
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
9,386 | 五个值得现在安装的火狐插件 | https://opensource.com/article/18/1/top-5-firefox-extensions | 2018-02-26T23:29:21 | [
"FireFox",
"插件"
] | /article-9386-1.html |
>
> 合适的插件能大大增强你浏览器的功能,但仔细挑选插件很重要。本文有五个值得一看的插件。
>
>
>

对于很多用户来说,网页浏览器已经成为电脑使用体验的重要环节。现代浏览器已经发展成强大、可拓展的平台。作为平台的一部分,*插件*能添加或修改浏览器的功能。火狐插件的构建使用了 WebExtensions API ,这是一个跨浏览器的开发系统。
你应该安装哪一个插件?一般而言,这个问题的答案取决于你如何使用你的浏览器、你对于隐私的看法、你信任插件开发者多少以及其他个人喜好。
首先,我想指出浏览器插件通常需要读取和(或者)修改你浏览的网页上的每项内容。你应该*非常*仔细地考虑这件事的后果。如果一个插件有修改所有你访问过的网页的权限,那么它可能记录你的按键、拦截信用卡信息、在线跟踪你、插入广告,以及其他各种各样邪恶的行为。
并不是每个插件都偷偷摸摸地做这些事,但是在你安装任何插件之前,你要慎重考虑下插件安装来源、涉及的权限、你的风险数据和其他因素。记住,你可以从个人数据的角度来管理一个插件如何影响你的攻击面( LCTT 译注:攻击面是指入侵者能尝试获取或提取数据的途径总和)——例如使用特定的配置、不使用插件来完成例如网上银行的操作。
考虑到这一点,这里有你或许想要考虑的五个火狐插件
### uBlock Origin

*ublock Origin 可以拦截广告和恶意网页,还允许用户定义自己的内容过滤器。*
[uBlock Origin](https://addons.mozilla.org/en-US/firefox/addon/ublock-origin/) 是一款快速、内存占用低、适用范围广的拦截器,它不仅能屏蔽广告,还能让你执行你自己定制的内容过滤。uBlock Origin 默认使用多份预定义好的过滤名单来拦截广告、跟踪器和恶意网页。它允许你任意地添加列表和规则,或者锁定在一个默认拒绝的模式。除了强大之外,这个插件已被证明是效率高、性能好。
### Privacy Badger

*Privacy Badger 运用了算法来无缝地屏蔽侵犯用户准则的广告和跟踪器。*
正如它名字所表明,[Privacy Badger](https://www.eff.org/privacybadger) 是一款专注于隐私的插件,它屏蔽广告和第三方跟踪器。EFF (LCTT 译注:EFF 全称是<ruby> 电子前哨基金会 <rt> Electronic Frontier Foundation </rt></ruby>,旨在宣传互联网版权和监督执法机构)说:“我们想要推荐一款能自动分析并屏蔽任何侵犯用户准则的跟踪器和广告,而 Privacy Badger 诞生于此目的;它不用任何设置、知识或者用户的配置,就能运行得很好;它是由一个明显为用户服务而不是为广告主服务的组织出品;它使用算法来确定正在跟踪什么,而没有跟踪什么。”
为什么 Privacy Badger 出现在这列表上的原因跟 uBlock Origin 如此相似?其中一个原因是 Privacy Badger 从根本上跟 uBlock Origin 的工作不同。另一个原因是纵深防御的做法是个可以遵循的合理策略。
### LastPass

*LastPass 是一款用户友好的密码管理插件,支持双因子认证。*
这个插件对于很多人来说是个有争议的补充。你是否应该使用密码管理器——如果你用了,你是否应该选择一个浏览器插件——这都是个热议的话题,而答案取决于你的风险资料。我想说大部分不关心的电脑用户应该用一个,因为这比起常见的选择:每一处使用相同的弱密码,都好太多了。
[LastPass](https://addons.mozilla.org/en-US/firefox/addon/lastpass-password-manager/) 对于用户很友好,支持双因子认证,相当安全。这家公司过去出过点安全事故,但是都处理得当,而且资金充足。记住使用密码管理器不是非此即彼的命题。很多用户选择使用密码管理器管理绝大部分密码,但是保持了一点复杂性,为例如银行这样重要的网页采用了精心设计的密码和多因子认证。
### Xmarks Sync
[Xmarks Sync](https://addons.mozilla.org/en-US/firefox/addon/xmarks-sync/) 是一款方便的插件,能跨实例同步你的书签、打开的标签页、配置项和浏览器历史。如果你有多台机器,想要在桌面设备和移动设备之间同步、或者在同一台设备使用不同的浏览器,那来看看 Xmarks Sync 。(注意这款插件最近被 LastPass 收购)
### Awesome Screenshot Plus
[Awesome Screenshot Plus](https://addons.mozilla.org/en-US/firefox/addon/screenshot-capture-annotate/) 允许你很容易捕获任意网页的全部或部分区域,也能添加注释、评论、使敏感信息模糊等。你还能用一个可选的在线服务来分享图片。我发现这工具在网页调试时截图、讨论设计和分享信息上很棒。这是一款比你预期中发现自己使用得多的工具。

*Awesome Screenshot Plus 允许你容易地截下任何网页的部分或全部内容。*
我发现这五款插件有用,我把它们推荐给其他人。这就是说,还有很多浏览器插件。我很感兴趣社区用户们正在使用哪些插件,请在评论中让我知道。
---
via: <https://opensource.com/article/18/1/top-5-firefox-extensions>
作者:[Jeremy Garcia](https://opensource.com/users/jeremy-garcia) 译者:[ypingcn](https://github.com/ypingcn) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,387 | Intel 设计缺陷背后的原因是什么? | https://arstechnica.com/gadgets/2018/01/whats-behind-the-intel-design-flaw-forcing-numerous-patches/ | 2018-02-26T23:53:21 | [
"KPTI",
"Intel",
"CPU"
] | https://linux.cn/article-9387-1.html |
>
> 我们知道有问题,但是并不知道问题的详细情况。
>
>
>

(本文发表于 1 月份)最近 Windows 和 Linux 都发送了重大安全更新,为防范这个尚未完全公开的问题,在最坏的情况下,它可能会导致性能下降多达一半。
在过去的几周,Linux 内核陆续打了几个补丁。Microsoft [自 11 月份开始也内部测试了 Windows 更新](https://twitter.com/aionescu/status/930412525111296000),并且它预计在下周二的例行补丁中将这个改进推送到主流 Windows 构建版中。Microsoft 的 Azure 也在下周的维护窗口中做好了安排,而 Amazon 的 AWS 也安排在周五对相关的设施进行维护。
自从 Linux 第一个补丁 (参见 [KPTI:内核页表隔离的当前的发展](/article-9201-1.html)) 明确描绘了出现的错误以后。虽然 Linux 和 Windows 基于不同的考虑,对此持有不同的看法,但是这两个操作系统 —— 当然还有其它的 x86 操作系统,比如 FreeBSD 和 [macOS](https://twitter.com/aionescu/status/948609809540046849) — 对系统内存的处理采用了相同的方式,因为对于操作系统在这一部分特性是与底层的处理器高度耦合的。
### 保持地址跟踪
在一个系统中的每个内存字节都是隐性编码的,这些编码数字是每个字节的地址。早期的操作系统使用物理内存地址,但是,物理内存地址由于各种原因,它并不很合适。例如,在地址中经常会有空隙,并且(尤其是 32 位的系统上)物理地址很难操作,需要 36 位数字,甚至更多。
因此,现在操作系统完全依赖一个叫虚拟内存的概念。虚拟内存系统允许程序和内核一起在一个简单、清晰、统一的环境中各自去操作。而不是使用空隙和其它奇怪的东西的物理内存,每个程序和内核自身都使用虚拟地址去访问内存。这些虚拟地址是连续的 —— 不用担心有空隙 —— 并且合适的大小也更便于操作。32 位的程序仅可以看到 32 位的地址,而不用管物理地址是 36 位还是更多位。
虽然虚拟地址对每个软件几乎是透明的,但是,处理器最终还是需要知道虚拟地址引用的物理地址是哪个。因此,有一个虚拟地址到物理地址的映射,它保存在一个被称为页面表的数据结构中。操作系统构建页面表,使用一个由处理器决定的布局,并且处理器和操作系统在虚拟地址和物理地址之间进行转换时就需要用到页面表。
这个映射过程是非常重要的,它也是现代操作系统和处理器的重要基础,处理器有专用的缓存 — Translation Lookaside Buffer(简称 TLB)—— 它保存了一定数量的虚拟地址到物理地址的映射,这样就不需要每次都使用全部页面。
虚拟内存的使用为我们提供了很多除了简单寻址之外的有用的特性。其中最主要的是,每个程序都有了自己独立的一组虚拟地址,有了它自己的一组虚拟地址到物理地址的映射。这就是用于提供“内存保护”的关键技术,一个程序不能破坏或者篡改其它程序使用的内存,因为其它程序的内存并不在它的地址映射范围之内。
由于每个进程使用一个单独的映射,因此每个程序也就有了一个额外的页面表,这就使得 TLB 缓存很拥挤。TLB 并不大 —— 一般情况下总共可以容纳几百个映射 —— 而系统使用的页面表越多,TLB 能够包含的任何特定的虚拟地址到物理地址的映射就越少。
### 一半一半
为了更好地使用 TLB,每个主流的操作系统都将虚拟地址范围一分为二。一半用于程序;另一半用于内核。当进程切换时,仅有一半的页面表条目发生变化 —— 仅属于程序的那一半。内核的那一半是每个程序公用的(因为只有一个内核)并且因此它可以为每个进程使用相同的页面表映射。这对 TLB 的帮助非常大;虽然它仍然会丢弃属于进程的那一半内存地址映射;但是它还保持着另一半属于内核的映射。
这种设计并不是一成不变的。在 Linux 上做了一项工作,使它可以为一个 32 位的进程提供整个地址范围,而不用在内核页面表和每个进程之间共享。虽然这样为程序提供了更多的地址空间,但这是以牺牲性能为代价的,因为每次内核代码需要运行时,TLB 重新加载内核的页面表条目。因此,这种方法并没有广泛应用到 x86 的系统上。
在内核和每个程序之间分割虚拟地址的这种做法的一个负面影响是,内存保护被削弱了。如果内核有它自己的一组页面表和虚拟地址,它将在不同的程序之间提供相同的保护;内核内存将是简单的不可见。但是使用地址分割之后,用户程序和内核使用了相同的地址范围,并且从原理上来说,一个用户程序有可能去读写内核内存。
为避免这种明显不好的情况,处理器和虚拟地址系统有一个 “Ring” 或者 “模式”的概念。x86 处理器有许多 Ring,但是对于这个问题,仅有两个是相关的:“user” (Ring 3)和 “supervisor”(ring 0)。当运行普通的用户程序时,处理器将置为用户模式 (Ring 3)。当运行内核代码时,处理器将处于 Ring 0 —— supervisor 模式,也称为内核模式。
这些 Ring 也用于从用户程序中保护内核内存。页面表并不仅仅有虚拟地址到物理地址的映射;它也包含关于这些地址的元数据,包含哪个 Ring 可能访问哪个地址的信息。内核页面表条目被标记为仅有 Ring 0 可以访问;程序的条目被标记为任何 Ring 都可以访问。如果一个处于 Ring 3 中的进程去尝试访问标记为 Ring 0 的内存,处理器将阻止这个访问并生成一个意外错误信息。运行在 Ring 3 中的用户程序不能得到内核以及运行在 Ring 0 内存中的任何东西。
至少理论上是这样的。大量的补丁和更新表明,这个地方已经被突破了。这就是最大的谜团所在。
### Ring 间迁移
这就是我们所知道的。每个现代处理器都执行一定数量的推测运行。例如,给一些指令,让两个数加起来,然后将结果保存在内存中,在查明内存中的目标是否可访问和可写入之前,一个处理器可能已经推测性地做了加法。在一些常见案例中,在地址可写入的地方,处理器节省了一些时间,因为它以并行方式计算出内存中的目标是什么。如果它发现目标位置不可写入 —— 例如,一个程序尝试去写入到一个没有映射的地址或压根就不存在的物理位置 —— 然后它将产生一个意外错误,而推测运行就白做了。
Intel 处理器,尤其是([虽然不是 AMD 的](https://lkml.org/lkml/2017/12/27/2))允许对 Ring 3 代码进行推测运行并写入到 Ring 0 内存中的处理器上。处理器并不完全阻止这种写入,但是推测运行轻微扰乱了处理器状态,因为,为了查明目标位置是否可写入,某些数据已经被加载到缓存和 TLB 中。这又意味着一些操作可能快几个周期,或者慢几个周期,这取决于它们所需要的数据是否仍然在缓存中。除此之外,Intel 的处理器还有一些特殊的功能,比如,在 Skylake 处理器上引入的软件保护扩展(SGX)指令,它改变了一点点访问内存的方式。同样的,处理器仍然是保护 Ring 0 的内存不被来自 Ring 3 的程序所访问,但是同样的,它的缓存和其它内部状态已经发生了变化,产生了可测量的差异。
我们至今仍然并不知道具体的情况,到底有多少内核的内存信息泄露给了用户程序,或者信息泄露的情况有多容易发生。以及有哪些 Intel 处理器会受到影响?也或者并不完全清楚,但是,有迹象表明每个 Intel 芯片都使用了推测运行(是自 1995 年 Pentium Pro 以来的所有主流处理器吗?),它们都可能会因此而泄露信息。
这个问题第一次被披露是由来自 [奥地利的 Graz Technical University](https://gruss.cc/files/kaiser.pdf) 的研究者。他们披露的信息表明这个问题已经足够破坏内核模式地址空间布局随机化(内核 ASLR,或称 KASLR)。ASLR 是防范 [缓冲区溢出](https://arstechnica.com/information-technology/2015/08/how-security-flaws-work-the-buffer-overflow/) 漏洞利用的最后一道防线。启用 ASLR 之后,程序和它们的数据被置于随机的内存地址中,它将使一些安全漏洞利用更加困难。KASLR 将这种随机化应用到内核中,这样就使内核的数据(包括页面表)和代码也随机化分布。
Graz 的研究者开发了 [KAISER](https://github.com/IAIK/KAISER),一组防范这个问题的 Linux 内核补丁。
如果这个问题正好使 ASLR 的随机化被破坏了,这或许将成为一个巨大的灾难。ASLR 是一个非常强大的保护措施,但是它并不是完美的,这意味着对于黑客来说将是一个很大的障碍,一个无法逾越的障碍。整个行业对此的反应是 —— Windows 和 Linux 都有一个非常重要的变化,秘密开发 —— 这表明不仅是 ASLR 被破坏了,而且从内核泄露出信息的更普遍的技术被开发出来了。确实是这样的,研究者已经 [在 Twitter 上发布信息](https://twitter.com/brainsmoke/status/948561799875502080),他们已经可以随意泄露和读取内核数据了。另一种可能是,漏洞可能被用于从虚拟机中“越狱”,并可能会危及 hypervisor。
Windows 和 Linux 选择的解决方案是非常相似的,将 KAISER 分为两个区域:内核页面表的条目不再是由每个进程共享。在 Linux 中,这被称为内核页面表隔离(KPTI)。
应用补丁后,内存地址仍然被一分为二:这样使内核的那一半几乎是空的。当然它并不是非常的空,因为一些内核片断需要永久映射,不论进程是运行在 Ring 3 还是 Ring 0 中,它都几乎是空的。这意味着如果恶意用户程序尝试去探测内核内存以及泄露信息,它将会失败 —— 因为那里几乎没有信息。而真正的内核页面中只有当内核自身运行的时刻它才能被用到。
这样做就破坏了最初将地址空间分割的理由。现在,每次切换到用户程序时,TLB 需要实时去清除与内核页面表相关的所有条目,这样就失去了启用分割带来的性能提升。
影响的具体大小取决于工作负载。每当一个程序被调入到内核 —— 从磁盘读入、发送数据到网络、打开一个文件等等 —— 这种调用的成本可能会增加一点点,因为它强制 TLB 清除了缓存并实时加载内核页面表。不使用内核的程序可能会观测到 2 - 3 个百分点的性能影响 —— 这里仍然有一些开销,因为内核仍然是偶尔会运行去处理一些事情,比如多任务等等。
但是大量调用进入到内核的工作负载将观测到很大的性能损失。在一个基准测试中,一个除了调入到内核之外什么都不做的程序,观察到 [它的性能下降大约为 50%](https://twitter.com/grsecurity/status/947257569906757638);换句话说就是,打补丁后每次对内核的调用的时间要比不打补丁调用内核的时间增加一倍。基准测试使用的 Linux 的网络回环(loopback)也观测到一个很大的影响,比如,在 Postgres 的基准测试中大约是 [17%](https://www.postgresql.org/message-id/[email protected])。真实的数据库负载使用了实时网络可能观测到的影响要低一些,因为使用实时网络时,内核调用的开销基本是使用真实网络的开销。
虽然对 Intel 系统的影响是众所周知的,但是它们可能并不是唯一受影响的。其它的一些平台,比如 SPARC 和 IBM 的 S390,是不受这个问题影响的,因为它们的处理器的内存管理并不需要分割地址空间和共享内核页面表;在这些平台上的操作系统一直就是将它们的内核页面表从用户模式中隔离出来的。但是其它的,比如 ARM,可能就没有这么幸运了;[适用于 ARM Linux 的类似补丁](https://lwn.net/Articles/740393/) 正在开发中。
---
[PETER BRIGHT](https://arstechnica.com/author/peter-bright) 是 Ars 的一位技术编辑。他涉及微软、编程及软件开发、Web 技术和浏览器、以及安全方面。它居住在纽约的布鲁克林。
---
via: <https://arstechnica.com/gadgets/2018/01/whats-behind-the-intel-design-flaw-forcing-numerous-patches/>
作者:[PETER BRIGHT](https://arstechnica.com/author/peter-bright/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Both Windows and Linux are receiving significant security updates that can, in the worst case, cause performance to drop by half, to defend against a problem that as yet hasn't been fully disclosed.
Patches to the Linux kernel have been trickling in over the past few weeks. Microsoft has been [testing the Windows updates in the Insider program since November](https://twitter.com/aionescu/status/930412525111296000), and it is expected to put the alterations into mainstream Windows builds on Patch Tuesday next week. Microsoft's Azure has scheduled maintenance next week, and Amazon's AWS is scheduled for maintenance on Friday—presumably related.
Since the Linux patches [first came to light](https://lwn.net/SubscriberLink/741878/eb6c9d3913d7cb2b/), a clearer picture of what seems to be wrong has emerged. While Linux and Windows differ in many regards, the basic elements of how these two operating systems—and indeed, every other x86 operating system such as FreeBSD and [macOS](https://twitter.com/aionescu/status/948609809540046849)—handle system memory is the same, because these parts of the operating system are so tightly coupled to the capabilities of the processor.
## Keeping track of addresses
Every byte of memory in a system is implicitly numbered, those numbers being each byte's address. The very earliest operating systems operated using physical memory addresses, but physical memory addresses are inconvenient for lots of reasons. For example, there are often gaps in the addresses, and (particularly on 32-bit systems), physical addresses can be awkward to manipulate, requiring 36-bit numbers, or even larger ones.
Accordingly, modern operating systems all depend on a broad concept called virtual memory. Virtual memory systems allow both programs and the kernels themselves to operate in a simple, clean, uniform environment. Instead of the physical addresses with their gaps and other oddities, every program, and the kernel itself, uses virtual addresses to access memory. These virtual addresses are contiguous—no need to worry about gaps—and sized conveniently to make them easy to manipulate. 32-bit programs see only 32-bit addresses, even if the physical address requires 36-bit or more numbering. |
9,388 | Torrents(种子):你需要知道的一切事情 | http://www.linuxandubuntu.com/home/torrents-everything-you-need-to-know | 2018-03-01T09:00:00 | [
"Torrent",
"种子"
] | https://linux.cn/article-9388-1.html | Torrents(种子):你需要知道的一切事情
=======================

**Torrents(种子)** — 每次听到这个词时,在我的脑海里想到的唯一的事情就是免费的电影、游戏、和被破解的软件。但是我们并不知道它们是如何工作的,在“种子”中涉及到各种概念。因此,通过这篇文章我们从技术的角度来了解**种子下载**是什么。
### “种子”是什么?
“种子”是一个到因特网上文件位置的链接。它们不是一个文件,它们仅仅是动态指向到你想去下载的原始文件上。
例如:如果你点击 [Google Chrome](https://www.google.com/chrome/),你可以从谷歌的服务器上下载 Google Chrome 浏览器。
如果你明天、或者下周、或者下个月再去点击那个链接,这个文件仍然可以从谷歌服务器上去下载。
但是当我们使用“种子”下载时,它并没有固定的服务器。文件是从以前使用“种子”下载的其它人的个人电脑上下载的。
### Torrents 是如何工作的?
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/torrent_orig.png)
假设 ‘A’ 上有一些视频,它希望以“种子”方式去下载。因此,他创建了一个“种子”,并将这个链接发送给 ‘B’,这个链接包含了那个视频在因特网上的准确 IP 地址的信息。因此,当 ‘B’ 开始下载那个文件的时候,‘B’ 连接到 ‘A’ 的计算机。在 ‘B’ 下载完成这个视频之后,‘B’ 将开始做为种子,也就是 ‘B’ 将允许其它的 ‘C’ 或者 ‘D’ 从 ‘B’ 的计算机上下载它。
因此每个人先下载文件然后会上传,下载的人越多,下载的速度也越快。并且在任何情况下,如果想停止上传,也没有问题,随时可以。这样做并不会成为什么问题,除非很多的人下载而上传的人很少。
### 播种者和索取者
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/seeders_orig.png)
下载完成特定文件的用户将会即刻做为上传者,因此,可以被新用户下载的已下载者称为播种者。
而一些还没有完成特定文件的下载者,并且还正在下载的用户称为索取者。
### 块
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/peers_orig.png)
所有的“种子”文件都独立分割成固定大小的数据包,因此,它们可以非线性顺序和随机顺序下载。每个块都有唯一的标识,因此,一旦所有的块下载完成之后,它们会被拼接出原始文件。
正是因为这种机制,如果你正在从某人处下载一个文件,假如这个时候因某些原因他停止了上传,你可以继续从其它的播种者处继续下载,而不需要从头开始重新下载。
### 对端
对端是指当前连接到你的索取者。一个正在上传的索取者,不论它下载了多少块,它就是一个对端。
**例如:**
一个已经下载了文件的前 50 个块的用户就是一个索取者,但是,他又同时上传这些文件,而你只有前 10 个块,因此,你可以从他那里下载最多 50 个块。这时候他就成了你的对端。
### 最佳实践
当你下载一个“种子”时,总是选择最大的播种者。这就是最佳经验。
这里并没有最小的标准,但是只要确保你选择的是最大的那一个播种者就可以了。
### “种子”相关的法律
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/torrent-laws_orig.png)
“种子”相关的法律和其它的法律并没有什么区别,对受版权保护的其它任何东西一样,侵权行为会受到法律的制裁。大多数的政府都拦截“种子”站点和协议,但是“种子”下载本身并不是有害的东西。
“种子”对快速分享文件是非常有用的,并且它们被用来共享开源社区的软件,因为它们能节约大量的服务器资源。但是,许多人却因为盗版而使用它们。
### 结束语
Torrenting 是降低服务器上负载的一个非常完美的技术。“种子”下载可以使我们将下载速度提升到网卡的极限,这是非常好的。但是,在这种非中心化的服务器上,盗版成为一种必然发生的事。限制我们分享的内容,从不去下载盗版的东西,这是我们的道德责任。
请在下面的评论中分享你使用“种子”的心得,分享你喜欢的、法律许可下载的“种子”网站。
---
via: <http://www.linuxandubuntu.com/home/torrents-everything-you-need-to-know>
作者:[LINUXANDUBUNTU](http://www.linuxandubuntu.com) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,389 | 关于处理器你所需要知道的一切 | http://www.theitstuff.com/processors-everything-need-know | 2018-02-27T06:46:55 | [
"CPU",
"处理器"
] | https://linux.cn/article-9389-1.html | [](http://www.theitstuff.com/wp-content/uploads/2017/10/processors-all-you-need-to-know.jpg)
我们的手机、主机以及笔记本电脑这样的数字设备已经变得如此成熟,以至于它们进化成为我们的一部分,而不只是一种设备。
在应用和软件的帮助下,处理器执行许多任务。我们是否曾经想过是什么给了这些软件这样的能力?它们是如何执行它们的逻辑的?它们的大脑在哪?
我们知道 CPU (或称处理器)是那些需要处理数据和执行逻辑任务的设备的大脑。
[](http://www.theitstuff.com/wp-content/uploads/2017/10/download.jpg)
在处理器的深处有那些不一样的概念呢?它们是如何演化的?一些处理器是如何做到比其它处理器更快的?让我们来看看关于处理器的主要术语,以及它们是如何影响处速度的。
### 架构
处理器有不同的架构,你一定遇到过不同类型的程序说它们是 64 位或 32 位的,这其中的意思就是程序支持特定的处理器架构。
如果一颗处理器是 32 位的架构,这意味着这颗处理器能够在一个处理周期内处理一个 32 位的数据。
同理可得,64 位的处理器能够在一个周期内处理一个 64 位的数据。
同时,你可以使用的内存大小决定于处理器的架构,你可以使用的内存总量为 2 的处理器架构的幂次方(如:`2^64`)。
16 位架构的处理器,仅仅有 64 kb 的内存使用。32 位架构的处理器,最大可使用的 RAM 是 4 GB,64 位架构的处理器的可用内存是 16 EB。
### 核心
在电脑上,核心是基本的处理单元。核心接收指令并且执行它。越多的核心带来越快的速度。把核心比作工厂里的工人,越多的工人使工作能够越快的完成。另一方面,工人越多,你所付出的薪水也就越多,工厂也会越拥挤;相对于核心来说,越多的核心消耗更多的能量,比核心少的 CPU 更容易发热。
### 时钟速度
[](http://www.theitstuff.com/wp-content/uploads/2017/10/download-1.jpg)
GHz 是 GigaHertz 的简写,Giga 意思是 10 亿次,Hertz (赫兹)意思是一秒有几个周期,2 GHz 的处理器意味着处理器一秒能够执行 20 亿个周期 。
它也以“频率”或者“时钟速度”而熟知。这项数值越高,CPU 的性能越好。
### CPU 缓存
CPU 缓存是处理器内部的一块小的存储单元,用来存储一些内存。不管如何,我们需要执行一些任务时,数据需要从内存传递到 CPU,CPU 的工作速度远快于内存,CPU 在大多数时间是在等待从内存传递过来的数据,而此时 CPU 是处于空闲状态的。为了解决这个问题,内存持续的向 CPU 缓存发送数据。
一般的处理器会有 2 ~ 3 Mb 的 CPU 缓存。高端的处理器会有 6 Mb 的 CPU 缓存,越大的缓存,意味着处理器更好。
### 印刷工艺
晶体管的大小就是处理器平板印刷的大小,尺寸通常是纳米,更小的尺寸意味者更紧凑。这可以让你有更多的核心,更小的面积,更小的能量消耗。
最新的 Intel 处理器有 14 nm 的印刷工艺。
### 热功耗设计(TDP)
代表着平均功耗,单位是瓦特,是在全核心激活以基础频率来处理 Intel 定义的高复杂度的负载时,处理器所散失的功耗。
所以,越低的热功耗设计对你越好。一个低的热功耗设计不仅可以更好的利用能量,而且产生更少的热量。
[](http://www.theitstuff.com/wp-content/uploads/2017/10/download-2.jpg)
桌面版的处理器通常消耗更多的能量,热功耗消耗的能量能在 40% 以上,相对应的移动版本只有不到桌面版本的 1/3。
### 内存支持
我们已经提到了处理器的架构是如何影响到我们能够使用的内存总量,但这只是理论上而已。在实际的应用中,我们所能够使用的内存的总量对于处理器的规格来说是足够的,它通常是由处理器规格详细规定的。
[](http://www.theitstuff.com/wp-content/uploads/2017/10/images.jpg)
它也指出了内存所支持的 DDR 的版本号。
### 超频
前面我们讲过时钟频率,超频是程序强迫 CPU 执行更多的周期。游戏玩家经常会使他们的处理器超频,以此来获得更好的性能。这样确实会增加速度,但也会增加消耗的能量,产生更多的热量。
一些高端的处理器允许超频,如果我们想让一个不支持超频的处理器超频,我们需要在主板上安装一个新的 BIOS 。 这样通常会成功,但这种情况是不安全的,也是不建议的。
### 超线程(HT)
如果不能添加核心以满足特定的处理需要,那么超线程是建立一个虚拟核心的方式。
如果一个双核处理器有超线程,那么这个双核处理器就有两个物理核心和两个虚拟核心,在技术上讲,一个双核处理器拥有四个核心。
### 结论
处理器有许多相关的数据,这些对数字设备来说是最重要的部分。我们在选择设备时,我们应该在脑海中仔细的检查处理器在上面提到的数据。
时钟速度、核心数、CPU 缓存,以及架构是最重要的数据。印刷尺寸以及热功耗设计重要性差一些 。
仍然有疑惑? 欢迎评论,我会尽快回复的。
---
via: <http://www.theitstuff.com/processors-everything-need-know>
作者:[Rishabh Kandari](http://www.theitstuff.com/author/reevkandari) 译者:[singledo](https://github.com/singledo) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 520 | null |
|
9,390 | 学习用工具来驾驭 Git 历史 | https://ieftimov.com/learn-your-tools-navigating-git-history | 2018-02-27T17:03:11 | [
"git",
"历史"
] | https://linux.cn/article-9390-1.html | 
在你的日常工作中,不可能每天都从头开始去开发一个新的应用程序。而真实的情况是,在日常工作中,我们大多数时候所面对的都是遗留下来的一个代码库,去修改一些特性的内容或者现存的一些代码行,这是我们在日常工作中很重要的一部分。而这也就是分布式版本控制系统 `git` 的价值所在。现在,我们来深入了解怎么去使用 `git` 的历史以及如何很轻松地去浏览它的历史。
### Git 历史
首先和最重要的事是,什么是 `git` 历史?正如其名字一样,它是一个 `git` 仓库的提交历史。它包含一堆提交信息,其中有它们的作者的名字、该提交的哈希值以及提交日期。查看一个 `git` 仓库历史的方法很简单,就是一个 `git log` 命令。
>
> *旁注:为便于本文的演示,我们使用 Ruby on Rails 的仓库的 `master` 分支。之所以选择它的理由是因为,Rails 有良好的 `git` 历史,漂亮的提交信息、引用以及对每个变更的解释。如果考虑到代码库的大小、维护者的年龄和数量,Rails 肯定是我见过的最好的仓库。当然了,我并不是说其它的 `git` 仓库做的不好,它只是我见过的比较好的一个仓库。*
>
>
>
那么,回到 Rails 仓库。如果你在 Ralis 仓库上运行 `git log`。你将看到如下所示的输出:
```
commit 66ebbc4952f6cfb37d719f63036441ef98149418
Author: Arthur Neves <[email protected]>
Date: Fri Jun 3 17:17:38 2016 -0400
Dont re-define class SQLite3Adapter on test
We were declaring in a few tests, which depending of the order load will cause an error, as the super class could change.
see https://github.com/rails/rails/commit/ac1c4e141b20c1067af2c2703db6e1b463b985da#commitcomment-17731383
commit 755f6bf3d3d568bc0af2c636be2f6df16c651eb1
Merge: 4e85538 f7b850e
Author: Eileen M. Uchitelle <[email protected]>
Date: Fri Jun 3 10:21:49 2016 -0400
Merge pull request #25263 from abhishekjain16/doc_accessor_thread
[skip ci] Fix grammar
commit f7b850ec9f6036802339e965c8ce74494f731b4a
Author: Abhishek Jain <[email protected]>
Date: Fri Jun 3 16:49:21 2016 +0530
[skip ci] Fix grammar
commit 4e85538dddf47877cacc65cea6c050e349af0405
Merge: 082a515 cf2158c
Author: Vijay Dev <[email protected]>
Date: Fri Jun 3 14:00:47 2016 +0000
Merge branch 'master' of github.com:rails/docrails
Conflicts:
guides/source/action_cable_overview.md
commit 082a5158251c6578714132e5c4f71bd39f462d71
Merge: 4bd11d4 3bd30d9
Author: Yves Senn <[email protected]>
Date: Fri Jun 3 11:30:19 2016 +0200
Merge pull request #25243 from sukesan1984/add_i18n_validation_test
Add i18n_validation_test
commit 4bd11d46de892676830bca51d3040f29200abbfa
Merge: 99d8d45 e98caf8
Author: Arthur Nogueira Neves <[email protected]>
Date: Thu Jun 2 22:55:52 2016 -0400
Merge pull request #25258 from alexcameron89/master
[skip ci] Make header bullets consistent in engines.md
commit e98caf81fef54746126d31076c6d346c48ae8e1b
Author: Alex Kitchens <[email protected]>
Date: Thu Jun 2 21:26:53 2016 -0500
[skip ci] Make header bullets consistent in engines.md
```
正如你所见,`git log` 展示了提交的哈希、作者及其 email 以及该提交创建的日期。当然,`git` 输出的可定制性很强大,它允许你去定制 `git log` 命令的输出格式。比如说,我们只想看提交信息的第一行,我们可以运行 `git log --oneline`,它将输出一个更紧凑的日志:
```
66ebbc4 Dont re-define class SQLite3Adapter on test
755f6bf Merge pull request #25263 from abhishekjain16/doc_accessor_thread
f7b850e [skip ci] Fix grammar4e85538 Merge branch 'master' of github.com:rails/docrails
082a515 Merge pull request #25243 from sukesan1984/add_i18n_validation_test
4bd11d4 Merge pull request #25258 from alexcameron89/master
e98caf8 [skip ci] Make header bullets consistent in engines.md
99d8d45 Merge pull request #25254 from kamipo/fix_debug_helper_test
818397c Merge pull request #25240 from matthewd/reloadable-channels
2c5a8ba Don't blank pad day of the month when formatting dates
14ff8e7 Fix debug helper test
```
如果你想看 `git log` 的全部选项,我建议你去查阅 `git log` 的 man 页面,你可以在一个终端中输入 `man git-log` 或者 `git help log` 来获得。
>
> *小提示:如果你觉得 `git log` 看起来太恐怖或者过于复杂,或者你觉得看它太无聊了,我建议你去寻找一些 `git` 的 GUI 或命令行工具。在之前,我使用过 [GitX](http://gitx.frim.nl/) ,我觉得它很不错,但是,由于我看命令行更“亲切”一些,在我尝试了 [tig](https://github.com/jonas/tig) 之后,就再也没有去用过它。*
>
>
>
### 寻找尼莫
现在,我们已经知道了关于 `git log` 命令的一些很基础的知识之后,我们来看一下,在我们的日常工作中如何使用它更加高效地浏览历史。
假如,我们怀疑在 `String#classify` 方法中有一个预期之外的行为,我们希望能够找出原因,并且定位出实现它的代码行。
为达到上述目的,你可以使用的第一个命令是 `git grep`,通过它可以找到这个方法定义在什么地方。简单来说,这个命令输出了匹配特定模式的那些行。现在,我们来找出定义它的方法,它非常简单 —— 我们对 `def classify` 运行 grep,然后看到的输出如下:
```
➜ git grep 'def classify'
activesupport/lib/active_support/core_ext/string/inflections.rb: def classifyactivesupport/lib/active_support/inflector/methods.rb: def classify(table_name)tools/profile: def classify
```
现在,虽然我们已经看到这个方法是在哪里创建的,但是,并不能够确定它是哪一行。如果,我们在 `git grep` 命令上增加 `-n` 标志,`git` 将提供匹配的行号:
```
➜ git grep -n 'def classify'
activesupport/lib/active_support/core_ext/string/inflections.rb:205: def classifyactivesupport/lib/active_support/inflector/methods.rb:186: def classify(table_name)tools/profile:112: def classify
```
更好看了,是吧?考虑到上下文,我们可以很轻松地找到,这个方法在 `activesupport/lib/active_support/core_ext/string/inflections.rb` 的第 205 行的 `classify` 方法,它看起来像这样,是不是很容易?
```
# Creates a class name from a plural table name like Rails does for table names to models.
# Note that this returns a string and not a class. (To convert to an actual class
# follow +classify+ with +constantize+.)
#
# 'ham_and_eggs'.classify # => "HamAndEgg"
# 'posts'.classify # => "Post"
def classify
ActiveSupport::Inflector.classify(self)
end
```
尽管我们找到的这个方法是在 `String` 上的一个常见的调用,它调用了 `ActiveSupport::Inflector` 上的另一个同名的方法。根据之前的 `git grep` 的结果,我们可以很轻松地发现结果的第二行, `activesupport/lib/active_support/inflector/methods.rb` 在 186 行上。我们正在寻找的方法是这样的:
```
# Creates a class name from a plural table name like Rails does for table
# names to models. Note that this returns a string and not a Class (To
# convert to an actual class follow +classify+ with constantize).
#
# classify('ham_and_eggs') # => "HamAndEgg"
# classify('posts') # => "Post"
#
# Singular names are not handled correctly:
#
# classify('calculus') # => "Calculus"
def classify(table_name)
# strip out any leading schema name
camelize(singularize(table_name.to_s.sub(/.*\./, ''.freeze)))
end
```
酷!考虑到 Rails 仓库的大小,我们借助 `git grep` 找到它,用时都没有超越 30 秒。
### 那么,最后的变更是什么?
现在,我们已经找到了所要找的方法,现在,我们需要搞清楚这个文件所经历的变更。由于我们已经知道了正确的文件名和行数,我们可以使用 `git blame`。这个命令展示了一个文件中每一行的最后修订者和修订的内容。我们来看一下这个文件最后的修订都做了什么:
```
git blame activesupport/lib/active_support/inflector/methods.rb
```
虽然我们得到了这个文件每一行的最后的变更,但是,我们更感兴趣的是对特定方法(176 到 189 行)的最后变更。让我们在 `git blame` 命令上增加一个选项,让它只显示那些行的变化。此外,我们将在命令上增加一个 `-s` (忽略)选项,去跳过那一行变更时的作者名字和修订(提交)的时间戳:
```
git blame -L 176,189 -s activesupport/lib/active_support/inflector/methods.rb
9fe8e19a 176) #Creates a class name from a plural table name like Rails does for table
5ea3f284 177) # names to models. Note that this returns a string and not a Class (To
9fe8e19a 178) # convert to an actual class follow +classify+ with #constantize).
51cd6bb8 179) #
6d077205 180) # classify('ham_and_eggs') # => "HamAndEgg"
9fe8e19a 181) # classify('posts') # => "Post"
51cd6bb8 182) #
51cd6bb8 183) # Singular names are not handled correctly:
5ea3f284 184) #
66d6e7be 185) # classify('calculus') # => "Calculus"
51cd6bb8 186) def classify(table_name)
51cd6bb8 187) # strip out any leading schema name
5bb1d4d2 188) camelize(singularize(table_name.to_s.sub(/.*\./, ''.freeze)))
51cd6bb8 189) end
```
现在,`git blame` 命令的输出展示了指定行的全部内容以及它们各自的修订。让我们来看一下指定的修订,换句话说就是,每个变更都修订了什么,我们可以使用 `git show` 命令。当指定一个修订哈希(像 `66d6e7be`)作为一个参数时,它将展示这个修订的全部内容。包括作者名字、时间戳以及完整的修订内容。我们来看一下 188 行最后的修订都做了什么?
```
git show 5bb1d4d2
```
你亲自做实验了吗?如果没有做,我直接告诉你结果,这个令人惊叹的 [提交](https://github.com/rails/rails/commit/5bb1d4d288d019e276335465d0389fd2f5246bfd) 是由 [Schneems](https://twitter.com/schneems) 完成的,他通过使用 frozen 字符串做了一个非常有趣的性能优化,这在我们当前的场景中是非常有意义的。但是,由于我们在这个假设的调试会话中,这样做并不能告诉我们当前问题所在。因此,我们怎么样才能够通过研究来发现,我们选定的方法经过了哪些变更?
### 搜索日志
现在,我们回到 `git` 日志,现在的问题是,怎么能够看到 `classify` 方法经历了哪些修订?
`git log` 命令非常强大,因此它提供了非常多的列表选项。我们尝试使用 `-p` 选项去看一下保存了这个文件的 `git` 日志内容,这个选项的意思是在 `git` 日志中显示这个文件的完整补丁:
```
git log -p activesupport/lib/active_support/inflector/methods.rb
```
这将给我们展示一个很长的修订列表,显示了对这个文件的每个修订。但是,正如下面所显示的,我们感兴趣的是对指定行的修订。对命令做一个小的修改,只显示我们希望的内容:
```
git log -L 176,189:activesupport/lib/active_support/inflector/methods.rb
```
`git log` 命令接受 `-L` 选项,它用一个行的范围和文件名做为参数。它的格式可能有点奇怪,格式解释如下:
```
git log -L <start-line>,<end-line>:<path-to-file>
```
当我们运行这个命令之后,我们可以看到对这些行的一个修订列表,它将带我们找到创建这个方法的第一个修订:
```
commit 51xd6bb829c418c5fbf75de1dfbb177233b1b154
Author: Foo Bar <[email protected]>
Date: Tue Jun 7 19:05:09 2011 -0700
Refactor
diff--git a/activesupport/lib/active_support/inflector/methods.rb b/activesupport/lib/active_support/inflector/methods.rb
--- a/activesupport/lib/active_support/inflector/methods.rb
+++ b/activesupport/lib/active_support/inflector/methods.rb
@@ -58,0 +135,14 @@
+ # Create a class name from a plural table name like Rails does for table names to models.
+ # Note that this returns a string and not a Class. (To convert to an actual class
+ # follow +classify+ with +constantize+.)
+ #
+ # Examples:
+ # "egg_and_hams".classify # => "EggAndHam"
+ # "posts".classify # => "Post"
+ #
+ # Singular names are not handled correctly:
+ # "business".classify # => "Busines"
+ def classify(table_name)
+ # strip out any leading schema name
+ camelize(singularize(table_name.to_s.sub(/.*\./, '')))
+ end
```
现在,我们再来看一下 —— 它是在 2011 年提交的。`git` 可以让我们重回到这个时间。这是一个很好的例子,它充分说明了足够的提交信息对于重新了解当时的上下文环境是多么的重要,因为从这个提交信息中,我们并不能获得足够的信息来重新理解当时的创建这个方法的上下文环境,但是,话说回来,你**不应该**对此感到恼怒,因为,你看到的这些项目,它们的作者都是无偿提供他们的工作时间和精力来做开源工作的。(向开源项目贡献者致敬!)
回到我们的正题,我们并不能确认 `classify` 方法最初实现是怎么回事,考虑到这个第一次的提交只是一个重构。现在,如果你认为,“或许、有可能、这个方法不在 176 行到 189 行的范围之内,那么就你应该在这个文件中扩大搜索范围”,这样想是对的。我们看到在它的修订提交的信息中提到了“重构”这个词,它意味着这个方法可能在那个文件中是真实存在的,而且是在重构之后它才存在于那个行的范围内。
但是,我们如何去确认这一点呢?不管你信不信,`git` 可以再次帮助你。`git log` 命令有一个 `-S` 选项,它可以传递一个特定的字符串作为参数,然后去查找代码变更(添加或者删除)。也就是说,如果我们执行 `git log -S classify` 这样的命令,我们可以看到所有包含 `classify` 字符串的变更行的提交。
如果你在 Ralis 仓库上运行上述命令,首先你会发现这个命令运行有点慢。但是,你应该会发现 `git` 实际上解析了在那个仓库中的所有修订来匹配这个字符串,其实它的运行速度是非常快的。在你的指尖下 `git` 再次展示了它的强大之处。因此,如果去找关于 `classify` 方法的第一个修订,我们可以运行如下的命令:
```
git log -S 'def classify'
```
它将返回所有这个方法的引用和修改的地方。如果你一直往下看,你将看到日志中它的最后的提交:
```
commit db045dbbf60b53dbe013ef25554fd013baf88134
Author: David Heinemeier Hansson <[email protected]>
Date: Wed Nov 24 01:04:44 2004 +0000
Initial
git-svn-id: http://svn-commit.rubyonrails.org/rails/trunk@4 5ecf4fe2-1ee6-0310-87b1-e25e094e27de
```
很酷!是吧?它初次被提交到 Rails,是由 DHH 在一个 `svn` 仓库上做的!这意味着 `classify` 大概在一开始就被提交到了 Rails 仓库。现在,我们去看一下这个提交的所有变更信息,我们运行如下的命令:
```
git show db045dbbf60b53dbe013ef25554fd013baf88134
```
非常好!我们终于找到它的根源了。现在,我们使用 `git log -S 'def classify'` 的输出,结合 `git log -L` 命令来跟踪这个方法都发生了哪些变更。
### 下次见
当然,我们并没有真的去修改任何 bug,因为我们只是去尝试使用一些 `git` 命令,来演示如何查看 `classify` 方法的演变历史。但是不管怎样,`git` 是一个非常强大的工具,我们必须学好它、用好它。我希望这篇文章可以帮助你掌握更多的关于如何使用 `git` 的知识。
你喜欢这些内容吗?
---
作者简介:
后端工程师,对 Ruby、Go、微服务、构建弹性架构来解决大规模部署带来的挑战很感兴趣。我在阿姆斯特丹的 Rails Girls 担任顾问,维护着一个小而精的列表,并且经常为开源做贡献。
那个列表是我写的关于软件开发、编程语言以及任何我感兴趣的东西。
---
via: <https://ieftimov.com/learn-your-tools-navigating-git-history>
作者:[Ilija Eftimov](https://ieftimov.com/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,391 | 如何在 Ubuntu 安装 Go 语言编写的 Git 服务器 Gogs | https://www.howtoforge.com/tutorial/how-to-install-gogs-go-git-service-on-ubuntu-1604/ | 2018-02-27T22:31:57 | [
"Gogs",
"Go",
"Git"
] | https://linux.cn/article-9391-1.html | 
Gogs 是由 Go 语言编写的,自由开源的 Git 服务。Gogs 是一款无痛式自托管的 Git 服务器,能在尽可能小的硬件资源开销上搭建并运行您的私有 Git 服务器。Gogs 的网页界面和 GitHub 十分相近,且提供 MySQL、PostgreSQL 和 SQLite 数据库支持。
在本教程中,我们将使用 Gogs 在 Ununtu 16.04 上按步骤指导您安装和配置您的私有 Git 服务器。这篇教程中涵盖了如何在 Ubuntu 上安装 Go 语言、PostgreSQL 和安装并且配置 Nginx 网页服务器作为 Go 应用的反向代理的细节内容。
### 搭建环境
* Ubuntu 16.04
* Root 权限
### 我们将会接触到的事物
1. 更新和升级系统
2. 安装和配置 PostgreSQL
3. 安装 Go 和 Git
4. 安装 Gogs
5. 配置 Gogs
6. 运行 Gogs 服务器
7. 安装和配置 Nginx 反向代理
8. 测试
### 步骤 1 - 更新和升级系统
继续之前,更新 Ubuntu 所有的库,升级所有包。
运行下面的 `apt` 命令:
```
sudo apt update
sudo apt upgrade
```
### 步骤 2 - 安装和配置 PostgreSQL
Gogs 提供 MySQL、PostgreSQL、SQLite 和 TiDB 数据库系统支持。
此步骤中,我们将使用 PostgreSQL 作为 Gogs 程序的数据库。
使用下面的 `apt` 命令安装 PostgreSQL。
```
sudo apt install -y postgresql postgresql-client libpq-dev
```
安装完成之后,启动 PostgreSQL 服务并设置为开机启动。
```
systemctl start postgresql
systemctl enable postgresql
```
此时 PostgreSQL 数据库在 Ubuntu 系统上完成安装了。
之后,我们需要为 Gogs 创建数据库和用户。
使用 `postgres` 用户登录并运行 `psql` 命令以访问 PostgreSQL 操作界面。
```
su - postgres
psql
```
创建一个名为 `git` 的新用户,给予此用户 `CREATEDB` 权限。
```
CREATE USER git CREATEDB;
\password git
```
创建名为 `gogs_production` 的数据库,设置 `git` 用户作为其所有者。
```
CREATE DATABASE gogs_production OWNER git;
```
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/1.png)
用于 Gogs 的 `gogs_production` PostgreSQL 数据库和 `git` 用户已经创建完毕。
### 步骤 3 - 安装 Go 和 Git
使用下面的 `apt` 命令从库中安装 Git。
```
sudo apt install git
```
此时,为系统创建名为 `git` 的新用户。
```
sudo adduser --disabled-login --gecos 'Gogs' git
```
登录 `git` 账户并且创建名为 `local` 的目录。
```
su - git
mkdir -p /home/git/local
```
切换到 `local` 目录,依照下方所展示的内容,使用 `wget` 命令下载 Go(最新版)。
```
cd ~/local
wget https://dl.google.com/go/go1.9.2.linux-amd64.tar.gz
```
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/2.png)
解压并且删除 go 的压缩文件。
```
tar -xf go1.9.2.linux-amd64.tar.gz
rm -f go1.9.2.linux-amd64.tar.gz
```
Go 二进制文件已经被下载到 `~/local/go` 目录。此时我们需要设置环境变量 - 设置 `GOROOT` 和 `GOPATH` 目录到系统环境,这样,我们就可以在 `git` 用户下执行 `go` 命令。
执行下方的命令。
```
cd ~/
echo 'export GOROOT=$HOME/local/go' >> $HOME/.bashrc
echo 'export GOPATH=$HOME/go' >> $HOME/.bashrc
echo 'export PATH=$PATH:$GOROOT/bin:$GOPATH/bin' >> $HOME/.bashrc
```
之后通过运行 `source ~/.bashrc` 重载 Bash,如下:
```
source ~/.bashrc
```
确定您使用的 Bash 是默认的 shell。
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/3.png)
现在运行 `go` 的版本查看命令。
```
go version
```
之后确保您得到下图所示的结果。
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/4.png)
现在,Go 已经安装在系统的 `git` 用户下了。
### 步骤 4 - 使用 Gogs 安装 Git 服务
使用 `git` 用户登录并且使用 `go` 命令从 GitHub 下载 Gogs。
```
su - git
go get -u github.com/gogits/gogs
```
此命令将在 `GOPATH/src` 目录下载 Gogs 的所有源代码。
切换至 `$GOPATH/src/github.com/gogits/gogs` 目录,并且使用下列命令搭建 Gogs。
```
cd $GOPATH/src/github.com/gogits/gogs
go build
```
确保您没有遇到错误。
现在使用下面的命令运行 Gogs Go Git 服务器。
```
./gogs web
```
此命令将会默认运行 Gogs 在 3000 端口上。
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/5.png)
打开网页浏览器,键入您的 IP 地址和端口号,我的是 <http://192.168.33.10:3000/> 。
您应该会得到与下方一致的反馈。
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/6.png)
Gogs 已经在您的 Ubuntu 系统上安装完毕。现在返回到您的终端,并且键入 `Ctrl + C` 中止服务。
### 步骤 5 - 配置 Gogs Go Git 服务器
本步骤中,我们将为 Gogs 创建惯例配置。
进入 Gogs 安装目录并新建 `custom/conf` 目录。
```
cd $GOPATH/src/github.com/gogits/gogs
mkdir -p custom/conf/
```
复制默认的配置文件到 `custom` 目录,并使用 [vim](https://www.howtoforge.com/vim-basics) 修改。
```
cp conf/app.ini custom/conf/app.ini
vim custom/conf/app.ini
```
在 `[server]` 小节中,修改 `HOST_ADDR` 为 `127.0.0.1`。
```
[server]
PROTOCOL = http
DOMAIN = localhost
ROOT_URL = %(PROTOCOL)s://%(DOMAIN)s:%(HTTP_PORT)s/
HTTP_ADDR = 127.0.0.1
HTTP_PORT = 3000
```
在 `[database]` 选项中,按照您的数据库信息修改。
```
[database]
DB_TYPE = postgres
HOST = 127.0.0.1:5432
NAME = gogs_production
USER = git
PASSWD = aqwe123@#
```
保存并退出。
运行下面的命令验证配置项。
```
./gogs web
```
并且确保您得到如下的结果。
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/7.png)
Gogs 现在已经按照自定义配置下运行在 `localhost` 的 3000 端口上了。
### 步骤 6 - 运行 Gogs 服务器
这一步,我们将在 Ubuntu 系统上配置 Gogs 服务器。我们会在 `/etc/systemd/system` 目录下创建一个新的服务器配置文件 `gogs.service`。
切换到 `/etc/systemd/system` 目录,使用 [vim](https://www.howtoforge.com/vim-basics) 创建服务器配置文件 `gogs.service`。
```
cd /etc/systemd/system
vim gogs.service
```
粘贴下面的代码到 Gogs 服务器配置文件中。
```
[Unit]
Description=Gogs
After=syslog.target
After=network.target
After=mariadb.service mysqld.service postgresql.service memcached.service redis.service
[Service]
# Modify these two values and uncomment them if you have
# repos with lots of files and get an HTTP error 500 because
# of that
###
#LimitMEMLOCK=infinity
#LimitNOFILE=65535
Type=simple
User=git
Group=git
WorkingDirectory=/home/git/go/src/github.com/gogits/gogs
ExecStart=/home/git/go/src/github.com/gogits/gogs/gogs web
Restart=always
Environment=USER=git HOME=/home/git
[Install]
WantedBy=multi-user.target
```
之后保存并且退出。
现在可以重载系统服务器。
```
systemctl daemon-reload
```
使用下面的命令开启 Gogs 服务器并设置为开机启动。
```
systemctl start gogs
systemctl enable gogs
```
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/8.png)
Gogs 服务器现在已经运行在 Ubuntu 系统上了。
使用下面的命令检测:
```
netstat -plntu
systemctl status gogs
```
您应该会得到下图所示的结果。
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/9.png)
### 步骤 7 - 为 Gogs 安装和配置 Nginx 反向代理
在本步中,我们将为 Gogs 安装和配置 Nginx 反向代理。我们会在自己的库中调用 Nginx 包。
使用下面的命令添加 Nginx 库。
```
sudo add-apt-repository -y ppa:nginx/stable
```
此时更新所有的库并且使用下面的命令安装 Nginx。
```
sudo apt update
sudo apt install nginx -y
```
之后,进入 `/etc/nginx/sites-available` 目录并且创建虚拟主机文件 `gogs`。
```
cd /etc/nginx/sites-available
vim gogs
```
粘贴下面的代码到配置文件。
```
server {
listen 80;
server_name git.hakase-labs.co;
location / {
proxy_pass http://localhost:3000;
}
}
```
保存退出。
**注意:** 请使用您的域名修改 `server_name` 项。
现在激活虚拟主机并且测试 nginx 配置。
```
ln -s /etc/nginx/sites-available/gogs /etc/nginx/sites-enabled/
nginx -t
```
确保没有遇到错误,重启 Nginx 服务器。
```
systemctl restart nginx
```
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/10.png)
### 步骤 8 - 测试
打开您的网页浏览器并且输入您的 Gogs URL,我的是 <http://git.hakase-labs.co>
现在您将进入安装界面。在页面的顶部,输入您所有的 PostgreSQL 数据库信息。
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/11.png)
之后,滚动到底部,点击 “Admin account settings” 下拉选项。
输入您的管理者用户名和邮箱。
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/12.png)
之后点击 “Install Gogs” 按钮。
然后您将会被重定向到下图显示的 Gogs 用户面板。
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/13.png)
下面是 Gogs 的 “Admin Dashboard(管理员面板)”。
[](https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/14.png)
现在,Gogs 已经通过 PostgreSQL 数据库和 Nginx 网页服务器在您的 Ubuntu 16.04 上完成安装。
---
via: <https://www.howtoforge.com/tutorial/how-to-install-gogs-go-git-service-on-ubuntu-1604/>
作者:[Muhammad Arul](https://www.howtoforge.com/tutorial/server-monitoring-with-shinken-on-ubuntu-16-04/) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # How to Install Gogs Go Git Service on Ubuntu 16.04
### On this page
[Prerequisites](#prerequisites)[What we will do](#what-we-will-do)[Step 1 - Update and Upgrade System](#step-update-and-upgrade-system)[Step 2 - Install and Configure PostgreSQL](#step-install-and-configure-postgresql)[Step 3 - Install Go and Git](#step-install-go-and-git)[Step 4 - Install Gogs Go Git Service](#step-install-gogs-go-git-service)[Step 5 - Configure Gogs Go Git Service](#step-configure-gogs-go-git-service)[Step 6 - Running Gogs as a Service](#step-running-gogs-as-a-service)[Step 7 - Configure Nginx as a Reverse Proxy for Gogs](#step-configure-nginx-as-a-reverse-proxy-for-gogs)[Step 8 - Testing](#step-testing)[Reference](#reference)
Gogs is free and open source Git service written in Go language. Gogs is a painless self-hosted git service that allows you to create and run your own Git server on a minimal hardware server. Gogs web-UI is very similar to GitHub and offers support for MySQL, PostgreSQL, and SQLite database.
In this tutorial, we will show you step-by-step how to install and configure your own Git service using Gogs on Ubuntu 16.04. This tutorial will cover details including, how to install Go on Ubuntu system, install PostgreSQL, and install and configure Nginx web server as a reverse proxy for Go application.
## Prerequisites
- Ubuntu 16.04
- Root privileges
## What we will do
- Update and Upgrade System
- Install and Configure PostgreSQL
- Install Go and Git
- Install Gogs
- Configure Gogs
- Running Gogs as a Service
- Install and Configure Nginx as a Reverse Proxy
- Testing
## Step 1 - Update and Upgrade System
Before going any further, update all Ubuntu repositories and upgrade all packages.
Run the apt commands below.
sudo apt update
sudo apt upgrade
## Step 2 - Install and Configure PostgreSQL
Gogs offers support for MySQL, PostgreSQL, SQLite3, MSSQL, and TiDB database systems.
In this guide, we will be using PostgreSQL as a database for our Gogs installations.
Install PostgreSQL using the apt command below.
sudo apt install -y postgresql postgresql-client libpq-dev
After the installation is complete, start the PostgreSQL service and enable it to launch everytime at system boot.
systemctl start postgresql
systemctl enable postgresql
PostgreSQL database has been installed on an Ubuntu system.
Next, we need to create a new database and user for Gogs.
Login as the 'postgres' user and run the 'psql' command to get the PostgreSQL shell.
su - postgres
psql
Create a new user named 'git', and give the user privileges for 'CREATEDB'.
CREATE USER git CREATEDB;
\password git
Create a database named 'gogs_production', and set the 'git' user as the owner of the database.
CREATE DATABASE gogs_production OWNER git;
New PostgreSQL database 'gogs_production' and user 'git' for Gogs installation has been created.
## Step 3 - Install Go and Git
Install Git from the repository using the apt command below.
sudo apt install git
Now add new user 'git' to the system.
sudo adduser --disabled-login --gecos 'Gogs' git
Login as the 'git' user and create a new 'local' directory.
su - git
mkdir -p /home/git/local
Go to the 'local' directory and download 'Go' (the latest version) using the wget command as shown below.
cd ~/local
wget https://dl.google.com/go/go1.9.2.linux-amd64.tar.gz
Extract the go compressed file, then remove it.
tar -xf go1.9.2.linux-amd64.tar.gz
rm -f go1.9.2.linux-amd64.tar.gz
'Go' binary file has been downloaded in the '~/local/go' directory. Now we need to setup the environment - we need to define the 'GOROOT' and 'GOPATH directories so we can run a 'go' command on the system under 'git' user.
Run all of the following commands.
cd ~/
echo 'export GOROOT=$HOME/local/go' >> $HOME/.bashrc
echo 'export GOPATH=$HOME/go' >> $HOME/.bashrc
echo 'export PATH=$PATH:$GOROOT/bin:$GOPATH/bin' >> $HOME/.bashrc
And reload Bash by running the 'source ~/.bashrc' command as shown below.
source ~/.bashrc
Make sure you're using Bash as your default shell.
Now run the 'go' command for checking the version.
go version
And make sure you get the result as shown in the following screenshot.
Go is now installed on the system under 'git' user.
## Step 4 - Install Gogs Go Git Service
Login as the 'git' user and download 'Gogs' from GitHub using the 'go' command.
su - git
go get -u github.com/gogits/gogs
The command will download all Gogs source code in the 'GOPATH/src' directory.
Go to the '$GOPATH/src/github.com/gogits/gogs' directory and build gogs using commands below.
cd $GOPATH/src/github.com/gogits/gogs
go build
And make sure you get no error.
Now run Gogs Go Git Service using the command below.
./gogs web
The command will run Gogs on the default port 3000.
Open your web browser and type your server IP address with port 3000, mine is http://192.168.33.10:3000/
And you should get the result as shown below.
Gogs is installed on the Ubuntu system. Now back to your terminal and press 'Ctrl + c' to exit.
## Step 5 - Configure Gogs Go Git Service
In this step, we will create a custom configuration for Gogs.
Goto the Gogs installation directory and create a new 'custom/conf' directory.
cd $GOPATH/src/github.com/gogits/gogs
mkdir -p custom/conf/
Copy default configuration to the custom directory and edit it using [vim](https://www.howtoforge.com/vim-basics).
cp conf/app.ini custom/conf/app.ini
vim custom/conf/app.ini
In the '**[server]**' section, change the server 'HOST_ADDR' with '127.0.0.1'.
[server]
PROTOCOL = http
DOMAIN = localhost
ROOT_URL = %(PROTOCOL)s://%(DOMAIN)s:%(HTTP_PORT)s/
HTTP_ADDR = 127.0.0.1
HTTP_PORT = 3000
In the '**[database]**' section, change everything with your own database info.
[database]
DB_TYPE = postgres
HOST = 127.0.0.1:5432
NAME = gogs_production
USER = git
PASSWD = aqwe123@#
Save and exit.
Now verify the configuration by running the command as shown below.
./gogs web
And make sure you get the result as following.
Gogs is now running with our custom configuration, under 'localhost' with port 3000.
## Step 6 - Running Gogs as a Service
In this step, we will configure Gogs as a service on Ubuntu system. We will create a new service file configuration 'gogs.service' under the '/etc/systemd/system' directory.
Go to the '/etc/systemd/system' directory and create a new service file 'gogs.service' using the [vim](https://www.howtoforge.com/vim-basics) editor.
cd /etc/systemd/system
vim gogs.service
Paste the following gogs service configuration there.
[Unit]
Description=Gogs
After=syslog.target
After=network.target
After=mariadb.service mysqld.service postgresql.service memcached.service redis.service
[Service]
# Modify these two values and uncomment them if you have
# repos with lots of files and get an HTTP error 500 because
# of that
###
#LimitMEMLOCK=infinity
#LimitNOFILE=65535
Type=simple
User=git
Group=git
WorkingDirectory=/home/git/go/src/github.com/gogits/gogs
ExecStart=/home/git/go/src/github.com/gogits/gogs/gogs web
Restart=always
Environment=USER=git HOME=/home/git
[Install]
WantedBy=multi-user.target
Save and exit.
Now reload the systemd services.
systemctl daemon-reload
Start gogs service and enable it to launch everytime at system boot using the systemctl command.
systemctl start gogs
systemctl enable gogs
Gogs is now running as a service on Ubuntu system.
Check it using the commands below.
netstat -plntu
systemctl status gogs
And you should get the result as shown below.
## Step 7 - Configure Nginx as a Reverse Proxy for Gogs
In this step, we will configure Nginx as a reverse proxy for Gogs. We will be using Nginx packages from its own repository.
Add Nginx repository using the add-apt command.
sudo add-apt-repository -y ppa:nginx/stable
Now update all Ubuntu repositories and install Nginx using the apt command below.
sudo apt update
sudo apt install nginx -y
Next, goto the '/etc/nginx/sites-available' directory and create new virtual host file 'gogs'.
cd /etc/nginx/sites-available
vim gogs
Paste the following configuration there.
server {
listen 80;
server_name git.hakase-labs.co;
location / {
proxy_pass http://localhost:3000;
}
}
Save and exit.
**Note:**
Change the 'server_name' line with your own domain name.
Now activate a new virtual host and test the nginx configuration.
ln -s /etc/nginx/sites-available/gogs /etc/nginx/sites-enabled/
nginx -t
Make sure there is no error, then restart the Nginx service.
systemctl restart nginx
## Step 8 - Testing
Open your web browser and type your gogs URL, mine is http://git.hakase-labs.co
Now you will get the installation page. On top of the page, type all of your PostgreSQL database info.
Now scroll to the bottom, and click the 'Admin account settings' dropdown.
Type your admin user, password, and email.
Then click the 'Install Gogs' button.
And you will be redirected to the Gogs user Dashboard as shown below.
Below is Gogs 'Admin Dashboard'.
Gogs is now installed with PostgreSQL database and Nginx web server on Ubuntu 16.04 server |
9,392 | 如何在 Linux/Unix 中不重启 Vim 而重新加载 .vimrc 文件 | https://www.cyberciti.biz/faq/how-to-reload-vimrc-file-without-restarting-vim-on-linux-unix/ | 2018-02-27T23:15:26 | [
"Vim"
] | https://linux.cn/article-9392-1.html | 
我是一位新的 Vim 编辑器用户。我通常使用 `:vs ~/.vimrc` 来加载 `~/.vimrc` 配置。而当编辑 `.vimrc` 时,我需要不重启 Vim 会话而重新加载它。在 Linux 或者类 Unix 系统中,如何在编辑 `.vimrc` 后,重新加载它而不用重启 Vim 呢?
Vim 是自由开源并且向上兼容 Vi 的编辑器。它可以用来编辑各种文本。它在编辑用 C/Perl/Python 编写的程序时特别有用。可以用它来编辑 Linux/Unix 配置文件。`~/.vimrc` 是你个人的 Vim 初始化和自定义文件。
### 如何在不重启 Vim 会话的情况下重新加载 .vimrc
在 Vim 中重新加载 `.vimrc` 而不重新启动的流程:
1. 输入 `vim filename` 启动 vim
2. 按下 `Esc` 接着输入 `:vs ~/.vimrc` 来加载 vim 配置
3. 像这样添加自定义配置:
```
filetype indent plugin on
set number
syntax on
```
4. 使用 `:wq` 保存文件,并从 `~/.vimrc` 窗口退出
5. 输入下面任一命令重载 `~/.vimrc`:`:so $MYVIMRC` 或者 `:source ~/.vimrc`。
[](https://www.cyberciti.biz/media/new/faq/2018/02/How-to-reload-.vimrc-file-without-restarting-vim.jpg)
*图1:编辑 ~/.vimrc 并在需要时重载它而不用退出 vim,这样你就可以继续编辑程序了*
`:so[urce]! {file}` 这个 vim 命令会从给定的文件比如 `~/.vimrc` 读取配置。就像你输入的一样,这些命令是在普通模式下执行的。当你在 `:global`、:`argdo`、 `:windo`、`:bufdo` 之后、循环中或者跟着另一个命令时,显示不会再在执行命令时更新。
### 如何设置按键来编辑并重载 ~/.vimrc
在你的 `~/.vimrc` 后面跟上这些:
```
" Edit vimr configuration file
nnoremap confe :e $MYVIMRC<CR>
" Reload vims configuration file
nnoremap confr :source $MYVIMRC<CR>
```
现在只要按下 `Esc` 接着输入 `confe` 就可以编辑 `~/.vimrc`。按下 `Esc` ,接着输入 `confr` 以重新加载。一些人喜欢在 `.vimrc` 中使用 `<Leader>` 键。因此上面的映射变成:
```
" Edit vimr configuration file
nnoremap <Leader>ve :e $MYVIMRC<CR>
" Reload vimr configuration file
nnoremap <Leader>vr :source $MYVIMRC<CR>
```
`<Leader>` 键默认映射成 `\` 键。因此只要输入 `\` 接着 `ve` 就能编辑文件。按下 `\` 接着 `vr` 就能重载 `~/vimrc`。
这就完成了,你可以不用再重启 Vim 就能重新加载 `.vimrc` 了。
### 关于作者
作者是 nixCraft 的创建者,经验丰富的系统管理员,也是 Linux / Unix shell 脚本的培训师。他曾与全球客户以及IT、教育、国防和太空研究以及非营利部门等多个行业合作。在 [Twitter][9]、[Facebook][10]、[Google +][11] 上关注他。通过[RSS/XML 订阅](https://www.cyberciti.biz/atom/atom.xml)获取最新的系统管理、Linux/Unix 以及开源主题教程。
---
via: <https://www.cyberciti.biz/faq/how-to-reload-vimrc-file-without-restarting-vim-on-linux-unix/>
作者:[Vivek Gite](https://www.cyberciti.biz/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,393 | 内核如何管理内存 | http://duartes.org/gustavo/blog/post/how-the-kernel-manages-your-memory/ | 2018-03-01T09:16:00 | [
"内存"
] | https://linux.cn/article-9393-1.html | 
在学习了进程的 [虚拟地址布局](/article-9255-1.html) 之后,让我们回到内核,来学习它管理用户内存的机制。这里再次使用 Gonzo:

Linux 进程在内核中是作为进程描述符 [task\_struct](http://lxr.linux.no/linux+v2.6.28.1/include/linux/sched.h#L1075) (LCTT 译注:它是在 Linux 中描述进程完整信息的一种数据结构)的实例来实现的。在 task\_struct 中的 [mm](http://lxr.linux.no/linux+v2.6.28.1/include/linux/sched.h#L1129) 域指向到**内存描述符**,[mm\_struct](http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L173) 是一个程序在内存中的执行摘要。如上图所示,它保存了起始和结束内存段,进程使用的物理内存页面的 [数量](http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L197)(RSS <ruby> 常驻内存大小 <rt> Resident Set Size </rt></ruby> )、虚拟地址空间使用的 [总数量](http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L206)、以及其它片断。 在内存描述符中,我们可以获悉它有两种管理内存的方式:**虚拟内存区域**集和**页面表**。Gonzo 的内存区域如下所示:

每个虚拟内存区域(VMA)是一个连续的虚拟地址范围;这些区域绝对不会重叠。一个 [vm\_area\_struct](http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L99) 的实例完整地描述了一个内存区域,包括它的起始和结束地址,[flags](http://lxr.linux.no/linux+v2.6.28/include/linux/mm.h#L76) 决定了访问权限和行为,并且 [vm\_file](http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L150) 域指定了映射到这个区域的文件(如果有的话)。(除了内存映射段的例外情况之外,)一个 VMA 是不能**匿名**映射文件的。上面的每个内存段(比如,堆、栈)都对应一个单个的 VMA。虽然它通常都使用在 x86 的机器上,但它并不是必需的。VMA 也不关心它们在哪个段中。
一个程序的 VMA 在内存描述符中是作为 [mmap](http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L174) 域的一个链接列表保存的,以起始虚拟地址为序进行排列,并且在 [mm\_rb](http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L175) 域中作为一个 [红黑树](http://en.wikipedia.org/wiki/Red_black_tree) 的根。红黑树允许内核通过给定的虚拟地址去快速搜索内存区域。在你读取文件 `/proc/pid_of_process/maps` 时,内核只是简单地读取每个进程的 VMA 的链接列表并[显示它们](http://lxr.linux.no/linux+v2.6.28.1/fs/proc/task_mmu.c#L201)。
在 Windows 中,[EPROCESS](http://www.nirsoft.net/kernel_struct/vista/EPROCESS.html) 块大致类似于一个 task\_struct 和 mm\_struct 的结合。在 Windows 中模拟一个 VMA 的是虚拟地址描述符,或称为 [VAD](http://www.nirsoft.net/kernel_struct/vista/MMVAD.html);它保存在一个 [AVL 树](http://en.wikipedia.org/wiki/AVL_tree) 中。你知道关于 Windows 和 Linux 之间最有趣的事情是什么吗?其实它们只有一点小差别。
4GB 虚拟地址空间被分配到**页面**中。在 32 位模式中的 x86 处理器中支持 4KB、2MB、以及 4MB 大小的页面。Linux 和 Windows 都使用大小为 4KB 的页面去映射用户的一部分虚拟地址空间。字节 0-4095 在页面 0 中,字节 4096-8191 在页面 1 中,依次类推。VMA 的大小 *必须是页面大小的倍数* 。下图是使用 4KB 大小页面的总数量为 3GB 的用户空间:

处理器通过查看**页面表**去转换一个虚拟内存地址到一个真实的物理内存地址。每个进程都有它自己的一组页面表;每当发生进程切换时,用户空间的页面表也同时切换。Linux 在内存描述符的 [pgd](http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L185) 域中保存了一个指向进程的页面表的指针。对于每个虚拟页面,页面表中都有一个相应的**页面表条目**(PTE),在常规的 x86 页面表中,它是一个简单的如下所示的大小为 4 字节的记录:

Linux 通过函数去 [读取](http://lxr.linux.no/linux+v2.6.28.1/arch/x86/include/asm/pgtable.h#L173) 和 [设置](http://lxr.linux.no/linux+v2.6.28.1/arch/x86/include/asm/pgtable.h#L230) PTE 条目中的每个标志位。标志位 P 告诉处理器这个虚拟页面是否**在**物理内存中。如果该位被清除(设置为 0),访问这个页面将触发一个页面故障。请记住,当这个标志位为 0 时,内核可以在剩余的域上**做任何想做的事**。R/W 标志位是读/写标志;如果被清除,这个页面将变成只读的。U/S 标志位表示用户/超级用户;如果被清除,这个页面将仅被内核访问。这些标志都是用于实现我们在前面看到的只读内存和内核空间保护。
标志位 D 和 A 用于标识页面是否是“**脏的**”或者是已**被访问过**。一个脏页面表示已经被写入,而一个被访问过的页面则表示有一个写入或者读取发生过。这两个标志位都是粘滞位:处理器只能设置它们,而清除则是由内核来完成的。最终,PTE 保存了这个页面相应的起始物理地址,它们按 4KB 进行整齐排列。这个看起来不起眼的域是一些痛苦的根源,因为它限制了物理内存最大为 [4 GB](http://www.google.com/search?hl=en&amp;amp;amp;amp;q=2%5E20+*+2%5E12+bytes+in+GB)。其它的 PTE 域留到下次再讲,因为它是涉及了物理地址扩展的知识。
由于在一个虚拟页面上的所有字节都共享一个 U/S 和 R/W 标志位,所以内存保护的最小单元是一个虚拟页面。但是,同一个物理内存可能被映射到不同的虚拟页面,这样就有可能会出现相同的物理内存出现不同的保护标志位的情况。请注意,在 PTE 中是看不到运行权限的。这就是为什么经典的 x86 页面上允许代码在栈上被执行的原因,这样会很容易导致挖掘出栈缓冲溢出漏洞(可能会通过使用 [return-to-libc](http://en.wikipedia.org/wiki/Return-to-libc_attack) 和其它技术来找出非可执行栈)。由于 PTE 缺少禁止运行标志位说明了一个更广泛的事实:在 VMA 中的权限标志位有可能或可能不完全转换为硬件保护。内核只能做它能做到的,但是,最终的架构限制了它能做的事情。
虚拟内存不保存任何东西,它只是简单地 *映射* 一个程序的地址空间到底层的物理内存上。物理内存被当作一个称之为**物理地址空间**的巨大块而由处理器访问。虽然内存的操作[涉及到某些](http://duartes.org/gustavo/blog/post/getting-physical-with-memory)总线,我们在这里先忽略它,并假设物理地址范围从 0 到可用的最大值按字节递增。物理地址空间被内核进一步分解为**页面帧**。处理器并不会关心帧的具体情况,这一点对内核也是至关重要的,因为,**页面帧是物理内存管理的最小单元**。Linux 和 Windows 在 32 位模式下都使用 4KB 大小的页面帧;下图是一个有 2 GB 内存的机器的例子:

在 Linux 上每个页面帧是被一个 [描述符](http://lxr.linux.no/linux+v2.6.28/include/linux/mm_types.h#L32) 和 [几个标志](http://lxr.linux.no/linux+v2.6.28/include/linux/page-flags.h#L14) 来跟踪的。通过这些描述符和标志,实现了对机器上整个物理内存的跟踪;每个页面帧的具体状态是公开的。物理内存是通过使用 [Buddy 内存分配](http://en.wikipedia.org/wiki/Buddy_memory_allocation) (LCTT 译注:一种内存分配算法)技术来管理的,因此,如果一个页面帧可以通过 Buddy 系统分配,那么它是**未分配的**(free)。一个被分配的页面帧可以是**匿名的**、持有程序数据的、或者它可能处于页面缓存中、持有数据保存在一个文件或者块设备中。还有其它的异形页面帧,但是这些异形页面帧现在已经不怎么使用了。Windows 有一个类似的页面帧号(Page Frame Number (PFN))数据库去跟踪物理内存。
我们把虚拟内存区域(VMA)、页面表条目(PTE),以及页面帧放在一起来理解它们是如何工作的。下面是一个用户堆的示例:

蓝色的矩形框表示在 VMA 范围内的页面,而箭头表示页面表条目映射页面到页面帧。一些缺少箭头的虚拟页面,表示它们对应的 PTE 的当前标志位被清除(置为 0)。这可能是因为这个页面从来没有被使用过,或者是它的内容已经被交换出去了。在这两种情况下,即便这些页面在 VMA 中,访问它们也将导致产生一个页面故障。对于这种 VMA 和页面表的不一致的情况,看上去似乎很奇怪,但是这种情况却经常发生。
一个 VMA 像一个在你的程序和内核之间的合约。你请求它做一些事情(分配内存、文件映射、等等),内核会回应“收到”,然后去创建或者更新相应的 VMA。 但是,它 *并不立刻* 去“兑现”对你的承诺,而是它会等待到发生一个页面故障时才去 *真正* 做这个工作。内核是个“懒惰的家伙”、“不诚实的人渣”;这就是虚拟内存的基本原理。它适用于大多数的情况,有一些类似情况和有一些意外的情况,但是,它是规则是,VMA 记录 *约定的* 内容,而 PTE 才反映这个“懒惰的内核” *真正做了什么*。通过这两种数据结构共同来管理程序的内存;它们共同来完成解决页面故障、释放内存、从内存中交换出数据、等等。下图是内存分配的一个简单案例:

当程序通过 [brk()](http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html) 系统调用来请求一些内存时,内核只是简单地 [更新](http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L2050) 堆的 VMA 并给程序回复“已搞定”。而在这个时候并没有真正地分配页面帧,并且新的页面也没有映射到物理内存上。一旦程序尝试去访问这个页面时,处理器将发生页面故障,然后调用 [do\_page\_fault()](http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L583)。这个函数将使用 [find\_vma()](http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1466) 去 [搜索](http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L692) 发生页面故障的 VMA。如果找到了,然后在 VMA 上进行权限检查以防范恶意访问(读取或者写入)。如果没有合适的 VMA,也没有所尝试访问的内存的“合约”,将会给进程返回段故障。
当[找到](http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L711)了一个合适的 VMA,内核必须通过查找 PTE 的内容和 VMA 的类型去[处理](http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2653)故障。在我们的案例中,PTE 显示这个页面是 [不存在的](http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2674)。事实上,我们的 PTE 是全部空白的(全部都是 0),在 Linux 中这表示虚拟内存还没有被映射。由于这是匿名 VMA,我们有一个完全的 RAM 事务,它必须被 [do\_anonymous\_page()](http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2681) 来处理,它分配页面帧,并且用一个 PTE 去映射故障虚拟页面到一个新分配的帧。
有时候,事情可能会有所不同。例如,对于被交换出内存的页面的 PTE,在当前(Present)标志位上是 0,但它并不是空白的。而是在交换位置仍有页面内容,它必须从磁盘上读取并且通过 [do\_swap\_page()](http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2280) 来加载到一个被称为 [major fault](http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2316) 的页面帧上。
这是我们通过探查内核的用户内存管理得出的前半部分的结论。在下一篇文章中,我们通过将文件加载到内存中,来构建一个完整的内存框架图,以及对性能的影响。
---
via: <http://duartes.org/gustavo/blog/post/how-the-kernel-manages-your-memory/>
作者:[Gustavo Duarte](http://duartes.org/gustavo/blog/about/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,394 | 20 个 OpenSSH 最佳安全实践 | https://www.cyberciti.biz/tips/linux-unix-bsd-openssh-server-best-practices.html | 2018-02-28T15:45:00 | [
"SSH",
"OpenSSH"
] | https://linux.cn/article-9394-1.html | 
OpenSSH 是 SSH 协议的一个实现。一般通过 `scp` 或 `sftp` 用于远程登录、备份、远程文件传输等功能。SSH能够完美保障两个网络或系统间数据传输的保密性和完整性。尽管如此,它最大的优势是使用公匙加密来进行服务器验证。时不时会出现关于 OpenSSH 零日漏洞的[传言](https://isc.sans.edu/diary/OpenSSH+Rumors/6742)。本文将描述如何设置你的 Linux 或类 Unix 系统以提高 sshd 的安全性。
### OpenSSH 默认设置
* TCP 端口 - 22
* OpenSSH 服务配置文件 - `sshd_config` (位于 `/etc/ssh/`)
### 1、 基于公匙的登录
OpenSSH 服务支持各种验证方式。推荐使用公匙加密验证。首先,使用以下 `ssh-keygen` 命令在本地电脑上创建密匙对:
>
> 1024 位或低于它的 DSA 和 RSA 加密是很弱的,请不要使用。当考虑 ssh 客户端向后兼容性的时候,请使用 RSA密匙代替 ECDSA 密匙。所有的 ssh 密钥要么使用 ED25519 ,要么使用 RSA,不要使用其它类型。
>
>
>
```
$ ssh-keygen -t key_type -b bits -C "comment"
```
示例:
```
$ ssh-keygen -t ed25519 -C "Login to production cluster at xyz corp"
或
$ ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa_aws_$(date +%Y-%m-%d) -C "AWS key for abc corp clients"
```
下一步,使用 `ssh-copy-id` 命令安装公匙:
```
$ ssh-copy-id -i /path/to/public-key-file user@host
或
$ ssh-copy-id user@remote-server-ip-or-dns-name
```
示例:
```
$ ssh-copy-id vivek@rhel7-aws-server
```
提示输入用户名和密码的时候,确认基于 ssh 公匙的登录是否工作:
```
$ ssh vivek@rhel7-aws-server
```
[](https://www.cyberciti.biz/tips/wp-content/uploads/2009/07/OpenSSH-server-security-best-practices.png)
更多有关 ssh 公匙的信息,参照以下文章:
* [为备份脚本设置无密码安全登录](https://www.cyberciti.biz/faq/ssh-passwordless-login-with-keychain-for-scripts/)
* [sshpass:使用脚本密码登录 SSH 服务器](/article-8086-1.html)
* [如何为一个 Linux/类 Unix 系统设置 SSH 登录密匙](https://www.cyberciti.biz/faq/how-to-set-up-ssh-keys-on-linux-unix/)
* [如何使用 Ansible 工具上传 ssh 登录授权公匙](https://www.cyberciti.biz/faq/how-to-upload-ssh-public-key-to-as-authorized_key-using-ansible/)
### 2、 禁用 root 用户登录
禁用 root 用户登录前,确认普通用户可以以 root 身份登录。例如,允许用户 vivek 使用 `sudo` 命令以 root 身份登录。
#### 在 Debian/Ubuntu 系统中如何将用户 vivek 添加到 sudo 组中
允许 sudo 组中的用户执行任何命令。 [将用户 vivek 添加到 sudo 组中](https://www.cyberciti.biz/faq/how-to-create-a-sudo-user-on-ubuntu-linux-server/):
```
$ sudo adduser vivek sudo
```
使用 [id 命令](https://www.cyberciti.biz/faq/unix-linux-id-command-examples-usage-syntax/ "See Linux/Unix id command examples for more info") 验证用户组。
```
$ id vivek
```
#### 在 CentOS/RHEL 系统中如何将用户 vivek 添加到 sudo 组中
在 CentOS/RHEL 和 Fedora 系统中允许 wheel 组中的用户执行所有的命令。使用 `usermod` 命令将用户 vivek 添加到 wheel 组中:
```
$ sudo usermod -aG wheel vivek
$ id vivek
```
#### 测试 sudo 权限并禁用 ssh root 登录
测试并确保用户 vivek 可以以 root 身份登录执行以下命令:
```
$ sudo -i
$ sudo /etc/init.d/sshd status
$ sudo systemctl status httpd
```
添加以下内容到 `sshd_config` 文件中来禁用 root 登录:
```
PermitRootLogin no
ChallengeResponseAuthentication no
PasswordAuthentication no
UsePAM no
```
更多信息参见“[如何通过禁用 Linux 的 ssh 密码登录来增强系统安全](https://www.cyberciti.biz/faq/how-to-disable-ssh-password-login-on-linux/)” 。
### 3、 禁用密码登录
所有的密码登录都应该禁用,仅留下公匙登录。添加以下内容到 `sshd_config` 文件中:
```
AuthenticationMethods publickey
PubkeyAuthentication yes
```
CentOS 6.x/RHEL 6.x 系统中老版本的 sshd 用户可以使用以下设置:
```
PubkeyAuthentication yes
```
### 4、 限制用户的 ssh 访问
默认状态下,所有的系统用户都可以使用密码或公匙登录。但是有些时候需要为 FTP 或者 email 服务创建 UNIX/Linux 用户。然而,这些用户也可以使用 ssh 登录系统。他们将获得访问系统工具的完整权限,包括编译器和诸如 Perl、Python(可以打开网络端口干很多疯狂的事情)等的脚本语言。通过添加以下内容到 `sshd_config` 文件中来仅允许用户 root、vivek 和 jerry 通过 SSH 登录系统:
```
AllowUsers vivek jerry
```
当然,你也可以添加以下内容到 `sshd_config` 文件中来达到仅拒绝一部分用户通过 SSH 登录系统的效果。
```
DenyUsers root saroj anjali foo
```
你也可以通过[配置 Linux PAM](https://www.cyberciti.biz/tips/linux-pam-configuration-that-allows-or-deny-login-via-the-sshd-server.html) 来禁用或允许用户通过 sshd 登录。也可以允许或禁止一个[用户组列表](https://www.cyberciti.biz/tips/openssh-deny-or-restrict-access-to-users-and-groups.html)通过 ssh 登录系统。
### 5、 禁用空密码
你需要明确禁止空密码账户远程登录系统,更新 `sshd_config` 文件的以下内容:
```
PermitEmptyPasswords no
```
### 6、 为 ssh 用户或者密匙使用强密码
为密匙使用强密码和短语的重要性再怎么强调都不过分。暴力破解可以起作用就是因为用户使用了基于字典的密码。你可以强制用户避开[字典密码](https://www.cyberciti.biz/tips/linux-check-passwords-against-a-dictionary-attack.html)并使用[约翰的开膛手工具](https://www.cyberciti.biz/faq/unix-linux-password-cracking-john-the-ripper/)来检测弱密码。以下是一个随机密码生成器(放到你的 `~/.bashrc` 下):
```
genpasswd() {
local l=$1
[ "$l" == "" ] && l=20
tr -dc A-Za-z0-9_ < /dev/urandom | head -c ${l} | xargs
}
```
运行:
```
genpasswd 16
```
输出:
```
uw8CnDVMwC6vOKgW
```
* [使用 mkpasswd / makepasswd / pwgen 生成随机密码](https://www.cyberciti.biz/faq/generating-random-password/)
* [Linux / UNIX: 生成密码](https://www.cyberciti.biz/faq/linux-unix-generating-passwords-command/)
* [Linux 随机密码生成命令](https://www.cyberciti.biz/faq/linux-random-password-generator/)
### 7、 为 SSH 的 22端口配置防火墙
你需要更新 `iptables`/`ufw`/`firewall-cmd` 或 pf 防火墙配置来为 ssh 的 TCP 端口 22 配置防火墙。一般来说,OpenSSH 服务应该仅允许本地或者其他的远端地址访问。
#### Netfilter(Iptables) 配置
更新 [/etc/sysconfig/iptables (Redhat 和其派生系统特有文件)](https://www.cyberciti.biz/faq/rhel-fedorta-linux-iptables-firewall-configuration-tutorial/) 实现仅接受来自于 192.168.1.0/24 和 202.54.1.5/29 的连接,输入:
```
-A RH-Firewall-1-INPUT -s 192.168.1.0/24 -m state --state NEW -p tcp --dport 22 -j ACCEPT
-A RH-Firewall-1-INPUT -s 202.54.1.5/29 -m state --state NEW -p tcp --dport 22 -j ACCEPT
```
如果同时使用 IPv6 的话,可以编辑 `/etc/sysconfig/ip6tables` (Redhat 和其派生系统特有文件),输入:
```
-A RH-Firewall-1-INPUT -s ipv6network::/ipv6mask -m tcp -p tcp --dport 22 -j ACCEPT
```
将 `ipv6network::/ipv6mask` 替换为实际的 IPv6 网段。
#### Debian/Ubuntu Linux 下的 UFW
[UFW 是 Uncomplicated FireWall 的首字母缩写,主要用来管理 Linux 防火墙](https://www.cyberciti.biz/faq/howto-configure-setup-firewall-with-ufw-on-ubuntu-linux/),目的是提供一种用户友好的界面。输入[以下命令使得系统仅允许网段 202.54.1.5/29 接入端口 22](https://www.cyberciti.biz/faq/ufw-allow-incoming-ssh-connections-from-a-specific-ip-address-subnet-on-ubuntu-debian/):
```
$ sudo ufw allow from 202.54.1.5/29 to any port 22
```
更多信息请参见 “[Linux:菜鸟管理员的 25 个 Iptables Netfilter 命令](https://www.cyberciti.biz/tips/linux-iptables-examples.html)”。
#### \*BSD PF 防火墙配置
如果使用 PF 防火墙 [/etc/pf.conf](https://bash.cyberciti.biz/firewall/pf-firewall-script/) 配置如下:
```
pass in on $ext_if inet proto tcp from {192.168.1.0/24, 202.54.1.5/29} to $ssh_server_ip port ssh flags S/SA synproxy state
```
### 8、 修改 SSH 端口和绑定 IP
ssh 默认监听系统中所有可用的网卡。修改并绑定 ssh 端口有助于避免暴力脚本的连接(许多暴力脚本只尝试端口 22)。更新文件 `sshd_config` 的以下内容来绑定端口 300 到 IP 192.168.1.5 和 202.54.1.5:
```
Port 300
ListenAddress 192.168.1.5
ListenAddress 202.54.1.5
```
当需要接受动态广域网地址的连接时,使用主动脚本是个不错的选择,比如 fail2ban 或 denyhosts。
### 9、 使用 TCP wrappers (可选的)
TCP wrapper 是一个基于主机的访问控制系统,用来过滤来自互联网的网络访问。OpenSSH 支持 TCP wrappers。只需要更新文件 `/etc/hosts.allow` 中的以下内容就可以使得 SSH 只接受来自于 192.168.1.2 和 172.16.23.12 的连接:
```
sshd : 192.168.1.2 172.16.23.12
```
在 Linux/Mac OS X 和类 UNIX 系统中参见 [TCP wrappers 设置和使用的常见问题](https://www.cyberciti.biz/faq/tcp-wrappers-hosts-allow-deny-tutorial/)。
### 10、 阻止 SSH 破解或暴力攻击
暴力破解是一种在单一或者分布式网络中使用大量(用户名和密码的)组合来尝试连接一个加密系统的方法。可以使用以下软件来应对暴力攻击:
* [DenyHosts](https://www.cyberciti.biz/faq/block-ssh-attacks-with-denyhosts/) 是一个基于 Python SSH 安全工具。该工具通过监控授权日志中的非法登录日志并封禁原始 IP 的方式来应对暴力攻击。
+ RHEL / Fedora 和 CentOS Linux 下如何设置 [DenyHosts](https://www.cyberciti.biz/faq/rhel-linux-block-ssh-dictionary-brute-force-attacks/)。
* [Fail2ban](https://www.fail2ban.org) 是另一个类似的用来预防针对 SSH 攻击的工具。
* [sshguard](https://sshguard.sourceforge.net/) 是一个使用 pf 来预防针对 SSH 和其他服务攻击的工具。
* [security/sshblock](http://www.bsdconsulting.no/tools/) 阻止滥用 SSH 尝试登录。
* [IPQ BDB filter](https://savannah.nongnu.org/projects/ipqbdb/) 可以看做是 fail2ban 的一个简化版。
### 11、 限制 TCP 端口 22 的传入速率(可选的)
netfilter 和 pf 都提供速率限制选项可以对端口 22 的传入速率进行简单的限制。
#### Iptables 示例
以下脚本将会阻止 60 秒内尝试登录 5 次以上的客户端的连入。
```
#!/bin/bash
inet_if=eth1
ssh_port=22
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --set
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --update --seconds 60 --hitcount 5
```
在你的 iptables 脚本中调用以上脚本。其他配置选项:
```
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state NEW -m limit --limit 3/min --limit-burst 3 -j ACCEPT
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
$IPT -A OUTPUT -o ${inet_if} -p tcp --sport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
# another one line example
# $IPT -A INPUT -i ${inet_if} -m state --state NEW,ESTABLISHED,RELATED -p tcp --dport 22 -m limit --limit 5/minute --limit-burst 5-j ACCEPT
```
其他细节参见 iptables 用户手册。
#### \*BSD PF 示例
以下脚本将限制每个客户端的连入数量为 20,并且 5 秒内的连接不超过 15 个。如果客户端触发此规则,则将其加入 abusive\_ips 表并限制该客户端连入。最后 flush 关键词杀死所有触发规则的客户端的连接。
```
sshd_server_ip = "202.54.1.5"
table <abusive_ips> persist
block in quick from <abusive_ips>
pass in on $ext_if proto tcp to $sshd_server_ip port ssh flags S/SA keep state (max-src-conn 20, max-src-conn-rate 15/5, overload <abusive_ips> flush)
```
### 12、 使用端口敲门(可选的)
[端口敲门](https://en.wikipedia.org/wiki/Port_knocking)是通过在一组预先指定的封闭端口上生成连接尝试,以便从外部打开防火墙上的端口的方法。一旦指定的端口连接顺序被触发,防火墙规则就被动态修改以允许发送连接的主机连入指定的端口。以下是一个使用 iptables 实现的端口敲门的示例:
```
$IPT -N stage1
$IPT -A stage1 -m recent --remove --name knock
$IPT -A stage1 -p tcp --dport 3456 -m recent --set --name knock2
$IPT -N stage2
$IPT -A stage2 -m recent --remove --name knock2
$IPT -A stage2 -p tcp --dport 2345 -m recent --set --name heaven
$IPT -N door
$IPT -A door -m recent --rcheck --seconds 5 --name knock2 -j stage2
$IPT -A door -m recent --rcheck --seconds 5 --name knock -j stage1
$IPT -A door -p tcp --dport 1234 -m recent --set --name knock
$IPT -A INPUT -m --state ESTABLISHED,RELATED -j ACCEPT
$IPT -A INPUT -p tcp --dport 22 -m recent --rcheck --seconds 5 --name heaven -j ACCEPT
$IPT -A INPUT -p tcp --syn -j door
```
更多信息请参见:
[Debian / Ubuntu: 使用 Knockd and Iptables 设置端口敲门](https://www.cyberciti.biz/faq/debian-ubuntu-linux-iptables-knockd-port-knocking-tutorial/)
### 13、 配置空闲超时注销时长
用户可以通过 ssh 连入服务器,可以配置一个超时时间间隔来避免无人值守的 ssh 会话。 打开 `sshd_config` 并确保配置以下值:
```
ClientAliveInterval 300
ClientAliveCountMax 0
```
以秒为单位设置一个空闲超时时间(300秒 = 5分钟)。一旦空闲时间超过这个值,空闲用户就会被踢出会话。更多细节参见[如何自动注销空闲超时的 BASH / TCSH / SSH 用户](https://www.cyberciti.biz/faq/linux-unix-login-bash-shell-force-time-outs/)。
### 14、 为 ssh 用户启用警示标语
更新 `sshd_config` 文件如下行来设置用户的警示标语:
```
Banner /etc/issue
```
`/etc/issue 示例文件:
```
----------------------------------------------------------------------------------------------
You are accessing a XYZ Government (XYZG) Information System (IS) that is provided for authorized use only.
By using this IS (which includes any device attached to this IS), you consent to the following conditions:
+ The XYZG routinely intercepts and monitors communications on this IS for purposes including, but not limited to,
penetration testing, COMSEC monitoring, network operations and defense, personnel misconduct (PM),
law enforcement (LE), and counterintelligence (CI) investigations.
+ At any time, the XYZG may inspect and seize data stored on this IS.
+ Communications using, or data stored on, this IS are not private, are subject to routine monitoring,
interception, and search, and may be disclosed or used for any XYZG authorized purpose.
+ This IS includes security measures (e.g., authentication and access controls) to protect XYZG interests--not
for your personal benefit or privacy.
+ Notwithstanding the above, using this IS does not constitute consent to PM, LE or CI investigative searching
or monitoring of the content of privileged communications, or work product, related to personal representation
or services by attorneys, psychotherapists, or clergy, and their assistants. Such communications and work
product are private and confidential. See User Agreement for details.
----------------------------------------------------------------------------------------------
```
以上是一个标准的示例,更多的用户协议和法律细节请咨询你的律师团队。
### 15、 禁用 .rhosts 文件(需核实)
禁止读取用户的 `~/.rhosts` 和 `~/.shosts` 文件。更新 `sshd_config` 文件中的以下内容:
```
IgnoreRhosts yes
```
SSH 可以模拟过时的 rsh 命令,所以应该禁用不安全的 RSH 连接。
### 16、 禁用基于主机的授权(需核实)
禁用基于主机的授权,更新 `sshd_config` 文件的以下选项:
```
HostbasedAuthentication no
```
### 17、 为 OpenSSH 和操作系统打补丁
推荐你使用类似 [yum](https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/)、[apt-get](https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html) 和 [freebsd-update](https://www.cyberciti.biz/tips/howto-keep-freebsd-system-upto-date.html) 等工具保持系统安装了最新的安全补丁。
### 18、 Chroot OpenSSH (将用户锁定在主目录)
默认设置下用户可以浏览诸如 `/etc`、`/bin` 等目录。可以使用 chroot 或者其他专有工具如 [rssh](https://www.cyberciti.biz/tips/rhel-centos-linux-install-configure-rssh-shell.html) 来保护 ssh 连接。从版本 4.8p1 或 4.9p1 起,OpenSSH 不再需要依赖诸如 rssh 或复杂的 chroot(1) 等第三方工具来将用户锁定在主目录中。可以使用新的 `ChrootDirectory` 指令将用户锁定在其主目录,参见[这篇博文](https://www.debian-administration.org/articles/590)。
### 19. 禁用客户端的 OpenSSH 服务
工作站和笔记本不需要 OpenSSH 服务。如果不需要提供 ssh 远程登录和文件传输功能的话,可以禁用 sshd 服务。CentOS / RHEL 用户可以使用 [yum 命令](https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ "See Linux/Unix yum command examples for more info") 禁用或删除 openssh-server:
```
$ sudo yum erase openssh-server
```
Debian / Ubuntu 用户可以使用 [apt 命令](https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ "See Linux/Unix apt command examples for more info")/[apt-get 命令](https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html "See Linux/Unix apt-get command examples for more info") 删除 openssh-server:
```
$ sudo apt-get remove openssh-server
```
有可能需要更新 iptables 脚本来移除 ssh 的例外规则。CentOS / RHEL / Fedora 系统可以编辑文件 `/etc/sysconfig/iptables` 和 `/etc/sysconfig/ip6tables`。最后[重启 iptables](https://www.cyberciti.biz/faq/howto-rhel-linux-open-port-using-iptables/) 服务:
```
# service iptables restart
# service ip6tables restart
```
### 20. 来自 Mozilla 的额外提示
如果使用 6.7+ 版本的 OpenSSH,可以尝试下[以下设置](https://wiki.mozilla.org/Security/Guidelines/OpenSSH):
```
#################[ WARNING ]########################
# Do not use any setting blindly. Read sshd_config #
# man page. You must understand cryptography to #
# tweak following settings. Otherwise use defaults #
####################################################
# Supported HostKey algorithms by order of preference.
HostKey /etc/ssh/ssh_host_ed25519_key
HostKey /etc/ssh/ssh_host_rsa_key
HostKey /etc/ssh/ssh_host_ecdsa_key
# Specifies the available KEX (Key Exchange) algorithms.
KexAlgorithms [email protected],ecdh-sha2-nistp521,ecdh-sha2-nistp384,ecdh-sha2-nistp256,diffie-hellman-group-exchange-sha256
# Specifies the ciphers allowed
Ciphers [email protected],[email protected],[email protected],aes256-ctr,aes192-ctr,aes128-ctr
#Specifies the available MAC (message authentication code) algorithms
MACs [email protected],[email protected],[email protected],hmac-sha2-512,hmac-sha2-256,[email protected]
# LogLevel VERBOSE logs user's key fingerprint on login. Needed to have a clear audit track of which key was using to log in.
LogLevel VERBOSE
# Log sftp level file access (read/write/etc.) that would not be easily logged otherwise.
Subsystem sftp /usr/lib/ssh/sftp-server -f AUTHPRIV -l INFO
```
使用以下命令获取 OpenSSH 支持的加密方法:
```
$ ssh -Q cipher
$ ssh -Q cipher-auth
$ ssh -Q mac
$ ssh -Q kex
$ ssh -Q key
```
[](https://www.cyberciti.biz/tips/wp-content/uploads/2009/07/OpenSSH-Security-Tutorial-Query-Ciphers-and-algorithms-choice.jpg)
### 如何测试 sshd\_config 文件并重启/重新加载 SSH 服务?
在重启 sshd 前检查配置文件的有效性和密匙的完整性,运行:
```
$ sudo sshd -t
```
扩展测试模式:
```
$ sudo sshd -T
```
最后,根据系统的的版本[重启 Linux 或类 Unix 系统中的 sshd 服务](https://www.cyberciti.biz/faq/howto-restart-ssh/):
```
$ [sudo systemctl start ssh][38] ## Debian/Ubunt Linux##
$ [sudo systemctl restart sshd.service][39] ## CentOS/RHEL/Fedora Linux##
$ doas /etc/rc.d/sshd restart ## OpenBSD##
$ sudo service sshd restart ## FreeBSD##
```
### 其他建议
1. [使用 2FA 加强 SSH 的安全性](https://www.cyberciti.biz/open-source/howto-protect-linux-ssh-login-with-google-authenticator/) - 可以使用 [OATH Toolkit](http://www.nongnu.org/oath-toolkit/) 或 [DuoSecurity](https://duo.com) 启用多重身份验证。
2. [基于密匙链的身份验证](https://www.cyberciti.biz/faq/ssh-passwordless-login-with-keychain-for-scripts/) - 密匙链是一个 bash 脚本,可以使得基于密匙的验证非常的灵活方便。相对于无密码密匙,它提供更好的安全性。
### 更多信息
* [OpenSSH 官方](https://www.openssh.com/) 项目。
* 用户手册: sshd(8)、ssh(1)、ssh-add(1)、ssh-agent(1)。
如果知道这里没用提及的方便的软件或者技术,请在下面的评论中分享,以帮助读者保持 OpenSSH 的安全。
### 关于作者
作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及 IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter](https://twitter.com/nixcraft)、[Facebook](https://facebook.com/nixcraft)、[Google+](https://plus.google.com/+CybercitiBiz) 上关注他。
---
via: <https://www.cyberciti.biz/tips/linux-unix-bsd-openssh-server-best-practices.html>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[shipsw](https://github.com/shipsw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,395 | 在 Linux 上安装必应桌面墙纸更换器 | https://www.2daygeek.com/bing-desktop-wallpaper-changer-linux-bing-photo-of-the-day/ | 2018-02-28T23:16:00 | [
"墙纸",
"bing"
] | https://linux.cn/article-9395-1.html | 你是否厌倦了 Linux 桌面背景,想要设置好看的壁纸,但是不知道在哪里可以找到?别担心,我们在这里会帮助你。
我们都知道必应搜索引擎,但是由于一些原因很少有人使用它,每个人都喜欢必应网站的背景壁纸,它是非常漂亮和惊人的高分辨率图像。
如果你想使用这些图片作为你的桌面壁纸,你可以手动下载它,但是很难去每天下载一个新的图片,然后把它设置为壁纸。这就是自动壁纸改变的地方。
[必应桌面墙纸更换器](https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer)会自动下载并将桌面壁纸更改为当天的必应照片。所有的壁纸都储存在 `/home/[user]/Pictures/BingWallpapers/`。
### 方法 1: 使用 Utkarsh Gupta Shell 脚本
这个小型 Python 脚本会自动下载并将桌面壁纸更改为当天的必应照片。该脚本在机器启动时自动运行,并工作于 GNU/Linux 上的 Gnome 或 Cinnamon 环境。它不需要手动工作,安装程序会为你做所有事情。
从 2.0+ 版本开始,该脚本的安装程序就可以像普通的 Linux 二进制命令一样工作,它会为某些任务请求 sudo 权限。
只需克隆仓库并切换到项目目录,然后运行 shell 脚本即可安装必应桌面墙纸更换器。
```
$ curl https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer/archive/master.zip
$ unzip master
$ cd bing-desktop-wallpaper-changer-master
```
运行 `installer.sh` 使用 `--install` 选项来安装必应桌面墙纸更换器。它会下载并设置必应照片为你的 Linux 桌面。
```
$ ./installer.sh --install
Bing-Desktop-Wallpaper-Changer
BDWC Installer v3_beta2
GitHub:
Contributors:
.
.
[sudo] password for daygeek: ******
.
Where do you want to install Bing-Desktop-Wallpaper-Changer?
Entering 'opt' or leaving input blank will install in /opt/bing-desktop-wallpaper-changer
Entering 'home' will install in /home/daygeek/bing-desktop-wallpaper-changer
Install Bing-Desktop-Wallpaper-Changer in (opt/home)? :Press Enter
Should we create bing-desktop-wallpaper-changer symlink to /usr/bin/bingwallpaper so you could easily execute it?
Create symlink for easy execution, e.g. in Terminal (y/n)? : y
Should bing-desktop-wallpaper-changer needs to autostart when you log in? (Add in Startup Application)
Add in Startup Application (y/n)? : y
.
.
Executing bing-desktop-wallpaper-changer...
Finished!!
```

要卸载该脚本:
```
$ ./installer.sh --uninstall
```
使用帮助页面了解更多关于此脚本的选项。
```
$ ./installer.sh --help
```
### 方法 2: 使用 GNOME Shell 扩展
这个轻量级 [GNOME shell 扩展](https://github.com/neffo/bing-wallpaper-gnome-extension),可将你的壁纸每天更改为微软必应的壁纸。它还会显示一个包含图像标题和解释的通知。
该扩展大部分基于 Elinvention 的 NASA APOD 扩展,受到了 Utkarsh Gupta 的 Bing Desktop WallpaperChanger 启发。
#### 特点
* 获取当天的必应壁纸并设置为锁屏和桌面墙纸(这两者都是用户可选的)
* 可强制选择某个特定区域(即地区)
* 为多个显示器自动选择最高分辨率(和最合适的墙纸)
* 可以选择在 1 到 7 天之后清理墙纸目录(删除最旧的)
* 只有当它们被更新时,才会尝试下载壁纸
* 不会持续进行更新 - 每天只进行一次,启动时也要进行一次(更新是在必应更新时进行的)
#### 如何安装
访问 [extenisons.gnome.org](https://extensions.gnome.org/extension/1262/bing-wallpaper-changer/) 网站并将切换按钮拖到 “ON”,然后点击 “Install” 按钮安装必应壁纸 GNOME 扩展。(LCTT 译注:页面上并没有发现 ON 按钮,但是有 Download 按钮)

安装必应壁纸 GNOME 扩展后,它会自动下载并为你的 Linux 桌面设置当天的必应照片,并显示关于壁纸的通知。

托盘指示器将帮助你执行少量操作,也可以打开设置。

根据你的要求自定义设置。

---
via: <https://www.2daygeek.com/bing-desktop-wallpaper-changer-linux-bing-photo-of-the-day/>
作者:[2daygeek](https://www.2daygeek.com/author/2daygeek/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,396 | 如何提供有帮助的回答 | https://jvns.ca/blog/answer-questions-well/ | 2018-03-01T22:10:18 | [
"提问",
"回答"
] | https://linux.cn/article-9396-1.html | 
如果你的同事问你一个不太清晰的问题,你会怎么回答?我认为提问题是一种技巧(可以看 [如何提出有意义的问题](https://jvns.ca/blog/good-questions/)) ,同时,合理地回答问题也是一种技巧,它们都是非常实用的。
一开始 —— 有时向你提问的人不尊重你的时间,这很糟糕。理想情况下,我们假设问你问题的人是一个理性的人并且正在尽力解决问题,而你想帮助他们。和我一起工作的人是这样,我所生活的世界也是这样。当然,现实生活并不是这样。
下面是有助于回答问题的一些方法!
### 如果他们的提问不清楚,帮他们澄清
通常初学者不会提出很清晰的问题,或者问一些对回答问题没有必要信息的问题。你可以尝试以下方法 澄清问题:
* **重述为一个更明确的问题**来回复他们(“你是想问 X 吗?”)
* **向他们了解更具体的他们并没有提供的信息** (“你使用 IPv6 ?”)
* **问是什么导致了他们的问题**。例如,有时有些人会进入我的团队频道,询问我们的<ruby> 服务发现 <rt> service discovery </rt></ruby>如何工作的。这通常是因为他们试图设置/重新配置服务。在这种情况下,如果问“你正在使用哪种服务?可以给我看看你正在处理的‘拉取请求’吗?”是有帮助的。
这些方法很多来自[如何提出有意义的问题](https://jvns.ca/blog/good-questions/)中的要点。(尽管我永远不会对某人说“噢,你得先看完《如何提出有意义的问题》这篇文章后再来向我提问)
### 弄清楚他们已经知道了什么
在回答问题之前,知道对方已经知道什么是非常有用的!
Harold Treen 给了我一个很好的例子:
>
> 前几天,有人请我解释 “Redux-Sagas”。与其深入解释,不如说 “它们就像监听 action 的工人线程,并可以让你更新 Redux store。
>
>
> 我开始搞清楚他们对 Redux、action、store 以及其他基本概念了解多少。将这些概念都联系在一起再来解释会容易得多。
>
>
>
弄清楚问你问题的人已经知道什么是非常重要的。因为有时他们可能会对基础概念感到疑惑(“Redux 是什么?”),或者他们可能是专家,但是恰巧遇到了微妙的<ruby> 极端情况 <rt> corner case </rt></ruby>。如果答案建立在他们不知道的概念上会令他们困惑,但如果重述他们已经知道的的又会是乏味的。
这里有一个很实用的技巧来了解他们已经知道什么 - 比如可以尝试用“你对 X 了解多少?”而不是问“你知道 X 吗?”。
### 给他们一个文档
“RTFM” (<ruby> “去读那些他妈的手册” <rt> Read The Fucking Manual </rt></ruby>)是一个典型的无用的回答,但事实上如果向他们指明一个特定的文档会是非常有用的!当我提问题的时候,我当然很乐意翻看那些能实际解决我的问题的文档,因为它也可能解决其他我想问的问题。
我认为明确你所给的文档的确能够解决问题是非常重要的,或者至少经过查阅后确认它对解决问题有帮助。否则,你可能将以下面这种情形结束对话(非常常见):
* Ali:我应该如何处理 X ?
* Jada:<文档链接>
* Ali: 这个没有实际解释如何处理 X ,它仅仅解释了如何处理 Y !
如果我所给的文档特别长,我会指明文档中那个我将会谈及的特定部分。[bash 手册](https://linux.die.net/man/1/bash) 有 44000 个字(真的!),所以如果只说“它在 bash 手册中有说明”是没有帮助的 :)
### 告诉他们一个有用的搜索
在工作中,我经常发现我可以利用我所知道的关键字进行搜索来找到能够解决我的问题的答案。对于初学者来说,这些关键字往往不是那么明显。所以说“这是我用来寻找这个答案的搜索”可能有用些。再次说明,回答时请经检查后以确保搜索能够得到他们所需要的答案 :)
### 写新文档
人们经常一次又一次地问我的团队同样的问题。很显然这并不是他们的错(他们怎么能够知道在他们之前已经有 10 个人问了这个问题,且知道答案是什么呢?)因此,我们会尝试写新文档,而不是直接回答回答问题。
1. 马上写新文档
2. 给他们我们刚刚写好的新文档
3. 公示
写文档有时往往比回答问题需要花很多时间,但这是值得的。写文档尤其重要,如果:
a. 这个问题被问了一遍又一遍 b. 随着时间的推移,这个答案不会变化太大(如果这个答案每一个星期或者一个月就会变化,文档就会过时并且令人受挫)
### 解释你做了什么
对于一个话题,作为初学者来说,这样的交流会真让人沮丧:
* 新人:“嗨!你如何处理 X ?”
* 有经验的人:“我已经处理过了,而且它已经完美解决了”
* 新人:”...... 但是你做了什么?!“
如果问你问题的人想知道事情是如何进行的,这样是有帮助的:
* 让他们去完成任务而不是自己做
* 告诉他们你是如何得到你给他们的答案的。
这可能比你自己做的时间还要长,但对于被问的人来说这是一个学习机会,因为那样做使得他们将来能够更好地解决问题。
这样,你可以进行更好的交流,像这:
* 新人:“这个网站出现了错误,发生了什么?”
* 有经验的人:(2分钟后)“oh 这是因为发生了数据库故障转移”
* 新人: “你是怎么知道的??!?!?”
* 有经验的人:“以下是我所做的!”:
1. 通常这些错误是因为服务器 Y 被关闭了。我查看了一下 `$PLACE` 但它表明服务器 Y 开着。所以,并不是这个原因导致的。
2. 然后我查看 X 的仪表盘 ,仪表盘的这个部分显示这里发生了数据库故障转移。
3. 然后我在日志中找到了相应服务器,并且它显示连接数据库错误,看起来错误就是这里。
如果你正在解释你是如何调试一个问题,解释你是如何发现问题,以及如何找出问题的。尽管看起来你好像已经得到正确答案,但感觉更好的是能够帮助他们提高学习和诊断能力,并了解可用的资源。
### 解决根本问题
这一点有点棘手。有时候人们认为他们依旧找到了解决问题的正确途径,且他们只要再多一点信息就可以解决问题。但他们可能并不是走在正确的道路上!比如:
* George:“我在处理 X 的时候遇到了错误,我该如何修复它?”
* Jasminda:“你是正在尝试解决 Y 吗?如果是这样,你不应该处理 X ,反而你应该处理 Z 。”
* George:“噢,你是对的!!!谢谢你!我回反过来处理 Z 的。”
Jasminda 一点都没有回答 George 的问题!反而,她猜测 George 并不想处理 X ,并且她是猜对了。这是非常有用的!
如果你这样做可能会产生高高在上的感觉:
* George:“我在处理 X 的时候遇到了错误,我该如何修复它?”
* Jasminda:“不要这样做,如果你想处理 Y ,你应该反过来完成 Z 。”
* George:“好吧,我并不是想处理 Y 。实际上我想处理 X 因为某些原因(REASONS)。所以我该如何处理 X 。”
所以不要高高在上,且要记住有时有些提问者可能已经偏离根本问题很远了。同时回答提问者提出的问题以及他们本该提出的问题都是合理的:“嗯,如果你想处理 X ,那么你可能需要这么做,但如果你想用这个解决 Y 问题,可能通过处理其他事情你可以更好地解决这个问题,这就是为什么可以做得更好的原因。”
### 询问“那个回答可以解决您的问题吗?”
我总是喜欢在我回答了问题之后核实是否真的已经解决了问题:“这个回答解决了您的问题吗?您还有其他问题吗?”在问完这个之后最好等待一会,因为人们通常需要一两分钟来知道他们是否已经找到了答案。
我发现尤其是问“这个回答解决了您的问题吗”这个额外的步骤在写完文档后是非常有用的。通常,在写关于我熟悉的东西的文档时,我会忽略掉重要的东西而不会意识到它。
### 结对编程和面对面交谈
我是远程工作的,所以我的很多对话都是基于文本的。我认为这是沟通的默认方式。
今天,我们生活在一个方便进行小视频会议和屏幕共享的世界!在工作时候,在任何时间我都可以点击一个按钮并快速加入与他人的视频对话或者屏幕共享的对话中!
例如,最近有人问如何自动调节他们的服务容量规划。我告诉他们我们有几样东西需要清理,但我还不太确定他们要清理的是什么。然后我们进行了一个简短的视频会话并在 5 分钟后,我们解决了他们问题。
我认为,特别是如果有人真的被困在该如何开始一项任务时,开启视频进行结对编程几分钟真的比电子邮件或者一些即时通信更有效。
### 不要表现得过于惊讶
这是源自 Recurse Center 的一则法则:[不要故作惊讶](https://jvns.ca/blog/2017/04/27/no-feigning-surprise/)。这里有一个常见的情景:
* 某甲:“什么是 Linux 内核”
* 某乙:“你竟然不知道什么是 Linux 内核?!!!!?!!!????”
某乙的表现(无论他们是否真的如此惊讶)是没有帮助的。这大部分只会让某甲不好受,因为他们确实不知道什么是 Linux 内核。
我一直在假装不惊讶,即使我事实上确实有点惊讶那个人不知道这种东西。
### 回答问题真的很棒
显然并不是所有方法都是合适的,但希望你能够发现这里有些是有帮助的!我发现花时间去回答问题并教导人们是其实是很有收获的。
特别感谢 Josh Triplett 的一些建议并做了很多有益的补充,以及感谢 Harold Treen、Vaibhav Sagar、Peter Bhat Hatkins、Wesley Aptekar Cassels 和 Paul Gowder 的阅读或评论。
---
via: <https://jvns.ca/blog/answer-questions-well/>
作者:[Julia Evans](https://jvns.ca/about) 译者:[HardworkFish](https://github.com/HardworkFish) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
9,397 | 并发服务器(四):libuv | https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/ | 2018-03-02T01:20:53 | [
"并发"
] | https://linux.cn/article-9397-1.html | 
这是并发网络服务器系列文章的第四部分。在这一部分中,我们将使用 libuv 再次重写我们的服务器,并且也会讨论关于使用一个线程池在回调中去处理耗时任务。最终,我们去看一下底层的 libuv,花一点时间去学习如何用异步 API 对文件系统阻塞操作进行封装。
本系列的所有文章:
* [第一节 - 简介](/article-8993-1.html)
* [第二节 - 线程](/article-9002-1.html)
* [第三节 - 事件驱动](/article-9117-1.html)
* [第四节 - libuv](http://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/)
### 使用 libuv 抽象出事件驱动循环
在 [第三节](/article-9117-1.html) 中,我们看到了基于 `select` 和 `epoll` 的服务器的相似之处,并且,我说过,在它们之间抽象出细微的差别是件很有吸引力的事。许多库已经做到了这些,所以在这一部分中我将去选一个并使用它。我选的这个库是 [libuv](http://libuv.org/),它最初设计用于 Node.js 底层的可移植平台层,并且,后来发现在其它的项目中也有使用。libuv 是用 C 写的,因此,它具有很高的可移植性,非常适用嵌入到像 JavaScript 和 Python 这样的高级语言中。
虽然 libuv 为了抽象出底层平台细节已经变成了一个相当大的框架,但它仍然是以 *事件循环* 思想为中心的。在我们第三部分的事件驱动服务器中,事件循环是显式定义在 `main` 函数中的;当使用 libuv 时,该循环通常隐藏在库自身中,而用户代码仅需要注册事件句柄(作为一个回调函数)和运行这个循环。此外,libuv 会在给定的平台上使用更快的事件循环实现,对于 Linux 它是 `epoll`,等等。

libuv 支持多路事件循环,因此事件循环在库中是非常重要的;它有一个句柄 —— `uv_loop_t`,以及创建/杀死/启动/停止循环的函数。也就是说,在这篇文章中,我将仅需要使用 “默认的” 循环,libuv 可通过 `uv_default_loop()` 提供它;多路循环大多用于多线程事件驱动的服务器,这是一个更高级别的话题,我将留在这一系列文章的以后部分。
### 使用 libuv 的并发服务器
为了对 libuv 有一个更深的印象,让我们跳转到我们的可靠协议的服务器,它通过我们的这个系列已经有了一个强大的重新实现。这个服务器的结构与第三部分中的基于 `select` 和 `epoll` 的服务器有一些相似之处,因为,它也依赖回调。完整的 [示例代码在这里](https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/uv-server.c);我们开始设置这个服务器的套接字绑定到一个本地端口:
```
int portnum = 9090;
if (argc >= 2) {
portnum = atoi(argv[1]);
}
printf("Serving on port %d\n", portnum);
int rc;
uv_tcp_t server_stream;
if ((rc = uv_tcp_init(uv_default_loop(), &server_stream)) < 0) {
die("uv_tcp_init failed: %s", uv_strerror(rc));
}
struct sockaddr_in server_address;
if ((rc = uv_ip4_addr("0.0.0.0", portnum, &server_address)) < 0) {
die("uv_ip4_addr failed: %s", uv_strerror(rc));
}
if ((rc = uv_tcp_bind(&server_stream, (const struct sockaddr*)&server_address, 0)) < 0) {
die("uv_tcp_bind failed: %s", uv_strerror(rc));
}
```
除了它被封装进 libuv API 中之外,你看到的是一个相当标准的套接字。在它的返回中,我们取得了一个可工作于任何 libuv 支持的平台上的可移植接口。
这些代码也展示了很认真负责的错误处理;多数的 libuv 函数返回一个整数状态,返回一个负数意味着出现了一个错误。在我们的服务器中,我们把这些错误看做致命问题进行处理,但也可以设想一个更优雅的错误恢复。
现在,那个套接字已经绑定,是时候去监听它了。这里我们运行首个回调注册:
```
// Listen on the socket for new peers to connect. When a new peer connects,
// the on_peer_connected callback will be invoked.
if ((rc = uv_listen((uv_stream_t*)&server_stream, N_BACKLOG, on_peer_connected)) < 0) {
die("uv_listen failed: %s", uv_strerror(rc));
}
```
`uv_listen` 注册一个事件回调,当新的对端连接到这个套接字时将会调用事件循环。我们的回调在这里被称为 `on_peer_connected`,我们一会儿将去查看它。
最终,`main` 运行这个 libuv 循环,直到它被停止(`uv_run` 仅在循环被停止或者发生错误时返回)。
```
// Run the libuv event loop.
uv_run(uv_default_loop(), UV_RUN_DEFAULT);
// If uv_run returned, close the default loop before exiting.
return uv_loop_close(uv_default_loop());
```
注意,在运行事件循环之前,只有一个回调是通过 `main` 注册的;我们稍后将看到怎么去添加更多的回调。在事件循环的整个运行过程中,添加和删除回调并不是一个问题 —— 事实上,大多数服务器就是这么写的。
这是一个 `on_peer_connected`,它处理到服务器的新的客户端连接:
```
void on_peer_connected(uv_stream_t* server_stream, int status) {
if (status < 0) {
fprintf(stderr, "Peer connection error: %s\n", uv_strerror(status));
return;
}
// client will represent this peer; it's allocated on the heap and only
// released when the client disconnects. The client holds a pointer to
// peer_state_t in its data field; this peer state tracks the protocol state
// with this client throughout interaction.
uv_tcp_t* client = (uv_tcp_t*)xmalloc(sizeof(*client));
int rc;
if ((rc = uv_tcp_init(uv_default_loop(), client)) < 0) {
die("uv_tcp_init failed: %s", uv_strerror(rc));
}
client->data = NULL;
if (uv_accept(server_stream, (uv_stream_t*)client) == 0) {
struct sockaddr_storage peername;
int namelen = sizeof(peername);
if ((rc = uv_tcp_getpeername(client, (struct sockaddr*)&peername,
&namelen)) < 0) {
die("uv_tcp_getpeername failed: %s", uv_strerror(rc));
}
report_peer_connected((const struct sockaddr_in*)&peername, namelen);
// Initialize the peer state for a new client: we start by sending the peer
// the initial '*' ack.
peer_state_t* peerstate = (peer_state_t*)xmalloc(sizeof(*peerstate));
peerstate->state = INITIAL_ACK;
peerstate->sendbuf[0] = '*';
peerstate->sendbuf_end = 1;
peerstate->client = client;
client->data = peerstate;
// Enqueue the write request to send the ack; when it's done,
// on_wrote_init_ack will be called. The peer state is passed to the write
// request via the data pointer; the write request does not own this peer
// state - it's owned by the client handle.
uv_buf_t writebuf = uv_buf_init(peerstate->sendbuf, peerstate->sendbuf_end);
uv_write_t* req = (uv_write_t*)xmalloc(sizeof(*req));
req->data = peerstate;
if ((rc = uv_write(req, (uv_stream_t*)client, &writebuf, 1,
on_wrote_init_ack)) < 0) {
die("uv_write failed: %s", uv_strerror(rc));
}
} else {
uv_close((uv_handle_t*)client, on_client_closed);
}
}
```
这些代码都有很好的注释,但是,这里有一些重要的 libuv 语法我想去强调一下:
* 传入自定义数据到回调中:因为 C 语言还没有闭包,这可能是个挑战,libuv 在它的所有的处理类型中有一个 `void* data` 字段;这些字段可以被用于传递用户数据。例如,注意 `client->data` 是如何指向到一个 `peer_state_t` 结构上,以便于 `uv_write` 和 `uv_read_start` 注册的回调可以知道它们正在处理的是哪个客户端的数据。
* 内存管理:在带有垃圾回收的语言中进行事件驱动编程是非常容易的,因为,回调通常运行在一个与它们注册的地方完全不同的栈帧中,使得基于栈的内存管理很困难。它总是需要传递堆分配的数据到 libuv 回调中(当所有回调运行时,除了 `main`,其它的都运行在栈上),并且,为了避免泄漏,许多情况下都要求这些数据去安全释放(`free()`)。这些都是些需要实践的内容 <sup> 注1</sup> 。
这个服务器上对端的状态如下:
```
typedef struct {
ProcessingState state;
char sendbuf[SENDBUF_SIZE];
int sendbuf_end;
uv_tcp_t* client;
} peer_state_t;
```
它与第三部分中的状态非常类似;我们不再需要 `sendptr`,因为,在调用 “done writing” 回调之前,`uv_write` 将确保发送它提供的整个缓冲。我们也为其它的回调使用保持了一个到客户端的指针。这里是 `on_wrote_init_ack`:
```
void on_wrote_init_ack(uv_write_t* req, int status) {
if (status) {
die("Write error: %s\n", uv_strerror(status));
}
peer_state_t* peerstate = (peer_state_t*)req->data;
// Flip the peer state to WAIT_FOR_MSG, and start listening for incoming data
// from this peer.
peerstate->state = WAIT_FOR_MSG;
peerstate->sendbuf_end = 0;
int rc;
if ((rc = uv_read_start((uv_stream_t*)peerstate->client, on_alloc_buffer,
on_peer_read)) < 0) {
die("uv_read_start failed: %s", uv_strerror(rc));
}
// Note: the write request doesn't own the peer state, hence we only free the
// request itself, not the state.
free(req);
}
```
然后,我们确信知道了这个初始的 `'*'` 已经被发送到对端,我们通过调用 `uv_read_start` 去监听从这个对端来的入站数据,它注册一个将被事件循环调用的回调(`on_peer_read`),不论什么时候,事件循环都在套接字上接收来自客户端的调用:
```
void on_peer_read(uv_stream_t* client, ssize_t nread, const uv_buf_t* buf) {
if (nread < 0) {
if (nread != uv_eof) {
fprintf(stderr, "read error: %s\n", uv_strerror(nread));
}
uv_close((uv_handle_t*)client, on_client_closed);
} else if (nread == 0) {
// from the documentation of uv_read_cb: nread might be 0, which does not
// indicate an error or eof. this is equivalent to eagain or ewouldblock
// under read(2).
} else {
// nread > 0
assert(buf->len >= nread);
peer_state_t* peerstate = (peer_state_t*)client->data;
if (peerstate->state == initial_ack) {
// if the initial ack hasn't been sent for some reason, ignore whatever
// the client sends in.
free(buf->base);
return;
}
// run the protocol state machine.
for (int i = 0; i < nread; ++i) {
switch (peerstate->state) {
case initial_ack:
assert(0 && "can't reach here");
break;
case wait_for_msg:
if (buf->base[i] == '^') {
peerstate->state = in_msg;
}
break;
case in_msg:
if (buf->base[i] == '$') {
peerstate->state = wait_for_msg;
} else {
assert(peerstate->sendbuf_end < sendbuf_size);
peerstate->sendbuf[peerstate->sendbuf_end++] = buf->base[i] + 1;
}
break;
}
}
if (peerstate->sendbuf_end > 0) {
// we have data to send. the write buffer will point to the buffer stored
// in the peer state for this client.
uv_buf_t writebuf =
uv_buf_init(peerstate->sendbuf, peerstate->sendbuf_end);
uv_write_t* writereq = (uv_write_t*)xmalloc(sizeof(*writereq));
writereq->data = peerstate;
int rc;
if ((rc = uv_write(writereq, (uv_stream_t*)client, &writebuf, 1,
on_wrote_buf)) < 0) {
die("uv_write failed: %s", uv_strerror(rc));
}
}
}
free(buf->base);
}
```
这个服务器的运行时行为非常类似于第三部分的事件驱动服务器:所有的客户端都在一个单个的线程中并发处理。并且类似的,一些特定的行为必须在服务器代码中维护:服务器的逻辑实现为一个集成的回调,并且长周期运行是禁止的,因为它会阻塞事件循环。这一点也很类似。让我们进一步探索这个问题。
### 在事件驱动循环中的长周期运行的操作
单线程的事件驱动代码使它先天就容易受到一些常见问题的影响:长周期运行的代码会阻塞整个循环。参见如下的程序:
```
void on_timer(uv_timer_t* timer) {
uint64_t timestamp = uv_hrtime();
printf("on_timer [%" PRIu64 " ms]\n", (timestamp / 1000000) % 100000);
// "Work"
if (random() % 5 == 0) {
printf("Sleeping...\n");
sleep(3);
}
}
int main(int argc, const char** argv) {
uv_timer_t timer;
uv_timer_init(uv_default_loop(), &timer);
uv_timer_start(&timer, on_timer, 0, 1000);
return uv_run(uv_default_loop(), UV_RUN_DEFAULT);
}
```
它用一个单个注册的回调运行一个 libuv 事件循环:`on_timer`,它被每秒钟循环调用一次。回调报告一个时间戳,并且,偶尔通过睡眠 3 秒去模拟一个长周期运行。这是运行示例:
```
$ ./uv-timer-sleep-demo
on_timer [4840 ms]
on_timer [5842 ms]
on_timer [6843 ms]
on_timer [7844 ms]
Sleeping...
on_timer [11845 ms]
on_timer [12846 ms]
Sleeping...
on_timer [16847 ms]
on_timer [17849 ms]
on_timer [18850 ms]
...
```
`on_timer` 忠实地每秒执行一次,直到随机出现的睡眠为止。在那个时间点,`on_timer` 不再被调用,直到睡眠时间结束;事实上,*没有其它的回调* 会在这个时间帧中被调用。这个睡眠调用阻塞了当前线程,它正是被调用的线程,并且也是事件循环使用的线程。当这个线程被阻塞后,事件循环也被阻塞。
这个示例演示了在事件驱动的调用中为什么回调不能被阻塞是多少的重要。并且,同样适用于 Node.js 服务器、客户端侧的 Javascript、大多数的 GUI 编程框架、以及许多其它的异步编程模型。
但是,有时候运行耗时的任务是不可避免的。并不是所有任务都有一个异步 API;例如,我们可能使用一些仅有同步 API 的库去处理,或者,正在执行一个可能的长周期计算。我们如何用事件驱动编程去结合这些代码?线程可以帮到你!
### “转换” 阻塞调用为异步调用的线程
一个线程池可以用于转换阻塞调用为异步调用,通过与事件循环并行运行,并且当任务完成时去由它去公布事件。以阻塞函数 `do_work()` 为例,这里介绍了它是怎么运行的:
1. 不在一个回调中直接调用 `do_work()` ,而是将它打包进一个 “任务”,让线程池去运行这个任务。当任务完成时,我们也为循环去调用它注册一个回调;我们称它为 `on_work_done()`。
2. 在这个时间点,我们的回调就可以返回了,而事件循环保持运行;在同一时间点,线程池中的有一个线程运行这个任务。
3. 一旦任务运行完成,通知主线程(指正在运行事件循环的线程),并且事件循环调用 `on_work_done()`。
让我们看一下,使用 libuv 的工作调度 API,是怎么去解决我们前面的计时器/睡眠示例中展示的问题的:
```
void on_after_work(uv_work_t* req, int status) {
free(req);
}
void on_work(uv_work_t* req) {
// "Work"
if (random() % 5 == 0) {
printf("Sleeping...\n");
sleep(3);
}
}
void on_timer(uv_timer_t* timer) {
uint64_t timestamp = uv_hrtime();
printf("on_timer [%" PRIu64 " ms]\n", (timestamp / 1000000) % 100000);
uv_work_t* work_req = (uv_work_t*)malloc(sizeof(*work_req));
uv_queue_work(uv_default_loop(), work_req, on_work, on_after_work);
}
int main(int argc, const char** argv) {
uv_timer_t timer;
uv_timer_init(uv_default_loop(), &timer);
uv_timer_start(&timer, on_timer, 0, 1000);
return uv_run(uv_default_loop(), UV_RUN_DEFAULT);
}
```
通过一个 `work_req` <sup> 注2</sup> 类型的句柄,我们进入一个任务队列,代替在 `on_timer` 上直接调用 sleep,这个函数在任务中(`on_work`)运行,并且,一旦任务完成(`on_after_work`),这个函数被调用一次。`on_work` 是指 “work”(阻塞中的/耗时的操作)进行的地方。注意在这两个回调传递到 `uv_queue_work` 时的一个关键区别:`on_work` 运行在线程池中,而 `on_after_work` 运行在事件循环中的主线程上 —— 就好像是其它的回调一样。
让我们看一下这种方式的运行:
```
$ ./uv-timer-work-demo
on_timer [89571 ms]
on_timer [90572 ms]
on_timer [91573 ms]
on_timer [92575 ms]
Sleeping...
on_timer [93576 ms]
on_timer [94577 ms]
Sleeping...
on_timer [95577 ms]
on_timer [96578 ms]
on_timer [97578 ms]
...
```
即便在 sleep 函数被调用时,定时器也每秒钟滴答一下,睡眠现在运行在一个单独的线程中,并且不会阻塞事件循环。
### 一个用于练习的素数测试服务器
因为通过睡眠去模拟工作并不是件让人兴奋的事,我有一个事先准备好的更综合的一个示例 —— 一个基于套接字接受来自客户端的数字的服务器,检查这个数字是否是素数,然后去返回一个 “prime" 或者 “composite”。完整的 [服务器代码在这里](https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/uv-isprime-server.c) —— 我不在这里粘贴了,因为它太长了,更希望读者在一些自己的练习中去体会它。
这个服务器使用了一个原生的素数测试算法,因此,对于大的素数可能花很长时间才返回一个回答。在我的机器中,对于 2305843009213693951,它花了 ~5 秒钟去计算,但是,你的方法可能不同。
练习 1:服务器有一个设置(通过一个名为 `MODE` 的环境变量)要么在套接字回调(意味着在主线程上)中运行素数测试,要么在 libuv 工作队列中。当多个客户端同时连接时,使用这个设置来观察服务器的行为。当它计算一个大的任务时,在阻塞模式中,服务器将不回复其它客户端,而在非阻塞模式中,它会回复。
练习 2:libuv 有一个缺省大小的线程池,并且线程池的大小可以通过环境变量配置。你可以通过使用多个客户端去实验找出它的缺省值是多少?找到线程池缺省值后,使用不同的设置去看一下,在重负载下怎么去影响服务器的响应能力。
### 在非阻塞文件系统中使用工作队列
对于只是呆板的演示和 CPU 密集型的计算来说,将可能的阻塞操作委托给一个线程池并不是明智的;libuv 在它的文件系统 API 中本身就大量使用了这种能力。通过这种方式,libuv 使用一个异步 API,以一个轻便的方式显示出它强大的文件系统的处理能力。
让我们使用 `uv_fs_read()`,例如,这个函数从一个文件中(表示为一个 `uv_fs_t` 句柄)读取一个文件到一个缓冲中 <sup> 注3,并且当读取完成后调用一个回调。换句话说, <code> uv_fs_read() </code> 总是立即返回,即使是文件在一个类似</sup> NFS 的系统上,而数据到达缓冲区可能需要一些时间。换句话说,这个 API 与这种方式中其它的 libuv API 是异步的。这是怎么工作的呢?
在这一点上,我们看一下 libuv 的底层;内部实际上非常简单,并且它是一个很好的练习。作为一个可移植的库,libuv 对于 Windows 和 Unix 系统在它的许多函数上有不同的实现。我们去看一下在 libuv 源树中的 `src/unix/fs.c`。
这是 `uv_fs_read` 的代码:
```
int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
uv_file file,
const uv_buf_t bufs[],
unsigned int nbufs,
int64_t off,
uv_fs_cb cb) {
if (bufs == NULL || nbufs == 0)
return -EINVAL;
INIT(READ);
req->file = file;
req->nbufs = nbufs;
req->bufs = req->bufsml;
if (nbufs > ARRAY_SIZE(req->bufsml))
req->bufs = uv__malloc(nbufs * sizeof(*bufs));
if (req->bufs == NULL) {
if (cb != NULL)
uv__req_unregister(loop, req);
return -ENOMEM;
}
memcpy(req->bufs, bufs, nbufs * sizeof(*bufs));
req->off = off;
POST;
}
```
第一次看可能觉得很困难,因为它延缓真实的工作到 `INIT` 和 `POST` 宏中,以及为 `POST` 设置了一些本地变量。这样做可以避免了文件中的许多重复代码。
这是 `INIT` 宏:
```
#define INIT(subtype) \
do { \
req->type = UV_FS; \
if (cb != NULL) \
uv__req_init(loop, req, UV_FS); \
req->fs_type = UV_FS_ ## subtype; \
req->result = 0; \
req->ptr = NULL; \
req->loop = loop; \
req->path = NULL; \
req->new_path = NULL; \
req->cb = cb; \
} \
while (0)
```
它设置了请求,并且更重要的是,设置 `req->fs_type` 域为真实的 FS 请求类型。因为 `uv_fs_read` 调用 `INIT(READ)`,它意味着 `req->fs_type` 被分配一个常数 `UV_FS_READ`。
这是 `POST` 宏:
```
#define POST \
do { \
if (cb != NULL) { \
uv__work_submit(loop, &req->work_req, uv__fs_work, uv__fs_done); \
return 0; \
} \
else { \
uv__fs_work(&req->work_req); \
return req->result; \
} \
} \
while (0)
```
它做什么取决于回调是否为 `NULL`。在 libuv 文件系统 API 中,一个 `NULL` 回调意味着我们真实地希望去执行一个 *同步* 操作。在这种情况下,`POST` 直接调用 `uv__fs_work`(我们需要了解一下这个函数的功能),而对于一个非 `NULL` 回调,它把 `uv__fs_work` 作为一个工作项提交到工作队列(指的是线程池),然后,注册 `uv__fs_done` 作为回调;该函数执行一些登记并调用用户提供的回调。
如果我们去看 `uv__fs_work` 的代码,我们将看到它使用很多宏按照需求将工作分发到实际的文件系统调用。在我们的案例中,对于 `UV_FS_READ` 这个调用将被 `uv__fs_read` 生成,它(最终)使用普通的 POSIX API 去读取。这个函数可以在一个 *阻塞* 方式中很安全地实现。因为,它通过异步 API 调用时被置于一个线程池中。
在 Node.js 中,`fs.readFile` 函数是映射到 `uv_fs_read` 上。因此,可以在一个非阻塞模式中读取文件,甚至是当底层文件系统 API 是阻塞方式时。
---
* 注1: 为确保服务器不泄露内存,我在一个启用泄露检查的 Valgrind 中运行它。因为服务器经常是被设计为永久运行,这是一个挑战;为克服这个问题,我在服务器上添加了一个 “kill 开关” —— 一个从客户端接收的特定序列,以使它可以停止事件循环并退出。这个代码在 `theon_wrote_buf` 句柄中。
* 注2: 在这里我们不过多地使用 `work_req`;讨论的素数测试服务器接下来将展示怎么被用于去传递上下文信息到回调中。
* 注3: `uv_fs_read()` 提供了一个类似于 `preadv` Linux 系统调用的通用 API:它使用多缓冲区用于排序,并且支持一个到文件中的偏移。基于我们讨论的目的可以忽略这些特性。
---
via: <https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/>
作者:[Eli Bendersky](https://eli.thegreenplace.net/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is part 4 of a series of posts on writing concurrent network servers. In
this part we're going to use `libuv` to rewrite our server once again, and
also talk about handling time-consuming tasks in callbacks using a thread pool.
Finally, we're going to look under the hood of `libuv` for a bit to study how
it wraps blocking file-system operations with an asynchronous API.
All posts in the series:
[Part 1 - Introduction](https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/)[Part 2 - Threads](https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/)[Part 3 - Event-driven](https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/)[Part 4 - libuv](https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/)[Part 5 - Redis case study](https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/)[Part 6 - Callbacks, Promises and async/await](https://eli.thegreenplace.net/2018/concurrent-servers-part-6-callbacks-promises-and-asyncawait/)
## Abstracting away event-driven loops with libuv
In [part 3](https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/),
we've seen how similar `select`-based and `epoll`-based servers are, and I
mentioned it's very tempting to abstract away the minor differences between
them. Numerous libraries are already doing this, however, so in this part I'm
going to pick one and use it. The library I'm picking is [libuv](http://libuv.org/), which was originally designed to serve as the underlying
portable platform layer for Node.js, and has since found use in additional
projects. `libuv` is written in C, which makes it highly portable and very
suitable for tying into high-level languages like JavaScript and Python.
While `libuv` has grown to be a fairly large framework for abstracting
low-level platform details, it remains centered on the concept of an *event
loop*. In our event-driven servers in part 3, the event loop was explicit
in the `main` function; when using `libuv`, the loop is usually hidden
inside the library itself, and user code just registers event handlers (as
callback functions) and runs the loop. Furthermore, `libuv` will use the
fastest event loop implementation for a given platform: for Linux this is
`epoll`, etc.

