
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
9,493 | 快捷教程:如何在命令行上编辑文件 | https://www.howtoforge.com/faq/how-to-edit-files-on-the-command-line | 2018-03-29T12:59:54 | [
"编辑器"
] | https://linux.cn/article-9493-1.html | 
此次教程中,我们将向您展示三种命令行编辑文件的方式。本文一共覆盖了三种命令行编辑器,vi(或 vim)、nano 和 emacs。
### 在命令行上使用 Vi 或 Vim 编辑文件
您可以使用 `vi` 编辑文件。运行如下命令,打开文件:
```
vi /path/to/file
```
现在,您可以看见文件中的内容了(如果文件存在。请注意,如果此文件不存在,该命令会创建文件)。
`vi` 最重要的命令莫过于此:
键入 `i` 进入<ruby> 编辑 <rt> Insert </rt></ruby>模式。如此,您可以编辑文本。
退出编辑模式请键入 `ESC`。
正处于光标之下的字符,使用 `x` 键删除(您千万不要在编辑模式这样做,如果您这样做了,将不会删除光标下的字符,而是会在光标下插入 `x` 字符)。因此,当您仅仅使用 `vi` 打开文本(LCTT 译注:此时默认进入指令模式),此时您可以使用 `x` 键立即删除字符。在编辑模式下,您需要键入 `ESC` 退出编辑模式。
如果您做了修改,想要保存文件,请键入 `:x`(同样,您不能在编辑模式执行此操作。请按 `ESC` 退出编辑模式,完成此操作)。
如果您并没有做修改,键入 `:q` 退出文本(您同样不能在编辑模式执行此操作)。
如果您做了修改,但却想不保存文本而之际退出,请键入 `:q!` (同样不能在编辑模式执行此作)。
请注意在上述所有操作中,您都可以使用方向键操控光标在文本中的位置。
以上所有都是 `vi` 编辑器的内容。请注意,`vim` 编辑器或多或少也会支持这些操作,如果您想深层次了解 `vim`,请看 [这里](https://www.howtoforge.com/vim-basics)。
### 使用 Nano 命令行编辑器编辑文件
接下来是 Nano 编辑器。您可以执行 `nano` 命令调用它:
```
nano
```
这里是 `nano` 的用户界面:

您同样可以使用它启动文件。
```
nano [filename]
```
例如:
```
nano test.txt
```

如您所见的用户界面,大致被分成四个部分。编辑器顶部显示编辑器版本、正在编辑的文件和编辑状态。然后是实际编辑区域,在这里,您能看见文件的内容。编辑器下方高亮区展示着重要的信息,最后两行显示能执行基础任务地快捷键,切实地帮助初学者。
这里是您前期应当了解的快捷键快表。
使用方向键浏览文本,退格键删除文本,`Ctrl+O` 保存文件修改。当您尝试保存时,`nano` 会征询您的确认(请参阅截图中主编辑器下方区域):

注意,在这个阶段,您有一个选项,可以保存不同的系统格式。键入 `Alt+D` 选择 DOS 格式,`Atl+M` 选择 Mac 格式。

敲回车保存更改。

继续,文本剪切使用 `Ctrl+K`,文本复制使用 `Ctrl+U`。这些快捷键同样可以用来粘贴剪切单个单词,但您需要先选择好单词,通常,您可以通过键入 `Alt+A`(光标在第一个单词下) 然后使用方向键选择完整的单词。
现在来进行搜索操作。使用 `Ctrl+W` 可以执行一个简单的搜索,同时搜索和替换您可以使用 `Ctrl+\\`。

这些就是 `nano` 的一些基础功,它能给您带来一些不错的开始,如果您是初次使用 `nano` 编辑器。更多内容,请阅读我们的完整内容,点击 [这里](https://www.howtoforge.com/linux-nano-command/)。
### 使用 Emacs 命令行编辑器编辑文件
接下来登场的是 Emacs。如果系统未安装此软件,您可以使用下面的命令在您的系统中安装它:
```
sudo apt-get install emacs
```
和 `nano` 一致,您可以使用下面的方式在 `emacs` 中直接打开文件:
```
emacs -nw [filename]
```
注意:`-nw` 选项确保 `emacs` 在本窗口启动,而不是打开一个新窗口,默认情况下,它会打开一个新窗口。
一个实例:
```
emacs -nw test.txt
```
下面是编辑器的用户界面:

和 `nano` 一样,`emacs` 的界面同样被分割成了几个部分。第一部分是最上方的菜单区域,和您在图形界面下的应用程序一致。接下来是显示文本(您打开的文件文本)内容的主编辑区域。
编辑区域下方坐落着另一个高亮菜单条,显示了文件名,编辑模式(如截图内的 ‘Text’)和状态(`**` 为已修改,`-` 为未修改,`%%` 为只读)。最后是提供输入指令的区域,同时也能查看输出。
现在开始基础操作,当您做了修改、想要保存时,在 `Ctrl+x` 之后键入 `Ctrl+s`。最后,在面板最后一行会向您显示一些信息:‘Wrote ........’。这里有一个例子:

现在,如果您放弃修改并且退出时,在 `Ctrl+x` 之后键入`Ctrl+c`。编辑器将会立即询问,如下图:

输入 `n` 之后键入 `yes`,之后编辑器将会不保存而直接退出。
请注意,Emacs 中 `C` 代表 `Ctrl`,`M` 代表 `Alt`。比如,当你看见 `C-x`,这意味着按下 `Ctrl+x`。
至于其他基本编辑器操作,以删除为例,大多数人都会,使用 `Backspace`/`Delete` 键。然而,这里的一些删除快捷键能够提高用户体验。比如,使用 `Ctrl+k` 删除一整行,`Alt+d` 删除一个单词,`Alt+k` 删除一个整句。
在键入 `Ctrl+k` 之后键入 `u` 将撤销操作,输入 `Ctrl+g` 之后输入 `Ctrl+_` 恢复撤销的操作。使用 `Ctrl+s` 向前搜索,`Ctrl+r` 反向搜索。

继续,使用 `Alt+Shift+%` 执行替换操作。您将被询问要替换单词。回复并回车。之后编辑器将会询问您是否替换。例如,下方截图展示了 `emacs` 询问使用者关于单词 ‘This’ 的替换操作。

输入替换文本并回车。每一个替换操作 `emacs` 都会等待询问,下面是首次询问:

键入 `y` 之后,单词将会被替换。

这些就是几乎所有的基础操作,您在开始使用 `emacs` 时需要了解掌握的。对了,我们忘记讨论如何访问顶部菜单,其实这些可以通过使用 `F10` 访问它们。

按 `Esc` 键三次,退出这些菜单。
---
via: <https://www.howtoforge.com/faq/how-to-edit-files-on-the-command-line>
作者:[Falko Timme, Himanshu Arora](https://www.howtoforge.com) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # How do I edit files on the command line?
**Authors:** Falko Timme, Himanshu Arora, Till Brehm
In this tutorial, we will show you how to edit files on the command line. This article covers three command-line editors, vi (or vim), nano, and emacs. These editors are available on all Linux distributions like Arch Linux, CentOS, Debian, Fedora, and Ubuntu.
## Editing Files with Vi or Vim Command Line Editor
To edit files on the command line, you can use an editor such as vi. To open the file, run
vi /path/to/file
Now you see the contents of the file (if there is any. Please note that the file is created if it does not exist yet.).
As an example. I opened the /etc/passwd file with vi:
The most important commands in vi are these:
Press i to enter the Insert mode. Now you can type in your text.
To leave the Insert mode press ESC.
To delete the character that is currently under the cursor you must press x (and you must not be in Insert mode because if you are you will insert the character x instead of deleting the character under the cursor). So if you have just opened the file with vi, you can immediately use x to delete characters. If you are in Insert mode you have to leave it first with ESC.
If you have made changes and want to save the file, press :x (again you must not be in Insert mode. If you are, press ESC to leave it).
If you haven't made any changes, press :q to leave the file (but you must not be in Insert mode).
If you have made changes, but want to leave the file without saving the changes, press :q! (but you must not be in Insert mode).
Please note that during all these operations you can use your keyboard's arrow keys to navigate the cursor through the text.
So that was all about the vi editor. Please note that the vim editor also works more or less in the same way, although if you'd like to know vim in depth, head [here](https://www.howtoforge.com/vim-basics).
## Editing Files with Nano Command Line Editor
Next up is the Nano editor. You can invoke it simply by running the 'nano' command:
nano
Here's how the nano UI looks like:
You can also launch the editor directly with a file.
nano [filename]
For example:
nano test.txt
The UI, as you can see, is broadly divided into four parts. The line at the top shows editor version, the file being edited, and the editing status. Then comes the actual edit area where you'll see the contents of the file. The highlighted line below the edit area shows important messages, and the last two lines are really helpful for beginners as they show keyboard shortcuts that you use to perform basic tasks in nano.
So here's a quick list of some of the shortcuts that you should know upfront.
Use arrow keys to navigate the text, the Backspace key to delete text, and **Ctrl+o** to save the changes you make. When you try saving the changes, nano will ask you for confirmation (see the line below the main editor area in screenshot below):
Note that at this stage, you also have an option to save in different OS formats. Pressing **Altd+d** enables the DOS format, while **Atl+m** enables the Mac format.
Press enter and your changes will be saved.
Moving on, to cut and paste lines of text use **Ctrl+k** and **Ctrl+u**. These keyboard shortcuts can also be used to cut and paste individual words, but you'll have to select the words first, something you can do by pressing **Alt+A** (with the cursor under the first character of the word) and then using the arrow to key select the complete word.
Now comes search operations. A simple search can be initiated using **Ctrl+w**, while a search and replace operation can be done using **Ctrl+\**.
So those were some of the basic features of nano that should give you a head start if you're new to the editor. For more details, read our comprehensive coverage [here](https://www.howtoforge.com/linux-nano-command/).
## Editing Files with Emacs Command Line Editor
Next comes **Emacs**. If not already, you can install the editor on your system using the following command:
sudo apt-get install emacs
Like nano, you can directly open a file to edit in emacs in the following way:
emacs -nw [filename]
**Note**: The **-nw** flag makes sure emacs launches in bash itself, instead of a separate window which is the default behavior.
For example:
`emacs -nw test.txt`
Here's the editor's UI:
Like nano, the emacs UI is also divided into several parts. The first part is the top menu area, which is similar to the one you'd see in graphical applications. Then comes the main edit area, where the text (of the file you've opened) is displayed.
Below the edit area sits another highlighted bar that shows things like name of the file, editing mode ('Text' in screenshot above), and status (** for modified, - for non-modified, and %% for read only). Then comes the final area where you provide input instructions, see output as well.
Now coming to basic operations, after making changes, if you want to save them, use **Ctrl+x** followed by **Ctrl+s**. The last section will show you a message saying something on the lines of '**Wrote ........' . **Here's an example:
Now, if you want to discard changes and quit the editor, use **Ctrl+x** followed by **Ctrl+c**. The editor will confirm this through a prompt - see screenshot below:
Type 'n' followed by a 'yes' and the editor will quit without saving the changes.
*Please note that Emacs represents 'Ctrl' as 'C' and 'Alt' as 'M'. So, for example, whenever you see something like C-x, it means Ctrl+x.*
As for other basic editing operations, deleting is simple, as it works through the Backspace/Delete keys that most of us are already used to. However, there are shortcuts that make your deleting experience smooth. For example, use **Ctrl+k** for deleting complete line, **Alt+d** for deleting a word, and **Alt+k** for a sentence.
Undoing is achieved through '**Ctrl+x**' followed by '**u**', and to re-do, press **Ctrl+g** followed by **Ctrl+_**. Use **Ctrl+s** for forward search and **Ctrl+r** for reverse search.
Moving on, to launch a replace operation, use the Alt+Shift+% keyboard shortcut. You'll be asked for the word you want to replace. Enter it. Then the editor will ask you for the replacement. For example, the following screenshot shows emacs asking user about the replacement for the word 'This'.
Input the replacement text and press Enter. For each replacement operation emacs will carry, it'll seek your permission first:
Press 'y' and the word will be replaced.
So that's pretty much all the basic editing operations that you should know to start using emacs. Oh, and yes, those menus at the top - we haven't discussed how to access them. Well, those can be accessed using the F10 key.
To come out of these menus, press the Esc key three times. |
9,494 | 发现 GPL 违规怎么办?多种法律救济可用 | https://opensource.com/article/18/3/gpl-and-license-contract-debate | 2018-03-29T13:30:51 | [
"GPL"
] | https://linux.cn/article-9494-1.html |
>
> 提要:最近一系列的法律案件为解决 GPL 违规问题提供了一些启示。
>
>
>

2017 年 4 月份,位于加州的一家美国联邦法院在 [Artifex Software, Inc. 诉 Hancom, Inc. 案](/article-8522-1.html)(2017 WL 1477373)中做出了一项[裁决](https://www.fsf.org/blogs/licensing/update-on-artifex-v-hancom-gnu-gpl-compliance-case-1),为针对 GPL 违规的救济方式提供了新的视角。令人遗憾的是,这起案件由于对法院裁定 GPL 是合同的一些错误解释而重新引发了已持续数十年之久的 GPL 究竟是许可还是合同的[辩论](/article-8971-1.html)。在研究救济措施的新进展之前,值得我们去重新审视为什么这种争辩依然存在。
当您考虑针对 GPL 违规的救济措施时,您可能会想到针对版权侵权主张权利,这种法律原则似乎适用于强制执行 GPL,因为版权侵权最有力的救济措施之一就是<ruby> 禁令救济 <rp> ( </rp> <rt> injunctive relief </rt> <rp> ) </rp></ruby>。对于 GPL 违规,这通常意味着防止侵权者分发违规软件。版权法还规定了实际和法定损害赔偿。相反,合同违约的救济措施相当有限,尽管也存在其他形式的救济,但通常只用于使一方完全避免造成损失。正如 Hancom 公司在其简易判决动议(虽然[被法院驳回](/article-8971-1.html))中所指出的,对于 GPL 软件来说,可能很难进行损失计算。
关于为什么 GPL 应该被视为许可而不是合同,已经有很多想法提出。例如,自由软件基金会(FSF)[一直认为](https://www.gnu.org/philosophy/enforcing-gpl.en.html) [GPL 不是合同](https://www.gnu.org/philosophy/enforcing-gpl.en.html)。合同和开源许可证之间的这种区别可以在协议的性质中找到:合同是契约或承诺的交换,而开源许可证则给出了使用许可证的条件。在 Jacobsen 诉 Katzer 案(535 F.3d 1373)中,法院支持这种看法,认为<ruby> 艺术许可协议 <rp> ( </rp> <rt> Artistic License </rt> <rp> ) </rp></ruby>列举了条件而非契约。有鉴于此,违反许可证将导致强有力救济措施的观点让许可/合同争辩陷入平息。
我们再来看 Artifex,该公司针对许可违规(根据上述分析)以及合同违约均提出了权利主张。有很多文章讨论了法院对 GPL 构成合同的分析,其中也包括 FSF [发表的文章](https://www.fsf.org/blogs/licensing/motion-to-dismiss-denied-in-recent-gnu-gpl-case),所以本文不会详细讨论这个看法。总结其分析结果,法院认为创建合同的要素(要约、接受和对价)得到了充分的陈述,其中大部分聚焦在对 GPL 的接受上(如果 GPL 被视为合同)。法院试图寻找 GPL 之外的接受证据,在 Hancom 制作的 Ghostscript 在线描述资料以及该产品的双重许可性质中已经找到。因此,法院认定可能存在合同。
在这里,我们关注的是法院合同分析之外的两个问题。首先,注意上面使用的“可能”这个词的重要性。Artifex 的判令来自于一个驳回动议,只评估 Artifex 主张的合理性而非优劣。法院对此事没有进一步的法律分析。所以如果这一点已经被提起诉讼,它可能会或可能没有找到合法的合同。既然这一点在第二个动议中已经得到了承认,并且[各方私下达成了和解](https://www.artifex.com/news/artifex-and-hancom-reach-settlement-over-ghostscript-open-source-dispute/),所以我们不知道这个争议会如何结束。
其次,尽管可能的合同权利主要很重要,但还有更有趣的第二个问题。在 Artifex 案之前,版权和合同的讨论也被搁置,其中一部分原因是由于<ruby> 优先适用 <rp> ( </rp> <rt> preemption </rt> <rp> ) </rp></ruby>问题。当美国国会颁布<ruby> 版权法 <rp> ( </rp> <rt> Copyright Act </rt> <rp> ) </rp></ruby>时,它取代了任何与其不一致的州法的权利主张,例如有的州法对等同权提供版权保护。如果州法的权利主张(例如违约)涉及与“(联邦)版权法本质上不同的权利”(引自 Artifex),则可以避免优先适用的问题。在确定是否存在优先适用问题时,法院会询问州法的权利主张是否有超出联邦版权法的“额外要素”。
在争论一个“额外要素”来证实其合同违约的权利主张时,Artifex 引用了 [Versata Software, Inc. 诉 Ameriprise Fin., Inc. 案](https://opensource.com/law/14/12/gplv2-court-decisions-versata)(2014 WL 950065)中版权法自身没有强加任何开源义务的主张。因此,任何“额外要素”(例如开源责任)都不在联邦版权法的范围之内,从而使得违反了州法中的合同权利主张变得可能。因此,Artifex 提出了这一概念以及与域外侵权有关的另一个概念(不在本文讨论范围),法院认定合同违约权利主张可以继续进行,同时允许进行合同法和版权法意义下的可能的救济,且不能对其中任意一个权利主张构成减损。
这一案件的最终效应仍有待观察,但结果是为针对 GPL 违规行为通过版权侵权和合同违约来实施多种救济措施铺平了道路。
---
作者简介:Chris Gillespie 就职于红帽公司(Redhat)。
译者简介:薛亮,集慧智佳知识产权咨询公司高级咨询师,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 200 | OK | Last April, a federal court in California [handed down a decision](https://www.fsf.org/blogs/licensing/update-on-artifex-v-hancom-gnu-gpl-compliance-case-1) in *Artifex Software, Inc. v. Hancom, Inc.,* 2017 WL 1477373 (N.D. Cal. 2017), adding a new perspective to the forms of remedies available for breach of the General Public License (GPL). Sadly, this case reignited the decades-old license/contract debate due to some misinterpretations under which the court ruled the GPL to be a contract. Before looking at the remedy developments, it’s worth reviewing why the license debate even exists.
When you think about remedies for a GPL breach, you probably imagine a claim for copyright infringement. This doctrine of law seems fit to enforce the GPL, as one of the most powerful remedies available for copyright infringement is injunctive relief. For GPL violations, this usually means preventing the infringer from distributing noncompliant software. Copyright law also provides for actual and statutory damages. In contrast, remedies for breach of contract are rather limited, typically only used to make a party whole from resulting losses, although other forms of recovery may be possible. For GPL software, loss calculations may be difficult, as Hancom pointed out in their motion for summary judgment (though this was rejected by the court).
There have been a number of ideas advanced as to why the GPL should be viewed as a license as opposed to a contract. For example, the Free Software Foundation [has long held that](https://www.gnu.org/philosophy/enforcing-gpl.en.html) the [GPL is not a contract](https://www.gnu.org/philosophy/enforcing-gpl.en.html). This distinction between a contract and an open source license can be found in the nature of the agreement: a contract is an exchange of *promises* or *covenants*, whereas an open source license gives *conditions* upon which the license may be used. Courts have supported this idea, with *Jacobsen v. Katzer*, 535 F.3d 1373 (Fed. Cir. 2008), holding that the Artistic License enumerated conditions and not covenants. In light of this, the license/contract debate has quieted with the idea that a breach of license is a viable cause of action with powerful remedies.
This leads us to *Artifex*, where a claim was brought for *both* breach of license (to be expected based on the above), *as well as* breach of contract. There have been a number of articles discussing the court’s contract analysis, including by the [FSF](https://www.fsf.org/blogs/licensing/motion-to-dismiss-denied-in-recent-gnu-gpl-case), so this article will not discuss this idea at length. To summarize the analysis, the court found that the elements creating a contract (offer, acceptance, and consideration) were sufficiently pleaded, with most of its focus on acceptance of the GPL if viewed as a contract. The court looked for indications of acceptance outside the GPL, finding it in online representations Hancom made about Ghostscript and the dual-licensing nature of the product. Accordingly, the court found that a contract *might* exist.
Here, we are focused on two issues beyond the court’s contract analysis. First, it’s important to note the significance of the word “might” as used above. *Artifex’s* order came from a motion to dismiss, assessing only the *plausibility* of Artifex’s claim, not the *merits* of it. The court conducted no further legal analysis on the matter, so if the point had actually been litigated, it may or may not have found a legal contract. Since the point was conceded in the second motion and [the parties settled privately](https://www.artifex.com/news/artifex-and-hancom-reach-settlement-over-ghostscript-open-source-dispute/), we won’t know how the argument would have played out.
Next, though a possible contract claim is important, there is a more interesting second issue. Pre-*Artifex*, the copyright versus contract discussion was also put in abeyance in part due to preemption. When Congress enacted the Copyright Act, it superseded any inconsistent state law claims, such as state-law copyright protections for equivalent rights. Preemption could be avoided if the state law claim (e.g., breach of contract) involved rights "qualitatively different from the [federal] copyright rights" (quoting Artifex). In determining whether preemption exists, a court will ask whether the state law claim has an “extra element” that reaches outside the scope of federal copyright law.
In arguing for an “extra element” to substantiate their breach of contract claim, Artifex relied on *Versata Software, Inc. v. Ameriprise Fin., Inc.*[, 2014 WL 950065 ](https://opensource.com/law/14/12/gplv2-court-decisions-versata)[(W.D. Tex. 2014](https://opensource.com/law/14/12/gplv2-court-decisions-versata)), which concluded that the copyright laws themselves do not impose any open source obligations. Thus any “extra elements” (such as an open source obligation) would be outside the scope of federal copyright law, thereby making a state-law breach of contract claim viable. Accordingly, *Artifex* advanced this concept along with another concept relating to extraterritorial infringement (which is outside the scope of this article), with the court finding that the breach of contract claim could proceed, allowing possible recovery under *both* contract and copyright law, without detracting from either claim.
The ultimate effect of this case remains to be seen, but the result paints a path of multiple remedies via copyright infringement and breach of contract for violations of the GPL.
## Comments are closed. |
9,495 | 如何在 Linux 中查找最大的 10 个文件 | https://www.2daygeek.com/how-to-find-search-check-print-top-10-largest-biggest-files-in-linux/ | 2018-03-30T16:08:00 | [
"find",
"du"
] | https://linux.cn/article-9495-1.html | 
当系统的磁盘空间不足时,您可能会使用 `df`、`du` 或 `ncdu` 命令进行检查,但这些命令只会显示当前目录的文件,并不会显示整个系统范围的文件。
您得花费大量的时间才能用上述命令获取系统中最大的文件,因为要进入到每个目录重复运行上述命令。
这种方法比较麻烦,也并不恰当。
如果是这样,那么该如何在 Linux 中找到最大的 10 个文件呢?
我在谷歌上搜索了很久,却没发现类似的文章,我反而看到了很多关于列出当前目录中最大的 10 个文件的文章。所以,我希望这篇文章对那些有类似需求的人有所帮助。
本教程中,我们将教您如何使用以下四种方法在 Linux 系统中查找最大的前 10 个文件。
### 方法 1
在 Linux 中没有特定的命令可以直接执行此操作,因此我们需要将多个命令结合使用。
```
# find / -type f -print0 | xargs -0 du -h | sort -rh | head -n 10
1.4G /swapfile
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
93M /usr/lib/firefox/libxul.so
84M /var/lib/snapd/snaps/core_3604.snap
84M /var/lib/snapd/snaps/core_3440.snap
84M /var/lib/snapd/snaps/core_3247.snap
```
详解:
* `find`:在目录结构中搜索文件的命令
* `/`:在整个系统(从根目录开始)中查找
* `-type`:指定文件类型
+ `f`:普通文件
* `-print0`:在标准输出显示完整的文件名,其后跟一个空字符(null)
* `|`:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
* `xargs`:将标准输入转换成命令行参数的命令
* `-0`:以空字符(null)而不是空白字符(LCTT 译者注:即空格、制表符和换行)来分割记录
* `du -h`:以可读格式计算磁盘空间使用情况的命令
* `sort`:对文本文件进行排序的命令
* `-r`:反转结果
* `-h`:用可读格式打印输出
* `head`:输出文件开头部分的命令
* `n -10`:打印前 10 个文件
### 方法 2
这是查找 Linux 系统中最大的前 10 个文件的另一种方法。我们依然使用多个命令共同完成这个任务。
```
# find / -type f -exec du -Sh {} + | sort -rh | head -n 10
1.4G /swapfile
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
93M /usr/lib/firefox/libxul.so
84M /var/lib/snapd/snaps/core_3604.snap
84M /var/lib/snapd/snaps/core_3440.snap
84M /var/lib/snapd/snaps/core_3247.snap
```
详解:
* `find`:在目录结构中搜索文件的命令
* `/`:在整个系统(从根目录开始)中查找
* `-type`:指定文件类型
+ `f`:普通文件
* `-exec`:在所选文件上运行指定命令
* `du`:计算文件占用的磁盘空间的命令
* `-S`:不包含子目录的大小
* `-h`:以可读格式打印
* `{}`:递归地查找目录,统计每个文件占用的磁盘空间
* `|`:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
* `sort`:对文本文件进行按行排序的命令
* `-r`:反转结果
* `-h`:用可读格式打印输出
* `head`:输出文件开头部分的命令
* `n -10`:打印前 10 个文件
### 方法 3
这里介绍另一种在 Linux 系统中搜索最大的前 10 个文件的方法。
```
# find / -type f -print0 | xargs -0 du | sort -n | tail -10 | cut -f2 | xargs -I{} du -sh {}
84M /var/lib/snapd/snaps/core_3247.snap
84M /var/lib/snapd/snaps/core_3440.snap
84M /var/lib/snapd/snaps/core_3604.snap
93M /usr/lib/firefox/libxul.so
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
1.4G /swapfile
```
详解:
* `find`:在目录结构中搜索文件的命令
* `/`:在整个系统(从根目录开始)中查找
* `-type`:指定文件类型
+ `f`:普通文件
* `-print0`:输出完整的文件名,其后跟一个空字符(null)
* `|`:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
* `xargs`:将标准输入转换成命令行参数的命令
* `-0`:以空字符(null)而不是空白字符来分割记录
* `du`:计算文件占用的磁盘空间的命令
* `sort`:对文本文件进行按行排序的命令
* `-n`:根据数字大小进行比较
* `tail -10`:输出文件结尾部分的命令(最后 10 个文件)
* `cut`:从每行删除特定部分的命令
* `-f2`:只选择特定字段值
* `-I{}`:将初始参数中出现的每个替换字符串都替换为从标准输入读取的名称
* `-s`:仅显示每个参数的总和
* `-h`:用可读格式打印输出
* `{}`:递归地查找目录,统计每个文件占用的磁盘空间
### 方法 4
还有一种在 Linux 系统中查找最大的前 10 个文件的方法。
```
# find / -type f -ls | sort -k 7 -r -n | head -10 | column -t | awk '{print $7,$11}'
1494845440 /swapfile
1085984380 /home/magi/ubuntu-17.04-desktop-amd64.iso
591003648 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
395770383 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
394891761 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
103999072 /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
97356256 /usr/lib/firefox/libxul.so
87896064 /var/lib/snapd/snaps/core_3604.snap
87793664 /var/lib/snapd/snaps/core_3440.snap
87089152 /var/lib/snapd/snaps/core_3247.snap
```
详解:
* `find`:在目录结构中搜索文件的命令
* `/`:在整个系统(从根目录开始)中查找
* `-type`:指定文件类型
+ `f`:普通文件
* `-ls`:在标准输出中以 `ls -dils` 的格式列出当前文件
* `|`:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
* `sort`:对文本文件进行按行排序的命令
* `-k`:按指定列进行排序
* `-r`:反转结果
* `-n`:根据数字大小进行比较
* `head`:输出文件开头部分的命令
* `-10`:打印前 10 个文件
* `column`:将其输入格式化为多列的命令
* `-t`:确定输入包含的列数并创建一个表
* `awk`:模式扫描和处理语言
* `'{print $7,$11}'`:只打印指定的列
---
via: <https://www.2daygeek.com/how-to-find-search-check-print-top-10-largest-biggest-files-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 译者:[jessie-pang](https://github.com/jessie-pang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,496 | 我是如何创造“开源”这个词的 | https://opensource.com/article/18/2/coining-term-open-source-software | 2018-03-30T09:47:00 | [
"开源"
] | https://linux.cn/article-9496-1.html |
>
> Christine Peterson 最终公开讲述了二十年前那决定命运的一天。
>
>
>

2 月 3 日是术语“<ruby> <a href="https://opensource.com/resources/what-open-source"> 开源软件 </a> <rt> open source software </rt></ruby>”创立 20 周年的纪念日。由于开源软件渐受欢迎,并且为这个时代强有力的重要变革提供了动力,我们仔细反思了它的初生到崛起。
我是 “开源软件” 这个词的始作俑者,它是我在<ruby> 前瞻协会 <rt> Foresight Institute </rt></ruby>担任执行董事时提出的。我不像其它人是个软件开发者,所以感谢 Linux 程序员 Todd Anderson 对这个术语的支持并将它提交小组讨论。
这是我对于它如何想到的,如何提出的,以及后续影响的记叙。当然,还有一些有关该术语的其它记叙,例如 Eric Raymond 和 Richard Stallman 写的,而我的,则写于 2006 年 1 月 2 日。
但直到今天,我才公诸于世。
---
推行术语“开源软件”是特别为了让新手和商业人士更加理解这个领域,对它的推广被认为对于更广泛的用户社区很有必要。早期的称呼“<ruby> 自由软件 <rt> free software </rt></ruby>”不适用并非是因为含有政治意义,而是对于新手来说会误导关注于价格。所以需要一个关注于关键的源代码,而且不会让新用户混淆概念的术语。第一个在正确时间出现并且满足这些要求的术语被迅速接受了:<ruby> 开源 <rt> open source </rt></ruby>。
这个术语很长一段时间被用在“情报”(即间谍活动)活动中,但据我所知,确实在 1998 年以前软件领域从未使用过该术语。下面这个就是讲述了术语“开源软件”如何流行起来,并且变成了一项产业和一场运动名称的故事。
### 计算机安全会议
在 1997 年的晚些时候,<ruby> 前瞻协会 <rt> Foresight Institute </rt></ruby>开始举办周会讨论计算机安全问题。这个协会是一个非盈利性智库,它专注于纳米技术和人工智能,而二者的安全性及可靠性取决于软件安全。我们确定了自由软件是一个改进软件安全可靠性且具有发展前景的方法,并将寻找推动它的方式。 对自由软件的兴趣开始在编程社区外开始增长,而且越来越清晰,一个改变世界的机会正在来临。然而,该怎么做我们并不清楚,因为我们当时正在摸索中。
在这些会议中,由于“容易混淆”的因素,我们讨论了采用一个新术语的必要性。观点主要如下:对于那些新接触“自由软件”的人会把 “free” 当成了价格上的 “免费” 。老资格的成员们开始解释,通常像下面所说的:“我们指的是 ‘freedom’ 中的自由,而不是‘免费啤酒’的免费。”在这一点上,关于软件方面的讨论就会变成了关于酒精饮料价格的讨论。问题不在于解释不了它的含义 —— 问题在于重要概念的术语不应该使新手们感到困惑。所以需要一个更清晰的术语。自由软件一词并没有政治上的问题;问题在于这个术语不能对新人清晰表明其概念。
### 开放的网景
1998 年 2 月 2 日,Eric Raymond 访问网景公司,并与它一起计划采用自由软件风格的许可证发布其浏览器的源代码。我们那晚在前瞻协会位于<ruby> 罗斯阿尔托斯 <rt> Los Altos </rt></ruby>的办公室开会,商讨并完善了我们的计划。除了 Eric 和我,积极参与者还有 Brian Behlendorf、Michael Tiemann、Todd Anderson、Mark S. Miller 和 Ka-Ping Yee。但在那次会议上,这一领域仍然被描述成“自由软件”,或者用 Brian 的话说, 叫“可获得源代码的” 软件。
在这个镇上,Eric 把前瞻协会作为行动的大本营。他访问行程期间,他接到了网景的法律和市场部门人员的电话。当他聊完后,我要求和他们(一男一女,可能是 Mitchell Baker)通电话,以便我告诉他们一个新的术语的必要性。他们原则上立即同意了,但我们在具体术语上并未达成一致。
在那周的会议中,我始终专注于起一个更好的名字并提出了 “开源软件”一词。 虽然不太理想,但我觉得足够好了。我找到至少四个人征求意见:Eric Drexler、Mark Miller 以及 Todd Anderson 都喜欢它,而一个从事市场公关的朋友觉得术语 “open” 被滥用了,并且觉得我们能找到一个更好。理论上他是对的,可我想不出更好的了,所以我想试着先推广它。事后想起来,我应该直接向 Eric Raymond 提议,但在那时我并不是很了解他,所以我采取了间接的策略。
Todd 强烈同意需要一个新的术语,并提供协助推广它。这很有帮助,因为作为一个非编程人员,我在自由软件社区的影响力很弱。我从事的纳米技术教育是一个加分项,但不足以让我在自由软件问题上非常得到重视。而作为一个 Linux 程序员,Todd 的话更容易被倾听。
### 关键性会议
那周稍晚时候,1998 年的 2 月 5 日,一伙人在 VA Research 进行头脑风暴商量对策。与会者除了 Eric Raymond、Todd 和我之外,还有 Larry Augustin、Sam Ockman,和 Jon Hall (“maddog”)通过电话参与。
会议的主要议题是推广策略,特别是要联系的公司。 我几乎没说什么,但是一直在寻找机会介绍提议的术语。我觉得我直接说“你们这些技术人员应当开始使用我的新术语了。”没有什么用。大多数与会者不认识我,而且据我所知,他们可能甚至不同意现在就迫切需要一个新术语。
幸运的是,Todd 一直留心着。他没有主张社区应该用哪个特定的术语,而是面对社区这些固执的人间接地做了一些事。他仅仅是在其它话题中使用了那个术语 —— 把它放进对话里看看会发生什么。我很紧张,期待得到回应,但是起初什么也没有。讨论继续进行原来的话题。似乎只有他和我注意了这个术语的使用。
不仅如此——模因演化(LCTT 译注:人类学术语)在起作用。几分钟后,另一个人使用了这个术语,显然没有注意到,而在继续进行话题讨论。Todd 和我用眼角互觑了一下:是的,我们都注意到发生了什么。我很激动——它或许有用!但我保持了安静:我在小组中仍然地位不高。可能有些人都奇怪为什么 Eric 会邀请我。
临近会议尾声,可能是 Todd 或 Eric,明确提出了[术语问题](https://wiki2.org/en/Alternative_terms_for_free_software)。Maddog 提及了一个早期的术语“可自由分发的”,和一个新的术语“合作开发的”。Eric 列出了“自由软件”、“开源软件”和“软件源”作为主要选项。Todd 提议使用“开源”,然后 Eric 支持了他。我没说太多,就让 Todd 和 Eric(轻松、非正式地)就“开源”这个名字达成了共识。显然对于大多数与会者,改名并不是在这讨论的最重要议题;那只是一个次要的相关议题。从我的会议记录中看只有大约 10% 的内容是术语的。
但是我很高兴。在那有许多社区的关键领导人,并且他们喜欢这新名字,或者至少没反对。这是一个好的信号。可能我帮不上什么忙; Eric Raymond 更适合宣传新的名称,而且他也这么做了。Bruce Perens 立即表示支持,帮助建立了 [Opensource.org](https://opensource.org/) 并在新术语的宣传中发挥了重要作用。
为了让这个名字获得认同,Tim O'Reilly 同意在代表社区的多个项目中积极使用它,这是很必要,甚至是非常值得的。并且在官方即将发布的 Netscape Navigator(网景浏览器)代码中也使用了此术语。 到二月底, O'Reilly & Associates 还有网景公司(Netscape) 已经开始使用新术语。
### 名字的宣传
在那之后的一段时间,这条术语由 Eric Raymond 向媒体推广,由 Tim O'Reilly 向商业推广,并由二人向编程社区推广,它似乎传播的相当快。
1998 年 4 月 17 日,Tim O'Reilly 召集了该领域的一些重要领袖的峰会,宣布为第一次 “[自由软件峰会](http://www.oreilly.com/pub/pr/636)” ,在 4 月14 日之后,它又被称作首届 “[开源峰会](http://www.oreilly.com/pub/pr/796)”。
这几个月对于开源来说是相当激动人心的。似乎每周都有一个新公司宣布加入计划。读 Slashdot(LCTT 译注:科技资讯网站)已经成了一个必需操作,甚至对于那些像我一样只能外围地参与者亦是如此。我坚信新术语能对快速传播到商业很有帮助,能被公众广泛使用。
尽管在谷歌搜索一下表明“开源”比“自由软件”出现的更多,但后者仍然有大量的使用,在和偏爱它的人们沟通的时候我们应该包容。
### 快乐的感觉
当 Eric Raymond 写的有关术语更改的[早期声明](https://ipfs.io/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Alternative_terms_for_free_software.html)被发布在了<ruby> 开源促进会 <rt> Open Source Initiative </rt></ruby>的网站上时,我被列在 VA 头脑风暴会议的名单上,但并不是作为术语的创始人。这是我自己的失误,我没告诉 Eric 细节。我的想法就是让它过去吧,我呆在幕后就好,但是 Todd 不这样认为。他认为我总有一天会为被称作“开源软件”这个名词的创造者而高兴。他向 Eric 解释了这个情况,Eric 及时更新了网站。
想出这个短语只是一个小贡献,但是我很感激那些把它归功于我的人。每次我听到它(现在经常听到了),它都给我些许的感动。
说服社区的巨大功劳要归功于 Eric Raymond 和 Tim O'Reilly,是他们让这一切成为可能。感谢他们对我的归功,并感谢 Todd Anderson 所做的一切。以上内容并非完整的开源一词的历史,让我对很多没有提及的关键人士表示歉意。那些寻求更完整讲述的人应该参考本文和网上其他地方的链接。
### 关于作者

Christine Peterson 撰写、举办讲座,并向媒体介绍未来强大的技术,特别是在纳米技术,人工智能和长寿方面。她是纳米科技公益组织前瞻协会的共同创始人和前任主席。前瞻协会向公众、技术团体和政策制定者提供未来强大的技术的教育以及告诉它是如何引导他们的长期影响。她服务于[机器智能](http://intelligence.org/)咨询委员会……[更多关于 Christine Peterson](https://opensource.com/users/christine-peterson)
---
via: <https://opensource.com/article/18/2/coining-term-open-source-software>
作者:[Christine Peterson](https://opensource.com/users/christine-peterson) 译者:[fuzheng1998](https://github.com/fuzheng1998) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In a few days, on February 3, the 20th anniversary of the introduction of the term "[open source software](https://opensource.com/resources/what-open-source)" is upon us. As open source software grows in popularity and powers some of the most robust and important innovations of our time, we reflect on its rise to prominence.
I am the originator of the term "open source software" and came up with it while executive director at Foresight Institute. Not a software developer like the rest, I thank Linux programmer Todd Anderson for supporting the term and proposing it to the group.
This is my account of how I came up with it, how it was proposed, and the subsequent reactions. Of course, there are a number of accounts of the coining of the term, for example by Eric Raymond and Richard Stallman, yet this is mine, written on January 2, 2006.
It has never been published, until today.
The introduction of the term "open source software" was a deliberate effort to make this field of endeavor more understandable to newcomers and to business, which was viewed as necessary to its spread to a broader community of users. The problem with the main earlier label, "free software," was not its political connotations, but that—to newcomers—its seeming focus on price is distracting. A term was needed that focuses on the key issue of source code and that does not immediately confuse those new to the concept. The first term that came along at the right time and fulfilled these requirements was rapidly adopted: open source.
This term had long been used in an "intelligence" (i.e., spying) context, but to my knowledge, use of the term with respect to software prior to 1998 has not been confirmed. The account below describes how the term [open source software](https://opensource.org/osd) caught on and became the name of both an industry and a movement.
## Meetings on computer security
In late 1997, weekly meetings were being held at Foresight Institute to discuss computer security. Foresight is a nonprofit think tank focused on nanotechnology and artificial intelligence, and software security is regarded as central to the reliability and security of both. We had identified free software as a promising approach to improving software security and reliability and were looking for ways to promote it. Interest in free software was starting to grow outside the programming community, and it was increasingly clear that an opportunity was coming to change the world. However, just how to do this was unclear, and we were groping for strategies.
At these meetings, we discussed the need for a new term due to the confusion factor. The argument was as follows: those new to the term "free software" assume it is referring to the price. Oldtimers must then launch into an explanation, usually given as follows: "We mean free as in freedom, not free as in beer." At this point, a discussion on software has turned into one about the price of an alcoholic beverage. The problem was not that explaining the meaning is impossible—the problem was that the name for an important idea should not be so confusing to newcomers. A clearer term was needed. No political issues were raised regarding the free software term; the issue was its lack of clarity to those new to the concept.
## Releasing Netscape
On February 2, 1998, Eric Raymond arrived on a visit to work with Netscape on the plan to release the browser code under a free-software-style license. We held a meeting that night at Foresight's office in Los Altos to strategize and refine our message. In addition to Eric and me, active participants included Brian Behlendorf, Michael Tiemann, Todd Anderson, Mark S. Miller, and Ka-Ping Yee. But at that meeting, the field was still described as free software or, by Brian, "source code available" software.
While in town, Eric used Foresight as a base of operations. At one point during his visit, he was called to the phone to talk with a couple of Netscape legal and/or marketing staff. When he was finished, I asked to be put on the phone with them—one man and one woman, perhaps Mitchell Baker—so I could bring up the need for a new term. They agreed in principle immediately, but no specific term was agreed upon.
Between meetings that week, I was still focused on the need for a better name and came up with the term "open source software." While not ideal, it struck me as good enough. I ran it by at least four others: Eric Drexler, Mark Miller, and Todd Anderson liked it, while a friend in marketing and public relations felt the term "open" had been overused and abused and believed we could do better. He was right in theory; however, I didn't have a better idea, so I thought I would try to go ahead and introduce it. In hindsight, I should have simply proposed it to Eric Raymond, but I didn't know him well at the time, so I took an indirect strategy instead.
Todd had agreed strongly about the need for a new term and offered to assist in getting the term introduced. This was helpful because, as a non-programmer, my influence within the free software community was weak. My work in nanotechnology education at Foresight was a plus, but not enough for me to be taken very seriously on free software questions. As a Linux programmer, Todd would be listened to more closely.
## The key meeting
Later that week, on February 5, 1998, a group was assembled at VA Research to brainstorm on strategy. Attending—in addition to Eric Raymond, Todd, and me—were Larry Augustin, Sam Ockman, and attending by phone, Jon "maddog" Hall.
The primary topic was promotion strategy, especially which companies to approach. I said little, but was looking for an opportunity to introduce the proposed term. I felt that it wouldn't work for me to just blurt out, "All you technical people should start using my new term." Most of those attending didn't know me, and for all I knew, they might not even agree that a new term was greatly needed, or even somewhat desirable.
Fortunately, Todd was on the ball. Instead of making an assertion that the community should use this specific new term, he did something less directive—a smart thing to do with this community of strong-willed individuals. He simply used the term in a sentence on another topic—just dropped it into the conversation to see what happened. I went on alert, hoping for a response, but there was none at first. The discussion continued on the original topic. It seemed only he and I had noticed the usage.
Not so—memetic evolution was in action. A few minutes later, one of the others used the term, evidently without noticing, still discussing a topic other than terminology. Todd and I looked at each other out of the corners of our eyes to check: yes, we had both noticed what happened. I was excited—it might work! But I kept quiet: I still had low status in this group. Probably some were wondering why Eric had invited me at all.
Toward the end of the meeting, the [question of terminology](https://wiki2.org/en/Alternative_terms_for_free_software) was brought up explicitly, probably by Todd or Eric. Maddog mentioned "freely distributable" as an earlier term, and "cooperatively developed" as a newer term. Eric listed "free software," "open source," and "sourceware" as the main options. Todd advocated the "open source" model, and Eric endorsed this. I didn't say much, letting Todd and Eric pull the (loose, informal) consensus together around the open source name. It was clear that to most of those at the meeting, the name change was not the most important thing discussed there; a relatively minor issue. Only about 10% of my notes from this meeting are on the terminology question.
But I was elated. These were some key leaders in the community, and they liked the new name, or at least didn't object. This was a very good sign. There was probably not much more I could do to help; Eric Raymond was far better positioned to spread the new meme, and he did. Bruce Perens signed on to the effort immediately, helping set up [Opensource.org](https://opensource.org/) and playing a key role in spreading the new term.
For the name to succeed, it was necessary, or at least highly desirable, that Tim O'Reilly agree and actively use it in his many projects on behalf of the community. Also helpful would be use of the term in the upcoming official release of the Netscape Navigator code. By late February, both O'Reilly & Associates and Netscape had started to use the term.
## Getting the name out
After this, there was a period during which the term was promoted by Eric Raymond to the media, by Tim O'Reilly to business, and by both to the programming community. It seemed to spread very quickly.
On April 7, 1998, Tim O'Reilly held a meeting of key leaders in the field. Announced in advance as the first "[Freeware Summit](http://www.oreilly.com/pub/pr/636)," by April 14 it was referred to as the first "[Open Source Summit](http://www.oreilly.com/pub/pr/796)."
These months were extremely exciting for open source. Every week, it seemed, a new company announced plans to participate. Reading Slashdot became a necessity, even for those like me who were only peripherally involved. I strongly believe that the new term was helpful in enabling this rapid spread into business, which then enabled wider use by the public.
A quick Google search indicates that "open source" appears more often than "free software," but there still is substantial use of the free software term, which remains useful and should be included when communicating with audiences who prefer it.
## A happy twinge
When an [early account](https://ipfs.io/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Alternative_terms_for_free_software.html) of the terminology change written by Eric Raymond was posted on the Open Source Initiative website, I was listed as being at the VA brainstorming meeting, but not as the originator of the term. This was my own fault; I had neglected to tell Eric the details. My impulse was to let it pass and stay in the background, but Todd felt otherwise. He suggested to me that one day I would be glad to be known as the person who coined the name "open source software." He explained the situation to Eric, who promptly updated his site.
Coming up with a phrase is a small contribution, but I admit to being grateful to those who remember to credit me with it. Every time I hear it, which is very often now, it gives me a little happy twinge.
The big credit for persuading the community goes to Eric Raymond and Tim O'Reilly, who made it happen. Thanks to them for crediting me, and to Todd Anderson for his role throughout. The above is not a complete account of open source history; apologies to the many key players whose names do not appear. Those seeking a more complete account should refer to the links in this article and elsewhere on the net.
## 20 Comments |
9,497 | 命令行乐趣:嘲讽输错 Bash 命令的用户 | https://www.cyberciti.biz/howto/insult-linux-unix-bash-user-when-typing-wrong-command/ | 2018-03-30T10:26:59 | [
"sudo",
"嘲讽"
] | https://linux.cn/article-9497-1.html | 
你可以通过配置 `sudo` 命令去嘲讽输入错误密码的用户。但是现在,当用户在 shell 输错命令时,就能嘲讽他了(滥用?)。
### 你好 bash-insulter
来自 Github 页面:
>
> 当用户键入错误命令,随机嘲讽。它使用了一个 bash4.x. 版本的全新内置错误处理函数,叫 `command_not_found_handle`。
>
>
>
### 安装
键入下列 git 命令克隆一个仓库:
```
git clone https://github.com/hkbakke/bash-insulter.git bash-insulter
```
示例输出:
```
Cloning into 'bash-insulter'...
remote: Counting objects: 52, done.
remote: Compressing objects: 100% (49/49), done.
remote: Total 52 (delta 12), reused 12 (delta 2), pack-reused 0
Unpacking objects: 100% (52/52), done.
```
用文本编辑器,比如说使用 `vi`,编辑你的 `~/.bashrc` 或者 `/etc/bash.bashrc` 文件:
```
$ vi ~/.bashrc
```
在其后追加这一行(具体了解请查看 [if..else..fi 声明](https://bash.cyberciti.biz/guide/If..else..fi) 和 [source 命令](https://bash.cyberciti.biz/guide/Source_command)):
```
if [ -f $HOME/bash-insulter/src/bash.command-not-found ]; then
source $HOME/bash-insulter/src/bash.command-not-found
fi
```
保存并关闭文件。重新登录,如果不想退出账号也可以手动运行它:
```
$ . $HOME/bash-insulter/src/bash.command-not-found
```
### 如何使用它?
尝试键入一些无效命令:
```
$ ifconfigs
$ dates
```
示例输出:
[](https://www.cyberciti.biz/media/new/cms/2017/11/bash-insulter-Insults-the-user-when-typing-wrong-command.jpg)
### 自定义
你需要编辑 `$HOME/bash-insulter/src/bash.command-not-found`:
```
$ vi $HOME/bash-insulter/src/bash.command-not-found
```
示例代码:
```
command_not_found_handle () {
local INSULTS=(
"Boooo!"
"Don't you know anything?"
"RTFM!"
"Hahaha, n00b!"
"Wow! That was impressively wrong!"
"What are you doing??"
"Pathetic"
"...and this is the best you can do??"
"The worst one today!"
"n00b alert!"
"Your application for reduced salary has been sent!"
"lol"
"u suk"
"lol... plz"
"plz uninstall"
"And the Darwin Award goes to.... ${USER}!"
"ERROR_INCOMPETENT_USER"
"Incompetence is also competence"
"Bad."
"Fake it till you make it!"
"What is this...? Amateur hour!?"
"Come on! You can do it!"
"Nice try."
"What if... you type an actual command the next time!"
"What if I told you... it is possible to type valid commands."
"Y u no speak computer???"
"This is not Windows"
"Perhaps you should leave the command line alone..."
"Please step away from the keyboard!"
"error code: 1D10T"
"ACHTUNG! ALLES TURISTEN UND NONTEKNISCHEN LOOKENPEEPERS! DAS KOMPUTERMASCHINE IST NICHT FÜR DER GEFINGERPOKEN UND MITTENGRABEN! ODERWISE IST EASY TO SCHNAPPEN DER SPRINGENWERK, BLOWENFUSEN UND POPPENCORKEN MIT SPITZENSPARKEN. IST NICHT FÜR GEWERKEN BEI DUMMKOPFEN. DER RUBBERNECKEN SIGHTSEEREN KEEPEN DAS COTTONPICKEN HÄNDER IN DAS POCKETS MUSS. ZO RELAXEN UND WATSCHEN DER BLINKENLICHTEN."
"Pro tip: type a valid command!"
)
# 设置“随机”种子发生器
RANDOM=$(date +%s%N)
VALUE=$((${RANDOM}%2))
if [[ ${VALUE} -lt 1 ]]; then
printf "\n $(tput bold)$(tput setaf 1)$(shuf -n 1 -e "${INSULTS[@]}")$(tput sgr0)\n\n"
fi
echo "-bash: $1: command not found"
# 无效命令,常规返回已存在的代码
return 127
}
```
### 赠品:sudo 嘲讽
编辑 `sudoers` 文件:
```
$ sudo visudo
```
追加下面这一行:
```
Defaults insults
```
或者像下面尾行增加一句嘲讽语:
```
Defaults !lecture,tty_tickets,!fqdn,insults
```
这是我的文件:
```
Defaults env_reset
Defaults mail_badpass
Defaults secure_path = "/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
## If set, sudo will insult users when they enter an incorrect password. ##
Defaults insults
# Host alias specification
# User alias specification
# Cmnd alias specification
# User privilege specification
root ALL = (ALL:ALL) ALL
# Members of the admin group may gain root privileges
% admin ALL = (ALL) ALL
# Allow members of group sudo to execute any command
% sudo ALL = (ALL:ALL) ALL
# See sudoers(5) for more information on "#include" directives:
#includedir /etc/sudoers.d
```
试一试:
```
$ sudo -k # 清除缓存,从头开始
$ sudo ls /root/
$ sudo -i
```
样例对话:
[](https://www.cyberciti.biz/media/new/cms/2017/11/sudo-insults.jpg)
### 赠品:你好 sl
[sl 或是 UNIX 经典捣蛋软件](https://www.cyberciti.biz/tips/displays-animations-when-accidentally-you-type-sl-instead-of-ls.html) 游戏。当你错误的把 `ls` 输入成 `sl`,将会有一辆蒸汽机车穿过你的屏幕。
```
$ sl
```
[](https://www.cyberciti.biz/tips/displays-animations-when-accidentally-you-type-sl-instead-of-ls.html)
---
via: <https://www.cyberciti.biz/howto/insult-linux-unix-bash-user-when-typing-wrong-command/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,498 | 你没听过的 10 个免费的 Linux 生产力应用程序 | https://www.maketecheasier.com/free-linux-productivity-apps-you-havent-heard-of/ | 2018-03-30T22:24:00 | [
"生产力"
] | https://linux.cn/article-9498-1.html | 
高效率的应用程序确实可以让你工作变得更轻松。如果你是一位 Linux 用户,这 10 个不太知名的 Linux 桌面应用程序可以帮助到你。事实上,Linux 用户可能已经听说过这个列表上的所有应用,但对于那些只用过主流应用的人来说,应该是不知道这些应用的。
### 1. Tomboy/Gnote

[Tomboy](https://wiki.gnome.org/Apps/Tomboy) 是一个简单的便签应用。它不仅仅适用于 Linux,你也可以在 Unix、Windows 和 macOS 上获得它。Tomboy 很容易使用——你写一个便条,选择是否让它粘贴在你的桌面上,当你完成它时删除它。
### 2. MyNotex

如果你想要一个更多功能的便签,但是仍喜欢一个小而简单的应用程序,而不是一个巨大的套件,请看看 [MyNotex](https://sites.google.com/site/mynotex/)。除了简单的笔记和检索之外,它还带有一些不错的功能,例如格式化、键盘快捷键和附件等等。你也可以将其用作图片管理器。
### 3. Trojitá

尽管你可以没有桌面电子邮件客户端,但如果你想要一个的话,在几十个的桌面电子邮件客户端里,请尝试下 [Trojita](http://trojita.flaska.net/)。这有利于生产力,因为它是一个快速而轻量级的电子邮件客户端,但它提供了一个好的电子邮件客户端所必须具备的所有功能(以及更多)。
### 4. Kontact

个人信息管理器(PIM)是一款出色的生产力工具。我的个人喜好是 [Kontact](https://userbase.kde.org/Kontact)。尽管它已经有几年没有更新,但它仍然是一个非常有用的 PIM 工具,用于管理电子邮件、地址簿、日历、任务、新闻源等。Kontact 是一个 KDE 原生程序,但你也可以在其他桌面上使用它。
### 5. Osmo

[Osmo](http://clayo.org/osmo/) 是一款更先进的应用,包括日历、任务、联系人和便签功能。它还附带一些额外的功能,比如加密私有数据备份和地图上的地理位置,以及对便签、任务、联系人等的强大搜索功能。
### 6. Catfish

没有好的搜索工具就没有高生产力。[Catfish](http://www.twotoasts.de/index.php/catfish/) 是一个必须尝试的搜索工具。它是一个 GTK+ 工具,非常快速,轻量级。Catfish 会利用 Zeitgeist 的自动完成功能,你还可以按日期和类型过滤搜索结果。
### 7. KOrganizer

[KOrganizer](https://userbase.kde.org/KOrganizer) 是我上面提到的 Kontact 应用程序的日历和计划组件。如果你不需要完整的 PIM 应用程序,只需要日历和日程安排,则可以使用 KOrganizer。KOrganizer 提供快速的待办事项和快速事件条目,以及事件和待办事项的附件。
### 8. Evolution

如果你不是 KDE 应用程序的粉丝,但你仍然需要一个好的 PIM,那么试试 GNOME 的 [Evolution](https://help.gnome.org/users/evolution/3.22/intro-main-window.html.en)。Evolution 并不是一个你从没听过的少见的应用程序,但因为它有用,所以它出现在这个列表中。也许你已经听说过 Evolution 是一个电子邮件客户端,但它远不止于此——你可以用它来管理日历、邮件、地址簿和任务。
### 9. Freeplane

我不知道你们中的大多数是否每天都使用思维导图软件,但是如果你使用,请选择 [Freeplane](https://www.freeplane.org/wiki/index.php/Home)。这是一款免费的思维导图和知识管理软件,可用于商业或娱乐。你可以创建笔记,将其排列在云图或图表中,使用日历和提醒设置任务等。
### 10. Calligra Flow

最后,如果你需要流程图和图表工具,请尝试 [Calligra Flow](https://www.calligra.org/flow/)。你可以将其视为开放源代码的 [Microsoft Visio](https://www.maketecheasier.com/5-best-free-alternatives-to-microsoft-visio/) 替代品,但 Calligra Flow 不提供 Viso 提供的所有特性。不过,你可以使用它来创建网络图、组织结构图、流程图等等。
生产力工具不仅可以加快工作速度,还可以让你更有条理。我敢打赌,几乎没有人不使用某种形式的生产力工具。尝试这里列出的应用程序可以使你的工作效率更高,还能让你的生活至少轻松一些。
---
via: <https://www.maketecheasier.com/free-linux-productivity-apps-you-havent-heard-of/>
作者:[Ada Ivanova](https://www.maketecheasier.com/author/adaivanoff/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Productivity apps can really make your work easier. If you are a Linux user, these 10 lesser-known free productivity apps for the Linux desktop can help you.. As a matter of fact, it’s possible keen Linux users have heard of all the apps on the list, but for somebody who hasn’t gone beyond the main apps, these should be unknown.
## 1. Tomboy/Gnote
[Tomboy](https://wiki.gnome.org/Apps/Tomboy) is a simple note-taking app. It’s not for Linux only – you can get it for Unix, Windows, and macOS, too. Tomboy is pretty straightforward to use – you write a note, choose whether to make it sticky on your desktop, and delete it when you are done with it.
## 2. MyNotex
If you want a note-taker with more features but still prefer a small and simple app rather than a huge suite, check [MyNotex](https://sites.google.com/site/mynotex/). In addition to simple note taking and retrieval, it comes with some nice perks, such as formatting abilities, keyboard shortcuts, and attachments, to name a few. You can also use it as a picture manager.
## 3. Trojitá
Though you can live without a desktop email client, if you are used to having one, out of the dozens that are available, try [Trojitá](https://trojita.flaska.net/). It’s good for productivity because it is a fast and lightweight email client, yet it offers all the basics (and more) a good email client must have.
## 4. Kontact
A Personal Information Manager (PIM) is a great productivity tool. My personal preferences go to [Kontact](https://userbase.kde.org/Kontact). Even though it hasn’t been updated in years, it’s still a very useful PIM tool to manage emails, address books, calendars, tasks, news feeds, etc. Kontact is a KDE native, but you can use it with other desktops as well.
## 5. Osmo
[Osmo](https://clayo.org/osmo/) is a much more up-to-date app with calendar, tasks, contacts, and notes functionality. It comes with some perks, such as encrypted private data backup and address locations on the map, as well as great search capabilities for notes, tasks, contacts, etc.
## 6. Catfish
You can’t be productive without a good searching tool. Catfish is one of the must-try search tools. It’s a GTK+ tool and is very fast and lightweight. Catfish uses autocompletion from Zeitgeist, and you can also filter results by date and type.
## 7. KOrganizer
[KOrganizer](https://userbase.kde.org/KOrganizer) is the calendar and scheduling component of the Kontact app I mentioned above. If you don’t need a full-fledged PIM app but only calendar and scheduling, you can go with KOrganizer instead. KOrganizer offers quick ToDo and quick event entry, as well as attachments for events and todos.
## 8. Evolution
If you are not a fan of KDE apps but still you need a good PIM, try GNOME’s [Evolution](https://help.gnome.org/users/evolution/3.22/intro-main-window.html.en). Evolution is not exactly a less popular app you haven’t heard of, but since it’s useful, it made the list. Maybe you’ve heard about Evolution as an email client ,but it’s much more than this – you can use it to manage calendars, mail, address books and tasks.
## 9. Freeplane
I don’t know if many of you use mind-mapping software on a daily basis, but if you do, check [Freeplane](https://www.freeplane.org/wiki/index.php/Home). This is a free mind mapping and knowledge management software you can use for business or fun. You create notes, arrange them in clouds or charts, set tasks with calendars and reminders, etc.
## 10. Calligra Flow
Finally, if you need a flowchart and diagramming tool, try [Calligra Flow](https://www.calligra.org/flow/). Think of it as the open source [alternative of Microsoft Visio](https://www.maketecheasier.com/5-best-free-alternatives-to-microsoft-visio/), though Calligra Flow doesn’t offer all the perks Visio offers. Still, you can use it to create network diagrams, organization charts, flowcharts and more.
Productivity tools not only speed up work, but they also make you more organized. I bet there is hardly a person who doesn’t use productivity tools in some form. Trying the apps listed here could make you more productive and could make your life at least a bit easier
Our latest tutorials delivered straight to your inbox |
9,499 | chkservice:在 Linux 终端管理 systemd 单元的工具 | https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/ | 2018-03-31T00:33:56 | [
"systemd"
] | https://linux.cn/article-9499-1.html | 
systemd 意即<ruby> 系统守护进程 <rt> system daemon </rt></ruby>,是一个新的初始化系统和系统管理工具,它现在非常流行,大部分的 Linux 发行版开始使用这种新的初始化系统。
`systemctl` 是一个 systemd 的工具,它可以帮助我们管理 systemd 守护进程。 它控制系统的启动程序和服务,使用并行化方式,为启动的服务激活套接字和 D-Bus,提供守护进程的按需启动,使用 Linux 控制组跟踪进程,维护挂载和自动挂载点。
此外,它还提供了日志守护进程、用于控制基本系统配置的功能,如主机名、日期、地区、维护已登录用户列表和运行容器和虚拟机、系统帐户、运行时目录和设置,以及管理简单网络配置、网络时间同步、日志转发和名称解析的守护进程。
### 什么是 chkservice
[chkservice](https://github.com/linuxenko/chkservice) 是一个基于 ncurses 的在终端中管理 systemd 单元的工具。它提供了一个非常全面的 systemd 服务的视图,使得它们非常容易修改。
只有拥有超级管理权限才能够改变 systemd 单元的状态和 sysv 系统启动脚本。
### 在 Linux 安装 chkservice
我们可以通过两种方式安装 `chkservice`,通过包安装或者手动安装。
对于 Debian/Ubuntu,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 安装 `chkservice`。
```
$ sudo add-apt-repository ppa:linuxenko/chkservice
$ sudo apt-get update
$ sudo apt-get install chkservice
```
对于 Arch Linux 系的系统,使用 [Yaourt 命令](https://www.2daygeek.com/install-yaourt-aur-helper-on-arch-linux/) 或 [Packer 命令](https://www.2daygeek.com/install-packer-aur-helper-on-arch-linux/) 从 AUR 库安装 `chkservice`。
```
$ yaourt -S chkservice
或
$ packer -S chkservice
```
对于 Fedora,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 安装 `chkservice`。
```
$ sudo dnf copr enable srakitnican/default
$ sudo dnf install chkservice
```
对于 Debian 系系统,使用 [DPKG 命令](https://www.2daygeek.com/dpkg-command-to-manage-packages-on-debian-ubuntu-linux-mint-systems/) 安装 `chkservice`。
```
$ wget https://github.com/linuxenko/chkservice/releases/download/0.1/chkservice_0.1.0-amd64.deb
$ sudo dpkg -i chkservice_0.1.0-amd64.deb
```
对于 RPM 系的系统,使用 [DNF 命令](https://www.2daygeek.com/rpm-command-examples/) 安装 `chkservice`。
```
$ sudo yum install https://github.com/linuxenko/chkservice/releases/download/0.1/chkservice_0.1.0-amd64.rpm
```
### 如何使用 chkservice
只需输入以下命令即可启动 `chkservice` 工具。 输出分为四部分。
* **第一部分:** 这一部分显示了守护进程的状态,比如可用的 `[X]` 或者不可用的 `[ ]` 或者静态的 `[s]` 或者被掩藏的 `-m-`
* **第二部分:** 这一部分显示守护进程的状态例如开始 `>` 或者停止 `=`
* **第三部分:** 这一部分显示单元的名称
* **第四部分:** 这一部分简短地显示了守护进程的一些信息
```
$ sudo chkservice
```

要查看帮助页面,按下 `?`。 这将向您显示管理 systemd 服务的可用选项。

选择要启用或禁用的守护进程,然后点击空格键。

选择你想开始或停止的守护进程,然后按下 `s`。

选择要重新启动的守护进程,然后按下 `r`,之后,您可以在顶部看到更新的提示。

按下 `q` 退出。
---
via: <https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/>
作者:[Ramya Nuvvula](https://www.2daygeek.com/author/ramya/) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,500 | 计算机系统进化论 | http://karl-voit.at/2017/02/10/evolution-of-systems/ | 2018-03-31T23:13:31 | [
"进化",
"计算机"
] | https://linux.cn/article-9500-1.html | 
纵观现代计算机的历史,从与系统的交互方式方面,可以划分为数个进化阶段。而我更倾向于将之归类为以下几个阶段:
1. 数字系统
2. 专用应用系统
3. 应用中心系统
4. 信息中心系统
5. 无应用系统
下面我们详细聊聊这几种分类。
### 数字系统
在我看来,[早期计算机](https://en.wikipedia.org/wiki/History_of_computing_hardware),只被设计用来处理数字。它们能够加、减、乘、除。在它们中有一些能够运行像是微分和积分之类的更复杂的数学操作。
当然,如果你把字符映射成数字,它们也可以计算字符串。但这多少有点“数字的创造性使用”的意思,而不是直接处理各种信息。
### 专用应用系统
对于更高层级的问题,纯粹的数字系统是不够的。专用应用系统被开发用来处理单一任务。它们和数字系统十分相似,但是,它们拥有足够的复杂数字计算能力。这些系统能够完成十分明确的高层级任务,像调度问题的相关计算或者其他优化问题。
这类系统为单一目的而搭建,它们解决的是单一明确的问题。
### 应用中心系统
应用中心系统是第一个真正的通用系统。它们的主要使用风格很像专用应用系统,但是它们拥有以时间片模式(一个接一个)或以多任务模式(多应用同时)运行的多个应用程序。
上世纪 70 年代的 [早期的个人电脑](https://en.wikipedia.org/wiki/Xerox_Alto)是第一种受人们欢迎的应用中心系统。
如今的现在操作系统 —— Windows 、macOS 、大多数 GNU/Linux 桌面环境 —— 一直遵循相同的法则。
当然,应用中心系统还可以再细分为两种子类:
1. 紧密型应用中心系统
2. 松散型应用中心系统
紧密型应用中心系统像是 [Windows 3.1](https://en.wikipedia.org/wiki/Windows_3.1x) (拥有程序管理器和文件管理器)或者甚至 [Windows 95](https://en.wikipedia.org/wiki/Windows_95) 的最初版本都没有预定义的文件夹层次。用户启动文本处理程序(像 [WinWord](https://en.wikipedia.org/wiki/Microsoft_Word) )并且把文件保存在 WinWord 的程序文件夹中。在使用表格处理程序的时候,又把文件保存在表格处理工具的程序文件夹中。诸如此类。用户几乎不创建自己的文件层次结构,可能由于此举的不方便、用户单方面的懒惰,或者他们认为根本没有必要。那时,每个用户拥有几十个至多几百个文件。
为了访问文件中的信息,用户常常先打开一个应用程序,然后通过程序中的“文件/打开”功能来获取处理过的数据文件。
在 Windows 平台的 [Windows 95](https://en.wikipedia.org/wiki/Windows_95) SP2 中,“[我的文档](https://en.wikipedia.org/wiki/My_Documents)”首次被使用。有了这样一个文件层次结构的样板,应用设计者开始把 “[我的文档](https://en.wikipedia.org/wiki/My_Documents)” 作为程序的默认的保存 / 打开目录,抛弃了原来将软件产品安装目录作为默认目录的做法。这样一来,用户渐渐适应了这种模式,并且开始自己维护文件夹层次。
松散型应用中心系统(通过文件管理器来提取文件)应运而生。在这种系统下,当打开一个文件的时候,操作系统会自动启动与之相关的应用程序。这是一次小而精妙的用法转变。这种应用中心系统的用法模式一直是个人电脑的主要用法模式。
然而,这种模式有很多的缺点。例如,为了防止数据提取出现问题,需要维护一个包含给定项目的所有相关文件的严格文件夹层次结构。不幸的是,人们并不总能这样做。更进一步说,[这种模式不能很好的扩展](http://karl-voit.at/tagstore/downloads/Voit2012b.pdf)。 桌面搜索引擎和高级数据组织工具(像 [tagstore](http://karl-voit.at/tagstore/))可以起到一点改善作用。正如研究显示的那样,只有一少部分人正在使用那些高级文件提取工具。大多数的用户不使用替代提取工具或者辅助提取技术在文件系统中寻找文件。
### 信息中心系统
解决上述需要将所有文件都放到一个文件夹的问题的可行办法之一就是从应用中心系统转换到信息中心系统。
信息中心系统将项目的所有信息联合起来,放在一个地方,放在同一个应用程序里。因此,我们再也不需要计算项目预算时,打开表格处理程序;写工程报告时,打开文本处理程序;处理图片文件时,又打开另一个工具。
上个月的预算情况在客户会议笔记的右下方,客户会议笔记又在画板的右下方,而画板又在另一些要去完成的任务的右下方。在各个层之间没有文件或者应用程序来回切换的麻烦。
早期,IBM [OS/2](https://en.wikipedia.org/wiki/OS/2)、 Microsoft [OLE](https://en.wikipedia.org/wiki/Object_Linking_and_Embedding) 和 [NeXT](https://en.wikipedia.org/wiki/NeXT) 都做过类似的尝试。但都由于种种原因没有取得重大成功。从 [Plan 9](https://en.wikipedia.org/wiki/Plan_9_from_Bell_Labs) 发展而来的 [ACme](https://en.wikipedia.org/wiki/Acme_%2528text_editor%2529) 是一个非常有趣的信息中心环境。它在一个应用程序中包含了[多种应用程序](https://en.wikipedia.org/wiki/List_of_Plan_9_applications)。但是即时是它移植到了 Windows 和 GNU/Linux,也从来没有成为一个引起关注的软件。
信息中心系统的现代形式是高级 [个人维基](https://en.wikipedia.org/wiki/Personal_wiki)(像 [TheBrain](https://en.wikipedia.org/wiki/TheBrain) 和 [Microsoft OneNote](https://en.wikipedia.org/wiki/Microsoft_OneNote))。
我选择的个人工具是带 [Org 模式](../../../../tags/emacs) 扩展的 [GNU/Emacs](https://github.com/novoid/Memacs) 平台。在用电脑的时候,我几乎不能没有 Org 模式 。为了访问外部数据资源,我创建了一个可以将多种数据导入 Org 模式的插件 —— [Memacs](https://github.com/novoid/Memacs) 。我喜欢将表格数据计算放到日程任务的右下方,然后是行内图片,内部和外部链接,等等。它是一个真正的用户不用必须操心程序或者严格的层次文件系统文件夹的信息中心系统。同时,用简单的或高级的标签也可以进行多分类。一个命令可以派生多种视图。比如,一个视图有日历,待办事项。另一个视图是租借事宜列表。等等。它对 Org 模式的用户没有限制。只有你想不到,没有它做不到。
进化结束了吗? 当然没有。
### 无应用系统
我能想到这样一类操作系统,我称之为无应用系统。在下一步的发展中,系统将不需要单一领域的应用程序,即使它们能和 Org 模式一样出色。计算机直接提供一个处理信息和使用功能的友好用户接口,而不通过文件和程序。甚至连传统的操作系统也不需要。
无应用系统也可能和 [人工智能](https://en.wikipedia.org/wiki/Artificial_intelligence) 联系起来。把它想象成 [2001 太空漫游](https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey) 中的 [HAL 9000](https://en.wikipedia.org/wiki/HAL_9000) 和星际迷航中的 [LCARS](https://en.wikipedia.org/wiki/LCARS) 一类的东西就可以了。
从基于应用的、基于供应商的软件文化到无应用系统的转化让人很难相信。 或许,缓慢但却不断发展的开源环境,可以使一个由各种各样组织和人们贡献的真正无应用环境成型。
信息和提取、操作信息的功能,这是系统应该具有的,同时也是我们所需要的。其他的东西仅仅是为了使我们不至于分散注意力。
---
via: <http://karl-voit.at/2017/02/10/evolution-of-systems/>
作者:[Karl Voit](http://karl-voit.at) 译者:[lontow](https://github.com/lontow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,501 | 为初学者准备的 ln 命令教程(5 个示例) | https://www.howtoforge.com/linux-ln-command/ | 2018-03-31T23:31:08 | [
"ln",
"链接",
"符号链接"
] | https://linux.cn/article-9501-1.html | 
当我们在命令行上工作时,您可能需要在文件之间创建链接。这时,您可以可以借助一个专用命令,`ln`。本教程中,我们将通过一些简单易理解的例子来讨论此工具的基础知识。在此之前,值得一提的是,本教程所有例子都已在 Ubuntu 16.04 上测试通过。
### Linux ln 命令
正如你现在所了解的,`ln` 命令能够让您在文件之间创建链接。下面就是 `ln` 工具的语法(或者使用其他一些可行的语法)。
```
ln [OPTION]... [-T] TARGET LINK_NAME (第一种形式)
ln [OPTION]... TARGET (第二种形式)
ln [OPTION]... TARGET... DIRECTORY (第三种形式)
ln [OPTION]... -t DIRECTORY TARGET... (第四种形式)
```
下面是 `ln` 工具 man 文档描述的内容:
>
> 在第一种形式下,为目标位置(TARGET)创建一个叫 LINK\_NAME 的链接。在第二种形式下,为目标位置(TARGET)在当前目录下创建一个链接(LCTT 译注:创建的为同名链接)。在第三和第四种形式中,在 DIRECTORY 目录下为每一个目标位置(TARGET)创建链接。默认创建硬链接,符号链接需要 `--symbolic` 选项。默认创建的每一个创建的链接(新链接的名字)都不能已经存在。当创建硬链接时,目标位置(TARGET)文件必须存在;符号链接可以保存任意文本,如果之后解析,相对链接的解析与其父目录有关。
>
>
>
通过下面问答风格的例子,可能会给你更好的理解。但是在此之前,建议您先了解 [硬链接和软链接的区别](https://medium.com/meatandmachines/explaining-the-difference-between-hard-links-symbolic-links-using-bruce-lee-32828832e8d3).
### Q1. 如何使用 ln 命令创建硬链接?
这很简单,你只需要像下面使用 `ln` 命令:
```
ln [file] [hard-link-to-file]
```
例如:
```
ln test.txt test_hard_link.txt
```
[](https://www.howtoforge.com/images/command-tutorial/big/ln-hard-link.png)
如此,您便可以看见一个已经创建好的,名为 `test_hard_link.txt` 的硬链接。
### Q2. 如何使用 ln 命令创建软/符号链接?
使用 `-s` 命令行选项:
```
ln -s [file] [soft-link-to-file]
```
例如:
```
ln -s test.txt test_soft_link.txt
```
[](https://www.howtoforge.com/images/command-tutorial/big/ln-soft-link.png)
`test_soft_link.txt` 文件就是一个软/符号链接,以天蓝色文本 [标识](https://askubuntu.com/questions/17299/what-do-the-different-colors-mean-in-ls)。
### Q3. 如何使用 ln 命令删除既存的同名目标文件?
默认情况下,`ln` 不允许您在目标目录下创建已存在的链接。
[](https://www.howtoforge.com/images/command-tutorial/big/ln-file-exists.png)
然而,如果一定要这么做,您可以使用 `-f` 命令行选项覆盖此行为。
[](https://www.howtoforge.com/images/command-tutorial/big/ln-f-option.png)
提示:如果您想在此删除过程中有所交互,您可以使用 `-i` 选项。
### Q4. 如何使用 ln 命令创建现有文件的同名备份?
如果您不想 `ln` 删除同名的现有文件,您可以为这些文件创建备份。使用 `-b` 即可实现此效果,以这种方式创建的备份文件,会在其文件名结尾处包含一个波浪号(`~`)。
[](https://www.howtoforge.com/images/command-tutorial/big/ln-b-option.png)
### Q5. 如何在当前目录以外的其它目录创建链接?
使用 `-t` 选项指定一个文件目录(除了当前目录)。比如:
```
ls test* | xargs ln -s -t /home/himanshu/Desktop/
```
上述命令会为(当前目录下的)所有 `test*` 文件创建链接,并放到桌面目录下。
### 总结
当然,尤其对于新手来说,`ln` 并不是日常必备命令。但是,这是一个有用的命令,因为你永远不知道它什么时候能够节省你一天的时间。对于这个命令,我们已经讨论了一些实用的选项,如果你已经完成了这些,可以查询 [man 文档](https://linux.die.net/man/1/ln) 来了解更多详情。
---
via: <https://www.howtoforge.com/linux-ln-command/>
作者:[Himanshu Arora](https://www.howtoforge.com) 译者:[CYLeft](https://github.com/CYLeft) 校对:[Locez](https://github.com/locez)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Linux ln Command Tutorial for Beginners (5 Examples)
### On this page
[Linux ln command](#linux-ln-command)[Q1. How to create a hard link using ln?](#q-how-to-create-a-hard-link-using-ln)[Q2. How to create soft/symbolic link using ln?](#q-how-to-create-softsymbolic-link-using-ln)[Q3. How to make ln remove existing destination files of same name?](#q-how-to-make-ln-remove-existing-destination-files-of-same-name)[Q4. How to make ln create a backup of existing files with the same name?](#q-how-to-make-ln-create-a-backup-of-existing-files-with-the-same-name)[Q5. How to create links in a directory other than the current directory?](#q-how-to-create-links-in-a-directory-other-than-the-current-directory)[Conclusion](#conclusion)
Sometimes, while working on the command line, you need to create links between files. This can be achieved using a dedicated command, dubbed **ln**. In this tutorial, we will discuss the basics of this tool using some easy-to-understand examples. But before we do that, it's worth mentioning that all examples here have been tested on an Ubuntu 22.04 machine.
## Linux ln command
As you have understood by now, the ln command lets you make links between files. Following is the syntax (or rather a different syntax available) for this tool:
ln [OPTION]... [-T] TARGET LINK_NAME (1st form)
ln [OPTION]... TARGET (2nd form)
ln [OPTION]... TARGET... DIRECTORY (3rd form)
ln [OPTION]... -t DIRECTORY TARGET... (4th form)
And here's how the tool's man page explains it:
In the 1st form, create a link to TARGET with the name LINK_NAME. In the 2nd form, create a link
to TARGET in the current directory. In the 3rd and 4th forms, create links to each TARGET in
DIRECTORY. Create hard links by default, symbolic links with --symbolic. By default, each
destination (name of new link) should not already exist. When creating hard links, each TARGET
must exist. Symbolic links can hold arbitrary text; if later resolved, a relative link is
interpreted in relation to its parent directory.
The following Q&A-styled examples will give you a better idea of how the ln command works. But before that, it's good for you to get an understanding of what's the [difference between hard links and soft links](https://medium.com/meatandmachines/explaining-the-difference-between-hard-links-symbolic-links-using-bruce-lee-32828832e8d3).
## Q1. How to create a hard link using ln?
That's pretty straightforward - all you have to do is to use the *ln* command in the following way:
ln [file] [hard-link-to-file]
For example:
ln test.txt test_hard_link.txt
So you can see a hard link was created with the name *test_hard_link.txt*.
## Q2. How to create soft/symbolic link using ln?
For this, use the -s command line option.
ln -s [file] [soft-link-to-file]
For example:
ln -s test.txt test_soft_link.txt
The test_soft_link.txt file is a soft/symbolic link, as [confirmed](https://askubuntu.com/questions/17299/what-do-the-different-colors-mean-in-ls) by its sky-blue text color.
## Q3. How to make ln remove existing destination files of same name?
By default, ln won't let you create a link if a file of the same name already exists in the destination directory.
However, if you want, you can make ln override this behavior by using the **-f** command line option.
**Note**: You can use the **-i** command line option if you want to make all this deletion process interactive.
## Q4. How to make ln create a backup of existing files with the same name?
If you don't want ln to delete existing files of the same name, you can make it create a backup of these files. This can be achieved using the **-b** command line option. Backup files created this way will contain a tilde (~) toward the end of their name.
## Q5. How to create links in a directory other than the current directory?
A particular destination directory (other than the current one) can be specified using the **-t** command line option. For example:
ls test* | xargs ln -s -t /home/himanshu/Desktop/
The aforementioned command will create links to all test* files (present in the current directory) and put them in the Desktop directory.
## Conclusion
Agreed, **ln** isn't something that you'll require on daily basis, especially if you're a newbie. But it's a helpful command to know about, as you never know when it'd save your day. We've discussed some useful command line options the tool offers. Once you're done with these, you can learn more about ln by heading to its [man page](https://linux.die.net/man/1/ln). Another interesting command you might want to check out is the [tee](https://www.howtoforge.com/linux-tee-command/) command. |
9,502 | 使用 Vagrant 测试 Ansible 剧本 | https://carlchenet.com/testing-ansible-playbooks-with-vagrant/ | 2018-04-01T09:24:00 | [
"Ansible",
"Vagrant"
] | /article-9502-1.html | 
我使用 Ansible 来自动部署站点 ([LinuxJobs.fr](https://www.linuxjobs.fr)、[Journal du hacker](https://www.journalduhacker.net)) 与应用 ([Feed2toot](https://gitlab.com/chaica/feed2toot)、[Feed2tweet](https://gitlab.com/chaica/feed2tweet))。在本文中将会讲述我是如何配置以实现在本地测试 Ansbile <ruby> 剧本 <rt> playbook </rt></ruby>的。

### 为何要测试 Ansible 剧本
我需要一种简单而迅速的方法来在我的本地笔记本上测试 Ansible 剧本的部署情况,尤其在刚开始写一个新剧本的时候,因为直接部署到生产服务器上不仅特别慢而且风险还很大。
我使用 [Vagrant](https://www.vagrantup.com/) 来将剧本部署到 [VirtualBox](https://www.virtualbox.org/) 虚拟机上而不是部署到远程服务器。这使得修改的结果很快就能看到,以实现快速迭代和修正。
责任声明:我并不是专业程序员。我只是描述一种我觉得适合我的,即简单又有效的用来测试 Ansible 剧本的解决方案,但可能还有其他更好的方法。
### 我的流程
1. 开始写新的 Ansible 剧本
2. 启动一台新的虚拟机(VM)并使用 Vagrantt 将剧本部署到这台虚拟机中
3. 修复剧本或应用中的错误
4. 重新在虚拟机上部署
5. 如果还有问题,回到第三步。否则销毁这台虚拟机,重新创建新虚拟机然后测试一次全新部署
6. 若没有问题出现,则标记你的 Ansible 剧本版本,可以在生产环境上发布产品了
### 你需要哪些东西
首先,你需要 Virtualbox。若你使用的是 [Debian](https://www.debian.org) 发行版,[这个链接](https://wiki.debian.org/VirtualBox) 描述了安装的方法,可以从 Debian 仓库中安装,也可以通过官网来安装。
[](https://www.virtualbox.org/)
其次,你需要 Vagrant。为什么要 Vagrant?因为它是介于开发环境和虚拟机之间的中间件,它允许通过编程的方式重复操作,而且可以很方便地将你的部署环境与虚拟机连接起来。通过下面命令可以安装 Vagrant:
```
# apt install vagrant
```
[](https://www.vagrantup.com/)
### 设置 Vagrant
Vagrant 的一切信息都存放在 `Vagrantfile` 文件中。这是我的内容:
```
Vagrant.require_version ">= 2.0.0"
Vagrant.configure(1) do |config|
config.vm.box = "debian/stretch64"
config.vm.provision "shell", inline: "apt install --yes git python3-pip"
config.vm.provision "ansible" do |ansible|
ansible.verbose = "v"
ansible.playbook = "site.yml"
ansible.vault_password_file = "vault_password_file"
end
end
```
1. 第一行指明了需要用哪个版本的 Vagrant 来执行 `Vagrantfile`。
2. 文件中的第一个循环,你要定义为多少台虚拟机执行下面的操作(这里为 `1`)。
3. 第三行指定了用来创建虚拟机的官方 Vagrant 镜像。
4. 第四行非常重要:有一些需要的应用没有安装到虚拟机中。这里我们用 `apt` 安装 `git` 和 `python3-pip`。
5. 下一行指明了 Ansible 配置开始的地方
6. 第六行说明我们想要 Ansible 输出详细信息。
7. 第七行,我们定义了 Ansible 剧本的入口。
8. 第八行,若你使用 Ansible Vault 加密了一些文件,在这里指定这些文件。
当 Vagrant 启动 Ansible 时,类似于执行这样的操作:
```
$ ansible-playbook --inventory-file=/home/me/ansible/test-ansible-playbook/.vagrant/provisioners/ansible/inventory -v --vault-password-file=vault_password_file site.yml
```
### 执行 Vagrant
写好 `Vagrantfile` 后,就可以启动虚拟机了。只需要简单地运行下面命令:
```
$ vagrant up
```
这个操作会很慢,因为它会启动虚拟机,安装 `Vagrantfile` 中定义的附加软件,最终应用你的剧本。你不要太频繁地使用这条命令。
Ok,现在你可以快速迭代了。在做出修改后,可以通过下面命令来快速测试你的部署:
```
$ vagrant provision
```
Ansible 剧本搞定后,通常要经过多次迭代(至少我是这样的),你应该一个全新安装的虚拟机上再测试一次,因为你在迭代的过程中可能会对虚拟机造成修改从而引发意料之外的结果。
使用下面命令进行全新测试:
```
$ vagrant destroy && vagrant up
```
这又是一个很慢的操作。你应该在 Ansible 剧本差不多完成了的情况下才这样做。在全新虚拟机上测试部署之后,就可以发布到生产上去了。至少准备要充分不少了吧 :p
### 有什么改进意见?请告诉我
本文中描述的配置对我自己来说很有用。我可以做到快速迭代(尤其在编写新的剧本的时候),除了剧本外,对我的最新应用,尚未准备好部署到生产环境上的应用也很有帮助。直接部署到远程服务器上对我的生产服务来说不仅缓慢而且很危险。
我本也可以使用持续集成(CI)服务器,但这不是本文的主题。如前所述,本文的目的是在编写新的 Ansible 剧本之初尽可能的快速迭代。
在编写 Ansible 剧本之初就提交,推送到你的 Git 仓库然后等待 CI 测试的执行结果,这有点太过了,因为这个时期的错误总是很多,你需要一一个地去调试。我觉得 CI 在编写 Ansible 剧本的后期会有用的多,尤其当多个人同时对它进行修改而且你有一整套代码质量规范要遵守的时候。不过,这只是我自己的观念,还有待讨论,再重申一遍,我不是个专业的程序员。
如果你有更好的测试 Ansible 剧本的方案或者能对这里描述的方法做出一些改进,请告诉我。你可以把它写到留言框中或者通过社交网络联系我,我会很高兴的。
---
via: <https://carlchenet.com/testing-ansible-playbooks-with-vagrant/>
作者:[Carl Chenet](https://carlchenet.com) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='carlchenet.com', port=443): Max retries exceeded with url: /testing-ansible-playbooks-with-vagrant/ (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7b83275c6ef0>, 'Connection to carlchenet.com timed out. (connect timeout=10)')) | null |
9,503 | 计算机语言的巨变 | http://esr.ibiblio.org/?p=7724 | 2018-04-02T08:16:00 | [
"C语言",
"Go"
] | https://linux.cn/article-9503-1.html | 
我的上一篇博文《[与 C 语言长别离](/article-9268-1.html)》引来了我的老朋友,一位 C++ 专家的评论。在评论里,他推荐把 C++ 作为 C 的替代品。这是不可能发生的,如果 C++ 代替 C 是趋势的话,那么 Go 和 Rust 也就不会出现了。

