areas of IT,” Newcomer says. “It doesn’t need to be this way. Enterprises that care deeply about security and also care deeply about their ability to quickly deliver business value through software are finding ways to move security left in their application development lifecycles. They’re adopting DevSecOps by integrating security practices, tooling, and automation throughout the CI/CD pipeline. To do this well, they’re integrating their teams – security professionals are embedded with application development teams from inception (design) through to production deployment. Both sides are seeing the value – each team expands their skill sets and knowledge base, making them more valuable technologists. DevOps done right – or DevSecOps – improves IT security.”
Beyond security, look for DevOps expansion into areas such as database teams, QA, and even potentially outside of IT altogether.
“This is a very DevOps thing to do: Identify areas of friction and resolve them,” Datical’s Reeves says. “Security and databases are currently the big bottlenecks for companies that have previously adopted DevOps.”
## 4. Expect ROI to increase
As companies get deeper into their DevOps work, IT teams will be able to show greater return on investment in methodologies, processes, containers, and microservices, says Eric Schabell, global technology evangelist director, Red Hat. “The Holy Grail was to be moving faster, accomplishing more and becoming flexible. As these components find broader adoption and organizations become more vested in their application the results shall appear,” Schabell says.
“Everything has a learning curve with a peak of excitement as the emerging technologies gain our attention, but also go through a trough of disillusionment when the realization hits that applying it all is hard. Finally, we’ll start to see a climb out of the trough and reap the benefits that we’ve been chasing with DevOps, containers, and microservices.”
## 5. Expect success metrics to keep evolving
“I believe that two of the core tenets of the DevOps culture, automation and measurement, are never ‘done,’” says Mike Kail, CTO at [CYBRIC](https://www.cybric.io/) and former CIO at Yahoo. “There will always be opportunities to automate a task or improve upon an already automated solution, and what is important to measure will likely change and expand over time. This maturation process is a continuous journey, not a destination or completed task.”
In the spirit of DevOps, that maturation and learning will also depend on collaboration and sharing. Kail thinks it’s still very much early days for Agile methodologies and DevOps culture, and that means plenty of room for growth.
“As more mature organizations continue to measure actionable metrics, I believe – [I] hope – that those learnings will be broadly shared so we can all learn and improve from them,” Kail says.
As Red Hat technology evangelist [Gordon Haff](https://enterprisersproject.com/user/122076) recently noted, organizations working hard to improve their DevOps metrics are using factors tied to business outcomes. “You probably don’t really care about how many lines of code your developers write, whether a server had a hardware failure overnight, or how comprehensive your test coverage is,” [writes Haff](https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters). “In fact, you may not even directly care about the responsiveness of your website or the rapidity of your updates. But you do care to the degree such metrics can be correlated with customers abandoning shopping carts or leaving for a competitor.”
Some examples of DevOps metrics tied to business outcomes include customer ticket volume (as an indicator of overall customer satisfaction) and Net Promoter Score (the willingness of customers to recommend a company’s products or services). For more on this topic, see his full article, [DevOps metrics: Are you measuring what matters? ](https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters)
## No rest for the speedy
By the way, if you were hoping things would get a little more leisurely anytime soon, you’re out of luck.
“If you think releases are fast today, you ain’t seen nothing yet,” Reeves says. “That’s why bringing all stakeholders, including security and database teams, into the DevOps tent is so crucial. The friction caused by these two groups today will only grow as releases increase exponentially.”
## Comments
At present most of the multinational companies are desired at attaining the best working infrastructure, the best working environment and the best methodologies for attaining the most out of the automation technology. DevOps is one such technology that has all the necessary functionalities that can fulfill all the desiring aspects of any industrial organization. Further, the benefits of effective implementation of DevOps strategies are quite profiting.
<a href="http://www.orienit.com/courses/devops-training-in-hyderabad" target="_blank">DevOps Training in Hyderabad</a>
One thing I hear all the time is Agile is a Methodology. IT's not ! even the founders tell people its Not a true Methodology. So please refer to it correctly, as its a insult to the founder's like: among others Jeff Sutherland, Ken Schwaber, and Alistair Cockburnand all of us knows it a Philosophy / Framework. People only think its a Methodology, because you all call it one and its NOT! But don't just take my word for it, here you go: https://agilescout.com/agile-is-not-a-methodology/ |
9,692 | 四个 Linux 上的网络信息嗅探工具 | https://www.linux.com/learn/intro-to-linux/2018/1/4-tools-network-snooping-linux | 2018-05-30T05:19:00 | [
"嗅探"
] | https://linux.cn/article-9692-1.html | 
在计算机网络中,数据是暴露的,因为数据包传输是无法隐藏的,所以让我们来使用 `whois`、`dig`、`nmcli` 和 `nmap` 这四个工具来嗅探网络吧。
请注意,不要在不属于自己的网络上运行 `nmap` ,因为这有可能会被其他人认为恶意攻击。
### 精简和详细域名信息查询
您可能已经注意到,之前我们用常用的老式 `whois` 命令查询域名信息,但现如今似乎没有提供同过去一样的详细程度。我们使用该命令查询 linux.com 的域名描述信息:
```
$ whois linux.com
Domain Name: LINUX.COM
Registry Domain ID: 4245540_DOMAIN_COM-VRSN
Registrar WHOIS Server: whois.namecheap.com
Registrar URL: http://www.namecheap.com
Updated Date: 2018-01-10T12:26:50Z
Creation Date: 1994-06-02T04:00:00Z
Registry Expiry Date: 2018-06-01T04:00:00Z
Registrar: NameCheap Inc.
Registrar IANA ID: 1068
Registrar Abuse Contact Email: [email protected]
Registrar Abuse Contact Phone: +1.6613102107
Domain Status: ok https://icann.org/epp#ok
Name Server: NS5.DNSMADEEASY.COM
Name Server: NS6.DNSMADEEASY.COM
Name Server: NS7.DNSMADEEASY.COM
DNSSEC: unsigned
[...]
```
有很多令人讨厌的法律声明。但在哪有联系信息呢?该网站位于 `whois.namecheap.com` 站点上(见上面输出的第三行):
```
$ whois -h whois.namecheap.com linux.com
```
我就不复制出来了,因为这实在太长了,包含了注册人,管理员和技术人员的联系信息。怎么回事啊,露西尔?(LCTT 译注:《行尸走肉》中尼根的棒子)有一些注册库,比如 .com 和 .net 是精简注册库,保存了一部分有限的域名信息。为了获取完整信息请使用 `-h` 或 `--host` 参数,该参数便会从域名的 `注册服务机构` 中获取。
大部分顶级域名是有详细的注册信息,如 .info。试着使用 `whois blockchain.info` 命令来查看。
想要摆脱这些烦人的法律声明?使用 `-H` 参数。
### DNS 解析
使用 `dig` 命令比较从不同的域名服务器返回的查询结果,去除陈旧的信息。域名服务器记录缓存各地的解析信息,并且不同的域名服务器有不同的刷新间隔。以下是一个简单的用法:
```
$ dig linux.com
<<>> DiG 9.10.3-P4-Ubuntu <<>> linux.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<<- opcode: QUERY, status: NOERROR, id: 13694
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1440
;; QUESTION SECTION:
;linux.com. IN A
;; ANSWER SECTION:
linux.com. 10800 IN A 151.101.129.5
linux.com. 10800 IN A 151.101.65.5
linux.com. 10800 IN A 151.101.1.5
linux.com. 10800 IN A 151.101.193.5
;; Query time: 92 msec
;; SERVER: 127.0.1.1#53(127.0.1.1)
;; WHEN: Tue Jan 16 15:17:04 PST 2018
;; MSG SIZE rcvd: 102
```
注意下靠近末尾的这行信息:`SERVER: 127.0.1.1#53(127.0.1.1)`,这是您默认的缓存解析器。当地址是本地时,就表明您的电脑上安装了 DNS 服务。在我看来这就是一个 Dnsmasq 工具(LCTT 译注:是一个小巧且方便地用于配置 DNS 和 DHCP 的工具),该工具被用作网络管理:
```
$ ps ax|grep dnsmasq
2842 ? S 0:00 /usr/sbin/dnsmasq --no-resolv --keep-in-foreground
--no-hosts --bind-interfaces --pid-file=/var/run/NetworkManager/dnsmasq.pid
--listen-address=127.0.1.1
```
`dig` 命令默认是返回 A 记录,也就是域名。IPv6 则有 AAAA 记录:
```
$ $ dig linux.com AAAA
[...]
;; ANSWER SECTION:
linux.com. 60 IN AAAA 64:ff9b::9765:105
linux.com. 60 IN AAAA 64:ff9b::9765:4105
linux.com. 60 IN AAAA 64:ff9b::9765:8105
linux.com. 60 IN AAAA 64:ff9b::9765:c105
[...]
```
仔细检查下,发现 linux.com 有 IPv6 地址。很好!如果您的网络服务支持 IPv6 那么您就可以用 IPv6 连接。(令人难过的是,我的移动宽带则没提供 IPv6)
假设您能对您的域名做一些 DNS 改变,又或是您使用 `dig` 查询的结果有误。试着用一个公共 DNS,如 OpenNIC:
```
$ dig @69.195.152.204 linux.com
[...]
;; Query time: 231 msec
;; SERVER: 69.195.152.204#53(69.195.152.204)
```
`dig` 回应您正在的查询是来自 69.195.152.204。您可以查询各种服务并且比较结果。
### 上游域名服务器
我想知道我的上游域名服务器(LCTT 译注:此处指解析器)是谁。为了查询,我首先看下 `/etc/resolv/conf` 的配置信息:
```
$ cat /etc/resolv.conf
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
nameserver 127.0.1.1
```
好吧,不过我已经知道了。您的 Linux 发行版可能配置不同,您会看到您的上游服务器。接下来我们来试试网络管理器命令行工具 `nmcli`:
```
$ nmcli dev show | grep DNS
IP4.DNS[1]: 192.168.1.1
```
很好,现在我们已经知道了,其实那是我的移动热点,我能确认。我能够登录到简易管理面板,来查询上游服务器。然而许多用户级互联网网关不会让您看到或改变这些设置,因此只能尝试其他的方法,如 [我的域名服务器是什么?](http://www.whatsmydnsserver.com/)
### 查找在您的网络中 IPv4 地址
您的网络上有哪些 IPv4 地址已启用并正在使用中?
```
$ nmap -sn 192.168.1.0/24
Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 14:03 PST
Nmap scan report for Mobile.Hotspot (192.168.1.1)
Host is up (0.011s latency).
Nmap scan report for studio (192.168.1.2)
Host is up (0.000071s latency).
Nmap scan report for nellybly (192.168.1.3)
Host is up (0.015s latency)
Nmap done: 256 IP addresses (2 hosts up) scanned in 2.23 seconds
```
每个人都想去扫描自己的局域网中开放的端口。下面的例子是寻找服务和他们的版本号:
```
$ nmap -sV 192.168.1.1/24
Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 16:46 PST
Nmap scan report for Mobile.Hotspot (192.168.1.1)
Host is up (0.0071s latency).
Not shown: 997 closed ports
PORT STATE SERVICE VERSION
22/tcp filtered ssh
53/tcp open domain dnsmasq 2.55
80/tcp open http GoAhead WebServer 2.5.0
Nmap scan report for studio (192.168.1.102)
Host is up (0.000087s latency).
Not shown: 998 closed ports
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 7.2p2 Ubuntu 4ubuntu2.2 (Ubuntu Linux; protocol 2.0)
631/tcp open ipp CUPS 2.1
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 256 IP addresses (2 hosts up) scanned in 11.65 seconds
```
这些是有趣的结果。让我们尝试从不同的互联网连接进行相同的操作,以查看这些服务是否暴露于互联网中。如果您有智能手机,相当于您有第二个网络。您可以下载应用程序,还可以为您的 Linux 电脑提供热点。从热点控制面板获取广域网IP地址,然后重试:
```
$ nmap -sV 12.34.56.78
Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 17:05 PST
Nmap scan report for 12.34.56.78
Host is up (0.0061s latency).
All 1000 scanned ports on 12.34.56.78 are closed
```
果然不出所料,结果和我想象的一样(LCTT 译注:这些服务和信息没有被暴露在公网上)。可以用手册来查询这些命令,以便了解更多有趣的嗅探技术。
了解更多 Linux 的相关知识可以从 Linux 基金会和 edX(LCTT译注:edX 是麻省理工和哈佛大学于 2012 年 4 月联手创建的大规模开放在线课堂平台)中获取免费的 [“介绍 Linux”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)课程。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/1/4-tools-network-snooping-linux>
作者:[Carla Schroder](https://www.linux.com/users/cschroder) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,693 | 如何在 Linux 中安装 Ncurses 库 | https://www.ostechnix.com/how-to-install-ncurses-library-in-linux/ | 2018-05-30T05:25:55 | [
"Ncurses"
] | https://linux.cn/article-9693-1.html | 
**GNU Ncurses** 是一个允许用户编写基于文本的用户界面(TUI)的编程库。许多基于文本的游戏都是使用这个库创建的。一个受欢迎的例子是 [PacVim](https://www.ostechnix.com/pacvim-a-cli-game-to-learn-vim-commands/),这是一款学习 VIM 命令的 CLI 游戏。在这篇简要的指南中,我将解释如何在类 Unix 操作系统中安装 Ncurses 库。
### 在 Linux 中安装 Ncurses 库
Ncurses 在大多数 Linux 发行版的默认仓库中都有。例如,你可以使用以下命令将其安装在基于 Arch 的系统上:
```
$ sudo pacman -S ncurses
```
在RHEL、CentOS 上:
```
$ sudo yum install ncurses-devel
```
在 Fedora 22 和更新版本上:
```
$ sudo dnf install ncurses-devel
```
在 Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt-get install libncurses5-dev libncursesw5-dev
```
默认仓库中的 GNU ncureses 可能有点老了。如果你想要最新的稳定版本,可以从源代码进行编译和安装,如下所示。
从[这里](https://ftp.gnu.org/pub/gnu/ncurses/)下载最新的 ncurses 版本。在写这篇文章时,最新版本是 6.1。
```
$ wget https://ftp.gnu.org/pub/gnu/ncurses/ncurses-6.1.tar.gz
```
解压 tar 文件:
```
$ tar xzf ncurses-6.1.tar.gz
```
这将在当前目录中创建一个名为 ncurses-6.1 的文件夹。cd 到该目录:
```
$ cd ncurses-6.1
$ ./configure --prefix=/opt/ncurses
```
最后,使用以下命令进行编译和安装:
```
$ make
$ sudo make install
```
使用命令验证安装:
```
$ ls -la /opt/ncurses
```
就是这样。Ncurses 已经安装在 Linux 发行版上。继续使用 Ncurses 创建漂亮的 TUI。
还会有更多的好东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-install-ncurses-library-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,694 | 你应该知道关于 Ubuntu 18.04 的一些事 | https://itsfoss.com/ubuntu-18-04-faq/ | 2018-05-30T05:38:14 | [
"Ubuntu"
] | https://linux.cn/article-9694-1.html | [Ubuntu 18.04 版本](/article-9583-1.html) 已经到来。我可以在各种 Facebook 群组和论坛中看到许多来自 Ubuntu 用户的提问。我还在 Facebook 和 Instagram 上组织了 Q&A 会议,以了解 Ubuntu 用户对 Ubuntu 18.04 的想法。
我试图在这里回答关于 Ubuntu 18.04 的常见问题。如果您有任何疑问,我希望这能帮助您解决疑问。如果您仍有问题,请随时在下面的评论区提问。
### Ubuntu 18.04 中有什么值得期待

解释一下,这里的一些问答会受到我个人的影响。如果您是一位经验丰富或了解 Ubuntu 的用户,其中一些问题可能对您而言很简单。如果是这样的话,就请忽略这些问题。
#### 我能够在 Ubuntu 18.04 中安装 Unity 吗?
当然能够哦!