`libuv` supports multiple event loops, and thus an event loop is
a first class citizen within the library; it has a handle - `uv_loop_t`, and
functions for creating/destroying/starting/stopping loops. That said, I will
only use the "default" loop in this post, which `libuv` makes available via
`uv_default_loop()`; multiple loops are mosly useful for multi-threaded
event-driven servers, a more advanced topic I'll leave for future parts in the
series.
## A concurrent server using libuv
To get a better feel for `libuv`, let's jump to our trusty protocol server
that we've been vigorously reimplementing throughout the series. The structure
of this server is going to be somewhat similar to the `select` and
`epoll`-based servers of part 3, since it also relies on callbacks. The full
[code sample is here](https://github.com/eliben/code-for-blog/blob/main/2017/async-socket-server/uv-server.c);
we start with setting up the server socket bound to a local port:
```
int portnum = 9090;
if (argc >= 2) {
portnum = atoi(argv[1]);
}
printf("Serving on port %d\n", portnum);
int rc;
uv_tcp_t server_stream;
if ((rc = uv_tcp_init(uv_default_loop(), &server_stream)) < 0) {
die("uv_tcp_init failed: %s", uv_strerror(rc));
}
struct sockaddr_in server_address;
if ((rc = uv_ip4_addr("0.0.0.0", portnum, &server_address)) < 0) {
die("uv_ip4_addr failed: %s", uv_strerror(rc));
}
if ((rc = uv_tcp_bind(&server_stream, (const struct sockaddr*)&server_address, 0)) < 0) {
die("uv_tcp_bind failed: %s", uv_strerror(rc));
}
```
Fairly standard socket fare here, except that it's all wrapped in `libuv`
APIs. In return we get a portable interface that should work on any platform
`libuv` supports.
This code also demonstrates conscientious error handling; most `libuv`
functions return an integer status, with a negative number meaning an error. In
our server we treat these errors as fatals, but one may imagine a more graceful
recovery.
Now that the socket is bound, it's time to listen on it. Here we run into our first callback registration:
```
// Listen on the socket for new peers to connect. When a new peer connects,
// the on_peer_connected callback will be invoked.
if ((rc = uv_listen((uv_stream_t*)&server_stream, N_BACKLOG, on_peer_connected)) < 0) {
die("uv_listen failed: %s", uv_strerror(rc));
}
```
`uv_listen` registers a callback that the event loop will invoke when new
peers connect to the socket. Our callback here is called `on_peer_connected`,
and we'll examine it soon.
Finally, `main` runs the `libuv` loop until it's stopped (`uv_run` only
returns when the loop has stopped or some error occurred).
```
// Run the libuv event loop.
uv_run(uv_default_loop(), UV_RUN_DEFAULT);
// If uv_run returned, close the default loop before exiting.
return uv_loop_close(uv_default_loop());
```
Note that only a single callback was registered by `main` prior to running the
event loop; we'll soon see how additional callbacks are added. It's not a
problem to add and remove callbacks throughout the runtime of the event loop -
in fact, this is how most servers are expected to be written.
This is `on_peer_connected`, which handles new client connections to the
server:
```
void on_peer_connected(uv_stream_t* server_stream, int status) {
if (status < 0) {
fprintf(stderr, "Peer connection error: %s\n", uv_strerror(status));
return;
}
// client will represent this peer; it's allocated on the heap and only
// released when the client disconnects. The client holds a pointer to
// peer_state_t in its data field; this peer state tracks the protocol state
// with this client throughout interaction.
uv_tcp_t* client = (uv_tcp_t*)xmalloc(sizeof(*client));
int rc;
if ((rc = uv_tcp_init(uv_default_loop(), client)) < 0) {
die("uv_tcp_init failed: %s", uv_strerror(rc));
}
client->data = NULL;
if (uv_accept(server_stream, (uv_stream_t*)client) == 0) {
struct sockaddr_storage peername;
int namelen = sizeof(peername);
if ((rc = uv_tcp_getpeername(client, (struct sockaddr*)&peername,
&namelen)) < 0) {
die("uv_tcp_getpeername failed: %s", uv_strerror(rc));
}
report_peer_connected((const struct sockaddr_in*)&peername, namelen);
// Initialize the peer state for a new client: we start by sending the peer
// the initial '*' ack.
peer_state_t* peerstate = (peer_state_t*)xmalloc(sizeof(*peerstate));
peerstate->state = INITIAL_ACK;
peerstate->sendbuf[0] = '*';
peerstate->sendbuf_end = 1;
peerstate->client = client;
client->data = peerstate;
// Enqueue the write request to send the ack; when it's done,
// on_wrote_init_ack will be called. The peer state is passed to the write
// request via the data pointer; the write request does not own this peer
// state - it's owned by the client handle.
uv_buf_t writebuf = uv_buf_init(peerstate->sendbuf, peerstate->sendbuf_end);
uv_write_t* req = (uv_write_t*)xmalloc(sizeof(*req));
req->data = peerstate;
if ((rc = uv_write(req, (uv_stream_t*)client, &writebuf, 1,
on_wrote_init_ack)) < 0) {
die("uv_write failed: %s", uv_strerror(rc));
}
} else {
uv_close((uv_handle_t*)client, on_client_closed);
}
}
```
This code is well commented, but there are a couple of important `libuv`
idioms I'd like to highlight:
- Passing custom data into callbacks: since C has no closures, this can be
challenging.
`libuv`has a`void* data`field in all its handle types; these fields can be used to pass user data. For example, note how`client->data`is made to point to a`peer_state_t`structure so that the callbacks registered by`uv_write`and`uv_read_start`can know which peer data they're dealing with. - Memory management: event-driven programming is much easier in languages with
garbage collection, because callbacks usually run in a completely different
stack frame from where they were registered, making stack-based memory
management difficult. It's almost always necessary to pass heap-allocated data
to
`libuv`callbacks (except in`main`, which remains alive on the stack when all callbacks run), and to avoid leaks much care is required about when these data are safe to`free()`. This is something that comes with a bit of practice[[1]](#footnote-1).
The peer state for this server is:
```
typedef struct {
ProcessingState state;
char sendbuf[SENDBUF_SIZE];
int sendbuf_end;
uv_tcp_t* client;
} peer_state_t;
```
It's fairly similar to the state in part 3; we no longer need `sendptr`,
since `uv_write` will make sure to send the whole buffer it's given before
invoking the "done writing" callback. We also keep a pointer to the client for
other callbacks to use. Here's `on_wrote_init_ack`:
```
void on_wrote_init_ack(uv_write_t* req, int status) {
if (status) {
die("Write error: %s\n", uv_strerror(status));
}
peer_state_t* peerstate = (peer_state_t*)req->data;
// Flip the peer state to WAIT_FOR_MSG, and start listening for incoming data
// from this peer.
peerstate->state = WAIT_FOR_MSG;
peerstate->sendbuf_end = 0;
int rc;
if ((rc = uv_read_start((uv_stream_t*)peerstate->client, on_alloc_buffer,
on_peer_read)) < 0) {
die("uv_read_start failed: %s", uv_strerror(rc));
}
// Note: the write request doesn't own the peer state, hence we only free the
// request itself, not the state.
free(req);
}
```
Then we know for sure that the initial `'*'` was sent to the peer, we start
listening to incoming data from this peer by calling `uv_read_start`, which
registers a callback (`on_peer_read`) that will be invoked by the event loop
whenever new data is received on the socket from the client:
```
void on_peer_read(uv_stream_t* client, ssize_t nread, const uv_buf_t* buf) {
if (nread < 0) {
if (nread != uv_eof) {
fprintf(stderr, "read error: %s\n", uv_strerror(nread));
}
uv_close((uv_handle_t*)client, on_client_closed);
} else if (nread == 0) {
// from the documentation of uv_read_cb: nread might be 0, which does not
// indicate an error or eof. this is equivalent to eagain or ewouldblock
// under read(2).
} else {
// nread > 0
assert(buf->len >= nread);
peer_state_t* peerstate = (peer_state_t*)client->data;
if (peerstate->state == initial_ack) {
// if the initial ack hasn't been sent for some reason, ignore whatever
// the client sends in.
free(buf->base);
return;
}
// run the protocol state machine.
for (int i = 0; i < nread; ++i) {
switch (peerstate->state) {
case initial_ack:
assert(0 && "can't reach here");
break;
case wait_for_msg:
if (buf->base[i] == '^') {
peerstate->state = in_msg;
}
break;
case in_msg:
if (buf->base[i] == '$') {
peerstate->state = wait_for_msg;
} else {
assert(peerstate->sendbuf_end < sendbuf_size);
peerstate->sendbuf[peerstate->sendbuf_end++] = buf->base[i] + 1;
}
break;
}
}
if (peerstate->sendbuf_end > 0) {
// we have data to send. the write buffer will point to the buffer stored
// in the peer state for this client.
uv_buf_t writebuf =
uv_buf_init(peerstate->sendbuf, peerstate->sendbuf_end);
uv_write_t* writereq = (uv_write_t*)xmalloc(sizeof(*writereq));
writereq->data = peerstate;
int rc;
if ((rc = uv_write(writereq, (uv_stream_t*)client, &writebuf, 1,
on_wrote_buf)) < 0) {
die("uv_write failed: %s", uv_strerror(rc));
}
}
}
free(buf->base);
}
```
The runtime behavior of this server is very similar to the event-driven servers of part 3: all clients are handled concurrently in a single thread. Also similarly, a certain discipline has to be maintained in the server's code: the server's logic is implemented as an ensemble of callbacks, and long-running operations are a big no-no since they block the event loop. Let's explore this issue a bit further.
## Long-running operations in event-driven loops
The single-threaded nature of event-driven code makes it very susceptible to a common issue: long-running code blocks the entire loop. Consider this program:
```
void on_timer(uv_timer_t* timer) {
uint64_t timestamp = uv_hrtime();
printf("on_timer [%" PRIu64 " ms]\n", (timestamp / 1000000) % 100000);
// "Work"
if (random() % 5 == 0) {
printf("Sleeping...\n");
sleep(3);
}
}
int main(int argc, const char** argv) {
uv_timer_t timer;
uv_timer_init(uv_default_loop(), &timer);
uv_timer_start(&timer, on_timer, 0, 1000);
return uv_run(uv_default_loop(), UV_RUN_DEFAULT);
}
```
It runs a `libuv` event loop with a single registered callback: `on_timer`,
which is invoked by the loop every second. The callback reports a timestamp, and
once in a while simulates some long-running task by sleeping for 3 seconds.
Here's a sample run:
```
$ ./uv-timer-sleep-demo
on_timer [4840 ms]
on_timer [5842 ms]
on_timer [6843 ms]
on_timer [7844 ms]
Sleeping...
on_timer [11845 ms]
on_timer [12846 ms]
Sleeping...
on_timer [16847 ms]
on_timer [17849 ms]
on_timer [18850 ms]
...
```
`on_timer` dutifully fires every second, until the random sleep hits in. At
that point, `on_timer` is not invoked again until the sleep is over; in fact,
*no other callbacks* will be invoked in this time frame. The `sleep` call
blocks the current thread, which is the only thread involved and is also the
thread the event loop uses. When this thread is blocked, the event loop is
blocked.
This example demonstrates why it's so important for callbacks to never block in event-driven calls, and applies equally to Node.js servers, client-side Javascript, most GUI programming frameworks, and many other asynchronous programming models.
But sometimes running time-consuming tasks is unavoidable. Not all tasks have asynchronous APIs; for example, we may be dealing with some library that only has a synchronous API, or just have to perform a potentially long computation. How can we combine such code with event-driven programming? Threads to the rescue!
## Threads for "converting" blocking calls into asynchronous calls
A thread pool can be used to turn blocking calls into asynchronous calls, by
running alongside the event loop and posting events onto it when tasks are
completed. Here's how it works, for a given blocking function `do_work()`:
- Instead of directly calling
`do_work()`in a callback, we package it into a "task" and ask the thread pool to execute the task. We also register a callback for the loop to invoke when the task has finished; let's call it`on_work_done()`. - At this point our callback can return and the event loop keeps spinning; at the same time, a thread in the pool is executing the task.
- Once the task has finished executing, the main thread (the one running the
event loop) is notified and
`on_work_done()`is invoked by the event loop.
Let's see how this solves our previous timer/sleep example, using `libuv`'s
work scheduling API:
```
void on_after_work(uv_work_t* req, int status) {
free(req);
}
void on_work(uv_work_t* req) {
// "Work"
if (random() % 5 == 0) {
printf("Sleeping...\n");
sleep(3);
}
}
void on_timer(uv_timer_t* timer) {
uint64_t timestamp = uv_hrtime();
printf("on_timer [%" PRIu64 " ms]\n", (timestamp / 1000000) % 100000);
uv_work_t* work_req = (uv_work_t*)malloc(sizeof(*work_req));
uv_queue_work(uv_default_loop(), work_req, on_work, on_after_work);
}
int main(int argc, const char** argv) {
uv_timer_t timer;
uv_timer_init(uv_default_loop(), &timer);
uv_timer_start(&timer, on_timer, 0, 1000);
return uv_run(uv_default_loop(), UV_RUN_DEFAULT);
}
```
Instead of calling `sleep` directly in `on_timer`, we enqueue a task,
represented by a handle of type `work_req` [[2]](#footnote-2), the function to run in the
task (`on_work`) and the function to invoke once the task is completed
(`on_after_work`). `on_work` is where the "work" (the
blocking/time-consuming operation) happens. Note a crucial difference between
the two callbacks passed into `uv_queue_work`: `on_work` runs in the thread
pool, while `on_after_work` runs on the main thread which also runs the event
loop - just like any other callback.
Let's see this version run:
```
$ ./uv-timer-work-demo
on_timer [89571 ms]
on_timer [90572 ms]
on_timer [91573 ms]
on_timer [92575 ms]
Sleeping...
on_timer [93576 ms]
on_timer [94577 ms]
Sleeping...
on_timer [95577 ms]
on_timer [96578 ms]
on_timer [97578 ms]
...
```
The timer ticks every second, even though the sleeping function is still invoked; sleeping is now done on a separate thread and doesn't block the event loop.
## A primality-testing server, with exercises
Since `sleep` isn't a very exciting way to simulate work, I've prepared a more
comprehensive example - a server that accepts numbers from clients over a
socket, checks whether these numbers are prime and sends back either "prime" or
"composite". The full [code for this server is here](https://github.com/eliben/code-for-blog/blob/main/2017/async-socket-server/uv-isprime-server.c)
- I won't post it here since it's long, but will rather give readers the
opportunity to explore it on their own with a couple of exercises.
The server deliberatly uses a naive primality test algorithm, so for large primes it can take quite a while to return an answer. On my machine it takes ~5 seconds to compute the answer for 2305843009213693951, but YMMV.
Exercise 1: the server has a setting (via an environment variable named
`MODE`) to either run the primality test in the socket callback (meaning on
the main thread) or in the `libuv` work queue. Play with this setting to
observe the server's behavior when multiple clients are connecting
simultaneously. In blocking mode, the server will not answer other clients while
it's computing a big task; in non-blocking mode it will.
Exercise 2: `libuv` has a default thread-pool size, and it can be configured
via an environment variable. Can you use multiple clients to discover
experimentally what the default size is? Having found the default thread-pool
size, play with different settings to see how it affects the server's
responsiveness under heavy load.
## Non-blocking file-system operations using work queues
Delegating potentially-blocking operations to a thread pool isn't good for just
silly demos and CPU-intensive computations; `libuv` itself makes heavy use of
this capability in its file-system APIs. This way, `libuv` accomplishes the
superpower of exposing the file-system with an asynchronous API, in a portable
way.
Let's take `uv_fs_read()`, for example. This function reads from a file
(represented by a `uv_fs_t` handle) into a buffer [[3]](#footnote-3), and invokes a
callback when the reading is completed. That is, `uv_fs_read()` always returns
immediately, even if the file sits on an NFS-like system and it may take a while
for the data to get to the buffer. In other words, this API is asynchronous in
the way other `libuv` APIs are. How does this work?
At this point we're going to look under the hood of `libuv`; the internals are
actually fairly straightforward, and it's a good exercise. Being a portable
library, `libuv` has different implementations of many of its functions for
Windows and Unix systems. We're going to be looking at `src/unix/fs.c` in the
`libuv` source tree.
The code for `uv_fs_read` is:
```
int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
uv_file file,
const uv_buf_t bufs[],
unsigned int nbufs,
int64_t off,
uv_fs_cb cb) {
if (bufs == NULL || nbufs == 0)
return -EINVAL;
INIT(READ);
req->file = file;
req->nbufs = nbufs;
req->bufs = req->bufsml;
if (nbufs > ARRAY_SIZE(req->bufsml))
req->bufs = uv__malloc(nbufs * sizeof(*bufs));
if (req->bufs == NULL) {
if (cb != NULL)
uv__req_unregister(loop, req);
return -ENOMEM;
}
memcpy(req->bufs, bufs, nbufs * sizeof(*bufs));
req->off = off;
POST;
}
```
It may seem puzzling at first, because it defers the real work to the `INIT`
and `POST` macros, with some local variable setup for `POST`. This is done
to avoid too much code duplication within the file.
The `INIT` macro is:
```
#define INIT(subtype) \
do { \
req->type = UV_FS; \
if (cb != NULL) \
uv__req_init(loop, req, UV_FS); \
req->fs_type = UV_FS_ ## subtype; \
req->result = 0; \
req->ptr = NULL; \
req->loop = loop; \
req->path = NULL; \
req->new_path = NULL; \
req->cb = cb; \
} \
while (0)
```
It sets up the request, and most importantly sets the `req->fs_type` field to
the actual FS request type. Since `uv_fs_read` invokes `INIT(READ)`, it
means `req->fs_type` gets assigned the constant `UV_FS_READ`.
The `POST` macro is:
```
#define POST \
do { \
if (cb != NULL) { \
uv__work_submit(loop, &req->work_req, uv__fs_work, uv__fs_done); \
return 0; \
} \
else { \
uv__fs_work(&req->work_req); \
return req->result; \
} \
} \
while (0)
```
What it does depends on whether the callback is NULL. In `libuv` file-system
APIs, a `NULL` callback means we actually want to perform the operation
*synchronously*. In this case `POST` invokes `uv__fs_work` directly (we'll
get to what this function does in just a bit), whereas for a non-`NULL`
callback, it submits `uv__fs_work` as a work item to the work queue (which is
the thread pool), and registers `uv__fs_done` as the callback; that function
does a bit of book-keeping and invokes the user-provided callback.
If we look at the code of `uv__fs_work`, we'll see it uses more macros to
route work to the actual file-system call as needed. In our case, for
`UV_FS_READ` the call will be made to `uv__fs_read`, which (at last!) does
the reading using regular POSIX APIs. This function can be safely implemented in
a *blocking* manner, since it's placed on a thread-pool when called through the
asynchronous API.
In Node.js, the `fs.readFile` function is mapped to `uv_fs_read`. Thus,
reading files can be done in a non-blocking fashion even though the underlying
file-system API is blocking.
|
`on_wrote_buf`handler.
|
`work_req`for much; the primality testing server discussed next will show how it's used to pass context information into the callback.
|
`uv_fs_read()`provides a generalized API similar to the`preadv`Linux system call: it takes multiple buffers which it fills in order, and supports an offset into the file. We can ignore these features for the sake of our discussion. |
9,398 | 使用 sar 和 kSar 来发现 Linux 性能瓶颈 | https://www.cyberciti.biz/tips/identifying-linux-bottlenecks-sar-graphs-with-ksar.html | 2018-03-02T20:27:35 | [
"sar",
"kSar"
] | https://linux.cn/article-9398-1.html | 
`sar` 命令用用收集、报告、或者保存 UNIX / Linux 系统的活动信息。它保存选择的计数器到操作系统的 `/var/log/sa/sadd` 文件中。从收集的数据中,你可以得到许多关于你的服务器的信息:
1. CPU 使用率
2. 内存页面和使用率
3. 网络 I/O 和传输统计
4. 进程创建活动
5. 所有的块设备活动
6. 每秒中断数等等
`sar` 命令的输出能够用于识别服务器瓶颈。但是,分析 `sar` 命令提供的信息可能比较困难,所以要使用 kSar 工具。kSar 工具可以将 `sar` 命令的输出绘制成基于时间周期的、易于理解的图表。
### sysstat 包
`sar`、`sa1`、和 `sa2` 命令都是 sysstat 包的一部分。它是 Linux 包含的性能监视工具集合。
1. `sar`:显示数据
2. `sa1` 和 `sa2`:收集和保存数据用于以后分析。`sa2` shell 脚本在 `/var/log/sa` 目录中每日写入一个报告。`sa1` shell 脚本将每日的系统活动信息以二进制数据的形式写入到文件中。
3. sadc —— 系统活动数据收集器。你可以通过修改 `sa1` 和 `sa2` 脚本去配置各种选项。它们位于以下的目录:
* `/usr/lib64/sa/sa1` (64 位)或者 `/usr/lib/sa/sa1` (32 位) —— 它调用 `sadc` 去记录报告到 `/var/log/sa/sadX` 格式。
* `/usr/lib64/sa/sa2` (64 位)或者 `/usr/lib/sa/sa2` (32 位) —— 它调用 `sar` 去记录报告到 `/var/log/sa/sarX` 格式。
#### 如何在我的系统上安装 sar?
在一个基于 CentOS/RHEL 的系统上,输入如下的 [yum 命令](https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ "See Linux/Unix yum command examples for more info") 去安装 sysstat:
```
# yum install sysstat
```
示例输出如下:
```
Loaded plugins: downloadonly, fastestmirror, priorities,
: protectbase, security
Loading mirror speeds from cached hostfile
* addons: mirror.cs.vt.edu
* base: mirror.ash.fastserv.com
* epel: serverbeach1.fedoraproject.org
* extras: mirror.cogentco.com
* updates: centos.mirror.nac.net
0 packages excluded due to repository protections
Setting up Install Process
Resolving Dependencies
--> Running transaction check
---> Package sysstat.x86_64 0:7.0.2-3.el5 set to be updated
--> Finished Dependency Resolution
Dependencies Resolved
====================================================================
Package Arch Version Repository Size
====================================================================
Installing:
sysstat x86_64 7.0.2-3.el5 base 173 k
Transaction Summary
====================================================================
Install 1 Package(s)
Update 0 Package(s)
Remove 0 Package(s)
Total download size: 173 k
Is this ok [y/N]: y
Downloading Packages:
sysstat-7.0.2-3.el5.x86_64.rpm | 173 kB 00:00
Running rpm_check_debug
Running Transaction Test
Finished Transaction Test
Transaction Test Succeeded
Running Transaction
Installing : sysstat 1/1
Installed:
sysstat.x86_64 0:7.0.2-3.el5
Complete!
```
#### 为 sysstat 配置文件
编辑 `/etc/sysconfig/sysstat` 文件去指定日志文件保存多少天(最长为一个月):
```
# vi /etc/sysconfig/sysstat
```
示例输出如下 :
```
# keep log for 28 days
# the default is 7
HISTORY=28
```
保存并关闭这个文件。
### 找到 sar 默认的 cron 作业
[默认的 cron 作业位于](https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/) `/etc/cron.d/sysstat`:
```
# cat /etc/cron.d/sysstat
```
示例输出如下:
```
# run system activity accounting tool every 10 minutes
*/10 * * * * root /usr/lib64/sa/sa1 1 1
# generate a daily summary of process accounting at 23:53
53 23 * * * root /usr/lib64/sa/sa2 -A
```
#### 告诉 sadc 去报告磁盘的统计数据
使用一个文本编辑器去编辑 `/etc/cron.d/sysstat` 文件,比如使用 `vim` 命令,输入如下:
```
# vi /etc/cron.d/sysstat
```
像下面的示例那样更新这个文件,以记录所有的硬盘统计数据(`-d` 选项强制记录每个块设备的统计数据,而 `-I` 选项强制记录所有系统中断的统计数据):
```
# run system activity accounting tool every 10 minutes
*/10 * * * * root /usr/lib64/sa/sa1 -I -d 1 1
# generate a daily summary of process accounting at 23:53
53 23 * * * root /usr/lib64/sa/sa2 -A
```
在 CentOS/RHEL 7.x 系统上你需要传递 `-S DISK` 选项去收集块设备的数据。传递 `-S XALL` 选项去采集如下所列的数据:
1. 磁盘
2. 分区
3. 系统中断
4. SNMP
5. IPv6
```
# Run system activity accounting tool every 10 minutes
*/10 * * * * root /usr/lib64/sa/sa1 -S DISK 1 1
# 0 * * * * root /usr/lib64/sa/sa1 600 6 &
# Generate a daily summary of process accounting at 23:53
53 23 * * * root /usr/lib64/sa/sa2 -A
# Run system activity accounting tool every 10 minutes
```
保存并关闭这个文件。
#### 打开 CentOS/RHEL 版本 5.x/6.x 的服务
输入如下命令:
```
chkconfig sysstat on
service sysstat start
```
示例输出如下:
```
Calling the system activity data collector (sadc):
```
对于 CentOS/RHEL 7.x,运行如下的命令:
```
# systemctl enable sysstat
# systemctl start sysstat.service
# systemctl status sysstat.service
```
示例输出:
```
● sysstat.service - Resets System Activity Logs
Loaded: loaded (/usr/lib/systemd/system/sysstat.service; enabled; vendor preset: enabled)
Active: active (exited) since Sat 2018-01-06 16:33:19 IST; 3s ago
Process: 28297 ExecStart=/usr/lib64/sa/sa1 --boot (code=exited, status=0/SUCCESS)
Main PID: 28297 (code=exited, status=0/SUCCESS)
Jan 06 16:33:19 centos7-box systemd[1]: Starting Resets System Activity Logs...
Jan 06 16:33:19 centos7-box systemd[1]: Started Resets System Activity Logs.
```
### 如何使用 sar?如何查看统计数据?
使用 `sar` 命令去显示操作系统中选定的累积活动计数器输出。在这个示例中,运行 `sar` 命令行,去实时获得 CPU 使用率的报告:
```
# sar -u 3 10
```
示例输出:
```
Linux 2.6.18-164.2.1.el5 (www-03.nixcraft.in) 12/14/2009
09:49:47 PM CPU %user %nice %system %iowait %steal %idle
09:49:50 PM all 5.66 0.00 1.22 0.04 0.00 93.08
09:49:53 PM all 12.29 0.00 1.93 0.04 0.00 85.74
09:49:56 PM all 9.30 0.00 1.61 0.00 0.00 89.10
09:49:59 PM all 10.86 0.00 1.51 0.04 0.00 87.58
09:50:02 PM all 14.21 0.00 3.27 0.04 0.00 82.47
09:50:05 PM all 13.98 0.00 4.04 0.04 0.00 81.93
09:50:08 PM all 6.60 6.89 1.26 0.00 0.00 85.25
09:50:11 PM all 7.25 0.00 1.55 0.04 0.00 91.15
09:50:14 PM all 6.61 0.00 1.09 0.00 0.00 92.31
09:50:17 PM all 5.71 0.00 0.96 0.00 0.00 93.33
Average: all 9.24 0.69 1.84 0.03 0.00 88.20
```
其中:
* 3 表示间隔时间
* 10 表示次数
查看进程创建的统计数据,输入:
```
# sar -c 3 10
```
查看 I/O 和传输率统计数据,输入:
```
# sar -b 3 10
```
查看内存页面统计数据,输入:
```
# sar -B 3 10
```
查看块设备统计数据,输入:
```
# sar -d 3 10
```
查看所有中断的统计数据,输入:
```
# sar -I XALL 3 10
```
查看网络设备特定的统计数据,输入:
```
# sar -n DEV 3 10
# sar -n EDEV 3 10
```
查看 CPU 特定的统计数据,输入:
```
# sar -P ALL
# Only 1st CPU stats
# sar -P 1 3 10
```
查看队列长度和平均负载的统计数据,输入:
```
# sar -q 3 10
```
查看内存和交换空间的使用统计数据,输入:
```
# sar -r 3 10
# sar -R 3 10
```
查看 inode、文件、和其它内核表统计数据状态,输入:
```
# sar -v 3 10
```
查看系统切换活动统计数据,输入:
```
# sar -w 3 10
```
查看交换统计数据,输入:
```
# sar -W 3 10
```
查看一个 PID 为 3256 的 Apache 进程,输入:
```
# sar -x 3256 3 10
```
### kSar 介绍
`sar` 和 `sadf` 提供了基于命令行界面的输出。这种输出可能会使新手用户/系统管理员感到无从下手。因此,你需要使用 kSar,它是一个图形化显示你的 `sar` 数据的 Java 应用程序。它也允许你以 PDF/JPG/PNG/CSV 格式导出数据。你可以用三种方式去加载数据:本地文件、运行本地命令、以及通过 SSH 远程运行的命令。kSar 可以处理下列操作系统的 `sar` 输出:
1. Solaris 8, 9 和 10
2. Mac OS/X 10.4+
3. Linux (Systat Version >= 5.0.5)
4. AIX (4.3 & 5.3)
5. HPUX 11.00+
#### 下载和安装 kSar
访问 [官方](https://github.com/vlsi/ksar) 网站去获得最新版本的源代码。使用 [wget](https://www.cyberciti.biz/tips/linux-wget-your-ultimate-command-line-downloader.html) 去下载源代码,输入:
```
$ wget https://github.com/vlsi/ksar/releases/download/v5.2.4-snapshot-652bf16/ksar-5.2.4-SNAPSHOT-all.jar
```
#### 如何运行 kSar?
首先要确保你的机器上 [JAVA jdk](https://www.cyberciti.biz/faq/howto-ubuntu-linux-install-configure-jdk-jre/) 已安装并能够正常工作。输入下列命令去启动 kSar:
```
$ java -jar ksar-5.2.4-SNAPSHOT-all.jar
```

接下来你将看到 kSar 的主窗口,和有两个菜单的面板。

左侧有一个列表,是 kSar 根据数据已经解析出的可用图表的列表。右侧窗口将展示你选定的图表。
#### 如何使用 kSar 去生成 sar 图表?
首先,你需要从命名为 server1 的服务器上采集 `sar` 命令的统计数据。输入如下的命令:
```
[ server1 ]# LC_ALL=C sar -A > /tmp/sar.data.txt
```
接下来,使用 `scp` 命令从本地桌面拷贝到远程电脑上:
```
[ desktop ]$ scp [email protected]:/tmp/sar.data.txt /tmp/
```
切换到 kSar 窗口,点击 “Data” > “Load data from text file” > 从 `/tmp/` 中选择 `sar.data.txt` > 点击 “Open” 按钮。
现在,图表类型树已经出现在左侧面板中并选定了一个图形:



##### 放大和缩小
通过移动你可以交互式缩放图像的一部分。在要缩放的图像的左上角点击并按下鼠标,移动到要缩放区域的右下角,可以选定要缩放的区域。返回到未缩放状态,点击并拖动鼠标到除了右下角外的任意位置,你也可以点击并选择 zoom 选项。
##### 了解 kSar 图像和 sar 数据
我强烈建议你去阅读 `sar` 和 `sadf` 命令的 man 页面:
```
$ man sar
$ man sadf
```
### 案例学习:识别 Linux 服务器的 CPU 瓶颈
使用 `sar` 命令和 kSar 工具,可以得到内存、CPU、以及其它子系统的详细快照。例如,如果 CPU 使用率在一个很长的时间内持续高于 80%,有可能就是出现了一个 CPU 瓶颈。使用 `sar -x ALL` 你可以找到大量消耗 CPU 的进程。
[mpstat 命令](https://www.cyberciti.biz/tips/how-do-i-find-out-linux-cpu-utilization.html) 的输出(sysstat 包的一部分)也会帮你去了解 CPU 的使用率。但你可以使用 kSar 很容易地去分析这些信息。
#### 找出 CPU 瓶颈后 …
对 CPU 执行如下的调整:
1. 确保没有不需要的进程在后台运行。关闭 [Linux 上所有不需要的服务](https://www.cyberciti.biz/faq/check-running-services-in-rhel-redhat-fedora-centoslinux/)。
2. 使用 [cron](https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/) 在一个非高峰时刻运行任务(比如,备份)。
3. 使用 [top 和 ps 命令](https://www.cyberciti.biz/faq/show-all-running-processes-in-linux/) 去找出所有非关键的后台作业/服务。使用 [renice 命令](https://www.cyberciti.biz/faq/howto-change-unix-linux-process-priority/) 去调整低优先级作业。
4. 使用 [taskset 命令去设置进程使用的 CPU](https://www.cyberciti.biz/faq/taskset-cpu-affinity-command/) (卸载所使用的 CPU),即,绑定进程到不同的 CPU 上。例如,在 2# CPU 上运行 MySQL 数据库,而在 3# CPU 上运行 Apache。
5. 确保你的系统使用了最新的驱动程序和固件。
6. 如有可能在系统上增加额外的 CPU。
7. 为单线程应用程序使用更快的 CPU(比如,Lighttpd web 服务器应用程序)。
8. 为多线程应用程序使用多个 CPU(比如,MySQL 数据库服务器应用程序)。
9. 为一个 web 应用程序使用多个计算节点并设置一个 [负载均衡器](https://www.cyberciti.biz/tips/load-balancer-open-source-software.html)。
### isag —— 交互式系统活动记录器(替代工具)
`isag` 命令图形化显示了以前运行 `sar` 命令时存储在二进制文件中的系统活动数据。`isag` 命令引用 `sar` 并提取出它的数据来绘制图形。与 kSar 相比,`isag` 的选项比较少。

### 关于作者
本文作者是 nixCraft 的创始人和一位经验丰富的 Linux 操作系统/Unix shell 脚本培训师。他与包括 IT、教育、国防和空间研究、以及非营利组织等全球各行业客户一起合作。可以在 [Twitter](https://twitter.com/nixcraft)、[Facebook](https://facebook.com/nixcraft)、[Google+](https://plus.google.com/+CybercitiBiz) 上关注他。
---
via: <https://www.cyberciti.biz/tips/identifying-linux-bottlenecks-sar-graphs-with-ksar.html>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,399 | 让我们做个简单的解释器(一) | https://ruslanspivak.com/lsbasi-part1/ | 2018-03-04T09:41:00 | [
"解释器",
"编译器"
] | https://linux.cn/article-9399-1.html |
>
> “如果你不知道编译器是怎么工作的,那你就不知道电脑是怎么工作的。如果你不能百分百确定,那就是不知道它们是如何工作的。” --Steve Yegge
>
>
>

就是这样。想一想。你是萌新还是一个资深的软件开发者实际上都无关紧要:如果你不知道<ruby> 编译器 <rt> compiler </rt></ruby>和<ruby> 解释器 <rt> interpreter </rt></ruby>是怎么工作的,那么你就不知道电脑是怎么工作的。就这么简单。
所以,你知道编译器和解释器是怎么工作的吗?我是说,你百分百确定自己知道他们怎么工作吗?如果不知道。

或者如果你不知道但你非常想要了解它。

不用担心。如果你能坚持跟着这个系列做下去,和我一起构建一个解释器和编译器,最后你将会知道他们是怎么工作的。并且你会变成一个自信满满的快乐的人。至少我希望如此。

为什么要学习编译器和解释器?有三点理由。
1. 要写出一个解释器或编译器,你需要有很多的专业知识,并能融会贯通。写一个解释器或编译器能帮你加强这些能力,成为一个更厉害的软件开发者。而且,你要学的技能对编写软件非常有用,而不是仅仅局限于解释器或编译器。
2. 你确实想要了解电脑是怎么工作的。通常解释器和编译器看上去很魔幻。你或许不习惯这种魔力。你会想去揭开构建解释器和编译器那层神秘的面纱,了解它们的原理,把事情做好。
3. 你想要创建自己的编程语言或者特定领域的语言。如果你创建了一个,你还要为它创建一个解释器或者编译器。最近,兴起了对新的编程语言的兴趣。你能看到几乎每天都有一门新的编程语言横空出世:Elixir,Go,Rust,还有很多。
好,但什么是解释器和编译器?
**解释器** 和 **编译器** 的任务是把用高级语言写的源程序翻译成其他的格式。很奇怪,是不是?忍一忍,稍后你会在这个系列学到到底把源程序翻译成什么东西。
这时你可能会奇怪解释器和编译器之间有什么区别。为了实现这个系列的目的,我们规定一下,如果有个翻译器把源程序翻译成机器语言,那它就是 **编译器**。如果一个翻译器可以处理并执行源程序,却不用把它翻译器机器语言,那它就是 **解释器**。直观上它看起来像这样:

我希望你现在确信你很想学习构建一个编译器和解释器。你期望在这个教程里学习解释器的哪些知识呢?
你看这样如何。你和我一起为 [Pascal](https://en.wikipedia.org/wiki/Pascal_%28programming_language%29) 语言的一个大子集做一个简单的解释器。在这个系列结束的时候你能做出一个可以运行的 Pascal 解释器和一个像 Python 的 [pdb](https://docs.python.org/2/library/pdb.html) 那样的源代码级别的调试器。
你或许会问,为什么是 Pascal?一方面,它不是我为了这个系列而提出的一个虚构的语言:它是真实存在的一门编程语言,有很多重要的语言结构。有些陈旧但有用的计算机书籍使用 Pascal 编程语言作为示例(我知道对于选择一门语言来构建解释器,这个理由并不令人信服,但我认为学一门非主流的语言也不错 :))。
这有个 Pascal 中的阶乘函数示例,你将能用自己的解释器解释代码,还能够用可交互的源码级调试器进行调试,你可以这样创造:
```
program factorial;
function factorial(n: integer): longint;
begin
if n = 0 then
factorial := 1
else
factorial := n * factorial(n - 1);
end;
var
n: integer;
begin
for n := 0 to 16 do
writeln(n, '! = ', factorial(n));
end.
```
这个 Pascal 解释器的实现语言会使用 Python,但你也可以用其他任何语言,因为这里展示的思想不依赖任何特殊的实现语言。好,让我们开始干活。准备好了,出发!
你会从编写一个简单的算术表达式解析器,也就是常说的计算器,开始学习解释器和编译器。今天的目标非常简单:让你的计算器能处理两个个位数相加,比如 `3+5`。下面是你的计算器的源代码——不好意思,是解释器:
```
# 标记类型
#
# EOF (end-of-file 文件末尾)标记是用来表示所有输入都解析完成
INTEGER, PLUS, EOF = 'INTEGER', 'PLUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token 类型: INTEGER, PLUS, MINUS, or EOF
self.type = type
# token 值: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, '+', 或 None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# 用户输入字符串, 例如 "3+5"
self.text = text
# self.pos 是 self.text 的索引
self.pos = 0
# 当前标记实例
self.current_token = None
def error(self):
raise Exception('Error parsing input')
def get_next_token(self):
"""词法分析器(也说成扫描器或者标记器)
该方法负责把一个句子分成若干个标记。每次处理一个标记
"""
text = self.text
# self.pos 索引到达了 self.text 的末尾吗?
# 如果到了,就返回 EOF 标记,因为没有更多的
# 能转换成标记的输入了
if self.pos > len(text) - 1:
return Token(EOF, None)
# 从 self.pos 位置获取当前的字符,
# 基于单个字符判断要生成哪种标记
current_char = text[self.pos]
# 如果字符是一个数字,就把他转换成一个整数,生成一个 INTEGER # 标记,累加 self.pos 索引,指向数字后面的下一个字符,
# 并返回 INTEGER 标记
if current_char.isdigit():
token = Token(INTEGER, int(current_char))
self.pos += 1
return token
if current_char == '+':
token = Token(PLUS, current_char)
self.pos += 1
return token
self.error()
def eat(self, token_type):
# 将当前的标记类型与传入的标记类型作比较,如果他们相匹配,就
# “eat” 掉当前的标记并将下一个标记赋给 self.current_token,
# 否则抛出一个异常
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def expr(self):
"""expr -> INTEGER PLUS INTEGER"""
# 将输入中的第一个标记设置成当前标记
self.current_token = self.get_next_token()
# 我们期望当前标记是个位数。
left = self.current_token
self.eat(INTEGER)
# 期望当前标记是 ‘+’ 号
op = self.current_token
self.eat(PLUS)
# 我们期望当前标记是个位数。
right = self.current_token
self.eat(INTEGER)
# 上述操作完成后,self.current_token 被设成 EOF 标记
# 这时成功找到 INTEGER PLUS INTEGER 标记序列
# 这个方法就可以返回两个整数相加的结果了,
# 即高效的解释了用户输入
result = left.value + right.value
return result
def main():
while True:
try:
# 要在 Python3 下运行,请把 ‘raw_input’ 换成 ‘input’
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
```
把上面的代码保存到 `calc1.py` 文件,或者直接从 [GitHub](https://github.com/rspivak/lsbasi/blob/master/part1/calc1.py) 上下载。在你深入研究代码前,在命令行里面运行它看看效果。试一试!这是我笔记本上的示例会话(如果你想在 Python3 下运行,你要把 `raw_input` 换成 `input`):
```
$ python calc1.py
calc> 3+4
7
calc> 3+5
8
calc> 3+9
12
calc>
```
要让你的简易计算器正常工作,不抛出异常,你的输入要遵守以下几个规则:
* 只允许输入个位数
* 此时支持的唯一一个运算符是加法
* 输入中不允许有任何的空格符号
要让计算器变得简单,这些限制非常必要。不用担心,你很快就会让它变得很复杂。
好,现在让我们深入它,看看解释器是怎么工作,它是怎么评估出算术表达式的。
当你在命令行中输入一个表达式 `3+5`,解释器就获得了字符串 “3+5”。为了让解释器能够真正理解要用这个字符串做什么,它首先要把输入 “3+5” 分到叫做 `token`(标记)的容器里。<ruby> 标记 <rt> token </rt></ruby> 是一个拥有类型和值的对象。比如说,对字符 “3” 而言,标记的类型是 INTEGER 整数,对应的值是 3。
把输入字符串分成标记的过程叫<ruby> 词法分析 <rt> lexical analysis </rt></ruby>。因此解释器的需要做的第一步是读取输入字符,并将其转换成标记流。解释器中的这一部分叫做<ruby> 词法分析器 <rt> lexical analyzer </rt></ruby>,或者简短点叫 **lexer**。你也可以给它起别的名字,诸如<ruby> 扫描器 <rt> scanner </rt></ruby>或者<ruby> 标记器 <rt> tokenizer </rt></ruby>。它们指的都是同一个东西:解释器或编译器中将输入字符转换成标记流的那部分。
`Interpreter` 类中的 `get_next_token` 方法就是词法分析器。每次调用它的时候,你都能从传入解释器的输入字符中获得创建的下一个标记。仔细看看这个方法,看看它是如何完成把字符转换成标记的任务的。输入被存在可变文本中,它保存了输入的字符串和关于该字符串的索引(把字符串想象成字符数组)。`pos` 开始时设为 0,指向字符 ‘3’。这个方法一开始检查字符是不是数字,如果是,就将 `pos` 加 1,并返回一个 INTEGER 类型的标记实例,并把字符 ‘3’ 的值设为整数,也就是整数 3:

现在 `pos` 指向文本中的 ‘+’ 号。下次调用这个方法的时候,它会测试 `pos` 位置的字符是不是个数字,然后检测下一个字符是不是个加号,就是这样。结果这个方法把 `pos` 加 1,返回一个新创建的标记,类型是 PLUS,值为 ‘+’。

`pos` 现在指向字符 ‘5’。当你再调用 `get_next_token` 方法时,该方法会检查这是不是个数字,就是这样,然后它把 `pos` 加 1,返回一个新的 INTEGER 标记,该标记的值被设为整数 5:

因为 `pos` 索引现在到了字符串 “3+5” 的末尾,你每次调用 `get_next_token` 方法时,它将会返回 EOF 标记:

自己试一试,看看计算器里的词法分析器的运行:
```
>>> from calc1 import Interpreter
>>>
>>> interpreter = Interpreter('3+5')
>>> interpreter.get_next_token()
Token(INTEGER, 3)
>>>
>>> interpreter.get_next_token()
Token(PLUS, '+')
>>>
>>> interpreter.get_next_token()
Token(INTEGER, 5)
>>>
>>> interpreter.get_next_token()
Token(EOF, None)
>>>
```
既然你的解释器能够从输入字符中获取标记流,解释器需要对它做点什么:它需要在词法分析器 `get_next_token` 中获取的标记流中找出相应的结构。你的解释器应该能够找到流中的结构:INTEGER -> PLUS -> INTEGER。就是这样,它尝试找出标记的序列:整数后面要跟着加号,加号后面要跟着整数。
负责找出并解释结构的方法就是 `expr`。该方法检验标记序列确实与期望的标记序列是对应的,比如 INTEGER -> PLUS -> INTEGER。成功确认了这个结构后,就会生成加号左右两边的标记的值相加的结果,这样就成功解释你输入到解释器中的算术表达式了。
`expr` 方法用了一个助手方法 `eat` 来检验传入的标记类型是否与当前的标记类型相匹配。在匹配到传入的标记类型后,`eat` 方法会获取下一个标记,并将其赋给 `current_token` 变量,然后高效地 “吃掉” 当前匹配的标记,并将标记流的虚拟指针向后移动。如果标记流的结构与期望的 INTEGER -> PLUS -> INTEGER 标记序列不对应,`eat` 方法就抛出一个异常。
让我们回顾下解释器做了什么来对算术表达式进行评估的:
* 解释器接受输入字符串,比如说 “3+5”
* 解释器调用 `expr` 方法,在词法分析器 `get_next_token` 返回的标记流中找出结构。这个结构就是 INTEGER -> PLUS -> INTEGER 这样的格式。在确认了格式后,它就通过把两个整型标记相加来解释输入,因为此时对于解释器来说很清楚,它要做的就是把两个整数 3 和 5 进行相加。
恭喜。你刚刚学习了怎么构建自己的第一个解释器!
现在是时候做练习了。

看了这篇文章,你肯定觉得不够,是吗?好,准备好做这些练习:
1. 修改代码,允许输入多位数,比如 “12+3”
2. 添加一个方法忽略空格符,让你的计算器能够处理带有空白的输入,比如 “12 + 3”
3. 修改代码,用 ‘-’ 号而非 ‘+’ 号去执行减法比如 “7-5”
**检验你的理解**
1. 什么是解释器?
2. 什么是编译器
3. 解释器和编译器有什么差别?
4. 什么是标记?
5. 将输入分隔成若干个标记的过程叫什么?
6. 解释器中进行词法分析的部分叫什么?
7. 解释器或编译器中进行词法分析的部分有哪些其他的常见名字?
在结束本文前,我衷心希望你能留下学习解释器和编译器的承诺。并且现在就开始做。不要把它留到以后。不要拖延。如果你已经看完了本文,就开始吧。如果已经仔细看完了但是还没做什么练习 —— 现在就开始做吧。如果已经开始做练习了,那就把剩下的做完。你懂得。而且你知道吗?签下承诺书,今天就开始学习解释器和编译器!
>
> 本人, \_\_\_\_\_\_,身体健全,思想正常,在此承诺从今天开始学习解释器和编译器,直到我百分百了解它们是怎么工作的!
>
>
> 签字人:
>
>
> 日期:
>
>
>

签字,写上日期,把它放在你每天都能看到的地方,确保你能坚守承诺。谨记你的承诺:
>
> “承诺就是,你说自己会去做的事,在你说完就一直陪着你的东西。” —— Darren Hardy
>
>
>
好,今天的就结束了。这个系列的下一篇文章里,你将会扩展自己的计算器,让它能够处理更复杂的算术表达式。敬请期待。
---
via: <https://ruslanspivak.com/lsbasi-part1/>
作者:[Ruslan Spivak](https://ruslanspivak.com) 译者:[BriFuture](https://github.com/BriFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | “If you don’t know how compilers work, then you don’t know how computers work. If you’re not 100% sure whether you know how compilers work, then you don’t know how they work.”— Steve Yegge
There you have it. Think about it. It doesn’t really matter whether you’re a newbie or a seasoned software developer: if you don’t know how compilers and interpreters work, then you don’t know how computers work. It’s that simple.
So, do you know how compilers and interpreters work? And I mean, are you 100% sure that you know how they work? If you don’t.
Or if you don’t and you’re really agitated about it.
Do not worry. If you stick around and work through the series and build an interpreter and a compiler with me you will know how they work in the end. And you will become a confident happy camper too. At least I hope so.
Why would you study interpreters and compilers? I will give you three reasons.
- To write an interpreter or a compiler you have to have a lot of technical skills that you need to use together. Writing an interpreter or a compiler will help you improve those skills and become a better software developer. As well, the skills you will learn are useful in writing any software, not just interpreters or compilers.
- You really want to know how computers work. Often interpreters and compilers look like magic. And you shouldn’t be comfortable with that magic. You want to demystify the process of building an interpreter and a compiler, understand how they work, and get in control of things.
- You want to create your own programming language or domain specific language. If you create one, you will also need to create either an interpreter or a compiler for it. Recently, there has been a resurgence of interest in new programming languages. And you can see a new programming language pop up almost every day: Elixir, Go, Rust just to name a few.
Okay, but what are interpreters and compilers?
The goal of an **interpreter** or a **compiler** is to translate a source program in some high-level language into some other form. Pretty vague, isn’t it? Just bear with me, later in the series you will learn exactly what the source program is translated into.
At this point you may also wonder what the difference is between an interpreter and a compiler.
For the purpose of this series, let’s agree that if a translator translates a source program into machine language, it is a **compiler**. If a translator processes and executes the source program without translating it into machine language first, it is an **interpreter**. Visually it looks something like this:
I hope that by now you’re convinced that you really want to study and build an interpreter and a compiler. What can you expect from this series on interpreters?
Here is the deal. You and I are going to create a simple interpreter for a large subset of [Pascal](https://en.wikipedia.org/wiki/Pascal_%28programming_language%29) language. At the end of this series you will have a working Pascal interpreter and a source-level debugger like Python’s [pdb](https://docs.python.org/2/library/pdb.html).
You might ask, why Pascal? For one thing, it’s not a made-up language that I came up with just for this series: it’s a real programming language that has many important language constructs. And some old, but useful, CS books use Pascal programming language in their examples (I understand that that’s not a particularly compelling reason to choose a language to build an interpreter for, but I thought it would be nice for a change to learn a non-mainstream language :)
Here is an example of a factorial function in Pascal that you will be able to interpret with your own interpreter and debug with the interactive source-level debugger that you will create along the way:
```
program factorial;
function factorial(n: integer): longint;
begin
if n = 0 then
factorial := 1
else
factorial := n * factorial(n - 1);
end;
var
n: integer;
begin
for n := 0 to 16 do
writeln(n, '! = ', factorial(n));
end.
```
The implementation language of the Pascal interpreter will be Python, but you can use any language you want because the ideas presented don’t depend on any particular implementation language. Okay, let’s get down to business. Ready, set, go!
You will start your first foray into interpreters and compilers by writing a simple interpreter of arithmetic expressions, also known as a calculator. Today the goal is pretty minimalistic: to make your calculator handle the addition of two single digit integers like **3+5**.
Here is the source code for your calculator, sorry, interpreter:
```
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, EOF = 'INTEGER', 'PLUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, PLUS, or EOF
self.type = type
# token value: 0, 1, 2. 3, 4, 5, 6, 7, 8, 9, '+', or None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# client string input, e.g. "3+5"
self.text = text
# self.pos is an index into self.text
self.pos = 0
# current token instance
self.current_token = None
def error(self):
raise Exception('Error parsing input')
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
text = self.text
# is self.pos index past the end of the self.text ?
# if so, then return EOF token because there is no more
# input left to convert into tokens
if self.pos > len(text) - 1:
return Token(EOF, None)
# get a character at the position self.pos and decide
# what token to create based on the single character
current_char = text[self.pos]
# if the character is a digit then convert it to
# integer, create an INTEGER token, increment self.pos
# index to point to the next character after the digit,
# and return the INTEGER token
if current_char.isdigit():
token = Token(INTEGER, int(current_char))
self.pos += 1
return token
if current_char == '+':
token = Token(PLUS, current_char)
self.pos += 1
return token
self.error()
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def expr(self):
"""expr -> INTEGER PLUS INTEGER"""
# set current token to the first token taken from the input
self.current_token = self.get_next_token()
# we expect the current token to be a single-digit integer
left = self.current_token
self.eat(INTEGER)
# we expect the current token to be a '+' token
op = self.current_token
self.eat(PLUS)
# we expect the current token to be a single-digit integer
right = self.current_token
self.eat(INTEGER)
# after the above call the self.current_token is set to
# EOF token
# at this point INTEGER PLUS INTEGER sequence of tokens
# has been successfully found and the method can just
# return the result of adding two integers, thus
# effectively interpreting client input
result = left.value + right.value
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
```
Save the above code into *calc1.py* file or download it directly from [GitHub](https://github.com/rspivak/lsbasi/blob/master/part1/calc1.py). Before you start digging deeper into the code, run the calculator on the command line and see it in action. Play with it! Here is a sample session on my laptop (if you want to run the calculator under Python3 you will need to replace *raw_input* with *input*):
```
$ python calc1.py
calc> 3+4
7
calc> 3+5
8
calc> 3+9
12
calc>
```
For your simple calculator to work properly without throwing an exception, your input needs to follow certain rules:
- Only single digit integers are allowed in the input
- The only arithmetic operation supported at the moment is addition
- No whitespace characters are allowed anywhere in the input
Those restrictions are necessary to make the calculator simple. Don’t worry, you’ll make it pretty complex pretty soon.
Okay, now let’s dive in and see how your interpreter works and how it evaluates arithmetic expressions.
When you enter an expression *3+5* on the command line your interpreter gets a string *“3+5”*. In order for the interpreter to actually understand what to do with that string it first needs to break the input *“3+5”* into components called **tokens**. A **token** is an object that has a type and a value. For example, for the string *“3”* the type of the token will be INTEGER and the corresponding value will be integer *3*.
The process of breaking the input string into tokens is called **lexical analysis**. So, the first step your interpreter needs to do is read the input of characters and convert it into a stream of tokens. The part of the interpreter that does it is called a **lexical analyzer**, or **lexer** for short. You might also encounter other names for the same component, like **scanner** or **tokenizer**. They all mean the same: the part of your interpreter or compiler that turns the input of characters into a stream of tokens.
The method *get_next_token* of the *Interpreter* class is your lexical analyzer. Every time you call it, you get the next token created from the input of characters passed to the interpreter. Let’s take a closer look at the method itself and see how it actually does its job of converting characters into tokens.
The input is stored in the variable *text* that holds the input string and *pos* is an index into that string (think of the string as an array of characters). *pos* is initially set to 0 and points to the character *‘3’*. The method first checks whether the character is a digit and if so, it increments *pos* and returns a token instance with the type INTEGER and the value set to the integer value of the string *‘3’*, which is an integer *3*:
The *pos* now points to the *‘+’* character in the *text*. The next time you call the method, it tests if a character at the position *pos* is a digit and then it tests if the character is a plus sign, which it is. As a result the method increments *pos* and returns a newly created token with the type PLUS and value *‘+’*:
The *pos* now points to character *‘5’*. When you call the *get_next_token* method again the method checks if it’s a digit, which it is, so it increments *pos* and returns a new INTEGER token with the value of the token set to integer *5*:
Because the *pos* index is now past the end of the string *“3+5”* the *get_next_token* method returns the EOF token every time you call it:
Try it out and see for yourself how the lexer component of your calculator works:
```
>>> from calc1 import Interpreter
>>>
>>> interpreter = Interpreter('3+5')
>>> interpreter.get_next_token()
Token(INTEGER, 3)
>>>
>>> interpreter.get_next_token()
Token(PLUS, '+')
>>>
>>> interpreter.get_next_token()
Token(INTEGER, 5)
>>>
>>> interpreter.get_next_token()
Token(EOF, None)
>>>
```
So now that your interpreter has access to the stream of tokens made from the input characters, the interpreter needs to do something with it: it needs to find the structure in the flat stream of tokens it gets from the lexer *get_next_token*. Your interpreter expects to find the following structure in that stream: INTEGER -> PLUS -> INTEGER. That is, it tries to find a sequence of tokens: integer followed by a plus sign followed by an integer.
The method responsible for finding and interpreting that structure is *expr*. This method verifies that the sequence of tokens does indeed correspond to the expected sequence of tokens, i.e INTEGER -> PLUS -> INTEGER. After it’s successfully confirmed the structure, it generates the result by adding the value of the token on the left side of the PLUS and the right side of the PLUS, thus successfully interpreting the arithmetic expression you passed to the interpreter.
The *expr* method itself uses the helper method *eat* to verify that the token type passed to the *eat* method matches the current token type. After matching the passed token type the *eat* method gets the next token and assigns it to the *current_token* variable, thus effectively “eating” the currently matched token and advancing the imaginary pointer in the stream of tokens. If the structure in the stream of tokens doesn’t correspond to the expected INTEGER PLUS INTEGER sequence of tokens the *eat* method throws an exception.
Let’s recap what your interpreter does to evaluate an arithmetic expression:
- The interpreter accepts an input string, let’s say “3+5”
- The interpreter calls the
*expr*method to find a structure in the stream of tokens returned by the lexical analyzer*get_next_token*. The structure it tries to find is of the form INTEGER PLUS INTEGER. After it’s confirmed the structure, it interprets the input by adding the values of two INTEGER tokens because it’s clear to the interpreter at that point that what it needs to do is add two integers, 3 and 5.
Congratulate yourself. You’ve just learned how to build your very first interpreter!
Now it’s time for exercises.
You didn’t think you would just read this article and that would be enough, did you? Okay, get your hands dirty and do the following exercises:
- Modify the code to allow multiple-digit integers in the input, for example “12+3”
- Add a method that skips whitespace characters so that your calculator can handle inputs with whitespace characters like ” 12 + 3”
- Modify the code and instead of ‘+’ handle ‘-‘ to evaluate subtractions like “7-5”
**Check your understanding**
- What is an interpreter?
- What is a compiler?
- What’s the difference between an interpreter and a compiler?
- What is a token?
- What is the name of the process that breaks input apart into tokens?
- What is the part of the interpreter that does lexical analysis called?
- What are the other common names for that part of an interpreter or a compiler?
Before I finish this article, I really want you to commit to studying interpreters and compilers. And I want you to do it right now. Don’t put it on the back burner. Don’t wait. If you’ve skimmed the article, start over. If you’ve read it carefully but haven’t done exercises - do them now. If you’ve done only some of them, finish the rest. You get the idea. And you know what? Sign the commitment pledge to start learning about interpreters and compilers today!
*
I, ________, of being sound mind and body, do hereby pledge to commit to studying interpreters and compilers starting today and get to a point where I know 100% how they work!*
Signature:
Date:
Sign it, date it, and put it somewhere where you can see it every day to make sure that you stick to your commitment. And keep in mind the definition of commitment:
“Commitment is doing the thing you said you were going to do long after the mood you said it in has left you.” — Darren Hardy
Okay, that’s it for today. In the next article of the mini series you will extend your calculator to handle more arithmetic expressions. Stay tuned.
If you can’t wait for the second article and are chomping at the bit to start digging deeper into interpreters and compilers, here is a list of books I recommend that will help you along the way:
Get the edge and stay sharp. Subscribe to Beyond Basics for free and get new posts without missing a beat!
**All articles in this series:**
-
[Let's Build A Simple Interpreter. Part 1.](/lsbasi-part1/) -
[Let's Build A Simple Interpreter. Part 2.](/lsbasi-part2/) -
[Let's Build A Simple Interpreter. Part 3.](/lsbasi-part3/) -
[Let's Build A Simple Interpreter. Part 4.](/lsbasi-part4/) -
[Let's Build A Simple Interpreter. Part 5.](/lsbasi-part5/) -
[Let's Build A Simple Interpreter. Part 6.](/lsbasi-part6/) -
[Let's Build A Simple Interpreter. Part 7.](/lsbasi-part7/) -
[Let's Build A Simple Interpreter. Part 8.](/lsbasi-part8/) -
[Let's Build A Simple Interpreter. Part 9.](/lsbasi-part9/) -
[Let's Build A Simple Interpreter. Part 10.](/lsbasi-part10/) -
[Let's Build A Simple Interpreter. Part 11.](/lsbasi-part11/) -
[Let's Build A Simple Interpreter. Part 12.](/lsbasi-part12/) -
[Let's Build A Simple Interpreter. Part 13.](/lsbasi-part13/) -
[Let's Build A Simple Interpreter. Part 14.](/lsbasi-part14/) -
[Let's Build A Simple Interpreter. Part 15.](/lsbasi-part15/) -
[Let's Build A Simple Interpreter. Part 16.](/lsbasi-part16/) -
[Let's Build A Simple Interpreter. Part 17.](/lsbasi-part17/) -
[Let's Build A Simple Interpreter. Part 18.](/lsbasi-part18/)
## Comments
comments powered by Disqus |
9,400 | 4 种绕过 Linux/Unix 命令别名的方法 | https://www.cyberciti.biz/faq/bash-bypass-alias-command-on-linux-macos-unix/ | 2018-03-02T22:45:00 | [
"别名",
"alias"
] | https://linux.cn/article-9400-1.html | 我在我的 Linux 系统上定义了如下 `mount` 别名:
```
alias mount='mount | column -t'
```
但是我需要在挂载文件系统和其他用途时绕过这个 bash 别名。我如何在 Linux、\*BSD、macOS 或者类 Unix 系统上临时禁用或者绕过 bash shell 呢?
你可以使用 `alias` 命令定义或显示 bash shell 别名。一旦创建了 bash shell 别名,它们将优先于外部或内部命令。本文将展示如何暂时绕过 bash 别名,以便你可以运行实际的内部或外部命令。

### 4 种绕过 bash 别名的方法
尝试以下任意一种方法来运行被 bash shell 别名绕过的命令。让我们[如下定义一个别名](https://bash.cyberciti.biz/guide/Create_and_use_aliases):
```
alias mount='mount | column -t'
```
运行如下:
```
mount
```
示例输出:
```
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
udev on /dev type devtmpfs (rw,nosuid,relatime,size=8023572k,nr_inodes=2005893,mode=755)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,noexec,relatime,size=1610240k,mode=755)
/dev/mapper/ubuntu--vg-root on / type ext4 (rw,relatime,errors=remount-ro,data=ordered)
/dev/sda1 on /boot type ext4 (rw,relatime,data=ordered)
binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_misc (rw,relatime)
lxcfs on /var/lib/lxcfs type fuse.lxcfs (rw,nosuid,nodev,relatime,user_id=0,group_id=0,allow_other)
```
#### 方法 1 - 使用 `\command`
输入以下命令暂时绕过名为 `mount` 的 bash 别名:
```
\mount
```
#### 方法 2 - 使用 `"command"` 或 `'command'`
如下引用 `mount` 命令调用实际的 `/bin/mount`:
```
"mount"
```
或者
```
'mount'
```
#### 方法 3 - 使用命令的完全路径
使用完整的二进制路径,如 `/bin/mount`:
```
/bin/mount
/bin/mount /dev/sda1 /mnt/sda
```
#### 方法 4 - 使用内部命令 `command`
语法是:
```
command cmd
command cmd arg1 arg2
```
要覆盖 `.bash_aliases` 中设置的别名,例如 `mount`:
```
command mount
command mount /dev/sdc /mnt/pendrive/
```
[“command” 直接运行命令或显示](https://bash.cyberciti.biz/guide/Command)关于命令的信息。它带参数运行命令会抑制 shell 函数查询或者别名,或者显示有关给定命令的信息。
### 关于 unalias 命令的说明
要从当前会话的已定义别名列表中移除别名,请使用 `unalias` 命令:
```
unalias mount
```
要从当前 bash 会话中删除所有别名定义:
```
unalias -a
```
确保你更新你的 `~/.bashrc` 或 `$HOME/.bash_aliases`。如果要永久删除定义的别名,则必须删除定义的别名:
```
vi ~/.bashrc
```
或者
```
joe $HOME/.bash_aliases
```
想了解更多信息,参考[这里](https://www.gnu.org/software/bash/manual/bash.html)的在线手册,或者输入下面的命令查看:
```
man bash
help command
help unalias
help alias
```
---
via: <https://www.cyberciti.biz/faq/bash-bypass-alias-command-on-linux-macos-unix/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,401 | Google 计划在 Chromebook 中增加容器化的 Linux 应用 | http://news.softpedia.com/news/google-plans-to-add-support-for-containerized-linux-apps-to-chromebooks-519950.shtml | 2018-03-04T00:29:00 | [
"Linux",
"容器",
"Chromebook"
] | https://linux.cn/article-9401-1.html | 
虽然大多数 Chromebook 已经能够运行 Android 应用程序,但似乎 Google 希望在其 Chrome OS 上增加在容器或虚拟机上运行 Linux 应用程序的支持。
据[一则 Reddit 消息](https://www.reddit.com/r/chromeos/comments/7ytpb1/project_crostini_linux_vms_on_chrome_os/),谷歌显然正在开发 Chrome OS 的 Crostini 项目,以在 Chrome OS 上支持 Linux 的虚拟机。这条消息指出,最近的 [Chromium 提交](https://chromium-review.googlesource.com/c/chromium/src/+/899767) 会解释一条新的设备策略,如果其设置为真,那么将允许在 Chrome OS 上运行 Linux 虚拟机。
>
> “如果该策略未设置或设置为真,那么在 Chrome OS 上运行 Linux 虚拟机是允许的。未设置也是允许的意味着非管理的设备是允许运行 Linux 虚拟机的。此时,要让 Linux 虚拟机运行起来,也需要启用 Finch 试验性特性,当该特性完全启用后,Finch 控制逻辑将被移除。”
>
>
>
### 在 Chrome OS 上运行 Linux 应用将让多少人梦想成真
这表明在你的 Chromebook 上运行 Linux 应用的梦想终于要变成了真的。不会让你等待太久,当这个新策略逐步经历 Chrome OS 的 Dev、Beta 和 Stable 等频道之后,你就可以在 Chrome OS 上尝鲜 Linux 应用了。
据 [ChromeUnboxed](https://chromeunboxed.com/news/chromebook-containers-virtual-machine-crostini-google-io) 的消息,该特性或许出现在五月份早一些的时候 Chrome OS 66 发布时。显然这是首次在 Chrome OS 上支持容器化的 Linux 应用,我们对此功能表示无比的高兴,而这也将进一步让更多的人去使用 Chrome OS。
Chromebook 操作系统的当前版本是 Google 上个月发布的 Chrome OS 64,它[支持并行运行 Android 应用](http://news.softpedia.com/news/chromebooks-will-soon-support-parallel-android-apps-with-the-chrome-os-64-update-519154.shtml),以及一些其它的核心功能,而且这个补丁也[为 Chromebook 解决了 Meltdown 和 Spectre 安全缺陷影响](http://news.softpedia.com/news/google-patches-chromebooks-against-meltdown-spectre-adds-new-chrome-os-features-519763.shtml)。
| 301 | Moved Permanently | null |
9,402 | 如何理解Apache 2.0许可证中的专利许可条款? | https://opensource.com/article/18/2/how-make-sense-apache-2-patent-license | 2018-03-04T08:36:00 | [
"专利",
"许可证"
] | https://linux.cn/article-9402-1.html |
>
> 提要:Apache 2.0许可证中的专利许可条款使得开源代码可以安全使用,但它经常被误解。
>
>
>

Apache 2.0 许可证包含许多关键条款,其中也包括根据我的经验经常被误解的<ruby> 专利许可 <rp> ( </rp> <rt> patent grant </rt> <rp> ) </rp></ruby>条款。专利许可对于开源代码的安全使用具有重大影响。我通过分析 Apache 2.0 许可证第 3 部分的其中一段来具体解释:
>
> 3.<ruby> 专利许可的授予 <rp> ( </rp> <rt> Grant of Patent License </rt> <rp> ) </rp></ruby>。根据本许可证的条款和条件,每个<ruby> 贡献者 <rp> ( </rp> <rt> Contributor </rt> <rp> ) </rp></ruby>特此授予您永久的、全球性的、非独占的、免费的、免版税的、不可撤销的(本节所述除外)专利许可,从而制作、委托制作、使用、许诺销售、销售、进口和以其他方式转移<ruby> 作品 <rp> ( </rp> <rt> the Work </rt> <rp> ) </rp></ruby>,该专利许可仅适用于贡献者提供的满足以下条件的专利权利要求:贡献者的<ruby> 贡献 <rp> ( </rp> <rt> Contribution </rt> <rp> ) </rp></ruby>单独对该权利要求必然构成侵权,或贡献者的贡献与贡献者提交此类贡献的作品之间的结合对该权利要求必然构成侵权。
>
>
>
实质上,当软件开发人员为项目(即 Apache 2.0 许可证中的“作品”)贡献代码,他/她就成为贡献者。在上述条款中,贡献者授予了使用任何可能与其贡献相关的专利的许可。这让用户感到安心,因为贡献者可能会被禁止向任何使用包含该贡献的软件的用户收取专利许可费。
但当软件开发人员贡献的代码仅其自身来说没有被贡献者的任何专利所覆盖,而只有与贡献者提交此类贡献的遵循 Apache 2.0 许可证的开源项目相结合才能被相关专利覆盖时,问题就变得复杂了。因此,拥有相关专利的贡献者可以向使用修订版作品的用户收取专利许可费。Apache 2.0 许可证的作者进行了前瞻性思考,对这种情况也进行了说明。第 3 条规定,该许可证适用于“贡献者提供的满足以下条件的专利权利要求:……贡献者的贡献与贡献者提交此类贡献的作品之间的结合对该权利要求必然构成侵权。”
一些贡献者可能担心他们的贡献会导致广泛的专利许可。例如,您向遵循 Apache 2.0 许可证的开源项目贡献代码,在您提交贡献的时候,无论是您的贡献自身还是其与开源项目的结合都没有对您的专利构成侵权,但后续该作品通过其他人而非您的贡献在功能上进行了扩展,从而被您的专利所覆盖,这种情况该怎么办呢?您的专利会被自动许可吗?按照 Apache 软件基金会的常见问题解答,情况并非如此。
这个结果似乎以一种开放/合作的方式,在向 Apache 2.0 开源项目贡献代码的专利所有者与保证相关专利不会针对依据 Apache 2.0 许可证享有权益的作品用户主张专利权的必要性之间,达成了一种明智的平衡。
关于依据 Apache 2.0 许可证向 Apache 软件基金会提交贡献的专利许可范围的相关问题和答案,可以在 Apache 软件基金会有关许可的[常见问题解答](http://www.apache.org/foundation/license-faq.html)里找到。
请记住,这是 Apache 软件基金会对 Apache 2.0 许可证的解释。使用 Apache 2.0 许可证的其他许可人可能会以不同的方式解释该许可证中专利许可条款的范围,但我认为那似乎不太可能会成功,Apache 软件基金会的常见问题解答对专利许可条款的解释看起来合情合理。
---
作者简介:Jeffrey R. Kaufman 是全球领先的开源软件解决方案供应商 Red Hat 公司的开源知识产权律师,还担任<ruby> 托马斯杰斐逊法学院 <rp> ( </rp> <rt> Thomas Jefferson School of Law </rt> <rp> ) </rp></ruby>的兼职教授。在任职 Red Hat 之前,Jeffrey曾担任<ruby> 高通公司 <rp> ( </rp> <rt> Qualcomm Incorporated </rt> <rp> ) </rp></ruby>的专利顾问,为<ruby> 首席科学家办公室 <rp> ( </rp> <rt> Office of the Chief Scientist </rt> <rp> ) </rp></ruby>提供开源事务咨询。
译者简介:薛亮,集慧智佳知识产权咨询公司高级咨询师,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 301 | Moved Permanently | null |
9,404 | 如何修复 WordPress 中的 HTTP 错误 | https://www.rosehosting.com/blog/http-error-wordpress/ | 2018-03-04T23:18:45 | [
"WordPress"
] | https://linux.cn/article-9404-1.html | 
我们会向你介绍,如何在 Linux VPS 上修复 WordPress 中的 HTTP 错误。 下面列出了 WordPress 用户遇到的最常见的 HTTP 错误,我们的建议侧重于如何发现错误原因以及解决方法。
### 1、 修复在上传图像时出现的 HTTP 错误
如果你在基于 WordPress 的网页中上传图像时出现错误,这也许是因为服务器上 PHP 的配置,例如存储空间不足或者其他配置问题造成的。
用如下命令查找 php 配置文件:
```
php -i | grep php.ini
Configuration File (php.ini) Path => /etc
Loaded Configuration File => /etc/php.ini
```
根据输出结果,php 配置文件位于 `/etc` 文件夹下。编辑 `/etc/php.ini` 文件,找出下列行,并按照下面的例子修改其中相对应的值:
```
vi /etc/php.ini
```
```
upload_max_filesize = 64M
post_max_size = 32M
max_execution_time = 300
max_input_time 300
memory_limit = 128M
```
当然,如果你不习惯使用 vi 文本编辑器,你可以选用自己喜欢的。
不要忘记重启你的网页服务器来让改动生效。
如果你安装的网页服务器是 Apache,你也可以使用 `.htaccess` 文件。首先,找到 `.htaccess` 文件。它位于 WordPress 安装路径的根文件夹下。如果没有找到 `.htaccess` 文件,需要自己手动创建一个,然后加入如下内容:
```
vi /www/html/path_to_wordpress/.htaccess
```
```
php_value upload_max_filesize 64M
php_value post_max_size 32M
php_value max_execution_time 180
php_value max_input_time 180
# BEGIN WordPress
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteRule ^index\.php$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
# END WordPress
```
如果你使用的网页服务器是 nginx,在 nginx 的 `server` 配置块中配置你的 WordPress 实例。详细配置和下面的例子相似:
```
server {
listen 80;
client_max_body_size 128m;
client_body_timeout 300;
server_name your-domain.com www.your-domain.com;
root /var/www/html/wordpress;
index index.php;
location = /favicon.ico {
log_not_found off;
access_log off;
}
location = /robots.txt {
allow all;
log_not_found off;
access_log off;
}
location / {
try_files $uri $uri/ /index.php?$args;
}
location ~ \.php$ {
include fastcgi_params;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
location ~* \.(js|css|png|jpg|jpeg|gif|ico)$ {
expires max;
log_not_found off;
}
}
```
根据自己的 PHP 配置,你需要将 `fastcgi_pass 127.0.0.1:9000;` 用类似于 `fastcgi_pass unix:/var/run/php7-fpm.sock;` 替换掉(依照实际连接方式)
重启 nginx 服务来使改动生效。
### 2、 修复因为不恰当的文件权限而产生的 HTTP 错误
如果你在 WordPress 中出现一个意外错误,也许是因为不恰当的文件权限导致的,所以需要给 WordPress 文件和文件夹设置一个正确的权限:
```
chown www-data:www-data -R /var/www/html/path_to_wordpress/
```
将 `www-data` 替换成实际的网页服务器用户,将 `/var/www/html/path_to_wordpress` 换成 WordPress 的实际安装路径。
### 3、 修复因为内存不足而产生的 HTTP 错误
你可以通过在 `wp-config.php` 中添加如下内容来设置 PHP 的最大内存限制:
```
define('WP_MEMORY_LIMIT', '128MB');
```
### 4、 修复因为 php.ini 文件错误配置而产生的 HTTP 错误
编辑 PHP 配置主文件,然后找到 `cgi.fix_pathinfo` 这一行。 这一行内容默认情况下是被注释掉的,默认值为 `1`。取消这一行的注释(删掉这一行最前面的分号),然后将 `1` 改为 `0` 。同时需要修改 `date.timezone` 这一 PHP 设置,再次编辑 PHP 配置文件并将这一选项改成 `date.timezone = Asia/Shanghai` (或者将等号后内容改为你所在的时区)。
```
vi /etc/php.ini
```
```
cgi.fix_pathinfo=0
date.timezone = Asia/Shanghai
```
### 5、 修复因为 Apache mod\_security 模块而产生的 HTTP 错误
如果你在使用 Apache mod\_security 模块,这可能也会引起问题。试着禁用这一模块,确认是否因为在 `.htaccess` 文件中加入如下内容而引起了问题:
```
<IfModule mod_security.c>
SecFilterEngine Off
SecFilterScanPOST Off
</IfModule>
```
### 6、 修复因为有问题的插件/主题而产生的 HTTP 错误
一些插件或主题也会导致 HTTP 错误以及其他问题。你可以首先禁用有问题的插件/主题,或暂时禁用所有 WordPress 插件。如果你有 phpMyAdmin,使用它来禁用所有插件:在其中找到 `wp_options` 数据表,在 `option_name` 这一列中找到 `active_plugins` 这一记录,然后将 `option_value` 改为 :`a:0:{}`。
或者用以下命令通过SSH重命名插件所在文件夹:
```
mv /www/html/path_to_wordpress/wp-content/plugins /www/html/path_to_wordpress/wp-content/plugins.old
```
通常情况下,HTTP 错误会被记录在网页服务器的日志文件中,所以寻找错误时一个很好的切入点就是查看服务器日志。
---
via: <https://www.rosehosting.com/blog/http-error-wordpress/>
作者:[rosehosting](https://www.rosehosting.com) 译者:[wenwensnow](https://github.com/wenwensnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We’ll show you, how to fix HTTP errors in WordPress, on a Linux VPS. Listed below are the most common HTTP errors in WordPress, experienced by WordPress users, and our suggestions on how to investigate and fix them.
Table of Contents
## 1. Fix HTTP error in WordPress when uploading images
If you get an error when uploading an image to your WordPress based site, it may be due to PHP configuration settings on your server, like insufficient memory limit or so.
Locate the php configuration file using the following command:
#php -i | grep php.ini Configuration File (php.ini) Path => /etc Loaded Configuration File => /etc/php.ini
According to the output, the PHP configuration file is located in the ‘/etc’ directory, so edit the ‘/etc/php.ini’ file, find the lines below and modify them with these values:
vi /etc/php.ini
upload_max_filesize = 64M post_max_size = 32M max_execution_time = 300 max_input_time 300 memory_limit = 128M
Of course if you are unfamiliar with the vi text editor, use your favorite one.
Do not forget to restart your web server for the changes to take effect.
If the web server installed on your server is Apache, you may use .htaccess. First, locate the .htaccess file. It should be in the document root directory of the WordPress installation. If there is no .htaccess file, create one, then add the following content:
vi /www/html/path_to_wordpress/.htaccess
php_value upload_max_filesize 64M php_value post_max_size 32M php_value max_execution_time 180 php_value max_input_time 180 # BEGIN WordPress <IfModule mod_rewrite.c> RewriteEngine On RewriteBase / RewriteRule ^index\.php$ - [L] RewriteCond %{REQUEST_FILENAME} !-f RewriteCond %{REQUEST_FILENAME} !-d RewriteRule . /index.php [L] </IfModule> # END WordPress
If you are using nginx, configure the nginx server block about your WordPress instance. It should look something like the example below:
server { listen 80; client_max_body_size 128m; client_body_timeout 300; server_name your-domain.com www.your-domain.com; root /var/www/html/wordpress; index index.php; location = /favicon.ico { log_not_found off; access_log off; } location = /robots.txt { allow all; log_not_found off; access_log off; } location / { try_files $uri $uri/ /index.php?$args; } location ~ \.php$ { include fastcgi_params; fastcgi_pass 127.0.0.1:9000; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; } location ~* \.(js|css|png|jpg|jpeg|gif|ico)$ { expires max; log_not_found off; } }
Depending on the PHP configuration, you may need to replace ‘fastcgi_pass 127.0.0.1:9000;’ with ‘fastcgi_pass unix:/var/run/php7-fpm.sock;’ or so.
Restart nginx service for the changes to take effect.
## 2. Fix HTTP error in WordPress due to incorrect file permissions
If you get an unexpected HTTP error in WordPress, it may be due to incorrect file permissions, so set a proper ownership of your WordPress files and directories:
chown www-data:www-data -R /var/www/html/path_to_wordpress/
Replace ‘www-data’ with the actual web server user, and ‘/var/www/html/path_to_wordpress’ with the actual path of the WordPress installation.
## 3. Fix HTTP error in WordPress due to memory limit
The PHP memory_limit value can be set by adding this to your wp-config.php file:
define('WP_MEMORY_LIMIT', '128MB');
## 4. Fix HTTP error in WordPress due to misconfiguration of PHP.INI
Edit the main PHP configuration file and locate the line with the content ‘cgi.fix_pathinfo’ . This will be commented by default and set to 1. Uncomment the line (remove the semi-colon) and change the value from 1 to 0. You may also want to change the ‘date.timezone’ PHP setting, so edit the PHP configuration file and modify this setting to ‘date.timezone = US/Central’ (or whatever your timezone is).
vi /etc/php.ini
cgi.fix_pathinfo=0 date.timezone = America/New_York
## 5. Fix HTTP error in WordPress due to Apache mod_security modul
If you are using the Apache mod_security module, it might be causing problems. Try to disable it to see if that is the problem by adding the following lines in .htaccess:
<IfModule mod_security.c> SecFilterEngine Off SecFilterScanPOST Off </IfModule>
## 6. Fix HTTP error in WordPress due to problematic plugin or theme
Some plugins and/or themes may cause HTTP errors and other problems in WordPress. You can try to disable the problematic plugins/themes, or temporarily disable all the plugins. If you have phpMyAdmin, use it to deactivate all plugins:
Locate the table wp_options, under the option_name column (field) find the ‘active_plugins’ row and change the option_value field to: a:0:{}
Or, temporarily rename your plugins directory via SSH using the following command:
mv /www/html/path_to_wordpress/wp-content/plugins /www/html/path_to_wordpress/wp-content/plugins.old
In general, HTTP errors are logged in the web server log files, so a good starting point is to check the web server error log on your server.
You don’t have to Fix HTTP errors in WordPress, if you use one of our [WordPress VPS Hosting](https://www.rosehosting.com/wordpress-hosting.html) services, in which case you can simply ask our expert Linux admins to **fix HTTP errors in WordPress** for you. They are available 24×7 and will take care of your request immediately.
**PS.** If you liked this post, on how to fix HTTP errors in WordPress, please share it with your friends on the social networks using the buttons on the left or simply leave a reply below. Thanks. |
9,405 | fold 命令入门示例教程 | https://www.ostechnix.com/fold-command-tutorial-examples-beginners/ | 2018-03-04T23:35:00 | [
"fold"
] | https://linux.cn/article-9405-1.html | 
你有没有发现自己在某种情况下想要折叠或中断命令的输出,以适应特定的宽度?在运行虚拟机的时候,我遇到了几次这种的情况,特别是没有 GUI 的服务器。 以防万一,如果你想限制一个命令的输出为一个特定的宽度,现在看看这里! `fold` 命令在这里就能派的上用场了! `fold` 命令会以适合指定的宽度调整输入文件中的每一行,并将其打印到标准输出。
在这个简短的教程中,我们将看到 `fold` 命令的用法,带有实例。
### fold 命令示例教程
`fold` 命令是 GNU coreutils 包的一部分,所以我们不用为安装的事情烦恼。
`fold` 命令的典型语法:
```
fold [OPTION]... [FILE]...
```
请允许我向您展示一些示例,以便您更好地了解 `fold` 命令。 我有一个名为 `linux.txt` 文件,内容是随机的。

要将上述文件中的每一行换行为默认宽度,请运行:
```
fold linux.txt
```
每行 80 列是默认的宽度。 这里是上述命令的输出:

正如你在上面的输出中看到的,`fold` 命令已经将输出限制为 80 个字符的宽度。
当然,我们可以指定您的首选宽度,例如 50,如下所示:
```
fold -w50 linux.txt
```
示例输出:

我们也可以将输出写入一个新的文件,如下所示:
```
fold -w50 linux.txt > linux1.txt
```
以上命令将把 `linux.txt` 的行宽度改为 50 个字符,并将输出写入到名为 `linux1.txt` 的新文件中。
让我们检查一下新文件的内容:
```
cat linux1.txt
```

你有没有注意到前面的命令的输出? 有些词在行之间被中断。 为了解决这个问题,我们可以使用 `-s` 标志来在空格处换行。
以下命令将给定文件中的每行调整为宽度 50,并在空格处换到新行:
```
fold -w50 -s linux.txt
```
示例输出:

看清楚了吗? 现在,输出很清楚。 换到新行中的单词都是用空格隔开的,所在行单词的长度大于 50 的时候就会被调整到下一行。
在所有上面的例子中,我们用列来限制输出宽度。 但是,我们可以使用 `-b` 选项将输出的宽度强制为指定的字节数。 以下命令以 20 个字节中断输出。
```
fold -b20 linux.txt
```
示例输出:

另请阅读:
* [Uniq 命令入门级示例教程](https://www.ostechnix.com/uniq-command-tutorial-examples-beginners/)
有关更多详细信息,请参阅 man 手册页。
```
man fold
```
这些就是所有的内容了。 您现在知道如何使用 `fold` 命令以适应特定的宽度来限制命令的输出。 我希望这是有用的。 我们将每天发布更多有用的指南。 敬请关注!
干杯!
---
via: <https://www.ostechnix.com/fold-command-tutorial-examples-beginners/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,406 | 什么是 CGManager? | https://linuxcontainers.org/cgmanager/introduction/ | 2018-03-05T00:28:00 | [
"容器",
"LXC",
"CGManager"
] | https://linux.cn/article-9406-1.html | 
CGManager 是一个核心的特权守护进程,通过一个简单的 D-Bus API 管理你所有的 cgroup。它被设计用来处理嵌套的 LXC 容器以及接受无特权的请求,包括解析用户名称空间的 UID/GID。
### 组件
#### cgmanager
这个守护进程在宿主机上运行,将 cgroupfs 挂载到一个独立的挂载名称空间(所以它不能从宿主机上看到),绑定 `/sys/fs/cgroup/cgmanager/sock` 用于传入的 D-Bus 查询,并通常处理宿主机上直接运行的所有客户端。
cgmanager 既接受使用 D-Bus + SCM 凭证的身份验证请求,用于在命名空间之间转换 uid、gid 和 pid,也可以使用简单的 “unauthenticated”(只是初始的 ucred)D-Bus 来查询来自宿主机级别的查询。
#### cgproxy
你可能会在两种情况下看到这个守护进程运行。在宿主机上,如果你的内核老于 3.8(没有 pidns 连接支持)或处于容器中(只有 cgproxy 运行)。
cgproxy 本身并不做任何 cgroup 配置更改,而是如其名称所示,代理请求给主 cgmanager 进程。
这是必要的,所以一个进程可以直接使用 D-Bus(例如使用 dbus-send)与 `/sys/fs/cgroup/cgmanager/sock` 进行通信。
之后 cgproxy 将从该查询中得到 ucred,并对真正的 cgmanager 套接字进行身份验证的 SCM 查询,并通过 ucred 结构体传递参数,使它们能够正确地转换为 cgmanager 可以理解的宿主机命名空间 。
#### cgm
一个简单的命令行工具,与 D-Bus 服务通信,并允许你从命令行执行所有常见的 cgroup 操作。
### 通信协议
如上所述,cgmanager 和 cgproxy 使用 D-Bus。建议外部客户端(所以不要是 cgproxy)使用标准的 D-Bus API,不要试图实现 SCM creds 协议,因为它是不必要的,并且容易出错。
相反,只要简单假设与 `/sys/fs/cgroup/cgmanager/sock` 的通信总是正确的。
cgmanager API 仅在独立的 D-Bus 套接字上可用,cgmanager 本身不连接到系统总线,所以 cgmanager/cgproxy 不要求有运行中的 dbus 守护进程。
你可以在[这里](https://linuxcontainers.org/cgmanager/dbus-api/)阅读更多关于 D-Bus API。
### 许可证
CGManager 是免费软件,大部分代码是根据 GNU LGPLv2.1+ 许可条款发布的,一些二进制文件是在 GNU GPLv2 许可下发布的。
该项目的默认许可证是 GNU LGPLv2.1+
### 支持
CGManager 的稳定版本支持依赖于 Linux 发行版以及它们自己承诺推出稳定修复和安全更新。
你可以从 [Canonical Ltd](http://www.canonical.com/) 获得对 Ubuntu LTS 版本的 CGManager 的商业支持。
---
via: <https://linuxcontainers.org/cgmanager/introduction/>
作者:[Canonical Ltd.](http://www.canonical.com/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # What's CGManager?[¶](#whats-cgmanager)
CGManager is a central privileged daemon that manages all your cgroups for you through a simple D-Bus API. It's designed to work with nested LXC containers as well as accepting unprivileged requests including resolving user namespaces UIDs/GIDs.
Note
CGManager was used by default with LXC in Ubuntu since April 2014 and then by other distributions as they started needing working unprivileged containers.
It has now been deprecated in favor of the CGroup namespace in recent Linux kernels. On older kernels, LXCFS still offers a cgroupfs emulation that can be used instead of CGManager and is more widely compatible with existing userspace.
# Components[¶](#components)
## cgmanager[¶](#cgmanager)
This daemon runs on the host, mounts cgroupfs into a separate mount namespace (so it's invisible from the host), binds /sys/fs/cgroup/cgmanager/sock for incoming D-Bus queries and generally handles all clients running directly on the host.
cgmanager accepts both authentication requests using D-Bus + SCM credentials used for translation of uid, gid and pid across namespaces or using simple "unauthenticated" (just the initial ucred) D-Bus for queries coming from the host level.
## cgproxy[¶](#cgproxy)
You may see this daemon run in two cases. On the host if your kernel is older than 3.8 (doesn't have pidns attach support) or in containers (where only cgproxy runs).
cgproxy doesn't itself do any cgroup configuration change but instead as its name indicates, proxies requests to the main cgmanager process.
This is necessary so a process may talk to /sys/fs/cgroup/cgmanager/sock using straight D-Bus (for example using dbus-send).
cgproxy will then catch the ucred from that query and do an authenticated SCM query to the real cgmanager socket, passing the arguments through ucred structs so that they get properly translated into something cgmanager in the host namespace can understand.
## cgm[¶](#cgm)
A simple command line tool which talks to the D-Bus service and lets you perform all the usual cgroup operations from the command line.
# Communication protocol[¶](#communication-protocol)
As mentioned above, cgmanager and cgproxy use D-Bus. It's recommended that external clients (so not cgproxy itself) use the standard D-Bus API and do not attempt to implement the SCM creds protocol as it's unnecessary and easy to get wrong.
Instead, simply assume that talking to /sys/fs/cgroup/cgmanager/sock will always do the right thing.
The cgmanager API is only available on that separate D-Bus socket, cgmanager itself doesn't attach to the system bus and so a running dbus daemon isn't a requirement of cgmanager/cgproxy.
You can read more about the D-Bus API [here](/cgmanager/dbus-api/).
# Licensing[¶](#licensing)
CGManager is free software, most of the code is released under the terms of the GNU LGPLv2.1+ license, some binaries are released under the GNU GPLv2 license.
The default license for the project is the GNU LGPLv2.1+.
# Support[¶](#support)
CGManager's stable release support relies on the Linux distributions and their own commitment to pushing stable fixes and security updates. |
9,407 | 使用 pass 密码管理器管理你的密码 | https://linuxconfig.org/how-to-organize-your-passwords-using-pass-password-manager | 2018-03-05T00:58:06 | [
"密码",
"pass",
"密码管理器"
] | https://linux.cn/article-9407-1.html | 
### 目标
学习在 Linux 上使用 pass 密码管理器来管理你的密码
### 条件
* 需要 root 权限来安装需要的包
### 难度
简单
### 约定
* `#` - 执行指定命令需要 root 权限,可以是直接使用 root 用户来执行或者使用 `sudo` 命令来执行
* `$` - 使用普通的非特权用户执行指定命令
### 介绍
如果你有根据不同的意图设置不同密码的好习惯,你可能已经感受到需要一个密码管理器的必要性了。在 Linux 上有很多选择,可以是专有软件(如果你敢用的话)也可以是开源软件。如果你跟我一样喜欢简洁的话,你可能会对 `pass` 感兴趣。
### 第一步
pass 作为一个密码管理器,其实际上是一些你可能早已每天使用的、可信赖且实用的工具的一种封装,比如 `gpg` 和 `git` 。虽然它也有图形界面,但它专门设计能成在命令行下工作的:因此它也可以在 headless 机器上工作(LCTT 译注:根据 wikipedia 的说法,所谓 headless 是指没有显示器、键盘和鼠标的机器,一般通过网络链接来控制)。
### 安装
pass 在主流的 Linux 发行版中都是可用的,你可以通过包管理器安装:
#### Fedora
```
# dnf install pass
```
#### RHEL 和 CentOS
pass 不在官方仓库中,但你可以从 `epel` 中获取道它。要在 CentOS7 上启用后面这个源,只需要执行:
```
# yum install epel-release
```
然而在 Red Hat 企业版的 Linux 上,这个额外的源是不可用的;你需要从 EPEL 官方网站上下载它。
#### Debian 和 Ubuntu
```
# apt-get install pass
```
#### Arch Linux
```
# pacman -S pass
```
### 初始化密码仓库
安装好 `pass` 后,就可以开始使用和配置它了。首先,由于 `pass` 依赖于 `gpg` 来对我们的密码进行加密并以安全的方式进行存储,我们必须准备好一个 gpg 密钥对。
首先我们要初始化密码仓库:这就是一个用来存放 gpg 加密后的密码的目录。默认情况下它会在你的 `$HOME` 创建一个隐藏目录,不过你也可以通过使用 `PASSWORD_STORE_DIR` 这一环境变量来指定另一个路径。让我们运行:
```
$ pass init
```
然后 `password-store` 目录就创建好了。现在,让我们来存储我们第一个密码:
```
$ pass edit mysite
```
这会打开默认文本编辑器,我么只需要输入密码就可以了。输入的内容会用 gpg 加密并存储为密码仓库目录中的 `mysite.gpg` 文件。
`pass` 以目录树的形式存储加密后的文件,也就是说我们可以在逻辑上将多个文件放在子目录中以实现更好的组织形式,我们只需要在创建文件时指定存在哪个目录下就行了,像这样:
```
$ pass edit foo/bar
```
跟上面的命令一样,它也会让你输入密码,但是创建的文件是放在密码仓库目录下的 `foo` 子目录中的。要查看文件组织结构,只需要不带任何参数运行 `pass` 命令即可:
```
$ pass
Password Store
├── foo
│ └── bar
└── mysite
```
若想修改密码,只需要重复创建密码的操作就行了。
### 获取密码
有两种方法可以获取密码:第一种会显示密码到终端上,方法是运行:
```
pass mysite
```
然而更好的方法是使用 `-c` 选项让 `pass` 将密码直接拷贝到剪切板上:
```
pass -c mysite
```
这种情况下剪切板中的内容会在 `45` 秒后自动清除。两种方法都会要求你输入 gpg 密码。
### 生成密码
`pass` 也可以为我们自动生成(并自动存储)安全密码。假设我们想要生成一个由 15 个字符组成的密码:包含字母,数字和特殊符号,其命令如下:
```
pass generate mysite 15
```
若希望密码只包含字母和数字则可以是使用 `--no-symbols` 选项。生成的密码会显示在屏幕上。也可以通过 `--clip` 或 `-c` 选项让 `pass` 把密码直接拷贝到剪切板中。通过使用 `-q` 或 `--qrcode` 选项来生成二维码:

从上面的截屏中可看出,生成了一个二维码,不过由于运行该命令时 `mysite` 的密码已经存在了,`pass` 会提示我们确认是否要覆盖原密码。
`pass` 使用 `/dev/urandom` 设备作为(伪)随机数据生成器来生成密码,同时它使用 `xclip` 工具来将密码拷贝到粘帖板中,而使用 `qrencode` 来将密码以二维码的形式显示出来。在我看来,这种模块化的设计正是它最大的优势:它并不重复造轮子,而只是将常用的工具包装起来完成任务。
你也可以使用 `pass mv`、`pass cp` 和 `pass rm` 来重命名、拷贝和删除密码仓库中的文件。
### 将密码仓库变成 git 仓库
`pass` 另一个很棒的功能就是可以将密码仓库当成 git 仓库来用:通过版本管理系统能让我们管理密码更方便。
```
pass git init
```
这会创建 git 仓库,并自动提交所有已存在的文件。下一步就是指定跟踪的远程仓库了:
```
pass git remote add <name> <url>
```
我们可以把这个密码仓库当成普通仓库来用。唯一的不同点在于每次我们新增或修改一个密码,`pass` 都会自动将该文件加入索引并创建一个提交。
`pass` 有一个叫做 `qtpass` 的图形界面,而且也支持 Windows 和 MacOs。通过使用 `PassFF` 插件,它还能获取 firefox 中存储的密码。在它的项目网站上可以查看更多详细信息。试一下 `pass` 吧,你不会失望的!
---
via: <https://linuxconfig.org/how-to-organize-your-passwords-using-pass-password-manager>
作者:[Egidio Docile](https://linuxconfig.org) 译者:[lujun9972](https://github.com/lujun9972) 校对:[Locez](https://github.com/locez)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,409 | 我的 Linux 主目录中的隐藏文件是干什么用的? | https://www.maketecheasier.com/hidden-files-linux-home-directory/ | 2018-03-05T18:21:43 | [
"主目录",
"隐藏文件"
] | https://linux.cn/article-9409-1.html | 
在 Linux 系统中,你可能会在主目录中存储了大量文件和文件夹。但在这些文件之外,你知道你的主目录还附带了很多隐藏的文件和文件夹吗?如果你在主目录中运行 `ls -a`,你会发现一堆带有点前缀的隐藏文件和目录。这些隐藏的文件到底做了什么?
### 在主目录中隐藏的文件是干什么用的?

通常,主目录中的隐藏文件和目录包含该用户程序访问的设置或数据。它们不打算让用户编辑,只需要应用程序进行编辑。这就是为什么它们被隐藏在用户的正常视图之外。
通常,删除和修改自己主目录中的文件不会损坏操作系统。然而,依赖这些隐藏文件的应用程序可能不那么灵活。从主目录中删除隐藏文件时,通常会丢失与其关联的应用程序的设置。
依赖该隐藏文件的程序通常会重新创建它。 但是,你将从“开箱即用”设置开始,如全新用户一般。如果你在使用应用程序时遇到问题,那实际上可能是一个巨大的帮助。它可以让你删除可能造成麻烦的自定义设置。但如果你不这样做,这意味着你需要把所有的东西都设置成原来的样子。
### 主目录中某些隐藏文件的特定用途是什么?

每个人在他们的主目录中都会有不同的隐藏文件。每个人都有一些。但是,无论应用程序如何,这些文件都有类似的用途。
#### 系统设置
系统设置包括桌面环境和 shell 的配置。
* shell 和命令行程序的**配置文件**:根据你使用的特定 shell 和类似命令的应用程序,特定的文件名称会变化。你会看到 `.bashrc`、`.vimrc` 和 `.zshrc`。这些文件包含你已经更改的有关 shell 的操作环境的任何设置,或者对 `vim` 等命令行实用工具的设置进行的调整。删除这些文件将使关联的应用程序返回到其默认状态。考虑到许多 Linux 用户多年来建立了一系列微妙的调整和设置,删除这个文件可能是一个非常头疼的问题。
* **用户配置文件**:像上面的配置文件一样,这些文件(通常是 `.profile` 或 `.bash_profile`)保存 shell 的用户设置。该文件通常包含你的 `PATH` 环境变量。它还包含你设置的[别名](https://www.maketecheasier.com/making-the-linux-command-line-a-little-friendlier/#aliases)。用户也可以在 `.bashrc` 或其他位置放置别名。`PATH` 环境变量控制着 shell 寻找可执行命令的位置。通过添加或修改 `PATH`,可以更改 shell 的命令查找位置。别名更改了原有命令的名称。例如:一个别名可能将 `ls -l` 设置为 `ll`。这为经常使用的命令提供基于文本的快捷方式。如果删除 `.profile` 文件,通常可以在 `/etc/skel` 目录中找到默认版本。
* **桌面环境设置**:这里保存你的桌面环境的任何定制。其中包括桌面背景、屏幕保护程序、快捷键、菜单栏和任务栏图标以及用户针对其桌面环境设置的其他任何内容。当你删除这个文件时,用户的环境会在下一次登录时恢复到新的用户环境。
#### 应用配置文件
你会在 Ubuntu 的 `.config` 文件夹中找到它们。 这些是针对特定应用程序的设置。 它们将包含喜好列表和设置等内容。
* **应用程序的配置文件**:这包括应用程序首选项菜单中的设置、工作区配置等。 你在这里找到的具体取决于应用程序。
* **Web 浏览器数据**:这可能包括书签和浏览历史记录等内容。这些文件大部分是缓存。这是 Web 浏览器临时存储下载文件(如图片)的地方。删除这些内容可能会降低你首次访问某些媒体网站的速度。
* **缓存**:如果用户应用程序缓存仅与该用户相关的数据(如 [Spotify 应用程序存储播放列表的缓存](https://www.maketecheasier.com/clear-spotify-cache/)),则主目录是存储该目录的默认地点。 这些缓存可能包含大量数据或仅包含几行代码:这取决于应用程序需要什么。 如果你删除这些文件,则应用程序会根据需要重新创建它们。
* **日志**:一些用户应用程序也可能在这里存储日志。根据开发人员设置应用程序的方式,你可能会发现存储在你的主目录中的日志文件。然而,这不是一个常见的选择。
### 结论
在大多数情况下,你的 Linux 主目录中的隐藏文件用于存储用户设置。 这包括命令行程序以及基于 GUI 的应用程序的设置。删除它们将删除用户设置。 通常情况下,它不会导致程序被破坏。
---
via: <https://www.maketecheasier.com/hidden-files-linux-home-directory/>
作者:[Alexander Fox](https://www.maketecheasier.com/author/alexfox/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
In your Linux system you probably store a lot of files and folders in your Home directory. But beneath those files, do you know that your Home directory also comes with a lot of hidden files and folders? If you run `ls -a`
on your home directory, you’ll discover a pile of hidden files and directories with dot prefixes. What do these hidden files do anyway?
## What are hidden files in the home directory for?
Most commonly, hidden files and directories in the home directory contain settings or data that’s accessed by that user’s programs. They’re not intended to be edited by the user, only the application. That’s why they’re hidden from the user’s normal view.
In general files from your own home directory can be removed and changed without damaging the operating system. The applications that rely on those hidden files, however, might not be as flexible. When you remove a hidden file from the home directory, you’ll typically lose the settings for the application associated with it.
The program that relied on that hidden file will typically recreate it. However, you’ll be starting from the “out-of-the-box” settings, like a brand new user. If you’re having trouble with an application, that can actually be a huge help. It lets you remove customizations that might be causing trouble. But if you’re not, it just means you’ll need to set everything back the way you like it.
## What are some specific uses of hidden files in the home directory?
Everyone will have different hidden files in their home directory. There are some that everyone has. However, the files serve a similar purpose, regardless of the parent application.
### System Settings
System settings include the configuration for your desktop environment and your shell.
**Configuration files**for your shell and command line utilities: Depending on the specific shell and command-like utilities you use, the specific file name will change. You’ll see files like “.bashrc,” “.vimrc” and “.zshrc.” These files contain any settings you’ve changed about your shell’s operating environment or tweaks you’ve made to the settings of command-line utilities like`vim`
. Removing these files will return the associated application to its default state. Considering many Linux users build up an array of subtle tweaks and settings over the years, removing this file could be a huge headache.**User profiles:**Like the configuration files above, these files (typically “.profile” or “.bash_profile”) save user settings for the shell. This file often contains your PATH. It also contains[aliases](https://www.maketecheasier.com/making-the-linux-command-line-a-little-friendlier/#aliases/)you’ve set. Users can also put aliases in`.bashrc`
or other locations. The PATH governs where the shell looks for executable commands. By appending or modifying your PATH, you can change where your shell looks for commands. Aliases change the names of commands. One alias might set`ll`
to call`ls -l`
, for example. This provides text-based shortcuts to often-used commands. If you delete`.profile`
, you can often find the default version in the “/etc/skel” directory.**Desktop environment settings:**This saves any customization of your desktop environment. That includes the desktop background, screensavers, shortcut keys, menu bar and taskbar icons, and anything else that the user has set about their desktop environment. When you remove this file, the user’s environment reverts to the new user environment at the next login.
### Application configuration files
You’ll find these in the “.config” folder in Ubuntu. These are settings for your specific applications. They’ll include things like the preference lists and settings.
**Configuration files for applications**: This includes settings from the application preferences menu, workspace configurations and more. Exactly what you’ll find here depends on the parent application.**Web browser data:**This may include things like bookmarks and browsing history. The majority of files make up the cache. This is where the web browser stores temporarily download files, like images. Removing this might slow down some media-heavy websites the first time you visit them.**Caches**: If a user application caches data that’s only relevant to that user (like the[Spotify app storing cache of your playlist](https://www.maketecheasier.com/clear-spotify-cache/)), the home directory is a natural place to store it. These caches might contain masses of data or just a few lines of code: it depends on what the parent application needs. If you remove these files, the application recreates them as necessary.**Logs:**Some user applications might store logs here as well. Depending on how developers set up the application, you might find log files stored in your home directory. This isn’t a common choice, however.
## Conclusion
In most cases the hidden files in your Linux home directory as used to store user settings. This includes settings for command-line utilities as well as GUI-based applications. Removing them will remove user settings. Typically, it won’t cause a program to break.
Our latest tutorials delivered straight to your inbox |
9,410 | 6 个开源的家庭自动化工具 | https://opensource.com/life/17/12/home-automation-tools | 2018-03-05T22:56:34 | [
"物联网",
"IoT"
] | https://linux.cn/article-9410-1.html |
>
> 用这些开源软件解决方案构建一个更智能的家庭。
>
>
>

[物联网](https://opensource.com/resources/internet-of-things) 不仅是一个时髦词,在现实中,自 2016 年我们发布了一篇关于家庭自动化工具的评论文章以来,它也在迅速占领着我们的生活。在 2017,[26.5% 的美国家庭](https://www.statista.com/outlook/279/109/smart-home/united-states) 已经使用了一些智能家居技术;预计五年内,这一数字还将翻倍。
随着这些数量持续增加的各种设备的使用,可以帮助你实现对家庭的自动化管理、安保、和监视,在家庭自动化方面,从来没有像现在这样容易和更加吸引人过。不论你是要远程控制你的 HVAC 系统,集成一个家庭影院,保护你的家免受盗窃、火灾、或是其它威胁,还是节省能源或只是控制几盏灯,现在都有无数的设备可以帮到你。
但同时,还有许多用户担心安装在他们家庭中的新设备带来的安全和隐私问题 —— 这是一个很现实也很 [严肃的问题](http://www.crn.com/slide-shows/internet-of-things/300089496/black-hat-2017-9-iot-security-threats-to-watch.htm)。他们想要去控制有谁可以接触到这个重要的系统,这个系统管理着他们的应用程序,记录了他们生活中的点点滴滴。这种想法是可以理解的:毕竟在一个连你的冰箱都是智能设备的今天,你不想要一个基本的保证吗?甚至是如果你授权了设备可以与外界通讯,它是否是仅被授权的人访问它呢?
[对安全的担心](https://opensource.com/business/15/5/why-open-source-means-stronger-security) 是为什么开源对我们将来使用的互联设备至关重要的众多理由之一。由于源代码运行在他们自己的设备上,完全可以去搞明白控制你的家庭的程序,也就是说你可以查看它的代码,如果必要的话甚至可以去修改它。
虽然联网设备通常都包含它们专有的组件,但是将开源引入家庭自动化的第一步是确保你的设备和这些设备可以共同工作 —— 它们为你提供一个接口 —— 并且是开源的。幸运的是,现在有许多解决方案可供选择,从 PC 到树莓派,你可以在它们上做任何事情。
这里有几个我比较喜欢的。
### Calaos
[Calaos](https://calaos.fr/en/) 是一个设计为全栈的家庭自动化平台,包含一个服务器应用程序、触摸屏界面、Web 应用程序、支持 iOS 和 Android 的原生移动应用、以及一个运行在底层的预配置好的 Linux 操作系统。Calaos 项目出自一个法国公司,因此它的支持论坛以法语为主,不过大量的介绍资料和文档都已经翻译为英语了。
Calaos 使用的是 [GPL](https://github.com/calaos/calaos-os/blob/master/LICENSE) v3 的许可证,你可以在 [GitHub](https://github.com/calaos) 上查看它的源代码。
### Domoticz
[Domoticz](https://domoticz.com/) 是一个有大量设备库支持的家庭自动化系统,在它的项目网站上有大量的文档,从气象站到远程控制的烟雾探测器,以及大量的第三方 [集成软件](https://www.domoticz.com/wiki/Integrations_and_Protocols) 。它使用一个 HTML5 前端,可以从桌面浏览器或者大多数现代的智能手机上访问它,它是一个轻量级的应用,可以运行在像树莓派这样的低功耗设备上。
Domoticz 是用 C++ 写的,使用 [GPLv3](https://github.com/domoticz/domoticz/blob/master/License.txt) 许可证。它的 [源代码](https://github.com/domoticz/domoticz) 在 GitHub 上。
### Home Assistant
[Home Assistant](https://home-assistant.io/) 是一个开源的家庭自动化平台,它可以轻松部署在任何能运行 Python 3 的机器上,从树莓派到网络存储(NAS),甚至可以使用 Docker 容器轻松地部署到其它系统上。它集成了大量的开源和商业的产品,允许你去连接它们,比如,IFTTT、天气信息、或者你的 Amazon Echo 设备,去控制从锁到灯的各种硬件。
Home Assistant 以 [MIT 许可证](https://github.com/home-assistant/home-assistant/blob/dev/LICENSE.md) 发布,它的源代码可以从 [GitHub](https://github.com/balloob/home-assistant) 上下载。
### MisterHouse
从 2016 年起,[MisterHouse](http://misterhouse.sourceforge.net/) 取得了很多的进展,我们把它作为一个“可以考虑的另外选择”列在这个清单上。它使用 Perl 脚本去监视任何东西,它可以通过一台计算机来查询或者控制任何可以远程控制的东西。它可以响应语音命令,查询当前时间、天气、位置、以及其它事件,比如去打开灯、唤醒你、记下你喜欢的电视节目、通报呼入的来电、开门报警、记录你儿子上了多长时间的网、如果你女儿汽车超速它也可以告诉你等等。它可以运行在 Linux、macOS、以及 Windows 计算机上,它可以读/写很多的设备,包括安全系统、气象站、来电显示、路由器、机动车位置系统等等。
MisterHouse 使用 [GPLv2](http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html) 许可证,你可以在 [GitHub](https://github.com/hollie/misterhouse) 上查看它的源代码。
### OpenHAB
[OpenHAB](http://www.openhab.org/)(开放家庭自动化总线的简称)是在开源爱好者中所熟知的家庭自动化工具,它拥有大量用户的社区以及支持和集成了大量的设备。它是用 Java 写的,OpenHAB 非常轻便,可以跨大多数主流操作系统使用,它甚至在树莓派上也运行的很好。支持成百上千的设备,OpenHAB 被设计为与设备无关的,这使开发者在系统中添加他们的设备或者插件很容易。OpenHAB 也支持通过 iOS 和 Android 应用来控制设备以及设计工具,因此,你可以为你的家庭系统创建你自己的 UI。
你可以在 GitHub 上找到 OpenHAB 的 [源代码](https://github.com/openhab/openhab),它使用 [Eclipse 公共许可证](https://github.com/openhab/openhab/blob/master/LICENSE.TXT)。
### OpenMotics
[OpenMotics](https://www.openmotics.com/) 是一个开源的硬件和软件家庭自动化系统。它的设计目标是为控制设备提供一个综合的系统,而不是从不同的供应商处将各种设备拼接在一起。不像其它的系统主要是为了方便改装而设计的,OpenMotics 专注于硬件解决方案。更多资料请查阅来自 OpenMotics 的后端开发者 Frederick Ryckbosch的 [完整文章](https://opensource.com/life/14/12/open-source-home-automation-system-opemmotics) 。
OpenMotics 使用 [GPLv2](http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html) 许可证,它的源代码可以从 [GitHub](https://github.com/openmotics) 上下载。
当然了,我们的选择不仅有这些。许多家庭自动化爱好者使用不同的解决方案,甚至是他们自己动手做。其它用户选择使用单独的智能家庭设备而无需集成它们到一个单一的综合系统中。
如果上面的解决方案并不能满足你的需求,下面还有一些潜在的替代者可以去考虑:
* [EventGhost](http://www.eventghost.net/) 是一个开源的([GPL v2](http://www.gnu.org/licenses/old-licenses/gpl-2.0.html))家庭影院自动化工具,它只能运行在 Microsoft Windows PC 上。它允许用户去控制多媒体电脑和连接的硬件,它通过触发宏指令的插件或者定制的 Python 脚本来使用。
* [ioBroker](http://iobroker.net/) 是一个基于 JavaScript 的物联网平台,它能够控制灯、锁、空调、多媒体、网络摄像头等等。它可以运行在任何可以运行 Node.js 的硬件上,包括 Windows、Linux、以及 macOS,它使用 [MIT 许可证](https://github.com/ioBroker/ioBroker#license)。
* [Jeedom](https://www.jeedom.com/site/en/index.html) 是一个由开源软件([GPL v2](http://www.gnu.org/licenses/old-licenses/gpl-2.0.html))构成的家庭自动化平台,它可以控制灯、锁、多媒体等等。它包含一个移动应用程序(Android 和 iOS),并且可以运行在 Linux PC 上;该公司也销售 hub,它为配置家庭自动化提供一个现成的解决方案。
* [LinuxMCE](http://www.linuxmce.com/) 标称它是你的多媒体与电子设备之间的“数字粘合剂”。它运行在 Linux(包括树莓派)上,它基于 Pluto 开源 [许可证](http://wiki.linuxmce.org/index.php/License) 发布,它可以用于家庭安全、电话(VoIP 和语音信箱)、A/V 设备、家庭自动化、以及玩视频游戏。
* [OpenNetHome](http://opennethome.org/),和这一类中的其它解决方案一样,是一个控制灯、报警、应用程序等等的一个开源软件。它基于 Java 和 Apache Maven,可以运行在 Windows、macOS、以及 Linux —— 包括树莓派,它以 [GPLv3](https://github.com/NetHome/NetHomeServer/blob/master/LICENSE) 许可证发布。
* [Smarthomatic](https://www.smarthomatic.org/) 是一个专注于硬件设备和软件的开源家庭自动化框架,而不仅是用户界面。它基于 [GPLv3](https://github.com/breaker27/smarthomatic/blob/develop/GPL3.txt) 许可证,它可用于控制灯、电器、以及空调、检测温度、提醒给植物浇水。
现在该轮到你了:你已经准备好家庭自动化系统了吗?或者正在研究去设计一个。你对家庭自动化的新手有什么建议,你会推荐什么样的系统?
---
via: <https://opensource.com/life/17/12/home-automation-tools>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,411 | 如何在 Linux 上安装/更新 Intel 微码固件 | https://www.cyberciti.biz/faq/install-update-intel-microcode-firmware-linux/ | 2018-03-06T09:13:53 | [
"CPU",
"微码"
] | https://linux.cn/article-9411-1.html | 
如果你是一个 Linux 系统管理方面的新手,如何在 Linux 上使用命令行方式去安装或者更新 Intel/AMD CPU 的微码固件呢?
<ruby> 微码 <rt> microcode </rt></ruby>就是由 Intel/AMD 提供的 CPU 固件。Linux 的内核可以在引导时更新 CPU 固件,而无需 BIOS 更新。处理器的微码保存在内存中,在每次启动系统时,内核可以更新这个微码。这些来自 Intel/AMD 的微码的更新可以去修复 bug 或者使用补丁来防范 bug。这篇文章演示了如何使用包管理器或由 lntel 提供的 Linux 处理器微码更新来安装 AMD 或 Intel 的微码更新。
### 如何查看当前的微码状态
以 root 用户运行下列命令:
```
# dmesg | grep microcode
```
输出如下:
[](https://www.cyberciti.biz/media/new/faq/2018/01/Verify-microcode-update-on-a-CentOS-RHEL-Fedora-Ubuntu-Debian-Linux.jpg)
请注意,你的 CPU 在这里完全有可能出现没有可用的微码更新的情况。如果是这种情况,它的输出可能是如下这样的:
```
[ 0.952699] microcode: sig=0x306a9, pf=0x10, revision=0x1c
[ 0.952773] microcode: Microcode Update Driver: v2.2.
```
### 如何在 Linux 上使用包管理器去安装微码固件更新
对于运行在 x86/amd64 架构的 CPU 上的 Linux 系统,Linux 自带了工具去更改或者部署微码固件。在 Linux 上安装 AMD 或者 Intel 的微码固件的过程如下:
1. 打开终端应用程序
2. Debian/Ubuntu Linux 用户推输入:`sudo apt install intel-microcode`
3. CentOS/RHEL Linux 用户输入:`sudo yum install microcode_ctl`
对于流行的 Linux 发行版,这个包的名字一般如下 :
* `microcode_ctl` 和 `linux-firmware` —— CentOS/RHEL 微码更新包
* `intel-microcode` —— Debian/Ubuntu 和衍生发行版的适用于 Intel CPU 的微码更新包
* `amd64-microcode` —— Debian/Ubuntu 和衍生发行版的适用于 AMD CPU 的微码固件
* `linux-firmware` —— 适用于 AMD CPU 的 Arch Linux 发行版的微码固件(你不用做任何操作,它是默认安装的)
* `intel-ucode` —— 适用于 Intel CPU 的 Arch Linux 发行版微码固件
* `microcode_ctl` 、`linux-firmware` 和 `ucode-intel` —— Suse/OpenSUSE Linux 微码更新包
**警告 :在某些情况下,微码更新可能会导致引导问题,比如,服务器在引导时被挂起或者自动重置。以下的步骤是在我的机器上运行过的,并且我是一个经验丰富的系统管理员。对于由此引发的任何硬件故障,我不承担任何责任。在做固件更新之前,请充分评估操作风险!**
#### 示例
在使用 Intel CPU 的 Debian/Ubuntu Linux 系统上,输入如下的 [apt 命令](https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ "See Linux/Unix apt command examples for more info")/[apt-get 命令](https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html "See Linux/Unix apt-get command examples for more info"):
```
$ sudo apt-get install intel-microcode
```
示例输出如下:
[](https://www.cyberciti.biz/media/new/faq/2018/01/How-to-install-Intel-microcode-firmware-Linux.jpg)
你 [必须重启服务器以激活微码](https://www.cyberciti.biz/faq/howto-reboot-linux/) 更新:
```
$ sudo reboot
```
重启后检查微码状态:
```
# dmesg | grep 'microcode'
```
示例输出如下:
```
[ 0.000000] microcode: microcode updated early to revision 0x1c, date = 2015-02-26
[ 1.604672] microcode: sig=0x306a9, pf=0x10, revision=0x1c
[ 1.604976] microcode: Microcode Update Driver: v2.01 <[email protected]>, Peter Oruba
```
如果你使用的是 RHEL/CentOS 系统,使用 [yum 命令](https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ "See Linux/Unix yum command examples for more info") 尝试去安装或者更新以下两个包:
```
$ sudo yum install linux-firmware microcode_ctl
$ sudo reboot
$ sudo dmesg | grep 'microcode'
```
### 如何更新/安装从 Intel 网站上下载的微码
只有在你的 CPU 制造商建议这么做的时候,才可以使用下列的方法去更新/安装微码,除此之外,都应该使用上面的方法去更新。大多数 Linux 发行版都可以通过包管理器来维护、更新微码。使用包管理器的方法是经过测试的,对大多数用户来说是最安全的方式。
#### 如何为 Linux 安装 Intel 处理器微码块(20180108 发布)
首先通过 AMD 或 [Intel 网站](https://downloadcenter.intel.com/download/27431/Linux-Processor-Microcode-Data-File) 去获取最新的微码固件。在本示例中,我有一个名称为 `~/Downloads/microcode-20180108.tgz` 的文件(不要忘了去验证它的检验和),它的用途是去防范 `meltdown/Spectre` bug。先使用 `tar` 命令去提取它:
```
$ mkdir firmware
$ cd firmware
$ tar xvf ~/Downloads/microcode-20180108.tgz
$ ls -l
```
示例输出如下:
```
drwxr-xr-x 2 vivek vivek 4096 Jan 8 12:41 intel-ucode
-rw-r--r-- 1 vivek vivek 4847056 Jan 8 12:39 microcode.dat
-rw-r--r-- 1 vivek vivek 1907 Jan 9 07:03 releasenote
```
>
> 我只在 CentOS 7.x/RHEL、 7.x/Debian 9.x 和 Ubuntu 17.10 上测试了如下操作。如果你没有找到 `/sys/devices/system/cpu/microcode/reload` 文件的话,更老的发行版所带的更老的内核也许不能使用此方法。参见下面的讨论。请注意,在应用了固件更新之后,有一些客户遇到了系统重启现象。特别是对于[那些运行 Intel Broadwell 和 Haswell CPU](https://newsroom.intel.com/news/intel-security-issue-update-addressing-reboot-issues/) 的用于客户机和数据中心服务器上的系统。不要在 Intel Broadwell 和 Haswell CPU 上应用 20180108 版本。尽可能使用软件包管理器方式。
>
>
>
检查一下,确保存在 `/sys/devices/system/cpu/microcode/reload`:
```
$ ls -l /sys/devices/system/cpu/microcode/reload
```
你必须使用 [cp 命令](https://www.cyberciti.biz/faq/cp-copy-command-in-unix-examples/ "See Linux/Unix cp command examples for more info") 拷贝 `intel-ucode` 目录下的所有文件到 `/lib/firmware/intel-ucode/` 下面:
```
$ sudo cp -v intel-ucode/* /lib/firmware/intel-ucode/
```
你只需要将 `intel-ucode` 这个目录整个拷贝到 `/lib/firmware/` 目录下即可。然后在重新加载接口中写入 `1` 去重新加载微码文件:
```
# echo 1 > /sys/devices/system/cpu/microcode/reload
```
更新现有的 initramfs,以便于下次启动时它能通过内核来加载:
```
$ sudo update-initramfs -u
$ sudo reboot
```
重启后通过以下的命令验证微码是否已经更新:
```
# dmesg | grep microcode
```
到此为止,就是更新处理器微码的全部步骤。如果一切顺利的话,你的 Intel CPU 的固件将已经是最新的版本了。
### 关于作者
作者是 nixCraft 的创始人、一位经验丰富的系统管理员、Linux/Unix 操作系统 shell 脚本培训师。他与全球的包括 IT、教育、国防和空间研究、以及非盈利组织等各行业的客户一起工作。可以在 [Twitter](https://twitter.com/nixcraft)、[Facebook](https://facebook.com/nixcraft)、[Google+](https://plus.google.com/+CybercitiBiz) 上关注他。
---
via: <https://www.cyberciti.biz/faq/install-update-intel-microcode-firmware-linux/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,412 | 去掉了 chrome-gnome-shell 的 Gnome | http://www.enricozini.org/blog/2018/debian/gnome-without-chrome-gnome-shell/ | 2018-03-06T09:27:30 | [
"GNOME"
] | https://linux.cn/article-9412-1.html | 
新的笔记本有触摸屏,它可以折叠成平板电脑,我听说 gnome-shell 将是桌面环境的一个很好的选择,我设法调整它以按照现有的习惯使用。
然而,我发现一个很大的问题,它怎么会鼓励人们从互联网上下载随机扩展,并将它们作为整个桌面环境的一部分运行呢? 一个更大的问题是,[gnome-core](https://packages.debian.org/gnome-core) 对 [chrome-gnome-shell](https://packages.debian.org/chrome-gnome-shell) 有强制依赖,这个插件如果不用 root 用户编辑 `/etc` 下的文件则无法禁用,这会给将我的桌面环境暴露给网站。
访问[这个网站](https://extensions.gnome.org/),它会知道你已经安装了哪些扩展,并且能够安装更多。我不信任它,我不需要那样,我不想那样。我为此感到震惊。
[我想出了一个临时解决方法](https://salsa.debian.org/enrico/contain-gnome-shell)。(LCTT 译注:作者做了一个空的依赖包来满足依赖,而不会做任何可能危害你的隐私和安全的操作。)
人们会在 firefox 中如何做呢?
### 描述
chrome-gnome-shell 是 gnome-core 的一个强制依赖项,它安装了一个你可能不需要的浏览器插件,并强制它使用系统级的 chrome 策略。
我认为使用 chrome-gnome-shell 会不必要地增加系统的攻击面,我作为主要用户,它会获取下载和执行随机未经审查代码的可疑特权。
(我做的)这个包满足了 chrome-gnome-shell 的依赖,但不会安装任何东西。
请注意,在安装此包之后,如果先前安装了 chrome-gnome-shell,则需要清除 chrome-gnome-shell,以使其在 `/etc/chromium` 中删除 chromium 策略文件。
### 说明
```
apt install equivs
equivs-build contain-gnome-shell
sudo dpkg -i contain-gnome-shell_1.0_all.deb
sudo dpkg --purge chrome-gnome-shell
```
---
via: <http://www.enricozini.org/blog/2018/debian/gnome-without-chrome-gnome-shell/>
作者:[Enrico Zini](http://www.enricozini.org/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 302 | Found | null |
9,413 | 程序员如何学习编码 | https://mybroadband.co.za/news/smartphones/246583-how-programmers-learn-to-code.html | 2018-03-06T12:52:12 | [
"程序员"
] | https://linux.cn/article-9413-1.html | [](https://mybroadband.co.za/news/smartphones/246583-how-programmers-learn-to-code.html)
HackerRank 最近公布了 2018 年开发者技能报告的结果,其中向程序员询问了他们何时开始编码。
39,441 名专业人员和学生开发者于 2016 年 10 月 16 日至 11 月 1 日完成了在线调查,超过 25% 的被调查的开发者在 16 岁前编写了他们的第一段代码。(LCTT 译注:日期恐有误)
### 程序员是如何学习的
报告称,就程序员如何学习编码而言,自学是所有年龄段开发者的常态。
“尽管 67% 的开发者拥有计算机科学学位,但大约 74% 的人表示他们至少一部分是自学的。”
开发者平均了解四种语言,但他们想学习更多语言。
对学习的渴望因人而异 —— 18 至 24 岁的开发者计划学习 6 种语言,而 35 岁以上的开发者只计划学习 3 种语言。
[](https://mybroadband.co.za/news/wp-content/uploads/2018/01/HackerRank-2018-how-did-you-learn-to-code.jpg)
### 程序员想要什么
HackerRank 还研究了开发者最想从雇主那里得到什么。
平均而言,良好的工作与生活平衡,紧随其后的是专业成长与学习,是最理想的要求。
按地区划分的数据显示,美国人比亚洲和欧洲的开发者更渴望工作与生活的平衡。
学生倾向于将成长和学习列在工作与生活的平衡之上,而专业人员对薪酬的排名比学生高得多。
在小公司工作的人倾向于降低工作与生活的平衡,但仍处于前三名。
年龄也制造了不同,25 岁以上的开发者将工作与生活的平衡评为最重要的,而 18 岁至 24 岁的人们则认为其重要性较低。
HackerRank 说:“在某些方面,我们发现了一个小矛盾。开发人员需要工作与生活的平衡,但他们也渴望学习“。
它建议,专注于做你喜欢的事情,而不是试图学习一切,这可以帮助实现更好的工作与生活的平衡。
[](https://mybroadband.co.za/news/wp-content/uploads/2018/01/HackerRank-2018-what-do-developers-want-most.jpg)
[](https://mybroadband.co.za/news/wp-content/uploads/2018/01/HackerRank-2018-how-to-improve-work-life-balance.jpg)
---
via: <https://mybroadband.co.za/news/smartphones/246583-how-programmers-learn-to-code.html>
作者:[Staff Writer](https://mybroadband.co.za/news/author/staff-writer) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,414 | 如何在 Linux 中轻松修正拼写错误的 Bash 命令 | https://www.ostechnix.com/easily-correct-misspelled-bash-commands-linux/ | 2018-03-07T00:59:00 | [
"命令行"
] | https://linux.cn/article-9414-1.html | 
我知道你可以按下向上箭头来调出你运行过的命令,然后使用左/右键移动到拼写错误的单词,并更正拼写错误的单词,最后按回车键再次运行它,对吗?可是等等。还有一种更简单的方法可以纠正 GNU/Linux 中拼写错误的 Bash 命令。这个教程解释了如何做到这一点。请继续阅读。
### 在 Linux 中纠正拼写错误的 Bash 命令
你有没有运行过类似于下面的错误输入命令?
```
$ unme -r
bash: unme: command not found
```
你注意到了吗?上面的命令中有一个错误。我在 `uname` 命令缺少了字母 `a`。
我在很多时候犯过这种愚蠢的错误。在我知道这个技巧之前,我习惯按下向上箭头来调出命令,并转到命令中拼写错误的单词,纠正拼写错误,然后按回车键再次运行该命令。但相信我。下面的技巧非常易于纠正你刚刚运行的命令中的任何拼写错误。
要轻松更正上述拼写错误的命令,只需运行:
```
$ ^nm^nam^
```
这会将 `uname` 命令中将 `nm` 替换为 `nam`。很酷,是吗?它不仅纠正错别字,而且还能运行命令。查看下面的截图。

当你在命令中输入错字时使用这个技巧。请注意,它仅适用于 Bash shell。
**额外提示:**
你有没有想过在使用 `cd` 命令时如何自动纠正拼写错误?没有么?没关系!下面的技巧将解释如何做到这一点。
这个技巧只能纠正使用 `cd` 命令时的拼写错误。
比如说,你想使用命令切换到 `Downloads` 目录:
```
$ cd Donloads
bash: cd: Donloads: No such file or directory
```
哎呀!没有名称为 `Donloads` 的文件或目录。是的,正确的名称是 `Downloads`。上面的命令中缺少 `w`。
要解决此问题并在使用 `cd` 命令时自动更正错误,请编辑你的 `.bashrc` 文件:
```
$ vi ~/.bashrc
```
最后添加以下行。
```
[...]
shopt -s cdspell
```
输入 `:wq` 保存并退出文件。
最后,运行以下命令更新更改。
```
$ source ~/.bashrc
```
现在,如果在使用 `cd` 命令时路径中存在任何拼写错误,它将自动更正并进入正确的目录。

正如你在上面的命令中看到的那样,我故意输错(`Donloads` 而不是 `Downloads`),但 Bash 自动检测到正确的目录名并 `cd` 进入它。
[Fish](https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/) 和 Zsh shell 内置的此功能。所以,如果你使用的是它们,那么你不需要这个技巧。
然而,这个技巧有一些局限性。它只适用于使用正确的大小写。在上面的例子中,如果你输入的是 `cd donloads` 而不是 `cd Donloads`,它将无法识别正确的路径。另外,如果路径中缺少多个字母,它也不起作用。
---
via: <https://www.ostechnix.com/easily-correct-misspelled-bash-commands-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,415 | 如何在 Linux 上使用 snap 安装 Spotify(声破天) | https://www.cyberciti.biz/faq/how-to-install-spotify-application-on-linux/ | 2018-03-07T10:01:16 | [
"spotify",
"snap"
] | https://linux.cn/article-9415-1.html | 
如何在 Ubuntu Linux 桌面上安装 spotify 来在线听音乐?
Spotify 是一个可让你访问大量歌曲的数字音乐流服务。你可以免费收听或者购买订阅,可以创建播放列表。订阅用户可以免广告收听音乐,你会得到更好的音质。本教程展示如何使用在 Ubuntu、Mint、Debian、Fedora、Arch 和其他更多发行版上的 snap 包管理器安装 Spotify。
### 在 Linux 上安装 spotify
在 Linux 上安装 spotify 的步骤如下:
1. 安装 snapd
2. 打开 snapd
3. 找到 Spotify snap:`snap find spotify`
4. 安装 spotify:`sudo snap install spotify`
5. 运行:`spotify &`
让我们详细看看所有的步骤和例子。
### 步骤 1 - 安装 snapd
你需要安装 snapd 包。它是一个守护进程(服务),并能在 Linux 系统上启用 snap 包管理。
#### Debian/Ubuntu/Mint Linux 上的 snapd
输入以下 [apt 命令](https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ "See Linux/Unix apt command examples for more info")/ [apt-get 命令](https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html "See Linux/Unix apt-get command examples for more info"):
```
$ sudo apt install snapd
```
#### 在 Arch Linux 上安装 snapd
snapd 只包含在 Arch User Repository(AUR)中。运行 `yaourt` 命令(参见[如何在 Archlinux 上安装 yaourt](https://www.cyberciti.biz/faq/how-to-install-yaourt-in-arch-linux/)):
```
$ sudo yaourt -S snapd
$ sudo systemctl enable --now snapd.socket
```
#### 在 Fedora 上获取 snapd
运行 snapd 命令:
```
sudo dnf install snapd
sudo ln -s /var/lib/snapd/snap /snap
```
#### OpenSUSE 安装 snapd
执行如下的 `zypper` 命令:
```
### Tumbleweed verson ###
$ sudo zypper addrepo http://download.opensuse.org/repositories/system:/snappy/openSUSE_Tumbleweed/ snappy
### Leap version ##
$ sudo zypper addrepo http://download.opensuse.org/repositories/system:/snappy/openSUSE_Leap_42.3/ snappy
```
安装:
```
$ sudo zypper install snapd
$ sudo systemctl enable --now snapd.socket
```
### 步骤 2 - 在 Linux 上使用 snap 安装 spofity
执行 snap 命令:
```
$ snap find spotify
```
[](https://www.cyberciti.biz/media/new/faq/2018/01/snap-search-for-spotify-app-command.jpg)
安装它:
```
$ sudo snap install spotify
```
[](https://www.cyberciti.biz/media/new/faq/2018/01/How-to-install-Spotify-application-on-Linux-using-snap-command.jpg)
### 步骤 3 - 运行 spotify 并享受它
从 GUI 运行它,或者只需输入:
```
$ spotify
```
在启动时自动登录你的帐户:
```
$ spotify --username [email protected]
$ spotify --username [email protected] --password 'myPasswordHere'
```
在初始化时使用给定的 URI 启动 Spotify 客户端:
```
$ spotify --uri=<uri>
```
以指定的网址启动:
```
$ spotify --url=<url>
```
[](https://www.cyberciti.biz/media/new/faq/2018/01/Spotify-client-app-running-on-my-Ubuntu-Linux-desktop.jpg)
### 关于作者
作者是 nixCraft 的创建者,是经验丰富的系统管理员,也是 Linux 操作系统/Unix shell 脚本的培训师。他曾与全球客户以及 IT、教育、国防和太空研究以及非营利部门等多个行业合作。在 [Twitter](https://twitter.com/nixcraft)、[Facebook](https://facebook.com/nixcraft)、[Google +](https://plus.google.com/+CybercitiBiz) 上关注他。
---
via: <https://www.cyberciti.biz/faq/how-to-install-spotify-application-on-linux/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,416 | 如何在 Linux 上使用 Vundle 管理 Vim 插件 | https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/ | 2018-03-07T10:42:41 | [
"Vundle",
"Vim",
"插件"
] | https://linux.cn/article-9416-1.html | 
毋庸置疑,Vim 是一款强大的文本文件处理的通用工具,能够管理系统配置文件和编写代码。通过插件,Vim 可以被拓展出不同层次的功能。通常,所有的插件和附属的配置文件都会存放在 `~/.vim` 目录中。由于所有的插件文件都被存储在同一个目录下,所以当你安装更多插件时,不同的插件文件之间相互混淆。因而,跟踪和管理它们将是一个恐怖的任务。然而,这正是 Vundle 所能处理的。Vundle,分别是 **V**im 和 B**undle** 的缩写,它是一款能够管理 Vim 插件的极其实用的工具。
Vundle 为每一个你安装的插件创建一个独立的目录树,并在相应的插件目录中存储附加的配置文件。因此,相互之间没有混淆的文件。简言之,Vundle 允许你安装新的插件、配置已有的插件、更新插件配置、搜索安装的插件和清理不使用的插件。所有的操作都可以在一键交互模式下完成。在这个简易的教程中,让我告诉你如何安装 Vundle,如何在 GNU/Linux 中使用它来管理 Vim 插件。
### Vundle 安装
如果你需要 Vundle,那我就当作你的系统中,已将安装好了 Vim。如果没有,请安装 Vim 和 git(以下载 Vundle)。在大部分 GNU/Linux 发行版中的官方仓库中都可以获取到这两个包。比如,在 Debian 系列系统中,你可以使用下面的命令安装这两个包。
```
sudo apt-get install vim git
```
#### 下载 Vundle
复制 Vundle 的 GitHub 仓库地址:
```
git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim
```
#### 配置 Vundle
创建 `~/.vimrc` 文件,以通知 Vim 使用新的插件管理器。安装、更新、配置和移除插件需要这个文件。
```
vim ~/.vimrc
```
在此文件顶部,加入如下若干行内容:
```
set nocompatible " be iMproved, required
filetype off " required
" set the runtime path to include Vundle and initialize
set rtp+=~/.vim/bundle/Vundle.vim
call vundle#begin()
" alternatively, pass a path where Vundle should install plugins
"call vundle#begin('~/some/path/here')
" let Vundle manage Vundle, required
Plugin 'VundleVim/Vundle.vim'
" The following are examples of different formats supported.
" Keep Plugin commands between vundle#begin/end.
" plugin on GitHub repo
Plugin 'tpope/vim-fugitive'
" plugin from http://vim-scripts.org/vim/scripts.html
" Plugin 'L9'
" Git plugin not hosted on GitHub
Plugin 'git://git.wincent.com/command-t.git'
" git repos on your local machine (i.e. when working on your own plugin)
Plugin 'file:///home/gmarik/path/to/plugin'
" The sparkup vim script is in a subdirectory of this repo called vim.
" Pass the path to set the runtimepath properly.
Plugin 'rstacruz/sparkup', {'rtp': 'vim/'}
" Install L9 and avoid a Naming conflict if you've already installed a
" different version somewhere else.
" Plugin 'ascenator/L9', {'name': 'newL9'}
" All of your Plugins must be added before the following line
call vundle#end() " required
filetype plugin indent on " required
" To ignore plugin indent changes, instead use:
"filetype plugin on
"
" Brief help
" :PluginList - lists configured plugins
" :PluginInstall - installs plugins; append `!` to update or just :PluginUpdate
" :PluginSearch foo - searches for foo; append `!` to refresh local cache
" :PluginClean - confirms removal of unused plugins; append `!` to auto-approve removal
"
" see :h vundle for more details or wiki for FAQ
" Put your non-Plugin stuff after this line
```
被标记为 “required” 的行是 Vundle 的所需配置。其余行仅是一些例子。如果你不想安装那些特定的插件,可以移除它们。完成后,键入 `:wq` 保存退出。
最后,打开 Vim:
```
vim
```
然后键入下列命令安装插件:
```
:PluginInstall
```

将会弹出一个新的分窗口,我们加在 `.vimrc` 文件中的所有插件都会自动安装。

安装完毕之后,键入下列命令,可以删除高速缓存区缓存并关闭窗口:
```
:bdelete
```
你也可以在终端上使用下面命令安装插件,而不用打开 Vim:
```
vim +PluginInstall +qall
```
使用 [fish shell](https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/) 的朋友,添加下面这行到你的 `.vimrc` 文件中。
```
set shell=/bin/bash
```
### 使用 Vundle 管理 Vim 插件
#### 添加新的插件
首先,使用下面的命令搜索可以使用的插件:
```
:PluginSearch
```
要从 vimscripts 网站刷新本地的列表,请在命令之后添加 `!`。
```
:PluginSearch!
```
会弹出一个列出可用插件列表的新分窗口:

你还可以通过直接指定插件名的方式,缩小搜索范围。
```
:PluginSearch vim
```
这样将会列出包含关键词 “vim” 的插件。
当然你也可以指定确切的插件名,比如:
```
:PluginSearch vim-dasm
```
移动焦点到正确的一行上,按下 `i` 键来安装插件。现在,被选择的插件将会被安装。

类似的,在你的系统中安装所有想要的插件。一旦安装成功,使用下列命令删除 Vundle 缓存:
```
:bdelete
```
现在,插件已经安装完成。为了让插件正确的自动加载,我们需要在 `.vimrc` 文件中添加安装好的插件名。
这样做:
```
:e ~/.vimrc
```
添加这一行:
```
[...]
Plugin 'vim-dasm'
[...]
```
用自己的插件名替换 vim-dasm。然后,敲击 `ESC`,键入 `:wq` 保存退出。
请注意,所有插件都必须在 `.vimrc` 文件中追加如下内容。
```
[...]
filetype plugin indent on
```
#### 列出已安装的插件
键入下面命令列出所有已安装的插件:
```
:PluginList
```

#### 更新插件
键入下列命令更新插件:
```
:PluginUpdate
```
键入下列命令重新安装所有插件:
```
:PluginInstall!
```
#### 卸载插件
首先,列出所有已安装的插件:
```
:PluginList
```
之后将焦点置于正确的一行上,按下 `SHITF+d` 组合键。

然后编辑你的 `.vimrc` 文件:
```
:e ~/.vimrc
```
删除插件入口。最后,键入 `:wq` 保存退出。
或者,你可以通过移除插件所在 `.vimrc` 文件行,并且执行下列命令,卸载插件:
```
:PluginClean
```
这个命令将会移除所有不在你的 `.vimrc` 文件中但是存在于 bundle 目录中的插件。
你应该已经掌握了 Vundle 管理插件的基本方法了。在 Vim 中使用下列命令,查询帮助文档,获取更多细节。
```
:h vundle
```
现在我已经把所有内容都告诉你了。很快,我就会出下一篇教程。保持关注!
干杯!
### 资源
[Vundle GitHub 仓库](https://github.com/VundleVim/Vundle.vim)
---
via: <https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,417 | 并发服务器(五):Redis 案例研究 | https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/ | 2018-03-07T19:31:28 | [
"并发",
"Redis"
] | https://linux.cn/article-9417-1.html | 
这是我写的并发网络服务器系列文章的第五部分。在前四部分中我们讨论了并发服务器的结构,这篇文章我们将去研究一个在生产系统中大量使用的服务器的案例—— [Redis](https://redis.io/)。

Redis 是一个非常有魅力的项目,我关注它很久了。它最让我着迷的一点就是它的 C 源代码非常清晰。它也是一个高性能、大并发的内存数据库服务器的非常好的例子,它是研究网络并发服务器的一个非常好的案例,因此,我们不能错过这个好机会。
我们来看看前四部分讨论的概念在真实世界中的应用程序。
本系列的所有文章有:
* [第一节 - 简介](/article-8993-1.html)
* [第二节 - 线程](/article-9002-1.html)
* [第三节 - 事件驱动](/article-9117-1.html)
* [第四节 - libuv](/article-9397-1.html)
* [第五节 - Redis 案例研究](http://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/)
### 事件处理库
Redis 最初发布于 2009 年,它最牛逼的一件事情大概就是它的速度 —— 它能够处理大量的并发客户端连接。需要特别指出的是,它是用*一个单线程*来完成的,而且还不对保存在内存中的数据使用任何复杂的锁或者同步机制。
Redis 之所以如此牛逼是因为,它在给定的系统上使用了其可用的最快的事件循环,并将它们封装成由它实现的事件循环库(在 Linux 上是 epoll,在 BSD 上是 kqueue,等等)。这个库的名字叫做 [ae](https://redis.io/topics/internals-rediseventlib)。ae 使得编写一个快速服务器变得很容易,只要在它内部没有阻塞即可,而 Redis 则保证 <sup> 注1</sup> 了这一点。
在这里,我们的兴趣点主要是它对*文件事件*的支持 —— 当文件描述符(如网络套接字)有一些有趣的未决事情时将调用注册的回调函数。与 libuv 类似,ae 支持多路事件循环(参阅本系列的[第三节](/article-9117-1.html)和[第四节](/article-9397-1.html))和不应该感到意外的 `aeCreateFileEvent` 信号:
```
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
aeFileProc *proc, void *clientData);
```
它在 `fd` 上使用一个给定的事件循环,为新的文件事件注册一个回调(`proc`)函数。当使用的是 epoll 时,它将调用 `epoll_ctl` 在文件描述符上添加一个事件(可能是 `EPOLLIN`、`EPOLLOUT`、也或许两者都有,取决于 `mask` 参数)。ae 的 `aeProcessEvents` 功能是 “运行事件循环和发送回调函数”,它在底层调用了 `epoll_wait`。
### 处理客户端请求
我们通过跟踪 Redis 服务器代码来看一下,ae 如何为客户端事件注册回调函数的。`initServer` 启动时,通过注册一个回调函数来读取正在监听的套接字上的事件,通过使用回调函数 `acceptTcpHandler` 来调用 `aeCreateFileEvent`。当新的连接可用时,这个回调函数被调用。它调用 `accept` <sup> 注2</sup> ,接下来是 `acceptCommonHandler`,它转而去调用 `createClient` 以初始化新客户端连接所需要的数据结构。
`createClient` 的工作是去监听来自客户端的入站数据。它将套接字设置为非阻塞模式(一个异步事件循环中的关键因素)并使用 `aeCreateFileEvent` 去注册另外一个文件事件回调函数以读取事件 —— `readQueryFromClient`。每当客户端发送数据,这个函数将被事件循环调用。
`readQueryFromClient` 就让我们期望的那样 —— 解析客户端命令和动作,并通过查询和/或操作数据来回复。因为客户端套接字是非阻塞的,所以这个函数必须能够处理 `EAGAIN`,以及部分数据;从客户端中读取的数据是累积在客户端专用的缓冲区中,而完整的查询可能被分割在回调函数的多个调用当中。
### 将数据发送回客户端
在前面的内容中,我说到了 `readQueryFromClient` 结束了发送给客户端的回复。这在逻辑上是正确的,因为 `readQueryFromClient` *准备*要发送回复,但它不真正去做实质的发送 —— 因为这里并不能保证客户端套接字已经准备好写入/发送数据。我们必须为此使用事件循环机制。
Redis 是这样做的,它注册一个 `beforeSleep` 函数,每次事件循环即将进入休眠时,调用它去等待套接字变得可以读取/写入。`beforeSleep` 做的其中一件事情就是调用 `handleClientsWithPendingWrites`。它的作用是通过调用 `writeToClient` 去尝试立即发送所有可用的回复;如果一些套接字不可用时,那么*当*套接字可用时,它将注册一个事件循环去调用 `sendReplyToClient`。这可以被看作为一种优化 —— 如果套接字可用于立即发送数据(一般是 TCP 套接字),这时并不需要注册事件 ——直接发送数据。因为套接字是非阻塞的,它从不会去阻塞循环。
### 为什么 Redis 要实现它自己的事件库?
在 [第四节](/article-9397-1.html) 中我们讨论了使用 libuv 来构建一个异步并发服务器。需要注意的是,Redis 并没有使用 libuv,或者任何类似的事件库,而是它去实现自己的事件库 —— ae,用 ae 来封装 epoll、kqueue 和 select。事实上,Antirez(Redis 的创建者)恰好在 [2011 年的一篇文章](http://oldblog.antirez.com/post/redis-win32-msft-patch.html) 中回答了这个问题。他的回答的要点是:ae 只有大约 770 行他理解的非常透彻的代码;而 libuv 代码量非常巨大,也没有提供 Redis 所需的额外功能。
现在,ae 的代码大约增长到 1300 多行,比起 libuv 的 26000 行(这是在没有 Windows、测试、示例、文档的情况下的数据)来说那是小巫见大巫了。libuv 是一个非常综合的库,这使它更复杂,并且很难去适应其它项目的特殊需求;另一方面,ae 是专门为 Redis 设计的,与 Redis 共同演进,只包含 Redis 所需要的东西。
这是我 [前些年在一篇文章中](http://eli.thegreenplace.net/2017/benefits-of-dependencies-in-software-projects-as-a-function-of-effort/) 提到的软件项目依赖关系的另一个很好的示例:
>
> 依赖的优势与在软件项目上花费的工作量成反比。
>
>
>
在某种程度上,Antirez 在他的文章中也提到了这一点。他提到,提供大量附加价值(在我的文章中的“基础” 依赖)的依赖比像 libuv 这样的依赖更有意义(它的例子是 jemalloc 和 Lua),对于 Redis 特定需求,其功能的实现相当容易。
### Redis 中的多线程
[在 Redis 的绝大多数历史中](http://antirez.com/news/93),它都是一个不折不扣的单线程的东西。一些人觉得这太不可思议了,有这种想法完全可以理解。Redis 本质上是受网络束缚的 —— 只要数据库大小合理,对于任何给定的客户端请求,其大部分延时都是浪费在网络等待上,而不是在 Redis 的数据结构上。
然而,现在事情已经不再那么简单了。Redis 现在有几个新功能都用到了线程:
1. “惰性” [内存释放](http://antirez.com/news/93)。
2. 在后台线程中使用 fsync 调用写一个 [持久化日志](https://redis.io/topics/persistence)。
3. 运行需要执行一个长周期运行的操作的用户定义模块。
对于前两个特性,Redis 使用它自己的一个简单的 bio(它是 “Background I/O" 的首字母缩写)库。这个库是根据 Redis 的需要进行了硬编码,它不能用到其它的地方 —— 它运行预设数量的线程,每个 Redis 后台作业类型需要一个线程。
而对于第三个特性,[Redis 模块](https://redis.io/topics/modules-intro) 可以定义新的 Redis 命令,并且遵循与普通 Redis 命令相同的标准,包括不阻塞主线程。如果在模块中自定义的一个 Redis 命令,希望去执行一个长周期运行的操作,这将创建一个线程在后台去运行它。在 Redis 源码树中的 `src/modules/helloblock.c` 提供了这样的一个示例。
有了这些特性,Redis 使用线程将一个事件循环结合起来,在一般的案例中,Redis 具有了更快的速度和弹性,这有点类似于在本系统文章中 [第四节](/article-9397-1.html) 讨论的工作队列。
* 注1: Redis 的一个核心部分是:它是一个 *内存中* 数据库;因此,查询从不会运行太长的时间。当然了,这将会带来各种各样的其它问题。在使用分区的情况下,服务器可能最终路由一个请求到另一个实例上;在这种情况下,将使用异步 I/O 来避免阻塞其它客户端。
* 注2: 使用 `anetAccept`;`anet` 是 Redis 对 TCP 套接字代码的封装。
---
via: <https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/>
作者:[Eli Bendersky](https://eli.thegreenplace.net/pages/about) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is part 5 in a series of posts on writing concurrent network servers. After
discussing techniques for constructing concurrent servers in parts 1-4, this
time we're going to do a case study of an existing production-quality server -
[Redis](https://redis.io/).