但是我不能只给我的读者一个光秃秃的看法(LCTT 译注:此处是双关语)。所以,在这篇文章中,我来讲述一下为什么我不再碰 C++ 的故事。这是关于计算机语言设计经济学专题文章的起始点。这篇文章会讨论为什么一些真心不好的决策会被做出来,然后进入语言的基础设计之中,以及我们该如何修正这些问题。
在这篇文章中,我会一点一点的指出人们(当然也包括我)自从 20 世纪 80 年代以来就存在的关于未来的编程语言的预见失误。直到最近,我们才找到了证明我们错了的证据。
我记得我第一次学习 C++ 是因为我需要使用 GNU eqn 输出 MathXML,而 eqn 是使用 C++ 写的。那个项目不错。在那之后,21 世纪初,我在<ruby> 韦诺之战 <rt> Battle For Wesnoth </rt></ruby>那边当了多年的资深开发人生,并且与 C++ 相处甚欢。
在那之后啊,有一天我们发现一个不小心被我们授予提交权限的人已经把游戏的 AI 核心搞崩掉了。显然,在团队中只有我是不那么害怕查看代码的。最终,我把一切都恢复正常了 —— 我折腾了整整两周。再那之后,我就发誓我再也不靠近 C++ 了。
在那次经历过后,我发现这个语言的问题就是它在尝试使得本来就复杂的东西更加复杂,来粗陋补上因为基础概念的缺失造成的漏洞。对于裸指针这样东西,它说“别这样做”,这没有问题。对于小规模的个人项目(比如我的魔改版 eqn),遵守这些规定没有问题。
但是对于大型项目,或者开发者水平参差不齐的多人项目(这是我经常要处理的情况)就不能这样。随着时间的推移以及代码行数的增加,有的人就会捅篓子。当别人指出有 BUG 时,因为诸如 STL 之类的东西给你增加了一层复杂度,你处理这种问题所需要的精力就比处理同等规模的 C 语言的问题就要难上很多。我在韦诺之战时,我就知道了,处理这种问题真的相当棘手。
我给 Stell Heller(我的老朋友,C++ 的支持者)写代码时不会发生的问题在我与非 Heller 们合作时就被放大了,我和他们合作的结局可能就是我得给他们擦屁股。所以我就不用 C++ ,我觉得不值得为了其花时间。 C 是有缺陷的,但是 C 有 C++ 没有的优点 —— 如果你能在脑内模拟出硬件,那么你就能很简单的看出程序是怎么运行的。如果 C++ 真的能解决 C 的问题(也就是说,C++ 是类型安全以及内存安全的),那么失去其透明性也是值得的。但是,C++ 并没有这样。
我们判断 C++ 做的还不够的方法之一是想象一个 C++ 已经搞得不错的世界。在那个世界里,老旧的 C 语言项目会被迁移到 C++ 上来。主流的操作系统内核会是 C++ 写就,而现存的内核实现,比如 Linux 会渐渐升级成那样。在现实世界,这些都没有发生。C++ 不仅没有打消语言设计者设想像 D、Go 以及 Rust 那样的新语言的想法,它甚至都没有取代它的前辈。不改变 C++ 的核心思想,它就没有未来,也因此,C++ 的<ruby> 抽象泄露 <rt> leaky abstraction </rt></ruby>也不会消失。
既然我刚刚提到了 D 语言,那我就说说为什么我不把 D 视为一个够格的 C 语言竞争者的原因吧。尽管它比 Rust 早出现了八年(和 Rust 相比是九年)Walter Bright 早在那时就有了构建那样一个语言的想法。但是在 2001 年,以 Python 和 Perl 为首的语言的出现已经确定了,专有语言能和开源语言抗衡的时代已经过去。官方 D 语言库/运行时和 Tangle 的无谓纷争也打击了其发展。它从未修正这些错误。
然后就是 Go 语言(我本来想说“以及 Rust”。但是如前文所述,我认为 Rust 还需要几年时间才能有竞争力)。它*的确是*类型安全以及内存安全的(好吧,是在大多数时候是这样,但是如果你要使用接口的话就不是如此了,但是自找麻烦可不是正常人的做法)。我的一位好友,Mark Atwood,曾指出过 Go 语言是脾气暴躁的老头子因为愤怒而创造出的语言,主要是 *C 语言的作者之一*(Ken Thompson) 因为 C++ 的混乱臃肿造成的愤怒,我深以为然。
我能理解 Ken 恼火的原因。这几十年来我就一直认为 C++ 搞错了需要解决的问题。C 语言的后继者有两条路可走。其一就是 C++ 那样,接受 C 的抽象泄漏、裸指针等等,以保证兼容性。然后以此为基础,构建一个最先进的语言。还有一条道路,就是从根源上解决问题 —— *修正* C语言的抽象泄露。这一来就会破环其兼容性,但是也会杜绝 C/C++ 现有的问题。
对于第二条道路,第一次严谨的尝试就是 1995 年出现的 Java。Java 搞得不错,但是在语言解释器上构建这门语言使其不适合系统编程。这就在系统编程那留下一个巨大的洞,在 Go 以及 Rust 出现之前的 15 年里,都没有语言来填补这个空白。这也就是我的 GPSD 和 NTPsec 等软件在 2017 年仍然主要用 C 写成的原因,尽管 C 的问题也很多。
在许多方面这都是很糟糕的情况。尽管由于缺少足够多样化的选择,我们很难认识到 C/C++ 做的不够好的地方。我们都认为在软件里面出现缺陷以及基于安全方面考虑的妥协是理所当然的,而不是想想这其中多少是真的由于语言的设计问题导致的,就像缓存区溢出漏洞一样。
所以,为什么我们花了这么长时间才开始解决这个问题?从 C 1972 年面世到 Go 2009 年出现,这其中隔了 37 年;Rust 也是在其仅仅一年之前出现。我想根本原因还是经济。
从最早的计算机语言开始,人们就已经知道,每种语言的设计都体现了程序员时间与机器资源的相对价值的权衡。在机器这端,就是汇编语言,以及之后的 C 语言,这些语言以牺牲开发人员的时间为代价来提高性能。 另一方面,像 Lisp 和(之后的)Python 这样的语言则试图自动处理尽可能多的细节,但这是以牺牲机器性能为代价的。
广义地说,这两端的语言的最重要的区别就是有没有自动内存管理。这与经验一致,内存管理缺陷是以机器为中心的语言中最常见的一类缺陷,程序员需要手动管理资源。
当相对价值断言与软件开发在某个特定领域的实际成本动因相匹配时,这个语言就是在经济上可行的。语言设计者通过设计一个适合处理现在或者不远的将来出现的情况的语言,而不是使用现有的语言来解决他们遇到的问题。
随着时间的推移,时兴的编程语言已经渐渐从需要手动管理内存的语言变为带有自动内存管理以及垃圾回收(GC)机制的语言。这种变化对应了摩尔定律导致的计算机硬件成本的降低,使得程序员的时间与之前相比更加的宝贵。但是,除了程序员的时间以及机器效率的变化之外,至少还有两个维度与这种变化相关。
其一就是距离底层硬件的距离。底层软件(内核与服务代码)的低效率会被成倍地扩大。因此我们可以发现,以机器为中心的语言向底层推进,而以程序员为中心的语言向着高级发展。因为大多数情况下面向用户的语言仅仅需要以人类的反应速度(0.1 秒)做出回应即可。
另一个维度就是项目的规模。由于程序员抽象发生的问题的漏洞以及自身的疏忽,任何语言都会有可预期的每千行代码的出错率。这个比率在以机器为中心的语言上很高,而在程序员为中心的带有 GC 的语言里就大大降低。随着项目规模的增大,带有 GC 的语言作为一个防止出错率不堪入目的策略就显得愈发重要起来。
当我们使用这三种维度来看当今的编程语言的形势 —— C 语言在底层,蓬勃发展的带有 GC 的语言在上层,我们会发现这基本上很合理。但是还有一些看似不合理的是 —— C 语言的应用不合理地广泛。
我为什么这么说?想想那些经典的 Unix 命令行工具吧。那些小程序通常都可以使用带有完整的 POSIX 支持的脚本语言快速实现出来。重新编码那些程序将使得它们调试、维护和拓展起来都会更加简单。
但是为什么还是使用 C (或者某些像 eqn 的项目,使用 C++)?因为有转换成本。就算是把相当小、相当简单的程序使用新的语言重写并且确认你已经忠实地保留了所有非错误行为都是相当困难的。笼统地说,在任何一个领域的应用编程或者系统编程在一种语言的权衡过时之后,仍然坚持使用它。
这就是我和其他预测者犯的大错。 我们认为,降低机器资源成本(增加程序员时间的相对成本)本身就足以取代 C 语言(以及没有 GC 的语言)。 在这个过程中,我们有一部分或者甚至一大部分都是错误的 —— 自 20 世纪 90 年代初以来,脚本语言、Java 以及像 Node.js 这样的东西的兴起显然都是这样兴起的。
但是,竞争系统编程语言的新浪潮并非如此。 Rust 和 Go 都明确地回应了*增加项目规模* 这一需求。 脚本语言是先是作为编写小程序的有效途径,并逐渐扩大规模,而 Rust 和 Go 从一开始就定位为减少*大型项目*中的缺陷率。 比如 Google 的搜索服务和 Facebook 的实时聊天复用。
我认为这就是对 “为什么不再早点儿” 这个问题的回答。Rust 和 Go 实际上并不算晚,它们相对迅速地回应了一个直到最近才被发现低估的成本动因问题。
好,说了这么多理论上的问题。按照这些理论我们能预言什么?它告诉我们在 C 之后会出现什么?
推动 GC 语言发展的趋势还没有扭转,也不要期待其扭转。这是大势所趋。因此:最终我们*将*拥有具有足够低延迟的 GC 技术,可用于内核和底层固件,这些技术将以语言实现方式被提供。 这些才是真正结束 C 长期统治的语言应有的特性。
我们能从 Go 语言开发团队的工作文件中发现端倪,他们正朝着这个方向前进 —— 可参见关于并发 GC 的学术研究 —— 从未停止研究。 如果 Go 语言自己没有选择这么做,其他的语言设计师也会这样。 但我认为他们会这么做 —— 谷歌推动他们的项目的能力是显而易见的(我们从 “Android 的发展”就能看出来)。
在我们拥有那么理想的 GC 之前,我把能替换 C 语言的赌注押在 Go 语言上。因为其 GC 的开销是可以接受的 —— 也就是说不只是应用,甚至是大部分内核外的服务都可以使用。原因很简单: C 的出错率无药可医,转化成本还很高。
上周我尝试将 C 语言项目转化到 Go 语言上,我发现了两件事。其一就是这活很简单, C 的语言和 Go 对应的很好。还有就是写出的代码相当简单。由于 GC 的存在以及把集合视为首要的数据结构,人们会预期代码减少,但是我意识到我写的代码比我最初期望的减少的更多,比例约为 2:1 —— 和 C 转 Python 类似。
抱歉呐,Rust 粉们。你们在内核以及底层固件上有着美好的未来,但是你们在别的 C 领域被 Go 压的很惨。没有 GC ,再加上难以从 C 语言转化过来,还有就是 API 的标准部分还是不够完善。(我的 `select(2)` 又哪去了啊?)。
对你们来说,唯一的安慰就是,C++ 粉比你们更糟糕 —— 如果这算是安慰的话。至少 Rust 还可以在 Go 顾及不到的 C 领域内大展宏图。C++ 可不能。
>
> 本站按:本文由著名开源领袖 ESR 撰写,了解 ESR 事迹的同学知道他拒绝去大公司荣养,而仍然主要负责一些互联网基础性项目的开发维护(如 NTPsec),所以,他在创造者赞助网站 [Patreon](https://www.patreon.com/) 上有一份[生活赞助计划](https://www.patreon.com/esr/overview),大家可以考虑献出一些微薄之力支持他,每个月 $20 也不过你一餐饭而已。
>
>
>
---
via: <http://esr.ibiblio.org/?p=7724>
作者:[Eric Raymond](http://esr.ibiblio.org/?author=2) 译者:[name1e5s](https://github.com/name1e5s) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | My last post ([The long goodbye to C](http://esr.ibiblio.org/?p=7711)) elicited a comment from a C++ expert I was friends with long ago, recommending C++ as the language to replace C. Which ain’t gonna happen; if that were a viable future, Go and Rust would never have been conceived.
But my readers deserve more than a bald assertion. So here, for the record, is the story of why I don’t touch C++ any more. This is a launch point for a disquisition on the economics of computer-language design, why some truly unfortunate choices got made and baked into our infrastructure, and how we’re probably going to fix them.
Along the way I will draw aside the veil from a rather basic mistake that people trying to see into the future of programming languages (including me) have been making since the 1980s. Only very recently do we have the field evidence to notice where we went wrong.
I think I first picked up C++ because I needed GNU eqn to be able to output MathXML, and eqn was written in C++. That project succeeded. Then I was a senior dev on Battle For Wesnoth for a number of years in the 2000s and got comfortable with the language.
Then came the day we discovered that a person we incautiously gave commit privileges to had fucked up the games’s AI core. It became apparent that I was the only dev on the team not too frightened of that code to go in. And I fixed it all right – took me two weeks of struggle. After which I swore a mighty oath never to go near C++ again.
My problem with the language, starkly revealed by that adventure, is that it piles complexity on complexity upon chrome upon gingerbread in an attempt to address problems that cannot actually be solved because the foundational abstractions are leaky. It’s all very well to say “well, don’t do that” about things like bare pointers, and for small-scale single-developer projects (like my eqn upgrade) it is realistic to expect the discipline can be enforced.
Not so on projects with larger scale or multiple devs at varying skill levels (the case I normally deal with). With probability asymptotically approaching one over time and increasing LOC, someone is inadvertently going to poke through one of the leaks. At which point you have a bug which, because of over-layers of gnarly complexity such as STL, is much more difficult to characterize and fix than the equivalent defect in C. My Battle For Wesnoth experience rubbed my nose in this problem pretty hard.
What works for a Steve Heller (my old friend and C++ advocate) doesn’t scale up when I’m dealing with multiple non-Steve-Hellers and might end up having to clean up their mess. So I just don’t go there any more. Not worth the aggravation. C is flawed, but it does have one immensely valuable property that C++ didn’t keep – if you can mentally model the hardware it’s running on, you can easily see all the way down. If C++ had actually eliminated C’s flaws (that it, been type-safe and memory-safe) giving away that transparency might be a trade worth making. As it is, nope.
One way we can tell that C++ is not sufficient is to imagine an alternate world in which it is. In that world, older C projects would routinely up-migrate to C++. Major OS kernels would be written in C++, and existing kernel implementations like Linux would be upgrading to it. In the real world, this ain’t happening. Not only has C++ failed to present enough of a value proposition to keep language designers uninterested in imagining languages like D, Go, and Rust, it has failed to displace its own ancestor. There’s no path forward from C++ without breaching its core assumptions; thus, the abstraction leaks won’t go away.
Since I’ve mentioned D, I suppose this is also the point at which I should explain why I don’t see it as a serious contender to replace C. Yes, it was spun up eight years before Rust and nine years before Go – props to Walter Bright for having the vision. But in 2001 the example of Perl and Python had already been set – the window when a proprietary language could compete seriously with open source was already closing. The wrestling match between the official D library/runtime and Tango hurt it, too. It has never recovered from those mistakes.
So now there’s Go (I’d say “…and Rust”, but for reasons I’ve discussed before I think it will be years before Rust is fully competitive). It *is* type-safe and memory-safe (well, almost; you can partway escape using interfaces, but it’s not normal to have to go to the unsafe places). One of my regulars, Mark Atwood, has correctly pointed out that Go is a language made of grumpy-old-man rage, specifically rage by *one of the designers of C* (Ken Thompson) at the bloated mess that C++ became.
I can relate to Ken’s grumpiness; I’ve been muttering for decades that C++ attacked the wrong problem. There were two directions a successor language to C might have gone. One was to do what C++ did – accept C’s leaky abstractions, bare pointers and all, for backward compatibility, than try to build a state-of-the-art language on top of them. The other would have been to attack C’s problems at their root – *fix* the leaky abstractions. That would break backward compatibility, but it would foreclose the class of problems that dominate C/C++ defects.
The first serious attempt at the second path was Java in 1995. It wasn’t a bad try, but the choice to build it over a j-code interpreter mode it unsuitable for systems programming. That left a huge hole in the options for systems programming that wouldn’t be properly addressed for another 15 years, until Rust and Go. In particular, it’s why software like my GPSD and NTPsec projects is still predominantly written in C in 2017 despite C’s manifest problems.
This is in many ways a bad situation. It was hard to really see this because of the lack of viable alternatives, but C/C++ has not scaled well. Most of us take for granted the escalating rate of defects and security compromises in infrastructure software without really thinking about how much of that is due to really fundamental language problems like buffer-overrun vulnerabilities.
So, why did it take so long to address that? It was 37 years from C (1972) to Go (2009); Rust only launched a year sooner. I think the underlying reasons are economic.
Ever since the very earliest computer languages it’s been understood that every language design embodies an assertion about the relative value of programmer time vs. machine resources. At one end of that spectrum you have languages like assembler and (later) C that are designed to extract maximum performance at the cost of also pessimizing developer time and costs; at the other, languages like Lisp and (later) Python that try to automate away as much housekeeping detail as possible, at the cost of pessimizing machine performance.
In broadest terms, the most important discriminator between the ends of this spectrum is the presence or absence of automatic memory management. This corresponds exactly to the empirical observation that memory-management bugs are by far the most common class of defects in machine-centric languages that require programmers to manage that resource by hand.
A language becomes economically viable where and when its relative-value assertion matches the actual cost drivers of some particular area of software development. Language designers respond to the conditions around them by inventing languages that are a better fit for present or near-future conditions than the languages they have available to use.
Over time, there’s been a gradual shift from languages that require manual memory management to languages with automatic memory management and garbage collection (GC). This shift corresponds to the Moore’s Law effect of decreasing hardware costs making programmer time relatively more expensive. But there are at least two other relevant dimensions.
One is distance from the bare metal. Inefficiency low in the software stack (kernels and service code) ripples multiplicatively up the stack. This, we see machine-centric languages down low and programmer-centric languages higher up, most often in user-facing software that only has to respond at human speed (time scale 0.1 sec).
Another is project scale. Every language also has an expected rate of induced defects per thousand lines of code due to programmers tripping over leaks and flaws in its abstractions. This rate runs higher in machine-centric languages, much lower in programmer-centric ones with GC. As project scale goes up, therefore, languages with GC become more and more important as a strategy against unacceptable defect rates.
When we view language deployments along these three dimensions, the observed pattern today – C down below, an increasing gallimaufry of languages with GC above – almost makes sense. Almost. But there is something else going on. C is stickier than it ought to be, and used way further up the stack than actually makes sense.
Why do I say this? Consider the classic Unix command-line utilities. These are generally pretty small programs that would run acceptably fast implemented in a scripting language with a full POSIX binding. Re-coded that way they would be vastly easier to debug, maintain and extend.
Why are these still in C (or, in unusual exceptions like eqn, in C++)? Transition costs. It’s difficult to translate even small, simple programs between languages and verify that you have faithfully preserved all non-error behaviors. More generally, any area of applications or systems programming can stay stuck to a language well after the tradeoff that language embodies is actually obsolete.
Here’s where I get to the big mistake I and other prognosticators made. We thought falling machine-resource costs – increasing the relative cost of programmer-hours – would be enough by themselves to displace C (and non-GC languages generally). In this we were not entirely or even mostly wrong – the rise of scripting languages, Java, and things like Node.js since the early 1990s was pretty obviously driven that way.
Not so the new wave of contending systems-programming languages, though. Rust and Go are both explicitly responses to *increasing project scale*. Where scripting languages got started as an effective way to write small programs and gradually scaled up, Rust and Go were positioned from the start as ways to reduce defect rates in *really large* projects. Like, Google’s search service and Facebook’s real-time-chat multiplexer.
I think this is the answer to the “why not sooner” question. Rust and Go aren’t actually late at all, they’re relatively prompt responses to a cost driver that was underweighted until recently.
OK, so much for theory. What predictions does this one generate? What does it tell us about what comes after C?
Here’s the big one. The largest trend driving development towards GC languages haven’t reversed, and there’s no reason to expect it will. Therefore: eventually we *will* have GC techniques with low enough latency overhead to be usable in kernels and low-level firmware, and those will ship in language implementations. Those are the languages that will truly end C’s long reign.
There are broad hints in the working papers from the Go development group that they’re headed in this direction – references to academic work on concurrent garbage collectors that never have stop-the-world pauses. If Go itself doesn’t pick up this option, other language designers will. But I think they will – the business case for Google to push them there is obvious (can you say “Android development”?).
Well before we get to GC that good, I’m putting my bet on Go to replace C anywhere that the GC it has now is affordable – which means not just applications but most systems work outside of kernels and embedded. The reason is simple: there is no path out of C’s defect rates with lower transition costs.
I’ve been experimenting with moving C code to Go over the last week, and I’m noticing two things. One is that it’s easy to do – C’s idioms map over pretty well. The other is that the resulting code is much simpler. One would expect that, with GC in the language and maps as a first-class data type, but I’m seeing larger reductions in code volume than initially expected – about 2:1, similar to what I see when moving C code to Python.
Sorry, Rustaceans – you’ve got a plausible future in kernels and deep firmware, but too many strikes against you to beat Go over most of C’s range. No GC, plus Rust is a harder transition from C because of the borrow checker, plus the standardized part of the API is still seriously incomplete (where’s my select(2), again?).
The only consolation you get, if it is one, is that the C++ fans are screwed worse than you are. At least Rust has a real prospect of dramatically lowering downstream defect rates relative to C anywhere it’s not crowded out by Go; C++ doesn’t have that.
An orthogonal problem is the type system: in most object-derived systems, there is a complex type system with at least single inheritance. This leads to an error a former customer made: we /completely/ modelled a tournament in the form of a type hierarchy.
Net result? When you wanted to change it, you had to change everything. When you wanted to add something new, you had to apply it to everything. We re-invented spagetti code, only this time it was spagetti data structures.
Instead of abstracting and simplifying, we made it more complex. Bummer!
>Instead of abstracting and simplifying, we made it more complex. Bummer!
Yeah, this is why Rust and Go don’t have class inheritance. Good call by both design teams.
Absolutely, inheritance in large projects tend to cause so many problems and makes it difficult to understand and follow! OOP with composition and interfaces is all you need.
Except for the lack of Sum types and Generics :D
At that point I am not even sure what is the point of OOP. Since SQL tables as a single “type” are useful for a tremendous range of purposes, while I never tried systems programming, if I would try I would probably use any “list of thingies with named properties” idiom that comes my way, be that a hash table or a struct.
OOP was pretty much *invented* for inheritance, at least the ways I was taught at school, these awesome chains of concepts that a BMW inherits from Car and Car from Vehicle, i.e. basically what David described was taught as good design at my school… but if it is not, then why even bother? I take an SQL table or the language equivalent thereof, hashtable, struct, whatever, name it Car, some of the fields will be Make and Model and call it a day.
Essentially I have to find the sweet spot in the conceptual category-subcategory tree, which in this case is car. Inheritance was meant to be able to move up and down on this tree, but the tree is not cast in stone because the Chevrolet company can acquire Daewoo and next week the Daewoo Matiz is called Chevrolet Matiz, then I am sure as hell not having any object class called BMW: that will be data, easily changed not part of the data structure!
Encapsulation is a better idea but unless I have massive, database-like data structures (which in real life I always do but system programmers maybe not), how am I going to automatically test any function that works not only with its own parameters but pretty much everything else it can find inside the same object? I mean great, objects cut down global variable hell to a protected variable minihell that is far easier to eyeball but is it good enough for automated testing? I think not.
I am afraid to write things like this, because only a narrow subset of my profession involves writing code and as such I am not a very experienced programmer so I should not really argue with major CS concepts. Still… for example Steve Yegge had precisely this beef with OOP: you are writing software yet OOP really seems to want you make you want to make something like unchangeable, fixed, cast in stone hardware.
OOP was hugely hyped, especially in the corporate world by Java marketers, whom extolled the virtues of how OOP and Java would solve all their business problems.
As it turns out, POP (protocol-oriented programming) is the better design, and so all modern languages are using it. POP’s critical feature is generics, so it’s baffling as to why Go does not have generics.
Basically, rather than separating structures into class hierarchies, you assign shared traits to structures in a flat hierarchy. You can then pull out trait-based generics to execute some rather fantastical solutions that would otherwise require an incredible degree of copying and pasting (a la Go).
This then allows you to interchangeably use a wide variety of types as inputs and fields into these generic functions and structures, in a manner that’s very efficient due to adhering to data-oriented design practices.
It’s incredibly useful when designing entity-component system architectures, where components are individual pieces of data that are stored in a map elsewhere; entities consist of multiple components (but rather than owning their components directly, they hold ID’s to their components), and are able to communicate with other entities; and systems, which are the traits that are implemented on each entity that is within the world map. Enables for some incredible flexibility and massively parallel solutions, from UIs to game engines.
Entities can have completely different types, but the programmer does not need to be aware of that, because they all implement the same traits, and so they can interact with each other via their trait impls. And in structuring your software architecture in this way, you ensure that specific components are only ever mutably borrowed when it is needed, and thus you can borrow many components and apply systems to them in parallel.
> POP’s critical feature is generics, so it’s baffling as to why Go does not have generics.
translation: I don’t know anything but will take a word anyway
Ah! Trying to directly mimic your prototype in the class structure. So tempting: it feels like you are encapsulating Reality,
andsaving lines of code all at the same time. Infinite wins For Great Justice!Right up until you slam into one of the many brick walls that litter the path (as I did earlier today).
> An orthogonal problem is the type system: in most object-derived systems, there is a complex type system with at least single inheritance.
Other language like python also provide multiple inheritance.
Either way, C++ moved past class hierarchies two decades ago. The standard algorithms and containers are built around regular types instead of class hierarchies. See “Inheritance Is The Base Class of Evil”:
https://channel9.msdn.com/Events/GoingNative/2013/Inheritance-Is-The-Base-Class-of-Evil
Have you seen design by introspection? A new paradigm outlined by Andrei Alexandrescu.
http://esr.ibiblio.org/?p=7724&cpage=1#comment-1912717
Also:
https://wiki.dlang.org/Component_programming_with_ranges
Code reuse with plasticity.
> Instead of abstracting and simplifying, we made it more complex.
Yep. Plus, not reusable. You can’t just snip out a useful bit of code for reuse because everything is dependent on something else. Effectively, every project is written in its own unique language.
@Eric, nice article, still you haven’t said a thing about Nim lang that is both high level, extensible like lisp, and has a GC suitable for embedded systems and kernels.
>still you haven’t said a thing about Nim lang
If you show me a Nim deployment that is more than a toy I might get interested.
There are some proprietary/internal services used in production as far as I’m aware. As for the publicly seen deployments – there’s a game on Facebook (mobiles are coming soon) which I happen to be a developer of. More info – https://yglukhov.github.io/Making-ReelValley-Overview
We use Nim in a data science deployment. We like it, because it shares a lot of go’s nice features but has much better c interoperability.
I prefer go, but Nim is pretty neat.
>I prefer go, but Nim is pretty neat.
Huh. And now it turns out that a guy who tried writing a Unix kernel in Rust bailed out to Nim.
This surprises me. I had bought into the pro-Rust argument that, once it matured, would be a good match for kernel development on theoretical grounds related to the tradeoff between the benefits of type safety versus the additional friction costs of Rust. Now someone actually working at that coal face says “Nope.”
More detail here.
I suppose it’s possible that sticking to Rust would have been a better choice and that the guy is just incompetent, but his discussion of the issues seems pretty thoughtful.
There are plenty of working Rust kernels, and fully fledged OSes
If anyone is interested Redox OS is an OS coded in rust.
C nonplussed is less nonplussed than C++.
There may be a wound, but the C++ band-aid over it obscures whether it is superficial or infected with gangrene.
One problem is that there are no non-manual mappers. One ought to be able to put the entire set of Posix commands with GNU extensions like grep or find, and have them pop out in Python, even if not terribly efficient (see below), but that doesn’t happen. Everything is recoding even when not trying to duplicate undocumented behavior.
But the performance is NOT trivial. Python will not be as effecient, so a “find . -… -exec grep … {}” can be interminably slow. Note we CAN do a Python COMPILER after the interpretave version passes all tests. But we don’t do that either.
Go looks nice, but I think it is chicken-egg. Only when a good portion is moved to Go and doesn’t merely duplicate C (at average equal LoC, efficency, etc.) will it be adopted. I can’t do linux kernel stuff in go.
This is something like the failing and flailing transitions to electric cars. The nearest “supercharger” is about 100 miles away – half a battery charge for a Tesla. But gasoline and diesel are easily available. There are worse locations even more impractical for electric cars near where I live.
Malcolm Gladwell discribes “The Tipping Point”. It has not occurred yet with C. Any bare metal programming is easier in that – go and rust aren’t alternatives to my knowledge, only assembler. Perhaps they can be but I won’t hold my breath until the Arduino IDE – the ultimate bare-metal IDE using C to create non-OS but very functional things – changes into Go or Rust.
Fortran isn’t even dead yet, nor Cobol, yet neither are at all versatile, and at best extensions are added so legacy defecations can be updated. At least I don’t have to use the keypunch machine.
But this is the universal problem. NO ONE will do a complete and verified auto-port so any arbitray ForTran or Cobol program can be translated – perfectly (even with legacy libraries) – in any other language. Y2K is 17 years old, but it was a serious problem. So is 2038 32 bit time in secs since 1970. No matter how much easier it might be to address in non-legacy languages, it won’t happen.
Another bit is the unix/posix call set – open/close/read/write/ioctl – reinvented badly many times. Never improved.
“I won’t hold my breath until the Arduino IDE – the ultimate bare-metal IDE using C to create non-OS but very functional things – changes into Go or Rust.”
Good heavens, no, at least not Rust. The target audience for Arduino is exactly the audience who Rust would send screaming off into the night, never to return.
Rust has an unofficial AVR target suitable for use with Arduino, and libraries to support that board.
The target audience for Arduino — young hardware hackers — is one of the most likely to appreciate the benefits of Rust, and they are tentatively embracing it.
The target audience for Arduino is people who are not experienced in low-level programming, perhaps not experienced at programming at all. Dropping those folks in the deep end with a language like Rust is more likely to scare them off than to induce them to learn.
Not actually. I have read many success stories from newcomers to programming. Even some which had tried to pick up programming several times in the past with C++ and C. Rust was able to take the cake because of it’s superior degree of documentation; a better, explicit syntax; an informative compiler that points out the mistakes, including the borrow checker, which helpfully points out memory unsafety; and a very vibrant and friendly community that’s always standing by to help newcomers get started and to demonstrate idiomatic Rust.
The problem with ESR, on the other hand, is that he never attempted to reach for any of these resources when he tried out Rust. I never saw him make a post in Reddit, the Rust users forum, or visit any IRC/Mattermost channels. He simply wrote a post a misinformed post about Rust because he was doing something he didn’t understand, and wasn’t aware that what he thought was missing in the standard library was actually there.
Even I, myself, come from a background of never having programmed anything before Rust. And yet Rust was the perfect entry into programming. I can now write quality C, C++, etc. because the rules enforced by Rust are the best practices in those languages. And I can now do everything from writing kernels and system shells to full stack web development and desktop GUI applications — all with Rust. All the rules in Rust are intuitive and instinctual for me today.
“All the rules in Rust are intuitive and instinctual for me today.”
Three years in. How instinctive were they the first time you tried it?How many times did you get frustrated and want to throw that damned computer out the window?
Honestly, I never got frustrated. I have a general philosophy that if you struggle with something, it’s probably because you’re going about it the wrong way, and that you should instead take a step back and review.
In addition, if you are having difficulty changing your perspective to figure out what you’re doing wrong, you’re free to reach out to the greater online community, where armies of other developers ahead of you are eager to answer your questions.
As it turns out, Rust’s borrow checker is like a Chinese finger trap — the more you resist it, the more you will struggle. If you instead go with the flow and internalize the rules, the struggles disappear, and the solutions become apparent. Everything suddenly makes sense when you simply accept the rules, rather than trying to fight the rules.
I initially struggled to wrap my mind around all the new concepts during the first week, but by the end of the second week, all of the concepts were well in-grained within my mind: what move semantics are and how they work, the borrowing and ownership model, sum types and pattern matching, traits and generics, mutexes and atomics, iterators and map/fold/filter/etc.
And that’s talking about the state of documentation that was really poor when I initially picked up Rust. Rust of today has significantly enhanced documentation that covers every area, and does so better than any other language I’ve ever seen. If I had that to reference when I started, then I’m sure that I could have mastered it within a week.
After learning Rust, I found that I could easily write C and C++ as well, because they were more or less ancient history in terms of systems language concepts. The rules enforced by the Rust compiler are best practices in C/C++. It’s just annoying how much boiler plate you need in those languages to achieve simple tasks that Rust’s standard library already encompasses, and how the core language is so critically lacking that you have to attempt to emulate sum types by hand.
Honestly, after 2 years of Rust, I often get frustrated at Go not providing the same safety and convenience.
I may be spending hours trying to make the borrow checker happy with my data usage, by I regularly spend days trying to debug segmentation faults in Go…
My point is that “instinctive” depends heavily on what you are used to use.
Go might be “instinctive” when you come form C, and Rust might be too different from common languages to be instinctive at all, but once you get used to it, you wish you never have to turn back.
>I may be spending hours trying to make the borrow checker happy with my data usage, by I regularly spend days trying to debug segmentation faults in Go…
Odd. How does that even happen without bare pointers in the language?
I’ve never seen one myself.
Lacking generics, many libraries accept interface{} to simulate them, then type-assert or just try to access the data counting on the fact that you will pass the correct type.
Sometimes they take a reference but don’t check if it’s nil.
Many just panic, because it’s simpler than trying to return the correct errors, counting on the fact that you will use goroutines and your main will keep running, so you have to handle the panic yourself, which may be easy if you are using http from the std lib, a little less if you’re writing your own process pool.
Maybe it’s not technically a segfault, but the effect is the same.
“All the rules in Rust are intuitive”
I call bullshit on anyone who says anything other than the nipple is intuitive (and some babies actually have to be taught how to use one of those).
What people really mean when they say “intuitive” is “I didn’t have to learn anything
newto do this”. That’s a very good thing, but it isn’t really “intuitive”.Perhaps you should look up the meaning of the word, rather than assume that everyone else is wrong.
I was highly disappointed when I found out that Google’s new microkernel, Magenta/Zircon, was written in C++ instead of Go.
What Google found, from developing and dogfooding Go, was that Go made a better Python replacement than it did a C++ or C replacement.
Go is
nota systems programming language.Oh, and fun fact: crosvm, Google’s virtualization layer for ChromeOS, is written in Rust.
Well, more specifically my disappointment was “Another C based operating system? When will we ever learn.” I kind of wrote off the whole project at that point. I didn’t care that they specifically didn’t use Go aside from that they had it on hand. I’d love to see them make a Zircon replacement in Rust.
Microkernels like Zircon are *exactly* the place where C/C++ will likely remain a reasonable choice, if not the best choice, for years to come. The primary requirements are performance and complete access to the bare metal. A true microkernel has a small code base (or it isn’t a *micro* kernel!), so it isn’t a “programming in the large” situation. A small team working on a small code base *can* maintain the discipline to use C++ effectively and avoid its pitfalls.
On the other hand, the various services built on top of Zircon are free to use other languages. Many are in C++ now, but they don’t have to be. The FAT filesystem service is written in go.
>Microkernels like Zircon are *exactly* the place where C/C++ will likely remain a reasonable choice, if not the best choice, for years to come […] On the other hand, the various services built on top of Zircon are free to use other languages. Many are in C++ now, but they don’t have to be. The FAT filesystem service is written in go.
This is what I think the relatively near-term future will look like, yes. Go pushing down the stack towards kernels, but not displacing C there.
Bwahaha. Where is the support for overlapped (asynchronous) I/O in the base POSIX call set? Answer: There is none. Sure, there’s an AIO
extensionto POSIX that no one uses, that is completely inadequate when compared to a kernel such as Windows that has support for async I/O with sophisticated control features like I/O completion ports designed in, and that is implemented under Linux by spinning off user-space worker threads. Since completion-based AIO is a first-class citizen under Windows, you can set up overlapped I/O operations — to network, devices, or disk — to notify you upon their completion and then busy your CPU cores with other tasks, rather than the POSIX model of spinning in select loops and interleaving “are we there yet? are we there yet?” polling with other processing.So yes, the POSIX model
hasbeen improved on. You know that old Dilbert cartoon where the Unix guy says “Here’s a quarter, get yourself a real operating system”? Dave Cutler — lead designer of VMS and Windows NT — does that to Unix guys.There have been entire papers written on that.
It’s not that “UNIXy OSes” are inferior to Windows, it’s that the standards organizations are derelict in their duty to provide a portable API in the style that everyone actually wants to use.
Be it Linux, FreeBSD, OSX, or what have you, there ARE heavily-used equivalents to the Windows APIs you mention in POSIXy OSes… they’re just all different.
(I say UNIXy and POSIXy because it’s intentional that Linux aims to be “certifiable but not officially certified” due to its rapid release cycle.)
There is no usable Linux-only async file I/O API.
Do you see anything replacing C in the small embedded systems (bare metal, 1MB flash, 256 KB RAM) space? I don’t. Possibly Rust for new development, but I just don’t see anything displacing C for a very long time.
And there are lots and lots of controllers out there that aren’t beefy enough to run a Linux, even if you could get real-time performance out of it…
>Do you see anything replacing C in the small embedded systems (bare metal, 1MB flash, 256 KB RAM) space? I don’t. Possibly Rust for new development, but I just don’t see anything displacing C for a very long time.
No argument. That’s pretty much the niche I foresee C holding longest, analogous to the persistence of assembler on small systems 30 years ago.
I find myself thinking that said small embedded systems are, in a way, echoes of the minicomputers that C was originally made to run on. I say echoes, because while I’m pretty sure a PDP-11 had more raw compute power and I/O throughput due to its architecture, the memory numbers seem similar. While I read that a PDP-11 could be configured with up to 4 MiB of core and multiple disks, I doubt a majority of them were delivered or later configured to be fully maxed out. And when I look up the PDP-11, I read that a great many of them were employed in the same job that today’s embedded systems are: as real-time automated control systems. Being a whippersnapper who wasn’t born until at least a decade later, I may well be overgeneralizing, but I don’t think I’m completely wrong either.
So, when considering that, it makes sense that the aforementioned niche is where C is likely to hold out the longest. It’s a similar environment to the one it was originally adapted to.
>I find myself thinking that said small embedded systems are, in a way, echoes of the minicomputers that C was originally made to run on.
Oh hell yeah. Dead obvious to those of us who remember the old days. Your conclusion “the aforementioned niche is where C is likely to hold out the longest” is also obviously correct.
While today’s proficient embedded programmer would be right at home with the PDP-11, and while this statement holds true for
someembedded systems, it’s certainly not true for all.Moore’s law has done some interesting things for us. Package pins are costly, so for a lot of small embedded systems, it may make more sense to have all the memory on-chip. Once you have all the memory on-chip, you don’t want too much of it, or your cost goes up again because of the die size. Performance costs are somewhat orthogonal to memory costs: performance increases by adding more transistors and by reducing feature size. Both of these are expensive, but not always as expensive as adding memory.
One cool thing about on-chip memory is that since you’re not constrained by pins for an external bus, you can have a really wide bus to memory. Another cool thing is that you can have interleaved buses if you want, simply by splitting memories up in odd ways. Interleaving buses allows for simultaneous access from a CPU to one word with DMA to an adjacent word.
So there are a lot of niche devices that fit in this C niche, in fact that are small enough to not even want to run an OS on, never mind an interpreter or garbage collector — that are nonetheless performant enough to, for example, saturate a few full-duplex gigabit ethernet links while doing complex DSP calculations. In other words, a $5.00 chip might very well exceed a PDP-11 by orders of magnitude in memory bandwidth, CPU power, and I/O bandwidth.
http://micropython.org/
That at least fits the memory requirements you’ve laid out.
Personally, I’d love to write Oberon-2 code for micro controllers. Much cleaner than C++, but just as fast. Unfortunately that language never really caught on outside of ethz.ch.
Which is a shame because Wirth essentially showed it to be capable systems programming language by developing the Oberon operating system.
It’s an excellent and small garbage collected language that could have supplanted efforts like Java. I suspect the only thing that actively prevented it from doing so was: promulgation, and the fact that it wasn’t a C-family language.
Oberon-07 did.
http://www.astrobe.com/default.htm
You can target ARM Cortex-M3, Cortex-M4 and Cortex-M7 Microcontrollers and Xilinx FPGA Systems with Oberon-07.
The interpreter will fit, but how much functionality also fits? With C, you can fit an application plus complete zigbee and bluetooth stacks in a 512k part.
I’m curious about Rust for new development, but C won’t get displaced in this space for a long time. There’s some value to a very limited subset of C++ to pick up things like namespaces and compiler enforced encapsulation, but that doesn’t fundamentally change things.
FORTH? It seems to be a good fit for small embedded, and it is nonetheless “high-level” in a sense, in that it trades off machine time for ease-of-development time. But I’m a bit skeptical about Moore’s law being relevant to small embedded systems these days – it seems to have stalled early there, so something closer to the metal ala Rust will also find plenty of use.
I agree about Moore’s law on small embedded systems, or more narrowly, on their CPU’s. I sometimes write code for these things – in C – because a customer uses them for their very low cost. The processors are a little faster than in the 1980’s, and they’ve added a few instructions, but basically, a PIC18 is still a tiny little machine with a horrible machine model, just like its 1980’s progenitor. A 68HC05 is still a 6805 which is just a bit more than a 6800, from the 1970’s.
However, Moore’s law does appear – the greatly increased chip density leads to very chap SoC’s – a dollar for a machine with RAM, Flash, EEPROM, and a whole bucket of built in peripherals and peripheral controllers.
The good news is that you can indeed use C on these things, rather than assembly (which is true torture on a PIC). And, the C optimizes pretty well.
Not all sub-$1 microcontrollers are PICs, thankfully. Some are 8051s (meh)…and some are ARM Cortex systems, on which C does very well, thank you. Microchip even has a PIC32 series that’s MIPS-based.
Check out this article that surveys 21 different microcontrollers, all under $1 each.
The embedded Rust community has been able to get Rust cross-compiled for targets like that. Pretty much the only thing you need is compiler support, and a language that doesn’t require a runtime. All systems languages get compiled down to the same machine code in the end (especially when they all use the same compiler backend).
Typos:
(At least, I assume this is a typo, but the E and I keys are nowhere near each other… Does your dialect smush those vowels together, or is
trepa jargonic verb I’m not familiar with?)I’ve never come close enough to the bare metal to have anything more substantial to add!
https://xkcd.com/1530/
They are, in Colemak. Home row: arstd hneio.
@esr:The first serious attempt at the second path was Java in 1995. It wasn’t a bad try, but the choice to build it over a j-code interpreter mode it unsuitable for systems programming.I agree Java was a poor choice for systems programming, but I don’t think it was ever intended to
bea systems programming language. The goal of Java was “Write once, run anywhere”. Java code compiled to bytecode targeting a virtual CPU, and the code would actually be executed by the JRE. If your hardware couldruna full JRE, the JRE handled the abstraction away from the underlying hardware and your code could run. The goal was cross-platform, because the bytecode was the same regardless of what system it was compiled on. (I have IBM’s open source Eclipse IDE here. Thesamebinary runs on both Windows and Linux.) For applications programming, that was amajorwin. (And unless I’m completely out of touch, the same comments apply to Python.)More generally, any area of applications or systems programming can stay stuck to a language well after the tradeoff that language embodies is actually obsolete.Which is why there are probably billions of lines of COBOL still in production. It’s just too expensive to replace, regardless of how attractive the idea is.
But I think they will – the business case for Google to push them there is obvious (can you say “Android development”?).Maybe. Android has a Linux kernel, but most stuff
runningon Android is written in Java and executed by the Dalvik JRE. The really disruptive change might be if Google either rewrote the Linux kernel in Go, or wrote a completely new kernel intended to look and act like Linux in Go. The question is whetherLinux’sdays are numbered in consequence.>DennisWe have an existence proof of a kernel in Rust. Has anyone written one exclusively in Go?
>We have an existence proof of a kernel in Rust. Has anyone written one exclusively in Go?
No, That would be a silly thing to try until the next major advance in GC technology. If then.
I won’t disagree with you that it’s a silly thing to try, but there is Gopher-OS.
The major advances in GC already exist, they are just only available in proprietary software: the Azul C4 Garbage Collector (Continuously Concurrent Compacting Collector) for their variant of the JVM, Zing. You pay the price of the GC read-barrier, but then you enjoy the benefits of a massively scalable concurrent GC with no pause.
Like a Lisp machine, on steroids. (And yes, the Lisp Machines had the entire OS in Lisp, and there was a variant with a guaranteed real-time collector.)
@esr Why is it silly? Honestly curious given that Niklaus Wirth developed the Oberon operating system back in the 80’s using a garbage collected descendant of the Modula-2 programming language (also named Oberon).
>@esr Why is it silly?
Latency overhead from the GC is still too high. This may change in the future.
If you’ve seen this recent post from Cloudflare regarding their usage of Go and how it’s GC kills performance majorly, I don’t think so.
https://blog.cloudflare.com/go-dont-collect-my-garbage/
I’m still curious as to how much the overhead is an issue. Wirth showed that one could develop an OS with a garbage collected language. Is this an issue with particular kinds of operating systems (real-time for example, I can see this being an issue)? For a general purpose system however, how much of an issue it?
OS’s with garbage-collected languages used to build their kernels and user space are often designed with serious tuning of the garbage collection cycles. Problem is, the more load you put onto these kernels, the more GC cycles are required, and thus they seriously buckle under stress.
Would you like a desktop OS with high-latency audio, video, and input responses? I’d think not.
Active Oberon, the last variantion of the Native Oberon OS, had multimedia support.
http://www.ocp.inf.ethz.ch/wiki/Documentation/WindowManager
Nice audio and video support running on a managed OS.
You evidently didn’t read the whole article. By tuning the Go GC he got the performance he desired. He also states that “… this type of benchmarking is definitely an edge case for garbage collection.”
Such tuning would not be required at all with a proper language that does not require a runtime garbage collector, a la Rust.
I really don’t understand the obsession with GC languages. Even with Go, you end up writing far more boiler plate code and overly-convoluted solutions in comparison to GC-free Rust. Why pay for GC when you don’t even need it?
Such tuning would not be required…It’s an “edge case”.
I really don’t understand the obsession with GC languages. … in comparison to GC-free Rust.Rust. Rust. Rust. Rust. Rust. Rust. Rust. Rust. Rust. Rust.
You’re an odd one to speak of obsessions.
Why pay for GC when you don’t even need it?Why pay for manual memory management when you don’t even need it? See how it is to write un-proveable assertions. Even I can do it.
Rust appears to have a lot to offer. It behooves all of us to get to know it.
The biggest impediment to Rust’s adoption is the people promoting it.
Amen. I’m about to quit following this post because of the monomaniacal Rust fanboyism. I’m not learning a damned thing about the language except that it incites Scientology-level cultism in its adherents.
> I’m not learning a damned thing about the language except that it incites Scientology-level cultism in its adherents.
Not all of them. I’ve had rational conversations with core Rust people on their fora. I cited some in my second Rust post.
The funny part is that Michael Aaron Murphy doubtless believes “I am an effective Rust advocate” when the reality is “I make people run screaming from the thought of having anything to do with Rust.” With friends like him the language doesn’t need enemies.
> It’s an “edge case”.
I spent two years experimenting with Go, and I can tell you that tuning the GC is not an edge case. It’s very common.
> Why pay for manual memory management when you don’t even need it? See how it is to write un-proveable assertions. Even I can do it.
You aren’t paying for manual memory management. Rust’s compiler and language does all of that for you. You’re trying to argue against an absolute. What a shame. Either you pay hardware costs to implement a solution, or you create a simpler solution that doesn’t need to pay those costs. It’s obvious which of the two are better options!
> The biggest impediment to Rust’s adoption is the people promoting it.
Purely false. Rust has a healthy adoption rate. It arrived at precisely the right time when it did, to take advantage of all the concepts and theories that had been developed at the time it started development, and has been adopted at precisely the correct rate, to enable the Crates ecosystem to catch up to the needs of the developers adopting it. Rust’s community is growing exponentially, regardless of how much you snarl your nose at it. It doesn’t matter what you or I say. Any publicity, is good publicity!
> Rust appears to have a lot to offer. It behooves all of us to get to know it.
It does nothing of the sort. It is simply the correct tool for the biggest problem in the software industry. Either you choose to use it of your own volition, or you fall behind into obscurity, and a new generation of software developers replaces you.
Michael Aaron Murphy:
Help is available. There are many new medications that show great promise. Support groups are nearby for you in your time of need. You don’t have to suffer alone.
In all fairness, the advantages of Rust’s approach to memory allocation and deallocation predate Rust itself, with antecedents in C++ and even Objective-C. Rust merely builds on and enhances these things.
But there is an
inherentcost to runtime garbage collection that simply is not paid when your language determines object lifetime at compile time. Tracing GCs are, in a word, obsolete: 1960s technology does not fare well in the face of 2010s problems of scalability and performance.Rust earned its position as the prime candidate to replace C as the default systems language in two ways: by not adopting a GC and not sucking as bad as C++. Three ways, actually, if you count being hipster-compliant (which Ada is not).
Why? People wrote kernels in Lisp 40 years ago.
Rust has tools such as corrode that makes transitioning from C relatively painless.
Regarding your question about select(), things are moving lately:
https://github.com/crossbeam-rs/rfcs/pull/22
But I agree that it will take another round or two of refinement (so about 2 years) to make the language painless for gps or ntp purposes.
Although it should be noted that it’s often times faster to rewrite something from scratch than to use tools like corrode and manually rewrite the converted code into something idiomatic to best practices.
You might enjoy the talk I gave as the interview presentation for my current job:
https://athornton.github.io/go-it-mostly-doesnt-suck/
I saw that when you posted it on G+. Mostly agreed with it, except that I thought the “training wheels” crack about Python was unjustified and I miss #ifdef more than you – my stuff wants to have code conditionalization for stripped-down builds.
You were right on about one thing, especially. Go is static typing done right – the compiler error messages are genuinely helpful to extent that after C and C++ is rather startling.
Ada and Rust also provide helpful compiler error messages.
If Go is “static typing done right”, why is the number one complaint among Go users about the weakness of Go’s type system?
I can make a good case that Go is the local optima (or the “done right”) of that type of manifest typing.
The problem is that the next local optima that we as a community know about is a fairly significant step up on the complexity curve. A lot of the nice type features really need
othernice type features to make them work, which then need support from other nice features, which need support from other features… this is not an infinite regress and you end up somewhere where you can do things that you really, really wouldn’t want to do in Go (Servo would be a nightmare in Go), but I tend to agree that Go is going to have a niche for a long, long time.>The problem is that the next local optima that we as a community know about is a fairly significant step up on the complexity curve.
Quite, and see “low transition costs out of C”. Ken Thompson is the single most brilliant systems engineer in the history of computing; where he drove this language wasn’t towards an optimum in theoretical design space but an optimum in terms of the economics of actual existing computing.
You know what? This doesn’t want to be a comment. It needs to be another blog post.
…Circa 1970. It’s reasonable to assert that the kinds of sophisticated type checking and static verification required in languages like Rust and Haskell would have been too costly on the hardware Thompson and Ritchie had to hand (and anyway, the type theory hadn’t even been developed yet). Besides which, they weren’t building software for flight avionics or radiation dosing machines, they were building more or less a sandbox for them and their fellow hackers to mess around in. At the time they designed C’s type system, they weren’t expecting their language to bear the full weight of the internet, including all its malicious actors; they could reasonably expect the average C program to be small, short-lived, and only used by persons within the same computing facility as the author. They didn’t even have to deal with today’s new normal: people carrying always-on internet machines in their pockets, Russian hackers swinging major elections, the Internet of Things. All of which swing the requisite standards of reliability, performance, and security far towards the “flight avionics and radiation dosing machines” end of the scale.
Unix was a reasonable system design in its time, far less so today. And there’s no need to provide a comfortable transition from what C hackers know because by 2017 standards, what C hackers know is broken. And most of today’s developers have spent their larval stages working in C++, Java, or C# anyway.
Exactly, which is why once you’re exposed to Haskell you tend not to take type systems weaker than Haskell’s seriously. You simply cannot do monads very well without Hindley-Milner, higher-kinded types, and type classes.
The difference between you and me is I see the added type complexity as essential complexity whereas you see it as accidental complexity. It’s complexity inherent in the system you’d have to deal with one way or another. Whatever you don’t pay for at compile time accrues interest at run time — and the APR is a bitch. So the more invariants that can be asserted by the type system (like Rust encoding object lifetimes directly within its types) at compile time before the program even runs, the less you’ll have to sweat about at run time. And, ultimately, the more money you’ll save in the long run.
Go’s littered with reflections and reflection-based errors. That’s a far cry from static typing.
What about OCaml as a systems language?
>What about OCaml as a systems language?
OK, what about it? Are there any deployments outside academia?
How about the finance industry?
https://stackoverflow.com/questions/1924367/why-do-hedge-funds-and-financial-services-often-use-ocaml
>Dennis– Citrix uses it in XenServer.
– MirageOS unikernel is developed in it.
Facebook uses it. They have a new “friendly” syntactic front-end to OCaml called Reason: https://reasonml.github.io
What about Ada and its recent offspring Spark? They seem to me to address your issues with C++, technically speaking, they also do have (very) large deployments, are mature and well supported. However, they did not and do not seem to replace C because of the vast mass of systems C programmers and code. There will continue to be a lot of job openings in C, making it worth learning, and maintaining the size of the programmers body. One will keep being more likely to easily find systems programmers that know C than ones mastering any other language. This should keep C going even if technically better options appear (they already exist, in fact).
One thing Eric’s been looking for that Ada has and Rust lacks, is standard POSIX bindings. And when I say “standard”, I mean IEEE Standard 1003.5b-1996 — Ada bindings are part of POSIX. An open source library that implements this standard, called Florist, is readily available for the GNAT compiler and there’s even an Ubuntu package for it.
Insightful post.
After a long break from programming it was seeing what they had done with UB that ruined C for me.
However, don’t you think that there is unlikely to be a single successor to C? That was a product of very different times and the size of the market was much smaller then.
I agree with you about the merits of Go for many purposes. But one gives back modelling power, and there are times when you need it.
When was the last time you checked out D? You sound like you are doing nothing more than repeating talking points. Languages develop at different rates and D is much more ambitious… Unsurprisingly then it wasn’t ready till quite recently for broader adoption – libraries, tooling, documentation.
Its taken off quite sharply since 2014. Have you seen the stats?
http://erdani.com/d/downloads.daily.png
And there’s a growing need for it because when your logs hit 30 GB a day Python is no longer quite fast enough.
Here are some commercial users:
https://dlang.org/orgs-using-d.html
I’m one of them (at a 3.6bn hedge fund).
@esr:
> Therefore: eventually we will have GC techniques with low enough latency overhead to be usable in kernels and low-level firmware, and those will ship in language implementations. Those are the languages that will truly end C’s long reign.
I don’t know. As I haven’t managed to write anything more than toy code at any level yet, I’ll defer to anyone that has shipped production code at that level of the stack, but the OS/firmware level is what is most interesting to me, and if I ever do manage to get off the ground, something in that regime is likely to be the kind of stuff I’ll be writing. And my gut feeling is this: people working at that level are going to be reluctant to use garbage collection that they did not write themselves. So low-latency garbage collection needs to be developed, and then it needs to be distilled into something that people whose expertise isn’t necessarily language development can implement. Because at the kernel level, while it isn’t very far to the bottom, you absolutely *have* to be able to see all the way down, and a GC implementation you didn’t write is a potential impediment to that.
One point that might be refined from your machine-centric/programmer-centric distinction is the asymmetry in adaptability, not just the asymmetric cost trends. Modifying the machine to better accommodate a programmer-centric language doesn’t often pan out well; you wind up with odd artifacts like Lisp machines. On the other hand, programmers self-modify; they adapt to such things as pointer semantics and registers as part of learning low-level languages.
I find Forth seems to live at a knee in the machine-efficiency/programmer-friendliness curve. Its RPN stack is fairly easy to wrap ones head around, and it’s close enough to the metal for use in low-level code like bootloaders. But that knee is pretty close to the machine-efficient end of the spectrum because of the asymmetry between how well programmers can mentally model a machine executing their code and how poorly computers emulate a human mind.
Rust and Go?
C++ will keep taking over for C until we get verification that scales. I’m betting on a language like Whiley (whiley.org) or Dafny/Boogie (Microsoft) in the long term.
For higher level server-oriented programming, most likely something based on actors such as Pony (ponylang.org), but with verification.
Such languages are in the works, so maybe a language like Creol (http://www.sciencedirect.com/science/article/pii/S0304397506004804) which appears to provide verification for high level concurrency mechanisms could be a starting point for real change.
Go has a nice runtime, but needs semantic improvements and a significant cleanup regarding how error handling and abstractions are done. Won’t happen with the current team. So it is a dead end… unfortunately. D is the same category. Necessary changes won’t happen with the current team.
Rust doesn’t really solve C++’s issues, except maybe the learning-curve. Lifetime management is not a big problem for proficient C++ programmers (i.e. C++11/17). C++98 is essentially a different language than C++17/20 in terms of idiomatic source code. So new idiomatic code bases would be incomparable to old code bases in terms of maintenance. (Assuming you have proficient people to do code review.)
> Lifetime management is not a big problem for proficient C++ programmers
Try telling that to the Firefox developers who’ve posted a review of their Project Quantum Stylo integration in the new release of Firefox today. They replaced 160,000 lines of C++ with 85,000 lines of Rust. And memory safety was the single-most reason for the project succeeding where all previous attempts in C++ failed. These are incredibly-experienced veteran C++ developers.
https://blog.rust-lang.org/2017/11/14/Fearless-Concurrency-In-Firefox-Quantum.html
Incredibly experienced might mean that they are stuck in a C++98 mentality. Anyway, no team is better than the process it is managed by… And Mozilla are hardly neutral when it comes to Rust.
That a rewrite leads to better code, well, hardly surprising. Is it?
Now, simple substructural subtyping like Rust provides can prevent you from doing some mistakes, but it might also ban valid code which introduces inefficiencies because you are forced to choose a particular structure.
I don’t mind it, but it doesn’t help much on the hard to find bugs I run into. Only more advanced behavioural typing and program verification is sufficient for preventing typically expensive low level bugs.
> Incredibly experienced might mean that they are stuck in a C++98 mentality. Anyway, no team is better than the process it is managed by…
Actually, Mozilla are well known for having some of the best C++ programmers in the field. They are among the first to adopt newer standards of C++. They are also quite versed in the latest research in computer science, especially given that they have around 30 people in the core Rust team with PhD’s in computer science.
These are both highly educated recent grads that are up to date with all the latest research, and highly experienced veterans of C++ that have been developing the most complex software in the world — web browsers. They can’t afford to not up to date with the latest strategies and techniques.
For example, Servo is actually constructed using an entity-component system architecture, rather than an OOP architecture. Servo’s been built with the latest techniques that modern game developers are using to build their AAA games. If these were people trapped in C++98 days, they’d have no knowledge of such concepts, or be able to create something as advanced as Rust.
> And Mozilla are hardly neutral when it comes to Rust.
No organization would support a product that isn’t giving them a benefit. You have to also realize that they are among the best-suited to represent Rust. Not only did they kickstart, orchestrate, and develop the language (with the help of three other companies), but they have managed to create very complex production-grade solutions with it, and it’s shipping today in one of the most widely used applications on the planet.
> Now, simple substructural subtyping like Rust provides can prevent you from doing some mistakes
Luckily, Rust does more than simple substructural subtyping.
> but it might also ban valid code which introduces inefficiencies because you are forced to choose a particular structure.
Nothing is banned in Rust (except undefined behavior) — you are not forced to choose a particular structure. You are heavily encouraged to choose the correct structure, on the other hand. Have any examples to provide?
> Only more advanced behavioural typing and program verification is sufficient for preventing typically expensive low level bugs.
Luckily, we have very well-educated experts on these topics that have gone about implementing formal verification techniques within Rust. Ticki comes to mind when he began talks about implementing a Hoare Logic in Rust within the MIR.
C++/Rust/browsers are mostly atheoretical, so not sure how phds would be relevant? Also not sure why people keep claiming that browsers are the most complicated… The complexity in browsers arise from being big and implementing big standards while having to work with existing web sites. But that domain isn’t particularly hard in terms of theory…
Typesystems are filters. They typically filter out both valid and invalid programs. Of course, you can get around it by writing more code, you only ned a TM to do that. But it isn’t convenient… C++ is currently more convenient than Rust as Rust still is quite immature with a limited eco system.
You probably meant to say that they are going to add asserts with quantifiers to MIR. Hoare logic is just a set of deduction rules.
> C++/Rust/browsers are mostly atheoretical, so not sure how phds would be relevant
You don’t understand why the well-educated would be interested in using their knowledge to develop new solutions and solve real problems that we are facing today? Or that Rust & Servo were research projects by Mozilla that have been ongoing for five years? The heck.
You should serious read some Rust RFCs[1]. Case in point is the generic associated traits RFC (HKTs)[2]. Each file there is basically a paper describing the specifications of that feature and it’s implementation. You’ll quickly realize why we have PhD’s on board helping to shape the future of Rust and it’s language design.
> Typesystems are filters. They typically filter out both valid and invalid programs. Of course, you can get around it by writing more code, you only ned a TM to do that.
I don’t think you understand what you think you understand, regarding Rust. Rust’s type system isn’t acting as a filter to filter out ‘valid programs’. The only thing that comes to mind that you seem to be referencing are Non-Lexical Lifetimes, whose RFC is almost fully implemented.
Yet the lack of NLL being fully implemented yet only serves catch newcomers to the language whom have yet to internalize the rules, and have no baring for the rest of us who never write software that falls into that trap (because we understand how lifetimes work, and how to properly use scopes to ensure that those lifetimes don’t conflict).
> But it isn’t convenient… C++ is currently more convenient than Rust
I think you’ll find many here and elsewhere who disagree with that. Otherwise, there would be no point in using Rust, and Mozilla would not have succeeded in their Project Quantum efforts to integrate components of Servo within Firefox. There’s a serious contradiction between what you’re stating here, and what people and companies are actually doing today with Rust.
From Patrick Walton: https://twitter.com/pcwalton/status/929065687632330753
> Rust still is quite immature with a limited eco system
Not true. Have you seen how many crates that we have today? And the quality of the top crates, and associated blessed crates by the community? We have a lot of top-notch solutions for everything under the sun. I’ve had major success developing all kinds of different software with Rust because of how powerful a lot of these solutions are, which C++ has no parallel to.
Can you automatically deserialize raw text of any given format into a native hierarchy of data structures, and vice versa serialize native data structures into a string without having to write any code? That’s what serde does. The following is how you can automatically GET JSON from a web server and deserialize it into a native data structure.
let data: Data = reqwest::get(URL).json()?;
Any type that has the #[Deserialize] attribute above the structure definition can be used in the above. That’s just one of many examples of how powerful Rust is at achieving complex tasks, simply.
[1] https://github.com/rust-lang/rfcs/tree/master/text
[2] https://github.com/rust-lang/rfcs/blob/master/text/1598-generic_associated_types.md
And here we go with the educational elitism. You come off like a Brie-eating bicoastal elite, CS subtype, who is bound, damned, and determined to tell us all how to think and work, just like the Brie-eating bicoastal elites are bound, damned, and determined to tell us all how to live.
Here’s a free clue: A PhD does not guarantee a damned thing except that the person who’s entitled to call himself one has put up with the leftist bullshit of academia for longer, with greater intensity, than those who merely have a bachelor’s, and has played the academic politics game – which inevitably involves hewing closely to the current SJW line of crap – better than the average student.
I don’t care about academic credentials. I care about getting work done. Period.
“Brie-eating”
Tastes differ, but real brie (from raw milk) is a good cheese. I do enjoy it regularly. But I am neither a member of the elite nor a CS programming language designer.
“A PhD does not guarantee a damned thing except …. than those who merely have a bachelor’s”
Do I sense some envy?
Anyhow, you got it totally wrong. A PhD is proof you can perform independent research and write it down, that is, you are a qualified scientist (or the equivalent in other academic disciplines). Nothing more, nothing less.
If you want to incorporate the latest progress in research, it often helps to hire relevant PhDs, as they generally have been exposed to the latest advances. Because that is their job.
If you try to create cutting edge technology, you are a fool if you discriminate against PhDs in particular, and people with different political ideas in general.
To be clear: I like Brie. I use it as an example of what the bicoastal elites do as opposed to the folks in America’s heartland, who rarely encounter it.
And no, you don’t sense envy. I’ve been out earning my way in the world, instead of sponging off others in academia and getting a good thorough Marxist indoctrination.
Computing doesn’t need esoteric scientists who know more and more about less and less until they know everything about nothing. It needs people who care about getting the work done, and have been there and done that.
Research is productive work. All technology is based on scientific research, so your livelihood is depended on past research. Scientific research is built on PhD students. No PhDs, no science and no technological progress.
Science and technology are agnostic towards politics an religion. If you are not, you would indeed not be suited to do science.
Moreover, you are so far to the right of the political spectrum that almost all of humanity is far out to the left of you. You cannot fault them for that.
You mean people like Turing and Shannon? Or Knuth? Or the guys at Bell Labs and Parc?
These people also had PhD’s. And they lived in the coastal regions of the US.
But these people you talk about use the legacy of those “esotheric scientists” all the way back to Shannon, Turing, Schrodinger, Maxwell, Herz,
Faraday, Ampere , and Volta.
Rejecting PhDs is rejecting future progress.
You missed *entirely* what he was getting at.
And were you an American you would identify more with the “costal elites” (they aren’t always on the coast, and they’re only elite in their own minds).
What Jay is complaining about is the Rustifarian’s attitude.
“And were you an American you would identify more with the “costal elites” ”
Indeed. I have been in the US several times and I can feel quite at home in the “coastal” areas. I particularly liked Portland and Boston. San Fransisco is nice too. I must admit that my experiences of inland US have been limited.
“What Jay is complaining about is the Rustifarian’s attitude.”
Could be. But he is attacking PhDs and science to do so. Therefore, I think his beef is with science more than with Rust.
Congratulations. You made no effort to refute any of my counter-arguments. You merely went into an off-topic tirade about people with PhDs. I definitely see some serious anger, denial, and envy in there.
A phd is usually a very narrow research project and typically has nothing to do with C++, you would usually be better off using a more powerful high level language for phd work. As far as programming goes a well rounded bachelor in either comp sci or software engineering covers most of what you need, from thereon it is all about your own exploration and desire to expand your horizons. A phd is just one way to do that, in a very narrow way.
All typesystems are filters. The formal definition of a languge is that it is a set of strings (programs). A type system will reduce that to a subset.
You’re going to need more than a bachelor’s degree to be capable of leading bleeding edge language research, and employing it successfully in practice at scale…
A bachelor’s degree only guarantees that you can write software using a language that’s already been constructed for you, by the people who have PhD’s!
Degrees are completely orthogonal to capability.
You’re completely missing the point…
> A bachelor’s degree only guarantees that you can
> write software using a language
No, no it doesn’t.
Very few books on advanced topics assume much more than a bachelor, if they did they wouldnt be able to use them in higher level courses. You usually also find whitepapers and surveys that can help. So, for an attentive person a bachelor opens the doors you need open if you have the interest.
“Modern C++” is nowhere near eliminating pernicious memory safety issues, such as use after free bugs. In some ways, it’s making things worse. Here’s an example: https://github.com/isocpp/CppCoreGuidelines/issues/1038
References are semantically equivalent to bare pointers, modern C++ uses them pervasively, and they create lots of opportunities for use-after-free whether or not you use smart pointers.
Beyond memory safety, Rust solves lots of other problems that C++ doesn’t, like preventing data races, proper type bounds for generic types (concepts will only solve half the problem), easy management of library dependencies, powerful metaprogramming facilities like “custom derive”, …
Sounds like somebody is not up to speed with modern C++. The issues you raise have been addressed.
The core issue ESR raised was C++’s backwards compatibility. How can you possibly claim that’s been addressed?
Until C++ is reformed into a brand new language with zero backwards compatibility, none of it’s issues have been address. All of the C++ developments have merely been adding lipstick on a pig, and by that I mean that each new major feature that should be the default behavior, requires a major degree of boiler plate to use, making the language incredibly verbose to use, while still providing zero guarantees about any of the code. How do you ensure that every usage of code in your own code base, and all dependent code bases, are using best practices? You can’t.
You’re talking about the past as if it were still the future, and you’re wrong about it. C++ is a massively successful language and isn’t going away anytime in the next 30 years.
– Every major browser is written in (mostly) C++
– Many major language implementations are written in C++ (LLVM/CLANG, GCC, V8, many or most JVM implementations, including Android’s Dalvik and ART which are installed on billions of devices)
– All of the big internet/software companies (Apple, Google, Facebook, Amazon, Microsoft) have hundreds of millions of lines of C++ in their backends and consumer products.
– Every big AAA game / game-engine includes C++ as a significant, if not majority component.
In addition, it is trending up. The number of C++ repos on github grew faster than the github average between 2012 and 2016: http://githut.info/
Lastly, on GC: It will never be cheap enough to be used in areas like games and kernels. It isn’t about the cost, it’s about the ability to reason locally and attribute the cost to the code that incurred it. If you have a latency problem in C++, its either the fault of the OS (true for all languages), or its the fault of the code that isn’t running fast enough. If you have a latency problem caused by GC pauses, its the fault of the entire system, and fixing it becomes a boil-the-ocean problem.
@Mark:You’re talking about the past as if it were still the future, and you’re wrong about it. C++ is a massively successful language and isn’t going away anytime in the next 30 years.I agree, but I’ve been watching the progression with interest. I think of the problem in linguistics in when a dialect of an existing language diverges enough to be a whole new language. The joke tends to be “A language is a dialect that has an army and navy.”
A chunk of the issues I’ve seen with C++ are precisely that sort of thing. Programmers were treating it as a dialect of standard C, and not properly comprehending the differences. They’d have been better served to think of it as a whole new language.
Another problem is that all compilers are not created equal. There’s a grimly amusing Mozilla Developers document on writing portable C++ code, and what you must do for your code to
beportable. A lot of it reduces to “Just because it works in Microsoft Visual C++, don’t assume it will work elsewhere!” Mozilla was trying to beveryportable in the early days, and the problem child was the C++ compiler shipped with HP-UX which choke on constructs everything else would compile. (These days, they support Windows, Linux, and OS/X, and if you run something else, getting the code to build and run is your problem.)>DennisEvery major browser is written in (mostly) C++Yes. And they all stink.
Memory leaks, excessive cpu consumption, an endless stream of security exploits, unexplained crashes … the usual complaints.
Having been on the receiving end of these applications for quite a long time, my cynical conclusion is that writing bug-free C++ code at scale, on deadlines, and with sizeable teams of skillset-diverse coders is testing the limits of what humans can do.
Aye. “AAA game studios do it” is a good way to find yourself sailing off a cliff with all the other lemmings.
How much of that is inertia though? I’d wager a lot, if not most of it.
Every major browser has a code base older than any of the up and coming systems languages. All the major language implementations listed were started before any of the upcomers were mature. All of major internet/software companies product lines and codebases are older than any of the upcommers. And new games continue to be written in C++ because once again, the tooling for making games is older than the upcommers. It makes sense; when you start a project, you reach for the best tools you can get, and for a while, C++ was that tool.
But the times, they are a changin’. C++ may well have been good enough for larger systems, compared to C, but that doesn’t mean wasn’t or is no longer without its flaws. As I understand, Rust was born because Mozilla knew they needed to move Firefox to a multi-thread/process model to make things faster, but also knew that attempting such in C++ was a recipe for Firefox having as many bugs as a AAA game does when first released. And now, the newest versions of Firefox running on the newer multi-thread/process design are incorporating components written in Rust.
I also have my doubts on GC becoming good enough for (some kinds of) games and OS kernels. But, how things have been and are they now does not mean they will forever be that way in the future. I may well be wrong about GC.
> Every major browser is written in (mostly) C++
Times are changing. Firefox just replaced 160,000 lines of C++ with 85,000 lines of Rust[1] — and that’s just the Stylo component. That’s not counting the upcoming WebRender and Pathfinder components that are about land in subsequent Firefox releases.
> All of the big internet/software companies (Apple, Google, Facebook, Amazon, Microsoft)
All of these (minus Apple) have been posting jobs looking for Rust software developers, so times are changing here too.
> Every big AAA game / game-engine includes C++ as a significant, if not majority component.
Maybe so today, but DICE and many other AAA and indie studios are highly interested in, or already are using Rust. DICE uses Rust extensively internally. I know that Chucklefish are creating a new game that will be available on consoles, written entirely in Rust.
[1] https://blog.rust-lang.org/2017/11/14/Fearless-Concurrency-In-Firefox-Quantum.html
Incredibly experienced might mean that they are stuck in a C++98 mentality. Anyway, no team is better than the process it is managed by… And Mozilla are hardly neutral when it comes to Rust.
That a rewrite leads to better code, well, hardly surprising. Is it?
Now, simple substuctural subtyping like Rust provides can prevent you from doing some mistakes, but it might also ban valid code which introduce inefficiencies because you are forced to choose a particular structure.
I don’t mind it, but it doesn’t help much on the hard to find bugs I run into. Only more advanced behavioural typing and program verification is sufficient for preventing typically expensive low level bugs.
(ack, my reply appeared on the wrong message)
> Times are changing. Firefox just replaced 160,000 lines of C++ with 85,000 lines of Rust[1] — and that’s just the Stylo component.
I rewrote a system with a base code being 20000 lines of PHP and another 80.000 lines of PHP in the framework, to a system that now uses 3000 lines of code in total that does a better job then the original.
The magic language with was called R … no, just simply PHP… So by your logic PHP is going to replace PHP because i reduced the code by 33 times and reduced the bugs and issues to almost zero. Good to know …
Those Rust number mean nothing. Any project will build up crud over the year and when you rewrite the entire code base, with the new knowledge of what it needs to look like, you will reduce your code by massive amounts. That is just basic knowledge that most programmers know.
Its not a argument to use how good Rust is… So please stick more to facts that are not # code lines on a project rewrite. I know few project when rewritten that will have the same or a increase in code lines.
To all the prior replies: Great points, all. I certainly wouldn’t claim that C++ is the pinnacle of language design or the evolutionary endgame of programming. Hopefully rust and others will replace C++ in areas where they are better suited. My only point was that ESR seems to be laying out an argument for why C++ can’t succeed, and my reply was intended to point out that it already has, in spades.
>ESR seems to be laying out an argument for why C++ can’t succeed,
Not exactly. I’m claiming it will not replace C and lower post-C defect rates, because it has C’s leaky-abstraction problem baked in.
I love C++ and am highly productive in it, and I particularly love C++11, because it supports garbage collection.
But because of backwards compatibility, all abstractions leak, and sometimes making them not leak is subtle and tricky, and worse, much worse, sometimes the very clever, nonobvious, and subtle things you do to prevent leakage fail on C++98, and work on C++11.
Having a program that crashes horribly because g++ defaults to C++98, and C++11 is an option, is really bad. “Gee, it works when I run it on my machine”
(Always put the following in CMakeLists.txt:
cmake_minimum_required(VERSION 3.5)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
Or else mystery bugs ensue between one man’s compile and another man’s compile. Because abstractions leak differently between C++98 and C++11!
If someone else’s abstractions leak badly and surprisingly, then you have bugs that are hard to track down.
I am unfamiliar with rust, but according to several commenters, Rust enforces C++ best practices – and is therefore backwards incompatible. It is C++ with backwards compatibility thrown overboard.
And, as I have discovered, C++11 is not perfectly backwards compatible with C++98
I think the value of debugged code has always been severely underestimated. Hence the periodical insanity of trying to re-start projects from scratch that only rarely succeed.
It seems to me that you’re giving short shrift to the value users place on very fast response times. The idea that 0.1 second response times ought to be fast enough for anyone has a Gatesian smell about it. Delays accumulate. Delays get magnified on old or limited systems, or when a system is under heavy load. There was a comment in the previous thread noting that Python can’t always be counted on to respond at human speeds.
Even when response times to the human-facing part of a system are reliably 100ms, there is still value in making the response even faster. 100ms shouldn’t be thought of as “ideal” but rather as “minimally acceptable.”
Acceptable response in a web browser for the reload button, not acceptable in a reflex-based videogame. Maybe barely acceptable for head tracking VR, maybe, but for eye tracking that is finally coming (attack helicopters had that decades ago!) surely not.
This video gives a good run-down of how C++’s recent efforts to retrofit modern features complicate rather than simplify the language: https://youtu.be/VSlBhAOLtFA?t=1411 . C++’s time is drawing to a close, it’s just a matter of which language replaces it.
However I’m not sure I share your pessimism about Rust’s future, for one simple reason: Rust is _extremely_ similar to Apple’s Swift, both in syntax and semantics. Rust has even inspired features in Swift, such as its error-model, and Apple has hired Rust compiler & library developers to work on its Swift team.
Consequently Rust benefits from association by Apple’s promotion efforts. For a Swift developer Rust is a lot easier to learn than Go, and Rust has support for features absent from Swift such as compile-time memory-management and race-detection.
I agree Rust needs another five years to be a solid platform, however I think its foundations and trajectory is such that in five years it will surpass Go. Python was released in 1992 after all, and trailed Perl for a decade, yet now, twenty years later, it has completely replaced it.
I think you make a lot of interesting points and generally characterize the current situation pretty well. Of course I do disagree with your last paragraph, as I do write rather a lot of Rust :P Personally garbage collection conceptually bothers me enough that I still prefer the borrow checker, even if it’s slightly harder to use. Why should I burn CPU cycles on memory management when I have the choice to just write code that doesn’t need GC?
> Rustaceans
Given the…passion of some of them, shouldn’t it be “Rustifarians”?
Ah, you’ve met the Rust Evangelism Strikeforce, I see. :)
How many times have we seen this movie?
New platform/framework/protocol emerges, young puppies get all excited about
teh new hotness, and run around yipping until they get the attention they crave.Look at what I can do, daddy!
What’s the quote about 2 types of languages – the ones people bitch about, and the ones nobody uses.
Personally, I don’t give a shit about the endless language pissing contest…they’re just tools in the toolbox.
>Personally, I don’t give a shit about the endless language pissing contest…they’re just tools in the toolbox.
Sadly. I think I have to give a shit. C isn’t good enough at scale, and C++ isn’t either for the same reasons. We’ve all been dancing around the problems for decades now but as LOC goes up we are entering a regime where they can no longer be evaded.
We’ve dealt with some pretty obnoxious Rust puppies, but I give them credit for being obnoxious about a real problem. This is not the classic My Favorite Toy Language scenario where it’s
just“Look at what I can do, daddy!”. If they’d been five years sooner and hadn’t had Ken fscking Thompson competing, I’d be sucking up the horrifying C to Rust transition costs now. As it is, I’m deeply grateful that I won’t need to.> If they’d been five years sooner and hadn’t had Ken fscking Thompson competing, I’d be sucking up the horrifying C to Rust transition costs now.
I really don’t understand why Go puppies like yourself would have a view like this. I mean, you’ve yet to come up with a rational argument to use as pro for Go over Rust — yet you have no problem talking down about Rust and championing Go religiously.
I picked up and experimented with Go for two years before I converted to Rust when it achieved the 1.0 status. If that’s the best Ken Thompson can do, then he’s clearly out of touch with best practices, and the last 40 years of progress in PLT. Well, here’s my rationale, again, for where Go has failed to the point that it’s basically a joke.
Go has made so many fatal mistakes that the language is simply non-redeemable. It’s not a replacement for C, and it’s not even a better replacement than Rust for rewriting Python scripts. Go solutions continually require more LOC and boiler plate to do the same job as a Rust solution, and this only serves to increase the incidences of logic errors.
Go should have had a trait system backed by generics, rather than this bizarre interface system with runtime pseudo-generics via reflections. This would have opened the door to major zero-cost abstractions, code flexibility, and would have eliminated a significant degree of boiler plate. As it stands, you can’t even implement a generic writer or iterator — both of which are critical in all software.
It also should have focused on making it safe to write multi-threaded applications, but instead it’s only equipped for the same jobs as you’d use Elixir and Erlang for (and honestly, Elixir may even be better than Go!). Channels are nice and all, but they aren’t revolutionary at all. Most modern languages feature channels, in addition to other mechanisms. Yet Go is basically choosing to use a hammer for every task, whereas Rust allows you choose to the correct tool for each scenario.
Rust provides channels too, but it also did not neglect taking advantage of generics to create Arc / Mutex / RwLock wrapper types, and utilize the borrowing and ownership model and traits (Send/Sync) to ensure thread safety; and easily-installed third party crates provide access to a wide range of lock and lock-free data structures. Maybe you want an atomic hashmap, or a lock-free stack.
Then there’s the issue of the double return types for error handling. This is beyond incredible stupidity. It is simply bizarre. Not only do you have to allocate the Ok type, but you also have to allocate the Err type too! In what world does that make sense!?
Decades ago, a better solution was created, and that solution is often referred to as sum types, which are backed by pattern matching. Rather than allocating for two types, you only allocate for one (typically an 8-bit tag + the size of the largest variant). This then allows you to beautifully handle errors using methods, and Rust’s early return operator was simply genius for eliminating the boiler plate of error handling entirely, which is empowered by the From/Into traits.
Then there’s the anemic Go standard library. You’ve touted it as being more complete than Rust’s, but I just don’t see how that’s possible. I’ve memorized by Go and Rust’s standard library, so I have a good inkling that you’re simply full of it with that remark. Go’s standard library is a complete catastrophe in a number of different ways.
Firstly, it’s incredibly anemic. It doesn’t ship with very many useful primitives. Those that it does provide are not equipped for a large number of use cases, Try comparing a primitive type in Go and all of it’s methods, to the same type in Rust and it’s methods too. Sorry to say, but Rust’s standard library is very comprehensive.
It covers significantly more use cases, and therefore enables Rust developers to get away with not having to re-invent the wheel and bloat the complexity of their code. It’s one reason why Rust implementations always use less lines of code than Go implementations.
Then there’s the issue of the complete lack of a good majority of higher level data structures that are commonly used across all kinds of software. Obvious sign that Go is half-baked and incomplete? I think so.
Then there’s the issue that, for some reason, Go includes some libraries within the standard library that don’t belong in the standard library! These implementations are quite awful, and have lead to many in the Go community to recommend to avoid using the libraries in the standard library, and to use superior alternatives from third party libraries. Another sign that Go is half-baked and incomplete? Definitely!
Go faces the same issue as Python, only it’s doing so right out of the box. Here you have a standard library that ships some libraries that should never have been included in the first place, but that Go will have to continue to support for the rest of it’s life. Third party libraries instead offer better libraries than what the standard library is providing, so a decent Go programmer will avoid using anything in the standard library.
And Go’s designers are already talking about a Go 2, so good luck porting all of your Go 1 software to Go 2! Go was not carefully designed or geared to be used in public, whereas Rust is. That’s why you have Go 2 now in development, whilst Rust’s designers will state that they have zero reasons to consider a Rust 2, because there are no critical issues to address that can’t already be addressed in a forward-compatible manner.
Then there’s the whole packaging issue. Go does not have an official package manager, nor does it handle semantic versioning. The best you get is directly embedding git URLs in your source code. This is inexcusable.
Tangentially related:
We all know Greenspun’s 10th rule. In that vein, I’m looking forward to the ‘return of the lisp machine’ – presumably, all we need is an open-source, high performance, concurrent GC with guaranteed low enough latency, and then you could write the entire stack from kernel to userland in a suitable lisp.
I’ve been playing with a theory that I call “Greenspun’s 10th dual”: any sufficiently complicated static type system is an ad-hoc, inelegant, more difficult to use version of something from the ML family. So while I don’t agree, I think I understand why Go doesn’t have generics: they’re trying to avoid adding cruft to make sure Go’s type system doesn’t turn into something resembling C++ templates or Java 8.
As garbage collectors get better and better, I think there’s an opportunity for a high-performance language that no one (as far as I know) is seriously looking at: a systems-level ML language. Something with good concurrency primitives (probably CSP style), a straightforward module system, eager evaluation by default and enough of a ‘safety hatch’ to do the functionally-impure things that are necessary for low level programming.
Haskell’s lazy evaluation rules this out right away and I don’t think OCaml can be adapted either – the entire standard library is not thread safe (I think the reference implementation has a global interpreter lock). I think a problem is that a lot of academic work focuses on making 100% functionally pure programming languages; I don’t think 100% functional languages work too well in practice, but “85% purity” is pretty great.
(I know, I know. If I were serious about this idea, I should write some code instead of just talking about it.)
Garbage collectors are getting «better» at having shorter pauses, but in terms of efficiency you would need a major change at the CPU level… Might happen over time, just like CPU designs for decades adapted to existing C code. An oddity today is that C doesn’t match up so well to the hardware as it once did. So something new ought to come along at some point… but a more drastic change than Rust or Go.
Academic work focus on publishing papers, so such languages tend die from a lack of funding… but:
ML -> DependentML -> ATS https://en.wikipedia.org/wiki/ATS_(programming_language)
You also have examples of refinement from Haskell to C:
http://www.cse.unsw.edu.au/~kleing/papers/sosp09.pdf
Today you have to be an expert in formal methods to get it right, the tricky part is getting this into a form where it can be done by non-experts in reasonable time.
The mill cpu will have some features to support the implementation of GCs. I expect that they will give a talk describing them somewhere in the next two years or so.
Sounds interesting! Hiding the cost of memory barriers is nontrivial, but probably doable if you choose a less intuitive memory model and architecture than x86. Might make low level programming harder, but that sounds like the right tradeoff when we look ahead…
I really wish mythryl hadn’t died (literally)
–
This seems relevant:
.. the things I would do if the project was resurrected and I had a mentor (for a couple of decades). Alas, it’s not even 64bit-capable.
While Swift is not yet ready to be used as a system language now; since that is one of its stated goals, I would be interested in any thoughts both on where it is now and and where it might go in the future in this respect.
Nice post.
> eventually we will have GC techniques with low enough latency overhead to be usable in kernels and low-level firmware, and those will ship in language implementations.
This hypothetical GC has been coming “real soon” since the LISP machines. I know of people that has been saying this for 20 years, and the only thing that has changed is that nowadays they can’t hold their poker face when I teld them “that’s exactly what you told me in 1995, what do you mean with _real soon_ ? In another 30 years? I’ll probably be dead by then” :D
> but too many strikes against you to beat Go over most of C’s range. No GC,
Wait what? If one could use a GC why would one be using C or C++ in the first place?
But from your article it seems that we cannot use a GC, or at least not one that introduce a cost.
So IIUC your assumption that Go is the right choice completely hangs from the hypothesis that the 40 year old promise of a zero-cost GC will become true “eventually”.
IMO your logic is then flawed. Go might be the right choice (or not) once its garbage collector becomes zero-cost. Until then, it is not even a language to consider for applications that cannot have a GC.
If right now I’ll had to spearhead a new boringly-coded high-erish performance large-scale application that can tolerate a GC, would I chose Go? I don’t know. There way to many boring languages with good GCs to choose from: Java, Kotlin, C#, Go, …
So far, one thing that was never questioned is the von Neuman’s architecture itself. It’s already demonstrated that there can exist chips which execute high-level instructions without performance prejudice, contrary to the c-machines we have today. For an example of inspiring ideas on the topic, see:
http://www.loper-os.org/?p=1361
as well as other posts at the same blog.
I suppose we could arrive at inspiring ideas by questioning the roundness or solidity of the Earth as well, but they won’t get anywhere. Those “inspiring ideas” sound like quite a bit of wanking without reference to real systems doing actual work. Show me a working general dataflow CPU architecture that doesn’t get mired in the sheer size and complexity of its own dependency graph, and I’ll start paying attention.
In the meantime, “C machines” won because they started trouncing Lisp machines in performance even while Lisp machines were commercially available. And CPU architectures and compiler technology have advanced to the point where Lisp code on a conventional arcitecture runs as fast as or faster than it would on a Lisp machine, even if you had a multi-gigahertz Lisp machine.
Another thing about “C machines” is that their instruction sets can encode assumptions and implement control structures that cannot be encoded or implemented in plain C. So “C machine” is a misnomer. You may as well call today’s computers “JavaScript machines”, since it seems that language will in due course dominate all others in terms of what gets run.
Nevertheless. Von Neumann is a Chesterton’s fence of computing: you will have to show us a good reason (as in real hardware doing actual work offering clear advantages) to remove it — and even then the economics may not favor displacing Von Neumann in all cases.
When discussing tools to get actual work done, mental masturbation about what could or might be is just hastening the heat death of the universe.
@Gregory GelfondIs this an issue with particular kinds of operating systems (real-time for example, I can see this being an issue)?I think there’s a fair bit of misunderstanding of “real-time”. This is generally parsed as “instantaneous response”, when the apparently correct definition is “guaranteed to respond within X period of time”, where X doesn’t have to be “instantaneously”. (It
doesstill have to be a lot faster than acceptable response time for human operator.)So whether the overhead of GC rules out a language for real time use may depend on the hardware it runs on and the number you need X to be. I don’t think there’s a one-size-fits-all answer to the question, though you can probably argue that you would like to avoid
needingto do GC.>DennisIn DSP-land, “realtime” means only that you ensure that your output keeps pace with your input – even if there’s a buffer of seconds in between.
Well, I don’t know what the technical definition of “realtime” is. What I care about is that, when I see a scale reading cross a specific threshold, I am able to close the gate or valve to stop product flow in a short and repeatable time period. It needs to be significantly shorter than the fraction of a second an air-powered gate takes to close. The idea is that we need to be able to set an anticipation value – how much before the product’s desired quantity do we need to start stopping the flow – and when that value is set right, have the delivered product consistently be within tolerance of the requested amount.
A PC running Windows can’t do this. The response time is just too unpredictable. But we don’t have to be exact down to the microsecond, either.
My favorite example of hard real-time is hourly worker payroll.
The D programming language, with betterC, is now an excellent step up from C. It’s 100% open source and Boost licensed. It only needs the C runtime library. Program files can be mixed and matched C and D code. It’s easy to translate C code to betterC. And then you’ve got modules, nested functions, compile time function execution, purity, templates, array bounds checking, scoped pointers, and RAII (next release).
(A bit long – please bear with me)
A computer language (plus its runtime) is supposed to help translate our thoughts on an algorithm or process into something a computer can actually accomplish via its instruction set. C comes close to mimicking an LSI-11 instruction set, so it was great for low-level programming on DEC machines and later, with adequate compiler support, not so bad with other architectures.
As esr points out, it breaks at scale in two main areas, memory management (because it has none) and abstraction (because what it has is too low-level). The discipline needed to make it work in large projects requires either very good programmers that place cooperation above egotism or people management that enforces project members’ continued paychecks over egotism. Otherwise the egos win and one ends up with an inconsistent convoluted mess.
C++ tried to address these areas but did it in such a way that it became hard to reason about program behavior. It’s possible to write systems in C++ that would be much more difficult in C, but they tend to have even more obscure bugs that are even harder to find. The existence of large programs doesn’t mean the language was good, it just shows that with enough time, energy, and money Frankenstein can be debugged into existence – warts, bolts, jumper cables, and all. Look at the comments of the previous post: there’s still new production Fortran code being written in the weather forecasting biz and all it takes is a fat Government contract administered by a sleek, low-overhead outfit like Raytheon. That doesn’t make Fortran the future.
Kernels still do pretty much what they did in the 70s and 80s so C is still an ok answer there. Same for many near-kernel system services and apps. Go might be incrementally better, but is it worth the effort to replace existing debugged code? Duh.
But what apps do and the environment they run in have changed quite a bit, at least on servers. Everything is bigger (needs automated memory management), extensibile (needs a type system that prevents interface mis-match), and is concurrent; single threaded apps on multi-processor 2U boxes (native or in VMs/containers) can’t scale to use available resources and services that don’t run across multiple boxes don’t scale much further in addition to missing modern availability requirements. C and C++ fail spectacularly here – add locking and distributed RPC faults to poor error handling and you have a recipe for buggy software and long-term job security. Java hasn’t really moved the needle very far.
I don’t know if Go does enough to really help here but I don’t think so. It’s incremental improvement at best in an area that’s just fine to all but the cognoscenti. esr and you guys reading this are cognoscenti; the NCGs assigned to maintain large code bases as immigration projects are hoi polloi.
Rust and Scala seem to have help for objects and local concurrency as do functional languages like the ML family (including OCAML) and Forth (the assembly language of functional programming) but isn’t quite ready for prime time and I don’t think functional languages have passed the test of long-term maintenance at scale yet. Erlang is a stab at distribution and has certainly met some scale and maintenance tests but hasn’t been picked up by the community at large.
Some may claim that the programming language isn’t the place to look for help, but I disagree. If it can prevent language errors in the first place (memory management, type systems) and help me use available resources (concurrency), and deal with expected failure (distribution) then I want it in the flow of the program (my description of what should happen), not in some box bolted onto the side. And it has to be efficient, because I’ve only a few cycles to waste and no IO or memory.
So that’s where I’d look for action in the programming language field – not to improve C, an imperfect solution to yesterday’s problems; I want something that helps with apps that are big, distributed, concurrent, and efficient because those are the more important problems people are solving today and in the future.
>The wrestling match between the official D library/runtime and Tango hurt it, too. It has never recovered from those mistakes.
Do you actually know what you’re talking about? The split was way too many years ago and has been recovered from since. In fact nobody is using Tango anymore, unless you’re stuck with D1, which barely anyone is.
Two points that are worth nothing, because I have no standing…
1. A language that requires precision about the entities you are handling and the methods you are calling, otherwise the build fails, seems incongruent with the whole concept of garbage collection. JavaScript, OK. Different assumption.
2. If you’re looking at future engineering of high performance applications do you create a new perfect language or do you go with the evolutionary approach. With multiple implementations across multiple platforms and a cross-industry committee that now seems on top of progress. Who wouldn’t want to be part of a new idealism? Yet Google just open-sourced millions of lines of C++ library code. Brave New World? Or standing on the shoulders of giants?
I like C++, but I wouldn’t go into battle for it. But I don’t see any actual need for anything else in the area from the metal up to Python or JavaScript. Go and similar overlap the junction, but without obviously justifying GC..
Paul
(Not sure it’s millions of lines, but certainly loads.)
Anything that involves maintaining a mutating graph justifies a GC from a maintenance POV. Without a GC you have to be careful which introduce design overhead that doesn’t really pay off. What C++ needs is some kind of local GC.
Go is a language with flaws, but having a tuned low latency GC is a big selling point that offsets its shortcomings.
I think can be reasonably straightforward within the language. Depending on the detail of course and especially if your structure has a lifetime and you can afford to wait until the end before cleaning up everything it has ever used. And whether those bits need actual destruction rather than simply returning resources to the OS.
And I see C++ has a garbage collector interface, but doesn’t supply an implementation as standard. Didn’t know that…. I guess this is because the people who would routinely use it would simply dig themselves into deeper holes than they do already, but there is a practical use case, especially in a typically crufty code base that is already leaking.
Paul.
Yes, you can write your own reference type and keep tabs on them and use that for pointer tracing, with some overhead.
But a language solution would be more efficient if it at compile time can statically reduce the memory regions it has to go through to find pointers into a specific heap. So it needs type system support and maybe complicated pointer analysis to cover the general case. And some runtime support. But it would involve some possibly draconian constraints on where pointers to a specific heap can be stored… Reasonable for C++, but not for a high level language.
C++ HAS some kind of local GC – local variables on the stack. If you can’t do most of your allocations on the stack, you have design issues.
Bahaha…you obviously haven’t seen most computer-science research. Sturgeon’s Law applies without question, and it’s not hard to identify 80% of the “crap” portion. A large part of my reason for dropping CS grad school was the “infosec” professor who spent two weeks going through SET, insisting that this was how you actually bought things online. Similar detachment from reality was rampant.On the other hand, open-source collaborations, groups like Sun’s Java team, and (as much as it pains me to say it) Microsoft Research have been making major strides in solving real problems relating to both computing and programming.
Oh. Oh, dear.
Software engineering is an engineering discipline. Just because people are allowed to attempt to build a doghouse without education doesn’t mean that we let the untrained free with I-beams to build sky-scrapers. Complaining that it’s possible to screw up with C++ is like complaining that it’s possible to screw up with dynamite. Lots of power, but nobody uses picks any more to carve through mountains when building freeways, either. Another example: it’s like writing off all firearms owners because of the sample shown on TV.
C++ provides a whole host of options available that C just doesn’t work for. It allows for the compiler to handle all sorts of validations automatically which aren’t really possible with naked C. For example, the STL iterator model makes it very easy for safe data access to different containers, all of which have been independently tested, and which concurrently provide bare-metal performance.
Another is the ability to use virtual classes to provide mocks and fakes for writing unit tests. It’s very hard to be able to write methods/modules/libraries in C which are supposed to operate against external I/O (whether it be network RPCs or worse, databases) which can be easily substituted for validation. But subclassing an interface allows you to use eg. an Oracle database for production but a lightweight in-memory database for unit tests just by changing the database object you pass in. Error injection is also made much easier. As exemplified in GoogleMock
My 10+ year career has mostly involved codebases with 1000+ people working on them. C++ makes using, and more importantly, re-using and testing them much easier. It’s the raw C code where I find the worst hacks, trying to get some of the features provided for with C++ without having the compiler to actually do the work reliably/safely for you. I find that it’s the larger codebases where the better interface design/description/clarity starts to outpace the initial overhead of understanding the additional overhead introduced by C++. For small projects, it’s probably irrelevant (until you need something which can easily be provided by an STL container at which point you should just use that).
I suspect that many of the C projects haven’t converted to C++ purely out of bigotry. The C++98 standard (from 19 years ago) required a fair bit more verbosity of scoping to be used which some might consider ugly, though this has been substantially reduced. The Linux kernel went out of its way to prevent any C++ from being used.
That’s all good, but C++ as it stands makes incremental learning difficult. In meta programming there are like 10 different ways to do the same thing, of which 1 or 2 are commendable. Slashdot is nearly useless because most of the advice there is either outdated, wrong or nonidiomatic. So that leaves us with cppreference.com as the only reliable source… And the insanely long list of C++ Core Guidelines… C++ is the better upgrade path from C, but it sure still is in need of a make over.
Rust is existence proof that a language that can get down to C++ levels of nitty-gritty can also be approached safely by n00bs. “If you don’t know how to use the language
properly, you deserve to have your totin’ chip taken away” doesn’t hold water as an argument. Requiring conscientious use not to blow up spectacularly in your face is a language design fail.Of course, it could then be argued that the absence of conscientiousness is evidence of a poor engineering mindset ;P
Bad code monkey blame toolz
“Bad code monkey blame toolz”
I’m actually kindof tired of this statement. Sure, it’s true that a good craftsman can do anything with any tool, and sometimes a craftsman doesn’t get to choose the tools available to use. However, a good craftsman also understands that you use the right tool for the job — and that if you have to use a lesser tool, it’s going to make the task that much more difficult.
And some tools are no longer used, because not only are they inherently dangerous, but there are better tools available now: they can be safer to use, or perhaps allow you to do more — or both. A modern carpenter would be silly not to use power tools nowadays — both because most of them make the work a lot easier, and some of them (despite the dangers they present, being powered) are ultimately safer to use as well.
And thus it is with computer languages. After all, how many of us elect to use INTERCAL or Br**nfudge for production code? These tools are useful, but only in showing just how mind-bendingly painful “Turing complete” can be.
And it’s perfectly fine make the case that languages like C++, Perl, and PHP have their place, which places being niches in a museum with shiny brass plaques explaining their historical importance.
The Linux kernel started with C++, but by 1993 Linus gave up on seriously trying to use it. In 1998 ksymoops stopped being a C++ program.
There was once a time when every few thousand lines of C++ code routinely tripped over a crash-the-compiler bug in GCC (or worse–it might have produced a binary, and then run into all the runtime library’s problems). I remember struggling through that myself in the mid to late 1990’s. It was possible to write C++ programs that worked, but you wouldn’t want to bet money on them working across multiple compiler versions or runtime environments.
C++ has finally caught up (at least to the point where the runtime or compiler aren’t the first things that are going to crash any more), but in the Linux kernel there is a different situation now: having two languages (and two–or at least N+1–toolchains) for kernel development is a serious maintenance challenge, one that is arguably even worse than using C as the only language.
> Sorry, Rustaceans – you’ve got a plausible future in kernels and deep firmware, but too many strikes against you to beat Go over most of C’s range. No GC …. Where’s my select(2) again?
“No GC”. Of course there is. It is decided at compile time for 95% of the objects or more, because the type system tracks ownership and lifetime of objects. Most data structures tend not to be complicated, and are in-fact tree-shaped, not graphs. For the few cases (relatively) speaking (such as compilers) where DAGs are required, the shared nodes can be under the aegis of a ref-counted node; the count management is _managed by the compiler_. In all cases, the compiler is aware of memory and where it needs to be deallocated.
Have you seen the Rayon library? It uses the facit that the compiler is aware of lifetimes to work with pointers to stack allocated objects in other threads. Fearless concurrency is now the new watchword.
—
select(2). Why? epoll is so much better. Have you seen mio, a Rustified libev?
https://github.com/carllerche/mio
—-
Go is primitive but fun,and its libraries and tooling are excellent. However, their shared memory concurrency behaviour is no better than Java. Miss a mutex lock and wonder what went wrong.
No, ref-counting does not catch cycles. That’s why people developed GCs over 50 years ago in the first place! ;-)
Sounds like you are pretty well behind on the capabilities of reference counting if you think that they can’t be used for cyclic data structures. Rust uses both lifetime annotations, as well as the generic Rc/RefCell/Arc wrapper types to solve this problem. See The Book[1]. There’s also the Learing Rust With Entirely Too Many Linked Lists[2] tutorial series.
With an advanced understanding of lifetimes, you can construct graph data structures that contain fields with differing lifetime annotations, to signal to the compiler that the lifetime of each reference is different from the lifetime of the structure as a whole, and other references.
Yet you can also easily avoid writing these kinds of data structures if you take a step back and look at techniques like ECS.
[1] https://doc.rust-lang.org/book/second-edition/ch15-06-reference-cycles.html
[2] http://cglab.ca/~abeinges/blah/too-many-lists/book/README.html
Sigh. No. There are (academic) solutions for catching cycles with refcounting, but they have been benchmarked as slower than using rc + tracing gc. And Rust doesnt provide them either…
I don’t know you, and you don’t know me. Yet you erroneously think you can speak for me and the programs I write. This is bullshit.
Yes, most application models are graphs, even tree stuctures like the HTML DOM is a graph…
>Most data structures tend not to be complicated, and are in-fact tree-shaped, not graphs. For the few cases (relatively) speaking (such as compilers) where DAGs are required, the shared nodes can be under the aegis of a ref-counted node; the count management is _managed by the compiler_.
I missed this silly claim earlier.
My code manipulates DAGs routinely – reposurgeon is only the best known example. I’m actually drawn to that kind of work by my math background; I
likethinking about graph-structure transformations.So what you’re telling me is that the Rust ownership model is inadequate for one of the kinds of programming I’m most interested in. I’m guessing this is not the information you intended to convey.
I’ve heard warning about trying to do code with graphs in Rust before, and a search turned up this. I’ve only scanned it thus far, but if I understand what I’ve read so far correctly, Rust’s ownership model isn’t easily compatible with graphs, because graphs have properties that are in conflict with it. I’ve not read all the way through yet, so I don’t understand the suggested remedy.
I don’t think that I’m into graph programming natively, but graphs struck me as the best way to model part of a project idea I’d had — routing data between sources and sinks in a real-time audio system. I was kinda excited about Rust, and was considering using it when I attempted to tackle said project, as I learn better when I have a thing I want to make. But if Rust isn’t suitable for dealing with graphs, well, damnit. Back to attempting to build everything myself from scratch with nothing but C’s raw pointers, and all the footguns that entails.
I am also into a bit of audio programming. Dataflow graphs are very common. Just look at Apple’s AudioUnit system or good old CSound’s internals. While you don’t necessarily need a cyclic graph, you usually want back pointers even in acyclic graphs for various reasons (either convenience or performance). Also if you do something feedback-like with wave-guides cycles will arise… The Rust people in this thread has already suggested a component model as a solution. Component based modelling was a business-oriented decoupling/reuse buzzword 15 years ago. So what they essentially want you to do is to replace your pointers with integers… and some indirections… Rust people: yes, we know that we can use array indices instead of pointers… but that just means that we have bypassed the type system and essentially have switched from a well-typed referential type to an essentially untyped referential type. Which you of course can remedy by wrapping the array indexes/integer identities in yet another nominal type… but geez… A language is supposed to support the implementation of a natural model for a program, not force an unnatural structure with arbitrary indirections onto your model just to satisfy a type system…
Here’s an example of a cyclic graph with pointers and _semantic_ cycles.
https://gist.github.com/sriram-srinivasan/05e781ef5f015bf6758222eebdf35824
Here’s an example of a cyclic graph with direct pointers, and ref counting. Note that one doesn’t have to worry about collecting the memory, the point that started this thread.
https://gist.github.com/sriram-srinivasan/517fe37c607099f6ae0c5d1cedde3556
The graph is readonly for the most part, but allows key-hole surgery. Again, there’s no issue of forgetting to decr the ref count or incrementing the ref count. The compiler will handle the former, and remind you about the latter.
(Also, see my reply to esr elsewhere).
Talking about semantics…
“readonly for the most part” is either meaningless, or needs to be parsed so finely that thinking about it would give me a headache, and having to program to that model — well, I’m sure I’ve done worse, but why would I subject myself to that if I didn’t have to?
I mean that by default it is readonly, and the values can be safely accessed without further ado as if it were a direct pointer.
But if you wish to mutate some internal value, you have to write some extra code to borrow it for writing purposes (requesting a write capability), and make that change. If you consider mutation and alienability to be a dangerous combination (as I do), this keeps a tight rein on things. You’ll be able to make a change only if the pointer is not shared with other consumers.
> The Rust people in this thread has already suggested a component model as a solution. Component based modelling was a business-oriented decoupling/reuse buzzword 15 years ago. So what they essentially want you to do is to replace your pointers with integers… and some indirections…
I would have hoped that you would have realized that pointers are also integers… and therefore pointer dereferencing is also…. an indirection!
Now imagine that you have your cyclic data structure where you need to derefence 10 pointers to get to the data you need, whereas an ECS model with components only needs 1 level of indirection!
> A language is supposed to support the implementation of a natural model for a program, not force an unnatural structure with arbitrary indirections onto your model just to satisfy a type system…
Well guess what? Graph data structures are entirely unnatural structures for hardware to work with, and they are incredibly inefficient. They are littered with arbitrary hierarchy of indirections.
There’s good reason why basically all AAA games today are being created with ECS models, instead of OOP models with graph data structures. Graph data structures are incredibly dangerous, and highly inflexible. It’s why most complex software written in C and C++ has remained to be single-threaded. Newer software and games written with ECS models, on the other hand, lead to incredibly flexible architectures that can be made massively parallel.
Games isn’t really the right place to look for wisdom. 1. They don’t have the life expectancy of real world application. 2. They can change the design spec to fit the hardware limits. 3. Failure is inconsequential.
90% of the development of a real world application happens AFTER deployment. So you better be prepared for change.
No, direct pointers are not indirections as such and more importantly they are usually statically typed which is very useful in a graph with many heterogeneous nodes like the high level audio data-flow graphs we are talking about here. These are big nodes that basically carry the equivalent of an oscillator or filter each. And each node has a different size so goodbye to your array of nodes. You need indirections if you use an array.
You’d be surprised. Most games these days are backed by the same game engines, which have had to adopt techniques like ECS because they have to support thousands of games and game developers, and to keep up the pace with hardware improvements and graphics API changes. That’s not an easy feat.
Rust’s ownership model is certainly compatible with graphs — you just have to model them in such a way to avoid pointer cycles. For example, have a vector of nodes and a vector of edges that reference the nodes by index. This complicates and slows down inserting or removing a node or edge, but those operations are usually less frequent than traversing the graph anyway. You can get some simplicity back by using a hashmap of nodes, each with a unique name, and having the edges reference the nodes by name rather than by index.
I assume you are talking about
https://en.wikipedia.org/wiki/Adjacency_list
That’s all fine for a very limited set of usecases where you deal with very uniform mathematical graph and a fixed requirement spec. It is no good when you want to support the implementation of a model that match the hardware.
The main challenge is to come up with a model that match the hardware and cachelines, if you also have to match the programming language then you have one ball to many to juggle. Substructural type systems and recursive structures are all good, for high level coding, but it predominantly forces you down the lane of a structure that suggest a functional implementation strategy, not iterative imperative programming.
>Rust’s ownership model is certainly compatible with graphs — you just have to model them in such a way to avoid pointer cycles
What Ola Fosheim Grøstad said. You’re telling me I have to use an overcomplicated, unnatural data representation that is going raise my expected downstream rare and like it because Rust is orgasms and rainbows. Nope.
Unnatural to whom? On modern CPUs, linked data structures are unnatural and you will suffer a huge slowdown by using them. It is a pearl of C++ wisdom to
alwaysprefer vectors to linked lists, because the latter force more accesses to main memory. The benefits to be had by keeping everything in cache as much as possible far exceed even the losses from having to copy every element fromn+1to the end of the list to insert an element at indexn, for realistic list sizes.If you’re going to be working at that level, you will have to choose your data representations carefully anyway — and the obvious choice may not be the right one. Game programmers learned this the hard way in the 90s.
But realistically, you would be using a crate that provides graphs as an abstract type and not have to worry about the implementation at the data-representation level at all.
A big assumption. The programs that esr are talking about don’t necessarily need to work at that level.
Game programmers in the 90s were predominantly young and selfeducated… Eventually game programmers rediscovered some basic strategies from array processing and HPC… Good for them, but their ignorance doesnt mean that rest of us are… Your “advice” is wasted without a context.
Of course you can do DAGs. The Rust compiler needs it, so we need look no further for examples.
My point with the “95%” is two fold.
Look at the large number of programs that work with simple values, hash tables and arrays (pretty much all enterprise apps, web apps, data analyses, etc) … that’s what I mean by tree-shaped. It is not to say that 95% of _your_ apps are like that; mine aren’t either.
Where we do need DAGs or graphs with cycles, there are a large number of graph representations possible that play with memory differently. For example, here’s one example (in Rust) of a graph that has cycles. Nodes don’t point to each other; edges contain pointers to nodes. But the cycles are semantic. All one needs to do is to convince the compiler that the nodes will not be deallocated before the edges (that’s what the lifetime annotation ‘a is for). The Rust compiler emits code to automatically deallocate all objects at the end of scope. Here the objects are on the stack, but with a little change, could be heap allocated as well. No matter.
https://gist.github.com/sriram-srinivasan/05e781ef5f015bf6758222eebdf35824
If we wish to represent a graph with mutability and direct pointers the way one is used to in C++/Java, we must suffer additional syntactic burden, where instead of ‘Node’ you’d pass around Rc, which wraps a node with a refcount. Note that the compiler still emits code for automatically decrementing the refcount.
https://gist.github.com/sriram-srinivasan/517fe37c607099f6ae0c5d1cedde3556
The point is there are many “container types” (such as Rc) that give you different levels of static and runtime guarantees. In all cases, the compiler takes care of deallocation. It is true that Rc _can_ create cycles, but there are standard patterns to avoid it, and a number of other Rust-specific mechanisms as well (weakref, for example). It doesn’t seem to be a worry in practice.
—-
That said, one does have to expend the mental energy for lifetimes, which is not something one ordinarily does in Go and Java. Or so it seems. The underlying problem — that of aliasing combined with mutability — is a fundamental one, particularly with concurrency, and especially so for library writers — who owns the objects returned by a library function, or by an iterator. You have to do the same lifetime and mutability thinking with ordinary GC’d languages as well. Except you get no compiler support, so you resort to conservative approaches like cloning objects (“just in case”)
I think we have different ideas about what low level programming is. Java isn’t it. Go isn’t it either, but Go is useful for writing smaller services that benefit from a GC and doesn’t need in memory caching. Maybe there is a 10-20% penalty in time and up to 100% overhead in space by using Go over C, but that’s ok if you do caching in another process. C++ is not great for writing full applications, but is currently the best alternative for the computational engine of an application. Rust currently seems to be best suited for things where I’ll gladly take a 30-40% penalty in time an 100% penalty in space to get a GC and high level semantics.
I agree with you, believe it or not. If Nim had its concurrency story straight, I’d prefer it to C/C++. For all IO-related stuff, I’d rather deal with Go or Python.
I think Rust’s core competence is in building concurrency-heavy applications that require fine-grained parallelism and complicated data structures — operating systems, browsers, databases and possibly games. That’s low-level _and_ error-prone.
For databases distribution seems to be more important than local performance.
For OS full verification and refinement seems like the only viable future.
For high level concurrency and protocols, again verification is around the corner.
So maybe Rust has something going for low level concurrency, but there no overhead is acceptable and lock free strategies are the ideal, so not sure how Rust will fare there either in the long run, but we’ll see. Rust is an interesting language, but one of many interesting languages.
Distribution is important no doubt, but performance is still non-negotiable.
Verification depends on all kinds of assumptions; the wider the assumptions, the worse the post-hoc verification gets. I have the scars from working with Coq and separation logic, where there are no aliasing guarantees in the code.
Given a constraint from the Rust compiler on separating aliasing and mutation, the job of a verifier is considerably simplified on that count. So I’d much prefer a verifier, or a process like IronFleet, but on Rust code. For some systems, of course. Otherwise, it is all a bit too much :)
Responsiveness is apparently more important than absolute performance when people are willing to write distributed databases in Erlang… It is basically a trade off between correctness, development cost, maintenance costs and running costs… You need a very large deployment to justify optimizing for the hardware, the hardware also changes every 2-4 years or so. So “optimal performance” isn’t a one time investment it is an expensive long term commitment. Are you willing to implement your indexes on GPUs or FPGAs? Because that is what you have to do to get performance out of contemporary hardware… So performance is very much negotiable. Always have been, always will be.
For operating systems I think refinement is the most obvious verification solution. You can have specialists on both the high level, the verification work (proving correspondence between the high level spec and the low level implementation) and the low level concrete code. Actually, OS development is one of the few areas of software development where it makes sense to let experts in formal methods run the process.
Let me expand a bit on this. I grew up with the C64. The 6510 is a very simple and predictable CPU. In the late 80s we thought we had seen the limits of this machine and what could be achieved with it in machine language. Turned out we were wrong. People have since then continued to explore how to get the most out of it for decades and some of the current demonstrations blows what was done in the 80s out of the water. So much for performance not being negotiable… We are nowhere near the limits of current hardware… Getting there is waaay to expensive and time consuming.
In every era, maximum performance is what has been widely accepted. It may not have endured, but slow stuff doesn’t get out of the gate.
There are exactly two databases written in/for Erlang: mnesia and Riak. They are negligibly used in production. Riak wrapped up months ago.
For low-level stuff, you want tight control over memory layout and usage. ;that’s where the performance gains are.
Sriram Srinivasan. No, not really. Performance should always be viewed in relation to a baseline. But acceptance is a psychological dimension related to customer expectations. For many end users performance is evaluated in terms of PERCEIVED latency, not in terms of throughput. And for many businesses firing up a few more instances is a negliable cost compared to paying someone to optimize the software… So easy scaling and latency are the more important dimensions IMO… Absolute performance, not so much.
I agree that there is a level of “good enough” performance, at which point attention goes to other aspects … maintainability, hirability, scalability, energy usage etc. When I say performance, I mean it as the 99.xx percentile user experience.
Of course, people turn to adding more instances when there’s more work than compute capacity. But given a choice of two products/approaches where one runs faster and hence requires fewer servers, people go for that. This is the exact reason people are moving from Python/Ruby to Go, not because Go is more fun to program in, and why Dropbox moved a lot of performance-critical work from Go to Rust. Performance is the reason why although cockroachdb has most of its upper level code in Go, its storage engine is RocksDB (C++).
Perhaps you have read the “Scalability! At what COST!” paper, for why “scalability” for large-scale graph analyses is a false metric. There are some published algorithms of analyses done on 100s of cores that this paper handles with a sequential algorithm on a single core. The latter is faster _and simpler_, because it avoids coordination. The message of the paper, as we both agree, is quickness of user-perceived result.
https://www.usenix.org/conference/hotos15/workshop-program/presentation/mcsherry
(The implementation of this and other papers of frank mcsherry (in Rust) is on his GitHub repo.)
I wouldn’t use Rust for most of my work (networked servers, applications), but where it is a mixture of high performance and concurrency, it would be my choice.
Yes, one doesnt pick the slower alternative if they otherwise have similar qualities. But I’ll take the one with slow writes as long as it has nippy and solid queues (eventual consistency). Anyway, most regular databases now fit in RAM, so I think programmer culture is lagging behind hardware in their preferences and how they think about storage…
I think Go isn’t so much replacing Python as it is used in addition to it, taking over in areas where performance got more important. Python is a more productive environment than Go, but dynamic typing is an issue… But then you have gravity. Python is the only language where I always find an existing solution/library to a problem I encounter,,,
Michael Aaron Murphy, while I can admire and often respect ardent passion, you’re starting to grate on me. Your posts here were reminding me of xkcd #386 even a couple days ago. If Rust truly is the ne plus ultra of modern systems programming languages, wouldn’t your time be more enjoyable and better spent using it to get shit done, rather than preaching at the unenlighted heathen barbarians?
>wouldn’t your time be more enjoyable and better spent using it to get shit done, rather than preaching at the unenlighted heathen barbarians?
You don’t understand the personality type you’re dealing with. Santayana: “Fanaticism consists of redoubling your efforts when you have forgotten your aim.”
I think it mostly is youngsters… They are trying to teach others stuff that they have recently discovered, but that we have internalized and take for granted… (As if anyone interested in low level programming needs a schooling in prefetching, keeping caches warm etc)
Who says one cannot have time to comment here and write a lot of software? I have made major strides with Rust in a number of different areas, from systems-level software in developing a next-generation system shell with superior performance to Dash[1], to a variety of GTK desktop applications[2], a GTK Rust tutorial series that’s currently a WIP[3], distributed computing client/servers[4][5], full stack web development stuff, a handful of random crates, and contributions to several projects (such as parallel command execution in fd[6]). All open source, and largely within the span of the last year. What have you been doing with your time?
[1] https://github.com/redox-os/ion/
[2] https://github.com/mmstick?utf8=%E2%9C%93&tab=repositories&q=GTK&type=public&language=
[3] https://mmstick.github.io/gtkrs-tutorials/
[4] https://github.com/mmstick/concurr
[5] https://github.com/mmstick/parallel
[6] https://github.com/sharkdp/fd/
Have you (or your Cx-designing friend) come across SPARK – the Ada subset? it’s statically type-safe, and has the runtime performance of C. It’s used on some seriously critical stuff like air-traffic control, and the EuroFighter Typhoon. See http://www.spark-2014.org/about
I wonder is one reason for C’s lingering use might be the distant possibility of bootstrapping. Most higher-level languages have some sort of dependency on C, so it could be imagined that if your tool didn’t need anything more advanced, it might be ported early on, so later tools can rely on its existence. That might also explain a significant chunk of build script cruft. Too much dreaming of unlikely just-in-cases to trim code paths that will never be needed anymore.
I can tell you that this is not the reason for C’s lingering use. C is not required to bootstrap an OS. Rust on Redox, for example, has zero dependency on C. Only itself. You’ll find C on Linux systems simply because Linux is written in C. Whereas C on Redox has to go through Rust, so the tables are turned.
I was thinking less about creating a new OS and more about porting Linux to a new platform. Unless you were going to cross-compile everything, keeping most of the classic Unix tools in C would make it that much easier to have a basic working system to build everything else on. I don’t think many people do that sort of thing anymore, if ever, but I think that the mere possibility that it might happen is one of the factors making it less likely for those classic tools to upgrade to a non-C language.
Increasing processing power and gradually improving tools make it a mostly irrelevant point now, outside of the rare occasion that someone chooses the inconvenience deliberately. But I think “this is a basic Unix tool, I want to keep dependencies (and especially dependency loops) low” will keep the default implementations on C for more decades to come.
> I was thinking less about creating a new OS and more about porting Linux to a new platform.
I’m not sure I understand the point. Rather than porting an existing monolithic kernel, why not do as Redox and create a next-gen microkernel to compete against Linux?
> Unless you were going to cross-compile everything, keeping most of the classic Unix tools in C would make it that much easier to have a basic working system to build everything else on.
We already have all of the ‘classic UNIX tools’ written in Rust from scratch, so there’s no need for C there. You can use them on Linux and Redox[1].
> I don’t think many people do that sort of thing anymore, if ever, but I think that the mere possibility that it might happen is one of the factors making it less likely for those classic tools to upgrade to a non-C language.
You’d be surprised.
> Increasing processing power and gradually improving tools make it a mostly irrelevant point now
Processors actually haven’t been getting much faster for some time now. It used to be that processors were getting major performance improvements every two years. Now they are basically stagnating with the same IPC, and increasing core counts instead. C is ill-equipped for writing highly parallel software architectures, and so that’s where Rust comes in. What was impossible to scale to multiple cores by human hands in C & C++ is now being done successfully with Rust in practice today[2].
> But I think “this is a basic Unix tool, I want to keep dependencies (and especially dependency loops) low” will keep the default implementations on C for more decades to come.
See [1]. There’s no reason for C to continue it’s existence from this point on. It’s up to you on whether or not you want to stick with a dying language though.
[1] https://github.com/uutils/coreutils
[2] https://blog.rust-lang.org/2017/11/14/Fearless-Concurrency-In-Firefox-Quantum.html
All general-purpose tracing GCs force you to make tradeoffs between latency, throughput, and memory overhead. Go has focused on minimizing latency at the expense of the rest; in particular, with the default value of GOGC, your heap memory usage will be about double the size of your live objects — i.e. about double the memory that a C or Rust version would use. There is no reason to believe any breakthrough is looming which allows these tradeoffs to be avoided; we haven’t seen one in the 40+ years of GC research so far.
But GC isn’t just a performance issue. One of the great things about C is that you can write a library that people can use from other languages via FFI. Go and other GC languages are not suitable for this because if the other language can’t use the same GC, at best someone has to write complex rooting logic at the boundaries, but more likely they just can’t use your library. On other other hand Rust can be used for these libraries; for example, see Federico Mena Quintero’s work on incrementally improving librsvg using Rust.
It’s also worth pointing out that Rust offers important safety benefits that Go doesn’t — data-race freedom, prevention of “single-threaded races” like iterator invalidation bugs, catching integer overflows in debug builds, stronger static typechecking with generics, etc.
Go certainly has a large niche. If you’re writing an application and you don’t need top-of-the-line performance or safety, it’s a fine choice. Rust’s niche is also quite large though, and it’s getting larger as the language and libraries evolve.
>Go has focused on minimizing latency at the expense of the rest; in particular, with the default value of GOGC, your heap memory usage will be about double the size of your live objects — i.e. about double the memory that a C or Rust version would use.
I think this is an excellent trade. It uses more of a resource that is cheap and still getting cheaper to minimize use of a resource that has stopped getting cheaper.
>Go and other GC languages are not suitable for this because if the other language can’t use the same GC, at best someone has to write complex rooting logic at the boundaries, but more likely they just can’t use your library
That is true, and a real problem. It remains to be seen whether it weighs heavily enough against the advantages of GC and low inward transition costs to scupper Go-like approaches.
Whether it’s a good trade-off depends on the project. For projects where you don’t have a huge number of users and you don’t face competition from alternative implementations which avoid GC overhead — or if memory pressure is insignificant enough to be a non-issue — it’s often a good trade-off. But for commodity software like a Web browser, saying “we use double the memory of the competition — but our development was quicker and RAM is cheap!” doesn’t go well.
> It remains to be seen whether it weighs heavily enough against the advantages of GC and low inward transition costs to scupper Go-like approaches.
AFAICT it weighs heavily enough for now that no-one is even trying to introduce GC languages in libraries to be used from other languages.
>but our development was quicker
That wouldn’t be the pitch. Lower defect rate due to no manual memory management errors would be the pitch.
Unfortunately it’s hard to get users to care about that. And if you’re competing against Rust, it won’t be true.
>Unfortunately it’s hard to get users to care about that. And if you’re competing against Rust, it won’t be true.
But normal users don’t give a shit about memory usage either, not on 2017 hardware.
Well, they care about memory
leaks, because those will eventually crash the app. But memory leaks are the problem garbage collection is designed to solve.Except a large number of users do care about memory usage in a world that’s now littered with bloated desktop applications consuming gobs of memory, and where not even 8GB of RAM is enough for basic desktop usage.
> not on 2017 hardware
Most people aren’t buying desktops with 16-64 GB of RAM. A lot of us are also purchasing simple, energy-efficient laptops with 4GB of RAM. I even develop from a budget laptop even though I have a much more powerful desktop, and memory usage is quite important to keep my dev environment running.
I have 32 GB of RAM on this machine that I built a month or two ago.
I care about memory usage because Mozilla’s memory use grows continuously, to the point that I have to restart it every few hours if I have a lot of tabs open.
I know how to fix that. All they have to do is to use a variable-length-string-capable virtual memory library like the one I have written in (of course) C++.
Then all of their data could be paged to and from backing store as necessary, without their having to manage it manually.
“What works for a Steve Heller (my old friend and C++ advocate) doesn’t scale up when I’m dealing with multiple non-Steve-Hellers and might end up having to clean up their mess. ”
Application programmers often don’t understand how to create reusable abstractions.
Fortunately in C++ that isn’t necessary, because library designers like myself can (and should) do the heavy lifting.
Let me design and implement the classes needed by the application programmers, and they won’t have to worry about misusing memory and other resources.
Of course this is not possible in C because it is impossible to create abstractions that take care of these issues.
(Note that I’m referring to applications, not system programming, which is a different beast that I haven’t spent much time doing.)
>(Note that I’m referring to applications, not system programming, which is a different beast that I haven’t spent much time doing.)
OK, Steve, trust me on this, you already thought like a pretty damn good systems programmer in 1980. :-)
Thanks, I appreciate that!
On a somewhat related note, I have a C++ library that I have been working on since before we met that allows access to an enormous amount of data, whether fixed- or variable-size.
If you are accessing fixed-size data sequentially or nearly sequentially, it can read or write at speeds of 1 GB/second with an NVMe SSD with “get/put” functions. If you are doing random access, or aren’t concerned about maximum speed in the sequential case, you can just say “x[i] = y;” and the library takes care of the rest.
(BTW, earlier versions of this library have been written in several other languages, C being the previous one.)
>Thanks, I appreciate that!
Actually, in 1980 you already had most of the mental habits of a good systems programmer and I didn’t yet – you just weren’t very conscious or articulate about them. Over the next decade I had a couple of “Oh, so
that’swhat Steve meant!” moments as I was growing into the role.The list of people who taught me important things (whether they intended to or not) when I was a progamming n00b is not a long one. You’re on it.
Like a good number of C developers who may have used C++ in the past, and haven’t kept up with the latest developments, you are underestimating the benefits of C++.
One of the key benefits as a systems programming language is the performance — the performance if well-written C++ code is hard to match in other languages, and it can even edge out C in many cases, due to the additional information available to the compiler for optimizations, including guaranteed compile-time constant expression evaluation. constexpr functions provide a lot of scope for evaluating things at compile time that would otherwise have required a separate configuration process to be run at compile time, or runtime evaluation.
Secondly, C++ has the many ways to express zero-overhead abstractions. This eliminates a lot of errors, because the code can force compilation errors on incorrect uses, and libraries can take care of things like managing memory and non-memory resources such as sockets and file handles. You don’t need a general-purpose GC when you have deterministic destruction and guaranteed resource cleanup. Many bugs that are commonplace in C code just can’t happen in well-written C++, and the source code is shorter and clearer to boot.
There is an increasingly powerful set of tools for analyzing C++, and migrating code to use more modern (and better) replacements for older error-prone constructs. e.g. clang-tidy
The C++ Core Guidelines (http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines) also provide a lot of guidance on how to write good C++, and the guideline support library (https://github.com/Microsoft/GSL) provides a set of useful library facilities to make this easier. Compilers and code analysis tools are adding automated checks to confirm adherence to the Core Guidelines.
C++ is an evolving language. When new languages come with useful facilities, we look at how those facilities can be incorporated into C++ in a clean fashion.
The upgrade path from C is almost non-existent — most C can be recompiled as C++ with only minor changes (e.g. adding casts to malloc calls). Then you can use the tool support to migrate your code to better C++, e.g replacing malloc and free calls with use of containers such as std::vector or std::string, or std::unique_ptr or std::shared_ptr for single objects.
There is a fairly long learning curve for programmers to get up to speed on C++, as it is a large and complicated language that has more than one way to do many things.
But if you do learn how to use it properly, it is unmatched in versatility and performance.
>But if you do learn how to use it properly, it is unmatched in versatility and performance.
Yeah, the problem is still that “if”. In the hands of people less competent and dedicated than you, C++ becomes a defect horror-show – I learned this the hard way by having to clean up one of the resulting messes. If that weren’t so, Google wouldn’t have had to fund Go development.
I’m glad you showed up to represent, though. Where are you living these days?
“At which point you have a bug which, because of over-layers of gnarly complexity such as STL, is much more difficult to characterize and fix than the equivalent defect in C.”
finally someone to admit it.
Hmm.. Good point. But you are missing 1 thing. Go and Rust are made to and specifically made to replace C and not C++. They are very similar with C with of course no Mem management (with GC) and other excellent inbuilt networking libs. Bravo. But but but, they can’t possible replace C++ as they are not meant to be.
If you look at Go and Rust performance wise, they are even slower then C# and Java, let aside C or C++. So if you have a security critical program or a legacy program written in C, they are best candidate to be switched over to Go or Rust.
How can you dream of getting 60+ FPS using Go or Rust in a games like Assassins creed Origins on a finite hardware like PS4/X1, that is impossible except C/C++.
So again for real time applications/games, C++ is not going to go anywhere. And probably Linus will not allow to write Linux kernel using Go, Neither MSFT will think of picking up poorly performing Go to write their Windows kernel, nor JVM will ever be written anything other then C.
But yes, we can still keep dreaming of a better and a secure language.
Also, in language charts all over the world, C/C++ has consistently been on top and improving(only after Java) and at the same time once Go seemed to pick up but it is falling again.
Some links :
https://jabroo.blogspot.in/2012/08/c-plus-plus-applications-list.html
http://benchmarksgame.alioth.debian.org/u64q/compare.php?lang=go&lang2=gcc
http://benchmarksgame.alioth.debian.org/u64q/compare.php?lang=go&lang2=gpp
https://benchmarksgame.alioth.debian.org/u64q/compare.php?lang=csharpcore&lang2=go
I find it interesting that your critique of C++ matches up precisely with my own experiences … with Python.
Python is great for short programs of a few hundred lines all written and maintained by one person. Where it runs into problems is with larger programs with multiple contributors. While easy to write, python code is hard to read and understand in isolation, because everything tends to depend on everything else, including what versions of which packages are installed. Debugging is a particular nightmare, as its easy to get objects of unexpected types in unexpected places, running through code apparently ok, but actually causing obscure problems that show up in some other completely unrelated part of the system.
What is a better alternative to Python?
Every time someone criticizes Rust, all their zealots, their devs and their minions close their code editors and start writing a wall of text rebuttal.
Please stop writing about how shitty Rust is otherwise they will never have time to improve it!
What about Ada programming language, why doesn’t that get more used?
Is the main reason over-verbosity?
If yes, why doesn’t someone create a language with same semantics as Ada, but much less verbose? |
9,504 | 六个例子带你入门 size 命令 | https://www.howtoforge.com/linux-size-command/ | 2018-04-01T19:17:56 | [
"size"
] | https://linux.cn/article-9504-1.html | 
正如你所知道的那样,Linux 中的目标文件或着说可执行文件由多个段组成(比如文本段和数据段)。若你想知道每个段的大小,那么确实存在这么一个命令行工具 —— 那就是 `size`。在本教程中,我们将会用几个简单易懂的案例来讲解该工具的基本用法。
在我们开始前,有必要先声明一下,本文的所有案例都在 Ubuntu 16.04 LTS 中测试过了。
### Linux size 命令
`size` 命令基本上就是输出指定输入文件各段及其总和的大小。下面是该命令的语法:
```
size [-A|-B|--format=compatibility]
[--help]
[-d|-o|-x|--radix=number]
[--common]
[-t|--totals]
[--target=bfdname] [-V|--version]
[objfile...]
```
man 页是这样描述它的:
>
> GNU 的 `size` 程序列出参数列表中各目标文件或存档库文件的段大小 — 以及总大小。默认情况下,对每个目标文件或存档库中的每个模块都会产生一行输出。
>
>
> `objfile...` 是待检查的目标文件。如果没有指定,则默认为文件 `a.out`。
>
>
>
下面是一些问答方式的案例,希望能让你对 `size` 命令有所了解。
### Q1、如何使用 size 命令?
`size` 的基本用法很简单。你只需要将目标文件/可执行文件名称作为输入就行了。下面是一个例子:
```
size apl
```
该命令在我的系统中的输出如下:
[](https://www.howtoforge.com/images/command-tutorial/big/size-basic-usage.png)
前三部分的内容是文本段、数据段和 bss 段及其相应的大小。然后是十进制格式和十六进制格式的总大小。最后是文件名。
### Q2、如何切换不同的输出格式?
根据 man 页的说法,`size` 的默认输出格式类似于 Berkeley 的格式。然而,如果你想的话,你也可以使用 System V 规范。要做到这一点,你可以使用 `--format` 选项加上 `SysV` 值。
```
size apl --format=SysV
```
下面是它的输出:
[](https://www.howtoforge.com/images/command-tutorial/big/size-format-option.png)
### Q3、如何切换使用其他的单位?
默认情况下,段的大小是以十进制的方式来展示。然而,如果你想的话,也可以使用八进制或十六进制来表示。对应的命令行参数分别为 `o` 和 `-x`。
[](https://www.howtoforge.com/images/command-tutorial/big/size-o-x-options.png)
关于这些参数,man 页是这么说的:
>
> -d
>
>
> -o
>
>
> -x
>
>
> --radix=number
>
>
> 使用这几个选项,你可以让各个段的大小以十进制(`-d` 或 `--radix 10`)、八进制(`-o` 或 `--radix 8`);或十六进制(`-x` 或 `--radix 16`)数字的格式显示。`--radix number` 只支持三个数值参数(8、 10、 16)。总共大小以两种进制给出; `-d` 或 `-x` 的十进制和十六进制输出,或 `-o` 的八进制和十六进制输出。
>
>
>
### Q4、如何让 size 命令显示所有对象文件的总大小?
如果你用 `size` 一次性查找多个文件的段大小,则通过使用 `-t` 选项还可以让它显示各列值的总和。
```
size -t [file1] [file2] ...
```
下面是该命令的执行的截屏:
[](https://www.howtoforge.com/images/command-tutorial/big/size-t-option.png)
`-t` 选项让它多加了最后那一行。
### Q5、如何让 size 输出每个文件中公共符号的总大小?
若你为 `size` 提供多个输入文件作为参数,而且想让它显示每个文件中公共符号(指 common segment 中的 symbol)的大小,则你可以带上 `--common` 选项。
```
size --common [file1] [file2] ...
```
另外需要指出的是,当使用 Berkeley 格式时,这些公共符号的大小被纳入了 bss 大小中。
### Q6、还有什么其他的选项?
除了刚才提到的那些选项外,`size` 还有一些一般性的命令行选项,比如 `v` (显示版本信息)和 `-h` (可选参数和选项的汇总)。
[](https://www.howtoforge.com/images/command-tutorial/big/size-v-x1.png)
除此之外,你也可以使用 `@file` 选项来让 `size` 从文件中读取命令行选项。下面是详细的相关说明:
>
> 读出来的选项会插入并替代原来的 `@file` 选项。若文件不存在或着无法读取,则该选项不会被替换,而是会以字面意义来解释该选项。文件中的选项以空格分隔。当选项中要包含空格时需要用单引号或双引号将整个选项包起来。通过在字符前面添加一个反斜杠可以将任何字符(包括反斜杠本身)纳入到选项中。文件本身也能包含其他的 `@file` 选项;任何这样的选项都会被递归处理。
>
>
>
### 结论
很明显,`size` 命令并不适用于所有人。它的目标群体是那些需要处理 Linux 中目标文件/可执行文件结构的人。因此,如果你刚好是目标受众,那么多试试我们这里提到的那些选项,你应该做好每天都使用这个工具的准备。想了解关于 `size` 的更多信息,请阅读它的 [man 页](https://linux.die.net/man/1/size) 。
---
via: <https://www.howtoforge.com/linux-size-command/>
作者:[Himanshu Arora](https://www.howtoforge.com) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Linux size Command Tutorial for Beginners (6 Examples)
### On this page
[Linux size command](#linux-size-command)[Q1. How to use size command?](#q-how-to-use-size-command)[Q2. How to switch between different output formats?](#q-how-to-switch-between-different-output-formats)[Q3. How to switch between different size units?](#q-how-to-switch-between-different-size-units)[Q4. How to make size command show totals of all object files?](#q-how-to-make-size-command-show-totals-of-all-object-files)[Q5. How to make size print total size of common symbols in each file?](#q-how-to-make-size-print-total-size-of-common-symbols-in-each-file)[Q6. What are the other available command line options?](#q-what-are-the-other-available-command-line-options)[Conclusion](#conclusion)
As some of you might already know, an object or executable file in Linux consists of several sections (like txt and data). In case you want to know the size of each section, there exists a command line utility - dubbed **size** - that provides you this information. In this tutorial, we will discuss the basics of this tool using some easy to understand examples.
*But before we do that, it's worth mentioning that all examples mentioned in this article have been tested on Ubuntu 16.04LTS.*
## Linux size command
The size command basically lists section sizes as well as total size for the input object file(s). Here's the syntax for the command:
size [-A|-B|--format=compatibility]
[--help]
[-d|-o|-x|--radix=number]
[--common]
[-t|--totals]
[--target=bfdname] [-V|--version]
[objfile...]
And here's how the man page describes this utility:
The GNU size utility lists the section sizes---and the total size---for each of the object or
archive files objfile in its argument list. By default, one line of output is generated for each
object file or each module in an archive.
objfile... are the object files to be examined. If none are specified, the file "a.out" will be
used.
Following are some Q&A-styled examples that'll give you a better idea about how the size command works.
## Q1. How to use size command?
Basic usage of size is very simple. All you have to do is to pass the object/executable file name as input to the tool. Following is an example:
size apl
Following is the output the above command produced on our system:
The first three entries are for text, data, and bss sections, with their corresponding sizes. Then comes the total in decimal and hexadecimal formats. And finally, the last entry is for the filename.
## Q2. How to switch between different output formats?
The default output format, the man page for size says, is similar to the Berkeley's format. However, if you want, you can go for System V convention as well. For this, you'll have to use the **--format** option with *SysV* as value.
size apl --format=SysV
Here's the output in this case:
## Q3. How to switch between different size units?
By default, the size of sections is displayed in decimal. However, if you want, you can have this information on octal as well as hexadecimal. For this, use the** -o** and **-x** command line options.
Here's what the man page says about these options:
-d
-o
-x
--radix=number
Using one of these options, you can control whether the size of each section is given in decimal
(-d, or --radix=10); octal (-o, or --radix=8); or hexadecimal (-x, or --radix=16). In
--radix=number, only the three values (8, 10, 16) are supported. The total size is always given in
two radices; decimal and hexadecimal for -d or -x output, or octal and hexadecimal if you're using
-o.
## Q4. How to make size command show totals of all object files?
If you are using size to find out section sizes for multiple files in one go, then if you want, you can also have the tool provide totals of all column values. You can enable this feature using the **-t** command line option.
size -t [file1] [file2] ...
The following screenshot shows this command line option in action:
The last row in the output has been added by the **-t** command line option.
## Q5. How to make size print total size of common symbols in each file?
If you are running the size command with multiple input files, and want the command to display common symbols in each file, then you can do this with the **--common** command line option.
size --common [file1] [file2] ...
It's also worth mentioning that when using Berkeley format these are included in the bss size.
## Q6. What are the other available command line options?
Aside from the ones discussed until now, size also offers some generic command line options like **-v** (for version info) and **-h** (for summary of eligible arguments and options)
In addition, you can also make *size* read command-line options from a file. This you can do using the **@file** option. Following are some details related to this option:
The options read are inserted in place of the original @file option. If file does not exist, or
cannot be read, then the option will be treated literally, and not removed. Options in file are
separated by whitespace. A whitespace character may be included in an option by surrounding the
entire option in either single or double quotes. Any character (including a backslash) may be
included by prefixing the character to be included with a backslash. The file may itself contain
additional @file options; any such options will be processed recursively.
## Conclusion
One thing is clear, the size command isn't for everybody. It's aimed at only those who deal with the structure of object/executable files in Linux. So if you are among the target audience, practice the options we've discussed here, and you should be ready to use the tool on daily basis. For more information on size, head to its [man page](https://linux.die.net/man/1/size). |
9,505 | 容器环境中的代理模型 | https://dzone.com/articles/proxy-models-in-container-environments | 2018-04-02T09:40:31 | [
"容器",
"代理"
] | https://linux.cn/article-9505-1.html |
>
> 我们大多数人都熟悉代理如何工作,但在基于容器的环境中有什么不同?让我们来看看有什么改变。
>
>
>

内联、<ruby> 侧臂 <rt> side-arm </rt></ruby>、反向和前向。这些曾经是我们用来描述网络代理架构布局的术语。
如今,容器使用一些相同的术语,但它们正在引入新的东西。这对我是个机会来阐述我最爱的所有主题:代理。
云的主要驱动之一(我们曾经有过成本控制的白日梦)就是可扩展性。在过去五年中,扩展在各种调查中面临着敏捷性的挑战(有时甚至获胜),因为这是机构在云计算环境中部署应用的最大追求。
这在一定程度上是因为在(我们现在运营的)数字经济中,应用已经成为像实体店的“营业/休息”的标牌和导购一样的东西。缓慢、无响应的应用如同商店关灯或缺少营业人员一样。
[](https://devcentral.f5.com/Portals/0/Users/038/38/38/unavailable_is_closed.png?ver=2017-09-12-082118-160)
应用需要随时可用且能够满足需求。扩展是实现这一业务目标的技术响应。云不仅提供了扩展的能力,而且还提供了*自动*扩展的能力。要做到这一点,需要一个负载均衡器。因为这就是我们扩展应用程序的方式 :使用代理来负载均衡流量/请求。
容器在扩展上与预期没有什么不同。容器必须进行扩展(并自动扩展)这意味着使用负载均衡器(代理)。
如果你使用的是原有的代理机制,那就是采用基于 TCP/UDP 进行基本的负载平衡。一般来说,基于容器的代理的实现在 HTTP 或其他应用层协议中并不流畅,并不能在旧式的负载均衡([POLB](https://f5.com/about-us/blog/articles/go-beyond-polb-plain-old-load-balancing))之外提供其他功能。这通常足够了,因为容器扩展是在一个克隆的、假定水平扩展的环境中进行的:要扩展一个应用程序,就添加另一个副本并在其上分发请求。在入口处(在[入口控制器](https://f5.com/about-us/blog/articles/ingress-controllers-new-name-familiar-function-27388)和 API 网关中)可以找到第 7 层(HTTP)路由功能,并且可以使用尽可能多(或更多)的应用路由来扩展应用程序。
然而,在某些情况下,这还不够。如果你希望(或需要)更多以应用程序为中心的扩展或插入其他服务的能力,那么你就可以获得更健壮的产品,可提供可编程性或以应用程序为中心的可伸缩性,或者两者兼而有之。
这意味着[插入代理](http://clouddocs.f5.com/products/asp/v1.0/)。你正在使用的容器编排环境在很大程度上决定了代理的部署模型,无论它是反向代理还是前向代理。更有趣的是,还有第三个模型挎斗模式 ,这是由新兴的服务网格实现支持的可扩展性的基础。
### 反向代理

反向代理最接近于传统模型,在这种模型中,虚拟服务器接受所有传入请求,并将其分发到资源池(服务器中心、集群)中。
每个“应用程序”有一个代理。任何想要连接到应用程序的客户端都连接到代理,代理然后选择并转发请求到适当的实例。如果绿色应用想要与蓝色应用通信,它会向蓝色代理发送请求,蓝色代理会确定蓝色应用的两个实例中的哪一个应该响应该请求。
在这个模型中,代理只关心它正在管理的应用程序。蓝色代理不关心与橙色代理关联的实例,反之亦然。
### 前向代理
[](https://devcentral.f5.com/Portals/0/Users/038/38/38/per-node_forward_proxy.jpg?ver=2017-09-14-072419-667)
这种模式更接近传统的出站防火墙的模式。
在这个模型中,每个容器 **节点** 都有一个关联的代理。如果客户端想要连接到特定的应用程序或服务,它将连接到正在运行的客户端所在的容器节点的本地代理。代理然后选择一个适当的应用实例,并转发客户端的请求。
橙色和蓝色的应用连接到与其节点相关的同一个代理。代理然后确定所请求的应用实例的哪个实例应该响应。
在这个模型中,每个代理必须知道每个应用,以确保它可以将请求转发给适当的实例。
### 挎斗代理
[](https://devcentral.f5.com/Portals/0/Users/038/38/38/per-pod_sidecar_proxy.jpg?ver=2017-09-14-072424-073)
这种模型也被称为服务网格路由。在这个模型中,每个**容器**都有自己的代理。
如果客户想要连接到一个应用,它将连接到挎斗代理,它会选择一个合适的应用程序实例并转发客户端的请求。此行为与*前向代理*模型相同。
挎斗代理和前向代理之间的区别在于,挎斗代理不需要修改容器编排环境。例如,为了插入一个前向代理到 k8s,你需要代理*和*一个 kube-proxy 的替代。挎斗代理不需要这种修改,因为应用会自动连接到 “挎斗” 代理而不是通过代理路由。
### 总结
每种模式都有其优点和缺点。三者共同依赖环境数据(远程监控和配置变化),以及融入生态系统的需求。有些模型是根据你选择的环境预先确定的,因此需要仔细考虑将来的需求(服务插入、安全性、网络复杂性)在建立模型之前需要进行评估。
在容器及其在企业中的发展方面,我们还处于早期阶段。随着它们继续延伸到生产环境中,了解容器化环境发布的应用程序的需求以及它们在代理模型实现上的差异是非常重要的。
这篇文章是匆匆写就的。现在就这么多。
---
via: <https://dzone.com/articles/proxy-models-in-container-environments>
作者:[Lori MacVittie](https://dzone.com/users/307701/lmacvittie.html) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 410 | Gone | null |
9,506 | 如何配置 Apache Web 服务器 | https://opensource.com/article/18/2/how-configure-apache-web-server | 2018-04-02T10:14:00 | [
"Apache"
] | https://linux.cn/article-9506-1.html |
>
> 学习如何在 Apache 上托管你自己的网站,这是一个可靠、流行且易于配置的 Web 服务器。
>
>
>