Canonical 公司知道有些人喜欢 Unity。这就是为什么它已经在 Universe 软件库(LCTT译者注:社区维护的软件库)中提供了 Unity 7。但这是一个社区维护版,官方并不直接参与开发。
不过我建议是使用默认的 GNOME,除非您真的无法容忍它,再在 [Ubuntu 18.04 上安装 Unity](https://itsfoss.com/use-unity-ubuntu-17-10/)。
#### GNOME 是什么版本?
在这次发行的 Ubuntu 18.04 版本中,GNOME 版本号是 3.28。
#### 我能够安装原装的 GNOME 吗?
当然没问题!
因为存在一些 GNOME 用户可能不喜欢 Ubuntu 18.04 中的 Unity 风格。在 Ubuntu 中的 main(LCTT译者注:官方支持的软件库)和 universe 软件库有安装包可安装,能使您在 [Ubuntu 18.04 中安装原装的 GNOME](https://itsfoss.com/vanilla-gnome-ubuntu/)。
#### GNOME 中的内存泄漏已修复了吗?
已经修复了。[GNOME 3.28 中臭名昭着的内存泄漏](https://feaneron.com/2018/04/20/the-infamous-gnome-shell-memory-leak/) 已经被修复了,并且 [Ubuntu 官方已经在测试这个修复程序](https://community.ubuntu.com/t/help-test-memory-leak-fixes-in-18-04-lts/5251)。
澄清一点,内存泄漏不是由 Ubuntu 系统引起的。它影响了所有使用 GNOME 3.28 的 Linux 发行版。GNOME 3.28.1 发布了一个新的补丁修复内存泄漏问题。
#### Ubuntu 18.04 将会被支持多久?
这是一个长期支持(LTS)版本,与任何 LTS 版本一样,官方会支持五年。这意味着 Ubuntu 18.04 将在 2023 年 4 月之前能获得安全和维护更新。这对于除 Ubuntu Studio 之外的所有基于 Ubuntu 的 Linux 发行版也一样。
#### Ubuntu 18.04 什么时候发布的?
Ubuntu 18.04 LTS 在 4 月 26 日发布。 所有基于 Ubuntu 的 Linux 发行版,如 Kubuntu、Lubuntu、Xubuntu、Budgie、MATE 等都会在同一天发布其 18.04 版本。
不过 [Ubuntu Studio 不会有 18.04 的 LTS 版本](https://www.omgubuntu.co.uk/2018/04/ubuntu-studio-plans-to-reboot)。
#### 是否能从 16.04/17.10 升级到 Ubuntu 18.04?我可以从使用 Unity 的 Ubuntu 16.04 升级到使用 GNOME 的 Ubuntu 18.04 吗?
绝对没问题。当 Ubuntu 18.04 LTS 发布后,您可以很容易的升级到最新版。
如果您使用的是 Ubuntu 17.10,请确保在“软件和更新”->“更新”中,将“有新版本时通知我”设置为“适用任何新版本”。

如果您使用的是 Ubuntu 16.04,请确保在“软件和更新”->“更新”中,将“有新版本时通知我”设置为“适用长期支持版本”。

然后您应该能获得有关新版本更新的系统通知。之后,升级到 Ubuntu 18.04 只需要点击几下鼠标而已。
即使 Ubuntu 16.04 使用的是 Unity,但您仍然可以 [升级到使用 GNOME 的 Ubuntu 18.04](https://itsfoss.com/upgrade-ubuntu-version/)。
#### 升级到 Ubuntu 18.04 意味着什么?我会丢失数据吗?
如果您使用的是 Ubuntu 17.10 或 Ubuntu 16.04,系统会提示您可升级到 Ubuntu 18.04。如果您从互联网上下载 1.5 Gb 的数据不成问题,则只需点击几下鼠标,即可在 30 分钟内升级到 Ubuntu 18.04。
您不需要通过 U 盘来重装系统。升级过程完成后,您将可以使用新的 Ubuntu 版本。
通常,您的数据和文档等在升级过程中是安全的。但是,对重要文档进行备份始终是一个好的习惯。
#### 我什么时候能升级到 Ubuntu 18.04?
如果您使用的是 Ubuntu 17.10 并且正确设置(设置方法在之前提到的问题中),那么在 Ubuntu 18.04 发布的几天内应该会通知您升级到 Ubuntu 18.04。为避免 Ubuntu 服务器在发布时的负载量过大,因此不是每个人都会在同一天收到升级提示。
对于 Ubuntu 16.04 用户,可能需要几周时间才能正式收到 Ubuntu 18.04 升级提示。通常,这将在第一次发布 Ubuntu 18.04.1 之后提示。该版本修复了 18.04 中发现的新 bug。
#### 如果我升级到 Ubuntu 18.04,我可以降级到 17.10/16.04?
抱歉,并不行。尽管升级到新版本很容易,但没有降级的选项。如果您想回到 Ubuntu 16.04,只能重新安装。
#### 我能使用 Ubuntu 18.04 在 32 位系统上吗?
可以,但最好不要这样做。
如果您已经在使用 32 位版本的 Ubuntu 16.04 或 17.10,您依旧可以升级到 Ubuntu 18.04。 但是,您找到不到 32 位的 Ubuntu 18.04 ISO 镜像。换句话说,您无法安装 32 位版本的 Ubuntu 18.04。
有一个好消息是,Ubuntu MATE、Lubuntu 等其他官方版本仍然具有其新版本的 32 位 ISO 镜像。
无论如何,如果您使用一个 32 位系统,那么很可能您的计算机硬件性能过低。在这样的电脑上使用轻量级 [Ubuntu MATE](https://ubuntu-mate.org/) 或 [Lubuntu](https://lubuntu.net/) 系统会更好。
#### 我可以在哪下载 Ubuntu 18.04?
18.04 已经发布了,您可以从其网站获得 Ubuntu 18.04 的 ISO 镜像。您既可以直接官网下载,也能用种子下载。其他官方版本将在其官方网站上提供下载。
#### 我应该重新安装 Ubuntu 18.04 还是从 16.04/17.10 升级上来?
如果您有重新安装的机会,建议备份您的数据并重新安装 Ubuntu 18.04。
从现有版本升级到 18.04 是一个方便的选择。不过,就我个人而言,它仍然保留了旧版本的依赖包。重新安装还是比较干净。
#### 对于重新安装来说,我应该安装 Ubuntu 16.04 还是 Ubuntu 18.04?
如果您要在计算机上安装 Ubuntu,请尽量使用 Ubuntu 18.04 而不是 16.04。
他们都是长期支持版本,并被支持很长一段时间。Ubuntu 16.04 会获得维护和安全更新服务直到 2021 年,而 18.04 则会到 2023 年。
不过,我建议您使用 Ubuntu 18.04。任何 LTS 版本都会在 [一段时间内获得硬件更新支持](https://www.ubuntu.com/info/release-end-of-life)(我认为是两年半的时间内)。之后,它只获得维护更新。如果您有更新的硬件,您将在 18.04 获得更好的支持。
此外,许多应用程序开发人员将很快开始关注 Ubuntu 18.04。新创建的 PPA 可能仅在几个月内支持 18.04。所以使用 18.04 比 16.04 更好。
#### 安装打印机-扫描仪驱动程序比使用 CLI 安装会更容易吗?
在打印机方面,我不是专家,所以我的观点是基于我在这方面有限的知识。大多数新打印机都支持 [IPP协议](https://www.pwg.org/ipp/everywhere.html),因此它们应该在 Ubuntu 18.04 中能够获到很好的支持。 然而对较旧的打印机我则无法保证。
#### Ubuntu 18.04 是否对 Realtek 和其他 WiFi 适配器有更好的支持?
抱歉,没有关于这部分的具体信息。
#### Ubuntu 18.04 的系统要求?
对于默认的 GNOME 版本,最好您应该有 [4 GB 的内存以便正常使用](https://help.ubuntu.com/community/Installation/SystemRequirements)。使用过去 8 年中发布的处理器也可以运行。但任何比这性能更差的硬件建议使用 [轻量级 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/),例如 [Lubuntu](https://lubuntu.net/)。
#### 有关 Ubuntu 18.04 的其问题?
如果还有其他疑问,请随时在下方评论区留言。如果您认为应将其他信息添加到列表中,请告诉我。
(LCTT 译注:本文原文写于 Ubuntu 18.04 LTS 发布之前,译文翻译于发布之后,因此对部分内容做了修改。)
---
via: <https://itsfoss.com/ubuntu-18-04-faq/>
作者:[Abhishek Prakash](http://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Ubuntu 18.04 has been released](https://itsfoss.com/ubuntu-18-04-release-features/). I see lots of questions about Ubuntu 18.04 from Linux users in various Facebook groups and forums.
I have tried to answer those frequently asked questions about Ubuntu 18.04 here. I hope it helps clear your doubts if you had any. And if you still have questions, feel free to ask in the comment section below.
## Ubuntu 18.04: Your Questions Answered

Just for clarification, some of the answers here are influenced by my personal opinion. If you are an experienced/aware Ubuntu user, some of the questions may sound *silly* to you. If that’s case, just ignore those questions.
### When will Ubuntu 18.04 be released?
Ubuntu 18.04 LTS has been released on 26th April. All the participating flavors like Kubuntu, Lubuntu, Xubuntu, Budgie, MATE etc will have their 18.04 release available on the same day.
It seems [Ubuntu Studio will not have 18.04 as LTS release](https://www.omgubuntu.co.uk/2018/04/ubuntu-studio-plans-to-reboot).
### What are the system requirements for Ubuntu 18.04?
For the default GNOME version, you should have a minimum 2GB RAM and 25 GB hard disk. However, I would advise having [4 GB of RAM for a comfortable use](https://help.ubuntu.com/community/Installation/SystemRequirements).
A processor released in last 8 years will work as well. Anything older than that should use a [lightweight Linux distribution](https://itsfoss.com/lightweight-linux-beginners/) such as [Lubuntu](https://lubuntu.net/).
### Can I use Ubuntu 18.04 on 32-bit systems?
Yes and no.
If you are already using the 32-bit version of Ubuntu 16.04 or 17.10, you may still get to upgrade to Ubuntu 18.04. However, you won’t find Ubuntu 18.04 bit ISO in 32-bit format anymore. In other words, you cannot do a fresh install of the 32-bit version of Ubuntu 18.04 GNOME.
The good news here is that other official flavors like Ubuntu MATE, Lubuntu etc still have the 32-bit ISO of their new versions.
In any case, if you have a 32-bit system, chances are that your system is weak on hardware. You’ll be better off using lightweight [Ubuntu MATE](https://ubuntu-mate.org/) or [Lubuntu](https://lubuntu.net/) on such system.
### Where can I download Ubuntu 18.04?
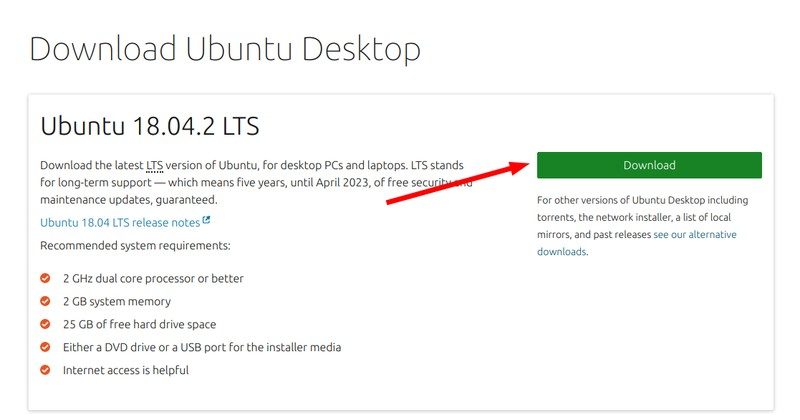
You can get the ISO image of Ubuntu 18.04 GNOME from its website. You have both direct download and torrent options. Other official flavors will be available on their official websites.
### Can I download Ubuntu 18.04 via torrent?
Yes. you can. If you have an inconsistent or slow internet, you can download Ubuntu ISO image via torrent as well. Just go to the Ubuntu download page and look for alternative downloads. Scroll down a bit and you’ll see the torrent options.
For your comfort, I have provided the link to the alternative downloads (i.e. torrents) page here.
### Do I have to pay for Ubuntu or purchase a license?
No, Ubuntu is completely free to use. You don’t have to buy a license key or activate Ubuntu like you do in Windows.
The download section of Ubuntu requests you to donate some money but it’s up to you if you want to give some money for developing this awesome operating system.
### Can I install Unity on Ubuntu 18.04?
Yes, you can.
Canonical knows that there are people who simply loved Unity. This is why it has made Unity 7 available in the Universe repository. This is a community maintained edition and Ubuntu doesn’t develop it directly.
I advise using the default GNOME first and if you really cannot tolerate it, then go on [installing Unity on Ubuntu 18.04](https://itsfoss.com/use-unity-ubuntu-17-10/).