Redis is a fascinating project and I've been following it with interest for a while now. One of the things I admire most about Redis is the clarity of its C source code. It also happens to be a great example of a high-performance concurrent in-memory database server, so the opportunity to use it as a case study for this series was too good to ignore.
Let's see how the ideas discussed in parts 1-4 apply to a real-world application.
All posts in the series:
[Part 1 - Introduction](https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/)[Part 2 - Threads](https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/)[Part 3 - Event-driven](https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/)[Part 4 - libuv](https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/)[Part 5 - Redis case study](https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/)[Part 6 - Callbacks, Promises and async/await](https://eli.thegreenplace.net/2018/concurrent-servers-part-6-callbacks-promises-and-asyncawait/)
## Event-handling library
One of Redis's main claims to fame around the time of its original release in
2009 was its *speed* - the sheer number of concurrent client connections the
server could handle. It was especially notable that Redis did this all *in a
single thread*, without any complex locking and synchronization schemes on the
data stored in memory.
This feat was achieved by Redis's own implementation of an event-driven library
which is wrapping the fastest event loop available on a system (`epoll` for
Linux, `kqueue` for BSD and so on). This library is called [ae](https://redis.io/topics/internals-rediseventlib). `ae` makes it possible to
write a fast server as long as none of the internals are blocking, which Redis
goes to great lengths to guarantee [[1]](#footnote-1).
What mainly interests us here is `ae`'s support of *file events* - registering
callbacks to be invoked when file descriptors (like network sockets) have
something interesting pending. Like `libuv`, `ae` supports multiple event
loops and - having read parts 3 and 4 in this series - the signature of
`aeCreateFileEvent` shouldn't be surprising:
```
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
aeFileProc *proc, void *clientData);
```
It registers a callback (`proc`) for new file events on `fd`, with the given
event loop. When using `epoll`, it will call `epoll_ctl` to add an event on
the file descriptor (either `EPOLLIN`, `EPOLLOUT` or both, depending on the
`mask` parameter). `ae`'s `aeProcessEvents` is the "run the event loop and
dispatch callbacks" function, and it calls `epoll_wait` under the hood.
## Handling client requests
Let's trace through the Redis server code to see how `ae` is used to register
callbacks for client events. `initServer` starts it by registering a callback
for read events on the socket(s) being listened to, by calling
`aeCreateFileEvent` with the callback `acceptTcpHandler`. This callback is
invoked when new client connections are available. It calls `accept` [[2]](#footnote-2) and
then `acceptCommonHandler`, which in turn calls `createClient` to initialize
the data structures required to track a new client connection.
`createClient`'s job is to start listening for data coming in from the client.
It sets the socket to non-blocking mode (a key ingredient in an asynchronous
event loop) and registers another file event callback with `aeCreateFileEvent`
- for read events - `readQueryFromClient`. This function will be invoked by
the event loop every time the client sends some data.
`readQueryFromClient` does just what we'd expect - parses the client's command
and acts on it by querying and/or manipulating data and sending a reply back.
Since the client socket is non-blocking, this function has to be able to handle
`EAGAIN`, as well as partial data; data read from the client is accumulated in
a client-specific buffer, and the full query may be split across multiple
invocations of the callback.
## Sending data back to clients
In the previous paragraph I said that `readQueryFromClient` ends up sending
replies back to clients. This is logically true, because `readQueryFromClient`
*prepares* the reply to be sent, but it doesn't actually do the physical sending
- since there's no guarantee the client socket is ready for writing/sending
data. We have to use the event loop machinery for that.
The way Redis does this is by registering a `beforeSleep` function to be
called every time the event loop is about to go sleeping waiting for sockets to
become available for reading/writing. One of the things `beforeSleep` does is
call `handleClientsWithPendingWrites`. This function tries to send all
available replies immediately by calling `writeToClient`; if some of the
sockets are unavailable, it registers an event-loop callback to invoke
`sendReplyToClient` when the socket *is* ready. This can be seen as a kind of
optimization - if the socket is immediately ready for sending (which often is
the case for TCP sockets), there's no need to register the event - just send the
data. Since sockets are non-blocking, this never actually blocks the loop.
## Why does Redis roll its own event library?
In [part 4](https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/) we've
discussed building asynchronous concurrent servers using `libuv`. It's
interesting to ponder the fact that Redis doesn't use `libuv`, or any similar
event library, and instead implements its own - `ae`, including wrappers for
`epoll`, `kqueue` and `select`. In fact, antirez (Redis's creator)
answered precisely this question [in a blog post in 2011](http://oldblog.antirez.com/post/redis-win32-msft-patch.html). The gist of
his answer: `ae` is ~770 lines of code he intimately understands; `libuv` is
huge, without providing additional functionality Redis needs.
Today, `ae` has grown to ~1300 lines, which is still trivial compared to
`libuv`'s 26K (this is *without* Windows, test, samples, docs). `libuv` is a
far more general library, which makes it more complex and more difficult to
adapt to the particular needs of another project; `ae`, on the other hand, was
designed for Redis, co-evolved with Redis and contains only what Redis needs.
This is another great example of the dependencies in software projects formula I
mentioned [in a post earlier this year](https://eli.thegreenplace.net/2017/benefits-of-dependencies-in-software-projects-as-a-function-of-effort/):
The benefit of dependencies is inversely proportional to the amount of effort spent on a software project.
antirez referred to this, to some extent, in his post. He mentioned that
dependencies that provide a lot of added value ("foundational" dependencies in
my post) make more sense (`jemalloc` and Lua are his examples) than
dependencies like `libuv`, whose functionality is fairly easy to implement for
the particular needs of Redis.
## Multi-threading in Redis
[For the vast majority of its history](http://antirez.com/news/93), Redis has
been a purely single-threaded affair. Some people find this surprising, but it
makes total sense with a bit of thought. Redis is inherently network-bound - as
long as the database size is reasonable, for any given client request, much more
time is spent waiting on the network than inside Redis's data structures.
These days, however, things are not quite that simple. There are several new capabilities in Redis that use threads:
- "Lazy"
[freeing of memory](http://antirez.com/news/93). - Writing a
[persistence journal](https://redis.io/topics/persistence)with`fsync`calls in a background thread. - Running user-defined modules that need to perform a long-running operation.
For the first two features, Redis uses its own simple `bio` library (the
acronym stands for "Background I/O"). The library is hard-coded for Redis's
needs and can't be used outside it - it runs a pre-set number of threads, one
per background job type Redis needs.
For the third feature, [Redis modules](https://redis.io/topics/modules-intro)
could define new Redis commands, and thus are held to the same standards as
regular Redis commands, including not blocking the main thread. If a custom
Redis command defined in a module wants to perform a long-running operation, it
has to spin up a thread to run it in the background.
`src/modules/helloblock.c` in the Redis tree provides an example.
With these features, Redis combines an event loop with threading to get both
speed in the common case and flexibility in the general case, similarly to the
work queue discussion in [part 4](https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/) of this
series.
|
*in-memory*database; therefore, queries should never take too long to execute. There are all kinds of complications, however. In case of partitioning, a server may end up routing the request to another instance; in this case async I/O is used to avoid blocking other clients.
|
`anetAccept`;`anet`is Redis's wrapper for TCP socket code. |
9,418 | 搭建私有云:OwnCloud | http://linuxtechlab.com/create-personal-cloud-install-owncloud/ | 2018-03-07T23:48:14 | [
"OwnCloud",
"云服务"
] | https://linux.cn/article-9418-1.html | 
所有人都在讨论云。尽管市面上有很多为我们提供云存储和其他云服务的主要服务商,但是我们还是可以为自己搭建一个私有云。
在本教程中,我们将讨论如何利用 OwnCloud 搭建私有云。OwnCloud 是一个可以安装在我们 Linux 设备上的 web 应用程序,能够存储和用我们的数据提供服务。OwnCloud 可以分享日历、联系人和书签,共享音/视频流等等。
本教程中,我们使用的是 CentOS 7 系统,但是本教程同样适用于其他 Linux 发行版中安装 OwnCloud。让我们开始安装 OwnCloud 并且做一些准备工作,
* 推荐阅读:[如何在 CentOS & RHEL 上使用 Apache 作为反向代理服务器](http://linuxtechlab.com/apache-as-reverse-proxy-centos-rhel/)
* 同时推荐:[实时 Linux 服务器监测和 GLANCES 监测工具](http://linuxtechlab.com/linux-server-glances-monitoring-tool/)
### 预备
* 我们需要在机器上配置 LAMP。参照阅读我们的文章《[在 CentOS/RHEL 上配置 LAMP 服务器最简单的教程](http://linuxtechlab.com/easiest-guide-creating-lamp-server/)》 & 《[在 Ubuntu 搭建 LAMP](http://linuxtechlab.com/install-lamp-stack-on-ubuntu/)》。
* 我们需要在自己的设备里安装这些包,`php-mysql`、 `php-json`、 `php-xml`、 `php-mbstring`、 `php-zip`、 `php-gd`、 `curl、`php-curl`、`php-pdo`。使用包管理器安装它们。
```
$ sudo yum install php-mysql php-json php-xml php-mbstring php-zip php-gd curl php-curl php-pdo
```
### 安装
安装 OwnCloud,我们现在需要在服务器上下载 OwnCloud 安装包。使用下面的命令从官方网站下载最新的安装包(10.0.4-1):
```
$ wget https://download.owncloud.org/community/owncloud-10.0.4.tar.bz2
```
使用下面的命令解压:
```
$ tar -xvf owncloud-10.0.4.tar.bz2
```
现在,将所有解压后的文件移动至 `/var/www/html`:
```
$ mv owncloud/* /var/www/html
```
下一步,我们需要在 Apache 的配置文件 `httpd.conf` 上做些修改:
```
$ sudo vim /etc/httpd/conf/httpd.conf
```
更改下面的选项:
```
AllowOverride All
```
保存该文件,并修改 OwnCloud 文件夹的文件权限:
```
$ sudo chown -R apache:apache /var/www/html/
$ sudo chmod 777 /var/www/html/config/
```
然后重启 Apache 服务器执行修改:
```
$ sudo systemctl restart httpd
```
现在,我们需要在 MariaDB 上创建一个数据库,保存来自 OwnCloud 的数据。使用下面的命令创建数据库和数据库用户:
```
$ mysql -u root -p
MariaDB [(none)] > create database owncloud;
MariaDB [(none)] > GRANT ALL ON owncloud.* TO ocuser@localhost IDENTIFIED BY 'owncloud';
MariaDB [(none)] > flush privileges;
MariaDB [(none)] > exit
```
服务器配置部分完成后,现在我们可以在网页浏览器上访问 OwnCloud。打开浏览器,输入您的服务器 IP 地址,我这边的服务器是 10.20.30.100:

一旦 URL 加载完毕,我们将呈现上述页面。这里,我们将创建管理员用户同时提供数据库信息。当所有信息提供完毕,点击“Finish setup”。
我们将被重定向到登录页面,在这里,我们需要输入先前创建的凭据:

认证成功之后,我们将进入 OwnCloud 面板:

我们可以使用手机应用程序,同样也可以使用网页界面更新我们的数据。现在,我们已经有自己的私有云了,同时,关于如何安装 OwnCloud 创建私有云的教程也进入尾声。请在评论区留下自己的问题或建议。
---
via: <http://linuxtechlab.com/create-personal-cloud-install-owncloud/>
作者:[SHUSAIN](http://linuxtechlab.com/author/shsuain/) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,419 | 区块链的商用之道 | https://mp.weixin.qq.com/s/SF1GNcCkPVUYt3g5hnhwFA | 2018-03-08T11:20:00 | [
"区块链"
] | https://linux.cn/article-9419-1.html | 
区块链之所以被称之为一种“颠覆性”的新兴技术,因为尽管其成名于比特币,但未来区块链的用武之地将远远超过加密货币。区块链的分布式共享账本这一技术本质能够在商业网络中使更多的参与方得以更加广泛的参与,并为商业网络或行业业务带来更低的沟通或整合成本,以及更高的业务效率。可以预见,区块链作为一个独立的技术板块,会在商业领域得到广泛应用。
### 1、区块链的 2.0 时代:商用区块链
自 2009 年比特币在交易领域迅速崛起以来,这种加密币受到了广泛关注,但也颇受争议。不过比特币的底层技术——区块链,由于能够快速改进银行、供应链以及其他的交易网络,在降低与业务运营相关的成本和风险的同时,创造新的创新和增长机会,是比较无争议的新兴技术模式,得到了商业世界的鼎力支持。
传统的商业业务模式存在很难在一个互信的网络中监视跨机构的交易执行的问题:每个参与方都有自己的账本,在交易发生时各自更改;协同各方导致的额外工作及中介等附加成本;由于业务条件,“合同”重复分散在各个参与方造成整体业务流程的不有效性;整个业务网络依赖于一个或几个中心系统,整个商业网络十分脆弱。
而区块链提供了共享的、复制的、授权的账本这样一个解决方案。区块链架构带来以下改变:区块链架构使每一个商业网络的参与方都具有一个共享的账本,当交易发生时,通过点对点的复制更改所有账本;使用密码算法确保网络上的参与者仅仅可以看到和他们相关的账本内容,交易是安全的、授权的和验证的;区块链也将资产转移交易相关的合同条款嵌入交易数据库以做到满足商务条件下交易才发生;网络参与者基于共识机制或类似的机制来保证交易时共同验证的,商业网络满足政府监管、合规及审计。总体而言,区块链在提高业务效率和简化流程上确实具有优势。
当前国内外区块链产业生态发展迅猛,产业链层次逐渐清晰,无论从底层基础架构和平台,还是细分产业板块的区块链应用,以及风险资本投资都已初具规模。综合来看,全球区块链在商业行业发展具有三大趋势:
1)从比特币向更丰富的应用场景发展。区块链 2.0 把之前“区块链就是比特币”的意义向前推进了一大步,区块链也不再是比特币的专有技术和代名词,而且在更加广泛的应用场景中,成为资产流转的价值表述。区块链当下不再依赖数字货币或资产这一类的单一场景,而是发展到支付汇兑、电子商务、移动社交、众筹、慈善、互助保险等面向终端用户的应用,以及数字资产、IP版权和交易、金融清算和结算、商品溯源等企业级应用领域。
2)全球区块链生态日益丰富,参与方开始出现明显的产业分工。从全球的视角来看,随着参与者越来越多,区块链形成了不同技术平台、行业以及发展路径的产业生态。对全球的区块链从业者来说,更看重区块链作为未来<ruby> 金融科技 <rp> ( </rp> <rt> FinTech </rt> <rp> ) </rp></ruby>的一个领域而提前布局,大胆尝试实践区块链在金融及其他行业中的各类业务场景。同时,高科技龙头企业也希望在区块链技术框架的建立上尽早发力,通过支持全球开源社区建立更扎实的底层区块链平台和更广泛的应用场景。区块链的热潮带动了更多创业者的热情,众多初创公司如雨后春笋般的应运而生。从行业角度来看,区块链初创公司覆盖了银行和保险服务、供应链、医疗、物联网、外贸等众多行业背景,可谓是百花齐放。
3)全球投资正在快速注入,重点关注企业级应用落地。区块链项目融资正呈现井喷式增长,从 2012 年到 2015 年,区块链领域吸引的风险投资从 200 万美元增长到 4.69 亿美元,增长超过了 200 倍,累计投资已达 10 亿美元左右。2016 年仅在金融领域,区块链技术投资额就占整体投资的七成以上。从全球的投资情况来看,由于越来越多的行业已经开始实践区块链,使得更多的投资人开始关注在行业内的区块链应用场景,投资上趋于理性,但更注重利用投资者自身资源帮助投资标的进行深度的行业孵化。
总之,市场,行业,投资等多方对于商用区块链的发展诉求十分强烈,作为“颠覆性创新”技术的区块链前景光明。
### 2、超级账本:商用区块链的“第五元素”
企业级区块链四大平台要素包括:共享账簿,共识,隐私和保密,智能合约。此外,还有第五要素,即商业网络。企业级的区块链一定是围绕业务场景展开的,因此在第五元素商业网络当中需要包含市场参与者的对等架构以及伙伴间的一个共识协议。
目前,以比特币为代表的公有链有一些加密货币之外的新型应用,但是却无法克服自身固有的一些问题,例如交易效率低,区块没有<ruby> 最终确定性 <rp> ( </rp> <rt> finality </rt> <rp> ) </rp></ruby>等,而且是由极客主导的,不符合商业主流趋势。为了克服上述不足,满足大多数商业应用的要求,设计开发适合商用的区块链平台迫在眉睫。
Linux 基金会于 2015 年 12 月启动了名为“超级账本”(Hyperledger)的开源项目应运而生。该项目旨在推动各方协作,共同打造基于区块链的企业级分布式账本底层技术,用于构建支撑业务的行业应用和平台,以便支持各种各样的商业应用场景。超级账本是代码数量最大社区参与度最高的区块链开源项目。
企业级商用区块链网络比较适合使用联盟链和许可制。这样在一个限定的范围内,只有授权的节点和用户才能参与到交易和智能合约的执行中来,而任何的匿名节点或非授权用户均被拒绝服务。从团体联盟的角度增加了区块链网络的安全可靠。当前,欧美主流的区块链应用大部分是行业链或者是联盟链,也就是某一个行业的上下游,或者是核心企业大家联合起来,一起来构建的半公开化的区块链。从这个角度讲,超级账本具备成为未来最主要的商用区块链技术平台的潜力,值得技术开发人员花时间和精力进行学习研究。
由于超级账本有个重要的设计原则就是按照<ruby> “用例驱动” <rp> ( </rp> <rt> use case driven </rt> <rp> ) </rp></ruby>的方式来实现的,所有功能都应该有对应的用例需求,因此学习研究的过程并不一定十分辛苦。此外,鉴于超级账本是个通用型框架,无法预先确定将来所有的应用场景,因此,定义出部分典型的用例,可使超级账本先满足这部分代表性的区块链应用需求,然后再用可替换模块满足其他需求。
### 3、区块链的商业应用场景
区块链的商业应用才刚刚起步,一般都将金融业应用作为切入口,很多其他领域的应用还在探索或试水阶段。最重要的是,不能为了技术而技术,为了区块链而区块链。商用区块链技术要解决企业的痛点,为客户创造新的价值。可喜的是,在金融和金融以外的各个细分领域,区块链都在加速落地。以下为一些应用实例和构想。
1)金融领域。21 世纪是金融的“大航海时代”,区块链在银行、保险、清算、股权登记交易、信用评级、公证等领域,既需要绝对的可信任,也需要隐私保密,特别适合区块链应用。举例来说,金融行业关心的资产分布式管存,可以把资产(如证券等)数据存放在区块链网络后,资产的利益相关人可以直接访问资产数据,而无需经过传统的中间人,可大幅提高效率和节约成本。区块链股权登记和交易平台脱胎于加密币交易所,也是比较合适、比较容易实现的应用。
2)产业互联网领域。供应链溯源和共享经济可以应用区块链。在供应链中,所有的参与者都通过区块链记录、追踪和共享各种数据,这些数据记录在区块链里面并贯穿货物的生产、运输和销售等环节,从而提供深度回溯查询等核心功能,实现信息公开透明,出了问题可以用来追责。附加值较高的食品、药品和疫苗、零部件生产检测结果等都可以使用区块链。
例如,现在市场上号称是北大荒地区生产的大米,特别是五常大米,是当地实际产量的很多倍,造成良莠不齐。消费者希望花比较高的价钱购买真正的北大荒大米,却苦于根本无法分辨哪些大米是真的。此处可以提现区块链在供应链溯源上的价值,就是利用区块链的数据记录的真实性或者是有效性。如果通过在原产地和各个流通环节中设置的传感设备在区块链上签名盖戳,一旦进入到区块链里面,每个人的签名就不能抵赖了。含有被区块链标记的时间戳、地理戳、品质戳的放心粮从源头上杜绝各个环节作弊的动机,市场上才能销售与当地产量相匹配的大米。
1)传统行业的转型创新。区块链的应用绝不仅局限于金融和互联网等前沿领域,还可以与能源,零售,电商、房地产等传统领域接轨,因此区块链不是个摆设。例如,高盛公司就提出,对于资产所有权需经过谨慎识别的房地产交易,如果能够利用区块链技术建立安全、共享的所有权数据库,那么房产交易纠纷和交易成本将大大缩小。
2)FinTech 2.0 的三驾马车:区块链、认知物联网和人工智能。未来,世界将进入人工智能、认知物联网和区块链三足鼎立的时期,如果能将三者有机结合将创造巨大的价值。例如,如果将闲置或未充分利用的资产(汽车、仓库、医疗设备等)接入物联网,那么区块链技术则可以帮助互不相识的这些资产的所有者进行资产使用的交易谈判。在共享经济的模式下,最需要解决的就是陌生人之间的信任问题,即资源的提供方和资源的租用者,如何在缺乏信任的基础上安全地完成交易。分布式区块链将是全新的一种去信任的方式,不使用任何中间平台,达到各方参与者的可靠交易的目的。这有点类似于分时用车和分时用房,将引爆以前隐藏在深处的过剩资产容量。
——本文摘自《深度探索区块链:Hyperledger 技术与应用》
---
想学习区块链知识的同学可以参加由 华章书院、智链 ChainNova 主办,Linux 中国协办的[第3届《洞见区块链·深度探索区块链》技术沙龙](http://www.huodongxing.com/event/5429319192800)。

时间: 2018 年 3 月 18 日 13:00 ~ 17:30 。
地点:北京市海淀区海淀西大街36号昊海写字楼3楼(清华经管创业者加速器)
限额 200 人
[点此报名](http://www.huodongxing.com/event/5429319192800),或扫描二维码报名。

| 200 | OK | 该公众号已迁移
该公众号已迁移至新的账号,原账号已回收。若需访问原文章链接,请点击下方按钮。
访问文章
:
,
。
视频
小程序
赞
,轻点两下取消赞
在看
,轻点两下取消在看
分享
留言
收藏 |
9,420 | 如何使用 syslog-ng 从远程 Linux 机器上收集日志 | https://www.techrepublic.com/article/how-to-use-syslog-ng-to-collect-logs-from-remote-linux-machines/ | 2018-03-08T22:49:23 | [
"日志",
"syslog"
] | https://linux.cn/article-9420-1.html | 
如果你的数据中心全是 Linux 服务器,而你就是系统管理员。那么你的其中一项工作内容就是查看服务器的日志文件。但是,如果你在大量的机器上去查看日志文件,那么意味着你需要挨个去登入到机器中来阅读日志文件。如果你管理的机器很多,仅这项工作就可以花费你一天的时间。
另外的选择是,你可以配置一台单独的 Linux 机器去收集这些日志。这将使你的每日工作更加高效。要实现这个目的,有很多的不同系统可供你选择,而 syslog-ng 就是其中之一。
syslog-ng 的不足是文档并不容易梳理。但是,我已经解决了这个问题,我可以通过这种方法马上进行安装和配置 syslog-ng。下面我将在 Ubuntu Server 16.04 上示范这两种方法:
* UBUNTUSERVERVM 的 IP 地址是 192.168.1.118 ,将配置为日志收集器
* UBUNTUSERVERVM2 将配置为一个客户端,发送日志文件到收集器
现在我们来开始安装和配置。
### 安装
安装很简单。为了尽可能容易,我将从标准仓库安装。打开一个终端窗口,运行如下命令:
```
sudo apt install syslog-ng
```
你必须在收集器和客户端的机器上都要运行上面的命令。安装完成之后,你将开始配置。
### 配置收集器
现在,我们开始日志收集器的配置。它的配置文件是 `/etc/syslog-ng/syslog-ng.conf`。syslog-ng 安装完成时就已经包含了一个配置文件。我们不使用这个默认的配置文件,可以使用 `mv /etc/syslog-ng/syslog-ng.conf /etc/syslog-ng/syslog-ng.conf.BAK` 将这个自带的默认配置文件重命名。现在使用 `sudo nano /etc/syslog/syslog-ng.conf` 命令创建一个新的配置文件。在这个文件中添加如下的行:
```
@version: 3.5
@include "scl.conf"
@include "`scl-root`/system/tty10.conf"
options {
time-reap(30);
mark-freq(10);
keep-hostname(yes);
};
source s_local { system(); internal(); };
source s_network {
syslog(transport(tcp) port(514));
};
destination d_local {
file("/var/log/syslog-ng/messages_${HOST}"); };
destination d_logs {
file(
"/var/log/syslog-ng/logs.txt"
owner("root")
group("root")
perm(0777)
); };
log { source(s_local); source(s_network); destination(d_logs); };
```
需要注意的是,syslog-ng 使用 514 端口,你需要确保在你的网络上它可以被访问。
保存并关闭这个文件。上面的配置将转存期望的日志文件(由 `system()` 和 `internal()` 指出)到 `/var/log/syslog-ng/logs.txt` 中。因此,你需要使用如下的命令去创建所需的目录和文件:
```
sudo mkdir /var/log/syslog-ng
sudo touch /var/log/syslog-ng/logs.txt
```
使用如下的命令启动和启用 syslog-ng:
```
sudo systemctl start syslog-ng
sudo systemctl enable syslog-ng
```
### 配置客户端
我们将在客户端上做同样的事情(移动默认配置文件并创建新配置文件)。拷贝下列文本到新的客户端配置文件中:
```
@version: 3.5
@include "scl.conf"
@include "`scl-root`/system/tty10.conf"
source s_local { system(); internal(); };
destination d_syslog_tcp {
syslog("192.168.1.118" transport("tcp") port(514)); };
log { source(s_local);destination(d_syslog_tcp); };
```
请注意:请将 IP 地址修改为收集器的 IP 地址。
保存和关闭这个文件。与在配置为收集器的机器上一样的方法启动和启用 syslog-ng。
查看日志文件
------
回到你的配置为收集器的服务器上,运行这个命令 `sudo tail -f /var/log/syslog-ng/logs.txt`。你将看到包含了收集器和客户端的日志条目的输出(图 A)。

恭喜你!syslog-ng 已经正常工作了。你现在可以登入到你的收集器上查看本地机器和远程客户端的日志了。如果你的数据中心有很多 Linux 服务器,在每台服务器上都安装上 syslog-ng 并配置它们作为客户端发送日志到收集器,这样你就不需要登入到每个机器去查看它们的日志了。
---
via: <https://www.techrepublic.com/article/how-to-use-syslog-ng-to-collect-logs-from-remote-linux-machines/>
作者:[Jack Wallen](%5B1%5D:https://tr1.cbsistatic.com/hub/i/r/2017/01/11/51204409-68e0-49b8-a637-01af26be85f6/resize/770x/688dfedad4ed30ec4baf548c2adb8cd4/linuxhero.jpg) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Let’s say your data center is filled with Linux servers and you need to administer them all. Part of that administration job is viewing log files. But if you’re looking at numerous machines, that means logging into each machine individually, reading log files, and then moving onto the next. Depending upon how many machines you have, that can take a large chunk of time from your day.
Or, you could set up a single Linux machine to collect those logs. That would make your day considerably more efficient. To do this, you could opt for a number of different system, one of which is syslog-ng.
The problem with syslog-ng is that the documentation isn’t the easiest to comb through. However, I’ve taken care of that and am going to lay out the installation and configuration in such a way that you can have syslog-ng up and running in no time. I’ll be demonstrating on Ubuntu Server 16.04 on a two system setup:
- UBUNTUSERVERVM at IP address 192.168.1.118 will serve as log collector
- UBUNTUSERVERVM2 will serve as a client, sending log files to the collector
Let’s install and configure.
## Installation
The installation is simple. I’ll be installing from the standard repositories, in order to make this as easy as possible. To do this, open up a terminal window and issue the command:
`sudo apt install syslog-ng`
You must issue the above command on both collector and client. Once that’s installed, you’re ready to configure.
## Configuration for the collector
We’ll start with the configuration of the log collector. The configuration file is */etc/syslog-ng/syslog-ng.conf*. Out of the box, syslog-ng includes a configuration file. We’re not going to use that. Let’s rename the default config file with the command *sudo mv /etc/syslog-ng/syslog-ng.conf /etc/syslog-ng/syslog-ng.conf.BAK*. Now create a new configuration file with the command *sudo nano /etc/syslog/syslog-ng.conf*. In that file add the following:
`@version: 3.5`
@include "scl.conf"
@include "`scl-root`/system/tty10.conf"
options {
time-reap(30);
mark-freq(10);
keep-hostname(yes);
};
source s_local { system(); internal(); };
source s_network {
syslog(transport(tcp) port(514));
};
destination d_local {
file("/var/log/syslog-ng/messages_${HOST}"); };
destination d_logs {
file(
"/var/log/syslog-ng/logs.txt"
owner("root")
group("root")
perm(0777)
); };
log { source(s_local); source(s_network); destination(d_logs); };
Do note that we are working with port 514, so you’ll need to make sure it is accessible on your network.
Save and close the file. The above configuration will dump the desired log files (denoted with system() and internal()) into */var/log/syslog-ng/logs.txt*. Because of this, you need to create the directory and file with the following commands:
`sudo mkdir /var/log/syslog-ng`
sudo touch /var/log/syslog-ng/logs.txt
Start and enable syslog-ng with the commands:
`sudo systemctl start syslog-ng`
sudo systemctl enable syslog-ng
## Configuration for the client
We’re going to do the very same thing on the client (moving the default configuration file and creating a new configuration file). Copy the following text into the new client configuration file:
`@version: 3.5`
@include "scl.conf"
@include "`scl-root`/system/tty10.conf"
source s_local { system(); internal(); };
destination d_syslog_tcp {
syslog("192.168.1.118" transport("tcp") port(514)); };
log { source(s_local);destination(d_syslog_tcp); };
Note: Change the IP address to match the address of your collector server.
Save and close that file. Start and enable syslog-ng in the same fashion you did on the collector.
## View the log files
Head back to your collector and issue the command *sudo tail -f /var/log/syslog-ng/logs.txt*. You should see output that includes log entries for both collector and client (**Figure A**).
**Figure A**
Congratulations, syslog-ng is working. You can now log into your collector to view logs from both the local machine and the remote client. If you have more Linux servers in your data center, walk through the process of installing syslog-ng and setting each of them up as a client to send their logs to the collector, so you no longer have to log into individual machines to view logs. |
9,421 | 下一次技术面试时要问的 3 个重要问题 | https://www.linux.com/blog/os-jobs/2017/12/3-essential-questions-ask-your-next-tech-interview | 2018-03-08T23:04:00 | [
"面试"
] | https://linux.cn/article-9421-1.html | 
>
> 面试可能会有压力,但 58% 的公司告诉 Dice 和 Linux 基金会,他们需要在未来几个月内聘请开源人才。学习如何提出正确的问题。
>
>
>
Dice 和 Linux 基金会的年度[开源工作报告](https://www.linuxfoundation.org/blog/2017-jobs-report-highlights-demand-open-source-skills/)揭示了开源专业人士的前景以及未来一年的招聘活动。在今年的报告中,86% 的科技专业人士表示,了解开源推动了他们的职业生涯。然而,当在他们自己的组织内推进或在别处申请新职位的时候,有这些经历会发生什么呢?
面试新工作绝非易事。除了在准备新职位时还要应付复杂的工作,当面试官问“你有什么问题要问吗?”时,适当的回答更增添了压力。
在 Dice,我们从事职业、建议,并将技术专家与雇主连接起来。但是我们也在公司里雇佣技术人才来开发开源项目。实际上,Dice 平台基于许多 Linux 发行版,我们利用开源数据库作为我们搜索功能的基础。总之,如果没有开源软件,我们就无法运行 Dice,因此聘请了解和热爱开源软件的专业人士至关重要。
多年来,我在面试中了解到提出好问题的重要性。这是一个了解你的潜在新雇主的机会,以及更好地了解他们是否与你的技能相匹配。
这里有三个要问的重要问题,以及其重要的原因:
### 1、 公司对员工在空闲时间致力于开源项目或编写代码的立场是什么?
这个问题的答案会告诉正在面试的公司的很多信息。一般来说,只要它与你在该公司所从事的工作没有冲突,公司会希望技术专家为网站或项目做出贡献。在公司之外允许这种情况,也会在技术组织中培养出一种创业精神,并教授技术技能,否则在正常的日常工作中你可能无法获得这些技能。
### 2、 项目如何区分优先级?
由于所有的公司都成为了科技公司,所以在创新的客户面对技术项目与改进平台本身之间往往存在着分歧。你会努力保持现有的平台最新么?或者致力于公众开发新产品?根据你的兴趣,答案可以决定公司是否适合你。
### 3、 谁主要决定新产品,开发者在决策过程中有多少投入?
这个问题是了解谁负责公司创新(以及与他/她有多少联系),还有一个是了解你在公司的职业道路。在开发新产品之前,一个好的公司会和开发人员和开源人才交流。这看起来不用多想,但有时会错过这步,意味着在新产品发布之前协作环境的不同或者混乱的过程。
面试可能会有压力,但是 58% 的公司告诉 Dice 和 Linux 基金会他们需要在未来几个月内聘用开源人才,所以记住高需求会让像你这样的专业人士成为雇员。以你想要的方向引导你的事业。
现在[下载](http://bit.ly/2017OSSjobsreport)完整的 2017 年开源工作报告。
---
via: <https://www.linux.com/blog/os-jobs/2017/12/3-essential-questions-ask-your-next-tech-interview>
作者:[Brian Hostetter](https://www.linux.com/users/brianhostetter) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,422 | 如何在 Linux 中配置 ssh 登录导语 | https://kerneltalks.com/tips-tricks/how-to-configure-login-banners-in-linux/ | 2018-03-08T23:23:50 | [
"登录",
"ssh"
] | https://linux.cn/article-9422-1.html |
>
> 了解如何在 Linux 中创建登录导语,来向要登录或登录后的用户显示不同的警告或消息。
>
>
>

无论何时登录公司的某些生产系统,你都会看到一些登录消息、警告或关于你将登录或已登录的服务器的信息,如下所示。这些是<ruby> 登录导语 <rt> login banner </rt></ruby>。

在本文中,我们将引导你配置它们。
你可以配置两种类型的导语。
1. 用户登录前显示的导语信息(在你选择的文件中配置,例如 `/etc/login.warn`)
2. 用户成功登录后显示的导语信息(在 `/etc/motd` 中配置)
### 如何在用户登录前连接系统时显示消息
当用户连接到服务器并且在登录之前,这个消息将被显示给他。意味着当他输入用户名时,该消息将在密码提示之前显示。
你可以使用任何文件名并在其中输入信息。在这里我们使用 `/etc/login.warn` 并且把我们的消息放在里面。
```
# cat /etc/login.warn
!!!! Welcome to KernelTalks test server !!!!
This server is meant for testing Linux commands and tools. If you are
not associated with kerneltalks.com and not authorized please dis-connect
immediately.
```
现在,需要将此文件和路径告诉 `sshd` 守护进程,以便它可以为每个用户登录请求获取此标语。对于此,打开 `/etc/sshd/sshd_config` 文件并搜索 `#Banner none`。
这里你需要编辑该配置文件,并写下你的文件名并删除注释标记(`#`)。它应该看起来像:`Banner /etc/login.warn`。
保存文件并重启 `sshd` 守护进程。为避免断开现有的连接用户,请使用 HUP 信号重启 sshd。
```
root@kerneltalks # ps -ef | grep -i sshd
root 14255 1 0 18:42 ? 00:00:00 /usr/sbin/sshd -D
root 19074 14255 0 18:46 ? 00:00:00 sshd: ec2-user [priv]
root 19177 19127 0 18:54 pts/0 00:00:00 grep -i sshd
root@kerneltalks # kill -HUP 14255
```
就是这样了!打开新的会话并尝试登录。你将看待你在上述步骤中配置的消息。

你可以在用户输入密码登录系统之前看到此消息。
### 如何在用户登录后显示消息
消息用户在成功登录系统后看到的<ruby> 当天消息 <rt> Message Of The Day </rt></ruby>(MOTD)由 `/etc/motd` 控制。编辑这个文件并输入当成功登录后欢迎用户的消息。
```
root@kerneltalks # cat /etc/motd
W E L C O M E
Welcome to the testing environment of kerneltalks.
Feel free to use this system for testing your Linux
skills. In case of any issues reach out to admin at
[email protected]. Thank you.
```
你不需要重启 `sshd` 守护进程来使更改生效。只要保存该文件,`sshd` 守护进程就会下一次登录请求时读取和显示。

你可以在上面的截图中看到:黄色框是由 `/etc/motd` 控制的 MOTD,绿色框就是我们之前看到的登录导语。
你可以使用 [cowsay](https://kerneltalks.com/tips-tricks/cowsay-fun-in-linux-terminal/)、[banner](https://kerneltalks.com/howto/create-nice-text-banner-hpux/)、[figlet](https://kerneltalks.com/tips-tricks/create-beautiful-ascii-text-banners-linux/)、[lolcat](https://kerneltalks.com/linux/lolcat-tool-to-rainbow-color-linux-terminal/) 等工具创建出色的引人注目的登录消息。此方法适用于几乎所有 Linux 发行版,如 RedHat、CentOs、Ubuntu、Fedora 等。
---
via: <https://kerneltalks.com/tips-tricks/how-to-configure-login-banners-in-linux/>
作者:[kerneltalks](https://kerneltalks.com) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Learn how to create login banners in Linux to display a different warning or information message to the user who is about to log in or after he logs in.*

Whenever you log in to some production systems of the firm, you get to see some login messages, warnings, or info about the server you are about to log in or already logged in like below. Those are the login banners.
In this article we will walk you through how to configure them.
There are two types of banners you can configure.
- Banner message to display before user logs in (configure in the file of your choice eg.
`/etc/login.warn`
) - Banner message to display after the user successfully logged in (configure in
`/etc/motd`
)
### How to display message when user connects to system before login
This message will be displayed to the user when he connects to the server and before he logged in. This means when he enter the username, this message will be displayed before the password prompt.
You can use any filename and enter your message within. Here we used `/etc/login.warn`
file and put our messages inside.
```
# cat /etc/login.warn
!!!! Welcome to KernelTalks test server !!!!
This server is meant for testing Linux commands and tools. If you are
not associated with kerneltalks.com and not authorized please dis-connect
immediately.
```
Now, you need to supply this file and path to `sshd`
daemon so that it can fetch this banner for each user login request. For that open `/etc/sshd/sshd_config`
file and search for the line `#Banner none`
Here you have to edit the file and write your filename and remove the hash mark. It should look like : `Banner /etc/login.warn`
Save the file and restart `sshd`
daemon. To avoid disconnecting existing connected users, use the HUP signal to restart sshd.
```
root@kerneltalks # ps -ef |grep -i sshd
root 14255 1 0 18:42 ? 00:00:00 /usr/sbin/sshd -D
root 19074 14255 0 18:46 ? 00:00:00 sshd: ec2-user [priv]
root 19177 19127 0 18:54 pts/0 00:00:00 grep -i sshd
root@kerneltalks # kill -HUP 14255
```
That’s it! Open new sessions and try login. You will be greeted with the message you configured in the above steps.
You can see the message is displayed before the user enters his password and log in to the system.
### How to display message after user logs in
Message user sees after he logs into the system successfully is **M**essage **O**f **T**he **D**ay & is controlled by `/etc/motd`
file. Edit this file and enter the message you want to greet the user with once he successfully logged in.
```
root@kerneltalks # cat /etc/motd
W E L C O M E
Welcome to the testing environment of kerneltalks.
Feel free to use this system for testing your Linux
skills. In case of any issues reach out to admin at
[email protected]. Thank you.
```
You don’t need to restart `sshd`
daemon to take this change effect. As soon as you save the file, its content will be read and displayed by sshd daemon from the very next login request it serves.
You can see in the above screenshot: Yellow box is MOTD controlled by `/etc/motd`
and the green box is what we saw earlier [login banner](#banner).
You can use tools like [cowsay](https://kerneltalks.com/tips-tricks/cowsay-fun-in-linux-terminal/), [banner](https://kerneltalks.com/howto/create-nice-text-banner-hpux/), [figlet](https://kerneltalks.com/tips-tricks/create-beautiful-ascii-text-banners-linux/), [lolcat ](https://kerneltalks.com/linux/lolcat-tool-to-rainbow-color-linux-terminal/)to create fancy, eye-catching messages to display at login. This method works on almost all Linux distros like RedHat, Centos, Ubuntu, Fedora, etc.
Thank you for this! Exactly what I needed.
Thanks for sharing the knowledge!! |
9,423 | 9 个提高系统运行速度的轻量级 Linux 应用 | https://itsfoss.com/lightweight-alternative-applications-ubuntu/ | 2018-03-08T23:45:18 | [
"应用程序",
"轻量级"
] | https://linux.cn/article-9423-1.html |
>
> **简介:** [加速 Ubuntu 系统](https://itsfoss.com/speed-up-ubuntu-1310/)有很多方法,办法之一是使用轻量级应用来替代一些常用应用程序。我们之前之前发布过一篇 [Linux 必备的应用程序](https://itsfoss.com/essential-linux-applications/),如今将分享这些应用程序在 Ubuntu 或其他 Linux 发行版的轻量级替代方案。
>
>
>

### 9 个常用 Linux 应用程序的轻量级替代方案
你的 Linux 系统很慢吗?应用程序是不是很久才能打开?你最好的选择是使用[轻量级的 Linux 系统](https://itsfoss.com/lightweight-linux-beginners/)。但是重装系统并非总是可行,不是吗?
所以如果你想坚持使用你现在用的 Linux 发行版,但是想要提高性能,你应该使用更轻量级应用来替代你一些常用的应用。这篇文章会列出各种 Linux 应用程序的轻量级替代方案。
由于我使用的是 Ubuntu,因此我只提供了基于 Ubuntu 的 Linux 发行版的安装说明。但是这些应用程序可以用于几乎所有其他 Linux 发行版。你只需去找这些轻量级应用在你的 Linux 发行版中的安装方法就可以了。
### 1. Midori: Web 浏览器
[Midori](http://midori-browser.org/) 是与现代互联网环境具有良好兼容性的最轻量级网页浏览器之一。它是开源的,使用与 Google Chrome 最初所基于的相同的渲染引擎 —— WebKit。并且超快速,最小化但高度可定制。

Midori 浏览器有很多可以定制的扩展和选项。如果你有最高权限,使用这个浏览器也是一个不错的选择。如果在浏览网页的时候遇到了某些问题,请查看其网站上[常见问题](http://midori-browser.org/faqs/)部分 -- 这包含了你可能遇到的常见问题及其解决方案。
#### 在基于 Ubuntu 的发行版上安装 Midori
在 Ubuntu 上,可通过官方源找到 Midori 。运行以下指令即可安装它:
```
sudo apt install midori
```
### 2. Trojita:电子邮件客户端
[Trojita](http://trojita.flaska.net/) 是一款开源强大的 IMAP 电子邮件客户端。它速度快,资源利用率高。我可以肯定地称它是 [Linux 最好的电子邮件客户端之一](https://itsfoss.com/best-email-clients-linux/)。如果你只需电子邮件客户端提供 IMAP 支持,那么也许你不用再进一步考虑了。

Trojita 使用各种技术 —— 按需电子邮件加载、离线缓存、带宽节省模式等 —— 以实现其令人印象深刻的性能。
#### 在基于 Ubuntu 的发行版上安装 Trojita
Trojita 目前没有针对 Ubuntu 的官方 PPA 。但这应该不成问题。您可以使用以下命令轻松安装它:
```
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/jkt-gentoo:/trojita/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/trojita.list"
wget http://download.opensuse.org/repositories/home:jkt-gentoo:trojita/xUbuntu_16.04/Release.key
sudo apt-key add - < Release.key
sudo apt update
sudo apt install trojita
```
### 3. GDebi:包安装程序
有时您需要快速安装 DEB 软件包。Ubuntu 软件中心是一个消耗资源严重的应用程序,仅用于安装 .deb 文件并不明智。
Gdebi 无疑是一款可以完成同样目的的漂亮工具,而它只有个极简的图形界面。

GDebi 是完全轻量级的,完美无缺地完成了它的工作。你甚至应该[让 Gdebi 成为 DEB 文件的默认安装程序](https://itsfoss.com/gdebi-default-ubuntu-software-center/)。
#### 在基于 Ubuntu 的发行版上安装 GDebi
只需一行指令,你便可以在 Ubuntu 上安装 GDebi:
```
sudo apt install gdebi
```
### 4. App Grid:软件中心
如果您经常在 Ubuntu 上使用软件中心搜索、安装和管理应用程序,则 [App Grid](http://www.appgrid.org/) 是必备的应用程序。它是默认的 Ubuntu 软件中心最具视觉吸引力且速度最快的替代方案。

App Grid 支持应用程序的评分、评论和屏幕截图。
#### 在基于 Ubuntu 的发行版上安装 App Grid
App Grid 拥有 Ubuntu 的官方 PPA。使用以下指令安装 App Grid:
```
sudo add-apt-repository ppa:appgrid/stable
sudo apt update
sudo apt install appgrid
```
### 5. Yarock:音乐播放器
[Yarock](https://seb-apps.github.io/yarock/) 是一个优雅的音乐播放器,拥有现代而最轻量级的用户界面。尽管在设计上是轻量级的,但 Yarock 有一个全面的高级功能列表。

Yarock 的主要功能包括多种音乐收藏、评级、智能播放列表、多种后端选项、桌面通知、音乐剪辑、上下文获取等。
### 在基于 Ubuntu 的发行版上安装 Yarock
您得通过 PPA 使用以下指令在 Ubuntu 上安装 Yarock:
```
sudo add-apt-repository ppa:nilarimogard/webupd8
sudo apt update
sudo apt install yarock
```
### 6. VLC:视频播放器
谁不需要视频播放器?谁还从未听说过 [VLC](http://www.videolan.org/index.html)?我想并不需要对它做任何介绍。

VLC 能满足你在 Ubuntu 上播放各种媒体文件的全部需求,而且它非常轻便。它甚至可以在非常旧的 PC 上完美运行。
#### 在基于 Ubuntu 的发行版上安装 VLC
VLC 为 Ubuntu 提供官方 PPA。可以输入以下命令来安装它:
```
sudo apt install vlc
```
### 7. PCManFM:文件管理器
PCManFM 是 LXDE 的标准文件管理器。与 LXDE 的其他应用程序一样,它也是轻量级的。如果您正在为文件管理器寻找更轻量级的替代品,可以尝试使用这个应用。

尽管来自 LXDE,PCManFM 也同样适用于其他桌面环境。
#### 在基于 Ubuntu 的发行版上安装 PCManFM
在 Ubuntu 上安装 PCManFM 只需要一条简单的指令:
```
sudo apt install pcmanfm
```
### 8. Mousepad:文本编辑器
在轻量级方面,没有什么可以击败像 nano、vim 等命令行文本编辑器。但是,如果你想要一个图形界面,你可以尝试一下 Mousepad -- 一个最轻量级的文本编辑器。它非常轻巧,速度非常快。带有简单的可定制的用户界面和多个主题。

Mousepad 支持语法高亮显示。所以,你也可以使用它作为基础的代码编辑器。
#### 在基于 Ubuntu 的发行版上安装 Mousepad
想要安装 Mousepad ,可以使用以下指令:
```
sudo apt install mousepad
```
### 9. GNOME Office:办公软件
许多人需要经常使用办公应用程序。通常,大多数办公应用程序体积庞大且很耗资源。Gnome Office 在这方面非常轻便。Gnome Office 在技术上不是一个完整的办公套件。它由不同的独立应用程序组成,在这之中 AbiWord&Gnumeric 脱颖而出。
**AbiWord** 是文字处理器。它比其他替代品轻巧并且快得多。但是这样做是有代价的 —— 你可能会失去宏、语法检查等一些功能。AdiWord 并不完美,但它可以满足你基本的需求。

**Gnumeric** 是电子表格编辑器。就像 AbiWord 一样,Gnumeric 也非常快速,提供了精确的计算功能。如果你正在寻找一个简单轻便的电子表格编辑器,Gnumeric 已经能满足你的需求了。

在 [Gnome Office](https://gnome.org/gnome-office/) 下面还有一些其它应用程序。你可以在官方页面找到它们。
#### 在基于 Ubuntu 的发行版上安装 AbiWord&Gnumeric
要安装 AbiWord&Gnumeric,只需在终端中输入以下指令:
```
sudo apt install abiword gnumeric
```
---
via: <https://itsfoss.com/lightweight-alternative-applications-ubuntu/>
作者:[Munif Tanjim](https://itsfoss.com/author/munif/) 译者:[imquanquan](https://github.com/imquanquan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

One of the many ways to [speed up Ubuntu](https://itsfoss.com/speed-up-ubuntu-1310/) system is to use lightweight alternatives of the popular applications.
You have already seen [must have Linux applications](https://itsfoss.com/essential-linux-applications/) earlier. Here, let's take a look at the lightweight alternative applications for Ubuntu and other Linux distributions.
[Must Have Essential Applications for Desktop Linux UsersBrief: What are the must-have applications for Linux? The answer is subjective, and it depends on what purposes you have for using desktop Linux. But there are still some essential Linux apps that are more likely to be used by most Linux users. Here, we’ve listed the best Linux](https://itsfoss.com/essential-linux-applications/)

## Lightweight alternatives to popular Linux applications
Is your Linux system slow? Are the applications taking a long time to open? The best solution for you is to use a [lightweight Linux distro](https://itsfoss.com/lightweight-linux-beginners/).
But it is not always possible to reinstall an operating system, is it?
So if you want to stick to your present Linux distribution, but want improved performance, you should use lightweight alternatives to the applications you are using.
Here, I will put together a list of lightweight alternatives to various popular Linux applications.
**Since I am using Ubuntu, I have provided installation instructions for Ubuntu-based Linux distributions. But these applications should work on most other Linux distributions. You have to find a way to install these lightweight Linux tools in your distro.**
### 1. Falkon: Web Browser

[Falkon browser](https://itsfoss.com/falkon-browser/) is a KDE project that aims to provide a clean and lightweight browsing experience.
It was previously known as QupZilla and now uses [QtWebEngine](https://wiki.qt.io/QtWebEngine) as its rendering engine.
As a cherry on top, it comes with a built-in AdBlock extension and offers essential options like keyboard shortcuts, password manager, limited extension support, and a few more things.
#### Installing Falkon in Linux
Midori is available on Ubuntu via the official repository. Just run the following commands for installing it:
`sudo apt install falkon`
You can also install it via Flatpak or Snap if you have any other Linux distribution installed.
### 2. Trojitá: email client
Trojitá is an open-source robust IMAP e-mail client. It is fast and resource-efficient. It utilizes Qt to offer a comforting and yet lightweight experience.
It could be one of the [best email clients for Linux](https://itsfoss.com/best-email-clients-linux/) if you can live with only IMAP support on your e-mail client. And if that is the case, you may not need to look any further.
Trojitá uses various techniques—on-demand e-mail loading, offline caching, bandwidth-saving mode, etc. — for achieving its impressive performance.
#### Installing Trojitá in Linux distributions
Unfortunately, it does not offer any pre-built binaries. You will have to [compile it from the source](https://itsfoss.com/install-software-from-source-code/) by following the [official instructions](http://trojita.flaska.net/download.html).
### 3. GDebi: Package Installer
Sometimes you need to quickly install DEB packages. Ubuntu Software Center is a resource-heavy application and using it just for installing .deb files may not be a pleasant experience.
Gdebi is certainly a nifty tool for the same purpose that offers a minimal graphical interface.
GDebi is totally lightweight and does its job flawlessly. You should even [make Gdebi the default installer for DEB files](https://itsfoss.com/gdebi-default-ubuntu-software-center/).
#### Installing GDebi in Ubuntu
You can install GDebi on Ubuntu with this simple one-liner:
`sudo apt install gdebi`
### 4. App Grid: Software Center
If you use the software center frequently for searching, installing, and managing applications on Ubuntu, [App Grid](https://itsfoss.com/app-grid-lighter-alternative-ubuntu-software-center/) is a must-have application.
It may not have evolved its user experience but it is a fast alternative to the default Ubuntu Software Center.
App Grid supports ratings, reviews, and screenshots for applications.
#### Installing App Grid on Ubuntu based distributions
App Grid has its official PPA for Ubuntu-based distributions. Use the following commands for installing App Grid:
```
sudo add-apt-repository ppa:appgrid/stable
sudo apt update
sudo apt install appgrid
```
### 5. Sayonara: Music Player
[Sayonara](https://itsfoss.com/sayonara-music-player/) is an elegant music player with essential audio format support and a lightweight user experience. Undoubtedly, one of the [best music players for Linux](https://itsfoss.com/best-music-players-linux/).
While it offers a fast experience, it also lets you customize a lot of things to tweak your experience.
It uses [GStreamer](https://gstreamer.freedesktop.org/) as its audio-backend, which ensures that all the major file formats should work as expected.
It supports playlists, library management, and several plugins, including an equalizer, spectrum analyzer, and more.
#### Installing Sayonara in Linux
You will have to install Sayonara on Ubuntu via PPA using the following commands:
```
sudo apt-add-repository ppa:lucioc/sayonara
sudo apt-get update
sudo apt-get install sayonara
```
You also get a Snap package and an AppImage file if you want to install it on any other Linux distribution.
### 6. Parole Media Player
If you are looking for an alternative to VLC Media Player but on the lighter side of things, Parole Media Player will be a great fit. It
Similar to the Sayonara music player, it also utilizes the GStreamer framework to ensure the best compatibility with file formats and codecs.
Distributions like Zorin OS Lite include Parole Media Player out of the box.
It is primarily tailored for Xfce desktop environments but works on other desktops as well.
#### Installing Parole in Linux
For Ubuntu-based distros, you should find it in the default repository. So, all you need to do is enter the following command in the terminal:
`sudo apt install parole`
### 7. Thunar: File Manager
Thunar file manager is yet another app originally tailored for the Xfce desktop environment but can be used anywhere else.
You should find all the essential features when compared to other file manager applications like Nemo on Linux Mint.
The user interface is simple and offers a side panel, which you cannot hide (I couldn’t find the option to). It may not offer bookmarking feature, but it provides a fast and useful experience.
#### Installing Thunar on Linux distributions
Installing Thunar on Ubuntu-based distros will just take one simple command:
`sudo apt install thunar`
You should also find packages available for your preferred Linux distribution.
[15 Best File Managers and File Explorers for LinuxLooking for file managers and explorers for your distro? Here are some of the best options!](https://itsfoss.com/file-managers-linux/)

### 8. Mousepad: Text Editor
Nothing can beat command-line text editors like – nano, vim, etc. in terms of being lightweight.
But if you want a graphical interface, Mousepad is here to the rescue. It’s extremely lightweight and blazing fast. It comes with a simple customizable user interface with multiple themes.
Mousepad supports syntax highlighting. So, you can also use it as a basic code editor. You also have the option to utilize a few plugins to extend the functionality if needed.
#### Installing Mousepad in Linux
For installing Mousepad, use the following command in the terminal:
`sudo apt install mousepad`
### 9. GNOME Office: Office Suite
Many of us need to use office applications quite often.
Generally, most office applications take up more storage space and are resource-hungry.
Gnome Office is quite the opposite in that respect. Gnome Office is technically not a complete office suite but it is composed of different standalone applications and among them, **AbiWord** &** Gnumeric** stands out.
**AbiWord** is the word processor. It is lightweight and faster than other alternatives. But that comes at a cost—you might miss some features like macros, grammar checking, etc. It’s not perfect but it works.
**Gnumeric** is the spreadsheet editor. Just like AbiWord, Gnumeric is also light on resources and provides accurate calculations. If you are looking for a simple and lightweight spreadsheet editor, Gnumeric has got you covered.
While these two are the key highlights of the collection, you can find the full list of applications in the official [Gnome Office wik](https://wiki.gnome.org/Attic/GnomeOffice)[i](https://wiki.gnome.org/Attic/GnomeOffice).
#### Installing AbiWord & Gnumeric in Linux
All the tools that are involved with the office suite should be available in the default repositories for most Linux distros. For Ubuntu-based distros, you can type in the following command to install Abiword and Gnumeric:
`sudo apt install abiword gnumeric`
[6 Best Open Source Alternatives to Microsoft Office for LinuxBrief: Looking for Microsoft Office on Linux? Here are the best free and open-source alternatives to Microsoft Office for Linux. Office Suites are a mandatory part of any operating system. It is difficult to imagine using a desktop OS without office software. While Windows offers Microsoft Off…](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/)

### 10. GNOME Paint: Drawing Application
GNOME Paint may not be a popular [open source paint application](https://itsfoss.com/open-source-paint-apps/) but it exists for a long time and is actively packaged for the latest Ubuntu releases.
It is a simple paint application without any bells and whistles. You can doodle around using the drawing tool, fill in paint, and do most of the basic tasks easily.
#### How to Install Gnome Drawing in Linux?
For Ubuntu-based distros, it is available in the default repositories, all you have to do is type in the following command to install it:
`sudo apt install gnome-drawing`
You should also find it in [AUR](https://itsfoss.com/aur-arch-linux/) if you are using Arch or any Arch-based distro.
### 11. Xfce terminal: Terminal Emulator
While there are several [terminal emulators](https://itsfoss.com/linux-terminal-emulators/) available for Linux, the Xfce terminal is potentially the lightest of the bunch.
You can also try other terminal emulators that aim to provide a fast experience but for starters, this should do.
The user interface is quite simple and offers essential functions.
#### How to Install Xfce terminal in Linux?
You should find it available in the default repositories for most of the distributions. To install it using the terminal on Ubuntu-based systems, simply type in the following command:
`sudo apt install xfce4-terminal`
### 12. Shotwell: Photo Manager
If you have got several photos to manage and fewer system resources to help you do that, Shotwell is your friend.
It is one of the [best Linux photo management software](https://itsfoss.com/linux-photo-management-software/) available out there with RAW photo support and useful features to help organize your photo collection.
#### How to Install Shotwell in Linux?
For Ubuntu-based distros, you can easily get it installed using the following command:
`sudo apt install shotwell`
You should also find it available for Arch Linux (in AUR) and other distributions.
### 13. Archive Manager GNOME
You should already be able to extract and create archives by default on your distribution. And chances are—GNOME’s archive manager is what you have pre-installed.
It supports different file formats and offers some advanced options to tweak.
In case, if you do not have it or if you just want a different standalone archive manager that is lightweight, Archive Manager by GNOME is the perfect option to have.
#### How to Install GNOME Archive Manager in Linux?
For Ubuntu-based distros, you should be able to find it in the default repositories. All you have to do is type in the command below in the terminal:
`sudo apt install file-roller`
### 14. Synaptic Package Manager
[Synaptic Package Manager](https://itsfoss.com/synaptic-package-manager/) is an impressive lightweight APT package management software.
It makes it easy to locate, update, find details, and manage package repositories. It may not offer a pleasant user experience but it works fast and is reliable enough.
To know more about it, you can take a look at our article that helps [using Synaptic package managing in Linux](https://itsfoss.com/synaptic-package-manager/).
#### How to install Synaptic in Linux?
You can [enable the universe repository](https://itsfoss.com/ubuntu-repositories/) on Ubuntu and then proceed to install it with the following command:
`sudo apt install synaptic`
It should be available in the default repositories on other Linux distributions but you can always refer to the official website for instructions on that.
### 15. Pitvi: Video Editor
What if you want to edit a video but have a lightweight application to do that?
Pitvi is the answer to that. You get most of the basic functionalities to edit a video. In fact, it is one of the best [open source video editing software](https://itsfoss.com/open-source-video-editors/) for Linux.
It may not offer a modern user experience but it is easy to use.
#### How to Install Pitvi in Linux?
The recommended way of installing Pitvi is through [Flatpak](https://itsfoss.com/what-is-flatpak/) as mentioned on their [official site](https://www.pitivi.org/download/).
Unfortunately, it is not available through the repositories. You will have to download the source code if you do not prefer Flatpak packages. |
9,424 | Linux 跟踪器之选 | http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html | 2018-03-09T12:55:00 | [
"ftrace",
"eBPF",
"追踪器"
] | https://linux.cn/article-9424-1.html |
>
> Linux 跟踪很神奇!
>
>
>

<ruby> 跟踪器 <rt> tracer </rt></ruby>是一个高级的性能分析和调试工具,如果你使用过 `strace(1)` 或者 `tcpdump(8)`,你不应该被它吓到 ... 你使用的就是跟踪器。系统跟踪器能让你看到很多的东西,而不仅是系统调用或者数据包,因为常见的跟踪器都可以跟踪内核或者应用程序的任何东西。
有大量的 Linux 跟踪器可供你选择。由于它们中的每个都有一个官方的(或者非官方的)的吉祥物,我们有足够多的选择给孩子们展示。
你喜欢使用哪一个呢?
我从两类读者的角度来回答这个问题:大多数人和性能/内核工程师。当然,随着时间的推移,这也可能会发生变化,因此,我需要及时去更新本文内容,或许是每年一次,或者更频繁。(LCTT 译注:本文最后更新于 2015 年)
### 对于大多数人
大多数人(开发者、系统管理员、运维人员、网络可靠性工程师(SRE)…)是不需要去学习系统跟踪器的底层细节的。以下是你需要去了解和做的事情:
#### 1. 使用 perf\_events 进行 CPU 剖析
可以使用 perf\_events 进行 CPU <ruby> 剖析 <rt> profiling </rt></ruby>。它可以用一个 [火焰图](http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html) 来形象地表示。比如:
```
git clone --depth 1 https://github.com/brendangregg/FlameGraph
perf record -F 99 -a -g -- sleep 30
perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg
```

Linux 的 perf\_events(即 `perf`,后者是它的命令)是官方为 Linux 用户准备的跟踪器/分析器。它位于内核源码中,并且维护的非常好(而且现在它的功能还在快速变强)。它一般是通过 linux-tools-common 这个包来添加的。
`perf` 可以做的事情很多,但是,如果我只能建议你学习其中的一个功能的话,那就是 CPU 剖析。虽然从技术角度来说,这并不是事件“跟踪”,而是<ruby> 采样 <rt> sampling </rt></ruby>。最难的部分是获得完整的栈和符号,这部分在我的 [Linux Profiling at Netflix](http://www.brendangregg.com/blog/2015-02-27/linux-profiling-at-netflix.html) 中针对 Java 和 Node.js 讨论过。
#### 2. 知道它能干什么
正如一位朋友所说的:“你不需要知道 X 光机是如何工作的,但你需要明白的是,如果你吞下了一个硬币,X 光机是你的一个选择!”你需要知道使用跟踪器能够做什么,因此,如果你在业务上确实需要它,你可以以后再去学习它,或者请会使用它的人来做。
简单地说:几乎任何事情都可以通过跟踪来了解它。内部文件系统、TCP/IP 处理过程、设备驱动、应用程序内部情况。阅读我在 lwn.net 上的 [ftrace](http://lwn.net/Articles/608497/) 的文章,也可以去浏览 [perf\_events 页面](http://www.brendangregg.com/perf.html),那里有一些跟踪(和剖析)能力的示例。
#### 3. 需要一个前端工具
如果你要购买一个性能分析工具(有许多公司销售这类产品),并要求支持 Linux 跟踪。想要一个直观的“点击”界面去探查内核的内部,以及包含一个在不同堆栈位置的延迟热力图。就像我在 [Monitorama 演讲](http://www.brendangregg.com/blog/2015-06-23/netflix-instance-analysis-requirements.html) 中描述的那样。
我创建并开源了我自己的一些前端工具,虽然它是基于 CLI 的(不是图形界面的)。这样可以使其它人使用跟踪器更快更容易。比如,我的 [perf-tools](http://www.brendangregg.com/blog/2015-03-17/linux-performance-analysis-perf-tools.html),跟踪新进程是这样的:
```
# ./execsnoop
Tracing exec()s. Ctrl-C to end.
PID PPID ARGS
22898 22004 man ls
22905 22898 preconv -e UTF-8
22908 22898 pager -s
22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8
[...]
```
在 Netflix 公司,我正在开发 [Vector](http://techblog.netflix.com/2015/04/introducing-vector-netflixs-on-host.html),它是一个实例分析工具,实际上它也是一个 Linux 跟踪器的前端。
### 对于性能或者内核工程师
一般来说,我们的工作都非常难,因为大多数人或许要求我们去搞清楚如何去跟踪某个事件,以及因此需要选择使用哪个跟踪器。为完全理解一个跟踪器,你通常需要花至少一百多个小时去使用它。理解所有的 Linux 跟踪器并能在它们之间做出正确的选择是件很难的事情。(我或许是唯一接近完成这件事的人)
在这里我建议选择如下,要么:
A)选择一个全能的跟踪器,并以它为标准。这需要在一个测试环境中花大量的时间来搞清楚它的细微差别和安全性。我现在的建议是 SystemTap 的最新版本(例如,从 [源代码](https://sourceware.org/git/?p=systemtap.git;a=blob_plain;f=README;hb=HEAD) 构建)。我知道有的公司选择的是 LTTng ,尽管它并不是很强大(但是它很安全),但他们也用的很好。如果在 `sysdig` 中添加了跟踪点或者是 kprobes,它也是另外的一个候选者。
B)按我的 [Velocity 教程中](http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools) 的流程图。这意味着尽可能使用 ftrace 或者 perf\_events,eBPF 已经集成到内核中了,然后用其它的跟踪器,如 SystemTap/LTTng 作为对 eBPF 的补充。我目前在 Netflix 的工作中就是这么做的。

以下是我对各个跟踪器的评价:
#### 1. ftrace
我爱 [ftrace](http://lwn.net/Articles/370423/),它是内核黑客最好的朋友。它被构建进内核中,它能够利用跟踪点、kprobes、以及 uprobes,以提供一些功能:使用可选的过滤器和参数进行事件跟踪;事件计数和计时,内核概览;<ruby> 函数流步进 <rt> function-flow walking </rt></ruby>。关于它的示例可以查看内核源代码树中的 [ftrace.txt](https://www.kernel.org/doc/Documentation/trace/ftrace.txt)。它通过 `/sys` 来管理,是面向单一的 root 用户的(虽然你可以使用缓冲实例以让其支持多用户),它的界面有时很繁琐,但是它比较容易<ruby> 调校 <rt> hackable </rt></ruby>,并且有个前端:ftrace 的主要创建者 Steven Rostedt 设计了一个 trace-cmd,而且我也创建了 perf-tools 集合。我最诟病的就是它不是<ruby> 可编程的 <rt> programmable </rt></ruby>,因此,举个例子说,你不能保存和获取时间戳、计算延迟,以及将其保存为直方图。你需要转储事件到用户级以便于进行后期处理,这需要花费一些成本。它也许可以通过 eBPF 实现可编程。
#### 2. perf\_events
[perf\_events](https://perf.wiki.kernel.org/index.php/Main_Page) 是 Linux 用户的主要跟踪工具,它的源代码位于 Linux 内核中,一般是通过 linux-tools-common 包来添加的。它又称为 `perf`,后者指的是它的前端,它相当高效(动态缓存),一般用于跟踪并转储到一个文件中(perf.data),然后可以在之后进行后期处理。它可以做大部分 ftrace 能做的事情。它不能进行函数流步进,并且不太容易调校(而它的安全/错误检查做的更好一些)。但它可以做剖析(采样)、CPU 性能计数、用户级的栈转换、以及使用本地变量利用<ruby> 调试信息 <rt> debuginfo </rt></ruby>进行<ruby> 行级跟踪 <rt> line tracing </rt></ruby>。它也支持多个并发用户。与 ftrace 一样,它也不是内核可编程的,除非 eBPF 支持(补丁已经在计划中)。如果只学习一个跟踪器,我建议大家去学习 perf,它可以解决大量的问题,并且它也相当安全。
#### 3. eBPF
<ruby> 扩展的伯克利包过滤器 <rt> extended Berkeley Packet Filter </rt></ruby>(eBPF)是一个<ruby> 内核内 <rt> in-kernel </rt></ruby>的虚拟机,可以在事件上运行程序,它非常高效(JIT)。它可能最终为 ftrace 和 perf\_events 提供<ruby> 内核内编程 <rt> in-kernel programming </rt></ruby>,并可以去增强其它跟踪器。它现在是由 Alexei Starovoitov 开发的,还没有实现完全的整合,但是对于一些令人印象深刻的工具,有些内核版本(比如,4.1)已经支持了:比如,块设备 I/O 的<ruby> 延迟热力图 <rt> latency heat map </rt></ruby>。更多参考资料,请查阅 Alexei 的 [BPF 演示](http://www.phoronix.com/scan.php?page=news_item&px=BPF-Understanding-Kernel-VM),和它的 [eBPF 示例](https://github.com/torvalds/linux/tree/master/samples/bpf)。
#### 4. SystemTap
[SystemTap](https://sourceware.org/systemtap/wiki) 是一个非常强大的跟踪器。它可以做任何事情:剖析、跟踪点、kprobes、uprobes(它就来自 SystemTap)、USDT、内核内编程等等。它将程序编译成内核模块并加载它们 —— 这是一种很难保证安全的方法。它开发是在内核代码树之外进行的,并且在过去出现过很多问题(内核崩溃或冻结)。许多并不是 SystemTap 的过错 —— 它通常是首次对内核使用某些跟踪功能,并率先遇到 bug。最新版本的 SystemTap 是非常好的(你需要从它的源代码编译),但是,许多人仍然没有从早期版本的问题阴影中走出来。如果你想去使用它,花一些时间去测试环境,然后,在 irc.freenode.net 的 #systemtap 频道与开发者进行讨论。(Netflix 有一个容错架构,我们使用了 SystemTap,但是我们或许比起你来说,更少担心它的安全性)我最诟病的事情是,它似乎假设你有办法得到内核调试信息,而我并没有这些信息。没有它我实际上可以做很多事情,但是缺少相关的文档和示例(我现在自己开始帮着做这些了)。
#### 5. LTTng
[LTTng](http://lttng.org/) 对事件收集进行了优化,性能要好于其它的跟踪器,也支持许多的事件类型,包括 USDT。它的开发是在内核代码树之外进行的。它的核心部分非常简单:通过一个很小的固定指令集写入事件到跟踪缓冲区。这样让它既安全又快速。缺点是做内核内编程不太容易。我觉得那不是个大问题,由于它优化的很好,可以充分的扩展,尽管需要后期处理。它也探索了一种不同的分析技术。很多的“黑匣子”记录了所有感兴趣的事件,以便可以在 GUI 中以后分析它。我担心该记录会错失之前没有预料的事件,我真的需要花一些时间去看看它在实践中是如何工作的。这个跟踪器上我花的时间最少(没有特别的原因)。
#### 6. ktap
[ktap](http://ktap.org/) 是一个很有前途的跟踪器,它在内核中使用了一个 lua 虚拟机,不需要调试信息和在嵌入时设备上可以工作的很好。这使得它进入了人们的视野,在某个时候似乎要成为 Linux 上最好的跟踪器。然而,由于 eBPF 开始集成到了内核,而 ktap 的集成工作被推迟了,直到它能够使用 eBPF 而不是它自己的虚拟机。由于 eBPF 在几个月过去之后仍然在集成过程中,ktap 的开发者已经等待了很长的时间。我希望在今年的晚些时间它能够重启开发。
#### 7. dtrace4linux
[dtrace4linux](https://github.com/dtrace4linux/linux) 主要由一个人(Paul Fox)利用业务时间将 Sun DTrace 移植到 Linux 中的。它令人印象深刻,一些<ruby> 供应器 <rt> provider </rt></ruby>可以工作,还不是很完美,它最多应该算是实验性的工具(不安全)。我认为对于许可证的担心,使人们对它保持谨慎:它可能永远也进入不了 Linux 内核,因为 Sun 是基于 CDDL 许可证发布的 DTrace;Paul 的方法是将它作为一个插件。我非常希望看到 Linux 上的 DTrace,并且希望这个项目能够完成,我想我加入 Netflix 时将花一些时间来帮它完成。但是,我一直在使用内置的跟踪器 ftrace 和 perf\_events。
#### 8. OL DTrace
[Oracle Linux DTrace](http://docs.oracle.com/cd/E37670_01/E38608/html/index.html) 是将 DTrace 移植到 Linux (尤其是 Oracle Linux)的重大努力。过去这些年的许多发布版本都一直稳定的进步,开发者甚至谈到了改善 DTrace 测试套件,这显示出这个项目很有前途。许多有用的功能已经完成:系统调用、剖析、sdt、proc、sched、以及 USDT。我一直在等待着 fbt(函数边界跟踪,对内核的动态跟踪),它将成为 Linux 内核上非常强大的功能。它最终能否成功取决于能否吸引足够多的人去使用 Oracle Linux(并为支持付费)。另一个羁绊是它并非完全开源的:内核组件是开源的,但用户级代码我没有看到。
#### 9. sysdig
[sysdig](http://www.sysdig.org/) 是一个很新的跟踪器,它可以使用类似 `tcpdump` 的语法来处理<ruby> 系统调用 <rt> syscall </rt></ruby>事件,并用 lua 做后期处理。它也是令人印象深刻的,并且很高兴能看到在系统跟踪领域的创新。它的局限性是,它的系统调用只能是在当时,并且,它转储所有事件到用户级进行后期处理。你可以使用系统调用来做许多事情,虽然我希望能看到它去支持跟踪点、kprobes、以及 uprobes。我也希望看到它支持 eBPF 以查看内核内概览。sysdig 的开发者现在正在增加对容器的支持。可以关注它的进一步发展。
### 深入阅读
我自己的工作中使用到的跟踪器包括:
* **ftrace** : 我的 [perf-tools](http://www.brendangregg.com/blog/2015-03-17/linux-performance-analysis-perf-tools.html) 集合(查看示例目录);我的 lwn.net 的 [ftrace 跟踪器的文章](http://lwn.net/Articles/608497/); 一个 [LISA14](http://www.brendangregg.com/blog/2015-03-17/linux-performance-analysis-perf-tools.html) 演讲;以及帖子: [函数计数](http://www.brendangregg.com/blog/2014-07-13/linux-ftrace-function-counting.html)、 [iosnoop](http://www.brendangregg.com/blog/2014-07-16/iosnoop-for-linux.html)、 [opensnoop](http://www.brendangregg.com/blog/2014-07-25/opensnoop-for-linux.html)、 [execsnoop](http://www.brendangregg.com/blog/2014-07-28/execsnoop-for-linux.html)、 [TCP retransmits](http://www.brendangregg.com/blog/2014-09-06/linux-ftrace-tcp-retransmit-tracing.html)、 [uprobes](http://www.brendangregg.com/blog/2015-06-28/linux-ftrace-uprobe.html) 和 [USDT](http://www.brendangregg.com/blog/2015-07-03/hacking-linux-usdt-ftrace.html)。
* **perf\_events** : 我的 [perf\_events 示例](http://www.brendangregg.com/perf.html) 页面;在 SCALE 的一个 [Linux Profiling at Netflix](http://www.brendangregg.com/blog/2015-02-27/linux-profiling-at-netflix.html) 演讲;和帖子:[CPU 采样](http://www.brendangregg.com/blog/2014-06-22/perf-cpu-sample.html)、[静态跟踪点](http://www.brendangregg.com/blog/2014-06-29/perf-static-tracepoints.html)、[热力图](http://www.brendangregg.com/blog/2014-07-01/perf-heat-maps.html)、[计数](http://www.brendangregg.com/blog/2014-07-03/perf-counting.html)、[内核行级跟踪](http://www.brendangregg.com/blog/2014-09-11/perf-kernel-line-tracing.html)、[off-CPU 时间火焰图](http://www.brendangregg.com/blog/2015-02-26/linux-perf-off-cpu-flame-graph.html)。
* **eBPF** : 帖子 [eBPF:一个小的进步](http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html),和一些 [BPF-tools](https://github.com/brendangregg/BPF-tools) (我需要发布更多)。
* **SystemTap** : 很久以前,我写了一篇 [使用 SystemTap](http://dtrace.org/blogs/brendan/2011/10/15/using-systemtap/) 的文章,它有点过时了。最近我发布了一些 [systemtap-lwtools](https://github.com/brendangregg/systemtap-lwtools),展示了在没有内核调试信息的情况下,SystemTap 是如何使用的。
* **LTTng** : 我使用它的时间很短,不足以发布什么文章。
* **ktap** : 我的 [ktap 示例](http://www.brendangregg.com/ktap.html) 页面包括一行程序和脚本,虽然它是早期的版本。
* **dtrace4linux** : 在我的 [系统性能](http://www.brendangregg.com/sysperfbook.html) 书中包含了一些示例,并且在过去我为了某些事情开发了一些小的修补,比如, [timestamps](https://github.com/dtrace4linux/linux/issues/55)。
* **OL DTrace** : 因为它是对 DTrace 的直接移植,我早期 DTrace 的工作大多与之相关(链接太多了,可以去 [我的主页](http://www.brendangregg.com) 上搜索)。一旦它更加完美,我可以开发很多专用工具。
* **sysdig** : 我贡献了 [fileslower](https://github.com/brendangregg/sysdig/commit/d0eeac1a32d6749dab24d1dc3fffb2ef0f9d7151) 和 [subsecond offset spectrogram](https://github.com/brendangregg/sysdig/commit/2f21604dce0b561407accb9dba869aa19c365952) 的 chisel。
* **其它** : 关于 [strace](http://www.brendangregg.com/blog/2014-05-11/strace-wow-much-syscall.html),我写了一些告诫文章。
不好意思,没有更多的跟踪器了! … 如果你想知道为什么 Linux 中的跟踪器不止一个,或者关于 DTrace 的内容,在我的 [从 DTrace 到 Linux](http://www.brendangregg.com/blog/2015-02-28/from-dtrace-to-linux.html) 的演讲中有答案,从 [第 28 张幻灯片](http://www.slideshare.net/brendangregg/from-dtrace-to-linux/28) 开始。
感谢 [Deirdre Straughan](http://www.beginningwithi.com/) 的编辑,以及跟踪小马的创建(General Zoi 是小马的创建者)。
---
via: <http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html>
作者:[Brendan Gregg](http://www.brendangregg.com) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 302 | Found | null |
9,425 | 给 “rm” 命令添加个“垃圾桶” | https://www.2daygeek.com/rm-command-to-move-files-to-trash-can-rm-alias/ | 2018-03-09T17:42:26 | [
"rm",
"垃圾桶"
] | https://linux.cn/article-9425-1.html | 
人类犯错误是因为我们不是一个可编程设备,所以,在使用 `rm` 命令时要额外注意,不要在任何时候使用 `rm -rf *`。当你使用 `rm` 命令时,它会永久删除文件,不会像文件管理器那样将这些文件移动到 “垃圾箱”。
有时我们会将不应该删除的文件删除掉,所以当错误地删除了文件时该怎么办? 你必须看看恢复工具(Linux 中有很多数据恢复工具),但我们不知道是否能将它百分之百恢复,所以要如何解决这个问题?
我们最近发表了一篇关于 [Trash-Cli](https://www.2daygeek.com/trash-cli-command-line-trashcan-linux-system/) 的文章,在评论部分,我们从用户 Eemil Lgz 那里获得了一个关于 [saferm.sh](https://github.com/lagerspetz/linux-stuff/blob/master/scripts/saferm.sh) 脚本的更新,它可以帮助我们将文件移动到“垃圾箱”而不是永久删除它们。
将文件移动到“垃圾桶”是一个好主意,当你无意中运行 `rm` 命令时,可以拯救你;但是很少有人会说这是一个坏习惯,如果你不注意“垃圾桶”,它可能会在一定的时间内被文件和文件夹堆积起来。在这种情况下,我建议你按照你的意愿去做一个定时任务。
这适用于服务器和桌面两种环境。 如果脚本检测到 GNOME 、KDE、Unity 或 LXDE 桌面环境(DE),则它将文件或文件夹安全地移动到默认垃圾箱 `$HOME/.local/share/Trash/files`,否则会在您的主目录中创建垃圾箱文件夹 `$HOME/Trash`。
`saferm.sh` 脚本托管在 Github 中,可以从仓库中克隆,也可以创建一个名为 `saferm.sh` 的文件并复制其上的代码。
```
$ git clone https://github.com/lagerspetz/linux-stuff
$ sudo mv linux-stuff/scripts/saferm.sh /bin
$ rm -Rf linux-stuff
```
在 `.bashrc` 文件中设置别名,
```
alias rm=saferm.sh
```
执行下面的命令使其生效,
```
$ source ~/.bashrc
```
一切就绪,现在你可以执行 `rm` 命令,自动将文件移动到”垃圾桶”,而不是永久删除它们。
测试一下,我们将删除一个名为 `magi.txt` 的文件,命令行明确的提醒了 `Moving magi.txt to $HOME/.local/share/Trash/file`。
```
$ rm -rf magi.txt
Moving magi.txt to /home/magi/.local/share/Trash/files
```
也可以通过 `ls` 命令或 `trash-cli` 进行验证。
```
$ ls -lh /home/magi/.local/share/Trash/files
Permissions Size User Date Modified Name
.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
```
或者我们可以通过文件管理器界面中查看相同的内容。
![![][3]](/data/attachment/album/201803/09/174228rxpmllt2pxc9h6hh.png)
(LCTT 译注:原文此处混淆了部分 trash-cli 的内容,考虑到文章衔接和逻辑,此处略。)
要了解 `saferm.sh` 的其他选项,请查看帮助。
```
$ saferm.sh -h
This is saferm.sh 1.16. LXDE and Gnome3 detection.
Will ask to unsafe-delete instead of cross-fs move. Allows unsafe (regular rm) delete (ignores trashinfo).
Creates trash and trashinfo directories if they do not exist. Handles symbolic link deletion.
Does not complain about different user any more.
Usage: /path/to/saferm.sh [OPTIONS] [--] files and dirs to safely remove
OPTIONS:
-r allows recursively removing directories.
-f Allow deleting special files (devices, ...).
-u Unsafe mode, bypass trash and delete files permanently.
-v Verbose, prints more messages. Default in this version.
-q Quiet mode. Opposite of verbose.
```
---
via: <https://www.2daygeek.com/rm-command-to-move-files-to-trash-can-rm-alias/>
作者:[2DAYGEEK](https://www.2daygeek.com/author/2daygeek/) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,426 | Partclone:多功能的分区和克隆的自由软件 | https://www.fossmint.com/partclone-linux-backup-clone-tool/ | 2018-03-10T09:05:13 | [
"分区",
"Partclone"
] | https://linux.cn/article-9426-1.html | 
[Partclone](https://partclone.org/) 是由 Clonezilla 的开发者们开发的用于创建和克隆分区镜像的自由开源软件。实际上,Partclone 是 Clonezilla 所基于的工具之一。
它为用户提供了备份与恢复已用分区的工具,并与多个文件系统高度兼容,这要归功于它能够使用像 e2fslibs 这样的现有库来读取和写入分区,例如 ext2。
它最大的优点是支持各种格式,包括 ext2、ext3、ext4、hfs+、reiserfs、reiser4、btrfs、vmfs3、vmfs5、xfs、jfs、ufs、ntfs、fat(12/16/32)、exfat、f2fs 和 nilfs。
它还有许多的程序,包括 partclone.ext2(ext3&ext4)、partclone.ntfs、partclone.exfat、partclone.hfsp 和 partclone.vmfs(v3和v5) 等等。
### Partclone中的功能
* 免费软件: Partclone 免费供所有人下载和使用。 \* 开源: Partclone 是在 GNU GPL 许可下发布的,并在 [GitHub](https://github.com/Thomas-Tsai/partclone) 上公开。 \* 跨平台:适用于 Linux、Windows、MAC、ESX 文件系统备份/恢复和 FreeBSD。 \* 一个在线的[文档页面](https://partclone.org/help/),你可以从中查看帮助文档并跟踪其 GitHub 问题。 \* 为初学者和专业人士提供的在线[用户手册](https://partclone.org/usage/)。 \* 支持救援。 \* 克隆分区成镜像文件。 \* 将镜像文件恢复到分区。 \* 快速复制分区。 \* 支持 raw 克隆。 \* 显示传输速率和持续时间。 \* 支持管道。 \* 支持 crc32 校验。 \* 支持 ESX vmware server 的 vmfs 和 FreeBSD 的文件系统 ufs。
Partclone 中还捆绑了更多功能,你可以在[这里](https://partclone.org/features/)查看其余的功能。
* [下载 Linux 中的 Partclone](https://partclone.org/download/)
### 如何安装和使用 Partclone
在 Linux 上安装 Partclone。
```
$ sudo apt install partclone [On Debian/Ubuntu]
$ sudo yum install partclone [On CentOS/RHEL/Fedora]
```
克隆分区为镜像。
```
# partclone.ext4 -d -c -s /dev/sda1 -o sda1.img
```
将镜像恢复到分区。
```
# partclone.ext4 -d -r -s sda1.img -o /dev/sda1
```
分区到分区克隆。
```
# partclone.ext4 -d -b -s /dev/sda1 -o /dev/sdb1
```
显示镜像信息。
```
# partclone.info -s sda1.img
```
检查镜像。
```
# partclone.chkimg -s sda1.img
```
你是 Partclone 的用户吗?我最近在 [Deepin Clone](https://www.fossmint.com/deepin-clone-system-backup-restore-for-deepin-users/) 上写了一篇文章,显然,Partclone 有擅长处理的任务。你使用其他备份和恢复工具的经验是什么?
请在下面的评论区与我们分享你的想法和建议。
---
via: <https://www.fossmint.com/partclone-linux-backup-clone-tool/>
作者:[Martins D. Okoi](https://www.fossmint.com/author/dillivine/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,427 | Linux 下最好的图片截取和视频截录工具 | http://www.linuxandubuntu.com/home/best-linux-screenshot-screencasting-tools | 2018-03-11T09:39:00 | [
"截屏"
] | https://linux.cn/article-9427-1.html | 
可能有一个困扰你多时的问题,当你想要获取一张屏幕截图向开发者反馈问题,或是在 Stack Overflow 寻求帮助时,你可能缺乏一个可靠的屏幕截图工具去保存和发送截图。在 GNOME 中有一些这种类型的程序和 shell 拓展工具。这里介绍的是 Linux 最好的屏幕截图工具,可以供你截取图片或截录视频。
### 1. Shutter
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/shutter-linux-screenshot-taking-tools_orig.jpg)
[Shutter](http://shutter-project.org/) 可以截取任意你想截取的屏幕,是 Linux 最好的截屏工具之一。得到截屏之后,它还可以在保存截屏之前预览图片。它也有一个扩展菜单,展示在 GNOME 顶部面板,使得用户进入软件变得更人性化,非常方便使用。
你可以截取选区、窗口、桌面、当前光标下的窗口、区域、菜单、提示框或网页。Shutter 允许用户直接上传屏幕截图到设置内首选的云服务商。它同样允许用户在保存截图之前编辑器图片;同时提供了一些可自由添加或移除的插件。
终端内键入下列命令安装此工具:
```
sudo add-apt-repository -y ppa:shutter/ppa
sudo apt-get update && sudo apt-get install shutter
```
### 2. Vokoscreen
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-screencasting-tool-for-linux_orig.jpg)
[Vokoscreen](https://github.com/vkohaupt/vokoscreen) 是一款允许你记录和叙述屏幕活动的一款软件。它易于使用,有一个简洁的界面和顶部面板的菜单,方便用户录制视频。
你可以选择记录整个屏幕,或是记录一个窗口,抑或是记录一个选区。自定义记录可以让你轻松得到所需的保存类型,你甚至可以将屏幕录制记录保存为 gif 文件。当然,你也可以使用网络摄像头记录自己的情况,用于你写作教程吸引学习者。记录完成后,你还可以在该应用程序中回放视频记录,这样就不必到处去找你记录的内容。
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-preferences_orig.jpg)
你可以从你的发行版仓库安装 Vocoscreen,或者你也可以在 [pkgs.org](https://pkgs.org/download/vokoscreen) 选择下载你需要的版本。
```
sudo dpkg -i vokoscreen_2.5.0-1_amd64.deb
```
### 3. OBS
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/obs-linux-screencasting-tool_orig.jpg)
[OBS](https://obsproject.com/) 可以用来录制自己的屏幕亦可用来录制互联网上的流媒体。它允许你看到自己所录制的内容或你叙述的屏幕录制。它允许你根据喜好选择录制视频的品质;它也允许你选择文件的保存类型。除了视频录制功能之外,你还可以切换到 Studio 模式,不借助其他软件进行视频编辑。要在你的 Linux 系统中安装 OBS,你必须确保你的电脑已安装 FFmpeg。ubuntu 14.04 或更早的版本安装 FFmpeg 可以使用如下命令:
```
sudo add-apt-repository ppa:kirillshkrogalev/ffmpeg-next
sudo apt-get update && sudo apt-get install ffmpeg
```
ubuntu 15.04 以及之后的版本,你可以在终端中键入如下命令安装 FFmpeg:
```
sudo apt-get install ffmpeg
```
如果 FFmpeg 安装完成,在终端中键入如下安装 OBS:
```
sudo add-apt-repository ppa:obsproject/obs-studio
sudo apt-get update
sudo apt-get install obs-studio
```
### 4. Green Recorder
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/green-recording-linux-tool_orig.jpg)
[Green recorder](https://github.com/foss-project/green-recorder) 是一款界面简单的程序,它可以让你记录屏幕。你可以选择包括视频和单纯的音频在内的录制内容,也可以显示鼠标指针,甚至可以跟随鼠标录制视频。同样,你可以选择记录窗口或是屏幕上的选区,以便于只在自己的记录中保留需要的内容;你还可以自定义最终保存的视频的帧数。如果你想要延迟录制,它提供给你一个选项可以设置出你想要的延迟时间。它还提供一个录制结束后的命令运行选项,这样,就可以在视频录制结束后立即运行。
在终端中键入如下命令来安装 green recorder:
```
sudo add-apt-repository ppa:fossproject/ppa
sudo apt update && sudo apt install green-recorder
```
### 5. Kazam
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/kazam-screencasting-tool-for-linux_orig.jpg)
[Kazam](https://launchpad.net/kazam) 在几乎所有使用截图工具的 Linux 用户中都十分流行。这是一款简单直观的软件,它可以让你做一个屏幕截图或是视频录制,也同样允许在屏幕截图或屏幕录制之前设置延时。它可以让你选择录制区域,窗口或是你想要抓取的整个屏幕。Kazam 的界面接口安排的非常好,和其它软件相比毫无复杂感。它的特点,就是让你优雅的截图。Kazam 在系统托盘和菜单中都有图标,无需打开应用本身,你就可以开始屏幕截图。
终端中键入如下命令来安装 Kazam:
```
sudo apt-get install kazam
```
如果没有找到该 PPA,你需要使用下面的命令安装它:
```
sudo add-apt-repository ppa:kazam-team/stable-series
sudo apt-get update && sudo apt-get install kazam
```
### 6. GNOME 扩展截屏工具
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-compressed_orig.jpg)
GNOME 的一个扩展软件就叫做 screenshot tool,它常驻系统面板,如果你没有设置禁用它的话。由于它是常驻系统面板的软件,所以它会一直等待你的调用,获取截图,方便和容易获取是它最主要的特点,除非你在调整工具中禁用,否则它将一直在你的系统面板中。这个工具也有用来设置首选项的选项窗口。在 extensions.gnome.org 中搜索 “*Screenshot Tool*”,在你的 GNOME 中安装它。
你需要安装 gnome 扩展的 chrome 扩展组件和 GNOME 调整工具才能使用这个工具。
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-preferences_orig.jpg)
当你碰到一个问题,不知道怎么处理,想要在 [Linux 社区](http://www.linuxandubuntu.com/home/top-10-communities-to-help-you-learn-linux) 或者其他开发社区分享、寻求帮助的的时候, **Linux 截图工具** 尤其合适。学习开发、程序或者其他任何事物都会发现这些工具在分享截图的时候真的很实用。Youtube 用户和教程制作爱好者会发现视频截录工具真的很适合录制可以发表的教程。
---
via: <http://www.linuxandubuntu.com/home/best-linux-screenshot-screencasting-tools>
作者:[linuxandubuntu](http://www.linuxandubuntu.com) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,428 | Linux 容器安全的 10 个层面 | https://opensource.com/article/17/10/10-layers-container-security | 2018-03-11T11:09:44 | [
"容器",
"安全"
] | https://linux.cn/article-9428-1.html |
>
> 应用这些策略来保护容器解决方案的各个层面和容器生命周期的各个阶段的安全。
>
>
>

容器提供了打包应用程序的一种简单方法,它实现了从开发到测试到投入生产系统的无缝传递。它也有助于确保跨不同环境的连贯性,包括物理服务器、虚拟机、以及公有云或私有云。这些好处使得一些组织为了更方便地部署和管理为他们提升业务价值的应用程序,而快速地采用了容器技术。

企业需要高度安全,在容器中运行核心服务的任何人都会问,“容器安全吗?”以及“我们能信任运行在容器中的应用程序吗?”
对容器进行安全保护就像是对运行中的进程进行安全保护一样。在你部署和运行你的容器之前,你需要去考虑整个解决方案各个层面的安全。你也需要去考虑贯穿了应用程序和容器整个生命周期的安全。
请尝试从这十个关键的因素去确保容器解决方案栈不同层面、以及容器生命周期的不同阶段的安全。
### 1. 容器宿主机操作系统和多租户环境
由于容器将应用程序和它的依赖作为一个单元来处理,使得开发者构建和升级应用程序变得更加容易,并且,容器可以启用多租户技术将许多应用程序和服务部署到一台共享主机上。在一台单独的主机上以容器方式部署多个应用程序、按需启动和关闭单个容器都是很容易的。为完全实现这种打包和部署技术的优势,运营团队需要运行容器的合适环境。运营者需要一个安全的操作系统,它能够在边界上保护容器安全、从容器中保护主机内核,以及保护容器彼此之间的安全。
容器是隔离而资源受限的 Linux 进程,允许你在一个共享的宿主机内核上运行沙盒化的应用程序。保护容器的方法与保护你的 Linux 中运行的任何进程的方法是一样的。降低权限是非常重要的,也是保护容器安全的最佳实践。最好使用尽可能小的权限去创建容器。容器应该以一个普通用户的权限来运行,而不是 root 权限的用户。在 Linux 中可以使用多个层面的安全加固手段,Linux 命名空间、安全强化 Linux([SELinux](https://en.wikipedia.org/wiki/Security-Enhanced_Linux))、[cgroups](https://en.wikipedia.org/wiki/Cgroups) 、capabilities(LCTT 译注:Linux 内核的一个安全特性,它打破了传统的普通用户与 root 用户的概念,在进程级提供更好的安全控制)、以及安全计算模式( [seccomp](https://en.wikipedia.org/wiki/Seccomp) ),这五种 Linux 的安全特性可以用于保护容器的安全。
### 2. 容器内容(使用可信来源)
在谈到安全时,首先要考虑你的容器里面有什么?例如 ,有些时候,应用程序和基础设施是由很多可用组件所构成的。它们中的一些是开源的软件包,比如,Linux 操作系统、Apache Web 服务器、Red Hat JBoss 企业应用平台、PostgreSQL,以及 Node.js。这些软件包的容器化版本已经可以使用了,因此,你没有必要自己去构建它们。但是,对于你从一些外部来源下载的任何代码,你需要知道这些软件包的原始来源,是谁构建的它,以及这些包里面是否包含恶意代码。
### 3. 容器注册(安全访问容器镜像)
你的团队的容器构建于下载的公共容器镜像,因此,访问和升级这些下载的容器镜像以及内部构建镜像,与管理和下载其它类型的二进制文件的方式是相同的,这一点至关重要。许多私有的注册库支持容器镜像的存储。选择一个私有的注册库,可以帮你将存储在它的注册中的容器镜像实现策略自动化。
### 4. 安全性与构建过程
在一个容器化环境中,软件构建过程是软件生命周期的一个阶段,它将所需的运行时库和应用程序代码集成到一起。管理这个构建过程对于保护软件栈安全来说是很关键的。遵守“一次构建,到处部署”的原则,可以确保构建过程的结果正是生产系统中需要的。保持容器的恒定不变也很重要 — 换句话说就是,不要对正在运行的容器打补丁,而是,重新构建和部署它们。
不论是因为你处于一个高强度监管的行业中,还是只希望简单地优化你的团队的成果,设计你的容器镜像管理以及构建过程,可以使用容器层的优势来实现控制分离,因此,你应该去这么做:
* 运营团队管理基础镜像
* 架构师管理中间件、运行时、数据库,以及其它解决方案
* 开发者专注于应用程序层面,并且只写代码

最后,标记好你的定制构建容器,这样可以确保在构建和部署时不会搞混乱。
### 5. 控制好在同一个集群内部署应用
如果是在构建过程中出现的任何问题,或者在镜像被部署之后发现的任何漏洞,那么,请在基于策略的、自动化工具上添加另外的安全层。
我们来看一下,一个应用程序的构建使用了三个容器镜像层:内核、中间件,以及应用程序。如果在内核镜像中发现了问题,那么只能重新构建镜像。一旦构建完成,镜像就会被发布到容器平台注册库中。这个平台可以自动检测到发生变化的镜像。对于基于这个镜像的其它构建将被触发一个预定义的动作,平台将自己重新构建应用镜像,合并该修复的库。
一旦构建完成,镜像将被发布到容器平台的内部注册库中。在它的内部注册库中,会立即检测到镜像发生变化,应用程序在这里将会被触发一个预定义的动作,自动部署更新镜像,确保运行在生产系统中的代码总是使用更新后的最新的镜像。所有的这些功能协同工作,将安全功能集成到你的持续集成和持续部署(CI/CD)过程和管道中。
### 6. 容器编配:保护容器平台安全
当然了,应用程序很少会以单一容器分发。甚至,简单的应用程序一般情况下都会有一个前端、一个后端、以及一个数据库。而在容器中以微服务模式部署的应用程序,意味着应用程序将部署在多个容器中,有时它们在同一台宿主机上,有时它们是分布在多个宿主机或者节点上,如下面的图所示:

在大规模的容器部署时,你应该考虑:
* 哪个容器应该被部署在哪个宿主机上?
* 那个宿主机应该有什么样的性能?
* 哪个容器需要访问其它容器?它们之间如何发现彼此?
* 你如何控制和管理对共享资源的访问,像网络和存储?
* 如何监视容器健康状况?
* 如何去自动扩展性能以满足应用程序的需要?
* 如何在满足安全需求的同时启用开发者的自助服务?
考虑到开发者和运营者的能力,提供基于角色的访问控制是容器平台的关键要素。例如,编配管理服务器是中心访问点,应该接受最高级别的安全检查。API 是规模化的自动容器平台管理的关键,可以用于为 pod、服务,以及复制控制器验证和配置数据;在入站请求上执行项目验证;以及调用其它主要系统组件上的触发器。
### 7. 网络隔离
在容器中部署现代微服务应用,经常意味着跨多个节点在多个容器上部署。考虑到网络防御,你需要一种在一个集群中的应用之间的相互隔离的方法。一个典型的公有云容器服务,像 Google 容器引擎(GKE)、Azure 容器服务,或者 Amazon Web 服务(AWS)容器服务,是单租户服务。他们让你在你初始化建立的虚拟机集群上运行你的容器。对于多租户容器的安全,你需要容器平台为你启用一个单一集群,并且分割流量以隔离不同的用户、团队、应用、以及在这个集群中的环境。
使用网络命名空间,容器内的每个集合(即大家熟知的 “pod”)都会得到它自己的 IP 和绑定的端口范围,以此来从一个节点上隔离每个 pod 网络。除使用下面所述的方式之外,默认情况下,来自不同命名空间(项目)的 pod 并不能发送或者接收其它 pod 上的包和不同项目的服务。你可以使用这些特性在同一个集群内隔离开发者环境、测试环境,以及生产环境。但是,这样会导致 IP 地址和端口数量的激增,使得网络管理更加复杂。另外,容器是被设计为反复使用的,你应该在处理这种复杂性的工具上进行投入。在容器平台上比较受欢迎的工具是使用 [软件定义网络](https://en.wikipedia.org/wiki/Software-defined_networking) (SDN) 提供一个定义的网络集群,它允许跨不同集群的容器进行通讯。
### 8. 存储
容器即可被用于无状态应用,也可被用于有状态应用。保护外加的存储是保护有状态服务的一个关键要素。容器平台对多种受欢迎的存储提供了插件,包括网络文件系统(NFS)、AWS 弹性块存储(EBS)、GCE 持久磁盘、GlusterFS、iSCSI、 RADOS(Ceph)、Cinder 等等。
一个持久卷(PV)可以通过资源提供者支持的任何方式装载到一个主机上。提供者有不同的性能,而每个 PV 的访问模式被设置为特定的卷支持的特定模式。例如,NFS 能够支持多路客户端同时读/写,但是,一个特定的 NFS 的 PV 可以在服务器上被发布为只读模式。每个 PV 有它自己的一组反应特定 PV 性能的访问模式的描述,比如,ReadWriteOnce、ReadOnlyMany、以及 ReadWriteMany。
### 9. API 管理、终端安全、以及单点登录(SSO)
保护你的应用安全,包括管理应用、以及 API 的认证和授权。
Web SSO 能力是现代应用程序的一个关键部分。在构建它们的应用时,容器平台带来了开发者可以使用的多种容器化服务。
API 是微服务构成的应用程序的关键所在。这些应用程序有多个独立的 API 服务,这导致了终端服务数量的激增,它就需要额外的管理工具。推荐使用 API 管理工具。所有的 API 平台应该提供多种 API 认证和安全所需要的标准选项,这些选项既可以单独使用,也可以组合使用,以用于发布证书或者控制访问。
这些选项包括标准的 API key、应用 ID 和密钥对,以及 OAuth 2.0。
### 10. 在一个联合集群中的角色和访问管理
在 2016 年 7 月份,Kubernetes 1.3 引入了 [Kubernetes 联合集群](https://kubernetes.io/docs/concepts/cluster-administration/federation/)。这是一个令人兴奋的新特性之一,它是在 Kubernetes 上游、当前的 Kubernetes 1.6 beta 中引用的。联合是用于部署和访问跨多集群运行在公有云或企业数据中心的应用程序服务的。多个集群能够用于去实现应用程序的高可用性,应用程序可以跨多个可用区域,或者去启用部署公共管理,或者跨不同的供应商进行迁移,比如,AWS、Google Cloud、以及 Azure。
当管理联合集群时,你必须确保你的编配工具能够提供你所需要的跨不同部署平台的实例的安全性。一般来说,认证和授权是很关键的 —— 不论你的应用程序运行在什么地方,将数据安全可靠地传递给它们,以及管理跨集群的多租户应用程序。Kubernetes 扩展了联合集群,包括对联合的秘密数据、联合的命名空间、以及 Ingress objects 的支持。
### 选择一个容器平台
当然,它并不仅关乎安全。你需要提供一个你的开发者团队和运营团队有相关经验的容器平台。他们需要一个安全的、企业级的基于容器的应用平台,它能够同时满足开发者和运营者的需要,而且还能够提高操作效率和基础设施利用率。
想从 Daniel 在 [欧盟开源峰会](http://events.linuxfoundation.org/events/open-source-summit-europe) 上的 [容器安全的十个层面](https://osseu17.sched.com/mobile/#session:f2deeabfc1640d002c1d55101ce81223) 的演讲中学习更多知识吗?这个峰会已于 10 月 23 - 26 日在 Prague 举行。
### 关于作者
Daniel Oh;Microservives;Agile;Devops;Java Ee;Container;Openshift;Jboss;Evangelism
---
via: <https://opensource.com/article/17/10/10-layers-container-security>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Containers provide an easy way to package applications and deliver them seamlessly from development to test to production. This helps ensure consistency across a variety of environments, including physical servers, virtual machines (VMs), or private or public clouds. These benefits are leading organizations to rapidly adopt containers in order to easily develop and manage the applications that add business value.

opensource.com
Enterprises require strong security, and anyone running essential services in containers will ask, "Are containers secure?" and "Can we trust containers with our applications?"
Securing containers is a lot like securing any running process. You need to think about security throughout the layers of the solution stack before you deploy and run your container. You also need to think about security throughout the application and container lifecycle.
Try these 10 key elements to secure different layers of the container solution stack and different stages of the container lifecycle.
## 1. The container host operating system and multi-tenancy
Containers make it easier for developers to build and promote an application and its dependencies as a unit and to get the most use of servers by enabling multi-tenant application deployments on a shared host. It's easy to deploy multiple applications on a single host, spinning up and shutting down individual containers as needed. To take full advantage of this packaging and deployment technology, the operations team needs the right environment for running containers. Operations needs an operating system that can secure containers at the boundaries, securing the host kernel from container escapes and securing containers from each other.
Containers are Linux processes with isolation and resource confinement that enable you to run sandboxed applications on a shared host kernel. Your approach to securing containers should be the same as your approach to securing any running process on Linux. Dropping privileges is important and still the best practice. Even better is to create containers with the least privilege possible. Containers should run as user, not root. Next, make use of the multiple levels of security available in Linux. Linux namespaces, Security-Enhanced Linux ([SELinux](https://en.wikipedia.org/wiki/Security-Enhanced_Linux)), [cgroups](https://en.wikipedia.org/wiki/Cgroups), capabilities, and secure computing mode ([seccomp](https://en.wikipedia.org/wiki/Seccomp)) are five of the security features available for securing containers.
## 2. Container content (use trusted sources)
When it comes to security, what's inside your container matters. For some time now, applications and infrastructures have been composed from readily available components. Many of these are open source packages, such as the Linux operating system, Apache Web Server, Red Hat JBoss Enterprise Application Platform, PostgreSQL, and Node.js. Containerized versions of these packages are now also readily available, so you don't have to build your own. But, as with any code you download from an external source, you need to know where the packages originated, who built them, and whether there's any malicious code inside them.
## 3. Container registries (secure access to container images)
Your teams are building containers that layer content on top of downloaded public container images, so it's critical to manage access to and promotion of the downloaded container images and the internally built images in the same way other types of binaries are managed. Many private registries support storage of container images. Select a private registry that helps to automate policies for the use of container images stored in the registry.
## 4. Security and the build process
In a containerized environment, the software-build process is the stage in the lifecycle where application code is integrated with needed runtime libraries. Managing this build process is key to securing the software stack. Adhering to a "build once, deploy everywhere" philosophy ensures that the product of the build process is exactly what is deployed in production. It's also important to maintain the immutability of your containers—in other words, do not patch running containers; rebuild and redeploy them instead.
Whether you work in a highly regulated industry or simply want to optimize your team's efforts, design your container image management and build process to take advantage of container layers to implement separation of control, so that the:
- Operations team manages base images
- Architects manage middleware, runtimes, databases, and other such solutions
- Developers focus on application layers and just write code
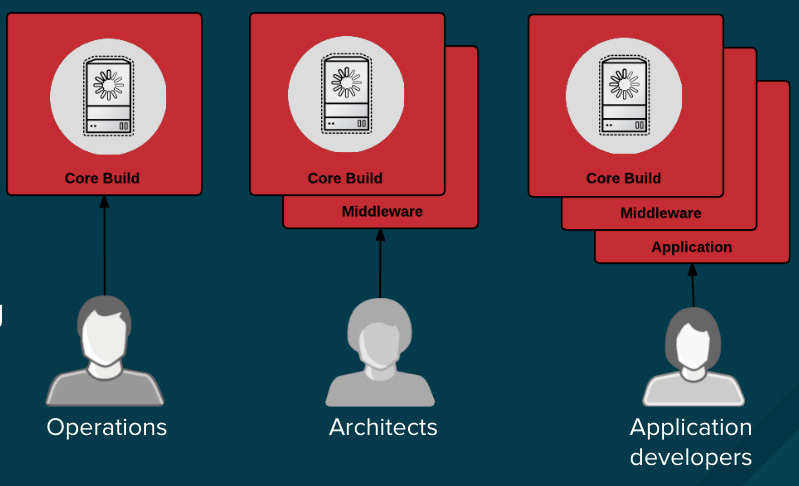
opensource.com
Finally, sign your custom-built containers so that you can be sure they are not tampered with between build and deployment.
## 5. Control what can be deployed within a cluster
In case anything falls through during the build process, or for situations where a vulnerability is discovered after an image has been deployed, add yet another layer of security in the form of tools for automated, policy-based deployment.
Let's look at an application that's built using three container image layers: core, middleware, and the application layer. An issue is discovered in the core image and that image is rebuilt. Once the build is complete, the image is pushed to the container platform registry. The platform can detect that the image has changed. For builds that are dependent on this image and have triggers defined, the platform will automatically rebuild the application image, incorporating the fixed libraries.
Once the build is complete, the image is pushed to container platform's internal registry. It immediately detects changes to images in its internal registry and, for applications where triggers are defined, automatically deploys the updated image, ensuring that the code running in production is always identical to the most recently updated image. All these capabilities work together to integrate security capabilities into your continuous integration and continuous deployment (CI/CD) process and pipeline.## 6. Container orchestration: Securing the container platform
Of course, applications are rarely delivered in a single container. Even simple applications typically have a frontend, a backend, and a database. And deploying modern microservices applications in containers means deploying multiple containers, sometimes on the same host and sometimes distributed across multiple hosts or nodes, as shown in this diagram.
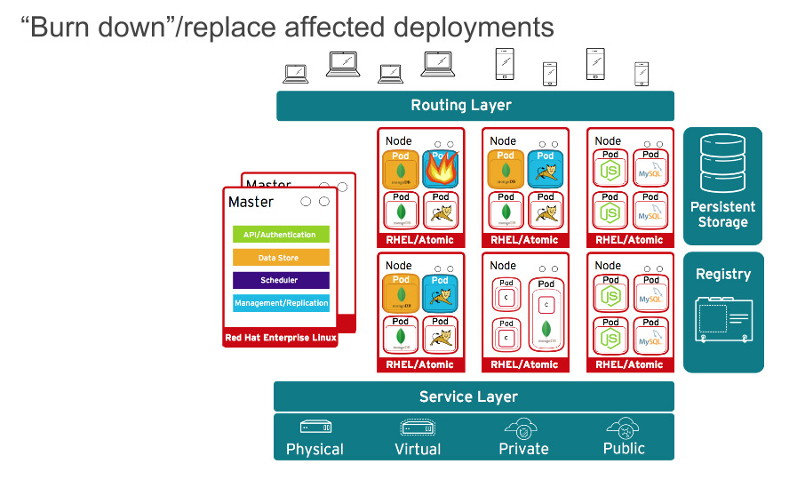
opensource.com
When managing container deployment at scale, you need to consider:
- Which containers should be deployed to which hosts?
- Which host has more capacity?
- Which containers need access to each other? How will they discover each other?
- How will you control access to—and management of—shared resources, like network and storage?
- How will you monitor container health?
- How will you automatically scale application capacity to meet demand?
- How will you enable developer self-service while also meeting security requirements?
Given the wealth of capabilities for both developers and operators, strong role-based access control is a critical element of the container platform. For example, the orchestration management servers are a central point of access and should receive the highest level of security scrutiny. APIs are key to automating container management at scale and used to validate and configure the data for pods, services, and replication controllers; perform project validation on incoming requests; and invoke triggers on other major system components.
## 7. Network isolation
Deploying modern microservices applications in containers often means deploying multiple containers distributed across multiple nodes. With network defense in mind, you need a way to isolate applications from one another within a cluster. A typical public cloud container service, like Google Container Engine (GKE), Azure Container Services, or Amazon Web Services (AWS) Container Service, are single-tenant services. They let you run your containers on the VM cluster that you initiate. For secure container multi-tenancy, you want a container platform that allows you to take a single cluster and segment the traffic to isolate different users, teams, applications, and environments within that cluster.
With network namespaces, each collection of containers (known as a "pod") gets its own IP and port range to bind to, thereby isolating pod networks from each other on the node. Pods from different namespaces (projects) cannot send packets to or receive packets from pods and services of a different project by default, with the exception of options noted below. You can use these features to isolate developer, test, and production environments within a cluster; however, this proliferation of IP addresses and ports makes networking more complicated. In addition, containers are designed to come and go. Invest in tools that handle this complexity for you. The preferred tool is a container platform that uses [software-defined networking](https://en.wikipedia.org/wiki/Software-defined_networking) (SDN) to provide a unified cluster network that enables communication between containers across the cluster.
## 8. Storage
Containers are useful for both stateless and stateful applications. Protecting attached storage is a key element of securing stateful services. Container platforms should provide plugins for multiple flavors of storage, including network file systems (NFS), AWS Elastic Block Stores (EBS), GCE Persistent Disks, GlusterFS, iSCSI, RADOS (Ceph), Cinder, etc.
A persistent volume (PV) can be mounted on a host in any way supported by the resource provider. Providers will have different capabilities, and each PV's access modes are set to the specific modes supported by that particular volume. For example, NFS can support multiple read/write clients, but a specific NFS PV might be exported on the server as read only. Each PV gets its own set of access modes describing that specific PV's capabilities, such as ReadWriteOnce, ReadOnlyMany, and ReadWriteMany.
## 9. API management, endpoint security, and single sign-on (SSO)
Securing your applications includes managing application and API authentication and authorization.
Web SSO capabilities are a key part of modern applications. Container platforms can come with various containerized services for developers to use when building their applications.
APIs are key to applications composed of microservices. These applications have multiple independent API services, leading to proliferation of service endpoints, which require additional tools for governance. An API management tool is also recommended. All API platforms should offer a variety of standard options for API authentication and security, which can be used alone or in combination, to issue credentials and control access.
These options include standard API keys, application ID and key pairs, and OAuth 2.0.## 10. Roles and access management in a cluster federation
In July 2016, Kubernetes 1.3 introduced [Kubernetes Federated Clusters](https://kubernetes.io/docs/concepts/cluster-administration/federation/). This is one of the exciting new features evolving in the Kubernetes upstream, currently in beta in Kubernetes 1.6. Federation is useful for deploying and accessing application services that span multiple clusters running in the public cloud or enterprise datacenters. Multiple clusters can be useful to enable application high availability across multiple availability zones or to enable common management of deployments or migrations across multiple cloud providers, such as AWS, Google Cloud, and Azure.
When managing federated clusters, you must be sure that your orchestration tools provide the security you need across the different deployment platform instances. As always, authentication and authorization are key—as well as the ability to securely pass data to your applications, wherever they run, and manage application multi-tenancy across clusters. Kubernetes is extending Cluster Federation to include support for Federated Secrets, Federated Namespaces, and Ingress objects.
## Choosing a container platform
Of course, it is not just about security. Your container platform needs to provide an experience that works for your developers and your operations team. It needs to offer a secure, enterprise-grade container-based application platform that enables both developers and operators, without compromising the functions needed by each team, while also improving operational efficiency and infrastructure utilization.
*Learn more in Daniel's talk, Ten Layers of Container Security, at Open Source Summit EU, which will be held October 23-26 in Prague.*
## 5 Comments |
9,429 | 5 个在视觉上最轻松的黑暗主题 | https://www.maketecheasier.com/best-linux-dark-themes/ | 2018-03-11T11:45:45 | [
"主题",
"桌面"
] | https://linux.cn/article-9429-1.html | 
人们在电脑上选择黑暗主题有几个原因。有些人觉得对于眼睛轻松,而另一些人因为他们的医学条件选择黑色。特别地,程序员喜欢黑暗的主题,因为可以减少眼睛的眩光。
如果你是一位 Linux 用户和黑暗主题爱好者,那么你很幸运。这里有五个最好的 Linux 黑暗主题。去看一下!
### 1. OSX-Arc-Shadow

顾名思义,这个主题受 OS X 的启发,它是基于 Arc 的平面主题。该主题支持 GTK 3 和 GTK 2 桌面环境,因此 Gnome、Cinnamon、Unity、Manjaro、Mate 和 XFCE 用户可以安装和使用该主题。[OSX-Arc-Shadow](https://github.com/LinxGem33/OSX-Arc-Shadow/) 是 OSX-Arc 主题集合的一部分。该集合还包括其他几个主题(黑暗和明亮)。你可以下载整个系列并使用黑色主题。
基于 Debian 和 Ubuntu 的发行版用户可以选择使用此[页面](https://github.com/LinxGem33/OSX-Arc-Shadow/releases)中找到的 .deb 文件来安装稳定版本。压缩的源文件也位于同一页面上。Arch Linux 用户,请查看此 [AUR 链接](https://aur.archlinux.org/packages/osx-arc-shadow/)。最后,要手动安装主题,请将 zip 解压到 `~/.themes` ,并将其设置为当前主题、控件和窗口边框。
### 2. Kiss-Kool-Red version 2

该主题发布不久。与 OSX-Arc-Shadow 相比它有更黑的外观和红色选择框。对于那些希望电脑屏幕上有更强对比度和更少眩光的人尤其有吸引力。因此,它可以减少在夜间使用或在光线较暗的地方使用时的注意力分散。它支持 GTK 3 和 GTK2。
前往 [gnome-looks](https://www.gnome-look.org/p/1207964/),在“文件”菜单下下载主题。安装过程很简单:将主题解压到 `~/.themes` 中,并将其设置为当前主题、控件和窗口边框。
### 3. Equilux

Equilux 是另一个基于 Materia 主题的简单的黑暗主题。它有一个中性的深色调,并不过分花哨。选择框之间的对比度也很小,并且没有 Kiss-Kool-Red 中红色的锐利。这个主题的确是为减轻眼睛疲劳而做的。
[下载压缩文件](https://www.gnome-look.org/p/1182169/)并将其解压缩到你的 `~/.themes` 中。然后,你可以将其设置为你的主题。你可以查看[它的 GitHub 页面](https://github.com/ddnexus/equilux-theme)了解最新的增加内容。
### 4. Deepin Dark

Deepin Dark 是一个完全黑暗的主题。对于那些喜欢更黑暗的人来说,这个主题绝对是值得考虑的。此外,它还可以减少电脑屏幕的眩光量。另外,它支持 Unity。[在这里下载 Deepin Dark](https://www.gnome-look.org/p/1190867/)。
### 5. Ambiance DS BlueSB12

Ambiance DS BlueSB12 是一个简单的黑暗主题,它使得重要细节突出。它有助于专注,不花哨。它与 Deepin Dark 非常相似。特别是对于 Ubuntu 用户,它与 Ubuntu 17.04 兼容。你可以从[这里](https://www.gnome-look.org/p/1013664/)下载并尝试。
### 总结
如果你长时间使用电脑,黑暗主题是减轻眼睛疲劳的好方法。即使你不这样做,黑暗主题也可以在其他方面帮助你,例如提高专注。让我们知道你最喜欢哪一个。
---
via: <https://www.maketecheasier.com/best-linux-dark-themes/>
作者:[Bruno Edoh](https://www.maketecheasier.com) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
There are several reasons people opt for dark themes on their computers. Some find them easy on the eye while others prefer them because of their medical condition. Programmers, especially, like dark themes because they reduce glare on the eyes.
If you are a Linux user and a dark theme lover, you are in luck. Here are five of the best dark themes for Linux. Check them out!
## 1. OSX-Arc-Shadow
As its name implies, this theme is inspired by OS X. It is a flat theme based on Arc. The theme supports GTK 3 and GTK 2 desktop environments, so Gnome, Cinnamon, Unity, Manjaro, Mate, and XFCE users can install and use the theme. OSX-Arc-Shadow is part of the OSX-Arc theme collection. The collection has several other themes (dark and light) included. You can download the whole collection and just use the dark variants.
Debian- and Ubuntu-based distro users have the option of installing the stable release using the .deb files found on this [page](https://github.com/LinxGem33/OSX-Arc-Shadow/releases). The compressed source files are also on the same page. Arch Linux users, check out this AUR link. Finally, to install the theme manually, extract the zip content to the “~/.themes” folder and set it as your current theme, controls, and window borders.
## 2. Kiss-Kool-Red version 2
The theme is only a few days old. It has a darker look compared to OSX-Arc-Shadow and red selection outlines. It is especially appealing to those who want more contrast and less glare from the computer screen. Hence, It reduces distraction when used at night or in places with low lights. It supports GTK 3 and GTK2.
Head to [gnome-looks](https://www.gnome-look.org/p/1207964/) to download the theme under the “Files” menu. The installation procedure is simple: extract the theme into the “~/.themes” folder and set it as your current theme, controls, and window borders.
## 3. Equilux
Equilux is another simple dark theme based on Materia Theme. It has a neutral dark color tone and is not overly fancy. The contrast between the selection outlines is also minimal and not as sharp as the red color in Kiss-Kool-Red. The theme is truly made with reduction of eye strain in mind.
Download the compressed file and unzip it into your “~/.themes” folder. Then, you can set it as your theme. You can check [its GitHub page](https://github.com/ddnexus/equilux-theme) for the latest additions.
## 4. Deepin Dark
Deepin Dark is a completely dark theme. For those who like a little more darkness, this theme is definitely one to consider. Moreover, it also reduces the amount of glare from the computer screen. Additionally, it supports Unity. Download Deepin Dark here.
## 5. Ambiance DS BlueSB12
Ambiance DS BlueSB12 is a simple dark theme, so it makes the important details stand out. It helps with focus as is not unnecessarily fancy. It is very similar to Deepin Dark. Especially relevant to Ubuntu users, it is compatible with Ubuntu 17.04. You can download and try it from [here](https://www.gnome-look.org/p/1013664/).
## Conclusion
If you use a computer for a very long time, dark themes are a great way to reduce the strain on your eyes. Even if you don’t, dark themes can help you in many other ways like improving your focus. Let us know which is your favorite.
Our latest tutorials delivered straight to your inbox |
9,430 | 有用的 Bash 快捷键清单 | https://www.ostechnix.com/list-useful-bash-keyboard-shortcuts/ | 2018-03-11T12:34:00 | [
"快捷键",
"bash"
] | https://linux.cn/article-9430-1.html | 
现如今,我在终端上花的时间更多,尝试在命令行完成比在图形界面更多的工作。随着时间推移,我学了许多 BASH 的技巧。这是一份每个 Linux 用户都应该知道的 BASH 快捷键,这样在终端做事就会快很多。我不会说这是一份完全的 BASH 快捷键清单,但是这足够让你的 BASH shell 操作比以前更快了。学习更快地使用 BASH 不仅节省了更多时间,也让你因为学到了有用的知识而感到自豪。那么,让我们开始吧。
### ALT 快捷键
1. `ALT+A` – 光标移动到行首。
2. `ALT+B` – 光标移动到所在单词词首。
3. `ALT+C` – 终止正在运行的命令/进程。与 `CTRL+C` 相同。
4. `ALT+D` – 关闭空的终端(也就是它会关闭没有输入的终端)。也删除光标后的全部字符。
5. `ALT+F` – 移动到光标所在单词词末。
6. `ALT+T` – 交换最后两个单词。
7. `ALT+U` – 将单词内光标后的字母转为大写。
8. `ALT+L` – 将单词内光标后的字母转为小写。
9. `ALT+R` – 撤销对从历史记录中带来的命令的修改。
正如你在上面输出所见,我使用反向搜索拉取了一个指令,并更改了那个指令的最后一个字母,并使用 `ALT+R` 撤销了更改。
10. `ALT+.` (注意末尾的点号) – 使用上一条命令的最后一个单词。
如果你想要对多个命令进行相同的操作的话,你可以使用这个快捷键来获取前几个指令的最后一个单词。例如,我需要使用 `ls -r` 命令输出以文件名逆序排列的目录内容。同时,我也想使用 `uname -r` 命令来查看我的内核版本。在这两个命令中,相同的单词是 `-r` 。这就是需要 `ALT+.` 的地方。快捷键很顺手。首先运行 `ls -r` 来按文件名逆序输出,然后在其他命令,比如 `uname` 中使用最后一个单词 `-r` 。
### CTRL 快捷键
1. `CTRL+A` – 快速移动到行首。
我们假设你输入了像下面这样的命令。当你在第 N 行时,你发现在行首字符有一个输入错误
```
$ gind . -mtime -1 -type
```
注意到了吗?上面的命令中我输入了 `gind` 而不是 `find` 。你可以通过一直按着左箭头键定位到第一个字母然后用 `g` 替换 `f` 。或者,仅通过 `CTRL+A` 或 `HOME` 键来立刻定位到行首,并替换拼错的单词。这将节省你几秒钟的时间。
2. `CTRL+B` – 光标向前移动一个字符。
这个快捷键可以使光标向前移动一个字符,即光标前的一个字符。或者,你可以使用左箭头键来向前移动一个字符。
3. `CTRL+C` – 停止当前运行的命令。
如果一个命令运行时间过久,或者你误运行了,你可以通过使用 `CTRL+C` 来强制停止或退出。
4. `CTRL+D` – 删除光标后的一个字符。
如果你的系统退格键无法工作的话,你可以使用 `CTRL+D` 来删除光标后的一个字符。这个快捷键也可以让你退出当前会话,和 exit 类似。
5. `CTRL+E` – 移动到行末。
当你修正了行首拼写错误的单词,按下 `CTRL+E` 来快速移动到行末。或者,你也可以使用你键盘上的 `END` 键。
6. `CTRL+F` – 光标向后移动一个字符。
如果你想将光标向后移动一个字符的话,按 `CTRL+F` 来替代右箭头键。
7. `CTRL+G` – 退出历史搜索模式,不运行命令。
正如你在上面的截图看到的,我进行了反向搜索,但是我执行命令,并退出了历史搜索模式。
8. `CTRL+H` – 删除光标前的一个字符,和退格键相同。
9. `CTRL+J` – 和 ENTER/RETURN 键相同。
回车键不工作?没问题! `CTRL+J` 或 `CTRL+M` 可以用来替换回车键。
10. `CTRL+K` – 删除光标后的所有字符。
你不必一直按着删除键来删除光标后的字符。只要按 `CTRL+K` 就能删除光标后的所有字符。
11. `CTRL+L` – 清空屏幕并重新显示当前行。
别输入 `clear` 来清空屏幕了。只需按 `CTRL+L` 即可清空并重新显示当前行。
12. `CTRL+M` – 和 `CTRL+J` 或 RETURN键相同。
13. `CTRL+N` – 在命令历史中显示下一行。
你也可以使用下箭头键。
14. `CTRL+O` – 运行你使用反向搜索时发现的命令,即 CTRL+R。
15. `CTRL+P` – 显示命令历史的上一条命令。
你也可以使用上箭头键。
16. `CTRL+R` – 向后搜索历史记录(反向搜索)。
17. `CTRL+S` – 向前搜索历史记录。
18. `CTRL+T` – 交换最后两个字符。
这是我最喜欢的一个快捷键。假设你输入了 `sl` 而不是 `ls` 。没问题!这个快捷键会像下面这张截图一样交换字符。

19. `CTRL+U` – 删除光标前的所有字符(从光标后的点删除到行首)。
这个快捷键立刻删除前面的所有字符。
20. `CTRL+V` – 逐字显示输入的下一个字符。
21. `CTRL+W` – 删除光标前的一个单词。
不要和 CTRL+U 弄混了。CTRL+W 不会删除光标前的所有东西,而是只删除一个单词。

22. `CTRL+X` – 列出当前单词可能的文件名补全。
23. `CTRL+XX` – 移动到行首位置(再移动回来)。
24. `CTRL+Y` – 恢复你上一个删除或剪切的条目。
记得吗,我们在第 21 个命令用 `CTRL+W` 删除了单词“-al”。你可以使用 `CTRL+Y` 立刻恢复。

看见了吧?我没有输入“-al”。取而代之,我按了 `CTRL+Y` 来恢复它。
25. `CTRL+Z` – 停止当前的命令。
你也许很了解这个快捷键。它终止了当前运行的命令。你可以在前台使用 `fg` 或在后台使用 `bg` 来恢复它。
26. `CTRL+[` – 和 `ESC` 键等同。
### 杂项
1. `!!` – 重复上一个命令。
2. `ESC+t` – 交换最后两个单词。
这就是我所能想到的了。将来我遇到 Bash 快捷键时我会持续添加的。如果你觉得文章有错的话,请在下方的评论区留言。我会尽快更新。
Cheers!
---
via: <https://www.ostechnix.com/list-useful-bash-keyboard-shortcuts/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[heart4lor](https://github.com/heart4lor) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,431 | Linux 如何成为我的工作 | https://opensource.com/article/18/2/my-open-source-story-phil-estes | 2018-03-11T22:31:37 | [
"开源",
"贡献"
] | https://linux.cn/article-9431-1.html |
>
> IBM 工程师 Phil Estes 分享了他的 Linux 爱好如何使他成为了一位开源领袖、贡献者和维护者。
>
>
>

从很早很早以前起,我就一直使用开源软件。那个时候,没有所谓的社交媒体。没有火狐,没有谷歌浏览器(甚至连谷歌也没有),没有亚马逊,甚至几乎没有互联网。事实上,那个时候最热门的是最新的 Linux 2.0 内核。当时的技术挑战是什么?嗯,是 Linux 发行版本中旧的 [a.out](https://en.wikipedia.org/wiki/A.out) 格式被 [ELF 格式](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format)代替,导致升级一些 [Linux](https://opensource.com/node/19796) 的安装可能有些棘手。
我如何将我自己对这个初出茅庐的年轻操作系统的兴趣转变为开源事业是一个有趣的故事。
### Linux 为乐趣为生,而非利益
1994 年我大学毕业时,计算机实验室是 UNIX 系统的小型网络;如果你幸运的话,它们会连接到这个叫做互联网的新东西上。我知道这难以置信!(那时,)“Web”(就是所知道的那个)大多是手写的 HTML,`cgi-bin` 目录是启用动态 Web 交互的一个新平台。我们许多人对这些新技术感到兴奋,我们还自学了 shell 脚本、[Perl](https://opensource.com/node/25456)、HTML,以及所有我们在父母的 Windows 3.1 PC 上从没有见过的简短的 UNIX 命令。
毕业后,我加入 IBM,工作在一个不能访问 UNIX 系统的 PC 操作系统上,不久,我的大学切断了我通往工程实验室的远程通道。我该如何继续通过 [Pine](https://opensource.com/article/17/10/alpine-email-client) 使用 `vi` 和 `ls` 读我的电子邮件的呢?我一直听说开源 Linux,但我还没有时间去研究它。
1996 年,我在德克萨斯大学奥斯丁分校开始读硕士学位。我知道这将涉及编程和写论文,不知道还有什么,但我不想使用专有的编辑器,编译器或者文字处理器。我想要的是我的 UNIX 体验!
所以我拿了一个旧电脑,找到了一个 Linux 发行版本 Slackware 3.0,在我的 IBM 办公室下载了一张又一张的软盘。可以说我在第一次安装 Linux 后就没有回过头了。在最初的那些日子里,我学习了很多关于 Makefile 和 `make` 系统、构建软件、补丁还有源码控制的知识。虽然我开始使用 Linux 只是为了兴趣和个人知识,但它最终改变了我的职业生涯。
虽然我是一个愉快的 Linux 用户,但我认为开源开发仍然是其他人的工作;我觉得在线邮件列表都是神秘的 [UNIX](https://opensource.com/node/22781) 极客的。我很感激像 Linux HOWTO 这样的项目,它们在我尝试添加软件包、升级 Linux 版本,或者安装新硬件和新 PC 的设备驱动程序撞得鼻青脸肿时帮助了我。但是要处理源代码并进行修改或提交到上游……那是别人的事,不是我。
### Linux 如何成为我的工作
1999 年,我终于有理由把我对 Linux 的个人兴趣与我在 IBM 的日常工作结合起来了。我接了一个研究项目,将 IBM 的 Java 虚拟机(JVM)移植到 Linux 上。为了确保我们在法律上是安全的,IBM 购买了一个塑封的盒装的 Red Hat Linux 6.1 副本来完成这项工作。在 IBM 东京研究实验室工作时,为了编写我们的 JVM 即时编译器(JIT),参考了 AIX JVM 源代码和 Windows 及 OS/2 的 JVM 源代码,我们在几周内就有了一个可以工作在 Linux 上的 JVM,击败了 SUN 公司官方宣告花了几个月才把 Java 移植到 Linux。既然我在 Linux 平台上做得了开发,我就更喜欢它了。
到 2000 年,IBM 使用 Linux 的频率迅速增加。由于 [Dan Frye](https://www.linkedin.com/in/danieldfrye/) 的远见和坚持,IBM 在 Linux 上下了“[一亿美元的赌注](http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/linux/)”,在 1999 年创建了 Linux 技术中心(LTC)。在 LTC 里面有内核开发者、开源贡献者、IBM 硬件设备的驱动程序编写者,以及各种各样的针对 Linux 的开源工作。比起留在与 LTC 联系不大的部门,我更想要成为这个令人兴奋的 IBM 新天地的一份子。
从 2003 年到 2013 年我深度参与了 IBM 的 Linux 战略和 Linux 发行版(在 IBM 内部)的使用,最终组成了一个团队成为大约 60 个产品的信息交换所,Linux 的使用涉及了 IBM 每个部门。我参与了收购,期望每个设备、管理系统和虚拟机或者基于物理设备的中间件都能运行 Linux。我开始熟悉 Linux 发行版的构建,包括打包、选择上游来源、开发发行版维护的补丁集、做定制,并通过我们的发行版合作伙伴提供支持。
由于我们的下游供应商,我很少提交补丁到上游,但我通过配合 [Ulrich Drepper](https://www.linkedin.com/in/ulrichdrepper/) (将一个小补丁提交到 glibc)和改变[时区数据库](https://en.wikipedia.org/wiki/Tz_database)的工作贡献了自己的力量(Arthur David Olson 在 NIH 的 FTP 站点维护它的时候接受了这个改变)。但我仍然没有把开源项目的正式贡献者的工作来当做我的工作的一部分。是该改变这种情况的时候了。
在 2013 年末,我加入了 IBM 在开源社区的云组织,并正在寻找一个上游社区参与进来。我会在 Cloud Foundry 工作,还是会加入 IBM 为 OpenStack 贡献的大组中呢?都不是,因为在 2014 年 Docker 席卷了全球,IBM 要我们几个参与到这个热门的新技术。我在接下来的几个月里,经历了许多的第一次:使用 GitHub,比起只是 `git clone` [学习了关于 Git 的更多知识](/article-9319-1.html),做过 Pull Request 的审查,用 Go 语言写代码,等等。在接下来的一年中,我在 Docker 引擎项目上成为一个维护者,为 Dockr 创造下一版的镜像规范(支持多个架构),并在一个关于容器技术的会议上出席和讲话。
### 如今的我
一晃几年过去,我已经成为了包括 CNCF 的 [containerd](https://github.com/containerd/containerd) 项目在内的开源项目的维护者。我还创建了项目(如 [manifest-tool](https://github.com/estesp/manifest-tool) 和 [bucketbench](https://github.com/estesp/bucketbench))。我也通过 OCI 参与了开源治理,我现在是技术监督委员会的成员;而在Moby 项目,我是技术指导委员会的成员。我乐于在世界各地的会议、沙龙、IBM 内部发表关于开源的演讲。
开源现在是我在 IBM 职业生涯的一部分。我与工程师、开发人员和行业领袖的联系可能比我在 IBM 内认识的人的联系还要多。虽然开源与专有开发团队和供应商合作伙伴有许多相同的挑战,但据我的经验,开源与全球各地的人们的关系和联系远远超过困难。随着不同的意见、观点和经验的不断优化,可以对软件和涉及的在其中的人产生一种不断学习和改进的文化。
这个旅程 —— 从我第一次使用 Linux 到今天成为一个领袖、贡献者,和现在云原生开源世界的维护者 —— 我获得了极大的收获。我期待着与全球各地的人们长久的进行开源协作和互动。
---
via: <https://opensource.com/article/18/2/my-open-source-story-phil-estes>
作者:[Phil Estes](https://opensource.com/users/estesp) 译者:[ranchong](https://github.com/ranchong) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,432 | 简单介绍 ldd 命令 | https://www.howtoforge.com/linux-ldd-command/ | 2018-03-12T08:38:40 | [
"ldd"
] | https://linux.cn/article-9432-1.html | 
如果您的工作涉及到 Linux 中的可执行文件和共享库的知识,则需要了解几种命令行工具。其中之一是 `ldd` ,您可以使用它来访问共享对象依赖关系。在本教程中,我们将使用一些易于理解的示例来讨论此实用程序的基础知识。
请注意,这里提到的所有示例都已在 Ubuntu 16.04 LTS 上进行了测试。
### Linux ldd 命令
正如开头已经提到的,`ldd` 命令打印共享对象依赖关系。以下是该命令的语法:
```
ldd [option]... file...
```
下面是该工具的手册页对它作出的解释:
>
> ldd 会输出命令行指定的每个程序或共享对象所需的共享对象(共享库)。
>
>
>
以下使用问答的方式让您更好地了解ldd的工作原理。
### 问题一、 如何使用 ldd 命令?
`ldd` 的基本用法非常简单,只需运行 `ldd` 命令以及可执行文件或共享对象的文件名称作为输入。
```
ldd [object-name]
```
例如:
```
ldd test
```
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-basic.png)
所以你可以看到所有的共享库依赖已经在输出中产生了。
### Q2、 如何使 ldd 在输出中生成详细的信息?
如果您想要 `ldd` 生成详细信息,包括符号版本控制数据,则可以使用 `-v` 命令行选项。例如,该命令
```
ldd -v test
```
当使用 `-v` 命令行选项时,在输出中产生以下内容:
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-v-option.png)
### Q3、 如何使 ldd 产生未使用的直接依赖关系?
对于这个信息,使用 `-u` 命令行选项。这是一个例子:
```
ldd -u test
```
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-u-test.png)
### Q4、 如何让 ldd 执行重定位?
您可以在这里使用几个命令行选项:`-d` 和 `-r`。 前者告诉 `ldd` 执行数据重定位,后者则使 `ldd` 为数据对象和函数执行重定位。在这两种情况下,该工具都会报告丢失的 ELF 对象(如果有的话)。
```
ldd -d
ldd -r
```
### Q5、 如何获得关于ldd的帮助?
`--help` 命令行选项使 `ldd` 为该工具生成有用的用法相关信息。
```
ldd --help
```
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-help-option.png)
### 总结
`ldd` 不像 `cd`、`rm` 和 `mkdir` 这样的工具类别。这是因为它是为特定目的而构建的。该实用程序提供了有限的命令行选项,我们在这里介绍了其中的大部分。要了解更多信息,请前往 `ldd` 的[手册页](https://linux.die.net/man/1/ldd)。
---
via: <https://www.howtoforge.com/linux-ldd-command/>
作者: [Himanshu Arora](https://www.howtoforge.com/) 选题: [lujun9972](https://github.com/lujun9972) 译者: [MonkeyDEcho](https://github.com/MonkeyDEcho) 校对: [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # How to list shared libraries used by a Linux binary using ldd command
The `ldd` (List Dynamic Dependencies) command on Linux is a crucial tool used for examining the shared libraries required by an executable or shared object file. By running `ldd` followed by the name of the executable or library, users can see which dynamic libraries are needed and where the system expects to find them. This command helps in troubleshooting issues related to missing or incompatible libraries, ensuring that all dependencies are correctly resolved. It displays the full paths to the libraries or indicates if any are missing, making it an essential utility for system administrators and developers managing software dependencies on Linux systems.
All the examples mentioned here have been tested on Ubuntu Linux, but the command works exactly the same way on other Distributions.
## Linux ldd command
As already mentioned in the beginning, the ldd command prints shared object dependencies. Following is the command's syntax:
ldd [option]... file...
And here's how the tool's man page explains it:
ldd prints the shared objects (shared libraries) required by each program or shared object
specified on the command line.
The following Q&A-styled examples should give you a better idea on how ldd works.
## Q1. How to use the ldd command?
Basic usage of ldd is fairly simple - just run the 'ldd' command along with an executable or shared object file name as input.
ldd [object-name]
For example:
ldd test
So you can see all shared library dependencies have been produced in output.
## Q2. How to make ldd produce detailed information in output?
If you want ldd to produce detailed information, including symbol versioning data, you can use the -v command line option. For example, the command
ldd -v test
produced the following in output when the **-v** command-line option was used:
## Q3. How to make ldd produce unused direct dependencies?
For this info, use the **-u** command-line option. Here's an example:
ldd -u test
## Q4. How make ldd perform relocations?
There are a couple of command line options you can use here: **-d** and **-r**. While the former tells ldd to perform data relocations, the latter makes ldd perform relocations for both data objects and functions. In both cases, the tool reports missing ELF objects (if any).
ldd -d
ldd -r
## Q5. How get help on ldd?
The --help command line option makes ldd produce useful usage-related information for the tool.
ldd --help
## Conclusion
Ldd doesn't fall into the category where tools like cd, rm, and mkdir fit in. That's because it's built for a specific purpose and does what it promises. The utility offers limited command line options; we've covered most of them here. To know more, head to ldd's [man page](https://linux.die.net/man/1/ldd). |
9,433 | 使用 Showterm 录制和分享终端会话 | https://www.maketecheasier.com/record-terminal-session-showterm/ | 2018-03-12T08:47:36 | [
"录制",
"终端"
] | https://linux.cn/article-9433-1.html | 
你可以使用几乎所有的屏幕录制程序轻松录制终端会话。但是,你很可能会得到超大的视频文件。Linux 中有几种终端录制程序,每种录制程序都有自己的优点和缺点。Showterm 是一个可以非常容易地记录终端会话、上传、分享,并将它们嵌入到任何网页中的工具。一个优点是,你不会有巨大的文件来处理。
Showterm 是开源的,该项目可以在这个 [GitHub 页面](https://github.com/ConradIrwin/showterm)上找到。
**相关**:[2 个简单的将你的终端会话录制为视频的 Linux 程序](https://www.maketecheasier.com/record-terminal-session-as-video/ "2 Simple Applications That Record Your Terminal Session as Video [Linux]")
### 在 Linux 中安装 Showterm
Showterm 要求你在计算机上安装了 Ruby。以下是如何安装该程序。
```
gem install showterm
```
如果你没有在 Linux 上安装 Ruby,可以这样:
```
sudo curl showterm.io/showterm > ~/bin/showterm
sudo chmod +x ~/bin/showterm
```
如果你只是想运行程序而不是安装:
```
bash <(curl record.showterm.io)
```
你可以在终端输入 `showterm --help` 得到帮助页面。如果没有出现帮助页面,那么可能是未安装 `showterm`。现在你已安装了 Showterm(或正在运行独立版本),让我们开始使用该工具进行录制。
**相关**:[如何在 Ubuntu 中录制终端会话](https://www.maketecheasier.com/record-terminal-session-in-ubuntu/ "How to Record Terminal Session in Ubuntu")
### 录制终端会话

录制终端会话非常简单。从命令行运行 `showterm`。这会在后台启动终端录制。所有从命令行输入的命令都由 Showterm 记录。完成录制后,请按 `Ctrl + D` 或在命令行中输入`exit` 停止录制。
Showterm 会上传你的视频并输出一个看起来像 `http://showterm.io/<一长串字符>` 的链接的视频。不幸的是,终端会话会立即上传,而没有任何提示。请不要惊慌!你可以通过输入 `showterm --delete <recording URL>` 删除任何已上传的视频。在上传视频之前,你可以通过在 `showterm` 命令中添加 `-e` 选项来改变计时。如果视频无法上传,你可以使用 `showterm --retry <script> <times>` 强制重试。
在查看录制内容时,还可以通过在 URL 中添加 `#slow`、`#fast` 或 `#stop` 来控制视频的计时。`#slow` 让视频以正常速度播放、`#fast` 是速度加倍、`#stop`,如名称所示,停止播放视频。
Showterm 终端录制视频可以通过 iframe 轻松嵌入到网页中。这可以通过将 iframe 源添加到 showterm 视频地址来实现,如下所示。

作为开源工具,Showterm 允许进一步定制。例如,要运行你自己的 Showterm 服务器,你需要运行以下命令:
```
export SHOWTERM_SERVER=https://showterm.myorg.local/
```
这样你的客户端可以和它通信。还有额外的功能只需很少的编程知识就可添加。Showterm 服务器项目可在此 [GitHub 页面](https://github.com/ConradIrwin/showterm)获得。
### 结论
如果你想与同事分享一些命令行教程,请务必记得 Showterm。Showterm 是基于文本的。因此,与其他屏幕录制机相比,它将产生相对较小的视频。该工具本身尺寸相当小 —— 只有几千字节。
---
via: <https://www.maketecheasier.com/record-terminal-session-showterm/>
作者:[Bruno Edoh](https://www.maketecheasier.com/author/brunoedoh/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You can easily record your terminal sessions with virtually all screen recording programs. However, you are very likely to end up with an oversized video file. There are several terminal recorders available in Linux, each with its own strengths and weakness. Showterm is a tool that makes it pretty easy to record terminal sessions, upload them, share, and embed them in any web page. On the plus side, you don’t end up with any huge file to deal with.
Showterm is open source, and the project can be found on this [GitHub page](https://github.com/ConradIrwin/showterm).
**Also read:** [2 Simple Applications That Record Your Terminal Session as Video [Linux]](https://www.maketecheasier.com/record-terminal-session-as-video/)
## Installing Showterm for Linux
Showterm requires that you have Ruby installed on your computer. Here’s how to go about installing the program.
`gem install showterm`
If you don’t have Ruby installed on your Linux system:
sudo curl showterm.io/showterm > ~/bin/showterm sudo chmod +x ~/bin/showterm
If you just want to run the application without installation:
bash <(curl record.showterm.io)
You can type `showterm --help`
for the help screen. If a help page doesn’t appear, showterm is probably not installed. Now that you have Showterm installed (or are running the standalone version), let us dive into using the tool to record.
**Also read:** [How to Record Terminal Session in Ubuntu](https://www.maketecheasier.com/record-terminal-session-in-ubuntu/)
## Recording Terminal Session
Recording a terminal session is pretty simple. From the command line run `showterm`
. This should start the terminal recording in the background. All commands entered in the command line from hereon are recorded by Showterm. Once you are done recording, press Ctrl + D or type `exit`
in the command line to stop your recording.
Showterm should upload your video and output a link to the video that looks like http://showterm.io/<long alpha-numeric characters>. It is rather unfortunate that terminal sessions are uploaded right away without any prompting. Don’t panic! You can delete any uploaded recording by entering `showterm --delete <recording URL>`
. Before uploading your recordings, you’ll have the chance to change the timing by adding the `-e`
option to the showterm command. If by any chance a recording fails to upload, you can use `showterm --retry <script> <times>`
to force a retry.
When viewing your recordings, the timing of the video can also be controlled by appending “#slow,” “#fast,” or “#stop” to the URL. Slow makes the video run at normal speed; fast doubles the speed; and stop, as the name suggests, stops the video.
Showterm terminal recordings can easily be embedded in web pages via iframes. This can be achieved by adding the iframe source to the showterm video URL as shown below.
As an open source tool, Showterm allows for further customization. For instance, to run your own Showterm server, you need to run the command:
export SHOWTERM_SERVER=https://showterm.myorg.local/
so your client can communicate with it. Additional features can be added with little programming knowledge. The Showterm server project is available from this [GitHub page](https://github.com/ConradIrwin/showterm).
## Conclusion
In case you are thinking of sharing some command line tutorials with a colleague, be sure to remember Showterm. Showterm is text-based; hence, it will yield a relatively small-sized video compared to other screen recorders. The tool itself is pretty small in size – only a few kilobytes.
Our latest tutorials delivered straight to your inbox |
9,434 | 在 Linux 中自动配置 IPv6 地址 | https://www.linux.com/learn/intro-to-linux/2017/12/ipv6-auto-configuration-linux | 2018-03-12T09:30:00 | [
"IPv6",
"IP"
] | https://linux.cn/article-9434-1.html | 
在 [KVM 中测试 IPv6 网络:第 1 部分](/article-9594-1.html) 一文中,我们学习了关于<ruby> 唯一本地地址 <rt> unique local addresses </rt></ruby>(ULA)的相关内容。在本文中,我们将学习如何为 ULA 自动配置 IP 地址。
### 何时使用唯一本地地址
<ruby> 唯一本地地址 <rt> unique local addresses </rt></ruby>(ULA)使用 `fd00::/8` 地址块,它类似于我们常用的 IPv4 的私有地址:`10.0.0.0/8`、`172.16.0.0/12`、以及 `192.168.0.0/16`。但它们并不能直接替换。IPv4 的私有地址分类和网络地址转换(NAT)功能是为了缓解 IPv4 地址短缺的问题,这是个明智的解决方案,它延缓了本该被替换的 IPv4 的生命周期。IPv6 也支持 NAT,但是我想不出使用它的理由。IPv6 的地址数量远远大于 IPv4;它是不一样的,因此需要做不一样的事情。
那么,ULA 存在的意义是什么呢?尤其是在我们已经有了<ruby> 本地链路地址 <rt> link-local addresses </rt></ruby>(`fe80::/10`)时,到底需不需要我们去配置它们呢?它们之间(LCTT 译注:指的是唯一本地地址和本地链路地址)有两个重要的区别。一是,本地链路地址是不可路由的,因此,你不能跨子网使用它。二是,ULA 是你自己管理的;你可以自己选择它用于子网的地址范围,并且它们是可路由的。
使用 ULA 的另一个好处是,如果你只是在局域网中“混日子”的话,你不需要为它们分配全局单播 IPv6 地址。当然了,如果你的 ISP 已经为你分配了 IPv6 的<ruby> 全局单播地址 <rt> global unicast addresses </rt></ruby>,就不需要使用 ULA 了。你也可以在同一个网络中混合使用全局单播地址和 ULA,但是,我想不出这样使用的一个好理由,并且要一定确保你不使用网络地址转换(NAT)以使 ULA 可公共访问。在我看来,这是很愚蠢的行为。
ULA 是仅为私有网络使用的,并且应该阻止其流出你的网络,不允许进入因特网。这很简单,在你的边界设备上只要阻止整个 `fd00::/8` 范围的 IPv6 地址即可实现。
### 地址自动配置
ULA 不像本地链路地址那样自动配置的,但是使用 radvd 设置自动配置是非常容易的,radva 是路由器公告守护程序。在你开始之前,运行 `ifconfig` 或者 `ip addr show` 去查看你现有的 IP 地址。
在生产系统上使用时,你应该将 radvd 安装在一台单独的路由器上,如果只是测试使用,你可以将它安装在你的网络中的任意 Linux PC 上。在我的小型 KVM 测试实验室中,我使用 `apt-get install radvd` 命令把它安装在 Ubuntu 上。安装完成之后,我先不启动它,因为它还没有配置文件:
```
$ sudo systemctl status radvd
● radvd.service - LSB: Router Advertising Daemon
Loaded: loaded (/etc/init.d/radvd; bad; vendor preset: enabled)
Active: active (exited) since Mon 2017-12-11 20:08:25 PST; 4min 59s ago
Docs: man:systemd-sysv-generator(8)
Dec 11 20:08:25 ubunut1 systemd[1]: Starting LSB: Router Advertising Daemon...
Dec 11 20:08:25 ubunut1 radvd[3541]: Starting radvd:
Dec 11 20:08:25 ubunut1 radvd[3541]: * /etc/radvd.conf does not exist or is empty.
Dec 11 20:08:25 ubunut1 radvd[3541]: * See /usr/share/doc/radvd/README.Debian
Dec 11 20:08:25 ubunut1 radvd[3541]: * radvd will *not* be started.
Dec 11 20:08:25 ubunut1 systemd[1]: Started LSB: Router Advertising Daemon.
```
这些所有的消息有点让人困惑,实际上 radvd 并没有运行,你可以使用经典命令 `ps | grep radvd` 来验证这一点。因此,我们现在需要去创建 `/etc/radvd.conf` 文件。拷贝这个示例,将第一行的网络接口名替换成你自己的接口名字:
```
interface ens7 {
AdvSendAdvert on;
MinRtrAdvInterval 3;
MaxRtrAdvInterval 10;
prefix fd7d:844d:3e17:f3ae::/64
{
AdvOnLink on;
AdvAutonomous on;
};
};
```
前缀(`prefix`)定义了你的网络地址,它是地址的前 64 位。前两个字符必须是 `fd`,前缀接下来的剩余部分你自己定义它,最后的 64 位留空,因为 radvd 将去分配最后的 64 位。前缀后面的 16 位用来定义子网,剩余的地址定义为主机地址。你的子网必须总是 `/64`。RFC 4193 要求地址必须随机生成;查看 [在 KVM 中测试 IPv6 Networking:第 1 部分](https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1) 学习创建和管理 ULAs 的更多知识。
### IPv6 转发
IPv6 转发必须要启用。下面的命令去启用它,重启后生效:
```
$ sudo sysctl -w net.ipv6.conf.all.forwarding=1
```
取消注释或者添加如下的行到 `/etc/sysctl.conf` 文件中,以使它永久生效:
```
net.ipv6.conf.all.forwarding = 1
```
启动 radvd 守护程序:
```
$ sudo systemctl stop radvd
$ sudo systemctl start radvd
```
这个示例在我的 Ubuntu 测试系统中遇到了一个怪事;radvd 总是停止,我查看它的状态却没有任何问题,做任何改变之后都需要重新启动 radvd。
启动成功后没有任何输出,并且失败也是如此,因此,需要运行 `sudo systemctl status radvd` 去查看它的运行状态。如果有错误,`systemctl` 会告诉你。一般常见的错误都是 `/etc/radvd.conf` 中的语法错误。
在 Twitter 上抱怨了上述问题之后,我学到了一件很酷的技巧:当你运行 `journalctl -xe --no-pager` 去调试 `systemctl` 错误时,你的输出会被换行,然后,你就可以看到错误信息。
现在检查你的主机,查看它们自动分配的新地址:
```
$ ifconfig
ens7 Link encap:Ethernet HWaddr 52:54:00:57:71:50
[...]
inet6 addr: fd7d:844d:3e17:f3ae:9808:98d5:bea9:14d9/64 Scope:Global
[...]
```
本文到此为止,下周继续学习如何为 ULA 管理 DNS,这样你就可以使用一个合适的主机名来代替这些长长的 IPv6 地址。
通过来自 Linux 基金会和 edX 的 [“Linux 入门”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 免费课程学习更多 Linux 的知识。
---
via: <https://www.linux.com/learn/intro-to-linux/2017/12/ipv6-auto-configuration-linux>
作者:[Carla Schroder](https://www.linux.com/users/cschroder) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,435 | 为初学者介绍的 Linux tee 命令(6 个例子) | https://www.howtoforge.com/linux-tee-command/ | 2018-03-12T11:25:03 | [
"tee",
"输出"
] | https://linux.cn/article-9435-1.html | 
有时候,你会想手动跟踪命令的输出内容,同时又想将输出的内容写入文件,确保之后可以用来参考。如果你想寻找这相关的工具,那么恭喜你,Linux 已经有了一个叫做 `tee` 的命令可以帮助你。
本教程中,我们将基于 `tee` 命令,用一些简单的例子开始讨论。但是在此之前,值得一提的是,本文我们所有的测试实例都基于 Ubuntu 16.04 LTS。
### Linux tee 命令
`tee` 命令基于标准输入读取数据,标准输出或文件写入数据。感受下这个命令的语法:
```
tee [OPTION]... [FILE]...
```
这里是帮助文档的说明:
>
> 从标准输入中复制到每一个文件,并输出到标准输出。
>
>
>
让 Q&A(问&答)风格的实例给我们带来更多灵感,深入了解这个命令。
### Q1、 如何在 Linux 上使用这个命令?
假设因为某些原因,你正在使用 `ping` 命令。
```
ping google.com
```
[](https://www.howtoforge.com/images/command-tutorial/big/ping-example.png)
然后同时,你想要输出的信息也同时能写入文件。这个时候,`tee` 命令就有其用武之地了。
```
ping google.com | tee output.txt
```
下面的截图展示了这个输出内容不仅被写入 `output.txt` 文件,也被显示在标准输出中。
[](https://www.howtoforge.com/images/command-tutorial/big/ping-with-tee.png)
如此应当明白了 `tee` 的基础用法。
### Q2、 如何确保 tee 命令追加信息到文件中?
默认情况下,在同一个文件下再次使用 `tee` 命令会覆盖之前的信息。如果你想的话,可以通过 `-a` 命令选项改变默认设置。
```
[command] | tee -a [file]
```
基本上,`-a` 选项强制 `tee` 命令追加信息到文件。
### Q3、 如何让 tee 写入多个文件?
这非常之简单。你仅仅只需要写明文件名即可。
```
[command] | tee [file1] [file2] [file3]
```
比如:
```
ping google.com | tee output1.txt output2.txt output3.txt
```
[](https://www.howtoforge.com/images/command-tutorial/big/tee-mult-files1.png)
### Q4. 如何让 tee 命令的输出内容直接作为另一个命令的输入内容?
使用 `tee` 命令,你不仅可以将输出内容写入文件,还可以把输出内容作为另一个命令的输入内容。比如说,下面的命令不仅会将文件名存入 `output.txt` 文件中,还会通过 `wc` 命令让你知道输入到 `output.txt` 中的文件数目。
```
ls file* | tee output.txt | wc -l
```
[](https://www.howtoforge.com/images/command-tutorial/big/tee-redirect-output.png)
### Q5. 如何使用 tee 命令提升文件写入权限?
假如你使用 [Vim 编辑器](https://www.howtoforge.com/vim-basics) 打开文件,并且做了很多更改,然后当你尝试保存修改时,你得到一个报错,让你意识到那是一个 root 所拥有的文件,这意味着你需要使用 `sudo` 权限保存修改。
[](https://www.howtoforge.com/images/command-tutorial/big/vim-write-error.png)
如此情况下,你可以(在 Vim 内)使用 `tee` 命令来提高权限。
```
:w !sudo tee %
```
上述命令会向你索要 root 密码,然后就能让你保存修改了。
### Q6. 如何让 tee 命令忽视中断?
`-i` 命令行选项使 `tee` 命令忽视通常由 `ctrl+c` 组合键发起的中断信号(`SIGINT`)。
```
[command] | tee -i [file]
```
当你想要使用 `ctrl+c` 中断该命令,同时让 `tee` 命令优雅的退出,这个选项尤为实用。
### 总结
现在你可能已经认同 `tee` 是一个非常实用的命令。基于 `tee` 命令的用法,我们已经介绍了其绝大多数的命令行选项。这个工具并没有什么陡峭的学习曲线,所以,只需跟随这几个例子练习,你就可以运用自如了。更多信息,请查看 [帮助文档](https://linux.die.net/man/1/tee).
---
via: <https://www.howtoforge.com/linux-tee-command/>
作者:[Himanshu Arora](https://www.howtoforge.com) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Linux tee Command Explained for Beginners (6 Examples)
### On this page
[Linux tee command](#linux-tee-command)[Q1. How to use tee command in Linux?](#q-how-to-use-tee-command-in-linux)[Q2. How to make sure tee appends information in files?](#q-how-to-make-sure-tee-appends-information-in-files)[Q3. How to make tee write to multiple files?](#q-how-to-make-tee-write-to-multiple-files)[Q4. How to make tee redirect output of one command to another?](#q-how-to-make-tee-redirect-output-of-one-command-to-another)[Q5. How to write to a file with elevated privileges using tee?](#q-how-to-write-to-a-file-with-elevated-privileges-using-tee)[Q6. How to make tee ignore interrupt?](#q-how-to-make-tee-ignore-interrupt)[Conclusion](#conclusion)
There are times when you want to manually track output of a command and also simultaneously make sure the output is being written to a file so that you can refer to it later. If you are looking for a Linux tool which can do this for you, you'll be glad to know there exists a command * tee* that's built for this purpose.
In this tutorial, we will discuss the basics of the tee command using some easy to understand examples. But before we do that, it's worth mentioning that all examples used in this article have been tested on Ubuntu 16.04 LTS.
## Linux tee command
The tee command basically reads from the standard input and writes to standard output and files. Following is the syntax of the command:
tee [OPTION]... [FILE]...
And here's how the man page explains it:
Copy standard input to each FILE, and also to standard output.
The following Q&A-styled examples should give you a better idea on how the command works.
## Q1. How to use tee command in Linux?
Suppose you are using the ping command for some reason.
ping google.com
And what you want, is that the output should also get written to a file in parallel. Then here's where you can use the tee command.
ping google.com | tee output.txt
The following screenshot shows the output was written to the 'output.txt' file along with being written on stdout.
So that should clear the basic usage of tee.
## Q2. How to make sure tee appends information in files?
By default, the tee command overwrites information in a file when used again. However, if you want, you can change this behavior by using the -a command line option.
[command] | tee -a [file]
So basically, the -a option forces tee to append information to the file.
## Q3. How to make tee write to multiple files?
That's pretty easy. You just have to mention their names.
[command] | tee [file1] [file2] [file3]
For example:
ping google.com | tee output1.txt output2.txt output3.txt
## Q4. How to make tee redirect output of one command to another?
You can not only use tee to simultaneously write output to files, but also to pass on the output as input to other commands. For example, the following command will not only store the filenames in 'output.txt' but also let you know - through wc - the number of entries in the output.txt file.
ls file* | tee output.txt | wc -l
## Q5. How to write to a file with elevated privileges using tee?
Suppose you opened a file in the [Vim editor](https://www.howtoforge.com/vim-basics), made a lot of changes, and then when you tried saving those changes, you got an error that made you realize that it's a root-owned file, meaning you need to have sudo privileges to save these changes.
In scenarios like these, you can use tee to elevate privileges on the go.
:w !sudo tee %
The aforementioned command will ask you for root password, and then let you save the changes.
## Q6. How to make tee ignore interrupt?
The -i command line option enables tee to ignore the interrupt signal (`SIGINT`
), which is usually issued when you press the crl+c key combination.
[command] | tee -i [file]
This is useful when you want to kill the command with ctrl+c but want tee to exit gracefully.
## Conclusion
You'll likely agree now that tee is an extremely useful command. We've discussed it's basic usage as well as majority of its command line options here. The tool doesn't have a steep learning curve, so just practice all these examples, and you should be good to go. For more information, head to the tool's [man page](https://linux.die.net/man/1/tee). |
9,436 | SPARTA:用于网络渗透测试的 GUI 工具套件 | https://gbhackers.com/sparta-network-penetration-testing-gui-toolkit/ | 2018-03-13T09:44:35 | [
"网络渗透",
"扫描"
] | https://linux.cn/article-9436-1.html | 
SPARTA 是使用 Python 开发的 GUI 应用程序,它是 Kali Linux 内置的网络渗透测试工具。它简化了扫描和枚举阶段,并更快速的得到结果。
SPARTA GUI 工具套件最擅长的事情是扫描和发现目标端口和运行的服务。
此外,作为枚举阶段的一部分功能,它提供对开放端口和服务的暴力攻击。
延伸阅读:[网络渗透检查清单](https://gbhackers.com/network-penetration-testing-checklist-examples/)
### 安装
请从 GitHub 上克隆最新版本的 SPARTA:
```
git clone https://github.com/secforce/sparta.git
```
或者,从 [这里](https://github.com/SECFORCE/sparta/archive/master.zip) 下载最新版本的 Zip 文件。
```
cd /usr/share/
git clone https://github.com/secforce/sparta.git
```
将 `sparta` 文件放到 `/usr/bin/` 目录下并赋于可运行权限。
在任意终端中输入 'sparta' 来启动应用程序。
### 网络渗透测试的范围
添加一个目标主机或者目标主机的列表到测试范围中,来发现一个组织的网络基础设备在安全方面的薄弱环节。
选择菜单条 - “File” -> “Add host(s) to scope”
[](https://i0.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-526.png?ssl=1)
[](https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-527.png?ssl=1)
上图展示了在扫描范围中添加 IP 地址。根据你网络的具体情况,你可以添加一个 IP 地址的范围去扫描。 扫描范围添加之后,Nmap 将开始扫描,并很快得到结果,扫描阶段结束。
### 打开的端口及服务
Nmap 扫描结果提供了目标上开放的端口和服务。
[](https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-528.png?ssl=1)
上图展示了扫描发现的目标操作系统、开发的端口和服务。
### 在开放端口上实施暴力攻击
我们来通过 445 端口的服务器消息块(SMB)协议来暴力获取用户列表和它们的有效密码。
[](https://i1.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-529.png?ssl=1)
右键并选择 “Send to Brute” 选项。也可以选择发现的目标上的开放端口和服务。
浏览和在用户名密码框中添加字典文件。
[](https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-531.png?ssl=1)
点击 “Run” 去启动对目标的暴力攻击。上图展示了对目标 IP 地址进行的暴力攻击取得成功,找到了有效的密码。
在 Windows 中失败的登陆尝试总是被记录到事件日志中。
密码每 15 到 30 天改变一次的策略是非常好的一个实践经验。
强烈建议使用强密码策略。密码锁定策略是阻止这种暴力攻击的最佳方法之一( 5 次失败的登录尝试之后将锁定帐户)。
将关键业务资产整合到 SIEM( 安全冲突 & 事件管理)中将尽可能快地检测到这类攻击行为。
SPARTA 对渗透测试的扫描和枚举阶段来说是一个非常省时的 GUI 工具套件。SPARTA 可以扫描和暴力破解各种协议。它有许多的功能!祝你测试顺利!
---
via: <https://gbhackers.com/sparta-network-penetration-testing-gui-toolkit/>
作者:[Balaganesh](https://gbhackers.com/author/balaganesh/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | SPARTA is a GUI application developed with Python and builds Network Penetration Testing [Kali Linux tool](https://gbhackers.com/anonymous-ddos-a-website-using-kali-linux/). It simplifies the scanning and enumeration phase with faster results.
The best thing about the **SPARTA GUI Toolkit** it scans and detects the service running on the target port.
Also, it provides **a Bruteforce attack** for scanned open ports and services as a part of the enumeration phase.
** Also Read: ****Most Important Network Penetration Testing Checklist**
**Installation**
Please clone the latest version of SPARTA from GitHub:
*git clone https://github.com/secforce/sparta.git*
Alternatively, download the latest zip file here.
```
cd /usr/share/
git clone https://github.com/secforce/sparta.git
Place the "sparta" file in /usr/bin/ and make it executable.
Type 'sparta' in any terminal to launch the application.
```
**The Scope of Network Penetration Testing Work:**
- Organizations’ security weaknesses in their network infrastructures are identified by a list of hosts or targeted hosts and add them to the scope.
- Select menu bar – File > Add host(s) to scope




- The above figures show target Ip is added to the scope. Your network can add a range of IPs to scan.
- After adding Nmap scan will begin and the results will be very faster. now scanning phase is done.
**Open Ports & Services:**
- Nmap results will provide target open ports and services.