我托管自己的网站已经有很多年了。自从 20 多年前从 OS/2 切换到 Linux 以来,我一直将 [Apache](https://httpd.apache.org/) 作为我的服务器软件。Apache 是可靠、流行的,且基本的安装配置也很容易。对于更复杂的设置(比如多个网站)也并不是那么困难。
Apache Web 服务器的安装和配置必须以 root 身份执行。 防火墙的配置也需要以 root 身份执行。 使用浏览器查看安装配置的结果应该以非 root 用户的身份完成。 (我在我的虚拟主机上使用 `student` 这个用户。)
### 安装
注意:我使用的实验环境是安装有 Fedora 27 的虚拟机,Apache 版本为 2.4.29。 如果您使用的是不同的发行版或不同版本的 Fedora,您的命令以及配置文件的位置和内容可能会有所不同。 但是,您需要修改的配置行是相同的。
Apache Web 服务器非常容易安装。 在我的 CentOS 6.x 服务器上,它只需要一个简单的 `yum` 命令。 它会安装所有必要的依赖(如果需要的话)。 我在我的 Fedora 虚拟机上使用了下面的 `dnf` 命令。 除了命令本身的名称之外, `dnf` 和 `yum` 的语法是相同的。
```
dnf -y install httpd
```
这个虚拟机是个非常基础的桌面环境,我正在使用它作为编写书籍的测试平台。 即使在这个系统上,也只安装了六个依赖项,用了一分钟。
Apache 的所有配置文件都位于 `/etc/httpd/conf` 和 `/etc/httpd/conf.d` 。网站的数据默认位于 `/var/www`,但如果你愿意,你可以改变它。
### 配置
Apache 主要的配置文件是 `/etc/httpd/conf/httpd.conf` 。 它包含许多在基本安装中不需要更改的配置。 实际上,只需对此文件进行一些更改即可启动并运行一个简单的网站。 该文件非常大,因此,我不会将这篇文章与大量不必要的东西混淆起来,而只会显示那些需要更改的指令。
首先,花点时间熟悉一下 `httpd.conf` 文件。我喜欢 Red Hat 的一个原因是它的配置文件注释非常的详细。 `httpd.conf` 文件也不例外,因为它有很好的注释。可以使用这些注释来了解文件的配置。
第一个要修改的是 `Listen` 配置项,它定义了 Apache 要监听页面请求的 IP 地址和端口。 现在,你只需要使这个网站可以从本地访问,所以使用 `localhost` 地址。 完成后,该行应该看起来像这样:( LCTT 译注:`localhost` 的 IP 地址是 `127.0.0.1`,`80` 是端口)
```
Listen 127.0.0.1:80
```
通过将此配置项设置为 `localhost`的 IP 地址,Apache 将只侦听来自本地主机的连接。 如果您希望 Web 服务器侦听来自远程主机的连接,则可以使用主机的外部 IP 地址。
`DocumentRoot` 配置项指定组成网站页面的 HTML 文件的位置。 该配置项不需要更改,因为它已经指向标准位置。 该行应该看起来像这样:
```
DocumentRoot "/var/www/html"
```
Apache 安装包会创建 `/var/www` 目录。 如果您想更改存储网站文件的位置,则使用此配置项来完成此操作。 例如,您可能想要为 `www` 目录使用不同的名称,以更明确地识别网站。 这可以是这样的:
```
DocumentRoot "/var/mywebsite/html"
```
这些是创建一个简单网站需要唯一修改的 Apache 配置项。 对于这个小练习,只对 `httpd.conf` 文件(`Listen` 配置项)进行了一些修改。 其它的配置项对于一个简单的 Web 服务器暂时无需配置。
另一个需要改变的地方是:在我们的防火墙中打开端口 80。 我使用 [iptables](https://en.wikipedia.org/wiki/Iptables) 作为我的防火墙,因此我更改 `/etc/sysconfig/iptables` 文件以添加允许使用 HTTP 协议。 整个文件看起来像这样:
```
# sample configuration for iptables service
# you can edit this manually or use system-config-firewall
# please do not ask us to add additional ports/services to this default configuration
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
COMMIT
```
我在文件的倒数第三行上添加了一个新行,它允许在端口 `80` 上输入流量。现在我重新加载 iptables 配置文件。
```
[root@testvm1 ~]# cd /etc/sysconfig/ ; iptables-restore iptables
```
### 创建 index.html 文件
`index.html` 文件是你使用域名访问网站而不是访问特定网页时的默认文件。在 `/var/www/html`中,创建一个名字为 `index.html` 的文件,在其中添加字符串 `Hello World` 。你不需要添加任何的 HTML 标志去完成这项工作。web 服务器的唯一任务是提供文本数据流,服务器不知道数据是什么,也不知道如何呈现它。它只是将数据流传输给请求主机。
保存文件后,将所有权设置为 `apache.apache` 。
```
[root@testvm1 html]# chown apache.apache index.html
```
### 启动 Apache
Apache 很容易启动。 当前版本的 Fedora 使用 systemd 。 运行以下命令启动它,然后检查服务器的状态:(LCTT 译注:`systemctl` 是一个 systemd 工具)
```
[root@testvm1 ~]# systemctl start httpd
[root@testvm1 ~]# systemctl status httpd
● httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; disabled; vendor preset: disabled)
Active: active (running) since Thu 2018-02-08 13:18:54 EST; 5s ago
Docs: man:httpd.service(8)
Main PID: 27107 (httpd)
Status: "Processing requests..."
Tasks: 213 (limit: 4915)
CGroup: /system.slice/httpd.service
├─27107 /usr/sbin/httpd -DFOREGROUND
├─27108 /usr/sbin/httpd -DFOREGROUND
├─27109 /usr/sbin/httpd -DFOREGROUND
├─27110 /usr/sbin/httpd -DFOREGROUND
└─27111 /usr/sbin/httpd -DFOREGROUND
Feb 08 13:18:54 testvm1 systemd[1]: Starting The Apache HTTP Server...
Feb 08 13:18:54 testvm1 systemd[1]: Started The Apache HTTP Server.
```
您的服务器上的命令可能不同。在使用 SystemV 启动脚本的 Linux 系统上,命令如下:
```
[root@testvm1 ~]# service httpd start
Starting httpd: [Fri Feb 09 08:18:07 2018] [ OK ]
[root@testvm1 ~]# service httpd status
httpd (pid 14649) is running...
```
如果您的主机上有像 Firefox 或 Chrome 这样的浏览器,您可以在浏览器的 URL 行上使用 URL `localhost` 来显示您的 web 页面,尽管看起来很简单。您还可以使用像 [Lynx](http://lynx.browser.org/) 这样的文本模式 web 浏览器来查看 web 页面。首先,安装 Lynx (如果它还没有被安装)。
```
[root@testvm1 ~]# dnf -y install lynx
```
然后使用下面的命令来显示网页。
```
[root@testvm1 ~]# lynx localhost
```
结果在我的终端中是这样的。我已经删除了页面上的很多空白。
```
Hello World
<snip>
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list```
```
接下来,编辑您的 `index.html` 文件并添加一些 HTML 标记,使其看起来像这样:
```
<h1>Hello World</h1>
```
现在刷新浏览器。对于 Lynx,使用组合键 `Ctrl + R` 。 结果看起来有点不同。如果你的终端支持彩色的话文本是彩色显示的,Lynx 会显示标题,现在它处于居中状态。 在 GUI 浏览器中,文本将以大字体显示。
```
Hello World
<snip>
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
```
### 后记
从这个小练习中可以看到,建立一个 Apache Web 服务器很容易。 具体情况取决于您的发行版和该发行版提供的 Apache 版本。 在我的环境中,这是一个非常简单的练习。
但不仅仅如此,因为 Apache 非常灵活强大。下个月,我将讨论使用单个 Apache 托管多个网站。
---
via: <https://opensource.com/article/18/2/how-configure-apache-web-server>
作者:[David Both](https://opensource.com/users/dboth) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,507 | 深入理解 BPF:一个阅读清单 | https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/ | 2018-04-03T12:25:00 | [
"跟踪器",
"BPF",
"eBPF",
"过滤器"
] | https://linux.cn/article-9507-1.html | 
*~ [更新于](https://github.com/qmonnet/whirl-offload/commits/gh-pages/_posts/2016-09-01-dive-into-bpf.md) 2017-11-02 ~*
什么是 BPF?
--------
BPF,及<ruby> 伯克利包过滤器 <rt> <strong> B </strong> erkeley <strong> P </strong> acket <strong> F </strong> ilter </rt></ruby>,最初构想提出于 1992 年,其目的是为了提供一种过滤包的方法,并且要避免从内核空间到用户空间的无用的数据包复制行为。它最初是由从用户空间注入到内核的一个简单的字节码构成,它在那个位置利用一个校验器进行检查 —— 以避免内核崩溃或者安全问题 —— 并附着到一个套接字上,接着在每个接收到的包上运行。几年后它被移植到 Linux 上,并且应用于一小部分应用程序上(例如,`tcpdump`)。其简化的语言以及存在于内核中的即时编译器(JIT),使 BPF 成为一个性能卓越的工具。
然后,在 2013 年,Alexei Starovoitov 对 BPF 进行彻底地改造,并增加了新的功能,改善了它的性能。这个新版本被命名为 eBPF (意思是 “extended BPF”),与此同时,将以前的 BPF 变成 cBPF(意思是 “classic” BPF)。新版本出现了如映射和<ruby> 尾调用 <rt> tail call </rt></ruby>这样的新特性,并且 JIT 编译器也被重写了。新的语言比 cBPF 更接近于原生机器语言。并且,在内核中创建了新的附着点。
感谢那些新的钩子,eBPF 程序才可以被设计用于各种各样的情形下,其分为两个应用领域。其中一个应用领域是内核跟踪和事件监控。BPF 程序可以被附着到探针(kprobe),而且它与其它跟踪模式相比,有很多的优点(有时也有一些缺点)。
另外一个应用领域是网络编程。除了套接字过滤器外,eBPF 程序还可以附加到 tc(Linux 流量控制工具)的入站或者出站接口上,以一种很高效的方式去执行各种包处理任务。这种使用方式在这个领域开创了一个新的天地。
并且 eBPF 通过使用为 IO Visor 项目开发的技术,使它的性能进一步得到提升:也为 XDP(“eXpress Data Path”)添加了新的钩子,XDP 是不久前添加到内核中的一种新式快速路径。XDP 与 Linux 栈组合,然后使用 BPF ,使包处理的速度更快。
甚至一些项目,如 P4、Open vSwitch,[考虑](http://openvswitch.org/pipermail/dev/2014-October/047421.html) 或者开始去接洽使用 BPF。其它的一些,如 CETH、Cilium,则是完全基于它的。BPF 是如此流行,因此,我们可以预计,不久之后,将围绕它有更多工具和项目出现 …
深入理解字节码
-------
就像我一样:我的一些工作(包括 [BEBA](https://qmonnet.github.io/whirl-offload/2016/07/15/beba-research-project/))是非常依赖 eBPF 的,并且在这个网站上以后的几篇文章将关注于这个主题。按理说,在深入到细节之前,我应该以某种方式去介绍 BPF —— 我的意思是,真正的介绍,在第一节所提供的简要介绍上更多地介绍在 BPF 上开发的新功能:什么是 BPF 映射?尾调用?内部结构是什么样子?等等。但是,在这个网站上已经有很多这个主题的介绍了,而且,我也不希望去写另一篇 “BPF 介绍” 的重复文章。
毕竟,我花费了很多的时间去阅读和学习关于 BPF 的知识,因此,在这里我们将要做什么呢,我收集了非常多的关于 BPF 的阅读材料:介绍、文档,也有教程或者示例。这里有很多的材料可以去阅读,但是,为了去阅读它,首先要去 *找到* 它。因此,为了能够帮助更多想去学习和使用 BPF 的人,现在的这篇文章给出了一个资源清单。这里有各种阅读材料,它可以帮你深入理解内核字节码的机制。
资源
--
### 简介
这篇文章中下面的链接提供了 BPF 的基本概述,或者,一些与它密切相关的一些主题。如果你对 BPF 非常陌生,你可以在这些介绍文章中挑选出一篇你喜欢的文章去阅读。如果你已经理解了 BPF,你可以针对特定的主题去阅读,下面是阅读清单。
#### 关于 BPF
**关于 eBPF 的常规介绍**:
* [全面介绍 eBPF](https://lwn.net/Articles/740157/)(Matt Flemming,on LWN.net,December 2017):
一篇写的很好的,并且易于理解的,介绍 eBPF 子系统组件的概述文章。
* [利用 BPF 和 XDP 实现可编程的内核网络数据路径](http://schd.ws/hosted_files/ossna2017/da/BPFandXDP.pdf) (Daniel Borkmann, OSSNA17, Los Angeles, September 2017):
快速理解所有的关于 eBPF 和 XDP 的基础概念的最好讲稿中的一篇(主要是关于网络处理的)
* [BSD 包过滤器](https://speakerdeck.com/tuxology/the-bsd-packet-filter) (Suchakra Sharma, June 2017):
一篇非常好的介绍文章,主要是关于跟踪方面的。
* [BPF:跟踪及更多](http://www.slideshare.net/brendangregg/bpf-tracing-and-more)(Brendan Gregg, January 2017):
主要内容是跟踪使用案例相关的。
* [Linux BPF 的超强功能](http://fr.slideshare.net/brendangregg/linux-bpf-superpowers) (Brendan Gregg, March 2016):
第一部分是关于<ruby> 火焰图 <rt> flame graph </rt></ruby>的使用。
* [IO Visor](https://www.socallinuxexpo.org/sites/default/files/presentations/Room%20211%20-%20IOVisor%20-%20SCaLE%2014x.pdf)(Brenden Blanco, SCaLE 14x, January 2016):
介绍了 **IO Visor 项目**。
* [大型机上的 eBPF](https://events.linuxfoundation.org/sites/events/files/slides/ebpf_on_the_mainframe_lcon_2015.pdf)(Michael Holzheu, LinuxCon, Dubin, October 2015)
* [在 Linux 上新的(令人激动的)跟踪新产品](https://events.linuxfoundation.org/sites/events/files/slides/tracing-linux-ezannoni-linuxcon-ja-2015_0.pdf)(Elena Zannoni, LinuxCon, Japan, 2015)
* [BPF — 内核中的虚拟机](https://events.linuxfoundation.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf)(Alexei Starovoitov, February 2015):
eBPF 的作者写的一篇讲稿。
* [扩展 extended BPF](https://lwn.net/Articles/603983/) (Jonathan Corbet, July 2014)
**BPF 内部结构**:
* Daniel Borkmann 正在做的一项令人称奇的工作,它用于去展现 eBPF 的 **内部结构**,尤其是,它的关于 **随同 tc 使用** 的几次演讲和论文。
+ [使用 tc 的 cls\_bpf 的高级可编程和它的最新更新](http://netdevconf.org/1.2/session.html?daniel-borkmann)(netdev 1.2, Tokyo, October 2016):
Daniel 介绍了 eBPF 的细节,及其用于隧道和封装、直接包访问和其它特性。
+ [自 netdev 1.1 以来的 cls\_bpf/eBPF 更新](http://netdevconf.org/1.2/slides/oct5/07_tcws_daniel_borkmann_2016_tcws.pdf) (netdev 1.2, Tokyo, October 2016, part of [this tc workshop](http://netdevconf.org/1.2/session.html?jamal-tc-workshop))
+ [使用 cls\_bpf 实现完全可编程的 tc 分类器](http://www.netdevconf.org/1.1/proceedings/slides/borkmann-tc-classifier-cls-bpf.pdf) (netdev 1.1, Sevilla, February 2016):
介绍 eBPF 之后,它提供了许多 BPF 内部机制(映射管理、尾调用、校验器)的见解。对于大多数有志于 BPF 的人来说,这是必读的。
+ [Linux tc 和 eBPF](https://archive.fosdem.org/2016/schedule/event/ebpf/attachments/slides/1159/export/events/attachments/ebpf/slides/1159/ebpf.pdf) (fosdem16, Brussels, Belgium, January 2016)
+ [eBPF 和 XDP 攻略和最新更新](https://fosdem.org/2017/schedule/event/ebpf_xdp/) (fosdem17, Brussels, Belgium, February 2017)
这些介绍可能是理解 eBPF 内部机制设计与实现的最佳文档资源之一。
[IO Visor 博客](https://www.iovisor.org/resources/blog) 有一些关于 BPF 的值得关注技术文章。它们中的一些包含了一点营销讨论。
**内核跟踪**:总结了所有的已有的方法,包括 BPF:
* [邂逅 eBPF 和内核跟踪](http://www.slideshare.net/vh21/meet-cutebetweenebpfandtracing) (Viller Hsiao, July 2016):
Kprobes、uprobes、ftrace
* [Linux 内核跟踪](http://www.slideshare.net/vh21/linux-kernel-tracing)(Viller Hsiao, July 2016):
Systemtap、Kernelshark、trace-cmd、LTTng、perf-tool、ftrace、hist-trigger、perf、function tracer、tracepoint、kprobe/uprobe …
关于 **事件跟踪和监视**,Brendan Gregg 大量使用了 eBPF,并且就其使用 eBPFR 的一些案例写了极好的文档。如果你正在做一些内核跟踪方面的工作,你应该去看一下他的关于 eBPF 和火焰图相关的博客文章。其中的大多数都可以 [从这篇文章中](http://www.brendangregg.com/blog/2016-03-05/linux-bpf-superpowers.html) 访问,或者浏览他的博客。
介绍 BPF,也介绍 **Linux 网络的一般概念**:
* [Linux 网络详解](http://www.slideshare.net/ThomasGraf5/linux-networking-explained) (Thomas Graf, LinuxCon, Toronto, August 2016)
* [内核网络攻略](http://www.slideshare.net/ThomasGraf5/linuxcon-2015-linux-kernel-networking-walkthrough) (Thomas Graf, LinuxCon, Seattle, August 2015)
**硬件<ruby> 卸载 <rt> offload </rt></ruby>**(LCTT 译注:“卸载”是指原本由软件来处理的一些操作交由硬件来完成,以提升吞吐量,降低 CPU 负荷。):
* eBPF 与 tc 或者 XDP 一起支持硬件卸载,开始于 Linux 内核版本 4.9,是由 Netronome 提出的。这里是关于这个特性的介绍:[eBPF/XDP 硬件卸载到 SmartNICs](http://netdevconf.org/1.2/session.html?jakub-kicinski)(Jakub Kicinski 和 Nic Viljoen, netdev 1.2, Tokyo, October 2016)
* 一年后出现的更新版:
[综合 XDP 卸载——处理边界案例](https://www.netdevconf.org/2.2/session.html?viljoen-xdpoffload-talk)(Jakub Kicinski 和 Nic Viljoen,netdev 2.2 ,Seoul,November 2017)
* 我现在有一个简短的,但是在 2018 年的 FOSDEM 上有一个更新版:
[XDP 硬件卸载的挑战](https://fosdem.org/2018/schedule/event/xdp/)(Quentin Monnet,FOSDEM 2018,Brussels,February 2018)
关于 **cBPF**:
* [BSD 包过滤器:一个用户级包捕获的新架构](http://www.tcpdump.org/papers/bpf-usenix93.pdf) (Steven McCanne 和 Van Jacobson, 1992):
它是关于(经典)BPF 的最早的论文。
* [BPF 的 FreeBSD 手册](http://www.gsp.com/cgi-bin/man.cgi?topic=bpf) 是理解 cBPF 程序有用的资源。
* 关于 cBPF,Daniel Borkmann 做至少两个演讲,[一是,在 2013 年 mmap 中,BPF 和 Netsniff-NG](http://borkmann.ch/talks/2013_devconf.pdf),以及 [在 2014 中关于 tc 和 cls\_bpf 的的一个非常完整的演讲](http://borkmann.ch/talks/2014_devconf.pdf)。
* 在 Cloudflare 的博客上,Marek Majkowski 提出的他的 [与 iptables 的 `xt_bpf` 模块一起使用 BPF 字节码](https://blog.cloudflare.com/introducing-the-bpf-tools/)。值得一提的是,从 Linux 内核 4.10 开始,eBPF 也是通过这个模块支持的。(虽然,我并不知道关于这件事的任何讨论或者文章)
* [Libpcap 过滤器语法](http://biot.com/capstats/bpf.html)
#### 关于 XDP
* 在 IO Visor 网站上的 [XDP 概述](https://www.iovisor.org/technology/xdp)。
* [eXpress Data Path (XDP)](https://github.com/iovisor/bpf-docs/raw/master/Express_Data_Path.pdf) (Tom Herbert, Alexei Starovoitov, March 2016):
这是第一个关于 XDP 的演讲。
* [BoF - BPF 能为你做什么?](https://events.linuxfoundation.org/sites/events/files/slides/iovisor-lc-bof-2016.pdf) (Brenden Blanco, LinuxCon, Toronto, August 2016)。
* [eXpress Data Path](http://www.slideshare.net/IOVisor/express-data-path-linux-meetup-santa-clara-july-2016) (Brenden Blanco, Linux Meetup at Santa Clara, July 2016):
包含一些(有点营销的意思?)**基准测试结果**!使用单一核心:
+ ip 路由丢弃: ~3.6 百万包每秒(Mpps)
+ 使用 BPF,tc(使用 clsact qdisc)丢弃: ~4.2 Mpps
+ 使用 BPF,XDP 丢弃:20 Mpps (CPU 利用率 < 10%)
+ XDP 重写转发(在端口上它接收到的包):10 Mpps(测试是用 mlx4 驱动程序执行的)。
* Jesper Dangaard Brouer 有几个非常好的幻灯片,它可以从本质上去理解 XDP 的内部结构。
+ [XDP − eXpress Data Path,介绍及将来的用法](http://people.netfilter.org/hawk/presentations/xdp2016/xdp_intro_and_use_cases_sep2016.pdf) (September 2016):
“Linux 内核与 DPDK 的斗争” 。**未来的计划**(在写这篇文章时)它用 XDP 和 DPDK 进行比较。
+ [网络性能研讨](http://netdevconf.org/1.2/session.html?jesper-performance-workshop) (netdev 1.2, Tokyo, October 2016):
关于 XDP 内部结构和预期演化的附加提示。
+ [XDP – eXpress Data Path, 可用于 DDoS 防护](http://people.netfilter.org/hawk/presentations/OpenSourceDays2017/XDP_DDoS_protecting_osd2017.pdf) (OpenSourceDays, March 2017):
包含了关于 XDP 的详细情况和使用案例,以及 **性能测试** 的 **性能测试结果** 和 **代码片断**,以及使用 eBPF/XDP(基于一个 IP 黑名单模式)的用于 **基本的 DDoS 防护**。
+ [内存 vs. 网络,激发和修复内存瓶颈](http://people.netfilter.org/hawk/presentations/MM-summit2017/MM-summit2017-JesperBrouer.pdf) (LSF Memory Management Summit, March 2017):
提供了许多 XDP 开发者当前所面对 **内存问题** 的许多细节。不要从这一个开始,但如果你已经理解了 XDP,并且想去了解它在页面分配方面的真实工作方式,这是一个非常有用的资源。
+ [XDP 能为其它人做什么](http://netdevconf.org/2.1/session.html?gospodarek)(netdev 2.1, Montreal, April 2017),及 Andy Gospodarek:
普通人怎么开始使用 eBPF 和 XDP。这个演讲也由 Julia Evans 在 [她的博客](http://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/) 上做了总结。
+ [XDP 能为其它人做什么](https://www.netdevconf.org/2.2/session.html?gospodarek-xdp-workshop),第二版(netdev 2.2, Seoul, November 2017),同一个作者:
该演讲的修订版本,包含了新的内容。
(Jesper 也创建了并且尝试去扩展了有关 eBPF 和 XDP 的一些文档,查看 [相关节](https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-xdp-1)。)
* [XDP 研讨 — 介绍、体验和未来发展](http://netdevconf.org/1.2/session.html?herbert-xdp-workshop)(Tom Herbert, netdev 1.2, Tokyo, October 2016)
在这篇文章中,只有视频可用,我不知道是否有幻灯片。
* [在 Linux 上进行高速包过滤](https://cdn.shopify.com/s/files/1/0177/9886/files/phv2017-gbertin.pdf) (Gilberto Bertin, DEF CON 25, Las Vegas, July 2017)
在 Linux 上的最先进的包过滤的介绍,面向 DDoS 的保护、讨论了关于在内核中进行包处理、内核旁通、XDP 和 eBPF。
#### 关于 基于 eBPF 或者 eBPF 相关的其它组件
* [在边界上的 P4](https://schd.ws/hosted_files/2016p4workshop/1d/Intel%20Fastabend-P4%20on%20the%20Edge.pdf) (John Fastabend, May 2016):
提出了使用 **P4**,一个包处理的描述语言,使用 BPF 去创建一个高性能的可编程交换机。
* 如果你喜欢音频的演讲,这里有一个相关的 [OvS Orbit 片断(#11),叫做 在边界上的 P4](https://ovsorbit.benpfaff.org/#e11),日期是 2016 年 8 月。OvS Orbit 是对 Ben Pfaff 的访谈,它是 Open vSwitch 的其中一个核心维护者。在这个场景中,John Fastabend 是被访谈者。
* [P4, EBPF 和 Linux TC 卸载](http://open-nfp.org/media/pdfs/Open_NFP_P4_EBPF_Linux_TC_Offload_FINAL.pdf) (Dinan Gunawardena 和 Jakub Kicinski, August 2016):
另一个 **P4** 的演讲,一些有关于 Netronome 的 **NFP**(网络流处理器)架构上的 eBPF 硬件卸载的因素。
* **Cilium** 是一个由 Cisco 最先发起的技术,它依赖 BPF 和 XDP 去提供 “基于 eBPF 程序即时生成的,用于容器的快速内核强制的网络和安全策略”。[这个项目的代码](https://github.com/cilium/cilium) 在 GitHub 上可以访问到。Thomas Graf 对这个主题做了很多的演讲:
+ [Cilium:对容器利用 BPF & XDP 实现网络 & 安全](http://www.slideshare.net/ThomasGraf5/clium-container-networking-with-bpf-xdp),也特别展示了一个负载均衡的使用案例(Linux Plumbers conference, Santa Fe, November 2016)
+ [Cilium:对容器利用 BPF & XDP 实现网络 & 安全](http://www.slideshare.net/Docker/cilium-bpf-xdp-for-containers-66969823) (Docker Distributed Systems Summit, October 2016 — [video](https://www.youtube.com/watch?v=TnJF7ht3ZYc&amp;amp;list=PLkA60AVN3hh8oPas3cq2VA9xB7WazcIgs))
+ [Cilium:使用 BPF 和 XDP 的快速 IPv6 容器网络](http://www.slideshare.net/ThomasGraf5/cilium-fast-ipv6-container-networking-with-bpf-and-xdp) (LinuxCon, Toronto, August 2016)
+ [Cilium: 用于容器的 BPF & XDP](https://fosdem.org/2017/schedule/event/cilium/) (fosdem17, Brussels, Belgium, February 2017)在上述不同的演讲中重复了大量的内容;嫌麻烦就选最近的一个。Daniel Borkmann 作为 Google 开源博客的特邀作者,也写了 [Cilium 简介](https://opensource.googleblog.com/2016/11/cilium-networking-and-security.html)。
* 这里也有一个关于 **Cilium** 的播客节目:一个是 [OvS Orbit episode (#4)](https://ovsorbit.benpfaff.org/),它是 Ben Pfaff 访谈 Thomas Graf (2016 年 5 月),和 [另外一个 Ivan Pepelnjak 的播客](http://blog.ipspace.net/2016/10/fast-linux-packet-forwarding-with.html),仍然是 Thomas Graf 关于 eBPF、P4、XDP 和 Cilium 方面的(2016 年 10 月)。
* **Open vSwitch** (OvS),它是 **Open Virtual Network**(OVN,一个开源的网络虚拟化解决方案)相关的项目,正在考虑在不同的层次上使用 eBPF,它已经实现了几个概念验证原型:
+ [使用 eBPF 卸载 OVS 流处理器](http://openvswitch.org/support/ovscon2016/7/1120-tu.pdf) (William (Cheng-Chun) Tu, OvS conference, San Jose, November 2016)
+ [将 OVN 的灵活性与 IOVisor 的高效率相结合](http://openvswitch.org/support/ovscon2016/7/1245-bertrone.pdf) (Fulvio Risso, Matteo Bertrone 和 Mauricio Vasquez Bernal, OvS conference, San Jose, November 2016)据我所知,这些 eBPF 的使用案例看上去仅处于提议阶段(并没有合并到 OvS 的主分支中),但是,看它带来了什么将是非常值得关注的事情。
* XDP 的设计对分布式拒绝访问(DDoS)攻击是非常有用的。越来越多的演讲都关注于它。例如,在 2017 年 4 月加拿大蒙特利尔举办的 netdev 2.1 会议上,来自 Cloudflare 的人们的讲话([XDP 实践:将 XDP 集成到我们的 DDoS 缓解管道](http://netdevconf.org/2.1/session.html?bertin))或者来自 Facebook 的([Droplet:由 BPF + XDP 驱动的 DDoS 对策](http://netdevconf.org/2.1/session.html?zhou))都存在这样的很多使用案例。
* Kubernetes 可以用很多种方式与 eBPF 交互。这里有一篇关于 [在 Kubernetes 中使用 eBPF](http://blog.kubernetes.io/2017/12/using-ebpf-in-kubernetes.html) 的文章,它解释了现有的产品(Cilium、Weave Scope)如何支持 eBPF 与 Kubernetes 一起工作,并且进一步描述了,在容器部署环境中,eBPF 感兴趣的交互内容是什么。
* [CETH for XDP](http://www.slideshare.net/IOVisor/ceth-for-xdp-linux-meetup-santa-clara-july-2016) (Yan Chan 和 Yunsong Lu、Linux Meetup、Santa Clara、July 2016):
**CETH**,是由 Mellanox 发起的,为实现更快的网络 I/O 而主张的通用以太网驱动程序架构。
* [**VALE 交换机**](http://info.iet.unipi.it/%7Eluigi/vale/),另一个虚拟交换机,它可以与 netmap 框架结合,有 [一个 BPF 扩展模块](https://github.com/YutaroHayakawa/vale-bpf)。
* **Suricata**,一个开源的入侵检测系统,它的旁路捕获旁特性依赖于 XDP。有一些关于它的资源:
+ [Suricate 文档的 eBPF 和 XDP 部分](http://suricata.readthedocs.io/en/latest/capture-hardware/ebpf-xdp.html?highlight=XDP#ebpf-and-xdp)
+ [SEPTun-Mark-II](https://github.com/pevma/SEPTun-Mark-II) (Suricata Extreme 性能调优指南 — Mark II), Michal Purzynski 和 Peter Manev 发布于 2018 年 3 月。
+ [介绍这个特性的博客文章](https://www.stamus-networks.com/2016/09/28/suricata-bypass-feature/) Éric Leblond 发布于 2016 年 9 月。
+ [Suricate 的 eBPF 历险记](http://netdevconf.org/1.2/slides/oct6/10_suricata_ebpf.pdf) (Éric Leblond, netdev 1.2, Tokyo, October 2016)
+ [eBPF 和 XDP 一窥](https://www.slideshare.net/ennael/kernel-recipes-2017-ebpf-and-xdp-eric-leblond) (Éric Leblond, Kernel Recipes, Paris, September 2017)当使用原生驱动的 XDP 时,这个项目要求实现非常高的性能。
* [InKeV:对于 DCN 的内核中分布式网络虚拟化](https://github.com/iovisor/bpf-docs/blob/master/university/sigcomm-ccr-InKev-2016.pdf) (Z. Ahmed, M. H. Alizai 和 A. A. Syed, SIGCOMM, August 2016):
**InKeV** 是一个基于 eBPF 的虚拟网络、目标数据中心网络的数据路径架构。它最初由 PLUMgrid 提出,并且声称相比基于 OvS 的 OpenStack 解决方案可以获得更好的性能。
* [gobpf - 在 Go 中使用 eBPF](https://fosdem.org/2017/schedule/event/go_bpf/) (Michael Schubert, fosdem17, Brussels, Belgium, February 2017):
“一个来自 Go 库,可以去创建、加载和使用 eBPF 程序”
* [ply](https://wkz.github.io/ply/) 是为 Linux 实现的一个小而灵活的开源动态 **跟踪器**,它的一些特性非常类似于 bcc 工具,是受 awk 和 dtrace 启发,但使用一个更简单的语言。它是由 Tobias Waldekranz 写的。
* 如果你读过我以前的文章,你可能对我在这篇文章中的讨论感兴趣,[使用 eBPF 实现 OpenState 接口](https://fosdem.org/2017/schedule/event/stateful_ebpf/),关于包状态处理,在 fosdem17 中。
### 文档
一旦你对 BPF 是做什么的有一个大体的理解。你可以抛开一般的演讲而深入到文档中了。下面是 BPF 的规范和功能的最全面的文档,按你的需要挑一个开始阅读吧!
#### 关于 BPF
* **BPF 的规范**(包含 classic 和 extended 版本)可以在 Linux 内核的文档中,和特定的文件 [linux/Documentation/networking/filter.txt](https://www.kernel.org/doc/Documentation/networking/filter.txt) 中找到。BPF 使用以及它的内部结构也被记录在那里。此外,当加载 BPF 代码失败时,在这里可以找到 **被校验器抛出的错误信息**,这有助于你排除不明确的错误信息。
* 此外,在内核树中,在 eBPF 那里有一个关于 **常见问答** 的文档,它在文件 [linux/Documentation/bpf/bpf\_design\_QA.txt](https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/Documentation/bpf/bpf_design_QA.txt?id=2e39748a4231a893f057567e9b880ab34ea47aef) 中。
* … 但是,内核文档是非常难懂的,并且非常不容易阅读。如果你只是去查找一个简单的 eBPF 语言的描述,可以去 IO Visor 的 GitHub 仓库,那儿有 [它的概括性描述](https://github.com/iovisor/bpf-docs/blob/master/eBPF.md)。
* 顺便说一下,IO Visor 项目收集了许多 **关于 BPF 的资源**。大部分分别在 bcc 仓库的 [文档目录](https://github.com/iovisor/bcc/tree/master/docs) 中,和 [bpf-docs 仓库](https://github.com/iovisor/bpf-docs/) 的整个内容中,它们都在 GitHub 上。注意,这个非常好的 [BPF 参考指南](https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md) 包含一个详细的 BPF C 和 bcc Python 的 helper 的描述。
* 想深入到 BPF,那里有一些必要的 **Linux 手册页**。第一个是 [bpf(2) man 页面](http://man7.org/linux/man-pages/man2/bpf.2.html) 关于 `bpf()` **系统调用**,它用于从用户空间去管理 BPF 程序和映射。它也包含一个 BPF 高级特性的描述(程序类型、映射等等)。第二个是主要是处理希望附加到 tc 接口的 BPF 程序:它是 [tc-bpf(8) man 页面](http://man7.org/linux/man-pages/man8/tc-bpf.8.html),是 **使用 BPF 和 tc** 的一个参考,并且包含一些示例命令和参考代码。
* Jesper Dangaard Brouer 发起了一个 **更新 eBPF Linux 文档** 的尝试,包含 **不同的映射**。[他有一个草案](https://prototype-kernel.readthedocs.io/en/latest/bpf/index.html),欢迎去贡献。一旦完成,这个文档将被合并进 man 页面并且进入到内核文档。
* Cilium 项目也有一个非常好的 [BPF 和 XDP 参考指南](http://docs.cilium.io/en/latest/bpf/),它是由核心的 eBPF 开发者写的,它被证明对于 eBPF 开发者是极其有用的。
* David Miller 在 [xdp-newbies](http://vger.kernel.org/vger-lists.html#xdp-newbies) 邮件列表中发了几封关于 eBPF/XDP 内部结构的富有启发性的电子邮件。我找不到一个单独的地方收集它们的链接,因此,这里是一个列表:
+ [bpf.h 和你 …](https://www.spinics.net/lists/xdp-newbies/msg00179.html)
+ [从语境上讲…](https://www.spinics.net/lists/xdp-newbies/msg00181.html)
+ [BPF 校验器概述](https://www.spinics.net/lists/xdp-newbies/msg00185.html)最后一个可能是目前来说关于校验器的最佳的总结。
* Ferris Ellis 发布的 [一个关于 eBPF 的系列博客文章](https://ferrisellis.com/tags/ebpf/)。作为我写的这个短文,第一篇文章是关于 eBPF 的历史背景和未来期望。接下来的文章将更多的是技术方面,和前景展望。
* [每个内核版本的 BPF 特性列表](https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md) 在 bcc 仓库中可以找到。如果你想去知道运行一个给定的特性所要求的最小的内核版本,它是非常有用的。我贡献和添加了链接到提交中,它介绍了每个特性,因此,你也可以从那里很容易地去访问提交历史。
#### 关于 tc
当为了网络目的结合使用 BPF 与 tc (Linux <ruby> 流量控制 <rt> <strong> t </strong> raffic <strong> c </strong> ontrol </rt> <rt> </rt></ruby>工具)时,它可用于收集 tc 的常规功能的信息。这里有几个关于它的资源。
* 找到关于 **Linux 上 QoS** 的简单教程是很困难的。这里有两个链接,它们很长而且很难懂,但是,如果你可以抽时间去阅读它,你将学习到几乎关于 tc 的任何东西(虽然,没有什么关于 BPF 的)。它们在这里:[怎么去实现流量控制 (Martin A. Brown, 2006)](http://linux-ip.net/articles/Traffic-Control-HOWTO/),和 [怎么去实现 Linux 的高级路由 & 流量控制 (LARTC) (Bert Hubert & al., 2002)](http://lartc.org/lartc.html)。
* 在你的系统上的 **tc 手册页面** 并不是最新的,因为它们中的几个最近已经增加了内容。如果你没有找到关于特定的队列规则、分类或者过滤器的文档,它可能在最新的 [tc 组件的手册页面](https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/man/man8) 中。
* 一些额外的材料可以在 iproute2 包自已的文件中找到:这个包中有 [一些文档](https://git.kernel.org/pub/scm/linux/kernel/git/shemminger/iproute2.git/tree/doc?h=v4.13.0),包括一些文件,它可以帮你去理解 [tc 的 action 的功能](https://git.kernel.org/pub/scm/linux/kernel/git/shemminger/iproute2.git/tree/doc/actions?h=v4.13.0)。
**注意:** 这些文件在 2017 年 10 月 已经从 iproute2 中删除,然而,从 Git 历史中却一直可用。
* 不完全是文档:[有一个关于 tc 的几个特性的研讨会](http://netdevconf.org/1.2/session.html?jamal-tc-workshop)(包含过滤、BPF、tc 卸载、…) 由 Jamal Hadi Salim 在 netdev 1.2 会议上组织的(October 2016)。
* 额外信息 — 如果你使用 `tc` 较多,这里有一些好消息:我用这个工具 [写了一个 bash 补完功能](https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/commit/bash-completion/tc?id=27d44f3a8a4708bcc99995a4d9b6fe6f81e3e15b),并且它被包 iproute2 带到内核版本 4.6 和更高版中!
#### 关于 XDP
* 对于 XDP 的一些 [进展中的文档(包括规范)](https://prototype-kernel.readthedocs.io/en/latest/networking/XDP/index.html) 已经由 Jesper Dangaard Brouer 启动,并且意味着将成为一个协作工作。正在推进的(2016 年 9 月):你期望它去改变,并且或许在一些节点上移动(Jesper [称为贡献](https://marc.info/?l=linux-netdev&amp;amp;m=147436253625672),如果你想去改善它)。
* 自来 Cilium 项目的 [BPF 和 XDP 参考指南](http://docs.cilium.io/en/latest/bpf/) … 好吧,这个名字已经说明了一切。
#### 关于 P4 和 BPF
[P4](http://p4.org/) 是一个用于指定交换机行为的语言。它可以为多种目标硬件或软件编译。因此,你可能猜到了,这些目标中的一个就是 BPF … 仅部分支持的:一些 P4 特性并不能被转化到 BPF 中,并且,用类似的方法,BPF 可以做的事情,而使用 P4 却不能表达出现。不过,**P4 与 BPF 使用** 的相关文档,[被隐藏在 bcc 仓库中](https://github.com/iovisor/bcc/tree/master/src/cc/frontends/p4)。这个改变在 P4\_16 版本中,p4c 引用的编辑器包含 [一个 eBPF 后端](https://github.com/p4lang/p4c/blob/master/backends/ebpf/README.md)。
### 教程
Brendan Gregg 为想要 **使用 bcc 工具** 跟踪和监视内核中的事件的人制作了一个非常好的 **教程**。[第一个教程是关于如何使用 bcc 工具](https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md),它有许多章节,可以教你去理解怎么去使用已有的工具,而 [针对 Python 开发者的一篇](https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md) 专注于开发新工具,它总共有十七节 “课程”。
Sasha Goldshtein 也有一些 [Linux 跟踪研究材料](https://github.com/goldshtn/linux-tracing-workshop) 涉及到使用几个 BPF 工具进行跟踪。
Jean-Tiare Le Bigot 的另一篇文章提供了一个详细的(和有指导意义的)[使用 perf 和 eBPF 去设置一个低级的跟踪器](https://blog.yadutaf.fr/2017/07/28/tracing-a-packet-journey-using-linux-tracepoints-perf-ebpf/) 的示例。
对于网络相关的 eBPF 使用案例也有几个教程。有一些值得关注的文档,包括一篇 *eBPF 卸载入门指南*,是关于在 [Open NFP](https://open-nfp.org/dataplanes-ebpf/technical-papers/) 平台上用 Netronome 操作的。其它的那些,来自 Jesper 的演讲,[XDP 能为其它人做什么](http://netdevconf.org/2.1/session.html?gospodarek)(及其[第二版](https://www.netdevconf.org/2.2/session.html?gospodarek-xdp-workshop)),可能是 XDP 入门的最好的方法之一。
### 示例
有示例是非常好的。看看它们是如何工作的。但是 BPF 程序示例是分散在几个项目中的,因此,我列出了我所知道的所有的示例。示例并不是总是使用相同的 helper(例如,tc 和 bcc 都有一套它们自己的 helper,使它可以很容易地去用 C 语言写 BPF 程序)
#### 来自内核的示例
内核中包含了大多数类型的程序:过滤器绑定到套接字或者 tc 接口、事件跟踪/监视、甚至是 XDP。你可以在 [linux/samples/bpf/](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/samples/bpf) 目录中找到这些示例。
现在,更多的示例已经作为单元测试被添加到 [linux/tools/testing/selftests/bpf](https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/tools/testing/selftests/bpf) 目录下,这里面包含对硬件卸载的测试或者对于 libbpf 的测试。
Jesper 的 Dangaard Brouer 在他的 [prototype-kernel](https://github.com/netoptimizer/prototype-kernel/tree/master/kernel/samples/bpf) 仓库中也维护了一套专门的示例。 这些示例与那些内核中提供的示例非常类似,但是它们可以脱离内核架构(Makefile 和头文件)编译。
也不要忘记去看一下 git 相关的提交历史,它们介绍了一些特定的特性,也许包含了一些特性的详细示例。
#### 来自包 iproute2 的示例
iproute2 包也提供了几个示例。它们都很明显地偏向网络编程,因此,这个程序是附着到 tc 入站或者出站接口上。这些示例在 [iproute2/examples/bpf/](https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/examples/bpf) 目录中。
#### 来自 bcc 工具集的示例
许多示例都是 [与 bcc 一起提供的](https://github.com/iovisor/bcc/tree/master/examples):
* 一些网络的示例放在相关的目录下面。它们包括套接字过滤器、tc 过滤器、和一个 XDP 程序。
* `tracing` 目录包含许多 **跟踪编程** 的示例。前面的教程中提到的都在那里。那些程序涉及了很大部分的事件监视功能,并且,它们中的一些是面向生产系统的。注意,某些 Linux 发行版(至少是 Debian、Ubuntu、Fedora、Arch Linux)、这些程序已经被 [打包了](https://github.com/iovisor/bcc/blob/master/INSTALL.md) 并且可以很 “容易地” 通过比如 `# apt install bcc-tools` 进行安装。但是在写这篇文章的时候(除了 Arch Linux),首先要求安装 IO Visor 的包仓库。
* 也有一些 **使用 Lua** 作为一个不同的 BPF 后端(那是因为 BPF 程序是用 Lua 写的,它是 C 语言的一个子集,它允许为前端和后端使用相同的语言)的一些示例,它在第三个目录中。
* 当然,[bcc 工具](https://github.com/iovisor/bcc/tree/master/tools) 自身就是 eBPF 程序使用案例的值得关注示例。
#### 手册页面
虽然 bcc 一般很容易在内核中去注入和运行一个 BPF 程序,将程序附着到 tc 接口也能通过 `tc` 工具自己完成。因此,如果你打算将 **BPF 与 tc 一起使用**,你可以在 [`tc-bpf(8)` 手册页面](http://man7.org/linux/man-pages/man8/tc-bpf.8.html) 中找到一些调用示例。
### 代码
有时候,BPF 文档或者示例并不够,而且你只想在你喜欢的文本编辑器(它当然应该是 Vim)中去显示代码并去阅读它。或者,你可能想深入到代码中去做一个补丁程序或者为机器增加一些新特性。因此,这里对有关的文件的几个建议,找到你想要的函数只取决于你自己!
#### 在内核中的 BPF 代码
* 文件 [linux/include/linux/bpf.h](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/bpf.h) 及其相对的 [linux/include/uapi/bpf.h](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/uapi/linux/bpf.h) 包含有关 eBPF 的 **定义**,它们分别用在内核中和用户空间程序的接口。
* 相同的方式,文件 [linux/include/linux/filter.h](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/filter.h) 和 [linux/include/uapi/filter.h](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/uapi/linux/filter.h) 包含了用于 **运行 BPF 程序** 的信息。
* BPF 相关的 **主要的代码片断** 在 [linux/kernel/bpf/](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/bpf) 目录下面。**系统调用的不同操作许可**,比如,程序加载或者映射管理是在文件 `syscall.c` 中实现,而 `core.c` 包含了 **解析器**。其它文件的命名显而易见:`verifier.c` 包含 **校验器**(不是开玩笑的),`arraymap.c` 的代码用于与数组类型的 **映射** 交互,等等。
* 有几个与网络(及 tc、XDP )相关的函数和 **helpers** 是用户可用,其实现在 [linux/net/core/filter.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/core/filter.c) 中。它也包含了移植 cBPF 字节码到 eBPF 的代码(因为在运行之前,内核中的所有的 cBPF 程序被转换成 eBPF)。
* 相关于 **事件跟踪** 的函数和 **helpers** 都在 [linux/kernel/trace/bpf\_trace.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/trace/bpf_trace.c) 中。
* **JIT 编译器** 在它们各自的架构目录下面,比如,x86 架构的在 [linux/arch/x86/net/bpf*jit*comp.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/arch/x86/net/bpf_jit_comp.c) 中。例外是用于硬件卸载的 JIT 编译器,它们放在它们的驱动程序下,例如 Netronome NFP 网卡的就放在 [linux/drivers/net/ethernet/netronome/nfp/bpf/jit.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/drivers/net/ethernet/netronome/nfp/bpf/jit.c) 。
* 在 [linux/net/sched/](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/sched) 目录下,你可以找到 **tc 的 BPF 组件** 相关的代码,尤其是在文件 `act_bpf.c` (action)和 `cls_bpf.c`(filter)中。
* 我并没有在 BPF 上深入到 **事件跟踪** 中,因此,我并不真正了解这些程序的钩子。在 [linux/kernel/trace/bpf\_trace.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/trace/bpf_trace.c) 那里有一些东西。如果你对它感 兴趣,并且想去了解更多,你可以在 Brendan Gregg 的演示或者博客文章上去深入挖掘。
* 我也没有使用过 **seccomp-BPF**,不过你能在 [linux/kernel/seccomp.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/seccomp.c) 找到它的代码,并且可以在 [linux/tools/testing/selftests/seccomp/seccomp\_bpf.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/tools/testing/selftests/seccomp/seccomp_bpf.c) 中找到一些它的使用示例。
#### XDP 钩子代码
一旦装载进内核的 BPF 虚拟机,由一个 Netlink 命令将 **XDP** 程序从用户空间钩入到内核网络路径中。接收它的是在 [linux/net/core/dev.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/core/dev.c) 文件中的 `dev_change_xdp_fd()` 函数,它被调用并设置一个 XDP 钩子。钩子被放在支持的网卡的驱动程序中。例如,用于 Netronome 硬件钩子的 ntp 驱动程序实现放在 [drivers/net/ethernet/netronome/nfp/](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/drivers/net/ethernet/netronome/nfp/) 中。文件 `nfp_net_common.c` 接受 Netlink 命令,并调用 `nfp_net_xdp_setup()`,它会转而调用 `nfp_net_xdp_setup_drv()` 实例来安装该程序。
#### 在 bcc 中的 BPF 逻辑
[在 bcc 的 GitHub 仓库](https://github.com/iovisor/bcc/) 能找到的 **bcc** 工具集的代码。其 **Python 代码**,包含在 `BPF` 类中,最初它在文件 [bcc/src/python/bcc/\_\_init\_\_.py](https://github.com/iovisor/bcc/blob/master/src/python/bcc/__init__.py) 中。但是许多我觉得有意思的东西,比如,加载 BPF 程序到内核中,出现在 [libbcc 的 C 库](https://github.com/iovisor/bcc/blob/master/src/cc/libbpf.c)中。
#### 使用 tc 去管理 BPF 的代码
当然,这些代码与 iproute2 包中的 **tc 中的** BPF 相关。其中的一些在 [iproute2/tc/](https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/tc) 目录中。文件 `f_bpf.c` 和 `m_bpf.c`(和 `e_bpf.c`)各自用于处理 BPF 的过滤器和动作的(和 tc `exec` 命令,等等)。文件 `q_clsact.c` 定义了为 BPF 特别创建的 `clsact` qdisc。但是,**大多数的 BPF 用户空间逻辑** 是在 [iproute2/lib/bpf.c](https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/lib/bpf.c) 库中实现的,因此,如果你想去使用 BPF 和 tc,这里可能是会将你搞混乱的地方(它是从文件 iproute2/tc/tc\_bpf.c 中移动而来的,你也可以在旧版本的包中找到相同的代码)。
#### BPF 实用工具
内核中也带有 BPF 相关的三个工具的源代码(`bpf_asm.c`、 `bpf_dbg.c`、 `bpf_jit_disasm.c`),根据你的版本不同,在 [linux/tools/net/](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/tools/net) (直到 Linux 4.14)或者 [linux/tools/bpf/](https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/tools/bpf) 目录下面:
* `bpf_asm` 是一个极小的 cBPF 汇编程序。
* `bpf_dbg` 是一个很小的 cBPF 程序调试器。
* `bpf_jit_disasm` 对于两种 BPF 都是通用的,并且对于 JIT 调试来说非常有用。
* `bpftool` 是由 Jakub Kicinski 写的通用工具,它可以与 eBPF 程序交互并从用户空间的映射,例如,去展示、转储、pin 程序、或者去展示、创建、pin、更新、删除映射。
阅读在源文件顶部的注释可以得到一个它们使用方法的概述。
与 eBPF 一起工作的其它必需的文件是来自内核树的两个**用户空间库**,它们可以用于管理 eBPF 程序或者映射来自外部的程序。这个函数可以通过 [linux/tools/lib/bpf/](https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/tools/lib/bpf) 目录中的头文件 `bpf.h` 和 `libbpf.h`(更高层面封装)来访问。比如,工具 `bpftool` 主要依赖这些库。
#### 其它值得关注的部分
如果你对关于 BPF 的不常见的语言的使用感兴趣,bcc 包含 [一个 BPF 目标的 **P4 编译器**](https://github.com/iovisor/bcc/tree/master/src/cc/frontends/p4/compiler)以及 [**一个 Lua 前端**](https://github.com/iovisor/bcc/tree/master/src/lua),它可以被用以代替 C 的一个子集,并且(用 Lua )替代 Python 工具。
#### LLVM 后端
这个 BPF 后端用于 clang / LLVM 将 C 编译到 eBPF ,是在 [这个提交](https://reviews.llvm.org/D6494) 中添加到 LLVM 源代码的(也可以在 [这个 GitHub 镜像](https://github.com/llvm-mirror/llvm/commit/4fe85c75482f9d11c5a1f92a1863ce30afad8d0d) 上访问)。
#### 在用户空间中运行
到目前为止,我知道那里有至少两种 eBPF 用户空间实现。第一个是 [uBPF](https://github.com/iovisor/ubpf/),它是用 C 写的。它包含一个解析器、一个 x86\_64 架构的 JIT 编译器、一个汇编器和一个反汇编器。
uBPF 的代码似乎被重用来产生了一个 [通用实现](https://github.com/YutaroHayakawa/generic-ebpf),其声称支持 FreeBSD 内核、FreeBSD 用户空间、Linux 内核、Linux 用户空间和 Mac OSX 用户空间。它被 [VALE 交换机的 BPF 扩展模块](https://github.com/YutaroHayakawa/vale-bpf)使用。
其它用户空间的实现是我做的:[rbpf](https://github.com/qmonnet/rbpf),基于 uBPF,但是用 Rust 写的。写了解析器和 JIT 编译器 (Linux 下两个都有,Mac OSX 和 Windows 下仅有解析器),以后可能会有更多。
#### 提交日志
正如前面所说的,如果你希望得到更多的关于一些特定的 BPF 特性的信息,不要犹豫,去看一些提交日志。你可以在许多地方搜索日志,比如,在 [git.kernel.org](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git)、[在 GitHub 上](https://github.com/torvalds/linux)、或者如果你克隆过它还有你的本地仓库中。如果你不熟悉 git,你可以尝试像这些去做 `git blame <file>` 去看看介绍特定代码行的提交内容,然后,`git show <commit>` 去看详细情况(或者在 `git log` 的结果中按关键字搜索,但是这样做通常比较单调乏味)也可以看在 bcc 仓库中的 [按内核版本区分的 eBPF 特性列表](https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md),它链接到相关的提交上。
### 排错
对 eBPF 的追捧是最近的事情,因此,到目前为止我还找不到许多关于怎么去排错的资源。所以这里只有几个,是我在使用 BPF 进行工作的时候,对自己遇到的问题进行的记录。
#### 编译时的错误
* 确保你有一个最新的 Linux 内核版本(也可以看 [这个文档](https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md))。
* 如果你自己编译内核:确保你安装了所有正确的组件,包括内核镜像、头文件和 libc。
* 当使用 `tc-bpf`(用于去编译 C 代码到 BPF 中)的 man 页面提供的 `bcc` shell 函数时:我曾经必须添加包含 clang 调用的头文件:
```
__bcc() {
clang -O2 -I "/usr/src/linux-headers-$(uname -r)/include/" \
-I "/usr/src/linux-headers-$(uname -r)/arch/x86/include/" \
-emit-llvm -c $1 -o - | \
llc -march=bpf -filetype=obj -o "`basename $1 .c`.o"
}
```
(现在似乎修复了)。
* 对于使用 `bcc` 的其它问题,不要忘了去看一看这个工具集的 [答疑](https://github.com/iovisor/bcc/blob/master/FAQ.txt)。
* 如果你从一个并不精确匹配你的内核版本的 iproute2 包中下载了示例,可能会由于在文件中包含的头文件触发一些错误。这些示例片断都假设安装在你的系统中内核的头文件与 iproute2 包是相同版本的。如果不是这种情况,下载正确的 iproute2 版本,或者编辑示例中包含的文件的路径,指向到 iproute2 中包含的头文件上(在运行时一些问题可能或者不可能发生,取决于你使用的特性)。
#### 在加载和运行时的错误
* 使用 `tc` 去加载一个程序,确保你使用了一个与使用中的内核版本等价的 iproute2 中的 `tc` 二进制文件。
* 使用 `bcc` 去加载一个程序,确保在你的系统上安装了 bcc(仅下载源代码去运行 Python 脚本是不够的)。
* 使用 `tc`,如果 BPF 程序不能返回一个预期值,检查调用它的方式:过滤器,或者动作,或者使用 “直传” 模式的过滤器。
* 还是 `tc`,注意不使用过滤器,动作不会直接附着到 qdiscs 或者接口。
* 通过内核校验器抛出错误到解析器可能很难。[内核文档](https://www.kernel.org/doc/Documentation/networking/filter.txt)或许可以提供帮助,因此,可以 [参考指南](https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md) 或者,万不得一的情况下,可以去看源代码(祝你好运!)。记住,校验器 *不运行* 程序,对于这种类型的错误,记住这点是非常重要的。如果你得到一个关于无效内存访问或者关于未初始化的数据的错误,它并不意味着那些问题真实发生了(或者有时候是,它们完全有可能发生)。它意味着你的程序是以校验器预计可能发生错误的方式写的,并且因此而拒绝这个程序。
* 注意 `tc` 工具有一个 `verbose` 模式,它与 BPF 一起工作的很好:在你的命令行尾部尝试追加一个 `verbose`。
* `bcc` 也有一个 `verbose` 选项:`BPF` 类有一个 `debug` 参数,它可以带 `DEBUG_LLVM_IR`、`DEBUG_BPF` 和 `DEBUG_PREPROCESSOR` 三个标志中任何组合(详细情况在 [源文件](https://github.com/iovisor/bcc/blob/master/src/python/bcc/__init__.py)中)。 为调试该代码,它甚至嵌入了 [一些条件去打印输出代码](https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#output)。
* LLVM v4.0+ 为 eBPF 程序 [嵌入一个反汇编器](https://www.spinics.net/lists/netdev/msg406926.html)。因此,如果你用 clang 编译你的程序,在编译时添加 `-g` 标志允许你通过内核校验器去以人类可读的格式去转储你的程序。处理转储文件,使用:
```
$ llvm-objdump -S -no-show-raw-insn bpf_program.o
```
* 使用映射?你应该去看看 [bpf-map](https://github.com/cilium/bpf-map),这是一个为 Cilium 项目而用 Go 创建的非常有用的工具,它可以用于去转储内核中 eBPF 映射的内容。也有一个用 Rust 开发的 [克隆](https://github.com/badboy/bpf-map)。
* [在 **StackOverflow** 上有个旧的 bpf 标签](https://stackoverflow.com/questions/tagged/bpf),但是,在这篇文章中从没用过它(并且那里几乎没有与新版本的 eBPF 相关的东西)。如果你是一位来自未来的阅读者,你可能想去看看在这方面是否有更多的活动(LCTT 译注:意即只有旧东西)。
### 更多!
* 如果你想轻松地 **测试 XDP**,有 [一个配置好的 Vagrant](https://github.com/iovisor/xdp-vagrant) 可以使用。你也可以 [在 Docker 容器中](https://github.com/zlim/bcc-docker) **测试 bcc**。
* 想知道 BPF 的 **开发和活动** 在哪里吗?好吧,内核补丁总是出自于 [netdev 上的邮件列表](http://lists.openwall.net/netdev/)(相关 Linux 内核的网络栈开发):以关键字 “BPF” 或者 “XDP” 来搜索。自 2017 年 4 月开始,那里也有 [一个专门用于 XDP 编程的邮件列表](http://vger.kernel.org/vger-lists.html#xdp-newbies)(是为了架构或者寻求帮助)。[在 IO Visor 的邮件列表上](http://lists.iovisor.org/pipermail/iovisor-dev/)也有许多的讨论和辨论,因为 BPF 是一个重要的项目。如果你只是想随时了解情况,那里也有一个 [@IOVisor Twitter 帐户](https://twitter.com/IOVisor)。
请经常会回到[这篇博客](https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/)中,来看一看 [关于 BPF](https://qmonnet.github.io/whirl-offload/categories/#BPF) 有没有新的文章!
*特别感谢 Daniel Borkmann 指引我找到了 [更多的文档](https://github.com/qmonnet/whirl-offload/commit/d694f8081ba00e686e34f86d5ee76abeb4d0e429),因此我才完成了这个合集。*
---
via: <https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/>
作者:[Quentin Monnet](https://qmonnet.github.io/whirl-offload/about/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Dive into BPF: a list of reading material
[What is BPF?](#what-is-bpf)[Dive into the bytecode](#dive-into-the-bytecode)[Resources](#resources)
*~ Updated 2019-01-10 ~*
# What is BPF?
BPF, as in **B**erkeley **P**acket **F**ilter, was initially conceived in 1992
so as to provide a way to filter packets and to avoid useless packet copies
from kernel to userspace. It initially consisted in a simple bytecode that is
injected from userspace into the kernel, where it is checked by a verifier—to
prevent kernel crashes or security issues—and attached to a socket, then run on
each received packet. It was ported to Linux a couple of years later, and used
for a small number of applications (tcpdump for example). The simplicity of the
language as well as the existence of an in-kernel Just-In-Time (JIT) compiling
machine for BPF were factors for the excellent performances of this tool.
Then in 2013, Alexei Starovoitov completely reshaped it, started to add new functionalities and to improve the performances of BPF. This new version is designated as eBPF (for “extended BPF”), while the former becomes cBPF (“classic” BPF). New features such as maps and tail calls appeared. The JIT machines were rewritten. The new language is even closer to native machine language than cBPF was. And also, new attach points in the kernel have been created.
Thanks to those new hooks, eBPF programs can be designed for a variety of use cases, that divide into two fields of applications. One of them is the domain of kernel tracing and event monitoring. BPF programs can be attached to kprobes and they compare with other tracing methods, with many advantages (and sometimes some drawbacks).
The other application domain remains network programming. In addition to socket filter, eBPF programs can be attached to tc (Linux traffic control tool) ingress or egress interfaces and perform a variety of packet processing tasks, in an efficient way. This opens new perspectives in the domain.
And eBPF performances are further leveraged through the technologies developed for the IO Visor project: new hooks have also been added for XDP (“eXpress Data Path”), a new fast path recently added to the kernel. XDP works in conjunction with the Linux stack, and relies on BPF to perform very fast packet processing.
Even some projects such as P4, Open vSwitch,
[consider](http://openvswitch.org/pipermail/ovs-dev/2014-October/047421.html)
or started to approach BPF. Some others, such as CETH, Cilium, are entirely
based on it. BPF is buzzing, so we can expect a lot of tools and projects to
orbit around it soon…
# Dive into the bytecode
As for me: some of my work (including for
[BEBA](/whirl-offload/2016/07/15/beba-research-project/))
is closely related to eBPF, and several future articles on this site will focus
on this topic. Logically, I wanted to somehow introduce BPF on this blog before
going down to the details—I mean, a real introduction, more developed on BPF
functionalities that the brief abstract provided in first section: What are BPF
maps? Tail calls? What do the internals look like? And so on. But there are a
lot of presentations on this topic available on the web already, and I do not
wish to create “yet another BPF introduction” that would come as a duplicate of
existing documents.
So instead, here is what we will do. After all, I spent some time reading and
learning about BPF, and while doing so, I gathered a fair amount of material
about BPF: introductions, documentation, but also tutorials or examples. There
is a lot to read, but in order to read it, one has to *find* it first.
Therefore, as an attempt to help people who wish to learn and use BPF, the
present article introduces a list of resources. These are various kinds of
readings, that hopefully will help you dive into the mechanics of this kernel
bytecode.
# Resources
## Generic presentations
The documents linked below provide a generic overview of BPF, or of some closely related topics. If you are very new to BPF, you can try picking a couple of presentation among the first ones and reading the ones you like most. If you know eBPF already, you probably want to target specific topics instead, lower down in the list.
### About BPF
Generic presentations about eBPF:
-
(Diego Pino García, January 2019):*A brief introduction to XDP and eBPF*
An excellent and accessible introduction providing context, history, and details about the functioning of eBPF. -
(Stanislav Kozina, January 2019):*Introduction to eBPF in Red Hat Enterprise Linux 7*
Focusing on the eBPF features arriving in Red Hat. -
(Fulvio Risso, HPSR 2018, Bucharest, June 2018):*Toward Flexible and Efficient In-Kernel Network Function Chaining with IO Visor*
A generic introduction to BPF, XDP, IO Visor, bcc and other components. -
(Matt Flemming, on LWN.net, December 2017):*A thorough introduction to eBPF*
A well-written and accessible introduction providing an overview of eBPF subsystem components. -
(Daniel Borkmann, OSSNA17, Los Angeles, September 2017):*Making the Kernel’s Networking Data Path Programmable with BPF and XDP*
One of the best set of slides available to understand quickly all the basics about eBPF and XDP (mostly for network processing). -
[The BSD Packet Filter](https://speakerdeck.com/tuxology/the-bsd-packet-filter)(Suchakra Sharma, June 2017):
A very nice introduction, mostly about the tracing aspects. -
(Brendan Gregg, January 2017):*BPF: tracing and more*
Mostly about the tracing use cases. -
(Brendan Gregg, March 2016):*Linux BPF Superpowers*
With a first part on the use of**flame graphs**. -
(Brenden Blanco, SCaLE 14x, January 2016):*IO Visor*
Also introduces**IO Visor project**. -
(Michael Holzheu, LinuxCon, Dublin, October 2015)*eBPF on the Mainframe* -
(Elena Zannoni, LinuxCon, Japan, 2015)*New (and Exciting!) Developments in Linux Tracing* -
(Alexei Starovoitov, February 2015):*BPF — in-kernel virtual machine*
Presentation by the author of eBPF. -
(Jonathan Corbet, July 2014)*Extending extended BPF*
**BPF internals**:
- Daniel Borkmann has been doing an amazing work to present
**the internals**of eBPF, in particular about**its use with tc**, through several talks and papers.(netdev 1.2, Tokyo, October 2016):*Advanced programmability and recent updates with tc’s cls_bpf*
Daniel provides details on eBPF, its use for tunneling and encapsulation, direct packet access, and other features.(netdev 1.2, Tokyo, October 2016, part of*cls_bpf/eBPF updates since netdev 1.1*[this tc workshop](http://netdevconf.org/1.2/session.html?jamal-tc-workshop))(netdev 1.1, Sevilla, February 2016):*On getting tc classifier fully programmable with cls_bpf*
After introducing eBPF, this presentation provides insights on many internal BPF mechanisms (map management, tail calls, verifier). A must-read! For the most ambitious,[the full paper is available here](http://www.netdevconf.org/1.1/proceedings/papers/On-getting-tc-classifier-fully-programmable-with-cls-bpf.pdf).(fosdem16, Brussels, Belgium, January 2016)*Linux tc and eBPF*(fosdem17, Brussels, Belgium, February 2017)*eBPF and XDP walkthrough and recent updates*
These presentations are probably one of the best sources of documentation to understand the design and implementation of internal mechanisms of eBPF.
The [ IO Visor blog](https://www.iovisor.org/resources/blog) has some
interesting technical articles about BPF. Some of them contain a bit of
marketing talks.
As of early 2019, there are more and more presentations being done around
multiple aspects of BPF. One nice example is
[the BPF track](http://vger.kernel.org/lpc-bpf.html) that was held in parallel
to the Linux Plumbers Conference in late 2018 (and should be held again on
coming years), where lots of topics related to eBPF development or use cases
were presented.
**Kernel tracing**: summing up all existing methods, including BPF:
-
(Viller Hsiao, July 2016):*Meet-cute between eBPF and Kerne Tracing*
Kprobes, uprobes, ftrace -
(Viller Hsiao, July 2016):*Linux Kernel Tracing*
Systemtap, Kernelshark, trace-cmd, LTTng, perf-tool, ftrace, hist-trigger, perf, function tracer, tracepoint, kprobe/uprobe…
Regarding **event tracing and monitoring**, Brendan Gregg uses eBPF a lot and
does an excellent job at documenting some of his use cases. If you are in
kernel tracing, you should see his blog articles related to eBPF or to flame
graphs. Most of it are accessible
[from this article](http://www.brendangregg.com/blog/2016-03-05/linux-bpf-superpowers.html)
or by browsing his blog.
Introducing BPF, but also presenting **generic concepts of Linux networking**:
-
(Thomas Graf, LinuxCon, Toronto, August 2016)*Linux Networking Explained* -
(Thomas Graf, LinuxCon, Seattle, August 2015)*Kernel Networking Walkthrough*
**Hardware offload**:
- eBPF with tc or XDP supports hardware offload, starting with Linux kernel
version 4.9 and introduced by Netronome. Here is a presentation about this
feature:
[eBPF/XDP hardware offload to SmartNICs](http://netdevconf.org/1.2/session.html?jakub-kicinski)(Jakub Kicinski and Nic Viljoen, netdev 1.2, Tokyo, October 2016) - An updated version was presented on year later:
[Comprehensive XDP offload—Handling the edge cases](https://www.netdevconf.org/2.2/session.html?viljoen-xdpoffload-talk)(Jakub Kicinski and Nic Viljoen, netdev 2.2, Seoul, November 2017) - I presented a shorter but updated version at FOSDEM 2018:
[The Challenges of XDP Hardware Offload](https://fosdem.org/2018/schedule/event/xdp/)(Quentin Monnet, FOSDEM’18, Brussels, February 2018)
About **cBPF**:
-
(Steven McCanne and Van Jacobson, 1992):*The BSD Packet Filter: A New Architecture for User-level Packet Capture*
The original paper about (classic) BPF. -
[The FreeBSD manual page about BPF](http://www.gsp.com/cgi-bin/man.cgi?topic=bpf)is a useful resource to understand cBPF programs. -
Daniel Borkmann realized at least two presentations on cBPF,
[one in 2013 on mmap, BPF and Netsniff-NG](http://borkmann.ch/talks/2013_devconf.pdf), and[a very complete one in 2014 on tc and cls_bpf](http://borkmann.ch/talks/2014_devconf.pdf). -
On Cloudflare’s blog, Marek Majkowski presented his
[use of BPF bytecode with the](https://blog.cloudflare.com/introducing-the-bpf-tools/). It is worth mentioning that eBPF is also supported by this module, starting with Linux kernel 4.10 (I do not know of any talk or article about this, though).`xt_bpf`
module for**iptables**
### About XDP
-
(Diego Pino García, January 2019):*The eXpress Data Path*
Probably one of the most accessible introduction to XDP, providing sample code to show how one can easily process packets. -
[XDP overview](https://www.iovisor.org/technology/xdp)on the IO Visor website. -
(Tom Herbert, Alexei Starovoitov, March 2016):*eXpress Data Path (XDP)*
The first presentation about XDP. -
(Brenden Blanco, LinuxCon, Toronto, August 2016).*BoF - What Can BPF Do For You?* (Brenden Blanco, Linux Meetup at Santa Clara, July 2016):*eXpress Data Path*
Contains some (somewhat marketing?)**benchmark results**! With a single core:- ip routing drop: ~3.6 million packets per second (Mpps)
- tc (with clsact qdisc) drop using BPF: ~4.2 Mpps
- XDP drop using BPF: 20 Mpps (<10 % CPU utilization)
- XDP forward (on port on which the packet was received) with rewrite: 10 Mpps
(Tests performed with the mlx4 driver).
- Jesper Dangaard Brouer has several excellent sets of slides, that are
essential to fully understand the internals of XDP.
(September 2016):*XDP − eXpress Data Path, Intro and future use-cases*
*“Linux Kernel’s fight against DPDK”*.**Future plans**(as of this writing) for XDP and comparison with DPDK.(netdev 1.2, Tokyo, October 2016):*Network Performance Workshop*
Additional hints about XDP internals and expected evolution.(OpenSourceDays, March 2017):*XDP – eXpress Data Path, Used for DDoS protection*
Contains details and use cases about XDP, with**benchmark results**, and**code snippets**for**benchmarking**as well as for**basic DDoS protection**with eBPF/XDP (based on an IP blacklisting scheme).(LSF Memory Management Summit, March 2017):*Memory vs. Networking, Provoking and fixing memory bottlenecks*
Provides a lot of details about current**memory issues**faced by XDP developers. Do not start with this one, but if you already know XDP and want to see how it really works on the page allocation side, this is a very helpful resource.(netdev 2.1, Montreal, April 2017), with Andy Gospodarek:*XDP for the Rest of Us*
How to get started with eBPF and XDP for normal humans. This presentation was also summarized by Julia Evans on[her blog](http://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/).… second edition (netdev 2.2, Seoul, November 2017), same authors:*XDP for the Rest of Us*
Revised version of the talk, with new contents.(LLC, Lund (Sweden), May 2018):*XDP now with REDIRECT*
Update on XDP, and in particular on the redirect actions (redirecting packets to other interfaces or other CPUs, with or without the use of eBPF maps for better performance).
(Jesper also created and tries to extend some documentation about eBPF and XDP, see
[related section](#about-xdp-1).) -
(Tom Herbert, netdev 1.2, Tokyo, October 2016) — as of this writing, only the video is available, I don’t know if the slides will be added.*XDP workshop — Introduction, experience, and future development* -
(Gilberto Bertin, DEF CON 25, Las Vegas, July 2017) — an excellent introduction to state-of-the-art packet filtering on Linux, oriented towards DDoS protection, talking about packet processing in the kernel, kernel bypass, XDP and eBPF.*High Speed Packet Filtering on Linux* -
**AF_XDP**is a new Linux socket type using eBPF filters to drive packets to user space at really high speed. Some of it is already in the kernel. There are a couple of presentations about the mechanism, such as[Fast Packet Processing in Linux with AF_XDP](https://archive.fosdem.org/2018/schedule/event/af_xdp/)(Björn Töpel and Magnus Karlsson, FOSDEM 2018, Brussels, February 2018). -
A full-length article describing the details of XDP is available, dating from December 2018. It is called
and was written by Toke Høiland-Jørgensen, Jesper Dangaard Brouer, Daniel Borkmann, John Fastabend, Tom Herbert, David Ahern and David Miller, all being essential eBPF and XDP contributors.*The eXpress Data Path: Fast Programmable Packet Processing in the Operating System Kernel* - As eBPF support is coming to Red Hat, engineers from the company publish
interesting content about it. Here is an article on
, from Paolo Abeni (December 2018).*Achieving high-performance, low-latency networking with XDP*(Part I)
### About other components related or based on eBPF
-
**bpfilter**is a new Linux mechanism trying to leverage eBPF programs to offer a replacement for netfilter, while remaining compatible with the iptables user utility.[Here is a high-level post](https://cilium.io/blog/2018/04/17/why-is-the-kernel-community-replacing-iptables/)by Thomas Graf about the motivations behind this project, and[there is my own presentation](https://qmo.fr/docs/talk_20180316_frnog_bpfilter.pdf)on the topic. -
Are you wondering why your fresh Linux install has BPF programs running, although you do not remember attaching any? Starting with version 235 (think Ubuntu 18.04),
uses BPF programs, in particular for IP traffic accounting and access control.**systemd**itself -
(John Fastabend, May 2016):*P4 on the Edge*
Presents the use of**P4**, a description language for packet processing, with BPF to create high-performance programmable switches. -
If you like audio presentations, there is an associated
[OvS Orbit episode (#11), called](https://ovsorbit.benpfaff.org/#e11), dating from August 2016. OvS Orbit are interviews realized by Ben Pfaff, who is one of the core maintainers of Open vSwitch. In this case, John Fastabend is interviewed.**P4**on the Edge -
(Dinan Gunawardena and Jakub Kicinski, August 2016):*P4, EBPF and Linux TC Offload*
Another presentation on**P4**, with some elements related to eBPF hardware offload on Netronome’s**NFP**(Network Flow Processor) architecture. **Cilium**is a technology initiated by Cisco and relying on BPF and XDP to provide “fast in-kernel networking and security policy enforcement for containers based on eBPF programs generated on the fly”.[The code of this project](https://github.com/cilium/cilium)is available on GitHub. Thomas Graf has been performing a number of presentations of this topic:, also featuring a load balancer use case (Linux Plumbers conference, Santa Fe, November 2016)*Cilium: Networking & Security for Containers with BPF & XDP*(Docker Distributed Systems Summit, October 2016 —*Cilium: Networking & Security for Containers with BPF & XDP*[video](https://www.youtube.com/watch?v=TnJF7ht3ZYc&list=PLkA60AVN3hh8oPas3cq2VA9xB7WazcIgs))(LinuxCon, Toronto, August 2016)*Cilium: Fast IPv6 container Networking with BPF and XDP*(fosdem17, Brussels, Belgium, February 2017)*Cilium: BPF & XDP for containers*
A good deal of contents is repeated between the different presentations; if in doubt, just pick the most recent one. Daniel Borkmann has also written
[a generic introduction to Cilium](https://opensource.googleblog.com/2016/11/cilium-networking-and-security.html)as a guest author on Google Open Source blog.-
There are also podcasts about
**Cilium**: an[OvS Orbit episode (#4)](https://ovsorbit.benpfaff.org/), in which Ben Pfaff interviews Thomas Graf (May 2016), and[another podcast by Ivan Pepelnjak](http://blog.ipspace.net/2016/10/fast-linux-packet-forwarding-with.html), still with Thomas Graf about eBPF, P4, XDP and Cilium (October 2016). **Open vSwitch**(OvS), and its related project**Open Virtual Network**(OVN, an open source network virtualization solution) are considering to use eBPF at various level, with several proof-of-concept prototypes already implemented:
[Offloading OVS Flow Processing using eBPF](http://openvswitch.org/support/ovscon2016/7/1120-tu.pdf)(William (Cheng-Chun) Tu, OvS conference, San Jose, November 2016)[Coupling the Flexibility of OVN with the Efficiency of IOVisor](http://openvswitch.org/support/ovscon2016/7/1245-bertrone.pdf)(Fulvio Risso, Matteo Bertrone and Mauricio Vasquez Bernal, OvS conference, San Jose, November 2016)
These use cases for eBPF seem to be only at the stage of proposals (nothing merge to OvS main branch) as far as I know, but it will be very interesting to see what comes out of it.
-
XDP is envisioned to be of great help for protection against Distributed Denial-of-Service (DDoS) attacks. More and more presentations focus on this. For example, the talks from people from Cloudflare (
) or from Facebook (*XDP in practice: integrating XDP in our DDoS mitigation pipeline*) at the netdev 2.1 conference in Montreal, Canada, in April 2017, present such use cases.*Droplet: DDoS countermeasures powered by BPF + XDP* -
**Katran**is an open source layer four (L4) load-balancer built by Facebook on top of XDP. There is a presentation[in this post](https://code.fb.com/open-source/open-sourcing-katran-a-scalable-network-load-balancer/), and the code is available[on GitHub](https://github.com/facebookincubator/katran). -
**Kubernetes**can interact in a number of ways with eBPF. There is and interesting article aboutthat explains how existing products (Cilium, Weave Scope) leverage eBPF to work with Kubernetes, or more generically describing what interactions with eBPF are interesting in the context of container deployment.*Using eBPF in Kubernetes* -
(Yan Chan and Yunsong Lu, Linux Meetup, Santa Clara, July 2016):*CETH for XDP*
**CETH**stands for Common Ethernet Driver Framework for faster network I/O, a technology initiated by Mellanox. -
, another virtual switch that can be used in conjunction with the netmap framework, has**The VALE switch**[a BPF extension module](https://github.com/YutaroHayakawa/vale-bpf). **Suricata**, an open source intrusion detection system, now relies on XDP for its “capture bypass” features. There is a number of resources about it:*eBPF and XDP*section of Suricata documentation(*SEPTun-Mark-II**Suricata Extreme Performance Tuning guide - Mark II*), published by Michal Purzynski and Peter Manev in March 2018[A blog post introducing the feature](https://www.stamus-networks.com/2016/09/28/suricata-bypass-feature/), published by Éric Leblond in September 2016, a talk on the subject (Éric Leblond, netdev 1.2, Tokyo, October 2016)*The adventures of a Suricate in eBPF land*a more recent talk (Éric Leblond, Kernel Recipes, Paris, September 2017)*eBPF and XDP seen from the eyes of a meerkat*
The project claims to attain excellent performances when using driver-native XDP.
-
[InKeV: In-Kernel Distributed Network Virtualization for DCN](https://github.com/iovisor/bpf-docs/blob/master/university/sigcomm-ccr-InKev-2016.pdf)(Z. Ahmed, M. H. Alizai and A. A. Syed, SIGCOMM, August 2016):
**InKeV**is an eBPF-based datapath architecture for virtual networks, targeting data center networks. It was initiated by PLUMgrid, and claims to achieve better performances than OvS-based OpenStack solutions. -
(Michael Schubert, fosdem17, Brussels, Belgium, February 2017):**gobpf**- utilizing eBPF from Go
A “library to create, load and use eBPF programs from Go” -
is a small but flexible open source dynamic**ply****tracer**for Linux, with some features similar to the bcc tools, but with a simpler language inspired by awk and DTrace, written by Tobias Waldekranz. -
is also a tool for tracing, again with its own DSL. It is flexible enough to be envisioned as a Linux replacement for DTrace and SystemTap. It was created by Alastair Robertson and Brendan Gregg.**BPFtrace** -
is a project trying to leverage the flexibility of the bcc tools to trace and debug remote targets, and in particular devices running with Android.**BPFd**is related, and provides a Linux shell environment for that purpose.**adeb** -
It is not to be confused with
, small letters, which claims to be a container-aware framework for running BPF tracers with rules on Linux as a daemon.**bpfd** -
Could
**DPDK**one day work in concert with BPF? It looks likely that the AF_XDP mechanism introduced in the kernel will be used to drive packets to user space and to feed them to applications using the framework. However, there were also some[discussions for replicating the eBPF interpreter and JIT compiler in DPDK itself](http://mails.dpdk.org/archives/dev/2018-March/092120.html). They did not seem to lead to the inclusion on the feature at this time. -
Even if it does not make it to the core of DPDK, eBPF, and in particular AF_XDP, using XDP programs to redirect packets to user space sockets, can be used to create
.**a poll-mode driver (PMD) for DPDK** -
, a tool for**Sysdig***universal system visibility with native support for containers*, now supports eBPF[as an instrumentation back end](https://github.com/draios/sysdig/wiki/eBPF). -
The user file system
**FUSE**is also considering using eBPF for improved performance. This was the topic of[a presentation at the Linux Foundation Open Source Summit 2017](https://events.linuxfoundation.org/wp-content/uploads/2017/11/When-eBPF-Meets-FUSE-Improving-Performance-of-User-File-Systems-Ashish-Bijlani-Georgia-Tech.pdf), and[a related page on the](https://extfuse.github.io/)is available.*ExtFUSE*project -
In order to help with measuring power consumption for servers, the
tool is using eBPF programs for in-kernel aggregation of data.**DEEP-mon** - If you read my previous article, you might be interested in this talk I gave
about
[implementing the OpenState interface with eBPF](https://fosdem.org/2017/schedule/event/stateful_ebpf/), for stateful packet processing, at fosdem17.
## Documentation
Once you managed to get a broad idea of what BPF is, you can put aside generic presentations and start diving into the documentation. Below are the most complete documents about BPF specifications and functioning. Pick the one you need and read them carefully!
### About BPF
-
The
**specification of BPF**(both classic and extended versions) can be found within the documentation of the Linux kernel, and in particular in file[linux/Documentation/networking/filter.txt](https://www.kernel.org/doc/Documentation/networking/filter.txt). The use of BPF as well as its internals are documented there. Also, this is where you can find**information about errors thrown by the verifier**when loading BPF code fails. Can be helpful to troubleshoot obscure error messages. -
Also in the kernel tree, there is a document about
**frequent Questions & Answers**on eBPF design in file[linux/Documentation/bpf/bpf_design_QA.rst](https://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf-next.git/tree/Documentation/bpf/bpf_design_QA.rst). -
… But the kernel documentation is dense and not especially easy to read. If you look for a simple description of eBPF language, head for
[its](https://github.com/iovisor/bpf-docs/blob/master/eBPF.md)on the IO Visor GitHub repository instead.**summarized description** -
By the way, the IO Visor project gathered a lot of
**resources about BPF**. Mostly, it is split between[the documentation directory](https://github.com/iovisor/bcc/tree/master/docs)of its bcc repository, and the whole content of[the bpf-docs repository](https://github.com/iovisor/bpf-docs/), both on GitHub. Note the existence of this excellent[BPF](https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md)containing a detailed description of BPF C and bcc Python helpers.**reference guide** -
To hack with BPF, there are some essential
**Linux manual pages**. The first one is[the](http://man7.org/linux/man-pages/man2/bpf.2.html)about the`bpf(2)`
man page`bpf()`
**system call**, which is used to manage BPF programs and maps from userspace. It also contains a description of BPF advanced features (program types, maps and so on). The second one is mostly addressed to people wanting to attach BPF programs to tc interface: it is[the](http://man7.org/linux/man-pages/man8/tc-bpf.8.html), which is a reference for`tc-bpf(8)`
man page**using BPF with tc**, and includes some example commands and samples of code. The eBPF helper functions, those white-listed functions that can be called from within an eBPF program, have been documented in the kernel source file that can be automatically converted into a`bpf-helpers(7)`
manual page (see[the relevant Makefile](https://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf-next.git/tree/tools/bpf/Makefile.helpers)). -
Jesper Dangaard Brouer initiated an attempt to
**update eBPF Linux documentation**, including**the different kinds of maps**.[He has a draft](https://prototype-kernel.readthedocs.io/en/latest/bpf/index.html)to which contributions are welcome. Once ready, this document should be merged into the man pages and into kernel documentation. -
The Cilium project also has an excellent
, written by core eBPF developers, that should prove immensely useful to any eBPF developer.**BPF and XDP Reference Guide** - David Miller has sent several enlightening emails about eBPF/XDP internals on
the
[xdp-newbies](http://vger.kernel.org/vger-lists.html#xdp-newbies)mailing list. I could not find a link that gathers them at a single place, so here is a list:The last one is possibly the best existing summary about the verifier at this date.
-
Ferris Ellis started
[a](https://ferrisellis.com/tags/ebpf/). As I write this paragraph, the first article is out, with some historical background and future expectations for eBPF. Next posts should be more technical, and look promising.**blog post series about eBPF** [A](https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md)is available in bcc repository. Useful is you want to know the minimal kernel version that is required to run a given feature. I contributed and added the links to the commits that introduced each feature, so you can also easily access the commit logs from there.**list of BPF features per kernel version**
### About tc
When using BPF for networking purposes in conjunction with tc, the Linux tool
for **t**raffic **c**ontrol, one may wish to gather information about tc’s
generic functioning. Here are a couple of resources about it.
-
It is difficult to find simple tutorials about
**QoS on Linux**. The two links I have are long and quite dense, but if you can find the time to read it you will learn nearly everything there is to know about tc (nothing about BPF, though). There they are:, and the*Traffic Control HOWTO*(Martin A. Brown, 2006).*Linux Advanced Routing & Traffic Control HOWTO*(“LARTC”) (Bert Hubert & al., 2002) -
**tc manual pages**may not be up-to-date on your system, since several of them have been added lately. If you cannot find the documentation for a particular queuing discipline (qdisc), class or filter, it may be worth checking the latest[manual pages for tc components](https://git.kernel.org/pub/scm/network/iproute2/iproute2-next.git/tree/man/man8). -
Some additional material can be found within the files of iproute2 package itself: the package contains
[some documentation](https://git.kernel.org/pub/scm/network/iproute2/iproute2.git/tree/doc?h=v4.13.0), including some files that helped me understand better[the functioning of](https://git.kernel.org/pub/scm/network/iproute2/iproute2.git/tree/doc/actions?h=v4.13.0).**tc’s actions**
**Edit:**While still available from the Git history, these files have been deleted from iproute2 in October 2017. -
Not exactly documentation: there was
[a workshop about several tc features](http://netdevconf.org/1.2/session.html?jamal-tc-workshop)(including filtering, BPF, tc offload, …) organized by Jamal Hadi Salim during the netdev 1.2 conference (October 2016). -
Bonus information—If you use
`tc`
a lot, here are some good news: I[wrote a bash completion function](https://git.kernel.org/pub/scm/network/iproute2/iproute2.git/commit/bash-completion/tc?id=27d44f3a8a4708bcc99995a4d9b6fe6f81e3e15b)for this tool, and it is now shipped with package iproute2 coming with kernel version 4.6 and higher!
### About XDP
-
Some
[work-in-progress documentation (including specifications)](https://prototype-kernel.readthedocs.io/en/latest/networking/XDP/index.html)for XDP started by Jesper Dangaard Brouer, but meant to be a collaborative work. Under progress (September 2016): you should expect it to change, and maybe to be moved at some point (Jesper[called for contribution](https://marc.info/?l=linux-netdev&m=147436253625672), if you feel like improving it). -
The
[BPF and XDP Reference Guide](http://docs.cilium.io/en/latest/bpf/)from Cilium project… Well, the name says it all.
### About flow dissectors
- LWN has an excellent article about
, contributed by Marta Rybczyńska in September 2018.*Writing network flow dissectors in BPF*
### About P4 and BPF
[P4](http://p4.org/) is a language used to specify the behavior of a switch. It
can be compiled for a number of hardware or software targets. As you may have
guessed, one of these targets is BPF… The support is only partial: some P4
features cannot be translated towards BPF, and in a similar way there are
things that BPF can do but that would not be possible to express with P4.
Anyway, the documentation related to **P4 use with BPF**
[used to be hidden in bcc repository](https://github.com/iovisor/bcc/tree/master/src/cc/frontends/p4).
This changed with P4_16 version, the p4c reference compiler including
[a backend for eBPF](https://github.com/p4lang/p4c/blob/master/backends/ebpf/README.md).
There is also an interesting presentation from Jamal Hadi Salim, presenting a
number of points from tc from which P4 could maybe get some inspiration:
[ What P4 Can Learn From Linux Traffic Control Architecture](https://p4.org/assets/P4WS_2018/Jamal_Salim.pdf).
## Tutorials
Brendan Gregg has initiated excellent **tutorials** intended for people who want
to **use bcc tools** for tracing and monitoring events in the kernel.
[The first tutorial about using bcc itself](https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md)
comes with many steps to understand how to use the existing tools, while
[the one intended for Python developers](https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md)
focuses on developing new tools, across seventeen “lessons”.
Lorenza Fontana has made a tutorial to explain how to
[ Load XDP programs using the ip (iproute2) command](https://medium.com/@fntlnz/load-xdp-programs-using-the-ip-iproute2-command-502043898263).
If you are unfamiliar to kernel compiling, Diego Pino García has a blog entry
on
[ How to build a kernel with [AF-]XDP support](https://blogs.igalia.com/dpino/2019/01/02/build-a-kernel/).
Sasha Goldshtein also has some
[Linux Tracing Workshops Materials](https://github.com/goldshtn/linux-tracing-workshop)
involving the use of several BPF tools for tracing.
Another post by Jean-Tiare Le Bigot provides a detailed (and instructive!)
example of
[using perf and eBPF to setup a low-level tracer](https://blog.yadutaf.fr/2017/07/28/tracing-a-packet-journey-using-linux-tracepoints-perf-ebpf/)
for ping requests and replies.
Few tutorials exist for network-related eBPF use cases. There are some
interesting documents, including an *eBPF Offload Starting Guide*, on the
[Open NFP](https://open-nfp.org/dataplanes-ebpf/technical-papers/) platform
operated by Netronome. Other than these, the talks from Jesper and Andy,
[ XDP for the Rest of Us](http://netdevconf.org/2.1/session.html?gospodarek)
(and
[its second edition](https://www.netdevconf.org/2.2/session.html?gospodarek-xdp-workshop)), are probably one of the best ways to get started with XDP.
If you really focus on hardware offload for eBPF, Netronome (my employer as I
edit this text) is the only vendor to propose it at the moment. Besides their
Open-NFP platform, the best source of information is their support platform:
[https://help.netronome.com](https://help.netronome.com). You will find there video tutorials from David
Beckett explaining how to run and offload XDP programs, user guides, and other
materials… including the firmware for the Agilio SmartNICs required to perform
eBPF offload!
## Examples
It is always nice to have examples. To see how things really work. But BPF program samples are scattered across several projects, so I listed all the ones I know of. The examples do not always use the same helpers (for instance, tc and bcc both have their own set of helpers to make it easier to write BPF programs in C language).
### From the kernel
The kernel contains examples for most types of program: filters to bind to
sockets or to tc interfaces, event tracing/monitoring, and even XDP. You can
find these examples under the
[linux/samples/bpf/](https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/samples/bpf)
directory.
Nowadays, most examples are added under
[linux/tools/testing/selftests/bpf](https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/tools/testing/selftests/bpf)
as unit tests. This includes tests for hardware offload or for libbpf.
Some additional tests regarding BPF with tc can be found in the kernel suite of
tests for tc itself, under
[linux/tools/testing/selftests/tc-tests](https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/tools/testing/selftests/tc-testing/tc-tests).
Jesper Dangaard Brouer also maintains a specific set of samples in his
[prototype-kernel](https://github.com/netoptimizer/prototype-kernel/tree/master/kernel/samples/bpf)
repository. They are very similar to those from the kernel, but can be compiled
outside of the kernel infrastructure (Makefiles and headers).
Also do not forget to have a look to the logs related to the (git) commits that introduced a particular feature, they may contain some detailed example of the feature.
### From package iproute2
The iproute2 package provide several examples as well. They are obviously
oriented towards network programming, since the programs are to be attached to
tc ingress or egress interfaces. The examples dwell under the
[iproute2/examples/bpf/](https://git.kernel.org/pub/scm/network/iproute2/iproute2-next.git/tree/examples/bpf)
directory.
### From bcc set of tools
Many examples are [provided with bcc](https://github.com/iovisor/bcc/tree/master/examples):
-
Some are networking example programs, under the associated directory. They include socket filters, tc filters, and a XDP program.
-
The
`tracing`
directory include a lot of example**tracing programs**. The tutorials mentioned earlier are based on these. These programs cover a wide range of event monitoring functions, and some of them are production-oriented. Note that on certain Linux distributions (at least for Debian, Ubuntu, Fedora, Arch Linux), these programs have been[packaged](https://github.com/iovisor/bcc/blob/master/INSTALL.md)and can be “easily” installed by typing e.g.`# apt install bcc-tools`
, but as of this writing (and except for Arch Linux), this first requires to set up IO Visor’s own package repository. -
There are also some examples
**using Lua**as a different BPF back-end (that is, BPF programs are written with Lua instead of a subset of C, allowing to use the same language for front-end and back-end), in the third directory. -
Of course,
[bcc tools](https://github.com/iovisor/bcc/tree/master/tools)themselves are interesting example use cases for eBPF programs.
### Other examples
Some other BPF programs are emerging here and there. Have a look at the different projects based on or using eBPF, mentioned above, and search their code to find how they inject programs into the kernel.
Netronome also has
[a GitHub repository with some samples XDP demo applications](https://github.com/Netronome/bpf-samples/),
some of them for hardware offload only, others for both driver and offloaded
XDP.
### Manual pages
While bcc is generally the easiest way to inject and run a BPF program in the
kernel, attaching programs to tc interfaces can also be performed by the `tc`
tool itself. So if you intend to **use BPF with tc**, you can find some example
invocations in the
[ tc-bpf(8) manual page](http://man7.org/linux/man-pages/man8/tc-bpf.8.html).
## The code
Sometimes, BPF documentation or examples are not enough, and you may have no other solution that to display the code in your favorite text editor (which should be Vim of course) and to read it. Or you may want to hack into the code so as to patch or add features to the machine. So here are a few pointers to the relevant files, finding the functions you want is up to you!
### BPF code in the kernel
-
The file
[linux/include/linux/bpf.h](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/bpf.h)and its counterpart[linux/include/uapi/bpf.h](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/uapi/linux/bpf.h)contain**definitions**related to eBPF, to be used respectively in the kernel and to interface with userspace programs. -
On the same pattern, files
[linux/include/linux/filter.h](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/filter.h)and[linux/include/uapi/filter.h](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/uapi/linux/filter.h)contain information used to**run the BPF programs**. -
The
**main pieces of code**related to BPF are under[linux/kernel/bpf/](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/bpf)directory.**The different operations permitted by the system call**, such as program loading or map management, are implemented in file`syscall.c`
, while`core.c`
contains the**interpreter**. The other files have self-explanatory names:`verifier.c`
contains the**verifier**(no kidding),`arraymap.c`
the code used to interact with**maps**of type array, and so on. -
Several functions as well as the
**helpers**related to**networking**(with tc, XDP…) and available to the user, are implemented in[linux/net/core/filter.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/core/filter.c). It also contains the code to migrate cBPF bytecode to eBPF (since all cBPF programs are now translated to eBPF in the kernel before being run). -
Function and
**helpers**related to**event tracing**are in[linux/kernel/trace/bpf_trace.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/trace/bpf_trace.c)instead. -
The
**JIT compilers**are under the directory of their respective architectures, such as file[linux/arch/x86/net/bpf_jit_comp.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/arch/x86/net/bpf_jit_comp.c)for x86. Exception is made for JIT compilers used for hardware offload, they sit in their driver, see for instance[linux/drivers/net/ethernet/netronome/nfp/bpf/jit.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/drivers/net/ethernet/netronome/nfp/bpf/jit.c)for Netronome NFP cards. -
You will find the code related to
**the BPF components of tc**in the[linux/net/sched/](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/sched)directory, and in particular in files`act_bpf.c`
(action) and`cls_bpf.c`
(filter). -
I have not used
**seccomp-BPF**much, but you should find the code in[linux/kernel/seccomp.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/seccomp.c), and some example use cases can be found in[linux/tools/testing/selftests/seccomp/seccomp_bpf.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/tools/testing/selftests/seccomp/seccomp_bpf.c).
### XDP hooks code
Once loaded into the in-kernel BPF virtual machine, **XDP** programs are hooked
from userspace into the kernel network path thanks to a Netlink command. On
reception, the function `dev_change_xdp_fd()`
in file
[linux/net/core/dev.c](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/core/dev.c)
is called and sets a XDP hook. Such hooks are located in the drivers of
supported NICs. For example, the nfp driver used for Netronome hardware has
hooks implemented in files under the
[drivers/net/ethernet/netronome/nfp/](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/drivers/net/ethernet/netronome/nfp/)
directory. File nfp_net_common.c receives Netlink commands and calls
`nfp_net_xdp_setup()`
, which in turns calls for instance
`nfp_net_xdp_setup_drv()`
to install the program.
### BPF logic in bcc
One can find the code for the **bcc** set of tools
[on the bcc GitHub repository](https://github.com/iovisor/bcc/).
The **Python code**, including the `BPF`
class, is initiated in file
[bcc/src/python/bcc/__init__.py](https://github.com/iovisor/bcc/blob/master/src/python/bcc/__init__.py).
But most of the interesting stuff—to my opinion—such as loading the BPF program
into the kernel, happens
[in the libbcc C library](https://github.com/iovisor/bcc/blob/master/src/cc/libbpf.c).
### Code to manage BPF with tc
The code related to BPF **in tc** comes with the iproute2 package, of course.
Some of it is under the
[iproute2/tc/](https://git.kernel.org/pub/scm/network/iproute2/iproute2-next.git/tree/tc)
directory. The files f_bpf.c and m_bpf.c (and e_bpf.c) are used respectively
to handle BPF filters and actions (and tc `exec`
command, whatever this may
be). File q_clsact.c defines the `clsact`
qdisc especially created for BPF.
But **most of the BPF userspace logic** is implemented in
[iproute2/lib/bpf.c](https://git.kernel.org/pub/scm/network/iproute2/iproute2-next.git/tree/lib/bpf.c)
library, so this is probably where you should head to if you want to mess up
with BPF and tc (it was moved from file iproute2/tc/tc_bpf.c, where you may
find the same code in older versions of the package).
### BPF utilities
The kernel also ships the sources of three tools (`bpf_asm.c`
, `bpf_dbg.c`
,
`bpf_jit_disasm.c`
) related to BPF, under the
linux/tools/net/ (until Linux 4.14)
or
[linux/tools/bpf/](https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/tools/bpf)
directory depending on your version:
`bpf_asm`
is a minimal cBPF assembler.`bpf_dbg`
is a small debugger for cBPF programs.`bpf_jit_disasm`
is generic for both BPF flavors and could be highly useful for JIT debugging.`bpftool`
is a generic utility written by Jakub Kicinski, and that can be used to interact with eBPF programs and maps from userspace, for example to show, dump, load, pin programs, or to show, create, pin, update, delete maps. It can also attach and detach programs to cgroups, and has JSON support. It keeps getting more and more features, and is expected to be the go-to tool for eBPF introspection and simple management.
Read the comments at the top of the source files to get an overview of their usage.
Other essential files to work with eBPF are the two **userspace libraries**
from the kernel tree, that can be used to manage eBPF programs or maps from
external programs. The functions are accessible through headers `bpf.h`
and
`libbpf.h`
(higher level) from directory
[linux/tools/lib/bpf/](https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/tools/lib/bpf).
The tool `bpftool`
heavily relies on those libraries, for example.
### Other interesting chunks
If you are interested the use of less common languages with BPF, bcc contains
[a P4 compiler for BPF targets](https://github.com/iovisor/bcc/tree/master/src/cc/frontends/p4/compiler)
as well as
[a](https://github.com/iovisor/bcc/tree/master/src/lua)that can be used as alternatives to the C subset and (in the case of Lua) to the Python tools.
**Lua front-end**### LLVM backend
The BPF backend used by clang / LLVM for compiling C into eBPF was added to the
LLVM sources in
[this commit](https://reviews.llvm.org/D6494)
(and can also be accessed on
[the GitHub mirror](https://github.com/llvm-mirror/llvm/commit/4fe85c75482f9d11c5a1f92a1863ce30afad8d0d)).
### Running in userspace
As far as I know there are at least two eBPF userspace implementations. The
first one, [uBPF](https://github.com/iovisor/ubpf/), is written in C. It
contains an interpreter, a JIT compiler for x86_64 architecture, an assembler
and a disassembler.
The code of uBPF seems to have been reused to produce a
[generic implementation](https://github.com/YutaroHayakawa/generic-ebpf),
that claims to support FreeBSD kernel, FreeBSD userspace, Linux kernel,
Linux userspace and MacOSX userspace. It is used for the [BPF extension module
for VALE switch](https://github.com/YutaroHayakawa/vale-bpf).
The other userspace implementation is my own work:
[rbpf](https://github.com/qmonnet/rbpf), based
on uBPF, but written in Rust. The interpreter and JIT-compiler work (both under
Linux, only the interpreter for MacOSX and Windows), there may
be more in the future.
### Commit logs
As stated earlier, do not hesitate to have a look at the commit log that
introduced a particular BPF feature if you want to have more information about
it. You can search the logs in many places, such as on
[git.kernel.org](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git),
[on GitHub](https://github.com/torvalds/linux), or on your local
repository if you have cloned it. If you are not familiar with git, try things
like `git blame <file>`
to see what commit introduced a particular line of
code, then `git show <commit>`
to have details (or search by keyword in ```
git
log
```
results, but this may be tedious). See also [the list of eBPF features per
kernel version](https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md) on bcc repository, that links to relevant
commits.
## Troubleshooting
The enthusiasm about eBPF is quite recent, and so far I have not found a lot of resources intending to help with troubleshooting. So here are the few I have, augmented with my own recollection of pitfalls encountered while working with BPF.
### Errors at compilation time
-
Make sure you have a recent enough version of the Linux kernel (see also
[this document](https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md)). -
If you compiled the kernel yourself: make sure you installed correctly all components, including kernel image, headers and libc.
-
When using the
`bcc`
shell function provided by`tc-bpf`
man page (to compile C code into BPF): I once had to add includes to the header for the clang call:`__bcc() { clang -O2 -I "/usr/src/linux-headers-$(uname -r)/include/" \ -I "/usr/src/linux-headers-$(uname -r)/arch/x86/include/" \ -emit-llvm -c $1 -o - | \ llc -march=bpf -filetype=obj -o "`basename $1 .c`.o" }`
(seems fixed as of today).
-
For other problems with
`bcc`
, do not forget to have a look at[the FAQ](https://github.com/iovisor/bcc/blob/master/FAQ.txt)of the tool set. -
If you downloaded the examples from the iproute2 package in a version that does not exactly match your kernel, some errors can be triggered by the headers included in the files. The example snippets indeed assume that the same version of iproute2 package and kernel headers are installed on the system. If this is not the case, download the correct version of iproute2, or edit the path of included files in the examples to point to the headers included in iproute2 (some problems may or may not occur at runtime, depending on the features in use).
### Errors at load and run time
-
To load a program with tc, make sure you use a tc binary coming from an iproute2 version equivalent to the kernel in use.
-
To load a program with bcc, make sure you have bcc installed on the system (just downloading the sources to run the Python script is not enough).
-
With tc, if the BPF program does not return the expected values, check that you called it in the correct fashion: filter, or action, or filter with “direct-action” mode.
-
With tc still, note that actions cannot be attached directly to qdiscs or interfaces without the use of a filter.
-
The errors thrown by the in-kernel verifier may be hard to interpret.
[The kernel documentation](https://www.kernel.org/doc/Documentation/networking/filter.txt)may help, so may[the reference guide](https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md)or, as a last resort, the source code (see above) (good luck!). For this kind of errors it is also important to keep in mind that the verifier*does not run*the program. If you get an error about an invalid memory access or about uninitialized data, it does not mean that these problems actually occurred (or sometimes, that they can possibly occur at all). It means that your program is written in such a way that the verifier estimates that such errors could happen, and therefore it rejects the program. -
Note that
`tc`
tool has a verbose mode, and that it works well with BPF: try appending`verbose`
at the end of your command line. -
bcc also has verbose options: the
`BPF`
class has a`debug`
argument that can take any combination of the three flags`DEBUG_LLVM_IR`
,`DEBUG_BPF`
and`DEBUG_PREPROCESSOR`
(see details in[the source file](https://github.com/iovisor/bcc/blob/master/src/python/bcc/__init__.py)). It even embeds[some facilities to print output messages](https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#output)for debugging the code. -
LLVM v4.0+
[embeds a disassembler](https://www.spinics.net/lists/netdev/msg406926.html)for eBPF programs. So if you compile your program with clang, adding the`-g`
flag for compiling enables you to later dump your program in the rather human-friendly format used by the kernel verifier. To proceed to the dump, use:`$ llvm-objdump -S -no-show-raw-insn bpf_program.o`
-
Working with maps? You want to have a look at
[bpf-map](https://github.com/cilium/bpf-map), a very userful tool in Go created for the Cilium project, that can be used to dump the contents of kernel eBPF maps. There also exists[a clone](https://github.com/badboy/bpf-map)in Rust. -
There is an old
, but as of this writing it has been hardly used—ever (and there is nearly nothing related to the new eBPF version). If you are a reader from the Future though, you may want to check whether there has been more activity on this side.`bpf`
tag on**StackOverflow**
## And still more!
-
[Completion in Vim](https://ops.tips/blog/developing-ebpf-with-autocompletion-support/)for working with eBPF and bcc. Yes, someone worked on it. -
In case you would like to easily
**test XDP**, there is[a Vagrant setup](https://github.com/iovisor/xdp-vagrant)available. You can also**test bcc**[in a Docker container](https://github.com/zlim/bcc-docker). -
Wondering where the
**development and activities**around BPF occur? Well, the kernel patches always end up[on the netdev mailing list](http://lists.openwall.net/netdev/)(related to the Linux kernel networking stack development, check also[bpf_devel_QA.rst](https://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf-next.git/tree/Documentation/bpf/bpf_devel_QA.rst)from the kernel documentation): search for “BPF” or “XDP” keywords. Since April 2017, there is also[a mailing list specially dedicated to XDP programming](http://vger.kernel.org/vger-lists.html#xdp-newbies)(both for architecture or for asking for help). Many discussions and debates also occur[on the IO Visor mailing list](http://lists.iovisor.org/pipermail/iovisor-dev/), since BPF is at the heart of the project. If you only want to keep informed from time to time, there is also an[@IOVisor Twitter account](https://twitter.com/IOVisor).
And come back on this blog from time to time to see if they are
new articles [about BPF](/whirl-offload/categories/#BPF)!
*Special thanks to Daniel Borkmann for the numerous
additional documents
he pointed to me so that I could complete this collection.* |
9,508 | cTop:用于容器监控的命令行工具 | https://www.2daygeek.com/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux/ | 2018-04-03T12:51:19 | [
"top",
"容器",
"监控",
"ctop"
] | https://linux.cn/article-9508-1.html | 
最近 Linux 容器很火,我们中的大多数人甚至已经在使用它,同时一些人也开始学习它。
我们已经介绍了有名的 GUI(用户图形界面) 工具如 Portainer 和 Rancher 。这将会有助于我们通过 GUI 管理容器。
这篇指南将会通过 [cTop](https://ctop.sh/) 命令帮助我们理解和监控 Linux 容器。它是一个类似 `top` 命令的命令行工具。
### 什么是 cTop
[ctop](https://github.com/bcicen/ctop) 为多个容器提供了一个简洁凝练的实时指标概览。它是一个类 `top` 的针对容器指标的界面。
它展示了容器指标比如 CPU 利用率、内存利用率、磁盘 I/O 读写、进程 ID(PID)和网络发送(TX - 从此服务器发送)以及接受(RX - 此服务器接受)。
`ctop` 带有对 Docker 和 runc 的内建支持;对其他容器和集群系统的连接计划在未来版本中推出。
它不需要任何参数并且默认使用 Docker 主机变量。
**建议阅读:**
* [Portainer – 一个简单的 Docker 图形管理界面](https://www.2daygeek.com/portainer-a-simple-docker-management-gui/)
* [Rancher – 一个完整的生产环境容器管理平台](https://www.2daygeek.com/rancher-a-complete-container-management-platform-for-production-environment/)
### 如何安装 cTop
开发者提供了一个简单的 shell 脚本来帮助我们直接使用 `ctop`。我们要做的,只是在 `/bin` 目录下下载 `ctop` shell 文件来保证全局访问。最后给予 `ctop` 脚本文件执行权限。
在 `/usr/local/bin` 目录下下载 ctop shell 脚本。
```
$ sudo wget https://github.com/bcicen/ctop/releases/download/v0.7/ctop-0.7-linux-amd64 -O /usr/local/bin/ctop
```
对 `ctop` shell 脚本设置执行权限。
```
$ sudo chmod +x /usr/local/bin/ctop
```
另外你可以通过 docker 来安装和运行 `ctop`。在此之前先确保你已经安装过 docker。为了安装 docker,参考以下链接。
**建议阅读:**
* [如何在 Linux 上安装 Docker](https://www.2daygeek.com/install-docker-on-centos-rhel-fedora-ubuntu-debian-oracle-archi-scentific-linux-mint-opensuse/)
* [如何在 Linux 上玩转 Docker 镜像](https://www.2daygeek.com/list-search-pull-download-remove-docker-images-on-linux/)
* [如何在 Linux 上玩转 Docker 容器](https://www.2daygeek.com/create-run-list-start-stop-attach-delete-interactive-daemonized-docker-containers-on-linux/)
* [如何在 Docker 容器中安装,运行应用](https://www.2daygeek.com/install-run-applications-inside-docker-containers/)
```
$ docker run --rm -ti \
--name=ctop \
-v /var/run/docker.sock:/var/run/docker.sock \
quay.io/vektorlab/ctop:latest
```
### 如何使用 cTop
直接启动 `ctop` 程序而不用任何参数。默认它绑定的 `a` 键用来展示所有容器(运行的和没运行的)。
`ctop` 头部显示你的系统时间和容器的总数。
```
$ ctop
```
你可能得到以下类似输出。

### 如何管理容器
你可以使用 `ctop` 来管理容器。选择一个你想要管理的容器然后按下回车键,选择所需选项如 `start`、`stop`、`remove` 等。

### 如何给容器排序
默认 `ctop` 使用 `state` 字段来给容器排序。按下 `s` 键来按不同的方面给容器排序。

### 如何查看容器指标
如何你想要查看关于容器的更多细节和指标,只用选择你想要查看的相应容器然后按 `o` 键。

### 如何查看容器日志
选择你想要查看日志的相应容器然后按 `l` 键。

### 仅显示活动容器
使用 `-a` 选项运行 `ctop` 命令来仅显示活动容器

### 打开帮助对话框
运行 `ctop`,只需按 `h` 键来打开帮助部分。

---
via: <https://www.2daygeek.com/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux/>
作者:[2DAYGEEK](https://www.2daygeek.com/author/2daygeek/) 译者:[kimii](https://github.com/kimii) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,509 | 在 Ubuntu 16.04 上配置 msmtp | https://codingproductivity.wordpress.com/2018/01/18/configuring-msmtp-on-ubuntu-16-04-again/ | 2018-04-03T13:05:04 | [
"邮件",
"msmtp"
] | https://linux.cn/article-9509-1.html | 
这篇文章是在我之前的博客中发表过的在 Ubuntu 16.04 上配置 MSMTP 的一个副本。我再次发表是为了后续,我并不知道它是否能在更高版本上工作。由于我没有再托管自己的 Ubuntu/MSMTP 服务器了,所以我现在看不到有需要更新的地方,但是如果我需要重新设置,我会创建一个更新的帖子!无论如何,这是我现有的。
我之前写了一篇在 Ubuntu 12.04 上配置 msmtp 的文章,但是正如我在之前的文章中暗示的那样,当我升级到 Ubuntu 16.04 后出现了一些问题。接下来的内容基本上是一样的,但 16.04 有一些小的更新。和以前一样,这里假定你使用 Apache 作为 Web 服务器,但是我相信如果你选择其他的 Web 服务器,也应该相差不多。
我使用 [msmtp](http://msmtp.sourceforge.net/) 发送来自这个博客的邮件俩通知我评论和更新等。这里我会记录如何配置它通过 Google Apps 帐户发送电子邮件,虽然这应该与标准的 Google 帐户一样。
首先,我们需要安装 3 个软件包:
```
sudo apt-get install msmtp msmtp-mta ca-certificates
```
安装完成后,就需要一个默认配置。默认情况下,msmtp 会在 `/etc/msmtprc` 中查找,所以我使用 `vim` 创建了这个文件,尽管任何文本编辑器都可以做到这一点。这个文件看起来像这样:
```
# Set defaults.
defaults
# Enable or disable TLS/SSL encryption.
tls on
tls_starttls on
tls_trust_file /etc/ssl/certs/ca-certificates.crt
# Setup WP account's settings.
account GMAIL
host smtp.gmail.com
port 587
auth login
user YOUR USERNAME
password YOUR PASSWORD
from FROM@ADDRESS
logfile /var/log/msmtp/msmtp.log
account default :
```
任何大写选项都是需要替换为你特定的配置。日志文件是一个例外,当然你也可以将活动/警告/错误放在任何你想要的地方。
文件保存后,我们将更新上述配置文件的权限 ,如果该文件的权限过于开放,msmtp 将不会运行,并且创建日志文件的目录。
```
sudo mkdir /var/log/msmtp
sudo chown -R www-data:adm /var/log/msmtp
sudo chmod 0600 /etc/msmtprc
```
接下来,我选择为 msmtp 日志配置 logrotate,以确保日志文件不会太大并让日志目录更加整洁。为此,我们创建 `/etc/logrotate.d/msmtp` 并使用按以下内容配置。请注意,这是可选的,你可以选择不这样做,或者你可以选择以不同方式配置日志。
```
/var/log/msmtp/*.log {
rotate 12
monthly
compress
missingok
notifempty
}
```
现在配置了日志,我们需要通过编辑 `/etc/php/7.0/apache2/php.ini` 告诉 PHP 使用 msmtp,并将 sendmail 路径从
```
sendmail_path =
```
变成
```
sendmail_path = "/usr/bin/msmtp -C /etc/msmtprc -a -t"
```
这里我遇到了一个问题,即使我指定了帐户名称,但是当我测试它时,它并没有正确发送电子邮件。这就是为什么 `account default :` 这行被放在 msmtp 配置文件的末尾。要测试配置,请确保 PHP 文件已保存并运行 `sudo service apache2 restart`,然后运行 `php -a` 并执行以下命令
```
mail ('[email protected]', 'Test Subject', 'Test body text');
exit();
```
此时发生的任何错误都将显示在输出中,因此错误诊断会相对容易。如果一切顺利,你现在应该可以使用 PHP sendmail(至少 WordPress 可以)中用 Gmail(或 Google Apps)从 Ubuntu 服务器发送电子邮件。
我没有说这是最安全的配置,所以当你看到并且意识要这个非常不安全,或者有其他严重的错误,请让我知道,我会相应地更新。
---
via: <https://codingproductivity.wordpress.com/2018/01/18/configuring-msmtp-on-ubuntu-16-04-again/>
作者:[JOE](https://codingproductivity.wordpress.com/author/joeb454/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 410 | Gone | null |
9,510 | 10 个增加 UNIX/Linux Shell 脚本趣味的工具 | https://www.cyberciti.biz/tips/spice-up-your-unix-linux-shell-scripts.html | 2018-04-03T17:48:27 | [
"GUI",
"脚本"
] | https://linux.cn/article-9510-1.html | 
有些误解认为 shell 脚本仅用于 CLI 环境。实际上在 KDE 或 Gnome 桌面下,你可以有效的使用各种工具编写 GUI 或者网络(socket)脚本。shell 脚本可以使用一些 GUI 组件(菜单、警告框、进度条等),你可以控制终端输出、光标位置以及各种输出效果等等。利用下面的工具,你可以构建强壮的、可交互的、对用户友好的 UNIX/Linux bash 脚本。
制作 GUI 应用不是一项困难的任务,但需要时间和耐心。幸运的是,UNIX 和 Linux 都带有大量编写漂亮 GUI 脚本的工具。以下工具是基于 FreeBSD 和 Linux 操作系统做的测试,而且也适用于其他类 UNIX 操作系统。
### 1、notify-send 命令
`notify-send` 命令允许你借助通知守护进程发送桌面通知给用户。这种避免打扰用户的方式,对于通知桌面用户一个事件或显示一些信息是有用的。在 Debian 或 Ubuntu 上,你需要使用 [apt 命令](https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ "See Linux/Unix apt command examples for more info") 或 [apt-get 命令](https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html "See Linux/Unix apt-get command examples for more info") 安装的包:
```
sudo apt-get install libnotify-bin
```
CentOS/RHEL 用户使用下面的 [yum 命令](https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ "See Linux/Unix yum command examples for more info"):
```
sudo yum install libnotify
```
Fedora Linux 用户使用下面的 dnf 命令:
```
`$ sudo dnf install libnotify`
In this example, send simple desktop notification from the command line, enter:
### 发送一些通知 ###
notify-send "rsnapshot done :)"
```
示例输出:

下面是另一个附加选项的代码:
```
...
alert=18000
live=$(lynx --dump http://money.rediff.com/ | grep 'BSE LIVE' | awk '{ print $5}' | sed 's/,//g;s/\.[0-9]*//g')
[ $notify_counter -eq 0 ] && [ $live -ge $alert ] && { notify-send -t 5000 -u low -i "BSE Sensex touched 18k"; notify_counter=1; }
...
```
示例输出:

这里:
* `-t 5000`:指定超时时间(毫秒) (5000 毫秒 = 5 秒)
* `-u low`: 设置紧急等级 (如:低、普通、紧急)
* `-i gtk-dialog-info`: 设置要显示的图标名称或者指定的图标(你可以设置路径为:`-i /path/to/your-icon.png`)
关于更多使用 `notify-send` 功能的信息,请参考 man 手册。在命令行下输入 `man notify-send` 即可看见:
```
man notify-send
```
### 2、tput 命令
`tput` 命令用于设置终端特性。通过 `tput` 你可以设置:
* 在屏幕上移动光标。
* 获取终端信息。
* 设置颜色(背景和前景)。
* 设置加粗模式。
* 设置反转模式等等。
下面有一段示例代码:
```
#!/bin/bash
# clear the screen
tput clear
# Move cursor to screen location X,Y (top left is 0,0)
tput cup 3 15
# Set a foreground colour using ANSI escape
tput setaf 3
echo "XYX Corp LTD."
tput sgr0
tput cup 5 17
# Set reverse video mode
tput rev
echo "M A I N - M E N U"
tput sgr0
tput cup 7 15
echo "1. User Management"
tput cup 8 15
echo "2. Service Management"
tput cup 9 15
echo "3. Process Management"
tput cup 10 15
echo "4. Backup"
# Set bold mode
tput bold
tput cup 12 15
read -p "Enter your choice [1-4] " choice
tput clear
tput sgr0
tput rc
```
示例输出:

关于 `tput` 命令的详细信息,参见手册:
```
man 5 terminfo
man tput
```
### 3、setleds 命令
`setleds` 命令允许你设置键盘灯。下面是打开数字键灯的示例:
```
setleds -D +num
```
关闭数字键灯,输入:
```
setleds -D -num
```
* `-caps`:关闭大小写锁定灯
* `+caps`:打开大小写锁定灯
* `-scroll`:关闭滚动锁定灯
* `+scroll`:打开滚动锁定灯
查看 `setleds` 手册可看见更多信息和选项 `man setleds`。
### 4、zenity 命令
[zenity 命令显示 GTK+ 对话框](https://bash.cyberciti.biz/guide/Zenity:_Shell_Scripting_with_Gnome),并且返回用户输入。它允许你使用各种 Shell 脚本向用户展示或请求信息。下面是一个 `whois` 指定域名目录服务的 GUI 客户端示例。
```
#!/bin/bash
# Get domain name
_zenity="/usr/bin/zenity"
_out="/tmp/whois.output.$$"
domain=$(${_zenity} --title "Enter domain" \
--entry --text "Enter the domain you would like to see whois info" )
if [ $? -eq 0 ]
then
# Display a progress dialog while searching whois database
whois $domain | tee >(${_zenity} --width=200 --height=100 \
--title="whois" --progress \
--pulsate --text="Searching domain info..." \
--auto-kill --auto-close \
--percentage=10) >${_out}
# Display back output
${_zenity} --width=800 --height=600 \
--title "Whois info for $domain" \
--text-info --filename="${_out}"
else
${_zenity} --error \
--text="No input provided"
fi
```
示例输出:

参见手册获取更多 `zenity` 信息以及其他支持 GTK+ 的组件:
```
zenity --help
man zenity
```
### 5、kdialog 命令
`kdialog` 命令与 `zenity` 类似,但它是为 KDE 桌面和 QT 应用设计。你可以使用 `kdialog` 展示对话框。下面示例将在屏幕上显示信息:
```
kdialog --dontagain myscript:nofilemsg --msgbox "File: '~/.backup/config' not found."
```
示例输出:

参见 《[KDE 对话框 Shell 脚本编程](http://techbase.kde.org/Development/Tutorials/Shell_Scripting_with_KDE_Dialogs)》 教程获取更多信息。
### 6、Dialog
[Dialog 是一个使用 Shell 脚本的应用](https://bash.cyberciti.biz/guide/Bash_display_dialog_boxes),显示用户界面组件的文本。它使用 curses 或者 ncurses 库。下面是一个示例代码:
```
#!/bin/bash
dialog --title "Delete file" \
--backtitle "Linux Shell Script Tutorial Example" \
--yesno "Are you sure you want to permanently delete \"/tmp/foo.txt\"?" 7 60
# Get exit status
# 0 means user hit [yes] button.
# 1 means user hit [no] button.
# 255 means user hit [Esc] key.
response=$?
case $response in
0) echo "File deleted.";;
1) echo "File not deleted.";;
255) echo "[ESC] key pressed.";;
esac
```
参见 `dialog` 手册获取详细信息:`man dialog`。
#### 关于其他用户界面工具的注意事项
UNIX、Linux 提供了大量其他工具来显示和控制命令行中的应用程序,shell 脚本可以使用一些 KDE、Gnome、X 组件集:
* `gmessage` - 基于 GTK xmessage 的克隆
* `xmessage` - 在窗口中显示或询问消息(基于 X 的 /bin/echo)
* `whiptail` - 显示来自 shell 脚本的对话框
* `python-dialog` - 用于制作简单文本或控制台模式用户界面的 Python 模块
### 7、logger 命令
`logger` 命令将信息写到系统日志文件,如:`/var/log/messages`。它为系统日志模块 syslog 提供了一个 shell 命令行接口:
```
logger "MySQL database backup failed."
tail -f /var/log/messages
logger -t mysqld -p daemon.error "Database Server failed"
tail -f /var/log/syslog
```
示例输出:
```
Apr 20 00:11:45 vivek-desktop kernel: [38600.515354] CPU0: Temperature/speed normal
Apr 20 00:12:20 vivek-desktop mysqld: Database Server failed
```
参见 《[如何写消息到 syslog 或 日志文件](https://www.cyberciti.biz/tips/howto-linux-unix-write-to-syslog.html)》 获得更多信息。此外,你也可以查看 logger 手册获取详细信息:`man logger`
### 8、setterm 命令
`setterm` 命令可设置不同的终端属性。下面的示例代码会强制屏幕在 15 分钟后变黑,监视器则 60 分钟后待机。
```
setterm -blank 15 -powersave powerdown -powerdown 60
```
下面的例子将 xterm 窗口中的文本以下划线展示:
```
setterm -underline on;
echo "Add Your Important Message Here"
setterm -underline off
```
另一个有用的选项是打开或关闭光标显示:
```
setterm -cursor off
```
打开光标:
```
setterm -cursor on
```
参见 setterm 命令手册获取详细信息:`man setterm`
### 9、smbclient:给 MS-Windows 工作站发送消息
`smbclient` 命令可以与 SMB/CIFS 服务器通讯。它可以向 MS-Windows 系统上选定或全部用户发送消息。
```
smbclient -M WinXPPro <<eof
Message 1
Message 2
...
..
EOF
```
或
```
echo "${Message}" | smbclient -M salesguy2
```
参见 `smbclient` 手册或者阅读我们之前发布的文章:《[给 Windows 工作站发送消息](https://www.cyberciti.biz/tips/freebsd-sending-a-message-to-windows-workstation.html)》:`man smbclient`
### 10、Bash 套接字编程
在 bash 下,你可以打开一个套接字并通过它发送数据。你不必使用 `curl` 或者 `lynx` 命令抓取远程服务器的数据。bash 和两个特殊的设备文件可用于打开网络套接字。以下选自 bash 手册:
1. `/dev/tcp/host/port` - 如果 `host` 是一个有效的主机名或者网络地址,而且端口是一个整数或者服务名,bash 会尝试打开一个相应的 TCP 连接套接字。
2. `/dev/udp/host/port` - 如果 `host` 是一个有效的主机名或者网络地址,而且端口是一个整数或者服务名,bash 会尝试打开一个相应的 UDP 连接套接字。
你可以使用这项技术来确定本地或远程服务器端口是打开或者关闭状态,而无需使用 `nmap` 或者其它的端口扫描器。
```
# find out if TCP port 25 open or not
(echo >/dev/tcp/localhost/25) &>/dev/null && echo "TCP port 25 open" || echo "TCP port 25 close"
```
下面的代码片段,你可以利用 [bash 循环找出已打开的端口](https://www.cyberciti.biz/faq/bash-for-loop/):
```
echo "Scanning TCP ports..."
for p in {1..1023}
do
(echo >/dev/tcp/localhost/$p) >/dev/null 2>&1 && echo "$p open"
done
```
示例输出:
```
Scanning TCP ports...
22 open
53 open
80 open
139 open
445 open
631 open
```
下面的示例中,你的 bash 脚本将像 HTTP 客户端一样工作:
```
#!/bin/bash
exec 3<> /dev/tcp/${1:-www.cyberciti.biz}/80
printf "GET / HTTP/1.0\r\n" >&3
printf "Accept: text/html, text/plain\r\n" >&3
printf "Accept-Language: en\r\n" >&3
printf "User-Agent: nixCraft_BashScript v.%s\r\n" "${BASH_VERSION}" >&3
printf "\r\n" >&3
while read LINE <&3
do
# do something on $LINE
# or send $LINE to grep or awk for grabbing data
# or simply display back data with echo command
echo $LINE
done
```
参见 bash 手册获取更多信息:`man bash`
### 关于 GUI 工具和 cron 任务的注意事项
如果你 [使用 crontab](https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/) 来启动你的脚本,你需要使用 `export DISPLAY=[用户机器]:0` 命令请求本地显示或输出服务。举个例子,使用 `zenity` 工具调用 `/home/vivek/scripts/monitor.stock.sh`:
```
@hourly DISPLAY=:0.0 /home/vivek/scripts/monitor.stock.sh
```
你有喜欢的可以增加 shell 脚本趣味的 UNIX 工具么?请在下面的评论区分享它吧。
### 关于作者
本文作者是 nixCraft 创始人、一个老练的系统管理员、Linux 操作系统和 UNIX shell 编程培训师。他服务来自全球的客户和不同的行业,包括 IT 、教育、防务和空间探索、还有非营利组织。你可以在 [Twitter](https://twitter.com/nixcraft),[Facebook](https://facebook.com/nixcraft),[Google+](https://plus.google.com/+CybercitiBiz) 上面关注他。
---
via: <https://www.cyberciti.biz/tips/spice-up-your-unix-linux-shell-scripts.html>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[pygmalion666](https://github.com/pygmalion666) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,511 | 为什么开源在计算机专业的学生中不那么流行? | https://opensource.com/article/17/12/students-and-open-source-3-common-preconceptions | 2018-04-04T08:54:35 | [
"开源",
"学生"
] | /article-9511-1.html |
>
> 高中和大学生们或许因先入为主的观念而畏于参与开源项目。
>
>
>

图片来自:opensource.com
年轻程序员的技术悟性和创造力是充满活力的。
这一点可以从我参加今年的(美国)国内最大的黑客马拉松 [PennApps](http://pennapps.com/) 时所目睹的他们勤奋的工作中可以看出。在 48 小时内,我的高中和大学年龄段的同龄人们创建了从[可以通过眨眼来让不能说话或行动不便的人来交流的设备](https://devpost.com/software/blink-9o2iln) 到 [带有物联网功能的煎饼机](https://devpost.com/software/daburrito) 的项目。在整个过程中,开源的精神是切实可见的,不同群体之间建立了共同的愿望,思想和技术诀窍的自由流通,无畏的实验和快速的原型设计,以及热衷于参与的渴望。
那么我想知道,为什么在我的这些技术极客伙伴中,开源并不是一个热门话题?
为了更多地了解大学生在听到“开源”时的想法,我调查了几个大学生,他们都是我所属的专业计算机科学团体的成员。这个社团的所有成员都必须在高中或大学期间申请,并根据他们的计算机科学成就和领导能力进行选择——即是否领导过一个学校的机器人团队,建立过将编码带入资金不足的课堂的非营利组织,或其他一些值得努力的地方。鉴于这些个人在计算机科学方面的成就,我认为他们的观点将有助于理解年轻程序员对开源项目的吸引力(或不吸引人)。
我编写和发布的在线调查包括以下问题:
* 你喜欢编写个人项目吗?您是否曾经参与过开源项目?
* 你觉得自己开发自己的编程项目,还是对现有的开源工作做出贡献会更有益处?
* 你将如何比较为开源软件组织和专有软件的组织编码获得的声望?
尽管绝大多数人表示,他们至少偶尔会喜欢在业余时间编写个人项目,但大多数人从未参与过开源项目。当我进一步探索这一趋势时,一些关于开源项目和组织的常见的偏见逐渐浮出水面。为了说服我的伙伴们,开源项目值得他们花时间,并且为教育工作者和开源组织提供他们对学生的见解,我将谈谈三个首要的偏见。
### 偏见 1:从零开始创建个人项目比为现有的开源项目做贡献更好。
在我所调查的大学年龄程序员中,26 人中有 24 人声称,开发自己的个人项目比开源项目更有益。
作为一名计算机科学专业的大一新生,我也相信这一点。我经常听到年长的同学说,个人项目会让我成为更有吸引力的实习生。没有人提到过为开源项目做出贡献的可能性——所以在我看来,这是无关紧要的。
我现在意识到开源项目为现实世界提供了强大的准备工作。对开源项目的贡献培养了一种意识,即[工具和语言如何拼合在一起](https://hackernoon.com/benefits-of-contributing-to-open-source-2c97b6f529e9),而单个项目却不能。而且,开源是一个协调与协作的练习,可以培养[学生的沟通,团队合作和解决问题的专业技能](https://opensource.com/education/16/8/5-reasons-student-involvement-open-source)。
### 偏见 2:我的编码技能是不够的。
一些受访者表示,他们被开源项目吓倒了,不知道该从哪里开始贡献,或者担心项目进展缓慢。不幸的是,自卑感往往也会对女性程序员产生影响,而这种感觉并不止于开源社区。事实上,“冒名顶替综合症”甚至可能会被放大,因为[开源的倡导者通常会拒绝官僚主义](https://opensource.com/open-organization/17/7/open-thinking-curb-bureaucracy) —— 而且和官僚主义一样难以在内部流动,它有助于新加入的人了解他们在一个组织中的位置。
我还记得第一次在 GitHub 上查看开源项目时,我对阅读贡献指南感到害怕。然而,这些指南并非旨在吓跑别人,而是提供[指导](https://opensource.com/life/16/3/contributor-guidelines-template-and-tips)。为此,我认为贡献指南是建立期望而不依赖于等级结构的一种方式。
有几个开源项目积极为新的项目贡献者创造了一个地方。[TEAMMATES](https://github.com/TEAMMATES/teammates/issues?q=is%3Aissue+is%3Aopen+label%3Ad.FirstTimers) 是一种教育反馈管理工具,是为初学者们解决了这个问题一个开源项目。在评论中,各种技能水平的程序员都详细阐述了实现的细节,这表明开源项目是属于热切的新程序员和经验丰富的软件老手的地方。对于那些还在犹豫的年轻程序员来说,一些[开源项目](https://github.com/adriennefriend/imposter-syndrome-disclaimer/blob/master/examples.md)已经考虑周全,采用了[冒名顶替综合症的免责声明](https://github.com/adriennefriend/imposter-syndrome-disclaimer)。
### 偏见 3:专有软件公司比开源软件组织做得更好。
在接受调查的 26 位受访者中,只有 5 位认为开源组织和专有软件组织在声望上是平等的。这可能是由于“开源”意味着“无利可图”,因此质量低下的误解(查看 [“开源”不只是意味着是免费](https://opensource.com/resources/what-open-source))。
然而,开源软件和盈利软件并不相互排斥。事实上,小型和大型企业通常都为免费的开源软件的技术支持服务而付款。正如[红帽公司首席执行官 Jim Whitehurst](https://hbr.org/2013/01/yes-you-can-make-money-with-op) 所解释的那样:“我们拥有一批工程团队,负责跟踪 Linux 的每一项变更--错误修复、安全性增强等等,确保我们客户的关键任务系统保持最新状态和稳定“。
另外,开源的本质是通过使更多的人能够检查源代码来提升而不是阻碍质量的提高。[Mobify 首席执行官 Igor Faletski](https://hbr.org/2012/10/open-sourcing-may-be-worth) 写道,Mobify 的 “25 位软件开发人员和专业的质量保证人员团队无法满足世界上所有可能使用 [Mobify 的开源]平台的软件开发者,而他们每个人都是该项目的潜在测试者或贡献者。”
另一个问题可能是年轻的程序员不知道他们每天使用的开源软件。 我使用了许多工具——包括 MySQL、Eclipse、Atom、Audacity 和 WordPress——几个月甚至几年,却没有意识到它们是开源的。 经常急于下载教学大纲指定软件以完成课堂作业的大学生可能不知道哪个软件是开源的。 这使得开源看起来比现在更加陌生。
所以学生们,在尝试之前不要敲开源码。 看看这个[初学者友好的项目](https://github.com/MunGell/awesome-for-beginners)列表和这[六个起点](https://opensource.com/life/16/1/6-beginner-open-source),开始你的开源之旅。
教育工作者们,提醒您的学生开源社区的成功创新的历史,并引导他们走向课堂之外的开源项目。你将帮助培养更敏锐、更有准备、更自信的学生。
**关于作者**
Susie Choi - Susie 是杜克大学计算机科学专业的本科生。她对技术革新和开放源码原则对教育和社会经济不平等问题的影响非常感兴趣。
---
via: <https://opensource.com/article/17/12/students-and-open-source-3-common-preconceptions>
作者:[Susie Choi](https://opensource.com/users/susiechoi) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,512 | 在 Debian 9 上使用 Rsyslog 安装一台中央日志服务器 | https://www.howtoforge.com/tutorial/rsyslog-centralized-log-server-in-debian-9/ | 2018-04-04T09:20:39 | [
"日志",
"syslogd",
"journald"
] | https://linux.cn/article-9512-1.html | 
在 Linux 上,日志文件包含了系统功能的信息,系统管理员经常使用日志来确认机器上的问题所在。日志可以帮助管理员还原在过去的时间中在系统中发生的事件。一般情况下,Linux 中所有的日志文件都保存在 `/var/log` 目录下。在这个目录中,有保存着各种信息的几种类型的日志文件。比如,记录系统事件的日志文件、记录安全相关信息的日志文件、内核专用的日志文件、用户或者 cron 作业使用的日志文件。日志文件的主要作用是系统调试。Linux 中的大部分的日志文件都由 rsyslogd 服务来管理。在最新的 Linux 发行版中,日志文件也可能是由 journald 系统服务来管理和控制的。journald 服务是 systemd 初始化程序的一部分。journald 以二进制的格式存储日志,以易失性的方式写入到内存和 `/run/log/journal/` 中的环状缓冲区中,但是,journald 也可以配置为永久存储到 syslog 中。
在 Linux 中,可以配置运行一个 Rsyslog 服务器来中央化管理日志,在流行的服务端—客户端模式中,通过 TCP 或者 UDP 传输协议基于网络来发送日志信息,或者从网络设备、服务器、路由器、交换机、以及其它系统或嵌入式设备中接受生成的日志。
Rsyslog 守护程序可以被同时配置为以客户端或者服务端方式运行。配置作为服务器时,Rsyslog 将缺省监听 TCP 和 UDP 的 514 端口,来收集远程系统基于网络发送的日志信息。配置为客户端运行时,Rsyslog 将通过相同的 TCP 或 UDP 端口基于网络来发送内部日志信息。
Rsyslog 可以根据选定的属性和动作来过滤 syslog 信息。Rsyslog 拥有的过滤器如下:
1. 设备或者优先级过滤器
2. 基于特性的过滤器
3. 基于表达式的过滤器
设备过滤器代表了生成日志的 Linux 内部子系统。它们目前的分类如下:
* `auth/authpriv` = 由验证进程产生的信息
* `cron` = cron 任务相关的日志
* `daemon` = 正在运行的系统服务相关的信息
* `kernel` = Linux 内核信息
* `mail` = 邮件服务器信息
* `syslog` = syslog 或者其它守护程序(DHCP 服务器发送的日志在这里)相关的信息
* `lpr` = 打印机或者打印服务器信息
* `local0` ~ `local7` = 管理员控制下的自定义信息
优先级或者严重程度级别分配如下所述的一个关键字或者一个数字。
* `emerg` = 紧急 - 0
* `alert` = 警报 - 1
* `err` = 错误 - 3
* `warn` = 警告 - 4
* `notice` = 提示 - 5
* `info` = 信息 - 6
* `debug` = 调试 - 7 (最高级别)
此外也有一些 Rsyslog 专用的关键字,比如星号(`*`)可以用来定义所有的设备和优先级,`none` 关键字更具体地表示没有优先级,等号(`=`)表示仅那个优先级,感叹号(`!`)表示取消这个优先级。
Rsyslog 的动作部分由声明的目的地来表示。日志信息的目的地可以是:存储在文件系统中的一个文件、 `/var/log/` 目录下的一个文件、通过命名管道或者 FIFO 作为输入的另一个本地进程。日志信息也可以直达用户,或者丢弃到一个“黑洞”(`/dev/null`)中、或者发送到标准输出、或者通过一个 TCP/UDP 协议发送到一个远程 syslog 服务器。日志信息也可以保存在一个数据库中,比如 MySQL 或者 PostgreSQL。
### 配置 Rsyslog 为服务器
在大多数 Linux 发行版中 Rsyslog 守护程序是自动安装的。如果你的系统中没有安装 Rsyslog,你可以根据你的系统发行版执行如下之一的命令去安装这个服务。*运行这个命令必须有 root 权限*。
在基于 Debian 的发行版中:
```
sudo apt-get install rsyslog
```
在基于 RHEL 的发行版中,比如像 CentOS:
```
sudo yum install rsyslog
```
验证 Rsyslog 守护进程是否在你的系统中运行,根据发行版不同,可以选择运行下列的命令:
在新的使用 systemd 的 Linux 发行版中:
```
systemctl status rsyslog.service
```
在老的使用 init 的 Linux 发行版中:
```
service rsyslog status
```
或
```
/etc/init.d/rsyslog status
```
启动 rsyslog 守护进程运行如下的命令。
在使用 init 的老的 Linux 版本:
```
service rsyslog start
```
或
```
/etc/init.d/rsyslog start
```
在最新的 Linux 发行版:
```
systemctl start rsyslog.service
```
安装一个 rsyslog 程序运行为服务器模式,可以编辑主要的配置文件 `/etc/rsyslog.conf` 。可以使用下列所示的命令去改变它。
```
sudo vi /etc/rsyslog.conf
```
为了允许在 UDP 的 514 端口上接收日志信息,找到并删除下列行前面的井号(`#`)以取消注释。缺省情况下,UDP 端口用于 syslog 去接收信息。
```
$ModLoad imudp
$UDPServerRun 514
```
因为在网络上使用 UDP 协议交换数据并不可靠,你可以设置 Rsyslog 使用 TCP 协议去向远程服务器输出日志信息。为了启用 TCP 协议去接受日志信息,打开 `/etc/rsyslog.conf` 文件并删除如下行前面的井号(`#`)以取消注释。这将允许 rsyslog 守护程序去绑定并监听 TCP 协议的 514 端口。
```
$ModLoad imtcp
$InputTCPServerRun 514
```
*在 rsyslog 上可以**同时**启用两种协议*。
如果你想去指定哪个发送者被允许访问 rsyslog 守护程序,可以在启用协议行的后面添加如下的行:
```
$AllowedSender TCP, 127.0.0.1, 10.110.50.0/24, *.yourdomain.com
```
在接收入站日志信息之前,你需要去创建一个 rsyslog 守护程序解析日志的新模板,这个模板将指示本地 Rsyslog 服务器在哪里保存入站的日志信息。在 `$AllowedSender` 行后以如下示例去创建一个合适的模板。
```
$template Incoming-logs,"/var/log/%HOSTNAME%/%PROGRAMNAME%.log"
*.* ?Incoming-logs
& ~
```
为了仅接收内核生成的日志信息,可以使用如下的语法。
```
kern.* ?Incoming-logs
```
接收到的日志由上面的模板来解析,它将保存在本地文件系统的 `/var/log/` 目录的文件中,之后的是以客户端主机名客户端设备名命名的日志文件名字:`%HOSTNAME%` 和 `%PROGRAMNAME%` 变量。
下面的 `& ~` 重定向规则,配置 Rsyslog 守护程序去保存入站日志信息到由上面的变量名字指定的文件中。否则,接收到的日志信息将被进一步处理,并将保存在本地的日志文件中,比如,`/var/log/syslog` 文件中。
为添加一个规则去丢弃所有与邮件相关的日志信息,你可以使用下列的语法。
```
mail.* ~
```
可以在输出文件名中使用的其它变量还有:`%syslogseverity%`、`%syslogfacility%`、`%timegenerated%`、`%HOSTNAME%`、`%syslogtag%`、`%msg%`、`%FROMHOST-IP%`、`%PRI%`、`%MSGID%`、`%APP-NAME%`、`%TIMESTAMP%`、%$year%、`%$month%`、`%$day%`。
从 Rsyslog 版本 7 开始,将使用一个新的配置格式,在一个 Rsyslog 服务器中声明一个模板。
一个版本 7 的模板应该看起来是如下行的样子。
```
template(name="MyTemplate" type="string"
string="/var/log/%FROMHOST-IP%/%PROGRAMNAME:::secpath-replace%.log"
)
```
另一种模式是,你也可以使用如下面所示的样子去写上面的模板:
```
template(name="MyTemplate" type="list") {
constant(value="/var/log/")
property(name="fromhost-ip")
constant(value="/")
property(name="programname" SecurePath="replace")
constant(value=".log")
}
```
为了让 Rsyslog 配置文件的变化生效,你必须重启守护程序来加载新的配置。
```
sudo service rsyslog restart
```
```
sudo systemctl restart rsyslog
```
在 Debian Linux 系统上去检查它监听哪个套接字,你可以用 root 权限去运行 `netstat` 命令。将输出传递给一个过滤程序,比如 `grep`。
```
sudo netstat -tulpn | grep rsyslog
```
请注意: 为了允许建立入站连接,你必须在防火墙上打开 Rsyslog 的端口。
在使用 Firewalld 的基于 RHEL 的发行版上,运行如下的命令:
```
firewall-cmd --permanent --add-port=514/tcp
firewall-cmd --permanent --add-port=514/tcp
firewall-cmd -reload
```
在使用 UFW 的基于 Debian 的发行版上,运行如下的命令:
```
ufw allow 514/tcp
ufw allow 514/udp
```
Iptables 防火墙规则:
```
iptables -A INPUT -p tcp -m tcp --dport 514 -j ACCEPT
iptables -A INPUT -p udp --dport 514 -j ACCEPT
```
### 配置 Rsyslog 作为一个客户端
启用 Rsyslog 守护程序以客户端模式运行,并将输出的本地日志信息发送到远程 Rsyslog 服务器,编辑 `/etc/rsyslog.conf` 文件并增加下列的行:
```
*. * @IP_REMOTE_RSYSLOG_SERVER:514
*. * @FQDN_RSYSLOG_SERVER:514
```
这个行启用了 Rsyslog 服务,并将输出的所有内部日志发送到一个远处的 UDP 的 514 端口上运行的 Rsyslog 服务器上。
为了使用 TCP 协议去发送日志信息,使用下列的模板:
```
*. * @@IP_reomte_syslog_server:514
```
输出所有优先级的、仅与 cron 相关的日志信息到一个 Rsyslog 服务器上,使用如下的模板:
```
cron.* @ IP_reomte_syslog_server:514
```
在 `/etc/rsyslog.conf` 文件中添加下列行,可以在 Rsyslog 服务器无法通过网络访问时,临时将客户端的日志信息存储在它的一个磁盘缓冲文件中,当网络或者服务器恢复时,再次进行发送。
```
$ActionQueueFileName queue
$ActionQueueMaxDiskSpace 1g
$ActionQueueSaveOnShutdown on
$ActionQueueType LinkedList
$ActionResumeRetryCount -1
```
为使上述规则生效,需要重新 Rsyslog 守护程序,以激活为客户端模式。
---
via: <https://www.howtoforge.com/tutorial/rsyslog-centralized-log-server-in-debian-9/>
作者:[Matt Vas](https://www.howtoforge.com) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Install a Centralized Log Server with Rsyslog in Debian 9
In Linux, the log files are files that contain messages about the system functions which are used by system administrators to identify eventual issues on the machines. The logs help administrators to visualize the events that happened in the system over time periods. Usually, all log files are kept under **/var/log** directory in Linux. In this location, there are several types of log files for storing various messages, such as a log file for recording system events, a log file for security related messages, other log files dedicated for kernel, users or cron jobs. The main purpose of log files is to troubleshoot system problems. Most log files in Linux are controlled by rsyslogd service. On newer releases of Linux distributions, the log files are also controlled and managed by the journald system service, which is a part of systemd initialization program. The logs stored by journal daemon are written in a binary format and are mainly volatile, stored in RAM and in a ring-buffer in /run/log/journal/. However, the journal service can be also configured to permanently store the Syslog messages.
In Linux, the rsyslog server can be configured to run a central log manager, in a service-client model fashion, and send log messages over the network via TCP or UDP transport protocols or receive logs from network devices, servers, routers, switches or other systems or embedded devices that generate logs.
Rsyslog daemon can be setup to run as a client and server at the same time. Configured to run as a server, Rsyslog will listen on default port 514 TCP and UDP and will start to collect log messages that are sent over the network by remote systems. As client, Rsyslog will send over the network the internal log messages to a remote Ryslog server via the same TCP or UDP ports.
Rsyslog will filter syslog messages according to selected properties and actions. The rsyslog filters are as follows:
- Facility or Priority filers
- Property-based filters
- Expression-based filters
The **facility** filter is represented by the Linux internal subsystem that produces the logs. They are categorized as presented below:
**auth/authpriv**= messages produced by authentication processes**cron**= logs related to cron tasks**daemon**= messages related to running system services**kernel**= Linux kernel messages**mail**= mail server messages**syslog**= messages related to syslog or other daemons (DHCP server sends logs here)**lpr**= printers or print server messages**local0 - local7**= custom messages under administrator control
The **priority or severity **levels are assigned to a keyword and a number as described below.
**emerg**= Emergency – 0**alert**= Alerts – 1**err**= Errors – 3**warn**= Warnings – 4**notice**= Notification – 5**info**= Information – 6**debug**= Debugging – 7 highest level
There are also some special Rsyslog keywords available such as the asterisk (*****) sign to define all
facilities or priorities, the **none** keyword which specify no priorities, the equal sign (**=**) which selects only that priority and the exclamation sign (**!**) which negates a priority.
The action part of the syslog is represented by the **destination** statement. The destination of a log message can be a file stored in the file system, a file in /var/log/ system path, another local process input via a named pipe or FIFO. The log messages can be also directed to users, discarded to a black hole (/dev/null) or sent to stdout or to a remote syslog server via TCP/UDP protocol. The log messages can be also stored in a database, such as MySQL or PostgreSQL.
## Configure Rsyslog as a Server
The Rsyslog daemon is automatically installed in most Linux distributions. However, if Rsyslog is not installed on your system you can issue one of the below commands in order to install the service> you will require root privileges to run the commands.
In Debian based distros:
sudo apt-get install rsyslog
In RHEL based distros like CentOS:
sudo yum install rsyslog
In order to verify if Rsyslog daemon is started on a system execute the below commands, depending on your distribution version.
On newer Linux distros with systemd:
systemctl status rsyslog.service
On older Linux versions with init:
service rsyslog status
/etc/init.d/rsyslog status
In order to start the rsyslog daemon issue the following command.
On older Linux versions with init:
service rsyslog start
/etc/init.d/rsyslog start
On latest Linux distros:
systemctl start rsyslog.service
To setup an rsyslog program to run in server mode, edit the main configuration file in **/etc/rsyslog.conf. **In this file make the following changes as shown in the below sample.
sudo vi /etc/rsyslog.conf
Locate and uncomment by removing the hashtag (#) the following lines in order to allow UDP log message reception on 514 port. By default, the UDP port is used by syslog to send-receive messages.
$ModLoad imudp
$UDPServerRun 514
Because the UDP protocol is not reliable to exchange data over a network, you can setup Rsyslog to output log messages to a remote server via TCP protocol. To enable TCP reception protocol, open **/etc/rsyslog.conf** file and uncomment the following lines as shown below. This will allow the rsyslog daemon to bind and listen on a TCP socket on port 514.
$ModLoad imtcp
$InputTCPServerRun 514
Both protocols can be enabled in rsyslog to run at the same time.
If you want to specify to which senders you permit access to rsyslog daemon, add the following line after the enabled protocol lines:
$AllowedSender TCP, 127.0.0.1, 10.110.50.0/24, *.yourdomain.com
You will also need to create a new template that will be parsed by rsyslog daemon before receiving the incoming logs. The template should instruct the local Rsyslog server where to store the incoming log messages. Define the template right after the **$AllowedSender **line as shown in the below sample.
$template Incoming-logs,"/var/log/%HOSTNAME%/%PROGRAMNAME%.log"*.*?Incoming-logs
& ~
** **To log only the messages generated by kern facility use the below syntax.
kern.* ?Incoming-logs
The received logs are parsed by the above template and will be stored in the local file system in /var/log/ directory, in files named after the client hostname client facility that produced the messages: *%HOSTNAME%* and *%PROGRAMNAME% *variables.
The below ** & ~** redirect rule configures the Rsyslog daemon to save the incoming log messages only to the above files specified by the variables names. Otherwise, the received logs will be further processed and also stored in the content of local logs, such as /var/log/syslog file.
To add a rule to discard all related log messages to mail, you can use the following statement.
mail.* ~
Other variables that can be used to output file names are: %syslogseverity%, %syslogfacility%, %timegenerated%, %HOSTNAME%, %syslogtag%, %msg%, %FROMHOST-IP%, %PRI%, %MSGID%, %APP-NAME%, %TIMESTAMP%, %$year%, %$month%, %$day%
Starting with Rsyslog version 7, a new configuration format can be used to declare a template in an Rsyslog server.
A version 7 template sample can look like shown in the below lines.
template(name="MyTemplate" type="string"
string="/var/log/%FROMHOST-IP%/%PROGRAMNAME:::secpath-replace%.log"
)
** **Another mode you can write the above template can also be as shown below:
template(name="MyTemplate" type="list") {
constant(value="/var/log/")
property(name="fromhost-ip")
constant(value="/")
property(name="programname" SecurePath="replace")
constant(value=".log")
}
In order to apply any changes made to rsyslog configuration file, you must restart the daemon to load the new configuration.
sudo service rsyslog restart
sudo systemctl restart rsyslog
To check which rsyslog sockets in listening state are opened on a Debian Linux system, you can execute the ** netstat** command with root privileges. Pass the results via a filter utility, such as
**grep**.
sudo netstat –tulpn | grep rsyslog
Be aware that you must also open Rsyslog ports in firewall in order to allow incoming connections to be established.
In RHEL based distros with Firewalld activated issue the below commands:
firewall-cmd --permanent --add-port=514/tcp
firewall-cmd --permanent --add-port=514/tcp
firewall-cmd –reload
In Debian based distros with UFW firewall active issue the below commands:
ufw allow 514/tcp
ufw allow 514/udp
Iptables firewall rules:
iptables -A INPUT -p tcp -m tcp --dport 514 -j ACCEPT
iptables -A INPUT -p udp --dport 514 -j ACCEPT
## Configure Rsyslog as a Client
To enable rsyslog daemon to run in client mode and output local log messages to a remote Rsyslog server, edit **/etc/rsyslog.conf** file and add one of the following lines:
*. * @IP_REMOTE_RSYSLOG_SERVER:514
*. * @FQDN_RSYSLOG_SERVER:514
This line enables the Rsyslog service to output all internal logs to a distant Rsyslog server on UDP port 514.
To send the logs over TCP protocol use the following template:
*. * @@IP_reomte_syslog_server:514
To output only cron related logs with all priorities to a rsyslog server, use the below template:
cron.* @ IP_reomte_syslog_server:514
In cases when the Rsyslog server is not reachable via network, append the below lines to /etc/rsyslog.conf file on the client side in order temporarily store the logs in a disk buffered file, until the server comes online.
$ActionQueueFileName queue
$ActionQueueMaxDiskSpace 1g
$ActionQueueSaveOnShutdown on
$ActionQueueType LinkedList
$ActionResumeRetryCount -1
To apply the above rules, Rsyslog daemon needs to be restarted in order to act as a client. |
9,513 | 如何在 Linux 里使用 nmcli 添加网桥 | https://www.cyberciti.biz/faq/how-to-add-network-bridge-with-nmcli-networkmanager-on-linux/ | 2018-04-04T20:26:40 | [
"网桥",
"nmcli"
] | https://linux.cn/article-9513-1.html | 
**Q:我正在电脑上使用 Debian Linux 9 “stretch”。 我想用 NetworkManager 来建网桥。但是根本就没有添加 br0的选项。我该如何在 Linux 里使用 nmcli 来为 NetworkManager 创建或者添加网桥呢?**
网桥没什么特别的,只是把两个网络连在一起。它工作在数据链路层,即 OSI 模型的第二层。网桥经常用在虚拟机或别的一些软件中。为了使用网桥而关闭桌面 Linux 上的 NetworkManager 显然是不明智的。`nmcli` 可以创建一个永久的网桥而不需要编辑任何文件。
本文将展示如何使用 NetworkManager 的命令行工具 `nmcli` 来创建网桥。
### 如何使用 nmcli 来创建/添加网桥
使用 NetworkManager 在 Linux 上添加网桥接口的步骤如下:
1. 打开终端
2. 获取当前连接状态: `nmcli con show`
3. 添加新的网桥: `nmcli con add type bridge ifname br0`
4. 创建子网卡: `nmcli con add type bridge-slave ifname eno1 master br0`
5. 打开 br0: `nmcli con up br0`
让我们从细节层面看看如何创建一个名为 br0 的网桥。
### 获取当前网络配置
你可以通过 NetworkManager 的 GUI 来了解本机的网络连接:
[](https://www.cyberciti.biz/media/new/faq/2018/01/Getting-Network-Info-on-Linux.jpg)
也可以使用如下命令行来查看:
```
$ nmcli con show
$ nmcli connection show --active
```
[](https://www.cyberciti.biz/media/new/faq/2018/01/View-the-connections-with-nmcli.jpg)
我有一个使用网卡 `eno1` 的 “有线连接”。我的系统还有一个 VPN 接口。我将要创建一个名为 `br0` 的网桥,并连接到 `eno1`。
### 如何创建一个名为 br0 的网桥
```
$ sudo nmcli con add ifname br0 type bridge con-name br0
$ sudo nmcli con add type bridge-slave ifname eno1 master br0
$ nmcli connection show
```
[](https://www.cyberciti.biz/media/new/faq/2018/01/Create-bridge-interface-using-nmcli-on-Linux.jpg)
你也可以禁用 STP:
```
$ sudo nmcli con modify br0 bridge.stp no
$ nmcli con show
$ nmcli -f bridge con show br0
```
最后一条命令展示了禁用 STP 后的网桥参数:
```
bridge.mac-address: --
bridge.stp: no
bridge.priority: 32768
bridge.forward-delay: 15
bridge.hello-time: 2
bridge.max-age: 20
bridge.ageing-time: 300
bridge.multicast-snooping: yes
```
### 如何打开网桥
你必须先关闭 `Wired connection 1` ,然后打开 `br0`:
```
$ sudo nmcli con down "Wired connection 1"
$ sudo nmcli con up br0
$ nmcli con show
```
使用 [ip 命令](https://www.cyberciti.biz/faq/linux-ip-command-examples-usage-syntax/ "See Linux/Unix ip command examples for more info") 来查看 IP 信息:
```
$ ip a s
$ ip a s br0
```
[](https://www.cyberciti.biz/media/new/faq/2018/01/Build-a-network-bridge-with-nmcli-on-Linux.jpg)
### 附录: 如何在 KVM 上使用 br0
现在你可以使用 KVM/VirtualBox/VMware workstation 创建的 VM(虚拟机)来直接连接网络而非通过 NAT。使用 `vi` 或者 [cat 命令](https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/ "See Linux/Unix cat command examples for more info")为虚拟机创建一个名为 `br0.xml` 的文件:
```
$ cat /tmp/br0.xml
```
添加以下代码:
```
<network>
<name>br0</name>
<forward mode="bridge"/>
<bridge name="br0" />
</network>
```
如下所示运行 `virsh`命令:
```
# virsh net-define /tmp/br0.xml
# virsh net-start br0
# virsh net-autostart br0
# virsh net-list --all
```
输出:
```
Name State Autostart Persistent
----------------------------------------------------------
br0 active yes yes
default inactive no yes
```
阅读 man 页面获取更多信息:
```
$ man ip
$ man nmcli
```
### 关于作者
作者是 nixCraft 的创建者、老练的系统管理员和一个 Linux/Unix shell 脚本编程培训师。他为全球客户和各种公司工作,包括 IT,教育,国防,空间研究以及非营利组织。 他的联系方式 [Twitter](https://twitter.com/nixcraft)、 [Facebook](https://facebook.com/nixcraft)、 [Google+](https://plus.google.com/+CybercitiBiz)。
---
via: <https://www.cyberciti.biz/faq/how-to-add-network-bridge-with-nmcli-networkmanager-on-linux/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[kennethXia](https://github.com/kennethXia) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,514 | 如何使用 CGI 脚本生成网页 | https://opensource.com/article/17/12/cgi-scripts | 2018-04-04T20:48:46 | [
"CGI"
] | https://linux.cn/article-9514-1.html |
>
> 通用网关接口(CGI)提供了使用任何语言生成动态网站的简易方法。
>
>
>

回到互联网的开端,当我第一次创建了我的第一个商业网站,生活是如此的美好。
我安装 Apache 并写了一些简单的 HTML 网页,网页上列出了一些关于我的业务的重要信息,比如产品概览以及如何联系我。这是一个静态网站,因为内容很少改变。由于网站的内容很少发生改变这一性质,因此维护起来也很简单。
### 静态内容
静态内容很简单,同时也很常见。让我们快速的浏览一些静态网页的例子。你不需要一个可运行网站来执行这些小实验,只需要把这些文件放到家目录,然后使用浏览器打开。你所看到的内容将和通过 Web 服务器提供这一文件看到的内容一样。
对于一个静态网站,你需要的第一件东西就是 `index.html` 文件,该文件通常放置在 `/var/www/html` 目录下。这个文件的内容可以非常简单,比如可以是像 “Hello, world” 这样一句短文本,没有任何 HTML 标记。它将简单的展示文本串内容。在你的家目录创建 `index.html` 文件,并添加 “hello, world” 作为内容(不需要引号)。在浏览器中通过下面的链接来打开这一文件:
```
file:///home/<你的家目录>/index.html
```
所以 HTML 不是必须的,但是,如果你有大量需要格式化的文本,那么,不用 HTML 编码的网页的结果将会令人难以理解。
所以,下一步就是通过使用一些 HTML 编码来提供格式化,从而使内容更加可读。下面这一命令创建了一个具有 HTML 静态网页所需要的绝对最小标记的页面。你也可以使用你最喜欢的编辑器来创建这一内容。
```
echo "<h1>Hello World</h1>" > test1.html
```
现在,再次查看 `index.html` 文件,将会看到和刚才有些不同。
当然,你可以在实际的内容行上添加大量的 HTML 标记,以形成更加完整和标准的网页。下面展示的是更加完整的版本,尽管在浏览器中会看到同样的内容,但这也为更加标准化的网站奠定了基础。继续在 `index.html` 中写入这些内容并通过浏览器查看。
```
<!DOCTYPE HTML PUBLIC "-//w3c//DD HTML 4.0//EN">
<html>
<head>
<title>My Web Page</title>
</head>
<body>
<h1>Hello World</h1>
</body>
</html>
```
我使用这些技术搭建了一些静态网站,但我的生活正在改变。
### 动态网页
我找了一份新工作,这份工作的主要任务就是创建并维护用于一个动态网站的 CGI(<ruby> <a href="https://en.wikipedia.org/wiki/Common_Gateway_Interface"> 公共网关接口 </a> <rt> Common Gateway InterfaceM </rt></ruby>)代码。字面意思来看,动态意味着在浏览器中生成的网页所需要的 HTML 是由每次访问页面时不同的数据所生成的。这些数据包括网页表单中的用户输入,以用来在数据库中进行数据查找,结果数据被一些恰当的 HTML 包围着并展示在所请求的浏览器中。但是这不需要非常复杂。
通过使用 CGI 脚本,你可以创建一些简单或复杂的交互式程序,通过运行这些程序能够生成基于输入、计算、服务器的当前条件等改变的动态页面。有许多种语言可以用来写 CGI 脚本,在这篇文章中,我将谈到的是 Perl 和 Bash ,其他非常受欢迎的 CGI 语言包括 PHP 和 Python 。
这篇文章不会介绍 Apache 或其他任何 web 服务器的安装和配置。如果你能够访问一个你可以进行实验的 Web 服务器,那么你可以直接查看它们在浏览器中出现的结果。否则,你可以在命令行中运行程序来查看它们所创建的 HTML 文本。你也可以重定向 HTML 输出到一个文件中,然后通过浏览器查看结果文件。
### 使用 Perl
Perl 是一门非常受欢迎的 CGI 脚本语言,它的优势是强大的文本操作能力。
为了使 CGI 脚本可执行,你需要在你的网站的 `httpd.conf` 中添加下面这行内容。这会告诉服务器可执行 CGI 文件的位置。在这次实验中,不必担心这个问题。
```
ScriptAlias /cgi-bin/ "/var/www/cgi-bin/"
```
把下面的 Perl 代码添加到文件 `index.cgi`,在这次实验中,这个文件应该放在你的家目录下。如果你使用 Web 服务器,那么应把文件的所有者更改为 `apache.apache`,同时将文件权限设置为 755,因为无论位于哪,它必须是可执行的。
```
#!/usr/bin/perl
print "Content-type: text/html\n\n";
print "<html><body>\n";
print "<h1>Hello World</h1>\n";
print "Using Perl<p>\n";
print "</body></html>\n";
```
在命令行中运行这个程序并查看结果,它将会展示出它所生成的 HTML 内容
现在,在浏览器中查看 `index.cgi` 文件,你所看到的只是文件的内容。浏览器需要将它看做 CGI 内容,但是,Apache 不知道需要将这个文件作为 CGI 程序运行,除非 Apache 的配置中包括上面所展示的 `ScriptAlias` 定义。没有这一配置,Apache 只会简单地将文件中的数据发送给浏览器。如果你能够访问 Web 服务器,那么你可以将可执行文件放到 `/var/www/cgi-bin` 目录下。
如果想知道这个脚本的运行结果在浏览器中长什么样,那么,重新运行程序并把输出重定向到一个新文件,名字可以是任何你想要的。然后使用浏览器来查看这一文件,它包含了脚本所生成的内容。
上面这个 CGI 程序依旧生成静态内容,因为它总是生成相同的输出。把下面这行内容添加到 CGI 程序中 “Hello, world” 这一行后面。Perl 的 `system` 命令将会执行跟在它后面的 shell 命令,并把结果返回给程序。此时,我们将会通过 `free` 命令获得当前的内存使用量。
```
system "free | grep Mem\n";
```
现在,重新运行这个程序,并把结果重定向到一个文件,在浏览器中重新加载这个文件。你将会看到额外的一行,它展示了系统的内存统计数据。多次运行程序并刷新浏览器,你将会发现,内存使用量应该是不断变化的。
### 使用 Bash
Bash 可能是用于 CGI 脚本中最简单的语言。用 Bash 来进行 CGI 编程的最大优势是它能够直接访问所有的标准 GNU 工具和系统程序。
把已经存在的 `index.cgi` 文件重命名为 `Perl.index.cgi`,然后创建一个新的 `index.cgi 文件并添加下面这些内容。记得设置权限使它可执行。
```
#!/bin/bash
echo "Content-type: text/html"
echo ""
echo '<html>'
echo '<head>'
echo '<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">'
echo '<title>Hello World</title>'
echo '</head>'
echo '<body>'
echo '<h1>Hello World</h1><p>'
echo 'Using Bash<p>'
free | grep Mem
echo '</body>'
echo '</html>'
exit 0
```
在命令行中执行这个文件并查看输出,然后再次运行并把结果重定向到一个临时结果文件中。然后,刷新浏览器查看它所展示的网页是什么样子。
### 结论
创建能够生成许多种动态网页的 CGI 程序实际上非常简单。尽管这是一个很简单的例子,但是现在你应该看到一些可能性了。
---
via: <https://opensource.com/article/17/12/cgi-scripts>
作者:[David Both](https://opensource.com/users/dboth) 译者:[ucasFL](https://github.com/ucasFL) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Back in the stone age of the Internet when I first created my first business website, life was good.
I installed Apache and created a few simple HTML pages that stated a few important things about my business and gave important information like an overview of my product and how to contact me. It was a static website because the content seldom changed. Maintenance was simple because of the unchanging nature of my site.
## Static content
Static content is easy and still common. Let's take a quick look at a couple sample static web pages. You don't need a working website to perform these little experiments. Just place the files in your home directory and open them with your browser. You will see exactly what you would if the file were served to your browser via a web server.
The first thing you need on a static website is the index.html file which is usually located in the /var/www/html directory. This file can be as simple as a text phrase such as “Hello world” without any HTML markup at all. This would simply display the text string. Create index.html in your home directory and add “Hello world” (without the quotes) as it's only content. Open the index.html in your browser with the following URL.
```
````file:///home/<yourhomedirectory>/index.html`
So HTML is not required, but if you had a large amount of text that needed formatting, the results of a web page with no HTML coding would be incomprehensible with everything running together.
So the next step is to make the content more readable by using a bit of HTML coding to provide some formatting. The following command creates a page with the absolute minimum markup required for a static web page with HTML. You could also use your favorite editor to create the content.
```
````echo "<h1>Hello World</h1>" > test1.html`
Now view index.html and see the difference.
Of course you can put a lot of additional HTML around the actual content line to make a more complete and standard web page. That more complete version as shown below will still display the same results in the browser, but it also forms the basis for more standardized web site. Go ahead and use this content for your index.html file and display it in your browser.
```
``````
<!DOCTYPE HTML PUBLIC "-//w3c//DD HTML 4.0//EN">
<html>
<head>
<title>My Web Page</title>
</head>
<body>
<h1>Hello World</h1>
</body>
</html>
```
I built a couple static websites using these techniques, but my life was about to change.
## Dynamic web pages for a new job
I took a new job in which my primary task was to create and maintain the CGI ([Common Gateway Interface](https://en.wikipedia.org/wiki/Common_Gateway_Interface)) code for a very dynamic website. In this context, dynamic means that the HTML needed to produce the web page on a browser was generated from data that could be different every time the page was accessed. This includes input from the user on a web form that is used to look up data in a database. The resulting data is surrounded by appropriate HTML and displayed on the requesting browser. But it does not need to be that complex.
Using CGI scripts for a website allows you to create simple or complex interactive programs that can be run to provide a dynamic web page that can change based on input, calculations, current conditions in the server, and so on. There are many languages that can be used for CGI scripts. We will look at two of them, Perl and Bash. Other popular CGI languages include PHP and Python.
This article does not cover installation and setup of Apache or any other web server. If you have access to a web server that you can experiment with, you can directly view the results as they would appear in a browser. Otherwise, you can still run the programs from the command line and view the HTML that would be created. You can also redirect that HTML output to a file and then display the resulting file in your browser.
## Using Perl
Perl is a very popular language for CGI scripts. Its strength is that it is a very powerful language for the manipulation of text.
To get CGI scripts to execute, you need the following line in the in httpd.conf for the website you are using. This tells the web server where your executable CGI files are located. For this experiment, let's not worry about that.
```
````ScriptAlias /cgi-bin/ "/var/www/cgi-bin/"`
Add the following Perl code to the file index.cgi, which should be located in your home directory for your experimentation. Set the ownership of the file to apache.apache when you use a web server, and set the permissions to 755 because it must be executable no matter where it is located.
```
``````
#!/usr/bin/perl
print "Content-type: text/html\n\n";
print "<html><body>\n";
print "<h1>Hello World</h1>\n";
print "Using Perl<p>\n";
print "</body></html>\n";
```
Run this program from the command line and view the results. It should display the HTML code it will generate.
Now view the index.cgi in your browser. Well, all you get is the contents of the file. Browsers really need to have this delivered as CGI content. Apache does not really know that it needs to run the file as a CGI program unless the Apache configuration for the web site includes the "ScriptAlias" definition as shown above. Without that bit of configuration Apache simply send the data in the file to the browser. If you have access to a web server, you could try this out with your executable index files in the /var/www/cgi-bin directory.
To see what this would look like in your browser, run the program again and redirect the output to a new file. Name it whatever you want. Then use your browser to view the file that contains the generated content.
The above CGI program is still generating static content because it always displays the same output. Add the following line to your CGI program immediately after the “Hello World” line. The Perl “system” command executes the commands following it in a system shell, and returns the result to the program. In this case, we simply grep the current RAM usage out of the results from the free command.
```
````system "free | grep Mem\n";`
Now run the program again and redirect the output to the results file. Reload the file in the browser. You should see an additional line so that displays the system memory statistics. Run the program and refresh the browser a couple more times and notice that the memory usage should change occasionally.
## Using Bash
Bash is probably the simplest language of all for use in CGI scripts. Its primary strength for CGI programming is that it has direct access to all of the standard GNU utilities and system programs.
Rename the existing index.cgi to Perl.index.cgi and create a new index.cgi with the following content. Remember to set the permissions correctly to executable.
```
``````
#!/bin/bash
echo "Content-type: text/html"
echo ""
echo '<html>'
echo '<head>'
echo '<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">'
echo '<title>Hello World</title>'
echo '</head>'
echo '<body>'
echo '<h1>Hello World</h1><p>'
echo 'Using Bash<p>'
free | grep Mem
echo '</body>'
echo '</html>'
exit 0
```
Execute this program from the command line and view the output, then run it and redirect the output to the temporary results file you created before. Then refresh the browser to view what it looks like displayed as a web page.
## Conclusion
It is actually very simple to create CGI programs that can be used to generate a wide range of dynamic web pages. This is a trivial example but you should now see some of the possibilities.
## 2 Comments |
9,515 | Oh My Fish! 让你的 Shell 漂亮起来 | https://www.ostechnix.com/oh-fish-make-shell-beautiful/ | 2018-04-04T21:36:00 | [
"Fish"
] | https://linux.cn/article-9515-1.html | 
几天前,我们讨论了如何[安装 Fish shell](https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/),这是一个健壮的、完全可用的 shell,带有许多很酷的功能,如自动建议、内置搜索功能、语法高亮显示、基于 web 配置等等。今天,我们将讨论如何使用 Oh My Fish (简称 `omf` ) ,让我们的 Fish shell 变得漂亮且优雅。它是一个 Fishshell 框架,允许你安装扩展或更改你的 shell 外观的软件包。它简单易用,快速可扩展。使用 `omf`,你可以根据你的想法,很容易地安装主题,丰富你的外观和安装插件来调整你的 Fish shell。
### 安装 Oh My Fish
安装 omf 很简单。你要做的只是在你的 Fish shell 中运行下面的命令。
```
curl -L https://get.oh-my.fish | fish
```

一旦安装完成,你将看到提示符已经自动更改,如上图所所示。另外,你会注意到当前时间在 shell 窗口的右边。
就是这样。让我们继续并调整我们的 fish shell。
### 现在,让我们将 Fish Shell 变漂亮
列出所有的安装包,运行:
```
omf list
```
这条命令将显示已安装的主题和插件。请注意,包可以是主题或插件。安装包意味着安装主题和插件。
所有官方和社区支持的包(包括插件和主题)都托管在 [Omf 主仓库](https://github.com/oh-my-fish) 中。在这个主仓库中,你可以看到大量的仓库,其中包含大量的插件和主题。
现在让我们看一下可用的和已安装的主题列表。为此,运行:
```
omf theme
```

如你所见,我们只有一个已安装的主题,这是默认的,但是还有大量可用的主题。在安装之前,你在[这里](https://github.com/oh-my-fish/oh-my-fish/blob/master/docs/Themes.md)可以预览所有可用的主题。这个页面包含了所有的主题细节,特性,每个主题的截图示例,以及哪个主题适合谁。
#### 安装一个新主题
请允许我安装一个主题,例如 clearance 主题,这是一个极简的 fish shell 主题,供那些经常使用 `git` 的人使用。为此,运行:
```
omf install clearance
```

如上图所示,在安装新主题后,Fish shell 的提示立即发生了变化。
让我浏览一下系统文件,看看它如何显示。

看起来不错!这是一个非常简单的主题。它将当前工作目录,文件夹和文件以不同的颜色区分开来。你可能会注意到,它还会在提示符的顶部显示当前工作目录。现在,clearance 是我的默认主题。
#### 改变主题
就像我之前说的一样,这个主题在安装后被立即应用。如果你有多个主题,你可以使用以下命令切换到另一个不同的主题:
```
omf theme <theme-name>
```
例如:
```
omf theme agnoster
```
现在我正在使用 agnoster 主题。 agnoster 就是这样改变了我 shell 的外观。

#### 安装插件
例如,我想安装一个天气插件。为此,只要运行:
```
omf install weather
```
天气插件依赖于 [jq](https://stedolan.github.io/jq/)(LCTT 译注:jq 是一个轻量级且灵活的命令行JSON处理器)。所以,你可能也需要安装 `jq`。它通常在 Linux 发行版的默认仓库中存在。因此,你可以使用默认的包管理器来安装它。例如,以下命令将在 Arch Linux 及其衍生版中安装 `jq`。
```
sudo pacman -S jq
```
现在,在 Fish shell 中使用以下命令查看天气:
```
weather
```

#### 寻找包
要搜索主题或插件,请执行以下操作:
```
omf search <search_string>
```
例如:
```
omf search nvm
```
为了限制搜索的主题范围,使用 `-t` 选项。
```
omf search -t chain
```
这条命令只会搜索主题名字中包含 “chain” 的主题。
为了限制搜索的插件范围,使用 `-p` 选项。
```
omf search -p emacs
```
#### 更新包
要仅更新核心功能(`omf` 本身),运行:
```
omf update omf
```
如果是最新的,你会看到以下输出:
```
Oh My Fish is up to date.
You are now using Oh My Fish version 6.
Updating https://github.com/oh-my-fish/packages-main master... Done!
```
更新所有包:
```
omf update
```
要有选择地更新软件包,只需包含如下所示的包名称:
```
omf update clearance agnoster
```
#### 显示关于包的信息
当你想知道关于一个主题或插件的信息时,使用以下命令:
```
omf describe clearance
```
这条命令将显示关于包的信息。
```
Package: clearance
Description: A minimalist fish shell theme for people who use git
Repository: https://github.com/oh-my-fish/theme-clearance
Maintainer:
```
#### 移除包
移除一个包,例如 emacs,运行:
```
omf remove emacs
```
#### 管理仓库
默认情况下,当你安装了 Oh My Fish 时,会自动添加官方仓库。这个仓库包含了开发人员构建的所有包。要管理用户安装的仓库包,使用这条命令:
```
omf repositories [list|add|remove]
```
列出所有安装的仓库,运行:
```
omf repositories list
```
添加一个仓库:
```
omf repositories add <URL>
```
例如:
```
omf repositories add https://github.com/ostechnix/theme-sk
```
移除一个仓库:
```
omf repositories remove <repository-name>
```
#### Oh My Fish 排错
如果出现了错误,`omf` 足够聪明来帮助你,它可以列出解决问题的方法。例如,我安装了 clearance 包,得到了文件冲突的错误。幸运的是,在继续之前,Oh My Fish 会指示我该怎么做。因此,我只是简单地运行了以下代码来了解如何修正错误。
```
omf doctor
```
通过运行以下命令来解决错误:
```
rm ~/.config/fish/functions/fish_prompt.fish
```

无论你何时遇到问题,只要运行 `omf doctor` 命令,并尝试所有的建议方法。
#### 获取帮助
显示帮助部分,运行:
```
omf -h
```
或者
```
omf --help
```
#### 卸载 Oh My Fish
卸载 Oh My Fish,运行以下命令:
```
omf destroy
```
继续前进,开始自定义你的 fish shell。获取更多细节,请参考项目的 GitHub 页面。
这就是全部了。我很快将会在这里开始另一个有趣的指导。在此之前,请继续关注我们!
干杯!
---
via: <https://www.ostechnix.com/oh-fish-make-shell-beautiful/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,516 | 如何知道 CPU 是否支持虚拟化技术(VT) | https://www.ostechnix.com/how-to-find-if-a-cpu-supports-virtualization-technology-vt/ | 2018-04-05T21:29:21 | [
"VT",
"虚拟化"
] | https://linux.cn/article-9516-1.html | 
我们已经知道如何[检查你的 Linux 操作系统是 32 位还是 64 位](https://www.ostechnix.com/check-linux-system-32-bit-64-bit/)以及如何[知道你的 Linux 系统是物理机还是虚拟机](https://www.ostechnix.com/check-linux-system-physical-virtual-machine/)。今天,我们将学习另一个有用的话题 - 如何知道 CPU 是否支持虚拟化技术 (VT)?在安装虚拟化程序(如 VirtualBox 或 VMWare workstation)以在 Linux 系统上运行虚拟机之前,你应该首先验证这一点。现在让我们来看看你的电脑是否支持 VT。相信我,这真的很简单!
### 了解 CPU 是否支持虚拟化技术 (VT)
我们可以通过几种方法检查 CPU 是否支持 VT。在这里我向你展示四种方法。
#### 方法 1:使用 egrep 命令
`egrep` 是 [grep](https://www.ostechnix.com/the-grep-command-tutorial-with-examples-for-beginners/) 命令的变体之一,用于使用正则表达式搜索文本文件。为了本指南的目的,我们将 grep `/cpu/procinfo/` 文件来确定 CPU 是否支持 VT。
要使用 `egrep` 命令查明你的CPU是否支持VT,请运行:
```
$ egrep "(svm|vmx)" /proc/cpuinfo
```
示例输出:
你将在输出中看到 `vmx`(Intel-VT 技术)或 `svm` (AMD-V 支持)。
```
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer xsave avx lahf_lm epb pti tpr_shadow vnmi flexpriority ept vpid xsaveopt dtherm arat pln pts
[...]
```
由于输出很长,你可能会发现很难在输出中找到 `vmx` 或 `svm`。别担心!你可以像下面那样用颜色来区分这些术语。
```
$ egrep --color -i "svm|vmx" /proc/cpuinfo
```

如果你没有看到任何输出,这意味着你的系统不支持虚拟化。
请注意,`cpuinfo` 中的这些 CPU 标志(`vmx` 或 `svm`)表示你的系统支持 VT。在某些 CPU 型号中,默认情况下,可能会在 BIOS 中禁用 VT 支持。在这种情况下,你应该检查 BIOS 设置以启用 VT 支持。
有关 `grep`/`egrep` 命令的更多详细信息,请参阅手册页。
```
$ man grep
```
#### 方法 2: 使用 lscpu 命令
`lscpu` 命令用于显示有关 CPU 架构的信息。它从 `sysfs`、`/proc/cpuinfo` 收集信息,并显示主机系统的 CPU、线程、内核、套接字和非统一内存访问 (NUMA) 节点的数量。
要确定是否启用 VT 支持,只需运行:
```
$ lscpu
```

有关更多详细信息,请查看手册页。
```
$ man lscpu
```
#### 方法 3:使用 cpu-checker 工具
cpu-checker 是另一个有用的工具,用于测试你的 CPU 是否支持虚拟化。就我在网上搜索得到的,该程序仅适用于基于 Ubuntu 的系统。要安装它,请运行:
```
$ sudo apt-get install cpu-checker
```
安装 cpu-checker 包之后,运行以下命令来检查是否启用 VT 支持:
```
$ sudo kvm-ok
```
如果您的 CPU 支持 VT,你将得到以下输出:
```
INFO: /dev/kvm exists
KVM acceleration can be used
```
如果你的 CPU 不支持 VT,你会看到如下的输出。
```
INFO: Your CPU does not support KVM extensions
KVM acceleration can NOT be used
```
#### 方法 4:使用 virt-host-validate 工具
该工具专门用于基于 RHEL 的发行版,如 CentOS 和 Scientific Linux。 libvirt-client 包提供 `virt-host-validate` 二进制文件。所以你需要安装 libvert-client 包来使用这个工具。
```
$ sudo yum install libvirt-client
```
现在,运行 `virt-host-validate` 命令来确定基于 RHEL 的系统中是否启用了 VT。
```
$ sudo virt-host-validate
```
如果所有的结果是 `pass`,那么你的系统支持 VT。
```
QEMU: Checking for hardware virtualization : PASS
QEMU: Checking if device /dev/vhost-net exists : PASS
QEMU: Checking if device /dev/net/tun exists : PASS
QEMU: Checking for cgroup 'memory' controller support : PASS
QEMU: Checking for cgroup 'memory' controller mount-point : PASS
QEMU: Checking for cgroup 'cpu' controller support : PASS
QEMU: Checking for cgroup 'cpu' controller mount-point : PASS
QEMU: Checking for cgroup 'cpuacct' controller support : PASS
QEMU: Checking for cgroup 'cpuacct' controller mount-point : PASS
QEMU: Checking for cgroup 'cpuset' controller support : PASS
QEMU: Checking for cgroup 'cpuset' controller mount-point : PASS
QEMU: Checking for cgroup 'devices' controller support : PASS
QEMU: Checking for cgroup 'devices' controller mount-point : PASS
QEMU: Checking for cgroup 'blkio' controller support : PASS
QEMU: Checking for cgroup 'blkio' controller mount-point : PASS
QEMU: Checking for device assignment IOMMU support : PASS
LXC: Checking for Linux >= 2.6.26 : PASS
LXC: Checking for namespace ipc : PASS
LXC: Checking for namespace mnt : PASS
LXC: Checking for namespace pid : PASS
LXC: Checking for namespace uts : PASS
LXC: Checking for namespace net : PASS
LXC: Checking for namespace user : PASS
LXC: Checking for cgroup 'memory' controller support : PASS
LXC: Checking for cgroup 'memory' controller mount-point : PASS
LXC: Checking for cgroup 'cpu' controller support : PASS
LXC: Checking for cgroup 'cpu' controller mount-point : PASS
LXC: Checking for cgroup 'cpuacct' controller support : PASS
LXC: Checking for cgroup 'cpuacct' controller mount-point : PASS
LXC: Checking for cgroup 'cpuset' controller support : PASS
LXC: Checking for cgroup 'cpuset' controller mount-point : PASS
LXC: Checking for cgroup 'devices' controller support : PASS
LXC: Checking for cgroup 'devices' controller mount-point : PASS
LXC: Checking for cgroup 'blkio' controller support : PASS
LXC: Checking for cgroup 'blkio' controller mount-point : PASS
```
如果你的系统不支持 VT,你会看到下面的输出。
```
QEMU: Checking for hardware virtualization : FAIL (Only emulated CPUs are available, performance will be significantly limited)
[...]
```
就是这样了。在本文中,我们讨论了确定 CPU 是否支持 VT 的不同方法。如你所见,这很简单。希望这个有用。还有更多好的东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-find-if-a-cpu-supports-virtualization-technology-vt/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,517 | 在 Git 中怎样克隆、修改、添加和删除文件? | https://opensource.com/article/18/2/how-clone-modify-add-delete-git-files | 2018-04-05T22:16:16 | [
"git"
] | https://linux.cn/article-9517-1.html | 
在 [本系列的第一篇文章](/article-9319-1.html) 开始使用 Git 时,我们创建了一个简单的 Git 仓库,并用我们的计算机连接到它,向其中添加一个文件。在本文中,我们将学习一些关于 Git 的其他内容,即如何克隆(下载)、修改、添加和删除 Git 仓库中的文件。
### 让我们来克隆一下
假设你在 GitHub 上已经有一个 Git 仓库,并且想从它那里获取你的文件——也许你在你的计算机上丢失了本地副本,或者你正在另一台计算机上工作,但是想访问仓库中的文件,你该怎么办?从 GitHub 下载你的文件?没错!在 Git 术语中我们称之为“<ruby> 克隆 <rt> clone </rt></ruby>”。(你也可以将仓库作为 ZIP 文件下载,但我们将在本文中探讨克隆方式。)
让我们克隆在上一篇文章中创建的名为 Demo 的仓库。(如果你还没有创建 Demo 仓库,请跳回到[那篇文章](/article-9319-1.html)并在继续之前执行那些步骤)要克隆文件,只需打开浏览器并导航到 `https://github.com/<your_username>/Demo` (其中 `<your_username>` 是你仓库的名称。例如,我的仓库是 `https://github.com/kedark3/Demo`)。一旦你导航到该 URL,点击“<ruby> 克隆或下载 <rt> Clone or download </rt></ruby>”按钮,你的浏览器看起来应该是这样的:

正如你在上面看到的,“<ruby> 使用 HTTPS 克隆 <rt> Clone with HTTPS </rt></ruby>”选项已打开。从该下拉框中复制你的仓库地址(`https://github.com/<your_username>/Demo.git`),打开终端并输入以下命令将 GitHub 仓库克隆到你的计算机:
```
git clone https://github.com/<your_username>/Demo.git
```
然后,要查看 `Demo` 目录中的文件列表,请输入以下命令:
```
ls Demo/
```
终端看起来应该是这样的:

### 修改文件
现在我们已经克隆了仓库,让我们修改文件并在 GitHub 上更新它们。首先,逐个输入下面的命令,将目录更改为 `Demo/`,检查 `README.md` 中的内容,添加新的(附加的)内容到 `README.md`,然后使用 `git status` 检查状态:
```
cd Demo/
ls
cat README.md
echo "Added another line to REAMD.md" >> README.md
cat README.md
git status
```
如果你逐一运行这些命令,终端看起开将会是这样:

让我们看一下 `git status` 的输出,并了解它的意思。不要担心这样的语句:
```
On branch master
Your branch is up-to-date with 'origin/master'.".
```
因为我们还没有学习这些。(LCTT 译注:学了你就知道了)下一行说:`Changes not staged for commit`(变化未筹划提交);这是告诉你,它下面列出的文件没有被标记准备(“<ruby> 筹划 <rt> stage </rt></ruby>”)提交。如果你运行 `git add`,Git 会把这些文件标记为 `Ready for commit`(准备提交);换句话说就是 `Changes staged for commit`(变化筹划提交)。在我们这样做之前,让我们用 `git diff` 命令来检查我们添加了什么到 Git 中,然后运行 `git add`。
这里是终端输出:

我们来分析一下:
* `diff --git a/README.md b/README.md` 是 Git 比较的内容(在这个例子中是 `README.md`)。
* `--- a/README.md` 会显示从文件中删除的任何东西。
* `+++ b/README.md` 会显示从文件中添加的任何东西。
* 任何添加到文件中的内容都以绿色文本打印,并在该行的开头加上 `+` 号。
* 如果我们删除了任何内容,它将以红色文本打印,并在该行的开头加上 `-` 号。
* 现在 `git status` 显示 `Changes to be committed:`(变化将被提交),并列出文件名(即 `README.md`)以及该文件发生了什么(即它已经被 `modified` 并准备提交)。
提示:如果你已经运行了 `git add`,现在你想看看文件有什么不同,通常 `git diff` 不会输出任何东西,因为你已经添加了文件。相反,你必须使用 `git diff --cached`。它会告诉你 Git 添加的当前版本和以前版本文件之间的差别。你的终端输出看起来会是这样:

### 上传文件到你的仓库
我们用一些新内容修改了 `README.md` 文件,现在是时候将它上传到 GitHub。
让我们提交更改并将其推送到 GitHub。运行:
```
git commit -m "Updated Readme file"
```
这告诉 Git 你正在“提交”已经“添加”的更改,你可能还记得,从本系列的第一部分中,添加一条消息来解释你在提交中所做的操作是非常重要的,以便你在稍后回顾 Git 日志时了解当时的目的。(我们将在下一篇文章中更多地关注这个话题。)`Updated Readme file` 是这个提交的消息——如果你认为这没有合理解释你所做的事情,那么请根据需要写下你的提交消息。
运行 `git push -u origin master`,这会提示你输入用户名和密码,然后将文件上传到你的 GitHub 仓库。刷新你的 GitHub 页面,你应该会看到刚刚对 `README.md` 所做的更改。

终端的右下角显示我提交了更改,检查了 Git 状态,并将更改推送到了 GitHub。`git status` 显示:
```
Your branch is ahead of 'origin/master' by 1 commit
(use "git push" to publish your local commits)
```
第一行表示在本地仓库中有一个提交,但不在 `origin/master` 中(即在 GitHub 上)。下一行指示我们将这些更改推送到 `origin/master` 中,这就是我们所做的。(在本例中,请参阅本系列的第一篇文章,以唤醒你对 `origin` 含义的记忆。我将在下一篇文章中讨论分支的时候,解释 `master` 的含义。)
### 添加新文件到 Git
现在我们修改了一个文件并在 GitHub 上更新了它,让我们创建一个新文件,将它添加到 Git,然后将其上传到 GitHub。 运行:
```
echo "This is a new file" >> file.txt
```
这将会创建一个名为 `file.txt` 的新文件。
如果使用 `cat` 查看它:
```
cat file.txt
```
你将看到文件的内容。现在继续运行:
```
git status
```
Git 报告说你的仓库中有一个未跟踪的文件(名为 `file.txt`)。这是 Git 告诉你说在你的计算机中的仓库目录下有一个新文件,然而你并没有告诉 Git,Git 也没有跟踪你所做的任何修改。

我们需要告诉 Git 跟踪这个文件,以便我们可以提交并上传文件到我们的仓库。以下是执行该操作的命令:
```
git add file.txt
git status
```
终端输出如下:

`git status` 告诉你有 `file.txt` 被修改,对于 Git 来说它是一个 `new file`,Git 在此之前并不知道。现在我们已经为 Git 添加了 `file.txt`,我们可以提交更改并将其推送到 `origin/master`。

Git 现在已经将这个新文件上传到 GitHub;如果刷新 GitHub 页面,则应该在 GitHub 上的仓库中看到新文件 `file.txt`。

通过这些步骤,你可以创建尽可能多的文件,将它们添加到 Git 中,然后提交并将它们推送到 GitHub。
### 从 Git 中删除文件
如果我们发现我们犯了一个错误,并且需要从我们的仓库中删除 `file.txt`,该怎么办?一种方法是使用以下命令从本地副本中删除文件:
```
rm file.txt
```
如果你现在做 `git status`,Git 就会说有一个文件 `not staged for commit`(未筹划提交),并且它已经从仓库的本地拷贝中删除了。如果我们现在运行:
```
git add file.txt
git status
```
我知道我们正在删除这个文件,但是我们仍然运行 `git add`,因为我们需要告诉 Git 我们正在做的**更改**,`git add` 可以用于我们添加新文件、修改一个已存在文件的内容、或者从仓库中删除文件时。实际上,`git add` 将所有更改考虑在内,并将这些筹划提交这些更改。如果有疑问,请仔细查看下面终端屏幕截图中每个命令的输出。
Git 会告诉我们已删除的文件正在进行提交。只要你提交此更改并将其推送到 GitHub,该文件也将从 GitHub 的仓库中删除。运行以下命令:
```
git commit -m "Delete file.txt"
git push -u origin master
```
现在你的终端看起来像这样:

你的 GitHub 看起来像这样:

现在你知道如何从你的仓库克隆、添加、修改和删除 Git 文件。本系列的下一篇文章将检查 Git 分支。
---
via: <https://opensource.com/article/18/2/how-clone-modify-add-delete-git-files>
作者:[Kedar Vijay Kulkarni](https://opensource.com/users/kkulkarn) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the [first article in this series](https://opensource.com/article/18/1/step-step-guide-git) on getting started with Git, we created a simple Git repo and added a file to it by connecting it with our computer. In this article, we will learn a handful of other things about Git, namely how to clone (download), modify, add, and delete files in a Git repo.
## Let's make some clones
Say you already have a Git repo on GitHub and you want to get your files from it—maybe you lost the local copy on your computer or you're working on a different computer and want access to the files in your repository. What should you do? Download your files from GitHub? Exactly! We call this "cloning" in Git terminology. (You could also download the repo as a ZIP file, but we'll explore the clone method in this article.)
Let's clone the repo, called *Demo*, we created in the last article. (If you have not yet created a *Demo* repo, jump back to that article and do those steps before you proceed here.) To clone your file, just open your browser and navigate to `https://github.com/<your_username>/Demo`
(where `<your_username>`
is the name of your own repo. For example, my repo is `https://github.com/kedark3/Demo`
). Once you navigate to that URL, click the "Clone or download" button, and your browser should look something like this:
opensource.com
As you can see above, the "Clone with HTTPS" option is open. Copy your repo's URL from that dropdown box (`https://github.com/<your_username>/Demo.git`
). Open the terminal and type the following command to clone your GitHub repo to your computer:
```
````git clone https://github.com/<your_username>/Demo.git`
Then, to see the list of files in the `Demo`
directory, enter the command:
```
````ls Demo/`
Your terminal should look like this:
opensource.com
## Modify files
Now that we have cloned the repo, let's modify the files and update them on GitHub. To begin, enter the commands below, one by one, to change the directory to `Demo/`
, check the contents of `README.md`
, echo new (additional) content to `README.md`
, and check the status with `git status`
:
```
``````
cd Demo/
ls
cat README.md
echo "Added another line to REAMD.md" >> README.md
cat README.md
git status
```
This is how it will look in the terminal if you run these commands one by one:
opensource.com
Let's look at the output of `git status`
and walk through what it means. Don't worry about the part that says:
```
``````
On branch master
Your branch is up-to-date with 'origin/master'.".
```
because we haven't learned it yet. The next line says: `Changes not staged for commit`
; this is telling you that the files listed below it aren't marked ready ("staged") to be committed. If you run `git add`
, Git takes those files and marks them as `Ready for commit`
; in other (Git) words, `Changes staged for commit`
. Before we do that, let's check what we are adding to Git with the `git diff`
command, then run `git add`
.
Here is your terminal output:
opensource.com
Let's break this down:
`diff --git a/README.md b/README.md`
is what Git is comparing (i.e.,`README.md`
in this example).`--- a/README.md`
would show anything removed from the file.`+++ b/README.md`
would show anything added to your file.- Anything added to the file is printed in green text with a + at the beginning of the line.
- If we had removed anything, it would be printed in red text with a - sign at the beginning.
- Git status now says
`Changes to be committed:`
and lists the filename (i.e.,`README.md`
) and what happened to that file (i.e., it has been`modified`
and is ready to be committed).
Tip: If you have already run `git add`
, and now you want to see what's different, the usual `git diff`
won't yield anything because you already added the file. Instead, you must use `git diff --cached`
. It will show you the difference between the current version and previous version of files that Git was told to add. Your terminal output would look like this:
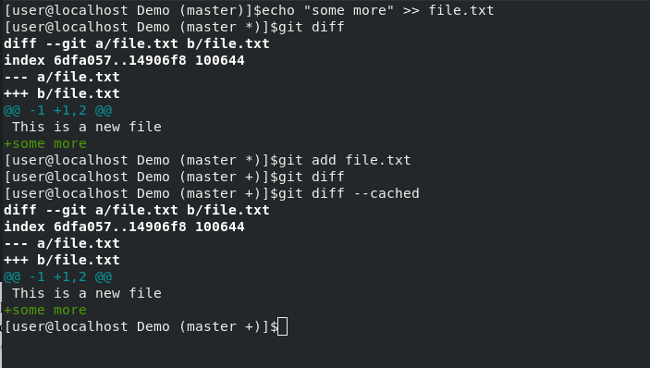
opensource.com
## Upload a file to your repo
We have modified the `README.md`
file with some new content and it's time to upload it to GitHub.
Let's commit the changes and push those to GitHub. Run:
```
````git commit -m "Updated Readme file"`
This tells Git that you are "committing" to changes that you have "added" to it. You may recall from the first part of this series that it's important to add a message to explain what you did in your commit so you know its purpose when you look back at your Git log later. (We will look more at this topic in the next article.) `Updated Readme file`
is the message for this commit—if you don't think this is the most logical way to explain what you did, feel free to write your commit message differently.
Run `git push -u origin master`
. This will prompt you for your username and password, then upload the file to your GitHub repo. Refresh your GitHub page, and you should see the changes you just made to `README.md`
.
opensource.com
The bottom-right corner of the terminal shows that I committed the changes, checked the Git status, and pushed the changes to GitHub. Git status says:
```
``````
Your branch is ahead of 'origin/master' by 1 commit
(use "git push" to publish your local commits)
```
The first line indicates there is one commit in the local repo but not present in origin/master (i.e., on GitHub). The next line directs us to push those changes to origin/master, and that is what we did. (To refresh your memory on what "origin" means in this case, refer to the first article in this series. I will explain what "master" means in the next article, when we discuss branching.)
## Add a new file to Git
Now that we have modified a file and updated it on GitHub, let's create a new file, add it to Git, and upload it to GitHub. Run:
```
````echo "This is a new file" >> file.txt`
This will create a new file named `file.txt`
.
If you `cat`
it out:
```
````cat file.txt`
You should see the contents of the file. Now run:
```
````git status`
Git reports that you have an untracked file (named `file.txt`
) in your repository. This is Git's way of telling you that there is a new file in the repo directory on your computer that you haven't told Git about, and Git is not tracking that file for any changes you make.
opensource.com
We need to tell Git to track this file so we can commit it and upload it to our repo. Here's the command to do that:
```
``````
git add file.txt
git status
```
Your terminal output is:
opensource.com
Git status is telling you there are changes to `file.txt`
to be committed, and that it is a `new file`
to Git, which it was not aware of before this. Now that we have added `file.txt`
to Git, we can commit the changes and push it to origin/master.
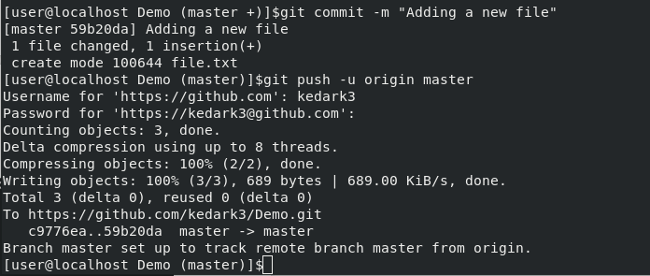
opensource.com
Git has now uploaded this new file to GitHub; if you refresh your GitHub page, you should see the new file, `file.txt`
, in your Git repo on GitHub.
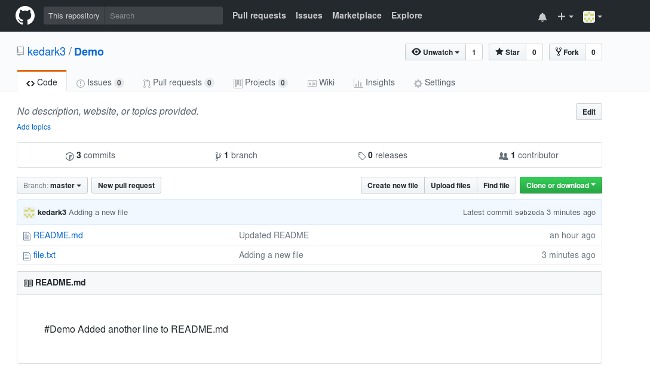
opensource.com
With these steps, you can create as many files as you like, add them to Git, and commit and push them up to GitHub.
## Delete a file from Git
What if we discovered we made an error and need to delete `file.txt`
from our repo. One way is to remove the file from our local copy of the repo with this command:
```
````rm file.txt`
If you do `git status`
now, Git says there is a file that is `not staged for commit`
and it has been `deleted`
from the local copy of the repo. If we now run:
```
``````
git add file.txt
git status
```
I know we are deleting the file, but we still run `git add`
* *because we need to tell Git about the **change** we are making. `git add`
* *can be used when we are adding a new file to Git, modifying contents of an existing file and adding it to Git, or deleting a file from a Git repo. Effectively, `git add`
takes all the changes into account and stages those changes for commit. If in doubt, carefully look at output of each command in the terminal screenshot below.
Git will tell us the deleted file is staged for commit. As soon as you commit this change and push it to GitHub, the file will be removed from the repo on GitHub as well. Do this by running:
```
``````
git commit -m "Delete file.txt"
git push -u origin master
```
Now your terminal looks like this:
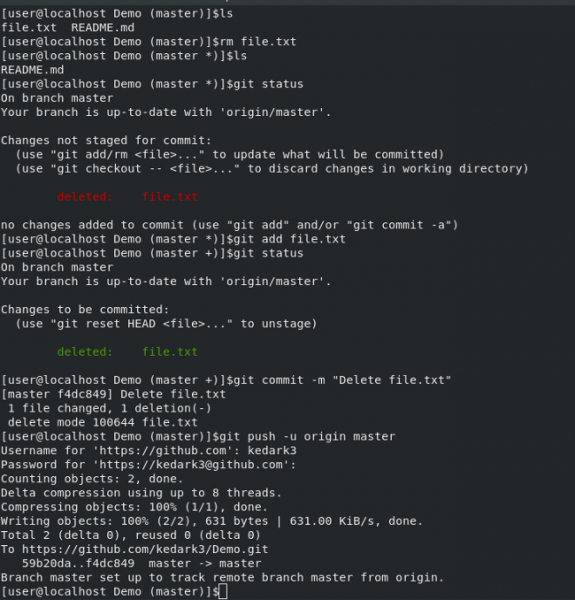
opensource.com
And your GitHub looks like this:
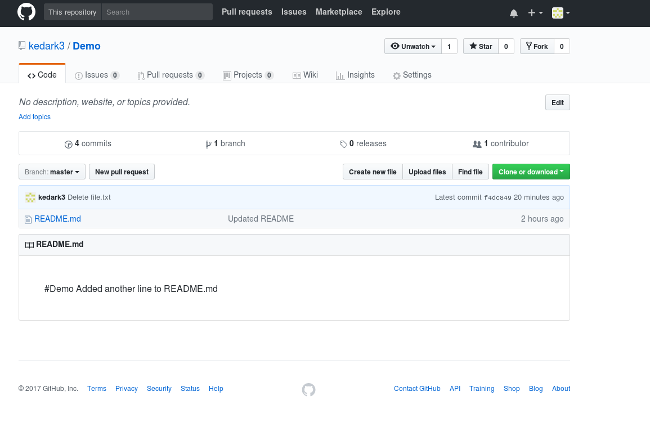
opensource.com
Now you know how to clone, add, modify, and delete Git files from your repo. The next article in this series will examine Git branching.
## 4 Comments |
9,518 | 如何记录 Linux 的系统运行时间的统计信息 | https://www.cyberciti.biz/hardware/see-records-statistics-about-a-linux-servers-uptime/ | 2018-04-05T22:57:56 | [
"uptime",
"运行时间"
] | https://linux.cn/article-9518-1.html | 
Linux/Unix 系统管理员对服务器的系统运行时间有一种奇怪的痴迷。这里有一个关于这个主题的 xkcd 漫画,一个好的系统管理员是一股不可阻挡的力量,他伫立在你家猫咪博客的服务器之前,对抗黑暗势力。
[](https://www.cyberciti.biz/media/new/cms/2017/11/devotion_to_duty.png)
我们可以使用 `uptime` 命令或 [w 命令](https://www.cyberciti.biz//www.cyberciti.biz/faq/unix-linux-w-command-examples-syntax-usage-2/ "See Linux/Unix w command examples for more info") 或 `top` 命令来判断 Linux 系统运行了多久。我可以使用 `tuptime` 工具保留每次重新启动的运行时间,以[获得系统运行时间的历史和统计报告](https://www.cyberciti.biz/hardware/howto-see-historical-statistical-uptime-on-linux-server/)。
这就像 `uptime` 命令一样,但输出结果更令人印象深刻。最近我发现了另一种称为 `uptimed` 的工具,用于记录关于机器的系统运行时间和统计信息。让我们看看如何使用 Linux 操作系统上的 `uptimed` 和 `uprecords` 来获得运行时间的记录统计信息。
查找系统运行时间非常简单,只需在基于 Linux 的系统上键入以下命令即可:
```
$ uptime -p
up 2 weeks, 4 days, 7 hours, 28 minutes
```
要保留有关 `uptime` 的历史统计信息,请使用 [tuptime](https://www.cyberciti.biz/hardware/howto-see-historical-statistical-uptime-on-linux-server/) 或 `uptimed` 工具。
### 安装 uptimed
安装 `uptimed` 的最简单的方式是通过你的软件包管理器,比如 apt/apt-get/yum 这些你的 Linux 发行版的朋友。
#### 在 Debian/Ubuntu Linux 上安装 uptimed
键入以下 [apt 命令](https://www.cyberciti.biz//www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ "See Linux/Unix apt command examples for more info")/[apt-get 命令](https://www.cyberciti.biz//www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html "See Linux/Unix apt-get command examples for more info"):
```
$ sudo apt-get install uptimed
```
示例输出:
```
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
libuptimed0
The following NEW packages will be installed:
libuptimed0 uptimed
0 upgraded, 2 newly installed, 0 to remove and 3 not upgraded.
Need to get 40.7 kB of archives.
After this operation, 228 kB of additional disk space will be used.
Do you want to continue? [Y/n] y
Get:1 http://mirrors.linode.com/ubuntu xenial/universe amd64 libuptimed0 amd64 1:0.3.17-4 [9,050 B]
Get:2 http://mirrors.linode.com/ubuntu xenial/universe amd64 uptimed amd64 1:0.3.17-4 [31.6 kB]
Fetched 40.7 kB in 0s (2,738 kB/s)
Preconfiguring packages ...
Selecting previously unselected package libuptimed0.
(Reading database ... 39163 files and directories currently installed.)
Preparing to unpack .../libuptimed0_1%3a0.3.17-4_amd64.deb ...
Unpacking libuptimed0 (1:0.3.17-4) ...
Selecting previously unselected package uptimed.
Preparing to unpack .../uptimed_1%3a0.3.17-4_amd64.deb ...
Unpacking uptimed (1:0.3.17-4) ...
Processing triggers for systemd (229-4ubuntu21) ...
Processing triggers for ureadahead (0.100.0-19) ...
Processing triggers for man-db (2.7.5-1) ...
Setting up libuptimed0 (1:0.3.17-4) ...
Setting up uptimed (1:0.3.17-4) ...
Processing triggers for libc-bin (2.23-0ubuntu9) ...
Processing triggers for systemd (229-4ubuntu21) ...
Processing triggers for ureadahead (0.100.0-19) ...
```
#### 在 CentOS/RHEL/Fedora/Oracle/Scientific Linux 上安装 uptimed
首先 [在 CentOS/RHEL 使用 EPEL 仓库](https://www.cyberciti.biz/faq/installing-rhel-epel-repo-on-centos-redhat-7-x/):
```
$ sudo yum -y install epel-release
```
然后,键入以下 [yum 命令](https://www.cyberciti.biz//www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ "See Linux/Unix yum command examples for more info"):
```
$ sudo yum install uptimed
```
示例输出:
```
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: centos.excellmedia.net
* epel: ftp.cuhk.edu.hk
* extras: centos.excellmedia.net
* updates: centos.excellmedia.net
Resolving Dependencies
--> Running transaction check
---> Package uptimed.x86_64 0:0.4.0-6.el7 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
===============================================================================
Package Arch Version Repository Size
===============================================================================
Installing:
uptimed x86_64 0.4.0-6.el7 epel 47 k
Transaction Summary
===============================================================================
Install 1 Package
Total download size: 47 k
Installed size: 98 k
Is this ok [y/d/N]: y
Downloading packages:
uptimed-0.4.0-6.el7.x86_64.rpm | 47 kB 00:01
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Installing : uptimed-0.4.0-6.el7.x86_64 1/1
Verifying : uptimed-0.4.0-6.el7.x86_64 1/1
Installed:
uptimed.x86_64 0:0.4.0-6.el7
Complete!
```
如果你正在使用 Fedora Linux,运行以下 `dnf` 命令:
```
$ sudo dnf install uptimed
```
#### 在 Arch Linux 上安装 uptimed
键入以下 `pacman` 命令:
```
$ sudo pacman -S uptimed
```
#### 在 Gentoo Linux 上安装 uptimed
键入以下 `emerge` 命令:
```
$ sudo emerge --ask uptimed
```
### 如何配置 uptimed
使用文本编辑器编辑 `/etc/uptimed.conf` 文件,例如 `vim` 命令:
```
$ sudo vim /etc/uptimed.conf
```
最少设置一个 email 地址来发送记录。假定有个兼容 sendmail 的 MTA 安装在 `/usr/lib/sendmail`。
```
[email protected]
```
保存并关闭文件。
### 如何在系统启动时启动 uptimed 服务?
使用 `systemctl` 命令启动 `uptimed` 服务:
```
$ sudo systemctl enable uptimed
```
### 我该如何 启动/停止/重启 或者查看 uptimed 服务的状态?
```
$ sudo systemctl start uptimed ## start it ##
$ sudo systemctl stop uptimed ## stop it ##
$ sudo systemctl restart uptimed ## restart it ##
$ sudo systemctl status uptimed ## view status ##
```
示例输出:
```
● uptimed.service - uptime record daemon
Loaded: loaded (/lib/systemd/system/uptimed.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2017-11-09 17:49:14 UTC; 18min ago
Main PID: 11137 (uptimed)
CGroup: /system.slice/uptimed.service
└─11137 /usr/sbin/uptimed -f
Nov 09 17:49:14 gfs04 systemd[1]: Started uptime record daemon.
```
### 如何查看 uptime 记录
只需键入以下命令即可查看 `uptimed(8)` 程序的统计信息:
```
$ uprecords
```
示例输出:
[](https://www.cyberciti.biz/media/new/cms/2017/11/uprecord-screenshot.jpg)
`uprecords` 有一些选项:
```
$ uprecords -?
```
示例输出:
```
usage: uprecords [OPTION]...
-? this help
-a do not print ansi codes
-b sort by boottime
-B reverse sort by boottime
-k sort by sysinfo
-K reverse sort by sysinfo
-d print downtime seen before every uptimes instead of system
-c do not show current entry if not in top entries
-f run continously in a loop
-s do not print extra statistics
-w wide output (more than 80 cols per line)
-i INTERVAL use INTERVAL seconds for loop instead of 5, implies -f
-m COUNT show a maximum of top COUNT entries instead of 10
-M show next milestone
-v version information
```
### 结论
这是一个极好的小工具,可以显示服务器正常运行时间的记录,以证明机器正常运行时间和你的业务连续性。在相关说明中,你可以看到官方的 [XKCD 系统管理员 T恤](https://store.xkcd.com/collections/apparel/products/sysadmin) 因为漫画被制作成衬衫,其中包括背面的新插图。
[](https://www.cyberciti.biz/media/new/cms/2017/11/sysadmin_shirt_5_1024x1024.jpg)
---
via: <https://www.cyberciti.biz/hardware/see-records-statistics-about-a-linux-servers-uptime/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,519 | 给初学者的 type 命令教程 | https://www.ostechnix.com/the-type-command-tutorial-with-examples-for-beginners/ | 2018-04-06T20:18:59 | [
"type",
"命令"
] | https://linux.cn/article-9519-1.html | 
`type` 命令用于查找 Linux 命令的信息。顾名思义,你可以使用 `type` 命令轻松找出给定的命令是否是别名、shell 内置命令、文件、函数或关键字。另外,你也可以找到命令的实际路径。为什么有人需要找到命令类型?例如,如果你经常在共享的计算机上工作,则某些人可能会故意或意外地为特定的 Linux 命令创建别名来执行不需要的操作,例如 `alias ls = rm -rf /`。因此,在发生更糟糕的事情之前检查它们总是一个好主意。这是 `type` 命令有用的地方。
让我给你看一些例子。
不带任何选项运行 `type` 命令。
```
$ type ls
ls is aliased to `ls --color=auto'
```
正如你在上面的输出中看到的那样,`ls` 命令已被别名为 `ls -color-auto`。但是,它是无害的。但只要想想 `ls` 如果被别名为了其他一些危险的命令。你不想那样,是吗?
你可以使用 `-t` 选项仅找出 Linux 命令的类型。例如:
```
$ type -t ls
alias
$ type -t mkdir
file
$ type -t pwd
builtin
$ type -t if
keyword
$ type -t rvm
function
```
该命令仅显示命令的类型,例如别名。它不显示被别名的内容。如果该命令找不到,你将在终端中看不到任何内容。
`type` 命令的另一个有用的地方是我们可以很容易地找出给定 Linux 命令的绝对路径。为此,请使用 `-p` 选项,如下所示。
```
$ type -p cal
/usr/bin/cal
```
这与 `which ls` 命令类似。如果给定的命令是别名,则不会打印任何内容。
要显示命令的所有信息,请使用 `-a` 选项。
```
$ type -a ls
ls is aliased to `ls --color=auto'
ls is /usr/bin/ls
ls is /bin/ls
```
如你所见,`-a` 标志显示给定命令的类型及其绝对路径。有关更多详细信息,请参阅手册页。
```
$ man type
```
希望这有帮助。会有更多的好东西。请继续访问!
干杯!
---
via: <https://www.ostechnix.com/the-type-command-tutorial-with-examples-for-beginners/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,520 | 让我们做个简单的解释器(二) | https://ruslanspivak.com/lsbasi-part2/ | 2018-04-07T10:31:05 | [
"解释器",
"编译器"
] | https://linux.cn/article-9520-1.html | 
在一本叫做 《高效思考的 5 要素》 的书中,作者 Burger 和 Starbird 讲述了一个关于他们如何研究 Tony Plog 的故事,他是一位举世闻名的交响曲名家,为一些有才华的演奏者开创了一个大师班。这些学生一开始演奏复杂的乐曲,他们演奏的非常好。然后他们被要求演奏非常基础简单的乐曲。当他们演奏这些乐曲时,与之前所演奏的相比,听起来非常幼稚。在他们结束演奏后,老师也演奏了同样的乐曲,但是听上去非常娴熟。差别令人震惊。Tony 解释道,精通简单音符可以让人更好的掌握复杂的部分。这个例子很清晰 —— 要成为真正的名家,必须要掌握简单基础的思想。
故事中的例子明显不仅仅适用于音乐,而且适用于软件开发。这个故事告诉我们不要忽视繁琐工作中简单基础的概念的重要性,哪怕有时候这让人感觉是一种倒退。尽管熟练掌握一门工具或者框架非常重要,了解它们背后的原理也是极其重要的。正如 Palph Waldo Emerson 所说:
>
> “如果你只学习方法,你就会被方法束缚。但如果你知道原理,就可以发明自己的方法。”
>
>
>
有鉴于此,让我们再次深入了解解释器和编译器。
今天我会向你们展示一个全新的计算器,与 [第一部分](/article-9399-1.html) 相比,它可以做到:
1. 处理输入字符串任意位置的空白符
2. 识别输入字符串中的多位整数
3. 做两个整数之间的减法(目前它仅能加减整数)
新版本计算器的源代码在这里,它可以做到上述的所有事情:
```
# 标记类型
# EOF (end-of-file 文件末尾)标记是用来表示所有输入都解析完成
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token 类型: INTEGER, PLUS, MINUS, or EOF
self.type = type
# token 值: 非负整数值, '+', '-', 或无
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# 客户端字符输入, 例如. "3 + 5", "12 - 5",
self.text = text
# self.pos 是 self.text 的索引
self.pos = 0
# 当前标记实例
self.current_token = None
self.current_char = self.text[self.pos]
def error(self):
raise Exception('Error parsing input')
def advance(self):
"""Advance the 'pos' pointer and set the 'current_char' variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '+':
self.advance()
return Token(PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
self.error()
return Token(EOF, None)
def eat(self, token_type):
# 将当前的标记类型与传入的标记类型作比较,如果他们相匹配,就
# “eat” 掉当前的标记并将下一个标记赋给 self.current_token,
# 否则抛出一个异常
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def expr(self):
"""Parser / Interpreter
expr -> INTEGER PLUS INTEGER
expr -> INTEGER MINUS INTEGER
"""
# 将输入中的第一个标记设置成当前标记
self.current_token = self.get_next_token()
# 当前标记应该是一个整数
left = self.current_token
self.eat(INTEGER)
# 当前标记应该是 ‘+’ 或 ‘-’
op = self.current_token
if op.type == PLUS:
self.eat(PLUS)
else:
self.eat(MINUS)
# 当前标记应该是一个整数
right = self.current_token
self.eat(INTEGER)
# 在上述函数调用后,self.current_token 就被设为 EOF 标记
# 这时要么是成功地找到 INTEGER PLUS INTEGER,要么是 INTEGER MINUS INTEGER
# 序列的标记,并且这个方法可以仅仅返回两个整数的加或减的结果,就能高效解释客户端的输入
if op.type == PLUS:
result = left.value + right.value
else:
result = left.value - right.value
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
```
把上面的代码保存到 `calc2.py` 文件中,或者直接从 [GitHub](https://github.com/rspivak/lsbasi/blob/master/part2/calc2.py) 上下载。试着运行它。看看它是不是正常工作:它应该能够处理输入中任意位置的空白符;能够接受多位的整数,并且能够对两个整数做减法和加法。
这是我在自己的笔记本上运行的示例:
```
$ python calc2.py
calc> 27 + 3
30
calc> 27 - 7
20
calc>
```
与 [第一部分](/article-9399-1.html) 的版本相比,主要的代码改动有:
1. `get_next_token` 方法重写了很多。增加指针位置的逻辑之前是放在一个单独的方法中。
2. 增加了一些方法:`skip_whitespace` 用于忽略空白字符,`integer` 用于处理输入字符的多位整数。
3. `expr` 方法修改成了可以识别 “整数 -> 减号 -> 整数” 词组和 “整数 -> 加号 -> 整数” 词组。在成功识别相应的词组后,这个方法现在可以解释加法和减法。
[第一部分](/article-9399-1.html) 中你学到了两个重要的概念,叫做 <ruby> 标记 <rt> token </rt></ruby> 和<ruby> 词法分析 <rt> lexical analyzer </rt></ruby>。现在我想谈一谈<ruby> 词法 <rt> lexeme </rt></ruby>、 <ruby> 解析 <rt> parsing </rt></ruby> 和<ruby> 解析器 <rt> parser </rt></ruby>。
你已经知道了标记。但是为了让我详细的讨论标记,我需要谈一谈词法。词法是什么?<ruby> 词法 <rt> lexeme </rt></ruby>是一个<ruby> 标记 <rt> token </rt></ruby>中的字符序列。在下图中你可以看到一些关于标记的例子,这可以让它们之间的关系变得清晰:

现在还记得我们的朋友,`expr` 方法吗?我之前说过,这是数学表达式实际被解释的地方。但是你要先识别这个表达式有哪些词组才能解释它,比如它是加法还是减法。`expr` 方法最重要的工作是:它从 `get_next_token` 方法中得到流,并找出该标记流的结构,然后解释已经识别出的词组,产生数学表达式的结果。
在标记流中找出结构的过程,或者换种说法,识别标记流中的词组的过程就叫<ruby> 解析 <rt> parsing </rt></ruby>。解释器或者编译器中执行这个任务的部分就叫做<ruby> 解析器 <rt> parser </rt></ruby>。
现在你知道 `expr` 方法就是你的解释器的部分,<ruby> 解析 <rt> parsing </rt></ruby>和<ruby> 解释 <rt> interpreting </rt></ruby>都在这里发生 —— `expr` 方法首先尝试识别(解析)标记流里的 “整数 -> 加法 -> 整数” 或者 “整数 -> 减法 -> 整数” 词组,成功识别后 (解析了) 其中一个词组,这个方法就开始解释它,返回两个整数的和或差。
又到了练习的时间。

1. 扩展这个计算器,让它能够计算两个整数的乘法
2. 扩展这个计算器,让它能够计算两个整数的除法
3. 修改代码,让它能够解释包含了任意数量的加法和减法的表达式,比如 “9 - 5 + 3 + 11”
**检验你的理解:**
1. 词法是什么?
2. 找出标记流结构的过程叫什么,或者换种说法,识别标记流中一个词组的过程叫什么?
3. 解释器(编译器)执行解析的部分叫什么?
希望你喜欢今天的内容。在该系列的下一篇文章里你就能扩展计算器从而处理更多复杂的算术表达式。敬请期待。
---
via: <https://ruslanspivak.com/lsbasi-part2/>
作者:[Ruslan Spivak](https://ruslanspivak.com) 译者:[BriFuture](https://github.com/BriFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In their amazing book “The 5 Elements of Effective Thinking” the authors Burger and Starbird share a story about how they observed Tony Plog, an internationally acclaimed trumpet virtuoso, conduct a master class for accomplished trumpet players. The students first played complex music phrases, which they played perfectly well. But then they were asked to play very basic, simple notes. When they played the notes, the notes sounded childish compared to the previously played complex phrases. After they finished playing, the master teacher also played the same notes, but when he played them, they did not sound childish. The difference was stunning. Tony explained that mastering the performance of simple notes allows one to play complex pieces with greater control. The lesson was clear - to build true virtuosity one must focus on mastering simple, basic ideas.[1](#fn:1)
The lesson in the story clearly applies not only to music but also to software development. The story is a good reminder to all of us to not lose sight of the importance of deep work on simple, basic ideas even if it sometimes feels like a step back. While it is important to be proficient with a tool or framework you use, it is also extremely important to know the principles behind them. As Ralph Waldo Emerson said:
“If you learn only methods, you’ll be tied to your methods. But if you learn principles, you can devise your own methods.”
On that note, let’s dive into interpreters and compilers again.
Today I will show you a new version of the calculator from [Part 1](http://ruslanspivak.com/lsbasi-part1/) that will be able to:
- Handle whitespace characters anywhere in the input string
- Consume multi-digit integers from the input
- Subtract two integers (currently it can only add integers)
Here is the source code for your new version of the calculator that can do all of the above:
```
# Token types
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, PLUS, MINUS, or EOF
self.type = type
# token value: non-negative integer value, '+', '-', or None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# client string input, e.g. "3 + 5", "12 - 5", etc
self.text = text
# self.pos is an index into self.text
self.pos = 0
# current token instance
self.current_token = None
self.current_char = self.text[self.pos]
def error(self):
raise Exception('Error parsing input')
def advance(self):
"""Advance the 'pos' pointer and set the 'current_char' variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '+':
self.advance()
return Token(PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
self.error()
return Token(EOF, None)
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def expr(self):
"""Parser / Interpreter
expr -> INTEGER PLUS INTEGER
expr -> INTEGER MINUS INTEGER
"""
# set current token to the first token taken from the input
self.current_token = self.get_next_token()
# we expect the current token to be an integer
left = self.current_token
self.eat(INTEGER)
# we expect the current token to be either a '+' or '-'
op = self.current_token
if op.type == PLUS:
self.eat(PLUS)
else:
self.eat(MINUS)
# we expect the current token to be an integer
right = self.current_token
self.eat(INTEGER)
# after the above call the self.current_token is set to
# EOF token
# at this point either the INTEGER PLUS INTEGER or
# the INTEGER MINUS INTEGER sequence of tokens
# has been successfully found and the method can just
# return the result of adding or subtracting two integers,
# thus effectively interpreting client input
if op.type == PLUS:
result = left.value + right.value
else:
result = left.value - right.value
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
```
Save the above code into the *calc2.py* file or download it directly from [GitHub](https://github.com/rspivak/lsbasi/blob/master/part2/calc2.py). Try it out. See for yourself that it works as expected: it can handle whitespace characters anywhere in the input; it can accept multi-digit integers, and it can also subtract two integers as well as add two integers.
Here is a sample session that I ran on my laptop:
```
$ python calc2.py
calc> 27 + 3
30
calc> 27 - 7
20
calc>
```
The major code changes compared with the version from [Part 1](http://ruslanspivak.com/lsbasi-part1/) are:
- The
*get_next_token*method was refactored a bit. The logic to increment the*pos*pointer was factored into a separate method*advance*. - Two more methods were added:
*skip_whitespace*to ignore whitespace characters and*integer*to handle multi-digit integers in the input. - The
*expr*method was modified to recognize INTEGER -> MINUS -> INTEGER phrase in addition to INTEGER -> PLUS -> INTEGER phrase. The method now also interprets both addition and subtraction after having successfully recognized the corresponding phrase.
In [Part 1](http://ruslanspivak.com/lsbasi-part1/) you learned two important concepts, namely that of a **token** and a **lexical analyzer**. Today I would like to talk a little bit about **lexemes**, **parsing**, and **parsers**.
You already know about tokens. But in order for me to round out the discussion of tokens I need to mention lexemes. What is a lexeme? A **lexeme** is a sequence of characters that form a token. In the following picture you can see some examples of tokens and sample lexemes and hopefully it will make the relationship between them clear:
Now, remember our friend, the *expr* method? I said before that that’s where the interpretation of an arithmetic expression actually happens. But before you can interpret an expression you first need to recognize what kind of phrase it is, whether it is addition or subtraction, for example. That’s what the *expr* method essentially does: it finds the structure in the stream of tokens it gets from the *get_next_token* method and then it interprets the phrase that is has recognized, generating the result of the arithmetic expression.
The process of finding the structure in the stream of tokens, or put differently, the process of recognizing a phrase in the stream of tokens is called **parsing**. The part of an interpreter or compiler that performs that job is called a **parser**.
So now you know that the *expr* method is the part of your interpreter where both **parsing** and **interpreting** happens - the *expr* method first tries to recognize (**parse**) the INTEGER -> PLUS -> INTEGER or the INTEGER -> MINUS -> INTEGER phrase in the stream of tokens and after it has successfully recognized (**parsed**) one of those phrases, the method interprets it and returns the result of either addition or subtraction of two integers to the caller.
And now it’s time for exercises again.
- Extend the calculator to handle multiplication of two integers
- Extend the calculator to handle division of two integers
- Modify the code to interpret expressions containing an arbitrary number of additions and subtractions, for example “9 - 5 + 3 + 11”
**Check your understanding.**
- What is a lexeme?
- What is the name of the process that finds the structure in the stream of tokens, or put differently, what is the name of the process that recognizes a certain phrase in that stream of tokens?
- What is the name of the part of the interpreter (compiler) that does parsing?
I hope you liked today’s material. In the next article of the series you will extend your calculator to handle more complex arithmetic expressions. Stay tuned.
And here is a list of books I recommend that will help you in your study of interpreters and compilers:
Get the edge and stay sharp. Subscribe to Beyond Basics for free and get new posts without missing a beat!
**All articles in this series:**
-
[Let's Build A Simple Interpreter. Part 1.](/lsbasi-part1/) -
[Let's Build A Simple Interpreter. Part 2.](/lsbasi-part2/) -
[Let's Build A Simple Interpreter. Part 3.](/lsbasi-part3/) -
[Let's Build A Simple Interpreter. Part 4.](/lsbasi-part4/) -
[Let's Build A Simple Interpreter. Part 5.](/lsbasi-part5/) -
[Let's Build A Simple Interpreter. Part 6.](/lsbasi-part6/) -
[Let's Build A Simple Interpreter. Part 7.](/lsbasi-part7/) -
[Let's Build A Simple Interpreter. Part 8.](/lsbasi-part8/) -
[Let's Build A Simple Interpreter. Part 9.](/lsbasi-part9/) -
[Let's Build A Simple Interpreter. Part 10.](/lsbasi-part10/) -
[Let's Build A Simple Interpreter. Part 11.](/lsbasi-part11/) -
[Let's Build A Simple Interpreter. Part 12.](/lsbasi-part12/) -
[Let's Build A Simple Interpreter. Part 13.](/lsbasi-part13/) -
[Let's Build A Simple Interpreter. Part 14.](/lsbasi-part14/) -
[Let's Build A Simple Interpreter. Part 15.](/lsbasi-part15/) -
[Let's Build A Simple Interpreter. Part 16.](/lsbasi-part16/) -
[Let's Build A Simple Interpreter. Part 17.](/lsbasi-part17/) -
[Let's Build A Simple Interpreter. Part 18.](/lsbasi-part18/)
## Comments
comments powered by Disqus |
9,521 | 让我们做个简单的解释器(三) | https://ruslanspivak.com/lsbasi-part3/ | 2018-04-09T09:01:00 | [
"解释器",
"编译器"
] | https://linux.cn/article-9521-1.html | 
早上醒来的时候,我就在想:“为什么我们学习一个新技能这么难?”
我不认为那是因为它很难。我认为原因可能在于我们花了太多的时间,而这件难事需要有丰富的阅历和足够的知识,然而我们要把这样的知识转换成技能所用的练习时间又不够。
拿游泳来说,你可以花上几天时间来阅读很多有关游泳的书籍,花几个小时和资深的游泳者和教练交流,观看所有可以获得的训练视频,但你第一次跳进水池的时候,仍然会像一个石头那样沉入水中,
要点在于:你认为自己有多了解那件事都无关紧要 —— 你得通过练习把知识变成技能。为了帮你练习,我把训练放在了这个系列的 [第一部分](/article-9399-1.html) 和 [第二部分](/article-9520-1.html) 了。当然,你会在今后的文章中看到更多练习,我保证 :)
好,让我们开始今天的学习。
到现在为止,你已经知道了怎样解释像 “7 + 3” 或者 “12 - 9” 这样的两个整数相加减的算术表达式。今天我要说的是怎么解析(识别)、解释有多个数字相加减的算术表达式,比如 “7 - 3 + 2 - 1”。
文中的这个算术表达式可以用下面的这个语法图表示:

什么是<ruby> 语法图 <rt> syntax diagram </rt></ruby>? **语法图** 是对一门编程语言中的语法规则进行图像化的表示。基本上,一个语法图就能告诉你哪些语句可以在程序中出现,哪些不能出现。
语法图很容易读懂:按照箭头指向的路径。某些路径表示的是判断,有些表示的是循环。
你可以按照以下的方式读上面的语法图:一个 term 后面可以是加号或者减号,接着可以是另一个 term,这个 term 后面又可以是一个加号或者减号,后面又是一个 term,如此循环。从字面上你就能读懂这个图片了。或许你会奇怪,“term” 是什么、对于本文来说,“term” 就是个整数。
语法图有两个主要的作用:
* 它们用图形的方式表示一个编程语言的特性(语法)。
* 它们可以用来帮你写出解析器 —— 你可以根据下列简单规则把图片转换成代码。
你已经知道,识别出记号流中的词组的过程就叫做 **解析**。解释器或者编译器执行这个任务的部分叫做 **解析器**。解析也称为 **语法分析**,并且解析器这个名字很合适,你猜的对,就是 **语法分析器**。
根据上面的语法图,下面这些表达式都是合法的:
* 3
* 3 + 4
* 7 - 3 + 2 - 1
因为算术表达式的语法规则在不同的编程语言里面是很相近的,我们可以用 Python shell 来“测试”语法图。打开 Python shell,运行下面的代码:
```
>>> 3
3
>>> 3 + 4
7
>>> 7 - 3 + 2 - 1
5
```
意料之中。
表达式 “3 + ” 不是一个有效的数学表达式,根据语法图,加号后面必须要有个 term (整数),否则就是语法错误。然后,自己在 Python shell 里面运行:
```
>>> 3 +
File "<stdin>", line 1
3 +
^
SyntaxError: invalid syntax
```
能用 Python shell 来做这样的测试非常棒,让我们把上面的语法图转换成代码,用我们自己的解释器来测试,怎么样?
从之前的文章里([第一部分](/article-9399-1.html) 和 [第二部分](/article-9520-1.html))你知道 `expr` 方法包含了我们的解析器和解释器。再说一遍,解析器仅仅识别出结构,确保它与某些特性对应,而解释器实际上是在解析器成功识别(解析)特性之后,就立即对表达式进行评估。
以下代码片段显示了对应于图表的解析器代码。语法图里面的矩形方框(term)变成了 term 方法,用于解析整数,expr 方法和语法图的流程一致:
```
def term(self):
self.eat(INTEGER)
def expr(self):
# 把当前标记设为从输入中拿到的第一个标记
self.current_token = self.get_next_token()
self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
self.term()
elif token.type == MINUS:
self.eat(MINUS)
self.term()
```
你能看到 `expr` 首先调用了 `term` 方法。然后 `expr` 方法里面的 `while` 循环可以执行 0 或多次。在循环里面解析器基于标记做出判断(是加号还是减号)。花一些时间,你就知道,上述代码确实是遵循着语法图的算术表达式流程。
解析器并不解释任何东西:如果它识别出了一个表达式,它就静默着,如果没有识别出来,就会抛出一个语法错误。改一下 `expr` 方法,加入解释器的代码:
```
def term(self):
"""Return an INTEGER token value"""
token = self.current_token
self.eat(INTEGER)
return token.value
def expr(self):
"""Parser / Interpreter """
# 将输入中的第一个标记设置成当前标记
self.current_token = self.get_next_token()
result = self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
result = result + self.term()
elif token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
return result
```
因为解释器需要评估一个表达式, `term` 方法被改成返回一个整型值,`expr` 方法被改成在合适的地方执行加法或减法操作,并返回解释的结果。尽管代码很直白,我建议花点时间去理解它。
进行下一步,看看完整的解释器代码,好不?
这是新版计算器的源代码,它可以处理包含有任意多个加法和减法运算的有效的数学表达式。
```
# 标记类型
#
# EOF (end-of-file 文件末尾)标记是用来表示所有输入都解析完成
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token 类型: INTEGER, PLUS, MINUS, or EOF
self.type = type
# token 值: 非负整数值, '+', '-', 或无
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS, '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# 客户端字符输入, 例如. "3 + 5", "12 - 5",
self.text = text
# self.pos is an index into self.text
self.pos = 0
# 当前标记实例
self.current_token = None
self.current_char = self.text[self.pos]
##########################################################
# Lexer code #
##########################################################
def error(self):
raise Exception('Invalid syntax')
def advance(self):
"""Advance the `pos` pointer and set the `current_char` variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '+':
self.advance()
return Token(PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
self.error()
return Token(EOF, None)
##########################################################
# Parser / Interpreter code #
##########################################################
def eat(self, token_type):
# 将当前的标记类型与传入的标记类型作比较,如果他们相匹配,就
# “eat” 掉当前的标记并将下一个标记赋给 self.current_token,
# 否则抛出一个异常
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def term(self):
"""Return an INTEGER token value."""
token = self.current_token
self.eat(INTEGER)
return token.value
def expr(self):
"""Arithmetic expression parser / interpreter."""
# 将输入中的第一个标记设置成当前标记
self.current_token = self.get_next_token()
result = self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
result = result + self.term()
elif token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# 要在 Python3 下运行,请把 ‘raw_input’ 的调用换成 ‘input’
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
```
把上面的代码保存到 `calc3.py` 文件中,或者直接从 [GitHub](https://github.com/rspivak/lsbasi/blob/master/part3/calc3.py) 上下载。试着运行它。看看它能不能处理我之前给你看过的语法图里面派生出的数学表达式。
这是我在自己的笔记本上运行的示例:
```
$ python calc3.py
calc> 3
3
calc> 7 - 4
3
calc> 10 + 5
15
calc> 7 - 3 + 2 - 1
5
calc> 10 + 1 + 2 - 3 + 4 + 6 - 15
5
calc> 3 +
Traceback (most recent call last):
File "calc3.py", line 147, in <module>
main()
File "calc3.py", line 142, in main
result = interpreter.expr()
File "calc3.py", line 123, in expr
result = result + self.term()
File "calc3.py", line 110, in term
self.eat(INTEGER)
File "calc3.py", line 105, in eat
self.error()
File "calc3.py", line 45, in error
raise Exception('Invalid syntax')
Exception: Invalid syntax
```
记得我在文章开始时提过的练习吗:它们在这儿,我保证过的:)

* 画出只包含乘法和除法的数学表达式的语法图,比如 “7 \* 4 / 2 \* 3”。认真点,拿只钢笔或铅笔,试着画一个。 修改计算器的源代码,解释只包含乘法和除法的数学表达式。比如 “7 \* 4 / 2 \* 3”。
* 从头写一个可以处理像 “7 - 3 + 2 - 1” 这样的数学表达式的解释器。用你熟悉的编程语言,不看示例代码自己思考着写出代码。做的时候要想一想这里面包含的组件:一个词法分析器,读取输入并转换成标记流,一个解析器,从词法分析器提供的记号流中获取,并且尝试识别流中的结构,一个解释器,在解析器成功解析(识别)有效的数学表达式后产生结果。把这些要点串起来。花一点时间把你获得的知识变成一个可以运行的数学表达式的解释器。
**检验你的理解:**
1. 什么是语法图?
2. 什么是语法分析?
3. 什么是语法分析器?
嘿,看!你看完了所有内容。感谢你们坚持到今天,而且没有忘记练习。:) 下次我会带着新的文章回来,尽请期待。
---
via: <https://ruslanspivak.com/lsbasi-part3/>
作者:[Ruslan Spivak](https://ruslanspivak.com) 译者:[BriFuture](https://github.com/BriFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I woke up this morning and I thought to myself: “Why do we find it so difficult to learn a new skill?”
I don’t think it’s just because of the hard work. I think that one of the reasons might be that we spend a lot of time and hard work acquiring knowledge by reading and watching and not enough time translating that knowledge into a skill by practicing it. Take swimming, for example. You can spend a lot of time reading hundreds of books about swimming, talk for hours with experienced swimmers and coaches, watch all the training videos available, and you still will sink like a rock the first time you jump in the pool.
The bottom line is: it doesn’t matter how well you think you know the subject - you have to put that knowledge into practice to turn it into a skill. To help you with the practice part I put exercises into [Part 1](http://ruslanspivak.com/lsbasi-part1/) and [Part 2](http://ruslanspivak.com/lsbasi-part2/) of the series. And yes, you will see more exercises in today’s article and in future articles, I promise :)
Okay, let’s get started with today’s material, shall we?
So far, you’ve learned how to interpret arithmetic expressions that add or subtract two integers like “7 + 3” or “12 - 9”. Today I’m going to talk about how to parse (recognize) and interpret arithmetic expressions that have any number of plus or minus operators in it, for example “7 - 3 + 2 - 1”.
Graphically, the arithmetic expressions in this article can be represented with the following syntax diagram:
What is a syntax diagram? A **syntax diagram** is a graphical representation of a programming language’s syntax rules. Basically, a syntax diagram visually shows you which statements are allowed in your programming language and which are not.
Syntax diagrams are pretty easy to read: just follow the paths indicated by the arrows. Some paths indicate choices. And some paths indicate loops.
You can read the above syntax diagram as following: a term optionally followed by a plus or minus sign, followed by another term, which in turn is optionally followed by a plus or minus sign followed by another term and so on. You get the picture, literally. You might wonder what a *“term”* is. For the purpose of this article a *“term”* is just an integer.
Syntax diagrams serve two main purposes:
- They graphically represent the specification (grammar) of a programming language.
- They can be used to help you write your parser - you can map a diagram to code by following simple rules.
You’ve learned that the process of recognizing a phrase in the stream of tokens is called **parsing**. And the part of an interpreter or compiler that performs that job is called a **parser**. Parsing is also called **syntax analysis**, and the parser is also aptly called, you guessed it right, a **syntax analyzer**.
According to the syntax diagram above, all of the following arithmetic expressions are valid:
- 3
- 3 + 4
- 7 - 3 + 2 - 1
Because syntax rules for arithmetic expressions in different programming languages are very similar we can use a Python shell to “test” our syntax diagram. Launch your Python shell and see for yourself:
```
>>> 3
3
>>> 3 + 4
7
>>> 7 - 3 + 2 - 1
5
```
No surprises here.
The expression “3 + ” is not a valid arithmetic expression though because according to the syntax diagram the plus sign must be followed by a *term* (integer), otherwise it’s a syntax error. Again, try it with a Python shell and see for yourself:
```
>>> 3 +
File "<stdin>", line 1
3 +
^
SyntaxError: invalid syntax
```
It’s great to be able to use a Python shell to do some testing but let’s map the above syntax diagram to code and use our own interpreter for testing, all right?
You know from the previous articles ([Part 1](http://ruslanspivak.com/lsbasi-part1/) and [Part 2](http://ruslanspivak.com/lsbasi-part2/)) that the *expr* method is where both our parser and interpreter live. Again, the parser just recognizes the structure making sure that it corresponds to some specifications and the interpreter actually evaluates the expression once the parser has successfully recognized (parsed) it.
The following code snippet shows the parser code corresponding to the diagram. The rectangular box from the syntax diagram (*term*) becomes a *term* method that parses an integer and the *expr* method just follows the syntax diagram flow:
```
def term(self):
self.eat(INTEGER)
def expr(self):
# set current token to the first token taken from the input
self.current_token = self.get_next_token()
self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
self.term()
elif token.type == MINUS:
self.eat(MINUS)
self.term()
```
You can see that *expr* first calls the *term* method. Then the *expr* method has a *while* loop which can execute zero or more times. And inside the loop the parser makes a choice based on the token (whether it’s a plus or minus sign). Spend some time proving to yourself that the code above does indeed follow the syntax diagram flow for arithmetic expressions.
The parser itself does not interpret anything though: if it recognizes an expression it’s silent and if it doesn’t, it throws out a syntax error. Let’s modify the *expr* method and add the interpreter code:
```
def term(self):
"""Return an INTEGER token value"""
token = self.current_token
self.eat(INTEGER)
return token.value
def expr(self):
"""Parser / Interpreter """
# set current token to the first token taken from the input
self.current_token = self.get_next_token()
result = self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
result = result + self.term()
elif token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
return result
```
Because the interpreter needs to evaluate an expression the *term* method was modified to return an integer value and the *expr* method was modified to perform addition and subtraction at the appropriate places and return the result of interpretation. Even though the code is pretty straightforward I recommend spending some time studying it.
Le’s get moving and see the complete code of the interpreter now, okay?
Here is the source code for your new version of the calculator that can handle valid arithmetic expressions containing integers and any number of addition and subtraction operators:
```
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, PLUS, MINUS, or EOF
self.type = type
# token value: non-negative integer value, '+', '-', or None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS, '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# client string input, e.g. "3 + 5", "12 - 5 + 3", etc
self.text = text
# self.pos is an index into self.text
self.pos = 0
# current token instance
self.current_token = None
self.current_char = self.text[self.pos]
##########################################################
# Lexer code #
##########################################################
def error(self):
raise Exception('Invalid syntax')
def advance(self):
"""Advance the `pos` pointer and set the `current_char` variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '+':
self.advance()
return Token(PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
self.error()
return Token(EOF, None)
##########################################################
# Parser / Interpreter code #
##########################################################
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def term(self):
"""Return an INTEGER token value."""
token = self.current_token
self.eat(INTEGER)
return token.value
def expr(self):
"""Arithmetic expression parser / interpreter."""
# set current token to the first token taken from the input
self.current_token = self.get_next_token()
result = self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
result = result + self.term()
elif token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
```
Save the above code into the *calc3.py* file or download it directly from [GitHub](https://github.com/rspivak/lsbasi/blob/master/part3/calc3.py). Try it out. See for yourself that it can handle arithmetic expressions that you can derive from the syntax diagram I showed you earlier.
Here is a sample session that I ran on my laptop:
```
$ python calc3.py
calc> 3
3
calc> 7 - 4
3
calc> 10 + 5
15
calc> 7 - 3 + 2 - 1
5
calc> 10 + 1 + 2 - 3 + 4 + 6 - 15
5
calc> 3 +
Traceback (most recent call last):
File "calc3.py", line 147, in <module>
main()
File "calc3.py", line 142, in main
result = interpreter.expr()
File "calc3.py", line 123, in expr
result = result + self.term()
File "calc3.py", line 110, in term
self.eat(INTEGER)
File "calc3.py", line 105, in eat
self.error()
File "calc3.py", line 45, in error
raise Exception('Invalid syntax')
Exception: Invalid syntax
```
Remember those exercises I mentioned at the beginning of the article: here they are, as promised :)
- Draw a syntax diagram for arithmetic expressions that contain only multiplication and division, for example “7 * 4 / 2 * 3”. Seriously, just grab a pen or a pencil and try to draw one.
- Modify the source code of the calculator to interpret arithmetic expressions that contain only multiplication and division, for example “7 * 4 / 2 * 3”.
- Write an interpreter that handles arithmetic expressions like “7 - 3 + 2 - 1” from scratch. Use any programming language you’re comfortable with and write it off the top of your head without looking at the examples. When you do that, think about components involved: a
*lexer*that takes an input and converts it into a stream of tokens, a*parser*that feeds off the stream of the tokens provided by the*lexer*and tries to recognize a structure in that stream, and an*interpreter*that generates results after the*parser*has successfully parsed (recognized) a valid arithmetic expression. String those pieces together. Spend some time translating the knowledge you’ve acquired into a working interpreter for arithmetic expressions.
**Check your understanding.**
- What is a syntax diagram?
- What is syntax analysis?
- What is a syntax analyzer?
Hey, look! You read all the way to the end. Thanks for hanging out here today and don’t forget to do the exercises. :) I’ll be back next time with a new article - stay tuned.
Here is a list of books I recommend that will help you in your study of interpreters and compilers:
Get the edge and stay sharp. Subscribe to Beyond Basics for free and get new posts without missing a beat!
**All articles in this series:**
-
[Let's Build A Simple Interpreter. Part 1.](/lsbasi-part1/) -
[Let's Build A Simple Interpreter. Part 2.](/lsbasi-part2/) -
[Let's Build A Simple Interpreter. Part 3.](/lsbasi-part3/) -
[Let's Build A Simple Interpreter. Part 4.](/lsbasi-part4/) -
[Let's Build A Simple Interpreter. Part 5.](/lsbasi-part5/) -
[Let's Build A Simple Interpreter. Part 6.](/lsbasi-part6/) -
[Let's Build A Simple Interpreter. Part 7.](/lsbasi-part7/) -
[Let's Build A Simple Interpreter. Part 8.](/lsbasi-part8/) -
[Let's Build A Simple Interpreter. Part 9.](/lsbasi-part9/) -
[Let's Build A Simple Interpreter. Part 10.](/lsbasi-part10/) -
[Let's Build A Simple Interpreter. Part 11.](/lsbasi-part11/) -
[Let's Build A Simple Interpreter. Part 12.](/lsbasi-part12/) -
[Let's Build A Simple Interpreter. Part 13.](/lsbasi-part13/) -
[Let's Build A Simple Interpreter. Part 14.](/lsbasi-part14/) -
[Let's Build A Simple Interpreter. Part 15.](/lsbasi-part15/) -
[Let's Build A Simple Interpreter. Part 16.](/lsbasi-part16/) -
[Let's Build A Simple Interpreter. Part 17.](/lsbasi-part17/) -
[Let's Build A Simple Interpreter. Part 18.](/lsbasi-part18/)
## Comments
comments powered by Disqus |
9,522 | 如何在 Ubuntu Linux 上使用 KVM 云镜像 | https://www.cyberciti.biz/faq/how-to-use-kvm-cloud-images-on-ubuntu-linux/ | 2018-04-07T11:37:26 | [
"KVM"
] | https://linux.cn/article-9522-1.html | 
如何下载并使用运行在 Ubuntu Linux 服务器上的 KVM 云镜像?如何在 Ubuntu Linux 16.04 LTS 服务器上无需完整安装即可创建虚拟机?如何在 Ubuntu Linux 上使用 KVM 云镜像?
基于内核的虚拟机(KVM)是 Linux 内核的虚拟化模块,可将其转变为虚拟机管理程序。你可以在命令行使用 Ubuntu 为 libvirt 和 KVM 提供的虚拟化前端通过 KVM 创建 Ubuntu 云镜像。
这个快速教程展示了如何安装和使用 uvtool,它为 Ubuntu 云镜像下载,libvirt 和 clout\_int 提供了统一的集成虚拟机前端。
### 步骤 1 - 安装 KVM
你必须安装并配置 KVM。使用 [apt 命令](https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ "See Linux/Unix apt command examples for more info")/[apt-get 命令](https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html "See Linux/Unix apt-get command examples for more info"),如下所示:
```
$ sudo apt install qemu-kvm libvirt-bin virtinst bridge-utils cpu-checker
$ kvm-ok
## [configure bridged networking as described here][3]
$ sudo vi /etc/network/interfaces
$ sudo systemctl restart networking
$ sudo brctl show
```
参阅[如何在 Ubuntu 16.04 LTS Headless 服务器上安装 KVM](https://www.cyberciti.biz/faq/installing-kvm-on-ubuntu-16-04-lts-server/) 以获得更多信息。(LCTT 译注:Headless 服务器是指没有本地接口的计算设备,专用于向其他计算机及其用户提供服务。)
### 步骤 2 - 安装 uvtool
键入以下 [apt 命令](https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ "See Linux/Unix apt command examples for more info")/[apt-get 命令](https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html "See Linux/Unix apt-get command examples for more info"):
```
$ sudo apt install uvtool
```
示例输出:
```
[sudo] password for vivek:
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages were automatically installed and are no longer required:
gksu libgksu2-0 libqt5designer5 libqt5help5 libqt5printsupport5 libqt5sql5 libqt5sql5-sqlite libqt5xml5 python3-dbus.mainloop.pyqt5 python3-notify2 python3-pyqt5 python3-sip
Use 'sudo apt autoremove' to remove them.
The following additional packages will be installed:
cloud-image-utils distro-info python-boto python-pyinotify python-simplestreams socat ubuntu-cloudimage-keyring uvtool-libvirt
Suggested packages:
cloud-utils-euca shunit2 python-pyinotify-doc
The following NEW packages will be installed:
cloud-image-utils distro-info python-boto python-pyinotify python-simplestreams socat ubuntu-cloudimage-keyring uvtool uvtool-libvirt
0 upgraded, 9 newly installed, 0 to remove and 0 not upgraded.
Need to get 1,211 kB of archives.
After this operation, 6,876 kB of additional disk space will be used.
Get:1 http://in.archive.ubuntu.com/ubuntu artful/main amd64 distro-info amd64 0.17 [20.3 kB]
Get:2 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 python-boto all 2.44.0-1ubuntu2 [740 kB]
Get:3 http://in.archive.ubuntu.com/ubuntu artful/main amd64 python-pyinotify all 0.9.6-1 [24.6 kB]
Get:4 http://in.archive.ubuntu.com/ubuntu artful/main amd64 ubuntu-cloudimage-keyring all 2013.11.11 [4,504 B]
Get:5 http://in.archive.ubuntu.com/ubuntu artful/main amd64 cloud-image-utils all 0.30-0ubuntu2 [17.2 kB]
Get:6 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 python-simplestreams all 0.1.0~bzr450-0ubuntu1 [29.7 kB]
Get:7 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 socat amd64 1.7.3.2-1 [342 kB]
Get:8 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 uvtool all 0~git122-0ubuntu1 [6,498 B]
Get:9 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 uvtool-libvirt all 0~git122-0ubuntu1 [26.9 kB]
Fetched 1,211 kB in 3s (393 kB/s)
Selecting previously unselected package distro-info.
(Reading database ... 199933 files and directories currently installed.)
Preparing to unpack .../0-distro-info_0.17_amd64.deb ...
Unpacking distro-info (0.17) ...
Selecting previously unselected package python-boto.
Preparing to unpack .../1-python-boto_2.44.0-1ubuntu2_all.deb ...
Unpacking python-boto (2.44.0-1ubuntu2) ...
Selecting previously unselected package python-pyinotify.
Preparing to unpack .../2-python-pyinotify_0.9.6-1_all.deb ...
Unpacking python-pyinotify (0.9.6-1) ...
Selecting previously unselected package ubuntu-cloudimage-keyring.
Preparing to unpack .../3-ubuntu-cloudimage-keyring_2013.11.11_all.deb ...
Unpacking ubuntu-cloudimage-keyring (2013.11.11) ...
Selecting previously unselected package cloud-image-utils.
Preparing to unpack .../4-cloud-image-utils_0.30-0ubuntu2_all.deb ...
Unpacking cloud-image-utils (0.30-0ubuntu2) ...
Selecting previously unselected package python-simplestreams.
Preparing to unpack .../5-python-simplestreams_0.1.0~bzr450-0ubuntu1_all.deb ...
Unpacking python-simplestreams (0.1.0~bzr450-0ubuntu1) ...
Selecting previously unselected package socat.
Preparing to unpack .../6-socat_1.7.3.2-1_amd64.deb ...
Unpacking socat (1.7.3.2-1) ...
Selecting previously unselected package uvtool.
Preparing to unpack .../7-uvtool_0~git122-0ubuntu1_all.deb ...
Unpacking uvtool (0~git122-0ubuntu1) ...
Selecting previously unselected package uvtool-libvirt.
Preparing to unpack .../8-uvtool-libvirt_0~git122-0ubuntu1_all.deb ...
Unpacking uvtool-libvirt (0~git122-0ubuntu1) ...
Setting up distro-info (0.17) ...
Setting up ubuntu-cloudimage-keyring (2013.11.11) ...
Setting up cloud-image-utils (0.30-0ubuntu2) ...
Setting up socat (1.7.3.2-1) ...
Setting up python-pyinotify (0.9.6-1) ...
Setting up python-boto (2.44.0-1ubuntu2) ...
Setting up python-simplestreams (0.1.0~bzr450-0ubuntu1) ...
Processing triggers for doc-base (0.10.7) ...
Processing 1 added doc-base file...
Setting up uvtool (0~git122-0ubuntu1) ...
Processing triggers for man-db (2.7.6.1-2) ...
Setting up uvtool-libvirt (0~git122-0ubuntu1) ...
```
### 步骤 3 - 下载 Ubuntu 云镜像
你需要使用 `uvt-simplestreams-libvirt` 命令。它维护一个 libvirt 容量存储池,作为一个<ruby> 简单流 <rt> simplestreams </rt></ruby>源的镜像子集的本地镜像,比如 Ubuntu 云镜像。要使用当前所有 amd64 镜像更新 uvtool 的 libvirt 容量存储池,运行:
```
$ uvt-simplestreams-libvirt sync arch=amd64
```
要更新/获取 Ubuntu 16.04 LTS (xenial/amd64) 镜像,运行:
```
$ uvt-simplestreams-libvirt --verbose sync release=xenial arch=amd64
```
示例输出:
```
Adding: com.ubuntu.cloud:server:16.04:amd64 20171121.1
```
通过 query 选项查询本地镜像:
```
$ uvt-simplestreams-libvirt query
```
示例输出:
```
release=xenial arch=amd64 label=release (20171121.1)
```
现在,我为 Ubuntu xenial 创建了一个镜像,接下来我会创建虚拟机。
### 步骤 4 - 创建 SSH 密钥
你需要使用 SSH 密钥才能登录到 KVM 虚拟机。如果你根本没有任何密钥,请使用 `ssh-keygen` 命令创建一个新的密钥。
```
$ ssh-keygen
```
参阅“[如何在 Linux / Unix 系统上设置 SSH 密钥](https://www.cyberciti.biz/faq/how-to-set-up-ssh-keys-on-linux-unix/)” 和 “[Linux / UNIX: 生成 SSH 密钥](https://www.cyberciti.biz/faq/linux-unix-generating-ssh-keys/)” 以获取更多信息。
### 步骤 5 - 创建 VM
是时候创建虚拟机了,它叫 vm1,即创建一个 Ubuntu Linux 16.04 LTS 虚拟机:
```
$ uvt-kvm create vm1
```
默认情况下 vm1 使用以下配置创建:
1. 内存:512M
2. 磁盘大小:8GiB
3. CPU:1 vCPU core
要控制内存、磁盘、CPU 和其他配置,使用以下语法:
```
$ uvt-kvm create vm1 \
--memory MEMORY \
--cpu CPU \
--disk DISK \
--bridge BRIDGE \
--ssh-public-key-file /path/to/your/SSH_PUBLIC_KEY_FILE \
--packages PACKAGES1, PACKAGES2, .. \
--run-script-once RUN_SCRIPT_ONCE \
--password PASSWORD
```
其中
1. `--password PASSWORD`:设置 ubuntu 用户的密码和允许使用 ubuntu 的用户登录(不推荐,使用 ssh 密钥)。
2. `--run-script-once RUN_SCRIPT_ONCE` : 第一次启动时,在虚拟机上以 root 身份运行 `RUN_SCRIPT_ONCE` 脚本,但再也不会运行。这里给出完整的路径。这对于在虚拟机上运行自定义任务时非常有用,例如设置安全性或其他内容。
3. `--packages PACKAGES1, PACKAGES2, ..` : 在第一次启动时安装以逗号分隔的软件包。
要获取帮助,运行:
```
$ uvt-kvm -h
$ uvt-kvm create -h
```
#### 如何删除虚拟机?
要销毁/删除名为 vm1 的虚拟机,运行(请小心使用以下命令,因为没有确认框):
```
$ uvt-kvm destroy vm1
```
#### 获取 vm1 的 IP 地址,运行:
```
$ uvt-kvm ip vm1
192.168.122.52
```
#### 列出所有运行的虚拟机
```
$ uvt-kvm list
```
示例输出:
```
vm1
freebsd11.1
```
### 步骤 6 - 如何登录 vm1
语法是:
```
$ uvt-kvm ssh vm1
```
示例输出:
```
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-101-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
0 packages can be updated.
0 updates are security updates.
Last login: Thu Dec 7 09:55:06 2017 from 192.168.122.1
```
另一个选择是从 macOS/Linux/Unix/Windows 客户端使用常规的 ssh 命令:
```
$ ssh [email protected]
$ ssh -i ~/.ssh/id_rsa [email protected]
```
示例输出:
[](https://www.cyberciti.biz/media/new/faq/2017/12/connect-to-the-running-VM-using-ssh.jpg)
一旦创建了 vim,你可以照常使用 `virsh` 命令:
```
$ virsh list
```
---
via: <https://www.cyberciti.biz/faq/how-to-use-kvm-cloud-images-on-ubuntu-linux/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,523 | 尝试 H2o 做机器学习 | https://veronneau.org/playing-with-water.html | 2018-04-07T23:44:21 | [
"机器学习",
"ML"
] | https://linux.cn/article-9523-1.html | 
我目前正在参加一个机器学习班,虽然工作量很疯狂,但我非常喜欢。我最初计划使用 [R](https://en.wikipedia.org/wiki/R_(programming_language)) 来训练我的数据库,但老师建议我使用一个 FOSS 机器学习框架 [H2o](https://www.h2o.ai)。
起初我有点怀疑,因为我已经对 R 掌握得不错了,但后来我发现你可以简单地将 H2o 作为 R 库导入。H2o 将大多数 R 函数替换为其自己的并行化函数,以减少处理时间(不再需要 `doParallel` 调用),并且使用“外部”服务端来运行,而不是直接调用 R。

直到我真正在实际中开始在 H2o 中使用 R 时,我对这种情况都非常满意。我在使用非常大的数据库时,库变得笨重,我几乎不能做任何有用得事情。大多数时候,我最后只是得到一个很长的 Java 回溯调用。
我相信正确地将 H2o 作为一个库使用将非常强大,但可惜的是,它似乎在我的 R 技能中无效。

我生了一整天的气 —— 无法实现我想做的事 —— 直到我意识到 H2o 有一个名为 Flow 的 WebUI。我通常不喜欢使用 web 来完成重要的工作,比如编写代码,但是 Flow 简直太不可思议了。
自动绘图功能,运行资源密集模型时集成 ETA(预计剩余时间),每个模型参数的描述(这些参数甚至会根据您熟悉的统计模型分成不同部分),Flow 似乎拥有所有功能。我很快就能够运行 3 种基本的机器学习模型并获得实际可解释的结果。
所以,如果你一直渴望使用最先进的机器学习模型分析非常大的数据库,我会推荐使用 H2o。首先尝试使用 Flow,而不是 Python 或 R 的钩子,来看看它能做什么。
唯一缺点是,H2o 是用 Java 编写的,并依赖 Java 1.7 来运行。并且需要警告的是:它需要非常强大的处理器和大量的内存。即使有 10 个可用的内核和 10Gb 的 RAM,我可怜的服务器也苦苦挣扎了一段时间。
---
via: <https://veronneau.org/playing-with-water.html>
作者:[Louis-Philippe Véronneau](https://veronneau.org/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
9,524 | 用 PGP 保护代码完整性(一): 基本概念和工具 | https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools | 2018-04-08T09:19:00 | [
"PGP",
"gpg"
] | https://linux.cn/article-9524-1.html | 
在本系列文章中,我们将深度探讨如何使用 PGP 确保软件完整性。这些文章将为工作于自由软件项目的开发者提供实用指南,并且将包含以下主题:
1. PGP 基础和最佳实践
2. 如何用 Git 使用 PGP
3. 如何保护你的开发者账户
我们使用与“Freedom”含义相同的词项 “Free”,但这个系列中列出的指南也可以被任何其它类型的依赖于分布式团队开发者贡献的软件中。如果你编写进入公共源仓库的代码,你可以从了解和遵循这篇指南中受益。
### 结构
每节分为两个部分:
* 适用于你项目需求的清单
* 形式自由的考虑事项的列表,解释这些决定取决于什么,并伴随着配置指令
#### 清单优先级
每个清单中各项包含着优先级,用来帮助指导你的决定:
* (必要)该项一定要排在考虑事项列表的前面。如果没有这样做,它们将给提交到开源项目中的代码带来高风险。
* (推荐)包含该项将提升整体安全性,但会影响你与工作环境的交互方式,并且可能需要学习新的习惯或者放弃旧的习惯。
记住,这些只是指导。如果你感到这些优先级不能反映你项目提交的安全,你应该根据自己的需要调整它们。
### PGP 基本概念和工具
#### 清单
1. 理解 PGP 在自由软件开发中的作用 (必要)
2. 理解<ruby> 公钥密码学 <rt> Public Key Cryptography </rt></ruby>的基础知识 (必要)
3. 理解 PGP 加密和签名的不同 (必要)
4. 理解 PGP <ruby> 密钥身份 <rt> key identities </rt></ruby> (必要)
5. 理解 PGP <ruby> 密钥有效性 <rt> key validity </rt></ruby> (必要)
6. 安装 GnuPG 工具(版本 2.x) (必要)
#### 考虑事项
自由软件社区长期依赖于 PGP 确保它生产的软件产品的真实性和完整性。你可能没有注意到,但无论你是一个 Linux 、Mac 和 Windowas 用户,你都曾依赖 PGP 来确保你电脑环境的完整性:
* Linux 发行版依赖 PGP 来确保当二进制或者原代码包从被生产出来到被终端用户安装之间没被更改过
* 自由软件项目通常会伴随发行软件的存档提供分离的 PGP 签名,使得下游的项目可以在把下载的版本集成到自己的分布式下载之前,验证下载版本的完整性。
* 自由软件项目通常依赖代码本身的 PGP 签名来跟踪起源,并验证项目开发者提交的代码的完整性
这与工作于专有平台的程序员使用的开发者证书或代码签名机制非常相似。实际上,这两种技术背后的核心概念非常相似 —— 尽管它们在实现的技术层面和它们委托信任方式的大多不同。PGP 不依赖于集中式认证机构,而是让每个用户为每个证书赋予自己的信任。
我们的目标是使你的项目通过使用 PGP 来进行代码起源和完整性追踪,遵循最佳实践并遵守基本的安全预防措施。
#### 极其基本的 PGP 操作概括
你不需要知道 PGP 如何工作的具体细节 —— 理解核心概念足以成功地达到我们的目的。PGP 依赖于公钥密码学来将明文转换为密文。这个过程需要两种不同的密钥:
* 公钥,被所有人知道
* 私钥,只被拥有者知道
##### 加密
对加密来说,PGP 使用拥有者的公钥创造一条只能通过拥有者私钥解密的消息:
1. 发送者生成一个随机的加密密钥(“会话密钥”)
2. 发送者使用该会话密钥(使用对称算法)加密内容
3. 发送者使用接收者的 PGP 公钥加密会话密钥
4. 发送者向接收者发送加密后的内容和加密后的会话密钥
要解密:
1. 接收者使用他们的 PGP 私钥解密会话密钥
2. 接收者使用会话密钥解密消息的内容
##### 签名
为了创建签名,PGP 私钥或公钥会以相反的方式使用:
1. 签名者生成内容的校检和哈希
2. 签名者使用自己的 PGP 私钥来加密该校检和
3. 签名者伴随内容提供加密后的校检和
要验证签名:
1. 验证者生成自己的内容校检和哈希
2. 验证者使用签名者的 PGP 公钥来解密提供的校检和
3. 如果校检和匹配,就验证了内容的完整性
##### 结合使用
通常,加密消息也被发送者自己的 PGP 密钥签名。无论何时使用加密消息,这应当是默认的,因为没有认证的加密没有很大意义(除非你是一个告密者或秘密代理并且需要可行的可否认性)
#### 理解密钥身份
每个 PGP 密钥必须有一个或多个与之关联的身份。通常,“<ruby> 身份 <rt> Identity </rt></ruby>”指的是以下格式中的人物全名和邮件地址:
```
Alice Engineer <[email protected]>
```
有时也会在括号中包含说明,来告诉终端用户关于该特定密钥的更多信息:
```
Bob Designer (obsolete 1024-bit key) <[email protected]>
```
由于人们可以和多个职业和个人实体相关联,因此在同一密钥上可以有多个身份:
```
Alice Engineer <[email protected]>
Alice Engineer <[email protected]>
Alice Engineer <[email protected]>
```
当使用多个身份时,其中之一将被标记为“<ruby> primary identity <rt> 主要身份 </rt></ruby>”来让检索更简单。
#### 理解密钥有效性
为了能使用其他人的公钥来加密或验证,你需要确保它确实属于正确的人(Alice)而不属于冒牌的(Eve)。在 PGP 中,这被称为“密钥有效性”:
* 有效性:<ruby> 完全 <rt> full </rt></ruby> -- 意味着非常确认该密钥属于 Alice
* 有效性:<ruby> 临界 <rt> marginal </rt></ruby> -- 意味着大致确认该密钥属于 Alice
* 有效性:<ruby> 未知 <rt> unknown </rt></ruby> -- 意味着不确认该密钥是否属于 Alice
#### Web of Trust (WOT) 与 Trust on First Use (TOFU)
PGP 使用了一种信任委托机制叫“Web of Trust”。它的核心是尝试替代 HTTPS/TLS 世界中对集中式认证机构的需求。PGP 把这个责任交给了每个用户,而不是各种软件开发商来决定谁应该是你的可信认证实体。
不幸的是,很少有人理解 Web of Trust 的是如何工作的,能使用它的人更少。它仍然是 OpenPGP 规范的一个重要方面,但 GnuPG 的近期版本(2.2 及以上)已经实现了一种替代机制叫“Trust on First Use”(TOFU)。
你可以把 TOFU 当作类似 SSH 的信任方式。使用 SSH,当你第一次连接到远程系统,它的密钥指纹会被记录和保存。如果将来密钥改变,SSH 客户端将会提醒你并拒绝连接,迫使你决定是否信任已改变的的密钥。
同样,当你第一次导入某人的 PGP 密钥,它被假定可信。如果在将来的任何时候,GnuPG 碰巧发现另一同样身份的密钥,过去导入的密钥和新密钥都将被标记为无效,并且你需要手动指出保留哪个。
#### 安装 OpenPGP 软件
首先,理解 PGP、OpenPGP、GnuPG 和 gpg 之间的不同很重要:
* PGP (“Pretty Good Privacy”) 是最初商业软件的名字
* OpenPGP 是与最初 PGP 工具兼容的 IETF 标准
* GnuPG (“Gnu Privacy Guard”)是实现了 OpenPGP 标准的自由软件
* GnuPG 的命令行工具称为 “gpg”
今天,“PGP”这个词几乎被普遍用来表示开放的 OpenPGP 标准,而不是最初的商业软件,因此“PGP”和“OpenPGP”是可以互换的。“GnuPG”和“pgp”这两个词应该仅在提及工具时使用,而不用于它们产生的输出或它们实现的 OpenPGP 功能。举例:
* PGP(而非 GnuPG 或 GPG)密钥
* PGP(而非 GnuPG 或 GPG)签名
* PGP(而非 GnuPG 或 GPG)密钥服务器
理解这一点应该可以保护你免受来自你遇到的其他 PGP 用户“实际上”不可避免的迂腐。
##### 安装 GnuPG
如果你正在使用 Linux,你应该已经安装过了 GnuPG。在 Mac 上,你应该安装 [GPG-Suite](https://gpgtools.org/),或者使用 `brew` 安装 `gnupg2`。在 Windows 上,你应该安装 [GPG4Win](https://www.gpg4win.org/),并且为了可以工作,你可能需要调整指南中的部分命令,除非你设置了类似 Unix 的环境。对其他平台来说,你需要自行查找正确的地址来下载和安装 GnuPG。
##### GnuPG 1 vs. 2
GnuPG v.1 和 GnuPG v.2 都实现了同样的标准,但它们提供不兼容的库和命令行工具,所以许多发行版都带有了旧的版本 1 和最新的版本 2。你需要确保你总是使用 GnuPG v.2。
首先,运行:
```
$ gpg --version | head -n1
```
如果你看到 `gpg (GnuPG) 1.4.x`,说明你正使用 GnuPG v.1。尝试下 `gpg2` 命令:
```
$ gpg2 --version | head -n1
```
如果你看到 `gpg (GnuPG) 2.x.x`,说明你可以继续了。这篇指南将假设你使用 GnuPG 2.2 版本(或更新)。如果你正使用 GnuPG 的 2.0 版本,本指南中某些命令可能无效,你应该考虑安装 GnuPG 最新的 2.2 版本
##### 确保你总是使用 GnuPG v.2
如果你 `gpg` 和 `gpg2` 命令都有,你应该确保总是使用 GnuPG v.2,而不是旧的版本。你可以通过设置别名来确保这一点:
```
$ alias gpg=gpg2
```
你可以把它放在你的 `.bashrc` 中,以确保它在你使用 `gpg` 命令时总是被加载。
在本系列的第 2 部分中,我们将介绍生成和保护你的 PGP 主密钥的基本步骤。
通过 Linux 基金会和 edX 的免费[“Introduction to Linux”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 课程了解关于 Linux 的更多信息。
---
via: <https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools>
作者:[Konstantin Ryabitsev](https://www.linux.com/users/mricon) 译者:[kimii](https://github.com/kimii) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,525 | Facebook 的开源计划一窥 | https://opensource.com/article/18/1/inside-facebooks-open-source-program | 2018-04-08T09:47:00 | [
"Facebook",
"开源"
] | /article-9525-1.html |
>
> Facebook 开发人员 Christine Abernathy 讨论了开源如何帮助公司分享见解并推动创新。
>
>
>

开源逐年变得无处不在,从[政府直辖市](https://opensource.com/article/17/8/tirana-government-chooses-open-source)到[大学](https://opensource.com/article/16/12/2016-election-night-hackathon)都有。各种规模的公司也越来越多地转向开源软件。事实上,一些公司正在通过财务支持项目或与开发人员合作进一步推进开源。
例如,Facebook 的开源计划鼓励其他人开源发布他们的代码,同时与社区合作支持开源项目。 [Christine Abernathy](https://twitter.com/abernathyca),是一名 Facebook 开发者、开源支持者,也是该公司开源团队成员,去年 11 月访问了罗切斯特理工学院,在 [11 月](https://www.eventbrite.com/e/fossmagic-talks-open-source-facebook-with-christine-abernathy-tickets-38955037566#) 的 FOSS 系列演讲中发表了演讲。在她的演讲中,Abernathy 解释了 Facebook 如何开源以及为什么它是公司所做工作的重要组成部分。
### Facebook 和开源
Abernathy 说,开源在 Facebook 创建社区并使世界更加紧密的使命中扮演着重要的角色。这种意识形态的匹配是 Facebook 参与开源的一个激励因素。此外,Facebook 面临着独特的基础设施和开发挑战,而开源则为公司提供了一个平台,以共享可帮助他人的解决方案。开源还提供了一种加速创新和创建更好软件的方法,帮助工程团队生产更好的软件并更透明地工作。今天,Facebook 在 GitHub 的 443 个项目有 122,000 个分支、292,000 个提交和 732,000 个关注。

*一些以开源方式发布的 Facebook 项目包括 React、GraphQL、Caffe2 等等。(图片提供:Christine Abernathy 图片,经许可使用)*
### 得到的教训
Abernathy 强调说 Facebook 已经从开源社区吸取了很多教训,并期待学到更多。她明确了三个最重要的:
* 分享有用的东西
* 突出你的英雄
* 修复常见的痛点
*Christine Abernathy 作为 FOSS 演讲系列的嘉宾一员参观了 RIT。每个月,来自开源世界的演讲嘉宾都会与对自由和开源软件感兴趣的学生分享关于开源世界智慧、见解、建议。 [FOSS @MAGIC](http://foss.rit.edu/)社区感谢 Abernathy 作为演讲嘉宾出席。*
### 关于作者
Justin 是[罗切斯特理工学院](https://www.rit.edu/)主修网络与系统管理的学生。他目前是 [Fedora Project](https://fedoraproject.org/wiki/Overview) 的贡献者。在 Fedora 中,Justin 是 [Fedora Magazine](https://fedoramagazine.org/) 的主编,[社区的领导](https://fedoraproject.org/wiki/CommOps)...
---
via: <https://opensource.com/article/18/1/inside-facebooks-open-source-program>
作者:[Justin W. Flory](https://opensource.com/users/jflory) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,526 | 防止文档陷阱的 7 条准则 | https://opensource.com/article/17/12/7-rules | 2018-04-08T10:11:29 | [
"写作",
"文档"
] | https://linux.cn/article-9526-1.html |
>
> 让我们了解一下如何使国外读者更容易理解你的技术文章。
>
>
>

英语是开源社区的通用语言。为了减少翻译成本,很多团队都改成用英语来写他们的文档。 但奇怪的是,为国际读者写英语并不一定就意味着以英语为母语的人就占据更多的优势。 相反, 他们往往忘记了该文档用的语言可能并不是读者的母语。
我们以下面这个简单的句子为例: “Encrypt the password using the `foo bar` command。”语法上来说,这个句子是正确的。 鉴于动名词的 “-ing” 形式在英语中很常见,大多数的母语人士都认为这是一种优雅的表达方式, 他们通常会很自然的写出这样的句子。 但是仔细观察, 这个句子存在歧义因为 “using” 可能指的宾语(“the password”)也可能指的动词(“encrypt”)。 因此这个句子有两种解读方式:
* “加密使用了 `foo bar` 命令的密码。”
* “使用命令 `foo bar` 来加密密码。”
如果你有相关的先验知识(密码加密或者 `foo bar` 命令),你可以消除这种不确定性并且明白第二种方式才是真正的意思。 但是若你没有足够深入的知识怎么办呢? 如果你并不是这方面的专家,而只是一个拥有泛泛相关知识的翻译者而已怎么办呢? 再或者,如果你只是个非母语人士且对像动名词这种高级语法不熟悉怎么办呢?
即使是英语为母语的人也需要经过训练才能写出清晰直接的技术文档。训练的第一步就是提高对文本可用性以及潜在问题的警觉性, 下面让我们来看一下可以帮助避免常见陷阱的 7 条规则。
### 1、了解你的目标读者并代入其中。
如果你是一名开发者,而写作的对象是最终用户, 那么你需要站在他们的角度来看这个产品。 文档的结构是否反映了用户的目标? [<ruby> 人格面具 <rt> persona </rt></ruby> 技术](https://en.wikipedia.org/wiki/Persona_(user_experience)) 能帮你专注于目标受众并为你的读者提供合适层次的细节。
### 2、遵循 KISS 原则——保持文档简短而简单
这个原则适用于多个层次,从语法,句子到单词。 比如:
* 使用合适的最简单时态。比如, 当提到一个动作的结果时使用现在时:
+ " ~~Click 'OK.' The 'Printer Options' dialog will appear.~~ " -> "Click 'OK.' The 'Printer Options' dialog appears."
* 按经验来说,一个句子表达一个主题;然而, 短句子并不一定就容易理解(尤其当这些句子都是由名词组成时)。 有时, 将句子裁剪过度可能会引起歧义,而反过来太多单词则又难以理解。
* 不常用的以及很长的单词会降低阅读速度,而且可能成为非母语人士的障碍。 使用更简单的替代词语:
+ " ~~utilize~~ " -> "use"
+ " ~~indicate~~ " -> "show","tell" 或 "say"
+ " ~~prerequisite~~ " -> "requirement"
### 3、不要干扰阅读流
将虚词和较长的插入语移到句子的首部或者尾部:
* " ~~They are not, however, marked as installed.~~ " -> "However, they are not marked as installed."
将长命令放在句子的末尾可以让自动/半自动的翻译拥有更好的断句。
### 4、区别对待两种基本的信息类型
描述型信息以及任务导向型信息有必要区分开来。描述型信息的一个典型例子就是命令行参考, 而 HOWTO 则是属于基于任务的信息;(LCTT 译注:HOWTO 文档是 Linux 文档中的一种)然而, 技术写作中都会涉及这两种类型的信息。 仔细观察, 就会发现许多文本都同时包含了两种类型的信息。 然而如果能够清晰地划分这两种类型的信息那必是极好的。 为了更好地区分它们,可以对它们进行分别标记。 标题应该能够反映章节的内容以及信息的类型。 对描述性章节使用基于名词的标题(比如“Types of Frobnicators”),而对基于任务的章节使用口头表达式的标题(例如“Installing Frobnicators”)。 这可以让读者快速定位感兴趣的章节而跳过对他无用的章节。
### 5、考虑不同的阅读场景和阅读模式
有些读者在阅读产品文档时会由于自己搞不定而感到十分的沮丧。他们在一个嘈杂的环境中工作,也很难专注于阅读。 同时,不要期望你的读者会一页一页的进行阅读,很多人都是快速浏览文本,搜索关键字或者通过表格、索引以及全文搜索的方式来查找主题。 请牢记这一点, 从不同的角度来看待你的文字。 通常需要折中才能找到一种适合多种情况的文本结构。
### 6、将复杂的信息分成小块
这会让读者更容易记住和吸收信息。例如, 过程不应该超过 7 到 10 个步骤(根据认知心理学中的 [米勒法则](https://en.wikipedia.org/wiki/The_Magical_Number_Seven,_Plus_or_Minus_Two))。 如果需要更多的步骤, 那么就将任务分拆成不同的过程。
### 7、形式遵循功能
根据以下问题检查你的文字:某句话/段落/章节的 *目的*(功能)是什么?比如,它是一个指令呢?还是一个结果呢?还是一个警告呢?如果是指令, 使用主动语气: “Configure the system.” 被动语气可能适合于进行描述: “The system is configured automatically.” 将警告放在危险操作的 *前面* 。 专注于目的还有助于发现冗余的内容,可以清除类似 “basically” 或者 “easily” 这一类的填充词,类似 “~~already~~ existing ” 或“ ~~completely~~ new” 这一类的不必要的修饰, 以及任何与你的目标大众无关的内容。
你现在可能已经猜到了,写作就是一个不断重写的过程。 好的写作需要付出努力和练习。 即使你只是偶尔写点东西, 你也可以通过关注目标大众并遵循上述规则来显著地改善你的文字。 文字的可读性越好, 理解就越容易, 这一点对不同语言能力的读者来说都是适合的。 尤其是当进行本地化时, 高质量的原始文本至关重要:“垃圾进, 垃圾出”。 如果原始文本就有缺陷, 翻译所需要的时间就会变长, 从而导致更高的成本。 最坏的情况下, 翻译会导致缺陷成倍增加,需要在不同的语言版本中修正这个缺陷。
---
via: <https://opensource.com/article/17/12/7-rules>
作者:[Tanja Roth](https://opensource.com) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | English serves as *lingua franca* in the open source community. To reduce translation costs, many teams have switched to English as the source language for their documentation. But surprisingly, writing in English for an international audience does not necessarily put native English speakers in a better position. On the contrary, they tend to forget that the document's language might not be the audience's first language.
Let's have a look at the following simple sentence as an example: "Encrypt the password using the `foo bar`
command." Grammatically, the sentence is correct. Given that '-ing' forms (gerunds) are frequently used in the English language and most native speakers consider them an elegant way of expressing things, native speakers usually do not hesitate to phrase a sentence like this. On closer inspection, the sentence is ambiguous because "using" may refer either to the object ("the password") or to the verb ("encrypt"). Thus, the sentence can be interpreted in two different ways:
- "Encrypt the password that uses the
`foo bar`
command." - "Encrypt the password by using the
`foo bar`
command."
As long as you have previous knowledge about the topic (password encryption or the `foo bar`
command), you can resolve this ambiguity and correctly decide that the second version is the intended meaning of this sentence. But what if you lack in-depth knowledge of the topic? What if you are not an expert, but a translator with only general knowledge of the subject? Or if you are a non-native speaker of English, unfamiliar with advanced grammatical forms like gerunds?
Even native English speakers need training to write clear and straightforward technical documentation. The first step is to raise awareness about the usability of texts and potential problems, so let's look at seven rules that can help avoid common pitfalls.
## 1. Know your target audience and step into their shoes.
If you are a developer writing for end users, view the product from their perspective. Does the structure reflect the users' goals? The [persona technique](https://en.wikipedia.org/wiki/Persona_(user_experience)) can help you to focus on the target audience and provide the right level of detail for your readers.
## 2. Follow the KISS principle—keep it short and simple.
The principle can be applied on several levels, such as grammar, sentences, or words. Here are examples:
- Use the simplest tense that is appropriate. For example, use present tense when mentioning the result of an action:
- "
~~Click 'OK.' The 'Printer Options' dialog will appear.~~" → "Click 'OK.' The 'Printer Options' dialog appears."
- "
- As a rule of thumb, present one idea in one sentence; however, short sentences are not automatically easy to understand (especially if they are an accumulation of nouns). Sometimes, trimming down sentences to a certain word count can introduce ambiguities. In turn, this makes the sentences more difficult to understand.
- Uncommon and long words slow reading and might be obstacles for non-native speakers. Use simpler alternatives:
- "
~~utilize~~" → "use" - "
~~indicate~~" → "show," "tell," or "say" - "
~~prerequisite~~" → "requirement"
- "
## 3. Avoid disturbing the reading flow.
Move particles or longer parentheses to the beginning or end of a sentence:
- "
~~They are not, however, marked as installed.~~" → "However, they are not marked as installed."
Place long commands at the end of a sentence. This also results in better segmentation of sentences for automatic or semi-automatic translations.
## 4. Discriminate between two basic information types.
Discriminating between *descriptive information* and *task-based information* is useful. Typical examples for descriptive information are command-line references, whereas how-to's are task-based information; however, both information types are needed in technical writing. On closer inspection, many texts contain a mixture of both information types. Clearly separating the information types is helpful. For better orientation, label them accordingly. Titles should reflect a section's content and information type. Use noun-based titles for descriptive sections ("Types of Frobnicators") and verbally phrased titles for task-based sections ("Installing Frobnicators"). This helps readers quickly identify the sections they are interested in and allows them to skip the ones they don't need at the moment.
## 5. Consider different reading situations and modes of text consumption.
Some of your readers are already frustrated when they turn to the product documentation because they could not achieve a certain goal on their own. They might also work in a noisy environment that makes it hard to focus on reading. Also, do not expect your audience to read cover to cover, as many people skim or browse texts for keywords or look up topics by using tables, indexes, or full-text search. With that in mind, look at your text from different perspectives. Often, compromises are needed to find a text structure that works well for multiple situations.
## 6. Break down complex information into smaller chunks.
This makes it easier for the audience to remember and process the information. For example, procedures should not exceed seven to 10 steps (according to [Miller's Law](https://en.wikipedia.org/wiki/The_Magical_Number_Seven,_Plus_or_Minus_Two) in cognitive psychology). If more steps are required, split the task into separate procedures.
## 7. Form follows function.
Examine your text according to the question: What is the *purpose* (function) of a certain sentence, a paragraph, or a section? For example, is it an instruction? A result? A warning? For instructions, use active voice: "Configure the system." Passive voice may be appropriate for descriptions: "The system is configured automatically." Add warnings *before* the step or action where danger arises. Focusing on the purpose also helps detect redundant content to help eliminate fillers like "basically" or "easily," unnecessary modifications like "~~already~~ existing" or "~~completely~~ new," or any content that is not relevant for your target audience.
As you might have guessed by now, writing is re-writing. Good writing requires effort and practice. Even if you write only occasionally, you can significantly improve your texts by focusing on the target audience and following the rules above. The better the readability of a text, the easier it is to process, even for audiences with varying language skills. Especially when it comes to localization, good quality of the source text is important: "Garbage in, garbage out." If the original text has deficiencies, translating the text takes longer, resulting in higher costs. In the worst case, flaws are multiplied during translation and must be corrected in various languages.
*This article is based on Tanja's presentation, " Technical writing for an international audience," at Open Source Summit Europe on October 24, 2017.*
## 2 Comments |
9,527 | Ansible 教程:简单 Ansible 命令介绍 | http://linuxtechlab.com/ansible-tutorial-simple-commands/ | 2018-04-08T15:18:43 | [
"Ansible"
] | https://linux.cn/article-9527-1.html | 
在我们之前的 Ansible 教程中,我们讨论了 [Ansible 的安装和配置](http://linuxtechlab.com/create-first-ansible-server-automation-setup/)。在这个 Ansible 教程中,我们将学习一些基本的 Ansible 命令的例子,我们将用它来管理基础设施。所以让我们先看看一个完整的 Ansible 命令的语法:
```
$ ansible <group> -m <module> -a <arguments>
```
在这里,我们可以用单个主机或用 `<group>` 代替一组主机,`<arguments>` 是可选的参数。现在我们来看看一些 Ansible 的基本命令。
### 检查主机的连通性
我们在之前的教程中也使用了这个命令。检查主机连接的命令是:
```
$ ansible <group> -m ping
```
### 重启主机
```
$ ansible <group> -a "/sbin/reboot"
```
### 检查主机的系统信息
Ansible 收集所有连接到它主机的信息。要显示主机的信息,请运行:
```
$ ansible <group> -m setup | less
```
其次,通过传递参数来从收集的信息中检查特定的信息:
```
$ ansible <group> -m setup -a "filter=ansible_distribution"
```
### 传输文件
对于传输文件,我们使用模块 `copy` ,完整的命令是这样的:
```
$ ansible <group> -m copy -a "src=/home/dan dest=/tmp/home"
```
### 管理用户
要管理已连接主机上的用户,我们使用一个名为 `user` 的模块,并如下使用它。
#### 创建新用户
```
$ ansible <group> -m user -a "name=testuser password=<encrypted password>"
```
#### 删除用户
```
$ ansible <group> -m user -a "name=testuser state=absent"
```
**注意:** 要创建加密密码,请使用 `"mkpasswd -method=sha-512"`。
### 更改权限和所有者
要改变已连接主机文件的所有者,我们使用名为 `file` 的模块,使用如下。
#### 更改文件权限
```
$ ansible <group> -m file -a "dest=/home/dan/file1.txt mode=777"
```
#### 更改文件的所有者
```
$ ansible <group> -m file -a "dest=/home/dan/file1.txt mode=777 owner=dan group=dan"
```
### 管理软件包
我们可以通过使用 `yum` 和 `apt` 模块来管理所有已连接主机的软件包,完整的命令如下:
#### 检查包是否已安装并更新
```
$ ansible <group> -m yum -a "name=ntp state=latest"
```
#### 检查包是否已安装,但不更新
```
$ ansible <group> -m yum -a "name=ntp state=present"
```
#### 检查包是否是特定的版本
```
$ ansible <group> -m yum -a "name= ntp-1.8 state=present"
```
#### 检查包是否没有安装
```
$ ansible <group> -m yum -a "name=ntp state=absent"
```
### 管理服务
要管理服务,我们使用模块 `service` ,完整命令如下:
#### 启动服务
```
$ansible <group> -m service -a "name=httpd state=started"
```
#### 停止服务
```
$ ansible <group> -m service -a "name=httpd state=stopped"
```
#### 重启服务
```
$ ansible <group> -m service -a "name=httpd state=restarted"
```
这样我们简单的、单行 Ansible 命令的教程就完成了。此外,在未来的教程中,我们将学习创建 playbook,来帮助我们更轻松高效地管理主机。
---
via: <http://linuxtechlab.com/ansible-tutorial-simple-commands/>
作者:[SHUSAIN](http://linuxtechlab.com/author/shsuain/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,528 | 页面缓存:内存和文件之间的那些事 | https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/ | 2018-04-08T19:17:00 | [
"缓存",
"内存管理"
] | https://linux.cn/article-9528-1.html | 
上一篇文章中我们学习了内核怎么为一个用户进程 [管理虚拟内存](/article-9393-1.html),而没有提及文件和 I/O。这一篇文章我们将专门去讲这个重要的主题 —— 页面缓存。文件和内存之间的关系常常很不好去理解,而它们对系统性能的影响却是非常大的。
在面对文件时,有两个很重要的问题需要操作系统去解决。第一个是相对内存而言,慢的让人发狂的硬盘驱动器,[尤其是磁盘寻道](https://manybutfinite.com/post/what-your-computer-does-while-you-wait)。第二个是需要将文件内容一次性地加载到物理内存中,以便程序间*共享*文件内容。如果你在 Windows 中使用 [进程浏览器](http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx) 去查看它的进程,你将会看到每个进程中加载了大约 ~15MB 的公共 DLL。我的 Windows 机器上现在大约运行着 100 个进程,因此,如果不共享的话,仅这些公共的 DLL 就要使用高达 ~1.5 GB 的物理内存。如果是那样的话,那就太糟糕了。同样的,几乎所有的 Linux 进程都需要 ld.so 和 libc,加上其它的公共库,它们占用的内存数量也不是一个小数目。
幸运的是,这两个问题都用一个办法解决了:页面缓存 —— 保存在内存中的页面大小的文件块。为了用图去说明页面缓存,我捏造出一个名为 `render` 的 Linux 程序,它打开了文件 `scene.dat`,并且一次读取 512 字节,并将文件内容存储到一个分配到堆中的块上。第一次读取的过程如下:

1. `render` 请求 `scene.dat` 从位移 0 开始的 512 字节。
2. 内核搜寻页面缓存中 `scene.dat` 的 4kb 块,以满足该请求。假设该数据没有缓存。
3. 内核分配页面帧,初始化 I/O 请求,将 `scend.dat` 从位移 0 开始的 4kb 复制到分配的页面帧。
4. 内核从页面缓存复制请求的 512 字节到用户缓冲区,系统调用 `read()` 结束。
读取完 12KB 的文件内容以后,`render` 程序的堆和相关的页面帧如下图所示:

它看起来很简单,其实这一过程做了很多的事情。首先,虽然这个程序使用了普通的读取(`read`)调用,但是,已经有三个 4KB 的页面帧将文件 scene.dat 的一部分内容保存在了页面缓存中。虽然有时让人觉得很惊奇,但是,**普通的文件 I/O 就是这样通过页面缓存来进行的**。在 x86 架构的 Linux 中,内核将文件认为是一系列的 4KB 大小的块。如果你从文件中读取单个字节,包含这个字节的整个 4KB 块将被从磁盘中读入到页面缓存中。这是可以理解的,因为磁盘通常是持续吞吐的,并且程序一般也不会从磁盘区域仅仅读取几个字节。页面缓存知道文件中的每个 4KB 块的位置,在上图中用 `#0`、`#1` 等等来描述。Windows 使用 256KB 大小的<ruby> 视图 <rt> view </rt></ruby>,类似于 Linux 的页面缓存中的<ruby> 页面 <rt> page </rt></ruby>。
不幸的是,在一个普通的文件读取中,内核必须拷贝页面缓存中的内容到用户缓冲区中,它不仅花费 CPU 时间和影响 [CPU 缓存](https://manybutfinite.com/post/intel-cpu-caches),**在复制数据时也浪费物理内存**。如前面的图示,`scene.dat` 的内存被存储了两次,并且,程序中的每个实例都用另外的时间去存储内容。我们虽然解决了从磁盘中读取文件缓慢的问题,但是在其它的方面带来了更痛苦的问题。内存映射文件是解决这种痛苦的一个方法:

当你使用文件映射时,内核直接在页面缓存上映射你的程序的虚拟页面。这样可以显著提升性能:[Windows 系统编程](http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/) 报告指出,在相关的普通文件读取上运行时性能提升多达 30% ,在 [Unix 环境中的高级编程](http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/) 的报告中,文件映射在 Linux 和 Solaris 也有类似的效果。这取决于你的应用程序类型的不同,通过使用文件映射,可以节约大量的物理内存。
对高性能的追求是永恒不变的目标,[测量是很重要的事情](https://manybutfinite.com/post/performance-is-a-science),内存映射应该是程序员始终要使用的工具。这个 API 提供了非常好用的实现方式,它允许你在内存中按字节去访问一个文件,而不需要为了这种好处而牺牲代码可读性。在一个类 Unix 的系统中,可以使用 [mmap](http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html) 查看你的 [地址空间](https://manybutfinite.com/post/anatomy-of-a-program-in-memory),在 Windows 中,可以使用 [CreateFileMapping](http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx),或者在高级编程语言中还有更多的可用封装。当你映射一个文件内容时,它并不是一次性将全部内容都映射到内存中,而是通过 [页面故障](http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678) 来按需映射的。在 [获取](http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424) 需要的文件内容的页面帧后,页面故障句柄 [映射你的虚拟页面](http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436) 到页面缓存上。如果一开始文件内容没有缓存,这还将涉及到磁盘 I/O。
现在出现一个突发的状况,假设我们的 `render` 程序的最后一个实例退出了。在页面缓存中保存着 `scene.dat` 内容的页面要立刻释放掉吗?人们通常会如此考虑,但是,那样做并不是个好主意。你应该想到,我们经常在一个程序中创建一个文件,退出程序,然后,在第二个程序去使用这个文件。页面缓存正好可以处理这种情况。如果考虑更多的情况,内核为什么要清除页面缓存的内容?请记住,磁盘读取的速度要慢于内存 5 个数量级,因此,命中一个页面缓存是一件有非常大收益的事情。因此,只要有足够大的物理内存,缓存就应该保持全满。并且,这一原则适用于所有的进程。如果你现在运行 `render` 一周后, `scene.dat` 的内容还在缓存中,那么应该恭喜你!这就是什么内核缓存越来越大,直至达到最大限制的原因。它并不是因为操作系统设计的太“垃圾”而浪费你的内存,其实这是一个非常好的行为,因为,释放物理内存才是一种“浪费”。(LCTT 译注:释放物理内存会导致页面缓存被清除,下次运行程序需要的相关数据,需要再次从磁盘上进行读取,会“浪费” CPU 和 I/O 资源)最好的做法是尽可能多的使用缓存。
由于页面缓存架构的原因,当程序调用 [write()](http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html) 时,字节只是被简单地拷贝到页面缓存中,并将这个页面标记为“脏”页面。磁盘 I/O 通常并**不会**立即发生,因此,你的程序并不会被阻塞在等待磁盘写入上。副作用是,如果这时候发生了电脑死机,你的写入将不会完成,因此,对于至关重要的文件,像数据库事务日志,要求必须进行 [fsync()](http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html)(仍然还需要去担心磁盘控制器的缓存失败问题),另一方面,读取将被你的程序阻塞,直到数据可用为止。内核采取预加载的方式来缓解这个矛盾,它一般提前预读取几个页面并将它加载到页面缓存中,以备你后来的读取。在你计划进行一个顺序或者随机读取时(请查看 [madvise()](http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html)、[readahead()](http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html)、[Windows 缓存提示](http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior) ),你可以通过<ruby> 提示 <rt> hint </rt></ruby>帮助内核去调整这个预加载行为。Linux 会对内存映射的文件进行 [预读取](http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424),但是我不确定 Windows 的行为。当然,在 Linux 中它可能会使用 [O\_DIRECT](http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html) 跳过预读取,或者,在 Windows 中使用 [NO\_BUFFERING](http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx) 去跳过预读,一些数据库软件就经常这么做。
一个文件映射可以是私有的,也可以是共享的。当然,这只是针对内存中内容的**更新**而言:在一个私有的内存映射上,更新并不会提交到磁盘或者被其它进程可见,然而,共享的内存映射,则正好相反,它的任何更新都会提交到磁盘上,并且对其它的进程可见。内核使用<ruby> 写时复制 <rt> copy on write </rt></ruby>(CoW)机制,这是通过<ruby> 页面表条目 <rt> page table entry </rt></ruby>(PTE)来实现这种私有的映射。在下面的例子中,`render` 和另一个被称为 `render3d` 的程序都私有映射到 `scene.dat` 上。然后 `render` 去写入映射的文件的虚拟内存区域:

1. 两个程序私有地映射 `scene.dat`,内核误导它们并将它们映射到页面缓存,但是使该页面表条目只读。
2. `render` 试图写入到映射 `scene.dat` 的虚拟页面,处理器发生页面故障。
3. 内核分配页面帧,复制 `scene.dat` 的第二块内容到其中,并映射故障的页面到新的页面帧。
4. 继续执行。程序就当做什么都没发生。
上面展示的只读页面表条目并不意味着映射是只读的,它只是内核的一个用于共享物理内存的技巧,直到尽可能的最后一刻之前。你可以认为“私有”一词用的有点不太恰当,你只需要记住,这个“私有”仅用于更新的情况。这种设计的重要性在于,要想看到被映射的文件的变化,其它程序只能读取它的虚拟页面。一旦“写时复制”发生,从其它地方是看不到这种变化的。但是,内核并不能保证这种行为,因为它是在 x86 中实现的,从 API 的角度来看,这是有意义的。相比之下,一个共享的映射只是将它简单地映射到页面缓存上。更新会被所有的进程看到并被写入到磁盘上。最终,如果上面的映射是只读的,页面故障将触发一个内存段失败而不是写到一个副本。
动态加载库是通过文件映射融入到你的程序的地址空间中的。这没有什么可奇怪的,它通过普通的 API 为你提供与私有文件映射相同的效果。下面的示例展示了映射文件的 `render` 程序的两个实例运行的地址空间的一部分,以及物理内存,尝试将我们看到的许多概念综合到一起。

这是内存架构系列的第三部分的结论。我希望这个系列文章对你有帮助,对理解操作系统的这些主题提供一个很好的思维模型。
---
via:<https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/>
作者:[Gustavo Duarte](http://duartes.org/gustavo/blog/about/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Previously we looked at how the kernel [manages virtual memory](/post/how-the-kernel-manages-your-memory)
for a user process, but files and I/O were left out. This post covers
the important and often misunderstood relationship between files and
memory and its consequences for performance.
Two serious problems must be solved by the OS when it comes to files. The first
one is the mind-blowing slowness of hard drives, and
[disk seeks in particular](/post/what-your-computer-does-while-you-wait),
relative to memory. The second is the need to load file contents in physical
memory once and *share* the contents among programs. If you use
[Process Explorer](http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx) to poke
at Windows processes, you’ll see there are ~15MB worth of common DLLs loaded in
every process. My Windows box right now is running 100 processes, so without
sharing I’d be using up to ~1.5 GB of physical RAM *just for common DLLs*. No
good. Likewise, nearly all Linux programs need [ld.so](http://ld.so) and libc, plus other common
libraries.
Happily, both problems can be dealt with in one shot: the **page
cache**, where the kernel stores page-sized chunks of files. To
illustrate the page cache, I’ll conjure a Linux program named
**render**, which opens file **scene.dat** and reads it 512 bytes at a
time, storing the file contents into a heap-allocated block. The first
read goes like this:
After 12KB have been read, `render`
's heap and the relevant page frames
look thus:
This looks innocent enough, but there’s a lot going on. First, even
though this program uses regular `read`
calls, three 4KB page frames are
now in the page cache storing part of `scene.dat`
. People are sometimes
surprised by this, but **all regular file I/O happens through the page
cache**. In x86 Linux, the kernel thinks of a file as a sequence of 4KB
chunks. If you read a single byte from a file, the whole 4KB chunk
containing the byte you asked for is read from disk and placed into the
page cache. This makes sense because sustained disk throughput is pretty
good and programs normally read more than just a few bytes from a file
region. The page cache knows the position of each 4KB chunk within the
file, depicted above as #0, #1, etc. Windows uses 256KB **views**
analogous to pages in the Linux page cache.
Sadly, in a regular file read the kernel must copy the contents of the
page cache into a user buffer, which not only takes cpu time and hurts
the [cpu caches](/post/intel-cpu-caches), but
also **wastes physical memory with duplicate data**. As per the diagram
above, the `scene.dat`
contents are stored twice, and each instance of
the program would store the contents an additional time. We’ve mitigated
the disk latency problem but failed miserably at everything else.
**Memory-mapped files** are the way out of this madness:
When you use file mapping, the kernel maps your program’s virtual pages
directly onto the page cache. This can deliver a significant performance
boost: [Windows System Programming](http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/)
reports run time improvements of 30% and up relative to regular file
reads, while similar figures are reported for Linux and Solaris in
[Advanced Programming in the Unix Environment](http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/).
You might also save large amounts of physical memory, depending on the
nature of your application.
As always with performance, [measurement is everything](/post/performance-is-a-science),
but memory mapping earns its keep in a programmer’s toolbox. The API is
pretty nice too, it allows you to access a file as bytes in memory and
does not require your soul and code readability in exchange for its
benefits. Mind your [address space](/post/anatomy-of-a-program-in-memory)
and experiment with
[mmap](http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html)
in Unix-like systems,
[CreateFileMapping](http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx)
in Windows, or the many wrappers available in high level languages. When
you map a file its contents are not brought into memory all at once, but
rather on demand via [page faults](http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678). The fault
handler [maps your virtual pages](http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436) onto the
page cache after
[obtaining](http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424) a page
frame with the needed file contents. This involves disk I/O if the
contents weren’t cached to begin with.
Now for a pop quiz. Imagine that the last instance of our `render`
program exits. Would the pages storing *scene.dat* in the page cache be
freed immediately? People often think so, but that would be a bad idea.
When you think about it, it is very common for us to create a file in
one program, exit, then use the file in a second program. The page cache
must handle that case. When you think *more* about it, why should the
kernel *ever* get rid of page cache contents? Remember that disk is 5
orders of magnitude slower than RAM, hence a page cache hit is a huge
win. So long as there’s enough free physical memory, the cache should be
kept full. It is therefore *not* dependent on a particular process, but
rather it’s a system-wide resource. If you run `render`
a week from now
and `scene.dat`
is still cached, bonus! This is why the kernel cache
size climbs steadily until it hits a ceiling. It’s not because the OS is
garbage and hogs your RAM, it’s actually good behavior because in a way
free physical memory is a waste. Better use as much of the stuff for
caching as possible.
Due to the page cache architecture, when a program calls
[write()](http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html)
bytes are simply copied to the page cache and the page is marked dirty.
Disk I/O normally does **not** happen immediately, thus your program
doesn’t block waiting for the disk. On the downside, if the computer
crashes your writes will never make it, hence critical files like
database transaction logs must be
[fsync()](http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html)ed
(though one must still worry about drive controller caches, oy!). Reads,
on the other hand, normally block your program until the data is
available. Kernels employ eager loading to mitigate this problem, an
example of which is **read ahead** where the kernel preloads a few pages
into the page cache in anticipation of your reads. You can help the
kernel tune its eager loading behavior by providing hints on whether you
plan to read a file sequentially or randomly (see
[madvise()](http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html),
[readahead()](http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html),
[Windows cache hints](http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior)
).
Linux [does read-ahead](http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424) for
memory-mapped files, but I’m not sure about Windows. Finally, it’s
possible to bypass the page cache using
[O_DIRECT](http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html)
in Linux or
[NO_BUFFERING](http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx)
in Windows, something database software often does.
A file mapping may be **private** or **shared**. This refers only to
**updates** made to the contents in memory: in a private mapping the
updates are not committed to disk or made visible to other processes,
whereas in a shared mapping they are. Kernels use the **copy on write**
mechanism, enabled by page table entries, to implement private mappings.
In the example below, both `render`
and another program called
`render3d`
(am I creative or what?) have mapped `scene.dat`
privately.
`Render`
then writes to its virtual memory area that maps the file:
The read-only page table entries shown above do *not* mean the mapping
is read only, they’re merely a kernel trick to share physical memory
until the last possible moment. You can see how ‘private’ is a bit of a
misnomer until you remember it only applies to updates. A consequence of
this design is that a virtual page that maps a file privately sees
changes done to the file by other programs *as long as the page has only
been read from*. Once copy-on-write is done, changes by others are no
longer seen. This behavior is not guaranteed by the kernel, but it’s
what you get in x86 and makes sense from an API perspective. By
contrast, a shared mapping is simply mapped onto the page cache and
that’s it. Updates are visible to other processes and end up in the
disk. Finally, if the mapping above were read-only, page faults would
trigger a segmentation fault instead of copy on write.
Dynamically loaded libraries are brought into your program’s address
space via file mapping. There’s nothing magical about it, it’s the same
private file mapping available to you via regular APIs. Below is an
example showing part of the address spaces from two running instances of
the file-mapping `render`
program, along with physical memory, to tie
together many of the concepts we’ve seen.
This concludes our 3-part series on memory fundamentals. I hope the series was useful and provided you with a good mental model of these OS topics. |
9,529 | 用 PGP 保护代码完整性(二):生成你的主密钥 | https://www.linux.com/blog/learn/PGP/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key | 2018-04-09T08:12:00 | [
"PGP",
"GPG"
] | https://linux.cn/article-9529-1.html | 
在本系列文章中,我们将深度探讨如何使用 PGP 以及为工作于自由软件项目的开发者提供实用指南。在前一篇文章中,我们介绍了[基本工具和概念](/article-9524-1.html)。在本文中,我们将展示如何生成和保护你的 PGP 主密钥。
#### 清单
1. 生成一个 4096 位的 RSA 主密钥 (必要)
2. 使用 paperkey 备份你的 RSA 主密钥 (必要)
3. 添加所有相关的身份 (必要)
#### 考虑事项
##### 理解“主”(认证)密钥
在本节和下一节中,我们将讨论“主密钥”和“子密钥”。理解以下内容很重要:
1. 在“主密钥”和“子密钥”之间没有技术上的区别。
2. 在创建时,我们赋予每个密钥特定的能力来分配功能限制。
3. 一个 PGP 密钥有四项能力
* [S] 密钥可以用于签名
* [E] 密钥可以用于加密
* [A] 密钥可以用于身份认证
* [C] 密钥可以用于认证其他密钥
4. 一个密钥可能有多种能力
带有 [C] (认证)能力的密钥被认为是“主”密钥,因为它是唯一可以用来表明与其他密钥关系的密钥。只有 [C] 密钥可以被用于:
* 添加或撤销其他密钥(子密钥)的 S/E/A 能力
* 添加、更改或撤销密钥关联的身份(uid)
* 添加或更改本身或其他子密钥的到期时间
* 为了网络信任目的为其它密钥签名
在自由软件的世界里,[C] 密钥就是你的数字身份。一旦你创建该密钥,你应该格外小心地保护它并且防止它落入坏人的手中。
#### 在你创建主密钥前
在你创建的你的主密钥前,你需要选择你的主要身份和主密码。
##### 主要身份
身份使用邮件中发件人一栏相同格式的字符串:
```
Alice Engineer <[email protected]>
```
你可以在任何时候创建新的身份,取消旧的,并且更改你的“主要”身份。由于主要身份在所有 GnuPG 操作中都展示,你应该选择正式的和最有可能用于 PGP 保护通信的名字和邮件地址,比如你的工作地址或者用于在项目<ruby> 提交 <rt> commit </rt></ruby>时签名的地址。
##### 密码
<ruby> 密码 <rt> passphrase </rt></ruby>专用于私钥存储在磁盘上时使用对称加密算法对其进行加密。如果你的 `.gnupg` 目录的内容被泄露,那么一个好的密码就是小偷能够在线假冒你的最后一道防线,这就是为什么设置一个好的密码很重要的原因。
一个强密码最好使用丰富或混合的词典的 3-4 个词,而不引用自流行来源(歌曲、书籍、口号)。由于你将相当频繁地使用该密码,所以它应当易于输入和记忆。
##### 算法和密钥强度
尽管现在 GnuPG 已经支持椭圆曲线加密一段时间了,但我们仍坚持使用 RSA 密钥,至少较长一段时间会这样。虽然现在就可以开始使用 ED25519 密钥,但你可能会碰到无法正确处理它们的工具和硬件设备。
在后续的指南中我们说 2048 位的密钥对 RSA 公钥加密的生命周期已经足够,你可能也会好奇主密钥为什么是 4096 位。 原因很大程度是由于社会因素而非技术上的:主密钥在密钥链上是最显眼的,如果你的主密钥位数比一些和你交互的开发者的少,他们肯定会鄙视你。
#### 生成主密钥
为了生成你的主密钥,请使用以下命令,并且将 “Alice Engineer” 替换为正确值。
```
$ gpg --quick-generate-key 'Alice Engineer <[email protected]>' rsa4096 cert
```
这将弹出一个要求输入密码的对话框。然后,你可能需要移动鼠标或随便按一些键才能生成足够的熵,直到该命令完成。
查看命令输出,它就像这样:
```
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
111122223333444455556666AAAABBBBCCCCDDDD
uid Alice Engineer <[email protected]>
```
注意第二行的长字符串 —— 它是你新生成的密钥的完整指纹。密钥 ID(Key ID)可以用以下三种不同形式表达:
* <ruby> 指纹 <rt> Fingerprint </rt></ruby>,一个完整的 40 个字符的密钥标识符
* <ruby> 长密钥 ID <rt> Long </rt></ruby>,指纹的最后 16 个字符(AAAABBBBCCCCDDDD)
* <ruby> 短密钥 ID <rt> Short </rt></ruby>,指纹的最后 8 个字符(CCCCDDDD)
你应该避免使用 8 个字符的短密钥 ID,因为它们不足够唯一。
这里,我建议你打开一个文本编辑器,复制你新密钥的指纹并粘贴。你需要在接下来几步中用到它,所以将它放在旁边会很方便。
#### 备份你的主密钥
出于灾后恢复的目的 —— 同时特别的如果你试图使用 Web of Trust 并且收集来自其他项目开发者的密钥签名 —— 你应该创建你的私钥的硬拷贝备份。万一所有其它的备份机制都失败了,这应当是最后的补救措施。
创建一个你的私钥的可打印的硬拷贝的最好方法是使用为此而写的软件 `paperkey`。`paperkey` 在所有 Linux 发行版上可用,在 Mac 上也可以通过 brew 安装 `paperkey`。
运行以下命令,用你密钥的完整指纹替换 `[fpr]`:
```
$ gpg --export-secret-key [fpr] | paperkey -o /tmp/key-backup.txt
```
输出将采用易于 OCR 或手动输入的格式,以防如果你需要恢复它的话。打印出该文件,然后拿支笔,并在纸的边缘写下密钥的密码。这是必要的一步,因为密钥输出仍然使用密码加密,并且如果你更改了密钥的密码,你不会记得第一次创建的密钥是什么 —— 我保证。
将打印结果和手写密码放入信封中,并存放在一个安全且保护好的地方,最好远离你家,例如银行保险库。
**打印机注意事项** 打印机连接到计算机的并行端口的时代已经过去了。现在他们拥有完整的操作系统,硬盘驱动器和云集成。由于我们发送给打印机的关键内容将使用密码进行加密,因此这是一项相当安全的操作,但请使用您最好的偏执判断。
#### 添加相关身份
如果你有多个相关的邮件地址(个人、工作、开源项目等),你应该将其添加到主密钥中。你不需要为任何你不希望用于 PGP 的地址(例如,可能不是你的校友地址)这样做。
该命令是(用你完整的密钥指纹替换 `[fpr]`):
```
$ gpg --quick-add-uid [fpr] 'Alice Engineer <[email protected]>'
```
你可以查看你已经使用的 UID:
```
$ gpg --list-key [fpr] | grep ^uid
```
#### 选择主 UID
GnuPG 将会把你最近添加的 UID 作为你的主 UID,如果这与你想的不同,你应该改回来:
```
$ gpg --quick-set-primary-uid [fpr] 'Alice Engineer <[email protected]>'
```
下次,我们将介绍如何生成 PGP 子密钥,它是你实际用于日常工作的密钥。
通过 Linux 基金会和 edX 的免费[“Introduction to Linux”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 课程了解关于 Linux 的更多信息。
---
via: <https://www.linux.com/blog/learn/PGP/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key>
作者:[KONSTANTIN RYABITSEV](https://www.linux.com/users/mricon) 译者:[kimii](https://github.com/kimii) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,530 | 如何解决 “mount.nfs: Stale file handle”错误 | https://kerneltalks.com/troubleshooting/resolve-mount-nfs-stale-file-handle-error/ | 2018-04-09T21:46:31 | [
"NFS"
] | https://linux.cn/article-9530-1.html |
>
> 了解如何解决 Linux 平台上的 `mount.nfs: Stale file handle` 错误。这个 NFS 错误可以在客户端或者服务端解决。
>
>
>

当你在你的环境中使用网络文件系统时,你一定不时看到 `mount.nfs:Stale file handle` 错误。此错误表示 NFS 共享无法挂载,因为自上次配置后有些东西已经更改。
无论是你重启 NFS 服务器或某些 NFS 进程未在客户端或服务器上运行,或者共享未在服务器上正确输出,这些都可能是导致这个错误的原因。此外,当这个错误发生在先前挂载的 NFS 共享上时,它会令人不快。因为这意味着配置部分是正确的,因为是以前挂载的。在这种情况下,可以尝试下面的命令:
确保 NFS 服务在客户端和服务器上运行良好。
```
# service nfs status
rpc.svcgssd is stopped
rpc.mountd (pid 11993) is running...
nfsd (pid 12009 12008 12007 12006 12005 12004 12003 12002) is running...
rpc.rquotad (pid 11988) is running...
```
如果 NFS 共享目前挂载在客户端上,则强制卸载它并尝试在 NFS 客户端上重新挂载它。通过 `df` 命令检查它是否正确挂载,并更改其中的目录。
```
# umount -f /mydata_nfs
# mount -t nfs server:/nfs_share /mydata_nfs
#df -k
------ output clipped -----
server:/nfs_share 41943040 892928 41050112 3% /mydata_nfs
```
在上面的挂载命令中,服务器可以是 NFS 服务器的 IP 或[主机名](https://kerneltalks.com/linux/all-you-need-to-know-about-hostname-in-linux/)。
如果你在强制取消挂载时遇到像下面错误:
```
# umount -f /mydata_nfs
umount2: Device or resource busy
umount: /mydata_nfs: device is busy
umount2: Device or resource busy
umount: /mydata_nfs: device is busy
```
然后你可以用 `lsof` 命令来检查哪个进程或用户正在使用该挂载点,如下所示:
```
# lsof |grep mydata_nfs
lsof: WARNING: can't stat() nfs file system /mydata_nfs
Output information may be incomplete.
su 3327 root cwd unknown /mydata_nfs/dir (stat: Stale NFS file handle)
bash 3484 grid cwd unknown /mydata_nfs/MYDB (stat: Stale NFS file handle)
bash 20092 oracle11 cwd unknown /mydata_nfs/MPRP (stat: Stale NFS file handle)
bash 25040 oracle11 cwd unknown /mydata_nfs/MUYR (stat: Stale NFS file handle)
```
如果你在上面的示例中看到共有 4 个 PID 正在使用该挂载点上的某些文件。尝试杀死它们以释放挂载点。完成后,你将能够正确卸载它。
有时 `mount` 命令会有相同的错误。接着使用下面的命令在客户端重启 NFS 服务后挂载。
```
# service nfs restart
Shutting down NFS daemon: [ OK ]
Shutting down NFS mountd: [ OK ]
Shutting down NFS quotas: [ OK ]
Shutting down RPC idmapd: [ OK ]
Starting NFS services: [ OK ]
Starting NFS quotas: [ OK ]
Starting NFS mountd: [ OK ]
Starting NFS daemon: [ OK ]
```
另请阅读:[如何在 HPUX 中逐步重启 NFS](http://kerneltalks.com/hpux/restart-nfs-in-hpux/)
即使这没有解决你的问题,最后一步是在 NFS 服务器上重启服务。警告!这将断开从该 NFS 服务器输出的所有 NFS 共享。所有客户端将看到挂载点断开。这一步将 99% 解决你的问题。如果没有,请务必检查 [NFS 配置](http://kerneltalks.com/linux/nfs-configuration-linux-hpux/),提供你修改的配置并发布你启动时看到的错误。
上面文章中的输出来自 RHEL6.3 服务器。请将你的评论发送给我们。
---
via: <https://kerneltalks.com/troubleshooting/resolve-mount-nfs-stale-file-handle-error/>
作者:[KernelTalks](https://kerneltalks.com) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Learn how to resolve mount.nfs: Stale file handle error on the Linux platform. This is a Network File System error that can be resolved from the client or server end.*

When you are using the Network File System in your environment, you must have seen `mount.nfs: Stale file handle`
error at times. This error denotes that the NFS share is unable to mount since something has changed since the last good known configuration.
Whenever you reboot the NFS server or some of the NFS processes are not running on the client or server or share is not properly exported at the server; these can be reasons for this error. Moreover, it’s irritating when this error comes to a previously mounted NFS share. Because this means the configuration part is correct since it was previously mounted. In such case once can try the following commands:
Make sure NFS service are running good on client and server.
```
# service nfs status
rpc.svcgssd is stopped
rpc.mountd (pid 11993) is running...
nfsd (pid 12009 12008 12007 12006 12005 12004 12003 12002) is running...
rpc.rquotad (pid 11988) is running...
```
If NFS share currently mounted on the client, then un-mount it forcefully and try to remount it on NFS client. Check if its properly mounted by `df`
command and changing directory inside it.
```
# umount -f /mydata_nfs
# mount -t nfs server:/nfs_share /mydata_nfs
#df -k
------ output clipped -----
server:/nfs_share 41943040 892928 41050112 3% /mydata_nfs
```
In above mount command, server can be IP or [hostname ](https://kerneltalks.com/linux/all-you-need-to-know-about-hostname-in-linux/)of NFS server.
If you are getting error while forcefully un-mounting like below :
```
# umount -f /mydata_nfs
umount2: Device or resource busy
umount: /mydata_nfs: device is busy
umount2: Device or resource busy
umount: /mydata_nfs: device is busy
```
Then you can check which all processes or users are using that mount point with `lsof`
command like below:
```
# lsof |grep mydata_nfs
lsof: WARNING: can't stat() nfs file system /mydata_nfs
Output information may be incomplete.
su 3327 root cwd unknown /mydata_nfs/dir (stat: Stale NFS file handle)
bash 3484 grid cwd unknown /mydata_nfs/MYDB (stat: Stale NFS file handle)
bash 20092 oracle11 cwd unknown /mydata_nfs/MPRP (stat: Stale NFS file handle)
bash 25040 oracle11 cwd unknown /mydata_nfs/MUYR (stat: Stale NFS file handle)
```
If you see in above example that 4 PID are using some files on said mount point. Try killing them off to free mount point. Once done you will be able to un-mount it properly.
Sometimes it still gives the same error for `mount`
command. Then try mounting after restarting NFS service at the client using the below command.
```
# service nfs restart
Shutting down NFS daemon: [ OK ]
Shutting down NFS mountd: [ OK ]
Shutting down NFS quotas: [ OK ]
Shutting down RPC idmapd: [ OK ]
Starting NFS services: [ OK ]
Starting NFS quotas: [ OK ]
Starting NFS mountd: [ OK ]
Starting NFS daemon: [ OK ]
Starting RPC idmapd: [ OK ]
```
Also read : [How to restart NFS step by step in HPUX](https://kerneltalks.com/hpux/restart-nfs-in-hpux/)
Even if this didn’t solve your issue, final step is to restart services at the NFS server. Caution! This will disconnect all NFS shares which are exported from the NFS server. All clients will see the mount point disconnect. This step is where 99% of you will get your issue resolved. If not then [NFS configurations](https://kerneltalks.com/linux/nfs-configuration-linux-hpux/) must be checked, provided you have changed configuration and post that you started seeing this error.
Outputs in above post are from RHEL6.3 server. Drop us your comments related to this post.
Thanks guys, for breaking the NFS mount problem down for me, it resolved my problem. |
9,531 | Linux 中的 5 个 SSH 别名例子 | https://www.linuxnix.com/5-ssh-alias-examples-using-ssh-config-file/ | 2018-04-09T22:46:53 | [
"SSH",
"别名"
] | https://linux.cn/article-9531-1.html | 
作为一个 Linux 用户,我们常用 [ssh 命令](https://www.linuxnix.com/ssh-access-remote-linux-server/) 来登入远程机器。`ssh` 命令你用得越多,你在键入一些重要的命令上花的时间也越多。我们可以用 [定义在你的 .bashrc 文件里的别名](https://www.linuxnix.com/linux-alias-command-explained-with-examples/) 或函数来大幅度缩减花在命令行界面(CLI)的时间。但这不是最佳解决之道。最佳办法是在 `ssh` 配置文件中使用 **SSH 别名** 。
这里是我们能把 `ssh` 命令用得更好的几个例子。
ssh 登入到 AWS(译注:Amazon Web Services,亚马逊公司旗下云计算服务平台)实例的连接是一种痛。仅仅输入以下命令,每次也完全是浪费你时间。
```
ssh -p 3000 -i /home/surendra/mysshkey.pem [email protected]
```
缩短到:
```
ssh aws1
```
调试时连接到系统。
```
ssh -vvv [email protected]
```
缩短到:
```
ssh xyz
```
在本篇中,我们将看到如何不使用 bash 别名或函数实现 `ssh` 命令的缩短。`ssh` 别名的主要优点是所有的 `ssh` 命令快捷方式都存储在一个单一文件,如此就易于维护。其他优点是 **对于类似于 SSH 和 SCP 的命令** 我们能用相同的别名。
在我们进入实际配置之前,我们应该知道 `/etc/ssh/ssh_config`、`/etc/ssh/sshd_config` 和 `~/.ssh/config` 文件三者的区别。以下是对这些文件的解释。
### /etc/ssh/ssh\_config 和 ~/.ssh/config 间的区别
系统级别的 SSH 配置项存放在 `/etc/ssh/ssh_config`,而用户级别的 SSH 配置项存放在 `~/.ssh/config` 文件中。
### /etc/ssh/ssh*config 和 /etc/ssh/sshd*config 间的区别
系统级别的 SSH 配置项是在 `/etc/ssh/ssh_config` 文件中,而系统级别的 SSH **服务端**配置项存放在 `/etc/ssh/sshd_config` 文件。
### 在 ~/.ssh/config 文件里配置项的语法
`~/.ssh/config` 文件内容的语法:
```
配置项 值
配置项 值1 值2
```
**例 1:** 创建主机(www.linuxnix.com)的 SSH 别名
编辑 `~/.ssh/config` 文件写入以下内容:
```
Host tlj
User root
HostName 18.197.176.13
port 22
```
保存此文件。
以上 ssh 别名用了
1. `tlj` 作为一个别名的名称
2. `root` 作为将要登入的用户
3. `18.197.176.13` 作为主机的 IP 地址
4. `22` 作为访问 SSH 服务的端口
输出:
```
sanne@Surendras-MacBook-Pro:~ > ssh tlj
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
Last login: Sat Oct 14 01:00:43 2017 from 20.244.25.231
root@linuxnix:~# exit
logout
Connection to 18.197.176.13 closed.
```
**例 2:** 不用密码用 ssh 密钥登到系统要用 `IdentityFile` 。
例:
```
Host aws
User ec2-users
HostName ec2-54-200-184-202.us-west-2.compute.amazonaws.com
IdentityFile ~/Downloads/surendra.pem
port 22
```
**例 3:** 对同一主机使用不同的别名。在下例中,我们对同一 IP/主机 18.197.176.13 用了 `tlj`、 `linuxnix`、`linuxnix.com` 三个别名。
~/.ssh/config 文件内容
```
Host tlj linuxnix linuxnix.com
User root
HostName 18.197.176.13
port 22
```
**输出:**
```
sanne@Surendras-MacBook-Pro:~ > ssh tlj
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
Last login: Sat Oct 14 01:00:43 2017 from 220.244.205.231
root@linuxnix:~# exit
logout
Connection to 18.197.176.13 closed.
sanne@Surendras-MacBook-Pro:~ > ssh linuxnix.com
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
```
```
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
Last login: Sun Oct 15 20:31:08 2017 from 1.129.110.13
root@linuxnix:~# exit
logout
Connection to 138.197.176.103 closed.
[6571] sanne@Surendras-MacBook-Pro:~ > ssh linuxnix
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
Last login: Sun Oct 15 20:31:20 2017 from 1.129.110.13
root@linuxnix:~# exit
logout
Connection to 18.197.176.13 closed.
```
**例 4:** 用相同的 SSH 别名复制文件到远程系统
语法:
```
scp <文件名> <ssh_别名>:<位置>
```
例子:
```
sanne@Surendras-MacBook-Pro:~ > scp abc.txt tlj:/tmp
abc.txt 100% 12KB 11.7KB/s 00:01
sanne@Surendras-MacBook-Pro:~ >
```
若我们已经将 ssh 主机设置好一个别名,由于 `ssh` 和 `scp` 两者用几乎相同的语法和选项,`scp` 也可以轻易使用。
请在下面尝试从本机 `scp` 一个文件到远程机器。
**例 5:** 解决 Linux 中的 SSH 超时问题。默认情况,如果你不积极地使用终端,你的 ssh 登入就会超时
[SSH 超时问题](https://www.linuxnix.com/how-to-auto-logout/) 是一个更痛的点意味着你在一段时间后不得不重新登入到远程机器。我们能在 `~/.ssh/config` 文件里边恰当地设置 SSH 超时时间来使你的会话不管在什么时间总是激活的。我们将用 2 个能保持会话存活的 SSH 选项来实现这一目的。之一是 `ServerAliveInterval` 保持你会话存活的秒数和 `ServerAliveCountMax` 在(经历了一个)给定数值的会话之后初始化会话。
```
ServerAliveInterval A
ServerAliveCountMax B
```
**例:**
```
Host tlj linuxnix linuxnix.com
User root
HostName 18.197.176.13
port 22
ServerAliveInterval 60
ServerAliveCountMax 30
```
在下篇中我们将会看到一些其他的退出方式。
---
via: <https://www.linuxnix.com/5-ssh-alias-examples-using-ssh-config-file/>
作者:[SURENDRA ANNE](https://www.linuxnix.com) 译者:[ch-cn](https://github.com/ch-cn) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As a Linux user, we use[ ssh command](https://www.linuxnix.com/ssh-access-remote-linux-server/) to log in to remote machines. The more you use ssh command, the more time you are wasting in typing some significant commands. We can use either [alias defined in your .bashrc file](https://www.linuxnix.com/linux-alias-command-explained-with-examples/) or functions to minimize the time you spend on CLI. But this is not a better solution. The better solution is to use **SSH-alias** in ssh config file.
A couple of examples where we can better the ssh commands we use.
Connecting to ssh to AWS instance is a pain. Just to type below command, every time is complete waste your time as well.
ssh -p 3000 -i /home/surendra/mysshkey.pem [email protected]
to
ssh aws1
Connecting to a system when debugging.
ssh -vvv [email protected]
to
ssh xyz
In this post, we will see how to achieve shorting of your ssh commands without using bash alias or functions. The main advantage of ssh alias is that all your ssh command shortcuts are stored in a single file and easy to maintain. The other advantage is we can use same alias **for both SSH and SCP commands alike**.
Before we jump into actual configurations, we should know difference between /etc/ssh/ssh_config, /etc/ssh/sshd_config, and ~/.ssh/config files. Below is the explanation for these files.
## Difference between /etc/ssh/ssh_config and ~/.ssh/config
System-level SSH configurations are stored in /etc/ssh/ssh_config. Whereas user-level ssh configurations are stored in ~/.ssh/config file.
## Difference between /etc/ssh/ssh_config and /etc/ssh/sshd_config
System-level SSH configurations are stored in /etc/ssh/ssh_config. Whereas system level SSH server configurations are stored in /etc/ssh/sshd_config file.
**Syntax for configuration in ~/.ssh/config file**
Syntax for ~/.ssh/config file content.
config val config val1 val2
**Example1:** Create SSH alias for a host(www.linuxnix.com)
Edit file ~/.ssh/config with following content
Host tljUser rootHostName 18.197.176.13port 22
Save the file
The above ssh alias uses
**tlj as an alias name****root as a user who will log in****18.197.176.13 as hostname IP address****22 as a port to access SSH service.**
Output:
sanne@Surendras-MacBook-Pro:~ > ssh tljWelcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)* Documentation: https://help.ubuntu.com* Management: https://landscape.canonical.com* Support: https://ubuntu.com/advantageGet cloud support with Ubuntu Advantage Cloud Guest:http://www.ubuntu.com/business/services/cloudLast login: Sat Oct 14 01:00:43 2017 from 20.244.25.231root@linuxnix:~# exitlogoutConnection to 18.197.176.13 closed.
**Example2:** Using ssh key to login to the system without using password using **IdentityFile**.
Example:
Host awsUser ec2-usersHostName ec2-54-200-184-202.us-west-2.compute.amazonaws.comIdentityFile ~/Downloads/surendra.pemport 22
**Example3:** Use a different alias for the same host. In below example, we use **tlj, linuxnix, linuxnix.com** for same IP/hostname 18.197.176.13.
~/.ssh/config file content
Host tlj linuxnix linuxnix.comUser rootHostName 18.197.176.13port 22
**Output:**
sanne@Surendras-MacBook-Pro:~ > sshtljWelcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)* Documentation: https://help.ubuntu.com* Management: https://landscape.canonical.com* Support: https://ubuntu.com/advantageGet cloud support with Ubuntu Advantage Cloud Guest:http://www.ubuntu.com/business/services/cloudLast login: Sat Oct 14 01:00:43 2017 from 220.244.205.231root@linuxnix:~# exitlogoutConnection to 18.197.176.13 closed.sanne@Surendras-MacBook-Pro:~ > ssh linuxnix.comWelcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)* Documentation: https://help.ubuntu.com* Management: https://landscape.canonical.com* Support: https://ubuntu.com/advantage
Get cloud support with Ubuntu Advantage Cloud Guest:http://www.ubuntu.com/business/services/cloudLast login: Sun Oct 15 20:31:08 2017 from 1.129.110.13root@linuxnix:~# exitlogoutConnection to 138.197.176.103 closed.[6571] sanne@Surendras-MacBook-Pro:~ > ssh linuxnixWelcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)* Documentation: https://help.ubuntu.com* Management: https://landscape.canonical.com* Support: https://ubuntu.com/advantageGet cloud support with Ubuntu Advantage Cloud Guest:http://www.ubuntu.com/business/services/cloudLast login: Sun Oct 15 20:31:20 2017 from 1.129.110.13root@linuxnix:~# exitlogoutConnection to 18.197.176.13 closed.
**Example4:** Copy a file to remote system using same SSH alias
Syntax:
scp <filename> <ssh_alias>:<location>
Example:
sanne@Surendras-MacBook-Pro:~ > scp abc.txt tlj:/tmpabc.txt 100% 12KB 11.7KB/s 00:01sanne@Surendras-MacBook-Pro:~ >
As we already set ssh host as an alias, using SCP is a breeze as both ssh and SCP use almost same syntax and options.
To do scp a file from local machine to remote one use below.
**Examaple5:** Resolve SSH timeout issues in Linux. By default, your ssh logins are timed out if you don’t activily use the terminial.
[SSH timeouts](https://www.linuxnix.com/how-to-auto-logout/) are one more pain where you have to re-login to a remote machine after a certain time. We can set SSH time out right in side your ~/.ssh/config file to make your session active for whatever time you want. To achieve this we will use two SSH options for keeping the session alive. One ServerAliveInterval keeps your session live for number of seconds and ServerAliveCountMax will initial session after session for a given number.
ServerAliveInterval AServerAliveCountMax B
**Example:**
Host tlj linuxnix linuxnix.comUser rootHostName 18.197.176.13port 22ServerAliveInterval 60ServerAliveCountMax 30
We will see some other exiting howto in our next post. Keep visiting linuxnix.com.
#### Latest posts by Surendra Anne ([see all](https://www.linuxnix.com/author/surendra/))
-
[Docker: How to copy files to/from docker container](https://www.linuxnix.com/docker-how-to-copy-files-to-from-docker-container/)- June 30, 2020 -
[Anisble: ERROR! unexpected parameter type in action:](https://www.linuxnix.com/anisble-error-unexpected-parameter-type-in-action-fix/)- June 29, 2020Fix -
[FREE: JOIN OUR DEVOPS TELEGRAM GROUPS](https://www.linuxnix.com/free-join-our-devops-telegram-group/)- August 2, 2019 -
[Review: Whizlabs Practice Tests for AWS Certified Solutions Architect Professional (CSAP)](https://www.linuxnix.com/review-whizlabs-practice-tests-for-aws-certified-solutions-architect-professional-csap/)- August 27, 2018 -
[How to use ohai/chef-shell to get node attributes](https://www.linuxnix.com/chef-get-node-attributes-or-values/)- July 19, 2018 |
9,532 | 区块链不适用的若干场景 | https://opensource.com/article/18/3/3-tests-not-moving-blockchain | 2018-04-10T16:01:22 | [
"区块链"
] | https://linux.cn/article-9532-1.html |
>
> 这三个问题可以帮你避开不实宣传。
>
>
>

不错,“区块链”这个概念异常的火热。
众所周知,我一直关注区块链及相关技术的成熟度发展情况,思考我们是否对其评价过高了;但从目前的情况来看,还没有这个迹象。我在文中提到的区块链技术是广义上的,包含了狭义上不属于区块链的分布式账本技术(DLT)。我对私有链permissioned blockchain更感兴趣,其中私有链的定义可以参考我的文章《[区块链是安全性方面的话题吗?](https://opensource.com/article/17/12/blockchain-security-topic)》。简而言之,我对加密货币之外的区块链业务应用特别感兴趣<sup> <a href="#footnote1"> 注1 </a></sup> 。
我们对区块链的技术成熟度的判断应该有一部分可以得到证实<sup> <a href="#footnote2"> 注2 </a></sup> 。如果我们判断正确,未来将会出现海量的区块链应用。这很可能会变成现实,但并不是所有的应用都是优秀的区块链应用,其中一部分很可能是非常糟糕的。
但区块链所处的技术成熟度意味着,大量业务将快速拥抱新技术<sup> <a href="#footnote3"> 注3 </a></sup> ,但对于可能的前景却一知半解。促成这种情况的原因可以大致分为三种:
1. 对于涉及多用户数据存储的业务应用,在投入精力的情况下,几乎都可以改造为基于区块链的版本;
2. 很多区块链相关的会议和“专家”呼吁尽快拥抱区块链,否则可能会在半年内被淘汰<sup> <a href="#footnote4"> 注4 </a></sup> ;
3. 完全理解区块链技术是很难的,支持其在企业中落地的往往是工程师。
对于最后一条,我必须补充几句,不然很容易被引起众怒<sup> <a href="#footnote5"> 注5 </a></sup> 。作为一名工程师,我显然无意贬低工程师。但工程师的天性使然,我们对见到的新鲜事物(亮点)热情澎湃,却对业务本身<ruby> 深入 <rt> fully grok </rt></ruby><sup> <a href="#footnote6"> 注6 </a></sup> 不足,故对于新技术给业务带来的影响理解可能并不深刻。在业务领导者看来,这些影响不一定是有利的。
上面提到的三种促因可能导致一种风险,即在没有充分评估利弊的情况下,将业务改造为区块链应用。在另一文([区块链:每个人都应该参与进来吗?](https://aliceevebob.com/2017/09/12/blockchain-should-we-all-play/))中提到几个场景,用于判断一个业务什么情况下适合采用区块链技术。这些场景是有益的,但更进一步,我坚信人们更加需要的是,业务完全不适用区块链的几种简单的场景判定。我总结了三种场景判定,如果对于其中任何一个问题你给出了肯定的回答,那么很大概率上区块链不适合你。
### 场景判定 1:业务是否需要集中式的管控或授权?
如果你给出了肯定的回答,那么区块链不适合你。
例如,假设你是一个普通销售商,具有唯一的订单系统,那么对于何时发货你有唯一的授权,显然区块链不适合你。假设你是一个内容提供商,所有提供的内容都会经过唯一的编辑和发布过程,显然区块链不适合你。
**经验总结:只有当任务对应的执行流程及相应的认证流程是分布于众多主体时,区块链是有价值的。**
### 场景判定 2:业务使用经典数据库是否工作良好?
如果你给出了肯定的回答,那么区块链不适合你。
该场景似乎与上一个场景是强相关的,但并不总是如此。在一些应用中,处理流程是分布的,但信息存储是中心化的;在另外一些应用中,处理流程需要中心化的授权,但信息存储是分布的,即总有一个并不是分布式的。但如果业务使用经典数据库可以工作量良好的话,使用经典数据库是一个好主意。
经典数据库不仅性能良好,在设计与运营成本方面低比区块链或分布式账本,而且我们在这方面技术积累丰厚。区块链让所有人<sup> <a href="#footnote8"> 注8 </a></sup> 可以查看和持有数据,但间接成本和潜在成本都比较高昂。
### 场景判定 3:业务采用新技术是否成本高昂或对合作伙伴有负面效果?
如果你给出了肯定的回答,那么区块链不适合你。
我曾听过这种观点,即区块链会让所有人获益。但这显然是不可能的。假设你正在为某个流程设计一个应用,改变合作伙伴与你及应用的交互方式,那么你需要判断这个改变是否符合合作伙伴的想法。不论是否涉及区块链,可以很容易的设计并引入一个应用,虽然降低了你自己的业务阻力,但与此同时增加了合作伙伴的业务阻力。
假设我为汽车行业生产发动机配件,那么使用区块链追溯和管理配件会让我受益匪浅。例如,我可以查看购买的滚珠轴承的生产商、生产时间和钢铁材料供应商等。换一个角度,假设我是滚珠轴承生产商,已经为40多个客户公司建立了处理流程。为一家客户引入新的流程会涉及工作方式、系统体系、储藏和安全性标准等方面的变更,这无法让我感兴趣,相反,这会导致复杂性和高开销。
### 总结
这几个场景判定用于提纲挈领,并不是一成不变的。其中数据库相关的那个场景判定更像是技术方面的,但也是紧密结合业务定位和功能的。希望这几个判定可以为区块链技术引进促因带来的过热进行降温。
* 注 1. 请不要误解我的意思,加密货币显然是一种有趣的区块链业务应用,只是不在本文的讨论范畴而已。
* 注 2. 知道具体是哪些部分是很有意义的,如果你知道,请告诉我好吗?
* 注 3. 坦率的说,它其实更像是一大堆技术的集合体。
* 注 4. 这显然是不太可能的,如果被淘汰的主体是这些会议和“专家”本身倒十分有可能。
* 注 5. 由于比方打得有些不恰当,估计还是会引起众怒。
* 注 6. 我太喜欢 grok 这个单词了,我把它放在这里作为我的工程师标志<sup> <a href="#footnote7"> 注7 </a></sup> 。
* 注 7. 你可能已经想到了,我读过*Stranger in a Strange Land*一书,包括删减版和原版。
* 注 8. 在合理的情况下。
原文最初发表于[爱丽丝, 夏娃和鲍勃 – 一个安全性主题博客](https://aliceevebob.com/2018/02/13/3-tests-for-not-moving-to-blockchain/),已获得转载许可。
---
via: <https://opensource.com/article/18/3/3-tests-not-moving-blockchain>
作者:[Mike Bursell](https://opensource.com/users/mikecamel) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | So, there's this thing called "blockchain" that is quite popular…
You know that already, of course. I keep wondering whether we've hit "peak hype" for blockchain and related technologies yet, but so far there's no sign of it. When I'm talking about blockchain here, I'm including distributed ledger technologies (DLTs), which are, by some tight definitions of the term, not really blockchains at all. I'm particularly interested, from a professional point of view, in permissioned blockchains. You can read more about how that's defined in my article * Is blockchain a security topic?* The key point here is that I'm interested in business applications of blockchain beyond cryptocurrency.
1And, if the hype is to be believed—and *some* of it probably should be[ 2](#2)—then there is an almost infinite set of applications for blockchain. That's probably correct, but it doesn't mean all of them are
*good*applications for blockchain. Some, in fact, are likely to be very bad applications for blockchain.
The hype associated with blockchain, however, means that businesses are rushing to embrace this new technology[ 3](#3) without really understanding what they're doing. The drivers towards this are arguably three-fold:
- You can, if you try, make almost any application with multiple users that stores data into a blockchain-enabled application.
- There are lots of conferences and "gurus" telling people that if they don't embrace blockchain now, they'll go out of business within six months
.4 - It's not easy technology to understand fully, and lots of its proponents "on-the-ground" in organisations are techies.
I want to unpack that last statement before I get a hail of trolls flaming me.[ 5](#5) I have nothing against techies—I'm one myself—but one of our characteristics tends to be enormous enthusiasm about new things ("shinies") that we understand, but whose impact on the business we don't always fully grok.
[That's not always a positive for business leaders.](#6)
6The danger, then, is that the confluence of those three drivers may lead to businesses moving to blockchain applications without fully understanding whether it's a good idea. I wrote in another post (* Blockchain: should we all play?*) about some tests to decide when a process is a good fit for blockchain and when it's not. They were useful, but the more I think about it, the more I'm convinced that we need some simple tests to tell us when we should definitely
*not*move a process or an application to a blockchain. I present my three tests. If your answer to
*any*of these questions is "yes," then you almost certainly don't need a blockchain.
## Test 1: Does it have a centralised controller or authority?
If the answer is "yes," then you don't need a blockchain.
If, for instance, you're selling, I don't know, futons, and you have a single ordering system, then you have a single authority for deciding when to send out a futon. You almost certainly don't need to make this a blockchain. If you are a purveyor of content that has to pass through a single editorial and publishing process, you almost certainly don't need to make this a blockchain.
The lesson is: Blockchains really don't make sense unless the tasks required in the process execution—and the trust associated with those tasks—is distributed among multiple entities.
## Test 2: Could it work fine with a standard database?
If the answer to this question is "yes," then you don't need a blockchain.
This and the previous question are somewhat intertwined but don't need to be. There are applications where you have distributed processes but need to store information centrally, or you have centralised authorities but distributed data, where one answer may be "yes" and the other is "no." But if your answer to this question is "yes," use a standard database.
Databases are good at what they do, they are cheaper in terms of design and operations than running a blockchain or distributed ledger, and we know how to make them work. Blockchains are about letting everybody[ 8](#8) see and hold data, but the overheads can be high and the implications costly.
## Test 3: Is adoption going to be costly or annoying to some stakeholders?
If the answer to this question is "yes," then you don't need a blockchain.
I've heard assertions that blockchains always benefit all users. This is patently false. If you are creating an application for a process and changing the way your stakeholders interact with you and it, you need to consider whether that change is in their best interests. It's very easy to create and introduce an application, blockchain or not, that reduces business friction for the owner of the process but increases it for other stakeholders.
If I make engine parts for the automotive industry, it may benefit me immensely to be able to track and manage the parts on a blockchain. I may be able to see at a glance who supplied what, when, and the quality of the steel used in the (for example) ball bearings I buy. On the other hand, if I'm a ball-bearing producer with an established process that works for the 40 other companies to whom I sell ball bearings, adopting a new process for one company—with associated changes to my method of work, systems, storage, and security requirements—is unlikely to be in my best interests. It's going to be both costly and annoying.
## In summary
Tests are guidelines; they're not fixed in stone. One of these tests looks like a technical test (the database one), but it's really as much about business roles and responsibilities as the other two. All of them, hopefully, can be used as a counterbalance to the three drivers of blockchain adoption I mentioned.
[1. Which, don't get me wrong, is definitely interesting and a business application—it's just not what I'm going to talk about in this post.]
[2. The trick is knowing which bits. Let me know if you work out how, OK?]
[3. It's actually quite a large set of technologies, to be honest.]
[4. Which is patently untrue, unless the word "they" refers to the conferences and gurus, in which case it's probably correct.]
[5. Which may happen anyway due to my egregious mixing of metaphors.]
[6. There's a word to love. I've put it in to exhibit my techie credentials.]7
[7. And before you doubt them, yes, I've read the book, in both cut and uncut versions.]
*This article originally appeared on Alice, Eve, and Bob – a security blog and is republished with permission.*
## Comments are closed. |
9,533 | 深度学习战争:Facebook 支持的 PyTorch 与 Google 的 TensorFlow | https://datahub.packtpub.com/deep-learning/dl-wars-pytorch-vs-tensorflow/ | 2018-04-11T15:34:00 | [
"深度学习",
"TensorFlow",
"DL",
"PyTorch"
] | https://linux.cn/article-9533-1.html | 
有一个令人震惊的事实,即人工智能和机器学习的工具和技术在近期迅速兴起。深度学习,或者说“注射了激素的机器学习”,数据科学家和机器学习专家在这个领域有数不胜数等可用的库和框架。很多这样的框架都是基于 Python 的,因为 Python 是一个更通用,相对简单的语言。[Theano](https://www.packtpub.com/web-development/deep-learning-theano)、[Keras](https://www.packtpub.com/big-data-and-business-intelligence/deep-learning-keras)、 [TensorFlow](https://www.packtpub.com/big-data-and-business-intelligence/deep-learning-tensorflow) 是几个基于 Python 构建的流行的深度学习库,目的是使机器学习专家更轻松。
Google 的 TensorFlow 是一个被广泛使用的机器学习和深度学习框架。 TensorFlow 开源于 2015 年,得到了机器学习专家社区的广泛支持,TensorFlow 已经迅速成长为许多机构根据其机器学习和深度学习等需求而选择的框架。 另一方面,PyTorch 是由 Facebook 最近开发的用于训练神经网络的 Python 包,改编自基于 Lua 的深度学习库 Torch。 PyTorch 是少数可用的深度学习框架之一,它使用<ruby> 基于磁带的自动梯度系统 <rt> tape-based autograd system </rt></ruby>,以快速和灵活的方式构建动态神经网络。
在这篇文章中,我们将 PyTorch 与 TensorFlow 进行不同方面的比较。
让我们开始吧!
### 什么编程语言支持 PyTorch 和 TensorFlow?
虽然主要是用 C++ 和 CUDA 编写的,但 TensorFlow 包含一个位于核心引擎上的 Python API,使得更便于被<ruby> Python 支持者 <rt> Pythonistas </rt></ruby>使用。 除了 Python,它还包括 C++、Haskell、Java、Go 和 Rust 等其他 API,这意味着开发人员可以用他们的首选语言进行编码。
虽然 PyTorch 是一个 Python 软件包,但你也可以提供使用基本的 C/C++ 语言的 API 进行编码。 如果你习惯使用 Lua 编程语言,你也可以使用 Torch API 在 PyTorch 中编写神经网络模型。
### PyTorch 和 TensorFlow 有多么易于使用?
如果将 TensorFlow 作为一个独立的框架使用,它可能会有点复杂,并且会给深度学习模型的训练带来一些困难。 为了减少这种复杂性,可以使用位于 TensorFlow 复杂引擎之上的 Keras 封装,以简化深度学习模型的开发和训练。 TensorFlow 也支持 PyTorch 目前没有的[分布式培训](https://www.tensorflow.org/deploy/distributed)。 由于包含 Python API,TensorFlow 也可以在生产环境中使用,即可用于培训练和部署企业级深度学习模型。
PyTorch 由于 Torch 的复杂用 Python 重写。 这使得 PyTorch 对于开发人员更为原生。 它有一个易于使用的框架,提供最大化的灵活和速度。 它还允许在训练过程中快速更改代码而不妨碍其性能。 如果你已经有了一些深度学习的经验,并且以前使用过 Torch,那么基于它的速度、效率和易用性,你会更喜欢 PyTorch。 PyTorch 包含定制的 GPU 分配器,这使得深度学习模型具有更高的内存效率。 由此,训练大型深度学习模型变得更容易。 因此,Pytorch 在 Facebook、Twitter、Salesforce 等大型组织广受欢迎。
### 用 PyTorch 和 TensorFlow 训练深度学习模型
PyTorch 和 TensorFlow 都可以用来建立和训练神经网络模型。
TensorFlow 工作于 SCG(静态计算图)上,包括在模型开始执行之前定义静态图。 但是,一旦开始执行,在模型内的调整更改的唯一方法是使用 [tf.session 和 tf.placeholder 张量](https://www.tensorflow.org/versions/r0.12/get_started/basic_usage)。
PyTorch 非常适合训练 RNN(递归神经网络),因为它们在 [PyTorch](https://www.reddit.com/r/MachineLearning/comments/66rriz/d_rnns_are_much_faster_in_pytorch_than_tensorflow/) 中比在 TensorFlow 中运行得更快。 它适用于 DCG(动态计算图),可以随时在模型中定义和更改。 在 DCG 中,每个模块可以单独调试,这使得神经网络的训练更简单。
TensorFlow 最近提出了 TensorFlow Fold,这是一个旨在创建 TensorFlow 模型的库,用于处理结构化数据。 像 PyTorch 一样,它实现了 DCG,在 CPU 上提供高达 10 倍的计算速度,在 GPU 上提供超过 100 倍的计算速度! 在 [Dynamic Batching](https://arxiv.org/abs/1702.02181) 的帮助下,你现在可以执行尺寸和结构都不相同的深度学习模型。
### GPU 和 CPU 优化的比较
TensorFlow 的编译时间比 PyTorch 短,为构建真实世界的应用程序提供了灵活性。 它可以从 CPU、GPU、TPU、移动设备到 Raspberry Pi(物联网设备)等各种处理器上运行。
另一方面,PyTorch 包括<ruby> 张量 <rt> tensor </rt></ruby>计算,可以使用 GPU 将深度神经网络模型加速到 [50 倍或更多](https://github.com/jcjohnson/pytorch-examples#pytorch-tensors)。 这些张量可以停留在 CPU 或 GPU 上。 CPU 和 GPU 都是独立的库, 无论神经网络大小如何,PyTorch 都可以高效地利用。
### 社区支持
TensorFlow 是当今最流行的深度学习框架之一,由此也给它带来了庞大的社区支持。 它有很好的文档和一套详细的在线教程。 TensorFlow 还包括许多预先训练过的模型,这些模型托管和提供于 [GitHub](https://github.com/tensorflow/models)。 这些模型提供给热衷于使用 TensorFlow 开发者和研究人员一些现成的材料来节省他们的时间和精力。
另一方面,PyTorch 的社区相对较小,因为它最近才发展起来。 与 TensorFlow 相比,文档并不是很好,代码也不是很容易获得。 然而,PyTorch 确实允许个人与他人分享他们的预训练模型。
### PyTorch 和 TensorFlow —— 力量悬殊的故事
就目前而言,由于各种原因,TensorFlow 显然比 PyTorch 更受青睐。
TensorFlow 很大,经验丰富,最适合实际应用。 是大多数机器学习和深度学习专家明显的选择,因为它提供了大量的功能,最重要的是它在市场上的成熟应用。 它具有更好的社区支持以及多语言 API 可用。 它有一个很好的文档库,由于从准备到使用的代码使之易于生产。 因此,它更适合想要开始深度学习的人,或者希望开发深度学习模型的组织。
虽然 PyTorch 相对较新,社区较小,但它速度快,效率高。 总之,它给你所有的优势在于 Python 的有用性和易用性。 由于其效率和速度,对于基于研究的小型项目来说,这是一个很好的选择。 如前所述,Facebook、Twitter 等公司正在使用 PyTorch 来训练深度学习模型。 但是,使用它尚未成为主流。 PyTorch 的潜力是显而易见的,但它还没有准备好去挑战这个 TensorFlow 野兽。 然而,考虑到它的增长,PyTorch 进一步优化并提供更多功能的日子并不遥远,直到与 TensorFlow可以 比较。
作者: Savia Lobo,非常喜欢数据科学。 喜欢更新世界各地的科技事件。 喜欢歌唱和创作歌曲。 相信才智上的艺术。
---
via: <https://datahub.packtpub.com/deep-learning/dl-wars-pytorch-vs-tensorflow/>
作者:[Savia Lobo](https://datahub.packtpub.com/author/savial/) 译者:[Wuod3n](https://github.com/Wuod3n) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 302 | Moved Temporarily | null |
9,534 | 使用 Graylog 和 Prometheus 监视 Kubernetes 集群 | https://insights.ubuntu.com/2018/01/16/monitor-your-kubernetes-cluster/ | 2018-04-10T18:28:32 | [
"Kubernetes",
"监控"
] | https://linux.cn/article-9534-1.html | 这篇文章最初发表在 [Kevin Monroe 的博客](https://medium.com/@kwmonroe/monitor-your-kubernetes-cluster-a856d2603ec3) 上。
监视日志和指标状态是集群管理员的重点工作。它的好处很明显:指标能帮你设置一个合理的性能目标,而日志分析可以发现影响你工作负载的问题。然而,困难的是如何找到一个与大量运行的应用程序一起工作的监视解决方案。
在本文中,我将使用 [Graylog](https://www.graylog.org/) (用于日志)和 [Prometheus](https://prometheus.io/) (用于指标)去打造一个 Kubernetes 集群的监视解决方案。当然了,这不仅是将三个东西连接起来那么简单,实现上,最终结果看起来应该如题图所示:

正如你所了解的,Kubernetes 不是一件东西 —— 它由主控节点、工作节点、网络连接、配置管理等等组成。同样,Graylog 是一个配角(apache2、mongodb、等等),Prometheus 也一样(telegraf、grafana 等等)。在部署中连接这些点看起来似乎有些让人恐惧,但是使用合适的工具将不会那么困难。
我将使用 [conjure-up](https://conjure-up.io/) 和 [Canonical 版本的 Kubernetes](https://jujucharms.com/canonical-kubernetes) (CDK) 去探索 Kubernetes。我发现 `conjure-up` 接口对部署大型软件很有帮助,但是我知道一些人可能不喜欢 GUI、TUI 以及其它用户界面。对于这些人,我将用命令行再去部署一遍。
在开始之前需要注意的一点是,Graylog 和 Prometheus 是部署在 Kubernetes 外侧而不是集群上。像 Kubernetes 仪表盘和 Heapster 是运行的集群的非常好的信息来源,但是我的目标是为日志/指标提供一个分析机制,而不管集群运行与否。
### 开始探索
如果你的系统上没有 `conjure-up`,首先要做的第一件事情是,请先安装它,在 Linux 上,这很简单:
```
sudo snap install conjure-up --classic
```
对于 macOS 用户也提供了 brew 包:
```
brew install conjure-up
```
你需要最新的 2.5.2 版,它的好处是添加了 CDK spell,因此,如果你的系统上已经安装了旧的版本,请使用 `sudo snap refresh conjure-up` 或者 `brew update && brew upgrade conjure-up` 去更新它。
安装完成后,运行它:
```
conjure-up
```

你将发现有一个 spell 列表。选择 CDK 然后按下回车。

这个时候,你将看到 CDK spell 可用的附加组件。我们感兴趣的是 Graylog 和 Prometheus,因此选择这两个,然后点击 “Continue”。
它将引导你选择各种云,以决定你的集群部署的地方。之后,你将看到一些部署的后续步骤,接下来是回顾屏幕,让你再次确认部署内容:

除了典型的 K8s 相关的应用程序(etcd、flannel、load-balancer、master 以及 workers)之外,你将看到我们选择的日志和指标相关的额外应用程序。
Graylog 栈包含如下:
* apache2:graylog web 界面的反向代理
* elasticsearch:日志使用的文档数据库
* filebeat:从 K8s master/workers 转发日志到 graylog
* graylog:为日志收集器提供一个 api,以及提供一个日志分析界面
* mongodb:保存 graylog 元数据的数据库
Prometheus 栈包含如下:
* grafana:指标相关的仪表板的 web 界面
* prometheus:指标收集器以及时序数据库
* telegraf:发送主机的指标到 prometheus 中
你可以在回顾屏幕上微调部署,但是默认组件是必选 的。点击 “Deploy all Remaining Applications” 继续。
部署工作将花费一些时间,它将部署你的机器和配置你的云。完成后,`conjure-up` 将展示一个摘要屏幕,它包含一些链接,你可以用你的终端去浏览各种感兴趣的内容:

#### 浏览日志
现在,Graylog 已经部署和配置完成,我们可以看一下采集到的一些数据。默认情况下,filebeat 应用程序将从 Kubernetes 的 master 和 worker 中转发系统日志( `/var/log/*.log` )和容器日志(`/var/log/containers/*.log`)到 graylog 中。
记住如下的 apache2 的地址和 graylog 的 admin 密码:
```
juju status --format yaml apache2/0 | grep public-address
public-address: <your-apache2-ip>
juju run-action --wait graylog/0 show-admin-password
admin-password: <your-graylog-password>
```
在浏览器中输入 `http://<your-apache2-ip>` ,然后以管理员用户名(admin)和密码(<your-graylog-password>)登入。
**注意:** 如果这个界面不可用,请等待大约 5 分钟时间,以便于配置的反向代理生效。
登入后,顶部的 “Sources” 选项卡可以看到从 K8s 的 master 和 workers 中收集日志的概述:

通过点击 “System / Inputs” 选项卡深入这些日志,选择 “Show received messages” 查看 filebeat 的输入:

在这里,你可以应用各种过滤或者设置 Graylog 仪表板去帮助识别大多数比较重要的事件。查看 [Graylog Dashboard](http://docs.graylog.org/en/2.3/pages/dashboards.html) 文档,可以了解如何定制你的视图的详细资料。
#### 浏览指标
我们的部署通过 grafana 仪表板提供了两种类型的指标:系统指标,包括像 K8s master 和 worker 的 CPU /内存/磁盘使用情况,以及集群指标,包括像从 K8s cAdvisor 端点上收集的容器级指标。
记住如下的 grafana 的地址和 admin 密码:
```
juju status --format yaml grafana/0 | grep public-address
public-address: <your-grafana-ip>
juju run-action --wait grafana/0 get-admin-password
password: <your-grafana-password>
```
在浏览器中输入 `http://<your-grafana-ip>:3000`,输入管理员用户(admin)和密码(<your-grafana-password>)登入。成功登入后,点击 “Home” 下拉框,选取 “Kubernetes Metrics (via Prometheus)” 去查看集群指标仪表板:

我们也可以通过下拉框切换到 “Node Metrics (via Telegraf) ” 去查看 K8s 主机的系统指标。

### 另一种方法
正如在文章开始的介绍中提到的,我喜欢用 `conjure-up` 的向导去完成像 Kubernetes 这种复杂软件的部署。现在,我们来看一下 `conjure-up` 的另一种方法,你可能希望去看到实现相同结果的一些命令行的方法。还有其它的可能已经部署了前面的 CDK,并想去扩展使用上述的 Graylog/Prometheus 组件。不管什么原因你既然看到这了,既来之则安之,继续向下看吧。
支持 `conjure-up` 的工具是 [Juju](https://jujucharms.com/)。CDK spell 所做的一切,都可以使用 `juju` 命令行来完成。我们来看一下,如何一步步完成这些工作。
#### 从 Scratch 中启动
如果你使用的是 Linux,安装 Juju 很简单,命令如下:
```
sudo snap install juju --classic
```
对于 macOS,Juju 也可以从 brew 中安装:
```
brew install juju
```
现在为你选择的云配置一个控制器。你或许会被提示请求一个凭据(用户名密码):
```
juju bootstrap
```
我们接下来需要基于 CDK 捆绑部署:
```
juju deploy canonical-kubernetes
```
#### 从 CDK 开始
使用我们部署的 Kubernetes 集群,我们需要去添加 Graylog 和 Prometheus 所需要的全部应用程序:
```
## deploy graylog-related applications
juju deploy xenial/apache2
juju deploy xenial/elasticsearch
juju deploy xenial/filebeat
juju deploy xenial/graylog
juju deploy xenial/mongodb
```
```
## deploy prometheus-related applications
juju deploy xenial/grafana
juju deploy xenial/prometheus
juju deploy xenial/telegraf
```
现在软件已经部署完毕,将它们连接到一起,以便于它们之间可以相互通讯:
```
## relate graylog applications
juju relate apache2:reverseproxy graylog:website
juju relate graylog:elasticsearch elasticsearch:client
juju relate graylog:mongodb mongodb:database
juju relate filebeat:beats-host kubernetes-master:juju-info
juju relate filebeat:beats-host kubernetes-worker:jujuu-info
```
```
## relate prometheus applications
juju relate prometheus:grafana-source grafana:grafana-source
juju relate telegraf:prometheus-client prometheus:target
juju relate kubernetes-master:juju-info telegraf:juju-info
juju relate kubernetes-worker:juju-info telegraf:juju-info
```
这个时候,所有的应用程序已经可以相互之间进行通讯了,但是我们还需要多做一点配置(比如,配置 apache2 反向代理、告诉 prometheus 如何从 K8s 中取数、导入到 grafana 仪表板等等):
```
## configure graylog applications
juju config apache2 enable_modules="headers proxy_html proxy_http"
juju config apache2 vhost_http_template="$(base64 <vhost-tmpl>)"
juju config elasticsearch firewall_enabled="false"
juju config filebeat \
logpath="/var/log/*.log /var/log/containers/*.log"
juju config filebeat logstash_hosts="<graylog-ip>:5044"
juju config graylog elasticsearch_cluster_name="<es-cluster>"
```
```
## configure prometheus applications
juju config prometheus scrape-jobs="<scraper-yaml>"
juju run-action --wait grafana/0 import-dashboard \
dashboard="$(base64 <dashboard-json>)"
```
以上的步骤需要根据你的部署来指定一些值。你可以用与 `conjure-up` 相同的方法得到这些:
* `<vhost-tmpl>`: 从 github 获取我们的示例 [模板](https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/graylog/steps/01_install-graylog/graylog-vhost.tmpl)
* `<graylog-ip>`: `juju run --unit graylog/0 'unit-get private-address'`
* `<es-cluster>`: `juju config elasticsearch cluster-name`
* `<scraper-yaml>`: 从 github 获取我们的示例 [scraper](https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/prometheus-scrape-k8s.yaml) ;`[K8S_PASSWORD][20]` 和 `[K8S_API_ENDPOINT][21]` [substitute](https://github.com/conjure-up/spells/blob/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/after-deploy#L25) 的正确值
* `<dashboard-json>`: 从 github 获取我们的 [主机](https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/grafana-telegraf.json) 和 [k8s](https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/grafana-k8s.json) 仪表板
最后,发布 apache2 和 grafana 应用程序,以便于可以通过它们的 web 界面访问:
```
## expose relevant endpoints
juju expose apache2
juju expose grafana
```
现在我们已经完成了所有的部署、配置、和发布工作,你可以使用与上面的**浏览日志**和**浏览指标**部分相同的方法去查看它们。
### 总结
我的目标是向你展示如何去部署一个 Kubernetes 集群,很方便地去监视它的日志和指标。无论你是喜欢向导的方式还是命令行的方式,我希望你清楚地看到部署一个监视系统并不复杂。关键是要搞清楚所有部分是如何工作的,并将它们连接到一起工作,通过断开/修复/重复的方式,直到它们每一个都能正常工作。
这里有一些像 conjure-up 和 Juju 一样非常好的工具。充分发挥这个生态系统贡献者的专长让管理大型软件变得更容易。从一套可靠的应用程序开始,按需定制,然后投入到工作中!
大胆去尝试吧,然后告诉我你用的如何。你可以在 Freenode IRC 的 **#conjure-up** 和 **#juju** 中找到像我这样的爱好者。感谢阅读!
### 关于作者
Kevin 在 2014 年加入 Canonical 公司,他专注于复杂软件建模。他在 Juju 大型软件团队中找到了自己的位置,他的任务是将大数据和机器学习应用程序转化成可重复的(可靠的)解决方案。
---
via: <https://insights.ubuntu.com/2018/01/16/monitor-your-kubernetes-cluster/>
作者:[Kevin Monroe](https://insights.ubuntu.com/author/kwmonroe/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | null |
|
9,536 | 怎样用 parted 管理硬盘分区 | https://www.2daygeek.com/how-to-manage-disk-partitions-using-parted-command/ | 2018-04-10T23:51:07 | [
"parted",
"fdisk",
"分区"
] | https://linux.cn/article-9536-1.html | 
众所周知,对硬盘分区是 Linux 管理员一项最重要的管理任务之一,他们不能不知道这个。
在最糟糕的时候,你至少每周会收到一次依赖小组的请求,而在更大的环境里会更加频繁 。
你可能会问为什么我们要用 `parted` 而不是 `fdisk`? 它们有什么区别?好问题,我会告诉你这两者的区别。
* `parted` 支持用户在大于 2TB 的硬盘上创建硬盘分区, 但 `fdisk` 命令不支持
* 对比 `fdisk` 来说,`parted` 是一个更高级的工具
* 支持更多的分区表类型,包括 GPT (LCTT 译注:全局唯一标识分区表)
* 它允许用户调整分区大小, 但当缩减分区空间的时候,它没有如我意料的工作,多数情况下我会得到错误消息。所以我会建议用户不要用 `parted` 来缩减分区大小。
### 什么是 parted
`parted` 是一个操作硬盘分区的程序。它支持多种分区表类型,包括 MS-DOS 和 GPT。
它允许用户创建、删除、调整、缩减、移动和复制分区,以及重新组织硬盘的使用,复制数据到新的硬盘上。`gparted` 是 `parted` 的图形界面前端。
### 怎样安装 parted
大部分发行版已经预安装了 `parted`。如果没有,用下列命令来安装 `parted`。
对于 Debian/Ubuntu 用户, 使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或者 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 `parted`。
```
$ sudo apt install parted
```
对于 RHEL/CentOS 用户,用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 来安装 `parted`。
```
$ sudo yum install parted
```
对于 Fedora 用户,用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 `parted`。
```
$ sudo dnf install parted
```
对于 Arch Linux 用户,用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/)来安装 `parted`。
```
$ sudo pacman -S parted
```
对于 openSUSE 用户, 用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/)来安装 `parted`。
```
$ sudo zypper in parted
```
### 怎样启动 parted
下面的 `parted` 命令会自动选择 `/dev/sda` ,因为这是系统的第一个硬盘。
```
$ sudo parted
GNU parted 3.2
Using /dev/sda
Welcome to GNU parted! Type 'help' to view a list of commands.
(parted)
```
同时我们也可以用下面的命令来重新选择对应的的硬盘。
```
(parted) select /dev/sdb
Using /dev/sdb
(parted)
```
如果你想选择特定的硬盘, 用下列的格式来输入命令。 这次 ,我们将选择 `/dev/sdb`。
```
$ sudo parted [Device Name]
```
```
$ sudo parted /dev/sdb
GNU parted 3.2
Using /dev/sdb
Welcome to GNU parted! Type 'help' to view a list of commands.
(parted)
```
### 怎样用 parted 列出所有可用的硬盘
如果你不知道你的电脑上有什么硬盘,只需要运行下列命令,该命令会显示所有可用硬盘的名字,以及其它的有用信息比如储存空间、型号、扇区大小、硬盘标志以及分区信息。
```
$ sudo parted -l
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sda: 32.2GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 32.2GB 32.2GB primary ext4 boot
Error: /dev/sdb: unrecognised disk label
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdb: 53.7GB
Sector size (logical/physical): 512B/512B
Partition Table: unknown
Disk Flags:
```
上面的错误信息清晰地显示出硬盘 `/dev/sdb` 没有有效的<ruby> 磁盘标签 <rt> disk label </rt></ruby>。 它不会自动得到磁盘标签,所以, 我们便要自己设置硬盘标签。
### 怎样用 parted 创建硬盘分区
`parted` 允许用户创建主分区或者拓展分区。创建这两种类型的分区的步骤还是一样,但请确保你已经指定了需要的分区类型,比如 `primary` (主分区)或者 `extended` (扩展分区)。
为了演示这项操作 ,我们安装了一个新的 `50 GB` 的硬盘到到电脑上,挂载在 `/dev/sdb` 上。
有两种方法创建分区,第一种是更详细的方法,另一种只是一个命令。 在下面的例子中,我们将用更详细的方法添加一个主分区。提醒一下, 我们应该先设置磁盘标签,因为它不会自动设置任何标签。
在下面的例子中,我们将要创建一个 `10 GB` 的分区
```
$ sudo parted /dev/sdb
GNU parted 3.2
Using /dev/sdb
Welcome to GNU parted! Type 'help' to view a list of commands.
(parted) mklabel msdos
(parted) unit GB
(parted) mkpart
Partition type? primary/extended? primary
File system type? [ext2]? ext4
Start? 0.00GB
End? 10.00GB
(parted) print
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdb: 53.7GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 0.00GB 10.0GB 10.0GB primary ext4 lba
(parted) quit
Information: You may need to update /etc/fstab.
```
同时,我们也可以使用单条 `parted` 命令
在下面的例子中,我们将在硬盘上创建一个 `10 GB` 的分区。
```
$ sudo parted [Disk Name] [mkpart] [Partition Type] [Filesystem Type] [Partition Start Size] [Partition End Size]
```
```
$ sudo parted /dev/sdb mkpart primary ext4 10.0GB 20.0GB
Information: You may need to update /etc/fstab.
```
### 怎样使用所有剩余空间创建分区
你已经创建了除了 `/home` 之外等所有要求的分区,而且你想要用硬盘上所有剩余的空间来创建 `/home` 分区,要怎样做?可以使用下面的命令来创建分区。
下面的命令创建了一个 33.7 GB 的分区,从 `20 GB` 开始到 `53 GB` 结束。 `100%` 使用率允许用户用硬盘上所有剩余的空余空间。
```
$ sudo parted [Disk Name] [mkpart] [Partition Type] [Filesystem Type] [Partition Start Size] [Partition End Size]
$ sudo parted /dev/sdb mkpart primary ext4 20.0GB 100%
Information: You may need to update /etc/fstab.
```
### 怎样用 parted 列出所有的分区
你也许注意到了,我们已经在上述步骤中创建了三个分区,如果你想要列出所有在硬盘上可用的分区,可以使用 `print` 命令。
```
$ sudo parted /dev/sdb print
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdb: 53.7GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 10.0GB 9999MB primary ext4
2 10.0GB 20.0GB 9999MB primary ext4
3 20.0GB 53.7GB 33.7GB primary ext4
```
### 怎样用 mkfs 格式化分区
用户可以用 `mkfs` 命令格式化分区。下面的步骤会用 `mkfs` 来格式化分区。
```
$ sudo mkfs.ext4 /dev/sdb1
mke2fs 1.43.4 (31-Jan-2017)
Creating filesystem with 2621440 4k blocks and 656640 inodes
Filesystem UUID: 415cf467-634c-4403-8c9f-47526bbaa381
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
```
同样的。
```
$ sudo mkfs.ext4 /dev/sdb2
$ sudo mkfs.ext4 /dev/sdb3
```
创建必要的文件夹然后将这些分区挂载在上面。
```
$ sudo mkdir /par1 /par2 /par3
```
```
$ sudo mount /dev/sdb1 /par1
$ sudo mount /dev/sdb2 /par2
$ sudo mount /dev/sdb3 /par3
```
运行下列命令来检查是否成功挂载上新创建的分区。
```
$ df -h /dev/sdb[1-3]
Filesystem Size Used Avail Use% Mounted on
/dev/sdb1 9.2G 37M 8.6G 1% /par1
/dev/sdb2 9.2G 37M 8.6G 1% /par2
/dev/sdb3 31G 49M 30G 1% /par3
```
### 怎样检查硬盘空闲空间
运行下列命令来检查硬盘上的空闲空间,这块硬盘上有 `25.7 GB` 的空闲空间。
```
$ sudo parted /dev/sdb print free
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdb: 53.7GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
32.3kB 1049kB 1016kB Free Space
1 1049kB 10.0GB 9999MB primary ext4
2 10.0GB 20.0GB 9999MB primary ext4
3 20.0GB 28.0GB 8001MB primary ext4
28.0GB 53.7GB 25.7GB Free Space
```
### 怎样使用 parted 命令来重新调整分区大小
`parted` 允许用户重新调整分区大小。不过我已在文章的开头说了,不要缩小分区大小,不然会有许多错误。
运行下列命令来检查硬盘分区以及所有可用空间。 可以看到硬盘上有 `25.7GB` 的可用空间。
```
$ sudo parted /dev/sdb print free
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdb: 53.7GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
32.3kB 1049kB 1016kB Free Space
1 1049kB 10.0GB 9999MB primary ext4
2 10.0GB 20.0GB 9999MB primary ext4
3 20.0GB 28.0GB 8001MB primary ext4
28.0GB 53.7GB 25.7GB Free Space
```
运行下列命令来重新调整分区大小。 我们将要重新调整(增加)分区 3 的结束位置,从 `28GB` 到 `33GB`。
```
$ sudo parted [Disk Name] [resizepart] [Partition Number] [Partition New End Size]
$ sudo parted /dev/sdb resizepart 3 33.0GB
Information: You may need to update /etc/fstab.
```
运行下列命令来确认分区是否已经扩容。可以看到,分区 3 已经从 `8GB` 增加到 `13GB`。
```
$ sudo parted /dev/sdb print
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdb: 53.7GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 10.0GB 9999MB primary ext4
2 10.0GB 20.0GB 9999MB primary ext4
3 20.0GB 33.0GB 13.0GB primary ext4
```
重新调整文件系统大小。
```
$ sudo resize2fs /dev/sdb3
resize2fs 1.43.4 (31-Jan-2017)
Resizing the filesystem on /dev/sdb3 to 3173952 (4k) blocks.
The filesystem on /dev/sdb3 is now 3173952 (4k) blocks long.
```
最后,确认分区是否已经扩容。
```
$ df -h /dev/sdb[1-3]
Filesystem Size Used Avail Use% Mounted on
/dev/sdb1 9.2G 5.1G 3.6G 59% /par1
/dev/sdb2 9.2G 2.1G 6.6G 24% /par2
/dev/sdb3 12G 1.1G 11G 10% /par3
```
### 怎样用 parted 删除分区
我们用 `rm` 命令方便地删除未使用的分区(如果该分区不会再被用到了)。下列步骤中,我们将会删除分区 3 (`/dev/sdb3`)。
```
$ sudo parted [Disk Name] [rm] [Partition Number]
$ sudo parted /dev/sdb rm 3
Warning: Partition /dev/sdb3 is being used. Are you sure you want to continue?
Yes/No? Yes
Error: Partition(s) 3 on /dev/sdb have been written, but we have been unable to inform the kernel of the change, probably because it/they are in use. As a result, the old partition(s) will remain in use.
You should reboot now before making further changes.
Ignore/Cancel? Ignore
Information: You may need to update /etc/fstab.
```
我们也可以用下列的命令检查。可以看到,分区 3 已经被成功移除。
```
$ sudo parted /dev/sdb print
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdb: 53.7GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 10.0GB 9999MB primary ext4
2 10.0GB 20.0GB 9999MB primary ext4
```
### 怎样用 parted 命令设置/更改分区标志
我们可以用下列的命令来轻易更改分区的标志。 我们将对 `/dev/sdb2` 设置 `lvm` 标志。
```
$ sudo parted [Disk Name] [set] [Partition Number] [Flags Name] [Flag On/Off]
$ sudo parted /dev/sdb set 2 lvm on
Information: You may need to update /etc/fstab.
```
我们可以列出分区来验证这次的更改。
```
$ sudo parted /dev/sdb print
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdb: 53.7GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 10.0GB 9999MB primary ext4
2 10.0GB 20.0GB 9999MB primary ext4 lvm
```
如果你想知道可用的标志,只需要用如下的命令。
```
$ (parted) help set
set NUMBER FLAG STATE change the FLAG on partition NUMBER
NUMBER is the partition number used by Linux. On MS-DOS disk labels, the primary partitions number from 1 to 4, logical partitions from 5 onwards.
FLAG is one of: boot, root, swap, hidden, raid, lvm, lba, hp-service, palo, prep, msftres, bios_grub, atvrecv, diag, legacy_boot, msftdata, irst, esp
STATE is one of: on, off
```
如果你想知道 `parted` 的其它可用命令, 只需要去到 `help` 页面。
```
$ sudo parted
GNU parted 3.2
Using /dev/sda
Welcome to GNU parted! Type 'help' to view a list of commands.
(parted) help
align-check TYPE N check partition N for TYPE(min|opt) alignment
help [COMMAND] print general help, or help on COMMAND
mklabel,mktable LABEL-TYPE create a new disklabel (partition table)
mkpart PART-TYPE [FS-TYPE] START END make a partition
name NUMBER NAME name partition NUMBER as NAME
print [devices|free|list,all|NUMBER] display the partition table, available devices, free space, all found partitions, or a particular partition
quit exit program
rescue START END rescue a lost partition near START and END
resizepart NUMBER END resize partition NUMBER
rm NUMBER delete partition NUMBER
select DEVICE choose the device to edit
disk_set FLAG STATE change the FLAG on selected device
disk_toggle [FLAG] toggle the state of FLAG on selected device
set NUMBER FLAG STATE change the FLAG on partition NUMBER
toggle [NUMBER [FLAG]] toggle the state of FLAG on partition NUMBER
unit UNIT set the default unit to UNIT
version display the version number and copyright information of GNU parted
(parted) quit
```
---
via: <https://www.2daygeek.com/how-to-manage-disk-partitions-using-parted-command/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 译者:[zyk2290](https://github.com/zyk2290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,537 | SQL 入门 | https://opensource.com/article/18/2/getting-started-sql | 2018-04-12T08:37:27 | [
"SQL",
"数据库"
] | https://linux.cn/article-9537-1.html |
>
> 使用 SQL 构建一个关系数据库比你想的更容易。
>
>
>

使用 SQL 构建数据库比大多数人想象得要简单。实际上,你甚至不需要成为一个有经验的程序员就可以使用 SQL 创建数据库。在本文中,我将解释如何使用 MySQL 5.6 来创建简单的关系型数据库管理系统(RDMS)。在开始之前,我想顺便感谢一下 [SQL Fiddle](http://sqlfiddle.com),这是我用来运行脚本的工具。它提供了一个用于测试简单脚本的有用的沙箱。
在本教程中,我将构建一个使用如下实体关系图(ERD)中显示的简单架构的数据库。数据库列出了学生和正在学习的课程。为了保持简单,我使用了两个实体(即表),只有一种关系和依赖。这两个实体称为 `dbo_students` 和 `dbo_courses`。

数据库的多样性是一对多的,因为每门课程可以包含很多学生,但每个学生只能学习一门课程。
关于术语的快速说明:
1. 一张表称为一个实体。
2. 一个字段称为一个属性。
3. 一条记录称为一个元组。
4. 用于构建数据库的脚本称为架构。
### 构建架构
要构建数据库,使用 `CREATE TABLE <表名>` 命令,然后定义每个字段的名称和数据类型。数据库使用 `VARCHAR(n)` (字符串)和 `INT(n)` (整数),其中 `n` 表示可以存储的值的长度。例如 `INT(2)` 可以是 `01`。
这是用于创建两个表的代码:
```
CREATE TABLE dbo_students
(
student_id INT(2) AUTO_INCREMENT NOT NULL,
student_name VARCHAR(50),
course_studied INT(2),
PRIMARY KEY (student_id)
);
CREATE TABLE dbo_courses
(
course_id INT(2) AUTO_INCREMENT NOT NULL,
course_name VARCHAR(30),
PRIMARY KEY (course_id)
);
```
`NOT NULL` 意味着字段不能为空,`AUTO_INCREMENT` 意味着当一个新的元组被添加时,ID 号将自动生成,是对先前存储的 ID 号加 1,以强化各实体之间的完整参照性。 `PRIMARY KEY` 是每个表的惟一标识符属性。这意味着每个元组都有自己的不同的标识。
### 关系作为一种约束
就目前来看,这两张表格是独立存在的,没有任何联系或关系。要连接它们,必须标识一个外键。在 `dbo_students` 中,外键是 `course_studied`,其来源在 `dbo_courses` 中,意味着该字段被引用。SQL 中的特定命令为 `CONSTRAINT`,并且将使用另一个名为 `ALTER TABLE` 的命令添加这种关系,这样即使在架构构建完毕后,也可以编辑表。
以下代码将关系添加到数据库构造脚本中:
```
ALTER TABLE dbo_students
ADD CONSTRAINT FK_course_studied
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
```
使用 `CONSTRAINT` 命令实际上并不是必要的,但这是一个好习惯,因为它意味着约束可以被命名并且使维护更容易。现在数据库已经完成了,是时候添加一些数据了。
### 将数据添加到数据库
`INSERT INTO <表名>` 是用于直接选择要添加哪些属性(即字段)数据的命令。首先声明实体名称,然后声明属性,下边是添加到实体的数据,从而创建一个元组。如果指定了 `NOT NULL`,这表示该属性不能留空。以下代码将展示如何向表中添加记录:
```
INSERT INTO dbo_courses(course_id,course_name)
VALUES(001,'Software Engineering');
INSERT INTO dbo_courses(course_id,course_name)
VALUES(002,'Computer Science');
INSERT INTO dbo_courses(course_id,course_name)
VALUES(003,'Computing');
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(001,'student1',001);
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(002,'student2',002);
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(003,'student3',002);
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(004,'student4',003);
```
现在数据库架构已经完成并添加了数据,现在是时候在数据库上运行查询了。
### 查询
查询遵循使用以下命令的集合结构:
```
SELECT <attributes>
FROM <entity>
WHERE <condition>
```
要显示 `dbo_courses` 实体内的所有记录并显示课程代码和课程名称,请使用 `*` 。 这是一个通配符,它消除了键入所有属性名称的需要。(在生产数据库中不建议使用它。)此处查询的代码是:
```
SELECT *
FROM dbo_courses
```
此处查询的输出显示表中的所有元组,因此可显示所有可用课程:
```
| course_id | course_name |
|-----------|----------------------|
| 1 | Software Engineering |
| 2 | Computer Science |
| 3 | Computing |
```
在后面的文章中,我将使用三种类型的连接之一来解释更复杂的查询:内连接、外连接和交叉连接。
这是完整的脚本:
```
CREATE TABLE dbo_students
(
student_id INT(2) AUTO_INCREMENT NOT NULL,
student_name VARCHAR(50),
course_studied INT(2),
PRIMARY KEY (student_id)
);
CREATE TABLE dbo_courses
(
course_id INT(2) AUTO_INCREMENT NOT NULL,
course_name VARCHAR(30),
PRIMARY KEY (course_id)
);
ALTER TABLE dbo_students
ADD CONSTRAINT FK_course_studied
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
INSERT INTO dbo_courses(course_id,course_name)
VALUES(001,'Software Engineering');
INSERT INTO dbo_courses(course_id,course_name)
VALUES(002,'Computer Science');
INSERT INTO dbo_courses(course_id,course_name)
VALUES(003,'Computing');
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(001,'student1',001);
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(002,'student2',002);
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(003,'student3',002);
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(004,'student4',003);
SELECT *
FROM dbo_courses
```
### 学习更多
SQL 并不困难;我认为它比编程简单,并且该语言对于不同的数据库系统是通用的。 请注意,实体关系图中 `dbo.<实体>` (LCTT 译注:文章中使用的是 `dbo_<实体>`)不是必需的实体命名约定;我之所以使用,仅仅是因为它是 Microsoft SQL Server 中的标准。
如果你想了解更多,在网络上这方面的最佳指南是 [W3Schools.com](https://www.w3schools.com/sql/default.asp) 中对所有数据库平台的 SQL 综合指南。
请随意使用我的数据库。另外,如果你有任何建议或疑问,请在评论中回复。
---
via: <https://opensource.com/article/18/2/getting-started-sql>
作者:[Aaron Cocker](https://opensource.com/users/aaroncocker) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Building a database using SQL is simpler than most people think. In fact, you don't even need to be an experienced programmer to use SQL to create a database. In this article, I'll explain how to create a simple relational database management system (RDMS) using MySQL 5.6. Before I get started, I want to quickly thank [SQL Fiddle](http://sqlfiddle.com), which I used to run my script. It provides a useful sandbox for testing simple scripts.
In this tutorial, I'll build a database that uses the simple schema shown in the entity relationship diagram (ERD) below. The database lists students and the course each is studying. I used two entities (i.e., tables) to keep things simple, with only a single relationship and dependency. The entities are called `dbo_students`
and `dbo_courses`
.
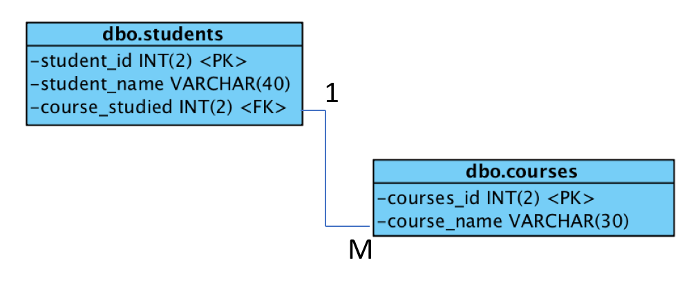
opensource.com
The multiplicity of the database is *1-to-many*, as each course can contain many students, but each student can study only one course.
A quick note on terminology:
- A table is called an
*entity*. - A field is called an
*attribute*. - A record is called a
*tuple*. - The script used to construct the database is called a
*schema*.
## Constructing the schema
To construct the database, use the `CREATE TABLE <table name>`
command, then define each field name and data type. This database uses `VARCHAR(n)`
(string) and `INT(n)`
(integer), where *n* refers to the number of values that can be stored. For example `INT(2)`
could be 01.
This is the code used to create the two tables:
```
``````
CREATE TABLE dbo_students
(
student_id INT(2) AUTO_INCREMENT NOT NULL,
student_name VARCHAR(50),
course_studied INT(2),
PRIMARY KEY (student_id)
);
CREATE TABLE dbo_courses
(
course_id INT(2) AUTO_INCREMENT NOT NULL,
course_name VARCHAR(30),
PRIMARY KEY (course_id)
);
```
`NOT NULL`
means that the field cannot be empty, and `AUTO_INCREMENT`
means that when a new tuple is added, the ID number will be auto-generated with 1 added to the previously stored ID number in order to enforce referential integrity across entities. `PRIMARY KEY`
is the unique identifier attribute for each table. This means each tuple has its own distinct *identity*.
## Relationships as a constraint
As it stands, the two tables exist on their own with no connections or relationships. To connect them, a *foreign key* must be identified. In `dbo_students`
, the foreign key is `course_studied`
, the source of which is within `dbo_courses`
, meaning that the field is *referenced*. The specific command within SQL is called a `CONSTRAINT`
, and this relationship will be added using another command called `ALTER TABLE`
, which allows tables to be edited even after the schema has been constructed.
The following code adds the relationship to the database construction script:
```
``````
ALTER TABLE dbo_students
ADD CONSTRAINT FK_course_studied
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
```
Using the `CONSTRAINT`
command is not actually necessary, but it's good practice because it means the constraint can be named and it makes maintenance easier. Now that the database is complete, it's time to add some data.
## Adding data to the database
`INSERT INTO <table name>`
is the command used to directly choose which attributes (i.e., fields) data is added to. The entity name is defined first, then the attributes. Underneath this command is the data that will be added to that entity, creating a tuple. If `NOT NULL`
has been specified, it means that the attribute cannot be left blank. The following code shows how to add records to the table:
```
``````
INSERT INTO dbo_courses(course_id,course_name)
VALUES(001,'Software Engineering');
INSERT INTO dbo_courses(course_id,course_name)
VALUES(002,'Computer Science');
INSERT INTO dbo_courses(course_id,course_name)
VALUES(003,'Computing');
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(001,'student1',001);
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(002,'student2',002);
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(003,'student3',002);
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(004,'student4',003);
```
Now that the database schema is complete and data is added, it's time to run queries on the database.
## Queries
Queries follow a set structure using these commands:
```
``````
SELECT <attributes>
FROM <entity>
WHERE <condition>
```
To display all records within the `dbo_courses`
entity and display the course code and course name, use an asterisk. This is a wildcard that eliminates the need to type all attribute names. (Its use is not recommended in production databases.) The code for this query is:
```
``````
SELECT *
FROM dbo_courses
```
The output of this query shows all tuples in the table, so all available courses can be displayed:
```
``````
| course_id | course_name |
|-----------|----------------------|
| 1 | Software Engineering |
| 2 | Computer Science |
| 3 | Computing |
```
In a future article, I'll explain more complicated queries using one of the three types of joins: Inner, Outer, or Cross.
Here is the completed script:
```
``````
CREATE TABLE dbo_students
(
student_id INT(2) AUTO_INCREMENT NOT NULL,
student_name VARCHAR(50),
course_studied INT(2),
PRIMARY KEY (student_id)
);
CREATE TABLE dbo_courses
(
course_id INT(2) AUTO_INCREMENT NOT NULL,
course_name VARCHAR(30),
PRIMARY KEY (course_id)
);
ALTER TABLE dbo_students
ADD CONSTRAINT FK_course_studied
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
INSERT INTO dbo_courses(course_id,course_name)
VALUES(001,'Software Engineering');
INSERT INTO dbo_courses(course_id,course_name)
VALUES(002,'Computer Science');
INSERT INTO dbo_courses(course_id,course_name)
VALUES(003,'Computing');
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(001,'student1',001);
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(002,'student2',002);
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(003,'student3',002);
INSERT INTO dbo_students(student_id,student_name,course_studied)
VALUES(004,'student4',003);
SELECT *
FROM dbo_courses
```
## Learning more
SQL isn't difficult; I think it is simpler than programming, and the language is universal to different database systems. Note that `dbo.<entity>`
is not a required entity-naming convention; I used it simply because it is the standard in Microsoft SQL Server.
If you'd like to learn more, the best guide this side of the internet is [W3Schools.com](https://www.w3schools.com/sql/default.asp)'s comprehensive guide to SQL for all database platforms.
Please feel free to play around with my database. Also, if you have suggestions or questions, please respond in the comments.
## 1 Comment |
9,538 | 完全指南:在 Linux 中如何打印和管理打印机 | https://www.ibm.com/developerworks/library/l-lpic1-108-4/index.html | 2018-04-12T13:43:05 | [
"打印",
"CUPS"
] | https://linux.cn/article-9538-1.html | 
### Linux 中的打印
虽然现在大量的沟通都是电子化和无纸化的,但是在我们的公司中还有大量的材料需要打印。银行结算单、公用事业帐单、财务和其它报告、以及收益结算单等一些东西还是需要打印的。本教程将介绍在 Linux 中如何使用 CUPS 去打印。
CUPS,是<ruby> 通用 Unix 打印系统 <rt> Common UNIX Printing System </rt></ruby>的首字母缩写,它是 Linux 中的打印机和打印任务的管理者。早期计算机上的打印机一般是在特定的字符集和字体大小下打印文本文件行。现在的图形打印机可以打印各种字体和大小的文本和图形。尽管如此,现在你所使用的一些命令,在古老的行式打印守护进程(LPD)技术的历史中仍能找到它们。
本教程将帮你了解 Linux 服务器专业考试(LPIC-1)的第 108 号主题的 108.4 目标。这个目标的权重为 2。
#### 前提条件
为了更好地学习本系列教程,你需要具备基本的 Linux 知识,和使用 Linux 系统实践本教程中的命令的能力,你应该熟悉 GNU 和 UNIX® 命令的使用。有时不同版本的程序输出可能会不同,因此,你的结果可能与本教程中的示例有所不同。
本教程中的示例使用的是 Fedora 27 的系统。
### 有关打印的一些历史
这一小部分历史并不是 LPI 目标的,但它有助于你理解这个目标的相关环境。
早期的计算机大都使用行式打印机。这些都是击打式打印机,那时,它们使用固定间距的字符和单一的字体来打印文本行。为提升整个系统性能,早期的主机要与慢速的外围设备(如读卡器、卡片穿孔机、和运行其它工作的行式打印机)交叉进行工作。因此就产生了在线的或者假脱机的同步外围操作,这一术语目前在谈到计算机打印时仍然在使用。
在 UNIX 和 Linux 系统上,打印初始化使用的是 BSD(<ruby> 伯克利软件分发版 <rt> Berkeley Software Distribution </rt></ruby>)打印子系统,它是由一个作为服务器运行的行式打印守护程序(LPD)组成,而客户端命令如 `lpr` 是用于提交打印作业。这个协议后来被 IETF 标准化为 RFC 1179 —— **行式打印机守护进程协议**。
System V 也有一个打印守护程序。它的功能与BSD 的 LPD 守护程序类似,但是它们的命令集不一样。你在后面会经常看到完成相同的任务使用不同选项的两个命令。例如,对于打印文件的命令,伯克利实现版本是 `lpr`,而 System V 实现版本是 `lp`。
随着打印机技术的进步,在一个页面上混合出现不同字体成为可能,并且可以将图片像文字一样打印。可变间距字体,以及更多先进的打印技术,比如间距和连字符,现在都已经标准化。出现了几种对基本的 lpd/lpr 方法等改进设计,比如 LPRng,下一代的 LPR,以及 CUPS。
许多可以打印图形的打印机,使用 Adobe PostScript 语言进行初始化。一个 PostScript 打印机有一个解释器引擎,它可以解释打印任务中的命令并从这些命令中生成最终的页面。PostScript 经常被用做原始文件(比如一个文本文件或者一个图像文件)和最终格式没有适合的 PostScript 功能的特定打印机之间的中间层。转换这些特定的打印任务,比如将一个 ASCII 文本文件或者一个 JPEG 图像转换为 PostScript,然后再使用过滤器转换 PostScript 到非 PostScript 打印机所需要的最终光栅格式。
现在的<ruby> 便携式文档格式 <rt> Portable Document Format </rt></ruby>(PDF),它就是基于 PostScript 的,已经替换了传统的原始 PostScript。PDF 设计为与硬件和软件无关,它封装了要打印的页面的完整描述。你可以查看 以及打印 PDF 文件。
### 管理打印队列
用户直接打印作业到一个名为<ruby> 打印队列 <rt> print queue </rt></ruby>的逻辑实体。在单用户系统中,打印队列和打印机通常是几乎相同的意思。但是,CUPS 允许系统不用连接到一个打印机上,而最终在一个远程系统上的排队打印作业,并且通过使用分类,允许将定向到一个分类的打印作业在该分类第一个可用的打印机上打印。
你可以检查和管理打印队列。对于 CUPS 来说,其中一些命令实现了一些新操作。另外的一些是源于 LPD 的兼容命令,不过现在的一些选项通常是最初的 LPD 打印系统选项的有限子集。
你可以使用 CUPS 的 `lpstat` 命令去检查队列,以了解打印系统。一些常见选项如下表 1。
| 选项 | 作用 |
| --- | --- |
| `-a` | 显示打印机状态 |
| `-c` | 显示打印分类 |
| `-p` | 显示打印状态:`enabled` 或者 `disabled` |
| `-s` | 显示默认打印机、打印机和类。相当于 `-d -c -v`。**注意:要指定多个选项,这些选项必须像值一样分隔开。** |
| `-v` | 显示打印机和它们的设备。 |
*表 1. lpstat 命令的选项*
你也可以使用 LPD 的 `lpc` 命令(它可以在 `/usr/sbin` 中找到)使用它的 `status` 选项。如果你不想指定打印机名字,将列出所有的队列。列表 1 展示了命令的一些示例。
```
[ian@atticf27 ~]$ lpstat -d
system default destination: HL-2280DW
[ian@atticf27 ~]$ lpstat -v HL-2280DW
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
[ian@atticf27 ~]$ lpstat -s
system default destination: HL-2280DW
members of class anyprint:
HL-2280DW
XP-610
device for anyprint: ///dev/null
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
device for XP-610: dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
[ian@atticf27 ~]$ lpstat -a XP-610
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
[ian@atticf27 ~]$ /usr/sbin/lpc status HL-2280DW
HL-2280DW:
printer is on device 'dnssd' speed -1
queuing is disabled
printing is enabled
no entries
daemon present
```
*列表 1. 显示可用打印队列*
这个示例展示了两台打印机 —— HL-2280DW 和 XP-610,和一个分类 `anyprint`,它允许打印作业定向到这两台打印机中的第一个可用打印机。
在这个示例中,已经禁用了打印到 HL-2280DW 队列,但是打印功能是启用的,这样便于将打印机脱机维护之前可以完成打印队列中的任务。启用还是禁用队列,可以使用 `cupsaccept` 和 `cupsreject` 命令来管理。以前它们叫做 `accept` 和 `reject`,你或许可能在 `/usr/sbin` 中找到这些命令,但它们现在都是符号链接到新的命令上了。同样,启用还是禁用打印,你可以使用 `cupsenable` 和 `cupsdisable` 命令来管理。在早期版本的 CUPS 中,这些被称为 `enable` 和 `disable`,它也许会与 bash shell 内置的 `enable` 混淆。列表 2 展示了如何去启用打印机 HL-2280DW 上的队列,而禁止它的打印。CUPS 的几个命令支持使用 `-r` 选项去提供一个该操作的理由。这个理由会在你使用 `lpstat` 时显示,但是如果你使用的是 `lpc` 命令则不会显示它。
```
[ian@atticf27 ~]$ lpstat -a -p HL-2280DW
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
HL-2280DW not accepting requests since Thu 27 Apr 2017 05:52:27 PM EDT -
Maintenance scheduled
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
printer HL-2280DW is idle. enabled since Thu 27 Apr 2017 05:52:27 PM EDT
Maintenance scheduled
[ian@atticf27 ~]$ accept HL-2280DW
[ian@atticf27 ~]$ cupsdisable -r "waiting for toner delivery" HL-2280DW
[ian@atticf27 ~]$ lpstat -p -a
printer anyprint is idle. enabled since Mon 29 Jan 2018 01:17:09 PM EST
printer HL-2280DW disabled since Mon 29 Jan 2018 04:03:50 PM EST -
waiting for toner delivery
printer XP-610 is idle. enabled since Thu 27 Apr 2017 05:53:59 PM EDT
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
HL-2280DW accepting requests since Mon 29 Jan 2018 04:03:50 PM EST
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
```
*列表 2. 启用队列和禁用打印*
注意:用户执行这些任务必须经过授权。它可能要求是 root 用户或者其它的授权用户。在 `/etc/cups/cups-files.conf` 中可以看到 `SystemGroup` 的条目,`cups-files.conf` 的 man 页面有更多授权用户组的信息。
### 管理用户打印作业
现在,你已经知道了一些如何去检查打印队列和类的方法,我将给你展示如何管理打印队列上的作业。你要做的第一件事是,如何找到一个特定打印机或者全部打印机上排队的任意作业。完成上述工作要使用 `lpq` 命令。如果没有指定任何选项,`lpq` 将显示默认打印机上的队列。使用 `-P` 选项和一个打印机名字将指定打印机,或者使用 `-a` 选项去指定所有的打印机,如下面的列表 3 所示。
```
[pat@atticf27 ~]$ # As user pat (non-administrator)
[pat@atticf27 ~]$ lpq
HL-2280DW is not ready
Rank Owner Job File(s) Total Size
1st unknown 4 unknown 6144 bytes
2nd pat 6 bitlib.h 6144 bytes
3rd pat 7 bitlib.C 6144 bytes
4th unknown 8 unknown 1024 bytes
5th unknown 9 unknown 1024 bytes
[ian@atticf27 ~]$ # As user ian (administrator)
[ian@atticf27 ~]$ lpq -P xp-610
xp-610 is ready
no entries
[ian@atticf27 ~]$ lpq -a
Rank Owner Job File(s) Total Size
1st ian 4 permutation.C 6144 bytes
2nd pat 6 bitlib.h 6144 bytes
3rd pat 7 bitlib.C 6144 bytes
4th ian 8 .bashrc 1024 bytes
5th ian 9 .bashrc 1024 bytes
```
*列表 3. 使用 lpq 检查打印队列*
在这个示例中,共有五个作业,它们是 4、6、7、8、和 9,并且它是名为 HL-2280DW 的打印机的队列,而不是 XP-610 的。在这个示例中使用 `-P` 选项,可简单地显示哪个打印机已经准备好,但是没有队列任务。注意,CUPS 的打印机命名,是大小写不敏感的。还要注意的是,用户 ian 提交了同样的作业两次,当一个作业没有第一时间打印时,经常能看到用户的这种动作。
一般情况下,你可能会查看或者维护你自己的打印作业,但是,root 用户或者其它授权的用户通常会去管理其它打印作业。大多数 CUPS 命令都可以使用一个 `-E` 选项,对 CUPS 服务器与客户端之间的通讯进行加密。
使用 `lprm` 命令从队列中去删除一个 `.bashrc` 作业。如果不使用选项,将删除当前的作业。使用 `-` 选项,将删除全部的作业。要么就如列表 4 那样,指定一个要删除的作业列表。
```
[[pat@atticf27 ~]$ # As user pat (non-administrator)
[pat@atticf27 ~]$ lprm
lprm: Forbidden
[ian@atticf27 ~]$ # As user ian (administrator)
[ian@atticf27 ~]$ lprm 8
[ian@atticf27 ~]$ lpq
HL-2280DW is not ready
Rank Owner Job File(s) Total Size
1st ian 4 permutation.C 6144 bytes
2nd pat 6 bitlib.h 6144 bytes
3rd pat 7 bitlib.C 6144 bytes
4th ian 9 .bashrc 1024 bytes
```
*列表 4. 使用 lprm 删除打印作业*
注意,用户 pat 不能删除队列中的第一个作业,因为它是用户 ian 的。但是,ian 可以删除他自己的 8 号作业。
另外的可以帮你操作打印队列中的作业的命令是 `lp`。使用它可以去修改作业属性,比如打印数量或者优先级。我们假设用户 ian 希望他的作业 9 在用户 pat 的作业之前打印,并且希望打印两份。作业优先级的默认值是 50,它的优先级范围从最低的 1 到最高的 100 之间。用户 ian 可以使用 `-i`、`-n`、以及 `-q` 选项去指定一个要修改的作业,而新的打印数量和优先级可以如下面的列表 5 所示的那样去修改。注意,使用 `-l` 选项的 `lpq` 命令可以提供更详细的输出。
```
[ian@atticf27 ~]$ lpq
HL-2280DW is not ready
Rank Owner Job File(s) Total Size
1st ian 4 permutation.C 6144 bytes
2nd pat 6 bitlib.h 6144 bytes
3rd pat 7 bitlib.C 6144 bytes
4th ian 9 .bashrc 1024 bytes
[ian@atticf27 ~]$ lp -i 9 -q 60 -n 2
[ian@atticf27 ~]$ lpq
HL-2280DW is not ready
Rank Owner Job File(s) Total Size
1st ian 9 .bashrc 1024 bytes
2nd ian 4 permutation.C 6144 bytes
3rd pat 6 bitlib.h 6144 bytes
4th pat 7 bitlib.C 6144 bytes
```
*列表 5. 使用 lp 去改变打印数量和优先级*
最后,`lpmove` 命令可以允许一个作业从一个队列移动到另一个队列。例如,我们可能因为打印机 HL-2280DW 现在不能使用,而想去移动一个作业到另外的队列上。你可以指定一个作业编号,比如 9,或者你可以用一个队列名加一个连字符去限定它,比如,HL-2280DW-0。`lpmove` 命令的操作要求是授权用户。列表 6 展示了如何去从一个队列移动作业到另外的队列,先是指定打印机和作业 ID 移动,然后是移动指定打印机的所有作业。稍后我们可以去再次检查队列,其中一个作业已经在打印中了。
```
[ian@atticf27 ~]$ lpmove HL-2280DW-9 anyprint
[ian@atticf27 ~]$ lpmove HL-2280DW xp-610
[ian@atticf27 ~]$ lpq -a
Rank Owner Job File(s) Total Size
active ian 9 .bashrc 1024 bytes
1st ian 4 permutation.C 6144 bytes
2nd pat 6 bitlib.h 6144 bytes
3rd pat 7 bitlib.C 6144 bytes
[ian@atticf27 ~]$ # A few minutes later
[ian@atticf27 ~]$ lpq -a
Rank Owner Job File(s) Total Size
active pat 6 bitlib.h 6144 bytes
1st pat 7 bitlib.C 6144 bytes
```
*列表 6. 使用 lpmove 移动作业到另外一个打印队列*
如果你使用的是 CUPS 之外的打印服务器,比如 LPD 或者 LPRng,大多数的队列管理功能是由 `lpc` 命令的子命令来处理的。例如,你可以使用 `lpc topq` 去移动一个作业到队列的顶端。其它的 `lpc` 子命令包括 `disable`、`down`、`enable`、`hold`、`move`、`redirect`、`release`、和 `start`。这些子命令在 CUPS 的兼容命令中没有实现。
#### 打印文件
如何去打印创建的作业?大多数图形界面程序都提供了一个打印方法,通常是 **文件** 菜单下面的选项。这些程序为选择打印机、设置页边距、彩色或者黑白打印、打印数量、选择每张纸打印的页面数(每张纸打印两个页面,通常用于讲义)等等,都提供了图形化的工具。现在,我将为你展示如何使用命令行工具去管理这些功能,然后和图形化实现进行比较。
打印文件最简单的方法是使用 `lpr` 命令,然后提供一个文件名字。这将在默认打印机上打印这个文件。而 `lp` 命令不仅可以打印文件,也可以修改打印作业。列表 7 展示了使用这个命令的一个简单示例。注意,`lpr` 会静默处理这个作业,但是 `lp` 会显示处理后的作业的 ID。
```
[ian@atticf27 ~]$ echo "Print this text" > printexample.txt
[ian@atticf27 ~]$ lpr printexample.txt
[ian@atticf27 ~]$ lp printexample.txt
request id is HL-2280DW-12 (1 file(s))
```
*列表 7. 使用 lpr 和 lp 打印*
表 2 展示了 `lpr` 上你可以使用的一些选项。注意, `lp` 的选项和 `lpr` 的很类似,但是名字可能不一样;例如,`-#` 在 `lpr` 上是相当于 `lp` 的 `-n` 选项。查看 man 页面了解更多的信息。
| 选项 | 作用 |
| --- | --- |
| `-C`, `-J` 或 `-T` | 设置一个作业名字。 |
| `-P` | 选择一个指定的打印机。 |
| `-#` | 指定打印数量。注意这不同于 `lp` 命令的 `-n` 选项。 |
| `-m` | 在作业完成时发送电子邮件。 |
| `-l` | 表示打印文件已经为打印做好格式准备。相当于 `-o raw`。 |
| `-o` | 设置一个作业选项。 |
| `-p` | 格式化一个带有阴影标题的文本文件。相关于 `-o prettyprint`。 |
| `-q` | 暂缓(或排队)后面的打印作业。 |
| `-r` | 在文件进入打印池之后,删除文件。 |
*表 2. lpr 的选项*
列表 8 展示了一些选项。我要求打印之后给我发确认电子邮件,那个作业被暂缓执行,并且在打印之后删除文件。
```
[ian@atticf27 ~]$ lpr -P HL-2280DW -J "Ian's text file" -#2 -m -p -q -r printexample.txt
[[ian@atticf27 ~]$ lpq -l
HL-2280DW is ready
ian: 1st [job 13 localhost]
2 copies of Ian's text file 1024 bytes
[ian@atticf27 ~]$ ls printexample.txt
ls: cannot access 'printexample.txt': No such file or directory
```
*列表 8. 使用 lpr 打印*
我现在有一个在 HL-2280DW 打印队列上暂缓执行的作业。然后怎么做?`lp` 命令可以通过使用 `-H` 的各种选项来暂缓或者投放作业。列表 9 展示了如何投放被暂缓的作业。查看 `lp` 命令的 man 页面了解其它选项的信息。
```
[ian@atticf27 ~]$ lp -i 13 -H resume
```
*列表 9. 重启一个暂缓的打印作业*
并不是所有的可用打印机都支持相同的选项集。使用 `lpoptions` 命令去查看一个打印机的常用选项。添加 `-l` 选项去显示打印机专用的选项。列表 10 展示了两个示例。许多常见的选项涉及到人像/风景打印、页面大小和输出在纸张上的布局。详细信息查看 man 页面。
```
[ian@atticf27 ~]$ lpoptions -p HL-2280DW
copies=1 device-uri=dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
finishings=3 job-cancel-after=10800 job-hold-until=no-hold job-priority=50
job-sheets=none,none marker-change-time=1517325288 marker-colors=#000000,#000000
marker-levels=-1,92 marker-names='Black\ Toner\ Cartridge,Drum\ Unit'
marker-types=toner,opc number-up=1 printer-commands=none
printer-info='Brother HL-2280DW' printer-is-accepting-jobs=true
printer-is-shared=true printer-is-temporary=false printer-location
printer-make-and-model='Brother HL-2250DN - CUPS+Gutenprint v5.2.13 Simplified'
printer-state=3 printer-state-change-time=1517325288 printer-state-reasons=none
printer-type=135188 printer-uri-supported=ipp://localhost/printers/HL-2280DW
sides=one-sided
[ian@atticf27 ~]$ lpoptions -l -p xp-610
PageSize/Media Size: *Letter Legal Executive Statement A4
ColorModel/Color Model: *Gray Black
InputSlot/Media Source: *Standard ManualAdj Manual MultiPurposeAdj MultiPurpose
UpperAdj Upper LowerAdj Lower LargeCapacityAdj LargeCapacity
StpQuality/Print Quality: None Draft *Standard High
Resolution/Resolution: *301x300dpi 150dpi 300dpi 600dpi
Duplex/2-Sided Printing: *None DuplexNoTumble DuplexTumble
StpiShrinkOutput/Shrink Page If Necessary to Fit Borders: *Shrink Crop Expand
StpColorCorrection/Color Correction: *None Accurate Bright Hue Uncorrected
Desaturated Threshold Density Raw Predithered
StpBrightness/Brightness: 0 100 200 300 400 500 600 700 800 900 *None 1100
1200 1300 1400 1500 1600 1700 1800 1900 2000 Custom.REAL
StpContrast/Contrast: 0 100 200 300 400 500 600 700 800 900 *None 1100 1200
1300 1400 1500 1600 1700 1800 1900 2000 2100 2200 2300 2400 2500 2600 2700
2800 2900 3000 3100 3200 3300 3400 3500 3600 3700 3800 3900 4000 Custom.REAL
StpImageType/Image Type: None Text Graphics *TextGraphics Photo LineArt
```
*列表 10. 检查打印机选项*
大多数的 GUI 应用程序有一个打印对话框,通常你可以使用 **文件 >打印** 菜单去选择它。图 1 展示了在 GIMP 中的一个示例,GIMP 是一个图像处理程序。

*图 1. 在 GIMP 中打印*
到目前为止,我们所有的命令都是隐式指向到本地的 CUPS 打印服务器上。你也可以通过指定 `-h` 选项和一个端口号(如果不是 CUPS 的默认端口号 631 的话)将打印转向到另外一个系统上的服务器。
### CUPS 和 CUPS 服务器
CUPS 打印系统的核心是 `cupsd` 打印服务器,它是一个运行的守护进程。CUPS 配置文件一般位于 `/etc/cups/cupsd.conf`。`/etc/cups` 目录也有与 CUPS 相关的其它的配置文件。CUPS 一般在系统初始化期间启动,根据你的发行版不同,它也可能通过位于 `/etc/rc.d/init.d` 或者 `/etc/init.d` 目录中的 CUPS 脚本来控制。对于 最新使用 systemd 来初始化的系统,CUPS 服务脚本可能在 `/usr/lib/systemd/system/cups.service` 中。和大多数使用脚本的服务一样,你可以停止、启动、或者重启守护程序。查看我们的教程:[学习 Linux,101:运行级别、引导目标、关闭、和重启动](https://www.ibm.com/developerworks/library/l-lpic1-101-3/),了解使用初始化脚本的更多信息。
配置文件 `/etc/cups/cupsd.conf` 包含一些管理参数,比如访问打印系统、是否允许远程打印、本地打印池文件等等。在一些系统上,第二部分单独描述了打印队列,它一般是由配置工具自动生成的。列表 11 展示了一个默认的 `cupsd.conf` 文件中的一些条目。注意,注释是以 `#` 字符开头的。默认值通常以注释的方式显示,并且可以通过删除前面的 `#` 字符去改变默认值。
```
# Only listen for connections from the local machine.
Listen localhost:631
Listen /var/run/cups/cups.sock
# Show shared printers on the local network.
Browsing On
BrowseLocalProtocols dnssd
# Default authentication type, when authentication is required...
DefaultAuthType Basic
# Web interface setting...
WebInterface Yes
# Set the default printer/job policies...
<Policy default>
# Job/subscription privacy...
JobPrivateAccess default
JobPrivateValues default
SubscriptionPrivateAccess default
SubscriptionPrivateValues default
# Job-related operations must be done by the owner or an administrator...
<Limit Create-Job Print-Job Print-URI Validate-Job>
Order deny,allow
</Limit>
```
*列表 11. 默认的 /etc/cups/cupsd.conf 文件的部分内容*
可以用在 `cupsd.conf` 中使用的文件、目录、和用户配置命令,现在都存储在作为替代的 `cups-files.conf` 中。这是为了防范某些类型的提权攻击。列表 12 展示了 `cups-files.conf` 文件中的一些条目。注意,正如在文件层次结构标准(FHS)中所期望的那样,打印池文件默认保存在文件系统的 `/var/spool` 目录中。查看 man 页面了解 `cupsd.conf` 和 `cups-files.conf` 配置文件的更多信息。
```
# Location of the file listing all of the local printers...
#Printcap /etc/printcap
# Format of the Printcap file...
#PrintcapFormat bsd
#PrintcapFormat plist
#PrintcapFormat solaris
# Location of all spool files...
#RequestRoot /var/spool/cups
# Location of helper programs...
#ServerBin /usr/lib/cups
# SSL/TLS keychain for the scheduler...
#ServerKeychain ssl
# Location of other configuration files...
#ServerRoot /etc/cups
```
*列表 12. 默认的 /etc/cups/cups-files.conf 配置文件的部分内容*
列表 12 提及了 `/etc/printcap` 文件。这是 LPD 打印服务器的配置文件的名字,并且一些应用程序仍然使用它去确定可用的打印机和它们的属性。它通常是在 CUPS 系统上自动生成的,因此,你可能没有必要去修改它。但是,如果你在诊断用户打印问题,你可能需要去检查它。列表 13 展示了一个示例。
```
# This file was automatically generated by cupsd(8) from the
# /etc/cups/printers.conf file. All changes to this file
# will be lost.
HL-2280DW|Brother HL-2280DW:rm=atticf27:rp=HL-2280DW:
anyprint|Any available printer:rm=atticf27:rp=anyprint:
XP-610|EPSON XP-610 Series:rm=atticf27:rp=XP-610:
```
*列表 13. 自动生成的 /etc/printcap*
这个文件中的每一行都有一个打印机名字、打印机描述,远程机器(`rm`)的名字、以及那个远程机器上的远程打印机(`rp`)。老的 `/etc/printcap` 文件也描述了打印机的能力。
#### 文件转换过滤器
你可以使用 CUPS 打印许多类型的文件,包括明文的文本文件、PDF、PostScript、和各种格式的图像文件,你只需要提供要打印的文件名,除此之外你再无需向 `lpr` 或 `lp` 命令提供更多的信息。这个神奇的壮举是通过使用过滤器来实现的。实际上,这些年来最流行的过滤器就就叫做 magicfilter(神奇的过滤器)。
当打印一个文件时,CUPS 使用多用途因特网邮件扩展(MIME)类型去决定合适的转换过滤器。其它的打印数据包可能使用由 `file` 命令使用的神奇数字机制。关于 `file` 或者神奇数的更多信息可以查看它们的 man 页面。
输入文件被过滤器转换成中间层的光栅格式或者 PostScript 格式。一些作业信息,比如打印数量也会被添加进去。数据最终通过一个后端发送到目标打印机。还有一些可以用手动过滤的输入文件的过滤器(如 a2ps 或 dvips)。你可以通过这些过滤器获得特殊格式的结果,或者去处理一些 CUPS 原生并不支持的文件格式。
#### 添加打印机
CUPS 支持多种打印机,包括:
* 本地连接的并行口和 USB 口打印机
* 因特网打印协议(IPP)打印机
* 远程 LPD 打印机
* 使用 SAMBA 的 Microsoft® Windows® 打印机
* 使用 NCP 的 Novell 打印机
* HP Jetdirect 打印机
当系统启动或者设备连接时,现在的大多数系统都会尝试自动检测和自动配置本地硬件。同样,许多网络打印机也可以被自动检测到。使用 CUPS 的 web 管理工具(<http://localhost:631> 或者 <http://127.0.0.1:631>)去搜索或添加打印机。许多发行版都包含它们自己的配置工具,比如,在 SUSE 系统上的 YaST。图 2 展示了使用 localhost:631 的 CUPS 界面,图 3 展示了 Fedora 27 上的 GNOME 打印机设置对话框。

*图 2. 使用 CUPS 的 web 界面*

*图 3. Fedora 27 上的打印机设置*
你也可以从命令行配置打印机。在配置打印机之前,你需要一些关于打印机和它的连接方式的基本信息。如果是一个远程系统,你还需要一个用户 ID 和密码。
你需要去知道你的打印机使用什么样的驱动程序。不是所有的打印机都支持 Linux,有些打印机在 Linux 上压根就不能使用,或者功能受限。你可以去 OpenPrinting.org 去查看是否有你的特定的打印机的驱动程序。`lpinfo` 命令也可以帮你识别有效的设备类型和驱动程序。使用 `-v` 选项去列出支持的设备,使用 `-m` 选项去列出驱动程序,如列表 14 所示。
```
[ian@atticf27 ~]$ lpinfo -m | grep -i xp-610
lsb/usr/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
EPSON XP-610 Series, Epson Inkjet Printer Driver (ESC/P-R) for Linux
[ian@atticf27 ~]$ locate "Epson-XP-610_Series-epson-escpr-en.ppd.gz"
/usr/share/ppd/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
[ian@atticf27 ~]$ lpinfo -v
network socket
network ipps
network lpd
network beh
network ipp
network http
network https
direct hp
serial serial:/dev/ttyS0?baud=115200
direct parallel:/dev/lp0
network smb
direct hpfax
network dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
network dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
network lpd://BRN001BA98A1891/BINARY_P1
network lpd://192.168.1.38:515/PASSTHRU
```
*列表 14. 可用的打印机驱动程序*
这个 Epson-XP-610\_Series-epson-escpr-en.ppd.gz 驱动程序在我的系统上位于 `/usr/share/ppd/Epson/epson-inkjet-printer-escpr/` 目录中。
如果你找不到驱动程序,你可以到打印机生产商的网站看看,说不定会有专用的驱动程序。例如,在写这篇文章的时候,Brother 就有一个我的 HL-2280DW 打印机的驱动程序,但是,这个驱动程序在 OpenPrinting.org 上还没有列出来。
如果你收集齐了基本信息,你可以如列表 15 所示的那样,使用 `lpadmin` 命令去配置打印机。为此,我将为我的 HL-2280DW 打印机创建另外一个实例,以便于双面打印。
```
[ian@atticf27 ~]$ lpinfo -m | grep -i "hl.*2280"
HL2280DW.ppd Brother HL2280DW for CUPS
lsb/usr/HL2280DW.ppd Brother HL2280DW for CUPS
[ian@atticf27 ~]$ lpadmin -p HL-2280DW-duplex -E -m HL2280DW.ppd \
> -v dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/ \
> -D "Brother 1" -o sides=two-sided-long-edge
[ian@atticf27 ~]$ lpstat -a
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
HL-2280DW accepting requests since Tue 30 Jan 2018 10:56:10 AM EST
HL-2280DW-duplex accepting requests since Wed 31 Jan 2018 11:41:16 AM EST
HXP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
```
*列表 15. 配置一台打印机*
你可以使用带 `-c` 选项的 `lpadmin` 命令去创建一个仅用于双面打印的新分类,而不用为了双面打印去创建一个打印机的副本。
如果你需要删除一台打印机,使用带 `-x` 选项的 `lpadmin` 命令。
列表 16 展示了如何去删除打印机和创建一个替代类。
```
[ian@atticf27 ~]$ lpadmin -x HL-2280DW-duplex
[ian@atticf27 ~]$ lpadmin -p HL-2280DW -c duplex -E -D "Duplex printing" -o sides=two-sided-long-edge
[ian@atticf27 ~]$ cupsenable duplex
[ian@atticf27 ~]$ cupsaccept duplex
[ian@atticf27 ~]$ lpstat -a
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
duplex accepting requests since Wed 31 Jan 2018 12:12:05 PM EST
HL-2280DW accepting requests since Wed 31 Jan 2018 11:51:16 AM EST
XP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
```
*列表 16. 删除一个打印机和创建一个类*
你也可以使用 `lpadmin` 或者 `lpoptions` 命令去设置各种打印机选项。详细信息请查看 man 页面。
### 排错
如果你有打印问题,尝试下列的提示:
* 确保 CUPS 服务器正在运行。你可以使用 `lpstat` 命令,如果它不能连接到 cupsd 守护程序,它将会报告一个错误。或者,你可以使用 `ps -ef` 命令在输出中去检查是否有 cupsd。
* 如果你试着排队一个打印作业而得到一个错误信息,指示打印机不接受这个作业,你可以使用 `lpstat -a` 或者 `lpc status` 去检查那个打印机是否接受作业。
* 如果一个队列中的作业没有打印,使用 `lpstat -p` 或 `lpc status` 去检查那个打印机是否接受作业。如前面所讨论的那样,你可能需要将这个作业移动到其它的打印机。
* 如果这个打印机是远程的,检查它在远程系统上是否存在,并且是可操作的。
* 检查配置文件,确保特定的用户或者远程系统允许在这个打印机上打印。
* 确保防火墙允许远程打印请求,是否允许从其它系统到你的系统,或者从你的系统到其它系统的数据包通讯。
* 验证是否有正确的驱动程序。
正如你所见,打印涉及到你的系统中的几个组件,甚至还有网络。在本教程中,基于篇幅的考虑,我们仅能给你的诊断提供了几个着手点。大多数的 CUPS 系统也有实现我们所讨论的命令行功能的图形界面。一般情况下,这个界面是从本地主机使用浏览器指向 631 端口(<http://localhost:631> 或 <http://127.0.0.1:631>)来访问的,如前面的图 2 所示。
你可以通过将 CUPS 运行在前台而不是做为一个守护进程来诊断它的问题。如果有需要,你也可以通过这种方式去测试替代的配置文件。运行 `cupsd -h` 获得更多信息,或者查看 man 页面。
CUPS 也带有一个访问日志和错误日志。你可以在 `cupsd.conf` 中使用 `LogLevel` 语句来改变日志级别。默认情况下,日志是保存在 `/var/log/cups` 目录。它们可以在浏览器界面(<http://localhost:631>)下,从 **Administration** 选项卡中查看。使用不带任何选项的 `cupsctl` 命令可以显示日志选项。也可以编辑 `cupsd.conf` 或者使用 `cupsctl` 去调整各种日志参数。查看 `cupsctl` 命令的 man 页面了解更多信息。
在 Ubuntu 的 Wiki 页面上的 [调试打印问题](https://wiki.ubuntu.com/DebuggingPrintingProblems) 页面也是一个非常好的学习的地方。
这就是关于打印和 CUPS 的介绍。
---
via: <https://www.ibm.com/developerworks/library/l-lpic1-108-4/index.html>
作者:[Ian Shields](https://www.ibm.com) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,539 | 我的冒险旅程之迁移回 Windows | https://www.chris-shaw.com/blog/my-adventure-migrating-back-to-windows | 2018-04-13T08:09:06 | [
"Windows"
] | https://linux.cn/article-9539-1.html | 我已经主要使用 Linux 大约 10 年了,而且主要是 Ubuntu。但在最新发布的版本中,我决定重新回到我通常不喜欢的操作系统: Windows 10。

我一直是 Linux 的粉丝,我最喜欢的两个发行版是 Debian 和 Ubuntu。现今作为一个服务器操作系统,Linux 是完美无暇的,但在桌面上一直存在不同程度的问题。
最近一系列的问题让我意识到,我不需要使用 Linux 作为我的桌面操作系统,我仍然是一个 Linux 粉丝,但基于我安装 Ubuntu 17.10 的经验,我已经决定回到 Windows。
### 什么使我选择了回归
问题是,当 Ubuntu 17.10 出来后,我像往常一样进行全新安装,但遇到了一些非常奇怪的新问题。
* Dell D3100 Dock 不再工作(包括临时规避方案也没用)
* Ubuntu 意外死机(随机)
* 双击桌面上的图标没反应
* 使用 HUD 搜索诸如“tweaks”之类的程序会尝试安装 META 桌面版本
* GUI 比标准的 GNOME 感觉更糟糕
现在我确实考虑回到使用 Ubuntu 16.04 或另一个发行版,但是我觉得 Unity 7 是最精致的桌面环境,而另外唯一一个优雅且稳定的是 Windows 10。
除此之外,使用 Linux 而不是使用 Windows 也有一些固有的问题,如:
* 大多数商用软件不可用,E.G Maya、 PhotoShop、 Microsoft Office(大多数情况下,替代品并不相同)等等。
* 大多数游戏都没有移植到 Linux 上,包括来自 EA、 Rockstar Ect. 等主要工作室的游戏。
* 对于大多数硬件来说,其 Linux 驱动程序是厂商的次要考虑。
在决定使用 Windows 之前,我确实考虑过其他发行版和操作系统。
与此同时,我看到了更多的“微软爱 Linux ”的行动,并且了解了 WSL。他们的新开发者的关注角度对我来说很有意思,于是我试了一下。
### 我在 Windows 找到了什么
我使用计算机主要是为了编程,我也使用虚拟机、git 和 ssh,并且大部分工作依赖于 bash。我偶尔也会玩游戏,观看 netflix 和一些轻松的办公室工作。
总之,我期待在 Ubuntu 中保留当前的工作流程并将其移植到 Windows 上。我也想利用 Windows 的优点。
* 所有的 PC 游戏支持 Windows
* 大多数程序是原生的
* 微软办公软件
虽然使用 Windows 有很多坑,但是我打算正确对待它,所以我不担心一般的 Windows 故障,例如病毒和恶意软件。
### Windows 的子系统 Linux(Windows 上的 Ubuntu 中的 Bash)
微软与 Canonical 的密切合作将 Ubuntu 带到了 Windows 上。在经过快速设置和启动程序之后,你将拥有非常熟悉的 bash 界面。
我一直在研究其局限性,但是在写这篇文章时我碰到的唯一真正的限制是它从硬件中抽象了出来。例如,`lsblk` 不会显示你有什么分区,因为子系统里的 Ubuntu 没有提供这些信息。
但是除了访问底层工具之外,我发现其体验非常熟悉,也很棒。
我在下面的工作流程中使用了它。
* 生成 SSH 密钥对
* 使用 Git 和 Github 来管理我的仓库
* SSH 到几个服务器,包括不用密码
* 为本地数据库运行 MySQL
* 监视系统资源
* 使用 Vim 编辑配置文件
* 运行 Bash 脚本
* 运行本地 Web 服务器
* 运行 PHP、NodeJS
到目前为止,它已经被证明是非常强大的工具。除了是在 Windows 10 用户界面之中,我的工作流程感觉和我在 Ubuntu 上几乎一样。尽管我的多数工作可以在 WSL 中处理,但我仍然打算通过虚拟机进行更深入的工作,这可能超出了 WSL 的范围。
### 不需要用 Wine
我遇到的另一个主要问题是兼容性问题。我很少使用 Wine 来使用 Windows 软件。(LCTT 译注:Wine 是可以使 Linux 上运行 Windows 应用的软件)但是有时它是必需的,尽管通常体验不是很好。
#### HeidiSQL
我首先安装的程序之一是 HeidiSQL,它是我最喜欢的数据库客户端之一。它可以在 Wine 下工作,但是感觉很不好,所以我在 Linux 下丢掉它而使用了 MySQL Workbench。回到了 Windows 中,就像一个可靠的老朋友回来了。
#### 游戏平台 / Steam
没有游戏的 Windows 电脑是无法想象的。我从 Steam 的网站上安装了它,我的 Linux 游戏,加上我的 Windows 游戏就变大了 5 倍,并且包括 GTA V (LCTT 译注: GTA V 是一款名叫侠盗飞车的游戏) 等 AAA 级游戏。而这些我在 Ubuntu 中只能梦想。
我对 SteamOS 有很大的期望,并且一直会持续如此。但是我认为在可预见的将来,它不会在任何地方的游戏市场中崭露头角。所以如果你想在 PC 上玩游戏,你确实需要 Windows。
还有一点需要注意的是, 你的 nvidia 显卡的驱动程序会得到很好的支持,这使得像 TF2 (LCTT 译注: 这是一款名叫军团要塞 2 的游戏)这样的一些 Linux 原生游戏运行的稍好一些。
**Windows 在游戏方面总是优越的,所以这并不令人感到意外。**
### 从 USB 硬盘运行,为什么
我在我的主固态硬盘上运行 Linux,但在过去,我是从 usb 棒和 usb 硬盘运行它的。我习惯了 Linux 的这种持久性,这让我可以在不丢失主要操作系统的情况下长期尝试多个版本。现在我尝试将 Windows 安装到 USB 连接的硬盘上时,它无法工作也不可能工作。所以当我将 Windows 硬盘分区的克隆作为备份时,我很惊讶我可以通过 USB 启动它。
这对我来说已经成为一个方便的选择,因为我打算将我的工作笔记本电脑迁移回 Windows,但如果不想冒险,那就把它扔在那里吧。
所以我在过去的几天里,我使用 USB 来运行它,除了一些错误的消息外,我没有通过 USB 运行发现它真正的缺点。
这样做主要的问题是:
* 较慢的启动速度
* 恼人的信息:不要拔掉你的 USB
* 无法激活它
**我可能会写一篇关于 USB 驱动器上的 Windows 的文章,这样我们可以有更详细的了解。**
### 那么结论是什么?
我使用 Windows 10 大约两周了,并没有注意到它对我的工作流程有任何的负面影响。尽管过程会有一些小问题,但我需要的所以工具都在手边,并且操作系统一般都在运行。
### 我会留在 Windows吗?
虽然现在还为时尚早,但我想在可见的未来我会坚持使用 Windows。
---
via: <https://www.chris-shaw.com/blog/my-adventure-migrating-back-to-windows>
作者:[Christopher Shaw](https://www.chris-shaw.com) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,540 | 高级 SSH 速查表 | https://opensource.com/sites/default/files/gated-content/cheat_sheet_ssh_v03.pdf | 2018-04-13T08:31:00 | [
"SSH"
] | https://linux.cn/article-9540-1.html | 
所有人都知道 SSH 是一种远程登录工具,然而它也有许多其他用途。
创建一个 SOCKS 代理来浏览网页(也就是翻墙啦):
>
>
> ```
> ssh -D <port> <remote_host>
>
> ```
>
> 设置 `localhost:<port>` 作为你浏览器的代理
>
>
>
连接一个堡垒机后的 Windows RDP 主机:
>
>
> ```
> ssh -L <port>:<target_host>:3389 <bastion_server>
>
> ```
>
> 让你的 RDP 客户端连接到 `localhost:<port>`
>
>
>
在不使用 VNC 端口的情况下,连接远程 VNC 主机:
>
>
> ```
> ssh -L 5901:localhost:5901 <remote_host>
>
> ```
>
> 让你的 VNC 客户端连接到 `localhost:5901`
>
>
>
按照这个思路,你可以映射任意端口:LDAP (389)、631 (CUPS)、8080 (替代的 HTTP),等等。
产生一个新的 SSH 密钥对:
>
>
> ```
> ssh-keygen
>
> ```
>
>
更新密钥对的密码:
>
>
> ```
> ssh-keygen -p
>
> ```
>
>
把公钥复制到远程主机上:
>
>
> ```
> ssh-copy-id -i <identity file> <remote_host>
>
> ```
>
>
SSH 有一堆命令行选项,但是如果有一些是你经常使用的,你可以为它们在 SSH 配置文件 (${HOME}/.ssh/config) 里创建一个入口。比如:
>
>
> ```
> host myhouse
> User itsme
> HostName house.example.com
>
> ```
>
>
那么你就可以输入 `ssh myhouse` 来代替 `ssh [email protected]`。
以下是常用的命令行选项和他们的配置文件写法。一些是常用的简化写法。请查看 `ssh(1)` 和 `ssh_config(5)` 的手册页来获取详尽信息。
| 命令行 | 配置文件 | 描述 |
| --- | --- | --- |
| `-l <login name>` | `User <login name>` | 远程主机的登录用户名。 |
| `-i <identity file>` | `IdentityFile <identity file>` | 指定要使用的鉴权文件(SSH 密码对)。 |
| `-p <remote port>` | `Port <remote port>` | 远程 SSH 守护进程监听的端口号。 (默认为 22) |
| `-C` | `Compression <yes,no>` | 压缩往来信息。 (默认为 no) |
| `-D <port>` | `DynamicForward <port>` | 把本地端口的报文转发到远程主机。 |
| `-X` | `ForwardX11 <yes,no>` | 把 X11 的图像数据转发到远程主机的端口. (默认为 no) |
| `-A` | `ForwardAgent <yes,no>` | 把授权代理的报文转发给远程主机。如果你使用第三方主机登录,这个功能将很有用。 (默认为 no) |
| `-4`(仅使用 IPv4) `-6` (仅使用 IPv6) | `AddressFamily <any,inet4,inet6>` | 指定仅使用 IPv4 或者 IPv6。 |
| `-L <local port>:<target host>:<target port>` | `LocalForward <local port>:<target host>:<target port>` | 把本地主机指定端口的报文转发到远程主机的某个端口。 |
opensource.com Twitter @opensourceway | facebook.com/opensourceway | IRC: #opensource.com on Freenode
---
作者简介:
Ben Cotton 是业余的气象学家和职业的高性能计算工程师。Ben 是微软 Azure 的产品营销经理,专注于高性能计算。他是一个 Fedora 用户和贡献者,共同创立了一个当地的开放源码群,并且是开源促进会的成员和保护自由软件的支持者。通过以下方式联系他 Twitter (@FunnelFiasco) 或者 FunnelFiasco.com.
---
via: <https://opensource.com/sites/default/files/gated-content/cheat_sheet_ssh_v03.pdf>
作者:[BEN COTTON](https://opensource.com/users/bcotton) 译者:[kennethXia](https://github.com/kennethXia) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,541 | 如何创建一个 Docker 镜像 | https://www.linux.com/blog/learn/intro-to-linux/2018/1/how-create-docker-image | 2018-04-13T20:32:00 | [
"容器",
"Docker"
] | https://linux.cn/article-9541-1.html | 
在 [前面的文章](/article-9773-1.html) 中,我们学习了在 Linux、macOS、以及 Windows 上如何使用 Docker 的基础知识。在这篇文章中,我们将学习创建 Docker 镜像的基本知识。我们可以在 DockerHub 上得到可用于你自己的项目的预构建镜像,并且也可以将你自己的镜像发布到这里。
我们使用预构建镜像得到一个基本的 Linux 子系统,因为,从头开始构建需要大量的工作。你可以使用 Alpine( Docker 版使用的官方版本)、Ubuntu、BusyBox、或者 scratch。在我们的示例中,我将使用 Ubuntu。
在我们开始构建镜像之前,让我们先“容器化”它们!我的意思是,为你的所有 Docker 镜像创建目录,这样你就可以维护不同的项目和阶段,并保持它们彼此隔离。
```
$ mkdir dockerprojects
cd dockerprojects
```
现在,在 `dockerprojects` 目录中,你可以使用自己喜欢的文本编辑器去创建一个 `Dockerfile` 文件;我喜欢使用 nano,它对新手来说很容易上手。
```
$ nano Dockerfile
```
然后添加这样的一行内容:
```
FROM Ubuntu
```

使用 `Ctrl+Exit` 然后选择 `Y` 去保存它。
现在开始创建你的新镜像,然后给它起一个名字(在刚才的目录中运行如下的命令):
```
$ docker build -t dockp .
```
(注意命令后面的圆点)这样就创建成功了,因此,你将看到如下内容:
```
Sending build context to Docker daemon 2.048kB
Step 1/1 : FROM ubuntu
---> 2a4cca5ac898
Successfully built 2a4cca5ac898
Successfully tagged dockp:latest
```
现在去运行和测试一下你的镜像:
```
$ docker run -it Ubuntu
```
你将看到 root 提示符:
```
root@c06fcd6af0e8:/#
```
这意味着在 Linux、Windows、或者 macOS 中你可以运行一个最小的 Ubuntu 了。你可以运行所有的 Ubuntu 原生命令或者 CLI 实用程序。

我们来查看一下在你的目录下你拥有的所有 Docker 镜像:
```
$docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
dockp latest 2a4cca5ac898 1 hour ago 111MB
ubuntu latest 2a4cca5ac898 1 hour ago 111MB
hello-world latest f2a91732366c 8 weeks ago 1.85kB
```
你可以看到共有三个镜像:`dockp`、`Ubuntu`、和 `hello-world`, `hello-world` 是我在几周前创建的,这一系列的前面的文章就是在它下面工作的。构建一个完整的 LAMP 栈可能是一个挑战,因此,我们使用 Dockerfile 去创建一个简单的 Apache 服务器镜像。
从本质上说,Dockerfile 是安装所有需要的包、配置、以及拷贝文件的一套指令。在这个案例中,它是安装配置 Apache 和 Nginx。
你也可以在 DockerHub 上去创建一个帐户,然后在构建镜像之前登入到你的帐户,在这个案例中,你需要从 DockerHub 上拉取一些东西。从命令行中登入 DockerHub,运行如下所求的命令:
```
$ docker login
```
在登入时输入你的用户名和密码。
接下来,为这个 Docker 项目,在目录中创建一个 Apache 目录:
```
$ mkdir apache
```
在 Apache 目录中创建 Dockerfile 文件:
```
$ nano Dockerfile
```
然后,粘贴下列内容:
```
FROM ubuntu
MAINTAINER Kimbro Staken version: 0.1
RUN apt-get update && apt-get install -y apache2 && apt-get clean && rm -rf /var/lib/apt/lists/*
ENV APACHE_RUN_USER www-data
ENV APACHE_RUN_GROUP www-data
ENV APACHE_LOG_DIR /var/log/apache2
EXPOSE 80
CMD ["/usr/sbin/apache2", "-D", "FOREGROUND"]
```
然后,构建镜像:
```
docker build -t apache .
```
(注意命令尾部的空格和圆点)
这将花费一些时间,然后你将看到如下的构建成功的消息:
```
Successfully built e7083fd898c7
Successfully tagged ng:latest
Swapnil:apache swapnil$
```
现在,我们来运行一下这个服务器:
```
$ docker run -d apache
a189a4db0f7c245dd6c934ef7164f3ddde09e1f3018b5b90350df8be85c8dc98
```
发现了吗,你的容器镜像已经运行了。可以运行如下的命令来检查所有运行的容器:
```
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED
a189a4db0f7 apache "/usr/sbin/apache2ctl" 10 seconds ago
```
你可以使用 `docker kill` 命令来杀死容器:
```
$docker kill a189a4db0f7
```
正如你所见,这个 “镜像” 它已经永久存在于你的目录中了,而不论运行与否。现在你可以根据你的需要创建很多的镜像,并且可以从这些镜像中繁衍出来更多的镜像。
这就是如何去创建镜像和运行容器。
想学习更多内容,你可以打开你的浏览器,然后找到更多的关于如何构建像 LAMP 栈这样的完整的 Docker 镜像的文档。这里有一个帮你实现它的 [Dockerfile](https://github.com/fauria/docker-lamp/blob/master/Dockerfile) 文件。在下一篇文章中,我将演示如何推送一个镜像到 DockerHub。
你可以通过来自 Linux 基金会和 edX 的 [“介绍 Linux”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 免费课程来学习更多的知识。
---
via: <https://www.linux.com/blog/learn/intro-to-linux/2018/1/how-create-docker-image>
作者:[SWAPNIL BHARTIYA](https://www.linux.com/users/arnieswap) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,542 | 为初学者提供的 uniq 命令教程及示例 | https://www.ostechnix.com/uniq-command-tutorial-examples-beginners/ | 2018-04-13T20:46:47 | [
"uniq"
] | https://linux.cn/article-9542-1.html | 
如果你主要是在命令行上工作,并且每天处理大量的文本文件,那么你应该了解下 `uniq` 命令。该命令会帮助你轻松地从文件中找到重复的行。它不仅用于查找重复项,而且我们还可以使用它来删除重复项,显示重复项的出现次数,只显示重复的行,只显示唯一的行等。由于 `uniq` 命令是 GNU coreutils 包的一部分,所以它预装在大多数 Linux 发行版中,让我们不需要费心安装。来看一些实际的例子。
请注意,除非重复行是相邻的,否则 `uniq` 不会删除它们。因此,你可能需要先对它们进行排序,或将排序命令与 `uniq` 组合以获得结果。让我给你看一些例子。
首先,让我们创建一个带有一些重复行的文件:
```
vi ostechnix.txt
```
```
welcome to ostechnix
welcome to ostechnix
Linus is the creator of Linux.
Linux is secure by default
Linus is the creator of Linux.
Top 500 super computers are powered by Linux
```
正如你在上面的文件中看到的,我们有一些重复的行(第一行和第二行,第三行和第五行是重复的)。
### 1、 使用 uniq 命令删除文件中的连续重复行
如果你在不使用任何参数的情况下使用 `uniq` 命令,它将删除所有连续的重复行,只显示唯一的行。
```
uniq ostechnix.txt
```
示例输出:

如你所见, `uniq` 命令删除了给定文件中的所有连续重复行。你可能还注意到,上面的输出仍然有第二行和第四行重复了。这是因为 `uniq` 命令只有在相邻的情况下才会删除重复的行,当然,我们也可以删除非连续的重复行。请看下面的第二个例子。
### 2、 删除所有重复的行
```
sort ostechnix.txt | uniq
```
示例输出:

看到了吗?没有重复的行。换句话说,上面的命令将显示在 `ostechnix.txt` 中只出现一次的行。我们使用 `sort` 命令与 `uniq` 命令结合,因为,就像我提到的,除非重复行是相邻的,否则 `uniq` 不会删除它们。
### 3、 只显示文件中唯一的一行
为了只显示文件中唯一的一行,可以这样做:
```
sort ostechnix.txt | uniq -u
```
示例输出:
```
Linux is secure by default
Top 500 super computers are powered by Linux
```
如你所见,在给定的文件中只有两行是唯一的。
### 4、 只显示重复的行
同样的,我们也可以显示文件中重复的行,就像下面这样:
```
sort ostechnix.txt | uniq -d
```
示例输出:
```
Linus is the creator of Linux.
welcome to ostechnix
```
这两行在 `ostechnix.txt` 文件中是重复的行。请注意 `-d`(小写 `d`) 将会只打印重复的行,每组显示一个。打印所有重复的行,使用 `-D`(大写 `D`),如下所示:
```
sort ostechnix.txt | uniq -D
```
在下面的截图中看两个选项的区别:

### 5、 显示文件中每一行的出现次数
由于某种原因,你可能想要检查给定文件中每一行重复出现的次数。要做到这一点,使用 `-c` 选项,如下所示:
```
sort ostechnix.txt | uniq -c
```
示例输出:
```
2 Linus is the creator of Linux.
1 Linux is secure by default
1 Top 500 super computers are powered by Linux
2 welcome to ostechnix
```
我们还可以按照每一行的出现次数进行排序,然后显示,如下所示:
```
sort ostechnix.txt | uniq -c | sort -nr
```
示例输出:
```
2 welcome to ostechnix
2 Linus is the creator of Linux.
1 Top 500 super computers are powered by Linux
1 Linux is secure by default
```
### 6、 将比较限制为 N 个字符
我们可以使用 `-w` 选项来限制对文件中特定数量字符的比较。例如,让我们比较文件中的前四个字符,并显示重复行,如下所示:
```
uniq -d -w 4 ostechnix.txt
```
### 7、 忽略比较指定的 N 个字符
像对文件中行的前 N 个字符进行限制比较一样,我们也可以使用 `-s` 选项来忽略比较前 N 个字符。
下面的命令将忽略在文件中每行的前四个字符进行比较:
```
uniq -d -s 4 ostechnix.txt
```
为了忽略比较前 N 个字段(LCTT 译注:即前几列)而不是字符,在上面的命令中使用 `-f` 选项。
欲了解更多详情,请参考帮助部分:
```
uniq --help
```
也可以使用 `man` 命令查看:
```
man uniq
```
今天就到这里!我希望你现在对 `uniq` 命令及其目的有一个基本的了解。如果你发现我们的指南有用,请在你的社交网络上分享,并继续支持我们。更多好东西要来了,请继续关注!
干杯!
---
via: <https://www.ostechnix.com/uniq-command-tutorial-examples-beginners/>
作者:[SK](https://www.ostechnix.com) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,543 | AI 和机器学习中暗含的算法偏见 | https://opensource.com/article/18/1/how-open-source-can-fight-algorithmic-bias | 2018-04-13T23:18:33 | [
"AI",
"机器学习",
"人工智能"
] | /article-9543-1.html |
>
> 我们又能通过开源社区做些什么?
>
>
>

在我们的世界里,算法无处不在,偏见也是一样。从社会媒体新闻的提供到流式媒体服务的推荐到线上购物,计算机算法,尤其是机器学习算法,已经渗透到我们日常生活的每一个角落。至于偏见,我们只需要参考 2016 年美国大选就可以知道,偏见是怎样在明处与暗处影响着我们的社会。
很难想像,我们经常忽略的一点是这二者的交集:计算机算法中存在的偏见。
与我们大多数人的认知相反,科技并不是客观的。 AI 算法和它们的决策程序是由它们的研发者塑造的,他们写入的代码,使用的“[训练](https://www.crowdflower.com/what-is-training-data/)”数据还有他们对算法进行[应力测试](https://medium.com/microsoft-design/how-to-recognize-exclusion-in-ai-ec2d6d89f850) 的过程,都会影响这些算法今后的选择。这意味着研发者的价值观、偏见和人类缺陷都会反映在软件上。如果我只给实验室中的人脸识别算法提供白人的照片,当遇到不是白人照片时,它[不会认为照片中的是人类](https://www.ted.com/talks/joy_buolamwini_how_i_m_fighting_bias_in_algorithms) 。这结论并不意味着 AI 是“愚蠢的”或是“天真的”,它显示的是训练数据的分布偏差:缺乏多种的脸部照片。这会引来非常严重的后果。
这样的例子并不少。全美范围内的[州法院系统](https://www.wired.com/2017/04/courts-using-ai-sentence-criminals-must-stop-now/) 都使用“黑盒”对罪犯进行宣判。由于训练数据的问题,[这些算法对黑人有偏见](https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing) ,他们对黑人罪犯会选择更长的服刑期,因此监狱中的种族差异会一直存在。而这些都发生在科技的客观性伪装下,这是“科学的”选择。
美国联邦政府使用机器学习算法来计算福利性支出和各类政府补贴。[但这些算法中的信息](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3012499),例如它们的创造者和训练信息,都很难找到。这增加了政府工作人员进行不平等补助金分发操作的几率。
算法偏见情况还不止这些。从 Facebook 的新闻算法到医疗系统再到警用携带相机,我们作为社会的一部分极有可能对这些算法输入各式各样的偏见、性别歧视、仇外思想、社会经济地位歧视、确认偏误等等。这些被输入了偏见的机器会大量生产分配,将种种社会偏见潜藏于科技客观性的面纱之下。
这种状况绝对不能再继续下去了。
在我们对人工智能进行不断开发研究的同时,需要降低它的开发速度,小心仔细地开发。算法偏见的危害已经足够大了。
### 我们能怎样减少算法偏见?
最好的方式是从算法训练的数据开始审查,根据 [微软的研究人员](https://medium.com/microsoft-design/how-to-recognize-exclusion-in-ai-ec2d6d89f850) 所说,这方法很有效。
数据分布本身就带有一定的偏见性。编程者手中的美国公民数据分布并不均衡,本地居民的数据多于移民者,富人的数据多于穷人,这是极有可能出现的情况。这种数据的不平均会使 AI 对我们是社会组成得出错误的结论。例如机器学习算法仅仅通过统计分析,就得出“大多数美国人都是富有的白人”这个结论。
即使男性和女性的样本在训练数据中等量分布,也可能出现偏见的结果。如果训练数据中所有男性的职业都是 CEO,而所有女性的职业都是秘书(即使现实中男性 CEO 的数量要多于女性),AI 也可能得出女性天生不适合做 CEO 的结论。
同样的,大量研究表明,用于执法部门的 AI 在检测新闻中出现的罪犯照片时,结果会 [惊人地偏向](https://www.hivlawandpolicy.org/sites/default/files/Race%20and%20Punishment-%20Racial%20Perceptions%20of%20Crime%20and%20Support%20for%20Punitive%20Policies%20%282014%29.pdf) 黑人及拉丁美洲裔居民。
在训练数据中存在的偏见还有很多其他形式,不幸的是比这里提到的要多得多。但是训练数据只是审查方式的一种,通过“应力测验”找出人类存在的偏见也同样重要。
如果提供一张印度人的照片,我们自己的相机能够识别吗?在两名同样水平的应聘者中,我们的 AI 是否会倾向于推荐住在市区的应聘者呢?对于情报中本地白人恐怖分子和伊拉克籍恐怖分子,反恐算法会怎样选择呢?急诊室的相机可以调出儿童的病历吗?
这些对于 AI 来说是十分复杂的数据,但我们可以通过多项测试对它们进行定义和传达。
### 为什么开源很适合这项任务?
开源方法和开源技术都有着极大的潜力改变算法偏见。
现代人工智能已经被开源软件占领,TensorFlow、IBM Watson 还有 [scikit-learn](http://scikit-learn.org/stable/) 这类的程序包都是开源软件。开源社区已经证明它能够开发出强健的,经得住严酷测试的机器学习工具。同样的,我相信,开源社区也能开发出消除偏见的测试程序,并将其应用于这些软件中。
调试工具如哥伦比亚大学和理海大学推出的 [DeepXplore](https://arxiv.org/pdf/1705.06640.pdf),增强了 AI 应力测试的强度,同时提高了其操控性。还有 [麻省理工学院的计算机科学和人工智能实验室](https://www.csail.mit.edu/research/understandable-deep-networks)完成的项目,它开发出敏捷快速的样机研究软件,这些应该会被开源社区采纳。
开源技术也已经证明了其在审查和分类大组数据方面的能力。最明显的体现在开源工具在数据分析市场的占有率上(Weka、Rapid Miner 等等)。应当由开源社区来设计识别数据偏见的工具,已经在网上发布的大量训练数据组比如 [Kaggle](https://www.kaggle.com/datasets) 也应当使用这种技术进行识别筛选。
开源方法本身十分适合消除偏见程序的设计。内部谈话、私人软件开发及非民主的决策制定引起了很多问题。开源社区能够进行软件公开的谈话,进行大众化,维持好与大众的关系,这对于处理以上问题是十分重要的。如果线上社团,组织和院校能够接受这些开源特质,那么由开源社区进行消除算法偏见的机器设计也会顺利很多。
### 我们怎样才能够参与其中?
教育是一个很重要的环节。我们身边有很多还没意识到算法偏见的人,但算法偏见在立法、社会公正、政策及更多领域产生的影响与他们息息相关。让这些人知道算法偏见是怎样形成的和它们带来的重要影响是很重要的,因为想要改变目前的局面,从我们自身做起是唯一的方法。
对于我们中间那些与人工智能一起工作的人来说,这种沟通尤其重要。不论是人工智能的研发者、警方或是科研人员,当他们为今后设计人工智能时,应当格外意识到现今这种偏见存在的危险性,很明显,想要消除人工智能中存在的偏见,就要从意识到偏见的存在开始。
最后,我们需要围绕 AI 伦理化建立并加强开源社区。不论是需要建立应力实验训练模型、软件工具,或是从千兆字节的训练数据中筛选,现在已经到了我们利用开源方法来应对数字化时代最大的威胁的时间了。
---
via: <https://opensource.com/article/18/1/how-open-source-can-fight-algorithmic-bias>
作者:[Justin Sherman](https://opensource.com/users/justinsherman) 译者:[Valoniakim](https://github.com/Valoniakim) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,544 | 在树莓派上运行 DOS 系统 | https://opensource.com/article/18/3/can-you-run-dos-raspberry-pi | 2018-04-14T22:28:46 | [
"树莓派",
"DOS"
] | https://linux.cn/article-9544-1.html |
>
> 不同的 CPU 架构意味着在树莓派上运行 DOS 并非唾手可得,但其实也没多麻烦。
>
>
>

[FreeDOS](http://www.freedos.org/) 对大家来说也许并不陌生。它是一个完整、免费并且对 DOS 兼容良好的操作系统,它可以运行一些比较老旧的 DOS 游戏或者商用软件,也可以开发嵌入式的应用。只要在 MS-DOS 上能够运行的程序,在 FreeDOS 上都可以运行。
作为 FreeDOS 的发起者和项目协调人员,很多用户会把我作为内行人士进行发问。而我最常被问到的问题是:“FreeDOS 可以在树莓派上运行吗?”
这个问题并不令人意外。毕竟 Linux 在树莓派上能够很好地运行,而 FreeDOS 和 Linux 相比是一个更古老、占用资源更少的操作系统,那 FreeDOS 为啥不能树莓派上运行呢?
简单来说。由于 CPU 架构的原因,FreeDOS 并不能在树莓派中独立运行。和其它 DOS 类的系统一样,FreeDOS 需要英特尔 x86 架构 CPU 以及 BIOS 来提供基础的运行时服务。而树莓派运行在 ARM 架构的 CPU 上,与英特尔 CPU 二进制不兼容,也没有 BIOS。因此树莓派在硬件层面就不支持 FreeDOS。
不过通过 PC 模拟器还是能在树莓派上运行 FreeDOS 的,虽然这样也许稍有不足,但也不失为一个能在树莓派上运行 FreeDOS 的方法。
### DOSBox 怎么样?
有人可能会问:“为什么不用 DOSBox 呢?” DOSBox 是一个开源的跨平台 x86 模拟器,在 Linux 上也能使用,它能够为应用软件尤其是游戏软件提供了一个类 DOS 的运行环境,所以如果你只是想玩 DOS 游戏的话,DOSBox 是一个不错的选择。但在大众眼中,DOSBox 是专为 DOS 游戏而设的,而在运行一些别的 DOS 应用软件方面,DOSBox 只是表现平平。
对多数人来说,这只是个人偏好的问题,我喜欢用 FreeDOS 来运行 DOS 游戏和其它程序,完整的 DOS 系统和 DOSBox 相比能让我体验到更好的灵活性和操控性。我只用 DOSBox 来玩游戏,在其它方面还是选择完整的 FreeDOS。
### 在树莓派上安装 FreeDOS
[QEMU](https://www.qemu.org/)(Quick EMUlator)是一款能在 Linux 系统上运行 DOS 系统的开源的虚拟机软件。很多流行的 Linux 系统都自带 QEMU。QEMU 在我的树莓派上的 Raspbian 系统中也同样能够运行,下文就有一些我在树莓派 [Raspbian GNU/Linux 9 (Stretch)](https://www.raspberrypi.org/downloads/) 系统中使用 QEMU 的截图。
去年我在写了一篇关于[如何在 Linux 系统中运行 DOS 程序](/article-9014-1.html)的文章的时候就用到了 QEMU,在树莓派上使用 QEMU 来安装运行 FreeDOS 的步骤基本上和在别的基于 GNOME 的系统上没有什么太大的区别。
在 QEMU 中你需要通过添加各种组件来搭建虚拟机。先指定一个用来安装运行 DOS 的虚拟磁盘镜像,通过 `qemu-img` 命令来创建一个虚拟磁盘镜像,对于 FreeDOS 来说不需要太大的空间,所以我只创建了一个 200MB 的虚拟磁盘:
```
qemu-img create freedos.img 200M
```
和 VMware 或者 VirtualBox 这些 PC 模拟器不同,使用 QEMU 需要通过添加各种组件来搭建虚拟机,尽管有点麻烦,但是并不困难。我使用了以下这些参数来在树莓派上使用 QEMU 安装 FreeDOS 系统:
```
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -hda freedos.img -cdrom FD12CD.iso -boot order=d
```
你可以在我其它的[文章](/article-9014-1.html)中找到这些命令的完整介绍。简单来说,上面这条命令指定了一个英特尔 i386 兼容虚拟机,并且分配了 16MB 内存、一个英文输入键盘、一个基于系统时间的实时时钟、一个声卡、一个音乐卡以及一个 VGA 卡。文件 `freedos.img` 指定为第一个硬盘(`C:`),`FD12CD.iso` 镜像作为 CD-ROM (`D:`)驱动。QEMU 设定为从 `D:` 的 CD-ROM 启动。
你只需要按照提示就可以轻松安装好 FreeDOS 1.2 了。但是由于 microSD 卡在面对大量的 I/O 时速度比较慢,所以安装操作系统需要花费很长时间。
### 在树莓派上运行 FreeDOS
你的运行情况取决于使用哪一种 microSD 卡。我用的是 SanDisk Ultra 64GB microSDXC UHS-I U1A1 ,其中 U1 这种型号专用于支持 1080p 的视频录制(例如 GoPro),它的最低串行写速度能够达到 10MB/s。相比之下,V60 型号专用于 4K 视频录制,最低连续写入速度能达到 60MB/s。如果你的树莓派使用的是 V60 的 microSD 卡甚至是 V30(也能达到 30MB/s),你就能明显看到它的 I/O 性能会比我的好。
FreeDOS 安装好之后,你可以直接从 `C:` 进行启动。只需要按照下面的命令用 `-boot order=c` 来指定 QEMU 的启动顺序即可:
```
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -hda freedos.img -cdrom FD12CD.iso -boot order=c
```
只要树莓派的 QEMU 上安装了 FreeDOS,就不会出现明显的性能问题。例如游戏通常在每一关开始的时候会加载地图、怪物、声音等一系列的数据,尽管这些内容需要加载一段时间,但在正常玩的时候并没有出现性能不足的现象。
FreeDOS 1.2 自带了很多游戏以及其它应用软件,可以使用 `FDIMPLES` 包管理程序来安装它们。FreeDOS 1.2 里面我最喜欢的是一款叫 WING 的太空射击游戏,让人想起经典的街机游戏 Galaga(WING 就是 Wing Is Not Galaga 的递归缩写词)。
As-Easy-As 是我最喜欢的一个 DOS 应用程序,作为 20 世纪八九十年代流行的电子表格程序,它和当时的 Lotus 1-2-3 以及现在的 Microsoft Excel、LibreOffice Calc 一样具有强大的威力。As-Easy-As 和 Lotus 1-2-3 都将数据保存为 WKS 文件,现在新版本的 Microsoft Excel 已经无法读取这种文件了,而 LibreOffice Calc 视兼容性而定有可能支持。鉴于 As-Easy-As 的初始版本是一个共享软件,TRIUS 仍然为 As-Easy-As 5.7 免费提供[激活码](http://www.triusinc.com/forums/viewtopic.php?t=10)。
我也非常喜欢 GNU Emacs 编辑器,FreeDOS 也自带了一个叫 Freemacs 的类 Emacs 的文本编辑器。它比 FreeDOS 默认的 FreeDOS Edit 编辑器更强大,也能带来 GNU Emacs 的体验。如果你也需要,可以在 FreeDOS 1.2 中通过`FDIMPLES`包管理程序来安装。
### 是的,你或许真的可以在树莓派上运行 DOS
即使树莓派在硬件上不支持 DOS,但是在模拟器的帮助下,DOS 还是能够在树莓派上运行。得益于 QEMU PC 模拟器,一些经典的 DOS 游戏和 DOS 应用程序能够运行在树莓派上。在执行磁盘 I/O ,尤其是大量密集操作(例如写入大量数据)的时候,性能可能会受到轻微的影响。当你使用 QEMU 并且在虚拟机里安装好 FreeDOS 之后,你就可以尽情享受经典的 DOS 程序了。
---
via: <https://opensource.com/article/18/3/can-you-run-dos-raspberry-pi>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You may be familiar with [The FreeDOS Project](http://www.freedos.org/). FreeDOS is a complete, free, DOS-compatible operating system that you can use to play classic DOS games, run legacy business software, or develop embedded PC applications. Any program that works on MS-DOS should also run on FreeDOS.
As the founder and project coordinator of the FreeDOS Project, I'm often the go-to person when users ask questions. And one question I seem to get a lot lately is: "Can you run FreeDOS on the Raspberry Pi?"
This question isn't surprising. After all, Linux runs great on the Raspberry Pi, and FreeDOS is an older operating system that requires fewer resources than Linux, so why shouldn't FreeDOS run on the Raspberry Pi.
**[Enter our Raspberry Pi week giveaway for a chance at this arcade gaming kit.]**
The simple answer is that FreeDOS cannot run on a Raspberry Pi by itself because of the CPU architecture. Like any DOS, FreeDOS requires an Intel x86 CPU and a BIOS to provide basic runtime services. But the Raspberry Pi is a completely different architecture. The Raspberry Pi runs an ARM CPU, which is not binary compatible with the Intel CPU and does not include a BIOS. So FreeDOS cannot run on the Raspberry Pi at the "bare hardware" level.
Fortunately, it's possible to run FreeDOS on the Raspberry Pi through PC emulation. Maybe that's not as cool as running FreeDOS natively, but it's a great way to run DOS applications on the Raspberry Pi.
## What about DOSBox?
Some might ask, "Why not use DOSBox instead?" DOSBox is an open source x86 emulator that runs on a variety of systems, including Linux. It is a great system that provides a DOS-like environment, mostly aimed at running games. So if you just want to run a classic DOS game, DOSBox can do that for you. But if you run want to run DOS applications, DOSBox isn't the best platform. And if you ask the DOSBox forums, they'll tell you DOSBox is really meant for games.
For most users, it's a matter of preference. It shouldn't be a surprise that I prefer to install FreeDOS to run classic DOS games and other programs. I find the full DOS experience gives me greater flexibility and control than running DOSBox. I use DOSBox for a few games, but for most things I prefer to run a full FreeDOS instead.
## Installing FreeDOS on Raspberry Pi
[QEMU](https://www.qemu.org/) (short for Quick EMUlator) is an open source virtual machine software system that can run DOS as a "guest" operating system on Linux. Most popular Linux systems include QEMU by default. QEMU is available for Raspbian, the Linux distribution I'm using on my Raspberry Pi. I took the QEMU screenshots in this article with my Raspberry Pi running [Raspbian GNU/Linux 9 (Stretch)](https://www.raspberrypi.org/downloads/).
Last year, I wrote an article about [how to run DOS programs in Linux](https://opensource.com/article/17/10/run-dos-applications-linux) using QEMU. The steps to install and run FreeDOS using QEMU are basically the same on the Raspberry Pi as they were for my GNOME-based system.
In QEMU, you need to "build" your virtual system by instructing QEMU to add each component of the virtual machine. Let's start by defining a virtual disk image that we'll use to install and run DOS. The `qemu-img`
command lets you create virtual disk images. For FreeDOS, we won't need much room, so I created my virtual disk with 200 megabytes:
`qemu-img create freedos.img 200M`
Unlike PC emulator systems like VMware or VirtualBox, you need to "build" your virtual system by instructing QEMU to add each component of the virtual machine. Although this may seem laborious, it's not that hard. I used these parameters to run QEMU to install FreeDOS on my Raspberry Pi:
```
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -hda freedos.img -cdrom FD12CD.iso -boot order=d
```
You can find the full description of that command line in my other [article](https://opensource.com/article/17/10/run-dos-applications-linux). In brief, the command line defines an Intel i386-compatible virtual machine with 16 megabytes of memory, a US/English keyboard, and a real-time clock based on my local system time. The command line also defines a classic Sound Blaster 16 sound card, Adlib digital music card, and standard Cirrus Logic VGA card. The file `freedos.img`
is defined as the first hard drive (`C:`
) and the `FD12CD.iso`
image as the CD-ROM (`D:`
) drive. QEMU is set to boot from that `D:`
CD-ROM drive.
The FreeDOS 1.2 distribution is easy to install. Just follow the prompts.
opensource.com
opensource.com
opensource.com
opensource.com
opensource.com
However, it takes forever to install because of the heavy disk I/O when you install the operating system, and the microSD card isn't exactly fast.
Your results may vary depending on the microSD card you use. I used a SanDisk Ultra 64GB microSDXC UHS-I U1A1 card. The U1 is designed to support 1080p video recording (such as you might use in a GoPro camera) at minimum serial write speeds of 10MB/s. By comparison, a V60 is aimed at cameras that do 4K video and has a minimum sequential write speed of 60MB/s. If your Pi has a V60 microSD card or even a V30 (30MB/s), you'll see noticeably better disk I/O performance than I did.
## Running FreeDOS on Raspberry Pi
After installing FreeDOS, you may prefer to boot directly from the virtual `C:`
drive. Modify your QEMU command line to change the boot order, using `-boot order=c`
, like this:
```
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -hda freedos.img -cdrom FD12CD.iso -boot order=c
```
Once you have installed FreeDOS in QEMU on the Raspberry Pi, you shouldn't notice any performance issues. For example, games usually load maps, sprites, sounds, and other data when you start each level. While starting a new level in a game might take a while, I didn't notice any performance lag while playing DOS games in FreeDOS on the Raspberry Pi.
The FreeDOS 1.2 distribution includes many games and other applications that might interest you. You may need to run the `FDIMPLES`
package manager program to install these extra packages. My favorite game in FreeDOS 1.2 is WING, a space-shooter game that's very reminiscent of the classic arcade game Galaga. (The name WING is a recursive acronym for Wing Is Not Galaga.)
opensource.com
opensource.com

opensource.com
One of my favorite DOS programs is the shareware As-Easy-As spreadsheet program. It was a popular spreadsheet application from the 1980s and 1990s, which does the same job Microsoft Excel and LibreOffice Calc fulfill today or that the DOS-based Lotus 1-2-3 spreadsheet did back in the day. As-Easy-As and Lotus 1-2-3 both saved data as WKS files, which newer versions of Microsoft Excel can't read, but LibreOffice Calc may still support, depending on compatibility. While the original version of As-Easy-As was shareware, TRIUS Software made the [activation code for As-Easy-As 5.7](http://www.triusinc.com/forums/viewtopic.php?t=10) available for free.
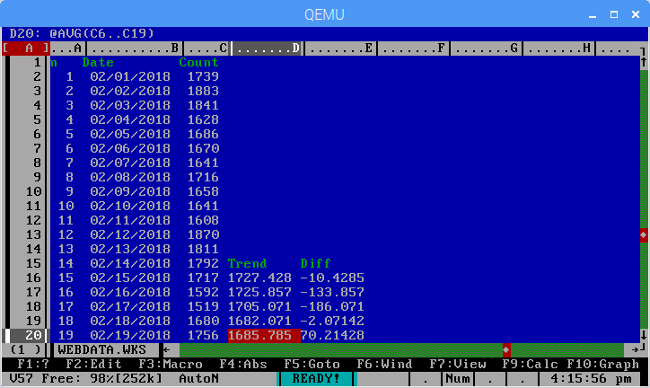
opensource.com
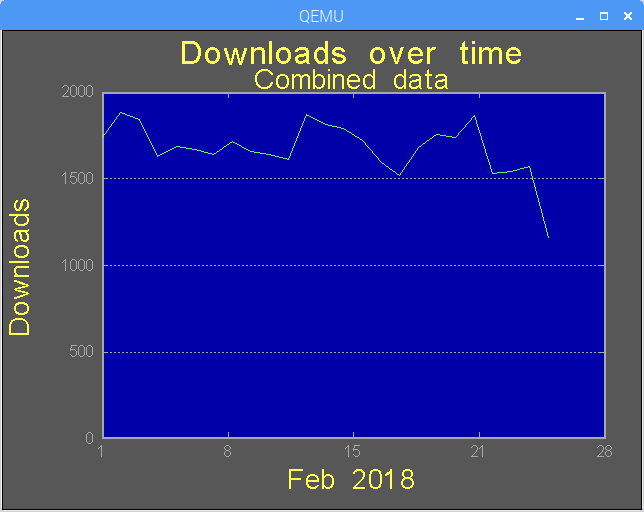
opensource.com
I'm also quite fond of the GNU Emacs editor, and FreeDOS includes a similar Emacs-like text editor called Freemacs. If you want a more powerful editor than the default FreeDOS Edit and desire an experience like GNU Emacs, then Freemacs is for you. You can install Freemacs using the `FDIMPLES`
package manager in the FreeDOS 1.2 distribution.
opensource.com
opensource.com
## Yes, you can run DOS on the Raspberry Pi (sort of)
While you can't run DOS on "bare hardware" on the Raspberry Pi, it's nice to know that you can still run DOS on the Raspberry Pi via an emulator. Thanks to the QEMU PC emulator and FreeDOS, it's possible to play classic DOS games and run other DOS programs on the Raspberry Pi. Expect a slight performance hit when doing any disk I/O, especially if you're doing something intensive on the disk, like writing large amounts of data, but things will run fine after that. Once you've set up QEMU as the virtual machine emulator and installed FreeDOS, you are all set to enjoy your favorite classic DOS programs on the Raspberry Pi.
## 3 Comments |
9,545 | 如何在 Windows 10 上开启 WSL 之旅 | https://www.linux.com/blog/learn/2018/2/how-get-started-using-wsl-windows-10 | 2018-04-15T08:48:00 | [
"WSL"
] | https://linux.cn/article-9545-1.html |
>
> WSL 可以让你访问 Windows 上的 Linux Bash shell。
>
>
>

在 [上一篇文章](https://www.linux.com/blog/learn/2018/2/windows-subsystem-linux-bridge-between-two-platforms) 中,我们讨论过关于 <ruby> Windows 的子系统 Linux <rt> Windows Subsystem for Linux </rt></ruby>(WSL)的目标用户。本文,我们将在 Windows 10 的设备上,开启 WSL 的旅程。
### 为 WSL 做准备
您必须使用最新版本的 Windows 10 Fall Creator Update。之后,通过在开始菜单栏搜索 “About”,检查 Windows 10 的版本。为了使用 WSL,您的版本应当为 1709 或者最新版。
这里有一张关于我的操作系统的截图。

如果您安装了之前的版本,您需要在 [这里](https://www.microsoft.com/en-us/software-download/windows10) 下载并且安装 Windows 10 Fall Creator Update (FCU)。安装完毕后,安装可用的更新(在开始菜单的搜索框中搜索 “updates”)。
前往 “启用或关闭 Windows 功能” ,然后滚动至底部,如截图所示,勾选 “适用于 Linux 的 Windows 子系统”,点击确定。它将会下载安装需要的包。

安装完成之后,系统将会询问是否重启。是的,重启设备吧。WSL 在系统重启之前不会启动,如下所示:

一旦您的系统重启,返回 “启用或关闭 Windows 功能” 页面,确认 “适用于 Linux 的 Windows 子系统” 已经被勾选。
### 在 Windows 中安装 Linux
在 Windows 中安装 Linux,有很多方式,这里我们选择一种最简单的方式。打开 Microsoft Store,搜索 Linux。您将看到下面的选项:

点击 “获取”,之后 Windows 商店将会提供三个选项:Ubuntu、openSUSE Leap 42 和 SUSE Linux Enterprise Server。您可以一并安装上述三个发行版,并且它们可以同时运行。为了能使用 SLE,您需要一份订阅。
在此,我将安装 openSUSE Leap 42 和 Ubuntu。选中您想要的发行版,点击“获得”按钮并安装。一旦安装完毕,您就可以在 Windows 中启动 openSUSE。为了方便访问,可以将其固定到开始菜单中。

### 在 Windwods 中使用 Linux
当您启动该发行版,它将会打开一个 Bash Shell 并且安装此发行版。安装完毕之后,您就可以开始使用了。您需要留意,openSUSE 中并没有(普通)用户,它直接运行在 `root` 用户下,但是 Ubuntu 会询问您是否创建用户。在 Ubuntu,您可以以 `sudo` 用户执行管理任务。
在 openSUSE 上,您可以很轻松的创建一个用户:
```
# useradd [username]
# passwd [username]
```
为此用户创建一个新的密码。例如:
```
# useradd swapnil
# passwd swapnil
```
您可以通过 `su` 命令从 root 用户切换过来。
```
su swapnil
```
您需要非根用户来执行许多任务,比如使用 `rsync` 移动文件到本地设备。
而首要任务是更新发行版。对于 openSUSE 来说,您应该:
```
zypper up
```
而对于 Ubuntu:
```
sudo apt-get update
sudo apt-get dist-upgrade
```

现在,您就在 Windows 上拥有了原生的 Linux Bash shell。想在 Windows 10 上通过 `ssh` 连接您的服务器?不需要安装 puTTY 或是 Cygwin。打开 Bash 之后,就可以通过 `ssh` 进入您的服务器。简单之至。
想通过 `rsync` 同步文件到您的服务器?直接使用 `rsync`。它切实的将我们的 Windows 设备转变得更为实用,帮助那些需要使用原生 Linux 命令和 Linux 工具的用户避开虚拟机,大开方便之门。
### Fedora 在哪里?
您可能奇怪为什么没有 Fedora。可惜,商城里并没有 Fedora。Fedora 项目发布负责人在 Twitter 上表示,“我们正在解决一些非技术性问题。现在可能提供不了更多了。”
我们并不确定这些非技术性问题是什么。当一些用户询问 WSL 团队为何不发布 Fedora,毕竟它也是一个开源项目。项目负责人 Rich Turner 在 Microsoft [回应](https://github.com/Microsoft/WSL/issues/2584),“我们有一个不发布其他知识产权到应用商店的政策。我们相信,相较于被微软或是其他非权威人士,社区更希望看到发行版由发行版所有者发布。”
因此,微软不方便在 Windows 商店中直接发布 Debian 或是 Arch 系统。这些任务应该落在他们的官方团队中,应该由他们将发行版带给 Windows 10 的用户。
### 欲知后事,下回分解
下一篇文章,我们会讨论关于将 Windows 10 作为 Linux 设备,并且向您展示,您可能会在 Linux 系统上使用的命令行工具。
---
via: <https://www.linux.com/blog/learn/2018/2/how-get-started-using-wsl-windows-10>
作者:[SWAPNIL BHARTIYA](https://www.linux.com/users/arnieswap) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,546 | 使用 ncurses 进行颜色编程 | http://www.linuxjournal.com/content/programming-color-ncurses | 2018-04-15T09:31:00 | [
"ncurses"
] | https://linux.cn/article-9546-1.html | 
>
> Jim 给他的终端冒险游戏添加了颜色,演示了如何用 curses 操纵颜色。
>
>
>
在我的使用 ncurses 库进行编程的系列文章的[第一篇](/article-9348-1.html)和[第二篇](/article-9383-1.html)中,我已经介绍了一些 curses 函数来在屏幕上作画、从屏幕上查询和从键盘读取字符。为了搞清楚这些函数,我使用 curses 来利用简单字符绘制游戏地图和玩家角色,创建了一个简单的冒险游戏。在这篇紧接着的文章里,我展示了如何为你的 curses 程序添加颜色。
在屏幕上绘图一切都挺好的,但是如果只有黑底白字的文本,你的程序可能看起来很无趣。颜色可以帮助传递更多的信息。举个例子,如果你的程序需要报告执行成功或者执行失败时。在这样的情况下你可以使用绿色或者红色来帮助强调输出。或者,你只是简单地想要“潮艺”一下给你的程序来让它看起来更美观。
在这篇文章中,我用一个简单的例子来展示通过 curses 函数进行颜色操作。在我先前的文章中,我写了一个可以让你在一个粗糙绘制的地图上移动玩家角色的初级冒险类游戏。但是那里面的地图完全是白色和黑色的文本,通过形状来表明是水(`~`)或者山(`^`)。所以,让我们将游戏更新到使用颜色的版本吧。
### 颜色要素
在你可以使用颜色之前,你的程序需要知道它是否可以依靠终端正确地显示颜色。在现代操作系统上,此处应该永远为true。但是在经典的计算机上,一些终端是单色的,例如古老的 VT52 和 VT100 终端,一般它们提供黑底白色或者黑底绿色的文本。
可以使用 `has_colors()` 函数查询终端的颜色功能。这个函数将会在终端可以显示颜色的时候返回 `true`,否则将会返回 `false`。这个函数一般用于 `if` 块的开头,就像这样:
```
if (has_colors() == FALSE) {
endwin();
printf("Your terminal does not support color\n");
exit(1);
}
```
在知道终端可以显示颜色之后,你可以使用 `start_color()` 函数来设置 curses 使用颜色。现在是时候定义程序将要使用的颜色了。
在 curses 中,你应该按对定义颜色:一个前景色放在一个背景色上。这样允许 curses 一次性设置两个颜色属性,这也是一般你想要使用的方式。通过 `init_pair()` 函数可以定义一个前景色和背景色并关联到索引数字来设置颜色对。大致语法如下:
```
init_pair(index, foreground, background);
```
控制台支持八种基础的颜色:黑色、红色、绿色、黄色、蓝色、品红色、青色和白色。这些颜色通过下面的名称为你定义好了:
* `COLOR_BLACK`
* `COLOR_RED`
* `COLOR_GREEN`
* `COLOR_YELLOW`
* `COLOR_BLUE`
* `COLOR_MAGENTA`
* `COLOR_CYAN`
* `COLOR_WHITE`
### 应用颜色
在我的冒险游戏中,我想要让草地呈现绿色而玩家的足迹变成不易察觉的绿底黄色点迹。水应该是蓝色,那些表示波浪的 `~` 符号应该是近似青色的。我想让山(`^`)是灰色的,但是我可以用白底黑色文本做一个可用的折中方案。(LCTT 译注:意为终端预设的颜色没有灰色,使用白底黑色文本做一个折中方案)为了让玩家的角色更易见,我想要使用一个刺目的品红底红色设计。我可以像这样定义这些颜色对:
```
start_color();
init_pair(1, COLOR_YELLOW, COLOR_GREEN);
init_pair(2, COLOR_CYAN, COLOR_BLUE);
init_pair(3, COLOR_BLACK, COLOR_WHITE);
init_pair(4, COLOR_RED, COLOR_MAGENTA);
```
为了让颜色对更容易记忆,我的程序中定义了一些符号常量:
```
#define GRASS_PAIR 1
#define EMPTY_PAIR 1
#define WATER_PAIR 2
#define MOUNTAIN_PAIR 3
#define PLAYER_PAIR 4
```
有了这些常量,我的颜色定义就变成了:
```
start_color();
init_pair(GRASS_PAIR, COLOR_YELLOW, COLOR_GREEN);
init_pair(WATER_PAIR, COLOR_CYAN, COLOR_BLUE);
init_pair(MOUNTAIN_PAIR, COLOR_BLACK, COLOR_WHITE);
init_pair(PLAYER_PAIR, COLOR_RED, COLOR_MAGENTA);
```
在任何时候你想要使用颜色显示文本,你只需要告诉 curses 设置哪种颜色属性。为了更好的编程实践,你同样应该在你完成了颜色使用的时候告诉 curses 取消颜色组合。为了设置颜色,应该在调用像 `mvaddch()` 这样的函数之前使用`attron()`,然后通过 `attroff()` 关闭颜色属性。例如,在我绘制玩家角色的时候,我应该这样做:
```
attron(COLOR_PAIR(PLAYER_PAIR));
mvaddch(y, x, PLAYER);
attroff(COLOR_PAIR(PLAYER_PAIR));
```
记住将颜色应用到你的程序对你如何查询屏幕有一些微妙的影响。一般来讲,由 `mvinch()` 函数返回的值是**没有**带颜色属性的类型 `chtype`,这个值基本上是一个整型值,也可以当作整型值来用。但是,由于使用颜色添加了额外的属性到屏幕上的字符上,所以 `chtype` 按照扩展的位模式携带了额外的颜色信息。一旦你使用 `mvinch()`,返回值将会包含这些额外的颜色值。为了只提取**文本**值,例如在 `is_move_okay()` 函数中,你需要和 `A_CHARTEXT` 做 `&` 位运算:
```
int is_move_okay(int y, int x)
{
int testch;
/* return true if the space is okay to move into */
testch = mvinch(y, x);
return (((testch & A_CHARTEXT) == GRASS)
|| ((testch & A_CHARTEXT) == EMPTY));
}
```
通过这些修改,我可以用颜色更新这个冒险游戏:
```
/* quest.c */
#include <curses.h>
#include <stdlib.h>
#define GRASS ' '
#define EMPTY '.'
#define WATER '~'
#define MOUNTAIN '^'
#define PLAYER '*'
#define GRASS_PAIR 1
#define EMPTY_PAIR 1
#define WATER_PAIR 2
#define MOUNTAIN_PAIR 3
#define PLAYER_PAIR 4
int is_move_okay(int y, int x);
void draw_map(void);
int main(void)
{
int y, x;
int ch;
/* 初始化curses */
initscr();
keypad(stdscr, TRUE);
cbreak();
noecho();
/* 初始化颜色 */
if (has_colors() == FALSE) {
endwin();
printf("Your terminal does not support color\n");
exit(1);
}
start_color();
init_pair(GRASS_PAIR, COLOR_YELLOW, COLOR_GREEN);
init_pair(WATER_PAIR, COLOR_CYAN, COLOR_BLUE);
init_pair(MOUNTAIN_PAIR, COLOR_BLACK, COLOR_WHITE);
init_pair(PLAYER_PAIR, COLOR_RED, COLOR_MAGENTA);
clear();
/* 初始化探索地图 */
draw_map();
/* 在左下角创建新角色 */
y = LINES - 1;
x = 0;
do {
/* 默认情况下,你获得了一个闪烁的光标--用来指明玩家 * */
attron(COLOR_PAIR(PLAYER_PAIR));
mvaddch(y, x, PLAYER);
attroff(COLOR_PAIR(PLAYER_PAIR));
move(y, x);
refresh();
ch = getch();
/* 测试输入键值并获取方向 */
switch (ch) {
case KEY_UP:
case 'w':
case 'W':
if ((y > 0) && is_move_okay(y - 1, x)) {
attron(COLOR_PAIR(EMPTY_PAIR));
mvaddch(y, x, EMPTY);
attroff(COLOR_PAIR(EMPTY_PAIR));
y = y - 1;
}
break;
case KEY_DOWN:
case 's':
case 'S':
if ((y < LINES - 1) && is_move_okay(y + 1, x)) {
attron(COLOR_PAIR(EMPTY_PAIR));
mvaddch(y, x, EMPTY);
attroff(COLOR_PAIR(EMPTY_PAIR));
y = y + 1;
}
break;
case KEY_LEFT:
case 'a':
case 'A':
if ((x > 0) && is_move_okay(y, x - 1)) {
attron(COLOR_PAIR(EMPTY_PAIR));
mvaddch(y, x, EMPTY);
attroff(COLOR_PAIR(EMPTY_PAIR));
x = x - 1;
}
break;
case KEY_RIGHT:
case 'd':
case 'D':
if ((x < COLS - 1) && is_move_okay(y, x + 1)) {
attron(COLOR_PAIR(EMPTY_PAIR));
mvaddch(y, x, EMPTY);
attroff(COLOR_PAIR(EMPTY_PAIR));
x = x + 1;
}
break;
}
}
while ((ch != 'q') && (ch != 'Q'));
endwin();
exit(0);
}
int is_move_okay(int y, int x)
{
int testch;
/* 当空白处可以进入的时候返回true */
testch = mvinch(y, x);
return (((testch & A_CHARTEXT) == GRASS)
|| ((testch & A_CHARTEXT) == EMPTY));
}
void draw_map(void)
{
int y, x;
/* 绘制探索地图 */
/* 背景 */
attron(COLOR_PAIR(GRASS_PAIR));
for (y = 0; y < LINES; y++) {
mvhline(y, 0, GRASS, COLS);
}
attroff(COLOR_PAIR(GRASS_PAIR));
/* 山峰和山路 */
attron(COLOR_PAIR(MOUNTAIN_PAIR));
for (x = COLS / 2; x < COLS * 3 / 4; x++) {
mvvline(0, x, MOUNTAIN, LINES);
}
attroff(COLOR_PAIR(MOUNTAIN_PAIR));
attron(COLOR_PAIR(GRASS_PAIR));
mvhline(LINES / 4, 0, GRASS, COLS);
attroff(COLOR_PAIR(GRASS_PAIR));
/* 湖 */
attron(COLOR_PAIR(WATER_PAIR));
for (y = 1; y < LINES / 2; y++) {
mvhline(y, 1, WATER, COLS / 3);
}
attroff(COLOR_PAIR(WATER_PAIR));
}
```
你可能不能认出所有为了在冒险游戏里面支持颜色需要的修改,除非你目光敏锐。`diff` 工具展示了所有为了支持颜色而添加的函数或者修改的代码:
```
$ diff quest-color/quest.c quest/quest.c
12,17d11
< #define GRASS_PAIR 1
< #define EMPTY_PAIR 1
< #define WATER_PAIR 2
< #define MOUNTAIN_PAIR 3
< #define PLAYER_PAIR 4
<
33,46d26
< /* initialize colors */
<
< if (has_colors() == FALSE) {
< endwin();
< printf("Your terminal does not support color\n");
< exit(1);
< }
<
< start_color();
< init_pair(GRASS_PAIR, COLOR_YELLOW, COLOR_GREEN);
< init_pair(WATER_PAIR, COLOR_CYAN, COLOR_BLUE);
< init_pair(MOUNTAIN_PAIR, COLOR_BLACK, COLOR_WHITE);
< init_pair(PLAYER_PAIR, COLOR_RED, COLOR_MAGENTA);
<
61d40
< attron(COLOR_PAIR(PLAYER_PAIR));
63d41
< attroff(COLOR_PAIR(PLAYER_PAIR));
76d53
< attron(COLOR_PAIR(EMPTY_PAIR));
78d54
< attroff(COLOR_PAIR(EMPTY_PAIR));
86d61
< attron(COLOR_PAIR(EMPTY_PAIR));
88d62
< attroff(COLOR_PAIR(EMPTY_PAIR));
96d69
< attron(COLOR_PAIR(EMPTY_PAIR));
98d70
< attroff(COLOR_PAIR(EMPTY_PAIR));
106d77
< attron(COLOR_PAIR(EMPTY_PAIR));
108d78
< attroff(COLOR_PAIR(EMPTY_PAIR));
128,129c98
< return (((testch & A_CHARTEXT) == GRASS)
< || ((testch & A_CHARTEXT) == EMPTY));
---
> return ((testch == GRASS) || (testch == EMPTY));
140d108
< attron(COLOR_PAIR(GRASS_PAIR));
144d111
< attroff(COLOR_PAIR(GRASS_PAIR));
148d114
< attron(COLOR_PAIR(MOUNTAIN_PAIR));
152d117
< attroff(COLOR_PAIR(MOUNTAIN_PAIR));
154d118
< attron(COLOR_PAIR(GRASS_PAIR));
156d119
< attroff(COLOR_PAIR(GRASS_PAIR));
160d122
< attron(COLOR_PAIR(WATER_PAIR));
164d125
< attroff(COLOR_PAIR(WATER_PAIR));
```
### 开始玩吧--现在有颜色了
程序现在有了更舒服的颜色设计了,更匹配原来的桌游地图,有绿色的地、蓝色的湖和壮观的灰色山峰。英雄穿着红色的制服十分夺目。

*图 1. 一个简单的带湖和山的桌游地图*

*图 2. 玩家站在左下角*

*图 3. 玩家可以在游戏区域移动,比如围绕湖,通过山的通道到达未知的区域。*
通过颜色,你可以更清楚地展示信息。这个例子使用颜色指出可游戏的区域(绿色)相对着不可通过的区域(蓝色或者灰色)。我希望你可以使用这个示例游戏作为你自己的程序的一个起点或者参照。这取决于你需要你的程序做什么,你可以通过 curses 做得更多。
在下一篇文章,我计划展示 ncurses 库的其它特性,比如怎样创建窗口和边框。同时,如果你对于学习 curses 有兴趣,我建议你去读位于 [Linux 文档计划](http://www.tldp.org) 的 Pradeep Padala 写的 [NCURSES Programming HOWTO](http://tldp.org/HOWTO/NCURSES-Programming-HOWTO)。
---
via: <http://www.linuxjournal.com/content/programming-color-ncurses>
作者:[Jim Hall](http://www.linuxjournal.com/users/jim-hall) 译者:[leemeans](https://github.com/leemeans) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,547 | Google Kubernetes Engine(GKE)使用初探 | https://blog.csdn.net/qianghaohao/article/details/79945821 | 2018-04-15T09:52:00 | [
"容器",
"GKE",
"k8s"
] | https://linux.cn/article-9547-1.html | 
### 概述
Google 的 k8s 在 2017 年已经从容器编排领域的竞争中取得主导地位,从 [Docker](https://www.docker.com/) 之前的一度排挤到最终完全拥抱 k8s,显然 k8s 已经成了目前业界的标准。
但是到目前为止能提供 k8s 完全托管服务的云服务商少之又少,即便是目前在云提供商有统治力的 AWS 也没有完全提供 k8s 托管服务,仅仅提供有限的定制服务,在这一方面并不成熟。
然而 Google 的 k8s 托管服务,即 GKE,却将 k8s 托管服务做到了极致(至少目前看来),不仅提供了全套的 k8s 托管服务,更引人注目的是 Google 已然将 Autoscaler 和 k8s 集成,实现了 k8s 节点的自动伸缩机制,能根据 pod 的需求自动化添加或删除节点,当现有节点无法承载新的服务时会自动添加节点来满足需求,当现有节点足够空闲时会启用调节机制自动化收缩节点,从某种意义上来说这几乎做到了无服务器的理念。
然而这也许只是冰山一角,更多强大的功能还需要进一步探索,本文只是一个入门指南,主要指导能快速开始上手基于 Google Cloud Platform 的 [GKE](https://cloud.google.com/kubernetes-engine/?hl=zh-cn) 服务(k8s 托管服务)。
### GKE 入门指南
接下来我们一步步指引如何使用 GKE 来部署服务,前提是对 k8s 有所了解,能简单使用 kubectl 命令。
#### 1. 安装并配置 Google Cloud SDK
Google Cloud SDK 是 访问 GCP(Google Cloud Platform)平台各种资源的命令行工具集,类似 aws 的 aws 命令行工具。
安装和配置就不多说了,点击下面链接选择相应操作系统版本的 tar 包下载,然后解压,在 PATH 环境变量中添加 `google-cloud-sdk/bin` 即可:
<https://cloud.google.com/sdk/?hl=zh-cn>
#### 2. 初始化 Google Cloud SDK
初始化 Google Cloud SDK 是将 `gcloud` 命令和 Google 账号绑定起来并设置一些其他的默认值,比如区域,代理,账号,项目(Google 账号中新建的项目)之类的。
在执行 `gcloud init` 初始化之前得先给 `gcloud` 配置 HTTP 代理(GFW 你懂得),具体配置见我之前[这篇文章](https://blog.csdn.net/qianghaohao/article/details/79942485)。然后执行 `gcloud init` 完成初始化,直接根据向导来即可。
#### 3. 到 Google Cloud Platform 控制台建一个 k8s 集群,记住名称

#### 4. 安装 gcloud kubectl 组件
```
gcloud components install kubectl
```
#### 5. 获取群集的身份验证凭据
创建群集后,您需要获取身份验证凭据以与群集进行交互。要为集群进行身份验证,请运行以下命令:
```
gcloud container clusters get-credentials <上一步创建的集群名称>
```
#### 6. 接下来部署一个简单的 hello-server 服务到 GKE
```
kubectl run hello-server --image gcr.io/google-samples/hello-app:1.0 --port 8080
```
### 相关链接
* <https://cloud.google.com/kubernetes-engine/docs/quickstart>
* <https://cloud.google.com/sdk/docs/quickstart-macos?hl=zh-cn>
### 附录
#### gloud 常用命令
```
gcloud auth login --no-launch-browser # gcloud 登录认证
gcloud config set compute/zone [COMPUTE_ZONE] # 设置默认区域
gcloud components list # 列出可安装组件
gcloud components install [组件名称] # 安装组件
gcloud components update # 更新所有已安装组件
gcloud components remove [组件名称] # 卸载已安装组件
```
#### 设置 gcloud http 代理
```
gcloud config set proxy/type http
gcloud config set proxy/address 127.0.0.1
gcloud config set proxy/port 1087
```
#### 设置集群 docker 私服认证
```
kubectl create secret docker-registry regcred --docker-server=<your-registry-server> --docker-username=<your-name> --docker-password=<your-pword> --docker-email=<your-email>
```
**注意**:设置 docker 私服后,要在 GKE 部署 k8s 服务,必须得在 k8s 资源文件(yaml 格式)中的 container
同一级指定 imagePullSecrets 键,要不然仍然无法拉取配置的私服的镜像,示例资源文件如下:
```
apiVersion: v1
kind: Pod
metadata:
name: private-reg
spec:
containers:
- name: private-reg-container
image: <your-private-image>
imagePullSecrets:
- name: regcred
```
#### 查看集群 docker 私服配置
```
kubectl get secret regcred --output=yaml #base64 格式 显示
kubectl get secret regcred --output="jsonpath={.data.\.dockerconfigjson}" | base64 -d # base64
```
| 200 | OK | ### Google Kubernetes Engine(GKE) 使用初探
#### 概述
Google 的 k8s 在 2017 年已经从容器编排领域的竞争中取得主导地位,从 [Docker](https://www.docker.com/) 之前的一度排挤到最终完全拥抱 k8s,显然 k8s 已经成了目前业界的标准。但是到目前为止能提供 k8s 完全托管服务的云服务商少之又少,即便是目前在云提供商有统治力的 AWS 也没有完全提供 k8s 托管服务,仅仅提供有限的定制服务,在这一方面并不成熟。然而 Google 的 k8s 托管服务,即 [GKE](https://cloud.google.com/kubernetes-engine/?hl=zh-cn),却将 k8s 托管服务做到了极致(至少目前看来),不仅提供了全套的 k8s 托管服务,更引人注目的是 Google 已然将 Autoscaler 和 k8s 集成,实现了 k8s 节点的自动伸缩机制,能根据 pod 的需求自动化添加或删除节点,当现有节点无法承载新的服务时会自动添加节点来满足需求,当现有节点足够空闲时会启用调节机制自动化收缩节点,从某种意义上来说这几乎做到了无服务器的理念。然而这也许只是冰山一角,更多强大的功能还需要进一步探索,本文只是一个入门指南,主要指导能快速开始上手基于 Google Cloud Platform 的 GKE 服务(k8s 托管服务)。
#### GKE 入门指南
接下来我们一步步指引如何使用 GKE 来部署服务,前提是对 k8s 有所了解,能简单使用 kubectl 命令。 |
9,548 | CIO 真正需要 DevOps 团队做什么? | https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio | 2018-04-16T10:17:00 | [
"DevOps"
] | https://linux.cn/article-9548-1.html |
>
> DevOps 团队需要 IT 领导者关注三件事:沟通、技术债务和信任。
>
>
>

IT 领导者可以从大量的 [DevOps](https://enterprisersproject.com/tags/devops) 材料和 [向 DevOps 转变](https://www.redhat.com/en/insights/devops?intcmp=701f2000000tjyaAAA) 所要求的文化挑战中学习。但是,你在一个 DevOps 团队面对长期或短期的团结挑战的调整中 —— 一个 CIO 真正需要他们做的是什么呢?
在我与 DevOps 团队成员的谈话中,我听到的其中一些内容让你感到非常的意外。DevOps 专家(无论是内部团队的还是外部团队的)都希望将下列的事情放在你的 CIO 优先关注的级别。
### 1. 沟通
第一个也是最重要的一个,DevOps 专家需要面对面的沟通。一个经验丰富的 DevOps 团队是非常了解当前 DevOps 的趋势,以及成功和失败的经验,并且他们非常乐意去分享这些信息。表达 DevOps 的概念是很困难的,因此,要在这种新的工作关系中保持开放,定期(不用担心,不用每周)讨论有关你的 IT 的当前状态,如何评价你的沟通环境,以及你的整体的 IT 产业。
相反,你应该准备好与 DevOps 团队去共享当前的业务需求和目标。业务不再是独立于 IT 的东西:它们现在是驱动 IT 发展的重要因素,并且 IT 决定了你的业务需求和目标运行的效果如何。
注重参与而不是领导。在需要做决策的时候,你仍然是最终的决策者,但是,理解这些决策的最好方式是协作,这样,你的 DevOps 团队将有更多的自主权,并因此受到更多激励。
### 2. 降低技术债务
第二,力争更好地理解技术债务,并在 DevOps 中努力降低它。你的 DevOps 团队都工作于一线。这里,“技术债务”是指在一个庞大的、不可持续发展的环境之中,通过维护和增加新功能而占用的人力资源和基础设备资源(查看 Rube Goldberg)。
CIO 常见的问题包括:
* 为什么我们要用一种新方法去做这件事情?
* 为什么我们要在它上面花费时间和金钱?
* 如果这里没有新功能,只是现有组件实现了自动化,那么我们的收益是什么?
“如果没有坏,就不要去修理它”,这样的事情是可以理解的。但是,如果你正在路上好好的开车,而每个人都加速超过你,这时候,你的环境就被破坏了。持续投入宝贵的资源去支撑或扩张拼凑起来的环境。
选择妥协,并且一个接一个的打补丁,以这种方式去处理每个独立的问题,结果将从一开始就变得很糟糕 —— 在一个不能支撑建筑物的地基上,一层摞一层地往上堆。事实上,这种方法就像不断地在电脑中插入坏磁盘一样。迟早有一天,面对出现的问题你将会毫无办法。在外面持续增加的压力下,整个事情将变得一团糟,完全吞噬掉你的资源。
这种情况下,解决方案就是:自动化。使用自动化的结果是良好的可伸缩性 —— 每个维护人员在 IT 环境的维护和增长方面花费更少的努力。如果增加人力资源是实现业务增长的唯一办法,那么,可伸缩性就是白日做梦。
自动化降低了你的人力资源需求,并且对持续进行的 IT 提供了更灵活的需求。很简单,对吗?是的,但是你必须为迟到的满意做好心理准备。为了在提高生产力和效率的基础上获得后端经济效益,需要预先投入时间和精力对架构和结构进行变更。为了你的 DevOps 团队能够成功,接受这些挑战,对 IT 领导者来说是非常重要的。
### 3. 信任
最后,相信你的 DevOps 团队并且一定要理解他们。DevOps 专家也知道这个要求很难,但是他们必须得到你的强大支持和你积极参与的意愿。因为 DevOps 团队持续改进你的 IT 环境,他们自身也在不断地适应这些变化的技术,而这些变化通常正是 “你要去学习的经验”。
倾听,倾听,倾听他们,并且相信他们。DevOps 的改变是非常有价值的,而且也是值的去投入时间和金钱的。它可以提高效率、生产力、和业务响应能力。信任你的 DevOps 团队,并且给予他们更多的自由,实现更高效率的 IT 改进。
新 CIO 的底线是:将你的 DevOps 团队的潜力最大化,离开你的领导 “舒适区”,拥抱一个 “CIOps" 的转变。通过 DevOps 转变,持续地与你的 DevOps 团队共同成长,以帮助你的组织获得长期的 IT 成功。
---
via: <https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio>
作者:[John Allessio](https://enterprisersproject.com/user/john-allessio) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | IT leaders can learn from plenty of material exploring [DevOps](https://enterprisersproject.com/taxonomy/term/76) and the challenging cultural shift required for [making the DevOps transition](https://www.redhat.com/en/insights/devops?intcmp=701f2000000tjyaAAA). But are you in tune with the short and long term challenges that a DevOps team faces – and what they really need from a CIO?
In my conversations with DevOps team members, some of what I heard might surprise you. DevOps pros (whether part of an internal or external team) want to put the following things at the top of your CIO radar screen.
## 1. Communication
First and foremost, DevOps pros need peer-level communication. An experienced DevOps team is extremely knowledgeable on current DevOps trends, successes, and failures in the industry and is interested in sharing this information. DevOps concepts are difficult to convey, so be open to a new working relationship in which there are regular (don’t worry, not weekly) conversations about the current state of your IT, how the pieces in the environment communicate, and your overall IT estate.
**[ Want even more wisdom from CIOs on leading DevOps? See our comprehensive resource, DevOps: The IT Leader's Guide. ]**
Conversely, be prepared to share current business needs and goals with the DevOps team. Business objectives no longer exist in isolation from IT: They are now an integral component of what drives your IT advancements, and your IT determines how effectively you can execute on your business needs and goals.
Focus on participating rather than leading. You are still the ultimate arbiter when it comes to decisions, but understand that these decisions are best made collaboratively in order to empower and motivate your DevOps team.
## 2. Reduction of technical debt
Second, strive to better understand technical debt and how DevOps efforts are going to reduce it. Your DevOps team is working hard on this front. In this case, technical debt refers to the manpower and infrastructure resources that are usurped daily by maintaining and adding new features on top of a monolithic, non-sustainable environment (read Rube Goldberg).
Common CIO questions include:
- Why do we need to do things in a new way?
- Why are we spending time and money on this?
- If there’s no new functionality, just existing pieces being broken out with automation, then where is the gain?
The “if it ain't broke don't fix it” thinking is understandable. But if the car is driving fine while everyone on the road accelerates past you, your environment IS broken. Precious resources continue to be sucked into propping up or augmenting an environmental kluge.
Addressing every issue in isolation results in a compromised choice from the start that is worsened with each successive patch – layer upon layer added to a foundation that wasn’t built to support it. In actuality, this approach is similar to plugging a continuously failing dike. Sooner or later you run out of fingers and the whole thing buckles under the added pressures, drowning your resources.
The solution: automation. The result of automation is scalability – less effort per person to maintain and grow your IT environment. If adding manpower is the only way to grow your business, then scalability is a pipe dream.
Automation reduces your manpower requirements and provides the flexibility required for continued IT evolution. Simple, right? Yes, but you must be prepared for delayed gratification. An upfront investment of time and effort for architectural and structural changes is required in order to reap the back-end financial benefits of automation with improved productivity and efficiency. Embracing these challenges as an IT leader is crucial in order for your DevOps team to successfully execute.
## 3. Trust
Lastly, trust your DevOps team and make sure they know it. DevOps experts understand that this is a tough request, but they must have your unquestionable support and your willingness to actively participate. It will often be a "learn as you go" experience for you as the DevOps team successively refines your IT environment, while they themselves adapt to ever-changing technology.
Listen, listen, listen to them and trust them. DevOps changes are valuable and well worth the time and money through increased efficiency, productivity, and business responsiveness. Trusting your DevOps team gives them the freedom to make the most effective IT improvements.
The new CIO bottom line: To maximize your DevOps team's potential, leave your leadership comfort zone and embrace a “CIOps” transition. Continuously work on finding common ground with the DevOps team throughout the DevOps transition, to help your organization achieve long-term IT success.
**Want more wisdom like this, IT leaders? Sign up for our weekly email newsletter.** |
9,549 | 用示例讲解 Linux gunzip 命令 | https://www.howtoforge.com/linux-gunzip-command/ | 2018-04-15T21:26:00 | [
"gzip",
"gunzip"
] | https://linux.cn/article-9549-1.html | 
我们已经讨论过 [Linux 下 gzip 命令的用法](https://www.howtoforge.com/linux-gzip-command/)。对于初学者来说,`gzip` 工具主要用于压缩或者展开文件。解压时,在 `gzip` 命令后添加 `-d` 选项即可,使用示例如下:
```
gzip -d [compressed-file-name]
```
不过,在解压或扩展 gzip 创建的压缩文件时,有另一款完全不同的工具可供使用。谈及的这款工具就是 `gunzip`。在本文中,我们会使用一些简单、易于理解的例子来解释 `gunzip` 命令的用法。文中所有示例及指南都在 Ubuntu 16.04 环境下测试。
### Linux gunzip 命令
我们现在知道压缩文件可以用 `gzip -d` 或 `gunzip` 命令解压。基本的 `gunzip` 语法为:
```
gunzip [compressed-file-name]
```
以下的 Q&A 例子将更清晰地展示 `gunzip` 工具如何工作:
### Q1. 如何使用 gunzip 解压压缩文件?
解压命令非常简单,仅仅需要将压缩文件名称作为参数传递到 `gunzip` 命令后。
```
gunzip [archive-name]
```
比如:
```
gunzip file1.gz
```
[](https://www.howtoforge.com/images/linux_gunzip_command/big/gunzip-basic-usage.png)
### Q2. 如何让 gunzip 不删除原始压缩文件?
正如你已注意到的那样,`gunzip` 命令解压后会删除原始压缩文件。如果你想保留原始压缩文件,可以使用 `-c` 选项。
```
gunzip -c [archive-name] > [outputfile-name]
```
比如:
```
gunzip -c file1.gz > file1
```
[](https://www.howtoforge.com/images/linux_gunzip_command/big/gunzip-c.png)
使用这种方式,原压缩文件不会被删除。
### Q3. 如何用 gunzip 解压文件到其他路径?
在 Q&A 中我们已经讨论过 `-c` 选项的用法。 使用 gunzip 解压文件到工作目录外的其他路径,仅需要在重定向操作符后添加目标目录的绝对路径即可。
```
gunzip -c [compressed-file] > [/complete/path/to/dest/dir/filename]
```
示例如下:
```
gunzip -c file1.gz > /home/himanshu/file1
```
### 更多信息
以下从 gzip/gunzip 的 man 页中摘录的细节,对于想了解更多的人会有所助益。
>
> `gunzip` 在命令行接受一系列的文件,并且将每个文件内容以正确的魔法数开始,且后缀名为 `.gz`、`-gz`、`.z`、`-z` 或 `_z` (忽略大小写)的压缩文件,用未压缩的文件替换它,并删除其原扩展名。 `gunzip` 也可识别一些特殊扩展名的压缩文件,如 `.tgz` 和 `.taz` 分别是 `.tar.gz` 和 `.tar.Z` 的缩写。在压缩时,`gzip` 在必要情况下使用 `.tgz` 作为扩展名,而不是只截取掉 `.tar` 后缀。
>
>
> `gunzip` 目前可以解压 `gzip`、`zip`、`compress`、`compress -H`(`pack`)产生的文件。`gunzip` 自动检测输入文件格式。在使用前两种压缩格式时,`gunzip` 会检验 32 位循环冗余校验码(CRC)。对于 pack 包,`gunzip` 会检验压缩长度。标准压缩格式在设计上不允许相容性检测。不过 `gunzip` 有时可以检测出坏的 `.Z` 文件。如果你解压 `.Z` 文件时出错,不要因为标准解压没报错就认为 `.Z` 文件一定是正确的。这通常意味着标准解压过程不检测它的输入,而是直接产生一个错误的输出。SCO 的 `compress -H` 格式(lzh 压缩方法)不包括 CRC 校验码,但也允许一些相容性检查。
>
>
>
### 结语
到目前为止提到的 `gunzip` 基本用法,并不需要过多的学习曲线。我们已包含了一个初学者开始使用它所必须了解的几乎全部知识。想要了解更多的用法,去看 [man 页面](https://linux.die.net/man/1/gzip) 吧。
---
via: <https://www.howtoforge.com/linux-gunzip-command/>
作者:[Himanshu Arora](https://www.howtoforge.com) 译者:[erialin](https://github.com/erialin) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Linux Gunzip Command Explained with Examples
We have [already discussed](https://www.howtoforge.com/linux-gzip-command/) the **gzip** command in Linux. For starters, the tool is used to compress or expand files. To uncompress, the command offers a command line option **-d**, which can be used in the following way:
gzip -d [compressed-file-name]
However, there's an entirely different tool that you can use for uncompressing or expanding archives created by gzip. The tool in question is **gunzip**. In this article, we will discuss the gunzip command using some easy-to-understand examples. All examples/instructions mentioned in the tutorial have been tested on Ubuntu 22.04.
## Linux gunzip command
So now we know that compressed files can be restored using either 'gzip -d' or the gunzip command. The basic syntax of gunzip is:
gunzip [compressed-file-name]
The following Q&A-style examples should give you a better idea of how the tool works:
## Q1. How to uncompress archives using gunzip?
This is very simple - just pass the name of the archive file as an argument to gunzip.
gunzip [archive-name]
For example:
gunzip file1.gz
## Q2. How to make gunzip not delete the archive file?
As you'd have noticed, the gunzip command deletes the archive file after uncompressing it. However, if you want the archive to stay, you can do that using the **-c** command line option.
gunzip -c [archive-name] > [outputfile-name]
For example:
gunzip -c file1.gz > file1
So you can see that the archive file wasn't deleted in this case.
## Q3. How to make gunzip put the uncompressed file in some other directory?
We've already discussed the **-c** option in the previous Q&A. To make gunzip put the uncompressed file in a directory other than the present working directory, just provide the absolute path after the redirection operator.
gunzip -c [compressed-file] > [/complete/path/to/dest/dir/filename]
Here's an example:
gunzip -c file1.gz > /home/himanshu/file1
## More info
The following details - taken from the common manpage of gzip/gunzip - should be beneficial for those who want to know more about the command:
gunzip takes a list of files on its command line and replaces each file
whose name ends with .gz, -gz, .z, -z, or _z (ignoring case) and which
begins with the correct magic number with an uncompressed file without
the original extension. gunzip also recognizes the special extensions
.tgz and .taz as shorthands for .tar.gz and .tar.Z respectively. When
compressing, gzip uses the .tgz extension if necessary instead of trun
cating a file with a .tar extension.
gunzip can currently decompress files created by gzip, zip, compress,
compress -H or pack. The detection of the input format is automatic.
When using the first two formats, gunzip checks a 32 bit CRC. For pack
and gunzip checks the uncompressed length. The standard compress format
was not designed to allow consistency checks. However gunzip is some
times able to detect a bad .Z file. If you get an error when uncom
pressing a .Z file, do not assume that the .Z file is correct simply
because the standard uncompress does not complain. This generally means
that the standard uncompress does not check its input, and happily gen
erates garbage output. The SCO compress -H format (lzh compression
method) does not include a CRC but also allows some consistency checks.
## Conclusion
As far as basic usage is concerned, there isn't much of a learning curve associated with Gunzip. We've covered pretty much everything that a beginner needs to learn about this command in order to start using it. For more information, head to its [man page](https://linux.die.net/man/1/gzip). |
9,550 | 使用 GitHub 和 Python 实现持续部署 | https://fedoramagazine.org/continuous-deployment-github-python/ | 2018-04-15T23:27:47 | [
"持续集成",
"GitHub"
] | https://linux.cn/article-9550-1.html | 
借助 GitHub 的<ruby> 网络钩子 <rt> webhook </rt></ruby>,开发者可以创建很多有用的服务。从触发一个 Jenkins 实例上的 CI(持续集成) 任务到配置云中的机器,几乎有着无限的可能性。这篇教程将展示如何使用 Python 和 Flask 框架来搭建一个简单的持续部署(CD)服务。
在这个例子中的持续部署服务是一个简单的 Flask 应用,其带有接受 GitHub 的<ruby> 网络钩子 <rt> webhook </rt></ruby>请求的 REST <ruby> 端点 <rt> endpoint </rt></ruby>。在验证每个请求都来自正确的 GitHub 仓库后,服务器将<ruby> 拉取 <rt> pull </rt></ruby>更改到仓库的本地副本。这样每次一个新的<ruby> 提交 <rt> commit </rt></ruby>推送到远程 GitHub 仓库,本地仓库就会自动更新。
### Flask web 服务
用 Flask 搭建一个小的 web 服务非常简单。这里可以先看看项目的结构。
```
├── app
│ ├── __init__.py
│ └── webhooks.py
├── requirements.txt
└── wsgi.py
```
首先,创建应用。应用代码在 `app` 目录下。
两个文件(`__init__.py` 和 `webhooks.py`)构成了 Flask 应用。前者包含有创建 Flask 应用并为其添加配置的代码。后者有<ruby> 端点 <rt> endpoint </rt></ruby>逻辑。这是该应用接收 GitHub 请求数据的地方。
这里是 `app/__init__.py` 的内容:
```
import os
from flask import Flask
from .webhooks import webhook
def create_app():
""" Create, configure and return the Flask application """
app = Flask(__name__)
app.config['GITHUB_SECRET'] = os.environ.get('GITHUB_SECRET')
app.config['REPO_PATH'] = os.environ.get('REPO_PATH')
app.register_blueprint(webhook)
return(app)
```
该函数创建了两个配置变量:
* `GITHUB_SECRET` 保存一个密码,用来认证 GitHub 请求。
* `REPO_PATH` 保存了自动更新的仓库路径。
这份代码使用<ruby> <a href="http://flask.pocoo.org/docs/0.12/blueprints/"> Flask 蓝图 </a> <rt> Flask Blueprints </rt></ruby>来组织应用的<ruby> 端点 <rt> endpoint </rt></ruby>。使用蓝图可以对 API 进行逻辑分组,使应用程序更易于维护。通常认为这是一种好的做法。
这里是 `app/webhooks.py` 的内容:
```
import hmac
from flask import request, Blueprint, jsonify, current_app
from git import Repo
webhook = Blueprint('webhook', __name__, url_prefix='')
@webhook.route('/github', methods=['POST'])
def handle_github_hook():
""" Entry point for github webhook """
signature = request.headers.get('X-Hub-Signature')
sha, signature = signature.split('=')
secret = str.encode(current_app.config.get('GITHUB_SECRET'))
hashhex = hmac.new(secret, request.data, digestmod='sha1').hexdigest()
if hmac.compare_digest(hashhex, signature):
repo = Repo(current_app.config.get('REPO_PATH'))
origin = repo.remotes.origin
origin.pull('--rebase')
commit = request.json['after'][0:6]
print('Repository updated with commit {}'.format(commit))
return jsonify({}), 200
```
首先代码创建了一个新的蓝图 `webhook`。然后它使用 Flask `route` 为蓝图添加了一个端点。任何请求 `/GitHub` URL 端点的 POST 请求都将调用这个路由。
#### 验证请求
当服务在该端点上接到请求时,首先它必须验证该请求是否来自 GitHub 以及来自正确的仓库。GitHub 在请求头的 `X-Hub-Signature` 中提供了一个签名。该签名由一个密码(`GITHUB_SECRET`),请求体的 HMAC 十六进制摘要,并使用 `sha1` 哈希生成。
为了验证请求,服务需要在本地计算签名并与请求头中收到的签名做比较。这可以由 `hmac.compare_digest` 函数完成。
#### 自定义钩子逻辑
在验证请求后,现在就可以处理了。这篇教程使用 [GitPython](https://gitpython.readthedocs.io/en/stable/index.html) 模块来与 git 仓库进行交互。GitPython 模块中的 `Repo` 对象用于访问远程仓库 `origin`。该服务在本地拉取 `origin` 仓库的最新更改,还用 `--rebase` 选项来避免合并的问题。
调试打印语句显示了从请求体收到的短提交哈希。这个例子展示了如何使用请求体。更多关于请求体的可用数据的信息,请查询 [GitHub 文档](https://developer.github.com/v3/activity/events/types/#webhook-payload-example-26)。
最后该服务返回了一个空的 JSON 字符串和 200 的状态码。这用于告诉 GitHub 的网络钩子服务已经收到了请求。
### 部署服务
为了运行该服务,这个例子使用 [gunicorn](http://gunicorn.org/) web 服务器。首先安装服务依赖。在支持的 Fedora 服务器上,以 [sudo](https://fedoramagazine.org/howto-use-sudo/) 运行这条命令:
```
sudo dnf install python3-gunicorn python3-flask python3-GitPython
```
现在编辑 gunicorn 使用的 `wsgi.py` 文件来运行该服务:
```
from app import create_app
application = create_app()
```
为了部署服务,使用以下命令克隆这个 git [仓库](https://github.com/cverna/github_hook_deployment.git)或者使用你自己的 git 仓库:
```
git clone https://github.com/cverna/github_hook_deployment.git /opt/
```
下一步是配置服务所需的环境变量。运行这些命令:
```
export GITHUB_SECRET=asecretpassphraseusebygithubwebhook
export REPO_PATH=/opt/github_hook_deployment/
```
这篇教程使用网络钩子服务的 GitHub 仓库,但你可以使用你想要的不同仓库。最后,使用这些命令开启该 web 服务:
```
cd /opt/github_hook_deployment/
gunicorn --bind 0.0.0.0 wsgi:application --reload
```
这些选项中绑定了 web 服务的 IP 地址为 `0.0.0.0`,意味着它将接收来自任何的主机的请求。选项 `--reload` 确保了当代码更改时重启 web 服务。这就是持续部署的魔力所在。每次接收到 GitHub 请求时将拉取仓库的最近更新,同时 gunicore 检测这些更改并且自动重启服务。
\**注意: \**为了能接收到 GitHub 请求,web 服务必须部署到具有公有 IP 地址的服务器上。做到这点的简单方法就是使用你最喜欢的云提供商比如 DigitalOcean,AWS,Linode等。
### 配置 GitHub
这篇教程的最后一部分是配置 GitHub 来发送网络钩子请求到 web 服务上。这是持续部署的关键。
从你的 GitHub 仓库的设置中,选择 Webhook 菜单,并且点击“Add Webhook”。输入以下信息:
* “Payload URL”: 服务的 URL,比如 `<http://public_ip_address:8000/github>`
* “Content type”: 选择 “application/json”
* “Secret”: 前面定义的 `GITHUB_SECRET` 环境变量
然后点击“Add Webhook” 按钮。

现在每当该仓库发生推送事件时,GitHub 将向服务发送请求。
### 总结
这篇教程向你展示了如何写一个基于 Flask 的用于接收 GitHub 的网络钩子请求,并实现持续集成的 web 服务。现在你应该能以本教程作为起点来搭建对自己有用的服务。
---
via: <https://fedoramagazine.org/continuous-deployment-github-python/>
作者:[Clément Verna](https://fedoramagazine.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[kimii](https://github.com/kimii) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Developers can create many useful services using Github’s webhooks. From triggering a CI job on a Jenkins instance to provisioning machines in the cloud, the possibilities are almost limitless. This tutorial shows how to use Python and the Flask framework to build a simple continuous deployment service.
The continuous deployment service in this example is a simple Flask application with a REST endpoint that will receive Github’s webhook requests. After validating each request to check that it comes from the correct Github repository, the service pulls changes to the local copy of the repository. That way every time a new commit is pushed to the remote Github repository, the local repository is automatically updated.
## Flask web service
It is easy to build a small web service with Flask. Here’s a look at the project structure.
├── app │ ├── __init__.py │ └── webhooks.py ├── requirements.txt └── wsgi.py
First, create the application. The application code goes under the *app *directory.
Two files ( *__init__.py *and* webhooks.py)* compose the Flask application*.* The former has the code needed to create the Flask application and add configuration to it. The latter has the endpoints logic. This is where the app receives the data from the Github request.
Here is the *app/__init__.py* content:
import os from flask import Flask from .webhooks import webhook def create_app(): """ Create, configure and return the Flask application """ app = Flask(__name__) app.config['GITHUB_SECRET'] = os.environ.get('GITHUB_SECRET') app.config['REPO_PATH'] = os.environ.get('REPO_PATH') app.register_blueprint(webhook) return(app)
The function creates two configuration variables:
**GITHUB_SECRET**holds a secret passphrase, used to authenticate the Github requests.**REPO_PATH**holds the path of the repository to automatically update.
This code uses [Flask Blueprints](http://flask.pocoo.org/docs/0.12/blueprints/) to organize the application endpoints. Using blueprints allows logical grouping of APIs, making applications easier to maintain. It is generally considered a good practice.
Here is the content of *app/webhooks.py:*
import hmac from flask import request, Blueprint, jsonify, current_app from git import Repo webhook = Blueprint('webhook', __name__, url_prefix='') @webhook.route('/github', methods=['POST']) def handle_github_hook(): """ Entry point for github webhook """ signature = request.headers.get('X-Hub-Signature') sha, signature = signature.split('=') secret = str.encode(current_app.config.get('GITHUB_SECRET')) hashhex = hmac.new(secret, request.data, digestmod='sha1').hexdigest() if hmac.compare_digest(hashhex, signature): repo = Repo(current_app.config.get('REPO_PATH')) origin = repo.remotes.origin origin.pull('--rebase') commit = request.json['after'][0:6] print('Repository updated with commit {}'.format(commit)) return jsonify({}), 200
First the code creates a new Blueprint *webhook*. Then it adds a new endpoint to the Blueprint using a Flask *route*. This route will be called by any POST request on the */github *URL endpoint.
### Verifying the request
When the service receives a request on this endpoint, it must first verify that the request comes from Github and from the correct repository. Github gives a signature in the request header *X-Hub-Signature*. This signature is generated using a secret (GITHUB_SECRET), the [HMAC](https://en.wikipedia.org/wiki/HMAC) hex digest of the request body, and then hashed using the *sha1* hash function.
To verify the request the service needs to calculate locally the signature and compare it to the signature received in the request header. This is done by the *hmac.compare_digest *function.
### Custom hook logic
After validating the request, it can now be processd. This tutorial uses the [GitPython](https://gitpython.readthedocs.io/en/stable/index.html) module to interface with a git repository. From the *GitPython* module the *Repo *object is used to access the remote repository called *origin.* The service pulls the latest changes locally from the *origin *repository, also using the *–rebase *option to avoid issues with merges.
A debug print statement displays the short commit hash received from the request body. This example shows how to use the request body. For more details about the data available in the body, check [github’s documentation](https://developer.github.com/v3/activity/events/types/#webhook-payload-example-26).
Finally the service returns a empty JSON string and a 200 status code. This tells Github’s webhook server the request was received.
## Deploying the service
To run the service, this example uses the [gunicorn](http://gunicorn.org/) web server. First install the service dependencies. On a supported Fedora server, use this command with [sudo](https://fedoramagazine.org/howto-use-sudo/):
sudo dnf install python3-gunicorn python3-flask python3-GitPython
Now edit the *wsgi.py* file used by *gunicorn* to run the service:
from app import create_app application = create_app()
To deploy this service, clone this git [repository](https://github.com/cverna/github_hook_deployment.git) or use your own git repository with this command:
git clone https://github.com/cverna/github_hook_deployment.git /opt/
The next step is to configure the environment variables needed by the service. Run these commands:
export GITHUB_SECRET=asecretpassphraseusebygithubwebhook export REPO_PATH=/opt/github_hook_deployment/
This tutorial uses the webhook service Github repository, but you could use a different repository if you wish. Finally, start the webserver with these commands:
cd /opt/github_hook_deployment/ gunicorn --bind 0.0.0.0 wsgi:application --reload
These options bind the web server to the 0.0.0.0 ip address, meaning it will accept requests coming from any host. The *–reload* option ensures the web server restarts when the code changes. This is where the continuous deployment magic happens. Every Github request received pulls the latest change in the repository, and *gunicorn* detects these changes and automatically restarts the application.
**Note: **In order to receive the requests from github, the web service must be deployed on a server with a public IP address. An easy way to do this is to use your favorite cloud provider such as DigitalOcean, AWS, Linode, etc.
## Configure Github
The last part of this tutorial configures Github to send the webhook request to the web service. This is key to continuous deployment.
From your Github repository settings, select the *Webhook* menu and click on *Add Webhook.* Enter the following information:
**Payload URL:**The URL of the service, for example*http://public_ip_address:8000/github***Content type:**Select*application/json***Secret:**The**GITHUB_SECRET**environment variable defined earlier
Then click the *Add Webhook* button.
Github will now send a request to the service every time a push event happens on this repository.
## Conclusion
This tutorial has shown you how to write a Flask based web service that receives requests from a Github webhook and does continuous deployment. You should now be able to build your own useful services using this tutorial as a starting base. |
9,551 | 如何使用 DockerHub | https://www.linux.com/blog/learn/intro-to-linux/2018/1/how-use-dockerhub | 2018-04-16T10:07:00 | [
"DockerHub",
"Docker"
] | https://linux.cn/article-9551-1.html |
>
> 在这个 Docker 系列的最后一篇文章中,我们将讲述在 DockerHub 上使用和发布镜像。
>
>
>

在前面的文章中,我们了解到了基本的 [Docker 术语](https://www.linux.com/blog/intro-to-linux/2017/12/container-basics-terms-you-need-know),在 Linux 桌面、MacOS 和 Windows上 [如何安装 Docker](/article-9773-1.html),[如何创建容器镜像](/article-9541-1.html) 并且在系统上运行它们。在本系列的最后一篇文章中,我们将讨论如何使用 DockerHub 中的镜像以及将自己的镜像发布到 DockerHub。
首先:什么是 DockerHub 以及为什么它很重要?DockerHub 是一个由 Docker 公司运行和管理的基于云的存储库。它是一个在线存储库,Docker 镜像可以由其他用户发布和使用。有两种库:公共存储库和私有存储库。如果你是一家公司,你可以在你自己的组织内拥有一个私有存储库,而公共镜像可以被任何人使用。
你也可以使用公开发布的官方 Docker 镜像。我使用了很多这样的镜像,包括我的试验 WordPress 环境、KDE plasma 应用程序等等。虽然我们上次学习了如何创建自己的 Docker 镜像,但你不必这样做。DockerHub 上发布了数千镜像供你使用。DockerHub 作为默认存储库硬编码到 Docker 中,所以当你对任何镜像运行 `docker pull` 命令时,它将从 DockerHub 下载。
### 从 Docker Hub 下载镜像并在本地运行
开始请查看本系列的前几篇文章,以便继续。然后,一旦 Docker 在你的系统上运行,你就可以打开终端并运行:
```
$ docker images
```
该命令将显示当前系统上所有的 docker 镜像。假设你想在本地机器上部署 Ubuntu,你可能会:
```
$ docker pull ubuntu
```
如果你的系统上已经存在 Ubuntu 镜像,那么该命令会自动将该系统更新到最新版本。因此,如果你想要更新现有的镜像,只需运行 `docker pull` 命令,易如反掌。这就像 `apt-get update` 一样,没有任何的混乱和麻烦。
你已经知道了如何运行镜像:
```
$ docker run -it <image name>
$ docker run -it ubuntu
```
命令提示符应该变为如下内容:
```
root@1b3ec4621737:/#
```
现在你可以运行任何属于 Ubuntu 的命令和实用程序,这些都被包含在内而且安全。你可以在 Ubuntu 上运行你想要的所有实验和测试。一旦你完成了测试,你就可以销毁镜像并下载一个新的。在虚拟机中不存在系统开销。
你可以通过运行 exit 命令退出该容器:
```
$ exit
```
现在假设你想在系统上安装 Nginx,运行 `search` 命令来找到需要的镜像:
```
$ docker search nginx
```

正如你所看到的,DockerHub 上有很多 Nginx 镜像。为什么?因为任何人都可以发布镜像,各种镜像针对不同的项目进行了优化,因此你可以选择合适的镜像。你只需要为你的需求安装合适的镜像。
假设你想要拉取 Bitnami 的 Nginx 镜像:
```
$ docker pull bitnami/nginx
```
现在运行:
```
$ docker run -it bitnami/nginx
```
### 如何发布镜像到 Docker Hub?
在此之前,[我们学习了如何创建 Docker 镜像](/article-9541-1.html),我们可以轻松地将该镜像发布到 DockerHub 中。首先,你需要登录 DockerHub,如果没有账户,请 [创建账户](https://hub.docker.com/)。然后,你可以打开终端应用,登录:
```
$ docker login --username=<USERNAME>
```
将 “” 替换为你自己的 Docker Hub 用户名。我这里是 arnieswap:
```
$ docker login --username=arnieswap
```
输入密码,你就登录了。现在运行 `docker images` 命令来获取你上次创建的镜像的 ID。
```
$ docker images
```

现在,假设你希望将镜像 `ng` 推送到 DockerHub,首先,我们需要标记该镜像([了解更多关于标记的信息](https://www.linux.com/blog/intro-to-linux/2017/12/container-basics-terms-you-need-know)):
```
$ docker tag e7083fd898c7 arnieswap/my_repo:testing
```
现在推送镜像:
```
$ docker push arnieswap/my_repo
```
推送指向的是 docker.io/arnieswap/my\_repo 仓库:
```
12628b20827e: Pushed
8600ee70176b: Mounted from library/ubuntu
2bbb3cec611d: Mounted from library/ubuntu
d2bb1fc88136: Mounted from library/ubuntu
a6a01ad8b53f: Mounted from library/ubuntu
833649a3e04c: Mounted from library/ubuntu
testing: digest: sha256:286cb866f34a2aa85c9fd810ac2cedd87699c02731db1b8ca1cfad16ef17c146 size: 1569
```
哦耶!你的镜像正在上传。一旦完成,打开 DockerHub,登录到你的账户,你就能看到你的第一个 Docker 镜像。现在任何人都可以部署你的镜像。这是开发软件和发布软件最简单,最快速的方式。无论你何时更新镜像,用户都可以简单地运行:
```
$ docker run arnieswap/my_repo
```
现在你知道为什么人们喜欢 Docker 容器了。它解决了传统工作负载所面临的许多问题,并允许你在任何时候开发、测试和部署应用程序。通过遵循本系列中的步骤,你自己可以尝试以下。
---
via: <https://www.linux.com/blog/learn/intro-to-linux/2018/1/how-use-dockerhub>
作者:[Swapnil Bhartiya](https://www.linux.com/users/arnieswap) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,552 | 可怕的万圣节 Linux 命令 | https://www.networkworld.com/article/3235219/linux/scary-linux-commands-for-halloween.html | 2018-04-17T00:16:02 | [
"命令",
"kill"
] | https://linux.cn/article-9552-1.html | 
虽然现在不是万圣节,也可以关注一下 Linux 可怕的一面。什么命令可能会显示鬼、巫婆和僵尸的图像?哪个会鼓励“不给糖果就捣蛋”的精神?
### crypt
好吧,我们一直看到 `crypt`。尽管名称不同,crypt 不是一个地窖,也不是垃圾文件的埋葬坑,而是一个加密文件内容的命令。现在,`crypt` 通常用一个脚本实现,通过调用一个名为 `mcrypt` 的二进制文件来模拟以前的 `crypt` 命令来完成它的工作。直接使用 `mycrypt` 命令是更好的选择。
```
$ mcrypt x
Enter the passphrase (maximum of 512 characters)
Please use a combination of upper and lower case letters and numbers.
Enter passphrase:
Enter passphrase:
File x was encrypted.
```
请注意,`mcrypt` 命令会创建第二个扩展名为 `.nc` 的文件。它不会覆盖你正在加密的文件。
`mcrypt` 命令有密钥大小和加密算法的选项。你也可以再选项中指定密钥,但 `mcrypt` 命令不鼓励这样做。
### kill
还有 `kill` 命令 - 当然并不是指谋杀,而是用来强制和非强制地结束进程,这取决于正确终止它们的要求。当然,Linux 并不止于此。相反,它有各种 `kill` 命令来终止进程。我们有 `kill`、`pkill`、`killall`、`killpg`、`rfkill`、`skill`()读作 es-kill)、`tgkill`、`tkill` 和 `xkill`。
```
$ killall runme
[1] Terminated ./runme
[2] Terminated ./runme
[3]- Terminated ./runme
[4]+ Terminated ./runme
```
### shred
Linux 系统也支持一个名为 `shred` 的命令。`shred` 命令会覆盖文件以隐藏其以前的内容,并确保使用硬盘恢复工具无法恢复它们。请记住,`rm` 命令基本上只是删除文件在目录文件中的引用,但不一定会从磁盘上删除内容或覆盖它。`shred` 命令覆盖文件的内容。
```
$ shred dupes.txt
$ more dupes.txt
▒oΛ▒▒9▒lm▒▒▒▒▒o▒1־▒▒f▒f▒▒▒i▒▒h^}&▒▒▒{▒▒
```
### 僵尸
虽然不是命令,但僵尸在 Linux 系统上是很顽固的存在。僵尸基本上是没有完全清理掉的死亡进程的遗骸。进程*不应该*这样工作 —— 让死亡进程四处游荡,而不是简单地让它们死亡并进入数字天堂,所以僵尸的存在表明了让他们遗留于此的进程有一些缺陷。
一个简单的方法来检查你的系统是否有僵尸进程遗留,看看 `top` 命令的标题行。
```
$ top
top - 18:50:38 up 6 days, 6:36, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 171 total, 1 running, 167 sleeping, 0 stopped, 3 zombie `< ==`
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni, 99.9 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 2003388 total, 250840 free, 545832 used, 1206716 buff/cache
KiB Swap: 9765884 total, 9765764 free, 120 used. 1156536 avail Mem
```
可怕!上面显示有三个僵尸进程。
### at midnight
有时会在万圣节这么说,死者的灵魂从日落开始游荡直到午夜。Linux 可以通过 `at midnight` 命令跟踪它们的离开。用于安排在下次到达指定时间时运行的作业,`at` 的作用类似于一次性的 cron。
```
$ at midnight
warning: commands will be executed using /bin/sh
at> echo 'the spirits of the dead have left'
at> <EOT>
job 3 at Thu Oct 31 00:00:00 2017
```
### 守护进程
Linux 系统也高度依赖守护进程 —— 在后台运行的进程,并提供系统的许多功能。许多守护进程的名称以 “d” 结尾。这个 “d” 代表<ruby> 守护进程 <rt> daemon </rt></ruby>,表明这个进程一直运行并支持一些重要功能。有的会用单词 “daemon” 。
```
$ ps -ef | grep sshd
root 1142 1 0 Oct19 ? 00:00:00 /usr/sbin/sshd -D
root 25342 1142 0 18:34 ? 00:00:00 sshd: shs [priv]
$ ps -ef | grep daemon | grep -v grep
message+ 790 1 0 Oct19 ? 00:00:01 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation
root 836 1 0 Oct19 ? 00:00:02 /usr/lib/accountsservice/accounts-daemon
```
### 万圣节快乐!
在 [Facebook](https://www.facebook.com/NetworkWorld/) 和 [LinkedIn](https://www.linkedin.com/company/network-world) 上加入 Network World 社区来对主题进行评论。
---
via: <https://www.networkworld.com/article/3235219/linux/scary-linux-commands-for-halloween.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,553 | 面向企业的最佳 Linux 发行版 | https://www.datamation.com/open-source/best-linux-distros-for-the-enterprise.html | 2018-04-17T09:51:16 | [
"Linux",
"RHEL",
"SLES"
] | https://linux.cn/article-9553-1.html | 
在这篇文章中,我将分享企业环境下顶级的 Linux 发行版。其中一些发行版用于服务器和云环境以及桌面任务。所有这些可选的 Linux 具有的一个共同点是它们都是企业级 Linux 发行版 —— 所以你可以期待更高程度的功能性,当然还有支持程度。
### 什么是企业级的 Linux 发行版?
企业级的 Linux 发行版可以归结为以下内容 —— 稳定性和支持。在企业环境中,使用的 Linux 版本必须满足这两点。稳定性意味着所提供的软件包既稳定又可用,同时仍然保持预期的安全性。
企业级的支持因素意味着有一个可靠的支持机制。有时这是单一的(官方)来源,如公司。在其他情况下,它可能是一个非营利性的治理机构,向优秀的第三方支持供应商提供可靠的建议。很明显,前者是最好的选择,但两者都可以接受。
### Red Hat 企业级 Linux(RHEL)
[Red Hat](https://www.redhat.com/en) 有很多很棒的产品,都有企业级的支持来保证可用。其核心重点如下:
* Red Hat 企业级 Linux 服务器:这是一组服务器产品,包括从容器托管到 SAP 服务的所有内容,还有其他衍生的服务器。
* Red Hat 企业级 Linux 桌面:这些是严格控制的用户环境,运行 Red Hat Linux,提供基本的桌面功能。这些功能包括访问最新的应用程序,如 web 浏览器、电子邮件、LibreOffice 等。
* Red Hat 企业级 Linux 工作站:这基本上是 Red Hat 企业级 Linux 桌面,但针对高性能任务进行了优化。它也非常适合于大型部署和持续管理。
#### 为什么选择 Red Hat 企业级 Linux?
Red Hat 是一家非常成功的大型公司,销售围绕 Linux 的服务。基本上,Red Hat 从那些想要避免供应商锁定和其他相关问题的公司赚钱。这些公司认识到聘用开源软件专家和管理他们的服务器和其他计算需求的价值。一家公司只需要购买订阅来让 Red Hat 做支持工作就行。
Red Hat 也是一个可靠的社会公民。他们赞助开源项目以及像 OpenSource.com 这样的 FoSS 支持网站(LCTT 译注:FoSS 是 Free and Open Source Software 的缩写,意为自由及开源软件),并为 Fedora 项目提供支持。Fedora 不是由 Red Hat 所有的,而是由它赞助开发的。这使 Fedora 得以发展,同时也使 Red Hat 受益匪浅。Red Hat 可以从 Fedora 项目中获得他们想要的,并将其用于他们的企业级 Linux 产品中。 就目前来看,Fedora 充当了红帽企业 Linux 的上游渠道。
### SUSE Linux 企业版本
[SUSE](https://www.suse.com/) 是一家非常棒的公司,为企业用户提供了可靠的 Linux 选择。SUSE 的产品类似于 Red Hat,桌面和服务器都是该公司所关注的。从我自己使用 SUSE 的经验来看,我相信 YaST 已经证明了,对于希望在工作场所使用 Linux 操作系统的非 Linux 管理员而言,它拥有巨大的优势。YaST 为那些需要一些基本的 Linux 命令行知识的任务提供了一个友好的 GUI。
SUSE 的核心重点如下:
* SUSE Linux 企业级服务器(SLES):包括任务特定的解决方案,从云到 SAP,以及任务关键计算和基于软件的数据存储。
* SUSE Linux 企业级桌面:对于那些希望为员工提供可靠的 Linux 工作站的公司来说,SUSE Linux 企业级桌面是一个不错的选择。和 Red Hat 一样,SUSE 通过订阅模式来对其提供支持。你可以选择三个不同级别的支持。
#### 为什么选择 SUSE Linux 企业版?
SUSE 是一家围绕 Linux 销售服务的公司,但他们仍然通过专注于简化操作来实现这一目标。从他们的网站到其提供的 Linux 发行版,重点是易用性,而不会牺牲安全性或可靠性。尽管在美国毫无疑问 Red Hat 是服务器的标准,但 SUSE 作为公司和开源社区的贡献成员都做得很好。
我还会继续说,SUSE 不会太严肃,当你在 IT 领域建立联系的时候,这是一件很棒的事情。从他们关于 Linux 的有趣音乐视频到 SUSE 贸易展位中使用的 Gecko 以获得有趣的照片机会,SUSE 将自己描述成简单易懂和平易近人的形象。
### Ubuntu LTS Linux
[Ubuntu Long Term Release](http://releases.ubuntu.com/16.04/) (LTS) Linux 是一个简单易用的企业级 Linux 发行版。Ubuntu 看起来比上面提到的其他发行版更新更频繁(有时候也更不稳定)。但请不要误解,Ubuntu LTS 版本被认为是相当稳定的,不过,我认为一些专家可能不太同意它们是安全可靠的。
#### Ubuntu 的核心重点如下:
* Ubuntu 桌面版:毫无疑问,Ubuntu 桌面非常简单,可以快速地学习并运行。也许在高级安装选项中缺少一些东西,但这使得其更简单直白。作为额外的奖励,Ubuntu 相比其他版本有更多的软件包(除了它的父亲,Debian 发行版)。我认为 Ubuntu 真正的亮点在于,你可以在网上找到许多销售 Ubuntu 的厂商,包括服务器、台式机和笔记本电脑。
* Ubuntu 服务器版:这包括服务器、云和容器产品。Ubuntu 还提供了 Juju 云“应用商店”这样一个有趣的概念。对于任何熟悉 Ubuntu 或 Debian 的人来说,Ubuntu 服务器都很有意义。对于这些人来说,它就像手套一样,为你提供了你已经熟知并喜爱的命令行工具。
* Ubuntu IoT:最近,Ubuntu 的开发团队已经把目标瞄准了“物联网”(IoT)的创建解决方案。包括数字标识、机器人技术和物联网网关。我的猜测是,我们将在 Ubuntu 中看到大量增长的物联网用户来自企业,而不是普通家庭用户。
#### 为什么选择 Ubuntu LTS?
社区是 Ubuntu 最大的优点。除了在已经拥挤的服务器市场上的巨大增长之外,它还与普通用户在一起。Ubuntu 的开发和用户社区是坚如磐石的。因此,虽然它可能被认为比其他企业版更不稳定,但是我发现将 Ubuntu LTS 安装锁定到 “security updates only” 模式下提供了非常稳定的体验。
### CentOS 或者 Scientific Linux 怎么样呢?
首先,让我们把 [CentOS](https://www.centos.org/) 作为一个企业发行版,如果你有自己的内部支持团队来维护它,那么安装 CentOS 是一个很好的选择。毕竟,它与 Red Hat 企业级 Linux 兼容,并提供了与 Red Hat 产品相同级别的稳定性。不幸的是,它不能完全取代 Red Hat 支持订阅。
那么 [Scientific Linux](https://www.scientificlinux.org/) 呢?它的发行版怎么样?好吧,它就像 CentOS,它是基于 Red Hat Linux 的。但与 CentOS 不同的是,它与 Red Hat 没有任何隶属关系。 Scientific Linux 从一开始就有一个目标 —— 为世界各地的实验室提供一个通用的 Linux 发行版。今天,Scientific Linux 基本上是 Red Hat 减去所包含的商标资料。
这两种发行版都不能真正地与 Red Hat 互换,因为它们缺少 Red Hat 支持组件。
哪一个是顶级企业发行版?我认为这取决于你需要为自己确定的许多因素:订阅范围、可用性、成本、服务和提供的功能。这些是每个公司必须自己决定的因素。就我个人而言,我认为 Red Hat 在服务器上获胜,而 SUSE 在桌面环境中轻松获胜,但这只是我的意见 —— 你不同意?点击下面的评论部分,让我们来谈谈它。
---
via: <https://www.datamation.com/open-source/best-linux-distros-for-the-enterprise.html>
作者:[Matt Hartley](https://www.datamation.com/author/Matt-Hartley-3080.html) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,554 | 自从上个 LTS 版本之后,Ubuntu 18.04 LTS 有什么新变化? | http://news.softpedia.com/news/what-s-new-in-ubuntu-18-04-lts-bionic-beaver-since-ubuntu-16-04-lts-520726.shtml | 2018-04-17T22:13:00 | [
"Ubuntu"
] | https://linux.cn/article-9554-1.html |
>
> 让我们回顾一下 Ubuntu 这两年有什么变化。
>
>
>

Canonical 将在这个月末的 26 日发布 Ubuntu 18.04 LTS(Bionic Beaver)操作系统。这是一个 LTS 发布版本,大多数 Ubuntu 16.04 LTS(Xenial Xerus)用户应该进行升级。
2016 年 4 月 21 日发布的 Ubuntu 16.04 LTS(Xenial Xerus)系列已经是两年前的事情了,它已经更新了五个计划维护更新中的四个,而上一个更新 Ubuntu 16.04.4 LTS 发布于 2018 年 3 月 1 日。
Ubuntu 16.04.4 LTS 将会有来自 Ubuntu 17.10(Artful Aardvark)最新的内核和显卡驱动,这和 Ubuntu 16.04 LTS 初次发布相比已经有了很大变化。作为 Ubuntu 16.04 LTS 用户,我想你或许想知道是否值得升级本月底发布的 Ubuntu 18.04 LTS。

### 从 Ubuntu 16.04 LTS 到 Ubuntu 18.04 LTS 有何新变化?
从 Ubuntu 16.04 LTS 到 Ubuntu 18.04 LTS 最显著的变化是我们喜爱的 Unity 用户界面被替换为 GNOME 桌面环境了,虽然 Ubuntu 的开发者们已经尽力将其打造得看起来像 Unity 桌面一样。
GNOME 桌面环境带来了许多视觉变化。最显眼的一个变化是窗口控制按钮现在被移动到了右边。上一个在右边摆放窗口控制按钮的 Ubuntu 版本是 Ubuntu 9.10 (Karmic Koala)。
另一个视觉变化可以在 Nautilus 文件管理器中看到,它现在有个暗色风格的左边栏。LightDM 登录管理器也被替换为 GNOME 的 GDM 显示管理器,并使用了 7 号虚拟终端取代了默认的 1 号虚拟终端。
此外,Ubuntu 18.04 LTS 使用 GNOME 的屏幕虚拟键盘替代了默认的 Onboard 键盘,而预装在现场版 ISO 镜像中的应用也是完全不同的一套,Ubuntu 16.04 LTS 以来新包括在 Ubuntu 18.04 LTS 中应用是 GNOME To Do。
在另一方面,如果你要查看 systemd journal 中的日志的话,“GNOME 日志”替换了原来的系统日志应用;gconf 默认不再安装,它被替换为 gsettings;还有一个变化是从 Ubuntu 16.04 LTS 升级时,Aisleriot 卡牌游戏的记录和设置都会丢失。
其它许多来自 GNOME 家族的应用都进行了 UI 重大重新设计,这包括 “Ubuntu 软件”、“系统设置”、“磁盘用量分析(Baobab)”、Remmina,并且 “GNOME 日历”现在有了周视图和支持重复事件。那些应用现在大多在其应用菜单中有键盘快捷键弹窗。

### Ubuntu 桌面版 32 位镜像没了,Ubuntu GNOME 断篇
现在 GNOME 成为了 Ubunut 默认桌面环境,因此 Ubuntu GNOME 分支就不再继续开发了。Ubuntu GNOME 16.04 用户将自动升级到 Ubuntu 标准版本。如果你安装了 gnome-session 软件包并在登录屏幕选择了 GNOME 的话,仍然可以使用原汁原味的 GNOME 会话。
最后同样重要是的,Canonical 放弃了 Ubuntu 18.04 LTS (Bionic Beaver)版本的 32 位桌面的支持,所以,如果你使用的是 32 位 Ubuntu 16.04 LTS 操作系统,推荐你下载 64 位 Ubuntu 18.04 LTS 镜像并重新安装(当然,你得是 64 位的机器)。
在底层,现在默认安装的是 Python 3,Python 2 不再安装; GPG 二进制现在由 GnuPG2 软件包提供;全新安装的 Ubuntu 系统中用交换文件取代了交换分区;现在是默认的 DNS 解析器是 systemd-resolved;重新打造的图形化安装程序的“加密家目录”选项消失了。
Ubuntu 18.04 LTS (Bionic Beaver)是 Canonical 的第七个长期支持版本,它会得到五年的安全和软件更新支持,直到 2023 年 4 月。最终的 Ubuntu 18.04 LTS 很快就可以下载了,2018 年 4 月 26 日 Ubuntu 16.04 LTS 和 Ubuntu 17.10 用户可以准备升级了。
[](https://news-cdn.softpedia.com/images/news2/what-s-new-in-ubuntu-18-04-lts-bionic-beaver-since-ubuntu-16-04-lts-520726-5.jpg "Click to view large image")
| 301 | Moved Permanently | null |
9,556 | 什么是 Linux “oops”? | https://www.networkworld.com/article/3254778/linux/what-is-a-linux-oops.html | 2018-04-18T22:28:25 | [
"内核",
"恐慌"
] | https://linux.cn/article-9556-1.html |
>
> Linux 内核正在盯着你,当它检测到系统上运行的某些东西违反了正常内核行为时,它会关闭系统并发出一个“oops”!
>
>
>

如果你检查你的 Linux 系统上运行的进程,你可能会对一个叫做 “kerneloops” 的进程感到好奇。提示一下,它是 “kernel oops”,而不是 “kerne loops”。
坦率地说,“oops” 是 Linux 内核的一部分出现了偏差行为。你有做错了什么吗?可能没有。但有一些不对劲。而那个做了错事的进程可能已经被 CPU 结束。最糟糕的是,内核可能会报错并突然关闭系统。
请注意,“oops” 不是首字母缩略词。它不代表像“<ruby> 面向对象的编程和系统 <rt> object-oriented programming and systems </rt></ruby>” 或“<ruby> 超出程序规范 <rt> out of procedural specs </rt></ruby>” 之类的东西。它实际上就是“哎呀” (oops),就像你刚掉下一杯酒或踩在你的猫身上。哎呀! “oops” 的复数是 “oopses”。
oops 意味着系统上运行的某些东西违反了内核有关正确行为的规则。也许代码尝试采取不允许的代码路径或使用无效指针。不管它是什么,内核 —— 总是在监测进程的错误行为 —— 很可能会阻止特定进程,并将它做了什么的消息写入控制台、 `/var/log/dmesg` 或 `/var/log/kern.log` 中。
oops 可能是由内核本身引起的,也可能是某些进程试图让内核违反在系统上能做的事以及它们被允许做的事。
oops 将生成一个<ruby> 崩溃签名 <rt> crash signature </rt></ruby>,这可以帮助内核开发人员找出错误并提高代码质量。
系统上运行的 kerneloops 进程可能如下所示:
```
kernoops 881 1 0 Feb11 ? 00:00:01 /usr/sbin/kerneloops
```
你可能会注意到该进程不是由 root 运行的,而是由名为 “kernoops” 的用户运行的,并且它的运行时间极少。实际上,分配给这个特定用户的唯一任务是运行 kerneloops。
```
$ sudo grep kernoops /etc/passwd
kernoops:x:113:65534:Kernel Oops Tracking Daemon,,,:/:/bin/false
```
如果你的 Linux 系统不带有 kerneloops(比如 Debian),你可以考虑添加它。查看这个 [Debian 页面](https://packages.debian.org/stretch/kerneloops)了解更多信息。
### 什么时候应该关注 oops?
一般 oops 没什么大不了的。它在一定程度上取决于特定进程所扮演的角色。它也取决于 oops 的类别。
有些 oops 很严重,会导致<ruby> 系统恐慌 <rt> system panic </rt></ruby>。从技术上讲,系统恐慌是 oops 的一个子集(即更严重的 oops)。当内核检测到的问题足够严重以至于内核认为它(内核)必须立即停止运行以防止数据丢失或对系统造成其他损害时会出现。因此,系统需要暂停并重新启动,以防止任何不一致导致不可用或不可靠。所以系统恐慌实际上是为了保护自己免受不可挽回的损害。
总之,所有的内核恐慌都是 oops,但并不是所有的 oops 都是内核恐慌。
`/var/log/kern.log` 和相关的轮转日志(`/var/log/kern.log.1`、`/var/log/kern.log.2` 等)包含由内核生成并由 syslog 处理的日志。
kerneloops 程序收集并默认将错误信息提交到 <http://oops.kernel.org/>,在那里它会被分析并呈现给内核开发者。此进程的配置详细信息在 `/etc/kerneloops.conf` 文件中指定。你可以使用下面的命令轻松查看设置:
```
$ sudo cat /etc/kerneloops.conf | grep -v ^# | grep -v ^$
[sudo] password for shs:
allow-submit = ask
allow-pass-on = yes
submit-url = http://oops.kernel.org/submitoops.php
log-file = /var/log/kern.log
submit-pipe = /usr/share/apport/kernel_oops
```
在上面的(默认)设置中,内核问题可以被提交,但要求用户获得许可。如果设置为 `allow-submit = always`,则不会询问用户。
调试内核问题是使用 Linux 系统的更高级技巧之一。幸运的是,大多数 Linux 用户很少或从没有经历过 oops 或内核恐慌。不过,知道 kerneloops 这样的进程在系统中执行什么操作,了解可能会报告什么以及系统何时遇到严重的内核冲突也是很好的。
---
via: <https://www.networkworld.com/article/3254778/linux/what-is-a-linux-oops.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,557 | 11 个超棒的 Vi 技巧和窍门 | https://opensource.com/article/18/1/top-11-vi-tips-and-tricks | 2018-04-18T23:22:24 | [
"Vi",
"Vim"
] | https://linux.cn/article-9557-1.html |
>
> 是否你刚刚接触 Vi 还是想进阶,这些技巧可以很快让你成为高级用户。
>
>
>

[Vi](http://ex-vi.sourceforge.net/) 编辑器是 Unix 和像 Linux 这样的类 Unix 系统中 Linux 最流行的编辑器之一。无论您是 vi 新手还是想进阶,这里有 11 个技巧可以增强你使用的方式。
### 编辑
编辑长文本时可能很难受,特别是编辑其中某一行时,需要移动许久才能到这行。这有个很快的方法:
1、 `:set number` 这个命令可是在编辑器左边显示行号。

您可以在命令行中输入 `vi +26 samp.txt` 命令直接打开文件到达 26 行,在 vi 编辑器中也可以输入 `:26` 跳转到 26 行。

### 快速导航
2、 `i` 将工作方式从“命令模式”更改为“输入模式”,并在当前光标位置开始插入内容。
3、 `a` 除了是光标之后开始插入内容,与上面的效果是一样的。
4、 `o` 在光标的下一行位置开始插入内容。
### 删除
如果您发现错误或错别字,能快速的修正是很重要的。好在 Vi 都事先想好了。
了解 Vi 的删除功能,保证你不会意外按下某个键并永久删除一行或多段内容,这点至关重要。
5、 `x` 删除当前光标的字符。
6、 `dd` 删除当前行 (是的,整行内容!)
下面看可怕的部分:`30dd` 从当前行开始删除以下 30 行!使用此命令请慎重。
### 搜索
您可以在“命令模式”搜索关键字,而不用在大量文本内容中手动导航查找特定的单词或内容。
7、 `:/<keyword>` 搜索 `< >` 中的单词并将光标移动到第一个匹配项。
8、 导航到该单词的下一个匹配项,请输入 `n` 并继续按下, 直到找到您要找的内容。
例如,在这个图像中我要搜索包含 `ssh` 的内容, Vi 光标就会突出第一个结果的开始位置。

按下 `n` 之后, Vi 光标就会突出下一个匹配项。

### 保存并退出
开发人员 (或其他人) 可能会发现这个命令很有用。
9、 `:x` 保存您的工作并退出 Vi 。

10、 如果你想节省哪怕是纳秒,那么这有个更快的回到终端的方法。不用在键盘上按 `Shift+:` ,而是按下 `Shift+q` (或者大写字母 Q ) 来进入 [Ex 模式](https://en.wikibooks.org/wiki/Learning_the_vi_Editor/Vim/Modes#Ex-mode) 。但是如果你只是想按下 `x` 来保存退出,那就没有什么区别(如上所示)。
### 替换
如果您想将文中的某个单词全部替换为一个单词,这有个很巧妙的招式。例如,如果您想在一个大文件中将 “desktop” 替换为 “laptop” ,那么单调的搜索每个出现的 “desktop” 将其删掉,然后再输入 “laotop” ,是很浪费时间的。
11、 `:%s/desktop/laptop/g` 这个命令将在整个文件中的 “desktop” 用 “laptop” 替换,他就像 Linux 的 `sed` 命令一样。
这个例子中我用 “user” 替换了 “root” :


这些技巧应该能帮组任何想开始学 Vi 的人。我有遗漏其他巧妙的提示吗?请在评论中分享他们。
---
via: <https://opensource.com/article/18/1/top-11-vi-tips-and-tricks>
作者:[Archit Modi](https://opensource.com/users/architmodi) 译者:[MZqk](https://github.com/MZqk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,558 | 如何在Linux的终端测试网速 | https://kerneltalks.com/tips-tricks/how-to-test-internet-speed-in-linux-terminal/ | 2018-04-19T01:16:00 | [
"测试",
"网速"
] | https://linux.cn/article-9558-1.html |
>
> 学习如何在 Linux 终端使用命令行工具 `speedtest` 测试网速,或者仅用一条 python 命令立刻获得网速的测试结果。
>
>
>

我们都会在连接到一个新的网络或者 WIFI 的时候去测试网络带宽。 为什么不用我们自己的服务器!下面将会教你如何在 Linux 终端测试网速。
我们多数都会使用 [Ookla 的 Speedtest](http://www.speedtest.net/) 来测试网速。 这在桌面上是很简单的操作,访问他们的网站点击“Go”浏览即可。它将使用最近的服务器来扫描你的本地主机来测试网速。 如果你使用的是移动设备,他们有对应的移动端 APP。但如果你使用的是只有命令行终端,界面的则会有些不同。下面让我们一起看看如何在Linux的终端来测试网速。
如果你只是想偶尔的做一次网速测试而不想去下载测试工具,那么请往下看如何使用命令完成测试。
### 第一步:下载网速测试命令行工具。
首先,你需要从 [GitHub](https://github.com/sivel/speedtest-cli) 上下载 `speedtest` 命令行工具。现在,它也被包含在许多其它的 Linux 仓库中,如果已经在你的库中,你可以直接[在你的 Linux 发行版上进行安装](https://kerneltalks.com/tools/package-installation-linux-yum-apt/)。
让我们继续下载和安装过程,安装的 git 包取决于你的 Linux 发行版。然后按照下面的方法来克隆 Github speedtest 存储库
```
[root@kerneltalks ~]# git clone https://github.com/sivel/speedtest-cli.git
Cloning into 'speedtest-cli'...
remote: Counting objects: 913, done.
remote: Total 913 (delta 0), reused 0 (delta 0), pack-reused 913
Receiving objects: 100% (913/913), 251.31 KiB | 143.00 KiB/s, done.
Resolving deltas: 100% (518/518), done.
```
它将会被克隆到你当前的工作目录,新的名为 `speedtest-cli` 的目录将会被创建,你将在新的目录下看到如下的文件。
```
[root@kerneltalks ~]# cd speedtest-cli
[root@kerneltalks speedtest-cli]# ll
total 96
-rw-r--r--. 1 root root 1671 Oct 7 16:55 CONTRIBUTING.md
-rw-r--r--. 1 root root 11358 Oct 7 16:55 LICENSE
-rw-r--r--. 1 root root 35 Oct 7 16:55 MANIFEST.in
-rw-r--r--. 1 root root 5215 Oct 7 16:55 README.rst
-rw-r--r--. 1 root root 20 Oct 7 16:55 setup.cfg
-rw-r--r--. 1 root root 3196 Oct 7 16:55 setup.py
-rw-r--r--. 1 root root 2385 Oct 7 16:55 speedtest-cli.1
-rw-r--r--. 1 root root 1200 Oct 7 16:55 speedtest_cli.py
-rwxr-xr-x. 1 root root 47228 Oct 7 16:55 speedtest.py
-rw-r--r--. 1 root root 333 Oct 7 16:55 tox.ini
```
名为 `speedtest.py` 的 Python 脚本文件就是用来测试网速的。
你可以将这个脚本链接到 `/usr/bin` 下,以便这台机器上的所有用户都能使用。或者你可以为这个脚本创建一个[命令别名](https://kerneltalks.com/commands/command-alias-in-linux-unix/),这样就能让所有用户很容易使用它。
### 运行 Python 脚本
现在,直接运行这个脚本,不需要添加任何参数,它将会搜寻最近的服务器来测试你的网速。
```
[root@kerneltalks speedtest-cli]# python speedtest.py
Retrieving speedtest.net configuration...
Testing from Amazon (35.154.184.126)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by Spectra (Mumbai) [1.15 km]: 8.174 ms
Testing download speed................................................................................
Download: 548.13 Mbit/s
Testing upload speed................................................................................................
Upload: 323.95 Mbit/s
```
Oh! 不要被这个网速惊讶道。我在 AWE EX2 的服务器上。那是亚马逊数据中心的网速!
### 这个脚本可以添加有不同的选项。
下面的几个选项对这个脚本可能会很有用处:
**要搜寻你附近的网路测试服务器**,使用 `--list` 和 `grep` 加上地名来列出所有附近的服务器。
```
[root@kerneltalks speedtest-cli]# python speedtest.py --list | grep -i mumbai
2827) Bharti Airtel Ltd (Mumbai, India) [1.15 km]
8978) Spectra (Mumbai, India) [1.15 km]
4310) Hathway Cable and Datacom Ltd (Mumbai, India) [1.15 km]
3315) Joister Broadband (Mumbai, India) [1.15 km]
1718) Vodafone India (Mumbai, India) [1.15 km]
6454) YOU Broadband India Pvt Ltd. (Mumbai, India) [1.15 km]
9764) Railtel Corporation of india Ltd (Mumbai, India) [1.15 km]
9584) Sheng Li Telecom (Mumbai, India) [1.15 km]
7605) Idea Cellular Ltd. (Mumbai, India) [1.15 km]
8122) Sify Technologies Ltd (Mumbai, India) [1.15 km]
9049) I-ON (Mumbai, India) [1.15 km]
6403) YOU Broadband India Pvt Ltd., Mumbai (Mumbai, India) [1.15 km]
```
然后你就能从搜寻结果中看到,第一列是服务器识别号,紧接着是公司的名称和所在地,最后是离你的距离。
**如果要使用指定的服务器来测试网速**,后面跟上 `--server` 加上服务器的识别号。
```
[root@kerneltalks speedtest-cli]# python speedtest.py --server 2827
Retrieving speedtest.net configuration...
Testing from Amazon (35.154.184.126)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by Bharti Airtel Ltd (Mumbai) [1.15 km]: 13.234 ms
Testing download speed................................................................................
Download: 93.47 Mbit/s
Testing upload speed................................................................................................
Upload: 69.25 Mbit/s
```
**如果想得到你的测试结果的分享链接**,使用 `--share`,你将会得到测试结果的链接。
```
[root@kerneltalks speedtest-cli]# python speedtest.py --share
Retrieving speedtest.net configuration...
Testing from Amazon (35.154.184.126)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by Spectra (Mumbai) [1.15 km]: 7.471 ms
Testing download speed................................................................................
Download: 621.00 Mbit/s
Testing upload speed................................................................................................
Upload: 367.37 Mbit/s
Share results: http://www.speedtest.net/result/6687428141.png
```
输出中的最后一行就是你的测试结果的链接。下载下来的图片内容如下 :

这就是全部的过程!如果你不想了解这些技术细节,你也可以使用如下的一行命令迅速测出你的网速。
### 要想在终端使用一条命令测试网速。
我们将使用 `curl` 工具来在线抓取上面使用的 Python 脚本然后直接用 Python 执行脚本。
```
[root@kerneltalks ~]# curl -s https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py | python -
```
上面的脚本将会运行脚本输出结果到屏幕上。
```
[root@kerneltalks speedtest-cli]# curl -s https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py | python -
Retrieving speedtest.net configuration...
Testing from Amazon (35.154.184.126)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by Spectra (Mumbai) [1.15 km]: 12.599 ms
Testing download speed................................................................................
Download: 670.88 Mbit/s
Testing upload speed................................................................................................
Upload: 355.84 Mbit/s
```
这是在 RHEL 7 上执行的结果,在 Ubuntu、Debian、Fedora 或者 CentOS 上一样可以执行。
---
via: <https://kerneltalks.com/tips-tricks/how-to-test-internet-speed-in-linux-terminal/>
作者:[Shrikant Lavhate](https://kerneltalks.com) 译者:[FelixYFZ](https://github.com/FelixYFZ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Learn how to use speedtest CLI tool to test internet speed in the Linux terminal. It also includes a one-liner python command to get speed details right away.*

Most of us check the internet bandwidth speed whenever we connect to a new network or wifi. So why not our servers! Here is a tutorial that will walk you through to test internet speed in the Linux terminal.
Every one of us generally uses [Speedtest by Ookla](http://www.speedtest.net/) to check internet speed. It’s a pretty simple process for a desktop. Go to their website and just click the GO button. It will scan your location and speed test with the nearest server. If you are on mobile, they have their app for you. But if you are on the terminal with command-line interface things are little different. Let’s see how to check internet speed from the Linux terminal.
If you want to speed check only once and don’t want to download the tool on the server, [jump here](#oneliner) and see one-liner command.
### Step 1 : Download speedtest cli tool
First of all, you have to download speedtest CLI tool from the [GitHub](https://github.com/sivel/speedtest-cli) repository. Nowadays, it also included in many well known Linux repositories as well. If it’s there then you can directly [install that package on your Linux distro](https://kerneltalks.com/tools/package-installation-linux-yum-apt/).
Let’s proceed with the Github download and install process. [Install the git package](https://kerneltalks.com/tools/package-installation-linux-yum-apt/) depending on your distro. Then clone Github repo of speedtest like below:
```
[root@kerneltalks ~]# git clone https://github.com/sivel/speedtest-cli.git
Cloning into 'speedtest-cli'...
remote: Counting objects: 913, done.
remote: Total 913 (delta 0), reused 0 (delta 0), pack-reused 913
Receiving objects: 100% (913/913), 251.31 KiB | 143.00 KiB/s, done.
Resolving deltas: 100% (518/518), done.
```
It will be cloned to your present working directory. A new directory named `speedtest-cli`
will be created. You can see the below files in it.
```
[root@kerneltalks ~]# cd speedtest-cli
[root@kerneltalks speedtest-cli]# ll
total 96
-rw-r--r--. 1 root root 1671 Oct 7 16:55 CONTRIBUTING.md
-rw-r--r--. 1 root root 11358 Oct 7 16:55 LICENSE
-rw-r--r--. 1 root root 35 Oct 7 16:55 MANIFEST.in
-rw-r--r--. 1 root root 5215 Oct 7 16:55 README.rst
-rw-r--r--. 1 root root 20 Oct 7 16:55 setup.cfg
-rw-r--r--. 1 root root 3196 Oct 7 16:55 setup.py
-rw-r--r--. 1 root root 2385 Oct 7 16:55 speedtest-cli.1
-rw-r--r--. 1 root root 1200 Oct 7 16:55 speedtest_cli.py
-rwxr-xr-x. 1 root root 47228 Oct 7 16:55 speedtest.py
-rw-r--r--. 1 root root 333 Oct 7 16:55 tox.ini
```
The python script `speedtest.py`
is the one we will be using to check internet speed.
You can link this script for a command in `/usr/bin`
so that all users on the server can use it. Or you can even create [command alias](https://kerneltalks.com/commands/command-alias-in-linux-unix/) for it and it will be easy for all users to use it.
### Step 2 : Run python script
Now, run a python script without any argument and it will search the nearest server and test your internet speed.
```
[root@kerneltalks speedtest-cli]# python speedtest.py
Retrieving speedtest.net configuration...
Testing from Amazon (35.154.184.126)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by Spectra (Mumbai) [1.15 km]: 8.174 ms
Testing download speed................................................................................
Download: 548.13 Mbit/s
Testing upload speed................................................................................................
Upload: 323.95 Mbit/s
```
I am on th[e AWS EC2 Linux server](https://kerneltalks.com/howto/install-ec2-linux-server-aws-with-screenshots/). That’s the bandwidth of the Amazon data center! 🙂
### Different options with script
Few options which might be useful are as below :
**To search speedtest servers** nearby your location use `--list`
switch and `grep`
for your location name.
```
[root@kerneltalks speedtest-cli]# python speedtest.py --list | grep -i mumbai
2827) Bharti Airtel Ltd (Mumbai, India) [1.15 km]
8978) Spectra (Mumbai, India) [1.15 km]
4310) Hathway Cable and Datacom Ltd (Mumbai, India) [1.15 km]
3315) Joister Broadband (Mumbai, India) [1.15 km]
1718) Vodafone India (Mumbai, India) [1.15 km]
6454) YOU Broadband India Pvt Ltd. (Mumbai, India) [1.15 km]
9764) Railtel Corporation of india Ltd (Mumbai, India) [1.15 km]
9584) Sheng Li Telecom (Mumbai, India) [1.15 km]
7605) Idea Cellular Ltd. (Mumbai, India) [1.15 km]
8122) Sify Technologies Ltd (Mumbai, India) [1.15 km]
9049) I-ON (Mumbai, India) [1.15 km]
6403) YOU Broadband India Pvt Ltd., Mumbai (Mumbai, India) [1.15 km]
```
You can see here, the first column is a server identifier followed by the name of the company hosting that server, location, and finally its distance from your location.
**To test the internet speed using specific server** use `--server`
switch and server identifier from the previous output as an argument.
```
[root@kerneltalks speedtest-cli]# python speedtest.py --server 2827
Retrieving speedtest.net configuration...
Testing from Amazon (35.154.184.126)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by Bharti Airtel Ltd (Mumbai) [1.15 km]: 13.234 ms
Testing download speed................................................................................
Download: 93.47 Mbit/s
Testing upload speed................................................................................................
Upload: 69.25 Mbit/s
```
**To get the **share link of your speed test, use –share switch. It will give you the URL of your test hosted on speedtest website. You can share this URL.
```
[root@kerneltalks speedtest-cli]# python speedtest.py --share
Retrieving speedtest.net configuration...
Testing from Amazon (35.154.184.126)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by Spectra (Mumbai) [1.15 km]: 7.471 ms
Testing download speed................................................................................
Download: 621.00 Mbit/s
Testing upload speed................................................................................................
Upload: 367.37 Mbit/s
Share results: http://www.speedtest.net/result/6687428141.png
```
Observe the last line which includes the URL of your test result. If I download that image its the one below :
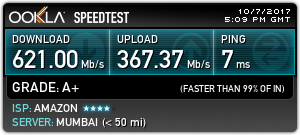
That’s it! But hey if you don’t want all this technical jargon, you can even use below one-liner to get speed test done right away.
### Internet speed test using one liner in terminal
We are going to use a [curl tool ](https://kerneltalks.com/tips-tricks/4-tools-download-file-using-command-line-linux/)to fetch the above python script online and supply it to python for execution on the go!
```
[root@kerneltalks ~]# curl -s https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py | python -
```
Above command will run the script and show you result on screen!
```
[root@kerneltalks speedtest-cli]# curl -s https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py | python -
Retrieving speedtest.net configuration...
Testing from Amazon (35.154.184.126)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by Spectra (Mumbai) [1.15 km]: 12.599 ms
Testing download speed................................................................................
Download: 670.88 Mbit/s
Testing upload speed................................................................................................
Upload: 355.84 Mbit/s
```
I tested this tool on RHEL 7 server but the process is same on Ubuntu, Debian, Fedora, or CentOS.
F.Y.I.
I am on Ubuntu 14.04-2 4.4.97.0
I had to clone from Github as using synaptic install speedtest was not found.
and had to use following:
~/.local/share/speedtest-cli /usr/bin/python speedtest.py
results:
Testing download speed………………………………….
Download: 11.10 Mbit/s
Testing upload speed…………………………………………..
Upload: 5.03 Mbit/s
via VPN
I do not have a landline but wireless on my desktop.
I AM happy with performance.
F.Y.i.
Thanks Richard for sharing this one. Will be helpful for other readers.
I’ve actually been using speedtest-cli for years. It’s a great CLI utility. It’s especially useful because it allows you to check the speed of your Internet connection, even when it’s too slow to be able to render speedtest.net in a reasonable amount of time. There’s also less visual fluff than using speedtest.net. I also think it looks cooler than just using speedtest.net directly. Though, I started using speedtest-cli on MacOS. Since MacOS doesn’t have a package manager like apt or RPM, I had to install it with a package manager called Homebrew – which does not come with MacOS. |
9,559 | Linux 系统中 sudo 命令的 10 个技巧 | https://www.linuxtechi.com/quick-tips-sudo-command-linux-systems/ | 2018-04-19T14:34:00 | [
"sudo",
"su"
] | https://linux.cn/article-9559-1.html | 
### 概览
`sudo` 表示 “**s**uper**u**ser **do**”。 它允许已验证的用户以其他用户的身份来运行命令。其他用户可以是普通用户或者超级用户。然而,大部分时候我们用它来以提升的权限来运行命令。
`sudo` 命令与安全策略配合使用,默认安全策略是 `sudoers`,可以通过文件 `/etc/sudoers` 来配置。其安全策略具有高度可拓展性。人们可以开发和分发他们自己的安全策略作为插件。
### 与 su 的区别
在 GNU/Linux 中,有两种方式可以用提升的权限来运行命令:
* 使用 `su` 命令
* 使用 `sudo` 命令
`su` 表示 “**s**witch **u**ser”。使用 `su`,我们可以切换到 root 用户并且执行命令。但是这种方式存在一些缺点:
* 我们需要与他人共享 root 的密码。
* 因为 root 用户为超级用户,我们不能授予受控的访问权限。
* 我们无法审查用户在做什么。
`sudo` 以独特的方式解决了这些问题。
1. 首先,我们不需要妥协来分享 root 用户的密码。普通用户使用他们自己的密码就可以用提升的权限来执行命令。
2. 我们可以控制 `sudo` 用户的访问,这意味着我们可以限制用户只执行某些命令。
3. 除此之外,`sudo` 用户的所有活动都会被记录下来,因此我们可以随时审查进行了哪些操作。在基于 Debian 的 GNU/Linux 中,所有活动都记录在 `/var/log/auth.log` 文件中。
本教程后面的部分阐述了这些要点。
### 实际动手操作 sudo
现在,我们对 sudo 有了大致的了解。让我们实际动手操作吧。为了演示,我使用 Ubuntu。但是,其它发行版本的操作应该是相同的。
#### 允许 sudo 权限
让我们添加普通用户为 `sudo` 用户吧。在我的情形中,用户名为 `linuxtechi`。
1) 按如下所示编辑 `/etc/sudoers` 文件:
```
$ sudo visudo
```
2) 添加以下行来允许用户 `linuxtechi` 有 sudo 权限:
```
linuxtechi ALL=(ALL) ALL
```
上述命令中:
* `linuxtechi` 表示用户名
* 第一个 `ALL` 指示允许从任何终端、机器访问 `sudo`
* 第二个 `(ALL)` 指示 `sudo` 命令被允许以任何用户身份执行
* 第三个 `ALL` 表示所有命令都可以作为 root 执行
#### 以提升的权限执行命令
要用提升的权限执行命令,只需要在命令前加上 `sudo`,如下所示:
```
$ sudo cat /etc/passwd
```
当你执行这个命令时,它会询问 `linuxtechi` 的密码,而不是 root 用户的密码。
#### 以其他用户执行命令
除此之外,我们可以使用 `sudo` 以另一个用户身份执行命令。例如,在下面的命令中,用户 `linuxtechi` 以用户 `devesh` 的身份执行命令:
```
$ sudo -u devesh whoami
[sudo] password for linuxtechi:
devesh
```
#### 内置命令行为
`sudo` 的一个限制是 —— 它无法使用 Shell 的内置命令。例如, `history` 记录是内置命令,如果你试图用 `sudo` 执行这个命令,那么会提示如下的未找到命令的错误:
```
$ sudo history
[sudo] password for linuxtechi:
sudo: history: command not found
```
**访问 root shell**
为了克服上述问题,我们可以访问 root shell,并在那里执行任何命令,包括 Shell 的内置命令。
要访问 root shell, 执行下面的命令:
```
$ sudo bash
```
执行完这个命令后——您将观察到提示符变为井号(`#`)。
### 技巧
这节我们将讨论一些有用的技巧,这将有助于提高生产力。大多数命令可用于完成日常任务。
#### 以 sudo 用户执行之前的命令
让我们假设你想用提升的权限执行之前的命令,那么下面的技巧将会很有用:
```
$ sudo !4
```
上面的命令将使用提升的权限执行历史记录中的第 4 条命令。
#### 在 Vim 里面使用 sudo 命令
很多时候,我们编辑系统的配置文件时,在保存时才意识到我们需要 root 访问权限来执行此操作。因为这个可能让我们丢失我们对文件的改动。没有必要惊慌,我们可以在 Vim 中使用下面的命令来解决这种情况:
```
:w !sudo tee %
```
上述命令中:
* 冒号 (`:`) 表明我们处于 Vim 的退出模式
* 感叹号 (`!`) 表明我们正在运行 shell 命令
* `sudo` 和 `tee` 都是 shell 命令
* 百分号 (`%`) 表明从当前行开始的所有行
#### 使用 sudo 执行多个命令
至今我们用 `sudo` 只执行了单个命令,但我们可以用它执行多个命令。只需要用分号 (`;`) 隔开命令,如下所示:
```
$ sudo -- bash -c 'pwd; hostname; whoami'
```
上述命令中
* 双连字符 (`--`) 停止命令行切换
* `bash` 表示要用于执行命令的 shell 名称
* `-c` 选项后面跟着要执行的命令
#### 无密码运行 sudo 命令
当第一次执行 `sudo` 命令时,它会提示输入密码,默认情形下密码被缓存 15 分钟。但是,我们可以避免这个操作,并使用 `NOPASSWD` 关键字禁用密码认证,如下所示:
```
linuxtechi ALL=(ALL) NOPASSWD: ALL
```
#### 限制用户执行某些命令
为了提供受控访问,我们可以限制 `sudo` 用户只执行某些命令。例如,下面的行只允许执行 `echo` 和 `ls` 命令 。
```
linuxtechi ALL=(ALL) NOPASSWD: /bin/echo /bin/ls
```
#### 深入了解 sudo
让我们进一步深入了解 `sudo` 命令。
```
$ ls -l /usr/bin/sudo
-rwsr-xr-x 1 root root 145040 Jun 13 2017 /usr/bin/sudo
```
如果仔细观察文件权限,则发现 `sudo` 上启用了 setuid 位。当任何用户运行这个二进制文件时,它将以拥有该文件的用户权限运行。在所示情形下,它是 root 用户。
为了演示这一点,我们可以使用 `id` 命令,如下所示:
```
$ id
uid=1002(linuxtechi) gid=1002(linuxtechi) groups=1002(linuxtechi)
```
当我们不使用 `sudo` 执行 `id` 命令时,将显示用户 `linuxtechi` 的 id。
```
$ sudo id
uid=0(root) gid=0(root) groups=0(root)
```
但是,如果我们使用 `sudo` 执行 `id` 命令时,则会显示 root 用户的 id。
### 结论
从这篇文章可以看出 —— `sudo` 为普通用户提供了更多受控访问。使用这些技术,多用户可以用安全的方式与 GNU/Linux 进行交互。
---
via: <https://www.linuxtechi.com/quick-tips-sudo-command-linux-systems/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 译者:[szcf-weiya](https://github.com/szcf-weiya) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ### Overview
**sudo** stands for **superuser do**. It allows authorized users to execute command as an another user. Another user can be regular user or superuser. However, most of the time we use it to execute command with elevated privileges.
sudo command works in conjunction with security policies, default security policy is sudoers and it is configurable via **/etc/sudoers** file. Its security policies are highly extendable. One can develop and distribute their own policies as plugins.
#### How it’s different than su
In GNU/Linux there are two ways to run command with elevated privileges:
- Using
**su**command - Using
**sudo**command
**su** stands for **switch user**. Using su, we can switch to root user and execute command. But there are few drawbacks with this approach.
- We need to share root password with another user.
- We cannot give controlled access as root user is superuser
- We cannot audit what user is doing.
sudo addresses these problems in unique way.
- First of all, we don’t need to compromise root user password. Regular user uses its own password to execute command with elevated privileges.
- We can control access of sudo user meaning we can restrict user to execute only certain commands.
- In addition to this all activities of sudo user are logged hence we can always audit what actions were done. On Debian based GNU/Linux all activities are logged in
**/var/log/auth.log**file.
Later sections of this tutorial sheds light on these points.
#### Hands on with sudo
Now, we have fair understanding about sudo. Let us get our hands dirty with practical. For demonstration, I am using Ubuntu. However, behavior with another distribution should be identical.
#### Allow sudo access
Let us add regular user as a sudo user. In my case user’s name is linuxtechi
1) Edit /etc/sudoers file as follows:
$ sudo visudo
2) Add below line to allow sudo access to user linuxtechi:
linuxtechi ALL=(ALL) ALL
In above command:
- linuxtechi indicates user name
- First ALL instructs to permit sudo access from any terminal/machine
- Second (ALL) instructs sudo command to be allowed to execute as any user
- Third ALL indicates all command can be executed as root
#### Execute command with elevated privileges
To execute command with elevated privileges, just prepend sudo word to command as follows:
$ sudo cat /etc/passwd
When you execute this command, it will ask linuxtechi’s password and not root user password.
#### Execute command as an another user
In addition to this we can use sudo to execute command as another user. For instance, in below command, user linuxtechi executes command as a devesh user:
$ sudo -u devesh whoami [sudo] password for linuxtechi: devesh
#### Built in command behavior
One of the limitation of sudo is – Shell’s built in command doesn’t work with it. For instance, history is built in command, if you try to execute this command with sudo then command not found error will be reported as follows:
$ sudo history [sudo] password for linuxtechi: sudo: history: command not found
**Access root shell**
To overcome above problem, we can get access to root shell and execute any command from there including Shell’s built in.
To access root shell, execute below command:
$ sudo bash
After executing this command – you will observe that prompt sign changes to pound (#) character.
**Recipes**
In this section we’ll discuss some useful recipes which will help you to improve productivity. Most of the commands can be used to complete day-to-day task.
#### Execute previous command as a sudo user
Let us suppose you want to execute previous command with elevated privileges, then below trick will be useful:
$ sudo !4
Above command will execute 4th command from history with elevated privileges.
If you want to execute the previous command with root privileges using sudo command, then use following command,
$ sudo !!
#### sudo command with Vim
Many times we edit system’s configuration files and while saving we realize that we need root access to do this. Because this we may lose our changes. There is no need to get panic, we can use below command in Vim to rescue from this situation:
:w !sudo tee %
In above command:
- Colon (:) indicates we are in Vim’s ex mode
- Exclamation (!) mark indicates that we are running shell command
- sudo and tee are the shell commands
- Percentage (%) sign indicates all lines from current line
#### Execute multiple commands using sudo
So far we have executed only single command with sudo but we can execute multiple commands with it. Just separate commands using semicolon (;) as follows:
$ sudo -- bash -c 'pwd; hostname; whoami'
In above command:
- Double hyphen (–) stops processing of command line switches
- bash indicates shell name to be used for execution
- Commands to be executed are followed by –c option
#### Run sudo command without password
When sudo command is executed first time then it will prompt for password and by default password will be cached for next 15 minutes. However, we can override this behavior and disable password authentication using NOPASSWD keyword as follows:
linuxtechi ALL=(ALL) NOPASSWD: ALL
#### Restrict user to execute certain commands
To provide controlled access we can restrict sudo user to execute only certain commands. For instance, below line allows execution of echo and ls commands only
linuxtechi ALL=(ALL) NOPASSWD: /bin/echo /bin/ls
#### Append line or text string to a file using sudo command
There are some scenarios where we to append a few lines to a existing file with local user who has sudo rights,
$ echo ‘text-string’ | sudo tee -a <path_of_file>
Example is shown below :
pkumar@linuxtechi:~$ echo "deb http://ftp.de.debian.org/debian buster main contrib" | sudo tee -a /etc/apt/sources.list deb http://ftp.de.debian.org/debian buster main contrib pkumar@linuxtechi:~$
Alternate way to append lines or text to existing file using sudo command,
sudo sh -c 'echo "deb http://ftp.de.debian.org/debian buster main contrib" >> /etc/apt/sources.list'
#### Insights about sudo
Let us dig more about sudo command to get insights about it.
$ ls -l /usr/bin/sudo -rwsr-xr-x 1 root root 145040 Jun 13 2017 /usr/bin/sudo
If you observe file permissions carefully, **setuid** bit is enabled on sudo. When any user runs this binary it will run with the privileges of the user that owns the file. In this case it is root user.
To demonstrate this, we can use id command with it as follows:
$ id uid=1002(linuxtechi) gid=1002(linuxtechi) groups=1002(linuxtechi)
When we execute id command without sudo then id of user linuxtechi will be displayed.
$ sudo id uid=0(root) gid=0(root) groups=0(root)
But if we execute id command with sudo then id of root user will be displayed.
#### Conclusion
Takeaway from this article is – sudo provides more controlled access to regular users. Using these techniques multiple users can interact with GNU/Linux in secure manner.
Read Also : [How to Create Hard and Soft (symlink) Links on Linux Systems](https://www.linuxtechi.com/tips-hard-soft-links-linux-unix-systems/)
Vince SHI always include the following lines in my /etc/sudoers:
Defaults logfile = /var/log/sudo.log, log_host, log_year
Defaults log_input, log_output, iolog_dir = /var/log/sudo-io/%{user}
The first line just adds hostname and the year parameter in /var/log/sudo.log. For viewing the logs from multiple servers, these parameters allow easier queries by hostname and date.
The second line is where the magic happens. This line tells sudo to log all input and output of each session. Using the sudoreplay command, I can replay any sudo session as though I was watching it happen live. The sudoreplay is great when people come to you and say, “I don’t know what I did, but something is broken.” Using the sudoreplay command, you will know EXACTLY what that person did. |
9,560 | 八种敏捷团队的提升方法 | https://opensource.com/article/18/1/foss-tools-agile-teams | 2018-04-19T21:32:17 | [
"敏捷"
] | /article-9560-1.html |
>
> 在这个列表中,没有项目管理软件,这里不包含清单,也没有与 GitHub 整合,只是几种组织思维和提高团队交流的方法。
>
>
>

你也许经常听说下面这句话:工具太多,时间太少。为了节约您的时间,我列出了几款我最常用的提高敏捷团队工作效率的工具。如果你也是一名敏捷主义者,你可能听说过类似的工具,但我这里提到的仅限于开源工具。
**请注意!** 这些工具和你想象的可能有点不同。它们并不是项目管理软件——这领域已经有一篇[好文章](https://opensource.com/business/16/3/top-project-management-tools-2016)了。因此这里不包含清单,也没有与 GitHub 整合,只是几种组织思维和提高团队交流的方法。
### 组建一个充满积极反馈的团队
如果在产业中大部分人都习惯了输出、接收负面消息,就很难有人对同事进行正面反馈的输出。这并不奇怪,当人们乐于给出赞美时,人们就会竞相向别人说“干得漂亮!”、“没有你我们很难完成任务。”赞美别人干的漂亮并不会使你痛苦,它通常能激励大家更好地为团队工作。下面两个软件可以帮助你向同事表达赞扬。
* 对开发团队来说,[Management 3.0](https://management30.com/) 是个有着大量[免费资源](https://management30.com/leadership-resource-hub/)的宝箱,可以尽情使用。其中 Feedback Wraps 的观念最引人注目(不仅仅是因为它让我们联想到墨西哥卷)。 [Feedback Wraps](https://management30.com/en/practice/feedback-wraps/) 是一个经过六步对用户进行反馈的程序,也许你会认为它是为了负面反馈而设计的,但我们发现它在表达积极评论方面十分有效。
* [Happiness Packets](https://happinesspackets.io/) 为用户提供了在开源社区内匿名正面反馈的服务。它尤其适合不太习惯人际交往的用户或是不知道说什么好的情况。Happiness Packets 拥有一份[公开的评论档案](https://www.happinesspackets.io/archive/)(这些评论都已经得到授权分享),你可以浏览大家的评论,从中得到灵感,对别人做出暖心的称赞。它还有个特殊功能,能够屏蔽恶意消息。
### 思考工作的意义
这很难定义。在敏捷领域中,成功的关键包括定义人物角色和产品愿景,还要向整个敏捷团队说明此项工作的意义。产品开发人员和项目负责人能够获得的开源工具数量极为有限,对于这一点我们有些失望。
在 Rat Hat 公司,最受尊敬也最为常用于训练敏捷团队的开源工具之一是 Product Vision Board 。它出自产品管理专家 Roman Pichler 之手,Roman Pichler 提供了[大量工具和模版](http://www.romanpichler.com/tools/)来帮助敏捷团队理解他们工作的意义。(你需要提供电子邮箱地址才能下载这些工具。)
* [Product Vision Board](http://www.romanpichler.com/tools/vision-board/) 的模版通过简单但有效的问题引导团队转变思考方式,将思考工作的意义置于具体工作方法之前。
* 我们也很喜欢 Roman 的 [Product Management Test](http://www.romanpichler.com/tools/romans-product-management-test/),它能够通过简便快捷的网页表单,引领团队重新定义产品开发人员的角色,并且找出程序漏洞。我们推荐产品开发团队周期性地完成此项测试,重新分析失败原因。
### 对工作内容的直观化
你是否曾为一个大案子焦头烂额,连熟悉的步骤也在脑海中乱成一团?我们也遇到过这种情况。使用思维导图可以梳理你脑海中的想法,使其直观化。你不需要一下就想出整件事该怎么进行,你只需要你的头脑,一块白板(或者是思维导图软件)和一些思考的时间。
* 在这个领域中我们最喜欢的开源工具是 [Xmind3](https://sourceforge.net/projects/xmind3/?source=recommended)。它支持多种平台运行(Linux、MacOS 和 Windows),以便与他人共享文件。如果你对工具的要求很高,推荐使用[其更新版本](http://www.xmind.net/),提供电子邮箱地址即可免费下载使用。
* 如果你很看重灵活性,Eduard Lucena 在 Fedora Magazine 中提供的 [三个附加选项](https://fedoramagazine.org/three-mind-mapping-tools-fedora/) 就十分适合。你可以在 Fedora 杂志上找到这些软件的获取方式,其他信息可以在它们的项目页找到。
+ [Labyrinth](https://people.gnome.org/%7Edscorgie/labyrinth.html)
+ [View Your Mind](http://www.insilmaril.de/vym/)
+ [FreeMind](http://freemind.sourceforge.net/wiki/index.php/Main_Page)
像我们开头说的一样,提高敏捷团队工作效率的工具有很多,如果你有特别喜欢的相关开源工具,请在评论中与大家分享。
### 作者简介
Jen Krieger :Red Hat 的首席敏捷架构师,在软件开发领域已经工作超过 20 年,曾在瀑布及敏捷生命周期等领域扮演多种角色。目前在 Red Hat 负责针对 CI/CD 最佳效果的部际 DevOps 活动。最近她在与 Project Atomic & OpenShift 团队合作。她最近在引领公司向着敏捷团队改革,并增加开源项目在公司内的认知度。
---
via: <https://opensource.com/article/18/1/foss-tools-agile-teams>
作者:[Jen Krieger](https://opensource.com/users/jkrieger) 译者:[Valoniakim](https://github.com/Valoniakim) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,561 | 初识 Python: global 关键字 | https://www.programiz.com/python-programming/global-keyword | 2018-04-19T21:44:00 | [
"Python"
] | https://linux.cn/article-9561-1.html | 
在读这篇文章之前,确保你对 [Python 全局、局部和非局部变量](https://www.programiz.com/python-programming/global-local-nonlocal-variables) 有一定的基础。
### global 关键字简介
在 Python 中,`global` 关键字允许你修改当前范围之外的变量。它用于创建全局变量并在本地上下文中更改变量。
### global 关键字的规则
在 Python 中,有关 `global` 关键字基本规则如下:
* 当我们在一个函数中创建一个变量时,默认情况下它是本地变量。
* 当我们在一个函数之外定义一个变量时,默认情况下它是全局变量。你不必使用 `global` 关键字。
* 我们使用 `global` 关键字在一个函数中来读写全局变量。
* 在一个函数外使用 `global` 关键字没有效果。
### 使用 global 关键字(含示例)
我们来举个例子。
#### 示例 1:从函数内部访问全局变量
```
c = 1 # 全局变量
def add():
print(c)
add()
```
运行程序,输出为:
```
1
```
但是我们可能有一些场景需要从函数内部修改全局变量。
#### 示例 2:在函数内部修改全局变量
```
c = 1 # 全局变量
def add():
c = c + 2 # 将 c 增加 2
print(c)
add()
```
运行程序,输出显示错误:
```
UnboundLocalError: local variable 'c' referenced before assignment
```
这是因为在函数中,我们只能访问全局变量但是不能修改它。
解决的办法是使用 `global` 关键字。
#### 示例 3:使用 global 在函数中改变全局变量
```
c = 0 # global variable
def add():
global c
c = c + 2 # 将 c 增加 2
print("Inside add():", c)
add()
print("In main:", c)
```
运行程序,输出为:
```
Inside add(): 2
In main: 2
```
在上面的程序中,我们在 `add()` 函数中定义了 `c` 将其作为全局关键字。
然后,我们给变量 `c` 增加 `2`,即 `c = c + 2`。之后,我们调用了 `add()` 函数。最后,打印全局变量 `c`。
正如我们所看到的,在函数外的全局变量也发生了变化,`c = 2`。
### Python 模块中的全局变量
在 Python 中,我们创建一个单独的模块 `config.py` 来保存全局变量并在同一个程序中的 Python 模块之间共享信息。
以下是如何通过 Python 模块共享全局变量。
#### 示例 4:在Python模块中共享全局变量
创建 `config.py` 文件来存储全局变量
```
a = 0
b = "empty"
```
创建 `update.py` 文件来改变全局变量
```
import config
config.a = 10
config.b = "alphabet"
```
创建 `main.py` 文件来测试其值的变化
```
import config
import update
print(config.a)
print(config.b)
```
运行 `main.py`,输出为:
```
10
alphabet
```
在上面,我们创建了三个文件: `config.py`, `update.py` 和 `main.py`。
在 `config.py` 模块中保存了全局变量 `a` 和 `b`。在 `update.py` 文件中,我们导入了 `config.py` 模块并改变了 `a` 和 `b` 的值。同样,在 `main.py` 文件,我们导入了 `config.py` 和 `update.py` 模块。最后,我们打印并测试全局变量的值,无论它们是否被改变。
### 在嵌套函数中的全局变量
以下是如何在嵌套函数中使用全局变量。
#### 示例 5:在嵌套函数中使用全局变量
```
def foo():
x = 20
def bar():
global x
x = 25
print("Before calling bar: ", x)
print("Calling bar now")
bar()
print("After calling bar: ", x)
foo()
print("x in main : ", x)
```
输出为:
```
Before calling bar: 20
Calling bar now
After calling bar: 20
x in main : 25
```
在上面的程序中,我们在一个嵌套函数 `bar()` 中声明了全局变量。在 `foo()` 函数中, 变量 `x` 没有全局关键字的作用。
调用 `bar()` 之前和之后, 变量 `x` 取本地变量的值,即 `x = 20`。在 `foo()` 函数之外,变量 `x` 会取在函数 `bar()` 中的值,即 `x = 25`。这是因为在 `bar()` 中,我们对 `x` 使用 `global` 关键字创建了一个全局变量(本地范围)。
如果我们在 `bar()` 函数内进行了任何修改,那么这些修改就会出现在本地范围之外,即 `foo()`。
---
via: <https://www.programiz.com/python-programming/global-keyword>
作者:[programiz](https://www.programiz.com) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In Python, the `global`
keyword allows us to modify the variable outside of the current scope.
It is used to create a global variable and make changes to the variable in a local context.
Before we learn about the `global`
keyword, make sure you have got some basics of [Python Variable Scope](/python-programming/global-local-nonlocal-variables).
## Access and Modify Python Global Variable
First let's try to access a global variable from the inside of a [function](https://www.programiz.com/python-programming/function),
```
``````
c = 1 # global variable
def add():
print(c)
add()
# Output: 1
```
Here, we can see that we have accessed a global variable from the inside of a function.
However, if we try to modify the global variable from inside a function as:
```
``````
# global variable
c = 1
def add():
# increment c by 2
c = c + 2
print(c)
add()
```
**Output**
UnboundLocalError: local variable 'c' referenced before assignment
This is because we can only access the global variable but cannot modify it from inside the function.
The solution for this is to use the `global`
keyword.
### Example: Changing Global Variable From Inside a Function using global
```
``````
# global variable
c = 1
def add():
# use of global keyword
global c
# increment c by 2
c = c + 2
print(c)
add()
# Output: 3
```
In the above example, we have defined `c` as the `global`
keyword inside `add()`
.
Then, we have incremented the variable `c` by **2**, i.e `c = c + 2`
.
As we can see while calling `add()`
, the value of global variable `c` is modified from **1** to **3**.
## Rules of global Keyword
The basic rules for `global`
keyword in Python are:
- When we create a variable inside a function, it is local by default.
- When we define a variable outside of a function, it is global by default. You don't have to use the
`global`
keyword. - We use the
`global`
keyword to modify (write to) a global variable inside a function. - Use of the
`global`
keyword outside a function has no effect.
**Also Read:** |
9,563 | 13 个 Git 技巧献给 Git 13 岁生日 | https://opensource.com/article/18/4/git-tips | 2018-04-20T16:24:00 | [
"版本控制",
"Git"
] | /article-9563-1.html |
>
> 这 13 个 Git 技巧将使你的版本控制技能 +1、+1、+1……
>
>
>