### What GNOME version does it have?
At the time of its release, Ubuntu 18.04 has GNOME 3.28.
### Can I install vanilla GNOME on it?
Yes, you can.
Existing GNOME users might not like the Unity resembling, customized GNOME desktop in Ubuntu 18.04. There are some packages available in Ubuntu’s main and universe repositories that allows you to [install vanilla GNOME on Ubuntu 18.04](https://itsfoss.com/vanilla-gnome-ubuntu/).
### Has the memory leak in GNOME fixed?
Yes. The [infamous memory leak in GNOME 3.28](https://feaneron.com/2018/04/20/the-infamous-gnome-shell-memory-leak/) has been fixed and [Ubuntu is already testing the fix](https://community.ubuntu.com/t/help-test-memory-leak-fixes-in-18-04-lts/5251).
Just to clarify, the memory leak was not caused by Ubuntu. It was/is impacting all Linux distributions that use GNOME 3.28. A new patch was released under GNOME 3.28.1 to fix this memory leak.
### How long will Ubuntu 18.04 be supported?
It is a long-term support (LTS) release and like any LTS release, it will be supported for five years. Which means that Ubuntu 18.04 will get security and maintenance updates until April 2023. This is also true for all participating flavors except Ubuntu Studio.
### Is it possible to upgrade to Ubuntu 18.04 from 16.04/17.10? Can I upgrade from Ubuntu 16.04 with Unity to Ubuntu 18.04 with GNOME?
Yes, absolutely. Once Ubuntu 18.04 LTS is released, you can easily upgrade to the new version.
If you are using Ubuntu 17.10, make sure that in Software & Updates -> Updates, the ‘Notify me of a new Ubuntu version’ is set to ‘For any new version’.
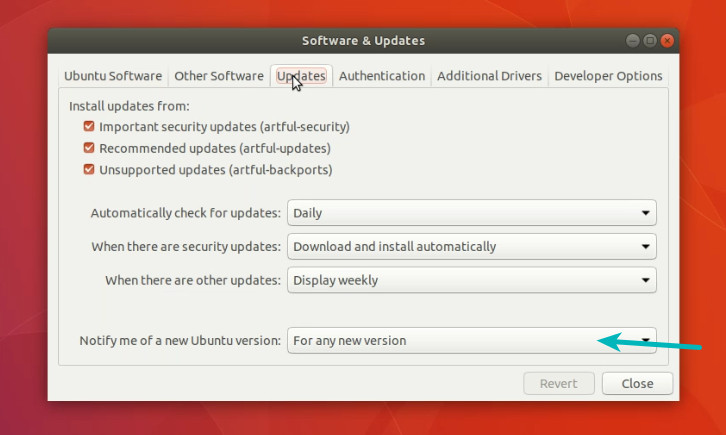
If you are using Ubuntu 16.04, make sure that in Software & Updates -> Updates, the ‘Notify me of a new Ubuntu version’ is set to ‘For long-term support versions’.
You should get system notification about the availability of the new versions. After that, upgrading to Ubuntu 18.04 is a matter of clicks.
Even if Ubuntu 16.04 was Unity, you can still [upgrade to Ubuntu 18.04](https://itsfoss.com/upgrade-ubuntu-version/) GNOME.
### What does upgrading to Ubuntu 18.04 mean? Will I lose my data?
If you are using Ubuntu 17.10 or Ubuntu 16.04, sooner or later, Ubuntu will notify you that Ubuntu 18.04 is available. If you have a good internet connection that can download 1.5 Gb of data, you can upgrade to Ubuntu 18.04 in a few clicks and in under 30 minutes.
You don’t need to create a new USB and do a fresh install. Once the upgrade procedure finishes, you’ll have the new Ubuntu version available.
Normally, your data, documents etc are safe in the upgrade procedure. However, keeping a backup of your important documents is always a good idea.
### When will I get to upgrade to Ubuntu 18.04?
If you are using Ubuntu 17.10 and have correct update settings in place (as mentioned in the previous section), you should be notified for upgrading to Ubuntu 18.04 within a few days of Ubuntu 18.04 release.
For Ubuntu 16.04 users, it may take some weeks before they are officially notified of the availability of Ubuntu 18.04. Usually, this will happen after the first point release Ubuntu 18.04.1. This point release fixes the newly discovered bugs in 18.04.
### If I upgrade to Ubuntu 18.04 can I downgrade to 17.10 or 16.04?
No, you cannot. While upgrading to the newer version is easy, there is no option to downgrade. If you want to go back to Ubuntu 16.04, you’ll have to do a fresh install.
### Should I do a fresh install of Ubuntu 18.04 or upgrade to it from 16.04/17.10?
If you have a choice, make a backup of your data and do a fresh install of Ubuntu 18.04.
Upgrading to 18.04 from an existing version is a convenient option. However, in my opinion, it still keeps some traces/packages of the older version. A fresh install is always cleaner.
For a fresh install, should I install Ubuntu 16.04 or Ubuntu 18.04?
If you are going to install Ubuntu on a system, go for Ubuntu 18.04 instead of 16.04.
Both of them are long-term support release and will be supported for a long time. Ubuntu 16.04 will get maintenance and security updates until 2021 and 18.04 until 2023.
However, I would suggest that you use Ubuntu 18.04. Any LTS release gets [hardware updates for a limited time](https://www.ubuntu.com/info/release-end-of-life) (two and a half years I think). After that, it only gets maintenance updates. If you have newer hardware, you’ll get better support in 18.04.
Also, many application developers will start focusing on Ubuntu 18.04 soon. Newly created PPAs might only support 18.04 in a few months. Using 18.04 has its advantages over 16.04.
### Will it be easier to install printer-scanner drivers instead of using the CLI?
I am not an expert when it comes to printers so my opinion is based on my limited knowledge in this field. Most of the new printers support [IPP protocol](https://www.pwg.org/ipp/everywhere.html) and thus they should be well supported in Ubuntu 18.04. I cannot say the same about older printers.
### Does Ubuntu 18.04 have better support for Realtek and other WiFi adapters?
No specific information on this part.
### Any other questions about Ubuntu 18.04?
If you have any other doubts regarding Ubuntu 18.04, please feel free to leave a comment below. If you think some other information should be added to the list, please let me know. |
9,695 | 微服务 vs. 整体服务:如何选择 | https://opensource.com/article/18/1/how-choose-between-monolith-microservices | 2018-05-30T05:58:08 | [
"架构",
"微服务"
] | https://linux.cn/article-9695-1.html |
>
> 任何一种架构都是有利有弊的,而能满足你组织的独特需要的决策才是正确的选择。
>
>
>

对于许多初创公司来说,传统的知识认为,从单一整体架构开始,而不是使用微服务。但是,我们还有别的选择吗?
这本新书 —— 《[初创公司的微服务](https://buttercms.com/books/microservices-for-startups/)》,从许多 CIO 们理解的微服务的角度,解释了微服务的优点与缺点。
对于初创公司,虽然不同的 CTO 对此给出的建议是不同的,但是他们都一致认为环境和性能很重要。如果你正考虑你的业务到底是采用微服务还是单一整体架构更好,下面讨论的这些因素正好可以为你提供一些参考。
### 理解范围
首先,我们先来准确定义我们所谓的 “整体服务” 和 “微服务” 是什么。
微服务是一种方法,它开发一个单一的应用程序来作为构成整体服务的小服务,每个小服务都运行在它自己的进程中,并且使用一个轻量级的机制进行通讯,通常是一个 HTTP 资源的 API。这些服务都围绕业务能力来构建,并且可依赖全自动部署机制来独立部署。
一个整体应用程序是按单个的、统一的单元来构建,并且,通常情况下它是基于一个大量的代码来实现的。一般来说,一个整体服务是由三部分组成的:数据库、客户端用户界面(由 HTML 页面和/或运行在浏览器中的 JavaScript 组成)、以及服务器端应用程序。
“系统架构处于一个范围之中”,Zachary Crockett,[Particle](https://www.particle.io/Particle) 的 CTO,在一次访谈中,他说,“在讨论微服务时,人们倾向于关注这个范围的一端:许多极小的应用程序给其它应用程序传递了过多的信息。在另一端,有一个巨大的整体服务做了太多的事情。在任何现实中的系统上,在这两个极端之间有很多合适的面向服务的架构”。
根据你的情况不同,不论是使用整体服务还是微服务都有很多很好的理由。
“我们希望为每个服务使用最好的工具”,Julien Lemoine 说,他是 Algolia 的 CTO。
与很多人的想法正好相反,整体服务并不是过去遗留下来的过时的架构。在某些情况下,整体服务是非常理想的。我采访了 Steven Czerwinski 之后,更好地理解了这一点,他是 [Scaylr](https://www.scalyr.com/) 的工程主管,前谷歌员工。
“尽管我们在谷歌时有使用微服务的一些好的经验,我们现在 [在 Scalyr] 却使用的是整体服务的架构,因为一个整体服务架构意味着我们的工作量更少,我们只有两位工程师。“ 他解释说。(采访他时,Scaylr 正处于早期阶段)
但是,如果你的团队使用微服务的经验很丰富,并且你对你们的发展方向有明确的想法,微服务可能是一个很好的替代者。
Julien Lemoine,[Algolia](https://www.algolia.com/) 的 CTO,在这个问题上,他认为:“我们通常从使用微服务开始,主要目的是我们可以使用不同的技术来构建我们的服务,因为如下的两个主要原因:
* 我们想为每个服务使用最好的工具。我们的搜索 API 是在底层做过高度优化的,而 C++ 是非常适合这项工作的。他说,在任何其它地方都使用 C++ 是一种生产力的浪费,尤其是在构建仪表板方面。
* 我们希望使用最好的人才,而只使用一种技术将极大地限制我们的选择。这就是为什么在公司中有不同语言的原因。
”
如果你的团队已经准备好从一开始就使用微服务,这样你的组织从一开始就可以适应微服务环境的开发节奏。
### 权衡利弊
在你决定那种方法更适合你的组织之前,考虑清楚每种方法的优缺点是非常重要的。
### 整体服务
#### 优点:
* **很少担心横向联系:** 大多数应用程序开发者都担心横向联系,比如,日志、速度限制、以及像审计跟踪和 DoS 防护这样的安全特性。当所有的东西都运行在同一个应用程序中时,通过组件钩子来处理这些关注点就非常容易了。
* **运营开销很少:** 只需要为一个应用程序设置日志、监视、以及测试。一般情况下,部署也相对要简单。
* **性能:** 一个整体的架构可能会有更好的性能,因为共享内存的访问速度要比进程间通讯(IPC)更快。
#### 缺点:
* **紧耦合:** 整体服务的应用程序倾向于紧耦合,并且应用程序是整体进化的,分离特定用途的服务是非常困难的,比如,独立扩展或者代码维护。
* **理解起来很困难:** 当你想查看一个特定的服务或者控制器时,因为依赖、副作用、和其它的不可预见因素,整体架构理解起来更困难。
### 微服务
#### 优点:
* **非常好组织:** 微服务架构一般很好组织它们,因为每个微服务都有一个特定的工作,并且还不用考虑其它组件的工作。
* **解耦合:** 解耦合的服务是能够非常容易地进行重组织和重配置,以服务于不同的应用程序(比如,同时向 Web 客户端和公共 API 提供服务)。它们在一个大的集成系统中,也允许快速、独立分发单个部分。
* **性能:** 根据组织的情况,微服务可以提供更好的性能,因为你可以分离热点服务,并根据其余应用程序的情况来扩展它们。
* **更少的错误:** 微服务允许系统中的不同部分,在维护良好边界的前提下进行并行开发。这样将使连接不该被连接的部分变得更困难,比如,需要连接的那些紧耦合部分。
#### 缺点:
* **跨每个服务的横向联系点:** 由于你构建了一个新的微服务架构,你可能会发现在设计时没有预料到的很多横向联系的问题。这也将导致需要每个横向联系点的独立模块(比如,测试)的开销增加,或者在其它服务层面因封装横向联系点,所导致的所有流量都需要路由。最终,即便是整体服务架构也倾向于通过横向联系点的外部服务层来路由流量,但是,如果使用整体架构,在项目更加成熟之前,也不过只是推迟了工作成本。
* **更高的运营开销:** 微服务在它所属的虚拟机或容器上部署非常频繁,导致虚拟机争用激增。这些任务都是使用容器管理工具进行频繁的自动化部署的。
### 决策时刻
当你了解了每种方法的利弊之后,如何在你的初创公司使用这些信息?通过与这些 CTO 们的访谈,这里有三个问题可以指导你的决策过程:
**你是在熟悉的领域吗?**
如果你的团队有以前的一些领域的经验(比如,电子商务)和了解你的客户需求,那么分割成微服务是低风险的。如果你从未做过这些,从另一个角度说,整体服务或许是一个更安全的选择。
**你的团队做好准备了吗?**
你的团队有使用微服务的经验吗?如果明年,你的团队扩充到现在的四倍,将为微服务提供更好的环境?评估团队大小对项目的成功是非常重要的。
**你的基础设施怎么样?**
实施微服务,你需要基于云的基础设施。
David Strauss,[Pantheon](https://pantheon.io/) 的 CTO,他解释说:"[以前],你使用整体服务是因为,你希望部署在一个数据库上。每个单个的微服务都需要配置数据库服务器,然后,扩展它将是一个很重大的任务。只有大的、技术力量雄厚的组织才能做到。现在,使用像谷歌云和亚马逊 AWS 这样的云服务,为部署一个小的东西而不需要为它们中的每个都提供持久存储,对于这种需求你有很多的选择。“
### 评估业务风险
技术力量雄厚的初创公司为追求较高的目标,可以考虑使用微服务。但是微服务可能会带来业务风险。Strauss 解释说,“许多团队一开始就过度构建他们的项目。每个人都认为,他们的公司会成为下一个 ‘独角兽’,因此,他们使用微服务构建任何一个东西,或者一些其它的高扩展性的基础设施。但是这通常是一种错误的做法”。Strauss 说,在那种情况下,他们认为需要扩大规模的领域往往并不是一开始真正需要扩展的领域,最后的结果是浪费了时间和努力。
### 态势感知
最终,环境是关键。以下是一些来自 CTO 们的提示:
#### 什么时候使用整体服务
* **你的团队还在创建阶段:** 你的团队很小 —— 也就是说,有 2 到 5 位成员 —— 还无法应对大范围、高成本的微服务架构。
* **你正在构建的是一个未经证实的产品或者概念验证:** 如果你将一个全新的产品推向市场,随着时间的推移,它有可能会成功,而对于一个快速迭代的产品,整体架构是最合适的。这个提示也同样适用于概念验证,你的目标是尽可能快地学习,即便最终你可能会放弃它。
* **你没有使用微服务的经验:** 除非你有合理的理由证明早期学习阶段的风险可控,否则,一个整体的架构更适用于一个没有经验的团队。
#### 什么时候开始使用微服务
* **你需要快速、独立的分发服务:** 微服务允许在一个大的集成系统中快速、独立分发单个部分。请注意,根据你的团队规模,获取与整体服务的比较优势,可能需要一些时间。
* **你的平台中的某些部分需要更高效:** 如果你的业务要求集中处理 PB 级别的日志卷,你可能需要使用一个像 C++ 这样的更高效的语言来构建这个服务,尽管你的用户仪表板或许还是用 [Ruby on Rails](http://rubyonrails.org/) 构建的。
* **计划扩展你的团队:** 使用微服务,将让你的团队从一开始就开发独立的小服务,而服务边界独立的团队更易于按需扩展。
要决定整体服务还是微服务更适合你的组织,要坦诚并正确认识自己的环境和能力。这将有助于你找到业务成长的最佳路径。
### 关于作者
jakelumetta - Jake 是 ButterCMS 的 CEO,它是一个 [API-first CMS](https://buttercms.com/)。他喜欢搅动出黄油双峰,以及构建让开发者工作更舒适的工具,喜欢他的更多内容,请在 Twitter 上关注 [@ButterCMS](https://twitter.com/ButterCMS),订阅 [他的博客](https://buttercms.com/blog/)。[关于他的更多信息](https://opensource.com/users/jakelumetta)……
---
via: <https://opensource.com/article/18/1/how-choose-between-monolith-microservices>
作者:[jakelumetta](https://opensource.com/users/jakelumetta) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,696 | 如何在无响应的 Linux 系统中杀掉内存消耗最大的进程 | https://www.ostechnix.com/kill-largest-process-unresponsive-linux-system/ | 2018-05-31T09:21:00 | [
"进程",
"内存",
"OOM"
] | https://linux.cn/article-9696-1.html | 
作为一名博客作者,我收藏了很多博客、网站和论坛用来寻找 Linux 和 Unix 相关的内容。有时候,我在浏览器中开启了非常多的标签页,导致操作系统会无响应好几分钟。我不能移动我的鼠标,也不能杀掉一个进程或关闭任何开启的标签页。在这种情况下,我别无选择,只能强制重启系统。当然我也用了 **OneTab** (LCTT 译注:OneTab 是一个 Chrome 的 Extension,可以将标签页转化成一个列表保存。)和 **Greate Suspender** (LCTT 译注:Great Suspender 是一个 Chrome 的 Extension, 可以自动冻结标签页)这样浏览器拓展,但它们在这里也起不到太大的作用。 我经常耗尽我的内存。而这就是 **Early OOM** 起作用的时候了。在情况严重时,它会杀掉一个未响应系统中的内存消耗最大的进程。Early OOM 每秒会检测可用内存和空余交换区 10 次,一旦两者都低于 10%,它就会把最大的进程杀死。