- The above figure shows that the target operating system, Open ports, and services are discovered as scan results.
**Brute Force Attack on Open Ports:**
- Let us Brute force Server Message Block (SMB) via port 445 to enumerate the list of users and their valid passwords.


- Right-click and Select the option Send to Brute. Also, select discovered Open ports and services on target.
- Browse and add dictionary files for Username and password fields.


- Click Run to start the Brute force attack on the target. The above Figure shows Brute force attack is successfully completed on the target IP and the valid password is Found!
- Always think failed login attempts will be logged as Event logs in Windows.
- Password changing policy should be 15 to 30 days will be a good practice.
- Always recommended to use a strong password as per policy.
- Password lockout policy is a good one to stop brute force attacks (After 5 failure attempts account will be locked)
- The integration of business-critical assets to SIEM( security incident & Event Management) will detect these kinds of attacks as soon as possible.
SPARTA is timing saving GUI Toolkit for pen-testers for the scanning and enumeration phase.SPARTA Scans and Bruteforce various protocols. It has many more features! Happy pentesting.
**Looking for the **Best WAF Solutions for your web applications environment?? Register for the Free WAF webinar & explore the expert’s** thoughts and Choose the Best one.. Very limited seats available.. grab it here at ProPhaze.**
**You can follow us on Linkedin, Twitter, and **
**Facebook**
**for daily Cybersecurity updates also you can take the Best Cybersecurity course online to keep yourself updated**.
**Also, Read**
[Microsoft Launches Identity Bounty Program That Rewards Up to $100,000](https://gbhackers.com/microsoft-launches-identity-bounty-program/) |
9,437 | Linux 启动过程分析 | https://opensource.com/article/18/1/analyzing-linux-boot-process | 2018-03-13T10:57:27 | [
"启动",
"内核"
] | https://linux.cn/article-9437-1.html |
>
> 理解运转良好的系统对于处理不可避免的故障是最好的准备。
>
>
>

关于开源软件最古老的笑话是:“代码是<ruby> 自具文档化的 <rt> self-documenting </rt></ruby>”。经验表明,阅读源代码就像听天气预报一样:明智的人依然出门会看看室外的天气。本文讲述了如何运用调试工具来观察和分析 Linux 系统的启动。分析一个功能正常的系统启动过程,有助于用户和开发人员应对不可避免的故障。
从某些方面看,启动过程非常简单。内核在单核上以单线程和同步状态启动,似乎可以理解。但内核本身是如何启动的呢?[initrd(initial ramdisk)](https://en.wikipedia.org/wiki/Initial_ramdisk) 和<ruby> 引导程序 <rt> bootloader </rt></ruby>具有哪些功能?还有,为什么以太网端口上的 LED 灯是常亮的呢?
请继续阅读寻找答案。在 GitHub 上也提供了 [介绍演示和练习的代码](https://github.com/chaiken/LCA2018-Demo-Code)。
### 启动的开始:OFF 状态
#### <ruby> 局域网唤醒 <rt> Wake-on-LAN </rt></ruby>
OFF 状态表示系统没有上电,没错吧?表面简单,其实不然。例如,如果系统启用了局域网唤醒机制(WOL),以太网指示灯将亮起。通过以下命令来检查是否是这种情况:
```
# sudo ethtool <interface name>
```
其中 `<interface name>` 是网络接口的名字,比如 `eth0`。(`ethtool` 可以在同名的 Linux 软件包中找到。)如果输出中的 `Wake-on` 显示 `g`,则远程主机可以通过发送 [<ruby> 魔法数据包 <rt> MagicPacket </rt></ruby>](https://en.wikipedia.org/wiki/Wake-on-LAN) 来启动系统。如果您无意远程唤醒系统,也不希望其他人这样做,请在系统 BIOS 菜单中将 WOL 关闭,或者用以下方式:
```
# sudo ethtool -s <interface name> wol d
```
响应魔法数据包的处理器可能是网络接口的一部分,也可能是 [<ruby> 底板管理控制器 <rt> Baseboard Management Controller </rt></ruby>](https://lwn.net/Articles/630778/)(BMC)。
#### 英特尔管理引擎、平台控制器单元和 Minix
BMC 不是唯一的在系统关闭时仍在监听的微控制器(MCU)。x86\_64 系统还包含了用于远程管理系统的英特尔管理引擎(IME)软件套件。从服务器到笔记本电脑,各种各样的设备都包含了这项技术,它开启了如 KVM 远程控制和英特尔功能许可服务等 [功能](https://www.youtube.com/watch?v=iffTJ1vPCSo&amp;amp;amp;amp;amp;index=65&amp;amp;amp;amp;amp;list=PLbzoR-pLrL6pISWAq-1cXP4_UZAyRtesk)。根据 [Intel 自己的检测工具](https://www.intel.com/content/www/us/en/support/articles/000025619/software.html),[IME 存在尚未修补的漏洞](https://security-center.intel.com/advisory.aspx?intelid=INTEL-SA-00086&amp;amp;amp;amp;amp;languageid=en-fr)。坏消息是,要禁用 IME 很难。Trammell Hudson 发起了一个 [me\_cleaner 项目](https://github.com/corna/me_cleaner),它可以清除一些相对恶劣的 IME 组件,比如嵌入式 Web 服务器,但也可能会影响运行它的系统。
IME 固件和<ruby> 系统管理模式 <rt> System Management Mode </rt></ruby>(SMM)软件是 [基于 Minix 操作系统](https://lwn.net/Articles/738649/) 的,并运行在单独的<ruby> 平台控制器单元 <rt> Platform Controller Hub </rt></ruby>上(LCTT 译注:即南桥芯片),而不是主 CPU 上。然后,SMM 启动位于主处理器上的<ruby> 通用可扩展固件接口 <rt> Universal Extensible Firmware Interface </rt></ruby>(UEFI)软件,相关内容 [已被提及多次](https://lwn.net/Articles/699551/)。Google 的 Coreboot 小组已经启动了一个雄心勃勃的 [<ruby> 非扩展性缩减版固件 <rt> Non-Extensible Reduced Firmware </rt></ruby>](https://trmm.net/NERF)(NERF)项目,其目的不仅是要取代 UEFI,还要取代早期的 Linux 用户空间组件,如 systemd。在我们等待这些新成果的同时,Linux 用户现在就可以从 Purism、System76 或 Dell 等处购买 [禁用了 IME](https://www.extremetech.com/computing/259879-dell-now-shipping-laptops-intels-management-engine-disabled) 的笔记本电脑,另外 [带有 ARM 64 位处理器笔记本电脑](https://lwn.net/Articles/733837/) 还是值得期待的。
#### 引导程序
除了启动那些问题不断的间谍软件外,早期引导固件还有什么功能呢?引导程序的作用是为新上电的处理器提供通用操作系统(如 Linux)所需的资源。在开机时,不但没有虚拟内存,在控制器启动之前连 DRAM 也没有。然后,引导程序打开电源,并扫描总线和接口,以定位内核镜像和根文件系统的位置。U-Boot 和 GRUB 等常见的引导程序支持 USB、PCI 和 NFS 等接口,以及更多的嵌入式专用设备,如 NOR 闪存和 NAND 闪存。引导程序还与 [<ruby> 可信平台模块 <rt> Trusted Platform Module </rt></ruby>](https://linuxplumbersconf.org/2017/ocw/events/LPC2017/tracks/639)(TPM)等硬件安全设备进行交互,在启动最开始建立信任链。

*在构建主机上的沙盒中运行 U-boot 引导程序。*
包括树莓派、任天堂设备、汽车主板和 Chromebook 在内的系统都支持广泛使用的开源引导程序 [U-Boot](http://www.denx.de/wiki/DULG/Manual)。它没有系统日志,当发生问题时,甚至没有任何控制台输出。为了便于调试,U-Boot 团队提供了一个沙盒,可以在构建主机甚至是夜间的持续集成(CI)系统上测试补丁程序。如果系统上安装了 Git 和 GNU Compiler Collection(GCC)等通用的开发工具,使用 U-Boot 沙盒会相对简单:
```
# git clone git://git.denx.de/u-boot; cd u-boot
# make ARCH=sandbox defconfig
# make; ./u-boot
=> printenv
=> help
```
在 x86\_64 上运行 U-Boot,可以测试一些棘手的功能,如 [模拟存储设备](https://github.com/chaiken/LCA2018-Demo-Code) 的重新分区、基于 TPM 的密钥操作以及 USB 设备热插拔等。U-Boot 沙盒甚至可以在 GDB 调试器下单步执行。使用沙盒进行开发的速度比将引导程序刷新到电路板上的测试快 10 倍,并且可以使用 `Ctrl + C` 恢复一个“变砖”的沙盒。
### 启动内核
#### 配置引导内核
引导程序完成任务后将跳转到已加载到主内存中的内核代码,并开始执行,传递用户指定的任何命令行选项。内核是什么样的程序呢?用命令 `file /boot/vmlinuz` 可以看到它是一个 “bzImage”,意思是一个大的压缩的镜像。Linux 源代码树包含了一个可以解压缩这个文件的工具—— [extract-vmlinux](https://github.com/torvalds/linux/blob/master/scripts/extract-vmlinux):
```
# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux
# file vmlinux
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically
linked, stripped
```
内核是一个 [<ruby> 可执行与可链接格式 <rt> Executable and Linking Format </rt></ruby>](http://man7.org/linux/man-pages/man5/elf.5.html)(ELF)的二进制文件,就像 Linux 的用户空间程序一样。这意味着我们可以使用 `binutils` 包中的命令,如 `readelf` 来检查它。比较一下输出,例如:
```
# readelf -S /bin/date
# readelf -S vmlinux
```
这两个二进制文件中的段内容大致相同。
所以内核必须像其他的 Linux ELF 文件一样启动,但用户空间程序是如何启动的呢?在 `main()` 函数中?并不确切。
在 `main()` 函数运行之前,程序需要一个执行上下文,包括堆栈内存以及 `stdio`、`stdout` 和 `stderr` 的文件描述符。用户空间程序从标准库(多数 Linux 系统在用 “glibc”)中获取这些资源。参照以下输出:
```
# file /bin/date
/bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically
linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32,
BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a,
stripped
```
ELF 二进制文件有一个解释器,就像 Bash 和 Python 脚本一样,但是解释器不需要像脚本那样用 `#!` 指定,因为 ELF 是 Linux 的原生格式。ELF 解释器通过调用 `_start()` 函数来用所需资源 [配置一个二进制文件](https://0xax.gitbooks.io/linux-insides/content/Misc/program_startup.html),这个函数可以从 glibc 源代码包中找到,可以 [用 GDB 查看](https://github.com/chaiken/LCA2018-Demo-Code/commit/e543d9812058f2dd65f6aed45b09dda886c5fd4e)。内核显然没有解释器,必须自我配置,这是怎么做到的呢?
用 GDB 检查内核的启动给出了答案。首先安装内核的调试软件包,内核中包含一个<ruby> 未剥离的 <rt> unstripped </rt></ruby> vmlinux,例如 `apt-get install linux-image-amd64-dbg`,或者从源代码编译和安装你自己的内核,可以参照 [Debian Kernel Handbook](http://kernel-handbook.alioth.debian.org/) 中的指令。`gdb vmlinux` 后加 `info files` 可显示 ELF 段 `init.text`。在 `init.text` 中用 `l *(address)` 列出程序执行的开头,其中 `address` 是 `init.text` 的十六进制开头。用 GDB 可以看到 x86\_64 内核从内核文件 [arch/x86/kernel/head\_64.S](https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/head_64.S) 开始启动,在这个文件中我们找到了汇编函数 `start_cpu0()`,以及一段明确的代码显示在调用 `x86_64 start_kernel()` 函数之前创建了堆栈并解压了 zImage。ARM 32 位内核也有类似的文件 [arch/arm/kernel/head.S](https://github.com/torvalds/linux/blob/master/arch/arm/boot/compressed/head.S)。`start_kernel()` 不针对特定的体系结构,所以这个函数驻留在内核的 [init/main.c](https://github.com/torvalds/linux/blob/master/init/main.c) 中。`start_kernel()` 可以说是 Linux 真正的 `main()` 函数。
### 从 start\_kernel() 到 PID 1
#### 内核的硬件清单:设备树和 ACPI 表
在引导时,内核需要硬件信息,不仅仅是已编译过的处理器类型。代码中的指令通过单独存储的配置数据进行扩充。有两种主要的数据存储方法:[<ruby> 设备树 <rt> device-tree </rt></ruby>](https://www.youtube.com/watch?v=m_NyYEBxfn8) 和 [高级配置和电源接口(ACPI)表](http://events.linuxfoundation.org/sites/events/files/slides/x86-platform.pdf)。内核通过读取这些文件了解每次启动时需要运行的硬件。
对于嵌入式设备,设备树是已安装硬件的清单。设备树只是一个与内核源代码同时编译的文件,通常与 `vmlinux` 一样位于 `/boot` 目录中。要查看 ARM 设备上的设备树的内容,只需对名称与 `/boot/*.dtb` 匹配的文件执行 `binutils` 包中的 `strings` 命令即可,这里 `dtb` 是指<ruby> 设备树二进制文件 <rt> device-tree binary </rt></ruby>。显然,只需编辑构成它的类 JSON 的文件并重新运行随内核源代码提供的特殊 `dtc` 编译器即可修改设备树。虽然设备树是一个静态文件,其文件路径通常由命令行引导程序传递给内核,但近年来增加了一个 [设备树覆盖](http://lwn.net/Articles/616859/) 的功能,内核在启动后可以动态加载热插拔的附加设备。
x86 系列和许多企业级的 ARM64 设备使用 [ACPI](http://events.linuxfoundation.org/sites/events/files/slides/x86-platform.pdf) 机制。与设备树不同的是,ACPI 信息存储在内核在启动时通过访问板载 ROM 而创建的 `/sys/firmware/acpi/tables` 虚拟文件系统中。读取 ACPI 表的简单方法是使用 `acpica-tools` 包中的 `acpidump` 命令。例如:

*联想笔记本电脑的 ACPI 表都是为 Windows 2001 设置的。*
是的,你的 Linux 系统已经准备好用于 Windows 2001 了,你要考虑安装吗?与设备树不同,ACPI 具有方法和数据,而设备树更多地是一种硬件描述语言。ACPI 方法在启动后仍处于活动状态。例如,运行 `acpi_listen` 命令(在 `apcid` 包中),然后打开和关闭笔记本机盖会发现 ACPI 功能一直在运行。暂时地和动态地 [覆盖 ACPI 表](https://www.mjmwired.net/kernel/Documentation/acpi/method-customizing.txt) 是可能的,而永久地改变它需要在引导时与 BIOS 菜单交互或刷新 ROM。如果你遇到那么多麻烦,也许你应该 [安装 coreboot](https://www.coreboot.org/Supported_Motherboards),这是开源固件的替代品。
#### 从 start\_kernel() 到用户空间
[init/main.c](https://github.com/torvalds/linux/blob/master/init/main.c) 中的代码竟然是可读的,而且有趣的是,它仍然在使用 1991 - 1992 年的 Linus Torvalds 的原始版权。在一个刚启动的系统上运行 `dmesg | head`,其输出主要来源于此文件。第一个 CPU 注册到系统中,全局数据结构被初始化,并且调度程序、中断处理程序(IRQ)、定时器和控制台按照严格的顺序逐一启动。在 `timekeeping_init()` 函数运行之前,所有的时间戳都是零。内核初始化的这部分是同步的,也就是说执行只发生在一个线程中,在最后一个完成并返回之前,没有任何函数会被执行。因此,即使在两个系统之间,`dmesg` 的输出也是完全可重复的,只要它们具有相同的设备树或 ACPI 表。Linux 的行为就像在 MCU 上运行的 RTOS(实时操作系统)一样,如 QNX 或 VxWorks。这种情况持续存在于函数 `rest_init()` 中,该函数在终止时由 `start_kernel()` 调用。

*早期的内核启动流程。*
函数 `rest_init()` 产生了一个新进程以运行 `kernel_init()`,并调用了 `do_initcalls()`。用户可以通过将 `initcall_debug` 附加到内核命令行来监控 `initcalls`,这样每运行一次 `initcall` 函数就会产生 一个 `dmesg` 条目。`initcalls` 会历经七个连续的级别:early、core、postcore、arch、subsys、fs、device 和 late。`initcalls` 最为用户可见的部分是所有处理器外围设备的探测和设置:总线、网络、存储和显示器等等,同时加载其内核模块。`rest_init()` 也会在引导处理器上产生第二个线程,它首先运行 `cpu_idle()`,然后等待调度器分配工作。
`kernel_init()` 也可以 [设置对称多处理(SMP)结构](http://free-electrons.com/pub/conferences/2014/elc/clement-smp-bring-up-on-arm-soc)。在较新的内核中,如果 `dmesg` 的输出中出现 “Bringing up secondary CPUs...” 等字样,系统便使用了 SMP。SMP 通过“热插拔” CPU 来进行,这意味着它用状态机来管理其生命周期,这种状态机在概念上类似于热插拔的 U 盘一样。内核的电源管理系统经常会使某个<ruby> 核 <rt> core </rt></ruby>离线,然后根据需要将其唤醒,以便在不忙的机器上反复调用同一段的 CPU 热插拔代码。观察电源管理系统调用 CPU 热插拔代码的 [BCC 工具](http://www.brendangregg.com/ebpf.html) 称为 `offcputime.py`。
请注意,`init/main.c` 中的代码在 `smp_init()` 运行时几乎已执行完毕:引导处理器已经完成了大部分一次性初始化操作,其它核无需重复。尽管如此,跨 CPU 的线程仍然要在每个核上生成,以管理每个核的中断(IRQ)、工作队列、定时器和电源事件。例如,通过 `ps -o psr` 命令可以查看服务每个 CPU 上的线程的 softirqs 和 workqueues。
```
# ps -o pid,psr,comm $(pgrep ksoftirqd)
PID PSR COMMAND
7 0 ksoftirqd/0
16 1 ksoftirqd/1
22 2 ksoftirqd/2
28 3 ksoftirqd/3
# ps -o pid,psr,comm $(pgrep kworker)
PID PSR COMMAND
4 0 kworker/0:0H
18 1 kworker/1:0H
24 2 kworker/2:0H
30 3 kworker/3:0H
[ . . . ]
```
其中,PSR 字段代表“<ruby> 处理器 <rt> processor </rt></ruby>”。每个核还必须拥有自己的定时器和 `cpuhp` 热插拔处理程序。
那么用户空间是如何启动的呢?在最后,`kernel_init()` 寻找可以代表它执行 `init` 进程的 `initrd`。如果没有找到,内核直接执行 `init` 本身。那么为什么需要 `initrd` 呢?
#### 早期的用户空间:谁规定要用 initrd?
除了设备树之外,在启动时可以提供给内核的另一个文件路径是 `initrd` 的路径。`initrd` 通常位于 `/boot` 目录中,与 x86 系统中的 bzImage 文件 vmlinuz 一样,或是与 ARM 系统中的 uImage 和设备树相同。用 `initramfs-tools-core` 软件包中的 `lsinitramfs` 工具可以列出 `initrd` 的内容。发行版的 `initrd` 方案包含了最小化的 `/bin`、`/sbin` 和 `/etc` 目录以及内核模块,还有 `/scripts` 中的一些文件。所有这些看起来都很熟悉,因为 `initrd` 大致上是一个简单的最小化 Linux 根文件系统。看似相似,其实不然,因为位于虚拟内存盘中的 `/bin` 和 `/sbin` 目录下的所有可执行文件几乎都是指向 [BusyBox 二进制文件](https://www.mjmwired.net/kernel/Documentation/acpi/initrd_table_override.txt) 的符号链接,由此导致 `/bin` 和 `/sbin` 目录比 glibc 的小 10 倍。
如果要做的只是加载一些模块,然后在普通的根文件系统上启动 `init`,为什么还要创建一个 `initrd` 呢?想想一个加密的根文件系统,解密可能依赖于加载一个位于根文件系统 `/lib/modules` 的内核模块,当然还有 `initrd` 中的。加密模块可能被静态地编译到内核中,而不是从文件加载,但有多种原因不希望这样做。例如,用模块静态编译内核可能会使其太大而不能适应存储空间,或者静态编译可能会违反软件许可条款。不出所料,存储、网络和人类输入设备(HID)驱动程序也可能存在于 `initrd` 中。`initrd` 基本上包含了任何挂载根文件系统所必需的非内核代码。`initrd` 也是用户存放 [自定义ACPI](https://www.mjmwired.net/kernel/Documentation/acpi/initrd_table_override.txt) 表代码的地方。

*救援模式的 shell 和自定义的 `initrd` 还是很有意思的。*
`initrd` 对测试文件系统和数据存储设备也很有用。将这些测试工具存放在 `initrd` 中,并从内存中运行测试,而不是从被测对象中运行。
最后,当 `init` 开始运行时,系统就启动啦!由于第二个处理器现在在运行,机器已经成为我们所熟知和喜爱的异步、可抢占、不可预测和高性能的生物。的确,`ps -o pid,psr,comm -p 1` 很容易显示用户空间的 `init` 进程已不在引导处理器上运行了。
### 总结
Linux 引导过程听起来或许令人生畏,即使是简单嵌入式设备上的软件数量也是如此。但换个角度来看,启动过程相当简单,因为启动中没有抢占、RCU 和竞争条件等扑朔迷离的复杂功能。只关注内核和 PID 1 会忽略了引导程序和辅助处理器为运行内核执行的大量准备工作。虽然内核在 Linux 程序中是独一无二的,但通过一些检查 ELF 文件的工具也可以了解其结构。学习一个正常的启动过程,可以帮助运维人员处理启动的故障。
要了解更多信息,请参阅 Alison Chaiken 的演讲——[Linux: The first second](https://rego.linux.conf.au/schedule/presentation/16/),已于 1 月 22 日至 26 日在悉尼举行。参见 [linux.conf.au](https://linux.conf.au/index.html)。
感谢 [Akkana Peck](http://shallowsky.com/) 的提议和指正。
---
via: <https://opensource.com/article/18/1/analyzing-linux-boot-process>
作者:[Alison Chaiken](https://opensource.com/users/don-watkins) 译者:[jessie-pang](https://github.com/jessie-pang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The oldest joke in open source software is the statement that "the code is self-documenting." Experience shows that reading the source is akin to listening to the weather forecast: sensible people still go outside and check the sky. What follows are some tips on how to inspect and observe Linux systems at boot by leveraging knowledge of familiar debugging tools. Analyzing the boot processes of systems that are functioning well prepares users and developers to deal with the inevitable failures.
In some ways, the boot process is surprisingly simple. The kernel starts up single-threaded and synchronous on a single core and seems almost comprehensible to the pitiful human mind. But how does the kernel itself get started? What functions do `initrd`
([initial ramdisk](https://en.wikipedia.org/wiki/Initial_ramdisk)) and bootloaders perform? And wait, why is the LED on the Ethernet port always on?
Read on for answers to these and other questions; the [code for the described demos and exercises](https://github.com/chaiken/LCA2018-Demo-Code) is also available on GitHub.
## The beginning of boot: the OFF state
### Wake-on-LAN
The OFF state means that the system has no power, right? The apparent simplicity is deceptive. For example, the Ethernet LED is illuminated because wake-on-LAN (WOL) is enabled on your system. Check whether this is the case by typing:
` $# sudo ethtool <interface name>`
where `<interface name>`
might be, for example, `eth0`
. (`ethtool`
is found in Linux packages of the same name.) If "Wake-on" in the output shows `g`
, remote hosts can boot the system by sending a [MagicPacket](https://en.wikipedia.org/wiki/Wake-on-LAN). If you have no intention of waking up your system remotely and do not wish others to do so, turn WOL off either in the system BIOS menu, or via:
`$# sudo ethtool -s <interface name> wol d`
The processor that responds to the MagicPacket may be part of the network interface or it may be the [Baseboard Management Controller](https://lwn.net/Articles/630778/) (BMC).
### Intel Management Engine, Platform Controller Hub, and Minix
The BMC is not the only microcontroller (MCU) that may be listening when the system is nominally off. x86_64 systems also include the Intel Management Engine (IME) software suite for remote management of systems. A wide variety of devices, from servers to laptops, includes this technology, [which enables functionality](https://www.youtube.com/watch?v=iffTJ1vPCSo&index=65&list=PLbzoR-pLrL6pISWAq-1cXP4_UZAyRtesk) such as KVM Remote Control and Intel Capability Licensing Service. The [IME has unpatched vulnerabilities](https://security-center.intel.com/advisory.aspx?intelid=INTEL-SA-00086&languageid=en-fr), according to [Intel's own detection tool](https://www.intel.com/content/www/us/en/support/articles/000025619/software.html). The bad news is, it's difficult to disable the IME. Trammell Hudson has created an [me_cleaner project](https://github.com/corna/me_cleaner) that wipes some of the more egregious IME components, like the embedded web server, but could also brick the system on which it is run.
The IME firmware and the System Management Mode (SMM) software that follows it at boot are [based on the Minix operating system](https://lwn.net/Articles/738649/) and run on the separate Platform Controller Hub processor, not the main system CPU. The SMM then launches the Universal Extensible Firmware Interface (UEFI) software, about which much has [already been written](https://lwn.net/Articles/699551/), on the main processor. The Coreboot group at Google has started a breathtakingly ambitious [Non-Extensible Reduced Firmware](https://trmm.net/NERF) (NERF) project that aims to replace not only UEFI but early Linux userspace components such as systemd. While we await the outcome of these new efforts, Linux users may now purchase laptops from Purism, System76, or Dell [with IME disabled](https://www.extremetech.com/computing/259879-dell-now-shipping-laptops-intels-management-engine-disabled), plus we can hope for laptops [with ARM 64-bit processors](https://lwn.net/Articles/733837/).
### Bootloaders
Besides starting buggy spyware, what function does early boot firmware serve? The job of a bootloader is to make available to a newly powered processor the resources it needs to run a general-purpose operating system like Linux. At power-on, there not only is no virtual memory, but no DRAM until its controller is brought up. A bootloader then turns on power supplies and scans buses and interfaces in order to locate the kernel image and the root filesystem. Popular bootloaders like U-Boot and GRUB have support for familiar interfaces like USB, PCI, and NFS, as well as more embedded-specific devices like NOR- and NAND-flash. Bootloaders also interact with hardware security devices like [Trusted Platform Modules](https://linuxplumbersconf.org/2017/ocw/events/LPC2017/tracks/639) (TPMs) to establish a chain of trust from earliest boot.
opensource.com
The open source, widely used [U-Boot ](http://www.denx.de/wiki/DULG/Manual)bootloader is supported on systems ranging from Raspberry Pi to Nintendo devices to automotive boards to Chromebooks. There is no syslog, and when things go sideways, often not even any console output. To facilitate debugging, the U-Boot team offers a sandbox in which patches can be tested on the build-host, or even in a nightly Continuous Integration system. Playing with U-Boot's sandbox is relatively simple on a system where common development tools like Git and the GNU Compiler Collection (GCC) are installed:
```
$# git clone git://git.denx.de/u-boot; cd u-boot
$# make ARCH=sandbox defconfig
$# make; ./u-boot
=> printenv
=> help
```
That's it: you're running U-Boot on x86_64 and can test tricky features like [mock storage device](https://github.com/chaiken/LCA2018-Demo-Code) repartitioning, TPM-based secret-key manipulation, and hotplug of USB devices. The U-Boot sandbox can even be single-stepped under the GDB debugger. Development using the sandbox is 10x faster than testing by reflashing the bootloader onto a board, and a "bricked" sandbox can be recovered with Ctrl+C.
## Starting up the kernel
### Provisioning a booting kernel
Upon completion of its tasks, the bootloader will execute a jump to kernel code that it has loaded into main memory and begin execution, passing along any command-line options that the user has specified. What kind of program is the kernel? `file /boot/vmlinuz`
indicates that it is a bzImage, meaning a big compressed one. The Linux source tree contains an [extract-vmlinux tool](https://github.com/torvalds/linux/blob/master/scripts/extract-vmlinux) that can be used to uncompress the file:
```
$# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux
$# file vmlinux
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically
linked, stripped
```
The kernel is an [Executable and Linking Format](http://man7.org/linux/man-pages/man5/elf.5.html) (ELF) binary, like Linux userspace programs. That means we can use commands from the `binutils`
package like `readelf`
to inspect it. Compare the output of, for example:
```
$# readelf -S /bin/date
$# readelf -S vmlinux
```
The list of sections in the binaries is largely the same.
So the kernel must start up something like other Linux ELF binaries ... but how do userspace programs actually start? In the `main()`
function, right? Not precisely.
Before the `main()`
function can run, programs need an execution context that includes heap and stack memory plus file descriptors for `stdio`
, `stdout`
, and `stderr`
. Userspace programs obtain these resources from the standard library, which is `glibc`
on most Linux systems. Consider the following:
```
$# file /bin/date
/bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically
linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32,
BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a,
stripped
```
ELF binaries have an interpreter, just as Bash and Python scripts do, but the interpreter need not be specified with `#!`
as in scripts, as ELF is Linux's native format. The ELF interpreter [provisions a binary](https://0xax.gitbooks.io/linux-insides/content/Misc/program_startup.html) with the needed resources by calling `_start()`
, a function available from the `glibc`
source package that can be [inspected via GDB](https://github.com/chaiken/LCA2018-Demo-Code/commit/e543d9812058f2dd65f6aed45b09dda886c5fd4e). The kernel obviously has no interpreter and must provision itself, but how?
Inspecting the kernel's startup with GDB gives the answer. First install the debug package for the kernel that contains an unstripped version of `vmlinux`
, for example `apt-get install linux-image-amd64-dbg`
, or compile and install your own kernel from source, for example, by following instructions in the excellent [Debian Kernel Handbook](http://kernel-handbook.alioth.debian.org/). `gdb vmlinux`
followed by `info files`
shows the ELF section `init.text`
. List the start of program execution in `init.text`
with `l *(address)`
, where `address`
is the hexadecimal start of `init.text`
. GDB will indicate that the x86_64 kernel starts up in the kernel's file [arch/x86/kernel/head_64.S](https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/head_64.S), where we find the assembly function `start_cpu0()`
and code that explicitly creates a stack and decompresses the zImage before calling the `x86_64 start_kernel()`
function. ARM 32-bit kernels have the similar [arch/arm/kernel/head.S](https://github.com/torvalds/linux/blob/master/arch/arm/boot/compressed/head.S). `start_kernel()`
is not architecture-specific, so the function lives in the kernel's [init/main.c](https://github.com/torvalds/linux/blob/master/init/main.c). `start_kernel()`
is arguably Linux's true `main()`
function.
## From start_kernel() to PID 1
### The kernel's hardware manifest: the device-tree and ACPI tables
At boot, the kernel needs information about the hardware beyond the processor type for which it has been compiled. The instructions in the code are augmented by configuration data that is stored separately. There are two main methods of storing this data: [device-trees](https://www.youtube.com/watch?v=m_NyYEBxfn8) and [ACPI tables](http://events.linuxfoundation.org/sites/events/files/slides/x86-platform.pdf). The kernel learns what hardware it must run at each boot by reading these files.
For embedded devices, the device-tree is a manifest of installed hardware. The device-tree is simply a file that is compiled at the same time as kernel source and is typically located in `/boot`
alongside `vmlinux`
. To see what's in the binary device-tree on an ARM device, just use the `strings`
command from the `binutils`
package on a file whose name matches `/boot/*.dtb`
, as `dtb`
refers to a device-tree binary. Clearly the device-tree can be modified simply by editing the JSON-like files that compose it and rerunning the special `dtc`
compiler that is provided with the kernel source. While the device-tree is a static file whose file path is typically passed to the kernel by the bootloader on the command line, a [device-tree overlay](http://lwn.net/Articles/616859/) facility has been added in recent years, where the kernel can dynamically load additional fragments in response to hotplug events after boot.
x86-family and many enterprise-grade ARM64 devices make use of the alternative Advanced Configuration and Power Interface ([ACPI](http://events.linuxfoundation.org/sites/events/files/slides/x86-platform.pdf)) mechanism. In contrast to the device-tree, the ACPI information is stored in the `/sys/firmware/acpi/tables`
virtual filesystem that is created by the kernel at boot by accessing onboard ROM. The easy way to read the ACPI tables is with the `acpidump`
command from the `acpica-tools`
package. Here's an example:
opensource.com
Yes, your Linux system is ready for Windows 2001, should you care to install it. ACPI has both methods and data, unlike the device-tree, which is more of a hardware-description language. ACPI methods continue to be active post-boot. For example, starting the command `acpi_listen`
(from package `apcid`
) and opening and closing the laptop lid will show that ACPI functionality is running all the time. While temporarily and dynamically [overwriting the ACPI tables](https://www.mjmwired.net/kernel/Documentation/acpi/method-customizing.txt) is possible, permanently changing them involves interacting with the BIOS menu at boot or reflashing the ROM. If you're going to that much trouble, perhaps you should just [install coreboot](https://www.coreboot.org/Supported_Motherboards), the open source firmware replacement.
### From start_kernel() to userspace
The code in [init/main.c](https://github.com/torvalds/linux/blob/master/init/main.c) is surprisingly readable and, amusingly, still carries Linus Torvalds' original copyright from 1991-1992. The lines found in `dmesg | head`
on a newly booted system originate mostly from this source file. The first CPU is registered with the system, global data structures are initialized, and the scheduler, interrupt handlers (IRQs), timers, and console are brought one-by-one, in strict order, online. Until the function `timekeeping_init()`
runs, all timestamps are zero. This part of the kernel initialization is synchronous, meaning that execution occurs in precisely one thread, and no function is executed until the last one completes and returns. As a result, the `dmesg`
output will be completely reproducible, even between two systems, as long as they have the same device-tree or ACPI tables. Linux is behaving like one of the RTOS (real-time operating systems) that runs on MCUs, for example QNX or VxWorks. The situation persists into the function `rest_init()`
, which is called by `start_kernel()`
at its termination.
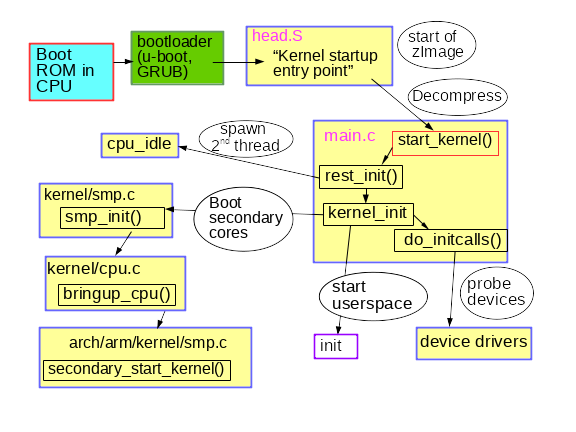
opensource.com
The rather humbly named `rest_init()`
spawns a new thread that runs `kernel_init()`
, which invokes `do_initcalls()`
. Users can spy on `initcalls`
in action by appending `initcall_debug`
to the kernel command line, resulting in `dmesg`
entries every time an `initcall`
function runs. `initcalls`
pass through seven sequential levels: early, core, postcore, arch, subsys, fs, device, and late. The most user-visible part of the `initcalls`
is the probing and setup of all the processors' peripherals: buses, network, storage, displays, etc., accompanied by the loading of their kernel modules. `rest_init()`
also spawns a second thread on the boot processor that begins by running `cpu_idle()`
while it waits for the scheduler to assign it work.
`kernel_init()`
also [sets up symmetric multiprocessing](http://free-electrons.com/pub/conferences/2014/elc/clement-smp-bring-up-on-arm-soc) (SMP). With more recent kernels, find this point in `dmesg`
output by looking for "Bringing up secondary CPUs..." SMP proceeds by "hotplugging" CPUs, meaning that it manages their lifecycle with a state machine that is notionally similar to that of devices like hotplugged USB sticks. The kernel's power-management system frequently takes individual cores offline, then wakes them as needed, so that the same CPU hotplug code is called over and over on a machine that is not busy. Observe the power-management system's invocation of CPU hotplug with the [BCC tool](http://www.brendangregg.com/ebpf.html) called `offcputime.py`
.
Note that the code in `init/main.c`
is nearly finished executing when `smp_init()`
runs: The boot processor has completed most of the one-time initialization that the other cores need not repeat. Nonetheless, the per-CPU threads must be spawned for each core to manage interrupts (IRQs), workqueues, timers, and power events on each. For example, see the per-CPU threads that service softirqs and workqueues in action via the `ps -o psr`
command.
```
$\# ps -o pid,psr,comm $(pgrep ksoftirqd)
PID PSR COMMAND
7 0 ksoftirqd/0
16 1 ksoftirqd/1
22 2 ksoftirqd/2
28 3 ksoftirqd/3
$\# ps -o pid,psr,comm $(pgrep kworker)
PID PSR COMMAND
4 0 kworker/0:0H
18 1 kworker/1:0H
24 2 kworker/2:0H
30 3 kworker/3:0H
[ . . . ]
```
where the PSR field stands for "processor." Each core must also host its own timers and `cpuhp`
hotplug handlers.
How is it, finally, that userspace starts? Near its end, `kernel_init()`
looks for an `initrd`
that can execute the `init`
process on its behalf. If it finds none, the kernel directly executes `init`
itself. Why then might one want an `initrd`
?
### Early userspace: who ordered the initrd?
Besides the device-tree, another file path that is optionally provided to the kernel at boot is that of the `initrd`
. The `initrd`
often lives in `/boot`
alongside the bzImage file vmlinuz on x86, or alongside the similar uImage and device-tree for ARM. List the contents of the `initrd`
with the `lsinitramfs`
tool that is part of the `initramfs-tools-core`
package. Distro `initrd`
schemes contain minimal `/bin`
, `/sbin`
, and `/etc`
directories along with kernel modules, plus some files in `/scripts`
. All of these should look pretty familiar, as the `initrd`
for the most part is simply a minimal Linux root filesystem. The apparent similarity is a bit deceptive, as nearly all the executables in `/bin`
and `/sbin`
inside the ramdisk are symlinks to the [BusyBox binary](https://www.busybox.net/), resulting in `/bin`
and `/sbin`
directories that are 10x smaller than glibc's.
Why bother to create an `initrd`
if all it does is load some modules and then start `init`
on the regular root filesystem? Consider an encrypted root filesystem. The decryption may rely on loading a kernel module that is stored in `/lib/modules`
on the root filesystem ... and, unsurprisingly, in the `initrd`
as well. The crypto module could be statically compiled into the kernel instead of loaded from a file, but there are various reasons for not wanting to do so. For example, statically compiling the kernel with modules could make it too large to fit on the available storage, or static compilation may violate the terms of a software license. Unsurprisingly, storage, network, and human input device (HID) drivers may also be present in the `initrd`
—basically any code that is not part of the kernel proper that is needed to mount the root filesystem. The `initrd`
is also a place where users can stash their own [custom ACPI](https://www.mjmwired.net/kernel/Documentation/acpi/initrd_table_override.txt) table code.
opensource.com
`initrd`
's are also great for testing filesystems and data-storage devices themselves. Stash these test tools in the `initrd`
and run your tests from memory rather than from the object under test.
At last, when `init`
runs, the system is up! Since the secondary processors are now running, the machine has become the asynchronous, preemptible, unpredictable, high-performance creature we know and love. Indeed, `ps -o pid,psr,comm -p 1`
is liable to show that userspace's `init`
process is no longer running on the boot processor.
## Summary
The Linux boot process sounds forbidding, considering the number of different pieces of software that participate even on simple embedded devices. Looked at differently, the boot process is rather simple, since the bewildering complexity caused by features like preemption, RCU, and race conditions are absent in boot. Focusing on just the kernel and PID 1 overlooks the large amount of work that bootloaders and subsidiary processors may do in preparing the platform for the kernel to run. While the kernel is certainly unique among Linux programs, some insight into its structure can be gleaned by applying to it some of the same tools used to inspect other ELF binaries. Studying the boot process while it's working well arms system maintainers for failures when they come.
*To learn more, attend Alison Chaiken's talk, Linux: The first second, at linux.conf.au, which will be held January 22-26 in Sydney.*
*Thanks to Akkana Peck for originally suggesting this topic and for many corrections.*
## 8 Comments |
9,438 | Dnsmasq 进阶技巧 | https://www.linux.com/learn/intro-to-linux/2018/2/advanced-dnsmasq-tips-and-tricks | 2018-03-14T00:03:53 | [
"dnsmasq",
"dns",
"域名"
] | https://linux.cn/article-9438-1.html | 
许多人熟知并热爱 Dnsmasq,并在他们的本地域名服务上使用它。今天我们将介绍进阶配置文件管理、如何测试你的配置、一些基础的安全知识、DNS 泛域名、快速 DNS 配置,以及其他一些技巧与窍门。下个星期我们将继续详细讲解如何配置 DNS 和 DHCP。
### 测试配置
当你测试新的配置的时候,你应该从命令行运行 Dnsmasq,而不是使用守护进程。下面的例子演示了如何不用守护进程运行它,同时显示指令的输出并保留运行日志:
```
# dnsmasq --no-daemon --log-queries
dnsmasq: started, version 2.75 cachesize 150
dnsmasq: compile time options: IPv6 GNU-getopt
DBus i18n IDN DHCP DHCPv6 no-Lua TFTP conntrack
ipset auth DNSSEC loop-detect inotify
dnsmasq: reading /etc/resolv.conf
dnsmasq: using nameserver 192.168.0.1#53
dnsmasq: read /etc/hosts - 9 addresses
```
在这个小例子中你能看到许多有用的信息,包括版本、编译参数、系统名字服务文件,以及它的监听地址。可以使用 `Ctrl+C` 停止进程。在默认情况下,Dnsmasq 没有自己的日志文件,所以日志会被记录到 `/var/log` 目录下的多个地方。你可以使用经典的 `grep` 来找到 Dnsmasq 的日志文件。下面这条指令会递归式地搜索 `/var/log`,在每个匹配的文件名之后显示匹配的行号,并忽略 `/var/log/dist-upgrade` 里的内容:
```
# grep -ir --exclude-dir=dist-upgrade dnsmasq /var/log/
```
使用 `grep --exclude-dir=` 时有一个有趣的小陷阱需要注意:不要使用完整路径,而应该只写目录名称。
你可以使用如下的命令行参数来让 Dnsmasq 使用你指定的文件作为它专属的日志文件:
```
# dnsmasq --no-daemon --log-queries --log-facility=/var/log/dnsmasq.log
```
或者在你的 Dnsmasq 配置文件中加上 `log-facility=/var/log/dnsmasq.log`。
### 配置文件
Dnsmasq 的配置文件位于 `/etc/dnsmasq.conf`。你的 Linux 发行版也可能会使用 `/etc/default/dnsmasq`、`/etc/dnsmasq.d/`,或者 `/etc/dnsmasq.d-available/`(不,我们不能统一标准,因为这违反了 <ruby> Linux 七嘴八舌秘密议会 <rt> Linux Cat Herd Ruling Cabal </rt></ruby>的旨意)。你有很多自由来随意安置你的配置文件。
`/etc/dnsmasq.conf` 是德高望重的老大。Dnsmasq 在启动时会最先读取它。`/etc/dnsmasq.conf` 可以使用 `conf-file=` 选项来调用其他的配置文件,例如 `conf-file=/etc/dnsmasqextrastuff.conf`,或使用 `conf-dir=` 选项来调用目录下的所有文件,例如 `conf-dir=/etc/dnsmasq.d`。
每当你对配置文件进行了修改,你都必须重启 Dnsmasq。
你也可以根据扩展名来包含或忽略配置文件。星号表示包含,不加星号表示排除:
```
conf-dir=/etc/dnsmasq.d/, *.conf, *.foo
conf-dir=/etc/dnsmasq.d, .old, .bak, .tmp
```
你可以用 `--addn-hosts=` 选项来把你的主机配置分布在多个文件中。
Dnsmasq 包含了一个语法检查器:
```
$ dnsmasq --test
dnsmasq: syntax check OK.
```
### 实用配置
永远加入这几行:
```
domain-needed
bogus-priv
```
它们可以避免含有格式出错的域名或私有 IP 地址的数据包离开你的网络。
让你的名字服务只使用 Dnsmasq,而不去使用 `/etc/resolv.conf` 或任何其他的名字服务文件:
```
no-resolv
```
使用其他的域名服务器。第一个例子是只对于某一个域名使用不同的域名服务器。第二个和第三个例子是 OpenDNS 公用服务器:
```
server=/fooxample.com/192.168.0.1
server=208.67.222.222
server=208.67.220.220
```
你也可以将某些域名限制为只能本地解析,但不影响其他域名。这些被限制的域名只能从 `/etc/hosts` 或 DHCP 解析:
```
local=/mehxample.com/
local=/fooxample.com/
```
限制 Dnsmasq 监听的网络接口:
```
interface=eth0
interface=wlan1
```
Dnsmasq 在默认设置下会读取并使用 `/etc/hosts`。这是一个又快又好的配置大量域名的方法,并且 `/etc/hosts` 只需要和 Dnsmasq 在同一台电脑上。你还可以让这个过程再快一些,可以在 `/etc/hosts` 文件中只写主机名,然后用 Dnsmasq 来添加域名。`/etc/hosts` 看上去是这样的:
```
127.0.0.1 localhost
192.168.0.1 host2
192.168.0.2 host3
192.168.0.3 host4
```
然后把下面这几行写入 `dnsmasq.conf`(当然,要换成你自己的域名):
```
expand-hosts
domain=mehxample.com
```
Dnsmasq 会自动把这些主机名扩展为完整的域名,比如 `host2` 会变为 `host2.mehxample.com`。
### DNS 泛域名
一般来说,使用 DNS 泛域名不是一个好习惯,因为它们太容易被误用了。但它们有时会很有用,比如在你的局域网的严密保护之下的时候。一个例子是使用 DNS 泛域名会让 Kubernetes 集群变得容易管理许多,除非你喜欢给你成百上千的应用写 DNS 记录。假设你的 Kubernetes 域名是 mehxample.com,那么下面这行配置可以让 Dnsmasq 解析所有对 mehxample.com 的请求:
```
address=/mehxample.com/192.168.0.5
```
这里使用的地址是你的集群的公网 IP 地址。这会响应对 mehxample.com 的所有主机名和子域名的请求,除非请求的目标地址已经在 DHCP 或者 `/etc/hosts` 中配置过。
下星期我们将探索更多的管理 DNS 和 DHCP 的细节,包括对不同的子网络使用不同的设置,以及提供权威域名服务器。
### 更多参考
* [使用 Dnsmasq 进行 DNS 伪装](https://www.linux.com/learn/intro-to-linux/2017/7/dns-spoofing-dnsmasq)
* [使用 Dnsmasq 配置简单的局域网域名服务](https://www.linux.com/learn/dnsmasq-easy-lan-name-services)
* [Dnsmasq](http://www.thekelleys.org.uk/dnsmasq/doc.html)
---
via: <https://www.linux.com/learn/intro-to-linux/2018/2/advanced-dnsmasq-tips-and-tricks>
作者:[CARLA SCHRODER](https://www.linux.com/users/cschroder) 译者:[yixunx](https://github.com/yixunx) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,439 | Docker 容器中的老式 DOS BBS | http://changelog.complete.org/archives/9836-an-old-dos-bbs-in-a-docker-container | 2018-03-14T00:17:00 | [
"容器",
"模拟器",
"DOS"
] | https://linux.cn/article-9439-1.html | 不久前,我写了一篇[我的 Debian Docker 基本映像](https://changelog.complete.org/archives/9794-fixing-the-problems-with-docker-images)。我决定进一步扩展这个概念:在 Docker 中运行 DOS 程序。
但首先,来看看题图。

事实证明这是可能的,但很难。我使用了所有三种主要的 DOS 模拟器(dosbox、qemu 和 dosemu)。我让它们都能在 Docker 容器中运行,但有很多有趣的问题需要解决。
都要做的事是在 DOS 环境下提供一个伪造的调制解调器。它需要作为 TCP 端口暴露在容器外部。有很多方法可以做到 —— 我使用的是 tcpser。dosbox 有一个 TCP 调制解调器接口,但事实证明,这样做太问题太多了。
挑战来自你希望能够一次接受多个传入 telnet(或 TCP)连接。DOS 不是一个多任务操作系统,所以当时有很多黑客式的方法。一种是有多台物理机,每个有一根传入电话线。或者它们可能会在 [DESQview](https://en.wikipedia.org/wiki/DESQview)、OS/2 甚至 Windows 3.1 等多任务层下运行多个伪 DOS 实例。
(注意:我刚刚了解到 [DESQview/X](http://toastytech.com/guis/dvx.html),它将 DESQview 与 X11R5 集成在一起,并[取代了 Windows 3 驱动程序](http://toastytech.com/guis/dvx3.html)来把 Windows 作为 X 应用程序运行。)
出于各种原因,我不想尝试在 Docker 中运行其中任何一个系统。这让我模拟了原来的多物理节点设置。从理论上讲,非常简单 —— 运行一组 DOS 实例,每个实例最多使用 1MB 的模拟 RAM,这就行了。但是这里面临挑战。
在多物理节点设置中,你需要某种文件共享,因为你的节点需要访问共享的消息和文件存储。在老式的 DOS 时代,有很多笨重的方法可以做到这一点 —— [Netware](https://en.wikipedia.org/wiki/NetWare)、[LAN manager](https://en.wikipedia.org/wiki/LAN_Manager),甚至一些 PC NFS 客户端。我没有访问 Netware。我尝试了 DOS 中的 Microsoft LM 客户端,与在 Docker 容器内运行的 Samba 服务器交互。这样可以使用,但 LM 客户端即使有各种高内存技巧还是占用了很多内存,BBS 软件也无法运行。我无法在多个 dosbox 实例中挂载底层文件系统,因为 dosbox 缓存不兼容。
这就是为什么我使用 dosemu 的原因。除了有比 dosbox 更完整的模拟器之外,它还有一种共享主机文件系统的方式。
所以,所有这一切都在此:[jgoerzen/docker-bbs-renegade](https://github.com/jgoerzen/docker-bbs-renegade)。
我还为其他想做类似事情的人准备了构建块:[docker-dos-bbs](https://github.com/jgoerzen/docker-dos-bbs) 和底层 [docker-dosemu](https://github.com/jgoerzen/docker-dosemu)。
意外的收获是,我也试图了在 Joyent 的 Triton(基于 Solaris 的 SmartOS)下运行它。让我感到高兴的印象是,几乎可以在这下面工作。是的,在 Solaris 机器上的一个基于 Linux 的 DOS 模拟器的容器中运行 Renegade DOS BBS。
---
via: <http://changelog.complete.org/archives/9836-an-old-dos-bbs-in-a-docker-container>
作者:[John Goerzen](http://changelog.complete.org/archives/author/jgoerzen) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 302 | Found | null |
9,441 | 如何检查你的计算机使用的是 UEFI 还是 BIOS | https://itsfoss.com/check-uefi-or-bios/ | 2018-03-14T09:11:37 | [
"UEFI",
"BIOS"
] | https://linux.cn/article-9441-1.html |
>
> 简介:这是一个快速的教程,来告诉你的系统使用的是现代 UEFI 或者传统 BIOS。同时提供 Windows 和 Linux 的说明。
>
>
>
当你尝试[双启动 Linux 和 Windows](https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/) 时,你需要知道系统上是否有 UEFI 或 BIOS 启动模式。它可以帮助你决定安装 Linux 的分区。
我不打算在这里讨论[什么是 BIOS](https://www.lifewire.com/bios-basic-input-output-system-2625820)。不过,我想通过 BIOS 告诉你一些 [UEFI](https://www.howtogeek.com/56958/htg-explains-how-uefi-will-replace-the-bios/) 的优点。
UEFI 即(<ruby> 统一可扩展固件接口 <rt> Unified Extensible Firmware Interface </rt></ruby>)旨在克服 BIOS 的某些限制。它增加了使用大于 2TB 磁盘的能力,并具有独立于 CPU 的体系结构和驱动程序。采用模块化设计,即使没有安装操作系统,也可以支持远程诊断和修复,以及灵活的无操作系统环境(包括网络功能)。
### UEFI 优于 BIOS 的地方
* UEFI 在初始化硬件时速度更快。
* 提供安全启动,这意味着你在加载操作系统之前加载的所有内容都必须签名。这为你的系统提供了额外的保护层。
* BIOS 不支持超过 2TB 的分区。
* 最重要的是,如果你是双引导,那么建议始终在相同的引导模式下安装两个操作系统。

如果试图查看你的系统运行的是 UEFI 还是 BIOS,这并不难。首先让我从 Windows 开始,然后看看如何在 Linux 系统上查看用的是 UEFI 还是 BIOS。
### 在 Windows 中检查使用的是 UEFI 还是 BIOS
在 Windows 中,在“开始”面板中的“系统信息”中,在 BIOS 模式下,可以找到启动模式。如果它显示的是 Legacy,那么你的系统是 BIOS。如果显示 UEFI,那么它是 UEFI。

**另一个方法**:如果你使用 Windows 10,可以打开文件资源管理器并进入到 `C:\Windows\Panther` 来查看你使用的是 UEFI 还是 BIOS。打开文件 setupact.log 并搜索下面的字符串。
```
Detected boot environment
```
我建议在 notepad++ 中打开这个文件,因为这是一个很大的文件,记事本很可能挂起(至少它对我来说是 6GB !)。
你会看到几行有用的信息。
```
2017-11-27 09:11:31, Info IBS Callback_BootEnvironmentDetect:FirmwareType 1.
2017-11-27 09:11:31, Info IBS Callback_BootEnvironmentDetect: Detected boot environment: BIOS
```
### 在 Linux 中检查使用的是 UEFI 还是 BIOS
最简单地找出使用的是 UEFI 还是 BIOS 的方法是查找 `/sys/firmware/efi` 文件夹。如果使用的 BIOS 那么该文件夹不存在。

**另一种方法**:安装名为 efibootmgr 的软件包。
在基于 Debian 和 Ubuntu 的发行版中,你可以使用以下命令安装 efibootmgr 包:
```
sudo apt install efibootmgr
```
完成后,输入以下命令:
```
sudo efibootmgr
```
如果你的系统支持 UEFI,它会输出不同的变量。如果没有,你将看到一条消息指出 EFI 变量不支持。

### 最后的话
查看你的系统使用的是 UEFI 还是 BIOS 很容易。一方面,像快速和安全的引导为 UEFI 提供了优势,如果你使用的是 BIOS 也不必担心太多,除非你打算使用 2TB 硬盘。
---
via: <https://itsfoss.com/check-uefi-or-bios/>
作者:[Ambarish Kumar](https://itsfoss.com/author/ambarish/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When you are trying to [ dual boot Linux with Windows](https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/), you would want to know if you have UEFI or BIOS boot mode on your system. It helps you decide in partition making for installing Linux.
If you are dual booting it’s always advisable to install both the OS in the same booting mode. So, you should first check if you’re using UEFI or BIOS and install accordingly.
I’ll show you how to check whether your system has UEFI or BIOS in both Windows and Linux.
## Why UEFI?
I am not going to discuss [ what BIOS is](https://en.wikipedia.org/wiki/BIOS) here. However, I would like to tell you a few advantages of
[over BIOS in case you’re wondering.](https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface)
__UEFI__UEFI or Unified Extensible Firmware Interface was designed to overcome some limitations of BIOS. It added the ability to use larger than 2 TB disks and had a CPU independent architecture and drivers.
With a modular design, it supported remote diagnostics and repairing even with no operating system installed and a flexible without-OS environment including networking capability. Overall, you should keep the following points in mind:
### Advantage of UEFI over BIOS
- UEFI is faster in initializing your hardware.
- Offers Secure Boot which means everything that loads up before the OS wakes up has to be signed. This gives your system an added layer of protection from running malware.
- BIOS does not support a partition of over 2 TB. But, UEFI does.
## Check if you are using UEFI or BIOS on Windows
On Windows, “**System Information**” in Start panel and under BIOS Mode, you can find the boot mode. If it says Legacy, your system has BIOS. If it says UEFI, well it’s UEFI.
### Alternative: Use CMD in Windows
You can launch a command prompt window as administrator and look for the path of the bootloader by running
`bcdedit`
Here, in the **Windows Boot Loader** section, look for **Path**. if the file extension for /Windows/System32/winload is **.exe**, your system uses legacy BIOS. If the extension is** .efi**, your system uses UEFI.
### Another way to check UEFI or BIOS in Windows 10
If you are using Windows 10, you can check whether you are using UEFI or BIOS by opening File Explorer and navigating to C:\Windows\Panther. Open file setupact.log and search for the below string.
`Detected boot environment`
I would advise opening this file in notepad++, since its a huge text file and notepad may hang (at least it did for me with 6GB RAM).
You will find a couple of lines which will give you the information.
```
2017-11-27 09:11:31, Info IBS Callback_BootEnvironmentDetect:FirmwareType 1.
2017-11-27 09:11:31, Info IBS Callback_BootEnvironmentDetect: Detected boot environment: BIOS
```
## Check if you are using UEFI or BIOS on Linux
The easiest way to find out if you are running UEFI or BIOS is to look for a folder /sys/firmware/efi. The folder will be missing if your system is using BIOS.

**/sys/firmware/efi exists means system uses UEFI**
**Alternative**: The other method is to install a package called efibootmgr.
On Debian and Ubuntu based distributions, you can install the efibootmgr package using the command below:
`sudo apt install efibootmgr`
Once done, type the below command:
`sudo efibootmgr`
If your system supports UEFI, it will output different variables. If not you will see a message saying EFI variables are not supported.
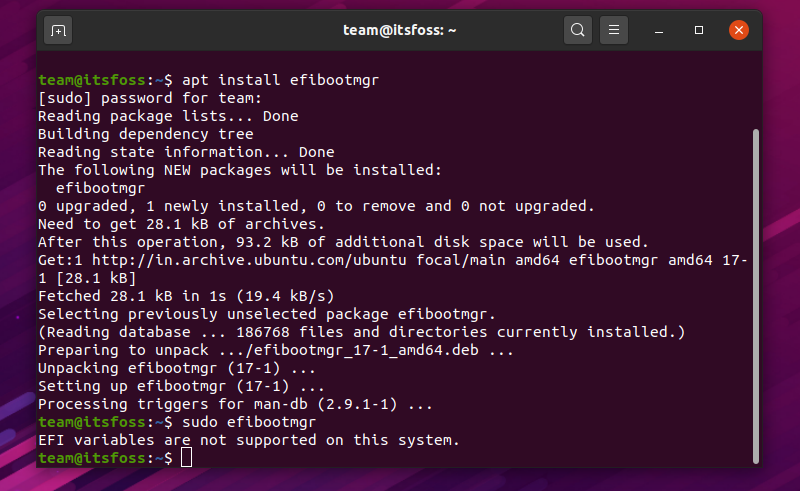
## Final Words
So, now you know that finding whether your system is using UEFI or BIOS isn’t tough. Wasn’t that very easy?
Even though features like faster boot and secure boot provides an upper hand to UEFI, you don’t need to worry if your system uses BIOS. Unless you have a specific requirement for UEFI or BIOS, no action is required from your end to change that. |
9,442 | 如何在使用 Vim 时访问/查看 Python 帮助 | https://www.cyberciti.biz/faq/how-to-access-view-python-help-when-using-vim/ | 2018-03-14T12:05:43 | [
"Python",
"Vim"
] | https://linux.cn/article-9442-1.html | 
我是一名新的 Vim 编辑器用户。我用它编写 Python 代码。有没有办法在 vim 中查看 Python 文档而无需访问互联网?假设我的光标在 Python 的 `print` 关键字下,然后按下 F1,我想查看关键字 `print` 的帮助。如何在 vim 中显示 python `help()` ?如何在不离开 vim 的情况下调用 `pydoc3`/`pydoc` 寻求帮助?
`pydoc` 或 `pydoc3` 命令可以根据 Python 关键字、主题、函数、模块或包的名称显示文本文档,或在模块内或包中的模块对类或函数的引用。你可以从 Vim 中调用 `pydoc`。让我们看看如何在 Vim 编辑器中使用 `pydoc` 访问 Python 文档。
### 使用 pydoc 访问 python 帮助
语法是:
```
pydoc keyword
pydoc3 keyword
pydoc len
pydoc print
```
编辑你的 `~/.vimrc`:
```
$ vim ~/.vimrc
```
为 `pydoc3` 添加以下配置(python v3.x 文档)。在正常模式下创建 `H` 键的映射:
```
nnoremap <buffer> H :<C-u>execute "!pydoc3 " . expand("<cword>")<CR>
```
保存并关闭文件。打开 Vim 编辑器:
```
$ vim file.py
```
写一些代码:
```
#!/usr/bin/python3
x=5
y=10
z=x+y
print(z)
print("Hello world")
```
将光标置于 Python 关键字 `print` 的下方,然后按下 `Shift`,然后按 `H`。你将看到下面的输出:
[](https://www.cyberciti.biz/media/new/faq/2018/01/Access-Python-Help-Within-Vim.gif)
*按 H 查看 Python 关键字 print 的帮助*
### 如何在使用 Vim 时查看 python 帮助
[jedi-vim](https://github.com/davidhalter/jedi-vim) 是一个绑定自动补全库 Jed 的 Vim 插件。它可以做很多事情,包括当你按下 `Shift` 后跟 `K` (即按大写 `K`) 就显示关键字的帮助。
#### 如何在 Linux 或类 Unix 系统上安装 jedi-vim
使用 [pathogen](https://github.com/tpope/vim-pathogen)、[vim-plug](https://www.cyberciti.biz/programming/vim-plug-a-beautiful-and-minimalist-vim-plugin-manager-for-unix-and-linux-users/) 或 [Vundle](https://github.com/gmarik/vundle) 安装 jedi-vim。我使用的是 vim-plug。在 `~/.vimrc` 中添加以下行:
```
Plug 'davidhalter/jedi-vim'
```
保存并关闭文件。启动 Vim 并输入:
```
PlugInstall
```
在 Arch Linux 上,你还可以使用 `pacman` 命令从官方仓库中的 vim-jedi 安装 jedi-vim:
```
$ sudo pacman -S vim-jedi
```
它也可以在 Debian(比如 8)和 Ubuntu( 比如 14.04)上使用 [apt-get command](https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ "See Linux/Unix apt command examples for more info")/[apt-get command](https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html "See Linux/Unix apt-get command examples for more info") 安装 vim-python-jedi:
```
$ sudo apt install vim-python-jedi
```
在 Fedora Linux 上,它可以用 `dnf` 安装 vim-jedi:
```
$ sudo dnf install vim-jedi
```
Jedi 默认是自动初始化的。所以你不需要进一步的配置。要查看 Documentation/Pydoc,请按 `K`。它将弹出帮助窗口:
[](https://www.cyberciti.biz/media/new/faq/2018/01/How-to-view-Python-Documentation-using-pydoc-within-vim-on-Linux-Unix.jpg)
### 关于作者
作者是 nixCraft 的创建者,也是经验丰富的系统管理员和 Linux 操作系统/Unix shell 脚本的培训师。他曾与全球客户以及 IT、教育、国防和太空研究以及非营利部门等多个行业合作。在 [Twitter](https://twitter.com/nixcraft)、[Facebook](https://facebook.com/nixcraft)、[Google +](https://plus.google.com/+CybercitiBiz) 上关注他。
---
via: <https://www.cyberciti.biz/faq/how-to-access-view-python-help-when-using-vim/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,443 | 440+ 个免费的编程 & 计算机科学的在线课程 | https://medium.freecodecamp.org/440-free-online-programming-computer-science-courses-you-can-start-in-february-e075f920cb5b | 2018-03-14T12:52:08 | [
"在线课程"
] | https://linux.cn/article-9443-1.html | 
六年前,一些大学如 MIT 和斯坦福首次向公共免费开放了他们的在线课程。现在,全世界超过 800 所学校已经创建了成千上万的免费课程。
我编制了一个有 440 多个免费在线课程的清单,你可以从这个月开始去学习它了。为了这个清单,我使用了[<ruby> 班级中心 <rt> Class Central </rt></ruby>](https://www.class-central.com/) 的数据库,它有超过 9000 门课程,我也包括了每个课程的平均评分。

*[班级中心](https://www.class-central.com/) 的主页*
按它们不同的级别,我将这些课程分成以下三类:
* 初级
* 中级
* 高级
对于首次出现的课程,我标记为 [NEW]。
这些课程中的大多数都是可以自学的。其余的将在二月份的某个时间为你奉上。在班级中心的 2018 年 [计算机科学](https://www.class-central.com/subject/cs)、[数据科学](https://www.class-central.com/subject/data-science)、和 [编程](https://www.class-central.com/subject/programming-and-software-development) 主题的页面上,你可以找到与这个技术相关的完整的清单。
我也知道,这个长长的清单,可能会让学习编程的新手望而却步。在这些课程中,你可以找到 [David Venturi](https://medium.com/@davidventuri) 推荐的非常有用的最佳 [数据科学在线课程](https://medium.freecodecamp.com/the-best-data-science-courses-on-the-internet-ranked-by-your-reviews-6dc5b910ea40) — 即使你不想学习数据科学。以后,我想去创建更多的这种指南。
最后,如果你不知道如何去注册这些免费课程,没关系 —— 我也写了一篇 [如何去注册](https://medium.freecodecamp.org/how-to-sign-up-for-coursera-courses-for-free-98266efaa531) 的文章。
### 初级(112)
* [Python 交互式编程入门(第 1 部分)](https://www.class-central.com/mooc/408/coursera-an-introduction-to-interactive-programming-in-python-part-1) 来自 *Rice University* ★★★★★(3018)
* [计算机科学入门和使用 Python 编程](https://www.class-central.com/mooc/1341/edx-introduction-to-computer-science-and-programming-using-python) 来自 *Massachusetts Institute of Technology* ★★★★★(115)
* [学习编程:基本原理](https://www.class-central.com/mooc/385/coursera-learn-to-program-the-fundamentals) 来自 *University of Toronto* ★★★★★(100)
* [计算机科学入门](https://www.class-central.com/mooc/320/udacity-intro-to-computer-science) 来自 *University of Virginia* ★★★★☆(68)
* [CS50 的计算机科学入门](https://www.class-central.com/mooc/442/edx-cs50-s-introduction-to-computer-science) 来自 *Harvard University* ★★★★★(65)
* [Python 交互式编程入门(第 2 部分)](https://www.class-central.com/mooc/3196/coursera-an-introduction-to-interactive-programming-in-python-part-2) 来自 *Rice University* ★★★★★(52)
* [如何使用 Git 和 GitHub](https://www.class-central.com/mooc/2661/udacity-how-to-use-git-and-github)
* [Linux 入门](https://www.class-central.com/mooc/1857/edx-introduction-to-linux) 来自 *Linux Foundation* ★★★★☆(37)
* [因特网历史、技术、和安全](https://www.class-central.com/mooc/335/coursera-internet-history-technology-and-security) 来自 *University of Michigan* ★★★★★(36)
* [HTML 和 CSS 入门](https://www.class-central.com/mooc/2659/udacity-intro-to-html-and-css)
* [VBA/Excel 编程入门](https://www.class-central.com/mooc/1797/open-education-by-blackboard-introduction-to-vba-excel-programming) 来自 *Cal Poly Pomona* ★★★★☆(26)
* [[New] CS50 的理解技术](https://www.class-central.com/mooc/10142/edx-cs50-s-understanding-technology) 来自 *Harvard University*
* [[New] CS50 的为商务人士的计算机科学](https://www.class-central.com/mooc/10143/edx-cs50-s-computer-science-for-business-professionals) 来自 *Harvard University*
* [[New] Java 编程导论:如何开始编程(西班牙语)](https://www.class-central.com/mooc/10316/edx-introduccion-a-la-programacion-en-java-como-comenzar-a-programar) 来自 *Universidad Carlos iii de Madrid*
* [[New] 物联网 (IoT) 入门](https://www.class-central.com/mooc/9750/edx-introduction-to-the-internet-of-things-iot) 来自 *Curtin University*
* [[New] 使用 Git 管理版本](https://www.class-central.com/mooc/10166/coursera-version-control-with-git) 来自 *Atlassian*
* [JavaScript 基础](https://www.class-central.com/mooc/2660/udacity-javascript-basics)
* [CS101: 计算机科学 101](https://www.class-central.com/mooc/2175/stanford-openedx-cs101-computer-science-101) 来自 *Stanford University* ★★★★☆(15)
* [编程基础](https://www.class-central.com/mooc/1650/edx-programming-basics) 来自 *Indian Institute of Technology Bombay* ★★☆☆☆(13)
* [Web 安全基本原理](https://www.class-central.com/mooc/8726/edx-web-security-fundamentals) 来自 *KU Leuven University* ★★★★☆(12)
* [Python 编程基础](https://www.class-central.com/mooc/2013/udacity-programming-foundations-with-python)
* [网络:计算机网络入门](https://www.class-central.com/mooc/1578/stanford-openedx-networking-introduction-to-computer-networking) 来自 *Stanford University* ★★★★★(11)
* [DB:数据库入门](https://www.class-central.com/mooc/1580/stanford-openedx-db-introduction-to-databases) 来自 *Stanford University* ★★★★★(11)
* [数字多媒体 & 移动应用创意编程](https://www.class-central.com/mooc/529/coursera-creative-programming-for-digital-media-mobile-apps) 来自 *University of London International Programmes* ★★★★☆(10)
* [使用 JavaScript、HTML 和 CSS 基础](https://www.class-central.com/mooc/4256/coursera-programming-foundations-with-javascript-html-and-css) 来自 *Duke University* ★★★★☆(9)
* [实用安全](https://www.class-central.com/mooc/1727/coursera-usable-security) 来自 *University of Maryland, College Park* ★★★☆☆(9)
* [Bootstrap 入门 — 一个教程](https://www.class-central.com/mooc/3338/edx-introduction-to-bootstrap-a-tutorial) 来自 *Microsoft* ★★★☆☆(9)
* [HTML5 编码基础和最佳实践](https://www.class-central.com/mooc/3444/edx-html5-coding-essentials-and-best-practices) 来自 *World Wide Web Consortium (W3C)* ★★★★☆(9)
* [大家都来学 Python — 浏览信息](https://www.class-central.com/mooc/7363/python-for-everybody-exploring-information)
* [学习编程:编写高品质代码](https://www.class-central.com/mooc/390/coursera-learn-to-program-crafting-quality-code) 来自 *University of Toronto* ★★★★☆(7)
* [使用 p5.js 入门视觉艺术编程](https://www.class-central.com/mooc/3770/kadenze-introduction-to-programming-for-the-visual-arts-with-p5-js) 来自 *University of California, Los Angeles* ★★★★★(7)
* [关系型数据库入门](https://www.class-central.com/mooc/3253/udacity-intro-to-relational-databases)
* [jQuery 入门](https://www.class-central.com/mooc/4062/edx-introduction-to-jquery) 来自 *Microsoft* ★★★★☆(5)
* [HTML5 和 CSS 基础](https://www.class-central.com/mooc/5764/edx-html5-and-css-fundamentals) 来自 *World Wide Web Consortium (W3C)* ★★★★☆(5)
* [Java 编程基础](https://www.class-central.com/mooc/6686/udacity-java-programming-basics)
* [Linux 命令行基础](https://www.class-central.com/mooc/4049/udacity-linux-command-line-basics)
* [Java 编程入门 — 第 1 部分](https://www.class-central.com/mooc/1983/edx-introduction-to-java-programming-part-1) 来自 *The Hong Kong University of Science and Technology* ★★★★☆(4)
* [Java 编程入门:用 Java 写代码](https://www.class-central.com/mooc/2813/edx-introduction-to-java-programming-starting-to-code-in-java) 来自 *Universidad Carlos iii de Madrid* ★★★★☆(4)
* [计算机编程范例 — 抽象和并发](https://www.class-central.com/mooc/2630/edx-paradigms-of-computer-programming-abstraction-and-concurrency)来自 *Université catholique de Louvain* ★★★★☆(4)
* [计算机编程范例 — 基本原理](https://www.class-central.com/mooc/2298/edx-paradigms-of-computer-programming-fundamentals) 来自 *Université catholique de Louvain* ★★★★★(4)
* [在 Scratch 中编程](https://www.class-central.com/mooc/2954/edx-programming-in-scratch) 来自 *Harvey Mudd College* ★★★★★(4)
* [使用 JavaScript 的 Web 编程](https://www.class-central.com/mooc/8518/edx-programming-for-the-web-with-javascript) 来自 *University of Pennsylvania* ★★★★★(2)
* [计算的美与乐 — AP® CS 原理 第 1 部分](https://www.class-central.com/mooc/2525/edx-the-beauty-and-joy-of-computing-ap-cs-principles-part-1) 来自 *University of California, Berkeley* ★★★★★(2)
* [Python 计算入门](https://www.class-central.com/mooc/7622/edx-introduction-to-computing-using-python) 来自 *Georgia Institute of Technology* ★★★★★(2)
* [面向对象的编程](https://www.class-central.com/mooc/1651/edx-object-oriented-programming) 来自 *Indian Institute of Technology Bombay* ★★★★☆(2)
* [思维·创新·代码](https://www.class-central.com/mooc/3231/edx-think-create-code) 来自 *University of Adelaide* ★★★★★(2)
* [智能手机中的计算技术](https://www.class-central.com/mooc/2809/edx-the-computing-technology-inside-your-smartphone) 来自 *Cornell University* ★★★★★(2)
* [Android 基础:编写你的第一个 App](https://www.class-central.com/mooc/7278/udacity-android-basics-make-your-first-app) 来自 *Google* ★★★★☆(2)
* [学习 Python 编程](https://www.class-central.com/mooc/3695/edx-learn-to-program-using-python) 来自 *University of Texas Arlington* ★★★★★(2)
* [HTML 和 JavaScript 入门](https://www.class-central.com/mooc/5923/edx-introduction-to-html-and-javascript) 来自 *Microsoft* ★★★★★(2)
* [大众计算机科学:计算机科学和 Python 编程入门](https://www.class-central.com/mooc/3483/edx-cs-for-all-introduction-to-computer-science-and-python-programming)来自 *Harvey Mudd College* ★★★★★(2)
* [JavaScript 入门](https://www.class-central.com/mooc/8059/udacity-intro-to-javascript)
* [Android 新手入门](https://www.class-central.com/mooc/7623/udacity-android-for-beginners)
* [网络:朋友、金钱和字节](https://www.class-central.com/mooc/359/coursera-networks-friends-money-and-bytes) 来自 *Princeton University* ★★★☆☆(1)
* [如何编码:数据基础](https://www.class-central.com/mooc/8202/edx-how-to-code-simple-data) 来自 *The University of British Columbia* ★★★★★(1)
* [使用 Wordpress 开发和设计 Web](https://www.class-central.com/mooc/6408/kadenze-web-development-and-design-using-wordpress) 来自 *California Institute of the Arts* ★★★★☆(1)
* [Android App 新手开发指南](https://www.class-central.com/mooc/7315/edx-android-app-development-for-beginners) 来自 *Galileo University* ★☆☆☆☆(1)
* [Android App 新手开发指南](https://www.class-central.com/mooc/7315/edx-android-app-development-for-beginners) 来自 *Galileo University* ★☆☆☆☆(1)
* [艺术家的 Web 编码基础](https://www.class-central.com/mooc/3781/kadenze-web-coding-fundamentals-for-artists) 来自 *National University of Singapore* ★★★★☆(1)
* [ReactJS 入门](https://www.class-central.com/mooc/8770/edx-introduction-to-reactjs) 来自 *Microsoft* ★★☆☆☆(1)
* [Node.js 入门](https://www.class-central.com/mooc/9597/edx-introduction-to-node-js) 来自 *Microsoft* ★★★★★(1)
* [学习 Java 编程](https://www.class-central.com/mooc/8718/edx-learn-to-program-in-java) 来自 *Microsoft* ★★★★★(1)
* [计算:艺术、魔法与科学](https://www.class-central.com/mooc/2195/edx-computing-art-magic-science) 来自 *ETH Zurich* ★★★★☆(1)
* [计算:艺术、魔法与科学 — 第 2 部分](https://www.class-central.com/mooc/4084/edx-computing-art-magic-science-part-ii) 来自 *ETH Zurich*
* [Cyber 安全:居家安全、在线与生活](https://www.class-central.com/mooc/6265/futurelearn-cyber-security-safety-at-home-online-in-life) 来自 *Newcastle University* ★★★☆☆(1)
* [软件工程师基础](https://www.class-central.com/mooc/8527/edx-software-engineering-essentials) 来自 *Technische Universität München (Technical University of Munich)* ★★★★★(1)
* [我的计算机科学: 计算机科学新手指南](https://www.class-central.com/mooc/2957/edx-mycs-computer-science-for-beginners) 来自 *Harvey Mudd College* ★★★☆☆(1)
* [使用 Git 管理版本](https://www.class-central.com/mooc/8430/udacity-version-control-with-git)
* [大众 Web 应用](https://www.class-central.com/mooc/7362/web-applications-for-everybody)
* [CS50’s AP® 计算机科学原理](https://www.class-central.com/mooc/7017/edx-cs50-s-ap-computer-science-principles) 来自 *Harvard University*
* [编程基础](https://www.class-central.com/mooc/9574/coursera-programming-fundamentals) 来自 *Duke University*
* [Cyber 安全入门](https://www.class-central.com/mooc/8651/edx-introduction-to-cybersecurity) 来自 *University of Washington*
* [Python 数据表现](https://www.class-central.com/mooc/9550/coursera-python-data-representations) 来自 *Rice University*
* [Python 编程基础](https://www.class-central.com/mooc/9549/coursera-python-programming-essentials) 来自 *Rice University*
* [软件工程师:入门](https://www.class-central.com/mooc/8205/edx-software-engineering-introduction) 来自 *The University of British Columbia*
* [Web 开发入门](https://www.class-central.com/mooc/7027/coursera-introduction-to-web-development) 来自 *University of California, Davis*
* [Java 编程入门 — 第 2 部分](https://www.class-central.com/mooc/3486/edx-introduction-to-java-programming-part-2) 来自 *The Hong Kong University of Science and Technology*
* [Excel/VBA 解决创意问题,第 2 部分](https://www.class-central.com/mooc/9943/coursera-excel-vba-for-creative-problem-solving-part-2) 来自 *University of Colorado Boulder*
* [AP 计算机科学 A:Java 编程的多态和高级数据结构](https://www.class-central.com/mooc/7219/edx-ap-computer-science-a-java-programming-polymorphism-and-advanced-data-structures) 来自 *Purdue University*
* [AP 计算机科学 A:Java 编程的循环和数据结构](https://www.class-central.com/mooc/7212/edx-ap-computer-science-a-java-programming-loops-and-data-structures)来自 *Purdue University*
* [AP 计算机科学 A:Java 编程的类和对象](https://www.class-central.com/mooc/7211/edx-ap-computer-science-a-java-programming-classes-and-objects) 来自 *Purdue University*
* [Android 开发的 Java 基础](https://www.class-central.com/mooc/7313/edx-java-fundamentals-for-android-development) 来自 *Galileo University*
* [很赚钱的 Android Apps 所使用的商业模式](https://www.class-central.com/mooc/7345/edx-monetize-android-apps-with-business-models) 来自 *Galileo University*
* [很赚钱的 Android Apps 所使用的商业模式](https://www.class-central.com/mooc/7345/edx-monetize-android-apps-with-business-models) 来自 *Galileo University*
* [Android 开发的 Java 基础](https://www.class-central.com/mooc/7313/edx-java-fundamentals-for-android-development) 来自 *Galileo University*
* [Java 编程入门:写出好代码](https://www.class-central.com/mooc/5735/edx-introduction-to-java-programming-writing-good-code) 来自 *Universidad Carlos iii de Madrid*
* [Cyber 安全基础:动手实践](https://www.class-central.com/mooc/7849/edx-cyber-security-basics-a-hands-on-approach) 来自 *Universidad Carlos iii de Madrid*
* [业务深度学习](https://www.class-central.com/mooc/9431/coursera-deep-learning-for-business) 来自 *Yonsei University*
* [TCP/IP 入门](https://www.class-central.com/mooc/9143/coursera-introduction-to-tcp-ip) 来自 *Yonsei University*
* [视频游戏设计和平衡](https://www.class-central.com/mooc/6660/edx-video-game-design-and-balance) 来自 *Rochester Institute of Technology*
* [Web 易用性](https://www.class-central.com/mooc/6531/udacity-web-accessibility) 来自 *Google*
* [移动 Web 开发](https://www.class-central.com/mooc/1046/udacity-mobile-web-development) 来自 *Google*
* [Python 编程入门](https://www.class-central.com/mooc/10134/edx-introduction-to-programming-using-python) 来自 *University of Texas Arlington*
* [Python 入门:从零开始](https://www.class-central.com/mooc/8671/edx-introduction-to-python-absolute-beginner) 来自 *Microsoft*
* [Python:基础](https://www.class-central.com/mooc/8650/edx-introduction-to-python-fundamentals) 来自 *Microsoft*
* [设计思想入门](https://www.class-central.com/mooc/8845/edx-introduction-to-design-thinking) 来自 *Microsoft*
* [逻辑和计算思维](https://www.class-central.com/mooc/8725/edx-logic-and-computational-thinking) 来自 *Microsoft*
* [像专家一样写代码](https://www.class-central.com/mooc/8808/edx-writing-professional-code) 来自 *Microsoft*
* [Java 中的面向对象编程](https://www.class-central.com/mooc/8723/edx-object-oriented-programming-in-java) 来自 *Microsoft*
* [CSS 基础 来自 *Microsoft*
* [JavaScript 入门](https://www.class-central.com/mooc/8496/edx-javascript-introduction) 来自 *World Wide Web Consortium (W3C)*
* [Python 的面向对象编程:创建你自己的冒险游戏](https://www.class-central.com/mooc/8884/futurelearn-object-oriented-programming-in-python-create-your-own-adventure-game) 来自 *Raspberry Pi Foundation*
* [学习 Swift 编程语法](https://www.class-central.com/mooc/3925/udacity-learn-swift-programming-syntax)
* [JavaScript 和 DOM](https://www.class-central.com/mooc/9990/udacity-javascript-and-the-dom)
* [能源行业中的区块链](https://www.class-central.com/mooc/9526/futurelearn-blockchain-in-the-energy-sector) 来自 *InnoEnergy*
* [虚拟现实入门](https://www.class-central.com/mooc/7379/udacity-introduction-to-virtual-reality)
* [ES6 — 改进后的 JavaScript](https://www.class-central.com/mooc/8543/udacity-es6-javascript-improved)
* [Python 入门](https://www.class-central.com/mooc/8577/udacity-introduction-to-python)
* [HTTP & Web 服务器](https://www.class-central.com/mooc/8374/udacity-http-web-servers)
* [GitHub & 合作](https://www.class-central.com/mooc/8542/udacity-github-collaboration)
* [Swift 新手指南](https://www.class-central.com/mooc/7494/udacity-swift-for-beginners)
### 中级(259)
* [机器学习](https://www.class-central.com/mooc/835/coursera-machine-learning) 来自 *Stanford University* ★★★★★(325)
* [算法,第 1 部分](https://www.class-central.com/mooc/339/coursera-algorithms-part-i) 来自 *Princeton University* ★★★★★(58)
* [算法,第 II 部分](https://www.class-central.com/mooc/340/coursera-algorithms-part-ii) 来自 *Princeton University* ★★★★★(21)
* [为音乐家和艺术家的机器学习](https://www.class-central.com/mooc/3768/kadenze-machine-learning-for-musicians-and-artists) 来自 *Goldsmiths, University of London* ★★★★★(57)
* [密码学 I](https://www.class-central.com/mooc/616/coursera-cryptography-i) 来自 *Stanford University* ★★★★★(49)
* [CS188.1x:人工智能](https://www.class-central.com/mooc/445/edx-cs188-1x-artificial-intelligence) 来自 *University of California, Berkeley* ★★★★★(30)
* [计算原理(第 1 部分)](https://www.class-central.com/mooc/1724/coursera-principles-of-computing-part-1) 来自 *Rice University* ★★★★★(29)
* [计算原理(第 2 部分)](https://www.class-central.com/mooc/3198/coursera-principles-of-computing-part-2) 来自 *Rice University* ★★★★☆(16)
* [[New] 算法设计和技术](https://www.class-central.com/mooc/10241/edx-algorithmic-design-and-techniques) 来自 *University of California, San Diego*
* [软件安全](https://www.class-central.com/mooc/1728/coursera-software-security)来自 *University of Maryland, College Park* ★★★★☆(25)
* [[New] 弹性计算入门](https://www.class-central.com/mooc/10053/nptel-introduction-to-soft-computing) 来自 *Indian Institute of Technology, Kharagpur*
* [[New] 云计算](https://www.class-central.com/mooc/10027/nptel-cloud-computing) 来自 *Indian Institute of Technology, Kharagpur*
* [[New] 数据库管理系统](https://www.class-central.com/mooc/9914/nptel-database-management-system) 来自 *Indian Institute of Technology, Kharagpur*
* [[New] Haskell 编程入门](https://www.class-central.com/mooc/10044/nptel-introduction-to-haskell-programming) 来自 *Chennai Mathematical Institute*
* [越来越容易的专业 Web 易访问性审计](https://www.class-central.com/mooc/5174/canvas-network-professional-web-accessibility-auditing-made-easy) 来自 *Chang School of Continuing Education* ★★★★★(21)
* [在 Rails 上使用 Ruby 进行敏捷开发 — 基础篇](https://www.class-central.com/mooc/443/edx-agile-development-using-ruby-on-rails-the-basics) 来自 *University of California, Berkeley* ★★★★★(19)
* [自动化理论](https://www.class-central.com/mooc/376/stanford-openedx-automata-theory) 来自 *Stanford University* ★★★★☆(18)
* [机器学习入门](https://www.class-central.com/mooc/2996/udacity-intro-to-machine-learning) 来自 *Stanford University* ★★★★☆(18)
* [Web 开发](https://www.class-central.com/mooc/324/udacity-web-development)
* [Android 开发新手指南](https://www.class-central.com/mooc/3579/udacity-android-development-for-beginners) 来自 *Google* ★★★★☆(16)
* [C 程序员学习 C++,Part A](https://www.class-central.com/mooc/671/coursera-c-for-c-programmers-part-a) 来自 *University of California, Santa Cruz* ★★★☆☆(16)
* [代码的本质](https://www.class-central.com/mooc/3777/kadenze-the-nature-of-code) 来自 *Processing Foundation* ★★★★★(16)
* [游戏开发的概念](https://www.class-central.com/mooc/1176/open2study-concepts-in-game-development) 来自 *Swinburne University of Technology* ★★★★☆(15)
* [算法的思想(第 1 部分)](https://www.class-central.com/mooc/1725/coursera-algorithmic-thinking-part-1) 来自 *Rice University* ★★★★☆(14)
* [算法的思想(第 2 部分)](https://www.class-central.com/mooc/3200/coursera-algorithmic-thinking-part-2) 来自 *Rice University* ★★★★☆(9)
* [计算机程序的设计](https://www.class-central.com/mooc/323/udacity-design-of-computer-programs) 来自 *Stanford University* ★★★★☆(13)
* [Java 编程:用软件解决问题](https://www.class-central.com/mooc/4305/coursera-java-programming-solving-problems-with-software) 来自 *Duke University* ★★★☆☆(13)
* [Web 响应设计](https://www.class-central.com/mooc/4200/coursera-responsive-web-design) 来自 *University of London International Programmes* ★★★★☆(12)
* [离散优化](https://www.class-central.com/mooc/487/coursera-discrete-optimization) 来自 *University of Melbourne* ★★★★☆(12)
* [游戏开发入门](https://www.class-central.com/mooc/4275/coursera-introduction-to-game-development) 来自 *Michigan State University* ★★★★★(12)
* [函数式编程入门](https://www.class-central.com/mooc/2147/edx-introduction-to-functional-programming) 来自 *Delft University of Technology* ★★★★☆(11)
* [开发 Android Apps](https://www.class-central.com/mooc/2211/udacity-developing-android-apps) 来自 *Google* ★★★☆☆(11)
* [面向对象的 JavaScript](https://www.class-central.com/mooc/2658/udacity-object-oriented-javascript) 来自 *Hack Reactor* ★★★★★(11)
* [编程语言](https://www.class-central.com/mooc/325/udacity-programming-languages) 来自 *University of Virginia* ★★★☆☆(10)
* [编程语言,Part B](https://www.class-central.com/mooc/6920/coursera-programming-languages-part-b) 来自 *University of Washington* ★★★★★(2)
* [编程语言,Part C](https://www.class-central.com/mooc/7187/coursera-programming-languages-part-c) 来自 *University of Washington* ★★★★★(1)
* [Web 响应设计基础](https://www.class-central.com/mooc/3255/udacity-responsive-web-design-fundamentals) 来自 *Google* ★★★★★(9)
* [图像和视频处理:从火星到好莱坞而止于医院](https://www.class-central.com/mooc/462/coursera-image-and-video-processing-from-mars-to-hollywood-with-a-stop-at-the-hospital) 来自 *Duke University* ★★★★☆(8)
* [密码学](https://www.class-central.com/mooc/1730/coursera-cryptography) 来自 *University of Maryland, College Park* ★★★★☆(8)
* [学习数据(机器学习入门)](https://www.class-central.com/mooc/366/learning-from-data-introductory-machine-learning-course) 来自 *California Institute of Technology* ★★★★★(8)
* [Julia 科学编程](https://www.class-central.com/mooc/7092/coursera-julia-scientific-programming) 来自 *University of Cape Town* ★★★★★(8)
* [云计算应用程序,第 1 部分:云系统和基础设施](https://www.class-central.com/mooc/2738/coursera-cloud-computing-applications-part-1-cloud-systems-and-infrastructure)来自 *University of Illinois at Urbana-Champaign* ★★★☆☆(7)
* [云计算概念:第 2 部分](https://www.class-central.com/mooc/2942/coursera-cloud-computing-concepts-part-2) 来自 *University of Illinois at Urbana-Champaign* ★★★★★(5)
* [Swift 编程入门](https://www.class-central.com/mooc/4248/coursera-introduction-to-swift-programming) 来自 *University of Toronto* ★☆☆☆☆(7)
* [Software 测试](https://www.class-central.com/mooc/365/udacity-software-testing) 来自 *University of Utah* ★★★★☆(7)
* [使用 MongoDB 管理数据](https://www.class-central.com/mooc/1479/udacity-data-wrangling-with-mongodb) 来自 *MongoDB University* ★★★★☆(7)
* [AJAX 入门](https://www.class-central.com/mooc/2997/udacity-intro-to-ajax)
* [计算机架构](https://www.class-central.com/mooc/342/coursera-computer-architecture) 来自 *Princeton University* ★★★★☆(6)
* [物联网:我们如何用它?](https://www.class-central.com/mooc/4276/coursera-internet-of-things-how-did-we-get-here) 来自 *University of California, San Diego* ★★☆☆☆(6)
* [Meteor.js 开发入门](https://www.class-central.com/mooc/4328/coursera-introduction-to-meteor-js-development)来自 *University of London International Programmes* ★★★★☆(6)
* [DevOps 入门](https://www.class-central.com/mooc/4013/udacity-intro-to-devops) 来自 *Nutanix* ★★★☆☆(6)
* [全栈基础](https://www.class-central.com/mooc/3254/udacity-full-stack-foundations)
* [算法入门](https://www.class-central.com/mooc/364/udacity-intro-to-algorithms)
* [Java 中的软件架构](https://www.class-central.com/mooc/6469/edx-software-construction-in-java) 来自 *Massachusetts Institute of Technology* ★★★★★(5)
* [在 Rails 上使用 Ruby 进行敏捷开发 — 高级篇](https://www.class-central.com/mooc/558/edx-agile-development-using-ruby-on-rails-advanced) 来自 *University of California, Berkeley* ★★★★★(5)
* [计算机图形](https://www.class-central.com/mooc/548/edx-computer-graphics) 来自 *University of California, Berkeley* ★★★★☆(5)
* [软件开发过程](https://www.class-central.com/mooc/2335/udacity-software-development-process) 来自 *Georgia Institute of Technology* ★★★★☆(5)
* [计算机网络](https://www.class-central.com/mooc/2336/udacity-computer-networking) 来自 *Georgia Institute of Technology* ★★★★☆(5)
* [Java 编程:数组、列表、和数据结构](https://www.class-central.com/mooc/4362/coursera-java-programming-arrays-lists-and-structured-data) 来自 *Duke University* ★★★★★(5)
* [HTML5 游戏开发](https://www.class-central.com/mooc/551/udacity-html5-game-development) 来自 *Google* ★★★☆☆(5)
* [C++ 入门](https://www.class-central.com/mooc/4758/edx-introduction-to-c) 来自 *Microsoft* ★★★★☆(5)
* [软件调试](https://www.class-central.com/mooc/457/udacity-software-debugging) 来自 *Saarland University* ★★★★★(5)
* [并行编程概念](https://www.class-central.com/mooc/1701/openhpi-parallel-programming-concepts)
* [使用 Swift 开发 iOS App 入门](https://www.class-central.com/mooc/2861/udacity-intro-to-ios-app-development-with-swift)
* [物联网:配置你的 DragonBoard™ 开发平台](https://www.class-central.com/mooc/4260/coursera-internet-of-things-setting-up-your-dragonboard-development-platform)来自 *University of California, San Diego* ★★★☆☆(4)
* [物联网 & 增强现实新技术](https://www.class-central.com/mooc/3934/coursera-internet-of-things-augmented-reality-emerging-technologies) 来自 *Yonsei University* ★★★☆☆(4)
* [Database 管理基础](https://www.class-central.com/mooc/4337/coursera-database-management-essentials) 来自 *University of Colorado System* ★★★★☆(4)
* [Web 网络性能优化](https://www.class-central.com/mooc/2189/udacity-website-performance-optimization) 来自 *Google* ★★★★☆(4)
* [移动开发者的 UX 设计](https://www.class-central.com/mooc/2212/udacity-ux-design-for-mobile-developers) 来自 *Google* ★★★★★(4)
* [使用 Transact-SQL 查询数据](https://www.class-central.com/mooc/3341/edx-querying-data-with-transact-sql) 来自 *Microsoft* ★★★★☆(4)
* [计算机图形交互](https://www.class-central.com/mooc/2067/coursera-interactive-computer-graphics) 来自 *The University of Tokyo* ★★☆☆☆(4)
* [jQuery 入门](https://www.class-central.com/mooc/2998/udacity-intro-to-jquery)
* [将 Python 用于研究](https://www.class-central.com/mooc/7204/edx-using-python-for-research) 来自 *Harvard University* ★★★☆☆(3)
* [图解网络:无需微积分](https://www.class-central.com/mooc/891/coursera-networks-illustrated-principles-without-calculus) 来自 *Princeton University* ★★★★☆(3)
* [VLSI CAD 第 I 部分:逻辑](https://www.class-central.com/mooc/428/coursera-vlsi-cad-part-i-logic) 来自 *University of Illinois at Urbana-Champaign* ★★★★★(3)
* [物联网:通讯技术](https://www.class-central.com/mooc/4173/coursera-internet-of-things-communication-technologies) 来自 *University of California, San Diego* ★★★☆☆(3)
* [MATLAB 和 Octave 的新手指南](https://www.class-central.com/mooc/7376/edx-matlab-and-octave-for-beginners) 来自 *École Polytechnique Fédérale de Lausanne* ★★★☆☆(3)
* [无线通讯新技术](https://www.class-central.com/mooc/3936/coursera-wireless-communication-emerging-technologies) 来自 *Yonsei University* ★★★★☆(3)
* [JavaScript Promises](https://www.class-central.com/mooc/5680/udacity-javascript-promises) 来自 *Google* ★★★★★(3)
* [Android 基础:多屏 Apps](https://www.class-central.com/mooc/6549/udacity-android-basics-multiscreen-apps) 来自 *Google* ★★★★☆(3)
* [Android 基础:用户输入](https://www.class-central.com/mooc/7343/udacity-android-basics-user-input) 来自 *Google* ★★★★☆(3)
* [DevOps:开发者如何入门](https://www.class-central.com/mooc/6333/edx-devops-for-developers-how-to-get-started) 来自 *Microsoft* ★★★★☆(3)
* [自主移动机器人](https://www.class-central.com/mooc/1564/edx-autonomous-mobile-robots) 来自 *ETH Zurich* ★★★☆☆(3)
* [敏捷软件开发](https://www.class-central.com/mooc/6878/edx-agile-software-development) 来自 *ETH Zurich* ★★★★☆(3)
* [JavaScript 调试](https://www.class-central.com/mooc/3351/udacity-javascript-testing)
* [配置 Linux Web 服务器](https://www.class-central.com/mooc/4050/udacity-configuring-linux-web-servers)
* [JavaScript 设计模式](https://www.class-central.com/mooc/3082/udacity-javascript-design-patterns)
* [编译器](https://www.class-central.com/mooc/2716/stanford-openedx-compilers) 来自 *Stanford University* ★★★★☆(2)
* [LPL: 语言,验证和逻辑](https://www.class-central.com/mooc/2340/stanford-openedx-lpl-language-proof-and-logic) 来自 *Stanford University* ★★★★★(2)
* [移动应用程序体验 第 1 部分:从一个领域到一个应用程序创意](https://www.class-central.com/mooc/1523/edx-mobile-application-experiences-part-1-from-a-domain-to-an-app-idea)来自 *Massachusetts Institute of Technology* ★★★★★(2)
* [移动应用程序体验 第 2 部分:移动应用设计](https://www.class-central.com/mooc/5724/edx-mobile-application-experiences-part-2-mobile-app-design) 来自 *Massachusetts Institute of Technology*
* [移动应用程序体验 第 3 部分:构建移动应用程序](https://www.class-central.com/mooc/5633/edx-mobile-application-experiences-part-3-building-mobile-apps) 来自 *Massachusetts Institute of Technology*
* [机器学习:自主学习](https://www.class-central.com/mooc/1848/udacity-machine-learning-unsupervised-learning) 来自 *Brown University* ★★★★★(2)
* [响应式 Web 网站教程和示例](https://www.class-central.com/mooc/4356/coursera-responsive-website-tutorial-and-examples) 来自 *University of London International Programmes* ★★★★★(2)
* [iOS App 开发基础](https://www.class-central.com/mooc/4348/coursera-ios-app-development-basics) 来自 *University of Toronto* ★★★★☆(2)
* [编程、数据结构和算法](https://www.class-central.com/mooc/2778/nptel-programming-data-structures-and-algorithms) 来自 *Indian Institute of Technology Madras* ★★☆☆☆(2)
* [Android App 组件 — 服务、本地 IPC、以及内容提供者](https://www.class-central.com/mooc/7763/coursera-android-app-components-services-local-ipc-and-content-providers)来自 *Vanderbilt University* ★★★☆☆(2)
* [Android App 组件 — Intents、Activities、和广播接收器](https://www.class-central.com/mooc/5500/coursera-android-app-components-intents-activities-and-broadcast-receivers)来自 *Vanderbilt University* ★★★☆☆(2)
* [Android 移动应用程序开发入门](https://www.class-central.com/mooc/3758/edx-introduction-to-mobile-application-development-using-android) 来自 *The Hong Kong University of Science and Technology* ★★★★☆(2)
* [因特网新兴技术](https://www.class-central.com/mooc/3933/coursera-internet-emerging-technologies) 来自 *Yonsei University* ★★★☆☆(2)
* [面向对象的设计](https://www.class-central.com/mooc/9216/coursera-object-oriented-design) 来自 *University of Alberta* ★★★☆☆(2)
* [Android 基础:网络](https://www.class-central.com/mooc/6728/udacity-android-basics-networking) 来自 *Google* ★★★★☆(2)
* [浏览器底层优化](https://www.class-central.com/mooc/3524/udacity-browser-rendering-optimization) 来自 *Google* ★★★★☆(2)
* [Google 云平台基础:核心基础设施](https://www.class-central.com/mooc/7784/coursera-google-cloud-platform-fundamentals-core-infrastructure) 来自 *Google* ★★★★☆(2)
* [客户端-服务器通讯](https://www.class-central.com/mooc/6527/udacity-client-server-communication) 来自 *Google* ★★★★★(2)
* [开发国际化软件,第 1 部分](https://www.class-central.com/mooc/3996/edx-developing-international-software-part-1) 来自 *Microsoft* ★★★★☆(2)
* [使用 Power BI 分析和可视化数据](https://www.class-central.com/mooc/5156/edx-analyzing-and-visualizing-data-with-power-bi) 来自 *Microsoft* ★★★★★(2)
* [Web 开发者之网络](https://www.class-central.com/mooc/5965/udacity-networking-for-web-developers)
* [计算结构2:计算机架构](https://www.class-central.com/mooc/4810/edx-computation-structures-2-computer-architecture) 来自 *Massachusetts Institute of Technology* ★★★★☆(1)
* [软件开发基础](https://www.class-central.com/mooc/8516/edx-software-development-fundamentals) 来自 *University of Pennsylvania* ★★★☆☆(1)
* [软件架构与设计](https://www.class-central.com/mooc/3418/udacity-software-architecture-design) 来自 *Georgia Institute of Technology* ★★★★★(1)
* [数据库系统概念与设计](https://www.class-central.com/mooc/8573/udacity-database-systems-concepts-design) 来自 *Georgia Institute of Technology* ★★★★☆(1)
* [如何编码:复杂数据](https://www.class-central.com/mooc/8199/edx-how-to-code-complex-data) 来自 *The University of British Columbia* ★★★★★(1)
* [产品设计冲刺](https://www.class-central.com/mooc/5592/coursera-running-product-design-sprints) 来自 *University of Virginia* ★★★☆☆(1)
* [Android 之 Java](https://www.class-central.com/mooc/5446/coursera-java-for-android) 来自 *Vanderbilt University* ★☆☆☆☆(1)
* [使用 NodeJS、Express 和 MongoDB 进行服务器侧开发](https://www.class-central.com/mooc/8888/coursera-server-side-development-with-nodejs-express-and-mongodb) 来自 *The Hong Kong University of Science and Technology* ★★★★★(1)
* [Cyber 安全经济](https://www.class-central.com/mooc/6991/edx-cyber-security-economics) 来自 *Delft University of Technology* ★★☆☆☆(1)
* [Web 应用程序开发:基本概念](https://www.class-central.com/mooc/5497/coursera-web-application-development-basic-concepts) 来自 *University of New Mexico* ★★★★☆(1)
* [算法](https://www.class-central.com/mooc/5752/edx-algorithms) 来自 *Indian Institute of Technology Bombay* ★★★★★(1)
* [Android:Introducción a la Programación](https://www.class-central.com/mooc/2964/edx-android-introduccion-a-la-programacion) 来自 *Universitat Politècnica de València* ★★★★☆(1)
* [面向服务的架构](https://www.class-central.com/mooc/9219/coursera-service-oriented-architecture) 来自 *University of Alberta* ★★★★★(1)
* 设计模式][235](https://www.class-central.com/mooc/9215/coursera-design-patterns) 来自 *University of Alberta* ★☆☆☆☆(1)
* [Cybersecurity 和便捷性](https://www.class-central.com/mooc/6584/coursera-cybersecurity-and-mobility) 来自 *University System of Georgia* ★☆☆☆☆(1)
* [Google 云平台基础之 AWS 安全专家篇](https://www.class-central.com/mooc/8614/coursera-google-cloud-platform-fundamentals-for-aws-professionals) 来自 *Google Cloud* ★★☆☆☆(1)
* [Android 基础:用户界面](https://www.class-central.com/mooc/7342/udacity-android-basics-user-interface) 来自 *Google* ★★☆☆☆(1)
* [使用 Kubernetes 的弹性微服务](https://www.class-central.com/mooc/6275/udacity-scalable-microservices-with-kubernetes) 来自 *Google* ★★★★☆(1)
* [用 Java 开发弹性应用程序](https://www.class-central.com/mooc/2215/udacity-developing-scalable-apps-in-java) 来自 *Google* ★★★★☆(1)
* [Android 性能](https://www.class-central.com/mooc/3455/udacity-android-performance) 来自 *Google* ★★★★★(1)
* [Android 基础:点击按钮](https://www.class-central.com/mooc/7279/udacity-android-basics-button-clicks) 来自 *Google* ★★★☆☆(1)
* [Android 和 Java 的 Gradle](https://www.class-central.com/mooc/3584/udacity-gradle-for-android-and-java) 来自 *Google* ★★★★★(1)
* [VR 软件开发](https://www.class-central.com/mooc/7463/udacity-vr-software-development) 来自 *Google* ★★★★☆(1)
* [用 Python 开发弹性应用程序](https://www.class-central.com/mooc/3525/udacity-developing-scalable-apps-in-python) 来自 *Google* ★★★★☆(1)
* [Android 开发者的内容设计](https://www.class-central.com/mooc/3581/udacity-material-design-for-android-developers) 来自 *Google* ★★★★★(1)
* [中级 C++](https://www.class-central.com/mooc/7590/edx-intermediate-c) 来自 *Microsoft* ★★★★☆(1)
* [C# 入门](https://www.class-central.com/mooc/8823/edx-introduction-to-c) 来自 *Microsoft* ★★☆☆☆(1)
* [AngularJS:高级框架技术](https://www.class-central.com/mooc/7384/edx-angularjs-advanced-framework-techniques) 来自 *Microsoft* ★★★★☆(1)
* [机器学习原理](https://www.class-central.com/mooc/6511/edx-principles-of-machine-learning) 来自 *Microsoft* ★★★★★(1)
* [Javascript 异步编程](https://www.class-central.com/mooc/8002/edx-asynchronous-programming-with-javascript) 来自 *Microsoft* ★★★★★(1)
* [从第一原则构建现代化计算机:Nand 到 Tetris 第 II 部分(以项目为中心的课程)](https://www.class-central.com/mooc/8025/coursera-build-a-modern-computer-from-first-principles-nand-to-tetris-part-ii-project-centered-course) 来自 *Hebrew University of Jerusalem* ★★★★★(1)
* [物联网开发者指南](https://www.class-central.com/mooc/6040/coursera-a-developer-s-guide-to-the-internet-of-things-iot) 来自 *IBM* ★★★★☆(1)
* [云基础设施技术入门](https://www.class-central.com/mooc/6000/edx-introduction-to-cloud-infrastructure-technologies) 来自 *Linux Foundation* ★★★★☆(1)
* [使用 libGDX 开发 2D 游戏](https://www.class-central.com/mooc/4856/udacity-2d-game-development-with-libgdx) 来自 *Amazon* ★★★★★(1)
* [实时系统入门](https://www.class-central.com/mooc/4990/edx-introduction-to-real-time-systems) 来自 *IEEE* ★★★★☆(1)
* [算法设计与分析](https://www.class-central.com/mooc/3984/nptel-design-and-analysis-of-algorithms) 来自 *Chennai Mathematical Institute* ★★★☆☆(1)
* [如何赢得编码比赛:冠军的秘密](https://www.class-central.com/mooc/6300/edx-how-to-win-coding-competitions-secrets-of-champions) 来自 *ITMO University* ★★★☆☆(1)
* [HTML5 应用程序和游戏](https://www.class-central.com/mooc/4671/edx-html5-apps-and-games) 来自 *World Wide Web Consortium (W3C)* ★★★☆☆(1)
* [面试技术](https://www.class-central.com/mooc/6143/udacity-technical-interview) 来自 *Pramp* ★★★★★(1)
* [Android 基础:数据存储](https://www.class-central.com/mooc/6956/udacity-android-basics-data-storage)
* [计算机科学理论入门](https://www.class-central.com/mooc/455/udacity-intro-to-theoretical-computer-science)
* [算法:设计与分析](https://www.class-central.com/mooc/8984/stanford-openedx-algorithms-design-and-analysis) 来自 *Stanford University*
* [最短路径回访、完整 NP 问题以及如何实现](https://www.class-central.com/mooc/7351/coursera-shortest-paths-revisited-np-complete-problems-and-what-to-do-about-them) 来自 *Stanford University*
* [Java 中的高级软件结构](https://www.class-central.com/mooc/6475/edx-advanced-software-construction-in-java) 来自 *Massachusetts Institute of Technology*
* [算法设计与分析](https://www.class-central.com/mooc/8520/edx-algorithm-design-and-analysis) 来自 *University of Pennsylvania*
* [数据结构与软件设计](https://www.class-central.com/mooc/8517/edx-data-structures-and-software-design) 来自 *University of Pennsylvania*
* [R 中的 Neurohacking 入门](https://www.class-central.com/mooc/6420/coursera-introduction-to-neurohacking-in-r) 来自 *Johns Hopkins University*
* [数据库系统概念与设计](https://www.class-central.com/mooc/8994/edx-database-systems-concepts-and-design) 来自 *Georgia Institute of Technology*
* [软件分析与测试](https://www.class-central.com/mooc/8568/udacity-software-analysis-testing) 来自 *Georgia Institute of Technology*
* [在 C 中编写、运行和修复代码](https://www.class-central.com/mooc/9797/coursera-writing-running-and-fixing-code-in-c) 来自 *Duke University*
* [动画和 CGI 手势](https://www.class-central.com/mooc/7242/edx-animation-and-cgi-motion) 来自 *Columbia University*
* [Minecraft、编码和测试](https://www.class-central.com/mooc/7480/edx-minecraft-coding-and-teaching) 来自 *University of California, San Diego*
* [物联网:来自设备的传感和驱动](https://www.class-central.com/mooc/4182/coursera-internet-of-things-sensing-and-actuation-from-devices) 来自 *University of California, San Diego*
* [虚拟现实如何工作](https://www.class-central.com/mooc/8514/edx-how-virtual-reality-vr-works) 来自 *University of California, San Diego*
* [创建虚拟现实应用程序](https://www.class-central.com/mooc/8515/edx-creating-virtual-reality-vr-apps) 来自 *University of California, San Diego*
* [构建一个Cybersecurity 工具箱](https://www.class-central.com/mooc/8653/edx-building-a-cybersecurity-toolkit) 来自 *University of Washington*
* [Cybersecurity: The CISO’s View](https://www.class-central.com/mooc/8652/edx-cybersecurity-the-ciso-s-view) 来自 *University of Washington*
* [构建你自己的 iOS App](https://www.class-central.com/mooc/6235/coursera-build-your-own-ios-app) 来自 *University of Toronto*
* [算法设计与分析](https://www.class-central.com/mooc/3230/coursera--design-and-analysis-of-algorithms) 来自 *Peking University*
* [面向对象技术高级课程](https://www.class-central.com/mooc/1737/coursera--the-advanced-object-oriented-technology)来自 *Peking University*
* [如何编码:系统化程序设计 — Part 1](https://www.class-central.com/mooc/3465/edx-how-to-code-systematic-program-design-part-1) 来自 *The University of British Columbia* ★★★★☆(6)
* [如何编码:系统化程序设计 — Part 2](https://www.class-central.com/mooc/3466/edx-how-to-code-systematic-program-design-part-2) 来自 *The University of British Columbia*
* [如何编码:系统化程序设计 — Part 3](https://www.class-central.com/mooc/3464/edx-how-to-code-systematic-program-design-part-3) 来自 *The University of British Columbia*
* [软件结构:数据抽象](https://www.class-central.com/mooc/8200/edx-software-construction-data-abstraction) 来自 *The University of British Columbia*
* [软件结构:面向对象的设计](https://www.class-central.com/mooc/8201/edx-software-construction-object-oriented-design) 来自 *The University of British Columbia*
* [敏捷测试](https://www.class-central.com/mooc/6523/coursera-testing-with-agile) 来自 *University of Virginia*
* [数据科学中的 SQL](https://www.class-central.com/mooc/9725/coursera-sql-for-data-science) 来自 *University of California, Davis*
* [LAFF — 正确编程](https://www.class-central.com/mooc/7852/edx-laff-on-programming-for-correctness) 来自 *The University of Texas at Austin*
* [使用 NativeScript 进行跨平台移动 App 开发](https://www.class-central.com/mooc/8684/coursera-multiplatform-mobile-app-development-with-nativescript) 来自 *The Hong Kong University of Science and Technology*
* [前后端 JavaScript 框架:Angular](https://www.class-central.com/mooc/8681/coursera-front-end-javascript-frameworks-angular) 来自 *The Hong Kong University of Science and Technology*
* [使用 Web 技术开发跨平台移动 App:Ionic 和 Cordova](https://www.class-central.com/mooc/8683/coursera-multiplatform-mobile-app-development-with-web-technologies-ionic-and-cordova) 来自 *The Hong Kong University of Science and Technology*
* [使用 App Inventor 开发 Android Apps](https://www.class-central.com/mooc/8687/coursera-developing-android-apps-with-app-inventor) 来自 *The Hong Kong University of Science and Technology*
* [前后端 Web UI 框架和工具:Bootstrap 4](https://www.class-central.com/mooc/8682/coursera-front-end-web-ui-frameworks-and-tools-bootstrap-4) 来自 *The Hong Kong University of Science and Technology*
* [全球软件发布引擎](https://www.class-central.com/mooc/9119/edx-globally-distributed-software-engineering) 来自 *Delft University of Technology*
* [C++ 开发基础(俄语)](https://www.class-central.com/mooc/10071/coursera----c--) 来自 *Moscow Institute of Physics and Technology*
* [构建机器人和设备](https://www.class-central.com/mooc/7785/coursera-building-arduino-robots-and-devices) 来自 *Moscow Institute of Physics and Technology*
* [数据结构实现](https://www.class-central.com/mooc/5753/edx-implementation-of-data-structures) 来自 *Indian Institute of Technology Bombay*
* [数据结构基础](https://www.class-central.com/mooc/5755/edx-foundations-of-data-structures) 来自 *Indian Institute of Technology Bombay*
* [专业 Android App 开发](https://www.class-central.com/mooc/7346/edx-professional-android-app-development) 来自 *Galileo University*
* [专业 Android App 开发](https://www.class-central.com/mooc/7346/edx-professional-android-app-development) 来自 *Galileo University*
* [软件架构师代码:构建数字世界](https://www.class-central.com/mooc/4812/edx-the-software-architect-code-building-the-digital-world) 来自 *Universidad Carlos iii de Madrid*
* [Java 编程入门:数据结构和算法基础](https://www.class-central.com/mooc/7454/edx-introduction-to-java-programming-fundamental-data-structures-and-algorithms) 来自 *Universidad Carlos iii de Madrid*
* [企业软件生命周期管理](https://www.class-central.com/mooc/6304/edx-enterprise-software-lifecycle-management) 来自 *National Research Nuclear University MEPhI*
* [在软件开发中使用操作系统机制(俄语)](https://www.class-central.com/mooc/10036/coursera--------) 来自 *National Research Nuclear University MEPhI*
* [需求获取:加工和利益相关者分析](https://www.class-central.com/mooc/9811/coursera-requirements-elicitation-artifact-and-stakeholder-analysis) 来自 *University of Colorado System*
* [Linux 服务器管理与安全性](https://www.class-central.com/mooc/9319/coursera-linux-server-management-and-security) 来自 *University of Colorado System*
* [特殊需求:目标和冲突分析](https://www.class-central.com/mooc/9807/coursera-requirements-specifications-goals-and-conflict-analysis) 来自 *University of Colorado System*
* [软件需求优先级:风险分析](https://www.class-central.com/mooc/9810/coursera-software-requirements-prioritization-risk-analysis) 来自 *University of Colorado System*
* [国家安全与 Cybersecurity 的联系 — 它是恐怖主义者的公证人](https://www.class-central.com/mooc/8820/coursera-homeland-security-cybersecurity-connection-it-s-not-about-the-terrorists) 来自 *University of Colorado System*
* [SRS 文档:需求与图解](https://www.class-central.com/mooc/9808/coursera-srs-documents-requirements-and-diagrammatic-notations) 来自 *University of Colorado System*
* [安全软件开发的需求收集](https://www.class-central.com/mooc/9809/coursera-requirements-gathering-for-secure-software-development) 来自 *University of Colorado System*
* [软件测试管理](https://www.class-central.com/mooc/8171/edx-software-testing-management) 来自 *University System of Maryland*
* [企业云计算](https://www.class-central.com/mooc/8168/edx-cloud-computing-for-enterprises) 来自 *University System of Maryland*
* [云计算基础设施](https://www.class-central.com/mooc/8181/edx-cloud-computing-infrastructure) 来自 *University System of Maryland*
* [软件验证形式](https://www.class-central.com/mooc/8180/edx-formal-software-verification) 来自 *University System of Maryland*
* [软件测试基础](https://www.class-central.com/mooc/8179/edx-software-testing-fundamentals) 来自 *University System of Maryland*
* [云计算管理](https://www.class-central.com/mooc/8172/edx-cloud-computing-management) 来自 *University System of Maryland*
* [数据结构入门](https://www.class-central.com/mooc/7391/edx-introduction-to-data-structures) 来自 *University of Adelaide*
* [视频游戏设计者的 Gameplay 编程](https://www.class-central.com/mooc/6657/edx-gameplay-programming-for-video-game-designers) 来自 *Rochester Institute of Technology*
* [团队工作与协作](https://www.class-central.com/mooc/6658/edx-teamwork-collaboration) 来自 *Rochester Institute of Technology*
* [嵌入式系统的 Web 连接与安全](https://www.class-central.com/mooc/7415/coursera-web-connectivity-and-security-in-embedded-systems) 来自 *EIT Digital*
* [物联网设备的智能架构](https://www.class-central.com/mooc/6839/coursera-architecting-smart-iot-devices) 来自 *EIT Digital*
* [物联网智能架构入门](https://www.class-central.com/mooc/6748/coursera-introduction-to-architecting-smart-iot-devices) 来自 *EIT Digital*
* [Cybersecurity 和 X-Factor](https://www.class-central.com/mooc/6585/coursera-cybersecurity-and-the-x-factor) 来自 *University System of Georgia*
* [循序渐进介绍 Web 应用程序](https://www.class-central.com/mooc/6548/udacity-intro-to-progressive-web-apps) 来自 *Google*
* [高级 Android 应用程序开发](https://www.class-central.com/mooc/3580/udacity-advanced-android-app-development) 来自 *Google*
* [Google 地图 APIs](https://www.class-central.com/mooc/6477/udacity-google-maps-apis) 来自 *Google*
* [离线 Web 应用程序](https://www.class-central.com/mooc/5679/udacity-offline-web-applications) 来自 *Google*
* [Android 的 Firebase 基础](https://www.class-central.com/mooc/5055/udacity-firebase-essentials-for-android) 来自 *Google*
* [开发聪明的 Apps 和机器人](https://www.class-central.com/mooc/6357/edx-developing-intelligent-apps-and-bots) 来自 *Microsoft*
* [开发 SQL 数据库](https://www.class-central.com/mooc/7405/edx-developing-sql-databases) 来自 *Microsoft*
* [使用 Node.js 构建功能原型](https://www.class-central.com/mooc/8722/edx-building-functional-prototypes-using-node-js) 来自 *Microsoft*
* [使用 JavaScript 构建交互原型](https://www.class-central.com/mooc/8719/edx-building-interactive-prototypes-using-javascript) 来自 *Microsoft*
* [算法和数据结构](https://www.class-central.com/mooc/8937/edx-algorithms-and-data-structures) 来自 *Microsoft*
* [在 C# 中的算法和数据结构](https://www.class-central.com/mooc/9483/edx-algorithms-and-data-structures-in-c) 来自 *Microsoft*
* [创建系统化的 SQL 数据库对象](https://www.class-central.com/mooc/7401/edx-creating-programmatic-sql-database-objects) 来自 *Microsoft*
* [AngularJS:框架基础](https://www.class-central.com/mooc/7377/edx-angularjs-framework-fundamentals) 来自 *Microsoft*
* [TypeScript 2 入门](https://www.class-central.com/mooc/8633/edx-introduction-to-typescript-2) 来自 *Microsoft*
* [高级 CSS 概念](https://www.class-central.com/mooc/7208/edx-advanced-css-concepts) 来自 *Microsoft*
* [实现 In-Memory SQL 数据库对象](https://www.class-central.com/mooc/7399/edx-implementing-in-memory-sql-database-objects) 来自 *Microsoft*
* [优化基于 SQL 的应用程序](https://www.class-central.com/mooc/7398/edx-optimizing-performance-for-sql-based-applications) 来自 *Microsoft*
* [并发编程 (avec Java)](https://www.class-central.com/mooc/8369/edx-programmation-concurrente-avec-java) 来自 *Sorbonne Universités*
* [C 程序员学习 C++,Part B](https://www.class-central.com/mooc/6931/coursera-c-for-c-programmers-part-b) 来自 *University of California, Santa Cruz*
* [Kubernetes 入门](https://www.class-central.com/mooc/8764/edx-introduction-to-kubernetes) 来自 *Linux Foundation*
* [DevOps 入门:转变和改善运营](https://www.class-central.com/mooc/7506/edx-introduction-to-devops-transforming-and-improving-operations) 来自 *Linux Foundation*
* [DevOps 入门:转变和改善运营](https://www.class-central.com/mooc/7506/edx-introduction-to-devops-transforming-and-improving-operations) 来自 *Linux Foundation*
* [软件工程师的 UML 类示意图](https://www.class-central.com/mooc/7837/edx-uml-class-diagrams-for-software-engineering) 来自 *KU Leuven University*
* [Android 的移动适用性与设计](https://www.class-central.com/mooc/9701/udacity-mobile-usability-and-design-for-android) 来自 *Facebook*
* [IOS 的移动适用性与设计](https://www.class-central.com/mooc/9700/udacity-mobile-usability-and-design-for-ios) 来自 *Facebook*
* [并发](https://www.class-central.com/mooc/6493/concurrency) 来自 *AdaCore University*
* [Red Hat 企业 Linux 基础](https://www.class-central.com/mooc/8670/edx-fundamentals-of-red-hat-enterprise-linux) 来自 *Red Hat*
* [Containers 基础、Kubernetes、和 Red Hat OpenShift](https://www.class-central.com/mooc/9105/edx-fundamentals-of-containers-kubernetes-and-red-hat-openshift) 来自 *Red Hat*
* [程序员的 C++](https://www.class-central.com/mooc/8839/udacity-c-for-programmers)
* [学习 Backbone.js](https://www.class-central.com/mooc/4071/udacity-learn-backbone-js)
* [如何在 Android 中创建](https://www.class-central.com/mooc/4419/udacity-how-to-create-anything-in-android)
* [如何制作一个 iOS App](https://www.class-central.com/mooc/3527/udacity-how-to-make-an-ios-app)
* [iOS 持久化与核心数据](https://www.class-central.com/mooc/3526/udacity-ios-persistence-and-core-data)
* [UIKit 基础](https://www.class-central.com/mooc/3350/udacity-uikit-fundamentals)
* [使用 Swift 实现 iOS 网络](https://www.class-central.com/mooc/3393/udacity-ios-networking-with-swift)
* [设计 RESTful APIs](https://www.class-central.com/mooc/4887/udacity-designing-restful-apis)
* [VR 平台与应用程序](https://www.class-central.com/mooc/8422/udacity-vr-platforms-applications)
* [为开发者的 Swift 语言](https://www.class-central.com/mooc/7495/udacity-swift-for-developers)
* [Ruby 中的 MVC 模式](https://www.class-central.com/mooc/6797/udacity-the-mvc-pattern-in-ruby)
* [使用 Heroku 部署应用程序](https://www.class-central.com/mooc/6798/udacity-deploying-applications-with-heroku)
* [使用 Sinatra 开发动态 Web 应用程序](https://www.class-central.com/mooc/6796/udacity-dynamic-web-applications-with-sinatra)
* [构建 iOS 界面](https://www.class-central.com/mooc/7753/udacity-building-ios-interfaces)
* [VR 设计](https://www.class-central.com/mooc/8394/udacity-vr-design)
* [[New] Android 基础](https://www.class-central.com/mooc/7755/udacity-new-android-fundamentals)
* [iOS 设计模式](https://www.class-central.com/mooc/7754/udacity-ios-design-patterns)
* [VR 场景与对象](https://www.class-central.com/mooc/7380/udacity-vr-scenes-and-objects)
### 高级(78)
* [使用 TensorFlow 深度学习创新应用程序](https://www.class-central.com/mooc/6679/kadenze-creative-applications-of-deep-learning-with-tensorflow)
* [[New] 计算中的概率入门](https://www.class-central.com/mooc/10029/nptel-an-introduction-to-probability-in-computing) 来自 *Indian Institute of Technology Madras*
* [[New] 信息安全 — IV](https://www.class-central.com/mooc/9913/nptel-information-security-iv) 来自 *Indian Institute of Technology Madras*
* [[New] 数学计算的 Matlab 编程](https://www.class-central.com/mooc/10094/nptel-matlab-programming-for-numerical-computation) 来自 *Indian Institute of Technology Madras*
* [[New] 数字开关 — I](https://www.class-central.com/mooc/10051/nptel-digital-switching-i) 来自 *Indian Institute of Technology Kanpur*
* [[New] 高级图形理论](https://www.class-central.com/mooc/9817/nptel-advanced-graph-theory) 来自 *Indian Institute of Technology Kanpur*
* [[New] 计算机视觉中的深度学习](https://www.class-central.com/mooc/9608/coursera-deep-learning-in-computer-vision) 来自 *Higher School of Economics*
* [[New] 自然语言处理](https://www.class-central.com/mooc/9603/coursera-natural-language-processing) 来自 *Higher School of Economics*
* [[New] 实践强化学习](https://www.class-central.com/mooc/9924/coursera-practical-reinforcement-learning) 来自 *Higher School of Economics*
* [[New] 实时操作系统](https://www.class-central.com/mooc/9848/nptel-real-time-operating-system) 来自 *Indian Institute of Technology, Kharagpur*
* [[New] 传统的和非传统的优化工具](https://www.class-central.com/mooc/10066/nptel-traditional-and-non-traditional-optimization-tools) 来自 *Indian Institute of Technology, Kharagpur*
* [[New] 软件定义无线与实际应用程序](https://www.class-central.com/mooc/10088/nptel-basics-of-software-defined-radios-and-practical-applications) 来自 *Indian Institute of Technology Roorkee*
* [[New] 图像处理中的稀疏表示:从理论到实践](https://www.class-central.com/mooc/9135/edx-sparse-representations-in-image-processing-from-theory-to-practice) 来自 *Technion — Israel Institute of Technology*
* [人工智能入门](https://www.class-central.com/mooc/301/udacity-introduction-to-artificial-intelligence) 来自 *Stanford University* ★★★★☆(24)
* [机器学习之神经网络](https://www.class-central.com/mooc/398/coursera-neural-networks-for-machine-learning) 来自 *University of Toronto* ★★★★☆(22)
* [机器学习之数据科学与分析](https://www.class-central.com/mooc/4912/edx-machine-learning-for-data-science-and-analytics) 来自 *Columbia University* ★★★☆☆(15)
* [机器学习之交易](https://www.class-central.com/mooc/1026/udacity-machine-learning-for-trading) 来自 *Georgia Institute of Technology* ★★★☆☆(13)
* [神经网络与深度学习](https://www.class-central.com/mooc/9058/coursera-neural-networks-and-deep-learning) 来自 *deeplearning.ai* ★★★★★(9)
* [人工智能(AI)](https://www.class-central.com/mooc/7230/edx-artificial-intelligence-ai) 来自 *Columbia University* ★★★★☆(9)
* [计算神经科学](https://www.class-central.com/mooc/449/coursera-computational-neuroscience) 来自 *University of Washington* ★★★★☆(8)
* [计算机视觉入门](https://www.class-central.com/mooc/1022/udacity-introduction-to-computer-vision) 来自 *Georgia Institute of Technology* ★★★★★(6)
* [强化学习](https://www.class-central.com/mooc/1849/udacity-reinforcement-learning) 来自 *Brown University* ★★☆☆☆(6)
* [并行编程入门](https://www.class-central.com/mooc/549/udacity-intro-to-parallel-programming) 来自 *Nvidia* ★★★★☆(6)
* [互动 3D 图形](https://www.class-central.com/mooc/552/udacity-interactive-3d-graphics) 来自 *Autodesk* ★★★★☆(6)
* [机器学习](https://www.class-central.com/mooc/1020/udacity-machine-learning) 来自 *Georgia Institute of Technology* ★★★★★(5)
* [数据科学与分析的可用技术:物联网](https://www.class-central.com/mooc/4911/edx-enabling-technologies-for-data-science-and-analytics-the-internet-of-things) 来自 *Columbia University* ★☆☆☆☆(5)
* [应用密码学](https://www.class-central.com/mooc/326/udacity-applied-cryptography) 来自 *University of Virginia* ★★★★☆(5)
* [开发者的深度学习实践:第 1 部分](https://www.class-central.com/mooc/7887/practical-deep-learning-for-coders-part-1) 来自 *fast.ai* ★★★★☆(5)
* [高级操作系统](https://www.class-central.com/mooc/1016/udacity-advanced-operating-systems) 来自 *Georgia Institute of Technology* ★★★★★(4)
* [机器学习](https://www.class-central.com/mooc/7231/edx-machine-learning) 来自 *Columbia University* ★★★★★(4)
* [计算机架构入门](https://www.class-central.com/mooc/642/introduction-to-computer-architecture) 来自 *Carnegie Mellon University* ★★★★★(4)
* [概率图形模型 2:推测](https://www.class-central.com/mooc/7292/coursera-probabilistic-graphical-models-2-inference) 来自 *Stanford University* ★★★★☆(3)
* [Python 中应用机器学习](https://www.class-central.com/mooc/6673/coursera-applied-machine-learning-in-python) 来自 *University of Michigan* ★★★★☆(3)
* [定量形式模型与最坏性能分析](https://www.class-central.com/mooc/4864/coursera-quantitative-formal-modeling-and-worst-case-performance-analysis) 来自 *EIT Digital* ★★★☆☆(3)
* [6.S191:深度学习入门](https://www.class-central.com/mooc/8083/6-s191-introduction-to-deep-learning) 来自 *Massachusetts Institute of Technology* ★★★★☆(2)
* [操作系统入门](https://www.class-central.com/mooc/3419/udacity-introduction-to-operating-systems) 来自 *Georgia Institute of Technology* ★★★★★(2)
* [近场合作过滤器](https://www.class-central.com/mooc/6927/coursera-nearest-neighbor-collaborative-filtering) 来自 *University of Minnesota* ★★☆☆☆(2)
* [6.S094:汽车自动驾驶之深度学习](https://www.class-central.com/mooc/8132/6-s094-deep-learning-for-self-driving-cars) 来自 *Massachusetts Institute of Technology* ★★★★☆(1)
* [高性能计算架构](https://www.class-central.com/mooc/1018/udacity-high-performance-computer-architecture) 来自 *Georgia Institute of Technology* ★★★★★(1)
* [可计算性、复杂性和算法](https://www.class-central.com/mooc/1024/udacity-computability-complexity-algorithms) 来自 *Georgia Institute of Technology* ★★★★(1)
* [计算摄影学](https://www.class-central.com/mooc/1023/udacity-computational-photography) 来自 *Georgia Institute of Technology* ★★★★☆(1)
* [信息安全入门](https://www.class-central.com/mooc/3420/udacity-intro-to-information-security) 来自 *Georgia Institute of Technology* ★☆☆☆☆(1)
* [AI 知识库:认知系统](https://www.class-central.com/mooc/1025/udacity-knowledge-based-ai-cognitive-systems) 来自 *Georgia Institute of Technology* ★★★☆☆(1)
* [嵌入式硬件和操作系统](https://www.class-central.com/mooc/6826/coursera-embedded-hardware-and-operating-systems) 来自 *EIT Digital* ★☆☆☆☆(1)
* [学习 TensorFlow 与深度学习](https://www.class-central.com/mooc/8480/learn-tensorflow-and-deep-learning-without-a-ph-d) 来自 *Google* ★★★★☆(1)
* [DevOps 实践和原则](https://www.class-central.com/mooc/9475/edx-devops-practices-and-principles) 来自 *Microsoft* ★★☆☆☆(1)
* [信号与图像处理中的稀疏表示:基础](https://www.class-central.com/mooc/9133/edx-sparse-representations-in-signal-and-image-processing-fundamentals)来自 *Technion — Israel Institute of Technology* ★★★★★(1)
* [云计算和云原生软件架构入门](https://www.class-central.com/mooc/8387/edx-introduction-to-cloud-foundry-and-cloud-native-software-architecture)来自 *Linux Foundation* ★★★★★(1)
* [商业应用区块链 — Hyperledger 技术](https://www.class-central.com/mooc/9484/edx-blockchain-for-business-an-introduction-to-hyperledger-technologies)来自 *Linux Foundation* ★★★★☆(1)
* [计算结构 3:计算机组织](https://www.class-central.com/mooc/6245/edx-computation-structures-3-computer-organization) 来自 *Massachusetts Institute of Technology*
* [GT — Refresher — Advanced OS](https://www.class-central.com/mooc/4734/udacity-gt-refresher-advanced-os) 来自 *Georgia Institute of Technology*
* [高性能计算](https://www.class-central.com/mooc/1028/udacity-high-performance-computing) 来自 *Georgia Institute of Technology*
* [编译器:理论与实践](https://www.class-central.com/mooc/8572/udacity-compilers-theory-and-practice) 来自 *Georgia Institute of Technology*
* [Cyber-物理系统安全](https://www.class-central.com/mooc/8569/udacity-cyber-physical-systems-security) 来自 *Georgia Institute of Technology*
* [网络安全](https://www.class-central.com/mooc/8570/udacity-network-security) 来自 *Georgia Institute of Technology*
* [人工智能](https://www.class-central.com/mooc/8565/udacity-artificial-intelligence) 来自 *Georgia Institute of Technology*
* [信息安全:环境与入门](https://www.class-central.com/mooc/8123/coursera-information-security-context-and-introduction) 来自 *University of London International Programmes*
* [离散优化之基本模型](https://www.class-central.com/mooc/7759/coursera-basic-modeling-for-discrete-optimization) 来自 *University of Melbourne*
* [离散优化之高级模型](https://www.class-central.com/mooc/7757/coursera-advanced-modeling-for-discrete-optimization) 来自 *University of Melbourne*
* [代码的本质:JavaScript 中的生物学](https://www.class-central.com/mooc/6881/edx-nature-in-code-biology-in-javascript) 来自 *École Polytechnique Fédérale de Lausanne*
* [模型因子与高级技术](https://www.class-central.com/mooc/6933/coursera-matrix-factorization-and-advanced-techniques) 来自 *University of Minnesota*
* [系统验证:自动化与等价行为](https://www.class-central.com/mooc/6825/coursera-system-validation-automata-and-behavioural-equivalences) 来自 *EIT Digital*
* [系统验证(2):建模过程行为](https://www.class-central.com/mooc/7420/coursera-system-validation-2-model-process-behaviour) 来自 *EIT Digital*
* [系统验证(4):软件模型、协议和其它行为](https://www.class-central.com/mooc/7803/coursera-system-validation-4-modelling-software-protocols-and-other-behaviour) 来自 *EIT Digital*
* [DevOps 测试](https://www.class-central.com/mooc/9479/edx-devops-testing) 来自 *Microsoft*
* [深度学习说明](https://www.class-central.com/mooc/8746/edx-deep-learning-explained) 来自 *Microsoft*
* [人工智能入门](https://www.class-central.com/mooc/9164/edx-introduction-to-artificial-intelligence-ai) 来自 *Microsoft*
* [DevOps 之数据库](https://www.class-central.com/mooc/9480/edx-devops-for-databases) 来自 *Microsoft*
* [基础设施代码化](https://www.class-central.com/mooc/9476/edx-infrastructure-as-code) 来自 *Microsoft*
* [深度学习之自然语言处理](https://www.class-central.com/mooc/8097/deep-learning-for-natural-language-processing) 来自 *University of Oxford*
* [机器学习之统计学](https://www.class-central.com/mooc/8509/statistical-machine-learning) 来自 *Carnegie Mellon University*
* [信息物理系统:建模与仿真](https://www.class-central.com/mooc/9791/coursera-cyber-physical-systems-modeling-and-simulation) 来自 *University of California, Santa Cruz*
* [OpenStack 入门](https://www.class-central.com/mooc/7202/edx-introduction-to-openstack) 来自 *Linux Foundation*
* [计算机系统设计:现代微处理器的高级概念](https://www.class-central.com/mooc/7046/edx-computer-system-design-advanced-concepts-of-modern-microprocessors)来自 *Chalmers University of Technology*
* [可靠的分布式算法,第 2 部分](https://www.class-central.com/mooc/6603/edx-reliable-distributed-algorithms-part-2) 来自 *KTH Royal Institute of Technology*
* [深度学习暑期课程](https://www.class-central.com/mooc/8481/deep-learning-summer-school)
* [持续集成与部署](https://www.class-central.com/mooc/8021/udacity-continuous-integration-and-deployment)
---
作者简介:
[www.class-central.com](http://www.class-central.com%E2%80%8A) — 最流行的在线课程搜索引擎的创始人
---
via: <https://medium.freecodecamp.org/440-free-online-programming-computer-science-courses-you-can-start-in-february-e075f920cb5b>
作者:[Dhawal Shah](https://medium.freecodecamp.org/@dhawalhs) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,445 | 使用 pelican 和 Github pages 来搭建博客 | https://rsip22.github.io/blog/create-a-blog-with-pelican-and-github-pages.html | 2018-03-15T00:07:46 | [
"博客",
"GitHub"
] | https://linux.cn/article-9445-1.html | 
今天我将谈一下[我这个博客](https://rsip22.github.io)是如何搭建的。在我们开始之前,我希望你熟悉使用 Github 并且可以搭建一个 Python 虚拟环境来进行开发。如果你不能做到这些,我推荐你去学习一下 [Django Girls 教程](https://tutorial.djangogirls.org),它包含以上和更多的内容。
这是一篇帮助你发布由 Github 托管的个人博客的教程。为此,你需要一个正常的 Github 用户账户 (而不是一个工程账户)。
你要做的第一件事是创建一个放置代码的 Github 仓库。如果你想要你的博客仅仅指向你的用户名 (比如 rsip22.github.io) 而不是一个子文件夹 (比如 rsip22.github.io/blog),你必须创建一个带有全名的仓库。