[Git](https://git-scm.com/) 是一个分布式版本控制系统,它已经成为开源世界中源代码控制的默认工具,在 4 月 7 日这天,它 13 岁了。使用 Git 令人沮丧的事情之一是你需要知道更多才能有效地使用 Git。但这也可能是使用 Git 比较美妙的一件事,因为没有什么比发现一个新技巧来简化或提高你的工作流的效率更令人快乐了。
为了纪念 Git 的 13 岁生日,这里有 13 条技巧和诀窍来让你的 Git 经验更加有用和强大。从你可能忽略的一些基本知识开始,并扩展到一些真正的高级用户技巧!
### 1、 你的 ~/.gitconfig 文件
当你第一次尝试使用 `git` 命令向仓库提交一个更改时,你可能会收到这样的欢迎信息:
```
*** Please tell me who you are.
Run
git config --global user.email "[email protected]"
git config --global user.name "Your Name"
to set your account's default identity.
```
你可能没有意识到正是这些命令在修改 `~/.gitconfig` 的内容,这是 Git 存储全局配置选项的地方。你可以通过 `~/.gitconfig` 文件来做大量的事,包括定义别名、永久性打开(或关闭)特定命令选项,以及修改 Git 工作方式(例如,`git diff` 使用哪个 diff 算法,或者默认使用什么类型的合并策略)。你甚至可以根据仓库的路径有条件地包含其他配置文件!所有细节请参阅 `man git-config`。
### 2、 你仓库中的 .git/config 文件
在之前的技巧中,你可能想知道 `git config` 命令中 `--global` 标志是干什么的。它告诉 Git 更新 `~/.gitconfig` 中的“全局”配置。当然,有全局配置也意味着会有本地配置,显然,如果你省略 `--global` 标志,`git config` 将改为更新仓库特有的配置,该配置存储在 `.git/config` 中。
在 `.git/config` 文件中设置的选项将覆盖 `~/.gitconfig` 文件中的所有设置。因此,例如,如果你需要为特定仓库使用不同的电子邮件地址,则可以运行 `git config user.email "[email protected]"`。然后,该仓库中的任何提交都将使用你单独配置的电子邮件地址。如果你在开源项目中工作,而且希望它们显示自己的电子邮件地址,同时仍然使用自己工作邮箱作为主 Git 配置,这非常有用。
几乎任何你可以在 `~/.gitconfig` 中设置的东西,你也可以在 `.git/config` 中进行设置,以使其作用于特定的仓库。在下面的技巧中,当我提到将某些内容添加到 `~/.gitconfig` 时,只需记住你也可以在特定仓库的 `.git/config` 中添加来设置那个选项。
### 3、 别名
别名是你可以在 `~/.gitconfig` 中做的另一件事。它的工作原理就像命令行中的 shell —— 它们设定一个新的命令名称,可以调用一个或多个其他命令,通常使用一组特定的选项或标志。它们对于那些你经常使用的又长又复杂的命令来说非常有效。
你可以使用 `git config` 命令来定义别名 —— 例如,运行 `git config --global --add alias.st status` 将使运行 `git st` 与运行 `git status` 做同样的事情 —— 但是我在定义别名时发现,直接编辑 `~/.gitconfig` 文件通常更容易。
如果你选择使用这种方法,你会发现 `~/.gitconfig` 文件是一个 [INI 文件](https://en.wikipedia.org/wiki/INI_file)。INI 是一种带有特定段落的键值对文件格式。当添加一个别名时,你将改变 `[alias]` 段落。例如,定义上面相同的 `git st` 别名时,添加如下到文件:
```
[alias]
st = status
```
(如果已经有 `[alias]` 段落,只需将第二行添加到现有部分。)
### 4、 shell 命令中的别名
别名不仅仅限于运行其他 Git 子命令 —— 你还可以定义运行其他 shell 命令的别名。这是一个用来处理一个反复发生的、罕见和复杂的任务的很好方式:一旦你确定了如何完成它,就可以在别名下保存该命令。例如,我有一些<ruby> 复刻 <rt> fork </rt></ruby>的开源项目的仓库,并进行了一些本地修改。我想跟上项目正在进行的开发工作,并保存我本地的变化。为了实现这个目标,我需要定期将来自上游仓库的更改合并到我复刻的项目中 —— 我通过使用我称之为 `upstream-merge` 的别名来完成。它是这样定义的:
```
upstream-merge = !"git fetch origin -v && git fetch upstream -v && git merge upstream/master && git push"
```
别名定义开头的 `!` 告诉 Git 通过 shell 运行这个命令。这个例子涉及到运行一些 `git` 命令,但是以这种方式定义的别名可以运行任何 shell 命令。
(注意,如果你想复制我的 `upstream-merge` 别名,你需要确保你有一个名为 `upstream` 的 Git 远程仓库,指向你已经分配的上游仓库,你可以通过运行 `git remote add upstream <URL to repo>` 来添加一个。)
### 5、 可视化提交图
如果你在一个有很多分支活动的项目上开发,有时可能很难掌握所有正在发生的工作以及它们之间的相关性。各种图形用户界面工具可让你获取不同分支的图片并在所谓的“提交图表”中提交。例如,以下是我使用 [GitLab](https://gitlab.com/) 提交图表查看器可视化的我的一个仓库的一部分:

如果你是一个专注于命令行的用户或者发现分支切换工具让人分心,那么可以从命令行获得类似的提交视图。这就是 `git log` 命令的 `--graph` 参数出现的地方:

以下命令可视化相同仓库可达到相同效果:
```
git log --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit --date=relative
```
`--graph` 选项将图添加到日志的左侧,`--abbrev-commit` 缩短提交的 [SHA](https://en.wikipedia.org/wiki/Secure_Hash_Algorithms) 值,`--date=relative` 以相对方式表示日期,以及 `--pretty` 来处理所有其他自定义格式。我有个 `git lg` 别名用于这个功能,它是我最常用的 10 个命令之一。
### 6、 更优雅的强制推送
有时,你越是想避开越避不开,你会发现你需要运行 `git push --force` 来覆盖仓库远程副本上的历史记录。你可能得到了一些反馈,需要你进行交互式<ruby> 变基 <rt> rebase </rt></ruby>,或者你可能已经搞砸了,并希望隐藏“罪证”。
当其他人在仓库的远程副本的同一分支上进行更改时,会发生强制推送的危险。当你强制推送已重写的历史记录时,这些提交将会丢失。这就是 `git push --force-with-lease` 出现的原因 -- 如果远程分支已经更新,它不会允许你强制推送,这确保你不会丢掉别人的工作。
### 7、 git add -N
你是否使用过 `git commit -a` 在一次行动中提交所有未完成的修改,但在你推送完提交后才发现 `git commit -a` 忽略了新添加的文件?你可以使用 `git add -N` (想想 “notify”) 来解决这个问题,告诉 Git 在第一次实际提交它们之前,你希望在提交中包含新增文件。
### 8、 git add -p
使用 Git 时的最佳做法是确保每次提交都只包含一个逻辑修改 —— 无论这是修复错误还是添加新功能。然而,有时当你在工作时,你的仓库中的修改最终应该使用多个提交。你怎样才能设法把事情分开,使每个提交只包含适当的修改呢?`git add --patch` 来拯救你了!
这个标志会让 `git add` 命令查看你工作副本中的所有变化,并为每个变化询问你是否想要将它提交、跳过,或者推迟决定(你可以在运行该命令后选择 `?` 来查看其他更强大的选项)。`git add -p` 是生成结构良好的提交的绝佳工具。
### 9、 git checkout -p
与 `git add -p` 类似,`git checkout` 命令也接受 `--patch` 或 `-p` 选项,这会使其在本地工作副本中显示每个“大块”的改动,并允许丢弃它 —— 简单来说就是将本地工作副本恢复到更改之前的状态。
这真的很棒。例如,当你追踪一个 bug 时引入了一堆调试日志语句,修正了这个 bug 之后,你可以先使用 `git checkout -p` 移除所有新的调试日志,然后 `git add -p` 来添加 bug 修复。没有比组合一个优雅的、结构良好的提交更令人满意!
### 10、 变基时执行命令
有些项目有一个规则,即存储库中的每个提交都必须处于可工作状态 —— 也就是说,在每次提交时,应该可以编译该代码,或者应该运行测试套件而不会失败。 当你在分支上工作时,这并不困难,但是如果你最终因为某种原因需要<ruby> 变基 <rt> rebase </rt></ruby>时,那么需要逐步完成每个变基的提交以确保你没有意外地引入一个中断,而这个过程是乏味的。
幸运的是,`git rebase` 已经覆盖了 `-x` 或 `--exec` 选项。`git rebase -x <cmd>` 将在每个提交在变基中被应用后运行该命令。因此,举个例子,如果你有一个项目,其中使用 `npm run tests` 运行你的测试套件,`git rebase -x npm run tests` 将在变基期间每次提交之后运行测试套件。这使你可以查看测试套件是否在任何变基的提交中失败,以便你可以确认测试套件在每次提交时仍能通过。
### 11、 基于时间的修订引用
很多 Git 子命令都接受一个修订参数来决定命令作用于仓库的哪个部分,可以是某次特定的提交的 SHA1 值,一个分支的名称,甚至是一个符号性的名称如 `HEAD`(代表当前检出分支最后一次的提交),除了这些简单的形式以外,你还可以附加一个指定的日期或时间作为参数,表示“这个时间的引用”。
这个功能在某些时候会变得十分有用。当你处理最新出现的 bug,自言自语道:“这个功能昨天还是好好的,到底又改了些什么”,不用盯着满屏的 `git log` 的输出试图弄清楚什么时候更改了提交,你只需运行 `git diff HEAD@{yesterday}`,看看从昨天以来的所有修改。这也适用于更长的时间段(例如 `git diff HEAD@{'2 months ago'}`),以及一个确切的日期(例如 `git diff HEAD@{'2010-01-01 12:00:00'}`)。
你也可以将这些基于日期的修订参数与使用修订参数的任何 Git 子命令一起使用。在 `gitrevisions` 手册页中有关于具体使用哪种格式的详细信息。
### 12、 全知的 reflog
你是不是试过在变基时干掉过某次提交,然后发现你需要保留那个提交中一些东西?你可能觉得这些信息已经永远找不回来了,只能重新创建。但是如果你在本地工作副本中提交了,提交就会被添加到引用日志(reflog)中 ,你仍然可以访问到。
运行 `git reflog` 将在本地工作副本中显示当前分支的所有活动的列表,并为你提供每个提交的 SHA1 值。一旦发现你变基时放弃的那个提交,你可以运行 `git checkout <SHA1>` 跳转到该提交,复制任何你需要的信息,然后再运行 `git checkout HEAD` 返回到分支最近的提交去。
### 13、 自己清理
哎呦! 事实证明,我的基本数学技能不如我的 Git 技能。 Git 最初是在 2005 年发布的,这意味着它今年会变成 13 岁,而不是 12 岁(LCTT 译注:本文原来是以 12 岁生日为题的)。为了弥补这个错误,这里有可以让我们变成十三岁的第 13 条技巧。
如果你使用基于分支的工作流,随着在一个长期项目上的工作,除非你在每个分支合并时清理干净,否则你最终会得到一大堆分支。这使得你难于找到想要的分支,分支的森林会让你无从找起。甚至更糟糕的是,如果你有大量活跃的分支,确定一个分支是否被合并(可以被安全删除)或仍然没有被合并而应该留下会非常繁琐。幸运的是,Git 可以帮到你:只需要运行 `git branch --merged` 就可以得到已经被合并到你的当前分支的分支列表,或者 `git branch --no-merged` 找出被合并到其它分支的分支。默认情况下这会列出你本地工作副本的分支,但是如果你在命令行包括 `--remote` 或 `-r` 参数,它也会列出仅存于远程仓库的已合并分支。
重要提示:如果你计划使用 `git branch --merged` 的输出来清理那些已合并的分支,你要小心它的输出也包括了当前分支(毕竟,这个当前的分支就被合并到当前分支!)。确保你在任何销毁动作之前排除了该分支(如果你忘记了,参见第 12 条技巧来学习 reflog 怎样帮你把分支找回来,希望有用……)。
### 以上是全部内容
希望这些技巧中至少有一个能够教给你一些关于 Git 的新东西,Git 是一个有 13 年历史的项目,并且在持续创新和增加新功能中。你最喜欢的 Git 技巧是什么?
---
via: <https://opensource.com/article/18/4/git-tips>
作者:[John SJ Anderson](https://opensource.com/users/genehack) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,564 | Fedora 社区的持续集成 | https://fedoramagazine.org/continuous-integration-fedora/ | 2018-04-20T22:31:44 | [
"CI",
"Fedora"
] | https://linux.cn/article-9564-1.html | 
<ruby> 持续集成 <rt> Continuous Integration </rt></ruby>(CI) 是为项目的每一项变更运行测试的过程,如同这是新的交付项目一样。如果持续执行,这意味着软件随时可以发布。 CI 是整个 IT 行业以及自由开源项目非常成熟的流程。Fedora 在这方面有点落后,但我们正在赶上。阅读以下内容了解进展。
### 我们为什么需要这个?
CI 将全面改善 Fedora。它通过尽早揭示 bug 提供更稳定和一致的操作系统。它让你在遇到问题时添加测试,以免再次发生(避免回归)。CI 可以运行来自上游的项目测试,还有测试集成在发行版中 Fedora 特定的测试。
最重要的是,一致的 CI 能自动化并减少手工劳动。它释放了我们宝贵的志愿者和贡献者,让他们将更多时间花在 Fedora 的新事物上。
### 它看起来如何?
对于初学者,我们将对在 Fedora 包仓库 (dist-git) 的每个提交运行测试。这些测试独立于构建时运行的每个软件包的测试。但是,它们在尽可能接近 Fedora 用户运行环境的环境中测试软件包的功能。除了特定的软件包测试外,Fedora 还运行一些发行版测试,例如从 F27 升级到 F28 或者全新安装。
软件包根据测试结果进行“控制”:测试失败会阻止将更新推送给用户。但是,有时由于各种原因,测试会失败。也许测试本身是错误的,或者不是最新的软件。或者可能发生基础架构问题,并阻止测试正常运行。维护人员能够重新触发测试或放弃测试结果,直到测试更新。
最终,当在 <https://src.fedoraproject.org> 上有合并请求或者更新时,Fedora 的 CI 将运行测试。这将使维护者了解建议的更改对包稳定性的影响,并帮助他们决定如何进行。
### 我们如今有什么?
目前,CI 管道在 Fedora Atomic Host 的部分软件包上运行测试。其他软件包可以在 dist-git 中进行测试,但它们不会自动运行。发行版特定的测试已经在我们所有的软件包上运行。这些测试结果被用于过滤测试失败的软件包。
### 我该如何参与?
最好的入门方法是阅读关于 [Fedora 持续集成](http://fedoraproject.org/wiki/CI)的文档。你应该熟悉[标准测试接口](http://fedoraproject.org/wiki/CI/Standard_Test_Interface),它描述了很多术语以及如何编写测试和使用现有的测试。
有了这些知识,如果你是一个软件包维护者,你可以开始添加测试到你的软件包。你可以在本地或虚拟机上运行它们。 (对于破坏性测试来说后者是明智的!)
标准测试接口使测试保持一致。因此,你可以轻松地将任何测试添加到你喜欢的包中,并在 [仓库][3](https://src.fedoraproject.org) 提交合并请求给维护人员。
在 irc.freenode.net 上与 #fedora-ci 联系,提供反馈,问题或关于 CI 的一般性讨论。
---
via: <https://fedoramagazine.org/continuous-integration-fedora/>
作者:[Pierre-Yves Chibon](https://fedoramagazine.org) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Continuous Integration (CI) is the process of running tests for every change made to a project, integrated as if this were the new deliverable. If done consistently, it means that software is always ready to be released. CI is a very well established process across the entire IT industry as well as free and open source projects. Fedora has been a little behind on this, but we’re catching up. Read below to find out how.
## Why do we need this?
CI will improve Fedora all around. It provides a more stable and consistent operating system by revealing bugs as early as possible. It lets you add tests when you encounter an issue so it doesn’t happen again (avoid regressions). CI can run tests from the upstream project as well as Fedora-specific ones that test the integration of the application in the distribution.
Above all, consistent CI allows automation and reduced manual labor. It frees up our valuable volunteers and contributors to spend more time on new things for Fedora.
## How will it look?
For starters, we’ll run tests for every commit to git repositories of Fedora’s packages (dist-git). These tests are independent of the tests each of these packages run when built. However, they test the functionality of the package in an environment as close as possible to what Fedora’s users run. In addition to package-specific tests, Fedora also runs some distribution-wide tests, such as upgrade testing from F27 to F28 or rawhide.
Packages are “gated” based on test results: test failures prevent an update being pushed to users. However, sometimes tests fail for various reasons. Perhaps the tests themselves are wrong, or not up to date with the software. Or perhaps an infrastructure issue occurred and prevented the tests from running correctly. Maintainers will be able to re-trigger the tests or waive their results until the tests are updated.
Eventually, Fedora’s CI will run tests when a new pull-request is opened or updated on [https://src.fedoraproject.org](https://src.fedoraproject.org). This will give maintainers information about the impact of the proposed change on the stability of the package, and help them decide how to proceed.
## What do we have today?
Currently, a CI pipeline runs tests on packages that are part of Fedora Atomic Host. Other packages can have tests in dist-git, but they won’t be run automatically yet. Distribution specific tests already run on all of our packages. These test results are used to gate packages with failures.
## How do I get involved?
The best way to get started is to read the documentation about [Continuous Integration in Fedora](http://fedoraproject.org/wiki/CI). You should get familiar with the [Standard Test Interface](http://fedoraproject.org/wiki/CI/Standard_Test_Interface), which describes a lot of the terminology as well as how to write tests and use existing ones.
With this knowledge, if you’re a package maintainer you can start adding tests to your packages. You can run them on your local machine or in a virtual machine. (This latter is advisable for destructive tests!)
The Standard Test Interface makes testing consistent. As a result, you can easily add any tests to a package you like, and submit them to the maintainers in a pull-request on its [repository](https://src.fedoraproject.org).
Reach out on #fedora-ci on irc.freenode.net with feedback, questions or for a general discussion on CI.
Photo by [Samuel Zeller](https://unsplash.com/photos/77oXlGwwOw0?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/search/photos/factory-line?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) |
9,565 | 迁移到 Linux:命令行环境 | https://www.linux.com/blog/learn/2018/1/migrating-linux-command-line | 2018-04-20T23:03:00 | [
"迁移"
] | https://linux.cn/article-9565-1.html |
>
> 刚接触 Linux?在这篇教程中将学习如何轻松地在命令行列出、移动和编辑文件。
>
>
>

这是关于迁徙到 Linux 系列的第四篇文章了。如果您错过了之前的内容,可以回顾我们之前谈到的内容 [新手之 Linux](/article-9212-1.html)、[文件和文件系统](/article-9213-1.html)、和 [图形环境](/article-9293-1.html)。Linux 无处不在,它可以用于运行大部分的网络服务器,如 Web、email 和其他服务器;它同样可以在您的手机、汽车控制台和其他很多设备上使用。现在,您可能会开始好奇 Linux 系统,并对学习 Linux 的工作原理萌发兴趣。
在 Linux 下,命令行非常实用。Linux 的桌面系统中,尽管命令行只是可选操作,但是您依旧能看见很多朋友开着一个命令行窗口和其他应用窗口并肩作战。在互联网服务器上和在设备中运行 Linux 时(LCTT 译注:指 IoT),命令行通常是唯一能直接与操作系统交互的工具。因此,命令行是有必要了解的,至少应当涉猎一些基础命令。
在命令行(通常称之为 Linux shell)中,所有操作都是通过键入命令完成。您可以执行查看文件列表、移动文件位置、显示文件内容、编辑文件内容等一系列操作,通过命令行,您甚至可以查看网页中的内容。
如果您在 Windows(CMD 或者 PowerShell) 上已经熟悉关于命令行的使用,您是否想跳转到“Windows 命令行用户”的章节上去?先阅读这些内容吧。
### 导航
在命令行中,这里有一个当前工作目录(文件夹和目录是同义词,在 Linux 中它们通常都被称为目录)的概念。如果没有特别指定目录,许多命令的执行会在当前目录下生效。比如,键入 `ls` 列出文件目录,当前工作目录的文件将会被列举出来。看一个例子:
```
$ ls
Desktop Documents Downloads Music Pictures README.txt Videos
```
`ls Documents` 这条命令将会列出 `Documents` 目录下的文件:
```
$ ls Documents
report.txt todo.txt EmailHowTo.pdf
```
通过 `pwd` 命令可以显示当前您的工作目录。比如:
```
$ pwd
/home/student
```
您可以通过 `cd` 命令改变当前目录并切换到您想要抵达的目录。比如:
```
$ pwd
/home/student
$ cd Downloads
$ pwd
/home/student/Downloads
```
路径中的目录由 `/`(左斜杠)字符分隔。路径中有一个隐含的层次关系,比如 `/home/student` 目录中,home 是顶层目录,而 `student` 是 `home` 的子目录。
路径要么是绝对路径,要么是相对路径。绝对路径由一个 `/` 字符打头。
相对路径由 `.` 或者 `..` 开始。在一个路径中,一个 `.` 意味着当前目录,`..` 意味着当前目录的上级目录。比如,`ls ../Documents` 意味着在此寻找当前目录的上级名为 `Documents` 的目录:
```
$ pwd
/home/student
$ ls
Desktop Documents Downloads Music Pictures README.txt Videos
$ cd Downloads
$ pwd
/home/student/Downloads
$ ls ../Documents
report.txt todo.txt EmailHowTo.pdf
```
当您第一次打开命令行窗口时,您当前的工作目录被设置为您的家目录,通常为 `/home/<您的登录名>`。家目录专用于登录之后存储您的专属文件。
环境变量 `$HOME` 会展开为您的家目录,比如:
```
$ echo $HOME
/home/student
```
下表显示了用于目录导航和管理简单的文本文件的一些命令摘要。

### 搜索
有时我们会遗忘文件的位置,或者忘记了我要寻找的文件名。Linux 命令行有几个命令可以帮助您搜索到文件。
第一个命令是 `find`。您可以使用 `find` 命令通过文件名或其他属性搜索文件和目录。举个例子,当您遗忘了 `todo.txt` 文件的位置,我们可以执行下面的代码:
```
$ find $HOME -name todo.txt
/home/student/Documents/todo.txt
```
`find` 程序有很多功能和选项。一个简单的例子:
```
find <要寻找的目录> -name <文件名>
```
如果这里有 `todo.txt` 文件且不止一个,它将向我们列出拥有这个名字的所有文件的所有所在位置。`find` 命令有很多便于搜索的选项比如类型(文件或是目录等等)、时间、大小和其他一些选项。更多内容您可以同通过 `man find` 获取关于如何使用 `find` 命令的帮助。
您还可以使用 `grep` 命令搜索文件的特定内容,比如:
```
grep "01/02/2018" todo.txt
```
这将为您展示 `todo` 文件中 `01/02/2018` 所在行。
### 获取帮助
Linux 有很多命令,这里,我们没有办法一一列举。授人以鱼不如授人以渔,所以下一步我们将向您介绍帮助命令。
`apropos` 命令可以帮助您查找需要使用的命令。也许您想要查找能够操作目录或是获得文件列表的所有命令,但是您不知道该运行哪个命令。您可以这样尝试:
```
apropos directory
```
要在帮助文档中,得到一个于 `directiory` 关键字的相关命令列表,您可以这样操作:
```
apropos "list open files"
```
这将提供一个 `lsof` 命令给您,帮助您列出打开文件的列表。
当您明确知道您要使用的命令,但是不确定应该使用什么选项完成预期工作,您可以使用 `man` 命令,它是 manual 的缩写。您可以这样使用:
```
man ls
```
您可以在自己的设备上尝试这个命令。它会提供给您关于使用这个命令的完整信息。
通常,很多命令都能够接受 `help` 选项(比如说,`ls --help`),列出命令使用的提示。`man` 页面的内容通常太繁琐,`--help` 选项可能更适合快速浏览。
### 脚本
Linux 命令行中最贴心的功能之一是能够运行脚本文件,并且能重复运行。Linux 命令可以存储在文本文件中,您可以在文件的开头写入 `#!/bin/sh`,后面的行是命令。之后,一旦文件被存储为可执行文件,您就可以像执行命令一样运行脚本文件,比如,
```
--- contents of get_todays_todos.sh ---
#!/bin/sh
todays_date=`date +"%m/%d/%y"`
grep $todays_date $HOME/todos.txt
```
脚本可以以一套可重复的步骤自动化执行特定命令。如果需要的话,脚本也可以很复杂,能够使用循环、判断语句等。限于篇幅,这里不细述,但是您可以在网上查询到相关信息。
### Windows 命令行用户
如果您对 Windows CMD 或者 PowerShell 程序很熟悉,在命令行输入命令应该是轻车熟路的。然而,它们之间有很多差异,如果您没有理解它们之间的差异可能会为之困扰。
首先,在 Linux 下的 `PATH` 环境与 Windows 不同。在 Windows 中,当前目录被认为是该搜索路径(`PATH`)中的第一个文件夹,尽管该目录没有在环境变量中列出。而在 Linux 下,当前目录不会明确的放在搜索路径中。Linux 下设置环境变量会被认为是风险操作。在 Linux 的当前目录执行程序,您需要使用 `./`(代表当前目录的相对目录表示方式) 前缀。这可能会搞糊涂很多 CMD 用户。比如:
```
./my_program
```
而不是
```
my_program
```
另外,在 Windows 环境变量的路径中是以 `;`(分号) 分割的。在 Linux 中,由 `:` 分割环境变量。同样,在 Linux 中路径由 `/` 字符分隔,而在 Windows 目录中路径由 `\` 字符分割。因此 Windows 中典型的环境变量会像这样:
```
PATH="C:\Program Files;C:\Program Files\Firefox;"
```
而在 Linux 中看起来像这样:
```
PATH="/usr/bin:/opt/mozilla/firefox"
```
还要注意,在 Linux 中环境变量由 `$` 拓展,而在 Windows 中您需要使用百分号(就是这样: `%PATH%`)。
在 Linux 中,通过 `-` 使用命令选项,而在 Windows 中,使用选项要通过 `/` 字符。所以,在 Linux 中您应该:
```
a_prog -h
```
而不是
```
a_prog /h
```
在 Linux 下,文件拓展名并没有意义。例如,将 `myscript` 重命名为 `myscript.bat` 并不会因此而变得可执行,需要设置文件的执行权限。文件执行权限会在下次的内容中覆盖到。
在 Linux 中,如果文件或者目录名以 `.` 字符开头,意味着它们是隐藏文件。比如,如果您申请编辑 `.bashrc` 文件,您不能在家目录中找到它,但是它可能真的存在,只不过它是隐藏文件。在命令行中,您可以通过 `ls` 命令的 `-a` 选项查看隐藏文件,比如:
```
ls -a
```
在 Linux 中,普通的命令与 Windows 的命令不尽相同。下面的表格显示了常用命令中 CMD 命令和 Linux 命令行的差异。

---
via: <https://www.linux.com/blog/learn/2018/1/migrating-linux-command-line>
作者:[John Bonesio](https://www.linux.com/users/johnbonesio) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,566 | 如何像 Linux 专家那样使用 WSL | https://www.linux.com/blog/learn/2018/2/how-use-wsl-linux-pro | 2018-04-22T00:59:59 | [
"WSL"
] | https://linux.cn/article-9566-1.html |
>
> 在本 WSL 教程中了解如何执行像挂载 USB 驱动器和操作文件等任务。
>
>
>

在[之前的教程](/article-9545-1.html)中,我们学习了如何在 Windows 10 上设置 WSL。你可以在 Windows 10 中使用 WSL 执行许多 Linux 命令。无论是基于 Linux 的系统还是 macOS,它们的许多系统管理任务都是在终端内部完成的。然而,Windows 10 缺乏这样的功能。你想运行一个 cron 任务么?不行。你想 SSH 进入你的服务器,然后 `rsync` 文件么?没门。如何用强大的命令行工具管理本地文件,而不是使用缓慢和不可靠的 GUI 工具呢?
在本教程中,你将看到如何使用 WSL 执行除了管理之外的任务 —— 例如挂载 USB 驱动器和操作文件。你需要运行一个完全更新的 Windows 10 并选择一个 Linux 发行版。我在[上一篇文章](/article-9545-1.html)中介绍了这些步骤,所以如果你跟上进度,那就从那里开始。让我们开始吧。
### 保持你的 Linux 系统更新
事实上,当你通过 WSL 运行 Ubuntu 或 openSUSE 时,其底层并没有运行 Linux 内核。然而,你必须保持你的发行版完整更新,以保护你的系统免受任何新的已知漏洞的影响。由于在 Windows 应用商店中只有两个免费的社区发行版,所以教程将只覆盖以下两个:openSUSE 和 Ubuntu。
更新你的 Ubuntu 系统:
```
# sudo apt-get update
# sudo apt-get dist-upgrade
```
运行 openSUSE 的更新:
```
# zypper up
```
您还可以使用 `dup` 命令将 openSUSE 升级到最新版本。但在运行系统升级之前,请使用上一个命令运行更新。
```
# zypper dup
```
**注意:** openSUSE 默认为 root 用户。如果你想执行任何非管理员任务,请切换到非特权用户。您可以这篇[文章](/article-9545-1.html)中了解如何在 openSUSE上 创建用户。
### 管理本地文件
如果你想使用优秀的 Linux 命令行工具来管理本地文件,你可以使用 WSL 轻松完成此操作。不幸的是,WSL 还不支持像 `lsblk` 或 `mount` 这样的东西来挂载本地驱动器。但是,你可以 `cd` 到 C 盘并管理文件:
```
/mnt/c/Users/swapnil/Music
```
我现在在 C 盘的 Music 目录下。
要安装其他驱动器、分区和外部 USB 驱动器,你需要创建一个挂载点,然后挂载该驱动器。
打开文件资源管理器并检查该驱动器的挂载点。假设它在 Windows 中被挂载为 S:\。
在 Ubuntu/openSUSE 终端中,为驱动器创建一个挂载点。
```
sudo mkdir /mnt/s
```
现在挂载驱动器:
```
mount -f drvfs S: /mnt/s
```
挂载完毕后,你现在可以从发行版访问该驱动器。请记住,使用 WSL 方式运行的发行版将会看到 Windows 能看到的内容。因此,你无法挂载在 Windows 上无法原生挂载的 ext4 驱动器。
现在你可以在这里使用所有这些神奇的 Linux 命令。想要将文件从一个文件夹复制或移动到另一个文件夹?只需运行 `cp` 或 `mv` 命令。
```
cp /source-folder/source-file.txt /destination-folder/
cp /music/classical/Beethoven/symphony-2.mp3 /plex-media/music/classical/
```
如果你想移动文件夹或大文件,我会推荐 `rsync` 而不是 `cp` 命令:
```
rsync -avzP /music/classical/Beethoven/symphonies/ /plex-media/music/classical/
```
耶!
想要在 Windows 驱动器中创建新目录,只需使用 `mkdir` 命令。
想要在某个时间设置一个 cron 作业来自动执行任务吗?继续使用 `crontab -e` 创建一个 cron 作业。十分简单。
你还可以在 Linux 中挂载网络/远程文件夹,以便你可以使用更好的工具管理它们。我的所有驱动器都插在树莓派或者服务器上,因此我只需 `ssh` 进入该机器并管理硬盘。在本地计算机和远程系统之间传输文件可以再次使用 `rsync` 命令完成。
WSL 现在已经不再是测试版了,它将继续获得更多新功能。我很兴奋的两个特性是 `lsblk` 命令和 `dd` 命令,它们允许我在 Windows 中本机管理我的驱动器并创建可引导的 Linux 驱动器。如果你是 Linux 命令行的新手,[前一篇教程](https://www.linux.com/learn/how-use-linux-command-line-basics-cli)将帮助你开始使用一些最基本的命令。
---
via: <https://www.linux.com/blog/learn/2018/2/how-use-wsl-linux-pro>
作者:[SWAPNIL BHARTIYA](https://www.linux.com/users/arnieswap) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,567 | 如何将字体添加到 Fedora | https://fedoramagazine.org/add-fonts-fedora/ | 2018-04-22T01:06:23 | [
"字体"
] | https://linux.cn/article-9567-1.html | 
字体可帮助你通过设计以创意的方式表达你的想法。无论给图片加标题、编写演示文稿,还是设计问候语或广告,字体都可以将你的想法提升到更高水平。很容易仅仅为了它们的审美品质而爱上它们。幸运的是,Fedora 使安装字体变得简单。以下是如何做的。
### 全系统安装
如果你在系统范围内安装字体,那么它可以让所有用户使用。此方式的最佳方法是使用官方软件库中的 RPM 软件包。
开始前打开 Fedora Workstation 中的 “Software” 工具,或者其他使用官方仓库的工具。选择横栏中选择 “Add-ons” 类别。接着在该类别中选择 “Fonts”。你会看到类似于下面截图中的可用字体:
[](https://fedoramagazine.org/wp-content/uploads/2017/11/Software-fonts.png)
当你选择一种字体时,会出现一些细节。根据几种情况,你可能能够预览字体的一些示例文本。点击 “Install” 按钮将其添加到你的系统。根据系统速度和网络带宽,完成此过程可能需要一些时间。
你还可以在字体细节中通过 “Remove” 按钮删除前面带有勾的已经安装的字体。
### 个人安装
如果你以兼容格式:.ttf、 otf 、.ttc、.pfa 、.pfb 或者 .pcf 下载了字体,则此方法效果更好。这些字体扩展名不应通过将它们放入系统文件夹来安装在系统范围内。这种类型的非打包字体不能自动更新。它们也可能会在稍后干扰一些软件操作。安装这些字体的最佳方法是安装在你自己的个人数据目录中。
打开 Fedora Workstation 中的 “Files” 应用或你选择的类似文件管理器应用。如果你使用 “Files”,那么可能需要使用 `Ctrl+H` 组合键来显示隐藏的文件和文件夹。查找 `.fonts` 文件夹并将其打开。如果你没有 `.fonts` 文件夹,请创建它。 (记住最前面的点并全部使用小写。)
将已下载的字体文件复制到 `.fonts` 文件夹中。此时你可以关闭文件管理器。打开一个终端并输入以下命令:
```
fc-cache
```
这将重建字体缓存,帮助 Fedora 可以找到并引用它。你可能还需要重新启动需要使用新字体的应用程序,例如 Inkscape 或 LibreOffice。你重新启动后,新的字体应该就可以使用了。
---
照片由 [Raphael Schaller](https://unsplash.com/photos/GkinCd2enIY?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 发布在 [Unsplash](https://unsplash.com/search/photos/fonts?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 中。
---
作者简介:
Paul W. Frields 自 1997 年以来一直是 Linux 用户和爱好者,并于 2003 年 Fedora 发布不久后加入项目。他是 Fedora 项目委员会的创始成员之一,并从事文档、网站发布、倡导、工具链开发和维护软件工作。他于 2008 年 2 月至 2010 年 7 月在红帽担任 Fedora 项目负责人,现任红帽公司工程部经理。他目前和他的妻子和两个孩子一起住在弗吉尼亚州。
---
via: <https://fedoramagazine.org/add-fonts-fedora/>
作者:[Paul W. Frields](https://fedoramagazine.org/author/pfrields/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fonts help you express your thoughts in creative ways through design. Whether you’re captioning an image, building a presentation, or designing a greeting or advertisement, fonts can boost your idea to the next level. It’s easy to fall in love with them just for their own aesthetic qualities. Fortunately, Fedora makes installation easy. Here’s how to do it.
## System-wide installation
If you install a font system-wide, it becomes available to all users. The best way to take advantage of this method is by using RPM packages from the official software repositories.
To get started, open the *Software* tool in your Fedora Workstation, or other tool that uses the official repositories. Choose the *Add-ons* category in the group of banners shown. Then in the add-on categories, select *Fonts.* You’ll see a list of available fonts similar to this screenshot:
When you select a font, some details appear. Depending on several conditions, you may be able to preview how the font looks with some example text. Select the *Install* button to add it to your system. It may take a few moments for the process to complete, based on your system speed and network bandwidth.
You can also remove previously installed font packages, shown with a check mark, with the *Remove* button shown in the font details.
## Personal installation
This method works better if you have a font you’ve downloaded in a compatible format: *.ttf*, *otf*, *.ttc*, *.pfa*, *.pfb* or .*pcf.* These font extensions shouldn’t be installed system-wide by dropping them into a system folder. Non-packaged fonts of this type can’t be updated automatically. They also can potentially interfere with some software operations later. The best way to install these fonts is in your own personal data directory.
Open the *Files* application in your Fedora Workstation, or a similar file manager app of your choice. If you’re using *Files*, you may need to use the *Ctrl+H* key combination to show hidden files and folders. Look for the *.fonts* folder and open it. If you don’t have a *.fonts* folder, create it. (Remember the leading dot and to use all lowercase.)
Copy the font file you’ve downloaded to your *.fonts* folder. You can close the file manager at this point. Open a terminal and type the following command:
fc-cache
This will rebuild font caches that help Fedora locate and reference the fonts it can use. You may also need to restart an application such as Inkscape or LibreOffice in which you want to use the new font. Once you restart, the new font should be available.
Photo by [Raphael Schaller](https://unsplash.com/photos/GkinCd2enIY?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/search/photos/fonts?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText).
## Daniel Aleksandersen
You can also use add custom fonts to ${XDG_DATA_HOME:-$HOME/.local/share/fonts instead of $HOME/.fonts if you prefer to keep your home directory clean.
## Dimitri
As a recent Linux full time user (Fedora KDE), I just tested this with a ttf font and it works great, thanks!
However, it would be nice to have some command-free option to refresh the font cache, or to be able to install the new font with a transparent font cache refresh. In too many cases I notice that anybody in my family (without IT knowledge) wouldn’t be able to do these things if they were using Linux, as the terminal is not an option for them.
Anyway, nice article!
## bitlord
Since you’re using KDE, you should be able to use font installer inside System Settings.
Take a look at https://userbase.kde.org/System_Settings/Font_Installer (System Settings > Fonts > Font Management) most likely outdated screenshot, but it should look similar to that one.
## Dimitri
Oh wow, I didn’t know about this. Thanks!
Glad to see that this is not one of those things necessarily requiring the command line!
I just tested this and it works perfectly 🙂
## LEMC
These were very helpful tips. To add some fonts, I have been using the method of creating the “.fonts” directory, but without running the “fc-cache” command. However, everything has been working as expected. So I wonder what exactly the fc-cache command does. Should I run it whenever I add a new font to the “.fonts” directory ?
I also would like to suggest that the FOSS serif font EB Garamond be added to the official Fedora repositories. This font is currently available at:
https://fonts.google.com/specimen/EB+Garamond
http://www.georgduffner.at/ebgaramond/
It is a classical, historically accurate Garamond font, and it is very well done. It is excellent for texts or anywhere an elegant serif font is appropriate.
## Nauris
And you may also copy your fonts to /usr/share/fonts/ for all users (and run fc-cache with root permissions)
## nicu
I prefer to install them in .fonts, this way my fonts choice will survive a system reinstall. They will survive also a system move, then you copy your home from a machine to another.
## nicu
…of, forgot to add this: most artistic fonts (if you do graphics, design, DTP) are not available as RPM packages, you have to download them as font files from sites like DaFont, another plus for .fonts
## Sasan
I’m too lazy to manually download and copy fonts, I just use what comes in the repos.
I only wish Fira Code was available.
## Andreas Jonsson
I normally just open downloaded fonts (e.g. a TTF downloaded from Google Fonts) with the Fonts application in Gnome. From there I install it by clicking the ‘Install’ button. The font is copied to $HOME/.local/share/fonts. Don’t know how this differs from the CLI method explained above?
## Joszko
My favorite font is labiryntowy-fonts
😉 it is creazy but very nice
## Joszko
@Sasan look at Inconsolata
and powerline fonts for prompt bash |
9,568 | 开发者的最佳 GNOME 扩展 | https://fedoramagazine.org/awesome-gnome-extensions-developers/ | 2018-04-22T22:42:00 | [
"开发",
"扩展",
"GNOME"
] | https://linux.cn/article-9568-1.html | 
扩展给予 GNOME3 桌面环境以非常大的灵活性,这种灵活性赋予了用户在定制化桌面上的优势,从而使他们的工作流程变得更加舒适和有效率。Fedora Magazine 已经介绍了一些很棒的桌面扩展,例如 [EasyScreenCast](https://fedoramagazine.org/screencast-gnome-extension/)、 [gTile](https://fedoramagazine.org/must-have-gnome-extension-gtile/) 和 [OpenWeather](https://fedoramagazine.org/weather-updates-openweather-gnome-shell-extension/) ,本文接下来会重点报道这些为开发者而改变的扩展。
如果你需要帮助来安装 GNOME 扩展,那么可以参考《[如何安装一个 GNOME Shell 扩展](/article-9447-1.html)》这篇文章。
### Docker 集成(Docker Integration)


对于为自己的应用使用 Docker 的开发者而言,这个 [Docker 集成](https://extensions.gnome.org/extension/1065/docker-status/) 扩展是必不可少的。这个状态菜单提供了一个带着启动、停止、暂停、甚至删除它们的选项的 Docker 容器列表,这个列表会在新容器加入到这个系统时自动更新。
在安装完这个扩展后,Fedora 用户可能会收到这么一条消息:“Error occurred when fetching containers.(获取容器时发生错误)”。这是因为 Docker 命令默认需要 `sudo` 或 root 权限。要设置你的用户权限来运行 Docker,可以参考 [Fedora 开发者门户网站上的 Docker 安装这一页](https://developer.fedoraproject.org/tools/docker/docker-installation.html)。
你可以在该[扩展的站点](https://github.com/gpouilloux/gnome-shell-extension-docker)上找到更多的信息。
### Jenkins CI 服务器指示器(Jenkins CI Server Indicator)


[Jenkins CI 服务器指示器](https://extensions.gnome.org/extension/399/jenkins-ci-server-indicator/)这个扩展可以使开发者在 Jenkins CI 服务器建立应用很简单,它展示了一个菜单,包含有任务列表及那些任务的状态。它也包括了一些如轻松访问 Jenkins 网页前端、任务完成提示、以及触发和过滤任务等特性。
如果想要更多的信息,请去浏览[开发者站点](https://www.philipphoffmann.de/gnome-3-shell-extension-jenkins-ci-server-indicator/)。
### 安卓工具(android-tool)


[安卓工具](https://extensions.gnome.org/extension/1232/android-tool/)对于 Android 开发者来说会是一个非常有价值的扩展,它的特性包括捕获错误报告、设备截屏和屏幕录像。它可以通过 usb 和 tcp 连接两种方式来连接 Android 设备。
这个扩展需要 `adb` 的包,从 Fedora 官方仓库安装 `adb` 只需要[运行这条命令](https://fedoramagazine.org/howto-use-sudo/):
```
sudo dnf install android-tools
```
你可以在这个[扩展的 GitHub 网页](https://github.com/naman14/gnome-android-tool)里找到更多信息。
### GnomeHub


对于自己的项目使用 GitHub 的 GNOME 用户来说,[GnomeHub](https://extensions.gnome.org/extension/1263/gnomehub/) 是一个非常好的扩展,它可以显示 GitHub 上的仓库,还可以通知用户有新提交的拉取请求。除此之外,用户可以把他们最喜欢的仓库加在这个扩展的设置里。
如果想要更多信息,可以参考一下这个[项目的 GitHub 页面](https://github.com/lagartoflojo/gnomehub)。
### gistnotes

简单地说,[gistnotes](https://extensions.gnome.org/extension/917/gistnotes/) 为 gist 用户提供了一种创建、存储和管理注释和代码片段的简单方式。如果想要更多的信息,可以参考这个[项目的网站](https://github.com/mohan43u/gistnotes)。

### Arduino 控制器(Arduino Control)

这个 [Arduino 控制器](https://extensions.gnome.org/extension/894/arduino-control/)扩展允许用户去连接或者控制他们自己的 Arduino 电路板,它同样允许用户在状态菜单里增加滑块或者开关。除此之外,开发者放在扩展目录里的脚本可以通过以太网或者 usb 来连接 Arduino 电路板。
最重要的是,这个扩展可以被定制化来适合你的项目,在器 README 文件里的提供例子是,它能够“通过网络上任意的电脑来控制你房间里的灯”。
你可以从这个[项目的 GitHub 页面](https://github.com/simonthechipmunk/arduinocontrol)上得到更多的产品信息并安装这个扩展。
### Hotel Manager


使用 Hotel 进程管理器开发网站的开发人员,应该尝试一下 [Hotel Manager](https://extensions.gnome.org/extension/1285/hotel-manager/) 这个扩展。它展示了一个增加到 Hotel 里的网页应用的列表,并给与了用户开始、停止和重启这些应用的能力。此外,还可以通过右边的电脑图标快速打开、浏览这些网页应用。这个扩展同样可以启动、停止或重启 Hotel 的后台程序。
本文发布时,GNOME 3.26 版本的 Hotel Manager 版本 4 没有在该扩展的下拉式菜单里列出网页应用。版本 4 还会在 Fedora 28 (GNOME 3.28) 上安装时报错。然而,版本 3 工作在 Fedora 27 和 Fedora 28。
如果想要更多细节,可以去看这个[项目在 GitHub 上的网页](https://github.com/hardpixel/hotel-manager)。
### VSCode 搜索插件(VSCode Search Provider)
[VSCode 搜索插件](https://extensions.gnome.org/extension/1207/vscode-search-provider/)是一个简单的扩展,它能够在 GNOME 综合搜索结果里展示 Visual Studio Code 项目。对于重度 VSCode 用户来说,这个扩展可以让用户快速连接到他们的项目,从而节省时间。你可以从这个[项目在 GitHub 上的页面](https://github.com/jomik/vscode-search-provider)来得到更多的信息。