### 为什么用 Early OOM?为什么不用系统内置的 OOM killer?
在继续讨论下去之前,我想先简短的介绍下 OOM killer,也就是 **O**ut **O**f **M**emory killer。OOM killer 是一个由内核在可用内存非常低的时候使用的进程。它的主要任务是不断的杀死进程,直到释放出足够的内存,使内核正在运行的其它进程能顺利运行。OOM killer 会找到系统中最不重要并且能释放出最多内存的进程,然后杀掉他们。在 `/proc` 目录下的 `pid` 目录中,我们可以看到每个进程的 `oom_score`。
示例:
```
$ cat /proc/10299/oom_score
1
```
一个进程的 `oom_score` 的值越高,这个进程越有可能在系统内存耗尽的时候被 OOM killer 杀死。
Early OOM 的开发者表示,相对于内置的 OOM killer,Early OOM 有一个很大的优点。就像我之前说的那样,OOM killer 会杀掉 `oom_score` 最高的进程,而这也导致 Chrome 浏览器总是会成为第一个被杀死的进程。为了避免这种情况发生,Early OOM 使用 `/proc/*/status` 而不是 `echo f > /proc/sysrq-trigger`(LCTT 译注:这条命令会调用 OOM killer 杀死进程)。开发者还表示,手动触发 OOM killer 在最新版本的 Linux 内核中很可能不会起作用。
### 安装 Early OOM
Early OOM 在 AUR(Arch User Repository)中可以找到,所以你可以在 Arch 和它的衍生版本中使用任何 AUR 工具安装它。
使用 [Pacaur](https://www.ostechnix.com/install-pacaur-arch-linux/):
```
pacaur -S earlyoom
```
使用 [Packer](https://www.ostechnix.com/install-packer-arch-linux-2/):
```
packer -S earlyoom
```
使用 [Yaourt](https://www.ostechnix.com/install-yaourt-arch-linux/):
```
yaourt -S earlyoom
```
启用并启动 Early OOM 守护进程:
```
sudo systemctl enable earlyoom
sudo systemctl start earlyoom
```
在其它的 Linux 发行版中,可以按如下方法编译安装它:
```
git clone https://github.com/rfjakob/earlyoom.git
cd earlyoom
make
sudo make install
```
### Early OOM - 杀掉无响应 Linux 系统中的最大的进程
运行如下命令启动 Early OOM:
```
earlyoom
```
如果是通过编译源代码安装的, 运行如下命令启动 Early OOM:
```
./earlyoom
```
示例输出:
```
earlyoom 0.12
mem total: 3863 MiB, min: 386 MiB (10 %)
swap total: 2047 MiB, min: 204 MiB (10 %)
mem avail: 1770 MiB (45 %), swap free: 2047 MiB (99 %)
mem avail: 1773 MiB (45 %), swap free: 2047 MiB (99 %)
mem avail: 1772 MiB (45 %), swap free: 2047 MiB (99 %)
mem avail: 1773 MiB (45 %), swap free: 2047 MiB (99 %)
mem avail: 1772 MiB (45 %), swap free: 2047 MiB (99 %)
mem avail: 1773 MiB (45 %), swap free: 2047 MiB (99 %)
mem avail: 1771 MiB (45 %), swap free: 2047 MiB (99 %)
mem avail: 1773 MiB (45 %), swap free: 2047 MiB (99 %)
mem avail: 1784 MiB (46 %), swap free: 2047 MiB (99 %)
[...]
```
就像你在上面的输出中可以看到的,Early OOM 将会显示你有多少内存和交换区,以及有多少可用的内存和交换区。记住它会一直保持运行,直到你按下 `CTRL+C`。
如果可用的内存和交换区大小都低于 10%,Early OOM 将会自动杀死最大的进程,直到系统有足够的内存可以流畅的运行。你也可以根据你的需求配置最小百分比值。
设置最小的可用内存百分比,运行:
```
earlyoom -m <PERCENT_HERE>
```
设置最小可用交换区百分比, 运行:
```
earlyoom -s <PERCENT_HERE>
```
在帮助部分,可以看到更多详细信息:
```
$ earlyoom -h
earlyoom 0.12
Usage: earlyoom [OPTION]...
-m PERCENT set available memory minimum to PERCENT of total (default 10 %)
-s PERCENT set free swap minimum to PERCENT of total (default 10 %)
-M SIZE set available memory minimum to SIZE KiB
-S SIZE set free swap minimum to SIZE KiB
-k use kernel oom killer instead of own user-space implementation
-i user-space oom killer should ignore positive oom_score_adj values
-d enable debugging messages
-v print version information and exit
-r INTERVAL memory report interval in seconds (default 1), set to 0 to
disable completely
-p set niceness of earlyoom to -20 and oom_score_adj to -1000
-h this help text
```
现在,你再也不用担心内存消耗最高的进程了。希望这能给你帮助。更多的好内容将会到来,敬请期待。
谢谢!
---
via: <https://www.ostechnix.com/kill-largest-process-unresponsive-linux-system/>
作者:[Aditya Goturu](https://www.ostechnix.com) 译者:[cizezsy](https://github.com/cizezsy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,697 | /dev/[u]random:对熵的解释 | http://jhurani.com/linux/2017/11/01/entropy-explained.html | 2018-05-31T10:05:00 | [
"随机数"
] | https://linux.cn/article-9697-1.html | 
### 熵
当谈到 `/dev/random` 和 `/dev/urandom` 的主题时,你总是会听到这个词:“<ruby> 熵 <rt> Entropy </rt></ruby>”。每个人对此似乎都有自己的比喻。那为我呢?我喜欢将熵视为“随机果汁”。它是果汁,随机数需要它变得更随机。
如果你曾经生成过 SSL 证书或 GPG 密钥,那么可能已经看到过像下面这样的内容:
```
We need to generate a lot of random bytes. It is a good idea to perform
some other action (type on the keyboard, move the mouse, utilize the
disks) during the prime generation; this gives the random number
generator a better chance to gain enough entropy.
++++++++++..+++++.+++++++++++++++.++++++++++...+++++++++++++++...++++++
+++++++++++++++++++++++++++++.+++++..+++++.+++++.+++++++++++++++++++++++++>.
++++++++++>+++++...........................................................+++++
Not enough random bytes available. Please do some other work to give
the OS a chance to collect more entropy! (Need 290 more bytes)
```
通过在键盘上打字并移动鼠标,你可以帮助生成熵或随机果汁。
你可能会问自己……为什么我需要熵?以及为什么它对于随机数真的变得随机如此重要?那么,假设我们的熵的来源仅限于键盘、鼠标和磁盘 IO 的数据。但是我们的系统是一个服务器,所以我知道没有鼠标和键盘输入。这意味着唯一的因素是你的 IO。如果它是一个单独的、几乎不使用的磁盘,你将拥有较低的熵。这意味着你的系统随机的能力很弱。换句话说,我可以玩概率游戏,并大幅减少破解 ssh 密钥或者解密你认为是加密会话的时间。
好的,但这是很难实现的对吧?不,实际上并非如此。看看这个 [Debian OpenSSH 漏洞](http://jhurani.com/linux/2017/11/01/%22https://jblevins.org/log/ssh-vulnkey%22)。这个特定的问题是由于某人删除了一些负责添加熵的代码引起的。有传言说,他们因为它导致 valgrind 发出警告而删除了它。然而,在这样做的时候,随机数现在少了很多随机性。事实上,熵少了很多,因此暴力破解变成了一个可行的攻击向量。
希望到现在为止,我们理解了熵对安全性的重要性。无论你是否意识到你正在使用它。
### /dev/random 和 /dev/urandom
`/dev/urandom` 是一个伪随机数生成器,缺乏熵它也**不会**停止。
`/dev/random` 是一个真随机数生成器,它会在缺乏熵的时候停止。
大多数情况下,如果我们正在处理实际的事情,并且它不包含你的核心信息,那么 `/dev/urandom` 是正确的选择。否则,如果就使用 `/dev/random`,那么当系统的熵耗尽时,你的程序就会变得有趣。无论它直接失败,或只是挂起——直到它获得足够的熵,这取决于你编写的程序。
### 检查熵
那么,你有多少熵?
```
[root@testbox test]# cat /proc/sys/kernel/random/poolsize
4096
[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
2975
```
`/proc/sys/kernel/random/poolsize`,说明熵池的大小(以位为单位)。例如:在停止抽水之前我们应该储存多少随机果汁。`/proc/sys/kernel/random/entropy_avail` 是当前池中随机果汁的数量(以位为单位)。
### 我们如何影响这个数字?
这个数字可以像我们使用它一样耗尽。我可以想出的最简单的例子是将 `/dev/random` 定向到 `/dev/null` 中:
```
[root@testbox test]# cat /dev/random > /dev/null &
[1] 19058
[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
0
[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
1
```
影响这个最简单的方法是运行 [Haveged](http://www.issihosts.com/haveged/)。Haveged 是一个守护进程,它使用处理器的“抖动”将熵添加到系统熵池中。安装和基本设置非常简单。
```
[root@b08s02ur ~]# systemctl enable haveged
Created symlink from /etc/systemd/system/multi-user.target.wants/haveged.service to /usr/lib/systemd/system/haveged.service.
[root@b08s02ur ~]# systemctl start haveged
```
在流量相对中等的机器上:
```
[root@testbox ~]# pv /dev/random > /dev/null
40 B 0:00:15 [ 0 B/s] [ <=> ]
52 B 0:00:23 [ 0 B/s] [ <=> ]
58 B 0:00:25 [5.92 B/s] [ <=> ]
64 B 0:00:30 [6.03 B/s] [ <=> ]
^C
[root@testbox ~]# systemctl start haveged
[root@testbox ~]# pv /dev/random > /dev/null
7.12MiB 0:00:05 [1.43MiB/s] [ <=> ]
15.7MiB 0:00:11 [1.44MiB/s] [ <=> ]
27.2MiB 0:00:19 [1.46MiB/s] [ <=> ]
43MiB 0:00:30 [1.47MiB/s] [ <=> ]
^C
```
使用 `pv` 我们可以看到我们通过管道传递了多少数据。正如你所看到的,在运行 `haveged` 之前,我们是 2.1 位/秒(B/s)。而在开始运行 `haveged` 之后,加入处理器的抖动到我们的熵池中,我们得到大约 1.5MiB/秒。
---
via: <http://jhurani.com/linux/2017/11/01/entropy-explained.html>
作者:[James J](https://jblevins.org/log/ssh-vulnkey) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ## Entropy
When the topic of /dev/random and /dev/urandom come up, you always hear this word: “Entropy”. Everyone seems to have their own analogy for it. So why not me? I like to think of Entropy as “Random juice”. It is juice, required for random to be more random.
If you have ever generated an SSL certificate, or a GPG key, you may have seen something like:
```
We need to generate a lot of random bytes. It is a good idea to perform
some other action (type on the keyboard, move the mouse, utilize the
disks) during the prime generation; this gives the random number
generator a better chance to gain enough entropy.
++++++++++..+++++.+++++++++++++++.++++++++++...+++++++++++++++...++++++
+++++++++++++++++++++++++++++.+++++..+++++.+++++.+++++++++++++++++++++++++>.