*Github 截图,打开了创建新仓库的菜单,正在以 'rsip22.github.io' 名字创建一个新的仓库*
我推荐你使用 `README`、用于 Python 的 `.gitignore` 和 [一个自由软件许可证](https://www.gnu.org/licenses/license-list.html) 初始化你的仓库。如果你使用自由软件许可证,你仍然拥有这些代码,但是你使得其他人能从中受益,允许他们学习和复用它,并且更重要的是允许他们享有这些代码。
既然仓库已经创建好了,那我们就克隆到本机中将用来保存代码的文件夹下:
```
$ git clone https://github.com/YOUR_USERNAME/YOUR_USERNAME.github.io.git
```
并且切换到新的目录:
```
$ cd YOUR_USERNAME.github.io
```
因为 Github Pages 偏好运行的方式是从 master 分支提供文件,你必须将你的源代码放到新的分支,防止 Pelican 产生的静态文件输出到 master 分支。为此,你必须创建一个名为 source 的分支。
```
$ git checkout -b source
```
用你的系统所安装的 Pyhton 3 创建该虚拟环境(virtualenv)。
在 GNU/Linux 系统中,命令可能如下:
```
$ python3 -m venv venv
```
或者像这样:
```
$ virtualenv --python=python3.5 venv
```
并且激活它:
```
$ source venv/bin/activate
```
在虚拟环境里,你需要安装 pelican 和它的依赖包。你也应该安装 ghp-import (来帮助我们发布到 Github 上)和 Markdown (为了使用 markdown 语法来写文章)。运行如下命令:
```
(venv)$ pip install pelican markdown ghp-import
```
一旦完成,你就可以使用 `pelican-quickstart` 开始创建你的博客了:
```
(venv)$ pelican-quickstart
```
这将会提示我们一系列的问题。在回答它们之前,请看一下如下我的答案:
```
> Where do you want to create your new web site? [.] ./
> What will be the title of this web site? Renata's blog
> Who will be the author of this web site? Renata
> What will be the default language of this web site? [pt] en
> Do you want to specify a URL prefix? e.g., http://example.com (Y/n) n
> Do you want to enable article pagination? (Y/n) y
> How many articles per page do you want? [10] 10
> What is your time zone? [Europe/Paris] America/Sao_Paulo
> Do you want to generate a Fabfile/Makefile to automate generation and publishing? (Y/n) Y **# PAY ATTENTION TO THIS!**
> Do you want an auto-reload & simpleHTTP script to assist with theme and site development? (Y/n) n
> Do you want to upload your website using FTP? (y/N) n
> Do you want to upload your website using SSH? (y/N) n
> Do you want to upload your website using Dropbox? (y/N) n
> Do you want to upload your website using S3? (y/N) n
> Do you want to upload your website using Rackspace Cloud Files? (y/N) n
> Do you want to upload your website using GitHub Pages? (y/N) y
> Is this your personal page (username.github.io)? (y/N) y
Done. Your new project is available at /home/username/YOUR_USERNAME.github.io
```
关于时区,应该指定为 TZ 时区(这里是全部列表: [tz 数据库时区列表](https://en.wikipedia.org/wiki/List_of_tz_database_time_zones))。
现在,继续往下走并开始创建你的第一篇博文!你可能想在你喜爱的代码编辑器里打开工程目录并且找到里面的 `content` 文件夹。然后创建一个新文件,它可以被命名为 `my-first-post.md` (别担心,这只是为了测试,以后你可以改变它)。在文章内容之前,应该以元数据开始,这些元数据标识标题、日期、目录及更多,像下面这样:
```
.lang="markdown" # DON'T COPY this line, it exists just for highlighting purposes
Title: My first post
Date: 2017-11-26 10:01
Modified: 2017-11-27 12:30
Category: misc
Tags: first, misc
Slug: My-first-post
Authors: Your name
Summary: What does your post talk about? Write here.
This is the *first post* from my Pelican blog. **YAY!**
```
让我们看看它长什么样?
进入终端,产生静态文件并且启动服务器。要这么做,使用下面命令:
```
(venv)$ make html && make serve
```
当这条命令正在运行,你应该可以在你喜爱的 web 浏览器地址栏中键入 `localhost:8000` 来访问它。

*博客主页的截图。它有一个带有 Renata's blog 标题的头部,第一篇博文在左边,文章的信息在右边,链接和社交在底部*
相当简洁,对吧?
现在,如果你想在文章中放一张图片,该怎么做呢?好,首先你在放置文章的内容目录里创建一个目录。为了引用简单,我们将这个目录命名为 `image`。现在你必须让 Pelican 使用它。找到 `pelicanconf.py` 文件,这个文件是你配置系统的地方,并且添加一个包含你的图片目录的变量:
```
.lang="python" # DON'T COPY this line, it exists just for highlighting purposes
STATIC_PATHS = ['images']
```
保存它。打开文章并且以如下方式添加图片:
```
.lang="markdown" # DON'T COPY this line, it exists just for highlighting purposes

```
你可以在终端中随时按下 `CTRL+C` 来中断服务器。但是你应该再次启动它并检查图片是否正确。你能记住怎么样做吗?
```
(venv)$ make html && make serve
```
在你代码完工之前的最后一步:你应该确保任何人都可以使用 ATOM 或 RSS 流来读你的文章。找到 `pelicanconf.py` 文件,这个文件是你配置系统的地方,并且编辑关于 RSS 流产生的部分:
```
.lang="python" # DON'T COPY this line, it exists just for highlighting purposes
FEED_ALL_ATOM = 'feeds/all.atom.xml'
FEED_ALL_RSS = 'feeds/all.rss.xml'
AUTHOR_FEED_RSS = 'feeds/%s.rss.xml'
RSS_FEED_SUMMARY_ONLY = False
```
保存所有,这样你才可以将代码上传到 Github 上。你可以通过添加所有文件,使用一个信息(“first commit”)来提交它,并且使用 `git push`。你将会被问起你的 Github 登录名和密码。
```
$ git add -A && git commit -a -m 'first commit' && git push --all
```
还有...记住在最开始的时候,我给你说的怎样防止 Pelican 产生的静态文件输出 master 分支吗。现在对你来说是时候产生它们了:
```
$ make github
```
你将会被再次问及 Github 登录名和密码。好了!你的新博客应该创建在 `https://YOUR_USERNAME.github.io`。
如果你在过程中任何一步遇到一个错误,请重新读一下这篇手册,尝试并看看你是否能发现错误发生的部分,因为这是调试的第一步。有时甚至一些简单的东西比如一个错字或者 Python 中错误的缩进都可以给我们带来麻烦。说出来并向网上或你的社区求助。
对于如何使用 Markdown 来写文章,你可以读一下 [Daring Fireball Markdown 指南](https://daringfireball.net/projects/markdown/syntax)。
为了获取其它主题,我建议你访问 [Pelican 主题](http://www.pelicanthemes.com/)。
这篇文章改编自 [Adrien Leger 的使用一个 Bottstrap3 主题来搭建由 Github 托管的 Pelican 博客](https://a-slide.github.io/blog/github-pelican)。
---
via: <https://rsip22.github.io/blog/create-a-blog-with-pelican-and-github-pages.html>
作者:[rsip22](https://rsip22.github.io) 译者:[liuxinyu123](https://github.com/liuxinyu123) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Creating a blog with pelican and Github pages
*~ 5 min read*
Today I'm going to talk about how this blog was created. Before we begin, I expect you to be familiarized with using Github and creating a Python virtual enviroment to develop. If you aren't, I recommend you to learn with the [Django Girls tutorial](https://tutorial.djangogirls.org), which covers that and more.
This is a tutorial to help you publish a personal blog hosted by Github. For that, you will need a regular Github user account (instead of a project account).
The first thing you will do is to create the Github repository where your code will live. If you want your blog to point to only your username (like rsip22.github.io) instead of a subfolder (like rsip22.github.io/blog), you have to create the repository with that full name.
I recommend that you initialize your repository with a README, with a .gitignore for Python and with a [free software license](https://www.gnu.org/licenses/license-list.html). If you use a free software license, *you still own the code*, but you make sure that others will benefit from it, by allowing them to study it, reuse it and, most importantly, keep sharing it.
Now that the repository is ready, let's clone it to the folder you will be using to store the code in your machine:
```
$ git clone https://github.com/YOUR_USERNAME/YOUR_USERNAME.github.io.git
```
And change to the new directory:
```
$ cd YOUR_USERNAME.github.io
```
Because of how Github Pages prefers to work, serving the files from the master branch, you have to put your source code in a new branch, preserving the "master" for the output of the static files generated by Pelican. To do that, you must create a new branch called "source":
```
$ git checkout -b source
```
Create the virtualenv with the Python3 version installed on your system.
On GNU/Linux systems, the command might go as:
```
$ python3 -m venv venv
```
or as
```
$ virtualenv --python=python3.5 venv
```
And activate it:
```
$ source venv/bin/activate
```
Inside the virtualenv, you have to install pelican and it's dependencies. You should also install ghp-import (to help us with publishing to github) and Markdown (for writing your posts using markdown). It goes like this:
```
(venv)$ pip install pelican markdown ghp-import
```
Once that is done, you can start creating your blog using pelican-quickstart:
```
(venv)$ pelican-quickstart
```
Which will prompt us a series of questions. Before answering them, take a look at my answers below:
```
> Where do you want to create your new web site? [.] ./
> What will be the title of this web site? Renata's blog
> Who will be the author of this web site? Renata
> What will be the default language of this web site? [pt] en
> Do you want to specify a URL prefix? e.g., http://example.com (Y/n) n
> Do you want to enable article pagination? (Y/n) y
> How many articles per page do you want? [10] 10
> What is your time zone? [Europe/Paris] America/Sao_Paulo
> Do you want to generate a Fabfile/Makefile to automate generation and publishing? (Y/n) Y **# PAY ATTENTION TO THIS!**
> Do you want an auto-reload & simpleHTTP script to assist with theme and site development? (Y/n) n
> Do you want to upload your website using FTP? (y/N) n
> Do you want to upload your website using SSH? (y/N) n
> Do you want to upload your website using Dropbox? (y/N) n
> Do you want to upload your website using S3? (y/N) n
> Do you want to upload your website using Rackspace Cloud Files? (y/N) n
> Do you want to upload your website using GitHub Pages? (y/N) y
> Is this your personal page (username.github.io)? (y/N) y
Done. Your new project is available at /home/username/YOUR_USERNAME.github.io
```
About the time zone, it should be specified as TZ Time zone (full list here: [List of tz database time zones](https://en.wikipedia.org/wiki/List_of_tz_database_time_zones)).
Now, go ahead and create your first blog post! You might want to open the project folder on your favorite code editor and find the "content" folder inside it. Then, create a *new* file, which can be called my-first-post.md (don't worry, this is just for testing, you can change it later). The contents should begin with the metadata which identifies the Title, Date, Category and more from the post before you start with the content, like this:
```
.lang="markdown" # DON'T COPY this line, it exists just for highlighting purposes
Title: My first post
Date: 2017-11-26 10:01
Modified: 2017-11-27 12:30
Category: misc
Tags: first, misc
Slug: My-first-post
Authors: Your name
Summary: What does your post talk about? Write here.
This is the *first post* from my Pelican blog. **YAY!**
```
Let's see how it looks?
Go to the terminal, generate the static files and start the server. To do that, use the following command:
```
(venv)$ make html && make serve
```
While this command is running, you should be able to visit it on your favorite web browser by typing localhost:8000 on the address bar.
Pretty neat, right?
Now, what if you want to put an image in a post, how do you do that? Well, first you create a directory *inside* your content directory, where your posts are. Let's call this directory 'images' for easy reference. Now, you have to tell Pelican to use it. Find the *pelicanconf.py*, the file where you configure the system, and add a variable that contains the directory with your images:
```
.lang="python" # DON'T COPY this line, it exists just for highlighting purposes
STATIC_PATHS = ['images']
```
Save it. Go to your post and add the image this way:
```
.lang="markdown" # DON'T COPY this line, it exists just for highlighting purposes

```
You can interrupt the server at anytime pressing CTRL+C on the terminal. But you should start it again and check if the image is correct. Can you remember how?
```
(venv)$ make html && make serve
```
One last step before your coding is "done": you should make sure anyone can read your posts using ATOM or RSS feeds. Find the *pelicanconf.py*, the file where you configure the system, and edit the part about feed generation:
```
.lang="python" # DON'T COPY this line, it exists just for highlighting purposes
FEED_ALL_ATOM = 'feeds/all.atom.xml'
FEED_ALL_RSS = 'feeds/all.rss.xml'
AUTHOR_FEED_RSS = 'feeds/%s.rss.xml'
RSS_FEED_SUMMARY_ONLY = False
```
Save everything so you can send the code to Github. You can do that by adding all files, committing it with a message ('first commit') and using git push. You will be asked for your Github login and password.
```
$ git add -A && git commit -a -m 'first commit' && git push --all
```
And... remember how at the very beginning I said you would be preserving the master branch for the output of the static files generated by Pelican? Now it's time for you to generate them:
```
$ make github
```
You will be asked for your Github login and password again. And... *voilà*! Your new blog should be live on https://YOUR_USERNAME.github.io.
If you had an error in any step of the way, please reread this tutorial, try and see if you can detect in which part the problem happened, because that is the first step to debbugging. Sometimes, even something simple like a typo or, with Python, a wrong indentation, can give us trouble. Shout out and ask for help online or on your community.
For tips on how to write your posts using Markdown, you should read the [Daring Fireball Markdown guide](https://daringfireball.net/projects/markdown/syntax).
To get other themes, I recommend you visit [Pelican Themes](http://www.pelicanthemes.com/).
This post was adapted from [Adrien Leger's Create a github hosted Pelican blog with a Bootstrap3 theme](https://a-slide.github.io/blog/github-pelican). I hope it was somewhat useful for you. |
9,447 | 如何使用 GNOME Shell 扩展 | https://itsfoss.com/gnome-shell-extensions/ | 2018-03-15T10:53:26 | [
"GNOME",
"扩展"
] | https://linux.cn/article-9447-1.html |
>
> 简介:这是一份详细指南,我将会向你展示如何手动或通过浏览器轻松安装 GNOME Shell <ruby> 扩展 <rt> Extension </rt></ruby>。
>
>
>

在讨论 [如何在 Ubuntu 17.10 上安装主题](https://itsfoss.com/install-themes-ubuntu/) 一文时,我简要地提到了 GNOME Shell 扩展,它用来安装用户主题。今天,我们将详细介绍 Ubuntu 17.10 中的 GNOME Shell 扩展。
我可能会使用术语 GNOME 扩展而不是 GNOME Shell 扩展,但是这两者在这里具有相同的含义。
什么是 GNOME Shell 扩展?如何安装 GNOME Shell 扩展,以及如何管理和删除 GNOME Shell 扩展?我会一一解释所有的问题。
在此之前,如果你喜欢视频,我已经在 [FOSS 的 YouTube 频道](https://www.youtube.com/c/itsfoss?sub_confirmation=1) 上展示了所有的这些操作。我强烈建议你订阅它来获得更多有关 Linux 的视频。
### 什么是 GNOME Shell 扩展?
[GNOME Shell 扩展](https://extensions.gnome.org/) 根本上来说是增强 GNOME 桌面功能的一小段代码。
把它看作是你的浏览器的一个附加组件。例如,你可以在浏览器中安装附加组件来禁用广告。这个附加组件是由第三方开发者开发的。虽然你的 Web 浏览器默认不提供此项功能,但安装此附加组件可增强你 Web 浏览器的功能。
同样, GNOME Shell 扩展就像那些可以安装在 GNOME 之上的第三方附加组件和插件。这些扩展程序是为执行特定任务而创建的,例如显示天气状况、网速等。大多数情况下,你可以在顶部面板中访问它们。

也有一些 GNOME 扩展在顶部面板上不可见,但它们仍然可以调整 GNOME 的行为。例如,有一个这样的扩展可以让鼠标中键来关闭应用程序。
### 安装 GNOME Shell 扩展
现在你知道了什么是 GNOME Shell 扩展,那么让我们来看看如何安装它吧。有三种方式可以使用 GNOME 扩展:
* 使用来自 Ubuntu (或你的 Linux 发行版)的最小扩展集
* 在 Web 浏览器中查找并安装扩展程序
* 下载并手动安装扩展
在你学习如何使用 GNOME Shell 扩展之前,你应该安装 GNOME Tweak Tool。你可以在软件中心找到它,或者你可以使用以下命令:
```
sudo apt install gnome-tweak-tool
```
有时候,你需要知道你正在使用的 GNOME Shell 的版本,这有助于你确定扩展是否与系统兼容。你可以使用下面的命令来找到它:
```
gnome-shell --version
```
#### 1. 使用 gnome-shell-extensions 包 [最简单最安全的方式]
Ubuntu(以及其他几个 Linux 发行版,如 Fedora )提供了一个包,这个包有最小集合的 GNOME 扩展。由于 Linux 发行版经过测试,所以你不必担心兼容性问题。
如果你不想费神,你只需获得这个包,你就可以安装 8-10 个 GNOME 扩展。
```
sudo apt install gnome-shell-extensions
```
你将需要重新启动系统(或者重新启动 GNOME Shell,我具体忘了是哪个)。之后,启动 GNOME Tweaks,你会发现一些扩展自动安装了,你只需切换按钮即可开始使用已安装的扩展程序。

#### 2. 从 Web 浏览器安装 GNOME Shell 扩展
GNOME 项目有一个专门用于扩展的网站,不干别的,你可以在这里找到并安装扩展,并管理它们,甚至不需要 GNOME Tweaks Tool。
* [GNOME Shell Extensions Website](https://extensions.gnome.org/)
但是为了安装 Web 浏览器扩展,你需要两件东西:浏览器附加组件和本地主机连接器。
**步骤 1: 安装 浏览器附加组件**
当你访问 GNOME Shell 扩展网站时,你会看到如下消息:
>
> “要使用此站点控制 GNOME Shell 扩展,你必须安装由两部分组成的 GNOME Shell 集成:浏览器扩展和本地主机消息应用。”
>
>
>

你只需在你的 Web 浏览器上点击建议的附加组件链接即可。你也可以从下面的链接安装它们:
* 对于 Google Chrome、Chromium 和 Vivaldi: [Chrome Web 商店](https://chrome.google.com/webstore/detail/gnome-shell-integration/gphhapmejobijbbhgpjhcjognlahblep)
* 对于 Firefox: [Mozilla Addons](https://addons.mozilla.org/en/firefox/addon/gnome-shell-integration/)
* 对于 Opera: [Opera Addons](https://addons.opera.com/en/extensions/details/gnome-shell-integration/)
**步骤 2: 安装本地连接器**
仅仅安装浏览器附加组件并没有帮助。你仍然会看到如下错误:
>
> “尽管 GNOME Shell 集成扩展正在运行,但未检测到本地主机连接器。请参阅文档以获取有关安装连接器的信息。”
>
>
>

这是因为你尚未安装主机连接器。要做到这一点,请使用以下命令:
```
sudo apt install chrome-gnome-shell
```
不要担心包名中的 “chrome” 前缀,它与 Chrome 无关,你无需再次安装 Firefox 或 Opera 的单独软件包。
**步骤 3: 在 Web 浏览器中安装 GNOME Shell 扩展**
一旦你完成了这两个要求,你就可以开始了。现在,你将看不到任何错误消息。

一件好的做法是按照 GNOME Shell 版本对扩展进行排序,但这不是强制性的。这是因为开发人员是为其当前的 GNOME 版本创建的扩展。而在一年之内,会发布两个或更多 GNOME 发行版本,但开发人员没有时间(在新的 GNOME 版本上)测试或更新他/她的扩展。
因此,你不知道该扩展是否与你的系统兼容。尽管扩展已经存在很长一段时间了,但是有可能在最新的 GNOME Shell 版本中,它也能正常工作。同样它也有可能不工作。
你也可以去搜索扩展程序。假设你想要安装有关天气的扩展,只要搜索它并选择一个搜索结果即可。
当你访问扩展页面时,你会看到一个切换按钮。

点击它,你会被提示是否要安装这个扩展:

显然,直接安装就好。安装完成后,你会看到切换按钮已打开,旁边有一个设置选项。你也可以使用设置选项配置扩展,也可以禁用扩展。

你也可以在 GNOME Tweaks Tool 中配置通过 Web 浏览器安装的扩展:

你可以在 GNOME 网站中 [已安装的扩展部分](https://extensions.gnome.org/local/) 下查看所有已安装的扩展。

使用 GNOME 扩展网站的一个主要优点是你可以查看扩展是否有可用的更新,你不会在 GNOME Tweaks 或系统更新中得到更新(和提示)。
#### 3. 手动安装 GNOME Shell 扩展
你不需要始终在线才能安装 GNOME Shell 扩展,你可以下载文件并稍后安装,这样就不必使用互联网了。
去 GNOME 扩展网站下载最新版本的扩展。

解压下载的文件,将该文件夹复制到 `~/.local/share/gnome-shell/extensions` 目录。到主目录下并按 `Ctrl+H` 显示隐藏的文件夹,在这里找到 `.local` 文件夹,你可以找到你的路径,直至 `extensions` 目录。
一旦你将文件复制到正确的目录后,进入它并打开 `metadata.json` 文件,寻找 `uuid` 的值。
确保该扩展的文件夹名称与 `metadata.json` 中的 `uuid` 值相同。如果不相同,请将目录重命名为 `uuid` 的值。

差不多了!现在重新启动 GNOME Shell。 按 `Alt+F2` 并输入 `r` 重新启动 GNOME Shell。

同样重新启动 GNOME Tweaks Tool。你现在应该可以在 Tweaks Tool 中看到手动安装的 GNOME 扩展,你可以在此处配置或启用新安装的扩展。
这就是安装 GNOME Shell 扩展你需要知道的所有内容。
### 移除 GNOME Shell 扩展
你可能想要删除一个已安装的 GNOME Shell 扩展,这是完全可以理解的。
如果你是通过 Web 浏览器安装的,你可以到 [GNOME 网站的以安装的扩展部分](https://extensions.gnome.org/local/) 那移除它(如前面的图片所示)。
如果你是手动安装的,可以从 `~/.local/share/gnome-shell/extensions` 目录中删除扩展文件来删除它。
### 特别提示:获得 GNOME Shell 扩展更新的通知
到目前为止,你已经意识到除了访问 GNOME 扩展网站之外,无法知道更新是否可用于 GNOME Shell 扩展。
幸运的是,有一个 GNOME Shell 扩展可以通知你是否有可用于已安装扩展的更新。你可以从下面的链接中获得它:
* [Extension Update Notifier](https://extensions.gnome.org/extension/1166/extension-update-notifier/)
### 你如何管理 GNOME Shell 扩展?
我觉得很奇怪不能通过系统更新来更新扩展,就好像 GNOME Shell 扩展不是系统的一部分。
如果你正在寻找一些建议,请阅读这篇文章: [关于最佳 GNOME 扩展](https://itsfoss.com/best-gnome-extensions/)。同时,你可以分享有关 GNOME Shell 扩展的经验。你经常使用它们吗?如果是,哪些是你最喜欢的?
---
via: <https://itsfoss.com/gnome-shell-extensions/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

**Brief: This is a detailed guide showing you how to install GNOME Shell Extensions manually or easily via a browser.**
While discussing [how to install themes in Ubuntu](https://itsfoss.com/install-themes-ubuntu/), I briefly mentioned GNOME Shell Extension. It was used to enable user themes. Today, we’ll have a detailed look at GNOME Shell Extensions in Ubuntu and other Linux distributions.
I may use the term GNOME Extensions instead of GNOME Shell Extensions but both have the same meaning here.
In this tutorial, I’ll explain the following:
- What are GNOME Shell Extensions?
- How to install GNOME Shell Extensions?
- How to manage and remove GNOME Shell Extensions?
## What is a GNOME Shell Extension?
A [GNOME Shell Extension](https://extensions.gnome.org/?ref=itsfoss.com) is basically a tiny piece of code that enhances the capability of the GNOME desktop. Think of it as an add-on in your browser. Just as a browser add-on adds additional features to the browser, the GNOME extension adds additional features to the GNOME desktop environment.
For example, you can install an add-on in your browser to disable ads. This add-on is developed by a third-party developer. Though your web browser doesn’t provide it by default, installing this add-on enhances the capability of your web browser.
Similarly, GNOME Shell Extensions are like those third-party add-ons and plugins that you can install on top of GNOME. These extensions are created to perform specific tasks such as displaying weather conditions, internet speed, etc. Mostly, you can access them in the top panel.
There are also GNOME Extensions that are not visible in the top panel. But they still tweak GNOME’s behavior. For example, the middle mouse button can be used to close an application with one such extension.
## Installing GNOME Shell Extensions
Now that you know what GNOME Shell Extensions are, let’s see how to install them.
There are three ways you can use GNOME Extensions:
- Use a minimal set of extensions from Ubuntu (or your Linux distribution)
- Find and install extensions in your web browser
- Install extensions using Extension Manager App
- Download and manually install extensions
Although GNOME Tweaks is not required for extensions to work, [installing GNOME Tweak Tool in Ubuntu](https://itsfoss.com/gnome-tweak-tool/) or whichever distribution you are using is better.
`sudo apt install gnome-tweaks`
At times, you would also need to know the version of GNOME Shell you are using. This helps determine whether an extension is compatible with your system. You can use the command below to find it:
`gnome-shell --version`
### Method 1: Use the gnome-shell-extensions package
Ubuntu (and several other Linux distributions such as Fedora) provide a package with a minimal set of GNOME extensions. You don’t have to worry about compatibility here as it is tested by your Linux distribution.
If you want a no-brainer, just get this package and you’ll have 8-10 GNOME extensions installed.
`sudo apt install gnome-shell-extensions`
Once installed, log out and re-login to your system. After that, start GNOME Extensions App from Overview. This extensions app will be installed as part of `gnome-shell-extensions`
package.
You’ll find a few extensions installed. You can just toggle the button to start using an installed extension.
### Method 2: Install GNOME Shell extensions from a web browser
The GNOME project has an entire website dedicated to extensions. That’s not it. You can find, install, and manage your extensions on this website itself. No need even for the GNOME Extensions app.
But to install extensions through a web browser, you need a browser add-on and a native host connector in your system.
#### Step 1: Install a browser add-on
When you visit the [GNOME Shell Extensions website](https://extensions.gnome.org/?ref=itsfoss.com), you’ll see a message like this:
“To control GNOME Shell extensions using this site you must install GNOME Shell integration that consists of two parts: browser extension and native host messaging application.”
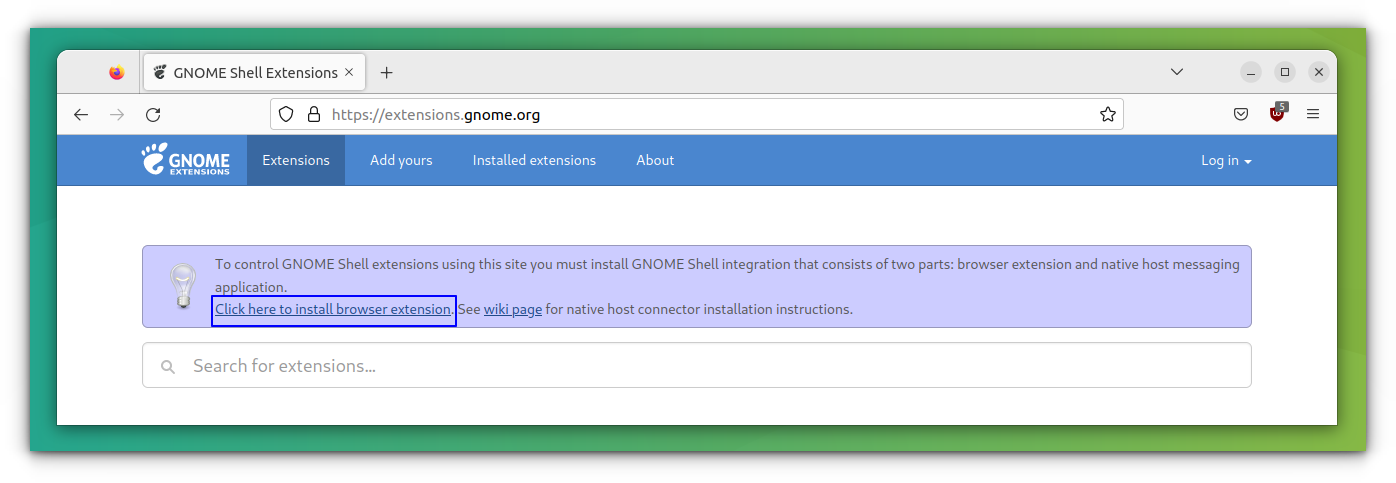
You can simply click on the suggested add-on link in your web browser.
#### Step 2: Install a native connector
Just installing a browser add-on won’t help you. You’ll still see an error like this:
“No such native application org.gnome.chrome_gnome_shell”
This is because you haven’t installed the host connector yet. There is [chrome-gnome-shell](https://wiki.gnome.org/Projects/GnomeShellIntegration/Installation?ref=itsfoss.com) to help you. To install it, use this command:
`sudo apt install chrome-gnome-shell`
Don’t worry about the ‘chrome’ prefix in the package name. It has nothing to do with Chrome. You don’t have to install a separate package for Firefox or Opera here.
Also, **for Arch Linux users, the package in AUR has been changed** to ** gnome-browser-connector**. So, you can install it with your favorite AUR helper.
`yay -S gnome-browser-connector`
#### Step 3: Installing GNOME Shell Extensions in the web browser
Once you have completed these two requirements, you are all set to roll. Now when you go to the [GNOME Extension website](https://extensions.gnome.org/?ref=itsfoss.com), you won’t see any error message.
A good thing to do would be to sort the extensions by your GNOME Shell version. It is not mandatory though. What happens here is that a developer creates an extension for the present GNOME version. In one year, there will be two more GNOME releases. But the developer didn’t have time to test or update his/her extension.
As a result, you wouldn’t know if that extension is compatible with your system or not. The extension may work fine even in the newer GNOME Shell version despite that the extension is years old. It is also possible that the extension doesn’t work in the newer GNOME Shell.
You can search for an extension as well. Let’s say you want to install a weather extension. Just search for it and go for one of the search results.
When you visit the extension page, you’ll see a toggle button.
Toggle the button to enable or disable GNOME Shell Extensions
Click on it and you’ll be prompted if you want to install this extension:
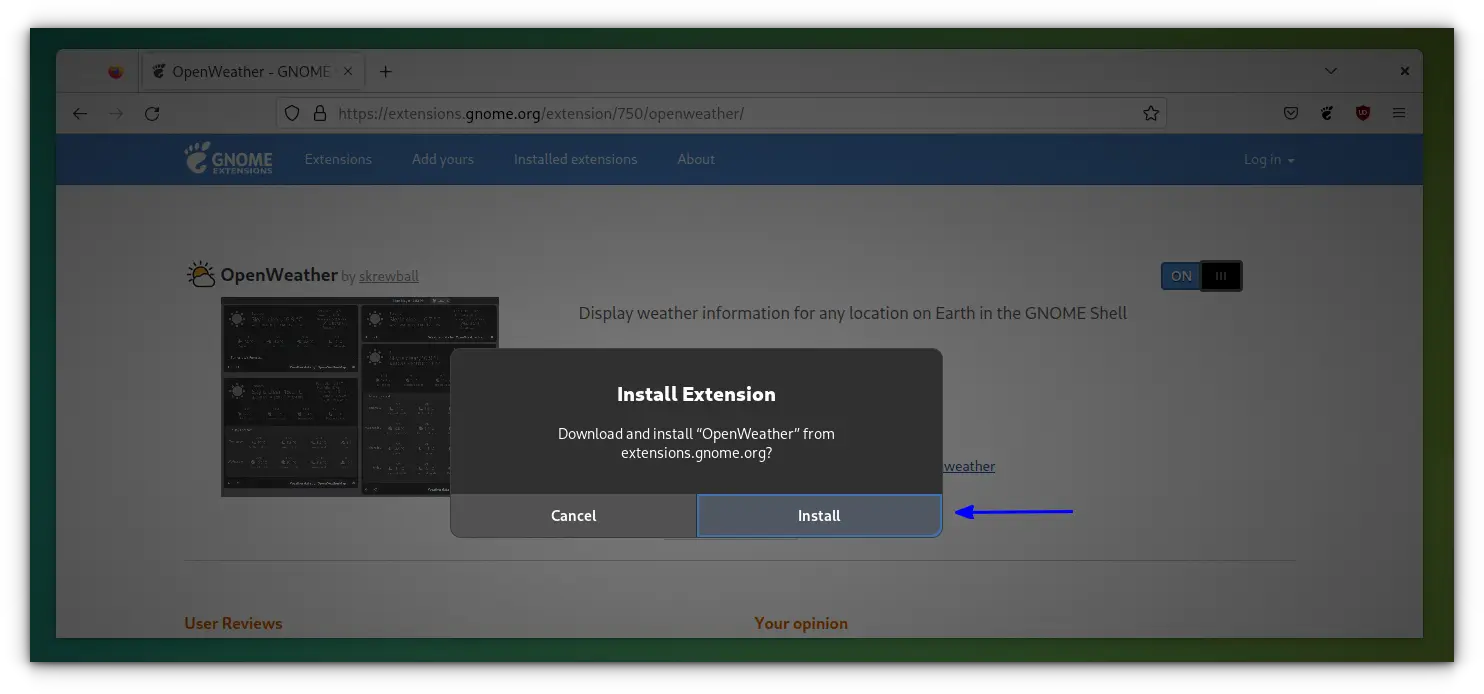
Obviously, go for Install here. Once installed, you’ll see that the toggle button is now on and a setting option is available next to it. You can configure the extension using the setting option. You can also disable the extension from here.
You can also configure the settings of an extension that you installed via the web browser in the GNOME Extensions App:
You can see all your installed extensions on the website under the [installed extensions section](https://extensions.gnome.org/local/?ref=itsfoss.com). You can also delete the extensions that you installed via the web browser here.
One significant advantage of using the GNOME Extensions website is that you can see if there is an update available for an extension.
### Method 3: Install GNOME Shell Extensions using the Extension Manager application
There is a dedicated application called [GNOME Shell Extension Manager](https://github.com/mjakeman/extension-manager?ref=itsfoss.com) to browse, install and manage your extensions. This application avoids the need for a web browser.
By default, it will not be installed on your system. So you can install this application through the command:
`sudo apt install gnome-shell-extension-manager`
If you are using Arch Linux, it is [available in AUR](https://aur.archlinux.org/packages/extension-manager?ref=itsfoss.com).
There is a known issue with this application as of now. Updates do not work out of the box on GNOME 40 and certain older versions of GNOME 41 and 42 **unless the official GNOME Extensions app is also installed.** There is a workaround for this issue, and you can refer to [their Wiki for the same](https://github.com/mjakeman/extension-manager/wiki/Known-Issue:-Updates?ref=itsfoss.com).
Now, search for the extension manager in Activities Overview and open the Extension-Manager app.
Inside the application, you can see the recommended extensions on the browse page. Search for extensions inside this browse page, and install those you want.
### Method 4: Install GNOME Shell Extensions manually (for intermediate to advanced users)
It’s not that you have to be always online to install GNOME Shell extensions. You can download and install the files later, without needing the internet.
Go to GNOME Extensions website and download the extension with the latest version. The download will automatically start once you select the required shell and the extension version.
Extract the downloaded file. Copy the folder to `~/.local/share/gnome-shell/extensions`
directory. Go to your Home directory and press Crl+H to show hidden folders. Locate the .local folder, and you can find your path to the extensions directory.
Once you have the files copied into the correct directory, go inside it and open the metadata.json file. Look for the value of `uuid`
.
Make sure that the name of the extension’s folder is the same as the value of uuid in the metadata.json file. If not, rename the directory to the value of this uuid.
The name of the extension folder should be the same as uuid.
Almost there! Now restart GNOME Shell. Press Alt+F2 and enter `r`
to restart GNOME Shell.
Restart the extensions app and you should see the manually installed GNOME extension there now. You can configure or enable the newly installed extension here.
And that’s all you need to know about installing GNOME Shell Extensions.
## Remove GNOME Shell Extensions
Understandably, you might want to remove an installed GNOME Shell Extension.
If you installed it via a web browser, you can go to the [installed extensions section on the GNOME website](https://extensions.gnome.org/local/?ref=itsfoss.com) and remove it from there (as shown in an earlier picture). Or you can remove it from the Extension App or Extension-Manager app.
Note that, only extensions installed either using the extensions app or through the browser can be removed using the browser or app. Any extension installed through package managers should be removed by uninstalling it using the respective package managers.
Or if you installed it manually, you can remove it by deleting the extension files from the `~/.local/share/gnome-shell/extensions`
directory.
## Bonus Tip: Get notified of GNOME Shell Extensions updates
GNOME Shell extensions that are installed on your system will get updates via the GNOME Shell Extension Manager app. Upon login to your system, the extensions that have updates to install will prompt notification for updates.
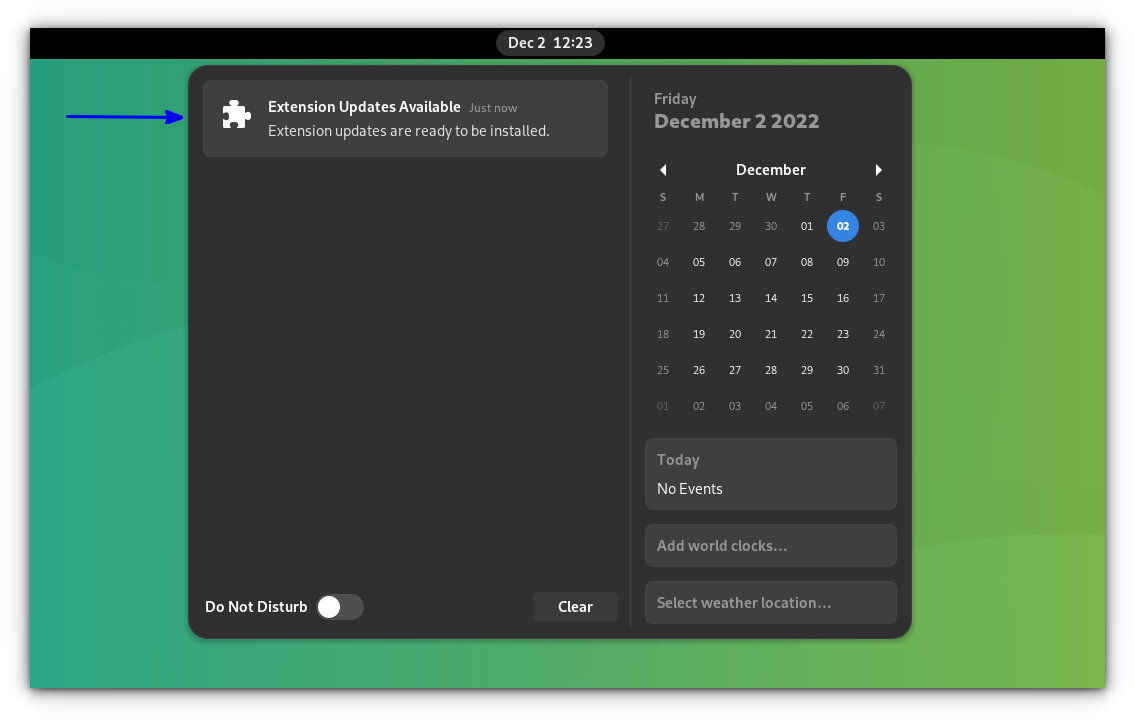
Opening the notification will bring you to the extension app. It will make the update ready and you need to log out and re-login to apply the updates.
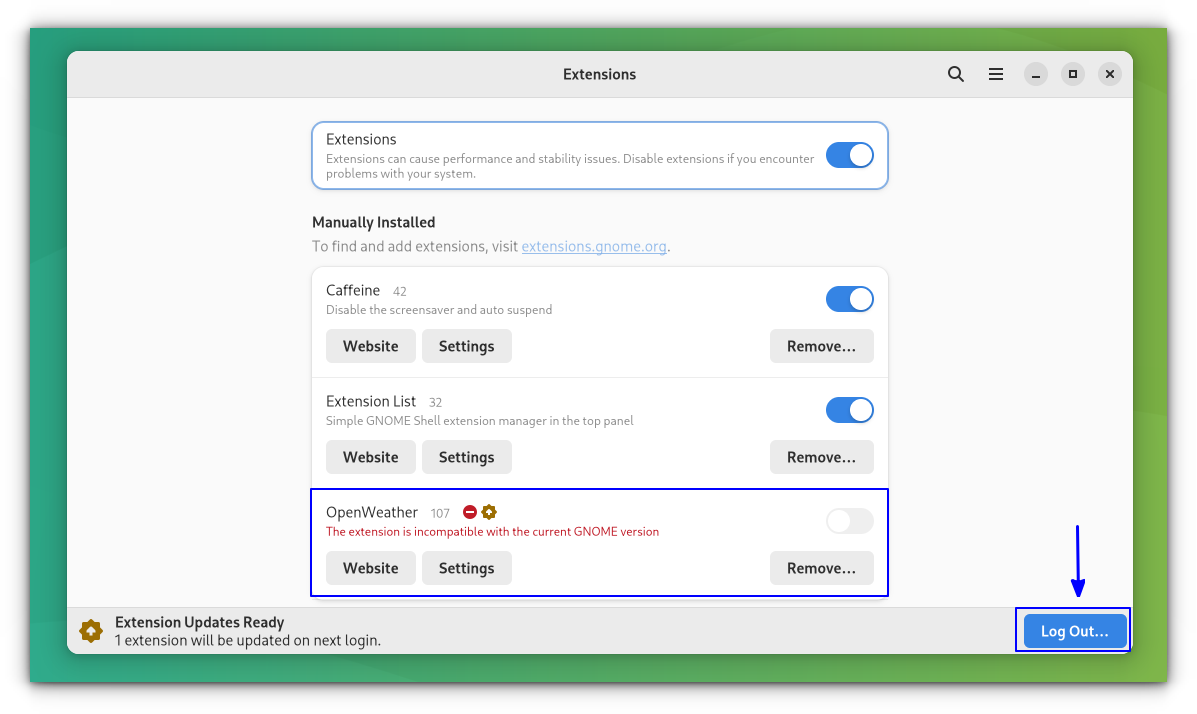
Also, there is a GNOME Shell Extension called **Extension List** that helps you manage your installed extensions and is accessible from the top panel.
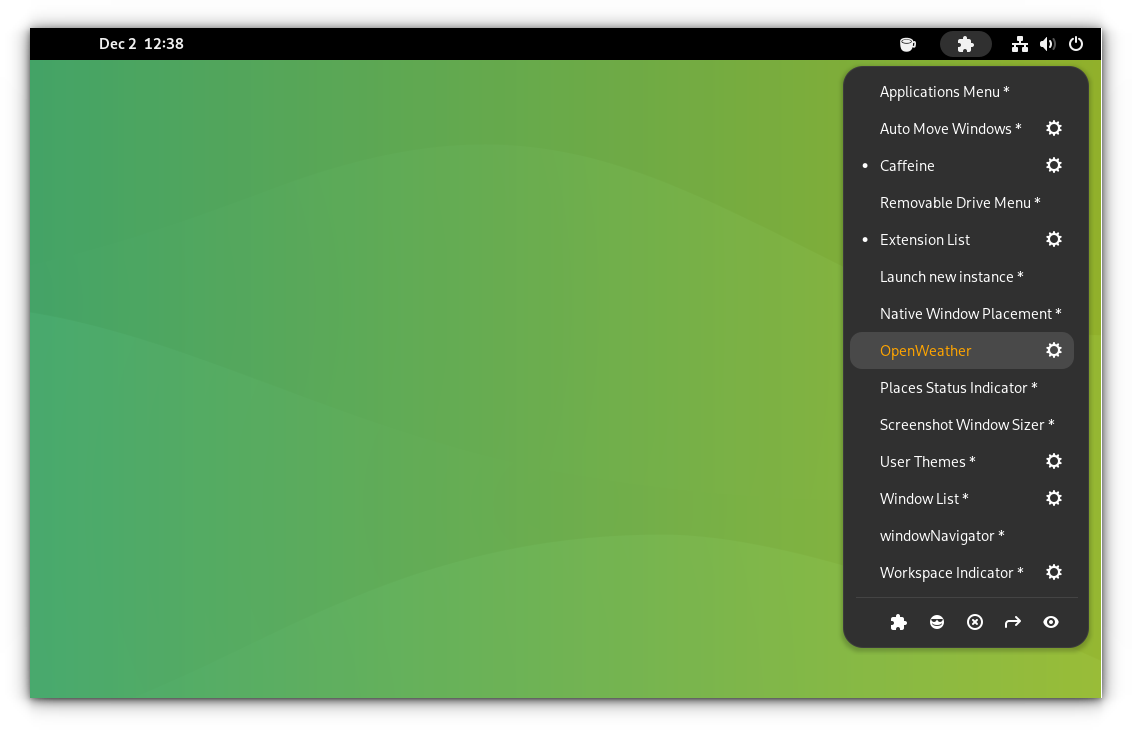
You can get it from the link below:
## How do you manage GNOME Shell Extensions?
I find it rather weird that you cannot update the extensions via the system updates. It’s as if GNOME Shell extensions are not even part of the system.
If you are looking for some recommendations, read this article about the [best GNOME extensions](https://itsfoss.com/best-gnome-extensions/).
[Top 20 GNOME Extensions You Should Be Using Right NowBrief: You can enhance the capacity of your GNOME desktop with extensions. Here, we list the best GNOME shell extensions to save you the trouble of finding them on your own. GNOME extensions are a major part of the GNOME experience. These extensions add a lot of value to the](https://itsfoss.com/best-gnome-extensions/)

At the same time, share your experience with GNOME Shell extensions. Do you often use them? If yes, which ones are your favorite? |
9,448 | GNU GPL 许可证常见问题解答(五) | https://www.gnu.org/licenses/gpl-faq.html | 2018-03-15T11:39:00 | [
"GPL",
"许可证"
] | https://linux.cn/article-9448-1.html | 
本文由高级咨询师薛亮据自由软件基金会(FSF)的[英文原文](https://www.gnu.org/licenses/gpl-faq.html)翻译而成,这篇常见问题解答澄清了在使用 GNU 许可证中遇到许多问题,对于企业和软件开发者在实际应用许可证和解决许可证问题时具有很强的实践指导意义。
1. [关于 GNU 项目、自由软件基金会(FSF)及其许可证的基本问题](/article-9062-1.html)
2. [对于 GNU 许可证的一般了解](/article-8834-1.html)
3. [在您的程序中使用 GNU 许可证](/article-8761-1.html)
4. [依据GNU许可证分发程序](/article-9222-1.html)
5. 在编写其他程序时采用依据 GNU 许可证发布的程序
6. 将作品与依据 GNU 许可证发布的代码相结合
7. 关于违反 GNU 许可证的问题
### 5 在编写其他程序时采用依据 GNU 许可证发布的程序
#### 5.1 我可以在同一台电脑上安装一个遵循 GPL 许可证的程序和一个不相关的非自由程序吗?(同 2.3)
可以。
#### 5.2 我可以使用遵循 GPL 许可证的编辑器(例如 GNU Emacs)来开发非自由程序吗?我可以使用遵循 GPL 许可证的工具(例如 GCC)来编译它们吗?
可以,因为编辑器和工具的版权并不覆盖您所编写的代码。从法律上来说,使用它们不会对适用于您代码的许可证施加任何限制。
有些程序出于技术原因将其自身某些部分复制到输出文件中,例如,Bison 将标准解析器程序复制到其输出文件中。在这种情况下,输出文件中复制的文本遵循其在源代码中所遵循的相同许可证。同时,源自程序输入部分的输出部分继承输入部分的版权状态。
正因为如此,Bison 也可以用来开发非自由程序。这是因为我们决定明确允许在 Bison 输出文件中不受限制地使用 Bison 标准解析器程序。我们之所以做出这个决定,是因为还有其他与 Bison 相媲美的工具已被许可用于非自由程序。
#### 5.3 有没有一些方法可以让使用我的程序的人们得到的输出物遵循 GPL?例如,如果我的程序用于开发硬件设计,我可以要求这些设计必须是自由的吗?(同 3.17)
一般来说,这在法律上是不可能的;针对人们通过使用您的程序获取数据形成的输出物如何使用,版权法并没有赋予您任何发言权。如果用户使用您的程序输入或转换自己的数据,输出物的版权属于他,而不是您。更一般来说,当程序将其输入物转换成其他形式时,输出物的版权状态将继承其得以生成的输入物的版权状态。
所以您对输出物的使用拥有发言权的唯一方式是输出物的实质部分(或多或少)是从您程序的文本中复制出来。例如,如果我们在这种具体情况下没有例外,那么Bison的一部分输出物(参见问题 5.2)将被 GNU GPL 所涵盖。
所以,即使没有技术原因,您也可以人为制作一个程序,将某些文本复制到其输出物中。但是,如果复制的文本没有实际用途,用户可以简单地从输出物中删除该文本,并且仅使用其余的内容。那么他就不必满足重新分发所复制文本的条件。
#### 5.4 在什么情况下,遵循 GPL 的程序其输出文件也必须遵循 GPL 呢?
程序的输出文件通常不受程序代码的版权保护。因此,程序代码的许可证不适用于输出文件,无论是将其导入文件,还是制作屏幕截图、屏幕录像或视频。
例外情况是,程序全屏显示来源于程序的文本和/或艺术品。该文本和/或艺术品的版权则会覆盖其输出文件。输出音频的程序(例如视频游戏)也将适用于此例外。
如果艺术品/音乐遵循 GPL,则无论您如何进行复制,GPL 都适用。不过,<ruby> <a href="https://www.gnu.org/licenses/gpl-faq.html#GPLFairUse"> 合理使用 </a> <rp> ( </rp> <rt> fair use </rt> <rp> ) </rp></ruby>可能仍然适用。
请记住,一些程序,特别是视频游戏,可以具有与底层遵循 GPL 的游戏分开许可的艺术品/音频。在这种情况下,艺术品/音频的许可证将规定视频/流媒体可以依之产生的条款。另请参阅:[1.6 我可以将GPL应用于软件以外的其他作品吗?](/article-8761-1.html#4_2799)
#### 5.5 如果我将我的程序移植到 GNU/Linux,这是否意味着我必须将其作为遵循 GPL 或其他自由软件许可证的自由软件进行发布?
一般来说,答案是否定的——这不是法律规定。具体来说,答案取决于您要使用哪些库以及许可证。大多数系统库都使用 [GNU LGPL 许可证](https://www.gnu.org/licenses/lgpl.html),或者使用 GNU GPL 加上允许将库与任何东西链接的例外声明。这些库可以在非自由程序中使用;但是在 LGPL 的情况下,它确实有一些必须遵循的要求。
一些库依据 GNU GPL 单独发布;您必须使用与 GPL 兼容的许可证才能使用这些库。但是这些通常是更特定的库,而在另一个平台不会有任何类似它们的库,所以您可能不会想要简单地移植使用这些库。
当然,如果您的软件不是自由软件,它不会对我们的社区做出贡献,而重视软件自由的人也会拒绝使用它。只有愿意放弃软件自由的人才会使用您的软件,这意味着它将有效地成为人们失去软件自由的诱因。
如果您希望有一天回头看您的职业生涯,觉得它有助于发展一个善良和自由的社会,您需要使您的软件成为自由软件。
#### 5.6 我想将遵循 GPL 的软件纳入我的专有系统。我只依据 GPL 给予我的权限来使用该软件。我可以这样做吗?
您不能将遵循 GPL 的软件纳入专有系统。GPL 的目标是授予每个人复制、再分发、理解和修改程序的自由。如果您可以将遵循 GPL 的软件整合到非自由系统中,则可能会使遵循 GPL 的软件不再是自由软件。
包含遵循 GPL 程序的系统是该 GPL 程序的扩展版本。GPL 规定,如果它最终发布的话,任何扩展版本的程序必须依据 GPL 发布。这有两个原因:确保获得软件的用户获得自己应该拥有的自由,并鼓励人们回馈他们所做的改进。
但是,在许多情况下,您可以将遵循 GPL 的软件与专有系统一起分发。要有效地做到这一点,您必须确保自由和非自由程序之间的通信保持<ruby> 一定距离 <rp> ( </rp> <rt> arms length </rt> <rp> ) </rp></ruby>,而不是将它们有效地结合成一个程序。
这种情况与“纳入”遵循 GPL 的软件之间的区别,部分是实质问题,部分是形式问题。实质上是这样的:如果两个程序结合起来,使它们成为一个程序的两个部分,那么您不能将它们视为两个单独的程序。所以整个作品必须遵循 GPL。
如果这两个程序保持良好的分离,就像编译器和内核,或者像编辑器和 shell 一样,那么您可以将它们视为两个单独的程序,但是您必须恰当执行。这个问题只是一个形式问题:您如何描述您在做什么。为什么我们关心这个?因为我们想确保用户清楚地了解软件集合中遵循 GPL 的软件的自由状态。
如果人们分发遵循 GPL 的软件,将其称为系统(用户已经知晓其中一部分为专有软件)的“一部分”,用户可能不确定其对遵循 GPL 的软件所拥有的权利。但是如果他们知道他们收到的是一个自由程序加上另外一个程序,那么他们的权利就会很清楚。
#### 5.7 如果我分发了一个与我修改后的遵循 LGPL v3 的库相链接的专有程序,那么为了确定我正在做出的明确的专利许可授权的范围,<ruby> “贡献者版本” <rp> ( </rp> <rt> contributor version </rt> <rp> ) </rp></ruby>是什么?它仅是库,还是整个组合?
“贡献者版本”仅是您的库版本。
#### 5.8 依据 AGPL v3,当我根据第 13 节修改程序时,必须提供什么样的<ruby> 相应源代码 <rp> ( </rp> <rt> Corresponding Source </rt> <rp> ) </rp></ruby>?
“相应源代码”在许可证的第 1 节中定义,您应该提供其列出的内容。因此,如果您的修改版本取决于遵循其他许可证的库,例如 Expat 许可证或 GPL v3,则相应源代码应包括这些库(除非是系统库)。如果您修改了这些库,则必须提供您修改后的源代码。
第 13 节第一段的最后一句只是为了强化大多数人所自然地认为的那样:尽管在第 13 节中通过特殊例外来处理与遵循 GPL v3 的代码相结合的情况,相应源代码仍然应该包括以这种方式与程序相结合的代码。这句话并不意味着您只需提供 GPL v3 所涵盖的源代码;而是意味着这样的代码不会从相应源代码的定义中排除。
#### 5.9 在哪里可以了解更多有关 GCC 运行时库例外的信息?
GCC 运行时库例外包含 libgcc、libstdc ++、libfortran、libgomp、libdecnumber 以及与 GCC 一起分发的其他库。这个例外是为了让人们根据自己选择的条件分发用 GCC 编译的程序,即使这些库的一部分作为编译过程的一部分被包含在可执行文件中。要了解更多信息,请阅读有关 [GCC 运行时库例外的常见问题](https://www.gnu.org/licenses/gcc-exception-faq.html)。
---
译者介绍:薛亮,集慧智佳知识产权咨询公司高级咨询师,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 200 | OK | ## Frequently Asked Questions about the GNU Licenses
### Table of Contents
**Basic questions about the GNU Project, the Free Software Foundation, and its licenses****General understanding of the GNU licenses****Using GNU licenses for your programs****Distribution of programs released under the GNU licenses****Using programs released under the GNU licenses when writing other programs****Combining work with code released under the GNU licenses****Questions about violations of the GNU licenses**
#### Basic questions about the GNU Project, the Free Software Foundation, and its licenses
[What does “GPL” stand for?](#WhatDoesGPLStandFor)[Does free software mean using the GPL?](#DoesFreeSoftwareMeanUsingTheGPL)[Why should I use the GNU GPL rather than other free software licenses?](#WhyUseGPL)[Does all GNU software use the GNU GPL as its license?](#DoesAllGNUSoftwareUseTheGNUGPLAsItsLicense)[Does using the GPL for a program make it GNU software?](#DoesUsingTheGPLForAProgramMakeItGNUSoftware)[Can I use the GPL for something other than software?](#GPLOtherThanSoftware)[Why don't you use the GPL for manuals?](#WhyNotGPLForManuals)[Are there translations of the GPL into other languages?](#GPLTranslations)[Why are some GNU libraries released under the ordinary GPL rather than the Lesser GPL?](#WhySomeGPLAndNotLGPL)[Who has the power to enforce the GPL?](#WhoHasThePower)[Why does the FSF require that contributors to FSF-copyrighted programs assign copyright to the FSF? If I hold copyright on a GPLed program, should I do this, too? If so, how?](#AssignCopyright)[Can I modify the GPL and make a modified license?](#ModifyGPL)[Why did you decide to write the GNU Affero GPLv3 as a separate license?](#SeparateAffero)
#### General understanding of the GNU licenses
[Why does the GPL permit users to publish their modified versions?](#WhyDoesTheGPLPermitUsersToPublishTheirModifiedVersions)[Does the GPL require that source code of modified versions be posted to the public?](#GPLRequireSourcePostedPublic)[Can I have a GPL-covered program and an unrelated nonfree program on the same computer?](#GPLAndNonfreeOnSameMachine)[If I know someone has a copy of a GPL-covered program, can I demand they give me a copy?](#CanIDemandACopy)[What does “written offer valid for any third party” mean in GPLv2? Does that mean everyone in the world can get the source to any GPLed program no matter what?](#WhatDoesWrittenOfferValid)[The GPL says that modified versions, if released, must be “licensed … to all third parties.” Who are these third parties?](#TheGPLSaysModifiedVersions)[Does the GPL allow me to sell copies of the program for money?](#DoesTheGPLAllowMoney)[Does the GPL allow me to charge a fee for downloading the program from my distribution site?](#DoesTheGPLAllowDownloadFee)[Does the GPL allow me to require that anyone who receives the software must pay me a fee and/or notify me?](#DoesTheGPLAllowRequireFee)[If I distribute GPLed software for a fee, am I required to also make it available to the public without a charge?](#DoesTheGPLRequireAvailabilityToPublic)[Does the GPL allow me to distribute a copy under a nondisclosure agreement?](#DoesTheGPLAllowNDA)[Does the GPL allow me to distribute a modified or beta version under a nondisclosure agreement?](#DoesTheGPLAllowModNDA)[Does the GPL allow me to develop a modified version under a nondisclosure agreement?](#DevelopChangesUnderNDA)[Why does the GPL require including a copy of the GPL with every copy of the program?](#WhyMustIInclude)[What if the work is not very long?](#WhatIfWorkIsShort)[Am I required to claim a copyright on my modifications to a GPL-covered program?](#RequiredToClaimCopyright)[What does the GPL say about translating some code to a different programming language?](#TranslateCode)[If a program combines public-domain code with GPL-covered code, can I take the public-domain part and use it as public domain code?](#CombinePublicDomainWithGPL)[I want to get credit for my work. I want people to know what I wrote. Can I still get credit if I use the GPL?](#IWantCredit)[Does the GPL allow me to add terms that would require citation or acknowledgment in research papers which use the GPL-covered software or its output?](#RequireCitation)[Can I omit the preamble of the GPL, or the instructions for how to use it on your own programs, to save space?](#GPLOmitPreamble)[What does it mean to say that two licenses are “compatible”?](#WhatIsCompatible)[What does it mean to say a license is “compatible with the GPL”?](#WhatDoesCompatMean)[Why is the original BSD license incompatible with the GPL?](#OrigBSD)[What is the difference between an “aggregate” and other kinds of “modified versions”?](#MereAggregation)[When it comes to determining whether two pieces of software form a single work, does the fact that the code is in one or more containers have any effect?](#AggregateContainers)[Why does the FSF require that contributors to FSF-copyrighted programs assign copyright to the FSF? If I hold copyright on a GPLed program, should I do this, too? If so, how?](#AssignCopyright)[If I use a piece of software that has been obtained under the GNU GPL, am I allowed to modify the original code into a new program, then distribute and sell that new program commercially?](#GPLCommercially)[Can I use the GPL for something other than software?](#GPLOtherThanSoftware)[I'd like to license my code under the GPL, but I'd also like to make it clear that it can't be used for military and/or commercial uses. Can I do this?](#NoMilitary)[Can I use the GPL to license hardware?](#GPLHardware)[Does prelinking a GPLed binary to various libraries on the system, to optimize its performance, count as modification?](#Prelinking)[How does the LGPL work with Java?](#LGPLJava)[Why did you invent the new terms “propagate” and “convey” in GPLv3?](#WhyPropagateAndConvey)[Is “convey” in GPLv3 the same thing as what GPLv2 means by “distribute”?](#ConveyVsDistribute)[If I only make copies of a GPL-covered program and run them, without distributing or conveying them to others, what does the license require of me?](#NoDistributionRequirements)[GPLv3 gives “making available to the public” as an example of propagation. What does this mean? Is making available a form of conveying?](#v3MakingAvailable)[Since distribution and making available to the public are forms of propagation that are also conveying in GPLv3, what are some examples of propagation that do not constitute conveying?](#PropagationNotConveying)[How does GPLv3 make BitTorrent distribution easier?](#BitTorrent)[What is tivoization? How does GPLv3 prevent it?](#Tivoization)[Does GPLv3 prohibit DRM?](#DRMProhibited)[Does GPLv3 require that voters be able to modify the software running in a voting machine?](#v3VotingMachine)[Does GPLv3 have a “patent retaliation clause”?](#v3PatentRetaliation)[In GPLv3 and AGPLv3, what does it mean when it says “notwithstanding any other provision of this License”?](#v3Notwithstanding)[In AGPLv3, what counts as “ interacting with [the software] remotely through a computer network?”](#AGPLv3InteractingRemotely)[How does GPLv3's concept of “you” compare to the definition of “Legal Entity” in the Apache License 2.0?](#ApacheLegalEntity)[In GPLv3, what does “the Program” refer to? Is it every program ever released under GPLv3?](#v3TheProgram)[If some network client software is released under AGPLv3, does it have to be able to provide source to the servers it interacts with?](#AGPLv3ServerAsUser)[For software that runs a proxy server licensed under the AGPL, how can I provide an offer of source to users interacting with that code?](#AGPLProxy)
#### Using GNU licenses for your programs
[How do I upgrade from (L)GPLv2 to (L)GPLv3?](#v3HowToUpgrade)[Could you give me step by step instructions on how to apply the GPL to my program?](#CouldYouHelpApplyGPL)[Why should I use the GNU GPL rather than other free software licenses?](#WhyUseGPL)[Why does the GPL require including a copy of the GPL with every copy of the program?](#WhyMustIInclude)[Is putting a copy of the GNU GPL in my repository enough to apply the GPL?](#LicenseCopyOnly)[Why should I put a license notice in each source file?](#NoticeInSourceFile)[What if the work is not very long?](#WhatIfWorkIsShort)[Can I omit the preamble of the GPL, or the instructions for how to use it on your own programs, to save space?](#GPLOmitPreamble)[How do I get a copyright on my program in order to release it under the GPL?](#HowIGetCopyright)[What if my school might want to make my program into its own proprietary software product?](#WhatIfSchool)[I would like to release a program I wrote under the GNU GPL, but I would like to use the same code in nonfree programs.](#ReleaseUnderGPLAndNF)[Can the developer of a program who distributed it under the GPL later license it to another party for exclusive use?](#CanDeveloperThirdParty)[Can the US Government release a program under the GNU GPL?](#GPLUSGov)[Can the US Government release improvements to a GPL-covered program?](#GPLUSGovAdd)[Why should programs say “Version 3 of the GPL or any later version”?](#VersionThreeOrLater)[Is it a good idea to use a license saying that a certain program can be used only under the latest version of the GNU GPL?](#OnlyLatestVersion)[Is there some way that I can GPL the output people get from use of my program? For example, if my program is used to develop hardware designs, can I require that these designs must be free?](#GPLOutput)[Why don't you use the GPL for manuals?](#WhyNotGPLForManuals)[How does the GPL apply to fonts?](#FontException)[What license should I use for website maintenance system templates?](#WMS)[Can I release a program under the GPL which I developed using nonfree tools?](#NonFreeTools)[I use public key cryptography to sign my code to assure its authenticity. Is it true that GPLv3 forces me to release my private signing keys?](#GiveUpKeys)[Does GPLv3 require that voters be able to modify the software running in a voting machine?](#v3VotingMachine)[The warranty and liability disclaimers in GPLv3 seem specific to U.S. law. Can I add my own disclaimers to my own code?](#v3InternationalDisclaimers)[My program has interactive user interfaces that are non-visual in nature. How can I comply with the Appropriate Legal Notices requirement in GPLv3?](#NonvisualLegalNotices)
#### Distribution of programs released under the GNU licenses
[Can I release a modified version of a GPL-covered program in binary form only?](#ModifiedJustBinary)[I downloaded just the binary from the net. If I distribute copies, do I have to get the source and distribute that too?](#UnchangedJustBinary)[I want to distribute binaries via physical media without accompanying sources. Can I provide source code by FTP instead of by mail order?](#DistributeWithSourceOnInternet)[My friend got a GPL-covered binary with an offer to supply source, and made a copy for me. Can I use the offer to obtain the source?](#RedistributedBinariesGetSource)[Can I put the binaries on my Internet server and put the source on a different Internet site?](#SourceAndBinaryOnDifferentSites)[I want to distribute an extended version of a GPL-covered program in binary form. Is it enough to distribute the source for the original version?](#DistributeExtendedBinary)[I want to distribute binaries, but distributing complete source is inconvenient. Is it ok if I give users the diffs from the “standard” version along with the binaries?](#DistributingSourceIsInconvenient)[Can I make binaries available on a network server, but send sources only to people who order them?](#AnonFTPAndSendSources)[How can I make sure each user who downloads the binaries also gets the source?](#HowCanIMakeSureEachDownloadGetsSource)[Does the GPL require me to provide source code that can be built to match the exact hash of the binary I am distributing?](#MustSourceBuildToMatchExactHashOfBinary)[Can I release a program with a license which says that you can distribute modified versions of it under the GPL but you can't distribute the original itself under the GPL?](#ReleaseNotOriginal)[I just found out that a company has a copy of a GPLed program, and it costs money to get it. Aren't they violating the GPL by not making it available on the Internet?](#CompanyGPLCostsMoney)[A company is running a modified version of a GPLed program on a web site. Does the GPL say they must release their modified sources?](#UnreleasedMods)[A company is running a modified version of a program licensed under the GNU Affero GPL (AGPL) on a web site. Does the AGPL say they must release their modified sources?](#UnreleasedModsAGPL)[Is use within one organization or company “distribution”?](#InternalDistribution)[If someone steals a CD containing a version of a GPL-covered program, does the GPL give him the right to redistribute that version?](#StolenCopy)[What if a company distributes a copy of some other developers' GPL-covered work to me as a trade secret?](#TradeSecretRelease)[What if a company distributes a copy of its own GPL-covered work to me as a trade secret?](#TradeSecretRelease2)[Do I have “fair use” rights in using the source code of a GPL-covered program?](#GPLFairUse)[Does moving a copy to a majority-owned, and controlled, subsidiary constitute distribution?](#DistributeSubsidiary)[Can software installers ask people to click to agree to the GPL? If I get some software under the GPL, do I have to agree to anything?](#ClickThrough)[I would like to bundle GPLed software with some sort of installation software. Does that installer need to have a GPL-compatible license?](#GPLCompatInstaller)[Does a distributor violate the GPL if they require me to “represent and warrant” that I am located in the US, or that I intend to distribute the software in compliance with relevant export control laws?](#ExportWarranties)[The beginning of GPLv3 section 6 says that I can convey a covered work in object code form “under the terms of sections 4 and 5” provided I also meet the conditions of section 6. What does that mean?](#v3Under4and5)[My company owns a lot of patents. Over the years we've contributed code to projects under “GPL version 2 or any later version”, and the project itself has been distributed under the same terms. If a user decides to take the project's code (incorporating my contributions) under GPLv3, does that mean I've automatically granted GPLv3's explicit patent license to that user?](#v2OrLaterPatentLicense)[If I distribute a GPLv3-covered program, can I provide a warranty that is voided if the user modifies the program?](#v3ConditionalWarranty)[If I give a copy of a GPLv3-covered program to a coworker at my company, have I “conveyed” the copy to that coworker?](#v3CoworkerConveying)[Am I complying with GPLv3 if I offer binaries on an FTP server and sources by way of a link to a source code repository in a version control system, like CVS or Subversion?](#SourceInCVS)[Can someone who conveys GPLv3-covered software in a User Product use remote attestation to prevent a user from modifying that software?](#RemoteAttestation)[What does “rules and protocols for communication across the network” mean in GPLv3?](#RulesProtocols)[Distributors that provide Installation Information under GPLv3 are not required to provide “support service” for the product. What kind of “support service” do you mean?](#SupportService)
#### Using programs released under the GNU licenses when writing other programs
[Can I have a GPL-covered program and an unrelated nonfree program on the same computer?](#GPLAndNonfreeOnSameMachine)[Can I use GPL-covered editors such as GNU Emacs to develop nonfree programs? Can I use GPL-covered tools such as GCC to compile them?](#CanIUseGPLToolsForNF)[Is there some way that I can GPL the output people get from use of my program? For example, if my program is used to develop hardware designs, can I require that these designs must be free?](#GPLOutput)[In what cases is the output of a GPL program covered by the GPL too?](#WhatCaseIsOutputGPL)[If I port my program to GNU/Linux, does that mean I have to release it as free software under the GPL or some other free software license?](#PortProgramToGPL)[I'd like to incorporate GPL-covered software in my proprietary system. I have no permission to use that software except what the GPL gives me. Can I do this?](#GPLInProprietarySystem)[If I distribute a proprietary program that links against an LGPLv3-covered library that I've modified, what is the “contributor version” for purposes of determining the scope of the explicit patent license grant I'm making—is it just the library, or is it the whole combination?](#LGPLv3ContributorVersion)[Under AGPLv3, when I modify the Program under section 13, what Corresponding Source does it have to offer?](#AGPLv3CorrespondingSource)[Where can I learn more about the GCC Runtime Library Exception?](#LibGCCException)
#### Combining work with code released under the GNU licenses
[Is GPLv3 compatible with GPLv2?](#v2v3Compatibility)[Does GPLv2 have a requirement about delivering installation information?](#InstInfo)[How are the various GNU licenses compatible with each other?](#AllCompatibility)[What is the difference between an “aggregate” and other kinds of “modified versions”?](#MereAggregation)[Do I have “fair use” rights in using the source code of a GPL-covered program?](#GPLFairUse)[Can the US Government release improvements to a GPL-covered program?](#GPLUSGovAdd)[Does the GPL have different requirements for statically vs dynamically linked modules with a covered work?](#GPLStaticVsDynamic)[Does the LGPL have different requirements for statically vs dynamically linked modules with a covered work?](#LGPLStaticVsDynamic)[If a library is released under the GPL (not the LGPL), does that mean that any software which uses it has to be under the GPL or a GPL-compatible license?](#IfLibraryIsGPL)[You have a GPLed program that I'd like to link with my code to build a proprietary program. Does the fact that I link with your program mean I have to GPL my program?](#LinkingWithGPL)[If so, is there any chance I could get a license of your program under the Lesser GPL?](#SwitchToLGPL)[If a programming language interpreter is released under the GPL, does that mean programs written to be interpreted by it must be under GPL-compatible licenses?](#IfInterpreterIsGPL)[If a programming language interpreter has a license that is incompatible with the GPL, can I run GPL-covered programs on it?](#InterpreterIncompat)[If I add a module to a GPL-covered program, do I have to use the GPL as the license for my module?](#GPLModuleLicense)[When is a program and its plug-ins considered a single combined program?](#GPLPlugins)[If I write a plug-in to use with a GPL-covered program, what requirements does that impose on the licenses I can use for distributing my plug-in?](#GPLAndPlugins)[Can I apply the GPL when writing a plug-in for a nonfree program?](#GPLPluginsInNF)[Can I release a nonfree program that's designed to load a GPL-covered plug-in?](#NFUseGPLPlugins)[I'd like to incorporate GPL-covered software in my proprietary system. I have no permission to use that software except what the GPL gives me. Can I do this?](#GPLInProprietarySystem)[Using a certain GNU program under the GPL does not fit our project to make proprietary software. Will you make an exception for us? It would mean more users of that program.](#WillYouMakeAnException)[I'd like to incorporate GPL-covered software in my proprietary system. Can I do this by putting a “wrapper” module, under a GPL-compatible lax permissive license (such as the X11 license) in between the GPL-covered part and the proprietary part?](#GPLWrapper)[Can I write free software that uses nonfree libraries?](#FSWithNFLibs)[Can I link a GPL program with a proprietary system library?](#SystemLibraryException)[In what ways can I link or combine AGPLv3-covered and GPLv3-covered code?](#AGPLGPL)[What legal issues come up if I use GPL-incompatible libraries with GPL software?](#GPLIncompatibleLibs)[I'm writing a Windows application with Microsoft Visual C++ and I will be releasing it under the GPL. Is dynamically linking my program with the Visual C++ runtime library permitted under the GPL?](#WindowsRuntimeAndGPL)[I'd like to modify GPL-covered programs and link them with the portability libraries from Money Guzzler Inc. I cannot distribute the source code for these libraries, so any user who wanted to change these versions would have to obtain those libraries separately. Why doesn't the GPL permit this?](#MoneyGuzzlerInc)[If license for a module Q has a requirement that's incompatible with the GPL, but the requirement applies only when Q is distributed by itself, not when Q is included in a larger program, does that make the license GPL-compatible? Can I combine or link Q with a GPL-covered program?](#GPLIncompatibleAlone)[In an object-oriented language such as Java, if I use a class that is GPLed without modifying, and subclass it, in what way does the GPL affect the larger program?](#OOPLang)[Does distributing a nonfree driver meant to link with the kernel Linux violate the GPL?](#NonfreeDriverKernelLinux)[How can I allow linking of proprietary modules with my GPL-covered library under a controlled interface only?](#LinkingOverControlledInterface)[Consider this situation: 1) X releases V1 of a project under the GPL. 2) Y contributes to the development of V2 with changes and new code based on V1. 3) X wants to convert V2 to a non-GPL license. Does X need Y's permission?](#Consider)[I have written an application that links with many different components, that have different licenses. I am very confused as to what licensing requirements are placed on my program. Can you please tell me what licenses I may use?](#ManyDifferentLicenses)[Can I use snippets of GPL-covered source code within documentation that is licensed under some license that is incompatible with the GPL?](#SourceCodeInDocumentation)
#### Questions about violations of the GNU licenses
[What should I do if I discover a possible violation of the GPL?](#ReportingViolation)[Who has the power to enforce the GPL?](#WhoHasThePower)[I heard that someone got a copy of a GPLed program under another license. Is this possible?](#HeardOtherLicense)[Is the developer of a GPL-covered program bound by the GPL? Could the developer's actions ever be a violation of the GPL?](#DeveloperViolate)[I just found out that a company has a copy of a GPLed program, and it costs money to get it. Aren't they violating the GPL by not making it available on the Internet?](#CompanyGPLCostsMoney)[Can I use GPLed software on a device that will stop operating if customers do not continue paying a subscription fee?](#SubscriptionFee)[What does it mean to “cure” a violation of GPLv3?](#Cure)[If someone installs GPLed software on a laptop, and then lends that laptop to a friend without providing source code for the software, have they violated the GPL?](#LaptopLoan)[Suppose that two companies try to circumvent the requirement to provide Installation Information by having one company release signed software, and the other release a User Product that only runs signed software from the first company. Is this a violation of GPLv3?](#TwoPartyTivoization)
This page is maintained by the Free Software
Foundation's Licensing and Compliance Lab. You can support our efforts by
[making a donation](http://donate.fsf.org) to the FSF.
You can use our publications to understand how GNU licenses work or help you advocate for free software, but they are not legal advice. The FSF cannot give legal advice. Legal advice is personalized advice from a lawyer who has agreed to work for you. Our answers address general questions and may not apply in your specific legal situation.
Have a
question not answered here? Check out some of our other [licensing resources](https://www.fsf.org/licensing) or contact the
Compliance Lab at [[email protected]](mailto:[email protected]).
- What does “GPL” stand for?
(
[#WhatDoesGPLStandFor](#WhatDoesGPLStandFor)) “GPL” stands for “General Public License”. The most widespread such license is the GNU General Public License, or GNU GPL for short. This can be further shortened to “GPL”, when it is understood that the GNU GPL is the one intended.
- Does free software mean using
the GPL?
(
[#DoesFreeSoftwareMeanUsingTheGPL](#DoesFreeSoftwareMeanUsingTheGPL)) Not at all—there are many other free software licenses. We have an
[incomplete list](/licenses/license-list.html). Any license that provides the user[certain specific freedoms](/philosophy/free-sw.html)is a free software license.- Why should I use the GNU GPL rather than other
free software licenses?
(
[#WhyUseGPL](#WhyUseGPL)) Using the GNU GPL will require that all the
[released improved versions be free software](/philosophy/pragmatic.html). This means you can avoid the risk of having to compete with a proprietary modified version of your own work. However, in some special situations it can be better to use a[more permissive license](/licenses/why-not-lgpl.html).- Does all GNU
software use the GNU GPL as its license?
(
[#DoesAllGNUSoftwareUseTheGNUGPLAsItsLicense](#DoesAllGNUSoftwareUseTheGNUGPLAsItsLicense)) Most GNU software packages use the GNU GPL, but there are a few GNU programs (and parts of programs) that use looser licenses, such as the Lesser GPL. When we do this, it is a matter of
[strategy](/licenses/why-not-lgpl.html).- Does using the
GPL for a program make it GNU software?
(
[#DoesUsingTheGPLForAProgramMakeItGNUSoftware](#DoesUsingTheGPLForAProgramMakeItGNUSoftware)) Anyone can release a program under the GNU GPL, but that does not make it a GNU package.
Making the program a GNU software package means explicitly contributing to the GNU Project. This happens when the program's developers and the GNU Project agree to do it. If you are interested in contributing a program to the GNU Project, please write to
[<[email protected]>](mailto:[email protected]).- What should I do if I discover a possible
violation of the GPL?
(
[#ReportingViolation](#ReportingViolation)) You should
[report it](/licenses/gpl-violation.html). First, check the facts as best you can. Then tell the publisher or copyright holder of the specific GPL-covered program. If that is the Free Software Foundation, write to[<[email protected]>](mailto:[email protected]). Otherwise, the program's maintainer may be the copyright holder, or else could tell you how to contact the copyright holder, so report it to the maintainer.- Why
does the GPL permit users to publish their modified versions?
(
[#WhyDoesTheGPLPermitUsersToPublishTheirModifiedVersions](#WhyDoesTheGPLPermitUsersToPublishTheirModifiedVersions)) A crucial aspect of free software is that users are free to cooperate. It is absolutely essential to permit users who wish to help each other to share their bug fixes and improvements with other users.
Some have proposed alternatives to the GPL that require modified versions to go through the original author. As long as the original author keeps up with the need for maintenance, this may work well in practice, but if the author stops (more or less) to do something else or does not attend to all the users' needs, this scheme falls down. Aside from the practical problems, this scheme does not allow users to help each other.
Sometimes control over modified versions is proposed as a means of preventing confusion between various versions made by users. In our experience, this confusion is not a major problem. Many versions of Emacs have been made outside the GNU Project, but users can tell them apart. The GPL requires the maker of a version to place his or her name on it, to distinguish it from other versions and to protect the reputations of other maintainers.
- Does the GPL require that
source code of modified versions be posted to the public?
(
[#GPLRequireSourcePostedPublic](#GPLRequireSourcePostedPublic)) The GPL does not require you to release your modified version, or any part of it. You are free to make modifications and use them privately, without ever releasing them. This applies to organizations (including companies), too; an organization can make a modified version and use it internally without ever releasing it outside the organization.
But
*if*you release the modified version to the public in some way, the GPL requires you to make the modified source code available to the program's users, under the GPL.Thus, the GPL gives permission to release the modified program in certain ways, and not in other ways; but the decision of whether to release it is up to you.
- Can I have a GPL-covered
program and an unrelated nonfree program on the same computer?
(
[#GPLAndNonfreeOnSameMachine](#GPLAndNonfreeOnSameMachine)) Yes.
- If I know someone has a copy of a GPL-covered
program, can I demand they give me a copy?
(
[#CanIDemandACopy](#CanIDemandACopy)) No. The GPL gives a person permission to make and redistribute copies of the program
*if and when that person chooses to do so*. That person also has the right not to choose to redistribute the program.- What does “written offer
valid for any third party” mean in GPLv2? Does that mean
everyone in the world can get the source to any GPLed program
no matter what?
(
[#WhatDoesWrittenOfferValid](#WhatDoesWrittenOfferValid)) If you choose to provide source through a written offer, then anybody who requests the source from you is entitled to receive it.
If you commercially distribute binaries not accompanied with source code, the GPL says you must provide a written offer to distribute the source code later. When users non-commercially redistribute the binaries they received from you, they must pass along a copy of this written offer. This means that people who did not get the binaries directly from you can still receive copies of the source code, along with the written offer.
The reason we require the offer to be valid for any third party is so that people who receive the binaries indirectly in that way can order the source code from you.
- GPLv2 says that modified
versions, if released, must be “licensed … to all third
parties.” Who are these third parties?
(
[#TheGPLSaysModifiedVersions](#TheGPLSaysModifiedVersions)) Section 2 says that modified versions you distribute must be licensed to all third parties under the GPL. “All third parties” means absolutely everyone—but this does not require you to
*do*anything physically for them. It only means they have a license from you, under the GPL, for your version.- Am I required to claim a copyright
on my modifications to a GPL-covered program?
(
[#RequiredToClaimCopyright](#RequiredToClaimCopyright)) You are not required to claim a copyright on your changes. In most countries, however, that happens automatically by default, so you need to place your changes explicitly in the public domain if you do not want them to be copyrighted.
Whether you claim a copyright on your changes or not, either way you must release the modified version, as a whole, under the GPL (
[if you release your modified version at all](#GPLRequireSourcePostedPublic)).- What does the GPL say about translating
some code to a different programming language?
(
[#TranslateCode](#TranslateCode)) Under copyright law, translation of a work is considered a kind of modification. Therefore, what the GPL says about modified versions applies also to translated versions. The translation is covered by the copyright on the original program.
If the original program carries a free license, that license gives permission to translate it. How you can use and license the translated program is determined by that license. If the original program is licensed under certain versions of the GNU GPL, the translated program must be covered by the same versions of the GNU GPL.
- If a program combines
public-domain code with GPL-covered code, can I take the
public-domain part and use it as public domain code?
(
[#CombinePublicDomainWithGPL](#CombinePublicDomainWithGPL)) You can do that, if you can figure out which part is the public domain part and separate it from the rest. If code was put in the public domain by its developer, it is in the public domain no matter where it has been.
- Does the GPL allow me to sell copies of
the program for money?
(
[#DoesTheGPLAllowMoney](#DoesTheGPLAllowMoney)) Yes, the GPL allows everyone to do this. The
[right to sell copies](/philosophy/selling.html)is part of the definition of free software. Except in one special situation, there is no limit on what price you can charge. (The one exception is the required written offer to provide source code that must accompany binary-only release.)- Does the GPL allow me to charge a
fee for downloading the program from my distribution site?
(
[#DoesTheGPLAllowDownloadFee](#DoesTheGPLAllowDownloadFee)) Yes. You can charge any fee you wish for distributing a copy of the program. Under GPLv2, if you distribute binaries by download, you must provide “equivalent access” to download the source—therefore, the fee to download source may not be greater than the fee to download the binary. If the binaries being distributed are licensed under the GPLv3, then you must offer equivalent access to the source code in the same way through the same place at no further charge.
- Does the GPL allow me to require
that anyone who receives the software must pay me a fee and/or
notify me?
(
[#DoesTheGPLAllowRequireFee](#DoesTheGPLAllowRequireFee)) No. In fact, a requirement like that would make the program nonfree. If people have to pay when they get a copy of a program, or if they have to notify anyone in particular, then the program is not free. See the
[definition of free software](/philosophy/free-sw.html).The GPL is a free software license, and therefore it permits people to use and even redistribute the software without being required to pay anyone a fee for doing so.
You
*can*charge people a fee to[get a copy](#DoesTheGPLAllowMoney). You can't require people to pay you when they get a copy*from you**from someone else*.- If I
distribute GPLed software for a fee, am I required to also make
it available to the public without a charge?
(
[#DoesTheGPLRequireAvailabilityToPublic](#DoesTheGPLRequireAvailabilityToPublic)) No. However, if someone pays your fee and gets a copy, the GPL gives them the freedom to release it to the public, with or without a fee. For example, someone could pay your fee, and then put her copy on a web site for the general public.
- Does the GPL allow me to distribute copies
under a nondisclosure agreement?
(
[#DoesTheGPLAllowNDA](#DoesTheGPLAllowNDA)) No. The GPL says that anyone who receives a copy from you has the right to redistribute copies, modified or not. You are not allowed to distribute the work on any more restrictive basis.
If someone asks you to sign an NDA for receiving GPL-covered software copyrighted by the FSF, please inform us immediately by writing to
[[email protected]](mailto:[email protected]).If the violation involves GPL-covered code that has some other copyright holder, please inform that copyright holder, just as you would for any other kind of violation of the GPL.
- Does the GPL allow me to distribute a
modified or beta version under a nondisclosure agreement?
(
[#DoesTheGPLAllowModNDA](#DoesTheGPLAllowModNDA)) No. The GPL says that your modified versions must carry all the freedoms stated in the GPL. Thus, anyone who receives a copy of your version from you has the right to redistribute copies (modified or not) of that version. You may not distribute any version of the work on a more restrictive basis.
- Does the GPL allow me to develop a
modified version under a nondisclosure agreement?
(
[#DevelopChangesUnderNDA](#DevelopChangesUnderNDA)) Yes. For instance, you can accept a contract to develop changes and agree not to release
*your changes*until the client says ok. This is permitted because in this case no GPL-covered code is being distributed under an NDA.You can also release your changes to the client under the GPL, but agree not to release them to anyone else unless the client says ok. In this case, too, no GPL-covered code is being distributed under an NDA, or under any additional restrictions.
The GPL would give the client the right to redistribute your version. In this scenario, the client will probably choose not to exercise that right, but does
*have*the right.- I want to get credit
for my work. I want people to know what I wrote. Can I still get
credit if I use the GPL?
(
[#IWantCredit](#IWantCredit)) You can certainly get credit for the work. Part of releasing a program under the GPL is writing a copyright notice in your own name (assuming you are the copyright holder). The GPL requires all copies to carry an appropriate copyright notice.
- Does the GPL allow me to add terms
that would require citation or acknowledgment in research papers
which use the GPL-covered software or its output?
(
[#RequireCitation](#RequireCitation)) No, this is not permitted under the terms of the GPL. While we recognize that proper citation is an important part of academic publications, citation cannot be added as an additional requirement to the GPL. Requiring citation in research papers which made use of GPLed software goes beyond what would be an acceptable additional requirement under section 7(b) of GPLv3, and therefore would be considered an additional restriction under Section 7 of the GPL. And copyright law does not allow you to place such a
[requirement on the output of software](#GPLOutput), regardless of whether it is licensed under the terms of the GPL or some other license.- Why does the GPL
require including a copy of the GPL with every copy of the program?
(
[#WhyMustIInclude](#WhyMustIInclude)) Including a copy of the license with the work is vital so that everyone who gets a copy of the program can know what their rights are.
It might be tempting to include a URL that refers to the license, instead of the license itself. But you cannot be sure that the URL will still be valid, five years or ten years from now. Twenty years from now, URLs as we know them today may no longer exist.
The only way to make sure that people who have copies of the program will continue to be able to see the license, despite all the changes that will happen in the network, is to include a copy of the license in the program.
- Is it enough just to put a copy
of the GNU GPL in my repository?
(
[#LicenseCopyOnly](#LicenseCopyOnly)) Just putting a copy of the GNU GPL in a file in your repository does not explicitly state that the code in the same repository may be used under the GNU GPL. Without such a statement, it's not entirely clear that the permissions in the license really apply to any particular source file. An explicit statement saying that eliminates all doubt.
A file containing just a license, without a statement that certain other files are covered by that license, resembles a file containing just a subroutine which is never called from anywhere else. The resemblance is not perfect: lawyers and courts might apply common sense and conclude that you must have put the copy of the GNU GPL there because you wanted to license the code that way. Or they might not. Why leave an uncertainty?
This statement should be in each source file. A clear statement in the program's README file is legally sufficient
*as long as that accompanies the code*, but it is easy for them to get separated. Why take a risk of[uncertainty about your code's license](#NoticeInSourceFile)?This has nothing to do with the specifics of the GNU GPL. It is true for any free license.
- Why should I put a license notice in each
source file?
(
[#NoticeInSourceFile](#NoticeInSourceFile)) You should put a notice at the start of each source file, stating what license it carries, in order to avoid risk of the code's getting disconnected from its license. If your repository's README says that source file is under the GNU GPL, what happens if someone copies that file to another program? That other context may not show what the file's license is. It may appear to have some other license, or
[no license at all](/licenses/license-list.html#NoLicense)(which would make the code nonfree).Adding a copyright notice and a license notice at the start of each source file is easy and makes such confusion unlikely.
This has nothing to do with the specifics of the GNU GPL. It is true for any free license.
- What if the work is not very long?
(
[#WhatIfWorkIsShort](#WhatIfWorkIsShort)) If a whole software package contains very little code—less than 300 lines is the benchmark we use—you may as well use a lax permissive license for it, rather than a copyleft license like the GNU GPL. (Unless, that is, the code is specially important.) We
[recommend the Apache License 2.0](/licenses/license-recommendations.html#software)for such cases.- Can I omit the preamble of the GPL, or the
instructions for how to use it on your own programs, to save space?
(
[#GPLOmitPreamble](#GPLOmitPreamble)) The preamble and instructions are integral parts of the GNU GPL and may not be omitted. In fact, the GPL is copyrighted, and its license permits only verbatim copying of the entire GPL. (You can use the legal terms to make
[another license](#ModifyGPL)but it won't be the GNU GPL.)The preamble and instructions add up to some 1000 words, less than 1/5 of the GPL's total size. They will not make a substantial fractional change in the size of a software package unless the package itself is quite small. In that case, you may as well use a simple all-permissive license rather than the GNU GPL.
- What does it
mean to say that two licenses are “compatible”?
(
[#WhatIsCompatible](#WhatIsCompatible)) In order to combine two programs (or substantial parts of them) into a larger work, you need to have permission to use both programs in this way. If the two programs' licenses permit this, they are compatible. If there is no way to satisfy both licenses at once, they are incompatible.
For some licenses, the way in which the combination is made may affect whether they are compatible—for instance, they may allow linking two modules together, but not allow merging their code into one module.
If you just want to install two separate programs in the same system, it is not necessary that their licenses be compatible, because this does not combine them into a larger work.
- What does it mean to say a license is
“compatible with the GPL?”
(
[#WhatDoesCompatMean](#WhatDoesCompatMean)) It means that the other license and the GNU GPL are compatible; you can combine code released under the other license with code released under the GNU GPL in one larger program.
All GNU GPL versions permit such combinations privately; they also permit distribution of such combinations provided the combination is released under the same GNU GPL version. The other license is compatible with the GPL if it permits this too.
GPLv3 is compatible with more licenses than GPLv2: it allows you to make combinations with code that has specific kinds of additional requirements that are not in GPLv3 itself. Section 7 has more information about this, including the list of additional requirements that are permitted.
- Can I write
free software that uses nonfree libraries?
(
[#FSWithNFLibs](#FSWithNFLibs)) If you do this, your program won't be fully usable in a free environment. If your program depends on a nonfree library to do a certain job, it cannot do that job in the Free World. If it depends on a nonfree library to run at all, it cannot be part of a free operating system such as GNU; it is entirely off limits to the Free World.
So please consider: can you find a way to get the job done without using this library? Can you write a free replacement for that library?
If the program is already written using the nonfree library, perhaps it is too late to change the decision. You may as well release the program as it stands, rather than not release it. But please mention in the README that the need for the nonfree library is a drawback, and suggest the task of changing the program so that it does the same job without the nonfree library. Please suggest that anyone who thinks of doing substantial further work on the program first free it from dependence on the nonfree library.
Note that there may also be legal issues with combining certain nonfree libraries with GPL-covered free software. Please see
[the question on GPL software with GPL-incompatible libraries](#GPLIncompatibleLibs)for more information.- Can I link a GPL program with a
proprietary system library? (
[#SystemLibraryException](#SystemLibraryException)) Both versions of the GPL have an exception to their copyleft, commonly called the system library exception. If the GPL-incompatible libraries you want to use meet the criteria for a system library, then you don't have to do anything special to use them; the requirement to distribute source code for the whole program does not include those libraries, even if you distribute a linked executable containing them.
The criteria for what counts as a “system library” vary between different versions of the GPL. GPLv3 explicitly defines “System Libraries” in section 1, to exclude it from the definition of “Corresponding Source.” GPLv2 deals with this issue slightly differently, near the end of section 3.
- In what ways can I link or combine
AGPLv3-covered and GPLv3-covered code?
(
[#AGPLGPL](#AGPLGPL)) Each of these licenses explicitly permits linking with code under the other license. You can always link GPLv3-covered modules with AGPLv3-covered modules, and vice versa. That is true regardless of whether some of the modules are libraries.
- What legal issues
come up if I use GPL-incompatible libraries with GPL software?
(
[#GPLIncompatibleLibs](#GPLIncompatibleLibs)) -
If you want your program to link against a library not covered by the system library exception, you need to provide permission to do that. Below are two example license notices that you can use to do that; one for GPLv3, and the other for GPLv2. In either case, you should put this text in each file to which you are granting this permission.
Only the copyright holders for the program can legally release their software under these terms. If you wrote the whole program yourself, then assuming your employer or school does not claim the copyright, you are the copyright holder—so you can authorize the exception. But if you want to use parts of other GPL-covered programs by other authors in your code, you cannot authorize the exception for them. You have to get the approval of the copyright holders of those programs.
When other people modify the program, they do not have to make the same exception for their code—it is their choice whether to do so.
If the libraries you intend to link with are nonfree, please also see
[the section on writing Free Software which uses nonfree libraries](#FSWithNFLibs).If you're using GPLv3, you can accomplish this goal by granting an additional permission under section 7. The following license notice will do that. You must replace all the text in brackets with text that is appropriate for your program. If not everybody can distribute source for the libraries you intend to link with, you should remove the text in braces; otherwise, just remove the braces themselves.
Copyright (C)
`[years]``[name of copyright holder]`This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 3 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, see <https://www.gnu.org/licenses>.
Additional permission under GNU GPL version 3 section 7
If you modify this Program, or any covered work, by linking or combining it with
`[name of library]`(or a modified version of that library), containing parts covered by the terms of`[name of library's license]`, the licensors of this Program grant you additional permission to convey the resulting work. {Corresponding Source for a non-source form of such a combination shall include the source code for the parts of`[name of library]`used as well as that of the covered work.}If you're using GPLv2, you can provide your own exception to the license's terms. The following license notice will do that. Again, you must replace all the text in brackets with text that is appropriate for your program. If not everybody can distribute source for the libraries you intend to link with, you should remove the text in braces; otherwise, just remove the braces themselves.
Copyright (C)
`[years]``[name of copyright holder]`This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, see <https://www.gnu.org/licenses>.
Linking
`[name of your program]`statically or dynamically with other modules is making a combined work based on`[name of your program]`. Thus, the terms and conditions of the GNU General Public License cover the whole combination.In addition, as a special exception, the copyright holders of
`[name of your program]`give you permission to combine`[name of your program]`with free software programs or libraries that are released under the GNU LGPL and with code included in the standard release of`[name of library]`under the`[name of library's license]`(or modified versions of such code, with unchanged license). You may copy and distribute such a system following the terms of the GNU GPL for`[name of your program]`and the licenses of the other code concerned{, provided that you include the source code of that other code when and as the GNU GPL requires distribution of source code}.Note that people who make modified versions of
`[name of your program]`are not obligated to grant this special exception for their modified versions; it is their choice whether to do so. The GNU General Public License gives permission to release a modified version without this exception; this exception also makes it possible to release a modified version which carries forward this exception. - How do I get a copyright on my program
in order to release it under the GPL?
(
[#HowIGetCopyright](#HowIGetCopyright)) Under the Berne Convention, everything written is automatically copyrighted from whenever it is put in fixed form. So you don't have to do anything to “get” the copyright on what you write—as long as nobody else can claim to own your work.
However, registering the copyright in the US is a very good idea. It will give you more clout in dealing with an infringer in the US.
The case when someone else might possibly claim the copyright is if you are an employee or student; then the employer or the school might claim you did the job for them and that the copyright belongs to them. Whether they would have a valid claim would depend on circumstances such as the laws of the place where you live, and on your employment contract and what sort of work you do. It is best to consult a lawyer if there is any possible doubt.
If you think that the employer or school might have a claim, you can resolve the problem clearly by getting a copyright disclaimer signed by a suitably authorized officer of the company or school. (Your immediate boss or a professor is usually NOT authorized to sign such a disclaimer.)
- What if my school
might want to make my program into its own proprietary software product?
(
[#WhatIfSchool](#WhatIfSchool)) Many universities nowadays try to raise funds by restricting the use of the knowledge and information they develop, in effect behaving little different from commercial businesses. (See “The Kept University”, Atlantic Monthly, March 2000, for a general discussion of this problem and its effects.)
If you see any chance that your school might refuse to allow your program to be released as free software, it is best to raise the issue at the earliest possible stage. The closer the program is to working usefully, the more temptation the administration might feel to take it from you and finish it without you. At an earlier stage, you have more leverage.
So we recommend that you approach them when the program is only half-done, saying, “If you will agree to releasing this as free software, I will finish it.” Don't think of this as a bluff. To prevail, you must have the courage to say, “My program will have liberty, or never be born.”
- Could
you give me step by step instructions on how to apply the GPL to my program?
(
[#CouldYouHelpApplyGPL](#CouldYouHelpApplyGPL)) See the page of
[GPL instructions](/licenses/gpl-howto.html).- I heard that someone got a copy
of a GPLed program under another license. Is this possible?
(
[#HeardOtherLicense](#HeardOtherLicense)) The GNU GPL does not give users permission to attach other licenses to the program. But the copyright holder for a program can release it under several different licenses in parallel. One of them may be the GNU GPL.
The license that comes in your copy, assuming it was put in by the copyright holder and that you got the copy legitimately, is the license that applies to your copy.
- I would like to release a program I wrote
under the GNU GPL, but I would
like to use the same code in nonfree programs.
(
[#ReleaseUnderGPLAndNF](#ReleaseUnderGPLAndNF)) To release a nonfree program is always ethically tainted, but legally there is no obstacle to your doing this. If you are the copyright holder for the code, you can release it under various different non-exclusive licenses at various times.
- Is the
developer of a GPL-covered program bound by the GPL? Could the
developer's actions ever be a violation of the GPL?
(
[#DeveloperViolate](#DeveloperViolate)) Strictly speaking, the GPL is a license from the developer for others to use, distribute and change the program. The developer itself is not bound by it, so no matter what the developer does, this is not a “violation” of the GPL.
However, if the developer does something that would violate the GPL if done by someone else, the developer will surely lose moral standing in the community.
- Can the developer of a program who distributed
it under the GPL later license it to another party for exclusive use?
(
[#CanDeveloperThirdParty](#CanDeveloperThirdParty)) No, because the public already has the right to use the program under the GPL, and this right cannot be withdrawn.
- Can I use GPL-covered editors such as
GNU Emacs to develop nonfree programs? Can I use GPL-covered tools
such as GCC to compile them?
(
[#CanIUseGPLToolsForNF](#CanIUseGPLToolsForNF)) Yes, because the copyright on the editors and tools does not cover the code you write. Using them does not place any restrictions, legally, on the license you use for your code.
Some programs copy parts of themselves into the output for technical reasons—for example, Bison copies a standard parser program into its output file. In such cases, the copied text in the output is covered by the same license that covers it in the source code. Meanwhile, the part of the output which is derived from the program's input inherits the copyright status of the input.
As it happens, Bison can also be used to develop nonfree programs. This is because we decided to explicitly permit the use of the Bison standard parser program in Bison output files without restriction. We made the decision because there were other tools comparable to Bison which already permitted use for nonfree programs.
- Do I have “fair use”
rights in using the source code of a GPL-covered program?
(
[#GPLFairUse](#GPLFairUse)) Yes, you do. “Fair use” is use that is allowed without any special permission. Since you don't need the developers' permission for such use, you can do it regardless of what the developers said about it—in the license or elsewhere, whether that license be the GNU GPL or any other free software license.
Note, however, that there is no world-wide principle of fair use; what kinds of use are considered “fair” varies from country to country.
- Can the US Government release a program under the GNU GPL?
(
[#GPLUSGov](#GPLUSGov)) If the program is written by US federal government employees in the course of their employment, it is in the public domain, which means it is not copyrighted. Since the GNU GPL is based on copyright, such a program cannot be released under the GNU GPL. (It can still be
[free software](/philosophy/free-sw.html), however; a public domain program is free.)However, when a US federal government agency uses contractors to develop software, that is a different situation. The contract can require the contractor to release it under the GNU GPL. (GNU Ada was developed in this way.) Or the contract can assign the copyright to the government agency, which can then release the software under the GNU GPL.
- Can the US Government
release improvements to a GPL-covered program?
(
[#GPLUSGovAdd](#GPLUSGovAdd)) Yes. If the improvements are written by US government employees in the course of their employment, then the improvements are in the public domain. However, the improved version, as a whole, is still covered by the GNU GPL. There is no problem in this situation.
If the US government uses contractors to do the job, then the improvements themselves can be GPL-covered.
- Does the GPL have different requirements
for statically vs dynamically linked modules with a covered
work? (
[#GPLStaticVsDynamic](#GPLStaticVsDynamic)) No. Linking a GPL covered work statically or dynamically with other modules is making a combined work based on the GPL covered work. Thus, the terms and conditions of the GNU General Public License cover the whole combination. See also
[What legal issues come up if I use GPL-incompatible libraries with GPL software?](#GPLIncompatibleLibs)- Does the LGPL have different requirements
for statically vs dynamically linked modules with a covered
work? (
[#LGPLStaticVsDynamic](#LGPLStaticVsDynamic)) For the purpose of complying with the LGPL (any extant version: v2, v2.1 or v3):
(1) If you statically link against an LGPLed library, you must also provide your application in an object (not necessarily source) format, so that a user has the opportunity to modify the library and relink the application.
(2) If you dynamically link against an LGPLed library
*already present on the user's computer*, you need not convey the library's source. On the other hand, if you yourself convey the executable LGPLed library along with your application, whether linked with statically or dynamically, you must also convey the library's sources, in one of the ways for which the LGPL provides.- Is there some way that
I can GPL the output people get from use of my program? For example,
if my program is used to develop hardware designs, can I require that
these designs must be free?
(
[#GPLOutput](#GPLOutput)) In general this is legally impossible; copyright law does not give you any say in the use of the output people make from their data using your program. If the user uses your program to enter or convert her own data, the copyright on the output belongs to her, not you. More generally, when a program translates its input into some other form, the copyright status of the output inherits that of the input it was generated from.
So the only way you have a say in the use of the output is if substantial parts of the output are copied (more or less) from text in your program. For instance, part of the output of Bison (see above) would be covered by the GNU GPL, if we had not made an exception in this specific case.
You could artificially make a program copy certain text into its output even if there is no technical reason to do so. But if that copied text serves no practical purpose, the user could simply delete that text from the output and use only the rest. Then he would not have to obey the conditions on redistribution of the copied text.
- In what cases is the output of a GPL
program covered by the GPL too?
(
[#WhatCaseIsOutputGPL](#WhatCaseIsOutputGPL)) The output of a program is not, in general, covered by the copyright on the code of the program. So the license of the code of the program does not apply to the output, whether you pipe it into a file, make a screenshot, screencast, or video.
The exception would be when the program displays a full screen of text and/or art that comes from the program. Then the copyright on that text and/or art covers the output. Programs that output audio, such as video games, would also fit into this exception.
If the art/music is under the GPL, then the GPL applies when you copy it no matter how you copy it. However,
[fair use](#GPLFairUse)may still apply.Keep in mind that some programs, particularly video games, can have artwork/audio that is licensed separately from the underlying GPLed game. In such cases, the license on the artwork/audio would dictate the terms under which video/streaming may occur. See also:
[Can I use the GPL for something other than software?](#GPLOtherThanSoftware)- If I add a module to a GPL-covered program,
do I have to use the GPL as the license for my module?
(
[#GPLModuleLicense](#GPLModuleLicense)) The GPL says that the whole combined program has to be released under the GPL. So your module has to be available for use under the GPL.
But you can give additional permission for the use of your code. You can, if you wish, release your module under a license which is more lax than the GPL but compatible with the GPL. The
[license list page](/licenses/license-list.html)gives a partial list of GPL-compatible licenses.- If a library is released under the GPL
(not the LGPL), does that mean that any software which uses it
has to be under the GPL or a GPL-compatible license?
(
[#IfLibraryIsGPL](#IfLibraryIsGPL)) Yes, because the program actually links to the library. As such, the terms of the GPL apply to the entire combination. The software modules that link with the library may be under various GPL compatible licenses, but the work as a whole must be licensed under the GPL. See also:
[What does it mean to say a license is “compatible with the GPL”?](#WhatDoesCompatMean)- If a programming language interpreter
is released under the GPL, does that mean programs written to be
interpreted by it must be under GPL-compatible licenses?
(
[#IfInterpreterIsGPL](#IfInterpreterIsGPL)) When the interpreter just interprets a language, the answer is no. The interpreted program, to the interpreter, is just data; a free software license like the GPL, based on copyright law, cannot limit what data you use the interpreter on. You can run it on any data (interpreted program), any way you like, and there are no requirements about licensing that data to anyone.
However, when the interpreter is extended to provide “bindings” to other facilities (often, but not necessarily, libraries), the interpreted program is effectively linked to the facilities it uses through these bindings. So if these facilities are released under the GPL, the interpreted program that uses them must be released in a GPL-compatible way. The JNI or Java Native Interface is an example of such a binding mechanism; libraries that are accessed in this way are linked dynamically with the Java programs that call them. These libraries are also linked with the interpreter. If the interpreter is linked statically with these libraries, or if it is designed to
[link dynamically with these specific libraries](#GPLPluginsInNF), then it too needs to be released in a GPL-compatible way.Another similar and very common case is to provide libraries with the interpreter which are themselves interpreted. For instance, Perl comes with many Perl modules, and a Java implementation comes with many Java classes. These libraries and the programs that call them are always dynamically linked together.
A consequence is that if you choose to use GPLed Perl modules or Java classes in your program, you must release the program in a GPL-compatible way, regardless of the license used in the Perl or Java interpreter that the combined Perl or Java program will run on.
- I'm writing a Windows application with
Microsoft Visual C++ (or Visual Basic) and I will be releasing it
under the GPL. Is dynamically linking my program with the Visual
C++ (or Visual Basic) runtime library permitted under the GPL?
(
[#WindowsRuntimeAndGPL](#WindowsRuntimeAndGPL)) You may link your program to these libraries, and distribute the compiled program to others. When you do this, the runtime libraries are “System Libraries” as GPLv3 defines them. That means that you don't need to worry about including their source code with the program's Corresponding Source. GPLv2 provides a similar exception in section 3.
You may not distribute these libraries in compiled DLL form with the program. To prevent unscrupulous distributors from trying to use the System Library exception as a loophole, the GPL says that libraries can only qualify as System Libraries as long as they're not distributed with the program itself. If you distribute the DLLs with the program, they won't be eligible for this exception anymore; then the only way to comply with the GPL would be to provide their source code, which you are unable to do.
It is possible to write free programs that only run on Windows, but it is not a good idea. These programs would be “
[trapped](/philosophy/java-trap.html)” by Windows, and therefore contribute zero to the Free World.- Why is the original BSD
license incompatible with the GPL?
(
[#OrigBSD](#OrigBSD)) Because it imposes a specific requirement that is not in the GPL; namely, the requirement on advertisements of the program. Section 6 of GPLv2 states:
You may not impose any further restrictions on the recipients' exercise of the rights granted herein.
GPLv3 says something similar in section 10. The advertising clause provides just such a further restriction, and thus is GPL-incompatible.
The revised BSD license does not have the advertising clause, which eliminates the problem.
- When is a program and its plug-ins considered a single combined program?
(
[#GPLPlugins](#GPLPlugins)) It depends on how the main program invokes its plug-ins. If the main program uses fork and exec to invoke plug-ins, and they establish intimate communication by sharing complex data structures, or shipping complex data structures back and forth, that can make them one single combined program. A main program that uses simple fork and exec to invoke plug-ins and does not establish intimate communication between them results in the plug-ins being a separate program.
If the main program dynamically links plug-ins, and they make function calls to each other and share data structures, we believe they form a single combined program, which must be treated as an extension of both the main program and the plug-ins. If the main program dynamically links plug-ins, but the communication between them is limited to invoking the ‘main’ function of the plug-in with some options and waiting for it to return, that is a borderline case.
Using shared memory to communicate with complex data structures is pretty much equivalent to dynamic linking.
- If I write a plug-in to use with a GPL-covered
program, what requirements does that impose on the licenses I can
use for distributing my plug-in?
(
[#GPLAndPlugins](#GPLAndPlugins)) Please see this question
[for determining when plug-ins and a main program are considered a single combined program and when they are considered separate works](#GPLPlugins).If the main program and the plugins are a single combined program then this means you must license the plug-in under the GPL or a GPL-compatible free software license and distribute it with source code in a GPL-compliant way. A main program that is separate from its plug-ins makes no requirements for the plug-ins.
- Can I apply the
GPL when writing a plug-in for a nonfree program?
(
[#GPLPluginsInNF](#GPLPluginsInNF)) Please see this question
[for determining when plug-ins and a main program are considered a single combined program and when they are considered separate programs](#GPLPlugins).If they form a single combined program this means that combination of the GPL-covered plug-in with the nonfree main program would violate the GPL. However, you can resolve that legal problem by adding an exception to your plug-in's license, giving permission to link it with the nonfree main program.
See also the question
[I am writing free software that uses a nonfree library.](#FSWithNFLibs)- Can I release a nonfree program
that's designed to load a GPL-covered plug-in?
(
[#NFUseGPLPlugins](#NFUseGPLPlugins)) Please see this question
[for determining when plug-ins and a main program are considered a single combined program and when they are considered separate programs](#GPLPlugins).If they form a single combined program then the main program must be released under the GPL or a GPL-compatible free software license, and the terms of the GPL must be followed when the main program is distributed for use with these plug-ins.
However, if they are separate works then the license of the plug-in makes no requirements about the main program.
See also the question
[I am writing free software that uses a nonfree library.](#FSWithNFLibs)- You have a GPLed program that I'd like
to link with my code to build a proprietary program. Does the fact
that I link with your program mean I have to GPL my program?
(
[#LinkingWithGPL](#LinkingWithGPL)) Not exactly. It means you must release your program under a license compatible with the GPL (more precisely, compatible with one or more GPL versions accepted by all the rest of the code in the combination that you link). The combination itself is then available under those GPL versions.
- If so, is there
any chance I could get a license of your program under the Lesser GPL?
(
[#SwitchToLGPL](#SwitchToLGPL)) You can ask, but most authors will stand firm and say no. The idea of the GPL is that if you want to include our code in your program, your program must also be free software. It is supposed to put pressure on you to release your program in a way that makes it part of our community.
You always have the legal alternative of not using our code.
- Does distributing a nonfree driver
meant to link with the kernel Linux violate the GPL?
(
[#NonfreeDriverKernelLinux](#NonfreeDriverKernelLinux)) Linux (the kernel in the GNU/Linux operating system) is distributed under GNU GPL version 2. Does distributing a nonfree driver meant to link with Linux violate the GPL?
Yes, this is a violation, because effectively this makes a larger combined work. The fact that the user is expected to put the pieces together does not really change anything.
Each contributor to Linux who holds copyright on a substantial part of the code can enforce the GPL and we encourage each of them to take action against those distributing nonfree Linux-drivers.
- How can I allow linking of
proprietary modules with my GPL-covered library under a controlled
interface only?
(
[#LinkingOverControlledInterface](#LinkingOverControlledInterface)) Add this text to the license notice of each file in the package, at the end of the text that says the file is distributed under the GNU GPL:
Linking ABC statically or dynamically with other modules is making a combined work based on ABC. Thus, the terms and conditions of the GNU General Public License cover the whole combination.
As a special exception, the copyright holders of ABC give you permission to combine ABC program with free software programs or libraries that are released under the GNU LGPL and with independent modules that communicate with ABC solely through the ABCDEF interface. You may copy and distribute such a system following the terms of the GNU GPL for ABC and the licenses of the other code concerned, provided that you include the source code of that other code when and as the GNU GPL requires distribution of source code and provided that you do not modify the ABCDEF interface.
Note that people who make modified versions of ABC are not obligated to grant this special exception for their modified versions; it is their choice whether to do so. The GNU General Public License gives permission to release a modified version without this exception; this exception also makes it possible to release a modified version which carries forward this exception. If you modify the ABCDEF interface, this exception does not apply to your modified version of ABC, and you must remove this exception when you distribute your modified version.
This exception is an additional permission under section 7 of the GNU General Public License, version 3 (“GPLv3”)
This exception enables linking with differently licensed modules over the specified interface (“ABCDEF”), while ensuring that users would still receive source code as they normally would under the GPL.
Only the copyright holders for the program can legally authorize this exception. If you wrote the whole program yourself, then assuming your employer or school does not claim the copyright, you are the copyright holder—so you can authorize the exception. But if you want to use parts of other GPL-covered programs by other authors in your code, you cannot authorize the exception for them. You have to get the approval of the copyright holders of those programs.
- I have written an application that links
with many different components, that have different licenses. I am
very confused as to what licensing requirements are placed on my
program. Can you please tell me what licenses I may use?
(
[#ManyDifferentLicenses](#ManyDifferentLicenses)) To answer this question, we would need to see a list of each component that your program uses, the license of that component, and a brief (a few sentences for each should suffice) describing how your library uses that component. Two examples would be:
- To make my software work, it must be linked to the FOO library, which is available under the Lesser GPL.
- My software makes a system call (with a command line that I built) to run the BAR program, which is licensed under “the GPL, with a special exception allowing for linking with QUUX”.
- What is the difference between an
“aggregate” and other kinds of “modified versions”?
(
[#MereAggregation](#MereAggregation)) An “aggregate” consists of a number of separate programs, distributed together on the same CD-ROM or other media. The GPL permits you to create and distribute an aggregate, even when the licenses of the other software are nonfree or GPL-incompatible. The only condition is that you cannot release the aggregate under a license that prohibits users from exercising rights that each program's individual license would grant them.
Where's the line between two separate programs, and one program with two parts? This is a legal question, which ultimately judges will decide. We believe that a proper criterion depends both on the mechanism of communication (exec, pipes, rpc, function calls within a shared address space, etc.) and the semantics of the communication (what kinds of information are interchanged).
If the modules are included in the same executable file, they are definitely combined in one program. If modules are designed to run linked together in a shared address space, that almost surely means combining them into one program.
By contrast, pipes, sockets and command-line arguments are communication mechanisms normally used between two separate programs. So when they are used for communication, the modules normally are separate programs. But if the semantics of the communication are intimate enough, exchanging complex internal data structures, that too could be a basis to consider the two parts as combined into a larger program.
- When it comes to determining
whether two pieces of software form a single work, does the fact
that the code is in one or more containers have any effect?
(
[#AggregateContainers](#AggregateContainers)) No, the analysis of whether they are a
[single work or an aggregate](#MereAggregation)is unchanged by the involvement of containers.- Why does
the FSF require that contributors to FSF-copyrighted programs assign
copyright to the FSF? If I hold copyright on a GPLed program, should
I do this, too? If so, how?
(
[#AssignCopyright](#AssignCopyright)) Our lawyers have told us that to be in the
[best position to enforce the GPL](/licenses/why-assign.html)in court against violators, we should keep the copyright status of the program as simple as possible. We do this by asking each contributor to either assign the copyright on contributions to the FSF, or disclaim copyright on contributions.We also ask individual contributors to get copyright disclaimers from their employers (if any) so that we can be sure those employers won't claim to own the contributions.
Of course, if all the contributors put their code in the public domain, there is no copyright with which to enforce the GPL. So we encourage people to assign copyright on large code contributions, and only put small changes in the public domain.
If you want to make an effort to enforce the GPL on your program, it is probably a good idea for you to follow a similar policy. Please contact
[<[email protected]>](mailto:[email protected])if you want more information.- Can I modify the GPL
and make a modified license?
(
[#ModifyGPL](#ModifyGPL)) It is possible to make modified versions of the GPL, but it tends to have practical consequences.
You can legally use the GPL terms (possibly modified) in another license provided that you call your license by another name and do not include the GPL preamble, and provided you modify the instructions-for-use at the end enough to make it clearly different in wording and not mention GNU (though the actual procedure you describe may be similar).
If you want to use our preamble in a modified license, please write to
[<[email protected]>](mailto:[email protected])for permission. For this purpose we would want to check the actual license requirements to see if we approve of them.Although we will not raise legal objections to your making a modified license in this way, we hope you will think twice and not do it. Such a modified license is almost certainly
[incompatible with the GNU GPL](#WhatIsCompatible), and that incompatibility blocks useful combinations of modules. The mere proliferation of different free software licenses is a burden in and of itself.Rather than modifying the GPL, please use the exception mechanism offered by GPL version 3.
- If I use a
piece of software that has been obtained under the GNU GPL, am I
allowed to modify the original code into a new program, then
distribute and sell that new program commercially?
(
[#GPLCommercially](#GPLCommercially)) You are allowed to sell copies of the modified program commercially, but only under the terms of the GNU GPL. Thus, for instance, you must make the source code available to the users of the program as described in the GPL, and they must be allowed to redistribute and modify it as described in the GPL.
These requirements are the condition for including the GPL-covered code you received in a program of your own.
- Can I use the GPL for something other than
software?
(
[#GPLOtherThanSoftware](#GPLOtherThanSoftware)) You can apply the GPL to any kind of work, as long as it is clear what constitutes the “source code” for the work. The GPL defines this as the preferred form of the work for making changes in it.
However, for manuals and textbooks, or more generally any sort of work that is meant to teach a subject, we recommend using the GFDL rather than the GPL.
- How does the LGPL work with Java?
(
[#LGPLJava](#LGPLJava)) [See this article for details.](/licenses/lgpl-java.html)It works as designed, intended, and expected.- Consider this situation:
1) X releases V1 of a project under the GPL.
2) Y contributes to the development of V2 with changes and new code
based on V1.
3) X wants to convert V2 to a non-GPL license.
Does X need Y's permission?
(
[#Consider](#Consider)) Yes. Y was required to release its version under the GNU GPL, as a consequence of basing it on X's version V1. Nothing required Y to agree to any other license for its code. Therefore, X must get Y's permission before releasing that code under another license.
- I'd like to incorporate GPL-covered
software in my proprietary system. I have no permission to use
that software except what the GPL gives me. Can I do this?
(
[#GPLInProprietarySystem](#GPLInProprietarySystem)) You cannot incorporate GPL-covered software in a proprietary system. The goal of the GPL is to grant everyone the freedom to copy, redistribute, understand, and modify a program. If you could incorporate GPL-covered software into a nonfree system, it would have the effect of making the GPL-covered software nonfree too.
A system incorporating a GPL-covered program is an extended version of that program. The GPL says that any extended version of the program must be released under the GPL if it is released at all. This is for two reasons: to make sure that users who get the software get the freedom they should have, and to encourage people to give back improvements that they make.
However, in many cases you can distribute the GPL-covered software alongside your proprietary system. To do this validly, you must make sure that the free and nonfree programs communicate at arms length, that they are not combined in a way that would make them effectively a single program.
The difference between this and “incorporating” the GPL-covered software is partly a matter of substance and partly form. The substantive part is this: if the two programs are combined so that they become effectively two parts of one program, then you can't treat them as two separate programs. So the GPL has to cover the whole thing.
If the two programs remain well separated, like the compiler and the kernel, or like an editor and a shell, then you can treat them as two separate programs—but you have to do it properly. The issue is simply one of form: how you describe what you are doing. Why do we care about this? Because we want to make sure the users clearly understand the free status of the GPL-covered software in the collection.
If people were to distribute GPL-covered software calling it “part of” a system that users know is partly proprietary, users might be uncertain of their rights regarding the GPL-covered software. But if they know that what they have received is a free program plus another program, side by side, their rights will be clear.
- Using a certain GNU program under the
GPL does not fit our project to make proprietary software. Will you
make an exception for us? It would mean more users of that program.
(
[#WillYouMakeAnException](#WillYouMakeAnException)) Sorry, we don't make such exceptions. It would not be right.
Maximizing the number of users is not our aim. Rather, we are trying to give the crucial freedoms to as many users as possible. In general, proprietary software projects hinder rather than help the cause of freedom.
We do occasionally make license exceptions to assist a project which is producing free software under a license other than the GPL. However, we have to see a good reason why this will advance the cause of free software.
We also do sometimes change the distribution terms of a package, when that seems clearly the right way to serve the cause of free software; but we are very cautious about this, so you will have to show us very convincing reasons.
- I'd like to incorporate GPL-covered software in
my proprietary system. Can I do this by putting a “wrapper”
module, under a GPL-compatible lax permissive license (such as the X11
license) in between the GPL-covered part and the proprietary part?
(
[#GPLWrapper](#GPLWrapper)) No. The X11 license is compatible with the GPL, so you can add a module to the GPL-covered program and put it under the X11 license. But if you were to incorporate them both in a larger program, that whole would include the GPL-covered part, so it would have to be licensed
*as a whole*under the GNU GPL.The fact that proprietary module A communicates with GPL-covered module C only through X11-licensed module B is legally irrelevant; what matters is the fact that module C is included in the whole.
- Where can I learn more about the GCC
Runtime Library Exception?
(
[#LibGCCException](#LibGCCException)) The GCC Runtime Library Exception covers libgcc, libstdc++, libfortran, libgomp, libdecnumber, and other libraries distributed with GCC. The exception is meant to allow people to distribute programs compiled with GCC under terms of their choice, even when parts of these libraries are included in the executable as part of the compilation process. To learn more, please read our
[FAQ about the GCC Runtime Library Exception](/licenses/gcc-exception-faq.html).- I'd like to
modify GPL-covered programs and link them with the portability
libraries from Money Guzzler Inc. I cannot distribute the source code
for these libraries, so any user who wanted to change these versions
would have to obtain those libraries separately. Why doesn't the
GPL permit this?
(
[#MoneyGuzzlerInc](#MoneyGuzzlerInc)) There are two reasons for this. First, a general one. If we permitted company A to make a proprietary file, and company B to distribute GPL-covered software linked with that file, the effect would be to make a hole in the GPL big enough to drive a truck through. This would be carte blanche for withholding the source code for all sorts of modifications and extensions to GPL-covered software.
Giving all users access to the source code is one of our main goals, so this consequence is definitely something we want to avoid.
More concretely, the versions of the programs linked with the Money Guzzler libraries would not really be free software as we understand the term—they would not come with full source code that enables users to change and recompile the program.
- If the license for a module Q has a
requirement that's incompatible with the GPL,
but the requirement applies only when Q is distributed by itself, not when
Q is included in a larger program, does that make the license
GPL-compatible? Can I combine or link Q with a GPL-covered program?
(
[#GPLIncompatibleAlone](#GPLIncompatibleAlone)) If a program P is released under the GPL that means *any and every part of it* can be used under the GPL. If you integrate module Q, and release the combined program P+Q under the GPL, that means any part of P+Q can be used under the GPL. One part of P+Q is Q. So releasing P+Q under the GPL says that Q any part of it can be used under the GPL. Putting it in other words, a user who obtains P+Q under the GPL can delete P, so that just Q remains, still under the GPL.
If the license of module Q permits you to give permission for that, then it is GPL-compatible. Otherwise, it is not GPL-compatible.
If the license for Q says in no uncertain terms that you must do certain things (not compatible with the GPL) when you redistribute Q on its own, then it does not permit you to distribute Q under the GPL. It follows that you can't release P+Q under the GPL either. So you cannot link or combine P with Q.
- Can I release a modified
version of a GPL-covered program in binary form only?
(
[#ModifiedJustBinary](#ModifiedJustBinary)) No. The whole point of the GPL is that all modified versions must be
[free software](/philosophy/free-sw.html)—which means, in particular, that the source code of the modified version is available to the users.- I
downloaded just the binary from the net. If I distribute copies,
do I have to get the source and distribute that too?
(
[#UnchangedJustBinary](#UnchangedJustBinary)) Yes. The general rule is, if you distribute binaries, you must distribute the complete corresponding source code too. The exception for the case where you received a written offer for source code is quite limited.
- I want to distribute
binaries via physical media without accompanying sources. Can I provide
source code by FTP?
(
[#DistributeWithSourceOnInternet](#DistributeWithSourceOnInternet)) Version 3 of the GPL allows this; see option 6(b) for the full details. Under version 2, you're certainly free to offer source via FTP, and most users will get it from there. However, if any of them would rather get the source on physical media by mail, you are required to provide that.
If you distribute binaries via FTP,
[you should distribute source via FTP.](#AnonFTPAndSendSources)- My friend got a GPL-covered
binary with an offer to supply source, and made a copy for me.
Can I use the offer myself to obtain the source?
(
[#RedistributedBinariesGetSource](#RedistributedBinariesGetSource)) Yes, you can. The offer must be open to everyone who has a copy of the binary that it accompanies. This is why the GPL says your friend must give you a copy of the offer along with a copy of the binary—so you can take advantage of it.
- Can I put the binaries on my
Internet server and put the source on a different Internet site?
(
[#SourceAndBinaryOnDifferentSites](#SourceAndBinaryOnDifferentSites)) Yes. Section 6(d) allows this. However, you must provide clear instructions people can follow to obtain the source, and you must take care to make sure that the source remains available for as long as you distribute the object code.
- I want to distribute an extended
version of a GPL-covered program in binary form. Is it enough to
distribute the source for the original version?
(
[#DistributeExtendedBinary](#DistributeExtendedBinary)) No, you must supply the source code that corresponds to the binary. Corresponding source means the source from which users can rebuild the same binary.
Part of the idea of free software is that users should have access to the source code for
*the programs they use*. Those using your version should have access to the source code for your version.A major goal of the GPL is to build up the Free World by making sure that improvement to a free program are themselves free. If you release an improved version of a GPL-covered program, you must release the improved source code under the GPL.
- I want to distribute
binaries, but distributing complete source is inconvenient. Is it ok if
I give users the diffs from the “standard” version along with
the binaries?
(
[#DistributingSourceIsInconvenient](#DistributingSourceIsInconvenient)) This is a well-meaning request, but this method of providing the source doesn't really do the job.
A user that wants the source a year from now may be unable to get the proper version from another site at that time. The standard distribution site may have a newer version, but the same diffs probably won't work with that version.
So you need to provide complete sources, not just diffs, with the binaries.
- Can I make binaries available
on a network server, but send sources only to people who order them?
(
[#AnonFTPAndSendSources](#AnonFTPAndSendSources)) If you make object code available on a network server, you have to provide the Corresponding Source on a network server as well. The easiest way to do this would be to publish them on the same server, but if you'd like, you can alternatively provide instructions for getting the source from another server, or even a
[version control system](#SourceInCVS). No matter what you do, the source should be just as easy to access as the object code, though. This is all specified in section 6(d) of GPLv3.The sources you provide must correspond exactly to the binaries. In particular, you must make sure they are for the same version of the program—not an older version and not a newer version.
- How can I make sure each
user who downloads the binaries also gets the source?
(
[#HowCanIMakeSureEachDownloadGetsSource](#HowCanIMakeSureEachDownloadGetsSource)) You don't have to make sure of this. As long as you make the source and binaries available so that the users can see what's available and take what they want, you have done what is required of you. It is up to the user whether to download the source.
Our requirements for redistributors are intended to make sure the users can get the source code, not to force users to download the source code even if they don't want it.
- Does the GPL require
me to provide source code that can be built to match the exact
hash of the binary I am distributing?
(
[#MustSourceBuildToMatchExactHashOfBinary](#MustSourceBuildToMatchExactHashOfBinary)) Complete corresponding source means the source that the binaries were made from, but that does not imply your tools must be able to make a binary that is an exact hash of the binary you are distributing. In some cases it could be (nearly) impossible to build a binary from source with an exact hash of the binary being distributed — consider the following examples: a system might put timestamps in binaries; or the program might have been built against a different (even unreleased) compiler version.
- A company
is running a modified version of a GPLed program on a web site.
Does the GPL say they must release their modified sources?
(
[#UnreleasedMods](#UnreleasedMods)) The GPL permits anyone to make a modified version and use it without ever distributing it to others. What this company is doing is a special case of that. Therefore, the company does not have to release the modified sources. The situation is different when the modified program is licensed under the terms of the
[GNU Affero GPL](#UnreleasedModsAGPL).Compare this to a situation where the web site contains or links to separate GPLed programs that are distributed to the user when they visit the web site (often written in
[JavaScript](/philosophy/javascript-trap.html), but other languages are used as well). In this situation the source code for the programs being distributed must be released to the user under the terms of the GPL.- A company is running a modified
version of a program licensed under the GNU Affero GPL (AGPL) on a
web site. Does the AGPL say they must release their modified
sources?
(
[#UnreleasedModsAGPL](#UnreleasedModsAGPL)) The
[GNU Affero GPL](/licenses/agpl.html)requires that modified versions of the software offer all users interacting with it over a computer network an opportunity to receive the source. What the company is doing falls under that meaning, so the company must release the modified source code.- Is making and using multiple copies
within one organization or company “distribution”?
(
[#InternalDistribution](#InternalDistribution)) No, in that case the organization is just making the copies for itself. As a consequence, a company or other organization can develop a modified version and install that version through its own facilities, without giving the staff permission to release that modified version to outsiders.
However, when the organization transfers copies to other organizations or individuals, that is distribution. In particular, providing copies to contractors for use off-site is distribution.
- If someone steals
a CD containing a version of a GPL-covered program, does the GPL
give the thief the right to redistribute that version?
(
[#StolenCopy](#StolenCopy)) If the version has been released elsewhere, then the thief probably does have the right to make copies and redistribute them under the GPL, but if thieves are imprisoned for stealing the CD, they may have to wait until their release before doing so.
If the version in question is unpublished and considered by a company to be its trade secret, then publishing it may be a violation of trade secret law, depending on other circumstances. The GPL does not change that. If the company tried to release its version and still treat it as a trade secret, that would violate the GPL, but if the company hasn't released this version, no such violation has occurred.
- What if a company distributes a copy of
some other developers' GPL-covered work to me as a trade secret?
(
[#TradeSecretRelease](#TradeSecretRelease)) The company has violated the GPL and will have to cease distribution of that program. Note how this differs from the theft case above; the company does not intentionally distribute a copy when a copy is stolen, so in that case the company has not violated the GPL.
- What if a company distributes a copy
of its own GPL-covered work to me as a trade secret?
(
[#TradeSecretRelease2](#TradeSecretRelease2)) If the program distributed does not incorporate anyone else's GPL-covered work, then the company is not violating the GPL (see “
[Is the developer of a GPL-covered program bound by the GPL?](#DeveloperViolate)” for more information). But it is making two contradictory statements about what you can do with that program: that you can redistribute it, and that you can't. It would make sense to demand clarification of the terms for use of that program before you accept a copy.- Why are some GNU libraries released under
the ordinary GPL rather than the Lesser GPL?
(
[#WhySomeGPLAndNotLGPL](#WhySomeGPLAndNotLGPL)) Using the Lesser GPL for any particular library constitutes a retreat for free software. It means we partially abandon the attempt to defend the users' freedom, and some of the requirements to share what is built on top of GPL-covered software. In themselves, those are changes for the worse.
Sometimes a localized retreat is a good strategy. Sometimes, using the LGPL for a library might lead to wider use of that library, and thus to more improvement for it, wider support for free software, and so on. This could be good for free software if it happens to a large extent. But how much will this happen? We can only speculate.
It would be nice to try out the LGPL on each library for a while, see whether it helps, and change back to the GPL if the LGPL didn't help. But this is not feasible. Once we use the LGPL for a particular library, changing back would be difficult.
So we decide which license to use for each library on a case-by-case basis. There is a
[long explanation](/licenses/why-not-lgpl.html)of how we judge the question.- Why should programs say
“Version 3 of the GPL or any later version”?
(
[#VersionThreeOrLater](#VersionThreeOrLater)) From time to time, at intervals of years, we change the GPL—sometimes to clarify it, sometimes to permit certain kinds of use not previously permitted, and sometimes to tighten up a requirement. (The last two changes were in 2007 and 1991.) Using this “indirect pointer” in each program makes it possible for us to change the distribution terms on the entire collection of GNU software, when we update the GPL.
If each program lacked the indirect pointer, we would be forced to discuss the change at length with numerous copyright holders, which would be a virtual impossibility. In practice, the chance of having uniform distribution terms for GNU software would be nil.
Suppose a program says “Version 3 of the GPL or any later version” and a new version of the GPL is released. If the new GPL version gives additional permission, that permission will be available immediately to all the users of the program. But if the new GPL version has a tighter requirement, it will not restrict use of the current version of the program, because it can still be used under GPL version 3. When a program says “Version 3 of the GPL or any later version”, users will always be permitted to use it, and even change it, according to the terms of GPL version 3—even after later versions of the GPL are available.
If a tighter requirement in a new version of the GPL need not be obeyed for existing software, how is it useful? Once GPL version 4 is available, the developers of most GPL-covered programs will release subsequent versions of their programs specifying “Version 4 of the GPL or any later version”. Then users will have to follow the tighter requirements in GPL version 4, for subsequent versions of the program.
However, developers are not obligated to do this; developers can continue allowing use of the previous version of the GPL, if that is their preference.
- Is it a good idea to use a license saying
that a certain program can be used only under the latest version
of the GNU GPL?
(
[#OnlyLatestVersion](#OnlyLatestVersion)) The reason you shouldn't do that is that it could result some day in withdrawing automatically some permissions that the users previously had.
Suppose a program was released in 2000 under “the latest GPL version”. At that time, people could have used it under GPLv2. The day we published GPLv3 in 2007, everyone would have been suddenly compelled to use it under GPLv3 instead.
Some users may not even have known about GPL version 3—but they would have been required to use it. They could have violated the program's license unintentionally just because they did not get the news. That's a bad way to treat people.
We think it is wrong to take back permissions already granted, except due to a violation. If your freedom could be revoked, then it isn't really freedom. Thus, if you get a copy of a program version under one version of a license, you should
*always*have the rights granted by that version of the license. Releasing under “GPL version N or any later version” upholds that principle.- Why don't you use the GPL for manuals?
(
[#WhyNotGPLForManuals](#WhyNotGPLForManuals)) It is possible to use the GPL for a manual, but the GNU Free Documentation License (GFDL) is much better for manuals.
The GPL was designed for programs; it contains lots of complex clauses that are crucial for programs, but that would be cumbersome and unnecessary for a book or manual. For instance, anyone publishing the book on paper would have to either include machine-readable “source code” of the book along with each printed copy, or provide a written offer to send the “source code” later.
Meanwhile, the GFDL has clauses that help publishers of free manuals make a profit from selling copies—cover texts, for instance. The special rules for Endorsements sections make it possible to use the GFDL for an official standard. This would permit modified versions, but they could not be labeled as “the standard”.
Using the GFDL, we permit changes in the text of a manual that covers its technical topic. It is important to be able to change the technical parts, because people who change a program ought to change the documentation to correspond. The freedom to do this is an ethical imperative.
Our manuals also include sections that state our political position about free software. We mark these as “invariant”, so that they cannot be changed or removed. The GFDL makes provisions for these “invariant sections”.
- How does the GPL apply to fonts?
(
[#FontException](#FontException)) Font licensing is a complex issue which needs serious consideration. The following license exception is experimental but approved for general use. We welcome suggestions on this subject—please see this this
[explanatory essay](http://www.fsf.org/blogs/licensing/20050425novalis)and write to[[email protected]](mailto:[email protected]).To use this exception, add this text to the license notice of each file in the package (to the extent possible), at the end of the text that says the file is distributed under the GNU GPL:
As a special exception, if you create a document which uses this font, and embed this font or unaltered portions of this font into the document, this font does not by itself cause the resulting document to be covered by the GNU General Public License. This exception does not however invalidate any other reasons why the document might be covered by the GNU General Public License. If you modify this font, you may extend this exception to your version of the font, but you are not obligated to do so. If you do not wish to do so, delete this exception statement from your version.
- I am writing a website maintenance system
(called a “
[content management system](/philosophy/words-to-avoid.html#Content)” by some), or some other application which generates web pages from templates. What license should I use for those templates? ([#WMS](#WMS)) Templates are minor enough that it is not worth using copyleft to protect them. It is normally harmless to use copyleft on minor works, but templates are a special case, because they are combined with data provided by users of the application and the combination is distributed. So, we recommend that you license your templates under simple permissive terms.
Some templates make calls into JavaScript functions. Since Javascript is often non-trivial, it is worth copylefting. Because the templates will be combined with user data, it's possible that template+user data+JavaScript would be considered one work under copyright law. A line needs to be drawn between the JavaScript (copylefted), and the user code (usually under incompatible terms).
Here's an exception for JavaScript code that does this:
As a special exception to the GPL, any HTML file which merely makes function calls to this code, and for that purpose includes it by reference shall be deemed a separate work for copyright law purposes. In addition, the copyright holders of this code give you permission to combine this code with free software libraries that are released under the GNU LGPL. You may copy and distribute such a system following the terms of the GNU GPL for this code and the LGPL for the libraries. If you modify this code, you may extend this exception to your version of the code, but you are not obligated to do so. If you do not wish to do so, delete this exception statement from your version.
- Can I release
a program under the GPL which I developed using nonfree tools?
(
[#NonFreeTools](#NonFreeTools)) Which programs you used to edit the source code, or to compile it, or study it, or record it, usually makes no difference for issues concerning the licensing of that source code.
However, if you link nonfree libraries with the source code, that would be an issue you need to deal with. It does not preclude releasing the source code under the GPL, but if the libraries don't fit under the “system library” exception, you should affix an explicit notice giving permission to link your program with them.
[The FAQ entry about using GPL-incompatible libraries](#GPLIncompatibleLibs)provides more information about how to do that.- Are there translations
of the GPL into other languages?
(
[#GPLTranslations](#GPLTranslations)) It would be useful to have translations of the GPL into languages other than English. People have even written translations and sent them to us. But we have not dared to approve them as officially valid. That carries a risk so great we do not dare accept it.
A legal document is in some ways like a program. Translating it is like translating a program from one language and operating system to another. Only a lawyer skilled in both languages can do it—and even then, there is a risk of introducing a bug.
If we were to approve, officially, a translation of the GPL, we would be giving everyone permission to do whatever the translation says they can do. If it is a completely accurate translation, that is fine. But if there is an error in the translation, the results could be a disaster which we could not fix.
If a program has a bug, we can release a new version, and eventually the old version will more or less disappear. But once we have given everyone permission to act according to a particular translation, we have no way of taking back that permission if we find, later on, that it had a bug.
Helpful people sometimes offer to do the work of translation for us. If the problem were a matter of finding someone to do the work, this would solve it. But the actual problem is the risk of error, and offering to do the work does not avoid the risk. We could not possibly authorize a translation written by a non-lawyer.
Therefore, for the time being, we are not approving translations of the GPL as globally valid and binding. Instead, we are doing two things:
Referring people to unofficial translations. This means that we permit people to write translations of the GPL, but we don't approve them as legally valid and binding.
An unapproved translation has no legal force, and it should say so explicitly. It should be marked as follows:
This translation of the GPL is informal, and not officially approved by the Free Software Foundation as valid. To be completely sure of what is permitted, refer to the original GPL (in English).
But the unapproved translation can serve as a hint for how to understand the English GPL. For many users, that is sufficient.
However, businesses using GNU software in commercial activity, and people doing public ftp distribution, should need to check the real English GPL to make sure of what it permits.
Publishing translations valid for a single country only.
We are considering the idea of publishing translations which are officially valid only for one country. This way, if there is a mistake, it will be limited to that country, and the damage will not be too great.
It will still take considerable expertise and effort from a sympathetic and capable lawyer to make a translation, so we cannot promise any such translations soon.
- If a programming language interpreter has a
license that is incompatible with the GPL, can I run GPL-covered
programs on it?
(
[#InterpreterIncompat](#InterpreterIncompat)) When the interpreter just interprets a language, the answer is yes. The interpreted program, to the interpreter, is just data; the GPL doesn't restrict what tools you process the program with.
However, when the interpreter is extended to provide “bindings” to other facilities (often, but not necessarily, libraries), the interpreted program is effectively linked to the facilities it uses through these bindings. The JNI or Java Native Interface is an example of such a facility; libraries that are accessed in this way are linked dynamically with the Java programs that call them.
So if these facilities are released under a GPL-incompatible license, the situation is like linking in any other way with a GPL-incompatible library. Which implies that:
- If you are writing code and releasing it under the GPL, you can state an explicit exception giving permission to link it with those GPL-incompatible facilities.
- If you wrote and released the program under the GPL, and you designed it specifically to work with those facilities, people can take that as an implicit exception permitting them to link it with those facilities. But if that is what you intend, it is better to say so explicitly.
- You can't take someone else's GPL-covered code and use it that way, or add such exceptions to it. Only the copyright holders of that code can add the exception.
- Who has the power to enforce the GPL?
(
[#WhoHasThePower](#WhoHasThePower)) Since the GPL is a copyright license, it can be enforced by the copyright holders of the software. If you see a violation of the GPL, you should inform the developers of the GPL-covered software involved. They either are the copyright holders, or are connected with the copyright holders.
In addition, we encourage the use of any legal mechanism available to users for obtaining complete and corresponding source code, as is their right, and enforcing full compliance with the GNU GPL. After all, we developed the GNU GPL to make software free for all its users.
- In an object-oriented language such as Java,
if I use a class that is GPLed without modifying, and subclass it,
in what way does the GPL affect the larger program?
(
[#OOPLang](#OOPLang)) Subclassing is creating a derivative work. Therefore, the terms of the GPL affect the whole program where you create a subclass of a GPLed class.
- If I port my program to GNU/Linux,
does that mean I have to release it as free software under the GPL
or some other Free Software license?
(
[#PortProgramToGPL](#PortProgramToGPL)) In general, the answer is no—this is not a legal requirement. In specific, the answer depends on which libraries you want to use and what their licenses are. Most system libraries either use the
[GNU Lesser GPL](/licenses/lgpl.html), or use the GNU GPL plus an exception permitting linking the library with anything. These libraries can be used in nonfree programs; but in the case of the Lesser GPL, it does have some requirements you must follow.Some libraries are released under the GNU GPL alone; you must use a GPL-compatible license to use those libraries. But these are normally the more specialized libraries, and you would not have had anything much like them on another platform, so you probably won't find yourself wanting to use these libraries for simple porting.
Of course, your software is not a contribution to our community if it is not free, and people who value their freedom will refuse to use it. Only people willing to give up their freedom will use your software, which means that it will effectively function as an inducement for people to lose their freedom.
If you hope some day to look back on your career and feel that it has contributed to the growth of a good and free society, you need to make your software free.
- I just found out that a company has a
copy of a GPLed program, and it costs money to get it. Aren't they
violating the GPL by not making it available on the Internet?
(
[#CompanyGPLCostsMoney](#CompanyGPLCostsMoney)) No. The GPL does not require anyone to use the Internet for distribution. It also does not require anyone in particular to redistribute the program. And (outside of one special case), even if someone does decide to redistribute the program sometimes, the GPL doesn't say he has to distribute a copy to you in particular, or any other person in particular.
What the GPL requires is that he must have the freedom to distribute a copy to you
*if he wishes to*. Once the copyright holder does distribute a copy of the program to someone, that someone can then redistribute the program to you, or to anyone else, as he sees fit.- Can I release a program with a license which
says that you can distribute modified versions of it under the GPL
but you can't distribute the original itself under the GPL?
(
[#ReleaseNotOriginal](#ReleaseNotOriginal)) No. Such a license would be self-contradictory. Let's look at its implications for me as a user.
Suppose I start with the original version (call it version A), add some code (let's imagine it is 1000 lines), and release that modified version (call it B) under the GPL. The GPL says anyone can change version B again and release the result under the GPL. So I (or someone else) can delete those 1000 lines, producing version C which has the same code as version A but is under the GPL.
If you try to block that path, by saying explicitly in the license that I'm not allowed to reproduce something identical to version A under the GPL by deleting those lines from version B, in effect the license now says that I can't fully use version B in all the ways that the GPL permits. In other words, the license does not in fact allow a user to release a modified version such as B under the GPL.
- Does moving a copy to a majority-owned,
and controlled, subsidiary constitute distribution?
(
[#DistributeSubsidiary](#DistributeSubsidiary)) Whether moving a copy to or from this subsidiary constitutes “distribution” is a matter to be decided in each case under the copyright law of the appropriate jurisdiction. The GPL does not and cannot override local laws. US copyright law is not entirely clear on the point, but appears not to consider this distribution.
If, in some country, this is considered distribution, and the subsidiary must receive the right to redistribute the program, that will not make a practical difference. The subsidiary is controlled by the parent company; rights or no rights, it won't redistribute the program unless the parent company decides to do so.
- Can software installers ask people
to click to agree to the GPL? If I get some software under the GPL,
do I have to agree to anything?
(
[#ClickThrough](#ClickThrough)) Some software packaging systems have a place which requires you to click through or otherwise indicate assent to the terms of the GPL. This is neither required nor forbidden. With or without a click through, the GPL's rules remain the same.
Merely agreeing to the GPL doesn't place any obligations on you. You are not required to agree to anything to merely use software which is licensed under the GPL. You only have obligations if you modify or distribute the software. If it really bothers you to click through the GPL, nothing stops you from hacking the GPLed software to bypass this.
- I would
like to bundle GPLed software with some sort of installation software.
Does that installer need to have a GPL-compatible license?
(
[#GPLCompatInstaller](#GPLCompatInstaller)) No. The installer and the files it installs are separate works. As a result, the terms of the GPL do not apply to the installation software.
- Some distributors of GPLed software
require me in their umbrella EULAs or as part of their downloading
process to “represent and warrant” that I am located in
the US or that I intend to distribute the software in compliance with
relevant export control laws. Why are they doing this and is it a
violation of those distributors' obligations under GPL?
(
[#ExportWarranties](#ExportWarranties)) This is not a violation of the GPL. Those distributors (almost all of whom are commercial businesses selling free software distributions and related services) are trying to reduce their own legal risks, not to control your behavior. Export control law in the United States
*might*make them liable if they knowingly export software into certain countries, or if they give software to parties they know will make such exports. By asking for these statements from their customers and others to whom they distribute software, they protect themselves in the event they are later asked by regulatory authorities what they knew about where software they distributed was going to wind up. They are not restricting what you can do with the software, only preventing themselves from being blamed with respect to anything you do. Because they are not placing additional restrictions on the software, they do not violate section 10 of GPLv3 or section 6 of GPLv2.The FSF opposes the application of US export control laws to free software. Not only are such laws incompatible with the general objective of software freedom, they achieve no reasonable governmental purpose, because free software is currently and should always be available from parties in almost every country, including countries that have no export control laws and which do not participate in US-led trade embargoes. Therefore, no country's government is actually deprived of free software by US export control laws, while no country's citizens
*should*be deprived of free software, regardless of their governments' policies, as far as we are concerned. Copies of all GPL-licensed software published by the FSF can be obtained from us without making any representation about where you live or what you intend to do. At the same time, the FSF understands the desire of commercial distributors located in the US to comply with US laws. They have a right to choose to whom they distribute particular copies of free software; exercise of that right does not violate the GPL unless they add contractual restrictions beyond those permitted by the GPL.- Can I use
GPLed software on a device that will stop operating if customers do
not continue paying a subscription fee?
(
[#SubscriptionFee](#SubscriptionFee)) No. In this scenario, the requirement to keep paying a fee limits the user's ability to run the program. This is an additional requirement on top of the GPL, and the license prohibits it.
- How do I upgrade from (L)GPLv2 to (L)GPLv3?
(
[#v3HowToUpgrade](#v3HowToUpgrade)) First, include the new version of the license in your package. If you're using LGPLv3 in your project, be sure to include copies of both GPLv3 and LGPLv3, since LGPLv3 is now written as a set of additional permissions on top of GPLv3.
Second, replace all your existing v2 license notices (usually at the top of each file) with the new recommended text available on
[the GNU licenses howto](/licenses/gpl-howto.html). It's more future-proof because it no longer includes the FSF's postal mailing address.Of course, any descriptive text (such as in a README) which talks about the package's license should also be updated appropriately.
- How does GPLv3 make BitTorrent distribution easier?
(
[#BitTorrent](#BitTorrent)) Because GPLv2 was written before peer-to-peer distribution of software was common, it is difficult to meet its requirements when you share code this way. The best way to make sure you are in compliance when distributing GPLv2 object code on BitTorrent would be to include all the corresponding source in the same torrent, which is prohibitively expensive.
GPLv3 addresses this problem in two ways. First, people who download this torrent and send the data to others as part of that process are not required to do anything. That's because section 9 says “Ancillary propagation of a covered work occurring solely as a consequence of using peer-to-peer transmission to receive a copy likewise does not require acceptance [of the license].”
Second, section 6(e) of GPLv3 is designed to give distributors—people who initially seed torrents—a clear and straightforward way to provide the source, by telling recipients where it is available on a public network server. This ensures that everyone who wants to get the source can do so, and it's almost no hassle for the distributor.
- What is tivoization? How does GPLv3 prevent it?
(
[#Tivoization](#Tivoization)) Some devices utilize free software that can be upgraded, but are designed so that users are not allowed to modify that software. There are lots of different ways to do this; for example, sometimes the hardware checksums the software that is installed, and shuts down if it doesn't match an expected signature. The manufacturers comply with GPLv2 by giving you the source code, but you still don't have the freedom to modify the software you're using. We call this practice tivoization.
When people distribute User Products that include software under GPLv3, section 6 requires that they provide you with information necessary to modify that software. User Products is a term specially defined in the license; examples of User Products include portable music players, digital video recorders, and home security systems.
- Does GPLv3 prohibit DRM?
(
[#DRMProhibited](#DRMProhibited)) It does not; you can use code released under GPLv3 to develop any kind of DRM technology you like. However, if you do this, section 3 says that the system will not count as an effective technological “protection” measure, which means that if someone breaks the DRM, she will be free to distribute her software too, unhindered by the DMCA and similar laws.
As usual, the GNU GPL does not restrict what people do in software, it just stops them from restricting others.
- Can I use the GPL to license hardware?
(
[#GPLHardware](#GPLHardware)) Any material that can be copyrighted can be licensed under the GPL. GPLv3 can also be used to license materials covered by other copyright-like laws, such as semiconductor masks. So, as an example, you can release a drawing of a physical object or circuit under the GPL.
In many situations, copyright does not cover making physical hardware from a drawing. In these situations, your license for the drawing simply can't exert any control over making or selling physical hardware, regardless of the license you use. When copyright does cover making hardware, for instance with IC masks, the GPL handles that case in a useful way.
- I use public key cryptography to sign my code to
assure its authenticity. Is it true that GPLv3 forces me to release
my private signing keys?
(
[#GiveUpKeys](#GiveUpKeys)) No. The only time you would be required to release signing keys is if you conveyed GPLed software inside a User Product, and its hardware checked the software for a valid cryptographic signature before it would function. In that specific case, you would be required to provide anyone who owned the device, on demand, with the key to sign and install modified software on the device so that it will run. If each instance of the device uses a different key, then you need only give each purchaser a key for that instance.
- Does GPLv3 require that voters be able to
modify the software running in a voting machine?
(
[#v3VotingMachine](#v3VotingMachine)) No. Companies distributing devices that include software under GPLv3 are at most required to provide the source and Installation Information for the software to people who possess a copy of the object code. The voter who uses a voting machine (like any other kiosk) doesn't get possession of it, not even temporarily, so the voter also does not get possession of the binary software in it.
Note, however, that voting is a very special case. Just because the software in a computer is free does not mean you can trust the computer for voting. We believe that computers cannot be trusted for voting. Voting should be done on paper.
- Does GPLv3 have a “patent retaliation
clause”?
(
[#v3PatentRetaliation](#v3PatentRetaliation)) In effect, yes. Section 10 prohibits people who convey the software from filing patent suits against other licensees. If someone did so anyway, section 8 explains how they would lose their license and any patent licenses that accompanied it.
- Can I use snippets of GPL-covered
source code within documentation that is licensed under some license
that is incompatible with the GPL?
(
[#SourceCodeInDocumentation](#SourceCodeInDocumentation)) If the snippets are small enough that you can incorporate them under fair use or similar laws, then yes. Otherwise, no.
- The beginning of GPLv3 section 6 says that I can
convey a covered work in object code form “under the terms of
sections 4 and 5” provided I also meet the conditions of
section 6. What does that mean?
(
[#v3Under4and5](#v3Under4and5)) This means that all the permissions and conditions you have to convey source code also apply when you convey object code: you may charge a fee, you must keep copyright notices intact, and so on.
- My company owns a lot of patents.
Over the years we've contributed code to projects under “GPL
version 2 or any later version”, and the project itself has
been distributed under the same terms. If a user decides to take the
project's code (incorporating my contributions) under GPLv3, does
that mean I've automatically granted GPLv3's explicit patent license
to that user?
(
[#v2OrLaterPatentLicense](#v2OrLaterPatentLicense)) No. When you convey GPLed software, you must follow the terms and conditions of one particular version of the license. When you do so, that version defines the obligations you have. If users may also elect to use later versions of the GPL, that's merely an additional permission they have—it does not require you to fulfill the terms of the later version of the GPL as well.
Do not take this to mean that you can threaten the community with your patents. In many countries, distributing software under GPLv2 provides recipients with an implicit patent license to exercise their rights under the GPL. Even if it didn't, anyone considering enforcing their patents aggressively is an enemy of the community, and we will defend ourselves against such an attack.
- If I distribute a proprietary
program that links against an LGPLv3-covered library that I've
modified, what is the “contributor version” for purposes of
determining the scope of the explicit patent license grant I'm
making—is it just the library, or is it the whole
combination?
(
[#LGPLv3ContributorVersion](#LGPLv3ContributorVersion)) The “contributor version” is only your version of the library.
- Is GPLv3 compatible with GPLv2?
(
[#v2v3Compatibility](#v2v3Compatibility)) No. Many requirements have changed from GPLv2 to GPLv3, which means that the precise requirement of GPLv2 is not present in GPLv3, and vice versa. For instance, the Termination conditions of GPLv3 are considerably more permissive than those of GPLv2, and thus different from the Termination conditions of GPLv2.
Due to these differences, the two licenses are not compatible: if you tried to combine code released under GPLv2 with code under GPLv3, you would violate section 6 of GPLv2.
However, if code is released under GPL “version 2 or later,” that is compatible with GPLv3 because GPLv3 is one of the options it permits.
- Does GPLv2 have a requirement about delivering installation
information?
(
[#InstInfo](#InstInfo)) GPLv3 explicitly requires redistribution to include the full necessary “Installation Information.” GPLv2 doesn't use that term, but it does require redistribution to include
scripts used to control compilation and installation of the executable
with the complete and corresponding source code. This covers part, but not all, of what GPLv3 calls “Installation Information.” Thus, GPLv3's requirement about installation information is stronger.- What does it mean to “cure” a violation of GPLv3?
(
[#Cure](#Cure)) To cure a violation means to adjust your practices to comply with the requirements of the license.
- The warranty and liability
disclaimers in GPLv3 seem specific to U.S. law. Can I add my own
disclaimers to my own code?
(
[#v3InternationalDisclaimers](#v3InternationalDisclaimers)) Yes. Section 7 gives you permission to add your own disclaimers, specifically 7(a).
- My program has interactive user
interfaces that are non-visual in nature. How can I comply with the
Appropriate Legal Notices requirement in GPLv3?
(
[#NonvisualLegalNotices](#NonvisualLegalNotices)) All you need to do is ensure that the Appropriate Legal Notices are readily available to the user in your interface. For example, if you have written an audio interface, you could include a command that reads the notices aloud.
- If I give a copy of a GPLv3-covered
program to a coworker at my company, have I “conveyed” the
copy to that coworker?
(
[#v3CoworkerConveying](#v3CoworkerConveying)) As long as you're both using the software in your work at the company, rather than personally, then the answer is no. The copies belong to the company, not to you or the coworker. This copying is propagation, not conveying, because the company is not making copies available to others.
- If I distribute a GPLv3-covered
program, can I provide a warranty that is voided if the user modifies
the program?
(
[#v3ConditionalWarranty](#v3ConditionalWarranty)) Yes. Just as devices do not need to be warranted if users modify the software inside them, you are not required to provide a warranty that covers all possible activities someone could undertake with GPLv3-covered software.
- Why did you decide to write the GNU Affero GPLv3
as a separate license?
(
[#SeparateAffero](#SeparateAffero)) Early drafts of GPLv3 allowed licensors to add an Affero-like requirement to publish source in section 7. However, some companies that develop and rely upon free software consider this requirement to be too burdensome. They want to avoid code with this requirement, and expressed concern about the administrative costs of checking code for this additional requirement. By publishing the GNU Affero GPLv3 as a separate license, with provisions in it and GPLv3 to allow code under these licenses to link to each other, we accomplish all of our original goals while making it easier to determine which code has the source publication requirement.
- Why did you invent the new terms
“propagate” and “convey” in GPLv3?
(
[#WhyPropagateAndConvey](#WhyPropagateAndConvey)) The term “distribute” used in GPLv2 was borrowed from United States copyright law. Over the years, we learned that some jurisdictions used this same word in their own copyright laws, but gave it different meanings. We invented these new terms to make our intent as clear as possible no matter where the license is interpreted. They are not used in any copyright law in the world, and we provide their definitions directly in the license.
- I'd like to license my code under the GPL, but I'd
also like to make it clear that it can't be used for military and/or
commercial uses. Can I do this?
(
[#NoMilitary](#NoMilitary)) No, because those two goals contradict each other. The GNU GPL is designed specifically to prevent the addition of further restrictions. GPLv3 allows a very limited set of them, in section 7, but any other added restriction can be removed by the user.
More generally, a license that limits who can use a program, or for what, is
[not a free software license](/philosophy/programs-must-not-limit-freedom-to-run.html).- Is “convey” in GPLv3 the same
thing as what GPLv2 means by “distribute”?
(
[#ConveyVsDistribute](#ConveyVsDistribute)) Yes, more or less. During the course of enforcing GPLv2, we learned that some jurisdictions used the word “distribute” in their own copyright laws, but gave it different meanings. We invented a new term to make our intent clear and avoid any problems that could be caused by these differences.
- GPLv3 gives “making available to the
public” as an example of propagation. What does this mean?
Is making available a form of conveying?
(
[#v3MakingAvailable](#v3MakingAvailable)) One example of “making available to the public” is putting the software on a public web or FTP server. After you do this, some time may pass before anybody actually obtains the software from you—but because it could happen right away, you need to fulfill the GPL's obligations right away as well. Hence, we defined conveying to include this activity.
- Since distribution and making
available to the public are forms of propagation that are also
conveying in GPLv3, what are some examples of propagation that do not
constitute conveying?
(
[#PropagationNotConveying](#PropagationNotConveying)) Making copies of the software for yourself is the main form of propagation that is not conveying. You might do this to install the software on multiple computers, or to make backups.
- Does prelinking a
GPLed binary to various libraries on the system, to optimize its
performance, count as modification?
(
[#Prelinking](#Prelinking)) No. Prelinking is part of a compilation process; it doesn't introduce any license requirements above and beyond what other aspects of compilation would. If you're allowed to link the program to the libraries at all, then it's fine to prelink with them as well. If you distribute prelinked object code, you need to follow the terms of section 6.
- If someone installs GPLed software on a laptop, and
then lends that laptop to a friend without providing source code for
the software, have they violated the GPL?
(
[#LaptopLoan](#LaptopLoan)) No. In the jurisdictions where we have investigated this issue, this sort of loan would not count as conveying. The laptop's owner would not have any obligations under the GPL.
- Suppose that two companies try to
circumvent the requirement to provide Installation Information by
having one company release signed software, and the other release a
User Product that only runs signed software from the first company. Is
this a violation of GPLv3?
(
[#TwoPartyTivoization](#TwoPartyTivoization)) Yes. If two parties try to work together to get around the requirements of the GPL, they can both be pursued for copyright infringement. This is especially true since the definition of convey explicitly includes activities that would make someone responsible for secondary infringement.
- Am I complying with GPLv3 if I offer binaries on an
FTP server and sources by way of a link to a source code repository
in a version control system, like CVS or Subversion?
(
[#SourceInCVS](#SourceInCVS)) This is acceptable as long as the source checkout process does not become burdensome or otherwise restrictive. Anybody who can download your object code should also be able to check out source from your version control system, using a publicly available free software client. Users should be provided with clear and convenient instructions for how to get the source for the exact object code they downloaded—they may not necessarily want the latest development code, after all.
- Can someone who conveys GPLv3-covered
software in a User Product use remote attestation to prevent a user
from modifying that software?
(
[#RemoteAttestation](#RemoteAttestation)) No. The definition of Installation Information, which must be provided with source when the software is conveyed inside a User Product, explicitly says: “The information must suffice to ensure that the continued functioning of the modified object code is in no case prevented or interfered with solely because modification has been made.” If the device uses remote attestation in some way, the Installation Information must provide you some means for your modified software to report itself as legitimate.
- What does “rules and protocols for
communication across the network” mean in GPLv3?
(
[#RulesProtocols](#RulesProtocols)) This refers to rules about traffic you can send over the network. For example, if there is a limit on the number of requests you can send to a server per day, or the size of a file you can upload somewhere, your access to those resources may be denied if you do not respect those limits.
These rules do not include anything that does not pertain directly to data traveling across the network. For instance, if a server on the network sent messages for users to your device, your access to the network could not be denied merely because you modified the software so that it did not display the messages.
- Distributors that provide Installation Information
under GPLv3 are not required to provide “support service”
for the product. What kind of “support service”do you mean?
(
[#SupportService](#SupportService)) This includes the kind of service many device manufacturers provide to help you install, use, or troubleshoot the product. If a device relies on access to web services or similar technology to function properly, those should normally still be available to modified versions, subject to the terms in section 6 regarding access to a network.
- In GPLv3 and AGPLv3, what does it mean when it
says “notwithstanding any other provision of this License”?
(
[#v3Notwithstanding](#v3Notwithstanding)) This simply means that the following terms prevail over anything else in the license that may conflict with them. For example, without this text, some people might have claimed that you could not combine code under GPLv3 with code under AGPLv3, because the AGPL's additional requirements would be classified as “further restrictions” under section 7 of GPLv3. This text makes clear that our intended interpretation is the correct one, and you can make the combination.
This text only resolves conflicts between different terms of the license. When there is no conflict between two conditions, then you must meet them both. These paragraphs don't grant you carte blanche to ignore the rest of the license—instead they're carving out very limited exceptions.
- Under AGPLv3, when I modify the Program
under section 13, what Corresponding Source does it have to offer?
(
[#AGPLv3CorrespondingSource](#AGPLv3CorrespondingSource)) “Corresponding Source” is defined in section 1 of the license, and you should provide what it lists. So, if your modified version depends on libraries under other licenses, such as the Expat license or GPLv3, the Corresponding Source should include those libraries (unless they are System Libraries). If you have modified those libraries, you must provide your modified source code for them.
The last sentence of the first paragraph of section 13 is only meant to reinforce what most people would have naturally assumed: even though combinations with code under GPLv3 are handled through a special exception in section 13, the Corresponding Source should still include the code that is combined with the Program this way. This sentence does not mean that you
*only*have to provide the source that's covered under GPLv3; instead it means that such code is*not*excluded from the definition of Corresponding Source.- In AGPLv3, what counts as
“interacting with [the software] remotely through a computer
network?”
(
[#AGPLv3InteractingRemotely](#AGPLv3InteractingRemotely)) If the program is expressly designed to accept user requests and send responses over a network, then it meets these criteria. Common examples of programs that would fall into this category include web and mail servers, interactive web-based applications, and servers for games that are played online.
If a program is not expressly designed to interact with a user through a network, but is being run in an environment where it happens to do so, then it does not fall into this category. For example, an application is not required to provide source merely because the user is running it over SSH, or a remote X session.
- How does GPLv3's concept of
“you” compare to the definition of “Legal Entity”
in the Apache License 2.0?
(
[#ApacheLegalEntity](#ApacheLegalEntity)) They're effectively identical. The definition of “Legal Entity” in the Apache License 2.0 is very standard in various kinds of legal agreements—so much so that it would be very surprising if a court did not interpret the term in the same way in the absence of an explicit definition. We fully expect them to do the same when they look at GPLv3 and consider who qualifies as a licensee.
- In GPLv3, what does “the Program”
refer to? Is it every program ever released under GPLv3?
(
[#v3TheProgram](#v3TheProgram)) The term “the Program” means one particular work that is licensed under GPLv3 and is received by a particular licensee from an upstream licensor or distributor. The Program is the particular work of software that you received in a given instance of GPLv3 licensing, as you received it.
“The Program” cannot mean “all the works ever licensed under GPLv3”; that interpretation makes no sense for a number of reasons. We've published an
[analysis of the term “the Program”](/licenses/gplv3-the-program.html)for those who would like to learn more about this.- If I only make copies of a
GPL-covered program and run them, without distributing or conveying them to
others, what does the license require of me?
(
[#NoDistributionRequirements](#NoDistributionRequirements)) Nothing. The GPL does not place any conditions on this activity.
- If some network client software is
released under AGPLv3, does it have to be able to provide source to
the servers it interacts with?
(
[#AGPLv3ServerAsUser](#AGPLv3ServerAsUser)) -
AGPLv3 requires a program to offer source code to “all users interacting with it remotely through a computer network.” It doesn't matter if you call the program a “client” or a “server,” the question you need to ask is whether or not there is a reasonable expectation that a person will be interacting with the program remotely over a network.
- For software that runs a proxy server licensed
under the AGPL, how can I provide an offer of source to users
interacting with that code?
(
[#AGPLProxy](#AGPLProxy)) For software on a proxy server, you can provide an offer of source through a normal method of delivering messages to users of that kind of proxy. For example, a Web proxy could use a landing page. When users initially start using the proxy, you can direct them to a page with the offer of source along with any other information you choose to provide.
The AGPL says you must make the offer to “all users.” If you know that a certain user has already been shown the offer, for the current version of the software, you don't have to repeat it to that user again.
- How are the various GNU licenses
compatible with each other?
(
[#AllCompatibility](#AllCompatibility)) The various GNU licenses enjoy broad compatibility between each other. The only time you may not be able to combine code under two of these licenses is when you want to use code that's
*only*under an older version of a license with code that's under a newer version.Below is a detailed compatibility matrix for various combinations of the GNU licenses, to provide an easy-to-use reference for specific cases. It assumes that someone else has written some software under one of these licenses, and you want to somehow incorporate code from that into a project that you're releasing (either your own original work, or a modified version of someone else's software). Find the license for your project in a column at the top of the table, and the license for the other code in a row on the left. The cell where they meet will tell you whether or not this combination is permitted.
When we say “copy code,” we mean just that: you're taking a section of code from one source, with or without modification, and inserting it into your own program, thus forming a work based on the first section of code. “Use a library” means that you're not copying any source directly, but instead interacting with it through linking, importing, or other typical mechanisms that bind the sources together when you compile or run the code.
Each place that the matrix states GPLv3, the same statement about compatibility is true for AGPLv3 as well.
I want to license my code under: | |||||||
---|---|---|---|---|---|---|---|
GPLv2 only | GPLv2 or later | GPLv3 or later | LGPLv2.1 only | LGPLv2.1 or later | LGPLv3 or later | ||
I want to copy code under: | GPLv2 only | OK | OK
|
[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[2]](#compat-matrix-footnote-2)[[1]](#compat-matrix-footnote-1)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[3]](#compat-matrix-footnote-3)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[6]](#compat-matrix-footnote-6)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[7]](#compat-matrix-footnote-7)[[1]](#compat-matrix-footnote-1)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[5]](#compat-matrix-footnote-5)[[8]](#compat-matrix-footnote-8)[[3]](#compat-matrix-footnote-3)[[8]](#compat-matrix-footnote-8)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[4]](#compat-matrix-footnote-4)[[2]](#compat-matrix-footnote-2)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[2]](#compat-matrix-footnote-2)[[1]](#compat-matrix-footnote-1)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[3]](#compat-matrix-footnote-3)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[9]](#compat-matrix-footnote-9)1: You must follow the terms of GPLv2 when incorporating the code in this case. You cannot take advantage of terms in later versions of the GPL.
2: While you may release under GPLv2-or-later both your original work, and/or modified versions of work you received under GPLv2-or-later, the GPLv2-only code that you're using must remain under GPLv2 only. As long as your project depends on that code, you won't be able to upgrade the license of your own code to GPLv3-or-later, and the work as a whole (any combination of both your project and the other code) can only be conveyed under the terms of GPLv2.
3: If you have the ability to release the project under GPLv2 or any later version, you can choose to release it under GPLv3 or any later version—and once you do that, you'll be able to incorporate the code released under GPLv3.
4: If you have the ability to release the project under LGPLv2.1 or any later version, you can choose to release it under LGPLv3 or any later version—and once you do that, you'll be able to incorporate the code released under LGPLv3.
5: You must follow the terms of LGPLv2.1 when incorporating the code in this case. You cannot take advantage of terms in later versions of the LGPL.
6: If you do this, as long as the project contains the code released under LGPLv2.1 only, you will not be able to upgrade the project's license to LGPLv3 or later.
7: LGPLv2.1 gives you permission to relicense the code under any version of the GPL since GPLv2. If you can switch the LGPLed code in this case to using an appropriate version of the GPL instead (as noted in the table), you can make this combination.
8: LGPLv3 is GPLv3 plus extra permissions that you can ignore in this case.
9: Because GPLv2 does not permit combinations with LGPLv3, you must convey the project under GPLv3's terms in this case, since it will allow that combination. |
9,449 | 如何使用看板(kanban)创建更好的文档 | https://opensource.com/article/17/11/kanban-boards-card-sorting | 2018-03-16T00:12:05 | [
"看板",
"文档"
] | https://linux.cn/article-9449-1.html |
>
> 通过卡片分类和看板来给用户提供他们想要的信息。
>
>
>