在开发环境方面,你有没有一个最喜欢的扩展呢?发在评论区里,一起来讨论下吧。
---
via: <https://fedoramagazine.org/awesome-gnome-extensions-developers/>
作者:[Shaun Assam](https://fedoramagazine.org/author/sassam/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Extensions add immense flexibility to the GNOME 3 desktop environment. They give users the advantage of customizing their desktop while adding ease and efficiency to their workflow. The Fedora Magazine has already covered some great desktop extensions such as [EasyScreenCast](https://fedoramagazine.org/screencast-gnome-extension/), [gTile](https://fedoramagazine.org/must-have-gnome-extension-gtile/), and [OpenWeather](https://fedoramagazine.org/weather-updates-openweather-gnome-shell-extension/). This article continues that coverage by focusing on extensions tailored for developers.
If you need assistance installing GNOME extensions, refer to the article [How to install a GNOME Shell extension](https://fedoramagazine.org/install-gnome-shell-extension/).
Docker Integration
The [Docker Integration](https://extensions.gnome.org/extension/1065/docker-status/) extension is a must for developers using Docker for their apps. The status menu provides a list of Docker containers with the option to start, stop, pause and even remove them. The list updates automatically as new containers are added to the system.
After installing this extension, Fedora users may get the message: “Error occurred when fetching containers.” This is because Docker commands require sudo or root permissions by default. To configure your user account to run Docker, refer to the [Docker Installation page on the Fedora Developer Portal](https://developer.fedoraproject.org/tools/docker/docker-installation.html).
You can find more information on the [extension’s website](https://github.com/gpouilloux/gnome-shell-extension-docker).
Jenkins CI Server Indicator
The [Jenkins CI Server Indicator](https://extensions.gnome.org/extension/399/jenkins-ci-server-indicator/) extension makes it easy for developers to build their apps on a Jenkins CI Server. It displays a menu with a list of jobs and the state of those jobs. It also includes features such as easy access to the Jenkins web front-end, notifications for completed jobs, and the ability to trigger and filter jobs.
For more information, visit the [developer’s site](https://www.philipphoffmann.de/gnome-3-shell-extension-jenkins-ci-server-indicator/).
android-tool
[android-tool](https://extensions.gnome.org/extension/1232/android-tool/) can be a valuable extension for Android developers. Features include capturing bug reports, device screenshots and screen-recording. It can also connect to the Android device via USB or TCP.
This extension does require the *adb* package. To install *adb* from the official Fedora repository [run this command](https://fedoramagazine.org/howto-use-sudo/):
sudo dnf install android-tools
You can find more information at [the extension Github site](https://github.com/naman14/gnome-android-tool).
GnomeHub
[GnomeHub](https://extensions.gnome.org/extension/1263/gnomehub/) is a great extension for GNOME users using Github for their projects. It displays Github repositories and notifies the user of opened pull requests. In addition, users can add their favorite repositories in the extension’s settings.
For more information, refer to [the project’s Github page](https://github.com/lagartoflojo/gnomehub).
gistnotes
Quite simply, [gistnotes](https://extensions.gnome.org/extension/917/gistnotes/) provides easy access for gist users to create, store and manage notes or code snippets. For more information refer to [the project’s website](https://github.com/mohan43u/gistnotes).
Arduino Control
The [Arduino Control](https://extensions.gnome.org/extension/894/arduino-control/) extension allows users to connect to, and control, their Arduino boards. It also lets users add sliders and switches in the status menu. In addition, the developer includes scripts in the extension’s directory to connect to the board via Ethernet or USB.
Most importantly, this extension can be customized to fit your project. An example provided in the README file is the ability to “Control your Room Lights from any Computer on the Network.”
You can read more about the features and setup of this extension on [the project’s Github page](https://github.com/simonthechipmunk/arduinocontrol).
Hotel Manager
Developers using the Hotel process manager for their web apps should explore the [Hotel Manager](https://extensions.gnome.org/extension/1285/hotel-manager/) extension. It displays a list of web apps added to Hotel, and gives users the ability to start, stop and restart those apps. Furthermore, the *computers* icon to the right gives quick access to open, or view, that web app. The extension can also start, stop, or restart the Hotel daemon.
As of the publication of this article, Hotel Manager version 4 for GNOME 3.26 does not list the web apps in the extension’s drop-down menu. Version 4 also gives errors when installing on Fedora 28 (GNOME 3.28). However, version 3 works with Fedora 27 and Fedora 28.
For more details, see [the project’s Github page](https://github.com/hardpixel/hotel-manager).
## VSCode Search Provider
[VSCode Search Provider](https://extensions.gnome.org/extension/1207/vscode-search-provider/) is a simple extension that displays Visual Studio Code projects in the GNOME overview search results. For heavy VSCode users, this extension saves time by giving developers quick access to their projects. You can find more information on [the project’s Github page](https://github.com/jomik/vscode-search-provider).
Do you have a favourite extension you use for development? Let us know in the comments.
## Leslie Satenstein
My favourite gnome-extension is difficult to choose from amongst three of the top ones.
My first is activities configurator
My 2nd is Gno-Menu
My 3rd is TaskBar by Zpydr
Right click on activities configurator icon extension and you will have the equivalent of the TweakTool for gnome extensions.
Gno-Menu adds Gnome-2 menus to Gnome 3.
TaskBar does away with Dash to Dock by providing functionality to Gnome in the form of a favourites bar list and windows list.
Gnome-extensions are written with javascrypt. I would love to have these extensions written in a compiled language.
Extensions can also be installed to
/usr/share/gnome-shell/extensions with the
org*.xml extracted from within the extension/schema and copied to
/usr/share/glib-2.0/schemas
After making the extension globally accessable (to all users), run
glib-compile-schemas /usr/share/glib-2.0/schemas.
(on reboot, the global schemas will be available to all)
## Paul W. Frields
Users should not write information directly into
/usr, since this is an area reserved for vendor packaged software, so we don’t encourage this procedure. It’s better to package the extension and provide a local repo for it if needed. Also, there isn’t a benefit in having these in a compiled language. That would require client side build tools any time an extension is updated. This is precisely why the extensions are in Javascript.## Krystian
How often one updates an extension – once a week?
Adding few more seconds to compile an extension once and make the Shell experience better by improving the performance is the right way to do it.
Besides that, JS has many limitations and problems as a language affecting the final code quality and system stability while using it with gnome shell.
In general, there’s no gain from limiting the support to just one language/format.
## Andy
The situation here is often mischaracterized and overblown. Extensions are written in GJS, which is more like PyGObject, in that they are essentially written in GLib, Gtk and Clutter (C libraries) via language bindings, and contrary to popular belief about 40% of Gnome Shell is written in C.
Truth be told, writing extensions in a compiled language is orthogonal code quality, will increase the time and difficulty required to review them properly, probably result in very speed difference (given how little most of them do), significantly reduce the amount of capable authors and alienate all the current ones.
## Frederik
Is 0 equal to 0? In javascript? Who knows! Who cares? Let’s just hope I didn’t make a mistake and the interpreter just glazes over the problem and makes coffee, with extra cyanide, in my bathroom instead of verifying my data.
I wouldn’t be caught dead writing javascript if I have the option of using a real programming language. By restricting extensions to one language, you’re alienating everybody who doesn’t know or want to use the language. Javascript is likely the most hated language on the face of the planet to ever have existed — performance is not part of that problem.
Why Python wasn’t chosen instead of javascript really baffles me. All of the benefits of javascript, pretty much none of the problems and it’s actually liked by some people.
## Philipp
Bad code is not a disadvantage owed by a specific programming language. It’s the developer writing bad code not the language that makes him writing bad code.
Let’s take C for example. It allows you to write even worse and even more dangerous code than most of the higher level programming languages.
Even tough it is possible to do so, a developer who is used to use a specific language might still be able to write code of a good quality.
If you are not satisfied with the possibilities provided by gnome and you are a developer yourself… write the required modifications yourself. The good thing is that you’re free to do so. 😉
## Andy
What would make you think 0 doesn’t equal 0 in Javascript, and what problems with javascript as a language are you referring to? Some reasons Python wasn’t chosen:
You can’t monkey-patch like JS can, which is essential for extensions (these aren’t plugins)
JS is just a language (ECMA Script), not a whole platform of libraries and event loops that compete with the Gnome platform (GLib, Gtk, Clutter, etc)
JS was designed for asynchronous user interaction
JS has
neverbroken backwards compatibilityMuch of the hate towards JavaScript is really directed at “your dad’s JavaScript”, which is not the current state of affairs. There are classes, iterators/generators, async functions, weak sets/maps, typed arrays, Symbols (ala
foo), and more that people erroneously complain JS can’t do.I really like Python; I use it and often prefer it. But really, dragging the whole early-90s JavaScript bogey man out from under the bed thing is becoming quite tiresome.
## Leslie Satenstein
Hi Paul
Why have multiple copies of the extensions in the 5 logons on my desktop when I, as admin,install them within /usr.
You mentioned “It’s better to package the extension and provide a local repo for it if needed”. is there a configuration for gnome to inform the shell that there is an additional global path to local provided extensions?
FYI, I wrote a script that does the migration, the extract from the extensions of the schemas/*.xml files to glib-2.0/schemas and a glib-compile-schemas. Please point me to documentation to do what you propose.
Off topic
The xml files are “schema compiled”. Why can the *.desktop be desktop compiled, as are the schemas? I could see this too, becoming a performance enhancement feature.
## Paul W. Frields
Because users typically want different configurations of extensions. While they can enable/disable them individually if installed system-wide, you’ve now created a situation where they can’t be updated except by tedious manual intervention by only one person (the admin). Besides this, you’re relying on a writable /usr which may not be the case in future systems (such as Atomic editions). By packaging as RPM you avoid at least the manual intervention problem. But extensions are designed for per-user use and I see no good reason to override that.
## Davi
All these extensions should have been gtk apps. It’s a shame that making and distributing gtk apps is so much harder. Flatpak is changing that, though.
## Brian Exelbierd
This is a fantastic list! I am now super bummed not to be developing full-time anymore.
I wonder if we could find folks to extend the gnomehub extension to work with pagure.io?
## John Smith
I use standard Gnome on Fedora. My favourite is “EasyScreenCast” – as far as I know, it is the only good screen recorder. It is also a very nicely done extension with many superb options.
After all, the “built-in” screen recorder in Gnome records all your monitors, which is fairly useless if you want to make a screencast for students or colleagues of one specific window (e.g., to demonstrate how to do something in LibreOffice).
My 2nd favorite extension is “OpenWeather”, it just shows the weather and forecast in the top line and on clicking the details, very convenient and I would not want to use gnome without it anymore.
But there are issues I hope the developers can attend:
1) It is not so clear how to find and install extensions. The only way I can do it is to use the Gnome epiphany browsers (aka “web”), then go to the exensions website (https://extensions.gnome.org/), and then you can easily search and install them.
And after that you can manage them with the tweak tool. Okay, I don’t mind it, but I wonder how new users would find out. It would be nice if there would be a simple Gnome program that can do this, or a link somewhere on the desktop saying “search and install extensions”.
2) They can terribly crash your system. Take for example my favorite “EasyScreenCast” (what I am writing is true for both Fedora 27 and 28) on Wayland: You install it; you then logout; upon login you get a grey screen and there is no way to fix it. After much searching online, I found the solution is this: i) logout. ii) login with Xorg-Gnome instead of Wayland (only one time is enough) iii) logout again, iv) Now it miraculously does not longer crash your Wayland gnome shell: https://bugzilla.redhat.com/show_bug.cgi?id=1394755 ; To me, this seems a really weird bug — what does the one login to Xorg fix the situation? Apparently, this has been an issue since 2016.
3) I have had the “Places” extension give me the same problem of not being able to login anymore and I had to remove it.
PS: I also would want to learn how to program extensions. Any recommendations for a tutorial?
## Andy
1) It is not so clear how to find and install extensions.
If you’re using any recent version of Gnome you can actually browse and install extensions in “Software” (eg gnome-software).
2) They can terribly crash your system.
Gnome Shell extensions aren’t sandboxed or limited in any way; they can use sockets, HTTP requests, spawn external programs, create/delete files and anything else a “real” program can do. The catch is they can also crash things like any other program, which why the review process can be quite long; but still you can’t test for everything.
To my knowledge there aren’t any (current) start-to-finish tutorials for writing extensions, but their are ‘gjs’ and ‘gnome-shell’ tags on StackOverflow, #javascript and #gnome-shell channels on GimpNET (IRC) and most extensions list their Github repository on the official website. Most of the gnome-shell UI is written in JS too, so you can learn a lot about writing extensions just from reading that code.
## Rene Reichenbach
VSCode Search Provider
3 words …
awesome awesome awesome ! |
9,569 | 对进程的监视 | https://etbe.coker.com.au/2017/09/28/process-monitoring/ | 2018-04-23T12:41:48 | [
"进程",
"监视"
] | https://linux.cn/article-9569-1.html | 
由于复刻了 mon 项目到 [etbemon](https://doc.coker.com.au/projects/etbe-mon/) 中,我花了一些时间做监视脚本。事实上监视一些事情通常很容易,但是决定监视什么才是困难的部分。进程监视脚本 `ps.monitor` 是我重新设计过的一个。
对于进程监视我有一些思路。如果你对进程监视如何做的更好有任何建议,请通过评论区告诉我。
给不使用 mon 的人介绍一下,如果一切 OK 该监视脚本就返回 0,而如果有问题它会返回 1,并使用标准输出显示错误信息。虽然我并不知道有谁将 mon 脚本挂进一个不同的监视系统中,但是,那样做其实很容易实现。我计划去做的一件事情就是,将来实现 mon 和其它的监视系统如 Nagios 之间的互操作性。
### 基本监视
```
ps.monitor tor:1-1 master:1-2 auditd:1-1 cron:1-5 rsyslogd:1-1 dbus-daemon:1- sshd:1- watchdog:1-2
```
我现在计划重写该进程监视脚本的某些部分。现在的功能是在命令行上列出进程名字,它包含了要监视的进程的最小和最大实例数量。上面的示例是一个监视的配置。在这里有一些限制,在这个实例中的 `master` 进程指的是 Postfix 的主进程,但是其它的守护进程使用了相同的进程名(这是那些错误的名字之一,因为它太直白了)。一个显而易见的解决方案是,给一个指定完整路径的选项,这样,那个 `/usr/lib/postfix/sbin/master` 就可以与其它命名为 `master` 的程序区分开了。
下一个问题是那些可能以多个用户身份运行的进程。比如 `sshd`,它有一个以 root 身份运行的单独的进程去接受新的连接请求,以及在每个登入用户的 UID 下运行的进程。因此,作为 root 用户运行的 sshd 进程的数量将比 root 登录会话的数量大 1。这意味着如果一个系统管理员直接以 root 身份通过 `ssh` 登入系统(这是有争议的,但它不是本文的主题—— 只是有些人需要这样做,所以我们必须支持这种情形),然后 master 进程崩溃了(或者系统管理员意外或者故意杀死了它),这时对于该进程丢失并不会产生警报。当然正确的做法是监视 22 号端口,查找字符串 `SSH-2.0-OpenSSH_`。有时候,守护进程的多个实例运行在需要单独监视的不同 UID 下面。因此,我们需要通过 UID 监视进程的能力。
在许多情形中,进程监视可以被替换为对服务端口的监视。因此,如果在 25 号端口上监视,那么有可能意味着,Postfix 的 `master` 在运行着,不用去理会其它的 `master` 进程。但是对于我而言,我可以在方便地进行多个监视,如果我得到一个关于无法向一个服务器发送邮件的 Jabber 消息,我可以通过这个来自服务器的 Jabber 消息断定 `master` 没有运行,而不需要挨个查找才能发现问题所在。
### SE Linux
我想要的一个功能就是,监视进程的 SE Linux 上下文,就像监视 UID 一样。虽然我对为其它安全系统编写一个测试不感兴趣,但是,我很乐意将别人写好的代码包含进去。因此,不管我做什么,都希望它能与多个安全系统一起灵活地工作。
### 短暂进程
大多数守护进程在进程启动期间都有一个相同名字的<ruby> 次级进程 <rt> second process </rt></ruby>。这意味着如果你为了精确地监视一个进程的一个实例,当 `logrotate` 或者类似的守护进程重启时,你或许会收到一个警报说有两个进程运行。如果在重启期间,恰好在一个错误的时间进行检查,你也或许会收到一个警报说,有 0 个实例。我现在处理这种情况的方法是,在与 `alertafter 2` 指令一起的次级进程失败事件之前我的服务器不发出警报。当监视处于一个失败的状态时,`failure_interval` 指令允许指定检查的时间间隔,将其设置为一个较低值时,意味着在等待一个次级进程失败结果时并不会使提示延迟太多。
为处理这种情况,我考虑让 `ps.monitor` 脚本在一个指定的延迟后再次进行自动检查。我认为使用一个单个参数的监视脚本来解决这个问题比起使用两个配置指令的 mon 要好一些。
### CPU 使用
mon 现在有一个 `loadavg.monitor` 脚本,它用于检查平均负载。但是它并不能捕获一个单个进程使用了太多的 CPU 时间而没有使系统平均负载上升的情况。同样,也没有捕获一个渴望获得 CPU 的进程进入沉默(例如,SETI at Home 停止运行)(LCTT 译注:SETI,由加州大学伯克利分校创建的一项利用全球的联网计算机的空闲计算资源来搜寻地外文明的科学实验计划),而其它的进程进入一个无限循环状态的情况。解决这种问题的一个方法是,让 `ps.monitor` 脚本也配置另外的一个选项去监视 CPU 的使用,但是这也可能会让人产生迷惑。另外的选择是,使用一个独立的脚本,它用来报警任何在它的生命周期或者最后几秒中,使用 CPU 时间超过指定百分比的进程,除非它在一个豁免这种检查的进程或用户的白名单中。或者每个普通用户都应该豁免这种检查,因为你压根就不知道他们什么时候运行一个文件压缩程序。也应该有一个包含排除的守护进程(像 BOINC)和系统进程(像 gzip,有几个定时任务会运行它)的简短列表。
### 对例外的监视
一个常见的编程错误是在 `setgid()` 之前调用 `setuid()`,这意味着那个程序没有权限去调用 `setgid()`。如果没有检查返回代码(而犯这种低级错误的人往往不会去检查返回代码),那么进程会保持较高的权限。检查以 GID 0 而不是 UID 0 运行的进程是很方便的。顺利说一下,对一个 Debian/Testing 工作站运行的一个快速检查显示,一个使用 GID 0 的进程并没有获得较高的权限,但是可以使用一个 `chmod 770` 命令去改变它。
在一个 SE Linux 系统上,应该只有一个进程与 `init_t` 域一起运行。目前在运行守护进程(比如,mysqld 和 tor)的 Debian Stretch 系统中,并不会发生策略与守护进程服务文件所请求的 systemd 的最新功能不匹配的情况。这样的问题将会不断发生,我们需要对它进行自动化测试。
对配置错误的自动测试可能会影响系统安全,这是一个很大的问题,我将来或许写一篇关于这方面的单独的博客文章。
---
via: <https://etbe.coker.com.au/2017/09/28/process-monitoring/>
作者:[Andrew](https://etbe.coker.com.au) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Since forking the Mon project to [etbemon [1]](https://doc.coker.com.au/projects/etbe-mon/) I’ve been spending a lot of time working on the monitor scripts. Actually monitoring something is usually quite easy, deciding what to monitor tends to be the hard part. The process monitoring script ps.monitor is the one I’m about to redesign.
Here are some of my ideas for monitoring processes. Please comment if you have any suggestions for how do do things better.
For people who don’t use mon, the monitor scripts return 0 if everything is OK and 1 if there’s a problem along with using stdout to display an error message. While I’m not aware of anyone hooking mon scripts into a different monitoring system that’s going to be easy to do. One thing I plan to work on in the future is interoperability between mon and other systems such as Nagios.
Table of Contents
### Basic Monitoring
ps.monitor tor:1-1 master:1-2 auditd:1-1 cron:1-5 rsyslogd:1-1 dbus-daemon:1- sshd:1- watchdog:1-2
I’m currently planning some sort of rewrite of the process monitoring script. The current functionality is to have a list of process names on the command line with minimum and maximum numbers for the instances of the process in question. The above is a sample of the configuration of the monitor. There are some limitations to this, the “master” process in this instance refers to the main process of Postfix, but other daemons use the same process name (it’s one of those names that’s wrong because it’s so obvious). One obvious solution to this is to give the option of specifying the full path so that /usr/lib/postfix/sbin/master can be differentiated from all the other programs named master.
The next issue is processes that may run on behalf of multiple users. With sshd there is a single process to accept new connections running as root and a process running under the UID of each logged in user. So the number of sshd processes running as root will be one greater than the number of root login sessions. This means that if a sysadmin logs in directly as root via ssh (which is controversial and not the topic of this post – merely something that people do which I have to support) and the master process then crashes (or the sysadmin stops it either accidentally or deliberately) there won’t be an alert about the missing process. Of course the correct thing to do is to have a monitor talk to port 22 and look for the string “SSH-2.0-OpenSSH_”. Sometimes there are multiple instances of a daemon running under different UIDs that need to be monitored separately. So obviously we need the ability to monitor processes by UID.
In many cases process monitoring can be replaced by monitoring of service ports. So if something is listening on port 25 then it probably means that the Postfix “master” process is running regardless of what other “master” processes there are. But for my use I find it handy to have multiple monitors, if I get a Jabber message about being unable to send mail to a server immediately followed by a Jabber message from that server saying that “master” isn’t running I don’t need to fully wake up to know where the problem is.
### SE Linux
One feature that I want is monitoring SE Linux contexts of processes in the same way as monitoring UIDs. While I’m not interested in writing tests for other security systems I would be happy to include code that other people write. So whatever I do I want to make it flexible enough to work with multiple security systems.
### Transient Processes
Most daemons have a second process of the same name running during the startup process. This means if you monitor for exactly 1 instance of a process you may get an alert about 2 processes running when “logrotate” or something similar restarts the daemon. Also you may get an alert about 0 instances if the check happens to run at exactly the wrong time during the restart. My current way of dealing with this on my servers is to not alert until the second failure event with the “alertafter 2” directive. The “failure_interval” directive allows specifying the time between checks when the monitor is in a failed state, setting that to a low value means that waiting for a second failure result doesn’t delay the notification much.
To deal with this I’ve been thinking of making the ps.monitor script automatically check again after a specified delay. I think that solving the problem with a single parameter to the monitor script is better than using 2 configuration directives to mon to work around it.
### CPU Use
Mon currently has a loadavg.monitor script that to check the load average. But that won’t catch the case of a single process using too much CPU time but not enough to raise the system load average. Also it won’t catch the case of a CPU hungry process going quiet (EG when the SETI at Home server goes down) while another process goes into an infinite loop. One way of addressing this would be to have the ps.monitor script have yet another configuration option to monitor CPU use, but this might get confusing. Another option would be to have a separate script that alerts on any process that uses more than a specified percentage of CPU time over it’s lifetime or over the last few seconds unless it’s in a whitelist of processes and users who are exempt from such checks. Probably every regular user would be exempt from such checks because you never know when they will run a file compression program. Also there is a short list of daemons that are excluded (like BOINC) and system processes (like gzip which is run from several cron jobs).
### Monitoring for Exclusion
A common programming mistake is to call setuid() before setgid() which means that the program doesn’t have permission to call setgid(). If return codes aren’t checked (and people who make such rookie mistakes tend not to check return codes) then the process keeps elevated permissions. Checking for processes running as GID 0 but not UID 0 would be handy. As an aside a quick examination of a Debian/Testing workstation didn’t show any obvious way that a process with GID 0 could gain elevated privileges, but that could change with one chmod 770 command.
On a SE Linux system there should be only one process running with the domain init_t. Currently that doesn’t happen in Stretch systems running daemons such as mysqld and tor due to policy not matching the recent functionality of systemd as requested by daemon service files. Such issues will keep occurring so we need automated tests for them.
Automated tests for configuration errors that might impact system security is a bigger issue, I’ll probably write a separate blog post about it. |
9,570 | 在 Ubuntu 17.10 上安装 AWFFull Web 服务器日志分析应用程序 | http://www.ubuntugeek.com/install-awffull-web-server-log-analysis-application-on-ubuntu-17-10.html | 2018-04-23T12:57:28 | [
"AWFFull",
"日志"
] | https://linux.cn/article-9570-1.html | 
AWFFull 是基于 “Webalizer” 的 Web 服务器日志分析程序。AWFFull 以 HTML 格式生成使用统计信息以便用浏览器查看。结果以柱状和图形两种格式显示,这有利于解释数据。它提供每年、每月、每日和每小时的使用统计数据,并显示网站、URL、referrer、user agent(浏览器)、用户名、搜索字符串、进入/退出页面和国家(如果一些信息不存在于处理后日志中那么就没有)。AWFFull 支持 CLF(通用日志格式)日志文件,以及由 NCSA 等定义的组合日志格式,它还能只能地处理这些格式的变体。另外,AWFFull 还支持 wu-ftpd xferlog 格式的日志文件,它能够分析 ftp 服务器和 squid 代理日志。日志也可以通过 gzip 压缩。
如果检测到压缩日志文件,它将在读取时自动解压缩。压缩日志必须是 .gz 扩展名的标准 gzip 压缩。
### 对于 Webalizer 的修改
AWFFull 基于 Webalizer 的代码,并有许多或大或小的变化。包括:
* 不止原始统计数据:利用已发布的公式,提供额外的网站使用情况。
* GeoIP IP 地址能更准确地检测国家。
* 可缩放的图形
* 与 GNU gettext 集成,能够轻松翻译。目前支持 32 种语言。
* 在首页显示超过 12 个月的网站历史记录。
* 额外的页面计数跟踪和排序。
* 一些小的可视化调整,包括 Geolizer 用量中使用 Kb、Mb。
* 额外的用于 URL 计数、进入和退出页面、站点的饼图
* 图形上的水平线更有意义,更易于阅读。
* User Agent 和 Referral 跟踪现在通过 PAGES 而非 HITS 进行计算。
* 现在支持 GNU 风格的长命令行选项(例如 --help)。
* 可以通过排除“什么不是”以及原始的“什么是”来选择页面。
* 对被分析站点的请求以匹配的引用 URL 显示。
* 404 错误表,并且可以生成引用 URL。
* 生成的 html 可以使用外部 CSS 文件。
* POST 分析总结使得手动优化配置文件性能更简单。
* 可以将指定的 IP 和地址分配给指定的国家。
* 便于使用其他工具详细分析的转储选项。
* 支持检测并处理 Lotus Domin- v6 日志。
### 在 Ubuntu 17.10 上安装 AWFFull
```
sud- apt-get install awffull
```
### 配置 AWFFull
你必须在 `/etc/awffull/awffull.conf` 中编辑 AWFFull 配置文件。如果你在同一台计算机上运行多个虚拟站点,则可以制作多个默认配置文件的副本。
```
sud- vi /etc/awffull/awffull.conf
```
确保有下面这几行:
```
LogFile /var/log/apache2/access.log.1
OutputDir /var/www/html/awffull
```
保存并退出文件。
你可以使用以下命令运行 awffull。
```
awffull -c [your config file name]
```
这将在 `/var/www/html/awffull` 目录下创建所有必需的文件,以便你可以使用 http://serverip/awffull/ 。
你应该看到类似于下面的页面:

如果你有更多站点,你可以使用 shell 和计划任务自动化这个过程。
---
via: <http://www.ubuntugeek.com/install-awffull-web-server-log-analysis-application-on-ubuntu-17-10.html>
作者:[ruchi](http://www.ubuntugeek.com/author/ubuntufix) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Install AWFFull web server log analysis application on ubuntu 17.10
**Sponsored Link**
AWFFull supports CLF (common log format) log files, as well as Combined log formats as defined by NCSA and others, and variations of these which it attempts to handle intelligently. In addition, AWFFull also supports wu-ftpd xferlog formatted log files, allowing analysis of ftp servers, and squid proxy logs. Logs may also be compressed, via gzip.
If a compressed log file is detected, it will be automatically uncompressed while it is read. Compressed logs must have the standard gzip extension of .gz.
**Changes from Webalizer**
AWFFull is based on the Webalizer code and has a number of large and small changes. These include:
o Beyond the raw statistics: Making use of published formulae to provide additional insights into site usage.
o GeoIP IP Address look-ups for more accurate country detection.
o Resizable graphs.
o Integration with GNU gettext allowing for ease of translations.Currently 32 languages are supported.
o Display more than 12 months of the site history on the front page.
o Additional page count tracking and sort by same.
o Some minor visual tweaks, including Geolizer’s use of Kb, Mb etc for Volumes.
o Additional Pie Charts for URL counts, Entry and Exit Pages, and Sites.
o Horizontal lines on graphs that are more sensible and easier to read.
o User Agent and Referral tracking is now calculated via PAGES not HITS.
o GNU style long command line options are now supported (eg --help).
o Can choose what is a page by excluding "what isn’t" vs the original "what is" method.
o Requests to the site being analysed are displayed with the matching referring URL.
o A Table of 404 Errors, and the referring URL can be generated.
o An external CSS file can be used with the generated html.
o Manual performance optimisation of the config file is now easier with a post analysis summary output.
o Specified IP’s & Addresses can be assigned to a given country.
o Additional Dump options for detailed analysis with other tools.
o Lotus Domino v6 logs are now detected and processed.
**Install awffull on ubuntu 17.10**
sudo apt-get install awffull
**Configuring AWFFULL**
You have to edit awffull config file at /etc/awffull/awffull.conf. If you have multiple virtual websites running in the same machine, you can make several copies of the default config file.
sudo vi /etc/awffull/awffull.conf
Make sure the following lines are there
LogFile /var/log/apache2/access.log.1
OutputDir /var/www/html/awffull
Save and exit the file
You can run the awffull config using the following command
awffull -c [your config file name]
This will create all the required files under /var/www/html/awffull directory so you can access your webserver stats using http://serverip/awffull/
You should see similar to the following screen
If you have more site and you can automate the process using shell script and cron job. |
9,571 | 如何设置 GNOME 显示自定义幻灯片 | https://opensource.com/article/17/12/create-your-own-wallpaper-slideshow-gnome | 2018-04-23T18:53:00 | [
"墙纸",
"GNOME"
] | /article-9571-1.html |
>
> 使用一个简单的 XML,你就可以设置 GNOME 能够在桌面上显示一个幻灯片。
>
>
>

在 GNOME 中,一个非常酷、但却鲜为人知的特性是它能够将幻灯片显示为墙纸。你可以从 [GNOME 控制中心](http://manpages.ubuntu.com/manpages/xenial/man1/gnome-control-center.1.html)的 “背景设置” 面板中选择墙纸幻灯片。在预览的右下角显示一个小时钟标志,可以将幻灯片的墙纸与静态墙纸区别开来。
一些发行版带有预装的幻灯片壁纸。 例如,Ubuntu 包含了库存的 GNOME 定时壁纸幻灯片,以及 Ubuntu 壁纸大赛胜出的墙纸。
如果你想创建自己的自定义幻灯片用作壁纸怎么办?虽然 GNOME 没有为此提供一个用户界面,但是在你的主目录中使用一些简单的 XML 文件来创建一个是非常容易的。 幸运的是,GNOME 控制中心的背景选择支持一些常见的目录路径,这样就可以轻松创建幻灯片,而不必编辑你的发行版所提供的任何内容。
### 开始
使用你最喜欢的文本编辑器在 `$HOME/.local/share/gnome-background-properties/` 创建一个 XML 文件。 虽然文件名不重要,但目录名称很重要(你可能需要创建该目录)。 举个例子,我创建了带有以下内容的 `/home/ken/.local/share/gnome-background-properties/osdc-wallpapers.xml`:
```
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE wallpapers SYSTEM "gnome-wp-list.dtd">
<wallpapers>
<wallpaper deleted="false">
<name>Opensource.com Wallpapers</name>
<filename>/home/ken/Pictures/Wallpapers/osdc/osdc.xml</filename>
<options>zoom</options>
</wallpaper>
</wallpapers>
```
每一个你需要包含在 GNOME 控制中心的 “背景面板”中的每个幻灯片或静态壁纸,你都要在上面的 XML 文件需要为其增加一个 `<wallpaper>` 节点。
在这个例子中,我的 `osdc.xml` 文件看起来是这样的:
```
<?xml version="1.0" ?>
<background>
<static>
<!-- Duration in seconds to display the background -->
<duration>30.0</duration>
<file>/home/ken/Pictures/Wallpapers/osdc/osdc_2.png</file>
</static>
<transition>
<!-- Duration of the transition in seconds, default is 2 seconds -->
<duration>0.5</duration>
<from>/home/ken/Pictures/Wallpapers/osdc/osdc_2.png</from>
<to>/home/ken/Pictures/Wallpapers/osdc/osdc_1.png</to>
</transition>
<static>
<duration>30.0</duration>
<file>/home/ken/Pictures/Wallpapers/osdc/osdc_1.png</file>
</static>
<transition>
<duration>0.5</duration>
<from>/home/ken/Pictures/Wallpapers/osdc/osdc_1.png</from>
<to>/home/ken/Pictures/Wallpapers/osdc/osdc_2.png</to>
</transition>
</background>
```
上面的 XML 中有几个重要的部分。 XML 中的 `<background>` 节点是你的外部节点。 每个背景都支持多个 `<static>` 和 `<transition>` 节点。
`<static>` 节点定义用 `<file>` 节点要显示的图像以及用 `<duration>` 显示它的持续时间。
`<transition>` 节点定义 `<duration>`(变换时长),`<from>` 和 `<to>` 定义了起止的图像。
### 全天更换壁纸
另一个很酷的 GNOME 功能是基于时间的幻灯片。 你可以定义幻灯片的开始时间,GNOME 将根据它计算时间。 这对于根据一天中的时间设置不同的壁纸很有用。 例如,你可以将开始时间设置为 06:00,并在 12:00 之前显示一张墙纸,然后在下午和 18:00 再次更改。
这是通过在 XML 中定义 `<starttime>` 来完成的,如下所示:
```
<starttime>
<!-- A start time in the past is fine -->
<year>2017</year>
<month>11</month>
<day>21</day>
<hour>6</hour>
<minute>00</minute>
<second>00</second>
</starttime>
```
上述 XML 文件定义于 2017 年 11 月 21 日 06:00 开始动画,时长为 21,600.00,相当于六个小时。 这段时间将显示你的早晨壁纸直到 12:00,12:00 时它会更改为你的下一张壁纸。 你可以继续以这种方式每隔一段时间更换一次壁纸,但确保所有持续时间的总计为 86,400 秒(等于 24 小时)。
GNOME 将计算开始时间和当前时间之间的增量,并显示当前时间的正确墙纸。 例如,如果你在 16:00 选择新壁纸,则GNOME 将在 06:00 开始时间之后显示 36,000 秒的适当壁纸。
有关完整示例,请参阅大多数发行版中由 gnome-backgrounds 包提供的 adwaita-timed 幻灯片。 它通常位于 `/usr/share/backgrounds/gnome/adwaita-timed.xml` 中。
### 了解更多信息
希望这可以鼓励你深入了解创建自己的幻灯片壁纸。 如果你想下载本文中引用的文件的完整版本,那么你可以在 [GitHub](https://github.com/kenvandine/misc/tree/master/articles/osdc/gnome/slide-show-backgrounds/osdc) 上找到它们。
如果你对用于生成 XML 文件的实用程序脚本感兴趣,你可以在互联网上搜索 `gnome-backearth-generator`。
---
via: <https://opensource.com/article/17/12/create-your-own-wallpaper-slideshow-gnome>
作者:[Ken Vandine](https://opensource.com/users/kenvandine) 译者:[Auk7F7](https://github.com/Auk7F7) 校对: [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,572 | 给初学者的 fc 示例教程 | https://www.ostechnix.com/the-fc-command-tutorial-with-examples-for-beginners/ | 2018-04-23T19:10:08 | [
"fc",
"命令行",
"历史",
"history"
] | https://linux.cn/article-9572-1.html | 
`fc` (**F**ix **C**ommands 的缩写)是个 shell 内置命令,用于在交互式 shell 里列出、编辑和执行最近输入的命令。你可以用你喜欢的编辑器编辑最近的命令并再次执行,而不用把它们整个重新输入一遍。除了可以避免重复输入又长又复杂的命令,它对修正拼写错误来说也很有用。因为是 shell 内置命令,大多 shell 都包含它,比如 Bash 、 Zsh 、 Ksh 等。在这篇短文中,我们来学一学在 Linux 中使用 `fc` 命令。
### fc 命令教程及示例
#### 列出最近执行的命令
执行不带其它参数的 `fc -l` 命令,它会列出最近 16 个命令。
```
$ fc -l
507 fish
508 fc -l
509 sudo netctl restart wlp9s0sktab
510 ls -l
511 pwd
512 uname -r
513 uname -a
514 touch ostechnix.txt
515 vi ostechnix.txt
516 echo "Welcome to OSTechNix"
517 sudo apcman -Syu
518 sudo pacman -Syu
519 more ostechnix.txt
520 wc -l ostechnix.txt
521 cat ostechnix.txt
522 clear
```
`-r` 选项用于将输出反向排序。
```
$ fc -lr
```
`-n` 选项用于隐藏行号。
```
$ fc -ln
nano ~/.profile
source ~/.profile
source ~/.profile
fc -ln
fc -l
sudo netctl restart wlp9s0sktab
ls -l
pwd
uname -r
uname -a
echo "Welcome to OSTechNix"
sudo apcman -Syu
cat ostechnix.txt
wc -l ostechnix.txt
more ostechnix.txt
clear
```
这样行号就不再显示了。
如果想以某个命令开始,只需在 `-l` 选项后面加上行号即可。比如,要显示行号 520 至最近的命令,可以这样:
```
$ fc -l 520
520 ls -l
521 pwd
522 uname -r
523 uname -a
524 echo "Welcome to OSTechNix"
525 sudo apcman -Syu
526 cat ostechnix.txt
527 wc -l ostechnix.txt
528 more ostechnix.txt
529 clear
530 fc -ln
531 fc -l
```
要列出一段范围内的命令,将始、末行号作为 `fc -l` 的参数即可,比如 520 至 525:
```
$ fc -l 520 525
520 ls -l
521 pwd
522 uname -r
523 uname -a
524 echo "Welcome to OSTechNix"
525 sudo apcman -Syu
```
除了使用行号,我们还可以使用字符。比如,要列出最近一个 `pwd` 至最近一个命令之间的所有命令,只需要像下面这样使用起始字母即可:
```
$ fc -l p
521 pwd
522 uname -r
523 uname -a
524 echo "Welcome to OSTechNix"
525 sudo apcman -Syu
526 cat ostechnix.txt
527 wc -l ostechnix.txt
528 more ostechnix.txt
529 clear
530 fc -ln
531 fc -l
532 fc -l 520
533 fc -l 520 525
534 fc -l 520
535 fc -l 522
536 fc -l l
```
要列出所有 `pwd` 和 `more` 之间的命令,你可以都使用起始字母,像这样:
```
$ fc -l p m
```
或者,使用开始命令的首字母以及结束命令的行号:
```
$ fc -l p 528
```
或者都使用行号:
```
$ fc -l 521 528
```
这三个命令都显示一样的结果。
#### 编辑并执行上一个命令
我们经常敲错命令,这时你可以用默认编辑器修正拼写错误并执行而不用将命令重新再敲一遍。
编辑并执行上一个命令:
```
$ fc
```
这会在默认编辑器里载入上一个命令。

你可以看到,我上一个命令是 `fc -l`。你可以随意修改,它会在你保存退出编辑器时自动执行。这在命令或参数又长又复杂时很有用。需要注意的是,它同时也可能是**毁灭性**的。比如,如果你的上一个命令是危险的 `rm -fr <some-path>`,当它自动执行时你可能丢掉你的重要数据。所以,小心谨慎对待每一个命令。
#### 更改默认编辑器
另一个有用的选项是 `-e` ,它可以用来为 `fc` 命令选择不同的编辑器。比如,如果我们想用 `nano` 来编辑上一个命令:
```
$ fc -e nano
```
这个命令会打开 `nano` 编辑器(而不是默认编辑器)编辑上一个命令。

如果你觉得用 `-e` 选项太麻烦,你可以修改你的默认编辑器,只需要将环境变量 `FCEDIT` 设为你想要让 `fc` 使用的编辑器名称即可。
比如,要把 `nano` 设为默认编辑器,编辑你的 `~/.profile` 或其他初始化文件: (LCTT 译注:如果 `~/.profile` 不存在可自己创建;如果使用的是 bash ,可以编辑 `~/.bash_profile` )
```
$ vi ~/.profile
```
添加下面一行:
```
FCEDIT=nano
# LCTT译注:如果在子 shell 中会用到 fc ,最好在这里 export FCEDIT
```
你也可以使用编辑器的完整路径:
```
FCEDIT=/usr/local/bin/emacs
```
输入 `:wq` 保存退出。要使改动立即生效,运行以下命令:
```
$ source ~/.profile
```
现在再输入 `fc` 就可以使用 `nano` 编辑器来编辑上一个命令了。
#### 不编辑而直接执行上一个命令
我们现在知道 `fc` 命令不带任何参数的话会将上一个命令载入编辑器。但有时你可能不想编辑,仅仅是想再次执行上一个命令。这很简单,在末尾加上连字符(`-`)就可以了:
```
$ echo "Welcome to OSTechNix"
Welcome to OSTechNix
$ fc -e -
echo "Welcome to OSTechNix"
Welcome to OSTechNix
```
如你所见,`fc` 带了 `-e` 选项,但并没有编辑上一个命令(例中的 `echo " Welcome to OSTechNix"`)。
需要注意的是,有些选项仅对指定 shell 有效。比如下面这些选项可以用在 zsh 中,但在 Bash 或 Ksh 中则不能用。
#### 显示命令的执行时间
想要知道命令是在什么时候执行的,可以用 `-d` 选项:
```
fc -ld
1 18:41 exit
2 18:41 clear
3 18:42 fc -l
4 18:42 sudo netctl restart wlp9s0sktab
5 18:42 ls -l
6 18:42 pwd
7 18:42 uname -r
8 18:43 uname -a
9 18:43 cat ostechnix.txt
10 18:43 echo "Welcome to OSTechNix"
11 18:43 more ostechnix.txt
12 18:43 wc -l ostechnix.txt
13 18:43 cat ostechnix.txt
14 18:43 clear
15 18:43 fc -l
```
这样你就可以查看最近命令的具体执行时间了。
使用选项 `-f` ,可以为每个命令显示完整的时间戳。
```
fc -lf
1 4/5/2018 18:41 exit
2 4/5/2018 18:41 clear
3 4/5/2018 18:42 fc -l
4 4/5/2018 18:42 sudo netctl restart wlp9s0sktab
5 4/5/2018 18:42 ls -l
6 4/5/2018 18:42 pwd
7 4/5/2018 18:42 uname -r
8 4/5/2018 18:43 uname -a
9 4/5/2018 18:43 cat ostechnix.txt
10 4/5/2018 18:43 echo "Welcome to OSTechNix"
11 4/5/2018 18:43 more ostechnix.txt
12 4/5/2018 18:43 wc -l ostechnix.txt
13 4/5/2018 18:43 cat ostechnix.txt
14 4/5/2018 18:43 clear
15 4/5/2018 18:43 fc -l
16 4/5/2018 18:43 fc -ld
```
当然,欧洲的老乡们还可以使用 `-E` 选项来显示欧洲时间格式。
```
fc -lE
2 5.4.2018 18:41 clear
3 5.4.2018 18:42 fc -l
4 5.4.2018 18:42 sudo netctl restart wlp9s0sktab
5 5.4.2018 18:42 ls -l
6 5.4.2018 18:42 pwd
7 5.4.2018 18:42 uname -r
8 5.4.2018 18:43 uname -a
9 5.4.2018 18:43 cat ostechnix.txt
10 5.4.2018 18:43 echo "Welcome to OSTechNix"
11 5.4.2018 18:43 more ostechnix.txt
12 5.4.2018 18:43 wc -l ostechnix.txt
13 5.4.2018 18:43 cat ostechnix.txt
14 5.4.2018 18:43 clear
15 5.4.2018 18:43 fc -l
16 5.4.2018 18:43 fc -ld
17 5.4.2018 18:49 fc -lf
```
### fc 用法总结
* 当不带任何参数时,`fc` 将上一个命令载入默认编辑器。
* 当带一个数字作为参数时,`fc` 将数字指定的命令载入默认编辑器。
* 当带一个字符作为参数时,`fc` 将最近一个以指定字符开头的命令载入默认编辑器。
* 当有两个参数时,它们分别指定需要列出的命令范围的开始和结束。
更多细节,请参考 man 手册。
```
$ man fc
```
好了,今天就这些。希望这篇文章能帮助到你。更多精彩内容,敬请期待!
---
via: <https://www.ostechnix.com/the-fc-command-tutorial-with-examples-for-beginners/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Dotcra](https://github.com/Dotcra) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,573 | 使用 Let's Encrypt 保护你的网站 | https://www.linux.com/learn/intro-to-linux/2018/3/protect-your-websites-lets-encrypt | 2018-04-23T21:15:00 | [
"HTTPS"
] | https://linux.cn/article-9573-1.html |
>
> 未加密的 HTTP 会话暴露于滥用之中,用 Let's Encrypt 把它们保护起来。
>
>
>

曾几何时,通过证书授权机构搭建基本的 HTTPS 网站需要每年花费数百美元,而且搭建的过程复杂且容易出错。现在我们免费使用 [Let's Encrypt](https://letsencrypt.org),而且搭建过程也只需要几分钟。
### 为何进行加密?
为什么要加密网站呢?这是因为未经加密的 HTTP 会话可以被多种方式滥用:
* 窃听用户数据包
* 捕捉用户登录
* 注入[广告](https://www.thesslstore.com/blog/third-party-content-injection/)和[“重要”消息](https://blog.ryankearney.com/2013/01/comcast-caught-intercepting-and-altering-your-web-traffic/)
* 注入[木马](https://www.eff.org/deeplinks/2018/03/we-still-need-more-https-government-middleboxes-caught-injecting-spyware-ads-and)
* 注入 [SEO 垃圾邮件和链接](https://techglimpse.com/wordpress-injected-with-spam-security/)
* 注入[挖矿脚本](https://thehackernews.com/2018/03/cryptocurrency-spyware-malware.html)
网络服务提供商就是最大的代码注入者。那么如何挫败它们的非法行径呢?你最好的防御手段就是 HTTPS。让我们回顾一下 HTTPS 的工作原理。
### 信任链
你可以在你的网站和每个授权访问用户之间建立非对称加密。这是一种非常强的保护:GPG(GNU Privacy Guard, 参考[如何在 Linux 中加密邮件](https://www.linux.com/learn/how-encrypt-email-linux))和 OpenSSH 就是非对称加密的通用工具。它们依赖于公钥-私钥对,其中公钥可以任意分享,但私钥必须受到保护且不能分享。公钥用于加密,私钥用于解密。
但上述方法无法适用于随机的网页浏览,因为建立会话之前需要交换公钥,你需要生成并管理密钥对。HTTPS 会话可以自动完成公钥分发,而且购物或银行之类的敏感网站还会使用第三方证书颁发机构(CA)验证证书,例如 Comodo、 Verisign 和 Thawte。
当你访问一个 HTTPS 网站时,网站给你的网页浏览器返回了一个数字证书。这个证书说明你的会话被强加密,而且提供了该网站信息,包括组织名称、颁发证书的组织和证书颁发机构名称等。你可以点击网页浏览器地址栏的小锁头来查看这些信息(图 1),也包括了证书本身。

*图1: 点击网页浏览器地址栏上的锁头标记查看信息*
包括 Opera、 Chromium 和 Chrome 在内的主流浏览器,验证网站数字证书的合法性都依赖于证书颁发机构。小锁头标记可以让你一眼看出证书状态;绿色意味着使用强 SSL 加密且运营实体经过验证。网页浏览器还会对恶意网站、SSL 证书配置有误的网站和不被信任的自签名证书网站给出警告。
那么网页浏览器如何判断网站是否可信呢?浏览器自带根证书库,包含了一系列根证书,存储在 `/usr/share/ca-certificates/mozilla/` 之类的地方。网站证书是否可信可以通过根证书库进行检查。就像你 Linux 系统上其它软件那样,根证书库也由包管理器维护。对于 Ubuntu,对应的包是 `ca-certificates`,这个 Linux 根证书库本身是[由 Mozilla 维护](https://www.mozilla.org/en-US/about/governance/policies/security-group/certs/policy/)的。
可见,整个工作流程需要复杂的基础设施才能完成。在你进行购物或金融等敏感在线操作时,你信任了无数陌生人对你的保护。
### 无处不加密
Let's Encrypt 是一家全球证书颁发机构,类似于其它商业根证书颁发机构。Let's Encrpt 由非营利性组织<ruby> 因特网安全研究小组 <rt> Internet Security Research Group </rt></ruby>(ISRG)创立,目标是简化网站的安全加密。在我看来,出于后面我会提到的原因,该证书不足以胜任购物及银行网站的安全加密,但很适合加密博客、新闻和信息门户这类不涉及金融操作的网站。
使用 Let's Encrypt 有三种方式。推荐使用<ruby> 电子前沿基金会 <rt> Electronic Frontier Foundation </rt></ruby>(EFF)开发的 [Cerbot 客户端](https://certbot.eff.org/)。使用该客户端需要在网站服务器上执行 shell 操作。
如果你使用的是共享托管主机,你很可能无法执行 shell 操作。这种情况下,最简单的方法是使用[支持 Let's Encrpt 的托管主机](https://community.letsencrypt.org/t/web-hosting-who-support-lets-encrypt/6920)。
如果你的托管主机不支持 Let's Encrypt,但支持自定义证书,那么你可以使用 Certbot [手动创建并上传你的证书](https://community.letsencrypt.org/t/web-hosting-who-support-lets-encrypt/6920)。这是一个复杂的过程,你需要彻底地研究文档。
安装证书后,使用 [SSL 服务器测试](https://www.ssllabs.com/ssltest/)来测试你的服务器。
Let's Encrypt 的电子证书有效期为 90 天。Certbot 安装过程中添加了一个证书自动续期的计划任务,也提供了测试证书自动续期是否成功的命令。允许使用已有的私钥或<ruby> 证书签名请求 <rt> certificate signing request </rt></ruby>(CSR),允许创建通配符证书。
### 限制
Let's Encrypt 有如下限制:它只执行域名验证,即只要有域名控制权就可以获得证书。这是比较基础的 SSL。它不支持<ruby> 组织验证 <rt> Organization Validation </rt></ruby>(OV)或<ruby> 扩展验证 <rt> Extended Validation </rt></ruby>(EV),因为运营实体验证无法自动完成。我不会信任使用 Let's Encrypt 证书的购物或银行网站,它们应该购买支持运营实体验证的完整版本。
作为非营利性组织提供的免费服务,不提供商业支持,只提供不错的文档和社区支持。
因特网中恶意无处不在,一切数据都应该加密。从使用 [Let's Encrypt](https://letsencrypt.org/) 保护你的网站用户开始吧。
想要学习更多 Linux 知识,请参考 Linux 基金会和 edX 提供的免费课程 [“Linux 入门”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/3/protect-your-websites-lets-encrypt>
作者:[CARLA SCHRODER](https://www.linux.com/users/cschroder) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,574 | 一个基于 Arch 的独立 Linux 发行版 MagpieOS | https://itsfoss.com/magpieos/ | 2018-04-24T17:46:00 | [
"发行版",
"MagpieOS",
"Arch"
] | https://linux.cn/article-9574-1.html | 目前使用的大多数 Linux 发行版都是由欧美创建和开发的。一位来自孟加拉国的年轻开发人员想要改变这一切。
### 谁是 Rizwan?
[Rizwan](https://twitter.com/Linux_Saikat) 是来自孟加拉国的计算机科学专业的学生。他目前正在学习成为一名专业的 Python 程序员。他在 2015 年开始使用 Linux。使用 Linux 启发他创建了自己的 Linux 发行版。他还希望让世界其他地方知道孟加拉国正在升级到 Linux。
他还致力于创建 [LFS 的 live 版本](https://itsfoss.com/linux-from-scratch-live-cd/)。

### 什么是 MagpieOS?
Rizwan 的新发行版被命名为 MagpieOS。 [MagpieOS](http://www.magpieos.net) 非常简单。它基本上是 GNOME3 桌面环境的 Arch。 MagpieOS 还包括一个自定义的仓库,其中包含图标和主题(据称)在其他基于 Arch 的发行版或 AUR 上都没有。
下面是 MagpieOS 包含的软件列表:Firefox、LibreOffice、Uget、Bleachbit、Notepadqq、SUSE Studio Image Writer、Pamac 软件包管理器、Gparted、Gimp、Rhythmbox、简单屏幕录像机等包括 Totem 视频播放器在内的所有默认 GNOME 软件,以及一套新的定制壁纸。
目前,MagpieOS 仅支持 GNOME 桌面环境。Rizwan 选择它是因为这是他的最爱。但是,他计划在未来添加更多的桌面环境。
不幸的是,MagpieOS 不支持孟加拉语或任何其他当地语言。它支持 GNOME 的默认语言,如英语、印地语等。
Rizwan 命名他的发行为 MagpieOS,因为<ruby> <a href="https://en.wikipedia.org/wiki/Magpie"> 喜鹊 </a> <rt> magpie </rt></ruby> 是孟加拉国的官方鸟。

### 为什么选择 Arch?
和大多数人一样,Rizwan 通过使用 [Ubuntu](https://www.ubuntu.com) 开始了他的 Linux 旅程。一开始,他对此感到满意。但是,有时他想安装的软件在仓库中没有,他不得不通过 Google 寻找正确的 PPA。他决定切换到 [Arch](https://www.archlinux.org),因为 Arch 有许多在 Ubuntu 上没有的软件包。Rizwan 也喜欢 Arch 是一个滚动版本,并且始终是最新的。
Arch 的问题在于它的安装非常复杂和耗时。所以,Rizwan 尝试了几个基于 Arch 的发行版,并且对任何一个都不满意。他不喜欢 [Manjaro](http://manjaro.org),因为它们没有权限使用 Arch 的仓库。此外,Arch 仓库镜像比 Manjaro 更快并且拥有更多软件。他喜欢 [Antergos](https://antergos.com),但要安装需要一个持续的互联网连接。如果在安装过程中连接失败,则必须重新开始。
由于这些问题,Rizwan 决定创建一个简单的发行版,让他和其他人无需麻烦地安装 Arch。他还希望通过使用他的发行版让他的祖国的开发人员从 Ubuntu 切换到 Arch。
### 如何通过 MagpieOS 帮助 Rizwan
如果你有兴趣帮助 Rizwan 开发 MagpieOS,你可以通过 [MagpieOS 网站](http://www.magpieos.net)与他联系。你也可以查看该项目的 [GitHub 页面](https://github.com/Rizwan-Hasan/MagpieOS)。Rizwan 表示,他目前不寻求财政支持。

### 最后的想法
我快速地安装过一次 MagpieOS。它使用 [Calamares 安装程序](https://calamares.io),这意味着安装它相对快速轻松。重新启动后,我听到一封欢迎我来到 MagpieOS 的音频消息。
说实话,这是我第一次听到安装后的问候。(Windows 10 可能也有,但我不确定)屏幕底部还有一个 Mac OS 风格的应用程序停靠栏。除此之外,它感觉像我用过的其他任何 GNOME 3 桌面。
考虑到这是一个刚刚起步的独立项目,我不会推荐它作为你的主要操作系统。但是,如果你是一个发行版尝试者,你一定会试试看。
话虽如此,对于一个想把自己的国家放在技术地图上的学生来说,这是一个不错的尝试。做得很好,Rizwan。
你有没有听说过 MagpieOS?你最喜欢的地区或本地制作的 Linux 发行版是什么?请在下面的评论中告诉我们。
如果你发现这篇文章有趣,请花点时间在社交媒体上分享。
---
via: <https://itsfoss.com/magpieos/>
作者:[John Paul](https://itsfoss.com/author/john/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Most of the Linux distros that are in use today are either created and developed in the US or Europe. A young developer from Bangladesh wants to change all that.
### Who is Rizwan?
[Rizwan](https://twitter.com/Linux_Saikat) is a computer science student from Bangladesh. He is currently studying to become a profession Python programmer. He started using Linux back in 2015. Working with Linux inspired him to create this own Linux distribution. He also wants to let the rest of the world know that Bangladesh is upgrading to Linux.
He has also worked on creating a [live version of Linux From Scratch](https://itsfoss.com/linux-from-scratch-live-cd/).
### What is MagpieOS?
Rizwan’s new distro is named MagpieOS. [MagpieOS](http://www.magpieos.net) is very simple. It is basically Arch with the GNOME3 desktop environment. MagpieOS also includes a custom repo with icons and themes (claimed to be) not available on other Arch-based distros or AUR.
Here is a list of the software included with MagpieOS: Firefox, LibreOffice, Uget, Bleachbit, Notepadqq, SUSE Studio Image Writer, Pamac Package Manager, Gparted, Gimp, Rhythmbox, Simple Screen Recorder, all default GNOME software including Totem Video Player, and a new set of custom wallpaper.
Currently, MagpieOS only supported the GNOME desktop environment. Rizwan picked it because it is his favorite. However, he plans to add more desktop environments in the future.
Unfortunately, MagpieOS does not support the Bangla language or any other local languages. It supports GNOME’s default language like English, Hindi etc.
Rizwan named his distro MagpieOS because the [magpie](https://en.wikipedia.org/wiki/Magpie) is the official bird of Bangladesh.
### Why Arch?
Like most people, Rizwan started his Linux journey by using [Ubuntu](https://www.ubuntu.com). In the beginning, he was happy with it. However, sometimes the software he wanted to install was not available in the repos and he had to hunt through Google looking for the correct PPA. He decided to switch to [Arch](https://www.archlinux.org) because Arch has many packages that were not available on Ubuntu. Rizwan also liked the fact that Arch is a rolling release and would always be up-to-date.
The problem with Arch is that it is complicated and time-consuming to install. So, Rizwan tried out several Arch-based distros and was not happy with any of them. He didn’t like [Manjaro](http://manjaro.org) because they did not have permission to use Arch’s repos. Also, Arch repo mirrors are faster than Manjaro’s and have more software. He liked [Antergos](https://antergos.com), but to install you need a constant internet connection. If your connection fails during installation, you have to start over.
Because of these issues, Rizwan decided to create a simple distro that would give him and others an Arch install without all the hassle. He also hopes to get developers from his home country to switch from Ubuntu to Arch by using his distro.
[irp posts=”25316″ name=”A Tale of Two Arches: ArchLabs and ArchMerge”]
### How to Help Rizwan with MagpieOS
If you are interested in helping Rizwan develop MagpieOS, you can contact him via the [MagpieOS website](http://www.magpieos.net). You can also check out the project’s [GitHub page](https://github.com/Rizwan-Hasan/MagpieOS). Rizwan said that he is not looking for financial support at the moment.
## Final Thoughts
I installed MagpieOS to give it a quick once-over. It uses the [Calamares installer](https://calamares.io), which means installing it was relatively quick and painless. After I rebooted, I was greeted by an audio message welcoming me to MagpieOS.
To be honest, it was the first time I have heard a post-install greeting. (Windows 10 might have one, but I’m not sure.) There was also a Mac OS-esque application dock at the bottom of the screen. Other than that, it felt like any other GNOME 3 desktop I have used.
Considering that it’s an indie project at the nascent stage, I won’t recommend it using as your main OS. But if you are a distrohopper, you can surely give it a try.
That being said, this is a good first try for a student seeking to put his country on the technological map. All the best, Rizwan.
Have you already heard of MagpieOS? What is your favorite region or locally made Linux distro? Please let us know in the comments below.
If you found this article interesting, please take a minute to share it on social media. |
9,575 | 3 个 Linux 命令行密码管理器 | https://opensource.com/article/18/4/3-password-managers-linux-command-line | 2018-04-24T18:03:36 | [
"密码",
"密码管理器"
] | https://linux.cn/article-9575-1.html |
>
> 给在终端窗口花费大量时间的人们的密码管理器。
>
>
>

我们都希望我们的密码安全可靠。为此,许多人转向密码管理应用程序,如 [KeePassX](https://www.keepassx.org/) 和 [Bitwarden](https://opensource.com/article/18/3/managing-passwords-bitwarden)。
如果你在终端中花费了大量时间而且正在寻找更简单的解决方案,那么你需要了解下诸多的 Linux 命令行密码管理器。它们快速,易于使用且安全。
让我们来看看其中的三个。
### Titan
[Titan](https://www.titanpasswordmanager.org/) 是一个密码管理器,也可作为文件加密工具。我不确定 Titan 在加密文件方面效果有多好;我只是把它看作密码管理器,在这方面,它确实做的很好。

Titan 将你的密码存储在加密的 [SQLite 数据库](https://en.wikipedia.org/wiki/SQLite)中,你可以在第一次启动该应用程序时创建并添加主密码。告诉 Titan 增加一个密码,它需要一个用来识别它的名字、用户名、密码本身、URL 和关于密码的注释。
你可以让 Titan 为你生成一个密码,你可以通过条目名称或数字 ID、名称、注释或使用正则表达式来搜索数据库,但是,查看特定的密码可能会有点笨拙,你要么必须列出所有密码滚动查找你想要使用的密码,要么你可以通过使用其数字 ID(如果你知道)列出条目的详细信息来查看密码。
### Gopass
[Gopass](https://www.justwatch.com/gopass/) 被称为“团队密码管理器”。不要因此感到失望,它对个人的使用也很好。

Gopass 是用 Go 语言编写的经典 Unix 和 Linux [Pass](https://www.passwordstore.org/) 密码管理器的更新版本。安装纯正的 Linux 方式,你可以[编译源代码](https://github.com/justwatchcom/gopass)或[使用安装程序](https://justwatch.com/gopass/#install)以在你的计算机上使用 gopass。
在开始使用 gopass 之前,确保你的系统上有 [GNU Privacy Guard (GPG)](https://www.gnupg.org) 和 [Git](https://git-scm.com/)。前者对你的密码存储进行加密和解密,后者将提交到一个 [Git 仓库](https://git-scm.com/book/en/v2/Git-Basics-Getting-a-Git-Repository)。如果 gopass 是给个人使用,你仍然需要 Git。你不需要担心提交到仓库。如果你感兴趣,你可以[在文档中](https://github.com/justwatchcom/gopass/blob/master/docs/setup.md)了解这些依赖关系。
当你第一次启动 gopass 时,你需要创建一个密码存储库并生成一个[密钥](http://searchsecurity.techtarget.com/definition/private-key)以确保存储的安全。当你想添加一个密码(gopass 中称之为“secret”)时,gopass 会要求你提供一些信息,比如 URL、用户名和密码。你可以让 gopass 为你添加的“secret”生成密码,或者你可以自己输入密码。
根据需要,你可以编辑、查看或删除密码。你还可以查看特定的密码或将其复制到剪贴板,以将其粘贴到登录表单或窗口中。
### Kpcli
许多人选择的是开源密码管理器 [KeePass](https://keepass.info/) 和 [KeePassX](https://www.keepassx.org)。 [Kpcli](http://kpcli.sourceforge.net/) 将 KeePass 和 KeePassX 的功能带到你的终端窗口。

Kpcli 是一个键盘驱动的 shell,可以完成其图形化的表亲的大部分功能。这包括打开密码数据库、添加和编辑密码和组(组帮助你组织密码),甚至重命名或删除密码和组。
当你需要时,你可以将用户名和密码复制到剪贴板以粘贴到登录表单中。为了保证这些信息的安全,kpcli 也有清除剪贴板的命令。对于一个小终端应用程序来说还不错。
你有最喜欢的命令行密码管理器吗?何不通过发表评论来分享它?
---
via: <https://opensource.com/article/18/4/3-password-managers-linux-command-line>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We all want our passwords to be safe and secure. To do that, many people turn to password management applications like [KeePassX](https://www.keepassx.org/) or [Bitwarden](https://opensource.com/article/18/3/managing-passwords-bitwarden).
If you spend a lot of time in a terminal window and are looking for a simpler solution, you'll want to check out one of the many password managers for the Linux command line. They're quick, easy to use, and secure.
Let's take a look at three of them.
## Titan
[Titan](https://www.titanpasswordmanager.org/) is a password manager that doubles as a file-encryption tool. I'm not sure how well Titan works at encrypting files; I only looked at it as a password manager. In that capacity, it does a solid job.
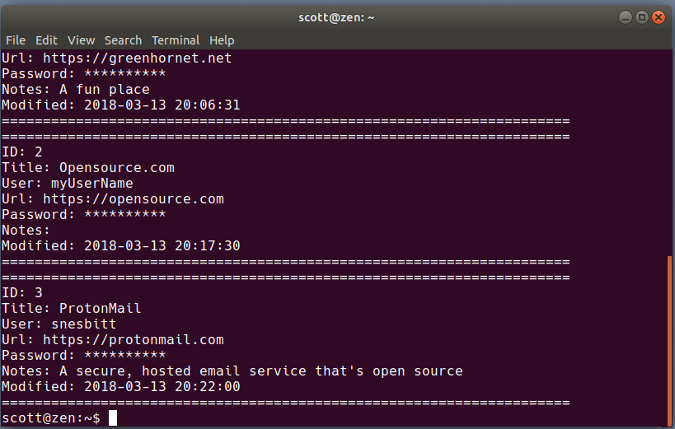
opensource.com
Titan stores your passwords in an encrypted [SQLite database](https://en.wikipedia.org/wiki/SQLite), which you create and add a master passphrase to when you first fire up the application. Tell Titan to add a password and it asks for a name to identify it, a username, the password itself, a URL, and a comment about the password.
You can get Titan to generate a password for you, and you can search your database by an entry's name or numeric ID, by the name or comment, or using regular expressions. Viewing a specific password, however, can be a bit clunky. You either have to list all passwords and scroll through them to find the one you want to use, or you can view the password by listing the details of an entry using its numeric ID (if you know it).
## Gopass
[Gopass](https://www.justwatch.com/gopass/) is billed as "the team password manager." Don't let that put you off. It's also great for personal use.
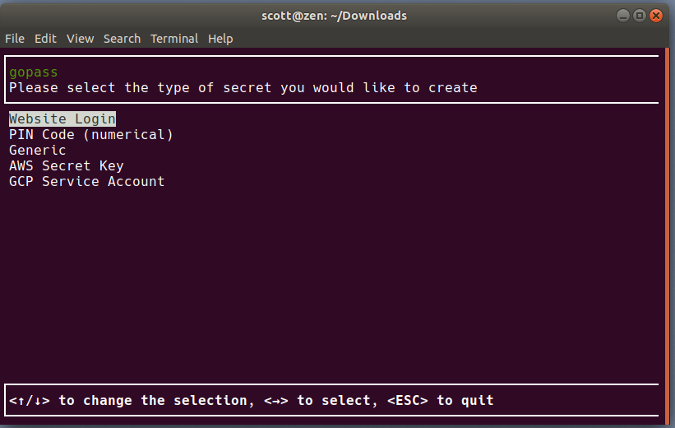
opensource.com
Gopass is an update of the venerable Unix and Linux [Pass](https://www.passwordstore.org/) password manager written in the Go programming language. In true Linux fashion, you can either [compile the source code](https://github.com/justwatchcom/gopass) or [use an installer](https://justwatch.com/gopass/#install) to get gopass on your computer.
Before you start using gopass, make sure you have [GNU Privacy Guard (GPG)](https://www.gnupg.org) and [Git](https://git-scm.com/) on your system. The former encrypts and decrypts your password store, and the latter signs commits to a [Git repository](https://git-scm.com/book/en/v2/Git-Basics-Getting-a-Git-Repository). If gopass is for personal use, you still need Git. You just don't need to worry about signing commits. If you're interested, you can learn about those dependencies [in the documentation](https://github.com/justwatchcom/gopass/blob/master/docs/setup.md).
When you first start gopass, you need to create a password store and generate a [secret key](http://searchsecurity.techtarget.com/definition/private-key) to secure that store. When you want to add a password (which gopass refers to as a *secret*), gopass asks you for information such as a URL, a username, and a note about the secret. You can have gopass generate the password for the secret you're adding, or you can enter one yourself.
As you need to, you can edit, view, or delete passwords. You can also view a specific password or copy it to your clipboard to paste it into a login form or window.
## Kpcli
The open source password manager of choice for many people is either [KeePass](https://keepass.info/) or [KeePassX](https://www.keepassx.org). [Kpcli](http://kpcli.sourceforge.net/) brings the features of KeePass and KeePassX to your nearest terminal window.
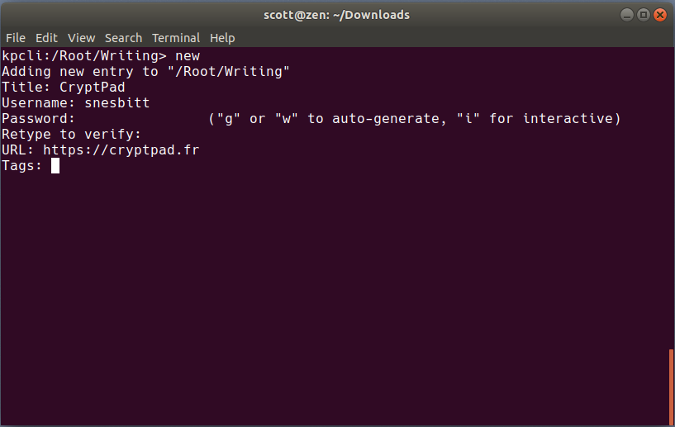
opensource.com
Kpcli is a keyboard-driven shell that does most of what its graphical cousins can do. That includes opening a password database; adding and editing passwords and groups (which help you organize your passwords); or even renaming or deleting passwords and groups.
When you need to, you can copy a username and password to your clipboard to paste into a login form. To keep that information safe, kpcli also has a command to clear the clipboard. Not bad for a little terminal app.
Do you have a favorite command-line password manager? Why not share it by leaving a comment?
## 10 Comments |
9,576 | 在 Linux 命令行上使用日历 | https://www.networkworld.com/article/3265752/linux/working-with-calendars-on-linux.html | 2018-04-25T10:14:59 | [
"日历"
] | https://linux.cn/article-9576-1.html |
>
> 通过 Linux 上的日历,不仅仅可以提醒你今天是星期几。诸如 date、cal、 ncal 和 calendar 等命令可以提供很多有用信息。
>
>
>

Linux 系统可以为你的日程安排提供更多帮助,而不仅仅是提醒你今天是星期几。日历显示有很多选项 —— 有些可能很有帮助,有些可能会让你大开眼界。
### 日期
首先,你可能知道可以使用 `date` 命令显示当前日期。
```
$ date
Mon Mar 26 08:01:41 EDT 2018
```
### cal 和 ncal
你可以使用 `cal` 命令显示整个月份。没有参数时,`cal` 显示当前月份,默认情况下,通过反转前景色和背景颜色来突出显示当天。
```
$ cal
March 2018
Su Mo Tu We Th Fr Sa
1 2 3
4 5 6 7 8 9 10
11 12 13 14 15 16 17
18 19 20 21 22 23 24
25 26 27 28 29 30 31
```
如果你想以“横向”格式显示当前月份,则可以使用 `ncal` 命令。
```
$ ncal
March 2018
Su 4 11 18 25
Mo 5 12 19 26
Tu 6 13 20 27
We 7 14 21 28
Th 1 8 15 22 29
Fr 2 9 16 23 30
Sa 3 10 17 24 31
```
例如,如果你只想查看特定周几的日期,这个命令可能特别有用。
```
$ ncal | grep Th
Th 1 8 15 22 29
```
`ncal` 命令还可以以“横向”格式显示一整年,只需在命令后提供年份。
```
$ ncal 2018
2018
January February March April
Su 7 14 21 28 4 11 18 25 4 11 18 25 1 8 15 22 29
Mo 1 8 15 22 29 5 12 19 26 5 12 19 26 2 9 16 23 30
Tu 2 9 16 23 30 6 13 20 27 6 13 20 27 3 10 17 24
We 3 10 17 24 31 7 14 21 28 7 14 21 28 4 11 18 25
Th 4 11 18 25 1 8 15 22 1 8 15 22 29 5 12 19 26
Fr 5 12 19 26 2 9 16 23 2 9 16 23 30 6 13 20 27
Sa 6 13 20 27 3 10 17 24 3 10 17 24 31 7 14 21 28
...
```
你也可以使用 `cal` 命令显示一整年。请记住,你需要输入年份的四位数字。如果你输入 `cal 18`,你将获得公元 18 年的历年,而不是 2018 年。
```
$ cal 2018
2018
January February March
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
1 2 3 4 5 6 1 2 3 1 2 3
7 8 9 10 11 12 13 4 5 6 7 8 9 10 4 5 6 7 8 9 10
14 15 16 17 18 19 20 11 12 13 14 15 16 17 11 12 13 14 15 16 17
21 22 23 24 25 26 27 18 19 20 21 22 23 24 18 19 20 21 22 23 24
28 29 30 31 25 26 27 28 25 26 27 28 29 30 31
April May June
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
1 2 3 4 5 6 7 1 2 3 4 5 1 2
8 9 10 11 12 13 14 6 7 8 9 10 11 12 3 4 5 6 7 8 9
15 16 17 18 19 20 21 13 14 15 16 17 18 19 10 11 12 13 14 15 16
22 23 24 25 26 27 28 20 21 22 23 24 25 26 17 18 19 20 21 22 23
29 30 27 28 29 30 31 24 25 26 27 28 29 30
July August September
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
1 2 3 4 5 6 7 1 2 3 4 1
8 9 10 11 12 13 14 5 6 7 8 9 10 11 2 3 4 5 6 7 8
15 16 17 18 19 20 21 12 13 14 15 16 17 18 9 10 11 12 13 14 15
22 23 24 25 26 27 28 19 20 21 22 23 24 25 16 17 18 19 20 21 22
29 30 31 26 27 28 29 30 31 23 24 25 26 27 28 29
30
October November December
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
1 2 3 4 5 6 1 2 3 1
7 8 9 10 11 12 13 4 5 6 7 8 9 10 2 3 4 5 6 7 8
14 15 16 17 18 19 20 11 12 13 14 15 16 17 9 10 11 12 13 14 15
21 22 23 24 25 26 27 18 19 20 21 22 23 24 16 17 18 19 20 21 22
28 29 30 31 25 26 27 28 29 30 23 24 25 26 27 28 29
30 31
```
要指定年份和月份,使用 `-d` 选项,如下所示:
```
$ cal -d 1949-03
March 1949
Su Mo Tu We Th Fr Sa
1 2 3 4 5
6 7 8 9 10 11 12
13 14 15 16 17 18 19
20 21 22 23 24 25 26
27 28 29 30 31
```
另一个可能有用的日历选项是 `cal` 命令的 `-j` 选项。让我们来看看它显示的是什么。
```
$ cal -j
March 2018
Su Mo Tu We Th Fr Sa
60 61 62
63 64 65 66 67 68 69
70 71 72 73 74 75 76
77 78 79 80 81 82 83
84 85 86 87 88 89 90
```
你可能会问:“什么鬼???” OK, `-j` 选项显示 Julian 日期 -- 一年中从 1 到 365 年的数字日期。所以,1 是 1 月 1 日,32 是 2 月 1 日。命令 `cal -j 2018` 将显示一整年的数字,像这样:
```
$ cal -j 2018 | tail -9
November December
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
305 306 307 335
308 309 310 311 312 313 314 336 337 338 339 340 341 342
315 316 317 318 319 320 321 343 344 345 346 347 348 349
322 323 324 325 326 327 328 350 351 352 353 354 355 356
329 330 331 332 333 334 357 358 359 360 361 362 363
364 365
```
这种显示可能有助于提醒你,自从你做了新年计划之后,你已经有多少天没有采取行动了。
运行类似的命令,对于 2020 年,你会注意到这是一个闰年:
```
$ cal -j 2020 | tail -9
November December
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
306 307 308 309 310 311 312 336 337 338 339 340
313 314 315 316 317 318 319 341 342 343 344 345 346 347
320 321 322 323 324 325 326 348 349 350 351 352 353 354
327 328 329 330 331 332 333 355 356 357 358 359 360 361
334 335 362 363 364 365 366
```
### calendar
另一个有趣但潜在的令人沮丧的命令可以告诉你关于假期的事情,这个命令有很多选项,但我们这里介绍下你想看到即将到来的假期和值得注意的日历列表。日历的 `-l` 选项允许你选择今天想要查看的天数,因此 `0` 表示“仅限今天”。
```
$ calendar -l 0
Mar 26 Benjamin Thompson born, 1753, Count Rumford; physicist
Mar 26 David Packard died, 1996; age of 83
Mar 26 Popeye statue unveiled, Crystal City TX Spinach Festival, 1937
Mar 26 Independence Day in Bangladesh
Mar 26 Prince Jonah Kuhio Kalanianaole Day in Hawaii
Mar 26* Seward's Day in Alaska (last Monday)
Mar 26 Emerson, Lake, and Palmer record "Pictures at an Exhibition" live, 1971
Mar 26 Ludwig van Beethoven dies in Vienna, Austria, 1827
Mar 26 Bonne fête aux Lara !
Mar 26 Aujourd'hui, c'est la St(e) Ludger.
Mar 26 N'oubliez pas les Larissa !
Mar 26 Ludwig van Beethoven in Wien gestorben, 1827
Mar 26 Emánuel
```
对于我们大多数人来说,这庆祝活动有点多。如果你看到类似这样的内容,可以将其归咎于你的 `calendar.all` 文件,该文件告诉系统你希望包含哪些国际日历。当然,你可以通过删除此文件中包含其他文件的一些行来削减此问题。文件看起来像这样:
```
#include <calendar.world>
#include <calendar.argentina>
#include <calendar.australia>
#include <calendar.belgium>
#include <calendar.birthday>
#include <calendar.christian>
#include <calendar.computer>
```
假设我们只通过移除除上面显示的第一个 `#include` 行之外的所有行,将我们的显示切换到世界日历。 我们会看到这个:
```
$ calendar -l 0
Mar 26 Benjamin Thompson born, 1753, Count Rumford; physicist
Mar 26 David Packard died, 1996; age of 83
Mar 26 Popeye statue unveiled, Crystal City TX Spinach Festival, 1937
Mar 26 Independence Day in Bangladesh
Mar 26 Prince Jonah Kuhio Kalanianaole Day in Hawaii
Mar 26* Seward's Day in Alaska (last Monday)
Mar 26 Emerson, Lake, and Palmer record "Pictures at an Exhibition" live, 1971
Mar 26 Ludwig van Beethoven dies in Vienna, Austria, 1827
```
显然,世界日历的特殊日子非常多。但是,像这样的展示可以让你不要忘记所有重要的“大力水手雕像”揭幕日以及在庆祝“世界菠菜之都”中它所扮演的角色。
更有用的日历选择可能是将与工作相关的日历放入特殊文件中,并在 `calendar.all` 文件中使用该日历来确定在运行命令时将看到哪些事件。
```
$ cat /usr/share/calendar/calendar.all
/*
* International and national calendar files
*
* This is the calendar master file. In the standard setup, it is
* included by /etc/calendar/default, so you can make any system-wide
* changes there and they will be kept when you upgrade. If you want
* to edit this file, copy it into /etc/calendar/calendar.all and
* edit it there.
*
*/
#ifndef _calendar_all_
#define _calendar_all_
#include <calendar.usholiday>
#include <calendar.work> <==
#endif /* !_calendar_all_ */
```
日历文件的格式非常简单 - `mm/dd` 格式日期,空格和事件描述。
```
$ cat calendar.work
03/26 Describe how the cal and calendar commands work
03/27 Throw a party!
```
### 注意事项和怀旧
注意,有关日历的命令可能不适用于所有 Linux 发行版,你可能必须记住自己的“大力水手”雕像。
如果你想知道,你可以显示一个日历,远至 9999 —— 即使是预言性的 [2525](https://www.youtube.com/watch?v=izQB2-Kmiic)。
在 [Facebook](https://www.facebook.com/NetworkWorld/) 和 [LinkedIn](https://www.linkedin.com/company/network-world) 上加入网络社区,对那些重要的话题发表评论。
---
via: <https://www.networkworld.com/article/3265752/linux/working-with-calendars-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,577 | 如何在企业中开展开源计划 | https://opensource.com/article/18/1/how-start-open-source-program-your-company | 2018-04-25T23:43:29 | [
"开源计划"
] | https://linux.cn/article-9577-1.html |
>
> 有 65% 的企业在使用开源软件,并非只有互联网企业才能受惠于开源计划。
>
>
>

很多互联网企业如 Google、 Facebook、 Twitter 等,都已经正式建立了开源计划(有的公司中建立了单独的<ruby> 开源计划部门 <rt> open source program office </rt></ruby>(OSPO)),这是在公司内部消化和支持开源产品的地方。在这样一个实际的部门中,企业可以清晰透明地执行开源策略,这是企业成功开源化的一个必要过程。开源计划部门的职责包括:制定使用、分配、选择和审查代码的相关政策;培育开源社区;培训开发技术人员和确保法律合规。
互联网企业并不是唯一建立开源计划的企业,有调查发现各种行业中有 [65% 的企业](https://www.blackducksoftware.com/2016-future-of-open-source)的在使用开源和向开源贡献。在过去几年中 [VMware](http://www.cio.com/article/3095843/open-source-tools/vmware-today-has-a-strong-investment-in-open-source-dirk-hohndel.html)、 [Amazon](http://fortune.com/2016/12/01/amazon-open-source-guru/)、 [Microsoft](https://opensource.microsoft.com/) 等企业,甚至连[英国政府](https://www.linkedin.com/jobs/view/169669924)都开始聘用开源管理人员,开展开源计划。可见近年来商业领域乃至政府都十分重视开源策略,在这样的环境下,各界也需要跟上他们的步伐,建立开源计划。
### 怎样建立开源计划
虽然根据企业的需求不同,各开源计划部门会有特殊的调整,但下面几个基本步骤是建立每个公司都会经历的,它们是:
* **选定一位领导者:** 选出一位合适的领导之是建立开源计划的第一步。 [TODO Group](http://todogroup.org) 发布了一份[开源人员基础工作任务清单](https://github.com/todogroup/job-descriptions),你可以根据这个清单筛选人员。
* **确定计划构架:** 开源计划部门可以根据其服务的企业类型的侧重点,来适应不同种类的企业需求,以在各类企业中成功运行。知识型企业可以把开源计划放在法律事务部运行,技术驱动型企业可以把开源计划放在着眼于提高企业效能的部门中,如工程部。其他类型的企业可以把开源计划放在市场部内运行,以此促进开源产品的销售。TODO Group 发布的[开源计划案例](https://github.com/todogroup/guides/tree/master/casestudies)或许可以给你些启发。
* **制定规章制度:** 开源策略的实施需要有一套规章制度,其中应当具体列出企业成员进行开源工作的标准流程,来减少失误的发生。这个流程应当简洁明了且简单易行,最好可以用设备进行自动化。如果工作人员有质疑标准流程的热情和能力,并提出改进意见,那再好不过了。许多活跃在开源领域的企业中,Google 发布的规章制度十分值得借鉴。你可以参照 [Google 发布的制度](https://opensource.google.com/docs/why/)起草适用于自己企业的规章制度,用 [TODO 提供其它开源策略](https://github.com/todogroup/policies)也可以参考。 ### 建立开源计划是企业发展中的关键一步
建立开源计划部门对很多企业来说是关键一步,尤其是对于那些软件公司或是想要转型进入软件领域的公司。不论雇员的满意度或是开发效率上,在开源计划中企业可以获得巨大的利益,这些利益远远大于对开源计划所需要的长期投资。在开源之路上有很多资源可以帮助你成功,例如 TODO Group 的[《怎样创建开源计划》](https://github.com/todogroup/guides/blob/master/creating-an-open-source-program.md)、[《开源计划的价值评估》](https://github.com/todogroup/guides/blob/master/measuring-your-open-source-program.md)和[《管理开源计划的几种工具》](https://github.com/todogroup/guides/blob/master/tools-for-managing-open-source-programs.md)都很适合初学者阅读。
随着越来越多的企业形成开源计划,开源社区自身的可持续性逐渐加强,这会对这些企业的开源计划产生积极影响,促进企业的发展,这是企业和开源间的良性循环。我希望以上这些信息能够帮到你,祝你在建立开源计划的路上一路顺风。
---
via: <https://opensource.com/article/18/1/how-start-open-source-program-your-company>
作者:[Chris Aniszczyk](https://opensource.com/users/caniszczyk) 译者:[Valoniakim](https://github.com/Valoniakim) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,578 | FreeTube:注重隐私的开源桌面 YouTube 播放器 | https://www.ostechnix.com/freetube-an-open-source-desktop-youtube-player-for-privacy-minded-people/ | 2018-04-25T23:51:10 | [
"YouTube",
"FreeTube"
] | https://linux.cn/article-9578-1.html | 
你已经知道我们需要 Google 帐户才能订阅频道并从 YouTube 下载视频。如果你不希望 Google 追踪你在 YouTube 上的行为,那么有一个名为 **“FreeTube”** 的开源 Youtube 播放器。它能让你无需使用帐户观看、搜索和下载 Youtube 视频并订阅你喜爱的频道,这可以防止 Google 获取你的信息。它为你提供完整的无广告体验。另一个值得注意的优势是它有一个内置的基础的 HTML5 播放器来观看视频。由于我们没有使用内置的 YouTube 播放器,因此 Google 无法跟踪“观看次数”,也无法视频分析。FreeTube 只会发送你的 IP 详细信息,但这也可以通过使用 VPN 来解决。它是完全免费、开源的,可用于 GNU/Linux、Mac OS X 和 Windows。
### 功能
* 观看没有广告的视频。
* 防止 Google 使用 Cookie 或 JavaScript 跟踪你观看的内容。
* 无须帐户订阅频道。
* 本地存储订阅、历史记录和已保存的视频。
* 导入/备份订阅。
* 迷你播放器。
* 亮/暗的主题。
* 免费、开源。
* 跨平台。
### 安装 FreeTube
进入[发布页面](https://github.com/FreeTubeApp/FreeTube/releases)并根据你使用的操作系统获取版本。在本指南中,我将使用 **.tar.gz** 文件。
```
$ wget https://github.com/FreeTubeApp/FreeTube/releases/download/v0.1.3-beta/FreeTube-linux-x64.tar.xz
```
解压下载的归档:
```
$ tar xf FreeTube-linux-x64.tar.xz
```
进入 Freetube 文件夹:
```
$ cd FreeTube-linux-x64/
```
使用命令启动 Freeube:
```
$ ./FreeTub
```
这就是 FreeTube 默认界面的样子。

### 用法
FreeTube 目前使用 **YouTube API** 搜索视频。然后,它使用 **Youtube-dl HTTP API** 获取原始视频文件并在基础的 HTML5 视频播放器中播放它们。由于订阅、历史记录和已保存的视频都存储在本地系统中,因此你的详细信息将不会发送给 Google 或其他任何人。
在搜索框中输入视频名称,然后按下回车键。FreeTube 会根据你的搜索查询列出结果。

你可以点击任何视频来播放它。

如果你想更改主题或默认 API、导入/导出订阅,请进入**设置**部分。

请注意,FreeTube 仍处于 **beta** 阶段,所以仍然有 bug。如果有任何 bug,请在本指南最后给出的 GitHub 页面上报告。
干杯!
---
via: <https://www.ostechnix.com/freetube-an-open-source-desktop-youtube-player-for-privacy-minded-people/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,579 | 如何在 Linux 中使用 LVM 创建和扩展交换分区 | https://www.2daygeek.com/how-to-create-extend-swap-partition-in-linux-using-lvm/ | 2018-04-26T00:00:35 | [
"交换分区",
"LVM"
] | https://linux.cn/article-9579-1.html | 
我们使用 LVM 进行灵活的卷管理,为什么我们不能将 LVM 用于交换分区呢?
这可以让用户在需要时增加交换分区。如果你升级系统中的内存,则需要添加更多交换空间。这有助于你管理运行需要大量内存的应用的系统。
可以通过三种方式创建交换分区
* 创建一个新的交换分区
* 创建一个新的交换文件
* 在现有逻辑卷(LVM)上扩展交换分区
建议创建专用交换分区而不是交换文件。
**建议阅读:**
* [3 种简单的方法在 Linux 中创建或扩展交换空间](https://www.2daygeek.com/add-extend-increase-swap-space-memory-file-partition-linux/)
* [使用 Shell 脚本在 Linux 中自动创建/删除和挂载交换文件](https://www.2daygeek.com/shell-script-create-add-extend-swap-space-linux/)
Linux 中推荐的交换大小是多少?
### 什么是交换空间
当物理内存 (RAM) 已满时,将使用 Linux 中的交换空间。当物理内存已满时,内存中的非活动页将移到交换空间。
这有助于系统连续运行应用程序,但它不能当做是更多内存的替代品。
交换空间位于硬盘上,因此它不能像物理内存那样处理请求。
### 如何使用 LVM 创建交换分区
由于我们已经知道如何创建逻辑卷,所以交换分区也是如此。只需按照以下过程。
创建你需要的逻辑卷。在我这里,我要创建 `5GB` 的交换分区。
```
$ sudo lvcreate -L 5G -n LogVol_swap1 vg00
Logical volume "LogVol_swap1" created.
```
格式化新的交换空间。
```
$ sudo mkswap /dev/vg00/LogVol_swap1
Setting up swapspace version 1, size = 5 GiB (5368705024 bytes)
no label, UUID=d278e9d6-4c37-4cb0-83e5-2745ca708582
```
将以下条目添加到 `/etc/fstab` 中。
```
# vi /etc/fstab
/dev/mapper/vg00-LogVol_swap1 swap swap defaults 0 0
```
启用扩展逻辑卷。
```
$ sudo swapon -va
swapon: /swapfile: already active -- ignored
swapon: /dev/mapper/vg00-LogVol_swap1: found signature [pagesize=4096, signature=swap]
swapon: /dev/mapper/vg00-LogVol_swap1: pagesize=4096, swapsize=5368709120, devsize=5368709120
swapon /dev/mapper/vg00-LogVol_swap1
```
测试交换空间是否已正确添加。
```
$ cat /proc/swaps
Filename Type Size Used Priority
/swapfile file 1459804 526336 -1
/dev/dm-0 partition 5242876 0 -2
$ free -g
total used free shared buff/cache available
Mem: 1 1 0 0 0 0
Swap: 6 0 6
```
### 如何使用 LVM 扩展交换分区
只需按照以下过程来扩展 LVM 交换逻辑卷。
禁用相关逻辑卷的交换。
```
$ sudo swapoff -v /dev/vg00/LogVol_swap1
swapoff /dev/vg00/LogVol_swap1
```
调整逻辑卷的大小。我将把交换空间从 `5GB` 增加到 `11GB`。
```
$ sudo lvresize /dev/vg00/LogVol_swap1 -L +6G
Size of logical volume vg00/LogVol_swap1 changed from 5.00 GiB (1280 extents) to 11.00 GiB (2816 extents).
Logical volume vg00/LogVol_swap1 successfully resized.
```
格式化新的交换空间。
```
$ sudo mkswap /dev/vg00/LogVol_swap1
mkswap: /dev/vg00/LogVol_swap1: warning: wiping old swap signature.
Setting up swapspace version 1, size = 11 GiB (11811155968 bytes)
no label, UUID=2e3b2ee0-ad0b-402c-bd12-5a9431b73623
```
启用扩展逻辑卷。
```
$ sudo swapon -va
swapon: /swapfile: already active -- ignored
swapon: /dev/mapper/vg00-LogVol_swap1: found signature [pagesize=4096, signature=swap]
swapon: /dev/mapper/vg00-LogVol_swap1: pagesize=4096, swapsize=11811160064, devsize=11811160064
swapon /dev/mapper/vg00-LogVol_swap1
```
测试逻辑卷是否已正确扩展。
```
$ free -g
total used free shared buff/cache available
Mem: 1 1 0 0 0 0
Swap: 12 0 12
$ cat /proc/swaps
Filename Type Size Used Priority
/swapfile file 1459804 237024 -1
/dev/dm-0 partition 11534332 0 -2
```
---
via: <https://www.2daygeek.com/how-to-create-extend-swap-partition-in-linux-using-lvm/>
作者:[Ramya Nuvvula](https://www.2daygeek.com/author/ramya/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,580 | Linux 目录结构:/lib 分析 | https://www.linuxnix.com/linux-directory-structure-lib-explained/ | 2018-04-26T21:14:00 | [
"目录"
] | https://linux.cn/article-9580-1.html | 
我们在之前的文章中已经分析了其他重要系统目录,比如 `/bin`、`/boot`、`/dev`、 `/etc` 等。可以根据自己的兴趣进入下列链接了解更多信息。本文中,让我们来看看 `/lib` 目录都有些什么。
* [目录结构分析:/bin 文件夹](https://www.linuxnix.com/linux-directory-structure-explained-bin-folder/)
* [目录结构分析:/boot 文件夹](https://www.linuxnix.com/linux-directory-structure-explained-boot-folder/)
* [目录结构分析:/dev 文件夹](https://www.linuxnix.com/linux-directory-structure-explained-dev-folder/)
* [目录结构分析:/etc 文件夹](https://www.linuxnix.com/linux-directory-structure-explainedetc-folder/)
* [目录结构分析:/lost+found 文件夹](https://www.linuxnix.com/lostfound-directory-linuxunix/)
* [目录结构分析:/home 文件夹](https://www.linuxnix.com/linux-directory-structure-home-root-folders/)
### Linux 中,/lib 文件夹是什么?
`/lib` 文件夹是 **库文件目录** ,包含了所有对系统有用的库文件。简单来说,它是应用程序、命令或进程正确执行所需要的文件。在 `/bin` 或 `/sbin` 目录中的命令的动态库文件正是在此目录中。内核模块同样也在这里。
以 `pwd` 命令执行为例。执行它需要调用一些库文件。让我们来探索一下 `pwd` 命令执行时都发生了什么。我们需要使用 [strace 命令](https://www.linuxnix.com/10-strace-command-examples-linuxunix/) 找出调用的库文件。
示例:
```
root@linuxnix:~# strace -e open pwd
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
open("/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
open("/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
/root
+++ exited with 0 +++
root@linuxnix:~#
```
如果你注意到的话,会发现我们使用的 `pwd` 命令的执行需要调用两个库文件。
### Linux 中 /lib 文件夹内部信息
正如之前所说,这个文件夹包含了目标文件和一些库文件,如果能了解这个文件夹的一些重要子文件,想必是极好的。下面列举的内容是基于我自己的系统,对于你的来说,可能会有所不同。
```
root@linuxnix:/lib# find . -maxdepth 1 -type d
./firmware
./modprobe.d
./xtables
./apparmor
./terminfo
./plymouth
./init
./lsb
./recovery-mode
./resolvconf
./crda
./modules
./hdparm
./udev
./ufw
./ifupdown
./systemd
./modules-load.d
```
`/lib/firmware` - 这个文件夹包含了一些硬件、<ruby> 固件 <rt> Firmware </rt></ruby>代码。
>
> **硬件和固件之间有什么不同?**
>
>
> 为了使硬件正常运行,很多设备软件由两部分软件组成。加载到实际硬件的代码部分就是固件,用于在固件和内核之间通讯的软件被称为驱动程序。这样一来,内核就可以直接与硬件通讯,并确保硬件完成内核指派的工作。
>
>
>
`/lib/modprobe.d` - modprobe 命令的配置目录。
`/lib/modules` - 所有的可加载内核模块都存储在这个目录下。如果你有多个内核,你会在这个目录下看到代表美国内核的目录。
`/lib/hdparm` - 包含 SATA/IDE 硬盘正确运行的参数。
`/lib/udev` - 用户空间 /dev 是 Linux 内核设备管理器。这个文件夹包含了所有的 udev 相关的文件和文件夹,例如 `rules.d` 包含了 udev 规范文件。
### /lib 的姊妹文件夹:/lib32 和 /lib64
这两个文件夹包含了特殊结构的库文件。它们几乎和 `/lib` 文件夹一样,除了架构级别的差异。
### Linux 其他的库文件
`/usr/lib` - 所有软件的库都安装在这里。但是不包含系统默认库文件和内核库文件。
`/usr/local/lib` - 放置额外的系统文件。这些库能够用于各种应用。
`/var/lib` - 存储动态数据的库和文件,例如 rpm/dpkg 数据和游戏记录。
---
via: <https://www.linuxnix.com/linux-directory-structure-lib-explained/>
作者:[Surendra Anne](https://www.linuxnix.com/author/surendra/) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We already explained other important system folders like /bin, /boot, /dev, /etc etc folders in our previous posts. Please check below links for more information about other stuff which you are interested. In this post, we will see what is /lib folder all about.
**Linux Directory Structure explained: /bin folder**
**Linux Directory Structure explained: /boot folder**
**Linux Directory Structure explained: /dev folder**
**Linux Directory Structure explained: /etc folder**
**Linux Directory Structure explained: /lost+found folder**
**Linux Directory Structure explained: /home folder**
## What is /lib folder in Linux?
The lib folder is a **library files directory** which contains all helpful library files used by the system. In simple terms, these are helpful files which are used by an application or a command or a process for their proper execution. The commands in /bin or /sbin dynamic library files are located just in this directory. The kernel modules are also located here.
Taken an example of executing pwd command. It requires some library files to execute properly. Let us prove what is happening with pwd command when executing. We will use [the strace command](https://www.linuxnix.com/10-strace-command-examples-linuxunix/) to figure out which library files are used.
Example:
root@linuxnix:~# strace -e open pwdopen("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3open("/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3open("/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3/root+++ exited with 0 +++root@linuxnix:~#
If you observe, We just used open kernel call for pwd command. The pwd command to execute properly it will require two lib files.
Contents of /lib folder in Linux
As said earlier this folder contains object files and libraries, it’s good to know some important subfolders with this directory. And below content are for my system and you may see some variants in your system.
root@linuxnix:/lib# find . -maxdepth 1 -type d./firmware./modprobe.d./xtables./apparmor./terminfo./plymouth./init./lsb./recovery-mode./resolvconf./crda./modules./hdparm./udev./ufw./ifupdown./systemd./modules-load.d
**/lib/firmware** – This is a folder which contains hardware firmware code.
### What is the difference between firmware and drivers?
Many devices software consists of two software piece to make that hardware properly. The piece of code that is loaded into actual hardware is firmware and the software which communicate between this firmware and kernel is called drivers. This way the kernel directly communicate with hardware and make sure hardware is doing the work assigned to it.
**/lib/modprobe.d** – Configuration directory for modprobe command
**/lib/modules** – All loadable kernel modules are stored in this directory. If you have more kernels you will see folders within this directory each represents a kernel.
**/lib/hdparm** – Contains SATA/IDE parameters for disks to run properly.
**/lib/udev** – Userspace /dev is a device manager for Linux Kernel. This folder contains all udev related files/folders like rules.d folder which contain udev specific rules.
## The /lib folder sister folders: /lib32 and /lib64
These folders contain their specific architecture library files. These folders are almost identical to /lib folder expects architecture level differences.
## Other library folders in Linux
**/usr/lib** – All software libraries are installed here. This does not contain system default or kernel libraries.
**/usr/local/lib** – To place extra system library files here. These library files can be used by different applications.
**/var/lib** – Holds dynamic data libraries/files like the rpm/dpkg database and game scores.
#### Latest posts by Surendra Anne ([see all](https://www.linuxnix.com/author/surendra/))
-
[Docker: How to copy files to/from docker container](https://www.linuxnix.com/docker-how-to-copy-files-to-from-docker-container/)- June 30, 2020 -
[Anisble: ERROR! unexpected parameter type in action:](https://www.linuxnix.com/anisble-error-unexpected-parameter-type-in-action-fix/)- June 29, 2020Fix -
[FREE: JOIN OUR DEVOPS TELEGRAM GROUPS](https://www.linuxnix.com/free-join-our-devops-telegram-group/)- August 2, 2019 -
[Review: Whizlabs Practice Tests for AWS Certified Solutions Architect Professional (CSAP)](https://www.linuxnix.com/review-whizlabs-practice-tests-for-aws-certified-solutions-architect-professional-csap/)- August 27, 2018 -
[How to use ohai/chef-shell to get node attributes](https://www.linuxnix.com/chef-get-node-attributes-or-values/)- July 19, 2018 |
9,581 | 如何在 Linux 系统中防止文件和目录被意外的删除或修改 | https://www.ostechnix.com/prevent-files-folders-accidental-deletion-modification-linux/ | 2018-04-26T21:42:47 | [
"chattr",
"删除"
] | https://linux.cn/article-9581-1.html | 
有时,我会不小心的按下 `SHIFT+DELETE`来删除我的文件数据。是的,我是个笨蛋,没有再次确认下我实际准备要删除的东西。而且我太笨或者说太懒,没有备份我的文件数据。结果呢?数据丢失了!在一瞬间就丢失了。
这种事时不时就会发生在我身上。如果你和我一样,有个好消息告诉你。有个简单又有用的命令行工具叫`chattr`(**Ch**ange **Attr**ibute 的缩写),在类 Unix 等发行版中,能够用来防止文件和目录被意外的删除或修改。
通过给文件或目录添加或删除某些属性,来保证用户不能删除或修改这些文件和目录,不管是有意的还是无意的,甚至 root 用户也不行。听起来很有用,是不是?
在这篇简短的教程中,我们一起来看看怎么在实际应用中使用 `chattr` 命令,来防止文件和目录被意外删除。
### Linux中防止文件和目录被意外删除和修改
默认,`chattr` 命令在大多数现代 Linux 操作系统中是可用的。
默认语法是:
```
chattr [operator] [switch] [file]
```
`chattr` 具有如下操作符:
* 操作符 `+`,追加指定属性到文件已存在属性中
* 操作符 `-`,删除指定属性
* 操作符 `=`,直接设置文件属性为指定属性
`chattr` 提供不同的属性,也就是 `aAcCdDeijsStTu`。每个字符代表一个特定文件属性。
* `a` – 只能向文件中添加数据
* `A` – 不更新文件或目录的最后访问时间
* `c` – 将文件或目录压缩后存放
* `C` – 不适用写入时复制机制(CoW)
* `d` – 设定文件不能成为 `dump` 程序的备份目标
* `D` – 同步目录更新
* `e` – extend 格式存储
* `i` – 文件或目录不可改变
* `j` – 设定此参数使得当通过 `mount` 参数:`data=ordered` 或者 `data=writeback` 挂载的文件系统,文件在写入时会先被记录在日志中
* `P` – project 层次结构
* `s` – 安全删除文件或目录
* `S` – 即时更新文件或目录
* `t` – 不进行尾部合并
* `T` – 顶层目录层次结构
* `u` – 不可删除
在本教程中,我们将讨论两个属性的使用,即 `a`、`i` ,这个两个属性可以用于防止文件和目录的被删除。这是我们今天的主题,对吧?来开始吧!
### 防止文件被意外删除和修改
我先在我的当前目录创建一个`file.txt`文件。
```
$ touch file.txt
```
现在,我将给文件应用 `i` 属性,让文件不可改变。就是说你不能删除或修改这个文件,就算你是文件的拥有者和 root 用户也不行。
```
$ sudo chattr +i file.txt
```
使用`lsattr`命令检查文件已有属性:
```
$ lsattr file.txt
```
输出:
```
----i---------e---- file.txt
```
现在,试着用普通用户去删除文件:
```
$ rm file.txt
```
输出:
```
# 不能删除文件,非法操作
rm: cannot remove 'file.txt': Operation not permitted
```
我来试试 `sudo` 特权:
```
$ sudo rm file.txt
```
输出:
```
# 不能删除文件,非法操作
rm: cannot remove 'file.txt': Operation not permitted
```
我们试试追加写内容到这个文本文件:
```
$ echo 'Hello World!' >> file.txt
```
输出:
```
# 非法操作
bash: file.txt: Operation not permitted
```
试试 `sudo` 特权:
```
$ sudo echo 'Hello World!' >> file.txt
```
输出:
```
# 非法操作
bash: file.txt: Operation not permitted
```
你应该注意到了,我们不能删除或修改这个文件,甚至 root 用户或者文件所有者也不行。
要撤销属性,使用 `-i` 即可。
```
$ sudo chattr -i file.txt
```
现在,这不可改变属性已经被删除掉了。你现在可以删除或修改这个文件了。
```
$ rm file.txt
```
类似的,你能够限制目录被意外删除或修改,如下一节所述。
### 防止目录被意外删除和修改
创建一个 `dir1` 目录,放入文件 `file.txt`。
```
$ mkdir dir1 && touch dir1/file.txt
```
现在,让目录及其内容(`file.txt` 文件)不可改变:
```
$ sudo chattr -R +i dir1
```
命令中,
* `-R` – 递归使 `dir1` 目录及其内容不可修改
* `+i` – 使目录不可修改
现在,来试试删除这个目录,要么用普通用户,要么用 `sudo` 特权。
```
$ rm -fr dir1
$ sudo rm -fr dir1
```
你会看到如下输出:
```
# 不可删除'dir1/file.txt':非法操作
rm: cannot remove 'dir1/file.txt': Operation not permitted
```
尝试用 `echo` 命令追加内容到文件,你成功了吗?当然,你做不到。
撤销此属性,输入:
```
$ sudo chattr -R -i dir1
```
现在你就能想平常一样删除或修改这个目录内容了。
### 防止文件和目录被意外删除,但允许追加操作
我们现已知道如何防止文件和目录被意外删除和修改了。接下来,我们将防止文件被删除但仅仅允许文件被追加内容。意思是你不可以编辑修改文件已存在的数据,或者重命名这个文件或者删除这个文件,你仅可以使用追加模式打开这个文件。
为了设置追加属性到文件或目录,我们像下面这么操作:
针对文件:
```
$ sudo chattr +a file.txt
```
针对目录:
```
$ sudo chattr -R +a dir1
```
一个文件或目录被设置了 `a` 这个属性就仅仅能够以追加模式打开进行写入。
添加些内容到这个文件以测试是否有效果。
```
$ echo 'Hello World!' >> file.txt
$ echo 'Hello World!' >> dir1/file.txt
```
查看文件内容使用cat命令
```
$ cat file.txt
$ cat dir1/file.txt
```
输出:
```
Hello World!
```
你将看到你现在可以追加内容。就表示我们可以修改这个文件或目录。
现在让我们试试删除这个文件或目录。
```
$ rm file.txt
```
输出:
```
# 不能删除文件'file.txt':非法操作
rm: cannot remove 'file.txt': Operation not permitted
```
让我们试试删除这个目录:
```
$ rm -fr dir1/
```
输出:
```
# 不能删除文件'dir1/file.txt':非法操作
rm: cannot remove 'dir1/file.txt': Operation not permitted
```
删除这个属性,执行下面这个命令:
针对文件:
```
$ sudo chattr -R -a file.txt
```
针对目录:
```
$ sudo chattr -R -a dir1/
```
现在,你可以想平常一样删除或修改这个文件和目录了。
更多详情,查看 man 页面。
```
man chattr
```
### 总结
保护数据是系统管理人员的主要工作之一。市场上有众多可用的免费和收费的数据保护软件。幸好,我们已经拥有这个内置命令可以帮助我们去保护数据被意外的删除和修改。在你的 Linux 系统中,`chattr` 可作为保护重要系统文件和数据的附加工具。
然后,这就是今天所有内容了。希望对大家有所帮助。接下来我将会在这提供其他有用的文章。在那之前,敬请期待。再见!
---
via: <https://www.ostechnix.com/prevent-files-folders-accidental-deletion-modification-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[yizhuoyan](https://github.com/yizhuoyan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,582 | 为什么微服务是一个安全问题 | https://opensource.com/article/17/11/microservices-are-security-issue | 2018-04-27T08:36:14 | [
"微服务"
] | /article-9582-1.html |
>
> 你可能并不想把所有的遗留应用全部分解为微服务,或许你可以考虑从安全功能开始。
>
>
>

我为了给这篇文章起个标题,使出 “洪荒之力”,也很担心这会变成标题党。如果你点击它,是因为它激起了你的好奇,那么我表示抱歉 <sup> <a href="https://opensource.com/article/17/11/microservices-are-security-issue#1"> 注1 </a></sup> 。我当然是希望你留下来阅读的 <sup> <a href="https://opensource.com/article/17/11/microservices-are-security-issue#2"> 注2 </a></sup> :我有很多有趣的观点以及很多 <sup> <a href="https://opensource.com/article/17/11/microservices-are-security-issue#3"> 注3 </a></sup> 脚注。我不是故意提出微服务会导致安全问题——尽管如同很多组件一样都有安全问题。当然,这些微服务是那些安全方面的人员的趣向所在。进一步地说,我认为对于那些担心安全的人来说,它们是优秀的架构。
为什么这样说?这是个好问题,对于我们这些有[系统安全](https://aliceevebob.com/2017/03/14/systems-security-why-it-matters/) 经验的人来说,此时这个世界才是一个有趣的地方。我们看到随着带宽便宜了并且延迟降低了,分布式系统在增长。加上部署到云愈加便利,越来越多的架构师们开始意识到应用是可以分解的,不只是分成多个层,并且层内还能分为多个组件。当然,均衡负载可以用于让一个层内的各个组件协同工作,但是将不同的服务输出为各种小组件的能力导致了微服务在设计、实施和部署方面的增长。
所以,[到底什么是微服务呢](https://opensource.com/resources/what-are-microservices)?我同意[维基百科的定义](https://en.wikipedia.org/wiki/Microservices),尽管没有提及安全性方面的内容<sup> <a href="https://opensource.com/article/17/11/microservices-are-security-issue#4"> 注4 </a></sup> 。 我喜欢微服务的一点是,经过精心设计,其符合 Peter H. Salus 描述的 [UNIX 哲学](https://en.wikipedia.org/wiki/Unix_philosophy) 的前俩点:
1. 程序应该只做一件事,并尽可能把它做好。
2. 让程序能够互相协同工作。
3. 应该让程序处理文本数据流,因为这是一个通用的接口。
三者中最后一个有点不太相关,因为 UNIX 哲学通常被用来指代独立应用,它常有一个实例化的命令。但是,它确实包含了微服务的基本要求之一:必须具有“定义明确”的接口。
这里的“定义明确”,我指的不仅仅是可外部访问的 API 的方法描述,也指正常的微服务输入输出操作——以及,如果有的话,还有其副作用。就像我之前的文章描述的,“[良好的系统架构的五个特征](https://opensource.com/article/17/10/systems-architect)”,如果你能够去设计一个系统,数据和主体描述是至关重要的。在此,在我们的微服务描述上,我们要去看看为什么这些是如此重要。因为对我来说,微服务架构的关键定义是可分解性。如果你要分解 <sup> <a href="https://opensource.com/article/17/11/microservices-are-security-issue#5"> 注5 </a></sup> 你的架构,你必须非常、非常地清楚每个细节(“组件”)要做什么。
在这里,就要开始考虑安全了。特定组件的准确描述可以让你:
* 审查您的设计
* 确保您的实现符合描述
* 提出可重用测试单元来审查功能
* 跟踪实施中的错误并纠正错误
* 测试意料之外的产出
* 监视不当行为
* 审核未来可能的实际行为
现在,这些微服务能用在一个大型架构里了吗?是的。但如果实体是在更复杂的配置中彼此链接或组合在一起,它们会随之越来越难。当你让一小部分可以彼此配合工作时,确保正确的实施和行为是非常、非常容易的。并且如果你不能确定单个组件正在做它们应该作的,那么确保其衍生出来的复杂系统的正确行为及不正确行为就困难的多了。
而且还不止于此。如我已经在许多[以往场合](https://opensource.com/users/mikecamel)提过的,写足够安全的代码是困难的<sup> <a href="https://opensource.com/article/17/11/microservices-are-security-issue#7"> 注7 </a></sup> ,证实它应该做的更加困难。因此,有理由限制有特定安全要求的代码——密码检测、加密、加密密钥管理、授权等等——将它们变成小而定义明确的代码块。然后你就可以执行我上面提及所有工作,以确保正确完成。
还有,我们都知道并不是每个人都擅长于编写与安全相关的代码。通过分解你的体系架构,将安全敏感的代码限制到定义明确的组件中,你就可以把你最棒的安全人员放到这方面,并限制了 J.佛系.码奴 <sup> <a href="https://opensource.com/article/17/11/microservices-are-security-issue#8"> 注8 </a></sup> 绕过或降级一些关键的安全控制措施的危险。
它可以作为学习的机会:它对于设计/实现/测试/监视的兄弟们都是好的,而且给他们说:“听、读、标记、学习,并且引为己用 <sup> <a href="https://opensource.com/article/17/11/microservices-are-security-issue#9"> 注9 </a></sup> 。这是应该做的。”
是否应该将所有遗留应用程序分解为微服务? 不一定。 但是考虑到其带来的好处,你可以考虑从安全入手。
---
* 注1、有一点——有读者总是好的。
* 注2、这是我写下文章的意义。
* 注3、可能没那么有趣。
* 注4、在我写这篇文章时。我或你们中的一个可能会去编辑改变它。
* 注5、这很有趣,听起来想一个园艺术语。并不是说我很喜欢园艺,但仍然... <sup> <a href="https://opensource.com/article/17/11/microservices-are-security-issue#6"> 注6 </a></sup>
* 注6、有意思的是,我最先写的 “如果你要分解你的架构....” 听起来想是一个 IT 主题的谋杀电影标题。
* 注7、长期读者可能会记得提到的优秀电影 “The Thick of It”
* 注8、其他的什么人:请随便选择。
* 注9、不是加密<ruby> 摘要 <rt> digest </rt></ruby>:我不认同原作者的想法。
这篇文章最初出在[爱丽丝、伊娃与鲍伯](https://zh.wikipedia.org/zh-hans/%E6%84%9B%E9%BA%97%E7%B5%B2%E8%88%87%E9%AE%91%E4%BC%AF)——一个安全博客上,并被许可转载。
---
via: <https://opensource.com/article/17/11/microservices-are-security-issue>
作者:[Mike Bursell](https://opensource.com/users/mikecamel) 译者:[erlinux](https://itxdm.me) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,583 | Ubuntu 18.04 LTS(仿生河狸)发布! | https://news.softpedia.com/news/ubuntu-18-04-lts-bionic-beaver-officially-released-here-is-what-s-new-520856.shtml | 2018-04-27T12:58:00 | [
"Ubuntu"
] | https://linux.cn/article-9583-1.html | 
Canonical 今天正式发布了可用于计算机、IoT 和云环境的 Ubuntu 18.04 LTS (<ruby> 仿生河狸 <rp> ( </rp> <rt> Bionic Beaver </rt> <rp> ) </rp></ruby>) 操作系统。
经过六个月的努力工作,被称之为(<ruby> 仿生河狸 <rp> ( </rp> <rt> Bionic Beaver </rt> <rp> ) </rp></ruby>)的 Ubnutu 18.04 LTS 正式发布了,这也是 Ubuntu 的第七个长期支持版(LTS)。在直到 2023 年 4 月的五年内 Canonical 将为其提供安全和软件的更新,这期间将至少会有 5 个维护性更新版本,会将以后发布的 Ubuntu 中的新内核和显卡驱动更新到这个 LTS 版本当中。
正如预期的那样,Ubuntu 18.04 LTS 带来了几个新功能和变化,它开始使用 X.Org 服务器作为默认显示服务器来再次取代在 Ubuntu 17.10 中使用的 Wayland。另一方面,Canonical 计划在 Ubuntu 20.04 LTS 中再次启用 Wayland 作为默认的显示服务器,而现在它将以技术预览版的方式提供,在登录屏幕上可以选择。
另一个很酷的新功能是图形化安装器中的“[最小安装](https://news.softpedia.com/news/ubuntu-18-04-lts-will-let-users-choose-between-normal-and-minimal-installation-520640.shtml)”方式,用户可以安装一个仅有 Mozilla 浏览器和一些方便的标准功能的操作系统。说到了图形安全器,它在这个新版本中进行了重新打造,所以你可以看到它添加了一些不同的选项,也有一些被移去了。
Ubuntu 18.04 LTS 也有了由微软合作开发的新的 Hyper-V 优化镜像,它是 Windows 桌面上最快的 Ubuntu 桌面环境。对于云环境,Ubuntu 18.04 LTS 云镜像集成了 Nvidia GPU 硬件加速功能。
Canonical CEO 及 Ubuntu 的创始人 Mark Shuttleworth 说,“多云操作现在是新业态,优化了启动时间和性能的 Ubuntu 18.04 LTS 在各个主流云平台上将成为用于云计算的最快、最高效的操作系统,特别是在存储和像机器学习这样的计算密集型任务方面。”
### GNOME 3.28 作为默认桌面
同 Ubuntu 17.10 一样,仿生河使用最新的 GNOME 桌面作为默认环境。除了 Nautilus 文件管理器仍旧是 3.26 之外,GNOME 所提供的所有应用都更新到了 3.28,因为事实上当前该版本不再由 GNOME 桌面管理。另外,在 Ubuntu 18.04 LTS 当中,Nautilus 以暗色风格重新进行了装扮。

如果你从使用 GNOME 3.26 的 Ubuntu 17.10 升级的话就会发现,**[GNOME 3.28 自身也带来了许多变化](https://news.softpedia.com/news/gnome-3-28-desktop-environment-officially-released-here-s-what-s-new-520231.shtml)**。一个需要重点提出的功能是 GNOME Shell 界面现在支持雷雳 3 连接。另外,GNOME 3.28 新打造的 GNOME To Do 应用也被默认包括在 Ubuntu 18.04 LTS 当中了。
在所选用的应用当中,我们能注意到 GNOME 日历现在支持气候预报,所包括的 GNOME 字符应用替换了老的字符映射功能,GNOME Boxes 现在使用 spice-vdagent 为 Spice 客户端提供了更好的性能。LibreOffice 6.0 是默认办公套件,Mozilla FireFox 59.0.2 是默认浏览器,OpenJDK 10 是默认 JRE/JDK。
### 多个应用以 Snap 的方式提供
由于 Canonical 在推广其 Snappy 技术,它提供了更好的隔离性和安全,以及贯穿整个 LTS 生命周期的持续升级支持,毫无疑问 Ubuntu 18.04 LTS 将预装几个默认采用 Snap 统一封装包的应用。

这些应用包括 GNOME 日历、GNOME 字符、GNOME 日志和 GNOME 系统监视器等。为了使用户更易于安装 Snap 软件包,Ubuntu 软件应用现在可以让你轻松切换不同的 Snap 商店。有超过 3000 个 Snap 可以从 Snap 商店安装,包括 Firefox、Spotify、Skype 和 Slack 等流行应用。
其它值得一提的还有,在大多数应用中支持彩色 emoji 字符。触摸板支持双指右击,而无需物理按键(可以在 GNOME 设置功能中修改该设置)。鼠标和触摸板有了新的驱动,即 libinput,如果你觉得它不适合你,你仍然可以通过设置来切换回 Synapics 驱动,但是 Canonical 将在以后版本移除它。最后,如果在电池供电时 20 分钟不操作的话,Ubuntu 18.04 LTS 将会自动休眠笔记本。
### Ubuntu 18.04 LTS 底层情况
在底层,Ubuntu 18.04 LTS 使用的是 Linux 4.15 系列的内核,该系列内核最近将结束支持期。不过,我们认为 Canonical 将会继续支持它,直到今年年底发布的第一个维护版本 Ubuntu 18.04.1 LTS 为止——它将使用新的内核和图形驱动。
Canonical 在[发布公告](https://wiki.ubuntu.com/BionicBeaver/ReleaseNotes)中称,“在 Ubuntu 18.04 LTS 中,gcc 现在默认编译程序为即时绑定的<ruby> 独立定位的可执行程序 <rp> ( </rp> <rt> position independent executable </rt> <rp> ) </rp></ruby>(PIE),以更有效的利用<ruby> 地址空间布局随机化 <rp> ( </rp> <rt> Address Space Layout Randomization </rt> <rp> ) </rp></ruby>(ASLR)技术。除了几个例外之外,所有主要的软件包都将重构以获得该能力。”对于 Meltdown 和 Spectre 安全漏洞的缓解措施也已经到位。
从 Ubuntu 17.10 以来有一些新的功能,不过如果你计划从更旧的版本升级,你应该看看“[从 Ubuntu 16.04 LTS 以来的新变化](/article-9183-1.html)”这篇文章。Ubuntu 18.04 LTS 现在可以下载了,在升级前,你应该看看如何[从之前的版本升级](https://news.softpedia.com/news/how-to-upgrade-ubuntu-17-10-or-ubuntu-16-04-lts-to-ubuntu-18-04-lts-520854.shtml)。
### Ubuntu 18.04 LTS 下载
* Ubuntu 桌面版和服务器版 <http://releases.ubuntu.com/18.04/>
* 其它架构的 Ubuntu 服务器 <http://cdimage.ubuntu.com/ubuntu/releases/18.04/release/>
* Ubuntu 云镜像 <https://www.ubuntu.com/download/cloud/>
* Ubuntu 物联网 <https://www.ubuntu.com/download/iot/>
*
| 403 | Forbidden | null |
9,584 | “开箱即用” 的 Kubernetes 集群 | https://blog.alexellis.io/your-instant-kubernetes-cluster/ | 2018-04-28T06:54:00 | [
"Kubernetes",
"K8S"
] | https://linux.cn/article-9584-1.html | 
这是我以前的 [10 分钟内配置 Kubernetes](https://www.youtube.com/watch?v=6xJwQgDnMFE) 教程的精简版和更新版。我删除了一些我认为可以去掉的内容,所以,这个指南仍然是通顺的。当你想在云上创建一个集群或者尽可能快地构建基础设施时,你可能会用到它。
### 1.0 挑选一个主机
我们在本指南中将使用 Ubuntu 16.04,这样你就可以直接拷贝/粘贴所有的指令。下面是我用本指南测试过的几种环境。根据你运行的主机,你可以从中挑选一个。
* [DigitalOcean](https://www.digitalocean.com/) - 开发者云
* [Civo](https://www.civo.com/) - UK 开发者云
* [Packet](https://packet.net/) - 裸机云
* 2x Dell Intel i7 服务器 —— 它在我家中
>
> Civo 是一个相对较新的开发者云,我比较喜欢的一点是,它开机时间只有 25 秒,我就在英国,因此,它的延迟很低。
>
>
>
### 1.1 准备机器
你可以使用一个单台主机进行测试,但是,我建议你至少使用三台机器,这样你就有一个主节点和两个工作节点。
下面是一些其他的指导原则:
* 最好选至少有 2 GB 内存的双核主机
* 在准备主机的时候,如果你可以自定义用户名,那么就不要使用 root。例如,Civo 通常让你在 `ubuntu`、`civo` 或者 `root` 中选一个。
现在,在每台机器上都运行以下的步骤。它将需要 5-10 钟时间。如果你觉得太慢了,你可以使用我[放在 Gist](https://gist.github.com/alexellis/e8bbec45c75ea38da5547746c0ca4b0c) 的脚本 :
```
$ curl -sL https://gist.githubusercontent.com/alexellis/e8bbec45c75ea38da5547746c0ca4b0c/raw/23fc4cd13910eac646b13c4f8812bab3eeebab4c/configure.sh | sh
```
### 1.2 登入和安装 Docker
从 Ubuntu 的 apt 仓库中安装 Docker。它的版本可能有点老,但是,Kubernetes 在老版本的 Docker 中是测试过的,工作的很好。
```
$ sudo apt-get update \
&& sudo apt-get install -qy docker.io
```
### 1.3 禁用 swap 文件
这是 Kubernetes 的强制步骤。实现它很简单,编辑 `/etc/fstab` 文件,然后注释掉引用 swap 的行即可。
保存它,重启后输入 `sudo swapoff -a`。
>
> 一开始就禁用 swap 内存,你可能觉得这个要求很奇怪,如果你对这个做法感到好奇,你可以去 [这里阅读它的相关内容](https://github.com/kubernetes/kubernetes/issues/53533)。
>
>
>
### 1.4 安装 Kubernetes 包
```
$ sudo apt-get update \
&& sudo apt-get install -y apt-transport-https \
&& curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
$ echo "deb http://apt.kubernetes.io/ kubernetes-xenial main" \
| sudo tee -a /etc/apt/sources.list.d/kubernetes.list \
&& sudo apt-get update
$ sudo apt-get update \
&& sudo apt-get install -y \
kubelet \
kubeadm \
kubernetes-cni
```
### 1.5 创建集群
这时候,我们使用 `kubeadm` 初始化主节点并创建集群。这一步仅在主节点上操作。
>
> 虽然有警告,但是 [Weaveworks](https://weave.works/) 和 Lucas(他们是维护者)向我保证,`kubeadm` 是可用于生产系统的。
>
>
>
```
$ sudo kubeadm init
```
如果你错过一个步骤或者有问题,`kubeadm` 将会及时告诉你。
我们复制一份 Kube 配置:
```
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
```
确保你一定要记下如下的加入 `token` 的命令。
```
$ sudo kubeadm join --token c30633.d178035db2b4bb9a 10.0.0.5:6443 --discovery-token-ca-cert-hash sha256:<hash>
```
### 2.0 安装网络
许多网络提供商提供了 Kubernetes 支持,但是,默认情况下 Kubernetes 都没有包括。这里我们使用来自 [Weaveworks](https://weave.works/) 的 Weave Net,它是 Kebernetes 社区中非常流行的选择之一。它近乎不需要额外配置的 “开箱即用”。
```
$ kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
```
如果在你的主机上启用了私有网络,那么,你可能需要去修改 Weavenet 使用的私有子网络,以便于为 Pod(容器)分配 IP 地址。下面是命令示例:
```
$ curl -SL "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')&env.IPALLOC_RANGE=172.16.6.64/27" \
| kubectl apply -f -
```
>
> Weave 也有很酷的称为 Weave Cloud 的可视化工具。它是免费的,你可以在它上面看到你的 Pod 之间的路径流量。[这里有一个使用 OpenFaaS 项目的示例](https://www.weave.works/blog/openfaas-gke)。
>
>
>
### 2.2 在集群中加入工作节点
现在,你可以切换到你的每一台工作节点,然后使用 1.5 节中的 `kubeadm join` 命令。运行完成后,登出那个工作节点。
### 3.0 收获
到此为止 —— 我们全部配置完成了。你现在有一个正在运行着的集群,你可以在它上面部署应用程序。如果你需要设置仪表板 UI,你可以去参考 [Kubernetes 文档](https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/)。
```
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
openfaas1 Ready master 20m v1.9.2
openfaas2 Ready <none> 19m v1.9.2
openfaas3 Ready <none> 19m v1.9.2
```
如果你想看到我一步一步创建集群并且展示 `kubectl` 如何工作的视频,你可以看下面我的视频,你可以订阅它。
你也可以在你的 Mac 电脑上,使用 Minikube 或者 Docker 的 Mac Edge 版本,安装一个 “开箱即用” 的 Kubernetes 集群。[阅读在这里的我的评估和第一印象](https://blog.alexellis.io/docker-for-mac-with-kubernetes/)。
---
via: <https://blog.alexellis.io/your-instant-kubernetes-cluster/>
作者:[Alex Ellis](https://blog.alexellis.io/author/alex/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is a condensed and updated version of my previous tutorial [Kubernetes in 10 minutes](https://www.youtube.com/watch?v=6xJwQgDnMFE). I've removed just about everything I can so this guide still makes sense. Use it when you want to create a cluster on the cloud or on-premises as fast as possible.
## 1.0 Pick a host
We will be using Ubuntu 16.04 for this guide so that you can copy/paste all the instructions. Here are several environments where I've tested this guide. Just pick where you want to run your hosts.
[DigitalOcean](https://www.digitalocean.com)- developer cloud[Civo](https://www.civo.com)- UK developer cloud[Equinix Metal](https://metal.equinix.com/)- bare metal cloud- 2x Dell Intel i7 boxes - at home
Civo is a relatively new developer cloud and one thing that I really liked was how quickly they can bring up hosts - in about 25 seconds. I'm based in the UK so I also get very low latency.
## 1.1 Provision the machines
You can get away with a single host for testing but I'd recommend at least three so we have a single master and two worker nodes.
Here are some other guidelines:
- Pick dual-core hosts with ideally at least 2GB RAM
- If you can pick a custom username when provisioning the host then do that rather than root. For example Civo offers an option of
`ubuntu`
,`civo`
or`root`
.
Now run through the following steps on each machine. It should take you less than 5-10 minutes. If that's too slow for you then you can use my utility script [kept in a Gist](https://gist.github.com/alexellis/e8bbec45c75ea38da5547746c0ca4b0c):
```
$ curl -sL https://gist.githubusercontent.com/alexellis/e8bbec45c75ea38da5547746c0ca4b0c/raw/23fc4cd13910eac646b13c4f8812bab3eeebab4c/configure.sh | sh
```
## 1.2 Login and install Docker
Install Docker from the Ubuntu apt repository. This will be an older version of Docker but as Kubernetes is tested with old versions of Docker it will work in our favour.
```
$ sudo apt-get update \
&& sudo apt-get install -qy docker.io
```
## 1.3 Disable the swap file
This is now a mandatory step for Kubernetes. The easiest way to do this is to edit `/etc/fstab`
and to comment out the line referring to swap.
To save a reboot then type in `sudo swapoff -a`
.
Disabling swap memory may appear like a strange requirement at first. If you are curious about this step then
[read more here].
## 1.4 Install Kubernetes packages
```
$ sudo apt-get update \
&& sudo apt-get install -y apt-transport-https \
&& curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
$ echo "deb http://apt.kubernetes.io/ kubernetes-xenial main" \
| sudo tee -a /etc/apt/sources.list.d/kubernetes.list \
&& sudo apt-get update
$ sudo apt-get update \
&& sudo apt-get install -y \
kubelet \
kubeadm \
kubernetes-cni
```
## 1.5 Create the cluster
At this point we create the cluster by initiating the master with `kubeadm`
. Only do this on the master node.
Despite any warnings I have been assured by
[Weaveworks]and Lucas (the maintainer) that`kubeadm`
is suitable for production use.
```
$ sudo kubeadm init
```
If you missed a step or there's a problem then `kubeadm`
will let you know at this point.
Take a copy of the Kube config:
```
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
```
Make sure you note down the join token command i.e.
```
$ sudo kubeadm join --token c30633.d178035db2b4bb9a 10.0.0.5:6443 --discovery-token-ca-cert-hash sha256:<hash>
```
## 2.0 Install networking
Many networking providers are available for Kubernetes, but none are included by default, so let's use Weave Net from [Weaveworks](https://weave.works) which is one of the most popular options in the Kubernetes community. It tends to work out of the box without additional configuration.
```
$ kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
```
If you have private networking enabled on your host then you may need to alter the private subnet that Weavenet uses for allocating IP addresses to Pods (containers). Here's an example of how to do that:
```
$ curl -SL "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')&env.IPALLOC_RANGE=172.16.6.64/27" \
| kubectl apply -f -
```
Weave also have a very cool visualisation tool called Weave Cloud. It's free and will show you the path traffic is taking between your Pods.
[See here for an example with the OpenFaaS project].
## 2.2 Join the worker nodes to the cluster
Now you can switch to each of your workers and use the `kubeadm join`
command from 1.5. Once you run that log out of the workers.
## 3.0 Profit
That's it - we're done. You have a cluster up and running and can deploy your applications. If you need to setup a dashboard UI then consult the [Kubernetes documentation](https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/).
```
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
openfaas1 Ready master 20m v1.9.2
openfaas2 Ready <none> 19m v1.9.2
openfaas3 Ready <none> 19m v1.9.2
```
If you want to see my running through creating a cluster step-by-step and showing you how `kubectl`
works then checkout my video below and make sure you subscribe
You can also get an "instant" Kubernetes cluster on your Mac for development using Minikube or Docker for Mac Edge edition. [Read my review and first impressions here](https://blog.alexellis.io/docker-for-mac-with-kubernetes/).
## 4.0 Keep learning
You can keep learning and get head with weekly emails from me as part of a GitHub Sponsorship. Sign up below to learn more about Kubernetes, Raspberry Pi and Docker from me. |
9,585 | 如何在 Linux 中查找文件 | https://opensource.com/article/18/4/how-find-files-linux | 2018-04-28T07:09:38 | [
"查找",
"搜索"
] | https://linux.cn/article-9585-1.html |
>
> 使用简单的命令在 Linux 下基于类型、内容等快速查找文件。
>
>
>

如果你是 Windows 或 OSX 的非资深用户,那么可能使用 GUI 来查找文件。你也可能发现界面受限,令人沮丧,或者两者兼而有之,并学会了组织文件并记住它们的确切顺序。你也可以在 Linux 中做到这一点 —— 但你不必这样做。
Linux 的好处之一是它提供了多种方式来处理。你可以打开任何文件管理器或按下 `Ctrl+F`,你也可以使用程序手动打开文件,或者你可以开始输入字母,它会过滤当前目录列表。

*使用 Ctrl+F 在 Linux 中查找文件的截图*
但是如果你不知道你的文件在哪里,又不想搜索整个磁盘呢?对于这个以及其他各种情况,Linux 都很合适。
### 按命令名查找程序位置
如果你习惯随心所欲地放文件,Linux 文件系统看起来会让人望而生畏。对我而言,最难习惯的一件事是找到程序在哪里。
例如,`which bash` 通常会返回 `/bin/bash`,但是如果你下载了一个程序并且它没有出现在你的菜单中,那么 `which` 命令就是一个很好的工具。
一个类似的工具是 `locate` 命令,我发现它对于查找配置文件很有用。我不喜欢输入程序名称,因为像 `locate php` 这样的简单程序通常会提供很多需要进一步过滤的结果。
有关 `locate` 和 `which` 的更多信息,请参阅 `man` 页面:
* `man which`
* `man locate`
### find
`find` 工具提供了更先进的功能。以下是我安装在许多服务器上的脚本示例,我用于确保特定模式的文件(也称为 glob)仅存在五天,并且所有早于此的文件都将被删除。 (自上次修改以来,分数用于保留最多 240 分钟的偏差)
```
find ./backup/core-files*.tar.gz -mtime +4.9 -exec rm {} \;
```
`find` 工具有许多高级用法,但最常见的是对结果执行命令,而不用链式地按照类型、创建日期、修改日期过滤文件。
`find` 的另一个有趣用处是找到所有有可执行权限的文件。这有助于确保没有人在你昂贵的服务器上安装比特币挖矿程序或僵尸网络。
```
find / -perm /+x
```
有关 `find` 的更多信息,请使用 `man find` 参考 `man` 页面。
### grep
想通过内容中查找文件? Linux 已经实现了。你可以使用许多 Linux 工具来高效搜索符合模式的文件,但是 `grep` 是我经常使用的工具。
假设你有一个程序发布代码引用和堆栈跟踪的错误消息。你要在日志中找到这些。 `grep` 不总是最好的方法,但如果文件是一个给定的值,我经常使用 `grep -R`。
越来越多的 IDE 正在实现查找功能,但是如果你正在访问远程系统或出于任何原因没有 GUI,或者如果你想在当前目录递归查找,请使用:`grep -R {searchterm}` 或在支持 `egrep` 别名的系统上,只需将 `-e` 标志添加到命令 `egrep -r {regex-pattern}`。
我在去年给 [Raspbian](https://www.raspbian.org/) 中的 `dhcpcd5` 打补丁时使用了这种技术,这样我就可以在[树莓派基金会](https://www.raspberrypi.org/)发布新的 Debian 时继续操作网络接入点了。
哪些提示可帮助你在 Linux 上更有效地搜索文件?
---
via: <https://opensource.com/article/18/4/how-find-files-linux>
作者:[Lewis Cowles](https://opensource.com/users/lewiscowles1986) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you're a Windows user or a non-power-user of OSX, you probably use a GUI to find files. You may also find the interface limited, frustrating, or both, and have learned to excel at organizing things and remembering the exact order of your files. You can do that in Linux, too—but you don't have to.
One of the best things about Linux is that it offers a variety of ways to do things. You can open any file manager and `ctrl`
+`f`
, you can use the program you are in to open files manually, or you can simply start typing letters and it'll filter the current directory listing.
Screenshot of how to find files in Linux with Ctrl+F
But what if you don't know where your file is and don't want to search the entire disk? Linux is well-tooled for this and a variety of other use-cases.
## Finding program locations by command name
The Linux file system can seem daunting if you're used to putting things wherever you like. For me, one of the hardest things to get used to was finding where programs are supposed to live.
For example, `which bash`
will usually return `/bin/bash`
, but if you download a program and it doesn't appear in your menus, the `which`
command can be a great tool.
A similar utility is the `locate`
command, which I find useful for finding configuration files. I don't like typing in program names because simple ones like `locate php`
often offer many results that need to be filtered further.
For more information about `locate`
and `which`
, see the `man`
pages:
`man which`
`man locate`
## Find
The `find`
utility offers much more advanced functionality. Below is an example from a script I've installed on a number of servers that I administer to ensure that a specific pattern of file (also known as a glob) exists for only five days and all files older than that are deleted. (Since its last modification, a decimal is used to account for up to 240 minutes difference.)
```
````find ./backup/core-files*.tar.gz -mtime +4.9 -exec rm {} \;`
The `find`
utility has many advanced use-cases, but most common is executing commands on results without chaining and filtering files by type, creation, and modification date.
Another interesting use of `find`
is to find all files with executable permissions. This can help ensure that nobody is installing bitcoin miners or botnets on your expensive servers.
```
````find / -perm /+x`
For more information on `find`
, see the `man`
page using `man find.`
## Grep
Want to find a file by its contents? Linux has it covered. You can use many Linux utilities to efficiently search for files that match a pattern, but `grep`
is one that I use often.
Suppose you have an application that's delivering error messages with a code reference and stack trace. You find these in your logs. Grepping is not always the go-to, but I always `grep -R`
if the issue is with a supplied value.
An increasing number of IDEs are implementing find functions, but if you're accessing a remote system or for whatever reason don't have a GUI, or if you want to iterate in-place, then use: `grep -R {searchterm}`
or on systems supporting `egrep`
alias; just add `-e`
flag to command `egrep -r {regex-pattern}`
.
I used this technique when patching the `dhcpcd5`
in [Raspbian](https://www.raspbian.org/) last year so I could continue to operate a network access point on newer Debian releases from the [Raspberry Pi Foundation](https://www.raspberrypi.org/).
What tips help you search for files more efficiently on Linux?
## 7 Comments |
9,586 | 查看 Linux 发行版名称和版本号的 8 种方法 | https://www.2daygeek.com/check-find-linux-distribution-name-and-version/ | 2018-04-28T22:49:32 | [
"发行版",
"版本"
] | https://linux.cn/article-9586-1.html | 
如果你加入了一家新公司,要为开发团队安装所需的软件并重启服务,这个时候首先要弄清楚它们运行在什么发行版以及哪个版本的系统上,你才能正确完成后续的工作。作为系统管理员,充分了解系统信息是首要的任务。
查看 Linux 发行版名称和版本号有很多种方法。你可能会问,为什么要去了解这些基本信息呢?
因为对于诸如 RHEL、Debian、openSUSE、Arch Linux 这几种主流发行版来说,它们各自拥有不同的包管理器来管理系统上的软件包,如果不知道所使用的是哪一个发行版的系统,在软件包安装的时候就会无从下手,而且由于大多数发行版都是用 systemd 命令而不是 SysVinit 脚本,在重启服务的时候也难以执行正确的命令。
下面来看看可以使用那些基本命令来查看 Linux 发行版名称和版本号。
### 方法总览
* `lsb_release` 命令
* `/etc/*-release` 文件
* `uname` 命令
* `/proc/version` 文件
* `dmesg` 命令
* YUM 或 DNF 命令
* RPM 命令
* APT-GET 命令
### 方法 1: lsb\_release 命令
LSB(<ruby> Linux 标准库 <rt> Linux Standard Base </rt></ruby>)能够打印发行版的具体信息,包括发行版名称、版本号、代号等。
```
# lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 16.04.3 LTS
Release: 16.04
Codename: xenial
```
### 方法 2: /etc/\*-release 文件
release 文件通常被视为操作系统的标识。在 `/etc` 目录下放置了很多记录着发行版各种信息的文件,每个发行版都各自有一套这样记录着相关信息的文件。下面是一组在 Ubuntu/Debian 系统上显示出来的文件内容。
```
# cat /etc/issue
Ubuntu 16.04.3 LTS \n \l
# cat /etc/issue.net
Ubuntu 16.04.3 LTS
# cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=16.04
DISTRIB_CODENAME=xenial
DISTRIB_DESCRIPTION="Ubuntu 16.04.3 LTS"
# cat /etc/os-release
NAME="Ubuntu"
VERSION="16.04.3 LTS (Xenial Xerus)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 16.04.3 LTS"
VERSION_ID="16.04"
HOME_URL="http://www.ubuntu.com/"
SUPPORT_URL="http://help.ubuntu.com/"
BUG_REPORT_URL="http://bugs.launchpad.net/ubuntu/"
VERSION_CODENAME=xenial
UBUNTU_CODENAME=xenial
# cat /etc/debian_version
9.3
```
下面这一组是在 RHEL/CentOS/Fedora 系统上显示出来的文件内容。其中 `/etc/redhat-release` 和 `/etc/system-release` 文件是指向 `/etc/[发行版名称]-release` 文件的一个连接。
```
# cat /etc/centos-release
CentOS release 6.9 (Final)
# cat /etc/fedora-release
Fedora release 27 (Twenty Seven)
# cat /etc/os-release
NAME=Fedora
VERSION="27 (Twenty Seven)"
ID=fedora
VERSION_ID=27
PRETTY_NAME="Fedora 27 (Twenty Seven)"
ANSI_COLOR="0;34"
CPE_NAME="cpe:/o:fedoraproject:fedora:27"
HOME_URL="https://fedoraproject.org/"
SUPPORT_URL="https://fedoraproject.org/wiki/Communicating_and_getting_help"
BUG_REPORT_URL="https://bugzilla.redhat.com/"
REDHAT_BUGZILLA_PRODUCT="Fedora"
REDHAT_BUGZILLA_PRODUCT_VERSION=27
REDHAT_SUPPORT_PRODUCT="Fedora"
REDHAT_SUPPORT_PRODUCT_VERSION=27
PRIVACY_POLICY_URL="https://fedoraproject.org/wiki/Legal:PrivacyPolicy"
# cat /etc/redhat-release
Fedora release 27 (Twenty Seven)
# cat /etc/system-release
Fedora release 27 (Twenty Seven)
```
### 方法 3: uname 命令
uname(unix name 的意思) 是一个打印系统信息的工具,包括内核名称、版本号、系统详细信息以及所运行的操作系统等等。
* **建议阅读:** [6种查看系统 Linux 内核的方法](https://www.2daygeek.com/check-find-determine-running-installed-linux-kernel-version/)
```
# uname -a
Linux localhost.localdomain 4.12.14-300.fc26.x86_64 #1 SMP Wed Sep 20 16:28:07 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
```
以上运行结果说明使用的操作系统版本是 Fedora 26。
### 方法 4: /proc/version 文件
这个文件记录了 Linux 内核的版本、用于编译内核的 gcc 的版本、内核编译的时间,以及内核编译者的用户名。
```
# cat /proc/version
Linux version 4.12.14-300.fc26.x86_64 ([email protected]) (gcc version 7.2.1 20170915 (Red Hat 7.2.1-2) (GCC) ) #1 SMP Wed Sep 20 16:28:07 UTC 2017
```
### 方法 5: dmesg 命令
dmesg(<ruby> 展示信息 <rt> display message </rt></ruby> 或<ruby> 驱动程序信息 <rt> driver message </rt></ruby>)是大多数类 Unix 操作系统上的一个命令,用于打印内核的消息缓冲区的信息。
```
# dmesg | grep "Linux"
[ 0.000000] Linux version 4.12.14-300.fc26.x86_64 ([email protected]) (gcc version 7.2.1 20170915 (Red Hat 7.2.1-2) (GCC) ) #1 SMP Wed Sep 20 16:28:07 UTC 2017
[ 0.001000] SELinux: Initializing.
[ 0.001000] SELinux: Starting in permissive mode
[ 0.470288] SELinux: Registering netfilter hooks
[ 0.616351] Linux agpgart interface v0.103
[ 0.630063] usb usb1: Manufacturer: Linux 4.12.14-300.fc26.x86_64 ehci_hcd
[ 0.688949] usb usb2: Manufacturer: Linux 4.12.14-300.fc26.x86_64 ohci_hcd
[ 2.564554] SELinux: Disabled at runtime.
[ 2.564584] SELinux: Unregistering netfilter hooks
```
### 方法 6: Yum/Dnf 命令
Yum(<ruby> Yellowdog 更新器修改版 <rt> Yellowdog Updater Modified </rt></ruby>)是 Linux 操作系统上的一个包管理工具,而 `yum` 命令被用于一些基于 RedHat 的 Linux 发行版上安装、更新、查找、删除软件包。
* **建议阅读:** [在 RHEL/CentOS 系统上使用 yum 命令管理软件包](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/)
```
# yum info nano
Loaded plugins: fastestmirror, ovl
Loading mirror speeds from cached hostfile
* base: centos.zswap.net
* extras: mirror2.evolution-host.com
* updates: centos.zswap.net
Available Packages
Name : nano
Arch : x86_64
Version : 2.3.1
Release : 10.el7
Size : 440 k
Repo : base/7/x86_64
Summary : A small text editor
URL : http://www.nano-editor.org
License : GPLv3+
Description : GNU nano is a small and friendly text editor.
```
下面的 `yum repolist` 命令执行后显示了 yum 的基础源仓库、额外源仓库、更新源仓库都来自 CentOS 7 仓库。
```
# yum repolist
Loaded plugins: fastestmirror, ovl
Loading mirror speeds from cached hostfile
* base: centos.zswap.net
* extras: mirror2.evolution-host.com
* updates: centos.zswap.net
repo id repo name status
base/7/x86_64 CentOS-7 - Base 9591
extras/7/x86_64 CentOS-7 - Extras 388
updates/7/x86_64 CentOS-7 - Updates 1929
repolist: 11908
```
使用 `dnf` 命令也同样可以查看发行版名称和版本号。
* **建议阅读:** [在 Fedora 系统上使用 DNF(YUM 的一个分支)命令管理软件包](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/)
```
# dnf info nano
Last metadata expiration check: 0:01:25 ago on Thu Feb 15 01:59:31 2018.
Installed Packages
Name : nano
Version : 2.8.7
Release : 1.fc27
Arch : x86_64
Size : 2.1 M
Source : nano-2.8.7-1.fc27.src.rpm
Repo : @System
From repo : fedora
Summary : A small text editor
URL : https://www.nano-editor.org
License : GPLv3+
Description : GNU nano is a small and friendly text editor.
```
### 方法 7: RPM 命令
RPM(<ruby> 红帽包管理器 <rt> RedHat Package Manager </rt></ruby>)是在 CentOS、Oracle Linux、Fedora 这些基于 RedHat 的操作系统上的一个强大的命令行包管理工具,同样也可以帮助我们查看系统的版本信息。
* **建议阅读:** [在基于 RHEL 的系统上使用 RPM 命令管理软件包](https://www.2daygeek.com/rpm-command-examples/)
```
# rpm -q nano
nano-2.8.7-1.fc27.x86_64
```
### 方法 8: APT-GET 命令
Apt-Get(<ruby> 高级打包工具 <rt> Advanced Packaging Tool </rt></ruby>)是一个强大的命令行工具,可以自动下载安装新软件包、更新已有的软件包、更新软件包列表索引,甚至更新整个 Debian 系统。
* **建议阅读:** [在基于 Debian 的系统上使用 Apt-Get 和 Apt-Cache 命令管理软件包](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/)
```
# apt-cache policy nano
nano:
Installed: 2.5.3-2ubuntu2
Candidate: 2.5.3-2ubuntu2
Version table:
* 2.5.3-2ubuntu2 500
500 http://nova.clouds.archive.ubuntu.com/ubuntu xenial-updates/main amd64 Packages
100 /var/lib/dpkg/status
2.5.3-2 500
500 http://nova.clouds.archive.ubuntu.com/ubuntu xenial/main amd64 Packages
```
---
via: <https://www.2daygeek.com/check-find-linux-distribution-name-and-version/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,588 | gdb 如何调用函数? | https://jvns.ca/blog/2018/01/04/how-does-gdb-call-functions/ | 2018-04-29T09:38:16 | [
"gdb",
"调试"
] | https://linux.cn/article-9588-1.html | 
(之前的 gdb 系列文章:[gdb 如何工作(2016)](/article-9491-1.html) 和[三步上手 gdb(2014)](/article-9276-1.html))
在这周,我发现我可以从 gdb 上调用 C 函数。这看起来很酷,因为在过去我认为 gdb 最多只是一个只读调试工具。
我对 gdb 能够调用函数感到很吃惊。正如往常所做的那样,我在 [Twitter](https://twitter.com/b0rk/status/948060808243765248) 上询问这是如何工作的。我得到了大量的有用答案。我最喜欢的答案是 [Evan Klitzke 的示例 C 代码](https://github.com/eklitzke/ptrace-call-userspace/blob/master/call_fprintf.c),它展示了 gdb 如何调用函数。代码能够运行,这很令人激动!
我(通过一些跟踪和实验)认为那个示例 C 代码和 gdb 实际上如何调用函数不同。因此,在这篇文章中,我将会阐述 gdb 是如何调用函数的,以及我是如何知道的。
关于 gdb 如何调用函数,还有许多我不知道的事情,并且,在这儿我写的内容有可能是错误的。
### 从 gdb 中调用 C 函数意味着什么?
在开始讲解这是如何工作之前,我先快速的谈论一下我是如何发现这件令人惊讶的事情的。
假如,你已经在运行一个 C 程序(目标程序)。你可以运行程序中的一个函数,只需要像下面这样做:
* 暂停程序(因为它已经在运行中)
* 找到你想调用的函数的地址(使用符号表)
* 使程序(目标程序)跳转到那个地址
* 当函数返回时,恢复之前的指令指针和寄存器
通过符号表来找到想要调用的函数的地址非常容易。下面是一段非常简单但能够工作的代码,我在 Linux 上使用这段代码作为例子来讲解如何找到地址。这段代码使用 [elf crate](https://cole14.github.io/rust-elf)。如果我想找到 PID 为 2345 的进程中的 `foo` 函数的地址,那么我可以运行 `elf_symbol_value("/proc/2345/exe", "foo")`。
```
fn elf_symbol_value(file_name: &str, symbol_name: &str) -> Result<u64, Box<std::error::Error>> {
// 打开 ELF 文件
let file = elf::File::open_path(file_name).ok().ok_or("parse error")?;
// 在所有的段 & 符号中循环,直到找到正确的那个
let sections = &file.sections;
for s in sections {
for sym in file.get_symbols(&s).ok().ok_or("parse error")? {
if sym.name == symbol_name {
return Ok(sym.value);
}
}
}
None.ok_or("No symbol found")?
}
```
这并不能够真的发挥作用,你还需要找到文件的内存映射,并将符号偏移量加到文件映射的起始位置。找到内存映射并不困难,它位于 `/proc/PID/maps` 中。
总之,找到想要调用的函数地址对我来说很直接,但是其余部分(改变指令指针,恢复寄存器等)看起来就不这么明显了。
### 你不能仅仅进行跳转
我已经说过,你不能够仅仅找到你想要运行的那个函数地址,然后跳转到那儿。我在 gdb 中尝试过那样做(`jump foo`),然后程序出现了段错误。毫无意义。
### 如何从 gdb 中调用 C 函数
首先,这是可能的。我写了一个非常简洁的 C 程序,它所做的事只有 `sleep` 1000 秒,把这个文件命名为 `test.c` :
```
#include <unistd.h>
int foo() {
return 3;
}
int main() {
sleep(1000);
}
```
接下来,编译并运行它:
```
$ gcc -o test test.c
$ ./test
```
最后,我们使用 gdb 来跟踪 `test` 这一程序:
```
$ sudo gdb -p $(pgrep -f test)
(gdb) p foo()
$1 = 3
(gdb) quit
```
我运行 `p foo()` 然后它运行了这个函数!这非常有趣。
### 这有什么用?
下面是一些可能的用途:
* 它使得你可以把 gdb 当成一个 C 应答式程序(REPL),这很有趣,我想对开发也会有用
* 在 gdb 中进行调试的时候展示/浏览复杂数据结构的功能函数(感谢 [@invalidop](https://twitter.com/invalidop/status/949161146526781440))
* [在进程运行时设置一个任意的名字空间](https://github.com/baloo/setns/blob/master/setns.c)(我的同事 [nelhage](https://github.com/nelhage) 对此非常惊讶)
* 可能还有许多我所不知道的用途
### 它是如何工作的
当我在 Twitter 上询问从 gdb 中调用函数是如何工作的时,我得到了大量有用的回答。许多答案是“你从符号表中得到了函数的地址”,但这并不是完整的答案。
有个人告诉了我两篇关于 gdb 如何工作的系列文章:[原生调试:第一部分](https://www.cl.cam.ac.uk/%7Esrk31/blog/2016/02/25/#native-debugging-part-1),[原生调试:第二部分](https://www.cl.cam.ac.uk/%7Esrk31/blog/2017/01/30/#native-debugging-part-2)。第一部分讲述了 gdb 是如何调用函数的(指出了 gdb 实际上完成这件事并不简单,但是我将会尽力)。
步骤列举如下:
1. 停止进程
2. 创建一个新的栈框(远离真实栈)
3. 保存所有寄存器
4. 设置你想要调用的函数的寄存器参数
5. 设置栈指针指向新的<ruby> 栈框 <rt> stack frame </rt></ruby>
6. 在内存中某个位置放置一条陷阱指令
7. 为陷阱指令设置返回地址
8. 设置指令寄存器的值为你想要调用的函数地址
9. 再次运行进程!
(LCTT 译注:如果将这个调用的函数看成一个单独的线程,gdb 实际上所做的事情就是一个简单的线程上下文切换)
我不知道 gdb 是如何完成这些所有事情的,但是今天晚上,我学到了这些所有事情中的其中几件。
#### 创建一个栈框
如果你想要运行一个 C 函数,那么你需要一个栈来存储变量。你肯定不想继续使用当前的栈。准确来说,在 gdb 调用函数之前(通过设置函数指针并跳转),它需要设置栈指针到某个地方。
这儿是 Twitter 上一些关于它如何工作的猜测:
>
> 我认为它在当前栈的栈顶上构造了一个新的栈框来进行调用!
>
>
>
以及
>
> 你确定是这样吗?它应该是分配一个伪栈,然后临时将 sp (栈指针寄存器)的值改为那个栈的地址。你可以试一试,你可以在那儿设置一个断点,然后看一看栈指针寄存器的值,它是否和当前程序寄存器的值相近?
>
>
>
我通过 gdb 做了一个试验:
```
(gdb) p $rsp
$7 = (void *) 0x7ffea3d0bca8
(gdb) break foo
Breakpoint 1 at 0x40052a
(gdb) p foo()
Breakpoint 1, 0x000000000040052a in foo ()
(gdb) p $rsp
$8 = (void *) 0x7ffea3d0bc00
```
这看起来符合“gdb 在当前栈的栈顶构造了一个新的栈框”这一理论。因为栈指针(`$rsp`)从 `0x7ffea3d0bca8` 变成了 `0x7ffea3d0bc00` —— 栈指针从高地址往低地址长。所以 `0x7ffea3d0bca8` 在 `0x7ffea3d0bc00` 的后面。真是有趣!
所以,看起来 gdb 只是在当前栈所在位置创建了一个新的栈框。这令我很惊讶!
#### 改变指令指针
让我们来看一看 gdb 是如何改变指令指针的!
```
(gdb) p $rip
$1 = (void (*)()) 0x7fae7d29a2f0 <__nanosleep_nocancel+7>
(gdb) b foo
Breakpoint 1 at 0x40052a
(gdb) p foo()
Breakpoint 1, 0x000000000040052a in foo ()
(gdb) p $rip
$3 = (void (*)()) 0x40052a <foo+4>
```
的确是!指令指针从 `0x7fae7d29a2f0` 变为了 `0x40052a`(`foo` 函数的地址)。
我盯着输出看了很久,但仍然不理解它是如何改变指令指针的,但这并不影响什么。
#### 如何设置断点
上面我写到 `break foo` 。我跟踪 gdb 运行程序的过程,但是没有任何发现。
下面是 gdb 用来设置断点的一些系统调用。它们非常简单。它把一条指令用 `cc` 代替了(这告诉我们 `int3` 意味着 `send SIGTRAP` [https://defuse.ca/online-x86-assembler.html](https://defuse.ca/online-x86-assembler.htm)),并且一旦程序被打断了,它就把指令恢复为原先的样子。
我在函数 `foo` 那儿设置了一个断点,地址为 `0x400528` 。
`PTRACE_POKEDATA` 展示了 gdb 如何改变正在运行的程序。
```
// 改变 0x400528 处的指令
25622 ptrace(PTRACE_PEEKTEXT, 25618, 0x400528, [0x5d00000003b8e589]) = 0
25622 ptrace(PTRACE_POKEDATA, 25618, 0x400528, 0x5d00000003cce589) = 0
// 开始运行程序
25622 ptrace(PTRACE_CONT, 25618, 0x1, SIG_0) = 0
// 当到达断点时获取一个信号
25622 ptrace(PTRACE_GETSIGINFO, 25618, NULL, {si_signo=SIGTRAP, si_code=SI_KERNEL, si_value={int=-1447215360, ptr=0x7ffda9bd3f00}}) = 0
// 将 0x400528 处的指令更改为之前的样子
25622 ptrace(PTRACE_PEEKTEXT, 25618, 0x400528, [0x5d00000003cce589]) = 0
25622 ptrace(PTRACE_POKEDATA, 25618, 0x400528, 0x5d00000003b8e589) = 0
```
#### 在某处放置一条陷阱指令
当 gdb 运行一个函数的时候,它也会在某个地方放置一条陷阱指令。这是其中一条。它基本上是用 `cc` 来替换一条指令(`int3`)。
```
5908 ptrace(PTRACE_PEEKTEXT, 5810, 0x7f6fa7c0b260, [0x48f389fd89485355]) = 0
5908 ptrace(PTRACE_PEEKTEXT, 5810, 0x7f6fa7c0b260, [0x48f389fd89485355]) = 0
5908 ptrace(PTRACE_POKEDATA, 5810, 0x7f6fa7c0b260, 0x48f389fd894853cc) = 0
```
`0x7f6fa7c0b260` 是什么?我查看了进程的内存映射,发现它位于 `/lib/x86_64-linux-gnu/libc-2.23.so` 中的某个位置。这很奇怪,为什么 gdb 将陷阱指令放在 libc 中?
让我们看一看里面的函数是什么,它是 `__libc_siglongjmp` 。其他 gdb 放置陷阱指令的地方的函数是 `__longjmp` 、`___longjmp_chk` 、`dl_main` 和 `_dl_close_worker` 。
为什么?我不知道!也许出于某种原因,当函数 `foo()` 返回时,它调用 `longjmp` ,从而 gdb 能够进行返回控制。我不确定。
### gdb 如何调用函数是很复杂的!
我将要在这儿停止了(现在已经凌晨 1 点),但是我知道的多一些了!
看起来“gdb 如何调用函数”这一问题的答案并不简单。我发现这很有趣并且努力找出其中一些答案,希望你也能够找到。
我依旧有很多未回答的问题,关于 gdb 是如何完成这些所有事的,但是可以了。我不需要真的知道关于 gdb 是如何工作的所有细节,但是我很开心,我有了一些进一步的理解。
---
via: <https://jvns.ca/blog/2018/01/04/how-does-gdb-call-functions/>
作者:[Julia Evans](https://jvns.ca/) 译者:[ucasFL](https://github.com/ucasFL) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
9,589 | 构建开源硬件的 5 个关键点 | https://opensource.com/article/18/2/5-steps-creating-successful-open-hardware | 2018-04-29T10:09:22 | [
"开源硬件",
"硬件"
] | https://linux.cn/article-9589-1.html |
>
> 最大化你的项目影响。
>
>
>