++++++++++>+++++...........................................................+++++
Not enough random bytes available. Please do some other work to give
the OS a chance to collect more entropy! (Need 290 more bytes)
```
By typing on the keyboard, and moving the mouse, you help generate Entropy, or Random Juice.
You might be asking yourself… Why do I need Entropy? and why it is so important for random to be actually random? Well, lets say our Entropy was limited to keyboard, mouse, and disk IO. But our system is a server, so I know there is no mouse and keyboard input. This means the only factor is your IO. If it is a single disk, that was barely used, you will have low Entropy. This means your systems ability to be random is weak. In other words, I could play the probability game, and significantly decrease the amount of time it would take to crack things like your ssh keys, or decrypt what you thought was an encrypted session.
Okay, but that is pretty unrealistic right? No, actually it isn’t. Take a look at this [Debian OpenSSH Vulnerability]("https://jblevins.org/log/ssh-vulnkey"). This particular issue was caused by someone removing some of the code responsible for adding Entropy. Rumor has it they removed it because it was causing valgrind to throw warnings. However, in doing that, random is now MUCH less random. In fact, so much less that Brute forcing the private ssh keys generated is now a fesible attack vector.
Hopefully by now we understand how important Entropy is to security. Whether you realize you are using it or not.
## /dev/random & /dev/urandom
/dev/urandom is a Psuedo Random Number Generator, and it **does not** block if you run out of Entropy.
/dev/random is a True Random Number Generator, and it **does** block if you run out of Entropy.
Most often, if we are dealing with something pragmatic, and it doesn’t contain the keys to your nukes, /dev/urandom is the right choice. Otherwise if you go with /dev/random, then when the system runs out of Entropy your application is just going to behave funny. Whether it outright fails, or just hangs until it has enough depends on how you wrote your application.
## Checking the Entropy
So, how much Entropy do you have?
```
[root@testbox test]# cat /proc/sys/kernel/random/poolsize
4096
[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
2975
[root@testbox test]#
```
/proc/sys/kernel/random/poolsize, to state the obvious is the size(in bits) of the Entropy Pool. eg: How much random-juice we should save before we stop pumping more. /proc/sys/kernel/random/entropy_avail, is the amount(in bits) of random-juice in the pool currently.
## How can we influence this number?
The number is drained as we use it. The most crude example I can come up with is catting /dev/random into /dev/null:
```
[root@testbox test]# cat /dev/random > /dev/null &
[1] 19058
[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
0
[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
1
[root@testbox test]#
```
The easiest way to influence this is to run [Haveged](http://www.issihosts.com/haveged/). Haveged is a daemon that uses the processor “flutter” to add Entropy to the systems Entropy Pool.
Installation and basic setup is pretty straight forward
```
[root@b08s02ur ~]# systemctl enable haveged
Created symlink from /etc/systemd/system/multi-user.target.wants/haveged.service to /usr/lib/systemd/system/haveged.service.
[root@b08s02ur ~]# systemctl start haveged
[root@b08s02ur ~]#
```
On a machine with relatively moderate traffic:
```
[root@testbox ~]# pv /dev/random > /dev/null
40 B 0:00:15 [ 0 B/s] [ <=> ]
52 B 0:00:23 [ 0 B/s] [ <=> ]
58 B 0:00:25 [5.92 B/s] [ <=> ]
64 B 0:00:30 [6.03 B/s] [ <=> ]
^C
[root@testbox ~]# systemctl start haveged
[root@testbox ~]# pv /dev/random > /dev/null
7.12MiB 0:00:05 [1.43MiB/s] [ <=> ]
15.7MiB 0:00:11 [1.44MiB/s] [ <=> ]
27.2MiB 0:00:19 [1.46MiB/s] [ <=> ]
43MiB 0:00:30 [1.47MiB/s] [ <=> ]
^C
[root@testbox ~]#
```
Using pv we are able to see how much data we are passing via pipe. As you can see, before haveged, we were getting 2.1 bits per second(B/s). Whereas after starting haveged, and adding processor flutter to our Entropy pool we get ~1.5MiB/sec. |
9,698 | 4 个现在就该去装的 Firefox 扩展 | https://opensource.com/article/18/5/firefox-extensions | 2018-05-31T10:30:44 | [
"Firefox",
"扩展",
"浏览器"
] | https://linux.cn/article-9698-1.html |
>
> 合适的扩展能极大地增强你的浏览器功能,但是仔细的选择也是很重要的。
>
>
>

正如我在关于 Firefox 扩展的[原创文章](https://opensource.com/article/18/1/top-5-firefox-extensions)中提到的,web 浏览器已成为许多用户计算机体验的关键组件。现代浏览器已经发展成为功能强大且可扩展的平台,扩展可以添加或修改其功能。Firefox 的扩展是使用 WebExtensions API(一种跨浏览器开发系统)构建的。
在第一篇文章中,我问读者:“你应该安装哪些扩展?” 重申一下,这一决定主要取决于你如何使用浏览器,你对隐私的看法,你对扩展程序开发人员的信任程度以及其他个人偏好。自文章发表以来,我推荐的一个扩展(Xmarks)已经停止维护。另外,该文章收到了大量的反馈,在这篇更新中,这些反馈已经被考虑到。
我想再次指出,浏览器扩展通常需要能够阅读和(或)更改你访问的网页上的所有内容。你应该仔细考虑这一点。如果扩展程序修改了你访问的所有网页的访问权限,那么它可能成为键盘记录程序、拦截信用卡信息、在线跟踪、插入广告以及执行各种其他恶意活动。这并不意味着每个扩展程序都会暗中执行这些操作,但在安装任何扩展程序之前,你应该仔细考虑安装源,涉及的权限,风险配置文件以及其他因素。请记住,你可以使用配置文件来管理扩展如何影响你的攻击面 —— 例如,使用没有扩展的专用配置文件来执行网上银行等任务。
考虑到这一点,这里有你可能想要考虑的四个开源 Firefox 扩展。
### uBlock Origin

我的第一个建议保持不变。[uBlock Origin](https://addons.mozilla.org/en-US/firefox/addon/ublock-origin/) 是一款快速、低内存消耗、广泛的拦截器,它不仅可以拦截广告,而且还可以执行你自己的内容过滤。 uBlock Origin 的默认行为是使用多个预定义的过滤器列表来拦截广告、跟踪器和恶意软件站点。它允许你任意添加列表和规则,甚至可以锁定到默认拒绝模式。尽管它很强大,但它已被证明是高效和高性能的。它将继续定期更新,并且是该功能的最佳选择之一。
### Privacy Badger

我的第二个建议也保持不变。如果说有什么区别的话,那就是自从我上一篇文章发表以来,隐私问题更被关注了,这使得这个扩展成为一个简单的建议。顾名思义,[Privacy Badger](https://www.eff.org/privacybadger) 是一个专注于隐私的扩展,可以拦截广告和其他第三方跟踪器。这是电子前哨基金会基金会(EFF)的一个项目,他们说:
>
> Privacy Badger 的诞生是我们希望能够推荐一个单独的扩展,它可以自动分析和拦截任何违反用户同意原则的追踪器或广告;在用户没有任何设置、有关知识或配置的情况下,它可以很好地运行;它是由一个明确为其用户而不是为广告商工作的组织所产生的;它使用了算法的方法来决定什么被跟踪,什么没有被跟踪。”
>
>
>
为什么 Privacy Badger 会出现在这个列表上,它的功能与上一个扩展看起来很类似?因为一些原因:首先,它从根本上工作原理与 uBlock Origin 不同。其次,深度防御的实践是一项合理的策略。说到深度防御,EFF 还维护着 [HTTPS Everywhere](https://www.eff.org/https-everywhere) 扩展,它自动确保 https 用于许多主流网站。当你安装 Privacy Badger 时,你也可以考虑使用 HTTPS Everywhere。
如果你开始认为这篇文章只是对上一篇文章的重新讨论,那么以下是我的建议分歧。
### Bitwarden

在上一篇文章中推荐 LastPass 时,我提到这可能是一个有争议的选择。这无疑属实。无论你是否应该使用密码管理器 —— 如果你使用,那么是否应该选择带有浏览器插件的密码管理器 —— 这是一个备受争议的话题,答案很大程度上取决于你的个人风险状况。我认为大多数普通的计算机用户应该使用一个,因为它比最常见的选择要好得多:在任何地方都使用相同的弱密码!我仍然相信这一点。
[Bitwarden](https://bitwarden.com/) 自从我上次点评以后确实更成熟了。像 LastPass 一样,它对用户友好,支持双因素身份验证,并且相当安全。与 LastPass 不同的是,它是[开源的](https://github.com/bitwarden)。它可以使用或不使用浏览器插件,并支持从其他解决方案(包括 LastPass)导入。它的核心功能完全免费,它还有一个 10 美元/年的高级版本。
### Vimium-FF

[Vimium](https://addons.mozilla.org/en-US/firefox/addon/vimium-ff/) 是另一个开源的扩展,它为 Firefox 键盘快捷键提供了类似 Vim 一样的导航和控制,其称之为“黑客的浏览器”。对于 `Ctrl+x`、 `Meta+x` 和 `Alt+x`,分别对应 `<c-x>`、`<m-x>` 和 `<a-x>`,默认值可以轻松定制。一旦你安装了 Vimium,你可以随时键入 `?` 来查看键盘绑定列表。请注意,如果你更喜欢 Emacs,那么也有一些针对这些键绑定的扩展。无论哪种方式,我认为键盘快捷键是未充分利用的生产力推动力。
### 额外福利: Grammarly
不是每个人都有幸在 Opensource.com 上撰写专栏 —— 尽管你应该认真考虑为这个网站撰写文章;如果你有问题,有兴趣,或者想要一个导师,伸出手,让我们聊聊吧。但是,即使没有专栏撰写,正确的语法在各种各样的情况下都是有益的。试一下 [Grammarly](https://www.grammarly.com/)。不幸的是,这个扩展不是开源的,但它确实可以确保你输入的所有东西都是清晰的 、有效的并且没有错误。它通过扫描你文本中的常见的和复杂的语法错误来实现这一点,涵盖了从主谓一致到文章使用,到修饰词的放置这些所有内容。它的基本功能是免费的,它有一个高级版本,每月收取额外的费用。我在这篇文章中使用了它,它发现了许多我的校对没有发现的错误。
再次说明,Grammarly 是这个列表中包含的唯一不是开源的扩展,因此如果你知道类似的高质量开源替代品,请在评论中告诉我们。
这些扩展是我发现有用并推荐给其他人的扩展。请在评论中告诉我你对更新建议的看法。
---
via: <https://opensource.com/article/18/5/firefox-extensions>
作者:[Jeremy Garcia](https://opensource.com/users/jeremy-garcia) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As I mentioned in my [original article](https://opensource.com/article/18/1/top-5-firefox-extensions) on Firefox extensions, the web browser has become a critical component of the computing experience for many users. Modern browsers have evolved into powerful and extensible platforms, and extensions can add or modify their functionality. Extensions for Firefox are built using the WebExtensions API, a cross-browser development system.
In the first article, I asked readers: "Which extensions should you install?" To reiterate, that decision largely comes down to how you use your browser, your views on privacy, how much you trust extension developers, and other personal preferences. Since that article was published, one extension I recommended (Xmarks) has been discontinued. Additionally, that article received a ton of feedback that has been taken into account for this update.
Once again, I'd like to point out that browser extensions often require the ability to read and/or change everything on the web pages you visit. You should consider the ramifications of this very carefully. If an extension has modify access to all the web pages you visit, it could act as a keylogger, intercept credit card information, track you online, insert advertisements, and perform a variety of other nefarious activities. That doesn't mean every extension will surreptitiously do these things, but you should carefully consider the installation source, the permissions involved, your risk profile, and other factors before you install any extension. Keep in mind you can use profiles to manage how an extension impacts your attack surface—for example, using a dedicated profile with no extensions to perform tasks such as online banking.
With that in mind, here are four open source Firefox extensions you may want to consider.
## uBlock Origin
My first recommendation remains unchanged. [uBlock Origin](https://addons.mozilla.org/en-US/firefox/addon/ublock-origin/) is a fast, low memory, wide-spectrum blocker that allows you to not only block ads but also enforce your own content filtering. The default behavior of uBlock Origin is to block ads, trackers, and malware sites using multiple, predefined filter lists. From there it allows you to arbitrarily add lists and rules, or even lock down to a default-deny mode. Despite being powerful, the extension has proven to be efficient and performant. It continues to be updated regularly and is one of the best options available for this functionality.
## Privacy Badger
My second recommendation also remains unchanged. If anything, privacy has been brought even more to the forefront since my previous article, making this extension an easy recommendation. As the name indicates, [Privacy Badger](https://www.eff.org/privacybadger) is a privacy-focused extension that blocks ads and other third-party trackers. It's a project of the Electronic Freedom Foundation, which says:
"Privacy Badger was born out of our desire to be able to recommend a single extension that would automatically analyze and block any tracker or ad that violated the principle of user consent; which could function well without any settings, knowledge, or configuration by the user; which is produced by an organization that is unambiguously working for its users rather than for advertisers; and which uses algorithmic methods to decide what is and isn't tracking."
Why is Privacy Badger on this list when the previous item may seem similar? A couple reasons. The first is that it fundamentally works differently than uBlock Origin. The second is that a practice of defense in depth is a sound policy to follow. Speaking of defense in depth, the EFF also maintains [HTTPS Everywhere](https://www.eff.org/https-everywhere) to automatically ensure https is used for many major websites. When you're installing Privacy Badger, you may want to consider HTTPS Everywhere as well.
In case you were starting to think this article was simply going to be a rehash of the last one, here's where my recommendations diverge.
## Bitwarden
When recommending LastPass in the previous article, I mentioned it was likely going to be a controversial selection. That certainly proved true. Whether you should use a password manager at all—and if you do, whether you should choose one that has a browser plugin—is a hotly debated topic, and the answer very much depends on your personal risk profile. I asserted that most casual computer users should use one because it's much better than the most common alternative: using the same weak password everywhere. I still believe that.
[Bitwarden](https://bitwarden.com/) has really matured since the last time I checked it out. Like LastPass, it is user-friendly, supports two-factor authentication, and is reasonably secure. Unlike LastPass, it is [open source](https://github.com/bitwarden). It can be used with or without the browser plugin and supports importing from other solutions including LastPass. The core functionality is completely free, and there is a premium version that is $10/year.