如果你正在处理文档、网站或其他面向用户的内容,那么了解用户希望找到的内容(包括他们想要的信息以及信息的组织和结构)很有帮助。毕竟,如果人们无法找到他们想要的东西,那么再出色的内容也没有用。
卡片分类是一种简单而有效的方式,可以从用户那里收集有关菜单界面和页面的内容。最简单的实现方式是在计划在网站或文档中的部分分类标注一些索引卡,并要求用户按照查找信息的方式对卡片进行分类。一个变体是让人们编写自己的菜单标题或内容元素。
我们的目标是了解用户的期望以及他们希望在哪里找到它,而不是自己弄清楚菜单和布局。当与用户处于相同的物理位置时,这是相对简单的,但当尝试从多个位置的人员获得反馈时,这会更具挑战性。
我发现[<ruby> 看板 <rt> kanban </rt></ruby>](https://en.wikipedia.org/wiki/Kanban)对于这些情况是一个很好的工具。它允许人们轻松拖动虚拟卡片进行分类和排名,而且与专门卡片分类软件不同,它们是多用途的。
我经常使用 Trello 进行卡片分类,但有几种你可能想尝试的[开源替代品](https://opensource.com/alternatives/trello)。
### 怎么运行的
我最成功的看板体验是在写 [Gluster](https://www.gluster.org/) 文档的时候 —— 这是一个自由开源的可扩展的网络存储文件系统。我需要携带大量随着时间而增长的文档,并将其分成若干类别以创建导航系统。由于我没有必要的技术知识来分类,我向 Gluster 团队和开发人员社区寻求指导。
首先,我创建了一个共享看板。我列出了一些通用名称,这些名称可以为我计划在文档中涵盖的所有主题排序和创建卡片。我标记了一些不同颜色的卡片,以表明某个主题缺失并需要创建,或者它存在并需要删除。然后,我把所有卡片放入“未排序”一列,并要求人们将它们拖到他们认为这些卡片应该组织到的地方,然后给我一个他们认为是理想状态的截图。
处理所有截图是最棘手的部分。我希望有一个合并或共识功能可以帮助我汇总每个人的数据,而不必检查一堆截图。幸运的是,在第一个人对卡片进行分类之后,人们或多或少地对该结构达成一致,而只做了很小的修改。当对某个主题的位置有不同意见时,我发起一个快速会议,让人们可以解释他们的想法,并且可以排除分歧。
### 使用数据
在这里,很容易将捕捉到的信息转换为菜单并对其进行优化。如果用户认为项目应该成为子菜单,他们通常会在评论中或在电话聊天时告诉我。对菜单组织的看法因人们的工作任务而异,所以从来没有完全达成一致意见,但用户进行测试意味着你不会对人们使用什么以及在哪里查找有很多盲点。
将卡片分类与分析功能配对,可以让你更深入地了解人们在寻找什么。有一次,当我对一些我正在写的培训文档进行分析时,我惊讶地发现搜索量最大的页面是关于资本的。所以我在顶层菜单层面上显示了该页面,即使我的“逻辑”设置将它放在了子菜单中。
我发现看板卡片分类是一种很好的方式,可以帮助我创建用户想要查看的内容,并将其放在希望被找到的位置。你是否发现了另一种对用户友好的组织内容的方法?或者看板的另一种有趣用途是什么?如果有的话,请在评论中分享你的想法。
---
via: <https://opensource.com/article/17/11/kanban-boards-card-sorting>
作者:[Heidi Waterhouse](https://opensource.com/users/hwaterhouse) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you're working on documentation, a website, or other user-facing content, it's helpful to know what users expect to find—both the information they want and how the information is organized and structured. After all, great content isn't very useful if people can't find what they're looking for.
Card sorting is a simple and effective way to gather input from users about what they expect from menu interfaces and pages. The simplest implementation is to label a stack of index cards with the sections you plan to include in your website or documentation and ask users to sort the cards in the way they would look for the information. Variations include letting people write their own menu headers or content elements.
The goal is to learn what your users expect and where they expect to find it, rather than having to figure out your menu and layout on your own. This is relatively straightforward when you have users in the same physical location, but it's more challenging when you are trying to get feedback from people in many locations.
I've found [kanban](https://en.wikipedia.org/wiki/Kanban) boards are a great tool for these situations. They allow people to easily drag virtual cards around to categorize and rank them, and they are multi-purpose, unlike dedicated card-sorting software.
I often use Trello for card sorting, but there are several [open source alternatives](https://opensource.com/alternatives/trello) that you might want to try.
## How it works
My most successful kanban experiment was when I was working on documentation for [Gluster](https://www.gluster.org/), a free and open source scalable network-attached storage filesystem. I needed to take a large pile of documentation that had grown over time and break it into categories to create a navigation system. BEcause I didn't have the technical knowledge necessary to sort it, I turned to the Gluster team and developer community for guidance.
First, I created a shared Kanban board. I gave the columns general names that would enable sorting and created cards for all the topics I planned to cover in the documentation. I flagged some cards with different colors to indicate either a topic was missing and needed to be created, or it was present and needed to be removed. Then I put all the cards into an "unsorted" column and asked people to drag them where they thought the cards should be organized and send me a screen capture of what they thought was the ideal state.
opensource.com
Dealing with all the screen captures was the trickiest part. I wish there was a merge or consensus feature that would've helped me aggregate everyone's data, rather than having to examine a bunch of screen captures. Fortunately, after the first person sorted the cards, people more or less agreed on the structure and made only minor modifications. When opinions differed on a topic's placement, I set up flash meetings where people could explain their thinking and we could hash out the disagreements.
## Using the data
From here, it was easy to convert the information I captured into menus and refine it. If users thought items should become submenus, they usually told me in comments or when we talked on the phone. Perceptions of menu organization vary depending upon people's job tasks, so you never have complete agreement, but testing with users means you won't have as many blind spots about what people use and where they will look for it.
Pairing card sorting with analytics gives you even more insight on what people are looking for. Once, when I ran analytics on some training documentation I was working on, I was surprised that to learn that the most searched page was about title capitalization. So I surfaced that page at the top-menu level, even though my "logical" setting put it far down in a sub-menu.
I've found kanban card-sorting a great way to help me create content that users want to see and put it where they expect to find it. Have you found another great way to organize your content for users' benefit? Or another interesting use for kanban boards? If so, please share your thoughts in the comments.
## 3 Comments |
9,450 | Linux 中的“大内存页”(hugepage)是个什么? | https://kerneltalks.com/services/what-is-huge-pages-in-linux/ | 2018-03-16T08:28:00 | [
"内存",
"hugepage"
] | https://linux.cn/article-9450-1.html |
>
> 学习 Linux 中的<ruby> 大内存页 <rt> hugepage </rt></ruby>。理解什么是“大内存页”,如何进行配置,如何查看当前状态以及如何禁用它。
>
>
>

本文中我们会详细介绍<ruby> 大内存页 <rt> huge page </rt></ruby>,让你能够回答:Linux 中的“大内存页”是什么?在 RHEL6、RHEL7、Ubuntu 等 Linux 中,如何启用/禁用“大内存页”?如何查看“大内存页”的当前值?
首先让我们从“大内存页”的基础知识开始讲起。
### Linux 中的“大内存页”是个什么玩意?
“大内存页”有助于 Linux 系统进行虚拟内存管理。顾名思义,除了标准的 4KB 大小的页面外,它们还能帮助管理内存中的巨大的页面。使用“大内存页”,你最大可以定义 1GB 的页面大小。
在系统启动期间,你能用“大内存页”为应用程序预留一部分内存。这部分内存,即被“大内存页”占用的这些存储器永远不会被交换出内存。它会一直保留其中,除非你修改了配置。这会极大地提高像 Oracle 数据库这样的需要海量内存的应用程序的性能。
### 为什么使用“大内存页”?
在虚拟内存管理中,内核维护一个将虚拟内存地址映射到物理地址的表,对于每个页面操作,内核都需要加载相关的映射。如果你的内存页很小,那么你需要加载的页就会很多,导致内核会加载更多的映射表。而这会降低性能。
使用“大内存页”,意味着所需要的页变少了。从而大大减少由内核加载的映射表的数量。这提高了内核级别的性能最终有利于应用程序的性能。
简而言之,通过启用“大内存页”,系统具只需要处理较少的页面映射表,从而减少访问/维护它们的开销!
### 如何配置“大内存页”?
运行下面命令来查看当前“大内存页”的详细内容。
```
root@kerneltalks # grep Huge /proc/meminfo
AnonHugePages: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
```
从上面输出可以看到,每个页的大小为 2MB(`Hugepagesize`),并且系统中目前有 `0` 个“大内存页”(`HugePages_Total`)。这里“大内存页”的大小可以从 `2MB` 增加到 `1GB`。
运行下面的脚本可以知道系统当前需要多少个巨大页。该脚本取之于 Oracle。
```
#!/bin/bash
#
# hugepages_settings.sh
#
# Linux bash script to compute values for the
# recommended HugePages/HugeTLB configuration
#
# Note: This script does calculation for all shared memory
# segments available when the script is run, no matter it
# is an Oracle RDBMS shared memory segment or not.
# Check for the kernel version
KERN=`uname -r | awk -F. '{ printf("%d.%d\n",$1,$2); }'`
# Find out the HugePage size
HPG_SZ=`grep Hugepagesize /proc/meminfo | awk {'print $2'}`
# Start from 1 pages to be on the safe side and guarantee 1 free HugePage
NUM_PG=1
# Cumulative number of pages required to handle the running shared memory segments
for SEG_BYTES in `ipcs -m | awk {'print $5'} | grep "[0-9][0-9]*"`
do
MIN_PG=`echo "$SEG_BYTES/($HPG_SZ*1024)" | bc -q`
if [ $MIN_PG -gt 0 ]; then
NUM_PG=`echo "$NUM_PG+$MIN_PG+1" | bc -q`
fi
done
# Finish with results
case $KERN in
'2.4') HUGETLB_POOL=`echo "$NUM_PG*$HPG_SZ/1024" | bc -q`;
echo "Recommended setting: vm.hugetlb_pool = $HUGETLB_POOL" ;;
'2.6' | '3.8' | '3.10' | '4.1' ) echo "Recommended setting: vm.nr_hugepages = $NUM_PG" ;;
*) echo "Unrecognized kernel version $KERN. Exiting." ;;
esac
# End
```
将它以 `hugepages_settings.sh` 为名保存到 `/tmp` 中,然后运行之:
```
root@kerneltalks # sh /tmp/hugepages_settings.sh
Recommended setting: vm.nr_hugepages = 124
```
你的输出类似如上结果,只是数字会有一些出入。
这意味着,你系统需要 124 个每个 2MB 的“大内存页”!若你设置页面大小为 4MB,则结果就变成了 62。你明白了吧?
### 配置内核中的“大内存页”
本文最后一部分内容是配置上面提到的 [内核参数](https://kerneltalks.com/linux/how-to-tune-kernel-parameters-in-linux/) ,然后重新加载。将下面内容添加到 `/etc/sysctl.conf` 中,然后输入 `sysctl -p` 命令重新加载配置。
```
vm.nr_hugepages=126
```
注意我们这里多加了两个额外的页,因为我们希望在实际需要的页面数量之外多一些额外的空闲页。
现在,内核已经配置好了,但是要让应用能够使用这些“大内存页”还需要提高内存的使用阀值。新的内存阀值应该为 126 个页 x 每个页 2 MB = 252 MB,也就是 258048 KB。
你需要编辑 `/etc/security/limits.conf` 中的如下配置:
```
soft memlock 258048
hard memlock 258048
```
某些情况下,这些设置是在指定应用的文件中配置的,比如 Oracle DB 就是在 `/etc/security/limits.d/99-grid-oracle-limits.conf` 中配置的。
这就完成了!你可能还需要重启应用来让应用来使用这些新的巨大页。
(LCTT 译注:此外原文有误,“透明大内存页”和“大内存页”不同,而且,在 Redhat 系统中,“大内存页” 不是默认启用的,而“透明大内存页”是启用的。因此这个段落删除了。)
---
via: <https://kerneltalks.com/services/what-is-huge-pages-in-linux/>
作者:[Shrikant Lavhate](https://kerneltalks.com) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Learn about huge pages in Linux. Understand what is huge pages, how to configure it, how to check the current state, and how to disable it.*

In this article, we will walk you through details about huge pages so that you will be able to answer: what are huge pages in Linux? How to enable/disable huge pages? How to determine huge page value? in Linux like RHEL6, RHEL7, Ubuntu, etc.
Lets start with Huge pages basics.
### What is Huge page in Linux?
Huge pages are helpful in virtual memory management in the Linux system. As the name suggests, they help is managing huge size pages in memory in addition to standard 4KB page size. You can define as huge as 1GB page size using huge pages.
During system boot, you reserve your memory portion with huge pages for your application. This memory portion i.e. these memory occupied by huge pages is never swapped out of memory. It will stick there until you change your configuration. This increases application performance to a great extent like Oracle database with pretty large memory requirements.
### Why use huge page?
In virtual memory management, the kernel maintains a table in which it has a mapping of the virtual memory address to a physical address. For every page transaction, the kernel needs to load related mapping. If you have small size pages then you need to load more numbers of pages resulting kernel to load more mapping tables. This decreases performance.
Using huge pages means you will need fewer pages. This decreases the number of mapping tables to load by the kernel to a great extent. This increases your kernel-level performance which ultimately benefits your application.
In short, by enabling huge pages, the system has fewer page tables to deal with and hence less overhead to access/maintain them!
### How to configure huge pages?
Run below command to check current huge pages details.
```
root@kerneltalks # grep Huge /proc/meminfo
AnonHugePages: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
```
In the above output, you can see the one-page size is 2MB `Hugepagesize`
and a total of 0 pages on the system `HugePages_Total`
. This huge page size can be increased from 2MB to max 1GB.
Run below script to get how much huge pages your system needs currently. The script is from Oracle and can be found.
```
#!/bin/bash
#
# hugepages_settings.sh
#
# Linux bash script to compute values for the
# recommended HugePages/HugeTLB configuration
#
# Note: This script does calculation for all shared memory
# segments available when the script is run, no matter it
# is an Oracle RDBMS shared memory segment or not.
# Check for the kernel version
KERN=`uname -r | awk -F. '{ printf("%d.%d\n",$1,$2); }'`
# Find out the HugePage size
HPG_SZ=`grep Hugepagesize /proc/meminfo | awk {'print $2'}`
# Start from 1 pages to be on the safe side and guarantee 1 free HugePage
NUM_PG=1
# Cumulative number of pages required to handle the running shared memory segments
for SEG_BYTES in `ipcs -m | awk {'print $5'} | grep "[0-9][0-9]*"`
do
MIN_PG=`echo "$SEG_BYTES/($HPG_SZ*1024)" | bc -q`
if [ $MIN_PG -gt 0 ]; then
NUM_PG=`echo "$NUM_PG+$MIN_PG+1" | bc -q`
fi
done
# Finish with results
case $KERN in
'2.4') HUGETLB_POOL=`echo "$NUM_PG*$HPG_SZ/1024" | bc -q`;
echo "Recommended setting: vm.hugetlb_pool = $HUGETLB_POOL" ;;
'2.6' | '3.8' | '3.10' | '4.1' ) echo "Recommended setting: vm.nr_hugepages = $NUM_PG" ;;
*) echo "Unrecognized kernel version $KERN. Exiting." ;;
esac
# End
```
You can save it in `/tmp`
as `hugepages_settings.sh`
and then run it like below :
```
root@kerneltalks # sh /tmp/hugepages_settings.sh
Recommended setting: vm.nr_hugepages = 124
```
Output will be similar to some number as shown in above sample output.
This means your system needs 124 huge pages of 2MB each! If you have set 4MB as page size then the output would have been 62. You got the point, right?
### Configure hugepages in kernel
Now last part is to configure the above-stated [kernel parameter](https://kerneltalks.com/linux/how-to-tune-kernel-parameters-in-linux/) and reload it. Add below value in `/etc/sysctl.conf`
and reload configuration by issuing `sysctl -p`
command.
```
vm.nr_hugepages=126
```
Notice that we added 2 extra pages in the kernel since we want to keep a couple of pages spare than the actual required number.
Now, huge pages have been configured in the kernel but to allow your application to use them you need to increase memory limits as well. The new memory limit should be 126 pages x 2 MB each = 252 MB i.e. 258048 KB.
You need to edit below settings in `/etc/security/limits.conf`
```
soft memlock 258048
hard memlock 258048
```
Sometimes these settings are configured in app-specific files like for Oracle DB its in `/etc/security/limits.d/99-grid-oracle-limits.conf`
That’s it! You might want to restart your application to make use of these new huge pages.
### How to disable hugepages?
HugePages are generally enabled by default. Use the below command to check the current state of huge pages.
```
root@kerneltalks # cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
```
`[always]`
flag in output shows that hugepages are enabled on system.
For RedHat based systems file path is `/sys/kernel/mm/redhat_transparent_hugepage/enabled`
If you want to disable huge pages then add `transparent_hugepage=never`
at the end of `kernel`
line in `/etc/grub.conf`
and reboot the system.
Hugepages and transparent hugepages are two distincts features.
Hugepage is not enabled by default in RHEL while transparent hugepage is.
It is recommended to have the SGA in hugepages (known as large page from Oracle) and have transparent hugepage disabled as this last one is not supported by Oracle.
The article seems to imply that this is a feature with no downsides. However, it is not enabled by default. Why?
It says it’s typically enabled by default, FWIW…
“less number of”? Oh, you mean fewer?
That’s not the only grammatical atrocity here.
!! Fewer seems appropriate! Edited.
Thanks.
Why would you be worried about grammatical atrocities in a page that talks about huge pages?
In the script you are checking the following kernel version:
‘2.6’ | ‘3.8’ | ‘3.10’ | ‘4.1’
My version is 4.15, I included it in the script and got an output. Just wanted to confirm if the script supports this kernel version and will provide a correct output for it ?
Hello there, Transparent HugePages and HugePages are two different things! Once you enable HugePages, you must disable TransparentHugePages. RHEL calls it as redhat_transparent_hugepage & oracle has it as transparent_hugepages. Once HugePages are configured for Oracle/other, the transparent hugepages must be disabled, using one of the methods.
Grammar? definitely 🙂 There are far more stuffs worry about.
Somehow, saving a script to be run as root in /tmp always looks like a great idea to tell the world about. |
9,451 | 如何使用 Seahorse 管理 PGP 和 SSH 密钥 | https://www.linux.com/learn/intro-to-linux/2018/2/how-manage-pgp-and-ssh-keys-seahorse | 2018-03-16T09:11:00 | [
"密钥",
"SSH",
"PGP"
] | https://linux.cn/article-9451-1.html | 
>
> 学习使用 Seahorse GUI 工具去管理 PGP 和 SSH 密钥。
>
>
>
安全即内心的平静。毕竟,安全是许多用户迁移到 Linux 的最大理由。但是为什么要止步于仅仅采用该平台,你还可以采用多种方法和技术去确保你的桌面或者服务器系统的安全。
其中一项技术涉及到密钥 —— 用在 PGP 和 SSH 中。PGP 密钥允许你去加密和解密电子邮件和文件,而 SSH 密钥允许你使用一个额外的安全层去登入服务器。
当然,你可以通过命令行接口(CLI)来管理这些密钥,但是,如果你使用一个华丽的 GUI 桌面环境呢?经验丰富的 Linux 用户可能对于脱离命令行来工作感到很不适应,但是,并不是所有用户都具备与他们相同的技术和水平,因此,使用 GUI 吧!
在本文中,我将带你探索如何使用 [Seahorse](https://wiki.gnome.org/Apps/Seahorse) GUI 工具来管理 PGP 和 SSH 密钥。Seahorse 有非常强大的功能,它可以:
* 加密/解密/签名文件和文本。
* 管理你的密钥和密钥对。
* 同步你的密钥和密钥对到远程密钥服务器。
* 签名和发布密钥。
* 缓存你的密码。
* 备份密钥和密钥对。
* 在任何一个 GDK 支持的格式中添加一个图像作为一个 OpenPGP photo ID。
* 创建、配置、和缓存 SSH 密钥。
对于那些不了解 Seahorse 的人来说,它是一个管理 GNOME 钥匙环中的加密密钥和密码的 GNOME 应用程序。不用担心,Seahorse 可以安装在许多的桌面环境上。并且由于 Seahorse 可以在标准的仓库中找到,你可以打开你的桌面应用商店(比如,Ubuntu Software 或者 Elementary OS AppCenter)去安装它。你可以在你的发行版的应用商店中点击去安装它。安装完成后,你就可以去使用这个很方便的工具了。
我们开始去使用它吧。
### PGP 密钥
我们需要做的第一件事情就是生成一个新的 PGP 密钥。正如前面所述,PGP 密钥可以用于加密电子邮件(通过一些工具,像 [Thunderbird](https://www.mozilla.org/en-US/thunderbird/) 的 [Enigmail](https://enigmail.net/index.php/en/) 或者使用 [Evolution](https://wiki.gnome.org/Apps/Evolution) 内置的加密功能)。PGP 密钥也可以用于加密文件。任何人都可以使用你的公钥加密电子邮件和文件发给你(LCTT 译注:原文此处“加密”误作“解密”)。没有 PGP 密钥是做不到的。
使用 Seahorse 创建一个新的 PGP 密钥对是非常简单的。以下是操作步骤:
1. 打开 Seahorse 应用程序
2. 在主面板的左上角点击 “+” 按钮
3. 选择 “<ruby> PGP 密钥 <rt> PGP Key </rt></ruby>”(如图 1 )
4. 点击 “<ruby> 继续 <rt> Continue </rt></ruby>”
5. 当提示时,输入完整的名字和电子邮件地址
6. 点击 “<ruby> 创建 <rt> Create </rt></ruby>”

*图 1:使用 Seahorse 创建一个 PGP 密钥。*
在创建你的 PGP 密钥期间,你可以点击 “<ruby> 高级密钥选项 <rt> Advanced key options </rt></ruby>” 展开选项部分,在那里你可以为密钥添加注释信息、加密类型、密钥长度、以及过期时间(如图 2)。

*图 2:PGP 密钥高级选项*
增加注释部分可以很方便帮你记住密钥的用途(或者其它的信息)。
要使用你创建的 PGP,可在密钥列表中双击它。在结果窗口中,点击 “<ruby> 名字 <rt> Names </rt></ruby>” 和 “<ruby> 签名 <rt> Signatures </rt></ruby>” 选项卡。在这个窗口中,你可以签名你的密钥(表示你信任这个密钥)。点击 “<ruby> 签名 <rt> Sign </rt></ruby>” 按钮然后(在结果窗口中)指出 “<ruby> 你是如何仔细的检查这个密钥的? <rt> how carefully you’ve checked this key? </rt></ruby>” 和 “<ruby> 其他人将如何看到该签名 <rt> how others will see the signature </rt></ruby>”(如图 3)。

*图 3:签名一个密钥表示信任级别。*
当你处理其它人的密钥时,密钥签名是非常重要的,因为一个签名的密钥将确保你的系统(和你)做了这项签名工作并且完全信任这个重要的密钥。
谈到导入的密钥,Seahorse 可以允许你很容易地去导入其他人的公钥文件(这个文件以 `.asc` 为后缀)。你的系统上有其他人的公钥,意味着你可以加密发送给他们的电子邮件和文件(LCTT 译注:原文将“加密”误作“解密”)。然而,Seahorse 在很长的一段时间内都存在一个 [已知的 bug](https://bugs.launchpad.net/ubuntu/+source/seahorse/+bug/1577198)。这个问题是,Seahorse 导入使用 GPG 版本 1,但是显示的是 GPG 版本 2。这意味着,在这个存在了很长时间的 bug 被修复之前,导入公钥总是失败的。如果你想导入一个公钥文件到 Seahorse 中,你只能去使用命令行。因此,如果有人发送给你一个文件 `olivia.asc`,你想去导入到 Seahorse 中使用它,你将只能运行命令 `gpg2 --import olivia.asc`。那个密钥将出现在 GnuPG 密钥列表中。你可以打开该密钥,点击 “<ruby> 我信任签名 <rt> I trust signatures </rt></ruby>” 按钮,然后在问题 “<ruby> 你是如何仔细地检查该密钥的? <rt> how carefully you’ve checked the key </rt></ruby>” 中,点击 “<ruby> 签名这个密钥 <rt> Sign this key </rt></ruby>” 按钮去签名。
### SSH 密钥
现在我们来谈谈我认为 Seahorse 中最重要的一个方面 — SSH 密钥。Seahorse 不仅可以很容易地生成一个 SSH 密钥,而且它也可以很容易地将生成的密钥发送到服务器上,因此,你可以享受到 SSH 密钥验证的好处。下面是如何生成一个新的密钥以及如何导出它到一个远程服务器上。
1. 打开 Seahorse 应用程序
2. 点击 “+” 按钮
3. 选择 “Secure Shell Key”
4. 点击 “Continue”
5. 提供一个密钥描述信息
6. 点击 “Set Up” 去创建密钥
7. 输入密钥的验证密钥
8. 点击 OK
9. 输入远程服务器地址和服务器上的登录名(如图 4)
10. 输入远程用户的密码
11. 点击 OK

*图 4:上传一个 SSH 密钥到远程服务器。*
新密钥将上传到远程服务器上以备使用。如果你的服务器已经设置为使用 SSH 密钥验证,那就一切就绪了。
需要注意的是,在创建一个 SSH 密钥期间,你可以点击 “<ruby> 高级密钥选项 <rt> Advanced key options </rt></ruby>”去展开它,配置加密类型和密钥长度(如图 5)。

*图 5:高级 SSH 密钥选项。*
### Linux 新手必备
任何 Linux 新手用户都可以很快熟悉使用 Seahorse。即便是它有缺陷,Seahorse 仍然是为你准备的一个极其方便的工具。有时候,你可能希望(或者需要)去加密或者解密一个电子邮件/文件,或者为使用 SSH 验证来管理 SSH 密钥。如果你想去这样做而不希望使用命令行,那么,Seahorse 将是非常适合你的工具。
*通过来自 Linux 基金会和 edX 的 ["Linux 入门"](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 免费课程学习更多 Linux 的知识。*
---
via: <https://www.linux.com/learn/intro-to-linux/2018/2/how-manage-pgp-and-ssh-keys-seahorse>
作者:[JACK WALLEN](https://www.linux.com/users/jlwallen) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,452 | Linux 中国入驻专业区块链内容平台「虎尔财经」 | https://m.hooah.com.cn/detail.html?id=3510&spm=Cl0JUAVuB1EfBwRaBhQCWW8NFQhSVV1IAQBSW1cDAwAHU1JaDAcFUg4DAgAaD1NXBh0ABAkJGw1R | 2018-03-16T18:47:00 | [
"区块链"
] | /article-9452-1.html | 
如今区块链技术伴随着大众关注而席卷全球,抛开各种炒作和投机,其底层的区块链技术已经日益得到了技术领域、经济领域乃至于国家层面的强烈关注。作为一个技术专业社区,我们也对区块链及相关的技术非常关注。因此,我们也将编发更多的区块链技术方面的内容分享给诸位读者。
而从即日起,Linux 中国也将同时入驻区块链垂直媒体「虎尔财经」 APP,将在虎尔财经同步发布区块链方面的文章。 关注区块链技术的同学可以在「虎尔财经」上获得更多的专业内容。
为回馈 Linux 中国的用户,从 3 月 17 日 — 3 月 24 日登录「虎尔财经」 APP 的用户,将获得 188FCB 的专属 Token 奖励。 同时,通过「虎尔财经」 APP ,你阅读、转发 Linux 中国任何一篇文章,都可以获得 Token 奖励,共享平台发展和内容流量收益。

*通过微信扫一扫,扫码登录虎尔财经,即可获赠 188 FCB Token!*
### 为何入驻「虎尔财经」
「虎尔财经」是专业的区块链内容平台,为投资者提供专业的研究型内容和及时、全面、准确的财经资讯。
「虎尔财经」运用区块链技术重新构建了内容生产关系,通过去中心化的内容生产方式重塑了生态价值分配机制,用户创作、阅读、转发都将获得 Token 奖励,激励优质内容创作和高效分发,真正实现用户共享平台发展和内容流量收益。
### 关于 FCB Token
FCB 全称为 Finance Content Bank,FCB Token 用于激励用户在「虎尔财经」 APP 平台进行财经内容创作、阅读及转发,虎尔财经将不定期回购 FCB Token。
FCB 获得方式
1. 作为创作者入驻平台发布文章,文章每被 1 人阅读,则获得 0.4 FCB /人次的 Token 奖励,例如某篇文章获得 10 万阅读量,则获得 4 万 FCB 的 Token 奖励。(前 1000 名入驻发文并被阅读 100 以上,获 10000 FCB )
2. 作为用户,每阅读一篇文章,或转发的文章被阅读,可获得 0.3 FCB /次的 Token 奖励,无上限。
3. 参加平台不定期举行的 FCB 赠送活动。
| null | ('Connection aborted.', ConnectionResetError(104, 'Connection reset by peer')) | null |
9,453 | 用 Python 构建一个极小的区块链 | https://medium.com/crypto-currently/lets-build-the-tiniest-blockchain-e70965a248b | 2018-03-17T02:17:00 | [
"Python",
"区块链"
] | https://linux.cn/article-9453-1.html | 
虽然有些人认为区块链是一个早晚会出现问题的解决方案,但是毫无疑问,这个创新技术是一个计算机技术上的奇迹。那么,究竟什么是区块链呢?
### 区块链
>
> 以<ruby> 比特币 <rp> ( </rp> <rt> Bitcoin </rt> <rp> ) </rp></ruby>或其它加密货币按时间顺序公开地记录交易的数字账本。
>
>
>
更通俗的说,它是一个公开的数据库,新的数据存储在被称之为<ruby> 区块 <rp> ( </rp> <rt> block </rt> <rp> ) </rp></ruby>的容器中,并被添加到一个不可变的<ruby> 链 <rp> ( </rp> <rt> chain </rt> <rp> ) </rp></ruby>中(因此被称为<ruby> 区块链 <rp> ( </rp> <rt> blockchain </rt> <rp> ) </rp></ruby>),之前添加的数据也在该链中。对于比特币或其它加密货币来说,这些数据就是一组组交易,不过,也可以是其它任何类型的数据。
区块链技术带来了全新的、完全数字化的货币,如比特币和<ruby> 莱特币 <rp> ( </rp> <rt> Litecoin </rt> <rp> ) </rp></ruby>,它们并不由任何中心机构管理。这给那些认为当今的银行系统是骗局并将最终走向失败的人带来了自由。区块链也革命性地改变了分布式计算的技术形式,如<ruby> 以太坊 <rp> ( </rp> <rt> Ethereum </rt> <rp> ) </rp></ruby>就引入了一种有趣的概念:<ruby> <a href="https://blockgeeks.com/guides/smart-contracts/"> 智能合约 </a> <rp> ( </rp> <rt> smart contract </rt> <rp> ) </rp></ruby>。
在这篇文章中,我将用不到 50 行的 Python 2.x 代码实现一个简单的区块链,我把它叫做 SnakeCoin。
### 不到 50 行代码的区块链
我们首先将从定义我们的区块是什么开始。在区块链中,每个区块随同时间戳及可选的索引一同存储。在 SnakeCoin 中,我们会存储这两者。为了确保整个区块链的完整性,每个区块都会有一个自识别的哈希值。如在比特币中,每个区块的哈希是该块的索引、时间戳、数据和前一个区块的哈希值等数据的加密哈希值。这里提及的“数据”可以是任何你想要的数据。
```
import hashlib as hasher
class Block:
def __init__(self, index, timestamp, data, previous_hash):
self.index = index
self.timestamp = timestamp
self.data = data
self.previous_hash = previous_hash
self.hash = self.hash_block()
def hash_block(self):
sha = hasher.sha256()
sha.update(str(self.index) +
str(self.timestamp) +
str(self.data) +
str(self.previous_hash))
return sha.hexdigest()
```
真棒,现在我们有了区块的结构了,不过我们需要创建的是一个区块链。我们需要把区块添加到一个实际的链中。如我们之前提到过的,每个区块都需要前一个区块的信息。但问题是,该区块链中的第一个区块在哪里?好吧,这个第一个区块,也称之为创世区块,是一个特别的区块。在很多情况下,它是手工添加的,或通过独特的逻辑添加的。
我们将创建一个函数来简单地返回一个创世区块解决这个问题。这个区块的索引为 0 ,其包含一些任意的数据值,其“前一哈希值”参数也是任意值。
```
import datetime as date
def create_genesis_block():
# Manually construct a block with
# index zero and arbitrary previous hash
return Block(0, date.datetime.now(), "Genesis Block", "0")
```
现在我们可以创建创世区块了,我们需要一个函数来生成该区块链中的后继区块。该函数将获取链中的前一个区块作为参数,为要生成的区块创建数据,并用相应的数据返回新的区块。新的区块的哈希值来自于之前的区块,这样每个新的区块都提升了该区块链的完整性。如果我们不这样做,外部参与者就很容易“改变过去”,把我们的链替换为他们的新链了。这个哈希链起到了加密的证明作用,并有助于确保一旦一个区块被添加到链中,就不能被替换或移除。
```
def next_block(last_block):
this_index = last_block.index + 1
this_timestamp = date.datetime.now()
this_data = "Hey! I'm block " + str(this_index)
this_hash = last_block.hash
return Block(this_index, this_timestamp, this_data, this_hash)
```
这就是主要的部分。
现在我们能创建自己的区块链了!在这里,这个区块链是一个简单的 Python 列表。其第一个的元素是我们的创世区块,我们会添加后继区块。因为 SnakeCoin 是一个极小的区块链,我们仅仅添加了 20 个区块。我们通过循环来完成它。
```
# Create the blockchain and add the genesis block
blockchain = [create_genesis_block()]
previous_block = blockchain[0]
# How many blocks should we add to the chain
# after the genesis block
num_of_blocks_to_add = 20
# Add blocks to the chain
for i in range(0, num_of_blocks_to_add):
block_to_add = next_block(previous_block)
blockchain.append(block_to_add)
previous_block = block_to_add
# Tell everyone about it!
print "Block #{} has been added to the blockchain!".format(block_to_add.index)
print "Hash: {}\n".format(block_to_add.hash)
```
让我们看看我们的成果:

*别担心,它将一直添加到 20 个区块*
很好,我们的区块链可以工作了。如果你想要在主控台查看更多的信息,你可以编辑其[完整的源代码](https://gist.github.com/aunyks/8f2c2fd51cc17f342737917e1c2582e2)并输出每个区块的时间戳或数据。
这就是 SnakeCoin 所具有的功能。要使 SnakeCoin 达到现今的产品级的区块链的高度,我们需要添加更多的功能,如服务器层,以在多台机器上跟踪链的改变,并通过[工作量证明算法(POW)](https://en.bitcoin.it/wiki/Proof_of_work)来限制给定时间周期内可以添加的区块数量。
如果你想了解更多技术细节,你可以在[这里](https://bitcoin.org/bitcoin.pdf)查看最初的[比特币白皮书](https://bitcoin.org/bitcoin.pdf)。
### 让这个极小区块链稍微变大些
这个极小的区块链及其简单,自然也相对容易完成。但是因其简单也带来了一些缺陷。首先,SnakeCoin 仅能运行在单一的一台机器上,所以它相距分布式甚远,更别提去中心化了。其次,区块添加到区块链中的速度同在主机上创建一个 Python 对象并添加到列表中一样快。在我们的这个简单的区块链中,这不是问题,但是如果我们想让 SnakeCoin 成为一个实际的加密货币,我们就需要控制在给定时间内能创建的区块(和币)的数量。
从现在开始,SnakeCoin 中的“数据”将是交易数据,每个区块的“数据”字段都将是一些交易信息的列表。接着我们来定义“交易”。每个“交易”是一个 JSON 对象,其记录了币的发送者、接收者和转移的 SnakeCoin 数量。注:交易信息是 JSON 格式,原因我很快就会说明。
```
{
"from": "71238uqirbfh894-random-public-key-a-alkjdflakjfewn204ij",
"to": "93j4ivnqiopvh43-random-public-key-b-qjrgvnoeirbnferinfo",
"amount": 3
}
```
现在我们知道了交易信息看起来的样子了,我们需要一个办法来将其加到我们的区块链网络中的一台计算机(称之为节点)中。要做这个事情,我们会创建一个简单的 HTTP 服务器,以便每个用户都可以让我们的节点知道发生了新的交易。节点可以接受 POST 请求,请求数据为如上的交易信息。这就是为什么交易信息是 JSON 格式的:我们需要它们可以放在请求信息中传递给服务器。
```
$ pip install flask # 首先安装 Web 服务器框架
```
```
from flask import Flask
from flask import request
node = Flask(__name__)
# Store the transactions that
# this node has in a list
this_nodes_transactions = []
@node.route('/txion', methods=['POST'])
def transaction():
if request.method == 'POST':
# On each new POST request,
# we extract the transaction data
new_txion = request.get_json()
# Then we add the transaction to our list
this_nodes_transactions.append(new_txion)
# Because the transaction was successfully
# submitted, we log it to our console
print "New transaction"
print "FROM: {}".format(new_txion['from'])
print "TO: {}".format(new_txion['to'])
print "AMOUNT: {}\n".format(new_txion['amount'])
# Then we let the client know it worked out
return "Transaction submission successful\n"
node.run()
```
真棒!现在我们有了一种保存用户彼此发送 SnakeCoin 的记录的方式。这就是为什么人们将区块链称之为公共的、分布式账本:所有的交易信息存储给所有人看,并被存储在该网络的每个节点上。
但是,有个问题:人们从哪里得到 SnakeCoin 呢?现在还没有办法得到,还没有一个称之为 SnakeCoin 这样的东西,因为我们还没有创建和分发任何一个币。要创建新的币,人们需要“挖”一个新的 SnakeCoin 区块。当他们成功地挖到了新区块,就会创建出一个新的 SnakeCoin ,并奖励给挖出该区块的人(矿工)。一旦挖矿的矿工将 SnakeCoin 发送给别人,这个币就流通起来了。
我们不想让挖新的 SnakeCoin 区块太容易,因为这将导致 SnakeCoin 太多了,其价值就变低了;同样,我们也不想让它变得太难,因为如果没有足够的币供每个人使用,它们对于我们来说就太昂贵了。为了控制挖新的 SnakeCoin 区块的难度,我们会实现一个<ruby> <a href="https://en.bitcoin.it/wiki/Proof_of_work"> 工作量证明 </a> <rp> ( </rp> <rt> Proof-of-Work </rt> <rp> ) </rp></ruby>(PoW)算法。工作量证明基本上就是一个生成某个项目比较难,但是容易验证(其正确性)的算法。这个项目被称之为“证明”,听起来就像是它证明了计算机执行了特定的工作量。
在 SnakeCoin 中,我们创建了一个简单的 PoW 算法。要创建一个新区块,矿工的计算机需要递增一个数字,当该数字能被 9 (“SnakeCoin” 这个单词的字母数)整除时,这就是最后这个区块的证明数字,就会挖出一个新的 SnakeCoin 区块,而该矿工就会得到一个新的 SnakeCoin。
```
# ...blockchain
# ...Block class definition
miner_address = "q3nf394hjg-random-miner-address-34nf3i4nflkn3oi"
def proof_of_work(last_proof):
# Create a variable that we will use to find
# our next proof of work
incrementor = last_proof + 1
# Keep incrementing the incrementor until
# it's equal to a number divisible by 9
# and the proof of work of the previous
# block in the chain
while not (incrementor % 9 == 0 and incrementor % last_proof == 0):
incrementor += 1
# Once that number is found,
# we can return it as a proof
# of our work
return incrementor
@node.route('/mine', methods = ['GET'])
def mine():
# Get the last proof of work
last_block = blockchain[len(blockchain) - 1]
last_proof = last_block.data['proof-of-work']
# Find the proof of work for
# the current block being mined
# Note: The program will hang here until a new
# proof of work is found
proof = proof_of_work(last_proof)
# Once we find a valid proof of work,
# we know we can mine a block so
# we reward the miner by adding a transaction
this_nodes_transactions.append(
{ "from": "network", "to": miner_address, "amount": 1 }
)
# Now we can gather the data needed
# to create the new block
new_block_data = {
"proof-of-work": proof,
"transactions": list(this_nodes_transactions)
}
new_block_index = last_block.index + 1
new_block_timestamp = this_timestamp = date.datetime.now()
last_block_hash = last_block.hash
# Empty transaction list
this_nodes_transactions[:] = []
# Now create the
# new block!
mined_block = Block(
new_block_index,
new_block_timestamp,
new_block_data,
last_block_hash
)
blockchain.append(mined_block)
# Let the client know we mined a block
return json.dumps({
"index": new_block_index,
"timestamp": str(new_block_timestamp),
"data": new_block_data,
"hash": last_block_hash
}) + "\n"
```
现在,我们能控制特定的时间段内挖到的区块数量,并且我们给了网络中的人新的币,让他们彼此发送。但是如我们说的,我们只是在一台计算机上做的。如果区块链是去中心化的,我们怎样才能确保每个节点都有相同的链呢?要做到这一点,我们会使每个节点都广播其(保存的)链的版本,并允许它们接受其它节点的链。然后,每个节点会校验其它节点的链,以便网络中每个节点都能够达成最终的链的共识。这称之为<ruby> <a href="https://en.wikipedia.org/wiki/Consensus_%28computer_science%29"> 共识算法 </a> <rp> ( </rp> <rt> consensus algorithm </rt> <rp> ) </rp></ruby>。
我们的共识算法很简单:如果一个节点的链与其它的节点的不同(例如有冲突),那么最长的链保留,更短的链会被删除。如果我们网络上的链没有了冲突,那么就可以继续了。
```
@node.route('/blocks', methods=['GET'])
def get_blocks():
chain_to_send = blockchain
# Convert our blocks into dictionaries
# so we can send them as json objects later
for block in chain_to_send:
block_index = str(block.index)
block_timestamp = str(block.timestamp)
block_data = str(block.data)
block_hash = block.hash
block = {
"index": block_index,
"timestamp": block_timestamp,
"data": block_data,
"hash": block_hash
}
# Send our chain to whomever requested it
chain_to_send = json.dumps(chain_to_send)
return chain_to_send
def find_new_chains():
# Get the blockchains of every
# other node
other_chains = []
for node_url in peer_nodes:
# Get their chains using a GET request
block = requests.get(node_url + "/blocks").content
# Convert the JSON object to a Python dictionary
block = json.loads(block)
# Add it to our list
other_chains.append(block)
return other_chains
def consensus():
# Get the blocks from other nodes
other_chains = find_new_chains()
# If our chain isn't longest,
# then we store the longest chain
longest_chain = blockchain
for chain in other_chains:
if len(longest_chain) < len(chain):
longest_chain = chain
# If the longest chain wasn't ours,
# then we set our chain to the longest
blockchain = longest_chain
```
我们差不多就要完成了。在运行了[完整的 SnakeCoin 服务器代码](https://gist.github.com/aunyks/47d157f8bc7d1829a729c2a6a919c173)之后,在你的终端可以运行如下代码。(假设你已经安装了 cCUL)。
#### 1、创建交易
```
curl "localhost:5000/txion" \
-H "Content-Type: application/json" \
-d '{"from": "akjflw", "to":"fjlakdj", "amount": 3}'
```
#### 2、挖一个新区块
```
curl localhost:5000/mine
```
#### 3、 查看结果。从客户端窗口,我们可以看到。

对代码做下美化处理,我们看到挖矿后我们得到的新区块的信息:
```
{
"index": 2,
"data": {
"transactions": [
{
"to": "fjlakdj",
"amount": 3,
"from": "akjflw"
},
{
"to": "q3nf394hjg-random-miner-address-34nf3i4nflkn3oi",
"amount": 1,
"from": "network"
}
],
"proof-of-work": 36
},
"hash": "151edd3ef6af2e7eb8272245cb8ea91b4ecfc3e60af22d8518ef0bba8b4a6b18",
"timestamp": "2017-07-23 11:23:10.140996"
}
```
大功告成!现在 SnakeCoin 可以运行在多个机器上,从而创建了一个网络,而且真实的 SnakeCoin 也能被挖到了。
你可以根据你的喜好去修改 SnakeCoin 服务器代码,并问各种问题了。
在下一篇(LCTT 译注:截止至本文翻译,作者还没有写出下一篇),我们将讨论创建一个 SnakeCoin 钱包,这样用户就可以发送、接收和存储他们的 SnakeCoin 了。
| 200 | OK | # Let’s Build the Tiniest Blockchain
## In Less Than 50 Lines of Python
*Note: Part 2 of this piece can be found **here**.*
Although some think blockchain is a solution waiting for problems, there’s no doubt that this novel technology is a marvel of computing. But, what exactly is a blockchain?
## Blockchain
In more general terms, *it’s a public database where new data are stored in a container called a block and are added to an immutable chain (hence blockchain) with data added in the past*. In the case of Bitcoin and other cryptocurrencies, these data are groups of transactions. But, the data can be of any type, of course.
Blockchain technology has given rise to new, fully digital currencies like Bitcoin and Litecoin that aren’t issued or managed by a central authority. This brings new freedom to individuals who believe that today’s banking systems are a scam or subject to failure. Blockchain has also revolutionized distributed computing in the form of technologies like Ethereum, which has introduced interesting concepts like [smart contracts](https://blockgeeks.com/guides/smart-contracts/).
In this article, I’ll make a simple blockchain in less than 50 lines of Python 2 code. It’ll be called SnakeCoin.
We’ll start by first defining what our blocks will look like. In blockchain, each block is stored with a timestamp and, optionally, an index. In SnakeCoin, we’re going to store both. And to help ensure integrity throughout the blockchain, each block will have a self-identifying hash. Like Bitcoin, each block’s hash will be a cryptographic hash of the block’s index, timestamp, data, and the hash of the previous block’s hash. Oh, and the data can be anything you want.
Awesome! We have our block structure, but we’re creating a block**chain**. We need to start adding blocks to the actual chain. As I mentioned earlier, each block requires information from the previous block. But with that being said, a question arises: **how does the first block in the blockchain get there?** Well, the first block, or *genesis block,* is a special block. In many cases, it’s added manually or has unique logic allowing it to be added.
We’ll create a function that simply returns a genesis block to make things easy. This block is of index 0, and it has an arbitrary data value and an arbitrary value in the “previous hash” parameter.
Now that we’re able to create a genesis block, we need a function that will generate succeeding blocks in the blockchain. This function will take the previous block in the chain as a parameter, create the data for the block to be generated, and return the new block with its appropriate data. When new blocks hash information from previous blocks, the integrity of the blockchain increases with each new block. If we didn’t do this, it would be easier for an outside party to “change the past” and replace our chain with an entirely new one of their own. This chain of hashes acts as cryptographic proof and helps ensure that once a block is added to the blockchain it cannot be replaced or removed.
That’s the majority of the hard work. Now, we can create our blockchain! In our case, the blockchain itself is a simple Python list. The first element of the list is the genesis block. And of course, we need to add the succeeding blocks. Because SnakeCoin is the tiniest blockchain, we’ll only add 20 new blocks. We can do this with a for loop.
Let’s test what we’ve made so far.
There we go! Our blockchain works. If you want to see more information in the console, you could [edit the complete source file](https://gist.github.com/aunyks/8f2c2fd51cc17f342737917e1c2582e2) and print each block’s timestamp or data.
That’s about all that SnakeCoin has to offer. To make SnakeCoin scale to the size of today’s production blockchains, we’d have to add more features like a server layer to track changes to the chain on multiple machines and a [proof-of-work algorithm](https://en.bitcoin.it/wiki/Proof_of_work) to limit the amount of blocks added in a given time period.
If you’d like to get more technical, you can view the original Bitcoin whitepaper [here](https://bitcoin.org/bitcoin.pdf). Best of luck and happy hacking!
*Note: Part 2 of this piece can be found **here**.*
Thank you very much for reading! |
9,454 | 使用一个命令重置 Linux 桌面为默认设置 | https://www.ostechnix.com/reset-linux-desktop-default-settings-single-command/ | 2018-03-17T12:13:00 | [
"重置",
"Resetter"
] | https://linux.cn/article-9454-1.html | 
前段时间,我们分享了一篇关于 [Resetter](/article-9217-1.html) 的文章 —— 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
### 将 Linux 桌面重置为默认设置
这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 Arch Linux MATE 和 Ubuntu 16.04 Unity 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中固定的应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
好的是它只会重置桌面设置。它不会影响其他不使用 `dconf` 的程序。此外,它不会删除你的个人资料。
现在,让我们开始。要将 Ubuntu Unity 或其他带有 GNOME/MATE 环境的 Linux 桌面重置,运行下面的命令:
```
dconf reset -f /
```
在运行上述命令之前,这是我的 Ubuntu 16.04 LTS 桌面:
[](http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png)
如你所见,我已经改变了桌面壁纸和主题。
这是运行该命令后,我的 Ubuntu 16.04 LTS 桌面的样子:
[](http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png)
看见了么?现在,我的 Ubuntu 桌面已经回到了出厂设置。
有关 `dconf` 命令的更多详细信息,请参阅手册页。
```
man dconf
```
在重置桌面上我个人更喜欢 “Resetter” 而不是 `dconf` 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 `dconf` 命令在几分钟内将你的 Linux 系统重置为默认设置。
就是这样了。希望这个有帮助。我将很快发布另一篇有用的指导。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/reset-linux-desktop-default-settings-single-command/>
作者:[Edwin Arteaga](https://www.ostechnix.com) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,455 | 如何使用 yum-cron 自动更新 RHEL/CentOS Linux | https://www.cyberciti.biz/faq/fedora-automatic-update-retrieval-installation-with-cron/ | 2018-03-17T23:02:38 | [
"yum",
"更新",
"cron"
] | https://linux.cn/article-9455-1.html | 
`yum` 命令是 RHEL / CentOS Linux 系统中用来安装和更新软件包的一个工具。我知道如何使用 [yum 命令行](https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/) 更新系统,但是我想用 cron 任务自动更新软件包。该如何配置才能使得 `yum` 使用 [cron 自动更新](https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses)系统补丁或更新呢?
首先需要安装 yum-cron 软件包。该软件包提供以 cron 命令运行 `yum` 更新所需的文件。如果你想要每晚通过 cron 自动更新可以安装这个软件包。
### CentOS/RHEL 6.x/7.x 上安装 yum cron
输入以下 [yum 命令][3]:
```
$ sudo yum install yum-cron
```

使用 CentOS/RHEL 7.x 上的 `systemctl` 启动服务:
```
$ sudo systemctl enable yum-cron.service
$ sudo systemctl start yum-cron.service
$ sudo systemctl status yum-cron.service
```
在 CentOS/RHEL 6.x 系统中,运行:
```
$ sudo chkconfig yum-cron on
$ sudo service yum-cron start
```

`yum-cron` 是 `yum` 的一个替代方式。使得 cron 调用 `yum` 变得非常方便。该软件提供了元数据更新、更新检查、下载和安装等功能。`yum-cron` 的各种功能可以使用配置文件配置,而不是输入一堆复杂的命令行参数。
### 配置 yum-cron 自动更新 RHEL/CentOS Linux
使用 vi 等编辑器编辑文件 `/etc/yum/yum-cron.conf` 和 `/etc/yum/yum-cron-hourly.conf`:
```
$ sudo vi /etc/yum/yum-cron.conf
```
确保更新可用时自动更新:
```
apply_updates = yes
```
可以设置通知 email 的发件地址。注意: localhost`将会被`system\_name` 的值代替。
```
email_from = root@localhost
```
列出发送到的 email 地址。
```
email_to = your-it-support@some-domain-name
```
发送 email 信息的主机名。
```
email_host = localhost
```
[CentOS/RHEL 7.x][4] 上不想更新内核的话,添加以下内容:
```
exclude=kernel*
```
RHEL/CentOS 6.x 下[添加以下内容来禁用内核更新](https://www.cyberciti.biz/faq/redhat-centos-linux-yum-update-exclude-packages/):
```
YUM_PARAMETER=kernel*
```
[保存并关闭文件](https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/)。如果想每小时更新系统的话修改文件 `/etc/yum/yum-cron-hourly.conf`,否则文件 `/etc/yum/yum-cron.conf` 将使用以下命令每天运行一次(使用 [cat 命令](https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/) 查看):
```
$ cat /etc/cron.daily/0yum-daily.cron
```
示例输出:
```
#!/bin/bash
# Only run if this flag is set. The flag is created by the yum-cron init
# script when the service is started -- this allows one to use chkconfig and
# the standard "service stop|start" commands to enable or disable yum-cron.
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
exit 0
fi
# Action!
exec /usr/sbin/yum-cron /etc/yum/yum-cron-hourly.conf
[root@centos7-box yum]# cat /etc/cron.daily/0yum-daily.cron
#!/bin/bash
# Only run if this flag is set. The flag is created by the yum-cron init
# script when the service is started -- this allows one to use chkconfig and
# the standard "service stop|start" commands to enable or disable yum-cron.
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
exit 0
fi
# Action!
exec /usr/sbin/yum-cron
```
完成配置。现在你的系统将每天自动更新一次。更多细节请参照 yum-cron 的说明手册。
```
$ man yum-cron
```
### 关于作者
作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter](https://twitter.com/nixcraft)、[Facebook](https://facebook.com/nixcraft)、[Google+](https://plus.google.com/+CybercitiBiz) 上关注他。获取更多有关系统管理、Linux/Unix 和开源话题请关注[我的 RSS/XML 地址](https://www.cyberciti.biz/atom/atom.xml)。
---
via: <https://www.cyberciti.biz/faq/fedora-automatic-update-retrieval-installation-with-cron/>
作者:[Vivek Gite](https://www.cyberciti.biz/) 译者:[shipsw](https://github.com/shipsw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[3]:<https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/> [4]:<https://www.cyberciti.biz/faq/yum-update-except-kernel-package-command/>
| 403 | Forbidden | null |
9,456 | RStudio IDE 入门 | https://opensource.com/article/18/2/getting-started-RStudio-IDE | 2018-03-18T00:10:00 | [
"统计",
"RStudio"
] | https://linux.cn/article-9456-1.html |
>
> 用于统计技术的 R 项目是分析数据的有力方式,而 RStudio IDE 则可使这一切更加容易。
>
>
>

从我记事起,我就一直喜欢摆弄数字。作为 20 世纪 70 年代后期的大学生,我上过统计学的课程,学习了如何检查和分析数据以揭示其意义。
那时候,我有一部科学计算器,它让统计计算变得比以往更容易。在 90 年代早期,作为一名从事 <ruby> t 检验 <rt> t-test </rt></ruby>、相关性以及 [ANOVA](https://en.wikipedia.org/wiki/Analysis_of_variance) 研究的教育心理学研究生,我开始通过精心编写输入到 IBM 主机的文本文件来进行计算。这个主机远超我的手持计算器,但是一个小的空格错误就会导致整个过程无效,而且这个过程仍然有点乏味。
撰写论文时,尤其是我的毕业论文,我需要一种方法能够根据我的数据来创建图表,并将它们嵌入到文字处理文档中。我着迷于 Microsoft Excel 及其数字运算能力以及可以用计算结果创建出的大量图表。但这条路每一步都有成本。在 20 世纪 90 年代,除了 Excel,还有其他专有软件包,比如 SAS 和 SPSS+,但对于我那已经满满的研究生时间表来说,学习曲线是一项艰巨的任务。
### 快速回到现在
最近,由于我对数据科学的兴趣浓厚,加上对 Linux 和开源软件感兴趣,我阅读了大量的数据科学文章,并在 Linux 会议上听了许多数据科学演讲者谈论他们的工作。因此,我开始对编程语言 R(一种开源的统计计算软件)非常感兴趣。
起初,这只是一个偶发的一个想法。当我和我的朋友 Michael J. Gallagher 博士谈论他如何在他的 [博士论文](https://www.michael-j-gallagher.com/high-performance-computing) 研究中使用 R 时,这个火花便增大了。最后,我访问了 [R 项目](https://www.r-project.org/) 的网站,并了解到我可以轻松地安装 [R for Linux](https://cran.r-project.org/index.html)。游戏开始!
### 安装 R
根据你的操作系统和发行版情况,安装 R 会稍有不同。请参阅 [Comprehensive R Archive Network](https://cran.r-project.org/) (CRAN)网站上的安装指南。CRAN 提供了在 [各种 Linux 发行版](https://cran.r-project.org/bin/linux/),[Fedora,RHEL,及其衍生版](https://cran.r-project.org/bin/linux/redhat/README),[MacOS](https://cran.r-project.org/bin/macosx/) 和 [Windows](https://cran.r-project.org/bin/windows/) 上的安装指示。
我在使用 Ubuntu,按照 CRAN 的指示,将以下行加入到我的 `/etc/apt/sources.list` 文件中:
```
deb https://<my.favorite.cran.mirror>/bin/linux/ubuntu artful/
```
接着我在终端运行下面命令:
```
$ sudo apt-get update
$ sudo apt-get install r-base
```
根据 CRAN 说明,“需要从源码编译 R 的用户[如包的维护者,或者任何通过 `install.packages()` 安装包的用户]也应该安装 `r-base-dev` 的包。”
### 使用 R 和 RStudio
安装好了 R,我就准备了解更多关于使用这个强大的工具的信息。Gallagher 博士推荐了 [DataCamp](https://www.datacamp.com/onboarding/learn?from=home&technology=r) 上的 “R 语言入门”,并且我也在 [Code School](http://tryr.codeschool.com/levels/1/challenges/1) 找到了适用于 R 新手的免费课程。两门课程都帮助我学习了 R 的命令和语法。我还参加了 [Udemy](https://www.udemy.com/r-programming) 上的 R 在线编程课程,并从 [No Starch 出版社](https://opensource.com/article/17/10/no-starch) 上购买了 [R 之书](https://nostarch.com/bookofr)。
在阅读更多内容并观看 YouTube 视频后,我意识到我还应该安装 [RStudio](https://www.rstudio.com/)。Rstudio 是 R 语言的开源 IDE,易于在 [Debian、Ubuntu、 Fedora 和 RHEL](https://www.rstudio.com/products/rstudio/download/) 上安装。它也可以安装在 MacOS 和 Windows 上。
根据 RStudio 网站的说明,可以根据你的偏好对 IDE 进行自定义,具体方法是选择工具菜单,然后从中选择全局选项。

R 提供了一些很棒的演示例子,可以通过在提示符处输入 `demo()` 从控制台访问。`demo(plotmath)` 和 `demo(perspective)` 选项为 R 强大的功能提供了很好的例证。我尝试过一些简单的 [vectors](http://www.r-tutor.com/r-introduction/vector) 并在 R 控制台的命令行中绘制,如下所示。

你可能想要开始学习如何将 R 和一些样本数据结合起来使用,然后将这些知识应用到自己的数据上得到描述性统计。我自己没有丰富的数据来分析,但我搜索了可以使用的数据集 [datasets](https://vincentarelbundock.github.io/Rdatasets/datasets.html);有一个这样的数据集(我并没有用这个例子)是由圣路易斯联邦储备银行提供的 [经济研究数据](https://fred.stlouisfed.org/)。我对一个题为“美国商业航空公司的乘客里程(1937-1960)”很感兴趣,因此我将它导入 RStudio 以测试 IDE 的功能。RStudio 可以接受各种格式的数据,包括 CSV、Excel、SPSS 和 SAS。

数据导入后,我使用 `summary(AirPassengers)` 命令获取数据的一些初始描述性统计信息。按回车键后,我得到了 1949-1960 年的每月航空公司旅客的摘要以及其他数据,包括飞机乘客数量的最小值、最大值、四分之一位数、四分之三位数、中位数以及平均数。

我从摘要统计信息中知道航空乘客样本的均值为 280.3。在命令行中输入 `sd(AirPassengers)` 会得到标准偏差,在 RStudio 控制台中可以看到:

接下来,我生成了一个数据直方图,通过输入 `hist(AirPassengers);` 得到,这会以图形的方式显示此数据集;RStudio 可以将数据导出为 PNG、PDF、JPEG、TIFF、SVG、EPS 或 BMP。