科学社区正在加速拥抱<ruby> 自由及开源硬件 <rt> Free and Open Source Hardware </rt></ruby>([FOSH](https://opensource.com/business/16/4/how-calculate-open-source-hardware-return-investment))。 研究员正忙于[改进他们自己的装备](https://opensource.com/node/16840)并创造数以百计的基于分布式数字制造模型的设备来推动他们的研究。
热衷于 FOSH 的主要原因还是钱: 有研究表明,和专用设备相比,FOSH 可以[节省 90% 到 99% 的花费](http://www.appropedia.org/Open-source_Lab)。基于[开源硬件商业模式](https://www.academia.edu/32004903/Emerging_Business_Models_for_Open_Source_Hardware)的科学 FOSH 的商业化已经推动其快速地发展为一个新的工程领域,并为此定期[举行 GOSH 年会](http://openhardware.science/)。
特别的是,不止一本,而是关于这个主题的[两本学术期刊]:[Journal of Open Hardware] (由 Ubiquity 出版,一个新的自由访问出版商,同时出版了 [Journal of Open Research Software](https://openresearchsoftware.metajnl.com/) )以及 [HardwareX](https://www.journals.elsevier.com/hardwarex)(由 Elsevier 出版的一种[自由访问期刊](https://opensource.com/node/30041),它是世界上最大的学术出版商之一)。
由于学术社区的支持,科学 FOSH 的开发者在获取制作乐趣并推进科学快速发展的同时获得学术声望。
### 科学 FOSH 的5个步骤
Shane Oberloier 和我在名为 Designs 的自由访问工程期刊上共同发表了一篇关于设计 FOSH 科学设备原则的[文章](https://www.academia.edu/35603319/General_Design_Procedure_for_Free_and_Open-Source_Hardware_for_Scientific_Equipment)。我们以滑动式烘干机为例,制造成本低于 20 美元,仅是专用设备价格的三百分之一。[科学](https://opensource.com/business/16/4/how-calculate-open-source-hardware-return-investment)和[医疗](https://www.academia.edu/35382852/Maximizing_Returns_for_Public_Funding_of_Medical_Research_with_Open_source_Hardware)设备往往比较复杂,开发 FOSH 替代品将带来巨大的回报。
我总结了 5 个步骤(包括 6 条设计原则),它们在 Shane Oberloier 和我发表的文章里有详细阐述。这些设计原则也可以推广到非科学设备,而且制作越复杂的设计越能带来更大的潜在收益。
如果你对科学项目的开源硬件设计感兴趣,这些步骤将使你的项目的影响最大化。
1. 评估类似现有工具的功能,你的 FOSH 设计目标应该针对实际效果而不是现有的设计(LCTT 译注:作者的意思应该是不要被现有设计缚住手脚)。必要的时候需进行概念证明。
2. 使用下列设计原则:
* 在设备生产中,仅使用自由和开源的软件工具链(比如,开源的 CAD 工具,例如 [OpenSCAD](http://www.openscad.org/)、 [FreeCAD](https://www.freecadweb.org/) 或 [Blender](https://www.blender.org/))和开源硬件。
* 尝试减少部件的数量和类型并降低工具的复杂度
* 减少材料的数量和制造成本。
* 尽量使用能够分发的部件或使用方便易得的工具(比如 [RepRap 3D 打印机](http://reprap.org/))进行部件的数字化生产。
* 对部件进行[参数化设计](https://en.wikipedia.org/wiki/Parametric_design),这使他人可以对你的设计进行个性化改动。相较于特例化设计,参数化设计会更有用。在未来的项目中,使用者可以通过修改核心参数来继续利用它们。
* 所有不能使用现有的开源硬件以分布式的方式轻松且经济地制造的零件,必须选择现货产品以方便采购。
3. 验证功能设计。
4. 提供关于设计、生产、装配、校准和操作的详尽设备文档。包括原始设计文件而不仅仅是用于生产的。<ruby> 开源硬件协会 <rt> Open Source Hardware Association </rt></ruby>对于开源设计的发布和文档化有额外的[指南](https://www.oshwa.org/sharing-best-practices/),总结如下:
* 以通用的形式分享设计文件。
* 提供详尽的材料清单,包括价格和采购信息。
* 如果涉及软件,确保代码对大众来说清晰易懂。
* 作为生产时的参考,必须提供足够的照片,以确保没有任何被遮挡的部分。
* 在描述方法的章节,整个制作过程必须被细化成简单步骤以便复制此设计。
* 在线上分享并指定许可证。这为用户提供了合理使用该设计的信息。
5. 主动分享!为了使 FOSH 发扬光大,设计必须被广泛、频繁和有效地分享以提升它们的存在感。所有的文档应该在自由访问文献中发表,并与适当的社区共享。<ruby> <a href="https://osf.io/"> 开源科学框架 </a> <rt> Open Science Framework </rt></ruby>是一个值得考虑的优雅的通用存储库,它由<ruby> 开源科学中心 <rt> Center for Open Science </rt></ruby>主办,该中心设置为接受任何类型的文件并处理大型数据集。
这篇文章得到了 [Fulbright Finland](http://www.fulbright.fi/en) 的支持,该公司赞助了芬兰 Fulbright-Aalto 大学的特聘校席 Joshua Pearce 在开源科学硬件方面的研究工作。
---
via: <https://opensource.com/article/18/2/5-steps-creating-successful-open-hardware>
作者:[Joshua Pearce](https://opensource.com/users/jmpearce) 译者:[kennethXia](https://github.com/kennethXia) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,590 | Yoda:您的 Linux 系统命令行个人助理 | https://www.ostechnix.com/yoda-the-command-line-personal-assistant-for-your-linux-system/ | 2018-04-29T17:42:10 | [
"虚拟助手"
] | https://linux.cn/article-9590-1.html | 
不久前,我们介绍了一个名为 [“Betty”](https://www.ostechnix.com/betty-siri-like-commandline-virtual-assistant-linux/) 的命令行虚拟助手。今天,我偶然发现了一个类似的实用程序,叫做 “Yoda”。Yoda 是一个命令行个人助理,可以帮助您在 Linux 中完成一些琐碎的任务。它是用 Python 编写的一个自由开源应用程序。在本指南中,我们将了解如何在 GNU/Linux 中安装和使用 Yoda。
### 安装 Yoda,命令行私人助理。
Yoda 需要 Python 2 和 PIP 。如果在您的 Linux 中没有安装 PIP,请参考下面的指南来安装它。只要确保已经安装了 python2-pip 。Yoda 可能不支持 Python 3。
* [如何使用 pip 管理 Python 包](https://www.ostechnix.com/manage-python-packages-using-pip/)
注意:我建议你在 Python 虚拟环境下试用 Yoda。 不仅仅是 Yoda,应该总在虚拟环境中尝试任何 Python 应用程序,让它们不会干扰全局安装的软件包。 您可以按照上文链接中标题为“创建虚拟环境”一节中所述设置虚拟环境。
在您的系统上安装了 `pip` 之后,使用下面的命令克隆 Yoda 库。
```
$ git clone https://github.com/yoda-pa/yoda
```
上面的命令将在当前工作目录中创建一个名为 `yoda` 的目录,并在其中克隆所有内容。转到 `yoda` 目录:
```
$ cd yoda/
```
运行以下命令安装 Yoda 应用程序。
```
$ pip install .
```
请注意最后的点(`.`)。 现在,所有必需的软件包将被下载并安装。
### 配置 Yoda
首先,设置配置以将您的信息保存在本地系统上。
运行下面的命令:
```
$ yoda setup new
```
填写下列的问题:
```
Enter your name:
Senthil Kumar
What's your email id?
[email protected]
What's your github username?
sk
Enter your github password:
Password:
Where shall your config be stored? (Default: ~/.yoda/)
A configuration file already exists. Are you sure you want to overwrite it? (y/n)
y
```
你的密码在加密后保存在配置文件中,所以不用担心。
要检查当前配置,请运行:
```
$ yoda setup check
```
你会看到如下的输出。
```
Name: Senthil Kumar
Email: [email protected]
Github username: sk
```
默认情况下,您的信息存储在 `~/.yoda` 目录中。
要删除现有配置,请执行以下操作:
```
$ yoda setup delete
```
### 用法
Yoda 包含一个简单的聊天机器人。您可以使用下面的聊天命令与它交互。
```
$ yoda chat who are you
```
样例输出:
```
Yoda speaks:
I'm a virtual agent
$ yoda chat how are you
Yoda speaks:
I'm doing very well. Thanks!
```
以下是我们可以用 Yoda 做的事情:
#### 测试网络速度
让我们问一下 Yoda 关于互联网速度的问题。运行:
```
$ yoda speedtest
Speed test results:
Ping: 108.45 ms
Download: 0.75 Mb/s
Upload: 1.95 Mb/s
```
#### 缩短和展开网址
Yoda 还有助于缩短任何网址:
```
$ yoda url shorten https://www.ostechnix.com/
Here's your shortened URL:
https://goo.gl/hVW6U0
```
要展开缩短的网址:
```
$ yoda url expand https://goo.gl/hVW6U0
Here's your original URL:
https://www.ostechnix.com/
```
#### 阅读 Hacker News
我是 Hacker News 网站的常客。 如果你像我一样,你可以使用 Yoda 从下面的 Hacker News 网站阅读新闻。
```
$ yoda hackernews
News-- 1/513
Title-- Show HN: a Yelp for iOS developers
Description-- I came up with this idea "a Yelp for developers" when talking with my colleagues. My hypothesis is that, it would be very helpful if we know more about a library before choosing to use it. It's similar to that we want to know more about a restaurant by checki…
url-- https://news.ycombinator.com/item?id=16636071
Continue? [press-"y"]
```
Yoda 将一次显示一个项目。 要阅读下一条新闻,只需输入 `y` 并按下回车。
#### 管理个人日记
我们也可以保留个人日记以记录重要事件。
使用命令创建一个新的日记:
```
$ yoda diary nn
Input your entry for note:
Today I learned about Yoda
```
要创建新笔记,请再次运行上述命令。
查看所有笔记:
```
$ yoda diary notes
Today's notes:
----------------
Time | Note
--------|-----
16:41:41| Today I learned about Yoda
```
不仅仅是笔记,Yoda 还可以帮助你创建任务。
要创建新任务,请运行:
```
$ yoda diary nt
Input your entry for task:
Write an article about Yoda and publish it on OSTechNix
```
要查看任务列表,请运行:
```
$ yoda diary tasks
Today's agenda:
----------------
Status | Time | Text
-------|---------|-----
O | 16:44:03: Write an article about Yoda and publish it on OSTechNix
----------------
Summary:
----------------
Incomplete tasks: 1
Completed tasks: 0
```
正如你在上面看到的,我有一个未完成的任务。 要将其标记为已完成,请运行以下命令并输入已完成的任务序列号并按下回车键:
```
$ yoda diary ct
Today's agenda:
----------------
Number | Time | Task
-------|---------|-----
1 | 16:44:03: Write an article about Yoda and publish it on OSTechNix
Enter the task number that you would like to set as completed
1
```
您可以随时使用命令分析当前月份的任务:
```
$ yoda diary analyze
Percentage of incomplete task : 0
Percentage of complete task : 100
Frequency of adding task (Task/Day) : 3
```
有时候,你可能想要记录一个关于你爱的或者敬佩的人的个人资料。
#### 记录关于爱人的笔记
首先,您需要设置配置来存储朋友的详细信息。 请运行:
```
$ yoda love setup
```
输入你的朋友的详细信息:
```
Enter their name:
Abdul Kalam
Enter sex(M/F):
M
Where do they live?
Rameswaram
```
要查看此人的详细信息,请运行:
```
$ yoda love status
{'place': 'Rameswaram', 'name': 'Abdul Kalam', 'sex': 'M'}
```
要添加你的爱人的生日:
```
$ yoda love addbirth
Enter birthday
15-10-1931
```
查看生日:
```
$ yoda love showbirth
Birthday is 15-10-1931
```
你甚至可以添加关于该人的笔记:
```
$ yoda love note
Avul Pakir Jainulabdeen Abdul Kalam better known as A. P. J. Abdul Kalam, was the 11th President of India from 2002 to 2007.
```
您可以使用命令查看笔记:
```
$ yoda love notes
Notes:
1: Avul Pakir Jainulabdeen Abdul Kalam better known as A. P. J. Abdul Kalam, was the 11th President of India from 2002 to 2007.
```
你也可以写下这个人喜欢的东西:
```
$ yoda love like
Add things they like
Physics, Aerospace
Want to add more things they like? [y/n]
n
```
要查看他们喜欢的东西,请运行:
```
$ yoda love likes
Likes:
1: Physics, Aerospace
```
#### 跟踪资金费用
您不需要单独的工具来维护您的财务支出。 Yoda 会替您处理好。
首先,使用命令设置您的金钱支出配置:
```
$ yoda money setup
```
输入您的货币代码和初始金额:
```
Enter default currency code:
INR
{u'USD': 0.015338, u'IDR': 211.06, u'BGN': 0.024436, u'ISK': 1.5305, u'ILS': 0.053402, u'GBP': 0.010959, u'DKK': 0.093063, u'CAD': 0.020041, u'MXN': 0.28748, u'HUF': 3.8873, u'RON': 0.058302, u'MYR': 0.060086, u'SEK': 0.12564, u'SGD': 0.020208, u'HKD': 0.12031, u'AUD': 0.019908, u'CHF': 0.014644, u'KRW': 16.429, u'CNY': 0.097135, u'TRY': 0.06027, u'HRK': 0.092986, u'NZD': 0.021289, u'THB': 0.47854, u'EUR': 0.012494, u'NOK': 0.11852, u'RUB': 0.88518, u'JPY': 1.6332, u'CZK': 0.31764, u'BRL': 0.050489, u'PLN': 0.052822, u'PHP': 0.79871, u'ZAR': 0.1834}
₹
Indian rupee
Enter initial amount:
10000
```
要查看金钱配置,只需运行:
```
$ yoda money status
{'initial_money': 10000, 'currency_code': 'INR'}
```
让我们假设你买了一本价值 250 卢比的书。 要添加此费用,请运行:
```
$ yoda money exp
Spend 250 INR on books
output:
```
要查看花费,请运行:
```
$ yoda money exps
2018-03-21 17:12:31 INR 250 books
```
#### 创建想法列表
创建一个新的想法:
```
$ yoda ideas add --task <task_name> --inside <project_name>
```
列出想法:
```
$ yoda ideas show
```
从任务中移除一个想法:
```
$ yoda ideas remove --task <task_name> --inside <project_name>
```
要完全删除这个想法,请运行:
```
$ yoda ideas remove --project <project_name>
```
#### 学习英语词汇
Yoda 帮助你学习随机英语单词并追踪你的学习进度。
要学习一个新单词,请输入:
```
$ yoda vocabulary word
```
它会随机显示一个单词。 按回车键显示单词的含义。 再一次,Yoda 问你是否已经知道这个词的意思。 如果您已经知道,请输入“是”。 如果您不知道,请输入“否”。 这可以帮助你跟踪你的进度。 使用以下命令来了解您的进度。
```
$ yoda vocabulary accuracy
```
此外,Yoda 可以帮助您做其他一些事情,比如找到单词的定义和创建插卡以轻松学习任何内容。 有关更多详细信息和可用选项列表,请参阅帮助部分。
```
$ yoda --help
```
更多好的东西来了。请继续关注!
干杯!
---
via: <https://www.ostechnix.com/yoda-the-command-line-personal-assistant-for-your-linux-system/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,591 | 假装很忙的三个命令行工具 | https://opensource.com/article/18/2/command-line-tools-productivity | 2018-04-30T10:24:00 | [
"黑客",
"终端"
] | /article-9591-1.html |
>
> 有时候你很忙。而有时候你只是需要看起来很忙,就像电影中的黑客一样。有一些开源工具就是干这个的。
>
>
>

如果在你在消磨时光时看过谍战片、动作片或犯罪片,那么你就会清晰地在脑海中勾勒出黑客的电脑屏幕的样子。就像是在《黑客帝国》电影中,[代码雨](http://tvtropes.org/pmwiki/pmwiki.php/Main/MatrixRainingCode) 一样的十六进制数字流,又或是一排排快速移动的代码。
也许电影中出现一幅世界地图,其中布满了闪烁的光点和一些快速更新的图表。不可或缺的,也可能有 3D 旋转的几何形状。甚至,这一切都会显示在一些完全不符合人类习惯的数量荒谬的显示屏上。 在《剑鱼行动》电影中黑客就使用了七个显示屏。
当然,我们这些从事计算机行业的人一下子就明白这完全是胡说八道。虽然在我们中,许多人都有双显示器(或更多),但一个闪烁的数据仪表盘、刷新的数据通常和专注工作是相互矛盾的。编写代码、项目管理和系统管理与日常工作不同。我们遇到的大多数情况,为了解决问题,都需要大量的思考,与客户沟通所得到一些研究和组织的资料,然后才是少许的 [敲代码](http://tvtropes.org/pmwiki/pmwiki.php/Main/RapidFireTyping)。
然而,这与我们想追求电影中的效果并不矛盾,也许,我们只是想要看起来“忙于工作”而已。
**注:当然,我仅仅是在此胡诌。**如果您公司实际上是根据您繁忙程度来评估您的工作时,无论您是蓝领还是白领,都需要亟待解决这样的工作文化。假装工作很忙是一种有毒的文化,对公司和员工都有害无益。
这就是说,让我们找些乐子,用一些老式的、毫无意义的数据和代码片段填充我们的屏幕。(当然,数据或许有意义,但不是在这种没有上下文的环境中。)当然有一些用于此用途的有趣的图形界面程序,如 [hackertyper.net](https://hackertyper.net/) 或是 [GEEKtyper.com](http://geektyper.com) 网站(LCTT 译注:是在线假装黑客操作的网站),为什么不使用标准的 Linux 终端程序呢?对于更老派的外观,可以考虑使用 [酷炫复古终端](https://github.com/Swordfish90/cool-retro-term),这听起来确实如此:一个酷炫的复古终端程序。我将在下面的屏幕截图中使用酷炫复古终端,因为它看起来的确很酷。
### Genact
我们来看下第一个工具——Genact。Genact 的原理很简单,就是慢慢地无尽循环播放您选择的一个序列,让您的代码在您外出休息时“编译”。由您来决定播放顺序,但是其中默认包含数字货币挖矿模拟器、Composer PHP 依赖关系管理工具、内核编译器、下载器、内存转储等工具。其中我最喜欢的是其中类似《模拟城市》加载显示。所以只要没有人仔细检查,你可以花一整个下午等待您的电脑完成进度条。
Genact [发布了](https://github.com/svenstaro/genact/releases) 支持 Linux、OS X 和 Windows 的版本。并且其 Rust [源代码](https://github.com/svenstaro/genact) 在 GitHub 上开源(遵循 [MIT 许可证](https://github.com/svenstaro/genact/blob/master/LICENSE))。

### Hollywood
Hollywood 采取更直接的方法。它本质上是在终端中创建一个随机的数量和配置的分屏,并启动那些看起来很繁忙的应用程序,如 htop、目录树、源代码文件等,并每隔几秒将其切换。它被组织成一个 shell 脚本,所以可以非常容易地根据需求进行修改。
Hollywood的 [源代码](https://github.com/dustinkirkland/hollywood) 在 GitHub 上开源(遵循 [Apache 2.0 许可证](http://www.apache.org/licenses/LICENSE-2.0))。

### Blessed-contrib
Blessed-contrib 是我个人最喜欢的应用,实际上并不是为了这种表演而专门设计的应用。相反地,它是一个基于 Node.js 的终端仪表盘的构建库的演示文件。与其他两个不同,实际上我已经在工作中使用 Blessed-contrib 的库,而不是用于假装忙于工作。因为它是一个相当有用的库,并且可以使用一组在命令行显示信息的小部件。与此同时填充虚拟数据也很容易,所以可以很容易实现你在计算机上模拟《战争游戏》的想法。
Blessed-contrib 的[源代码](https://github.com/yaronn/blessed-contrib)在 GitHub 上(遵循 [MIT 许可证](http://opensource.org/licenses/MIT))。

当然,尽管这些工具很容易使用,但也有很多其他的方式使你的屏幕丰富。在你看到电影中最常用的工具之一就是Nmap,这是一个开源的网络安全扫描工具。实际上,它被广泛用作展示好莱坞电影中,黑客电脑屏幕上的工具。因此 Nmap 的开发者创建了一个 [页面](https://nmap.org/movies/),列出了它出现在其中的一些电影,从《黑客帝国 2:重装上阵》到《谍影重重3》、《龙纹身的女孩》,甚至《虎胆龙威 4》。
当然,您可以创建自己的组合,使用终端多路复用器(如 `screen` 或 `tmux`)启动您希望使用的任何数据切分程序。
那么,您是如何使用您的屏幕的呢?
---
via: <https://opensource.com/article/18/2/command-line-tools-productivity>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,592 | 使用 Tripwire 保护 Linux 文件系统 | https://opensource.com/article/18/1/securing-linux-filesystem-tripwire | 2018-04-30T11:28:00 | [
"Tripwire"
] | https://linux.cn/article-9592-1.html |
>
> 如果恶意软件或其情况改变了你的文件系统,Linux 完整性检查工具会提示你。
>
>
>

尽管 Linux 被认为是最安全的操作系统(排在 Windows 和 MacOS 之前),但它仍然容易受到 rootkit 和其他恶意软件的影响。因此,Linux 用户需要知道如何保护他们的服务器或个人电脑免遭破坏,他们需要采取的第一步就是保护文件系统。
在本文中,我们将看看 [Tripwire](https://www.tripwire.com/),这是保护 Linux 文件系统的绝佳工具。Tripwire 是一个完整性检查工具,使得系统管理员、安全工程师和其他人能够检测系统文件的变更。虽然它不是唯一的选择([AIDE](http://aide.sourceforge.net/) 和 [Samhain](http://www.la-samhna.de/samhain/) 提供类似功能),但 Tripwire 可以说是 Linux 系统文件中最常用的完整性检查程序,并在 GPLv2 许可证下开源。
### Tripwire 如何工作
了解 Tripwire 如何运行对了解 Tripwire 在安装后会做什么有所帮助。Tripwire 主要由两个部分组成:策略和数据库。策略列出了完整性检查器应该生成快照的所有文件和目录,还创建了用于识别对目录和文件更改违规的规则。数据库由 Tripwire 生成的快照组成。
Tripwire 还有一个配置文件,它指定数据库、策略文件和 Tripwire 可执行文件的位置。它还提供两个加密密钥 —— 站点密钥和本地密钥 —— 以保护重要文件免遭篡改。站点密钥保护策略和配置文件,而本地密钥保护数据库和生成的报告。
Tripwire 会定期将目录和文件与数据库中的快照进行比较并报告所有的更改。
### 安装 Tripwire
要 Tripwire,我们需要先下载并安装它。Tripwire 适用于几乎所有的 Linux 发行版。你可以从 [Sourceforge](http://sourceforge.net/projects/tripwire) 下载一个开源版本,并如下根据你的 Linux 版本进行安装。
Debian 和 Ubuntu 用户可以使用 `apt-get` 直接从仓库安装 Tripwire。非 root 用户应该输入 `sudo` 命令通过 `apt-get` 安装 Tripwire。
```
sudo apt-get update
sudo apt-get install tripwire
```
CentOS 和其他基于 RPM 的发行版使用类似的过程。为了最佳实践,请在安装新软件包(如 Tripwire)之前更新仓库。命令 `yum install epel-release` 意思是我们想要安装额外的存储库。 (`epel` 代表 Extra Packages for Enterprise Linux。)
```
yum update
yum install epel-release
yum install tripwire
```
此命令会在安装中运行让 Tripwire 有效运行所需的配置。另外,它会在安装过程中询问你是否使用密码。你可以两个选择都选择 “Yes”。
另外,如果需要构建配置文件,请选择 “Yes”。选择并确认站点密钥和本地密钥的密码。(建议使用复杂的密码,例如 `Il0ve0pens0urce` 这样的。)
### 建立并初始化 Tripwire 数据库
接下来,按照以下步骤初始化 Tripwire 数据库:
```
tripwire --init
```
你需要提供本地密钥密码才能运行这些命令。
### 使用 Tripwire 进行基本的完整性检查
你可以使用以下命令让 Tripwire 检查你的文件或目录是否已被修改。Tripwire 将文件和目录与数据库中的初始快照进行比较的能力依赖于你在活动策略中创建的规则。
```
tripwire --check
```
你还可以将 `-check` 命令限制为特定的文件或目录,如下所示:
```
tripwire --check /usr/tmp
```
另外,如果你需要使用 Tripwire 的 `-check` 命令的更多帮助,该命令能够查阅 Tripwire 的手册:
```
tripwire --check --help
```
### 使用 Tripwire 生成报告
要轻松生成每日系统完整性报告,请使用以下命令创建一个 crontab 任务:
```
crontab -e
```
之后,你可以编辑此文件(使用你选择的文本编辑器)来引入由 cron 运行的任务。例如,你可以使用以下命令设置一个 cron 任务,在每天的 5:40 将 Tripwire 的报告发送到你的邮箱:
```
40 5 * * * usr/sbin/tripwire --check
```
无论你决定使用 Tripwire 还是其他具有类似功能的完整性检查程序,关键问题都是确保你有解决方案来保护 Linux 文件系统的安全。
---
via: <https://opensource.com/article/18/1/securing-linux-filesystem-tripwire>
作者:[Michael Kwaku Aboagye](https://opensource.com/users/revoks) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | While Linux is considered to be the most secure operating system (ahead of Windows and MacOS), it is still vulnerable to rootkits and other variants of malware. Thus, Linux users need to know how to protect their servers or personal computers from destruction, and the first step they need to take is to protect the filesystem.
In this article, we'll look at [Tripwire](https://github.com/Tripwire/tripwire-open-source), an excellent tool for protecting Linux filesystems. Tripwire is an integrity checking tool that enables system administrators, security engineers, and others to detect alterations to system files. Although it's not the only option available ([AIDE](http://aide.sourceforge.net/) and [Samhain](http://www.la-samhna.de/samhain/) offer similar features), Tripwire is a popular integrity checker for Linux system files and is available as open source under GPLv2.
## How Tripwire works
It's helpful to know how Tripwire operates in order to understand what it does once it's installed. Tripwire is made up of two major components: policy and database. Policy lists all the files and directories that the integrity checker should take a snapshot of, in addition to creating rules for identifying violations of changes to directories and files. Database consists of the snapshot taken by Tripwire.
Tripwire also has a configuration file, which specifies the locations of the database, policy file, and Tripwire executable. It also provides two cryptographic keys—site key and local key—to protect important files against tampering. The site key protects the policy and configuration files, while the local key protects the database and generated reports.
Tripwire works by periodically comparing the directories and files against the snapshot in the database and reporting any changes.
## Installing Tripwire
In order to use Tripwire, we need to download and install it first. Tripwire works on almost all Linux distributions; you can download an open source version from [Sourceforge](http://sourceforge.net/projects/tripwire) and install it as follows, depending on your version of Linux.
Debian and Ubuntu users can install Tripwire directly from the repository using `apt-get`
. Non-root users should type the `sudo`
command to install Tripwire via `apt-get`
.
```
sudo apt-get update
sudo apt-get install tripwire
```
CentOS and other rpm-based distributions use a similar process. For the sake of best practice, update your repository before installing a new package such as Tripwire. The command `yum install epel-release`
simply means we want to install extra repositories. (`epel`
stands for Extra Packages for Enterprise Linux.)
```
yum update
yum install epel-release
yum install tripwire
```
This command causes the installation to run a configuration of packages that are required for Tripwire to function effectively. In addition, it will ask if you want to select passphrases during installation. You can select "Yes" to both prompts.
Also, select or choose "Yes" if it's required to build the configuration file. Choose and confirm a passphrase for a site key and for a local key. (A complex passphrase such as `Il0ve0pens0urce`
is recommended.)
## Build and initialize Tripwire's database
Next, initialize the Tripwire database as follows:
`tripwire –-init `
You'll need to provide your local key passphrase to run the commands.
## Basic integrity checking using Tripwire
You can use the following command to instruct Tripwire to check whether your files or directories have been modified. Tripwire's ability to compare files and directories against the initial snapshot in the database is based on the rules you created in the active policy.
`tripwire --check `
You can also limit the `–check`
command to specific files or directories, such as in this example:
`tripwire –-check /usr/tmp `
In addition, if you need extended help on using Tripwire's `–check`
command, this command allows you to consult Tripwire's manual:
`tripwire --check --help `
## Generating reports using Tripwire
To easily generate a daily system integrity report, create a `crontab`
with this command:
`crontab -e `
Afterward, you can edit this file (with the text editor of your choice) to introduce tasks to be run by cron. For instance, you can set up a cron job to send Tripwire reports to your email daily at 5:40 a.m. by using this command:
`40 5 * * * usr/sbin/tripwire --check`
Whether you decide to use Tripwire or another integrity checker with similar features, the key issue is making sure you have a solution to protect the security of your Linux filesystem.
## 4 Comments |
9,593 | 使用 Docker 和 Elasticsearch 构建一个全文搜索应用程序 | https://blog.patricktriest.com/text-search-docker-elasticsearch/ | 2018-05-01T09:56:00 | [
"Elasticsearch",
"全文搜索",
"搜索"
] | https://linux.cn/article-9593-1.html | 
*如何在超过 500 万篇文章的 Wikipedia 上找到与你研究相关的文章?*
*如何在超过 20 亿用户的 Facebook 中找到你的朋友(并且还拼错了名字)?*
*谷歌如何在整个因特网上搜索你的模糊的、充满拼写错误的查询?*
在本教程中,我们将带你探索如何配置我们自己的全文搜索应用程序(与上述问题中的系统相比,它的复杂度要小很多)。我们的示例应用程序将提供一个 UI 和 API 去从 100 部经典文学(比如,《彼得·潘》 、 《弗兰肯斯坦》 和 《金银岛》)中搜索完整的文本。
你可以在这里([https://search.patricktriest.com](https://search.patricktriest.com/))预览该教程应用的完整版本。

这个应用程序的源代码是 100% 开源的,可以在 GitHub 仓库上找到它们 —— <https://github.com/triestpa/guttenberg-search> 。
在应用程序中添加一个快速灵活的全文搜索可能是个挑战。大多数的主流数据库,比如,[PostgreSQL](https://www.postgresql.org/) 和 [MongoDB](https://www.mongodb.com/),由于受其查询和索引结构的限制只能提供一个非常基础的文本搜索功能。为实现高质量的全文搜索,通常的最佳选择是单独的数据存储。[Elasticsearch](https://www.elastic.co/) 是一个开源数据存储的领导者,它专门为执行灵活而快速的全文搜索进行了优化。
我们将使用 [Docker](https://www.docker.com/) 去配置我们自己的项目环境和依赖。Docker 是一个容器化引擎,它被 [Uber](https://www.uber.com/)、[Spotify](https://www.spotify.com/us/)、[ADP](https://www.adp.com/) 以及 [Paypal](https://www.paypal.com/us/home) 使用。构建容器化应用的一个主要优势是,项目的设置在 Windows、macOS、以及 Linux 上都是相同的 —— 这使我写这个教程快速又简单。如果你还没有使用过 Docker,不用担心,我们接下来将经历完整的项目配置。
我也会使用 [Node.js](https://nodejs.org/en/) (使用 [Koa](http://koajs.com/) 框架)和 [Vue.js](https://vuejs.org/),用它们分别去构建我们自己的搜索 API 和前端 Web 应用程序。
### 1 - Elasticsearch 是什么?
全文搜索在现代应用程序中是一个有大量需求的特性。搜索也可能是最难的一项特性 —— 许多流行的网站的搜索功能都不合格,要么返回结果太慢,要么找不到精确的结果。通常,这种情况是被底层的数据库所局限:大多数标准的关系型数据库局限于基本的 `CONTAINS` 或 `LIKE` SQL 查询上,它仅提供最基本的字符串匹配功能。
我们的搜索应用程序将具备:
1. **快速** - 搜索结果将快速返回,为用户提供一个良好的体验。
2. **灵活** - 我们希望能够去修改搜索如何执行的方式,这是为了便于在不同的数据库和用户场景下进行优化。
3. **容错** - 如果所搜索的内容有拼写错误,我们将仍然会返回相关的结果,而这个结果可能正是用户希望去搜索的结果。
4. **全文** - 我们不想限制我们的搜索只能与指定的关键字或者标签相匹配 —— 我们希望它可以搜索在我们的数据存储中的任何东西(包括大的文本字段)。

为了构建一个功能强大的搜索功能,通常最理想的方法是使用一个为全文搜索任务优化过的数据存储。在这里我们使用 [Elasticsearch](https://www.elastic.co/),Elasticsearch 是一个开源的内存中的数据存储,它是用 Java 写的,最初是在 [Apache Lucene](https://lucene.apache.org/core/) 库上构建的。
这里有一些来自 [Elastic 官方网站](https://www.elastic.co/guide/en/elasticsearch/guide/2.x/getting-started.html) 上的 Elasticsearch 真实使用案例。
* Wikipedia 使用 Elasticsearch 去提供带高亮搜索片断的全文搜索功能,并且提供按类型搜索和 “did-you-mean” 建议。
* Guardian 使用 Elasticsearch 把社交网络数据和访客日志相结合,为编辑去提供新文章的公众意见的实时反馈。
* Stack Overflow 将全文搜索和地理查询相结合,并使用 “类似” 的方法去找到相关的查询和回答。
* GitHub 使用 Elasticsearch 对 1300 亿行代码进行查询。
### 与 “普通的” 数据库相比,Elasticsearch 有什么不一样的地方?
Elasticsearch 之所以能够提供快速灵活的全文搜索,秘密在于它使用<ruby> 反转索引 <rt> inverted index </rt></ruby> 。
“索引” 是数据库中的一种数据结构,它能够以超快的速度进行数据查询和检索操作。数据库通过存储与表中行相关联的字段来生成索引。在一种可搜索的数据结构(一般是 [B 树](https://en.wikipedia.org/wiki/B-tree))中排序索引,在优化过的查询中,数据库能够达到接近线性的时间(比如,“使用 ID=5 查找行”)。

我们可以将数据库索引想像成一个图书馆中老式的卡片式目录 —— 只要你知道书的作者和书名,它就会告诉你书的准确位置。为加速特定字段上的查询速度,数据库表一般有多个索引(比如,在 `name` 列上的索引可以加速指定名字的查询)。
反转索引本质上是不一样的。每行(或文档)的内容是分开的,并且每个独立的条目(在本案例中是单词)反向指向到包含它的任何文档上。

这种反转索引数据结构可以使我们非常快地查询到,所有出现 “football” 的文档。通过使用大量优化过的内存中的反转索引,Elasticsearch 可以让我们在存储的数据上,执行一些非常强大的和自定义的全文搜索。
### 2 - 项目设置
#### 2.0 - Docker
我们在这个项目上使用 [Docker](https://www.docker.com/) 管理环境和依赖。Docker 是个容器引擎,它允许应用程序运行在一个独立的环境中,不会受到来自主机操作系统和本地开发环境的影响。现在,许多公司将它们的大规模 Web 应用程序主要运行在容器架构上。这样将提升灵活性和容器化应用程序组件的可组构性。

对我来说,使用 Docker 的优势是,它对本教程的作者非常方便,它的本地环境设置量最小,并且跨 Windows、macOS 和 Linux 系统的一致性很好。我们只需要在 Docker 配置文件中定义这些依赖关系,而不是按安装说明分别去安装 Node.js、Elasticsearch 和 Nginx,然后,就可以使用这个配置文件在任何其它地方运行我们的应用程序。而且,因为每个应用程序组件都运行在它自己的独立容器中,它们受本地机器上的其它 “垃圾” 干扰的可能性非常小,因此,在调试问题时,像“它在我这里可以工作!”这类的问题将非常少。
#### 2.1 - 安装 Docker & Docker-Compose
这个项目只依赖 [Docker](https://www.docker.com/) 和 [docker-compose](https://docs.docker.com/compose/),docker-compose 是 Docker 官方支持的一个工具,它用来将定义的多个容器配置 *组装* 成单一的应用程序栈。
* 安装 Docker - <https://docs.docker.com/engine/installation/>
* 安装 Docker Compose - <https://docs.docker.com/compose/install/>
#### 2.2 - 设置项目主目录
为项目创建一个主目录(名为 `guttenberg_search`)。我们的项目将工作在主目录的以下两个子目录中。
* `/public` - 保存前端 Vue.js Web 应用程序。
* `/server` - 服务器端 Node.js 源代码。
#### 2.3 - 添加 Docker-Compose 配置
接下来,我们将创建一个 `docker-compose.yml` 文件来定义我们的应用程序栈中的每个容器。
1. `gs-api` - 后端应用程序逻辑使用的 Node.js 容器
2. `gs-frontend` - 前端 Web 应用程序使用的 Ngnix 容器。
3. `gs-search` - 保存和搜索数据的 Elasticsearch 容器。
```
version: '3'
services:
api: # Node.js App
container_name: gs-api
build: .
ports:
- "3000:3000" # Expose API port
- "9229:9229" # Expose Node process debug port (disable in production)
environment: # Set ENV vars
- NODE_ENV=local
- ES_HOST=elasticsearch
- PORT=3000
volumes: # Attach local book data directory
- ./books:/usr/src/app/books
frontend: # Nginx Server For Frontend App
container_name: gs-frontend
image: nginx
volumes: # Serve local "public" dir
- ./public:/usr/share/nginx/html
ports:
- "8080:80" # Forward site to localhost:8080
elasticsearch: # Elasticsearch Instance
container_name: gs-search
image: docker.elastic.co/elasticsearch/elasticsearch:6.1.1
volumes: # Persist ES data in seperate "esdata" volume
- esdata:/usr/share/elasticsearch/data
environment:
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.type=single-node
ports: # Expose Elasticsearch ports
- "9300:9300"
- "9200:9200"
volumes: # Define seperate volume for Elasticsearch data
esdata:
```
这个文件定义了我们全部的应用程序栈 —— 不需要在你的本地系统上安装 Elasticsearch、Node 和 Nginx。每个容器都将端口转发到宿主机系统(`localhost`)上,以便于我们在宿主机上去访问和调试 Node API、Elasticsearch 实例和前端 Web 应用程序。
#### 2.4 - 添加 Dockerfile
对于 Nginx 和 Elasticsearch,我们使用了官方预构建的镜像,而 Node.js 应用程序需要我们自己去构建。
在应用程序的根目录下定义一个简单的 `Dockerfile` 配置文件。
```
# Use Node v8.9.0 LTS
FROM node:carbon
# Setup app working directory
WORKDIR /usr/src/app
# Copy package.json and package-lock.json
COPY package*.json ./
# Install app dependencies
RUN npm install
# Copy sourcecode
COPY . .
# Start app
CMD [ "npm", "start" ]
```
这个 Docker 配置扩展了官方的 Node.js 镜像、拷贝我们的应用程序源代码、以及在容器内安装 NPM 依赖。
我们也增加了一个 `.dockerignore` 文件,以防止我们不需要的文件拷贝到容器中。
```
node_modules/
npm-debug.log
books/
public/
```
>
> 请注意:我们之所以不拷贝 `node_modules` 目录到我们的容器中 —— 是因为我们要在容器构建过程里面运行 `npm install`。从宿主机系统拷贝 `node_modules` 到容器里面可能会引起错误,因为一些包需要为某些操作系统专门构建。比如说,在 macOS 上安装 `bcrypt` 包,然后尝试将这个模块直接拷贝到一个 Ubuntu 容器上将不能工作,因为 `bcyrpt` 需要为每个操作系统构建一个特定的二进制文件。
>
>
>
#### 2.5 - 添加基本文件
为了测试我们的配置,我们需要添加一些占位符文件到应用程序目录中。
在 `public/index.html` 文件中添加如下内容。
```
<html><body>Hello World From The Frontend Container</body></html>
```
接下来,在 `server/app.js` 中添加 Node.js 占位符文件。
```
const Koa = require('koa')
const app = new Koa()
app.use(async (ctx, next) => {
ctx.body = 'Hello World From the Backend Container'
})
const port = process.env.PORT || 3000
app.listen(port, err => {
if (err) console.error(err)
console.log(`App Listening on Port ${port}`)
})
```
最后,添加我们的 `package.json` Node 应用配置。
```
{
"name": "guttenberg-search",
"version": "0.0.1",
"description": "Source code for Elasticsearch tutorial using 100 classic open source books.",
"scripts": {
"start": "node --inspect=0.0.0.0:9229 server/app.js"
},
"repository": {
"type": "git",
"url": "git+https://github.com/triestpa/guttenberg-search.git"
},
"author": "[email protected]",
"license": "MIT",
"bugs": {
"url": "https://github.com/triestpa/guttenberg-search/issues"
},
"homepage": "https://github.com/triestpa/guttenberg-search#readme",
"dependencies": {
"elasticsearch": "13.3.1",
"joi": "13.0.1",
"koa": "2.4.1",
"koa-joi-validate": "0.5.1",
"koa-router": "7.2.1"
}
}
```
这个文件定义了应用程序启动命令和 Node.js 包依赖。
>
> 注意:不要运行 `npm install` —— 当它构建时,依赖会在容器内安装。
>
>
>
#### 2.6 - 测试它的输出
现在一切新绪,我们来测试应用程序的每个组件的输出。从应用程序的主目录运行 `docker-compose build`,它将构建我们的 Node.js 应用程序容器。

接下来,运行 `docker-compose up` 去启动整个应用程序栈。

>
> 这一步可能需要几分钟时间,因为 Docker 要为每个容器去下载基础镜像。以后再次运行,启动应用程序会非常快,因为所需要的镜像已经下载完成了。
>
>
>
在你的浏览器中尝试访问 `localhost:8080` —— 你将看到简单的 “Hello World” Web 页面。

访问 `localhost:3000` 去验证我们的 Node 服务器,它将返回 “Hello World” 信息。

最后,访问 `localhost:9200` 去检查 Elasticsearch 运行状态。它将返回类似如下的内容。
```
{
"name" : "SLTcfpI",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "iId8e0ZeS_mgh9ALlWQ7-w",
"version" : {
"number" : "6.1.1",
"build_hash" : "bd92e7f",
"build_date" : "2017-12-17T20:23:25.338Z",
"build_snapshot" : false,
"lucene_version" : "7.1.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
```
如果三个 URL 都显示成功,祝贺你!整个容器栈已经正常运行了,接下来我们进入最有趣的部分。
### 3 - 连接到 Elasticsearch
我们要做的第一件事情是,让我们的应用程序连接到我们本地的 Elasticsearch 实例上。
#### 3.0 - 添加 ES 连接模块
在新文件 `server/connection.js` 中添加如下的 Elasticsearch 初始化代码。
```
const elasticsearch = require('elasticsearch')
// Core ES variables for this project
const index = 'library'
const type = 'novel'
const port = 9200
const host = process.env.ES_HOST || 'localhost'
const client = new elasticsearch.Client({ host: { host, port } })
/** Check the ES connection status */
async function checkConnection () {
let isConnected = false
while (!isConnected) {
console.log('Connecting to ES')
try {
const health = await client.cluster.health({})
console.log(health)
isConnected = true
} catch (err) {
console.log('Connection Failed, Retrying...', err)
}
}
}
checkConnection()
```
现在,我们重新构建我们的 Node 应用程序,我们将使用 `docker-compose build` 来做一些改变。接下来,运行 `docker-compose up -d` 去启动应用程序栈,它将以守护进程的方式在后台运行。
应用程序启动之后,在命令行中运行 `docker exec gs-api "node" "server/connection.js"`,以便于在容器内运行我们的脚本。你将看到类似如下的系统输出信息。
```
{ cluster_name: 'docker-cluster',
status: 'yellow',
timed_out: false,
number_of_nodes: 1,
number_of_data_nodes: 1,
active_primary_shards: 1,
active_shards: 1,
relocating_shards: 0,
initializing_shards: 0,
unassigned_shards: 1,
delayed_unassigned_shards: 0,
number_of_pending_tasks: 0,
number_of_in_flight_fetch: 0,
task_max_waiting_in_queue_millis: 0,
active_shards_percent_as_number: 50 }
```
继续之前,我们先删除最下面的 `checkConnection()` 调用,因为,我们最终的应用程序将调用外部的连接模块。
#### 3.1 - 添加函数去重置索引
在 `server/connection.js` 中的 `checkConnection` 下面添加如下的函数,以便于重置 Elasticsearch 索引。
```
/** Clear the index, recreate it, and add mappings */
async function resetIndex (index) {
if (await client.indices.exists({ index })) {
await client.indices.delete({ index })
}
await client.indices.create({ index })
await putBookMapping()
}
```
#### 3.2 - 添加图书模式
接下来,我们将为图书的数据模式添加一个 “映射”。在 `server/connection.js` 中的 `resetIndex` 函数下面添加如下的函数。
```
/** Add book section schema mapping to ES */
async function putBookMapping () {
const schema = {
title: { type: 'keyword' },
author: { type: 'keyword' },
location: { type: 'integer' },
text: { type: 'text' }
}
return client.indices.putMapping({ index, type, body: { properties: schema } })
}
```
这是为 `book` 索引定义了一个映射。Elasticsearch 中的 `index` 大概类似于 SQL 的 `table` 或者 MongoDB 的 `collection`。我们通过添加映射来为存储的文档指定每个字段和它的数据类型。Elasticsearch 是无模式的,因此,从技术角度来看,我们是不需要添加映射的,但是,这样做,我们可以更好地控制如何处理数据。
比如,我们给 `title` 和 `author` 字段分配 `keyword` 类型,给 `text` 字段分配 `text` 类型。之所以这样做的原因是,搜索引擎可以区别处理这些字符串字段 —— 在搜索的时候,搜索引擎将在 `text` 字段中搜索可能的匹配项,而对于 `keyword` 类型字段,将对它们进行全文匹配。这看上去差别很小,但是它们对在不同的搜索上的速度和行为的影响非常大。
在文件的底部,导出对外发布的属性和函数,这样我们的应用程序中的其它模块就可以访问它们了。
```
module.exports = {
client, index, type, checkConnection, resetIndex
}
```
### 4 - 加载原始数据
我们将使用来自 [古登堡项目](https://www.gutenberg.org/) 的数据 —— 它致力于为公共提供免费的线上电子书。在这个项目中,我们将使用 100 本经典图书来充实我们的图书馆,包括《福尔摩斯探案集》、《金银岛》、《基督山复仇记》、《环游世界八十天》、《罗密欧与朱丽叶》 和《奥德赛》。

#### 4.1 - 下载图书文件
我将这 100 本书打包成一个文件,你可以从这里下载它 —— <https://cdn.patricktriest.com/data/books.zip>
将这个文件解压到你的项目的 `books/` 目录中。
你可以使用以下的命令来完成(需要在命令行下使用 [wget](https://www.gnu.org/software/wget/) 和 [The Unarchiver](https://theunarchiver.com/command-line))。
```
wget https://cdn.patricktriest.com/data/books.zip
unar books.zip
```
#### 4.2 - 预览一本书
尝试打开其中的一本书的文件,假设打开的是 `219-0.txt`。你将注意到它开头是一个公开访问的协议,接下来是一些标识这本书的书名、作者、发行日期、语言和字符编码的行。
```
Title: Heart of Darkness
Author: Joseph Conrad
Release Date: February 1995 [EBook #219]
Last Updated: September 7, 2016
Language: English
Character set encoding: UTF-8
```
在 `*** START OF THIS PROJECT GUTENBERG EBOOK HEART OF DARKNESS ***` 这些行后面,是这本书的正式内容。
如果你滚动到本书的底部,你将看到类似 `*** END OF THIS PROJECT GUTENBERG EBOOK HEART OF DARKNESS ***` 信息,接下来是本书更详细的协议版本。
下一步,我们将使用程序从文件头部来解析书的元数据,提取 `*** START OF` 和 `***END OF` 之间的内容。
#### 4.3 - 读取数据目录
我们将写一个脚本来读取每本书的内容,并将这些数据添加到 Elasticsearch。我们将定义一个新的 Javascript 文件 `server/load_data.js` 来执行这些操作。
首先,我们将从 `books/` 目录中获取每个文件的列表。
在 `server/load_data.js` 中添加下列内容。
```
const fs = require('fs')
const path = require('path')
const esConnection = require('./connection')
/** Clear ES index, parse and index all files from the books directory */
async function readAndInsertBooks () {
try {
// Clear previous ES index
await esConnection.resetIndex()
// Read books directory
let files = fs.readdirSync('./books').filter(file => file.slice(-4) === '.txt')
console.log(`Found ${files.length} Files`)
// Read each book file, and index each paragraph in elasticsearch
for (let file of files) {
console.log(`Reading File - ${file}`)
const filePath = path.join('./books', file)
const { title, author, paragraphs } = parseBookFile(filePath)
await insertBookData(title, author, paragraphs)
}
} catch (err) {
console.error(err)
}
}
readAndInsertBooks()
```
我们将使用一个快捷命令来重构我们的 Node.js 应用程序,并更新运行的容器。
运行 `docker-compose up -d --build` 去更新应用程序。这是运行 `docker-compose build` 和 `docker-compose up -d` 的快捷命令。

为了在容器中运行我们的 `load_data` 脚本,我们运行 `docker exec gs-api "node" "server/load_data.js"` 。你将看到 Elasticsearch 的状态输出 `Found 100 Books`。
这之后,脚本发生了错误退出,原因是我们调用了一个没有定义的辅助函数(`parseBookFile`)。

#### 4.4 - 读取数据文件
接下来,我们读取元数据和每本书的内容。
在 `server/load_data.js` 中定义新函数。
```
/** Read an individual book text file, and extract the title, author, and paragraphs */
function parseBookFile (filePath) {
// Read text file
const book = fs.readFileSync(filePath, 'utf8')
// Find book title and author
const title = book.match(/^Title:\s(.+)$/m)[1]
const authorMatch = book.match(/^Author:\s(.+)$/m)
const author = (!authorMatch || authorMatch[1].trim() === '') ? 'Unknown Author' : authorMatch[1]
console.log(`Reading Book - ${title} By ${author}`)
// Find Guttenberg metadata header and footer
const startOfBookMatch = book.match(/^\*{3}\s*START OF (THIS|THE) PROJECT GUTENBERG EBOOK.+\*{3}$/m)
const startOfBookIndex = startOfBookMatch.index + startOfBookMatch[0].length
const endOfBookIndex = book.match(/^\*{3}\s*END OF (THIS|THE) PROJECT GUTENBERG EBOOK.+\*{3}$/m).index
// Clean book text and split into array of paragraphs
const paragraphs = book
.slice(startOfBookIndex, endOfBookIndex) // Remove Guttenberg header and footer
.split(/\n\s+\n/g) // Split each paragraph into it's own array entry
.map(line => line.replace(/\r\n/g, ' ').trim()) // Remove paragraph line breaks and whitespace
.map(line => line.replace(/_/g, '')) // Guttenberg uses "_" to signify italics. We'll remove it, since it makes the raw text look messy.
.filter((line) => (line && line.length !== '')) // Remove empty lines
console.log(`Parsed ${paragraphs.length} Paragraphs\n`)
return { title, author, paragraphs }
}
```
这个函数执行几个重要的任务。
1. 从文件系统中读取书的文本。
2. 使用正则表达式(关于正则表达式,请参阅 [这篇文章](https://blog.patricktriest.com/you-should-learn-regex/) )解析书名和作者。
3. 通过匹配 “古登堡项目” 的头部和尾部,识别书的正文内容。
4. 提取书的内容文本。
5. 分割每个段落到它的数组中。
6. 清理文本并删除空白行。
它的返回值,我们将构建一个对象,这个对象包含书名、作者、以及书中各段落的数组。
再次运行 `docker-compose up -d --build` 和 `docker exec gs-api "node" "server/load_data.js"`,你将看到输出同之前一样,在输出的末尾有三个额外的行。

成功!我们的脚本从文本文件中成功解析出了书名和作者。脚本再次以错误结束,因为到现在为止,我们还没有定义辅助函数。
#### 4.5 - 在 ES 中索引数据文件
最后一步,我们将批量上传每个段落的数组到 Elasticsearch 索引中。
在 `load_data.js` 中添加新的 `insertBookData` 函数。
```
/** Bulk index the book data in Elasticsearch */
async function insertBookData (title, author, paragraphs) {
let bulkOps = [] // Array to store bulk operations
// Add an index operation for each section in the book
for (let i = 0; i < paragraphs.length; i++) {
// Describe action
bulkOps.push({ index: { _index: esConnection.index, _type: esConnection.type } })
// Add document
bulkOps.push({
author,
title,
location: i,
text: paragraphs[i]
})
if (i > 0 && i % 500 === 0) { // Do bulk insert in 500 paragraph batches
await esConnection.client.bulk({ body: bulkOps })
bulkOps = []
console.log(`Indexed Paragraphs ${i - 499} - ${i}`)
}
}
// Insert remainder of bulk ops array
await esConnection.client.bulk({ body: bulkOps })
console.log(`Indexed Paragraphs ${paragraphs.length - (bulkOps.length / 2)} - ${paragraphs.length}\n\n\n`)
}
```
这个函数将使用书名、作者和附加元数据的段落位置来索引书中的每个段落。我们通过批量操作来插入段落,它比逐个段落插入要快的多。
>
> 我们分批索引段落,而不是一次性插入全部,是为运行这个应用程序的内存稍有点小(1.7 GB)的服务器 `search.patricktriest.com` 上做的一个重要优化。如果你的机器内存还行(4 GB 以上),你或许不用分批上传。
>
>
>
运行 `docker-compose up -d --build` 和 `docker exec gs-api "node" "server/load_data.js"` 一次或多次 —— 现在你将看到前面解析的 100 本书的完整输出,并插入到了 Elasticsearch。这可能需要几分钟时间,甚至更长。

### 5 - 搜索
现在,Elasticsearch 中已经有了 100 本书了(大约有 230000 个段落),现在我们尝试搜索查询。
#### 5.0 - 简单的 HTTP 查询
首先,我们使用 Elasticsearch 的 HTTP API 对它进行直接查询。
在你的浏览器上访问这个 URL - `http://localhost:9200/library/_search?q=text:Java&pretty`
在这里,我们将执行一个极简的全文搜索,在我们的图书馆的书中查找 “Java” 这个词。
你将看到类似于下面的一个 JSON 格式的响应。
```
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 13,
"max_score" : 14.259304,
"hits" : [
{
"_index" : "library",
"_type" : "novel",
"_id" : "p_GwFWEBaZvLlaAUdQgV",
"_score" : 14.259304,
"_source" : {
"author" : "Charles Darwin",
"title" : "On the Origin of Species",
"location" : 1080,
"text" : "Java, plants of, 375."
}
},
{
"_index" : "library",
"_type" : "novel",
"_id" : "wfKwFWEBaZvLlaAUkjfk",
"_score" : 10.186235,
"_source" : {
"author" : "Edgar Allan Poe",
"title" : "The Works of Edgar Allan Poe",
"location" : 827,
"text" : "After many years spent in foreign travel, I sailed in the year 18-- , from the port of Batavia, in the rich and populous island of Java, on a voyage to the Archipelago of the Sunda islands. I went as passenger--having no other inducement than a kind of nervous restlessness which haunted me as a fiend."
}
},
...
]
}
}
```
用 Elasticseach 的 HTTP 接口可以测试我们插入的数据是否成功,但是如果直接将这个 API 暴露给 Web 应用程序将有极大的风险。这个 API 将会暴露管理功能(比如直接添加和删除文档),最理想的情况是完全不要对外暴露它。而是写一个简单的 Node.js API 去接收来自客户端的请求,然后(在我们的本地网络中)生成一个正确的查询发送给 Elasticsearch。
#### 5.1 - 查询脚本
我们现在尝试从我们写的 Node.js 脚本中查询 Elasticsearch。
创建一个新文件,`server/search.js`。
```
const { client, index, type } = require('./connection')
module.exports = {
/** Query ES index for the provided term */
queryTerm (term, offset = 0) {
const body = {
from: offset,
query: { match: {
text: {
query: term,
operator: 'and',
fuzziness: 'auto'
} } },
highlight: { fields: { text: {} } }
}
return client.search({ index, type, body })
}
}
```
我们的搜索模块定义一个简单的 `search` 函数,它将使用输入的词 `match` 查询。
这是查询的字段分解 -
* `from` - 允许我们分页查询结果。默认每个查询返回 10 个结果,因此,指定 `from: 10` 将允许我们取回 10-20 的结果。
* `query` - 这里我们指定要查询的词。
* `operator` - 我们可以修改搜索行为;在本案例中,我们使用 `and` 操作去对查询中包含所有字元(要查询的词)的结果来确定优先顺序。
* `fuzziness` - 对拼写错误的容错调整,`auto` 的默认为 `fuzziness: 2`。模糊值越高,结果越需要更多校正。比如,`fuzziness: 1` 将允许以 `Patricc` 为关键字的查询中返回与 `Patrick` 匹配的结果。
* `highlights` - 为结果返回一个额外的字段,这个字段包含 HTML,以显示精确的文本字集和查询中匹配的关键词。
你可以去浏览 [Elastic Full-Text Query DSL](https://www.elastic.co/guide/en/elasticsearch/reference/current/full-text-queries.html),学习如何随意调整这些参数,以进一步自定义搜索查询。
### 6 - API
为了能够从前端应用程序中访问我们的搜索功能,我们来写一个快速的 HTTP API。
#### 6.0 - API 服务器
用以下的内容替换现有的 `server/app.js` 文件。
```
const Koa = require('koa')
const Router = require('koa-router')
const joi = require('joi')
const validate = require('koa-joi-validate')
const search = require('./search')
const app = new Koa()
const router = new Router()
// Log each request to the console
app.use(async (ctx, next) => {
const start = Date.now()
await next()
const ms = Date.now() - start
console.log(`${ctx.method} ${ctx.url} - ${ms}`)
})
// Log percolated errors to the console
app.on('error', err => {
console.error('Server Error', err)
})
// Set permissive CORS header
app.use(async (ctx, next) => {
ctx.set('Access-Control-Allow-Origin', '*')
return next()
})
// ADD ENDPOINTS HERE
const port = process.env.PORT || 3000
app
.use(router.routes())
.use(router.allowedMethods())
.listen(port, err => {
if (err) throw err
console.log(`App Listening on Port ${port}`)
})
```
这些代码将为 [Koa.js](http://koajs.com/) Node API 服务器导入服务器依赖,设置简单的日志,以及错误处理。
### 6.1 - 使用查询连接端点
接下来,我们将在服务器上添加一个端点,以便于发布我们的 Elasticsearch 查询功能。
在 `server/app.js` 文件的 `// ADD ENDPOINTS HERE` 下面插入下列的代码。
```
/**
* GET /search
* Search for a term in the library
*/
router.get('/search', async (ctx, next) => {
const { term, offset } = ctx.request.query
ctx.body = await search.queryTerm(term, offset)
}
)
```
使用 `docker-compose up -d --build` 重启动应用程序。之后在你的浏览器中尝试调用这个搜索端点。比如,`http://localhost:3000/search?term=java` 这个请求将搜索整个图书馆中提到 “Java” 的内容。
结果与前面直接调用 Elasticsearch HTTP 界面的结果非常类似。
```
{
"took": 242,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 93,
"max_score": 13.356944,
"hits": [{
"_index": "library",
"_type": "novel",
"_id": "eHYHJmEBpQg9B4622421",
"_score": 13.356944,
"_source": {
"author": "Charles Darwin",
"title": "On the Origin of Species",
"location": 1080,
"text": "Java, plants of, 375."
},
"highlight": {
"text": ["<em>Java</em>, plants of, 375."]
}
}, {
"_index": "library",
"_type": "novel",
"_id": "2HUHJmEBpQg9B462xdNg",
"_score": 9.030668,
"_source": {
"author": "Unknown Author",
"title": "The King James Bible",
"location": 186,
"text": "10:4 And the sons of Javan; Elishah, and Tarshish, Kittim, and Dodanim."
},
"highlight": {
"text": ["10:4 And the sons of <em>Javan</em>; Elishah, and Tarshish, Kittim, and Dodanim."]
}
}
...
]
}
}
```
### 6.2 - 输入校验
这个端点现在还很脆弱 —— 我们没有对请求参数做任何的校验,因此,如果是无效的或者错误的值将使服务器出错。
我们将添加一些使用 [Joi](https://github.com/hapijs/joi) 和 [Koa-Joi-Validate](https://github.com/triestpa/koa-joi-validate) 库的中间件,以对输入做校验。
```
/**
* GET /search
* Search for a term in the library
* Query Params -
* term: string under 60 characters
* offset: positive integer
*/
router.get('/search',
validate({
query: {
term: joi.string().max(60).required(),
offset: joi.number().integer().min(0).default(0)
}
}),
async (ctx, next) => {
const { term, offset } = ctx.request.query
ctx.body = await search.queryTerm(term, offset)
}
)
```
现在,重启服务器,如果你使用一个没有搜索关键字的请求(`http://localhost:3000/search`),你将返回一个带相关消息的 HTTP 400 错误,比如像 `Invalid URL Query - child "term" fails because ["term" is required]`。
如果想从 Node 应用程序中查看实时日志,你可以运行 `docker-compose logs -f api`。
### 7 - 前端应用程序
现在我们的 `/search` 端点已经就绪,我们来连接到一个简单的 Web 应用程序来测试这个 API。
#### 7.0 - Vue.js 应用程序
我们将使用 Vue.js 去协调我们的前端。
添加一个新文件 `/public/app.js`,去控制我们的 Vue.js 应用程序代码。
```
const vm = new Vue ({
el: '#vue-instance',
data () {
return {
baseUrl: 'http://localhost:3000', // API url
searchTerm: 'Hello World', // Default search term
searchDebounce: null, // Timeout for search bar debounce
searchResults: [], // Displayed search results
numHits: null, // Total search results found
searchOffset: 0, // Search result pagination offset
selectedParagraph: null, // Selected paragraph object
bookOffset: 0, // Offset for book paragraphs being displayed
paragraphs: [] // Paragraphs being displayed in book preview window
}
},
async created () {
this.searchResults = await this.search() // Search for default term
},
methods: {
/** Debounce search input by 100 ms */
onSearchInput () {
clearTimeout(this.searchDebounce)
this.searchDebounce = setTimeout(async () => {
this.searchOffset = 0
this.searchResults = await this.search()
}, 100)
},
/** Call API to search for inputted term */
async search () {
const response = await axios.get(`${this.baseUrl}/search`, { params: { term: this.searchTerm, offset: this.searchOffset } })
this.numHits = response.data.hits.total
return response.data.hits.hits
},
/** Get next page of search results */
async nextResultsPage () {
if (this.numHits > 10) {
this.searchOffset += 10
if (this.searchOffset + 10 > this.numHits) { this.searchOffset = this.numHits - 10}
this.searchResults = await this.search()
document.documentElement.scrollTop = 0
}
},
/** Get previous page of search results */
async prevResultsPage () {
this.searchOffset -= 10
if (this.searchOffset < 0) { this.searchOffset = 0 }
this.searchResults = await this.search()
document.documentElement.scrollTop = 0
}
}
})
```
这个应用程序非常简单 —— 我们只定义了一些共享的数据属性,以及添加了检索和分页搜索结果的方法。为防止每次按键一次都调用 API,搜索输入有一个 100 毫秒的除颤功能。
解释 Vue.js 是如何工作的已经超出了本教程的范围,如果你使用过 Angular 或者 React,其实一些也不可怕。如果你完全不熟悉 Vue,想快速了解它的功能,我建议你从官方的快速指南入手 —— <https://vuejs.org/v2/guide/>
#### 7.1 - HTML
使用以下的内容替换 `/public/index.html` 文件中的占位符,以便于加载我们的 Vue.js 应用程序和设计一个基本的搜索界面。
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Elastic Library</title>
<meta name="description" content="Literary Classic Search Engine.">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no">
<link href="https://cdnjs.cloudflare.com/ajax/libs/normalize/7.0.0/normalize.min.css" rel="stylesheet" type="text/css" />
<link href="https://cdn.muicss.com/mui-0.9.20/css/mui.min.css" rel="stylesheet" type="text/css" />
<link href="https://fonts.googleapis.com/css?family=EB+Garamond:400,700|Open+Sans" rel="stylesheet">
<link href="styles.css" rel="stylesheet" />
</head>
<body>
<div class="app-container" id="vue-instance">
<!-- Search Bar Header -->
<div class="mui-panel">
<div class="mui-textfield">
<input v-model="searchTerm" type="text" v-on:keyup="onSearchInput()">
<label>Search</label>
</div>
</div>
<!-- Search Metadata Card -->
<div class="mui-panel">
<div class="mui--text-headline">{{ numHits }} Hits</div>
<div class="mui--text-subhead">Displaying Results {{ searchOffset }} - {{ searchOffset + 9 }}</div>
</div>
<!-- Top Pagination Card -->
<div class="mui-panel pagination-panel">
<button class="mui-btn mui-btn--flat" v-on:click="prevResultsPage()">Prev Page</button>
<button class="mui-btn mui-btn--flat" v-on:click="nextResultsPage()">Next Page</button>
</div>
<!-- Search Results Card List -->
<div class="search-results" ref="searchResults">
<div class="mui-panel" v-for="hit in searchResults" v-on:click="showBookModal(hit)">
<div class="mui--text-title" v-html="hit.highlight.text[0]"></div>
<div class="mui-divider"></div>
<div class="mui--text-subhead">{{ hit._source.title }} - {{ hit._source.author }}</div>
<div class="mui--text-body2">Location {{ hit._source.location }}</div>
</div>
</div>
<!-- Bottom Pagination Card -->
<div class="mui-panel pagination-panel">
<button class="mui-btn mui-btn--flat" v-on:click="prevResultsPage()">Prev Page</button>
<button class="mui-btn mui-btn--flat" v-on:click="nextResultsPage()">Next Page</button>
</div>
<!-- INSERT BOOK MODAL HERE -->
</div>
<script src="https://cdn.muicss.com/mui-0.9.28/js/mui.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/vue/2.5.3/vue.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/axios/0.17.0/axios.min.js"></script>
<script src="app.js"></script>
</body>
</html>
```
#### 7.2 - CSS
添加一个新文件 `/public/styles.css`,使用一些自定义的 UI 样式。
```
body { font-family: 'EB Garamond', serif; }
.mui-textfield > input, .mui-btn, .mui--text-subhead, .mui-panel > .mui--text-headline {
font-family: 'Open Sans', sans-serif;
}
.all-caps { text-transform: uppercase; }
.app-container { padding: 16px; }
.search-results em { font-weight: bold; }
.book-modal > button { width: 100%; }
.search-results .mui-divider { margin: 14px 0; }
.search-results {
display: flex;
flex-direction: row;
flex-wrap: wrap;
justify-content: space-around;
}
.search-results > div {
flex-basis: 45%;
box-sizing: border-box;
cursor: pointer;
}
@media (max-width: 600px) {
.search-results > div { flex-basis: 100%; }
}
.paragraphs-container {
max-width: 800px;
margin: 0 auto;
margin-bottom: 48px;
}
.paragraphs-container .mui--text-body1, .paragraphs-container .mui--text-body2 {
font-size: 1.8rem;
line-height: 35px;
}
.book-modal {
width: 100%;
height: 100%;
padding: 40px 10%;
box-sizing: border-box;
margin: 0 auto;
background-color: white;
overflow-y: scroll;
position: fixed;
top: 0;
left: 0;
}
.pagination-panel {
display: flex;
justify-content: space-between;
}
.title-row {
display: flex;
justify-content: space-between;
align-items: flex-end;
}
@media (max-width: 600px) {
.title-row{
flex-direction: column;
text-align: center;
align-items: center
}
}
.locations-label {
text-align: center;
margin: 8px;
}
.modal-footer {
position: fixed;
bottom: 0;
left: 0;
width: 100%;
display: flex;
justify-content: space-around;
background: white;
}
```
#### 7.3 - 尝试输出
在你的浏览器中打开 `localhost:8080`,你将看到一个简单的带结果分页功能的搜索界面。在顶部的搜索框中尝试输入不同的关键字来查看它们的搜索情况。

>
> 你没有必要重新运行 `docker-compose up` 命令以使更改生效。本地的 `public` 目录是装载在我们的 Nginx 文件服务器容器中,因此,在本地系统中前端的变化将在容器化应用程序中自动反映出来。
>
>
>
如果你尝试点击任何搜索结果,什么反应也没有 —— 因为我们还没有为这个应用程序添加进一步的相关功能。
### 8 - 分页预览
如果能点击每个搜索结果,然后查看到来自书中的内容,那将是非常棒的体验。
### 8.0 - 添加 Elasticsearch 查询
首先,我们需要定义一个简单的查询去从给定的书中获取段落范围。
在 `server/search.js` 文件中添加如下的函数到 `module.exports` 块中。
```
/** Get the specified range of paragraphs from a book */
getParagraphs (bookTitle, startLocation, endLocation) {
const filter = [
{ term: { title: bookTitle } },
{ range: { location: { gte: startLocation, lte: endLocation } } }
]
const body = {
size: endLocation - startLocation,
sort: { location: 'asc' },
query: { bool: { filter } }
}
return client.search({ index, type, body })
}
```
这个新函数将返回给定的书的开始位置和结束位置之间的一个排序后的段落数组。
#### 8.1 - 添加 API 端点
现在,我们将这个函数链接到 API 端点。
添加下列内容到 `server/app.js` 文件中最初的 `/search` 端点下面。
```
/**
* GET /paragraphs
* Get a range of paragraphs from the specified book
* Query Params -
* bookTitle: string under 256 characters
* start: positive integer
* end: positive integer greater than start
*/
router.get('/paragraphs',
validate({
query: {
bookTitle: joi.string().max(256).required(),
start: joi.number().integer().min(0).default(0),
end: joi.number().integer().greater(joi.ref('start')).default(10)
}
}),
async (ctx, next) => {
const { bookTitle, start, end } = ctx.request.query
ctx.body = await search.getParagraphs(bookTitle, start, end)
}
)
```
#### 8.2 - 添加 UI 功能
现在,我们的新端点已经就绪,我们为应用程序添加一些从书中查询和显示全部页面的前端功能。
在 `/public/app.js` 文件的 `methods` 块中添加如下的函数。
```
/** Call the API to get current page of paragraphs */
async getParagraphs (bookTitle, offset) {
try {
this.bookOffset = offset
const start = this.bookOffset
const end = this.bookOffset + 10
const response = await axios.get(`${this.baseUrl}/paragraphs`, { params: { bookTitle, start, end } })
return response.data.hits.hits
} catch (err) {
console.error(err)
}
},
/** Get next page (next 10 paragraphs) of selected book */
async nextBookPage () {
this.$refs.bookModal.scrollTop = 0
this.paragraphs = await this.getParagraphs(this.selectedParagraph._source.title, this.bookOffset + 10)
},
/** Get previous page (previous 10 paragraphs) of selected book */
async prevBookPage () {
this.$refs.bookModal.scrollTop = 0
this.paragraphs = await this.getParagraphs(this.selectedParagraph._source.title, this.bookOffset - 10)
},
/** Display paragraphs from selected book in modal window */
async showBookModal (searchHit) {
try {
document.body.style.overflow = 'hidden'
this.selectedParagraph = searchHit
this.paragraphs = await this.getParagraphs(searchHit._source.title, searchHit._source.location - 5)
} catch (err) {
console.error(err)
}
},
/** Close the book detail modal */
closeBookModal () {
document.body.style.overflow = 'auto'
this.selectedParagraph = null
}
```
这五个函数提供了通过页码从书中下载和分页(每次十个段落)的逻辑。
现在,我们需要添加一个 UI 去显示书的页面。在 `/public/index.html` 的 `<!-- INSERT BOOK MODAL HERE -->` 注释下面添加如下的内容。
```
<!-- Book Paragraphs Modal Window -->
<div v-if="selectedParagraph" ref="bookModal" class="book-modal">
<div class="paragraphs-container">
<!-- Book Section Metadata -->
<div class="title-row">
<div class="mui--text-display2 all-caps">{{ selectedParagraph._source.title }}</div>
<div class="mui--text-display1">{{ selectedParagraph._source.author }}</div>
</div>
<br>
<div class="mui-divider"></div>
<div class="mui--text-subhead locations-label">Locations {{ bookOffset - 5 }} to {{ bookOffset + 5 }}</div>
<div class="mui-divider"></div>
<br>
<!-- Book Paragraphs -->
<div v-for="paragraph in paragraphs">
<div v-if="paragraph._source.location === selectedParagraph._source.location" class="mui--text-body2">
<strong>{{ paragraph._source.text }}</strong>
</div>
<div v-else class="mui--text-body1">
{{ paragraph._source.text }}
</div>
<br>
</div>
</div>
<!-- Book Pagination Footer -->
<div class="modal-footer">
<button class="mui-btn mui-btn--flat" v-on:click="prevBookPage()">Prev Page</button>
<button class="mui-btn mui-btn--flat" v-on:click="closeBookModal()">Close</button>
<button class="mui-btn mui-btn--flat" v-on:click="nextBookPage()">Next Page</button>
</div>
</div>
```
再次重启应用程序服务器(`docker-compose up -d --build`),然后打开 `localhost:8080`。当你再次点击搜索结果时,你将能看到关键字附近的段落。如果你感兴趣,你现在甚至可以看这本书的剩余部分。

祝贺你!你现在已经完成了本教程的应用程序。
你可以去比较你的本地结果与托管在这里的完整示例 —— <https://search.patricktriest.com/>。
### 9 - Elasticsearch 的缺点
#### 9.0 - 耗费资源
Elasticsearch 是计算密集型的。[官方建议](https://www.elastic.co/guide/en/elasticsearch/guide/current/hardware.html) 运行 ES 的机器最好有 64 GB 的内存,强烈反对在低于 8 GB 内存的机器上运行它。Elasticsearch 是一个 *内存中* 数据库,这样使它的查询速度非常快,但这也非常占用系统内存。在生产系统中使用时,[他们强烈建议在一个集群中运行多个 Elasticsearch 节点](https://www.elastic.co/guide/en/elasticsearch/guide/2.x/distributed-cluster.html),以实现高可用、自动分区和一个节点失败时的数据冗余。
我们的这个教程中的应用程序运行在一个 $15/月 的 GCP 计算实例中( [search.patricktriest.com](https://search.patricktriest.com/)),它只有 1.7 GB 的内存,它勉强能运行这个 Elasticsearch 节点;有时候在进行初始的数据加载过程中,整个机器就 ”假死机“ 了。在我的经验中,Elasticsearch 比传统的那些数据库,比如,PostgreSQL 和 MongoDB 耗费的资源要多很多,这样会使托管主机的成本增加很多。
### 9.1 - 与数据库的同步
对于大多数应用程序,将数据全部保存在 Elasticsearch 并不是个好的选择。可以使用 ES 作为应用程序的主要事务数据库,但是一般不推荐这样做,因为在 Elasticsearch 中缺少 ACID,如果大量读取数据的时候,它能导致写操作丢失。在许多案例中,ES 服务器更多是一个特定的角色,比如做应用程序中的一个文本搜索功能。这种特定的用途,要求它从主数据库中复制数据到 Elasticsearch 实例中。
比如,假设我们将用户信息保存在一个 PostgreSQL 表中,但是用 Elasticsearch 去提供我们的用户搜索功能。如果一个用户,比如,“Albert”,决定将他的名字改成 “Al”,我们将需要把这个变化同时反映到我们主要的 PostgreSQL 数据库和辅助的 Elasticsearch 集群中。
正确地集成它们可能比较棘手,最好的答案将取决于你现有的应用程序栈。这有多种开源方案可选,从 [用一个进程去关注 MongoDB 操作日志](https://github.com/mongodb-labs/mongo-connector) 并自动同步检测到的变化到 ES,到使用一个 [PostgresSQL 插件](https://github.com/zombodb/zombodb) 去创建一个定制的、基于 PSQL 的索引来与 Elasticsearch 进行自动沟通。
如果没有有效的预构建选项可用,你可能需要在你的服务器代码中增加一些钩子,这样可以基于数据库的变化来手动更新 Elasticsearch 索引。最后一招,我认为是一个最后的选择,因为,使用定制的业务逻辑去保持 ES 的同步可能很复杂,这将会给应用程序引入很多的 bug。
让 Elasticsearch 与一个主数据库同步,将使它的架构更加复杂,其复杂性已经超越了 ES 的相关缺点,但是当在你的应用程序中考虑添加一个专用的搜索引擎的利弊得失时,这个问题是值的好好考虑的。
### 总结
在很多现在流行的应用程序中,全文搜索是一个非常重要的功能 —— 而且是很难实现的一个功能。对于在你的应用程序中添加一个快速而又可定制的文本搜索,Elasticsearch 是一个非常好的选择,但是,在这里也有一个替代者。[Apache Solr](https://lucene.apache.org/solr/) 是一个类似的开源搜索平台,它是基于 Apache Lucene 构建的,与 Elasticsearch 的核心库是相同的。[Algolia](https://www.algolia.com/) 是一个搜索即服务的 Web 平台,它已经很快流行了起来,并且它对新手非常友好,很易于上手(但是作为折衷,它的可定制性较小,并且使用成本较高)。
“搜索” 特性并不是 Elasticsearch 唯一功能。ES 也是日志存储和分析的常用工具,在一个 ELK(Elasticsearch、Logstash、Kibana)架构配置中通常会使用它。灵活的全文搜索功能使得 Elasticsearch 在数据量非常大的科学任务中用处很大 —— 比如,在一个数据集中正确的/标准化的条目拼写,或者为了类似的词组搜索一个文本数据集。
对于你自己的项目,这里有一些创意。
* 添加更多你喜欢的书到教程的应用程序中,然后创建你自己的私人图书馆搜索引擎。
* 利用来自 [Google Scholar](https://scholar.google.com/) 的论文索引,创建一个学术抄袭检测引擎。
* 通过将字典中的每个词索引到 Elasticsearch,创建一个拼写检查应用程序。
* 通过将 [Common Crawl Corpus](https://aws.amazon.com/public-datasets/common-crawl/) 加载到 Elasticsearch 中,构建你自己的与谷歌竞争的因特网搜索引擎(注意,它可能会超过 50 亿个页面,这是一个成本极高的数据集)。
* 在 journalism 上使用 Elasticsearch:在最近的大规模泄露的文档中搜索特定的名字和关键词,比如, [Panama Papers](https://en.wikipedia.org/wiki/Panama_Papers) 和 [Paradise Papers](https://en.wikipedia.org/wiki/Paradise_Papers)。
本教程中应用程序的源代码是 100% 公开的,你可以在 GitHub 仓库上找到它们 —— <https://github.com/triestpa/guttenberg-search>
我希望你喜欢这个教程!你可以在下面的评论区,发表任何你的想法、问题、或者评论。
---
作者简介:
全栈工程师,数据爱好者,学霸,“构建强迫症患者”,探险爱好者。
---
via: <https://blog.patricktriest.com/text-search-docker-elasticsearch/>
作者:[Patrick Triest](https://blog.patricktriest.com/author/patrick/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *How does Wikipedia sort though 5+ million articles to find the most relevant one for your research?*
*How does Facebook find the friend who you're looking for (and whose name you've misspelled), across a userbase of 2+ billion people?*
*How does Google search the entire internet for webpages relevant to your vague, typo-filled search query?*
In this tutorial, we'll walk through setting up our own full-text search application (of an admittedly lesser complexity than the systems in the questions above). Our example app will provide a UI and API to search the complete texts of 100 literary classics such as *Peter Pan*, *Frankenstein*, and *Treasure Island*.
You can preview a completed version of the tutorial app here - [https://search.patricktriest.com](https://search.patricktriest.com)
The source code for the application is 100% open-source and can be found at the GitHub repository here - [https://github.com/triestpa/guttenberg-search](https://github.com/triestpa/guttenberg-search)
Adding fast, flexible full-text search to apps can be a challenge. Most mainstream databases, such as [PostgreSQL](https://www.postgresql.org/) and [MongoDB](https://www.mongodb.com/), offer very basic text searching capabilities due to limitations on their existing query and index structures. In order to implement high quality full-text search, a separate datastore is often the best option. [Elasticsearch](https://www.elastic.co/) is a leading open-source datastore that is optimized to perform incredibly flexible and fast full-text search.
We'll be using [Docker](https://www.docker.com/) to setup our project environment and dependencies. Docker is a containerization engine used by the likes of [Uber](https://www.uber.com/), [Spotify](https://www.spotify.com/us/), [ADP](https://www.adp.com/), and [Paypal](https://www.paypal.com/us/home). A major advantage of building a containerized app is that the project setup is virtually the same on Windows, macOS, and Linux - which makes writing this tutorial quite a bit simpler for me. Don't worry if you've never used Docker, we'll go through the full project configuration further down.
We'll also be using [Node.js](https://nodejs.org/en/) (with the [Koa](http://koajs.com/) framework), and [Vue.js](https://vuejs.org/) to build our search API and frontend web app respectively.
## 1 - What is Elasticsearch?
Full-text search is a heavily requested feature in modern applications. Search can also be one of the most difficult features to implement competently - many popular websites have subpar search functionality that returns results slowly and has trouble finding non-exact matches. Often, this is due to limitations in the underlying database: most standard relational databases are limited to basic `CONTAINS`
or `LIKE`
SQL queries, which provide only the most basic string matching functionality.
We'd like our search app to be :
**Fast**- Search results should be returned almost instantly, in order to provide a responsive user experience.**Flexible**- We'll want to be able to modify how the search is performed, in order to optimize for different datasets and use cases.**Forgiving**- If a search contains a typo, we'd still like to return relevant results for what the user might have been trying to search for.**Full-Text**- We don't want to limit our search to specific matching keywords or tags - we want to search*everything*in our datastore (including large text fields) for a match.
In order to build a super-powered search feature, it’s often most ideal to use a datastore that is optimized for the task of full-text search. This is where [Elasticsearch](https://www.elastic.co/) comes into play; Elasticsearch is an open-source in-memory datastore written in Java and originally built on the [Apache Lucene](https://lucene.apache.org/core/) library.
Here are some examples of real-world Elasticsearch use cases from the official [Elastic website](https://www.elastic.co/guide/en/elasticsearch/guide/2.x/getting-started.html).
- Wikipedia uses Elasticsearch to provide full-text search with highlighted search snippets, and search-as-you-type and did-you-mean suggestions.
- The Guardian uses Elasticsearch to combine visitor logs with social -network data to provide real-time feedback to its editors about the public’s response to new articles.
- Stack Overflow combines full-text search with geolocation queries and uses more-like-this to find related questions and answers.
- GitHub uses Elasticsearch to query 130 billion lines of code.
### What makes Elasticsearch different from a "normal" database?
At its core, Elasticsearch is able to provide fast and flexible full-text search through the use of *inverted indices*.
An "index" is a data structure to allow for ultra-fast data query and retrieval operations in databases. Databases generally index entries by storing an association of fields with the matching table rows. By storing the index in a searchable data structure (often a [B-Tree](https://en.wikipedia.org/wiki/B-tree)), databases can achieve sub-linear time on optimized queries (such as “Find the row with ID = 5”).
We can think of a database index like an old-school library card catalog - it tells you precisely where the entry that you're searching for is located, as long as you already know the title and author of the book. Database tables generally have multiple indices in order to speed up queries on specific fields (i.e. an index on the `name`
column would greatly speed up queries for rows with a specific name).
Inverted indexes work in a substantially different manner. The content of each row (or document) is split up, and each individual entry (in this case each word) points back to any documents that it was found within.
This inverted-index data structure allows us to very quickly find, say, all of the documents where “football” was mentioned. Through the use of a heavily optimized in-memory inverted index, Elasticsearch enables us to perform some very powerful and customizable full-text searches on our stored data.
## 2 - Project Setup
### 2.0 - Docker
We'll be using [Docker](https://www.docker.com/) to manage the environments and dependencies for this project. Docker is a containerization engine that allows applications to be run in isolated environments, unaffected by the host operating system and local development environment. Many web-scale companies run a majority of their server infrastructure in containers now, due to the increased flexibility and composability of containerized application components.
The advantage of using Docker for me, as the friendly author of this tutorial, is that the local environment setup is minimal and consistent across Windows, macOS, and Linux systems. Instead of going through divergent installation instructions for Node.js, Elasticsearch, and Nginx, we can instead just define these dependencies in Docker configuration files, and then run our app anywhere using this configuration. Furthermore, since each application component will run in it's own isolated container, there is much less potential for existing junk on our local machines to interfere, so "But it works on my machine!" types of scenarios will be much more rare when debugging issues.
### 2.1 - Install Docker & Docker-Compose
The only dependencies for this project are [Docker](https://www.docker.com/) and [docker-compose](https://docs.docker.com/compose/), the later of which is an officially supported tool for defining multiple container configurations to *compose* into a single application stack.
Install Docker - [https://docs.docker.com/engine/installation/](https://docs.docker.com/engine/installation/)
Install Docker Compose - [https://docs.docker.com/compose/install/](https://docs.docker.com/compose/install/)
### 2.2 - Setup Project Directories
Create a base directory (say `guttenberg_search`
) for the project. To organize our project we'll work within two main subdirectories.
`/public`
- Store files for the frontend Vue.js webapp.`/server`
- Server-side Node.js source code
### 2.3 - Add Docker-Compose Config
Next, we'll create a `docker-compose.yml`
file to define each container in our application stack.
`gs-api`
- The Node.js container for the backend application logic.`gs-frontend`
- An Ngnix container for serving the frontend webapp files.`gs-search`
- An Elasticsearch container for storing and searching data.
```
version: '3'
services:
api: # Node.js App
container_name: gs-api
build: .
ports:
- "3000:3000" # Expose API port
- "9229:9229" # Expose Node process debug port (disable in production)
environment: # Set ENV vars
- NODE_ENV=local
- ES_HOST=elasticsearch
- PORT=3000
volumes: # Attach local book data directory
- ./books:/usr/src/app/books
frontend: # Nginx Server For Frontend App
container_name: gs-frontend
image: nginx
volumes: # Serve local "public" dir
- ./public:/usr/share/nginx/html
ports:
- "8080:80" # Forward site to localhost:8080
elasticsearch: # Elasticsearch Instance
container_name: gs-search
image: docker.elastic.co/elasticsearch/elasticsearch:6.1.1
volumes: # Persist ES data in seperate "esdata" volume
- esdata:/usr/share/elasticsearch/data
environment:
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.type=single-node
ports: # Expose Elasticsearch ports
- "9300:9300"
- "9200:9200"
volumes: # Define seperate volume for Elasticsearch data
esdata:
```
This file defines our entire application stack - no need to install Elasticsearch, Node, or Nginx on your local system. Each container is forwarding ports to the host system (`localhost`
), in order for us to access and debug the Node API, Elasticsearch instance, and fronted web app from our host machine.
### 2.4 - Add Dockerfile
We are using official prebuilt images for Nginx and Elasticsearch, but we'll need to build our own image for the Node.js app.
Define a simple `Dockerfile`
configuration in the application root directory.
```
# Use Node v8.9.0 LTS
FROM node:carbon
# Setup app working directory
WORKDIR /usr/src/app
# Copy package.json and package-lock.json
COPY package*.json ./
# Install app dependencies
RUN npm install
# Copy sourcecode
COPY . .
# Start app
CMD [ "npm", "start" ]
```
This Docker configuration extends the official Node.js image, copies our application source code, and installs the NPM dependencies within the container.
We'll also add a `.dockerignore`
file to avoid copying unneeded files into the container.
```
node_modules/
npm-debug.log
books/
public/
```
Note that we're not copying the
`node_modules`
directory into our container - this is because we'll be running`npm install`
from within the container build process. Attempting to copy the`node_modules`
from the host system into a container can cause errors since some packages need to be specifically built for certain operating systems. For instance, installing the`bcrypt`
package on macOS and attempting to copy that module directly to an Ubuntu container will not work because`bcyrpt`
relies on a binary that needs to be built specifically for each operating system.
### 2.5 - Add Base Files
In order to test out the configuration, we'll need to add some placeholder files to the app directories.
Add this base HTML file at `public/index.html`
```
<html><body>Hello World From The Frontend Container</body></html>
```
Next, add the placeholder Node.js app file at `server/app.js`
.
```
const Koa = require('koa')
const app = new Koa()
app.use(async (ctx, next) => {
ctx.body = 'Hello World From the Backend Container'
})
const port = process.env.PORT || 3000
app.listen(port, err => {
if (err) console.error(err)
console.log(`App Listening on Port ${port}`)
})
```
Finally, add our `package.json`
Node app configuration.
```
{
"name": "guttenberg-search",
"version": "0.0.1",
"description": "Source code for Elasticsearch tutorial using 100 classic open source books.",
"scripts": {
"start": "node --inspect=0.0.0.0:9229 server/app.js"
},
"repository": {
"type": "git",
"url": "git+https://github.com/triestpa/guttenberg-search.git"
},
"author": "
```[[email protected]](/cdn-cgi/l/email-protection)",
"license": "MIT",
"bugs": {
"url": "https://github.com/triestpa/guttenberg-search/issues"
},
"homepage": "https://github.com/triestpa/guttenberg-search#readme",
"dependencies": {
"elasticsearch": "13.3.1",
"joi": "13.0.1",
"koa": "2.4.1",
"koa-joi-validate": "0.5.1",
"koa-router": "7.2.1"
}
}
This file defines the application start command and the Node.js package dependencies.
Note - You don't have to run
`npm install`
- the dependencies will be installed inside the container when it is built.
### 2.6 - Try it Out
Everything is in place now to test out each component of the app. From the base directory, run `docker-compose build`
, which will build our Node.js application container.
Next, run `docker-compose up`
to launch our entire application stack.
This step might take a few minutes since Docker has to download the base images for each container. In subsequent runs, starting the app should be nearly instantaneous, since the required images will have already been downloaded.
Try visiting `localhost:8080`
in your browser - you should see a simple "Hello World" webpage.
Visit `localhost:3000`
to verify that our Node server returns it's own "Hello World" message.
Finally, visit `localhost:9200`
to check that Elasticsearch is running. It should return information similar to this.
```
{
"name" : "SLTcfpI",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "iId8e0ZeS_mgh9ALlWQ7-w",
"version" : {
"number" : "6.1.1",
"build_hash" : "bd92e7f",
"build_date" : "2017-12-17T20:23:25.338Z",
"build_snapshot" : false,
"lucene_version" : "7.1.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
```
If all three URLs display data successfully, congrats! The entire containerized stack is running, so now we can move on to the fun part.
## 3 - Connect To Elasticsearch
The first thing that we'll need to do in our app is connect to our local Elasticsearch instance.
### 3.0 - Add ES Connection Module
Add the following Elasticsearch initialization code to a new file `server/connection.js`
.
```
const elasticsearch = require('elasticsearch')
// Core ES variables for this project
const index = 'library'
const type = 'novel'
const port = 9200
const host = process.env.ES_HOST || 'localhost'
const client = new elasticsearch.Client({ host: { host, port } })
/** Check the ES connection status */
async function checkConnection () {
let isConnected = false
while (!isConnected) {
console.log('Connecting to ES')
try {
const health = await client.cluster.health({})
console.log(health)
isConnected = true
} catch (err) {
console.log('Connection Failed, Retrying...', err)
}
}
}
checkConnection()
```
Let's rebuild our Node app now that we've made changes, using `docker-compose build`
. Next, run `docker-compose up -d`
to start the application stack as a background daemon process.
With the app started, run `docker exec gs-api "node" "server/connection.js"`
on the command line in order to run our script within the container. You should see some system output similar to the following.
```
{ cluster_name: 'docker-cluster',
status: 'yellow',
timed_out: false,
number_of_nodes: 1,
number_of_data_nodes: 1,
active_primary_shards: 1,
active_shards: 1,
relocating_shards: 0,
initializing_shards: 0,
unassigned_shards: 1,
delayed_unassigned_shards: 0,
number_of_pending_tasks: 0,
number_of_in_flight_fetch: 0,
task_max_waiting_in_queue_millis: 0,
active_shards_percent_as_number: 50 }
```
Go ahead and remove the `checkConnection()`
call at the bottom before moving on, since in our final app we'll be making that call from outside the connection module.
### 3.1 - Add Helper Function To Reset Index
In `server/connection.js`
add the following function below `checkConnection`
, in order to provide an easy way to reset our Elasticsearch index.
```
/** Clear the index, recreate it, and add mappings */
async function resetIndex () {
if (await client.indices.exists({ index })) {
await client.indices.delete({ index })
}
await client.indices.create({ index })
await putBookMapping()
}
```
### 3.2 - Add Book Schema
Next, we'll want to add a "mapping" for the book data schema. Add the following function below `resetIndex`
in `server/connection.js`
.
```
/** Add book section schema mapping to ES */
async function putBookMapping () {
const schema = {
title: { type: 'keyword' },
author: { type: 'keyword' },
location: { type: 'integer' },
text: { type: 'text' }
}
return client.indices.putMapping({ index, type, body: { properties: schema } })
}
```
Here we are defining a mapping for the `book`
index. An Elasticsearch `index`
is roughly analogous to a SQL `table`
or a MongoDB `collection`
. Adding a mapping allows us to specify each field and datatype for the stored documents. Elasticsearch is schema-less, so we don't technically need to add a mapping, but doing so will give us more control over how the data is handled.
For instance - we're assigning the `keyword`
type to the "title" and "author" fields, and the `text`
type to the "text" field. Doing so will cause the search engine to treat these string fields differently - During a search, the engine will search *within* the `text`
field for potential matches, whereas `keyword`
fields will be matched based on their full content. This might seem like a minor distinction, but it can have a huge impact on the behavior and speed of different searches.
Export the exposed properties and functions at the bottom of the file, so that they can be accessed by other modules in our app.
```
module.exports = {
client, index, type, checkConnection, resetIndex
}
```
## 4 - Load The Raw Data
We'll be using data from [Project Gutenberg](http://www.gutenberg.org/) - an online effort dedicated to providing free, digital copies of books within the public domain. For this project, we'll be populating our library with 100 classic books, including texts such as *The Adventures of Sherlock Holmes*, *Treasure Island*, *The Count of Monte Cristo*, *Around the World in 80 Days*, *Romeo and Juliet*, and *The Odyssey*.
### 4.1 - Download Book Files
I've zipped the 100 books into a file that you can download here -
[https://cdn.patricktriest.com/data/books.zip](https://cdn.patricktriest.com/data/books.zip)
Extract this file into a `books/`
directory in your project.
If you want, you can do this by using the following commands (requires [wget](https://www.gnu.org/software/wget/) and ["The Unarchiver" CLI](https://theunarchiver.com/command-line)).
```
wget https://cdn.patricktriest.com/data/books.zip
unar books.zip
```
### 4.2 - Preview A Book
Try opening one of the book files, say `219-0.txt`
. You'll notice that it starts with an open access license, followed by some lines identifying the book title, author, release dates, language and character encoding.
```
Title: Heart of Darkness
Author: Joseph Conrad
Release Date: February 1995 [EBook #219]
Last Updated: September 7, 2016
Language: English
Character set encoding: UTF-8
```
After these lines comes `*** START OF THIS PROJECT GUTENBERG EBOOK HEART OF DARKNESS ***`
, after which the book content actually starts.
If you scroll to the end of the book you'll see the matching message `*** END OF THIS PROJECT GUTENBERG EBOOK HEART OF DARKNESS ***`
, which is followed by a much more detailed version of the book's license.
In the next steps, we'll programmatically parse the book metadata from this header and extract the book content from between the `*** START OF`
and `***END OF`
place markers.
### 4.3 - Read Data Dir
Let's write a script to read the content of each book and to add that data to Elasticsearch. We'll define a new Javascript file `server/load_data.js`
in order to perform these operations.
First, we'll obtain a list of every file within the `books/`
data directory.
Add the following content to `server/load_data.js`
.
```
const fs = require('fs')
const path = require('path')
const esConnection = require('./connection')
/** Clear ES index, parse and index all files from the books directory */
async function readAndInsertBooks () {
try {
// Clear previous ES index
await esConnection.resetIndex()
// Read books directory
let files = fs.readdirSync('./books').filter(file => file.slice(-4) === '.txt')
console.log(`Found ${files.length} Files`)
// Read each book file, and index each paragraph in elasticsearch
for (let file of files) {
console.log(`Reading File - ${file}`)
const filePath = path.join('./books', file)
const { title, author, paragraphs } = parseBookFile(filePath)
await insertBookData(title, author, paragraphs)
}
} catch (err) {
console.error(err)
}
}
readAndInsertBooks()
```
We'll use a shortcut command to rebuild our Node.js app and update the running container.
Run `docker-compose up -d --build`
to update the application. This is a shortcut for running `docker-compose build`
and `docker-compose up -d`
.
Run`docker exec gs-api "node" "server/load_data.js"`
in order to run our `load_data`
script within the container. You should see the Elasticsearch status output, followed by `Found 100 Books`
.
After this, the script will exit due to an error because we're calling a helper function (`parseBookFile`
) that we have not yet defined.
### 4.4 - Read Data File
Next, we'll read the metadata and content for each book.
Define a new function in `server/load_data.js`
.
```
/** Read an individual book text file, and extract the title, author, and paragraphs */
function parseBookFile (filePath) {
// Read text file
const book = fs.readFileSync(filePath, 'utf8')
// Find book title and author
const title = book.match(/^Title:\s(.+)$/m)[1]
const authorMatch = book.match(/^Author:\s(.+)$/m)
const author = (!authorMatch || authorMatch[1].trim() === '') ? 'Unknown Author' : authorMatch[1]
console.log(`Reading Book - ${title} By ${author}`)
// Find Guttenberg metadata header and footer
const startOfBookMatch = book.match(/^\*{3}\s*START OF (THIS|THE) PROJECT GUTENBERG EBOOK.+\*{3}$/m)
const startOfBookIndex = startOfBookMatch.index + startOfBookMatch[0].length
const endOfBookIndex = book.match(/^\*{3}\s*END OF (THIS|THE) PROJECT GUTENBERG EBOOK.+\*{3}$/m).index
// Clean book text and split into array of paragraphs
const paragraphs = book
.slice(startOfBookIndex, endOfBookIndex) // Remove Guttenberg header and footer
.split(/\n\s+\n/g) // Split each paragraph into it's own array entry
.map(line => line.replace(/\r\n/g, ' ').trim()) // Remove paragraph line breaks and whitespace
.map(line => line.replace(/_/g, '')) // Guttenberg uses "_" to signify italics. We'll remove it, since it makes the raw text look messy.
.filter((line) => (line && line !== '')) // Remove empty lines
console.log(`Parsed ${paragraphs.length} Paragraphs\n`)
return { title, author, paragraphs }
}
```
This function performs a few important tasks.
- Read book text from the file system.
- Use regular expressions (check out
[this post](https://blog.patricktriest.com/you-should-learn-regex/)for a primer on using regex) to parse the book title and author. - Identify the start and end of the book content, by matching on the all-caps "Project Guttenberg" header and footer.
- Extract the book text content.
- Split each paragraph into its own array.
- Clean up the text and remove blank lines.
As a return value, we'll form an object containing the book's title, author, and an array of paragraphs within the book.
Run `docker-compose up -d --build`
and `docker exec gs-api "node" "server/load_data.js"`
again, and you should see the same output as before, this time with three extra lines at the end of the output.
Success! Our script successfully parsed the title and author from the text file. The script will again end with an error since we still have to define one more helper function.
### 4.5 - Index Datafile in ES
As a final step, we'll bulk-upload each array of paragraphs into the Elasticsearch index.
Add a new `insertBookData`
function to `load_data.js`
.
```
/** Bulk index the book data in Elasticsearch */
async function insertBookData (title, author, paragraphs) {
let bulkOps = [] // Array to store bulk operations
// Add an index operation for each section in the book
for (let i = 0; i < paragraphs.length; i++) {
// Describe action
bulkOps.push({ index: { _index: esConnection.index, _type: esConnection.type } })
// Add document
bulkOps.push({
author,
title,
location: i,
text: paragraphs[i]
})
if (i > 0 && i % 500 === 0) { // Do bulk insert in 500 paragraph batches
await esConnection.client.bulk({ body: bulkOps })
bulkOps = []
console.log(`Indexed Paragraphs ${i - 499} - ${i}`)
}
}
// Insert remainder of bulk ops array
await esConnection.client.bulk({ body: bulkOps })
console.log(`Indexed Paragraphs ${paragraphs.length - (bulkOps.length / 2)} - ${paragraphs.length}\n\n\n`)
}
```
This function will index each paragraph of the book, with author, title, and paragraph location metadata attached. We are inserting the paragraphs using a bulk operation, which is much faster than indexing each paragraph individually.
We're bulk indexing the paragraphs in batches, instead of inserting all of them at once. This was a last minute optimization which I added in order for the app to run on the low-ish memory (1.7 GB) host machine that serves
`search.patricktriest.com`
. If you have a reasonable amount of RAM (4+ GB), you probably don't need to worry about batching each bulk upload,
Run `docker-compose up -d --build`
and `docker exec gs-api "node" "server/load_data.js"`
one more time - you should now see a full output of 100 books being parsed and inserted in Elasticsearch. This might take a minute or so.
## 5 - Search
Now that Elasticsearch has been populated with one hundred books (amounting to roughly 230,000 paragraphs), let's try out some search queries.
### 5.0 - Simple HTTP Query
First, let's just query Elasticsearch directly using it's HTTP API.
Visit this URL in your browser - `http://localhost:9200/library/_search?q=text:Java&pretty`
Here, we are performing a bare-bones full-text search to find the word "Java" within our library of books.
You should see a JSON response similar to the following.
```
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 13,
"max_score" : 14.259304,
"hits" : [
{
"_index" : "library",
"_type" : "novel",
"_id" : "p_GwFWEBaZvLlaAUdQgV",
"_score" : 14.259304,
"_source" : {
"author" : "Charles Darwin",
"title" : "On the Origin of Species",
"location" : 1080,
"text" : "Java, plants of, 375."
}
},
{
"_index" : "library",
"_type" : "novel",
"_id" : "wfKwFWEBaZvLlaAUkjfk",
"_score" : 10.186235,
"_source" : {
"author" : "Edgar Allan Poe",
"title" : "The Works of Edgar Allan Poe",
"location" : 827,
"text" : "After many years spent in foreign travel, I sailed in the year 18-- , from the port of Batavia, in the rich and populous island of Java, on a voyage to the Archipelago of the Sunda islands. I went as passenger--having no other inducement than a kind of nervous restlessness which haunted me as a fiend."
}
},
...
]
}
}
```
The Elasticseach HTTP interface is useful for testing that our data is inserted successfully, but exposing this API directly to the web app would be a huge security risk. The API exposes administrative functionality (such as directly adding and deleting documents), and should ideally not ever be exposed publicly. Instead, we'll write a simple Node.js API to receive requests from the client, and make the appropriate query (within our private local network) to Elasticsearch.
### 5.1 - Query Script
Let's now try querying Elasticsearch from our Node.js application.
Create a new file, `server/search.js`
.
```
const { client, index, type } = require('./connection')
module.exports = {
/** Query ES index for the provided term */
queryTerm (term, offset = 0) {
const body = {
from: offset,
query: { match: {
text: {
query: term,
operator: 'and',
fuzziness: 'auto'
} } },
highlight: { fields: { text: {} } }
}
return client.search({ index, type, body })
}
}
```
Our search module defines a simple `search`
function, which will perform a `match`
query using the input term.
Here are query fields broken down -
`from`
- Allows us to paginate the results. Each query returns 10 results by default, so specifying`from: 10`
would allow us to retrieve results 10-20.`query`
- Where we specify the actual term that we are searching for.`operator`
- We can modify the search behavior; in this case, we're using the "and" operator to prioritize results that contain all of the tokens (words) in the query.`fuzziness`
- Adjusts tolerance for spelling mistakes,`auto`
defaults to`fuzziness: 2`
. A higher fuzziness will allow for more corrections in result hits. For instance,`fuzziness: 1`
would allow`Patricc`
to return`Patrick`
as a match.`highlights`
- Returns an extra field with the result, containing HTML to display the exact text subset and terms that were matched with the query.
Feel free to play around with these parameters, and to customize the search query further by exploring the [Elastic Full-Text Query DSL](https://www.elastic.co/guide/en/elasticsearch/reference/current/full-text-queries.html).
## 6 - API
Let's write a quick HTTP API in order to access our search functionality from a frontend app.
### 6.0 - API Server
Replace our existing `server/app.js`
file with the following contents.
```
const Koa = require('koa')
const Router = require('koa-router')
const joi = require('joi')
const validate = require('koa-joi-validate')
const search = require('./search')
const app = new Koa()
const router = new Router()
// Log each request to the console
app.use(async (ctx, next) => {
const start = Date.now()
await next()
const ms = Date.now() - start
console.log(`${ctx.method} ${ctx.url} - ${ms}`)
})
// Log percolated errors to the console
app.on('error', err => {
console.error('Server Error', err)
})
// Set permissive CORS header
app.use(async (ctx, next) => {
ctx.set('Access-Control-Allow-Origin', '*')
return next()
})
// ADD ENDPOINTS HERE
const port = process.env.PORT || 3000
app
.use(router.routes())
.use(router.allowedMethods())
.listen(port, err => {
if (err) throw err
console.log(`App Listening on Port ${port}`)
})
```
This code will import our server dependencies and set up simple logging and error handling for a [Koa.js](http://koajs.com/) Node API server.
### 6.1 - Link endpoint with queries
Next, we'll add an endpoint to our server in order to expose our Elasticsearch query function.
Insert the following code below the `// ADD ENDPOINTS HERE`
comment in `server/app.js`
.
```
/**
* GET /search
* Search for a term in the library
*/
router.get('/search', async (ctx, next) => {
const { term, offset } = ctx.request.query
ctx.body = await search.queryTerm(term, offset)
}
)
```
Restart the app using `docker-compose up -d --build`
. In your browser, try calling the search endpoint. For example, this request would search the entire library for passages mentioning "Java" - `http://localhost:3000/search?term=java`
The result will look quite similar to the response from earlier when we called the Elasticsearch HTTP interface directly.
```
{
"took": 242,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 93,
"max_score": 13.356944,
"hits": [{
"_index": "library",
"_type": "novel",
"_id": "eHYHJmEBpQg9B4622421",
"_score": 13.356944,
"_source": {
"author": "Charles Darwin",
"title": "On the Origin of Species",
"location": 1080,
"text": "Java, plants of, 375."
},
"highlight": {
"text": ["<em>Java</em>, plants of, 375."]
}
}, {
"_index": "library",
"_type": "novel",
"_id": "2HUHJmEBpQg9B462xdNg",
"_score": 9.030668,
"_source": {
"author": "Unknown Author",
"title": "The King James Bible",
"location": 186,
"text": "10:4 And the sons of Javan; Elishah, and Tarshish, Kittim, and Dodanim."
},
"highlight": {
"text": ["10:4 And the sons of <em>Javan</em>; Elishah, and Tarshish, Kittim, and Dodanim."]
}
}
...
]
}
}
```
### 6.2 - Input validation
This endpoint is still brittle - we are not doing any checks on the request parameters, so invalid or missing values would result in a server error.
We'll add some middleware to the endpoint in order to validate input parameters using [Joi](https://github.com/hapijs/joi) and the [Koa-Joi-Validate](https://github.com/triestpa/koa-joi-validate) library.
```
/**
* GET /search
* Search for a term in the library
* Query Params -
* term: string under 60 characters
* offset: positive integer
*/
router.get('/search',
validate({
query: {
term: joi.string().max(60).required(),
offset: joi.number().integer().min(0).default(0)
}
}),
async (ctx, next) => {
const { term, offset } = ctx.request.query
ctx.body = await search.queryTerm(term, offset)
}
)
```
Now, if you restart the server and make a request with a missing term(`http://localhost:3000/search`
), you will get back an HTTP 400 error with a relevant message, such as `Invalid URL Query - child "term" fails because ["term" is required]`
.
To view live logs from the Node app, you can run `docker-compose logs -f api`
.
## 7 - Front-End Application
Now that our `/search`
endpoint is in place, let's wire up a simple web app to test out the API.
### 7.0 - Vue.js App
We'll be using Vue.js to coordinate our frontend.
Add a new file, `/public/app.js`
, to hold our Vue.js application code.
```
const vm = new Vue ({
el: '#vue-instance',
data () {
return {
baseUrl: 'http://localhost:3000', // API url
searchTerm: 'Hello World', // Default search term
searchDebounce: null, // Timeout for search bar debounce
searchResults: [], // Displayed search results
numHits: null, // Total search results found
searchOffset: 0, // Search result pagination offset
selectedParagraph: null, // Selected paragraph object
bookOffset: 0, // Offset for book paragraphs being displayed
paragraphs: [] // Paragraphs being displayed in book preview window
}
},
async created () {
this.searchResults = await this.search() // Search for default term
},
methods: {
/** Debounce search input by 100 ms */
onSearchInput () {
clearTimeout(this.searchDebounce)
this.searchDebounce = setTimeout(async () => {
this.searchOffset = 0
this.searchResults = await this.search()
}, 100)
},
/** Call API to search for inputted term */
async search () {
const response = await axios.get(`${this.baseUrl}/search`, { params: { term: this.searchTerm, offset: this.searchOffset } })
this.numHits = response.data.hits.total
return response.data.hits.hits
},
/** Get next page of search results */
async nextResultsPage () {
if (this.numHits > 10) {
this.searchOffset += 10
if (this.searchOffset + 10 > this.numHits) { this.searchOffset = this.numHits - 10}
this.searchResults = await this.search()
document.documentElement.scrollTop = 0
}
},
/** Get previous page of search results */
async prevResultsPage () {
this.searchOffset -= 10
if (this.searchOffset < 0) { this.searchOffset = 0 }
this.searchResults = await this.search()
document.documentElement.scrollTop = 0
}
}
})
```
The app is pretty simple - we're just defining some shared data properties, and adding methods to retrieve and paginate through search results. The search input is debounced by 100ms, to prevent the API from being called with every keystroke.
Explaining how Vue.js works is outside the scope of this tutorial, but this probably won't look too crazy if you've used Angular or React. If you're completely unfamiliar with Vue, and if you want something quick to get started with, I would recommend the official quick-start guide - [https://vuejs.org/v2/guide/](https://vuejs.org/v2/guide/)
### 7.1 - HTML
Replace our placeholder `/public/index.html`
file with the following contents, in order to load our Vue.js app and to layout a basic search interface.
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Elastic Library</title>
<meta name="description" content="Literary Classic Search Engine.">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no">
<link href="https://cdnjs.cloudflare.com/ajax/libs/normalize/7.0.0/normalize.min.css" rel="stylesheet" type="text/css" />
<link href="https://cdn.muicss.com/mui-0.9.20/css/mui.min.css" rel="stylesheet" type="text/css" />
<link href="https://fonts.googleapis.com/css?family=EB+Garamond:400,700|Open+Sans" rel="stylesheet">
<link href="styles.css" rel="stylesheet" />
</head>
<body>
<div class="app-container" id="vue-instance">
<!-- Search Bar Header -->
<div class="mui-panel">
<div class="mui-textfield">
<input v-model="searchTerm" type="text" v-on:keyup="onSearchInput()">
<label>Search</label>
</div>
</div>
<!-- Search Metadata Card -->
<div class="mui-panel">
<div class="mui--text-headline">{{ numHits }} Hits</div>
<div class="mui--text-subhead">Displaying Results {{ searchOffset }} - {{ searchOffset + 9 }}</div>
</div>
<!-- Top Pagination Card -->
<div class="mui-panel pagination-panel">
<button class="mui-btn mui-btn--flat" v-on:click="prevResultsPage()">Prev Page</button>
<button class="mui-btn mui-btn--flat" v-on:click="nextResultsPage()">Next Page</button>
</div>
<!-- Search Results Card List -->
<div class="search-results" ref="searchResults">
<div class="mui-panel" v-for="hit in searchResults" v-on:click="showBookModal(hit)">
<div class="mui--text-title" v-html="hit.highlight.text[0]"></div>
<div class="mui-divider"></div>
<div class="mui--text-subhead">{{ hit._source.title }} - {{ hit._source.author }}</div>
<div class="mui--text-body2">Location {{ hit._source.location }}</div>
</div>
</div>
<!-- Bottom Pagination Card -->
<div class="mui-panel pagination-panel">
<button class="mui-btn mui-btn--flat" v-on:click="prevResultsPage()">Prev Page</button>
<button class="mui-btn mui-btn--flat" v-on:click="nextResultsPage()">Next Page</button>
</div>
<!-- INSERT BOOK MODAL HERE -->
</div>
<script src="https://cdn.muicss.com/mui-0.9.28/js/mui.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/vue/2.5.3/vue.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/axios/0.17.0/axios.min.js"></script>
<script src="app.js"></script>
</body>
</html>
```
### 7.2 - CSS
Add a new file, `/public/styles.css`
, with some custom UI styling.
```
body { font-family: 'EB Garamond', serif; }
.mui-textfield > input, .mui-btn, .mui--text-subhead, .mui-panel > .mui--text-headline {
font-family: 'Open Sans', sans-serif;
}
.all-caps { text-transform: uppercase; }
.app-container { padding: 16px; }
.search-results em { font-weight: bold; }
.book-modal > button { width: 100%; }
.search-results .mui-divider { margin: 14px 0; }
.search-results {
display: flex;
flex-direction: row;
flex-wrap: wrap;
justify-content: space-around;
}
.search-results > div {
flex-basis: 45%;
box-sizing: border-box;
cursor: pointer;
}
@media (max-width: 600px) {
.search-results > div { flex-basis: 100%; }
}
.paragraphs-container {
max-width: 800px;
margin: 0 auto;
margin-bottom: 48px;
}
.paragraphs-container .mui--text-body1, .paragraphs-container .mui--text-body2 {
font-size: 1.8rem;
line-height: 35px;
}
.book-modal {
width: 100%;
height: 100%;
padding: 40px 10%;
box-sizing: border-box;
margin: 0 auto;
background-color: white;
overflow-y: scroll;
position: fixed;
top: 0;
left: 0;
}
.pagination-panel {
display: flex;
justify-content: space-between;
}
.title-row {
display: flex;
justify-content: space-between;
align-items: flex-end;
}
@media (max-width: 600px) {
.title-row{
flex-direction: column;
text-align: center;
align-items: center
}
}
.locations-label {
text-align: center;
margin: 8px;
}
.modal-footer {
position: fixed;
bottom: 0;
left: 0;
width: 100%;
display: flex;
justify-content: space-around;
background: white;
}
```
### 7.3 - Try it out
Open `localhost:8080`
in your web browser, you should see a simple search interface with paginated results. Try typing in the top search bar to find matches from different terms.
You
do nothave to re-run the`docker-compose up`
command for the changes to take effect. The local`public`
directory is mounted to our Nginx fileserver container, so frontend changes on the local system will be automatically reflected in the containerized app.
If you try clicking on any result, nothing happens - we still have one more feature to add to the app.
## 8 - Page Previews
It would be nice to be able to click on each search result and view it in the context of the book that it's from.
### 8.0 - Add Elasticsearch Query
First, we'll need to define a simple query to get a range of paragraphs from a given book.
Add the following function to the `module.exports`
block in `server/search.js`
.
```
/** Get the specified range of paragraphs from a book */
getParagraphs (bookTitle, startLocation, endLocation) {
const filter = [
{ term: { title: bookTitle } },
{ range: { location: { gte: startLocation, lte: endLocation } } }
]
const body = {
size: endLocation - startLocation,
sort: { location: 'asc' },
query: { bool: { filter } }
}
return client.search({ index, type, body })
}
```
This new function will return an ordered array of paragraphs between the start and end locations of a given book.
### 8.1 - Add API Endpoint
Now, let's link this function to an API endpoint.
Add the following to `server/app.js`
, below the original `/search`
endpoint.
```
/**
* GET /paragraphs
* Get a range of paragraphs from the specified book
* Query Params -
* bookTitle: string under 256 characters
* start: positive integer
* end: positive integer greater than start
*/
router.get('/paragraphs',
validate({
query: {
bookTitle: joi.string().max(256).required(),
start: joi.number().integer().min(0).default(0),
end: joi.number().integer().greater(joi.ref('start')).default(10)
}
}),
async (ctx, next) => {
const { bookTitle, start, end } = ctx.request.query
ctx.body = await search.getParagraphs(bookTitle, start, end)
}
)
```
### 8.2 - Add UI functionality
Now that our new endpoint is in place, let's add some frontend functionality to query and display full pages from the book.
Add the following functions to the `methods`
block of `/public/app.js`
.
```
/** Call the API to get current page of paragraphs */
async getParagraphs (bookTitle, offset) {
try {
this.bookOffset = offset
const start = this.bookOffset
const end = this.bookOffset + 10
const response = await axios.get(`${this.baseUrl}/paragraphs`, { params: { bookTitle, start, end } })
return response.data.hits.hits
} catch (err) {
console.error(err)
}
},
/** Get next page (next 10 paragraphs) of selected book */
async nextBookPage () {
this.$refs.bookModal.scrollTop = 0
this.paragraphs = await this.getParagraphs(this.selectedParagraph._source.title, this.bookOffset + 10)
},
/** Get previous page (previous 10 paragraphs) of selected book */
async prevBookPage () {
this.$refs.bookModal.scrollTop = 0
this.paragraphs = await this.getParagraphs(this.selectedParagraph._source.title, this.bookOffset - 10)
},
/** Display paragraphs from selected book in modal window */
async showBookModal (searchHit) {
try {
document.body.style.overflow = 'hidden'
this.selectedParagraph = searchHit
this.paragraphs = await this.getParagraphs(searchHit._source.title, searchHit._source.location - 5)
} catch (err) {
console.error(err)
}
},
/** Close the book detail modal */
closeBookModal () {
document.body.style.overflow = 'auto'
this.selectedParagraph = null
}
```
These five functions provide the logic for downloading and paginating through pages (ten paragraphs each) in a book.
Now we just need to add a UI to display the book pages. Add this markup below the `<!-- INSERT BOOK MODAL HERE -->`
comment in `/public/index.html`
.
```
<!-- Book Paragraphs Modal Window -->
<div v-if="selectedParagraph" ref="bookModal" class="book-modal">
<div class="paragraphs-container">
<!-- Book Section Metadata -->
<div class="title-row">
<div class="mui--text-display2 all-caps">{{ selectedParagraph._source.title }}</div>
<div class="mui--text-display1">{{ selectedParagraph._source.author }}</div>
</div>
<br>
<div class="mui-divider"></div>
<div class="mui--text-subhead locations-label">Locations {{ bookOffset - 5 }} to {{ bookOffset + 5 }}</div>
<div class="mui-divider"></div>
<br>
<!-- Book Paragraphs -->
<div v-for="paragraph in paragraphs">
<div v-if="paragraph._source.location === selectedParagraph._source.location" class="mui--text-body2">
<strong>{{ paragraph._source.text }}</strong>
</div>
<div v-else class="mui--text-body1">
{{ paragraph._source.text }}
</div>
<br>
</div>
</div>
<!-- Book Pagination Footer -->
<div class="modal-footer">
<button class="mui-btn mui-btn--flat" v-on:click="prevBookPage()">Prev Page</button>
<button class="mui-btn mui-btn--flat" v-on:click="closeBookModal()">Close</button>
<button class="mui-btn mui-btn--flat" v-on:click="nextBookPage()">Next Page</button>
</div>
</div>
```
Restart the app server (`docker-compose up -d --build`
) again and open up `localhost:8080`
. When you click on a search result, you are now able to view the surrounding paragraphs. You can now even read the rest of the book to completion if you're entertained by what you find.
Congrats, you've completed the tutorial application!
Feel free to compare your local result against the completed sample hosted here - [https://search.patricktriest.com/](https://search.patricktriest.com/)
## 9 - Disadvantages of Elasticsearch
### 9.0 - Resource Hog
Elasticsearch is computationally demanding. The [official recommendation](https://www.elastic.co/guide/en/elasticsearch/guide/current/hardware.html) is to run ES on a machine with 64 GB of RAM, and they strongly discourage running it on anything with under 8 GB of RAM. Elasticsearch is an *in-memory* datastore, which allows it to return results extremely quickly, but also results in a very significant system memory footprint. In production, [it is strongly recommended to run multiple Elasticsearch nodes in a cluster](https://www.elastic.co/guide/en/elasticsearch/guide/2.x/distributed-cluster.html) to allow for high server availability, automatic sharding, and data redundancy in case of a node failure.
I've got our tutorial application running on a $15/month GCP compute instance (at [search.patricktriest.com](https://search.patricktriest.com)) with 1.7 GB of RAM, and it *just barely* is able to run the Elasticsearch node; sometimes the entire machine freezes up during the initial data-loading step. Elasticsearch is, in my experience, much more of a resource hog than more traditional databases such as PostgreSQL and MongoDB, and can be significantly more expensive to host as a result.
### 9.1 - Syncing with Databases
In most applications, storing all of the data in Elasticsearch is not an ideal option. It is possible to use ES as the primary transactional database for an app, but this is generally not recommended due to the lack of ACID compliance in Elasticsearch, which can lead to lost write operations when ingesting data at scale. In many cases, ES serves a more specialized role, such as powering the text searching features of the app. This specialized use requires that some of the data from the primary database is replicated to the Elasticsearch instance.
For instance, let's imagine that we're storing our users in a PostgreSQL table, but using Elasticsearch to power our user-search functionality. If a user, "Albert", decides to change his name to "Al", we'll need this change to be reflected in both our primary PostgreSQL database and in our auxiliary Elasticsearch cluster.
This can be a tricky integration to get right, and the best answer will depend on your existing stack. There are a multitude of open-source options available, from [a process to watch a MongoDB operation log](https://github.com/mongodb-labs/mongo-connector) and automatically sync detected changes to ES, to a [PostgresSQL plugin](https://github.com/zombodb/zombodb) to create a custom PSQL-based index that communicates automatically with Elasticsearch.
If none of the available pre-built options work, you could always just add some hooks into your server code to update the Elasticsearch index manually based on database changes. I would consider this final option to be a last resort, since keeping ES in sync using custom business logic can be complex, and is likely to introduce numerous bugs to the application.
The need to sync Elasticsearch with a primary database is more of an architectural complexity than it is a specific weakness of ES, but it's certainly worth keeping in mind when considering the tradeoffs of adding a dedicated search engine to your app.
## Conclusion
Full-text search is one of the most important features in many modern applications - and is one of the most difficult to implement well. Elasticsearch is a fantastic option for adding fast and customizable text search to your application, but there are alternatives. [Apache Solr](http://lucene.apache.org/solr/) is a similar open source search platform that is built on Apache Lucene - the same library at the core of Elasticsearch. [Algolia](https://www.algolia.com/) is a search-as-a-service web platform which is growing quickly in popularity and is likely to be easier to get started with for beginners (but as a tradeoff is less customizable and can get quite expensive).
"Search-bar" style features are far from the only use-case for Elasticsearch. ES is also a very common tool for log storage and analysis, commonly used in an ELK (Elasticsearch, Logstash, Kibana) stack configuration. The flexible full-text search allowed by Elasticsearch can also be very useful for a wide variety of data science tasks - such as correcting/standardizing the spellings of entities within a dataset or searching a large text dataset for similar phrases.
Here are some ideas for your own projects.
- Add more of your favorite books to our tutorial app and create your own private library search engine.
- Create an academic plagiarism detection engine by indexing papers from
[Google Scholar](https://scholar.google.com/). - Build a spell checking application by indexing every word in the dictionary to Elasticsearch.
- Build your own Google-competitor internet search engine by loading the
[Common Crawl Corpus](https://aws.amazon.com/public-datasets/common-crawl/)into Elasticsearch (caution - with over 5 billion pages, this can be a very expensive dataset play with). - Use Elasticsearch for journalism: search for specific names and terms in recent large-scale document leaks such as the
[Panama Papers](https://en.wikipedia.org/wiki/Panama_Papers)and[Paradise Papers](https://en.wikipedia.org/wiki/Paradise_Papers).
The source code for this tutorial application is 100% open-source and can be found at the GitHub repository here - [https://github.com/triestpa/guttenberg-search](https://github.com/triestpa/guttenberg-search)
I hope you enjoyed the tutorial! Please feel free to post any thoughts, questions, or criticisms in the comments below. |
9,594 | 在 KVM 中测试 IPv6 网络(第 1 部分) | https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1 | 2018-04-30T20:07:30 | [
"IPv6",
"KVM"
] | https://linux.cn/article-9594-1.html |
>
> 在这个两篇的系列当中,我们将学习关于 IPv6 私有地址的知识,以及如何在 KVM 中配置测试网络。
>
>
>

要理解 IPv6 地址是如何工作的,没有比亲自动手去实践更好的方法了,在 KVM 中配置一个小的测试实验室非常容易 —— 也很有趣。这个系列的文章共有两个部分,我们将学习关于 IPv6 私有地址的知识,以及如何在 KVM 中配置测试网络。
### QEMU/KVM/虚拟机管理器
我们先来了解什么是 KVM。在这里,我将使用 KVM 来表示 QEMU、KVM、以及虚拟机管理器的一个组合,虚拟机管理器在 Linux 发行版中一般都内置了。简单解释就是,QEMU 模拟硬件,而 KVM 是一个内核模块,它在你的 CPU 上创建一个 “访客领地”,并去管理它们对内存和 CPU 的访问。虚拟机管理器是一个涵盖虚拟化和管理程序的图形工具。
但是你不能被图形界面下 “点击” 操作的方式 “缠住” ,因为,它们也有命令行工具可以使用 —— 比如 `virsh` 和 `virt-install`。
如果你在使用 KVM 方面没有什么经验,你可以从 [在 KVM 中创建虚拟机:第 1 部分](https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-1) 和 [在 KVM 中创建虚拟机:第 2 部分 - 网络](https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-2-networking) 开始学起。
### IPv6 唯一本地地址
在 KVM 中配置 IPv6 网络与配置 IPv4 网络很类似。它们的主要不同在于这些怪异的长地址。[上一次](https://www.linux.com/learn/intro-to-linux/2017/10/calculating-ipv6-subnets-linux),我们讨论了 IPv6 地址的不同类型。其中有一个 IPv6 单播地址类,`fc00::/7`(详细情况请查阅 [RFC 4193](https://tools.ietf.org/html/rfc4193)),它类似于 IPv4 中的私有地址 —— `10.0.0.0/8`、`172.16.0.0/12`、和 `192.168.0.0/16`。
下图解释了这个唯一本地地址空间的结构。前 48 位定义了前缀和全局 ID,随后的 16 位是子网,剩余的 64 位是接口 ID:
```
| 7 bits |1| 40 bits | 16 bits | 64 bits |
+--------+-+------------+-----------+----------------------------+
| Prefix |L| Global ID | Subnet ID | Interface ID |
+--------+-+------------+-----------+----------------------------+
```
下面是另外一种表示方法,它可能更有助于你理解这些地址是如何管理的:
```
| Prefix | Global ID | Subnet ID | Interface ID |
+--------+--------------+-------------+----------------------+
| fd | 00:0000:0000 | 0000 | 0000:0000:0000:0000 |
+--------+--------------+-------------+----------------------+
```
`fc00::/7` 共分成两个 `/8` 地址块,`fc00::/8` 和 `fd00::/8`。`fc00::/8` 是为以后使用保留的。因此,唯一本地地址通常都是以 `fd` 开头的,而剩余部分是由你使用的。`L` 位,也就是第八位,它总是设置为 `1`,这样它可以表示为 `fd00::/8`。设置为 `0` 时,它就表示为 `fc00::/8`。你可以使用 `subnetcalc` 来看到这些东西:
```
$ subnetcalc fd00::/8 -n
Address = fd00::
fd00 = 11111101 00000000
$ subnetcalc fc00::/8 -n
Address = fc00::
fc00 = 11111100 00000000
```
RFC 4193 要求地址必须随机产生。你可以用你选择的任何方法来造出个地址,只要它们以 `fd` 打头就可以,因为 IPv6 范围非常大,它不会因为地址耗尽而无法使用。当然,最佳实践还是按 RFC 的要求来做。地址不能按顺序分配或者使用众所周知的数字。RFC 4193 包含一个构建伪随机地址生成器的算法,或者你可以找到各种在线生成器。
唯一本地地址不像全局单播地址(它由你的因特网服务提供商分配)那样进行中心化管理,即使如此,发生地址冲突的可能性也是非常低的。当你需要去合并一些本地网络或者想去在不相关的私有网络之间路由时,这是一个非常好的优势。
在同一个子网中,你可以混用唯一本地地址和全局单播地址。唯一本地地址是可路由的,并且它并不会因此要求对路由器做任何调整。但是,你应该在你的边界路由器和防火墙上配置为不允许它们离开你的网络,除非是在不同位置的两个私有网络之间。
RFC4193 建议,不要混用全局单播地址的 AAAA 和 PTR 记录,因为虽然它们重复的机率非常低,但是并不能保证它们就是独一无二的。就像我们使用的 IPv4 地址一样,要保持你本地的私有名称服务和公共名称服务的独立。将本地名称服务使用的 Dnsmasq 和公共名称服务使用的 BIND 组合起来,是一个在 IPv4 网络上经过实战检验的可靠组合,这个组合也同样适用于 IPv6 网络。
### 伪随机地址生成器
在线地址生成器的一个示例是 [本地 IPv6 地址生成器](https://www.ultratools.com/tools/rangeGenerator)。你可以在线找到许多这样很酷的工具。你可以使用它来为你创建一个新地址,或者使用它在你的现有全局 ID 下为你创建子网。
下周我们将讲解如何在 KVM 中配置这些 IPv6 的地址,并现场测试它们。
通过来自 Linux 基金会和 edX 的免费在线课程 [“Linux 入门”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 学习更多的 Linux 知识。
---
via: <https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1>
作者:[Carla Schroder](https://www.linux.com/users/cschroder) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,595 | 通过扫描二维码将文件从计算机传输到移动设备 | https://www.ostechnix.com/transfer-files-from-computer-to-mobile-devices-by-scanning-qr-codes/ | 2018-04-30T20:21:04 | [
"文件传输",
"二维码"
] | https://linux.cn/article-9595-1.html | 
将文件从计算机传输到智能手机并不是什么大问题。你可以使用 USB 线将手机挂载到系统上,然后从文件管理器传输文件。此外,某些第三方应用程序(例如 [KDE Connect](https://www.ostechnix.com/kde-connect-access-files-notifications-android-devices/) 和 [AirDroid](https://www.ostechnix.com/airdroid-share-files-and-folders-between-linux-and-android/))可帮助你轻松管理和传输系统中的文件至 Android 设备。今天,我偶然发现了一个名为 “Qr-filetransfer” 的超酷工具。它允许你通过扫描二维码通过 WiFi 将文件从计算机传输到移动设备而无须离开终端。是的,你没有看错! Qr-filetransfer 是一个使用 Go 语言编写的自由开源命令行工具。在这个简短的教程中,我们将学习如何使用 Qr-filetransfer 将文件从 Linux 传输到任何移动设备。
### 安装 Qr-filetransfer
首先,在你的系统上安装 Go 语言。
在 Arch Linux 及其衍生版上:
```
$ sudo pacman -S go
```
在基于 RPM 的系统(如 RHEL、CentOS、Fedora)上运行:
```
$ sudo yum install golang
```
或者:
```
$ sudo dnf install golang
```
在基于 DEB 的系统上,例如 Debian、Ubuntu、Linux Mint,你可以使用命令安装它:
```
$ sudo apt-get install golang
```
在 SUSE/openSUSE 上:
```
$ sudo zypper install golang
```
安装 Go 语言后,运行以下命令下载 Qr-filetransfer 应用。
```
$ go get github.com/claudiodangelis/qr-filetransfer
```
上述命令将在当前工作目录下的一个名为 `go` 的目录中下载 Qr-filetransfer GitHub 仓库的内容。
将 Qr-filetransfer 的二进制文件复制到 PATH 中,例如 `/usr/local/bin/`。
```
$ sudo cp go/bin/qr-filetransfer /usr/local/bin/
```
最后,如下使其可执行:
```
$ sudo chmod +x /usr/local/bin/qr-filetransfer
```
### 通过扫描二维码将文件从计算机传输到移动设备
确保你的智能手机已连接到与计算机相同的 WiFi 网络。
然后,使用要传输的文件的完整路径启动 `qt-filetransfer`。
比如,我要传输一个 mp3 文件。
```
$ qr-filetransfer Chill\ Study\ Beats.mp3
```
首次启动时,`qr-filetransfer` 会要求你选择使用的网络接口,如下所示。
```
Choose the network interface to use (type the number):
[0] enp5s0
[1] wlp9s0
```
我打算使用 wlp9s0 接口传输文件,因此我输入 “1”。`qr-filetransfer` 会记住这个选择,除非你通过 `-force` 参数或删除程序存储在当前用户的家目录中的 `.qr-filetransfer.json` 文件,否则永远不会再提示你。
然后,你将看到二维码,如下图所示。

打开二维码应用(如果尚未安装,请从 Play 商店安装任何一个二维码读取程序)并扫描终端中显示的二维码。
读取二维码后,系统会询问你是要复制链接还是打开链接。你可以复制链接并手动将其粘贴到移动网络浏览器上,或者选择“打开链接”以在移动浏览器中自动打开它。

共享链接打开后,该文件将下载到智能手机中。

如果文件太大,请压缩文件,然后传输它:
```
$ qr-filetransfer -zip /path/to/file.txt
```
要传输整个目录,请运行:
```
$ qr-filetransfer /path/to/directory
```
请注意,目录在传输之前会被压缩。
`qr-filetransfer` 只能将系统中的内容传输到移动设备,反之不能。这个项目非常新,所以会有 bug。如果你遇到了任何 bug,请在本指南最后给出的 GitHub 页面上报告。
干杯!
---
via: <https://www.ostechnix.com/transfer-files-from-computer-to-mobile-devices-by-scanning-qr-codes/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,596 | 如何将树莓派配置为打印服务器 | https://opensource.com/article/18/3/print-server-raspberry-pi | 2018-05-02T12:26:17 | [
"打印机",
"树莓派"
] | https://linux.cn/article-9596-1.html |
>
> 用树莓派和 CUPS 打印服务器将你的打印机变成网络打印机。
>
>
>

我喜欢在家做一些小项目,因此,今年我买了一个 [树莓派 3 Model B](https://www.raspberrypi.org/products/raspberry-pi-3-model-b/),这是一个非常适合像我这样的业余爱好者的东西。使用树莓派 3 Model B 的内置无线功能,我可以不使用线缆就将树莓派连接到我的家庭网络中。这样可以很容易地将树莓派用到各种所需要的地方。
在家里,我和我的妻子都使用笔记本电脑,但是我们只有一台打印机:一台使用的并不频繁的 HP 彩色激光打印机。因为我们的打印机并不内置无线网卡,因此,它不能直接连接到无线网络中,我们一般把打印机连接到我的笔记本电脑上,因为通常是我在打印。虽然这种安排在大多数时间都没有问题,但是,有时候,我的妻子想在不 “麻烦” 我的情况下,自己去打印一些东西。
我觉得我们需要一个将打印机连接到无线网络的解决方案,以便于我们都能够随时随地打印。我本想买一个无线打印服务器将我的 USB 打印机连接到家里的无线网络上。后来,我决定使用我的树莓派,将它设置为打印服务器,这样就可以让家里的每个人都可以随时来打印。
### 基本设置
设置树莓派是非常简单的事。我下载了 [Raspbian](https://www.raspberrypi.org/downloads/) 镜像,并将它写入到我的 microSD 卡中。然后,使用它来引导一个连接了 HDMI 显示器、 USB 键盘和 USB 鼠标的树莓派。之后,我们开始对它进行设置!
这个树莓派系统自动引导到一个图形桌面,然后我做了一些基本设置:设置键盘语言、连接无线网络、设置普通用户帐户(`pi`)的密码、设置管理员用户(`root`)的密码。
我并不打算将树莓派运行在桌面环境下。我一般是通过我的普通的 Linux 计算机远程来使用它。因此,我使用树莓派的图形化管理工具,去设置将树莓派引导到控制台模式,但不以 `pi` 用户自动登入。
重新启动树莓派之后,我需要做一些其它的系统方面的小调整,以便于我在家用网络中使用树莓派做为 “服务器”。我设置它的 DHCP 客户端为使用静态 IP 地址;默认情况下,DHCP 客户端可能任选一个可用的网络地址,这样我会不知道应该用哪个地址连接到树莓派。我的家用网络使用一个私有的 A 类地址,因此,我的路由器的 IP 地址是 `10.0.0.1`,并且我的全部可用地 IP 地址是 `10.0.0.x`。在我的案例中,低位的 IP 地址是安全的,因此,我通过在 `/etc/dhcpcd.conf` 中添加如下的行,设置它的无线网络使用 `10.0.0.11` 这个静态地址。
```
interface wlan0
static ip_address=10.0.0.11/24
static routers=10.0.0.1
static domain_name_servers=8.8.8.8 8.8.4.4
```
在我再次重启之前,我需要去确认安全 shell 守护程序(SSHD)已经正常运行(你可以在 “偏好” 中设置哪些服务在引导时启动它)。这样我就可以使用 SSH 从普通的 Linux 系统上基于网络连接到树莓派中。
### 打印设置
现在,我的树莓派已经连到网络上了,我通过 SSH 从我的 Linux 电脑上远程连接它,接着做剩余的设置。在继续设置之前,确保你的打印机已经连接到树莓派上。
设置打印机很容易。现代的打印服务器被称为 CUPS,意即“通用 Unix 打印系统”。任何最新的 Unix 系统都可以通过 CUPS 打印服务器来打印。为了在树莓派上设置 CUPS 打印服务器。你需要通过几个命令去安装 CUPS 软件,并使用新的配置来重启打印服务器,这样就可以允许其它系统来打印了。
```
$ sudo apt-get install cups
$ sudo cupsctl --remote-any
$ sudo /etc/init.d/cups restart
```
在 CUPS 中设置打印机也是非常简单的,你可以通过一个 Web 界面来完成。CUPS 监听端口是 631,因此你用常用的浏览器来访问这个地址:
```
https://10.0.0.11:631/
```
你的 Web 浏览器可能会弹出警告,因为它不认可这个 Web 浏览器的 https 证书;选择 “接受它”,然后以管理员用户登入系统,你将看到如下的标准的 CUPS 面板:

这时候,导航到管理标签,选择 “Add Printer”。

如果打印机已经通过 USB 连接,你只需要简单地选择这个打印机和型号。不要忘记去勾选共享这个打印机的选择框,因为其它人也要使用它。现在,你的打印机已经在 CUPS 中设置好了。

### 客户端设置
从 Linux 中设置一台网络打印机非常简单。我的桌面环境是 GNOME,你可以从 GNOME 的“设置”应用程序中添加网络打印机。只需要导航到“设备和打印机”,然后解锁这个面板。点击 “添加” 按钮去添加打印机。
在我的系统中,GNOME 的“设置”应用程序会自动发现网络打印机并添加它。如果你的系统不是这样,你需要通过树莓派的 IP 地址,手动去添加打印机。

设置到此为止!我们现在已经可以通过家中的无线网络来使用这台打印机了。我不再需要物理连接到这台打印机了,家里的任何人都可以使用它了!
---
via: <https://opensource.com/article/18/3/print-server-raspberry-pi>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I like to work on small projects at home, so this year I picked up a [Raspberry Pi 3 Model B](https://www.raspberrypi.org/products/raspberry-pi-3-model-b/), a great model for home hobbyists like me. With built-in wireless on the Raspberry Pi 3 Model B, I can connect the Pi to my home network without a cable. This makes it really easy to put the Raspberry Pi to use right where it is needed.
At our house, my wife and I both have laptops, but we have just one printer: a slightly used HP Color LaserJet. Because our printer doesn't have a wireless card and can't connect to wireless networks, we usually leave the LaserJet connected to my laptop, since I do most of the printing. While that arrangement works most of the time, sometimes my wife would like to print something without having to go through me.
I realized we really needed a solution to connect the printer to the wireless network so both of us could print to it whenever we wanted. I could buy a wireless print server to connect the USB printer to the wireless network, but I decided instead to use my Raspberry Pi to build a print server to make the LaserJet available to anyone in our house.
## Basic setup
Setting up the Raspberry Pi is fairly straightforward. I downloaded the [Raspbian](https://www.raspberrypi.org/downloads/) image and wrote that to my microSD card. Then, I booted the Raspberry Pi with an HDMI display, a USB keyboard, and a USB mouse. With that, I was ready to go!
The Raspbian system automatically boots into a graphical desktop environment where I performed most of the basic setup: setting the keyboard language, connecting to my wireless network, setting the password for the regular user account (`pi`
), and setting the password for the system administrator account (`root`
).
I don't plan to use the Raspberry Pi as a desktop system. I only want to use it remotely from my regular Linux computer. So, I also used Raspbian's graphical administration tool to set the Raspberry Pi to boot into console mode, but not to automatically login as the `pi`
user.
Once I rebooted the Raspberry Pi, I needed to make a few other system tweaks so I could use the Pi as a "server" on my network. I set the Dynamic Host Configuration Protocol (DHCP) client to use a static IP address; by default, the DHCP client might pick any available network address, which would make it tricky to know how to connect to the Raspberry Pi over the network. My home network uses a private class A network, so my router's IP address is `10.0.0.1`
and all my IP addresses are `10.0.0.`
. In my case, IP addresses in the lower range are safe, so I set up a static IP address on the wireless network at *x*`10.0.0.11`
by adding these lines to the `/etc/dhcpcd.conf`
file:
```
``````
interface wlan0
static ip_address=10.0.0.11/24
static routers=10.0.0.1
static domain_name_servers=8.8.8.8 8.8.4.4
```
Before I rebooted again, I made sure that the secure shell daemon (SSHD) was running (you can set what services start at boot-up in Preferences). This allowed me to use a secure shell (SSH) client from my regular Linux system to connect to the Raspberry Pi over the network.
## Print setup
Now that my Raspberry Pi was on the network, I did the rest of the setup remotely, using SSH, from my regular Linux desktop machine. Make sure your printer is connected to the Raspberry Pi before taking the following steps.
Setting up printing is fairly easy. The modern print server is called CUPS, which stands for the Common Unix Printing System. Any recent Unix system should be able to print through a CUPS print server. To set up CUPS on Raspberry Pi, you just need to enter a few commands to install the CUPS software, allow printing by other systems, and restart the print server with the new configuration:
```
``````
$ sudo apt-get install cups
$ sudo cupsctl --remote-any
$ sudo /etc/init.d/cups restart
```
Setting up a printer in CUPS is also straightforward and can be done through a web browser. CUPS listens on port 631, so just use your favorite web browser and surf to:
```
````https://10.0.0.11:631/`
Your web browser may complain that it doesn't recognize the web server's https certificate; just accept it, and login as the system administrator. You should see the standard CUPS panel:
opensource.com
From there, navigate to the Administration tab, and select Add Printer.
opensource.com
If your printer is already connected via USB, you should be able to easily select the printer's make and model. Don't forget to tick the Share This Printer box so others can use it, too. And now your printer should be set up in CUPS:
opensource.com
## Client setup
Setting up a network printer from the Linux desktop should be quite simple. My desktop is GNOME, and you can add the network printer right from the GNOME Settings application. Just navigate to Devices and Printers and unlock the panel. Click on the Add button to add the printer.
On my system, GNOME Settings automatically discovered the network printer and added it. If that doesn't happen for you, you may need to add the IP address for your Raspberry Pi to manually add the printer.
opensource.com
And that's it! We are now able to print to the Color LaserJet over the wireless network from wherever we are in the house. I no longer need to be physically connected to the printer, and everyone in the family can print on their own.
## 2 Comments |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.