## Vimium-FF
[Vimium](https://addons.mozilla.org/en-US/firefox/addon/vimium-ff/) is another open source extension that provides Firefox keyboard shortcuts for navigation and control in the spirit of Vim. They call it "The Hacker's Browser." Modifier keys are specified as **<c-x>**, **<m-x>**, and **<a-x>** for Ctrl+x, Meta+x, and Alt+x, respectively, and the defaults can be easily customized. Once you have Vimium installed, you can see this list of key bindings at any time by typing **?**. Note that if you prefer Emacs, there are also a couple of extensions for those keybindings as well. Either way, I think keyboard shortcuts are an underutilized productivity booster.
## Bonus: Grammarly
Not everyone is lucky enough to write a column on Opensource.com—although you should seriously consider writing for the site; if you have questions, are interested, or would like a mentor, reach out and let's chat. But even without a column to write, proper grammar is beneficial in a large variety of situations. Enter [Grammarly](https://www.grammarly.com/). This extension is not open source, unfortunately, but it does make sure everything you type is clear, effective, and mistake-free. It does this by scanning your text for common and complex grammatical mistakes, spanning everything from subject-verb agreement to article use to modifier placement. Basic functionality is free, with a premium version with additional checks available for a monthly charge. I used it for this article and it caught multiple errors that my proofreading didn't.
Again, Grammarly is the only extension included on this list that is not open source, so if you know of a similar high-quality open source replacement, let us know in the comments.
These extensions are ones I've found useful and recommend to others. Let me know in the comments what you think of the updated recommendations.
## 17 Comments |
9,700 | 编写有趣且有价值的 Systemd 服务 | https://www.linux.com/blog/learn/intro-to-linux/2018/5/writing-systemd-services-fun-and-profit | 2018-05-31T23:15:35 | [
"systemd"
] | https://linux.cn/article-9700-1.html | 
让我们假设你希望搭建一个游戏服务器,运行 [Minetest](https://www.minetest.net/) 这款非常酷、开源的,以采集 & 合成为主题的沙盒游戏。你希望将游戏运行在位于客厅的服务器中,以便搭建完成后可供你的学校或朋友使用。你知道内核邮件列表的管理就不过就是如此,那么对你来说也是足够的。
但你很快发现每次开机之后需要启动服务进程,每次关机之前需要安全地关闭服务器,十分繁琐和麻烦。
最初,你可能用守护进程的方式运行服务器:
```
minetest --server &
```
记住进程 PID 以便后续使用。
接着,你还需要通过邮件或短信的方式将服务器已经启动的信息告知你的朋友。然后你就可以开始游戏了。
转眼之间,已经凌晨三点,今天的战斗即将告一段落。但在你关闭主机、睡个好觉之前,还需要做一些操作。首先,你需要通知其它玩家服务器即将关闭,找到记录我们之前提到的 PID 的纸条,然后友好地关闭 Minetest 服务进程。
```
kill -2 <PID>
```
这是因为直接关闭主机电源很可能导致文件损坏。下一步也是最后一步,关闭主机电源。
一定有方法能让事情变得更简单。
### 让 Systemd 服务拯救你
让我们从构建一个普通用户可以(手动)运行的 systemd 服务开始,然后再逐步增加内容。
不需要管理员权限即可运行的服务位于 `~/.config/systemd/user/`,故首先需要创建这个目录:
```
cd
mkdir -p ~/.config/systemd/user/
```
有很多类型的 systemd 单元 (曾经叫做 systemd 脚本),包括“计时器”和“路径”等,但我们这里关注的是“服务”类型。在 `~/.config/systemd/user/` 目录中创建 `minetest.service` 文件,使用文本编辑器打开并输入如下内容:
```
# minetest.service
[Unit]
Description= Minetest server
Documentation= https://wiki.minetest.net/Main_Page
[Service]
Type= simple
ExecStart= /usr/games/minetest --server
```
可以看到该单元中包含不同的段,其中 `[Unit]` 段主要为用户提供信息,给出该单元的描述及如何获得更多相关文档。
脚本核心位于 `[Service]` 段,首先使用 `Type` 指令确定服务类型。服务[有多种类型](http://man7.org/linux/man-pages/man5/systemd.service.5.html),下面给出两个示例。如果你运行的进程设置环境变量、调用另外一个进程(主进程)、退出运行,那么你应该使用的服务类型为 `forking`。如果你希望在你的单元对应进程结束运行前阻断其他单元运行,那么你应该使用的服务类型为 `oneshot`。
但 Minetest 服务器的情形与上面两种都不同,你希望启动服务器并使其在后台持续运行;这种情况下应该使用 `simple` 类型。
下面来看 `ExecStart` 指令,它给出 systemd 需要运行的程序。在本例中,你希望在后台运行 `minetest` 服务器。如上所示,你可以在可执行程序后面添加参数,但不能将一系列 Bash 命令通过管道连接起来。下面给出的例子无法工作:
```
ExecStart: lsmod | grep nvidia > videodrive.txt
```
如果你需要将 Bash 命令通过管道连接起来,可以将其封装到一个脚本中,然后运行该脚本。
还需要注意一点,systemd 要求你给出程序的完整路径。故如果你想使用 `simple` 类型运行类似 `ls` 的命令,你需要使用 `ExecStart= /bin/ls`。
另外还有 `ExecStop` 指令用于定制服务终止的方式。我们会在第二部分讨论这个指令,但你要了解,如果你没有指定 `ExecStop`,systemd 会帮你尽可能友好地终止进程。
`systemd.directives` 的帮助页中包含完整指令列表,另外你可以在该[网站](http://man7.org/linux/man-pages/man7/systemd.directives.7.html)上找到同样的列表,点击即可查看每个指令的具体信息。
虽然只有 6 行,但你的 `minetest.service` 已经是一个有完整功能的 systemd 单元。执行如下命令启动服务:
```
systemd --user start minetest
```
执行如下命令终止服务:
```
systemd --user stop minetest
```
选项 `--user` 告知 systemd 在你的本地目录中检索服务并用你的用户权限执行服务。
我们的服务器管理故事到此完成了第一部分。在第二部分,我们将在启动和终止服务的基础上,学习如何给用户发邮件、告知用户服务器的可用性。敬请期待。
可以通过 Linux 基金会和 edX 的免费课程 “[Linux 入门](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)”学习更多 Linux 知识。
---
via: <https://www.linux.com/blog/learn/intro-to-linux/2018/5/writing-systemd-services-fun-and-profit>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,701 | 在 Linux 中如何归档文件和目录 | https://www.ostechnix.com/how-to-archive-files-and-directories-in-linux-part-1/ | 2018-06-01T10:02:16 | [
"tar",
"归档"
] | https://linux.cn/article-9701-1.html | 
在我们之前的教程中,我们讨论了如何[使用 gzip 和 bzip2 压缩和解压缩文件](https://www.ostechnix.com/how-to-compress-and-decompress-files-in-linux/)。在本教程中,我们将学习如何在 Linux 归档文件。归档和压缩有什么不同吗?你们中的一些人可能经常认为这些术语有相同的含义。但是,这两者完全不同。归档是将多个文件和目录(相同或不同大小)组合成一个文件的过程。另一方面,压缩是减小文件或目录大小的过程。归档通常用作系统备份的一部分,或者将数据从一个系统移至另一个系统时。希望你了解归档和压缩之间的区别。现在,让我们进入主题。
### 归档文件和目录
归档文件和目录最常见的程序是:
1. tar
2. zip
这是一个很大的话题,所以,我将分两部分发表这篇文章。在第一部分中,我们将看到如何使用 tar 命令来归档文件和目录。
### 使用 tar 命令归档文件和目录
**Tar** 是一个 Unix 命令,代表 **T**ape **A**rchive(磁带归档)。它用于将多个文件(相同或不同大小)组合或存储到一个文件中。在 tar 实用程序中有 4 种主要的操作模式。
1. `c` – 从文件或目录中建立归档
2. `x` – 提取归档
3. `r` – 将文件追加到归档
4. `t` – 列出归档的内容
有关完整的模式列表,参阅 man 手册页。
#### 创建一个新的归档
为了本指南,我将使用名为 `ostechnix` 的文件夹,其中包含三种不同类型的文件。
```
$ ls ostechnix/
file.odt image.png song.mp3
```
现在,让我们为 `ostechnix` 目录创建一个新的 tar 归档。
```
$ tar cf ostechnix.tar ostechnix/
```
这里,`c` 标志指的是创建新的归档,`f` 是指定归档文件。
同样,对当前工作目录中的一组文件创建归档文件,使用以下命令:
```
$ tar cf archive.tar file1 file2 file 3
```
#### 提取归档
要在当前目录中提取归档文件,只需执行以下操作:
```
$ tar xf ostechnix.tar
```
我们还可以使用 `C` 标志(大写字母 C)将归档提取到不同的目录中。例如,以下命令将归档文件提取到 `Downloads` 目录中。
```
$ tar xf ostechnix.tar -C Downloads/
```
或者,转到 `Downloads` 文件夹并像下面一样提取其中的归档。
```
$ cd Downloads/
$ tar xf ../ostechnix.tar
```
有时,你可能想要提取特定类型的文件。例如,以下命令提取 “.png” 类型的文件。
```
$ tar xf ostechnix.tar --wildcards "*.png"
```
#### 创建 gzip 和 bzip 格式的压缩归档
默认情况下,tar 创建归档文件以 `.tar` 结尾。另外,`tar` 命令可以与压缩实用程序 `gzip` 和 `bzip` 结合使用。文件结尾以 `.tar` 为扩展名使用普通 tar 来归档文件,文件以 `tar.gz` 或 `.tgz` 结尾使用 `gzip` 归档并压缩文件,文件以 `tar.bz2` 或 `.tbz` 结尾使用 `bzip` 归档并压缩。
首先,让我们来创建一个 gzip 归档:
```
$ tar czf ostechnix.tar.gz ostechnix/
```
或者:
```
$ tar czf ostechnix.tgz ostechnix/
```
这里,我们使用 `z` 标志来使用 gzip 压缩方法压缩归档文件。
你可以使用 `v` 标志在创建归档时查看进度。
```
$ tar czvf ostechnix.tar.gz ostechnix/
ostechnix/
ostechnix/file.odt
ostechnix/image.png
ostechnix/song.mp3
```
这里,`v` 指显示进度。
从一个文件列表创建 gzip 归档文件:
```
$ tar czf archive.tgz file1 file2 file3
```
要提取当前目录中的 gzip 归档文件,使用:
```
$ tar xzf ostechnix.tgz
```
要提取到其他文件夹,使用 `-C` 标志:
```
$ tar xzf ostechnix.tgz -C Downloads/
```
现在,让我们创建 **bzip 归档**。为此,请使用下面的 `j` 标志。
创建一个目录的归档:
```
$ tar cjf ostechnix.tar.bz2 ostechnix/
```
或
```
$ tar cjf ostechnix.tbz ostechnix/
```
从一个列表文件中创建归档:
```
$ tar cjf archive.tar.bz2 file1 file2 file3
```
或
```
$ tar cjf archive.tbz file1 file2 file3
```
为了显示进度,使用 `v` 标志。
现在,在当前目录下,让我们提取一个 bzip 归档。这样做:
```
$ tar xjf ostechnix.tar.bz2
```
或者,提取归档文件到其他目录:
```
$ tar xjf ostechnix.tar.bz2 -C Downloads
```
#### 一次创建多个目录和/或文件的归档
这是 `tar` 命令的另一个最酷的功能。要一次创建多个目录或文件的 gzip 归档文件,使用以下文件:
```
$ tar czvf ostechnix.tgz Downloads/ Documents/ ostechnix/file.odt
```
上述命令创建 `Downloads`、 `Documents` 目录和 `ostechnix` 目录下的 `file.odt` 文件的归档,并将归档保存在当前工作目录中。
#### 在创建归档时跳过目录和/或文件
这在备份数据时非常有用。你可以在备份中排除不重要的文件或目录,这是 `–exclude` 选项所能帮助的。例如你想要创建 `/home` 目录的归档,但不希望包括 `Downloads`、 `Documents`、 `Pictures`、 `Music` 这些目录。
这是我们的做法:
```
$ tar czvf ostechnix.tgz /home/sk --exclude=/home/sk/Downloads --exclude=/home/sk/Documents --exclude=/home/sk/Pictures --exclude=/home/sk/Music
```
上述命令将对我的 `$HOME` 目录创建一个 gzip 归档,其中不包括 `Downloads`、`Documents`、`Pictures` 和 `Music` 目录。要创建 bzip 归档,将 `z` 替换为 `j`,并在上例中使用扩展名 `.bz2`。
#### 列出归档文件但不提取它们
要列出归档文件的内容,我们使用 `t` 标志。
```
$ tar tf ostechnix.tar
ostechnix/
ostechnix/file.odt
ostechnix/image.png
ostechnix/song.mp3
```
要查看详细输出,使用 `v` 标志。
```
$ tar tvf ostechnix.tar
drwxr-xr-x sk/users 0 2018-03-26 19:52 ostechnix/
-rw-r--r-- sk/users 9942 2018-03-24 13:49 ostechnix/file.odt
-rw-r--r-- sk/users 36013 2015-09-30 11:52 ostechnix/image.png
-rw-r--r-- sk/users 112383 2018-02-22 14:35 ostechnix/song.mp3
```
#### 追加文件到归档
文件或目录可以使用 `r` 标志添加/更新到现有的归档。看看下面的命令:
```
$ tar rf ostechnix.tar ostechnix/ sk/ example.txt
```
上面的命令会将名为 `sk` 的目录和名为 `exmple.txt` 添加到 `ostechnix.tar` 归档文件中。
你可以使用以下命令验证文件是否已添加:
```
$ tar tvf ostechnix.tar
drwxr-xr-x sk/users 0 2018-03-26 19:52 ostechnix/
-rw-r--r-- sk/users 9942 2018-03-24 13:49 ostechnix/file.odt
-rw-r--r-- sk/users 36013 2015-09-30 11:52 ostechnix/image.png
-rw-r--r-- sk/users 112383 2018-02-22 14:35 ostechnix/song.mp3
drwxr-xr-x sk/users 0 2018-03-26 19:52 sk/
-rw-r--r-- sk/users 0 2018-03-26 19:39 sk/linux.txt
-rw-r--r-- sk/users 0 2018-03-26 19:56 example.txt
```
### TL;DR
创建 tar 归档:
* **普通 tar 归档:** `tar -cf archive.tar file1 file2 file3`
* **Gzip tar 归档:** `tar -czf archive.tgz file1 file2 file3`
* **Bzip tar 归档:** `tar -cjf archive.tbz file1 file2 file3`
提取 tar 归档:
* **普通 tar 归档:** `tar -xf archive.tar`
* **Gzip tar 归档:** `tar -xzf archive.tgz`
* **Bzip tar 归档:** `tar -xjf archive.tbz`
我们只介绍了 `tar` 命令的基本用法,这些对于开始使用 `tar` 命令足够了。但是,如果你想了解更多详细信息,参阅 man 手册页。
```
$ man tar
```
好吧,这就是全部了。在下一部分中,我们将看到如何使用 Zip 实用程序来归档文件和目录。
干杯!