除了生成统计数据和图形数据外,R 还记录了我所有的历史操作。这使得我能够返回先前的操作,并且我可以保存此历史记录以供将来参考。

在 RStudio 的脚本编辑器中,我可以编写我发出的所有命令的脚本,然后保存该脚本以便在我的数据更改后能再次运行,或者想重新访问它。

### 获得帮助
在 R 提示符下输入 `help()` 可以很容易找到帮助信息。输入你正在寻找的信息的特定主题可以找到具体的帮助信息,例如 `help(sd)` 可以获得有关标准差的帮助。通过在提示符处输入 `contributors()` 可以获得有关 R 项目贡献者的信息。您可以通过在提示符处输入 `citation()` 来了解如何引用 R。通过在提示符出输入 `license()` 可以很容易地获得 R 的许可证信息。
R 是在 GNU General Public License(1991 年 6 月的版本 2,或者 2007 年 6 月的版本 3)的条款下发布的。有关 R 许可证的更多信息,请参考 [R 项目官网](https://www.r-project.org/Licenses/)。
另外,RStudio 在 GUI 中提供了完美的帮助菜单。该区域包括 RStudio 快捷表(可作为 PDF 下载),[RStudio](https://www.rstudio.com/online-learning/#R)的在线学习、RStudio 文档、支持和 [许可证信息](https://support.rstudio.com/hc/en-us/articles/217801078-What-license-is-RStudio-available-under-)。
---
via: <https://opensource.com/article/18/2/getting-started-RStudio-IDE>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 译者:[szcf-weiya](https://github.com/szcf-weiya) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For as long as I can remember, I've been toying with numbers. As an undergraduate student in the late 1970s, I began taking statistics courses, learning ways to examine and analyze data to uncover some meaning.
Back then, I had a scientific calculator that made statistical calculations much easier than ever before. In the early '90s, as a graduate student in educational psychology working on t-tests, correlations, and [ANOVA](https://en.wikipedia.org/wiki/Analysis_of_variance), I started doing my calculations by meticulously writing text files that were fed into an IBM mainframe. The mainframe was an improvement over my handheld calculator, but one minor spacing error rendered the whole process null and void, and the process was still somewhat tedious.
For writing papers and especially my thesis, I needed a way to create charts from my data and embed them in word processing documents. I was fascinated with Microsoft Excel and its number-crunching capabilities and the myriad charts I could create with the computed results. But there were costs at every step of the way. In the 1990s, along with Excel, there were other proprietary packages available like SAS and SPSS+, but the learning curve was a steep task for my already cramped graduate student schedule.
## Fast forward to the present
More recently, due to my budding interest in data science, combined with my keen interest in Linux and open source software, I've read a lot of data science articles and listened to a lot of data science speakers talk about their work at Linux conferences. As a result, I became very interested in the programming language R, an open source statistical computing software.
At first, it was just a spark. That spark grew when I talked to my friend Michael J. Gallagher, PhD, about how he used R in his [dissertation research](https://www.michael-j-gallagher.com/high-performance-computing). Finally, I visited the [R Project](https://www.r-project.org/) website and learned I could easily install [R for Linux](https://cran.r-project.org/index.html). Game on!
## Installing R
Installing R varies slightly depending on your operating system or distribution. Refer to the installation guide found at the [Comprehensive R Archive Network](https://cran.r-project.org/) (CRAN) website. CRAN offers detailed instructions for installing R on [various Linux distributions](https://cran.r-project.org/bin/linux/), [Fedora, RHEL, and derivatives](https://cran.r-project.org/bin/linux/redhat/README), [MacOS](https://cran.r-project.org/bin/macosx/), and [Windows](https://cran.r-project.org/bin/windows/).
I was using Ubuntu and, as specified at CRAN, added the following line to my `/etc/apt/sources.list`
file:
```
````deb https://<my.favorite.cran.mirror>/bin/linux/ubuntu artful/`
Then I ran the following commands in the terminal:
```
``````
$ sudo apt-get update
$ sudo apt-get install r-base
```
According to CRAN, "Users who need to compile R packages from source [e.g. package maintainers, or anyone installing packages with `install.packages()`
] should also install the `r-base-dev`
package."
## Using R and RStudio
Once I installed R, I was ready to learn more about using this powerful tool. Dr. Gallagher recommended "Start learning R" on [DataCamp](https://www.datacamp.com/onboarding/learn?from=home&technology=r), and I also found a free course for R newbies on [Code School](http://tryr.codeschool.com/levels/1/challenges/1). Both courses helped me learn R's commands and syntax. I also enrolled in an online course in R programming at [Udemy](https://www.udemy.com/r-programming) and purchased the * Book of R* from
[No Starch Press](https://opensource.com/article/17/10/no-starch).
After more reading and watching YouTube videos, I realized I should also install [RStudio](https://www.rstudio.com/). RStudio is an open source IDE for R that's easy to install on [Debian, Ubuntu, Fedora, and RHEL](https://www.rstudio.com/products/rstudio/download/). It can also be installed on MacOS and Windows.
According to the RStudio website, the IDE can be customized to your preferences by selecting the Tools menu and, from there, Global Options.
opensource.com
R provides some great demonstration examples that can be accessed from the console by entering `demo()`
at the prompt. The `demo(plotmath)`
and `demo(perspective)`
options provide great illustrations of the power of R. I experimented with some simple [vectors](http://www.r-tutor.com/r-introduction/vector) and plotting at the command line in the R console, which is shown below.
opensource.com
You may want to start learning ways to use R with some sample data, then later apply that knowledge to yield descriptive statistics on your own data. Not having an abundance of data of my own to analyze, I searched for [datasets](https://vincentarelbundock.github.io/Rdatasets/datasets.html) that I could use; one such source (which I didn't use for this example) is [economic research data](https://fred.stlouisfed.org/) provided by the Federal Reserve Bank of St. Louis. I was intrigued by a dataset I found titled "Passenger Miles on Commercial US Airlines, 1937-1960," so I imported it into RStudio to test out the IDE's capabilities. RStudio can accept data in a variety of formats, including CSV, Excel, SPSS, and SAS.
opensource.com
Once the data is imported, I used the `summary(AirPassengers)`
command to get some initial descriptive statistics of the data. After pressing Enter, I got a summary of monthly airline passengers from 1949-1960, as well as other data, including the minimum, maximum, first quarter, third quarter, median, and mean number of air passengers.

opensource.com
I knew from my summary statistics that the mean of this sample of airline passengers is 280.3. Entering `sd(AirPassengers)`
at the console yields the standard deviation, seen here in the RStudio console:

opensource.com
I next generated a histogram of my data, which shows this dataset graphically, by entering `hist(AirPassengers);`
RStudio can export the data as a PNG, PDF, JPEG, TIFF, SVG, EPS, or BMP.
opensource.com
In addition to generating statistics and graphical data, R keeps a history of all my operations. This enables me to return to a previous operation, and I can save this history for future reference.
opensource.com
In RStudio's script editor, I can write a script of all the commands that I issue, then save that script to run again if my data changes or I want to revisit it.
opensource.com
## Getting help
Help can easily be found by entering `help()`
at the R prompt. Specific help information can be found by entering the specific topic you are looking for information about, e.g., `help(sd)`
for help with standard deviation. Information on contributors to the R project can be obtained by entering `contributors()`
at the prompt. You can find out how to cite R by entering `citation()`
at the prompt. License information for R can be easily obtained by entering `license()`
at the prompt.
R is distributed under the terms of the GNU General Public License, either Version 2, June 1991, or Version 3, June 2007. For more information about licensing R, refer to the[ R Project website.](https://www.r-project.org/Licenses/)
In addition, RStudio provides an excellent Help menu within the GUI. This area includes links to an RStudio cheat sheet (which can be downloaded as a PDF), online learning at [RStudio](https://www.rstudio.com/online-learning/#R), RStudio documentation, support, and [license information](https://support.rstudio.com/hc/en-us/articles/217801078-What-license-is-RStudio-available-under-).
Are you doing data science with R? Let us know how you are using it by leaving a comment below.
## 2 Comments |
9,457 | du 及 df 命令的使用(附带示例) | http://linuxtechlab.com/du-df-commands-examples/ | 2018-03-18T10:13:54 | [
"du",
"df"
] | https://linux.cn/article-9457-1.html | 
在本文中,我将讨论 `du` 和 `df` 命令。`du` 和 `df` 命令都是 Linux 系统的重要工具,来显示 Linux 文件系统的磁盘使用情况。这里我们将通过一些例子来分享这两个命令的用法。
* **(推荐阅读:[使用 scp 和 rsync 命令传输文件](http://linuxtechlab.com/files-transfer-scp-rsync-commands/))**
* **(另请阅读:[使用 dd 和 cat 命令为 Linux 系统克隆磁盘](http://linuxtechlab.com/linux-cloning-disks-using-dd-cat-commands/))**
### du 命令
`du`(disk usage 的简称)是用于查找文件和目录的磁盘使用情况的命令。`du` 命令在与各种选项一起使用时能以多种格式提供结果。
下面是一些例子:
#### 1、 得到一个目录下所有子目录的磁盘使用概况
```
$ du /home
```

该命令的输出将显示 `/home` 中的所有文件和目录以及显示块大小。
#### 2、 以人类可读格式也就是 kb、mb 等显示文件/目录大小
```
$ du -h /home
```

#### 3、 目录的总磁盘大小
```
$ du -s /home
```

它是 `/home` 目录的总大小
### df 命令
df(disk filesystem 的简称)用于显示 Linux 系统的磁盘利用率。(LCTT 译注:`df` 可能应该是 disk free 的简称。)
下面是一些例子。
#### 1、 显示设备名称、总块数、总磁盘空间、已用磁盘空间、可用磁盘空间和文件系统上的挂载点。
```
$ df
```

#### 2、 人类可读格式的信息
```
$ df -h
```

上面的命令以人类可读格式显示信息。
#### 3、 显示特定分区的信息
```
$ df -hT /etc
```

`-hT` 加上目标目录将以可读格式显示 `/etc` 的信息。
虽然 `du` 和 `df` 命令有更多选项,但是这些例子可以让你初步了解。如果在这里找不到你要找的东西,那么你可以参考有关命令的 man 页面。
另外,[**在这**](http://linuxtechlab.com/tips-tricks/)阅读我的其他帖子,在那里我分享了一些其他重要和经常使用的 Linux 命令。
如往常一样,欢迎你留下评论和疑问,因此在下面留下你的评论和疑问,我会回复你。
---
via: <http://linuxtechlab.com/du-df-commands-examples/>
作者:[SHUSAIN](http://linuxtechlab.com/author/shsuain/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,458 | Linux 新用户?来试试这 8 款重要的软件 | https://www.maketecheasier.com/essential-linux-apps/ | 2018-03-20T09:14:00 | [
"软件"
] | https://linux.cn/article-9458-1.html | 
即便您不是计算机的新手,刚接触 Linux 时,通常都会面临选择使用应用软件的问题。在数百万 Linux 应用程序中,做起选择来并不轻松。本文中,您将能发现八个重要的 Linux 应用,帮助您快速选择应用程序。
下面这些应用程序大多不是 Linux 独有的。如果有过使用 Windows/Mac 的经验,您很可能会熟悉其中一些软件。根据兴趣和需求,下面的程序可能不全符合您的要求,但是在我看来,清单里大多数甚至全部的软件,对于新用户开启 Linux 之旅都是有帮助的。
**相关链接** : [每一个 Linux 用户都应该使用的 11 个可移植软件](https://www.maketecheasier.com/portable-apps-for-linux/ "11 Portable Apps Every Linux User Should Use")
### 1. Chromium 网页浏览器

几乎不会不需要使用网页浏览器的用户。您可以看到陈旧的 Linux 发行版几乎都会附带 Firefox(火狐浏览器)或者其他 [Linux 浏览器](https://www.maketecheasier.com/linux-browsers-you-probably-havent-heard-of/),关于浏览器,强烈建议您尝试 [Chromium](http://www.chromium.org/)。它是谷歌浏览器的开源版。Chromium 的主要优点是速度和安全性。它同样拥有大量的附加组件。
### 2. LibreOffice

[LibreOffice](https://www.libreoffice.org/) 是一个开源办公套件,其包括文字处理(Writer)、电子表格(Calc)、演示(Impress)、数据库(Base)、公式编辑器(Math)、矢量图和流程图(Draw)应用程序。它与 Microsoft Office 文档兼容,如果其基本功能不能满足需求,您可以使用 [LibreOffice 拓展](https://www.maketecheasier.com/best-libreoffice-extensions/)。
LibreOffice 显然是 Linux 应用中至关重要的一员,如果您使用 Linux 的计算机,安装它是有必要的。
### 3. GIMP(<ruby> GUN 图像处理程序 <rt> GNU Image Manipulation Program </rt></ruby>)

[GIMP](https://www.gimp.org/) 是一款非常强大的开源图片处理程序,它类似于 Photoshop。通过 GIMP,您可以编辑或是创建用于 Web 或是打印的光栅图(位图)。如果您对专业的图片处理没有概念,Linux 自然提供有更简单的图像编辑器,GIMP 看上去可能会复杂一点。GIMP 并不单纯提供图片裁剪和大小调整,它更覆盖了图层、滤镜、遮罩、路径和其他一些高级功能。
### 4. VLC 媒体播放器

[VLC](http://www.videolan.org/) 也许就是最好的影音播放器了。它是跨平台的,所以您可能在 Windows 上也听说过它。VLC 最特殊的地方是其拥有大量解码器(并不是所有的解码器都开放源代码),所以它几乎可以播放所有的影音文件。
### 5. Jitsy

[Jitsy](https://jitsi.org/) 完全是关于通讯的。您可以借助它使用 Google talk、Facebook chat、Yahoo、ICQ 和 XMPP。它是用于音视频通话(包括电话会议),<ruby> 桌面流 <rt> desktop streaming </rt></ruby>和群组聊天的多用户工具。会话会被加密。Jistsy 同样能帮助您传输文件或记录电话。
### 6. Synaptic

[Synaptic](http://www.nongnu.org/synaptic/) 是一款基于 Debian 系统发行版的另一款应用程序安装程序。并不是所有基于 Debian 的 Linux 都安装有它,如果您使用基于 Debian 的 Linux 操作系统没有预装,也许您可以试一试。Synaptic 是一款用于添加或移除系统应用的 GUI 工具,甚至相对于许多发行版默认安装的 [软件中心包管理器](https://www.maketecheasier.com/are-linux-gui-software-centers-any-good/) ,经验丰富的 Linux 用户更亲睐于 Sunaptic。
**相关链接** : [10 款您没听说过的 Linux 生产力应用程序](https://www.maketecheasier.com/free-linux-productivity-apps-you-havent-heard-of/ "10 Free Linux Productivity Apps You Haven’t Heard Of")
### 7. VirtualBox

[VirtualBox](https://www.virtualbox.org/) 能支持您在计算机上运行虚拟机。当您想在当前 Linux 发行版上安装其他发行版或操作系统时,使用虚拟机会方便许多。您同样可以通过它运行 Windows 应用程序,性能可能会稍弱,但是如果您有一台强大的计算机,就不会那么糟。
### 8. AisleRiot Solitaire(纸牌游戏)

对于 Linux 的新用户来说,一款纸牌游戏并不是刚需,但是它真的太有趣了。当您进入这款纸牌游戏,您会发现,这是一款极好的纸牌游戏包。[AisleRiot](https://wiki.gnome.org/Aisleriot) 是 Linux 标志性的应用程序,原因是 - 它涵盖超过八十种纸牌游戏,包括流行的 Klondike、Bakers Dozen、Camelot 等等,作为预警 - 它是会上瘾的,您可能会花很长时间沉迷于此!
根据您所使用的发行版,这些软件会有不同的安装方法。但是大多数都可以通过您使用的发行版中的包管理器安装使用,甚至它们可能会预装在您的发行版上。安装并且尝试它们想必是最好的,如果不合您的胃口,您可以轻松地删除它们。
---
via: <https://www.maketecheasier.com/essential-linux-apps/>
作者:[Ada Ivanova](https://www.maketecheasier.com/author/adaivanoff/) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
When you are new to Linux, even if you are not new to computers in general, one of the problems you will face is which apps to use. With millions of Linux apps, the choice is certainly not easy. Below you will find eight (out of millions) essential Linux apps to get you settled in quickly.
Most of these apps are not exclusive to Linux. If you have used Windows/Mac before, chances are you are familiar with some of them. Depending on what your needs and interests are, you might not need all these apps, but in my opinion, most or all of the apps on this list are useful for newbies who are just starting out on Linux.
**Also read:** [11 Portable Apps Every Linux User Should Use](https://www.maketecheasier.com/portable-apps-for-linux/)
## 1. Chromium Web Browser
There is hardly a user who doesn’t need a web browser. While you can find good old Firefox for almost any Linux distro, and there is also a bunch of other [Linux browsers](https://www.maketecheasier.com/best-web-browsers-for-linux/), a browser you should definitely try is [Chromium](https://www.chromium.org/). It’s the open source counterpart of Google’s Chrome browser. The main advantages of Chromium is that it is secure and fast. There are also tons of add-ons for it.
## 2. LibreOffice
[LibreOffice](https://www.libreoffice.org/) is an open source Office suite that comes with word processor (Writer), spreadsheet (Calc), presentation (Impress), database (Base), formula editor (Math), and vector graphics and flowcharts (Draw) applications. It’s compatible with Microsoft Office documents, and there are even [LibreOffice extensions](https://www.maketecheasier.com/best-libreoffice-extensions/) if the default functionality isn’t enough for you.
LibreOffice is definitely one essential Linux app that you should have on your Linux computer.
## 3. GIMP
[GIMP](https://www.gimp.org/) is a very powerful open-source image editor. It’s similar to Photoshop. With GIMP you can edit photos and create and edit raster images for the Web and print. It’s true there are simpler image editors for Linux, so if you have no idea about image processing at all, GIMP might look too complicated to you. GIMP goes way beyond simple image crop and resize – it offers layers, filters, masks, paths, etc.
## 4. VLC Media Player
[VLC](https://www.videolan.org/) is probably the best movie player. It’s cross-platform, so you might know it from Windows. What’s really special about VLC is that it comes with lots of codecs (not all of which are open source, though), so it will play (almost) any music or video file.
## 5. Jitsi
[Jitsi](https://jitsi.org/) is all about communication. You can use it for Google Talk, Facebook chat, Yahoo, ICQ and XMPP. It’s a multi-user tool for audio and video calls (including conference calls), as well as desktop streaming and group chats. Conversations are encrypted. With Jitsi you can also transfer files and record your calls.
## 6. Synaptic
[Synaptic](https://www.nongnu.org/synaptic/) is an alternative app installer for Debian-based distros. It comes with some distros but not all, so if you are using a Debian-based Linux, but there is no Synaptic in it, you might want to give it a try. Synaptic is a GUI tool for adding and removing apps from your system, and typically veteran Linux users favor it over the [Software Center package manager](https://www.maketecheasier.com/are-linux-gui-software-centers-any-good/) that comes with many distros as a default.
**Also read:** [10 Free Linux Productivity Apps You Haven’t Heard Of](https://www.maketecheasier.com/free-linux-productivity-apps-you-havent-heard-of/)
## 7. VirtualBox
[VirtualBox](https://www.virtualbox.org/) allows you to run a virtual machine on your computer. A virtual machine comes in handy when you want to install another Linux distro or operating system from within your current Linux distro. You can use it to run Windows apps as well. Performance will be slower, but if you have a powerful computer, it won’t be that bad.
## 8. AisleRiot Solitaire
A solitaire pack is hardly an absolute necessity for a new Linux user, but since it’s so fun. If you are into solitaire games, this is a great solitaire pack. [AisleRiot](https://wiki.gnome.org/Aisleriot) is one of the emblematic Linux apps, and this is for a reason – it comes with more than eighty solitaire games, including the popular Klondike, Bakers Dozen, Camelot, etc. Just be warned – it’s addictive and you might end up spending long hours playing with it!
Depending on the distro you are using, the way to install these apps is not the same. However, most, if not all, of these apps will be available for install with a package manager for your distro, or even come pre-installed with your distro. The best thing is, you can install and try them out and easily remove them if you don’t like them.
Our latest tutorials delivered straight to your inbox |
9,459 | 如何在 CentOS 7 / RHEL 7 终端服务器上安装 KVM | https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/ | 2018-03-18T21:12:05 | [
"KVM",
"虚拟机"
] | https://linux.cn/article-9459-1.html | 
如何在 CnetOS 7 或 RHEL 7(Red Hat 企业版 Linux)服务器上安装和配置 KVM(基于内核的虚拟机)?如何在 CentOS 7 上设置 KVM 并使用云镜像 / cloud-init 来安装客户虚拟机?
基于内核的虚拟机(KVM)是 CentOS 或 RHEL 7 的虚拟化软件。KVM 可以将你的服务器变成虚拟机管理器。本文介绍如何在 CentOS 7 或 RHEL 7 中使用 KVM 设置和管理虚拟化环境。还介绍了如何使用命令行在物理服务器上安装和管理虚拟机(VM)。请确保在服务器的 BIOS 中启用了**虚拟化技术(VT)**。你也可以运行以下命令[测试 CPU 是否支持 Intel VT 和 AMD\_V 虚拟化技术](https://www.cyberciti.biz/faq/linux-xen-vmware-kvm-intel-vt-amd-v-support/)。
```
$ lscpu | grep Virtualization
Virtualization: VT-x
```
按照 CentOS 7/RHEL 7 终端服务器上的 KVM 安装步骤进行操作。
### 步骤 1: 安装 kvm
输入以下 [yum 命令](https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ "See Linux/Unix yum command examples for more info"):
```
# yum install qemu-kvm libvirt libvirt-python libguestfs-tools virt-install
```
[](https://www.cyberciti.biz/media/new/faq/2018/01/How-to-install-KVM-on-CentOS-7-RHEL-7-Headless-Server.jpg)
启动 libvirtd 服务:
```
# systemctl enable libvirtd
# systemctl start libvirtd
```
### 步骤 2: 确认 kvm 安装
使用 `lsmod` 命令和 [grep命令](https://www.cyberciti.biz/faq/howto-use-grep-command-in-linux-unix/ "See Linux/Unix grep command examples for more info") 确认加载了 KVM 模块:
```
# lsmod | grep -i kvm
```
### 步骤 3: 配置桥接网络
默认情况下,由 libvirtd 配置基于 dhcpd 的网桥。你可以使用以下命令验证:
```
# brctl show
# virsh net-list
```
[](https://www.cyberciti.biz/media/new/faq/2018/01/KVM-default-networking.jpg)
所有虚拟机(客户机)只能对同一台服务器上的其它虚拟机进行网络访问。为你创建的私有网络是 192.168.122.0/24。验证:
```
# virsh net-dumpxml default
```
如果你希望你的虚拟机可用于 LAN 上的其他服务器,请在连接到你的 LAN 的服务器上设置一个网桥。更新你的网卡配置文件,如 ifcfg-enp3s0 或 em1:
```
# vi /etc/sysconfig/network-scripts/ifcfg-enp3s0
```
添加一行:
```
BRIDGE=br0
```
[使用 vi 保存并关闭文件](https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/)。编辑 `/etc/sysconfig/network-scripts/ifcfg-br0`:
```
# vi /etc/sysconfig/network-scripts/ifcfg-br0
```
添加以下内容:
```
DEVICE="br0"
# I am getting ip from DHCP server #
BOOTPROTO="dhcp"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
ONBOOT="yes"
TYPE="Bridge"
DELAY="0"
```
重新启动网络服务(警告:ssh 命令将断开连接,最好重新启动该设备):
```
# systemctl restart NetworkManager
```
用 `brctl` 命令验证它:
```
# brctl show
```
### 步骤 4: 创建你的第一个虚拟机
我将会创建一个 CentOS 7.x 虚拟机。首先,使用 `wget` 命令获取 CentOS 7.x 最新的 ISO 镜像:
```
# cd /var/lib/libvirt/boot/
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/CentOS-7-x86_64-Minimal-1708.iso
```
验证 ISO 镜像:
```
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/sha256sum.txt
# sha256sum -c sha256sum.txt
```
#### 创建 CentOS 7.x 虚拟机
在这个例子中,我创建了 2GB RAM,2 个 CPU 核心,1 个网卡和 40 GB 磁盘空间的 CentOS 7.x 虚拟机,输入:
```
# virt-install \
--virt-type=kvm \
--name centos7 \
--ram 2048 \
--vcpus=1 \
--os-variant=centos7.0 \
--cdrom=/var/lib/libvirt/boot/CentOS-7-x86_64-Minimal-1708.iso \
--network=bridge=br0,model=virtio \
--graphics vnc \
--disk path=/var/lib/libvirt/images/centos7.qcow2,size=40,bus=virtio,format=qcow2
```
从另一个终端通过 `ssh` 配置 vnc 登录,输入:
```
# virsh dumpxml centos7 | grep v nc
<graphics type='vnc' port='5901' autoport='yes' listen='127.0.0.1'>
```
请记录下端口值(即 5901)。你需要使用 SSH 客户端来建立隧道和 VNC 客户端才能访问远程 vnc 服务器。在客户端/桌面/ macbook pro 系统中输入以下 SSH 端口转发命令:
```
$ ssh [email protected] -L 5901:127.0.0.1:5901
```
一旦你建立了 ssh 隧道,你可以将你的 VNC 客户端指向你自己的 127.0.0.1 (localhost) 地址和端口 5901,如下所示:
[](https://www.cyberciti.biz/media/new/faq/2016/01/vnc-client.jpg)
你应该看到 CentOS Linux 7 客户虚拟机安装屏幕如下:
[](https://www.cyberciti.biz/media/new/faq/2016/01/centos7-guest-vnc.jpg)
现在只需按照屏幕说明进行操作并安装CentOS 7。一旦安装完成后,请继续并单击重启按钮。 远程服务器关闭了我们的 VNC 客户端的连接。 你可以通过 KVM 客户端重新连接,以配置服务器的其余部分,包括基于 SSH 的会话或防火墙。
### 使用云镜像
以上安装方法对于学习目的或单个虚拟机而言是可行的。你需要部署大量的虚拟机吗? 可以试试云镜像。你可以根据需要修改预先构建的云镜像。例如,使用 [Cloud-init](https://cloudinit.readthedocs.io/en/latest/index.html) 添加用户、ssh 密钥、设置时区等等,这是处理云实例的早期初始化的事实上的多分发包。让我们看看如何创建带有 1024MB RAM,20GB 磁盘空间和 1 个 vCPU 的 CentOS 7 虚拟机。(LCTT 译注: vCPU 即电脑中的虚拟处理器)
#### 获取 CentOS 7 云镜像
```
# cd /var/lib/libvirt/boot
# wget http://cloud.centos.org/centos/7/images/CentOS-7-x86_64-GenericCloud.qcow2
```
#### 创建所需的目录
```
# D=/var/lib/libvirt/images
# VM=centos7-vm1 ## vm name ##
# mkdir -vp $D/$VM
mkdir: created directory '/var/lib/libvirt/images/centos7-vm1'
```
#### 创建元数据文件
```
# cd $D/$VM
# vi meta-data
```
添加以下内容:
```
instance-id: centos7-vm1
local-hostname: centos7-vm1
```
#### 创建用户数据文件
我将使用 ssh 密钥登录到虚拟机。所以确保你有 ssh 密钥:
```
# ssh-keygen -t ed25519 -C "VM Login ssh key"
```
[](https://www.cyberciti.biz/faq/linux-unix-generating-ssh-keys/)
请参阅 “[如何在 Linux/Unix 系统上设置 SSH 密钥](https://www.cyberciti.biz/faq/how-to-set-up-ssh-keys-on-linux-unix/)” 来获取更多信息。编辑用户数据如下:
```
# cd $D/$VM
# vi user-data
```
添加如下(根据你的设置替换 `hostname`、`users`、`ssh-authorized-keys`):
```
#cloud-config
# Hostname management
preserve_hostname: False
hostname: centos7-vm1
fqdn: centos7-vm1.nixcraft.com
# Users
users:
- default
- name: vivek
groups: ['wheel']
shell: /bin/bash
sudo: ALL=(ALL) NOPASSWD:ALL
ssh-authorized-keys:
- ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIIMP3MOF2ot8MOdNXCpHem0e2Wemg4nNmL2Tio4Ik1JY VM Login ssh key
# Configure where output will go
output:
all: ">> /var/log/cloud-init.log"
# configure interaction with ssh server
ssh_genkeytypes: ['ed25519', 'rsa']
# Install my public ssh key to the first user-defined user configured
# in cloud.cfg in the template (which is centos for CentOS cloud images)
ssh_authorized_keys:
- ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIIMP3MOF2ot8MOdNXCpHem0e2Wemg4nNmL2Tio4Ik1JY VM Login ssh key
# set timezone for VM
timezone: Asia/Kolkata
# Remove cloud-init
runcmd:
- systemctl stop network && systemctl start network
- yum -y remove cloud-init
```
#### 复制云镜像
```
# cd $D/$VM
# cp /var/lib/libvirt/boot/CentOS-7-x86_64-GenericCloud.qcow2 $VM.qcow2
```
#### 创建 20GB 磁盘映像
```
# cd $D/$VM
# export LIBGUESTFS_BACKEND=direct
# qemu-img create -f qcow2 -o preallocation=metadata $VM.new.image 20G
# virt-resize --quiet --expand /dev/sda1 $VM.qcow2 $VM.new.image
```
[](https://www.cyberciti.biz/media/new/faq/2018/01/Set-VM-image-disk-size.jpg)
用缩放后的镜像覆盖它:
```
# cd $D/$VM
# mv $VM.new.image $VM.qcow2
```
#### 创建一个 cloud-init ISO
```
# mkisofs -o $VM-cidata.iso -V cidata -J -r user-data meta-data
```
[](https://www.cyberciti.biz/media/new/faq/2018/01/Creating-a-cloud-init-ISO.jpg)
#### 创建一个池
```
# virsh pool-create-as --name $VM --type dir --target $D/$VM
Pool centos7-vm1 created
```
#### 安装 CentOS 7 虚拟机
```
# cd $D/$VM
# virt-install --import --name $VM \
--memory 1024 --vcpus 1 --cpu host \
--disk $VM.qcow2,format=qcow2,bus=virtio \
--disk $VM-cidata.iso,device=cdrom \
--network bridge=virbr0,model=virtio \
--os-type=linux \
--os-variant=centos7.0 \
--graphics spice \
--noautoconsole
```
删除不需要的文件:
```
# cd $D/$VM
# virsh change-media $VM hda --eject --config
# rm meta-data user-data centos7-vm1-cidata.iso
```
#### 查找虚拟机的 IP 地址
```
# virsh net-dhcp-leases default
```
[](https://www.cyberciti.biz/media/new/faq/2018/01/CentOS7-VM1-Created.jpg)
#### 登录到你的虚拟机
使用 ssh 命令:
```
# ssh [email protected]
```
[](https://www.cyberciti.biz/media/new/faq/2018/01/Sample-VM-session.jpg)
### 有用的命令
让我们看看管理虚拟机的一些有用的命令。
#### 列出所有虚拟机
```
# virsh list --all
```
#### 获取虚拟机信息
```
# virsh dominfo vmName
# virsh dominfo centos7-vm1
```
#### 停止/关闭虚拟机
```
# virsh shutdown centos7-vm1
```
#### 开启虚拟机
```
# virsh start centos7-vm1
```
#### 将虚拟机标记为在引导时自动启动
```
# virsh autostart centos7-vm1
```
#### 重新启动(软安全重启)虚拟机
```
# virsh reboot centos7-vm1
```
重置(硬重置/不安全)虚拟机
```
# virsh reset centos7-vm1
```
#### 删除虚拟机
```
# virsh shutdown centos7-vm1
# virsh undefine centos7-vm1
# virsh pool-destroy centos7-vm1
# D=/var/lib/libvirt/images
# VM=centos7-vm1
# rm -ri $D/$VM
```
查看 virsh 命令类型的完整列表:
```
# virsh help | less
# virsh help | grep reboot
```
### 关于作者
作者是 nixCraft 的创建者,也是经验丰富的系统管理员和 Linux 操作系统/ Unix shell 脚本的培训师。 他曾与全球客户以及 IT,教育,国防和空间研究以及非营利部门等多个行业合作。 在 [Twitter](https://twitter.com/nixcraft),[Facebook](https://facebook.com/nixcraft),[Google +](https://plus.google.com/+CybercitiBiz) 上关注他。
---
via: <https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,461 | LKRG:用于运行时完整性检查的可加载内核模块 | https://www.bleepingcomputer.com/news/linux/lkrg-linux-to-get-a-loadable-kernel-module-for-runtime-integrity-checking/ | 2018-03-18T23:31:36 | [
"LKRG",
"内核",
"安全"
] | https://linux.cn/article-9461-1.html | 
开源社区的人们正在致力于一个 Linux 内核的新项目,它可以让内核更安全。命名为 <ruby> Linux 内核运行时防护 <rp> ( </rp> <rt> Linux Kernel Runtime Guard </rt> <rp> ) </rp></ruby>(LKRG),它是一个在 Linux 内核执行运行时完整性检查的可加载内核模块(LKM)。
它的用途是检测对 Linux 内核的已知的或未知的安全漏洞利用企图,以及去阻止这种攻击企图。
LKRG 也可以检测正在运行的进程的提权行为,在漏洞利用代码运行之前杀掉这个运行进程。
### 这个项目开发始于 2011 年,首个版本已经发布
因为这个项目开发的较早,LKRG 的当前版本仅仅是通过内核消息去报告违反内核完整性的行为,但是随着这个项目的成熟,将会部署一个完整的漏洞利用缓减系统。
LKRG 的成员 Alexander Peslyak 解释说,这个项目从 2011 年启动,并且 LKRG 已经经历了一个“重新开发"阶段。
LKRG 的首个公开版本是 LKRG v0.0,它现在可以从 [这个页面](http://www.openwall.com/lkrg/) 下载使用。[这里](http://openwall.info/wiki/p_lkrg/Main) 是这个项目的维基,为支持这个项目,它也有一个 [Patreon 页面](https://www.patreon.com/p_lkrg)。
虽然 LKRG 仍然是一个开源项目,LKRG 的维护者也计划做一个 LKRG Pro 版本,这个版本将包含一个专用的 LKRG 发行版,它将支持对特定漏洞利用的检测,比如,容器泄漏。开发团队计划从 LKRG Pro 基金中提取部分资金用于保证项目的剩余工作。
### LKRG 是一个内核模块而不是一个补丁。
一个类似的项目是<ruby> 附加内核监视器 <rt> Additional Kernel Observer </rt></ruby>(AKO),但是 LKRG 与 AKO 是不一样的,因为 LKRG 是一个内核加载模块而不是一个补丁。LKRG 开发团队决定将它设计为一个内核模块是因为,在内核上打补丁对安全性、系统稳定性以及性能都有很直接的影响。
而以内核模块的方式提供,可以在每个系统上更容易部署 LKRG,而不必去修改核心的内核代码,修改核心的内核代码非常复杂并且很容易出错。
LKRG 内核模块在目前主流的 Linux 发行版上都可以使用,比如,RHEL7、OpenVZ 7、Virtuozzo 7、以及 Ubuntu 16.04 到最新的主线版本。
### 它并非是一个完美的解决方案
LKRG 的创建者警告用户,他们并不认为 LKRG 是一个完美的解决方案,它**提供不了**坚不可摧和 100% 的安全。他们说,LKRG 是 “设计为**可旁通**的”,并且仅仅提供了“多元化安全” 的**一个**方面。
>
> 虽然 LKRG 可以防御许多已有的 Linux 内核漏洞利用,而且也有可能会防御将来许多的(包括未知的)未特意设计去绕过 LKRG 的安全漏洞利用。它是设计为可旁通的(尽管有时候是以更复杂和/或低可利用为代价的)。因此,他们说 LKRG 通过多元化提供安全,就像运行一个不常见的操作系统内核一样,也就不会有真实运行一个不常见的操作系统的可用性弊端。
>
>
>
LKRG 有点像基于 Windows 的防病毒软件,它也是工作于内核级别去检测漏洞利用和恶意软件。但是,LKRG 团队说,他们的产品比防病毒软件以及其它终端安全软件更加安全,因为它的基础代码量比较小,所以在内核级别引入新 bug 和漏洞的可能性就更小。
### 运行当前版本的 LKRG 大约会带来 6.5% 的性能损失
Peslyak 说 LKRG 是非常适用于 Linux 机器的,它在修补内核的安全漏洞后不需要重启动机器。LKRG 允许用户持续运行带有安全措施的机器,直到在一个计划的维护窗口中测试和部署关键的安全补丁为止。
经测试显示,安装 LKRG v0.0 后大约会产生 6.5% 性能影响,但是,Peslyak 说将在后续的开发中持续降低这种影响。
测试也显示,LKRG 检测到了 CVE-2014-9322 (BadIRET)、CVE-2017-5123 (waitid(2) missing access\_ok)、以及 CVE-2017-6074 (use-after-free in DCCP protocol) 的漏洞利用企图,但是没有检测到 CVE-2016-5195 (Dirty COW) 的漏洞利用企图。开发团队说,由于前面提到的“可旁通”的设计策略,LKRG 没有检测到 Dirty COW 提权攻击。
>
> 在 Dirty COW 的测试案例中,由于 bug 机制的原因,使得 LKRG 发生了 “旁通”,并且这也是一种利用方法,它也是将来类似的以用户空间为目标的绕过 LKRG 的一种方法。这样的漏洞利用是否会是普通情况(不太可能!除非 LKRG 或者类似机制的软件流行起来),以及对它的可用性的(负面的)影响是什么?(对于那些直接目标是用户空间的内核漏洞来说,这不太重要,也并不简单)。
>
>
>
---
via: <https://www.bleepingcomputer.com/news/linux/lkrg-linux-to-get-a-loadable-kernel-module-for-runtime-integrity-checking/>
作者:[Catalin Cimpanu](https://www.bleepingcomputer.com/author/catalin-cimpanu/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Members of the open source community are working on a new security-focused project for the Linux kernel. Named Linux Kernel Runtime Guard (LKRG), this is a loadable kernel module that will perform runtime integrity checking of the Linux kernel.
Its purpose is to detect exploitation attempts for known and unknwon security vulnerabilities against the Linux kernel and attempt to block attacks.
LKRG will also detect privilege escalation for running processes, and kill the running process before the exploit code runs.
## Project under development since 2011. First versions released.
Since the project is in such early development, current versions of LKRG will only report kernel integrity violations via kernel messages, but a full exploit mitigation system will be deployed as the system matures.
Work on this project started in 2011, and LKRG has gone through a "re-development" phase, as LKRG member Alexander Peslyak described the process.
The first public version of LKRG —LKRG v0.0— is now live and available for download on [this page](http://www.openwall.com/lkrg/). A wiki is also available [here](http://openwall.info/wiki/p_lkrg/Main), and a [Patreon page](https://www.patreon.com/p_lkrg) for supporting the project has also been set up.
While LKRG will remain an open source project, LKRG maintainers also have plans for an LKRG Pro version that will include distro-specific LKRG builds and support for the detection of specific exploits, such as container escapes. The team plans to use the funds from LKRG Pro to fund the rest of the project.
## LKRG is a kernel module. Not a patch.
A similar project is Additional Kernel Observer (AKO), but AKO differs from LKRG because it's a kernel load-on module and not a patch. The LKRG team chose to create a kernel module because patching the kernel has a direct impact on the security, system stability, and performance.
By offering a kernel module this also makes LKRG easier to deploy on a per-system basis without having to tinker with core kernel code, a very complicated and error-prone process.
LKRG kernel modules are currently available for main Linux distros such as RHEL7, OpenVZ 7, Virtuozzo 7, and Ubuntu 16.04 to latest mainlines.
## Not a perfect solution
But LKRG's creators are warning users not to consider their tool as unbreakable and 100% secure. They said LKRG is "bypassable by design," and only provides "security through diversity."
While LKRG defeats many pre-existing exploits of Linux kernel vulnerabilities, and will likely defeat many future exploits (including of yet unknown vulnerabilities) that do not specifically attempt to bypass LKRG, it is bypassable by design (albeit sometimes at the expense of more complicated and/or less reliable exploits). Thus, it can be said that LKRG provides security through diversity, much like running an uncommon OS kernel would, yet without the usability drawbacks of actually running an uncommon OS.
LKRG is similar to Windows-based antivirus software, which also works at the kernel level to detect exploits and malware. Nonetheless, the LKRG team says their product is much safer then antivirus and other endpoint security software because it has a much smaller codebase, hence a smaller footprint for introducing new bugs and vulnerabilities at the kernel level.
## Current LKRG version adds a 6.5% performance dip
Peslyak says LKRG is most suited for Linux machines that can't be rebooted right in the aftermath of a security flaw to patch the kernel. LKRG allows owners to continue to run the machine with a security measure in place until patches for critical vulnerabilities can be tested and deployed during planned maintenance windows.
Tests showed that installing LKRG v0.0 added a 6.5% performance impact, but Peslyak says this will be reduced as development moves forward.
Tests also showed that LKRG detected exploitation attempts for CVE-2014-9322 (BadIRET), CVE-2017-5123 (waitid(2) missing access_ok), and CVE-2017-6074 (use-after-free in DCCP protocol), but failed to detect CVE-2016-5195 (Dirty COW). The team said LKRG failed to spot the Dirty COW privilege escalation because of the previously mentioned "bypassable by design" strategy.
In case of Dirty COW the LKRG "bypass" happened due to the nature of the bug and this being the way to exploit it, it's also a way for future exploits to bypass LKRG by similarly directly targeting userspace. It remains to be seen whether such exploits become common (unlikely unless LKRG or similar become popular?) and what (negative?) effect on their reliability this will have (for kernel vulnerabilities where directly targeting the userspace isn't essential and possibly not straightforward).
*Article updated to add that LKRG can also detect unknown kernel exploits and remote mention that LKRG borrows ideas from AKO.*
## Comments
## _LC_ - 6 years ago
Here's me thinking that something like 'Tripwire' should be in all the big distros. It would be fairly easy to implement, yet they're not even doing this. |
9,462 | 在 Linux 上使用 NTP 保持精确的时间 | https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp | 2018-03-19T13:38:25 | [
"NTP",
"时间"
] | https://linux.cn/article-9462-1.html | 
如何保持正确的时间,如何使用 NTP 和 systemd 让你的计算机在不滥用时间服务器的前提下保持同步。
### 它的时间是多少?
让 Linux 来告诉你时间的时候,它是很奇怪的。你可能认为是使用 `time` 命令来告诉你时间,其实并不是,因为 `time` 只是一个测量一个进程运行了多少时间的计时器。为得到时间,你需要运行的是 `date` 命令,你想查看更多的日期,你可以运行 `cal` 命令。文件上的时间戳也是一个容易混淆的地方,因为根据你的发行版默认情况不同,它一般有两种不同的显示方法。下面是来自 Ubuntu 16.04 LTS 的示例:
```
$ ls -l
drwxrwxr-x 5 carla carla 4096 Mar 27 2017 stuff
drwxrwxr-x 2 carla carla 4096 Dec 8 11:32 things
-rw-rw-r-- 1 carla carla 626052 Nov 21 12:07 fatpdf.pdf
-rw-rw-r-- 1 carla carla 2781 Apr 18 2017 oddlots.txt
```
有些显示年,有些显示时间,这样的方式让你的文件更混乱。GNU 默认的情况是,如果你的文件在六个月以内,则显示时间而不是年。我想这样做可能是有原因的。如果你的 Linux 是这样的,尝试用 `ls -l --time-style=long-iso` 命令,让时间戳用同一种方式去显示,按字母顺序排序。请查阅 [如何更改 Linux 的日期和时间:简单的命令](https://www.linux.com/learn/how-change-linux-date-and-time-simple-commands) 去学习 Linux 上管理时间的各种方法。
### 检查当前设置
NTP —— 网络时间协议,它是保持计算机正确时间的老式方法。`ntpd` 是 NTP 守护程序,它通过周期性地查询公共时间服务器来按需调整你的计算机时间。它是一个简单的、轻量级的协议,使用它的基本功能时设置非常容易。systemd 通过使用 `systemd-timesyncd.service` 已经越俎代庖地 “干了 NTP 的活”,它可以用作 `ntpd` 的客户端。
在我们开始与 NTP “打交道” 之前,先花一些时间来了检查一下当前的时间设置是否正确。
你的系统上(至少)有两个时钟:系统时间 —— 它由 Linux 内核管理,第二个是你的主板上的硬件时钟,它也称为实时时钟(RTC)。当你进入系统的 BIOS 时,你可以看到你的硬件时钟的时间,你也可以去改变它的设置。当你安装一个新的 Linux 时,在一些图形化的时间管理器中,你会被询问是否设置你的 RTC 为 UTC(<ruby> 世界标准时间 <rt> Coordinated Universal Time </rt></ruby>)时区,因为所有的时区和夏令时都是基于 UTC 的。你可以使用 `hwclock` 命令去检查:
```
$ sudo hwclock --debug
hwclock from util-linux 2.27.1
Using the /dev interface to the clock.
Hardware clock is on UTC time
Assuming hardware clock is kept in UTC time.
Waiting for clock tick...
...got clock tick
Time read from Hardware Clock: 2018/01/22 22:14:31
Hw clock time : 2018/01/22 22:14:31 = 1516659271 seconds since 1969
Time since last adjustment is 1516659271 seconds
Calculated Hardware Clock drift is 0.000000 seconds
Mon 22 Jan 2018 02:14:30 PM PST .202760 seconds
```
`Hardware clock is on UTC time` 表明了你的计算机的 RTC 是使用 UTC 时间的,虽然它把该时间转换为你的本地时间。如果它被设置为本地时间,它将显示 `Hardware clock is on local time`。
你应该有一个 `/etc/adjtime` 文件。如果没有的话,使用如下命令同步你的 RTC 为系统时间,
```
$ sudo hwclock -w
```
这个命令将生成该文件,内容看起来类似如下:
```
$ cat /etc/adjtime
0.000000 1516661953 0.000000
1516661953
UTC
```
新发明的 systemd 方式是去运行 `timedatectl` 命令,运行它不需要 root 权限:
```
$ timedatectl
Local time: Mon 2018-01-22 14:17:51 PST
Universal time: Mon 2018-01-22 22:17:51 UTC
RTC time: Mon 2018-01-22 22:17:51
Time zone: America/Los_Angeles (PST, -0800)
Network time on: yes
NTP synchronized: yes
RTC in local TZ: no
```
`RTC in local TZ: no` 表明它使用 UTC 时间。那么怎么改成使用本地时间?这里有许多种方法可以做到。最简单的方法是使用一个图形配置工具,比如像 openSUSE 中的 YaST。你也可使用 `timedatectl`:
```
$ timedatectl set-local-rtc 0
```
或者编辑 `/etc/adjtime`,将 `UTC` 替换为 `LOCAL`。
### systemd-timesyncd 客户端
现在,我已经累了,但是我们刚到非常精彩的部分。谁能想到计时如此复杂?我们甚至还没有了解到它的皮毛;阅读 `man 8 hwclock` 去了解你的计算机如何保持时间的详细内容。
systemd 提供了 `systemd-timesyncd.service` 客户端,它可以查询远程时间服务器并调整你的本地系统时间。在 `/etc/systemd/timesyncd.conf` 中配置你的(时间)服务器。大多数 Linux 发行版都提供了一个默认配置,它指向他们维护的时间服务器上,比如,以下是 Fedora 的:
```
[Time]
#NTP=
#FallbackNTP=0.fedora.pool.ntp.org 1.fedora.pool.ntp.org
```
你可以输入你希望使用的其它时间服务器,比如你自己的本地 NTP 服务器,在 `NTP=` 行上输入一个以空格分隔的服务器列表。(别忘了取消这一行的注释)`NTP=` 行上的任何内容都将覆盖掉 `FallbackNTP` 行上的配置项。
如果你不想使用 systemd 呢?那么,你将需要 NTP 就行。
### 配置 NTP 服务器和客户端
配置你自己的局域网 NTP 服务器是一个非常好的实践,这样你的网内计算机就不需要不停查询公共 NTP 服务器。在大多数 Linux 上的 NTP 都来自 `ntp` 包,它们大多都提供 `/etc/ntp.conf` 文件去配置时间服务器。查阅 [NTP 时间服务器池](http://support.ntp.org/bin/view/Servers/NTPPoolServers) 去找到你所在的区域的合适的 NTP 服务器池。然后在你的 `/etc/ntp.conf` 中输入 4 - 5 个服务器,每个服务器用单独的一行:
```
driftfile /var/ntp.drift
logfile /var/log/ntp.log
server 0.europe.pool.ntp.org
server 1.europe.pool.ntp.org
server 2.europe.pool.ntp.org
server 3.europe.pool.ntp.org
```
`driftfile` 告诉 `ntpd` 它需要保存用于启动时使用时间服务器快速同步你的系统时钟的信息。而日志也将保存在他们自己指定的目录中,而不是转储到 syslog 中。如果你的 Linux 发行版默认提供了这些文件,请使用它们。
现在去启动守护程序;在大多数主流的 Linux 中它的命令是 `sudo systemctl start ntpd`。让它运行几分钟之后,我们再次去检查它的状态:
```
$ ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================
+dev.smatwebdesi 192.168.194.89 3 u 25 64 37 92.456 -6.395 18.530
*chl.la 127.67.113.92 2 u 23 64 37 75.175 8.820 8.230
+four0.fairy.mat 35.73.197.144 2 u 22 64 37 116.272 -10.033 40.151
-195.21.152.161 195.66.241.2 2 u 27 64 37 107.559 1.822 27.346
```
我不知道这些内容是什么意思,但重要的是,你的守护程序已经与时间服务器开始对话了,而这正是我们所需要的。你可以去运行 `sudo systemctl enable ntpd` 命令,永久启用它。如果你的 Linux 没有使用 systemd,那么,给你留下的家庭作业就是找出如何去运行 `ntpd`。
现在,你可以在你的局域网中的其它计算机上设置 `systemd-timesyncd`,这样它们就可以使用你的本地 NTP 服务器了,或者,在它们上面安装 NTP,然后在它们的 `/etc/ntp.conf` 上输入你的本地 NTP 服务器。
NTP 服务器会受到攻击,而且需求在不断增加。你可以通过运行你自己的公共 NTP 服务器来提供帮助。下周我们将学习如何运行你自己的公共服务器。
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 来学习更多 Linux 的知识。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp>
作者:[CARLA SCHRODER](https://www.linux.com/users/cschroder) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,463 | 我喜欢 Vue 的 10 个方面 | https://medium.com/@dalaidunc/10-things-i-love-about-vue-505886ddaff2 | 2018-03-20T12:55:50 | [
"Vue.js",
"JavaScript"
] | https://linux.cn/article-9463-1.html | 
我喜欢 Vue。当我在 2016 年第一次接触它时,也许那时我已经对 JavaScript 框架感到疲劳了,因为我已经具有Backbone、Angular、React 等框架的经验,没有太多的热情去尝试一个新的框架。直到我在 Hacker News 上读到一份评论,其描述 Vue 是类似于“新 jQuery” 的 JavaScript 框架,从而激发了我的好奇心。在那之前,我已经相当满意 React 这个框架,它是一个很好的框架,建立于可靠的设计原则之上,围绕着视图模板、虚拟 DOM 和状态响应等技术。而 Vue 也提供了这些重要的内容。
在这篇文章中,我旨在解释为什么 Vue 适合我,为什么在上文中那些我尝试过的框架中选择它。也许你将同意我的一些观点,但至少我希望能够给大家使用 Vue 开发现代 JavaScript 应用一些灵感。
### 1、 极少的模板语法
Vue 默认提供的视图模板语法是极小的、简洁的和可扩展的。像其他 Vue 部分一样,可以很简单的使用类似 JSX 一样语法,而不使用标准的模板语法(甚至有官方文档说明了如何做),但是我觉得没必要这么做。JSX 有好的方面,也有一些有依据的批评,如混淆了 JavaScript 和 HTML,使得很容易导致在模板中出现复杂的代码,而本来应该分开写在不同的地方的。
Vue 没有使用标准的 HTML 来编写视图模板,而是使用极少的模板语法来处理简单的事情,如基于视图数据迭代创建元素。
```
<template>
<div id="app">
<ul>
<li v-for='number in numbers' :key='number'>{{ number }}</li>
</ul>
<form @submit.prevent='addNumber'>
<input type='text' v-model='newNumber'>
<button type='submit'>Add another number</button>
</form>
</div>
</template>
<script>
export default {
name: 'app',
methods: {
addNumber() {
const num = +this.newNumber;
if (typeof num === 'number' && !isNaN(num)) {
this.numbers.push(num);
}
}
},
data() {
return {
newNumber: null,
numbers: [1, 23, 52, 46]
};
}
}
</script>
<style lang="scss">
ul {
padding: 0;
li {
list-style-type: none;
color: blue;
}
}
</style>
```
我也喜欢 Vue 提供的简短绑定语法,`:` 用于在模板中绑定数据变量,`@` 用于绑定事件。这是一个细节,但写起来很爽而且能够让你的组件代码简洁。
### 2、 单文件组件
大多数人使用 Vue,都使用“单文件组件”。本质上就是一个 .vue 文件对应一个组件,其中包含三部分(CSS、HTML和JavaScript)。
这种技术结合是对的。它让人很容易在一个单独的地方了解每个组件,同时也非常好的鼓励了大家保持每个组件代码的简短。如果你的组件中 JavaScript、CSS 和 HTML 代码占了很多行,那么就到了进一步模块化的时刻了。
在使用 Vue 组件中的 `<style>` 标签时,我们可以添加 `scoped` 属性。这会让整个样式完全的封装到当前组件,意思是在组件中如果我们写了 `.name` 的 css 选择器,它不会把样式应用到其他组件中。我非常喜欢这种方式来应用样式而不是像其他主要框架流行在 JS 中编写 CSS 的方式。
关于单文件组件另一个好处是 .vue 文件实际上是一个有效的 HTML 5 文件。`<template>`、 `<script>`、 `<style>` 都是 w3c 官方规范的标签。这就表示很多如 linters (LCTT 译注:一种代码检查工具插件)这样我们用于开发过程中的工具能够开箱即用或者添加一些适配后使用。
### 3、 Vue “新的 jQuery”
事实上,这两个库不相似而且用于做不同的事。让我提供给你一个很精辟的类比(我实际上非常喜欢描述 Vue 和 jQuery 之间的关系):披头士乐队和齐柏林飞船乐队(LCTT 译注:两个都是英国著名的乐队)。披头士乐队不需要介绍,他们是 20 世纪 60 年代最大的和最有影响力的乐队。但很难说披头士乐队是 20 世纪 70 年代最大的乐队,因为有时这个荣耀属于是齐柏林飞船乐队。你可以说两个乐队之间有着微妙的音乐联系或者说他们的音乐是明显不同的,但两者一些先前的艺术和影响力是不可否认的。也许 21 世纪初 JavaScript 的世界就像 20 世纪 70 年代的音乐世界一样,随着 Vue 获得更多关注使用,只会吸引更多粉丝。
一些使 jQuery 牛逼的哲学理念在 Vue 中也有呈现:非常容易的学习曲线但却具有基于现代 web 标准构建牛逼 web 应用所有你需要的功能。Vue 的核心本质上就是在 JavaScript 对象上包装了一层。
### 4、 极易扩展
正如前述,Vue 默认使用标准的 HTML、JS 和 CSS 构建组件,但可以很容易插入其他技术。如果我们想使用pug(LCTT译注:一款功能丰富的模板引擎,专门为 Node.js 平台开发)替换 HTML 或者使用 Typescript(LCTT译注:一种由微软开发的编程语言,是 JavaScript 的一个超集)替换 js 或者 Sass (LCTT 译注:一种 CSS 扩展语言)替换 CSS,只需要安装相关的 node 模块和在我们的单文件组件中添加一个属性到相关的标签即可。你甚至可以在一个项目中混合搭配使用 —— 如一些组件使用 HTML 其他使用 pug ——然而我不太确定这么做是最好的做法。
### 5、 虚拟 DOM
虚拟 DOM 是很好的技术,被用于现如今很多框架。其意味着这些框架能够做到根据我们状态的改变来高效的完成 DOM 更新,减少重新渲染,从而优化我们应用的性能。现如今每个框架都有虚拟 DOM 技术,所以虽然它不是什么独特的东西,但它仍然很出色。
### 6、 Vuex 很棒
对于大多数应用,管理状态成为一个棘手的问题,单独使用一个视图库不能解决这个问题。Vue 使用 Vuex 库来解决这个问题。Vuex 很容易构建而且和 Vue 集成的很好。熟悉 redux(另一个管理状态的库)的人学习 Vuex 会觉得轻车熟路,但是我发现 Vue 和 Vuex 集成起来更加简洁。最新 JavaScript 草案中(LCTT 译注:应该是指 ES7)提供了对象展开运算符(LCTT 译注:符号为 `...`),允许我们在状态或函数中进行合并,以操纵从 Vuex 到需要它的 Vue 组件中的状态。
### 7、 Vue 的命令行界面(CLI)
Vue 提供的命令行界面非常不错,很容易用 Vue 搭建一个基于 Webpack(LCTT 译注:一个前端资源加载/打包工具)的项目。单文件组件支持、babel(LCTT 译注:js 语法转换器)、linting(LCTT译注:代码检查工具)、测试工具支持,以及合理的项目结构,都可以在终端中一行命令创建。
然而有一个命令,我在 CLI 中没有找到,那就是 `vue build`。
>
> 如:
>
>
>
> ```
> echo '<template><h1>Hello World!</h1></template>' > Hello.vue && vue build Hello.vue -o
>
> ```
>
>
`vue build` 命令构建和运行组件并在浏览器中测试看起来非常简单。很不幸这个命令后来在 Vue 中删除了,现在推荐使用 Poi。Poi 本质上是在 Webpack 工具上封装了一层,但我不认我它像推特上说的那样简单。
### 8、 重新渲染优化
使用 Vue,你不必手动声明 DOM 的哪部分应该被重新渲染。我从来都不喜欢操纵 React 组件的渲染,像在`shouldComponentUpdate` 方法中停止整个 DOM 树重新渲染这种。Vue 在这方面非常巧妙。
### 9、 容易获得帮助
Vue 已经达到了使用这个框架来构建各种各样的应用的一种群聚效应。开发文档非常完善。如果你需要进一步的帮助,有多种渠道可用,每个渠道都有很多活跃开发者:stackoverflow、discord、twitter 等。相对于其他用户量少的框架,这就应该给你更多的信心来使用Vue构建应用。
### 10、 多机构维护
我认为,一个开源库,在发展方向方面的投票权利没有被单一机构操纵过多,是一个好事。就如同 React 的许可证问题(现已解决),Vue 就不可能涉及到。
总之,作为你接下来要开发的任何 JavaScript 项目,我认为 Vue 都是一个极好的选择。Vue 可用的生态圈比我博客中涉及到的其他库都要大。如果想要更全面的产品,你可以关注 Nuxt.js。如果你需要一些可重复使用的样式组件你可以关注类似 Vuetify 的库。
Vue 是 2017 年增长最快的库之一,我预测在 2018 年增长速度不会放缓。
如果你有空闲的 30 分钟,为什么不尝试下 Vue,看它可以给你提供什么呢?
P.S. — 这篇文档很好的展示了 Vue 和其他框架的比较:<https://vuejs.org/v2/guide/comparison.html>
---
via: <https://medium.com/@dalaidunc/10-things-i-love-about-vue-505886ddaff2>
作者:[Duncan Grant](https://medium.com/@dalaidunc) 译者:[yizhuoyan](https://github.com/yizhuoyan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # 10 things I love about Vue
I love Vue. When I first looked at it in 2016, perhaps I was coming from a perspective of JavaScript framework fatigue. I’d already had experience with Backbone, Angular, React, among others and I wasn’t overly enthusiastic to try a new framework. It wasn’t until I read a comment on hacker news describing Vue as the ‘new jquery’ of JavaScript, that my curiosity was piqued. Until that point, I had been relatively content with React — it is a good framework based on solid design principles centred around view templates, virtual DOM and reacting to state, and Vue also provides these great things. In this blog post, I aim to explore why Vue is the framework for me. I choose it above any other that I have tried. Perhaps you will agree with some of my points, but at the very least I hope to give you some insight into what it is like to develop modern JavaScript applications with Vue.
**1. Minimal Template Syntax**
The template syntax which you are given by default from Vue is minimal, succinct and extendable. Like many parts of Vue, it’s easy to not use the standard template syntax and instead use something like JSX (there is even an official page of documentation about how to do this), but I don’t know why you would want to do that to be honest. For all that is good about JSX, there are some valid criticisms: by blurring the line between JavaScript and HTML, it makes it a bit too easy to start writing complex code in your template which should instead be separated out and written elsewhere in your JavaScript view code.
Vue instead uses standard HTML to write your templates, with a minimal template syntax for simple things such as iteratively creating elements based on the view data.
I also like the short-bindings provided by Vue, ‘:’ for binding data variables into your template and ‘@’ for binding to events. It’s a small thing, but it feels nice to type and keeps your components succinct.
**2. Single File Components**
When most people write Vue, they do so using ‘single file components’. Essentially it is a file with the suffix .vue containing up to 3 parts (the css, html and javascript) for each component.
This coupling of technologies feels right. It makes it easy to understand each component in a single place. It also has the nice side effect of encouraging you to keep your code short for each component. If the JavaScript, CSS and HTML for your component is taking up too many lines then it might be time to modularise further.
When it comes to the <style> tag of a Vue component, we can add the ‘scoped’ attribute. This will fully encapsulate the styling to this component. Meaning if we had a .name CSS selector defined in this component, it won’t apply that style in any other component. I much prefer this approach of styling view components to the approaches of writing CSS in JS which seems popular in other leading frameworks.
Another very nice thing about single file components is that they are actually valid HTML5 files. <template>, <script>, <style> are all part of the official w3c specification. This means that many tools you use as part of your development process (such as linters) can work out of the box or with minimal adaptation.
**3. Vue as the new jQuery**
Really these two libraries are not similar and are doing different things. Let me provide you with a terrible analogy that I am actually quite fond of to describe the relationship of Vue and jQuery: The Beatles and Led Zeppelin. The Beatles need no introduction, they were the biggest group of the 1960s and were supremely influential. It gets harder to pin the accolade of ‘biggest group of the 1970s’ but sometimes that goes to Led Zeppelin. You could say that the musical relationship between the Beatles and Led Zeppelin is tenuous and their music is distinctively different, but there is some prior art and influence to accept. Maybe 2010s JavaScript world is like the 1970s music world and as Vue gets more radio plays, it will only attract more fans.
Some of the philosophy that made jQuery so great is also present in Vue: a really easy learning curve but with all the power you need to build great web applications based on modern web standards. At its core, Vue is really just a wrapper around JavaScript objects.
**4. Easily extensible**
As mentioned, Vue uses standard HTML, JS and CSS to build its components as a default, but it is really easy to plug in other technologies. If we want to use pug instead of HTML or typescript instead of JS or sass instead of CSS, it’s just a matter of installing the relevant node modules and adding an attribute to the relevant section of our single file component. You could even mix and match components within a project — e.g. some components using HTML and others using pug — although I’m not sure doing this is the best practice.
**5. Virtual DOM**
The virtual DOM is used in many frameworks these days and it is great. It means the framework can work out what has changed in our state and then efficiently apply DOM updates, minimizing re-rendering and optimising the performance of our application. Everyone and their mother has a Virtual DOM these days, so whilst it’s not something unique, it’s still very cool.
**6. Vuex is great**
For most applications, managing state becomes a tricky issue which using a view library alone can not solve. Vue’s solution to this is the vuex library. It’s easy to setup and integrates very well with vue. Those familiar with redux will be at home here, but I find that the integration between vue and vuex is neater and more minimal than that of react and redux. Soon-to-be-standard JavaScript provides the object spread operator which allows us to merge in state or functions to manipulate state from vuex into the components that need it.
**7. Vue CLI**
The CLI provided by Vue is really great and makes it easy to get started with a webpack project with Vue. Single file components support, babel, linting, testing and a sensible project structure can all be created with a single command in your terminal.
There is one thing, however I miss from the CLI and that is the ‘vue build’.
It looked so simple to build and run components and test them in the browser. Unfortunately this command was later removed from vue, instead the recommendation is to now use poi. Poi is basically a wrapper around webpack, but I don’t think it quite gets to the same point of simplicity as the quoted tweet.
**8. Re-rendering optimizations worked out for you**
In Vue, you don’t have to manually state which parts of the DOM should be re-rendered. I never was a fan of the management on react components, such as ‘shouldComponentUpdate’ in order to stop the whole DOM tree re-rendering. Vue is smart about this.
**9. Easy to get help**
Vue has reached a critical mass of developers using the framework to build a wide variety of applications. The documentation is very good. Should you need further help, there are multiple channels available with many active users: stackoverflow, discord, twitter etc. — this should give you some more confidence in building an application over some other frameworks with less users.
**10. Not maintained by a single corporation**
I think it’s a good thing for an open source library to not have the voting rights of its direction steered too much by a single corporation. Issues such as the react licensing issue (now resolved) are not something Vue has had to deal with.
In summary, I think Vue is an excellent choice for whatever JavaScript project you might be starting next. The available ecosystem is larger than I covered in this blog post. For a more full-stack offering you could look at Nuxt.js. And if you want some re-usable styled components you could look at something like Vuetify. Vue has been one of the fastest growing frameworks of 2017 and I predict the growth is not going to slow down for 2018. If you have a spare 30 minutes, why not dip your toes in and see what Vue has to offer for yourself?
P.S. — The documentation gives you a great comparison to other frameworks here: [https://vuejs.org/v2/guide/comparison.html](https://vuejs.org/v2/guide/comparison.html) |
9,464 | 使用 Zim 在你的 Linux 桌面上创建一个维基 | https://opensource.com/article/18/2/create-wiki-your-linux-desktop-zim | 2018-03-20T17:31:03 | [
"维基",
"Wiki"
] | https://linux.cn/article-9464-1.html |
>
> 用强大而小巧的 Zim 在桌面上像维基一样管理信息。
>
>
>

不可否认<ruby> 维基 <rt> wiki </rt></ruby>的用处,即使对于一个极客来说也是如此。你可以用它做很多事——写笔记和手稿,协作项目,建立完整的网站。还有更多的事。
这些年来,我已经使用了几个维基,要么是为了我自己的工作,要么就是为了我接到的各种合同和全职工作。虽然传统的维基很好,但我真的喜欢[桌面版维基](https://opensource.com/article/17/2/3-desktop-wikis) 这个想法。它们体积小,易于安装和维护,甚至更容易使用。而且,正如你可能猜到的那样,有许多可以用在 Linux 中的桌面版维基。
让我们来看看更好的桌面版的 维基 之一: [Zim](http://zim-wiki.org/)。
### 开始吧
你可以从 Zim 的官网[下载](http://zim-wiki.org/downloads.html)并安装 Zim,或者通过发行版的软件包管理器轻松地安装。
安装好了 Zim,就启动它。
在 Zim 中的一个关键概念是<ruby> 笔记本 <rt> notebook </rt></ruby>,它们就像某个单一主题的维基页面的集合。当你第一次启动 Zim 时,它要求你为你的笔记本指定一个文件夹和笔记本的名称。Zim 建议用 `Notes` 来表示文件夹的名称和指定文件夹为 `~/Notebooks/`。如果你愿意,你可以改变它。我是这么做的。

在为笔记本设置好名称和指定好文件夹后,单击 “OK” 。你得到的本质上是你的维基页面的容器。

### 将页面添加到笔记本
所以你有了一个容器。那现在怎么办?你应该开始往里面添加页面。当然,为此,选择 “File > New Page”。

输入该页面的名称,然后单击 “OK”。从那里开始,你可以开始输入信息以向该页面添加信息。

这一页可以是你想要的任何内容:你正在选修的课程的笔记、一本书或者一片文章或论文的大纲,或者是你的书的清单。这取决于你。
Zim 有一些格式化的选项,其中包括:
* 标题
* 字符格式
* 圆点和编号清单
* 核对清单
你可以添加图片和附加文件到你的维基页面,甚至可以从文本文件中提取文本。
### Zim 的维基语法
你可以使用工具栏向一个页面添加格式。但这不是唯一的方法。如果你像我一样是个老派人士,你可以使用维基标记来进行格式化。
[Zim 的标记](http://zim-wiki.org/manual/Help/Wiki_Syntax.html) 是基于在 [DokuWiki](https://www.dokuwiki.org/wiki:syntax) 中使用的标记。它本质上是有一些小变化的 [WikiText](http://en.wikipedia.org/wiki/Wikilink) 。例如,要创建一个子弹列表,输入一个星号(`*`)。用两个星号包围一个单词或短语来使它加黑。
### 添加链接
如果你在笔记本上有一些页面,很容易将它们联系起来。有两种方法可以做到这一点。
第一种方法是使用 [驼峰命名法](https://en.wikipedia.org/wiki/Camel_case) 来命名这些页面。假设我有个叫做 “Course Notes” 的笔记本。我可以通过输入 “AnalysisCourse” 来重命名为我正在学习的数据分析课程。 当我想从笔记本的另一个页面链接到它时,我只需要输入 “AnalysisCourse” 然后按下空格键。即时超链接。
第二种方法是点击工具栏上的 “Insert link” 按钮。 在 “Link to” 中输入你想要链接到的页面的名称,从显示的列表中选择它,然后点击 “Link”。

我只能在同一个笔记本中的页面之间进行链接。每当我试图连接到另一个笔记本中的一个页面时,这个文件(有 .txt 的后缀名)总是在文本编辑器中被打开。
### 输出你的维基页面
也许有一天你会想在别的地方使用笔记本上的信息 —— 比如,在一份文件或网页上。你可以将笔记本页面导出到以下格式中的任何一种。而不是复制和粘贴(和丢失格式):
* HTML
* LaTeX
* Markdown
* ReStructuredText
为此,点击你想要导出的维基页面。然后,选择 “File > Export”。决定是要导出整个笔记本还是一个页面,然后点击 “Forward”。

选择要用来保存页面或笔记本的文件格式。使用 HTML 和 LaTeX,你可以选择一个模板。 随便看看什么最适合你。 例如,如果你想把你的维基页面变成 HTML 演示幻灯片,你可以在 “Template” 中选择 “SlideShow s5”。 如果你想知道,这会产生由 [S5 幻灯片框架](https://meyerweb.com/eric/tools/s5/)驱动的幻灯片。

点击 “Forward”,如果你在导出一个笔记本,你可以选择将页面作为单个文件或一个文件导出。 你还可以指向要保存导出文件的文件夹。

### Zim 能做的就这些吗?
远远不止这些,还有一些 [插件](http://zim-wiki.org/manual/Plugins.html) 可以扩展它的功能。它甚至包含一个内置的 Web 服务器,可以让你将你的笔记本作为静态的 HTML 文件。这对于在内部网络上分享你的页面和笔记本是非常有用的。
总的来说,Zim 是一个用来管理你的信息的强大而又紧凑的工具。这是我使用过的最好的桌面版维基,而且我一直在使用它。
---
via: <https://opensource.com/article/18/2/create-wiki-your-linux-desktop-zim>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 译者:[Auk7F7](https://github.com/Auk7F7) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,465 | 初识 Python:Hello World 和字符串操作 | https://www.codementor.io/mgalarny/python-hello-world-and-string-manipulation-gdgwd8ymp | 2018-03-21T11:10:00 | [
"Python"
] | https://linux.cn/article-9465-1.html | 
开始之前,说一下本文中的[代码](https://github.com/mGalarnyk/Python_Tutorials/blob/master/Python_Basics/Intro/Python3Basics_Part1.ipynb)和[视频](https://www.youtube.com/watch?v=JqGjkNzzU4s)可以在我的 GitHub 上找到。
那么,让我们开始吧!如果你糊涂了,我建议你在单独的选项卡中打开下面的视频。
* [Python 的 Hello World 和字符串操作视频](https://www.youtube.com/watch?v=JqGjkNzzU4s)
### 开始 (先决条件)
首先在你的操作系统上安装 Anaconda (Python)。你可以从[官方网站](https://www.continuum.io/downloads)下载 anaconda 并自行安装,或者你可以按照以下这些 anaconda 安装教程进行安装。
* 在 Windows 上安装 Anaconda: [链接[5](https://medium.com/@GalarnykMichael/install-python-on-windows-anaconda-c63c7c3d1444)
* 在 Mac 上安装 Anaconda: [链接](https://medium.com/@GalarnykMichael/install-python-on-mac-anaconda-ccd9f2014072)
* 在 Ubuntu (Linux) 上安装 Anaconda:[链接](https://medium.com/@GalarnykMichael/install-python-on-ubuntu-anaconda-65623042cb5a)
### 打开一个 Jupyter Notebook
打开你的终端(Mac)或命令行,并输入以下内容([请参考视频中的 1:16 处](https://youtu.be/JqGjkNzzU4s?t=1m16s))来打开 Jupyter Notebook:
```
jupyter notebook
```
### 打印语句/Hello World
在 Jupyter 的单元格中输入以下内容并按下 `shift + 回车`来执行代码。
```
# This is a one line comment
print('Hello World!')
```

*打印输出 “Hello World!”*
### 字符串和字符串操作
字符串是 Python 类的一种特殊类型。作为对象,在类中,你可以使用 `.methodName()` 来调用字符串对象的方法。字符串类在 Python 中默认是可用的,所以你不需要 `import` 语句来使用字符串对象接口。
```
# Create a variable
# Variables are used to store information to be referenced
# and manipulated in a computer program.
firstVariable = 'Hello World'
print(firstVariable)
```

*输出打印变量 firstVariable*
```
# Explore what various string methods
print(firstVariable.lower())
print(firstVariable.upper())
print(firstVariable.title())
```

*使用 .lower()、.upper() 和 title() 方法输出*
```
# Use the split method to convert your string into a list
print(firstVariable.split(' '))
```

*使用 split 方法输出(此例中以空格分隔)*
```
# You can add strings together.
a = "Fizz" + "Buzz"
print(a)
```

*字符串连接*
### 查询方法的功能
对于新程序员,他们经常问你如何知道每种方法的功能。Python 提供了两种方法来实现。
1、(在不在 Jupyter Notebook 中都可用)使用 `help` 查询每个方法的功能。

*查询每个方法的功能*
2.(Jupyter Notebook 专用)你也可以通过在方法之后添加问号来查找方法的功能。
```
# To look up what each method does in jupyter (doesnt work outside of jupyter)
firstVariable.lower?
```

*在 Jupyter 中查找每个方法的功能*
### 结束语
如果你对本文或在 [YouTube 视频](https://www.youtube.com/watch?v=JqGjkNzzU4s)的评论部分有任何疑问,请告诉我们。文章中的代码也可以在我的 [GitHub](https://github.com/mGalarnyk/Python_Tutorials/blob/master/Python_Basics/Intro/Python3Basics_Part1.ipynb) 上找到。本系列教程的第 2 部分是[简单的数学操作](https://medium.com/@GalarnykMichael/python-basics-2-simple-math-4ac7cc928738)。
---
via: <https://www.codementor.io/mgalarny/python-hello-world-and-string-manipulation-gdgwd8ymp>
作者:[Michael](https://www.codementor.io/mgalarny) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 202 | Accepted | null |
9,466 | Ansible:像系统管理员一样思考的自动化框架 | http://www.linuxjournal.com/content/ansible-automation-framework-thinks-sysadmin | 2018-03-21T22:42:01 | [
"Ansible"
] | https://linux.cn/article-9466-1.html | 
这些年来,我已经写了许多关于 DevOps 工具的文章,也培训了这方面的人员。尽管这些工具很棒,但很明显,大多数都是按照开发人员的思路设计出来的。这也没有什么问题,因为以编程的方式接近配置管理是重点。不过,直到我开始接触 Ansible,我才觉得这才是系统管理员喜欢的东西。
喜欢的一部分原因是 Ansible 与客户端计算机通信的方式,是通过 SSH 的。作为系统管理员,你们都非常熟悉通过 SSH 连接到计算机,所以从单词“去”的角度来看,相对于其它选择,你更容易理解 Ansible。
考虑到这一点,我打算写一些文章,探讨如何使用 Ansible。这是一个很好的系统,但是当我第一次接触到这个系统的时候,不知道如何开始。这并不是学习曲线陡峭。事实上,问题是在开始使用 Ansible 之前,我并没有太多的东西要学,这才是让人感到困惑的。例如,如果您不必安装客户端程序(Ansible 没有在客户端计算机上安装任何软件),那么您将如何启动?
### 踏出第一步
起初 Ansible 对我来说非常困难的原因在于配置服务器/客户端的关系是非常灵活的,我不知道我该从何入手。事实是,Ansible 并不关心你如何设置 SSH 系统。它会利用你现有的任何配置。需要考虑以下几件事情:
1. Ansible 需要通过 SSH 连接到客户端计算机。
2. 连接后,Ansible 需要提升权限才能配置系统,安装软件包等等。
不幸的是,这两个考虑真的带来了一堆蠕虫。连接到远程计算机并提升权限是一件可怕的事情。当您在远程计算机上安装代理并使用 Chef 或 Puppet 处理特权升级问题时,似乎感觉就没那么可怕了。 Ansible 并非不安全,而是安全的决定权在你手中。
接下来,我将列出一系列潜在的配置,以及每个配置的优缺点。这不是一个详尽的清单,但是你会受到正确的启发,去思考在你自己的环境中什么是理想的配置。也需要注意,我不会提到像 Vagrant 这样的系统,因为尽管 Vagrant 在构建测试和开发的敏捷架构时非常棒,但是和一堆服务器是非常不同的,因此考虑因素是极不相似的。
### 一些 SSH 场景
#### 1)在 Ansible 配置中,root 用户以密码进入远程计算机。
拥有这个想法是一个非常可怕的开始。这个设置的“优点”是它消除了对特权提升的需要,并且远程服务器上不需要其他用户帐户。 但是,这种便利的成本是不值得的。 首先,大多数系统不会让你在不改变默认配置的情况下以 root 身份进行 SSH 登录。默认的配置之所以如此,坦率地说,是因为允许 root 用户远程连接是一个不好的主意。 其次,将 root 密码放在 Ansible 机器上的纯文本配置文件中是不合适的。 真的,我提到了这种可能性,因为这是可以的,但这是应该避免的。 请记住,Ansible 允许你自己配置连接,它可以让你做真正愚蠢的事情。 但是请不要这么做。
#### 2)使用存储在 Ansible 配置中的密码,以普通用户的身份进入远程计算机。
这种情况的一个优点是它不需要太多的客户端配置。 大多数用户默认情况下都可以使用 SSH,因此 Ansible 应该能够使用用户凭据并且能够正常登录。 我个人不喜欢在配置文件中以纯文本形式存储密码,但至少它不是 root 密码。 如果您使用此方法,请务必考虑远程服务器上的权限提升方式。 我知道我还没有谈到权限提升,但是如果你在配置文件中配置了一个密码,这个密码可能会被用来获得 sudo 访问权限。 因此,一旦发生泄露,您不仅已经泄露了远程用户的帐户,还可能泄露整个系统。
#### 3)使用具有空密码的密钥对进行身份验证,以普通用户身份进入远程计算机。
这消除了将密码存储在配置文件中的弊端,至少在登录的过程中消除了。 没有密码的密钥对并不理想,但这是我经常做的事情。 在我的个人内部网络中,我通常使用没有密码的密钥对来自动执行许多事情,如需要身份验证的定时任务。 这不是最安全的选择,因为私钥泄露意味着可以无限制地访问远程用户的帐户,但是相对于在配置文件中存储密码我更喜欢这种方式。
#### 4)使用通过密码保护的密钥对进行身份验证,以普通用户的身份通过 SSH 连接到远程计算机。
这是处理远程访问的一种非常安全的方式,因为它需要两种不同的身份验证因素来解密:私钥和密码。 如果你只是以交互方式运行 Ansible,这可能是理想的设置。 当你运行命令时,Ansible 会提示你输入私钥的密码,然后使用密钥对登录到远程系统。 是的,只需使用标准密码登录并且不用在配置文件中指定密码即可完成,但是如果不管怎样都要在命令行上输入密码,那为什么不在保护层添加密钥对呢?
#### 5)使用密码保护密钥对进行 SSH 连接,但是使用 ssh-agent “解锁”私钥。
这并不能完美地解决无人值守、自动化的 Ansible 命令的问题,但是它确实也使安全设置变得相当方便。 ssh-agent 程序一次验证密码,然后使用该验证进行后续连接。当我使用 Ansible 时,这是我想要做的事情。如果我是完全值得信任的,我通常仍然使用没有密码的密钥对,但是这通常是因为我在我的家庭服务器上工作,是不是容易受到攻击的。
在配置 SSH 环境时还要记住一些其他注意事项。 也许你可以限制 Ansible 用户(通常是你的本地用户),以便它只能从一个特定的 IP 地址登录。 也许您的 Ansible 服务器可以位于不同的子网中,位于强大的防火墙之后,因此其私钥更难以远程访问。 也许 Ansible 服务器本身没有安装 SSH 服务器,所以根本没法访问。 同样,Ansible 的优势之一是它使用 SSH 协议进行通信,而且这是一个你用了多年的协议,你已经把你的系统调整到最适合你的环境了。 我不是宣传“最佳实践”的忠实粉丝,因为实际上最好的做法是考虑你的环境,并选择最适合你情况的设置。
### 权限提升
一旦您的 Ansible 服务器通过 SSH 连接到它的客户端,就需要能够提升特权。 如果你选择了上面的选项 1,那么你已经是 root 了,这是一个有争议的问题。 但是由于没有人选择选项 1(对吧?),您需要考虑客户端计算机上的普通用户如何获得访问权限。 Ansible 支持各种权限提升的系统,但在 Linux 中,最常用的选项是 `sudo` 和 `su`。 和 SSH 一样,有几种情况需要考虑,虽然肯定还有其他选择。
#### 1)使用 su 提升权限。
对于 RedHat/CentOS 用户来说,可能默认是使用 `su` 来获得系统访问权限。 默认情况下,这些系统在安装过程中配置了 root 密码,要想获得特殊访问权限,您需要输入该密码。使用 `su` 的问题在于,虽说它可以给了您完全访问远程系统,而您确实也可以完全访问远程系统。 (是的,这是讽刺。)另外,`su` 程序没有使用密钥对进行身份验证的能力,所以密码必须以交互方式输入或存储在配置文件中。 由于它实际上是 root 密码,因此将其存储在配置文件中听起来像、也确实是一个可怕的想法。
#### 2)使用 sudo 提升权限。
这就是 Debian/Ubuntu 系统的配置方式。 正常用户组中的用户可以使用 `sudo` 命令并使用 root 权限执行该命令。 随之而来的是,这仍然存在密码存储或交互式输入的问题。 由于在配置文件中存储用户的密码看起来不太可怕,我猜这是使用 `su` 的一个进步,但是如果密码被泄露,仍然可以完全访问系统。 (毕竟,输入 `sudo` 和 `su -` 都将允许用户成为 root 用户,就像拥有 root 密码一样。)
#### 3) 使用 sudo 提升权限,并在 sudoers 文件中配置 NOPASSWD。
再次,在我的本地环境中,我就是这么做的。 这并不完美,因为它给予用户帐户无限制的 root 权限,并且不需要任何密码。 但是,当我这样做并且使用没有密码短语的 SSH 密钥对时,我可以让 Ansible 命令更轻松的自动化。 再次提示,虽然这很方便,但这不是一个非常安全的想法。
#### 4)使用 sudo 提升权限,并在特定的可执行文件上配置 NOPASSWD。
这个想法可能是安全性和便利性的最佳折衷。 基本上,如果你知道你打算用 Ansible 做什么,那么你可以为远程用户使用的那些应用程序提供 NOPASSWD 权限。 这可能会让人有些困惑,因为 Ansible 使用 Python 来处理很多事情,但是经过足够的尝试和错误,你应该能够弄清原理。 这是额外的工作,但确实消除了一些明显的安全漏洞。
### 计划实施
一旦你决定如何处理 Ansible 认证和权限提升,就需要设置它。 在熟悉 Ansible 之后,您可能会使用该工具来帮助“引导”新客户端,但首先手动配置客户端非常重要,以便您知道发生了什么事情。 将你熟悉的事情变得自动化比从头开始自动化要好。
我已经写过关于 SSH 密钥对的文章,网上有无数的设置类的文章。 来自 Ansible 服务器的简短版本看起来像这样:
```
# ssh-keygen
# ssh-copy-id -i .ssh/id_dsa.pub [email protected]
# ssh [email protected]
```
如果您在创建密钥对时选择不使用密码,最后一步您应该可以直接进入远程计算机,而不用输入密码或密钥串。
为了在 `sudo` 中设置权限提升,您需要编辑 `sudoers` 文件。 你不应该直接编辑文件,而是使用:
```
# sudo visudo
```
这将打开 `sudoers` 文件并允许您安全地进行更改(保存时会进行错误检查,所以您不会意外地因为输入错误将自己锁住)。 这个文件中有一些例子,所以你应该能够弄清楚如何分配你想要的确切的权限。
一旦配置完成,您应该在使用 Ansible 之前进行手动测试。 尝试 SSH 到远程客户端,然后尝试使用您选择的任何方法提升权限。 一旦你确认配置的方式可以连接,就可以安装 Ansible 了。
### 安装 Ansible
由于 Ansible 程序仅安装在一台计算机上,因此开始并不是一件繁重的工作。 Red Hat/Ubuntu 系统的软件包安装有点不同,但都不是很困难。
在 Red Hat/CentOS 中,首先启用 EPEL 库:
```
sudo yum install epel-release
```
然后安装 Ansible:
```
sudo yum install ansible
```
在 Ubuntu 中,首先启用 Ansible PPA:
```
sudo apt-add-repository spa:ansible/ansible
(press ENTER to access the key and add the repo)
```
然后安装 Ansible:
```
sudo apt-get update
sudo apt-get install ansible
```
### Ansible 主机文件配置
Ansible 系统无法知道您希望它控制哪个客户端,除非您给它一个计算机列表。 该列表非常简单,看起来像这样:
```
# file /etc/ansible/hosts
[webservers]
blogserver ansible_host=192.168.1.5
wikiserver ansible_host=192.168.1.10
[dbservers]
mysql_1 ansible_host=192.168.1.22
pgsql_1 ansible_host=192.168.1.23
```
方括号内的部分是指定的组。 单个主机可以列在多个组中,而 Ansible 可以指向单个主机或组。 这也是配置文件,比如纯文本密码的东西将被存储,如果这是你计划的那种设置。 配置文件中的每一行配置一个主机地址,并且可以在 `ansible_host` 语句之后添加多个声明。 一些有用的选项是:
```
ansible_ssh_pass
ansible_become
ansible_become_method
ansible_become_user
ansible_become_pass
```
### Ansible <ruby> 保险库 <rt> Vault </rt></ruby>
(LCTT 译注:Vault 作为 ansible 的一项新功能可将例如密码、密钥等敏感数据文件进行加密,而非明文存放)
我也应该注意到,尽管安装程序比较复杂,而且这不是在您首次进入 Ansible 世界时可能会做的事情,但该程序确实提供了一种加密保险库中的密码的方法。 一旦您熟悉 Ansible,并且希望将其投入生产,将这些密码存储在加密的 Ansible 保险库中是非常理想的。 但是本着先学会爬再学会走的精神,我建议首先在非生产环境下使用无密码方法。
### 系统测试
最后,你应该测试你的系统,以确保客户端可以正常连接。 `ping` 测试将确保 Ansible 计算机可以 `ping` 每个主机:
```
ansible -m ping all
```
运行后,如果 `ping` 成功,您应该看到每个定义的主机显示 `ping` 的消息:`pong`。 这实际上并没有测试认证,只是测试网络连接。 试试这个来测试你的认证:
```
ansible -m shell -a 'uptime' webservers
```
您应该可以看到 webservers 组中每个主机的运行时间命令的结果。
在后续文章中,我计划开始深入 Ansible 管理远程计算机的功能。 我将介绍各种模块,以及如何使用 ad-hoc 模式来完成一些按键操作,这些操作在命令行上单独处理都需要很长时间。 如果您没有从上面的示例 Ansible 命令中获得预期的结果,请花些时间确保身份验证可以工作。 如果遇到困难,请查阅 [Ansible 文档](http://docs.ansible.com)获取更多帮助。
---
via: <http://www.linuxjournal.com/content/ansible-automation-framework-thinks-sysadmin>
作者:[Shawn Powers](http://www.linuxjournal.com/users/shawn-powers) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,467 | 如何使用 GNU Stow 来管理从源代码安装的程序和点文件 | https://linuxconfig.org/how-to-use-gnu-stow-to-manage-programs-installed-from-source-and-dotfiles | 2018-03-22T00:45:12 | [
"stow",
"编译",
"源代码",
"安装"
] | https://linux.cn/article-9467-1.html | 
### 目的
使用 GNU Stow 轻松管理从源代码安装的程序和点文件(LCTT 译注:<ruby> 点文件 <rt> dotfile </rt></ruby>,即以 `.` 开头的文件,在 \*nix 下默认为隐藏文件,常用于存储程序的配置信息。)
### 要求
* root 权限
### 难度
简单
### 约定
* `#` - 给定的命令要求直接以 root 用户身份或使用 `sudo` 命令以 root 权限执行
* `$` - 给定的命令将作为普通的非特权用户来执行
### 介绍
有时候我们必须从源代码安装程序,因为它们也许不能通过标准渠道获得,或者我们可能需要特定版本的软件。 GNU Stow 是一个非常不错的<ruby> 符号链接工厂 <rt> symlinks factory </rt></ruby>程序,它可以帮助我们保持文件的整洁,易于维护。
### 获得 stow
你的 Linux 发行版本很可能包含 `stow`,例如在 Fedora,你安装它只需要:
```
# dnf install stow
```
在 Ubuntu/Debian 中,安装 `stow` 需要执行:
```
# apt install stow
```
在某些 Linux 发行版中,`stow` 在标准库中是不可用的,但是可以通过一些额外的软件源(例如 RHEL 和 CentOS7 中的EPEL )轻松获得,或者,作为最后的手段,你可以从源代码编译它。只需要很少的依赖关系。
### 从源代码编译
最新的可用 stow 版本是 `2.2.2`。源码包可以在这里下载:`https://ftp.gnu.org/gnu/stow/`。
一旦你下载了源码包,你就必须解压它。切换到你下载软件包的目录,然后运行:
```
$ tar -xvpzf stow-2.2.2.tar.gz
```
解压源文件后,切换到 `stow-2.2.2` 目录中,然后编译该程序,只需运行:
```
$ ./configure
$ make
```
最后,安装软件包:
```
# make install
```
默认情况下,软件包将安装在 `/usr/local/` 目录中,但是我们可以改变它,通过配置脚本的 `--prefix` 选项指定目录,或者在运行 `make install` 时添加 `prefix="/your/dir"`。
此时,如果所有工作都按预期工作,我们应该已经在系统上安装了 `stow`。
### stow 是如何工作的?
`stow` 背后主要的概念在程序手册中有很好的解释:
>
> Stow 使用的方法是将每个软件包安装到自己的目录树中,然后使用符号链接使它看起来像文件一样安装在公共的目录树中
>
>
>
为了更好地理解这个软件的运作,我们来分析一下它的关键概念:
#### stow 文件目录
stow 目录是包含所有 stow 软件包的根目录,每个包都有自己的子目录。典型的 stow 目录是 `/usr/local/stow`:在其中,每个子目录代表一个软件包。
#### stow 软件包
如上所述,stow 目录包含多个“软件包”,每个软件包都位于自己单独的子目录中,通常以程序本身命名。包就是与特定软件相关的文件和目录列表,作为一个实体进行管理。
#### stow 目标目录
stow 目标目录解释起来是一个非常简单的概念。它是包文件应该安装到的目录。默认情况下,stow 目标目录被视作是调用 stow 的目录。这种行为可以通过使用 `-t` 选项( `--target` 的简写)轻松改变,这使我们可以指定一个替代目录。
### 一个实际的例子
我相信一个好的例子胜过 1000 句话,所以让我来展示 `stow` 如何工作。假设我们想编译并安装 `libx264`,首先我们克隆包含其源代码的仓库:
```
$ git clone git://git.videolan.org/x264.git
```
运行该命令几秒钟后,将创建 `x264` 目录,它将包含准备编译的源代码。我们切换到 `x264` 目录中并运行 `configure` 脚本,将 `--prefix` 指定为 `/usr/local/stow/libx264` 目录。
```
$ cd x264 && ./configure --prefix=/usr/local/stow/libx264
```
然后我们构建该程序并安装它:
```
$ make
# make install
```
`x264` 目录应该创建在 `stow` 目录内:它包含了所有通常直接安装在系统中的东西。 现在,我们所要做的就是调用 `stow`。 我们必须从 `stow` 目录内运行这个命令,通过使用 `-d` 选项来手动指定 `stow` 目录的路径(默认为当前目录),或者通过如前所述用 `-t` 指定目标。我们还应该提供要作为参数存储的软件包的名称。 在这里,我们从 `stow` 目录运行程序,所以我们需要输入的内容是:
```
# stow libx264
```
libx264 软件包中包含的所有文件和目录现在已经在调用 stow 的父目录 (/usr/local) 中进行了符号链接,因此,例如在 `/usr/local/ stow/x264/bin` 中包含的 libx264 二进制文件现在符号链接在 `/usr/local/bin` 之中,`/usr/local/stow/x264/etc` 中的文件现在符号链接在 `/usr/local/etc` 之中等等。通过这种方式,系统将显示文件已正常安装,并且我们可以容易地跟踪我们编译和安装的每个程序。要反转该操作,我们只需使用 `-D` 选项:
```
# stow -d libx264
```
完成了!符号链接不再存在:我们只是“卸载”了一个 stow 包,使我们的系统保持在一个干净且一致的状态。 在这一点上,我们应该清楚为什么 stow 还可以用于管理点文件。 通常的做法是在 git 仓库中包含用户特定的所有配置文件,以便轻松管理它们并使它们在任何地方都可用,然后使用 stow 将它们放在适当位置,如放在用户主目录中。
stow 还会阻止你错误地覆盖文件:如果目标文件已经存在,并且没有指向 stow 目录中的包时,它将拒绝创建符号链接。 这种情况在 stow 术语中称为冲突。
就是这样!有关选项的完整列表,请参阅 stow 帮助页,并且不要忘记在评论中告诉我们你对此的看法。
---
via: <https://linuxconfig.org/how-to-use-gnu-stow-to-manage-programs-installed-from-source-and-dotfiles>
作者:[Egidio Docile](https://linuxconfig.org) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,468 | 什么是容器?为什么我们关注它? | https://www.linux.com/blog/intro-to-Linux/2017/12/what-are-containers-and-why-should-you-care | 2018-03-22T08:37:37 | [
"容器",
"Docker"
] | https://linux.cn/article-9468-1.html | 
什么是容器?你需要它们吗?为什么?在这篇文章中,我们会回答这些基本问题。
但是,为了回答这些问题,我们要提出更多的问题。当你开始考虑怎么用容器适配你的工作时,你需要弄清楚:你在哪开发应用?你在哪测试它?你在哪使用它?
你可能在你的笔记本电脑上开发应用,你的电脑上已经装好了所需要的库文件、扩展包、开发工具和开发框架。它在一个模拟生产环境的机器上进行测试,然后被用于生产环境。问题是这三种环境不一定都是一样的;它们没有同样的工具、框架和库。你在你机器上开发的应用不一定可以在生产环境中正常工作。
容器解决了这个问题。正如 Docker 解释的,“容器镜像是软件的一个轻量的、独立的、可执行的包,包括了执行它所需要的所有东西:代码、运行环境、系统工具、系统库、设置。”
这代表着,一旦一个应用被封装成容器,那么它所依赖的下层环境就不再重要了。它可以在任何地方运行,甚至在混合云环境下也可以。这是容器在开发人员,执行团队,甚至 CIO (信息主管)中变得如此流行的原因之一。
### 容器对开发人员的好处
现在开发人员或运维人员不再需要关注他们要使用什么平台来运行应用。开发人员不会再说:“这在我的系统上运行得好好的。”
容器的另一个重大优势是它的隔离性和安全性。因为容器将应用和运行平台隔离开了,应用以及它周边的东西都会变得安全。同时,不同的团队可以在一台设备上同时运行不同的应用——对于传统应用来说这是不可以的。
这不是虚拟机( VM )所提供的吗?既是,也不是。虚拟机可以隔离应用,但它负载太高了。[在一份文献中](https://www.ubuntu.com/containers),Canonical 比较了容器和虚拟机,结果是:“容器提供了一种新的虚拟化方法,它有着和传统虚拟机几乎相同的资源隔离水平。但容器的负载更小,它占用更少的内存,更为高效。这意味着可以实现高密度的虚拟化:一旦安装,你可以在相同的硬件上运行更多应用。”另外,虚拟机启动前需要更多的准备,而容器只需几秒就能运行,可以瞬间启动。
### 容器对应用生态的好处
现在,一个庞大的,由供应商和解决方案组成的生态系统已经可以让公司大规模地运用容器,不管是用于编排、监控、记录或者生命周期管理。
为了保证容器可以运行在任何地方,容器生态系统一起成立了[开源容器倡议](https://www.opencontainers.org/)(OCI)。这是一个 Linux 基金会的项目,目标在于创建关于容器运行环境和容器镜像格式这两个容器核心部分的规范。这两个规范确保容器领域中不会有任何不一致。
在很长的一段时间里,容器是专门用于 Linux 内核的,但微软和 Docker 的密切合作将容器带到了微软平台上。现在你可以在 Linux、Windows、Azure、AWS、Google 计算引擎、Rackspace,以及大型计算机上使用容器。甚至 VMware 也正在发展容器,它的 [vSphere Integrated Container](https://www.vmware.com/products/vsphere/integrated-containers.html)(VIC)允许 IT 专业人员在他们平台的传统工作负载上运行容器。
### 容器对 CIO 的好处
容器在开发人员中因为以上的原因而变得十分流行,同时他们也给 CIO 提供了很大的便利。将工作负载迁移到容器中的优势正在改变着公司运行的模式。
传统的应用有大约十年的生命周期。新版本的发布需要多年的努力,因为应用是依赖于平台的,有时几年也不能到达产品阶段。由于这个生命周期,开发人员会尽可能在应用里塞满各种功能,这会使应用变得庞大笨拙,漏洞百出。
这个过程影响了公司内部的创新文化。当人们几个月甚至几年都不能看到他们的创意被实现时,他们就不再有动力了。
容器解决了这个问题。因为你可以将应用切分成更小的微服务。你可以在几周或几天内开发、测试和部署。新特性可以添加成为新的容器。他们可以在测试结束后以最快的速度被投入生产。公司可以更快转型,超过他们的竞争者。因为想法可以被很快转化为容器并部署,这个方式使得创意爆炸式增长。
### 结论
容器解决了许多传统工作负载所面对的问题。但是,它并不能解决所有 IT 专业人员面对的问题。它只是众多解决方案中的一个。在下一篇文章中,我们将会覆盖一些容器的基本术语,然后我们会解释如何开始构建容器。
通过 Linux 基金会和 edX 提供的免费的 [“Introduction to Linux”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 课程学习更多 Linux 知识。
---
via: <https://www.linux.com/blog/intro-to-Linux/2017/12/what-are-containers-and-why-should-you-care>
作者:[wapnil Bhartiya](https://www.linux.com/users/arnieswap) 译者:[lonaparte](https://github.com/lonaparte) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,469 | 用 Python 构建你自己的 RSS 提示系统 | https://fedoramagazine.org/never-miss-magazines-article-build-rss-notification-system/ | 2018-03-22T08:51:57 | [
"RSS",
"Python"
] | https://linux.cn/article-9469-1.html | 
人生苦短,我用 Python,Python 是非常棒的快速构建应用程序的编程语言。在这篇文章中我们将学习如何使用 Python 去构建一个 RSS 提示系统,目标是使用 Fedora 快乐地学习 Python。如果你正在寻找一个完整的 RSS 提示应用程序,在 Fedora 中已经准备好了几个包。
### Fedora 和 Python —— 入门知识
Python 3.6 在 Fedora 中是默认安装的,它包含了 Python 的很多标准库。标准库提供了一些可以让我们的任务更加简单完成的模块的集合。例如,在我们的案例中,我们将使用 [sqlite3](https://docs.python.org/3/library/sqlite3.html) 模块在数据库中去创建表、添加和读取数据。在这个案例中,我们试图去解决的是这样的一个特定问题,在标准库中没有包含,而有可能已经有人为我们开发了这样一个模块。最好是使用像大家熟知的 [PyPI](https://pypi.python.org/pypi) Python 包索引去搜索一下。在我们的示例中,我们将使用 [feedparser](https://pypi.python.org/pypi/feedparser/5.2.1) 去解析 RSS 源。
因为 feedparser 并不是标准库,我们需要将它安装到我们的系统上。幸运的是,在 Fedora 中有这个 RPM 包,因此,我们可以运行如下的命令去安装 feedparser:
```
$ sudo dnf install python3-feedparser
```
我们现在已经拥有了编写我们的应用程序所需的东西了。
### 存储源数据
我们需要存储已经发布的文章的数据,这样我们的系统就可以只提示新发布的文章。我们要保存的数据将是用来辨别一篇文章的唯一方法。因此,我们将存储文章的标题和发布日期。
因此,我们来使用 Python sqlite3 模块和一个简单的 SQL 语句来创建我们的数据库。同时也添加一些后面将要用到的模块(feedparse,smtplib,和 email)。
#### 创建数据库
```
#!/usr/bin/python3
import sqlite3
import smtplib
from email.mime.text import MIMEText
import feedparser
db_connection = sqlite3.connect('/var/tmp/magazine_rss.sqlite')
db = db_connection.cursor()
db.execute(' CREATE TABLE IF NOT EXISTS magazine (title TEXT, date TEXT)')
```
这几行代码创建一个名为 `magazine_rss.sqlite` 文件的新 sqlite 数据库,然后在数据库创建一个名为 `magazine` 的新表。这个表有两个列 —— `title` 和 `date` —— 它们能存诸 TEXT 类型的数据,也就是说每个列的值都是文本字符。
#### 检查数据库中的旧文章
由于我们仅希望增加新的文章到我们的数据库中,因此我们需要一个功能去检查 RSS 源中的文章在数据库中是否存在。我们将根据它来判断是否发送(有新文章的)邮件提示。Ok,现在我们来写这个功能的代码。
```
def article_is_not_db(article_title, article_date):
""" Check if a given pair of article title and date
is in the database.
Args:
article_title (str): The title of an article
article_date (str): The publication date of an article
Return:
True if the article is not in the database
False if the article is already present in the database
"""
db.execute("SELECT * from magazine WHERE title=? AND date=?", (article_title, article_date))
if not db.fetchall():
return True
else:
return False
```
这个功能的主要部分是一个 SQL 查询,我们运行它去搜索数据库。我们使用一个 `SELECT` 命令去定义我们将要在哪个列上运行这个查询。我们使用 `*` 符号去选取所有列(`title` 和 `date`)。然后,我们使用查询的 `WHERE` 条件 `article_title` 和 `article_date` 去匹配标题和日期列中的值,以检索出我们需要的内容。
最后,我们使用一个简单的返回 `True` 或者 `False` 的逻辑来表示是否在数据库中找到匹配的文章。
#### 在数据库中添加新文章
现在我们可以写一些代码去添加新文章到数据库中。
```
def add_article_to_db(article_title, article_date):
""" Add a new article title and date to the database
Args:
article_title (str): The title of an article
article_date (str): The publication date of an article
"""
db.execute("INSERT INTO magazine VALUES (?,?)", (article_title, article_date))
db_connection.commit()
```
这个功能很简单,我们使用了一个 SQL 查询去插入一个新行到 `magazine` 表的 `article_title` 和 `article_date` 列中。然后提交它到数据库中永久保存。
这些就是在数据库中所需要的东西,接下来我们看一下,如何使用 Python 实现提示系统和发送电子邮件。
### 发送电子邮件提示
我们使用 Python 标准库模块 smtplib 来创建一个发送电子邮件的功能。我们也可以使用标准库中的 email 模块去格式化我们的电子邮件信息。
```
def send_notification(article_title, article_url):
""" Add a new article title and date to the database
Args:
article_title (str): The title of an article
article_url (str): The url to access the article
"""
smtp_server = smtplib.SMTP('smtp.gmail.com', 587)
smtp_server.ehlo()
smtp_server.starttls()
smtp_server.login('[email protected]', '123your_password')
msg = MIMEText(f'\nHi there is a new Fedora Magazine article : {article_title}. \nYou can read it here {article_url}')
msg['Subject'] = 'New Fedora Magazine Article Available'
msg['From'] = '[email protected]'
msg['To'] = '[email protected]'
smtp_server.send_message(msg)
smtp_server.quit()
```
在这个示例中,我使用了谷歌邮件系统的 smtp 服务器去发送电子邮件,在你自己的代码中你需要将它更改为你自己的电子邮件服务提供者的 SMTP 服务器。这个功能是个样板,大多数的内容要根据你的 smtp 服务器的参数来配置。代码中的电子邮件地址和凭证也要更改为你自己的。
如果在你的 Gmail 帐户中使用了双因子认证,那么你需要配置一个密码应用程序为你的这个应用程序提供一个唯一密码。可以看这个 [帮助页面](https://support.google.com/accounts/answer/185833?hl=en)。
### 读取 Fedora Magazine 的 RSS 源
我们已经有了在数据库中存储文章和发送提示电子邮件的功能,现在来创建一个解析 Fedora Magazine RSS 源并提取文章数据的功能。
```
def read_article_feed():
""" Get articles from RSS feed """
feed = feedparser.parse('https://fedoramagazine.org/feed/')
for article in feed['entries']:
if article_is_not_db(article['title'], article['published']):
send_notification(article['title'], article['link'])
add_article_to_db(article['title'], article['published'])
if __name__ == '__main__':
read_article_feed()
db_connection.close()
```
在这里我们将使用 `feedparser.parse` 功能。这个功能返回一个用字典表示的 RSS 源,对于 feedparser 的完整描述可以参考它的 [文档](https://pythonhosted.org/feedparser/reference.html)。
RSS 源解析将返回最后的 10 篇文章作为 `entries`,然后我们提取以下信息:标题、链接、文章发布日期。因此,我们现在可以使用前面定义的检查文章是否在数据库中存在的功能,然后,发送提示电子邮件并将这个文章添加到数据库中。
当运行我们的脚本时,最后的 `if` 语句运行我们的 `read_article_feed` 功能,然后关闭数据库连接。
### 运行我们的脚本
给脚本文件赋于正确运行权限。接下来,我们使用 cron 实用程序去每小时自动运行一次我们的脚本。cron 是一个作业计划程序,我们可以使用它在一个固定的时间去运行一个任务。
```
$ chmod a+x my_rss_notifier.py
$ sudo cp my_rss_notifier.py /etc/cron.hourly
```
为了使该教程保持简单,我们使用了 `cron.hourly` 目录每小时运行一次我们的脚本,如果你想学习关于 cron 的更多知识以及如何配置 crontab,请阅读 cron 的 wikipedia [页面](https://en.wikipedia.org/wiki/Cron)。
### 总结
在本教程中,我们学习了如何使用 Python 去创建一个简单的 sqlite 数据库、解析一个 RSS 源、以及发送电子邮件。我希望通过这篇文章能够向你展示,使用 Python 和 Fedora 构建你自己的应用程序是件多么容易的事。
这个脚本在 [GitHub](https://github.com/cverna/rss_feed_notifier) 上可以找到。
---
via: <https://fedoramagazine.org/never-miss-magazines-article-build-rss-notification-system/>
作者:[Clément Verna](https://fedoramagazine.org) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Python is a great programming language to quickly build applications that make our life easier. In this article we will learn how to use Python to build a RSS notification system, the goal being to have fun learning Python using Fedora. If you are looking for a complete RSS notifier application, there are a few already packaged in Fedora.
### Fedora and Python – getting started
Python 3.6 is available by default in Fedora, that includes Python’s extensive standard library. The standard library provides a collection of modules which make some tasks simpler for us. For example, in our case we will use the [ sqlite3](https://docs.python.org/3/library/sqlite3.html) module to create, add and read data from a database. In the case where a particular problem we are trying to solve is not covered by the standard library, the chance is that someone has already developed a module for everyone to use. The best place to search for such modules is the Python Package Index known as
[PyPI](https://pypi.python.org/pypi). In our example we are going to use the
[to parse an RSS feed.](https://pypi.python.org/pypi/feedparser/5.2.1)
**feedparser**Since **feedparser **is not in the standard library, we have to install it in our system. Luckily for us there is an rpm package in Fedora, so the installation of **feedparser** is as simple as:
$ sudo dnf install python3-feedparser
We now have everything we need to start coding our application.
### Storing the feed data
We need to store data from the articles that have already been published so that we send a notification only for new articles. The data we want to store will give us a unique way to identify an article. Therefore we will store the **title** and the **publication date** of the article.
So let’s create our database using python **sqlite3** module and a simple SQL query. We are also adding the modules we are going to use later (**feedparser**, **smtplib** and **email**).
#### Creating the Database
```
#!/usr/bin/python3
import sqlite3
import smtplib
from email.mime.text import MIMEText
import feedparser
db_connection = sqlite3.connect('/var/tmp/magazine_rss.sqlite')
db = db_connection.cursor()
db.execute('CREATE TABLE IF NOT EXISTS magazine (title TEXT, date TEXT)')
```
These few lines of code create a new sqlite database stored in a file called *‘magazine_rss.sqlite’, *and then create a new table within the database called *‘magazine’. *This table has two columns – *‘title’ *and *‘date’ – *that can store data of the type TEXT, which means that the value of each column will be a text string.
#### Checking the Database for old articles
Since we only want to add new articles to our database we need a function that will check if the article we get from the RSS feed is already in our database or not. We will use it to decide if we should send an email notification (new article) or not (old article). Ok let’s code this function.
def article_is_not_db(article_title, article_date): """ Check if a given pair of article title and date is in the database. Args: article_title (str): The title of an article article_date (str): The publication date of an article Return: True if the article is not in the database False if the article is already present in the database """ db.execute("SELECT * from magazine WHERE title=? AND date=?", (article_title, article_date)) if not db.fetchall(): return True else: return False
The main part of this function is the SQL query we execute to search through the database. We are using a *SELECT* instruction to define which column of our *magazine* table we will run the query on. We are using the *** symbol to select all columns ( *title* and *date*). Then we ask to select only the rows of the table *WHERE *the *article_title* and *article_date* string are equal to the value of the *title* and *date* column.
To finish, we have a simple logic that will return True if the query did not return any results and False if the query found an article in database matching our *title*, *date* pair.
#### Adding a new article to the Database
Now we can code the function to add a new article to the database.
def add_article_to_db(article_title, article_date): """ Add a new article title and date to the database Args: article_title (str): The title of an article article_date (str): The publication date of an article """ db.execute("INSERT INTO magazine VALUES (?,?)", (article_title, article_date)) db_connection.commit()
This function is straight forward, we are using a SQL query to *INSERT* a new row *INTO* the *magazine* table with the *VALUES *of the *article_title *and *article_date*. Then we commit the change to make it persistent.
That’s all we need from the database’s point of view, let’s look at the notification system and how we can use python to send emails.
### Sending an email notification
Let’s create a function to send an email using the python standard library module **smtplib.** We are also using the **email **module from the standard library to format our email message.
def send_notification(article_title, article_url): """ Add a new article title and date to the database Args: article_title (str): The title of an article article_url (str): The url to access the article """ smtp_server = smtplib.SMTP('smtp.gmail.com', 587) smtp_server.ehlo() smtp_server.starttls() smtp_server.login('[email protected]', '123your_password') msg = MIMEText(f'\nHi there is a new Fedora Magazine article : {article_title}. \nYou can read it here {article_url}') msg['Subject'] = 'New Fedora Magazine Article Available' msg['From'] = '[email protected]' msg['To'] = '[email protected]' smtp_server.send_message(msg) smtp_server.quit()
In this example I am using the Google mail smtp server to send an email, but this will work with any email services that provides you with a SMTP server. Most of this function is boilerplate needed to configure the access to the smtp server. You will need to update the code with your email address and credentials.
If you are using 2 Factor Authentication with your gmail account you can setup a password app that will give you a unique password to use for this application. Check out this help [page](https://support.google.com/accounts/answer/185833?hl=en).
### Reading Fedora Magazine RSS feed
We now have functions to store an article in the database and send an email notification, let’s create a function that parses the Fedora Magazine RSS feed and extract the articles’ data.
def read_article_feed(): """ Get articles from RSS feed """ feed = feedparser.parse('https://fedoramagazine.org/feed/') for article in feed['entries']: if article_is_not_db(article['title'], article['published']): send_notification(article['title'], article['link']) add_article_to_db(article['title'], article['published']) if __name__ == '__main__': read_article_feed() db_connection.close()
Here we are making use of the **feedparser.parse **function. The function returns a dictionary representation of the RSS feed, for the full reference of the representation you can consult **feedparser** ‘s [documentation](https://pythonhosted.org/feedparser/reference.html).
The RSS feed parser will return the last 10 articles as *entries * and then we extract the following information: the *title, *the *link* and the date the article was *published*. As a result, we can now use the functions we have previously defined to check if the article is not in the database, then send a notification email and finally, add the article to our database.
The last if statement is used to execute our *read_article_feed *function and then close the database connection when we execute our script.
### Running our script
Finally, to run our script we need to give the correct permission to the file. Next, we make use of the **cron** utility to automatically execute our script every hour (1 minute past the hour). **cron **is a job scheduler that we can use to run a task at a fixed time.
$ chmod a+x my_rss_notifier.py $ sudo cp my_rss_notifier.py /etc/cron.hourly
To keep this tutorial simple, we are using the cron.hourly directory to execute the script every hours, I you wish to learn more about **cron** and how to configure the **crontab, **please read **cron’s** wikipedia [page](https://en.wikipedia.org/wiki/Cron).
### Conclusion
In this tutorial we have learned how to use Python to create a simple sqlite database, parse an RSS feed and send emails. I hope that this showed you how you can easily build your own application using Python and Fedora.
The script is available on github [here](https://github.com/cverna/rss_feed_notifier).
## Frafra
Really nice post 🙂
Beware of the SQL injection attack 😉
“Usually your SQL operations will need to use values from Python variables. You shouldn’t assemble your query using Python’s string operations because doing so is insecure; it makes your program vulnerable to an SQL injection attack (see https://xkcd.com/327/ for humorous example of what can go wrong).
Instead, use the DB-API’s parameter substitution. Put ? as a placeholder wherever you want to use a value, and then provide a tuple of values as the second argument to the cursor’s execute() method.”
— https://docs.python.org/3.6/library/sqlite3.html
Here is the proposed fix: https://github.com/cverna/rss_feed_notifier/pull/1
## Clément Verna
Thanks I have merged the PR and I have updated the article too
## Matěj Cepl
And if you continue on this way a bit further you get to rss2email :). Install it from a Fedora package.
## Brenton Horne
Nice, surprised you didn’t teach how to create a pop-up with the notification, instead of emailing. After all wouldn’t that be more secure? Storing your password (even just your email one, as opposed to your user/root password) in a plain text file like a Python script isn’t exactly secure.
## José Monteiro
Great. Exactly like it must be: good code used in a practical situation. I would like very much to see more of this. How to validate user data? Could you write a series of articles, for instance, building an inventory control?
## steve allen
Really enjoyed this article. Short, simple and useful.
I made one minor change. I changed the code to send one email rather than multiple. My email was getting swamped with messages:
def send_notification(message_text):
“”” Add a new article title and date to the database
Args:
article_title (str): The title of an article
article_url (str): The url to access the article
“””
smtp_server = smtplib.SMTP(‘smtp.gmail.com’, 587)
smtp_server.ehlo()
smtp_server.starttls()
smtp_server.login(‘[email protected]’, ‘123your_password’)
msg = MIMEText( message_text,’html’ )
msg[‘Subject’] = ‘New Fedora Magazine Article(s) Available’
msg[‘From’] = ‘[email protected]’
msg[‘To’] = ‘[email protected]’
smtp_server.send_message(msg)
smtp_server.quit()
def read_article_feed():
“”” Get articles from RSS feed “””
feed = feedparser.parse(‘https://fedoramag.wpengine.com/feed/’)
article_count = 0
msg_body = ”
if article_is_not_db(article['title'], article['published']):
article_count = article_count + 1
msg_body = msg_body + '<p><a href="' + article['link'] + '">' + article['title'] + '</a></p>'
add_article_to_db(article['title'], article['published'])
if article_count > 0:
send_notification(msg_body)
## Clément Verna
@steve allen
Cool feel free to send a Pull Request on the github project with you change 🙂 |
9,470 | 如何检查你的 Linux 系统是否存在 Meltdown 或者 Spectre 漏洞 | https://www.maketecheasier.com/check-linux-meltdown-spectre-vulnerability/ | 2018-03-22T16:03:00 | [
"Meltdown",
"Specter",
"CPU"
] | https://linux.cn/article-9470-1.html | 
Meltdown 和 Specter 漏洞的最恐怖的现实之一是它们涉及非常广泛。几乎每台现代计算机都会受到一些影响。真正的问题是*你*是否受到了影响?每个系统都处于不同的脆弱状态,具体取决于已经或者还没有打补丁的软件。
由于 Meltdown 和 Spectre 都是相当新的漏洞,并且事情正在迅速发展,所以告诉你需要注意什么或在系统上修复了什么并非易事。有一些工具可以提供帮助。它们并不完美,但它们可以帮助你找出你需要知道的东西。
### 简单测试
顶级的 Linux 内核开发人员之一提供了一种简单的方式来检查系统在 Meltdown 和 Specter 漏洞方面的状态。它是简单的,也是最简洁的,但它不适用于每个系统。有些发行版不支持它。即使如此,也值得一试。
```
grep . /sys/devices/system/cpu/vulnerabilities/*
```

你应该看到与上面截图类似的输出。很有可能你会发现系统中至少有一个漏洞还存在。这的确是真的,因为 Linux 在减轻 Specter v1 影响方面还没有取得任何进展。
### 脚本
如果上面的方法不适合你,或者你希望看到更详细的系统报告,一位开发人员已创建了一个 shell 脚本,它将检查你的系统来查看系统收到什么漏洞影响,还有做了什么来减轻 Meltdown 和 Spectre 的影响。
要得到脚本,请确保你的系统上安装了 Git,然后将脚本仓库克隆到一个你不介意运行它的目录中。
```
cd ~/Downloads
git clone https://github.com/speed47/spectre-meltdown-checker.git
```
这不是一个大型仓库,所以它应该只需要几秒钟就克隆完成。完成后,输入新创建的目录并运行提供的脚本。
```
cd spectre-meltdown-checker
./spectre-meltdown-checker.sh
```
你会在终端看到很多输出。别担心,它不是太难理解。首先,脚本检查你的硬件,然后运行三个漏洞检查:Specter v1、Spectre v2 和 Meltdown。每个漏洞都有自己的部分。在这之间,脚本明确地告诉你是否受到这三个漏洞的影响。

每个部分为你提供了潜在的可用的缓解方案,以及它们是否已被应用。这里需要你的一点常识。它给出的决定可能看起来有冲突。研究一下,看看它所说的修复是否实际上完全缓解了这个问题。
### 这意味着什么
所以,要点是什么?大多数 Linux 系统已经针对 Meltdown 进行了修补。如果你还没有更新,你应该更新一下。 Specter v1 仍然是一个大问题,到目前为止还没有取得很大进展。Spectre v2 将取决于你的发行版以及它选择应用的补丁。无论哪种工具都说,没有什么是完美的。做好研究并留意直接来自内核和发行版开发者的信息。
---
via: <https://www.maketecheasier.com/check-linux-meltdown-spectre-vulnerability/>
作者:[Nick Congleton](https://www.maketecheasier.com/author/nickcongleton/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
One of the scariest realities of the Meltdown and Spectre vulnerabilities is just how widespread they are. Virtually every modern computer is affected in some way. The real question is how exactly are *you* affected? Every system is at a different state of vulnerability depending on which software has and hasn’t been patched.
Since Meltdown and Spectre are both fairly new and things are moving quickly, it’s not all that easy to tell what you need to look out for or what’s been fixed on your system. There are a couple of tools available that can help. They’re not perfect, but they can help you figure out what you need to know.
**Also read:** [How to Use the Nessus Vulnerability Scanner on Linux](https://www.maketecheasier.com/use-nessus-vulnerability-scanner-linux/)
## Simple Test
One of the top Linux kernel developers provided a simple way of checking the status of your system in regards to the Meltdown and Spectre vulnerabilities. This one is the easiest, and is most concise, but it doesn’t work on every system. Some distributions decided not to include support for this report. Even still, it’s worth a shot to check.
grep . /sys/devices/system/cpu/vulnerabilities/*
You should see output similar to the image above. Chances are, you’ll see that at least one of the vulnerabilities remains unchecked on your system. This is especially true since Linux hasn’t made any progress in mitigating Spectre v1 yet.
## The Script
If the above method didn’t work for you, or you want a more detailed report of your system, a developer has created a shell script that will check your system to see what exactly it is susceptible to and what has been done to mitigate Meltdown and Spectre.
In order to get the script, make sure you have Git installed on your system, and then clone the script’s repository into a directory that you don’t mind running it out of.
cd ~/Downloads git clone https://github.com/speed47/spectre-meltdown-checker.git
It’s not a large repository, so it should only take a few seconds to clone. When it’s done, enter the newly created directory and run the provided script.
cd spectre-meltdown-checker ./spectre-meltdown-checker.sh
You’ll see a bunch of junk spit out into the terminal. Don’t worry, its not too hard to follow. First, the script checks your hardware, and then it runs through the three vulnerabilities: Spectre v1, Spectre v2, and Meltdown. Each gets its own section. In between, the script tells you plainly whether you are vulnerable to each of the three.
Each section provides you with a breakdown of potential mitigation and whether or not they have been applied. Here’s where you need to exercise a bit of common sense. The determinations that it gives might seem like they’re in conflict. Do a bit of digging to see if the fixes that it says are applied actually do fully mitigate the problem or not.
## What This Means
So, what’s the takeaway? Most Linux systems have been patched against Meltdown. If you haven’t updated yet for that, you should. Spectre v1 is still a big problem, and not a lot of progress has been made there as of yet. Spectre v2 will depend a lot on your distribution and what patches it’s chosen to apply. Regardless of what either tool says, nothing is perfect. Do your research and stay on the lookout for information coming straight from the kernel and distribution developers.
Our latest tutorials delivered straight to your inbox |
9,471 | Python Plumbum 简介:用 Python 来写脚本 | https://plumbum.readthedocs.io/en/latest/ | 2018-03-22T10:11:40 | [
"Shell"
] | https://linux.cn/article-9471-1.html | 
### Plumbum:Shell 组合器
你是否曾希望将 shell 脚本紧凑地融入到**真正**的编程语言里面? 那么可以了解下 Plumbum Shell 组合器。Plumbum (lead 的拉丁语,以前用来制作管道)是一个小型但功能丰富的类库,用于以 Python 进行类似 shell 脚本编程。该库的理念是 “**永远不要再写 shell 脚本**”,因此它试图合理地模仿 shell 语法(shell 组合器),同时保持 **Python 特性和跨平台**。
除了[类似 shell 的语法](https://plumbum.readthedocs.io/en/latest/local_commands.html#guide-local-commands)和[便捷的快捷方式](https://plumbum.readthedocs.io/en/latest/utils.html#guide-utils)之外,该库还提供本地和[远程](https://plumbum.readthedocs.io/en/latest/remote.html#guide-remote-commands)命令执行(通过 SSH)、本地和远程文件系统[路径](https://plumbum.readthedocs.io/en/latest/paths.html#guide-paths)、简单的工作目录和环境[操作](https://plumbum.readthedocs.io/en/latest/local_machine.html#guide-local-machine)、快捷访问 ANSI 颜色,以及[编程命令行接口(CLI)](https://plumbum.readthedocs.io/en/latest/cli.html#guide-cli)应用程序工具包。现在让我们看一些代码!
其最新版本 1.6.6 发布于 2018 年 2 月 12 日。
### 快捷使用指南
####
#### 基本使用
```
>>> from plumbum import local
>>> ls = local["ls"]
>>> ls
LocalCommand(<LocalPath /bin/ls>)
>>> ls()
u'build.py\ndist\ndocs\nLICENSE\nplumbum\nREADME.rst\nsetup.py\ntests\ntodo.txt\n'
>>> notepad = local["c:\\windows\\notepad.exe"]
>>> notepad() # Notepad window pops up
u'' # Notepad window is closed by user, command returns
```
不需要为每个你想使用的命令写 `xxx = local["xxx"]`,你可以[导入命令行](https://plumbum.readthedocs.io/en/latest/local_commands.html#import-hack):
```
>>> from plumbum.cmd import grep, wc, cat, head
>>> grep
LocalCommand(<LocalPath /bin/grep>)
```
参见[本地命令行](https://plumbum.readthedocs.io/en/latest/local_commands.html#guide-local-commands) 。
#### 管道
```
>>> chain = ls["-a"] | grep["-v", "\\.py"] | wc["-l"]
>>> print chain
/bin/ls -a | /bin/grep -v '\.py' | /usr/bin/wc -l
>>> chain()
u'13\n'
```
参见[管道](https://plumbum.readthedocs.io/en/latest/local_commands.html#guide-local-commands-pipelining)。
#### 重定向
```
>>> ((cat < "setup.py") | head["-n", 4])()
u'#!/usr/bin/env python\nimport os\n\ntry:\n'
>>> (ls["-a"] > "file.list")()
u''
>>> (cat["file.list"] | wc["-l"])()
u'17\n'
```
参见[输入/输出重定向](https://plumbum.readthedocs.io/en/latest/local_commands.html#guide-local-commands-redir)。
#### 工作目录操作
```
>>> local.cwd
<Workdir /home/tomer/workspace/plumbum>
>>> with local.cwd(local.cwd / "docs"):
... chain()
...
u'15\n'
```
参见[路径](https://plumbum.readthedocs.io/en/latest/paths.html#guide-paths)和[本地对象](https://plumbum.readthedocs.io/en/latest/local_machine.html#guide-local-machine) 。
#### 前台后和后台执行
```
>>> from plumbum import FG, BG
>>> (ls["-a"] | grep["\\.py"]) & FG # The output is printed to stdout directly
build.py
.pydevproject
setup.py
>>> (ls["-a"] | grep["\\.py"]) & BG # The process runs "in the background"
<Future ['/bin/grep', '\\.py'] (running)>
```
参见[前台和后台](https://plumbum.readthedocs.io/en/latest/local_commands.html#guide-local-commands-bgfg)。
#### 命令行嵌套
```
>>> from plumbum.cmd import sudo
>>> print sudo[ifconfig["-a"]]
/usr/bin/sudo /sbin/ifconfig -a
>>> (sudo[ifconfig["-a"]] | grep["-i", "loop"]) & FG
lo Link encap:Local Loopback
UP LOOPBACK RUNNING MTU:16436 Metric:1
```
参见[命令行嵌套](https://plumbum.readthedocs.io/en/latest/local_commands.html#guide-local-commands-nesting)。
#### 远程命令(通过 SSH)
```
>>> from plumbum import SshMachine
>>> remote = SshMachine("somehost", user = "john", keyfile = "/path/to/idrsa")
>>> r_ls = remote["ls"]
>>> with remote.cwd("/lib"):
... (r_ls | grep["0.so.0"])()
...
u'libusb-1.0.so.0\nlibusb-1.0.so.0.0.0\n'
```
参见[远程](https://plumbum.readthedocs.io/en/latest/remote.html#guide-remote)。
#### CLI 应用程序
```
import logging
from plumbum import cli
class MyCompiler(cli.Application):
verbose = cli.Flag(["-v", "--verbose"], help = "Enable verbose mode")
include_dirs = cli.SwitchAttr("-I", list = True, help = "Specify include directories")
@cli.switch("-loglevel", int)
def set_log_level(self, level):
"""Sets the log-level of the logger"""
logging.root.setLevel(level)
def main(self, *srcfiles):
print "Verbose:", self.verbose
print "Include dirs:", self.include_dirs
print "Compiling:", srcfiles
if __name__ == "__main__":
MyCompiler.run()
```
输出样例:
```
$ python simple_cli.py -v -I foo/bar -Ispam/eggs x.cpp y.cpp z.cpp
Verbose: True
Include dirs: ['foo/bar', 'spam/eggs']
Compiling: ('x.cpp', 'y.cpp', 'z.cpp')
```
参见[命令行应用程序](https://plumbum.readthedocs.io/en/latest/cli.html#guide-cli)。
#### 颜色和风格
```
from plumbum import colors
with colors.red:
print("This library provides safe, flexible color access.")
print(colors.bold | "(and styles in general)", "are easy!")
print("The simple 16 colors or",
colors.orchid & colors.underline | '256 named colors,',
colors.rgb(18, 146, 64) | "or full rgb colors" ,
'can be used.')
print("Unsafe " + colors.bg.dark_khaki + "color access" + colors.bg.reset + " is available too.")
```
输出样例:
```
This library provides safe color access.
Color (and styles in general) are easy!
The simple 16 colors, 256 named colors, or full hex colors can be used.
Unsafe color access is available too.
```
参见[颜色](https://plumbum.readthedocs.io/en/latest/colors.html#guide-colors)。
### 开发和安装
该库在 [Github](https://github.com/tomerfiliba/plumbum) 上开发,非常乐意接受来自用户的[补丁](https://help.github.com/send-pull-requests/)。请使用 GitHub 的内置 [issue 跟踪器](https://github.com/tomerfiliba/plumbum/issues)报告您遇到的任何问题或提出功能上的需求。该库在 [IMIT 许可](https://github.com/tomerfiliba/plumbum/blob/master/LICENSE)下发布。
#### 要求
Plumbum 支持 Python 2.6-3.6 和 PyPy,并且通过 [Travis CI](https://travis-ci.org/tomerfiliba/plumbum) 和 [Appveyor](https://ci.appveyor.com/project/HenrySchreiner/plumbum/branch/master) 持续地在 Linux,Mac 和 Windows 机器上测试。Plumbum 在任何类 Unix 的机器都应该可以正常工作,但是在 Windows 上,你也许需要安装一个合适的 [coreutils](https://www.wikiwand.com/en/Coreutils) 环境并把其加入到你的`PATH`环境变量中。我推荐 [mingw](http://mingw.org/)(与 [Windows Git](http://msysgit.github.io/) 捆绑在一起),但是 [cygwin](http://www.cygwin.com/) 应该也可以。如果你仅仅是使用 Plumbum 代替 Popen 来运行 Windows 程序,那么就不需要 Unix 工具了。 注意远程命令的执行,你需要一个 openSHH 兼容的客户端(同样与 Windows Git 捆绑在一起)和一个 bash 兼容的 shell,也需要在主机上有一个 coreutils 环境。
#### 下载
你可以在 [**Python Package Index**](https://pypi.python.org/pypi/plumbum#downloads) (多种格式)下载该库,或者直接运行 `pip install plumbum`。如果你使用 Anaconda,你可以使用 `conda install -c conda-forge plumbum` 从 `conda-forge` 通道获取。
### 用户指南
用户指南涵盖了 Plumbum 大部分功能,拥有大量的代码片段,你可以不用花多少时间即可开始使用。该指南逐渐介绍概念和"语法",因此推荐你按照顺序阅读。一个[**有效的快速参考指南**](https://plumbum.readthedocs.io/en/latest/quickref.html#guide-quickref)。 *略。。。*
####
### 关于
Plumburn 最初的目的是让本地和远程程序轻松地执行,假设没有比老的 ssh 更时髦的东西了。在此基础上,设计了一个文件系统抽象层,以便能够无缝地处理本地和远程文件。 我有这个想法一段时间了,直到我必须要个给我当前工作的项目写一个构建脚本,我决定使用 shell 脚本,现在是实现它的时候了。Plumbum 诞生自 `Path` 类的片段和我为 [**RPyC**](http://rpyc.readthedocs.io/en/latest/) 写的 `SshContext` 和 `SshTunnel` 类。`Path` 类是我为前面说的构建系统写的。当我将两者与 *shell 组合器*(因为 shell 脚本在这里确实有优势)组合在一起时,奇迹就发生了,便产生了Plumbun。
### 致谢
该项目受到了 [**Andrew Moffat**](https://github.com/amoffat) 的 **PBS**(现在被称作 [**sh**](http://amoffat.github.io/sh/))启发,并且借用了他的一些思想(即像函数一样看待程序,导入命令行的技巧)。然而我感觉在 PBS 中有太多的神秘的东西,当我编写类 shell 程序时,语法不是我想要的。关于这个问题我联系了 Andrew,但是他想让 PBS 保持这种状态。除此之外,两个库走不同的方向,Plumbum 试图提供一种更合理的方法。
Plumbum 也向 [**Rotem Yaari**](https://github.com/vmalloc/) 致敬,他为特定的目的建议了一个代号为 `pyplatform` 的库,但是尚未实现过。
| 200 | OK | # Plumbum: Shell Combinators and More[¶](#plumbum-shell-combinators-and-more)
Ever wished the compactness of shell scripts be put into a **real** programming language?
Say hello to *Plumbum Shell Combinators*. Plumbum (Latin for *lead*, which was used to create
pipes back in the day) is a small yet feature-rich library for shell script-like programs in Python.
The motto of the library is **“Never write shell scripts again”**, and thus it attempts to mimic
the **shell syntax** (*shell combinators*) where it makes sense, while keeping it all **Pythonic
and cross-platform**.
Apart from [shell-like syntax](local_commands.html#guide-local-commands) and [handy shortcuts](utils.html#guide-utils),
the library provides local and [remote](remote.html#guide-remote-commands) command execution (over SSH),
local and remote file-system [paths](paths.html#guide-paths), easy working-directory and
environment [manipulation](local_machine.html#guide-local-machine), quick access to ANSI [colors](colors.html#guide-colors), and a programmatic
[Command-Line Interface (CLI)](cli.html#guide-cli) application toolkit. Now let’s see some code!
# News[¶](#news)
**2023.10.05**: Version 1.9.0 released with Python 3.8-3.13 support, and some small fixes.**2024.04.29**: Version 1.8.3 released with some small fixes, final version to support Python 3.6 and 3.7.**2023.05.30**: Version 1.8.2 released with a PyPI metadata fix, Python 3.12b1 testing, and a bit more typing.**2023.01.01**: Version 1.8.1 released with hatchling replacing setuptools for the build system, and support for Path objects in local.**2022.10.05**: Version 1.8.0 released with`NO_COLOR`
/`FORCE_COLOR`
,`all_markers`
& future annotations for the CLI, some command enhancements, & Python 3.11 testing.**2021.12.23**: Version 1.7.2 released with very minor fixes, final version to support Python 2.7 and 3.5.**2021.11.23**: Version 1.7.1 released with a few features like reverse tunnels, color group titles, and a glob path fix. Better Python 3.10 support.**2021.02.08**: Version 1.7.0 released with a few new features like`.with_cwd`
, some useful bugfixes, and lots of cleanup.**2020.03.23**: Version 1.6.9 released with several Path fixes, final version to support Python 2.6.**2019.10.30**: Version 1.6.8 released with`local.cmd`
, a few command updates,`Set`
improvements, and`TypedEnv`
.**2018.08.10**: Version 1.6.7 released with several minor additions, mostly to CLI apps, and`run_*`
modifiers added.**2018.02.12**: Version 1.6.6 released with one more critical bugfix for a error message regression in 1.6.5.**2017.12.29**: Version 1.6.5 released with mostly bugfixes, including a critical one that could break pip installs on some platforms. English cli apps now load as fast as before the localization update.**2017.11.27**: Version 1.6.4 released with new CLI localization support. Several bugfixes and better pathlib compatibility, along with better separation between Plumbum’s internal packages.**2016.12.31**: Version 1.6.3 released to provide Python 3.6 compatibility. Mostly bugfixes, several smaller improvements to paths, and a provisional config parser added.**2016.12.3**: Version 1.6.2 is now available through[conda-forge](https://conda-forge.github.io), as well.**2016.6.25**: Version 1.6.2 released. This is mostly a bug fix release, but a few new features are included. Modifiers allow some new arguments, and`Progress`
is improved. Better support for SunOS and other OS’s.**2015.12.18**: Version 1.6.1 released. The release mostly contains smaller fixes for CLI, 2.6/3.5 support, and colors. PyTest is now used for tests, and Conda is supported.**2015.10.16**: Version 1.6.0 released. Highlights include Python 3.5 compatibility, the`plumbum.colors`
package,`Path`
becoming a subclass of`str`
and a host of bugfixes. Special thanks go to Henry for his efforts.**2015.07.17**: Version 1.5.0 released. This release brings a host of bug fixes, code cleanups and some experimental new features (be sure to check the changelog). Also, say hi to[Henry Schreiner](https://github.com/henryiii), who has joined as a member of the project.
# Cheat Sheet[¶](#cheat-sheet)
## Basics[¶](#basics)
```
>>> from plumbum import local
>>> ls = local["ls"]
>>> ls
LocalCommand(<LocalPath /bin/ls>)
>>> ls()
'build.py\ndist\ndocs\nLICENSE\nplumbum\nREADME.rst\nsetup.py\ntests\ntodo.txt\n'
>>> notepad = local["c:\\windows\\notepad.exe"]
>>> notepad() # Notepad window pops up
'' # Notepad window is closed by user, command returns
```
Instead of writing `xxx = local["xxx"]`
for every program you wish to use, you can
also [import commands](local_commands.html#import-hack):
```
>>> from plumbum.cmd import grep, wc, cat, head
>>> grep
LocalCommand(<LocalPath /bin/grep>)
```
Or, use the `local.cmd`
syntactic-sugar:
```
>>> local.cmd.ls
LocalCommand(<LocalPath /bin/ls>)
>>> local.cmd.ls()
'build.py\ndist\ndocs\nLICENSE\nplumbum\nREADME.rst\nsetup.py\ntests\ntodo.txt\n'
```
See [Local Commands](local_commands.html#guide-local-commands).
## Piping[¶](#piping)
```
>>> chain = ls["-a"] | grep["-v", "\\.py"] | wc["-l"]
>>> print(chain)
/bin/ls -a | /bin/grep -v '\.py' | /usr/bin/wc -l
>>> chain()
'13\n'
```
See [Pipelining](local_commands.html#guide-local-commands-pipelining).
## Redirection[¶](#redirection)
```
>>> ((cat < "setup.py") | head["-n", 4])()
'#!/usr/bin/env python3\nimport os\n\ntry:\n'
>>> (ls["-a"] > "file.list")()
''
>>> (cat["file.list"] | wc["-l"])()
'17\n'
```
## Working-directory manipulation[¶](#working-directory-manipulation)
```
>>> local.cwd
<Workdir /home/tomer/workspace/plumbum>
>>> with local.cwd(local.cwd / "docs"):
... chain()
...
'15\n'
```
A more explicit, and thread-safe way of running a command in a different directory is using the `.with_cwd()`
method:
```
.. code-block:: python
```
```
>>> ls_in_docs = local.cmd.ls.with_cwd("docs")
>>> ls_in_docs()
'api\nchangelog.rst\n_cheatsheet.rst\ncli.rst\ncolorlib.rst\n_color_list.html\ncolors.rst\nconf.py\nindex.rst\nlocal_commands.rst\nlocal_machine.rst\nmake.bat\nMakefile\n_news.rst\npaths.rst\nquickref.rst\nremote.rst\n_static\n_templates\ntyped_env.rst\nutils.rst\n'
```
See [Paths](paths.html#guide-paths) and [The Local Object](local_machine.html#guide-local-machine).
## Foreground and background execution[¶](#foreground-and-background-execution)
```
>>> from plumbum import FG, BG
>>> (ls["-a"] | grep["\\.py"]) & FG # The output is printed to stdout directly
build.py
.pydevproject
setup.py
>>> (ls["-a"] | grep["\\.py"]) & BG # The process runs "in the background"
<Future ['/bin/grep', '\\.py'] (running)>
```
## Command nesting[¶](#command-nesting)
```
>>> from plumbum.cmd import sudo
>>> print(sudo[ifconfig["-a"]])
/usr/bin/sudo /sbin/ifconfig -a
>>> (sudo[ifconfig["-a"]] | grep["-i", "loop"]) & FG
lo Link encap:Local Loopback
UP LOOPBACK RUNNING MTU:16436 Metric:1
```
See [Command Nesting](local_commands.html#guide-local-commands-nesting).
## Remote commands (over SSH)[¶](#remote-commands-over-ssh)
Supports [openSSH](https://www.openssh.com/)-compatible clients,
[PuTTY](https://www.chiark.greenend.org.uk/~sgtatham/putty/) (on Windows)
and [Paramiko](https://github.com/paramiko/paramiko/) (a pure-Python implementation of SSH2):
```
>>> from plumbum import SshMachine
>>> remote = SshMachine("somehost", user = "john", keyfile = "/path/to/idrsa")
>>> r_ls = remote["ls"]
>>> with remote.cwd("/lib"):
... (r_ls | grep["0.so.0"])()
...
'libusb-1.0.so.0\nlibusb-1.0.so.0.0.0\n'
```
See [Remote](remote.html#guide-remote).
## CLI applications[¶](#cli-applications)
```
import logging
from plumbum import cli
class MyCompiler(cli.Application):
verbose = cli.Flag(["-v", "--verbose"], help = "Enable verbose mode")
include_dirs = cli.SwitchAttr("-I", list = True, help = "Specify include directories")
@cli.switch("-loglevel", int)
def set_log_level(self, level):
"""Sets the log-level of the logger"""
logging.root.setLevel(level)
def main(self, *srcfiles):
print("Verbose:", self.verbose)
print("Include dirs:", self.include_dirs)
print("Compiling:", srcfiles)
if __name__ == "__main__":
MyCompiler.run()
```
### Sample output[¶](#sample-output)
```
$ python3 simple_cli.py -v -I foo/bar -Ispam/eggs x.cpp y.cpp z.cpp
Verbose: True
Include dirs: ['foo/bar', 'spam/eggs']
Compiling: ('x.cpp', 'y.cpp', 'z.cpp')
```
## Colors and Styles[¶](#colors-and-styles)
```
from plumbum import colors
with colors.red:
print("This library provides safe, flexible color access.")
print(colors.bold | "(and styles in general)", "are easy!")
print("The simple 16 colors or",
colors.orchid & colors.underline | '256 named colors,',
colors.rgb(18, 146, 64) | "or full rgb colors" ,
'can be used.')
print("Unsafe " + colors.bg.dark_khaki + "color access" + colors.bg.reset + " is available too.")
```
### Sample output[¶](#id1)
```
```This library provides safe color access.
Color **(and styles in general)** are easy!
The simple 16 colors, 256 named colors, or full hex colors can be used.
Unsafe color access is available too.
See [Colors](colors.html#guide-colors).
# Development and Installation[¶](#development-and-installation)
The library is developed on [GitHub](https://github.com/tomerfiliba/plumbum), and will happily
accept [patches](https://docs.github.com/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request) from users. Please use the GitHub’s
built-in [issue tracker](https://github.com/tomerfiliba/plumbum/issues) to report any problem
you encounter or to request features. The library is released under the permissive [MIT license](https://github.com/tomerfiliba/plumbum/blob/master/LICENSE).
## Requirements[¶](#requirements)
Plumbum supports **Python 3.6-3.10** and **PyPy** and is continually tested on
**Linux**, **Mac**, and **Windows** machines through [GitHub Actions](https://github.com/tomerfiliba/plumbum/actions). Any Unix-like machine
should work fine out of the box, but on Windows, you’ll probably want to
install a decent [coreutils](https://en.wikipedia.org/wiki/GNU_Core_Utilities/)
environment and add it to your `PATH`
, or use WSL(2). I can recommend [mingw](https://mingw.osdn.io/) (which comes bundled with [Git for Windows](https://gitforwindows.org/)), but [cygwin](http://www.cygwin.com/) should
work too. If you only wish to use Plumbum as a Popen-replacement to run Windows
programs, then there’s no need for the Unix tools.
Note that for remote command execution, an **openSSH-compatible** client is
required (also bundled with *Git for Windows*), and a `bash`
-compatible shell
and a coreutils environment is also expected on the host machine.
This project uses `setuptools`
to build wheels; and `setuptools_scm`
is
required for building SDists. These dependencies will be handled for you by PEP
518 compatible builders, like [build](https://github.com/pypa/build) and `pip 10+`
.
## Download[¶](#download)
You can **download** the library from the [Python Package Index](https://pypi.org/pypi/plumbum/#files) (in a variety of formats), or
run `pip install plumbum`
directly. If you use Anaconda, you can also get it
from the `conda-forge`
channel with `conda install -c conda-forge plumbum`
.
# User Guide[¶](#user-guide)
The user guide covers most of the features of Plumbum, with lots of code-snippets to get you
swimming in no time. It introduces the concepts and “syntax” gradually, so it’s recommended
you read it in order. A quick [reference guide is available](quickref.html#guide-quickref).
# API Reference[¶](#api-reference)
The API reference (generated from the *docstrings* within the library) covers all of the
exposed APIs of the library. Note that some “advanced” features and some function parameters are
missing from the guide, so you might want to consult with the API reference in these cases.
[Package plumbum.cli](api/cli.html)`ShowHelp`
`ShowHelpAll`
`ShowVersion`
`Application`
`SwitchError`
`PositionalArgumentsError`
`SwitchCombinationError`
`UnknownSwitch`
`MissingArgument`
`MissingMandatorySwitch`
`WrongArgumentType`
`SubcommandError`
`switch()`
`autoswitch()`
`SwitchAttr`
`Flag`
`CountOf`
`positional`
`Validator`
`Range`
`Set`
`Predicate`
[Terminal-related utilities](api/cli.html#terminal-related-utilities)`readline()`
`ask()`
`choose()`
`prompt()`
`get_terminal_size()`
`Progress`
[Terminal size utility](api/cli.html#terminal-size-utility)`get_terminal_size()`
[Progress bar](api/cli.html#progress-bar)`ProgressBase`
`Progress`
`ProgressIPy`
`ProgressAuto`
[Package plumbum.commands](api/commands.html)`iter_lines()`
`run_proc()`
`shquote()`
`RedirectionError`
`BaseCommand`
`Pipeline`
`BaseRedirection`
`BoundCommand`
`BoundEnvCommand`
`ConcreteCommand`
`StdinRedirection`
`StdoutRedirection`
`StderrRedirection`
`AppendingStdoutRedirection`
`StdinDataRedirection`
`Future`
`PipeToLoggerMixin`
`ProcessExecutionError`
`ProcessTimedOut`
`ProcessLineTimedOut`
`CommandNotFound`
`run_proc()`
`iter_lines()`
[Package plumbum.machines](api/machines.html)[Package plumbum.path](api/path.html)[Package plumbum.fs](api/fs.html)[Package plumbum.colors](api/colors.html)[Colorlib design](colorlib.html)
Note
The `local`
object is an instance of a `machine`
.
# About[¶](#about)
The original purpose of Plumbum was to enable local and remote program execution with ease, assuming nothing fancier than good-old SSH. On top of this, a file-system abstraction layer was devised, so that working with local and remote files would be seamless.
I’ve toyed with this idea for some time now, but it wasn’t until I had to write build scripts
for a project I’ve been working on that I decided I’ve had it with shell scripts and it’s time
to make it happen. Plumbum was born from the scraps of the `Path`
class, which I
wrote for the aforementioned build system, and the `SshContext`
and `SshTunnel`
classes
that I wrote for [RPyC](https://rpyc.readthedocs.io/). When I combined the two with *shell combinators*
(because shell scripts do have an edge there) the magic happened and here we are.
# Credits[¶](#credits)
The project has been inspired by **PBS** (now called [sh](http://sh.rtfd.org))
of [Andrew Moffat](https://github.com/amoffat),
and has borrowed some of his ideas (namely treating programs like functions and the
nice trick for importing commands). However, I felt there was too much magic going on in PBS,
and that the syntax wasn’t what I had in mind when I came to write shell-like programs.
I contacted Andrew about these issues, but he wanted to keep PBS this way. Other than that,
the two libraries go in different directions, where Plumbum attempts to provide a more
wholesome approach.
Plumbum also pays tribute to [Rotem Yaari](https://github.com/vmalloc/) who suggested a
library code-named `pyplatform`
for that very purpose, but which had never materialized. |
9,473 | Red 语言建立基金会,发力区块链 | http://www.red-lang.org/2018/03/red-foundation-news.html | 2018-03-23T14:42:00 | [
"Red",
"区块链"
] | https://linux.cn/article-9473-1.html | Red 语言在其官网宣布,其于 2018 年 1 月在法国巴黎建立了基金会。Red 基金会托管在 [法国高等研究实践学院(EPHE)](https://www.ephe.fr/en) ,由 [François Jouen](https://www.ephe.fr/ecole/nos-enseignants-chercheurs/francois-jouen) 所领导的“人与人工认知研究”部门所管理,[François Jouen](https://www.ephe.fr/ecole/nos-enseignants-chercheurs/francois-jouen) 是 Red 语言中著名的图像处理框架 [RedCV](https://github.com/ldci/redCV) 的作者。

基金会的职能如在其[宣告](http://www.red-lang.org/2017/12/leaping-into-future-red-goes-blockchain.html)和 [RED 白皮书](https://ico.red-lang.org/RED-whitepaper.pdf)中所说,是管理整个 Red 开源项目,并使用 RED 通证来建立一个新的开源项目经济模式。为达成此目标,位于 GitHub 上的 Red 代码库中的所有版权拥有者都被要求将其权力让渡到基金会。而 Nenad 作为其源代码中最大的版权拥有者,将率先让渡(即修改源代码中的文件头和许可证文件)。
据 Red 基金会去年底[发布的消息](http://www.red-lang.org/2017/12/leaping-into-future-red-goes-blockchain.html),Red 语言将发起多个支持区块链的子项目,包括用于智能合约编程的 Red/CCC,可以直接编译成支持以太坊虚拟机的字节码,也将会支持其它链,如 NEO;更小的运行时环境(大约 1mb,压缩后约 300kb)的 Red DApp,而采用 [Electron](https://en.wikipedia.org/wiki/Electron_(software_framework)) 框架的 DApp 需要 50 ~ 150 Mb。
Red 基金会由以下几个部门组成:
* 管理团队
+ Nenad Rakocevic,总裁
+ Francois Jouen,副总裁
+ Azouz Guizani,财务主管
* 由 [Gregg Irwin](https://github.com/greggirwin) 领导的运营团队。[Peter W A Wood](https://github.com/peterwawood) 是首位成员,将来还会有更多正式成员。
* 由荣誉会员组成的顾问团队。
运营团队当前正在进行如下工作:
* 基金会网站,功能包括:
+ 定期发布报告的博客平台。
+ 关于 RED 通证的全部信息(使用情况、奖励规则和金额)。
+ 悬赏的贡献任务(支付 RED 通证)。
* 制定为之前的贡献者的既往贡献发放 RED 通证的规则(从 2011 年 Red 的 GitHub 仓库建立开始算起)。当规则和要奖励的通证数量确定之后会尽快发放。这需要收集贡献及贡献者的列表。
* 确定运营团队的决策流程。
* 确定基金会的成员资格规则。
* 负责重新设计 red-lang.org 网站,并将其移动到新平台。
出于信息传递和透明度的考虑,所有这些任务及结果都将发布到基金会的网站上。
此外,Red 基金会也在寻求合作伙伴,以实现其简化人类编程的愿景,特别是在区块链领域。目前大部分这些工作都由其合作伙伴如 [NEO 委员会](https://neo.org/)、 [Enuma](https://www.enuma.io/index.html)(一家领先的香港区块链服务公司)来完成。
| 301 | Moved Permanently | null |
9,474 | Tlog:录制/播放终端 IO 和会话的工具 | https://linoxide.com/linux-how-to/tlog-tool-record-play-terminal-io-sessions/ | 2018-03-24T10:48:19 | [
"录制",
"终端"
] | /article-9474-1.html | 
Tlog 是 Linux 中终端 I/O 录制和回放软件包。它用于实现一个集中式用户会话录制。它将所有经过的消息录制为 JSON 消息。录制为 JSON 格式的主要目的是将数据传送到 ElasticSearch 之类的存储服务,可以从中搜索和查询,以及回放。同时,它们保留所有通过的数据和时序。
Tlog 包含三个工具,分别是 `tlog-rec`、tlog-rec-session`和`tlog-play`。
* `tlog-rec` 工具一般用于录制终端、程序或 shell 的输入或输出。
* `tlog-rec-session` 工具用于录制整个终端会话的 I/O,包括录制的用户。
* `tlog-play` 工具用于回放录制。
在本文中,我将解释如何在 CentOS 7.4 服务器上安装 Tlog。
### 安装
在安装之前,我们需要确保我们的系统满足编译和安装程序的所有软件要求。在第一步中,使用以下命令更新系统仓库和软件包。
```
# yum update
```
我们需要安装此软件安装所需的依赖项。在安装之前,我已经使用这些命令安装了所有依赖包。
```
# yum install wget gcc
# yum install systemd-devel json-c-devel libcurl-devel m4
```
完成这些安装后,我们可以下载该工具的[源码包](https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz)并根据需要将其解压到服务器上:
```
# wget https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
# tar -xvf tlog-3.tar.gz
# cd tlog-3
```
现在,你可以使用我们通常的配置和编译方法开始构建此工具。
```
# ./configure --prefix=/usr --sysconfdir=/etc && make
# make install
# ldconfig
```
最后,你需要运行 `ldconfig`。它对命令行中指定目录、`/etc/ld.so.conf` 文件,以及信任的目录( `/lib` 和 `/usr/lib`)中最近的共享库创建必要的链接和缓存。
### Tlog 工作流程图

首先,用户通过 PAM 进行身份验证登录。名称服务交换器(NSS)提供的 `tlog` 信息是用户的 shell。这初始化了 tlog 部分,并从环境变量/配置文件收集关于实际 shell 的信息,并在 PTY 中启动实际的 shell。然后通过 syslog 或 sd-journal 开始录制在终端和 PTY 之间传递的所有内容。
### 用法
你可以使用 `tlog-rec` 录制一个会话并使用 `tlog-play` 回放它,以测试新安装的 tlog 是否能够正常录制和回放会话。
#### 录制到文件中
要将会话录制到文件中,请在命令行中执行 `tlog-rec`,如下所示:
```
tlog-rec --writer=file --file-path=tlog.log
```
该命令会将我们的终端会话录制到名为 `tlog.log` 的文件中,并将其保存在命令中指定的路径中。
#### 从文件中回放
你可以在录制过程中或录制后使用 `tlog-play` 命令回放录制的会话。
```
tlog-play --reader=file --file-path=tlog.log
```
该命令从指定的路径读取先前录制的文件 `tlog.log`。
### 总结
Tlog 是一个开源软件包,可用于实现集中式用户会话录制。它主要是作为一个更大的用户会话录制解决方案的一部分使用,但它被设计为独立且可重用的。该工具可以帮助录制用户所做的一切,并将其存储在服务器的某个位置,以备将来参考。你可以从这个[文档](https://github.com/Scribery/tlog/blob/master/README.md)中获得关于这个软件包使用的更多细节。我希望这篇文章对你有用。请发表你的宝贵建议和意见。
**关于 Saheetha Shameer (作者)**
我正在担任高级系统管理员。我是一名快速学习者,有轻微的倾向跟随行业中目前和正在出现的趋势。我的爱好包括听音乐、玩策略游戏、阅读和园艺。我对尝试各种美食也有很高的热情 :-)
---
via: <https://linoxide.com/linux-how-to/tlog-tool-record-play-terminal-io-sessions/>
作者:[Saheetha Shameer](https://linoxide.com/author/saheethas/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='linoxide.com', port=443): Max retries exceeded with url: /linux-how-to/tlog-tool-record-play-terminal-io-sessions/ (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7b83275c5c00>, 'Connection to linoxide.com timed out. (connect timeout=10)')) | null |
9,475 | 如何在 Linux 上运行你自己的公共时间服务器 | https://www.linux.com/learn/intro-to-linux/2018/2/how-run-your-own-public-time-server-linux | 2018-03-24T11:40:26 | [
"NTP",
"时间"
] | https://linux.cn/article-9475-1.html | 
最重要的公共服务之一就是<ruby> 报时 <rt> timekeeping </rt></ruby>,但是很多人并没有意识到这一点。大多数公共时间服务器都是由志愿者管理,以满足不断增长的需求。这里学习一下如何运行你自己的时间服务器,为基础公共利益做贡献。(查看 [在 Linux 上使用 NTP 保持精确时间](/article-9462-1.html) 去学习如何设置一台局域网时间服务器)
### 著名的时间服务器滥用事件
就像现实生活中任何一件事情一样,即便是像时间服务器这样的公益项目,也会遭受不称职的或者恶意的滥用。
消费类网络设备的供应商因制造了大混乱而臭名昭著。我回想起的第一件事发生在 2003 年,那时,NetGear 在它们的路由器中硬编码了威斯康星大学的 NTP 时间服务器地址。使得时间服务器的查询请求突然增加,随着 NetGear 卖出越来越多的路由器,这种情况越发严重。更有意思的是,路由器的程序设置是每秒钟发送一次请求,这将使服务器难堪重负。后来 Netgear 发布了升级固件,但是,升级他们的设备的用户很少,并且他们的其中一些用户的设备,到今天为止,还在不停地每秒钟查询一次威斯康星大学的 NTP 服务器。Netgear 给威斯康星大学捐献了一些钱,以帮助弥补他们带来的成本增加,直到这些路由器全部淘汰。类似的事件还有 D-Link、Snapchat、TP-Link 等等。
对 NTP 协议进行反射和放大,已经成为发起 DDoS 攻击的一个选择。当攻击者使用一个伪造的目标受害者的源地址向时间服务器发送请求,称为反射攻击;攻击者发送请求到多个服务器,这些服务器将回复请求,这样就使伪造的源地址受到轰炸。放大攻击是指一个很小的请求收到大量的回复信息。例如,在 Linux 上,`ntpq` 命令是一个查询你的 NTP 服务器并验证它们的系统时间是否正确的很有用的工具。一些回复,比如,对端列表,是非常大的。组合使用反射和放大,攻击者可以将 10 倍甚至更多带宽的数据量发送到被攻击者。
那么,如何保护提供公益服务的公共 NTP 服务器呢?从使用 NTP 4.2.7p26 或者更新的版本开始,它们可以帮助你的 Linux 发行版不会发生前面所说的这种问题,因为它们都是在 2010 年以后发布的。这个发行版都默认禁用了最常见的滥用攻击。目前,[最新版本是 4.2.8p10](http://www.ntp.org/downloads.html),它发布于 2017 年。
你可以采用的另一个措施是,在你的网络上启用入站和出站过滤器。阻塞宣称来自你的网络的数据包进入你的网络,以及拦截发送到伪造返回地址的出站数据包。入站过滤器可以帮助你,而出站过滤器则帮助你和其他人。阅读 [BCP38.info](http://www.bcp38.info/index.php/Main_Page) 了解更多信息。
### 层级为 0、1、2 的时间服务器
NTP 有超过 30 年的历史了,它是至今还在使用的最老的因特网协议之一。它的用途是保持计算机与世界标准时间(UTC)的同步。NTP 网络是分层组织的,并且同层的设备是对等的。<ruby> 层次 <rt> Stratum </rt></ruby> 0 包含主报时设备,比如,原子钟。层级 1 的时间服务器与层级 0 的设备同步。层级 2 的设备与层级 1 的设备同步,层级 3 的设备与层级 2 的设备同步。NTP 协议支持 16 个层级,现实中并没有使用那么多的层级。同一个层级的服务器是相互对等的。
过去很长一段时间内,我们都为客户端选择配置单一的 NTP 服务器,而现在更好的做法是使用 [NTP 服务器地址池](http://www.pool.ntp.org/en/use.html),它使用轮询的 DNS 信息去共享负载。池地址只是为客户端服务的,比如单一的 PC 和你的本地局域网 NTP 服务器。当你运行一台自己的公共服务器时,你不用使用这些池地址。
### 公共 NTP 服务器配置
运行一台公共 NTP 服务器只有两步:设置你的服务器,然后申请加入到 NTP 服务器池。运行一台公共的 NTP 服务器是一种很高尚的行为,但是你得先知道这意味着什么。加入 NTP 服务器池是一种长期责任,因为即使你加入服务器池后,运行了很短的时间马上退出,然后接下来的很多年你仍然会接收到请求。
你需要一个静态的公共 IP 地址,一个至少 512Kb/s 带宽的、可靠的、持久的因特网连接。NTP 使用的是 UDP 的 123 端口。它对机器本身要求并不高,很多管理员在其它的面向公共的服务器(比如,Web 服务器)上顺带架设了 NTP 服务。
配置一台公共的 NTP 服务器与配置一台用于局域网的 NTP 服务器是一样的,只需要几个配置。我们从阅读 [协议规则](http://support.ntp.org/bin/view/Servers/RulesOfEngagement) 开始。遵守规则并注意你的行为;几乎每个时间服务器的维护者都是像你这样的志愿者。然后,从 [StratumTwoTimeServers](http://support.ntp.org/bin/view/Servers/StratumTwoTimeServers?redirectedfrom=Servers.StratumTwo) 中选择 4 到 7 个层级 2 的上游服务器。选择的时候,选取地理位置上靠近(小于 300 英里的)你的因特网服务提供商的上游服务器,阅读他们的访问规则,然后,使用 `ping` 和 `mtr` 去找到延迟和跳数最小的服务器。
以下的 `/etc/ntp.conf` 配置示例文件,包括了 IPv4 和 IPv6,以及基本的安全防护:
```
# stratum 2 server list
server servername_1 iburst
server servername_2 iburst
server servername_3 iburst
server servername_4 iburst
server servername_5 iburst
# access restrictions
restrict -4 default kod noquery nomodify notrap nopeer limited
restrict -6 default kod noquery nomodify notrap nopeer limited
# Allow ntpq and ntpdc queries only from localhost
restrict 127.0.0.1
restrict ::1
```
启动你的 NTP 服务器,让它运行几分钟,然后测试它对远程服务器的查询:
```
$ ntpq -p
remote refid st t when poll reach delay offset jitter
=================================================================
+tock.no-such-ag 200.98.196.212 2 u 36 64 7 98.654 88.439 65.123
+PBX.cytranet.ne 45.33.84.208 3 u 37 64 7 72.419 113.535 129.313
*eterna.binary.n 199.102.46.70 2 u 39 64 7 92.933 98.475 56.778
+time.mclarkdev. 132.236.56.250 3 u 37 64 5 111.059 88.029 74.919
```
目前表现很好。现在从另一台 PC 上使用你的 NTP 服务器名字进行测试。以下的示例是一个正确的输出。如果有不正确的地方,你将看到一些错误信息。
```
$ ntpdate -q yourservername
server 66.96.99.10, stratum 2, offset 0.017690, delay 0.12794
server 98.191.213.2, stratum 1, offset 0.014798, delay 0.22887
server 173.49.198.27, stratum 2, offset 0.020665, delay 0.15012
server 129.6.15.28, stratum 1, offset -0.018846, delay 0.20966
26 Jan 11:13:54 ntpdate[17293]: adjust time server 98.191.213.2 offset 0.014798 sec
```
一旦你的服务器运行的很好,你就可以向 [manage.ntppool.org](https://manage.ntppool.org/manage) 申请加入池中。
查看官方的手册 [分布式网络时间服务器(NTP)](https://www.eecis.udel.edu/%7Emills/ntp/html/index.html) 学习所有的命令、配置选项、以及高级特性,比如,管理、查询、和验证。访问以下的站点学习关于运行一台时间服务器所需要的一切东西。
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 学习更多 Linux 的知识。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/2/how-run-your-own-public-time-server-linux>
作者:[CARLA SCHRODER](https://www.linux.com/users/cschroder) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,476 | 解读 ip 命令展示的网络连接信息 | https://www.networkworld.com/article/3262045/linux/checking-your-network-connections-on-linux.html | 2018-03-24T11:52:00 | [
"ip",
"网络"
] | https://linux.cn/article-9476-1.html | 
`ip` 命令可以告诉你很多网络连接配置和状态的信息,但是所有这些词和数字意味着什么? 让我们深入了解一下,看看所有显示的值都试图告诉你什么。
当您使用 `ip a`(或 `ip addr`)命令获取系统上所有网络接口的信息时,您将看到如下所示的内容:
```
$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s25: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:1e:4f:c8:43:fc brd ff:ff:ff:ff:ff:ff
inet 192.168.0.24/24 brd 192.168.0.255 scope global dynamic enp0s25
valid_lft 57295sec preferred_lft 57295sec
inet6 fe80::2c8e:1de0:a862:14fd/64 scope link
valid_lft forever preferred_lft forever
```
这个系统上的两个接口 - 环回(`lo`)和网络(`enp0s25`)——显示了很多统计数据。 `lo` 接口显然是<ruby> 环回地址 <rt> loolback </rt></ruby>。 我们可以在列表中看到环回 IPv4 地址(`127.0.0.1`)和环回 IPv6(`::1`)。 而普通的网络接口更有趣。
### 为什么是 enp0s25 而不是 eth0
如果你想知道为什么它在这个系统上被称为 `enp0s25`,而不是可能更熟悉的 `eth0`,那我们可以稍微解释一下。
新的命名方案被称为“<ruby> 可预测的网络接口 <rt> Predictable Network Interface </rt></ruby>”。 它已经在基于systemd 的 Linux 系统上使用了一段时间了。 接口名称取决于硬件的物理位置。 `en` 仅仅就是 “ethernet” 的意思,就像 “eth” 用于对应 `eth0`,一样。 `p` 是以太网卡的总线编号,`s` 是插槽编号。 所以 `enp0s25` 告诉我们很多我们正在使用的硬件的信息。
`<BROADCAST,MULTICAST,UP,LOWER_UP>` 这个配置串告诉我们:
```
BROADCAST 该接口支持广播
MULTICAST 该接口支持多播
UP 网络接口已启用
LOWER_UP 网络电缆已插入,设备已连接至网络
```
列出的其他值也告诉了我们很多关于接口的知识,但我们需要知道 `brd` 和 `qlen` 这些词代表什么意思。 所以,这里显示的是上面展示的 `ip` 信息的其余部分的翻译。
```
mtu 1500 最大传输单位(数据包大小)为1,500字节
qdisc pfifo_fast 用于数据包排队
state UP 网络接口已启用
group default 接口组
qlen 1000 传输队列长度
link/ether 00:1e:4f:c8:43:fc 接口的 MAC(硬件)地址
brd ff:ff:ff:ff:ff:ff 广播地址
inet 192.168.0.24/24 IPv4 地址
brd 192.168.0.255 广播地址
scope global 全局有效
dynamic enp0s25 地址是动态分配的
valid_lft 80866sec IPv4 地址的有效使用期限
preferred_lft 80866sec IPv4 地址的首选生存期
inet6 fe80::2c8e:1de0:a862:14fd/64 IPv6 地址
scope link 仅在此设备上有效
valid_lft forever IPv6 地址的有效使用期限
preferred_lft forever IPv6 地址的首选生存期
```
您可能已经注意到,`ifconfig` 命令提供的一些信息未包含在 `ip a` 命令的输出中 —— 例如传输数据包的统计信息。 如果您想查看发送和接收的数据包数量以及冲突数量的列表,可以使用以下 `ip` 命令:
```
$ ip -s link show enp0s25
2: enp0s25: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:1e:4f:c8:43:fc brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
224258568 418718 0 0 0 84376
TX: bytes packets errors dropped carrier collsns
6131373 78152 0 0 0 0
```
另一个 `ip` 命令提供有关系统路由表的信息。
```
$ ip route show
default via 192.168.0.1 dev enp0s25 proto static metric 100
169.254.0.0/16 dev enp0s25 scope link metric 1000
192.168.0.0/24 dev enp0s25 proto kernel scope link src 192.168.0.24 metric 100
```
`ip` 命令是非常通用的。 您可以从 `ip` 命令及其来自[Red Hat](https://access.redhat.com/sites/default/files/attachments/rh_ip_command_cheatsheet_1214_jcs_print.pdf)的选项获得有用的备忘单。
---
via: <https://www.networkworld.com/article/3262045/linux/checking-your-network-connections-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,477 | Zsync:一个仅下载文件新的部分的传输工具 | https://www.ostechnix.com/zsync-file-transfer-utility-download-new-parts-file/ | 2018-03-24T12:05:36 | [
"Zsync",
"下载"
] | https://linux.cn/article-9477-1.html | 
就算是网费每天变得越来越便宜,你也不应该重复下载相同的东西来浪费你的流量。一个很好的例子就是下载 Ubuntu 或任何 Linux 镜像的开发版本。如你所知,Ubuntu 开发人员每隔几个月就会发布一次日常构建、alpha、beta 版 ISO 镜像以供测试。在过去,一旦发布我就会下载这些镜像,并审查每个版本。现在不用了!感谢 Zsync 文件传输程序。现在可以仅下载 ISO 镜像新的部分。这将为你节省大量时间和 Internet 带宽。不仅时间和带宽,它将为你节省服务端和客户端的资源。
Zsync 使用与 Rsync 相同的算法,如果你会得到一份已有文件旧版本,它只下载该文件新的部分。 Rsync 主要用于在计算机之间同步数据,而 Zsync 则用于分发数据。简单地说,可以使用 Zsync 将中心的一个文件分发给数千个下载者。它在 Artistic License V2 许可证下发布,完全免费且开源。
### 安装 Zsync
Zsync 在大多数 Linux 发行版的默认仓库中有。
在 Arch Linux 及其衍生版上,使用命令安装它:
```
$ sudo pacman -S zsync
```
在 Fedora 上,启用 Zsync 仓库:
```
$ sudo dnf copr enable ngompa/zsync
```
并使用命令安装它:
```
$ sudo dnf install zsync
```
在 Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt-get install zsync
```
对于其他发行版,你可以从 [Zsync 下载页面](http://zsync.moria.org.uk/downloads)下载二进制打包文件,并手动编译安装它,如下所示。
```
$ wget http://zsync.moria.org.uk/download/zsync-0.6.2.tar.bz2
$ tar xjf zsync-0.6.2.tar.bz2
$ cd zsync-0.6.2/
$ configure
$ make
$ sudo make install
```
### 用法
请注意,只有当人们提供 zsync 下载方式时,zsync 才有用。目前,Debian、Ubuntu(所有版本)的 ISO 镜像都有 .zsync 下载链接。例如,请访问以下链接。
你可能注意到,Ubuntu 18.04 LTS 每日构建版有直接的 ISO 和 .zsync 文件。如果你下载 .ISO 文件,则必须在 ISO 更新时下载完整的 ISO 文件。但是,如果你下载的是 .zsync 文件,那么 Zsync 以后仅会下载新的更改。你不需要每次都下载整个 ISO 映像。
.zsync 文件包含 zsync 程序所需的元数据。该文件包含 rsync 算法的预先计算的校验和。它在服务器上生成一次,然后由任意数量的下载器使用。要使用 Zsync 客户端程序下载 .zsync 文件,你只需执行以下操作:
```
$ zsync <.zsync-file-URL>
```
例如:
```
$ zsync http://cdimage.ubuntu.com/ubuntu/daily-live/current/bionic-desktop-amd64.iso.zsync
```
如果你的系统中已有以前的镜像文件,那么 Zsync 将计算远程服务器中旧文件和新文件之间的差异,并仅下载新的部分。你将在终端看见计算过程一系列的点或星星。
如果你下载的文件的旧版本存在于当前工作目录,那么 Zsync 将只下载新的部分。下载完成后,你将看到两个镜像,一个你刚下载的镜像和以 .iso.zs-old 为扩展名的旧镜像。
如果没有找到相关的本地数据,Zsync 会下载整个文件。

你可以随时按 `CTRL-C` 取消下载过程。
试想一下,如果你直接下载 .ISO 文件或使用 torrent,每当你下载新镜像时,你将损失约 1.4GB 流量。因此,Zsync 不会下载整个 Alpha、beta 和日常构建映像,而只是在你的系统上下载了 ISO 文件的新部分,并在系统中有一个旧版本的拷贝。
今天就到这里。希望对你有帮助。我将很快另外写一篇有用的指南。在此之前,请保持关注!
干杯!
---
via: <https://www.ostechnix.com/zsync-file-transfer-utility-download-new-parts-file/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,478 | 如何安全地生成随机数 | https://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/ | 2018-03-25T10:33:32 | [
"随机数",
"加密"
] | https://linux.cn/article-9478-1.html | 
### 使用 urandom
使用 [urandom](http://blog.cr.yp.to/20140205-entropy.html)!使用 [urandom](http://cr.yp.to/talks/2011.09.28/slides.pdf)!使用 [urandom](http://golang.org/src/pkg/crypto/rand/rand_unix.go)!
使用 [urandom](http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key)!使用 [urandom](http://stackoverflow.com/a/5639631)!使用 [urandom](https://twitter.com/bramcohen/status/206146075487240194)!
### 但对于密码学密钥呢?
仍然使用 [urandom](https://twitter.com/bramcohen/status/206146075487240194)。
### 为什么不是 SecureRandom、OpenSSL、havaged 或者 c 语言实现呢?
这些是用户空间的 CSPRNG(伪随机数生成器)。你应该用内核的 CSPRNG,因为:
* 内核可以访问原始设备熵。
* 它可以确保不在应用程序之间共享相同的状态。
* 一个好的内核 CSPRNG,像 FreeBSD 中的,也可以保证它播种之前不给你随机数据。
研究过去十年中的随机失败案例,你会看到一连串的用户空间的随机失败案例。[Debian 的 OpenSSH 崩溃](http://research.swtch.com/openssl)?用户空间随机!安卓的比特币钱包[重复 ECDSA 随机 k 值](http://arstechnica.com/security/2013/08/google-confirms-critical-android-crypto-flaw-used-in-5700-bitcoin-heist/)?用户空间随机!可预测洗牌的赌博网站?用户空间随机!
用户空间的生成器几乎总是依赖于内核的生成器。即使它们不这样做,整个系统的安全性也会确保如此。**但用户空间的 CSPRNG 不会增加防御深度;相反,它会产生两个单点故障。**
### 手册页不是说使用 /dev/random 嘛?
这个稍后详述,保留你的意见。你应该忽略掉手册页。不要使用 `/dev/random`。`/dev/random` 和 `/dev/urandom` 之间的区别是 Unix 设计缺陷。手册页不想承认这一点,因此它产生了一个并不存在的安全顾虑。把 `random(4)` 中的密码学上的建议当作传说,继续你的生活吧。
### 但是如果我需要的是真随机值,而非伪随机值呢?
urandom 和 `/dev/random` 提供的是同一类型的随机。与流行的观念相反,`/dev/random` 不提供“真正的随机”。从密码学上来说,你通常不需要“真正的随机”。
urandom 和 `/dev/random` 都基于一个简单的想法。它们的设计与流密码的设计密切相关:一个小秘密被延伸到不可预测值的不确定流中。 这里的秘密是“熵”,而流是“输出”。
只在 Linux 上 `/dev/random` 和 urandom 仍然有意义上的不同。Linux 内核的 CSPRNG 定期进行密钥更新(通过收集更多的熵)。但是 `/dev/random` 也试图跟踪内核池中剩余的熵,并且如果它没有足够的剩余熵时,偶尔也会罢工。这种设计和我所说的一样蠢;这与基于“密钥流”中剩下多少“密钥”的 AES-CTR 设计类似。
如果你使用 `/dev/random` 而非 urandom,那么当 Linux 对自己的 RNG(随机数生成器)如何工作感到困惑时,你的程序将不可预测地(或者如果你是攻击者,非常可预测地)挂起。使用 `/dev/random` 会使你的程序不太稳定,但这不会让你在密码学上更安全。
### 这是个缺陷,对吗?
不是,但存在一个你可能想要了解的 Linux 内核 bug,即使这并不能改变你应该使用哪一个 RNG。
在 Linux 上,如果你的软件在引导时立即运行,或者这个操作系统你刚刚安装好,那么你的代码可能会与 RNG 发生竞争。这很糟糕,因为如果你赢了竞争,那么你可能会在一段时间内从 urandom 获得可预测的输出。这是 Linux 中的一个 bug,如果你正在为 Linux 嵌入式设备构建平台级代码,那你需要了解它。
在 Linux 上,这确实是 urandom(而不是 `/dev/random`)的问题。这也是 [Linux 内核中的错误](https://factorable.net/weakkeys12.extended.pdf)。 但它也容易在用户空间中修复:在引导时,明确地为 urandom 提供种子。长期以来,大多数 Linux 发行版都是这么做的。但**不要**切换到不同的 CSPRNG。
### 在其它操作系统上呢?
FreeBSD 和 OS X 消除了 urandom 和 `/dev/random` 之间的区别;这两个设备的行为是相同的。不幸的是,手册页在解释为什么这样做上干的很糟糕,并延续了 Linux 上 urandom 可怕的神话。
无论你使用 `/dev/random` 还是 urandom,FreeBSD 的内核加密 RNG 都不会停摆。 除非它没有被提供种子,在这种情况下,这两者都会停摆。与 Linux 不同,这种行为是有道理的。Linux 应该采用它。但是,如果你是一名应用程序开发人员,这对你几乎没有什么影响:Linux、FreeBSD、iOS,无论什么:使用 urandom 吧。
### 太长了,懒得看
直接使用 urandom 吧。
### 结语
[ruby-trunk Feature #9569](https://bugs.ruby-lang.org/issues/9569)
>
> 现在,在尝试检测 `/dev/urandom` 之前,SecureRandom.random\_bytes 会尝试检测要使用的 OpenSSL。 我认为这应该反过来。在这两种情况下,你只需要将随机字节进行解压,所以 SecureRandom 可以跳过中间人(和第二个故障点),如果可用的话可以直接与 `/dev/urandom` 进行交互。
>
>
>
总结:
>
> `/dev/urandom` 不适合用来直接生成会话密钥和频繁生成其他应用程序级随机数据。
>
>
> GNU/Linux 上的 random(4) 手册所述......
>
>
>
感谢 Matthew Green、 Nate Lawson、 Sean Devlin、 Coda Hale 和 Alex Balducci 阅读了本文草稿。公正警告:Matthew 只是大多同意我的观点。
---
via: <https://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/>
作者:[Thomas & Erin Ptacek](https://sockpuppet.org/blog) 译者:[kimii](https://github.com/kimii) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [How To Safely Generate A Random Number](/blog/2014/02/25/safely-generate-random-numbers/)
## Use urandom
Use [urandom](http://blog.cr.yp.to/20140205-entropy.html). Use [urandom](http://cr.yp.to/talks/2011.09.28/slides.pdf). Use [urandom](http://golang.org/src/pkg/crypto/rand/rand_unix.go). Use [urandom](http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key). Use [urandom](http://stackoverflow.com/a/5639631). Use
[urandom](https://twitter.com/bramcohen/status/206146075487240194).
## But what about for crypto keys?
Still [urandom](https://twitter.com/bramcohen/status/206146075487240194).
## Why not {SecureRandom, OpenSSL, havaged, &c}?
These are userspace CSPRNGs. You want to use the kernel’s CSPRNG, because:
The kernel has access to raw device entropy.
It can promise not to share the same state between applications.
A good kernel CSPRNG, like FreeBSD’s, can also promise not to feed you random data before it’s seeded.
Study the last ten years of randomness failures and you’ll read a
litany of userspace randomness failures. [Debian’s OpenSSH debacle](http://research.swtch.com/openssl)?
Userspace random. Android Bitcoin wallets [repeating ECDSA k’s](http://arstechnica.com/security/2013/08/google-confirms-critical-android-crypto-flaw-used-in-5700-bitcoin-heist/)?
Userspace random. Gambling sites with predictable shuffles? Userspace
random.
Userspace OpenSSL also seeds itself from “from uninitialized memory, magical fairy dust and unicorn horns” generators almost always depend on the kernel’s generator
anyways. Even if they don’t, the security of your whole system sure
does. **A userspace CSPRNG doesn’t add defense-in-depth; instead, it
creates two single points of failure.**
## Doesn’t the man page say to use /dev/random?
You But, more on this later. Stay your pitchforks. should ignore the man page. Don’t use /dev/random. The distinction between /dev/random and /dev/urandom is a Unix design wart. The man page doesn’t want to admit that, so it invents a security concern that doesn’t really exist. Consider the cryptographic advice in random(4) an urban legend and get on with your life.
## But what if I need real random values, not psuedorandom values?
Both urandom and /dev/random provide the same kind of randomness. Contrary to popular belief, /dev/random doesn’t provide “true random” data. For cryptography, you don’t usually want “true random”.
Both urandom and /dev/random are based on a simple idea. Their design is closely related to that of a stream cipher: a small secret is stretched into an indefinite stream of unpredictable values. Here the secrets are “entropy”, and the stream is “output”.
Only on Linux are /dev/random and urandom still meaningfully different. The Linux kernel CSPRNG rekeys itself regularly (by collecting more entropy). But /dev/random also tries to keep track of how much entropy remains in its kernel pool, and will occasionally go on strike if it decides not enough remains. This design is as silly as I’ve made it sound; it’s akin to AES-CTR blocking based on how much “key” is left in the “keystream”.
If you use /dev/random instead of urandom, your program will
unpredictably (or, if you’re an attacker, *very predictably*) hang
when Linux gets confused about how its own RNG works. Using
/dev/random will make your programs less stable, but it won’t make
them any more cryptographically safe.
## There’s a catch here, isn’t there?
No, but there’s a Linux kernel bug you might want to know about, even though it doesn’t change which RNG you should use.
On Linux, if your software runs immediately at boot, and/or the OS has just been installed, your code might be in a race with the RNG. That’s bad, because if you win the race, there could be a window of time where you get predictable outputs from urandom. This is a bug in Linux, and you need to know about it if you’re building platform-level code for a Linux embedded device.
This is indeed a problem with urandom (and not /dev/random) on
Linux. It’s also a [bug in the Linux kernel](https://factorable.net/weakkeys12.extended.pdf). But it’s also easily
fixed in userland: at boot, seed urandom explicitly. Most Linux
distributions have done this for a long time. But *don’t* switch to a
different CSPRNG.
## What about on other operating systems?
FreeBSD and OS X do away with the distinction between urandom and /dev/random; the two devices behave identically. Unfortunately, the man page does a poor job of explaining why this is, and perpetuates the myth that Linux urandom is scary.
FreeBSD’s kernel crypto RNG doesn’t block regardless of whether you use /dev/random or urandom. Unless it hasn’t been seeded, in which case both block. This behavior, unlike Linux’s, makes sense. Linux should adopt it. But if you’re an app developer, this makes little difference to you: Linux, FreeBSD, iOS, whatever: use urandom.
## tl;dr
Use urandom.
## Epilog
Right now, SecureRandom.random_bytes tries to detect an OpenSSL to use before it tries to detect /dev/urandom. I think it should be the other way around. In both cases, you just need random bytes to unpack, so SecureRandom could skip the middleman (and second point of failure) and just talk to /dev/urandom directly if it’s available.
*Resolution:*
/dev/urandom is not suitable to be used to generate directly session keys and other application level random data which is generated frequently.
[the] random(4) [man page] on GNU/Linux [says]…
*Thanks to Matthew Green, Nate Lawson, Sean Devlin, Coda Hale, and
Alex Balducci for reading drafts of this. Fair warning: Matthew only
mostly agrees with me.* |
9,479 | 使用 Ansible 在树莓派上构建一个基于 Linux 的高性能计算系统 | https://opensource.com/article/18/1/how-build-hpc-system-raspberry-pi-and-openhpc | 2018-03-25T11:01:10 | [
"HPC",
"树莓派"
] | https://linux.cn/article-9479-1.html |
>
> 使用低成本的硬件和开源软件设计一个高性能计算集群。
>
>
>

在我的 [之前发表在 Opensource.com 上的文章中](https://opensource.com/article/17/11/openhpc),我介绍了 [OpenHPC](https://openhpc.community/) 项目,它的目标是致力于加速高性能计算(HPC)的创新。这篇文章将更深入来介绍使用 OpenHPC 的特性来构建一个小型的 HPC 系统。将它称为 *HPC 系统* 可能有点“扯虎皮拉大旗”的意思,因此,更确切的说法应该是,它是一个基于 OpenHPC 项目发布的 [集群构建方法](https://openhpc.community/downloads/) 的系统。
这个集群由两台树莓派 3 系统作为计算节点,以及一台虚拟机作为主节点,结构示意如下:

我的主节点运行的是 x86\_64 架构的 CentOS 操作系统,而计算节点运行了 aarch64 的轻度修改版的 CentOS 操作系统。
下图是真实的设备工作照:

要把我的系统配置成像上图这样的 HPC 系统,我是按照 OpenHPC 的集群构建方法的 [CentOS 7.4/aarch64 + Warewulf + Slurm 安装指南](https://github.com/openhpc/ohpc/releases/download/v1.3.3.GA/Install_guide-CentOS7-Warewulf-SLURM-1.3.3-aarch64.pdf) (PDF)的一些步骤来做的。这个方法包括了使用 [Warewulf](https://en.wikipedia.org/wiki/Warewulf) 的配置说明;因为我的那三个系统是手动安装的,我跳过了 Warewulf 部分以及创建 [Ansible 剧本](http://people.redhat.com/areber/openhpc/ansible/) 的一些步骤。
在 [Ansible](https://www.ansible.com/) 剧本中设置完成我的集群之后,我就可以向资源管理器提交作业了。在我的这个案例中, [Slurm](https://slurm.schedmd.com/) 充当了资源管理器,它是集群中的一个实例,由它来决定我的作业什么时候在哪里运行。在集群上启动一个简单的作业的方式之一:
```
[ohpc@centos01 ~]$ srun hostname
calvin
```
如果需要更多的资源,我可以去告诉 Slurm,我希望在 8 个 CPU 上去运行我的命令:
```
[ohpc@centos01 ~]$ srun -n 8 hostname
hobbes
hobbes
hobbes
hobbes
calvin
calvin
calvin
calvin
```
在第一个示例中,Slurm 在一个单个的 CPU 上运行了指定的命令(`hostname`),而在第二个示例中,Slurm 在 8 个 CPU 上运行了那个命令。我的计算节点一个命名为 `calvin`,而另一个命名为 `hobbes`;在上面的命令输出部分可以看到它们的名字。每个计算节点都是由 4 个 CPU 核心的树莓派 3 构成的。
在我的集群中提交作业的另一种方法是使用命令 `sbatch`,它可以用于运行脚本,将输出写入到一个文件,而不是我的终端上。
```
[ohpc@centos01 ~]$ cat script1.sh
#!/bin/sh
date
hostname
sleep 10
date
[ohpc@centos01 ~]$ sbatch script1.sh
Submitted batch job 101
```
它将创建一个名为 `slurm-101.out` 的输出文件,这个输出文件包含下列的内容:
```
Mon 11 Dec 16:42:31 UTC 2017
calvin
Mon 11 Dec 16:42:41 UTC 2017
```
为示范资源管理器的基本功能,简单的串行命令行工具就行,但是,做各种工作去配置一个类似 HPC 系统就有点无聊了。
一个更有趣的应用是在这个集群的所有可用 CPU 上运行一个 [Open MPI](https://www.open-mpi.org/) 的并行作业。我使用了一个基于 [康威生命游戏](https://en.wikipedia.org/wiki/Conway%27s_Game_of_Life) 的应用,它被用于一个名为“使用 Red Hat 企业版 Linux 跨多种架构运行康威生命游戏”的 [视频](https://www.youtube.com/watch?v=n8DvxMcOMXk)。除了以前基于 MPI 的 `Game of Life` 版本之外,在我的集群中现在运行的这个版本对每个涉及的主机的单元格颜色都是不同的。下面的脚本以图形输出的方式来交互式启动应用:
```
$ cat life.mpi
#!/bin/bash
module load gnu6 openmpi3
if [[ "$SLURM_PROCID" != "0" ]]; then
exit
fi
mpirun ./mpi_life -a -p -b
```
我使用下面的命令来启动作业,它告诉 Slurm,为这个作业分配 8 个 CPU:
```
$ srun -n 8 --x11 life.mpi
```
为了演示,这个作业有一个图形界面,它展示了当前计算的结果:

红色单元格是由其中一个计算节点来计算的,而绿色单元格是由另外一个计算节点来计算的。我也可以让康威生命游戏程序为使用的每个 CPU 核心(这里的每个计算节点有四个核心)去生成不同的颜色,这样它的输出如下:

感谢 OpenHPC 提供的软件包和安装方法,因为它们让我可以去配置一个由两个计算节点和一个主节点的 HPC 式的系统。我可以在资源管理器上提交作业,然后使用 OpenHPC 提供的软件在我的树莓派的 CPU 上去启动 MPI 应用程序。
---
*想学习更多的关于使用 OpenHPC 去构建树莓派集群,请参与 Adrian Reber 在 [DevConf.cz 2018](https://devconfcz2018.sched.com/event/DJYi/openhpc-introduction) 的讨论,它于 1月 26-28 日在 Brno,Czech Republic 举行,以及在 [CentOS Dojo 2018](https://wiki.centos.org/Events/Dojo/Brussels2018) ,它于 2 月 2 日在 Brussels 举行。*
### 关于作者
Adrian Reber —— Adrian 是 Red Hat 的高级软件工程师,他早在 2010 年就开始了迁移处理过程到高性能计算环境,从那个时候起迁移了许多的处理过程,并因此获得了博士学位,然后加入了 Red Hat 公司并开始去迁移到容器。偶尔他仍然去迁移单个处理过程,并且它至今仍然对高性能计算非常感兴趣。[关于我的更多信息点这里](https://opensource.com/users/adrianreber)
---
via: <https://opensource.com/article/18/1/how-build-hpc-system-raspberry-pi-and-openhpc>
作者:[Adrian Reber](https://opensource.com/users/adrianreber) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,480 | 如何搭建“我的世界”服务器 | https://thishosting.rocks/how-to-make-a-minecraft-server/ | 2018-03-25T21:59:00 | [
"游戏",
"Minecraft"
] | https://linux.cn/article-9480-1.html | 
我们将通过一个一步步的、新手友好的教程来向你展示如何搭建一个“我的世界(Minecraft)”服务器。这将会是一个长期的多人游戏服务器,你可以与来自世界各地的朋友们一起玩,而不用在同一个局域网下。
### 如何搭建一个“我的世界”服务器 - 快速指南
在你开始行动之前,要先了解一些事情:
#### 为什么你**不**应该使用专门的“我的世界”服务器提供商
既然你正在阅读这篇文章,你肯定对搭建自己的“我的世界”服务器感兴趣。不应该使用专门的“我的世界”服务器提供商的原因有很多,以下是其中一些:
* 它们通常很慢。这是因为你是在和很多用户一起共享资源。这有的时候会超负荷,他们中很多都会超售。
* 你并不能完全控制“我的世界”服务端或真正的服务器。你没法按照你的意愿进行自定义。
* 你是受限制的。这种主机套餐或多或少都会有限制。
当然,使用现成的提供商也是有优点的。最好的就是你不用做下面这些操作。但是那还有什么意思呢?!
#### 为什么不应该用你的个人电脑作为“我的世界”服务器
我们注意到很多教程都展示的是如何在你自己的电脑上搭建服务器。这样做有一些弊端,比如:
* 你的家庭网络不够安全,无法抵挡 DDoS 攻击。游戏服务器通常容易被 DDoS 攻击,而你的家庭网络设置通常不够安全,来抵挡它们。很可能连小型攻击都无法阻挡。
* 你得处理端口转发。如果你试着在家庭网络中搭建“我的世界”服务器的话,你肯定会偶然发现端口转发的问题,并且处理时可能会有问题。
* 你得保持你的电脑一直开着。你的电费将会突破天际,并且你会增加不必要的硬件负载。大部分服务器硬件都是企业级的,提升了稳定性和持久性,专门设计用来处理负载。
* 你的家庭网络速度不够快。家庭网络并不是设计用来负载多人联机游戏的。即使你想搭建一个小型服务器,你也需要一个更好的网络套餐。幸运的是,数据中心有多个高速的、企业级的互联网连接,来保证他们达到(或尽量达到)100%在线。
* 你的硬件很可能不够好。再说一次,服务器使用的都是企业级硬件,最新最快的处理器、固态硬盘,等等。你的个人电脑很可能不是的。
* 你的个人电脑很可能是 Windows/MacOS。尽管这有所争议,但我们相信 Linux 更适合搭建游戏服务器。不用担心,搭建“我的世界”服务器不需要完全了解 Linux(尽管推荐这样)。我们会向你展示你需要了解的。
我们的建议是不要使用个人电脑,即使从技术角度来说你能做到。买一个云服务器并不是很贵。下面我们会向你展示如何在云服务器上搭建“我的世界”服务端。小心地遵守以下步骤,就很简单。
### 搭建一个“我的世界”服务器 - 需求
这是一些需求,你在教程开始之前需要拥有并了解它们:
* 你需要一个 [Linux 云服务器](https://thishosting.rocks/cheap-cloud-hosting-providers-comparison/)。我们推荐 [Vultr](https://thishosting.rocks/go/vultr/)。这家价格便宜,服务质量高,客户支持很好,并且所有的服务器硬件都很高端。检查[“我的世界”服务器需求](https://minecraft.gamepedia.com/Server/Requirements/Dedicated)来选择你需要哪种类型的服务器(像内存和硬盘之类的资源)。我们推荐每月 20 美元的套餐。他们也支持按小时收费,所以如果你只是临时需要服务器和朋友们联机的话,你的花费会更少。注册时选择 Ubuntu 16.04 发行版。在注册时选择离你的朋友们最近的地域。这样的话你就需要保护并管理服务器。如果你不想这样的话,你可以选择[托管的服务器](https://thishosting.rocks/best-cheap-managed-vps/),这样的话服务器提供商可能会给你搭建好一个“我的世界”服务器。
* 你需要一个 SSH 客户端来连接到你的 Linux 云服务器。新手通常建议使用 [PuTTy](https://www.chiark.greenend.org.uk/%7Esgtatham/putty/),但我们也推荐使用 [MobaXTerm](https://mobaxterm.mobatek.net/)。也有很多 SSH 客户端,所以挑一个你喜欢的吧。
* 你需要设置你的服务器(至少做好基本的安全设置)。谷歌一下你会发现很多教程。你也可以按照 [Linode 的 安全指南](https://www.linode.com/docs/security/securing-your-server/),然后在你的 [Vultr](https://thishosting.rocks/go/vultr/) 服务器上一步步操作。
* 下面我们将会处理软件依赖,比如 Java。
终于,到我们真正的教程了:
### 如何在 Ubuntu(Linux)上搭建一个“我的世界”服务器
这篇教程是为 [Vultr](https://thishosting.rocks/go/vultr/) 上的 Ubuntu 16.04 撰写并测试可行的。但是这对 Ubuntu 14.04, [Ubuntu 18.04](https://thishosting.rocks/ubuntu-18-04-new-features-release-date/),以及其他基于 Ubuntu 的发行版、其他服务器提供商也是可行的。
我们使用默认的 Vanilla 服务端。你也可以使用像 CraftBukkit 或 Spigot 这样的服务端,来支持更多的自定义和插件。虽然如果你使用过多插件的话会影响服务端。这各有优缺点。不管怎么说,下面的教程使用默认的 Vanilla 服务端,来使事情变得简单和更新手友好。如果有兴趣的话我们可能会发表一篇 CraftBukkit 的教程。
#### 1. 登录到你的服务器
我们将使用 root 账户。如果你使用受限的账户的话,大部分命令都需要 `sudo`。做你没有权限的事情时会出现警告。
你可以通过 SSH 客户端来登录你的服务器。使用你的 IP 和端口(大部分都是 22)。
在你登录之后,确保你的[服务器安全](https://www.linode.com/docs/security/securing-your-server/)。
#### 2. 更新 Ubuntu
在你做任何事之前都要先更新你的 Ubuntu。你可以通过以下命令更新:
```
apt-get update && apt-get upgrade
```
在提示时敲击“回车键” 和/或 `y`。
#### 3. 安装必要的工具
在这篇教程中你需要一些工具和软件来编辑文本、长久保持服务端运行等。使用下面的命令安装:
```
apt-get install nano wget screen bash default-jdk ufw
```
其中一些可能已经安装好了。
#### 4. 下载“我的世界”服务端
首先,创建一个目录来保存你的“我的世界”服务端和其他文件:
```
mkdir /opt/minecraft
```
然后进入新目录:
```
cd /opt/minecraft
```
现在你可以下载“我的世界“服务端文件了。去往[下载页面](https://minecraft.net/en-us/download/server)获取下载链接。使用 `wget` 下载文件:
```
wget https://s3.amazonaws.com/Minecraft.Download/versions/1.12.2/minecraft_server.1.12.2.jar
```
#### 5. 安装“我的世界”服务端
下载好了服务端的 .jar 文件之后,你就需要先运行一下,它会生成一些文件,包括一个 `eula.txt` 许可文件。第一次运行的时候,它会返回一个错误并退出。这是正常的。使用下面的命令运行它:
```
java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.2.jar nogui
```
`-Xms2048M` 是你的服务端能使用的最小的内存,`-Xmx3472M` 是最大的内存。[调整](https://minecraft.gamepedia.com/Commands)基于你服务器的硬件资源。如果你在 [Vultr](https://thishosting.rocks/go/vultr/) 服务器上有 4GB 内存,并且不用服务器来干其他事情的话可以就这样留着不动。
在这条命令结束并返回一个错误之后,将会生成一个新的 `eula.txt` 文件。你需要同意那个文件里的协议。你可以通过下面这条命令将 `eula=true` 添加到文件中:
```
sed -i.orig 's/eula=false/eula=true/g' eula.txt
```
你现在可以通过和上面一样的命令来开启服务端并进入“我的世界”服务端控制台了:
```
java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.2.jar nogui
```
确保你在 `/opt/minecraft` 目录,或者其他你安装你的 MC 服务端的目录下。
如果你只是测试或暂时需要的话,到这里就可以停了。如果你在登录服务器时有问题的话,你就需要[配置你的防火墙](https://thishosting.rocks/how-to-make-a-minecraft-server/#configure-minecraft-server)。
第一次成功启动服务端时会花费一点时间来生成。
我们将向你展示如何创建一个脚本来启动。
#### 6. 使用脚本启动“我的世界”服务端,让服务端长期运行并在启动时开启
方便起见,我们将创建一个自动启动服务端的 bash 脚本。
首先,使用 nano 创建一个 bash 脚本:
```
nano /opt/minecraft/startminecraft.sh
```
这将会打开一个新的(空白)文件。粘贴以下内容:
```
#!/bin/bash
cd /opt/minecraft/ && java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.2.jar nogui
```
如果你不熟悉 nano 的话 - 你可以使用 `CTRL + X`,再敲击 `Y`,然后回车。这个脚本将进入你先前创建的“我的世界”服务端并运行 Java 命令来开启服务端。你需要执行下面的命令来使脚本可执行:
```
chmod +x startminecraft.sh
```
然后,你就可以通过下面的命令随时运行服务端了:
```
/opt/minecraft/startminecraft.sh
```
但是,如果/当你登出 SSH 会话的话,服务端就会关闭。要想让服务端不登录也持续运行的话,你可以使用 `screen` 会话。`screen` 会话会一直运行,直到实际的服务器被关闭或重启。
使用下面的命令开启一个 screen 会话:
```
screen -S minecraft
```
一旦你进入了 `screen` 会话(看起来就像是你新建了一个 SSH 会话),你就可以使用先前创建的 bash 脚本来启动服务端:
```
/opt/minecraft/startminecraft.sh
```
要退出 `screen` 会话的话,你应该按 `CTRL+A-D`。即使你离开 `screen` 会话(断开的),服务端也会继续运行。你现在可以安全的登出 Ubuntu 服务器了,你创建的“我的世界”服务端将会继续运行。
但是,如果 Ubuntu 服务器重启或关闭了的话,`screen` 会话将不再起作用。所以**为了让我们之前做的这些在启动时自动运行**,做下面这些:
打开 `/etc/rc.local` 文件:
```
nano /etc/rc.local
```
在 `exit 0` 语句前添加如下内容:
```
screen -dm -S minecraft /opt/minecraft/startminecraft.sh
exit 0
```
保存并关闭文件。
要访问“我的世界”服务端控制台,只需运行下面的命令来重新连接 `screen` 会话:
```
screen -r minecraft
```
现在就是这样。祝贺你,玩的开心!你现在可以连接到你的“我的世界”服务端或配置/修改它了。
### 配置你的 Ubuntu 服务器
你首先肯定要设置并确保你的 Ubuntu 服务器安全,如果你还没有这么做的话。按照[我们之前提及的指南](https://www.linode.com/docs/security/securing-your-server/)并谷歌一下来获取更多信息。你需要在服务器上配置的有这些:
#### 开启并配置防火墙
首先,如果防火墙还没有开启的话,你应该先开启先前安装的 UFW:
```
ufw enable
```
你应该开放默认的“我的世界”服务端端口:
```
ufw allow 25565/tcp
```
你应该根据你的使用情况开放或拒绝其他规则。如果你不用服务器负载网站的话,就应该拒绝 80 和 443 端口。谷歌一下 Ubuntu 的 UFW/防火墙指南,你会得到建议的。设置防火墙的时候小心一些,如果你屏蔽了 SSH 端口的话你会把自己锁在服务器外面。
由于这是默认端口,这个端口经常被扫描以及攻击。你可以通过屏蔽白名单之外的访问权限来阻挡攻击。
首先,你需要在你的 [server.properties](https://minecraft.gamepedia.com/Server.properties) 文件中开启白名单模式。要开启的话,打开文件:
```
nano /opt/minecraft/server.properties
```
并将 `white-list` 行改为 `true`:
```
white-list=true
```
保存并关闭文件。
然后重启你的服务器(重启你的服务器或重新运行启动脚本):
```
/opt/minecraft/startminecraft.sh
```
访问“我的世界”服务端控制台:
```
screen -r minecraft
```
如果你想要某人进入你的服务端,你需要通过以下命令把他们添加到白名单:
```
whitelist add PlayerUsername
```
运行以下命令来将他们移出白名单:
```
whitelist remove PlayerUsername
```
使用 `CTRL+A-D` 来退出 `screen`(服务器控制台)。值得注意的是,这会拒绝除白名单以外的所有人连接到服务端。
### 如何搭建“我的世界”服务器 - 常见问题
我们将解答一些有关“我的世界”服务器和我们的指南的常见问题。
#### 我该如何重启“我的世界”服务器?
如果你按照我们的教程来的话,包括开启了服务端随系统启动,你可以直接重启你的 Ubuntu 服务器。如果没有设置岁系统启动的话,你可以通过重新运行启动脚本来重启“我的世界”服务端:
```
/opt/minecraft/startminecraft.sh
```
#### 我该如何配置我的“我的世界”服务端?
你可以使用 [server.properties](https://minecraft.gamepedia.com/Server.properties) 文件来配置你的服务端。查看“我的世界”维基来获取更多信息,你也可以什么都不动,它会工作的很好。
如果你想改变游戏模式、难度等诸如此类的东西,你可以使用服务端控制台。通过下面的命令访问服务端控制台:
```
screen -r minecraft
```
并执行[命令](https://minecraft.gamepedia.com/Commands)。像下面这些命令:
```
difficulty hard
```
```
gamemode survival @a
```
你可能需要重新启动服务端,这取决于你使用了什么命令。你可以使用很多命令,查看[维基](https://minecraft.gamepedia.com/Commands)来获取更多。
#### 我该如何升级我的“我的世界”服务端?
如果有新版本发布的话,你需要这样做:
进入“我的世界”目录:
```
cd /opt/minecraft
```
下载最新的版本,比如使用 wget 下载 1.12.3 版本:
```
wget https://s3.amazonaws.com/Minecraft.Download/versions/1.12.3/minecraft_server.1.12.3.jar
```
接下来,运行并构建新服务端:
```
java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.3.jar nogui
```
最后,更新你的启动脚本:
```
nano /opt/minecraft/startminecraft.sh
```
更新版本号数字:
```
#!/bin/bash
cd /opt/minecraft/ && java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.3.jar nogui
```
现在你可以重启服务端了,一切都应该没有问题。
#### 为什么你们的教程这么长,而其他的只有 2 行那么长?!
我们想让这个教程对新手来说更友好,并且尽可能详细。我们还向你展示了如何让服务端长期运行并跟随系统启动,我们向你展示了如何配置你的服务端以及所有的东西。我是说,你当然可以用几行来启动“我的世界”服务器,但那样的话绝对很烂,从不仅一方面说。
#### 我不知道 Linux 或者这里说的什么东西,我该如何搭建一个“我的世界”服务器呢?
只要通篇阅读我们的文章,复制粘贴几个命令就行了。如果你真的不知道该如何做的话,[我们可以帮你](https://thishosting.rocks/support/),或者直接找一个[托管的](https://thishosting.rocks/best-cheap-managed-vps/)服务器[提供商](https://thishosting.rocks/best-cheap-managed-vps/),让他们帮你做这些。
#### 我该如何在服务端上安装 mod 和插件?
我们的文章意图作一篇入门指南,你应该查看[“我的世界维基”](https://minecraft.gamepedia.com/Minecraft_Wiki),或者谷歌一下来获取更多信息。网上有很多教程。
---
via: <https://thishosting.rocks/how-to-make-a-minecraft-server/>
作者:[ThisHosting.Rocks](https://thishosting.rocks) 译者:[heart4lor](https://github.com/heart4lor) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We’ll show you how to make a Minecraft server with beginner-friendly step-by-step instructions. It will be a persistent multiplayer server that you can play on with your friends from all around the world. You don’t have to be in a LAN.
## How to Make a Minecraft Server – Quick Guide
This is our “Table of contents” if you’re in a hurry and want to go straight to the point. We recommend reading everything though.
[Learn stuff](#reasons)(optional)[Learn more stuff](#not-pc)(optional)[Requirements](#requirements)(required)[Install and start the Minecraft server](#make-minecraft-server)(required)[Run the server even after you log out of your VPS](#persistent)(optional)[Make the server automatically start at boot](#boot)(optional)[Configure your Minecraft server](#configure-minecraft-server)(required)[FAQs](#faqs)(optional)
Need specialized managed Minecraft server hosting? Get server from
[Surf Hosting]
Before going into the actual instructions, a few things you should know:
## Reasons why you would NOT use a specialized Minecraft server hosting provider
Since you’re here, you’re obviously interested in hosting your own Minecraft server. There are more reasons why you would not use a specialized Minecraft hosting provider, but here are a few:
**They’re slow most of the time**. This is because you actually share the resources with multiple users. It becomes overloaded at some point. Most of them oversell their servers too.**You don’t have full control**over the Minecraft server or the actual server. You cannot customize anything you want to.**You’re limited.**Those kinds of hosting plans are always limited in one way or another.
Of course, there are positives to using a Minecraft hosting provider. The best upside is that you don’t actually have to do all the stuff we’ll write about below. But where’s the fun in that? 🙂
## Why you should NOT use your personal computer to make a Minecraft server
We noticed lots of tutorials showing you how to host a server on your own computer. There are downsides to doing that, like:
**Your home internet is not secured enough**to handle DDoS attacks. Game servers are often prone to DDoS attacks, and your home network setup is most probably not secured enough to handle them. It’s most likely not powerful enough to handle a small attack.**You’ll need to handle port forwarding.**If you’ve tried making a Minecraft server on your home network, you’ve surely stumbled upon port forwarding and had issues with it.**You’ll need to keep your computer on at all times.**Your electricity bill will sky-rocket and you’ll add unnecessary load to your hardware. The hardware most servers use is enterprise-grade and designed to handle loads, with improved stability and longevity.**Your home internet is not fast enough**. Home networks are not designed to handle multiplayer games. You’ll need a much larger internet plan to even consider making a small server. Luckily, data centers have multiple high-speed, enterprise-grade internet connections making sure they have (or strive to have) 100% uptime.**Your hardware is most likely not good enough**. Again, servers use enterprise-grade hardware, latest and fastest CPUs, SSDs, and much more. Your personal computer most likely does not.- You probably use Windows/MacOS on your personal computer. Though this is debatable, we believe that
**Linux is much better for game hosting**. Don’t worry, you don’t really need to know everything about Linux to make a Minecraft server (though it’s recommended). We’ll show you everything you need to know.
Our tip is not to use your personal computer, though technically you can. It’s not expensive to buy a cloud server. We’ll show you how to make a Minecraft server on cloud hosting below. It’s easy if you carefully follow the steps.
## Making a Minecraft Server – Requirements
There are a few requirements. You should have and know all of this before continuing to the tutorial:
**You’ll need a**. We recommend[Linux cloud server](https://thishosting.rocks/cheap-cloud-hosting-providers-comparison/)[Linode](https://thishosting.rocks/go/linode/). Their prices are cheap, services are high-quality, customer support is great, all server hardware is high-end. Check the[Minecraft server requirements](https://minecraft.gamepedia.com/Server/Requirements/Dedicated)to find out what kind of server you should get (resources like RAM and Disk space). We recommend getting the $20 per month server. They support hourly pricing so if you only need the server temporary for playing with friends, you’ll pay less. Choose the[Ubuntu 22.04](https://thishosting.rocks/ubuntu-22-04-release-date-whats-new/)distro during signup. Choose the closest server location to where your players live during the signup process. Keep in mind that you’ll be responsible for your server. So you’ll have to secure it and manage it. If you don’t want to do that, you can get a[managed server](https://thishosting.rocks/best-cheap-managed-vps/), in which case the[hosting provider](https://thishosting.rocks/best-game-server-hosting/)will likely make a Minecraft server for you.**You’ll need an SSH client**to connect to the Linux cloud server.[PuTTy](https://www.chiark.greenend.org.uk/~sgtatham/putty/)is often recommended for beginners, but we also recommend[MobaXTerm](https://mobaxterm.mobatek.net/). There are many other SSH clients to choose from, so pick your favorite.**You’ll need to setup your server**(basic security setup at least). Google it and you’ll find many tutorials. You can use[Linode’s Security Guide](https://www.linode.com/docs/security/securing-your-server/)and follow the exact steps on your[Linode](https://thishosting.rocks/go/linode/)server.- We’ll handle the software requirements like Java below.
And finally, onto our actual tutorial:
## How to Make a Minecraft Server on Ubuntu (Linux)
These instructions are written for and tested on an Ubuntu 22.04 server from [Linode](https://thishosting.rocks/go/linode/). Though they’ll also work on [Ubuntu 20.04](https://thishosting.rocks/ubuntu-20-04-release-date-features-more/), [Ubuntu 18.04](https://thishosting.rocks/ubuntu-18-04-new-features-release-date/), and any other Ubuntu-based distro, and any other server provider.
We’re using the default **Vanilla server** from Minecraft. You can use alternatives like CraftBukkit or Spigot that allow more customizations and plugins. Though if you use too many plugins you’ll essentially ruin the server. There are pros and cons to each one. Nevertheless, the instructions below are for the default Vanilla server to keep things simple and beginner-friendly. We may publish a tutorial for CraftBukkit soon if there’s an interest.
Here are the step-by-step instructions on how to make a Minecraft server:
### 1. Login to your server
We’ll use the root user. If you use a limited-user, you’ll have to execute most commands with ‘sudo’. You’ll get a warning if you’re doing something you don’t have enough permissions for.
You can login to your server via your SSH client. Use your server IP and your port (most likely 22).
After you log in, make sure you [secure your server](https://www.linode.com/docs/security/securing-your-server/).
### 2. Update Ubuntu
You should always first update your Ubuntu before you do anything else. You can update it with the following commands:
apt-get update && apt-get upgrade
Hit “enter” and/or “y” when prompted.
### 3. Install necessary tools
You’ll need a few packages and tools for various things in this tutorial like text editing, making your server persistent etc. Install them with the following command:
apt-get install nano wget screen bash default-jdk ufw
Some of them may already be installed.
### 4. Download Minecraft Server
First, create a directory where you’ll store your Minecraft server and all other files:
mkdir /opt/minecraft
And navigate to the new directory:
cd /opt/minecraft
Now you can download the Minecraft Server file. Go to the [download page](https://minecraft.net/en-us/download/server) and get the link there. Download the file with wget:
wget https://launcher.mojang.com/v1/objects/125e5adf40c659fd3bce3e66e67a16bb49ecc1b9/server.jar
### 5. Install the Minecraft server
Once you’ve downloaded the server .jar file, you need to run it once and it will generate some files, including an eula.txt license file. The first time you run it, it will return an error and exit. That’s supposed to happen. Run in with the following command:
java -Xms2048M -Xmx3472M -jar server.jar nogui
“-Xms2048M” is the minimum RAM that your Minecraft server can use and “-Xmx3472M” is the maximum. [Adjust](https://minecraft.gamepedia.com/Commands) this based on your server’s resources. If you got the 4GB RAM server from [Linode](https://thishosting.rocks/go/linode/) you can leave them as-is, if you don’t use the server for anything else other than Minecraft.
**After that command ends and returns an error**, a new eula.txt file will be generated. You need to accept the license in that file. You can do that by adding “eula=true” to the file with the following command:
sed -i.orig 's/eula=false/eula=true/g' eula.txt
You can now start the server again and access the Minecraft server console with that same java command from before:
java -Xms2048M -Xmx3472M -jar server.jar nogui
Make sure you’re in the /opt/minecraft directory, or the directory where you installed your MC server.
You’re free to stop here if you’re just testing this and need it for the short-term. If you’re having trouble loggin into the server, you’ll need to [configure your firewall](#configure-minecraft-server).
The first time you successfully start the server it will take a bit longer to generate
We’ll show you how to create a script so you can start the server with it.
### 6. Start the Minecraft server with a script, make it persistent, and enable it at boot
To make things easier, we’ll create a bash script that will **start the server automatically**.
So first, create a bash script with nano:
nano /opt/minecraft/startminecraft.sh
A new (blank) file will open. Paste the following:
#!/bin/bash cd /opt/minecraft/ && java -Xms2048M -Xmx3472M -jar server.jar nogui
If you’re new to nano – you can save and close the file with “CTRL + X”, then “Y”, and hitting enter. This script navigates to your Minecraft server directory you created previously and runs the java command for starting the server. You need to make it executable with the following command:
chmod +x startminecraft.sh
Then, you can start the server anytime with the following command:
/opt/minecraft/startminecraft.sh
Start a screen session with this command:
screen -S minecraft
Once you’re in the screen session (looks like you would start a new ssh session), you can use the bash script from earlier to start the server:
/opt/minecraft/startminecraft.sh
To get out of the screen session, you should press CTRL + A-D. Even after you get out of the screen session (detach), **the server will keep running**. You can safely log off your Ubuntu server now, and the Minecraft server you created will keep running.
**to do everything we did before automatically at boot**, do the following:
Open the /etc/rc.local file:
nano /etc/rc.local
and add the following line above the “exit 0” line:
screen -dm -S minecraft /opt/minecraft/startminecraft.sh exit 0
Save and close the file.
To access the Minecraft server console, just run the following command to attach to the screen session:
screen -r minecraft
**That’s it for now.** Congrats and have fun! You can now connect to your Minecraft server or configure/modify it.
## Configure your Ubuntu Server
You’ll, of course, need to set up your Ubuntu server and secure it if you haven’t already done so. Follow the [guide we mentioned earlier](https://www.linode.com/docs/security/securing-your-server/) and google it for more info. The configurations you need to do for your Minecraft server on your Ubuntu server are:
### Enable and configure the firewall
First, if it’s not already enabled, you should enable UFW that you previously installed:
ufw enable
You should allow the default Minecraft server port:
ufw allow 25565/tcp
You should allow and deny other rules depending on how you use your server. You should deny ports like 80 and 443 if you don’t use the server for hosting websites. Google a UFW/Firewall guide for Ubuntu and you’ll get recommendations. Be careful when setting up your firewall, you may lock yourself out of your server if you block the SSH port.
Since this is the default port, it often gets automatically scanned and attacked. You can prevent attacks by **blocking access to anyone that’s not of your whitelist**.
First, you need to enable the whitelist mode in your [server.properties](https://minecraft.gamepedia.com/Server.properties) file. To do that, open the file:
nano /opt/minecraft/server.properties
And change “white-list” line to “true”:
white-list=true
Save and close the file.
Then restart your server (either by restarting your Ubuntu server or by running the start bash script again):
/opt/minecraft/startminecraft.sh
Access the Minecraft server console:
screen -r minecraft
And if you want someone to be able to join your server, you need to add them to the whitelist with the following command:
whitelist add PlayerUsername
To remove them from the whitelist, use:
whitelist remove PlayerUsername
Exit the screen session (server console) with CTRL + A-D. It’s worth noting that this will deny access to everyone but the whitelisted usernames.
## How to Make a Minecraft Server – FAQs
We’ll answer some frequently asked questions about Minecraft Servers and our guide.
### How do I restart the Minecraft server?
If you followed every step from our tutorial, including enabling the server to start on boot, you can just reboot your Ubuntu server. If you didn’t set it up to start at boot, you can just run the start script again which will restart the Minecraft server:
/opt/minecraft/startminecraft.sh
### How do I configure my Minecraft server?
You can configure your server using the [server.properties](https://minecraft.gamepedia.com/Server.properties) file. Check the Minecraft Wiki for more info, though you can leave everything as-is and it will work perfectly fine.
If you want to change the **game mode, difficulty** and stuff like that, you can use the server console. Access the server console by running:
screen -r minecraft
And execute [commands](https://minecraft.gamepedia.com/Commands) there. Commands like:
difficulty hard
gamemode survival @a
You may need to restart the server depending on what command you used. There are many more commands you can use, check the [wiki](https://minecraft.gamepedia.com/Commands) for more.
### How do I upgrade my Minecraft server?
If there’s a new release, you need to do this:
Navigate to the minecraft directory:
cd /opt/minecraft
Download the latest version with wget (like the step from the beginning of the tutorial)
wget https://launcher.mojang.com/v1/objects/125e5adf40c659fd3bce3e66e67a16bb49ecc1b9/server.jar
Next, run and build the new server:
java -Xms2048M -Xmx3472M -jar server.jar nogui
Finally, update your start script:
nano /opt/minecraft/startminecraft.sh
And update the version number accordingly:
#!/bin/bash cd /opt/minecraft/ && java -Xms2048M -Xmx3472M -jar server.jar nogui
Now you can restart the server and everything should go well.
### Why is your Minecraft server tutorial so long, and yet others are only 2 lines long?!
We tried to make this beginner-friendly and be as detailed as possible. We also showed you how to make the Minecraft server persistent and start it automatically at boot, we showed you how to configure your server and everything. I mean, sure, you can start a Minecraft server with a couple of lines, but it would definitely suck, for more than one reason.
### I don’t know Linux or anything you wrote about here, how do I make a Minecraft server?
Just read all of our article and copy and paste the commands. If you really don’t know how to do it all, [we can do it for you](https://thishosting.rocks/support/), or just get a [managed server provider](https://thishosting.rocks/best-cheap-managed-vps/) and let them do it for you.
### How do I install mods on my server? How do I install plugins?
Our article is intended to be a starting guide. You should check the [Minecraft wiki](https://minecraft.gamepedia.com/Minecraft_Wiki) for more info, or just google it. There are plenty of tutorials online.
### Any other questions?
Leave a comment below and we’ll reply ASAP.
In the meantime, you can read other content:
## 5 thoughts on “How to Make a Minecraft Server”
Hello, how can I set up more RAM for server. I have 30GB but if I set more than you it doesnt work.
Hello
Is setting up a white-list the only way to secure the server from attacks?
You talked about a default port, isn’t there way to protect it?
Thank you very much, the tutorial was great!
After following your tutorial, on my iPad I get “Unable to connect to world”
Minecraft on ipads use a bedrock minecraft client. This is different from the java minecraft server which is installed here. Bedrock clients cannot connect to a java server.
Hi,
How can I resolve the problem having two MC servers on one machine with different java versions and wanting them to run at the same time (Ubuntu)? Is there a start script to define which java version a server has to use? |
9,481 | 在你的网络中使用树莓派和 Pi-hole 拦截广告 | https://opensource.com/article/18/2/block-ads-raspberry-pi | 2018-03-25T22:45:56 | [
"树莓派",
"广告"
] | https://linux.cn/article-9481-1.html |
>
> 痛恨上网时看到广告?学习这篇教程来设置 Pi-hole。
>
>
>

有一个闲置的树莓派?在浏览网页时讨厌广告?[Pi-hole](https://pi-hole.net/) 是一个拦截广告的开源软件项目,它可以将你的家庭网络上的所有广告路由到一个不存在的地方,从而实现在你的设备上拦截广告的目的。这么好的方法只需要花几钟的时间来设置,你就可以使用它了。
Pi-hole 拦截了超过 100,000 个提供广告的域名,它可以拦截任何设备(包括移动设备、平板电脑、以及个人电脑)上的广告,并且它是完整的拦截了广告,而不是仅将它们隐藏起来,这样做可以提升总体的网络性能(因为广告不需要下载)。你可以在一个 web 界面上、或者也可以使用一个 API 来监视性能和统计数据。
### 你需要:
* 树莓派 + SD 卡
* USB 电源线
* 以太网线
   
你不需要使用一个最新型号的树莓派 — 一个老款足够完成这项工作,只要它的内存不小于 512MB 就可以 — 因此一个一代树莓派 Model B(rev 2)就足够,一个 Model B+、或者二代的或者三代的树莓派都可以。你可以使用 Pi Zero,但需要一个 USB micro 以太网适配器。你可以使用一个带 WiFi 的 Pi Zero W 而不是以太网。但是,作为你的网络基础设施的一部分,我建议你使用一个性能良好、稳定的有线连接来代替 WiFi 连接。
### 准备 SD 卡
开始的第一步,你可能需要将 Raspbian Stretch Lite 安装到一个 SD 卡上。SD 卡至少需要 4GB 大小(完整的桌面版 Raspbian 镜像至少要 8GB,但是 Lite 版镜像更小更轻量化,足够完成这项工作)。如果你喜欢,也可以使用完整的 Raspbian 桌面版镜像,但是作为一个去运行简单应用程序的树莓派,你没必要做更多的事情。

使用你的个人电脑,从树莓派的网站上下载 Raspbian Stretch Lite 镜像。解压它并提取出里面的 `.img` 文件,然后将这个 `.img` 文件写入到你的 SD 卡。不论你的 SD 卡是否是空白的,这一步都不会有什么麻烦,因为在写入前它会清空上面的数据。
如果你使用的是 Linux,写入镜像文件更简单的办法是使用命令行工具 `dd`。或者,你也可以使用跨平台的软件 [Etcher](https://etcher.io/) (可以去参考 Les Pounder 写的指南 “[如何为树莓派准备 SD 卡](https://opensource.com/article/17/3/how-write-sd-cards-raspberry-pi)“)。

SD 卡准备完成之后,你可以将它插入到你的树莓派,连接上键盘、显示器和以太网,然后为树莓派接上电源。在初始化设置之后,这个树莓派就不需要键盘或显示器了。如果你有使用“<ruby> 无末端 <rt> headless </rt></ruby>”树莓派工作的经验,你可以 [启用 SSH](https://www.raspberrypi.org/blog/a-security-update-for-raspbian-pixel/) 然后去设置它 [启用远程连接](https://www.raspberrypi.org/documentation/remote-access/ssh/README.md)。
### 安装 Pi-hole
在你的树莓派引导完成之后,用缺省用户名(`pi`)和密码(`raspberry`)登入。现在你就可以运行命令行了,可以去安装 Pi-hole 了。简单地输入下列命令并回车:
```
curl -sSL https://install.pi-hole.net | bash
```
这个命令下载了 Pi-hole 安装脚本然后去运行它。你可以在你的电脑浏览器中输入 `https://install.pi-hole.net` 来查看它的内容,你将会看到这个脚本做了些什么。它为你生成了一个**管理员密码**,并和其它安装信息一起显示在你的屏幕上。
就是这么简单,几分钟之后,你的树莓派将准备好为你拦截广告。
在你断开树莓派连接之前,你需要知道它的 IP 地址和你的路由器的 IP 地址。(如果你不知道),在你的终端中输入 `hostname -I` 来查看你的树莓派的 IP 地址,输入 `ip route | grep default` 来找到你的路由器的 IP 地址。你看到的将是像 `192.168.1.1` 这样的地址。
### 配置你的路由器
你的树莓派现在运行着一个 DNS 服务器,接下来你需要告诉你的路由器去使用 Pi-hole 作为它的 DNS 服务器而不是你的 ISP 提供给你的缺省 DNS。进入路由器的管理控制台 web 界面。这个界面一般是输入你的路由器的 IP 地址来进入的。
找到 LAN 设置下面的 DHCP/DNS 设置,然后将你的主 DNS 服务器的 IP 地址设置为你的 Pi-hole 的 IP 地址。设置完成之后,它应该你下图的样子:

关于这一步的更多信息,可以查看 [Pi-hole discourse](https://discourse.pi-hole.net/t/how-do-i-configure-my-devices-to-use-pi-hole-as-their-dns-server/245)。
你还需要确保你的 Pi-hole 始终保持相同的 IP 地址,因此,你需要去查看 DHCP 设置,将你的树莓派的 IP 地址条目添加到保留地址中。
### 外部测试
现在,在命令行下输入 `sudo halt` 关闭运行的树莓派,并断开它的电源。你可以拔掉显示器连接线和键盘,然后将你的树莓派放置到一个合适的固定的地方 — 或许应该将它放在你的路由器附近。确保连接着以太网线,然后重新连接电源以启动它。
在你的个人电脑上导航到一个网站(强烈建议访问 [Opensource.com](https://opensource.com/) 网站),或者用你的 WiFi 中的一个设备去检查你的因特网访问是否正常(如果不能正常访问,可能是你的 DNS 配置错误)。如果在浏览器中看到了预期的结果,说明它的工作正常。现在,你浏览网站时,应该再也看不到广告了!甚至在你的 app 中提供的广告也无法出现在你的移动设备中!祝你“冲浪”愉快!
如果你想去测试一下你的广告拦截的新功能,你可以去这个 [测试页面](https://pi-hole.net/pages-to-test-ad-blocking-performance/) 尝试浏览一些内置广告的网站。
现在你可以在你的电脑浏览器上输入 Pi-hole 的 IP 地址来访问它的 web 界面(比如,`http://192.168.1.4/admin` 或者 `http://pi.hole/admin` 也可能会工作)。你将看到 Pi-hole 管理面板和一些统计数据(在这时可能数字比较小)。在你输入(在安装时显示在屏幕上的)密码后,你将看到更漂亮的图形界面:

你也可以微调你的 Pi-hole 的设置,像域名的白名单和黑名单、永久和临时禁止、访问拦截统计信息等等。
个别情况下,你可能需要去升级你的 Pi-hole 安装。当软件需要更新时,这个 web 界面会出现一个更新提示。如果你启用了 SSH,你可以远程登入,否则,那你只能再次连接键盘和显示器。远程登入之后,输入 `pihole -up`命令来更新它。

如果你使用过 Pi-hole 或者其它的开源广告拦截器,请在下面的评论区把你的经验共享出来。
---
via: <https://opensource.com/article/18/2/block-ads-raspberry-pi>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Got an old Raspberry Pi lying around? Hate seeing ads while browsing the web? [Pi-hole](https://pi-hole.net/) is an open source software project that blocks ads for all devices on your home network by routing all advertising servers into nowhere. What's best is it takes just a few minutes to set up.
Pi-hole blocks over 100,000 ad-serving domains, blocks advertisements on any device (including mobiles, tablets, and PCs), and because it completely blocks ads rather than just hiding them, this improves overall network performance (because ads are never downloaded). You can monitor performance and statistics in a web interface, and there's even an API you can use.
## What you will need
- Raspberry Pi + SD card
- USB power cable
- Ethernet cable
![]() opensource.com |
![]() opensource.com |
![]() opensource.com |
![]() opensource.com |
You don't need a recent Raspberry Pi model—an older one will do the job, as long as it's got at least 512MB RAM—so a Pi 1 Model B (rev 2), a Model B+, or a Pi 2 or 3 would do. You could use a Pi Zero, but you'll need a USB micro Ethernet adapter too. You could use a Pi Zero W with WiFi rather than Ethernet, but as it's part of your network infrastructure, I'd recommend a good, solid, wired connection instead.
## Prepare the SD card
First of all, you'll probably want to install Raspbian Stretch Lite onto an SD card. The card should be at least 4GB (the full desktop Raspbian image requires at least 8GB but the Lite image is, well, lighter). You can use the full Raspbian desktop image if you prefer, but as this is going to be running as a headless application, you don't need anything more.
opensource.com
Using your main PC, download the Raspbian Stretch Lite image from the Raspberry Pi website. Now unzip it to extract the `.img`
file within, and you'll write this image to your SD card. It doesn't matter if the SD card is blank or not, as everything on it will be wiped.
If you're using Linux, the easiest way to write the image is using the command-line tool `dd`
. Alternatively, you can use cross-platform software [Etcher](https://etcher.io/) (follow the guide "[How to write SD cards for the Raspberry Pi](https://opensource.com/article/17/3/how-write-sd-cards-raspberry-pi)" by Les Pounder).
Les Pounder, CC-BY-SA 4.0
opensource.com
Once your SD card image has burned, you can insert it into your Raspberry Pi, connect a keyboard, monitor, and Ethernet cable, and then plug in the power. After the initial setup, the Pi won't need the keyboard or monitor. If you're experienced in working with the Pi headless, you can [enable SSH](https://www.raspberrypi.org/blog/a-security-update-for-raspbian-pixel/) and set it up [remotely](https://www.raspberrypi.org/documentation/remote-access/ssh/README.md).
## Install Pi-hole
Once your Raspberry Pi boots up, log in with the default username (`pi`
) and password (`raspberry`
). Now you're at the command line, and you're ready to install Pi-hole. Simply type the following command and press Enter:
```
``````
curl -sSL https://install.pi-hole.net | bash
```
This command downloads the Pi-hole installer script and executes it. You can take a look at the contents by browsing `https://install.pi-hole.net`
in your browser and see what it's doing. It will generate an admin password for you, and print it to the screen along with other installer information.
That's it! In just a few minutes, your Pi will be ready to start blocking ads.
Before you disconnect the Pi, you need to know its IP address and your router's IP address (if you don't already know it). Just type `hostname -I`
in the terminal for the Pi's IP address, and `ip route | grep default`
to locate your router. It will look something like `192.168.1.1`
.
## Configure your router
Your Raspberry Pi is now running a DNS server, and you can tell your router to use Pi-hole as its DNS server instead of your ISP's default. Log into your router's management console web interface. This can usually be found by typing your router's IP address into your web browser's address bar.
Look for DHCP/DNS settings under LAN settings and set your primary DNS server to the IP address of the Pi-hole. It should look something like this:
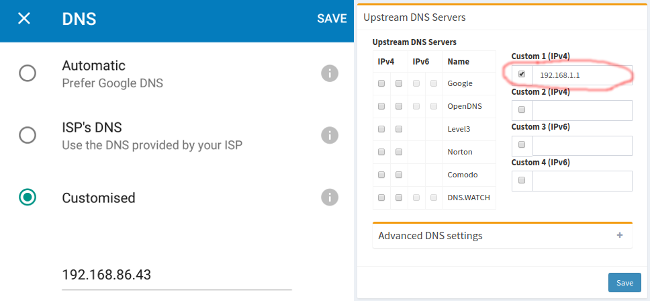
opensource.com
See the [Pi-hole discourse](https://discourse.pi-hole.net/t/how-do-i-configure-my-devices-to-use-pi-hole-as-their-dns-server/245) for more information on this step.
You'll also want to make sure your Pi-hole maintains the same IP address, so also look for DHCP IP reservations and add an entry for your Pi.
## Test it out
Now shut down the Pi by running the command `sudo halt`
and disconnecting the power. You can remove the monitor cable and the keyboard and place the Pi-hole in its permanent location—probably plugged in near your router. Ensure the Ethernet is connected and boot it back up by reconnecting the power.
Navigate to a website on your PC or a device on your WiFi (I highly recommend [Opensource.com](https://opensource.com/)) to check that your internet access is working correctly (if not, you may have misconfigured your DNS settings). If web browsing seems to work as expected, it's set up correctly. Now, when you browse the web, it should be ad-free! Even ads served within apps on your mobile devices won't get through! Happy surfing!
If you really want to flex your new ad-blocking muscles, you can try browsing some of the ad-ridden websites listed on this [test page](https://pi-hole.net/pages-to-test-ad-blocking-performance/).
Now access the Pi-hole's web interface by entering its IP address into your web browser's address bar (e.g. [http://192.168.1.4/admin](http://192.168.1.4/admin)
should work too). You should see the Pi-hole dashboard and some statistics (they will be very low at this stage). Once you login using the password you were given during installation, you'll see some pretty graphs too:[http://pi.hole/admin](http://pi.hole/admin)
opensource.com
You can also tweak your Pi-hole's settings, like whitelist and blacklist domains, disable permanently or temporarily, access the stats for blocked queries, and more.
Occasionally, you'll want to upgrade your Pi-hole installation. The web interface includes an update notification when one is available. If you have enabled SSH, you can log in remotely, otherwise you'll have to reconnect the monitor and keyboard. When logged in, simply run the command `pihole -up`
.
opensource.com
Have you used Pi-hole or another open source ad blocker? Please share your experience in the comments.
## 8 Comments |
9,482 | 如何在 Web 服务器文档根目录上设置只读文件权限 | https://www.cyberciti.biz/faq/howto-set-readonly-file-permission-in-linux-unix/ | 2018-03-25T23:53:42 | [
"只读"
] | https://linux.cn/article-9482-1.html | **Q:如何对我存放在 `/var/www/html/` 目录中的所有文件设置只读权限?**
你可以使用 `chmod` 命令对 Linux/Unix/macOS/OS X/\*BSD 操作系统上的所有文件来设置只读权限。这篇文章介绍如何在 Linux/Unix 的 web 服务器(如 Nginx、 Lighttpd、 Apache 等)上来设置只读文件权限。

### 如何设置文件为只读模式
语法为:
```
### 仅针对文件 ###
chmod 0444 /var/www/html/*
chmod 0444 /var/www/html/*.php
```
### 如何设置目录为只读模式
语法为:
```
### 仅针对目录 ###
chmod 0444 /var/www/html/
chmod 0444 /path/to/your/dir/
# ***************************************************************************
# 假如 web 服务器的用户/用户组是 www-data,文件拥有者是 ftp-data 用户/用户组
# ***************************************************************************
# 设置目录所有文件为只读
chmod -R 0444 /var/www/html/
# 设置文件/目录拥有者为 ftp-data
chown -R ftp-data:ftp-data /var/www/html/
# 所有目录和子目录的权限为 0445 (这样 web 服务器的用户或用户组就可以读取我们的文件)
find /var/www/html/ -type d -print0 | xargs -0 -I {} chmod 0445 "{}"
```
找到所有 `/var/www/html` 下的所有文件(包括子目录),键入:
```
### 仅对文件有效 ###
find /var/www/html -type f -iname "*" -print0 | xargs -I {} -0 chmod 0444 {}
```
然而,你需要在 `/var/www/html` 目录及其子目录上设置只读和执行权限,如此才能让 web 服务器能够访问根目录,键入:
```
### 仅对目录有效 ###
find /var/www/html -type d -iname "*" -print0 | xargs -I {} -0 chmod 0544 {}
```
### 警惕写权限
请注意在 `/var/www/html/` 目录上的写权限会允许任何人删除文件或添加新文件。也就是说,你可能需要设置一个只读权限给 `/var/www/html/` 目录本身。
```
### web根目录只读 ###
chmod 0555 /var/www/html
```
在某些情况下,根据你的设置要求,你可以改变文件的属主和属组来设置严格的权限。
```
### 如果 /var/www/html 目录的拥有人是普通用户,你可以设置拥有人为:root:root 或 httpd:httpd (推荐) ###
chown -R root:root /var/www/html/
### 确保 apache 拥有 /var/www/html/ ###
chown -R apache:apache /var/www/html/
```
### 关于 NFS 导出目录
你可以在 `/etc/exports` 文件中指定哪个目录应该拥有[只读或者读写权限](https://www.cyberciti.biz//www.cyberciti.biz/faq/centos-fedora-rhel-nfs-v4-configuration/) 。这个文件定义各种各样的共享在 NFS 服务器和他们的权限。如:
```
# 对任何人只读权限
/var/www/html *(ro,sync)
# 对192.168.1.10(upload.example.com)客户端读写权限访问
/var/www/html 192.168.1.10(rw,sync)
```
### 关于用于 MS-Windows客户端的 Samba(CIFS)只读共享
要以只读共享 `sales`,更新 `smb.conf`,如下:
```
[sales]
comment = Sales Data
path = /export/cifs/sales
read only = Yes
guest ok = Yes
```
### 关于文件系统表(fstab)
你可以在 Unix/Linux 上的 `/etc/fstab` 文件中配置挂载某些文件为只读模式。
你需要有专用分区,不要设置其他系统分区为只读模式。
如下在 `/etc/fstab` 文件中设置 `/srv/html` 为只读模式。
```
/dev/sda6 /srv/html ext4 ro 1 1
```
你可以使用 `mount` 命令[重新挂载分区为只读模式](https://www.cyberciti.biz/faq/howto-freebsd-remount-partition/)(使用 root 用户)
```
# mount -o remount,ro /dev/sda6 /srv/html
```
或者
```
# mount -o remount,ro /srv/html
```
上面的命令会尝试重新挂载已挂载的文件系统到 `/srv/html`上。这是改变文件系统挂载标志的常用方法,特别是让只读文件改为可写的。这种方式不会改变设备或者挂载点。让文件变得再次可写,键入:
```
# mount -o remount,rw /dev/sda6 /srv/html
```
或
```
# mount -o remount,rw /srv/html
```
### Linux:chattr 命令
你可以在 Linux 文件系统上使用 `chattr` 命令[改变文件属性为只读](https://www.cyberciti.biz/tips/linux-password-trick.html),如:
```
chattr +i /path/to/file.php
chattr +i /var/www/html/
# 查找任何在/var/www/html下的文件并设置为只读#
find /var/www/html -iname "*" -print0 | xargs -I {} -0 chattr +i {}
```
通过提供 `-i` 选项可删除只读属性:
```
chattr -i /path/to/file.php
```
FreeBSD、Mac OS X 和其他 BSD Unix 用户可使用[`chflags`命令](https://www.cyberciti.biz/tips/howto-write-protect-file-with-immutable-bit.html):
```
### 设置只读 ##
chflags schg /path/to/file.php
### 删除只读 ##
chflags noschg /path/to/file.php
```
---
via: <https://www.cyberciti.biz/faq/howto-set-readonly-file-permission-in-linux-unix/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[yizhuoyan](https://github.com/yizhuoyan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,483 | 可以运行在 Windows 10 中的最实用的 Linux 命令 | https://www.linux.com/blog/learn/2018/3/most-useful-linux-commands-you-can-run-windows-10 | 2018-03-26T10:29:46 | [
"WSL"
] | https://linux.cn/article-9483-1.html | 
在本系列早先的文章中,我们讨论了关于如何在 [Windows 10 上开启 WSL 之旅](https://www.linux.com/blog/learn/2018/2/how-get-started-using-wsl-windows-10) 的内容。作为本系列的最后一篇文章,我们准备探讨一些能在 Windows 10 上广泛使用的 Linux 命令。
话题深入之前,请先让我们明确本教程所适用的人群。本文适用于使用 Windows 10 系统,但是又想在 Azure、AWS 或是私有云平台上学习 Linux 的初级开发者。换句话说,就是为了帮助初次接触 Linux 系统的 Windows 10 用户。
您的工作任务决定了您所需要的命令,而我的需求可能和您的不一样。本文旨在帮助您在 Windwos 10 上舒服的使用 Linux。不过请牢记,WSL 并不提供硬件访问的功能,比如声卡、GPU,至少官方是这么描述的。但是这可能并不能阻止 Linux 用户的折腾精神。很多用户不仅完成了硬件访问,甚至已经在 Windows 10 上安装上了 Linux 桌面程序。但是本文并不会涉及这些内容,我们可能会讨论这些,但不是现在。
下面是我们需要着手的任务。
### 如何让您的 Linux 系统保持到最新的版本
因为 Linux 运行在了 Windows 系统中,所以您将被剥夺 Linux 系统所提供的所有安全特性。另外,如果不及时给 Linux 系统打补丁,你的 Windows 设备将被迫暴露在外界威胁中,所以还请保持您的 Linux 为最新版本。
WSL 官方支持 openSUSE/SUSE Linux Enterprise 和 Ubuntu。您也可以安装其他发行版,但是我只需要它们当中的二者之一就可以完成我的所有工作,毕竟,我只需要访问一些 Linux 基础程序。
**更新 openSUSE Leap:**
```
sudo zypper up
```
如果您想升级系统,您可以运行下面的命令:
```
sudo zypper dup
```
**更新 Ubuntu:**
```
sudo apt-get update
sudo apt-get dist-upgrade
```
这样你就安全了,由于 Linux 系统的更新是渐进式的,所以更新系统成为了我的日常。不像 Windows 10 的更新通常需要重启系统,而 Linux 不同,一般只有 KB 或是 MB 级的更新,无需重启。
### 管理文件目录
系统更新之后,我们来看看一些或普通或不太普通的任务。
系统更新之外的第二重要的任务是使用 Linux 管理本地和远程文件。我承认我更青睐图形界面程序,但是终端能提供更可靠、更有价值的服务。要不你使用资源管理器移动 1 TB 的文件试试?我通常使用 `rsync` 命令来移动大量文件。如果中断任务,`rsync` 可以在上次停止的位置继续工作。
虽然您可能更习惯使用 `cp` 或是 `mv` 命令复制、移动文件,但是我还是喜欢灵活的 `rsync` 命令,了解 `rsync` 对远程文件传输也有帮助。使用 `rsync` 大半为了完成下面三个任务:
**使用 rsync 复制整个目录:**
```
rsync -avzP /source-directory /destination directory
```
**使用 rsync 移动文件:**
```
rsync --remove-source-files -avzP /source-directory /destination-directory
```
在成功复制目标目录之后,此命令将删除源文件。
**使用 rsync 同步文件:**
我的文件可能在多处存储。但是,我只会在主要位置中增加或是删除。如果不使用专业的软件,同步文件可能会给用户带来挑战,而 `rsync` 刚好可以简化这个过程。这个命令可以让两个目录文件内容同步。不过要注意,这是一个单向同步,即从源位置同步到目标位置。
```
rsync --delete -avzP /source-directory /destination-directory
```
如果源目录中没有找到文件,上述命令将删除目标目录中的文件。换言之,它创建了源目录的一个镜像。
### 文件自动备份
保持文件备份是一项乏味的工作。为了保持我的设备的完全同步,我运行了一个 cron 作业在夜间保持我的所有目录同步。不过我会留一个外部驱动器,基本上每周我都会手动同步一次。由于可能删掉我不想删除的文件,所以我并没有使用 `--delete` 选项。我会根据情况手动决定是否使用这个选项。
**创建 cron 作业,打开 crontab:**
```
crontab -e
```
移动大文件时,我会选择在系统空闲的深夜执行该命令。此命令将在每天早上 1 点运行,您大概可以这样修改它:
```
# 0 1 * * * rsync -avzP /source-directory /destination-directory
```
这是使用 crontab 的定时作业的命令结构:
```
# m h dom mon dow command
```
在此,`m` = 分钟,`h` = 小时,`dom` = 本月的某天,`mon` = 月,`dow` = 本周的某天。
我们将在每天早上 1 点运行这条命令。您可以选择 `dow` 或是 `dom`(比如,每月 5 号)等。您可以在 [这里](http://www.adminschoice.com/crontab-quick-reference) 阅读更多相关内容。
### 管理远程服务器
在 Windows 系统上使用 WSL 的优势之一就是能方便管理云上的 Linux 服务器,WSL 能提供原生的 Linux 工具给您。首先,您需要使用 `ssh` 命令登录远程 Linux 服务器。
比如,我的服务器 ip 是 192.168.0.112;端口为 2018(不是默认的 22 端口);Linux 用户名是 swapnil,密码是 “就不告诉你”。
```
ssh -p2018 [email protected]
```
它会向您询问用户密码,然后您就可以登录到 Linux 服务器了。现在您可以在 Linux 服务器上执行任意您想执行的所有操作了。不需使用 PuTTY 程序了。
使用 `rsync` ,您可以很轻易的在本地机器和远程机器之间传输文件。源目录还是目标目录取决于您是上传文件到服务器,还是下载文件到本地目录,您可以使用 `username@IP-address-of-server:/path-of-directory` 来指定目录。
如果我想复制一些文本内容到服务器的 home 目录,命令如下:
```
rsync -avzP /source-directory-on-local-machine ‘ssh -p2018’ [email protected]:/home/swapnil/Documents/
```
这将会复制这些文件到远程服务器中 `Documents` 目录。
### 总结
本教程主要是为了证明您可以在 Windows 10 系统上通过 WSL 完成 Linux 方面的很大一部分的任务。通常来说,它提高了生产效率。现在,Linux 的世界已经向 Windwos 10 系统张开怀抱了,尽情探索吧。如果您有任何疑问,或是想了解 WSL 涉及到的其他层面,欢迎在下方的评论区分享您的想法。
在 [Administering Linux on Azure (LFS205)](https://training.linuxfoundation.org/linux-courses/system-administration-training/administering-linux-on-azure) 课程中了解更多,可以在 [这里](http://bit.ly/2FpFtPg) 注册。
---
via: <https://www.linux.com/blog/learn/2018/3/most-useful-linux-commands-you-can-run-windows-10>
作者:[SAPNIL BHARTIYA](https://www.linux.com/users/arnieswap) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,484 | 3 种扩展 Kubernetes 能力的方式 | https://www.linux.com/blog/event/kubecon/2018/2/3-ways-extend-power-kubernetes | 2018-03-27T10:41:52 | [
"Kubernetes"
] | https://linux.cn/article-9484-1.html | 
Google 的工程总监 Chen Goldberg 在最近的奥斯汀 [KubeCon 和 CloudNativeCon](http://events17.linuxfoundation.org/events/kubecon-and-cloudnativecon-north-america)上说,Kubernetes 的扩展能力是它的秘密武器。
在建立帮助工程师提高工作效率的工具的竞赛中,Goldberg 谈到他曾经领导过一个开发这样一个平台的团队。尽管平台最初有用,但它无法扩展,并且修改也很困难。
幸运的是,Goldberg 说,Kubernetes 没有这些问题。首先,Kubernetes 是一个自我修复系统,因为它使用的控制器实现了“<ruby> 协调环 <rt> Reconciliation Loop </rt></ruby>”。在协调环中,控制器观察系统的当前状态并将其与所需状态进行比较。一旦它确定了这两个状态之间的差异,它就会努力实现所需的状态。这使得 Kubernetes 非常适合动态环境。
### 3 种扩展 Kubernetes 的方式
Goldberg 然后解释说,要建立控制器,你需要资源,也就是说,你需要扩展 Kubernetes。有三种方法可以做到这一点,从最灵活(但也更困难)到最简单的依次是:使用 Kube 聚合器、使用 API 服务器构建器或创建<ruby> 自定义资源定义 <rt> Custom Resource Definition </rt></ruby>(CRD)。
后者甚至可以使用极少的代码来扩展 Kubernetes 的功能。为了演示它是如何完成的,Goggle 软件工程师 Anthony Yeh 上台展示了为 Kubernetes 添加一个状态集。 (状态集对象用于管理有状态应用,即需要存储应用状态的程序,跟踪例如用户身份及其个人设置。)使用 *catset*,在一个 100 行 JavaScript 的文件中实现的 CRD,Yeh 展示了如何将状态集添加到 Kubernetes 部署中。之前的扩展不是 CRD,需要 24 个文件和 3000 多行代码。
为解决 CRD 可靠性问题,Goldberg 表示,Kubernetes 已经启动了一项认证计划,允许公司在 Kubernetes 社区注册和认证其扩展。在一个月内,已有 30 多家公司报名参加该计划。
Goldberg 继续解释 Kubernetes 的可扩展性如何成为今年 KubeCon 的热门话题,以及 Google 和 IBM 如何构建一个使用 CRD 管理和保护微服务的平台。或者一些开发人员如何将机器学习带入 Kubernetes,另外展示开放服务代理以及在混合设置上的服务消费。
Goldberg 总结说,可扩展性是种增能。而且,Kubernetes 的可扩展性使其成为开发者的通用平台,并且易于使用,这使得他们可以运行任何应用程序。
你可以在下面观看整个视频:
---
via: <https://www.linux.com/blog/event/kubecon/2018/2/3-ways-extend-power-kubernetes>
作者:[PAUL BROWN](https://www.linux.com/users/bro66) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,485 | 如何用 Python 解析 HTML | https://opensource.com/article/18/1/parsing-html-python | 2018-03-27T11:19:10 | [
"HTML",
"Python"
] | https://linux.cn/article-9485-1.html |
>
> 用一些简单的脚本,可以很容易地清理文档和其它大量的 HTML 文件。但是首先你需要解析它们。
>
>
>

作为 Scribus 文档团队的长期成员,我要随时了解最新的源代码更新,以便对文档进行更新和补充。 我最近在刚升级到 Fedora 27 系统的计算机上使用 Subversion 进行检出操作时,对于下载该文档所需要的时间我感到很惊讶,文档由 HTML 页面和相关图像组成。 我恐怕该项目的文档看起来比项目本身大得多,并且怀疑其中的一些内容是“僵尸”文档——不再使用的 HTML 文件以及 HTML 中无法访问到的图像。
我决定为自己创建一个项目来解决这个问题。 一种方法是搜索未使用的现有图像文件。 如果我可以扫描所有 HTML 文件中的图像引用,然后将该列表与实际图像文件进行比较,那么我可能会看到不匹配的文件。
这是一个典型的图像标签:
```
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
```
我对 `src=` 之后的第一组引号之间的部分很感兴趣。 在寻找了一些解决方案后,我找到一个名为 [BeautifulSoup](https://www.crummy.com/software/BeautifulSoup/) 的 Python 模块。 脚本的核心部分如下所示:
```
soup = BeautifulSoup(all_text, 'html.parser')
match = soup.findAll("img")
if len(match) > 0:
for m in match:
imagelist.append(str(m))
```
我们可以使用这个 `findAll` 方法来挖出图片标签。 这是一小部分输出:
```
<img src="images/pdf-form-ht3.png"/><img src="images/pdf-form-ht4.png"/><img src="images/pdf-form-ht5.png"/><img src="images/pdf-form-ht6.png"/><img align="middle" alt="GSview - Advanced Options Panel" src="images/gsadv1.png" title="GSview - Advanced Options Panel"/><img align="middle" alt="Scribus External Tools Preferences" src="images/gsadv2.png" title="Scribus External Tools Preferences"/>
```
到现在为止还挺好。我原以为下一步就可以搞定了,但是当我在脚本中尝试了一些字符串方法时,它返回了有关标记的错误而不是字符串的错误。 我将输出保存到一个文件中,并在 [KWrite](https://www.kde.org/applications/utilities/kwrite/) 中进行编辑。 KWrite 的一个好处是你可以使用正则表达式(regex)来做“查找和替换”操作,所以我可以用 `\n<img` 替换 `<img`,这样可以看得更清楚。 KWrite 的另一个好处是,如果你用正则表达式做了一个不明智的选择,你还可以撤消。
但我认为,肯定有比这更好的东西,所以我转而使用正则表达式,或者更具体地说 Python 的 `re` 模块。 这个新脚本的相关部分如下所示:
```
match = re.findall(r'src="(.*)/>', all_text)
if len(match)>0:
for m in match:
imagelist.append(m)
```
它的一小部分输出如下所示:
```
images/cmcanvas.png" title="Context Menu for the document canvas" alt="Context Menu for the document canvas" /></td></tr></table><br images/eps-imp1.png" title="EPS preview in a file dialog" alt="EPS preview in a file dialog" images/eps-imp5.png" title="Colors imported from an EPS file" alt="Colors imported from an EPS file" images/eps-imp4.png" title="EPS font substitution" alt="EPS font substitution" images/eps-imp2.png" title="EPS import progress" alt="EPS import progress" images/eps-imp3.png" title="Bitmap conversion failure" alt="Bitmap conversion failure"
```
乍一看,它看起来与上面的输出类似,并且附带有去除图像的标签部分的好处,但是有令人费解的是还夹杂着表格标签和其他内容。 我认为这涉及到这个正则表达式 `src="(.*)/>`,这被称为*贪婪*,意味着它不一定停止在遇到 `/>` 的第一个实例。我应该补充一点,我也尝试过 `src="(.*)"`,这真的没有什么更好的效果,我不是一个正则表达式专家(只是做了这个),找了各种方法来改进这一点但是并没什么用。
做了一系列的事情之后,甚至尝试了 Perl 的 `HTML::Parser` 模块,最终我试图将这与我为 Scribus 编写的一些脚本进行比较,这些脚本逐个字符的分析文本内容,然后采取一些行动。 为了最终目的,我终于想出了所有这些方法,并且完全不需要正则表达式或 HTML 解析器。 让我们回到展示的那个 `img` 标签的例子。
```
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
```
我决定回到 `src=` 这一块。 一种方法是等待 `s` 出现,然后看下一个字符是否是 `r`,下一个是 `c`,下一个是否 `=`。 如果是这样,那就匹配上了! 那么两个双引号之间的内容就是我所需要的。 这种方法的问题在于需要连续识别上面这样的结构。 一种查看代表一行 HTML 文本的字符串的方法是:
```
for c in all_text:
```
但是这个逻辑太乱了,以至于不能持续匹配到前面的 `c`,还有之前的字符,更之前的字符,更更之前的字符。
最后,我决定专注于 `=` 并使用索引方法,以便我可以轻松地引用字符串中的任何先前或将来的字符。 这里是搜索部分:
```
index = 3
while index < linelength:
if (all_text[index] == '='):
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and (all_text[index-1] == 'c'):
imagefound(all_text, imagelist, index)
index += 1
else:
index += 1
else:
index += 1
```
我用第四个字符开始搜索(索引从 0 开始),所以我在下面没有出现索引错误,并且实际上,在每一行的第四个字符之前不会有等号。 第一个测试是看字符串中是否出现了 `=`,如果没有,我们就会前进。 如果我们确实看到一个等号,那么我们会看前三个字符是否是 `s`、`r` 和 `c`。 如果全都匹配了,就调用函数 `imagefound`:
```
def imagefound(all_text, imagelist, index):
end = 0
index += 2
newimage = ''
while end == 0:
if (all_text[index] != '"'):
newimage = newimage + all_text[index]
index += 1
else:
newimage = newimage + '\n'
imagelist.append(newimage)
end = 1
return
```
我们给函数发送当前索引,它代表着 `=`。 我们知道下一个字符将会是 `"`,所以我们跳过两个字符,并开始向名为 `newimage` 的控制字符串添加字符,直到我们发现下一个 `"`,此时我们完成了一次匹配。 我们将字符串加一个换行符(`\n`)添加到列表 `imagelist` 中并返回(`return`),请记住,在剩余的这个 HTML 字符串中可能会有更多图片标签,所以我们马上回到搜索循环中。
以下是我们的输出现在的样子:
```
images/text-frame-link.png
images/text-frame-unlink.png
images/gimpoptions1.png
images/gimpoptions3.png
images/gimpoptions2.png
images/fontpref3.png
images/font-subst.png
images/fontpref2.png
images/fontpref1.png
images/dtp-studio.png
```
啊,干净多了,而这只花费几秒钟的时间。 我本可以将索引前移 7 步来剪切 `images/` 部分,但我更愿意把这个部分保存下来,以确保我没有剪切掉图像文件名的第一个字母,这很容易用 KWrite 编辑成功 —— 你甚至不需要正则表达式。 做完这些并保存文件后,下一步就是运行我编写的另一个脚本 `sortlist.py`:
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# sortlist.py
import os
imagelist = []
for line in open('/tmp/imagelist_parse4.txt').xreadlines():
imagelist.append(line)
imagelist.sort()
outfile = open('/tmp/imagelist_parse4_sorted.txt', 'w')
outfile.writelines(imagelist)
outfile.close()
```
这会读取文件内容,并存储为列表,对其排序,然后另存为另一个文件。 之后,我可以做到以下几点:
```
ls /home/gregp/development/Scribus15x/doc/en/images/*.png > '/tmp/actual_images.txt'
```
然后我需要在该文件上运行 `sortlist.py`,因为 `ls` 方法的排序与 Python 不同。 我原本可以在这些文件上运行比较脚本,但我更愿意以可视方式进行操作。 最后,我成功找到了 42 个图像,这些图像没有来自文档的 HTML 引用。
这是我的完整解析脚本:
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# parseimg4.py
import os
def imagefound(all_text, imagelist, index):
end = 0
index += 2
newimage = ''
while end == 0:
if (all_text[index] != '"'):
newimage = newimage + all_text[index]
index += 1
else:
newimage = newimage + '\n'
imagelist.append(newimage)
end = 1
return
htmlnames = []
imagelist = []
tempstring = ''
filenames = os.listdir('/home/gregp/development/Scribus15x/doc/en/')
for name in filenames:
if name.endswith('.html'):
htmlnames.append(name)
#print htmlnames
for htmlfile in htmlnames:
all_text = open('/home/gregp/development/Scribus15x/doc/en/' + htmlfile).read()
linelength = len(all_text)
index = 3
while index < linelength:
if (all_text[index] == '='):
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and
(all_text[index-1] == 'c'):
imagefound(all_text, imagelist, index)
index += 1
else:
index += 1
else:
index += 1
outfile = open('/tmp/imagelist_parse4.txt', 'w')
outfile.writelines(imagelist)
outfile.close()
imageno = len(imagelist)
print str(imageno) + " images were found and saved"
```
脚本名称为 `parseimg4.py`,这并不能真实反映我陆续编写的脚本数量(包括微调的和大改的以及丢弃并重新开始写的)。 请注意,我已经对这些目录和文件名进行了硬编码,但是很容易变得通用化,让用户输入这些信息。 同样,因为它们是工作脚本,所以我将输出发送到 `/tmp` 目录,所以一旦重新启动系统,它们就会消失。
这不是故事的结尾,因为下一个问题是:僵尸 HTML 文件怎么办? 任何未使用的文件都可能会引用图像,不能被前面的方法所找出。 我们有一个 `menu.xml` 文件作为联机手册的目录,但我还需要考虑 TOC(LCTT 译注:TOC 是 table of contents 的缩写)中列出的某些文件可能引用了不在 TOC 中的文件,是的,我确实找到了一些这样的文件。
最后我可以说,这是一个比图像搜索更简单的任务,而且开发的过程对我有很大的帮助。
### 关于作者
Greg Pittman 是 Kentucky 州 Louisville 市的一名退休的神经学家,从二十世纪六十年代的 Fortran IV 语言开始长期以来对计算机和编程有着浓厚的兴趣。 当 Linux 和开源软件出现的时候,Greg 深受启发,去学习更多知识,并实现最终贡献的承诺。 他是 Scribus 团队的成员。[更多关于我](https://opensource.com/users/greg-p)
---
via: <https://opensource.com/article/18/1/parsing-html-python>
作者:[Greg Pittman](https://opensource.com/users/greg-p) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,486 | 如何在 Linux 上安装应用程序 | https://opensource.com/article/18/1/how-install-apps-linux | 2018-03-27T12:59:14 | [
"软件"
] | https://linux.cn/article-9486-1.html |
>
> 学习在你的 Linux 计算机上摆弄那些软件。
>
>
>

如何在 Linux 上安装应用程序?因为有许多操作系统,这个问题不止有一个答案。应用程序可以可以来自许多来源 —— 几乎不可能数的清,并且每个开发团队都可以以他们认为最好的方式提供软件。知道如何安装你所得到的软件是成为操作系统高级用户的一部分。
### 仓库
十多年来,Linux 已经在使用软件库来分发软件。在这种情况下,“仓库”是一个托管可安装软件包的公共服务器。Linux 发行版提供了一条命令,以及该命令的图形界面,用于从服务器获取软件并将其安装到你的计算机。这是一个非常简单的概念,它已经成为所有主流手机操作系统的模式,最近,该模式也成为了两大闭源计算机操作系统的“应用商店”。

*不是应用程序商店*
从软件仓库安装是在 Linux 上安装应用程序的主要方法,它应该是你寻找想要安装的任何应用程序的首选地方。
从软件仓库安装,通常需要一个命令,如:
```
$ sudo dnf install inkscape
```
实际使用的命令取决于你所使用的 Linux 发行版。Fedora 使用 `dnf`,OpenSUSE 使用 `zypper`,Debian 和 Ubuntu 使用 `apt`,Slackware 使用 `sbopkg`,FreeBSD 使用 `pkg_add`,而基于 lllumos 的 Openlndiana 使用 `pkg`。无论你使用什么,该命令通常要搜索你想要安装应用程序的正确名称,因为有时候你认为的软件名称不是它官方或独有的名称:
```
$ sudo dnf search pyqt
PyQt.x86_64 : Python bindings for Qt3
PyQt4.x86_64 : Python bindings for Qt4
python-qt5.x86_64 : PyQt5 is Python bindings for Qt5
```
一旦你找到要安装的软件包的名称后,使用 `install` 子命令执行实际的下载和自动安装:
```
$ sudo dnf install python-qt5
```
有关从软件仓库安装的具体信息,请参阅你的 Linux 发行版的文档。
图形工具通常也是如此。搜索你认为你想要的,然后安装它。

与底层命令一样,图形安装程序的名称取决于你正在运行的 Linux 发行版。相关的应用程序通常使用“软件(software)”或“包(package)”等关键字进行标记,因此请在你的启动项或菜单中搜索这些词汇,然后你将找到所需的内容。 由于开源全由用户来选择,所以如果你不喜欢你的发行版提供的图形用户界面(GUI),那么你可以选择安装替代品。 你知道该如何做到这一点。
#### 额外仓库
你的 Linux 发行版为其打包的软件提供了标准仓库,通常也有额外的仓库。例如,[EPEL](https://fedoraproject.org/wiki/EPEL) 服务于 Red Hat Enterprise Linux 和 CentOS,[RPMFusion](http://rpmfusion.org) 服务于 Fedora,Ubuntu 有各种级别的支持以及个人包存档(PPA),[Packman](http://packman.links2linux.org/) 为 OpenSUSE 提供额外的软件以及 [SlackBuilds.org](http://slackbuilds.org) 为 Slackware 提供社区构建脚本。
默认情况下,你的 Linux 操作系统设置为只查看其官方仓库,因此如果你想使用其他软件集合,则必须自己添加额外库。你通常可以像安装软件包一样安装仓库。实际上,当你安装例如 [GNU Ring](https://ring.cx/en/download/gnu-linux) 视频聊天,[Vivaldi](http://vivaldi.com) web 浏览器,谷歌浏览器等许多软件时,你的实际安装是访问他们的私有仓库,从中将最新版本的应用程序安装到你的机器上。

*安装仓库*
你还可以通过编辑文本文件将仓库手动添加到你的软件包管理器的配置目录,或者运行命令来添加添加仓库。像往常一样,你使用的确切命令取决于 Linux 发行版本。例如,这是一个 `dnf` 命令,它将一个仓库添加到系统中:
```
$ sudo dnf config-manager --add-repo=http://example.com/pub/centos/7
```
### 不使用仓库来安装应用程序
仓库模型非常流行,因为它提供了用户(你)和开发人员之间的链接。重要更新发布之后,系统会提示你接受更新,并且你可以从一个集中位置接受所有更新。
然而,有时候一个软件包还没有放到仓库中时。这些安装包有几种形式。
#### Linux 包
有时候,开发人员会以通用的 Linux 打包格式分发软件,例如 RPM、DEB 或较新但非常流行的 FlatPak 或 Snap 格式。你不是访问仓库下载的,你只是得到了这个包。
例如,视频编辑器 [Lightworks](https://www.lwks.com/) 为 APT 用户提供了一个 `.deb` 文件,RPM 用户提供了 `.rpm` 文件。当你想要更新时,可以到网站下载最新的适合的文件。
这些一次性软件包可以使用从仓库进行安装时所用的一样的工具进行安装。如果双击下载的软件包,图形安装程序将启动并逐步完成安装过程。
或者,你可以从终端进行安装。这里的区别在于你从互联网下载的独立包文件不是来自仓库。这是一个“本地”安装,这意味着你的软件安装包不需要下载来安装。大多数软件包管理器都是透明处理的:
```
$ sudo dnf install ~/Downloads/lwks-14.0.0-amd64.rpm
```
在某些情况下,你需要采取额外的步骤才能使应用程序运行,因此请仔细阅读有关你正在安装软件的文档。
#### 通用安装脚本
一些开发人员以几种通用格式发布他们的包。常见的扩展名包括 `.run` 和 `.sh`。NVIDIA 显卡驱动程序、像 Nuke 和 Mari 这样的 Foundry visual FX 软件包以及来自 [GOG](http://gog.com) 的许多非 DRM 游戏都是用这种安装程序。(LCTT 译注:DRM 是数字版权管理。)
这种安装模式依赖于开发人员提供安装“向导”。一些安装程序是图形化的,而另一些只是在终端中运行。
有两种方式来运行这些类型的安装程序。
1、 你可以直接从终端运行安装程序:
```
$ sh ./game/gog_warsow_x.y.z.sh
```
2、 另外,你可以通过标记其为可执行文件来运行它。要标记为安装程序可执行文件,右键单击它的图标并选择其属性。

*给安装程序可执行权限。*
一旦你允许其运行,双击图标就可以安装了。

*GOG 安装程序*
对于其余的安装程序,只需要按照屏幕上的说明进行操作。
#### AppImage 便携式应用程序
AppImage 格式对于 Linux 相对来说比较新,尽管它的概念是基于 NeXT 和 Rox 的。这个想法很简单:运行应用程序所需的一切都应该放在一个目录中,然后该目录被视为一个“应用程序”。要运行该应用程序,只需双击该图标即可运行。不需要也要不应该把应用程序安装在传统意义的地方;它从你在硬盘上的任何地方运行都行。
尽管它可以作为独立应用运行,但 AppImage 通常提供一些系统集成。

*AppImage 系统集成*
如果你接受此条件,则将一个本地的 `.desktop` 文件安装到你的主目录。`.desktop` 文件是 Linux 桌面的应用程序菜单和 mimetype 系统使用的一个小配置文件。实质上,只是将桌面配置文件放置在主目录的应用程序列表中“安装”应用程序,而不实际安装它。你获得了安装某些东西的所有好处,以及能够在本地运行某些东西的好处,即“便携式应用程序”。
#### 应用程序目录
有时,开发人员只是编译一个应用程序,然后将结果发布到下载中,没有安装脚本,也没有打包。通常,这意味着你下载了一个 TAR 文件,然后 [解压缩](https://opensource.com/article/17/7/how-unzip-targz-file),然后双击可执行文件(通常是你下载软件的名称)。

*下载 Twine*
当使用这种软件方式交付时,你可以将它放在你下载的地方,当你需要它时,你可以手动启动它,或者你可以自己进行快速但是麻烦的安装。这包括两个简单的步骤:
1. 将目录保存到一个标准位置,并在需要时手动启动它。
2. 将目录保存到一个标准位置,并创建一个 `.desktop` 文件,将其集成到你的系统中。
如果你只是为自己安装应用程序,那么传统上会在你的主目录中放个 `bin` (“<ruby> 二进制文件 <rt> binary </rt></ruby>” 的简称)目录作为本地安装的应用程序和脚本的存储位置。如果你的系统上有其他用户需要访问这些应用程序,传统上将二进制文件放置在 `/opt` 中。最后,这取决于你存储应用程序的位置。
下载通常以带版本名称的目录进行,如 `twine_2.13` 或者 `pcgen-v6.07.04`。由于假设你将在某个时候更新应用程序,因此将版本号删除或创建目录的符号链接是个不错的主意。这样,即使你更新应用程序本身,为应用程序创建的启动程序也可以保持不变。
要创建一个 `.desktop` 启动文件,打开一个文本编辑器并创建一个名为 `twine.desktop` 的文件。[桌面条目规范](https://specifications.freedesktop.org/desktop-entry-spec/desktop-entry-spec-latest.html) 由 [FreeDesktop.org](http://freedesktop.org) 定义。下面是一个简单的启动器,用于一个名为 Twine 的游戏开发 IDE,安装在系统范围的 `/opt` 目录中:
```
[Desktop Entry]
Encoding=UTF-8
Name=Twine
GenericName=Twine
Comment=Twine
Exec=/opt/twine/Twine
Icon=/usr/share/icons/oxygen/64x64/categories/applications-games.png
Terminal=false
Type=Application
Categories=Development;IDE;
```
棘手的一行是 `Exec` 行。它必须包含一个有效的命令来启动应用程序。通常,它只是你下载的东西的完整路径,但在某些情况下,它更复杂一些。例如,Java 应用程序可能需要作为 Java 自身的参数启动。
```
Exec=java -jar /path/to/foo.jar
```
有时,一个项目包含一个可以运行的包装脚本,这样你就不必找出正确的命令:
```
Exec=/opt/foo/foo-launcher.sh
```
在这个 Twine 例子中,没有与该下载的软件捆绑的图标,因此示例 `.desktop` 文件指定了 KDE 桌面附带的通用游戏图标。你可以使用类似的解决方法,但如果你更具艺术性,可以创建自己的图标,或者可以在 Internet 上搜索一个好的图标。只要 `Icon` 行指向一个有效的 PNG 或 SVG 文件,你的应用程序就会以该图标为代表。
示例脚本还将应用程序类别主要设置为 Development,因此在 KDE、GNOME 和大多数其他应用程序菜单中,Twine 出现在开发类别下。
为了让这个例子出现在应用程序菜单中,把 `twine.desktop` 文件放这到两个地方之一:
* 如果你将应用程序存储在你自己的家目录下,那么请将其放在 `~/.local/share/applications`。
* 如果你将应用程序存储在 `/opt` 目录或者其他系统范围的位置,并希望它出现在所有用户的应用程序菜单中,请将它放在 `/usr/share/applications` 目录中。
现在,该应用程序已安装,因为它需要与系统的其他部分集成。
### 从源代码编译
最后,还有真正的通用格式安装格式:源代码。从源代码编译应用程序是学习如何构建应用程序,如何与系统交互以及如何定制应用程序的好方法。尽管如此,它绝不是一个点击按钮式过程。它需要一个构建环境,通常需要安装依赖库和头文件,有时还要进行一些调试。
要了解更多关于从源代码编译的内容,请阅读[我这篇文章](https://opensource.com/article/17/10/open-source-cats)。
### 现在你明白了
有些人认为安装软件是一个神奇的过程,只有开发人员理解,或者他们认为它“激活”了应用程序,就好像二进制可执行文件在“安装”之前无效。学习许多不同的安装方法会告诉你安装实际上只是“将文件从一个地方复制到系统中适当位置”的简写。 没有什么神秘的。只要你去了解每次安装,不是期望应该如何发生,并且寻找开发者为安装过程设置了什么,那么通常很容易,即使它与你的习惯不同。
重要的是安装器要诚实于你。 如果你遇到未经你的同意尝试安装其他软件的安装程序(或者它可能会以混淆或误导的方式请求同意),或者尝试在没有明显原因的情况下对系统执行检查,则不要继续安装。
好的软件是灵活的、诚实的、开放的。 现在你知道如何在你的计算机上获得好软件了。
---
via: <https://opensource.com/article/18/1/how-install-apps-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | How do you install an application on Linux? As with many operating systems, there isn't just one answer to that question. Applications can come from so many sources—it's nearly impossible to count—and each development team may deliver their software whatever way they feel is best. Knowing how to install what you're given is part of being a true power user of your OS.
## Repositories
For well over a decade, Linux has used software repositories to distribute software. A "repository" in this context is a public server hosting installable software packages. A Linux distribution provides a command, and usually a graphical interface to that command, that pulls the software from the server and installs it onto your computer. It's such a simple concept that it has served as the model for all major cellphone operating systems and, more recently, the "app stores" of the two major closed source computer operating systems.
opensource.com
Installing from a software repository is the primary method of installing apps on Linux. It should be the first place you look for any application you intend to install.
To install from a software repository, there's usually a command:
```
``````
$ sudo dnf install inkscape
```
The actual command you use depends on what distribution of Linux you use. Fedora uses `dnf`
, OpenSUSE uses `zypper`
, Debian and Ubuntu use `apt`
, Slackware uses `sbopkg`
, FreeBSD uses `pkg_add`
, and Illumos-based OpenIndiana uses `pkg`
. Whatever you use, the incantation usually involves searching for the proper name of what you want to install, because sometimes what you call software is not its official or solitary designation:
```
``````
$ sudo dnf search pyqt
PyQt.x86_64 : Python bindings for Qt3
PyQt4.x86_64 : Python bindings for Qt4
python-qt5.x86_64 : PyQt5 is Python bindings for Qt5
```
Once you have located the name of the package you want to install, use the `install`
subcommand to perform the actual download and automated install:
```
``````
$ sudo dnf install python-qt5
```
For specifics on installing from a software repository, see your distribution's documentation.
The same generally holds true with the graphical tools. Search for what you think you want, and then install it.
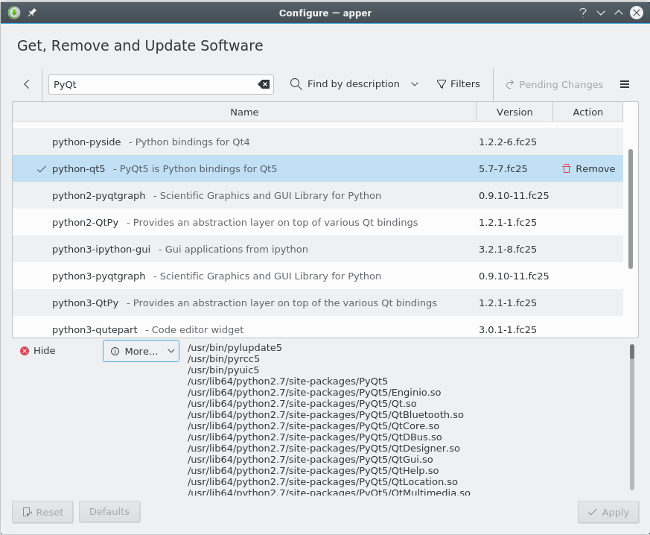
opensource.com
Like the underlying command, the name of the graphical installer depends on what distribution you are running. The relevant application is usually tagged with the *software* or *package* keywords, so search your launcher or menu for those terms, and you'll find what you need. Since open source is all about user choice, if you don't like the graphical user interface (GUI) that your distribution provides, there may be an alternative that you can install. And now you know how to do that.
### Extra repositories
Your distribution has its standard repository for software that it packages for you, and there are usually extra repositories common to your distribution. For example, [EPEL](https://fedoraproject.org/wiki/EPEL) serves Red Hat Enterprise Linux and CentOS, [RPMFusion](http://rpmfusion.org) serves Fedora, Ubuntu has various levels of support as well as a Personal Package Archive (PPA) network, [Packman](http://packman.links2linux.org/) provides extra software for OpenSUSE, and [SlackBuilds.org](http://slackbuilds.org) provides community build scripts for Slackware.
By default, your Linux OS is set to look at just its official repositories, so if you want to use additional software collections, you must add extra repositories yourself. You can usually install a repository as though it were a software package. In fact, when you install certain software, such as [GNU Ring](https://ring.cx/en/download/gnu-linux) video chat, the [Vivaldi](http://vivaldi.com) web browser, Google Chrome, and many others, what you are actually installing is access to their private repositories, from which the latest version of their application is installed to your machine.
opensource.com
You can also add the repository manually by editing a text file and adding it to your package manager's configuration directory, or by running a command to install the repository. As usual, the exact command you use depends on the distribution you are running; for example, here is a `dnf`
command that adds a repository to the system:
```
``````
$ sudo dnf config-manager --add-repo=http://example.com/pub/centos/7
```
## Installing apps without repositories
The repository model is so popular because it provides a link between the user (you) and the developer. When important updates are released, your system kindly prompts you to accept the updates, and you can accept them all from one centralized location.
Sometimes, though, there are times when a package is made available with no repository attached. These installable packages come in several forms.
### Linux packages
Sometimes, a developer distributes software in a common Linux packaging format, such as RPM, DEB, or the newer but very popular FlatPak or Snap formats. You make not get access to a repository with this download; you might just get the package.
The video editor [Lightworks](https://www.lwks.com/), for example, provides a `.deb`
file for APT users and an `.rpm`
file for RPM users. When you want to update, you return to the website and download the latest appropriate file.
These one-off packages can be installed with all the same tools used when installing from a repository. If you double-click the package you download, a graphical installer launches and steps you through the install process.
Alternately, you can install from a terminal. The difference here is that a lone package file you've downloaded from the internet isn't coming from a repository. It's a "local" install, meaning your package management software doesn't need to download it to install it. Most package managers handle this transparently:
```
``````
$ sudo dnf install ~/Downloads/lwks-14.0.0-amd64.rpm
```
In some cases, you need to take additional steps to get the application to run, so carefully read the documentation about the software you're installing.
### Generic install scripts
Some developers release their packages in one of several generic formats. Common extensions include `.run`
and `.sh`
. NVIDIA graphic card drivers, Foundry visual FX packages like Nuke and Mari, and many DRM-free games from [GOG](http://gog.com) use this style of installer.
This model of installation relies on the developer to deliver an installation "wizard." Some of the installers are graphical, while others just run in a terminal.
There are two ways to run these types of installers.
- You can run the installer directly from a terminal:
```
``````
$ sh ./game/gog_warsow_x.y.z.sh
```
- Alternately, you can run it from your desktop by marking it as executable. To mark an installer executable, right-click on its icon and select
**Properties**.
opensource.com
Once you've given permission for it to run, double-click the icon to start the install.
opensource.com
For the rest of the install, just follow the instructions on the screen.
### AppImage portable apps
The AppImage format is relatively new to Linux, although its concept is based on both NeXT and Rox. The idea is simple: everything required to run an application is placed into one directory, and then that directory is treated as an "app." To run the application, you just double-click the icon, and it runs. There's no need or expectation that the application is installed in the traditional sense; it just runs from wherever you have it lying around on your hard drive.
Despite its ability to run as a self-contained app, an AppImage usually offers to do some soft system integration.
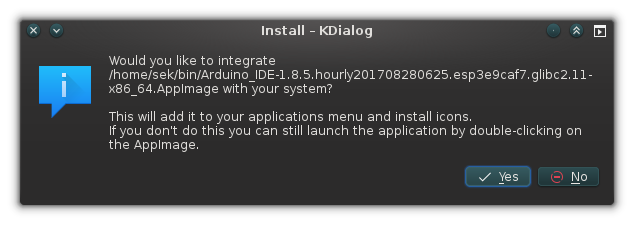
opensource.com
If you accept this offer, a local `.desktop`
file is installed to your home directory. A `.desktop`
file is a small configuration file used by the Applications menu and mimetype system of a Linux desktop. Essentially, placing the desktop config file in your home directory's application list "installs" the application without actually installing it. You get all the benefits of having installed something, and the benefits of being able to run something locally, as a "portable app."
### Application directory
Sometimes, a developer just compiles an application and posts the result as a download, with no install script and no packaging. Usually, this means that you download a TAR file, [extract it](https://opensource.com/article/17/7/how-unzip-targz-file), and then double-click the executable file (it's usually the one with the name of the software you downloaded).
opensource.com
When presented with this style of software delivery, you can either leave it where you downloaded it and launch it manually when you need it, or you can do a quick and dirty install yourself. This involves two simple steps:
- Save the directory to a standard location and launch it manually when you need it.
- Save the directory to a standard location and create a
`.desktop`
file to integrate it into your system.
If you're just installing applications for yourself, it's traditional to keep a `bin`
directory (short for "binary") in your home directory as a storage location for locally installed applications and scripts. If you have other users on your system who need access to the applications, it's traditional to place the binaries in `/opt`
. Ultimately, it's up to you where you store the application.
Downloads often come in directories with versioned names, such as `twine_2.13`
or `pcgen-v6.07.04`
. Since it's reasonable to assume you'll update the application at some point, it's a good idea to either remove the version number or to create a symlink to the directory. This way, the launcher that you create for the application can remain the same, even though you update the application itself.
To create a `.desktop`
launcher file, open a text editor and create a file called `twine.desktop`
. The [Desktop Entry Specification](https://specifications.freedesktop.org/desktop-entry-spec/desktop-entry-spec-latest.html) is defined by [FreeDesktop.org](http://freedesktop.org). Here is a simple launcher for a game development IDE called Twine, installed to the system-wide `/opt`
directory:
```
``````
[Desktop Entry]
Encoding=UTF-8
Name=Twine
GenericName=Twine
Comment=Twine
Exec=/opt/twine/Twine
Icon=/usr/share/icons/oxygen/64x64/categories/applications-games.png
Terminal=false
Type=Application
Categories=Development;IDE;
```
The tricky line is the `Exec`
line. It must contain a valid command to start the application. Usually, it's just the full path to the thing you downloaded, but in some cases, it's something more complex. For example, a Java application might need to be launched as an argument to Java itself:
```
``````
Exec=java -jar /path/to/foo.jar
```
Sometimes, a project includes a wrapper script that you can run so you don't have to figure out the right command:
```
``````
Exec=/opt/foo/foo-launcher.sh
```
In the Twine example, there's no icon bundled with the download, so the example `.desktop`
file assigns a generic gaming icon that shipped with the KDE desktop. You can use workarounds like that, but if you're more artistic, you can just create your own icon, or you can search the Internet for a good icon. As long as the `Icon`
line points to a valid PNG or SVG file, your application will inherit the icon.
The example script also sets the application category primarily to Development, so in KDE, GNOME, and most other Application menus, Twine appears under the Development category.
To get this example to appear in an Application menu, place the `twine.desktop`
file into one of two places:
- Place it in
`~/.local/share/applications`
if you're storing the application in your own home directory. - Place it in
`/usr/share/applications`
if you're storing the application in`/opt`
or another system-wide location and want it to appear in all your users' Application menus.
And now the application is installed as it needs to be and integrated with the rest of your system.
## Compiling from source
Finally, there's the truly universal install format: source code. Compiling an application from source code is a great way to learn how applications are structured, how they interact with your system, and how they can be customized. It's by no means a push-button process, though. It requires a build environment, it usually involves installing dependency libraries and header files, and sometimes a little bit of debugging.
To learn more about compiling from source code, [read my article](https://opensource.com/article/21/11/compiling-code) on the topic.
## Now you know
Some people think installing software is a magical process that only developers understand, or they think it "activates" an application, as if the binary executable file isn't valid until it has been "installed." Hopefully, learning about the many different methods of installing has shown you that *install* is really just shorthand for "copying files from one place to the appropriate places on your system." There's nothing mysterious about it. As long as you approach each install without expectations of how it's supposed to happen, and instead look for what the developer has set up as the install process, it's generally easy, even if it is different from what you're used to.
The important thing is that an installer is honest with you. If you come across an installer that attempts to install additional software without your consent (or maybe it asks for consent, but in a confusing or misleading way), or that attempts to run checks on your system for no apparent reason, then don't continue an install.
Good software is flexible, honest, and open. And now you know how to get good software onto your computer.
## 1 Comment |
9,487 | 如何在 Linux / Unix 上使用 awk 打印文件名 | https://www.cyberciti.biz/faq/how-to-print-filename-with-awk-on-linux-unix/ | 2018-03-28T17:40:45 | [
"awk"
] | https://linux.cn/article-9487-1.html | 
Q:我想在 Linux / 类Unix 系统上使用 awk 打印文件名。 如何使用 awk 的 `BEGIN` 特殊模式打印文件名? 我可以使用 gawk/awk 打印当前输入文件的名称吗?(LCTT 译注:读者最好能有一些 awk 的背景知识,否则阅读本文的时候会有一些困惑)
在 `FILENAME` 变量中存放着当前输入文件的名称。 您可以使用 `FILENAME` 显示或打印当前输入文件名,如果在命令行中未指定文件,则 `FILENAME` 的值为 `-` (标准输入)(LCTT 译注:多次按下回车键即可看到效果)。 但是,除非由 `getline` 设置,否则 `FILENAME` 在 `BEGIN` 特殊模式中未定义。
### 使用 awk 打印文件名
使用语法如下:
```
awk '{ print FILENAME }' fileNameHere
awk '{ print FILENAME }' /etc/hosts
```
因 awk 逐行读取文件,因此,你可能看到多个文件名,为了避免这个情况,你可以使用如下的命令:(LCTT 译注:`FNR` 表示当前记录数,只在文件中有效)
```
awk 'FNR == 1{ print FILENAME } ' /etc/passwd
awk 'FNR == 1{ print FILENAME } ' /etc/hosts
```

### 使用 awk 的 BEGIN 特殊规则打印文件名
使用下面的语法:(LCTT 译注:`ARGV[I]` 表示输入的第 i 个参数)
```
awk 'BEGIN{print ARGV[1]}' fileNameHere
awk 'BEGIN{print ARGV[1]}{ print "someting or do something on data" }END{}' fileNameHere
awk 'BEGIN{print ARGV[1]}' /etc/hosts
```
示例输出:
```
/etc/hosts
```
然而,`ARGV[1]` 并不是每一次都能奏效,例如:
```
ls -l /etc/hosts | awk 'BEGIN{print ARGV[1]} { print }'
```
你需要将它修改如下(假设 `ls -l` 只产生一行输出):
```
ls -l /etc/hosts | awk '{ print "File: " $9 ", Owner:" $3 ", Group: " $4 }'
```
示例输出:
```
File: /etc/hosts, Owner:root, Group: root
```
### 处理由通配符指定的多个文件名
使用如下的示例语法:
```
awk '{ print FILENAME; nextfile } ' *.c
awk 'BEGIN{ print "Starting..."} { print FILENAME; nextfile }END{ print "....DONE"} ' *.conf
```
示例输出:
```
Starting...
blkid.conf
cryptconfig.conf
dhclient6.conf
dhclient.conf
dracut.conf
gai.conf
gnome_defaults.conf
host.conf
idmapd.conf
idnalias.conf
idn.conf
insserv.conf
iscsid.conf
krb5.conf
ld.so.conf
logrotate.conf
mke2fs.conf
mtools.conf
netscsid.conf
nfsmount.conf
nscd.conf
nsswitch.conf
openct.conf
opensc.conf
request-key.conf
resolv.conf
rsyncd.conf
sensors3.conf
slp.conf
smartd.conf
sysctl.conf
vconsole.conf
warnquota.conf
wodim.conf
xattr.conf
xinetd.conf
yp.conf
....DONE
```
`nextfile` 告诉 awk 停止处理当前的输入文件。 下一个输入记录读取来自下一个输入文件。 更多信息,请参见 awk/[gawk](https://www.gnu.org/software/gawk/manual/) 命令手册页:
```
man awk
man gawk
```
**关于作者**
作者是 nixCraft 的创立者,也是经验丰富的系统管理员和 Linux/Unix shell 脚本的培训师。 他曾与全球各行各业的客户合作,涉及 IT,教育,国防和空间研究以及非营利部门等多个行业。 您可以在 [Twitter](https://twitter.com/nixcraft),[Facebook](https://facebook.com/nixcraft) 和 [Google+](https://plus.google.com/+CybercitiBiz)上关注他。 可以通过订阅我的 [RSS](https://www.cyberciti.biz/atom/atom.xml) 来获取更多的关于**系统管理,Linux/Unix ,和开源主题**的相关资料。
---
via: <https://www.cyberciti.biz/faq/how-to-print-filename-with-awk-on-linux-unix/>
作者:[Vivek Gite](https://www.cyberciti.biz/) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,488 | COPR 仓库中 4 个很酷的新软件 | https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-january/ | 2018-03-28T18:10:48 | [
"COPR",
"Fedora"
] | https://linux.cn/article-9488-1.html | 
COPR 是一个个人软件仓库[集合](https://copr.fedorainfracloud.org/),它们不存在于 Fedora 中。有些软件不符合标准而不容易打包。或者它可能不符合其他的 Fedora 标准,尽管它是自由和开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己签名的。但是,它是尝试新的或实验性软件的一种很好的方法。
这是 COPR 中一系列新的和有趣的项目。
### Elisa
[Elisa](https://community.kde.org/Elisa) 是一个极小的音乐播放器。它可以让你通过专辑、艺术家或曲目浏览音乐。它会自动检测你的 `~/Music` 目录中的所有可播放音乐,因此它根本不需要设置 - 它也不提供任何音乐。目前,Elisa 专注于做一个简单的音乐播放器,所以它不提供管理音乐收藏的工具。

#### 安装说明
仓库目前为 Fedora 26、27 和 Rawhide 提供 Elisa。要安装 Elisa,请使用以下命令:
```
sudo dnf copr enable eclipseo/elisa
sudo dnf install elisa
```
### 必应壁纸
[必应壁纸](http://bingwallpapers.lekgoara.com/)是一个简单的程序,它会下载当日的必应壁纸,并将其设置为桌面壁纸或锁屏图片。该程序可以在设定的时间间隔内轮转目录中的图片,并在一段时间后删除旧图片。
#### 安装说明
仓库目前为 Fedora 25、26、27 和 Rawhide 提供必应壁纸。要安装必应壁纸,请使用以下命令:
```
sudo dnf copr enable julekgwa/Bingwallpapers
sudo dnf install bingwallpapers
```
### Polybar
[Polybar](https://github.com/jaagr/polybar) 是一个创建状态栏的工具。它有很多自定义选项以及显示常用服务的信息的内置功能,例如 [bspwm](https://github.com/baskerville/bspwm)、[i3](https://i3wm.org/) 的系统托盘图标、窗口标题、工作区和桌面面板等。你也可以为你的状态栏配置你自己的模块。有关使用和配置的更多信息,请参考 [Polybar 的 wiki](https://github.com/jaagr/polybar/wiki)。
#### 安装说明
仓库目前为 Fedora 27 提供 Polybar。要安装 Polybar,请使用以下命令:
```
sudo dnf copr enable tomwishaupt/polybar
sudo dnf install polybar
```
### Netdata
[Netdata](http://my-netdata.io/) 是一个分布式监控系统。它可以运行在包括个人电脑、服务器、容器和物联网设备在内的所有系统上,从中实时收集指标。所有的信息都可以使用 netdata 的 web 面板访问。此外,Netdata 还提供预配置的警报和通知来检测性能问题,以及用于创建自己的警报的模板。

#### 安装说明
仓库目前提供 EPEL 7、Fedora 27 和 Rawhide 提供 netdata。要安装 netdata,请使用以下命令:
```
sudo dnf copr enable recteurlp/netdata
sudo dnf install netdata
```
---
via: <https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-january/>
作者:[Dominik Turecek](https://fedoramagazine.org) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | COPR is a [collection](https://copr.fedorainfracloud.org/) of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
Here’s a set of new and interesting projects in COPR.
### Elisa
[Elisa](https://community.kde.org/Elisa) is a minimal music player. It lets you browse music by albums, artists or tracks. It automatically detects all playable music in your ~/Music directory, thus it requires no set up at all – neither does it offer any. Currently, Elisa focuses on being a simple music player, so it offers no tools for managing your music collection.
#### Installation instructions
The repo currently provides Elisa for Fedora 26, 27 and Rawhide. To install Elisa, use these commands:
sudo dnf copr enable eclipseo/elisa sudo dnf install elisa
### Bing Wallpapers
[Bing Wallpapers](http://bingwallpapers.lekgoara.com/) is a simple program that downloads Bing’s wallpaper of the day and sets it as a desktop wallpaper or a lock screen image. The program can rotate over pictures in its directory in set intervals as well as delete old pictures after a set amount of time.
#### Installation instructions
The repo currently provides Bing Wallpapers for Fedora 25, 26, 27 and Rawhide. To install Bing Wallpapers, use these commands:
sudo dnf copr enable julekgwa/Bingwallpapers sudo dnf install bingwallpapers
### Polybar
[Polybar](https://github.com/jaagr/polybar) is a tool for creating status bars. It has a lot of customization options as well as built-in functionality to display information about commonly used services, such as systray icons, window title, workspace and desktop panel for [bspwm](https://github.com/baskerville/bspwm), [i3](https://i3wm.org/), and more. You can also configure your own modules for your status bar. See [Polybar’s wiki](https://github.com/jaagr/polybar/wiki) for more information about usage and configuration.
#### Installation instructions
The repo currently provides Polybar for Fedora 27. To install Polybar, use these commands:
sudo dnf copr enable tomwishaupt/polybar sudo dnf install polybar
### Netdata
[Netdata](http://my-netdata.io/) is a distributed monitoring system. It can run on all your systems including PCs, servers, containers and IoT devices, from which it collects metrics in real time. All the information then can be accessed using netdata’s web dashboard. Additionally, Netdata provides pre-configured alarms and notifications for detecting performance issue, as well as templates for creating your own alarms.
#### Installation instructions
The repo currently provides netdata for EPEL 7, Fedora 27 and Rawhide. To install netdata, use these commands:
sudo dnf copr enable recteurlp/netdata sudo dnf install netdata
## Costa A.
How “safe” are packages from the copr repo?
## Bruce Schneider
Nice way to give root on your system to random strangers…
COPR badly needs a sandboxing mechanism.
## Tiago
Very good article.
But it is good to add to his series the previous articles about copr apps, like
https://fedoramag.wpengine.com/4-cool-new-projects-try-copr-december/
https://fedoramag.wpengine.com/4-cool-new-projects-try-copr-3/
https://fedoramag.wpengine.com/4-cool-new-projects-try-copr-2/
https://fedoramag.wpengine.com/4-cool-new-projects-try-copr/
Thakns.
## Clime
I guess it depends on how much trust you put into individual COPR projects. COPR is not koji but a lot could be done if we had an established review process or at least possibility to give feedback on packages in a COPR project.
## Rene Reichenbach
Due to gnome boxes its easy to have a fedora VM running to test in case of knowledge and distrust … besides this i guess the author of this article at least is confident that the packages are clean and provides kind of a review for the presented packages.
Thx for sharing its good to have an eye on new software. |
9,489 | 邮件传输代理(MTA)基础 | https://www.ibm.com/developerworks/library/l-lpic1-108-3/index.html | 2018-03-28T18:56:00 | [
"邮件",
"MTA",
"Sendmail"
] | https://linux.cn/article-9489-1.html | 
### 概述
本教程中,你将学习:
* 使用 `mail` 命令。
* 创建邮件别名。
* 配置电子邮件转发。
* 了解常见邮件传输代理(MTA),比如,postfix、sendmail、qmail、以及 exim。
### 控制邮件去向
Linux 系统上的电子邮件是使用 MTA 投递的。你的 MTA 投递邮件到你的系统上的其他用户,并且 MTA 彼此通讯跨越系统投递到全世界。
Sendmail 是最古老的 Linux MTA。它最初起源于 1979 年用于阿帕网(ARPANET)的 delivermail 程序。如今它有几个替代品,在本教程中,我也会介绍它们。
### 前提条件
为完成本系列教程的大部分内容,你需要具备 Linux 的基础知识,你需要拥有一个 Linux 系统来实践本教程中的命令。你应该熟悉 GNU 以及 UNIX 命令。有时候不同版本的程序的输出格式可能不同,因此,在你的系统中输出的结果可能与我在下面列出的稍有不同。
在本教程中,我使用的是 Ubuntu 14.04 LTS 和 sendmail 8.14.4 来做的演示。
### 邮件传输
邮件传输代理(比如 sendmail)在用户之间和系统之间投递邮件。大量的因特网邮件使用简单邮件传输协议(SMTP),但是本地邮件可能是通过文件或者套接字等其它可能的方式来传输的。邮件是一种存储和转发的操作,因此,在用户接收邮件或者接收系统和通讯联系可用之前,邮件一直是存储在某种文件或者数据库中。配置和确保 MTA 的安全是非常复杂的任务,它们中的大部分内容都已经超出了本教程的范围。
### mail 命令
如果你使用 SMTP 协议传输电子邮件,你或许知道你可以使用许多邮件客户端,包括 `mail`、`mutt`、`alpine`、`notmuch`、以及其它基于主机控制台或者图形界面的邮件客户端。`mail` 命令是最老的、可用于脚本中的、发送和接收以及管理收到的邮件的备用命令。
你可以使用 `mail` 命令交互式的向列表中的收件人发送信息,或者不使用参数去查看你收到的邮件。清单 1 展示了如何在你的系统上去发送信息到用户 steve 和 pat,同时抄送拷贝给用户 bob。当提示 `Cc:` 和 `subject:` 时,输入相应的抄送用户以及邮件主题,接着输入邮件正文,输入完成后按下 `Ctrl+D` (按下 `Ctrl` 键并保持再按下 `D` 之后全部松开)。
```
ian@attic4-u14:~$ mail steve,pat
Cc: bob
Subject: Test message 1
This is a test message
Ian
```
*清单 1. 使用 `mail` 交互式发送邮件*
如果一切顺利,你的邮件已经发出。如果在这里发生错误,你将看到错误信息。例如,如果你在接收者列表中输入一个无效的用户名,邮件将无法发送。注意在本示例中,所有的用户都在本地系统上存在,因此他们都是有效用户。
你也可以使用命令行以非交互式发送邮件。清单 2 展示了如何给用户 steve 和 pat 发送一封邮件。这种方式可以用在脚本中。在不同的软件包中 `mail` 命令的版本不同。对于抄送(`Cc:`)有些支持一个 `-c` 选项,但是我使用的这个版本不支持这个选项,因此,我仅将邮件发送到收件人。
```
ian@attic4-u14:~$ mail -t steve,pat -s "Test message 2" <<< "Another test.\n\nIan"
```
*清单 2. 使用 `mail` 命令非交互式发送邮件*
如果你使用没有选项的 `mail` 命令,你将看到一个如清单 3 中所展示的那样一个收到信息的列表。你将看到用户 steve 有我上面发送的两个信息,再加上我以前发送的一个信息和后来用户 bob 发送的信息。所有的邮件都用 'N' 标记为新邮件。
```
steve@attic4-u14:~$ mail
"/var/mail/steve": 4 messages 4 new
>N 1 Ian Shields Tue Dec 12 21:03 16/704 test message
N 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
N 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
?
```
*清单 3. 使用 `mail` 查看收到的邮件*
当前选中的信息使用一个 `>` 来标识,它是清单 3 中的第一封邮件。如果你按下回车键(`Enter`),将显示下一封未读邮件的第一页。按下空格楗将显示这个邮件的下一页。当你读完这个邮件并想返回到 `?` 提示符时,按下回车键再次查看下一封邮件,依次类推。在 `?` 提示符下,你可以输入 `h` 再次去查看邮件头。你看过的邮件前面将显示一个 `R` 状态,如清单 4 所示。
```
? h
R 1 Ian Shields Tue Dec 12 21:03 16/704 test message
R 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
>R 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
?
```
*清单 4. 使用 `h` 去显示邮件头*
在这个图中,Steve 已经读了三个邮件,但是没有读来自 bob 的邮件。你可以通过数字来选择单个的信息,你也可以通过输入 `d` 删除你不想要的信息,或者输入 `3d` 去删除第三个信息。如果你输入 `q` 你将退出 `mail` 命令。已读的信息将被转移到你的家目录下的 `mbox` 文件中,而未读的信息仍然保留在你的收件箱中,默认在 `/var/mail/$(id -un)`。如清单 5 所示。
```
? h
R 1 Ian Shields Tue Dec 12 21:03 16/704 test message
R 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
>R 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
? q
Saved 3 messages in /home/steve/mbox
Held 1 message in /var/mail/steve
You have mail in /var/mail/steve
```
*清单 5. 使用 `q` 退出 `mail`*
如果你输入 `x` 而不是使用 `q` 去退出,你的邮箱在退出后将不保留你做的改变。因为这在 `/var` 文件系统中,你的系统管理员可能仅允许邮件在一个有限的时间范围内保留。要重新读取或者以其它方式再次处理保存在你的本地邮箱中的邮件,你可以使用 `-f` 选项去指定想要去读的文件。比如,`mail -f mbox`。
### 邮件别名
在前面的节中,看了如何在系统上给许多用户发送邮件。你可以使用一个全限定名字(比如 [[email protected]](mailto:[email protected]))给其它系统上的用户发送邮件。
有时候你可能希望用户的所有邮件都可以发送到其它地方。比如,你有一个服务器群,你希望所有的 root 用户的邮件都发给中心的系统管理员。或者你可能希望去创建一个邮件列表,将邮件发送给一些人。为实现上述目标,你可以使用别名,别名允许你为一个给定的用户名定义一个或者多个目的地。这个目的地或者是其它用户的邮箱、文件、管道、或者是某个进一步处理的命令。你可以在 `/etc/mail/aliases` 或者 `/etc/aliases` 中创建别名来实现上述目的。根据你的系统的不同,你可以找到上述其中一个,符号链接到它们、或者其中之一。改变别名文件你需要有 root 权限。
别名的格式一般是:
```
name: addr_1, addr_2, addr_3, ...
```
这里 `name` 是一个要别名的本地用户名字(即别名),而 `addr_1`,`addr_2`,... 可以是一个或多个别名。别名可以是一个本地用户、一个本地文件名、另一个别名、一个命令、一个包含文件,或者一个外部地址。
因此,发送邮件时如何区分别名呢(addr-N)?
* 本地用户名是你机器上系统中的一个用户名字。从技术角度来说,它可以通过调用 `getpwnam` 命令找到它。
* 本地文件名是以 `/` 开始的完全路径和文件名。它必须是 `sendmail` 可写的。信息会追加到这个文件上。
* 命令是以一个管道符号开始的(`|`)。信息是通过标准输入的方式发送到命令的。
* 包含文件别名是以 `:include:` 和指定的路径和文件名开始的。在该文件中的别名被添加到该名字所代表的别名中。
* 外部地址是一个电子邮件地址,比如 [[email protected]](mailto:[email protected])。
你可以在你的系统中找到一个示例文件,它是与你的 sendmail 包一起安装的,它的位置在 `/usr/share/sendmail/examples/db/aliases`。它包含一些给 `postmaster`、`MAILER-DAEMON`、`abuse` 和 `spam 的别名建议。在清单 6,我把我的 Ubuntu 14.04 LTS 系统上的一些示例文件,和人工修改的示例结合起来说明一些可能的情况。
```
ian@attic4-u14:~$ cat /etc/mail/aliases
# First include some default system aliases from
# /usr/share/sendmail/examples/db/aliases
#
# Mail aliases for sendmail
#
# You must run newaliases(1) after making changes to this file.
#
# Required aliases
postmaster: root
MAILER-DAEMON: postmaster
# Common aliases
abuse: postmaster
spam: postmaster
# Other aliases
# Send steve's mail to bob and pat instead
steve: bob,pat
# Send pat's mail to a file in her home directory and also to her inbox.
# Finally send it to a command that will make another copy.
pat: /home/pat/accumulated-mail,
\pat,
|/home/pat/makemailcopy.sh
# Mailing list for system administrators
sysadmins: :include: /etc/aliases-sysadmins
```
*清单 6. 人工修改的 /etc/mail/aliases 示例*
注意那个 pat 既是一个别名也是一个系统中的用户。别名是以递归的方式展开的,因此,如果一个别名也是一个名字,那么它将被展开。Sendmail 并不会给同一个用户发送相同的邮件两遍,因此,如果你正好将 pat 作为 pat 的别名,那么 sendmail 在已经找到并处理完用户 pat 之后,将忽略别名 pat。为避免这种问题,你可以在别名前使用一个 `\` 做为前缀去指示它是一个不要进一步引起混淆的名字。在这种情况下,pat 的邮件除了文件和命令之外,其余的可能会被发送到他的正常的邮箱中。
在 `aliases` 文件中以 `#` 开始的行是注释,它会被忽略。以空白开始的行会以延续行来处理。
清单 7 展示了包含文件 `/etc/aliases-sysadmins`。
```
ian@attic4-u14:~$ cat /etc/aliases-sysadmins
# Mailing list for system administrators
bob,pat
```
*清单 7 包含文件 /etc/aliases-sysadmins*
### newaliases 命令
sendmail 使用的主要配置文件会被编译成数据库文件。邮件别名也是如此。你可以使用 `newaliases` 命令去编译你的 `/etc/mail/aliases` 和任何包含文件到 `/etc/mail/aliases.db` 中。注意,`newaliases` 命令等价于 `sendmail -bi`。清单 8 展示了一个示例。
```
ian@attic4-u14:~$ sudo newaliases
/etc/mail/aliases: 7 aliases, longest 62 bytes, 184 bytes total
ian@attic4-u14:~$ ls -l /etc/mail/aliases*
lrwxrwxrwx 1 root smmsp 10 Dec 8 15:48 /etc/mail/aliases -> ../aliases
-rw-r----- 1 smmta smmsp 12288 Dec 13 23:18 /etc/mail/aliases.db
```
*清单 8. 为邮件别名重建数据库*
### 使用别名的示例
清单 9 展示了一个简单的 shell 脚本,它在我的别名示例中以一个命令的方式来使用。
```
ian@attic4-u14:~$ cat ~pat/makemailcopy.sh
#!/bin/bash
# Note: Target file ~/mail-copy must be writeable by sendmail!
cat >> ~pat/mail-copy
```
*清单 9. makemailcopy.sh 脚本*
清单 10 展示了用于测试时更新的文件。
```
ian@attic4-u14:~$ date
Wed Dec 13 22:54:22 EST 2017
ian@attic4-u14:~$ mail -t sysadmins -s "sysadmin test 1" <<< "Testing mail"
ian@attic4-u14:~$ ls -lrt $(find /var/mail ~pat -type f -mmin -3 2>/dev/null )
-rw-rw---- 1 pat mail 2046 Dec 13 22:54 /home/pat/mail-copy
-rw------- 1 pat mail 13240 Dec 13 22:54 /var/mail/pat
-rw-rw---- 1 pat mail 9442 Dec 13 22:54 /home/pat/accumulated-mail
-rw-rw---- 1 bob mail 12522 Dec 13 22:54 /var/mail/bob
```
*清单 10. /etc/aliases-sysadmins 包含文件*
需要注意的几点:
* sendmail 使用的用户和组的名字是 mail。
* sendmail 在 `/var/mail` 保存用户邮件,它也是用户 mail 的家目录。用户 ian 的默认收件箱在 `/var/mail/ian` 中。
* 如果你希望 sendmail 在用户目录下写入文件,这个文件必须允许 sendmail 可写入。与其让任何人都可以写入,还不如定义一个组可写入,组名称为 mail。这需要系统管理员来帮你完成。
### 使用一个 `.forward` 文件去转发邮件
别名文件是由系统管理员来管理的。个人用户可以使用它们自己的家目录下的 `.forward` 文件去转发他们自己的邮件。你可以在你的 `.forward` 文件中放任何可以出现在别名文件的右侧的东西。这个文件的内容是明文的,不需要编译。当你收到邮件时,sendmail 将检查你的家目录中的 `.forward` 文件,然后就像处理别名一样处理它。
### 邮件队列和 mailq 命令
Linux 邮件使用存储-转发的处理模式。你已经看到的已接收邮件,在你读它之前一直保存在文件 `/var/mail` 中。你发出的邮件在接收服务器连接可用之前也会被保存。你可以使用 `mailq` 命令去查看邮件队列。清单 11 展示了一个发送给外部用户 ian@attic4-c6 的一个邮件示例,以及运行 `mailq` 命令的结果。在这个案例中,当前服务器没有连接到 attic4-c6,因此邮件在与对方服务器连接可用之前一直保存在队列中。
```
ian@attic4-u14:~$ mail -t ian@attic4-c6 -s "External mail" <<< "Testing external mail queues"
ian@attic4-u14:~$ mailq
MSP Queue status...
/var/spool/mqueue-client is empty
Total requests: 0
MTA Queue status...
/var/spool/mqueue (1 request)
-----Q-ID----- --Size-- -----Q-Time----- ------------Sender/Recipient-----------
vBE4mdE7025908* 29 Wed Dec 13 23:48 <[email protected]>
<[email protected]>
Total requests: 1
```
*清单 11. 使用 `mailq` 命令*
### 其它邮件传输代理
为解决使用 sendmail 时安全方面的问题,在上世纪九十年代开发了几个其它的邮件传输代理。Postfix 或许是最流行的一个,但是 qmail 和 exim 也大量使用。
Postfix 是 IBM 为代替 sendmail 而研发的。它更快、也易于管理、安全性更好一些。从外表看它非常像 sendmail,但是它的内部完全与 sendmail 不同。
Qmail 是一个安全、可靠、高效、简单的邮件传输代理,它由 Dan Bernstein 开发。但是,最近几年以来,它的核心包已经不再更新了。Qmail 和几个其它的包已经被吸收到 IndiMail 中了。
Exim 是另外一个 MTA,它由 University of Cambridge 开发。最初,它的名字是 `EXperimental Internet Mailer`。
所有的这些 MTA 都是为代替 sendmail 而设计的,因此,它们它们都兼容 sendmail 的一些格式。它们都能够处理别名和 `.forward` 文件。有些封装了一个 `sendmail` 命令作为一个到特定的 MTA 自有命令的前端。尽管一些选项可能会被静默忽略,但是大多数都允许使用常见的 sendmail 选项。`mailq` 命令是被直接支持的,或者使用一个类似功能的命令来代替。比如,你可以使用 `mailq` 或者 `exim -bp` 去显示 exim 邮件队列。当然,输出可以看到与 sendmail 的 `mailq` 命令的不同之外。
查看相关的主题,你可以找到更多的关于这些 MTA 的更多信息。
对 Linux 上的邮件传输代理的介绍到此结束。
---
via: <https://www.ibm.com/developerworks/library/l-lpic1-108-3/index.html>
作者:[Ian Shields](https://www.ibm.com) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,490 | 通过玩命令行游戏来测试你的 BASH 技能 | https://www.ostechnix.com/test-your-bash-skills-by-playing-command-line-games/ | 2018-03-28T19:17:06 | [
"游戏",
"命令行"
] | https://linux.cn/article-9490-1.html | 
如果我们经常在实际场景中使用 Linux 命令,我们就会更有效的学习和记忆它们。除非你经常使用 Linux 命令,否则你可能会在一段时间内忘记它们。无论你是新手还是老手,总会有一些趣味的方法来测试你的 BASH 技能。在本教程中,我将解释如何通过玩命令行游戏来测试你的 BASH 技能。其实从技术上讲,这些并不是像 Super TuxKart、极品飞车或 CS 等真正的游戏。这些只是 Linux 命令培训课程的游戏化版本。你将需要根据游戏本身的某些指示来完成一个任务。
现在,我们来看看几款能帮助你实时学习和练习 Linux 命令的游戏。这些游戏不是消磨时间或者令人惊诧的,这些游戏将帮助你获得终端命令的真实体验。请继续阅读:
### 使用 “Wargames” 来测试 BASH 技能
这是一个在线游戏,所以你必须联网。这些游戏可以帮助你以充满乐趣的游戏形式学习和练习 Linux 命令。Wargames 是一个 shell 游戏的集合,每款游戏有很多关卡。只有通过解决先前的关卡才能访问下一个关卡。不要担心!每个游戏都提供了有关如何进入下一关的清晰简洁说明。
要玩 Wargames,请点击以下链接:[Wargames](http://overthewire.org/wargames/) 。

如你所见,左边列出了许多 shell 游戏。每个 shell 游戏都有自己的 SSH 端口。所以,你必须通过本地系统配置 SSH 连接到游戏,你可以在 Wargames 网站的左上角找到关于如何使用 SSH 连接到每个游戏的信息。
例如,让我们来玩 Bandit 游戏吧。为此,单击 Wargames 主页上的 Bandit 链接。在左上角,你会看到 Bandit 游戏的 SSH 信息。

正如你在上面的屏幕截图中看到的,有很多关卡。要进入每个关卡,请单机左侧列中的相应链接。此外,右侧还有适合初学者的说明。如果你对如何玩此游戏有任何疑问,请阅读它们。
现在,让我们点击它进入关卡 0。在下一个屏幕中,你将获得该关卡的 SSH 信息。

正如你在上面的屏幕截图中看到的,你需要配置 SSH 端口 2220 连接 `bandit.labs.overthewire.org`,用户名是 `bandit0`,密码是 `bandit0`。
让我们连接到 Bandit 游戏关卡 0。
```
$ ssh [email protected] -p 2220
```
输入密码 `bandit0`。
示例输出将是:

登录后,输入 `ls` 命令查看内容或者进入关卡 1 页面,了解如何通过关卡 1 等等。建议的命令列表已在每个关卡提供。所以,你可以选择和使用任何合适的命令来解决每个关卡。
我必须承认,Wargames 是令人上瘾的,并且解决每个关卡是非常有趣的。 尽管有些关卡确实很具挑战性,你可能需要谷歌才能知道如何解决问题。 试一试,你会很喜欢它。
### 使用 “Terminus” 来测试 BASH 技能
这是另一个基于浏览器的在线 CLI 游戏,可用于改进或测试你的 Linux 命令技能。要玩这个游戏,请打开你的 web 浏览器并导航到以下 URL:[Play Terminus Game](http://web.mit.edu/mprat/Public/web/Terminus/Web/main.html)
一旦你进入游戏,你会看到有关如何玩游戏的说明。与 Wargames 不同,你不需要连接到它们的游戏服务器来玩游戏。Terminus 有一个内置的 CLI,你可以在其中找到有关如何使用它的说明。
你可以使用命令 `ls` 查看周围的环境,使用命令 `cd 位置` 移动到新的位置,返回使用命令 `cd ..`,与这个世界进行交互使用命令 `less 项目` 等等。要知道你当前的位置,只需输入 `pwd`。

### 使用 “clmystery” 来测试 BASH 技能
与上述游戏不同,你可以在本地玩这款游戏。你不需要连接任何远程系统,这是完全离线的游戏。
相信我,这家伙是一个有趣的游戏。按照给定的说明,你将扮演一个侦探角色来解决一个神秘案件。
首先,克隆仓库:
```
$ git clone https://github.com/veltman/clmystery.git
```
或者,从 [这里](https://github.com/veltman/clmystery/archive/master.zip) 将其作为 zip 文件下载。解压缩并切换到下载文件的地方。最后,通过阅读 `instructions` 文件来开启宝箱。
```
[sk@sk]: clmystery-master>$ ls
cheatsheet.md cheatsheet.pdf encoded hint1 hint2 hint3 hint4 hint5 hint6 hint7 hint8 instructions LICENSE.md mystery README.md solution
```
这里是玩这个游戏的说明:
终端城发生了一起谋杀案,TCPD 需要你的帮助。你需要帮助它们弄清楚是谁犯罪了。
为了查明是谁干的,你需要到 `mystery` 子目录并从那里开始工作。你可能需要查看犯罪现场的所有线索( `crimescene` 文件)。现场的警官相当谨慎,所以他们在警官报告中写下了一切。幸运的是,警官以全部大写的 “CLUE” 一词把真正的线索标记了出来。
如果里遇到任何问题,请打开其中一个提示文件,例如 “hint1”,“hint2” 等。你可以使用下面的 `cat` 命令打开提示文件。
```
$ cat hint1
$ cat hint2
```
要检查你的答案或找出解决方案,请在 `clmystery` 目录中打开文件 `solution`。
```
$ cat solution
```
要了解如何使用命令行,请参阅 `cheatsheet.md` 或 `cheatsheet.pdf` (在命令行中,你可以输入 ‘nano cheatsheet.md’)。请勿使用文本编辑器查看除 `instructions`、`cheatsheet` 和 `hint` 以外的任何文件。
有关更多详细信息,请参阅 [clmystery GitHub](https://github.com/veltman/clmystery) 页面。
推荐阅读:
而这就是我现在所知道的。如果将来遇到任何问题,我会继续添加更多游戏。将此链接加入书签并不时访问。如果你知道其他类似的游戏,请在下面的评论部分告诉我,我将测试和更新本指南。
还有更多好东西,敬请关注!
干杯!
---
via: <https://www.ostechnix.com/test-your-bash-skills-by-playing-command-line-games/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,491 | gdb 如何工作? | https://jvns.ca/blog/2016/08/10/how-does-gdb-work/ | 2018-03-29T09:39:45 | [
"gdb",
"调试"
] | https://linux.cn/article-9491-1.html | 
大家好!今天,我开始进行我的 [ruby 堆栈跟踪项目](http://jvns.ca/blog/2016/06/12/a-weird-system-call-process-vm-readv/),我发觉我现在了解了一些关于 `gdb` 内部如何工作的内容。
最近,我使用 `gdb` 来查看我的 Ruby 程序,所以,我们将对一个 Ruby 程序运行 `gdb` 。它实际上就是一个 Ruby 解释器。首先,我们需要打印出一个全局变量的地址:`ruby_current_thread`。
### 获取全局变量
下面展示了如何获取全局变量 `ruby_current_thread` 的地址:
```
$ sudo gdb -p 2983
(gdb) p & ruby_current_thread
$2 = (rb_thread_t **) 0x5598a9a8f7f0 <ruby_current_thread>
```
变量能够位于的地方有<ruby> 堆 <rt> heap </rt></ruby>、<ruby> 栈 <rt> stack </rt></ruby>或者程序的<ruby> 文本段 <rt> text </rt></ruby>。全局变量是程序的一部分。某种程度上,你可以把它们想象成是在编译的时候分配的。因此,我们可以很容易的找出全局变量的地址。让我们来看看,`gdb` 是如何找出 `0x5598a9a87f0` 这个地址的。
我们可以通过查看位于 `/proc` 目录下一个叫做 `/proc/$pid/maps` 的文件,来找到这个变量所位于的大致区域。
```
$ sudo cat /proc/2983/maps | grep bin/ruby
5598a9605000-5598a9886000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
5598a9a86000-5598a9a8b000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
5598a9a8b000-5598a9a8d000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
```
所以,我们看到,起始地址 `5598a9605000` 和 `0x5598a9a8f7f0` 很像,但并不一样。哪里不一样呢,我们把两个数相减,看看结果是多少:
```
(gdb) p/x 0x5598a9a8f7f0 - 0x5598a9605000
$4 = 0x48a7f0
```
你可能会问,这个数是什么?让我们使用 `nm` 来查看一下程序的符号表。
```
sudo nm /proc/2983/exe | grep ruby_current_thread
000000000048a7f0 b ruby_current_thread
```
我们看到了什么?能够看到 `0x48a7f0` 吗?是的,没错。所以,如果我们想找到程序中一个全局变量的地址,那么只需在符号表中查找变量的名字,然后再加上在 `/proc/whatever/maps` 中的起始地址,就得到了。
所以现在,我们知道 `gdb` 做了什么。但是,`gdb` 实际做的事情更多,让我们跳过直接转到…
### 解引用指针
```
(gdb) p ruby_current_thread
$1 = (rb_thread_t *) 0x5598ab3235b0
```
我们要做的下一件事就是解引用 `ruby_current_thread` 这一指针。我们想看一下它所指向的地址。为了完成这件事,`gdb` 会运行大量系统调用比如:
```
ptrace(PTRACE_PEEKTEXT, 2983, 0x5598a9a8f7f0, [0x5598ab3235b0]) = 0
```
你是否还记得 `0x5598a9a8f7f0` 这个地址?`gdb` 会问:“嘿,在这个地址中的实际内容是什么?”。`2983` 是我们运行 gdb 这个进程的 ID。gdb 使用 `ptrace` 这一系统调用来完成这一件事。
好极了!因此,我们可以解引用内存并找出内存地址中存储的内容。有一些有用的 `gdb` 命令,比如 `x/40w 变量` 和 `x/40b 变量` 分别会显示给定地址的 40 个字/字节。
### 描述结构
一个内存地址中的内容可能看起来像下面这样。可以看到很多字节!
```
(gdb) x/40b ruby_current_thread
0x5598ab3235b0: 16 -90 55 -85 -104 85 0 0
0x5598ab3235b8: 32 47 50 -85 -104 85 0 0
0x5598ab3235c0: 16 -64 -55 115 -97 127 0 0
0x5598ab3235c8: 0 0 2 0 0 0 0 0
0x5598ab3235d0: -96 -83 -39 115 -97 127 0 0
```
这很有用,但也不是非常有用!如果你是一个像我一样的人类并且想知道它代表什么,那么你需要更多内容,比如像这样:
```
(gdb) p *(ruby_current_thread)
$8 = {self = 94114195940880, vm = 0x5598ab322f20, stack = 0x7f9f73c9c010,
stack_size = 131072, cfp = 0x7f9f73d9ada0, safe_level = 0, raised_flag = 0,
last_status = 8, state = 0, waiting_fd = -1, passed_block = 0x0,
passed_bmethod_me = 0x0, passed_ci = 0x0, top_self = 94114195612680,
top_wrapper = 0, base_block = 0x0, root_lep = 0x0, root_svar = 8, thread_id =
140322820187904,
```
太好了。现在就更加有用了。`gdb` 是如何知道这些所有域的,比如 `stack_size` ?是从 `DWARF` 得知的。`DWARF` 是存储额外程序调试数据的一种方式,从而像 `gdb` 这样的调试器能够工作的更好。它通常存储为二进制的一部分。如果我对我的 Ruby 二进制文件运行 `dwarfdump` 命令,那么我将会得到下面的输出:
(我已经重新编排使得它更容易理解)
```
DW_AT_name "rb_thread_struct"
DW_AT_byte_size 0x000003e8
DW_TAG_member
DW_AT_name "self"
DW_AT_type <0x00000579>
DW_AT_data_member_location DW_OP_plus_uconst 0
DW_TAG_member
DW_AT_name "vm"
DW_AT_type <0x0000270c>
DW_AT_data_member_location DW_OP_plus_uconst 8
DW_TAG_member
DW_AT_name "stack"
DW_AT_type <0x000006b3>
DW_AT_data_member_location DW_OP_plus_uconst 16
DW_TAG_member
DW_AT_name "stack_size"
DW_AT_type <0x00000031>
DW_AT_data_member_location DW_OP_plus_uconst 24
DW_TAG_member
DW_AT_name "cfp"
DW_AT_type <0x00002712>
DW_AT_data_member_location DW_OP_plus_uconst 32
DW_TAG_member
DW_AT_name "safe_level"
DW_AT_type <0x00000066>
```
所以,`ruby_current_thread` 的类型名为 `rb_thread_struct`,它的大小为 `0x3e8` (即 1000 字节),它有许多成员项,`stack_size` 是其中之一,在偏移为 `24` 的地方,它有类型 `31` 。`31` 是什么?不用担心,我们也可以在 DWARF 信息中查看。
```
< 1><0x00000031> DW_TAG_typedef
DW_AT_name "size_t"
DW_AT_type <0x0000003c>
< 1><0x0000003c> DW_TAG_base_type
DW_AT_byte_size 0x00000008
DW_AT_encoding DW_ATE_unsigned
DW_AT_name "long unsigned int"
```
所以,`stack_size` 具有类型 `size_t`,即 `long unsigned int`,它是 8 字节的。这意味着我们可以查看该栈的大小。
如果我们有了 DWARF 调试数据,该如何分解:
1. 查看 `ruby_current_thread` 所指向的内存区域
2. 加上 `24` 字节来得到 `stack_size`
3. 读 8 字节(以小端的格式,因为是在 x86 上)
4. 得到答案!
在上面这个例子中是 `131072`(即 128 kb)。
对我来说,这使得调试信息的用途更加明显。如果我们不知道这些所有变量所表示的额外的元数据,那么我们无法知道存储在 `0x5598ab325b0` 这一地址的字节是什么。
这就是为什么你可以为你的程序单独安装程序的调试信息,因为 `gdb` 并不关心从何处获取这些额外的调试信息。
### DWARF 令人迷惑
我最近阅读了大量的 DWARF 知识。现在,我使用 libdwarf,使用体验不是很好,这个 API 令人迷惑,你将以一种奇怪的方式初始化所有东西,它真的很慢(需要花费 0.3 秒的时间来读取我的 Ruby 程序的所有调试信息,这真是可笑)。有人告诉我,来自 elfutils 的 libdw 要好一些。
同样,再提及一点,你可以查看 `DW_AT_data_member_location` 来查看结构成员的偏移。我在 Stack Overflow 上查找如何完成这件事,并且得到[这个答案](https://stackoverflow.com/questions/25047329/how-to-get-struct-member-offset-from-dwarf-info)。基本上,以下面这样一个检查开始:
```
dwarf_whatform(attrs[i], &form, &error);
if (form == DW_FORM_data1 || form == DW_FORM_data2
form == DW_FORM_data2 || form == DW_FORM_data4
form == DW_FORM_data8 || form == DW_FORM_udata) {
```
继续往前。为什么会有 800 万种不同的 `DW_FORM_data` 需要检查?发生了什么?我没有头绪。
不管怎么说,我的印象是,DWARF 是一个庞大而复杂的标准(可能是人们用来生成 DWARF 的库稍微不兼容),但是我们有的就是这些,所以我们只能用它来工作。
我能够编写代码并查看 DWARF ,这就很酷了,并且我的代码实际上大多数能够工作。除了程序崩溃的时候。我就是这样工作的。
### 展开栈路径
在这篇文章的早期版本中,我说过,`gdb` 使用 libunwind 来展开栈路径,这样说并不总是对的。
有一位对 `gdb` 有深入研究的人发了大量邮件告诉我,为了能够做得比 libunwind 更好,他们花费了大量时间来尝试如何展开栈路径。这意味着,如果你在程序的一个奇怪的中间位置停下来了,你所能够获取的调试信息又很少,那么你可以对栈做一些奇怪的事情,`gdb` 会尝试找出你位于何处。
### gdb 能做的其他事
我在这儿所描述的一些事请(查看内存,理解 DWARF 所展示的结构)并不是 `gdb` 能够做的全部事情。阅读 Brendan Gregg 的[昔日 gdb 例子](http://www.brendangregg.com/blog/2016-08-09/gdb-example-ncurses.html),我们可以知道,`gdb` 也能够完成下面这些事情:
* 反汇编
* 查看寄存器内容
在操作程序方面,它可以:
* 设置断点,单步运行程序
* 修改内存(这是一个危险行为)
了解 `gdb` 如何工作使得当我使用它的时候更加自信。我过去经常感到迷惑,因为 `gdb` 有点像 C,当你输入 `ruby_current_thread->cfp->iseq`,就好像是在写 C 代码。但是你并不是在写 C 代码。我很容易遇到 `gdb` 的限制,不知道为什么。
知道使用 DWARF 来找出结构内容给了我一个更好的心智模型和更加正确的期望!这真是极好的!
---
via: <https://jvns.ca/blog/2016/08/10/how-does-gdb-work/>
作者:[Julia Evans](https://jvns.ca/) 译者:[ucasFL](https://github.com/ucasFL) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello! Today I was working a bit on my [ruby stacktrace project](http://jvns.ca/blog/2016/06/12/a-weird-system-call-process-vm-readv/) and I realized that now I know a couple of things about how gdb works internally.
Lately I’ve been using gdb to look at Ruby programs, so we’re going to be running gdb on a Ruby program. This really means the Ruby interpreter. First, we’re going to print out the address of a global variable: `ruby_current_thread`
:
### getting a global variable
Here’s how to get the address of the global `ruby_current_thread`
:
```
$ sudo gdb -p 2983
(gdb) p & ruby_current_thread
$2 = (rb_thread_t **) 0x5598a9a8f7f0 <ruby_current_thread>
```
There are a few places a variable can live: on the heap, the stack, or in your program’s text. Global variables are part of your program! You can think of them as being allocated at compile time, kind of. It turns out we can figure out the address of a global variable pretty easily! Let’s see how `gdb`
came up with `0x5598a9a8f7f0`
.
We can find the approximate region this variable lives in by looking at a cool file in `/proc`
called `/proc/$pid/maps`
.
```
$ sudo cat /proc/2983/maps | grep bin/ruby
5598a9605000-5598a9886000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
5598a9a86000-5598a9a8b000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
5598a9a8b000-5598a9a8d000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
```
So! There’s this starting address `5598a9605000`
That’s *like* `0x5598a9a8f7f0`
, but different. How different? Well, here’s what I get when I subtract them:
```
(gdb) p/x 0x5598a9a8f7f0 - 0x5598a9605000
$4 = 0x48a7f0
```
“What’s that number?”, you might ask? WELL. Let’s look at the **symbol table** for our program with `nm`
.
```
sudo nm /proc/2983/exe | grep ruby_current_thread
000000000048a7f0 b ruby_current_thread
```
What’s that we see? Could it be `0x48a7f0`
? Yes it is! So!! If we want to find the address of a global variable in our program, all we need to do is look up the name of the variable in the symbol table, and then add that to the start of the range in `/proc/whatever/maps`
, and we’re done!
So now we know how gdb does that. But gdb does so much more!! Let’s skip ahead to…
### dereferencing pointers
```
(gdb) p ruby_current_thread
$1 = (rb_thread_t *) 0x5598ab3235b0
```
The next thing we’re going to do is **dereference** that `ruby_current_thread`
pointer. We want to see what’s in that address! To do that, gdb will run a bunch of system calls like this:
```
ptrace(PTRACE_PEEKTEXT, 2983, 0x5598a9a8f7f0, [0x5598ab3235b0]) = 0
```
You remember this address `0x5598a9a8f7f0`
? gdb is asking “hey, what’s in that address exactly”? `2983`
is the PID of the process we’re running gdb on. It’s using the `ptrace`
system call which is how gdb does everything.
Awesome! So we can dereference memory and figure out what bytes are at what memory addresses. Some useful gdb commands to know here are `x/40w variable`
and `x/40b variable`
which will display 40 words / bytes at a given address, respectively.
### describing structs
The memory at an address looks like this. A bunch of bytes!
```
(gdb) x/40b ruby_current_thread
0x5598ab3235b0: 16 -90 55 -85 -104 85 0 0
0x5598ab3235b8: 32 47 50 -85 -104 85 0 0
0x5598ab3235c0: 16 -64 -55 115 -97 127 0 0
0x5598ab3235c8: 0 0 2 0 0 0 0 0
0x5598ab3235d0: -96 -83 -39 115 -97 127 0 0
```
That’s useful, but not that useful! If you are a human like me and want to know what it MEANS, you need more. Like this:
```
(gdb) p *(ruby_current_thread)
$8 = {self = 94114195940880, vm = 0x5598ab322f20, stack = 0x7f9f73c9c010,
stack_size = 131072, cfp = 0x7f9f73d9ada0, safe_level = 0, raised_flag = 0,
last_status = 8, state = 0, waiting_fd = -1, passed_block = 0x0,
passed_bmethod_me = 0x0, passed_ci = 0x0, top_self = 94114195612680,
top_wrapper = 0, base_block = 0x0, root_lep = 0x0, root_svar = 8, thread_id =
140322820187904,
```
GOODNESS. That is a lot more useful. How does gdb know that there are all these cool fields like `stack_size`
? Enter DWARF. DWARF is a way to store extra debugging data about your program, so that debuggers like gdb can do their job better! It’s generally stored as part of a binary. If I run `dwarfdump`
on my Ruby binary, I get some output like this:
(I’ve redacted it heavily to make it easier to understand)
```
DW_AT_name "rb_thread_struct"
DW_AT_byte_size 0x000003e8
DW_TAG_member
DW_AT_name "self"
DW_AT_type <0x00000579>
DW_AT_data_member_location DW_OP_plus_uconst 0
DW_TAG_member
DW_AT_name "vm"
DW_AT_type <0x0000270c>
DW_AT_data_member_location DW_OP_plus_uconst 8
DW_TAG_member
DW_AT_name "stack"
DW_AT_type <0x000006b3>
DW_AT_data_member_location DW_OP_plus_uconst 16
DW_TAG_member
DW_AT_name "stack_size"
DW_AT_type <0x00000031>
DW_AT_data_member_location DW_OP_plus_uconst 24
DW_TAG_member
DW_AT_name "cfp"
DW_AT_type <0x00002712>
DW_AT_data_member_location DW_OP_plus_uconst 32
DW_TAG_member
DW_AT_name "safe_level"
DW_AT_type <0x00000066>
```
So. The name of the type of `ruby_current_thread`
is `rb_thread_struct`
. It has size `0x3e8`
(or 1000 bytes), and it has a bunch of member items. `stack_size`
is one of them, at an offset of 24, and it has type 31. What’s 31? No worries! We can look that up in the DWARF info too!
```
< 1><0x00000031> DW_TAG_typedef
DW_AT_name "size_t"
DW_AT_type <0x0000003c>
< 1><0x0000003c> DW_TAG_base_type
DW_AT_byte_size 0x00000008
DW_AT_encoding DW_ATE_unsigned
DW_AT_name "long unsigned int"
```
So! `stack_size`
has type `size_t`
, which means `long unsigned int`
, and is 8 bytes. That means that we can read the stack size!
How that would break down, once we have the DWARF debugging data, is:
- Read the region of memory that
`ruby_current_thread`
is pointing to - Add 24 bytes to get to
`stack_size`
- Read 8 bytes (in little-endian format, since we’re on x86)
- Get the answer!
Which in this case is 131072 or 128 kb.
To me, this makes it a lot more obvious what debugging info is **for** – if we didn’t have all this extra metadata about what all these variables meant, we would have no idea what the bytes at address `0x5598ab3235b0`
meant.
This is also why you can install debug info for a program separately from your program – gdb doesn’t care where it gets the extra debug info from.
### DWARF is confusing
I’ve been reading a bunch of DWARF info recently. Right now I’m using libdwarf which hasn’t been the best experience – the API is confusing, you initialize everything in a weird way, and it’s really slow (it takes 0.3 seconds to read all the debugging data out of my Ruby program which seems ridiculous). I’ve been told that libdw from elfutils is better.
Also, I casually remarked that you can look at `DW_AT_data_member_location`
to get the offset of a struct member! But I looked up on Stack Overflow how to actually do that and I got [this answer](http://stackoverflow.com/questions/25047329/how-to-get-struct-member-offset-from-dwarf-info). Basically you start with a check like:
```
dwarf_whatform(attrs[i], &form, &error);
if (form == DW_FORM_data1 || form == DW_FORM_data2
form == DW_FORM_data2 || form == DW_FORM_data4
form == DW_FORM_data8 || form == DW_FORM_udata) {
```
and then it keeps GOING. Why are there 8 million different `DW_FORM_data`
things I need to check for? What is happening? I have no idea.
Anyway my impression is that DWARF is a large and complicated standard (and possibly the libraries people use to generate DWARF are subtly incompatible?), but it’s what we have, so that’s what we work with!
I think it’s really cool that I can write code that reads DWARF and my code actually mostly works. Except when it crashes. I’m working on that.
### unwinding stacktraces
In an earlier version of this post, I said that gdb unwinds stacktraces using libunwind. It turns out that this isn’t true at all!
Someone who’s worked on gdb a lot emailed me to say that they actually spent a ton of time figuring out how to unwind stacktraces so that they can do a better job than libunwind does. This means that if you get stopped in the middle of a weird program with less debug info than you might hope for that’s done something strange with its stack, gdb will try to figure out where you are anyway. Thanks <3
### other things gdb does
The few things I’ve described here (reading memory, understanding DWARF to show you structs) aren’t everything gdb does – just looking through Brendan Gregg’s [gdb example from yesterday](http://www.brendangregg.com/blog/2016-08-09/gdb-example-ncurses.html), we see that gdb also knows how to
- disassemble assembly
- show you the contents of your registers
and in terms of manipulating your program, it can
- set breakpoints and step through a program
- modify memory (!! danger !!)
Knowing more about how gdb works makes me feel a lot more confident when using
it! I used to get really confused because gdb kind of acts like a C REPL
sometimes – you type `ruby_current_thread->cfp->iseq`
, and it feels like
writing C code! But you’re not really writing C at all, and it was easy for
me to run into limitations in gdb and not understand why.
Knowing that it’s using DWARF to figure out the contents of the structs gives me a better mental model and have more correct expectations! Awesome. |
9,492 | 如何在 Debian Linux 上设置和配置网桥 | https://www.cyberciti.biz/faq/how-to-configuring-bridging-in-debian-linux/ | 2018-03-29T10:52:00 | [
"网桥"
] | https://linux.cn/article-9492-1.html | 
Q:我是一个新 Debian Linux 用户,我想为 Debian Linux 上运行的虚拟化环境(KVM)设置网桥。那么我该如何在 Debian Linux 9.x 服务器上的 `/etc/network/interfaces` 中设置桥接网络呢?
如何你想为你的虚拟机分配 IP 地址并使其可从你的局域网访问,则需要设置网络桥接器。默认情况下,虚拟机使用 KVM 创建的专用网桥。但你需要手动设置接口,避免与网络管理员发生冲突。
### 怎样安装 brctl
输入以下 [apt-get 命令](https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html "See Linux/Unix apt-get command examples for more info"):
```
$ sudo apt install bridge-utils
```
### 怎样在 Debian Linux 上设置网桥
你需要编辑 `/etc/network/interface` 文件。不过,我建议在 `/etc/network/interface.d/` 目录下放置一个全新的配置。在 Debian Linux 配置网桥的过程如下:
#### 步骤 1 - 找出你的物理接口
使用 [ip 命令](https://www.cyberciti.biz/faq/linux-ip-command-examples-usage-syntax/ "See Linux/Unix ip command examples for more info"):
```
$ ip -f inet a s
```
示例输出如下:
```
2: eno1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.2.23/24 brd 192.168.2.255 scope global eno1
valid_lft forever preferred_lft forever
```
`eno1` 是我的物理网卡。
#### 步骤 2 - 更新 /etc/network/interface 文件
确保只有 `lo`(loopback 在 `/etc/network/interface` 中处于活动状态)。(LCTT 译注:loopback 指本地环回接口,也称为回送地址)删除与 `eno1` 相关的任何配置。这是我使用 [cat 命令](https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/ "See Linux/Unix cat command examples for more info") 打印的配置文件:
```
$ cat /etc/network/interface
```
```
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
source /etc/network/interfaces.d/*
# The loopback network interface
auto lo
iface lo inet loopback
```
#### 步骤 3 - 在 /etc/network/interfaces.d/br0 中配置网桥(br0)
使用文本编辑器创建一个文本文件,比如 `vi` 命令:
```
$ sudo vi /etc/network/interfaces.d/br0
```
在其中添加配置:
```
## static ip config file for br0 ##
auto br0
iface br0 inet static
address 192.168.2.23
broadcast 192.168.2.255
netmask 255.255.255.0
gateway 192.168.2.254
# If the resolvconf package is installed, you should not edit
# the resolv.conf configuration file manually. Set name server here
#dns-nameservers 192.168.2.254
# If you have muliple interfaces such as eth0 and eth1
# bridge_ports eth0 eth1
bridge_ports eno1
bridge_stp off # disable Spanning Tree Protocol
bridge_waitport 0 # no delay before a port becomes available
bridge_fd 0 # no forwarding delay
```
如果你想使用 DHCP 来获得 IP 地址:
```
## DHCP ip config file for br0 ##
auto br0
# Bridge setup
iface br0 inet dhcp
bridge_ports eno1
```
[在 vi/vim 中保存并关闭文件](https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/)。
#### 步骤 4 - 重新启动网络服务
在重新启动网络服务之前,请确保防火墙已关闭。防火墙可能会引用较老的接口,例如 `eno1`。一旦服务重新启动,你必须更新 `br0` 接口的防火墙规则。键入以下命令重新启动防火墙:
```
$ sudo systemctl restart network-manager
```
确认服务已经重新启动:
```
$ systemctl status network-manager
```
借助 [ip 命令](https://www.cyberciti.biz/faq/linux-ip-command-examples-usage-syntax/ "See Linux/Unix ip command examples for more info")寻找新的 `br0` 接口和路由表:
```
$ ip a s $ ip r $ ping -c 2 cyberciti.biz
```
示例输出:

你可以使用 brctl 命令查看网桥有关信息:
```
$ brctl show
```
显示当前网桥:
```
$ bridge link
```

### 关于作者
作者是 nixCraft 的创建者,也是经验丰富的系统管理员,DevOps 工程师以及 Linux 操作系统/ Unix shell 脚本的培训师。通过订阅 [RSS/XML 流](https://www.cyberciti.biz/atom/atom.xml) 或者 [每周邮件推送](https://www.cyberciti.biz/subscribe-to-weekly-linux-unix-newsletter-for-sysadmin/)获得关于 SysAdmin, Linux/Unix 和开源主题的最新教程。
---
via: <https://www.cyberciti.biz/faq/how-to-configuring-bridging-in-debian-linux/>
作者:[Vivek GIte](https://www.cyberciti.biz/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.