---
via: <https://www.ostechnix.com/how-to-archive-files-and-directories-in-linux-part-1/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,702 | Orbital Apps:新一代 Linux 程序 | https://www.ostechnix.com/orbitalapps-new-generation-ubuntu-linux-applications/ | 2018-06-01T10:08:55 | [
"ORB"
] | https://linux.cn/article-9702-1.html | 
今天,我们要了解 **Orbital Apps** 或 **ORB**(**O**pen **R**unnable **B**undle)**apps**(开放可运行程序包),一个自由的、跨平台的开源程序集合。所有 ORB 程序都是可移动的。你可以将它们安装在你的 Linux 系统或 USB 驱动器上,以便你可以在任何系统上使用相同的程序。它们不需要 root 权限,并且没有依赖关系。所有必需的依赖关系都包含在程序中。只需将 ORB 程序复制到 USB 驱动器并将其插入到任何 Linux 系统中就立即开始使用它们。所有设置和配置以及程序的数据都将存储在 USB 驱动器上。由于不需要在本地驱动器上安装程序,我们可以在联机或脱机的计算机上运行应用程序。这意味着我们不需要 Internet 来下载任何依赖。
ORB 程序压缩了 60%,因此我们甚至可以从小型 USB 驱动器存储和使用它们。所有 ORB 应用程序都使用 PGP / RSA 进行签名,并通过 TLS 1.2 进行分发。所有应用程序打包时都不做任何修改,甚至不会重新编译。以下是当前可用的便携式 ORB 应用程序列表。
* abiword
* audacious
* audacity
* darktable
* deluge
* filezilla
* firefox
* gimp
* gnome-mplayer
* hexchat
* inkscape
* isomaster
* kodi
* libreoffice
* qbittorrent
* sound-juicer
* thunderbird
* tomahawk
* uget
* vlc
* 未来还有更多
Orb 是开源的,所以如果你是开发人员,欢迎协作并添加更多程序。
### 下载并使用可移动 ORB 程序
正如我已经提到的,我们不需要安装可移动 ORB 程序。但是,ORB 团队强烈建议你使用 **ORB 启动器** 来获得更好的体验。 ORB 启动器是一个小的安装程序(小于 5MB),它可帮助你启动 ORB 程序,并获得更好,更流畅的体验。
让我们先安装 ORB 启动器。为此,[下载 ORB 启动器](https://www.orbital-apps.com/documentation/orb-launcher-all-installers)。你可以手动下载 ORB 启动器的 ISO 并将其挂载到文件管理器上。或者在终端中运行以下任一命令来安装它:
```
$ wget -O - https://www.orbital-apps.com/orb.sh | bash
```
如果你没有 wget,请运行:
```
$ curl https://www.orbital-apps.com/orb.sh | bash
```
询问时输入 root 用户和密码。
就是这样。Orbit 启动器已安装并可以使用。
现在,进入 [ORB 可移动程序下载页面](https://www.orbital-apps.com/download/portable_apps_linux/),并下载你选择的程序。在本教程中,我会下载 Firefox。
下载完后,进入下载位置并双击 ORB 程序来启动它。点击 Yes 确认。

Firefox ORB 程序能用了!

同样,你可以立即下载并运行任何程序。
如果你不想使用 ORB 启动器,请将下载的 `.orb` 安装程序设置为可执行文件,然后双击它进行安装。不过,建议使用 ORB 启动器,它可让你在使用 ORB 程序时更轻松、更顺畅。
就我测试的 ORB 程序而言,它们打开即可使用。希望这篇文章有帮助。今天就是这些。祝你有美好的一天!
干杯!!
---
via: <https://www.ostechnix.com/orbitalapps-new-generation-ubuntu-linux-applications/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,703 | Systemd 服务:比启动停止服务更进一步 | https://www.linux.com/blog/learn/2018/5/systemd-services-beyond-starting-and-stopping | 2018-06-02T05:26:50 | [
"systemd"
] | https://linux.cn/article-9703-1.html | 
在上一篇[文章](/article-9700-1.html)中,我们展示了如何创建一个 systemd 服务并使普通用户可以启动和终止游戏服务器。但到目前为止,使用这个服务并不比直接运行服务器高明多少。让我们更进一步,让其可以向玩家发邮件,包括在服务器可用时通知玩家,在服务器关闭前警告玩家:
```
# minetest.service
[Unit]
Description= Minetest server
Documentation= https://wiki.minetest.net/Main_Page
[Service]
Type= simple
ExecStart= /usr/games/minetest --server
ExecStartPost= /home/<username>/bin/mtsendmail.sh "Ready to rumble?" "Minetest Starting up"
TimeoutStopSec= 180
ExecStop= /home/<username>/bin/mtsendmail.sh "Off to bed. Nightie night!" "
Minetest Stopping in 2 minutes"
ExecStop= /bin/sleep 120
ExecStop= /bin/kill -2 $MAINPID
```
这里涉及几个新的指令。首先是 `ExecStartPost` 指令,该指令可以在主进程启动后马上执行任何你指定的操作。在本例中,你执行了一个自定义脚本 `mtsendmail` (内容如下),该脚本以邮件形式通知你的朋友服务器已经启动。
```
#!/bin/bash
# mtsendmail
echo $1 | mutt -F /home/<username>/.muttrc -s "$2" my_minetest@mailing_list.com
```
我们使用 [Mutt](http://www.mutt.org/) 这个命令后邮件客户端发送消息。虽然从实际效果来看,上述脚本仅有 1 行,但 systemd 单元的参数中不能包含管道及重定向操作,故我们需要将其封装到脚本中。
顺便提一下,还有一个 `ExecStartPre` 指令,用于在服务主进程执行之前进行指定操作。
接下来我们看到,关闭服务器涉及了好几条指令。`TimeoutStopSec` 指令用于设置 systemd 友好关闭服务的最大等候时间,默认值大约是 90 秒。超过这个最大等候时间,systemd 会强制关闭服务并报错。考虑到你希望在彻底关闭服务器前给用户预留几分钟的时间,你需要将超时时间提高至 3 分钟,这样 systemd 就不会误认为服务关闭时出现问题。
接下来是关闭服务的具体指令部分。虽然没有 `ExecStopPre` 这样的指令,但你可以通过多次使用 `ExecStop` 指令实现关闭服务器前执行操作的目标。多个 `ExecStop` 指令按从上到下的顺序依次运行,这样你就可以在服务器真正关闭前向用户发送消息。
通过这个特性,你首先应该向你的朋友发邮件,警告其服务器即将关闭,然后等待两分钟,最后关闭服务器。可以使用 `Ctrl + c` 关闭 Minetest 服务器,该操作会被转换为一个中断信号(`SIGINT`);当你执行 `kill -2 $MAINPID` 时就会发送该中断信号,其中 `$MAINPID` 是 systemd 变量,用于记录你服务中主进程的 PID 信息。
看上去好多了!如果你此时启动服务:
```
systemctl --user start minetest
```
服务会启动 Minetest 服务器并向你的用户发送邮件。关闭服务的情形基本类似,只不过会额外留给用户 2 分钟时间退出登录。
### 开机自启动
下一步我们让你的服务在主机启动后立即可用,在主机关闭时自动关闭。
我们需要将你的服务文件移动到系统服务目录,即 `/etc/systemd/system/`:
```
sudo mv /home/<username>/.config/systemd/user/minetest.service /etc/systemd/system/
```
如果你希望此时启动该服务,你需要拥有超级用户权限:
```
sudo systemctl start minetest
```
另外,可以使用如下命令检查服务状态:
```
sudo systemctl status minetest
```
你会发现服务很糟糕地处于失败状态,这是因为 systemd 不能通过上下文信息、特征、配置文件得知具体使用哪个用户运行该服务。在单元文件中增加 `User` 指令可以解决这个问题。
```
# minetest.service
[Unit]
Description= Minetest server
Documentation= https://wiki.minetest.net/Main_Page
[Service]
Type= simple
User= <username>
ExecStart= /usr/games/minetest --server
ExecStartPost= /home/<username>/bin/mtsendmail.sh "Ready to rumble?"
"Minetest Starting up"
TimeoutStopSec= 180
ExecStop= /home/<username>/bin/mtsendmail.sh "Off to bed. Nightie night!"
"Minetest Stopping in 2 minutes"
ExecStop= /bin/sleep 120
ExecStop= /bin/kill -2 $MAINPID
```
systemd 从 `User` 指令中得知应使用哪个用户的环境变量来正确运行该服务。你可以使用 root 用户,但这可能产生安全风险;使用你的个人用户会好一些,但不少管理员的做法是为服务单独创建一个用户,这样可以有效地将服务与其它用户和系统组件相互隔离。
下一步我们让你的服务在系统启动时自动启动,系统关闭时自动关闭。要达到这个目的,你需要 *启用* 你的服务;但在这之前,你还需要告知 systemd 从哪里 *安装* 它。
对于 systemd 而言,*安装* 意味着告知 systemd 在系统启动的具体哪个步骤激活你的服务。以通用 Unix 打印系统(`cups.service`)为例,它的启动在网络框架启动之后、其它打印服务启动之前。又如,`minetest.server` 需要使用用户邮件(及其它组件),需要等待网络和普通用户对应的服务就绪后才可启动。
你只需要在单元文件中添加一个新段和新指令:
```
...
[Install]
WantedBy= multi-user.target
```
你可以将其理解为“等待多用户系统的全部内容就绪”。systemd 中的“目标”类似于旧系统中的运行级别,可以用于将主机转移到一个或另一个状态,也可以像本例中这样让你的服务等待指定状态出现后运行。
你的最终 `minetest.service` 文件如下:
```
# minetest.service
[Unit]
Description= Minetest server
Documentation= https://wiki.minetest.net/Main_Page
[Service]
Type= simple
User= <username>
ExecStart= /usr/games/minetest --server
ExecStartPost= /home/<username>/bin/mtsendmail.sh "Ready to rumble?"
"Minetest Starting up"
TimeoutStopSec= 180
ExecStop= /home/<username>/bin/mtsendmail.sh "Off to bed. Nightie night!"
"Minetest Stopping in 2 minutes"
ExecStop= /bin/sleep 120
ExecStop= /bin/kill -2 $MAINPID
[Install]
WantedBy= multi-user.target
```
在尝试新的服务之前,你还需要对邮件脚本做一些调整:
```
#!/bin/bash
# mtsendmail
sleep 20
echo $1 | mutt -F /home/<username>/.muttrc -s "$2" my_minetest@mailing_list.com
sleep 10
```
这是因为系统需要一定的时间启动邮件系统(这里等待 20 秒),也需要一定时间完成邮件发送(这里等待 10 秒)。注意脚本中的等待时间数值适用于我的系统,你可能需要针对你的系统调整数值。
大功告成啦。执行如下操作:
```
sudo systemctl enable minetest
```
你的 Minetest 服务将在系统启动时自动启动,在系统关闭时友好关闭并通知你的用户。
### 总结
事实上 Debian、 Ubuntu 和一些族类的发行版提供了 `minetest-server` 这个特别的软件包,可以提供一部分上述功能,(但不包括邮件通知功能)。即使如此,你还是可以建立你独有的自定义服务;事实上,你目前建立的服务比 Debian 默认提供的服务更加通用,可以提供更多功能。
更进一步的说,我们这里描述的流程可以让你将大多数简单服务器转换为服务,类型可以是游戏、网站应用或其它应用。同时,这也是你名副其实地踏入 systemd 大师殿堂的第一步。
---
via: <https://www.linux.com/blog/learn/2018/5/systemd-services-beyond-starting-and-stopping>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,704 | 你可以用 Linux 中的 IP 工具做 3 件有用的事情 | https://opensource.com/article/18/5/useful-things-you-can-do-with-IP-tool-Linux | 2018-06-02T05:40:47 | [
"ip",
"ifconfig"
] | https://linux.cn/article-9704-1.html |
>
> 如何使用 IP 工具来快速轻松地找到你的 IP 地址、显示路由表等等。
>
>
>

`ifconfig` 命令在 Linux 上被弃用已有十多年的时间了,而 `iproute2` 项目包含了神奇的工具 `ip`。许多在线教程资源仍然采用旧的命令行工具,如 `ifconfig`、`route` 和 `netstat`。本教程的目标是分享一些可以使用 `ip` 工具轻松完成的网络相关的事情。
### 找出你的 IP 地址
```
[dneary@host]$ ip addr show
[snip]
44: wlp4s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 5c:e0:c5:c7:f0:f1 brd ff:ff:ff:ff:ff:ff
inet 10.16.196.113/23 brd 10.16.197.255 scope global dynamic wlp4s0
valid_lft 74830sec preferred_lft 74830sec
inet6 fe80::5ee0:c5ff:fec7:f0f1/64 scope link
valid_lft forever preferred_lft forever
```
`ip addr show` 会告诉你很多关于你的所有网络链接设备的信息。在这里,我的无线以太网卡(`wlp4s0`)是 IPv4 地址(`inet` 字段)`10.16.196.113/23`。 `/23` 表示 32 位 IP 地址中的 23 位将被该子网中的所有 IP 地址共享。子网中的 IP 地址范围从 `10.16.196.0` 到 `10.16.197.254`。子网的广播地址(IP 地址后面的 `brd` 字段)`10.16.197.255` 保留给子网上所有主机的广播流量。
我们能只使用 `ip addr show dev wlp4s0` 来显示单个设备的信息。
### 显示你的路由表
```
[dneary@host]$ ip route list
default via 10.16.197.254 dev wlp4s0 proto static metric 600
10.16.196.0/23 dev wlp4s0 proto kernel scope link src 10.16.196.113 metric 601
192.168.122.0/24 dev virbr0 proto kernel scope link src 192.168.122.1 linkdown
```
路由表是本地主机帮助网络流量确定去哪里的方式。它包含一组路标,将流量发送到特定的接口,以及在其旅途中的特定下一个地点。
如果你运行任何虚拟机或容器,它们将获得自己的 IP 地址和子网,这可能会使这些路由表非常复杂,但在单个主机中,通常有两条指令。对于本地流量,将其发送到本地以太网上,并且网络交换机将找出(使用称为 ARP 的协议)哪个主机拥有目标 IP 地址,并且要将流量发送到哪里。对于到互联网的流量,将其发送到本地网关节点,它将更好地了解如何到达目的地。
在上面的情况中,第一行代表外部流量的外部网关,第二行代表本地流量,第三行代表主机上运行的虚拟机的虚拟网桥,但该链接当前未激活。
### 监视你的网络配置
```
[dneary@host]$ ip monitor all
[dneary@host]$ ip -s link list wlp4s0
```
`ip monitor` 命令可用于监视路由表(网络接口上的网络寻址)的更改或本地主机上 ARP 表的更改。此命令在调试与容器和网络相关的网络问题时特别有用,如当两个虚拟机应该能彼此通信,但实际不能。
在使用 `all` 时,`ip monitor` 会报告所有的更改,前缀以 `[LINK]`(网络接口更改)、`[ROUTE]`(更改路由表)、`[ADDR]`(IP 地址更改)或 `[NEIGH]`(与马无关 —— 与邻居的 ARP 地址相关的变化)。
你还可以监视特定对象上的更改(例如,特定的路由表或 IP 地址)。
另一个适用于许多命令的有用选项是 `ip -s`,它提供了一些统计信息。添加第二个 `-s` 选项可以添加更多统计信息。上面的 `ip -s link list wlp4s0` 会给出很多关于接收和发送的数据包的信息、丢弃的数据包数量、检测到的错误等等。
### 提示:缩短你的命令
一般来说,对于 `ip` 工具,你只需要包含足够的字母来唯一标识你想要做的事情。你可以使用 `ip mon` 来代替 `ip monitor`。你可以使用 `ip a l`,而不是 `ip addr list`,并且可以使用 `ip r`来代替 `ip route`。`ip link list` 可以缩写为 `ip l ls`。要了解可用于更改命令行为的许多选项,请浏览 [ip 手册页](https://www.systutorials.com/docs/linux/man/8-ip-route/)。
---
via: <https://opensource.com/article/18/5/useful-things-you-can-do-with-IP-tool-Linux>
作者:[Dave Neary](https://opensource.com/users/dneary) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It has been more than a decade since the `ifconfig`
command has been deprecated on Linux in favor of the `iproute2`
project, which contains the magical tool `ip`
. Many online tutorial resources still refer to old command-line tools like `ifconfig`
, `route`
, and `netstat`
. The goal of this tutorial is to share some of the simple networking-related things you can do easily using the `ip`
tool instead.
## Find your IP address
```
[dneary@host]$ ip addr show
[snip]
44: wlp4s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 5c:e0:c5:c7:f0:f1 brd ff:ff:ff:ff:ff:ff
inet 10.16.196.113/23 brd 10.16.197.255 scope global dynamic wlp4s0
valid_lft 74830sec preferred_lft 74830sec
inet6 fe80::5ee0:c5ff:fec7:f0f1/64 scope link
valid_lft forever preferred_lft forever
```
`ip addr show`
will show you a lot of information about all of your network link devices. In this case, my wireless Ethernet card (wlp4s0) is the IPv4 address (the `inet`
field) `10.16.196.113/23`
. The `/23`
means that there are 23 bits of the 32 bits in the IP address, which will be shared by all of the IP addresses in this subnet. IP addresses in the subnet will range from `10.16.196.0 to 10.16.197.254`
. The broadcast address for the subnet (the `brd`
field after the IP address) `10.16.197.255`
is reserved for broadcast traffic to all hosts on the subnet.
We can show only the information about a single device using `ip addr show dev wlp4s0`
, for example.
## Display your routing table
```
[dneary@host]$ ip route list
default via 10.16.197.254 dev wlp4s0 proto static metric 600
10.16.196.0/23 dev wlp4s0 proto kernel scope link src 10.16.196.113 metric 601
192.168.122.0/24 dev virbr0 proto kernel scope link src 192.168.122.1 linkdown
```
The routing table is the local host's way of helping network traffic figure out where to go. It contains a set of signposts, sending traffic to a specific interface, and a specific next waypoint on its journey.
If you run any virtual machines or containers, these will get their own IP addresses and subnets, which can make these routing tables quite complicated, but in a single host, there are typically two instructions. For local traffic, send it out onto the local Ethernet, and the network switches will figure out (using a protocol called ARP) which host owns the destination IP address, and thus where the traffic should be sent. For traffic to the internet, send it to the local gateway node, which will have a better idea how to get to the destination.
In the situation above, the first line represents the external gateway for external traffic, the second line is for local traffic, and the third is reserved for a virtual bridge for VMs running on the host, but this link is not currently active.
## Monitor your network configuration
```
[dneary@host]$ ip monitor all
[dneary@host]$ ip -s link list wlp4s0
```
The `ip monitor`
command can be used to monitor changes in routing tables, network addressing on network interfaces, or changes in ARP tables on the local host. This command can be particularly useful in debugging network issues related to containers and networking, when two VMs should be able to communicate with each other but cannot.
When used with `all`
, `ip monitor`
will report all changes, prefixed with one of `[LINK]`
(network interface changes), `[ROUTE]`
(changes to a routing table), `[ADDR]`
(IP address changes), or `[NEIGH]`
(nothing to do with horses—changes related to ARP addresses of neighbors).
You can also monitor changes on specific objects (for example, a specific routing table or an IP address).
Another useful option that works with many commands is `ip -s`
, which gives some statistics. Adding a second `-s`
option adds even more statistics. `ip -s link list wlp4s0`
above will give lots of information about packets received and transmitted, with the number of packets dropped, errors detected, and so on.
## Handy tip: Shorten your commands
In general, for the `ip`
tool, you need to include only enough letters to uniquely identify what you want to do. Instead of `ip monitor`
, you can use `ip mon`
. Instead of `ip addr list`
, you can use `ip a l`
, and you can use `ip r`
in place of `ip route`
. `Ip link list`
can be shorted to `ip l ls`
. To read about the many options you can use to change the behavior of a command, visit the [ip manpage](https://www.systutorials.com/docs/linux/man/8-ip-route/).
## 5 Comments |
9,705 | 容器化,原子化发行版以及 Linux 的未来 | https://www.linux.com/blog/2018/4/containerization-atomic-distributions-and-future-linux | 2018-06-02T06:07:22 | [
"发行版",
"容器"
] | https://linux.cn/article-9705-1.html |
>
> 容器支持者认为未来属于容器化操作系统,而其他人或许有不同看法。
>
>
>

自从 Linus Torvalds 在 1991 年发布 Linux 以来,Linux 已历经漫长的岁月。它已经成为企业级领域的主流操作系统。同时,我们看到桌面级领域出现了很多改进和调整,但在过去的 25 年来,主流 Linux 发行版的模式很大程度上没有变化。基于软件包管理的传统模式依然统治着桌面级和服务器级市场。
但随着 Google 发布了基于 Linux 的 Chrome OS,情况出现了微妙的转变,Chrome OS 采用镜像模式。Core OS (目前归属于 Red Hat) 受 Google 启发推出了一款操作系统 Container Linux,主要面向企业级用户。
Container Linux 改变了操作系统更新的方式,也改变了应用分发和更新的方式。这会是 Linux 发行版的未来吗?这是否会取代基于软件包的传统发行版模式呢?
### 三种模式
SLE (SUSE Linux Enterprise) 的产品管理总监 Matthias Eckermann 认为目前存在 3 种模式,而不是 2 种。Eckermann 提到:“除了传统模式(RHEL/SLE)和镜像模式(RedHat 的 Atomic Host),还存在第三种模型:事务模式。[SUSE CaaS 平台](https://www.suse.com/products/caas-platform/) 及 SUSE MicroOS 就采用这种模式。”
### 差异有哪些
Linux 用户对传统模式非常熟悉,它由独立的软件包和共享库组成。这种模式有独特的优势,让应用开发者无需将共享库捆绑在应用中。由于库不会多次引入,使得系统简洁和轻便。这也让用户无需下载很多软件包,节省了带宽。发行版对软件包全权负责,通过推送系统级别的更新,可以轻松地解决安全隐患。
RHEL (Red Hat Enterprise Linux)的产品管理总监 Ron Pacheco 表示,“传统的打包方式继续为我们提供精心构建和优化操作系统的机会,以便支持需要经过时间考验的任务关键型工作负载。”
但传统模式也有一些弊端。应用开发者受限使用发行版包含的库,使其无法从发行版不支持的新软件中获益。这也可能导致不同版本之间相互冲突。最终,传统模式给管理员增加了挑战,使其难以让软件包一直处于最新版本状态。
### 镜像模式
镜像模式应运而生。Eckermann 表示,“镜像模式解决了传统模式遇到的问题,它在每次迭代更新时替换整个操作系统,而不是单个的软件包”。
Pacheco 表示,“当我们用镜像作为操作系统的代名词进行讨论时,我们真正关心的是可编程式的开发和部署以及更好的集成式生命周期管理”,基于 RHEL 搭建的 OpenShift 被他用作示例。
Pacheco 认为基于镜像的操作系统是一种延续,从手工打造并部署镜像,到可大规模管理的高度自动化基础设施;无论客户使用哪种类型,都需要运行同样的应用。他说,“你肯定不希望使用一个完全不同的部署模式,这需要重做很多工作”。
镜像模式用新的库和软件包替代来整个操作系统,但也面临一系列问题。在镜像模式中,需要重建镜像才能适应特殊环境的需求。例如,用户有特殊需求,需要安装特定硬件的驱动或安装底层监控功能,镜像模式无法满足,需要重新设计功能以实现细粒度操作。
### 事务模式
第三种模式采用事务更新,基于传统的软件包更新,但将全部的软件包视为一个镜像,就像镜像那样在一次操作中更新全部软件包。
Eckermann 表示,“由于安装或回滚时操作对象是打包在一起的单一软件包,用户在需要时能够做相应的调整,这就是差别所在。结合传统模式和镜像模式的优点,避免两种模式的缺点,事务模式给用户提供了额外的灵活性。”
Pacheco 表示,将精心构造的工作负载部署成镜像的做法越来越成为主流,因为这种部署方式具有一致性和可靠性,而且可以弹性部署。“这正是我们用户目前的做法,部署环境包括在预置设备或公有/私有云上创建并部署的虚拟机,或在传统的裸机上。”
Pacheco 建议我们将这几种模式视为操作系统角色的进化和扩展,而不是仅仅“使用场景的比较和对比”。
### 原子化更新的问世
Google 的 Chrome OS 和 Core OS 为我们普及了事务更新的概念,该模型也被 Red Hat 和 SUSE 采用。
Eckermann 表示,“我们必须认识到,用于容器主机的操作系统已经不再是关注点 —— 至少不是管理员的关注点。RedHat Atomic 主机和 SUSE CaaS 平台都解决了该问题,实现方式在用户看来很相似。”
SUSE CaaS 平台、Red Hat Atomic Host和 Container Linux (前身是 Core OS)提供的[<ruby> 不可变基础设施 <rt> Immutable infrastructure </rt></ruby>](https://www.digitalocean.com/community/tutorials/what-is-immutable-infrastructure) 推广了事务更新的使用。Red Hat 高级技术产品经理 Ben Breard 表示,“在事务模式中,主机总是会变更到已确认正确的新状态,这让我们更有信心执行更新,进而实现更快速的功能流、安全优势以及易于采用的操作模式。”
这些新型操作系统使用 Linux 容器将应用与底层系统隔离,解除了传统模式中基础设施更新的诸多限制。
Breard 补充道,“当编排层可以智能处理更新、部署,甚至最终实现无缝操作时,我们才会真正意识到该模式的威力和好处”。
### 展望未来
Linux 的未来会是什么样子?不同的人会给出不同的回答。容器支持者认为未来属于容器化的操作系统,但依然拥有庞大市场的 Linux 供应商显然不这么认为。
当被问到原子化发行版是否会在很久以后将替换传统发行版时,Eckermann 表示,“如果我回答肯定的,那么表示我顺应潮流;如果回答是否定的,意味着我还是站在传统阵营。然而,我的回答是否定的,即 atomic 发行版在很久以后也不会替换传统发行版,传统负载和容器化负载将在数据中心、私有云以及公有云环境中共存。”
Pacheco 认为,从 Linux 的部署增长情况来看,一般情况下很难想象一种模式替换另一种模式。与其将多种模式视为相互竞争的关系,不如将原子化发行版视为操作系统进化和部署的一部分。
此外,在一些使用案例中,我们需要同时使用多种 Linux 发行版。Eckermann 表示,“想一想银行和保险公司中大量的 PL/1 和 Cobol 系统。再想一想内存数据库和核心数据总线系统。”
这些应用大多数无法进行容器化。就我们目前来看,容器化不是解决所有问题的万金油。总是会同时存在多种不同的技术。
Eckermann 相信,随着时间的推移,大量新的开发和部署将采用容器化,但仍然有不错的理由,促使我们在企业级环境中保留传统的部署方式和应用。
Pacheco 认为,“用户需要经历业务、设计和文化的转型,才能最大化基于容器的部署带来的优势。好消息是业界已经认识到并开始大规模转变,就像历史上大型机转变成 UNIX,UNIX 转变成 x86,x86 转变成虚拟化那样”。
### 结论
很明显,未来容器化负载的使用量会持续增长,也就意味着原子化发行版的需求量持续增长。与此同时,仍会有不少工作负载运行在传统发行版中。重要的是,这两类用户都在新模式上大规模投入,以便市场改变时可以做相应的策略改变。从外部观察者的视角来看,未来属于事务/原子化模式。我们已经见证了数据中心的发展,我们花了很长时间完成了从每个服务器一个应用到“函数即服务”模型的转变。Linux 发行版进入原子化时代的日子也不会太远了。
---
via: <https://www.linux.com/blog/2018/4/containerization-atomic-distributions-and-future-linux>
作者:[SWAPNIL BHARTIYA](https://www.linux.com/users/arnieswap) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.